mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
19ab87c463
@ -1,2 +1,3 @@
|
||||
language: c
|
||||
script: make -s check
|
||||
script:
|
||||
- make -s check
|
||||
|
||||
9
Makefile
9
Makefile
@ -18,7 +18,7 @@ check: $(CHANGE_FILE)
|
||||
make -k $(RULES) 2>/dev/null | grep '^Rule Matched: '
|
||||
|
||||
$(CHANGE_FILE):
|
||||
git --no-pager diff $(TRAVIS_BRANCH) FETCH_HEAD --no-renames --name-status > $@
|
||||
git --no-pager diff $(TRAVIS_BRANCH) origin/master --no-renames --name-status > $@
|
||||
|
||||
rule-source-added:
|
||||
echo 'Unmatched Files:'
|
||||
@ -49,3 +49,10 @@ rule-translation-published:
|
||||
[ $(shell egrep '^A\s*"?published/$(NAME_PATTERN)' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
badge:
|
||||
mkdir -p build/badge
|
||||
./lctt-scripts/show_status.sh -s published >build/badge/published.svg
|
||||
./lctt-scripts/show_status.sh -s translated >build/badge/translated.svg
|
||||
./lctt-scripts/show_status.sh -s translating >build/badge/translating.svg
|
||||
./lctt-scripts/show_status.sh -s sources >build/badge/sources.svg
|
||||
|
||||
@ -1,6 +1,11 @@
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||
|
||||
LCTT 是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的Linux志愿者加入我们的团队。
|
||||
|
||||
@ -2,19 +2,20 @@
|
||||
======
|
||||
|
||||

|
||||
Linux 桌面生态中有多种窗口管理器 (WM)。有些是作为桌面环境的一部分开发的。有的则被用作独立程序。平铺 WM 就是这种情况,它提供了一个更轻量级的自定义环境。本文介绍了五种这样的平铺 WM 供你试用。
|
||||
|
||||
Linux 桌面生态中有多种窗口管理器(WM)。有些是作为桌面环境的一部分开发的。有的则被用作独立程序。平铺窗口管理器就是这种情况,它提供了一个更轻量级的自定义环境。本文介绍了五种这样的平铺窗口管理器供你试用。
|
||||
|
||||
### i3
|
||||
|
||||
[i3][1] 是最受欢迎的平铺窗口管理器之一。与大多数其他此类 WM 一样,i3 专注于低资源消耗和用户可定制性。
|
||||
|
||||
您可以参考[Magazine 上的这篇文章][2]了解 i3 安装细节以及如何配置它。
|
||||
您可以参考 [Magazine 上的这篇文章][2]了解 i3 安装细节以及如何配置它。
|
||||
|
||||
### sway
|
||||
|
||||
[sway][3] 是一个平铺 Wayland 合成器。它有与现有 i3 配置兼容的优点,因此你可以使用它来替换 i3 并使用 Wayland 作为显示协议。
|
||||
|
||||
您可以使用 dnf 从 Fedora 仓库安装 sway:
|
||||
您可以使用 `dnf` 从 Fedora 仓库安装 sway:
|
||||
|
||||
```
|
||||
$ sudo dnf install sway
|
||||
@ -24,7 +25,7 @@ $ sudo dnf install sway
|
||||
|
||||
### Qtile
|
||||
|
||||
[Qtile][5] 是另一个平铺管理器,也恰好是用 Python 编写的。默认情况下,你在位于 ~/.config/qtile/config.py 下的 Python 脚本中配置 Qtile。当此脚本不存在时,Qtile 会使用默认[配置][6]。
|
||||
[Qtile][5] 是另一个平铺管理器,也恰好是用 Python 编写的。默认情况下,你在位于 `~/.config/qtile/config.py` 下的 Python 脚本中配置 Qtile。当此脚本不存在时,Qtile 会使用默认[配置][6]。
|
||||
|
||||
Qtile 使用 Python 的一个好处是你可以编写脚本来控制 WM。例如,以下脚本打印屏幕详细信息:
|
||||
|
||||
@ -45,13 +46,13 @@ $ sudo dnf install qtile
|
||||
|
||||
[dwm][7] 窗口管理器更侧重于轻量级。该项目的一个目标是保持 dwm 最小。例如,整个代码库从未超过 2000 行代码。另一方面,dwm 不容易定制和配置。实际上,改变 dwm 默认配置的唯一方法是[编辑源代码并重新编译程序][8]。
|
||||
|
||||
如果你想尝试默认配置,你可以使用 dnf 在 Fedora 中安装 dwm:
|
||||
如果你想尝试默认配置,你可以使用 `dnf` 在 Fedora 中安装 dwm:
|
||||
|
||||
```
|
||||
$ sudo dnf install dwm
|
||||
```
|
||||
|
||||
对于那些想要改变 dwm 配置的人,Fedora 中有一个 dwm-user 包。该软件包使用用户主目录中 ~/.dwm/config.h 的配置自动重新编译 dwm。
|
||||
对于那些想要改变 dwm 配置的人,Fedora 中有一个 dwm-user 包。该软件包使用用户主目录中 `~/.dwm/config.h` 的配置自动重新编译 dwm。
|
||||
|
||||
### awesome
|
||||
|
||||
@ -71,7 +72,7 @@ via: https://fedoramagazine.org/5-cool-tiling-window-managers/
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
What is an SRE and how does it relate to DevOps?
|
||||
======
|
||||
The SRE role is common in large enterprises, but smaller businesses need it, too.
|
||||
|
||||

|
||||
|
||||
Even though the site reliability engineer (SRE) role has become prevalent in recent years, many people—even in the software industry—don't know what it is or does. This article aims to clear that up by explaining what an SRE is, how it relates to DevOps, and how an SRE works when your entire engineering organization can fit in a coffee shop.
|
||||
|
||||
### What is site reliability engineering?
|
||||
|
||||
[Site Reliability Engineering: How Google Runs Production Systems][1], written by a group of Google engineers, is considered the definitive book on site reliability engineering. Google vice president of engineering Ben Treynor Sloss [coined the term][2] back in the early 2000s. He defined it as: "It's what happens when you ask a software engineer to design an operations function."
|
||||
|
||||
Sysadmins have been writing code for a long time, but for many of those years, a team of sysadmins managed many machines manually. Back then, "many" may have been dozens or hundreds, but when you scale to thousands or hundreds of thousands of hosts, you simply can't continue to throw people at the problem. When the number of machines gets that large, the obvious solution is to use code to manage hosts (and the software that runs on them).
|
||||
|
||||
Also, until fairly recently, the operations team was completely separate from the developers. The skillsets for each job were considered completely different. The SRE role tries to bring both jobs together.
|
||||
|
||||
Before we dig deeper into what makes an SRE and how SREs work with the development team, we need to understand how site reliability engineering works within the DevOps paradigm.
|
||||
|
||||
### Site reliability engineering and DevOps
|
||||
|
||||
At its core, site reliability engineering is an implementation of the DevOps paradigm. There seems to be a wide array of ways to [define DevOps][3]. The traditional model, where the development ("devs") and operations ("ops") teams were separated, led to the team that writes the code not being responsible for how it works when customers start using it. The development team would "throw the code over the wall" to the operations team to install and support.
|
||||
|
||||
This situation can lead to a significant amount of dysfunction. The goals of the dev and ops teams are constantly at odds—a developer wants customers to use the "latest and greatest" piece of code, but the operations team wants a steady system with as little change as possible. Their premise is that any change can introduce instability, while a system with no changes should continue to behave in the same manner. (Noting that minimizing change on the software side is not the only factor in preventing instability is important. For example, if your web application stays exactly the same, but the number of customers grows by 10x, your application may break in many different ways.)
|
||||
|
||||
The premise of DevOps is that by merging these two distinct jobs into one, you eliminate contention. If the "dev" wants to deploy new code all the time, they have to deal with any fallout the new code creates. As Amazon's [Werner Vogels said][4], "you build it, you run it" (in production). But developers already have a lot to worry about. They are continually pushed to develop new features for their employer's products. Asking them to understand the infrastructure, including how to deploy, configure, and monitor their service, may be asking a little too much from them. This is where an SRE steps in.
|
||||
|
||||
When a web application is developed, there are often many people that contribute. There are user interface designers, graphic designers, frontend engineers, backend engineers, and a whole host of other specialties (depending on the technologies used). Requirements include how the code gets managed (e.g., deployed, configured, monitored)—which are the SRE's areas of specialty. But, just as an engineer developing a nice look and feel for an application benefits from knowledge of the backend-engineer's job (e.g., how data is fetched from a database), the SRE understands how the deployment system works and how to adapt it to the specific needs of that particular codebase or project.
|
||||
|
||||
So, an SRE is not just "an ops person who codes." Rather, the SRE is another member of the development team with a different set of skills particularly around deployment, configuration management, monitoring, metrics, etc. But, just as an engineer developing a nice look and feel for an application must know how data is fetched from a data store, an SRE is not singly responsible for these areas. The entire team works together to deliver a product that can be easily updated, managed, and monitored.
|
||||
|
||||
The need for an SRE naturally comes about when a team is implementing DevOps but realizes they are asking too much of the developers and need a specialist for what the ops team used to handle.
|
||||
|
||||
### How the SRE works at a startup
|
||||
|
||||
This is great when there are hundreds of employees (let alone when you are the size of Google or Facebook). Large companies have SRE teams that are split up and embedded into each development team. But a startup doesn't have those economies of scale, and engineers often wear many hats. So, where does the "SRE hat" sit in a small company? One approach is to fully adopt DevOps and have the developers be responsible for the typical tasks an SRE would perform at a larger company. On the other side of the spectrum, you hire specialists — a.k.a., SREs.
