mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
19f0d12560
@ -1,16 +1,19 @@
|
||||
密码学及公钥基础设施入门
|
||||
======
|
||||
|
||||
> 学习密码学背后的基本概念,主要是保密性、完整性和身份认证。
|
||||
|
||||

|
||||
|
||||
安全通信正快速成为当今互联网的规范。从 2018 年 7 月起,Google Chrome 将对**全部**使用 HTTP 传输(而不是 HTTPS 传输)的站点[开始显示“不安全”警告][1]。虽然密码学已经逐渐变广为人知,但其本身并没有变得更容易理解。[Let's Encrypt][3] 设计并实现了一套令人惊叹的解决方案,可以提供免费安全证书和周期性续签;但如果不了解底层概念和缺陷,你也不过是加入了类似”[<ruby>船货崇拜<rt>cargo cult</rt></ruby>][4]“的技术崇拜的程序员大军。
|
||||
安全通信正快速成为当今互联网的规范。从 2018 年 7 月起,Google Chrome 将对**全部**使用 HTTP 传输(而不是 HTTPS 传输)的站点[开始显示“不安全”警告][1]。虽然密码学已经逐渐变广为人知,但其本身并没有变得更容易理解。[Let's Encrypt][3] 设计并实现了一套令人惊叹的解决方案,可以提供免费安全证书和周期性续签;但如果不了解底层概念和缺陷,你也不过是加入了类似“[<ruby>货物崇拜<rt>cargo cult</rt></ruby>][4]”的技术崇拜的程序员大军。
|
||||
|
||||
### 安全通信的特性
|
||||
|
||||
密码学最直观明显的目标是<ruby>保密性<rt>confidentiality</rt></ruby>:<ruby>消息<rt>message</rt></ruby>传输过程中不会被窥探内容。为了保密性,我们对消息进行加密:对于给定消息,我们结合一个<ruby>密钥<rt>key</rt></ruby>生成一个无意义的乱码,只有通过相同的密钥逆转加密过程(即解密过程)才能将其转换为可读的消息。假设我们有两个朋友 [Alice 和 Bob][5],以及他们的<ruby>八卦<rt>nosy</rt></ruby>邻居 Eve。Alice 加密类似 "Eve 很讨厌" 的消息,将其发送给 Bob,期间不用担心 Eve 会窥探到这条消息的内容。
|
||||
|
||||
对于真正的安全通信,保密性是不够的。假如 Eve 收集了足够多 Alice 和 Bob 之间的消息,发现单词 "Eve" 被加密为 "Xyzzy"。除此之外,Eve 还知道 Alice 和 Bob 正在准备一个派对,Alice 会将访客名单发送给 Bob。如果 Eve 拦截了消息并将 "Xyzzy" 加到访客列表的末尾,那么她已经成功的破坏了这个派对。因此,Alice 和 Bob 需要他们之间的通信可以提供<ruby>完整性<rt>integrity</rt></ruby>:消息应该不会被篡改。
|
||||
对于真正的安全通信,保密性是不够的。假如 Eve 收集了足够多 Alice 和 Bob 之间的消息,发现单词 “Eve” 被加密为 "Xyzzy"。除此之外,Eve 还知道 Alice 和 Bob 正在准备一个派对,Alice 会将访客名单发送给 Bob。如果 Eve 拦截了消息并将 “Xyzzy” 加到访客列表的末尾,那么她已经成功的破坏了这个派对。因此,Alice 和 Bob 需要他们之间的通信可以提供<ruby>完整性<rt>integrity</rt></ruby>:消息应该不会被篡改。
|
||||
|
||||
而且我们还有一个问题有待解决。假如 Eve 观察到 Bob 打开了标记为”来自 Alice“的信封,信封中包含一条来自 Alice 的消息”再买一加仑冰淇淋“。Eve 看到 Bob 外出,回家时带着冰淇淋,这样虽然 Eve 并不知道消息的完整内容,但她对消息有了大致的了解。Bob 将上述消息丢弃,但 Eve 找出了它并在下一周中的每一天都向 Bob 的邮箱中投递一封标记为”来自 Alice“的信封,内容拷贝自之前 Bob 丢弃的那封信。这样到了派对的时候,冰淇淋严重超量;派对当晚结束后,Bob 分发剩余的冰淇淋,Eve 带着免费的冰淇淋回到家。消息是加密的,完整性也没问题,但 Bob 被误导了,没有认出发信人的真实身份。<ruby>身份认证<rt>Authentication</rt></ruby>这个特性用于保证你正在通信的人的确是其声称的那样。
|
||||
而且我们还有一个问题有待解决。假如 Eve 观察到 Bob 打开了标记为“来自 Alice”的信封,信封中包含一条来自 Alice 的消息“再买一加仑冰淇淋”。Eve 看到 Bob 外出,回家时带着冰淇淋,这样虽然 Eve 并不知道消息的完整内容,但她对消息有了大致的了解。Bob 将上述消息丢弃,但 Eve 找出了它并在下一周中的每一天都向 Bob 的邮箱中投递一封标记为“来自 Alice”的信封,内容拷贝自之前 Bob 丢弃的那封信。这样到了派对的时候,冰淇淋严重超量;派对当晚结束后,Bob 分发剩余的冰淇淋,Eve 带着免费的冰淇淋回到家。消息是加密的,完整性也没问题,但 Bob 被误导了,没有认出发信人的真实身份。<ruby>身份认证<rt>Authentication</rt></ruby>这个特性用于保证你正在通信的人的确是其声称的那样。
|
||||
|
||||
信息安全还有[其它特性][6],但保密性、完整性和身份验证是你必须了解的三大特性。
|
||||
|
||||
@ -20,17 +23,17 @@
|
||||
|
||||
(LCTT 译注:cipher 一般被翻译为密码,但其具体表达的意思是加密算法,这里采用加密算法的翻译)
|
||||
|
||||
加密算法使用密钥加密明文。考虑到希望能够解密密文,我们用到的加密算法也必须是<ruby>可逆的<rt>reversible</rt></ruby>。作为简单示例,我们可以使用 [XOR][7]。该算子可逆,而且逆算子就是本身(P ^ K = C; C ^ K = P),故可同时用于加密和解密。该算子的平凡应用可以是<ruby>一次性密码本<rt>one-time pad</rt></ruby>,但一般而言并不[可行][9]。但可以将 XOR 与一个基于单个密钥生成<ruby>任意随机数据流<rt>arbitrary stream of random data</rt></ruby>的函数结合起来。现代加密算法 AES 和 Chacha20 就是这么设计的。
