mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Update 20160817 Building a Real-Time Recommendation Engine with Data Science.md
This commit is contained in:
parent
11099bd670
commit
1a4ce623e8
@ -69,52 +69,67 @@ The MATCH clause is very similar to the MATCH clause of our first Cypher query,
|
||||

|
||||
|
||||
The first three lines are the same, but for the user in question – the user that’s “logged in” – we want to find their friends through the :FRIENDS_WITH relationship along with the places those friends liked. With just a few added lines of Cypher, we are now taking a social aspect into account for our recommendation engine.
|
||||
前三行是完全一样的,但是现在正在考虑的是关于那些登录的用户,我们想要通过`
|
||||
前三行是完全一样的,但是现在正在考虑的是关于那些登录的用户,我们想要通过喜欢相同的地方这一关系来找到他们的朋友。仅需通过在 Cypher 中增加一些行内容,我们现在已经把社会层面考虑到了我们的推荐引擎中。
|
||||
|
||||
Again, we’re only showing categories that the user explicitly asked for that are in the same terminals the user is in. And, of course, we want to filter this by the user who is logged in and making this request, and it returns the name of the place along with its location and category. We are also accounting for how many friends have liked that place and the absolute value of the distance of the place from the gate, all returned in the RETURN clause.
|
||||
在次说明,我们仅仅显示了用户明确请求的目录,并且这些目录中的地点与用户进入的地方有相同的终点。当然,我们希望通过登录用户做出请求来滤过这些目录,然后返回地点的名字、位置以及所在目录。我们也要显示出有多少朋友已经“喜欢”那个地点以及那个地点到出入口的确切距离,然后在返回项目中把这些内容都返回。
|
||||
|
||||
### Similarity Recommendation
|
||||
### 相似性推荐
|
||||
|
||||
Now let’s take a look at a similarity recommendation engine:
|
||||
现在,让我们看一看相似性推荐引擎:
|
||||
|
||||

|
||||
|
||||
Similarly to our earlier data model, we have users who can like places, but this time they can also rate places with an integer between one and 10. This is easily modeled in Neo4j by adding a property to the relationship.
|
||||
和前面的数据模型相似,用户可以标记“喜欢”的地点,但是这一次他们可以用 1 到 10 的整数给地点评定等级。这是通过前期在 Neo4j 中增加一些属性到关系中建模实现的。
|
||||
|
||||
This allows us to find other similar users, like in the example of Greta and Alice. We’ve queried the places they’ve mutually liked, and for each of those places, we can see the weights they have assigned. Presumably, we can use these numbers to determine how similar they are to each other:
|
||||
这将允许我们找到其他相似的用户,比如以 Greta 和 Alice 为例,我们都已经查询了他们共同喜欢的地点,并且对于每一个地点,我们可以看到他们给设定的等级。大概地,我们可以通过他们评定的数字等级来确定他们之间的相似性大小。
|
||||
|
||||
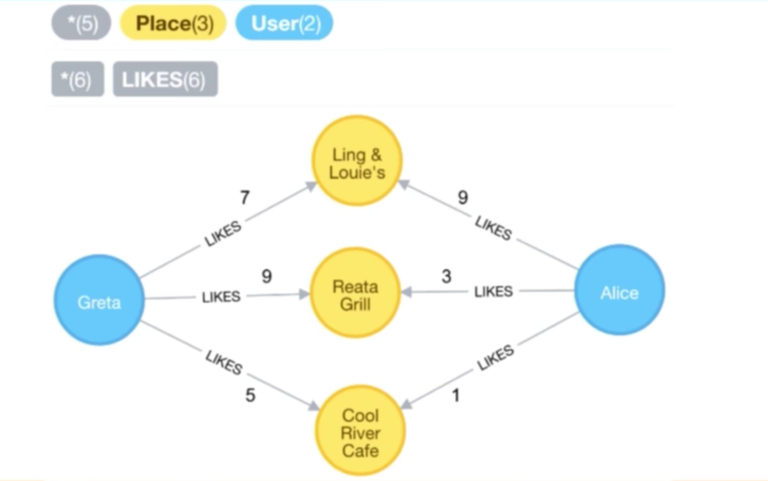
|
||||
|
||||
Now we have two vectors:
|
||||
现在我们有两个向量:
|
||||
|
||||