|
||||
|
||||
The most obvious advantage of trying to put the SRE hat on a developer's head is it scales well as your team grows. Also, the developer will understand all the quirks of the application. But many startups use a wide variety of SaaS products to power their infrastructure. The most obvious is the infrastructure platform itself. Then you add in metrics systems, site monitoring, log analysis, containers, and more. While these technologies solve some problems, they create an additional complexity cost. The developer would need to understand all those technologies and services in addition to the core technologies (e.g., languages) the application uses. In the end, keeping on top of all of that technology can be overwhelming.
|
||||
|
||||
The other option is to hire a specialist to handle the SRE job. Their responsibility would be to focus on deployment, configuration, monitoring, and metrics, freeing up the developer's time to write the application. The disadvantage is that the SRE would have to split their time between multiple, different applications (i.e., the SRE needs to support the breadth of applications throughout engineering). This likely means they may not have the time to gain any depth of knowledge of any of the applications; however, they would be in a position to see how all the different pieces fit together. This "30,000-foot view" can help prioritize the weak spots to fix in the system as a whole.
|
||||
|
||||
There is one key piece of information I am ignoring: your other engineers. They may have a deep desire to understand how deployment works and how to use the metrics system to the best of their ability. Also, hiring an SRE is not an easy task. You are looking for a mix of sysadmin skills and software engineering skills. (I am specific about software engineers, vs. just "being able to code," because software engineering involves more than just writing code [e.g., writing good tests or documentation].)
|
||||
|
||||
Therefore, in some cases, it may make more sense for the "SRE hat" to live on a developer's head. If so, keep an eye on the amount of complexity in both the code and the infrastructure (SaaS or internal). At some point, the complexity on either end will likely push toward more specialization.
|
||||
|
||||
### Conclusion
|
||||
|
||||
An SRE team is one of the most efficient ways to implement the DevOps paradigm in a startup. I have seen a couple of different approaches, but I believe that hiring a dedicated SRE (pretty early) at your startup will free up time for the developers to focus on their specific challenges. The SRE can focus on improving the tools (and processes) that make the developers more productive. Also, an SRE will focus on making sure your customers have a product that is reliable and secure.
|
||||
|
||||
Craig Sebenik will present [SRE (and DevOps) at a Startup][5] at [LISA18][6], October 29-31 in Nashville, Tennessee.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/sre-startup
|
||||
|
||||
作者:[Craig Sebenik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/craig5
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://shop.oreilly.com/product/0636920041528.do
|
||||
[2]: https://landing.google.com/sre/interview/ben-treynor.html
|
||||
[3]: https://opensource.com/resources/devops
|
||||
[4]: https://queue.acm.org/detail.cfm?id=1142065
|
||||
[5]: https://www.usenix.org/conference/lisa18/presentation/sebenik
|
||||
[6]: https://www.usenix.org/conference/lisa18
|
||||
@ -1,4 +1,4 @@
|
||||
[haoqixu翻译中]Writing a Time Series Database from Scratch
|
||||
Writing a Time Series Database from Scratch
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
@ -1,188 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How To Rename Multiple Files At Once In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
As you may already know, we use **mv** command to rename or move files and directories in Unix-like operating systems. But, the mv command won’t support renaming multiple files at once. Worry not. In this tutorial, we are going to learn to rename multiple files at once using **“mmv”** command in Linux. This command is used to move, copy, append and rename files in bulk using standard wildcards in Unix-like operating systems.
|
||||
|
||||
### Rename Multiple Files At Once In Linux
|
||||
|
||||
The mmv utility is available in the default repositories of Debian-based systems. To install it on Debian, Ubuntu, Linux Mint, run the following command:
|
||||
```
|
||||
$ sudo apt-get install mmv
|
||||
|
||||
```
|
||||
|
||||
Let us say, you have the following files in your current directory.
|
||||
```
|
||||
$ ls
|
||||
a1.txt a2.txt a3.txt
|
||||
|
||||
```
|
||||
|
||||
Now you want to rename all files that starts with letter “a” to “b”. Of course, you can do this manually in few seconds. But just think if you have hundreds of files and want to rename them? It is quite time consuming process. Here is where **mmv** command comes in help.
|
||||
|
||||
To rename all files starting with letter “a” to “b”, simply run:
|
||||
```
|
||||
$ mmv a\* b\#1
|
||||
|
||||
```
|
||||
|
||||
Let us check if the files have been renamed or not.
|
||||
```
|
||||
$ ls
|
||||
b1.txt b2.txt b3.txt
|
||||
|
||||
```
|
||||
|
||||
As you can see, all files starts with letter “a” (i.e a1.txt, a2.txt, a3.txt) are renamed to b1.txt, b2.txt, b3.txt.
|
||||
|
||||
**Explanation**
|
||||
|
||||
In the above example, the first parameter (a\\*) is the ‘from’ pattern and the second parameter is ‘to’ pattern ( b\\#1 ). As per the above example, mmv will look for any filenames staring with letter ‘a’ and rename the matched files according to second parameter i.e ‘to’ pattern. We use wildcards, such as ‘*’, ‘?’ and ‘[]‘, to match one or more arbitrary characters. Please be mindful that you must escape the wildcard characters, otherwise they will be expanded by the shell and mmv won’t understand them.
|
||||
|
||||
The ‘#1′ in the ‘to’ pattern is a wildcard index. It matches the first wildcard found in the ‘from’ pattern. A ‘#2′ in the ‘to’ pattern would match the second wildcard and so on. In our example, we have only one wildcard (the asterisk), so we write a #1. And, the hash sign should be escaped as well. Also, you can enclose the patterns with quotes too.
|
||||
|
||||
You can even rename all files with a certain extension to a different extension. For example, to rename all **.txt** files to **.doc** file format in the current directory, simply run:
|
||||
```
|
||||
$ mmv \*.txt \#1.doc
|
||||
|
||||
```
|
||||
|
||||
Here is an another example. Let us say you have the following files.
|
||||
```
|
||||
$ ls
|
||||
abcd1.txt abcd2.txt abcd3.txt
|
||||
|
||||
```
|
||||
|
||||
You want to replace the the first occurrence of **abc** with **xyz** in all files in the current directory. How would you do?
|
||||
|
||||
Simple.
|
||||
```
|
||||
$ mmv '*abc*' '#1xyz#2'
|
||||
|
||||
```
|
||||
|
||||
Please note that in the above example, I have enclosed the patterns in single quotes.
|
||||
|
||||
Let us check if “abc” is actually replaced with “xyz” or not.
|
||||
```
|
||||
$ ls
|
||||
xyzd1.txt xyzd2.txt xyzd3.txt
|
||||
|
||||
```
|
||||
|
||||
See? The files **abcd1.txt** , **abcd2.txt** , and **abcd3.txt** have been renamed to **xyzd1.txt** , **xyzd2.txt** , and **xyzd3.txt**.
|
||||
|
||||
Another notable feature of mmv command is you can just print output instead of renaming the files using **-n** option like below.
|
||||
```
|
||||
$ mmv -n a\* b\#1
|
||||
a1.txt -> b1.txt
|
||||
a2.txt -> b2.txt
|
||||
a3.txt -> b3.txt
|
||||
|
||||
```
|
||||
|
||||
This way you can simply verify what mmv command would actually do before renaming the files.
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man mmv
|
||||
|
||||
```
|
||||
|
||||
**Update:**
|
||||
|
||||
The **Thunar file manager** has built-in **bulk rename** option by default. If you’re using thunar, it much easier to rename files than using mmv command.
|
||||
|
||||
Thunar is available in the default repositories of most Linux distributions.
|
||||
|
||||
To install it on Arch-based systems, run:
|
||||
```
|
||||
$ sudo pacman -S thunar
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
```
|
||||
$ sudo yum install thunar
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
```
|
||||
$ sudo dnf install thunar
|
||||
|
||||
```
|
||||
|
||||
On openSUSE:
|
||||
```
|
||||
$ sudo zypper install thunar
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt-get install thunar
|
||||
|
||||
```
|
||||
|
||||
Once installed, you can launch bulk rename utility from menu or from the application launcher. To launch it from Terminal, use the following command:
|
||||
```
|
||||
$ thunar -B
|
||||
|
||||
```
|
||||
|
||||
This is how bulk rename looks like.
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
Click the plus sign and choose the list of files you want to rename. Bulk rename can rename the name of the files, the suffix of the files or both the name and the suffix of the files. Thunar currently supports the following Bulk Renamers:
|
||||
|
||||
* Insert Date or Time
|
||||
|
||||
* Insert or Overwrite
|
||||
|
||||
* Numbering
|
||||
|
||||
* Remove Characters
|
||||
|
||||
* Search & Replace
|
||||
|
||||
* Uppercase / Lowercase
|
||||
|
||||
|
||||
|
||||
|
||||
When you select one of these criteria from the picklist, you will see a preview of your changes in the New Name column, as shown in the below screenshot.
|
||||
|
||||
![][3]
|
||||
|
||||
Once you choose the criteria, click on **Rename Files** option to rename the files.
|
||||
|
||||
You can also open bulk renamer from within Thunar by selecting two or more files. After choosing the files, press F2 or right click and choose **Rename**.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-rename-multiple-files-at-once-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/06/bulk-rename.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/06/bulk-rename-1.png
|
||||
@ -1,173 +0,0 @@
|
||||
Translating by way-ww
|
||||
|
||||
Why Linux users should try Rust
|
||||
======
|
||||
|
||||

|
||||
|
||||
Rust is a fairly young and modern programming language with a lot of features that make it incredibly flexible and very secure. It's also becoming quite popular, having won first place for the "most loved programming language" in the Stack Overflow Developer Survey three years in a row — [2016][1], [2017][2], and [2018][3].
