mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
1a81f2409d
76
README.md
76
README.md
@ -1,9 +1,9 @@
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||
LCTT是“Linux中国”([http://linux.cn/](http://linux.cn/))的翻译组,负责从国外优秀媒体翻译Linux相关的技术、资讯、杂文等内容。
|
||||
LCTT是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译Linux相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT已经拥有近百余名活跃成员,并欢迎更多的Linux志愿者加入我们的团队。
|
||||
LCTT已经拥有几百名活跃成员,并欢迎更多的Linux志愿者加入我们的团队。
|
||||
|
||||

|
||||
|
||||
@ -52,13 +52,15 @@ LCTT的组成
|
||||
* 2015/04/19 发起 LFS-BOOK-7.7-systemd 项目。
|
||||
* 2015/06/09 提升ictlyh和dongfengweixiao为Core Translators成员。
|
||||
* 2015/11/10 提升strugglingyouth、FSSlc、Vic020、alim0x为Core Translators成员。
|
||||
* 2016/05/09 提升PurlingNayuki为校对。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
|
||||
目前 TP 活跃成员有:
|
||||
- CORE @wxy,
|
||||
- CORE @DeadFire,
|
||||
- Leader @wxy,
|
||||
- Source @oska874,
|
||||
- Proofreader @PurlingNayuki,
|
||||
- CORE @geekpi,
|
||||
- CORE @GOLinux,
|
||||
- CORE @ictlyh,
|
||||
@ -71,6 +73,7 @@ LCTT的组成
|
||||
- CORE @Vic020,
|
||||
- CORE @dongfengweixiao,
|
||||
- CORE @alim0x,
|
||||
- Senior @DeadFire,
|
||||
- Senior @reinoir,
|
||||
- Senior @tinyeyeser,
|
||||
- Senior @vito-L,
|
||||
@ -80,41 +83,42 @@ LCTT的组成
|
||||
- ZTinoZ,
|
||||
- theo-l,
|
||||
- luoxcat,
|
||||
- disylee,
|
||||
- martin2011qi,
|
||||
- wi-cuckoo,
|
||||
- disylee,
|
||||
- haimingfg,
|
||||
- KayGuoWhu,
|
||||
- wwy-hust,
|
||||
- martin2011qi,
|
||||
- cvsher,
|
||||
- felixonmars,
|
||||
- su-kaiyao,
|
||||
- ivo-wang,
|
||||
- GHLandy,
|
||||
- cvsher,
|
||||
- wyangsun,
|
||||
- DongShuaike,
|
||||
- flsf,
|
||||
- SPccman,
|
||||
- Stevearzh
|
||||
- mr-ping,
|
||||
- Linchenguang,
|
||||
- oska874
|
||||
- Linux-pdz,
|
||||
- 2q1w2007,
|
||||
- felixonmars,
|
||||
- wyangsun,
|
||||
- MikeCoder,
|
||||
- mr-ping,
|
||||
- xiqingongzi
|
||||
- H-mudcup,
|
||||
- zhangboyue,
|
||||
- cposture,
|
||||
- xiqingongzi,
|
||||
- goreliu,
|
||||
- DongShuaike,
|
||||
- NearTan,
|
||||
- TxmszLou,
|
||||
- ZhouJ-sh,
|
||||
- wangjiezhe,
|
||||
- NearTan,
|
||||
- icybreaker,
|
||||
- shipsw,
|
||||
- johnhoow,
|
||||
- soooogreen,
|
||||
- linuhap,
|
||||
- boredivan,
|
||||
- blueabysm,
|
||||
- liaoishere,
|
||||
- boredivan,
|
||||
- name1e5s,
|
||||
- yechunxiao19,
|
||||
- l3b2w1,
|
||||
- XLCYun,
|
||||
@ -122,43 +126,55 @@ LCTT的组成
|
||||
- tenght,
|
||||
- coloka,
|
||||
- luoyutiantang,
|
||||
- yupmoon,
|
||||
- sonofelice,
|
||||
- jiajia9linuxer,
|
||||
- scusjs,
|
||||
- tnuoccalanosrep,
|
||||
- woodboow,
|
||||
- 1w2b3l,
|
||||
- JonathanKang,
|
||||
- crowner,
|
||||
- mtunique,
|
||||
- dingdongnigetou,
|
||||
- CNprober,
|
||||
- JonathanKang,
|
||||
- Medusar,
|
||||
- hyaocuk,
|
||||
- szrlee,
|
||||
- KnightJoker,
|
||||
- Xuanwo,
|
||||
- nd0104,
|
||||
- jerryling315,
|
||||
- xiaoyu33,
|
||||
- guodongxiaren,
|
||||
- zzlyzq,
|
||||
- yujianxuechuan,
|
||||
- ailurus1991,
|
||||
- ynmlml,
|
||||
- kylepeng93,
|
||||
- ggaaooppeenngg,
|
||||
- Ricky-Gong,
|
||||
- zky001,
|
||||
- Flowsnow,
|
||||
- lfzark,
|
||||
- 213edu,
|
||||
- Tanete,
|
||||
- liuaiping,
|
||||
- jerryling315,
|
||||
- bestony,
|
||||
- Timeszoro,
|
||||
- rogetfan,
|
||||
- itsang,
|
||||
- JeffDing,
|
||||
- Yuking-net,
|
||||
|
||||
- MikeCoder,
|
||||
- zhangboyue,
|
||||
- liaoishere,
|
||||
- yupmoon,
|
||||
- Medusar,
|
||||
- zzlyzq,
|
||||
- yujianxuechuan,
|
||||
- ailurus1991,
|
||||
- tomatoKiller,
|
||||
- stduolc,
|
||||
- shaohaolin,
|
||||
- Timeszoro,
|
||||
- rogetfan,
|
||||
- FineFan,
|
||||
- kingname,
|
||||
- jasminepeng,
|
||||
- JeffDing,
|
||||
- CHINAANSHE,
|
||||
|
||||
(按提交行数排名前百)
|
||||
@ -173,7 +189,7 @@ LFS 项目活跃成员有:
|
||||
- @KevinSJ
|
||||
- @Yuking-net
|
||||
|
||||
(更新于2015/11/29)
|
||||
(更新于2016/05/09)
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
如果总统候选人们要使用 Linux 发行版,他们会选择哪个?
|
||||
================================================================================
|
||||

|
||||
|
||||
*共和党总统候选人 Donald Trump【译者注:唐纳德·特朗普,美国地产大亨、作家、主持人】*
|
||||
|
||||
如果要竞选总统的人们使用 Linux 或其他的开源操作系统,那么会使用哪个发行版呢?问题的关键是存在许多其它的因素,比如,一些“政治立场”问题,或者是给一个发行版的名字添加上感叹号是否合适——而这问题一直被忽视。先不管这些忽视:接下来是时事新闻工作者关于总统大选和 Linux 发行版的报道。
|
||||
|
||||
对于那些已经看了很多年我的文字的人来说(除了我亲爱的的编辑之外,他们一直听我的瞎扯是不是倒霉到家了?),这篇文章听起来很熟悉,这是因为我在去年的总统选举期间写了一篇[类似的文章][1]。一些读者把这篇文章的内容看的比我想象的还要严肃,所以我会花点时间阐述我的观点:事实上,我不认为开源软件和政治运动彼此之间有多大的关系。我写那样的文章仅仅是新的一周的自我消遣罢了。
|
||||
|
||||
当然,你也可以认为它们彼此相关,毕竟你才是读者。
|
||||
|
||||
### Linux 发行版之选:共和党人们 ###
|
||||
|
||||
今天,我只是谈及一些有关共和党人们的话题,我甚至只会谈论他们的其中一部分。因为共和党的提名人太多了,以至于我写满了整篇文章。由此开始:
|
||||
|
||||
如果 **Jeb (Jeb!?) Bush** 使用 Linux,它一定是 [Debian][2]。Debian 属于一个相当无趣的分支,它是为真正意义上的、成熟的黑客设计的,这些人将清理那些由经验不甚丰富的开源爱好者所造成的混乱视为一大使命。当然,这也使得 Debian 显得很枯燥,所以它已有的用户基数一直在缩减。
|
||||
|
||||
**Scott Walker** ,对于他来说,应该是一个 [Damn Small Linux][3] (DSL) 用户。这个系统仅仅需要 50MB 的硬盘空间和 16MB 的 RAM 便可运行。DSL 可以使一台 20 年前的 486 计算机焕发新春,而这恰好符合了 **Scott Walker** 所主张的消减成本计划。当然,你在 DSL 上的用户体验也十分原始,这个系统平台只能够运行一个浏览器。但是至少你不用浪费钱财购买新的电脑硬件,你那台 1993 年购买的机器仍然可以为你好好的工作。
|
||||
|
||||
**Chris Christie** 会使用哪种系统呢?他肯定会使用 [Relax-and-Recover Linux][4],它号称“一次搞定(Setup-and-forget)的裸机 Linux 灾难恢复方案” 。从那次不幸的华盛顿大桥事故后,“一次搞定(Setup-and-forget)”基本上便成了 Christie 的政治主张。不管灾难恢复是否能够让 Christie 最终挽回一切,但是当他的电脑死机的时候,至少可以找到一两封意外丢失的机密邮件。
|
||||
|
||||
至于 **Carly Fiorina**,她无疑将要使用 [惠普][6] (HPQ)为“[The Machine][5]”开发的操作系统,她在 1999 年到 2005 年这 6 年期间管理该公司。事实上,The Machine 可以运行几种不同的操作系统,也许是基于 Linux 的,也许不是,我们并不太清楚,它的开发始于 **Carly Fiorina** 在惠普公司的任期结束后。不管怎么说,作为 IT 圈里一个成功的管理者,这是她履历里面重要的组成部分,同时这也意味着她很难与惠普彻底断绝关系。
|
||||
|
||||
最后,但并不是不重要,你也猜到了——**Donald Trump**。他显然会动用数百万美元去雇佣一个精英黑客团队去定制属于自己的操作系统——尽管他原本是想要免费获得一个完美的、现成的操作系统——然后还能向别人炫耀自己的财力。他可能会吹嘘自己的操作系统是目前最好的系统,虽然它可能没有兼容 POSIX 或者一些其它的标准,因为那样的话就需要花掉更多的钱。同时这个系统也将根本不会提供任何文档,因为如果 **Donald Trump** 向人们解释他的系统的实际运行方式,他会冒着所有机密被泄露至伊斯兰国家的风险,绝对是这样的。
|
||||
|
||||
另外,如果 **Donald Trump** 非要选择一种已有的 Linux 平台的话, [Ubuntu][7] 应该是明智的选择。就像 **Donald Trump** 一样, Ubuntu 的开发者秉承“我们做自己想要做的”原则,通过他们自己的实现来构建开源软件。自由软件纯化论者却很反感 Ubuntu 这一点,但是很多普通用户却更喜欢一些。当然,无论你是不是一个纯粹论者,无论是在软件领域还是政治领域,还需要时间才能知道分晓。
|
||||
|
||||
### 敬请期待 ###
|
||||
|
||||
如果你想知道为什么我还没有提到民主党候选人,别想多了。我没有在这篇文章中提及他们,是因为我对民主党并不比共和党喜欢更多或更少一点(我个人认为,这种只有两个政党的美国特色是不荒谬的,根本不能体现民主,我也不相信这些党派候选人)。
|
||||
|
||||
另一方面,也可能会有很多人关心民主党候选人使用的 Linux 发行版。后续的帖子中我会提及的,请拭目以待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/081715/which-open-source-linux-distributions-would-presidential-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki), [wxy](https://github.com/wxy/)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://thevarguy.com/open-source-application-software-companies/aligning-linux-distributions-presidential-hopefuls
|
||||
[2]:http://debian.org/
|
||||
[3]:http://www.damnsmalllinux.org/
|
||||
[4]:http://relax-and-recover.org/
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/061614/hps-machine-open-source-os-truly-revolutionary
|
||||
[6]:http://hp.com/
|
||||
[7]:http://ubuntu.com/
|
||||
200
published/20151019 Gaming On Linux--All You Need To Know.md
Normal file
200
published/20151019 Gaming On Linux--All You Need To Know.md
Normal file
@ -0,0 +1,200 @@
|
||||
Linux上的游戏:所有你需要知道的
|
||||
================================================================================
|
||||

|
||||
|
||||
**我能在 Linux 上玩游戏吗 ?**
|
||||
|
||||
这是打算[投奔 Linux 阵营][1]的人最经常问的问题之一。毕竟,在 Linux 上面玩游戏经常被认为有点难以实现。事实上,一些人甚至考虑他们能不能在 Linux 上看电影或者听音乐。考虑到这些,关于 Linux 的平台的游戏的问题是很现实的。
|
||||
|
||||
在本文中,我将解答大多数 Linux 新手关于在 Linux 中打游戏的问题。例如 Linux 下能不能玩游戏,如果能的话,在哪里**下载游戏**或者如何获取有关游戏的信息。
|
||||
|
||||
但是在此之前,我需要说明一下。我不是一个 PC 上的玩家或者说我不认为我是一个在 Linux 桌面游戏玩家。我更喜欢在 PS4 上玩游戏并且我不关心 PC 上的游戏甚至也不关心手机上的游戏(我没有给我的任何一个朋友安利糖果传奇)。这也就是你很少能在 It's FOSS 上很少看见关于 [Linux 上的游戏][2]的原因。
|
||||
|
||||
所以我为什么要提到这个主题?
|
||||
|
||||
因为别人问过我几次有关 Linux 上的游戏的问题并且我想要写出来一个能解答这些问题的 Linux 游戏指南。注意,在这里我不只是讨论在 Ubuntu 上玩游戏。我讨论的是在所有的 Linux 上的游戏。
|
||||
|
||||
### 我能在 Linux 上玩游戏吗 ? ###
|
||||
|
||||
是,但不是完全是。
|
||||
|
||||
“是”,是指你能在Linux上玩游戏;“不完全是”,是指你不能在 Linux 上玩 ‘所有的游戏’。
|
||||
|
||||
感到迷惑了吗?不必这样。我的意思是你能在 Linux 上玩很多流行的游戏,比如[反恐精英以及地铁:最后的曙光][3]等。但是你可能不能玩到所有在 Windows 上流行的最新游戏,比如[实况足球 2015 ][4]。
|
||||
|
||||
在我看来,造成这种情况的原因是 Linux 在桌面系统中仅占不到 2%,这样的占比使得大多数开发者没有开发其游戏的 Linux 版的动力。
|
||||
|
||||
这就意味指大多数近年来被提及的比较多的游戏很有可能不能在 Linux 上玩。不要灰心。还有别的方式在 Linux 上玩这些游戏,我们将在下面的章节中讨论这些方法。但是,在此之前,让我们看看在 Linux 上能玩的游戏的种类。
|
||||
|
||||
要我说的话,我会把那些游戏分为四类:
|
||||
|
||||
1. Linux 原生游戏
|
||||
2. Linux 上的 Windows 游戏
|
||||
3. 浏览器里的游戏
|
||||
4. 终端里的游戏
|
||||
|
||||
让我们以最重要的一类, Linux 的原生游戏开始。
|
||||
|
||||
---------
|
||||
|
||||
### 1. 在哪里去找 Llinux 原生游戏 ?###
|
||||
|
||||
原生游戏指的是官方支持 Linux 的游戏。这些游戏有原生的 Linux 客户端并且能像在 Linux 上的其他软件一样不需要附加的步骤就能安装在 Linux 上面(我们将在下一节讨论)。
|
||||
|
||||
所以,如你所见,有一些为 Linux 开发的游戏,下一个问题就是在哪能找到这些游戏以及如何安装。我将列出一些让你玩到游戏的渠道。
|
||||
|
||||
#### Steam ####
|
||||
|
||||

|
||||
|
||||
“[Steam][5] 是一个游戏的分发平台。就如同 Kindle 是电子书的分发平台, iTunes 是音乐的分发平台一样, Steam 也具有那样的功能。它提供购买和安装游戏,玩多人游戏以及在它的平台上关注其他游戏的选项。其上的游戏被[ DRM ][6]所保护。”
|
||||
|
||||
两年以前,游戏平台 Steam 宣布支持 Linux ,这在当时是一个大新闻。这是 Linux 上玩游戏被严肃对待的一个迹象。尽管这个决定更多地影响了他们自己的基于 Linux 游戏平台以及一个独立 Linux 发行版[ Steam OS][7] ,这仍然是令人欣慰的事情,因为它给 Linux 带来了一大堆游戏。
|
||||
|
||||
我已经写了一篇详细的关于安装以及使用 Steam 的文章。如果你想开始使用 Steam 的话,读读那篇文章。
|
||||
|
||||
- [在 Linux 上安装以及使用 Steam ][8]
|
||||
|
||||
#### GOG.com ####
|
||||
|
||||
[GOG.com][9] 是另一个与 Steam 类似的平台。与 Steam 一样,你能在这上面找到数以百计的 Linux 游戏,并购买和安装它们。如果游戏支持好几个平台,你可以在多个操作系统上安装他们。你可以随时游玩使用你的账户购买的游戏。你也可以在任何时间下载。
|
||||
|
||||
GOG.com 与 Steam 不同的是前者仅提供没有 DRM 保护的游戏以及电影。而且,GOG.com 完全是基于网页的,所以你不需要安装类似 Steam 的客户端。你只需要用浏览器下载游戏然后安装到你的系统上。
|
||||
|
||||
#### Portable Linux Games ####
|
||||
|
||||
[Portable Linux Games][10] 是一个集聚了不少 Linux 游戏的网站。这家网站最特别以及最好的点就是你能离线安装这些游戏。
|
||||
|
||||
你下载到的文件包含所有的依赖(仅需 Wine 以及 Perl)并且他们也是与平台无关的。你所需要的仅仅是下载文件并且双击来启动安装程序。你也可以把文件储存起来以用于将来的安装。如果你网速不够快的话,我很推荐你这样做。
|
||||
|
||||
#### Game Drift 游戏商店 ####
|
||||
|
||||
[Game Drift][11] 是一个只专注于游戏的基于 Ubuntu 的 Linux 发行版。但是如果你不想只为游戏就去安装这个发行版的话,你也可以经常去它的在线游戏商店去看哪个游戏可以在 Linux 上运行并且安装他们。
|
||||
|
||||
#### Linux Game Database ####
|
||||
|
||||
如其名字所示,[Linux Game Database][12]是一个收集了很多 Linux 游戏的网站。你能在这里浏览诸多类型的游戏并从游戏开发者的网站下载/安装这些游戏。作为这家网站的会员,你甚至可以为游戏打分。 LGDB 有点像 Linux 游戏界的 IMDB 或者 IGN.
|
||||
|
||||
#### Penguspy ####
|
||||
|
||||
此网站由一个不想用 Windows 玩游戏的玩家创立。[Penguspy][13] 聚集了一些 Linux 下最好的游戏。在这里你也能分类浏览游戏,如果你喜欢这个游戏的话,你可以跳转到游戏开发者的网站去下载安装。
|
||||
|
||||
#### 软件源 ####
|
||||
|
||||
看看你自己的发行版的软件源。其中可能有一些游戏。如果你用 Ubuntu 的话,它的软件中心里有一个游戏的分类。在一些其他的发行版里也有,比如 Linux Mint 等。
|
||||
|
||||
----------
|
||||
|
||||
### 2. 如何在 Linux 上玩 Windows 的游戏 ?###
|
||||
|
||||

|
||||
|
||||
到现在为止,我们一直在讨论 Linux 的原生游戏。但是并没有很多 Linux 上的原生游戏,或者更准确地说,火的不要不要的游戏大多不支持 Linux,但是都支持 Windows PC 。所以,如何在 Linux 上玩 Windows 的游戏?
|
||||
|
||||
幸好,由于我们有 Wine 、 PlayOnLinux 和 CrossOver 等工具,我们能在 Linux 上玩不少的 Windows 游戏。
|
||||
|
||||
#### Wine ####
|
||||
|
||||
Wine 是一个能使 Windows 应用在类似 Linux , BSD 和 OS X 上运行的兼容层。在 Wine 的帮助下,你可以在 Linux 下安装以及使用很多 Windows 下的应用。
|
||||
|
||||
[在 Ubuntu 上安装 Wine][14]或者在其他 Linux 上安装 Wine 是很简单的,因为大多数发行版的软件源里都有它。这里也有一个很大的[ Wine 支持的应用的数据库][15]供您浏览。
|
||||
|
||||
#### CrossOver ####
|
||||
|
||||
[CrossOver][16] 是 Wine 的增强版,它给 Wine 提供了专业的技术上的支持。但是与 Wine 不同, CrossOver 不是免费的。你需要购买许可。好消息是它会把更新也贡献到 Wine 的开发者那里并且事实上加速了 Wine 的开发使得 Wine 能支持更多的 Windows 上的游戏和应用。如果你可以接受每年支付 48 美元,你可以购买 CrossOver 并得到他们提供的技术支持。
|
||||
|
||||
### PlayOnLinux ###
|
||||
|
||||
PlayOnLinux 也基于 Wine 但是执行程序的方式略有不同。它有着更好用的,不同的界面。与 Wine 一样,PlayOnLinux 也是免费使用。你可以在[开发者自己的数据库里查看它支持的应用以及游戏][17]。
|
||||
|
||||
----------
|
||||
|
||||
### 3. 网页游戏 ###
|
||||
|
||||

|
||||
|
||||
不必说你也应该知道有非常多的基于网页的游戏,这些游戏都可以在任何操作系统里运行,无论是 Windows ,Linux ,还是 OS X 。大多数让人上瘾的手机游戏,比如[帝国之战][18]就有官方的网页版。
|
||||
|
||||
除了这些,还有 [Google Chrome 在线商店][19],你可以在 Linux 上玩更多的这些游戏。这些 Chrome 上的游戏可以像一个单独的应用一样安装并从应用菜单中打开,一些游戏就算是离线也能运行。
|
||||
|
||||
----------
|
||||
|
||||
### 4. 终端游戏 ###
|
||||
|
||||

|
||||
|
||||
使用 Linux 的一个附加优势就是可以使用命令行终端玩游戏。我知道这不是最好的玩游戏的方法,但是在终端里玩[贪吃蛇][20]或者 [2048][21] 很有趣。在[这个博客][21]中有一些好玩的的终端游戏。你可以浏览并安装你喜欢的游戏。
|
||||
|
||||
----------
|
||||
|
||||
### 如何保证游戏的版本是最新的 ?###
|
||||
|
||||
当你了解了不少的在 Linux 上你可以玩到的游戏以及你如何使用他们,下一个问题就是如何保持游戏的版本是最新的。对于这件事,我建议你看看下面的博客,这些博客能告诉你 Linux 游戏世界的最新消息:
|
||||
|
||||
- [Gaming on Linux][23]:我认为我把它叫做 Linux 游戏专业门户并没有错误。在这你可以得到关于 Linux 的游戏的最新的传言以及新闻。它经常更新, 还有由 Linux 游戏爱好者组成的优秀社区。
|
||||
- [Free Gamer][24]:一个专注于免费开源的游戏的博客。
|
||||
- [Linux Game News][25]:一个提供很多的 Linux 游戏的升级的 Tumbler 博客。
|
||||
|
||||
#### 还有别的要说的吗? ####
|
||||
|
||||
我认为让你知道如何开始在 Linux 上的游戏人生是一个好事。如果你仍然不能被说服,我推荐你做个[双系统][26],把 Linux 作为你的主要桌面系统,当你想玩游戏时,重启到 Windows。这是一个对游戏妥协的解决办法。
|
||||
|
||||
现在,这里是你说出你自己的想法的时候了。你在 Linux 上玩游戏吗?你最喜欢什么游戏?你关注了哪些游戏博客?
|
||||
|
||||
|
||||
投票项目:
|
||||
你怎样在 Linux 上玩游戏?
|
||||
|
||||
- 我玩原生 Linux 游戏,也用 Wine 以及 PlayOnLinux 运行 Windows 游戏
|
||||
- 我喜欢网页游戏
|
||||
- 我喜欢终端游戏
|
||||
- 我只玩原生 Linux 游戏
|
||||
- 我用 Steam
|
||||
- 我用双系统,要玩游戏时就换到 Windows
|
||||
- 我不玩游戏
|
||||
|
||||
注:投票代码
|
||||
<div class="PDS_Poll" id="PDI_container9132962" style="display:inline-block;"></div>
|
||||
<div id="PD_superContainer"></div>
|
||||
<script type="text/javascript" charset="UTF-8" src="http://static.polldaddy.com/p/9132962.js"></script>
|
||||
<noscript><a href="http://polldaddy.com/poll/9132962">Take Our Poll</a></noscript>
|
||||
|
||||
注,发布时根据情况看怎么处理
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/linux-gaming-guide/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[2]:http://itsfoss.com/category/games/
|
||||
[3]:http://blog.counter-strike.net/
|
||||
[4]:https://pes.konami.com/tag/pes-2015/
|
||||
[5]:http://store.steampowered.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Digital_rights_management
|
||||
[7]:http://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[8]:http://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[9]:http://www.gog.com/
|
||||
[10]:http://www.portablelinuxgames.org/
|
||||
[11]:http://gamedrift.org/GameStore.html
|
||||
[12]:http://www.lgdb.org/
|
||||
[13]:http://www.penguspy.com/
|
||||
[14]:http://itsfoss.com/wine-1-5-11-released-ppa-available-to-download/
|
||||
[15]:https://appdb.winehq.org/
|
||||
[16]:https://www.codeweavers.com/products/
|
||||
[17]:https://www.playonlinux.com/en/supported_apps.html
|
||||
[18]:http://empire.goodgamestudios.com/
|
||||
[19]:https://chrome.google.com/webstore/category/apps
|
||||
[20]:http://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[21]:http://itsfoss.com/play-2048-linux-terminal/
|
||||
[22]:https://ttygames.wordpress.com/
|
||||
[23]:https://www.gamingonlinux.com/
|
||||
[24]:http://freegamer.blogspot.fr/
|
||||
[25]:http://linuxgamenews.com/
|
||||
[26]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
@ -4,10 +4,9 @@ Linux 内核里的数据结构——双向链表
|
||||
双向链表
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Linux 内核中自己实现了双向链表,可以在 [include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h) 找到定义。我们将会首先从双向链表数据结构开始介绍**内核里的数据结构**。为什么?因为它在内核里使用的很广泛,你只需要在 [free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
|
||||
Linux 内核自己实现了双向链表,可以在[include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h)找到定义。我们将会从双向链表数据结构开始`内核的数据结构`。为什么?因为它在内核里使用的很广泛,你只需要在[free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
|
||||
首先让我们看一下在[include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
|
||||
首先让我们看一下在 [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
|
||||
|
||||
```C
|
||||
struct list_head {
|
||||
@ -15,7 +14,7 @@ struct list_head {
|
||||
};
|
||||
```
|
||||
|
||||
你可能注意到这和你以前见过的双向链表的实现方法是不同的。举个例子来说,在[glib](http://www.gnu.org/software/libc/) 库里是这样实现的:
|
||||
你可能注意到这和你以前见过的双向链表的实现方法是不同的。举个例子来说,在 [glib](http://www.gnu.org/software/libc/) 库里是这样实现的:
|
||||
|
||||
```C
|
||||
struct GList {
|
||||
@ -25,7 +24,7 @@ struct GList {
|
||||
};
|
||||
```
|
||||
|
||||
通常来说一个链表会包含一个指向某个项目的指针。但是内核的实现并没有这样做。所以问题来了:`链表在哪里保存数据呢?`。实际上内核里实现的链表实际上是`侵入式链表`。侵入式链表并不在节点内保存数据-节点仅仅包含指向前后节点的指针,然后把数据是附加到链表的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
通常来说一个链表结构会包含一个指向某个项目的指针。但是 Linux 内核中的链表实现并没有这样做。所以问题来了:**链表在哪里保存数据呢?**。实际上,内核里实现的链表是**侵入式链表(Intrusive list)**。侵入式链表并不在节点内保存数据-它的节点仅仅包含指向前后节点的指针,以及指向链表节点数据部分的指针——数据就是这样附加在链表上的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
|
||||
比如:
|
||||
|
||||
@ -36,7 +35,7 @@ struct nmi_desc {
|
||||
};
|
||||
```
|
||||
|
||||
让我们看几个例子来理解一下在内核里是如何使用`list_head` 的。如上所述,在内核里有实在很多不同的地方用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动API 被用来编写处理小型硬件和虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
让我们看几个例子来理解一下在内核里是如何使用 `list_head` 的。如上所述,在内核里有很多很多不同的地方都用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动 API 被用来编写处理小型硬件或虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
@ -68,7 +67,7 @@ crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
|
||||
crw------- 1 root root 10, 137 Mar 21 12:01 vhci
|
||||
```
|
||||
|
||||
现在让我们看看它是如何使用链表的。首先看一下结构体`miscdevice`:
|
||||
现在让我们看看它是如何使用链表的。首先看一下结构体 `miscdevice`:
|
||||
|
||||
```C
|
||||
struct miscdevice
|
||||
@ -84,7 +83,7 @@ struct miscdevice
|
||||
};
|
||||
```
|
||||
|
||||
可以看到结构体的第四个变量`list` 是所有注册过的设备的链表。在源代码文件的开始可以看到这个链表的定义:
|
||||
可以看到结构体`miscdevice`的第四个变量`list` 是所有注册过的设备的链表。在源代码文件的开始可以看到这个链表的定义:
|
||||
|
||||
```C
|
||||
static LIST_HEAD(misc_list);
|
||||
@ -97,13 +96,13 @@ static LIST_HEAD(misc_list);
|
||||
struct list_head name = LIST_HEAD_INIT(name)
|
||||
```
|
||||
|
||||
然后使用宏`LIST_HEAD_INIT` 进行初始化,这会使用变量`name` 的地址来填充`prev`和`next` 结构体的两个变量。
|
||||
然后使用宏 `LIST_HEAD_INIT` 进行初始化,这会使用变量`name` 的地址来填充`prev`和`next` 结构体的两个变量。
|
||||
|
||||
```C
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在开始就用 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在一开始就用函数 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
@ -119,13 +118,13 @@ static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
}
|
||||
```
|
||||
|
||||
在函数`device_create` 创建了设备后我们就用下面的语句将设备添加到设备链表:
|
||||
接下来,在函数`device_create` 创建了设备后,我们就用下面的语句将设备添加到设备链表:
|
||||
|
||||
```
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
内核文件`list.h` 提供了项链表添加新项的API 接口。我们来看看它的实现:
|
||||
内核文件`list.h` 提供了向链表添加新项的 API 接口。我们来看看它的实现:
|
||||
|
||||
|
||||
```C
|
||||
@ -138,8 +137,8 @@ static inline void list_add(struct list_head *new, struct list_head *head)
|
||||
实际上就是使用3个指定的参数来调用了内部函数`__list_add`:
|
||||
|
||||
* new - 新项。
|
||||
* head - 新项将会被添加到`head`之前.
|
||||
* head->next - `head` 之后的项。
|
||||
* head - 新项将会插在`head`的后面
|
||||
* head->next - 插入前,`head` 后面的项。
|
||||
|
||||
`__list_add`的实现非常简单:
|
||||
|
||||
@ -155,9 +154,9 @@ static inline void __list_add(struct list_head *new,
|
||||
}
|
||||
```
|
||||
|
||||
我们会在`prev`和`next` 之间添加一个新项。所以我们用宏`LIST_HEAD_INIT`定义的`misc` 链表会包含指向`miscdevice->list` 的向前指针和向后指针。
|
||||
这里,我们在`prev`和`next` 之间添加了一个新项。所以我们开始时用宏`LIST_HEAD_INIT`定义的`misc` 链表会包含指向`miscdevice->list` 的向前指针和向后指针。
|
||||
|
||||
这里有一个问题:如何得到列表的内容呢?这里有一个特殊的宏:
|
||||
这儿还有一个问题:如何得到列表的内容呢?这里有一个特殊的宏:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
@ -166,7 +165,7 @@ static inline void __list_add(struct list_head *new,
|
||||
|
||||
使用了三个参数:
|
||||
|
||||
* ptr - 指向链表头的指针;
|
||||
* ptr - 指向结构 `list_head` 的指针;
|
||||
* type - 结构体类型;
|
||||
* member - 在结构体内类型为`list_head` 的变量的名字;
|
||||
|
||||
@ -205,9 +204,9 @@ int main() {
|
||||
}
|
||||
```
|
||||
|
||||
最终会打印`2`
|
||||
最终会打印出`2`
|
||||
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是`container_of`中的0.实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是表达式`((type *)0)`中的0。实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
@ -226,33 +225,35 @@ int main() {
|
||||
|
||||
结果显示`0x5`。
|
||||
|
||||
下一个宏`offsetof` 会计算从结构体的某个变量的相对于结构体起始地址的偏移。它的实现和上面类似:
|
||||
下一个宏`offsetof`会计算从结构体起始地址到某个给定结构字段的偏移。它的实现和上面类似:
|
||||
|
||||
```C
|
||||
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
|
||||
```
|
||||
|
||||
现在我们来总结一下宏`container_of`。只需要知道结构体里面类型为`list_head` 的变量的名字和结构体容器的类型,它可以通过结构体的变量`list_head`获得结构体的起始地址。在宏定义的第一行,声明了一个指向结构体成员变量`ptr`的指针`__mptr`,并且把`ptr` 的地址赋给它。现在`ptr` 和`__mptr` 指向了同一个地址。从技术上讲我们并不需要这一行,但是它可以方便的进行类型检查。第一行保证了特定的结构体(参数`type`)包含成员变量`member`。第二行代码会用宏`offsetof`计算成员变量相对于结构体起始地址的偏移,然后从结构体的地址减去这个偏移,最后就得到了结构体。
|
||||
现在我们来总结一下宏`container_of`。只需给定结构体中`list_head`类型 字段的地址、名字和结构体容器的类型,它就可以返回结构体的起始地址。在宏定义的第一行,声明了一个指向结构体成员变量`ptr`的指针`__mptr`,并且把`ptr` 的地址赋给它。现在`ptr` 和`__mptr` 指向了同一个地址。从技术上讲我们并不需要这一行,但是它可以方便地进行类型检查。第一行保证了特定的结构体(参数`type`)包含成员变量`member`。第二行代码会用宏`offsetof`计算成员变量相对于结构体起始地址的偏移,然后从结构体的地址减去这个偏移,最后就得到了结构体。
|
||||
|
||||
当然了`list_add` 和 `list_entry`不是`<linux/list.h>`提供的唯一功能。双向链表的实现还提供了如下API:
|
||||
|
||||
* list_add
|
||||
* list_add_tail
|
||||
* list_del
|
||||
* list_replace
|
||||
* list_move
|
||||
* list_is_last
|
||||
* list_empty
|
||||
* list_cut_position
|
||||
* list_splice
|
||||
* list_for_each
|
||||
* list_for_each_entry
|
||||
* list\_add
|
||||
* list\_add\_tail
|
||||
* list\_del
|
||||
* list\_replace
|
||||
* list\_move
|
||||
* list\_is\_last
|
||||
* list\_empty
|
||||
* list\_cut\_position
|
||||
* list\_splice
|
||||
* list\_for\_each
|
||||
* list\_for\_each\_entry
|
||||
|
||||
等等很多其它API。
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
----
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/DataStructures/dlist.md
|
||||
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
198
published/20151123 Data Structures in the Linux Kernel.md
Normal file
198
published/20151123 Data Structures in the Linux Kernel.md
Normal file
@ -0,0 +1,198 @@
|
||||
Linux 内核里的数据结构 —— 基数树
|
||||
================================================================================
|
||||
|
||||
基数树 Radix tree
|
||||
--------------------------------------------------------------------------------
|
||||
正如你所知道的,Linux内核提供了许多不同的库和函数,它们实现了不同的数据结构和算法。在这部分,我们将研究其中一种数据结构——[基数树 Radix tree](http://en.wikipedia.org/wiki/Radix_tree)。在 Linux 内核中,有两个文件与基数树的实现和API相关:
|
||||
|
||||
* [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)
|
||||
* [lib/radix-tree.c](https://github.com/torvalds/linux/blob/master/lib/radix-tree.c)
|
||||
|
||||
让我们先说说什么是 `基数树` 吧。基数树是一种 `压缩的字典树 (compressed trie)` ,而[字典树](http://en.wikipedia.org/wiki/Trie)是实现了关联数组接口并允许以 `键值对` 方式存储值的一种数据结构。这里的键通常是字符串,但可以使用任意数据类型。字典树因为它的节点而与 `n叉树` 不同。字典树的节点不存储键,而是存储单个字符的标签。与一个给定节点关联的键可以通过从根遍历到该节点获得。举个例子:
|
||||
|
||||
```
|
||||
+-----------+
|
||||
| |
|
||||
| " " |
|
||||
| |
|
||||
+------+-----------+------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| g | | c |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| o | | a |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
|
|
||||
|
|
||||
+-----v-----+
|
||||
| |
|
||||
| t |
|
||||
| |
|
||||
+-----------+
|
||||
```
|
||||
|
||||
因此在这个例子中,我们可以看到一个有着两个键 `go` 和 `cat` 的 `字典树` 。压缩的字典树也叫做 `基数树` ,它和 `字典树` 的不同之处在于,所有只有一个子节点的中间节点都被删除。
|
||||
|
||||
Linux 内核中的基数树是把值映射到整形键的一种数据结构。[include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)文件中的以下结构体描述了基数树:
|
||||
|
||||
```C
|
||||
struct radix_tree_root {
|
||||
unsigned int height;
|
||||
gfp_t gfp_mask;
|
||||
struct radix_tree_node __rcu *rnode;
|
||||
};
|
||||
```
|
||||
|
||||
这个结构体描述了一个基数树的根,它包含了3个域成员:
|
||||
|
||||
* `height` - 树的高度;
|
||||
* `gfp_mask` - 告知如何执行动态内存分配;
|
||||
* `rnode` - 孩子节点指针.
|
||||
|
||||
我们第一个要讨论的字段是 `gfp_mask` :
|
||||
|
||||
底层内核的内存动态分配函数以一组标志作为 `gfp_mask` ,用于描述如何执行动态内存分配。这些控制分配进程的 `GFP_` 标志拥有以下值:( `GF_NOIO` 标志)意味着睡眠以及等待内存,( `__GFP_HIGHMEM` 标志)意味着高端内存能够被使用,( `GFP_ATOMIC` 标志)意味着分配进程拥有高优先级并不能睡眠等等。
|
||||
|
||||
* `GFP_NOIO` - 睡眠等待内存
|
||||
* `__GFP_HIGHMEM` - 高端内存能够被使用;
|
||||
* `GFP_ATOMIC` - 分配进程拥有高优先级并且不能睡眠;
|
||||
|
||||
等等。
|
||||
|
||||
下一个字段是`rnode`:
|
||||
|
||||
```C
|
||||
struct radix_tree_node {
|
||||
unsigned int path;
|
||||
unsigned int count;
|
||||
union {
|
||||
struct {
|
||||
struct radix_tree_node *parent;
|
||||
void *private_data;
|
||||
};
|
||||
struct rcu_head rcu_head;
|
||||
};
|
||||
/* For tree user */
|
||||
struct list_head private_list;
|
||||
void __rcu *slots[RADIX_TREE_MAP_SIZE];
|
||||
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
|
||||
};
|
||||
```
|
||||
这个结构体包含的信息有父节点中的偏移以及到底端(叶节点)的高度、子节点的个数以及用于访问和释放节点的字段成员。这些字段成员描述如下:
|
||||
|
||||
* `path` - 父节点中的偏移和到底端(叶节点)的高度
|
||||
* `count` - 子节点的个数;
|
||||
* `parent` - 父节点指针;
|
||||
* `private_data` - 由树的用户使用;
|
||||
* `rcu_head` - 用于释放节点;
|
||||
* `private_list` - 由树的用户使用;
|
||||
|
||||
`radix_tree_node` 的最后两个成员—— `tags` 和 `slots` 非常重要且令人关注。Linux 内核基数树的每个节点都包含了一组指针槽( slots ),槽里存储着指向数据的指针。在Linux内核基数树的实现中,空槽存储的是 `NULL` 。Linux内核中的基数树也支持标签( tags ),它与 `radix_tree_node` 结构体的 `tags` 字段相关联。有了标签,我们就可以对基数树中存储的记录以单个比特位( bit )进行设置。
|
||||
|
||||
既然我们了解了基数树的结构,那么该是时候看一下它的API了。
|
||||
|
||||
Linux内核基数树API
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
我们从结构体的初始化开始。有两种方法初始化一个新的基数树。第一种是使用 `RADIX_TREE` 宏:
|
||||
|
||||
```C
|
||||
RADIX_TREE(name, gfp_mask);
|
||||
````
|
||||
|
||||
正如你所看到的,我们传递了 `name` 参数,所以通过 `RADIX_TREE` 宏,我们能够定义和初始化基数树为给定的名字。`RADIX_TREE` 的实现很简单:
|
||||
|
||||
```C
|
||||
#define RADIX_TREE(name, mask) \
|
||||
struct radix_tree_root name = RADIX_TREE_INIT(mask)
|
||||
|
||||
#define RADIX_TREE_INIT(mask) { \
|
||||
.height = 0, \
|
||||
.gfp_mask = (mask), \
|
||||
.rnode = NULL, \
|
||||
}
|
||||
```
|
||||
|
||||
在 `RADIX_TREE` 宏的开始,我们使用给定的名字定义 `radix_tree_root` 结构体实例,并使用给定的 mask 调用 `RADIX_TREE_INIT` 宏。 而 `RADIX_TREE_INIT` 宏则是使用默认值和给定的mask对 `radix_tree_root` 结构体进行了初始化。
|
||||
|
||||
第二种方法是手动定义`radix_tree_root`结构体,并且将它和mask传给 `INIT_RADIX_TREE` 宏:
|
||||
|
||||
```C
|
||||
struct radix_tree_root my_radix_tree;
|
||||
INIT_RADIX_TREE(my_tree, gfp_mask_for_my_radix_tree);
|
||||
```
|
||||
|
||||
`INIT_RADIX_TREE` 宏的定义如下:
|
||||
|
||||
```C
|
||||
#define INIT_RADIX_TREE(root, mask) \
|
||||
do { \
|
||||
(root)->height = 0; \
|
||||
(root)->gfp_mask = (mask); \
|
||||
(root)->rnode = NULL; \
|
||||
} while (0)
|
||||
```
|
||||
|
||||
和`RADIX_TREE_INIT`宏所做的初始化工作一样,`INIT_RADIX_TREE` 宏使用默认值和给定的 mask 完成初始化工作。
|
||||
|
||||
接下来是用于向基数树插入和删除数据的两个函数:
|
||||
|
||||
* `radix_tree_insert`;
|
||||
* `radix_tree_delete`;
|
||||
|
||||
第一个函数 `radix_tree_insert` 需要3个参数:
|
||||
|
||||
* 基数树的根;
|
||||
* 索引键;
|
||||
* 插入的数据;
|
||||
|
||||
`radix_tree_delete` 函数需要和 `radix_tree_insert` 一样的一组参数,但是不需要传入要删除的数据。
|
||||
|
||||
基数树的搜索以两种方法实现:
|
||||
|
||||
* `radix_tree_lookup`;
|
||||
* `radix_tree_gang_lookup`;
|
||||
* `radix_tree_lookup_slot`.
|
||||
|
||||
第一个函数`radix_tree_lookup`需要两个参数:
|
||||
|
||||
* 基数树的根;
|
||||
* 索引键;
|
||||
|
||||
这个函数尝试在树中查找给定的键,并返回和该键相关联的记录。第二个函数 `radix_tree_gang_lookup` 有以下的函数签名:
|
||||
|
||||
```C
|
||||
unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
|
||||
void **results,
|
||||
unsigned long first_index,
|
||||
unsigned int max_items);
|
||||
```
|
||||
|
||||
它返回的是记录的个数。 `results` 中的结果,按键排序,并从第一个索引开始。返回的记录个数将不会超过 `max_items` 的值。
|
||||
|
||||
最后一个函数`radix_tree_lookup_slot`将会返回包含数据的指针槽。
|
||||
|
||||
链接
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
* [Radix tree](http://en.wikipedia.org/wiki/Radix_tree)
|
||||
* [Trie](http://en.wikipedia.org/wiki/Trie)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/DataStructures/radix-tree.md
|
||||
|
||||
作者:0xAX
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,302 @@
|
||||
点评五款用于 Linux 编程的内存调试器
|
||||
================================================================================
|
||||

|
||||
>Credit: [Moini][1]
|
||||
|
||||
作为一个程序员,我知道我肯定会犯错误——怎么可能不犯错!程序员也是人啊。有的错误能在编码过程中及时发现,而有些却得等到软件测试了才能显露出来。然而,还有一类错误并不能在这两个阶段被解决,这就导致软件不能正常运行,甚至是提前终止。
|
||||
|
||||
如果你还没猜出是那种错误,我说的就是和内存相关的错误。手动调试这些错误不仅耗时,而且很难发现并纠正。值得一提的是,这种错误很常见,特别是在用 C/C++ 这类允许[手动管理内存][2]的语言编写的软件里。
|
||||
|
||||
幸运的是,现行有一些编程工具能够帮你在软件程序中找到这些和内存相关的错误。在这些工具集中,我评估了五款支持 Linux 的、流行的、自由开源的内存调试器: Dmalloc 、 Electric Fence 、 Memcheck 、 Memwatch 以及 Mtrace 。在日常编码中,我已经用过这五个调试器了,所以这些评估是建立在我的实际体验之上的。
|
||||
|
||||
### [Dmalloc][3] ###
|
||||
|
||||
**开发者**:Gray Watson
|
||||
|
||||
**评估版本**:5.5.2
|
||||
|
||||
**支持的 Linux 版本**:所有种类
|
||||
|
||||
**许可**: CC 3.0
|
||||
|
||||
Dmalloc 是 Gray Watson 开发的一款内存调试工具。它是作为库来实现的,封装了标准内存管理函数如`malloc() , calloc() , free()`等,使程序员得以检测出有问题的代码。
|
||||
|
||||

|
||||
|
||||
*Dmalloc*
|
||||
|
||||
如同工具的网页所示,这个调试器提供的特性包括内存泄漏跟踪、[重复释放内存(double free)][4]错误跟踪、以及[越界写入(fence-post write)][5]检测。其它特性包括报告错误的文件/行号、通用的数据统计记录。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
5.5.2 版本是一个 [bug 修正发行版][6],修复了几个有关构建和安装的问题。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Dmalloc 最大的优点就是高度可配置性。比如说,你可以配置它以支持 C++ 程序和多线程应用。 Dmalloc 还提供一个有用的功能:运行时可配置,这表示在 Dmalloc 执行时,可以轻易地启用或者禁用它提供的一些特性。
|
||||
|
||||
你还可以配合 [GNU Project Debugger (GDB)][7]来使用 Dmalloc ,只需要将`dmalloc.gdb`文件(位于 Dmalloc 源码包中的 contrib 子目录里)的内容添加到你的主目录中的`.gdbinit`文件里即可。
|
||||
|
||||
另外一个让我对 Dmalloc 爱不释手的优点是它有大量的资料文献。前往官网的 [Documentation 栏目][8],可以获取所有关于如何下载、安装、运行、怎样使用库,和 Dmalloc 所提供特性的细节描述,及其生成的输出文件的解释。其中还有一个章节介绍了一般问题的解决方法。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟 Mtrace 一样, Dmalloc 需要程序员改动他们的源代码。比如说你可以(也是必须的)添加头文件`dmalloc.h`,工具就能汇报产生问题的调用的文件或行号。这个功能非常有用,因为它节省了调试的时间。
|
||||
|
||||
除此之外,还需要在编译你的程序时,把 Dmalloc 库(编译 Dmalloc 源码包时产生的)链接进去。
|
||||
|
||||
然而,还有点更麻烦的事,需要设置一个环境变量,命名为`DMALLOC_OPTION`,以供工具在运行时配置内存调试特性,比如定义输出文件的路径。可以手动为该环境变量分配一个值,不过初学者可能会觉得这个过程有点困难,因为该值的一部分用来表示要启用的 Dmalloc 特性——以十六进制值的累加值表示。[这里][9]有详细介绍。
|
||||
|
||||
一个比较简单方法设置这个环境变量是使用 [Dmalloc 实用指令][10],这是专为这个目的设计的方法。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
Dmalloc 真正的优势在于它的可配置选项。而且高度可移植,曾经成功移植到多种操作系统如 AIX 、 BSD/OS 、 DG/UX 、 Free/Net/OpenBSD 、 GNU/Hurd 、 HPUX 、 Irix 、 Linux 、 MS-DOG 、 NeXT 、 OSF 、 SCO 、 Solaris 、 SunOS 、 Ultrix 、 Unixware 甚至 Unicos(运行在 Cray T3E 主机上)。虽然使用 Dmalloc 需要学习许多知识,但是它所提供的特性值得为之付出。
|
||||
|
||||
### [Electric Fence][15] ###
|
||||
|
||||
**开发者**:Bruce Perens
|
||||
|
||||
**评估版本**:2.2.3
|
||||
|
||||
**支持的 Linux 版本**:所有种类
|
||||
|
||||
**许可**:GPL v2
|
||||
|
||||
Electric Fence 是 Bruce Perens 开发的一款内存调试工具,它以库的形式实现,你的程序需要链接它。Electric Fence 能检测出[堆][11]内存溢出和访问已经释放的内存。
|
||||
|
||||
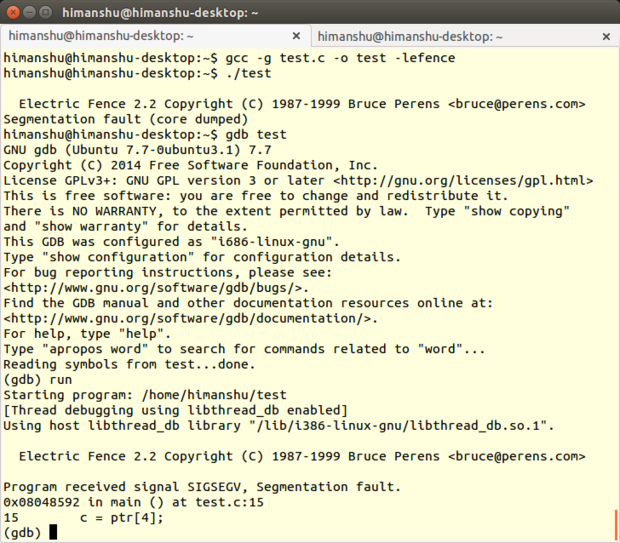
|
||||
|
||||
*Electric Fence*
|
||||
|
||||
顾名思义, Electric Fence 在每个所申请的缓存边界建立了虚拟围栏,这样一来任何非法的内存访问都会导致[段错误][12]。这个调试工具同时支持 C 和 C++ 程序。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
2.2.3 版本修复了工具的构建系统,使得 `-fno-builtin-malloc` 选项能真正传给 [GNU Compiler Collection (GCC)][13]。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
我喜欢 Electric Fence 的首要一点是它不同于 Memwatch 、 Dmalloc 和 Mtrace ,不需要对你的源码做任何的改动,你只需要在编译的时候把它的库链接进你的程序即可。
|
||||
|
||||
其次, Electric Fence 的实现保证了产生越界访问的第一个指令就会引起段错误。这比在后面再发现问题要好多了。
|
||||
|
||||
不管是否有检测出错误, Electric Fence 都会在输出产生版权信息。这一点非常有用,由此可以确定你所运行的程序已经启用了 Electric Fence 。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
另一方面,我对 Electric Fence 真正念念不忘的是它检测内存泄漏的能力。内存泄漏是 C/C++ 软件最常见也是最不容易发现的问题之一。不过, Electric Fence 不能检测出栈溢出,而且也不是线程安全的。
|
||||
|
||||
由于 Electric Fence 会在用户分配内存区的前后分配禁止访问的虚拟内存页,如果你过多的进行动态内存分配,将会导致你的程序消耗大量的额外内存。
|
||||
|
||||
Electric Fence 还有一个局限是不能明确指出错误代码所在的行号。它所能做只是在检测到内存相关错误时产生段错误。想要定位错误的行号,需要借助 [GDB][14]这样的调试工具来调试启用了 Electric Fence 的程序。
|
||||
|
||||
最后一点,尽管 Electric Fence 能检测出大部分的缓冲区溢出,有一个例外是,如果所申请的缓冲区大小不是系统字长的倍数,这时候溢出(即使只有几个字节)就不能被检测出来。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
尽管局限性较大, Electric Fence 的易用性仍然是加分项。只要链接一次程序, Electric Fence 就可以在监测出内存相关问题的时候报警。不过,如同前面所说, Electric Fence 需要配合像 GDB 这样的源码调试器使用。
|
||||
|
||||
### [Memcheck][16] ###
|
||||
|
||||
**开发者**:[Valgrind 开发团队][17]
|
||||
|
||||
**评估版本**:3.10.1
|
||||
|
||||
**支持的 Linux 发行版**:所有种类
|
||||
|
||||
**许可**:GPL
|
||||
|
||||
[Valgrind][18] 是一个提供好几款调试和分析 Linux 程序性能的工具的套件。虽然 Valgrind 能和不同语言——Java 、 Perl 、 Python 、 Assembly code 、 ortran 、 Ada 等——编写的程序一起工作,但是它主要还是针对使用 C/C++ 所编写的程序。
|
||||
|
||||
Memcheck ,一款内存错误检测器,是其中最受欢迎的工具。它能够检测出如内存泄漏、无效的内存访问、未定义变量的使用以及堆内存分配和释放相关的问题等诸多问题。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
[工具套件( 3.10.1 )][19]主要修复了 3.10.0 版本发现的 bug 。除此之外,“从主干开发版本向后移植的一些补丁,修复了缺失的 AArch64 ARMv8 指令和系统调用”。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
同其它所有 Valgrind 工具一样, Memcheck 也是命令行程序。它的操作非常简单:通常我们会使用诸如 `prog arg1 arg2` 格式的命令来运行程序,而 Memcheck 只要求你多加几个值即可,如 `valgrind --leak-check=full prog arg1 arg2` 。
|
||||
|
||||
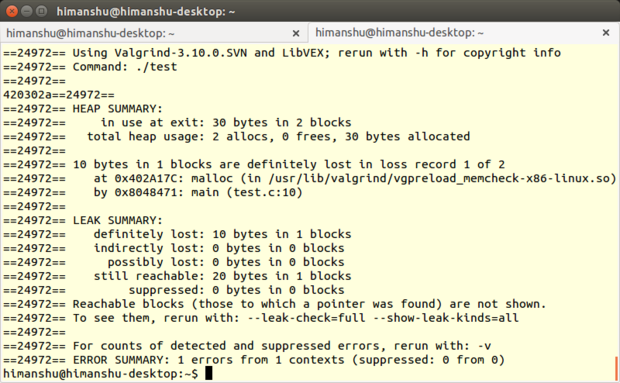
|
||||
|
||||
*Memcheck*
|
||||
|
||||
(注意:因为 Memcheck 是 Valgrind 的默认工具,所以在命令行执行命令时无需提及 Memcheck。但是,需要在编译程序之初带上 `-g` 参数选项,这一步会添加调试信息,使得 Memcheck 的错误信息会包含正确的行号。)
|
||||
|
||||
我真正倾心于 Memcheck 的是它提供了很多命令行选项(如上所述的`--leak-check`选项),如此不仅能控制工具运转还可以控制它的输出。
|
||||
|
||||
举个例子,可以开启`--track-origins`选项,以查看程序源码中未初始化的数据;可以开启`--show-mismatched-frees`选项让 Memcheck 匹配内存的分配和释放技术。对于 C 语言所写的代码, Memcheck 会确保只能使用`free()`函数来释放内存,`malloc()`函数来申请内存。而对 C++ 所写的源码, Memcheck 会检查是否使用了`delete`或`delete[]`操作符来释放内存,以及`new`或者`new[]`来申请内存。
|
||||
|
||||
Memcheck 最好的特点,尤其是对于初学者来说,是它会给用户建议使用哪个命令行选项能让输出更加有意义。比如说,如果你不使用基本的`--leak-check`选项, Memcheck 会在输出时给出建议:“使用 --leak-check=full 重新运行以查看更多泄漏内存细节”。如果程序有未初始化的变量, Memcheck 会产生信息:“使用 --track-origins=yes 以查看未初始化变量的定位”。
|
||||
|
||||
Memcheck 另外一个有用的特性是它可以[创建抑制文件( suppression files )][20],由此可以略过特定的不能修正的错误,这样 Memcheck 运行时就不会每次都报警了。值得一提的是, Memcheck 会去读取默认抑制文件来忽略系统库(比如 C 库)中的报错,这些错误在系统创建之前就已经存在了。可以选择创建一个新的抑制文件,或是编辑现有的文件(通常是`/usr/lib/valgrind/default.supp`)。
|
||||
|
||||
Memcheck 还有高级功能,比如可以使用[定制内存分配器][22]来[检测内存错误][21]。除此之外, Memcheck 提供[监控命令][23],当用到 Valgrind 内置的 gdbserver ,以及[客户端请求][24]机制(不仅能把程序的行为告知 Memcheck ,还可以进行查询)时可以使用。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
毫无疑问, Memcheck 可以节省很多调试时间以及省去很多麻烦。但是它使用了很多内存,导致程序执行变慢([由文档可知][25],大概会花费 20 至 30 倍时间)。
|
||||
|
||||
除此之外, Memcheck 还有其它局限。根据用户评论, Memcheck 很明显不是[线程安全][26]的;它不能检测出 [静态缓冲区溢出][27];还有就是,一些 Linux 程序如 [GNU Emacs][28] 目前还不能配合 Memcheck 工作。
|
||||
|
||||
如果有兴趣,可以在[这里][29]查看 Valgrind 局限性的详细说明。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
无论是对于初学者还是那些需要高级特性的人来说, Memcheck 都是一款便捷的内存调试工具。如果你仅需要基本调试和错误检查, Memcheck 会非常容易上手。而当你想要使用像抑制文件或者监控指令这样的特性,就需要花一些功夫学习了。
|
||||
|
||||
虽然罗列了大量的局限性,但是 Valgrind(包括 Memcheck )在它的网站上声称全球有[成千上万程序员][30]使用了此工具。开发团队称收到来自超过 30 个国家的用户反馈,而这些用户的工程代码有的高达两千五百万行。
|
||||
|
||||
### [Memwatch][31] ###
|
||||
|
||||
**开发者**:Johan Lindh
|
||||
|
||||
**评估版本**:2.71
|
||||
|
||||
**支持的 Linux 发行版**:所有种类
|
||||
|
||||
**许可**:GNU GPL
|
||||
|
||||
Memwatch 是由 Johan Lindh 开发的内存调试工具,虽然它扮演的主要角色是内存泄漏检测器,但是(根据网页介绍)它也具有检测其它如[内存重复释放和错误释放][32]、缓冲区溢出和下溢、[野指针][33]写入等等内存相关问题的能力。
|
||||
|
||||
Memwatch 支持用 C 语言所编写的程序。也可以在 C++ 程序中使用它,但是这种做法并不提倡(由 Memwatch 源码包随附的 Q&A 文件中可知)。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
这个版本添加了`ULONG_LONG_MAX`以区分 32 位和 64 位程序。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
跟 Dmalloc 一样, Memwatch 也有优秀的文档资料。参考 USING 文件,可以学习如何使用 Memwatch ,可以了解 Memwatch 是如何初始化、如何清理以及如何进行 I/O 操作,等等。还有一个 FAQ 文件,旨在帮助用户解决使用过程遇到的一般问题。最后还有一个`test.c`文件提供工作案例参考。
|
||||
|
||||
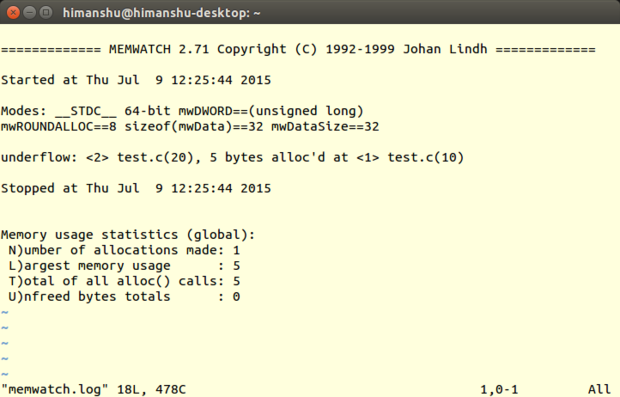
|
||||
|
||||
*Memwatch*
|
||||
|
||||
不同于 Mtrace , Memwatch 产生的日志文件(通常是`memwatch.log`)是人类可阅读的格式。而且, Memwatch 每次运行时总会把内存调试结果拼接到输出该文件的末尾。如此便可在需要之时轻松查看之前的输出信息。
|
||||
|
||||
同样值得一提的是当你执行了启用 Memwatch 的程序, Memwatch 会在[标准输出][34]中产生一个单行输出,告知发现了错误,然后你可以在日志文件中查看输出细节。如果没有产生错误信息,就可以确保日志文件不会写入任何错误,多次运行的话确实能节省时间。
|
||||
|
||||
另一个我喜欢的优点是 Memwatch 还提供了在源码中获取其输出信息的方式,你可以获取信息,然后任由你进行处理(参考 Memwatch 源码中的`mwSetOutFunc()`函数获取更多有关的信息)。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
跟 Mtrace 和 Dmalloc 一样, Memwatch 也需要你往你的源文件里增加代码:你需要把`memwatch.h`这个头文件包含进你的代码。而且,编译程序的时候,你需要连同`memwatch.c`一块编译;或者你可以把已经编译好的目标模块包含起来,然后在命令行定义`MEMWATCH`和`MW_STDIO`变量。不用说,想要在输出中定位行号, -g 编译器选项也少不了。
|
||||
|
||||
此外, Memwatch 缺少一些特性。比如 Memwatch 不能检测出对一块已经被释放的内存进行写入操作,或是在分配的内存块之外的进行读取操作。而且, Memwatch 也不是线程安全的。还有一点,正如我在开始时指出,在 C++ 程序上运行 Memwatch 的结果是不能预料的。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
Memcheck 可以检测很多内存相关的问题,在处理 C 程序时是非常便捷的调试工具。因为源码小巧,所以可以从中了解 Memcheck 如何运转,有需要的话可以调试它,甚至可以根据自身需求扩展升级它的功能。
|
||||
|
||||
### [Mtrace][35] ###
|
||||
|
||||
**开发者**: Roland McGrath 和 Ulrich Drepper
|
||||
|
||||
**评估版本**: 2.21
|
||||
|
||||
**支持的 Linux 发行版**:所有种类
|
||||
|
||||
**许可**:GNU GPL
|
||||
|
||||
Mtrace 是 [GNU C 库][36]中的一款内存调试工具,同时支持 Linux 上的 C 和 C++ 程序,可以检测由函数`malloc()`和`free()`不匹配的调用所引起的内存泄漏问题。
|
||||
|
||||
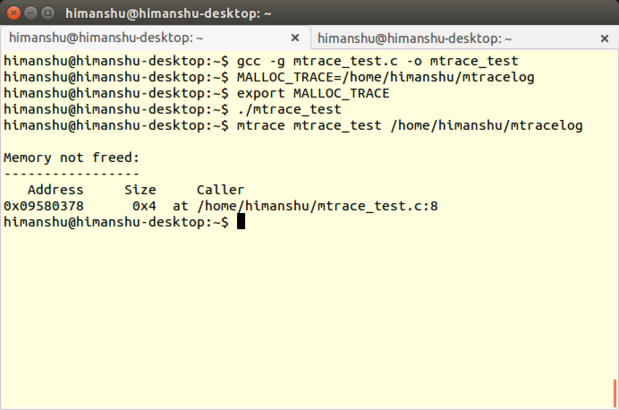
|
||||
|
||||
*Mtrace*
|
||||
|
||||
Mtrace 实际上是实现了一个名为`mtrace()`的函数,它可以跟踪程序中所有 malloc/free 调用,并在用户指定的文件中记录相关信息。文件以一种机器可读的格式记录数据,所以有一个 Perl 脚本——同样命名为 mtrace ——用来把文件转换并为人类可读格式。
|
||||
|
||||
#### 更新内容 ####
|
||||
|
||||
[Mtrace 源码][37]和 [Perl 文件][38]同 GNU C 库( 2.21 版本)一起释出,除了更新版权日期,其它别无改动。
|
||||
|
||||
#### 有何优点 ####
|
||||
|
||||
Mtrace 最好的地方是它非常简单易学。你只需要了解在你的源码中如何以及何处添加 mtrace() 及对应的 muntrace() 函数,还有如何使用 Mtrace 的 Perl 脚本。后者非常简单,只需要运行指令`mtrace <program-executable> <log-file-generated-upon-program-execution>`(例子见开头截图最后一条指令)。
|
||||
|
||||
Mtrace 另外一个优点是它的可伸缩性,这体现在不仅可以使用它来调试完整的程序,还可以使用它来检测程序中独立模块的内存泄漏。只需在每个模块里调用`mtrace()`和`muntrace()`即可。
|
||||
|
||||
最后一点,因为 Mtrace 会在`mtrace()`——在源码中添加的函数——执行时被触发,因此可以很灵活地[使用信号][39]动态地(在程序执行时)使能 Mtrace 。
|
||||
|
||||
#### 注意事项 ####
|
||||
|
||||
因为`mtrace()`和`mauntrace()`函数 —— 声明在`mcheck.h`文件中,所以必须在源码中包含此头文件 —— 的调用是 Mtrace 工作的基础(`mauntrace()`函数并非[总是必要][40]),因此 Mtrace 要求程序员至少改动源码一次。
|
||||
|
||||
需要注意的是,在编译程序的时候带上 -g 选项( [GCC][41] 和 [G++][42] 编译器均有提供),才能使调试工具在输出结果时展示正确的行号。除此之外,有些程序(取决于源码体积有多大)可能会花很长时间进行编译。最后,带 -g 选项编译会增加了可执行文件的大小(因为提供了额外的调试信息),因此记得程序需要在测试结束后,不带 -g 选项重新进行编译。
|
||||
|
||||
使用 Mtrace ,你需要掌握 Linux 环境变量的基本知识,因为在程序执行之前,需要把用户把环境变量`MALLOC_TRACE`的值设为指定的文件(`mtrace()`函数将会记录全部信息到其中)路径。
|
||||
|
||||
Mtrace 在检测内存泄漏和试图释放未经过分配的内存方面存在局限。它不能检测其它内存相关问题如非法内存访问、使用未初始化内存。而且,[有人抱怨][43] Mtrace 不是[线程安全][44]的。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
不言自明,我在此讨论的每款内存调试器都有其优点和局限。所以,哪一款适合你取决于你所需要的特性,虽然有时候容易安装和使用也是一个决定因素。
|
||||
|
||||
要想捕获软件程序中的内存泄漏, Mtrace 最适合不过了。它还可以节省时间。由于 Linux 系统已经预装了此工具,对于不能联网或者不可以下载第三方调试调试工具的情况, Mtrace 也是极有助益的。
|
||||
|
||||
另一方面,相比 Mtrace , Dmalloc 不仅能检测更多错误类型,还提供更多特性,比如运行时可配置、 GDB 集成。而且, Dmalloc 不像这里所说的其它工具,它是线程安全的。更不用说它的详细资料了,这让 Dmalloc 成为初学者的理想选择。
|
||||
|
||||
虽然 Memwatch 的资料比 Dmalloc 的更加丰富,而且还能检测更多的错误种类,但是你只能在 C 语言写就的程序中使用它。一个让 Memwatch 脱颖而出的特性是它允许在你的程序源码中处理它的输出,这对于想要定制输出格式来说是非常有用的。
|
||||
|
||||
如果改动程序源码非你所愿,那么使用 Electric Fence 吧。不过,请记住, Electric Fence 只能检测两种错误类型,而此二者均非内存泄漏。还有就是,需要基本了解 GDB 以最大化发挥这款内存调试工具的作用。
|
||||
|
||||
Memcheck 可能是其中综合性最好的了。相比这里提及的其它工具,它能检测更多的错误类型,提供更多的特性,而且不需要你的源码做任何改动。但请注意,基本功能并不难上手,但是想要使用它的高级特性,就必须学习相关的专业知识了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3003957/linux/review-5-memory-debuggers-for-linux-coding.html
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[soooogreen](https://github.com/soooogreen)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki),[ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Himanshu-Arora/
|
||||
[1]:https://openclipart.org/detail/132427/penguin-admin
|
||||
[2]:https://en.wikipedia.org/wiki/Manual_memory_management
|
||||
[3]:http://dmalloc.com/
|
||||
[4]:https://www.owasp.org/index.php/Double_Free
|
||||
[5]:https://stuff.mit.edu/afs/sipb/project/gnucash-test/src/dmalloc-4.8.2/dmalloc.html#Fence-Post%20Overruns
|
||||
[6]:http://dmalloc.com/releases/notes/dmalloc-5.5.2.html
|
||||
[7]:http://www.gnu.org/software/gdb/
|
||||
[8]:http://dmalloc.com/docs/
|
||||
[9]:http://dmalloc.com/docs/latest/online/dmalloc_26.html#SEC32
|
||||
[10]:http://dmalloc.com/docs/latest/online/dmalloc_23.html#SEC29
|
||||
[11]:https://en.wikipedia.org/wiki/Memory_management#Dynamic_memory_allocation
|
||||
[12]:https://en.wikipedia.org/wiki/Segmentation_fault
|
||||
[13]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[14]:http://www.gnu.org/software/gdb/
|
||||
[15]:https://launchpad.net/ubuntu/+source/electric-fence/2.2.3
|
||||
[16]:http://valgrind.org/docs/manual/mc-manual.html
|
||||
[17]:http://valgrind.org/info/developers.html
|
||||
[18]:http://valgrind.org/
|
||||
[19]:http://valgrind.org/docs/manual/dist.news.html
|
||||
[20]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.suppfiles
|
||||
[21]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.mempools
|
||||
[22]:http://stackoverflow.com/questions/4642671/c-memory-allocators
|
||||
[23]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.monitor-commands
|
||||
[24]:http://valgrind.org/docs/manual/mc-manual.html#mc-manual.clientreqs
|
||||
[25]:http://valgrind.org/docs/manual/valgrind_manual.pdf
|
||||
[26]:http://sourceforge.net/p/valgrind/mailman/message/30292453/
|
||||
[27]:https://msdn.microsoft.com/en-us/library/ee798431%28v=cs.20%29.aspx
|
||||
[28]:http://www.computerworld.com/article/2484425/linux/5-free-linux-text-editors-for-programming-and-word-processing.html?nsdr=true&page=2
|
||||
[29]:http://valgrind.org/docs/manual/manual-core.html#manual-core.limits
|
||||
[30]:http://valgrind.org/info/
|
||||
[31]:http://www.linkdata.se/sourcecode/memwatch/
|
||||
[32]:http://www.cecalc.ula.ve/documentacion/tutoriales/WorkshopDebugger/007-2579-007/sgi_html/ch09.html
|
||||
[33]:http://c2.com/cgi/wiki?WildPointer
|
||||
[34]:https://en.wikipedia.org/wiki/Standard_streams#Standard_output_.28stdout.29
|
||||
[35]:http://www.gnu.org/software/libc/manual/html_node/Tracing-malloc.html
|
||||
[36]:https://www.gnu.org/software/libc/
|
||||
[37]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.c;h=df10128b872b4adc4086cf74e5d965c1c11d35d2;hb=HEAD
|
||||
[38]:https://sourceware.org/git/?p=glibc.git;a=history;f=malloc/mtrace.pl;h=0737890510e9837f26ebee2ba36c9058affb0bf1;hb=HEAD
|
||||
[39]:http://webcache.googleusercontent.com/search?q=cache:s6ywlLtkSqQJ:www.gnu.org/s/libc/manual/html_node/Tips-for-the-Memory-Debugger.html+&cd=1&hl=en&ct=clnk&gl=in&client=Ubuntu
|
||||
[40]:http://www.gnu.org/software/libc/manual/html_node/Using-the-Memory-Debugger.html#Using-the-Memory-Debugger
|
||||
[41]:http://linux.die.net/man/1/gcc
|
||||
[42]:http://linux.die.net/man/1/g++
|
||||
[43]:https://sourceware.org/ml/libc-help/2014-05/msg00008.html
|
||||
[44]:https://en.wikipedia.org/wiki/Thread_safety
|
||||
@ -1,6 +1,6 @@
|
||||
15条给系统管理员的实用 Linux/Unix 磁带管理命令
|
||||
给系统管理员的15条实用 Linux/Unix 磁带管理命令
|
||||
================================================================================
|
||||
磁带设备应只用于定期的文件归档或将数据从一台服务器传送至另一台。通常磁带设备与 Unix 机器连接,用 mt 或 mtx 控制。你可以将所有的数据备份到磁盘(也许是云中)和磁带设备。在这个教程中你将会了解到:
|
||||
磁带设备应只用于定期的文件归档或将数据从一台服务器传送至另一台。通常磁带设备与 Unix 机器连接,用 mt 或 mtx 控制。强烈建议您将所有的数据同时备份到磁盘(也许是云中)和磁带设备中。在本教程中你将会了解到:
|
||||
|
||||
- 磁带设备名
|
||||
- 管理磁带驱动器的基本命令
|
||||
@ -8,12 +8,13 @@
|
||||
|
||||
### 为什么备份? ###
|
||||
|
||||
一个备份设备是很重要的:
|
||||
一个备份计划对定期备份文件来说很有必要,如果你宁愿选择不备份,那么丢失重要数据的风险会大大增加。有了备份,你就有了从磁盘故障中恢复的能力。备份还可以帮助你抵御:
|
||||
|
||||
- 从磁盘故障中恢复的能力
|
||||
- 意外的文件删除
|
||||
- 文件或文件系统损坏
|
||||
- 服务器完全毁坏,包括由于火灾或其他问题导致的同盘备份毁坏
|
||||
- 硬盘或 SSD 崩溃
|
||||
- 病毒或勒索软件破坏或删除文件
|
||||
|
||||
你可以使用磁带归档备份整个服务器并将其离线存储。
|
||||
|
||||
@ -21,15 +22,15 @@
|
||||
|
||||
|
||||
|
||||
图01:磁带文件标记
|
||||
*图01:磁带文件标记*
|
||||
|
||||
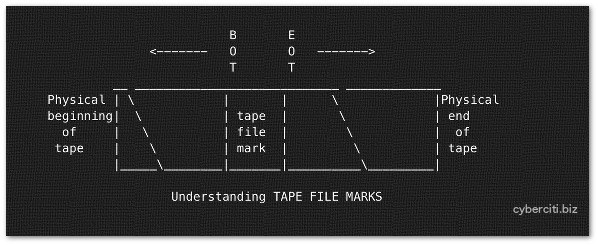
每个磁带设备能存储多个备份文件。磁带备份文件通过 cpio,tar,dd 等命令创建。但是,磁带设备可以由各种程序打开,写入数据,并关闭。你可以存储若干备份(磁带文件)到一个物理磁带上。在每个磁带文件之间有个“磁带文件标记”。这个是用来指示一个物理磁带上磁带文件的结尾以及另一个文件的开始。你需要使用 mt 命令来定位磁带(快进,倒带和标记)。
|
||||
每个磁带设备能存储多个备份文件。磁带备份文件通过 cpio,tar,dd 等命令创建。同时,磁带设备可以由多种程序打开、写入数据、及关闭。你可以存储若干备份(磁带文件)到一个物理磁带上。在每个磁带文件之间有个“磁带文件标记”。这用来指示一个物理磁带上磁带文件的结尾以及另一个文件的开始。你需要使用 mt 命令来定位磁带(快进,倒带和标记)。
|
||||
|
||||
#### 磁带上的数据是如何存储的 ####
|
||||
|
||||
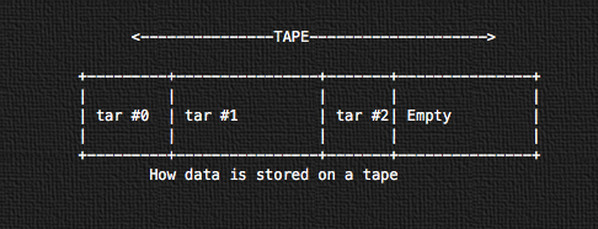
|
||||
|
||||
图02:磁带上的数据是如何存储的
|
||||
*图02:磁带上的数据是如何存储的*
|
||||
|
||||
所有的数据使用 tar 以连续磁带存储格式连续地存储。第一个磁带归档会从磁带的物理开始端开始存储(tar #0)。接下来的就是 tar #1,以此类推。
|
||||
|
||||
@ -59,22 +60,22 @@
|
||||
|
||||
输入下列命令:
|
||||
|
||||
## Linux(更多信息参阅 man) ##
|
||||
### Linux(更多信息参阅 man) ###
|
||||
lsscsi
|
||||
lsscsi -g
|
||||
|
||||
## IBM AIX ##
|
||||
### IBM AIX ###
|
||||
lsdev -Cc tape
|
||||
lsdev -Cc adsm
|
||||
lscfg -vl rmt*
|
||||
|
||||
## Solaris Unix ##
|
||||
### Solaris Unix ###
|
||||
cfgadm –a
|
||||
cfgadm -al
|
||||
luxadm probe
|
||||
iostat -En
|
||||
|
||||
## HP-UX Unix ##
|
||||
### HP-UX Unix ###
|
||||
ioscan Cf
|
||||
ioscan -funC tape
|
||||
ioscan -fnC tape
|
||||
@ -85,11 +86,11 @@
|
||||
|
||||
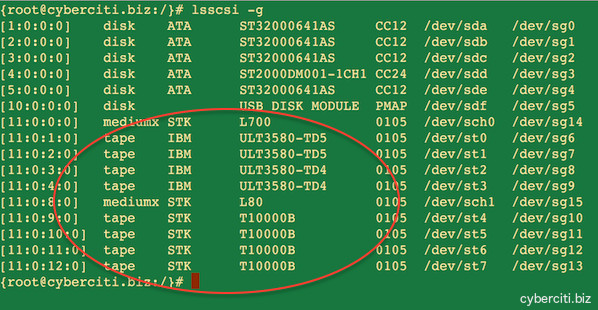
|
||||
|
||||
图03:Linux 服务器上已安装的磁带设备
|
||||
*图03:Linux 服务器上已安装的磁带设备*
|
||||
|
||||
### mt 命令实例 ###
|
||||
### mt 命令示例 ###
|
||||
|
||||
在 Linux 和类Unix系统上,mt 命令用来控制磁带驱动器的操作,比如查看状态或查找磁带上的文件或写入磁带控制标记。下列大多数命令需要作为 root 用户执行。语法如下:
|
||||
在 Linux 和类 Unix 系统上,mt 命令用来控制磁带驱动器的操作,比如查看状态或查找磁带上的文件或写入磁带控制标记。下列大多数命令需要作为 root 用户执行。语法如下:
|
||||
|
||||
mt -f /tape/device/name operation
|
||||
|
||||
@ -97,7 +98,7 @@
|
||||
|
||||
你可以设置 TAPE shell 变量。这是磁带驱动器的路径名。在 FreeBSD 上默认的(如果变量没有设置,而不是 null)是 /dev/nsa0。可以通过 mt 命令的 -f 参数传递变量覆盖它,就像下面解释的那样。
|
||||
|
||||
## 添加到你的 shell 配置文件 ##
|
||||
### 添加到你的 shell 配置文件 ###
|
||||
TAPE=/dev/st1 #Linux
|
||||
TAPE=/dev/rmt/2 #Unix
|
||||
TAPE=/dev/nsa3 #FreeBSD
|
||||
@ -105,13 +106,13 @@
|
||||
|
||||
### 1:显示磁带/驱动器状态 ###
|
||||
|
||||
mt status #Use default
|
||||
mt -f /dev/rmt/0 status #Unix
|
||||
mt -f /dev/st0 status #Linux
|
||||
mt -f /dev/nsa0 status #FreeBSD
|
||||
mt -f /dev/rmt/1 status #Unix unity 1 也就是 tape device no. 1
|
||||
mt status ### Use default
|
||||
mt -f /dev/rmt/0 status ### Unix
|
||||
mt -f /dev/st0 status ### Linux
|
||||
mt -f /dev/nsa0 status ### FreeBSD
|
||||
mt -f /dev/rmt/1 status ### Unix unity 1 也就是 tape device no. 1
|
||||
|
||||
你可以像下面一样使用 shell 循环调查系统并定位所有的磁带驱动器:
|
||||
你可以像下面一样使用 shell 循环语句遍历一个系统并定位其所有的磁带驱动器:
|
||||
|
||||
for d in 0 1 2 3 4 5
|
||||
do
|
||||
@ -133,7 +134,7 @@
|
||||
mt -f /dev/mt/0 off
|
||||
mt -f /dev/st0 eject
|
||||
|
||||
### 4:擦除磁带(倒带,在可以的情况下卸载磁带) ###
|
||||
### 4:擦除磁带(倒带,在支持的情况下卸载磁带) ###
|
||||
|
||||
mt erase
|
||||
mt -f /dev/st0 erase #Linux
|
||||
@ -179,7 +180,7 @@
|
||||
|
||||
bsfm 后退指定的文件标记数目。磁带定位在下一个文件的第一块。
|
||||
|
||||
asf The tape is positioned at the beginning of the count file. Positioning is done by first rewinding the tape and then spacing forward over count filemarks.磁带定位在
|
||||
asf 磁带定位在指定文件标记数目的开始位置。定位通过先倒带,再前进指定的文件标记数目来实现。
|
||||
|
||||
fsr 前进指定的记录数。
|
||||
|
||||
@ -207,7 +208,7 @@
|
||||
|
||||
mt -f /dev/st0 rewind; dd if=/dev/st0 of=-
|
||||
|
||||
## tar 格式 ##
|
||||
### tar 格式 ###
|
||||
tar tvf {DEVICE} {Directory-FileName}
|
||||
tar tvf /dev/st0
|
||||
tar tvf /dev/st0 desktop
|
||||
@ -215,40 +216,40 @@
|
||||
|
||||
### 12:使用 dump 或 ufsdump 备份分区 ###
|
||||
|
||||
## Unix 备份 c0t0d0s2 分区 ##
|
||||
### Unix 备份 c0t0d0s2 分区 ###
|
||||
ufsdump 0uf /dev/rmt/0 /dev/rdsk/c0t0d0s2
|
||||
|
||||
## Linux 备份 /home 分区 ##
|
||||
### Linux 备份 /home 分区 ###
|
||||
dump 0uf /dev/nst0 /dev/sda5
|
||||
dump 0uf /dev/nst0 /home
|
||||
|
||||
## FreeBSD 备份 /usr 分区 ##
|
||||
### FreeBSD 备份 /usr 分区 ###
|
||||
dump -0aL -b64 -f /dev/nsa0 /usr
|
||||
|
||||
### 12:使用 ufsrestore 或 restore 恢复分区 ###
|
||||
|
||||
## Unix ##
|
||||
### Unix ###
|
||||
ufsrestore xf /dev/rmt/0
|
||||
## Unix 交互式恢复 ##
|
||||
### Unix 交互式恢复 ###
|
||||
ufsrestore if /dev/rmt/0
|
||||
|
||||
## Linux ##
|
||||
### Linux ###
|
||||
restore rf /dev/nst0
|
||||
## 从磁带媒介上的第6个备份交互式恢复 ##
|
||||
### 从磁带媒介上的第6个备份交互式恢复 ###
|
||||
restore isf 6 /dev/nst0
|
||||
|
||||
## FreeBSD 恢复 ufsdump 格式 ##
|
||||
### FreeBSD 恢复 ufsdump 格式 ###
|
||||
restore -i -f /dev/nsa0
|
||||
|
||||
### 13:从磁带开头开始写入(见图02) ###
|
||||
|
||||
## 这会覆盖磁带上的所有数据 ##
|
||||
### 这会覆盖磁带上的所有数据 ###
|
||||
mt -f /dev/st1 rewind
|
||||
|
||||
### 备份 home ##
|
||||
### 备份 home ###
|
||||
tar cvf /dev/st1 /home
|
||||
|
||||
## 离线并卸载磁带 ##
|
||||
### 离线并卸载磁带 ###
|
||||
mt -f /dev/st0 offline
|
||||
|
||||
从磁带开头开始恢复:
|
||||
@ -259,22 +260,22 @@
|
||||
|
||||
### 14:从最后一个 tar 后开始写入(见图02) ###
|
||||
|
||||
## 这会保留之前写入的数据 ##
|
||||
### 这会保留之前写入的数据 ###
|
||||
mt -f /dev/st1 eom
|
||||
|
||||
### 备份 home ##
|
||||
### 备份 home ###
|
||||
tar cvf /dev/st1 /home
|
||||
|
||||
## 卸载 ##
|
||||
### 卸载 ###
|
||||
mt -f /dev/st0 offline
|
||||
|
||||
### 15:从 tar number 2 后开始写入(见图02) ###
|
||||
|
||||
## 在 tar number 2 之后写入(应该是 2+1)
|
||||
### 在 tar number 2 之后写入(应该是 2+1)###
|
||||
mt -f /dev/st0 asf 3
|
||||
tar cvf /dev/st0 /usr
|
||||
|
||||
## asf 等效于 fsf ##
|
||||
### asf 等效于 fsf ###
|
||||
mt -f /dev/sf0 rewind
|
||||
mt -f /dev/st0 fsf 2
|
||||
|
||||
@ -413,7 +414,7 @@ via: http://www.cyberciti.biz/hardware/unix-linux-basic-tape-management-commands
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,44 @@
|
||||
使用 SystemBack 备份/还原你的 Ubuntu/Linux Mint
|
||||
=================================================
|
||||
|
||||
对于任何一款允许用户还原电脑到之前状态(包括文件系统,安装的应用,以及系统设置)的操作系统来说,系统还原功能都是必备功能,它可以恢复系统故障以及其他的问题。
|
||||
|
||||
有的时候安装一个程序或者驱动可能让你的系统黑屏。系统还原则可以让你电脑里面的系统文件(LCTT 译注:是系统文件,并非普通文件,详情请看**注意**部分)和程序恢复到之前工作正常时候的状态,进而让你远离那让人头痛的排障过程了,而且它也不会影响你的文件,照片或者其他数据。
|
||||
|
||||
简单的系统备份还原工具 [Systemback](https://launchpad.net/systemback) 可以让你很容易地创建系统备份以及用户配置文件。一旦遇到问题,你可以简单地恢复到系统先前的状态。它还有一些额外的特征包括系统复制,系统安装以及Live系统创建。
|
||||
|
||||
**截图**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
**注意**:使用系统还原不会还原你自己的文件、音乐、电子邮件或者其他任何类型的私人文件。对不同用户来讲,这既是优点又是缺点。坏消息是它不会还原你意外删除的文件,不过你可以通过一个文件恢复程序来解决这个问题。如果你的计算机没有创建还原点,那么系统恢复就无法奏效,所以这个工具就无法帮助你(还原系统),如果你尝试恢复一个主要问题,你将需要移步到另外的步骤来进行故障排除。
|
||||
|
||||
> 适用于 Ubuntu 15.10 Wily/16.04/15.04 Vivid/14.04 Trusty/Linux Mint 14.x/其他Ubuntu衍生版,打开终端,将下面这些命令复制过去:
|
||||
|
||||
终端命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nemh/systemback
|
||||
sudo apt-get update
|
||||
sudo apt-get install systemback
|
||||
|
||||
```
|
||||
|
||||
大功告成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.noobslab.com/2015/11/backup-system-restore-point-your.html
|
||||
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://launchpad.net/systemback
|
||||
@ -0,0 +1,111 @@
|
||||
安装 openSUSE Leap 42.1 之后要做的 8 件事
|
||||
================================================================================
|
||||

|
||||
|
||||
*致谢:[Metropolitan Transportation/Flicrk][1]*
|
||||
|
||||
> 如果你已经在你的电脑上安装了 openSUSE,这就是你接下来要做的。
|
||||
|
||||
[openSUSE Leap 确实是个巨大的飞跃][2],它允许用户运行一个和 SUSE Linux 企业版拥有同样基因的发行版。和其它系统一样,为了实现最佳的使用效果,在使用它之前需要做些优化设置。
|
||||
|
||||
下面是一些我在我的电脑上安装 openSUSE Leap 之后做的一些事情(不适用于服务器)。这里面没有强制性的设置,基本安装对你来说也可能足够了。但如果你想获得更好的 openSUSE Leap 体验,那就跟着我往下看吧。
|
||||
|
||||
### 1. 添加 Packman 仓库 ###
|
||||
|
||||
由于专利和授权等原因,openSUSE 和许多 Linux 发行版一样,不通过官方仓库(repos)提供一些软件、解码器,以及驱动等。取而代之的是通过第三方或社区仓库来提供。第一个也是最重要的仓库是“Packman”。因为这些仓库不是默认启用的,我们需要添加它们。你可以通过 YaST(openSUSE 的特色之一)或者命令行完成(如下方介绍)。
|
||||
|
||||
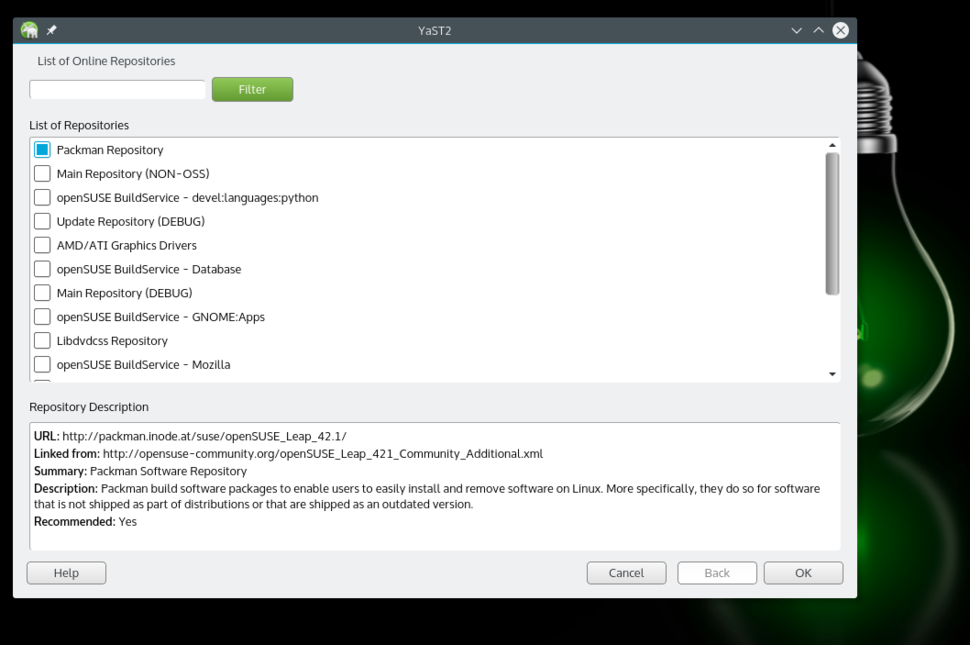
|
||||
|
||||
*添加 Packman 仓库。*
|
||||
|
||||
使用 YaST,打开软件源部分。点击“添加”按钮并选择“社区仓库(Community Repositories)”。点击“下一步”。一旦仓库列表加载出来了,选择 Packman 仓库。点击“确认”,然后点击“信任”导入信任的 GnuPG 密钥。
|
||||
|
||||
或者在终端里使用以下命令添加并启用 Packman 仓库:
|
||||
|
||||
zypper ar -f -n packmanhttp://ftp.gwdg.de/pub/linux/misc/packman/suse/openSUSE_Leap_42.1/ packman
|
||||
|
||||
仓库添加之后,你就可以使用更多的包了。想安装任意软件或包,打开 YaST 软件管理器,搜索并安装即可。
|
||||
|
||||
### 2. 安装 VLC ###
|
||||
|
||||
VLC 是媒体播放器里的瑞士军刀,几乎可以播放任何媒体文件。你可以从 YaST 软件管理器 或 software.opensuse.org 安装 VLC。你需要安装两个包:vlc 和 vlc-codecs。
|
||||
|
||||
如果你用终端,运行以下命令:
|
||||
|
||||
sudo zypper install vlc vlc-codecs
|
||||
|
||||
### 3. 安装 Handbrake ###
|
||||
|
||||
如果你需要转码或转换视频文件格式,[Handbrake 是你的不二之选][3]。Handbrake 就在我们启用的仓库中,所以只需要在 YaST 中搜索并安装它即可。
|
||||
|
||||
如果你用终端,运行以下命令:
|
||||
|
||||
sudo zypper install handbrake-cli handbrake-gtk
|
||||
|
||||
(提示:VLC 也能转码音频和视频文件。)
|
||||
|
||||
### 4. 安装 Chrome ###
|
||||
|
||||
openSUSE 的默认浏览器是 Firefox。但是因为 Firefox 不能够播放专有媒体,比如 Netflix,我推荐安装 Chrome。这需要额外的工作。首先你需要从谷歌导入信任密钥。打开终端执行“wget”命令下载密钥:
|
||||
|
||||
wget https://dl.google.com/linux/linux_signing_key.pub
|
||||
|
||||
然后导入密钥:
|
||||
|
||||
sudo rpm --import linux_signing_key.pub
|
||||
|
||||
现在到 [Google Chrome 网站][4] 去,下载 64 位 .rpm 文件。下载完成后执行以下命令安装浏览器:
|
||||
|
||||
sudo zypper install /PATH_OF_GOOGLE_CHROME.rpm
|
||||
|
||||
### 5. 安装 Nvidia 驱动 ###
|
||||
|
||||
即便你使用 Nvidia 或 ATI 显卡,openSUSE Leap 也能够开箱即用。但是,如果你需要专有驱动来游戏或其它目的,你可以安装这些驱动,但需要一点额外的工作。
|
||||
|
||||
首先你需要添加 Nvidia 源;它的步骤和使用 YaST 添加 Packman 仓库是一样的。唯一的不同是你需要在社区仓库部分选择 Nvidia。添加好了之后,到 **软件管理 > 附加** 去并选择“附加/安装所有匹配的推荐包”。
|
||||
|
||||
|
||||
|
||||
它会打开一个对话框,显示所有将要安装的包,点击确认后按介绍操作。添加了 Nvidia 源之后你也可以通过命令安装需要的 Nvidia 驱动:
|
||||
|
||||
sudo zypper inr
|
||||
|
||||
(注:我没使用过 AMD/ATI 显卡,所以这方面我没有经验。)
|
||||
|
||||
### 6. 安装媒体解码器 ###
|
||||
|
||||
你安装 VLC 之后就不需要安装媒体解码器了,但如果你要使用其它软件来播放媒体的话就需要安装了。一些开发者写了脚本/工具来简化这个过程。打开[这个页面][5]并点击合适的按钮安装完整的包。它会打开 YaST 并自动安装包(当然通常你还需要提供 root 权限密码并信任 GnuPG 密钥)。
|
||||
|
||||
### 7. 安装你喜欢的电子邮件客户端 ###
|
||||
|
||||
openSUSE 自带 Kmail 或 Evolution,这取决于你安装的桌面环境。我用的是 KDE Plasma 自带的 Kmail,这个邮件客户端还有许多地方有待改进。我建议可以试试 Thunderbird 或 Evolution。所有主要的邮件客户端都能在官方仓库找到。你还可以看看我[精心挑选的 Linux 最佳邮件客户端][7]。
|
||||
|
||||
### 8. 在防火墙允许 Samba 服务 ###
|
||||
|
||||
相比于其它发行版,openSUSE 默认提供了更加安全的系统。但对新用户来说它也需要一点设置。如果你正在使用 Samba 协议分享文件到本地网络的话,你需要在防火墙允许该服务。
|
||||
|
||||
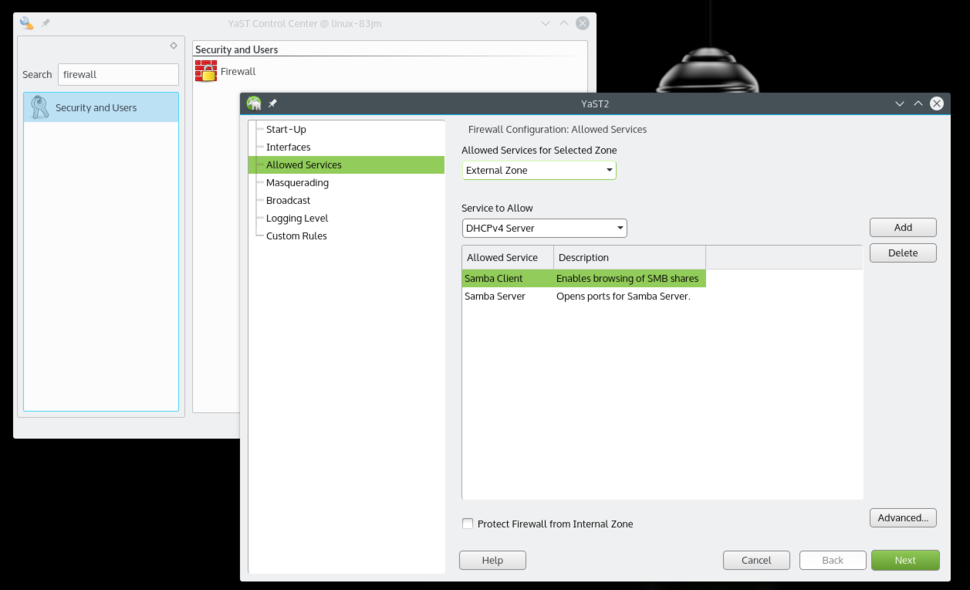
|
||||
|
||||
*在防火墙设置里允许 Samba 客户端和服务端*
|
||||
|
||||
打开 YaST 并搜索 Firewall。在防火墙设置里,进入到“允许的服务(Allowed Services)”,你会在“要允许的服务(Service to allow)”下面看到一个下拉列表。选择“Samba 客户端”,然后点击“添加”。同样方法添加“Samba 服务器”。都添加了之后,点击“下一步”,然后点击“完成”,现在你就可以通过本地网络从你的 openSUSE 分享文件以及访问其它机器了。
|
||||
|
||||
这差不多就是我以我喜欢的方式对我的新 openSUSE 系统做的所有设置了。如果你有任何问题,欢迎在评论区提问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/3003865/open-source-tools/8-things-to-do-after-installing-opensuse-leap-421.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Swapnil-Bhartiya/
|
||||
[1]:https://www.flickr.com/photos/mtaphotos/11200079265/
|
||||
[2]:https://www.linux.com/news/software/applications/865760-opensuse-leap-421-review-the-most-mature-linux-distribution
|
||||
[3]:https://www.linux.com/learn/tutorials/857788-how-to-convert-videos-in-linux-using-the-command-line
|
||||
[4]:https://www.google.com/intl/en/chrome/browser/desktop/index.html#brand=CHMB&utm_campaign=en&utm_source=en-ha-na-us-sk&utm_medium=ha
|
||||
[5]:http://opensuse-community.org/
|
||||
[6]:http://www.itworld.com/article/2875981/the-5-best-open-source-email-clients-for-linux.html
|
||||
53
published/20151202 KDE vs GNOME vs XFCE Desktop.md
Normal file
53
published/20151202 KDE vs GNOME vs XFCE Desktop.md
Normal file
@ -0,0 +1,53 @@
|
||||
KDE、GNOME 和 XFCE 桌面比较
|
||||
================================================================================
|
||||

|
||||
|
||||
这么多年来,很多人一直都在他们的 linux 桌面端使用 KDE 或者 GNOME 桌面环境。在这两个桌面环境多年不断发展的同时,其它的桌面也在持续增加它们的用户规模。举个例子说,在轻量级桌面环境下,XFCE 一举成为了最受欢迎的桌面环境,相较于 LXDE 缺少的优美视觉效果,默认配置下的 XFCE 在这方面就可以打败前者。XFCE 提供的功能特性都能在 GNOME2 下得到,然而,在一些较老的计算机上,它的轻量级的特性却能取得更好的效果。
|
||||
|
||||
### 桌面主题定制 ###
|
||||
|
||||
用户完成安装之后,XFCE 看起来可能会有一点无趣,因为它在视觉上还缺少一些吸引力。但是,请不要误解我的话, XFCE 仍然拥有漂亮的桌面,但是对于大多数刚刚接触 XFCE 桌面环境的人来说,可能它看起来像香草一样普普通通。不过好消息是当我们想要给 XFCE 安装新的主题的时候,这会是一个十分轻松的过程,因为你能够快速的找到你喜欢的 XFCE 主题,之后你就可以将它解压到一个合适的目录中。从这一点上来说,XFCE 自带的一个放在“外观”下的重要的图形界面工具可以帮助用户更加容易的选择中意的主题,这可能是目前在 XFCE 上这方面最好用的工具了。如果用户按照上面的建议去做的话,对于想要尝试使用 XFCE 的任何用户来说都将不存在困难。
|
||||
|
||||
在 GNOME 桌面上,用户也可以按照类似上面的方法去做。不过,其中最主要的不同点就是在你做之前,用户必须手动下载并安装 GNOME Tweak Tool。当然,对于使用来说都不会有什么障碍,但是对于用户来说,使用 XFCE 安装和激活主题并不需要去额外去下载安装各种调整工具,这可能是他们无法忽略的一个优势。而在 GNOME 上,尤其是在用户已经下载并安装了 GNOME Tweak tool 之后,你仍将必须确保你已经安装了“用户主题扩展”。
|
||||
|
||||
同 XFCE 一样,用户需要去搜索并下载自己喜欢的主题,然后,用户可以再次使用 GNOME Tweak tool,并点击该工具界面左边的“外观”按钮,接着用户便可以直接查看页面底部并点击文件浏览按钮,然后浏览到那个压缩的文件夹并打开。当完成这些之后,用户将会看到一个告诉用户已经成功应用了主题的对话框,这样你的主题便已经安装完成。然后用户就可以简单的使用下拉菜单来选择他们想要的主题。和 XFCE 一样,主题激活的过程也是十分简单的,然而,对于因为要使用一个新的主题而去下载一个没有预先安装到系统里面的应用,这种情况也是需要考虑的。
|
||||
|
||||
最后,就是 KDE 桌面主题定制的过程了。和 XFCE 一样,不需要去下载额外的工具来安装主题。从这点来看,让人有种XFCE 可能要被 KDE 战胜了的感觉。不仅在 KDE 上可以完全使用图形用户界面来安装主题,而且甚至只需要用户点击获取新主题的按钮就可以找到、查看新的主题,并且最后自动安装。
|
||||
|
||||
然而,我们应该注意到 KDE 相比 XFCE 而言,是一个更加健壮完善的桌面环境。当然,对于主要以极简设计为目的的桌面来说,缺失一些更多的功能是有一定的道理的。为此,我们要为这样优秀的功能给 KDE 加分。
|
||||
|
||||
### MATE 不是一个轻量级的桌面环境 ###
|
||||
|
||||
在继续比较 XFCE、GNOME3 和 KDE 之前,对于老手我们需要澄清一下,我们没有将 MATE 桌面环境加入到我们的比较中。MATE 可被看作是 GNOME2 的另一个衍生品,但是它并没有主要作为一款轻量级或者快捷桌面出现。相反,它的主要目的是成为一款更加传统和舒适的桌面环境,并使它的用户在使用它时就像在家里一样舒适。
|
||||
|
||||
另一方面,XFCE 生来就是要实现他自己的一系列使命。XFCE 给它的用户提供了一个更轻量而仍保持吸引人的视觉体验的桌面环境。然后,对于一些认为 MATE 也是一款轻量级的桌面环境的人来说,其实 MATE 真正的目标并不是成为一款轻量级的桌面环境。这两种选择在各自安装了一款好的主题之后看起来都会让人觉得非常具有吸引力。
|
||||
|
||||
### 桌面导航 ###
|
||||
|
||||
XFCE 除了桌面,还提供了一个醒目的导航器。任何使用过传统的 Windows 或者 GNOME 2/MATE 桌面环境的用户都可以在没有任何帮助的情况下自如的使用新安装的 XFCE 桌面环境的导航器。紧接着,添加小程序到面板中也是很显眼的。就像找一个已经安装的应用程序一样,直接使用启动器并点击你想要运行的应用程序图标就行。除了 LXDE 和 MATE 之外,还没有其他的桌面的导航器可以做到如此简单。不仅如此,更好的是控制面板的使用是非常容易使用的,对于刚刚使用这个新桌面的用户来说这是一个非常大的好处。如果用户更喜欢通过老式的方法去使用他们的桌面,那么 GNOME 就不合适。通过热角而取代了最小化按钮,加上其他的应用排布方式,这可以让大多数新用户易于使用它。
|
||||
|
||||
如果用户来自类似 Windows 这样的桌面环境,那么这些用户需要摒弃这些习惯,不能简单的通过鼠标右击一下就将一个小程序添加到他们的工作空间顶部。与此相反,它可以通过使用扩展来实现。GNOME 是可以安装拓展的,并且是非常的容易,这些容易之处体现在只需要用户简单的使用位于 GNOME 扩展页面上的 on/off 开关即可。不过,用户必须知道这个东西,才能真正使用上这个功能。
|
||||
|
||||
另一方面,GNOME 正在它的外观中体现它的设计理念,即为用户提供一个直观和易用的控制面板。你可能认为那并不是什么大事,但是,在我看来,它确实是我认为值得称赞并且有必要被提及的方面。KDE 给它的用户提供了更多的传统桌面使用体验,并通过提供相似的启动器和一种更加类似的获取软件的方式的能力来迎合来自 Windows 的用户。添加小部件或者小程序到 KDE 桌面是件非常简单的事情,只需要在桌面上右击即可。唯一的问题是 KDE 中这个功能不好发现,就像 KDE 中的其它东西一样,对于用户来说好像是隐藏的。KDE 的用户可能不同意我的观点,但我仍然坚持我的说法。
|
||||
|
||||
要增加一个小部件,只要在“我的面板”上右击就可以看见面板选项,但是并不是安装小部件的一个直观的方法。你并不能看见“添加部件”,除非你选择了“面板选项”,然后才能看见“添加部件”。这对我来说不是个问题,但是对于一些用户来说,它变成了不必要的困惑。而使事情变得更复杂的是,在用户能够找到部件区域后,他们后来发现一种称为“活动”的新术语。它和部件在同一个地方,可是它在自己的区域却是另外一种行为。
|
||||
|
||||
现在请不要误解我,KDE 中的活动特性是很不错的,也是很有价值的,但是从可用性的角度看,为了不让新手感到困惑,它更加适合于放在另一个菜单项。用户各有不同,但是让新用户多测试一段时间可以让它不断改进。对“活动”的批评先放一边,KDE 添加新部件的方法的确很棒。与 KDE 的主题一样,用户不能通过使用提供的图形用户界面浏览和自动安装部件。这是一个有点神奇的功能,但是它这样也可以工作。KDE 的控制面板可能和用户希望的样子不一样,它不是足够的简单。但是有一点很清楚,这将是他们致力于改进的地方。
|
||||
|
||||
### 因此,XFCE 是最好的桌面环境,对吗? ###
|
||||
|
||||
就我自己而言,我在我的计算机上使用 GNOME、KDE,并在我的办公室和家里的电脑上使用 Xfce。我也有一些老机器在使用 Openbox 和 LXDE。每一个桌面的体验都可以给我提供一些有用的东西,可以帮助我以适合的方式使用每台机器。对我来说,Xfce 是我的心中的挚爱,因为 Xfce 是一个我使用了多年的桌面环境。但对于这篇文章,我是用我日常使用的机器来撰写的,事实上,它用的是 GNOME。
|
||||
|
||||
这篇文章的主要思想是,对于那些正在寻找稳定的、传统的、容易理解的桌面环境的用户来说,我还是觉得 Xfce 能提供好一点的用户体验。欢迎您在评论部分和我们分享你的意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/kde-vs-gnome-vs-xfce-desktop/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[kylepeng93](https://github.com/kylepeng93)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -0,0 +1,94 @@
|
||||
5 个很适合在课堂上演示的树莓派项目
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
### 1. 我的世界: Pi
|
||||
|
||||
|
||||
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
“我的世界”是世界上几乎每一个青少年都特别喜欢的一款游戏,而且它成功抓住了年轻人眼球,成为目前最能激发年轻人创造力的游戏之一。这个树莓派版本自带的我的世界不仅仅是一个具有创造性的建筑游戏,还是一个具有编程接口,可以通过 Python 与之交互的版本。
|
||||
|
||||
我的世界:Pi 版对于老师来说是一个教授学生解决问题和编写代码完成任务的好方式。你可以使用 Python API 创建一个房子,并且一直跟随这你的脚步移动,在所到之处建造一座桥,让天空落下熔岩雨滴,在空中显示温度,以及其它你可以想象到的一切东西。
|
||||
|
||||
详情请见 "[我的世界: Pi 入门][2]"
|
||||
|
||||
### 2. 反应游戏和交通灯
|
||||
|
||||

|
||||
|
||||
*源于 [Low Voltage Labs][3]. [CC BY-SA 4.0][1]*
|
||||
|
||||
使用树莓派可以很轻松地进行物理计算,只需要连接几个 LED 和按钮到开发板上的 GPIO 接口,再用几行代码你就可以按下按钮来开灯。一旦你了解了如何使用代码来完成这些基本的操作,接下来就可以根据你的想象来做其它事情了。
|
||||
|
||||
如果你知道如何让一个灯闪烁,你就可以控制三个灯闪烁。挑选三个和交通灯一样颜色的 LED 灯,然后编写控制交通灯的代码。如果你知道如何使用按钮触发事件,那么你就可以模拟一个行人过马路。同时你可以参考其它已经完成的交通灯附件,比如[PI-TRAFFIC][4], [PI-STOP][5], [Traffic HAT][6],等等。
|
||||
|
||||
代码并不是全部——这只是一个演练,让你理解现实世界里系统是如何完成设计的。计算思维是一个让你终身受用的技能。
|
||||
|
||||

|
||||
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
接下来试着接通两个按钮和 LED 灯的电源,实现一个双玩家的反应游戏 —— 让 LED 灯随机时间点亮,然后看是谁抢先按下按钮。
|
||||
|
||||
要想了解更多可以看看 [GPIO Zero recipes][7]。你所需要的资料都可以在 [CamJam EduKit 1][8] 找到。
|
||||
|
||||
### 3. Sense HAT 电子宠物
|
||||
|
||||
Astro Pi —— 一个增强版的树莓派 —— 将在 12 月问世,但是你并没有错过亲手把玩这个硬件的机会。Sense HAT 是使用在 Astro Pi 的一个传感器扩展板,现在已经开放购买了。你可以使用它来进行数据搜集、科学实验,游戏等等。可以看看下面树莓派的 Carrie Anne 拍摄的 Gurl Geek Diaries 的视频,里面演示了一种很棒的入门途径——在 Sense HAT 屏幕上自己设计一个生动的像素宠物:
|
||||
|
||||
[video](https://youtu.be/gfRDFvEVz-w)
|
||||
|
||||
> 详见 "[探索 Sense HAT][9]."
|
||||
|
||||
### 4. 红外鸟笼
|
||||
|
||||

|
||||
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
让整个班级都可以参与进来的好主意是在鸟笼里放置一个树莓派和夜视镜头,以及一些红外线灯,这样子你就可以在黑暗中看见鸟笼里的情况了,然后使用树莓派通过网络串流视频。然后就可以等待小鸟归笼了,你可以在不打扰的情况下近距离观察小窝里的它们了。
|
||||
|
||||
要了解更多有关红外线和光谱的知识,以及如何校准摄像头焦点和使用软件控制摄像头,可以访问 [打造一个红外鸟笼][10]。
|
||||
|
||||
### 5. 机器人
|
||||
|
||||

|
||||
|
||||
*源于 Raspberry Pi 基金会. [CC BY-SA 4.0][1]*
|
||||
|
||||
只需要一个树莓派、很少的几个电机和电机控制器,你就可以自己动手制作一个机器人。可以制作的机器人有很多种,从简单的由几个轮子和自制底盘拼凑的简单小车,到由游戏控制器驱动、具有自我意识、配备了传感器,安装了摄像头的金属小马。
|
||||
|
||||
要学习如何控制不同的电机,可以使用 RTK 电机驱动开发板入门或者使用配置了电机、轮子和传感器的 CamJam 机器人开发套件——具有很大的价值和大量的学习潜力。
|
||||
|
||||
或者,如果你还想了解更多核心内容,可以试试 PiBorg 的 [4Borg][11](£99/$150)和 [DiddyBorg][12](£180/$273),或者购买 Metal 版 DoodleBorg (£250/$380),然后构建一个最小版本的 [DoodleBorg tank][13](非卖品)。
|
||||
|
||||
详情可见 [机器人装备表][14]。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/15/12/5-great-raspberry-pi-projects-classroom
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[1]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]: https://opensource.com/life/15/5/getting-started-minecraft-pi
|
||||
[3]: http://lowvoltagelabs.com/
|
||||
[4]: http://lowvoltagelabs.com/products/pi-traffic/
|
||||
[5]: http://4tronix.co.uk/store/index.php?rt=product/product&product_id=390
|
||||
[6]: https://ryanteck.uk/hats/1-traffichat-0635648607122.html
|
||||
[7]: http://pythonhosted.org/gpiozero/recipes/
|
||||
[8]: http://camjam.me/?page_id=236
|
||||
[9]: https://opensource.com/life/15/10/exploring-raspberry-pi-sense-hat
|
||||
[10]: https://www.raspberrypi.org/learning/infrared-bird-box/
|
||||
[11]: https://www.piborg.org/4borg
|
||||
[12]: https://www.piborg.org/diddyborg
|
||||
[13]: https://www.piborg.org/doodleborg
|
||||
[14]: http://camjam.me/?page_id=1035#worksheets
|
||||
67
published/20151227 Upheaval in the Debian Live project.md
Normal file
67
published/20151227 Upheaval in the Debian Live project.md
Normal file
@ -0,0 +1,67 @@
|
||||
Debian Live项目的剧变
|
||||
==================================================================================
|
||||
|
||||
尽管围绕 Debian Live 项目发生了很多戏剧性事件,关于 [Debian Live 项目][1]结束的[公告][2]的影响力甚至小于该项目首次出现时的公告。主要开发者的离开是最显而易见的损失,而社区对他本人及其项目的态度是很令人困惑的,但是这个项目也许还是会以其他的形式继续下去。所以 Debian 仍然会有更多的工具去创造启动光盘和其他介质。尽管是用这样一种有遗憾的方式,项目创始人 Dabiel Baumann 和 Debian CD 团队以及安装检测团队之间出现的长期争论已经被「解决」了。
|
||||
在 11 月 9 日, Baumann 发表了题为「 Debian Live 项目的突然结束」的一篇公告。在那篇短文中,他一一列举出了自从这个和他有关的[项目被发起][3]以来近 10 年间发生的不同的事件,这些事件可以表明他在 Debian Live 项目上的努力一直没有被重视或没有被足够重视。最具决定性的因素是因为在「包的含义」上存在冲突, R.Learmonth [申请][4]了新的包名,而这侵犯了在 Debian Live 上使用的命名空间。
|
||||
|
||||
考虑到最主要的 Debian Live 包之一被命名为 live-build ,而 R.Learmonth 申请的新包名却是 live-build-ng ,这简直是对 live-build 的挑战。 live-build-ng 意为一种围绕 [vmdebootstrap][5]【译者注:创造真实的和虚拟机Debian的磁盘映像】工具的外部包装,这种包装是为了创造 live 介质(光盘和USB的插入),也是 Debian Live 最需要的的部分。但是当 Baumann Learmonth [要求][6]为他的包换一个不同的名字的时候,他得到了一个「有趣」的[回复][7]:
|
||||
|
||||
```
|
||||
应该注意到, live-build 不是一个 Debian 项目,它是一个声称自己是官方 Debian 项目的外部项目,这是一个需要我们解决的问题。
|
||||
这不是命名空间的问题,我们要将以目前维护的 live-config 和 live-boot 包为基础,把它们加入到 Debian 的本地项目。如果迫不得已的话,这将会有很多分支,但是我希望它不要发生,这样的话我们就可以把这些包整合到 Debian 中并继续以一种协作的方式去开发。
|
||||
live-build 已经被 debian-cd 放弃,live-build-ng 将会取代它。至少在一个精简的 Debian 环境中,live-build 会被放弃。我们(开发团队)正在与 debian-cd 和 Debian Installer 团队合作开发 live-build-ng 。
|
||||
```
|
||||
|
||||
Debian Live 是一个「官方的」 Debian 项目(也可以是狭义的「官方」),尽管它因为思路上的不同产生过争论。除此之外, vmdebootstrap 的维护者 Neil Willians 为脱离 Debian Live 项目[提供了如下的解释][8]:
|
||||
|
||||
```
|
||||
为了更好的支持 live-build 的代替者, vmdebootstrap 肯定会被推广。为了能够用 live-build 解决目前存在的问题,这项工作会由 debian-cd 团队来负责。这些问题包括可靠性问题,以及不能很好的支持多种机器和 UEFI 等。 vmdebootstrap 也存在着这些问题,我们用来自于对 live-boot 和 live-config 的支持情况来确定 vmdebootstrap 的功能。
|
||||
```
|
||||
|
||||
这些抱怨听起来合情合理,但是它们可能已经在目前的项目中得到了解决。然而一些秘密的项目有很明显的取代 live-build 的意图。正如 Baumann [指出][9]的,这些计划没有被发布到 debian-live 的邮件列表中。人们首次从 Debian Live 项目中获知这些计划正是因为这一次的ITP事件,所以它看起来像是一个「秘密计划」——有些事情在像 Debian 这样的项目中得不到很好的安排。
|
||||
|
||||
人们可能已经猜到了,有很多帖子都支持 Baumann [重命名][10] live-build-ng 的请求,但是紧接着,人们就因为他要停止继续在 Debian Live 上工作的决定而变得沮丧。然而 Learmonth 和 Williams 却坚持认为取代 live-build 很有必要。Learmonth 给 live-build-ng 换了一个争议性也许小一些的名字: live-wrapper 。他说他的目标是为 Debian Live 项目加入新的工具(并且「把 Debian Live 项目引入 Debian 里面」),但是完成这件事还需要很大的努力。
|
||||
|
||||
```
|
||||
我向已经被 ITP 问题所困扰的每个人道歉。我们已经告知大家 live-wrapper 还不足以完全替代 live-build 且开发工作仍在进行以收集反馈。尽管有了这部分的工作,我们收到的反馈缺并不是我们所需要的。
|
||||
```
|
||||
|
||||
这种对于取代 live-build 的强烈反对或许已经被预知到了。自由软件社区的沟通和交流很关键,所以,计划去替换一个项目的核心很容易引起争议——更何况是一个一直不为人所知的计划。从 Banumann 的角度来说,他当然不是完美的,他因为上传个不合适的 [syslinux 包][11]导致了 wheezy 的延迟发布,并且从那以后他被从 Debian 开发者暂时[降级][12]为 Debian 维护者。但是这不意味着他应该受到这种对待。当然,这个项目还有其他人参与,所以不仅仅是 Baumann 受到了影响。
|
||||
|
||||
Ben Armstrong 是其他参与者中的一位,在这个事件中,他很圆滑地处理了一些事,并且想从这个事件中全身而退。他从一封邮件[13]开始,这个邮件是为了庆祝这个项目,以及他和他的团队在过去几年取得的成果。正如他所说, Debian Live 的[下游项目列表][14]是很令人振奋的。在另一封邮件中,他也[指出][15]了这个项目不是没有生命力的:
|
||||
|
||||
```
|
||||
如果 Debian CD 开发团队通过他们的努力开发出可行的、可靠的、经过完善测试替代品,以及一个合适的取代 live-build 的候选者,这对于 Debian 项目有利无害。如果他们继续做这件事,他们不会「用一个官方改良,但不可靠且几乎没有经过测试的待选者取代 live-build 」。到目前为止,我还没有看到他们那样做的迹象。其间, live-build 仍保留在存档中——它仍然处于良好状态,且没有一种经过改良的继任者来取代它,因此开发团队没有必要尽快删除它。
|
||||
```
|
||||
|
||||
11 月 24 号, Armstrong 也在[他的博客][16]上[发布][17]了一个有关 Debian Live 的新消息。它展示了从 Baumann 退出起两周内的令人高兴的进展。甚至有迹象表明 Debian Live 项目与 live-wrapper 开发者开展了合作。博客上也有了一个[计划表][18],同时不可避免地寻求更多的帮助。这让人们有理由相信围绕项目发生的戏剧性事件仅仅是一个小摩擦——也许不可避免,但绝不是像现在看起来这么糟糕。
|
||||
|
||||
---------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/665839/
|
||||
|
||||
作者:Jake Edge
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://lwn.net/Articles/666127/
|
||||
[2]: http://live.debian.net/
|
||||
[3]: https://www.debian.org/News/weekly/2006/08/
|
||||
[4]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=804315
|
||||
[5]: http://liw.fi/vmdebootstrap/
|
||||
[6]: https://lwn.net/Articles/666173/
|
||||
[7]: https://lwn.net/Articles/666176/
|
||||
[8]: https://lwn.net/Articles/666181/
|
||||
[9]: https://lwn.net/Articles/666208/
|
||||
[10]: https://lwn.net/Articles/666321/
|
||||
[11]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=699808
|
||||
[12]: https://nm.debian.org/public/process/14450
|
||||
[13]: https://lwn.net/Articles/666336/
|
||||
[14]: http://live.debian.net/project/downstream/
|
||||
[15]: https://lwn.net/Articles/666338/
|
||||
[16]: https://lwn.net/Articles/666340/
|
||||
[17]: http://syn.theti.ca/2015/11/24/debian-live-after-debian-live/
|
||||
[18]: https://wiki.debian.org/DebianLive/TODO
|
||||
@ -0,0 +1,371 @@
|
||||
怎样在 ubuntu 和 debian 中通过命令行管理 KVM
|
||||
================================================================================
|
||||
|
||||
有很多不同的方式去管理运行在 KVM 管理程序上的虚拟机。例如,virt-manager 就是一个流行的基于图形界面的前端虚拟机管理工具。然而,如果你想要在没有图形窗口的服务器环境下使用 KVM ,那么基于图形界面的解决方案显然是行不通的。事实上,你可以单纯使用包装了 kvm 命令行脚本的命令行来管理 KVM 虚拟机。作为替代方案,你可以使用 virsh 这个容易使用的命令行程序来管理客户虚拟机。在 virsh 中,它通过和 libvirtd 服务通信来达到控制虚拟机的目的,而 libvirtd 可以控制多个不同的虚拟机管理器,包括 KVM,Xen,QEMU,LXC 和 OpenVZ。
|
||||
|
||||
当你想要对虚拟机的前期准备和后期管理实现自动化操作时,像 virsh 这样的命令行管理工具是非常有用的。同样,virsh 支持多个管理器也就意味着你可以通过相同的 virsh 接口去管理不同的虚拟机管理器。
|
||||
|
||||
在这篇文章中,我会示范**怎样在 ubuntu 和 debian 上通过使用 virsh 命令行去运行 KVM**。
|
||||
|
||||
### 第一步:确认你的硬件平台支持虚拟化 ###
|
||||
|
||||
第一步,首先要确认你的 CPU 支持硬件虚拟化扩展(e.g.,Intel VT 或者 AMD-V),这是 KVM 对硬件的要求。下面的命令可以检查硬件是否支持虚拟化。
|
||||
|
||||
```
|
||||
$ egrep '(vmx|svm)' --color /proc/cpuinfo
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果在输出中不包含 vmx 或者 svm 标识,那么就意味着你的 cpu 不支持硬件虚拟化。因此你不能在你的机器上使用 KVM 。确认了 cpu 支持 vmx 或者 svm 之后,接下来开始安装 KVM。
|
||||
|
||||
对于 KVM 来说,它不要求运行在拥有 64 位内核系统的主机上,但是通常我们会推荐在 64 位系统的主机上面运行 KVM。
|
||||
|
||||
### 第二步:安装KVM ###
|
||||
|
||||
使用 `apt-get` 安装 KVM 和相关的用户空间工具。
|
||||
|
||||
```
|
||||
$ sudo apt-get install qemu-kvm libvirt-bin
|
||||
```
|
||||
|
||||
安装期间,libvirtd 用户组(在 debian 上是 libvirtd-qemu 用户组)将会被创建,并且你的用户 id 将会被自动添加到该组中。这样做的目的是让你可以以一个普通用户而不是 root 用户的身份去管理虚拟机。你可以使用 `id` 命令来确认这一点,下面将会告诉你怎么去显示你的组 id:
|
||||
|
||||
```
|
||||
$ id <your-userID>
|
||||
```
|
||||
|
||||