|
||||
|
||||
And now let’s apply Euclidean distance to find the distance between those two vectors:
|
||||
现在让我们按照欧几里得距离的定义来计算这两个向量之间的距离:
|
||||
|
||||

|
||||
|
||||
And when we plug in all the numbers, we get the following similarity metric, which is really the distance metric between the two users:
|
||||
当我们把所有的数字带入公式中计算,我们得到下面的相似度,这就是两个用户之间的“距离”:
|
||||
|
||||

|
||||
|
||||
You can do this between two specific users easily in Cypher, especially if they’ve only mutually liked a small subset of places. Again, here we’re matching on two users, Alice and Greta, and are trying to find places they’ve mutually liked:
|
||||
你可以提前在 Cypher 中计算两个特定用户的“距离”,特别是如果他们仅仅同时“喜欢”一个很小的地点子集。再次说明,这儿我们依据两个用户 Alice 和 Greta 来进行匹配,并尝试去找到他们同时“喜欢”的地点:
|
||||
|
||||

|
||||
|
||||
They both have to have a :LIKES relationship to the place for it to be found in this result, and then we can easily calculate the Euclidean distance between them with the square root of the sum of their squared differences in Cypher.
|
||||
他们都有对最后找到的地点的“喜爱”关系,然后我们可以在 Cypher 中很容易的计算出他们之间的欧几里得距离,计算方法为他们对各个地点等级差的平方和再开平方根。
|
||||
|
||||
While this may work in an example with two specific people, it doesn’t necessarily work in real time when you’re trying to infer similar users from another user on the fly, by comparing them against every other user in the database in real time. Needless to say, this doesn’t work very well.
|
||||
在两个特定用户的例子中上面这个方法或许能够工作。但是,在实时情况下,当你想要从一架飞机上的一个用户推断相似用户,通过把他们和实时数据库中的其他用户比较,这时候这个方法就不一定能够工作。不用说,它不能够很好的工作。
|
||||
|
||||
To find a way around this, we pre-compute this calculation and store it in an actual relationship:
|
||||
为了找到解决这个问题的好方法,我们可以预先计算好距离并存入实际关系中:
|
||||
|
||||

|
||||
|
||||
While in large datasets we would do this in batches, in this small example dataset, we can match on a Cartesian product of all the users and places they’ve mutually liked. When we use WHERE id(u1) < id(u2) as part of our Cypher query, this is just a trick to ensure we’re not finding the same pair twice on both the left and the right.
|
||||
当遇到一个很大的数据集的时候,我们需要成批处理这件事,在这个很小的示例数据集中,我们可以按照所有用户的迪卡尔乘积和他们共同“喜欢”的地点来进行匹配。当我们使用 WHERE id(u1) < id(u2) 作为 Cypher 查询的一部分,它只是来确定我们在左边和右边没有找到相同的对的一个技巧。
|
||||
|
||||
Then with their Euclidean distance and themselves, we’re going to create a relationship between them called :DISTANCE and set a Euclidean property called euclidean. In theory, we could also store other similarity metrics on some relationship between users to capture different similarity metrics, since some might be more useful than others in certain contexts.
|
||||
通过他们之间的欧几里得距离,我们创建了他们之间的一种关系,叫做“距离”,并且设置了一个欧几里得属性,也叫做“欧几里得”。理论上,我们可以也通过用户间的一些关系来存储其他相似度从而获取不同的相似度,因为在确定的环境下一些相似度可能比其他相似度更有用。
|
||||
|
||||
And it’s really this ability to model properties on relationships in Neo4j that makes things like this incredibly easy. However, in practice you don’t want to store every single relationship that can possibly exist because you’ll only want to return the top few people of their neighbors.
|
||||
|
||||
|
||||
So you can just store the top in according to some threshold so you don’t have this fully connected graph. This allows you to perform graph database queries like the below in real time, because we’ve pre-computed it and stored it on the relationship, and in Cypher we’ll be able to grab that very quickly:
|
||||
|
||||

|
||||
|
||||
Loading…
Reference in New Issue
Block a user