mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
commit
19e1e39d96
@ -1,4 +1,4 @@
|
||||
不要害怕命令行
|
||||
不要害怕命令行——Mac OS 篇
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -6,13 +6,13 @@
|
||||
|
||||
你应该在电影中见到过,尽管从没在自己电脑上调出来:一个空白屏幕,带有一些简单文字提示和一个光标,等着你去输入几个神秘的命令,就会听你的吩咐。
|
||||
|
||||
这就是命令行。它是基于字符的接口,早于现在更加熟悉的主流操作系统上的窗口,图标和`瓦片 tiles`,包括Windows到Mac OS X和Linux。
|
||||
这就是命令行。它是基于字符的接口,它比现在人们都熟悉的主流操作系统(包括Windows到Mac OS X和Linux)上的窗口,图标和`瓦片 tiles`都要早。
|
||||
|
||||
命令行是一个使用你电脑基本功能的超级强大的工具。对于大多数人来说,它也是一个让人困惑的,难以理解的,看上去无关紧要的东西。不必那么夸张。
|
||||
命令行是一个使用你电脑基本功能的超级强大的工具。对于大多数人来说,它也是一个让人困惑的,难以理解的,看上去无关紧要的东西。但是其实不是这样的。
|
||||
|
||||
### 在你的命令控制下的电脑 ###
|
||||
|
||||
输入字符指令再敲下回车来让电脑做点事情,和在移动设备的触摸界面上滑动点击比较,听起来像是退了一大步。即使是刚学走路的小孩都可以用iPad,对吧?不过,如果你知道怎么用的话,命令可以节省你的时间和烦恼。
|
||||
输入字符指令再敲下回车来让电脑做点事情,和在移动设备的触摸界面上滑动点击比较,听起来像是退了一大步。即使是刚学走路的小孩都可以用iPad,对吧?不过,如果你知道怎么用的话,命令可以节省你的时间,减少烦恼。
|
||||
|
||||
如果你很认真想学习编程-或者想理解计算机技术-你完全有必要掌握命令行。
|
||||
|
||||
@ -20,7 +20,7 @@
|
||||
|
||||
更重要的是,你会更容易理解[像Python那样的编程语言][1]和[像Git那样的软件][2],需要有一点命令行基础。在熟悉了命令行以后,你就可以打破过去阻止你学习编程的障碍了。
|
||||
|
||||
所以在这里介绍一点关于命令行的快速,基础指导。它主要专注于Mac OS X的类Unix环境,只是因为这是我比较熟悉的。Linux用户应该已经很熟悉命令行了,不过新手也许还是会觉得这些小窍门有点用。如果你用的是Chromebook,Google已经给出了有用的指导,用来打开它自带的[命令行工具][3],它和Mac或Linux系统有点类似。对于Windows用户,很不幸,受限于从MS-DOS衍生出的命令语言,它和Unix只有一点点交集,所以这篇指导对你没什么用;不过可以去看下[dosprompt.info网站里的资料][4]。
|
||||
所以在这里介绍一点关于命令行的快速的、基础的指导。它**主要专注于Mac OS X的类Unix环境**,只是因为这是我比较熟悉的。Linux用户应该已经很熟悉命令行了,不过新手也许还是会觉得这些小窍门有点用。如果你用的是Chromebook,Google对如何打开它自带的[命令行工具][3]已经给出了有用的指导,它和Mac或Linux系统有点类似。对于Windows用户,很不幸,受限于从MS-DOS衍生出的命令语言,它和Unix只有一点点交集,所以这篇指导对你没什么用;不过可以去看下[dosprompt.info网站里的资料][4]。
|
||||
|
||||
### 如何开始 ###
|
||||
|
||||
@ -30,7 +30,7 @@
|
||||
|
||||
你进来了,但是所有你看到的只是一个有输入空间的空白盒子。这就是命令行!让我们来更好地了解一下这个窗口。
|
||||
|
||||
输入`pwd`,它的意思是打印当前工作目录。在计算机语言里,“打印”什么和纸没一点关系。它实际上只是意味着吐点东西到屏幕上。这个命令运行的结果是让计算机返回你当前正处在的目录路径。
|
||||
输入`pwd`,它的意思是打印当前工作目录。在计算机语言里,“打印”什么和纸没一点关系。它实际上只是意味着吐点东西到屏幕上。这个命令运行的结果是让计算机返回你当前正处在的目录路径。(LCTT 译注,“打印”源于早期计算机的输出设备不是显示器,而是行式打印机,所以输出就是“打印”;在后期,有了显示器之后,在哑终端上操作远程主机时,输出才是“回显 echo”)
|
||||
|
||||

|
||||
|
||||
@ -40,7 +40,7 @@
|
||||
|
||||

|
||||
|
||||
现在我们有一个新目录了。如果使用图形界面的话,我们可以用自己的眼睛判断我们已经创建了一个新目录。当然,如果我打开Finder然后进入我的主目录-用一个小房子图标标记的-就会看到一个叫“experiments”的目录。我通过命令行实现的!(反过来:你可以在桌面系统里建立一个文件夹,然后在命令行下去查看。这只是同一套系统的两种不同表现方式。)
|
||||
现在我们有一个新目录了。如果使用图形界面的话,我们可以用自己的眼睛判断我们已经创建了一个新目录。当然,如果我打开Finder然后进入我的主目录(用一个小房子图标标记的)就会看到一个叫“experiments”的目录。我通过命令行实现的!(反过来:你可以在桌面系统里建立一个文件夹,然后在命令行下去查看。这只是同一套系统的两种不同表现方式。)
|
||||
|
||||

|
||||
|
||||
@ -58,7 +58,7 @@
|
||||
|
||||

|
||||
|
||||
哦不!我拼错“newfile”了。这经常会碰到。让我们用两个步骤来改正它。首先,我将创建一个拼写正确的文件...
|
||||
哦不!我拼错“newfile”了。这经常会碰到。让我们用两个步骤来改正它。首先,我将创建一个拼写正确的文件...(LCTT 译注:完全不必创建新文件,直接 mv 即可,相当于改名。)
|
||||
|
||||

|
||||
|
||||
@ -76,7 +76,7 @@
|
||||
|
||||

|
||||
|
||||
但是,它只是个空白文本文件。让我们用文本编辑器来输入点内容进去。在命令行下,我喜欢用`nano`编辑器,因为它很简单而且几乎在所有类型电脑上都可以使用。
|
||||
但是,它只是个空白文本文件(LCTT 译注,不是空白的,其内容是“Hello World”)。让我们用文本编辑器来输入点内容进去。在命令行下,我喜欢用`nano`编辑器,因为它很简单而且几乎在所有类型电脑上都可以使用。(LCTT 译注,作为 Linux 党,那肯定是要用 vi 的,不过 vi 对于初学者来说有一点点难。)
|
||||
|
||||
这会在你的命令行窗口中马上打开编辑屏幕。一些基本的命令都为你列出来了。
|
||||
|
||||
@ -92,7 +92,7 @@
|
||||
|
||||

|
||||
|
||||
注意一下,**rm**命令非常强大!在黑客论坛里有个[常用伎俩][7]就是说服一个命令行新手输入**rm -rf /**,然后他就把自己整个电脑上的所有文件都删掉了。命令里的“/”意思是电脑的最高级根目录-所有一切都在它之下。千万不要输入那行命令!
|
||||
注意一下,**rm**命令非常强大!在黑客论坛里有个[常用伎俩][7]就是说服一个命令行新手输入**rm -rf /**,然后他就把自己整个电脑上的所有文件都删掉了。命令里的“/”意思是电脑的最高级根目录-所有一切都在它之下。千万不要输入那行命令!(LCTT 译注:希望你在看完这句话之前没有真的输入了 rm -rf / !!!)
|
||||
|
||||
### 延伸阅读 ###
|
||||
|
||||
@ -104,11 +104,11 @@
|
||||
|
||||
[命令行初学者启蒙][9]。Lifehacker收藏的一些适合初学者的很有用的命令。
|
||||
|
||||
[Mac OS X命令行入门][10]。在线教育网站Treehouse极尽详细地介绍了命令行的基础。
|
||||
[Mac OS X 命令行入门][10]。在线教育网站Treehouse极尽详细地介绍了命令行的基础。
|
||||
|
||||
现在文章看完了,你就更容易理解我之前写的那些代码教程了,因为如果不敲几个命令根本没法完成。如果你准备好了,我建议你去看看ReadWrite的[Git教程][11],它使用命令行来向你介绍协同编程。运算快乐!
|
||||
现在文章看完了,你就更容易理解我之前写的那些代码教程了,因为如果不敲几个命令根本没法完成。如果你准备好了,我建议你去看看ReadWrite的[Git教程][11],它使用命令行来向你介绍协同编程。计算与你同在!
|
||||
|
||||
*开头图片来自[Jason Scott][12];其他屏幕截图由Lauren Orsini提供给ReadWrite*
|
||||
*题图来自[Jason Scott][12];其他屏幕截图由Lauren Orsini提供给ReadWrite*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -116,7 +116,7 @@ via: http://readwrite.com/2014/07/18/command-line-tutorial-intro
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
自制一台树莓派街机
|
||||
给那些怀旧的游戏骨灰粉丝们:自制一台树莓派街机
|
||||
================================================================================
|
||||
**利用当代神奇设备来重温80年代的黄金威严。**
|
||||
**利用当代神奇设备来重温80年代的黄金记忆。**
|
||||
|
||||
### 你需要以下硬件 ###
|
||||
|
||||
@ -10,17 +10,17 @@
|
||||
- 一个JAMMA街机游戏机外壳机箱
|
||||
- J-Pac或者I-Pac
|
||||
|
||||
80年代有太多难忘的记忆;冷战结束,Quatro碳酸饮料,Korg Polysix合成器,以及Commodore 64家用电脑。但对于某些年轻人来说,这些都没有街机游戏机那样有说服力,或那种甜蜜的叛逆。笼罩着烟味和此起彼伏的8比特音效,它们就是在挤出来的时间里去探索的洞穴:50分钱和一份代币能让你消耗整个午餐时间,在这些游戏上磨练着你的技能:小蜜蜂,城市大金刚,蜈蚣,行星射击,吃豆小姐,火凤凰,R-Rype,大金刚,雷霆计划,铁手套,街头霸王,超越赛车,防卫者争战...这个列表太长了。
|
||||
80年代有太多难忘的记忆;冷战结束,Quatro碳酸饮料,Korg Polysix合成器,以及Commodore 64家用电脑。但对于某些年轻人来说,这些都没有街机游戏机那样有说服力,或那种甜蜜的叛逆。笼罩着烟味和此起彼伏的8比特音效,它们就是在挤出来的时间里去探索的洞穴:50分钱和一个游戏币能让你消耗整个午餐时间,在这些游戏上磨练着你的技能:小蜜蜂,城市大金刚,蜈蚣,行星射击,吃豆小姐,火凤凰,R-Rype,大金刚,雷霆计划,铁手套,街头霸王,超越赛车,防卫者争战...噢,这个列表太长了。
|
||||
|
||||
这些游戏,以及玩这些游戏的街机机器,仍然像30年前那样有吸引力。不像年轻时候那样,现在可以不用装一兜零钱就能玩了,最终让你超越那些有钱的孩子以及他们无休止的‘继续游戏’。所以是时候打造一个你自己的基于Linux的街机游戏机了,然后挑战一下过去的最高分。
|
||||
|
||||
我们将会覆盖所有的步骤,来将一个便宜的街机游戏机器外壳变成一台Linux驱动的多平台复古游戏系统。但是这并不意味着你就一定要搭建一个同样的系统。比如说,你可以放弃那个又大又重还有潜在致癌性外壳的箱子本身,而是将内部控制核心装进一个旧游戏主机或同等大小的盒子里。或者说,你也可以简单地放弃小巧的树莓派,而将系统的大脑换成一台更强劲的Linux主机。举个例子,它可以作为运行SteamOS的一个理想平台,用来玩那些更优秀的现代街机游戏。
|
||||
我们将会包括所有的步骤,来将一个便宜的街机游戏机器外壳变成一台Linux驱动的多平台复古游戏系统。但是这并不意味着你就一定要搭建一个同样的系统。比如说,你可以放弃那个又大又重还有潜在致癌性外壳的箱子本身,而是将内部控制核心装进一个旧游戏主机或同等大小的盒子里。或者说,你也可以简单地放弃小巧的树莓派,而将系统的大脑换成一台更强劲的Linux主机。举个例子,它可以作为运行SteamOS的一个理想平台,用来玩那些更优秀的现代街机游戏。
|
||||
|
||||
在之后的几个页面里,我们将搭建一台基于树莓派的街机游戏机,你应该也能从其中发现很多点子应用到你自己的项目上,即使它们和我们这个项目不太一样。然后因为我们是用无比强大的MAME来做这件事情,你几乎可以让它在任意平台上运行。
|
||||
|
||||

|
||||
|
||||
我们在B+型号出来以前完成的这个项目。它应该也可以同样工作在更新的主板上,你应该不用一个带电源的USB Hub也可以(点击看大图)。
|
||||
*我们是在B+型号出来以前完成的这个项目。它应该也可以同样工作在更新的主板上,你应该不用一个带电源的USB Hub也可以*
|
||||
|
||||
### 声明 ###
|
||||
|
||||
@ -34,9 +34,9 @@
|
||||
|
||||

|
||||
|
||||
这种机柜可能很便宜,但是他们都很重。不要一个人去搬。一些更古老的机器可能还会需要一点小关怀,例如重新喷个漆以及一些修理工作(点击看大图)。
|
||||
*这种机柜可能很便宜,但是他们都很重。不要一个人去搬。一些更古老的机器可能还会需要一点小关怀,例如重新喷个漆以及一些修理工作*
|
||||
|
||||
除了获得更加真实的游戏体验以外,购买原版的街机机柜的一个绝佳理由是可以使用原版的控制器。从eBay上买到的大多数机器都支持两个人同时玩,有两个摇杆以及每个玩家各自的一些按钮,再加上玩家一和玩家二的选择按钮。为了兼容更多游戏,我们建议您找一台每个玩家都有6个按键,这个是通用配置。也许你还想看看支持超过两位玩家的控制台,或者有空间放其他游戏控制器的,比如说街机轨迹球(类似疯狂弹珠这种游戏需要的),或者一个旋钮(打砖块)。这些待会都可以轻松装上去,因为有现成的现代USB设备。
|
||||
除了获得更加真实的游戏体验以外,购买原版的街机机柜的一个绝佳理由是可以使用原版的控制器。从eBay上买到的大多数机器都支持两个人同时玩,有两个摇杆以及每个玩家各自的一些按钮,再加上玩家一和玩家二的选择按钮。为了兼容更多游戏,我们建议您找一台每个玩家都有6个按键的型号,这个是通用配置。也许你还想看看支持超过两位玩家的控制台,或者有空间放其他游戏控制器的,比如说街机轨迹球(类似疯狂弹珠这种游戏需要的),或者一个旋钮(打砖块)。这些待会都可以轻松装上去,因为有现成的现代USB设备。
|
||||
|
||||
控制器是第二考虑的,而且我们认为是最重要的,因为要通过它把你的摇动和拍打转变成游戏里的动作。当你准备买一个机柜时需要考虑一种叫JAMMA的东西,它是日本娱乐机械制造商协会(Japan Amusement Machinery Manufacturers Association)的缩写。JAMMA是街机游戏机里的行业标准,定义了包含游戏芯片的电路板和游戏控制器的连接方式,以及投币机制。它是一个连接两个玩家的摇杆和按钮的所有线缆的接口电路,把它们统一到一个标准的连接头。JAMMA就是这个连接头的大小以及引脚定义,这就意味着不管你安装的主板是什么,按钮和控制器都将会连接到相同功能接口,所以街机的主人只需要再更换下机柜上的外观图片,就可以招揽新玩家了。
|
||||
|
||||
@ -48,13 +48,13 @@
|
||||
|
||||
有一点非常方便,你可以买到这样一种设备,连接街机机柜里的JAMMA接头和电脑的USB端口,将机柜上的摇杆和按键动作都转换成(可配置的)键盘命令,它们可以在Linux里用来控制任何想玩的游戏。这个设备就叫J-Pac([www.ultimarc.com/jpac.html][1] – 大概£54)。
|
||||
|
||||
它最大的特点不是它的连接性;而是它处理和转换输入信号的方式,因为它比标准的USB手柄强太多太多了。每一个输入都有自己独立的中断,而且没有限制同时按下或按住的按钮或摇杆方向的数量。这对于类似街头霸王的游戏来说非常关键,因为他们依赖于同时迅速按下的组合键,而且用来对那些发飙后按下自己所有按键的不良对手发出致命一击时也必不可少。许多其他控制器,特别是那些生成键盘输入的,受到他们所采用的USB控制器的同时六个输入的限制,以及一堆的Alt,Shift和Ctrl键的特殊处理的限制。J-Pac还可以接入倾角传感器,甚至某些投币装置,不用预先配置就可以在Linux下工作了。
|
||||
它最大的特点不是它的连接性;而是它处理和转换输入信号的方式,因为它比标准的USB手柄强太多太多了。每一个输入都有自己独立的中断,而且没有限制同时按下或按住的按钮或摇杆方向的数量。这对于类似街头霸王的游戏来说非常关键,因为他们依赖于同时迅速按下的组合键,而且用来对那些发飙后按下自己所有按键的不良对手发出致命一击时也必不可少。许多其他控制器,特别是那些生成键盘输入的,受到了他们所采用的USB控制器的同时六个输入的限制,以及一堆的Alt,Shift和Ctrl键的特殊处理的限制。J-Pac还可以接入倾角传感器,甚至某些投币装置,不用预先配置就可以在Linux下工作了。
|
||||
|
||||
另外的选择是一个类似的叫I-Pac的设备。它做了和J-Pac相同的事情,只不过不支持JAMMA接头。这意味着你不能把JAMMA控制器接上去,但同时也就是说你可以设计你自己的控制器布局,再把每个控制接到I-Pac上去。这对第一个项目来说也许有点小难,但是这却是许多街机迷们选择的方式,特别是他们想设计一个支持四个玩家的控制板的时候,或者是一个整合许多不同类型控制的面板的时候。我们采用的方式并不是我们推荐必须要做的,我们改造了一个输入有问题的二手X-Arcade Tankstick控制面板,换上了新的摇杆和按钮,再接到新的JAMMA接口,这样有一个非常好的地方就是可以用便宜的价格(£8)买到所有用到的线材包括电路板边缘插头。
|
||||
|
||||

|
||||
|
||||
我们的已经装到机柜上的J-Pac。右边的蓝色和红色导线接到我们的机柜上额外的1号和2号玩家按钮(点击看大图)。
|
||||
*上图是我们已经装到机柜上的J-Pac。右边的蓝色和红色导线接到我们的机柜上额外的1号和2号玩家按钮*
|
||||
|
||||
不管你选择的是I-Pac或是J-Pac,它们产生的按键都是MAME的默认值。也就是说运行模拟器之后不需要手动调整输入。例如玩家1,会默认将键盘方向键映射成上下左右,以及将左边的Ctrl,左边的ALT,空格和左边的Shift键映射到按钮1-4。但是真正实用的功能是,对于我们来说,是双键快捷方式。当按下并按住玩家1按钮后,就可以通过把玩家1的摇杆拉到下的位置发出用来暂停游戏的P按键,推到上的位置调整音量,以及推到右的位置来进入MAME自己的设置界面。这些特殊组合键设计的很巧妙,不会对正常玩游戏带来任何干扰,因为他们只有在按住玩家1按钮后才会生效,然后可以让你正在运行游戏的时候也能做任何需要的事情。例如,你可以完全地重新配置MAME,使用它自己的菜单,在玩游戏的时候改变输入绑定和灵敏度。
|
||||
|
||||
@ -76,13 +76,13 @@ J-Pac模块直接插到JAMMA接口上,但你可能还需要一点手动调整
|
||||
|
||||