|
||||
加密算法使用密钥加密明文。考虑到希望能够解密密文,我们用到的加密算法也必须是<ruby>可逆的<rt>reversible</rt></ruby>。作为简单示例,我们可以使用 [XOR][7]。该算子可逆,而且逆算子就是本身(`P ^ K = C; C ^ K = P`),故可同时用于加密和解密。该算子的平凡应用可以是<ruby>一次性密码本<rt>one-time pad</rt></ruby>,不过一般而言并不[可行][9]。但可以将 XOR 与一个基于单个密钥生成<ruby>任意随机数据流<rt>arbitrary stream of random data</rt></ruby>的函数结合起来。现代加密算法 AES 和 Chacha20 就是这么设计的。
|
||||
|
||||
我们把加密和解密使用同一个密钥的加密算法称为<ruby>对称加密算法<rt>symmetric cipher</rt></ruby>。对称加密算法分为<ruby>流加密算法<rt>stream ciphers</rt></ruby>和分组加密算法两类。流加密算法依次对明文中的每个比特或字节进行加密。例如,我们上面提到的 XOR 加密算法就是一个流加密算法。流加密算法适用于明文长度未知的情形,例如数据从管道或 socket 传入。[RC4][10] 是最为人知的流加密算法,但在多种不同的攻击面前比较脆弱,以至于最新版本 (1.3)的 TLS ("HTTPS" 中的 "S")已经不再支持该加密算法。[Efforts][11] 正着手创建新的加密算法,候选算法 [ChaCha20][12] 已经被 TLS 支持。
|
||||
我们把加密和解密使用同一个密钥的加密算法称为<ruby>对称加密算法<rt>symmetric cipher</rt></ruby>。对称加密算法分为<ruby>流加密算法<rt>stream ciphers</rt></ruby>和分组加密算法两类。流加密算法依次对明文中的每个比特或字节进行加密。例如,我们上面提到的 XOR 加密算法就是一个流加密算法。流加密算法适用于明文长度未知的情形,例如数据从管道或 socket 传入。[RC4][10] 是最为人知的流加密算法,但在多种不同的攻击面前比较脆弱,以至于最新版本 (1.3)的 TLS (“HTTPS” 中的 “S”)已经不再支持该加密算法。[Efforts][11] 正着手创建新的加密算法,候选算法 [ChaCha20][12] 已经被 TLS 支持。
|
||||
|
||||
分组加密算法对固定长度的分组,使用固定长度的密钥加密。在分组加密算法领域,排行第一的是 [<ruby>先进加密标准<rt>Advanced Encryption Standard, AES</rt></ruby>][13],使用的分组长度为 128 比特。分组包含的数据并不多,因而分组加密算法包含一个[工作模式][14],用于描述如何对任意长度的明文执行分组加密。最简单的工作模式是 [<ruby>电子密码本<rt>Electronic Code Book, ECB</rt></ruby>][15],将明文按分组大小划分成多个分组(在必要情况下,填充最后一个分组),使用密钥独立的加密各个分组。
|
||||
分组加密算法对固定长度的分组,使用固定长度的密钥加密。在分组加密算法领域,排行第一的是 [<ruby>先进加密标准<rt>Advanced Encryption Standard</rt></ruby>][13](AES),使用的分组长度为 128 比特。分组包含的数据并不多,因而分组加密算法包含一个[工作模式][14],用于描述如何对任意长度的明文执行分组加密。最简单的工作模式是 [<ruby>电子密码本<rt>Electronic Code Book</rt></ruby>][15](ECB),将明文按分组大小划分成多个分组(在必要情况下,填充最后一个分组),使用密钥独立的加密各个分组。
|
||||
|
||||

|
||||
|
||||
这里我们留意到一个问题:如果相同的分组在明文中出现多次(例如互联网流量中的 "GET / HTTP/1.1" 词组),由于我们使用相同的密钥加密分组,我们会得到相同的加密结果。我们的安全通信中会出现一种<ruby>模式规律<rt>pattern</rt></ruby>,容易受到攻击。
|
||||
这里我们留意到一个问题:如果相同的分组在明文中出现多次(例如互联网流量中的 `GET / HTTP/1.1` 词组),由于我们使用相同的密钥加密分组,我们会得到相同的加密结果。我们的安全通信中会出现一种<ruby>模式规律<rt>pattern</rt></ruby>,容易受到攻击。
|
||||
|
||||
因此还有很多高级的工作模式,例如 [<ruby>密码分组链接<rt>Cipher Block Chaining, CBC</rt></ruby>][16],其中每个分组的明文在加密前会与前一个分组的密文进行 XOR 操作,而第一个分组的明文与一个随机数构成的初始化向量进行 XOR 操作。还有其它一些工作模式,在安全性和执行速度方面各有优缺点。甚至还有 Counter (CTR) 这种工作模式,可以将分组加密算法转换为流加密算法。
|
||||
因此还有很多高级的工作模式,例如 [<ruby>密码分组链接<rt>Cipher Block Chaining</rt></ruby>][16](CBC),其中每个分组的明文在加密前会与前一个分组的密文进行 XOR 操作,而第一个分组的明文与一个随机数构成的初始化向量进行 XOR 操作。还有其它一些工作模式,在安全性和执行速度方面各有优缺点。甚至还有 Counter (CTR) 这种工作模式,可以将分组加密算法转换为流加密算法。
|
||||
|
||||
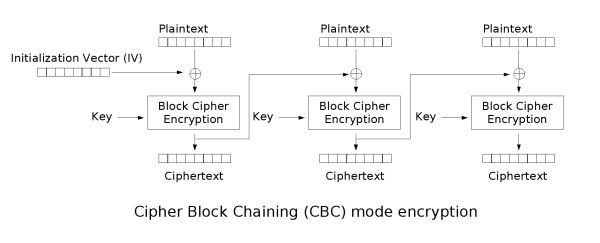
|
||||
|
||||
@ -54,7 +57,7 @@
|
||||
|
||||
如果我们同时发送消息及其摘要,接收者可以使用相同的哈希函数独立计算摘要。如果两个摘要相同,可以认为消息没有被篡改。考虑到 [SHA-1][25] 已经变得[有些过时][26],目前最流行的密码散列函数是 [SHA-256][24]。