|
||||
|
||||
如果因为某些原因,libvirt(在 debian 中是 libvirt-qemu)没有在你的组 id 中被找到,你也可以手动将你自己添加到对应的组中,如下所示:
|
||||
|
||||
在 ubuntu 上:
|
||||
|
||||
```
|
||||
$ sudo adduser [youruserID] libvirtd
|
||||
```
|
||||
|
||||
在 debian 上:
|
||||
|
||||
```
|
||||
$ sudo adduser [youruserID] libvirt-qemu
|
||||
```
|
||||
|
||||
按照如下命令重新载入更新后的组成员关系。如果要求输入密码,那么输入你的登陆密码即可。
|
||||
|
||||
```
|
||||
$ exec su -l $USER
|
||||
```
|
||||
|
||||
这时,你应该可以以普通用户的身份去执行 virsh 了。做一个如下所示的测试,这个命令将会以列表的形式列出可用的虚拟机(当前的列表是空的)。如果你没有遇到权限问题,那意味着到目前为止一切都是正常的。
|
||||
|
||||
$ virsh list
|
||||
|
||||
----------
|
||||
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
|
||||
### 第三步:配置桥接网络 ###
|
||||
|
||||
为了使 KVM 虚拟机能够访问外部网络,一种方法是通过在 KVM 宿主机上创建 Linux 桥来实现。创建之后的桥能够将虚拟机的虚拟网卡和宿主机的物理网卡连接起来,因此,虚拟机能够发送和接收由物理网卡传输的数据包。这种方式叫做网络桥接。
|
||||
|
||||
下面将告诉你如何创建并且配置网桥,我们创建一个网桥称它为 br0。
|
||||
|
||||
首先,安装一个必需的包,然后用命令行创建一个网桥。
|
||||
|
||||
```
|
||||
$ sudo apt-get install bridge-utils
|
||||
$ sudo brctl addbr br0
|
||||
```
|
||||
|
||||
下一步就是配置已经创建好的网桥,即修改位于 `/etc/network/interfaces` 的配置文件。我们需要将该桥接网卡设置成开机启动。为了修改该配置文件,你需要关闭你的操作系统上的网络管理器(如果你在使用它的话)。跟随[操作指南][1]的说明去关闭网络管理器。
|
||||
|
||||
关闭网络管理器之后,接下来就是通过修改配置文件来配置网桥了。
|
||||
|
||||
```
|
||||
#auto eth0
|
||||
#iface eth0 inet dhcp
|
||||
|
||||
auto br0
|
||||
iface br0 inet dhcp
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
在上面的配置中,我假设 eth0 是主要网卡,它也是连接到外网的网卡,同样,我假设 eth0 将会通过 DHCP 协议自动获取 ip 地址。注意,之前在 `/etc/network/interfaces` 中还没有对 eth0 进行任何配置。桥接网卡 br0 引用了 eth0 的配置,而 eth0 也会受到 br0 的制约。
|
||||
|
||||
重启网络服务,并确认网桥已经被成功的配置好。如果成功的话,br0 的 ip 地址将会是 eth0 自动分配的 ip 地址,而且 eth0 不会被分配任何 ip 地址。
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/networking restart
|
||||
$ ifconfig
|
||||
```
|
||||
|
||||
如果因为某些原因,eth0 仍然保留了之前分配给了 br0 的 ip 地址,那么你可能必须手动删除 eth0 的 ip 地址。
|
||||
|
||||

|
||||
|
||||
### 第四步:用命令行创建一个虚拟机 ###
|
||||
|
||||
对于虚拟机来说,它的配置信息被存储在它对应的xml文件中。因此,创建一个虚拟机的第一步就是准备一个与虚拟机对应的 xml 文件。
|
||||
|
||||
下面是一个示例 xml 文件,你可以根据需要手动修改它。
|
||||
|
||||
```
|
||||
<domain type='kvm'>
|
||||
<name>alice</name>
|
||||
<uuid>f5b8c05b-9c7a-3211-49b9-2bd635f7e2aa</uuid>
|
||||
<memory>1048576</memory>
|
||||
<currentMemory>1048576</currentMemory>
|
||||
<vcpu>1</vcpu>
|
||||
<os>
|
||||
<type>hvm</type>
|
||||
<boot dev='cdrom'/>
|
||||
</os>
|
||||
<features>
|
||||
<acpi/>
|
||||
</features>
|
||||
<clock offset='utc'/>
|
||||
<on_poweroff>destroy</on_poweroff>
|
||||
<on_reboot>restart</on_reboot>
|
||||
<on_crash>destroy</on_crash>
|
||||
<devices>
|
||||
<emulator>/usr/bin/kvm</emulator>
|
||||
<disk type="file" device="disk">
|
||||
<driver name="qemu" type="raw"/>
|
||||
<source file="/home/dev/images/alice.img"/>
|
||||
<target dev="vda" bus="virtio"/>
|
||||
<address type="pci" domain="0x0000" bus="0x00" slot="0x04" function="0x0"/>
|
||||
</disk>
|
||||
<disk type="file" device="cdrom">
|
||||
<driver name="qemu" type="raw"/>
|
||||
<source file="/home/dev/iso/CentOS-6.5-x86_64-minimal.iso"/>
|
||||
<target dev="hdc" bus="ide"/>
|
||||
<readonly/>
|
||||
<address type="drive" controller="0" bus="1" target="0" unit="0"/>
|
||||
</disk>
|
||||
<interface type='bridge'>
|
||||
<source bridge='br0'/>
|
||||
<mac address="00:00:A3:B0:56:10"/>
|
||||
</interface>
|
||||
<controller type="ide" index="0">
|
||||
<address type="pci" domain="0x0000" bus="0x00" slot="0x01" function="0x1"/>
|
||||
</controller>
|
||||
<input type='mouse' bus='ps2'/>
|
||||
<graphics type='vnc' port='-1' autoport="yes" listen='0.0.0.0'/>
|
||||
<console type='pty'>
|
||||
<target port='0'/>
|
||||
</console>
|
||||
</devices>
|
||||
</domain>
|
||||
```
|
||||
|
||||
上面的主机xml配置文件定义了如下的虚拟机内容。
|
||||
|
||||
- 1GB内存,一个虚拟cpu和一个硬件驱动
|
||||
|
||||
- 磁盘镜像:`/home/dev/images/alice.img`
|
||||
|
||||
- 从 CD-ROM 引导(`/home/dev/iso/CentOS-6.5-x86_64-minomal.iso`)
|
||||
|
||||
- 网络:一个桥接到 br0 的虚拟网卡
|
||||
|
||||
- 通过 VNC 远程访问
|
||||
|
||||
`<uuid></uuid>` 中的 UUID 字符串可以随机生成。为了得到一个随机的 uuid 字符串,你可能需要使用 uuid 命令行工具。
|
||||
|
||||
```
|
||||
$ sudo apt-get install uuid
|
||||
$ uuid
|
||||
```
|
||||
|
||||
生成一个主机 xml 配置文件的方式就是通过一个已经存在的虚拟机来导出它的 xml 配置文件。如下所示。
|
||||
|
||||
```
|
||||
$ virsh dumpxml alice > bob.xml
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 第五步:使用命令行启动虚拟机 ###
|
||||
|
||||
在启动虚拟机之前,我们需要创建它的初始磁盘镜像。为此,你需要使用 qemu-img 命令来生成一个 qemu-kvm 镜像。下面的命令将会创建 10 GB 大小的空磁盘,并且它是 qcow2 格式的。
|
||||
|
||||
```
|
||||
$ qemu-img create -f qcow2 /home/dev/images/alice.img 10G
|
||||
```
|
||||
|
||||
使用 qcow2 格式的磁盘镜像的好处就是它在创建之初并不会给它分配全部大小磁盘容量(这里是 10 GB),而是随着虚拟机中文件的增加而逐渐增大。因此,它对空间的使用更加有效。
|
||||
|
||||
现在,你可以通过使用之前创建的 xml 配置文件启动你的虚拟机了。下面的命令将会创建一个虚拟机,然后自动启动它。
|
||||
|
||||
```
|
||||
$ virsh create alice.xml
|
||||
Domain alice created from alice.xml
|
||||
```
|
||||
|
||||
**注意**: 如果你对一个已经存在的虚拟机执行了了上面的命令,那么这个操作将会在没有任何警告的情况下抹去那个已经存在的虚拟机的全部信息。如果你已经创建了一个虚拟机,你可能会使用下面的命令来启动虚拟机。
|
||||
|
||||
```
|
||||
$ virsh start alice.xml
|
||||
```
|
||||
|
||||
使用如下命令确认一个新的虚拟机已经被创建并成功的被启动。
|
||||
|
||||
```
|
||||
$ virsh list
|
||||
```
|
||||
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
3 alice running
|
||||
|
||||
同样,使用如下命令确认你的虚拟机的虚拟网卡已经被成功的添加到了你先前创建的 br0 网桥中。
|
||||
|
||||
$ sudo brctl show
|
||||
|
||||

|
||||
|
||||
### 远程连接虚拟机 ###
|
||||
|
||||
为了远程访问一个正在运行的虚拟机的控制台,你可以使用VNC客户端。
|
||||
|
||||
首先,你需要使用如下命令找出用于虚拟机的VNC端口号。
|
||||
|
||||
```
|
||||
$ sudo netstat -nap | egrep '(kvm|qemu)'
|
||||
```
|
||||
|
||||

|
||||
|
||||
在这个例子中,用于 alice 虚拟机的 VNC 端口号是 5900。 然后启动一个VNC客户端,连接到一个端口号为5900的VNC服务器。在我们的例子中,虚拟机支持由CentOS光盘文件启动。
|
||||
|
||||

|
||||
|
||||
### 使用 virsh 管理虚拟机 ###
|
||||
|
||||
下面列出了 virsh 命令的常规用法:
|
||||
|
||||
创建客户机并且启动虚拟机:
|
||||
|
||||
```
|
||||
$ virsh create alice.xml
|
||||
```
|
||||
|
||||
停止虚拟机并且删除客户机:
|
||||
|
||||
```
|
||||
$ virsh destroy alice
|
||||
```
|
||||
|
||||
关闭虚拟机(不用删除它):
|
||||
|
||||
```
|
||||
$ virsh shutdown alice
|
||||
```
|
||||
|
||||
暂停虚拟机:
|
||||
|
||||
```
|
||||
$ virsh suspend alice
|
||||
```
|
||||
|
||||
恢复虚拟机:
|
||||
|
||||
```
|
||||
$ virsh resume alice
|
||||
```
|
||||
|
||||
访问正在运行的虚拟机的控制台:
|
||||
|
||||
```
|
||||
$ virsh console alice
|
||||
```
|
||||
|
||||
设置虚拟机开机启动:
|
||||
|
||||
```
|
||||
$ virsh autostart alice
|
||||
```
|
||||
|
||||
查看虚拟机的详细信息:
|
||||
|
||||
```
|
||||
$ virsh dominfo alice
|
||||
```
|
||||
|
||||
编辑虚拟机的配置文件:
|
||||
|
||||
```
|
||||
$ virsh edit alice
|
||||
```
|
||||
|
||||
上面的这个命令将会使用一个默认的编辑器来调用主机配置文件。该配置文件中的任何改变都将自动被libvirt验证其正确性。
|
||||
|
||||
你也可以在一个virsh会话中管理虚拟机。下面的命令会创建并进入到一个virsh会话中:
|
||||
|
||||
```
|
||||
$ virsh
|
||||
```
|
||||
|
||||
在 virsh 提示中,你可以使用任何 virsh 命令。
|
||||
|
||||
|
||||
|
||||
### 问题处理 ###
|
||||
|
||||
1. 我在创建虚拟机的时候遇到了一个错误:
|
||||
|
||||
error: internal error: no supported architecture for os type 'hvm'
|
||||
|
||||
如果你的硬件不支持虚拟化的话你可能就会遇到这个错误。(例如,Intel VT或者AMD-V),这是运行KVM所必需的。如果你遇到了这个错误,而你的cpu支持虚拟化,那么这里可以给你一些可用的解决方案:
|
||||
|
||||
首先,检查你的内核模块是否丢失。
|
||||
|
||||
```
|
||||
$ lsmod | grep kvm
|
||||
```
|
||||
|
||||
如果内核模块没有加载,你必须按照如下方式加载它。
|
||||
|
||||
```
|
||||
$ sudo modprobe kvm_intel (for Intel processor)
|
||||
$ sudo modprobe kvm_amd (for AMD processor)
|
||||
```
|
||||
|
||||
第二个解决方案就是添加 `--connect qemu:///system` 参数到 `virsh` 命令中,如下所示。当你正在你的硬件平台上使用超过一个虚拟机管理器的时候就需要添加这个参数(例如,VirtualBox,VMware)。
|
||||
|
||||
```
|
||||
$ virsh --connect qemu:///system create alice.xml
|
||||
```
|
||||
|
||||
2. 当我试着访问我的虚拟机的登陆控制台的时候遇到了错误:
|
||||
|
||||
```
|
||||
$ virsh console alice
|
||||
error: internal error: cannot find character device <null>
|
||||
```
|
||||
|
||||
这个错误发生的原因是你没有在你的虚拟机配置文件中定义控制台设备。在 xml 文件中加上下面的内部设备部分即可。
|
||||
|
||||
```
|
||||
<console type='pty'>
|
||||
<target port='0'/>
|
||||
</console>
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/use-kvm-command-line-debian-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[kylepeng93](https://github.com/kylepeng93 )
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
118
published/201602/20160218 The Best Linux Distros of 2016.md
Normal file
118
published/201602/20160218 The Best Linux Distros of 2016.md
Normal file
@ -0,0 +1,118 @@
|
||||
2016:如何选择 Linux 发行版
|
||||
================================
|
||||
|
||||
|
||||
|
||||
[不管是在企业级应用还是在消费者领域](http://www.cio.com/article/3017983/linux/2015s-most-exciting-linux-devices.html),2015 对于 Linux 来说都是极其重要的一年。作为一个从 2005 年就开始使用 Linux 的老用户,我有幸见证了 Linux 过去这 10 年里的重大发展,[并且,我相信它在 2016 年里会更加令人激动](http://www.cio.com/article/3017177/linux/11-predictions-for-linux-in-2016.html)。在这篇文章里,我会挑选几个将在 2016 年里大放光彩的最佳发行版给大家介绍一下。
|
||||
|
||||
## 强势归来的发行版:openSUSE
|
||||
|
||||
SUSE 是 openSUSE 发行版背后的公司,同时也是起步最早的 Linux 公司;[它在 Linus Torvalds 发布 Linux 的第二年就成立了](http://www.linux.com/news/software/applications/866964-exclusive-interview-with-suse-president-nils-brauckmann)。该公司的成立实际上早于现在的 Linux 公司之王 —— Red Hat。同时 SUSE 也是 [openSUSE](https://www.opensuse.org/) 社区发行版的发起者和赞助商。
|
||||
|
||||
2015 年,openSUSE 的开发团队决定向 SUSE Linux 企业版 (SLE) 靠拢,以便让用户可以获得企业服务器特性的发行版——类似于 CentOS 和 Ubuntu 那样。因此,openSUSE 变成了 [openSUSE Leap](https://en.opensuse.org/Portal:Leap),一个直接基于 SLE SP1 的发行版。
|
||||
|
||||
两个发行版共用相同的基础代码,相互受益 —— SUSE 会选用 openSUSE 中好的代码,反之亦然。如此,openSUSE 也放弃了原本常规的发布周期,新版本与 SLE 同步发行。这意味着每个版本将会有更长的生命周期。
|
||||
|
||||
这样做的结果是,openSUSE 就成了一个非常重要的发行版,因为潜在的 SLE 用户现在可以使用 openSUSE Leap 了。不过,这还不是全部,openSUSE 同样也有发行版 [Tumbleweed](http://www.cio.com/article/3008856/open-source-tools/is-opensuse-tumbleweed-good-enough-for-a-seasoned-arch-user.html) —— 一个纯净的滚动式版本。所以,用户们可以选择使用很稳定的 openSUSE Leap 或者经常更新的 openSUSE Tumbleweed。
|
||||
|
||||
在我的记忆中,还没有其他的发行版做了这样一个令人印象深刻的强势归来。
|
||||
|
||||
## 最高可定制性的发行版:Arch Linux
|
||||
|
||||
Arch Linux 是目前最好的滚动式更新的发行版。好吧,我可能有些偏见,因为我是一名 Arch Linux 用户 ( LCTT 译注:译者也是 Arch Linux 用户,它的定制性真的很好)。然而,我认为它好的真正原因是 Arch 在很多其他领域也都表现的非常优越,并且这才是我为什么用它作为主系统的原因。
|
||||
|
||||
- 对于那些想要学习 Linux 方方面面的用户来说,[Arch Linux](https://www.archlinux.org/) 无疑是一个绝佳的选择。因为你需要手动安装所有自己需要的东西,这样你会慢慢学到 Linux 系统的所有细节。
|
||||
|
||||
- Arch 是一个可高度定制发行版。任何桌面环境 (DE) 都没有了 “Arch” 的原味。你能够得到的只是一个基础系统,然后你可以在上边构建你所想要的发行版。无论好坏,也不像 openSUSE 或者 Ubuntu 那样,Arch 没有额外的补丁或者集成环境。你得到的基本就是上游开发者所创建的原始软件。
|
||||
|
||||
- Arch Linux 同时也是最好的滚动式更新的发行版之一。它需要经常保持着更新。用户所运行的基本上是最新的软件,当然,也可以通过非稳定仓库运行预发行版的软件。
|
||||
|
||||
- Arch 闻名于拥有为数众多的优秀文档。Arch Wiki 是我用以了解所有 Linux 相关事情的完整资源。
|
||||
|
||||
- Arch 中,我最喜欢的是,它提供了“任何”其他发行版中可用的的包和软件,同时还要感谢 AUR (Arch User Repository,Arch 用户仓库)。
|
||||
|
||||
## 最美观的发行版:elementary OS
|
||||
|
||||
不同的发行版会有不同的关注点——多数情况下表现为技术的不同。在大多数的 Linux 发行版中,外观和用户感觉并非他们优先考虑的事情 —— 这通常是桌面环境需要考虑的事情。
|
||||
|
||||
[elementary OS](https://elementary.io/) 正在尝试改变这一事实。在这个发行版中,设计是占据重要位置,并且原因明显——这个发行版是由那些以在 Linux 世界创建漂亮图标而闻名的设计人员所开发的。
|
||||
|
||||
elementary OS 相当注重整体外观和用户感觉。开发者创建了他们自己的组件,包括桌面环境。此外,他们只会选择那些符合设计规范的应用来加入到软件仓库。你可以发现 elementary OS 有很浓重的 Mac OS X 气息。
|
||||
|
||||
## 最好的新晋发行版:Solus
|
||||
|
||||
|
||||
|
||||
[Solus](https://solus-project.com/) 最近获得非常大的关注程度。它是一个看起来中规中矩、从零开始构建的操作系统,它并非 Debian 或者 Ubuntu 的衍生版本。它使用的 Budgie 桌面环境同样是从零开始构建的,但它的目标是兼容 Gnome。Solus 和 Google 的 Chrome OS 一样——一切从简。
|
||||
|
||||
我个人没怎么玩过 Solus,但它看起来很有前途。Solus 实际上并不是一个 “新” 系统。它曾以不同的形式和名称存在了很长时间,但直到 2015 年整个项目才以现在这个新名称重归大众视野。
|
||||
|
||||
## 最好的云操作系统:Chrome OS
|
||||
|
||||
[Chrome OS](https://www.chromium.org/chromium-os) 可能不会成为你的典型 Linux 发行版,毕竟它是基于浏览器的操作系统,主要用以在线使用。但由于它基于 Linux ,任何人都可以获取其源码进行编译,它同样是一个吸引人的系统。我每天都使用 Chrome OS,它是一个优秀、不用自己维护并且总是保持最新状态的系统,每个人都可以单纯地用它来进行 web 相关的用途。Chrome OS 和 Android 对于推动 Linux 在 PC 市场和移动市场的占有率有着不可或缺的功劳。
|
||||
|
||||
## 最好的笔记本计算机操作系统:Ubuntu MATE
|
||||
|
||||
大多数的笔记本计算机都没有高端的硬件,假如你运行了一个很耗费资源的桌面环境,那么你可能没有足够的系统资源或电量来维持你的使用 —— 因为基本上被操作系统自身消耗了。于是我找到了 [Ubuntu MATE](http://www.cio.com/article/2848475/ubuntu-mate-enterprise-customers.html) 这个优秀的系统。它是轻量级的环境,但提供了能让你拥有不错体验的所有软件。也幸好它的轻量级设计,大部分的系统资源都留来给你的软件使用,让你依旧可以完成一些繁重的任务。我认为它对于低端硬件来说是最好的发行版。
|
||||
|
||||
## 为老旧硬件支持而生的发行版:Lubuntu
|
||||
|
||||
假如你身边拥有一些过时的笔记本或 PC,给它安装 [Lubuntu](http://lubuntu.net/) 来获得重生吧。Lubuntu 使用的是 LXDE 桌面环境,但该项目与 Razor Qt 合并之后,变成了 LXQt。尽管最新的版本 15.04 依旧使用 LXDE,但之后的版本将会使用 LXQt。Lubuntu 对于老旧硬件来说是最合适不过的系统了。
|
||||
|
||||
## 为物联网 (IoT) 而生的发行版:Snappy Ubuntu Core
|
||||
|
||||
|
||||
|
||||
Snappy Ubuntu Core 是为物联网 (IoT) 及此类设备而生的 Linux 操作系统。该系统拥有巨大潜力,它可以将我们身边绝大多数的东西 —— 如路由器、咖啡机和无人机等——变成智能设备。让它更有趣的是,软件管理更新的方式以及为增加安全而提供的容器化支持。
|
||||
|
||||
## 为桌面系统而生的发行版:Linux Mint Cinnamon
|
||||
|
||||
[Linux Mint Cinnamon](http://www.linux.com/news/software/applications/838569-review-linux-mint-172-release/) 对于台式机和一些有强大硬件的笔记本来说是最好的操作系统。我一般把它叫做 Linux 世界里的 Mac OS X。老实说,由于 Cinnamon 的不稳定,我在很长一段时间内并不是 Linux Mint 的忠实粉丝。但是,在开发者使用Ubuntu LTS (Long Term Support,长期支持)作为基础版本之后,该发行版就变得难以想象的稳定。因为开发者不必花费精力来跟上 Ubuntu 的开发进度,他们现在可以将所有精力放到提升 Cinnamon 上。
|
||||
|
||||
## 为游戏而生的发行版:Steam OS
|
||||
|
||||
对于桌面版 Linux 来说,玩游戏同样是短板。很多用户为了能够玩游戏,安装了 Linux 和 Windows 双系统。而 Valve 则尝试改变这个局面。Valve 是一个游戏发行商,它提供一个可以在不同平台上运行游戏的客户端。并且,Valve 也同样创建了它自己的开源操作系统——[Steam OS](http://store.steampowered.com/steamos/)——为了创建一个基于 Linux 的游戏平台。截至 2015 年底,它的合作伙伴开始把搭载了 Steam OS 的机器推向市场。
|
||||
|
||||
## 为隐私而生的发行版:Tails
|
||||
|
||||
在充斥着大量监控和营销者的跟踪 (对目标内容进行的匿名跟踪通常是可接受的)的岁月,隐私保护就变成了一个重要问题。如果你想脱离政府或者市场机构的监控和跟踪,那么你需要一款始终考虑到隐私问题的操作系统。
|
||||
|
||||
在出于保护隐私的考虑上,没有任何一款系统可以超越 [Tails](https://tails.boum.org/)。它是一款基于 Debian 的发行版,并且在设计之初就考虑了隐私和匿名的支持。Tails 非常优秀,而且据报道说,NSA 认为这是对他们的监控的主要威胁之一。
|
||||
|
||||
## 为多媒体制作而生的发行版:Ubuntu Studio
|
||||
|
||||
基于 Linux 的操作系统有一个明显的弱点,那就是对多媒体制作的支持并不友好。所有专业级应用基本只能运行在 Windows 或者 Mac OS X 上。Linux 系统从来都不缺乏像样的音频/视频制作软件,但这样还是远远不够的。应该要有一款轻量级的桌面环境,使得那些宝贵的系统资源——如 CPU 和 RAM——尽量少占用,以便用于多媒体制作。目前,[Ubuntu Studio](https://ubuntustudio.org/tour/) 对多媒体制作的支持最好。它使用了 Xfce 桌面环境,并且有各种各样的音频、视频以及图像编辑应用。
|
||||
|
||||
## 最好的企业发行版:SLE/RHEL
|
||||
|
||||
企业级用户并不会通过浏览像这样的文章来了解他们的服务器该运行什么发行版。他们通常非常明确地知道该到哪里获取信息:即 [Red Hat Enterprise Linux](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux) 或 [SUSE Linux Enterprise](https://www.suse.com/)。这两个名字已经成了企业服务器的代名词了。同时,这些公司也都通过创新来推动将一切都容器化和变成软件定义的。
|
||||
|
||||
## 最好的服务器操作系统:Debian/CentOS
|
||||
|
||||
假如你在考虑自己运行一台服务器,但有不希望支付 RHEL 或者 SLE 授权的费用,那么 [Debian](https://www.debian.org/) 或者 [CentOS](https://www.centos.org/) 将是你最好的选择。这两个发行版是社区主导的服务器操作系统,具有不可动摇的地位。并且它们有着长期支持,你不必担忧需要经常去升级系统。
|
||||
|
||||
## 最好的移动操作系统:Plasma Mobile
|
||||
|
||||
尽管,基于 Linux 的 Android 系统称雄于移动操作系统市场,但是大多数的开源社区——也包括我在内——也仍然强烈希望能有一个发行版可以为移动设备提供传统 Linux 的桌面应用。同时,这样的一个发行版由开源社区来维护会比由商业公司来维护好的多,只有这样,用户才能成为这个发行版的关注点,而不是由公司的商业目标来决定这个发行版的发展趋势。KDE 的 [Plasma Mobile](https://community.kde.org/Plasma/Mobile) 刚好实现了我们的愿望。
|
||||
|
||||
这个基于 Kubuntu 的发行版始于 2015 年。因为 KDE 社区以坚守标准和为公众开发应用而闻名,我非常期待 Plasma Mobile 能够一直坚持下去。
|
||||
|
||||
## 为 ARM 设备而生的发行版:Arch Linux ARM
|
||||
|
||||
随着 Android 系统的成功,我们的生活也围绕者越来越多的 ARM 设备——从树莓派 (Raspberry Pi) 到 Chromebook 以及 Nvidia Shield。为 Intel/AMD 架构的 CPU 而编写的传统发行版并不能够在这些 ARM 架构的设备上运行。而一些为 ARM 而编写的发行版却仅仅只能在特定的硬件上运行,比如只能运行在树莓派 (Raspberry Pi) 上的 Raspbian 系统。这就是为什么 [Arch Linux ARM](http://archlinuxarm.org/) (ALARM) 让人眼前一亮的原因。它是一个基于 Arch Linux 的纯粹由社区主导的发行版,可以在树梅派 (Raspberry Pi)、Chromebook、Android 设备以及 Nvidia Shield 等设备上运行。同时,更好的是,也由于 AUR,你可以安装很多在其他发行版可能无法获取的软件。
|
||||
|
||||
## 结论
|
||||
|
||||
在我写完本文的时候,连我自己都震惊了。能够在 Linux 的世界里为大家写点东西真的是很令人激动。不必去管 Linux 统治桌面电脑的时代是否会到来,我们都要一样享受自己使用 Linux 的每一刻快乐时光。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/software/applications/878620-the-best-linux-distros-of-2016
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[mudongliang](https://github.com/mudongliang),[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/61003
|
||||
@ -0,0 +1,60 @@
|
||||
Linux Mint 18 将拥有自己的应用集
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
对于发行版开发者来说,创建和发布一系列专为他们发行版设计的应用是再平常不过的事情。一个最典型的例子就是 [elementary OS](https://elementary.io/) 。而在经过九年的努力后,Linux Mint 终于孤注一掷做了相同的事情。
|
||||
|
||||
[Linux Mint](http://www.linuxmint.com/) 是现今最著名的 Linux 发行版之一。其基于 Ubuntu 和 Debian,Linux Mint 努力去创建一个现代的、优雅的、舒适的操作系统,不但强大而且易用。(LCTT 译注:Linux Mint 基于 Ubuntu,而 Linux Mint Debian Edition 基于 Debian。)Linux Mint 背后的团队同时也积极参与 [MATE](http://itsfoss.com/install-mate-desktop-ubuntu-14-04/) 和 [Cinnamon](http://itsfoss.com/install-cinnamon-ubuntu-14-04/) 桌面环境开发。
|
||||
|
||||
## 前有 X 战警(X-men),后有 X 应用(X-Apps)
|
||||
|
||||
周四, Linux Mint 项目领导者 Clement Lefebvre [宣布](http://blog.linuxmint.com/?p=2985) X-Apps 的创建。X-Apps 被设计为不依赖特定桌面环境,以便开发者可以直接更新它们而不必针对每一种桌面环境做调整。Lefebvre 声明这些 X-Apps 将会被作为 Cinnamon、MATE 和 Xfce 桌面环境的默认应用。
|
||||
|
||||
## Linux 是否需要更多的应用?
|
||||
|
||||
据 Lefebvre 所述,X-Apps 的创建是因 GNOME 3.18 发布所需。对于 GNOME 3.18 的发布,他这样说:
|
||||
|
||||
> “GTK 本身和一些 GNOME 应用都在 GNOME SHELL 上集成地很好,而且看起来风格很一致。坏消息就是它们在任何别的地方看起来很不相称。使事情变得更糟的是,Ubuntu 的旗舰产品 Unity 重度依赖 GTK、GNOME 应用及 GNOME 环境本身,所以我们这里不能在上游的 3.18 版本中处理,而这一系列的补丁会带来它们自己的问题(举一个例子,Ubuntu 在应用中重新引入菜单条和标题栏,但是不重写它们的头部栏..所以你有时会看到它们三者一起出现)。”
|
||||
|
||||
在过去,Linux Mint 团队通过“应用降级(例如 Linux Mint 17 使用 gedit 2.30),给 GNOME 打补丁以及使用替代品(大部分在 MATE 和 Xfce)”来处理这个问题。
|
||||
|
||||
Lefebvre 也说为 Cinnamon 和 MATE 构建特定应用没有意义。这就是为什么他们选择开发那些通用的,可以完美地适应运行在 Cinnamon,MATE 和 Xfce(以及其他可能的桌面环境)的应用。
|
||||
|
||||
他进一步补充道:
|
||||
|
||||
>“X-Apps 将会是一个通用的,使用传统的接口 GTK3 应用的集合。它能被用作 Cinnamon,MATE 和 Xfce 默认的桌面组件。在 Mint 18 中,“X apps” 将允许我们去维护一个本地风格及更高层面的集成。因为它们将会被用于替代看起来很不一致的 GNOME 桌面应用。长期来讲,X-App 项目将会允许我们去开发新的功能和改进应用本身(这是一些我们无法通过打补丁,临时分支或者特定桌面的分支做到的事情,比如说 MATE 桌面应用,因为它代价太高)。”
|
||||
|
||||
## 将会有什么类型的应用?
|
||||
|
||||

|
||||
|
||||
Lefebvre 只透露其中一个即将来临的 X-Apps:一个名为 xedit 的文本编辑器。下面是这个软件提供的一些特性:
|
||||
|
||||
- 基于 Pluma,很容易学会使用
|
||||
- 使用 GTK3
|
||||
- 不依赖 GNOME 或 MATE
|
||||
|
||||
## 何时呢?
|
||||
|
||||
X-Apps 将会和 [Linux Mint 18](http://itsfoss.com/linux-mint-18-codenamed-sarah/) 一同到来。而 Linux Mint 18 将会在 Ubuntu 16.04 LTS 发布之后数月后发布。[Ubuntu 16.04 LTS 计划于四月发布。](http://itsfoss.com/ubuntu-1604-release-schedule/)
|
||||
|
||||
## 总结
|
||||
|
||||
就我而言,无论何时当我听见某人发布一个新发行版特定的应用,我都会局促不安。Linux 世界本身已经难以想象的碎片化了。我们真的需要花费时间和精力去创建更多的重复的项目吗?但不要误解我,我喜欢桌面无关软件的想法。它将修复大量的一个桌面一个应用样子的问题。
|
||||
|
||||
使我发愁的问题是“它们是否会成功?”。正如我之前所说,Linux Mint 团队成员也在两种桌面环境工作。目前增加了应用开发就让这些混在一起了。我自己没有写过一个软件(除了 Hello World),但是我知道当你尝试且使一个项目复杂化,就会发生不好的事情。许多项目已经变成了不断膨胀的恶龙。我希望这样的事不要发生在这里。
|
||||
|
||||
你有不同的想法吗?在下方评论以便让我知道。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/linux-mint-own-apps/
|
||||
|
||||
作者:[JOHN PAUL][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/john/
|
||||
@ -0,0 +1,28 @@
|
||||
我们能通过快速、开放的研究来战胜寨卡病毒吗?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
关于寨卡病毒,最主要的问题就是我们对于它了解的太少了。这意味着我们需要尽快对它作出很多研究。
|
||||
|
||||
寨卡病毒现已严重威胁到世界人民的健康。在 2015 年爆发之后,它就成为了全球性的突发公共卫生事件,并且这个病毒也可能与儿童的出生缺陷有关。根据[维基百科][4],在这个病毒在 40 年代末期被发现以后,早在 1952 年就被观测到了对于人类的影响。
|
||||
|
||||
在 2 月 10 日,开放杂志 PLoS [发布了一个声明][1],这个是声明是关于有关公众紧急状况的信息共享。在此之后,刊登在研究期刊 F1000 的一篇文章 [对于能治疗寨卡病毒的开源药物(Open drug)的研究][2],它讨论了寨卡病毒及其开放研究的状况。那篇来自 PLoS 的声明列出了超过 30 个开放了对于寨卡病毒的研究进度的数据的重要组织。并且世界卫生组织实施了一个特别规定,以[创作共用许可证][3]公布提交到他们那里的资料。
|
||||
|
||||
快速公布,无限制的重复利用,以及强调研究结果的传播是推动开放科研社区的战略性一步。看到我们所关注的突发公共卫生事件能够以这样的方式开始是很令人受鼓舞的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-rapid-open-science-could-change-game-zika-virus
|
||||
|
||||
作者:[Marcus D. Hanwell][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhanwell
|
||||
[1]: http://blogs.plos.org/plos/2016/02/statement-on-data-sharing-in-public-health-emergencies/
|
||||
[2]: http://f1000research.com/articles/5-150/v1
|
||||
[3]: https://creativecommons.org/licenses/by/3.0/igo/
|
||||
[4]: https://en.wikipedia.org/wiki/Zika_virus
|
||||
127
published/20160204 An Introduction to SELinux.md
Normal file
127
published/20160204 An Introduction to SELinux.md
Normal file
@ -0,0 +1,127 @@
|
||||
SELinux 入门
|
||||
===============================
|
||||
|
||||
回到 Kernel 2.6 时代,那时候引入了一个新的安全系统,用以提供访问控制安全策略的机制。这个系统就是 [Security Enhanced Linux (SELinux)][1],它是由[美国国家安全局(NSA)][2]贡献的,它为 Linux 内核子系统引入了一个健壮的强制控制访问(Mandatory Access Control)架构。
|
||||
|
||||
如果你在之前的 Linux 生涯中都禁用或忽略了 SELinux,这篇文章就是专门为你写的:这是一篇对存在于你的 Linux 桌面或服务器之下的 SELinux 系统的介绍,它能够限制权限,甚至消除程序或守护进程的脆弱性而造成破坏的可能性。
|
||||
|
||||
在我开始之前,你应该已经了解的是 SELinux 主要是红帽 Red Hat Linux 以及它的衍生发行版上的一个工具。类似地, Ubuntu 和 SUSE(以及它们的衍生发行版)使用的是 AppArmor。SELinux 和 AppArmor 有显著的不同。你可以在 SUSE,openSUSE,Ubuntu 等等发行版上安装 SELinux,但这是项难以置信的挑战,除非你十分精通 Linux。
|
||||
|
||||
说了这么多,让我来向你介绍 SELinux。
|
||||
|
||||
### DAC vs. MAC
|
||||
|
||||
Linux 上传统的访问控制标准是自主访问控制(Discretionary Access Control,DAC)。在这种形式下,一个软件或守护进程以 User ID(UID)或 Set owner User ID(SUID)的身份运行,并且拥有该用户的目标(文件、套接字、以及其它进程)权限。这使得恶意代码很容易运行在特定权限之下,从而取得访问关键的子系统的权限。
|
||||
|
||||
另一方面,强制访问控制(Mandatory Access Control,MAC)基于保密性和完整性强制信息的隔离以限制破坏。该限制单元独立于传统的 Linux 安全机制运作,并且没有超级用户的概念。
|
||||
|
||||
### SELinux 如何工作
|
||||
|
||||
考虑一下 SELinux 的相关概念:
|
||||
|
||||
- 主体(Subjects)
|
||||
- 目标(Objects)
|
||||
- 策略(Policy)
|
||||
- 模式(Mode)
|
||||
|
||||
当一个主体(Subject,如一个程序)尝试访问一个目标(Object,如一个文件),SELinux 安全服务器(SELinux Security Server,在内核中)从策略数据库(Policy Database)中运行一个检查。基于当前的模式(mode),如果 SELinux 安全服务器授予权限,该主体就能够访问该目标。如果 SELinux 安全服务器拒绝了权限,就会在 /var/log/messages 中记录一条拒绝信息。
|
||||
|
||||
听起来相对比较简单是不是?实际上过程要更加复杂,但为了简化介绍,只列出了重要的步骤。
|
||||
|
||||
### 模式
|
||||
|
||||
SELinux 有三个模式(可以由用户设置)。这些模式将规定 SELinux 在主体请求时如何应对。这些模式是:
|
||||
|
||||
- Enforcing (强制)— SELinux 策略强制执行,基于 SELinux 策略规则授予或拒绝主体对目标的访问
|
||||
- Permissive (宽容)— SELinux 策略不强制执行,不实际拒绝访问,但会有拒绝信息写入日志
|
||||
- Disabled (禁用)— 完全禁用 SELinux
|
||||
|
||||

|
||||
|
||||
*图 1:getenforce 命令显示 SELinux 的状态是 Enforcing 启用状态。*
|
||||
|
||||
默认情况下,大部分系统的 SELinux 设置为 Enforcing。你要如何知道你的系统当前是什么模式?你可以使用一条简单的命令来查看,这条命令就是 `getenforce`。这个命令用起来难以置信的简单(因为它仅仅用来报告 SELinux 的模式)。要使用这个工具,打开一个终端窗口并执行 `getenforce` 命令。命令会返回 Enforcing、Permissive,或者 Disabled(见上方图 1)。
|
||||
|
||||
设置 SELinux 的模式实际上很简单——取决于你想设置什么模式。记住:**永远不推荐关闭 SELinux**。为什么?当你这么做了,就会出现这种可能性:你磁盘上的文件可能会被打上错误的权限标签,需要你重新标记权限才能修复。而且你无法修改一个以 Disabled 模式启动的系统的模式。你的最佳模式是 Enforcing 或者 Permissive。
|
||||
|
||||
你可以从命令行或 `/etc/selinux/config` 文件更改 SELinux 的模式。要从命令行设置模式,你可以使用 `setenforce` 工具。要设置 Enforcing 模式,按下面这么做:
|
||||
|
||||
1. 打开一个终端窗口
|
||||
2. 执行 `su` 然后输入你的管理员密码
|
||||
3. 执行 `setenforce 1`
|
||||
4. 执行 `getenforce` 确定模式已经正确设置(图 2)
|
||||
|
||||

|
||||
|
||||
*图 2:设置 SELinux 模式为 Enforcing。*
|
||||
|
||||
要设置模式为 Permissive,这么做:
|
||||
|
||||
1. 打开一个终端窗口
|
||||
2. 执行 `su` 然后输入你的管理员密码
|
||||
3. 执行 `setenforce 0`
|
||||
4. 执行 `getenforce` 确定模式已经正确设置(图 3)
|
||||
|
||||

|
||||
|
||||
*图 3:设置 SELinux 模式为 Permissive。*
|
||||
|
||||
注:通过命令行设置模式会覆盖 SELinux 配置文件中的设置。
|
||||
|
||||
如果你更愿意在 SELinux 命令文件中设置模式,用你喜欢的编辑器打开那个文件找到这一行:
|
||||
|
||||
SELINUX=permissive
|
||||
|
||||
你可以按你的偏好设置模式,然后保存文件。
|
||||
|
||||
还有第三种方法修改 SELinux 的模式(通过 bootloader),但我不推荐新用户这么做。
|
||||
|
||||
### 策略类型
|
||||
|
||||
SELinux 策略有两种:
|
||||
|
||||
- Targeted — 只有目标网络进程(dhcpd,httpd,named,nscd,ntpd,portmap,snmpd,squid,以及 syslogd)受保护
|
||||
- Strict — 对所有进程完全的 SELinux 保护
|
||||
|
||||
你可以在 `/etc/selinux/config` 文件中修改策略类型。用你喜欢的编辑器打开这个文件找到这一行:
|
||||
|
||||
SELINUXTYPE=targeted
|
||||
|
||||
修改这个选项为 targeted 或 strict 以满足你的需求。
|
||||
|
||||
### 检查完整的 SELinux 状态
|
||||
|
||||
有个方便的 SELinux 工具,你可能想要用它来获取你启用了 SELinux 的系统的详细状态报告。这个命令在终端像这样运行:
|
||||
|
||||
sestatus -v
|
||||
|
||||
你可以看到像图 4 那样的输出。
|
||||
|
||||

|
||||
|
||||
*图 4:sestatus -v 命令的输出。*
|
||||
|
||||
### 仅是皮毛
|
||||
|
||||
和你预想的一样,我只介绍了 SELinux 的一点皮毛。SELinux 的确是个复杂的系统,想要更扎实地理解它是如何工作的,以及了解如何让它更好地为你的桌面或服务器工作需要更加地深入学习。我的内容还没有覆盖到疑难解答和创建自定义 SELinux 策略。
|
||||
|
||||
SELinux 是所有 Linux 管理员都应该知道的强大工具。现在已经向你介绍了 SELinux,我强烈推荐你回到 Linux.com(当有更多关于此话题的文章发表的时候)或看看 [NSA SELinux 文档][3] 获得更加深入的指南。
|
||||
|
||||
LCTT - 相关阅读:[鸟哥的 Linux 私房菜——程序管理与 SELinux 初探][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/docs/ldp/883671-an-introduction-to-selinux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/community/forums/person/93
|
||||
[1]: http://selinuxproject.org/page/Main_Page
|
||||
[2]: https://www.nsa.gov/research/selinux/
|
||||
[3]: https://www.nsa.gov/research/selinux/docs.shtml
|
||||
[4]: http://vbird.dic.ksu.edu.tw/linux_basic/0440processcontrol_5.php
|
||||
200
published/20160225 The Tao of project management.md
Normal file
200
published/20160225 The Tao of project management.md
Normal file
@ -0,0 +1,200 @@
|
||||
《道德经》之项目管理
|
||||
=================================
|
||||
|
||||
|
||||

|
||||
|
||||
[道德经][1],[被认为][2]是由圣人[老子][3]于公元前六世纪时所编写,是现存最为广泛翻译的经文之一。从[宗教][4]到[关于约会的有趣电影][5]等方方面面,它都深深地影响着它们,作者们借用它来做隐喻,以解释各种各样的事情(甚至是[编程][6])。
|
||||
|
||||
在思考有关开放性组织的项目管理时,我的脑海中便立马浮现出上面的这段文字。
|
||||
|
||||
这听起来可能会有点奇怪。若要理解我的这种想法从何而来,你应该读读 *《开放性组织:点燃激情提升执行力》* 这本书,它是红帽公司总裁、首席执行官 Jim Whitehurst 所写的一本有关企业文化和新领导力范式的宣言。在这本书中,Jim(还有来自其他红帽人的一点帮助)解释了传统组织机构(一种 “自上而下” 的方式,来自高层的决策被传达到员工,而员工通过晋升和薪酬来激励)和开放性组织机构(一种 自下而上 的方式,领导专注于激励和鼓励,员工被充分授权以各尽其能)之间的差异。
|
||||
|
||||
在开放性组织中的员工都是被激情、目标和参与感所激励,这个观点正是我认为项目管理者所应该关注的。
|
||||
|
||||
要解释这一切,我将从*道德经*上寻找依据。
|
||||
|
||||
### 不要让工作职衔框住自身
|
||||
|
||||
> 道,可道也,(The tao that can be told)
|
||||
|
||||
> 非恒道也。(is not the eternal Tao)
|
||||
|
||||
> 名,可名也,(The name that can be named)
|
||||
|
||||
> 非恒名也。(is not the eternal Name.)
|
||||
|
||||
> “无”,名天地之始;(The unnameable is the eternally real.)
|
||||
|
||||
> “有”,名万物之母。(Naming is the origin of all particular things.)
|
||||
[[1]][7]
|
||||
|
||||
项目管理到底是什么?作为一个项目管理者应该做些什么呢?
|
||||
|
||||
如您所想,项目管理者的一部分工作就是管理项目:收集需求、与项目相关人员沟通、设置项目优先级、安排任务、帮助团队解决困扰。许多机构都可以教你如何做好项目管理,并且这些技能你值得拥有。
|
||||
|
||||
然而,在开放性组织中,字面上的项目管理技能仅仅只是项目管理者需要做到的一小部分,这些组织需要更多其他的东西:即勇气。如果你擅长于管理项目(或者是真的擅长于任何工作),那么你就进入了舒适区。这时候就是需要鼓起勇气开始尝试冒险之时。
|
||||
|
||||
您有勇气跨出舒适区吗?向权威人士提出挑战性的问题,可能会引发对方的不快,但也可能会开启一个更好的方法,您有勇气这样做吗?有确定需要做的下一件事,然后真正去完成它的勇气吗?有主动去解决因为交流的鸿沟而遗留下来的问题的勇气吗?有去尝试各种事情的勇气吗?有失败的勇气吗?
|
||||
|
||||
道德经的开篇(上面引用的)就表明词语(words)、标签(labels)、名字(names)这些是有限制的,当然也包括工作职衔。在开放性组织中,项目经理不仅仅是执行管理项目所需的机械任务,而且要帮助团队完成组织的使命,尽管这已经被限定了。
|
||||
|
||||
### 联系起合适的人
|
||||
|
||||
> 三十辐共一轂,(We join spokes together in a wheel,)
|
||||
|
||||
> 当其无,(but it is the center hole)
|
||||
|
||||
> 有车之用。(that makes the wagon move.)
|
||||
[[11]][8]
|
||||
|
||||
当我过渡到项目管理的工作时,我必须学会的最为困难的一课是:并不是所有解决方案都是可完全地接受,甚至有的连预期都达不到。这对我来说是全新的一页。我*喜欢*全部都能解决。但作为项目管理者,我的角色更多的是与人沟通--使得那些确实有解决方案的人可以更高效地合作。
|
||||
|
||||
这并不是逃避责任或者不负责。这意味着可以很舒适的说,“我不知道,但我会给你找出答案”,然后就可迅速地结束这个循环。
|
||||
|
||||
想像一下马车的车轮,如果没有毂中的孔洞所提供的稳定性和方向,辐条便会失去支持,车轮也会散架。在一个开放性的组织中,项目管理者可以通过把合适的人凝聚在一起,培养正确的讨论话题来帮助团队保持持续向前的动力。
|
||||
|
||||
### 信任你的团队
|
||||
|
||||
>太上,不知有之;(When the Master governs, the people
|
||||
are hardly aware that he exists.)
|
||||
|
||||
> 其次,亲而誉之;(Next best is a leader who is loved.)
|
||||
|
||||
> 其次,畏之;(Next, one who is feared.)
|
||||
|
||||
> 其次,侮之。(The worst is one who is despised.)
|
||||
|
||||
>信不足焉,(If you don't trust the people,)
|
||||
|
||||
>有不信焉。(you make them untrustworthy.)
|
||||
|
||||
>悠兮,其贵言。(The Master doesn't talk, he acts.)
|
||||
|
||||
> 功成事遂,(When his work is done,)
|
||||
|
||||
> 百姓皆谓:“我自然”。(the people say, "Amazing:
|
||||
we did it, all by ourselves!")
|
||||
[[17]][9]
|
||||
|
||||
[Rebecca Fernandez][10] 曾经告诉我开放性组织的领导与其它组织的领导者最大的不同点在于,我们不是去取得别人的信任,而是信任别人。
|
||||
|
||||
开放性组织会雇佣那些非常聪明的,且对公司正在做的事情充满激情的人来做工作。为了能使他们能更好的工作,我们会提供其所需,并尊重他们的工作方式。
|
||||
|
||||
至于原因,我认为从道德经中摘出的上面一段就说的很清楚。
|
||||
|
||||
### 顺其自然
|
||||
|
||||
>上德无为而无以为;(The Master does nothing
|
||||
yet he leaves nothing undone.)
|
||||
|
||||
>下德为之而有以为。(The ordinary man is always doing things,
|
||||
yet many more are left to be done.)
|
||||
[[38]][11]
|
||||
|
||||
你认识那类总是极其忙碌的人吗?认识那些因为有太多事情要做而看起来疲倦和压抑的人吗?
|
||||
|
||||
不要成为那样的人。
|
||||
|
||||
我知道说比做容易。帮助我没有成为那类人的最重要的东西是:我时刻记着*大家都很忙*这件事。我没有一个那样无聊的同事。
|
||||
|
||||
但总需要有人成为在狂风暴雨中仍保持镇定的人。总需要有人能够宽慰团队告诉他们一切都会好起来,我们将在现实和一天中工作时间有限的情况下,找到方法使得任务能够完成(因为事实就是这样的,而且我们必须这样)。
|
||||
|
||||
成为那样的人吧。
|
||||
|
||||
对于上面这段道德经所说的,我的理解是那些总是谈论他或她正在做什么的人实际上并*没有时间*去做他们谈论的事。如果相比于你周围的人,你能把你的工作做的毫不费劲,那就说明你的工作做对了。
|
||||
|
||||
### 做一名文化传教士
|
||||
|
||||
>上士闻道,(When a superior man hears of the Tao,)
|
||||
|
||||
> 勤而行之;(he immediately begins to embody it.)
|
||||
|
||||
> 中士闻道,(When an average man hears of the Tao,)
|
||||
|
||||
>若存若亡;(he half believes it, half doubts it.)
|
||||
|
||||
> 下士闻道,(When a foolish man hears of the Tao,)
|
||||
|
||||
> 大笑之。(he laughs out loud.)
|
||||
|
||||
> 不笑不足以為道。(If he didn't laugh,it wouldn't be the Tao.)
|
||||
[[41]][12]
|
||||
|
||||
去年秋天,我和一群联邦雇员参加了一堂 MBA 的商业准则课程。当我开始介绍我们公司的文化、价值和伦理框架时,我得到的直接印象是:我的同学和教授都认为我就像一个天真可爱的小姑娘,做着许多关于公司应该如何运作的[甜美白日梦][13]。他们告诉我事情不可能是他们看起来的那样,他们还告诉我应该进一步考察。
|
||||
|
||||
所以我照做了。
|
||||
|
||||
然而我发现的是:事情*恰好*是他们看起来的那样。
|
||||
|
||||
在开放性组织,关于企业文化,人们应该随着企业的成长而时时维护那些文化,以使它随时精神焕发,充满斗志。我(和其它开源组织的成员)并不想过着如我同学们所描述的那样,“为生活而工作”。我需要有激情、有目标,需要明白自己的日常工作是如何对那些我所坚信的东西做贡献的。
|
||||
|
||||
作为一个项目管理者,你可能会认为在你的团队中,你的工作对培养你们公司的企业文化没有多少帮助。然而你的工作正是孕育文化本身。
|
||||
|
||||
### Kaizen (持续改善)
|
||||
|
||||
>为学日益,(In pursuit of knowledge,every day something is added.)
|
||||
|
||||
> 为道日损。(In the practice of the Tao,every day something is dropped.)
|
||||
|
||||
> 损之又损,(Less and less do you need to force things,)
|
||||
|
||||
> 以至于无为。(until finally you arrive at non-action. )
|
||||
|
||||
> 无为而无不为。(When nothing is done,nothing is left undone.)
|
||||
[[48]][14]
|
||||
|
||||
项目管理的常规领域都太过于专注最新、最强大的的工具,但对于应该使用哪种工具,这个问题的答案总是一致的:“最简单的”。
|
||||
|
||||
例如,我将任务列表放在桌面的一个文本文件中,因为它很单纯,不会受到不必要的干扰。您想介绍给团队的,无论是何种工具、流程和程序都应该是能提高效率,排除障碍的,而不是引入额外的复杂性。所以与其专注于工具,还不如专注于要使用这些工具来解决的*问题*。
|
||||
|
||||
作为一个项目经理,我最喜爱的部分是在敏捷世界中,我有自由抛弃那些没有成效的东西的权利。这与 [kaizen][16] 的概念相关,或叫 “持续改进”。不要害怕尝试和失败。失败是我们在探索什么能够起作用,什么不能起作用的过程中所用的标签,这是提高的唯一方式。
|
||||
|
||||
最好的过程都不是一蹴而就的。作为项目管理者,你应该通过支持他们,而不是强迫他们去做某些事来帮助你的团队。
|
||||
|
||||
### 实践
|
||||
|
||||
>天下皆谓我"道"大,(Some say that my teaching is nonsense.)
|
||||
|
||||
> 似不肖。(Others call it lofty but impractical.)
|
||||
|
||||
> 夫唯大,(But to those who have looked inside themselves,)
|
||||
|
||||
> 故似不肖。(this nonsense makes perfect sense.)
|
||||
|
||||
>若肖,(And to those who put it into practice,)
|
||||
|
||||
> 久矣其细也夫!(this loftiness has roots that go deep.)
|
||||
[[67]][15]
|
||||
|
||||
我相信开放性组织正在做的事。开放性组织在管理领域的工作几乎与他们提供的产品和服务一样重要。我们有机会以身作则,激发他人的激情和目的,创造激励和充分授权的工作环境。
|
||||
|
||||
我鼓励你们找到办法把这些想法融入到自己的项目和团队中,看看会发生什么。了解你们组织的使命,知晓你的项目是如何为这个使命做贡献的。鼓起勇气,尝试某些看起来没有多少成效的事,同时不要忘记和我们的社区分享你所学到的经验,这样我们就可以继续改进。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/16/2/tao-project-management
|
||||
|
||||
作者:[Allison Matlack][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[FSSlc](https://github.com/FSSlc)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amatlack
|
||||
[1]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html
|
||||
[2]: https://en.wikipedia.org/wiki/Tao_Te_Ching
|
||||
[3]: http://plato.stanford.edu/entries/laozi/
|
||||
[4]: https://en.wikipedia.org/wiki/Taoism
|
||||
[5]: http://www.imdb.com/title/tt0234853/
|
||||
[6]: http://www.mit.edu/~xela/tao.html
|
||||
[7]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#1
|
||||
[8]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#11
|
||||
[9]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#17
|
||||
[10]: https://opensource.com/users/rebecca
|
||||
[11]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#38
|
||||
[12]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#41
|
||||
[13]: https://opensource.com/open-organization/15/9/reflections-open-organization-starry-eyed-dreamer
|
||||
[14]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#48
|
||||
[15]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#67
|
||||
[16]: https://www.kaizen.com/about-us/definition-of-kaizen.html
|
||||
@ -1,12 +1,11 @@
|
||||
年轻人,你为啥使用 linux
|
||||
================================================================================
|
||||
> 今天的开源综述:是什么带你进入 linux 的世界?号外:IBM 基于 Linux 的大型机。以及,你应该抛弃 win10 选择 Linux 的原因。
|
||||
|
||||
### 当初你为何使用 Linux? ###
|
||||
|
||||
Linux 越来越流行,很多 OS X 或 Windows 用户都转移到 Linux 阵营了。但是你知道是什么让他们开始使用 Linux 的吗?一个 Reddit 用户在网站上问了这个问题,并且得到了很多有趣的回答。
|
||||
|
||||
一个名为 SilverKnight 的用户在 Reddit 的 Linux 板块上问了如下问题:
|
||||
一个名为 SilverKnight 的用户在 Reddit 的 Linux 版块上问了如下问题:
|
||||
|
||||
> 我知道这个问题肯定被问过了,但我还是想听听年轻一代使用 Linux 的原因,以及是什么让他们坚定地成为 Linux 用户。
|
||||
>
|
||||
@ -18,7 +17,7 @@ Linux 越来越流行,很多 OS X 或 Windows 用户都转移到 Linux 阵营
|
||||
|
||||
以下是网站上的回复:
|
||||
|
||||
> **DoublePlusGood**:我12岁开始使用 Backtrack(现在改名为 Kali),因为我想成为一名黑客(LCTT 译注:原文1337 haxor,1337 是 leet 的火星文写法,意为'火星文',haxor 为 hackor 的火星文写法,意为'黑客',另一种写法是 1377 h4x0r,满满的火星文文化)。我现在一直使用 ArchLinux,因为它给我无限自由,让我对我的电脑可以为所欲为。
|
||||
> **DoublePlusGood**:我12岁开始使用 Backtrack(现在改名为 Kali),因为我想成为一名黑客(LCTT 译注:原文“1337 haxor”,1337 是 leet 的火星文写法,意为'火星文',haxor 为 hackor 的火星文写法,意为'黑客',另一种写法是 1377 h4x0r,满满的火星文文化)。我现在一直使用 ArchLinux,因为它给我无限自由,让我对我的电脑可以为所欲为。
|
||||
>
|
||||
> **Zack**:我记得是12、3岁的时候使用 Linux,现在15岁了。
|
||||
>
|
||||
@ -44,9 +43,9 @@ Linux 越来越流行,很多 OS X 或 Windows 用户都转移到 Linux 阵营
|
||||
>
|
||||
> 我很喜欢这个系统。然后在圣诞节的时候我得到树莓派,上面只能跑 Debian,还不能支持其它发行版。
|
||||
>
|
||||
> **Cqz**:我9岁的时候有一次玩 Windows 98,结果这货当机了,原因未知。我没有 Windows 安装盘,但我爸的一本介绍编程的杂志上有一张随书附赠的光盘,这张光盘上刚好有 Mandrake Linux 的安装软件,于是我瞬间就成为了 Linux 用户。我当时还不知道自己在玩什么,但是玩得很嗨皮。这些年我虽然在电脑上装了多种 Windows 版本,但是 FLOSS 世界才是我的家。现在我只把 Windows 装在虚拟机上,用来玩游戏。
|
||||
> **Cqz**:我9岁的时候有一次玩 Windows 98,结果这货当机了,原因未知。我没有 Windows 安装盘,但我爸的一本介绍编程的杂志上有一张随书附赠的光盘,这张光盘上刚好有 Mandrake Linux 的安装软件,于是我瞬间就成为了 Linux 用户。我当时还不知道自己在玩什么,但是玩得很嗨皮。这些年我虽然在电脑上装了多种 Windows 版本,但是 FLOSS 世界才是我的家(LCTT 译注:FLOSS —— Free/Libre and Open Source Software,自由/开源软件)。现在我只把 Windows 装在虚拟机上,用来玩游戏。
|
||||
>
|
||||
> **Tosmarcel**:15岁那年对'编程'这个概念很好奇,然后我开始了哈佛课程'CS50',这个课程要我们安装 Linux 虚拟机用来执行一些命令。当时我问自己为什么 Windows 没有这些命令?于是我 Google 了 Linux,搜索结果出现了 Ubuntu,在安装 Ubuntu。的时候不小心把 Windows 分区给删了。。。当时对 Linux 毫无所知,适应这个系统非常困难。我现在16岁,用 ArchLinux,不想用回 Windows,我爱 ArchLinux。
|
||||
> **Tosmarcel**:15岁那年对'编程'这个概念很好奇,然后我开始了哈佛课程'CS50',这个课程要我们安装 Linux 虚拟机用来执行一些命令。当时我问自己为什么 Windows 没有这些命令?于是我 Google 了 Linux,搜索结果出现了 Ubuntu,在安装 Ubuntu 的时候不小心把 Windows 分区给删了。。。当时对 Linux 毫无所知,适应这个系统非常困难。我现在16岁,用 ArchLinux,不想用回 Windows,我爱 ArchLinux。
|
||||
>
|
||||
> **Micioonthet**:第一次听说 Linux 是在我5年级的时候,当时去我一朋友家,他的笔记本装的就是 MEPIS(Debian的一个比较老的衍生版),而不是 XP。
|
||||
>
|
||||
@ -54,7 +53,7 @@ Linux 越来越流行,很多 OS X 或 Windows 用户都转移到 Linux 阵营
|
||||
>
|
||||
> 我13岁那年还没有自己的笔记本电脑,而我另一位朋友总是抱怨他的电脑有多慢,所以我打算把它买下来并修好它。我花了20美元买下了这台装着 Windows Vista 系统、跑满病毒、完全无法使用的惠普笔记本。我不想重装讨厌的 Windows 系统,记得 Linux 是免费的,所以我刻了一张 Ubuntu 14.04 光盘,马上把它装起来,然后我被它的高性能给震精了。
|
||||
>
|
||||
> 我的世界(由于它允运行在 JAVA 上,所以当时它是 Linux 下为数不多的几个游戏之一)在 Vista 上只能跑5帧每秒,而在 Ubuntu 上能跑到25帧。
|
||||
> “我的世界(Minecraft)”(由于它允许运行在 JAVA 上,所以当时它是 Linux 下为数不多的几个游戏之一)在 Vista 上只能跑5帧每秒,而在 Ubuntu 上能跑到25帧。
|
||||
>
|
||||
> 我到现在还会偶尔使用一下那台笔记本,Linux 可不会在乎你的硬件设备有多老。
|
||||
>
|
||||
@ -62,9 +61,9 @@ Linux 越来越流行,很多 OS X 或 Windows 用户都转移到 Linux 阵营
|
||||
>
|
||||
> **Webtm**:我爹每台电脑都会装多个发行版,有几台是 opensuse 和 Debian,他的个人电脑装的是 Slackware。所以我记得很小的时候一直在玩 debian,但没有投入很多精力,我用了几年的 Windows,然后我爹问我有没有兴趣试试 debian。这是个有趣的经历,在那之后我一直使用 debian。而现在我不用 Linux,转投 freeBSD,5个月了,用得很开心。
|
||||
>
|
||||
> 完全控制自己的系统是个很奇妙的体验。开源届有好多酷酷的软件,我认为在自己解决一些问题并且利用这些工具解决其他事情的过程是最有趣的。当然稳定和高效也是吸引我的地方。更不用说它的保密级别了。
|
||||
> 完全控制自己的系统是个很奇妙的体验。开源界有好多酷酷的软件,我认为在自己解决一些问题并且利用这些工具解决其他事情的过程是最有趣的。当然稳定和高效也是吸引我的地方。更不用说它的保密级别了。
|
||||
>
|
||||
> **Wyronaut**:我今年18,第一次玩 Linux 是13岁,当时玩的 Ubuntu,为啥要碰 Linux?因为我想搭一个'我的世界'的服务器来和小伙伴玩游戏,当时'我的世界'可是个新鲜玩意儿。而搭个私服需要用 Linux 系统。
|
||||
> **Wyronaut**:我今年18,第一次玩 Linux 是13岁,当时玩的 Ubuntu,为啥要碰 Linux?因为我想搭一个“我的世界”的服务器来和小伙伴玩游戏,当时“我的世界”可是个新鲜玩意儿。而搭个私服需要用 Linux 系统。
|
||||
>
|
||||
> 当时我还是个新手,对着 Linux 的命令行有些傻眼,因为很多东西都要我自己处理。还是多亏了 Google 和维基,我成功地在多台老 PC 上部署了一些简单的服务器,那些早已无人问津的老古董机器又能发挥余热了。
|
||||
>
|
||||
@ -90,7 +89,7 @@ Linux 越来越流行,很多 OS X 或 Windows 用户都转移到 Linux 阵营
|
||||
>
|
||||
> 老实说我对电脑挺感兴趣的,当我还没接触'自由软件哲学'的时候,我认为 free 是免费的意思。我也不认为命令行界面很让人难以接受,因为我小时候就接触过 DOS 系统。
|
||||
>
|
||||
> 我第一个发行版是 Mandrake,在我11岁还是12岁那年我把家里的电脑弄得乱七八糟,然后我一直折腾那台电脑,试着让我技的技能提升一个台阶。现在我在一家公司全职使用 Linux。(请允许我耸个肩)。
|
||||
> 我第一个发行版是 Mandrake,在我11岁还是12岁那年我把家里的电脑弄得乱七八糟,然后我一直折腾那台电脑,试着让我自己的技能提升一个台阶。现在我在一家公司全职使用 Linux。(请允许我耸个肩)。
|
||||
>
|
||||
> **Matto**:我的电脑是旧货市场淘回来的,装 XP,跑得慢,于是我想换个系统。Google 了一下,发现 Ubuntu。当年我15、6岁,现在23了,就职的公司内部使用 Linux。
|
||||
>
|
||||
@ -133,7 +132,7 @@ via: http://www.itworld.com/article/2972587/linux/why-did-you-start-using-linux.
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,200 @@
|
||||
|
||||
一步一脚印:GNOME十八年进化史
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/MtmcO5vRNFQ?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
[GNOME][1] (GNU Object Model Environment)由两位墨西哥的程序员 Miguel de Icaza 和 Federico Mena 始创于1997年8月15日。GNOME 自由软件计划由志愿者和全职开发者来开发一个桌面环境及其应用程序。GNOME 桌面环境的所有部分都由开源软件组成,并且支持Linux, FreeBSD, OpenBSD 等操作系统。
|
||||
|
||||
现在就让我穿越到1997年来看看 GNOME 的第一个版本:
|
||||
|
||||
### GNOME 1 ###
|
||||
|
||||