|
||||
|
||||
Rust is also an _open-source_ language with a suite of special features that allow it to be adapted to many different programming projects. It grew out of what was a personal project of a Mozilla employee back in 2006, was picked up as a special project by Mozilla a few years later (2009), and then announced for public use in 2010.
|
||||
|
||||
Rust programs run incredibly fast, prevent segfaults, and guarantee thread safety. These attributes make the language tremendously appealing to developers focused on application security. Rust is also a very readable language and one that can be used for anything from simple programs to very large and complex projects.
|
||||
|
||||
Rust is:
|
||||
|
||||
* Memory safe — Rust will not suffer from dangling pointers, buffer overflows, or other memory-related errors. And it provides memory safety without garbage collection.
|
||||
* General purpose — Rust is an appropriate language for any type of programming
|
||||
* Fast — Rust is comparable in performance to C/C++ but with far better security features.
|
||||
* Efficient — Rust is built to facilitate concurrent programming.
|
||||
* Project-oriented — Rust has a built-in dependency and build management system called Cargo.
|
||||
* Well supported — Rust has an impressive [support community][4].
|
||||
|
||||
|
||||
|
||||
Rust also enforces RAII (Resource Acquisition Is Initialization). That means when an object goes out of scope, its destructor will be called and its resources will be freed, providing a shield against resource leaks. It provides functional abstractions and a great [type system][5] together with speed and mathematical soundness.
|
||||
|
||||
In short, Rust is an impressive systems programming language with features that other most languages lack, making it a serious contender for languages like C, C++ and Objective-C that have been used for years.
|
||||
|
||||
### Installing Rust
|
||||
|
||||
Installing Rust is a fairly simple process.
|
||||
|
||||
```
|
||||
$ curl https://sh.rustup.rs -sSf | sh
|
||||
```
|
||||
|
||||
Once Rust in installed, calling rustc with the **\--version** argument or using the **which** command displays version information.
|
||||
|
||||
```
|
||||
$ which rustc
|
||||
rustc 1.27.2 (58cc626de 2018-07-18)
|
||||
$ rustc --version
|
||||
rustc 1.27.2 (58cc626de 2018-07-18)
|
||||
```
|
||||
|
||||
### Getting started with Rust
|
||||
|
||||
The simplest code example is not all that different from what you'd enter if you were using one of many scripting languages.
|
||||
|
||||
```
|
||||
$ cat hello.rs
|
||||
fn main() {
|
||||
// Print a greeting
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
In these lines, we are setting up a function (main), adding a comment describing the function, and using a println statement to create output. You could compile and then run a program like this using the command shown below.
|
||||
|
||||
```
|
||||
$ rustc hello.rs
|
||||
$ ./hello
|
||||
Hello, world!
|
||||
```
|
||||
|
||||
Alternately, you might create a "project" (generally used only for more complex programs than this one!) to keep your code organized.
|
||||
|
||||
```
|
||||
$ mkdir ~/projects
|
||||
$ cd ~/projects
|
||||
$ mkdir hello_world
|
||||
$ cd hello_world
|
||||
```
|
||||
|
||||
Notice that even a simple program, once compiled, becomes a fairly large executable.
|
||||
|
||||
```
|
||||
$ ./hello
|
||||
Hello, world!
|
||||
$ ls -l hello*
|
||||
-rwxrwxr-x 1 shs shs 5486784 Sep 23 19:02 hello <== executable
|
||||
-rw-rw-r-- 1 shs shs 68 Sep 23 15:25 hello.rs
|
||||
```
|
||||
|
||||
And, of course, that's just a start — the traditional "Hello, world!" program. The Rust language has a suite of features to get you moving quickly to advanced levels of programming skill.
|
||||
|
||||
### Learning Rust
|
||||
|
||||
![rust programming language book cover][6]
|
||||
No Starch Press
|
||||
|
||||
The Rust Programming Language book by Steve Klabnik and Carol Nichols (2018) provides one of the best ways to learn Rust. Written by two members of the core development team, this book is available in print from [No Starch Press][7] or in ebook format at [rust-lang.org][8]. It has earned its reference as "the book" among the Rust developer community.
|
||||
|
||||
Among the many topics covered, you will learn about these advanced topics:
|
||||
|
||||
* Ownership and borrowing
|
||||
* Safety guarantees
|
||||
* Testing and error handling
|
||||
* Smart pointers and multi-threading
|
||||
* Advanced pattern matching
|
||||
* Using Cargo (the built-in package manager)
|
||||
* Using Rust's advanced compiler
|
||||
|
||||
|
||||
|
||||
#### Table of Contents
|
||||
|
||||
The table of contents is shown below.
|
||||
|
||||
```
|
||||
Foreword by Nicholas Matsakis and Aaron Turon
|
||||
Acknowledgements
|
||||
Introduction
|
||||
Chapter 1: Getting Started
|
||||
Chapter 2: Guessing Game
|
||||
Chapter 3: Common Programming Concepts
|
||||
Chapter 4: Understanding Ownership
|
||||
Chapter 5: Structs
|
||||
Chapter 6: Enums and Pattern Matching
|
||||
Chapter 7: Modules
|
||||
Chapter 8: Common Collections
|
||||
Chapter 9: Error Handling
|
||||
Chapter 10: Generic Types, Traits, and Lifetimes
|
||||
Chapter 11: Testing
|
||||
Chapter 12: An Input/Output Project
|
||||
Chapter 13: Iterators and Closures
|
||||
Chapter 14: More About Cargo and Crates.io
|
||||
Chapter 15: Smart Pointers
|
||||
Chapter 16: Concurrency
|
||||
Chapter 17: Is Rust Object Oriented?
|
||||
Chapter 18: Patterns
|
||||
Chapter 19: More About Lifetimes
|
||||
Chapter 20: Advanced Type System Features
|
||||
Appendix A: Keywords
|
||||
Appendix B: Operators and Symbols
|
||||
Appendix C: Derivable Traits
|
||||
Appendix D: Macros
|
||||
Index
|
||||
|
||||
```
|
||||
|
||||
[The Rust Programming Language][7] takes you from basic installation and language syntax to complex topics, such as modules, error handling, crates (synonymous with a ‘library’ or ‘package’ in other languages), modules (allowing you to partition your code within the crate itself), lifetimes, etc.
|
||||
|
||||
Probably the most important thing to say is that the book can move you from basic programming skills to building and compiling complex, secure and very useful programs.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
If you're ready to get into some serious programming with a language that's well worth the time and effort to study and becoming increasingly popular, Rust is a good bet!
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3308162/linux/why-you-should-try-rust.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://insights.stackoverflow.com/survey/2016#technology-most-loved-dreaded-and-wanted
|
||||
[2]: https://insights.stackoverflow.com/survey/2017#technology-most-loved-dreaded-and-wanted-languages
|
||||
[3]: https://insights.stackoverflow.com/survey/2018#technology-most-loved-dreaded-and-wanted-languages
|
||||
[4]: https://www.rust-lang.org/en-US/community.html
|
||||
[5]: https://doc.rust-lang.org/reference/type-system.html
|
||||
[6]: https://images.idgesg.net/images/article/2018/09/rust-programming-language_book-cover-100773679-small.jpg
|
||||
[7]: https://nostarch.com/Rust
|
||||
[8]: https://doc.rust-lang.org/book/2018-edition/index.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by way-ww
|
||||
|
||||
How to Enable or Disable Services on Boot in Linux Using chkconfig and systemctl Command
|
||||
======
|
||||
It’s a important topic for Linux admin (such a wonderful topic) so, everyone must be aware of this and practice how to use this in the efficient way.
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
5 tips for choosing the right open source database
|
||||
======
|
||||
When selecting a mission-critical application, you can't afford to make mistakes.
|
||||
|
||||

|
||||
|
||||
So, your company has a directive to adopt more open source database technologies, and they've recruited you to select the right direction. Whether you are an open source technology veteran or a newcomer, this is a daunting and overwhelming task.
|
||||
|
||||
Over the past several years, open source technology adoption has steadily increased in the enterprise space. With its popularity comes a crowded marketplace with open source software companies promising that their solution will solve every problem and fit every workload. Be wary of these promises. Choosing the right open source technology—especially a database—is an important and difficult decision you can't make lightly.
|
||||
|
||||
In my experience as an IT professional at [Percona][1] and other companies, I've been fortunate to work hands-on in adopting open source technologies and guiding others in making the right decisions. There are many important factors to consider; hopefully, this article will shine a light on a few.
|
||||
|
||||
### 1. Have a goal.
|
||||
|
||||
This may seem simple, but based on my many conversations with people exploring MySQL, MongoDB, or PostgreSQL, it is top of the list in importance.
|
||||
|
||||
To avoid getting overwhelmed by the unlimited combinations of open source database software in the market, have a specific goal in mind. Maybe your goal is to provide your internal developers with a standardized, open source database backend that is managed by your internal database team. Perhaps your goal is to rip and replace the entire functionality of a legacy application and database backend with new open source technology.
|
||||
|
||||
Once you have defined a goal, you can focus your efforts. This will lead to better conversations internally as well as externally with open source database software vendors and advocates.
|
||||
|
||||
### 2. Understand your workload.
|
||||
|
||||
Despite the increasing ability of database technologies to wear many hats, each specializes in certain areas, e.g., MongoDB is now transactional, MySQL now has JSON storage. A growing trend in open source databases involves providing check boxes claiming certain features are available. One of the biggest mistakes is not using the right tool for the right job. Something leads a company down the wrong path—perhaps an overzealous developer or a manager with tunnel vision. The unfortunate thing is that the wrong tool can work fine for smaller volumes of transactions and data, but later there will be bottlenecks that can be solved only by using a different tool.
|
||||
|
||||
If you want a data analytics warehouse, an open source relational database is probably not the right choice. If you want a transaction-processing app with rigid data integrity and consistency, NoSQL options may not be the right option.