|
||||
|
||||
散列函数看起来不错,但如果有人可以同时篡改消息及其摘要,那么消息发送仍然是不安全的。我们需要将哈希与加密算法结合起来。在对称加密算法领域,我们有<ruby>消息认证码<rt>message authentication codes, MACs</rt></ruby>技术。MACs 有多种形式,但<ruby>哈希消息认证码<rt>hash message authentication codes, HMAC</rt></ruby> 这类是基于哈希的。[HMAC][27] 使用哈希函数 H 处理密钥 K、消息 M,公式为 H(K + H(K + M)),其中 "+" 代表<ruby>连接<rt>concatenation</rt></ruby>。公式的独特之处并不在本文讨论范围内,大致来说与保护 HMAC 自身的完整性有关。发送加密消息的同时也发送 MAC。Eve 可以任意篡改消息,但一旦 Bob 独立计算 MAC 并与接收到的 MAC 做比较,就会发现消息已经被篡改。
|
||||
散列函数看起来不错,但如果有人可以同时篡改消息及其摘要,那么消息发送仍然是不安全的。我们需要将哈希与加密算法结合起来。在对称加密算法领域,我们有<ruby>消息认证码<rt>message authentication codes</rt></ruby>(MAC)技术。MAC 有多种形式,但<ruby>哈希消息认证码<rt>hash message authentication codes</rt></ruby>(HMAC) 这类是基于哈希的。[HMAC][27] 使用哈希函数 H 处理密钥 K、消息 M,公式为 `H(K + H(K + M))`,其中 `+` 代表<ruby>连接<rt>concatenation</rt></ruby>。公式的独特之处并不在本文讨论范围内,大致来说与保护 HMAC 自身的完整性有关。发送加密消息的同时也发送 MAC。Eve 可以任意篡改消息,但一旦 Bob 独立计算 MAC 并与接收到的 MAC 做比较,就会发现消息已经被篡改。
|
||||
|
||||
在非对称加密算法领域,我们有<ruby>数字签名<rt>digital signatures</rt></ruby>技术。如果使用 RSA,使用公钥加密的内容只能通过私钥解密,反过来也是如此;这种机制可用于创建一种签名。如果只有我持有私钥并用其加密文档,那么只有我的公钥可以用于解密,那么大家潜在的承认文档是我写的:这是一种身份验证。事实上,我们无需加密整个文档。如果生成文档的摘要,只要对这个指纹加密即可。对摘要签名比对整个文档签名要快得多,而且可以解决非对称加密存在的消息长度限制问题。接收者解密出摘要信息,独立计算消息的摘要并进行比对,可以确保消息的完整性。对于不同的非对称加密算法,数字签名的方法也各不相同;但核心都是使用公钥来检验已有签名。
|
||||
|
||||
@ -64,7 +67,7 @@
|
||||
|
||||
密码学的世界博大精深,我希望这篇文章能让你对密码学的核心目标及其组件有一个大致的了解。这些概念为你打下坚实的基础,让你可以继续深入学习。
|
||||
|
||||
感谢 Hubert Kario,Florian Weimer 和 Mike Bursell 在本文写作过程中提供的帮助。
|
||||
感谢 Hubert Kario、Florian Weimer 和 Mike Bursell 在本文写作过程中提供的帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -73,7 +76,7 @@ via: https://opensource.com/article/18/5/cryptography-pki
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
如何暂时禁用 iptables 防火墙
|
||||
======
|
||||
|
||||
了解如何在 Linux 中暂时禁用 iptables 防火墙来进行故障排除。还要学习如何保存策略以及如何在启用防火墙时恢复它们。
|
||||
> 了解如何在 Linux 中暂时禁用 iptables 防火墙来进行故障排除。还要学习如何保存策略以及如何在启用防火墙时恢复它们。
|
||||
|
||||
![How to disable iptables firewall temporarily][1]
|
||||
|
||||
@ -32,6 +32,7 @@ root@kerneltalks # iptables-save > /root/firewall_rules.backup
|
||||
对于较老的 Linux 内核,你可以选择使用 `service iptables stop` 停止 iptables 服务,但是如果你在用新内核,则只需清除所有策略并允许所有流量通过防火墙。这和你停止防火墙效果一样。
|
||||
|
||||
使用下面的命令列表来做到这一点。
|
||||
|
||||
```
|
||||
root@kerneltalks # iptables -F
|
||||
root@kerneltalks # iptables -X
|
||||
@ -42,11 +43,9 @@ root@kerneltalks # iptables -P FORWARD ACCEPT
|
||||
|
||||
这里 –
|
||||
|
||||
* -F:删除所有策略链
|
||||
* -X:删除用户定义的链
|
||||
* -P INPUT/OUTPUT/FORWARD :接受指定的流量
|
||||
|
||||
|
||||
* `-F`:删除所有策略链
|
||||
* `-X`:删除用户定义的链
|
||||
* `-P INPUT/OUTPUT/FORWARD` :接受指定的流量
|
||||
|
||||
完成后,检查当前的防火墙策略。它应该看起来像下面这样接受所有流量(和禁用/停止防火墙一样)
|
||||
|
||||
@ -69,6 +68,7 @@ target prot opt source destination
|
||||
```
|
||||
root@kerneltalks # iptables-restore </root/firewall_rules.backup
|
||||
```
|
||||
|
||||
### 启动 iptables 防火墙
|