|
||||
|
||||
*GNOME 1.0 (1997) – GNOME 发布的第一个重大版本*
|
||||
|
||||

|
||||
|
||||
*GNOME 1.2 “Bongo”,2000*
|
||||
|
||||

|
||||
|
||||
*GNOME 1.4 “Tranquility”, 2001*
|
||||
|
||||
### GNOME 2 ###
|
||||
|
||||

|
||||
|
||||
*GNOME 2.0, 2002*
|
||||
|
||||
重大更新,基于 GTK+ 2。引入了人机界面指南(Human Interface Guidelines)。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.2 2003*
|
||||
|
||||
改进了多媒体和文件管理器。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.4 “Temujin”, 2003*
|
||||
|
||||
首次发布 Epiphany 浏览器,增添了辅助功能(accessibility)。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.6, 2004*
|
||||
|
||||
Nautilus 成为主要的文件管理工具,同时引入了新的 GTK+ 对话框。作为对这个版本中变化的结果,创建了一个存在时间不久的分叉版本:GoneME。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.8, 2004*
|
||||
|
||||
改良了对可移动设备的支持,并新增了 Evolution 邮件应用。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.10, 2005*
|
||||
|
||||
减小了内存需求和提升了性能。增加了新的面板小应用(调制解调器控制、磁盘挂载器和回收站组件)以及 Totem 影片播放器和 Sound Juicer CD抓取工具。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.12, 2005*
|
||||
|
||||
改进了 Nautilus,改进了应用程序间的剪切/粘贴功能和 freedesktop.org 的整合。 新增 Evince PDF 阅读器;新默认主题 Clearlooks;菜单编辑器、钥匙环管理器和管理员工具。基于 GTK+2.8,支持 Cairo。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.14, 2006*
|
||||
|
||||
性能提升(某些情况下超过 100%);增强用户界面的易用性;GStreamer 0.10 多媒体框架。增加了 Ekiga 视频会议应用、Deskbar 搜索工具、Pessulus 权限管理器、快速切换用户功能和 Sabayon 系统管理员工具。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.16, 2006*
|
||||
|
||||
性能提升。增加了 Tomboy 笔记应用、Baobab 磁盘用量分析应用、Orca 屏幕阅读器以及 GNOME 电源管理程序(延长了笔记本电池寿命)。改进了 Totem、Nautilus。Metacity 窗口管理器的合成(compositing)支持。新的图标主题。基于 GTK+ 2.0 的全新打印对话框。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.18, 2007*
|
||||
|
||||
性能提升。增加了 Seahorse GPG 安全应用,可以对邮件和本地文件进行加密。Baobab 改进了环状图表显示方式的支持。Orca 屏幕阅读器。改进了 Evince、Epiphany、GNOME 电源管理、音量控制。增加了两款新游戏:GNOME 数独和 glChess 国际象棋。支持 MP3 和 AAC 音频解码。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.20, 2007*
|
||||
|
||||
发布十周年版本。Evolution 增加了备份功能。改进了 Epiphany、EOG、GNOME 电源管理。Seahorse 中的钥匙环密码管理功能。增加:在 Evince 中可以编辑PDF文档、文件管理界面中整合了搜索模块、自动安装多媒体解码器。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.22, 2008*
|
||||
|
||||
新增 Cheese 应用,它是一个可以截取网络摄像头和远程桌面图像的工具。Metacity 支持基本的窗口合成(compositing)。引入 GVFS(LCTT译注:GNOME Virtual file system,GNOME 虚拟文件系统)。改善了Totem 播放 DVD 和 YouTube 的效果,支持播放 MythTV。时钟小应用支持国际化。在 Evolution 中新增了谷歌日历以及为信息添加标签的功能。改进了 Evince、Tomboy、 Sound Juicer 和计算器。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.24, 2008*
|
||||
|
||||
新增了 Empathy 即时通讯软件。Ekiga 升级至3.0版本。Nautilus 支持标签式浏览,更好的支持了多屏幕显示方式和数字电视功能。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.26, 2009*
|
||||
|
||||
新增光盘刻录应用 Brasero。简化了文件分享的流程。改进了媒体播放器的性能。支持多显示器和指纹识别器。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.28, 2009*
|
||||
|
||||
增加了 GNOME 蓝牙模块。改进了 Epiphany 网页浏览器、Empathy 即时通讯软件、时间追踪器和辅助功能。GTK+ 升级至2.18版本。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.30, 2010*
|
||||
|
||||
改进了 Nautilus 文件管理器、Empathy 即时通讯软件、Tomboy、Evince、时间追踪器、Epiphany 和 Vinagre。借助 GVFS 通过 libimobiledevice(LCTT 译注:支持iOS®设备跨平台使用的工具协议库)部分地支持了 iPod 和 iPod Touch 设备。
|
||||
|
||||

|
||||
|
||||
*GNOME 2.32, 2010*
|
||||
|
||||
新增 Rygel 媒体分享工具和 GNOME 色彩管理器。改进了 Empathy 即时通讯软件、Evince、Nautilus 文件管理器等。由于计划于2010年9月发布3.0版本,因此大部分开发者的精力都由2.3x转移至了3.0版本。
|
||||
|
||||
### GNOME 3 ###
|
||||
|
||||

|
||||
|
||||
*GNOME 3.0, 2011*
|
||||
|
||||
引入 GNOME Shell,这是一个重新设计的、具有更简练更集中的选项的框架。基于 Mallard 标记语言的话题导向型帮助系统。支持窗口并列堆叠。启用新的视觉主题和默认字体。采用 GTK+ 3.0,具有更好的语言绑定、主题、触控以及多平台支持。去除了那些长期弃用的 API。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.2、 2011*
|
||||
|
||||
支持在线帐户、“浏览器”应用。新增通讯录应用和文档文件管理器。“文件管理器”支持快速预览。较大的整合,文档更完善,以及对外观的改善和各种性能提升。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.4, 2012*
|
||||
|
||||
全新外观的 GNOME 3 应用程序:“文件”、Epiphany(更名为“浏览器”)、“GNOME 通讯录”。可以在活动概览中搜索本地文件。支持应用菜单。焕然一新的界面元素:新的颜色拾取器、重新设计的滚动条、更易使用的旋钮以及可隐藏的标题栏。支持平滑滚动。全新的动态壁纸。在系统设置中改进了对 Wacom 数位板的支持。更简便的扩展应用管理。更好的硬件支持。面向主题的帮助文档。在 Empathy 中提供了对视频电话和动态信息的支持。更好的辅助功能:提升 Orca 整合度,增强高对比度模式,以及全新的缩放设置。大量的应用增强和对细节的改进。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.6, 2012*
|
||||
|
||||
全新设计的核心元素:新的应用按钮和改进的活动概览布局。新的登录和锁定界面。重新设计的通知栏。通知现在更智能,可见性更高,同时更容易关闭。改进了系统设置的界面和设定逻辑。用户菜单默认显示关闭电源操作。整合的输入方式。辅助功能一直开启。新的应用:Boxes 桌面虚拟化,曾在 GNOME 3.4中发布过预览版。Clocks 时钟,可以显示世界时间。更新了磁盘用量分析、Empathy 和字体查看器的外观。改进了 Orca 对布莱叶盲文的支持。 在“浏览器”中,用最常访问页面取代了之前的空白起始页,增添了更好的全屏模式并使用了 WebKit2 测试版引擎。 Evolution 开始使用 WebKit 显示邮件内容。 改进了“磁盘”功能。 改进了“文件”应用(即之前的 Nautilus),新增诸如最近访问的文件和搜索等功能。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.8, 2013*
|
||||
|
||||
令人耳目一新的核心组件:新应用界面可以分别显示常用应用及全部应用。窗口布局得到全面改造。新的屏幕即现式(OSD)输入法开关。通知和信息现在会对屏幕边缘的点击作出回应。为那些喜欢传统桌面的用户提供了经典模式。重新设计了设置界面的工具栏。新的初始化引导流程。“GNOME 在线帐户”添加了对更多供应商的支持。“浏览器”正式启用 WebKit2 引擎,有了一个新的私密浏览模式。“文档”支持双页模式并且整合了 “Google 文档”。“通讯录”的 UI 升级。“GNOME 文件”、“GNOME Boxes”和“GNOME 磁盘”都得到了大幅改进。集成了 ownCloud。两款全新的 GNOME 核心应用:“GNOME 时钟”和“GNOME 天气”。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.10, 2013*
|
||||
|
||||
全新打造的系统状态区,能够更直观的纵览全局。一系列新应用,包括 “GNOME 地图”、“GNOME 备忘录”、 “GNOME 音乐”和“GNOME 照片”。新的基于位置的功能,如自动时区和世界时钟。支持高分辨率及智能卡。 基于 GLib 2.38 提供了对 D-Bus 的支持。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.12, 2014*
|
||||
|
||||
改进了概览中的键盘导航和窗口选择,基于易用性测试对初始设置进行了修改。有线网络图标重新回到了状态栏上,在“应用”视图中可以自定义应用文件夹。在大量应用的对话框中引入了新的 GTK+ 小工具,同时使用了新的 GTK+ 标签风格。“GNOME 视频”,“GNOME 终端”以及 Gedit 都改用了全新外观,更贴合 HIG(LCTT 译注:Human Interface Guidelines,人机界面指南)。在 GNOME Shell 的终端仿真器中提供了搜索预测功能。增强了对 “GNOME 软件”和高分辨率显示屏的支持。提供了新的录音工具。增加了新的桌面通知接口。在向 Wayland 移植的进度中达到了可用的程度,可用选择性地预览体验。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.14, 2014*
|
||||
|
||||
更炫酷的桌面环境效果,改善了对触摸屏的支持。“GNOME 软件”可以管理安装的插件。在“GNOME 照片”中可以访问 “Google 相册”。重绘了 Evince、数独、扫雷和天气应用的用户界面,同时增加了一款叫做 Hitori 的 GNOME 游戏。
|
||||
|
||||

|
||||
|
||||
*GNOME 3.16, 2015*
|
||||
|
||||
33000 处改变。主要的修改包括 UI 的配色方案从黑色变成了炭黑色。 增加了即现式滚动条。通知窗口中整合了日历应用。对“文件”,图像查看器和“地图”等大量应用进行了微调。可以预览应用程序。进一步从 X11 向 Wayland 移植。
|
||||
|
||||
感谢 GNOME Project 及 [Wikipedia][2] 提供的变更日志!感谢阅读!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/18-years-of-gnome-evolution/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[Haohong WANG](https://github.com/HaohongWANG)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:https://www.gnome.org/
|
||||
[2]:https://en.wikipedia.org/wiki/GNOME
|
||||
@ -1,6 +1,6 @@
|
||||
如何在 FreeBSD 10.2 上安装使用 Nginx 的 Ghost
|
||||
================================================================================
|
||||
Node.js 是用于开发服务器端应用程序的开源运行时环境。Node.js 应用使用 JavaScript 编写,能在任何有 Node.js 运行时的服务器上运行。它跨平台支持 Linux、Windows、OSX、IBM AIX,也包括 FreeBSD。Node.js 是 Ryan Dahl 以及在 Joyent 工作的其他开发者于 2009 年创建的。它的设计目标就是构建可扩展的网络应用程序。
|
||||
Node.js 是用于开发服务器端应用程序的开源的运行时环境。Node.js 应用使用 JavaScript 编写,能在任何有 Node.js 运行时的服务器上运行。它跨平台支持 Linux、Windows、OSX、IBM AIX,也包括 FreeBSD。Node.js 是 Ryan Dahl 以及在 Joyent 工作的其他开发者于 2009 年创建的。它的设计目标就是构建可扩展的网络应用程序。
|
||||
|
||||
Ghost 是使用 Node.js 编写的博客平台。它不仅开源,而且有很漂亮的界面设计、对用户友好并且免费。它允许你快速地在网络上发布内容,或者创建你的混合网站。
|
||||
|
||||
@ -97,7 +97,7 @@ Ghost 是使用 Node.js 编写的博客平台。它不仅开源,而且有很
|
||||
|
||||
npm start --production
|
||||
|
||||
通过访问服务器 ip 和 2368 号端口验证。
|
||||
通过访问服务器 ip 和 2368 号端口验证一下。
|
||||
|
||||

|
||||
|
||||
@ -189,7 +189,7 @@ Ghost 是使用 Node.js 编写的博客平台。它不仅开源,而且有很
|
||||
|
||||
### 第五步 - 为 Ghost 安装和配置 Nginx ###
|
||||
|
||||
默认情况下,ghost 会以单机模式运行,你可以不用 Nginx、apache 或 IIS web 服务器直接运行它。但在这篇指南中我们会安装和配置 nginx 和 ghost 一起使用。
|
||||
默认情况下,ghost 会以独立模式运行,你可以不用 Nginx、apache 或 IIS web 服务器直接运行它。但在这篇指南中我们会安装和配置 nginx 和 ghost 一起使用。
|
||||
|
||||
用 pkg 命令从 freebsd 库中安装 nginx:
|
||||
|
||||
@ -289,7 +289,7 @@ via: http://linoxide.com/linux-how-to/install-ghost-nginx-freebsd-10-2/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,162 @@
|
||||
网络与安全方面的最佳开源软件
|
||||
================================================================================
|
||||
InfoWorld 在部署、运营和保障网络安全领域精选出了年度开源工具获奖者。
|
||||
|
||||

|
||||
|
||||
### 最佳开源网络和安全软件 ###
|
||||
|
||||
[BIND](https://en.wikipedia.org/wiki/BIND), [Sendmail](https://en.wikipedia.org/wiki/Sendmail), [OpenSSH](https://en.wikipedia.org/wiki/OpenSSH), [Cacti](https://en.wikipedia.org/wiki/Cactus), [Nagios](https://en.wikipedia.org/wiki/Nagios), [Snort](https://en.wikipedia.org/wiki/Snort_%28software%29) -- 这些为了网络而生的开源软件,好些家伙们老而弥坚。今年在这个范畴的最佳选择中,你会发现中坚、支柱、新人和新贵云集,他们正在完善网络管理,安全监控,漏洞评估,[rootkit](https://en.wikipedia.org/wiki/Rootkit) 检测,以及很多方面。
|
||||
|
||||

|
||||
|
||||
### Icinga 2 ###
|
||||
|
||||
Icinga 起先只是系统监控应用 Nagios 的一个衍生分支。[Icinga 2][1] 经历了完全的重写,为用户带来了时尚的界面、对多数据库的支持,以及一个集成了众多扩展的 API。凭借着开箱即用的负载均衡、通知和配置文件,Icinga 2 缩短了在复杂环境下安装的时间。Icinga 2 原生支持 [Graphite](https://github.com/graphite-project/graphite-web)(系统监控应用),轻松为管理员呈现实时性能图表。不过真的让 Icinga 今年重新火起来的原因是 Icinga Web 2 的发布,那是一个支持可拖放定制的 仪表盘 和一些流式监控工具的前端图形界面系统。
|
||||
|
||||
管理员可以查看、过滤、并按优先顺序排列发现的问题,同时可以跟踪已经采取的动作。一个新的矩阵视图使管理员能够在单一页面上查看主机和服务。你可以通过查看特定时间段的事件或筛选事件类型来了解哪些事件需要立即关注。虽然 Icinga Web 2 有着全新界面和更为强劲的性能,不过对于传统版 Icinga 和 Web 版 Icinga 的所有常用命令还是照旧支持的。这意味着学习新版工具不耗费额外的时间。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Zenoss Core ###
|
||||
|
||||
这是另一个强大的开源软件,[Zenoss Core][2] 为网络管理员提供了一个完整的、一站式解决方案来跟踪和管理所有的应用程序、服务器、存储、网络组件、虚拟化工具、以及企业基础架构的其他元素。管理员可以确保硬件的运行效率并利用 ZenPacks 中模块化设计的插件来扩展功能。
|
||||
|
||||
在2015年二月发布的 Zenoss Core 5 保留了已经很强大的工具,并进一步改进以增强用户界面和扩展 仪表盘。基于 Web 的控制台和 仪表盘 可以高度可定制并动态调整,而现在的新版本还能让管理员混搭多个组件图表到一个图表中。想来这应该是一个更好的根源分析和因果分析的工具。
|
||||
|
||||
Portlets 为网络映射、设备问题、守护进程、产品状态、监视列表和事件视图等等提供了深入的分析。而且新版 HTML5 图表可以从工具导出。Zenoss 的控制中心支持带外管理并且可监控所有 Zenoss 组件。Zenoss Core 现在拥有一些新工具,用于在线备份和恢复、快照和回滚以及多主机部署等方面。更重要的是,凭借对 Docker 的全面支持,部署起来更快了。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenNMS ###
|
||||
|
||||
作为一个非常灵活的网络管理解决方案,[OpenNMS][3] 可以处理任何网络管理任务,无论是设备管理、应用性能监控、库存控制,或事件管理。凭借对 IPv6 的支持、强大的警报系统和记录用户脚本来测试 Web 应用程序的能力,OpenNMS 拥有网络管理员和测试人员需要的一切。OpenNMS 现在变得像一款移动版 仪表盘,称之为 OpenNMS Compass,可让网络专家随时,甚至在外出时都可以监视他们的网络。
|
||||
|
||||
该应用程序的 IOS 版本,可从 [iTunes App Store][4] 上获取,可以显示故障、节点和告警。下一个版本将提供更多的事件细节、资源图表、以及关于 IP 和 SNMP 接口的信息。安卓版可从 [Google Play][5] 上获取,可在 仪表盘 上显示网络可用性,故障和告警,以及可以确认、提升或清除告警。移动客户端与 OpenNMS Horizon 1.12 或更高版本以及 OpenNMS Meridian 2015.1.0 或更高版本兼容。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Security Onion ###
|
||||
|
||||
如同一个洋葱,网络安全监控是由许多层组成。没有任何一个单一的工具可以让你洞察每一次攻击,为你显示对你的公司网络中的每一次侦查或是会话的足迹。[Security Onion][6] 在一个简单易用的 Ubuntu 发行版中打包了许多久经考验的工具,可以让你看到谁留在你的网络里,并帮助你隔离这些坏家伙。
|
||||
|
||||
无论你是采取主动式的网络安全监测还是追查可能的攻击,Security Onion 都可以帮助你。Onion 由传感器、服务器和显示层组成,结合了基于网络和基于主机的入侵检测,全面的网络数据包捕获,并提供了所有类型的日志以供检查和分析。
|
||||
|
||||
这是一个众星云集的的网络安全工具链,包括用于网络抓包的 [Netsniff-NG](http://www.netsniff-ng.org/)、基于规则的网络入侵检测系统 Snort 和 [Suricata](https://en.wikipedia.org/wiki/Suricata_%28software%29),基于分析的网络监控系统 Bro,基于主机的入侵检测系统 OSSEC 和用于显示、分析和日志管理的 Sguil、Squert、Snorby 和 ELSA (企业日志搜索和归档(Enterprise Log Search and Archive))。它是一个经过精挑细选的工具集,所有的这些全被打包进一个向导式的安装程序并有完整的文档支持,可以帮助你尽可能快地上手监控。
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
### Kali Linux ###
|
||||
|
||||
[Kali Linux][7] 背后的团队今年为这个流行的安全 Linux 发行版发布了新版本,使其更快,更全能。Kali 采用全新 4.0 版的内核,改进了对硬件和无线驱动程序的支持,并且界面更为流畅。最常用的工具都可从屏幕的侧边栏上轻松找到。而最大的改变是 Kali Linux 现在是一个滚动发行版,具有持续不断的软件更新。Kali 的核心系统是基于 Debian Jessie,而且该团队会不断地从 Debian 测试版拉取最新的软件包,并持续的在上面添加 Kali 风格的新特性。
|
||||
|
||||
该发行版仍然配备了很多的渗透测试,漏洞分析,安全审查,网络应用分析,无线网络评估,逆向工程,和漏洞利用工具。现在该发行版具有上游版本检测系统,当有个别工具可更新时系统会自动通知用户。该发行版还提过了一系列 ARM 设备的镜像,包括树莓派、[Chromebook](https://en.wikipedia.org/wiki/Chromebook) 和 [Odroid](https://en.wikipedia.org/wiki/ODROID),同时也更新了 Android 设备上运行的 [NetHunter](https://www.kali.org/kali-linux-nethunter/) 渗透测试平台。还有其他的变化:Metasploit 的社区版/专业版不再包括在内,因为 Kali 2.0 还没有 [Rapid7 的官方支持][8]。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenVAS ###
|
||||
|
||||
开放式漏洞评估系统(Open Vulnerability Assessment System) [OpenVAS][9],是一个整合多种服务和工具来提供漏洞扫描和漏洞管理的软件框架。该扫描器可以使用每周更新一次的网络漏洞测试数据,或者你也可以使用商业服务的数据。该软件框架包括一个命令行界面(以使其可以用脚本调用)和一个带 SSL 安全机制的基于 [Greenbone 安全助手][10] 的浏览器界面。OpenVAS 提供了用于附加功能的各种插件。扫描可以预定运行或按需运行。
|
||||
|
||||
可通过单一的主控来控制多个安装好 OpenVAS 的系统,这使其成为了一个可扩展的企业漏洞评估工具。该项目兼容的标准使其可以将扫描结果和配置存储在 SQL 数据库中,这样它们可以容易地被外部报告工具访问。客户端工具通过基于 XML 的无状态 OpenVAS 管理协议访问 OpenVAS 管理器,所以安全管理员可以扩展该框架的功能。该软件能以软件包或源代码的方式安装在 Windows 或 Linux 上运行,或者作为一个虚拟应用下载。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### OWASP ###
|
||||
|
||||
[OWASP][11](开放式 Web 应用程序安全项目(Open Web Application Security Project))是一个专注于提高软件安全性的在全球各地拥有分会的非营利组织。这个社区性的组织提供测试工具、文档、培训和几乎任何你可以想象到的开发安全软件相关的软件安全评估和最佳实践。有一些 OWASP 项目已成为很多安全从业者工具箱中的重要组件:
|
||||
|
||||
[ZAP][12](ZED 攻击代理项目(Zed Attack Proxy Project))是一个在 Web 应用程序中寻找漏洞的渗透测试工具。ZAP 的设计目标之一是使之易于使用,以便于那些并非安全领域专家的开发人员和测试人员能便于使用。ZAP 提供了自动扫描和一套手动测试工具集。
|
||||
|
||||
[Xenotix XSS Exploit Framework][13] 是一个先进的跨站点脚本漏洞检测和漏洞利用框架,该框架通过在浏览器引擎内执行扫描以获取真实的结果。Xenotix 扫描模块使用了三个智能模糊器( intelligent fuzzers),使其可以运行近 5000 种不同的 XSS 有效载荷。它有个 API 可以让安全管理员扩展和定制漏洞测试工具包。
|
||||
|
||||
[O-Saft][14](OWASP SSL 高级审查工具(OWASP SSL advanced forensic tool))是一个查看 SSL 证书详细信息和测试 SSL 连接的 SSL 审计工具。这个命令行工具可以在线或离线运行来评估 SSL ,比如算法和配置是否安全。O-Saft 内置提供了常见漏洞的检查,你可以容易地通过编写脚本来扩展这些功能。在 2015 年 5 月加入了一个简单的图形用户界面作为可选的下载项。
|
||||
|
||||
[OWTF][15](攻击性 Web 测试框架(Offensive Web Testing Framework))是一个遵循 OWASP 测试指南和 NIST 和 PTES 标准的自动化测试工具。该框架同时支持 Web 用户界面和命令行,用于探测 Web 和应用服务器的常见漏洞,如配置失当和软件未打补丁。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### BeEF ###
|
||||
|
||||
Web 浏览器已经成为用于针对客户端的攻击中最常见的载体。[BeEF][15] (浏览器漏洞利用框架项目(Browser Exploitation Framework Project)),是一种广泛使用的用以评估 Web 浏览器安全性的渗透工具。BeEF 通过浏览器来启动客户端攻击,帮助你暴露出客户端系统的安全弱点。BeEF 建立了一个恶意网站,安全管理员用想要测试的浏览器访问该网站。然后 BeEF 发送命令来攻击 Web 浏览器并使用命令在客户端机器上植入软件。随后管理员就可以把客户端机器看作不设防般发动攻击了。
|
||||
|
||||
BeEF 自带键盘记录器、端口扫描器和 Web 代理这样的常用模块,此外你可以编写你自己的模块或直接将命令发送到被控制的测试机上。BeEF 带有少量的演示网页来帮你快速入门,使得编写更多的网页和攻击模块变得非常简单,让你可以因地适宜的自定义你的测试。BeEF 是一个非常有价值的评估浏览器和终端安全、学习如何发起基于浏览器攻击的测试工具。可以使用它来向你的用户综合演示,那些恶意软件通常是如何感染客户端设备的。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### Unhide ###
|
||||
|
||||
[Unhide][16] 是一个用于定位开放的 TCP/UDP 端口和隐藏在 UNIX、Linux 和 Windows 上的进程的审查工具。隐藏的端口和进程可能是由于运行 Rootkit 或 LKM(可加载的内核模块(loadable kernel module)) 导致的。Rootkit 可能很难找到并移除,因为它们就是专门针对隐蔽性而设计的,可以在操作系统和用户前隐藏自己。一个 Rootkit 可以使用 LKM 隐藏其进程或冒充其他进程,让它在机器上运行很长一段时间而不被发现。而 Unhide 则可以使管理员们确信他们的系统是干净的。
|
||||
|
||||
Unhide 实际上是两个单独的脚本:一个用于进程,一个用于端口。该工具查询正在运行的进程、线程和开放的端口并将这些信息与系统中注册的活动比较,报告之间的差异。Unhide 和 WinUnhide 是非常轻量级的脚本,可以运行命令行而产生文本输出。它们不算优美,但是极为有用。Unhide 也包括在 [Rootkit Hunter][17] 项目中。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### 查看更多的开源软件优胜者 ###
|
||||
|
||||
InfoWorld 网站的 2015 年最佳开源奖由下至上表扬了 100 多个开源项目。通过以下链接可以查看更多开源软件中的翘楚:
|
||||
|
||||
[2015 Bossie 评选:最佳开源应用程序][18]
|
||||
|
||||
[2015 Bossie 评选:最佳开源应用程序开发工具][19]
|
||||
|
||||
[2015 Bossie 评选:最佳开源大数据工具][20]
|
||||
|
||||
[2015 Bossie 评选:最佳开源数据中心和云计算软件][21]
|
||||
|
||||
[2015 Bossie 评选:最佳开源桌面和移动端软件][22]
|
||||
|
||||
[2015 Bossie 评选:最佳开源网络和安全软件][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982962/open-source-tools/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[robot527](https://github.com/robot527)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://www.icinga.org/icinga/icinga-2/
|
||||
[2]:http://www.zenoss.com/
|
||||
[3]:http://www.opennms.org/
|
||||
[4]:https://itunes.apple.com/us/app/opennms-compass/id968875097?mt=8
|
||||
[5]:https://play.google.com/store/apps/details?id=com.opennms.compass&hl=en
|
||||
[6]:http://blog.securityonion.net/p/securityonion.html
|
||||
[7]:https://www.kali.org/
|
||||
[8]:https://community.rapid7.com/community/metasploit/blog/2015/08/12/metasploit-on-kali-linux-20
|
||||
[9]:http://www.openvas.org/
|
||||
[10]:http://www.greenbone.net/
|
||||
[11]:https://www.owasp.org/index.php/Main_Page
|
||||
[12]:https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project
|
||||
[13]:https://www.owasp.org/index.php/O-Saft
|
||||
[14]:https://www.owasp.org/index.php/OWASP_OWTF
|
||||
[15]:http://www.beefproject.com/
|
||||
[16]:http://www.unhide-forensics.info/
|
||||
[17]:http://www.rootkit.nl/projects/rootkit_hunter.html
|
||||
[18]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[19]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[20]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[21]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[22]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[23]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -0,0 +1,204 @@
|
||||
五大开源 Web 代理软件横向比较:Squid、Privoxy、Varnish、Polipo、Tinyproxy
|
||||
================================================================================
|
||||
Web 代理软件转发 HTTP 请求时并不会改变数据流量。它们可以配置成透明代理,而无需客户端配置。它们还可以作为反向代理放在网站的前端;这样缓存服务器可以为一台或多台 web 服务器提供无限量的用户服务。
|
||||
|
||||
网站代理功能多样,有着宽泛的用途:从缓存页面、DNS 和其他查询,到加速 web 服务器响应、降低带宽消耗。代理软件广泛用于大型高访问量的网站,比如纽约时报、卫报, 以及社交媒体网站如 Twitter、Facebook 和 Wikipedia。
|
||||
|
||||
页面缓存已经成为优化单位时间内所能吞吐的数据量的至关重要的机制。好的 Web 缓存还能降低延迟,尽可能快地响应页面,让终端用户不至于因等待内容的时间过久而失去耐心。它们还能将频繁访问的内容缓存起来以节省带宽。如果你需要降低服务器负载并改善网站内容响应速度,那缓存软件能带来的好处就绝对值得探索一番。
|
||||
|
||||
为深入探查 Linux 下可用的相关软件的质量,我列出了下边5个优秀的开源 web 代理工具。它们中有些功能完备强大,也有几个只需很低的资源就能运行。
|
||||
|
||||
### Squid ###
|
||||
|
||||
Squid 是一个高性能、开源的代理缓存服务器和 Web 缓存进程,支持 FTP、Internet Gopher、HTTPS 和 SSL 等多种协议。它通过一个非阻塞的、I/O 事件驱动的单一进程处理所有的 IPV4 或 IPV6 协议请求。
|
||||
|
||||
Squid 由一个主服务程序 squid,和 DNS 查询程序 dnsserver,另外还有一些可选的请求重写、执行认证程序组件,及一些管理和客户端工具构成。
|
||||
|
||||
Squid 提供了丰富的访问控制、认证和日志环境, 用于开发 web 代理和内容服务网站应用。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- Web 代理:
|
||||
- 通过缓存来降低访问时间和带宽使用
|
||||
- 将元数据和访问特别频繁的对象缓存到内存中
|
||||
- 缓存 DNS 查询
|
||||
- 支持非阻塞的 DNS 查询
|
||||
- 实现了失败请求的未果缓存
|
||||
- Squid 缓存可架设为层次结构,或网状结构以节省额外的带宽
|
||||
- 通过广泛的访问控制来执行网站访问策略
|
||||
- 隐匿请求,如禁用或修改客户端 HTTP 请求头特定属性
|
||||
- 反向代理
|
||||
- 媒体范围(media-range)限制
|
||||
- 支持 SSL
|
||||
- 支持 IPv6
|
||||
- 错误页面的本地化 - Squid 可以根据访问者的语言选项对每个请求展示本地化的错误页面
|
||||
- 连接固定(Connection Pinning )(用于 NTLM Auth Passthrough) - 一种允许 Web 服务器通过 Web 代理使用Microsoft NTLM 安全认证替代 HTTP 标准认证的方案
|
||||
- 支持服务质量 (QoS, Quality of Service) 流
|
||||
- 选择一个 TOS/Diffserv 值来标记本地命中
|
||||
- 选择一个 TOS/Diffserv 值来标记对端命中
|
||||
- 选择性地仅标记同级或上级请求
|
||||
- 允许任意发往客户端的 HTTP 响应保持由远程服务器处响应的 TOS 值
|
||||
- 对收到的远程服务器的 TOS 值,在复制之前对指定位进行掩码操作,再发送到客户端
|
||||
- SSL Bump (用于 HTTPS 过滤和适配) - Squid-in-the-middle,在 CONNECT 方式的 SSL 隧道中,用配置化的客户端和服务器端证书,对流量进行解密和加密
|
||||
- 支持适配模块
|
||||
- ICAP 旁路和重试增强 - 通过完全的旁路和动态链式路由扩展 ICAP,来处理多多个适应性服务。
|
||||
- 支持 ICY 流式协议 - 俗称 SHOUTcast 多媒体流
|
||||
- 动态 SSL 证书生成
|
||||
- 支持 ICAP 协议 (Internet Content Adaptation Protocol)
|
||||
- 完整的请求日志记录
|
||||
- 匿名连接
|
||||
|
||||
--
|
||||
- 网站: [www.squid-cache.org][1]
|
||||
- 开发: 美国国家应用网络研究实验室(NLANR)和网络志愿者
|
||||
- 授权: GNU GPL v2
|
||||
- 版本号: 4.0.1
|
||||
|
||||
### Privoxy ###
|
||||
|
||||
Privoxy (Privacy Enhancing Proxy) 是一个非缓存类 Web 代理软件,它自带的高级过滤功能可以用来增强隐私保护、修改页面内容和 HTTP 头部信息、访问控制,以及去除广告和其它招人反感的互联网垃圾。Privoxy 的配置非常灵活,能充分定制已满足各种各样的需求和偏好。它支持单机和多用户网络两种模式。
|
||||
|
||||
Privoxy 使用 action 规则来处理浏览器和远程站点间的数据流。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- 高度配置化——可以完全定制你的配置
|
||||
- 广告拦截
|
||||
- Cookie 管理
|
||||
- 支持“Connection: keep-alive”。可以无视客户端配置而保持外发的持久连接
|
||||
- 支持 IPv6
|
||||
- 标签化(Tagging),允许按照客户端和服务器的请求头进行处理
|
||||
- 作为拦截(intercepting)代理器运行
|
||||
- 巧妙的动作(action)和过滤机制用来处理服务器和客户端的 HTTP 头部
|
||||
- 可以与其他代理软件链式使用
|
||||
- 整合了基于浏览器的配置和控制工具,能在线跟踪规则和过滤效果,可远程开关
|
||||
- 页面过滤(文本替换、根据尺寸大小删除广告栏, 隐藏的“web-bugs”元素和 HTML 容错等)
|
||||
- 模块化的配置使得标准配置和用户配置可以存放于不同文件中,这样安装更新就不会覆盖用户的个性化设置
|
||||
- 配置文件支持 Perl 兼容的正则表达式,以及更为精妙和灵活的配置语法
|
||||
- GIF 去动画
|
||||
- 旁路处理大量点击跟踪(click-tracking)脚本(避免脚本重定向)
|
||||
- 大多数代理生成的页面(例如 "访问受限" 页面)可由用户自定义HTML模板
|
||||
- 自动监测配置文件的修改并重新读取
|
||||
- 大多数功能可以基于每个站点或每个 URL 位置来进行控制
|
||||
|
||||
--
|
||||
|
||||
- 网站: [www.privoxy.org][2]
|
||||
- 开发: Fabian Keil(开发领导者), David Schmidt, 和众多其他贡献者
|
||||
- 授权: GNU GPL v2
|
||||
- 版本号: 3.4.2
|
||||
|
||||
### Varnish Cache ###
|
||||
|
||||
Varnish Cache 是一个为性能和灵活性而生的 web 加速器。它新颖的架构设计能带来显著的性能提升。根据你的架构,通常情况下它能加速响应速度300-1000倍。Varnish 将页面存储到内存,这样 web 服务器就无需重复地创建相同的页面,只需要在页面发生变化后重新生成。页面内容直接从内存中访问,当然比其他方式更快。
|
||||
|
||||
此外 Varnish 能大大提升响应 web 页面的速度,用在任何应用服务器上都能使网站访问速度大幅度地提升。
|
||||
|
||||
按经验,Varnish Cache 比较经济的配置是1-16GB内存+ SSD 固态硬盘。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- 新颖的设计
|
||||
- VCL - 非常灵活的配置语言。VCL 配置会转换成 C,然后编译、加载、运行,灵活且高效
|
||||
- 能使用 round-robin 轮询和随机分发两种方式来负载均衡,两种方式下后端服务器都可以设置权重
|
||||
- 基于 DNS、随机、散列和客户端 IP 的分发器(Director)
|
||||
- 多台后端主机间的负载均衡
|
||||
- 支持 Edge Side Includes,包括拼装压缩后的 ESI 片段
|
||||
- 重度多线程并发
|
||||
- URL 重写
|
||||
- 单 Varnish 能够缓存多个虚拟主机
|
||||
- 日志数据存储在共享内存中
|
||||
- 基本的后端服务器健康检查
|
||||
- 优雅地处理后端服务器“挂掉”
|
||||
- 命令行界面的管理控制台
|
||||
- 使用内联 C 语言来扩展 Varnish
|
||||
- 可以与 Apache 用在相同的系统上
|
||||
- 单个系统可运行多个 Varnish
|
||||
- 支持 HAProxy 代理协议。该协议在每个收到的 TCP 请求——例如 SSL 终止过程中——附加一小段 http 头信息,以记录客户端的真实地址
|
||||
- 冷热 VCL 状态
|
||||
- 可以用名为 VMOD 的 Varnish 模块来提供插件扩展
|
||||
- 通过 VMOD 定义后端主机
|
||||
- Gzip 压缩及解压
|
||||
- HTTP 流的通过和获取
|
||||
- 神圣模式和优雅模式。用 Varnish 作为负载均衡器,神圣模式下可以将不稳定的后端服务器在一段时间内打入黑名单,阻止它们继续提供流量服务。优雅模式允许 Varnish 在获取不到后端服务器状态良好的响应时,提供已过期版本的页面或其它内容。
|
||||
- 实验性支持持久化存储,无需 LRU 缓存淘汰
|
||||
|
||||
--
|
||||
|
||||
- 网站: [www.varnish-cache.org][3]
|
||||
- 开发: Varnish Software
|
||||
- 授权: FreeBSD
|
||||
- 版本号: 4.1.0
|
||||
|
||||
### Polipo ###
|
||||
|
||||
Polipo 是一个开源的 HTTP 缓存代理,只需要非常低的资源开销。
|
||||
|
||||
它监听来自浏览器的 web 页面请求,转发到 web 服务器,然后将服务器的响应转发到浏览器。在此过程中,它能优化和整形网络流量。从本质来讲 Polipo 与 WWWOFFLE 很相似,但其实现技术更接近于 Squid。
|
||||
|
||||
Polipo 最开始的目标是作为一个兼容 HTTP/1.1 的代理,理论它能在任何兼容 HTTP/1.1 或更早的 HTTP/1.0 的站点上运行。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- HTTP 1.1、IPv4 & IPv6、流量过滤和隐私保护增强
|
||||
- 如确认远程服务器支持的话,则无论收到的请求是管道处理过的还是在多个连接上同时收到的,都使用 HTTP/1.1 管道(pipelining)
|
||||
- 下载被中断时缓存起始部分,当需要续传时用区间(Range)请求来完成下载
|
||||
- 将 HTTP/1.0 的客户端请求升级为 HTTP/1.1,然后按照客户端支持的级别进行升级或降级后回复
|
||||
- 全面支持 IPv6 (作用域(链路本地)地址除外)
|
||||
- 作为 IPv4 和 IPv6 网络的网桥
|
||||
- 内容过滤
|
||||
- 能使用 Poor Man 多路复用技术(Poor Man's Multiplexing)降低延迟
|
||||
- 支持 SOCKS 4 和 SOCKS 5 协议
|
||||
- HTTPS 代理
|
||||
- 扮演透明代理的角色
|
||||
- 可以与 Privoxy 或 tor 一起运行
|
||||
|
||||
--
|
||||
|
||||
- 网站: [www.pps.univ-paris-diderot.fr/~jch/software/polipo/][4]
|
||||
- 开发: Juliusz Chroboczek, Christopher Davis
|
||||
- 授权: MIT License
|
||||
- 版本号: 1.1.1
|
||||
|
||||
### Tinyproxy ###
|
||||
|
||||
Tinyproxy 是一个轻量级的开源 web 代理守护进程,其设计目标是快而小。它适用于需要完整 HTTP 代理特性,但系统资源又不足以运行大型代理的场景,比如嵌入式部署。
|
||||
|
||||
Tinyproxy 对小规模网络非常有用,这样的场合下大型代理会使系统资源紧张,或有安全风险。Tinyproxy 的一个关键特性是其缓冲连接的理念。从效果上看, Tinyproxy 对服务器的响应进行了高速缓冲,然后按照客户端能够处理的最高速度进行响应。该特性极大的降低了网络延滞带来的问题。
|
||||
|
||||
特性:
|
||||
|
||||
- 易于修改
|
||||
- 隐匿模式 - 定义哪些 HTTP 头允许通过,哪些又会被拦截
|
||||
- 支持 HTTPS - Tinyproxy 允许通过 CONNECT 方法转发 HTTPS 连接,任何情况下都不会修改数据流量
|
||||
- 远程监控 - 远程访问代理统计数据,让你能清楚了解代理服务当前的忙碌状态
|
||||
- 平均负载监控 - 通过配置,当服务器的负载接近一定值后拒绝新连接
|
||||
- 访问控制 - 通过配置,仅允许指定子网或 IP 地址的访问
|
||||
- 安全 - 运行无需额外权限,减小了系统受到威胁的概率
|
||||
- 基于 URL 的过滤 - 允许基于域和URL的黑白名单
|
||||
- 透明代理 - 配置为透明代理,这样客户端就无需任何配置
|
||||
- 代理链 - 在流量出口处采用上游代理服务器,而不是直接转发到目标服务器,创建我们所说的代理链
|
||||
- 隐私特性 - 限制允许从浏览器收到的来自 HTTP 服务器的数据(例如 cookies),同时限制允许通过的从浏览器到 HTTP 服务器的数据(例如版本信息)
|
||||
- 低开销 - 使用 glibc 内存开销只有2MB,CPU 负载按并发连接数线性增长(取决于网络连接速度)。 Tinyproxy 可以运行在老旧的机器上而无需担心性能问题。
|
||||
|
||||
--
|
||||
|
||||
- 网站: [banu.com/tinyproxy][5]
|
||||
- 开发: Robert James Kaes和其他贡献者
|
||||
- 授权: GNU GPL v2
|
||||
- 版本号: 1.8.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151101020309690/WebDelivery.html
|
||||
|
||||
译者:[fw8899](https://github.com/fw8899)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.squid-cache.org/
|
||||
[2]:http://www.privoxy.org/
|
||||
[3]:https://www.varnish-cache.org/
|
||||
[4]:http://www.pps.univ-paris-diderot.fr/%7Ejch/software/polipo/
|
||||
[5]:https://banu.com/tinyproxy/
|
||||
@ -1,5 +1,4 @@
|
||||
|
||||
Linux 有问必答 - 如何通过代理服务器安装 Ubuntu 桌面
|
||||
Linux 有问必答:如何通过代理服务器安装 Ubuntu 桌面版
|
||||
================================================================================
|
||||
> **问题**: 我的电脑通过 HTTP 代理连接到公司网络。当我尝试从 CD-ROM 在计算机上安装 Ubuntu 桌面时,在检索文件时安装程序会被挂起,检索则不会完成,这可能是由于代理造成的。然而问题是,Ubuntu 的安装程序从不要求我在安装过程中配置代理。那我该怎么使用代理来安装 Ubuntu 桌面?
|
||||
|
||||
@ -56,7 +55,7 @@ via: http://ask.xmodulo.com/install-ubuntu-desktop-behind-proxy.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,156 @@
|
||||
如何在 Linux 上使用 Gmail SMTP 服务器发送邮件通知
|
||||
================================================================================
|
||||
假定你想配置一个 Linux 应用,用于从你的服务器或桌面客户端发送邮件信息。邮件信息可能是邮件简报、状态更新(如 [Cachet][1])、监控警报(如 [Monit][2])、磁盘时间(如 [RAID mdadm][3])等等。当你要建立自己的 [邮件发送服务器][4] 传递信息时 ,你可以替代使用一个免费的公共 SMTP 服务器,从而避免遭受维护之苦。
|
||||
|
||||
谷歌的 Gmail 服务就是最可靠的 **免费 SMTP 服务器** 之一。想要从应用中发送邮件通知,你仅需在应用中添加 Gmail 的 SMTP 服务器地址和你的身份凭证即可。
|
||||
|
||||
使用 Gmail 的 SMTP 服务器会遇到一些限制,这些限制主要用于阻止那些经常滥用服务器来发送垃圾邮件和使用邮件营销的家伙。举个例子,你一次只能给至多 100 个地址发送信息,并且一天不能超过 500 个收件人。同样,如果你不想被标为垃圾邮件发送者,你就不能发送过多的不可投递的邮件。当你达到任何一个限制,你的 Gmail 账户将被暂时的锁定一天。简而言之,Gmail 的 SMTP 服务器对于你个人的使用是非常棒的,但不适合商业的批量邮件。
|
||||
|
||||
说了这么多,是时候向你们展示 **如何在 Linux 环境下使用 Gmail 的 SMTP 服务器** 了。
|
||||
|
||||
### Google Gmail SMTP 服务器设置 ###
|
||||
|
||||
如果你想要通过你的应用使用 Gmail 的 SMTP 服务器发送邮件,请牢记接下来的详细说明。
|
||||
|
||||
- **邮件发送服务器 (SMTP 服务器)**: smtp.gmail.com
|
||||
- **使用认证**: 是
|
||||
- **使用安全连接**: 是
|
||||
- **用户名**: 你的 Gmail 账户 ID (比如 "alice" ,如果你的邮箱为 alice@gmail.com)
|
||||
- **密码**: 你的 Gmail 密码
|
||||
- **端口**: 587
|
||||
|
||||
确切的配置根据应用会有所不同。在本教程的剩余部分,我将向你展示一些在 Linux 上使用 Gmail SMTP 服务器的应用示例。
|
||||
|
||||
### 从命令行发送邮件 ###
|
||||
|
||||
作为第一个例子,让我们尝试最基本的邮件功能:使用 Gmail SMTP 服务器从命令行发送一封邮件。为此,我将使用一个称为 mutt 的命令行邮件客户端。
|
||||
|
||||
先安装 mutt:
|
||||
|
||||
对于 Debian-based 系统:
|
||||
|
||||
$ sudo apt-get install mutt
|
||||
|
||||
对于 Red Hat based 系统:
|
||||
|
||||
$ sudo yum install mutt
|
||||
|
||||
创建一个 mutt 配置文件(~/.muttrc),并和下面一样,在文件中指定 Gmail SMTP 服务器信息。将 \<gmail-id> 替换成自己的 Gmail ID。注意该配置只是为了发送邮件而已(而非接收邮件)。
|
||||
|
||||
$ vi ~/.muttrc
|
||||
|
||||
----------
|
||||
|
||||
set from = "<gmail-id>@gmail.com"
|
||||
set realname = "Dan Nanni"
|
||||
set smtp_url = "smtp://<gmail-id>@smtp.gmail.com:587/"
|
||||
set smtp_pass = "<gmail-password>"
|
||||
|
||||
一切就绪,使用 mutt 发送一封邮件:
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com
|
||||
|
||||
想在一封邮件中添加附件,使用 "-a" 选项
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com -a ~/test_attachment.jpg
|
||||
|
||||

|
||||
|
||||
使用 Gmail SMTP 服务器意味着邮件将显示是从你 Gmail 账户发出的。换句话说,收件人将视你的 Gmail 地址为发件人地址。如果你想要使用自己的域名作为邮件发送方,你需要使用 Gmail SMTP 转发服务。
|
||||
|
||||
### 当服务器重启时发送邮件通知 ###
|
||||
|
||||
如果你在 [虚拟专用服务器(VPS)][5] 上跑了些重要的网站,建议监控 VPS 的重启行为。作为一个更为实用的例子,让我们研究如何在你的 VPS 上为每一次重启事件建立邮件通知。这里假设你的 VPS 上使用的是 systemd,并向你展示如何为自动邮件通知创建一个自定义的 systemd 启动服务。
|
||||
|
||||
首先创建下面的脚本 reboot_notify.sh,用于负责邮件通知。
|
||||
|
||||
$ sudo vi /usr/local/bin/reboot_notify.sh
|
||||
|
||||
----------
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
echo "`hostname` was rebooted on `date`" | mutt -F /etc/muttrc -s "Notification on `hostname`" alice@yahoo.com
|
||||
|
||||
----------
|
||||
|
||||
$ sudo chmod +x /usr/local/bin/reboot_notify.sh
|
||||
|
||||
在这个脚本中,我使用 "-F" 选项,用于指定系统级的 mutt 配置文件位置。因此不要忘了创建 /etc/muttrc 文件,并如前面描述的那样填入 Gmail SMTP 信息。
|
||||
|
||||
现在让我们创建如下一个自定义的 systemd 服务。
|
||||
|
||||
$ sudo mkdir -p /usr/local/lib/systemd/system
|
||||
$ sudo vi /usr/local/lib/systemd/system/reboot-task.service
|
||||
|
||||
----------
|
||||
|
||||
[Unit]
|
||||
Description=Send a notification email when the server gets rebooted
|
||||
DefaultDependencies=no
|
||||
Before=reboot.target
|
||||
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=/usr/local/bin/reboot_notify.sh
|
||||
|
||||
[Install]
|
||||
WantedBy=reboot.target
|
||||
|
||||
在创建服务后,添加并启动该服务。
|
||||
|
||||
$ sudo systemctl enable reboot-task
|
||||
$ sudo systemctl start reboot-task
|
||||
|
||||
从现在起,在每次 VPS 重启时,你将会收到一封通知邮件。
|
||||
|
||||
|
||||
|
||||
### 通过服务器使用监控发送邮件通知 ###
|
||||
|
||||
作为最后一个例子,让我展示一个现实生活中的应用程序,[Monit][6],这是一款极其有用的服务器监控应用程序。它带有全面的 [VPS][7] 监控能力(比如 CPU、内存、进程、文件系统)和邮件通知功能。
|
||||
|
||||
如果你想要接收 VPS 上由 Monit 产生的任何事件的邮件通知,你可以在 Monit 配置文件中添加以下 SMTP 信息。
|
||||
|
||||
set mailserver smtp.gmail.com port 587
|
||||
username "<your-gmail-ID>" password "<gmail-password>"
|
||||
using tlsv12
|
||||
|
||||
set mail-format {
|
||||
from: <your-gmail-ID>@gmail.com
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
}
|
||||
|
||||
# the person who will receive notification emails
|
||||
set alert alice@yahoo.com
|
||||
|
||||
这是一个因为 CPU 负载超载而由 Monit 发送的邮件通知的例子。
|
||||
|
||||
|
||||
|
||||
### 总结 ###
|
||||
|
||||
如你所见,类似 Gmail 这样免费的 SMTP 服务器有着这么多不同的运用方式 。但再次重申,请牢记免费的 SMTP 服务器不适用于商业用途,仅仅适用于个人项目。无论你正在哪款应用中使用 Gmail SMTP 服务器,欢迎自由分享你的用例。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/send-email-notifications-gmail-smtp-server-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[martin2011qi](https://github.com/martin2011qi), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/setup-system-status-page.html
|
||||
[2]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[3]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[4]:http://xmodulo.com/mail-server-ubuntu-debian.html
|
||||
[5]:http://xmodulo.com/go/digitalocean
|
||||
[6]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[7]:http://xmodulo.com/go/digitalocean
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
如果你正好拥有全球第一支运行 Ubuntu 的手机并且希望将 **BQ Aquaris E4.5 自带的 Ubuntu 系统换成 Android **,那这篇文章能帮你点小忙。
|
||||
|
||||
有一万种理由来解释为什么要将 Ubuntu 换成主流 Android OS。其中最主要的一个,就是这个系统本身仍然处于非常早期的阶段,针对的目标用户仍然是开发者和爱好者。不管你的理由是什么,要谢谢 bq 提供的工具,让我们能非常轻松地在 BQ Aquaris 上安装 Android OS。
|
||||
有一万种理由来解释为什么要将 Ubuntu 换成主流 Android OS。其中最主要的一个,就是这个系统本身仍然处于非常早期的阶段,针对的目标用户仍然是开发者和爱好者。不管你的理由是什么,要谢谢 BQ 提供的工具,让我们能非常轻松地在 BQ Aquaris 上安装 Android OS。
|
||||
|
||||
下面让我们一起看下在 BQ Aquaris 上安装 Android 需要做哪些事情。
|
||||
|
||||
@ -20,7 +20,7 @@
|
||||
|
||||
#### 第一步:下载 Android 固件 ####
|
||||
|
||||
首先是下载可以在 BQ Aquaris E4.5 上运行的 Android 固件。幸运的是我们可以在 bq 的技术支持网站找到。可以从下面的链接直接下载,差不多 650 MB:
|
||||
首先是下载可以在 BQ Aquaris E4.5 上运行的 Android 固件。幸运的是我们可以在 BQ 的技术支持网站找到。可以从下面的链接直接下载,差不多 650 MB:
|
||||
|
||||
- [下载为 BQ Aquaris E4.5 制作的 Android][1]
|
||||
|
||||
@ -28,21 +28,21 @@
|
||||
|
||||
我建议去[ bq 的技术支持网站][2]下载最新的固件。
|
||||
|
||||
下载完成后解压。在解压后的目录里,找到一个名字是 **MT6582_Android_scatter.txt** 的文件。后面将要用到它。
|
||||
下载完成后解压。在解压后的目录里,找到一个名字是 **MT6582\_Android\_scatter.txt** 的文件。后面将要用到它。
|
||||
|
||||
#### 第二步:下载刷机工具 ####
|
||||
|
||||
bq 已经提供了自己的刷机工具,Herramienta MTK Flash Tool,可以轻松地给设备安装 Andriod 或者 Ubuntu 系统。你可以从下面的链接下载工具:
|
||||
BQ 已经提供了自己的刷机工具,Herramienta MTK Flash Tool,可以轻松地给设备安装 Andriod 或者 Ubuntu 系统。你可以从下面的链接下载工具:
|
||||
|
||||
- [下载 MTK Flash Tool][3]
|
||||
|
||||
考虑到刷机工具在以后可能会升级,你总是可以从[bq 技术支持网站][4]上找到最新的版本。
|
||||
考虑到刷机工具在以后可能会升级,你总是可以从 [BQ 技术支持网站][4]上找到最新的版本。
|
||||
|
||||
下载完后解压。之后应该可以在目录里找到一个叫 **flash_tool** 的可执行文件。我们稍后会用到。
|
||||
|
||||
#### 第三步:移除冲突的软件包(可选) ####
|
||||
|
||||
如果你正在用最新版本的 Ubuntu 或 基于 Ubuntu 的 Linux 发行版,稍后可能会碰到 “BROM ERROR : S_UNDEFINED_ERROR (1001)” 错误。
|
||||
如果你正在用最新版本的 Ubuntu 或 基于 Ubuntu 的 Linux 发行版,稍后可能会碰到 “BROM ERROR : S\_UNDEFINED\_ERROR (1001)” 错误。
|
||||
|
||||
要避免这个错误,你需要卸载有冲突的软件包。可以使用下面的命令:
|
||||
|
||||
@ -52,7 +52,7 @@ bq 已经提供了自己的刷机工具,Herramienta MTK Flash Tool,可以轻
|
||||
|
||||
sudo service udev restart
|
||||
|
||||
检查一下内核模块 cdc_acm 可能存在的边际效应,运行下面的命令:
|
||||
检查一下内核模块 cdc_acm 可能存在的副作用,运行下面的命令:
|
||||
|
||||
lsmod | grep cdc_acm
|
||||
|
||||
@ -76,7 +76,7 @@ bq 已经提供了自己的刷机工具,Herramienta MTK Flash Tool,可以轻
|
||||
|
||||

|
||||
|
||||
还记得之前第一步里提到的 **MT6582_Android_scatter.txt** 文件吗?这个文本文件就在你第一步中下载的 Android 固件解压后的目录里。点击 Scatter-loading(上图中)然后选中 MT6582_Android_scatter.txt 文件。
|
||||
还记得之前第一步里提到的 **MT6582\_Android\_scatter.txt** 文件吗?这个文本文件就在你第一步中下载的 Android 固件解压后的目录里。点击 Scatter-loading(上图中)然后选中 MT6582\_Android\_scatter.txt 文件。
|
||||
|
||||
之后,你将看到类似下面图片里的一些绿色线条:
|
||||
|
||||
@ -104,7 +104,7 @@ bq 已经提供了自己的刷机工具,Herramienta MTK Flash Tool,可以轻
|
||||
|
||||
### 总结 ###
|
||||
|
||||
要感谢厂商提供的工具,让我们可以轻松地 **在 bq Ubuntu 手机上刷 Android**。当然,你可以使用相同的步骤将 Android 替换回 Ubuntu。只是下载的时候选 Ubuntu 固件而不是 Android。
|
||||
要感谢厂商提供的工具,让我们可以轻松地 **在 BQ Ubuntu 手机上刷 Android**。当然,你可以使用相同的步骤将 Android 替换回 Ubuntu。只是下载的时候选 Ubuntu 固件而不是 Android。
|
||||
|
||||
希望这篇文章可以帮你将你的 bq 手机上的 Ubuntu 刷成 Android。如果有什么问题或建议,可以在下面留言区里讨论。
|
||||
|
||||
@ -114,7 +114,7 @@ via: http://itsfoss.com/install-android-ubuntu-phone/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
Linux 有问必答 - 如何在 Linux 上安装 Node.js
|
||||
Linux 有问必答:如何在 Linux 上安装 Node.js
|
||||
================================================================================
|
||||
> **问题**: 如何在你的 Linux 发行版上安装 Node.js?
|
||||
|
||||
[Node.js][1] 是建立在谷歌的 V8 JavaScript 引擎服务器端的软件平台上。在构建高性能的服务器端应用程序上,Node.js 在 JavaScript 中已是首选方案。是什么让使用 Node.js 库和应用程序的 [庞大生态系统][2] 来开发服务器后台变得如此流行。Node.js 自带一个被称为 npm 的命令行工具可以让你轻松地安装它,进行版本控制并使用 npm 的在线仓库来管理 Node.js 库和应用程序的依赖关系。
|
||||
[Node.js][1] 是建立在谷歌的 V8 JavaScript 引擎服务器端的软件平台上。在构建高性能的服务器端应用程序上,Node.js 在 JavaScript 中已是首选方案。是什么让使用 Node.js 库和应用程序的[庞大生态系统][2]来开发服务器后台变得如此流行。Node.js 自带一个被称为 npm 的命令行工具可以让你轻松地安装它,进行版本控制并使用 npm 的在线仓库来管理 Node.js 库和应用程序的依赖关系。
|
||||
|
||||
在本教程中,我将介绍 **如何在主流 Linux 发行版上安装 Node.js,包括Debian,Ubuntu,Fedora 和 CentOS** 。
|
||||
在本教程中,我将介绍 **如何在主流 Linux 发行版上安装 Node.js,包括 Debian,Ubuntu,Fedora 和 CentOS** 。
|
||||
|
||||
Node.js 在一些发行版上作为预构建的程序包(如,Fedora 或 Ubuntu),而在其他发行版上你需要源码安装。由于 Node.js 发展比较快,建议从源码安装最新版而不是安装一个过时的预构建的程序包。最新的 Node.js 自带 npm(Node.js 的包管理器),让你可以轻松的安装 Node.js 的外部模块。
|
||||
Node.js 在一些发行版上有预构建的程序包(如,Fedora 或 Ubuntu),而在其他发行版上你需要通过源码安装。由于 Node.js 发展比较快,建议从源码安装最新版而不是安装一个过时的预构建的程序包。最新的 Node.js 自带 npm(Node.js 的包管理器),让你可以轻松的安装 Node.js 的外部模块。
|
||||
|
||||
### 在 Debian 上安装 Node.js on ###
|
||||
|
||||
@ -64,7 +64,6 @@ Node.js 被包含在 Fedora 的 base 仓库中。因此,你可以在 Fedora
|
||||
|
||||
### 在 Arch Linux 上安装 Node.js ###
|
||||
|
||||
Node.js is available in the Arch Linux community repository. Thus installation is as simple as running:
|
||||
|
||||
Node.js 在 Arch Linux 的社区库中可以找到。所以安装很简单,只要运行:
|
||||
|
||||
@ -82,7 +81,7 @@ via: http://ask.xmodulo.com/install-node-js-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyou](https://github.com/strugglingyou)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,57 +1,51 @@
|
||||
GHLandy Translated
|
||||
|
||||
GIMP 过去的 20 年:一点一滴的进步
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/PSJAzJ6mkVw?feature=oembed"></iframe>
|
||||
|
||||
[GIMP][1](GNU 图像处理程序)—— 一流的开源免费图像处理程序。加州大学伯克利分校的 Peter Mattis 和 Spencer Kimball 最早在 1995 年的时候就进行了该程序的开发。到了 1997 年,该程序成为了 [GNU Project][2] 官方的一部分,并正式更名为 GIMP。时至今日,GIMP 已经成为了最好的图像编辑器之一,并有最受欢迎的 “GIMP vs Photoshop” 之争。
|
||||
[GIMP][1](GNU 图像处理程序(GNU Image Manipulation Program))—— 一流的开源自由的图像处理程序。加州大学伯克利分校的 Peter Mattis 和 Spencer Kimball 早在 1995 年的时候开始了该程序的开发。到了 1997 年,该程序成为了 [GNU Project][2] 官方的一部分,并正式更名为 GIMP。时至今日,GIMP 已经成为了最好的图像编辑器之一,并有经常有 “GIMP vs Photoshop” 之争。
|
||||
|
||||
1995 年 11 月 21 日,首版发布:
|
||||
### 1995 年 11 月 21 日,首版发布###
|
||||
|
||||
> 发布者: Peter Mattis
|
||||
>
|
||||
> 发布主题: ANNOUNCE: The GIMP
|
||||
>
|
||||
> 日期: 1995-11-21
|
||||
>
|
||||
> 消息ID: <48s543$r7b@agate.berkeley.edu>
|
||||
>
|
||||
> 新闻组: comp.os.linux.development.apps,comp.os.linux.misc,comp.windows.x.apps
|
||||
>
|
||||
> GIMP:通用图像处理程序
|
||||
> ------------------------------------------------
|
||||
>
|
||||
> GIMP 是为各种图像编辑操作提供一个直观的图形界面而设计的。
|
||||
>
|
||||
> 以下是 GIMP 的主要功能介绍:
|
||||
>
|
||||
> 图像查看
|
||||
> -------------
|
||||
>
|
||||
> * 支持 8 位,15 位,16 位和 24 位颜色
|
||||
> * 8 位色显示的图像序列的稳定算法
|
||||
> * 以 RGB 色、灰度和索引色模式查看图像
|
||||
> * 同时编辑多个图像
|
||||
> * 实时缩放和全图查看
|
||||
> * 支持 GIF、JPEG、PNG、TIFF 和 XPM 格式
|
||||
>
|
||||
> 图像编辑
|
||||
> -------------
|
||||
>
|
||||
> * 选区工具:包括矩形、椭圆、自由、模糊、贝尔赛曲线以及智能
|
||||
> * 变换工具:包括旋转、缩放、剪切和翻转
|
||||
> * 绘画工具:包括油漆桶、笔刷、喷枪、克隆、卷积、混合和文本
|
||||
> * 效果滤镜:如模糊和边缘检测
|
||||
> * 通道和颜色操作:叠加、反相和分解
|
||||
> * 组件功能:允许你方便的添加新的文件格式和效果滤镜
|
||||
> * 多步撤销/重做功能
|
||||
```
|
||||
From: Peter Mattis
|
||||
Subject: ANNOUNCE: The GIMP
|
||||
Date: 1995-11-21
|
||||
Message-ID: <48s543$r7b@agate.berkeley.edu>
|
||||
Newsgroups: comp.os.linux.development.apps,comp.os.linux.misc,comp.windows.x.apps
|
||||
|
||||
1996 年,GIMP 0.54 版
|
||||
GIMP:通用图像处理程序
|
||||
------------------------------------------------
|
||||
|
||||
GIMP 是为各种图像编辑操作提供一个直观的图形界面而设计的。
|
||||
以下是 GIMP 的主要功能介绍:
|
||||
图像查看
|
||||
-------------
|
||||
|
||||
* 支持 8 位,15 位,16 位和 24 位颜色
|
||||
* 8 位色显示图像的排序和 Floyd-Steinberg 抖动算法
|
||||
* 以 RGB 色、灰度和索引色模式查看图像
|
||||
* 同时编辑多个图像
|
||||
* 实时缩放和全图查看
|
||||
* 支持 GIF、JPEG、PNG、TIFF 和 XPM 格式
|
||||
|
||||
图像编辑
|
||||
-------------
|
||||
|
||||
* 选区工具:包括矩形、椭圆、自由、模糊、贝尔赛曲线以及智能
|
||||
* 变换工具:包括旋转、缩放、剪切和翻转
|
||||
* 绘画工具:包括油漆桶、笔刷、喷枪、克隆、卷积、混合和文本
|
||||
* 效果滤镜:如模糊和边缘检测
|
||||
* 通道和颜色操作:叠加、反相和分解
|
||||
* 组件功能:允许你方便的添加新的文件格式和效果滤镜
|
||||
* 多步撤销/重做功能
|
||||
```
|
||||
|
||||
### 1996 年,GIMP 0.54 版 ###
|
||||
|
||||

|
||||
|
||||
GIMP 0.54 版需要具备 X11 显示、X-server 以及 Motif 1.2 微件,支持 8 位、15 位、16 位和 24 位的颜色深度和灰度,支持 GIF、JPEG、PNG、TIFF 和 XPM 图像格式。
|
||||
GIMP 0.54 版需要具备 X11 显示、X-server 以及 Motif 1.2 组件,支持 8 位、15 位、16 位和 24 位的颜色深度和灰度,支持 GIF、JPEG、PNG、TIFF 和 XPM 图像格式。
|
||||
|
||||
基本功能:具备矩形、椭圆、自由、模糊、贝塞尔曲线和智能等选择工具,旋转、缩放、剪切、克隆、混合和翻转等变换工具。
|
||||
|
||||
@ -66,7 +60,7 @@ GIMP 0.54 版可以在 Linux、HP-UX、Solaris 和 SGI IRIX 中运行。
|
||||
这只是一个开发版本,并非面向用户发布的。GIMP 有了新的工具包——GDK(GIMP Drawing Kit,GIMP 绘图工具)和 GTK(GIMP Toolkit,GIMP 工具包),并弃用 Motif。GIMP 工具包随后也发展成为了 GTK+ 跨平台的微件工具包。新特性:
|
||||
|
||||
- 基本的图层功能
|
||||
- 子像素采集
|
||||
- 子像素取样
|
||||
- 笔刷间距
|
||||
- 改进剂喷枪功能
|
||||
- 绘制模式
|
||||
@ -75,7 +69,7 @@ GIMP 0.54 版可以在 Linux、HP-UX、Solaris 和 SGI IRIX 中运行。
|
||||
|
||||

|
||||
|
||||
从 0.99 版本开始,GIMP 有了宏脚本的支持。GTK 及 GTK 功能增强版正式更名为 GTK+。其他更新:
|
||||
从 0.99 版本开始,GIMP 有了宏脚本的支持。GTK 及 GDK 功能增强版正式更名为 GTK+。其他更新:
|
||||
|
||||
- 支持大体积图像(大于 100M)
|
||||
- 新增原生格式 – XCF
|
||||
@ -87,8 +81,8 @@ GIMP 0.54 版可以在 Linux、HP-UX、Solaris 和 SGI IRIX 中运行。
|
||||
|
||||
GIMP 和 GTK+ 开始分为两个不同的项目。GIMP 官网进行重构,包含新教程、组件和文档。新特性:
|
||||
|
||||
- 基于瓦片式的内存管理
|
||||
- 组件 API 做了较大改变
|
||||
- 基于瓦片式(tile)的内存管理
|
||||
- 组件 API 做了大量改变
|
||||
- XFC 格式现在支持图层、导航和选择
|
||||
- web 界面
|
||||
- 在线图像生成
|
||||
@ -98,7 +92,7 @@ GIMP 和 GTK+ 开始分为两个不同的项目。GIMP 官网进行重构,包
|
||||
新特性:
|
||||
|
||||
- 进行了非英文语言翻译
|
||||
- 修复 GTK+ 和 GIMP 中的大量bug
|
||||
- 修复 GTK+ 和 GIMP 中的大量 bug
|
||||
- 增加大量组件
|
||||
- 图像映射
|
||||
- 新工具:调整大小、测量、加亮、燃烧效果、颜色吸管和翻转等。
|
||||
@ -106,7 +100,7 @@ GIMP 和 GTK+ 开始分为两个不同的项目。GIMP 官网进行重构,包
|
||||
- 保存前可以进行图像预览
|
||||
- 按比例缩放的笔刷进行预览
|
||||
- 通过路径进行递归选择
|
||||
- 新的窗口导航
|
||||
- 新的导航窗口
|
||||
- 支持图像拖拽
|
||||
- 支持水印
|
||||
|
||||
@ -138,7 +132,7 @@ GIMP 和 GTK+ 开始分为两个不同的项目。GIMP 官网进行重构,包
|
||||
|
||||
- 更新了图形界面
|
||||
- 新的选择工具
|
||||
- 继承了 GEGL (GEneric Graphics Library,通用图形库)
|
||||
- 集成了 GEGL (GEneric Graphics Library,通用图形库)
|
||||
- 为 MDI 行为实现了实用程序窗口提示
|
||||
|
||||
### 2012 年,GIMP 2.8 版 ###
|
||||
@ -160,7 +154,7 @@ via: https://tlhp.cf/20-years-of-gimp-evolution/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
65
published/201603/20151204 Review EXT4 vs. Btrfs vs. XFS.md
Normal file
65
published/201603/20151204 Review EXT4 vs. Btrfs vs. XFS.md
Normal file
@ -0,0 +1,65 @@
|
||||
如何选择文件系统:EXT4、Btrfs 和 XFS
|
||||
================================================================================
|
||||

|
||||
|
||||
老实说,人们最不曾思考的问题之一是他们的个人电脑中使用了什么文件系统。Windows 和 Mac OS X 用户更没有理由去考虑,因为对于他们的操作系统,只有一种选择,那就是 NTFS 和 HFS+。相反,对于 Linux 系统而言,有很多种文件系统可以选择,现在默认的是广泛采用的 ext4。然而,现在也有改用一种称为 btrfs 文件系统的趋势。那是什么使得 btrfs 更优秀,其它的文件系统又是什么,什么时候我们又能看到 Linux 发行版作出改变呢?
|
||||
|
||||
首先让我们对文件系统以及它们真正干什么有个总体的认识,然后我们再对一些有名的文件系统做详细的比较。
|
||||
|
||||
### 文件系统是干什么的? ###
|
||||
|
||||
如果你不清楚文件系统是干什么的,一句话总结起来也非常简单。文件系统主要用于控制所有程序在不使用数据时如何存储数据、如何访问数据以及有什么其它信息(元数据)和数据本身相关,等等。听起来要编程实现并不是轻而易举的事情,实际上也确实如此。文件系统一直在改进,包括了更多的功能、更高效地完成它需要做的事情。总而言之,它是所有计算机的基本需求、但并不像听起来那么简单。
|
||||
|
||||
### 为什么要分区? ###
|
||||
|
||||
由于每个操作系统都能创建或者删除分区,很多人对分区都有模糊的认识。Linux 操作系统即便使用标准安装过程,在同一块磁盘上仍使用多个分区,这看起来很奇怪,因此需要一些解释。拥有不同分区的一个主要目的就是为了在灾难发生时能获得更好的数据安全性。
|
||||
|
||||
通过将硬盘划分为分区,数据会被分隔以及重组。当事故发生的时候,只有存储在被损坏分区上的数据会被破坏,很大可能上其它分区的数据能得以保留。这个原因可以追溯到 Linux 操作系统还没有日志文件系统、任何电力故障都有可能导致灾难发生的时候。
|
||||
|
||||
使用分区也考虑到了安全和健壮性原因,因此操作系统部分损坏并不意味着整个计算机就有风险或者会受到破坏。这也是当前采用分区的一个最重要因素。举个例子,用户创建了一些会填满磁盘的脚本、程序或者 web 应用,如果该磁盘只有一个大的分区,如果磁盘满了那么整个系统就不能工作。如果用户把数据保存在不同的分区,那么就只有那个分区会受到影响,而系统分区或者其它数据分区仍能正常运行。
|
||||
|
||||
记住,拥有一个日志文件系统只能在掉电或者和存储设备意外断开连接时提供数据安全性,并不能在文件系统出现坏块或者发生逻辑错误时保护数据。对于这种情况,用户可以采用廉价磁盘冗余阵列(RAID:Redundant Array of Inexpensive Disks)的方案。
|
||||
|
||||
### 为什么要切换文件系统? ###
|
||||
|
||||
ext4 文件系统由 ext3 文件系统改进而来,而后者又是从 ext2 文件系统改进而来。虽然 ext4 文件系统已经非常稳定,是过去几年中绝大部分发行版的默认选择,但它是基于陈旧的代码开发而来。另外, Linux 操作系统用户也需要很多 ext4 文件系统本身不提供的新功能。虽然通过某些软件能满足这种需求,但性能会受到影响,在文件系统层次做到这些能获得更好的性能。
|
||||
|
||||
### Ext4 文件系统 ###
|
||||
|
||||
ext4 还有一些明显的限制。最大文件大小是 16 tebibytes(大概是 17.6 terabytes),这比普通用户当前能买到的硬盘还要大的多。使用 ext4 能创建的最大卷/分区是 1 exbibyte(大概是 1,152,921.5 terabytes)。通过使用多种技巧, ext4 比 ext3 有很大的速度提升。类似一些最先进的文件系统,它是一个日志文件系统,意味着它会对文件在磁盘中的位置以及任何其它对磁盘的更改做记录。纵观它的所有功能,它还不支持透明压缩、重复数据删除或者透明加密。技术上支持了快照,但该功能还处于实验性阶段。
|
||||
|
||||
### Btrfs 文件系统 ###
|
||||
|
||||
btrfs 有很多不同的叫法,例如 Better FS、Butter FS 或者 B-Tree FS。它是一个几乎完全从头开发的文件系统。btrfs 出现的原因是它的开发者起初希望扩展文件系统的功能使得它包括快照、池化(pooling)、校验以及其它一些功能。虽然和 ext4 无关,它也希望能保留 ext4 中能使消费者和企业受益的功能,并整合额外的能使每个人,尤其是企业受益的功能。对于使用大型软件以及大规模数据库的企业,让多种不同的硬盘看起来一致的文件系统能使他们受益并且使数据整合变得更加简单。删除重复数据能降低数据实际使用的空间,当需要镜像一个单一而巨大的文件系统时使用 btrfs 也能使数据镜像变得简单。
|
||||
|
||||
用户当然可以继续选择创建多个分区从而无需镜像任何东西。考虑到这种情况,btrfs 能横跨多种硬盘,和 ext4 相比,它能支持 16 倍以上的磁盘空间。btrfs 文件系统一个分区最大是 16 exbibytes,最大的文件大小也是 16 exbibytes。
|
||||
|
||||
### XFS 文件系统 ###
|
||||
|
||||
XFS 文件系统是扩展文件系统(extent file system)的一个扩展。XFS 是 64 位高性能日志文件系统。对 XFS 的支持大概在 2002 年合并到了 Linux 内核,到了 2009 年,红帽企业版 Linux 5.4 也支持了 XFS 文件系统。对于 64 位文件系统,XFS 支持最大文件系统大小为 8 exbibytes。XFS 文件系统有一些缺陷,例如它不能压缩,删除大量文件时性能低下。目前RHEL 7.0 文件系统默认使用 XFS。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
不幸的是,还不知道 btrfs 什么时候能到来。官方说,其下一代文件系统仍然被归类为“不稳定”,但是如果用户下载最新版本的 Ubuntu,就可以选择安装到 btrfs 分区上。什么时候 btrfs 会被归类到 “稳定” 仍然是个谜, 直到真的认为它“稳定”之前,用户也不应该期望 Ubuntu 会默认采用 btrfs。有报道说 Fedora 18 会用 btrfs 作为它的默认文件系统,因为到了发布它的时候,应该有了 btrfs 文件系统校验器。由于还没有实现所有的功能,另外和 ext4 相比性能上也比较缓慢,btrfs 还有很多的工作要做。
|
||||
|
||||
那么,究竟使用哪个更好呢?尽管性能几乎相同,但 ext4 还是赢家。为什么呢?答案在于易用性以及广泛性。对于桌面或者工作站, ext4 仍然是一个很好的文件系统。由于它是默认提供的文件系统,用户可以在上面安装操作系统。同时, ext4 支持最大 1 exabytes 的卷和 16 terabytes 的文件,因此考虑到大小,它也还有很大的进步空间。
|
||||
|
||||
btrfs 能提供更大的高达 16 exabytes 的卷以及更好的容错,但是,到现在为止,它感觉更像是一个附加的文件系统,而部署一个集成到 Linux 操作系统的文件系统。比如,尽管 btrfs 支持不同的发行版,使用 btrfs 格式化硬盘之前先要有 btrfs-tools 工具,这意味着安装 Linux 操作系统的时候它并不是一个可选项,即便不同发行版之间会有所不同。
|
||||
|
||||
尽管传输速率非常重要,评价一个文件系统除了文件传输速度之外还有很多因素。btrfs 有很多好用的功能,例如写复制(Copy-on-Write)、扩展校验、快照、清洗、自修复数据、冗余删除以及其它保证数据完整性的功能。和 ZFS 相比 btrfs 缺少 RAID-Z 功能,因此对于 btrfs, RAID 还处于实验性阶段。对于单纯的数据存储,和 ext4 相比 btrfs 似乎更加优秀,但时间会验证一切。
|
||||
|
||||
迄今为止,对于桌面系统而言,ext4 似乎是一个更好的选择,因为它是默认的文件系统,传输文件时也比 btrfs 更快。btrfs 当然值得尝试、但要在桌面 Linux 上完全取代 ext4 可能还需要一些时间。数据场和大存储池会揭示关于 ext4、XCF 以及 btrfs 不同的场景和差异。
|
||||
|
||||
如果你有不同或者其它的观点,在下面的评论框中告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/review-ext4-vs-btrfs-vs-xfs/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -1,45 +1,42 @@
|
||||
如何在 Ubuntu 14.04, 15.10 中安装Light Table 0.8
|
||||
如何在 Ubuntu 中安装 Light Table 0.8
|
||||
================================================================================
|
||||

|
||||
|
||||
Light Table 在经过一年以上的开发,已经推出了新的稳定发行版本。现在它只为Linux提供64位的二进制包。
|
||||
Light Table 在经过一年以上的开发,已经推出了新的稳定发行版本。现在它只为 Linux 提供64位的二进制包。
|
||||
|
||||
LightTable 0.8.0的改动:
|
||||
|
||||
- 更改: 我们从 NW.js 中选择了 Electron
|
||||
- 更改: LT’s 发行版本与自更新进程在github上面完全的公开
|
||||
- 增加: LT 可以由提供的脚本从源码在支持的不同平台上安装
|
||||
- 增加: LT’s 大部分的代码库将用npm依赖来安装以取代以forked库安装
|
||||
- 增加: 有效文档. 更多详情内容见下面
|
||||
- 修复: 版本号>= OSX 10.10的系统下工作的主要的可用性问题
|
||||
- 更改: 32位Linux不再提供官方包文件下载,从源码安装仍旧将被支持
|
||||
- 修复: ClojureScript eval 在ClojureScript的现代版本可以正常工作
|
||||
- 更改: 我们从 NW.js 切换到了 Electron
|
||||
- 更改: Light Table 的发行与自更新进程完全地公开在github上
|
||||
- 增加: Light Table 可以用提供的脚本在各个支持的平台上从源码构建
|
||||
- 增加: Light Table 大部分的 node 代码库将通过 npm 依赖来安装,以取代以前采用分叉库的方式
|
||||
- 增加: 有效文档。更多详情内容见下面
|
||||
- 修复: 版本号 >= OSX 10.10的系统下的主要的可用性问题
|
||||
- 更改: 官方不再提供 32位 Linux 软件包下载,不过仍然支持从源码构建
|
||||
- 修复: ClojureScript eval 支持 ClojureScript 的现代版本
|
||||
- 参阅更多 [github.com/LightTable/LightTable/releases][1]
|
||||
|
||||
|
||||
|
||||
### 如何在Ubuntu中安Light Table 0.8.0: ###
|
||||
### 如何在 Ubuntu 中安装 Light Table 0.8.0 ###
|
||||
|
||||
下面的步骤回指导你怎么样在Ubuntu下安装官方的二进制包,在目前Ubuntu发行版本都适用(**仅仅针对64位**)。
|
||||
下面的步骤会指导你怎么样在 Ubuntu 下安装官方的二进制包,在目前的 Ubuntu 发行版本中都适用(**仅仅针对64位**)。
|
||||
|
||||
在开始之前,如果你安装了之前的版本请做好备份。
|
||||
|
||||
**1.**
|
||||
从以下链接下载LightTable Linux下的二进制文件:
|
||||
**1.** 从以下链接下载 LightTable Linux 下的二进制文件:
|
||||
|
||||
- [lighttable-0.8.0-linux.tar.gz][2]
|
||||
|
||||
**2.**
|
||||
从dash或是应用启动器,或者是Ctrl+Alt+T快捷键打开终端,并且在输入以下命令后敲击回车键:
|
||||
**2.** 从 dash 或是应用启动器,或者是 Ctrl+Alt+T 快捷键打开终端,并且在输入以下命令后敲击回车键:
|
||||
|
||||
gksudo file-roller ~/Downloads/lighttable-0.8.0-linux.tar.gz
|
||||
|
||||

|
||||
|
||||
如果命令不工作的话从Ubuntu软件中心安装`gksu`。
|
||||
|
||||
**3.**
|
||||
之前的命令使用了root用户权限通过档案管理器打开了下载好的存档。
|
||||
如果命令不工作的话从 Ubuntu 软件中心安装`gksu`。
|
||||
|
||||
**3.** 之前的命令使用了 root 用户权限通过档案管理器打开了下载好的存档。
|
||||
|
||||
打开它后,请做以下步骤:
|
||||
|
||||
@ -48,17 +45,17 @@ LightTable 0.8.0的改动:
|
||||
|
||||
|
||||
|
||||
最终你应该安装好了LightTable,可以在/opt/ 目录下查看:
|
||||
最终你应该安装好了 LightTable,可以在 /opt/ 目录下查看:
|
||||
|
||||
|
||||
|
||||
**4.** 创建一个启动器使你可以从dash工具或是应用启动器打开LightTable。
|
||||
**4.** 创建一个启动器使你可以从 dash 工具或是应用启动器打开 LightTable。
|
||||
|
||||
打开终端,运行以下命令来创建与编辑一个LightTable的启动文件:
|
||||
打开终端,运行以下命令来创建与编辑一个 LightTable 的启动文件:
|
||||
|
||||
gksudo gedit /usr/share/applications/lighttable.desktop
|
||||
|
||||
通过Gedit文本编辑器打开文件后, 粘贴下面的内容并保存:
|
||||
通过 Gedit 文本编辑器打开文件后,粘贴下面的内容并保存:
|
||||
|
||||
[Desktop Entry]
|
||||
Version=1.0
|
||||
@ -81,7 +78,7 @@ LightTable 0.8.0的改动:
|
||||
Exec=/opt/LightTable/LightTable -n
|
||||
OnlyShowIn=Unity;
|
||||
|
||||
[Desktop Action Document]
|
||||
[Desktop Action Document]
|
||||
Name=New File
|
||||
Exec=/opt/LightTable/LightTable --command new_file
|
||||
OnlyShowIn=Unity;
|
||||
@ -90,15 +87,15 @@ LightTable 0.8.0的改动:
|
||||
|
||||
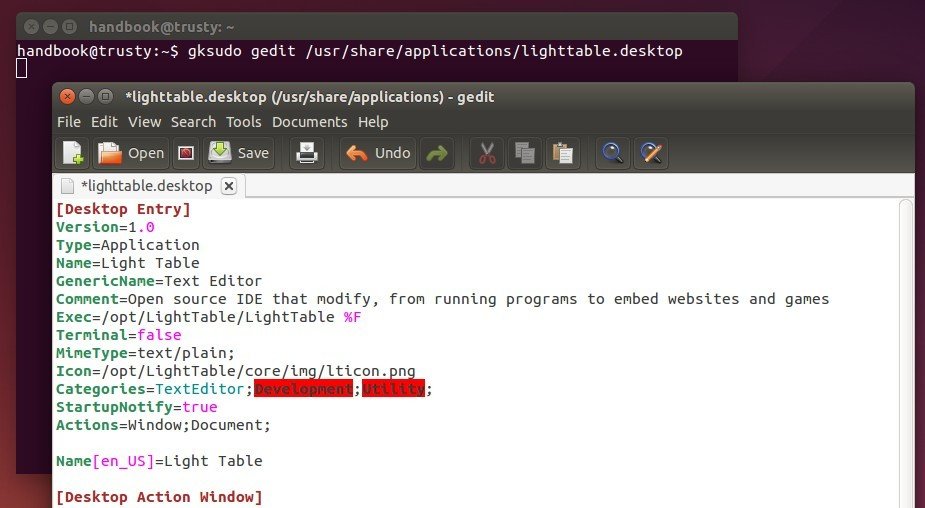
|
||||
|
||||
最后,从dash工具或者是应用启动器打开IDE,好好享受它吧!
|
||||
最后,从 dash 工具或者是应用启动器打开 IDE,好好享受它吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/12/install-light-table-0-8-ubuntu-14-04/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +1,43 @@
|
||||
Linux Desktop Fun: Summon Swarms Of Penguins To Waddle About The Desktop
|
||||
Linux/Unix 桌面趣事:召唤一群企鹅在桌面上行走
|
||||
================================================================================
|
||||
XPenguins is a program for animating cute cartoons animals in your root window. By default it will be penguins they drop in from the top of the screen, walk along the tops of your windows, up the side of your windows, levitate, skateboard, and do other similarly exciting things. Now you can send an army of cute little penguins to invade the screen of someone else on your network.
|
||||
XPenguins 是一个在窗口播放可爱动物动画的程序。默认情况下,将会从屏幕上方掉落企鹅,沿着你的窗口顶部行走,在窗口漂浮起来,踩上滑板,和做其他类似的有趣的事情。现在,你可以把这些可爱的小企鹅大军入侵别人的桌面了。
|
||||
|
||||
### Install XPenguins ###
|
||||
### 安装XPenguins ###
|
||||
|
||||
Open a command-line terminal (select Applications > Accessories > Terminal), and then type the following commands to install XPenguins program. First, type the command apt-get update to tell apt to refresh its package information by querying the configured repositories and then install the required program:
|
||||
打开终端(选择程序->附件->终端),接着输入下面的命令来安装 XPenguins。首先,输入 `apt-get update` 通过请求配置的仓库刷新包的信息,接着安装需要的程序:
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install xpenguins
|
||||
|
||||
### How do I Start XPenguins Locally? ###
|
||||
### 我本地如何启动 XPenguins? ###
|
||||
|
||||
Type the following command:
|
||||
输入下面的命令:
|
||||
|
||||
$ xpenguins
|
||||
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
An army of cute little penguins invading the screen
|
||||
*一支可爱企鹅军队正在入侵屏幕。*
|
||||
|
||||

|
||||
|
||||
Linux: Cute little penguins walking along the tops of your windows
|
||||
*可爱的小企鹅沿着窗口的顶部行走。*
|
||||
|
||||