|
||||
|
||||
我们的树莓派已经接到J-Pac左边,也已经连接了显示屏和USB hub(点击看大图)。
|
||||
*我们的树莓派已经接到J-Pac左边,也已经连接了显示屏和USB hub*
|
||||
|
||||
然后把J-Pac或I-Pac模块通过PS2转USB连接线接到你的PC或树莓派,也可以直接接到PC的PS2接口。要用旧的PS2接头的话额外还有个要求,你的电脑得足够古老还有这个,但是我们测试发现用USB性能是一样的。当然,这个不能用于不带PS2的树莓派,而且别忘了树莓派也需要供电。我们一般建议使用一个带电源的USB hub,因为没有供电是树莓派不工作最常见的错误。你还需要保证树莓派的网络正常,要么通过以太网(也许使用一个藏到机柜里的电力线适配器),或者通过无线USB设备。网络很关键是因为在树莓派被藏到机柜里后你还可以重新配置它,不用接键盘或鼠标就可以让你调整设置以及执行管理任务。
|
||||
|
||||
> ### 投币装置 ###
|
||||
|
||||
> 在街机模拟社区里,让投币装置工作在模拟器上工作就会和商业产品太接近了。这就意味着你有潜在的可能对使用你机器的人收取费用。这不仅仅只是不正当,考虑到运行在你自己街机上的那些游戏的来源,这将会是非法的。这很显然违背了模拟的精神。不过,我们和其他热爱者觉得一个能工作的投币装置更进一步地靠近了街机的真实,而且值得付出努力来营造对那个过去街机的怀念。丢个10便士硬币到投币口然后再听到机器发出增加点数的声音,没有什么比得上。
|
||||
> 在街机模拟社区里,让投币装置工作在模拟器上工作就会和商业产品太接近了。这就意味着你有潜在的可能对使用你机器的人收取费用。这不仅仅只是不正当,考虑到运行在你自己街机上的那些游戏的来源,这将会是非法的。这很显然违背了模拟的精神。不过,我们和其他热爱者觉得一个能工作的投币装置更进一步地靠近了街机的真实,而且值得付出努力来营造对那个过去街机的怀念。丢个10便士硬币到投币口然后再听到机器发出增加点数的声音,没有什么比得上这种感受了。
|
||||
|
||||
> 实际上难度也不大。取决于你街机上的投币装置,以及它如何发信号通知投了几个币。大多数投币装置分为两个部分。较大的一部分是硬币接收和验证装置。这是投币过程的物理部分,用于检测硬币是否真实以及确定它的价值。这是通过一个游戏点数逻辑电路板来实现的,通常用一个排线连接,上边还带有很多DIP开关。这些开关用来决定接受哪种硬币,以及一个硬币能产生多少点数。然后就是简单地找到输出开关,每个点数都会触发它一次,然后把它接到JAMMA连接头的投币输入上,或者直接接到J-Pac。我们的投币装置型号是Mars MS111,在90年代早期的英国很常见,网上有大量关于每个DIP开关作用的信息,也有如何重新编程控制器来接受新硬币的方法。我们还能在这个装置的12V上接个小灯用来照亮投币孔。
|
||||
|
||||
@ -90,7 +90,7 @@ J-Pac模块直接插到JAMMA接口上,但你可能还需要一点手动调整
|
||||
|
||||
MAME是这种规模项目唯一可行的模拟器,它如今支持运行在数不清的不同平台上的各种各样的游戏,从第一代街机到一些最近的机器。从这个项目中还孕育出了MESS,一个多模拟器的超级系统,针对的平台是80到90年代的家庭电脑以及电视游戏机。
|
||||
|
||||
如何配置MAME本身都可以写上六页的文章了。它是一个复杂的,无序的,伟大的软件程序,模拟了如此之多的CPU,声卡,芯片,控制器以及那么多的选项,就像MythTV,你都永远不能真正停止配置它。
|
||||
如何配置MAME本身都可以写上六页的文章了。它是一个复杂的,无序的,伟大的软件程序,模拟了如此之多的CPU,声卡,芯片,控制器以及那么多的选项,就像MythTV,你都永远不能真正配置好它。
|
||||
|
||||
但是也有个相对省事的方式,一个特别为树莓派构建的版本。它叫PiMAME。它是一个可下载的发布版和脚本,基于Raspbian,这是树莓派的默认发布版。它不仅仅会把MAME装到树莓派上(这很有用因为没有哪个默认仓库里有这个),还会安装其他一些精选出来的模拟器,并通过一个前端来管理他们。MAME,举个例子,是一个有数十个参数的命令行应用。但是PiMAME还有一个妙招 - 它安装了一个简单的网页服务器,可以在连接上网络后让你通过浏览器来安装新游戏。这是一个很好的优点,因为把游戏文件放到正确的目录下是使用MAME的困难之一,这还能让你连接到树莓派的存储设备得到最优使用。还有,PiMAME会通过用来安装它的脚本更新自己,所以保持最新版本就太简单了。目前来说这个非常有用,因为在编写这个项目的时候,正好在0.8版这样一个重大更新发布的时间点上。我们在三月份早期时发现有一些轻微的不稳定,但是我们确定在你读到这篇文章的时候一切都会解决。
|
||||
|
||||
@ -127,7 +127,7 @@ via: http://www.linuxvoice.com/arcade-machine/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
Linux 教程:安装 Ansible 配置管理和 IT 自动化工具
|
||||
Ansible :一个配置管理和IT自动化工具
|
||||
================================================================================
|
||||
|
||||
|
||||
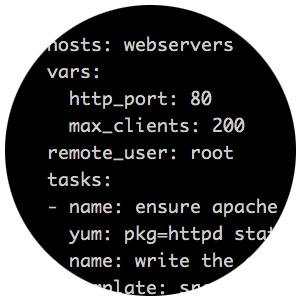
今天我来谈谈 ansible,一个由 Python 编写的强大的配置管理解决方案。尽管市面上已经有很多可供选择的配置管理解决方案,但他们各有优劣,而 ansible 的特点就在于它的简洁。让 ansible 在主流的配置管理系统中与众不同的一点便是,它并不需要你在想要配置的每个节点上安装自己的组件。同时提供的一个优点在于,如果需要的话,你可以在不止一个地方控制你的整个基础结构。最后一点是它的正确性,或许这里有些争议,但是我认为在大多数时候这仍然可以作为它的一个优点。说得足够多了,让我们来着手在 RHEL/CentOS 和基于 Debian/Ubuntu 的系统中安装和配置 Ansible.
|
||||
今天我来谈谈 ansible,一个由 Python 编写的强大的配置管理解决方案。尽管市面上已经有很多可供选择的配置管理解决方案,但他们各有优劣,而 ansible 的特点就在于它的简洁。让 ansible 在主流的配置管理系统中与众不同的一点便是,它并不需要你在想要配置的每个节点上安装自己的组件。同时提供的一个优点在于,如果需要的话,你可以在不止一个地方控制你的整个基础架构。最后一点是它的正确性,或许这里有些争议,但是我认为在大多数时候这仍然可以作为它的一个优点。说得足够多了,让我们来着手在 RHEL/CentOS 和基于 Debian/Ubuntu 的系统中安装和配置 Ansible。
|
||||
|
||||
### 准备工作 ####
|
||||
|
||||
1. 发行版:RHEL/CentOS/Debian/Ubuntu Linux
|
||||
1. Jinja2:Python 的一个对设计师友好的现代模板语言
|
||||
1. PyYAML:Python 的一个 YAML 编码/反编码函数库
|
||||
1. paramiko:纯 Python 编写的 SSHv2 协议函数库 (译者注:原文对函数库名有拼写错误,校对时请去掉此条注解)
|
||||
1. paramiko:纯 Python 编写的 SSHv2 协议函数库 (译者注:原文对函数库名有拼写错误)
|
||||
1. httplib2:一个功能全面的 HTTP 客户端函数库
|
||||
1. 本文中列出的绝大部分操作已经假设你将在 bash 或者其他任何现代的 shell 中以 root 用户执行。
|
||||
|
||||
Ansible 如何工作
|
||||
### Ansible 如何工作 ###
|
||||
|
||||
Ansible 工具并不使用守护进程,它也不需要任何额外的自定义安全架构,因此它的部署可以说是十分容易。你需要的全部东西便是 SSH 客户端和服务器了。
|
||||
|
||||
@ -442,15 +442,13 @@ ansible 的 hosts 文件包括了一系列它能操作的主机。默认情况
|
||||
- [多级环境与 Ansible][9].
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/python-tutorials/linux-tutorial-install-ansible-configuration-management-and-it-automation-tool/
|
||||
|
||||
作者:[Nix Craft][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,20 +1,20 @@
|
||||
CentOS监控用户登录历史之utmpdump
|
||||
使用 utmpdump 监控 CentOS 用户登录历史
|
||||
================================================================================
|
||||
保留、维护和分析日志(如某个特定时期内发生过的,或正在发生的帐号事件),是Linux系统管理员最基础和最重要的任务之一。对于用户管理,检查用户的登入和登出日志(不管是失败的,还是成功的)可以让我们对任何潜在的安全隐患或未经授权使用系统的情况保持警惕。例如,工作时间之外或例假期间的来自未知IP地址或帐号的远程登录应当发出红色警报。
|
||||
保留、维护和分析日志(如某个特定时期内发生过的,或正在发生的帐号事件),是Linux系统管理员最基础和最重要的任务之一。对于用户管理,检查用户的登入和登出日志(不管是失败的,还是成功的)可以让我们对任何潜在的安全隐患或未经授权使用系统的情况保持警惕。例如,工作时间之外或放假期间的来自未知IP地址或帐号的远程登录应当发出红色警报。
|
||||
|
||||
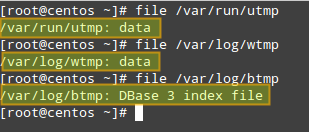
在CentOS系统上,用户登录历史存储在以下这些文件中:
|
||||
|
||||
- /var/run/utmp(用于记录当前打开的会话)who和w工具用来记录当前有谁登录以及他们正在做什么,而uptime用来记录系统启动时间。
|
||||
- /var/log/wtmp (用于存储系统连接历史记录)last工具用来记录最后登录的用户的列表。
|
||||
- /var/log/btmp(记录失败的登录尝试)lastb工具用来记录最后失败的登录尝试的列表。
|
||||
- /var/run/utmp(用于记录当前打开的会话)被who和w工具用来记录当前有谁登录以及他们正在做什么,而uptime用来记录系统启动时间。
|
||||
- /var/log/wtmp (用于存储系统连接历史记录)被last工具用来记录最后登录的用户的列表。
|
||||
- /var/log/btmp(记录失败的登录尝试)被lastb工具用来记录最后失败的登录尝试的列表。
|
||||
|
||||
|
||||
|
||||
在本帖中,我将介绍如何使用utmpdump,这个小程序来自sysvinit-tools包,可以用于转储二进制日志文件到文本格式的文件以便检查。此工具默认在CentOS 6和7家族上可用。utmpdump收集到的信息比先前提到过的工具的输出要更全面,这让它成为一个胜任该工作的很不错的工具。除此之外,utmpdump可以用于修改utmp或wtmp。如果你想要修复二进制日志中的任何损坏条目,它会很有用。
|
||||
在本文中,我将介绍如何使用utmpdump,这个小程序来自sysvinit-tools包,可以用于转储二进制日志文件到文本格式的文件以便检查。此工具默认在CentOS 6和7系列上可用。utmpdump收集到的信息比先前提到过的工具的输出要更全面,这让它成为一个胜任该工作的很不错的工具。除此之外,utmpdump可以用于修改utmp或wtmp。如果你想要修复二进制日志中的任何损坏条目,它会很有用(LCTT 译注:我怎么觉得这像是做坏事的前奏?)。
|
||||
|
||||
### Utmpdump的使用及其输出说明 ###
|
||||
|
||||
正如我们之前提到的,这些日志文件,与我们大多数人熟悉的其它日志相比(如/var/log/messages,/var/log/cron,/var/log/maillog),是以二进制格式存储的,因而我们不能使用像less或more这样的文件命令来查看它们的内容。那样看来,utmpdump拯救了世界。
|
||||
正如我们之前提到的,这些日志文件,与我们大多数人熟悉的其它日志相比(如/var/log/messages,/var/log/cron,/var/log/maillog),是以二进制格式存储的,因而我们不能使用像less或more这样的文件命令来查看它们的内容。所以,utmpdump的出现拯救了世界。
|
||||
|
||||
为了要显示/var/run/utmp的内容,请运行以下命令:
|
||||
|
||||
@ -34,15 +34,15 @@ CentOS监控用户登录历史之utmpdump
|
||||
|
||||

|
||||
|
||||
正如你所能看到的,三种情况下的输出结果是一样的,除了utmp和btmp的记录是按时间排序,而wtmp的顺序是颠倒的这个原因外。
|
||||
正如你所能看到的,三种情况下的输出结果是一样的,除了utmp和btmp的记录是按时间排序,而wtmp的顺序是颠倒的这个原因外(LCTT 译注:此处原文有误,实际上都是按照时间顺序排列的)。
|
||||
|
||||
每个日志行格式化成了多列,说明如下。第一个字段显示了会话识别符,而第二个字段则是PID。第三个字段可以是以下值:~~(表示运行等级改变或系统重启),bw(启动守候进程),数字(表示TTY编号),或者字符和数字(表示伪终端)。第四个字段可以为空或用户名、重启或运行级别。第五个字段是主TTY或PTY(伪终端),如果此信息可获得的话。第六个字段是远程主机名(如果是本地登录,该字段为空,运行级别信息除外,它会返回内核版本)。第七个字段是远程系统的IP地址(如果是本地登录,该字段为0.0.0.0)。如果没有提供DNS解析,第六和第七字段会显示相同的信息(远程系统的IP地址)。最后一个(第八)字段指明了记录创建的日期和时间。
|
||||
每个日志行格式化成了多列,说明如下。第一个字段显示了会话识别符,而第二个字段则是PID。第三个字段可以是以下值:--(表示运行等级改变或系统重启),bw(启动守候进程),数字(表示TTY编号),或者字符和数字(表示伪终端)。第四个字段可以为空或用户名、重启或运行级别。第五个字段是主TTY或PTY(伪终端),如果此信息可获得的话。第六个字段是远程主机名(如果是本地登录,该字段为空,运行级别信息除外,它会返回内核版本)。第七个字段是远程系统的IP地址(如果是本地登录,该字段为0.0.0.0)。如果没有提供DNS解析,第六和第七字段会显示相同的信息(远程系统的IP地址)。最后一个(第八)字段指明了该记录创建的日期和时间。
|
||||
|
||||
### Utmpdump使用样例 ###
|
||||
|
||||
下面提供了一些utmpdump的简单使用情况。
|
||||
|
||||
1. 检查8月18日到9月17日之间某个特定用户(如gacanepa)的登录次数。
|
||||
1、 检查8月18日到9月17日之间某个特定用户(如gacanepa)的登录次数。
|
||||
|
||||
# utmpdump /var/log/wtmp | grep gacanepa
|
||||
|
||||
@ -50,13 +50,13 @@ CentOS监控用户登录历史之utmpdump
|
||||
|
||||
如果你需要回顾先前日期的登录信息,你可以检查/var/log下的wtmp-YYYYMMDD(或wtmp.[1...N])和btmp-YYYYMMDD(或btmp.[1...N])文件,这些是由[logrotate][1]生成的旧wtmp和btmp的归档文件。
|
||||
|
||||
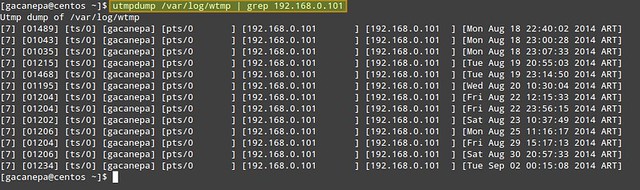
2. 统计来自IP地址192.168.0.101的登录次数。
|
||||
2、 统计来自IP地址192.168.0.101的登录次数。
|
||||
|
||||
# utmpdump /var/log/wtmp | grep 192.168.0.101
|
||||
|
||||
|
||||
|
||||
3. 显示失败的登录尝试。
|
||||
3、 显示失败的登录尝试。
|
||||
|
||||
# utmpdump /var/log/btmp
|
||||
|
||||
@ -64,7 +64,7 @@ CentOS监控用户登录历史之utmpdump
|
||||
|
||||
在/var/log/btmp输出中,每个日志行都与一个失败的登录尝试相关(如使用不正确的密码,或者一个不存在的用户ID)。上面图片中高亮部分显示了使用不存在的用户ID登录,这警告你有人尝试猜测常用帐号名来闯入系统。这在使用tty1的情况下是个极其严重的问题,因为这意味着某人对你机器上的终端具有访问权限(该检查一下谁拿到了进入你数据中心的钥匙了,也许吧?)
|
||||
|
||||
4. 显示每个用户会话的登入和登出信息
|
||||
4、 显示每个用户会话的登入和登出信息
|
||||
|
||||
# utmpdump /var/log/wtmp
|
||||
|
||||
@ -72,9 +72,9 @@ CentOS监控用户登录历史之utmpdump
|
||||
|
||||
在/var/logwtmp中,一次新的登录事件的特征是,第一个字段为‘7’,第三个字段是一个终端编号(或伪终端id),第四个字段为用户名。相关的登出事件会在第一个字段显示‘8’,第二个字段显示与登录一样的PID,而终端编号字段空白。例如,仔细观察上面图片中PID 1463的行。
|
||||
|
||||
- On [Fri Sep 19 11:57:40 2014 ART] the login prompt appeared in tty1.
|
||||
- On [Fri Sep 19 12:04:21 2014 ART], user root logged on.
|
||||
- On [Fri Sep 19 12:07:24 2014 ART], root logged out.
|
||||
- 在 [Fri Sep 19 11:57:40 2014 ART],TTY1上显示登录提示符。
|
||||
- 在 [Fri Sep 19 12:04:21 2014 ART],用户 root 登入。
|
||||
- 在 [Fri Sep 19 12:07:24 2014 ART],用户 root 登出。
|
||||
|
||||
旁注:第四个字段的LOGIN意味着出现了一次登录到第五字段指定的终端的提示。
|
||||
|
||||
@ -86,7 +86,7 @@ CentOS监控用户登录历史之utmpdump
|
||||
|
||||
|
||||
|
||||
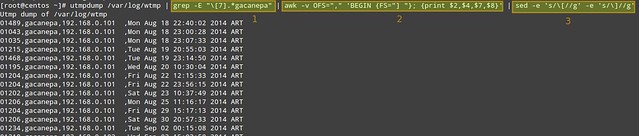
就像上面图片中三个块描绘的那样,过滤逻辑操作是由三个管道步骤组成的。第一步用于查找由用户gacanepa触发的登录事件([7]);第二步和第三部用于选择期望的字段,移除utmpdump输出的方括号并设置输出字段分隔符为逗号。
|
||||
就像上面图片中三个高亮区域描绘的那样,过滤逻辑操作是由三个管道步骤组成的。第一步用于查找由用户gacanepa触发的登录事件([7]);第二步和第三部用于选择期望的字段,移除utmpdump输出的方括号并设置输出字段分隔符为逗号。
|
||||
|
||||
当然,如果你想要在以后打开来看,你需要重定向上面的命令输出到文件(添加“>[文件名].csv”到命令后面)。
|
||||
|
||||
@ -97,12 +97,12 @@ CentOS监控用户登录历史之utmpdump
|
||||
在进行总结之前,让我们简要地展示一下utmpdump的另外一种使用情况:修改utmp或wtmp。由于这些都是二进制日志文件,你不能像编辑文件一样来编辑它们。取而代之是,你可以将其内容输出成为文本格式,并修改文本输出内容,然后将修改后的内容导入回二进制日志中。如下:
|
||||
|
||||
# utmpdump /var/log/utmp > tmp_output
|
||||
<modify tmp_output using a text editor>
|
||||
<使用文本编辑器修改 tmp_output>
|
||||
# utmpdump -r tmp_output > /var/log/utmp
|
||||
|
||||
这在你想要移除或修复二进制日志中的任何伪造条目时很有用。
|
||||
|
||||
下面小结一下,utmpdump通过转储详细的登录事件到utmp、wtmp和btmp日志文件,也可以是轮循的旧归档文件,来补充如who,w,uptime,last,lastb之类的标准工具的不足,这也使得它成为一个很棒的工具。
|
||||
下面小结一下,utmpdump从utmp、wtmp和btmp日志文件或轮循的旧归档文件来读取详细的登录事件,来补充如who,w,uptime,last,lastb之类的标准工具的不足,这也使得它成为一个很棒的工具。
|
||||
|
||||
你可以随意添加评论以加强本帖的含金量。
|
||||
|
||||
@ -112,9 +112,9 @@ via: http://xmodulo.com/2014/09/monitor-user-login-history-centos-utmpdump.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/2014/09/logrotate-manage-log-files-linux.html
|
||||
[1]:http://linux.cn/article-4126-1.html
|
||||
@ -1,8 +1,8 @@
|
||||
如何使用Quagga将CentOS放入OSPF路由器中
|
||||
想玩路由器吗?使用 Quagga 将你的 CentOS 变成 OSPF 路由器
|
||||
================================================================================
|
||||
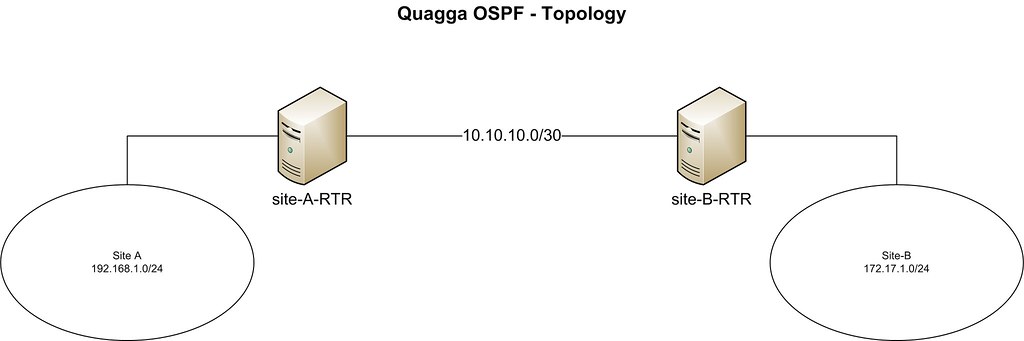
[Quagga][1]是一个可以将Linux放入支持如RIP、OSPF、BGP和IS-IS等主要路由协议的路由器的一个开源路由软件套件。它具有对IPv4和IPv6的完整规定,并支持路由/前缀过滤。Quagga可以是你生命中的救星,以防你的生产路由器一旦宕机,而你没有备用的设备而只能等待更换。通过适当的配置,Quagga甚至可以作为生产路由器。
|
||||
[Quagga][1]是一个开源路由软件套件,可以将Linux变成支持如RIP、OSPF、BGP和IS-IS等主要路由协议的路由器。它具有对IPv4和IPv6的完整支持,并支持路由/前缀过滤。Quagga可以是你生命中的救星,以防你的生产路由器一旦宕机,而你没有备用的设备而只能等待更换。通过适当的配置,Quagga甚至可以作为生产路由器。
|
||||
|
||||
本教程中,我们将连接两个假设之间具有专线连接的分支机构网络(例如,192.168.1.0/24和172.17.1.0/24)。
|
||||
本教程中,我们将连接假设之间具有专线连接的两个分支机构网络(例如,192.168.1.0/24和172.17.1.0/24)。
|
||||
|
||||
|
||||
|
||||
@ -10,12 +10,12 @@
|
||||
|
||||
- **Site-A**: 192.168.1.0/24
|
||||
- **Site-B**: 172.16.1.0/24
|
||||
- **Peering between 2 Linux boxes**: 10.10.10.0/30
|
||||
- **两个 Linux 路由器之间的对等网络**: 10.10.10.0/30
|
||||
|
||||
Quagga包括了几个协同工作的守护进程。在本教程中,我们将重点建立以下守护进程。
|
||||
|
||||
1. **Zebra**: 核心守护进程,负责内核接口和静态路由。
|
||||
1. **Ospfd**: IPv4 OSPF 守护进程.
|
||||
1. **Ospfd**: IPv4 OSPF 守护进程。
|
||||
|
||||
### 在CentOS上安装Quagga ###
|
||||
|
||||
@ -23,11 +23,11 @@ Quagga包括了几个协同工作的守护进程。在本教程中,我们将
|
||||
|
||||
# yum install quagga
|
||||
|
||||
在CentOS7,SELinux默认会阻止quagga将配置文件写到/usr/sbin/zebra。这个SELinux策略会干涉我们接下来要介绍的安装过程,所以我们要禁用此策略。对于这一点,无论是[关闭SELinux][2](这里不推荐),还是如下启用“zebra_write_config'。如果你使用的是CentOS 6的请跳过此步骤。
|
||||
在CentOS7,SELinux默认会阻止quagga将配置文件写到/usr/sbin/zebra。这个SELinux策略会干扰我们接下来要介绍的安装过程,所以我们要禁用此策略。对于这一点,无论是[关闭SELinux][2](这里不推荐),还是如下启用“zebra_write_config”都可以。如果你使用的是CentOS 6的请跳过此步骤。
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
如果没有这个改变,在我们尝试在Quagga命令行中保存配置的时候看到如下错误。
|
||||
如果没有做这个修改,在我们尝试在Quagga命令行中保存配置的时候看到如下错误。
|
||||
|
||||
Can't open configuration file /etc/quagga/zebra.conf.OS1Uu5.
|
||||
|
||||
@ -45,7 +45,7 @@ Quagga包括了几个协同工作的守护进程。在本教程中,我们将
|
||||
|
||||
# vtysh
|
||||
|
||||
首先,我们为Zebra被指日志文件。输入下面的命令进入vtysh的全局配置模式:
|
||||
首先,我们为Zebra配置日志文件。输入下面的命令进入vtysh的全局配置模式:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
|
||||
@ -117,7 +117,7 @@ Quagga包括了几个协同工作的守护进程。在本教程中,我们将
|
||||
|
||||
如果一切顺利,你应该可以在site-A的服务器上ping通site-B上的对等IP地址10.10.10.2了。
|
||||
|
||||
注意一旦Zebra的守护进程启动了,在vtysh命令行中的任何改变都会立即生效。因此没有必要在更改配置后重启Zebra守护进程。
|
||||
注意:一旦Zebra的守护进程启动了,在vtysh命令行中的任何改变都会立即生效。因此没有必要在更改配置后重启Zebra守护进程。
|
||||
|
||||
### 步骤 2: 配置OSPF ###
|
||||
|
||||
@ -157,7 +157,7 @@ Quagga包括了几个协同工作的守护进程。在本教程中,我们将
|
||||
|
||||
OSPF的邻居现在应该启动了。只要ospfd在运行,通过vtysh的任何OSPF相关配置的改变都会立即生效而不必重启ospfd。
|
||||
|
||||
下一章节,我们会验证我们的Quagga设置。
|
||||
下一节,我们会验证我们的Quagga设置。
|
||||
|
||||
### 验证 ###
|
||||
|
||||
@ -215,7 +215,7 @@ via: http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux 有问必答 -- 在 Linux 如何更改文本文件的字符编码
|
||||
Linux 有问必答:在 Linux 如何更改文本文件的字符编码
|
||||
================================================================================
|
||||
> **问题**:在我的 Linux 系统中有一个编码为 iso-8859-1 的字幕文件,其中部分字符无法正常显示,我想把文本改为 utf8 编码。在 Linux 张, 有没有一个好的工具来转换文本文件的字符编码?
|
||||
> **问题**:在我的 Linux 系统中有一个编码为 iso-8859-1 的字幕文件,其中部分字符无法正常显示,我想把文本改为 utf8 编码。在 Linux 中, 有没有一个好的工具来转换文本文件的字符编码?
|
||||
|
||||
正如我们所知道的那样,电脑只能够处理低级的二进制数字,并不能直接处理字符。当一个文本文件被存储时,文件中的每一个字符都被映射成二进制数字,实际存储在硬盘中的正是这些“二进制数字”。之后当程序打开文本文件时,所有二进制数字都被读入并映射回原始的可读字符。只有当所有需要访问这个文件的程序都能够“理解”它的编码,即二进制数字到字符的映射时,这个“保存和打开”的过程才能很好地完成,这也确保了可理解数据的往返过程。
|
||||
正如我们所知道的那样,电脑只能够处理低级的二进制值,并不能直接处理字符。当一个文本文件被存储时,文件中的每一个字符都被映射成二进制值,实际存储在硬盘中的正是这些“二进制值”。之后当程序打开文本文件时,所有二进制值都被读入并映射回原始的可读字符。只有当所有需要访问这个文件的程序都能够“理解”它的编码,即二进制值到字符的映射时,这个“保存和打开”的过程才能很好地完成,这也确保了可理解数据的往返过程。
|
||||
|
||||
如果不同的程序使用不同的编码来处理同一个文件,源文件中的特殊字符就无法正常显示。这里的特殊字符指的是非英文字母的字符,例如带重音的字符(比如 ñ,á,ü)。
|
||||
|
||||
@ -20,7 +20,7 @@ Linux 有问必答 -- 在 Linux 如何更改文本文件的字符编码
|
||||
|
||||
### 步骤二 ###
|
||||
|
||||
下一步是查看你的 Linux 系统所支持的文件编码种类。为此,我们使用名为 iconv 短工具及 “-l” 选项(L 的小写)来列出所有当前支持的编码。
|
||||
下一步是查看你的 Linux 系统所支持的文件编码种类。为此,我们使用名为 iconv 的工具及 “-l” 选项(L 的小写)来列出所有当前支持的编码。
|
||||
|
||||
$ iconv -l
|
||||
|
||||
@ -47,6 +47,6 @@ iconv 工具是 GNU libc 库组成部分,因此它在所有 Linux 发行版中
|
||||
via: http://ask.xmodulo.com/change-character-encoding-text-file-linux.html
|
||||
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,12 +1,15 @@
|
||||
在Ubuntu 14.10/14.04/13.10上安装LEMP服务(Nginx,MySQL或MariaDB,PHP和phpMyAdmin)
|
||||
在 Ubuntu 14.10/14.04/13.10 上安装 LEMP 服务(Nginx,MySQL 或 MariaDB,PHP 和 phpMyAdmin)
|
||||
================================================================================
|
||||
**LEMP**是一个操作系统和几个开源软件包的合称。缩写LEMP来自**L**inux,Nginx(发音是**e**ngine-x)HTTP服务器,**M**ySQL数据库,和**P**HP/**P**erl/**P**ython的首字母。
|
||||
|
||||
在这篇教程里,让我们看一下如何在Ubuntu 14.10上安装Nginx,MySQL或MariaDB,PHP和phpMyAdmin。
|
||||