||||
|
||||
然后启动 iptables 服务,以防止你在上一步中使用 `service iptables start` 停止了它。如果你已经停止服务,那么只有恢复策略才能有用。检查所有策略是否恢复到 iptables 配置中:
|
||||
@ -94,7 +94,7 @@ via: https://kerneltalks.com/howto/how-to-disable-iptables-firewall-temporarily/
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
用这样的 Vi 配置来保存和组织你的笔记
|
||||
===============
|
||||
|
||||
> Vimwiki 和 GitLab 是记录笔记的强大组合。
|
||||
|
||||
![1][]
|
||||
|
||||
用 vi 来管理 wiki 来记录你的笔记,这听起来不像是一个符合常规的主意,但当你的日常工作都会用到 vi , 那它是有意义的。
|
||||
|
||||
作为一个软件开发人员,使用同编码一样的工具来写笔记会更加简单。我想将我的笔记变成一种编辑器命令,无论我在哪里,都能够用管理我代码的方法来管理我的笔记。这便是我创建一个基于 vi 的环境来搭建我自己的知识库的原因。简单概括起来,我在笔记本电脑上用 vi 插件 [Viwiki][2] 来本地管理我的 wiki。用 Git 来进行版本控制(以保留一个中心化的更新版本),并用 GitLab 来进行在线修改(例如在我的手机上)。
|
||||
|
||||
### 为什么用 wiki 来进行笔记保存是有意义
|
||||
|
||||
我尝试过许多不同的工具来持续的记录我的笔记,笔记里保存着我的灵感以及需要记住的任务安排。这包括线下的笔记本 (没错,纸质的)、特殊的记录笔记的软件,以及思维导图软件。
|
||||
|
||||
但每种方案都有不好一面,没有一个能够满足我所有的需求。例如[思维导图][6],能够很好的形象化你的想法(因而得名),但是这种工具的搜索功能很差(和纸质笔记本一样)。此外,当一段时间过去,思维导图会变得很难阅读,所以思维导图不适合长时间保存的笔记。
|
||||
|
||||
我为一个合作项目配置了 [DokuWiki][2],我发现这个 wiki 模型符合了我大多数的需求。在 wiki 上,你能够创建一个笔记(和你在文本编辑器中所作的一样),并在笔记间创建链接。如果一个链接指向一个不存在的页面(你想让本页面添加一条还没有创建的信息), wiki 会为你建立这个页面。这个特性使得 wiki 很好的适应了那些需要快速写下心中所想的人的需求,而仍将你的笔记保持在能够容易浏览和搜索关键字的页面结构中。
|
||||
|
||||
这看起来很有希望,并且配置 DokuWiki 也很容易,但我发现只是为了记个笔记而配置整个 wiki 需要花费太多工作。在一番搜索后,我发现了 Vimwiki,这是一个我想要的 vi 插件。因为我每天使用 vi,记录笔记就行编辑代码一样。甚至在 vimwiki 创建一个页面比 Dokuwiki 更简单。你只需要对光标下的单词按下回车键就行。如果没有文件是这个名字,vimwiki 会为你创建一个。
|
||||
|
||||
为了更一步的实现用每天都会使用的工具来做笔记的计划,我不仅用这个我最爱的 IDE 来写笔记,而且用 Git 和 GitLab —— 我最爱的代码管理工具 —— 在我的各个机器间分发我的笔记,以便我可以在线访问它们。我也是在 Gitlab 的在线 markdown 工具上用 markdown 语法来写的这篇文章。
|
||||
|
||||
### 配置 vimwiki
|
||||
|
||||
用你已有的插件管理工具来安装 vimwiki 很简单,只需要添加 vimwiki/vimwiki 到你的插件。对于我的喜爱的插件管理器 Vundle 来说,你只需要在 `/.vimrc` 中添加 `plugin vimwiki/vimwiki` 这一行,然后执行 `:source ~/.vimrc | PluginInstall` 就行。
|
||||
|
||||
下面是我的文件 `.vimrc` 的一部分,展示了一些 vimwiki 配置。你能在 [vimwiki][2] 页面学到更多的配置和使用的的信息。
|
||||
|
||||
```
|
||||
let wiki_1 = {}
|
||||
let wiki_1.path = '~/vimwiki_work_md/'
|
||||
let wiki_1.syntax = 'markdown'
|
||||
let wiki_1.ext = '.md'
|
||||
|
||||
let wiki_2 = {}
|
||||
let wiki_2.path = '~/vimwiki_personal_md/'
|
||||
let wiki_2.syntax = 'markdown'
|
||||
let wiki_2.ext = '.md'
|
||||
|
||||
let g:vimwiki_list = [wiki_1, wiki_2]
|
||||
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
|
||||
```
|
||||
|
||||
如你在上述配置中所见,我的配置还有一个优点。你能简单的区分个人和工作相关的笔记,而不用切换笔记软件。我想让我的个人笔记可以随时随地访问,而不想我的工作笔记同步到我私人的 GitLab 和计算机中。在 vimwiki 这样配置要比我试过的其他软件都要简单。
|
||||
|
||||
这个配置告诉 vimwiki 有两个不同 Wiki,都使用 markdown 语法(再一次,因为我的日常工作中天天都在用 markdown 语法)。我也告诉 Vimwiki 在哪个文件夹存储 wiki 页面。
|
||||
|
||||
如果你进入存储 wiki 页面的文件夹,你会找到你的 wiki 的普通的 markdown 页面文件,而没有其他特殊的 Vimwiki 相关内容,这使得很容易的初始化 Git 仓库和同步你的 wiki 到中心仓库。
|
||||
|
||||
### 同步你的 wiki 到 GitLab
|
||||
|
||||