|
||||
|
||||
Xpenguins Screenshot
|
||||
*Xpenguins 截图*
|
||||
|
||||
Be careful when you move windows as the little guys squash easily. If you send the program an interupt signal (Ctrl-C) they will burst.
|
||||
移动窗口时小心点,小家伙们很容易被压坏。如果你发送中断程序(Ctrl-C),它们会爆炸。
|
||||
|
||||
### Themes ###
|
||||
### 主题 ###
|
||||
|
||||
To list themes, enter:
|
||||
要列出主题,输入:
|
||||
|
||||
$ xpenguins -l
|
||||
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
Big Penguins
|
||||
Bill
|
||||
@ -45,11 +45,11 @@ Sample outputs:
|
||||
Penguins
|
||||
Turtles
|
||||
|
||||
You can use alternative themes as follows:
|
||||
你可以用下面的命令使用其他的主题:
|
||||
|
||||
$ xpenguins --theme "Big Penguins" --theme "Turtles"
|
||||
|
||||
You can install additional themes as follows:
|
||||
你可以用下面的命令安装额外的主题:
|
||||
|
||||
$ cd /tmp
|
||||
$ wget http://xpenguins.seul.org/xpenguins_themes-1.0.tar.gz
|
||||
@ -58,7 +58,7 @@ You can install additional themes as follows:
|
||||
$ mv -v themes ~/.xpenguins/
|
||||
$ xpenguins -l
|
||||
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
Lemmings
|
||||
Sonic the Hedgehog
|
||||
@ -71,30 +71,32 @@ Sample outputs:
|
||||
Penguins
|
||||
Turtles
|
||||
|
||||
To start with a random theme, enter:
|
||||
已一个随机主题开始,输入:
|
||||
|
||||
$ xpenguins --random-theme
|
||||
|
||||
To load all available themes and run them simultaneously, enter:
|
||||
要加载所有的主题并且同时运行,输入:
|
||||
|
||||
$ xpenguins --all
|
||||
|
||||
More links and information:
|
||||
更多链接何信息:
|
||||
|
||||
- [XPenguins][1] home page.
|
||||
- [XPenguins][1] 主页。
|
||||
- man penguins
|
||||
- More Linux / UNIX desktop fun with [Steam Locomotive][2] and [Terminal ASCII Aquarium][3].
|
||||
- 更多 Linux/Unix 桌面乐趣在[蒸汽火车][2]和[终端ASCII水族馆][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/tips/linux-cute-little-xpenguins-walk-along-tops-ofyour-windows.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xpenguins.seul.org/
|
||||
[2]:http://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html
|
||||
[3]:http://www.cyberciti.biz/tips/linux-unix-apple-osx-terminal-ascii-aquarium.html
|
||||
|
||||
|
||||
@ -0,0 +1,90 @@
|
||||
2016:如何选择 Linux 桌面环境
|
||||
=============================================
|
||||
|
||||
|
||||
|
||||
Linux 创建了一个友好的环境,为我们提供了选择的可能。比方说,现代大多数的 Linux 发行版都提供不同桌面环境给我们来选择。在本文中,我将挑选一些你可能会在 Linux 中见到的最棒的桌面环境来介绍。
|
||||
|
||||
## Plasma
|
||||
|
||||
我认为,[KDE 的 Plasma 桌面](https://www.kde.org/workspaces/plasmadesktop/) 是最先进的桌面环境 (LCTT 译注:译者认为,没有什么是最好的,只有最合适的,毕竟每个人的喜好都不可能完全相同)。它是我见过功能最完善和定制性最高的桌面环境;在用户完全自主控制方面,即使是 Mac OS X 和 Windows 也无法与之比拟。
|
||||
|
||||
我爱 Plasma,因为它自带了一个非常好的文件管理器 —— Dolphin。而相对应 Gnome 环境,我更喜欢 Plasma 的原因就在于这个文件管理器。使用 Gnome 最大的痛苦就是,它的文件管理器——Files——使我无法完成一些基本任务,比如说,批量文件重命名操作。而这个操作对我来说相当重要,因为我喜欢拍摄,但 Gnome 却让我无法批量重命名这些图像文件。而使用 Dolphin 的话,这个操作就像在公园散步一样简单。
|
||||
|
||||
而且,你可以通过插件来增强 Plasma 的功能。Plasma 有大量的基础软件,如 Krita、Kdenlive、Calligra 办公套件、digiKam、Kwrite 以及由 KDE 社区开发维护的大量应用。
|
||||
|
||||
Plasma 桌面环境唯一的缺陷就是它默认的邮件客户端——Kmail。它的设置比较困难,我希望 Kmail 设置可以配置地址簿和日历。
|
||||
|
||||
包括 openSUSE 在内的多数主流发行版多使用 Plasma 作为默认桌面。
|
||||
|
||||
## GNOME
|
||||
|
||||
[GNOME](https://www.gnome.org/) (GNU Network Object Model Environment,GNU 网络对象模型环境) 由 [Miguel de Icaza](https://en.wikipedia.org/wiki/Miguel_de_Icaza) 和 Federico Mena 在 1997 年的时候创立,这是因为 KDE 使用了 Qt 工具包,而这个工具包是使用专属许可证 (proprietary license) 发布的。不像提供了大量定制的 KDE,GNOME 专注于让事情变得简单。因为其自身的简单性和易用性,GNOME 变得相当流行。而我认为 GNOME 之所以流行的原因在于,Ubuntu——使用 GNOME 作为默认桌面的主流 Linux 发行版之一——对其有着巨大的推动作用。
|
||||
|
||||
随着时代变化,GNOME 也需要作出相应的改变了。因此,开发者在 GNOME 3 中推出了 GNOME 3 Shell,从而引出了它的全新设计规范。但这同时与 Canonical 的 Ubuntu 计划存在者一些冲突,所以 Canonical 为 GNOME 开发了叫做 Unity 的自己的 Shell。最初,GNOME 3 Shell 因很多争议 (issues) 而困扰不已——最明显的是,升级之后会导致很多扩展无法正常工作。由于设计上的重大改版以及各种问题的出现,GNOME 便产生了很多分支(fork),比如 Cinnamon 和 Mate 桌面。
|
||||
|
||||
另外,使得 GNOME 让人感兴趣的是,它针对触摸设备做了优化,所以,如果你有一台触屏笔记本电脑的话,GNOME 则是最合适你这台电脑的桌面环境。
|
||||
|
||||
在 3.18 版本中,GNOME 已经作出了一些令人印象深刻的改动。其中他们所做的最让人感兴趣的是集成了 Google Drive,用户可以把他们的 Google Drive 挂载为远程存储设备,这样就不必再使用浏览器来查看里边的文件了。我也很喜欢 GNOME 里边自带的那个优秀的邮件客户端,它带有日历和地址簿功能。尽管有这么多些优秀的特性,但它的文件管理器使我不再使用 GNOME ,因为我无法处理批量文件重命名。我会坚持使用 Plasma,一直到 GNOME 的开发者修复了这个小缺陷。
|
||||
|
||||

|
||||
|
||||
## Unity
|
||||
|
||||
从技术上来说,[Unity](https://unity.ubuntu.com/) 并不是一个桌面环境,它只是 Canonical 为 Ubuntu 开发的一个图形化 Shell。Unity 运行于 GNOME 桌面之上,并使用很多 GNOME 的应用和工具。Ubuntu 团队分支了一些 GNOME 组件,以便更好的满足 Unity 用户的需求。
|
||||
|
||||
Unity 在 Ubuntu 的融合(convergence)计划中扮演着重要角色, 在 Unity 8 中,Canonical 公司正在努力将电脑桌面和移动世界结合到一起。Canonical 同时还为 Unity 开发了许多的有趣技术,比如 HUD (Head-up Display,平视显示)。他们还在 lenses 和 scopes 中通过一种独特的技术来让用户方便地找到特定内容。
|
||||
|
||||
即将发行的 Ubuntu 16.04,将会搭载 Unity 8,那时候用户就可以完全体验开发者为该开源软件添加的所有特性了。其中最大的争议之一,Unity 可选取消集成了 Amazon Ads 和其他服务。而在即将发行的版本,Canonical 从 Dash 移除了 Amazon ads,但却默认保证了系统的隐私性。
|
||||
|
||||
## Cinnamon
|
||||
|
||||
最初,[Cinnamon](https://en.wikipedia.org/wiki/Cinnamon_(software\)) 由 [Linux Mint](http://www.linuxmint.com/) 开发 —— 这是 DistroWatch.com 上统计出来最流行的发行版。就像 Unity,Cinnamon 是 GNOME Shell 的一个分支。但最后进化为一个独立的桌面环境,这是因为 Linux Mint 的开发者分支了 GNOME 桌面中很多的组件到 Cinnamon,包括 Files ——以满足自身用户的需求。
|
||||
|
||||
由于 Linux Mint 基于普通版本的 Ubuntu,开发者仍需要去完成 Ubuntu 尚未完成的目标。结果,尽管前途光明,但 Cinnamon 却充满了 Bugs 和问题。随着 17.x 本版的发布,Linux Mint 开始转移到 Ubuntu 的 LTS 版本上,从而他们可以专注于开发 Cinnamon 的核心组件,而不必再去担心代码库。转移到 LTS 的好处是,Cinnamon 变得非常稳定并且基本没有 Bugs 出现。现在,开发者已经开始向桌面环境中添加更多的新特性了。
|
||||
|
||||
对于那些更喜欢在 GNOME 基础上有一个很好的类 Windows 用户界面的用户来说,Cinnamon 是他们最好的桌面环境。
|
||||
|
||||
## MATE 桌面
|
||||
|
||||
[MATE 桌面](http://mate-desktop.com/) 同样是 GNOME 的一个分支,然而,它并不像 Cinnamon 那样由 GNOME 3 分支而来,而是现在已经没有人维护的 GNOME 2 代码库的一个分支。MATE 桌面中的一些开发者并不喜欢 GNOME 3 并且想要“继续坚持” GNOME 2,所以他们使用这个代码库来创建来 MATE。为避免和 GNOME 3 的冲突,他们重命名了全部的包:Nautilus 改为 Caja、Gedit 改为 Pluma 以及 Evince 改为 Atril 等。
|
||||
|
||||
尽管 MATE 延续了 GNOME 2,但这并不意味着他们使用过时的技术;相反,他们使用了更新的技术来提供一个现代的 GNOME 2 体验。
|
||||
|
||||
拥有相当高的资源使用率才是 MATE 最令人印象深刻之处。你可将它运行在老旧硬件或者更新一些的但不太强大的硬件上,如树梅派 (Raspberry Pi) 或者 Chromebook Flip。使得它更有让人感兴趣的是,把它运行在一些强大的硬件上,可以节省大多数的资源给其他应用,而桌面环境本身只占用很少的资源。
|
||||
|
||||
## LXQt
|
||||
|
||||
[LXQt](http://lxqt.org/) 继承了 LXDE ——最轻量级的桌面环境之一。它融合了 LXDE 和 Razor-Qt 两个开源项目。LXQt 的首个可用本版(v 0.9)发布于 2015 年。最初,开发者使用了 Qt4 ,之后为了加快开发速度,而放弃了兼容性,他们移动到 Qt5 和 KDE 框架上。我也在自己的 Arch 系统上尝试使用了 LXQt,它的确是一个非常好的轻量级桌面环境。但在完全接过 LXDE 的传承之前,LXQt 仍有一段很长的路需要走。
|
||||
|
||||
## Xfce
|
||||
|
||||
[Xfce](http://www.xfce.org/) 早于 KDE 桌面环境,它是最古老和最轻量级的桌面环境。Xfce 的最新版本是 4.15,发布于 2015 年,使用了诸如 GTK+ 3 的大量的现代科技。很多发行版都使用了 Xfce 环境以满足特定需求,比如 Ubuntu Studio ——与 MATE 类似——尽量节省系统资源给其他的应用。并且,许多的著名的 Linux 发行版——包括 Manjaro Linux、PC/OS、Salix 和 Mythbuntu ——都把它作为默认桌面环境。
|
||||
|
||||
## Budgie
|
||||
|
||||
[Budgie](https://solus-project.com/budgie/) 是一个新型的桌面环境,由 Solus Linux 团队开发和维护。Solus 是一个从零开始构建的新型发行版,而 Budgie 则是它的一个核心组件。Budgie 使用了大量的 GNOME 组件,从而提供一个华丽的用户界面。由于没有该桌面环境的更多信息,我特地联系了 Solus 的核心开发者—— Ikey Doherty。他解释说:“我们搭载了自己的桌面环境—— Budgie 桌面。与其他桌面环境不同的是,Budgie 并不是其他桌面的一个分支,它的目标是彻底融入到 GNOME 协议栈之中。它完全从零开始编写,并特意设计来迎合 Solus 提供的体验。我们会尽可能的和 GNOME 的上游团队协同工作,修复 Bugs,并提倡和支持他们的工作”。
|
||||
|
||||
## Pantheon
|
||||
|
||||
我想,[Pantheon](https://elementary.io/) 不需要特别介绍了吧,那个优美的 elementary OS 就使用它作为桌面。类似于 Budgie,很多人都认为 Pantheon 也不是 GNOME 的一个分支。elementary OS 团队大多拥有良好的设计从业背景,所以他们会近距离关注每一个细节,这使得 Pantheon 成为一个非常优美的桌面环境。偶尔,它可能缺少像 Plasma 等桌面中的某些特性,但开发者实际上是尽其所能的去坚持设计原则。
|
||||
|
||||

|
||||
|
||||
## 结论
|
||||
|
||||
当我写完本文后,我突然意识到来开源和 Linux 的重大好处。总有一些东西适合你。就像 Jon “maddog” Hall 在最近的 SCaLE 14 上说的那样:“是的,现在有 300 多个 Linux 发行版。我可以一个一个去尝试,然后坚持使用我最喜欢的那一个”。
|
||||
|
||||
所以,尽情享受 Linux 的多样性吧,最后使用最合你意的那一个。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/software/applications/881107-best-linux-desktop-environments-for-2016
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/61003
|
||||
@ -0,0 +1,24 @@
|
||||
Ubuntu 16.04 为更好支持容器化而采用 ZFS
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
Ubuntu 开发者正在为 [Ubuntu 16.04 加上 ZFS 支持](http://www.phoronix.com/scan.php?page=news_item&px=ZFS-For-Ubuntu-16.04) ,并且对该文件系统的所有支持都已经准备就绪。
|
||||
|
||||
Ubuntu 16.04 的默认安装将会继续是 ext4,但是 ZFS 支持将会自动构建进 Ubuntu 发布中,模块将在需要时自动加载,zfsutils-linux 将放到 Ubuntu 主分支内,并且通过 Canonical 对商业客户提供支持。
|
||||
|
||||
对于那些对 Ubuntu 中的 ZFS 感兴趣的人,Canonical 的 Dustin Kirkland 已经写了[一篇新的博客](http://blog.dustinkirkland.com/2016/02/zfs-is-fs-for-containers-in-ubuntu-1604.html),介绍了一些细节及为何“ZFS 是 Ubuntu 16.04 中面向容器使用的文件系统!”
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-ZFS-Continues-16.04&utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+Phoronix+%28Phoronix%29
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
|
||||
|
||||
@ -1,14 +1,16 @@
|
||||
Linux最大版本4.1.18 LTS发布,带来大量修改
|
||||
Linux 4.1 系列的最大版本 4.1.18 LTS发布,带来大量修改
|
||||
=================================================================================
|
||||
(LCTT 译注:这是一则过期的消息,但是为了披露更新内容,还是发布出来给大家参考)
|
||||
|
||||
**著名的内核维护者Greg Kroah-Hartman貌似正在度假中,因为Sasha Levin有幸在今天,2016年2月16日,的早些时候来[宣布](http://lkml.iu.edu/hypermail/linux/kernel/1602.2/00520.html),第十八个Linux内核维护版本Linux Kernel 4.1 LTS通用版本正式发布。**
|
||||
**著名的内核维护者Greg Kroah-Hartman貌似正在度假中,因为Sasha Levin2016年2月16日的早些时候来[宣布](http://lkml.iu.edu/hypermail/linux/kernel/1602.2/00520.html),第十八个Linux内核维护版本Linux Kernel 4.1 LTS通用版本正式发布。**
|
||||
|
||||
作为长期支持的内核分支,Linux 4.1将再多几年接收到更新和补丁,而今天的维护构建版本也证明一点,就是内核开发者们正致力于统保持该系列在所有使用该版本的GNU/Linux操作系统上稳定和可靠。Linux Kernel 4.1.18 LTS是一个大规模发行版,它带来了总计达228个文件修改,这些修改包含了多达5304个插入修改和1128个删除修改。
|
||||
作为长期支持的内核分支,Linux 4.1还会在几年内得到更新和补丁,而今天的维护构建版本也证明一点,就是内核开发者们正致力于保持该系列在所有使用该版本的GNU/Linux操作系统上稳定和可靠。Linux Kernel 4.1.18 LTS是一个大的发布版本,它带来了总计达228个文件修改,这些修改包含了多达5304个插入修改和1128个删除修改。
|
||||
|
||||
Linux Kernel 4.1.18 LTS更新了什么呢?好吧,首先是对ARM,ARM64(AArch64),MIPS,PA-RISC,m32r,PowerPC(PPC),s390以及x86等硬件架构的改进。此外,还有对Btrfs,CIFS,NFS,XFS,OCFS2,OverlayFS以及UDF文件系统的加强。对网络堆栈的修复,尤其是对mac80211的修复。同时,还有多核心、加密和mm等方面的改进和对声音的更新。
|
||||
|
||||
“我宣布4.1.18内核正式发布,所有4.1内核系列的用户都应当升级。”Sasha Levin说,“更新的4.1.y git树可以在这里找到:git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git linux-4.1.y,并且可以在常规kernel.org git网站浏览器:http://git.kernel.org/?p=linux/kernel/git/stable/linux-stable.git;a=summary 进行浏览。”
|
||||
## 大量驱动被更新
|
||||
“我宣布4.1.18内核正式发布,所有4.1内核系列的用户都应当升级。”Sasha Levin说,“更新的4.1.y git树可以在这里找到:git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git linux-4.1.y,并且可以在 kernel.org 的 git 网站上浏览:http://git.kernel.org/?p=linux/kernel/git/stable/linux-stable.git;a=summary 进行浏览。”
|
||||
|
||||
### 大量驱动被更新
|
||||
|
||||
除了架构、文件系统、声音、网络、加密、mm和核心内核方面的改进之外,Linux Kernel 4.1.18 LTS更新了各个驱动,以提供更好的硬件支持,特别是像蓝牙、DMA、EDAC、GPU(主要是Radeon和Intel i915)、无限带宽技术、IOMMU、IRQ芯片、MD、MMC、DVB、网络(主要是无线)、PCI、SCSI、USB、散热、暂存和Virtio等此类东西。
|
||||
|
||||
@ -18,9 +20,9 @@ Linux Kernel 4.1.18 LTS更新了什么呢?好吧,首先是对ARM,ARM64(A
|
||||
|
||||
via: http://news.softpedia.com/news/linux-kernel-4-1-18-lts-is-the-biggest-in-the-series-with-hundreds-of-changes-500500.shtml
|
||||
|
||||
作者:[Marius Nestor ][a]
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,38 @@
|
||||
Mozilla 贡献者为大众创建糖尿病项目
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
我的开源生涯从我还是一名高中生开始,我总想着自己能成为一名黑客,没有什么恶意的,只是喜欢钻研代码和硬件那种。我第一次接触开源是2001年,我安装了我的第一个Linux发行版[Lindows](https://en.wikipedia.org/wiki/Linspire)。当然,我也是[Mozilla Firefox](https://www.mozilla.org/en-US/firefox/new/?utm_source=firefox-com&utm_medium=referral)的早期用户。
|
||||
|
||||
由于我很早使用Linux,我用的第一个版本是 Lindows 1.0.4(如果我没记错的话),我就立即爱上了它。我没在Lindows上呆太久,而是活跃于多个发行版([Debian](https://www.debian.org/),
|
||||
[Puppy Linux](http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm), [SUSE](https://www.suse.com/),
|
||||
[Slackware](http://www.slackware.com/), [Ubuntu](http://ubuntu.com/)),多年来我一直每天使用着开源软件,从青少年时候直到我成年。
|
||||
|
||||
最后,我坚持使用Ubuntu。大概是在Hardy Heron(LCTT 译注:Ubuntu8.04 LTS)发布时候,我开始第一次为Ubuntu做些贡献,在IRC频道和当地社区帮助那些需要帮助的用户。我是通过Ubuntu认识开源的,它在我心里总有着特殊的意义。Ubuntu背后的社区的是非常多样化的、热情的、友好的,每个人都做些共享,是他们共同的目标也是个人目标,这成为他们为开源贡献的动力。
|
||||
|
||||
在为Ubuntu贡献一段时间后,我开始了为一些上游项目作贡献,比如Debian、[GNOME](https://www.gnome.org/)、 [Ganeti](https://code.google.com/p/ganeti/),还有许多其他的开源项目。在过去的几年里,我为超过40个开源项目贡献过,有些小的,也有很大的。
|
||||
|
||||
在Ubuntu项目方向上有些变化之后,我最终觉得,这不仅对于我是一个尝试新东西的机遇,而且也是我给一些新东西贡献的时候。所以我在2009年参与了Mozilla项目,在IRC帮忙,最终通过参与[Mozilla WebFWD program](https://webfwd.org/),成为一名团队成员,然后是[Mozilla Reps Program](https://reps.mozilla.org/),[Mozilla DevRel Program](https://wiki.mozilla.org/Devrel),刚过两年时间,我成为了火狐社区的发布经理,负责监督Firefox Nightly和Firefox ESR的发布。相比其他开源项目,在为Mozilla贡献中会获得更多有益的经验。在所有我参与过的开源社区中,Mozilla是最不同的,最大的也是最友好的。
|
||||
|
||||
这些年来,关于开源我觉得,我越来越遵循自由软件价值观、捍卫隐私和许可协议合规,以及在开放的氛围下工作。我相信这三个主题对于开源来说是非常重要的,虽然许多人并没在意到提倡它们是很重要的。
|
||||
|
||||
今天在这,我已不再是别人的开源项目的全职贡献者。最近我被诊断出患有糖尿病,我看到了开源软件中健康软件不是很丰富这一缺口。确实,它不像其它开源软件应用如Linux发行版或浏览器那样活跃。
|
||||
|
||||
我最近创立了自己的开源项目[Glucosio](http://www.glucosio.org/),带给人们糖尿病管理和研究的开源软件。经过几年来对开源项目的贡献,和见识过的多种组织结构,使得我作为项目领导能够得心应手。我对于Glucosio的未来很兴奋,但最重要的是未来的开源将在医疗健康领域发展的如何。
|
||||
|
||||
医疗保健软件的创新具有很大潜力,我想我们很快就会看到用于改善医疗卫生保健的开源新方案。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/15/11/my-open-source-story-ben-kerensa
|
||||
|
||||
作者:[Benjamin Kerensa][a]
|
||||
译者:[ynmlml](https://github.com/ynmll)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bkerensa
|
||||
@ -0,0 +1,54 @@
|
||||
意法半导体为 32 位微控制器发布了一款自由的 Linux 集成开发环境
|
||||
=================================================
|
||||
|
||||

|
||||
|
||||
32 位微控制器世界向 Linux 敞开大门。前一段时间,领先的 ARM Cortex-M 供应商意法半导体(ST)[发布了](http://www.st.com/web/en/press/p3781) 一款自由的 Linux 桌面版开发程序,该软件面向其旗下的 STM32 微控制单元(MCU)。包含了 ST 的 STM32CubeMX 配置器和初始化工具,以及其 STM32 [系统工作台(SW4STM32)](http://www.st.com/web/catalog/tools/FM147/CL1794/SC961/SS1533/PF261797) ,这个基于 Eclipse 的 IDE 由工具 Ac6 创建。支撑 SW4STM32 的工具链,论坛,博客以及技术会由 [openSTM32.org](http://www.openstm32.org/tiki-index.php?page=HomePage) 开发社区提供。
|
||||
|
||||
“Linux 社区以吸引富有创意的自由思想者而闻名,他们善于交流心得、高效地克服挑战。” Laurent Desseignes,意法半导体微控制器产品部,微控制器生态系统市场经理这么说道:“我们正着手做的是让他们能极端简单的借力 STM32 系列的特性和性能施展自己的才能,运用到富有想象力的新产品的创造中去。
|
||||
|
||||
Linux 是物联网(IoT)网关和枢纽,及高端 IoT 终端的领先平台。但是,大部分 IoT 革命,以及可穿戴设备市场基于小型的低功耗微控制器,对 Cortex-M 芯片的运用越来越多。虽然其中的一小部分可以运行精简的 uCLinux (见下文),却没能支持更全面的 Linux 发行版。取而代之的是实时操作系统(RTOS)们或者有时干脆不用 OS 来控制。固件的开发工作一般会在基于 Windows 的集成开发环境(IDE)上完成。
|
||||
|
||||
通过 ST 的自由工具,Linux 开发者们可以更容易的开疆拓土。ST 工具中的一些技术在第二季度应该会登录 Mac OS/X 平台,与 [STM32 Nucleo](http://www.st.com/web/en/catalog/tools/FM146/CL2167/SC2003?icmp=sc2003_pron_pr-stm32f446_dec2014&sc=stm32nucleo-pr5) 、开发套件、以及评估板同时面世。Nucleo 支持 32 针、64 针、和 144 针的版本,并且提供类似 Arduino 连接器这样的插件。
|
||||
|
||||
STM32CubeMX 配置器和 IDE SW4STM32 使 Linux 开发者能够配置微控制器并开发调试代码。SW4STM32 支持在 Linux 下通过社区更改版的 [OpenOCD](http://openocd.org/) 使用调试工具 ST-LINK/V2。
|
||||
|
||||
据 ST 称,软件兼容 STM32Cube 软件包及标准外设库中的微控制器固件。目标是囊括 ST 的全系列 MCU,从入门级的 Cortex-M0 内核到高性能的 M7 芯片,包括 M0+,M3 和 DSP 扩展的 M4 内核。
|
||||
|
||||
ST 并非首个为 Linux 准备 Cortex-M 芯片 IDE 的 32 位 MCU 供应商,但似乎是第一大自由的 Linux 平台。例如 NXP,MCU 的市场份额随着近期收购了 Freescale (Kinetis 系列 MCU,等)而增加,提供了一款 IDE [LPCXpresso IDE](http://www.nxp.com/pages/lpcxpresso-ide:LPCXPRESSO),支持 Linux 、Windows 和 Mac。然而,LPCXpresso 每份售价 $450。
|
||||
|
||||
在其 [SmartFusion FPGA 系统级芯片(SoC)](http://www.microsemi.com/products/fpga-soc/soc-processors/arm-cortex-m3)上集成了 Cortex-M3 芯片的 Microsemi,拥有一款 IDE [Libero IDE](http://www.linux.com/news/embedded-mobile/mobile-linux/884961-st-releases-free-linux-ide-for-32-bit-mcus#device-support),适用于 RHEL 和 Windows。然而,Libero 需要许可证才行,并且 RHEL 版缺乏如 FlashPro 和 SoftConsole 的插件。
|
||||
|
||||
### 为什么要学习 MCU?
|
||||
|
||||
即便 Linux 开发者并没有计划在 Cortex-M 上使用 uClinux,但是 MCU 的知识总会派上用场。特别是牵扯到复杂的 IoT 工程,需要扩展 MCU 终端至云端。
|
||||
|
||||
对于原型和业余爱好者的项目,Arduino 板为其访问 MCU 提供了非常便利的接口。然而原型之外,开发者常常就会用更快的 32 位 Cortex-M 芯片以及所带来的附加功能来替代 Arduino 板和板上的那块 8 位 MCU ATmega32u4。这些附加功能包括改进的存储器寻址,用于芯片和各种总线的独立时钟设置,以及芯片 [Cortex-M7](http://www.electronicsnews.com.au/products/stm32-mcus-with-arm-cortex-m7-processors-and-graph) 自带的入门级显示芯片。
|
||||
|
||||
还有些可能需求 MCU 开发技术的地方包括可穿戴设备,低功耗、低成本和小尺寸给了 MCU 一席之地,还有机器人和无人机这些使用实时处理和电机控制的地方更为受用。在机器人上,你更是有可能看看 Cortex-A 与 Cortex-M 集成在同一个产品中的样子。
|
||||
|
||||
对于 SoC 芯片还有这样的一种温和的局势,即将 MCU 加入到 Linux 驱动的 Cortex-A 核心中,就如同 [NXP i.MX6 SoloX](http://linuxgizmos.com/freescales-popular-i-mx6-soc-sprouts-a-cortex-m4-mcu/)。虽然大多数的嵌入式项目并不使用这种混合型 SoC 或者说将应用处理器和 MCU 结合在同一产品中,但开发者会渐渐地发现自己工作的生产线、设计所基于的芯片正渐渐的从低端的 MCU 模块发展到 Linux 或安卓驱动的 Cortex-A。
|
||||
|
||||
### uClinux 是 Linux 在 MCU 领域的筹码
|
||||
|
||||
随着物联网的兴起,我们见到越来越多的 SBC 和模块计算机,它们在 32 位的 MCU 上运行着 uClinux。不同于其他的 Linux 发行版,uClinux 并不需要内存管理单元(MMU)。然而,uClinux 对市面上可见 MCU 有更高的内存需求。需求更高端的 Cortex-M4 和 Cortex-M4 微控制器内置内存控制器来支持外部 DRAM 芯片。
|
||||
|
||||
[Amptek](http://www.semiconductorstore.com/Amptek/) SBC 在 NXP LPC Cortex-M3 和 -M4 芯片上运行 uClinux,以提供常用的功能类似 WiFi、蓝牙、USB 等众多接口。Arrow 的 [SF2+](http://linuxgizmos.com/iot-dev-kit-runs-uclinux-on-a-microsemi-cortex-m3-fpga-soc/) 物联网开发套件将 uClinux 运行于 SmartFusion2 模块计算机的 Emcraft 系统上,该模块计算机是 Microsemi 的 166MHz Cortex-M3/FPGA SmartFusion2 混合 SoC。
|
||||
|
||||
[Emcraft](http://www.emcraft.com/) 销售基于 uClinux 的模块计算机,有 ST 和 NXP 的,也有 Microsemi 的 MCU,是 32 位 MCU 上积极推进 uClinux 的重要角色。日益频繁的 uClinux 开始了与 ARM 本身 [Mbed OS](http://linuxgizmos.com/arm-announces-mbed-os-for-iot-devices/)的对抗,至少在高端的 MCU 工程中需要无线通信和更为复杂的操作规则。Mbed 和 modern 的支持者,开源的 RTOS 们,类似 FreeRTOS 认为 uClinux 需要对 RAM 的需求太高以至于难以压低 IoT 终端的价格,然而 Emcraft 与其他 uCLinux 拥趸表示价格并没有如此夸张,而且扩展 Linux 的无线和接口也是相当值得的,即使只是在像 uClinux 这样的精简版上。
|
||||
|
||||
当被问及对于这次 ST 发布的看法,Emcraft 的主任工程师 Vladimir Khusainov 表示:“ST决定将这款开发工具 移植至 Linux 对于 Emcraft 是个好消息,它使得 Linux 用户能轻易的在嵌入式 STM MCU 上展开工作。我们希望那些有机会熟悉 STM 设备,使用 ST 配置器和嵌入式库的用户可能对在目标机上使用嵌入式 Linux (以 uClinux 的形式)感兴趣。”
|
||||
|
||||
最近关于 Cortex-M4 上运行 uClinux 的概述,可以查看去年 Jim Huang 与 Jeff Liaws 在嵌入式 Linux 大会上使用的[幻灯片](http://events.linuxfoundation.org/sites/events/files/slides/optimize-uclinux.pdf)。更多关于 Cortex-M 处理器可以查看这里过的 [AnandTech 总结](http://www.anandtech.com/show/8400/arms-cortex-m-even-smaller-and-lower-power-cpu-cores)。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/embedded-mobile/mobile-linux/884961-st-releases-free-linux-ide-for-32-bit-mcus
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/42808
|
||||
@ -0,0 +1,33 @@
|
||||
前 Kubuntu 领袖发起了新的 KDE 项目
|
||||
==============================================
|
||||
|
||||
如果你经常阅读 Linux 和[开源新闻](http://itsfoss.com/category/news/)的话应该会对 Jonathan Riddell 这人很熟悉。它是 [Kubuntu](http://www.kubuntu.org/) 发行版的创建者及长期的开发领导。他由于敢于质询 Canonical 基金会对 Kubuntu 的资金筹集情况[而被 Ubuntu 的老板 Mark Shuttleworth 所驱逐](http://www.cio.com/article/2926838/linux/mark-shuttleworth-ubuntu-community-council-ask-kubuntu-developer-to-step-down-as-leader.html) (据我所知,Canonical 从来没有真正回答过他的这个关于财务的问题。)
|
||||
|
||||

|
||||
|
||||
*KDE neon 标志*
|
||||
|
||||
在周日,Riddell [宣布](https://dot.kde.org/2016/01/30/fosdem-announcing-kde-neon)了一个新项目:[KDE neon](http://neon.kde.org.uk/)。根据 Riddell 的声明,“Neon 将会提供一个在最新的 KDE 软件一发布就可以获得的途径。”
|
||||
|
||||
在看了声明和网站后,**neon 似乎主要是一个“快速的软件更新仓库”,它让 KDE 粉丝可以用上最新的软件**。除了等上数月来等到开发者在他们的仓库中发布新的 KDE 软件外,你将可以在软件一出来就得到它。
|
||||
|
||||
KDE 的确在 [noen FAQ](http://neon.kde.org.uk/faq) 中声明过这不是一个 KDE 创建的发行版。事实上,他们说“KDE 相信与许多发行版协作是很重要的,因为它们每个都能给用户提供独特的价值和专长。这是 KDE 成千上万项目中的一个。”
|
||||
|
||||

|
||||
|
||||
然而,网站和公告显示 neon 会运行在 Ubuntu 15.10 中(直到有下个长期支持版本)并很快会有让我惊奇的情景。KDE 可能要让 Canonical 把此项目视作 Kubuntu 的竞争对手。如果他们发现 KDE neon 有前景,他们就能把它变成一个完整的发行版。网站和通告声称这是一个 KDE 孵化项目,因此未来可能会包含任何东西。
|
||||
|
||||
neon 听上去对你有用么,或者你是否对你当前的发行版的 KDE 发布速度满意?你认为是否还有其他 KDE 发行版的空间(如果 KDE 决定朝这个方向进发)?让我在评论栏知道你们的想法。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/kde-neon-unveiled/
|
||||
|
||||
作者:[JOHN PAUL][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/john/
|
||||
|
||||
@ -0,0 +1,36 @@
|
||||
Manjaro Linux 即将推出支持 ARM 处理器的 Manjaro-ARM
|
||||
===================================================
|
||||
|
||||

|
||||
|
||||
最近,Manjaro 的开发者为 ARM 处理器发布了一个 [alpha 版本](https://manjaro.github.io/Manjaro-ARM-launched/)。这是这个基于 Archlinux 的发行版的一大进步,在此之前,它只能在 32 位或者 64 位的个人电脑上运行。
|
||||
|
||||
根据公告, “[Manjaro Arm](http://manjaro-arm.org/) 项目致力于将简洁可定制的 Manjaro 移植到使用 [ARM 处理器](https://www.arm.com/)的设备上去。这些设备的数量越来越多并且应用范围广泛。这些设备中最出名的是树莓派和 BeagleBoard“。目前 Alpha 版本仅支持树莓派2,但是毫无疑问,支持的设备数量会随时间增长。
|
||||
|
||||
现在这个项目的开发者有 dodgejcr, Torei, Strit, 和 Ringo32。他们正在寻求更多的人来帮助这个项目发展。除了开发者,[他们还在寻找维护者,论坛版主,管理员,以及设计师](http://manjaro-arm.org/forums/website/looking-for-contributors/?PHPSESSID=876d5c11400e9c25eb727e9965300a9a)。
|
||||
|
||||
Manjaro-ARM 将会有四个版本:
|
||||
|
||||
- 媒体版本将可以运行 Kodi 并且允许你用很少的配置就能创建一个媒体中心。
|
||||
- 服务器版将会预先配置好 SSH,FTP,LAMP ,你能把你的 ARM 设备当作服务器使用。
|
||||
- 基本版是一个桌面版本,自带一个 XFCE 桌面。
|
||||
- 如果你想自己从头折腾系统的话你可以选择迷你版,它没有任何预先配置的软件包,仅仅包含一个 root 用户。
|
||||
|
||||
### 我的想法
|
||||
|
||||
作为一个 Manjaro 的粉丝(我在 4 个电脑上都安了 Manjaro),听说他们分支出一个 ARM 版我很高兴。 ARM 处理器被用到了越来越多的设备当中。如同评论员 Robert Cringely 所说, [设备制造商开始注意到昂贵的因特尔、AMD 处理器之外的便宜的多的 ARM 处理器](http://www.cringely.com/2016/01/21/prediction-8-intel-starts-to-become-irrelevent/)。甚至微软(别打我)都开始考虑将自己的一些软件移植到 ARM 处理器上去。随着 ARM 处理器设备数量的增多,Manjaro 将会带给用户良好的体验。
|
||||
|
||||
对此,你怎样看?你希望更多的发行版支持 ARM 吗?或者你认为 ARM 将是昙花一现?在评论区告诉我们。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manjaro-linux-arm/
|
||||
|
||||
作者:[JOHN PAUL][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/john/
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
初学者 Vi 备忘单
|
||||
================================================
|
||||
|
||||

|
||||
|
||||
一直以来,我都在给你们分享我使用 Linux 的经验。今天我想分享我的 **Vi 备忘单**。这份备忘单节省了我很多时间,因为我再也不用使用 Google 去搜索这些命令了。
|
||||
|
||||
## 基本 Vi 命令
|
||||
|
||||
这并不是一个教你使用 [Vi 编辑器](https://en.wikipedia.org/wiki/Vi)的各个方面的详尽教程。事实上,这根本就不是一个教程。这仅仅是一些基本 Vi 命令以及这些命令简单介绍的集合。
|
||||
|
||||
命令|解释
|
||||
:--|:--
|
||||
`:x`|保存文件并退出
|
||||
`:q!`|退出但不保存文件
|
||||
`i`|在光标左侧插入
|
||||
`a`|在光标右侧插入
|
||||
`ESC`按键|退出插入模式
|
||||
光标键|移动光标
|
||||
`/text`|搜索字符串text(大小写敏感)
|
||||
`n`|跳到下一个搜索结果
|
||||
`x`|删除当前光标处的字符
|
||||
`dd`|删除当前光标所在的行
|
||||
`u`|撤销上次改变
|
||||
`:0`(数字0)|将光标移动到文件开头
|
||||
`:n`|将光标移动到第n行
|
||||
`G`|将光标移动到文件结尾
|
||||
`^`|将光标移动到该行开头
|
||||
`$`|将光标移动到该行结尾
|
||||
`:set list`|查看文件中特殊字符
|
||||
`yy`|复制光标所在行
|
||||
`5yy`|复制从光标所在行开始的5行
|
||||
`p`|在光标所在行下面粘贴
|
||||
|
||||
你可以通过下面的链接下载 PDF 格式的 Vi 备忘录:
|
||||
|
||||
[下载 Vi 备忘录](https://drive.google.com/file/d/0By49_3Av9sT1X3dlWkNQa3g2b2c/view?usp=sharing)
|
||||
|
||||
你可以把它打印出来放到你的办公桌上,或者把它保存到你的电脑上来使用。
|
||||
|
||||
## 我为什么要建立这个 Vi 备忘录?
|
||||
|
||||
几年前,当我刚刚接触 Linux 终端时,使用命令行编辑器这个主意使我一惊。我之前在我自己的电脑上使用过桌面版本的 Linux,所以我很乐意使用像 Gedit 这样的有图形界面的编辑器。但是在工作环境中,我不得不使用命令行,并且无法使用图形界面版的编辑器。
|
||||
|
||||
我就这么被强迫地使用 Vi 来对远程 Linux 终端上的文件做一些基本的编辑。从这时候我开始了解并钦佩 Vi 的强大之处。
|
||||
|
||||
因为在那时候我还是一个 Vi 新手,所以我经常对 Vi 一些操作很困惑。仍然记得第一次使用 Vi 的时候,由于我不知道如何退出 Vi,所以我都无法关闭某个文件。我也只能通过 Google 搜索来找到解决办法。我不得不接受这个尴尬的事实。
|
||||
|
||||
从那以后,我就决定制作一个列表来列出我经常会用到的基本 Vi 操作。这个列表,或者你可能称它为备忘录。在我早期使用 Vi 的时候,它对我非常有用。慢慢地,我对 Vi 更加熟悉,我已经可以熟记那些基本编辑命令。到现在,我甚至不需要再去查看我的 Vi 备忘录了。
|
||||
|
||||
## 你为什么需要 Vi 备忘录?
|
||||
|
||||
我能理解一个刚刚接触 Vi 的人的感受。你最喜欢的 `Ctrl`+`S` 快捷键不能像在其他编辑器那样方便地保存文件。`Ctrl`+`C`和`Ctrl`+`V`理应是通用的用来复制和粘贴的快捷键,但是在 Vi 中却不是这样。
|
||||
|
||||
很多人都在使用类似的备忘录帮助他们熟悉各种编程语言或工具,以便让他们可以快速找到常用的下一步或命令。相信我,使用备忘录会给程序员日常工作带来很大便利。
|
||||
|
||||
如果你刚刚开始接触 Vi 或者你经常使用但是总是记不住 Vi 操作,那么这份 Vi 备忘录对于你来说是非常有用的。你可以把它保存下来留作以后查询使用。
|
||||
|
||||
## 你怎么看待这份备忘录?
|
||||
|
||||
至今为止,我一直在克制我自己不要过于依赖终端。我想知道你是怎么发现这篇文章的?你是否想让我分享更多类似的备忘录出来以供你们下载?我很期待你的意见和建议。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/download-vi-cheat-sheet/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[JonathanKang](https://github.com/JonathanKang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,27 @@
|
||||
Xubuntu 16.04 Beta 1 开发者版本发布
|
||||
============================================
|
||||
|
||||
Ubuntu 发布团队宣布为选定的社区版本而准备的最新的 beta 测试镜像已经可以使用了。新的发布版本名称是 16.04 beta 1 ,这个版本只推荐给测试人员测试用,并不适合普通人进行日常使用。
|
||||
|
||||
|
||||
|
||||
“这个 beta 特性的镜像主要是为 [Lubuntu][1], Ubuntu Cloud, [Ubuntu GNOME][2], [Ubuntu MATE][3], [Ubuntu Kylin][4], [Ubuntu Studio][5] 和 [Xubuntu][6] 这几个发布版准备的。Xenial Xerus (LCTT 译注: ubuntu 16.04 的开发代号)的这个预发布版本并不推荐那些需要稳定版本的人员使用,同时那些不希望在系统运行中偶尔或频繁的出现 bug 的人也不建议使用这个版本。这个版本主要还是推荐给那些喜欢 ubuntu 的开发人员,以及那些想协助我们测试、报告 bug 和修改 bug 的人使用,和我们一起努力让这个发布版本早日准备就绪。” 更多的信息可以从 [发布日志][7] 获取。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/software/applications/888731-development-release-xubuntu-1604-beta-1
|
||||
|
||||
作者:[DistroWatch][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/284
|
||||
[1]: http://distrowatch.com/lubuntu
|
||||
[2]: http://distrowatch.com/ubuntugnome
|
||||
[3]: http://distrowatch.com/ubuntumate
|
||||
[4]: http://distrowatch.com/ubuntukylin
|
||||
[5]: http://distrowatch.com/ubuntustudio
|
||||
[6]: http://distrowatch.com/xubuntu
|
||||
[7]: https://lists.ubuntu.com/archives/ubuntu-devel-announce/2016-February/001173.html
|
||||
@ -0,0 +1,30 @@
|
||||
OpenSSH 7.2发布,支持 SHA-256/512 的 RSA 签名
|
||||
========================================================
|
||||
|
||||
**2016.2.29,OpenBSD 项目很高兴地宣布 OpenSSH 7.2发布了,并且很块可在所有支持的平台下载。**
|
||||
|
||||
根据内部[发布公告][1],OpenSSH 7.2 主要是 bug 修复,修改了自 OpenSSH 7.1p2 以来由用户报告和开发团队发现的问题,但是我们可以看到几个新功能。
|
||||
|
||||
这其中,我们可以提到使用了 SHA-256 或者 SHA-256 512 哈希算法的 RSA 签名;增加了一个 AddKeysToAgent 客户端选项,以添加用于身份验证的 ssh-agent 的私钥;和实现了一个“restrict”级别的 authorized_keys 选项,用于存储密钥限制。
|
||||
|
||||
此外,现在 ssh_config 中 CertificateFile 选项可以明确列出证书,ssh-keygen 现在能够改变所有支持的格式的密钥注释、密钥指纹现在可以来自标准输入,多个公钥可以放到一个文件。
|
||||
|
||||
### ssh-keygen 现在支持多证书
|
||||
|
||||
除了上面提到的,OpenSSH 7.2 增加了 ssh-keygen 多证书的支持,一个一行,实现了 sshd_config ChrootDirectory 及Foreground 的“none”参数,“-c”标志允许 ssh-keyscan 获取证书而不是文本密钥。
|
||||
|
||||
最后但并非最不重要的,OpenSSH 7.3 不再默认启用 rijndael-cbc(即 AES),blowfish-cbc、cast128-cbc 等古老的算法,同样的还有基于 MD5 和截断的 HMAC 算法。在 Linux 中支持 getrandom() 系统调用。[下载 OpenSSH 7.2][2] 并查看更新日志中的更多细节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/openssh-7-2-out-now-with-support-for-rsa-signatures-using-sha-256-512-algorithms-501111.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]: http://www.openssh.com/txt/release-7.2
|
||||
[2]: http://linux.softpedia.com/get/Security/OpenSSH-4474.shtml
|
||||
@ -0,0 +1,25 @@
|
||||
逾千万使用 https 的站点受到新型解密攻击的威胁
|
||||
===========================================================================
|
||||
|
||||
|
||||
|
||||
|
||||
低成本的 DROWN 攻击能在数小时内完成数据解密,该攻击对采用了 TLS 的邮件服务器也同样奏效。
|
||||
|
||||
一个国际研究小组于周二发出警告,据称逾 1100 万家网站和邮件服务采用的用以保证服务安全的 [传输层安全协议 TLS][1],对于一种新发现的、成本低廉的攻击而言异常脆弱,这种攻击会在几个小时内解密敏感的通信,在某些情况下解密甚至能瞬间完成。 前一百万家最大的网站中有超过 81,000 个站点正处于这种脆弱的 HTTPS 协议保护之下。
|
||||
|
||||
这种攻击主要针对依赖于 [RSA 加密系统][2]的 TLS 所保护的通信,密钥会间接的通过 SSLv2 暴露,这是一种在 20 年前就因为自身缺陷而退休了的 TLS 前代协议。该漏洞允许攻击者可以通过反复使用 SSLv2 创建与服务器连接的方式,解密截获的 TLS 连接。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/software/applications/889455--more-than-11-million-https-websites-imperiled-by-new-decryption-attack
|
||||
|
||||
作者:[ArsTechnica][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[martin2011qi](https://github.com/martin2011qi), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/112
|
||||
[1]: https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[2]: https://en.wikipedia.org/wiki/RSA_(cryptosystem)
|
||||
@ -0,0 +1,49 @@
|
||||
AlphaGo 的首尔之战带来的启示
|
||||
================================================================================
|
||||
围棋并不仅仅是一个游戏——她是一伙活生生的玩家们,分析家们,爱好者们以及传奇大师们。在过去的十天里,在韩国首尔,我们有幸亲眼目睹那份难以置信的激动。我们也有幸也目睹了那前所未有的场景:[DeepMind][1] 的 AlphaGo 迎战并战胜了传奇围棋大师,李世石(职业9段,身负 18 个世界头衔),这是人工智能的里程碑。
|
||||
|
||||

|
||||
|
||||
虽说围棋可能是存世的最为悠久的游戏之一了,但对于这五盘比赛的关注度还是大大的超出了我们的想象。搜索围棋规则和围棋盘的用户在美国迅速飙升。在中国,数以千万计的用户通过直播观看了这场比赛,并且新浪微博“人机围棋大战”话题的浏览量破 2 亿。韩国的围棋盘也销量[激增][2]。
|
||||
|
||||
然而我们如此公开的测试 AlphaGo,并不仅仅是为了赢棋而已。我们自 2010 年成立 DeepMind,为的是创造出具有独立学习能力的通用型人工智能(AI),并致力于将其作为工具协助解决,从气候变化到诊断疾病,这类最为棘手且急迫的问题为最终目标。
|
||||
|
||||
亦如许多前辈学者们一样,我们也是通过游戏来开发并测试我们的算法的。在一月份,我们第一次披露了 [AlphaGo][3]——作为第一个通过使用 [深度学习][4] 和 [强化学习][5],可以在人类发明的最为复杂的棋盘类游戏中击败职业选手的 AI 程序。而 AlphaGo 迎战过去十年间最厉害的围棋选手——李世石,绝对称得上是 [终极挑战][6]。
|
||||
|
||||
结果震惊了包括我们在内的每个人,AlphaGo 五战四胜。评论家指出了 AlphaGo 下出的许多前所未见、极富创意或者要用 [“漂亮”][7] 来形容的妙手。基于我们的数据分析,AlphaGo 在第 2 局中的 [37 手][8],在人类选手中出现的几率仅有万分之一。而李一反常态的创新下法,如第 4 局中的 [78 手][9]——也是既存下法中的万中之一的——这一手也最终造就了一场胜利。
|
||||
|
||||
最后比分定格在 4-1。我们为支持科学、技术、工程、数学(STEM)教育和围棋的组织,以及 UNICEF (联合国儿童基金会)赢得了 $1 百万的捐助。
|
||||
|
||||
经此一役,我们将收获总结成以下两点:第一,此次测试很好的预示了 AI 有解决其他问题的潜力。AlphaGo 在棋盘上能够做到兼顾“全局”——并找出人类已经被训化而不会走或想到的妙手。运用 AlphaGo 这类的技术,在人类目所不能及的领域中探索,会有很大的潜力。第二,虽说这场比赛已经被广泛的标榜成“人机大战”,但 AlphaGo 却是人类实实在在的成果。无论是李世石还是 AlphaGo 团队相互之间互相促进,产生了新的想法、观点和答案——并且长远来看,我们都将从中受益。
|
||||
|
||||
但正如韩国对于围棋的观点:“胜而不骄,是以常胜。”这只是使机器聪明的漫长道路中的一个小小而显著的一步而已。我们已经证明了尖端深度强化学习技术可以被用作制作强大的围棋选手和 [Atari][10] 玩家。深度神经网络在 Google 已经与 [图像识别][11],[语音识别][12] 以及 [搜索排名][13] 一样被应用到具体的任务中了。然而,从会学习的机器到可以像人一样全方位灵活实施智能任务——真正达到 [强人工智能][14] 的特性,此中的道路还很漫长。
|
||||
|
||||

|
||||
|
||||
我们想通过这场比赛来测试 AlphaGo 的极限。李世石大师做的十分出色—我们在接下来的数周内会研究他与 AlphaGo 的对战细节。同时因为我们在 AlphaGo 中使用的机器学习方法是通用型的,我们十分希望在不久的将来,将这种技术应用于其他的挑战中。游戏开始!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://googleblog.blogspot.com/2016/03/what-we-learned-in-seoul-with-alphago.html
|
||||
|
||||
作者:[Demis Hassabis][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://demishassabis.com/
|
||||
[1]:https://deepmind.com/
|
||||
[2]:http://www.hankookilbo.com/m/v/3e7deaa26a834f76929a1689ecd388ea
|
||||
[3]:https://googleblog.blogspot.com/2016/01/alphago-machine-learning-game-go.html
|
||||
[4]:https://en.wikipedia.org/wiki/Deep_learning
|
||||
[5]:https://en.wikipedia.org/wiki/Reinforcement_learning
|
||||
[6]:https://deepmind.com/alpha-go.html
|
||||
[7]:http://www.wired.com/2016/03/sadness-beauty-watching-googles-ai-play-go/
|
||||
[8]:https://youtu.be/l-GsfyVCBu0?t=1h17m50s
|
||||
[9]:https://youtu.be/yCALyQRN3hw?t=3h10m25s
|
||||
[10]:http://googleresearch.blogspot.sg/2015/02/from-pixels-to-actions-human-level.html
|
||||
[11]:http://googleresearch.blogspot.sg/2013/06/improving-photo-search-step-across.html
|
||||
[12]:http://googleresearch.blogspot.sg/2015/08/the-neural-networks-behind-google-voice.html
|
||||
[13]:http://www.bloomberg.com/news/articles/2015-10-26/google-turning-its-lucrative-web-search-over-to-ai-machines
|
||||
[14]:https://en.wikipedia.org/wiki/Artificial_general_intelligence
|
||||
@ -0,0 +1,36 @@
|
||||
ownCloud Pi 设备将运行在 Snappy Ubuntu Core 16.04 LTS 及树莓派3上
|
||||
===============================================================================
|
||||
|
||||
|
||||
我们去年[报道了][1] ownCloud 正与西部数据(Western Digital)实验室沟通,帮助他们开发一个社区项目,将给用户带来可以在家中自托管的云存储设备。
|
||||
|
||||
自托管设备背后的理念,是由 ownCloud 服务端软件承载的,它结合了树莓派和西数硬盘到一个易安装和开箱即用的容器中。
|
||||
|
||||
社区的反应看上去很积极,ownCloud Pi 项目收到了许多好的提议和点子。今天,我们收到了一个更好的消息,首个镜像可以[下载][2]了。
|
||||
|
||||
ownCloud Pi 基于最新的 Snappy Ubuntu Core 16.04 LTS 系统,它由 Canonical 为嵌入式和 物联网(Internet of Things)设备所设计,包括新的树莓派3 Model B。
|
||||
|
||||
ownCloud 的开发者在今天的[声明][3]中称:“我们正在寻求来自 ownCloud、Ubuntu、树莓派和西数实验室等社区的帮助来测试和提高它们,并且可以在下周发布首批30台设备”。
|
||||
|
||||
### 目前的阻碍、挑战及前进的路
|
||||
|
||||
目前团队正致力于在基于 Xenial Xerus 版本的 Snappy Ubuntu 内核上完成他们的 ownCloud Pi 设备方案。这样,新的64位树莓派3可以帮助它们克服之前在树莓派2上遇到的阻碍,比如支持大于2GB的文件。
|
||||
|
||||
由此看来,最终的 ownCloud Pi 将在今年春天发布预览版,它将会在树莓派3上运行。之后,我们应该就可以购买首批可用于产品环境版本的 ownCloud Pi 设备了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/owncloud-pi-device-to-run-on-snappy-ubuntu-core-16-04-lts-and-raspberry-pi-3-501904.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]: http://news.softpedia.com/news/owncloud-partnerships-with-wd-to-bring-self-hosted-cloud-storage-in-users-homes-497512.shtml
|
||||
[2]: http://people.canonical.com/~kyrofa/owncloud-pi/
|
||||
[3]: https://owncloud.org/blog/wd-labs-raspberry-pi-owncloud-and-ubuntu/
|
||||
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
将 Ubuntu 和 FreeBSD 融合在一起的发行版 :UbuntuBSD
|
||||
========================================================
|
||||
|
||||

|
||||
|
||||
不止是在 Linux 的内核上面你才能体验到 Ubuntu 的快捷方便,伙计们。UbuntuBSD 可以让你在 FreeBSD 的内核上面也能体验到那种方便快捷。
|
||||
|
||||
UbuntuBSD 称自己是 ‘Unix for human beings’,这一点也不人惊讶。如过你能想起来的话,Ubuntu 使用的标语是 ‘Linux for human beings’ 并且在过去的 11 年里它确实让一个‘正常人’有可能用上 Linux。
|
||||
|
||||
UbuntuBSD 有着同样的想法。它想让新手能够接触到 Unix ,以及能使用它——如果我能这样说的话。至少,这就是它的目标。
|
||||
|
||||
### 什么是 BSD ? 它和 Linux 有哪些不同? ###
|
||||
|
||||
如果你是新手,那么你需要知道 [Unix 和 Linux 的区别][2].
|
||||
|
||||
在 Linux 出现之前,Unix 由 [AT&T][3] 的 [Ken Thompson][4]、 [Denis Ricthie][5] 以及他们的团队设计。这是在可以算作计算机上古时期的 1970 发生的事。当你知道 Unix 是一个闭源的,有产权的操作系统时你可能会感到惊讶。AT&T 给了很多第三方许可,包括学术机构和企业。
|
||||
|
||||
美国加州大学伯克利分校是其中一个拿到许可的学术机构。在那里开发的 Unix 系统叫做 [BSD (Berkeley Software Distribution)][6]。BSD 的最出名的开源分支是 [FreeBSD][7],另一个最流行的闭源分支是苹果的 Mac OS X。
|
||||
|
||||
在 1991 年。芬兰的计算机系大学生 Linus Torvalds 从头写了自己的 Unix 系统的复制品。这就是我们今天熟知的 Linux 内核。Linux 的发行版在内核的基础上添加了图形界面、GNU 的那一套(cp, mv, ls,date, bash 什么的)、安装/管理工具,GNU C/C++ 编译器以及很多应用。
|
||||
|
||||
### UbuntuBSD 不是这种发行版的开端
|
||||
|
||||
在你知道了 Linux,Unix,FreeBSD 之间的区别之后。我要告诉你的是 UbuntuBSD 不是第一个要在 FreeBSD 内核上作出类似 Linux 的感觉的发行版。
|
||||
|
||||
当 Debian 选择使用 [systemd][8] 之后,[Debian GNU/kFreeBSD][9]诞生了。它使用的不是通常的 Linux 内核,而是 将 Debian 移植到了 FreeBSD 内核上。
|
||||
|
||||
与 Debian GNU/kFreeBSD 类似,UbuntuBSD 是将 Ubuntu 移植到了 FreeBSD 内核上。
|
||||
|
||||
### UbuntuBSD Beta 版代号: Escape From SystemD
|
||||
|
||||
UbuntuBSD 的第一个版本已经发布,代号为“Escape From SystemD ”。它基于 Ubuntu 15.10 和 FreeBSD 10.1.
|
||||
|
||||
它的默认桌面环境为 [Xfce][10] ,桌面以及服务器均可使用。 对于 [ZFS][11] 的支持也包含在这个版本中。开发者还提供了一个文本界面的安装器。
|
||||
|
||||
### 想试试?
|
||||
|
||||
我不建议任何人马上就去开心地去尝试这个系统。它仍在开发并且安装器还是文本界面的。不过如果你足够自信的话,直接去下载体验吧。但是如果你是新手的话,请等一段时间,至少不要现在就去尝试:
|
||||
|
||||
[UbuntuBSD][12]
|
||||
|
||||
你认为 UbuntuBSD 怎么样? 兹瓷不兹瓷它?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/ubuntubsd-ubuntu-freebsd/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]: http://itsfoss.com/tag/linux/
|
||||
[2]: https://linux.cn/article-3159-1.html
|
||||
[3]: https://en.wikipedia.org/wiki/AT%26T
|
||||
[4]: https://en.wikipedia.org/wiki/Ken_Thompson
|
||||
[5]: https://en.wikipedia.org/wiki/Dennis_Ritchie
|
||||
[6]: http://www.bsd.org/
|
||||
[7]: https://www.freebsd.org/
|
||||
[8]: https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[9]: https://www.debian.org/ports/kfreebsd-gnu/
|
||||
[10]: http://www.xfce.org/
|
||||
[11]: https://en.wikipedia.org/wiki/ZFS
|
||||
[12]: https://sourceforge.net/projects/ubuntubsd/
|
||||
@ -0,0 +1,276 @@
|
||||
将程序性能提高十倍的10条建议
|
||||
================================================================================
|
||||
|
||||
提高 web 应用的性能从来没有比现在更重要过。网络经济的比重一直在增长;全球经济超过 5% 的价值是在因特网上产生的(数据参见下面的资料)。这个时刻在线的超连接世界意味着用户对其的期望值也处于历史上的最高点。如果你的网站不能及时的响应,或者你的 app 不能无延时的工作,用户会很快的投奔到你的竞争对手那里。
|
||||
|
||||
举一个例子,一份亚马逊十年前做过的研究可以证明,甚至在那个时候,网页加载时间每减少100毫秒,收入就会增加1%。另一个最近的研究特别强调一个事实,即超过一半的网站拥有者在调查中承认它们会因为应用程序性能的问题流失用户。
|
||||
|
||||
网站到底需要多快呢?对于页面加载,每增加1秒钟就有4%的用户放弃使用。顶级的电子商务站点的页面在第一次交互时可以做到1秒到3秒加载时间,而这是提供最高舒适度的速度。很明显这种利害关系对于 web 应用来说很高,而且在不断的增加。
|
||||
|
||||
想要提高效率很简单,但是看到实际结果很难。为了在你的探索之旅上帮助到你,这篇文章会给你提供10条最高可以提升10倍网站性能的建议。这是系列介绍提高应用程序性能的第一篇文章,包括充分测试的优化技术和一点 NGINX 的帮助。这个系列也给出了潜在的提高安全性的帮助。
|
||||
|
||||
### Tip #1: 通过反向代理来提高性能和增加安全性 ###
|
||||
|
||||
如果你的 web 应用运行在单个机器上,那么这个办法会明显的提升性能:只需要换一个更快的机器,更好的处理器,更多的内存,更快的磁盘阵列,等等。然后新机器就可以更快的运行你的 WordPress 服务器, Node.js 程序, Java 程序,以及其它程序。(如果你的程序要访问数据库服务器,那么解决方法依然很简单:添加两个更快的机器,以及在两台电脑之间使用一个更快的链路。)
|
||||
|
||||
问题是,机器速度可能并不是问题。web 程序运行慢经常是因为计算机一直在不同的任务之间切换:通过成千上万的连接和用户交互,从磁盘访问文件,运行代码,等等。应用服务器可能会抖动(thrashing)-比如说内存不足、将内存数据交换到磁盘,以及有多个请求要等待某个任务完成,如磁盘I/O。
|
||||
|
||||
你可以采取一个完全不同的方案来替代升级硬件:添加一个反向代理服务器来分担部分任务。[反向代理服务器][1] 位于运行应用的机器的前端,是用来处理网络流量的。只有反向代理服务器是直接连接到互联网的;和应用服务器的通讯都是通过一个快速的内部网络完成的。
|
||||
|
||||
使用反向代理服务器可以将应用服务器从等待用户与 web 程序交互解放出来,这样应用服务器就可以专注于为反向代理服务器构建网页,让其能够传输到互联网上。而应用服务器就不需要等待客户端的响应,其运行速度可以接近于优化后的性能水平。
|
||||
|
||||
添加反向代理服务器还可以给你的 web 服务器安装带来灵活性。比如,一个某种类型的服务器已经超载了,那么就可以轻松的添加另一个相同的服务器;如果某个机器宕机了,也可以很容易替代一个新的。
|
||||
|
||||
因为反向代理带来的灵活性,所以反向代理也是一些性能加速功能的必要前提,比如:
|
||||
|
||||
- **负载均衡** (参见 [Tip #2][2]) – 负载均衡运行在反向代理服务器上,用来将流量均衡分配给一批应用。有了合适的负载均衡,你就可以添加应用服务器而根本不用修改应用。
|
||||
- **缓存静态文件** (参见 [Tip #3][3]) – 直接读取的文件,比如图片或者客户端代码,可以保存在反向代理服务器,然后直接发给客户端,这样就可以提高速度、分担应用服务器的负载,可以让应用运行的更快。
|
||||
- **网站安全** – 反向代理服务器可以提高网站安全性,以及快速的发现和响应攻击,保证应用服务器处于被保护状态。
|
||||
|
||||
NGINX 软件为用作反向代理服务器而专门设计,也包含了上述的多种功能。NGINX 使用事件驱动的方式处理请求,这会比传统的服务器更加有效率。NGINX plus 添加了更多高级的反向代理特性,比如应用的[健康度检查][4],专门用来处理请求路由、高级缓冲和相关支持。
|
||||
|
||||
|
||||
|
||||
### Tip #2: 添加负载平衡 ###
|
||||
|
||||
添加一个[负载均衡服务器][5] 是一个相当简单的用来提高性能和网站安全性的的方法。与其将核心 Web 服务器变得越来越大和越来越强,不如使用负载均衡将流量分配到多个服务器。即使程序写的不好,或者在扩容方面有困难,仅是使用负载均衡服务器就可以很好的提高用户体验。
|
||||
|
||||
负载均衡服务器首先是一个反向代理服务器(参见[Tip #1][6])——它接受来自互联网的流量,然后转发请求给另一个服务器。特别是负载均衡服务器支持两个或多个应用服务器,使用[分配算法][7]将请求转发给不同服务器。最简单的负载均衡方法是轮转法(round robin),每个新的请求都会发给列表里的下一个服务器。其它的复制均衡方法包括将请求发给活动连接最少的服务器。NGINX plus 拥有将特定用户的会话分配给同一个服务器的[能力][8]。
|
||||
|
||||
负载均衡可以很好的提高性能是因为它可以避免某个服务器过载而另一些服务器却没有需要处理的流量。它也可以简单的扩展服务器规模,因为你可以添加多个价格相对便宜的服务器并且保证它们被充分利用了。
|
||||
|
||||
可以进行负载均衡的协议包括 HTTP、HTTPS、SPDY、HTTP/2、WebSocket、[FastCGI][9]、SCGI、uwsgi、 memcached 等,以及几种其它的应用类型,包括基于 TCP 的应用和其它的第4层协议的程序。分析你的 web 应用来决定你要使用哪些以及哪些地方性能不足。
|
||||
|
||||
相同的服务器或服务器群可以被用来进行负载均衡,也可以用来处理其它的任务,如 SSL 末端服务器,支持客户端的 HTTP/1.x 和 HTTP/2 请求,以及缓存静态文件。
|
||||
|
||||
NGINX 经常被用于进行负载均衡;要想了解更多的情况,可以下载我们的电子书 [选择软件负载均衡器的五个理由][10]。你也可以从 [使用 NGINX 和 NGINX Plus 配置负载均衡,第一部分][11] 中了解基本的配置指导,在 NGINX Plus 管理员指南中有完整的 [NGINX 负载均衡][12]的文档。。我们的商业版本 [NGINX Plus][15] 支持更多优化了的负载均衡特性,如基于服务器响应时间的加载路由和Microsoft’s NTLM 协议上的负载均衡。
|
||||
|
||||
### Tip #3: 缓存静态和动态的内容 ###
|
||||
|
||||
缓存可以通过加速内容的传输速度来提高 web 应用的性能。它可以采用以下几种策略:当需要的时候预处理要传输的内容,保存数据到速度更快的设备,把数据存储在距离客户端更近的位置,或者将这几种方法结合起来使用。
|
||||
|
||||
有两种不同类型数据的缓冲:
|
||||
|
||||
- **静态内容缓存**。不经常变化的文件,比如图像(JPEG、PNG) 和代码(CSS,JavaScript),可以保存在外围服务器上,这样就可以快速的从内存和磁盘上提取。
|
||||
- **动态内容缓存**。很多 web 应用会针对每次网页请求生成一个新的 HTML 页面。在短时间内简单的缓存生成的 HTML 内容,就可以很好的减少要生成的内容的数量,而且这些页面足够新,可以满足你的需要。
|
||||
|
||||
举个例子,如果一个页面每秒会被浏览10次,你将它缓存 1 秒,90%请求的页面都会直接从缓存提取。如果你分开缓存静态内容,甚至新生成的页面可能都是由这些缓存构成的。
|
||||
|
||||
下面由是 web 应用发明的三种主要的缓存技术:
|
||||
|
||||
- **缩短数据与用户的网络距离**。把一份内容的拷贝放的离用户更近的节点来减少传输时间。
|
||||
- **提高内容服务器的速度**。内容可以保存在一个更快的服务器上来减少提取文件的时间。
|
||||
- **从过载服务器上移走数据**。机器经常因为要完成某些其它的任务而造成某个任务的执行速度比测试结果要差。将数据缓存在不同的机器上可以提高缓存资源和非缓存资源的性能,而这是因为主机没有被过度使用。
|
||||
|
||||
对 web 应用的缓存机制可以在 web 应用服务器内部实现。首先,缓存动态内容是用来减少应用服务器加载动态内容的时间。其次,缓存静态内容(包括动态内容的临时拷贝)是为了更进一步的分担应用服务器的负载。而且缓存之后会从应用服务器转移到对用户而言更快、更近的机器,从而减少应用服务器的压力,减少提取数据和传输数据的时间。
|
||||
|
||||
改进过的缓存方案可以极大的提高应用的速度。对于大多数网页来说,静态数据,比如大图像文件,构成了超过一半的内容。如果没有缓存,那么这可能会花费几秒的时间来提取和传输这类数据,但是采用了缓存之后不到1秒就可以完成。
|
||||
|
||||
举一个在实际中缓存是如何使用的例子, NGINX 和 NGINX Plus 使用了两条指令来[设置缓存机制][16]:proxy_cache_path 和 proxy_cache。你可以指定缓存的位置和大小、文件在缓存中保存的最长时间和其它一些参数。使用第三条(而且是相当受欢迎的一条)指令 proxy_cache_use_stale,如果提供新鲜内容的服务器忙碌或者挂掉了,你甚至可以让缓存提供较旧的内容,这样客户端就不会一无所得。从用户的角度来看这可以很好的提高你的网站或者应用的可用时间。
|
||||
|
||||
NGINX plus 有个[高级缓存特性][17],包括对[缓存清除][18]的支持和在[仪表盘][19]上显示缓存状态信息。
|
||||
|
||||
要想获得更多关于 NGINX 的缓存机制的信息可以浏览 NGINX Plus 管理员指南中的 [参考文档][20] 和 [NGINX 内容缓存][21] 。
|
||||
|
||||
**注意**:缓存机制分布于应用开发者、投资决策者以及实际的系统运维人员之间。本文提到的一些复杂的缓存机制从[DevOps 的角度][23]来看很具有价值,即对集应用开发者、架构师以及运维操作人员的功能为一体的工程师来说可以满足它们对站点功能性、响应时间、安全性和商业结果(如完成的交易数)等需要。
|
||||
|
||||
### Tip #4: 压缩数据 ###
|
||||
|
||||
压缩是一个具有很大潜力的提高性能的加速方法。现在已经有一些针对照片(JPEG 和PNG)、视频(MPEG-4)和音乐(MP3)等各类文件精心设计和高压缩率的标准。每一个标准都或多或少的减少了文件的大小。
|
||||
|
||||
文本数据 —— 包括HTML(包含了纯文本和 HTML 标签),CSS 和代码,比如 Javascript —— 经常是未经压缩就传输的。压缩这类数据会在对应用程序性能的感觉上,特别是处于慢速或受限的移动网络的客户端,产生更大的影响。
|
||||
|
||||
这是因为文本数据经常是用户与网页交互的有效数据,而多媒体数据可能更多的是起提供支持或者装饰的作用。智能的内容压缩可以减少 HTML,Javascript,CSS和其它文本内容对带宽的要求,通常可以减少 30% 甚至更多的带宽和相应的页面加载时间。
|
||||
|
||||
如果你使用 SSL,压缩可以减少需要进行 SSL 编码的的数据量,而这些编码操作会占用一些 CPU 时间而抵消了压缩数据减少的时间。
|
||||
|
||||
压缩文本数据的方法很多,举个例子,在定义小说文本压缩模式的 [HTTP/2 部分]就对于头数据来特别适合。另一个例子是可以在 NGINX 里打开使用 GZIP 压缩。你在你的服务里[预先压缩文本数据][25]之后,你就可以直接使用 gzip_static 指令来处理压缩过的 .gz 版本。
|
||||
|
||||
### Tip #5: 优化 SSL/TLS ###
|
||||
|
||||
安全套接字([SSL][26]) 协议和它的下一代版本传输层安全(TLS)协议正在被越来越多的网站采用。SSL/TLS 对从原始服务器发往用户的数据进行加密提高了网站的安全性。影响这个趋势的部分原因是 Google 正在使用 SSL/TLS,这在搜索引擎排名上是一个正面的影响因素。
|
||||
|
||||
尽管 SSL/TLS 越来越流行,但是使用加密对速度的影响也让很多网站望而却步。SSL/TLS 之所以让网站变的更慢,原因有二:
|
||||
|
||||
1. 任何一个连接第一次连接时的握手过程都需要传递密钥。而采用 HTTP/1.x 协议的浏览器在建立多个连接时会对每个连接重复上述操作。
|
||||
2. 数据在传输过程中需要不断的在服务器端加密、在客户端解密。
|
||||
|
||||
为了鼓励使用 SSL/TLS,HTTP/2 和 SPDY(在[下一章][27]会描述)的作者设计了新的协议来让浏览器只需要对一个浏览器会话使用一个连接。这会大大的减少上述第一个原因所浪费的时间。然而现在可以用来提高应用程序使用 SSL/TLS 传输数据的性能的方法不止这些。
|
||||
|
||||
web 服务器有对应的机制优化 SSL/TLS 传输。举个例子,NGINX 使用 [OpenSSL][28] 运行在普通的硬件上提供了接近专用硬件的传输性能。NGINX 的 [SSL 性能][29] 有详细的文档,而且把对 SSL/TLS 数据进行加解密的时间和 CPU 占用率降低了很多。
|
||||
|
||||
更进一步,参考这篇[文章][30]了解如何提高 SSL/TLS 性能的更多细节,可以总结为一下几点:
|
||||
|
||||
- **会话缓冲**。使用指令 [ssl_session_cache][31] 可以缓存每个新的 SSL/TLS 连接使用的参数。
|
||||
- **会话票据或者 ID**。把 SSL/TLS 的信息保存在一个票据或者 ID 里可以流畅的复用而不需要重新握手。
|
||||
- **OCSP 分割**。通过缓存 SSL/TLS 证书信息来减少握手时间。
|
||||
|
||||
NGINX 和 NGINX Plus 可以被用作 SSL/TLS 服务端,用于处理客户端流量的加密和解密,而同时以明文方式和其它服务器进行通信。要设置 NGINX 和 NGINX Plus 作为 SSL/TLS 服务端,参看 [HTTPS 连接][32] 和[加密的 TCP 连接][33]
|
||||
|
||||
### Tip #6: 使用 HTTP/2 或 SPDY ###
|
||||
|
||||
对于已经使用了 SSL/TLS 的站点,HTTP/2 和 SPDY 可以很好的提高性能,因为每个连接只需要一次握手。而对于没有使用 SSL/TLS 的站点来说,从响应速度的角度来说 HTTP/2 和 SPDY 将让迁移到 SSL/TLS 没有什么压力(原本会降低效率)。
|
||||
|
||||
Google 在2012年开始把 SPDY 作为一个比 HTTP/1.x 更快速的协议来推荐。HTTP/2 是目前 IETF 通过的标准,是基于 SPDY 的。SPDY 已经被广泛的支持了,但是很快就会被 HTTP/2 替代。
|
||||
|
||||
SPDY 和 HTTP/2 的关键是用单一连接来替代多路连接。单个连接是被复用的,所以它可以同时携带多个请求和响应的分片。
|
||||
|
||||
通过使用单一连接,这些协议可以避免像在实现了 HTTP/1.x 的浏览器中一样建立和管理多个连接。单一连接在对 SSL 特别有效,这是因为它可以最小化 SSL/TLS 建立安全链接时的握手时间。
|
||||
|
||||
SPDY 协议需要使用 SSL/TLS,而 HTTP/2 官方标准并不需要,但是目前所有支持 HTTP/2 的浏览器只有在启用了 SSL/TLS 的情况下才能使用它。这就意味着支持 HTTP/2 的浏览器只有在网站使用了 SSL 并且服务器接收 HTTP/2 流量的情况下才会启用 HTTP/2。否则的话浏览器就会使用 HTTP/1.x 协议。
|
||||
|
||||
当你实现 SPDY 或者 HTTP/2 时,你不再需要那些常规的 HTTP 性能优化方案,比如按域分割、资源聚合,以及图像拼合。这些改变可以让你的代码和部署变得更简单和更易于管理。要了解 HTTP/2 带来的这些变化可以浏览我们的[白皮书][34]。
|
||||
|
||||

|
||||
|
||||
作为支持这些协议的一个样例,NGINX 已经从一开始就支持了 SPDY,而且[大部分使用 SPDY 协议的网站][35]都运行的是 NGINX。NGINX 同时也[很早][36]对 HTTP/2 的提供了支持,从2015 年9月开始,开源版 NGINX 和 NGINX Plus 就[支持][37]它了。
|
||||
|
||||
经过一段时间,我们 NGINX 希望更多的站点完全启用 SSL 并且向 HTTP/2 迁移。这将会提高安全性,同时也会找到并实现新的优化手段,简化的代码表现的会更加优异。
|
||||
|
||||
### Tip #7: 升级软件版本 ###
|
||||
|
||||
一个提高应用性能的简单办法是根据软件的稳定性和性能的评价来选在你的软件栈。进一步说,因为高性能组件的开发者更愿意追求更高的性能和解决 bug ,所以值得使用最新版本的软件。新版本往往更受开发者和用户社区的关注。更新的版本往往会利用到新的编译器优化,包括对新硬件的调优。
|
||||
|
||||
稳定的新版本通常比旧版本具有更好的兼容性和更高的性能。一直进行软件更新,可以非常简单的保持软件保持最佳的优化,解决掉 bug,以及提高安全性。
|
||||
|
||||
一直使用旧版软件也会阻止你利用新的特性。比如上面说到的 HTTP/2,目前要求 OpenSSL 1.0.1。在2016 年中期开始将会要求1.0.2 ,而它是在2015年1月才发布的。
|
||||
|
||||
NGINX 用户可以开始迁移到 [NGINX 最新的开源软件][38] 或者 [NGINX Plus][39];它们都包含了最新的能力,如 socket 分割和线程池(见下文),这些都已经为性能优化过了。然后好好看看的你软件栈,把它们升级到你能升级到的最新版本吧。
|
||||
|
||||
### Tip #8: Linux 系统性能调优 ###
|
||||
|
||||
Linux 是大多数 web 服务器使用的操作系统,而且作为你的架构的基础,Linux 显然有不少提高性能的可能。默认情况下,很多 Linux 系统都被设置为使用很少的资源,以符合典型的桌面应用使用。这就意味着 web 应用需要一些微调才能达到最大效能。
|
||||
|
||||
这里的 Linux 优化是专门针对 web 服务器方面的。以 NGINX 为例,这里有一些在加速 Linux 时需要强调的变化:
|
||||
|
||||
- **缓冲队列**。如果你有挂起的连接,那么你应该考虑增加 net.core.somaxconn 的值,它代表了可以缓存的连接的最大数量。如果连接限制太小,那么你将会看到错误信息,而你可以逐渐的增加这个参数直到错误信息停止出现。
|
||||
- **文件描述符**。NGINX 对一个连接使用最多2个文件描述符。如果你的系统有很多连接请求,你可能就需要提高sys.fs.file_max ,以增加系统对文件描述符数量整体的限制,这样才能支持不断增加的负载需求。
|
||||
- **临时端口**。当使用代理时,NGINX 会为每个上游服务器创建临时端口。你可以设置net.ipv4.ip_local_port_range 来提高这些端口的范围,增加可用的端口号。你也可以减少非活动的端口的超时判断来重复使用端口,这可以通过 net.ipv4.tcp_fin_timeout 来设置,这可以快速的提高流量。
|
||||
|
||||
对于 NGINX 来说,可以查阅 [NGINX 性能调优指南][40]来学习如果优化你的 Linux 系统,这样它就可以很好的适应大规模网络流量而不会超过工作极限。
|
||||
|
||||
### Tip #9: web 服务器性能调优 ###
|
||||
|
||||
无论你是用哪种 web 服务器,你都需要对它进行优化来提高性能。下面的推荐手段可以用于任何 web 服务器,但是一些设置是针对 NGINX 的。关键的优化手段包括:
|
||||
|
||||
- **访问日志**。不要把每个请求的日志都直接写回磁盘,你可以在内存将日志缓存起来然后批量写回磁盘。对于NGINX 来说,给指令 **access_log** 添加参数 **buffer=size** 可以让系统在缓存满了的情况下才把日志写到磁盘。如果你添加了参数 **flush=time** ,那么缓存内容会每隔一段时间再写回磁盘。
|
||||
- **缓存**。缓存会在内存中存放部分响应,直到满了为止,这可以让与客户端的通信更加高效。内存放不下的响应会写回磁盘,而这就会降低效能。当 NGINX [启用][42]了缓存机制后,你可以使用指令 **proxy_buffer_size** 和 **proxy_buffers** 来管理缓存。
|
||||
- **客户端保活**。保活连接可以减少开销,特别是使用 SSL/TLS 时。对于 NGINX 来说,你可以从 **keepalive_requests** 的默认值 100 开始增加最大连接数,这样一个客户端就可以在一个指定的连接上请求多次,而且你也可以通过增加 **keepalive_timeout** 的值来允许保活连接存活更长时间,这样就可以让后来的请求处理的更快速。
|
||||
- **上游保活**。上游的连接——即连接到应用服务器、数据库服务器等机器的连接——同样也会受益于连接保活。对于上游连接来说,你可以增加 **keepalive**,即每个工人进程的空闲保活连接个数。这就可以提高连接的复用次数,减少需要重新打开全新连接的次数。更多关于保活连接的信息可以参见[这篇“ HTTP 保活连接和性能”][41]。
|
||||
- **限制**。限制客户端使用的资源可以提高性能和安全性。对于 NGINX 来说,指令 **limit_conn** 和 **limit_conn_zone** 限制了给定来源的连接数量,而 **limit_rate** 限制了带宽。这些限制都可以阻止合法用户*扒取*资源,同时也避免了攻击。指令 **limit_req** 和 **limit_req_zone** 限制了客户端请求。对于上游服务器来说,可以在 upstream 的配置块里的 server 指令使用 max_conns 参数来限制连接到上游服务器的连接数。 这样可以避免服务器过载。关联的 queue 指令会创建一个队列来在连接数抵达 **max_conn** 限制时在指定长度的时间内保存特定数量的请求。
|
||||
- **工人进程**。工人进程负责处理请求。NGINX 采用事件驱动模型和操作系统特定的机制来有效的将请求分发给不同的工人进程。这条建议推荐设置 **worker_processes** 为每个 CPU 一个 。worker_connections 的最大数(默认512)可以在大部分系统上根据需要增加,实验性地找到最适合你的系统的值。
|
||||
- **套接字分割**。通常一个套接字监听器会把新连接分配给所有工人进程。套接字分割会为每个工人进程创建一个套接字监听器,这样一来以当套接字监听器可用时,内核就会将连接分配给它。这可以减少锁竞争,并且提高多核系统的性能,要启用[套接字分隔][43]需要在 **listen** 指令里面加上 **reuseport** 参数。
|
||||
- **线程池**。计算机进程可能被一个单一的缓慢的操作所占用。对于 web 服务器软件来说,磁盘访问会影响很多更快的操作,比如计算或者在内存中拷贝。使用了线程池之后慢操作可以分配到不同的任务集,而主进程可以一直运行快速操作。当磁盘操作完成后结果会返回给主进程的循环。在 NGINX 里有两个操作——read() 系统调用和 sendfile() ——被分配到了[线程池][44]
|
||||
|
||||
|
||||
|
||||
**技巧**。当改变任何操作系统或支持服务的设置时,一次只改变一个参数然后测试性能。如果修改引起问题了,或者不能让你的系统更快,那么就改回去。
|
||||
|
||||
在[文章“调优 NGINX 性能”][45]里可以看到更详细的 NGINX 调优方法。
|
||||
|
||||
### Tip #10: 监视系统活动来解决问题和瓶颈 ###
|
||||
|
||||
在应用开发中要使得系统变得非常高效的关键是监视你的系统在现实世界运行的性能。你必须能通过特定的设备和你的 web 基础设施上监控程序活动。
|
||||
|
||||
监视活动是最积极的——它会告诉你发生了什么,把问题留给你发现和最终解决掉。
|
||||
|
||||
监视可以发现几种不同的问题。它们包括:
|
||||
|
||||
- 服务器宕机。
|
||||
- 服务器出问题一直在丢失连接。
|
||||
- 服务器出现大量的缓存未命中。
|
||||
- 服务器没有发送正确的内容。
|
||||
|
||||
应用的总体性能监控工具,比如 New Relic 和 Dynatrace,可以帮助你监控到从远程加载网页的时间,而 NGINX 可以帮助你监控到应用交付端。当你需要考虑为基础设施添加容量以满足流量需求时,应用性能数据可以告诉你你的优化措施的确起作用了。
|
||||
|
||||
为了帮助开发者快速的发现、解决问题,NGINX Plus 增加了[应用感知健康度检查][46] ——对重复出现的常规事件进行综合分析并在问题出现时向你发出警告。NGINX Plus 同时提供[会话过滤][47] 功能,这可以阻止当前任务完成之前接受新的连接,另一个功能是慢启动,允许一个从错误恢复过来的服务器追赶上负载均衡服务器群的进度。当使用得当时,健康度检查可以让你在问题变得严重到影响用户体验前就发现它,而会话过滤和慢启动可以让你替换服务器,并且这个过程不会对性能和正常运行时间产生负面影响。下图就展示了内建的 NGINX Plus 模块[实时活动监视][48]的仪表盘,包括了服务器群,TCP 连接和缓存信息等 Web 架构信息。
|
||||
|
||||

|
||||
|
||||
### 总结: 看看10倍性能提升的效果 ###
|
||||
|
||||
这些性能提升方案对任何一个 web 应用都可用并且效果都很好,而实际效果取决于你的预算、你能花费的时间、目前实现方案的差距。所以你该如何对你自己的应用实现10倍性能提升?
|
||||
|
||||
为了指导你了解每种优化手段的潜在影响,这里是上面详述的每个优化方法的关键点,虽然你的情况肯定大不相同:
|
||||
|
||||
- **反向代理服务器和负载均衡**。没有负载均衡或者负载均衡很差都会造成间歇的性能低谷。增加一个反向代理,比如 NGINX ,可以避免 web 应用程序在内存和磁盘之间波动。负载均衡可以将过载服务器的任务转移到空闲的服务器,还可以轻松的进行扩容。这些改变都可以产生巨大的性能提升,很容易就可以比你现在的实现方案的最差性能提高10倍,对于总体性能来说可能提高的不多,但是也是有实质性的提升。
|
||||
- **缓存动态和静态数据**。如果你有一个负担过重的 web 服务器,那么毫无疑问肯定是你的应用服务器,只通过缓存动态数据就可以在峰值时间提高10倍的性能。缓存静态文件可以提高几倍的性能。
|
||||
- **压缩数据**。使用媒体文件压缩格式,比如图像格式 JPEG,图形格式 PNG,视频格式 MPEG-4,音乐文件格式 MP3 可以极大的提高性能。一旦这些都用上了,然后压缩文件数据可以将初始页面加载速度提高两倍。
|
||||
- **优化 SSL/TLS**。安全握手会对性能产生巨大的影响,对它们的优化可能会对初始响应产生2倍的提升,特别是对于大量文本的站点。优化 SSL/TLS 下媒体文件只会产生很小的性能提升。
|
||||
- **使用 HTTP/2 和 SPDY*。当你使用了 SSL/TLS,这些协议就可以提高整个站点的性能。
|
||||
- **对 Linux 和 web 服务器软件进行调优**。比如优化缓存机制,使用保活连接,分配时间敏感型任务到不同的线程池可以明显的提高性能;举个例子,线程池可以加速对磁盘敏感的任务[近一个数量级][49]。
|
||||
|
||||
我们希望你亲自尝试这些技术。我们希望知道你说取得的各种性能提升案例。请在下面评论栏分享你的结果或者在标签 #NGINX 和 #webperf 下 tweet 你的故事。
|
||||
|
||||
### 网上资源 ###
|
||||
|
||||
[Statista.com – Share of the internet economy in the gross domestic product in G-20 countries in 2016][50]
|
||||
|
||||
[Load Impact – How Bad Performance Impacts Ecommerce Sales][51]
|
||||
|
||||
[Kissmetrics – How Loading Time Affects Your Bottom Line (infographic)][52]
|
||||
|
||||
[Econsultancy – Site speed: case studies, tips and tools for improving your conversion rate][53]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/10-tips-for-10x-application-performance/
|
||||
|
||||
作者:[Floyd Smith][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/floyd/
|
||||
[1]:https://www.nginx.com/resources/glossary/reverse-proxy-server
|
||||
[2]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip2
|
||||
[3]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip3
|
||||
[4]:https://www.nginx.com/products/application-health-checks/
|
||||
[5]:https://www.nginx.com/solutions/load-balancing/
|
||||
[6]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip1
|
||||
[7]:https://www.nginx.com/resources/admin-guide/load-balancer/
|
||||
[8]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[9]:https://www.digitalocean.com/community/tutorials/understanding-and-implementing-fastcgi-proxying-in-nginx
|
||||
[10]:https://www.nginx.com/resources/library/five-reasons-choose-software-load-balancer/
|
||||
[11]:https://www.nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[12]:https://www.nginx.com/resources/admin-guide/load-balancer//
|
||||
[15]:https://www.nginx.com/products/
|
||||
[16]:https://www.nginx.com/blog/nginx-caching-guide/
|
||||
[17]:https://www.nginx.com/products/content-caching-nginx-plus/
|
||||
[18]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&_ga=1.95342300.1348073562.1438712874#proxy_cache_purge
|
||||
[19]:https://www.nginx.com/products/live-activity-monitoring/
|
||||
[20]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html?&&&_ga=1.61156076.1348073562.1438712874#proxy_cache
|
||||
[21]:https://www.nginx.com/resources/admin-guide/content-caching
|
||||
[22]:https://www.nginx.com/blog/network-vs-devops-how-to-manage-your-control-issues/
|
||||
[23]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
|
||||
[24]:https://www.nginx.com/resources/admin-guide/compression-and-decompression/
|
||||
[25]:http://nginx.org/en/docs/http/ngx_http_gzip_static_module.html
|
||||
[26]:https://www.digicert.com/ssl.htm
|
||||
[27]:https://www.nginx.com/blog/10-tips-for-10x-application-performance/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io#tip6
|
||||
[28]:http://openssl.org/
|
||||
[29]:https://www.nginx.com/blog/nginx-ssl-performance/
|
||||
[30]:https://www.nginx.com/blog/improve-seo-https-nginx/
|
||||
[31]:http://nginx.org/en/docs/http/ngx_http_ssl_module.html#ssl_session_cache
|
||||
[32]:https://www.nginx.com/resources/admin-guide/nginx-ssl-termination/
|
||||
[33]:https://www.nginx.com/resources/admin-guide/nginx-tcp-ssl-termination/
|
||||
[34]:https://www.nginx.com/resources/datasheet/datasheet-nginx-http2-whitepaper/
|
||||
[35]:http://w3techs.com/blog/entry/25_percent_of_the_web_runs_nginx_including_46_6_percent_of_the_top_10000_sites
|
||||
[36]:https://www.nginx.com/blog/how-nginx-plans-to-support-http2/
|
||||
[37]:https://www.nginx.com/blog/nginx-plus-r7-released/
|
||||
[38]:http://nginx.org/en/download.html
|
||||
[39]:https://www.nginx.com/products/
|
||||
[40]:https://www.nginx.com/blog/tuning-nginx/
|
||||
[41]:https://www.nginx.com/blog/http-keepalives-and-web-performance/
|
||||
[42]:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_buffering
|
||||
[43]:https://www.nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[44]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
|
||||
[45]:https://www.nginx.com/blog/tuning-nginx/
|
||||
[46]:https://www.nginx.com/products/application-health-checks/
|
||||
[47]:https://www.nginx.com/products/session-persistence/#session-draining
|
||||
[48]:https://www.nginx.com/products/live-activity-monitoring/
|
||||
[49]:https://www.nginx.com/blog/thread-pools-boost-performance-9x/
|
||||
[50]:http://www.statista.com/statistics/250703/forecast-of-internet-economy-as-percentage-of-gdp-in-g-20-countries/
|
||||
[51]:http://blog.loadimpact.com/blog/how-bad-performance-impacts-ecommerce-sales-part-i/
|
||||
[52]:https://blog.kissmetrics.com/loading-time/?wide=1
|
||||
[53]:https://econsultancy.com/blog/10936-site-speed-case-studies-tips-and-tools-for-improving-your-conversion-rate/
|
||||
@ -1,39 +1,38 @@
|
||||
如何在Debian中配置Tripewire IDS
|
||||
如何在 Debian 中配置 Tripewire IDS
|
||||
================================================================================
|
||||
本文是一篇关于Debian中安装和配置Tripewire的文章。它是Linux环境下基于主机的入侵检测系统(IDS)。tripwire的高级功能有检测并报告任何Linux中未授权的更改(文件和目录)。tripewire安装之后,会先创建一个基本的数据库,tripewire监控并检测新文件的创建修改和谁修改了它等等。如果修改过是合法的,你可以接受修改并更新tripwire的数据库。
|
||||
本文是一篇关于 Debian 中安装和配置 Tripewire 的文章。它是 Linux 环境下基于主机的入侵检测系统(IDS)。tripwire 的高级功能有检测并报告任何 Linux 中未授权的(文件和目录)的更改。tripewire 安装之后,会先创建一个基本的数据库,tripewire 监控并检测新文件的创建修改和谁修改了它等等。如果修改是合法的,你可以接受修改并更新 tripwire 的数据库。
|
||||
|
||||
### 安装和配置 ###
|
||||
|
||||
tripwire在Debian VM中的安装如下。
|
||||
tripwire 在 Debian VM 中的安装如下。
|
||||
|
||||
# apt-get install tripwire
|
||||
|
||||

|
||||
|
||||
安装中,tripwire会有下面的配置提示。
|
||||
安装中,tripwire 会有下面的配置提示。
|
||||
|
||||
#### 站点密钥创建 ####
|
||||
|
||||
tripwire需要一个站点口令来加密tripwire的配置文件tw.cfg和策略文件tw.pol。tripewire使用指定的密码加密两个文件。一个tripewire实例必须指定站点口令。
|
||||
|
||||
tripwire 需要一个站点口令(site passphrase)来加密 tripwire 的配置文件 tw.cfg 和策略文件 tw.pol。tripewire 使用指定的密码加密两个文件。一个 tripewire 实例必须指定站点口令。
|
||||
|
||||

|
||||
|
||||
#### 本地密钥口令 ####
|
||||
|
||||
本地口令用来保护tripwire数据库和报告文件。本地密钥用于阻止非授权的tripewire数据库修改。
|
||||
本地口令用来保护 tripwire 数据库和报告文件。本地密钥用于阻止非授权的 tripewire 数据库修改。
|
||||
|
||||

|
||||
|
||||
#### Tripwire配置路径 ####
|
||||
#### tripwire 配置路径 ####
|
||||
|
||||
tripewire配置存储在/etc/tripwire/twcfg.txt。它用于生成加密的配置文件tw.cfg。
|
||||
tripewire 配置存储在 /etc/tripwire/twcfg.txt。它用于生成加密的配置文件 tw.cfg。
|
||||
|
||||