|
||||
|
||||
### 3. Don't reinvent the wheel.
|
||||
|
||||
Open source database technologies have rapidly grown, expanded, and hardened over the past several decades. We've seen a transformation from new, questionably production-ready databases to proven, enterprise-grade database backends. It's no longer necessary to be a bleeding edge, early adopter to choose open source database technologies. Organizations have grown around these communities to provide production support and tooling in the open source database space for a growing number of startups, midsized businesses, and Fortune 500 companies.
|
||||
|
||||
Battery Ventures, a tech-focused investment firm, recently introduced its [BOSS Index][2] for tracking the most popular open source projects. It's not perfect, but it provides great insight into some of the most widely adopted and active open source projects. Not surprisingly, database technologies dominate the list, comprising five of the top 10 technologies. This is a great starting point for someone new to the open source database space. A lot of times, vendors have already produced suitable architectures for solving specific problems.
|
||||
|
||||
My point is that someone has probably already done what you are trying to do. Learn from their successes and failures. Even if it is not a perfect fit, a solution can likely be modified to suit your needs. For example, Amazon provides a [CloudFormation script][3] for deploying MongoDB in its EC2 environment.
|
||||
|
||||
If you are a bleeding-edge early adopter, that doesn't mean you can't explore. If you have a unique challenge or workload that seems to fit a new open source database technology, go for it. Keep in mind that there are inherent risks (and rewards!) to being an early adopter.
|
||||
|
||||
### 4\. Start simple
|
||||
|
||||
|
||||
How many [nines][4] does your database truly need? "Achieving high availability" is often a nebulous goal for many companies. Of course, the most common answer is "it's mission-critical, and we cannot afford any downtime."
|
||||
|
||||
The more complicated your database environment, the more difficult and costly it is to manage. You can theoretically achieve higher uptime, but the tradeoffs will be the feasibility of management and performance. When in doubt, start simple. There are always options to scale out when the need arises.
|
||||
|
||||
For example, Booking.com is a widely known travel reservation site. It might be less widely known that it uses MySQL as a database backend. Nicolai Plum, a Booking.com senior systems architect, gave [a talk][5] outlining the evolution of the company's MySQL database. One of the takeaways was that the database started simple. It had to evolve over time, but in the beginning, simple master–replica architecture sufficed. As the workload and dataset increased, it introduced load balancers, multiple read replicas, archiving to Hadoop for analytics, etc. However, the early architecture was extremely simple.
|
||||
|
||||
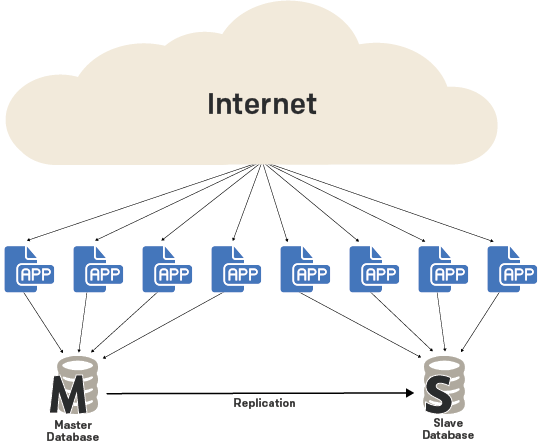
|
||||
|
||||
### 5. When in doubt, ask an expert.
|
||||
|
||||
If you're unsure whether a database would be a good fit, reach out on forums, websites, or to vendors and strike up a conversation. This can be exciting as you research which database technologies meet your requirements and which do not. Often there are suitable alternatives that you haven't considered. The open source community is all about sharing knowledge.
|
||||
|
||||
There is one important thing to be aware of when reaching out to open source software and services vendors. Many have open-core business models that incentivize adopting their database software. Take their advice or guidance with a grain of salt and use your own ability to research, create proofs of concept, and explore alternatives.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Choosing the right open source database is an important decision. Start by asking the right questions. All too often, people put the cart before the horse, making decisions before really understanding their needs.
|
||||
|
||||
Barrett Chambers will present [Choosing the Right Open Source Database][6] at [All Things Open][7], October 21-23 in Raleigh, N.C.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/tips-choosing-right-open-source-database
|
||||
|
||||
作者:[Barrett Chambers][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barrettc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.percona.com/
|
||||
[2]: https://techcrunch.com/2017/04/07/tracking-the-explosive-growth-of-open-source-software/
|
||||
[3]: https://docs.aws.amazon.com/quickstart/latest/mongodb/welcome.html
|
||||
[4]: https://en.wikipedia.org/wiki/Five_nines
|
||||
[5]: https://www.percona.com/live/mysql-conference-2015/sessions/bookingcom-evolution-mysql-system-design
|
||||
[6]: https://allthingsopen.org/talk/choosing-the-right-open-source-database/
|
||||
[7]: https://allthingsopen.org/
|
||||
@ -0,0 +1,281 @@
|
||||
How to set up WordPress on a Raspberry Pi
|
||||
======
|
||||
|
||||
Run your WordPress website on your Raspberry Pi with this simple tutorial.
|
||||
|
||||

|
||||
|
||||
WordPress is a popular open source blogging platform and content management system (CMS). It's easy to set up and has a thriving community of developers building websites and creating themes and plugins for others to use.
|
||||
|
||||
Although getting hosting packages with a "one-click WordPress setup" is easy, it's also simple to set up your own on a Linux server with only command-line access, and the [Raspberry Pi][1] is a perfect way to try it out and learn something along the way.
|
||||
|
||||
The four components of a commonly used web stack are Linux, Apache, MySQL, and PHP. Here's what you need to know about each.
|
||||
|
||||
### Linux
|
||||
|
||||
The Raspberry Pi runs Raspbian, which is a Linux distribution based on Debian and optimized to run well on Raspberry Pi hardware. It comes with two options to start: Desktop or Lite. The Desktop version boots to a familiar-looking desktop and comes with lots of educational software and programming tools, as well as the LibreOffice suite, Minecraft, and a web browser. The Lite version has no desktop environment, so it's command-line only and comes with only the essential software.
|
||||
|
||||
This tutorial will work with either version, but if you use the Lite version you'll have to use another computer to access your website.
|
||||
|
||||
### Apache
|
||||
|
||||
Apache is a popular web server application you can install on the Raspberry Pi to serve web pages. On its own, Apache can serve static HTML files over HTTP. With additional modules, it can serve dynamic web pages using scripting languages such as PHP.
|
||||
|
||||
Installing Apache is very simple. Open a terminal window and type the following command:
|
||||
|
||||
```
|
||||
sudo apt install apache2 -y
|
||||
```
|
||||
|
||||
By default, Apache puts a test HTML file in a web folder you can view from your Pi or another computer on your network. Just open the web browser and enter the address **<http://localhost>**. Alternatively (particularly if you're using Raspbian Lite), enter the Pi's IP address instead of **localhost**. You should see this in your browser window:
|
||||
|
||||
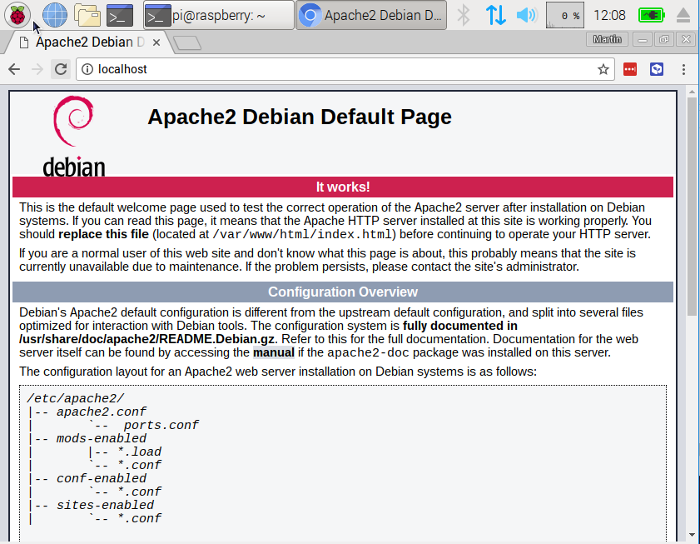
|
||||
|
||||
This means you have Apache working!
|
||||
|
||||
This default webpage is just an HTML file on the filesystem. It is located at **/var/www/html/index.html**. You can try replacing this file with some HTML of your own using the [Leafpad][2] text editor:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo leafpad index.html
|
||||
```
|
||||
|
||||
Save and close Leafpad then refresh the browser to see your changes.
|
||||
|
||||
### MySQL
|
||||
|
||||
MySQL (pronounced "my S-Q-L" or "my sequel") is a popular database engine. Like PHP, it's widely used on web servers, which is why projects like WordPress use it and why those projects are so popular.
|
||||
|
||||
Install MySQL Server by entering the following command into the terminal window:
|
||||
|
||||
```
|
||||
sudo apt-get install mysql-server -y
|
||||
```
|
||||
|
||||
WordPress uses MySQL to store posts, pages, user data, and lots of other content.
|
||||
|
||||
### PHP
|
||||
|
||||
PHP is a preprocessor: it's code that runs when the server receives a request for a web page via a web browser. It works out what needs to be shown on the page, then sends that page to the browser. Unlike static HTML, PHP can show different content under different circumstances. PHP is a very popular language on the web; huge projects like Facebook and Wikipedia are written in PHP.