这一步检出一个 GitLab 项目到本地的 VimWiki 文件夹,这步操作和你操作任何 GitHub 的仓库相同,只不过因为我更喜欢保存我的笔记到我的私人 GitLab 仓库,所以我运行了一个 GitLab 实例用于我个人的项目。
|
||||
|
||||
GitLab 的 wiki 功能可以用来为你的项目创建 wiki 页面。这些 wiki 就是 Git 仓库本身。它们使用 markdown 语法,你懂得。
|
||||
|
||||
只需要初始化你需要的 wiki ,让它与你为笔记而创建的项目的 wiki 同步即可。
|
||||
|
||||
```
|
||||
cd ~/vimwiki_personal_md/
|
||||
git init
|
||||
git remote add origin git@your.gitlab.com:your_user/vimwiki_personal_md.wiki
|
||||
git add .
|
||||
git commit -m "Initial commit"
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
在 GitLab 创建一个新的项目后,你就可以从页面上复制这些步骤的代码。唯一的改变是仓库地址结尾是 .wiki(而不是 .git)。 这会告诉 Git 克隆 wiki 仓库而不是项目本身。
|
||||
|
||||
就是这样!现在你能够通过 Git 来管理你的笔记,通过 GitLab wiki 用户界面来修改笔记。
|
||||
|
||||
你可能(像我一样)不想手动的为每个添加到笔记本的笔记创建一个提交。为了解决这个问题,我使用了 Vim 插件 [chazy/dirsetting][4]。我添加一个 `.vimaddr` 文件,已经下面的内容:
|
||||
|
||||
```
|
||||
:cd %:p:h
|
||||
silent! !git pull > /dev/null
|
||||
:e!
|
||||
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
|
||||
```
|
||||
|
||||
每当我打开 Wiki 文件按下 `:w` 发布我的修改时,它就会更新到最新的版本。这样做会使你的本地文件与中心仓库保持同步。如果你有合并冲突,通常你需要解决它们。
|
||||
|
||||
目前,这就是以我的知识来互动的方法,我很喜欢这方法;请告诉我你对于这个方法的想法,可以在评论区分享你如何追踪笔记的方法。
|
||||
|
||||
-----------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/vimwiki-gitlab-notes
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[octopus](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:https://camo.githubusercontent.com/9901c750dce2008ea7a459201121077c355fc257/68747470733a2f2f6f70656e736f757263652e636f6d2f73697465732f64656661756c742f66696c65732f7374796c65732f696d6167652d66756c6c2d73697a652f7075626c69632f6c6561642d696d616765732f636865636b6c6973745f68616e64735f7465616d5f636f6c6c61626f726174696f6e2e706e673f69746f6b3d753832516570506b
|
||||
[2]:https://vimwiki.github.io/
|
||||
[3]:https://www.dokuwiki.org/dokuwiki
|
||||
[4]:https://github.com/chazy/dirsettings
|
||||
[6]:https://opensource.com/article/17/8/mind-maps-creative-dashboard
|
||||
@ -1,3 +1,4 @@
|
||||
翻译中 by ZenMoore
|
||||
5 open source puzzle games for Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
翻译中 by ZenMoore
|
||||
How to build a professional network when you work in a bazaar
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
翻译中 by ZenMoore
|
||||
World Cup football on the command line
|
||||
======
|
||||
|
||||
|
||||
@ -1,50 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Container Basics: Terms You Need to Know
|
||||
======
|
||||
|
||||

|
||||
|
||||
[In the previous article][1], we talked about what containers are and how they breed innovation and help companies move faster. And, in the following articles in this series, we will discuss how to use them. Before we dive more deeply into the topic, however, we need to understand some of the terms and commands used in the container world. Without a confident grasp of this terminology, things could get confusing.