|
||||
|
||||
**Tripwire策略路径**
|
||||
**tripwire 策略路径**
|
||||
|
||||
tripwire在/etc/tripwire/twpol.txt中保存策略文件。它用于生成加密的策略文件tw.pol。
|
||||
tripwire 在 /etc/tripwire/twpol.txt 中保存策略文件。它用于生成加密的策略文件 tw.pol。
|
||||
|
||||

|
||||
|
||||
@ -41,9 +40,9 @@ tripwire在/etc/tripwire/twpol.txt中保存策略文件。它用于生成加密
|
||||
|
||||

|
||||
|
||||
#### Tripwire配置文件 (twcfg.txt) ####
|
||||
#### tripwire 配置文件 (twcfg.txt) ####
|
||||
|
||||
tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件(tw.pol),站点密钥(site.key)和本地密钥(hostname-local.key)如下所示。
|
||||
tripewire 配置文件(twcfg.txt)细节如下图所示。加密策略文件(tw.pol)、站点密钥(site.key)和本地密钥(hostname-local.key)在后面展示。
|
||||
|
||||
ROOT =/usr/sbin
|
||||
|
||||
@ -79,9 +78,9 @@ tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件
|
||||
|
||||
TEMPDIRECTORY =/tmp
|
||||
|
||||
#### Tripwire策略配置 ####
|
||||
#### tripwire 策略配置 ####
|
||||
|
||||
在生成基础数据库之前先配置tripwire配置。有必要经用一些策略如/dev、 /proc 、/root/mail等。详细的twpol.txt策略文件如下所示。
|
||||
在生成基础数据库之前先配置 tripwire 配置。有必要经用一些策略如 /dev、 /proc 、/root/mail 等。详细的 twpol.txt 策略文件如下所示。
|
||||
|
||||
@@section GLOBAL
|
||||
TWBIN = /usr/sbin;
|
||||
@ -121,10 +120,10 @@ tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件
|
||||
# vulnerability
|
||||
|
||||
#
|
||||
# Tripwire Binaries
|
||||
# tripwire Binaries
|
||||
#
|
||||
(
|
||||
rulename = "Tripwire Binaries",
|
||||
rulename = "tripwire Binaries",
|
||||
severity = $(SIG_HI)
|
||||
)
|
||||
{
|
||||
@ -237,9 +236,9 @@ tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件
|
||||
#/proc -> $(Device) ;
|
||||
}
|
||||
|
||||
#### Tripwire 报告 ####
|
||||
#### tripwire 报告 ####
|
||||
|
||||
**tripwire –check** 命令检查twpol.txt文件并基于此文件生成tripwire报告如下。如果twpol.txt中有任何错误,tripwire不会生成报告。
|
||||
**tripwire-check** 命令检查 twpol.txt 文件并基于此文件生成 tripwire 报告如下。如果 twpol.txt 中有任何错误,tripwire 不会生成报告。
|
||||
|
||||

|
||||
|
||||
@ -255,7 +254,7 @@ tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件
|
||||
|
||||
Wrote report file: /var/lib/tripwire/report/VMdebian-20151024-122322.twr
|
||||
|
||||
Open Source Tripwire(R) 2.4.2.2 Integrity Check Report
|
||||
Open Source tripwire(R) 2.4.2.2 Integrity Check Report
|
||||
|
||||
Report generated by: root
|
||||
|
||||
@ -299,13 +298,13 @@ tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件
|
||||
|
||||
Other binaries 66 0 0 0
|
||||
|
||||
Tripwire Binaries 100 0 0 0
|
||||
tripwire Binaries 100 0 0 0
|
||||
|
||||
Other libraries 66 0 0 0
|
||||
|
||||
Root file-system executables 100 0 0 0
|
||||
|
||||
Tripwire Data Files 100 0 0 0
|
||||
tripwire Data Files 100 0 0 0
|
||||
|
||||
System boot changes 100 0 0 0
|
||||
|
||||
@ -351,9 +350,9 @@ tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件
|
||||
|
||||
*** End of report ***
|
||||
|
||||
Open Source Tripwire 2.4 Portions copyright 2000 Tripwire, Inc. Tripwire is a registered
|
||||
Open Source tripwire 2.4 Portions copyright 2000 tripwire, Inc. tripwire is a registered
|
||||
|
||||
trademark of Tripwire, Inc. This software comes with ABSOLUTELY NO WARRANTY;
|
||||
trademark of tripwire, Inc. This software comes with ABSOLUTELY NO WARRANTY;
|
||||
|
||||
for details use --version. This is free software which may be redistributed
|
||||
|
||||
@ -365,7 +364,7 @@ tripewire配置文件(twcfg.txt)细节如下图所示。加密策略文件
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇中,我们学习安装配置开源入侵检测软件tripwire。首先生成基础数据库并通过比较检测出任何改动(文件/文件夹)。然而,tripwire并不是实时监测的IDS。
|
||||
本篇中,我们学习安装配置开源入侵检测软件 tripwire。首先生成基础数据库并通过比较检测出任何改动(文件/文件夹)。然而,tripwire 并不是实时监测的 IDS。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -373,7 +372,7 @@ via: http://linoxide.com/security/configure-tripwire-ids-debian/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,317 @@
|
||||
如何在 linux 上配置持续集成服务 - Drone
|
||||
==============================================================
|
||||
|
||||
如果你对一次又一次的克隆、构建、测试和部署代码感到厌倦了,可以考虑一下持续集成。持续集成简称 CI,是一种像我们一样的频繁提交的代码库,构建、测试和部署的软件工程实践。CI 可以帮助我们快速的集成新代码到已有的代码库。如果这个过程是自动化进行的,那么就会提高开发的速度,因为这可以减少开发人员手工构建和测试的时间。[Drone][1] 是一个自由开源项目,用来提供一个非常棒的持续集成服务的环境,采用 Apache 2.0 协议发布。它已经集成近很多代码库提供商,比如 Github、Bitbucket 以及 Google Code,它可以从代码库提取代码,使我们可以对包括 PHP, Node, Ruby, Go, Dart, Python, C/C++, JAVA 等等在内的各种语言编译构建。它是如此一个强大的平台,它使用了容器和 docker 技术,这让用户每次构建都可以在保证隔离的条件下完全控制他们自己的构建环境。
|
||||
|
||||
### 1. 安装 Docker ###
|
||||
|
||||
首先,我们要安装 docker,因为这是 Drone 的工作流的最关键的元素。Drone 合理的利用了 docker 来构建和测试应用。容器技术提高了应用部署的效率。要安装 docker ,我们需要在不同的 linux 发行版本运行下面对应的命令,我们这里会说明 Ubuntu 14.04 和 CentOS 7 两个版本。
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
要在 Ubuntu 上安装 Docker ,我们只需要运行下面的命令。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install docker.io
|
||||
|
||||
安装之后我们需要使用`service` 命令重启 docker 引擎。
|
||||
|
||||
# service docker restart
|
||||
|
||||
然后我们让 docker 在系统启动时自动启动。
|
||||
|
||||
# update-rc.d docker defaults
|
||||
|
||||
Adding system startup for /etc/init.d/docker ...
|
||||
/etc/rc0.d/K20docker -> ../init.d/docker
|
||||
/etc/rc1.d/K20docker -> ../init.d/docker
|
||||
/etc/rc6.d/K20docker -> ../init.d/docker
|
||||
/etc/rc2.d/S20docker -> ../init.d/docker
|
||||
/etc/rc3.d/S20docker -> ../init.d/docker
|
||||
/etc/rc4.d/S20docker -> ../init.d/docker
|
||||
/etc/rc5.d/S20docker -> ../init.d/docker
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
第一,我们要更新机器上已经安装的软件包。我们可以使用下面的命令。
|
||||
|
||||
# sudo yum update
|
||||
|
||||
要在 centos 上安装 docker,我们可以简单的运行下面的命令。
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||
安装好 docker 引擎之后我么只需要简单使用下面的`systemd` 命令启动 docker,因为 centos 7 的默认初始化系统是 systemd。
|
||||
|
||||
# systemctl start docker
|
||||
|
||||
然后我们要让 docker 在系统启动时自动启动。
|
||||
|
||||
# systemctl enable docker
|
||||
|
||||
ln -s '/usr/lib/systemd/system/docker.service' '/etc/systemd/system/multi-user.target.wants/docker.service'
|
||||
|
||||
### 2. 安装 SQlite 驱动 ###
|
||||
|
||||
Drone 默认使用 SQlite3 数据库服务器来保存数据和信息。它会在 /var/lib/drone/ 自动创建名为 drone.sqlite 的数据库来处理数据库模式的创建和迁移。要安装 SQlite3 我们要完成以下几步。
|
||||
|
||||
#### Ubuntu 14.04 ####
|
||||
|
||||
因为 SQlite3 存在于 Ubuntu 14.04 的默认软件库,我们只需要简单的使用 apt 命令安装它。
|
||||
|
||||
# apt-get install libsqlite3-dev
|
||||
|
||||
#### CentOS 7 ####
|
||||
|
||||
要在 Centos 7 上安装需要使用下面的 yum 命令。
|
||||
|
||||
# yum install sqlite-devel
|
||||
|
||||
### 3. 安装 Drone ###
|
||||
|
||||
最后,我们安装好依赖的软件,我们现在更进一步的接近安装 Drone。在这一步里我们只简单的从官方链接下载对应的二进制软件包,然后使用默认软件包管理器安装 Drone。
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
我们将使用 wget 从官方的 [Debian 文件下载链接][2]下载 drone 的 debian 软件包。下面就是下载命令。
|
||||
|
||||
# wget downloads.drone.io/master/drone.deb
|
||||
|
||||
Resolving downloads.drone.io (downloads.drone.io)... 54.231.48.98
|
||||
Connecting to downloads.drone.io (downloads.drone.io)|54.231.48.98|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7722384 (7.4M) [application/x-debian-package]
|
||||
Saving to: 'drone.deb'
|
||||
100%[======================================>] 7,722,384 1.38MB/s in 17s
|
||||
2015-11-06 14:09:28 (456 KB/s) - 'drone.deb' saved [7722384/7722384]
|
||||
|
||||
下载好之后,我们将使用 dpkg 软件包管理器安装它。
|
||||
|
||||
# dpkg -i drone.deb
|
||||
|
||||
Selecting previously unselected package drone.
|
||||
(Reading database ... 28077 files and directories currently installed.)
|
||||
Preparing to unpack drone.deb ...
|
||||
Unpacking drone (0.3.0-alpha-1442513246) ...
|
||||
Setting up drone (0.3.0-alpha-1442513246) ...
|
||||
Your system ubuntu 14: using upstart to control Drone
|
||||
drone start/running, process 9512
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
在 CentOS 机器上我们要使用 wget 命令从[下载链接][3]下载 RPM 包。
|
||||
|
||||
# wget downloads.drone.io/master/drone.rpm
|
||||
|
||||
--2015-11-06 11:06:45-- http://downloads.drone.io/master/drone.rpm
|
||||
Resolving downloads.drone.io (downloads.drone.io)... 54.231.114.18
|
||||
Connecting to downloads.drone.io (downloads.drone.io)|54.231.114.18|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7763311 (7.4M) [application/x-redhat-package-manager]
|
||||
Saving to: ‘drone.rpm’
|
||||
100%[======================================>] 7,763,311 1.18MB/s in 20s
|
||||
2015-11-06 11:07:06 (374 KB/s) - ‘drone.rpm’ saved [7763311/7763311]
|
||||
|
||||
然后我们使用 yum 安装 rpm 包。
|
||||
|
||||
# yum localinstall drone.rpm
|
||||
|
||||
### 4. 配置端口 ###
|
||||
|
||||
安装完成之后,我们要先进行配置才能工作起来。drone 的配置文件在**/etc/drone/drone.toml** 。默认情况下 drone 的 web 接口使用的是80,而这也是 http 默认的端口,如果我们修改它,请按下面所示的修改配置文件里 server 块对应的值。
|
||||
|
||||
[server]
|
||||
port=":80"
|
||||
|
||||
### 5. 集成 Github ###
|
||||
|
||||
为了运行 Drone 我们必须设置最少一个和 GitHub、GitHub 企业版,Gitlab,Gogs,Bitbucket 关联的集成点。在本文里我们只集成了 github,但是如果我们要集成其他的服务,我们可以在配置文件做修改。为了集成 github 我们需要在github 的设置里创建一个新的应用:https://github.com/settings/developers 。
|
||||
|
||||

|
||||
|
||||
要创建一个应用,我们需要在 `New Application` 页面点击 `Register`,然后如下所示填表。
|
||||
|
||||

|
||||
|
||||
我们应该保证在应用的配置项里设置了**授权回调链接**,链接看起来类似 `http://drone.linoxide.com/api/auth/github.com`。然后我们点击注册应用。所有都做好之后我们会看到我们需要在我们的 Drone 配置文件里配置的客户端 ID 和客户端密钥。
|
||||
|
||||

|
||||
|
||||
在这些都完成之后我们需要使用文本编辑器编辑 drone 配置文件,比如使用下面的命令。
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
然后我们会在 drone 的配置文件里面找到`[github]` 部分,紧接着的是下面所示的配置内容
|
||||
|
||||
[github]
|
||||
client="3dd44b969709c518603c"
|
||||
secret="4ee261abdb431bdc5e96b19cc3c498403853632a"
|
||||
# orgs=[]
|
||||
# open=false
|
||||
|
||||

|
||||
|
||||
### 6. 配置 SMTP 服务器 ###
|
||||
|
||||
如果我们想让 drone 使用 email 发送通知,那么我们需要在 SMTP 配置里面设置我们的 SMTP 服务器。如果我们已经有了一个 SMTP 服务,那就只需要简单的使用它的配置文件就行了,但是因为我们没有一个 SMTP 服务器,我们需要安装一个 MTA 比如 Postfix,然后在 drone 配置文件里配置好 SMTP。
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
在 ubuntu 里使用下面的 apt 命令安装 postfix。
|
||||
|
||||
# apt-get install postfix
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
在 CentOS 里使用下面的 yum 命令安装 postfix。
|
||||
|
||||
# yum install postfix
|
||||
|
||||
安装好之后,我们需要编辑我们的 postfix 配置文件。
|
||||
|
||||
# nano /etc/postfix/main.cf
|
||||
|
||||
然后我们要把 myhostname 的值替换为我们自己的 FQDN,比如 drone.linoxide.com。
|
||||
|
||||
myhostname = drone.linoxide.com
|
||||
|
||||
现在开始配置 drone 配置文件里的 SMTP 部分。
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
找到`[smtp]` 部分补充上下面的内容。
|
||||
|
||||
[smtp]
|
||||
host = "drone.linoxide.com"
|
||||
port = "587"
|
||||
from = "root@drone.linoxide.com"
|
||||
user = "root"
|
||||
pass = "password"
|
||||
|
||||

|
||||
|
||||
注意:这里的 **user** 和 **pass** 参数强烈推荐一定要改成某个具体用户的配置。
|
||||
|
||||
### 7. 配置 Worker ###
|
||||
|
||||
如我们所知的 drone 利用了 docker 完成构建、测试任务,我们需要把 docker 配置为 drone 的 worker。要完成这些需要修改 drone 配置文件里的`[worker]` 部分。
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
然后取消底下几行的注释并且补充上下面的内容。
|
||||
|
||||
[worker]
|
||||
nodes=[
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock"
|
||||
]
|
||||
|
||||
这里我们只设置了两个节点,这意味着上面的配置文件只能同时执行2 个构建操作。要提高并发性可以增大节点的值。
|
||||
|
||||
[worker]
|
||||
nodes=[
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock"
|
||||
]
|
||||
|
||||
使用上面的配置文件 drone 被配置为使用本地的 docker 守护程序可以同时构建4个任务。
|
||||
|
||||
### 8. 重启 Drone ###
|
||||
|
||||
最后,当所有的安装和配置都准备好之后,我们现在要在本地的 linux 机器上启动 drone 服务器。
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
因为 ubuntu 14.04 使用了 sysvinit 作为默认的初始化系统,所以只需要简单执行下面的 service 命令就可以启动 drone 了。
|
||||
|
||||
# service drone restart
|
||||
|
||||
要让 drone 在系统启动时也自动运行,需要运行下面的命令。
|
||||
|
||||
# update-rc.d drone defaults
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
因为 CentOS 7使用 systemd 作为初始化系统,所以只需要运行下面的 systemd 命令就可以重启 drone。
|
||||
|
||||
# systemctl restart drone
|
||||
|
||||
要让 drone 自动运行只需要运行下面的命令。
|
||||
|
||||
# systemctl enable drone
|
||||
|
||||
### 9. 添加防火墙例外规则 ###
|
||||
|
||||
众所周知 drone 默认使用了80 端口而我们又没有修改它,所以我们需要配置防火墙程序允许80 端口(http)开放并允许其他机器可以通过网络连接。
|
||||
|
||||
#### Ubuntu 14.04 ####
|
||||
|
||||
iptables 是最流行的防火墙程序,并且 ubuntu 默认安装了它。我们需要修改 iptable 以暴露端口80,这样我们才能让 drone 的 web 界面在网络上被大家访问。
|
||||
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
# /etc/init.d/iptables save
|
||||
|
||||
#### CentOS 7 ####
|
||||
|
||||
因为 CentOS 7 默认安装了 systemd,它使用 firewalld 作为防火墙程序。为了在 firewalld 上打开80端口(http 服务),我们需要执行下面的命令。
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
|
||||
success
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||
### 10. 访问 web 界面 ###
|
||||
|
||||
现在我们将在我们最喜欢的浏览器上通过 web 界面打开 drone。要完成这些我们要把浏览器指向运行 drone 的服务器。因为 drone 默认使用80 端口而我们有没有修改过,所以我们只需要在浏览器里根据我们的配置输入`http://ip-address/` 或 `http://drone.linoxide.com` 就行了。在我们正确的完成了上述操作后,我们就可以看到登录界面了。
|
||||
|
||||

|
||||
|
||||
因为在上面的步骤里配置了 Github,我们现在只需要简单的选择 github 然后进入应用授权步骤,这些完成后我们就可以进入工作台了。
|
||||
|
||||

|
||||
|
||||
这里它会同步我们在 github 上的代码库,然后询问我们要在 drone 上构建那个代码库。
|
||||
|
||||

|
||||
|
||||
这一步完成后,它会询问我们在代码库里添加`.drone.yml` 文件的新名称,并且在这个文件里定义构建的过程和配置项,比如使用那个 docker 镜像,执行那些命令和脚本来编译,等等。
|
||||
|
||||
我们按照下面的内容来配置我们的`.drone.yml`。
|
||||
|
||||
image: python
|
||||
script:
|
||||
- python helloworld.py
|
||||
- echo "Build has been completed."
|
||||
|
||||
这一步完成后我们就可以使用 drone 应用里的 YAML 格式的配置文件来构建我们的应用了。所有对代码库的提交和改变此时都会同步到这个仓库。一旦提交完成了,drone 就会自动开始构建。
|
||||
|
||||

|
||||
|
||||
所有操作都完成后,我们就能在终端看到构建的结果了。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本文中我们学习了如何安装一个可以工作的使用 drone 的持续集成平台。如果我们愿意我们甚至可以从 drone.io 官方提供的服务开始工作。我们可以根据自己的需求从免费的服务或者收费服务开始。它通过漂亮的 web 界面和强大的功能改变了持续集成的世界。它可以集成很多第三方应用和部署平台。如果你有任何问题、建议可以直接反馈给我们,谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-drone-continuous-integration-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://drone.io/
|
||||
[2]:http://downloads.drone.io/master/drone.deb
|
||||
[3]:http://downloads.drone.io/master/drone.rpm
|
||||
[4]:https://github.com/settings/developers
|
||||
@ -1,42 +1,41 @@
|
||||
要超越Hello World 容器是件困难的事情
|
||||
从 Hello World 容器进阶是件困难的事情
|
||||
================================================================================
|
||||
|
||||
在[我的上一篇文章里][1], 我介绍了Linux 容器背后的技术的概念。我写了我知道的一切。容器对我来说也是比较新的概念。我写这篇文章的目的就是鼓励我真正的来学习这些东西。
|
||||
在[我的上一篇文章里][1], 我介绍了 Linux 容器背后的技术的概念。我写了我知道的一切。容器对我来说也是比较新的概念。我写这篇文章的目的就是鼓励我真正的来学习这些东西。
|
||||
|
||||
我打算在使用中学习。首先实践,然后上手并记录下我是怎么走过来的。我假设这里肯定有很多想"Hello World" 这种类型的知识帮助我快速的掌握基础。然后我能够更进一步,构建一个微服务容器或者其它东西。
|
||||
我打算在使用中学习。首先实践,然后上手并记录下我是怎么走过来的。我假设这里肯定有很多像 "Hello World" 这种类型的知识帮助我快速的掌握基础。然后我能够更进一步,构建一个微服务容器或者其它东西。
|
||||
|
||||
我的意思是还会比着更难吗,对吧?
|
||||
我想,它应该不会有多难的。
|
||||
|
||||
错了。
|
||||
但是我错了。
|
||||
|
||||
可能对某些人来说这很简单,因为他们会耗费大量的时间专注在操作工作上。但是对我来说实际上是很困难的,可以从我在Facebook 上的状态展示出来的挫折感就可以看出了。
|
||||
可能对某些人来说这很简单,因为他们在运维工作方面付出了大量的时间。但是对我来说实际上是很困难的,可以从我在Facebook 上的状态展示出来的挫折感就可以看出了。
|
||||
|
||||
但是还有一个好消息:我最终让它工作了。而且他工作的还不错。所以我准备分享向你分享我如何制作我的第一个微服务容器。我的痛苦可能会节省你不少时间呢。
|
||||
但是还有一个好消息:我最终搞定了。而且它工作的还不错。所以我准备分享向你分享我如何制作我的第一个微服务容器。我的痛苦可能会节省你不少时间呢。
|
||||
|
||||
如果你曾经发现或者从来都没有发现自己处在这种境地:像我这样的人在这里解决一些你不需要解决的问题。
|
||||
如果你曾经发现你也处于过这种境地,不要害怕:像我这样的人都能搞定,所以你也肯定行。
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
|
||||
### 一个缩略图微服务 ###
|
||||
|
||||
我设计的微服务在理论上很简单。以JPG 或者PNG 格式在HTTP 终端发布一张数字照片,然后获得一个100像素宽的缩略图。
|
||||
我设计的微服务在理论上很简单。以 JPG 或者 PNG 格式在 HTTP 终端发布一张数字照片,然后获得一个100像素宽的缩略图。
|
||||
|
||||
下面是它实际的效果:
|
||||
下面是它的流程:
|
||||
|
||||

|
||||
|
||||
我决定使用NodeJS 作为我的开发语言,使用[ImageMagick][2] 来转换缩略图。
|
||||
我决定使用 NodeJS 作为我的开发语言,使用 [ImageMagick][2] 来转换缩略图。
|
||||
|
||||
我的服务的第一版的逻辑如下所示:
|
||||
|
||||

|
||||
|
||||
我下载了[Docker Toolbox][3],用它安装了Docker 的快速启动终端。Docker 快速启动终端使得创建容器更简单了。终端会启动一个装好了Docker 的Linux 虚拟机,它允许你在一个终端里运行Docker 命令。
|
||||
我下载了 [Docker Toolbox][3],用它安装了 Docker 的快速启动终端(Docker Quickstart Terminal)。Docker 快速启动终端使得创建容器更简单了。终端会启动一个装好了 Docker 的 Linux 虚拟机,它允许你在一个终端里运行 Docker 命令。
|
||||
|
||||
虽然在我的例子里,我的操作系统是Mac OS X。但是Windows 下也有相同的工具。
|
||||
虽然在我的例子里,我的操作系统是 Mac OS X。但是 Windows 下也有相同的工具。
|
||||
|
||||
我准备使用Docker 快速启动终端里为我的微服务创建一个容器镜像,然后从这个镜像运行容器。
|
||||
我准备使用 Docker 快速启动终端里为我的微服务创建一个容器镜像,然后从这个镜像运行容器。
|
||||
|
||||
Docker 快速启动终端就运行在你使用的普通终端里,就像这样:
|
||||
|
||||
@ -44,11 +43,11 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
### 第一个小问题和第一个大问题###
|
||||
|
||||
所以我用NodeJS 和ImageMagick 瞎搞了一通然后让我的服务在本地运行起来了。
|
||||
我用 NodeJS 和 ImageMagick 瞎搞了一通,然后让我的服务在本地运行起来了。
|
||||
|
||||
然后我创建了Dockerfile,这是Docker 用来构建容器的配置脚本。(我会在后面深入介绍构建和Dockerfile)
|
||||
然后我创建了 Dockerfile,这是 Docker 用来构建容器的配置脚本。(我会在后面深入介绍构建过程和 Dockerfile)
|
||||
|
||||
这是我运行Docker 快速启动终端的命令:
|
||||
这是我运行 Docker 快速启动终端的命令:
|
||||
|
||||
$ docker build -t thumbnailer:0.1
|
||||
|
||||
@ -58,32 +57,31 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
呃。
|
||||
|
||||
我估摸着过了15分钟:我忘记了在末尾参数输入一个点`.`。
|
||||
我估摸着过了15分钟我才反应过来:我忘记了在末尾参数输入一个点`.`。
|
||||
|
||||
正确的指令应该是这样的:
|
||||
|
||||
$ docker build -t thumbnailer:0.1 .
|
||||
|
||||
但是这不是我遇到的最后一个问题。
|
||||
|
||||
但是这不是我最后一个问题。
|
||||
|
||||
我让这个镜像构建好了,然后我Docker 快速启动终端输入了[`run` 命令][4]来启动容器,名字叫`thumbnailer:0.1`:
|
||||
我让这个镜像构建好了,然后我在 Docker 快速启动终端输入了 [`run` 命令][4]来启动容器,名字叫 `thumbnailer:0.1`:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
参数`-p 3001:3000` 让NodeJS 微服务在Docker 内运行在端口3000,而在主机上则是3001。
|
||||
参数 `-p 3001:3000` 让 NodeJS 微服务在 Docker 内运行在端口3000,而绑定在宿主主机上的3001。
|
||||
|
||||
到目前卡起来都很好,对吧?
|
||||
到目前看起来都很好,对吧?
|
||||
|
||||
错了。事情要马上变糟了。
|
||||
|
||||
我指定了在Docker 快速启动中端里用命令`docker-machine` 运行的Docker 虚拟机的ip地址:
|
||||
我通过运行 `docker-machine` 命令为这个 Docker 快速启动终端里创建的虚拟机指定了 ip 地址:
|
||||
|
||||
$ docker-machine ip default
|
||||
|
||||
这句话返回了默认虚拟机的IP地址,即运行docker 的虚拟机。对于我来说,这个ip 地址是192.168.99.100。
|
||||
这句话返回了默认虚拟机的 IP 地址,它运行在 Docker 快速启动终端里。在我这里,这个 ip 地址是 192.168.99.100。
|
||||
|
||||
我浏览网页http://192.168.99.100:3001/ ,然后找到了我创建的上传图片的网页:
|
||||
我浏览网页 http://192.168.99.100:3001/ ,然后找到了我创建的上传图片的网页:
|
||||
|
||||

|
||||
|
||||
@ -91,13 +89,13 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
但是它并没有工作。
|
||||
|
||||
终端告诉我他无法找到我的微服务需要的`/upload` 目录。
|
||||
终端告诉我他无法找到我的微服务需要的 `/upload` 目录。
|
||||
|
||||
现在开始记住,我已经在此耗费了将近一天的时间-从浪费时间到研究问题。我此时感到了一些挫折感。
|
||||
现在,你要知道,我已经在此耗费了将近一天的时间-从浪费时间到研究问题。我此时感到了一些挫折感。
|
||||
|
||||
然后灵光一闪。某人记起来微服务不应该自己做任何数据持久化的工作!保存数据应该是另一个服务的工作。
|
||||
|
||||
所以容器找不到目录`/upload` 的原因到底是什么?这个问题的根本就是我的微服务在基础设计上就有问题。
|
||||
所以容器找不到目录 `/upload` 的原因到底是什么?这个问题的根本就是我的微服务在基础设计上就有问题。
|
||||
|
||||
让我们看看另一幅图:
|
||||
|
||||
@ -109,7 +107,7 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||

|
||||
|
||||
这是我用NodeJS 写的在内存工作、生成缩略图的代码:
|
||||
这是我用 NodeJS 写的在内存运行、生成缩略图的代码:
|
||||
|
||||
// Bind to the packages
|
||||
var express = require('express');
|
||||
@ -171,19 +169,19 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
module.exports = router;
|
||||
|
||||
好了,回到正轨,已经可以在我的本地机器正常工作了。我该去休息了。
|
||||
好了,一切回到了正轨,已经可以在我的本地机器正常工作了。我该去休息了。
|
||||
|
||||
但是,在我测试把这个微服务当作一个普通的Node 应用运行在本地时...
|
||||
但是,在我测试把这个微服务当作一个普通的 Node 应用运行在本地时...
|
||||
|
||||

|
||||
|
||||
它工作的很好。现在我要做的就是让他在容器里面工作。
|
||||
它工作的很好。现在我要做的就是让它在容器里面工作。
|
||||
|
||||
第二天我起床后喝点咖啡,然后创建一个镜像——这次没有忘记那个"."!
|
||||
|
||||
$ docker build -t thumbnailer:01 .
|
||||
|
||||
我从缩略图工程的根目录开始构建。构建命令使用了根目录下的Dockerfile。它是这样工作的:把Dockerfile 放到你想构建镜像的地方,然后系统就默认使用这个Dockerfile。
|
||||
我从缩略图项目的根目录开始构建。构建命令使用了根目录下的 Dockerfile。它是这样工作的:把 Dockerfile 放到你想构建镜像的地方,然后系统就默认使用这个 Dockerfile。
|
||||
|
||||
下面是我使用的Dockerfile 的内容:
|
||||
|
||||
@ -209,7 +207,7 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
### 第二个大问题 ###
|
||||
|
||||
我运行了`build` 命令,然后出了这个错:
|
||||
我运行了 `build` 命令,然后出了这个错:
|
||||
|
||||
Do you want to continue? [Y/n] Abort.
|
||||
|
||||
@ -217,7 +215,7 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
我猜测微服务出错了。我回到本地机器,从本机启动微服务,然后试着上传文件。
|
||||
|
||||
然后我从NodeJS 获得了这个错误:
|
||||
然后我从 NodeJS 获得了这个错误:
|
||||
|
||||
Error: spawn convert ENOENT
|
||||
|
||||
@ -225,25 +223,25 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
我搜索了我能想到的所有的错误原因。差不多4个小时后,我想:为什么不重启一下机器呢?
|
||||
|
||||
重启了,你猜猜结果?错误消失了!(译注:万能的重启)
|
||||
重启了,你猜猜结果?错误消失了!(LCTT 译注:万能的“重启试试”)
|
||||
|
||||
继续。
|
||||
|
||||
### 将精灵关进瓶子 ###
|
||||
### 将精灵关进瓶子里 ###
|
||||
|
||||
跳回正题:我需要完成构建工作。
|
||||
|
||||
我使用[`rm` 命令][5]删除了虚拟机里所有的容器。
|
||||
我使用 [`rm` 命令][5]删除了虚拟机里所有的容器。
|
||||
|
||||
$ docker rm -f $(docker ps -a -q)
|
||||
|
||||
`-f` 在这里的用处是强制删除运行中的镜像。
|
||||
|
||||
然后删除了全部Docker 镜像,用的是[命令`rmi`][6]:
|
||||
然后删除了全部 Docker 镜像,用的是[命令 `rmi`][6]:
|
||||
|
||||
$ docker rmi if $(docker images | tail -n +2 | awk '{print $3}')
|
||||
|
||||
我重新执行了命令构建镜像,安装容器,运行微服务。然后过了一个充满自我怀疑和沮丧的一个小时,我告诉我自己:这个错误可能不是微服务的原因。
|
||||
我重新执行了重新构建镜像、安装容器、运行微服务的整个过程。然后过了一个充满自我怀疑和沮丧的一个小时,我告诉我自己:这个错误可能不是微服务的原因。
|
||||
|
||||
所以我重新看到了这个错误:
|
||||
|
||||
@ -251,19 +249,17 @@ Docker 快速启动终端就运行在你使用的普通终端里,就像这样
|
||||
|
||||
The command '/bin/sh -c apt-get install imagemagick libmagickcore-dev libmagickwand-dev' returned a non-zero code: 1
|
||||
|
||||
这太打击我了:构建脚本好像需要有人从键盘输入Y! 但是,这是一个非交互的Dockerfile 脚本啊。这里并没有键盘。
|
||||
这太打击我了:构建脚本好像需要有人从键盘输入 Y! 但是,这是一个非交互的 Dockerfile 脚本啊。这里并没有键盘。
|
||||
|
||||
回到Dockerfile,脚本元来时这样的:
|
||||
回到 Dockerfile,脚本原来是这样的:
|
||||
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y nodejs nodejs-legacy npm
|
||||
RUN apt-get install imagemagick libmagickcore-dev libmagickwand-dev
|
||||
RUN apt-get clean
|
||||
|
||||
The second `apt-get` command is missing the `-y` flag which causes "yes" to be given automatically where usually it would be prompted for.
|
||||
第二个`apt-get` 忘记了`-y` 标志,这才是错误的根本原因。
|
||||
第二个`apt-get` 忘记了`-y` 标志,它用于自动应答提示所需要的“yes”。这才是错误的根本原因。
|
||||
|
||||
I added the missing `-y` to the command:
|
||||
我在这条命令后面添加了`-y` :
|
||||
|
||||
RUN apt-get update
|
||||
@ -281,7 +277,6 @@ I added the missing `-y` to the command:
|
||||
|
||||
$ docker run -d -p 3001:3000 thumbnailer:0.1
|
||||
|
||||
Got the IP address of the Virtual Machine:
|
||||
获取了虚拟机的IP 地址:
|
||||
|
||||
$ docker-machine ip default
|
||||
@ -298,11 +293,11 @@ Got the IP address of the Virtual Machine:
|
||||
|
||||
在容器里面工作了,我的第一次啊!
|
||||
|
||||
### 这意味着什么? ###
|
||||
### 这让我学到了什么? ###
|
||||
|
||||
很久以前,我接受了这样一个道理:当你刚开始尝试某项技术时,即使是最简单的事情也会变得很困难。因此,我压抑了要成为房间里最聪明的人的欲望。然而最近几天尝试容器的过程就是一个充满自我怀疑的旅程。
|
||||
很久以前,我接受了这样一个道理:当你刚开始尝试某项技术时,即使是最简单的事情也会变得很困难。因此,我不会把自己当成最聪明的那个人,然而最近几天尝试容器的过程就是一个充满自我怀疑的旅程。
|
||||
|
||||
但是你想知道一些其它的事情吗?这篇文章是我在凌晨2点完成的,而每一个折磨的小时都值得了。为什么?因为这段时间你将自己全身心投入了喜欢的工作里。这件事很难,对于所有人来说都不是很容易就获得结果的。但是不要忘记:你在学习技术,运行世界的技术。
|
||||
但是你想知道一些其它的事情吗?这篇文章是我在凌晨2点完成的,而每一个受折磨的时刻都值得了。为什么?因为这段时间你将自己全身心投入了喜欢的工作里。这件事很难,对于所有人来说都不是很容易就获得结果的。但是不要忘记:你在学习技术,运行世界的技术。
|
||||
|
||||
P.S. 了解一下Hello World 容器的两段视频,这里会有 [Raziel Tabib’s][7] 的精彩工作内容。
|
||||
|
||||
@ -320,12 +315,12 @@ via: https://deis.com/blog/2015/beyond-hello-world-containers-hard-stuff
|
||||
|
||||
作者:[Bob Reselman][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deis.com/blog
|
||||
[1]:http://deis.com/blog/2015/developer-journey-linux-containers
|
||||
[1]:https://linux.cn/article-6594-1.html
|
||||
[2]:https://github.com/rsms/node-imagemagick
|
||||
[3]:https://www.docker.com/toolbox
|
||||
[4]:https://docs.docker.com/reference/commandline/run/
|
||||
@ -0,0 +1,77 @@
|
||||
微软和 Linux :真正的浪漫还是有毒的爱情?
|
||||
================================================================================
|
||||
时不时的我们会读到一个能让你喝咖啡呛到或者把热拿铁喷到你显示器上的新闻故事。微软最近宣布的对 Linux 的钟爱就是这样一个鲜明的例子。
|
||||
|
||||
从常识来讲,微软和自由开源软件(FOSS)运动就是恒久的敌人。在很多人眼里,微软体现了过分的贪婪,而这正为自由开源软件运动(FOSS)所拒绝。另外,之前微软就已经给自由开源软件社区贴上了"一伙强盗"的标签。
|
||||
|
||||
我们能够理解为什么微软一直以来都害怕免费的操作系统。免费操作系统结合挑战微软核心产品线的开源应用时,就威胁到了微软在台式机和笔记本电脑市场的控制地位。
|
||||
|
||||
尽管微软有对在台式机主导地位的担忧,在网络服务器市场 Linux 却有着最高的影响力。今天,大多数的服务器都是 Linux 系统。包括世界上最繁忙的站点服务器。对微软来说,看到这么多无法装到兜里的许可证的营收一定是非常痛苦的。
|
||||
|
||||
掌上设备是微软输给自由软件的另一个领域。曾几何时,微软的 Windows CE 和 Pocket PC 操作系统走在移动计算的前沿。Windows PDA 设备是最闪亮的和豪华的产品。但是这一切在苹果公司发布了iphone之后都结束了。从那时起,安卓就开始进入公众视野,Windows 的移动产品开始被忽略被遗忘。而安卓平台是建立在自由开源的组件的基础上的。
|
||||
|
||||
由于安卓平台的开放性,安卓的市场份额在迅速扩大。不像 IOS,任何一个手机制造商都可以发布安卓手机。也不像Windows 手机,安卓没有许可费用。这对消费者来说是件好事。这也导致了许多强大却又价格低廉的手机制造商在世界各地涌现。这非常明确的证明了自由开源软件(FOSS)的价值。
|
||||
|
||||
在服务器和移动计算的角逐中失利对微软来说是非常惨重的损失。考虑一下服务器和移动计算这两个加起来所占有的市场大小,台式机市场似乎是死水一潭。没有人喜欢失败,尤其是涉及到金钱。并且,微软确实有许多东西正在慢慢失去。你可能期望着微软自尝苦果。在过去,确实如此。
|
||||
|
||||
微软使用了各种可以支配的手段来对 Linux 和自由开源软件(FOSS)进行反击,从宣传到专利威胁。尽管这种攻击确实减慢了适配 Linux 的步伐,但却从来没有让 Linux 的脚步停下。
|
||||
|
||||
所以,当微软在开源大会和重大事件上拿出印有“Microsoft Loves Linux”的T恤和徽章时,请原谅我们表现出来的震惊。这是真的吗?微软真的爱 Linux ?
|
||||
|
||||
当然,公关的口号和免费的T恤并不代表真理。行动胜于雄辩。当你思考一下微软的行动时,微软的立场就变得有点模棱两可了。
|
||||
|
||||
一方面,微软招募了几百名 Linux 开发者和系统管理员。将 .NET 核心框架作为一个开源的项目进行了发布,并提供了跨平台的支持(这样 .NET 就可以跑在 OS X 和 Linux 上了)。并且,微软与 Linux 公司合作把最流行的发行版本放到了 Azure 平台上。事实上,微软已经走的如此之远以至于要为 Azure 数据中心开发自己的 Linux 发行版了。
|
||||
|
||||
另一方面,微软继续直接通过法律或者傀儡公司来对开源项目进行攻击。很明显,微软在与自由软件的所有权较量上并没有发自内心的进行大的道德转变。那为什么要公开申明对 Linux 的钟爱之情呢?
|
||||
|
||||
一个显而易见的事实:微软是一个经营性实体。对股东来说是一个投资工具,对雇员来说是收入来源。微软所做的只有一个终极目标:盈利。微软并没有表现出来爱或者恨(尽管这是一个最常见的指控)。
|
||||
|
||||
所以问题不应该是"微软真的爱 Linux 吗?"相反,我们应该问,微软是怎么从这一切中获利的。
|
||||
|
||||
让我们以 .NET 核心框架的开源发行为例。这一举动使得 .NET 的运行时环境移植到任何平台都很轻松。这使得微软的 .NET 框架所涉及到的范围远远大于 Windows 平台。
|
||||
|
||||
开放 .NET 的核心包,最终使得 .NET 开发者开发跨平台的 app 成为可能,比如 OS X、Linux 甚至安卓——都基于同一个核心代码库。
|
||||
|
||||
从开发者角度来讲,这使得 .NET 框架比之前更有吸引力了。能够从单一的代码库触及到多个平台,使得使用 .NET 框架开发的任何 app 戏剧性的扩大了潜在的目标市场。
|
||||
|
||||
另外,一个强大的开源社区能够提供给开发者一些代码来在他们自己的项目中进行复用。所以,开源项目的可利用性也将会成就 .NET 框架。
|
||||
|
||||
更进一步讲,开放 .NET 的核心代码能够减少跨越不同平台所产生的碎片,意味着对消费者来说有对 app 更广的选择。无论是开源软件还是专用的 app,都有更多的选择。
|
||||
|
||||
从微软的角度来讲,会得到一队开发者大军。微软可以通过销售培训、证书、技术支持、开发者工具(包括 Visual Studio)和应用扩展来获利。
|
||||
|
||||
我们应该自问的是,这对自由软件社区有利还是有弊?
|
||||
|
||||
.NET 框架的大范围适用意味着许多参与竞争的开源项目的消亡,迫使我们会跟着微软的节奏走下去。
|
||||
|
||||
先抛开 .NET 不谈,微软正在花费大量的精力在 Azure 云计算平台对 Linux 的支持上。要记得,Azure 最初是 Windows 的 Azure。Windows 服务器是唯一能够支持 Azure 的操作系统。今天,Azure 也提供了对多个 Linux 发行版的支持。
|
||||
|
||||
关于此,有一个原因:付费给需要或者想要 Linux 服务的顾客。如果微软不提供 Linux 虚拟机,那些顾客就会跟别人合作了。
|
||||
|
||||
看上去好像是微软意识到“Linux 就在这里”的这样一个现实。微软不能真正的消灭它,所以必须接收它。
|
||||
|
||||
这又把我们带回到那个问题:关于微软和 Linux 为什么有这么多的流言?我们在谈论这个问题,因为微软希望我们思考这个问题。毕竟,所有这些谈资都会追溯到微软,不管是在新闻稿、博客还是会议上的公开声明。微软在努力吸引大家对其在 Linux 专业知识方面的注意力。
|
||||
|
||||
首席架构师 Kamala Subramaniam 的博文声明 Azure Cloud Switch 背后的其他企图会是什么?ACS 是一个定制的 Linux 发行版。微软用它来对 Azure 数据中心的交换机硬件进行自动配置。
|
||||
|
||||
ACS 不是公开的。它是用于 Azure 内部使用的。别人也不太可能找到这个发行版其他的用途。事实上,Subramaniam 在她的博文中也表述了同样的观点。
|
||||
|
||||
所以,微软不会通过卖 ACS 来获利,也不会通过赠送它而增加用户基数。相反,微软在 Linux 和 Azure 上花费精力,以加强其在 Linux 云计算平台方面的地位。
|
||||
|
||||
微软最近迷上 Linux 对社区来说是好消息吗?
|
||||
|
||||
我们不应该慢慢忘记微软的“拥抱、扩展、消灭(Embrace, Extend and Exterminate)”的诅咒。现在,微软处在拥抱 Linux 的初期阶段。微软会通过定制扩展和专有“标准”来分裂社区吗?
|
||||
|
||||
发表评论吧,让我们知道你是怎么想的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/microsoft-and-linux-true-romance-or-toxic-love-0
|
||||
|
||||
作者:[James Darvell][a]
|
||||
译者:[sonofelice](https://github.com/sonofelice)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/james-darvell
|
||||
@ -0,0 +1,172 @@
|
||||
如何在 CentOS 7 中添加新磁盘而不用重启系统
|
||||
================================================================================
|
||||
|
||||
对大多数系统管理员来说扩充 Linux 服务器的磁盘空间是日常的工作之一。因此这篇文章会通过使用 Linux 命令,在 CentOS 7 系统上演示一些简单的操作步骤来扩充您的磁盘空间而不需要重启您的生产服务器。关于扩充和增加新的磁盘到 Linux 系统,我们会提及多种方法和多种可行性,可按您所需选择最适用的一种。
|
||||
|
||||
### 1. 在虚拟机客户端扩充磁盘空间: ###
|
||||
|
||||
在为 Linux 系统增加磁盘卷之前,您首先需要添加一块新的物理磁盘,或在 VMware vShere、VMware 工作站以及你使用的其它虚拟环境软件中进行设置来增加一块虚拟磁盘的容量。
|
||||
|
||||

|
||||
|
||||
### 2. 检查磁盘空间: ###
|
||||
|
||||
运行如下命令来检查当前磁盘空间大小。
|
||||
|
||||
# df -h
|
||||
# fdisk -l
|
||||
|
||||

|
||||
|
||||
可以看到,虽然我们已经在后端给其增加到 50 GB 的空间,但此时的总磁盘大小仍然为 10 GB。
|
||||
|
||||
### 3. 扩展空间而无需重启虚拟机 ###
|
||||
|
||||
现在运行如下命令,通过重新扫描 SCSI (注:Small Computer System Interface 小型计算机系统接口)总线并添加 SCSI 设备,系统就可以扩展操作系统的物理卷磁盘空间,而且不需要重启虚拟机。
|
||||
|
||||
# ls /sys/class/scsi_host/
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host1/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host2/scan
|
||||
|
||||
使用下面的命令来检查 SCSI 设备的名称,然后重新扫描 SCSI 总线。
|
||||
|
||||
# ls /sys/class/scsi_device/
|
||||
# echo 1 > /sys/class/scsi_device/0\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/2\:0\:0\:0/device/rescan
|
||||
|
||||
如下图所示,会重新扫描 SCSI 总线,随后我们在虚拟机客户端设置的磁盘大小会正常显示。
|
||||
|
||||

|
||||
|
||||
### 4. 创建新磁盘分区: ###
|
||||
|
||||
一旦在系统中可以看到扩展的磁盘空间,就可以运行如下命令来格式化您的磁盘以创建一个新的分区。请按如下操作步骤来扩充您的物理磁盘卷。
|
||||
|
||||
# fdisk /dev/sda
|
||||
Welcome to fdisk (util-linux 2.23.2) press the 'm' key for help
|
||||
Command (m for help): m
|
||||
Command action
|
||||
a toggle a bootable flag
|
||||
b edit bsd disklabel
|
||||
c toggle the dos compatibility flag
|
||||
d delete a partition
|
||||
g create a new empty GPT partition table
|
||||
G create an IRIX (SGI) partition table
|
||||
l list known partition types
|
||||
m print this menu
|
||||
n add a new partition
|
||||
o create a new empty DOS partition table
|
||||
p print the partition table
|
||||
q quit without saving changes
|
||||
s create a new empty Sun disklabel
|
||||
t change a partition's system id
|
||||
u change display/entry units
|
||||
v verify the partition table
|
||||
w write table to disk and exit
|
||||
x extra functionality (experts only)
|
||||
|
||||
Command (m for help):
|
||||
|
||||
键入 'p' 来查看当前的分区表信息,然后键入 'n' 键来创建一个新的主分区,选择所有可用的扇区。 使用 't' 命令改变磁盘类型为 'Linux LVM',然后选择编码 '8e' 或者默认不选,它默认的类型编码为 '83'。
|
||||
|
||||
现在输入 'w' 来保存分区表信息并且退出命令环境,如下示:
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered!
|
||||
|
||||
Calling ioctl() to re-read partition table.
|
||||
|
||||
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
|
||||
The kernel still uses the old table. The new table will be used at
|
||||
the next reboot or after you run partprobe(8) or kpartx(8)
|
||||
|
||||

|
||||
|
||||
### 5. 创建物理卷: ###
|
||||
|
||||
根据上述提示,运行 'partprob' 或 'kpartx' 命令以使分区表生效,然后使用如下的命令来创建新的物理卷。
|
||||
|
||||
# partprobe
|
||||
# pvresize /dev/sda3
|
||||
|
||||
要检查新创建的卷,运行如下的命令可以看出新的物理卷是否已经被创建,是否可用。接下来,我们就可以使用这个新的物理卷来扩展 'centos' 卷组了,如下示:
|
||||
|
||||
# pvdisplay
|
||||
# vgextend centos /dev/sda3
|
||||
|
||||

|
||||
|
||||
### 6. 扩展逻辑卷: ###
|
||||
|
||||
现在我们使用如下的命令扩展逻辑卷,以增加我们系统正使用的磁盘空间。
|
||||
|
||||
# lvextend -L +40G /dev/mapper/centos-root
|
||||
|
||||
一旦返回增加成功的消息,就可以运行如下命令来扩展您的逻辑卷大小。
|
||||
|
||||
# xfs_growfs /dev/mapper/centos-root
|
||||
|
||||
'/' 分区的大小已经成功的增加了,可以使用 'df' 命令来检查您磁盘驱动器的大小。如图示。
|
||||
|
||||

|
||||
|
||||
### 7. 通过增加新的磁盘来扩充根分区而不用重启系统: ###
|
||||
|
||||
这是第二种方法,它使用的命令非常简单, 用来增加 CentOS 7 系统上逻辑卷空间大小。
|
||||
|
||||
所以第一步是打开您的虚拟机客户端的设置页面,点击 ‘增加’ 按纽,然后继续下一步操作。
|
||||
|
||||

|
||||
|
||||
选择新磁盘所需要的配置信息,如下图所示的,选择新磁盘的大小和它的类型。
|
||||
|
||||

|
||||
|
||||
然后进入服务端重复如下的命令来扫描您的磁盘设备,以使新磁盘在系统中可见。
|
||||
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host1/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host2/scan
|
||||
|
||||
列出您的 SCSI 设备的名称:
|
||||
|
||||
# ls /sys/class/scsi_device/
|
||||
# echo 1 > /sys/class/scsi_device/1\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/2\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/3\:0\:0\:0/device/rescan
|
||||
# fdisk -l
|
||||
|
||||

|
||||
|
||||
一旦新增的磁盘可见,就可以运行下面的命令来创建新的物理卷,然后增加到卷组,如下示。
|
||||
|
||||
# pvcreate /dev/sdb
|
||||
# vgextend centos /dev/sdb
|
||||
# vgdisplay
|
||||
|
||||

|
||||
|
||||
现在根据此磁盘的空间大小来扩展逻辑卷,然后添加到根分区。
|
||||
|
||||
# lvextend -L +20G /dev/mapper/centos-root
|
||||
# xfs_growfs /dev/mapper/centos-root
|
||||
# df -h
|
||||
|
||||

|
||||
|
||||
### 结论: ###
|
||||
|
||||
在 Linux CentOS 7 系统上管理磁盘分区的操作过程是非常简单的,可以使用这篇文章所述的操作步骤来扩充您的任意逻辑卷的磁盘空间。您不需要重启生产线上的服务器,只是简单的重扫描下 SCSI 设备,和扩展您想要的 LVM(逻辑卷管理)。我们希望这文章对您有用。请随意的发表有用的评论和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/add-new-disk-centos-7-without-rebooting/
|
||||
|
||||
作者:[Kashif S][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,58 @@
|
||||
输错密码?这个 sudo 会“嘲讽”你
|
||||
===========================================================
|
||||
|
||||
你在 Linux 终端中会有很多的乐趣。我今天要讲的不是在[终端中跑火车](http://itsfoss.com/ubuntu-terminal-train/)。
|
||||
|
||||
我今天要讲的技巧可以放松你的心情。前面一篇文章中,你学习了[如何在命令行中增加 sudo 命令的超时](http://itsfoss.com/change-sudo-password-timeout-ubuntu/)。今天的文章中,我会向你展示如何让 sudo 在输错密码的时候“嘲讽”你(或者其他人)。
|
||||
|
||||
对我讲的感到疑惑?这里,让我们看下这张 gif 来了解下 sudo 是如何在你输错密码之后“嘲讽”你的。
|
||||
|
||||

|
||||
|
||||
那么,为什么要这么做?毕竟,“嘲讽”不会让你的一天开心,不是么?
|
||||
|
||||
对我来说,一点小技巧都是有趣的,并且要比以前的“密码错误”的错误提示更有趣。另外,我可以向我的朋友展示来逗弄他们(这个例子中是通过自由开源软件)。我很肯定你有你自己的理由来使用这个技巧的。
|
||||
|
||||
## 在 sudo 中启用“嘲讽”
|
||||
|
||||
你可以在`sudo`配置中增加下面的行来启用“嘲讽”功能:
|
||||
|
||||
```
|
||||
Defaults insults
|
||||
```
|
||||
|
||||
让我们看看该如何做。打开终端并使用下面的命令:
|
||||
|
||||
```
|
||||
sudo visudo
|
||||
```
|
||||
|
||||
这会在 [nano](http://www.nano-editor.org/)中打开配置文件。
|
||||
|
||||
> 是的,我知道传统的 ‘visudo’ 应该在 vi 中打开 `/etc/sudoers` 文件,但是 Ubuntu 及基于它的发行版会使用 nano 打开。由于我们在讨论vi,这里有一份 [vi 速查表](http://itsfoss.com/download-vi-cheat-sheet)可以在你决定使用 vi 的时候使用。
|
||||
|
||||
回到编辑 sudeors 文件界面,你需要找出 Defaults 所在的行。简单的很,只需要在文件的开头加上`Defaults insults`,就像这样:
|
||||
|
||||

|
||||
|
||||
如果你正在使用 nano,使用`Ctrl+X`来退出编辑器。在退出的时候,它会询问你是否保存更改。要保存更改,按下“Y”。
|
||||
|
||||
一旦你保存了 sudoers 文件之后,打开终端并使用 sudo 运行各种命令。故意输错密码并享受嘲讽吧:)
|
||||
|
||||
sudo 可能会生气的。看见没,他甚至在我再次输错之后威胁我。哈哈。
|
||||
|
||||

|
||||
|
||||
如果你喜欢这个终端技巧,你也可以查看[其他终端技巧的文章](http://itsfoss.com/category/terminal-tricks/)。如果你有其他有趣的技巧,在评论中分享。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/sudo-insult-linux/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
@ -0,0 +1,32 @@
|
||||
并行文件系统 BeeGFS 现已开源
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
2月23日 ThinkParQ 宣布完整的 [BeeGFS 并行文件系统][1] 的源码现已开源。由于 BeeGFS 是专为要求性能的环境开发的,所以它在开发时十分注重安装的简易性以及高度灵活性,包括融合了在存储服务器同时做计算任务时需要的设置。随着系统中的服务器以及存储设备的增加,文件系统的容量以及性能将是需求的拓展点,无论是小型集群还是多达上千个节点的企业级系统。
|
||||
|
||||
官方第一次声明开放 BeeGFS 的源码是在 2013 年的国际超级计算大会上发布的。这个声明是在欧洲的百亿亿次级超算项目 [DEEP-ER][2] 的背景下做出的,在这个项目里为了得到更好的 I/O 要求,做出了一些新的改进。对于运算量高达百亿亿次的系统,不同的软硬件必须有效的协同工作才能得到最佳的拓展性。因此,开源 BeeGFS 是让一个百亿亿次的集群的所有组成部分高效的发挥作用的一步。
|
||||
|
||||
“当我们的一些用户对于 BeeGFS 十分容易安装并且不用费心管理而感到高兴时,另外一些用户则想要知道它是如何运行的以便于更好的优化他们的应用,使得他们可以监控它或者把它移植到其他的平台上,比如 BSD,” Sven Breuner 说道,他是 ThinkParQ (BeeGFS 背后的公司)的 CEO,“而且,把 BeeGFS 移植到其他的非 X86 架构,比如 ARM 或者 Power,也是社区即将要做的一件事。”
|
||||
|
||||
对于未来的采购来说,ARM 技术的稳步发展确实使得它成为了一个越来越有趣的技术。因此, BeeGFS 的团队也参与了 [ExaNeSt][3],一个来自欧洲的新的百亿亿次级超算计划,这个计划致力于使 ARM 的生态能为高性能的工作负载做好准备。“尽管现在 BeeGFS 在 ARM 处理器上可以算是开箱即用,这个项目也将给我们机会来证明我们在这个架构上也能完全发挥其性能。”, Bernd Lietzow , BeeGFS 中 ExaNeSt 的领导者补充道。
|
||||
|
||||
作为一个有着 25 K 行 C++ 代码的元数据服务以及约 15 K 行存储服务的项目,BeeGFS 相对比较容易理解和拓展,不只是对于大神,对于对文件系统有兴趣的大学生也是这样。在 GitHub 上已经有很多的为 BeeGFS 写的项目,比如基于浏览器的监控或者 Docker 一体化。
|
||||
|
||||
有关新闻显示, [BeeGFS 用户大会][4]将于 5 月 18-19 日在德国凯泽斯劳滕举行。
|
||||
|
||||
-----------------------------------------------------------------------------------------
|
||||
|
||||
via: http://insidehpc.com/2016/02/beegfs-parallel-file-system-now-open-source/
|
||||
|
||||
作者:[staff][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://insidehpc.com/author/staff/
|
||||
[1]: http://www.beegfs.com/
|
||||
[2]: http://www.deep-project.eu/deep-project/EN/Home/home_node.html
|
||||
[3]: http://www.exanest.eu/
|
||||
[4]: http://www.beegfs.com/content/user-meeting-2016/
|
||||
@ -0,0 +1,209 @@
|
||||
用 Python 打造你的 Eclipse
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
Eclipse 高级脚本环境([EASE][1])项目虽然还在开发中,但是必须要承认它非常强大,它让我们可以快速打造自己的Eclipse 开发环境。
|
||||
|
||||
依据 Eclipse 强大的框架,可以通过其内建的插件系统全方面的扩展 Eclipse。然而,编写和部署一个新的插件还是十分麻烦,即使你只是需要一个额外的小功能。不过,现在依托于 EASE,你可以不用写任何一行 Java 代码就可以方便的做到这点。EASE 是一种使用 Python 或者 Javascript 这样的脚本语言自动实现这些功能的平台。
|
||||
|
||||
本文中,根据我在今年北美的 EclipseCon 大会上的[演讲][2],我将介绍如何用 Python 和 EASE 设置你的 Eclipse 环境,并告诉如何发挥 Python 的能量让你的 IDE 跑的飞起。
|
||||
|
||||
### 安装并运行 "Hello World"
|
||||
|
||||
本文中的例子使用 Python 的 Java 实现 Jython。你可以将 EASE 直接安装到你已有的 Eclipse IDE 中。本例中使用[Eclipse Mars][3],并安装 EASE 环境本身以及它的模块和 Jython 引擎。
|
||||
|
||||
使用 Eclipse 安装对话框(`Help>Install New Software`...),安装 EASE[http://download.eclipse.org/ease/update/nightly][4],
|
||||
|
||||
选择下列组件:
|
||||
|
||||
- EASE Core feature
|
||||
- EASE core UI feature
|
||||
- EASE Python Developer Resources
|
||||
- EASE modules (Incubation)
|
||||
|
||||
这会安装 EASE 及其模块。这里我们要注意一下 Resource 模块,此模块可以访问 Eclipse 工作空间、项目和文件 API。
|
||||
|
||||
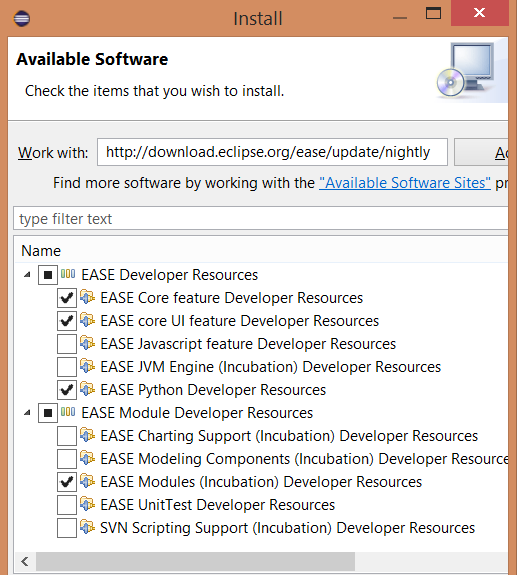
|
||||
|
||||
成功安装后,接下来安装 EASE Jython 引擎 [https://dl.bintray.com/pontesegger/ease-jython/][5] 。完成后,测试下。新建一个项目并新建一个 hello.py 文件,输入:
|
||||
|
||||
```
|
||||
print "hello world"
|
||||
```
|
||||
|
||||
选中这个文件,右击并选择“Run as -> EASE script”。这样就可以在控制台看到“Hello world”的输出。
|
||||
|
||||
现在就可以编写 Python 脚本来访问工作空间和项目了。这种方法可以用于各种定制,下面只是一些思路。
|
||||
|
||||
### 提升你的代码质量
|
||||
|
||||
管理良好的代码质量本身是一件非常烦恼的事情,尤其是当需要处理一个大型代码库或者要许多工程师参与的时候。而这些痛苦可以通过脚本来减轻,比如批量格式化一些文件,或者[去掉文件中的 unix 式的行结束符][6]来使得在 git 之类的源代码控制系统中比较差异更加容易。另外一个更好的用途是使用脚本来生成 Eclipse markers 以高亮你可以改善的代码。这里有一些示例脚本,你可以用来在 java 文件中所有找到的“printStackTrace”方法中加入task markers 。请看[源码][7]。
|
||||
|
||||
拷贝该文件到工作空间来运行,右击并选择“Run as -> EASE script”。
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
|
||||
from org.eclipse.core.resources import IMarker
|
||||
|
||||
for ifile in findFiles("*.java"):
|
||||
file_name = str(ifile.getLocation())
|
||||
print "Processing " + file_name
|
||||
with open(file_name) as f:
|
||||
for line_no, line in enumerate(f, start=1):
|
||||
if "printStackTrace" in line:
|
||||
marker = ifile.createMarker(IMarker.TASK)
|
||||
marker.setAttribute(IMarker.TRANSIENT, True)
|
||||
marker.setAttribute(IMarker.LINE_NUMBER, line_no)
|
||||
marker.setAttribute(IMarker.MESSAGE, "Fix in Sprint 2: " + line.strip())
|
||||
|
||||
```
|
||||
|
||||
如果你的 java 文件中包含了 printStackTraces,你就可以看见任务视图和编辑器侧边栏上自动新加的标记。
|
||||
|
||||
|
||||
|
||||
### 自动构建繁琐任务
|
||||
|
||||
当同时工作在多个项目的时候,肯定需要完成许多繁杂、重复的任务。可能你需要在所有源文件头上加入版权信息,或者采用新框架时候自动更新文件。例如,当首次切换到 Tycho 和 Maven 的时候,我们需要 giel每个项目添加 pom.xml 文件。使用几行 Python 代码可以很轻松的完成这个任务。然后当 Tycho 支持无 pom 构建后,我们需要移除不要的 pom 文件。同样,几行代码就可以搞定这个任务,例如,这里有个脚本可以在每一个打开的工作空间项目上加入 README.md。请看源代码 [add_readme.py][8]。
|
||||
|
||||
拷贝该文件到工作空间来运行,右击并选择“Run as -> EASE script”。
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
|
||||
for iproject in getWorkspace().getProjects():
|
||||
if not iproject.isOpen():
|
||||
continue
|
||||
|
||||
ifile = iproject.getFile("README.md")
|
||||
|
||||
if not ifile.exists():
|
||||
contents = "# " + iproject.getName() + "\n\n"
|
||||
if iproject.hasNature("org.eclipse.jdt.core.javanature"):
|
||||
contents += "A Java Project\n"
|
||||
elif iproject.hasNature("org.python.pydev.pythonNature"):
|
||||
contents += "A Python Project\n"
|
||||
writeFile(ifile, contents)
|
||||
```
|
||||
|
||||
脚本运行的结果会在每个打开的项目中加入 README.md,java 和 Python 的项目还会自动加上一行描述。
|
||||
|
||||
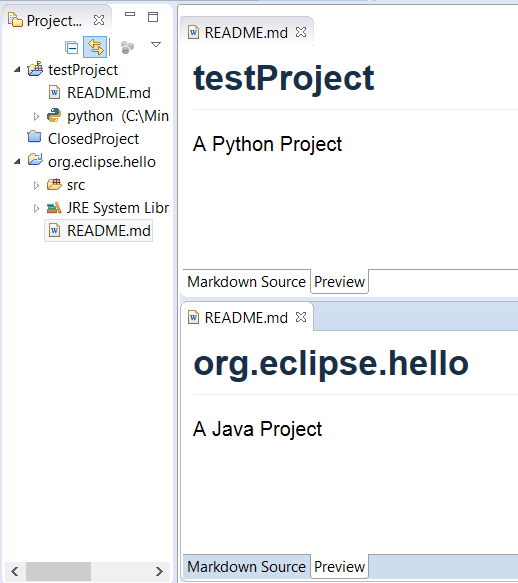
|
||||
|
||||
### 构建新功能
|
||||
|
||||
你可以使用 Python 脚本来快速构建一些急需的功能,或者做个原型给团队和用户演示你想要的功能。例如,一个 Eclipse 目前不支持的功能是自动保存你正在工作的文件。即使这个功能将会很快提供,但是你现在就可以马上拥有一个能每隔 30 秒或处于后台时自动保存的编辑器。以下是主要方法的片段。请看下列代码:[autosave.py][9]。
|
||||
|
||||
```
|
||||
def save_dirty_editors():
|
||||
workbench = getService(org.eclipse.ui.IWorkbench)
|
||||
for window in workbench.getWorkbenchWindows():
|
||||
for page in window.getPages():
|
||||
for editor_ref in page.getEditorReferences():
|
||||
part = editor_ref.getPart(False)
|
||||
if part and part.isDirty():
|
||||
print "Auto-Saving", part.getTitle()
|
||||
part.doSave(None)
|
||||
```
|
||||
|
||||
在运行脚本之前,你需要勾选 'Allow Scripts to run code in UI thread' 设定,这个设定在 Window > Preferences > Scripting 中。然后添加该脚本到工作空间,右击并选择“Run as > EASE Script”。每次编辑器自动保存时,控制台就会输出一个保存的信息。要关掉自动保存脚本,只需要点击控制台的红色方块的停止按钮即可。
|
||||
|
||||
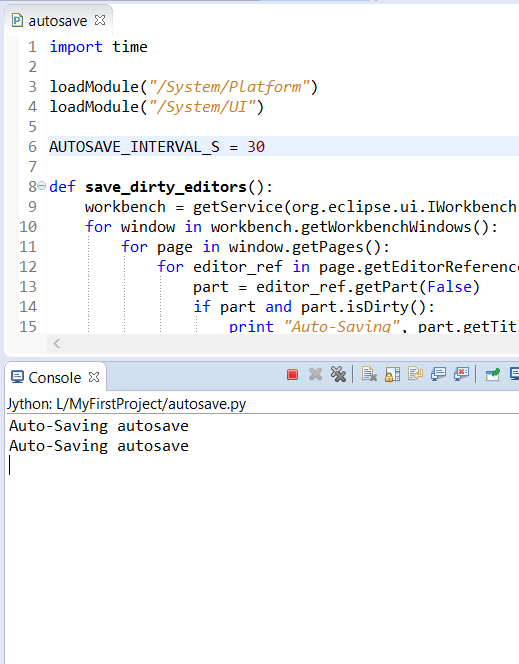
|
||||
|
||||
### 快速扩展用户界面
|
||||
|
||||
EASE 最棒的事情是可以将你的脚本与 IDE 界面上元素(比如一个新的按钮或菜单)结合起来。不需要编写 java 代码或者安装新的插件,只需要在你的脚本前面增加几行代码。
|
||||
|
||||
下面是一个简单的脚本示例,用来创建三个新项目。
|
||||
|
||||
```
|
||||
# name : Create fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Create fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
createProject(name)
|
||||
```
|
||||
|
||||
上述注释会专门告诉 EASE 增加了一个按钮到 Project Explorer 工具条。下面这个脚本是用来增加一个删除这三个项目的按钮的。请看源码 [createProjects.py][10] 和 [deleteProjects.py][11]。
|
||||
|
||||
```
|
||||
# name :Delete fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Get rid of the fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
project = getProject(name)
|
||||
project.delete(0, None)
|
||||
```
|
||||
|
||||
为了使按钮显示出来,增加这两个脚本到一个新的项目,假如叫做 'ScriptsProject'。然后到 Windows > Preference > Scripting > Script Location,点击 'Add Workspace' 按钮并选择 ScriptProject 项目。这个项目现在会成为放置脚本的默认位置。你可以发现 Project Explorer 上出现了这两个按钮,这样你就可以通过这两个新加的按钮快速增加和删除项目。
|
||||
|
||||
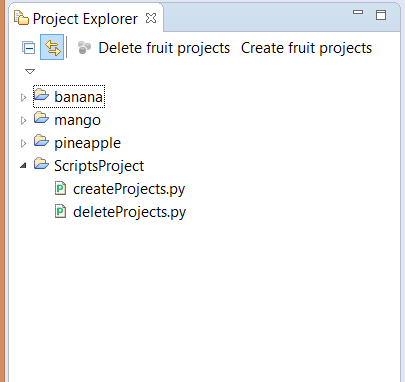
|
||||
|
||||
### 整合第三方工具
|
||||
|
||||
不管怎么说,你可能需要除了 Eclipse 生态系统以外的工具(这是真的,虽然 Eclipse 已经很丰富了,但是不是什么都有)。这些时候你会发现将他们包装在一个脚本来调用会非常方便。这里有一个简单的例子让你整合资源管理器,并将它加入到右键菜单栏,这样点击图标就可以打开资源管理器浏览当前文件。请看源码 [explorer.py][12]。
|
||||
|
||||
```
|
||||
# name : Explore from here
|
||||
# popup : enableFor(org.eclipse.core.resources.IResource)
|
||||
# description : Start a file browser using current selection
|
||||
loadModule("/System/Platform")
|
||||
loadModule('/System/UI')
|
||||
|
||||
selection = getSelection()
|
||||
if isinstance(selection, org.eclipse.jface.viewers.IStructuredSelection):
|
||||
selection = selection.getFirstElement()
|
||||
|
||||
if not isinstance(selection, org.eclipse.core.resources.IResource):
|
||||
selection = adapt(selection, org.eclipse.core.resources.IResource)
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IFile):
|
||||
selection = selection.getParent()
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IContainer):
|
||||
runProcess("explorer.exe", [selection.getLocation().toFile().toString()])
|
||||
```
|
||||
|
||||
为了让这个菜单显示出来,像之前一样将该文件加入一个新项目,比如说 'ScriptProject'。然后到 Windows > Preference > Scripting > Script Locations,点击“Add Workspace”并选择 'ScriptProject' 项目。当你在文件上右击鼠标键,你会看到弹出菜单出现了新的菜单项。点击它就会出现资源管理器。(注意,这个功能已经出现在 Eclipse 中了,但是你可以在这个例子中换成其它第三方工具。)
|
||||
|
||||
|
||||
|
||||
Eclipse 高级基本环境 (EASE)提供一套很棒的扩展功能,使得 Eclipse IDE 能使用 Python 来轻松扩展。虽然这个项目还在早期,但是[关于这个项目][13]更多更棒的功能也正在加紧开发中,如果你想为它做出贡献,请到[论坛][14]讨论。
|
||||
|
||||
我会在 2016 年的 [Eclipsecon North America][15] 会议上发布更多 EASE 细节。我的演讲 [Scripting Eclipse with Python][16] 也会不单会介绍 Jython,也包括 C-Python 和这个功能在科学领域是如何扩展的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-use-python-hack-your-ide
|
||||
|
||||
作者:[Tracy Miranda][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tracymiranda
|
||||
[1]: https://eclipse.org/ease/
|
||||
[2]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
[3]: https://www.eclipse.org/downloads/packages/eclipse-ide-eclipse-committers-451/mars1
|
||||
[4]: http://download.eclipse.org/ease/update/nightly
|
||||
[5]: https://dl.bintray.com/pontesegger/ease-jython/
|
||||
[6]: http://code.activestate.com/recipes/66434-change-line-endings/
|
||||
[7]: https://gist.github.com/tracymiranda/6556482e278c9afc421d
|
||||
[8]: https://gist.github.com/tracymiranda/f20f233b40f1f79b1df2
|
||||
[9]: https://gist.github.com/tracymiranda/e9588d0976c46a987463
|
||||
[10]: https://gist.github.com/tracymiranda/55995daaea9a4db584dc
|
||||
[11]: https://gist.github.com/tracymiranda/baa218fc2c1a8e898194
|
||||
[12]: https://gist.github.com/tracymiranda/8aa3f0fc4bf44f4a5cd3
|
||||
[13]: https://eclipse.org/ease/
|
||||
[14]: https://dev.eclipse.org/mailman/listinfo/ease-dev
|
||||
[15]: https://www.eclipsecon.org/na2016
|
||||
[16]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
@ -0,0 +1,43 @@
|
||||
Ubuntu Budgie 将在 Ubuntu 16.10 中成为新官方分支发行版
|
||||
===
|
||||
|
||||
> Budgie-Remix Beta 2 已经就绪以供测试。
|
||||
|
||||
上个月我们介绍了一个新 GNU/Linux 发行版 [Budgie-Remix][1],它的终极目标是成为一个 Ubuntu 官方分支发行版,可能会使用 Ubuntu Budgie 这个名字。
|
||||
|
||||

|
||||
|
||||
今天,Budgie-Remix 的开发者 David Mohammed 向 Softpedia 通报了项目进度,以及为即将到来的 16.04 发布了第二个 Beta 版本。Cononical 的创始人 [Mark Shuttleworth 说过][2]如果能够有围绕这个发行版的社区,它肯定会得到支持。
|
||||
|
||||
自我们[最初的报道][3]以来,David Mohammed 似乎与 Ubuntu MATE 项目的领导者 Martin Wimpress 取得了联系,后者敦促他以 Ubuntu 16.10 作为他还未正式命名的 Ubuntu 分支的官方版本目标。这个分支发行版构建于 Budgie 桌面环境之上,该桌面环境是由超赞的 [Solus][4] 开发者团队创建的。
|
||||
|
||||
“我们本周完成了 Beta 2 版本的开发以及很多其它东西,而且我们还有 Martin Wimpress (Ubuntu MATE 项目领导者)的支持,”David Mohammed 对 Softpedia 独家爆料。”他还敦促我们以 16.10 作为成为官方版本的目标——那当然是个主要的挑战——并且我们还需要社区的帮助/加入我们来让这一切成为现实!”
|
||||
|
||||
### Ubuntu Budgie 16.10 可能在 2016 年 10 月到来 ###
|
||||
|
||||
4 月 21 日,Canonical 将会发布 Ubuntu Linux 的下一个 LTS(Long Term Support,长期支持)版本:Xenial Xerus——好客的非洲地松鼠——也就是 Ubuntu 16.04。我们有可能能够提前体验到 Budgie-Remix 16.04,以后它也许成为了官方分支的 Ubuntu Budgie 。但在那之前,你可以帮助开发者[测试 Beta 2 版本][5]。
|
||||
|
||||
在 Ubuntu 16.04 LTS(Xenial Xerus)发布之后,Ubuntu 的开发者们就会立即将注意力转移到下一个版本的开发上。下一个版本 Ubuntu 16.10 应该会在 10 月底到来,并且 Ubuntu Budgie 也可能宣布成为 Ubuntu 官方分支发行版。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
----------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/ubuntu-budgie-could-be-the-new-flavor-of-ubuntu-linux-as-part-of-ubuntu-16-10-502573.shtml
|
||||
|
||||
作者:Marius Nestor
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://launchpad.net/budgie-remix
|
||||
[2]: https://plus.google.com/+programmerslab/posts/CSvbSvgcdcv
|
||||
[3]: http://news.softpedia.com/news/budgie-remix-could-become-ubuntu-budgie-download-and-test-it-501231.shtml
|
||||
[4]: https://solus-project.com/
|
||||
[5]: https://sourceforge.net/projects/budgie-remix/files/beta2/
|
||||
@ -0,0 +1,31 @@
|
||||
因 SUSE Linux Enterprise 12,Linux Kernel 3.12 的支持延长至 2017 年
|
||||
==================================================================================
|
||||
|
||||
>Linux 内核开发者 Jiri Slaby 已经宣布了 Linux 3.12 系列内核的第 58 个长期支持维护版本,以及关于生命周期状态的一些修改。
|
||||
|
||||
Linux Kernel 3.12.58 LTS(长期支持版)已经可用,那些运行该版本内核的 Linux 操作系统应尽快升级。有个好消息是 Linux 3.12 分支的支持将延长一年至 2017 年,因为 SUSE Linux Enterprise (SLE) 12 Service Pack 1 正是基于该分支。
|
||||
|
||||
“因为 SLE12-SP1 基于 3.12 之上,并且它的生命周期持续到 2017 年,所以将 3.12 的生命周期结束也修改到 2017 年,”Jiri Slaby 在发到 Linux 内核邮件列表的一个[补丁声明][1]中说道,同时他还公布了其它内核分支的生命周期结束时间(EOL,end of life),比如 Linux 3.14 为 2016 年 8 月,Linux 3.18 为 2017 年 1 月,Linux 4.1 是 2017 年 9 月。
|
||||
|
||||
### Linux kernel 3.12.58 LTS 改动
|
||||
|
||||
如果你想知道 Linux kernel 3.12.58 LTS 中有哪些改动,我们能告诉你的是,通过[附加的短日志][2]可知,这是一个健康的更新,改动涉及 114 个文件,有 835 行插入和 298 行删除。在这些改动之中,我们注意到多数是声音和网络栈的改进,以及许多驱动的更新。
|
||||
|
||||
更新中还有多个对 x86 硬件架构的改进,以及一些对 Xtensa 和 s390 的小修复。文件系统,如 NFS,OCFS2,Btrfs,JBD2 还有 XFS 也都收到了不同的修复,在驱动的更新中可以提到的还有 USB,Xen,MD,MTD,媒体,SCSI,TTY,网络,ATA,蓝牙,hwmon,EDAC 以及 CPUFreq。
|
||||
|
||||
和往常一样,你现在就可以从我们网站(linux.com)或直接从 kernel.org [下载 Linux kernel 3.12.58 LTS 的源码][3]。如果您的 GNU/Linux 操作系统运行的是 Linux 3.12 系列内核,请尽快升级您的内核。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/featured-blogs/191-linux-training/834644-7-steps-to-start-your-linux-sysadmin-career
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]: http://lkml.iu.edu/hypermail/linux/kernel/1604.1/00792.html
|
||||
[2]: http://www.spinics.net/lists/stable/msg128634.html
|
||||
[3]: http://linux.softpedia.com/get/System/Operating-Systems/Kernels/Linux-Kernel-Stable-1960.shtml
|
||||
@ -0,0 +1,48 @@
|
||||
Docker 1.11 采纳了开源容器项目(OCP)组件
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
> Docker 在开放容器项目(Open Container Project,OCP)中的参与度达成圆满,最新构建的Docker采用了Docker 贡献给 OCP 的组件。
|
||||
|
||||
新发布的 [Docker 1.11][1] 的最大新闻并不是它的功能,而是它使用了在 OCP 支持下的标准化的组件版本。
|
||||
|
||||
去年,Docker 贡献了它的 [runC][2] 核心给 OCP 作为构建构建容器工具的基础。同样还有 [containerd][3],作为守护进程或者服务端用于控制 runC 的实例。Docker 1.11 现在使用的就是这个捐赠和公开的版本。
|
||||
|
||||
|
||||
Docker 此举挑战了它的容器生态仍[主要由 Docker 自身决定][6]这个说法。它并不是为了作秀才将容器规范和运行时细节贡献给 OCP。它希望项目将来的开发越开放和广泛越好。
|
||||
|
||||
|
||||
|
||||
> Docker 1.11 已经用贡献给 OCP 的 runC 和 containerd 进行了重构。runC 如果需要的话可以换成另外一个。
|
||||
|
||||
runC 的[两位主要提交者][7]来自 Docker,但是来自 Virtuozzo(Parallels fame)、OpenShift、Project Atomic、华为、GE Healthcare、Suse Linux 也都是提交人员里面的常客。
|
||||
|
||||
Docker 1.11 中一个更明显的变化是先前 Docker runtime 在 Docker 中是唯一可用的,并且评论家认为这个会限制用户的选择。runC runtime 现在是可替换的;虽然 Docker 在发布时将 runC 作为默认引擎,但是任何兼容的引擎都可以用来替换它。(Docker 同样希望它可以不用杀死并重启现在运行的容器,但是这个作为今后的改进规划。)
|
||||
|
||||
Docker 正在将基于 OCP 的开发流程作为内部创建其产品的更好方式。在它发布 1.11 的[官方博客中称][8]:“将 Docker 切分成独立的工具意味着更专注的维护者,最终会有更好的软件质量。”
|
||||
|
||||
除了修复长期以来存在的问题和确保 Docker 的 runC/containerd 跟上步伐,Docker 还在 Docker 1.11 中加入了一些改进。Docker Engine 现在支持 VLAN 和 IPv6 服务发现,并且会自动在多个相同别名容器间执行 DNS 轮询负载均衡。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3055966/open-source-tools/docker-111-adopts-open-container-project-components.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]: https://blog.docker.com/2016/04/docker-engine-1-11-runc/
|
||||
[2]: http://runc.io/
|
||||
[3]: https://containerd.tools/
|
||||
[4]: http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker#tk.ifw-infsb
|
||||
[5]: http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[6]: http://www.infoworld.com/article/2876801/application-virtualization/docker-reorganization-grows-up.html
|
||||
[7]: https://github.com/opencontainers/runc/graphs/contributors
|
||||
[8]: https://blog.docker.com/2016/04/docker-engine-1-11-runc/
|
||||
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
Ubuntu 的 snap 软件包封装真的安全吗?
|
||||
==========================================
|
||||
|
||||
最近发布的 [Ubuntu 16.04 LTS 版本带来了一些新功能[1],其中之一就是对 [ZFS 格式文件系统的支持][2]。另一个值得广为讨论的特性就是 Snap 软件包格式。不过,据 [CoreOS][3] 的开发者之一所述,Snap 软件包并不像声称的那样安全。
|
||||
|
||||
### 什么是 Snap 软件包?
|
||||
|
||||
Snap 软件包的灵感来自容器。这种新的封装格式允许[开发人员为运行于 Ubuntu 长期支持版本 (LTS)之上的应用程序发布更新][4]。这就可以让用户虽然运行着稳定版本的操作系统,但却能够让应用程序保持最新的状态。之所以能够这样,是因为软件包本身就包含了程序运行的所有依赖。这可以防止依赖的软件更新后软件挂掉。
|
||||
|
||||
snap 软件包的另外一个优势是应用与系统的其它部分是隔离的。这意味着如果你改变了 snap 软件包的一些东西,它不会影响到系统的其它部分。这也可以防止其它的应用访问你的隐私信息,从而使骇客根据难以获取你的数据。
|
||||
|
||||
### 然而……
|
||||
|
||||
据 [Matthew Garrett][5] 的说法,Snap 软件包不能完全兑现上述承诺。Garret 作为 Linux 内核的开发人员和 CoreOS 的安全性方面的开发者,我想他一定知道自己在说些什么。
|
||||
|
||||
[据 Garret 说][6], “仅需要克服一点点困难,安装的任何 Snap 格式的软件包就完全能够将你所有的私有数据复制到任何地方”。
|
||||
|
||||
[ZDnet][7] 的报道:
|
||||
|
||||
> “为了证明自己的观点,他在 Snap 中构建了一个仅用于验证其原理的用于破坏的软件包,它首先会显示一个可爱的泰迪熊,然后将会记录 Firefox 的键盘按键事件,并且能够窃取 SSH 私钥。这个仅用于验证原理的软件包实际上注入的是一个无害的命令,但是却能够修改成一个窃取 SSH 密钥的 cURL 会话。”
|
||||
|
||||
### 但是稍等……
|
||||
|
||||
难道 Snap 真的有安全缺陷?事实上却不是!
|
||||
|
||||
Garret 自己也说,此问题仅出现在使用 X11 窗口系统上,而对于那些使用 Mir 的移动设备无效。所以这个缺陷是 X11 的而不是 Snap 的。
|
||||
|
||||
> X11 是如何信任应用程序的,这是一个众所周知的安全风险。Snap 并没有更改 X11 的信任模型。所以一个应用程序能够看到其它应用程序的行为并不是这种新的封装格式的缺点,而是 X11 的。
|
||||
|
||||
Garrett 实际上想表达的只是,当 Canonical 歌颂 Snap 和它的安全性时,Snap 应用程序并不是完全沙盒化的。和其他二进制文件一样,它们也存在风险。
|
||||
|
||||
请牢记 Ubuntu 16.04 当前还在使用 X11 而不是 Mir 的事实,从未知的源下载和安装 Snap 格式的软件包也许还是有风险的,然而其它不也是如此嘛?!
|
||||
|
||||
相关链接: [如何在 Ubuntu 16.04 中使用 Snap 软件包][8]。期待您分享关于 Snap 格式及其安全性的观点。
|
||||
|
||||
----------
|
||||
via: http://itsfoss.com/snap-package-securrity-issue/
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[dongfengweixiao](https://github.com/dongfengweixiao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://itsfoss.com/author/john/
|
||||
[1]: http://itsfoss.com/features-ubuntu-1604/
|
||||
[2]: http://itsfoss.com/oracle-canonical-lawsuit/
|
||||
[3]: https://en.wikipedia.org/wiki/CoreOS
|
||||
[4]: https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/
|
||||
[5]: https://mjg59.dreamwidth.org/l
|
||||
[6]: https://mjg59.dreamwidth.org/42320.html
|
||||
[7]: http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/
|
||||
[8]: http://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
@ -0,0 +1,226 @@
|
||||
LFCS 系列第一讲:如何在 Linux 上使用 GNU sed 等命令来创建、编辑和操作文件
|
||||
================================================================================
|
||||
Linux 基金会宣布了一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证计划。这一计划旨在帮助遍布全世界的人们获得其在处理 Linux 系统管理任务上能力的认证。这些能力包括支持运行的系统服务,以及第一手的故障诊断、分析,以及为工程师团队在升级时提供明智的决策。
|
||||
|
||||

|
||||
|
||||
*Linux 基金会认证系统管理员——第一讲*
|
||||
|
||||
请观看下面关于 Linux 基金会认证计划的演示:
|
||||
|
||||
<embed src="http://static.video.qq.com/TPout.swf?vid=l0163eohhs9&auto=0" allowFullScreen="true" quality="high" width="480" height="400" align="middle" allowScriptAccess="always" type="application/x-shockwave-flash"></embed>
|
||||
|
||||
该系列将命名为《LFCS 系列第一讲》至《LFCS 系列第十讲》并覆盖关于 Ubuntu、CentOS 以及 openSUSE 的下列话题。
|
||||
|
||||
- 第一讲:如何在 Linux 上使用 GNU sed 等命令来创建、编辑和操作文件
|
||||
- 第二讲:如何安装和使用 vi/m 全功能文字编辑器
|
||||
- 第三讲:归档文件/目录并在文件系统中寻找文件
|
||||
- 第四讲:为存储设备分区,格式化文件系统和配置交换分区
|
||||
- 第五讲:在 Linux 中挂载/卸载本地和网络(Samba & NFS)文件系统
|
||||
- 第六讲:组合分区作为 RAID 设备——创建&管理系统备份
|
||||
- 第七讲:管理系统启动进程和服务(使用 SysVinit, Systemd 和 Upstart)
|
||||
- 第八讲:管理用户和组,文件权限和属性以及启用账户的 sudo 权限
|
||||
- 第九讲:用 Yum,RPM,Apt,Dpkg,Aptitude,Zypper 进行 Linux 软件包管理
|
||||
- 第十讲:学习简单的 Shell 脚本编程和文件系统故障排除
|
||||
|
||||
重要提示:由于自 2016/2 开始 LFCS 认证要求有所变化,我们增加发布了下列必需的内容。要准备这个考试,推荐你也看看我们的 LFCE 系列。
|
||||
|
||||
- 第十一讲:怎样使用 vgcreate、lvcreate 和 lvextend 命令创建和管理 LVM
|
||||
- 第十二讲:怎样安装帮助文档和工具来探索 Linux
|
||||
- 第十三讲:怎样配置和排错 GRUB
|
||||
|
||||
本文是覆盖这个参加 LFCS 认证考试的所必需的范围和技能的十三个教程的第一讲。话说了那么多,快打开你的终端,让我们开始吧!
|
||||
|
||||
### 处理 Linux 中的文本流 ###
|
||||
|
||||
Linux 将程序中的输入和输出当成字符流或者字符序列。在开始理解重定向和管道之前,我们必须先了解三种最重要的I/O(Input and Output,输入和输出)流,事实上,它们都是特殊的文件(根据 UNIX 和 Linux 中的约定,数据流和外围设备(设备文件)也被视为普通文件)。
|
||||
|
||||
在 \> (重定向操作符) 和 | (管道操作符)之间的区别是:前者将命令与文件相连接,而后者将命令的输出和另一个命令相连接。
|
||||
|
||||
# command > file
|
||||
# command1 | command2
|
||||
|
||||
由于重定向操作符会静默地创建或覆盖文件,我们必须特别小心谨慎地使用它,并且永远不要把它和管道混淆起来。在 Linux 和 UNIX 系统上管道的优势是:第一个命令的输出不会写入一个文件而是直接被第二个命令读取。
|
||||
|
||||
在下面的操作练习中,我们将会使用这首诗——《A happy child》(作者未知)
|
||||
|
||||
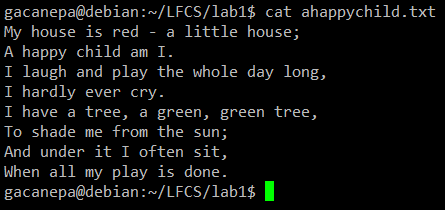
|
||||
|
||||
*cat 命令样例*
|
||||
|
||||
#### 使用 sed ####
|
||||
|
||||
sed 是流编辑器(stream editor)的缩写。为那些不懂术语的人额外解释一下,流编辑器是用来在一个输入流(文件或者管道中的输入)执行基本的文本转换的工具。
|
||||
|
||||
sed 最基本的用法是字符替换。我们将通过把每个出现的小写 y 改写为大写 Y 并且将输出重定向到 ahappychild2.txt 开始。g 标志表示 sed 应该替换文件每一行中所有应当替换的实例。如果这个标志省略了,sed 将会只替换每一行中第一次出现的实例。
|
||||
|
||||
**基本语法:**
|
||||
|
||||
# sed 's/term/replacement/flag' file
|
||||
|
||||
**我们的样例:**
|
||||
|
||||
# sed 's/y/Y/g' ahappychild.txt > ahappychild2.txt
|
||||
|
||||

|
||||
|
||||
*sed 命令样例*
|
||||
|
||||
如果你要在替换文本中搜索或者替换特殊字符(如 /,\,&),你需要使用反斜杠对它进行转义。
|
||||
|
||||
例如,我们要用一个符号来替换一个文字,与此同时我们将把一行最开始出现的第一个 I 替换为 You。
|
||||
|
||||
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
|
||||
|
||||

|
||||
|
||||
*sed 替换字符串*
|
||||
|
||||
在上面的命令中,众所周知 \^(插入符号)是正则表达式中用来表示一行开头的符号。
|
||||
|
||||
正如你所看到的,我们可以通过使用分号分隔以及用括号包裹来把两个或者更多的替换命令(并在它们中使用正则表达式)连接起来。
|
||||
|
||||
另一种 sed 的用法是显示或者删除文件中选中的一部分。在下面的样例中,将会显示 /var/log/messages 中从6月8日开始的头五行。
|
||||
|
||||
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
|
||||
|
||||
请注意,在默认的情况下,sed 会打印每一行。我们可以使用 -n 选项来覆盖这一行为并且告诉 sed 只需要打印(用 p来表示)文件(或管道)中匹配的部分(第一个命令中指定以“Jun 8” 开头的行,第二个命令中指定一到五行)。
|
||||
|
||||
最后,可能有用的技巧是当检查脚本或者配置文件的时候可以保留文件本身并且删除注释。下面的单行 sed 命令删除(d)空行或者是开头为`#`的行(| 字符对两个正则表达式进行布尔 OR 操作)。
|
||||
|
||||
# sed '/^#\|^$/d' apache2.conf
|
||||
|
||||