|
||||
|
||||
**LEMP**是一个操作系统和几个开源软件包的合称。缩写LEMP来自 **L** inux,Nginx(发音是 **e** ngine-x)HTTP服务器, **M** ySQL数据库,和 **P** HP/ **P** erl/ **P** ython的首字母。
|
||||
|
||||
在这篇教程里,让我们看一下如何在 Ubuntu 14.10 上安装 Nginx,MySQL 或 MariaDB,PHP 和 phpMyAdmin。
|
||||
|
||||
### 安装Nginx ###
|
||||
|
||||
**Nginx** (发音是engine-x)是一个免费的、开源的、高性能HTTP服务器和反向代理,也可以用作IMAP/POP3代理服务器,由Igor Sysoev开发。
|
||||
**Nginx** (发音是engine-x)是一个免费的、开源的、高性能HTTP服务器和反向代理,也可以用作IMAP/POP3代理服务器,它是由Igor Sysoev开发。
|
||||
|
||||
要安装Nginx,在你的终端里输入下面的命令:
|
||||
|
||||
@ -20,26 +23,26 @@
|
||||
sudo apt-get install nginx
|
||||
|
||||
用下面的命令启用Nginx服务:
|
||||
|
||||
|
||||
sudo service nginx start
|
||||
|
||||
### 测试nginx ###
|
||||
### 测试 nginx ###
|
||||
|
||||
打开你的浏览器访问http://IP地址/或者http://localhost/。将可以看到类似下面的截图。
|
||||
|
||||

|
||||
|
||||
### 配置Nginx ###
|
||||
### 配置 Nginx ###
|
||||
|
||||
用任意文本编辑器打开文件**/etc/nginx/nginx.conf**
|
||||
|
||||
sudo nano /etc/nginx/nginx.conf
|
||||
|
||||
设置worker_processes(例如,你系统里CPU数目)。查看CPU数目,可以使用命令“lscpu”。在我这里是“1”。所以我把这个值设为1。
|
||||
设置 worker_processes(例如,你系统里CPU数目)。查看CPU数目,可以使用命令“lscpu”。在我这里是“1”。所以我把这个值设为1。
|
||||
|
||||
worker_processes 1;
|
||||
|
||||
重启Nginx服务:
|
||||
重启 Nginx 服务:
|
||||
|
||||
sudo service nginx restart
|
||||
|
||||
@ -65,7 +68,7 @@
|
||||
|
||||
- **listen 80;** –> 监听ipv4端口
|
||||
- **listen [::]:80 default_server ipv6only=on;** –> 监听ipv6宽口
|
||||
- **root /usr/share/nginx/html;** –> 网站根目录
|
||||
- **root /usr/share/nginx/html;** –> 文件根目录
|
||||
- **server_name server.unixmen.local;** –> 服务器FQDN
|
||||
|
||||
现在,向下滚动找到区域#location **~ \.php$**。去掉注释并按如下修改:
|
||||
@ -87,7 +90,7 @@
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
### 测试nginx配置 ###
|
||||
### 测试 nginx 配置 ###
|
||||
|
||||
使用下面的命令测试nginx配置是否存在语法错误:
|
||||
|
||||
@ -102,9 +105,9 @@
|
||||
|
||||
sudo service nginx restart
|
||||
|
||||
### 安装MySQL ###
|
||||
### 安装 MySQL ###
|
||||
|
||||
**MySQL**是一个关系型数据库管理系统(RDBMS),作为服务启动提供给多用户访问多种数据库,尽管可能大多集成布置的SQLite。
|
||||
**MySQL**是一个关系型数据库管理系统(RDBMS),作为服务启动提供给多用户访问多种数据库,尽管SQLite可能有更多的嵌入式部署。
|
||||
|
||||
sudo apt-get install mysql-server mysql-client
|
||||
|
||||
@ -118,7 +121,7 @@
|
||||
|
||||
现在,MySQL服务器就安装好了。
|
||||
|
||||
你可以用下面的命令检查MySQL服务器状态:
|
||||
你可以用下面的命令检查 MySQL 服务器状态:
|
||||
|
||||
sudo service mysql status
|
||||
|
||||
@ -128,11 +131,11 @@
|
||||
|
||||
**注意**:如果你希望使用MariaDB而不是MySQL,可以参考下面的步骤。
|
||||
|
||||
### 安装MariaDB ###
|
||||
### 安装 MariaDB ###
|
||||
|
||||
**MariaDB**是MySQL的一个直接替代软件。它是一个稳定的、可扩展的和可靠的SQL服务器,包含许多增强功能。
|
||||
**MariaDB**是 MySQL 的一个直接替代软件。它是一个稳定、可扩展又可靠的SQL服务器,包含许多增强功能。
|
||||
|
||||
首先,如果有的话你得先卸载掉MySQL。要完全卸载MySQL包括配置文件,输入如下命令:
|
||||
首先,如果有的话你得先卸载掉 MySQL。要完全卸载 MySQL 包括配置文件,输入如下命令:
|
||||
|
||||
sudo apt-get purge mysql*
|
||||
|
||||
@ -144,7 +147,7 @@
|
||||
|
||||
sudo apt-get install mariadb-server mariadb-client
|
||||
|
||||
另外,如果你希望体验最新版的MariaDB的话,可以从[MariaDB仓库][1]安装。运行下面的命令添加PPA。在写这篇文章的时候,MariaDB PPA还没有更新Ubuntu 14.10。不过,我们还是可以使用Ubuntu 14.04的仓库。
|
||||
另外,如果你希望体验最新版的MariaDB,可以从[MariaDB仓库][1]安装。运行下面的命令添加PPA。在写这篇文章的时候,MariaDB PPA还没有更新 Ubuntu 14.10。不过,我们还是可以使用 Ubuntu 14.04 的仓库来替代。
|
||||
|
||||
sudo apt-get install software-properties-common
|
||||
sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
|
||||
@ -163,11 +166,11 @@
|
||||
|
||||

|
||||
|
||||
点击‘是’迁移到MariaDB。注意一下,如果在安装MariaDB之前没有装过MySQL的话,不会提示你这个问题。
|
||||
点击‘是’迁移到 MariaDB。注意一下,如果在安装MariaDB之前没有装过 MySQL 的话,不会提示你这个问题。
|
||||
|
||||

|
||||
|
||||
你可以用如下命令检查MariaDB版本:
|
||||
你可以用如下命令检查 MariaDB 版本:
|
||||
|
||||
sudo mysql -v -u root -p
|
||||
|
||||
@ -199,9 +202,9 @@
|
||||
|
||||
Threads: 1 Questions: 566 Slow queries: 0 Opens: 330 Flush tables: 4 Open tables: 22 Queries per second avg: 4.014
|
||||
|
||||
### 安装PHP ###
|
||||
### 安装 PHP ###
|
||||
|
||||
**PHP**(PHP: Hypertext Preprocessor的递归缩写)是一个应用广泛的开源通用脚本语言,特别适合于网页开发,可以直接嵌入到HTML中。
|
||||
**PHP**(PHP: Hypertext Preprocessor的递归缩写)是一个应用广泛的开源通用脚本语言,特别适合于网页开发,可以直接嵌入到 HTML 中。
|
||||
|
||||
使用如下命令安装PHP:
|
||||
|
||||
@ -221,7 +224,7 @@
|
||||
|
||||
sudo service php5-fpm restart
|
||||
|
||||
### 测试PHP ###
|
||||
### 测试 PHP ###
|
||||
|
||||
在nginx文档根目录下创建一个测试文件“testphp.php”。
|
||||
|
||||
@ -235,7 +238,7 @@
|
||||
|
||||
保存文件并退出。
|
||||
|
||||
访问地址**http://server-ip-address/testphp.php**。将打印出所有关于php的信息,比如版本、构建日期以及命令等等。
|
||||
访问地址**http://server-ip-address/testphp.php**。将显示出所有关于 php 的信息,比如版本、构建日期以及命令等等。
|
||||
|
||||

|
||||
|
||||
@ -251,15 +254,15 @@ PHP-FPM会默认监听套接字**/var/run/php5-fpm.sock**。如果你希望PHP-F
|
||||
|
||||
listen = 127.0.0.1:9000
|
||||
|
||||
保存退出。重启php5-fpm服务。
|
||||
保存退出。重启 php5-fpm 服务。
|
||||
|
||||
sudo service php5-fpm restart
|
||||
|
||||
现在打开nginx配置文件:
|
||||
现在打开 nginx 配置文件:
|
||||
|
||||
sudo nano /etc/nginx/sites-available/default
|
||||
|
||||
找到这一行**fastcgi_pass unix:/var/run/php5-fpm.sock;**,参考下面把它改成fastcgi_pass 127.0.0.1:9000;。
|
||||
找到这一行**fastcgi_pass unix:/var/run/php5-fpm.sock;**,参考下面把它改成 fastcgi_pass 127.0.0.1:9000;。
|
||||
|
||||
location ~ \.php$ {
|
||||
try_files $uri =404;
|
||||
@ -274,21 +277,21 @@ PHP-FPM会默认监听套接字**/var/run/php5-fpm.sock**。如果你希望PHP-F
|
||||
include fastcgi.conf;
|
||||
}
|
||||
|
||||
保存退出。最后重启nginx服务。
|
||||
保存退出。最后重启 nginx 服务。
|
||||
|
||||
sudo service nginx restart
|
||||
|
||||
### 使用phpMyAdmin管理MySQL数据库(可选) ###
|
||||
### 使用 phpMyAdmin 管理 MySQL 数据库(可选) ###
|
||||
|
||||
**phpMyAdmin**是一个免费的开源网页界面工具,用来管理你的MySQL数据库。
|
||||
**phpMyAdmin**是一个免费的开源网页界面工具,用来管理你的 MySQL 数据库。
|
||||
|
||||
### 安装phpMyAdmin ###
|
||||
### 安装 phpMyAdmin ###
|
||||
|
||||
在Debian官方仓库里就有。所以可以用下面的命令安装:
|
||||
在 Debian 官方仓库里就有。所以可以用下面的命令安装:
|
||||
|
||||
sudo apt-get install phpmyadmin
|
||||
|
||||
选择一个网页服务器。默认情况下,这里不会显示nginx。所以,选择apache或者lighttpd,然后我们再把phpMyAdmin和nginx连接起来工作。
|
||||
选择一个网页服务器。默认情况下,这里不会显示 nginx。所以,选择 apache 或者 lighttpd,然后我们再把 phpMyAdmin 和 nginx 连接起来工作。
|
||||
|
||||

|
||||
|
||||
@ -300,7 +303,7 @@ PHP-FPM会默认监听套接字**/var/run/php5-fpm.sock**。如果你希望PHP-F
|
||||
|
||||

|
||||
|
||||
输入phpmyadmin帐号的MySQL密码:
|
||||
输入 phpmyadmin 帐号的 MySQL 密码:
|
||||
|
||||

|
||||
|
||||
@ -308,31 +311,31 @@ PHP-FPM会默认监听套接字**/var/run/php5-fpm.sock**。如果你希望PHP-F
|
||||
|
||||

|
||||
|
||||
phpMyAdmin的安装就完成了。
|
||||
phpMyAdmin 就安装完成了。
|
||||
|
||||
创建一个phpMyAdmin的软连接到网站根目录。这里我们的网站跟文档目录是/usr/share/nginx/html/。
|
||||
创建一个 phpMyAdmin 的软连接到网站根目录。这里我们的网站根文档目录是/usr/share/nginx/html/。
|
||||
|
||||
sudo ln -s /usr/share/phpmyadmin/ /usr/share/nginx/html
|
||||
|
||||
重启nginx服务。
|
||||
重启 nginx 服务。
|
||||
|
||||
sudo service nginx restart
|
||||
|
||||
### 访问phpMyAdmin网页控制台 ###
|
||||
### 访问 phpMyAdmin 网页控制台 ###
|
||||
|
||||
现在你可以在浏览器中通过地址**http://server-ip-address/phpmyadmin/**访问phpMyAdmin的控制台了。
|
||||
现在你可以在浏览器中通过地址**http://server-ip-address/phpmyadmin/**访问 phpMyAdmin 的控制台了。
|
||||
|
||||
输入你在前面步骤里留下的MySQL用户名和密码。在我这里是“root”和“ubuntu”。
|
||||
输入你在前面步骤里留下的 MySQL 用户名和密码。在我这里是“root”和“ubuntu”。
|
||||
|
||||

|
||||
|
||||
就可以重定向到phpMyAdmin的网页管理首页。
|
||||
就可以重定向到 phpMyAdmin 的网页管理首页。
|
||||
|
||||

|
||||
|
||||
现在你就可以在phpMyAdmin网页里管理你的MyQL数据库了。
|
||||
现在你就可以在 phpMyAdmin 网页里管理你的 MyQL 数据库了。
|
||||
|
||||
就这样。你的LEMP服务器已经配置完毕可以投入使用了。
|
||||
就这样。你的 LEMP 服务器已经配置完毕,可以使用了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -340,7 +343,7 @@ via: http://www.unixmen.com/install-lemp-server-nginx-mysql-mariadb-php-phpmyadm
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,30 @@
|
||||
最新版本的 Ubuntu 在 Google 云平台上架
|
||||
================================================================================
|
||||