|
||||
|
||||
Let's explore some of the basic terms used in the [Docker][2] container world.
|
||||
|
||||
**Container** **:** What exactly is container? It 's a runtime instance of a Docker image. It contains a Docker image, an execution environment, and instructions. It's totally isolated from the system so multiple containers can run on the system, completely oblivious of each other. You can replicate multiple containers from the same image and scale the service when the demand is high and nuke those containers when demand is low.
|
||||
|
||||
**Docker Image** **:** This is no different from the image of a Linux distribution that you download. It's a package of dependencies and information for creating, deploying, and executing a container. You can spin up as many containers as you want in a matter of seconds. Each behaves exactly the same. Images are built on top of one another in layers. Once an image is created, it doesn't change. If you want to make changes to your container, you simply create a new image and deploy new containers from that image.
|
||||
|
||||
**Repository (repo)** **:** Linux users will already be familiar with the term repository; it's a reservoir where packages are stored that can be downloaded and installed on a system. In the context of Docker containers, the only difference is that it hosts Docker images which are categorized via labels. You can have different variants of the same applications or different versions, all tagged appropriately.
|
||||
|
||||
**Registry** **:** Think of this as like GitHub. It 's an online service that hosts and provides access to repositories of docker images. DockerHub, for example is the default registry for public images. Vendors can upload their repositories on DockerHub so that their customers can download and use official images. Some companies offer their own registries for their images. Registries don't have to be run and managed by third party vendors. Organizations can have on-prem registries to manage organization-wide access to repositories.
|
||||
|
||||
**Tag** **:** When you create a Docker image, you can tag it appropriately so that different variants or versions can be easily identified. It's no different from what you see in any software package. Docker images are tagged when you add them to the repository.
|
||||
|
||||
Now that you have an understanding of the basics, the next phase is understanding the terminology used when working with actual Docker containers.
|
||||
|
||||
**Dockerfile** **:** This is a text file that comprises the commands that are executed manually in order to build a Docker image. These instructions are used by Docker to automatically build images.
|
||||
|
||||
**Build** **:** This is the process that creates an image from Dockerfile.
|
||||
|
||||
**Push** **:** Once the image is created, "push" is the process to publish that image to the repository. The term is also used as part of a command that we will learn in the next articles.
|
||||
|
||||
**Pull** **:** A user can retrieve that image from repository through the "pull" process.
|
||||
|
||||
**Compose** **:** Most complex applications comprise more than one container. Compose is a command-line tool that 's used to run a multi-container application. It allows you to run a multi-container application with one command. It eases the headache of running multiple containers needed for that application.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The scope of container terminology is massive, but these are some basic terms that you will frequently encounter. The next time you see these terms, you will know exactly what they mean. In the next article, we will get started working with Docker containers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/intro-to-linux/2017/12/what-are-containers-and-why-should-you-care
|