|
||||
|
||||
Install PHP and the MySQL extension:
|
||||
|
||||
```
|
||||
sudo apt-get install php php-mysql -y
|
||||
```
|
||||
|
||||
Delete the **index.html** file and create **index.php** :
|
||||
|
||||
```
|
||||
sudo rm index.html
|
||||
sudo leafpad index.php
|
||||
```
|
||||
|
||||
Add the following line:
|
||||
|
||||
```
|
||||
<?php phpinfo(); ?>
|
||||
```
|
||||
|
||||
Save, exit, and refresh your browser. You'll see the PHP status page:
|
||||
|
||||
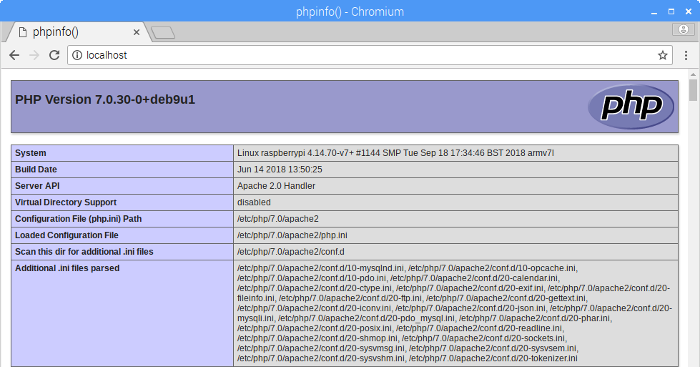
|
||||
|
||||
### WordPress
|
||||
|
||||
You can download WordPress from [wordpress.org][3] using the **wget** command. Helpfully, the latest version of WordPress is always available at [wordpress.org/latest.tar.gz][4], so you can grab it without having to look it up on the website. As I'm writing, this is version 4.9.8.
|
||||
|
||||
Make sure you're in **/var/www/html** and delete everything in it:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo rm *
|
||||
```
|
||||
|
||||
Download WordPress using **wget** , then extract the contents and move the WordPress files to the **html** directory:
|
||||
|
||||
```
|
||||
sudo wget http://wordpress.org/latest.tar.gz
|
||||
sudo tar xzf latest.tar.gz
|
||||
sudo mv wordpress/* .
|
||||
```
|
||||
|
||||
Tidy up by removing the tarball and the now-empty **wordpress** directory:
|
||||
|
||||
```
|
||||
sudo rm -rf wordpress latest.tar.gz
|
||||
```
|
||||
|
||||
Running the **ls** or **tree -L 1** command will show the contents of a WordPress project:
|
||||
|
||||
```
|
||||
.
|
||||
├── index.php
|
||||
├── license.txt
|
||||
├── readme.html
|
||||
├── wp-activate.php
|
||||
├── wp-admin
|
||||
├── wp-blog-header.php
|
||||
├── wp-comments-post.php
|
||||
├── wp-config-sample.php
|
||||
├── wp-content
|
||||
├── wp-cron.php
|
||||
├── wp-includes
|
||||
├── wp-links-opml.php
|
||||
├── wp-load.php
|
||||
├── wp-login.php
|
||||
├── wp-mail.php
|
||||
├── wp-settings.php
|
||||
├── wp-signup.php
|
||||
├── wp-trackback.php
|
||||
└── xmlrpc.php
|
||||
|
||||
3 directories, 16 files
|
||||
```
|
||||
|
||||
This is the source of a default WordPress installation. The files you edit to customize your installation belong in the **wp-content** folder.
|
||||
|
||||
You should now change the ownership of all these files to the Apache user:
|
||||
|
||||
```
|
||||
sudo chown -R www-data: .
|
||||
```
|
||||
|
||||
### WordPress database
|
||||
|
||||
To get your WordPress site set up, you need a database. This is where MySQL comes in!
|
||||
|
||||
Run the MySQL secure installation command in the terminal window:
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
You will be asked a series of questions. There's no password set up initially, but you should set one in the second step. Make sure you enter a password you will remember, as you'll need it to connect to WordPress. Press Enter to say Yes to each question that follows.
|
||||
|
||||
When it's complete, you will see the messages "All done!" and "Thanks for using MariaDB!"
|
||||
|
||||
Run **mysql** in the terminal window:
|
||||
|
||||
```
|
||||
sudo mysql -uroot -p
|
||||
```
|
||||
|
||||
Enter the root password you created. You will be greeted by the message "Welcome to the MariaDB monitor." Create the database for your WordPress installation at the **MariaDB [(none)] >** prompt using:
|
||||
|
||||
```
|
||||
create database wordpress;
|
||||
```
|
||||
|
||||
Note the semicolon at the end of the statement. If the command is successful, you should see this:
|
||||
|
||||
```
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
```
|
||||
|
||||
Grant database privileges to the root user, entering your password at the end of the statement:
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';
|
||||
```
|
||||
|
||||
For the changes to take effect, you will need to flush the database privileges:
|
||||
|
||||
```
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Exit the MariaDB prompt with **Ctrl+D** to return to the Bash shell.
|
||||
|
||||
### WordPress configuration
|
||||
|
||||
Open the web browser on your Raspberry Pi and open **<http://localhost>**. You should see a WordPress page asking you to pick your language. Select your language and click **Continue**. You will be presented with the WordPress welcome screen. Click the **Let's go!** button.
|
||||
|
||||
Fill out the basic site information as follows:
|
||||
|
||||
```
|
||||
Database Name: wordpress
|
||||
User Name: root
|
||||
Password: <YOUR PASSWORD>
|
||||
Database Host: localhost
|
||||
Table Prefix: wp_
|
||||
```
|
||||
|
||||
Click **Submit** to proceed, then click **Run the install**.
|
||||
|
||||
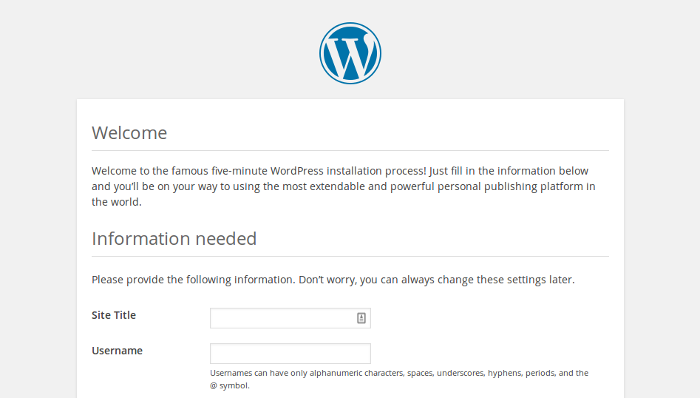
|
||||
|
||||
Fill in the form: Give your site a title, create a username and password, and enter your email address. Hit the **Install WordPress** button, then log in using the account you just created. Now that you're logged in and your site is set up, you can see your website by visiting **<http://localhost/wp-admin>**.
|
||||
|
||||
### Permalinks
|
||||
|
||||
It's a good idea to change your permalink settings to make your URLs more friendly.
|
||||
|
||||
To do this, log into WordPress and go to the dashboard. Go to **Settings** , then **Permalinks**. Select the **Post name** option and click **Save Changes**. You'll need to enable Apache's **rewrite** module:
|
||||
|
||||
```
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
|
||||
You'll also need to tell the virtual host serving the site to allow requests to be overwritten. Edit the Apache configuration file for your virtual host:
|
||||
|
||||
```
|
||||
sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
```
|
||||
|
||||
Add the following lines after line 1:
|
||||
|
||||
```
|
||||
<Directory "/var/www/html">
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
```
|
||||
|
||||
Ensure it's within the **< VirtualHost *:80>** like so:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
<Directory "/var/www/html">
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
...
|
||||
```
|
||||
|
||||
Save the file and exit, then restart Apache:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
### What's next?
|
||||
|
||||
WordPress is very customizable. By clicking your site name in the WordPress banner at the top of the page (when you're logged in), you'll be taken to the Dashboard. From there, you can change the theme, add pages and posts, edit the menu, add plugins, and do lots more.
|
||||
|
||||
Here are some interesting things you can try on the Raspberry Pi's web server.
|
||||
|
||||
* Add pages and posts to your website
|
||||
* Install different themes from the Appearance menu
|
||||
* Customize your website's theme or create your own
|
||||
* Use your web server to display useful information for people on your network
|
||||
|
||||
|
||||
|
||||
Don't forget, the Raspberry Pi is a Linux computer. You can also follow these instructions to install WordPress on a server running Debian or Ubuntu.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/setting-wordpress-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sitewide-search?search_api_views_fulltext=raspberry%20pi
|
||||
[2]: https://en.wikipedia.org/wiki/Leafpad
|
||||
[3]: http://wordpress.org/
|
||||
[4]: https://wordpress.org/latest.tar.gz
|
||||
@ -0,0 +1,183 @@
|
||||
Improve login security with challenge-response authentication
|
||||
======
|
||||
|
||||

|
||||
|
||||
### Introduction
|
||||
|
||||
Today, Fedora offers multiple ways to improve the secure authentication of our user accounts. Of course it has the familiar user name and password to login. It also offers additional authentication options such as biometric, fingerprint, smart card, one-time password, and even challenge-response authentication.
|
||||
|
||||
Each authentication method has clear pros and cons. That, in itself, could be a topic for a rather lengthy article. Fedora Magazine has covered a few of these options previously:
|
||||
|
||||
|
||||
+ [Using the YubiKey4 with Fedora][1]
|
||||
+ [Fedora 28: Better smart card support in OpenSSH][2]
|
||||
|
||||
|
||||
One of the most secure methods in modern Fedora releases is offline hardware challenge-response. It’s also one of the easiest to deploy. Here’s how.
|
||||
|
||||
### Challenge-response authentication
|
||||
|
||||
Technically, when you provide a password, you’re responding to a user name challenge. The offline challenge response covered here requires your user name first. Next, Fedora challenges you to provide an encrypted physical hardware token. The token responds to the challenge with another encrypted key it stores via the Pluggable Authentication Modules (PAM) framework. Finally, Fedora prompts you for the password. This prevents someone from just using a found hardware token, or just using a user name and password without the correct encrypted key.