|
||||
|
||||
自从Canonical和Google合作后,Canonical宣布已经在Google云平台发布Ubuntu14.04LTS、12.04LTS和14.10的公开beta版本。“从今天起,可以在Google云平台上选择优化过的、最新的、十分安全和一致的Ubuntu镜像”Canonical的公告称,“Canonical将会继续地维护、测试和更新认证的Ubuntu镜像,在官方版本发布后,Google云平台马上就会拥有最新版本”。
|
||||
|
||||
Ubuntu 在云环境和作为云分发基础中已经日益流行,因此为Google云平台提供镜像可以吸引更多的用户。
|
||||
|
||||
对于所有Ubuntu LTS版本,Canonical会为之提供维护和安全更新5年的版本,这些会吸引更多的Canonical已经日益重视的企业级用户。
|
||||
|
||||
领先的开源云管理平台Scalr的创始人Sebastian Stadil说道:“官方Ubuntu镜像的缺乏已经阻止我们部分迁移我们的基础设施到Google云平台,我们很高兴看到Ubuntu技术提供给我们所有企业客户。”
|
||||
|
||||
认证公有云(CPC) 的项目经理Federico Lucifredi 提到:“越来越多的企业开始创业,从而转向公有云环境来运行大量的关键的向外扩展的工作负载,Google作为全球领先的竞争者之一,Google 云平台已经快速建成。给Google云平台增加Ubuntu镜像是顺理成章的一步,我们确信这样的合作在开发者和企业部署云时,便于寻找到一个易于使用和信赖的操作系统。”
|
||||
|
||||
通过Canonical得知,在作为所有公有云的操作系统选择上,Ubuntu事实上已经有显著业绩,70%的工作负载运行在Ubuntu上。据OpenStack基金会消息,Ubuntu已经是OpenStack部署的基础。
|
||||
|
||||
浏览[Google Cloud Platform][1]获得更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/the-latest-ubuntu-images-arrive-on-google-cloud-platform
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[Vic020/VicYu](http://www.vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/samdean
|
||||
[1]:https://cloud.google.com/compute/docs/operating-systems
|
||||
@ -0,0 +1,45 @@
|
||||
对,你没看错!Ubuntu MATE 14.04 LTS 现在发布了
|
||||
================================================================================
|
||||
|
||||
|
||||
**传统桌面的粉丝现在可以欢呼了,Ubuntu MATE的第一个长期支持版本现在发布了,马上去下载吧!**
|
||||
|
||||
这个社区产物使用基于 GNOME2 的MATE桌面环境,这个分支还继续着积极的开发和提升。Ubuntu MATE 14.04 LTS跟随着上月发布的Ubuntu 14.10一起发布了。
|
||||
|
||||
### 回顾补充 ###
|
||||
|
||||
你大概会想我是不是打错了(我是Joey Sneddon,这大概可以肯定)。但这此是没错的,你看到的是对的。Ubuntu MATE团队决定追溯创建一个LTS版本。
|
||||
|
||||
**Ubuntu MATE 14.04 LTS** 确切地应该叫Ubuntu MATE 14.11 LTS。[如项目领导者 Martin Wimpress 注明的][1]:不只是因为他在11月份发布,还因为它混合了14.04和14.10的代码。
|
||||
|
||||
> “该版本并不寻常,它虽然基于Ubuntu MATE 14.10 但是加入了很多新的特性,并且修复了很多bug。虽然这是一个14.04版本,但是你可以认为它是一个比14.10 更新的版本...”
|
||||
|
||||
如其他社区产物一样,Ubuntu MATE 14.04也将至少支持接下来的三年,但是应该同样会得到来自上游的严重安全更新。
|
||||
|
||||
**与14.10相比的改变**包括:
|
||||
|
||||
- 更新了主题和壁纸
|
||||
- 增加了两个新的应用: MATE Menu 和 MATE Tweak
|
||||
- 改善辅助功能
|
||||
- VLC 代替了 Totem 视频播放器
|
||||
- 更新了几个 MATE 桌面包
|
||||
|
||||
### 下载 ###
|
||||
|
||||
要知道更多细节,以及硬件需求和支持信息,可以在官方网站上找到,也可以点击下面的链接。
|
||||
|
||||
- [下载 Ubuntu MATE 14.04 LTS][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/11/ubuntu-mate-14-04-download-released
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://ubuntu-mate.org/blog/ubuntu-mate-trusty-final-release/
|
||||
[2]:https://ubuntu-mate.org/longterm/
|
||||
@ -1,8 +1,8 @@
|
||||
在Linux中使用Openswan搭建站点到站点IPsec VPN 隧道
|
||||
在Linux中使用Openswan搭建站点到站点的IPsec VPN 隧道
|
||||
================================================================================
|
||||
虚拟私有网络(VPN)隧道通过Internet隧道技术将两个不同地理位置的网络安全的连接起来。当这两个网络是使用私有IP地址的私有局域网络时,那么两个网络之间是不能相互访问的,这时使用隧道技术就可以使得子网间的主机进行通讯。例如,VPN隧道技术经常被用于大型机构中不同办公区域子网的连接。
|
||||
虚拟私有网络(VPN)隧道是通过Internet隧道技术将两个不同地理位置的网络安全的连接起来的技术。当两个网络是使用私有IP地址的私有局域网络时,它们之间是不能相互访问的,这时使用隧道技术就可以使得两个子网内的主机进行通讯。例如,VPN隧道技术经常被用于大型机构中不同办公区域子网的连接。
|
||||
|
||||
有时,使用VPN隧道仅仅是因为它很安全。服务提供商与公司会使用这样一种方式设网络,他们将重要的服务器(如,数据库,VoIP,银行服务器)放置到一个子网内,仅仅让有权限的用户通过VPN隧道进行访问。如果需要搭建一个安的VPN隧道,通常会选用[IPsec][1],因为IPsec VPN隧道被多重安全层所保护。
|
||||
有时,使用VPN隧道仅仅是因为它很安全。服务提供商与公司会使用这样一种方式架设网络,他们将重要的服务器(如,数据库,VoIP,银行服务器)放置到一个子网内,仅仅让有权限的用户通过VPN隧道进行访问。如果需要搭建一个安全的VPN隧道,通常会选用[IPsec][1],因为IPsec VPN隧道被多重安全层所保护。
|
||||
|
||||
这篇指导文章将会告诉你如何构建站点到站点的 VPN隧道。
|
||||
|
||||
@ -58,17 +58,18 @@
|
||||
最后,我们为NAT创建防火墙规则。
|
||||
|
||||
# iptables -t nat -A POSTROUTING -s site-A-private-subnet -d site-B-private-subnet -j SNAT --to site-A-Public-IP
|
||||
确保防火墙规则的健壮性。
|
||||
|
||||
请确保上述防火墙规则是持久有效的(LCTT 译注:你可以save这些规则或加到启动脚本中)。
|
||||
|
||||
#### 注意: ####
|
||||
|
||||
- 你可以使用MASQUERAD替代SNAT(iptables).理论上说它也能正常工作,但是有可能会与VPS发生冲突,所以我任然建议使用SNAT.
|
||||
- 你可以使用MASQUERAD替代SNAT(iptables)。理论上说它也能正常工作,但是有可能会与VPS发生冲突,所以我仍然建议使用SNAT。
|
||||
- 如果你同时在管理B点,那么在B点也设置同样的规则。
|
||||
- 直连路由则不需要SNAT。
|
||||
|
||||
### 准配置文件 ###
|
||||
### 准备配置文件 ###
|
||||
|
||||
我们将要用配置的第一个文件是ipsec.conf。不论你将要配置哪一台服务器,总是将你这端的服务器看成是左边的,而将远端的看作是右边的。以下配置是在站点A的VPN服务器做的。
|
||||
我们将要用来配置的第一个文件是ipsec.conf。不论你将要配置哪一台服务器,总是将你这端的服务器看成是左边的,而将远端的看作是右边的。以下配置是在站点A的VPN服务器做的。
|
||||
|
||||
# vim /etc/ipsec.conf
|
||||
|
||||
@ -130,7 +131,7 @@
|
||||
right=<siteB-public-IP>
|
||||
rightsubnet=<siteB-private-subnet>/netmask
|
||||
|
||||
有许多方式实现身份验证。这里使用预共享密钥,并将它添加到文件 file /etc/ipsec.secrets。
|
||||
有许多方式实现身份验证。这里使用预共享密钥,并将它添加到文件 /etc/ipsec.secrets。
|
||||
|
||||
# vim /etc/ipsec.secrets
|
||||
|
||||
@ -148,10 +149,10 @@
|
||||
|
||||
如果所有服务器没有问题的话,那么可以打通隧道了。注意以下内容后,你可以使用ping命令来测试隧道。
|
||||
|
||||
1.A点不可达B点的子网,当隧道没有启动时ping无效。
|
||||
1.隧道启动后,在A点直接ping B点的子网IP。是可以ping通的。
|
||||
1. A点不可达B点的子网,当隧道没有启动时ping不通。
|
||||
1. 隧道启动后,在A点直接ping B点的子网IP,是可以ping通的。
|
||||
|
||||
并且,到达目的子网的路由也会出现在服务器的路由表中。(译者:子网指的是site-B,服务器指的是site-A)
|
||||
并且,到达目的子网的路由也会出现在服务器的路由表中。(LCTT译注:这里“子网”指的是site-B,“服务器”指的是site-A)
|
||||
|
||||
# ip route
|
||||
|
||||
@ -192,21 +193,23 @@
|
||||
|
||||
如果你确信所有配置都是正确的,但是你的隧道任然无法启动,那么你需要检查以下的事件。
|
||||
|
||||
1.很多ISP会过滤IPsec端口。确认你的网络ISP允许使用UDP 500, TCP/UDP 4500端口。你可以试着在远端通过talnet连接服务器的IPsec端口。
|
||||
1.确认所用的端口在服务器防火墙规则中是允许的。
|
||||
1.确认两端服务器的预共享密钥是一致的。
|
||||
1.左边和右边的参数应该正确配置在两端的服务器上
|
||||
1.如果你遇到的是NAT问题,试着使用SNAT替换MASQUERADING。
|
||||
1. 很多ISP会过滤IPsec端口。确认你的网络ISP允许使用UDP 500, TCP/UDP 4500端口。你可以试着在远端通过telnet连接服务器的IPsec端口。
|
||||
1. 确认所用的端口在服务器防火墙规则中是允许的。
|
||||
1. 确认两端服务器的预共享密钥是一致的。
|
||||
1. 左边和右边的参数应该正确配置在两端的服务器上
|
||||
1. 如果你遇到的是NAT问题,试着使用SNAT替换MASQUERADING。
|
||||
|
||||
总结,这篇指导重点在于使用Openswa搭建站点到站点IPsec VPN的流程。管理员可以使用VPN使得一些重要的资源仅能通过隧道来获取,这对于加强安全性很有效果。同时VPN确保数据不被监听以及截。
|
||||
总结,这篇指导重点在于使用Openswan搭建站点到站点IPsec VPN的流程。管理员可以使用VPN使得一些重要的资源仅能通过隧道来获取,这对于加强安全性很有效果。同时VPN确保数据不被监听以及劫持。
|
||||
|
||||
希望对你有帮助。让我知道你的意。
|
||||
|
||||
---
|
||||
|
||||
via: http://xmodulo.com/2014/08/create-site-to-site-ipsec-vpn-tunnel-openswan-linux.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating By instdio
|
||||
"Fork Debian" Project Aims to Put Pressure on Debian Community and Systemd Adoption
|
||||
================================================================================
|
||||
> There is still a great deal of resistance in the Debian community towards the upcoming adoption of systemd
|
||||
@ -34,4 +35,4 @@ via: http://news.softpedia.com/news/Fork-Debian-Project-Started-to-Put-Pressure-
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://debianfork.org/
|
||||
[2]:https://lists.debian.org/debian-vote/2014/10/msg00001.html
|
||||
[2]:https://lists.debian.org/debian-vote/2014/10/msg00001.html
|
||||
|
||||
@ -1,32 +0,0 @@
|
||||
Vic020
|
||||
|
||||
The Latest Ubuntu Images Arrive on Google Cloud Platform
|
||||
================================================================================
|
||||

|
||||
|
||||
Canonical, working with Google, has announced that it is launching the public beta of Ubuntu 14.04 LTS, 12.04 LTS and 14.10 on Google Cloud Platform. "Starting today, it is possible to select optimized, up to date, fully secure and consistent Ubuntu images on Google Cloud Platform," Canonical's post noted, adding that "Canonical continually maintains, tests and updates certified Ubuntu images, making the latest versions available on Google Cloud Platform within minutes of them being officially released."
|
||||
|
||||
Ubuntu has been shown to be an increasingly popular platform for use in the cloud and as the basis for cloud deployments, and making it available on Google's cloud platform should attract many users.
|
||||
|
||||
For all Ubuntu LTS versions, Canonical provides maintenance and security updates for five years, which will appeal to the enterprise users that Canonical is increasingly focused on.
|
||||
|
||||
“The lack of official Ubuntu images had been holding us back in migrating portions of our infrastructure to Google Cloud Platform,” says Sebastian Stadil, founder of the leading open source cloud management platform, Scalr. “We are pleased to see Ubuntu technologies be made available to all our enterprise customers.”
|
||||
|
||||
Federico Lucifredi, Certified Public Cloud product manager said, in a statement: “As more enterprises join start-ups in turning to public cloud environments to run mission critical and scale-out workloads, Google Cloud Platform has quickly established itself as one of the world’s leading contenders for their business. Bringing Ubuntu to Google Cloud Platform is a logical first step in what we believe will be a great collaboration, benefitting developers and enterprises looking for an easy to use, reliable OS for their cloud deployments.”
|
||||
|
||||
Ubuntu actually has a remarkable track record as a guest operating system of choice on all major public clouds, with around 70 percent of workloads running on Ubuntu, according to Canonical. Ubuntu is also the basis for many OpenStack deployments, according to data from the OpenStack Foundation.
|
||||
|
||||
Check in on the [Google Cloud Platform][1] site for more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/the-latest-ubuntu-images-arrive-on-google-cloud-platform
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/samdean
|
||||
[1]:https://cloud.google.com/compute/docs/operating-systems
|
||||
@ -0,0 +1,54 @@
|
||||
Open-Source Vs Groupon: GNOME Battle To Protect Their Trademark
|
||||
================================================================================
|
||||

|
||||
|
||||
**GNOME is a name synonymous with open-source software, but if the billion-dollar company Groupon has its way it could soon mean something different.**
|
||||
|
||||
[Groupon][1], famed for its ‘deal-of-the-day’ website, recently unveiled a “tablet-based platform“ called ‘GNOME’, and has filed requisite trademark filings — 10 so far — seeking ownership of the name.
|
||||
|
||||
Naturally, this has the GNOME Foundation ‘concerned’. GNOME is a [registered trademark][2] of the foundation, and has been since 2006. This mark was issued under a number of sections, including ‘operating system’ – which the Chicago-based Groupon is also claiming against.
|
||||
|
||||
Could it just be that they’ve never heard of GNOME before? Highly unlikely.
|
||||
|
||||

|
||||
|
||||
Groupon’s POS system. Ahem.
|
||||
|
||||
Even the most Saul Goodman-y of lawyers would first check existing trademarks and investigate the company(s) owning or contesting. Even assuming that lapse in professionalism, most would have at least given the name a quick Google. Damningly, the company has previously [claimed to be ‘fuelled by open-source’][3].
|
||||
|
||||
Groupon clearly knows of GNOME, knows what it does, what it stands for and how long it’s been around yet considers itself better placed to “own” the name for its brand of hokey in-store point-of-sale terminals.
|
||||
|
||||
*Hrm.*
|
||||
|
||||
### Campaign to Protect GNOME ###
|
||||
|
||||
Ask not what GNOME can do for you, but what you can do for GNOME. This morning the GNOME Foundation [launched a campaign][4] to raise (an estimated) US$80,000 to battle the first found of marks Groupon has applied to register.
|
||||
|
||||
“**We must not let a billion-dollar-company take the well-established name of one of the biggest Free Software communities,**” says Tobias Mueller, a GNOME Foundation director.
|
||||
|
||||
**“If you want to help GNOME defend its trademark and promote Free Software, visit the campaign’s page, share the link, and let Groupon know that they behaved terribly”.**
|
||||
|
||||
Lucas Nussbaum, **Debian Project Leader**, sums the whole situation up succinctly:
|
||||
|
||||
“**This legal defense is not just about protecting GNOME’s trademark; it is about asserting to the corporate world that FLOSS trademarks can and will be guarded. Not just by the project in question, but by the community as a whole. As a result, all FLOSS trademarks will be strengthened at once.**”
|
||||
|
||||
More details can be found on the GNOME Groupon Campaign page.
|
||||
|
||||
- [GNOME vs Groupon Campaign Page][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/11/gnome-groupon-trademark-battle
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://groupon.com/
|
||||
[2]:http://tsdr.uspto.gov/#caseNumber=76368848&caseType=SERIAL_NO&searchType=statusSearch
|
||||
[3]:https://engineering.groupon.com/2014/open-source/sharing-is-caring-open-source-at-groupon/
|
||||
[4]:https://mail.gnome.org/archives/foundation-list/2014-November/msg00020.html
|
||||
[5]:http://www.gnome.org/groupon/
|
||||
@ -0,0 +1,56 @@
|
||||
Chakra Linux 2014.11 Brings a Custom and Cool KDE 4.14.2 Desktop – Gallery
|
||||
================================================================================
|
||||
> A new version of Chakra Linux has been released
|
||||
|
||||
**Chakra Linux, a distribution specially built to take advantage of KDE Software Compilation and the Plasma desktop, has been upgraded to version 2014.11 and is now ready for download.**
|
||||
|
||||
The developers of this distribution usually choose names of famous scientists. The current iteration of the Chakra Linux, which is actually the second version in the branch, has been dubbed Euler, after Swiss mathematician and physicist Leonhard Euler, who refined calculus and graph theory. Because it follows the KDE releases, it means that we will probably get another version in a few months.
|
||||
|
||||
Surprisingly, if you already have Chakra Linux installed, it won't be enough just to keep your system up to date. Upgrading the OS with the provided ISO is quite easy, but if you're doing it manually, then you'll have to follow a rather intricate tutorial on how to do it properly. It's not unusual for developers to make such big changes that result in the usual updating process not working, but sometimes it's necessary.
|
||||
|
||||
### The latest Chakra Linux is using KDE 4.14.2 ###
|
||||
|
||||
The Chakra Linux developers are following the latest KDE branch very closely, but not the latest version. Case in point, KDE 4.14.3 was released yesterday, but Chakra features KDE 4.14.2. On the other hand, the developers go through great lengths to customize the KDE desktop so that it's unique to this particular distribution.
|
||||
|
||||
"The Chakra team is happy to announce the second release of the Chakra Euler series, which follows the KDE Applications and Platform 4.14 releases. The main reason for providing this new ISO, in addition to providing a new KDE release, is that Chakra has now implemented the /usr merge changes. If you already have Chakra installed on your system manual intervention is needed, so please follow the [instructions][1] on how to properly update. For new installations using this ISO, this is of course not needed."
|
||||
|
||||
"The extra repository, which is disabled by default, provides the must-have GTK-based applications and their dependencies. Kapudan, our desktop greeter which runs after the first boot, will allow you to enable it. Please have in mind that our installer, Tribe, does not currently officially support UEFI, RAID, LVM and GPT, although you might find some workarounds in our forums," [reads][2] the official website.
|
||||
|
||||
The developers also say that the Linux kernel has been updated to version 3.16.4, the systemd component has been updated to version 216, and all of the video drivers, free or proprietary, have been updated as well.
|
||||
|
||||
A complete list of new features and updates can be found in the official announcement.
|
||||
|
||||
Download Chakra Linux 2014.11:
|
||||
|
||||
- [Chakra GNU/Linux 2014.11 (ISO) 64-bitFile size: 1.7 GB][3]
|
||||
- [MD5][4]
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Chakra-Linux-2014-11-Brings-a-Custom-and-Cool-KDE-4-14-2-Desktop-Gallery-464889.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://chakraos.org/news/index.php?/archives/134-Warning-Manual-intervention-needed-on-your-next-major-update.html
|
||||
[2]:http://chakraos.org/news/index.php?/archives/135-Chakra-2014.11-Euler-released.html
|
||||
[3]:http://sourceforge.net/projects/chakra/files/2014.11/chakra-2014.11-euler-x86_64.iso
|
||||
[4]:http://chakra-project.org/get/checksums.txt
|
||||
@ -0,0 +1,50 @@
|
||||
GNOME 3.14.2 Officially Released, Finally Drops SSLv3
|
||||
================================================================================
|
||||
> Users will find the new version in the repositories
|
||||
|
||||

|
||||
|
||||
**The GNOME development team has released the second update for the for GNOME 3.14.x branch and it brings a large number of fixes and improvements for a lot of the packages from the stack.**
|
||||
|
||||
GNOME 3.14 was initially released a few weeks ago and the developers are still ironing out a few issues. The new version has been received very well by the community and it's been adopted already by numerous Linux distributions. It's very likely that GNOME 3.14.2 will be integrated in most of the big repositories, as soon as possible.
|
||||
|
||||
The GNOME project managed to stay on track and the new release has arrived on time. Not all of the packages in the stack have been updated, but there are more than enough to get the users interested. It's a good idea to upgrade your desktop environment as soon as possible in order to get all of these enhancement.
|
||||
|
||||
### GNOME 3.14.2 gets a ton of improvements ###
|
||||
|
||||
Just like the previous iteration, the 3.14.2 release does have a few things that really stand out. For example, the NetworkManager dependency of GNOME Shell has been removed, the queued up notifications are now summarized, the handling of multi-day events has been improved, the GtkMenu use has been refined, various fixes for Mutter have been added, and the SSLv3 use has been disabled.
|
||||
|
||||
"Here comes our second update to GNOME 3.14, it has many fixes, various improvements, documentation and translation updates, we hope you'll enjoy it. Individual modules may get new stable 3.14 releases but our focus is now on the development branches, we released a first snapshot as 3.15.1 two weeks ago and will get another one by the end of the month.," [says][1] GNOME developer Frederic Peters.
|
||||
|
||||
GNOME 3.14.2 comes with updates for these core apps: Adwaita Icon Theme, Eye of GNOME, Epiphany, evolution-data-server, Glib, GNOME Calculator, GNOME Contacts, GNOME Desktop, GNOME Shell, GNOME Terminal, Mutter, Nautilus, Tracker, and more.
|
||||
|
||||
The apps that receive upgrades in the 3.14.2 branch include Aisleriot, Bijiben, Brasero, Cheese, Evolution, File Roller, Gedit, Four in a Row, GNOME Boxes, GNOME Maps, GNOME Music, Hitori, Orca, Rygel, Vinagre, and more.
|
||||
|
||||
We [detailed the GNOME 3.14.x release][2] when it was made available and you can find more details in the original report.
|
||||
|
||||
Download the GNOME 3.14.2 stack
|
||||
|
||||
- [GNOME 3.14.2 Stable Sources][3]
|
||||
- [GNOME 3.14.2 Stable Modules][4]
|
||||
- [GNOME 3.15.1 Unstable Sources][5]
|
||||
- [GNOME 3.15.1 Unstable Modules][6]
|
||||
|
||||
But keep in mind that these are the source packages. If you want an easy upgrade or install, be sure to check the repositories.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/GNOME-3-14-2-Officially-Released-Finally-Drops-SSLv3-464903.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://permalink.gmane.org/gmane.comp.gnome.devel.announce/397
|
||||
[2]:http://news.softpedia.com/news/GNOME-3-14-Officially-Released-Screenshot-Tour-and-Video-459865.shtml
|
||||
[3]:https://download.gnome.org/core/3.14/3.14.2/sources/
|
||||
[4]:https://download.gnome.org/teams/releng/3.14.2/
|
||||
[5]:https://download.gnome.org/core/3.15/3.15.1/sources/
|
||||
[6]:https://download.gnome.org/teams/releng/3.15.1/
|
||||
@ -0,0 +1,57 @@
|
||||
LibreOffice 4.3.4 Released With 60 Bug Fixes, v4.4 Shaping Up Nicely
|
||||
================================================================================
|
||||