||||
[2]:https://www.docker.com/
|
||||
@ -0,0 +1,49 @@
|
||||
容器基础知识:你需要知道的术语
|
||||
======
|
||||
|
||||

|
||||
|
||||
[在前一篇文章中][1],我们谈到了容器(container)是什么以及它是如何培育创新并助力企业快速发展的。在以后的文章中,我们将讨论如何使用容器。然而,在深入探讨这个话题之前,我们需要了解关于容器的一些术语和命令。掌握了这些术语,才不至于产生混淆。
|
||||
|
||||
让我们来探讨 [Docker][2] 容器世界中使用的一些基本术语吧。
|
||||
|
||||
**容器(Container)** **:** 到底什么是容器呢?它是一个 Docker 镜像(image)的运行实例。它包含一个 Docker 镜像、执行环境和说明。它与系统完全隔离,所以多个容器可以在系统上运行,并且完全无视对方的存在。你可以从同一镜像中复制出多个容器,并在需求较高时扩展服务,在需求低时对这些容器进行缩减。
|
||||
|
||||
**Docker 镜像(Image)** **:** 这与你下载的 Linux 发行版的镜像别无二致。它是一个安装包,包含了用于创建、部署和执行容器的一系列依赖关系和信息。你可以在几秒钟内创建任意数量的完全相同的容器。镜像是分层叠加的。一旦镜像被创建出来,是不能更改的。如果你想对容器进行更改,则只需创建一个新的镜像并从该镜像部署新的容器即可。
|
||||
|
||||
**仓库(Repository / repo)** **:** Linux 的用户对于仓库这个术语一定不陌生吧。它是一个软件库,存储了可下载并安装在系统中的软件包。在 Docker 容器中,唯一的区别是它管理的是通过标签分类的 Docker 镜像。你可以找到同一个应用程序的不同版本或不同变体,他们都有适当的标记。
|
||||
|
||||
**镜像管理服务(Registry)** **:** 可以将其想象成 GitHub。这是一个在线服务,管理并提供了对 Docker 镜像仓库的访问,例如默认的公共镜像仓库——DockerHub。供应商可以将他们的镜像库上传到 DockerHub 上,以便他们的客户下载和使用官方镜像。一些公司为他们的镜像提供自己的服务。镜像管理服务不必由第三方机构来运行和管理。组织机构可以使用预置的服务来管理内部范围的镜像库访问。
|
||||
|
||||
**标签(Tag)** **:** 当你创建 Docker 镜像时,可以给它添加一个合适的标签,以便轻松识别不同的变体或版本。这与你在任何软件包中看到的并无区别。Docker 镜像在添加到镜像仓库时被标记。
|
||||
|
||||
现在你已经掌握了基本知识,下一个阶段是理解实际使用 Docker 容器时用到的术语。
|
||||
|
||||
**Dockerfile** **:** 这是一个文本文件,包含为了为构建 Docker 镜像需手动执行的命令。Docker 使用这些指令自动构建镜像。
|
||||
|
||||
**Build** **:** 这是从 Dockerfile 创建成镜像的过程。
|
||||
|
||||
**Push** **:** 一旦镜像被被创建,“push”是将镜像发布到仓库的过程。该术语也是我们下一篇文章要学习的命令之一。
|
||||
|
||||
**Pull** **:** 用户可以通过“pull”过程从仓库检索该镜像。
|
||||
|
||||
**Compose** **:** 复杂的应用程序会包含多个容器。Compose 是一个用于运行多容器应用程序的命令行工具。它允许你用单条命令运行一个多容器的应用程序,简化了多容器带来的问题。
|
||||
|
||||
|
||||
### 总结
|
||||
|
||||
容器术语的范围很广泛,这里是经常遇到的一些基本术语。下一次当你看到这些术语时,你会确切地知道它们的含义。在下一篇文章中,我们将开始使用 Docker 容器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/intro-to-linux/2017/12/what-are-containers-and-why-should-you-care
|
||||
[2]:https://www.docker.com/
|
||||
@ -1,94 +0,0 @@
|
||||
# 用这样的 VI 配置来保存和组织你的笔记
|
||||
|
||||
![1][]
|
||||
|
||||
用 vi 来管理 wiki 笔记 , 这听起来不像是一个符合常规的主意 ; 但当你的日常工作都会用到 vi , 那它是有意义的 ;
|
||||
|
||||
作为一个软件开发人员 , 用编码工具来写笔记会更加简单 ; 我想将我的笔记变成一种编辑器命令 , 无论我在哪 , 都能够用管理我代码的方法来管理我的笔记 , 这便是我在我知识基础上建立这个 vi 配置的原因 ; 简单概括起来 ,在笔记本上我用 vi 插件 [Viwiki][2] 来管理我的本地百科 ; 用 GIT 来进行版本控制 ( 保持中心节点和更新版本 ) ; 用 Gitlab 来进行在线修改 ( 例如在我的手机上 ) .
|
||||
|
||||
## 为什么用百科来进行笔记保存是有意义
|
||||
|
||||
我尝试过许多不同的工具来持续的追踪我的笔记 , 笔记里保存着我的灵感以及不应该被忘记的任务模型 . 这包括离线笔记本 ( 是的 , 包含纸质笔记本 ) , 特殊的笔记软件 , 以及思维导图软件 .
|
||||
|
||||
但每种方案都有不好一面 , 没有一个能够满足我所有的需求 . 例如思维导图 , 能够很好的形象化你的想法 ( 因此得名 ) . 我尝试提供一些简单的搜索方法 ( 和纸质笔记一样 ) ; 但当一段时间过去 , 思维导图会变得很难阅读 , 所以思维导图不适合长时间保存的笔记 .
|
||||
|
||||
我为一个合作项目配置 [DokuWiki][2] , 我发现这个 wiki 模型符合了我大多数的需求 . 在百科上 , 你能够创建一个文件 ( 和你在文本编辑器中所作的一样 ) , 创建一个笔记的链接 . 如果一个链接指向一个不存在的页面 ( 你想让本页面添加一条还没有创建的信息 ) , wiki 会为你建立这个页面 . 这个特性使得 wiki 很好的适应了那些需要快速写下心中所想的人的需求 . 然而笔记页面仍保持在能够容易浏览和搜索关键字的界面 .
|
||||
|
||||
这看起来很有希望 , 并且配置 DokuWiki 也很容易 , 但我发现配置整个 wiki 太复杂 , 而仅仅只是为了追踪笔记 . 在一番搜索后 , 我发现了 Vimwiki , 我想要的 vi 插件 . 自从我每天使用 vi , 做笔记和修改代码一样简单 . 创建一个界面 , vimwiki 比 Dokuwiki 简单 . 你只需要在光标下的单词按下 Enter 键 , 如果本地没有文件是这个名字 , vimwiki 会为你创建一个 . 为了更一步的实现用每天都会使用的工具来做笔记的计划 , 我不仅用我最爱的 IDE 来写笔记 , 而且用 GIT - 我最爱的代码管理工具 , Gilab - 发布我的笔记并且在线访问 . 我也在 Gitlab markdown 在线工具上用 markdown 语法来写这篇文章 .