|
||||
|
||||
*sed 匹配字符串*
|
||||
|
||||
#### uniq 命令 ####
|
||||
|
||||
uniq 命令允许我们返回或者删除文件中重复的行,默认写到标准输出。我们必须注意到,除非两个重复的行相邻,否则uniq 命令不会删除他们。因此,uniq 经常和一个前置的 sort 命令(一种用来对文本行进行排序的算法)搭配使用。默认情况下,sort 使用第一个字段(用空格分隔)作为关键字段。要指定一个不同的关键字段,我们需要使用 -k 选项。
|
||||
|
||||
**样例**
|
||||
|
||||
du –sch /path/to/directory/* 命令将会以人类可读的格式返回在指定目录下每一个子文件夹和文件的磁盘空间使用情况(也会显示每个目录总体的情况),而且不是按照大小输出,而是按照子文件夹和文件的名称。我们可以使用下面的命令来让它通过大小排序。
|
||||
|
||||
# du -sch /var/* | sort -h
|
||||
|
||||
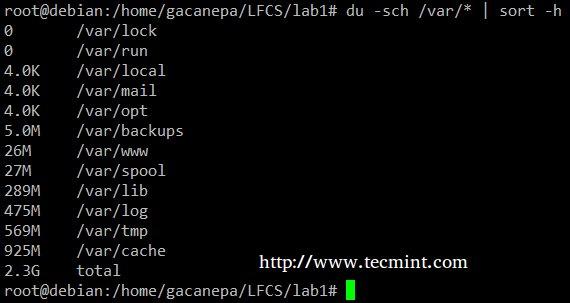
|
||||
|
||||
*sort 命令样例*
|
||||
|
||||
你可以通过使用下面的命令告诉 uniq 比较每一行的前6个字符(-w 6)(这里是指定的日期)来统计日志事件的个数,而且在每一行的开头输出出现的次数(-c)。
|
||||
|
||||
|
||||
# cat /var/log/mail.log | uniq -c -w 6
|
||||
|
||||

|
||||
|
||||
*文件中的统计数字*
|
||||
|
||||
最后,你可以组合使用 sort 和 uniq 命令(通常如此)。看看下面文件中捐助者、捐助日期和金额的列表。假设我们想知道有多少个捐助者。我们可以使用下面的命令来分隔第一字段(字段由冒号分隔),按名称排序并且删除重复的行。
|
||||
|
||||
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
|
||||
|
||||

|
||||
|
||||
*寻找文件中不重复的记录*
|
||||
|
||||
- 也可阅读: [13个“cat”命令样例][1]
|
||||
|
||||
#### grep 命令 ####
|
||||
|
||||
grep 在文件(或命令输出)中搜索指定正则表达式,并且在标准输出中输出匹配的行。
|
||||
|
||||
**样例**
|
||||
|
||||
显示文件 /etc/passwd 中用户 gacanepa 的信息,忽略大小写。
|
||||
|
||||
# grep -i gacanepa /etc/passwd
|
||||
|
||||

|
||||
|
||||
*grep 命令样例*
|
||||
|
||||
显示 /etc 文件夹下所有 rc 开头并跟随任意数字的内容。
|
||||
|
||||
# ls -l /etc | grep rc[0-9]
|
||||
|
||||

|
||||
|
||||
*使用 grep 列出内容*
|
||||
|
||||
- 也可阅读: [12个“grep”命令样例][2]
|
||||
|
||||
#### tr 命令使用技巧 ####
|
||||
|
||||
tr 命令可以用来从标准输入中转换(改变)或者删除字符,并将结果写入到标准输出中。
|
||||
|
||||
**样例**
|
||||
|
||||
把 sortuniq.txt 文件中所有的小写改为大写。
|
||||
|
||||
# cat sortuniq.txt | tr [:lower:] [:upper:]
|
||||
|
||||

|
||||
|
||||
*排序文件中的字符串*
|
||||
|
||||
压缩`ls –l`输出中的分隔符为一个空格。
|
||||
|
||||
# ls -l | tr -s ' '
|
||||
|
||||

|
||||
|
||||
*压缩分隔符*
|
||||
|
||||
#### cut 命令使用方法 ####
|
||||
|
||||
cut 命令可以基于字节(-b选项)、字符(-c)或者字段(-f)提取部分输入(从标准输入或者文件中)并且将结果输出到标准输出。在最后一种情况下(基于字段),默认的字段分隔符是一个制表符,但可以由 -d 选项来指定不同的分隔符。
|
||||
|
||||
**样例**
|
||||
|
||||
从 /etc/passwd 中提取用户账户和他们被分配的默认 shell(-d 选项允许我们指定分界符,-f 选项指定那些字段将被提取)。
|
||||
|
||||
# cat /etc/passwd | cut -d: -f1,7
|
||||
|
||||

|
||||
|
||||
*提取用户账户*
|
||||
|
||||
将以上命令结合起来,我们将使用 last 命令的输出中第一和第三个非空文件创建一个文本流。我们将使用 grep 作为第一过滤器来检查用户 gacanepa 的会话,然后将分隔符压缩至一个空格(tr -s ' ')。下一步,我们将使用 cut 来提取第一和第三个字段,最后使用第二个字段(本样例中,指的是IP地址)来排序之后,再用 uniq 去重。
|
||||
|
||||
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
|
||||
|
||||

|
||||
|
||||
*last 命令样例*
|
||||
|
||||
上面的命令显示了如何将多个命令和管道结合起来,以便根据我们的要求得到过滤后的数据。你也可以逐步地使用它以帮助你理解输出是如何从一个命令传输到下一个命令的(顺便说一句,这是一个非常好的学习经验!)
|
||||
|
||||
### 总结 ###
|
||||
|
||||
尽管这个例子(以及在当前教程中的其他实例)第一眼看上去可能不是非常有用,但是他们是体验在 Linux 命令行中创建、编辑和操作文件的一个非常好的开始。请随时留下你的问题和意见——不胜感激!
|
||||
|
||||
#### 参考链接 ####
|
||||
|
||||
- [关于 LFCS][3]
|
||||
- [为什么需要 Linux 基金会认证?][4]
|
||||
- [注册 LFCS 考试][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[Xuanwo](https://github.com/Xuanwo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-2336-1.html
|
||||
[2]:https://linux.cn/article-2250-1.html
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
[6]:http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
@ -0,0 +1,251 @@
|
||||
LFCS 系列第二讲:如何安装和使用纯文本编辑器 vi/vim
|
||||
================================================================================
|
||||
|
||||
几个月前, Linux 基金会发起了 LFCS (Linux Foundation Certified System administrator,Linux 基金会认证系统管理员)认证,以帮助世界各地的人来验证他们能够在 Linux 系统上做从基础的到中级的系统管理任务:如系统支持、第一手的故障诊断和处理、以及何时向上游支持团队提出问题的智能决策。
|
||||
|
||||

|
||||
|
||||
*在 Linux 中学习 vi 编辑器*
|
||||
|
||||
请简要看看一下视频,里边介绍了 Linux 基金会认证的程序。
|
||||
|
||||
注:youtube 视频
|
||||
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
这篇文章是系列教程的第二讲,在这个部分中,我们会介绍 vi/vim 基本的文件编辑操作,帮助读者理解编辑器中的三个模式,这是 LFCS 认证考试中必须掌握的。
|
||||
|
||||
### 使用 vi/vim 执行基本的文件编辑操作 ###
|
||||
|
||||
vi 是为 Unix 而生的第一个全屏文本编辑器。它的设计小巧简单,对于仅仅使用过诸如 NotePad++ 或 gedit 等图形界面的文本编辑器的用户来说,使用起来可能存在一些困难。
|
||||
|
||||
为了使用 vi,我们必须首先理解这个强大的程序操作中的三种模式,方便我们后边学习这个强大的文本处理软件的相关操作。
|
||||
|
||||
请注意,大多数的现代 Linux 发行版都集成了 vi 的变种——— vim(Vi IMproved,改进版 VI),相比于 vi,它有更多新功能。所以,我们会在本教程中交替使用 vi 和 vim。
|
||||
|
||||
如果你的发行版还没有安装 vim,你可以通过以下方法来安装:
|
||||
|
||||
- Ubuntu 及其衍生版:apt-get update && apt-get install vim
|
||||
- 以 Red-Hat 为基础的发行版:yum update && yum install vim
|
||||
- openSUSE :zypper update && zypper install vim
|
||||
|
||||
### 我为什么要学习 vi ###
|
||||
|
||||
至少有以下两个理由:
|
||||
|
||||
1. 因为它是 POSIX 标准的一部分,所以不管你使用什么发行版 vi 总是可用的。
|
||||
|
||||
2. vi 基本不消耗多少系统资源,并且允许我们仅仅通过键盘来完成任何可能的任务。
|
||||
|
||||
此外,vi 有着非常丰富的内置帮助手册,程序打开后就可以通过 `:help` 命令来查看。这个内置帮助手册比 vi/vim 的 man 页面包含了更多信息。
|
||||
|
||||

|
||||
|
||||
*vi Man 页面*
|
||||
|
||||
#### 启动 vi ####
|
||||
|
||||
可以通过在命令提示符下输入 vi 来启动。
|
||||
|
||||

|
||||
|
||||
*使用 vi 编辑器*
|
||||
|
||||
然后按下字母 i,你就可以开始输入了。或者通过下面的方法来启动 vi:
|
||||
|
||||
# vi filename
|
||||
|
||||
这样会打开一个名为 filename 的缓存区(buffer)(稍后会详细介绍缓存区),在你编辑完成之后就可以存储在磁盘中了。
|
||||
|
||||
#### 理解 vi 的三个模式 ####
|
||||
|
||||
1. 在命令(command)模式中,vi 允许用户浏览该文件并输入由一个或多个字母组成的、简短的、大小写敏感的 vi 命令。这些命令的大部分都可以增加一个前缀数字表示执行次数。
|
||||
|
||||
比如:`yy`(或`Y`) 复制当前的整行,`3yy`(或`3Y`) 复制当前整行和下边紧接着的两行(总共3行)。通过 `Esc` 键可以随时进入命令模式(而不管当前工作在什么模式下)。事实上,在命令模式下,键盘上所有的输入都被解释为命令而非文本,这往往使得初学者困惑不已。
|
||||
|
||||
2. 在末行(ex)模式中,我们可以处理文件(包括保存当前文件和运行外部程序)。我们必须在命令模式下输入一个冒号(`:`),才能进入这个模式,紧接着是要在末行模式下使用的命令。执行之后 vi 自动回到命令模式。
|
||||
|
||||
3. 在文本输入(insert)模式(通常在命令模式下使用字母 `i` 进入这个模式)中,我们可以随意输入文本。大多数的键入将以文本形式输出到屏幕(一个重要的例外是`Esc`键,它将退出文本编辑模式并回到命令模式)。
|
||||
|
||||

|
||||
|
||||
*vi 文本插入模式*
|
||||
|
||||
#### vi 命令 ####
|
||||
|
||||
下面的表格列出常用的 vi 命令。文件编辑的命令可以通过添加叹号的命令强制执行(如,`:q!` 命令强制退出编辑器而不保存文件)。
|
||||
|
||||
|关键命令|描述|
|
||||
|------|:--:|
|
||||
|`h` 或 ←|光标左移一个字符|
|
||||
|`j` 或 ↓|光标下移一行|
|
||||
|`k` 或 ↑|光标上移一行|
|
||||
|`l` (小写字母 L) 或 →|光标右移一个字符|
|
||||
|`H`|光标移至屏幕顶行|
|
||||
|`L`|光标移至屏幕末行|
|
||||
|`G`|光标移至文件末行|
|
||||
|`w`|光标右移一个词|
|
||||
|`b`|光标左移一个词|
|
||||
|`0` (数字零)|光标移至行首|
|
||||
|`^`|光标移至当前行第一个非空格字符|
|
||||
|`$`|光标移至当前行行尾|
|
||||
|`Ctrl-B`|向后翻页|
|
||||
|`Ctrl-F`|向前翻页|
|
||||
|`i`|在光标所在位置插入文本|
|
||||
|`I` (大写字母 i)|在当前行首插入文本|
|
||||
|`J` (大写字母 j)|将下一行与当前行合并(下一行上移到当前行)|
|
||||
|`a`|在光标所在位置后追加文本|
|
||||
|`o` (小写字母 O)|在当前行下边插入空白行|
|
||||
|`O` (大写字母 O)|在当前行上边插入空白行|
|
||||
|`r`|替换光标所在位置的一个字符|
|
||||
|`R`|从光标所在位置开始覆盖插入文本|
|
||||
|`x`|删除光标所在位置的字符|
|
||||
|`X`|立即删除光标所在位置之前(左边)的一个字符|
|
||||
|`dd`|剪切当前整行文本(为了之后进行粘贴)|
|
||||
|`D`|剪切光标所在位置到行末的文本(该命令等效于 `d$`)|
|
||||
|`yX`|给出一个移动命令 X (如 `h`、`j`、`H`、`L` 等),复制适当数量的字符、单词或者从光标开始到一定数量的行|
|
||||
|`yy` 或 `Y`|复制当前整行|
|
||||
|`p`|粘贴在光标所在位置之后(下一行)|
|
||||
|`P`|粘贴在光标所在位置之前(上一行)
|
||||
|`.` (句点)|重复最后一个命令|
|
||||
|`u`|撤销最后一个命令|
|
||||
|`U`|撤销最后一行的最后一个命令,只有光标仍在最后一行才能执行。|
|
||||
|`n`|在查找中跳到下一个匹配项|
|
||||
|`N`|在查找中跳到前一个匹配项|
|
||||
|`:n`|下一个文件,编辑多个指定文件时,该命令加载下一个文件。|
|
||||
|`:e file`|加载新文件来替代当前文件|
|
||||
|`:r file`|将新文件的内容插入到光标所在位置的下一行|
|
||||
|`:q`|退出并放弃更改|
|
||||
|`:w file`|将当期打开的缓存区保存为file。如果是追加到已存在的文件中,则使用 :`w >> file` 命令|
|
||||
|`:wq`|保存当前文件的内容并退出。等效于 `x!` 和 `ZZ`|
|
||||
|`:r! command`|执行 command 命令,并将命令的输出插入到光标所在位置的下一行|
|
||||
|
||||
#### vi 选项 ####
|
||||
|
||||
下列选项可以让你在运行 Vim 的时候很方便(需要写入到 `~/.vimrc` 文件):
|
||||
|
||||
# echo set number >> ~/.vimrc
|
||||
# echo syntax on >> ~/.vimrc
|
||||
# echo set tabstop=4 >> ~/.vimrc
|
||||
# echo set autoindent >> ~/.vimrc
|
||||
|
||||
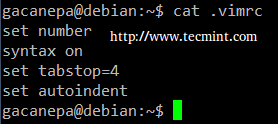
|
||||
|
||||
*vi编辑器选项*
|
||||
|
||||
- set number 当 vi 打开或新建文件时,显示行号。
|
||||
- syntax on 打开语法高亮(对应多个文件扩展名),以便源码文件和配置文件更具可读性。
|
||||
- set tabstop=4 设置制表符间距为 4 个空格(默认为 8)。
|
||||
- set autoindent 将前一行的缩进应用于下一行。
|
||||
|
||||
#### 查找和替换 ####
|
||||
|
||||
vi 具有通过查找将光标移动到(在单独一行或者整个文件中的)指定位置。它还可自动或者通过用户确认来执行文本替换。
|
||||
|
||||
a) 在行内查找。`f` 命令在当前行查找指定字符,并将光标移动到指定字符出现的位置。
|
||||
|
||||
例如,命令 `fh` 会在本行中将光标移动到字母`h`下一次出现的位置。注意,字母 `f` 和你要查找的字符都不会出现在屏幕上,但是当你按下回车的时候,要查找的字符会被高亮显示。
|
||||
|
||||
比如,以下是在命令模式按下 `f4` 之后的结果。
|
||||
|
||||

|
||||
|
||||
*在 vi 中查找字符*
|
||||
|
||||
b) 在整个文件内查找。使用 `/` 命令,紧接着需要查找的单词或短语。这个查找可以通过使用 `n` 命令或者 `N` 重复查找上一个查找的字符串。以下是在命令模式键入 `/Jane` 的查找结果。
|
||||
|
||||
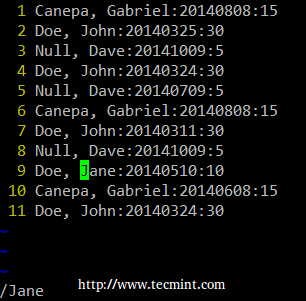
|
||||
|
||||
*在 vi 中查找字符*
|
||||
|
||||
c) vi 通过使用命令来完成多行或者整个文件的替换操作(类似于 sed)。我们可以使用以下命令,使得整个文件中的单词 “old” 替换为 “young”。
|
||||
|
||||
:%s/old/young/g
|
||||
|
||||
**注意**:冒号位于命令的最前面。
|
||||
|
||||
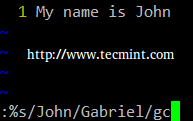
|
||||
|
||||
*vi 的查找和替换*
|
||||
|
||||
冒号 (`:`) 进入末行模式,在本例中 `s` 表示替换,`%` 是从第一行到最后一行的表示方式(也可以使用 nm 表示范围,即第 n 行到第 m 行),old 是查找模式,young 是用来替换的文本,`g` 表示在每个查找出来的字符串都进行替换。
|
||||
|
||||
另外,在命令最后增加一个 `c`,可以在每一个匹配项替换前进行确认。
|
||||
|
||||
:%s/old/young/gc
|
||||
|
||||
将旧文本替换为新文本前,vi/vim 会向我们显示以下信息:
|
||||
|
||||
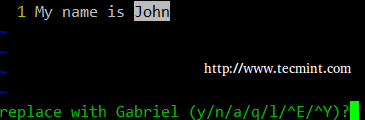
|
||||
|
||||
*vi 中替换字符串*
|
||||
|
||||
- `y`: 执行替换(yes)
|
||||
- `n`: 跳过这个匹配字符的替换并转到下一个(no)
|
||||
- `a`: 在当前匹配字符及后边的相同项全部执行替换
|
||||
- `q` 或 `Esc`: 取消替换
|
||||
- `l` (小写 L): 执行本次替换并退出
|
||||
- `Ctrl-e`, `Ctrl-y`: 下翻页,上翻页,查看相应的文本来进行替换
|
||||
|
||||
#### 同时编辑多个文件 ####
|
||||
|
||||
我们在命令提示符输入 vim file1 file2 file3 如下:
|
||||
|
||||
# vim file1 file2 file3
|
||||
|
||||
vim 会首先打开 file1,要跳到 file2 需用 :n 命令。当需要打开前一个文件时,:N 就可以了。
|
||||
|
||||
为了从 file1 跳到 file3
|
||||
|
||||
a) `:buffers` 命令会显示当前正在编辑的文件列表
|
||||
|
||||
:buffers
|
||||
|
||||
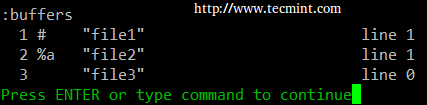
|
||||
|
||||
*编辑多个文件*
|
||||
|
||||
b) `:buffer 3` 命令(后边没有 s)会打开第三个文件 file3 进行编辑。
|
||||
|
||||
在上边的图片中,标记符号 `#` 表示该文件当前已被打开,但是是在后台,而 `%a` 标记的文件是正在被编辑的。另外,文件号(如上边例子的 3)后边的空格表示该文件还没有被打开。
|
||||
|
||||
#### vi 的临时缓存区 ####
|
||||
|
||||
为了复制连续的多行(比如,假设为 4 行)到一个名为 a 的临时缓存区(与文件无关),并且还要将这些行粘贴到在当前 vi 会话文件中的其它位置,我们需要:
|
||||
|
||||
1. 按下 `Esc` 键以确认 vi 处在命令模式
|
||||
|
||||
2. 将光标放在我们希望复制的第一行文本
|
||||
|
||||
3. 输入 `a4yy` 复制当前行和接下来的 3 行,进入一个名为 a 的缓存区。我们可以继续编辑我们的文件————我们不需要立即插入刚刚复制的行。
|
||||
|
||||
4. 当到了需要使用刚刚复制的那些行的位置,在 `p`(小写)或 `P`(大写)命令前使用`a`来将复制行插入到名为 a 的 缓存区:
|
||||
- 输入 `ap`,复制行将插入到光标位置所在行的下一行。
|
||||
- 输入 `aP`,复制行将插入到光标位置所在行的上一行。
|
||||
|
||||
如果愿意,我们可以重复上述步骤,将缓存区 a 中的内容插入到我们文件的多个位置。像本节中这样的一个临时缓存区,会在当前窗口关闭时释放掉。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
像我们看到的一样,vi/vim 在命令接口下是一个强大而灵活的文本编辑器。通过以下链接,随时分享你自己的技巧和评论。
|
||||
|
||||
#### 参考链接 ####
|
||||
|
||||
- [关于 LFCS][1]
|
||||
- [为什么需要 Linux 基金会认证?][2]
|
||||
- [注册 LFCS 考试][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/vi-editor-usage/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[东风唯笑](https://github.com/dongfengweixiao), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[2]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[3]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -1,165 +1,72 @@
|
||||
GHLandy Translated
|
||||
|
||||
LFCS 系列第三讲:如何在 Linux 中归档/压缩文件及目录、设置文件属性和搜索文件
|
||||
|
||||
LFCS 系列第三讲:归档/压缩文件及目录、设置文件属性和搜索文件
|
||||
================================================================================
|
||||
最近,Linux 基金会发起了 一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,旨在让遍布全世界的人都有机会参加该认证的考试,并且通过考试的人将会得到关于他们有能力在 Linux 上执行基本的中间系统管理任务的认证证书。这项认证包括了对已运行的系统和服务的支持、一流水平的问题解决和分析以及决定何时将问题反映给工程师团队的能力。
|
||||
|
||||
最近,Linux 基金会发起了一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,旨在让遍布全世界的人都有机会参加该认证的考试,通过考试的人将表明他们有能力在 Linux 上执行基本的中级系统管理任务。这项认证包括了对已运行的系统和服务的支持、一流水平的问题解决和分析以及决定何时将问题反映给工程师团队的能力。
|
||||
|
||||

|
||||
|
||||
LFCS 系列第三讲
|
||||
*LFCS 系列第三讲*
|
||||
|
||||
请看以下视频,这里边讲给出 Linux 基金会认证程序的一些想法。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本讲是《十套教程》系列中的第三讲,在这一讲中,我们会涵盖如何在文件系统中归档/压缩文件及目录、设置文件属性和搜索文件等内容,这些都是 LFCS 认证中必须掌握的知识。
|
||||
本讲是系列教程中的第三讲,在这一讲中,我们会涵盖如何在文件系统中归档/压缩文件及目录、设置文件属性和搜索文件等内容,这些都是 LFCS 认证中必须掌握的知识。
|
||||
|
||||
### 归档和压缩的相关工具 ###
|
||||
|
||||
文件归档工具将一堆文件整合到一个单独的归档文件之后,我们可以将归档文件备份到不同类型的媒介或者通过网络传输和发送 Email 来备份。在 Linux 中使用频率最高的归档实用工具是 tar。当归档工具和压缩工具一起使用的时候,可以减少同一文件和信息在硬盘中的存储空间。
|
||||
文件归档工具将一堆文件整合到一个单独的归档文件之后,我们可以将归档文件备份到不同类型的介质或者通过网络传输和发送 Email 来备份。在 Linux 中使用频率最高的归档实用工具是 tar。当归档工具和压缩工具一起使用的时候,可以减少同一文件和信息在硬盘中的存储空间。
|
||||
|
||||
#### tar 使用工具 ####
|
||||
|
||||
tar 将一组文件打包到一个单独的归档文件(通常叫做 tar 文件或者 tarball)。tar 这个名称最初代表磁带存档程序(tape archiver),但现在我们可以用它来归档任意类型的可读写媒介上边的数据,而不是只能归档磁带数据。tar 通常与 gzip、bzip2 或者 xz 等压缩工具一起使用,生成一个压缩的 tarball。
|
||||
tar 将一组文件打包到一个单独的归档文件(通常叫做 tar 文件或者 tarball)。tar 这个名称最初代表磁带存档程序(tape archiver),但现在我们可以用它来归档任意类型的可读写介质上边的数据,而不是只能归档磁带数据。tar 通常与 gzip、bzip2 或者 xz 等压缩工具一起使用,生成一个压缩的 tarball。
|
||||
|
||||
**基本语法:**
|
||||
|
||||
# tar [选项] [路径名 ...]
|
||||
|
||||
其中 ... 代表指定那些文件进行归档操作的表达式
|
||||
其中 ... 代表指定哪些文件进行归档操作的表达式
|
||||
|
||||
#### tar 的常用命令 ####
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="150">
|
||||
</colgroup>
|
||||
<colgroup width="109">
|
||||
</colgroup>
|
||||
<colgroup width="351">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td bgcolor="#999999" height="18" align="CENTER" style="border: 1px solid #000001;"><b>长选项</b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b>简写</b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b>描述</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –create</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> c</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 创建 tar 归档文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –concatenate</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 将一存档与已有的存档合并</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –append</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 把要存档的文件追加到归档文件的末尾</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –update</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> u</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 更新新文件到归档文件中去</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –diff 或 –compare</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 比较存档与当前文件的不同之处</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –file archive</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> f</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 使用档案文件或设备</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –list</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 列出 tarball 中的内容</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –extract 或 –get</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 从归档文件中释放文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|长选项|简写|描述|
|
||||
|-----|:---:|:---|
|
||||
| -create| c| 创建 tar 归档文件|
|
||||
| -concatenate| A| 将一存档与已有的存档合并|
|
||||
| -append| r| 把要存档的文件追加到归档文件的末尾|
|
||||
| -update| u| 更新新文件到归档文件中去|
|
||||
| -diff 或 -compare| d| 比较存档与当前文件的不同之处|
|
||||
| -file archive| f| 使用档案文件或归档设备|
|
||||
| -list| t| 列出 tarball 中的内容|
|
||||
| -extract 或 -get| x| 从归档文件中释放文件|
|
||||
|
||||
|
||||
#### 常用的操作修饰符 ####
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="162">
|
||||
</colgroup>
|
||||
<colgroup width="109">
|
||||
</colgroup>
|
||||
<colgroup width="743">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr class="alt">
|
||||
<td bgcolor="#999999" height="18" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">长选项</span></b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">缩写</span></b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">描述</span></b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –directory dir</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> C</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 执行归档操作前,先转到指定目录</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –same-permissions</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> 保持原始的文件权限</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="38" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 列出所有的读取或提取文件。但这个标识符与 –list 一起使用的时候,还会显示出文件大小、属主和时间戳的信息</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –verify</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> W</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> 写入存档后进行校验</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –exclude file</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 不把指定文件包含在内</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –exclude=pattern</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> X</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> 以PATTERN模式排除文件</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –gzip 或 –gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 通过gzip压缩归档</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> j</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 通过bzip2压缩归档</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> 通过xz压缩归档</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Gzip 是最古老的压缩工具,压缩率最小,bzip2 的压缩率稍微高一点。另外,xz是最新的压缩工具,压缩率最好。xz 具有最佳压缩率的代价是:完成压缩操作花费最多时间,压缩过程中占有较多系统资源。
|
||||
|长选项|缩写|描述|
|
||||
|-----|:--:|:--|
|
||||
| -directory dir| C| 执行归档操作前,先转到指定目录|
|
||||
| -same-permissions| p| 保持原始的文件权限|
|
||||
| -verbose| v| 列出所有的读取或提取的文件。但这个标识符与 -list 一起使用的时候,还会显示出文件大小、属主和时间戳的信息|
|
||||
| -verify| W| 写入存档后进行校验|
|
||||
| -exclude file| | 不把指定文件包含在内|
|
||||
| -exclude=pattern| X| 以PATTERN模式排除文件|
|
||||
| -gzip 或 -gunzip| z| 通过gzip压缩归档|
|
||||
| -bzip2| j| 通过bzip2压缩归档|
|
||||
| -xz| J| 通过xz压缩归档|
|
||||
|
||||
|
||||
Gzip 是最古老的压缩工具,压缩率最小,bzip2 的压缩率稍微高一点。另外,xz 是最新的压缩工具,压缩率最好。xz 具有最佳压缩率的代价是:完成压缩操作花费最多时间,压缩过程中占有较多系统资源。
|
||||
|
||||
通常,通过这些工具压缩的 tar 文件相应的具有 .gz、.bz2 或 .xz的扩展名。在下列的例子中,我们使用 file1、file2、file3、file4 和 file5 进行演示。
|
||||
|
||||
**通过 gzip、bzip2 和 xz 压缩归档**
|
||||
|
||||
归档当前工作目录的所有文件,并以 gzip、bzip2 和 xz 压缩刚刚的归档文件(请注意,用正则表达式来指定那些文件应该归档——这是为了防止归档工具包前一步生成的文件打包进来)。
|
||||
归档当前工作目录的所有文件,并以 gzip、bzip2 和 xz 压缩刚刚的归档文件(请注意,用正则表达式来指定哪些文件应该归档——这是为了防止将归档工具包前一步生成的文件打包进来)。
|
||||
|
||||
# tar czf myfiles.tar.gz file[0-9]
|
||||
# tar cjf myfiles.tar.bz2 file[0-9]
|
||||
@ -167,7 +74,7 @@ Gzip 是最古老的压缩工具,压缩率最小,bzip2 的压缩率稍微高
|
||||
|
||||

|
||||
|
||||
压缩多个文件
|
||||
*压缩多个文件*
|
||||
|
||||
**列举 tarball 中的内容和更新/追加文件到归档文件中**
|
||||
|
||||
@ -177,7 +84,7 @@ Gzip 是最古老的压缩工具,压缩率最小,bzip2 的压缩率稍微高
|
||||
|
||||
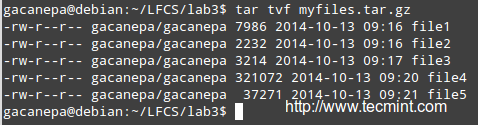
|
||||
|
||||
列举归档文件中的内容
|
||||
*列举归档文件中的内容*
|
||||
|
||||
运行一下任意一条命令:
|
||||
|
||||
@ -206,19 +113,19 @@ Gzip 是最古老的压缩工具,压缩率最小,bzip2 的压缩率稍微高
|
||||
|
||||
假设你现在需要备份用户的家目录。一个有经验的系统管理员会选择忽略所有视频和音频文件再备份(也可能是公司规定)。
|
||||
|
||||
可能你最先想到的方法是在备份是时候,忽略扩展名为 .mp3 和 .mp4(或者其他格式)的文件。但如果你有些自作聪明的用户将扩展名改为 .txt 或者 .bkp,那你的方法就不灵了。为了发现并排除音频或者视频文件,你需要先检查文件类型。以下 shell 脚本可以代你完成类型检查:
|
||||
可能你最先想到的方法是在备份的时候,忽略扩展名为 .mp3 和 .mp4(或者其他格式)的文件。但如果你有些自作聪明的用户将扩展名改为 .txt 或者 .bkp,那你的方法就不灵了。为了发现并排除音频或者视频文件,你需要先检查文件类型。以下 shell 脚本可以代你完成类型检查:
|
||||
|
||||
#!/bin/bash
|
||||
# 把需要进行备份的目录传递给 $1 参数.
|
||||
DIR=$1
|
||||
#排除文件类型中包含了 mpeg 字符串的文件,然后创建 tarball 并进行压缩。
|
||||
# 排除文件类型中包含了 mpeg 字符串的文件,然后创建 tarball 并进行压缩。
|
||||
# -若文件类型中包含 mpeg 字符串, $?(最后执行的命令的退出状态)返回 0,然后文件名被定向到排除选项。否则返回 1。
|
||||
# -若 $? 等于 0,该文件从需要备份文件的列表排除。
|
||||
tar X <(for i in $DIR/*; do file $i | grep -i mpeg; if [ $? -eq 0 ]; then echo $i; fi;done) -cjf backupfile.tar.bz2 $DIR/*
|
||||
|
||||

|
||||
|
||||
排除文件进行备份
|
||||
*排除文件进行备份*
|
||||
|
||||
**使用 tar 保持文件的原有权限进行恢复**
|
||||
|
||||
@ -228,7 +135,7 @@ Gzip 是最古老的压缩工具,压缩率最小,bzip2 的压缩率稍微高
|
||||
|
||||

|
||||
|
||||
从归档文件中恢复
|
||||
*从归档文件中恢复*
|
||||
|
||||
**扩展阅读:**
|
||||
|
||||
@ -243,31 +150,31 @@ find 命令用于递归搜索目录树中包含指定字符的文件和目录,
|
||||
|
||||
#### 基本语法:####
|
||||
|
||||
# find [需搜索的目录] [表达式]
|
||||
# find [需搜索的目录] [表达式]
|
||||
|
||||
**通过文件大小递归搜索文件**
|
||||
|
||||
以下命令会搜索当前目录(.)及其下两层子目录(-maxdepth 3,包含当前目录及往下两层的子目录)大于 2 MB(-size +2M)的所有文件(-f)。
|
||||
以下命令会搜索当前目录(.)及其下两层子目录(-maxdepth 3,包含当前目录及往下两层的子目录)中大于 2 MB(-size +2M)的所有文件(-f)。
|
||||
|
||||
# find . -maxdepth 3 -type f -size +2M
|
||||
|
||||
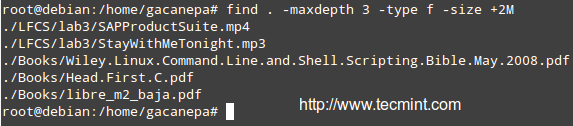
|
||||
|
||||
通过文件大小搜索文件
|
||||
*
|
||||
通过文件大小搜索文件*
|
||||
|
||||
**搜索符合一定规则的文件并将其删除**
|
||||
|
||||
有时候,777 权限的文件通常为外部攻击者打开便利之门。不管是以何种方式,让所有人都可以对文件进行任意操作都是不安全的。对此,我们采取一个相对激进的方法——删除这些文件(‘{ }’用来“聚集”搜索的结果)。
|
||||
有时候,777 权限的文件通常为外部攻击者打开便利之门。不管是以何种方式,让所有人都可以对文件进行任意操作都是不安全的。对此,我们采取一个相对激进的方法——删除这些文件('{}' + 用来“聚集”搜索的结果)。
|
||||
|
||||
# find /home/user -perm 777 -exec rm '{}' +
|
||||
|
||||

|
||||
|
||||
搜索 777 权限的文件
|
||||
*搜索 777 权限的文件*
|
||||
|
||||
**按访问时间和修改时间搜索文件**
|
||||
|
||||
搜索 /etc 目录下访问时间(-atime)或修改时间(-mtime)大于或小于 6 个月或者刚好 6 个月的配置文件。
|
||||
搜索 /etc 目录下访问时间(-atime)或修改时间(-mtime)大于(+180)或小于(-180) 6 个月或者刚好(180) 6 个月的配置文件。
|
||||
|
||||
按照下面例子对命令进行修改:
|
||||
|
||||
@ -275,7 +182,7 @@ find 命令用于递归搜索目录树中包含指定字符的文件和目录,
|
||||
|
||||

|
||||
|
||||
按修改时间搜索文件
|
||||
*按修改时间搜索文件*
|
||||
|
||||
- 扩展阅读: [35 Practical Examples of Linux ‘find’ Command][3]
|
||||
|
||||
@ -301,11 +208,11 @@ new_mode 可以是 3 位八进制数值或者对应权限的表达式。
|
||||
|
||||
八进制数值可以从二进制数值进行等值转换,通过下列方法来计算文件属主、同组用户和其他用户权限对应的二进制数值:
|
||||
|
||||
一个确定权限的二进制数值表现为 2 的幂(r=2^2,w=2^1,x=2^0),当权限省缺时,二进制数值为 0。如下:
|
||||
一个确定权限的二进制数值表现为 2 的幂(r=2\^2,w=2\^1,x=2\^0),当权限省缺时,二进制数值为 0。如下:
|
||||
|
||||

|
||||
|
||||
文件权限
|
||||
*文件权限*
|
||||
|
||||
使用八进制数值设置上图的文件权限,请输入:
|
||||
|
||||
@ -313,7 +220,6 @@ new_mode 可以是 3 位八进制数值或者对应权限的表达式。
|
||||
|
||||
通过 u、g 和 o 分别代表用户、同组用户和其他用户,然后你也可以使用权限表达式来单独对用户设置文件的权限模式。也可以通过 a 代表所有用户,然后设置文件权限。通过 + 号或者 - 号相应的赋予或移除文件权限。
|
||||
|
||||
|
||||
**为所有用户撤销一个 shell 脚本的执行权限**
|
||||
|
||||
正如之前解释的那样,我们可以通过 - 号为需要移除权限的属主、同组用户、其他用户或者所有用户去掉指定的文件权限。下面命令中的短横线(-)可以理解为:移除(-)所有用户(a)的 backup.sh 文件执行权限(x)。
|
||||
@ -324,11 +230,13 @@ new_mode 可以是 3 位八进制数值或者对应权限的表达式。
|
||||
|
||||
当我们使用 3 位八进制数值为文件设置权限的时候,第一位数字代表属主权限,第二位数字代表同组用户权限,第三位数字代表其他用户的权限:
|
||||
|
||||
- 属主:(r=2^2 + w=2^1 + x=2^0 = 7)
|
||||
- 同组用户:(r=2^2 + w=2^1 + x=2^0 = 7)
|
||||
- 其他用户:(r=2^2 + w=0 + x=0 = 4),
|
||||
- 属主:(r=2\^2 + w=2\^1 + x=2\^0 = 7)
|
||||
- 同组用户:(r=2\^2 + w=2\^1 + x=2\^0 = 7)
|
||||
- 其他用户:(r=2\^2 + w=0 + x=0 = 4)
|
||||
|
||||
# chmod 774 myfile
|
||||
命令如下:
|
||||
|
||||
# chmod 774 myfile
|
||||
|
||||
随着练习时间的推移,你会知道何种情况下使用哪种方式来更改文件的权限模式的效果最好。
|
||||
|
||||
@ -336,7 +244,7 @@ new_mode 可以是 3 位八进制数值或者对应权限的表达式。
|
||||
|
||||

|
||||
|
||||
列举 Linux 文件
|
||||
*列举 Linux 文件*
|
||||
|
||||
通过 chown 命令可以对文件的归属权进行更改,可以同时或者分开更改属主和属组。其基本语法为:
|
||||
|
||||
@ -367,9 +275,9 @@ new_mode 可以是 3 位八进制数值或者对应权限的表达式。
|
||||
先行感谢!
|
||||
|
||||
参考链接
|
||||
- [About the LFCS][4]
|
||||
- [Why get a Linux Foundation Certification?][5]
|
||||
- [Register for the LFCS exam][6]
|
||||
- [关于 LFCS][4]
|
||||
- [为什么需要 Linux 基金会认证?][5]
|
||||
- [注册 LFCS 考试][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -377,7 +285,7 @@ via: http://www.tecmint.com/compress-files-and-finding-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,11 @@
|
||||
GHLandy Translated
|
||||
|
||||
LFCS 系列第四讲:分区存储设备、格式化文件系统和配置交换分区
|
||||
|
||||
LFCS 系列第四讲:对存储设备分区、格式化文件系统和配置交换分区
|
||||
================================================================================
|
||||
|
||||
去年八月份,Linux 基金会发起了 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,给所有系统管理员一个展现自己的机会。通过基础考试后,他们可以胜任在 Linux 上的整体运维工作:包括系统支持、一流水平的诊断和监控以及在必要之时向其他支持团队提交帮助请求等。
|
||||
|
||||

|
||||
|
||||
LFCS 系列第四讲
|
||||
*LFCS 系列第四讲*
|
||||
|
||||
需要注意的是,Linux 基金会认证是非常严格的,通过与否完全要看个人能力。通过在线链接,你可以随时随地参加 Linux 基金会认证考试。所以,你再也不用到考试中心了,只需要不断提高自己的专业技能和经验就可去参加考试了。
|
||||
|
||||
@ -16,13 +14,13 @@ LFCS 系列第四讲
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本讲是《十套教程》系列中的第四讲。在本讲中,我们将涵盖分区存储设备、格式化文件系统和配置交换分区等内容,这些都是 LFCS 认证中的必备知识。
|
||||
本讲是系列教程中的第四讲。在本讲中,我们将涵盖对存储设备进行分区、格式化文件系统和配置交换分区等内容,这些都是 LFCS 认证中的必备知识。
|
||||
|
||||
### 分区存储设备 ###
|
||||
### 对存储设备分区 ###
|
||||
|
||||
分区是一种将单独的硬盘分成一个或多个区的手段。一个分区只是硬盘的一部分,我们可以认为这部分是独立的磁盘,里边包含一个单一类型的文件系统。分区表则是将硬盘上这些分区与分区标识符联系起来的索引。
|
||||
|
||||
在 Linux 中,IBM PC 兼容系统里边用于管理传统 MBR(最新到2009年)分区的工具是 fdisk。对于 GPT(2010年至今)分区,我们使用 gdisk。这两个工具都可以通过程序名后面加上设备名称(如 /dev/sdb)进行调用。
|
||||
在 Linux 上,IBM PC 兼容系统里边用于管理传统 MBR(用到2009年)分区的工具是 fdisk。对于 GPT(2010年至今)分区,我们使用 gdisk。这两个工具都可以通过程序名后面加上设备名称(如 /dev/sdb)进行调用。
|
||||
|
||||
#### 使用 fdisk 管理 MBR 分区 ####
|
||||
|
||||
@ -34,17 +32,17 @@ LFCS 系列第四讲
|
||||
|
||||

|
||||
|
||||
fdisk 帮助菜单
|
||||
*fdisk 帮助菜单*
|
||||
|
||||
上图中,使用频率最高的选项已高亮显示。你可以随时按下 “p” 显示分区表。
|
||||
|
||||

|
||||
|
||||
显示分区表
|
||||
*显示分区表*
|
||||
|
||||
Id 列显示由 fdisk 分配给每个分区的分区类型(分区 id)。一个分区类型代表一种文件系统的标识符,简单来说,包括该分区上数据的访问方法。
|
||||
|
||||
请注意,每个分区类型的全面都全面讲解将超出了本教程的范围——本系列教材主要专注于 LFCS 测试,因能力为主。
|
||||
请注意,每个分区类型的全面讲解将超出了本教程的范围——本系列教材主要专注于 LFCS 测试,以考试为主。
|
||||
|
||||
**下面列出一些 fdisk 常用选项:**
|
||||
|
||||
@ -58,25 +56,25 @@ Id 列显示由 fdisk 分配给每个分区的分区类型(分区 id)。一
|
||||
|
||||

|
||||
|
||||
fdisk 命令选项
|
||||
*fdisk 命令选项*
|
||||
|
||||
按下 “n” 后接着按下 “p” 会创建新一个主分区。最后,你可以使用所有的默认值(这将占用所有的可用空间),或者像下面一样自定义分区大小。
|
||||
|
||||

|
||||
|
||||
创建新分区
|
||||
*创建新分区*
|
||||
|
||||
若 fdisk 分配的分区 Id 并不是我们想用的,可以按下 “t” 来更改。
|
||||
|
||||

|
||||
|
||||
更改分区类型
|
||||
*更改分区类型*
|
||||
|
||||
全部设置好分区后,按下 “w” 将更改保存到硬盘分区表上。
|
||||
|
||||

|
||||
|
||||
保存分区更改
|
||||
*保存分区更改*
|
||||
|
||||
#### 使用 gdisk 管理 GPT 分区 ####
|
||||
|
||||
@ -88,7 +86,7 @@ fdisk 命令选项
|
||||
|
||||

|
||||
|
||||
创建 GPT 分区
|
||||
*创建 GPT 分区*
|
||||
|
||||
使用 GPT 分区方案,我们可以在同一个硬盘上创建最多 128 个分区,单个分区最大以 PB 为单位,而 MBR 分区方案最大的只能 2TB。
|
||||
|
||||
@ -96,7 +94,7 @@ fdisk 命令选项
|
||||
|
||||

|
||||
|
||||
gdisk 命令选项
|
||||
*gdisk 命令选项*
|
||||
|
||||
### 格式化文件系统 ###
|
||||
|
||||
@ -106,14 +104,14 @@ gdisk 命令选项
|
||||
|
||||

|
||||
|
||||
检查文件系统类型
|
||||
*检查文件系统类型*
|
||||
|
||||
选择文件系统取决于你的需求。你应该考虑到每个文件系统的优缺点以及其特点。选择文件系统需要看的两个重要属性:
|
||||
|
||||
- 日志支持,允许从系统崩溃事件中快速恢复数据。
|
||||
- 安全增强式 Linux(SELinux)支持,按照项目 wiki 所说,“安全增强式 Linux 允许用户和管理员更好的把握访问控制权限”。
|
||||
- 安全增强式 Linux(SELinux)支持,按照项目 wiki 所说,“安全增强式 Linux 允许用户和管理员更好的控制访问控制权限”。
|
||||
|
||||
在接下来的例子中,我们通过 mkfs 在 /dev/sdb1上创建 ext4 文件系统(支持日志和 SELinux),标卷为 Tecmint。mkfs 基本语法如下:
|
||||
在接下来的例子中,我们通过 mkfs 在 /dev/sdb1 上创建 ext4 文件系统(支持日志和 SELinux),标卷为 Tecmint。mkfs 基本语法如下:
|
||||
|
||||
# mkfs -t [filesystem] -L [label] device
|
||||
或者
|
||||
@ -121,7 +119,7 @@ gdisk 命令选项
|
||||
|
||||
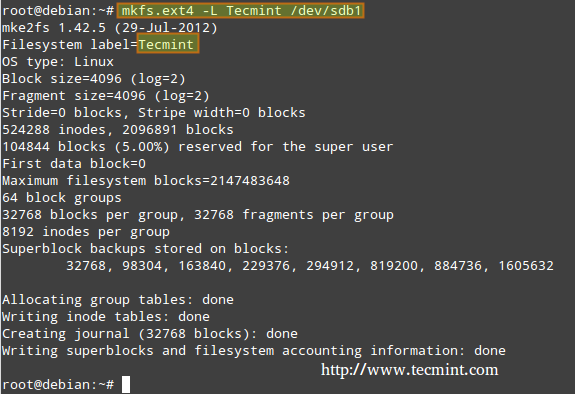
|
||||
|
||||
创建 ext4 文件系统
|
||||
*创建 ext4 文件系统*
|
||||
|
||||
### 创建并启用交换分区 ###
|
||||
|
||||
@ -129,7 +127,7 @@ gdisk 命令选项
|
||||
|
||||
下面列出选择交换分区大小的经验法则:
|
||||
|
||||
物理内存不高于 2GB 时,取两倍物理内存大小即可;物理内存在 2GB 以上时,取一倍物理内存大小即可;并且所取大小应该大于 32MB。
|
||||
> 物理内存不高于 2GB 时,取两倍物理内存大小即可;物理内存在 2GB 以上时,取一倍物理内存大小即可;并且所取大小应该大于 32MB。
|
||||
|
||||
所以,如果:
|
||||
|
||||
@ -142,7 +140,7 @@ M为物理内存大小,S 为交换分区大小,单位 GB,那么:
|
||||
|
||||
记住,这只是基本的经验。对于作为系统管理员的你,才是决定是否使用交换分区及其大小的关键。
|
||||
|
||||
要配置交换分区,首先要划分一个常规分区,大小像我们之前演示的那样来选取。然后添加以下条目到 /etc/fstab 文件中(其中的X要更改为对应的 b 或 c)。
|
||||
要配置交换分区,首先要划分一个常规分区,大小像我们之前演示的那样来选取。然后添加以下条目到 /etc/fstab 文件中(其中的 X 要更改为对应的 b 或 c)。
|
||||
|
||||
/dev/sdX1 swap swap sw 0 0
|
||||
|
||||
@ -163,15 +161,15 @@ M为物理内存大小,S 为交换分区大小,单位 GB,那么:
|
||||
|
||||

|
||||
|
||||
创建交换分区
|
||||
*创建交换分区*
|
||||
|
||||

|
||||
|
||||
启用交换分区
|
||||
*启用交换分区*
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在你的系统管理员之路上,创建分区(包括交换分区)和格式化文件系统是非常重要的一部。我希望本文中所给出的技巧指导你到达你的管理员目标。随时在本讲评论区中发表你的技巧和想法,一起为社区做贡献。
|
||||
在你的系统管理员之路上,创建分区(包括交换分区)和格式化文件系统是非常重要的一步。我希望本文中所给出的技巧指导你到达你的管理员目标。随时在本讲评论区中发表你的技巧和想法,一起为社区做贡献。
|
||||
|
||||
参考链接
|
||||
|
||||
@ -185,7 +183,7 @@ via: http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,18 @@
|
||||
GHLandy Translated
|
||||
|
||||
LFCS 系列第五讲:如何在 Linux 中挂载/卸载本地文件系统和网络文件系统(Samba 和 NFS)
|
||||
|
||||
================================================================================
|
||||
|
||||
Linux 基金会已经发起了一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,旨在让来自世界各地的人有机会参加到 LFCS 测试,获得关于有能力在 Linux 系统中执行中间系统管理任务的认证。该认证包括:维护正在运行的系统和服务的能力、全面监控和分析的能力以及何时上游团队请求支持的决策能力。
|
||||
Linux 基金会已经发起了一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,旨在让来自世界各地的人有机会参加到 LFCS 测试,获得关于有能力在 Linux 系统中执行中间系统管理任务的认证。该认证包括:维护正在运行的系统和服务的能力、全面监控和分析的能力以及何时向上游团队请求支持的决策能力。
|
||||
|
||||

|
||||
|
||||
LFCS 系列第五讲
|
||||
*LFCS 系列第五讲*
|
||||
|
||||
请看以下视频,这里边介绍了 Linux 基金会认证程序。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本讲是《十套教程》系列中的第三讲,在这一讲里边,我们会解释如何在 Linux 中挂载/卸载本地和网络文件系统。这些都是 LFCS 认证中的必备知识。
|
||||
|
||||
本讲是系列教程中的第五讲,在这一讲里边,我们会解释如何在 Linux 中挂载/卸载本地和网络文件系统。这些都是 LFCS 认证中的必备知识。
|
||||
|
||||
### 挂载文件系统 ###
|
||||
|
||||
@ -26,20 +22,19 @@ LFCS 系列第五讲
|
||||
|
||||
换句话说,管理存储设备的第一步就是把设备关联到文件系统树。要完成这一步,通常可以这样:用 mount 命令来进行临时挂载(用完的时候,使用 umount 命令来卸载),或者通过编辑 /etc/fstab 文件之后重启系统来永久性挂载,这样每次开机都会进行挂载。
|
||||
|
||||
|
||||
不带任何选项的 mount 命令,可以显示当前已挂载的文件系统。
|
||||
|
||||
# mount
|
||||
|
||||

|
||||
|
||||
检查已挂载的文件系统
|
||||
*检查已挂载的文件系统*
|
||||
|
||||
另外,mount 命令通常用来挂载文件系统。其基本语法如下:
|
||||
|
||||
# mount -t type device dir -o options
|
||||
|
||||
该命令会指引内核在设备上找到的文件系统(如已格式化为指定类型的文件系统)挂载到指定目录。像这样的形式,mount 命令不会再到 /etc/fstab 文件中进行确认。
|
||||
该命令会指引内核将在设备上找到的文件系统(如已格式化为指定类型的文件系统)挂载到指定目录。像这样的形式,mount 命令不会再到 /etc/fstab 文件中进行确认。
|
||||
|
||||
除非像下面,挂载指定的目录或者设备:
|
||||
|
||||
@ -59,20 +54,17 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
读作:
|
||||
|
||||
设备 dev/mapper/debian-home 的格式为 ext4,挂载在 /home 下,并且有以下挂载选项: rw,relatime,user_xattr,barrier=1,data=ordered。
|
||||
设备 dev/mapper/debian-home 挂载在 /home 下,它被格式化为 ext4,并且有以下挂载选项: rw,relatime,user_xattr,barrier=1,data=ordered。
|
||||
|
||||
**mount 命令选项**
|
||||
|
||||
下面列出 mount 命令的常用选项
|
||||
|
||||
|
||||
- async:运许在将要挂载的文件系统上进行异步 I/O 操作
|
||||
- auto:标志文件系统通过 mount -a 命令挂载,与 noauto 相反。
|
||||
|
||||
- defaults:该选项为 async,auto,dev,exec,nouser,rw,suid 的一个别名。注意,多个选项必须由逗号隔开并且中间没有空格。倘若你不小心在两个选项中间输入了一个空格,mount 命令会把后边的字符解释为另一个参数。
|
||||
- async:允许在将要挂载的文件系统上进行异步 I/O 操作
|
||||
- auto:标示该文件系统通过 mount -a 命令挂载,与 noauto 相反。
|
||||
- defaults:该选项相当于 `async,auto,dev,exec,nouser,rw,suid` 的组合。注意,多个选项必须由逗号隔开并且中间没有空格。倘若你不小心在两个选项中间输入了一个空格,mount 命令会把后边的字符解释为另一个参数。
|
||||
- loop:将镜像文件(如 .iso 文件)挂载为 loop 设备。该选项可以用来模拟显示光盘中的文件内容。
|
||||
- noexec:阻止该文件系统中可执行文件的执行。与 exec 选项相反。
|
||||
|
||||
- nouser:阻止任何用户(除 root 用户外) 挂载或卸载文件系统。与 user 选项相反。
|
||||
- remount:重新挂载文件系统。
|
||||
- ro:只读模式挂载。
|
||||
@ -91,7 +83,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
可读写模式挂载设备
|
||||
*可读写模式挂载设备*
|
||||
|
||||
**以默认模式挂载设备**
|
||||
|
||||
@ -102,26 +94,25 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
挂载设备
|
||||
*挂载设备*
|
||||
|
||||
在这个例子中,我们发现写入文件和命令都完美执行了。
|
||||
|
||||
### 卸载设备 ###
|
||||
|
||||
使用 umount 命令卸载设备,意味着将所有的“在使用”数据全部写入到文件系统了,然后可以安全移除文件系统。请注意,倘若你移除一个没有事先正确卸载的文件系统,就会有造成设备损坏和数据丢失的风险。
|
||||
使用 umount 命令卸载设备,意味着将所有的“在使用”数据全部写入到文件系统,然后可以安全移除文件系统。请注意,倘若你移除一个没有事先正确卸载的设备,就会有造成设备损坏和数据丢失的风险。
|
||||
|
||||
也就是说,你必须设备的盘符或者挂载点中退出,才能卸载设备。换言之,当前工作目录不能是需要卸载设备的挂载点。否则,系统将返回设备繁忙的提示信息。
|
||||
也就是说,你必须“离开”设备的块设备描述符或者挂载点,才能卸载设备。换言之,你的当前工作目录不能是需要卸载设备的挂载点。否则,系统将返回设备繁忙的提示信息。
|
||||
|
||||
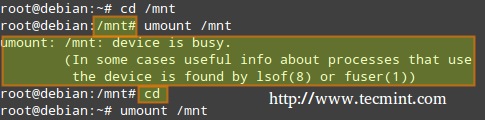
|
||||
|
||||
卸载设备
|
||||
*卸载设备*
|
||||
|
||||
离开需卸载设备的挂载点最简单的方法就是,运行不带任何选项的 cd 命令,这样会回到当前用户的家目录。
|
||||
|
||||
|
||||
### 挂载常见的网络文件系统 ###
|
||||
最常用的两种网络文件系统是 SMB(Server Message Block,服务器消息块)和 NFS(Network File System,网络文件系统)。如果你只向类 Unix 客户端提供共享,用 NFS 就可以了,如果是向 Windows 和其他类 Unix客户端提供共享服务,就需要用到 Samba 了。
|
||||
|
||||
最常用的两种网络文件系统是 SMB(Server Message Block,服务器消息块)和 NFS(Network File System,网络文件系统)。如果你只向类 Unix 客户端提供共享,用 NFS 就可以了,如果是向 Windows 和其他类 Unix 客户端提供共享服务,就需要用到 Samba 了。
|
||||
|
||||
扩展阅读
|
||||
|
||||
@ -130,13 +121,13 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
下面的例子中,假设 Samba 和 NFS 已经在地址为 192.168.0.10 的服务器上架设好了(请注意,架设 NFS 服务器也是 LFCS 考试中需要考核的能力,我们会在后边中提到)。
|
||||
|
||||
|
||||
#### 在 Linux 中挂载 Samba 共享 ####
|
||||
|
||||
第一步:在 Red Hat 以 Debian 系发行版中安装 samba-client、samba-common 和 cifs-utils 软件包,如下:
|
||||
|
||||
# yum update && yum install samba-client samba-common cifs-utils
|
||||
# aptitude update && aptitude install samba-client samba-common cifs-utils
|
||||
|
||||
然后运行下列命令,查看服务器上可用的 Samba 共享。
|
||||
|
||||
# smbclient -L 192.168.0.10
|
||||
@ -145,7 +136,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
挂载 Samba 共享
|
||||
*挂载 Samba 共享*
|
||||
|
||||
上图中,已经对可以挂载到我们本地系统上的共享进行高亮显示。你只需要与一个远程服务器上的合法用户名及密码就可以访问共享了。
|
||||
|
||||
@ -164,7 +155,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||

|
||||
|
||||
挂载有密码保护的 Samba 共享
|
||||
*挂载有密码保护的 Samba 共享*
|
||||
|
||||
#### 在 Linux 系统中挂载 NFS 共享 ####
|
||||
|
||||
@ -185,7 +176,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
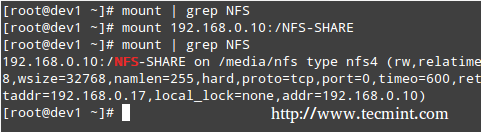
|
||||
|
||||
挂载 NFS 共享
|
||||
*挂载 NFS 共享*
|
||||
|
||||
### 永久性挂载文件系统 ###
|
||||
|
||||
@ -197,13 +188,12 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
其中:
|
||||
|
||||
- <file system>: 第一个字段指定挂载的设备。大多数发行版本都通过分区的标卷(label)或者 UUID 来指定。这样做可以避免分区号改变是带来的错误。
|
||||
- <mount point>: 第二字段指定挂载点。
|
||||
- <type> :文件系统的类型代码与 mount 命令挂载文件系统时使用的类型代码是一样的。通过 auto 类型代码可以让内核自动检测文件系统,这对于可移动设备来说非常方便。注意,该选项可能不是对所有文件系统可用。
|
||||
- <options>: 一个(或多个)挂载选项。
|
||||
- <dump>: 你可能把这个字段设置为 0(否则设置为 1),使得系统启动时禁用 dump 工具(dump 程序曾经是一个常用的备份工具,但现在越来越少用了)对文件系统进行备份。
|
||||
|
||||
- <pass>: 这个字段指定启动系统是是否通过 fsck 来检查文件系统的完整性。0 表示 fsck 不对文件系统进行检查。数字越大,优先级越低。因此,根分区(/)最可能使用数字 1,其他所有需要检查的分区则是以数字 2.
|
||||
- \<file system>: 第一个字段指定挂载的设备。大多数发行版本都通过分区的标卷(label)或者 UUID 来指定。这样做可以避免分区号改变时带来的错误。
|
||||
- \<mount point>: 第二个字段指定挂载点。
|
||||
- \<type> :文件系统的类型代码与 mount 命令挂载文件系统时使用的类型代码是一样的。通过 auto 类型代码可以让内核自动检测文件系统,这对于可移动设备来说非常方便。注意,该选项可能不是对所有文件系统可用。
|
||||
- \<options>: 一个(或多个)挂载选项。
|
||||
- \<dump>: 你可能把这个字段设置为 0(否则设置为 1),使得系统启动时禁用 dump 工具(dump 程序曾经是一个常用的备份工具,但现在越来越少用了)对文件系统进行备份。
|
||||
- \<pass>: 这个字段指定启动系统是是否通过 fsck 来检查文件系统的完整性。0 表示 fsck 不对文件系统进行检查。数字越大,优先级越低。因此,根分区(/)最可能使用数字 1,其他所有需要检查的分区则是以数字 2.
|
||||
|
||||
**Mount 命令例示**
|
||||
|
||||
@ -211,7 +201,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
LABEL=TECMINT /mnt ext4 rw,noexec 0 0
|
||||
|
||||
2. 若你想在系统启动时挂载 DVD 光驱中的内容,添加已下语句。
|
||||
2. 若你想在系统启动时挂载 DVD 光驱中的内容,添加以下语句。
|
||||
|
||||
/dev/sr0 /media/cdrom0 iso9660 ro,user,noauto 0 0
|
||||
|
||||
@ -219,7 +209,7 @@ mount 命令会尝试寻找挂载点,如果找不到就会查找设备(上
|
||||
|
||||
### 总结 ###
|
||||
|
||||
可以放心,在命令行中挂载/卸载本地和网络文件系统将是你作为系统管理员的日常责任的一部分。同时,你需要掌握 /etc/fstab 文件的编写。希望本文对你有帮助。随时在下边发表评论(或者提问),并分享本文到你的朋友圈。
|
||||
不用怀疑,在命令行中挂载/卸载本地和网络文件系统将是你作为系统管理员的日常责任的一部分。同时,你需要掌握 /etc/fstab 文件的编写。希望本文对你有帮助。随时在下边发表评论(或者提问),并分享本文到你的朋友圈。
|
||||
|
||||
|
||||
参考链接
|
||||
@ -234,7 +224,7 @@ via: http://www.tecmint.com/mount-filesystem-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,283 @@
|
||||
LFCS 系列第六讲:组装分区为RAID设备——创建和管理系统备份
|
||||
=========================================================
|
||||
Linux 基金会已经发起了一个全新的 LFCS(Linux Foundation Certified Sysadmin,Linux 基金会认证系统管理员)认证,旨在让来自世界各地的人有机会参加到 LFCS 测试,获得关于有能力在 Linux 系统中执行中级系统管理任务的认证。该认证包括:维护正在运行的系统和服务的能力、全面监控和分析的能力以及何时向上游团队请求支持的决策能力。
|
||||
|
||||

|
||||
|
||||
*LFCS 系列第六讲*
|
||||
|
||||
以下视频介绍了 Linux 基金会认证程序。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本讲是系列教程中的第六讲,在这一讲里,我们将会解释如何将分区组装为 RAID 设备——创建和管理系统备份。这些都是 LFCS 认证中的必备知识。
|
||||
|
||||
### 了解RAID ###
|
||||
|
||||
这种被称为独立磁盘冗余阵列(Redundant Array of Independent Disks)(RAID)的技术是将多个硬盘组合成一个单独逻辑单元的存储解决方案,它提供了数据冗余功能并且改善硬盘的读写操作性能。
|
||||
|
||||
然而,实际的容错和磁盘 I/O 性能硬盘取决于如何将多个硬盘组装成磁盘阵列。根据可用的设备和容错/性能的需求,RAID 被分为不同的级别,你可以参考 RAID 系列文章以获得每个 RAID 级别更详细的解释。
|
||||
|
||||
- [在 Linux 下使用 RAID(一):介绍 RAID 的级别和概念][1]
|
||||
|
||||
我们选择用于创建、组装、管理、监视软件 RAID 的工具,叫做 mdadm (multiple disk admin 的简写)。
|
||||
|
||||
```
|
||||
---------------- Debian 及衍生版 ----------------
|
||||
# aptitude update && aptitude install mdadm
|
||||
```
|
||||
|
||||
```
|
||||
---------------- Red Hat 和基于 CentOS 的系统 ----------------
|
||||
# yum update && yum install mdadm
|
||||
```
|
||||
|
||||
```
|
||||
---------------- openSUSE 上 ----------------
|
||||
# zypper refresh && zypper install mdadm #
|
||||
```
|
||||
|
||||
#### 将分区组装成 RAID 设备 ####
|
||||
|
||||
组装已有分区作为 RAID 设备的过程由以下步骤组成。
|
||||
|
||||
**1. 使用 mdadm 创建阵列**
|
||||
|
||||
如果先前其中一个分区已经格式化,或者作为了另一个 RAID 阵列的一部分,你会被提示以确认创建一个新的阵列。假设你已经采取了必要的预防措施以避免丢失重要数据,那么可以安全地输入 Y 并且按下回车。
|
||||
|
||||
```
|
||||
# mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
```
|
||||
|
||||

|
||||
|
||||
*创建 RAID 阵列*
|
||||
|
||||
**2. 检查阵列的创建状态**
|
||||
|
||||
在创建了 RAID 阵列之后,你可以检查使用以下命令检查阵列的状态。
|
||||
|
||||
|
||||
# cat /proc/mdstat
|
||||
or
|
||||
# mdadm --detail /dev/md0 [More detailed summary]
|
||||
|
||||

|
||||
|
||||
*检查 RAID 阵列的状态*
|
||||
|
||||
**3. 格式化 RAID 设备**
|
||||
|
||||
如本系列[第四讲][2]所介绍的,按照你的需求/要求采用某种文件系统格式化你的设备。
|
||||
|
||||
**4. 监控 RAID 阵列服务**
|
||||
|
||||
让监控服务时刻监视你的 RAID 阵列。把`# mdadm --detail --scan`命令输出结果添加到 `/etc/mdadm/mdadm.conf`(Debian及其衍生版)或者`/etc/mdadm.conf`(Cent0S/openSUSE),如下。
|
||||
|
||||
# mdadm --detail --scan
|
||||
|
||||
|
||||

|
||||
|
||||
*监控 RAID 阵列*
|
||||
|
||||
# mdadm --assemble --scan [Assemble the array]
|
||||
|
||||
为了确保服务能够开机启动,需要以 root 权限运行以下命令。
|
||||
|
||||
**Debian 及其衍生版**
|
||||
|
||||
Debian 及其衍生版能够通过下面步骤使服务默认开机启动:
|
||||
|
||||
# update-rc.d mdadm defaults
|
||||
|
||||
在 `/etc/default/mdadm` 文件中添加下面这一行
|
||||
|
||||
AUTOSTART=true
|
||||
|
||||
|
||||
**CentOS 和 openSUSE(systemd-based)**
|
||||
|
||||
# systemctl start mdmonitor
|
||||
# systemctl enable mdmonitor
|
||||
|
||||
**CentOS 和 openSUSE(SysVinit-based)**
|
||||
|
||||
# service mdmonitor start
|
||||
# chkconfig mdmonitor on
|
||||
|
||||
**5. 检查RAID磁盘故障**
|
||||
|
||||
在支持冗余的的 RAID 级别中,在需要时会替换故障的驱动器。当磁盘阵列中的设备出现故障时,仅当存在我们第一次创建阵列时预留的备用设备时,磁盘阵列会将自动启动重建。
|
||||
|
||||

|
||||
|
||||
*检查 RAID 故障磁盘*
|
||||
|
||||
否则,我们需要手动将一个额外的物理驱动器插入到我们的系统,并且运行。
|
||||
|
||||
# mdadm /dev/md0 --add /dev/sdX1
|
||||
|
||||
/dev/md0 是出现了问题的阵列,而 /dev/sdx1 是新添加的设备。
|
||||
|
||||
**6. 拆解一个工作阵列**
|
||||
|
||||
如果你需要使用工作阵列的设备创建一个新的阵列,你可能不得不去拆解已有工作阵列——(可选步骤)
|
||||
|
||||
# mdadm --stop /dev/md0 # Stop the array
|
||||
# mdadm --remove /dev/md0 # Remove the RAID device
|
||||
# mdadm --zero-superblock /dev/sdX1 # Overwrite the existing md superblock with zeroes
|
||||
|
||||
**7. 设置邮件通知**
|
||||
|
||||
你可以配置一个用于发送通知的有效邮件地址或者系统账号(确保在 mdadm.conf 文件中有下面这一行)。——(可选步骤)
|
||||
|
||||
MAILADDR root
|
||||
|
||||
在这种情况下,来自 RAID 后台监控程序所有的通知将会发送到你的本地 root 账号的邮件箱中。其中一个类似的通知如下。
|
||||
|
||||
说明:此次通知事件和第5步中的例子相关。此处一个设备被标志为错误,并且一个空闲的设备自动地被 mdadm 加入到阵列。我们用完了所有“健康的”空闲设备,因此我们得到了通知。
|
||||
|
||||
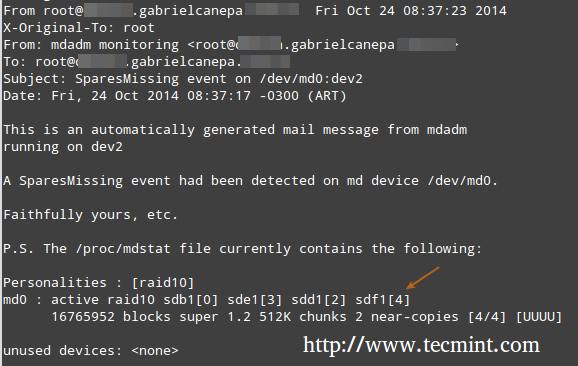
|
||||
|
||||
*RAID 监控通知*
|
||||
|
||||
#### 了解 RAID 级别 ####
|
||||
|
||||
**RAID 0**
|
||||
|
||||
阵列总大小是最小分区大小的 n 倍,n 是阵列中独立磁盘的个数(你至少需要两个驱动器/磁盘)。运行下面命令,使用 /dev/sdb1 和 /dev/sdc1 分区组装一个 RAID 0 阵列。
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
常见用途:用于支持性能比容错更重要的实时应用程序的设置
|
||||
|
||||
**RAID 1 (又名镜像)**
|
||||
|
||||
阵列总大小等于最小分区大小(你至少需要两个驱动器/磁盘)。运行下面命令,使用 /dev/sdb1 和 /dev/sdc1 分区组装一个 RAID 1 阵列。
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
|
||||
|
||||
常见用途:操作系统的安装或者重要的子文件夹,例如 /home
|
||||
|
||||
**RAID 5 (又名奇偶校验码盘)**
|
||||
|
||||
阵列总大小将是最小分区大小的 (n-1) 倍。所减少的大小用于奇偶校验(冗余)计算(你至少需要3个驱动器/磁盘)。
|
||||
|
||||
说明:你可以指定一个空闲设备 (/dev/sde1) 替换问题出现时的故障部分(分区)。运行下面命令,使用 /dev/sdb1, /dev/sdc1, /dev/sdd1,/dev/sde1 组装一个 RAID 5 阵列,其中 /dev/sde1 作为空闲分区。
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1 --spare-devices=1 /dev/sde1
|
||||
|
||||
常见用途:Web 和文件服务
|
||||
|
||||
**RAID 6 (又名双重奇偶校验码盘)**
|
||||
|
||||
阵列总大小为(n*s)-2*s,其中n为阵列中独立磁盘的个数,s为最小磁盘大小。
|
||||
|
||||
说明:你可以指定一个空闲分区(在这个例子为 /dev/sdf1)替换问题出现时的故障部分(分区)。
|
||||
|
||||
运行下面命令,使用 /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1 和 /dev/sdf1 组装 RAID 6 阵列,其中 /dev/sdf1 作为空闲分区。
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde --spare-devices=1 /dev/sdf1
|
||||
|
||||
常见用途:大容量、高可用性要求的文件服务器和备份服务器。
|
||||
|
||||
**RAID 1+0 (又名镜像条带)**
|
||||
|
||||
因为 RAID 1+0 是 RAID 0 和 RAID 1 的组合,所以阵列总大小是基于两者的公式计算的。首先,计算每一个镜像的大小,然后再计算条带的大小。
|
||||
|
||||
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1 --spare-devices=1 /dev/sdf1
|
||||
|
||||
常见用途:需要快速 IO 操作的数据库和应用服务器
|
||||
|
||||
#### 创建和管理系统备份 ####
|
||||
|
||||
记住, RAID 其所有的价值不是在于备份的替换者!在黑板上写上1000次,如果你需要的话,但无论何时一定要记住它。在我们开始前,我们必须注意的是,没有一个放之四海皆准的针对所有系统备份的解决方案,但这里有一些东西,是你在规划一个备份策略时需要考虑的。
|
||||
|
||||
- 你的系统将用于什么?(桌面或者服务器?如果系统是应用于后者,那么最重要的服务是什么?哪个配置是痛点?)
|
||||
- 你每隔多久备份你的系统?
|
||||
- 你需要备份的数据是什么(比如文件/文件夹/数据库转储)?你还可以考虑是否需要备份大型文件(比如音频和视频文件)。
|
||||
- 这些备份将会存储在哪里(物理位置和媒体)?
|
||||
|
||||
**备份你的数据**
|
||||
|
||||
方法1:使用 dd 命令备份整个磁盘。你可以在任意时间点通过创建一个准确的镜像来备份一整个硬盘或者是分区。注意当设备是离线时,这种方法效果最好,也就是说它没有被挂载并且没有任何进程的 I/O 操作访问它。
|
||||
|
||||
这种备份方法的缺点是镜像将具有和磁盘或分区一样的大小,即使实际数据占用的是一个很小的比例。比如,如果你想要为只使用了10%的20GB的分区创建镜像,那么镜像文件将仍旧是20GB。换句话来讲,它不仅包含了备份的实际数据,而且也包含了整个分区。如果你想完整备份你的设备,那么你可以考虑使用这个方法。
|
||||
|
||||
**从现有的设备创建一个镜像文件**
|
||||
|
||||
# dd if=/dev/sda of=/system_images/sda.img
|
||||
或者
|
||||
--------------------- 可选地,你可以压缩镜像文件 -------------------
|
||||
# dd if=/dev/sda | gzip -c > /system_images/sda.img.gz
|
||||
|
||||
**从镜像文件恢复备份**
|
||||
|
||||
# dd if=/system_images/sda.img of=/dev/sda
|
||||
或者
|
||||
--------------------- 根据你创建镜像文件时的选择(译者注:比如压缩) ----------------
|
||||
# gzip -dc /system_images/sda.img.gz | dd of=/dev/sda
|
||||
|
||||
方法2:使用 tar 命令备份确定的文件/文件夹——已经在本系列[第三讲][3]中讲了。如果你想要备份指定的文件/文件夹(配置文件,用户主目录等等),你可以使用这种方法。
|
||||
|
||||
方法3:使用 rsync 命令同步文件。rsync 是一种多功能远程(和本地)文件复制工具。如果你想要从网络设备备份或同步文件,rsync 是一种选择。
|
||||
|
||||
|
||||
无论是你是正在同步两个本地文件夹还是本地 < — > 挂载在本地文件系统的远程文件夹,其基本语法是一样的。
|
||||
|
||||
# rsync -av source_directory destination_directory
|
||||
|
||||
在这里,-a 递归遍历子目录(如果它们存在的话),维持符号链接、时间戳、权限以及原本的属主/属组,-v 显示详细过程。
|
||||
|
||||
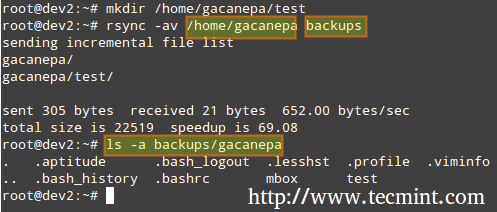
|
||||
|
||||
*rsync 同步文件*
|
||||
|
||||
除此之外,如果你想增加在网络上传输数据的安全性,你可以通过 ssh 协议使用 rsync。
|
||||
|
||||
**通过 ssh 同步本地到远程文件夹**
|
||||
|
||||
# rsync -avzhe ssh backups root@remote_host:/remote_directory/
|
||||
|
||||
这个示例,本地主机上的 backups 文件夹将与远程主机上的 /root/remote_directory 的内容同步。
|
||||
|
||||
在这里,-h 选项以易读的格式显示文件的大小,-e 标志用于表示一个 ssh 连接。
|
||||
|
||||

|
||||
|
||||
*rsync 同步远程文件*
|
||||
|
||||
**通过ssh同步远程到本地文件夹**
|
||||
|
||||
在这种情况下,交换前面示例中的 source 和 destination 文件夹。
|
||||
|
||||
# rsync -avzhe ssh root@remote_host:/remote_directory/ backups
|
||||
|
||||
请注意这些只是 rsync 用法的三个示例而已(你可能遇到的最常见的情形)。对于更多有关 rsync 命令的示例和用法 ,你可以查看下面的文章。
|
||||
|
||||
- [在 Linux 下同步文件的10个 rsync命令][4]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
作为一个系统管理员,你需要确保你的系统表现得尽可能好。如果你做好了充分准备,并且如果你的数据完整性能被诸如 RAID 和系统日常备份的存储技术支持,那你将是安全的。
|
||||
|
||||
如果你有有关完善这篇文章的问题、评论或者进一步的想法,可以在下面畅所欲言。除此之外,请考虑通过你的社交网络简介分享这系列文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/creating-and-managing-raid-backups-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[cpsoture](https://github.com/cposture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-7187-1.html
|
||||
[3]:https://linux.cn/article-7171-1.html
|
||||
[4]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
|
||||
@ -0,0 +1,341 @@
|
||||
LFCS 系列第七讲:通过 SysVinit、Systemd 和 Upstart 管理系统自启动进程和服务
|
||||
================================================================================
|
||||
几个月前, Linux 基金会宣布 LFCS (Linux 基金会认证系统管理员) 认证诞生了,这个令人兴奋的新计划定位于让来自全球各地的初级到中级的 Linux 系统管理员得到认证。这其中包括维护已经在运行的系统和服务的能力、第一手的问题查找和分析能力、以及决定何时向开发团队提交问题的能力。
|
||||
|
||||

|
||||
|
||||
*第七讲: Linux 基金会认证系统管理员*
|
||||
|
||||
下面的视频简要介绍了 Linux 基金会认证计划。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
本讲是系列教程中的第七讲,在这篇文章中,我们会介绍如何管理 Linux 系统自启动进程和服务,这是 LFCS 认证考试要求的一部分。
|
||||
|
||||
### 管理 Linux 自启动进程 ###
|
||||
|
||||
Linux 系统的启动程序包括多个阶段,每个阶段由一个不同的图示块表示。下面的图示简要总结了启动过程以及所有包括的主要组件。
|
||||
|
||||

|
||||
|
||||
*Linux 启动过程*
|
||||
|
||||
当你按下你机器上的电源键时,存储在主板 EEPROM 芯片中的固件初始化 POST(通电自检) 检查系统硬件资源的状态。POST 结束后,固件会搜索并加载位于第一块可用磁盘上的 MBR 或 EFI 分区的第一阶段引导程序,并把控制权交给引导程序。
|
||||
|
||||
#### MBR 方式 ####
|
||||
|
||||
MBR 是位于 BIOS 设置中标记为可启动磁盘上的第一个扇区,大小是 512 个字节。
|
||||
|
||||
- 前面 446 个字节:包括可执行代码和错误信息文本的引导程序
|
||||
- 接下来的 64 个字节:四个分区(主分区或扩展分区)中每个分区一条记录的分区表。其中,每条记录标示了每个一个分区的状态(是否活跃)、大小以及开始和结束扇区。
|
||||
- 最后 2 个字节: MBR 有效性检查的魔法数。
|
||||
|
||||
下面的命令对 MBR 进行备份(在本例中,/dev/sda 是第一块硬盘)。结果文件 mbr.bkp 在分区表被破坏、例如系统不可引导时能排上用场。
|
||||
|
||||
当然,为了后面需要的时候能使用它,我们需要把它保存到别的地方(例如一个 USB 设备)。该文件能帮助我们重新恢复 MBR,这只在我们操作过程中没有改变硬盘驱动布局时才有效。
|
||||
|
||||
**备份 MBR**
|
||||
|
||||
# dd if=/dev/sda of=mbr.bkp bs=512 count=1
|
||||
|
||||

|
||||
|
||||
*在 Linux 中备份 MBR*
|
||||
|
||||
**恢复 MBR**
|
||||
|
||||
# dd if=mbr.bkp of=/dev/sda bs=512 count=1
|
||||
|
||||
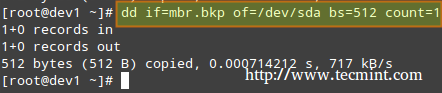
|
||||
|
||||
*在 Linux 中恢复 MBR*
|
||||
|
||||
#### EFI/UEFI 方式 ####
|
||||
|
||||
对于使用 EFI/UEFI 方式的系统, UEFI 固件读取它的设置来决定从哪里启动哪个 UEFI 应用。(例如, EFI 分区位于哪块磁盘或分区。
|
||||
|
||||
接下来,加载并运行第二阶段引导程序(又名引导管理器)。GRUB[GRand Unified Boot] 是 Linux 中最常使用的引导管理器。今天大部分使用的系统中都能找到它两个中的其中一个版本。
|
||||
|
||||
- GRUB 有效配置文件: /boot/grub/menu.lst(旧发行版, EFI/UEFI 固件不支持)。
|
||||
- GRUB2 配置文件: 通常是 /etc/default/grub。
|
||||
|
||||
尽管 LFCS 考试目标没有明确要求了解 GRUB 内部知识,但如果你足够大胆并且不怕把你的系统搞乱(为了以防万一,你可以先在虚拟机上进行尝试)你可以运行:
|
||||
|
||||
# update-grub
|
||||
|
||||
为了使更改生效,你需要以 root 用户修改 GRUB 的配置。
|
||||
|
||||
首先, GRUB 加载默认的内核以及 initrd 或 initramfs 镜像。补充一句,initrd 或者 initramfs 帮助完成硬件检测、内核模块加载、以及发现挂载根目录文件系统需要的设备。
|
||||
|
||||
一旦真正的根目录文件系统启动,为了显示用户界面,内核就会执行系统和服务管理器(init 或 systemd,进程号 PID 一般为 1)开始普通用户态的引导程序。
|
||||
|
||||
init 和 systemd 都是管理其它守护进程的守护进程(后台进程),它们总是最先启动(系统引导时),最后结束(系统关闭时)。
|
||||
|
||||

|
||||
|
||||
*Systemd 和 Init*
|
||||
|
||||
### 自启动服务(SysVinit) ###
|
||||
|
||||
Linux 中运行等级通过控制运行哪些服务来以不同方式使用系统。换句话说,运行等级控制着当前执行状态下可以完成什么任务(以及什么不能完成)。
|
||||
|
||||
传统上,这个启动过程是基于起源于 System V Unix 的形式,通过执行脚本启动或者停止服务从而使机器进入指定的运行等级(换句话说,是一个不同的系统运行模式)。
|
||||
|
||||
在每个运行等级中,独立服务可以设置为运行、或者在运行时关闭。一些主流发行版的最新版本中,已经移除了标准的 System V,而用一个称为 systemd(表示系统守护进程)的新服务和系统管理器代替,但为了兼容性,通常也支持 sysv 命令。这意味着你可以在基于 systemd 的发行版中运行大部分有名的 sysv 初始化工具。
|
||||
|
||||
- 推荐阅读: [Linux 为什么用 ‘systemd’ 代替 ‘init’][1]
|
||||
|
||||
除了启动系统进程,init 还会查看 /etc/inittab 来决定进入哪个运行等级。
|
||||
|
||||
|
||||
|Runlevel| Description|
|
||||
|--------|------------|
|
||||
|0|停止系统。运行等级 0 是一个用于快速关闭系统的特殊过渡状态。|
|
||||
|1|别名为 s 或 S,这个运行等级有时候也称为维护模式。在这个运行等级启动的服务由于发行版不同而不同。通常用于正常系统操作损坏时低级别的系统维护。|
|
||||
|2|多用户。在 Debian 系统及其衍生版中,这是默认的运行等级,还包括了一个图形化登录(如果有的话)。在基于红帽的系统中,这是没有网络的多用户模式。|
|
||||
|3|在基于红帽的系统中,这是默认的多用户模式,运行除了图形化环境以外的所有东西。基于 Debian 的系统中通常不会使用这个运行等级以及等级 4 和 5。|
|
||||
|4|通常默认情况下不使用,可用于自定制。|
|
||||
|5|基于红帽的系统中,支持 GUI 登录的完全多用户模式。这个运行等级和等级 3 类似,但是有可用的 GUI 登录。|
|
||||
|6|重启系统。|
|
||||
|
||||
|
||||
要在运行等级之间切换,我们只需要使用 init 命令更改运行等级:init N(其中 N 是上面列出的一个运行等级)。
|
||||
请注意这并不是运行中的系统切换运行等级的推荐方式,因为它不会给已经登录的用户发送警告(因而导致他们丢失工作以及进程异常终结)。
|
||||
|
||||
相反,应该用 shutdown 命令重启系统(它首先发送警告信息给所有已经登录的用户,并锁住任何新的登录;然后再给 init 发送信号切换运行等级)但是,首先要在 /etc/inittab 文件中设置好默认的运行等级(系统引导到的等级)。
|
||||
|
||||
因为这个原因,按照下面的步骤切当地切换运行等级。以 root 用户在 /etc/inittab 中查找下面的行。
|
||||
|
||||
id:2:initdefault:
|
||||
|
||||
并用你喜欢的文本编辑器,例如 vim(本系列的 [LFCS 系列第二讲:如何安装和使用纯文本编辑器 vi/vim][2]),更改数字 2 为想要的运行等级。
|
||||
|
||||
然后,以 root 用户执行
|
||||
|
||||
# shutdown -r now
|
||||
|
||||
最后一个命令会重启系统,并使它在下一次引导时进入指定的运行等级,并会执行保存在 /etc/rc[runlevel].d 目录中的脚本以决定应该启动什么服务、不应该启动什么服务。例如,在下面的系统中运行等级 2。
|
||||
|
||||

|
||||
|
||||
*在 Linux 中更改运行等级*
|
||||
|
||||
#### 使用 chkconfig 管理服务 ####
|
||||
|
||||
为了在启动时启动或者停用系统服务,我们可以在 CentOS / openSUSE 中使用 [chkconfig 命令][3],在 Debian 及其衍生版中使用 sysv-rc-conf 命令。这个工具还能告诉我们对于一个指定的运行等级预先配置的状态是什么。
|
||||
|
||||
- 推荐阅读: [如何在 Linux 中停止和停用不想要的服务][4]
|
||||
|
||||
列出某个服务的运行等级配置。
|
||||
|
||||
# chkconfig --list [service name]
|
||||
# chkconfig --list postfix
|
||||
# chkconfig --list mysqld
|
||||
|
||||

|
||||
|
||||
*列出运行等级配置*
|
||||
|
||||
从上图中我们可以看出,当系统进入运行等级 2 到 5 的时候就会启动 postfix,而默认情况下运行等级 2 到 4 时会运行 mysqld。现在假设我们并不希望如此。
|
||||
|
||||
例如,我们希望运行等级为 5 时也启动 mysqld,运行等级为 4 或 5 时关闭 postfix。下面分别针对两种情况进行设置(以 root 用户执行以下命令)。
|
||||
|
||||
**为特定运行等级启用服务**
|
||||
|
||||
# chkconfig --level [level(s)] service on
|
||||
# chkconfig --level 5 mysqld on
|
||||
|
||||
**为特定运行等级停用服务**
|
||||
|
||||
# chkconfig --level [level(s)] service off
|
||||
# chkconfig --level 45 postfix off
|
||||
|
||||
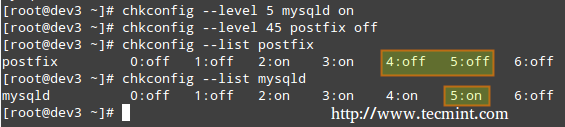
|
||||
|
||||
*启用/停用服务*
|
||||
|
||||
我们在基于 Debian 的系统中使用 sysv-rc-conf 完成类似任务。
|
||||
|
||||
#### 使用 sysv-rc-conf 管理服务 ####
|
||||
|
||||
配置服务自动启动时进入指定运行等级,同时禁止启动时进入其它运行等级。
|
||||
|
||||
1. 我们可以用下面的命令查看启动 mdadm 时的运行等级。
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||
|
||||

|
||||
|
||||
*查看运行中服务的运行等级*
|
||||
|
||||
2. 我们使用 sysv-rc-conf 设置防止 mdadm 在运行等级2 之外的其它等级启动。只需根据需要(你可以使用上下左右按键)选中或取消选中(通过空格键)。
|
||||
|
||||
# sysv-rc-conf
|
||||
|
||||

|
||||
|
||||
*Sysv 运行等级配置*
|
||||
|
||||
然后输入 q 退出。
|
||||
|
||||
3. 重启系统并从步骤 1 开始再操作一遍。
|
||||
|
||||
# ls -l /etc/rc[0-6].d | grep -E 'rc[0-6]|mdadm'
|
||||
|
||||

|
||||
|
||||
*验证服务运行等级*
|
||||
|
||||
从上图中我们可以看出 mdadm 配置为只在运行等级 2 上启动。
|
||||
|
||||
### 那关于 systemd 呢? ###
|
||||
|
||||
systemd 是另外一个被多种主流 Linux 发行版采用的服务和系统管理器。它的目标是允许系统启动时多个任务尽可能并行(而 sysvinit 并非如此,sysvinit 一般比较慢,因为它每次只启动一个进程,而且会检查彼此之间是否有依赖,在启动其它服务之前还要等待守护进程启动),充当运行中系统动态资源管理的角色。
|
||||
|
||||
因此,服务只在需要的时候启动,而不是系统启动时毫无缘由地启动(为了防止消耗系统资源)。
|
||||
|
||||
要查看你系统中运行的原生 systemd 服务和 Sysv 服务,可以用以下的命令。
|
||||
|
||||
# systemctl
|
||||
|
||||

|
||||
|
||||
*查看运行中的进程*
|
||||
|
||||
LOAD 一列显示了单元(UNIT 列,显示服务或者由 systemd 维护的其它进程)是否正确加载,ACTIVE 和 SUB 列则显示了该单元当前的状态。
|
||||
|
||||
**显示服务当前状态的信息**
|
||||
|
||||
当 ACTIVE 列显示某个单元状态并非活跃时,我们可以使用以下命令查看具体原因。
|
||||
|
||||
# systemctl status [unit]
|
||||
|
||||
例如,上图中 media-samba.mount 处于失败状态。我们可以运行:
|
||||
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
*查看服务状态*
|
||||
|
||||
我们可以看到 media-samba.mount 失败的原因是 host dev1 上的挂载进程无法找到 //192.168.0.10/gacanepa 上的共享网络。
|
||||
|
||||
### 启动或停止服务 ###
|
||||
|
||||
一旦 //192.168.0.10/gacanepa 上的共享网络可用,我们可以再来尝试启动、停止以及重启 media-samba.mount 单元。执行每次操作之后,我们都执行 systemctl stats media-samba.mout 来查看它的状态。
|
||||
|
||||
# systemctl start media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
# systemctl stop media-samba.mount
|
||||
# systemctl restart media-samba.mount
|
||||
# systemctl status media-samba.mount
|
||||
|
||||

|
||||
|
||||
*启动停止服务*
|
||||
|
||||
**启用或停用某服务随系统启动**
|
||||
|
||||
使用 systemd 你可以在系统启动时启用或停用某服务
|
||||
|
||||
# systemctl enable [service] # 启用服务
|
||||
# systemctl disable [service] # 阻止服务随系统启动
|
||||
|
||||
|
||||
启用或停用某服务随系统启动包括在 /etc/systemd/system/multi-user.target.wants 目录添加或者删除符号链接。
|
||||
|
||||