|
||||
|
||||
**Two weeks on [from the last][1], The Document Foundation is back with yet another minor release of its open-source LibreOffice productivity suite.**
|
||||
|
||||
LibreOffice 4.3.4, the fourth such minor release in the ‘fresh’ series, is composed solely of bug fixes, which is par for the course in these point releases.
|
||||
|
||||
Adding to the sense of deja vu is the number of bugs the foundation say have been caught in the developers’ butterfly net: around 60 or so.
|
||||
|
||||
- Sorting behaviour now defaults to old style again (Calc)
|
||||
- Restore focus window after preview (Impress)
|
||||
- Chart wizard dialog no longer ‘cut off’
|
||||
- Word count with recorded changes fixed (Writer)
|
||||
- Various RTF fixes, including image border import (Writer)
|
||||
|
||||
A full list of changes can be [found on the LibreOffice Wiki page][2].
|
||||
|
||||
### Download ###
|
||||
|
||||
Many folks have the whole LibreOffice schaboodle installed but rarely ever use it. If you count yourself among them, you could hold off on this release and never notice.
|
||||
|
||||
If you do fancy upgrading you can find all of the relevant download links on the official project website.
|
||||
|
||||
- [Download LibreOffice 4.3.4][3]
|
||||
|
||||
### Looking Ahead to LibreOffice 4.4 ###
|
||||
|
||||

|
||||
|
||||
Info bar coming in LibreOffice 4.4
|
||||
|
||||
LibreOffice 4.4 should be a little more promising.
|
||||
|
||||
[A wiki page details][4] the ongoing GUI tweaks in progress, with a new color picker, restyled paragraph line-spacing selector and an info bar to denote ‘read only’ mode among the many, many highlights.
|
||||
|
||||
While the sum of these won’t amount to the huge wholesale interface changes I know the desktop community clamours for, they are sure-footed steps in the right direction.
|
||||
|
||||
It’s also salient to remember that LibreOffice is a staple — in some cases integral — software for businesses and institutions. Any dramatic overhaul in look or layout would have a big knock on effect.
|
||||
|
||||
Thanks Tim W!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/11/libreoffice-4-3-4-arrives-bundle-bug-fixes
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2014/10/libreoffice-4-3-3-released-62-bug-fixes
|
||||
[2]:https://wiki.documentfoundation.org/Releases/4.3.4/RC1
|
||||
[3]:http://www.libreoffice.org/download/libreoffice-fresh/
|
||||
[4]:https://wiki.documentfoundation.org/ReleaseNotes/4.4#GUI
|
||||
@ -1,142 +0,0 @@
|
||||
[bazz222222222]
|
||||
How to create and manage LXC containers on Ubuntu
|
||||
================================================================================
|
||||
While the concept of containers was introduced more than a decade ago to manage shared hosting environments securely (e.g., FreeBSD jails), Linux containers such as LXC or [Docker][1] have gone mainstream only recently with the rising need to deploy applications for the cloud. While [Docker][2] is getting all the media spotlight these days with strong backing from major cloud providers (e.g., Amazon AWS, Microsoft Azure) and distro providers (e.g., Red Hat, Ubuntu), LXC is in fact the original container technology developed for Linux platforms.
|
||||
|
||||
If you are an average Linux user, what good does Docker/LXC bring to you? Well, containers are actually a great means to switch between distros literally instantly. Suppose your current desktop is Debian. You want Debian's stability. At the same time, you also want to play the latest Ubuntu games. Then instead of bothering to dual boot into a Ubuntu partition, or boot up a heavyweight Ubuntu VM, simply spin off a Ubuntu container on the spot, and you are done.
|
||||
|
||||
Even without all the goodies of Docker, what I like about LXC containers is the fact that LXC can be managed by libvirt interface, which is not the case for Docker. If you have been using libvirt-based management tools (e.g., virt-manager or virsh), you can use those same tools to manage LXC containers.
|
||||
|
||||
In this tutorial, I focus on the command-line usage of standard LXC container tools, and demonstrate **how to create and manage LXC containers from the command line on Ubuntu**.
|
||||
|
||||
### Install LXC on Ubuntu ###
|
||||
|
||||
To use LXC on Ubuntu, install LXC user-space tools as follows.
|
||||
|
||||
$ sudo apt-get install lxc
|
||||
|
||||
After that, check the current Linux kernel for LXC support by running lxc-checkconifg tool. If everything is enabled, kernel's LXC support is ready.
|
||||
|
||||
$ lxc-checkconfig
|
||||
|
||||
|
||||
|
||||
After installing LXC tools, you will find that an LXC's default bridge interface (lxcbr0) is automatically created (as configured in /etc/lxc/default.conf).
|
||||
|
||||
|
||||
|
||||
When you create an LXC container, the container's interface will automatically be attached to this bridge, so the container can communicate with the world.
|
||||
|
||||
### Create an LXC Container ###
|
||||
|
||||
To be able to create an LXC container of a particular target environment (e.g., Debian Wheezy 64bit), you need a corresponding LXC template. Fortunately, LXC user space tools on Ubuntu come with a collection of ready-made LXC templates. You can find available LXC templates in /usr/share/lxc/templates directory.
|
||||
|
||||
$ ls /usr/share/lxc/templates
|
||||
|
||||

|
||||
|
||||
An LXC template is nothing more than a script which builds a container for a particular Linux environment. When you create an LXC container, you need to use one of these templates.
|
||||
|
||||
To create a Ubuntu container, for example, use the following command-line:
|
||||
|
||||
$ sudo lxc-create -n <container-name> -t ubuntu
|
||||
|
||||

|
||||
|
||||
By default, it will create a minimal Ubuntu install of the same release version and architecture as the local host, in this case Saucy Salamander (13.10) 64-bit.
|
||||
|
||||
If you want, you can create Ubuntu containers of any arbitrary version by passing the release parameter. For example, to create a Ubuntu 14.10 container:
|
||||
|
||||
$ sudo lxc-create -n <container-name> -t ubuntu -- --release utopic
|
||||
|
||||
It will download and validate all the packages needed by a target container environment. The whole process can take a couple of minutes or more depending on the type of container. So be patient.
|
||||
|
||||
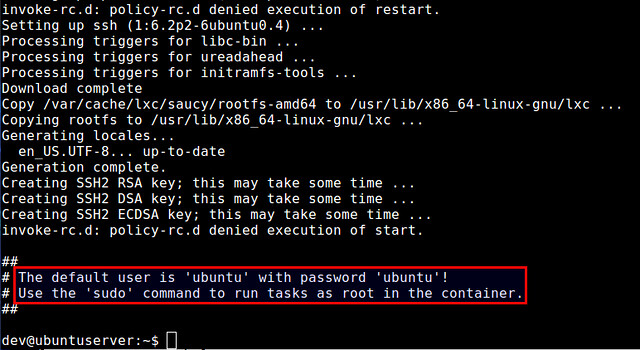
|
||||
|
||||
After a series of package downloads and validation, an LXC container image are finally created, and you will see a default login credential to use. The container is stored in /var/lib/lxc/<container-name>. Its root filesystem is found in /var/lib/lxc/<container-name>/rootfs.
|
||||
|
||||
All the packages downloaded during LXC creation get cached in /var/cache/lxc, so that creating additional containers with the same LXC template will take no time.
|
||||
|
||||
Let's see a list of LXC containers on the host:
|
||||
|
||||
$ sudo lxc-ls --fancy
|
||||
|
||||
----------
|
||||
|
||||
NAME STATE IPV4 IPV6 AUTOSTART
|
||||
------------------------------------
|
||||
test-lxc STOPPED - - NO
|
||||
|
||||
To boot up a container, use the command below. The "-d" option launches the container as a daemon. Without this option, you will directly be attached to console right after you launch the container.
|
||||
|
||||
$ sudo lxc-start -n <container-name> -d
|
||||
|
||||
After launching the container, let's check the state of the container again:
|
||||
|
||||
$ sudo lxc-ls --fancy
|
||||
|
||||
----------
|
||||
|
||||
NAME STATE IPV4 IPV6 AUTOSTART
|
||||
-----------------------------------------
|
||||
lxc RUNNING 10.0.3.55 - NO
|
||||
|
||||
You will see that the container is in "RUNNING" state with an IP address assigned to it.
|
||||
|
||||
You can also verify that the container's interface (e.g., vethJ06SFL) is automatically attached to LXC's internal bridge (lxcbr0) as follows.
|
||||
|
||||
$ brctl show lxcbr0
|
||||
|
||||

|
||||
|
||||
### Manage an LXC Container ###
|
||||
|
||||
Now that we know how to create and start an LXC container, let's see what we can do with a running container.
|
||||
|
||||
First of all, we want to access the container's console. For this, type this command:
|
||||
|
||||
$ sudo lxc-console -n <container-name>
|
||||
|
||||
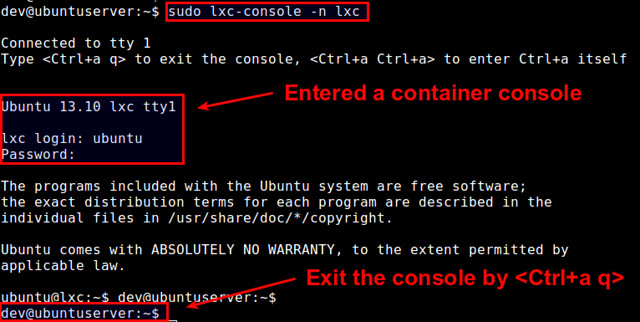
|
||||
|
||||
Type <Ctrl+a q> to exit the console.
|
||||
|
||||
To stop and destroy a container:
|
||||
|
||||
$ sudo lxc-stop -n <container-name>
|
||||
$ sudo lxc-destroy -n <container-name>
|
||||
|
||||
To clone an existing container to another, use these commands:
|
||||
|
||||
$ sudo lxc-stop -n <container-name>
|
||||
$ sudo lxc-clone -o <container-name> -n <new-container-name>
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
For those of you who encounter errors with LXC, here are some troubleshooting tips.
|
||||
|
||||
1. You fail to create an LXC container with the following error.
|
||||
|
||||
$ sudo lxc-create -n test-lxc -t ubuntu
|
||||
|
||||
----------
|
||||
|
||||
lxc-create: symbol lookup error: /usr/lib/x86_64-linux-gnu/liblxc.so.1: undefined symbol: cgmanager_get_pid_cgroup_abs_sync
|
||||
|
||||
This means that you are running the latest LXC, but with an older libcgmanager. To fix this problem, you need to update libcgmanager.
|
||||
|
||||
$ sudo apt-get install libcgmanager0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/lxc-containers-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/docker-containers-centos-fedora.html
|
||||
[2]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
|
||||
@ -0,0 +1,155 @@
|
||||
翻译中 by coloka
|
||||
How to Debug CPU Regressions Using Flame Graphs
|
||||
================================================================================
|
||||
How quickly can you debug a CPU performance regression? If your environment is complex and changing quickly, this becomes challenging with existing tools. If it takes a week to root cause a regression, the code may have changed multiple times, and now you have new regressions to debug.
|
||||
|
||||
Debugging CPU usage is easy in most cases, thanks to [CPU flame graphs][1]. To debug regressions, I would load before and after flame graphs in separate browser tabs, and then blink between them like searching for [Pluto][2]. It got the job done, but I wondered about a better way.
|
||||
|
||||
Introducing **red/blue differential flame graphs**:
|
||||
|
||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg" type="image/svg+xml" width=720 height=296>
|
||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg" width=720 />
|
||||
</object></p>
|
||||
|
||||
This is an interactive SVG (direct [link][3]). The color shows **red for growth**, and **blue for reductions**.
|
||||
|
||||
The size and shape of the flame graph is the same as a CPU flame graph for the second profile (y-axis is stack depth, x-axis is population, and the width of each frame is proportional to its presence in the profile; the top edge is what's actually running on CPU, and everything beneath it is ancestry.)
|
||||
|
||||
In this example, a workload saw a CPU increase after a system update. Here's the CPU flame graph ([SVG][4]):
|
||||
|
||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" type="image/svg+xml" width=720 height=296>
|
||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" width=720 />
|
||||
</object></p>
|
||||
|
||||
Normally, the colors are picked at random to differentiate frames and towers. Red/blue differential flame graphs use color to show the difference between two profiles.
|
||||
|
||||
The deflate_slow() code and children were running more in the second profile, highlighted earlier as red frames. The cause was that ZFS compression was enabled in the system update, which it wasn't previously.
|
||||
|
||||
While this makes for a clear example, I didn't really need a differential flame graph for this one. Imagine tracking down subtle regressions, of less than 5%, and where the code is also more complex.
|
||||
|
||||
### Red/Blue Differential Flame Graphs ###
|
||||
|
||||
I've had many discussions about this for years, and finally wrote an implementation that I hope makes sense. It works like this:
|
||||
|
||||
1. Take stack profile 1.
|
||||
1. Take stack profile 2.
|
||||
1. Generate a flame graph using 2. (This sets the width of all frames using profile 2.)
|
||||
1. Colorize the flame graph using the "2 - 1" delta. If a frame appeared more times in 2, it is red, less times, it is blue. The saturation is relative to the delta.
|
||||
|
||||
The intent is for use with before & after profiles, such as for **non-regression testing** or benchmarking code changes. The flame graph is drawn using the "after" profile (such that the frame widths show the current CPU consumption), and then colorized by the delta to show how we got there.
|
||||
|
||||
The colors show the difference that function directly contributed (eg, being on-CPU), not its children.
|
||||
|
||||
### Generation ###
|
||||
|
||||
I've pushed a simple implementation to github (see [FlameGraph][5]), which includes a new program, difffolded.pl. To show how it works, here are the steps using Linux [perf_events][6] (you can use other profilers).
|
||||
|
||||
#### Collect profile 1: ####
|
||||
|
||||
# perf record -F 99 -a -g -- sleep 30
|
||||
# perf script > out.stacks1
|
||||
|
||||
#### Some time later (or after a code change), collect profile 2: ####
|
||||
|
||||
# perf record -F 99 -a -g -- sleep 30
|
||||
# perf script > out.stacks2
|
||||
|
||||
#### Now fold these profile files, and generate a differential flame graph: ####
|
||||
|
||||
$ git clone --depth 1 http://github.com/brendangregg/FlameGraph
|
||||
$ cd FlameGraph
|
||||
$ ./stackcollapse-perf.pl ../out.stacks1 > out.folded1
|
||||
$ ./stackcollapse-perf.pl ../out.stacks2 > out.folded2
|
||||
$ ./difffolded.pl out.folded1 out.folded2 | ./flamegraph.pl > diff2.svg
|
||||
|
||||
difffolded.pl operates on the "folded" style of stack profiles, which are generated by the stackcollapse collection of tools (see the files in [FlameGraph][7]). It emits a three column output, with the folded stack trace and two value columns, one for each profile. Eg:
|
||||
|
||||
func_a;func_b;func_c 31 33
|
||||
[...]
|
||||
|
||||
This would mean the stack composed of "func_a()->func_b()->func_c()" was seen 31 times in profile 1, and in 33 times in profile 2. If flamegraph.pl is handed this three column input, it will automatically generate a red/blue differential flame graph.
|
||||
|
||||
### Options ###
|
||||
|
||||
Some options you'll want to know about:
|
||||
|
||||
**difffolded.pl -n**: This normalizes the first profile count to match the second. If you don't do this, and take profiles at different times of day, then all the stack counts will naturally differ due to varied load. Everything will look red if the load increased, or blue if load decreased. The -n option balances the first profile, so you get the full red/blue spectrum.
|
||||
|
||||
**difffolded.pl -x**: This strips hex addresses. Sometimes profilers can't translate addresses into symbols, and include raw hex addresses. If these addresses differ between profiles, then they'll be shown as differences, when in fact the executed function was the same. Fix with -x.
|
||||
|
||||
**flamegraph.pl --negate**: Inverts the red/blue scale. See the next section.
|
||||
|
||||
### Negation ###
|
||||
|
||||
While my red/blue differential flame graphs are useful, there is a problem: if code paths vanish completely in the second profile, then there's nothing to color blue. You'll be looking at the current CPU usage, but missing information on how we got there.
|
||||
|
||||
One solution is to reverse the order of the profiles and draw a negated flame graph differential. Eg:
|
||||
|
||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-negated.svg" type="image/svg+xml" width=720 height=296>
|
||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-negated.svg" width=720 />
|
||||
</object></p>
|
||||
|
||||
Now the widths show the first profile, and the colors show what will happen. The blue highlighting on the right shows we're about to spend a lot less time in the CPU idle path. (Note that I usually filter out cpu_idle from the folded files, by including a grep -v cpu_idle.)
|
||||
|
||||
This also highlights the vanishing code problem (or rather, doesn't highlight), as since compression wasn't enabled in the "before" profile, there is nothing to color red.
|
||||
|
||||
This was generated using:
|
||||
|
||||
$ ./difffolded.pl out.folded2 out.folded1 | ./flamegraph.pl --negate > diff1.svg
|
||||
|
||||
Which, along with the earlier diff2.svg, gives us:
|
||||
|
||||
- **diff1.svg**: widths show the before profile, colored by what WILL happen
|
||||
- **diff2.svg**: widths show the after profile, colored by what DID happen
|
||||
|
||||
If I were to automate this for non-regression testing, I'd generate and show both side by side.
|
||||
|
||||
### CPI Flame Graphs ###
|
||||
|
||||
I first used this code for my [CPI flame graphs][8], where instead of doing a difference between two profiles, I showed the difference between CPU cycles and stall cycles, which highlights what the CPUs were doing.
|
||||
|
||||
### Other Differential Flame Graphs ###
|
||||
|
||||
[][9]
|
||||
|
||||
There's other ways flame graph differentials can be done. [Robert Mustacchi][10] experimented with [differentials][11] a while ago, and used an approach similar to a colored code review: only the difference is shown, colored red for added (increased) code paths, and blue for removed (decreased) code paths. The key difference is that the frame widths are now relative to the size of the difference only. An example is on the right. It's a good idea, but in practice I found it a bit weird, and hard to follow without the bigger picture context: a standard flame graph showing the full profile.
|
||||
|
||||
[][12]
|
||||
|
||||
Cor-Paul Bezemer has created [flamegraphdiff][13], which shows the profile difference using three flame graphs at the same time: the standard before and after flame graphs, and then a differential flame graph where the widths show the difference. See the [example][14]. You can mouse-over frames in the differential, which highlights frames in all profiles. This solves the context problem, since you can see the standard flame graph profiles.
|
||||
|
||||
My red/blue flame graphs, Robert's hue differential, and Cor-Paul's triple-view, all have their strengths. These could be combined: the top two flame graphs in Cor-Paul's view could be my diff1.svg and diff2.svg. Then the bottom flame graph colored using Robert's approach. For consistency, the bottom flame graph could use the same palette range as mine: blue->white->red.
|
||||
|
||||
Flame graphs are spreading, and are now used by many companies. I wouldn't be surprised if there were already other implementations of flame graph differentials I didn't know about. (Leave a comment!)
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
If you have problems with performance regressions, red/blue differential flame graphs may be the quickest way to find the root cause. These take a normal flame graph and then use colors to show the difference between two profiles: red for greater samples, and blue for fewer. The size and shape of the flame graph shows the current ("after") profile, so that you can easily see where the samples are based on the widths, and then the colors show how we got there: the profile difference.
|
||||
|
||||
These differential flame graphs could also be generated by a nightly non-regression test suite, so that performance regressions can be quickly debugged after the fact.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/60160
|
||||
[1]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[2]:http://en.wikipedia.org/wiki/Planets_beyond_Neptune#Discovery_of_Pluto
|
||||
[3]:http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg
|
||||
[4]:http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg
|
||||
[5]:https://github.com/brendangregg/FlameGraph
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:https://github.com/brendangregg/FlameGraph
|
||||
[8]:http://www.brendangregg.com/blog/2014-10-31/cpi-flame-graphs.html
|
||||
[9]:http://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs/167
|
||||
[10]:http://dtrace.org/blogs/rm
|
||||
[11]:http://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs/167
|
||||
[12]:https://github.com/corpaul/flamegraphdiff
|
||||
[13]:http://corpaul.github.io/flamegraphdiff/
|
||||
[14]:http://corpaul.github.io/flamegraphdiff/demos/dispersy/dispersy_diff.html
|
||||
@ -0,0 +1,65 @@
|
||||
disylee来翻译
|
||||
How to Remove Music Players from Ubuntu Sound Menu
|
||||
================================================================================
|
||||