|
||||
|
||||
This means that in addition to your user name and password, you must have previously registered one or more encrypted hardware tokens with the OS. And you have to provide that physical hardware token to be able to authenticate with your user name.
|
||||
|
||||
Some challenge-response methods, like one time passwords (OTP), take an encrypted code key on the hardware token, and pass that key across the network to a remote authentication server. The server then tells Fedora’s PAM framework if it’s is a valid token for that user name. This is great if the authentication server(s) are on the local network. The downside is if the network connection is down or you’re working remote without a network connection, you can’t use this remote authentication method. You could be locked out of the system until you can connect through the network to the server.
|
||||
|
||||
Sometimes a workplace requires use of Yubikey One Time Passwords (OTP) configuration. However, on home or personal systems you may prefer a local challenge-response configuration. Everything is local, and the method requires no remote network calls. The following process works on Fedora 27, 28, and 29.
|
||||
|
||||
### Preparation
|
||||
|
||||
#### Hardware token keys
|
||||
|
||||
First you need a secure hardware token key. Specifically, this process requires a Yubikey 4, Yubikey NEO, or a recently released Yubikey 5 series device which also supports FIDO2. You should purchase two of them to provide a backup in case one becomes lost or damaged. You can use these keys on numerous workstations. The simpler FIDO or FIDO U2F only versions don’t work for this process, but are great for online services that use FIDO.
|
||||
|
||||
#### Backup, backup, and backup
|
||||
|
||||
Next, make a backup of all your important data. You may want to test the configuration in a Fedora 27/28/29 cloned VM to make sure you understand the process before setting up your personal workstation.
|
||||
|
||||
#### Updating and installing
|
||||
|
||||
Now make sure Fedora is up to date. Then install the required Fedora Yubikey packages via these dnf commands:
|
||||
|
||||
```
|
||||
$ sudo dnf upgrade
|
||||
$ sudo dnf install ykclient* ykpers* pam_yubico*
|
||||
$ cd
|
||||
```
|
||||
|
||||
If you’re in a VM environment, such as Virtual Box, make sure the Yubikey device is inserted in a USB port, and enable USB access to the Yubikey in the VM control.
|
||||
|
||||
### Configuring Yubikey
|
||||
|
||||
Verify that your user account has access to the USB Yubikey:
|
||||
|
||||
```
|
||||
$ ykinfo -v
|
||||
version: 3.5.0
|
||||
```
|
||||
|
||||
If the YubiKey is not detected, the following error message appears:
|
||||
|
||||
```
|
||||
Yubikey core error: no yubikey present
|
||||
```
|
||||
|
||||
Next, initialize each of your new Yubikeys with the following ykpersonalize command. This sets up the Yubikey configuration slot 2 with a Challenge Response using the HMAC-SHA1 algorithm, even with less than 64 characters. If you have already setup your Yubikeys for challenge-response, you don’t need to run ykpersonalize again.
|
||||
|
||||
```
|
||||
ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -oserial-api-visible
|
||||
```
|
||||
|
||||
Some users leave the YubiKey in their workstation while using it, and even use challenge-response for virtual machines. However, for more security you may prefer to manually trigger the Yubikey to respond to challenge.
|
||||
|
||||
To add that manual challenge button trigger, add the -ochal-btn-trig flag. This flag causes the Yubikey to flash the yubikey LED on a request. It waits for you to press the button on the hardware key area within 15 seconds to produce the response key.
|
||||
|
||||
```
|
||||
$ ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -ochal-btn-trig -oserial-api-visible
|
||||
```
|
||||
|
||||
Do this for each of your new hardware keys, only once per key. Once you have programmed your keys, store the Yubikey configuration to ~/.yubico with the following command:
|
||||
|
||||
```
|
||||
$ ykpamcfg -2 -v
|
||||
debug: util.c:222 (check_firmware_version): YubiKey Firmware version: 4.3.4
|
||||
|
||||
Sending 63 bytes HMAC challenge to slot 2
|
||||
Sending 63 bytes HMAC challenge to slot 2
|
||||
Stored initial challenge and expected response in '/home/chuckfinley/.yubico/challenge-9992567'.
|
||||
```
|
||||
|
||||
If you are setting up multiple keys for backup purposes, configure all the keys the same, and store each key’s challenge-response using the ykpamcfg utility. If you run the command ykpersonalize on an existing registered key, you must store the configuration again.
|
||||
|
||||
### Configuring /etc/pam.d/sudo
|
||||
|
||||
Now to verify this configuration worked, **in the same terminal window** you’ll setup sudo to require the use of the Yubikey challenge-response. Insert the following line into the /etc/pam.d/sudo file:
|
||||
|
||||
```
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
```
|
||||
|
||||
Insert the above auth line into the file above the auth include system-auth line. Then save the file and exit the editor. In a default Fedora 29 setup, /etc/pam.d/sudo should now look like this:
|
||||
|
||||
```
|
||||
#%PAM-1.0
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
auth include system-auth
|
||||
account include system-auth
|
||||
password include system-auth
|
||||
session optional pam_keyinit.so revoke
|
||||
session required pam_limits.so
|
||||
session include system-auth
|
||||
```
|
||||
|
||||
**Keep this original terminal window open** , and test by opening another new terminal window. In the new terminal window type:
|
||||
|
||||
```
|
||||
$ sudo echo testing
|
||||
```
|
||||
|
||||
You should notice the LED blinking on the key. Tap the Yubikey button and you should see a prompt for your sudo password. After you enter your password, you should see “testing” echoed in the terminal screen.
|
||||
|
||||
Now test to ensure a correct failure. Start another terminal window and remove the Yubikey from the USB port. Verify that sudo no longer works without the Yubikey with this command:
|
||||
|
||||
```
|
||||
$ sudo echo testing fail
|
||||
```
|
||||
|
||||
You should immediately be prompted for the sudo password. Even if you enter the password, it should fail.
|
||||
|
||||
### Configuring Gnome Desktop Manager
|
||||
|
||||
Once your testing is complete, now you can add challenge-response support for the graphical login. Re-insert your Yubikey into the USB port. Next you’ll add the following line to the /etc/pam.d/gdm-password file:
|
||||
|
||||
```
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
```
|
||||
|
||||
Open a terminal window, and issue the following command. You can use another editor if desired:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/pam.d/gdm-password
|
||||
```
|
||||
|
||||
You should see the yubikey LED blinking. Press the yubikey button, then enter the password at the prompt.
|
||||
|
||||
Modify the /etc/pam.d/gdm-password file to add the new auth line above the existing line auth substack password-auth. The top of the file should now look like this:
|
||||
|
||||
```
|
||||
auth [success=done ignore=ignore default=bad] pam_selinux_permit.so
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
auth substack password-auth
|
||||
auth optional pam_gnome_keyring.so
|
||||
auth include postlogin
|
||||
|
||||
account required pam_nologin.so
|
||||
```
|
||||
|
||||
Save the changes and exit the editor. If you use vi, the key sequence is to hit the **Esc** key, then type wq! at the prompt to save and exit.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Now log out of GNOME. With the Yubikey inserted into the USB port, click on your user name in the graphical login. The Yubikey LED begins to flash. Touch the button, and you will be prompted for your password.
|
||||
|
||||
If you lose the Yubikey, you can still use the secondary backup Yubikey in addition to your set password. You can also add additional Yubikey configurations to your user account.
|
||||
|
||||
If someone gains access to your password, they still can’t login without your physical hardware Yubikey. Congratulations! You’ve now dramatically increased the security of your workstation login.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/login-challenge-response-authentication/
|
||||
|
||||
作者:[nabooengineer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nabooengineer/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/using-the-yubikey4-with-fedora/
|
||||
[2]: https://fedoramagazine.org/fedora-28-better-smart-card-support-openssh/
|
||||
|
||||
@ -1,24 +1,25 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Peeking into your Linux packages
|
||||
探秘你的Linux软件包
|
||||
======
|
||||
Do you ever wonder how many _thousands_ of packages are installed on your Linux system? And, yes, I said "thousands." Even a fairly modest Linux system is likely to have well over a thousand packages installed. And there are many ways to get details on what they are.
|
||||
你有没有想过你的 Linux 系统上安装了多少千个软件包? 是的,我说的是“千”。 即使是相当一般的 Linux 系统也可能安装了超过一千个软件包。 有很多方法可以获得这些包到底是什么包的详细信息。
|
||||
|
||||
首先,要在基于 Debian 的发行版(如 Ubuntu)上快速得到已安装的软件包数量,请使用 **apt list --installed**, 如下:
|
||||
|
||||
First, to get a quick count of your installed packages on a Debian-based distribution such as Ubuntu, use the command **apt list --installed** like this:
|
||||
```
|
||||
$ apt list --installed | wc -l
|
||||
2067
|
||||
|
||||
```
|
||||
|
||||
This number is actually one too high because the output contains "Listing..." as its first line. This command would be more accurate:
|
||||
这个数字实际上多了一个,因为输出中包含了 “Listing ...” 作为它的第一行。 这个命令会更准确:
|
||||
|
||||
```
|
||||
$ apt list --installed | grep -v "^Listing" | wc -l
|
||||
2066
|
||||
|
||||
```
|
||||
|
||||
To get some details on what all these packages are, browse the list like this:
|
||||
要获得所有这些包的详细信息,请按以下方式浏览列表:
|
||||
|
||||
```
|
||||
$ apt list --installed | more
|
||||
Listing...