|
||||
|
||||
*启用或停用服务*
|
||||
|
||||
你也可以用下面的命令查看某个服务的当前状态(启用或者停用)。
|
||||
|
||||
# systemctl is-enabled [service]
|
||||
|
||||
例如,
|
||||
|
||||
# systemctl is-enabled postfix.service
|
||||
|
||||
另外,你可以用下面的命令重启或者关闭系统。
|
||||
|
||||
# systemctl reboot
|
||||
# systemctl shutdown
|
||||
|
||||
### Upstart ###
|
||||
|
||||
基于事件的 Upstart 是 /sbin/init 守护进程的替代品,它仅为在需要那些服务的时候启动服务而生,(或者当它们在运行时管理它们),以及处理发生的实践,因此 Upstart 优于基于依赖的 sysvinit 系统。
|
||||
|
||||
一开始它是为 Ubuntu 发行版开发的,但在红帽企业版 Linux 6.0 中得到使用。尽管希望它能在所有 Linux 发行版中替代 sysvinit,但它已经被 systemd 超越。2014 年 2 月 14 日,Mark Shuttleworth(Canonical Ltd. 创建者)发布声明之后的 Ubuntu 发行版采用 systemd 作为默认初始化守护进程。
|
||||
|
||||
由于 Sysv 启动脚本已经流行很长时间了,很多软件包中都包括了 Sysv 启动脚本。为了兼容这些软件, Upstart 提供了兼容模式:它可以运行保存在常用位置(/etc/rc.d/rc?.d, /etc/init.d/rc?.d, /etc/rc?.d或其它类似的位置)的Sysv 启动脚本。因此,如果我们安装了一个还没有 Upstart 配置脚本的软件,仍然可以用原来的方式启动它。
|
||||
|
||||
另外,如果我们还安装了类似 [chkconfig][5] 的工具,你还可以和在基于 sysvinit 的系统中一样用它们管理基于 Sysv 的服务。
|
||||
|
||||
Upstart 脚本除了支持 Sysv 启动脚本,还支持基于多种方式启动或者停用服务;例如, Upstart 可以在一个特定硬件设备连接上的时候启动一个服务。
|
||||
|
||||
使用 Upstart以及它原生脚本的系统替换了 /etc/inittab 文件和 /etc/init 目录下和运行等级相关的以 .conf 作为后缀的 Sysv 启动脚本目录。
|
||||
|
||||
这些 *.conf 脚本(也称为任务定义)通常包括以下几部分:
|
||||
|
||||
- 进程描述
|
||||
- 进程的运行等级或者应该触发它们的事件
|
||||
- 应该停止进程的运行等级或者触发停止进程的事件
|
||||
- 选项
|
||||
- 启动进程的命令
|
||||
|
||||
例如,
|
||||
|
||||
# My test service - Upstart script demo description "Here goes the description of 'My test service'" author "Dave Null <dave.null@example.com>"
|
||||
# Stanzas
|
||||
|
||||
#
|
||||
# Stanzas define when and how a process is started and stopped
|
||||
# See a list of stanzas here: http://upstart.ubuntu.com/wiki/Stanzas#respawn
|
||||
# When to start the service
|
||||
start on runlevel [2345]
|
||||
# When to stop the service
|
||||
stop on runlevel [016]
|
||||
# Automatically restart process in case of crash
|
||||
respawn
|
||||
# Specify working directory
|
||||
chdir /home/dave/myfiles
|
||||
# Specify the process/command (add arguments if needed) to run
|
||||
exec bash backup.sh arg1 arg2
|
||||
|
||||
要使更改生效,你要让 upstart 重新加载它的配置文件。
|
||||
|
||||
# initctl reload-configuration
|
||||
|
||||
然后用下面的命令启动你的任务。
|
||||
|
||||
$ sudo start yourjobname
|
||||
|
||||
其中 yourjobname 是之前 yourjobname.conf 脚本中添加的任务名称。
|
||||
|
||||
关于 Upstart 更完整和详细的介绍可以参考该项目网站的 “[Cookbook][6]” 栏目。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
了解 Linux 启动进程对于你进行错误处理、调整计算机系统以及根据需要运行服务非常有用。
|
||||
|
||||
在这篇文章中,我们分析了你按下电源键启动机器的一刻到你看到完整的可操作用户界面这段时间发生了什么。我希望你能像我一样把它们放在一起阅读。欢迎在下面留下你的评论或者疑问。我们总是期待听到读者的回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[2]:https://linux.cn/article-7165-1.html
|
||||
[3]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[4]:http://www.tecmint.com/remove-unwanted-services-from-linux/
|
||||
[5]:http://www.tecmint.com/chkconfig-command-examples/
|
||||
[6]:http://upstart.ubuntu.com/cookbook/
|
||||
@ -1,53 +0,0 @@
|
||||
# Recognizing correct code
|
||||
|
||||
Automatic bug-repair system fixes 10 times as many errors as its predecessors.
|
||||
------
|
||||
DongShuaike is translating.
|
||||
|
||||
MIT researchers have developed a machine-learning system that can comb through repairs to open-source computer programs and learn their general properties, in order to produce new repairs for a different set of programs.
|
||||
|
||||
The researchers tested their system on a set of programming errors, culled from real open-source applications, that had been compiled to evaluate automatic bug-repair systems. Where those earlier systems were able to repair one or two of the bugs, the MIT system repaired between 15 and 18, depending on whether it settled on the first solution it found or was allowed to run longer.
|
||||
|
||||
While an automatic bug-repair tool would be useful in its own right, professor of electrical engineering and computer science Martin Rinard, whose group developed the new system, believes that the work could have broader ramifications.
|
||||
|
||||
“One of the most intriguing aspects of this research is that we’ve found that there are indeed universal properties of correct code that you can learn from one set of applications and apply to another set of applications,” Rinard says. “If you can recognize correct code, that has enormous implications across all software engineering. This is just the first application of what we hope will be a brand-new, fabulous technique.”
|
||||
|
||||
Fan Long, a graduate student in electrical engineering and computer science at MIT, presented a paper describing the new system at the Symposium on Principles of Programming Languages last week. He and Rinard, his advisor, are co-authors.
|
||||
|
||||
Users of open-source programs catalogue bugs they encounter on project websites, and contributors to the projects post code corrections, or “patches,” to the same sites. So Long was able to write a computer script that automatically extracted both the uncorrected code and patches for 777 errors in eight common open-source applications stored in the online repository GitHub.
|
||||
|
||||
**Feature performance**
|
||||
|
||||
As with [all][1] machine-learning systems, the crucial aspect of Long and Rinard’s design was the selection of a “[feature set][2]” that the system would analyze. The researchers concentrated on values stored in memory — either variables, which can be modified during a program’s execution, or constants, which can’t. They identified 30 prime characteristics of a given value: It might be involved in an operation, such as addition or multiplication, or a comparison, such as greater than or equal to; it might be local, meaning it occurs only within a single block of code, or global, meaning that it’s accessible to the program as a whole; it might be the variable that represents the final result of a calculation; and so on.
|
||||
|
||||
Long and Rinard wrote a computer program that evaluated all the possible relationships between these characteristics in successive lines of code. More than 3,500 such relationships constitute their feature set. Their machine-learning algorithm then tried to determine what combination of features most consistently predicted the success of a patch.
|
||||
|
||||
“All the features we’re trying to look at are relationships between the patch you insert and the code you are trying to patch,” Long says. “Typically, there will be good connections in the correct patches, corresponding to useful or productive program logic. And there will be bad patterns that mean disconnections in program logic or redundant program logic that are less likely to be successful.”
|
||||
|
||||
**Ranking candidates**
|
||||
|
||||
In earlier work, Long had developed an algorithm that attempts to repair program bugs by systematically modifying program code. The modified code is then subjected to a suite of tests designed to elicit the buggy behavior. This approach may find a modification that passes the tests, but it could take a prohibitively long time. Moreover, the modified code may still contain errors that the tests don’t trigger.
|
||||
|
||||
Long and Rinard’s machine-learning system works in conjunction with this earlier algorithm, ranking proposed modifications according to the probability that they are correct before subjecting them to time-consuming tests.
|
||||
|
||||
The researchers tested their system, which they call Prophet, on a set of 69 program errors that had cropped up in eight popular open-source programs. Of those, 19 are amenable to the type of modifications that Long’s algorithm uses; the other 50 have more complicated problems that involve logical inconsistencies across larger swaths of code.
|
||||
|
||||
When Long and Rinard configured their system to settle for the first solution that passed the bug-eliciting tests, it was able to correctly repair 15 of the 19 errors; when they allowed it to run for 12 hours per problem, it repaired 18.
|
||||
|
||||
Of course, that still leaves the other 50 errors in the test set untouched. In ongoing work, Long is working on a machine-learning system that will look at more coarse-grained manipulation of program values across larger stretches of code, in the hope of producing a bug-repair system that can handle more complex errors.
|
||||
|
||||
“A revolutionary aspect of Prophet is how it leverages past successful patches to learn new ones,” says Eran Yahav, an associate professor of computer science at the Technion in Israel. “It relies on the insight that despite differences between software projects, fixes — patches — applied to projects often have commonalities that can be learned from. Using machine learning to learn from ‘big code’ holds the promise to revolutionize many programming tasks — code completion, reverse-engineering, et cetera.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.mit.edu/2016/faster-automatic-bug-repair-code-errors-0129
|
||||
|
||||
作者:Larry Hardesty
|
||||
译者:[译者ID](https://github.com/翻译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://news.mit.edu/2013/teaching-computers-to-see-by-learning-to-see-like-computers-0919
|
||||
[2]:http://news.mit.edu/2015/automating-big-data-analysis-1016
|
||||
|
||||
@ -1,194 +0,0 @@
|
||||
5 best open source board games to play online
|
||||
================================================================================
|
||||
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
|
||||
|
||||
I had a panache for abstract strategy games such as chess and draughts, as well as word games. I can still never resist a game of Escape from Colditz, a strategy card and dice-based board game, or Risk; two timeless multi-player strategy board games. But Catan remains my favourite board game.
|
||||
|
||||
Board games have seen a resurgence in recent years, and Linux has a good range of board games to choose from. There is a credible implementation of Catan called Pioneers. But for my favourite implementations of classic board games to play online, check out the recommendations below.
|
||||
|
||||
----------
|
||||
|
||||
### TripleA ###
|
||||
|
||||

|
||||
|
||||
TripleA is an open source online turn based strategy game. It allows people to implement and play various strategy board games (ie. Axis & Allies). The TripleA engine has full networking support for online play, support for sounds, XML support for game files, and has its own imaging subsystem that allows for customized user editable maps to be used. TripleA is versatile, scalable and robust.
|
||||
|
||||
TripleA started out as a World War II simulation, but now includes different conflicts, as well as variations and mods of popular games and maps. TripleA comes with multiple games and over 100 more games can be downloaded from the user community.
|
||||
|
||||
Features include:
|
||||
|
||||
- Good interface and attractive graphics
|
||||
- Optional scenarios
|
||||
- Multiplayer games
|
||||
- TripleA comes with the following supported games that uses its game engine (just to name a few):
|
||||
- Axis & Allies : Classic edition (2nd, 3rd with options enabled)
|
||||
- Axis & Allies : Revised Edition
|
||||
- Pact of Steel A&A Variant
|
||||
- Big World 1942 A&A Variant
|
||||
- Four if by Sea
|
||||
- Battle Ship Row
|
||||
- Capture The Flag
|
||||
- Minimap
|
||||
- Hot-seat
|
||||
- Play By EMail mode allows persons to play a game via EMail without having to be connected to each other online
|
||||
- More time to think out moves
|
||||
- Only need to come online to send your turn to the next player
|
||||
- Dice rolls are done by a dedicated dice server that is independent of TripleA
|
||||
- All dice rolls are PGP Verified and email to every player
|
||||
- Every move and every dice roll is logged and saved in TripleA's History Window
|
||||
- An online game can be later continued under PBEM mode
|
||||
- Hard for others to cheat
|
||||
- Hosted online lobby
|
||||
- Utilities for editing maps
|
||||
- Website: [triplea.sourceforge.net][1]
|
||||
- Developer: Sean Bridges (original developer), Mark Christopher Duncan
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.8.0.7
|
||||
|
||||
----------
|
||||
|
||||
### Domination ###
|
||||
|
||||

|
||||
|
||||
Domination is an open source game that shares common themes with the hugely popular Risk board game. It has many game options and includes many maps.
|
||||
|
||||
In the classic “World Domination” game of military strategy, you are battling to conquer the world. To win, you must launch daring attacks, defend yourself to all fronts, and sweep across vast continents with boldness and cunning. But remember, the dangers, as well as the rewards, are high. Just when the world is within your grasp, your opponent might strike and take it all away!
|
||||
|
||||
Features include:
|
||||
|
||||
- Simple to learn
|
||||
- Domination - you must occupy all countries on the map, and thereby eliminate all opponents. These can be long, drawn out games
|
||||
- Capital - each player has a country they have selected as a Capital. To win the game, you must occupy all Capitals
|
||||
- Mission - each player draws a random mission. The first to complete their mission wins. Missions may include the elimination of a certain colour, occupation of a particular continent, or a mix of both
|
||||
- Map editor
|
||||
- Simple map format
|
||||
- Multiplayer network play
|
||||
- Single player
|
||||
- Hotseat
|
||||
- 5 user interfaces
|
||||
- Game types:
|
||||
- Play online
|
||||
- Website: [domination.sourceforge.net][2]
|
||||
- Developer: Yura Mamyrin, Christian Weiske, Mike Chaten, and many others
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 1.1.1.5
|
||||
|
||||
----------
|
||||
|
||||
### PyChess ###
|
||||
|
||||

|
||||
|
||||
PyChess is a Gnome inspired chess client written in Python.
|
||||
|
||||
The goal of PyChess, is to provide a fully featured, nice looking, easy to use chess client for the gnome-desktop.
|
||||
|
||||
The client should be usable both to those totally new to chess, those who want to play an occasional game, and those who wants to use the computer to further enhance their play.
|
||||
|
||||
Features include:
|
||||
|
||||
- Attractive interface
|
||||
- Chess Engine Communication Protocol (CECP) and Univeral Chess Interface (UCI) Engine support
|
||||
- Free online play on the Free Internet Chess Server (FICS)
|
||||
- Read and writes PGN, EPD and FEN chess file formats
|
||||
- Built-in Python based engine
|
||||
- Undo and pause functions
|
||||
- Board and piece animation
|
||||
- Drag and drop
|
||||
- Tabbed interface
|
||||
- Hints and spyarrows
|
||||
- Opening book sidepanel using sqlite
|
||||
- Score plot sidepanel
|
||||
- "Enter game" in pgn dialog
|
||||
- Optional sounds
|
||||
- Legal move highlighting
|
||||
- Internationalised or figure pieces in notation
|
||||
- Website: [www.pychess.org][3]
|
||||
- Developer: Thomas Dybdahl Ahle
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 0.12 Anderssen rc4
|
||||
|
||||
----------
|
||||
|
||||
### Scrabble ###
|
||||
|
||||

|
||||
|
||||
Scrabble3D is a highly customizable Scrabble game that not only supports Classic Scrabble and Superscrabble but also 3D games and own boards. You can play local against the computer or connect to a game server to find other players.
|
||||
|
||||
Scrabble is a board game with the goal to place letters crossword like. Up to four players take part and get a limited amount of letters (usually 7 or 8). Consecutively, each player tries to compose his letters to one or more word combining with the placed words on the game array. The value of the move depends on the letters (rare letter get more points) and bonus fields which multiply the value of a letter or the whole word. The player with most points win.
|
||||
|
||||
This idea is extended with Scrabble3D to the third dimension. Of course, a classic game with 15x15 fields or Superscrabble with 21x21 fields can be played and you may configure any field setting by yourself. The game can be played by the provided freeware program against Computer, other local players or via internet. Last but not least it's possible to connect to a game server to find other players and to obtain a rating. Most options are configurable, including the number and valuation of letters, the used dictionary, the language of dialogs and certainly colors, fonts etc.
|
||||
|
||||
Features include:
|
||||
|
||||
- Configurable board, letterset and design
|
||||
- Board in OpenGL graphics with user-definable wavefront model
|
||||
- Game against computer with support of multithreading
|
||||
- Post-hoc game analysis with calculation of best move by computer
|
||||
- Match with other players connected on a game server
|
||||
- NSA rating and highscore at game server
|
||||
- Time limit of games
|
||||
- Localization; use of non-standard digraphs like CH, RR, LL and right to left reading
|
||||
- Multilanguage help / wiki
|
||||
- Network games are buffered and asynchronous games are possible
|
||||
- Running games can be kibitzed
|
||||
- International rules including italian "Cambio Secco"
|
||||
- Challenge mode, What-if-variant, CLABBERS, etc
|
||||
- Website: [sourceforge.net/projects/scrabble][4]
|
||||
- Developer: Heiko Tietze
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 3.1.3
|
||||
|
||||
----------
|
||||
|
||||
### Backgammon ###
|
||||
|
||||

|
||||
|
||||
GNU Backgammon (gnubg) is a strong backgammon program (world-class with a bearoff database installed) usable either as an engine by other programs or as a standalone backgammon game. It is able to play and analyze both money games and tournament matches, evaluate and roll out positions, and more.
|
||||
|
||||
In addition to supporting simple play, it also has extensive analysis features, a tutor mode, adjustable difficulty, and support for exporting annotated games.
|
||||
|
||||
It currently plays at about the level of a championship flight tournament player and is gradually improving.
|
||||
|
||||
gnubg can be played on numerous on-line backgammon servers, such as the First Internet Backgammon Server (FIBS).
|
||||
|
||||
Features include:
|
||||
|
||||
- A command line interface (with full command editing features if GNU readline is available) that lets you play matches and sessions against GNU Backgammon with a rough ASCII representation of the board on text terminals
|
||||
- Support for a GTK+ interface with a graphical board window. Both 2D and 3D graphics are available
|
||||
- Tournament match and money session cube handling and cubeful play
|
||||
- Support for both 1-sided and 2-sided bearoff databases: 1-sided bearoff database for 15 checkers on the first 6 points and optional 2-sided database kept in memory. Optional larger 1-sided and 2-sided databases stored on disk
|
||||
- Automated rollouts of positions, with lookahead and race variance reduction where appropriate. Rollouts may be extended
|
||||
- Functions to generate legal moves and evaluate positions at varying search depths
|
||||
- Neural net functions for giving cubeless evaluations of all other contact and race positions
|
||||
- Automatic and manual annotation (analysis and commentary) of games and matches
|
||||
- Record keeping of statistics of players in games and matches (both native inside GNU Backgammon and externally using relational databases and Python)
|
||||
- Loading and saving analyzed games and matches as .sgf files (Smart Game Format)
|
||||
- Exporting positions, games and matches to: (.eps) Encapsulated Postscript, (.gam) Jellyfish Game, (.html) HTML, (.mat) Jellyfish Match, (.pdf) PDF, (.png) Portable Network Graphics, (.pos) Jellyfish Position, (.ps) PostScript, (.sgf) Gnu Backgammon File, (.tex) LaTeX, (.txt) Plain Text, (.txt) Snowie Text
|
||||
- Import of matches and positions from a number of file formats: (.bkg) Hans Berliner's BKG Format, (.gam) GammonEmpire Game, (.gam) PartyGammon Game, (.mat) Jellyfish Match, (.pos) Jellyfish Position, (.sgf) Gnu Backgammon File, (.sgg) GamesGrid Save Game, (.tmg) TrueMoneyGames, (.txt) Snowie Text
|
||||
- Python Scripting
|
||||
- Native language support; 10 languages complete or in progress
|
||||
- Website: [www.gnubg.org][5]
|
||||
- Developer: Joseph Heled, Oystein Johansen, Jonathan Kinsey, David Montgomery, Jim Segrave, Joern Thyssen, Gary Wong and contributors
|
||||
- License: GPL v2
|
||||
- Version Number: 1.05.000
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150830011533893/BoardGames.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://triplea.sourceforge.net/
|
||||
[2]:http://domination.sourceforge.net/
|
||||
[3]:http://www.pychess.org/
|
||||
[4]:http://sourceforge.net/projects/scrabble/
|
||||
[5]:http://www.gnubg.org/
|
||||
@ -1,336 +0,0 @@
|
||||
Bossie Awards 2015: The best open source application development tools
|
||||
================================================================================
|
||||
InfoWorld's top picks among platforms, frameworks, databases, and all the other tools that programmers use
|
||||
|
||||

|
||||
|
||||
### The best open source development tools ###
|
||||
|
||||
There must be a better way, right? The developers are the ones who find it. This year's winning projects in the application development category include client-side frameworks, server-side frameworks, mobile frameworks, databases, languages, libraries, editors, and yeah, Docker. These are our top picks among all of the tools that make it faster and easier to build better applications.
|
||||
|
||||

|
||||
|
||||
### Docker ###
|
||||
|
||||
The darling of container fans almost everywhere, [Docker][2] provides a low-overhead way to isolate an application or service’s environment, which serves its stated goal of being an open platform for building, shipping, and running distributed applications. Docker has been widely supported, even among those seeking to replace the Docker container format with an alternative, more secure runtime and format, specifically Rkt and AppC. Heck, Microsoft Visual Studio now supports deploying into a Docker container too.
|
||||
|
||||
Docker’s biggest impact has been on virtual machine environments. Since Docker containers run inside the operating system, many more Docker containers than virtual machines can run in a given amount of RAM. This is important because RAM is usually the scarcest and most expensive resource in a virtualized environment.
|
||||
|
||||
There are hundreds of thousands of runnable public images on Docker Hub, of which a few hundred are official, and the rest are from the community. You describe Docker images with a Dockerfile and build images locally from the Docker command line. You can add both public and private image repositories to Docker Hub.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Node.js and io.js ###
|
||||
|
||||
[Node.js][2] -- and its recently reunited fork [io.js][3] -- is a platform built on [Google Chrome's V8 JavaScript runtime][4] for building fast, scalable, network applications. Node uses an event-driven, nonblocking I/O model without threads. In general, Node tends to take less memory and CPU resources than other runtime engines, such as Java and the .Net Framework. For example, a typical Node.js Web server can run well in a 512MB instance on Cloud Foundry or a 512MB Docker container.
|
||||
|
||||
The Node repository on GitHub has more than 35,000 stars and more than 8,000 forks. The project, sponsored primarily by Joyent, has more than 600 contributors. Some of the more famous Node applications are 37Signals, [Ancestry.com][5], Chomp, the Wall Street Journal online, FeedHenry, [GE.com][6], Mockingbird, [Pearson.com][7], Shutterstock, and Uber. The popular IoT back-end Node-RED is built on Node, as are many client apps, such as Brackets and Nuclide.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### AngularJS ###
|
||||
|
||||
[AngularJS][8] (or simply Angular, among friends) is a Model-View-Whatever (MVW) JavaScript AJAX framework that extends HTML with markup for dynamic views and data binding. Angular is especially good for developing single-page Web applications and linking HTML forms to models and JavaScript controllers.
|
||||
|
||||
The weird sounding Model-View-Whatever pattern is an attempt to include the Model-View-Controller, Model-View-ViewModel, and Model-View-Presenter patterns under one moniker. The differences among these three closely related patterns are the sorts of topics that programmers love to argue about fiercely; the Angular developers decided to opt out of the discussion.
|
||||
|
||||
Basically, Angular automatically synchronizes data from your UI (view) with your JavaScript objects (model) through two-way data binding. To help you structure your application better and make it easy to test, AngularJS teaches the browser how to do dependency injection and inversion of control.
|
||||
|
||||
Angular was created by Google and open-sourced under the MIT license; there are currently more than 1,200 contributors to the project on GitHub, and the repository has more than 40,000 stars and 18,000 forks. The Angular site lists [210 “neat things” built with Angular][9].
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### React ###
|
||||
|
||||
[React][10] is a JavaScript library for building a UI or view, typically for single-page applications. Note that React does not implement anything having to do with a model or controller. React pages can render on the server or the client; rendering on the server (with Node.js) is typically much faster. People often combine React with AngularJS to create complete applications.
|
||||
|
||||
React combines JavaScript and HTML in a single file, optionally a JSX component. React fans like the way JSX components combine views and their related functionality in one file, though that flies in the face of the last decade of Web development trends, which were all about separating the markup and the code. React fans also claim that you can’t understand it until you’ve tried it. Perhaps you should; the React repository on GitHub has 26,000 stars.
|
||||
|
||||
[React Native][11] implements React with native iOS controls; the React Native command line uses Node and Xcode. [ReactJS.Net][12] integrates React with [ASP.Net][13] and C#. React is available under a BSD license with a patent license grant from Facebook.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Atom ###
|
||||
|
||||
[Atom][14] is an open source, hackable desktop editor from GitHub, based on Web technologies. It’s a full-featured tool with a fuzzy finder; fast projectwide search and replace; multiple cursors and selections; multiple panes, snippets, code folding; and the ability to import TextMate grammars and themes. Out of the box, Atom displayed proper syntax highlighting for every programming language on which I tried it, except for F# and C#; I fixed that easily by loading those packages from within Atom. Not surprising, Atom has tight integration with GitHub.
|
||||
|
||||
The skeleton of Atom has been separated from the guts and called the Electron shell, providing an open source way to build cross-platform desktop apps with Web technologies. Visual Studio Code is built on the Electron shell, as are a number of proprietary and open source apps, including Slack and Kitematic. Facebook Nuclide adds significant functionality to Atom, including remote development and support for Flow, Hack, and Mercurial.
|
||||
|
||||
On the downside, updating Atom packages can become painful, especially if you have many of them installed. The Nuclide packages seem to be the worst offenders -- they not only take a long time to update, they run CPU-intensive Node processes to do so.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Brackets ###
|
||||
|
||||
[Brackets][15] is a lightweight editor for Web design that Adobe developed and open-sourced, drawing heavily on other open source projects. The idea is to build better tooling for JavaScript, HTML, CSS, and related open Web technologies. Brackets itself is written in JavaScript, HTML, and CSS, and the developers use Brackets to build Brackets. The editor portion is based on another open source project, CodeMirror, and the Brackets native shell is based on Google’s Chromium Embedded Framework.
|
||||
|
||||
Brackets features a clean UI, with the ability to open a quick inline editor that displays all of the related CSS for some HTML, or all of the related JavaScript for some scripting, and a live preview for Web pages that you are editing. New in Brackets 1.4 is instant search in files, easier preferences editing, the ability to enable and disable extensions individually, improved text rendering on Macs, and Greek and Cyrillic character support. Last November, Adobe started shipping a preview version of Extract for Brackets, which can pull out design information from Photoshop files, as part of the default download for Brackets.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### TypeScript ###
|
||||
|
||||
[TypeScript][16] is a portable, duck-typed superset of JavaScript that compiles to plain JavaScript. The goal of the project is to make JavaScript usable for large applications. In pursuit of that goal, TypeScript adds optional types, classes, and modules to JavaScript, and it supports tools for large-scale JavaScript applications. Typing gets rid of some of the nonsensical and potentially buggy default behavior in JavaScript, for example:
|
||||
|
||||
> 1 + "1"
|
||||
'11'
|
||||
|
||||
“Duck” typing means that the type checking focuses on the shape of the data values; TypeScript describes basic types, interfaces, and classes. While the current version of JavaScript does not support traditional, class-based, object-oriented programming, the ECMAScript 6 specification does. TypeScript compiles ES6 classes into plain, compatible JavaScript, with prototype-based objects, unless you enable ES6 output using the `--target` compiler option.
|
||||
|
||||
Visual Studio includes TypeScript in the box, starting with Visual Studio 2013 Update 2. You can also edit TypeScript in Visual Studio Code, WebStorm, Atom, Sublime Text, and Eclipse.
|
||||
|
||||
When using an external JavaScript library, or new host API, you'll need to use a declaration file (.d.ts) to describe the shape of the library. You can often find declaration files in the [DefinitelyTyped][17] repository, either by browsing, using the [TSD definition manager][18], or using NuGet.
|
||||
|
||||
TypeScript’s GitHub repository has more than 6,000 stars.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Swagger ###
|
||||
|
||||
[Swagger][19] is a language-agnostic interface to RESTful APIs, with tooling that gives you interactive documentation, client SDK generation, and discoverability. It’s one of several recent attempts to codify the description of RESTful APIs, in the spirit of WSDL for XML Web Services (2000) and CORBA for distributed object interfaces (1991).
|
||||
|
||||
The tooling makes Swagger especially interesting. [Swagger-UI][20] automatically generates beautiful documentation and a live API sandbox from a Swagger-compliant API. The [Swagger codegen][21] project allows generation of client libraries automatically from a Swagger-compliant server.
|
||||
|
||||
[Swagger Editor][22] lets you edit Swagger API specifications in YAML inside your browser and preview documentations in real time. Valid Swagger JSON descriptions can then be generated and used with the full Swagger tooling.
|
||||
|
||||
The [Swagger JS][23] library is a fast way to enable a JavaScript client to communicate with a Swagger-enabled server. Additional clients exist for Clojure, Go, Java, .Net, Node.js, Perl, PHP, Python, Ruby, and Scala.
|
||||
|
||||
The [Amazon API Gateway][24] is a managed service for API management at scale. It can import Swagger specifications using an open source [Swagger Importer][25] tool.
|
||||
|
||||
Swagger and friends use the Apache 2.0 license.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Polymer ###
|
||||
|
||||
The [Polymer][26] library is a lightweight, “sugaring” layer on top of the Web components APIs to help in building your own Web components. It adds several features for greater ease in building complex elements, such as creating custom element registration, adding markup to your element, configuring properties on your element, setting the properties with attributes, data binding with mustache syntax, and internal styling of elements.
|
||||
|
||||
Polymer also includes libraries of prebuilt elements. The Iron library includes elements for working with layout, user input, selection, and scaffolding apps. The Paper elements implement Google's Material Design. The Gold library includes elements for credit card input fields for e-commerce, the Neon elements implement animations, the Platinum library implements push messages and offline caching, and the Google Web Components library is exactly what it says; it includes wrappers for YouTube, Firebase, Google Docs, Hangouts, Google Maps, and Google Charts.
|
||||
|
||||
Polymer Molecules are elements that wrap other JavaScript libraries. The only Molecule currently implemented is for marked, a Markdown library. The Polymer repository on GitHub currently has 12,000 stars. The software is distributed under a BSD-style license.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Ionic ###
|
||||
|
||||
The [Ionic][27] framework is a front-end SDK for building hybrid mobile apps, using Angular.js and Cordova, PhoneGap, or Trigger.io. Ionic was designed to be similar in spirit to the Android and iOS SDKs, and to do a minimum of DOM manipulation and use hardware-accelerated transitions to keep the rendering speed high. Ionic is focused mainly on the look and feel and UI interaction of your app.
|
||||
|
||||
In addition to the framework, Ionic encompasses an ecosystem of mobile development tools and resources. These include Chrome-based tools, Angular extensions for Cordova capabilities, back-end services, a development server, and a shell View App to enable testers to use your Ionic code on their devices without the need for you to distribute beta apps through the App Store or Google Play.
|
||||
|
||||
Appery.io integrated Ionic into its low-code builder in July 2015. Ionic’s GitHub repository has more than 18,000 stars and more than 3,000 forks. Ionic is distributed under an MIT license and currently runs in UIWebView for iOS 7 and later, and in Android 4.1 and up.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Cordova ###
|
||||
|
||||
[Apache Cordova][28] is the open source project spun off when Adobe acquired PhoneGap from Nitobi. Cordova is a set of device APIs, plus some tooling, that allows a mobile app developer to access native device functionality like the camera and accelerometer from JavaScript. When combined with a UI framework like Angular, it allows a smartphone app to be developed with only HTML, CSS, and JavaScript. By using Cordova plug-ins for multiple devices, you can generate hybrid apps that share a large portion of their code but also have access to a wide range of platform capabilities. The HTML5 markup and code runs in a WebView hosted by the Cordova shell.
|
||||
|
||||
Cordova is one of the cross-platform mobile app options supported by Visual Studio 2015. Several companies offer online builders for Cordova apps, similar to the Adobe PhoneGap Build service. Online builders save you from having to install and maintain most of the device SDKs on which Cordova relies.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Famous Engine ###
|
||||
|
||||
The high-performance Famo.us JavaScript framework introduced last year has become the [Famous Engine][29] and [Famous Framework][30]. The Famous Engine runs in a mixed mode, with the DOM and WebGL under a single coordinate system. As before, Famous structures applications in a scene graph hierarchy, but now it produces very little garbage (reducing the garbage collector overhead) and sustains 60FPS animations.
|
||||
|
||||
The Famous Physics engine has been refactored to its own, fine-grained module so that you can load only the features you need. Other improvements since last year include streamlined eventing, improved sizing, decoupling the scene graph from the rendering pipeline by using a draw command buffer, and switching to a fully open MIT license.
|
||||
|
||||
The new Famous Framework is an alpha-stage developer preview built on the Famous Engine; its goal is creating reusable, composable, and interchangeable UI widgets and applications. Eventually, Famous hopes to replace the jQuery UI widgets with Famous Framework widgets, but while it's promising, the Famous Framework is nowhere near production-ready.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### MongoDB ###
|
||||
|
||||
[MongoDB][31] is no stranger to the Bossies or to the ever-growing and ever-competitive NoSQL market. If you still aren't familiar with this very popular technology, here's a brief overview: MongoDB is a cross-platform document-oriented database, favoring JSON-like documents with dynamic schemas that make data integration easier and faster.
|
||||
|
||||
MongoDB has attractive features, including but not limited to ad hoc queries, flexible indexing, replication, high availability, automatic sharding, load balancing, and aggregation.
|
||||
|
||||
The big, bold move with [version 3.0 this year][32] was the new WiredTiger storage engine. We can now have document-level locking. This makes “normal” applications a whole lot more scalable and makes MongoDB available to more use cases.
|
||||
|
||||
MongoDB has a growing open source ecosystem with such offerings as the [TokuMX engine][33], from the famous MySQL bad boys Percona. The long list of MongoDB customers includes heavy hitters such as Craigslist, eBay, Facebook, Foursquare, Viacom, and the New York Times.
|
||||
|
||||
-- Andrew Oliver
|
||||
|
||||

|
||||
|
||||
### Couchbase ###
|
||||
|
||||
[Couchbase][34] is another distributed, document-oriented database that has been making waves in the NoSQL world for quite some time now. Couchbase and MongoDB often compete, but they each have their sweet spots. Couchbase tends to outperform MongoDB when doing more in memory is possible.
|
||||
|
||||
Additionally, Couchbase’s mobile features allow you to disconnect and ship a database in compact format. This allows you to scale down as well as up. This is useful not just for mobile devices but also for specialized applications, like shipping medical records across radio waves in Africa.
|
||||
|
||||
This year Couchbase added N1QL, a SQL-based query language that did away with Couchbase’s biggest obstacle, requiring static views. The new release also introduced multidimensional scaling. This allows individual scaling of services such as querying, indexing, and data storage to improve performance, instead of adding an entire, duplicate node.
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### Cassandra ###
|
||||
|
||||
[Cassandra][35] is the other white meat of column family databases. HBase might be included with your favorite Hadoop distribution, but Cassandra is the one people deliberately deploy for specialized applications. There are good reasons for this.
|
||||
|
||||
Cassandra was designed for high workloads of both writes and reads where millisecond consistency isn't as important as throughput. HBase is optimized for reads and greater write consistency. To a large degree, Cassandra tends to be used for operational systems and HBase more for data warehouse and batch-system-type use cases.
|
||||
|
||||
While Cassandra has not received as much attention as other NoSQL databases and slipped into a quiet period a couple years back, it is widely used and deployed, and it's a great fit for time series, product catalog, recommendations, and other applications. If you want to keep a cluster up “no matter what” with multiple masters and multiple data centers, and you need to scale with lots of reads and lots of writes, Cassandra might just be your Huckleberry.
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### OrientDB ###
|
||||
|
||||
[OrientDB][36] is an interesting hybrid in the NoSQL world, combining features from a document database, where individual documents can have multiple fields without necessarily defining a schema, and a graph database, which consists of a set of nodes and edges. At a basic level, OrientDB considers the document as a vertex, and relationships between fields as graph edges. Because the relationships between elements are part of the record, no costly joins are required when querying data.
|
||||
|
||||
Like most databases today, OrientDB offers linear scalability via a distributed architecture. Adding capacity is a matter of simply adding more nodes to the cluster. Queries are written in a variant of SQL that is extended to support graph concepts. It's not exactly SQL, but data analysts shouldn't have too much trouble adapting. Language bindings are available for most commonly used languages, such as R, Scala, .Net, and C, and those integrating OrientDB into their applications will find an active user community to get help from.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### RethinkDB ###
|
||||
|
||||
[RethinkDB][37] is a scalable, real-time JSON database with the ability to continuously push updated query results to applications that subscribe to changes. There are official RethinkDB drivers for Ruby, Python, and JavaScript/Node.js, and community-supported drivers for more than a dozen other languages, including C#, Go, and PHP.
|
||||
|
||||
It’s temping to confuse RethinkDB with real-time sync APIs, such as Firebase and PubNub. RethinkDB can be run as a cloud service like Firebase and PubNub, but you can also install it on your own hardware or Docker containers. RethinkDB does more than synchronize: You can run arbitrary RethinkDB queries, including table joins, subqueries, geospatial queries, and aggregation. Finally, RethinkDB is designed to be accessed from an application server, not a browser.
|
||||
|
||||
Where MongoDB requires you to poll the database to see changes, RethinkDB lets you subscribe to a stream of changes to a query result. You can shard and scale RethinkDB easily, unlike MongoDB. Also unlike relational databases, RethinkDB does not give you full ACID support or strong schema enforcement, although it can perform joins.
|
||||
|
||||
The RethinkDB repository has 10,000 stars on GitHub, a remarkably high number for a database. It is licensed with the Affero GPL 3.0; the drivers are licensed with Apache 2.0.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Rust ###
|
||||
|
||||
[Rust][38] is a syntactically C-like systems programming language from Mozilla Research that guarantees memory safety and offers painless concurrency (that is, no data races). It does not have a garbage collector and has minimal runtime overhead. Rust is strongly typed with type inference. This is all promising.
|
||||
|
||||
Rust was designed for performance. It doesn’t yet demonstrate great performance, however, so now the mantra seems to be that it runs as fast as C++ code that implements all the safety checks built into Rust. I’m not sure whether I believe that, as in many cases the strictest safety checks for C/C++ code are done by static and dynamic analysis and testing, which don’t add any runtime overhead. Perhaps Rust performance will come with time.
|
||||
|
||||
So far, the only tools for Rust are the Cargo package manager and the rustdoc documentation generator, plus a couple of simple Rust plug-ins for programming editors. As far as we have heard, there is no shipping software that was actually built with Rust. Now that Rust has reached the 1.0 milestone, we might expect that to change.
|
||||
|
||||
Rust is distributed with a dual Apache 2.0 and MIT license. With 13,000 stars on its GitHub repository, Rust is certainly attracting attention, but when and how it will deliver real benefits remains to be seen.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### OpenCV ###
|
||||
|
||||
[OpenCV][39] (Open Source Computer Vision Library) is a computer vision and machine learning library that contains about 500 algorithms, such as face detection, moving object tracking, image stitching, red-eye removal, machine learning, and eye movement tracking. It runs on Windows, Mac OS X, Linux, Android, and iOS.
|
||||
|
||||
OpenCV has official C++, C, Python, Java, and MATLAB interfaces, and wrappers in other languages such as C#, Perl, and Ruby. CUDA and OpenCL interfaces are under active development. OpenCV was originally (1999) an Intel Research project in Russia; from there it moved to the robotics research lab Willow Garage (2008) and finally to [OpenCV.org][39] (2012) with a core team at Itseez, current source on GitHub, and stable snapshots on SourceForge.
|
||||
|
||||
Users of OpenCV include Google, Yahoo, Microsoft, Intel, IBM, Sony, Honda, and Toyota. There are currently more than 6,000 stars and 5,000 forks on the GitHub repository. The project uses a BSD license.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### LLVM ###
|
||||
|
||||
The [LLVM Project][40] is a collection of modular and reusable compiler and tool chain technologies, which originated at the University of Illinois. LLVM has grown to include a number of subprojects, several of which are interesting in their own right. LLVM is distributed with Debian, Ubuntu, and Apple Xcode, among others, and it’s used in commercial products from the likes of Adobe (including After Effects), Apple (including Objective-C and Swift), Cray, Intel, NVIDIA, and Siemens. A few of the open source projects that depend on LLVM are PyPy, Mono, Rubinius, Pure, Emscripten, Rust, and Julia. Microsoft has recently contributed LLILC, a new LLVM-based compiler for .Net, to the .Net Foundation.
|
||||
|
||||
The main LLVM subprojects are the core libraries, which provide optimization and code generation; Clang, a C/C++/Objective-C compiler that’s about three times faster than GCC; LLDB, a much faster debugger than GDB; libc++, an implementation of the C++ 11 Standard Library; and OpenMP, for parallel programming.
|
||||
|
||||
-- Martin Heller
|
||||
|
||||

|
||||
|
||||
### Read about more open source winners ###
|
||||
|
||||
InfoWorld's Best of Open Source Awards for 2014 celebrate more than 100 open source projects, from the bottom of the stack to the top. Follow these links to more open source winners:
|
||||
|
||||
[Bossie Awards 2015: The best open source applications][41]
|
||||
|
||||
[Bossie Awards 2015: The best open source application development tools][42]
|
||||
|
||||
[Bossie Awards 2015: The best open source big data tools][43]
|
||||
|
||||
[Bossie Awards 2015: The best open source data center and cloud software][44]
|
||||
|
||||
[Bossie Awards 2015: The best open source desktop and mobile software][45]
|
||||
|
||||
[Bossie Awards 2015: The best open source networking and security software][46]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982920/open-source-tools/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://www.docker.com/
|
||||
[2]:https://nodejs.org/en/
|
||||
[3]:https://iojs.org/en/
|
||||
[4]:https://developers.google.com/v8/?hl=en
|
||||
[5]:http://www.ancestry.com/
|
||||
[6]:http://www.ge.com/
|
||||
[7]:https://www.pearson.com/
|
||||
[8]:https://angularjs.org/
|
||||
[9]:https://builtwith.angularjs.org/
|
||||
[10]:https://facebook.github.io/react/
|
||||
[11]:https://facebook.github.io/react-native/
|
||||
[12]:http://reactjs.net/
|
||||
[13]:http://asp.net/
|
||||
[14]:https://atom.io/
|
||||
[15]:http://brackets.io/
|
||||
[16]:http://www.typescriptlang.org/
|
||||
[17]:http://definitelytyped.org/
|
||||
[18]:http://definitelytyped.org/tsd/
|
||||
[19]:http://swagger.io/
|
||||
[20]:https://github.com/swagger-api/swagger-ui
|
||||
[21]:https://github.com/swagger-api/swagger-codegen
|
||||
[22]:https://github.com/swagger-api/swagger-editor
|
||||
[23]:https://github.com/swagger-api/swagger-js
|
||||
[24]:http://aws.amazon.com/cn/api-gateway/
|
||||
[25]:https://github.com/awslabs/aws-apigateway-importer
|
||||
[26]:https://www.polymer-project.org/
|
||||
[27]:http://ionicframework.com/
|
||||
[28]:https://cordova.apache.org/
|
||||
[29]:http://famous.org/
|
||||
[30]:http://famous.org/framework/
|
||||
[31]:https://www.mongodb.org/
|
||||
[32]:http://www.infoworld.com/article/2878738/nosql/first-look-mongodb-30-for-mature-audiences.html
|
||||
[33]:http://www.infoworld.com/article/2929772/nosql/mongodb-crossroads-growth-or-openness.html
|
||||
[34]:http://www.couchbase.com/nosql-databases/couchbase-server
|
||||
[35]:https://cassandra.apache.org/
|
||||
[36]:http://orientdb.com/
|
||||
[37]:http://rethinkdb.com/
|
||||
[38]:https://www.rust-lang.org/
|
||||
[39]:http://opencv.org/
|
||||
[40]:http://llvm.org/
|
||||
[41]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[42]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[43]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[44]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[45]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[46]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -1,238 +0,0 @@
|
||||
Bossie Awards 2015: The best open source applications
|
||||
================================================================================
|
||||
InfoWorld's top picks in open source business applications, enterprise integration, and middleware
|
||||
|
||||

|
||||
|
||||
### The best open source applications ###
|
||||
|
||||
Applications -- ERP, CRM, HRM, CMS, BPM -- are not only fertile ground for three-letter acronyms, they're the engines behind every modern business. Our top picks in the category include back- and front-office solutions, marketing automation, lightweight middleware, heavyweight middleware, and other tools for moving data around, mixing it together, and magically transforming it into smarter business decisions.
|
||||
|
||||

|
||||
|
||||
### xTuple ###
|
||||
|
||||
Small and midsize companies with light manufacturing or distribution needs have a friend in [xTuple][1]. This modular ERP/CRM combo bundles operations and financial control, product and inventory management, and CRM and sales support. Its relatively simple install lets you deploy all of the modules or only what you need today -- helping trim support costs without sacrificing customization later.
|
||||
|
||||
This summer’s release brought usability improvements to the UI and a generous number of bug fixes. Recent updates also yielded barcode scanning and label printing for mobile warehouse workers, an enhanced workflow module (built with Plv8, a wrapper around Google’s V8 JavaScript engine that lets you write stored procedures for PostgreSQL in JavaScript), and quality management tools that are sure to get mileage on shop floors.
|
||||
|
||||
The xTuple codebase is JavaScript from stem to stern. The server components can all be installed locally, in xTuple’s cloud, or deployed as an appliance. A mobile Web client, and mobile CRM features, augment a good native desktop client.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### Odoo ###
|
||||
|
||||
[Odoo][2] used to be known as OpenERP. Last year the company raised private capital and broadened its scope. Today Odoo is a one-stop shop for back office and customer-facing applications -- replete with content management, business intelligence, and e-commerce modules.
|
||||
|
||||
Odoo 8 fronts accounting, invoicing, project management, resource planning, and customer relationship management tools with a flexible Web interface that can be tailored to your company’s workflow. Add-on modules for warehouse management and HR, as well as for live chat and analytics, round out the solution.
|
||||
|
||||
This year saw Odoo focused primarily on usability updates. A recently released sales planner helps sales groups track KPIs, and a new tips feature lends in-context help. Odoo 9 is right around the corner with alpha builds showing customer portals, Web form creation tools, mobile and VoIP services, and integration hooks to eBay and Amazon.
|
||||
|
||||
Available for Windows and Linux, and as a SaaS offering, Odoo gives small and midsized companies an accessible set of tools to manage virtually every aspect of their business.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### iDempiere ###
|
||||
|
||||
Small and midsize companies have great choices in Odoo and xTuple. Larger manufacturing and distribution companies will need something more. For them, there’s [iDempiere][3] -- a well maintained offshoot of ADempiere with OSGi modularity.
|
||||
|
||||
iDempiere implements a fully loaded ERP, supply chain, and CRM suite right out of the box. Built with Java, iDempiere supports both PostgreSQL and Oracle Database, and it can be customized extensively through modules built to the OSGi specification. iDempiere is perfectly suited to managing complex business scenarios involving multiple partners, requiring dynamic reporting, or employing point-of-sale and warehouse services.
|
||||
|
||||
Being enterprise-ready comes with a price. iDempiere’s feature-rich tools and complexity impose a steep learning curve and require a commitment to integration support. Of course, those costs are offset by savings from the software’s free GPL2 licensing. iDempiere’s easy install script, small resource footprint, and clean interface also help alleviate some of the startup pains. There’s even a virtual appliance available on Sourceforge to get you started.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### SuiteCRM ###
|
||||
|
||||
SugarCRM held the sweet spot in open source CRM since, well, forever. Then last year Sugar announced it would no longer contribute to the open source Community Edition. Into the ensuing vacuum rushed [SuiteCRM][4] – a fork of the final Sugar code.
|
||||
|
||||
SuiteCRM 7.2 creates an experience on a par with SugarCRM Professional’s marketing, sales, and service tools. With add-on modules for workflow, reporting, and security, as well as new innovations like Lucene-driven search, taps for social media, and a beta reveal of new desktop notifications, SuiteCRM is on solid footing.
|
||||
|
||||
The Advanced Open Sales module provides a familiar migration path from Sugar, while commercial support is available from the likes of [SalesAgility][5], the company that forked SuiteCRM in the first place. In little more than a year, SuiteCRM rescued the code, rallied an inspired community, and emerged as a new leader in open source CRM. Who needs Sugar?
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### CiviCRM ###
|
||||
|
||||
We typically focus attention on CRM vis-à-vis small and midsize business requirements. But nonprofit and advocacy groups need to engage with their “customers” too. Enter [CiviCRM][6].
|
||||
|
||||
CiviCRM addresses the needs of nonprofits with tools for fundraising and donation processing, membership management, email tracking, and event planning. Granular access control and security bring role-based permissions to views, keeping paid staff and volunteers partitioned and productive. This year CiviCRM continued to develop with new features like simple A/B testing and monitoring for email campaigns.
|
||||
|
||||
CiviCRM deploys as a plug-in to your WordPress, Drupal, or Joomla content management system -- a dead-simple install if you already have one of these systems in place. If you don’t, CiviCRM is an excellent reason to deploy the CMS. It’s a niche-filling solution that allows nonprofits to start using smarter, tailored tools for managing constituencies, without steep hurdles and training costs.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### Mautic ###
|
||||
|
||||
For marketers, the Internet -- Web, email, social, all of it -- is the stuff dreams are made on. [Mautic][7] allows you to create Web and email campaigns that track and nurture customer engagement, then roll all of the data into detailed reports to gain insight into customer needs and wants and how to meet them.
|
||||
|
||||
Open source options in marketing automation are few, but Mautic’s extensibility stands out even against closed solutions like IBM’s Silverpop. Mautic even integrates with popular third-party email marketing solutions (MailChimp, Constant Contact) and social media platforms (Facebook, Twitter, Google+, Instagram) with quick-connect widgets.
|
||||
|
||||
The developers of Mautic could stand to broaden the features for list segmentation and improve the navigability of their UI. Usability is also hindered by sparse documentation. But if you’re willing to rough it out long enough to learn your way, you’ll find a gem -- and possibly even gold -- in Mautic.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### OrangeHRM ###
|
||||
|
||||
The commercial software market in the human resource management space is rather fragmented, with Talent, HR, and Workforce Management startups all vying for a slice of the pie. It’s little wonder the open source world hasn’t found much direction either, with the most ambitious HRM solutions often locked inside larger ERP distributions. [OrangeHRM][8] is a standout.
|
||||
|
||||
OrangeHRM tackles employee administration from recruitment and applicant tracking to performance reviews, with good audit trails throughout. An employee portal provides self-serve access to personal employment information, time cards, leave requests, and personnel documents, helping reduce demands on HR staff.
|
||||
|
||||
OrangeHRM doesn’t yet address niche aspects like talent management (social media, collaboration, knowledge banks), but it’s remarkably full-featured. Professional and Enterprise options offer more advanced functionality (in areas such as recruitment, training, on/off-boarding, document management, and mobile device access), while community modules are available for the likes of Active Directory/LDAP integration, advanced reporting, and even insurance benefit management.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### LibreOffice ###
|
||||
|
||||
[LibreOffice][9] is the easy choice for best open source office productivity suite. Originally forked from OpenOffice, Libre has been moving at a faster clip than OpenOffice ever since, drawing more developers and producing more new features than its rival.
|
||||
|
||||
LibreOffice 5.0, released only last month, offers UX improvements that truly enhance usability (like visual previews to style changes in the sidebar), brings document editing to Android devices (previously a view-only prospect), and finally delivers on a 64-bit Windows codebase.
|
||||
|
||||
LibreOffice still lacks a built-in email client and a personal information manager, not to mention the real-time collaborative document editing available in Microsoft Office. But Libre can run off of a USB flash disk for portability, natively supports a greater number of graphic and file formats, and creates hybrid PDFs with embedded ODF files for full-on editing. Libre even imports Apple Pages documents, in addition to opening and saving all Microsoft Office formats.
|
||||
|
||||
LibreOffice has done a solid job of tightening its codebase and delivering enhancements at a regular clip. With a new cloud version under development, LibreOffice will soon be more liberating than ever.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### Bonita BPM ###
|
||||
|
||||
Open source BPM has become a mature, cost-effective alternative to the top proprietary solutions. Having led the charge since 2009, Bonitasoft continues to raise the bar. The new [Bonita BPM 7][10] release impresses with innovative features that simplify code generation and shorten development cycles for BPM app creation.
|
||||
|
||||
Most important to the new version, though, is better abstraction of underlying core business logic from UI and data components, allowing UIs and processes to be developed independently. This new MVC approach reduces downtime for live upgrades (no more recompilation!) and eases application maintenance.
|
||||
|
||||
Bonita contains a winning set of connectors to a broad range of enterprise systems (ERP, CRM, databases) as well as to Web services. Complementing its process weaving tools, a new form designer (built on AngularJS/Bootstrap) goes a long way toward improving UI creation for the Web-centric and mobile workforce.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### Camunda BPM ###
|
||||
|
||||
Many open source solutions, like Bonita BPM, offer solid, drop-in functionality. Dig into the code base, though, and you may find it’s not the cleanest to build upon. Enterprise Java developers who hang out under the hood should check out [Camunda BPM][11].
|
||||
|
||||
Forked from Alfresco Activiti (a creation of former Red Hat jBPM developers), Camunda BPM delivers a tight, Java-based BPMN 2.0 engine in support of human workflow activities, case management, and systems process automation that can be embedded in your Java apps or run as a container service in Tomcat. Camunda’s ecosystem offers an Eclipse plug-in for process modeling and the Cockpit dashboard brings real-time monitoring and management over running processes.
|
||||
|
||||
The Enterprise version adds WebSphere and WebLogic Server support. Additional incentives for the Enterprise upgrade include Saxon-driven XSLT templating (sidestepping the scripting engine) and add-ons to improve process management and exception handling.
|
||||
|
||||
Camunda is a solid BPM engine ready for build-out and one of the first open source process managers to introduce DMN (Decision Model and Notation) support, which helps to simplify complex rules-based modeling alongside BPMN. DMN support is currently at the alpha stage.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### Talend Open Studio ###
|
||||
|
||||
No open source ETL or EAI solution comes close to [Talend Open Studio][12] in functionality, performance, or support of modern integration trends. This year Talend unleashed Open Studio 6, a new version with a streamlined UI and smarter tooling that brings it more in line with Talend’s cloud-based offering.
|
||||
|
||||
Using Open Studio you can visually design, test, and debug orchestrations that connect, transform, and synchronize data across a broad range of real-time applications and data resources. Talend’s wealth of connectors provides support for most any endpoint -- from flat files to Hadoop to Amazon S3. Packaged editions focus on specific scenarios such as big data integration, ESB, and data integrity monitoring.
|
||||
|
||||
New support for Java 8 brings a speed boost. The addition of support for MariaDB and for in-memory processing with MemSQL, as well as updates to the ESB engine, keep Talend in step with the community’s needs. Version 6 was a long time coming, but no less welcome for that. Talend Open Studio is still first in managing complex data integration -- in-house, in the cloud, or increasingly, a combination of the two.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### Warewolf ESB ###
|
||||
|
||||
Complex integration patterns may demand the strengths of a Talend to get the job done. But for many lightweight microservices, the overhead of a full-fledged enterprise integration solution is extreme overkill.
|
||||
|
||||
[Warewolf ESB][13] combines a streamlined .Net-based process engine with visual development tools to provide for dead simple messaging and application payload routing in a native Windows environment. The Warewolf ESB is an “easy service bus,” not an enterprise service bus.
|
||||
|
||||
Drag-and-drop tooling in the design studio makes quick work of configuring connections and logic flows. Built-in wizardry handles Web services definitions and database calls, and it can even tap Windows DLLs and the command line directly. Using the visual debugger, you can inspect execution streams (if not yet actually step through them), then package everything for remote deployment.
|
||||
|
||||
Warewolf is still a .40.5 release and undergoing major code changes. It also lacks native connectors, easy transforms, and any means of scalability management. Be aware that the precompiled install demands collection of some usage statistics (I wish they would stop that). But Warewolf ESB is fast, free, and extensible. It’s a quirky, upstart project that offers definite benefits to Windows integration architects.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### KNIME ###
|
||||
|
||||
[KNIME][14] takes a code-free approach to predictive analytics. Using a graphical workbench, you wire together workflows from an abundant library of processing nodes, which handle data access, transformation, analysis, and visualization. With KNIME, you can pull data from databases and big data platforms, run ETL transformations, perform data mining with R, and produce custom reports in the end.
|
||||
|
||||
The company was busy this year rolling out the KNIME 2.12 update. The new release introduces MongoDB support, XPath nodes with autoquery creation, and a new view controller (based on the D3 JavaScript library) that creates interactive data visualizations on the fly. It also includes additional statistical nodes and a REST interface (KNIME Server edition) that provides services-based access to workflows.
|
||||
|
||||
KNIME’s core analytics engine is free open source. The company offers several fee-based extensions for clustering and collaboration. (A portion of your licensing fee actually funds the open source project.) KNIME Server (on-premise or cloud) ups the ante with security, collaboration, and workflow repositories -- all serving to inject analytics more productively throughout your business lines.
|
||||
|
||||
-- James R. Borck
|
||||
|
||||

|
||||
|
||||
### Teiid ###
|
||||
|
||||
[Teiid][15] is a data virtualization system that allows applications to use data from multiple, heterogeneous data stores. Currently a JBoss project, Teiid is backed by years of development from MetaMatrix and a long history of addressing the data access needs of the largest enterprise environments. I even see [uses for Teiid in Hadoop and big data environments][16].
|
||||
|
||||
In essence, Teiid allows you to connect all of your data sources into a “virtual” mega data source. You can define caching semantics, transforms, and other “configuration not code” transforms to load from multiple data sources using plain old SQL, XQuery, or procedural queries.
|
||||
|
||||
Teiid is primarily accessible through JBDC and has built-in support for Web services. Red Hat sells Teiid as [JBoss Data Virtualization][17].
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### Read about more open source winners ###
|
||||
|
||||
InfoWorld's Best of Open Source Awards for 2014 celebrate more than 100 open source projects, from the bottom of the stack to the top. Follow these links to more open source winners:
|
||||
|
||||
[Bossie Awards 2015: The best open source applications][18]
|
||||
|
||||
[Bossie Awards 2015: The best open source application development tools][19]
|
||||
|
||||
[Bossie Awards 2015: The best open source big data tools][20]
|
||||
|
||||
[Bossie Awards 2015: The best open source data center and cloud software][21]
|
||||
|
||||
[Bossie Awards 2015: The best open source desktop and mobile software][22]
|
||||
|
||||
[Bossie Awards 2015: The best open source networking and security software][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982622/open-source-tools/bossie-awards-2015-the-best-open-source-applications.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:http://xtuple.org/
|
||||
[2]:http://odoo.com/
|
||||
[3]:http://idempiere.org/
|
||||
[4]:http://suitecrm.com/
|
||||
[5]:http://salesagility.com/
|
||||
[6]:http://civicrm.org/
|
||||
[7]:https://www.mautic.org/
|
||||
[8]:http://www.orangehrm.com/
|
||||
[9]:http://libreoffice.org/
|
||||
[10]:http://www.bonitasoft.com/
|
||||
[11]:http://camunda.com/
|
||||
[12]:http://talend.com/
|
||||
[13]:http://warewolf.io/
|
||||
[14]:http://www.knime.org/
|
||||
[15]:http://teiid.jboss.org/
|
||||
[16]:http://www.infoworld.com/article/2922180/application-development/database-virtualization-or-i-dont-want-to-do-etl-anymore.html
|
||||
[17]:http://www.jboss.org/products/datavirt/overview/
|
||||
[18]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[19]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[20]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[21]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[22]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[23]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -1,287 +0,0 @@
|
||||
Bossie Awards 2015: The best open source big data tools
|
||||
================================================================================
|
||||
InfoWorld's top picks in distributed data processing, streaming analytics, machine learning, and other corners of large-scale data analytics
|
||||
|
||||

|
||||
|
||||
### The best open source big data tools ###
|
||||
|
||||
How many Apache projects can sit on a pile of big data? Fire up your Hadoop cluster, and you might be able to count them. Among this year's Bossies in big data, you'll find the fastest, widest, and deepest newfangled solutions for large-scale SQL, stream processing, sort-of stream processing, and in-memory analytics, not to mention our favorite maturing members of the Hadoop ecosystem. It seems everyone has a nail to drive into MapReduce's coffin.
|
||||
|
||||

|
||||
|
||||
### Spark ###
|
||||
|
||||
With hundreds of contributors, [Spark][1] is one of the most active and fastest-growing Apache projects, and with heavyweights like IBM throwing their weight behind the project and major corporations bringing applications into large-scale production, the momentum shows no signs of letting up.
|
||||
|
||||
The sweet spot for Spark continues to be machine learning. Highlights since last year include the replacement of the SchemaRDD with a Dataframes API, similar to those found in R and Pandas, making data access much simpler than with the raw RDD interface. Also new are ML pipelines for building repeatable machine learning workflows, expanded and optimized support for various storage formats, simpler interfaces to machine learning algorithms, improvements in the display of cluster resources usage, and task tracking.
|
||||
|
||||
On by default in Spark 1.5 is the off-heap memory manager, Tungsten, which offers much faster processing by fine-tuning data structure layout in memory. Finally, the new website, [spark-packages.org][2], with more than 100 third-party libraries, adds many useful features from the community.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Storm ###
|
||||
|
||||
[Apache Storm][3] is a Clojure-based distributed computation framework primarily for streaming real-time analytics. Storm is based on the [disruptor pattern][4] for low-latency complex event processing created LMAX. Unlike Spark, Storm can do single events as opposed to “micro-batches,” and it has a lower memory footprint. In my experience, it scales better for streaming, especially when you’re mainly streaming to ingest data into other data sources.
|
||||
|
||||
Storm’s profile has been eclipsed by Spark, but Spark is inappropriate for many streaming applications. Storm is frequently used with Apache Kafka.
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### H2O ###
|
||||
|
||||
[H2O][5] is a distributed, in-memory processing engine for machine learning that boasts an impressive array of algorithms. Previously only available for R users, version 3.0 adds Python and Java language bindings, as well as a Spark execution engine for the back end. The best way to view H20 is as a very large memory extension of your R environment. Instead of working directly on large data sets, the R extensions communicate via a REST API with the H2O cluster, where H2O does the heavy lifting.
|
||||
|
||||
Several useful R packages such as ddply have been wrapped, allowing you to use them on data sets larger than the amount of RAM on the local machine. You can run H2O on EC2, on a Hadoop/YARN cluster, and on Docker containers. With Sparkling Water (Spark plus H2O) you can access Spark RDDs on the cluster side by side to, for example, process a data frame with Spark before passing it to an H2O machine learning algorithm.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Apex ###
|
||||
|
||||
[Apex][6] is an enterprise-grade, big data-in-motion platform that unifies stream processing as well as batch processing. A native YARN application, Apex processes streaming data in a scalable, fault-tolerant manner and provides all the common stream operators out of the box. One of the best things about Apex is that it natively supports the common event processing guarantees (exactly once, at least once, at most once). Formerly a commercial product by DataTorrent, Apex's roots show in the quality of the documentation, examples, code, and design. Devops and application development are cleanly separated, and user code generally doesn't have to be aware that it is running in a streaming cluster.
|
||||
|
||||
A related project, [Malhar][7], offers more than 300 commonly used operators and application templates that implement common business logic. The Malhar libraries significantly reduce the time it takes to develop an Apex application, and there are connectors (operators) for storage, file systems, messaging systems, databases, and nearly anything else you might want to connect to from an application. The operators can all be extended or customized to meet individual business's requirements. All Malhar components are available under the Apache license.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Druid ###
|
||||
|
||||
[Druid][8], which moved to a commercially friendly Apache license in February of this year, is best described as a hybrid, “event streams meet OLAP” solution. Originally developed to analyze online events for ad markets, Druid allows users to do arbitrary and interactive exploration of time series data. Some of the key features include low-latency ingest of events, fast aggregations, and approximate and exact calculations.
|
||||
|
||||
At the heart of Druid is a custom data store that uses specialized nodes to handle each part of the problem. Real-time ingest is managed by real-time nodes (JVMs) that eventually flush data to historical nodes that are responsible for data that has aged. Broker nodes direct queries in a scatter-gather fashion to both real-time and historical nodes to give the user a complete picture of events. Benchmarked at a sustained 500K events per second and 1 million events per second peak, Druid is ideal as a real-time dashboard for ad-tech, network traffic, and other activity streams.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Flink ###
|
||||
|
||||
At its core, [Flink][9] is a data flow engine for event streams. Although superficially similar to Spark, Flink takes a different approach to in-memory processing. First, Flink was designed from the start as a stream processor. Batch is simply a special case of a stream with a beginning and an end, and Flink offers APIs for dealing with each case, the DataSet API (batch) and the DataStream API. Developers coming from the MapReduce world should feel right at home working with the DataSet API, and porting applications to Flink should be straightforward. In many ways Flink mirrors the simplicity and consistency that helped make Spark so popular. Like Spark, Flink is written in Scala.
|
||||
|
||||
The developers of Flink clearly thought out usage and operations too: Flink works natively with YARN and Tez, and it uses an off-heap memory management scheme to work around some of the JVM limitations. A peek at the Flink JIRA site shows a healthy pace of development, and you’ll find an active community on the mailing lists and on StackOverflow as well.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Elasticsearch ###
|
||||
|
||||
[Elasticsearch][10] is a distributed document search server based on [Apache Lucene][11]. At its heart, Elasticsearch builds indices on JSON-formatted documents in nearly real time, enabling fast, full-text, schema-free queries. Combined with the open source Kibana dashboard, you can create impressive visualizations of your real-time data in a simple point-and-click fashion.
|
||||
|
||||
Elasticsearch is easy to set up and easy to scale, automatically making use of new hardware by rebalancing shards as required. The query syntax isn't at all SQL-like, but it is intuitive enough for anyone familiar with JSON. Most users won't be interacting at that level anyway. Developers can use the native JSON-over-HTTP interface or one of the several language bindings available, including Ruby, Python, PHP, Perl, .Net, Java, and JavaScript.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### SlamData ###
|
||||
|
||||
If you are seeking a user-friendly tool to visualize and understand your newfangled NoSQL data, take a look at [SlamData][12]. SlamData allows you to query nested JSON data using familiar SQL syntax, without relocation or transformation.
|
||||
|
||||
One of the technology’s main features is its connectors. From MongoDB to HBase, Cassandra, and Apache Spark, SlamData taps external data sources with the industry's most advanced “pushdown” processing technology, performing transformations and analytics close to the data.
|
||||
|
||||
While you might ask, “Wouldn’t I be better off building a data lake or data warehouse?” consider the companies that were born in NoSQL. Skipping the ETL and simply connecting a visualization tool to a replica offers distinct advantages -- not only in terms of how up-to-date the data is, but in how many moving parts you have to maintain.
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### Drill ###
|
||||
|
||||
[Drill][13] is a distributed system for interactive analysis of large-scale data sets, inspired by [Google's Dremel][14]. Designed for low-latency analysis of nested data, Drill has a stated design goal of scaling to 10,000 servers and querying petabytes of data and trillions of records.
|
||||
|
||||
Nested data can be obtained from a variety of data sources (such as HDFS, HBase, Amazon S3, and Azure Blobs) and in multiple formats (including JSON, Avro, and protocol buffers), and you don't need to specify a schema up front (“schema on read”).
|
||||
|
||||
Drill uses ANSI SQL:2003 for its query language, so there's no learning curve for data engineers to overcome, and it allows you to join data across multiple data sources (for example, joining a table in HBase with logs in HDFS). Finally, Drill offers ODBC and JDBC interfaces to connect your favorite BI tools.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### HBase ###
|
||||
|
||||
[HBase][15] reached the 1.x milestone this year and continues to improve. Like other nonrelational distributed datastores, HBase excels at returning search results very quickly and for this reason is often used to back search engines, such as the ones at eBay, Bloomberg, and Yahoo. As a stable and mature software offering, HBase does not get fresh features as frequently as newer projects, but that's often good for enterprises.
|
||||
|
||||
Recent improvements include the addition of high-availability region servers, support for rolling upgrades, and YARN compatibility. Features in the works include scanner updates that promise to improve performance and the ability to use HBase as a persistent store for streaming applications like Storm and Spark. HBase can also be queried SQL style via the [Phoenix][16] project, now out of incubation, whose SQL compatibility is steadily improving. Phoenix recently added a Spark connector and the ability to add custom user-defined functions.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Hive ###
|
||||
|
||||
Although stable and mature for several years, [Hive][17] reached the 1.0 version milestone this year and continues to be the best solution when really heavy SQL lifting (many petabytes) is required. The community continues to focus on improving the speed, scale, and SQL compliance of Hive. Currently at version 1.2, significant improvements since its last Bossie include full ACID semantics, cross-data center replication, and a cost-based optimizer.
|
||||
|
||||
Hive 1.2 also brought improved SQL compliance, making it easier for organizations to use it to off-load ETL jobs from their existing data warehouses. In the pipeline are speed improvements with an in-memory cache called LLAP (which, from the looks of the JIRAs, is about ready for release), the integration of Spark machine learning libraries, and improved SQL constructs like nonequi joins, interval types, and subqueries.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Kylin ###
|
||||
|
||||
[Kylin][18] is an application developed at eBay for processing very large OLAP cubes via ANSI SQL, a task familiar to most data analysts. If you think about how many items are on sale now and in the past at eBay, and all the ways eBay might want to slice and dice data related to those items, you will begin to understand the types of queries Kylin was designed for.
|
||||
|
||||
Like most other analysis applications, Kylin supports multiple access methods, including JDBC, ODBC, and a REST API for programmatic access. Although Kylin is still in incubation at Apache, and the community nascent, the project is well documented and the developers are responsive and eager to understand customer use cases. Getting up and running with a starter cube was a snap. If you have a need for analysis of extremely large cubes, you should take a look at Kylin.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### CDAP ###
|
||||
|
||||
[CDAP][19] (Cask Data Access Platform) is a framework running on top of Hadoop that abstracts away the complexity of building and running big data applications. CDAP is organized around two core abstractions: data and applications. CDAP Datasets are logical representations of data that behave uniformly regardless of the underlying storage layer; CDAP Streams provide similar support for real-time data.
|
||||
|
||||
Applications use CDAP services for things such as distributed transactions and service discovery to shield developers from the low-level details of Hadoop. CDAP comes with a data ingestion framework and a few prebuilt applications and “packs” for common tasks like ETL and website analytics, along with support for testing, debugging, and security. Like most formerly commercial (closed source) projects, CDAP benefits from good documentation, tutorials, and examples.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Ranger ###
|
||||
|
||||
Security has long been a sore spot with Hadoop. It isn’t (as is frequently reported) that Hadoop is “insecure” or “has no security.” Rather, the truth was more that Hadoop had too much security, though not in a good way. I mean that every component had its own authentication and authorization implementation that wasn’t integrated with the rest of platform.
|
||||
|
||||
Hortonworks acquired XA/Secure in May, and [a few renames later][20] we have [Ranger][21]. Ranger pulls many of the key components of Hadoop together under one security umbrella, allowing you to set a “policy” that ties your Hadoop security to your existing ACL-based Active Directory authentication and authorization. Ranger gives you one place to manage Hadoop access control, one place to audit, one place to manage the encryption, and a pretty Web page to do it from.
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### Mesos ###
|
||||
|
||||
[Mesos][22], developed at the [AMPLab][23] at U.C. Berkeley that also brought us Spark, takes a different approach to managing cluster computing resources. The best way to describe Mesos is as a distributed microkernel for the data center. Mesos provides a minimal set of operating system mechanisms like inter-process communications, disk access, and memory to higher-level applications, called “frameworks” in Mesos-speak, that run in what is analogous to user space. Popular frameworks for Mesos include [Chronos][24] and [Aurora][25] for building ETL pipelines and job scheduling, and a few big data processing applications including Hadoop, Storm, and Spark, which have been ported to run as Mesos frameworks.
|
||||
|
||||
Mesos applications (frameworks) negotiate for cluster resources using a two-level scheduling mechanism, so writing a Mesos application is unlikely to feel like a familiar experience to most developers. Although Mesos is a young project, momentum is growing, and with Spark being an exceptionally good fit for Mesos, we're likely to see more from Mesos in the coming years.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### NiFi ###
|
||||
|
||||
[NiFi][26] is an incubating Apache project to automate the flow of data between systems. It doesn't operate in the traditional space that Kafka and Storm do, but rather in the space between external devices and the data center. NiFi was originally developed by the NSA and donated to the open source community in 2014. It has a strong community of developers and users within various government agencies.
|
||||
|
||||
NiFi isn't like anything else in the current big data ecosystem. It is much closer to a tradition EAI (enterprise application integration) tool than a data processing platform, although simple transformations are possible. One interesting feature is the ability to debug and change data flows in real time. Although not quite a REPL (read, eval, print loop), this kind of paradigm dramatically shortens the development cycle by not requiring a compile-deploy-test-debug workflow. Other interesting features include a strong “chain of custody,” where each piece of data can be tracked from beginning to end, along with any changes made along the way. You can also prioritize data flows so that time-sensitive information can be received as quickly as possible, bypassing less time-critical events.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Kafka ###
|
||||
|
||||
[Kafka][27] has emerged as the de-facto standard for distributed publish-subscribe messaging in the big data space. Its design allows brokers to support thousands of clients at high rates of sustained message throughput, while maintaining durability through a distributed commit log. Kafka does this by maintaining what is essentially a single log file in HDFS. Since HDFS is a distributed storage system that keeps redundant copies, Kafka is protected.
|
||||
|
||||
When consumers want to read messages, Kafka looks up their offset in the central log and sends them. Because messages are not deleted immediately, adding consumers or replaying historical messages does not impose additional costs. Kafka has been benchmarked at 2 million writes per second by its developers at LinkedIn. Despite Kafka’s sub-1.0 version number, Kafka is a mature and stable product, in use in some of the largest clusters in the world.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### OpenTSDB ###
|
||||
|
||||
[OpenTSDB][28] is a time series database built on HBase. It was designed specifically for analyzing data collected from applications, mobile devices, networking equipment, and other hardware devices. The custom HBase schema used to store the time series data has been designed for fast aggregations and minimal storage requirements.
|
||||
|
||||
By using HBase as the underlying storage layer, OpenTSDB gains the distributed and reliable characteristics of that system. Users don't interact with HBase directly; instead events are written to the system via the time series daemon (TSD), which can be scaled out as required to handle high-throughput situations. There are a number of prebuilt connectors to publish data to OpenTSDB, and clients to read data from Ruby, Python, and other languages. OpenTSDB isn't strong on creating interactive graphics, but several third-party tools fill that gap. If you are already using HBase and want a simple way to store event data, OpenTSDB might be just the thing.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Jupyter ###
|
||||
|
||||
Everybody's favorite notebook application went generic. [Jupyter][29] is “the language-agnostic parts of IPython” spun out into an independent package. Although Jupyter itself is written in Python, the system is modular. Now you can have an IPython-like interface, along with notebooks for sharing code, documentation, and data visualizations, for nearly any language you like.
|
||||
|
||||
At least [50 language][30] kernels are already supported, including LISP, R, Ruby, F#, Perl, and Scala. In fact, even IPython itself is simply a Python module for Jupyter. Communication with the language kernel is via a REPL (read, eval, print loop) protocol, similar to [nREPL][31] or [Slime][32]. It is nice to see such a useful piece of software receiving significant [nonprofit funding][33] to further its development, such as parallel execution and multi-user notebooks. Behold, open source at its best.
|
||||
|
||||
-- Steven Nunez
|
||||
|
||||

|
||||
|
||||
### Zeppelin ###
|
||||
|
||||
While still in incubation, [Apache Zeppelin][34] is nevertheless stirring the data analytics and visualization pot. The Web-based notebook enables users to ingest, discover, analyze, and visualize their data. The notebook also allows you to collaborate with others to make data-driven, interactive documents incorporating a growing number of programming languages.
|
||||
|
||||
This technology also boasts an integration with Spark and an interpreter concept allowing any language or data processing back end to be plugged into Zeppelin. Currently Zeppelin supports interpreters such as Scala, Python, SparkSQL, Hive, Markdown, and Shell.
|
||||
|
||||
Zeppelin is still immature. I wanted to put a demo up but couldn’t find an easy way to disable “shell” as an execution option (among other things). However, it already looks better visually than IPython Notebook, which is the popular incumbent in this space. If you don’t want to spring for DataBricks Cloud or need something open source and extensible, this is the most promising distributed computing notebook around -- especially if you’re a Sparky type.
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### Read about more open source winners ###
|
||||
|
||||
InfoWorld's Best of Open Source Awards for 2014 celebrate more than 100 open source projects, from the bottom of the stack to the top. Follow these links to more open source winners:
|
||||
|
||||
[Bossie Awards 2015: The best open source applications][35]
|
||||
|
||||
[Bossie Awards 2015: The best open source application development tools][36]
|
||||
|
||||
[Bossie Awards 2015: The best open source big data tools][37]
|
||||
|
||||
[Bossie Awards 2015: The best open source data center and cloud software][38]
|
||||
|
||||
[Bossie Awards 2015: The best open source desktop and mobile software][39]
|
||||
|
||||
[Bossie Awards 2015: The best open source networking and security software][40]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982429/open-source-tools/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://spark.apache.org/
|
||||
[2]:http://spark-packages.org/
|
||||
[3]:https://storm.apache.org/
|
||||
[4]:https://lmax-exchange.github.io/disruptor/
|
||||
[5]:http://h2o.ai/product/
|
||||
[6]:https://www.datatorrent.com/apex/
|
||||
[7]:https://github.com/DataTorrent/Malhar
|
||||
[8]:https://druid.io/
|
||||
[9]:https://flink.apache.org/
|
||||
[10]:https://www.elastic.co/products/elasticsearch
|
||||
[11]:http://lucene.apache.org/
|
||||
[12]:http://teiid.jboss.org/
|
||||
[13]:https://drill.apache.org/
|
||||
[14]:http://research.google.com/pubs/pub36632.html
|
||||
[15]:http://hbase.apache.org/
|
||||
[16]:http://phoenix.apache.org/
|
||||
[17]:https://hive.apache.org/
|
||||
[18]:https://kylin.incubator.apache.org/
|
||||
[19]:http://cdap.io/
|
||||
[20]:http://www.infoworld.com/article/2973381/application-development/apache-ranger-chuck-norris-hadoop-security.html
|
||||
[21]:https://ranger.incubator.apache.org/
|
||||
[22]:http://mesos.apache.org/
|
||||
[23]:https://amplab.cs.berkeley.edu/
|
||||
[24]:http://nerds.airbnb.com/introducing-chronos/
|
||||
[25]:http://aurora.apache.org/
|
||||
[26]:http://nifi.apache.org/
|
||||
[27]:https://kafka.apache.org/
|
||||
[28]:http://opentsdb.net/
|
||||
[29]:http://jupyter.org/
|
||||
[30]:http://https//github.com/ipython/ipython/wiki/IPython-kernels-for-other-languages
|
||||
[31]:https://github.com/clojure/tools.nrepl
|
||||
[32]:https://github.com/slime/slime
|
||||
[33]:http://blog.jupyter.org/2015/07/07/jupyter-funding-2015/
|
||||
[34]:https://zeppelin.incubator.apache.org/
|
||||
[35]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[36]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[37]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[38]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[39]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[40]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -1,261 +0,0 @@
|
||||
Bossie Awards 2015: The best open source data center and cloud software
|
||||
================================================================================
|
||||
InfoWorld's top picks of the year in open source platforms, infrastructure, management, and orchestration software
|
||||
|
||||

|
||||
|
||||
### The best open source data center and cloud software ###
|
||||
|
||||
You might have heard about this new thing called Docker containers. Developers love them because you can build them with a script, add services in layers, and push them right from your MacBook Pro to a server for testing. It works because they're superlightweight, unlike those now-archaic virtual machines. Containers -- and other lightweight approaches to deliver services -- are changing the shape of operating systems, applications, and the tools to manage them. Our Bossie winners in data center and cloud are leading the charge.
|
||||
|
||||

|
||||
|
||||
### Docker Machine, Compose, and Swarm ###
|
||||
|
||||
Docker’s open source container technology has been adopted by the major public clouds and is being built into the next version of Windows Server. Allowing developers and operations teams to separate applications from infrastructure, Docker is a powerful data center automation tool.
|
||||
|
||||
However, containers are only part of the Docker story. Docker also provides a series of tools that allow you to use the Docker API to automate the entire container lifecycle, as well as handling application design and orchestration.
|
||||
|
||||
[Machine][1] allows you to automate the provisioning of Docker Containers. Starting with a command line, you can use a single line of code to target one or more hosts, deploy the Docker engine, and even join it to a Swarm cluster. There’s support for most hypervisors and cloud platforms – all you need are your access credentials.
|
||||
|
||||
[Swarm][2] handles clustering and scheduling, and it can be integrated with Mesos for more advanced scheduling capabilities. You can use Swarm to build a pool of container hosts, allowing your apps to scale out as demand increases. Applications and all of their dependencies can be defined with [Compose][3], which lets you link containers together into a distributed application and launch them as a group. Compose descriptions work across platforms, so you can take a developer configuration and quickly deploy in production.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### CoreOS and Rkt ###
|
||||
|
||||
A thin, lightweight server OS, [CoreOS][4] is based on Google’s Chromium OS. Instead of using a package manager to install functions, it’s designed to be used with Linux containers. By using containers to extend a thin core, CoreOS allows you to quickly deploy applications, working well on cloud infrastructures.
|
||||
|
||||
CoreOS’s container management tooling, fleet, is designed to treat a cluster of CoreOS servers as a single unit, with tools for managing high availability and for deploying containers to the cluster based on resource availability. A cross-cluster key/value store, etcd, handles device management and supports service discovery. If a node fails, etcd can quickly restore state on a new replica, giving you a distributed configuration management platform that’s linked to CoreOS’s automated update service.
|
||||
|
||||
While CoreOS is perhaps best known for its Docker support, the CoreOS team is developing its own container runtime, rkt, with its own container format, the App Container Image. Also compatible with Docker containers, rkt has a modular architecture that allows different containerization systems (even hardware virtualization, in a proof of concept from Intel) to be plugged in. However, rkt is still in the early stages of development, so isn’t quite production ready.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### RancherOS ###
|
||||
|
||||
As we abstract more and more services away from the underlying operating system using containers, we can start thinking about what tomorrow’s operating system will look like. Similar to our applications, it’s going to be a modular set of services running on a thin kernel, self-configuring to offer only the services our applications need.
|
||||
|
||||
[RancherOS][5] is a glimpse of what that OS might look like. Blending the Linux kernel with Docker, RancherOS is a minimal OS suitable for hosting container-based applications in cloud infrastructures. Instead of using standard Linux packaging techniques, RancherOS leverages Docker to host Linux user-space services and applications in separate container layers. A low-level Docker instance is first to boot, hosting system services in their own containers. Users' applications run in a higher-level Docker instance, separate from the system containers. If one of your containers crashes, the host keeps running.
|
||||
|
||||
RancherOS is only 20MB in size, so it's easy to replicate across a data center. It’s also designed to be managed using automation tools, not manually, with API-level access that works with Docker’s management tools as well as with Rancher Labs’ own cloud infrastructure and management tools.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Kubernetes ###
|
||||
|
||||
Google’s [Kubernetes][6] container orchestration system is designed to manage and run applications built in Docker and Rocket containers. Focused on managing microservice applications, Kubernetes lets you distribute your containers across a cluster of hosts, while handling scaling and ensuring managed services run reliably.
|
||||
|
||||
With containers providing an application abstraction layer, Kubernetes is an application-centric management service that supports many modern development paradigms, with a focus on user intent. That means you launch applications, and Kubernetes will manage the containers to run within the parameters you set, using the Kubernetes scheduler to make sure it gets the resources it needs. Containers are grouped into pods and managed by a replication engine that can recover failed containers or add more pods as applications scale.
|
||||
|
||||
Kubernetes powers Google’s own Container Engine, and it runs on a range of other cloud and data center services, including AWS and Azure, as well as vSphere and Mesos. Containers can be either loosely or tightly coupled, so applications not designed for cloud PaaS operations can be migrated to the cloud as a tightly coupled set of containers. Kubernetes also supports rapid deployment of applications to a cluster, giving you an endpoint for a continuous delivery process.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Mesos ###
|
||||
|
||||
Turning a data center into a private or public cloud requires more than a hypervisor. It requires a new operating layer that can manage the data center resources as if they were a single computer, handling resources and scheduling. Described as a “distributed systems kernel,” [Apache Mesos][7] allows you to manage thousands of servers, using containers to host applications and APIs to support parallel application development.
|
||||
|
||||
At the heart of Mesos is a set of daemons that expose resources to a central scheduler. Tasks are distributed across nodes, taking advantage of available CPU and memory. One key approach is the ability for applications to reject offered resources if they don’t meet requirements. It’s an approach that works well for big data applications, and you can use Mesos to run Hadoop and Cassandra distributed databases, as well as Apache’s own Spark data processing engine. There’s also support for the Jenkins continuous integration server, allowing you to run build and test workers in parallel on a cluster of servers, dynamically adjusting the tasks depending on workload.
|
||||
|
||||
Designed to run on Linux and Mac OS X, Mesos has also recently been ported to Windows to support the development of scalable parallel applications on Azure.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### SmartOS and SmartDataCenter ###
|
||||
|
||||
Joyent’s [SmartDataCenter][8] is the software that runs its public cloud, adding a management platform on top of its [SmartOS][9] thin server OS. A descendent of OpenSolaris that combines Zones containers and the KVM hypervisor, SmartOS is an in-memory operating system, quick to boot from a USB stick and run on bare-metal servers.
|
||||
|
||||
Using SmartOS, you can quickly deploy a set of lightweight servers that can be programmatically managed via a set of JSON APIs, with functionality delivered via virtual machines, downloaded by built-in image management tools. Through the use of VMs, all userland operations are isolated from the underlying OS, reducing the security exposure of both the host and guests.
|
||||
|
||||
SmartDataCenter runs on SmartOS servers, with one server running as a dedicated management node, and the rest of a cluster operating as compute nodes. You can get started with a Cloud On A Laptop build (available as a VMware virtual appliance) that lets you experiment with the management server. In a live data center, you’ll deploy SmartOS on your servers, using ZFS to handle storage – which includes your local image library. Services are deployed as images, with components stored in an object repository.
|
||||
|
||||
The combination of SmartDataCenter and SmartOS builds on the experience of Joyent’s public cloud, giving you a tried and tested set of tools that can help you bootstrap your own cloud data center. It’s an infrastructure focused on virtual machines today, but laying the groundwork for tomorrow. A related Joyent project, [sdc-docker][10], exposes an entire SmartDataCenter cluster as a single Docker host, driven by native Docker commands.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Sensu ###
|
||||
|
||||
Managing large-scale data centers isn’t about working with server GUIs, it’s about automating scripts based on information from monitoring tools and services, routing information from sensors and logs, and then delivering actions to applications. One tool that’s beginning to offer this functionality is [Sensu][11], often described as a “monitoring router.”
|
||||
|
||||
Scripts running across your data center deliver information to Sensu, which then routes it to the appropriate handler, using a publish-and-subscribe architecture based on RabbitMQ. Servers can be distributed, delivering published check results to handler code. You might see results in email, or in a Slack room, or in Sensu’s own dashboards. Message formats are defined in JSON files, or mutators used to format data on the fly, and messages can be filtered to one or more event handlers.
|
||||
|
||||
Sensu is still a relatively young tool, but it’s one that shows a lot of promise. If you’re going to automate your data center, you’re going to need a tool like this not only to show you what’s happening, but to deliver that information where it’s most needed. A commercial option adds support for integration with third-party applications, but much of what you need to manage a data center is in the open source release.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Prometheus ###
|
||||
|
||||
Managing a modern data center is a complex task. Racks of servers need to be treated like cattle rather than pets, and you need a monitoring system designed to handle hundreds and thousands of nodes. Monitoring applications presents special challenges, and that’s where [Prometheus][12] comes in to play. A service monitoring system designed to deliver alerts to operators, Prometheus can run on everything from a single laptop to a highly available cluster of monitoring servers.
|
||||
|
||||
Time series data is captured and stored, then compared against patterns to identify faults and problems. You’ll need to expose data on HTTP endpoints, using a YAML file to configure the server. A browser-based reporting tool handles displaying data, with an expression console where you can experiment with queries. Dashboards can be created with a GUI builder, or written using a series of templates, letting you deliver application consoles that can be managed using version control systems such as Git.
|
||||
|
||||
Captured data can be managed using expressions, which make it easy to aggregate data from several sources -- for example, letting you bring performance data from a series of Web endpoints into one store. An experimental alert manager module delivers alerts to common collaboration and devops tools, including Slack and PagerDuty. Official client libraries for common languages like Go and Java mean it’s easy to add Prometheus support to your applications and services, while third-party options extend Prometheus to Node.js and .Net.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Elasticsearch, Logstash, and Kibana ###
|
||||
|
||||
Running a modern data center generates a lot of data, and it requires tools to get information out of that data. That’s where the combination of Elasticsearch, Logstash, and Kibana, often referred to as the ELK stack, comes into play.
|
||||
|
||||
Designed to handle scalable search across a mix of content types, including structured and unstructured documents, [Elasticsearch][13] builds on Apache’s Lucene information retrieval tools, with a RESTful JSON API. It’s used to provide search for sites like Wikipedia and GitHub, using a distributed index with automated load balancing and routing.
|
||||
|
||||
Under the fabric of a modern cloud is a physical array of servers, running as VM hosts. Monitoring many thousands of servers needs centralized logs. [Logstash][14] harvests and filters the logs generated by those servers (and by the applications running on them), using a forwarder on each physical and virtual machine. Logstash-formatted data is then delivered to Elasticsearch, giving you a search index that can be quickly scaled as you add more servers.
|
||||
|
||||
At a higher level, [Kibana][15] adds a visualization layer to Elasticsearch, providing a Web dashboard for exploring and analyzing the data. Dashboards can be created around custom searches and shared with your team, providing a quick, easy-to-digest devops information feed.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Ansible ###
|
||||
|
||||
Managing server configuration is a key element of any devops approach to managing a modern data center or a cloud infrastructure. Configuration management tooling that takes a desired state approach to simplifies systems management at cloud scale, using server and application descriptions to handle server and application deployment.
|
||||
|
||||
[Ansible][16] offers a minimal management service, using SSH to manage Unix nodes and PowerShell to work with Windows servers, with no need to deploy agents. An Ansible Playbook describes the state of a server or service in YAML, deploying Ansible modules to servers that handle configuration and removing them once the service is running. You can use Playbooks to orchestrate tasks -- for example, deploying several Web endpoints with a single script.
|
||||
|
||||
It’s possible to make module creation and Playbook delivery part of a continuous delivery process, using build tools to deliver configurations and automate deployment. Ansible can pull in information from cloud service providers, simplifying management of virtual machines and networks. Monitoring tools in Ansible are able to trigger additional deployments automatically, helping manage and control cloud services, as well as working to manage resources used by large-scale data platforms like Hadoop.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Jenkins ###
|
||||
|
||||
Getting continuous delivery right requires more than a structured way of handling development; it also requires tools for managing test and build. That’s where the [Jenkins][17] continuous integration server comes in. Jenkins works with your choice of source control, your test harnesses, and your build server. It’s a flexible tool, initially designed for working with Java but now extended to support Web and mobile development and even to build Windows applications.
|
||||
|
||||
Jenkins is perhaps best thought of as a switching network, shunting files through a test and build process, and responding to signals from the various tools you’re using – thanks to a library of more than 1,000 plug-ins. These include tools for integrating Jenkins with both local Git instances and GitHub so that it's possible to extend a continuous development model into your build and delivery processes.
|
||||
|
||||
Using an automation tool like Jenkins is as much about adopting a philosophy as it is about implementing a build process. Once you commit to continuous integration as part of a continuous delivery model, you’ll be running test and build cycles as soon as code is delivered to your source control release branch – and delivering it to users as soon as it’s in the main branch.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Node.js and io.js ###
|
||||
|
||||
Modern cloud applications are built using different design patterns from the familiar n-tier enterprise and Web apps. They’re distributed, event-driven collections of services that can be quickly scaled and can support many thousands of simultaneous users. One key technology in this new paradigm is [Node.js][18], used by many major cloud platforms and easy to install as part of a thin server or container on cloud infrastructure.
|
||||
|
||||
Key to the success of Node.js is the Npm package format, which allows you to quickly install extensions to the core Node.js service. These include frameworks like Express and Seneca, which help build scalable applications. A central registry handles package distribution, and dependencies are automatically installed.
|
||||
|
||||
While the [io.js][19] fork exposed issues with project governance, it also allowed a group of developers to push forward adding ECMAScript 6 support to an Npm-compatible engine. After reconciliation between the two teams, the Node.js and io.js codebases have been merged, with new releases now coming from the io.js code repository.
|
||||
|
||||
Other forks, like Microsoft’s io.js fork to add support for its 64-bit Chakra JavaScript engine alongside Google’s V8, are likely to be merged back into the main branch over the next year, keeping the Node.js platform evolving and cementing its role as the preferred host for cloud-scale microservices.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### Seneca ###
|
||||
|
||||
The developers of the [Seneca][20] microservice framework have a motto: “Build it now, scale it later!” It’s an apt maxim for anyone thinking about developing microservices, as it allows you to start small, then add functionality as your service grows.
|
||||
|
||||
Seneca is at heart an implementation of the [actor/message design pattern][21], focused on using Node.js as a switching engine that takes in messages, processes their contents, and sends an appropriate response, either to the message originator or to another service. By focusing on the message patterns that map to business use cases, it’s relatively easy to take Seneca and quickly build a minimum viable product for your application. A plug-in architecture makes it easy to integrate Seneca with other tools and to quickly add functionality to your services.
|
||||
|
||||
You can easily add new patterns to your codebase or break existing patterns into separate services as the needs of your application grow or change. One pattern can also call another, allowing quick code reuse. It’s also easy to add Seneca to a message bus, so you can use it as a framework for working with data from Internet of things devices, as all you need to do is define a listening port where JSON data is delivered.
|
||||
|
||||
Services may not be persistent, and Seneca gives you the option of using a built-in object relational mapping layer to handle data abstraction, with plug-ins for common databases.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### .Net Core and ASP.Net vNext ###
|
||||
|
||||
Microsoft’s [open-sourcing of .Net][22] is bringing much of the company’s Web platform into the open. The new [.Net Core][23] release runs on Windows, on OS X, and on Linux. Currently migrating from Microsoft’s Codeplex repository to GitHub, .Net Core offers a more modular approach to .Net, allowing you to install the functions you need as you need them.
|
||||
|
||||
Currently under development is [ASP.Net 5][24], an open source version of the Web platform, which runs on .Net Core. You can work with it as the basis of Web apps using Microsoft’s MVC 6 framework. There’s also support for the new SignalR libraries, which add support for WebSockets and other real-time communications protocols.
|
||||
|
||||
If you’re planning on using Microsoft’s new Nano server, you’ll be writing code against .Net Core, as it’s designed for thin environments. The new DNX, the .Net Execution environment, simplifies deployment of ASP.Net applications on a wide range of platforms, with tools for packaging code and for booting a runtime on a host. Features are added using the NuGet package manager, letting you use only the libraries you want.
|
||||
|
||||
Microsoft’s open source .Net is still very young, but there’s a commitment in Redmond to ensure it’s successful. Support in Microsoft’s own next-generation server operating systems means it has a place in both the data center and the cloud.
|
||||
|
||||
-- Simon Bisson
|
||||
|
||||