|
||||
|
||||
**Since its introduction back in 2010, the Ubuntu Sound Menu has proven to be one of the most popular and unique features of the Unity desktop.**
|
||||
|
||||
Allowing music players to integrate with the volume applet – i.e., where one would expect to find sound-related tomfoolery – through a standard interface is inspired. One wonders why other operating systems haven’t followed suit!
|
||||
|
||||
#### Overstuffed ####
|
||||
|
||||
Handy though it may be there is a “problem” with the applet as it currently exists: pretty much anything that so much as looks at an MP3 can, should it want, lodge itself inside. While useful, an omnipresent listing for apps you have installed but don’t use that often is annoying and unsightly.
|
||||
|
||||
I’m going to wager that the screenshot above looks familiar to a great many of you reading this! Never fear, **dconf-editor** is here.
|
||||
|
||||
### Remove Players from Ubuntu Sound Menu ###
|
||||
|
||||
#### Part One: Basics ####
|
||||
|
||||
The quickest and easiest way to remove entries from the Sound Menu is to uninstall the apps afflicting it. But that’s extreme; as I said, you may want the app, just not the integration.
|
||||
|
||||
To remove players without ditching the apps we need to use a scary looking tool called dconf-editor.
|
||||
|
||||
You may have it installed already, but if you don’t you’ll find it in the Ubuntu Software Center waiting.
|
||||
|
||||
- [Click to Install Dconf-Editor in Ubuntu][1]
|
||||
|
||||
Once installed, head to the Unity Dash to open it. Don’t panic when it opens; you’ve not been shunted back to the 2002, it’s supposed to look like that.
|
||||
|
||||
Using the left-hand sidebar you need to navigate to com > canonical > indicator > sound. The following pane will appear.
|
||||
|
||||
|
||||
|
||||
Double click on the closed brackets next to interested-media-players and delete the players you wish to remove from the Sound Menu, but leave in the square brackets and don’t delete any commas or apostrophes from items you wish to keep.
|
||||
|
||||
For example, I removed ‘**rhythmbox.desktop**’, ‘**pithos.desktop**’, ‘**clementine.desktop**’, to leave a line that reads:
|
||||
|
||||
['tomahawk.desktop']
|
||||
|
||||
Now, when I open the Sound menu I only see Tomahawk:
|
||||
|
||||

|
||||
|
||||
#### Part Two: Blacklisting ####
|
||||
|
||||
Wait! Don’t close dconf-editor yet. While the steps above makes things look nice and tidy some players will instantly re-add themselves to the sound menu when opened. To avoid having to repeat the process add them to the **blacklisted-media-player** section.
|
||||
|
||||
Remember to enclose each player in apostrophes with a comma separating multiple entries. They must also be inside the square brackets — so double check before exiting.
|
||||
|
||||
The net result:
|
||||
|
||||
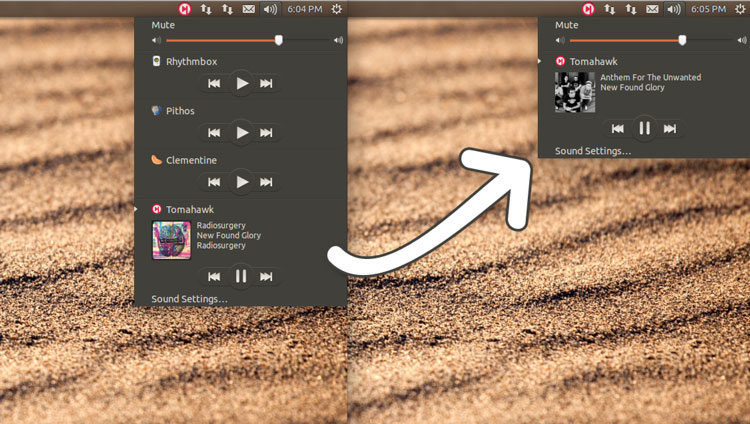
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/11/remove-players-ubuntu-sound-menu
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://dconf-editor
|
||||
@ -0,0 +1,91 @@
|
||||
How To Use Emoji Anywhere With Twitter's Open Source Library
|
||||
================================================================================
|
||||
> Embed them in webpages and other projects via GitHub.
|
||||
|
||||

|
||||
|
||||
Emoji, tiny characters from Japan that convey emotions through images, have already conquered the world of cellphone text messaging.
|
||||
|
||||
Now, you can post them everywhere else in the virtual world, too. Twitter has just [open-sourced][1] its emoji library so you can use them for your own websites, apps, and projects.
|
||||
|
||||
This will require a little bit of heavy lifting. Unicode has recognized and even standardized the emoji alphabet, but emoji still [aren’t fully compliant with all Web browsers][2], meaning they'll show up as “tofu,” or blank boxes, most of the time. When Twitter wanted to make emoji available, the social network teamed up with a company called [Icon Factory][3] to render browser imitations of the text message symbols. As a result, Twitter says there’s been lots of demand for access to its emoji.
|
||||
|
||||
Now, you can clone Twitter’s entire library on [GitHub][4] to use in your development projects. Here’s how to do that, and how to make emoji easier to use after you do.
|
||||
|
||||
### Obtain Unicode Support For Emoji ###
|
||||
|
||||
Unicode is an international encoding standard that assigns a string of characters to any symbol, letter, or digit people want to use online. In other words, it’s the missing link between how you read text on a computer, and how the computer reads text. For example, while you are looking at an empty space between these words, the computer sees “&mbsp.”
|
||||
|
||||
Unicode even has its own [primitive emoji][5] that can be read in the browser without any effort on your part. For example while you see a ♥, your computer is decoding the string “2665.”
|
||||
|
||||
To use Twitter’s emoji library in most cases, you simply need to add a script inside the <head> section of your HTML page:
|
||||
|
||||
<script src="//twemoji.maxcdn.com/twemoji.min.js"></script>
|
||||
|
||||
This grants your project access to the JavaScript library that contains the hundreds of emoji that work on Twitter. However, creating a document with simply this script isn’t going to make emoji appear on your site. You also need to actually insert some emoji!
|
||||
|
||||
In the <body> section, paste a few of the emoji strings you can find in Twitter’s [preview.html source code][6]. I used 🎹 and 🏁 without really knowing how they'd appear in the browser window. Yeah, you’ll have to just paste and guess. You can already see the problem we're going to fix in section two.
|
||||
|
||||
However, through some trial and error, you can turn a raw HTML file that looks like this—
|
||||
|
||||

|
||||
|
||||
—into a webpage that looks something like this:
|
||||
|
||||

|
||||
|
||||
### Convert Emoji Into Readable Language ###
|
||||
|
||||
Twitter’s solution is all well and good for making a site or app emoji compliant. But if you want to be able to easily insert your favorite emoji at will via HTML, you’re going to need an easier solution than memorizing all those Unicode strings.
|
||||
|
||||
That’s where programmer Elle Kasai’s [Twemoji Awesome][7] styles come in.
|
||||
|
||||
By adding Elle’s open-source stylesheet to any webpage, you can use English words to understand which emoji you’re inserting. So if you want a heart emoji to show up, you can simply type this :
|
||||
|
||||
<i class="twa twa-heart"></i>
|
||||
|
||||
In order to do this, let’s download Elle’s project with the “Download ZIP” button on GitHub.
|
||||
|
||||
Next, let’s make a new folder on the desktop. Inside this folder, we’ll put emoji.html—the raw HTML file I showed you before, and also Elle’s [twemoji-awesome.css][8].
|
||||
|
||||
We’ll need the HTML file to acknowledge the CSS file, so in the <head> section of the html page you’ll want to add a link from the css file:
|
||||
|
||||
<link rel="stylesheet" href="twemoji-awesome.css">
|
||||
|
||||
Once you put this in, you can delete Twitter's script from before. Elle's styles each link to the Unicode string for the relevant emoji, so you no longer have to.
|
||||
|
||||
Now, go down to the body section and add a few emoji. I used <i class="twa twa-sparkling-heart"></i>, <i class="twa twa-exclamation"></i>, <i class="twa twa-lg twa-sparkles"></i> and <i class="twa twa-beer"></i>.
|
||||
|
||||
You'll end up with something like this:
|
||||
|
||||

|
||||
|
||||
Save and view your creation in the browser:
|
||||
|
||||

|
||||
|
||||
Ta-da! Not only have you gotten a basic webpage to support emoji in the browser, you’ve also made it easy to do. Feel free to check out this tutorial on [my GitHub][9] for actual files you can clone instead of screenshots.
|
||||
|
||||
Lead image via [Get Emoji][10]; screenshots by Lauren Orsini
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://readwrite.com/2014/11/12/how-to-use-emoji-in-the-browser-window
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://readwrite.com/author/lauren-orsini
|
||||
[1]:https://blog.twitter.com/2014/open-sourcing-twitter-emoji-for-everyone
|
||||
[2]:http://www.unicode.org/reports/tr51/full-emoji-list.html
|
||||
[3]:https://twitter.com/iconfactory
|
||||
[4]:https://github.com/twitter/twemoji
|
||||
[5]:http://www.unicode.org/reports/tr51/full-emoji-list.html
|
||||
[6]:https://github.com/twitter/twemoji/blob/gh-pages/preview.html
|
||||
[7]:http://ellekasai.github.io/twemoji-awesome/
|
||||
[8]:https://github.com/ellekasai/twemoji-awesome/blob/gh-pages/twemoji-awesome.css
|
||||
[9]:https://github.com/laurenorsini/Emoji-Everywhere
|
||||
[10]:http://getemoji.com/
|
||||
@ -0,0 +1,155 @@
|
||||
How to perform system backup with backup-manager on Linux
|
||||
================================================================================
|
||||
One thing that we all may have had the chance to learn in either easy or hard ways is that the importance of backups can never be underestimated. Considering that there are as many backup methods as the number of fish in the sea, you may wonder how you can effectively choose the right tool and strategy for your system.
|
||||
|
||||
In this article I will introduce you to [backup-manager][1], a simple yet handy command-line backup tool which is available in the standard repositories of most Linux distributions.
|
||||
|
||||
What makes backup-manager stand out among other backup tools or strategies? Let me mention just a few of its distinguishing features:
|
||||
|
||||
|
||||
- **Simple design and management**: configuration file is easy to read and edit, even for beginners.
|
||||
- **Set and forget**: can be scheduled to run through cron on a periodic basis.
|
||||
- **Multi-protocol support for remote backup**: integrates seamlessly with various transfer protocols, applications and cloud backend (e.g., FTP, SCP, SSH-GPG, rsync, AWS S3) to transfer generated archives to a list of remote hosts.
|
||||
- **Database backup support**: includes out-of-the-box support for backing up MySQL/MariaDB and PostgreSQL databases.
|
||||
- **Encryption support**: supports GPG-based file encryption during backup.
|
||||
|
||||
### Installing Backup-Manager on Linux ###
|
||||
|
||||
Installation of backup-manager is quick and effortless since it is included in the base repositories of most Linux distributions.
|
||||
|
||||
#### Debian, Ubuntu and their derivatives ####
|
||||
|
||||
# aptitude install backup-manager
|
||||
|
||||
During the installation process on Debian-based systems, you will be prompted to enter the directory where you want to store generated backup archives. If the chosen directory does not exist, it will be created automatically when you run backup-manager for the first time.
|
||||
|
||||
Select OK and press ENTER.
|
||||
|
||||

|
||||
|
||||
In the next step, you will be asked to enter all the directories (separated by space) that you want to be backed up. It is advised, though not strictly required, to list several sub-directories of the same parent directory instead of entering only the parent directory.
|
||||
|
||||
You can skip this step and configure the list of directories later using the variable BM_TARBALL_DIRECTORIES in the configuration file. Otherwise, feel free to add as many directories as you wish, and then choose OK:
|
||||
|
||||
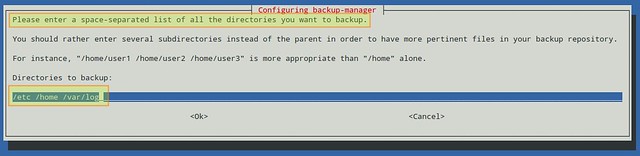
|
||||
|
||||
#### Fedora or CentOS/RHEL ####
|
||||
|
||||
# yum install backup-manager
|
||||
|
||||
On CentOS/RHEL, you will need to enable [EPEL repository][2] first before running the above yum command.
|
||||
|
||||
### Configuring Backup-Manager ###
|
||||
|
||||
The main configuration file for backup-manager is /etc/backup-manager.conf. This file is divided into sections where the backup methods and their associated variables (or "keys") are defined, making backup-manager a versatile tool that can be used in a wide variety of cases.
|
||||
|
||||
For demonstration purposes, we will consider the following scenario:
|
||||
|
||||
- Perform a full system backup of the /etc, /home, and /var/log directories on a weekly basis (we will set up the frequency later through cron).
|
||||
- Transfer generated .tar.gz backup archives to a specific target directory in two different hosts, dev1 and dev3, over SSH.
|
||||
- Back up a local MySQL database to the same destination hosts over SSH.
|
||||
|
||||
Open /etc/backup-manager.conf with your favorite text editor and edit the following variables. Feel free to disregard the lines beginning with # if you want. They are provided only as explanatory comments in this article:
|
||||
|
||||
# Specify the backup method(s) that will be used.
|
||||
# tarball: takes a list of directories and builds the corresponding tarballs.
|
||||
# mysql: archives MySQL databases using mysqldump. To restore the database, you # need to use the same tool manually.
|
||||
export BM_ARCHIVE_METHOD="tarball mysql"
|
||||
|
||||
# Where to store the backups.
|
||||
export BM_REPOSITORY_ROOT="/var/archives"
|
||||
|
||||
# The following directive indicates backup-manager to name
|
||||
# the generated files after the directory that was backed up.
|
||||
export BM_TARBALL_NAMEFORMAT="long"
|
||||
|
||||
# Define the compression type for the generated files.
|
||||
export BM_TARBALL_FILETYPE="tar.gz"
|
||||
|
||||
# List the directories that you want to backup.
|
||||
export BM_TARBALL_DIRECTORIES="/etc /home /var/log"
|
||||
|
||||
# Exclude some subdirectories or file extensions.
|
||||
export BM_TARBALL_BLACKLIST="/var/log/myotherapp.log *.mp3 *.mp4"
|
||||
|
||||
# List the database(s) that you want to backup, separated by spaces.
|
||||
export BM_MYSQL_DATABASES="mysql mybase wordpress dotclear phpbb2"
|
||||
|
||||
# MySQL username.
|
||||
export BM_MYSQL_ADMINLOGIN="root"
|
||||
|
||||
# MySQL password for username.
|
||||
export BM_MYSQL_ADMINPASS="mypassword"
|
||||
|
||||
# Add support for DROP statements (optional).
|
||||
export BM_MYSQL_SAFEDUMPS="true"
|
||||
|
||||
# The hostname or IP address where the database(s) reside.
|
||||
export BM_MYSQL_HOST="localhost"
|
||||
|
||||
# Port where MySQL server is listening.
|
||||
export BM_MYSQL_PORT="3306"
|
||||
|
||||
# Compression type (optional).
|
||||
export BM_MYSQL_FILETYPE="gzip"
|
||||
|
||||
# Do not archive remote hosts, but only localhost.
|
||||
BM_TARBALL_OVER_SSH="false"
|
||||
|
||||
# User account for SSH upload.
|
||||
export BM_UPLOAD_SSH_USER="root"
|
||||
|
||||
# Absolute path of the user's private key for passwordless SSH login.
|
||||
export BM_UPLOAD_SSH_KEY="/root/.ssh/id_rsa"
|
||||
|
||||
# Remote hosts (make sure you have exported your public key to them):
|
||||
export BM_UPLOAD_SSH_HOSTS="dev1 dev3"
|
||||
|
||||
# Remote destination for uploading backups. If it doesn't exist,
|
||||
# this directory will be created automatically the first time
|
||||
# backup-manager runs.
|
||||
export BM_UPLOAD_SSH_DESTINATION="/var/archives/backups/$HOSTNAME"
|
||||
|
||||
### Running Backup-Manager ###
|
||||
|
||||
To run backup-manager manually, type the following command. Optionally, you can add the '-v' flag in order to examine the process step by step, in a verbose way.
|
||||
|
||||
# backup-manager
|
||||
|
||||
The directories listed in BM_TARBALL_DIRECTORIES will be backed up in BM_REPOSITORY_ROOT as tarballs, and then transferred over SSH to hosts dev1 and dev3 specified in BM_UPLOAD_SSH_DESTINATION.
|
||||
|
||||

|
||||
|
||||
As can be seen in the above image, backup-manager during runtime creates a file named /root/.backup-manager_my.cnf with the MySQL password provided in BM_MYSQL_ ADMINPASS. That way, mysqldump can authenticate to a MySQL server without having to accept login password through the command line in plain-text format, which poses a security risk.
|
||||
|
||||
### Running Backup-Manager through Cron ###
|
||||
|
||||
Once you have decided what is the best day of the week (and the best time) to perform your weekly backup, you can have cron run backup-manager for you.
|
||||
|
||||
Open root's crontab file (note that you must be logged on as root):
|
||||
|
||||
# crontab -e
|
||||
|
||||
Assuming that you want to run backup-manager on Sunday at 5:15 am, add the following line.
|
||||
|
||||
15 05 * * 0 /usr/sbin/backup-manager > /dev/null 2>&1
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have shown how backup-manager is a simple, yet powerful and easy-to-use backup tool. There are several other options that you may want to consider in your backup strategy, so feel free to refer to the man page or to the user guide, which also contains several implementation examples and advice.
|
||||
|
||||
Hope it helps. Feel free to leave your questions and comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/linux-backup-manager.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:https://github.com/sukria/Backup-Manager
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,214 @@
|
||||
wangjiezhe translating...
|
||||
|
||||
What are some obscure but useful Vim commands
|
||||
================================================================================
|
||||
If my [latest post on the topic][1] did not tip you off, I am a Vim fan. So before some of you start stoning me, let me present you a list of "obscure Vim commands." What I mean by that is: a collection of commands that you might have not encountered before, but that might be useful to you. As a second disclaimer, I do not know which commands you might know and which one you find useful. So this list really is a collection of relatively less known Vim commands, but which can still probably be useful.
|
||||
|
||||
### Saving a file and exiting ###
|
||||
|
||||
I am a bit ashamed of myself for that one, but I only recently learned that the command
|
||||
|
||||
:x
|
||||
|
||||
is equivalent to:
|
||||
|
||||
:wq
|
||||
|
||||
which is saving and quitting the current file.
|
||||
|
||||
### Basic calculator ###
|
||||
|
||||
While in insert mode, you can press Ctrl+r then type '=' followed by a simple calculation. Press ENTER, and the result will be inserted in the document. For example, try:
|
||||
|
||||
Ctrl+r '=2+2' ENTER
|
||||
|
||||
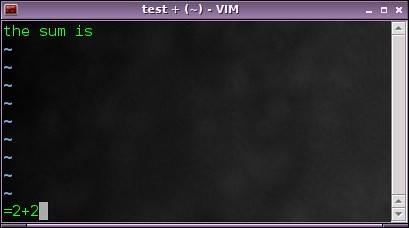
|
||||
|
||||
And 4 will be inserted in the document.
|
||||
|
||||
### Finding duplicate consecutive words ###
|
||||
|
||||
When you type something quickly, it happens that you write a word twice in a row. Just like this this. This kind of error can fool anyone, even when re-reading yourself. Hopefully, there is a simple regular expression to prevent this. Use the search ('/' by default) and type:
|
||||
|
||||
\(\<\w\+\>\)\_s*\1
|
||||
|
||||
This should display all the duplicate words. And for maximum effect, don't forget to place:
|
||||
|
||||
set hlsearch
|
||||
|
||||
in your .vimrc file to highlight all search hits.
|
||||
|
||||

|
||||
|
||||
### Abbreviations ###
|
||||
|
||||
Probably one of the most impressive tricks, you can define abbreviations in Vim, which will replace what you type with somethig else in real time. The syntax is the following:
|
||||
|
||||
:ab [abbreviation] [what to replace it with]
|
||||
|
||||
The generic example is:
|
||||
|
||||
:ab asap as soon as possible
|
||||
|
||||
Which will replace "asap" with "as soon as possible" as you write.
|
||||
|
||||
### Save a file that you forgot to open as root ###
|
||||
|
||||
This is maybe an all time favorite in the forums. Whenever you open a file that you do not have permission to write to (say a system configuration file for example) and make some changes, Vim will not save them with the normal command: ':w'
|
||||
|
||||
Instead of redoing the changes after opening it again as root, simply run:
|
||||
|
||||
:w !sudo tee %
|
||||
|
||||
Which will save it as root directly.
|
||||
|
||||
### Crypt your text on the go ###
|
||||
|
||||
If you do not want someone to be able to read whatever is on your screen, Vim has the built in option to [ROT13][2]-encode your text with the following command:
|
||||
|
||||
ggVGg?
|
||||
|
||||