|
||||
@ -32,9 +33,9 @@ account-plugin-salut/xenial,now 3.12.11-0ubuntu3 amd64 [installed]
|
||||
|
||||
```
|
||||
|
||||
That's a lot of detail to absorb -- especially if you let your eyes wander through all 2,000+ files rolling by. It contains the package names, versions, and more but isn't the easiest information display for us humans to parse. The dpkg-query makes the descriptions quite a bit easier to understand, but they will wrap around your command window unless it's _very_ wide. So, the data display below has been split into the left and right hand sides to make this post easier to read.
|
||||
这需要观察很多细节--特别是让你的眼睛在所有 2000 多个文件中徘徊。 它包含包名称,版本等,但不是我们人类解析的最简单的信息显示。 dpkg-query 使得描述更容易理解,但这些描述塞满你的命令窗口,除非窗口非常宽。 因此,为了让此篇文章更容易阅读,下面的数据显示已经分成了左右两侧。
|
||||
|
||||
Left side:
|
||||
左侧:
|
||||
```
|
||||
$ dpkg-query -l | more
|
||||
Desired=Unknown/Install/Remove/Purge/Hold
|
||||
@ -54,7 +55,7 @@ rc account-plugin-windows-live 0.11+14.04.20140409.1-0ubuntu2
|
||||
|
||||
```
|
||||
|
||||
Right side:
|
||||
右侧:
|
||||
```
|
||||
Architecture Description
|
||||
============-=====================================================================
|
||||
@ -70,7 +71,8 @@ all GNOME Control Center account plugin for single signon - windows live
|
||||
|
||||
```
|
||||
|
||||
The "ii" and "rc" designations at the beginning of each line (see "Left side" above) are package state indicators. The first letter represents the desirable package state:
|
||||
每行开头的 “ii” 和 “rc” 名称(见上文“左侧”)是包状态指示符。 第一个字母表示包的理想状态:
|
||||
|
||||
```
|
||||
u -- unknown
|
||||
i -- install
|
||||
@ -80,7 +82,8 @@ h -- hold
|
||||
|
||||
```
|
||||
|
||||
The second represents the current package state:
|
||||
第二个代表包的当前状态:
|
||||
|
||||
```
|
||||
n -- not-installed
|
||||
i -- installed
|
||||
@ -93,9 +96,10 @@ t -- triggers-pending (the package has been triggered)
|
||||
|
||||
```
|
||||
|
||||
An added "R" at the end of the normally two-character field would indicate that reinstallation is required. You may never run into these.
|
||||
在通常的双字符字段末尾添加的 “R” 表示需要重新安装。 你可能永远不会碰到这些。
|
||||
|
||||
快速查看整体包状态的一种简单方法是计算在不同状态中包含的包的数量:
|
||||
|
||||
One easy way to take a quick look at your overall package status is to count how many packages are in which of the different states:
|
||||
```
|
||||
$ dpkg-query -l | tail -n +6 | awk '{print $1}' | sort | uniq -c
|
||||
2066 ii
|
||||
@ -103,25 +107,24 @@ $ dpkg-query -l | tail -n +6 | awk '{print $1}' | sort | uniq -c
|
||||
|
||||
```
|
||||
|
||||
I excluded the top five lines from the dpkg-query output above because these are the header lines that would have confused the output.
|
||||
我从上面的 dpkg-query 输出中排除了前五行,因为这些是标题行,会混淆输出。
|
||||
|
||||
这两行基本上告诉我们,在这个系统上,应该安装了 2066 个软件包,而 134 个其他的软件包已被删除,但已经留下了配置文件。 你始终可以使用以下命令删除程序包的剩余配置文件:
|
||||
|
||||
The two lines basically tell us that on this system, 2,066 packages should be and are installed, while 134 other packages have been removed but have left configuration files behind. You can always remove a package's remaining configuration files with a command like this:
|
||||
```
|
||||
$ sudo dpkg --purge xfont-mathml
|
||||
|
||||
```
|
||||
|
||||
Note that the command above would have removed the package binaries along with the configuration files if both were still installed.
|
||||
|
||||
请注意,如果程序包二进制文件和配置文件都已经安装了,则上面的命令将两者都删除。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3242808/linux/peeking-into-your-linux-packages.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -0,0 +1,182 @@
|
||||
如何在 Linux 中一次重命名多个文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
你可能已经知道,我们使用 mv 命令在类 Unix 操作系统中重命名或者移动文件和目录。 但是,mv 命令不支持一次重命名多个文件。 不用担心。 在本教程中,我们将学习使用 Linux 中的 “mmv” 命令一次重命名多个文件。 此命令用于在类 Unix 操作系统中使用标准通配符批量移动,复制,追加和重命名文件。
|
||||
|
||||
### 在 Linux 中一次重命名多个文件
|
||||
|
||||
mmv 程序可在基于 Debian 的系统的默认仓库中使用。 要想在 Debian,Ubuntu,Linux Mint 上安装它,请运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get install mmv
|
||||
```
|
||||
|
||||
我们假设你在当前目录中有以下文件。
|
||||
|
||||
```
|
||||
$ ls
|
||||
a1.txt a2.txt a3.txt
|
||||
```
|
||||
|
||||
现在,你想要将所有以字母 “a” 开头的文件重命名为以 “b” 开头的。 当然,你可以在几秒钟内手动执行此操作。 但是想想你是否有数百个文件想要重命名? 这是一个非常耗时的过程。 这时候 **mmv** 命令就很有帮助了。
|
||||
|
||||
要将所有以字母 “a” 开头的文件重命名为以字母 “b” 开头的,只需要运行:
|
||||
|
||||
```
|
||||
$ mmv a\* b\#1
|
||||
```
|
||||
|
||||
让我们检查一下文件是否都已经重命名了。
|
||||
|
||||
```
|
||||
$ ls
|
||||
b1.txt b2.txt b3.txt
|
||||
|
||||
```
|
||||
|
||||
如你所见,所有以字母 “a” 开头的文件(即 a1.txt,a2.txt,a3.txt)都重命名为 b1.txt,b2.txt,b3.txt。
|
||||
|
||||
**解释**
|
||||
|
||||
在上面的例子中,第一个参数(a\\*)是 'from' 模式,第二个参数是 'to' 模式(b\\#1)。根据上面的例子,mmv 将查找任何以字母 'a' 开头的文件名,并根据第二个参数重命名匹配的文件,即 'to' 模式。我们使用通配符,例如用 '*','?' 和 '[]' 来匹配一个或多个任意字符。请注意,你必须避免使用通配符,否则它们将被 shell 扩展,mmv 将无法理解。
|
||||
|
||||
'to' 模式中的 '#1' 是通配符索引。它匹配 'from' 模式中的第一个通配符。 'to' 模式中的 '#2' 将匹配第二个通配符,依此类推。在我们的例子中,我们只有一个通配符(星号),所以我们写了一个 #1。并且,哈希标志也应该被转义。此外,你也可以用引号括起模式。
|
||||
|
||||
你甚至可以将具有特定扩展名的所有文件重命名为其他扩展名。例如,要将当前目录中的所有 **.txt** 文件重命名为 **.doc** 文件格式,只需运行:
|
||||
|
||||
```
|
||||
$ mmv \*.txt \#1.doc
|
||||
|
||||
```
|
||||
|
||||
这是另一个例子。 我们假设你有以下文件。
|
||||
|
||||
```
|
||||
$ ls
|
||||
abcd1.txt abcd2.txt abcd3.txt
|
||||
|
||||
```
|
||||
|
||||
你希望在当前目录下的所有文件中将第一次出现的 **abc** 替换为 **xyz**。 你会怎么做呢?
|
||||
|
||||
很简单。
|
||||
|
||||
```
|
||||
$ mmv '*abc*' '#1xyz#2'
|
||||
|
||||
```
|
||||
|
||||
请注意,在上面的示例中,模式被单引号括起来了。
|
||||
|
||||
让我们检查下 “abc” 是否实际上被替换为 “xyz”。
|
||||
|
||||
```
|
||||
$ ls
|
||||
xyzd1.txt xyzd2.txt xyzd3.txt
|
||||
|
||||
```
|
||||
|
||||
看到没? 文件 **abcd1.txt**,**abcd2.txt** 和 **abcd3.txt** 已经重命名为 **xyzd1.txt**,**xyzd2.txt** 和 **xyzd3.txt**。
|
||||
|
||||
mmv 命令的另一个值得注意的功能是你可以使用 **-n** 选项打印输出而不是重命名文件,如下所示。
|
||||
|
||||
```
|
||||
$ mmv -n a\* b\#1
|
||||
a1.txt -> b1.txt
|
||||
a2.txt -> b2.txt
|
||||
a3.txt -> b3.txt
|
||||
|
||||
```
|
||||
|
||||
这样,你可以在重命名文件之前简单地验证 mmv 命令实际执行的操作。
|
||||
|
||||
有关更多详细信息,请参阅 man 页面。
|
||||
|
||||
```
|
||||
$ man mmv
|
||||
|
||||
```
|
||||
|
||||
**更新:**
|
||||
|
||||
**Thunar 文件管理器**默认具有内置**批量重命名**选项。 如果你正在使用thunar,那么重命名文件要比使用mmv命令容易得多。
|
||||
|
||||
Thunar在大多数Linux发行版的默认仓库库中都可用。
|
||||
|
||||
要在基于Arch的系统上安装它,请运行:
|
||||
|
||||
```
|
||||
$ sudo pacman -S thunar
|
||||
```
|
||||
|
||||
在 RHEL,CentOS 上:
|
||||
```
|
||||
$ sudo yum install thunar
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
```
|
||||
$ sudo dnf install thunar
|
||||
|
||||
```
|
||||
|
||||
在 openSUSE 上:
|
||||
```
|
||||
$ sudo zypper install thunar
|
||||
|
||||
```
|
||||
|
||||
在 Debian,Ubuntu,Linux Mint 上:
|
||||
```
|
||||
$ sudo apt-get install thunar
|
||||
|
||||
```
|
||||
|
||||
安装后,你可以从菜单或应用程序启动器中启动批量重命名程序。 要从终端启动它,请使用以下命令:
|
||||
|
||||
```
|
||||
$ thunar -B
|
||||
|
||||
```
|
||||
|
||||
批量重命名就是这么回事。
|
||||
|
||||
![][1]
|
||||
|
||||
单击加号,然后选择要重命名的文件列表。 批量重命名可以重命名文件的名称,文件的后缀或者同事重命名文件的名称和后缀。 Thunar 目前支持以下批量重命名:
|
||||
|
||||
- 插入日期或时间
|
||||
- 插入或覆盖
|
||||
- 编号
|
||||
- 删除字符
|
||||
- 搜索和替换
|
||||
- 大写或小写
|
||||
|
||||
当你从选项列表中选择其中一个条件时,你将在“新名称”列中看到更改的预览,如下面的屏幕截图所示。
|
||||
|
||||
![][2]
|
||||
|
||||
选择条件后,单击**重命名文件**选项来重命名文件。
|
||||
|
||||
你还可以通过选择两个或更多文件从 Thunar 中打开批量重命名器。 选择文件后,按F2或右键单击并选择**重命名**。
|
||||
|
||||
嗯,这就是本次的所有内容了。希望有所帮助。更多干货即将到来。敬请关注!