|
||||
|
||||
## 配置 vimwiki
|
||||
|
||||
用存在的插件管理工具来安装 vimwiki 很简单 , 只需要添加 vimwiki/vimwiki 到你的插件 . 对于我的喜爱的插件管理器 , Vundle , 你只需要在 /.vimrc 中添加 "plugin vimwiki/vimwiki " 这一行 . 然后执行 :source ~/.vimrc | PluginInstall .
|
||||
|
||||
下面是我的文件 .vimrc 的一部分 , 展示一些 vimwiki 配置 . 你能在 [vimwiki][2] 页面学到更多的配置和使用的的信息 .
|
||||
|
||||
```code
|
||||
let wiki_1 = {}
|
||||
let wiki_1.path = '~/vimwiki_work_md/'
|
||||
let wiki_1.syntax = 'markdown'
|
||||
let wiki_1.ext = '.md'
|
||||
|
||||
let wiki_2 = {}
|
||||
let wiki_2.path = '~/vimwiki_personal_md/'
|
||||
let wiki_2.syntax = 'markdown'
|
||||
let wiki_2.ext = '.md'
|
||||
|
||||
let g:vimwiki_list = [wiki_1, wiki_2]
|
||||
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
|
||||
|
||||
```
|
||||
|
||||
我的配置有一个优点 , 你能简单的区分个人和工作相关的文件 , 而不用切换笔记软件 . 我想能随时随地访问我的个人笔记 , 而不想我的工作笔记同步到我私人的 GitLab 和 电脑 . 这样配置对于 vimwiki 要比其他软件简单 . 这个配置告诉 vimwiki 有两个不同 Wiki , 两个 wiki 都使用 markdown 语法 ( 我用 markdown 语法在每天的工作 ) . 同样的告诉 Vimwiki wiki 页面存储到那个文件夹 .
|
||||
|
||||
如果你操作 wiki 页面存储的文件夹 , 你会你的单一的 wiki 的 markdown 页面文件而没有其他特殊的 Vimwiki 内容 , 这使得很容易的初始化 GIT 仓库和同步你的 wiki 到中心仓库 .
|
||||
|
||||
## 同步你的 wiki 到 GitLab
|
||||
|
||||
这一步检查 GitLab 工程到本地的 VimWiki 文件夹 , 这步操作和你操作任何 GitHub 的仓库相同 . 只是我更喜欢保存我的笔记到我的私人 GitLab 仓库 , 所以我为我个人的工程保持运行 GitLab .
|
||||
|
||||
你可以使用 GitLab 的 wiki 功能来为你的工程创建 wiki 页面 . 这些 wiki 是 GIT 仓库本身 , 用 markdown 语法 , 你到主要的地址 .
|
||||
|
||||
只需要初始化你想要的笔记 , 那些你为你的笔记所创建的 wiki 工程 :
|
||||
|
||||
```codecd ~/vimwiki_personal_md/
|
||||
git init
|
||||
git remote add origin git@your.gitlab.com:your_user/vimwiki_personal_md.wiki
|
||||
git add .
|
||||
git commit -m "Initial commit"
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
能够在 GitLab 创建一个新的工程后 , 这些步骤能复制到你导入的界面到新的工程 . 唯一的改变是仓库地址结尾是 .wiki ( 而不是 .git ) . 告诉 git 拷贝 wiki 仓库而不是工程本身 .
|
||||
|
||||
就是这样 ! 现在你能够通过 git 来管理你的笔记 , 通过 GitLab wiki 用户接口来修改笔记 .
|
||||
|
||||
你可能不想手动的为每个添加到笔记本的笔记创建提交 , 为了解决这个问题 , 我使用 Vim 插件 [chazy/dirsetting][4] , 我添加一个 .vimaddr 文件 , 通过下面的内容 :
|
||||
|
||||
```code
|
||||
:cd %:p:h
|
||||
silent! !git pull > /dev/null
|
||||
:e!
|
||||
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
|
||||
```
|
||||
|
||||
当我打开 Wiki 文件时会更新到最新的版本 , 没一次的写入命令 ( :w ) 都会提交 ; 这样做会同步你的本地文件到中心仓库 . 如果你有合并冲突 ,通常你需要解决它们 .
|
||||
|
||||
目前 , 这就是以我的知识基础来互动的方法 , 我很喜欢这方法 ; 请告诉我你对于这个方法的想法 , 可以在评论区分享你最爱的方法 , 对于如何追踪笔记 .
|
||||
|
||||
-----------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/vimwiki-gitlab-notes
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[octopus][5]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]:https://camo.githubusercontent.com/9901c750dce2008ea7a459201121077c355fc257/68747470733a2f2f6f70656e736f757263652e636f6d2f73697465732f64656661756c742f66696c65732f7374796c65732f696d6167652d66756c6c2d73697a652f7075626c69632f6c6561642d696d616765732f636865636b6c6973745f68616e64735f7465616d5f636f6c6c61626f726174696f6e2e706e673f69746f6b3d753832516570506b
|
||||
[2]:https://vimwiki.github.io/
|
||||
[3]:https://www.dokuwiki.org/dokuwiki
|
||||
[4]:https://github.com/chazy/dirsettings
|
||||
[5]:https://github.com/singledo
|
||||
Loading…
Reference in New Issue
Block a user