|
||||
|
||||
'gg' for moving the cursor to the first line of the Vim buffer, 'V' for entering visual mode, and 'G' for moving the cursor to the last line of the buffer. So 'ggVG' will make the visual mode cover the entire buffer. Finally 'g?' applies ROT13 encoding to the selected region.
|
||||
|
||||
Notice that this should be mapped to a key for maximum efficiency. It also works best with alphabetical characters. And to undo it, the best is simply to use the undo command: 'u'
|
||||
|
||||
### Auto-completion ###
|
||||
|
||||
Another one to be ashamed of, but I see a lot of people around me not knowing it. Vim has by default an auto-completion features. Yes it is very basic, and can be enhanced by plugins, but it can still help you. The process is simple. Vim can try to guess the end of your word based on the word you wrote earlier. If you are typing the word "compiler" for the second time in the same file for example, just start typing "com" and still in insertion mode, press Ctrl+n to see Vim finish your word for you. Simple but handy.
|
||||
|
||||
### Look at the diff between two files ###
|
||||
|
||||
Probably a lot of you know about vimdiff command, which allows you to open Vim in split mode and compare two files with the syntax:
|
||||
|
||||
$ vimdiff [file1] [file2]
|
||||
|
||||
But the same result is achievable with the Vim command:
|
||||
|
||||
:diffthis
|
||||
|
||||
First open your initial file in Vim. Then open the second one in split mode with:
|
||||
|
||||
:vsp [file2]
|
||||
|
||||
Finally launch:
|
||||
|
||||
:diffthis
|
||||
|
||||
in the first buffer, switch buffer with Ctrl+w and type:
|
||||
|
||||
:diffthis
|
||||
|
||||
again.
|
||||
|
||||
The two files will then be highlighted with focus on their differences.
|
||||
|
||||
To turn the diff off, simply use:
|
||||
|
||||
:diffoff
|
||||
|
||||
### Revert the document in time ###
|
||||
|
||||
Vim keeps track of the changes you make to a file, and can easily revert it to what it was earlier in time. The command is quite intuitive. For example:
|
||||
|
||||
:earlier 1m
|
||||
|
||||
will revert the document to what it was a minute ago.
|
||||
|
||||
Note that you can inverse this with the command:
|
||||
|
||||
:later
|
||||
|
||||
### Delete inside markers ###
|
||||
|
||||
Something that I always wanted to be comfortable doing when I started using Vim: easily delete text between brackets or parenthesis. Go to the first marker and simply use the syntax:
|
||||
|
||||
di[marker]
|
||||
|
||||
So for example, deleting between parenthesis would be:
|
||||
|
||||
di(
|
||||
|
||||
once your cursor is on the first parenthesis. For brackets or quotation marks, it would be:
|
||||
|
||||
di{
|
||||
|
||||
and:
|
||||
|
||||
di"
|
||||
|
||||
### Delete until a specific maker ###
|
||||
|
||||
A bit similar to deleting inside a marker but for different purpose, the command:
|
||||
|
||||
dt[marker]
|
||||
|
||||
will delete everything in between your cursor and the marker (leaving it safe) if the marker is found on the same line. For example:
|
||||
|
||||
dt.
|
||||
|
||||
will delete the end of your sentence, leaving the '.' intact.
|
||||
|
||||
### Turn Vim into a hex editor ###
|
||||
|
||||
This is not my favorite trick, but some might find it interesting. You can chain Vim and the xxd utility to convert the text into hexadecimal with the command:
|
||||
|
||||
:%!xxd
|
||||
|
||||
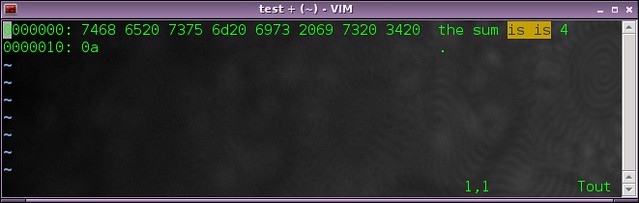
|
||||
|
||||
And similarly, you can revert this with:
|
||||
|
||||
:%!xxd -r
|
||||
|
||||
### Place the text under your cursor in the middle of the screen ###
|
||||
|
||||
Everything is in the title. If you want to force the screen to scroll and place whatever is under your cursor in the middle, use the command:
|
||||
|
||||
zz
|
||||
|
||||
in visual mode.
|
||||
|
||||
### Jump to previous/next position ###
|
||||
|
||||
When editing a very big file, it is frequent to make changes somewhere, and jump to another place right after. If you wish to jump back simply, use:
|
||||
|
||||
Ctrl+o
|
||||
|
||||
to go back to where you were.
|
||||
|
||||
And similarly:
|
||||
|
||||
Ctrl+i
|
||||
|
||||
will revert such jump back.
|
||||
|
||||
### Render the current file as a web page ###
|
||||
|
||||
This will generate an HTML page displaying your text, and show the code in a split screen:
|
||||
|
||||
:%Tohtml
|
||||
|
||||

|
||||
|
||||
Very basic but so fancy.
|
||||
|
||||
To conclude, this list was assembled after reading some various forum threads and the [Vim Tips wiki][3], which I really recommend if you want to boost your knowledge about the editor.
|
||||
|
||||
If you know any Vim command that you find useful and that you think most people do not know about, feel free to share it in the comments. As said in the introduction, an "obscure but useful" command is very subjective, but sharing is always good.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/useful-vim-commands.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/turn-vim-full-fledged-ide.html
|
||||
[2]:https://en.wikipedia.org/wiki/ROT13
|
||||
[3]:http://vim.wikia.com/wiki/Vim_Tips_Wiki
|
||||
@ -1,4 +1,4 @@
|
||||
Linux有问必答——如何修复“sshd error: could not load host key”
|
||||
Linux有问必答:如何修复“sshd error: could not load host key”
|
||||
================================================================================
|
||||
> **问题**:当我尝试SSH到一台远程服务器时,SSH客户端登陆失败并提示“Connection closed by X.X.X.X”。在SSH服务器那端,我看到这样的错误消息:“sshd error: could not load host key.”。这发生了什么问题,我怎样才能修复该错误?
|
||||
|
||||
@ -23,7 +23,7 @@ Linux有问必答——如何修复“sshd error: could not load host key”
|
||||
|
||||

|
||||
|
||||
如果SSH主机密钥在那里找不到,或者它们的大小被切短成为0(就像上面那样),你需要从头开始重新生成主机密钥。
|
||||
如果SSH主机密钥在那里找不到,或者它们的大小被截断成为0(就像上面那样),你需要从头开始重新生成主机密钥。
|
||||
|
||||
### 重新生成SSH主机密钥 ###
|
||||
|
||||
@ -58,6 +58,6 @@ Linux有问必答——如何修复“sshd error: could not load host key”
|
||||
via: http://ask.xmodulo.com/sshd-error-could-not-load-host-key.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,141 @@
|
||||
教你在 Ubuntu 上使用 LXC 容器
|
||||
================================================================================
|
||||
使用“容器”来保证主机环境的安全性,这个概念早在十年前就已经存在(例如 FreeBSD 的 jail 虚拟化技术),但是直到最近,随着部署云架构需求越来越多,像 LXC 和 [Docker][1] 这种 Linux 下的容器才成为被关注的焦点。当然,由于主流厂商(云供应商如亚马逊主推 AWS,微软主推 Azure;发行版如红帽、Ubuntu等)组成的强大靠山,[Docker][2] 已经被放在媒体的聚光灯下面,其实,Docker 里面所谓的“容器”技术是由 LXC 提供的。
|
||||
|
||||
你只是一个普通的 Linux 用户,那 Docker/LXC 能为你带来什么好处呢?容器可以将你的应用在不同的 Linux 发行版之间迁移。想像一下这个场景:你正在用的发行版是 Debian,你喜欢它的稳定性,同时你又想玩一款最新的 Ubuntu 游戏,你不需要在电脑上装双系统然后重启进入 Ubuntu,也不需要在 Debian 上跑一个耗资源的 Ubuntu 虚拟机,你只需要简单地生成一个 Ubuntu 容器就够了。
|
||||
|
||||
抛开 Docker 的好处不谈,让我们聊一下 LXC 容器的好处:我可以使用 libvirt 提供的接口来管理 LXC,这些接口和 Docker 没有任何关系。如果你有使用基于 libvirt 库的管理工具(例如 virt-manager 和 virsh),你就可以使用它们来管理 LXC 容器。
|
||||
|
||||
在这篇教程中,我只介绍标准 LXC 容器管理工具的命令行操作,来教你**如何在 Ubuntu 下创建和管理 LXC 容器**。
|
||||
|
||||
### Ubuntu 下安装 LXC ###
|
||||
|
||||
使用下面的命令安装 LXC 在用户态的工具:
|
||||
|
||||
$ sudo apt-get install lxc
|
||||
|
||||
然后检查当前内核是否支持 LXC。如果所有结果都是“enable”,说明内核支持:
|
||||
|
||||
$ lxc-checkconfig
|
||||
|
||||

|
||||
|
||||
安装完 LXC 工具后,就能看到 LXC 自动创建了一块桥接网卡(lxcbr0,在 /etc/lxc/default.conf 中设置)。
|
||||
|
||||

|
||||
|
||||
当你创建了 LXC 容器后,它的网口会自动链接到这个桥接网卡上,然后这个容器就能和外部世界通信了。
|
||||
|
||||
### 创建 LXC 容器 ###
|
||||
|
||||
为了在指定环境下(比如 Debian Wheezy 64位)创建 LXC 容器,你需要一个相应的 LXC 模板。幸运的是 LXC 提供的工具集成了一整套现成的 LXC 模板,你可以在 /usr/share/lxc/templates 目录下找到它们。
|
||||
|
||||
$ ls /usr/share/lxc/templates
|
||||
|
||||

|
||||
|
||||
一个 LXC 模板实质上就是一个脚本,用于创建指定环境下的容器。当你创建 LXC 容器时,你需要用到它们。
|
||||
|
||||
比如你要新建 Ubuntu 容器,使用下面的命令即可:
|
||||
|
||||
$ sudo lxc-create -n <container-name> -t ubuntu
|
||||
|
||||

|
||||
|
||||
默认情况下,这个命令会创建一个最小的 Ubuntu 环境,版本号与你的宿主机一致,我这边是“活泼的蝾螈”(版本号是13.10),64位。
|
||||
|
||||
当然你也可以创建任何你喜欢的版本,只要在命令里面加一个版本参数即可。举个例子,创建 Ubuntu 14.10 的容器:
|
||||
|
||||
$ sudo lxc-create -n <container-name> -t ubuntu -- --release utopic
|
||||
|
||||
这个命令就会下载安装指定环境下的软件包,创建新容器。整个过程需要几分钟时间,与容器的类型有关,所以,你可能需要耐心等待。
|
||||
|
||||

|
||||
|
||||
下载安装完所有软件包后,LXC 容器镜像就创建完成了,你可以看到默认的登录界面。容器被放到 /var/lib/lxc/<容器名> 这个目录下,容器的根文件系统放在 /var/lib/lxc/<容器名>/rootfs 目录下。
|
||||
|
||||
创建过程中下载的软件包保存在 /var/cache/lxc 目录下面,当你想另外建一个一样的容器时,可以省去很多下载时间。
|
||||
|
||||
用下面的命令看看主机上所有的 LXC 容器:
|
||||
|
||||
$ sudo lxc-ls --fancy
|
||||
|
||||
----------
|
||||
|
||||
NAME STATE IPV4 IPV6 AUTOSTART
|
||||
------------------------------------
|
||||
test-lxc STOPPED - - NO
|
||||
|
||||
使用下面的命令启动容器。参数“-d”将容器作为后台进程打开。如果没有指定这个参数,你可以在控制台界面上直接把容器的运行程序关闭(LCTT:Ctrl+C组合键)。
|
||||
|
||||
$ sudo lxc-start -n <container-name> -d
|
||||
|
||||
开容器后,看看状态:
|
||||
|
||||
$ sudo lxc-ls --fancy
|
||||
|
||||
----------
|
||||
|
||||
NAME STATE IPV4 IPV6 AUTOSTART
|
||||
-----------------------------------------
|
||||
lxc RUNNING 10.0.3.55 - NO
|
||||
|
||||
容器状态是“运行中”,容器 IP 是10.0.3.55。
|
||||
|
||||
你也可以看到容器的网络接口(比如我这里是 vethJ06SFL)自动与 LXC 内部网桥(lxcbr0)连上了:
|
||||
|
||||
$ brctl show lxcbr0
|
||||
|
||||

|
||||
|
||||
### 管理 LXC 容器 ###
|
||||
|
||||
我们已经学习了怎么创建和启动 LXC 容器,现在来看看怎么玩一个正在运行着的容器。
|
||||
|
||||
第一步:打开容器控制台:
|
||||
|
||||
$ sudo lxc-console -n <container-name>
|
||||
|
||||

|
||||
|
||||
使用“Crtl+a q”组合键退出控制台。
|
||||
|
||||
停止、删除容器:
|
||||
|
||||
$ sudo lxc-stop -n <container-name>
|
||||
$ sudo lxc-destroy -n <container-name>
|
||||
|
||||
复制容器,用下面的命令:
|
||||
|
||||
$ sudo lxc-stop -n <container-name>
|
||||
$ sudo lxc-clone -o <container-name> -n <new-container-name>
|
||||
|
||||
### 常见问题 ###
|
||||
|
||||
这个小节主要介绍你们在使用 LXC 过程中碰到过的问题。
|
||||
|
||||
1. 创建 LXC 容器时遇到下面的错误:
|
||||
|
||||
$ sudo lxc-create -n test-lxc -t ubuntu
|
||||
|
||||
----------
|
||||
|
||||
lxc-create: symbol lookup error: /usr/lib/x86_64-linux-gnu/liblxc.so.1: undefined symbol: cgmanager_get_pid_cgroup_abs_sync
|
||||
|
||||
错误的原因是你运行了最新的 LXC,但是它所依赖的 libcgmanager 版本较老,两者不兼容。升级下 libcmanager 即可解决问题:
|
||||
|
||||
$ sudo apt-get install libcgmanager0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/lxc-containers-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/docker-containers-centos-fedora.html
|
||||
[2]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
|
||||
@ -1,26 +1,25 @@
|
||||
Translating by ZTinoZ
|
||||
8 Tips to Solve Linux & Unix Systems Hard Disk Problmes Like Disk Full Or Can’t Write to the Disk
|
||||
磁盘写满或磁盘不可写?解决Linux和UNIX系统这些硬盘问题的8个小贴士
|
||||
================================================================================
|
||||
Can't write to the hard disk on a Linux or Unix-like systems? Want to diagnose corrupt disk issues on a server? Want to find out why you are getting "disk full" messages on screen? Want to learn how to solve full/corrupt and failed disk issues. Try these eight tips to diagnose a Linux and Unix server hard disk drive problems.
|
||||
不能在Linux或者类UNIX系统的硬盘上写入数据?想解决服务器上磁盘损坏的问题吗?想知道你为什么总是在屏幕上看到“磁盘已满”的字眼吗?想学习处理这些问题的办法吗?试试一下这8个解决Linux及UNIX服务器硬盘问题的小贴士吧。
|
||||
|
||||