|
||||
|
||||
祝快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-rename-multiple-files-at-once-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: http://www.ostechnix.com/wp-content/uploads/2018/06/bulk-rename.png
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2018/06/bulk-rename-1.png
|
||||
177
translated/tech/20180924 Why Linux users should try Rust.md
Normal file
177
translated/tech/20180924 Why Linux users should try Rust.md
Normal file
@ -0,0 +1,177 @@
|
||||
为什么linux用户应该尝试Rust
|
||||
======
|
||||
|
||||

|
||||
|
||||
Rust是一种相当年轻和现代的编程语言,因为具有许多功能,所以它非常灵活而且非常安全。 数据显示它正在变得非常受欢迎,连续三年在Stack Overflow开发者调查中获得“最受喜爱的编程语言”的第一名 - [2016] [1],[2017] [2]和[2018] [3]。
|
||||
|
||||
Rust也是开源语言的一种,它具有一系列特功能,使得它可以适应许多不同的编程项目。 它最初源于2006年Mozilla员工的个人项目,几年后(2009年)被Mozilla收集为特别项目,然后在2010年宣布供公众使用。
|
||||
|
||||
Rust程序运行速度极快,可防止段错误,并保证线程安全。 这些属性使该语言极大地吸引了专注于应用程序安全性的开发人员。 Rust也是一种非常易读的语言,可用于从简单程序到非常大而复杂的项目。
|
||||
|
||||
Rust 优点:
|
||||
|
||||
* 内存安全—— Rust不会受到悬空指针,缓冲区溢出或其他与内存相关的错误的影响。 它提供内存安全,无回收垃圾。
|
||||
* 通用 - Rust是适用于任何类型编程的适当语言
|
||||
* 快速 - Rust在性能上与C / C ++相当,但具有更好的安全功能。
|
||||
* 高效 - Rust是为了便于并发编程而构建的。
|
||||
* 面向项目 - Rust具有内置的依赖关系和构建管理系统Cargo。
|
||||
* 得到很好的支持 - Rust有一个令人印象深刻的[支持社区] [4]。
|
||||
|
||||
|
||||
|
||||
Rust还强制执行RAII(资源获取初始化)。 这意味着当一个对象超出范围时,将调用其析构函数并释放其资源,从而提供防止资源泄漏的屏蔽。 它提供了功能抽象和一个伟大的[类型系统] [5]以及速度和数学健全性。
|
||||
|
||||
简而言之,Rust是一种令人印象深刻的系统编程语言,具有其他大多数语言所缺乏的功能,使其成为C,C++和Objective-C等多年来一直被使用的语言的有力竞争者。
|
||||
|
||||
### 安装 Rust
|
||||
|
||||
安装Rust是一个相当简单的过程。
|
||||
|
||||
```
|
||||
$ curl https://sh.rustup.rs -sSf | sh
|
||||
```
|
||||
|
||||
安装Rust后,使用rustc** --version **或** which **命令显示版本信息。
|
||||
|
||||
```
|
||||
$ which rustc
|
||||
rustc 1.27.2 (58cc626de 2018-07-18)
|
||||
$ rustc --version
|
||||
rustc 1.27.2 (58cc626de 2018-07-18)
|
||||
```
|
||||
|
||||
### Rust入门
|
||||
|
||||
Rust即使是最简单的代码也与你之前使用过的语言的输入完全不同。
|
||||
|
||||
```
|
||||
$ cat hello.rs
|
||||
fn main() {
|
||||
// Print a greeting
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
在这些行中,我们正在设置一个函数(main),添加一个描述该函数的注释,并使用println语句来创建输出。 您可以使用下面显示的命令编译然后运行这样的程序。
|
||||
|
||||
```
|
||||
$ rustc hello.rs
|
||||
$ ./hello
|
||||
Hello, world!
|
||||
```
|
||||
|
||||
你可以创建一个“项目”(通常仅用于比这个更复杂的程序!)来保持代码的有序性。
|
||||
|
||||
```
|
||||
$ mkdir ~/projects
|
||||
$ cd ~/projects
|
||||
$ mkdir hello_world
|
||||
$ cd hello_world
|
||||
```
|
||||
|
||||
请注意,即使是简单的程序,一旦编译,就会变成相当大的可执行文件。
|
||||
|
||||
```
|
||||
$ ./hello
|
||||
Hello, world!
|
||||
$ ls -l hello*
|
||||
-rwxrwxr-x 1 shs shs 5486784 Sep 23 19:02 hello <== executable
|
||||
-rw-rw-r-- 1 shs shs 68 Sep 23 15:25 hello.rs
|
||||
```
|
||||
|
||||
当然,这只是一个开始且传统的“Hello, world!” 程序。 Rust语言具有一系列功能,可帮助你快速进入高级编程技能。
|
||||
|
||||
### 学习 Rust
|
||||
|
||||
![rust programming language book cover][6]
|
||||
No Starch Press
|
||||
|
||||
Steve Klabnik和Carol Nichols(2018)的Rust Programming Language一书提供了学习Rust的最佳方法之一。 这本书由核心开发团队的两名成员撰写,可从[No Starch Press] [7]出版社获得纸制书或者从[rust-lang.org] [8]获得电子书。 它已经成为Rust开发者社区中的参考书。
|
||||
|
||||
在所涉及的众多主题中,你将了解这些高级主题:
|
||||
|
||||
* 所有权和borrowing
|
||||
|
||||
* 安全保障
|
||||
|
||||
* 测试和错误处理
|
||||
|
||||
* 智能指针和多线程
|
||||
|
||||
* 高级模式匹配
|
||||
|
||||
* 使用Cargo(内置包管理器)
|
||||
|
||||
* 使用Rust的高级编译器
|
||||
|
||||
|
||||
|
||||
#### 目录
|
||||
|
||||
|
||||
```
|
||||
前言(Nicholas Matsakis和Aaron Turon编写)
|
||||
致谢
|
||||
介绍
|
||||
第1章:新手入门
|
||||
第2章:猜谜游戏
|
||||
第3章:通用编程概念
|
||||
第4章:了解所有权
|
||||
第五章:结构
|
||||
第6章:枚举和模式匹配
|
||||
第7章:模块
|
||||
第8章:常见集合
|
||||
第9章:错误处理
|
||||
第10章:通用类型,特征和生命周期
|
||||
第11章:测试
|
||||
第12章:输入/输出项目
|
||||
第13章:迭代器和闭包
|
||||
第14章:关于货物和Crates.io的更多信息
|
||||
第15章:智能指针
|
||||
第16章:并发
|
||||
第17章:Rust面向对象?
|
||||
第18章:模式
|
||||
第19章:关于生命周期的更多信息
|
||||
第20章:高级类型系统功能
|
||||
附录A:关键字
|
||||
附录B:运算符和符号
|
||||
附录C:可衍生的特征
|
||||
附录D:宏
|
||||
索引
|
||||
|
||||
```
|
||||
|
||||
[Rust编程语言] [7]将你从基本安装和语言语法带到复杂的主题,例如模块,错误处理,crates(与其他语言中的'library'或'package'同义),模块(允许你 将你的代码分配到包箱本身,生命周期等。
|
||||
|
||||
可能最重要的是,本书可以让您从基本的编程技巧转向构建和编译复杂,安全且非常有用的程序。
|
||||
|
||||
### 结束
|
||||
|
||||
如果你已经准备好用一种非常值得花时间和精力学习并且越来越受欢迎的语言进行一些严肃的编程,那么Rust是一个不错的选择!
|
||||
|
||||
加入[Facebook] [9]和[LinkedIn] [10]上的Network World社区,评论最重要的话题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.networkworld.com/article/3308162/linux/why-you-should-try-rust.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://insights.stackoverflow.com/survey/2016#technology-most-loved-dreaded-and-wanted
|
||||
[2]: https://insights.stackoverflow.com/survey/2017#technology-most-loved-dreaded-and-wanted-languages
|
||||
[3]: https://insights.stackoverflow.com/survey/2018#technology-most-loved-dreaded-and-wanted-languages
|
||||
[4]: https://www.rust-lang.org/en-US/community.html
|
||||
[5]: https://doc.rust-lang.org/reference/type-system.html
|
||||
[6]: https://images.idgesg.net/images/article/2018/09/rust-programming-language_book-cover-100773679-small.jpg
|
||||
[7]: https://nostarch.com/Rust
|
||||
[8]: https://doc.rust-lang.org/book/2018-edition/index.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
Loading…
Reference in New Issue
Block a user