|
||||
|
||||
### GlusterFS ###
|
||||
|
||||
[GlusterFS][25] is a distributed file system. Gluster aggregates various storage servers into one large parallel network file system. You can [even use it in place of HDFS in a Hadoop cluster][26] or in place of an expensive SAN system -- or both. While HDFS is great for Hadoop, having a general-purpose distributed file system that doesn’t require you to transfer data to another location to analyze it is a key advantage.
|
||||
|
||||
In an era of commoditized hardware, commoditized computing, and increased performance and latency requirements, buying a big, fat expensive EMC SAN and hoping it fits all of your needs (it won’t) is no longer your sole viable option. GlusterFS was acquired by Red Hat in 2011.
|
||||
|
||||
-- Andrew C. Oliver
|
||||
|
||||

|
||||
|
||||
### Read about more open source winners ###
|
||||
|
||||
InfoWorld's Best of Open Source Awards for 2014 celebrate more than 100 open source projects, from the bottom of the stack to the top. Follow these links to more open source winners:
|
||||
|
||||
[Bossie Awards 2015: The best open source applications][27]
|
||||
|
||||
[Bossie Awards 2015: The best open source application development tools][28]
|
||||
|
||||
[Bossie Awards 2015: The best open source big data tools][29]
|
||||
|
||||
[Bossie Awards 2015: The best open source data center and cloud software][30]
|
||||
|
||||
[Bossie Awards 2015: The best open source desktop and mobile software][31]
|
||||
|
||||
[Bossie Awards 2015: The best open source networking and security software][32]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982923/open-source-tools/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://www.docker.com/docker-machine
|
||||
[2]:https://www.docker.com/docker-swarm
|
||||
[3]:https://www.docker.com/docker-compose
|
||||
[4]:https://coreos.com/
|
||||
[5]:http://rancher.com/rancher-os/
|
||||
[6]:http://kubernetes.io/
|
||||
[7]:https://mesos.apache.org/
|
||||
[8]:https://github.com/joyent/sdc
|
||||
[9]:https://smartos.org/
|
||||
[10]:https://github.com/joyent/sdc-docker
|
||||
[11]:https://sensuapp.org/
|
||||
[12]:http://prometheus.io/
|
||||
[13]:https://www.elastic.co/products/elasticsearch
|
||||
[14]:https://www.elastic.co/products/logstash
|
||||
[15]:https://www.elastic.co/products/kibana
|
||||
[16]:http://www.ansible.com/home
|
||||
[17]:https://jenkins-ci.org/
|
||||
[18]:https://nodejs.org/en/
|
||||
[19]:https://iojs.org/en/
|
||||
[20]:http://senecajs.org/
|
||||
[21]:http://www.infoworld.com/article/2976422/application-development/how-to-use-actors-in-distributed-applications.html
|
||||
[22]:http://www.infoworld.com/article/2846450/microsoft-net/microsoft-open-sources-server-side-net-launches-visual-studio-2015-preview.html
|
||||
[23]:https://dotnet.github.io/core/
|
||||
[24]:http://www.asp.net/vnext
|
||||
[25]:http://www.gluster.org/
|
||||
[26]:http://www.gluster.org/community/documentation/index.php/Hadoop
|
||||
[27]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[28]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[29]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[30]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[31]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[32]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -1,223 +0,0 @@
|
||||
Bossie Awards 2015: The best open source desktop and mobile software
|
||||
================================================================================
|
||||
InfoWorld's top picks in open source productivity tools, desktop utilities, and mobile apps
|
||||
|
||||

|
||||
|
||||
### The best open source desktop and mobile software ###
|
||||
|
||||
Open source on the desktop has a long and distinguished history, and many of our Bossie winners in this category go back many years. Packed with features and still improving, some of these tools offer compelling alternatives to pricey commercial software. Others are utilities that we lean on daily for one reason or another -- the can openers and potato peelers of desktop productivity. One or two of them either plug holes in Windows, or they go the distance where Windows falls short.
|
||||
|
||||

|
||||
|
||||
### LibreOffice ###
|
||||
|
||||
With the major release of version 5 in August, the Document Foundation’s [LibreOffice][1] offers a completely redesigned user interface, better compatibility with Microsoft Office (including good-but-not-great DOCX, XLSX, and PPTX file format support), and significant improvements to Calc, the spreadsheet application.
|
||||
|
||||
Set against a turbulent background, the LibreOffice effort split from OpenOffice.org in 2010. In 2011, Oracle announced it would no longer support OpenOffice.org, and handed the trademark to the Apache Software Foundation. Since then, it has become [increasingly clear][2] that LibreOffice is winning the race for developers, features, and users.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### Firefox ###
|
||||
|
||||
In the battle of the big browsers, [Firefox][3] gets our vote over its longtime open source rival Chromium for two important reasons:
|
||||
|
||||
• **Memory use**. Chromium, like its commercial cousin Chrome, has a nasty propensity to glom onto massive amounts of memory.
|
||||
|
||||
• **Privacy**. Witness the [recent controversy][4] over Chromium automatically downloading a microphone snooping program to respond to “OK, Google.”
|
||||
|
||||
Firefox may not have the most features or the down-to-the-millisecond fastest rendering engine. But it’s solid, stingy with resources, highly extensible, and most of all, it comes with no strings attached. There’s no ulterior data-gathering motive.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### Thunderbird ###
|
||||
|
||||
A longtime favorite email client, Mozilla’s [Thunderbird][5], may be getting a bit long in the tooth, but it’s still supported and showing signs of life. The latest version, 38.2, arrived in August, and there are plans for more development.
|
||||
|
||||
Mozilla officially pulled its people off the project back in July 2012, but a hardcore group of volunteers, led by Kent James and the all-volunteer Thunderbird Council, continues to toil away. While you won’t find the latest email innovations in Thunderbird, you will find a solid core of basic functions based on local storage. If having mail in the cloud spooks you, it’s a good, private alternative. And if James goes ahead with his idea of encrypting Thunderbird mail end-to-end, there may be significant new life in the old bird.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### Notepad++ ###
|
||||
|
||||
If Windows Notepad handles all of your text editing (and source code editing and HTML editing) needs, more power to ya. For Windows users who yearn for a little bit more in a text editor, there’s Don Ho’s [Notepad++][6], which is the editor I turn to, over and over again.
|
||||
|
||||
With tabbed views, drag-and-drop, color-coded hints for completing HTML commands, bookmarks, macro recording, shortcut keys, and every text encoding format you’re likely to encounter, Notepad++ takes text to a new level. We get frequent updates, too, with the latest in August.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### VLC ###
|
||||
|
||||
The stalwart [VLC][7] (formerly known as VideoLan Client) runs almost any kind of media file on almost any platform. Yes, it even works as a remote control on Apple Watch.
|
||||
|
||||
The tiled Universal app version for Windows 10, in the Windows Store, draws some criticism for instability and lack of control, but in most cases VLC works, and it works well -- without external codecs. It even supports Blu-ray formats with two new libraries.
|
||||
|
||||
The desktop version is a must-have for Windows 10, unless you’re ready to run the advertising gauntlets that are the Universal Groove Music and Movies & TV apps from Microsoft. VLC received a major [feature update][8] in February and a comprehensive bug fix in April.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### 7-Zip ###
|
||||
|
||||
Long recognized as the preeminent open source ZIP archive manager for Windows, [7-Zip][9] works like a champ, even on the Windows 10 desktop. Full coverage for RAR files, which can be problematic in Windows, combine with password-protected file creation and support for self-extracting ZIPs. It’s one of those programs that just works.
|
||||
|
||||
Yes, it would be nice to get a more modern file picker. Yes, it would be interesting to see a tiled Universal app version. But even without the fancy bells and whistles, 7-Zip deserves a place on every Windows desktop.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### Handbrake ###
|
||||
|
||||
If you want to convert your DVDs (or video files in any commonly used format) into a file in some other format, or simply scrape them off a silver coaster, [Handbrake][10] is the way to do it. If you’re a Windows user, Handbrake is almost indispensible, since Microsoft doesn’t believe in ripping DVDs.
|
||||
|
||||
Handbrake presents a number of handy presets for optimizing conversions for your target device (iPod, iPad, Android Tablet, and so on) It’s simple, and it’s fast. With the latest round of bug fixes released in June, Handbrake’s keeping up on maintenance -- and it works fine on the Windows 10 desktop.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### KeePass ###
|
||||
|
||||
I’ll confess that I almost gave up on [KeePass][11] because the primary download site goes to Sourceforge. That means you have to be extremely careful which boxes are checked and what you click on (and when) as you attempt to download and install the software. While KeePass itself is 100 percent clean open source (GNU GPL), Sourceforge doesn’t feel so constrained, and its [installers reek of crapware][12].
|
||||
|
||||
One of many local-file password storage programs, KeePass distinguishes itself with broad scope, as well as its ability to run on all sorts of platforms, no installation required. KeePass will save not only passwords, but also credit card information and freely structured information. It provides a strong random password generator, and the database itself is locked with AES and Twofish, so nobody’s going to crack it. And it’s kept up to date, with a new stable release last month.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### VirtualBox ###
|
||||
|
||||
With a major release published in July, Oracle’s open source [VirtualBox][13] -- available for Windows, OS X, Linux, even Solaris --continues to give commercial counterparts VMware Workstation, VMware Fusion, Parallels Desktop, and Microsoft’s Hyper-V a hard run for their money. The Oracle team is still getting the final Windows 10 bugs ironed out, but come to think of it, so is Microsoft.
|
||||
|
||||
VirtualBox doesn’t quite match the performance or polish of the VMware and Parallels products, but it’s getting closer. Version 5 brought long-awaited drag-and-drop support, making it easier to move files between VMs and host.
|
||||
|
||||
I prefer VirtualBox over Hyper-V because it’s easy to control external devices. In Hyper-V, for example, getting sound to work is a pain in the neck, but in VirtualBox it only takes a click in setup. The shared clipboard between VM and host works wonders. Running speed on both is roughly the same, with a slight advantage to Hyper-V. But managing VirtualBox machines is much easier.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### Inkscape ###
|
||||
|
||||
If you stand in awe of the designs created with Adobe Illustrator (or even CorelDraw), take a close look at [Inkscape][14]. Scalable vector images never looked so good.
|
||||
|
||||
Version 0.91, released in January, uses a new internal graphics rendering engine called Cairo, sponsored by Google, to make the app run faster and allow for more accurate rendering. Inkscape will read and write SVG, PNG, PDF, even EPS, and many other formats. It can export Flash XML Graphics, HTML5 Canvas, and XAML, among others.
|
||||
|
||||
There’s a strong community around Inkscape, and it’s built for easy extensibility. It’s available for Windows, OS X, and Linux.
|
||||
|
||||
-- Woody Leonhard
|
||||
|
||||

|
||||
|
||||
### KeePassDroid ###
|
||||
|
||||
Trying to remember all of the passwords we need today is impossible, and creating new ones to meet stringent password policy requirements can be agonizing. A port of KeePass for Android, [KeePassDroid][15] brings sanity preserving password management to mobile devices.
|
||||
|
||||
Like KeyPass, KeyPassDroid makes creating and accessing passwords easy, requiring you to recall only a single master password. It supports both DES and Twofish algorithms for encrypting all passwords, and it goes a step further by encrypting the entire password database, not only the password fields. Notes and other password pertinent information are encrypted too.
|
||||
|
||||
While KeePassDroid's interface is minimal -- dated, some would say -- it gets the job done with bare-bones efficiency. Need to generate passwords that have certain character sets and lengths? KeePassDroid can do that with ease. With more than a million downloads on the Google Play Store, you could say this app definitely fills a need.
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
### Prey ###
|
||||
|
||||
Loss or theft of mobile devices is all too common these days. While there are many tools in the enterprise to manage and erase data either misplaced or stolen from an organization, [Prey][16] facilitates the recovery of the phone, laptop, or tablet, and not just the wiping of potentially sensitive information from the device.
|
||||
|
||||
Prey is a Web service that works with an open source installed agent for Linux, OS X, Windows, Android, and iOS devices. Prey tracks your lost or stolen device by using either the device's GPS, the native geolocation provided by newer operating systems, or an associated Wi-Fi hotspot to home in on the location.
|
||||
|
||||
If your smartphone is lost or stolen, send a text message to the device to activate Prey. For stolen tablets or laptops, use the Prey Project's cloud-based control panel to select the device as missing. The Prey agent on any device can then take a screenshot of the active applications, turn on the camera to catch a thief's image, reset the device to the factory settings, or fully lock down the device.
|
||||
|
||||
Should you want to retrieve your lost items, the Prey Project strongly suggests you contact your local police to have them assist you.
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
### Orbot ###
|
||||
|
||||
The premiere proxy application for Android, [Orbot][17] leverages the volunteer-operated network of virtual tunnels called Tor (The Onion Router) to keep all communications private. Orbot works with companion applications [Orweb][18] for secure Web browsing and [ChatSecure][19] for secure chat. In fact, any Android app that allows its proxy settings to be changed can be secured with Orbot.
|
||||
|
||||
One thing to remember about the Tor network is that it's designed for secure, lightweight communications, not for pulling down torrents or watching YouTube videos. Surfing media-rich sites like Facebook can be painfully slow. Your Orbot communications won't be blazing fast, but they will stay private and confidential.
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
### Tails ###
|
||||
|
||||
[Tails][20], or The Amnesic Incognito Live System, is a Linux Live OS that can be booted from a USB stick, DVD, or SD card. It’s often used covertly in the Deep Web to secure traffic when purchasing illicit substances, but it can also be used to avoid tracking, support freedom of speech, circumvent censorship, and promote liberty.
|
||||
|
||||
Leveraging Tor (The Onion Router), Tails keeps all communications secure and private and promises to leave no trace on any computer after it’s used. It performs disk encryption with LUKS, protects instant messages with OTR, encrypts Web traffic with the Tor Browser and HTTPS Everywhere, and securely deletes files via Nautilus Wipe. Tails even has an office suite, image editor, and the like.
|
||||
|
||||
Now, it's always possible to be traced while using any system if you're not careful, so be vigilant when using Tails and follow good privacy practices, like turning off JavaScript while using Tor. And be aware that Tails isn't necessarily going to be speedy, even while using a fiber connect, but that's what you pay for anonymity.
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
### Read about more open source winners ###
|
||||
|
||||
InfoWorld's Best of Open Source Awards for 2014 celebrate more than 100 open source projects, from the bottom of the stack to the top. Follow these links to more open source winners:
|
||||
|
||||
[Bossie Awards 2015: The best open source applications][21]
|
||||
|
||||
[Bossie Awards 2015: The best open source application development tools][22]
|
||||
|
||||
[Bossie Awards 2015: The best open source big data tools][23]
|
||||
|
||||
[Bossie Awards 2015: The best open source data center and cloud software][24]
|
||||
|
||||
[Bossie Awards 2015: The best open source desktop and mobile software][25]
|
||||
|
||||
[Bossie Awards 2015: The best open source networking and security software][26]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982630/open-source-tools/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://www.libreoffice.org/download/libreoffice-fresh/
|
||||
[2]:http://lwn.net/Articles/637735/
|
||||
[3]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[4]:https://nakedsecurity.sophos.com/2015/06/24/not-ok-google-privacy-advocates-take-on-the-chromium-team-and-win/
|
||||
[5]:https://www.mozilla.org/en-US/thunderbird/
|
||||
[6]:https://notepad-plus-plus.org/
|
||||
[7]:http://www.videolan.org/vlc/index.html
|
||||
[8]:http://www.videolan.org/press/vlc-2.2.0.html
|
||||
[9]:http://www.7-zip.org/
|
||||
[10]:https://handbrake.fr/
|
||||
[11]:http://keepass.info/
|
||||
[12]:http://www.infoworld.com/article/2931753/open-source-software/sourceforge-the-end-cant-come-too-soon.html
|
||||
[13]:https://www.virtualbox.org/
|
||||
[14]:https://inkscape.org/en/download/windows/
|
||||
[15]:http://www.keepassdroid.com/
|
||||
[16]:http://preyproject.com/
|
||||
[17]:https://www.torproject.org/docs/android.html.en
|
||||
[18]:https://guardianproject.info/apps/orweb/
|
||||
[19]:https://guardianproject.info/apps/chatsecure/
|
||||
[20]:https://tails.boum.org/
|
||||
[21]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[22]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[23]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[24]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[25]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[26]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -1,162 +0,0 @@
|
||||
Bossie Awards 2015: The best open source networking and security software
|
||||
================================================================================
|
||||
InfoWorld's top picks of the year among open source tools for building, operating, and securing networks
|
||||
|
||||

|
||||
|
||||
### The best open source networking and security software ###
|
||||
|
||||
BIND, Sendmail, OpenSSH, Cacti, Nagios, Snort -- open source software seems to have been invented for networks, and many of the oldies and goodies are still going strong. Among our top picks in the category this year, you'll find a mix of stalwarts, mainstays, newcomers, and upstarts perfecting the arts of network management, security monitoring, vulnerability assessment, rootkit detection, and much more.
|
||||
|
||||

|
||||
|
||||
### Icinga 2 ###
|
||||
|
||||
Icinga began life as a fork of system monitoring application Nagios. [Icinga 2][1] was completely rewritten to give users a modern interface, support for multiple databases, and an API to integrate numerous extensions. With out-of-the-box load balancing, notifications, and configuration, Icinga 2 shortens the time to installation for complex environments. Icinga 2 supports Graphite natively, giving administrators real-time performance graphing without any fuss. But what puts Icinga back on the radar this year is its release of Icinga Web 2, a graphical front end with drag-and-drop customizable dashboards and streamlined monitoring tools.
|
||||
|
||||
Administrators can view, filter, and prioritize problems, while keeping track of which actions have already been taken. A new matrix view lets administrators view hosts and services on one page. You can view events over a particular time period or filter incidents to understand which ones need immediate attention. Icinga Web 2 may boast a new interface and zippier performance, but all the usual commands from Icinga Classic and Icinga Web are still available. That means there is no downtime trying to learn a new version of the tool.
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Zenoss Core ###
|
||||
|
||||
Another open source stalwart, [Zenoss Core][2] gives network administrators a complete, one-stop solution for tracking and managing all of the applications, servers, storage, networking components, virtualization tools, and other elements of an enterprise infrastructure. Administrators can make sure the hardware is running efficiently and take advantage of the modular design to plug in ZenPacks for extended functionality.
|
||||
|
||||
Zenoss Core 5, released in February of this year, takes the already powerful tool and improves it further, with an enhanced user interface and expanded dashboard. The Web-based console and dashboards were already highly customizable and dynamic, and the new version now lets administrators mash up multiple component charts onto a single chart. Think of it as the tool for better root cause and cause/effect analysis.
|
||||
|
||||
Portlets give additional insights for network mapping, device issues, daemon processes, production states, watch lists, and event views, to name a few. And new HTML5 charts can be exported outside the tool. The Zenoss Control Center allows out-of-band management and monitoring of all Zenoss components. Zenoss Core has new tools for online backup and restore, snapshots and rollbacks, and multihost deployment. Even more important, deployments are faster with full Docker support.
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenNMS ###
|
||||
|
||||
An extremely flexible network management solution, [OpenNMS][3] can handle any network management task, whether it's device management, application performance monitoring, inventory control, or events management. With IPv6 support, a robust alerts system, and the ability to record user scripts to test Web applications, OpenNMS has everything network administrators and testers need. OpenNMS has become, as now a mobile dashboard, called OpenNMS Compass, lets networking pros keep an eye on their network even when they're out and about.
|
||||
|
||||
The iOS version of the app, which is available on the [iTunes App Store][4], displays outages, nodes, and alarms. The next version will offer additional event details, resource graphs, and information about IP and SNMP interfaces. The Android version, available on [Google Play][5], displays network availability, outages, and alarms on the dashboard, as well as the ability to acknowledge, escalate, or clear alarms. The mobile clients are compatible with OpenNMS Horizon 1.12 or greater and OpenNMS Meridian 2015.1.0 or greater.
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Security Onion ###
|
||||
|
||||
Like an onion, network security monitoring is made of many layers. No single tool will give you visibility into every attack or show you every reconnaissance or foot-printing session on your company network. [Security Onion][6] bundles scores of proven tools into one handy Ubuntu distro that will allow you to see who's inside your network and help keep the bad guys out.
|
||||
|
||||
Whether you're taking a proactive approach to network security monitoring or following up on a potential attack, Security Onion can assist. Consisting of sensor, server, and display layers, the Onion combines full network packet capture with network-based and host-based intrusion detection, and it serves up all of the various logs for inspection and analysis.
|
||||
|
||||
The star-studded network security toolchain includes Netsniff-NG for packet capture, Snort and Suricata for rules-based network intrusion detection, Bro for analysis-based network monitoring, OSSEC for host intrusion detection, and Sguil, Squert, Snorby, and ELSA (Enterprise Log Search and Archive) for display, analysis, and log management. It’s a carefully vetted collection of tools, all wrapped in a wizard-driven installer and backed by thorough documentation, that can help you get from zero to monitoring as fast as possible.
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
Kali Linux
|
||||
|
||||
The team behind [Kali Linux][7] revamped the popular security Linux distribution this year to make it faster and even more versatile. Kali sports a new 4.0 kernel, improved hardware and wireless driver support, and a snappier interface. The most popular tools are easily accessible from a dock on the side of the screen. The biggest change? Kali Linux is now a rolling distribution, with a continuous stream of software updates. Kali's core system is based on Debian Jessie, and the team will pull packages continuously from Debian Testing, while continuing to add new Kali-flavored features on top.
|
||||
|
||||
The distribution still comes jam-packed with tools for penetration testing, vulnerability analysis, security forensics, Web application analysis, wireless networking and assessment, reverse engineering, and exploitation tools. Now the distribution has an upstream version checking system that will automatically notify users when updates are available for the individual tools. The distribution also features ARM images for a range of devices, including Raspberry Pi, Chromebook, and Odroids, as well as updates to the NetHunter penetration testing platform that runs on Android devices. There are other changes too: Metasploit Community/Pro is no longer included, because Kali 2.0 is not yet [officially supported by Rapid7][8].
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenVAS ###
|
||||
|
||||
[OpenVAS][9], the Open Vulnerability Assessment System, is a framework that combines multiple services and tools to offer vulnerability scanning and vulnerability management. The scanner is coupled with a weekly feed of network vulnerability tests, or you can use a feed from a commercial service. The framework includes a command-line interface (so it can be scripted) and an SSL-secured, browser-based interface via the [Greenbone Security Assistant][10]. OpenVAS accommodates various plug-ins for additional functionality. Scans can be scheduled or run on-demand.
|
||||
|
||||
Multiple OpenVAS installations can be controlled through a single master, which makes this a scalable vulnerability assessment tool for enterprises. The project is as compatible with standards as can be: Scan results and configurations are stored in a SQL database, where they can be accessed easily by external reporting tools. Client tools access the OpenVAS Manager via the XML-based stateless OpenVAS Management Protocol, so security administrators can extend the functionality of the framework. The software can be installed from packages or source code to run on Windows or Linux, or downloaded as a virtual appliance.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### OWASP ###
|
||||
|
||||
[OWASP][11], the Open Web Application Security Project, is a nonprofit organization with worldwide chapters focused on improving software security. The community-driven organization provides test tools, documentation, training, and almost anything you could imagine that’s related to assessing software security and best practices for developing secure software. Several OWASP projects have become valuable components of many a security practitioner's toolkit:
|
||||
|
||||
[ZAP][12], the Zed Attack Proxy Project, is a penetration test tool for finding vulnerabilities in Web applications. One of the design goals of ZAP was to make it easy to use so that developers and functional testers who aren't security experts can benefit from using it. ZAP provides automated scanners and a set of manual test tools.
|
||||
|
||||
The [Xenotix XSS Exploit Framework][13] is an advanced cross-site scripting vulnerability detection and exploitation framework that runs scans within browser engines to get real-world results. The Xenotix Scanner Module uses three intelligent fuzzers, and it can run through nearly 5,000 distinct XSS payloads. An API lets security administrators extend and customize the exploit toolkit.
|
||||
|
||||
[O-Saft][14], or the OWASP SSL advanced forensic tool, is an SSL auditing tool that shows detailed information about SSL certificates and tests SSL connections. This command-line tool can run online or offline to assess SSL security such as ciphers and configurations. O-Saft provides built-in checks for common vulnerabilities, and you can easily extend these through scripting. In May 2015 a simple GUI was added as an optional download.
|
||||
|
||||
[OWTF][15], the Offensive Web Testing Framework, is an automated test tool that follows OWASP testing guidelines and the NIST and PTES standards. The framework uses both a Web UI and a CLI, and it probes Web and application servers for common vulnerabilities such as improper configuration and unpatched software.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### BeEF ###
|
||||
|
||||
The Web browser has become the most common vector for attacks against clients. [BeEF][15], the Browser Exploitation Framework Project, is a widely used penetration tool to assess Web browser security. BeEF helps you expose the security weaknesses of client systems using client-side attacks launched through the browser. BeEF sets up a malicious website, which security administrators visit from the browser they want to test. BeEF then sends commands to attack the Web browser and use it to plant software on the client machine. Administrators can then launch attacks on the client machine as if they were zombies.
|
||||
|
||||
BeEF comes with commonly used modules like a key logger, a port scanner, and a Web proxy, plus you can write your own modules or send commands directly to the zombified test machine. BeEF comes with a handful of demo Web pages to help you get started and makes it very easy to write additional Web pages and attack modules so you can customize testing to your environment. BeEF is a valuable test tool for assessing browser and endpoint security and for learning how browser-based attacks are launched. Use it to put together a demo to show your users how malware typically infects client devices.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### Unhide ###
|
||||
|
||||
[Unhide][16] is a forensic tool that locates open TCP/UDP ports and hidden process on UNIX, Linux, and Windows. Hidden ports and processes can be the result of rootkit or LKM (loadable kernel module) activity. Rootkits can be difficult to find and remove because they are designed to be stealthy, hiding themselves from the OS and user. A rootkit can use LKMs to hide its processes or impersonate other processes, allowing it to run on machines undiscovered for a long time. Unhide can provide the assurance that administrators need to know their systems are clean.
|
||||
|
||||
Unhide is really two separate scripts: one for processes and one for ports. The tool interrogates running processes, threads, and open ports and compares this info to what's registered with the system as active, reporting discrepancies. Unhide and WinUnhide are extremely lightweight scripts that run from the command line to produce text output. They're not pretty, but they are extremely useful. Unhide is also included in the [Rootkit Hunter][17] project.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
Read about more open source winners
|
||||
|
||||
InfoWorld's Best of Open Source Awards for 2014 celebrate more than 100 open source projects, from the bottom of the stack to the top. Follow these links to more open source winners:
|
||||
|
||||
[Bossie Awards 2015: The best open source applications][18]
|
||||
|
||||
[Bossie Awards 2015: The best open source application development tools][19]
|
||||
|
||||
[Bossie Awards 2015: The best open source big data tools][20]
|
||||
|
||||
[Bossie Awards 2015: The best open source data center and cloud software][21]
|
||||
|
||||
[Bossie Awards 2015: The best open source desktop and mobile software][22]
|
||||
|
||||
[Bossie Awards 2015: The best open source networking and security software][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982962/open-source-tools/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://www.icinga.org/icinga/icinga-2/
|
||||
[2]:http://www.zenoss.com/
|
||||
[3]:http://www.opennms.org/
|
||||
[4]:https://itunes.apple.com/us/app/opennms-compass/id968875097?mt=8
|
||||
[5]:https://play.google.com/store/apps/details?id=com.opennms.compass&hl=en
|
||||
[6]:http://blog.securityonion.net/p/securityonion.html
|
||||
[7]:https://www.kali.org/
|
||||
[8]:https://community.rapid7.com/community/metasploit/blog/2015/08/12/metasploit-on-kali-linux-20
|
||||
[9]:http://www.openvas.org/
|
||||
[10]:http://www.greenbone.net/
|
||||
[11]:https://www.owasp.org/index.php/Main_Page
|
||||
[12]:https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project
|
||||
[13]:https://www.owasp.org/index.php/O-Saft
|
||||
[14]:https://www.owasp.org/index.php/OWASP_OWTF
|
||||
[15]:http://www.beefproject.com/
|
||||
[16]:http://www.unhide-forensics.info/
|
||||
[17]:http://www.rootkit.nl/projects/rootkit_hunter.html
|
||||
[18]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[19]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[20]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[21]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[22]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[23]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -1,66 +0,0 @@
|
||||
ictlyh Translating
|
||||
Review EXT4 vs. Btrfs vs. XFS
|
||||
================================================================================
|
||||

|
||||
|
||||
To be honest, one of the things that comes last in people’s thinking is to look at which file system on their PC is being used. Windows users as well as Mac OS X users even have less reason for looking as they have really only 1 choice for their operating system which are NTFS and HFS+. Linux operating system, on the other side, has plenty of various file system options, with the current default is being widely used ext4. However, there is another push for changing the file system to something other which is called btrfs. But what makes btrfs better, what are other file systems, and when can we see the distributions making the change?
|
||||
|
||||
Let’s first have a general look at file systems and what they really do, then we will make a small comparison between famous file systems.
|
||||
|
||||
### So, What Do File Systems Do? ###
|
||||
|
||||
Just in case if you are unfamiliar about what file systems really do, it is actually simple when it is summarized. The file systems are mainly used in order for controlling how the data is stored after any program is no longer using it, how access to the data is controlled, what other information (metadata) is attached to the data itself, etc. I know that it does not sound like an easy thing to be programmed, and it is definitely not. The file systems are continually still being revised for including more functionality while becoming more efficient in what it simply needs to do. Therefore, however, it is a basic need for all computers, it is not quite as basic as it sounds like.
|
||||
|
||||
### Why Partitioning? ###
|
||||
|
||||
Many people have a vague knowledge of what the partitions are since each operating system has an ability for creating or removing them. It can seem strange that Linux operating system uses more than 1 partition on the same disk, even while using the standard installation procedure, so few explanations are called for them. One of the main goals of having different partitions is achieving higher data security in the disaster case.
|
||||
|
||||
By dividing your hard disk into partitions, the data may be grouped and also separated. When the accidents occur, only the data stored in the partition which got the hit will only be damaged, while data on the other partitions will survive most likely. These principles date from the days when the Linux operating system didn’t have a journaled file system and any power failure might have led to a disaster.
|
||||
|
||||
The using of partitions will remain for security and the robustness reasons, then the breach on 1 part of the operating system does not automatically mean that whole computer is under risk or danger. This is currently most important factor for the partitioning process. For example, the users create scripts, the programs or web applications which start filling up the disk. If that disk contains only 1 big partition, then entire system may stop functioning if that disk is full. If the users store data on separate partitions, then only that data partition can be affected, while system partitions and the possible other data partitions will keep functioning.
|
||||
|
||||
Mind that to have a journaled file system will only provide data security in case if there is a power failure as well as sudden disconnection of the storage devices. Such will not protect the data against the bad blocks and the logical errors in the file system. In such cases, the user should use a Redundant Array of Inexpensive Disks (RAID) solution.
|
||||
|
||||
### Why Switch File Systems? ###
|
||||
|
||||
The ext4 file system has been an improvement for the ext3 file system that was also an improvement over the ext2 file system. While the ext4 is a very solid file system which has been the default choice for almost all distributions for the past few years, it is made from an aging code base. Additionally, Linux operating system users are seeking many new different features in file systems which ext4 does not handle on its own. There is software which takes care of some of such needs, but in the performance aspect, being able to do such things on the file system level could be faster.
|
||||
|
||||
### Ext4 File System ###
|
||||
|
||||
The ext4 has some limits which are still a bit impressive. The maximum file size is 16 tebibytes (which is roughly 17.6 terabytes) and is much bigger than any hard drive a regular consumer can currently buy. While, the largest volume/partition you can make with ext4 is 1 exbibyte (which is roughly 1,152,921.5 terabytes). The ext4 is known to bring the speed improvements over ext3 by using multiple various techniques. Like in the most modern file systems, it is a journaling file system that means that it will keep a journal of where the files are mainly located on the disk and of any other changes that happen to the disk. Regardless all of its features, it doesn’t support the transparent compression, the data deduplication, or the transparent encryption. The snapshots are supported technically, but such feature is experimental at best.
|
||||
|
||||
### Btrfs File System ###
|
||||
|
||||
The btrfs, many of us pronounce it different ways, as an example, Better FS, Butter FS, or B-Tree FS. It is a file system which is completely made from scratch. The btrfs exists because its developers firstly wanted to expand the file system functionality in order to include snapshots, pooling, as well as checksums among the other things. While it is independent from the ext4, it also wants to build off the ideas present in the ext4 that are great for the consumers and the businesses alike as well as incorporate those additional features that will benefit everybody, but specifically the enterprises. For the enterprises who are using very large programs with very large databases, they are having a seemingly continuous file system across the multiple hard drives could be very beneficial as it will make a consolidation of the data much easier. The data deduplication could reduce the amount of the actual space data could occupy, and the data mirroring could become easier with the btrfs as well when there is a single and broad file system which needs to be mirrored.
|
||||
|
||||
The user certainly can still choose to create multiple partitions so that he does not need to mirror everything. Considering that the btrfs will be able for spanning over the multiple hard drives, it is a very good thing that it can support 16 times more drive space than the ext4. A maximum partition size of the btrfs file system is 16 exbibytes, as well as maximum file size is 16 exbibytes too.
|
||||
|
||||
### XFS File System ###
|
||||
|
||||
The XFS file system is an extension of the extent file system. The XFS is a high-performance 64-bit journaling file system. The support of the XFS was merged into Linux kernel in around 2002 and In 2009 Red Hat Enterprise Linux version 5.4 usage of the XFS file system. XFS supports maximum file system size of 8 exbibytes for the 64-bit file system. There is some comparison of XFS file system is XFS file system can’t be shrunk and poor performance with deletions of the large numbers of files. Now, the RHEL 7.0 uses XFS as the default filesystem.
|
||||
|
||||
### Final Thoughts ###
|
||||
|
||||
Unfortunately, the arrival date for the btrfs is not quite known. But officially, the next-generation file system is still classified as “unstable”, but if the user downloads the latest version of Ubuntu, he will be able to choose to install on a btrfs partition. When the btrfs will be classified actually as “stable” is still a mystery, but users shouldn’t expect the Ubuntu to use the btrfs by default until it’s indeed considered “stable”. It has been reported that Fedora 18 will use the btrfs as its default file system as by the time of its release a file system checker for the btrfs should exist. There is a good amount of work still left for the btrfs, as not all the features are yet implemented and the performance is a little sluggish if we compare it to the ext4.
|
||||
|
||||
So, which is better to use? Till now, the ext4 will be the winner despite the identical performance. But why? The answer will be the convenience as well as the ubiquity. The ext4 is still excellent file system for the desktop or workstation use. It is provided by default, so the user can install the operating system on it. Also, the ext4 supports volumes up to 1 Exabyte and files up to 16 Terabyte in size, so there’s still a plenty of room for the growth where space is concerned.
|
||||
|
||||
The btrfs might offer greater volumes up to 16 Exabyte and improved fault tolerance, but, till now, it feels more as an add-on file system rather than one integrated into the Linux operating system. For example, the btrfs-tools have to be present before a drive will be formatted with the btrfs, which means that the btrfs is not an option during the Linux operating system installation though that could vary with the distribution.
|
||||
|
||||
Even though the transfer rates are so important, there’s more to a just file system than speed of the file transfers. The btrfs has many useful features such as Copy-on-Write (CoW), extensive checksums, snapshots, scrubbing, self-healing data, deduplication, as well as many more good improvements that ensure the data integrity. The btrfs lacks the RAID-Z features of ZFS, so the RAID is still in an experimental state with the btrfs. For pure data storage, however, the btrfs is the winner over the ext4, but time still will tell.
|
||||
|
||||
Till the moment, the ext4 seems to be a better choice on the desktop system since it is presented as a default file system, as well as it is faster than the btrfs when transferring files. The btrfs is definitely worth to look into, but to completely switch to replace the ext4 on desktop Linux might be few years later. The data farms and the large storage pools could reveal different stories and show the right differences between ext4, XCF, and btrfs.
|
||||
|
||||
If you have a different or additional opinion, kindly let us know by commenting on this article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/review-ext4-vs-btrfs-vs-xfs/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -1,186 +0,0 @@
|
||||
[translating by ray]
|
||||
|
||||
Interviews: Linus Torvalds Answers Your Question
|
||||
================================================================================
|
||||
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
||||
|
||||
**Productivity**
|
||||
by DoofusOfDeath
|
||||
|
||||
> You've somehow managed to originate two insanely useful pieces of software: Linux, and Git. Do you think there's anything in your work habits, your approach to choosing projects, etc., that have helped you achieve that level of productivity? Or is it just the traditional combination of talent, effort, and luck?
|
||||
|
||||
**Linus**: I'm sure it's pretty much always that "talent, effort and luck". I'll leave it to others to debate how much of each...
|
||||
|
||||
I'd love to point out some magical work habit that makes it all happen, but I doubt there really is any. Especially as the work habits I had wrt the kernel and Git have been so different.
|
||||
|
||||
With Git, I think it was a lot about coming at a problem with fresh eyes (not having ever really bought into the traditional SCM mindset), and really trying to think about the issues, and spending a fair amount of time thinking about what the real problems were and what I wanted the design to be. And then the initial self-hosting code took about a day to write (ok, that was "self-hosting" in only the weakest sense, but still).
|
||||
|
||||
And with Linux, obviously, things were very different - the big designs came from the outside, and it took half a year to host itself, and it hadn't even started out as a kernel to begin with. Clearly not a lot of thinking ahead and planning involved ;). So very different circumstances indeed.
|
||||
|
||||
What both the kernel and Git have, and what I think is really important (and I guess that counts as a "work habit"), is a maintainer that stuck to it, and was responsive, responsible and sane. Too many projects falter because they don't have people that stick with them, or have people who have an agenda that doesn't match reality or the user expectations.
|
||||
|
||||
But it's very important to point out that for Git, that maintainer was not me. Junio Hamano really should get pretty much all the credit for Git. Credit where credit is due. I'll take credit for the initial implementation and design of Git - it may not be perfect, but ten years on it still is very solid and very clearly the same basic design. But I'll take even _more_ credit for recognizing that Junio had his head screwed on right, and was the person to drive the project. And all the rest of the credit goes to him.
|
||||
|
||||
Of course, that kind of segues into something else the kernel and Git do have in common: while I still maintain the kernel, I did end up finding a lot of smart people to maintain all the different parts of it. So while one important work habit is that "stick to it" persistence that you need to really take a project from a not-quite-usable prototype to something bigger and better, another important work-habit is probably to also "let go" and not try to own and control the project too much. Let other people really help you - guide the process but don't get in their way.
|
||||
|
||||
**init system**
|
||||
by lorinc
|
||||
|
||||
> There wasn't a decent unix-like kernel, you wrote one which ultimately became the most used. There wasn't a decent version control software, you wrote one which ultimately became the most love. Do you think we already have a decent init system, or do you have plan to write one that will ultimately settle the world on that hot topic?
|
||||
|
||||
**Linus**: You can say the word "systemd", It's not a four-letter word. Seven letters. Count them.
|
||||
|
||||
I have to say, I don't really get the hatred of systemd. I think it improves a lot on the state of init, and no, I don't see myself getting into that whole area.
|
||||
|
||||
Yeah, it may have a few odd corners here and there, and I'm sure you'll find things to despise. That happens in every project. I'm not a huge fan of the binary logging, for example. But that's just an example. I much prefer systemd's infrastructure for starting services over traditional init, and I think that's a much bigger design decision.
|
||||
|
||||
Yeah, I've had some personality issues with some of the maintainers, but that's about how you handle bug reports and accept blame (or not) for when things go wrong. If people thought that meant that I dislike systemd, I will have to disappoint you guys.
|
||||
|
||||
**Can Valve change the Linux gaming market?**
|
||||
by Anonymous Coward
|
||||
|
||||
> Do you think Valve is capable of making Linux a primary choice for gamers?
|
||||
|
||||
**Linus**: "Primary"? Probably not where it's even aiming. I think consoles (and all those handheld and various mobile platforms that "real gamers" seem to dismiss as toys) are likely much more primary, and will stay so.
|
||||
|
||||
I think Valve wants to make sure they can control their own future, and Linux and ValveOS is probably partly to explore a more "console-like" Valve experience (ie the whole "get a box set up for a single main purpose", as opposed to a more PC-like experience), and partly as a "second source" against Microsoft, who is a competitor in the console area. Keeping your infrastructure suppliers honest by making sure you have alternatives sounds like a good strategy, and particularly so when those suppliers may be competing with you directly elsewhere.
|
||||
|
||||
So I don't think the aim is really "primary". "Solid alternative" is I think the aim. Of course, let's see where it goes after that.
|
||||
|
||||
But I really have not been involved. People like Greg and the actual graphics driver guys have been in much more direct contact with Valve. I think it's great to see gaming on Linux, but at the same time, I'm personally not really much of a gamer.
|
||||
|
||||
**The future of RT-Linux?**
|
||||
by nurhussein
|
||||
|
||||
> According to Thomas Gleixner, [the future of the realtime patchset to Linux is in doubt][2], as it is difficult to secure funding from interested parties on this functionality even though it is both useful and important: What are your thoughts on this, and what do you think we need to do to get more support behind the RT patchset, especially considering Linux's increasing use in embedded systems where realtime functionality is undoubtedly useful.
|
||||
|
||||
**Linus**: So I think this is one of those things where the markets decide how important rtLinux ends up being, and I suspect there are more than enough companies who end up wanting and using rtLinux that the project isn't really going anywhere. The complaints by Thomas were - I think - a wake-up call to the companies who end up wanting the extended hard realtime patches.
|
||||
|
||||
So I suspect there are companies and groups like OSADL that end up funding and helping with rtLinux, and that it isn't going away.
|
||||
|
||||
**Rigor and developments**
|
||||
by hcs_$reboot
|
||||
|
||||
> The most complex program running on a machine is arguably its OS, especially the kernel. Linux (kernel) reached the top level in terms of performance, reliability and versatility. You have been criticized quite a few times for some virulent mails addressed to developers. Do you think Linux would be where it is without managing the project with an iron fist? To go further, do you think some other main OSS project would benefit from a more rigorous management approach?
|
||||
|
||||
**Linus**: One of the nice things about open source is how it allows people to really concentrate on what they are good at, and it has been a huge advantage for Linux that we've had people who are interested in the marketing side and selling Linux, as well as the legal side etc.
|
||||
|
||||
And that is all in addition, of course, to the original "we're motivated by the technology" people like me. And even within that "we're motivated by technology" group, you most certainly don't need to find _everything_ interesting, you can find the area you are passionate about and really care about and want to work on.
|
||||
|
||||
That's _fundamentally_ how open source works.
|
||||
|
||||
Now, if somebody is passionate about some "good management" thing, go wild, and try to get involved, and try to manage things. It's not what _I_ am interested in, but hey, the proof is in the pudding - anybody who thinks they have a new rigorous management approach that they think will help some part of the process, go wild.
|
||||
|
||||
Now, I personally suspect that it wouldn't work - not only are tech people an ornery lot to begin with (that whole "herding cats" thing), just look at all the crazy arguments on the internet. And ask yourself what actually holds an open source project like the kernel together? I think you need to be very oriented towards the purely technical solutions, simply because then you have tangible and real issues you can discuss (and argue about) with fairly clear-cut hard answers. It's the only thing people can really agree on in the big picture.
|
||||
|
||||
So the Linux approach to "management" has been to put technology first. That's rigorous enough for me. But as mentioned, it's a free-for-all. Anybody can come in and try to do better. Really.
|
||||
|
||||
And btw, it's worth noting that there are obviously specific smaller development teams where other management models work fine. Most of the individual developers are parts of teams inside particular companies, and within the confines of that company, there may well be a very strict rigorous management model. Similarly, within the confines of a particular productization effort there may be particular goals and models for that particular team that transcend that general "technical issues" thing.
|
||||
|
||||
Just to give a concrete example, the "development kernel" tree that I maintain works fundamentally differently and with very different rules from the "stable tree" that Greg does, which in turn is maintained very differently from what a distribution team within a Linux company does inside its maintenance kernel team.
|
||||
|
||||
So there's certainly room for different approaches to managing those very different groups. But do I think you can "rigorously manage" people on the internet? No.
|
||||
|
||||
**Functional languages?**
|
||||
by EmeraldBot
|
||||
|
||||
> While historically you've been a C and Assembly guy (and the odd shell scripting and such), what do you think of functional languages such as Lisp, Closure, Haskell, etc? Do you see any advantages to them, or do you view them as frivolous and impractical? If you decide to do so, thanks for taking the time to answer my question! You're a legend at what you do, and I think it's awesome that the significantly less interesting me can ask you a question like this.
|
||||
|
||||
**Linus**: I may be a fan of C (with a certain fondness for assembly, just because it's so close to the machine), but that's very much about a certain context. I work at a level where those languages make sense. I certainly don't think that tools like Haskell etc are "frivolous and impractical" in general, although on a kernel level (or in a source control management system) I suspect they kind of are.
|
||||
|
||||
Many moons ago I worked on sparse (the C parser and analyzer), and one of my coworkers was a Haskell fan, and did incredible example transformations in very simple (well, to him) code - stuff that is just nasty to write in C because it's pretty high-level, there's tons of memory management, and you're really talking about implementing fairly abstract and high-level rules with pattern matching etc.
|
||||
|
||||
So I'm definitely not a functional language kind of guy - it's not how I learnt programming, and it really isn't very relevant to what I do, and I wouldn't recognize Haskell code if it bit me in the ass and called me names. But no, I wouldn't call them frivolous.
|
||||
|
||||
**Critical software to the use of Linux**
|
||||
by TWX
|
||||
|
||||
> Mr. Torvalds, For many uses of Linux such as on the desktop, other software beyond the kernel and the base GNU tools are required. What other projects would you like to see given priority, and what would you like to see implemented or improved? Admittedly I thought most about X-Windows when asking this question; but I don't doubt that other daemons or systems can be just as important to the user experience. Thank you for your efforts all these years.
|
||||
|
||||
**Linus**: Hey, I don't really have any particular project I would want to champion, largely because we all have so different requirements on the desktop. There's just no single thing that stands out as being hugely more important than others to me.
|
||||
|
||||
What I do wish particularly desktop developers cared about is "consistency of experience". And by that I don't mean some kind of enforced visual consistency between different applications to make things "look coherent". No, I'm just talking about the pain and uncertainty users go through with upgrades, and understanding that while your project may be the most important project to *you* (because it's what you do), to your users, your project is likely just a fairly small and irrelevant part of their experience, and it's not very central at all, and they've learnt the quirks about that thing they don't even care about, and you really shouldn't break their expectations. Because it turns out that that is how you really make people hate their desktop.
|
||||
|
||||
This is not at all Linux-specific, of course - just look at the less than enthusiastic reception that other operating system redesigns have received. But I really wish that we hadn't had *both* of the major Linux desktop environments have to learn this (well, I hope they learnt) the hard way, and both of them ending up blaming their users rather than themselves.
|
||||
|
||||
**"anykernel"-style portable drivers?**
|
||||
by staalmannen
|
||||
|
||||
> What do you think about the "anykernel" concept (invented by another Finn btw) used in NetBSD? Basically, they have modularized the code so that a driver can be built either in a monolithic kernel or for user space without source code changes ( rumpkernel.org ). The drivers are highly portable and used in Genode os (L4 type kernels), minix etc... Would this be possible or desirable for Linux? Apparently there is one attempt called "libos"...
|
||||
|
||||
**Linus**: So I have bad experiences with "portable" drivers. Writing drivers to some common environment tends to force some ridiculously nasty impedance matching abstractions that just get in the way and make things really hard to read and modify. It gets particularly nasty when everybody ends up having complicated - and differently so - driver subsystems to handle a lot of commonalities for a certain class of drivers (say a network driver, or a USB driver), and the different operating systems really have very different approaches and locking rules etc.
|
||||
|
||||
I haven't seen anykernel drivers, but from past experience my reaction to "portable device drivers" is to run away, screaming like little girl. As they say in Swedish "Bränt barn luktar illa".
|
||||
|
||||
**Processor Architecture**
|
||||
by swv3752
|
||||
|
||||
> Several years ago, you were employed by Transmeta designing the Crusoe processor. I understand you are quite knowledgeable about cpu architecture. What are your thoughts on the Current Intel and AMD x86 CPUs particularly in comparison with ARM and IBM's Power8 CPUs? Where do you see the advantages of each one?
|
||||
|
||||
**Linus**: I'm no CPU architect, I just play one on TV.
|
||||
|
||||
But yes, I've been close to the CPU both as part of my kernel work, and as part of a processor company, and working at that level for a long time just means that you end up having fairly strong opinions. One of the things that my experiences at Transmeta convinced me of, for example, was that there's definitely very much a limit to what software should care about. I loved working at Transmeta, I loved the whole startup company environment, I loved working with really smart people, but in the end I ended up absolutely *not* loving to work with overly simple hardware (I also didn't love the whole IPO process, and what that did to the company culture, but that's a different thing).
|
||||
|
||||
Because there's only so much that software can do to compensate.
|
||||
|
||||
Something similar happened with my kernel work on the alpha architecture, which also started out as being an overly simplified implementation in the name of being small and supposedly running really fast. While I really started out liking the alpha architecture for being so clean, I ended up detesting how fragile the architecture implementations were (and by the time that got fixed in the 21264, I had given up on alpha).
|
||||
|
||||
So I've come to absolutely detest CPU's that need a lot of compiler smarts or special tuning to go fast. Life is too short to waste on in-order CPU's, or on hardware designers who think software should take care of the pieces that they find to be too complicated to handle themselves, and as a result just left undone. "Weak memory ordering" is just another example.
|
||||
|
||||
Thankfully, most of the industry these days seems to agree. Yes, there are still in-order cores, but nobody tries to make excuses for them any more: they are for the truly cheap and low-end market.
|
||||
|
||||
I tend to really like the modern Intel cores in particular, which tend to take that "let's not be stupid" really to heart. With the kernel being so threaded, I end up caring a lot about things like memory ordering etc, and the Intel big-core CPU's tend to be in a class of their own there. As a software person who cares about performance and looks at instruction profiles etc, it's just so *nice* to see that the CPU doesn't have some crazy glass jaw where you have to be very careful.
|
||||
|
||||
**GPU kernels**
|
||||
by maraist
|
||||
|
||||
> Is there any inspiration that a GPU based kernel / scheduler has for you? How might Linux be improved to better take advantage of GPU-type batch execution models. Given that you worked transmeta and JIT compiled host-targeted runtimes. GPUs 1,000-thread schedulers seem like the next great paradigm for the exact type of machines that Linux does best on.
|
||||
|
||||
**Linus**: I don't think we'll see the kernel ever treat GPU threads the way we treat CPU threads. Not with the current model of GPU's (and that model doesn't really seem to be changing all that much any more).
|
||||
|
||||
Yes, GPU's are getting much better, and now generally have virtual memory and the ability to preempt execution, and you could run an OS on them. But the scheduling latencies are pretty high, and the threads are not really "independent" (ie they tend to share a lot of state - like the virtual address space and a large shared register set), so GPU "threads" don't tend to work like CPU threads. You'd schedule them all-or-nothing, so if you were to switch processes, you'd treat the GPU as one entity where you switch all the threads at once.
|
||||
|
||||
So it really wouldn't look like a thousand threads to the kernel. The GPU would still be scheduled as one single entity (or maybe a couple of entities depending on how the GPU is partitioned). The fact that that single entity works by doing a lot of things in massive parallelism is kind of immaterial for the kernel that doesn't end up seeing that parallelism as separate threads.
|
||||
|
||||
**alleged danger of Artificial Intelligence**
|
||||
by peter303
|
||||
|
||||
> Some computer experts like Marvin Minsky, Larry Page, Ray Kuzweil think A.I. will be a great gift to Mankind. Others like Bill Joy and Elon Musk are fearful of potential danger. Where do you stand, Linus?
|
||||
|
||||
**Linus**: I just don't see the thing to be fearful of.
|
||||
|
||||
We'll get AI, and it will almost certainly be through something very much like recurrent neural networks. And the thing is, since that kind of AI will need training, it won't be "reliable" in the traditional computer sense. It's not the old rule-based prolog days, when people thought they'd *understand* what the actual decisions were in an AI.
|
||||
|
||||
And that all makes it very interesting, of course, but it also makes it hard to productize. Which will very much limit where you'll actually find those neural networks, and what kinds of network sizes and inputs and outputs they'll have.
|
||||
|
||||
So I'd expect just more of (and much fancier) rather targeted AI, rather than anything human-like at all. Language recognition, pattern recognition, things like that. I just don't see the situation where you suddenly have some existential crisis because your dishwasher is starting to discuss Sartre with you.
|
||||
|
||||
The whole "Singularity" kind of event? Yeah, it's science fiction, and not very good SciFi at that, in my opinion. Unending exponential growth? What drugs are those people on? I mean, really..
|
||||
|
||||
It's like Moore's law - yeah, it's very impressive when something can (almost) be plotted on an exponential curve for a long time. Very impressive indeed when it's over many decades. But it's _still_ just the beginning of the "S curve". Anybody who thinks any different is just deluding themselves. There are no unending exponentials.
|
||||
|
||||
**Is the kernel basically a finished project?**
|
||||
by NaCh0
|
||||
|
||||
> Aside from adding drivers and refactoring algorithms when performance limits are discovered, is there anything left for the kernel? Maybe it's a failure of tech journalism but we never hear about the next big thing in kernel land anymore.
|
||||
|
||||
**Linus**: I don't think there's much of a "next big thing" in the kernel.
|
||||
|
||||
I wouldn't say that there is nothing but drivers (and architectures are kind of "CPU drivers) and improving scalability left, because I'm constantly amazed by how many new things people figure out are still good ideas. But they tend to still be pretty incremental improvements. An OS kernel doesn't look *that* radically different from what it was 40 years ago, and that's fine. I think radical new ideas are often overrated, and the thing that really matters in the end is that plodding detail work. That's how technology evolves.
|
||||
|
||||
And judging by how our kernel releases are going, there's no end in sight for that "plodding detail work". And it's still as interesting as it ever was.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linux.slashdot.org/story/15/06/30/0058243/interviews-linus-torvalds-answers-your-question
|
||||
|
||||
作者:[samzenpus][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:samzenpus@slashdot.org
|
||||
[1]:http://interviews.slashdot.org/story/15/06/24/1718247/interview-ask-linus-torvalds-a-question
|
||||
[2]:http://meta.slashdot.org/story/12/10/11/0030249/linus-torvalds-answers-your-questions
|
||||
[3]:https://lwn.net/Articles/604695/
|
||||
@ -78,4 +78,4 @@ via: http://opensource.com/life/15/8/patricia-torvalds-interview
|
||||
[4]:https://www.facebook.com/guerrillafeminism
|
||||
[5]:https://modelviewculture.com/
|
||||
[6]:https://www.aspirations.org/
|
||||
[7]:https://www.facebook.com/groups/LadiesStormHackathons/
|
||||
[7]:https://www.facebook.com/groups/LadiesStormHackathons/
|
||||
|
||||
@ -1,53 +0,0 @@
|
||||
Which Open Source Linux Distributions Would Presidential Hopefuls Run?
|
||||
================================================================================
|
||||

|
||||
|
||||
Republican presidential candidate Donald Trump
|
||||
|
||||
If people running for president used Linux or another open source operating system, which distribution would it be? That's a key question that the rest of the press—distracted by issues of questionable relevance such as "policy platforms" and whether it's appropriate to add an exclamation point to one's Christian name—has been ignoring. But the ignorance ends here: Read on for this sometime-journalist's take on presidential elections and Linux distributions.
|
||||
|
||||
If this sounds like a familiar topic to those of you who have been reading my drivel for years (is anyone, other than my dear editor, unfortunate enough to have actually done that?), it's because I wrote a [similar post][1] during the last presidential election cycle. Some kind readers took that article more seriously than I intended, so I'll take a moment to point out that I don't actually believe that open source software and political campaigns have anything meaningful to do with one another. I am just trying to amuse myself at the start of a new week.
|
||||
|
||||
But you can make of this what you will. You're the reader, after all.
|
||||
|
||||
### Linux Distributions of Choice: Republicans ###
|
||||
|
||||
Today, I'll cover just the Republicans. And I won't even discuss all of them, since the candidates hoping for the Republican party's nomination are too numerous to cover fully here in one post. But for starters:
|
||||
|
||||
If **Jeb (Jeb!?) Bush** ran Linux, it would be [Debian][2]. It's a relatively boring distribution designed for serious, grown-up hackers—the kind who see it as their mission to be the adults in the pack and clean up the messes that less-experienced open source fans create. Of course, this also makes Debian relatively unexciting, and its user base remains perennially small as a result.
|
||||
|
||||
**Scott Walker**, for his part, would be a [Damn Small Linux][3] (DSL) user. Requiring merely 50MB of disk space and 16MB of RAM to run, DSL can breathe new life into 20-year-old 486 computers—which is exactly what a cost-cutting guru like Walker would want. Of course, the user experience you get from DSL is damn primitive; the platform barely runs a browser. But at least you won't be wasting money on new computer hardware when the stuff you bought in 1993 can still serve you perfectly well.
|
||||
|
||||
How about **Chris Christie**? He'd obviously be clinging to [Relax-and-Recover Linux][4], which bills itself as a "setup-and-forget Linux bare metal disaster recovery solution." "Setup-and-forget" has basically been Christie's political strategy ever since that unfortunate incident on the George Washington Bridge stymied his political momentum. Disaster recovery may or may not bring back everything for Christie in the end, but at least he might succeed in recovering a confidential email or two that accidentally disappeared when his computer crashed.
|
||||
|
||||
As for **Carly Fiorina**, she'd no doubt be using software developed for "[The Machine][5]" operating system from [Hewlett-Packard][6] (HPQ), the company she led from 1999 to 2005. The Machine actually may run several different operating systems, which may or may not be based on Linux—details remain unclear—and its development began well after Fiorina's tenure at HP came to a conclusion. Still, her roots as a successful executive in the IT world form an important part of her profile today, meaning that her ties to HP have hardly been severed fully.
|
||||
|
||||
Last but not least—and you knew this was coming—there's **Donald Trump**. He'd most likely pay a team of elite hackers millions of dollars to custom-build an operating system just for him—even though he could obtain a perfectly good, ready-made operating system for free—to show off how much money he has to waste. He'd then brag about it being the best operating system ever made, though it would of course not be compliant with POSIX or anything else, because that would mean catering to the establishment. The platform would also be totally undocumented, since, if Trump explained how his operating system actually worked, he'd risk giving away all his secrets to the Islamic State—obviously.
|
||||
|
||||
Alternatively, if Trump had to go with a Linux platform already out there, [Ubuntu][7] seems like the most obvious choice. Like Trump, the Ubuntu developers have taken a we-do-what-we-want approach to building open source software by implementing their own, sometimes proprietary applications and interfaces. Free-software purists hate Ubuntu for that, but plenty of ordinary people like it a lot. Of course, whether playing purely by your own rules—in the realms of either software or politics—is sustainable in the long run remains to be seen.
|
||||
|
||||
### Stay Tuned ###
|
||||
|
||||
If you're wondering why I haven't yet mentioned the Democratic candidates, worry not. I am not leaving them out of today's writing because I like them any more or less than the Republicans. (Personally, I think the peculiar American practice of having only two viable political parties—which virtually no other functioning democracy does—is ridiculous, and I am suspicious of all of these candidates as a result.)
|
||||
|
||||
On the contrary, there's plenty to say about the Linux distributions the Democrats might use, too. And I will, in a future post. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/081715/which-open-source-linux-distributions-would-presidential-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://thevarguy.com/open-source-application-software-companies/aligning-linux-distributions-presidential-hopefuls
|
||||
[2]:http://debian.org/
|
||||
[3]:http://www.damnsmalllinux.org/
|
||||
[4]:http://relax-and-recover.org/
|
||||
[5]:http://thevarguy.com/open-source-application-software-companies/061614/hps-machine-open-source-os-truly-revolutionary
|
||||
[6]:http://hp.com/
|
||||
[7]:http://ubuntu.com/
|
||||
@ -1,203 +0,0 @@
|
||||
Gaming On Linux: All You Need To Know
|
||||
================================================================================
|
||||

|
||||
|
||||
**Can I play games on Linux?**
|
||||
|
||||
This is one of the most frequently asked questions by people who are thinking about [switching to Linux][1]. After all, gaming on Linux often termed as a distant possibility. In fact, some people even wonder if they can listen to music or watch movies on Linux. Considering that, question about native Linux games seem genuine.
|
||||
|
||||
In this article, I am going to answer most of the Linux gaming questions a Linux beginner may have. For example, if it is possible to play games on Linux, if yes, what are the Linux games available, where can you **download Linux games** from or how do you get more information of gaming on Linux.
|
||||
|
||||
But before I do that, let me make a confession. I am not a PC gamer or rather I should say, I am not desktop Linux gamer. I prefer to play games on my PS4 and I don’t care about PC games or even mobile games (no candy crush request sent to anyone in my friend list). This is the reason you see only a few articles in [Linux games][2] section of It’s FOSS.
|
||||
|
||||
So why am I covering this topic then?
|
||||
|
||||
Because I have been asked questions about playing games on Linux several times and I wanted to come up with a Linux gaming guide that could answer all those question. And remember, it’s not just gaming on Ubuntu I am talking about here. I am talking about Linux in general.
|
||||
|
||||
### Can you play games on Linux? ###
|
||||
|
||||
Yes and no!
|
||||
|
||||
Yes, you can play games on Linux and no, you cannot play ‘all the games’ in Linux.
|
||||
|
||||
Confused? Don’t be. What I meant here is that you can get plenty of popular games on Linux such as [Counter Strike, Metro Last Night][3] etc. But you might not get all the latest and popular Windows games on Linux, for e.g., [PES 2015][4].
|
||||
|
||||
The reason, in my opinion, is that Linux has less than 2% of desktop market share and these numbers are demotivating enough for most game developers to avoid working on the Linux version of their games.
|
||||
|
||||
Which means that there is huge possibility that the most talked about games of the year may not be playable in Linux. Don’t despair, there are ‘other means’ to get these games on Linux and we shall see it in coming sections, but before that let’s talk about what kind of games are available for Linux.
|
||||
|
||||
If I have to categorize, I’ll divide them in four categories:
|
||||
|
||||
1. Native Linux Games
|
||||
1. Windows games in Linux
|
||||
1. Browser Games
|
||||
1. Terminal Games
|
||||
|
||||
Let’s start with the most important one, native Linux games, first.
|
||||
|
||||
----------
|
||||
|
||||
### 1. Where to find native Linux games? ###
|
||||
|
||||
Native Linux games mean those games which are officially supported in Linux. These games have native Linux client and can be installed like most other applications in Linux without requiring any additional effort (we’ll see about these in next section).
|
||||
|
||||
So, as you see, there are games developed for Linux. Next question that arises is where can you find these Linux games and how can you play them. I am going to list some of the resources where you can get Linux games.
|
||||
|
||||
#### Steam ####
|
||||
|
||||

|
||||
|
||||
“[Steam][5] is a digital distribution platform for video games. As Amazon Kindle is digital distribution platform for e-Books, iTunes for music, similarly Steam is for games. It provides you the option to buy and install games, play multiplayer and stay in touch with other games via social networking on its platform. The games are protected with [DRM][6].”
|
||||
|
||||
A couple of years ago, when gaming platform Steam announced support for Linux, it was a big news. It was an indication that gaming on Linux is being taken seriously. Though Steam’s decision was more influenced with its own Linux-based gaming console and a separate [Linux distribution called Steam OS][7], it still was a reassuring move that has brought a number of games on Linux.
|
||||
|
||||
I have written a detailed article about installing and using Steam. If you are getting started with Steam, do read it.
|
||||
|
||||
- [Install and use Steam for gaming on Linux][8]
|
||||
|
||||
#### GOG.com ####
|
||||
|
||||
[GOG.com][9] is another platform similar to Steam. Like Steam, you can browse and find hundreds of native Linux games on GOG.com, purchase the games and install them. If the games support several platforms, you can download and use them across various operating systems. Your purchased games are available for you all the time in your account. You can download them anytime you wish.
|
||||
|
||||
One main difference between the two is that GOG.com offers only DRM free games and movies. Also, GOG.com is entirely web based. So you don’t need to install a client like Steam. You can simply download the games from browser and install them in your system.
|
||||
|
||||
#### Portable Linux Games ####
|
||||
|
||||
[Portable Linux Games][10] is a website that has a collection of a number of Linux games. The unique and best thing about Portable Linux Games is that you can download and store the games for offline installation.
|
||||
|
||||
The downloaded files have all the dependencies (at times Wine and Perl installation) and these are also platform independent. All you need to do is to download the files and double click to install them. Store the downloadable file on external hard disk and use them in future. Highly recommend if you don’t have continuous access to high speed internet.
|
||||
|
||||
#### Game Drift Game Store ####
|
||||
|
||||
[Game Drift][11] is actually a Linux distribution based on Ubuntu with sole focus on gaming. While you might not want to start using this Linux distribution for the sole purpose of gaming, you can always visit its game store online and see what games are available for Linux and install them.
|
||||
|
||||
#### Linux Game Database ####
|
||||
|
||||
As the name suggests, [Linux Game Database][12] is a website with a huge collection of Linux games. You can browse through various category of games and download/install them from the game developer’s website. As a member of Linux Game Database, you can even rate the games. LGDB, kind of, aims to be the IGN or IMDB for Linux games.
|
||||
|
||||
#### Penguspy ####
|
||||
|
||||
Created by a gamer who refused to use Windows for playing games, [Penguspy][13] showcases a collection of some of the best Linux games. You can browse games based on category and if you like the game, you’ll have to go to the respective game developer’s website.
|
||||
|
||||
#### Software Repositories ####
|
||||
|
||||
Look into the software repositories of your own Linux distribution. There always will be some games in it. If you are using Ubuntu, Ubuntu Software Center itself has an entire section for games. Same is true for other Linux distributions such as Linux Mint etc.
|
||||
|
||||
----------
|
||||
|
||||
### 2. How to play Windows games in Linux? ###
|
||||
|
||||

|
||||
|
||||
So far we talked about native Linux games. But there are not many Linux games, or to be more precise, most popular Linux games are not available for Linux but they are available for Windows PC. So the questions arises, how to play Windows games in Linux?
|
||||
|
||||
Good thing is that with the help of tools like Wine, PlayOnLinux and CrossOver, you can play a number of popular Windows games in Linux.
|
||||
|
||||
#### Wine ####
|
||||
|
||||
Wine is a compatibility layer which is capable of running Windows applications in systems like Linux, BSD and OS X. With the help of Wine, you can install and use a number of Windows applications in Linux.
|
||||
|
||||
[Installing Wine in Ubuntu][14] or any other Linux is easy as it is available in most Linux distributions’ repository. There is a huge [database of applications and games supported by Wine][15] that you can browse.
|
||||
|
||||
#### CrossOver ####
|
||||
|
||||
[CrossOver][16] is an improved version of Wine that brings professional and technical support to Wine. But unlike Wine, CrossOver is not free. You’ll have to purchase the yearly license for it. Good thing about CrossOver is that every purchase contributes to Wine developers and that in fact boosts the development of Wine to support more Windows games and applications. If you can afford $48 a year, you should buy CrossOver for the support they provide.
|
||||
|
||||
### PlayOnLinux ###
|
||||
|
||||
PlayOnLinux too is based on Wine but implemented differently. It has different interface and slightly easier to use than Wine. Like Wine, PlayOnLinux too is free to use. You can browse the [applications and games supported by PlayOnLinux on its database][17].
|
||||
|
||||
----------
|
||||
|
||||
### 3. Browser Games ###
|
||||
|
||||

|
||||
|
||||
Needless to say that there are tons of browser based games that are available to play in any operating system, be it Windows or Linux or Mac OS X. Most of the addictive mobile games, such as [GoodGame Empire][18], also have their web browser counterparts.
|
||||
|
||||
Apart from that, thanks to [Google Chrome Web Store][19], you can play some more games in Linux. These Chrome games are installed like a standalone app and they can be accessed from the application menu of your Linux OS. Some of these Chrome games are playable offline as well.
|
||||
|
||||
----------
|
||||
|
||||
### 4. Terminal Games ###
|
||||
|
||||

|
||||
|
||||
Added advantage of using Linux is that you can use the command line terminal to play games. I know that it’s not the best way to play games but at times, it’s fun to play games like [Snake][20] or [2048][21] in terminal. There is a good collection of Linux terminal games at [this blog][22]. You can browse through it and play the ones you want.
|
||||
|
||||
----------
|
||||
|
||||
### How to stay updated about Linux games? ###
|
||||
|
||||
When you have learned a lot about what kind of games are available on Linux and how could you use them, next question is how to stay updated about new games on Linux? And for that, I advise you to follow these blogs that provide you with the latest happenings of the Linux gaming world:
|
||||
|
||||
- [Gaming on Linux][23]: I won’t be wrong if I call it the nest Linux gaming news portal. You get all the latest rumblings and news about Linux games. Frequently updated, Gaming on Linux has dedicated fan following which makes it a nice community of Linux game lovers.
|
||||
- [Free Gamer][24]: A blog focusing on free and open source games.
|
||||
- [Linux Game News][25]: A Tumbler blog that updates on various Linux games.
|
||||
|
||||
#### What else? ####
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][26]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][27]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
It’s time for you to add your inputs. Do you play games on your Linux desktop? What are your favorites? What blogs you follow to stay updated on latest Linux games?
|
||||
|
||||
|
||||
投票项目:
|
||||
How do you play games on Linux?
|
||||
|
||||
- I use Wine and PlayOnLinux along with native Linux Games
|
||||
- I am happy with Browser Games
|
||||
- I prefer the Terminal Games
|
||||
- I use native Linux games only
|
||||
- I play it on Steam
|
||||
- I dual boot and go in to Windows to play games
|
||||
- I don't play games at all
|
||||
|
||||
注:投票代码
|
||||
<div class="PDS_Poll" id="PDI_container9132962" style="display:inline-block;"></div>
|
||||
<div id="PD_superContainer"></div>
|
||||
<script type="text/javascript" charset="UTF-8" src="http://static.polldaddy.com/p/9132962.js"></script>
|
||||
<noscript><a href="http://polldaddy.com/poll/9132962">Take Our Poll</a></noscript>
|
||||
|
||||
注,发布时根据情况看怎么处理
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/linux-gaming-guide/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[2]:http://itsfoss.com/category/games/
|
||||
[3]:http://blog.counter-strike.net/
|
||||
[4]:https://pes.konami.com/tag/pes-2015/
|
||||
[5]:http://store.steampowered.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Digital_rights_management
|
||||
[7]:http://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[8]:http://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[9]:http://www.gog.com/
|
||||
[10]:http://www.portablelinuxgames.org/
|
||||
[11]:http://gamedrift.org/GameStore.html
|
||||
[12]:http://www.lgdb.org/
|
||||
[13]:http://www.penguspy.com/
|
||||
[14]:http://itsfoss.com/wine-1-5-11-released-ppa-available-to-download/
|
||||
[15]:https://appdb.winehq.org/
|
||||
[16]:https://www.codeweavers.com/products/
|
||||
[17]:https://www.playonlinux.com/en/supported_apps.html
|
||||
[18]:http://empire.goodgamestudios.com/
|
||||
[19]:https://chrome.google.com/webstore/category/apps
|
||||
[20]:http://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[21]:http://itsfoss.com/play-2048-linux-terminal/
|
||||
[22]:https://ttygames.wordpress.com/
|
||||
[23]:https://www.gamingonlinux.com/
|
||||
[24]:http://freegamer.blogspot.fr/
|
||||
[25]:http://linuxgamenews.com/
|
||||
[26]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[27]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
@ -75,4 +75,4 @@ via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-i
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
|
||||
@ -1,66 +0,0 @@
|
||||
While the event had a certain amount of drama surrounding it, the [announcement][1] of the end for the [Debian Live project][2] seems likely to have less of an impact than it first appeared. The loss of the lead developer will certainly be felt—and the treatment he and the project received seems rather baffling—but the project looks like it will continue in some form. So Debian will still have tools to create live CDs and other media going forward, but what appears to be a long-simmering dispute between project founder and leader Daniel Baumann and the Debian CD and installer teams has been "resolved", albeit in an unfortunate fashion.
|
||||
|
||||
The November 9 announcement from Baumann was titled "An abrupt End to Debian Live". In that message, he pointed to a number of different events over the nearly ten years since the [project was founded][3] that indicated to him that his efforts on Debian Live were not being valued, at least by some. The final straw, it seems, was an "intent to package" (ITP) bug [filed][4] by Iain R. Learmonth that impinged on the namespace used by Debian Live.
|
||||
|
||||
Given that one of the main Debian Live packages is called "live-build", the new package's name, "live-build-ng", was fairly confrontational in and of itself. Live-build-ng is meant to be a wrapper around the [vmdebootstrap][5] tool for creating live media (CDs and USB sticks), which is precisely the role Debian Live is filling. But when Baumann [asked][6] Learmonth to choose a different name for his package, he got an "interesting" [reply][7]:
|
||||
|
||||
```
|
||||
It is worth noting that live-build is not a Debian project, it is an external project that claims to be an official Debian project. This is something that needs to be fixed.
|
||||
There is no namespace issue, we are building on the existing live-config and live-boot packages that are maintained and bringing these into Debian as native projects. If necessary, these will be forks, but I'm hoping that won't have to happen and that we can integrate these packages into Debian and continue development in a collaborative manner.
|
||||
live-build has been deprecated by debian-cd, and live-build-ng is replacing it. In a purely Debian context at least, live-build is deprecated. live-build-ng is being developed in collaboration with debian-cd and D-I [Debian Installer].
|
||||
```
|
||||
|
||||
Whether or not Debian Live is an "official" Debian project (or even what "official" means in this context) has been disputed in the thread. Beyond that, though, Neil Williams (who is the maintainer of vmdebootstrap) [provided some][8] explanation for the switch away from Debian Live:
|
||||
|
||||
```
|
||||
vmdebootstrap is being extended explicitly to provide support for a replacement for live-build. This work is happening within the debian-cd team to be able to solve the existing problems with live-build. These problems include reliability issues, lack of multiple architecture support and lack of UEFI support. vmdebootstrap has all of these, we do use support from live-boot and live-config as these are out of the scope for vmdebootstrap.
|
||||
```
|
||||
|
||||
Those seem like legitimate complaints, but ones that could have been fixed within the existing project. Instead, though, something of a stealth project was evidently undertaken to replace live-build. As Baumann [pointed out][9], nothing was posted to the debian-live mailing list about the plans. The ITP was the first notice that anyone from the Debian Live project got about the plans, so it all looks like a "secret plan"—something that doesn't sit well in a project like Debian.
|
||||
|
||||
As might be guessed, there were multiple postings that supported Baumann's request to rename "live-build-ng", followed by many that expressed dismay at his decision to stop working on Debian Live. But Learmonth and Williams were adamant that replacing live-build is needed. Learmonth did [rename][10] live-build-ng to a perhaps less confrontational name: live-wrapper. He noted that his aim had been to add the new tool to the Debian Live project (and "bring the Debian Live project into Debian"), but things did not play out that way.
|
||||
|
||||
```
|
||||
I apologise to everyone that has been upset by the ITP bug. The software is not yet ready for use as a full replacement for live-build, and it was filed to let people know that the work was ongoing and to collect feedback. This sort of worked, but the feedback wasn't the kind I was looking for.
|
||||
```
|
||||
|
||||
The backlash could perhaps have been foreseen. Communication is a key aspect of free-software communities, so a plan to replace the guts of a project seems likely to be controversial—more so if it is kept under wraps. For his part, Baumann has certainly not been perfect—he delayed the "wheezy" release by [uploading an unsuitable syslinux package][11] and [dropped down][12] from a Debian Developer to a Debian Maintainer shortly thereafter—but that doesn't mean he deserves this kind of treatment. There are others involved in the project as well, of course, so it is not just Baumann who is affected.
|
||||
|
||||
One of those other people is Ben Armstrong, who has been something of a diplomat during the event and has tried to smooth the waters. He started with a [post][13] that celebrated the project and what Baumann and the team had accomplished over the years. As he noted, the [list of downstream projects][14] for Debian Live is quite impressive. In another post, he also [pointed out][15] that the project is not dead:
|
||||
|
||||
```
|
||||
If the Debian CD team succeeds in their efforts and produces a replacement that is viable, reliable, well-tested, and a suitable candidate to replace live-build, this can only be good for Debian. If they are doing their job, they will not "[replace live-build with] an officially improved, unreliable, little-tested alternative". I've seen no evidence so far that they operate that way. And in the meantime, live-build remains in the archive -- there is no hurry to remove it, so long as it remains in good shape, and there is not yet an improved successor to replace it.
|
||||
```
|
||||
|
||||
On November 24, Armstrong also [posted][16] an update (and to [his blog][17]) on Debian Live. It shows some good progress made in the two weeks since Baumann's exit; there are even signs of collaboration between the project and the live-wrapper developers. There is also a [to-do list][18], as well as the inevitable call for more help. That gives reason to believe that all of the drama surrounding the project was just a glitch—avoidable, perhaps, but not quite as dire as it might have seemed.
|
||||
|
||||
|
||||
---------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/665839/
|
||||
|
||||
作者:Jake Edge
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://lwn.net/Articles/666127/
|
||||
[2]: http://live.debian.net/
|
||||
[3]: https://www.debian.org/News/weekly/2006/08/
|
||||
[4]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=804315
|
||||
[5]: http://liw.fi/vmdebootstrap/
|
||||
[6]: https://lwn.net/Articles/666173/
|
||||
[7]: https://lwn.net/Articles/666176/
|
||||
[8]: https://lwn.net/Articles/666181/
|
||||
[9]: https://lwn.net/Articles/666208/
|
||||
[10]: https://lwn.net/Articles/666321/
|
||||
[11]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=699808
|
||||
[12]: https://nm.debian.org/public/process/14450
|
||||
[13]: https://lwn.net/Articles/666336/
|
||||
[14]: http://live.debian.net/project/downstream/
|
||||
[15]: https://lwn.net/Articles/666338/
|
||||
[16]: https://lwn.net/Articles/666340/
|
||||
[17]: http://syn.theti.ca/2015/11/24/debian-live-after-debian-live/
|
||||
[18]: https://wiki.debian.org/DebianLive/TODO
|
||||
@ -0,0 +1,76 @@
|
||||
vim-kakali translating
|
||||
|
||||
|
||||
|
||||
Confessions of a cross-platform developer
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
[Andreia Gaita][1] is giving a talk at this year's OSCON, titled [Confessions of a cross-platform developer][2]. She's a long-time open source and [Mono][3] contributor, and develops primarily in C#/C++. Andreia works at GitHub, where she's focused on building the GitHub Extension manager for Visual Studio.
|
||||
|
||||
I caught up with Andreia ahead of her talk to ask about cross-platform development and what she's learned in her 16 years as a cross-platform developer.
|
||||
|
||||

|
||||
|
||||
**What languages have you found easiest and hardest to develop cross-platform code for?**
|
||||
|
||||
It's less about which languages are good and more about the libraries and tooling available for those languages. The compilers/interpreters/build systems available for languages determine how easy it is to do cross-platform work with them (or whether it's even possible), and the libraries available for UI and native system access determine how deep you can integrate with the OS. With that in mind, I found C# to be the best for cross-platform work. The language itself includes features that allow fast native calls and accurate memory mapping, which you really need if you want your code to talk to the OS and native libraries. When I need very specific OS integration, I switch to C or C++.
|
||||
|
||||
**What cross-platform toolkits/abstractions have you used?**
|
||||
|
||||
Most of my cross-platform work has been developing tools, libraries and bindings for other people to develop cross-platform applications with, mostly in Mono/C# and C/C++. I don't get to use a lot of abstractions at that level, beyond glib and friends. I mostly rely on Mono for any cross-platform app that includes a UI, and Unity3D for the occasional game development. I play with Electron every now and then.
|
||||
|
||||
**What has been your approach to build systems, and how does this vary by language or platform?**
|
||||
|
||||
I try to pick the build system that is most suited for the language(s) I'm using. That way, it'll (hopefully) give me less headaches. It needs to allow for platform and architecture selection, be smart about build artifact locations (for multiple parallel builds), and be decently configurable. Most of the time I have projects combining C/C++ and C# and I want to build all the different configurations at the same time from the same source tree (Debug, Release, Windows, OSX, Linux, Android, iOS, etc, etc.), and that usually requires selecting and invoking different compilers with different flags per output build artifact. So the build system has to let me do all of this without getting (too much) in my way. I try out different build systems every now and then, just to see what's new, but in the end, I end up going back to makefiles and a combination of either shell and batch scripts or Perl scripts for driving them (because if I want users to build my things, I'd better pick a command line script language that is available everywhere).
|
||||
|
||||
**How do you balance the desire for native look and feel with the need for uniform user interfaces?**
|
||||
|
||||
Cross-platform UI is hard! I've implemented several cross-platform GUIs over the years, and it's the one thing for which I don't think there's an optimal solution. There's basically two options. You can pick a cross-platform GUI toolkit and do a UI that doesn't feel quite right in all the platforms you support, with a small codebase and low maintenance cost. Or you can choose to develop platform-specific UIs that will look and feel native and well integrated with a larger codebase and higher maintenance cost. The decision really depends on the type of app, how many features it has, how many resources you have, and how many platforms you're shipping to.
|
||||
|
||||
In the end, I think there's an increase in users' tolerance for "One UI To Rule Them All" with frameworks like Electron. I have a Chromium+C+C# framework side project that will one day hopefully allow me build Electron-style apps in C#, giving me the best of both worlds.
|
||||
|
||||
**Has building/packaging dependencies been an issue for you?**
|
||||
|
||||
I'm very conservative about my use of dependencies, having been bitten so many times by breaking ABIs, clashing symbols, and missing packages. I decide which OS version(s) I'm targeting and pick the lowest common denominator release available of a dependency to minimize issues. That usually means having five different copies of Xcode and OSX Framework libraries, five different versions of Visual Studio installed side-to-side on the same machine, multiple clang and gcc versions, and a bunch of VMs running various other distros. If I'm unsure of the state of packages in the OS I'm targeting, I will sometimes link statically and sometimes submodule dependencies to make sure they're always available. And most of all, I avoid the bleeding edge unless I really, really need something there.
|
||||
|
||||
**Do you use continuous integration, code review, and related tools?**
|
||||
|
||||
All the time! It's the only way to keep sane. The first thing I do on a project is set up cross-platform build scripts to ensure everything is automateable as early as possible. When you're targeting multiple platforms, CI is essential. It's impossible for everyone to build all the different combinations of platforms in one machine, and as soon as you're not building all of them you're going to break something without being aware of it. In a shared multi-platform codebase, different people own different platforms and features, so the only way to guarantee quality is to have cross-team code reviews combined with CI and other analysis tools. It's no different than other software projects, there's just more points of failure.
|
||||
|
||||
**Do you rely on automated build testing, or do you tend to build on each platform and test locally?**
|
||||
|
||||
For tools and libraries that don't include UIs, I can usually get away with automated build testing. If there's a UI, then I need to do both—reliable, scriptable UI automation for existing GUI toolkits is rare to non-existent, so I would have to either invest in creating UI automation tools that work across all the platforms I want to support, or I do it manually. If a project uses a custom UI toolkit (like, say, an OpenGL UI like Unity3D does), then it's fairly easy to develop scriptable automation tools and automate most of that stuff. Still, there's nothing like the human ability to break things with a couple of clicks!
|
||||
|
||||
**If you are developing cross-platform, do you support cross-editor build systems so that you can use Visual Studio on Windows, Qt Creator on Linux, and XCode on Mac? Or do you tend toward supporting one platform such as Eclipse on all platforms?**
|
||||
|
||||
I favor cross-editor build systems. I prefer generating project files for different IDEs (preferably in a way that makes it easier to add more IDEs), with build scripts that can drive builds from the IDEs for the platform they're on. Editors are the most important tool for a developer. It takes time and effort to learn them, and they're not interchangeable. I have my favorite editors and tools, and everyone else should be able to use their favorite tool, too.
|
||||
|
||||
**What is your preferred editor/development environment/IDE for cross-platform development?**
|
||||
|
||||
The cross-platform developer is cursed with having to pick the lowest common denominator editor that works across the most platforms. I love Visual Studio, but I can't rely on it for anything except Windows work (and you really don't want to make Windows your primary cross-compiling platform), so I can't make it my primary IDE. Even if I could, an essential skill of cross-platform development is to know and use as many platforms as possible. That means really knowing them—using the platform's editors and libraries, getting to know the OS and its assumptions, behaviors, and limitations, etc. To do that and keep my sanity (and my shortcut muscle memory), I have to rely on cross-platform editors. So, I use Emacs and Sublime.
|
||||
|
||||
**What are some of your favorite past and current cross-platform projects?**
|
||||
|
||||
Mono is my all-time favorite, hands down, and most of the others revolve around it in some way. Gluezilla was a Mozilla binding I did years ago to allow C# apps to embed web browser views, and that one was a doozy. At one point I had a Winforms app, built on Linux, running on Windows with an embedded GTK view in it that was running a Mozilla browser view. The CppSharp project (formerly Cxxi, formerly CppInterop) is a project I started to generate C# bindings for C++ libraries so that you could call, create instances of, and subclass C++ classes from C#. It was done in such a way that it would detect at runtime what platform you'd be running on and what compiler was used to create the native library and generate the correct C# bindings for it. That was fun!
|
||||
|
||||
**Where do you see cross-platform development heading in the future?**
|
||||
|
||||
The way we build native applications is already changing, and I feel like the visual differences between the various desktop operating systems are going to become even more blurred so that it will become easier to build cross-platform apps that integrate reasonably well without being fully native. Unfortunately, that might mean applications will be worse in terms of accessibility and less innovative when it comes to using the OS to its full potential. Cross-platform development of tools, libraries, and runtimes is something that we know how to do well, but there's still a lot of work to do with cross-platform application development.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/oscon-interview-andreia-gaita
|
||||
|
||||
作者:[Marcus D. Hanwell ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhanwell
|
||||
[1]: https://twitter.com/sh4na
|
||||
[2]: http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/48702
|
||||
[3]: http://www.mono-project.com/
|
||||
@ -0,0 +1,46 @@
|
||||
Linus Torvalds Talks IoT, Smart Devices, Security Concerns, and More[video]
|
||||
===========================================================================
|
||||
|
||||

|
||||
>Dirk Hohndel interviews Linus Torvalds at ELC.
|
||||
|
||||
For the first time in the 11-year history of the [Embedded Linux Conference (ELC)][0], held in San Diego, April 4-6, the keynotes included a discussion with Linus Torvalds. The creator and lead overseer of the Linux kernel, and “the reason we are all here,” in the words of his interviewer, Intel Chief Linux and Open Source Technologist Dirk Hohndel, seemed upbeat about the state of Linux in embedded and Internet of Things applications. Torvalds very presence signaled that embedded Linux, which has often been overshadowed by Linux desktop, server, and cloud technologies, had come of age.
|
||||
|
||||

|
||||
>Linus Torvalds speaking at Embedded Linux Conference.
|
||||
|
||||
IoT was the main topic at ELC, which included an OpenIoT Summit track, and the chief topic in the Torvalds interview.
|
||||
|
||||
“Maybe you won’t see Linux at the IoT leaf nodes, but anytime you have a hub, you will need it,” Torvalds told Hohndel. “You need smart devices especially if you have 23 [IoT standards]. If you have all these stupid devices that don’t necessarily run Linux, and they all talk with slightly different standards, you will need a lot of smart devices. We will never have one completely open standard, one ring to rule them all, but you will have three of four major protocols, and then all these smart hubs that translate.”
|
||||
|
||||
Torvalds remained customarily philosophical when Hohndel asked about the gaping security holes in IoT. “I don’t worry about security because there’s not a lot we can do,” he said. “IoT is unpatchable -- it’s a fact of life.”
|
||||
|
||||
The Linux creator seemed more concerned about the lack of timely upstream contributions from one-off embedded projects, although he noted there have been significant improvements in recent years, partially due to consolidation on hardware.
|
||||
|
||||
“The embedded world has traditionally been hard to interact with as an open source developer, but I think that’s improving,” Torvalds said. “The ARM community has become so much better. Kernel people can now actually keep up with some of the hardware improvements. It’s improving, but we’re not nearly there yet.”
|
||||
|
||||
Torvalds admitted to being more at home on the desktop than in embedded and to having “two left hands” when it comes to hardware.
|
||||
|
||||
“I’ve destroyed things with a soldering iron many times,” he said. “I’m not really set up to do hardware.” On the other hand, Torvalds guessed that if he were a teenager today, he would be fiddling around with a Raspberry Pi or BeagleBone. “The great part is if you’re not great at soldering, you can just buy a new one.”
|
||||
|
||||
Meanwhile, Torvalds vowed to continue fighting for desktop Linux for another 25 years. “I’ll wear them down,” he said with a smile.
|
||||
|
||||
Watch the full video, below.
|
||||
|
||||
Get the Latest on Embedded Linux and IoT. Access 150+ recorded sessions from Embedded Linux Conference 2016. [Watch Now][1].
|
||||
|
||||
[video](https://youtu.be/tQKUWkR-wtM)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
@ -0,0 +1,63 @@
|
||||
65% of companies are contributing to open source projects
|
||||
==========================================================
|
||||
|
||||

|
||||
|
||||
This year marks the 10th annual Future of Open Source Survey to examine trends in open source, hosted by Black Duck and North Bridge. The big takeaway from the survey this year centers around the mainstream acceptance of open source today and how much has changed over the last decade.
|
||||
|
||||
The [2016 Future of Open Source Survey][1] analyzed responses from nearly 3,400 professionals. Developers made their voices heard in the survey this year, comprising roughly 70% of the participants. The group that showed exponential growth were security professionals, whose participation increased by over 450%. Their participation shows the increasing interest in ensuring that the open source community pays attention to security issues in open source software and securing new technologies as they emerge.
|
||||
|
||||
Black Duck's [Open Source Rookies][2] of the Year awards identify some of these emerging technologies, like Docker and Kontena in containers. Containers themselves have seen huge growth this year–76% of respondents say their company has some plans to use containers. And an amazing 59% of respondents are already using containers in a variety of deployments, from development and testing to internal and external production environment. The developer community has embraced containers as a way to get their code out quickly and easily.
|
||||
|
||||
It's not surprising that the survey shows a miniscule number of organizations having no developers contributing to open source software. When large corporations like Microsoft and Apple open source some of their solutions, developers gain new opportunities to participate in open source. I certainly hope this trend will continue, with more software developers contributing to open source projects at work and outside of work.
|
||||
|
||||
### Highlights from the 2016 survey
|
||||
|
||||
#### Business value
|
||||
|
||||
* Open source is an essential element in development strategy with more than 65% of respondents relying on open source to speed development.
|
||||
* More than 55% leverage open source within their production environments.
|
||||
|
||||
#### Engine for innovation
|
||||
|
||||
* Respondents reported use of open source to drive innovation through faster, more agile development; accelerated time to market and vastly superior interoperability.
|
||||
* Additional innovation is afforded by open source's quality of solutions; competitive features and technical capabilities; and ability to customize.
|
||||
|
||||
#### Proliferation of open source business models and investment
|
||||
|
||||
* More diverse business models are emerging that promise to deliver more value to open source companies than ever before. They are not as dependent on SaaS and services/support.
|
||||
* Open source private financing has increased almost 4x in five years.
|
||||
|
||||
#### Security and management
|
||||
|
||||
The development of best-in-class open source security and management practices has not kept pace with growth in adoption. Despite a proliferation of expensive, high-profile open source breaches in recent years, the survey revealed that:
|
||||
|
||||
* 50% of companies have no formal policy for selecting and approving open source code.
|
||||
* 47% of companies don’t have formal processes in place to track open source code, limiting their visibility into their open source and therefore their ability to control it.
|
||||
* More than one-third of companies have no process for identifying, tracking or remediating known open source vulnerabilities.
|
||||
|
||||
#### Open source participation on the rise
|
||||
|
||||
The survey revealed an active corporate open source community that spurs innovation, delivers exponential value and shares camaraderie:
|
||||
|
||||
* 67% of respondents report actively encouraging developers to engage in and contribute to open source projects.
|
||||
* 65% of companies are contributing to open source projects.
|
||||
* One in three companies have a fulltime resource dedicated to open source projects.
|
||||
* 59% of respondents participate in open source projects to gain competitive edge.
|
||||
|
||||
Black Duck and North Bridge learned a great deal this year about security, policy, business models and more from the survey, and we’re excited to share these findings. Thank you to our many collaborators and all the respondents for taking the time to take the survey. It’s been a great ten years, and I am happy that we can safely say that the future of open source is full of possibilities.
|
||||
|
||||
Learn more, see the [full results][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/2016-future-open-source-survey
|
||||
|
||||
作者:[Haidee LeClair][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/blackduck2016
|
||||
[1]: http://www.slideshare.net/blackducksoftware/2016-future-of-open-source-survey-results
|
||||
[2]: https://info.blackducksoftware.com/OpenSourceRookies2015.html
|
||||
[3]: http://www.slideshare.net/blackducksoftware/2016-future-of-open-source-survey-results%C2%A0
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user