|
||||
|
||||
### #1 - Error: No space left on device ###
|
||||
### #1 - 错误: 设备上无剩余空间 ###
|
||||
|
||||
When the Disk is full on Unix-like system you get an error message on screen. In this example, I'm running [fallocate command][1] and my system run out of disk space:
|
||||
当你的类UNIX系统磁盘写满了时你会在屏幕上看到这样的信息。本例中,我运行[fallocate命令][1]然后我的系统就会提示磁盘空间已经耗尽:
|
||||
|
||||
$ fallocate -l 1G test4.img
|
||||
fallocate: test4.img: fallocate failed: No space left on device
|
||||
|
||||
The first step is to run the df command to find out information about total space and available space on a file system including partitions:
|
||||
第一步是运行df命令来查看一个有分区的文件系统的总磁盘空间和可用空间的信息:
|
||||
|
||||
$ df
|
||||
|
||||
OR try human readable output format:
|
||||
或者试试可读性比较强的输出格式:
|
||||
|
||||
$ df -h
|
||||
|
||||
Sample outputs:
|
||||
部分输出内容:
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/sda6 117G 54G 57G 49% /
|
||||
@ -34,201 +33,200 @@ Sample outputs:
|
||||
/dev/sda8 94G 579M 89G 1% /ftpusers
|
||||
/dev/sda10 4.0G 4.0G 0 100% /ftpusers/tmp
|
||||
|
||||
From the df command output it is clear that /dev/sda10 has 4.0Gb of total space of which 4.0Gb is used.
|
||||
使用df命令输出可以清楚地发现,在 /dev/sda10 分区下总共4.0Gb的空间被全部写满了。
|
||||
|
||||
#### Fixing problem when the disk is full ####
|
||||
#### 修复磁盘写满的问题 ####
|
||||
|
||||
1.[Compress uncompressed log and other files][2] using gzip or bzip2 or tar command:
|
||||
1.[用gzip,bzip2或tar命令压缩未压缩的日志和其它文件][2]:
|
||||
|
||||
gzip /ftpusers/tmp/*.log
|
||||
bzip2 /ftpusers/tmp/large.file.name
|
||||
|
||||
2.Delete [unwanted files using rm command][3] on a Unix-like system:
|
||||
2.在类UNIX系统中[用rm命令删除不想要的文件][3]:
|
||||
|
||||
m -rf /ftpusers/tmp/*.bmp
|
||||
rm -rf /ftpusers/tmp/*.bmp
|
||||
|
||||
3.Move files to other [system or external hard disk using rsync command][4]:
|
||||
3.[用rsync命令移动文件至其它系统或外置硬盘][4]:
|
||||
|
||||
rsync --remove-source-files -azv /ftpusers/tmp/*.mov /mnt/usbdisk/
|
||||
rsync --remove-source-files -azv /ftpusers/tmp/*.mov server2:/path/to/dest/dir/
|
||||
|
||||
4.[Find out the largest directories or files eating disk space][5] on a Unix-like systesm:
|
||||
4.在类UNIX系统中[找出最占磁盘空间的目录或文件][5]:
|
||||
|
||||
du -a /ftpusers/tmp | sort -n -r | head -n 10
|
||||
du -cks * | sort -rn | head
|
||||
|
||||
5.[Truncate a particular file][6]. This is useful for log file:
|
||||
5.[清空指定文件][6]。这招对日志文件很有效:
|
||||
|
||||
truncate -s 0 /ftpusers/ftp.upload.log
|
||||
### bash/sh etc ##
|
||||
### bash/sh等 ##
|
||||
>/ftpusers/ftp.upload.log
|
||||
## perl ##
|
||||
perl -e'truncate "filename", LENGTH'
|
||||
|
||||
6.Find and remove large files that are open but have been deleted on Linux or Unix:
|
||||
6.在Linux和UNIX中找出并删除显示着但已经被删除的大文件:
|
||||
|
||||
## Works on Linux/Unix/OSX/BSD etc ##
|
||||
## 基于Linux/Unix/OSX/BSD等系统 ##
|
||||
lsof -nP | grep '(deleted)'
|
||||
|
||||
## Only works on Linux ##
|
||||
## 只基于Linux ##
|
||||
find /proc/*/fd -ls | grep '(deleted)'
|
||||
|
||||
To truncate it:
|
||||
清空它:
|
||||
|
||||
## works on Linux/Unix/BSD/OSX etc all ##
|
||||
## 基于Linux/Unix/OSX/BSD等所有系统 ##
|
||||
> "/path/to/the/deleted/file.name"
|
||||
## works on Linux only ##
|
||||
## 只基于Linux ##
|
||||
> "/proc/PID-HERE/fd/FD-HERE"
|
||||
|
||||
### #2 - Is the file system is in read-only mode? ###
|
||||
### #2 - 文件系统是只读模式吗? ###
|
||||
|
||||
You may end up getting an error such as follows when you try to create a file or save a file:
|
||||
当你尝试新建或保存一个文件时,你可能最终得到诸如以下的错误:
|
||||
|
||||
$ cat > file
|
||||
-bash: file: Read-only file system
|
||||
|
||||
Run mount command to find out if the file system is mounted in read-only mode:
|
||||
运行mount命令来查看被挂载的文件系统是否处于只读状态:
|
||||
|
||||
$ mount
|
||||
$ mount | grep '/ftpusers'
|
||||
|
||||
To fix this problem, simply remount the file system in read-write mode on a Linux based system:
|
||||
在基于Linux的系统中要修复这个问题,只需将这个处于只读状态的文件系统重新挂载即可:
|
||||
|
||||
# mount -o remount,rw /ftpusers/tmp
|
||||
|
||||
Another example, from my [FreeBSD 9.x server to remount / in rw mode][7]:
|
||||
另外,我是这样[用rw模式重新挂载FreeBSD 9.x服务器的根目录][7]的:
|
||||
|
||||
# mount -o rw /dev/ad0s1a /
|
||||
|
||||
### #3 - Am I running out of inodes? ###
|
||||
|
||||
Sometimes, df command reports that there is enough free space but system claims file-system is full. You need to check [for the inode][8] which identifies the file and its attributes on a file systems using the following command:
|
||||
有时候,df命令能显示出磁盘有空余的空间但是系统却声称文件系统已经写满了。此时你需要用以下命令来检查能在文件系统中识别文件及其属性的[索引节点][8]:
|
||||
|
||||
$ df -i
|
||||
$ df -i /ftpusers/
|
||||
|
||||
Sample outputs:
|
||||
部分输出内容:
|
||||
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
/dev/sda8 6250496 11568 6238928 1% /ftpusers
|
||||
|
||||
So /ftpusers has 62,50,496 total inodes but only 11,568 are used. You are free to create another 62,38,928 files on /ftpusers partition. If 100% of your inodes are used, try the following options:
|
||||
所以 /ftpusers 下有总计62,50,496KB大小的索引节点但是只有11,568KB被使用。你可以在 /ftpusers 位置下另外创建62,38,928KB大小的文件。如果你的索引节点100%被使用了,试试看以下的选项:
|
||||
|
||||
- Find unwanted files and delete or move to another server.
|
||||
- Find unwanted large files and delete or move to another server.
|
||||
- 找出不想要的文件并删除它,或者把它移动到其它服务器上。
|
||||
- 找出不想要的大文件并删除它,或者把它移动到其它服务器上。
|
||||
|
||||
### #4 - Is my hard drive is dying? ###
|
||||
### #4 - 我的硬盘驱动器宕了吗? ###
|
||||
|
||||
[I/O errors in log file (such as /var/log/messages) indicates][9] that something is wrong with the hard disk and it may be failing. You can check hard disk for errors using smartctl command, which is control and monitor utility for SMART disks under Linux and UNIX like operating systems. The syntax is:
|
||||
[日志文件中的输入/输出错误(例如 /var/log/messages)][9]说明硬盘出了一些问题并且可能已经失效,你可以用smartctl命令来查看硬盘的错误,这是一个在类UNIX系统下控制和监控硬盘状态的一个命令。语法如下:
|
||||
|
||||
smartctl -a /dev/DEVICE
|
||||
# check for /dev/sda on a Linux server
|
||||
# 在Linux服务器下检查 /dev/sda
|
||||
smartctl -a /dev/sda
|
||||
|
||||
You can also use "Disk Utility" to get the same information
|
||||
你也可以用"Disk Utility"这个软件来获得同样的信息。
|
||||
|
||||
[][10]
|
||||
|
||||
Fig. 01: Gnome disk utility (Applications > System Tools > Disk Utility)
|
||||
图 01: Gnome磁盘工具(Applications > System Tools > Disk Utility)
|
||||
|
||||
> **Note**: Don't expect too much from SMART tool. It may not work in some cases. Make backup on a regular basis.
|
||||
> **注意**: 不要对SMART工具期望太高,它在某些状况下无法工作,我们要定期做备份。
|
||||
|
||||
### #5 - Is my hard drive and server is too hot? ###
|
||||
|
||||
High temperatures can cause server to function poorly. So you need to maintain the proper temperature of the server and disk. High temperatures can result into server shutdown or damage to file system and disk. [Use hddtemp or smartctl utility to find out the temperature of your hard on a Linux or Unix based system][11] by reading data from S.M.A.R.T. on drives that support this feature. Only modern hard drives have a temperature sensor. hddtemp supports reading S.M.A.R.T. information from SCSI drives too. hddtemp can work as simple command line tool or as a daemon to get information from all servers:
|
||||
### #5 - 我的硬盘驱动器和服务器是不是太热了? ###
|
||||
|
||||
高温会引起服务器低效,所以你需要把服务器和磁盘维持在一个平稳适当的温度,高温甚至能导致服务器宕机或损坏文件系统和磁盘。[用hddtemp或smartctl功能,通过从支持此特点的驱动上的SMART技术来读取数据的方式,从而查出你的Linux或基于UNIX系统上的硬件温度。][11]只有现代硬驱动器有温度传感器。hddtemp功能也支持从SCSI驱动器读取SMART信息。hddtemp能作为一个简单的命令行工具或守护程序来从所有服务器中获取信息:
|
||||
hddtemp /dev/DISK
|
||||
hddtemp /dev/sg0
|
||||
|
||||
Sample outputs:
|
||||
部分输出内容:
|
||||
|
||||
[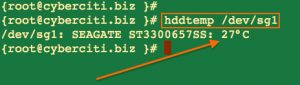][12]
|
||||
|
||||
Fig.02: hddtemp in action
|
||||
图 02: hddtemp正在运行
|
||||
|
||||
You can use the smartctl command as follows too:
|
||||
你也可以像下面显示的那样使用smartctl命令:
|
||||
|
||||
smartctl -d ata -A /dev/sda | grep -i temperature
|
||||
|
||||
#### How do I get the CPU temperature? ####
|
||||
#### 我怎么获取CPU的温度 ####
|
||||
|
||||
You can use Linux hardware monitoring tool such as [lm_sensor to get the cpu temperature on a Linux based][13] system:
|
||||
你可以使用Linux硬件监控工具例如像[用基于Linux系统的lm_sensor功能来获取CPU温度][13]:
|
||||
|
||||
sensors
|
||||
|
||||
Sample outputs from Debian Linux server:
|
||||
Debian服务器的部分输出内容:
|
||||
|
||||
[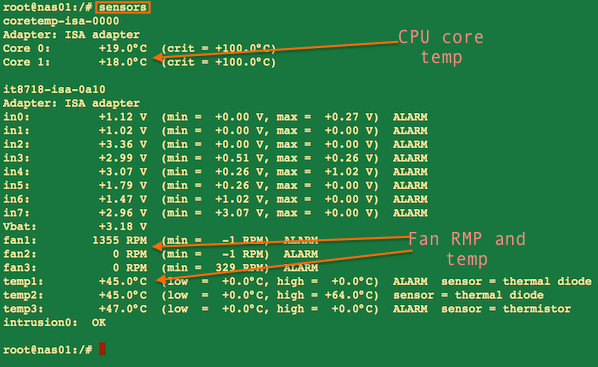][14]
|
||||
|
||||
Fig.03: sensors command providing cpu core temperature and other info on a Linux
|
||||
图 03: sensors命令提供了一台Linux计算机的CPU核心温度和其它信息
|
||||
|
||||
### #6 - Dealing with corrupted file systems ###
|
||||
### #6 - 处理损坏的文件系统 ###
|
||||
|
||||
File system on server may be get corrupted due to a hard reboot or some other error such as bad blocks. You can [repair corrupted file systems with the following fsck command][15]:
|
||||
服务器上的文件系统可能会因为硬件重启或一些其它的错误比如坏区而损坏。你可以[用fsck命令来修复损坏的文件系统][15]:
|
||||
|
||||
umount /ftpusers
|
||||
fsck -y /dev/sda8
|
||||
|
||||
See [how to surviving a Linux filesystem failures][16] for more info.
|
||||
来看看[怎么应对Linux文件系统故障][16]的更多信息。
|
||||
|
||||
### #7 - Dealing with software RAID on a Linux ###
|
||||
### #7 - 处理Linux中的软阵列 ###
|
||||
|
||||
To find the current status of a Linux software raid type the following command:
|
||||
输入以下命令来查看Linux软阵列的最近状态:
|
||||
|
||||
## get detail on /dev/md0 raid ##
|
||||
## 获得 /dev/md0 上磁盘阵列的具体内容 ##
|
||||
mdadm --detail /dev/md0
|
||||
|
||||
## Find status ##
|
||||
## 查看状态 ##
|
||||
cat /proc/mdstat
|
||||
watch cat /proc/mdstat
|
||||
|
||||
Sample outputs:
|
||||
部分输出内容:
|
||||
|
||||
[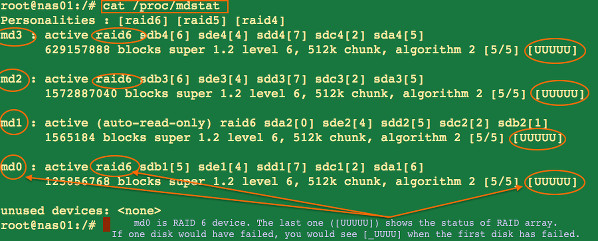][17]
|
||||
|
||||
Fig. 04: Find the status of a Linux software raid command
|
||||
图 04: 查看Linux软阵列状态命令
|
||||
|
||||
You need to replace a failed hard drive. You must u remove the correct failed drive. In this example, I'm going to replace /dev/sdb (2nd hard drive of RAID 6). It is not necessary to take the storage offline to repair the RAID on Linux. This only works if your server support hot-swappable hard disk:
|
||||
你需要把有故障的硬件驱动器更换掉,别删错了。本例中,我更换了 /dev/sdb (RAID 6中的第二个硬件驱动器)。没必要依靠离线存储文件来修复Linux上的磁盘阵列,因为这只在你的服务器支持热插拔硬盘的情况下才能工作:
|
||||
|
||||
## remove disk from an array md0 ##
|
||||
## 从一个md0阵列中删除磁盘 ##
|
||||
mdadm --manage /dev/md0 --fail /dev/sdb1
|
||||
mdadm --manage /dev/md0 --remove /dev/sdb1
|
||||
|
||||
# Do the same steps again for rest of /dev/sdbX ##
|
||||
# Power down if not hot-swappable hard disk: ##
|
||||
# 对 /dev/sdbX 的剩余部分做相同操作 ##
|
||||
# 如果不是热插拔硬盘就执行关机操作 ##
|
||||
shutdown -h now
|
||||
|
||||
## copy partition table from /dev/sda to newly replaced /dev/sdb ##
|
||||
## 从 /dev/sda 复制分区表至新的 /dev/sdb 下 ##
|
||||
sfdisk -d /dev/sda | sfdisk /dev/sdb
|
||||
fdisk -l
|
||||
|
||||
## Add it ##
|
||||
## 添加 ##
|
||||
mdadm --manage /dev/md0 --add /dev/sdb1
|
||||
# do the same steps again for rest of /dev/sdbX ##
|
||||
# 对 /dev/sdbX 的剩余部分做相同操作 ##
|
||||
|
||||
# Now md0 will sync again. See it on screen ##
|
||||
# 现在md0会再次同步,通过显示屏查看 ##
|
||||
watch cat /proc/mdstat
|
||||
|
||||
See our [tips on increasing RAID sync speed on Linux][18] for more information.
|
||||
来看看[加快Linux磁盘阵列同步速度的小贴士][18]来获取更多信息。
|
||||
|
||||
### #8 - Dealing with hardware RAID ###
|
||||
### #8 - 处理硬阵列 ###
|
||||
|
||||
You can use the samrtctl command or vendor specific command to find out the status of RAID and disks in your controller:
|
||||
你可以用samrtctl命令或者供应商特定的命令来查看磁盘阵列和你所管理的磁盘的状态:
|
||||
|
||||
## SCSI disk
|
||||
## SCSI磁盘
|
||||
smartctl -d scsi --all /dev/sgX
|
||||
|
||||
## Adaptec RAID array
|
||||
## Adaptec磁盘阵列
|
||||
/usr/StorMan/arcconf getconfig 1
|
||||
|
||||
## 3ware RAID Array
|
||||
## 3ware磁盘阵列
|
||||
tw_cli /c0 show
|
||||
|
||||
See your vendor specific documentation to replace a failed disk.
|
||||
对照供应商特定文档来更换你的故障磁盘。
|
||||
|
||||
### Monitoring disk health ###
|
||||
### 监控磁盘的健康状况 ###
|
||||
|
||||
See our previous tutorials:
|
||||
来看看我们先前的教程:
|
||||
|
||||
1. [Monitoring hard disk health with smartd under Linux or UNIX operating systems][19]
|
||||
1. [Shell script to watch the disk space][20]
|
||||
@ -237,9 +235,9 @@ See our previous tutorials:
|
||||
1. [Perl script to monitor disk space and send an email][23]
|
||||
1. [NAS backup server disk monitoring shell script][24]
|
||||
|
||||
### Conclusion ###
|
||||
### 结论 ###
|
||||
|
||||
I hope these tips will help you troubleshoot system disk issue on a Linux/Unix based server. I also recommend implementing a good backup plan in order to have the ability to recover from disk failure, accidental file deletion, file corruption, or complete server destruction:
|
||||
我希望以上这些小贴士会帮助你改善在基于Linux/Unix服务器上的系统磁盘问题。我还建议执行一个好的备份计划从而有能力从磁盘故障、意外的文件删除操作、文件损坏和服务器完全被破坏等意外情况中恢复:
|
||||
|
||||
- [Debian / Ubuntu: Install Duplicity for encrypted backup in cloud][25]
|
||||
- [HowTo: Backup MySQL databases, web server files to a FTP server automatically][26]
|
||||
@ -252,7 +250,7 @@ I hope these tips will help you troubleshoot system disk issue on a Linux/Unix b
|
||||
via: http://www.cyberciti.biz/datacenter/linux-unix-bsd-osx-cannot-write-to-hard-disk/
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,125 @@
|
||||
运行级别与服务管理命令systemd简介
|
||||
================================================================================
|
||||
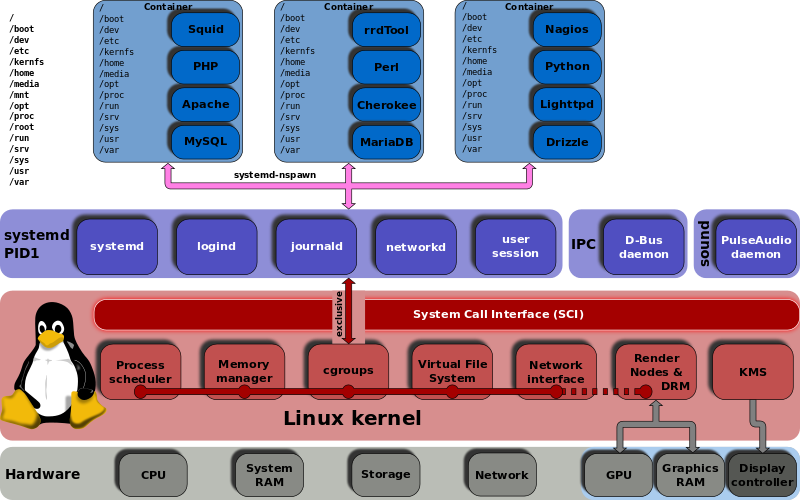
|
||||
|
||||
从很久很久以前我们就在使用静态运行级别。而systemd提供了更为动态灵活的机制,来管控你的系统。
|
||||
|
||||
在开始介绍systemd命令前,让我们先简单的回顾一下历史。在Linux世界里,有一个很奇怪的现象,一方面Linux和自由软件(FOSS)在不断的向前推进,另一方面人们对这些变化却不断的抱怨。这就是为什么我要在此稍稍提及那些反对systemd所引起的争论的原因,因为我依然记得历史上有不少类似的争论:
|
||||
|
||||
- 软件包(Pacakge)是邪恶的,因为正真的Linux用户会从源码构建他所想要的的一切,并严格的管理系统中安装的软件。
|
||||
- 解析依赖关系的包管理器是邪恶的,正真的Linux用户会手动解决这些该死的依赖关系。
|
||||
- apt-get总能把事情干好,所以只有Yum是邪恶的。
|
||||
- Red Hat简直就是Linux中的微软。
|
||||
- 好样的,Ubuntu!
|
||||
- 滚蛋吧,Ubuntu!
|
||||
|
||||
诸如此类...就像我之前常常说的一样,变化总是让人沮丧。这些该死的变化搅乱了我的工作流程,这可不是一件小事情,任何业务流程的中断,都会直接影响到生产力。但是,我们现在还处于计算机发展的婴儿期,在未来的很长的一段时间内将会持续有快速的变化和发展。想必大家应该都认识一些因循守旧的人,在他们的心里,商品一旦买回家以后就是恒久不变的,就像是买了一把扳手、一套家具或是一个粉红色的火烈鸟草坪装饰品。就是这些人,仍然在坚持使用Windows Vista,甚至还有人在使用运行Windows95的老破烂机器和CRT显示器。他们不能理解为什么要去换一台新机器。老的还能用啊,不是么?
|
||||
|
||||
这让我回忆起了我在维护老电脑上的一项伟大的成就,那台破电脑真的早就该淘汰掉。从前我有个朋友有一台286的老机器,安装了一个极其老的MS-DOS版本。她使用这台电脑来处理一些简单的任务,比如说约会、日记、记账等,我还用BASIC给她写了一个简单的记账软件。她不用关注任何安全更新,是这样么?因为它压根都没有联网。所以我会时不时给她维修一下电脑,更换电阻、电容、电源或者是CMOS电池什么的。它竟然还一直能用。它那袖珍的琥珀CRT显示器变得越来越暗,在使用了20多年后,终于退出了历史舞台。现在我的这位朋友,换了一台运行Linux的老Thinkpad,来干同样的活。
|
||||
|
||||
前面的话题有点偏题了,下面抓紧时间开始介绍systemd。
|
||||
|
||||
###运行级别 vs. 状态###
|
||||
SysVInit使用静态的运行级别来构建不同的启动状态,大部分发布版本中提供了以下5个运行级别:
|
||||
|
||||
- 单用户模式(Single-user mode)
|
||||
- 多用户模式,不启动网络服务(Multi-user mode without network services started)
|
||||
- 多用户模式,启动网络服务(Multi-user mode with network services started)
|
||||
- 系统关机(System shutdown)
|
||||
- 系统重启(System reboot)
|
||||
|
||||
对于我来说,使用多个运行级别并没有太大的好处,但它们却一直在系统中存在着。 不同于运行级别,systemd可以创建不同的状态,状态提供了灵活的机制来设置启动时的配置项。这些状态是由多个unit文件组成的,状态又叫做启动目标(target)。启动目标有一个漂亮的描述性命名,而不是像运行级别那样使用数字。unit文件可以控制服务、设备、套接字和挂载点。参考/usr/lib/systemd/system/graphical.target,这是CentOS 7默认的启动目标:
|
||||
|
||||
[Unit]
|
||||
Description=Graphical Interface
|
||||
Documentation=man:systemd.special(7)
|
||||
Requires=multi-user.target
|
||||
After=multi-user.target
|
||||
Conflicts=rescue.target
|
||||
Wants=display-manager.service
|
||||
AllowIsolate=yes
|
||||
[Install]
|
||||
Alias=default.target
|
||||
|
||||
现在再看看unit文件长什么样? 我来给大家找个例子。 unit文件存放在下面的两个目录下:
|
||||
|
||||
- /etc/systemd/system/
|
||||
- /usr/lib/systemd/system/
|
||||
|
||||
我们可以修改第一个目录中的文件来进行自定义配置,而第二个目录中的文件是包安装时保存的备份。**/etc/systemd/system/**的优先级高于**/usr/lib/systemd/system/**。不错,用户优先级高于机器。下面是Apache Web server的unit文件:
|
||||
|
||||
[Unit]
|
||||
Description=The Apache HTTP Server
|
||||
After=network.target remote-fs.target nss-lookup.target
|
||||
[Service]
|
||||
Type=notify
|
||||
EnvironmentFile=/etc/sysconfig/httpd
|
||||
ExecStart=/usr/sbin/httpd/ $OPTIONS -DFOREGROUND
|
||||
ExecReload=/usr/sbin/httpd $OPTIONS -k graceful
|
||||
ExecStop=/bin/kill -WINCH ${MAINPID}
|
||||
KillSignal=SIGCONT
|
||||
PrivateTmp=true
|
||||
[Install]
|
||||
WantedBy=multi.user.target
|
||||
|
||||
就算是对于新手而言,上面的文件也是非常简单易懂的。这可比SysVInit的init文件要简单多了,为了便于比较,下面截取了/etc/init.d/apache2的一个片段:
|
||||
|
||||
SCRIPTNAME="${0##*/}"
|
||||
SCRIPTNAME="${SCRIPTNAME##[KS][0-9][0-9]}"
|
||||
if [ -n "$APACHE_CONFDIR" ] ; then
|
||||
if [ "${APACHE_CONFDIR##/etc/apache2-}" != "${APACHE_CONFDIR}" ] ; then
|
||||
DIR_SUFFIX="${APACHE_CONFDIR##/etc/apache2-}"
|
||||
else
|
||||
DIR_SUFFIX=
|
||||
整个文件一共有410行。
|
||||
|
||||
你可以检查unit件的依赖关系,我常常被这些复杂的依赖关系给吓到:
|
||||
|
||||
$ systemctl list-dependencies httpd.service
|
||||
|
||||
### cgroups ###
|
||||
|
||||
cgroups,或者叫控制组,在Linux内核里已经出现好几年了,但直到systemd的出现才被真正使用起来。[The kernel documentation][1]中是这样描述cgroups的:“控制组提供层次化的机制来管理任务组,使用它可以聚合和拆分任务组,并管理任务组后续产生的子任务。”换句话说,它提供了多种有效的方式来控制、限制和分配资源。systemd使用了cgroups,你可以便捷得查看它,使用下面的命令可以展示你系统中的整个cgroup树:
|
||||
|
||||
$ systemd-cgls
|
||||
|
||||
你可以使用ps命令来进行查看cgroup树:
|
||||
|
||||
$ ps xawf -eo pid,user,cgroup,args
|
||||
|
||||
###常用命令集###
|
||||
|
||||
下面的命令行展示了如何为守护进程重新装载配置文件,注意不是systemd服务文件。 使用这个命令能够激活新的配置项,且尽可能少的打断业务进程,下面以Apache为例:
|
||||
|
||||
# systemctl reload httpd.service
|
||||
|
||||
重新装载服务文件(service file)需要完全停止和重新启动服务。如果服务挂死了,用下面的命令行可以恢复它:
|
||||
|
||||
# systemctl restart httpd.service
|
||||
|
||||
你还可以用一个命令重启所有的守护进程。这个命令会重新装载所有守护进程的unit文件,然后重新生成依赖关系树:
|
||||
|
||||
# systemctl daemon-reload
|
||||
|
||||
在非特权模式下,你也可以进行重启、挂起、关机操作:
|
||||
|
||||
$ systemctl reboot
|
||||
$ systemctl suspend
|
||||
$ systemctl poweroff
|
||||
|
||||
按照惯例,最后给大家介绍一些systemd的学习材料。[Here We Go Again, Another Linux Init: Intro to systemd][2] 和 [Understanding and Using Systemd][3] 是不错的入门材料,这两份文档里会链接到更多其他资源。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/794615-systemd-runlevels-and-service-management
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/3734
|
||||
[1]:https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
|
||||
[2]:http://www.linux.com/learn/tutorials/524577-here-we-go-again-another-linux-init-intro-to-systemd
|
||||
[3]:http://www.linux.com/learn/tutorials/788613-understanding-and-using-systemd
|
||||
@ -0,0 +1,39 @@
|
||||
[Quick Tip]如何修复Lubuntu中的Docky混合错误
|
||||
================================================================================
|
||||
总所周知,**Docky**是Unix/Linux类系统中的轻量级应用启动器。我是 Lubuntu 和 Docky的忠实粉丝,因为他们不需要占用我的所有系统资源,这样就可以同时运行更多应用。我在笔记本上使用Docky应用启动器,系统为Lubuntu 14.04.
|
||||
|
||||
但是,如果你使用LXDE发行版,你也许肯定遇到过使用Docky时报混合的错误。看下面的截图。
|
||||
|
||||

|
||||
|
||||
如果不开启混合功能,就不能使用Docky一些特别功能,如3D背景、自动隐藏。如果你想开启这些Docky的功能,那么你需要在你的LXDE系统中开启混合功能。
|
||||
|
||||
就像这样,首先安装 **xcompmgr**包:
|
||||
|
||||
sudo apt-get install xcompmgr
|
||||
|
||||
然后,选择**菜单(Menu) -> 偏好(Preferences) -> LXSession默认程序(Default applications for LXSession)**。选择自动开始(Autostart)选项卡。 在**(+增加)+Add**框中输入“**@xcompmgr -n**”不带引号。最后点击增加按钮。
|
||||
|
||||

|
||||
|
||||
这样就搞定了。关掉LXSession配置窗口,注销或重启系统。之后,你就可以看见混合功能已经打开。
|
||||
|
||||

|
||||
|
||||
这时,你结可以使用3D背景和隐藏功能,如自动隐藏(Auto-hide),Intellihide和窗口闪烁(Window dodge)等。
|
||||
|
||||

|
||||
|
||||
搞定!干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/quick-tip-fix-docky-compositing-error-lubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[Vic020/VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
Loading…
Reference in New Issue
Block a user