mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
19117ecabf
@ -3,15 +3,15 @@ Linux 局域网路由新手指南:第 2 部分
|
||||
|
||||

|
||||
|
||||
上周 [我们学习了 IPv4 地址][1] 和如何使用管理员不可或缺的工具 —— ipcalc,今天我们继续学习更精彩的内容:局域网路由器。
|
||||
上周 [我们学习了 IPv4 地址][1] 和如何使用管理员不可或缺的工具 —— `ipcalc`,今天我们继续学习更精彩的内容:局域网路由器。
|
||||
|
||||
VirtualBox 和 KVM 是测试路由的好工具,在本文中的所有示例都是在 KVM 中执行的。如果你喜欢使用物理硬件去做测试,那么你需要三台计算机:一台用作路由器,另外两台用于表示两个不同的网络。你也需要两台以太网交换机和相应的线缆。
|
||||
|
||||
我们假设示例是一个有线以太局域网,为了更符合真实使用场景,我们将假设有一些桥接的无线接入点,当然我并不会使用这些无线接入点做任何事情。(我也不会去尝试所有的无线路由器,以及使用一个移动宽带设备连接到以太网的局域网口进行混合组网,因为它们需要进一步的安装和设置)
|
||||
我们假设这个示例是一个有线以太局域网,为了更符合真实使用场景,我们将假设有一些桥接的无线接入点,当然我并不会使用这些无线接入点做任何事情。(我也不会去尝试所有的无线路由器,以及使用一个移动宽带设备连接到以太网的局域网口进行混合组网,因为它们需要进一步的安装和设置)
|
||||
|
||||
### 网段
|
||||
|
||||
最简单的网段是两台计算机连接在同一个交换机上的相同地址空间中。这样两台计算机不需要路由器就可以相互通讯。这就是我们常说的术语 —— “广播域”,它表示所有在相同的网络中的一组主机。它们可能连接到一台单个的以太网交换机上,也可能是连接到多台交换机上。一个广播域可以包括通过以太网桥连接的两个不同的网络,通过网桥可以让两个网络像一个单个网络一样运转。无线访问点一般是桥接到有线以太网上。
|
||||
最简单的网段是两台计算机连接在同一个交换机上的相同地址空间中。这样两台计算机不需要路由器就可以相互通讯。这就是我们常说的术语 —— “广播域”,它表示所有在相同的网络中的一组主机。它们可能连接到一台单个的以太网交换机上,也可能是连接到多台交换机上。一个广播域可以包括通过以太网桥连接的两个不同的网络,通过网桥可以让两个网络像一个单个网络一样运转。无线访问点一般是桥接到有线以太网上。
|
||||
|
||||
一个广播域仅当在它们通过一台网络路由器连接的情况下,才可以与不同的广播域进行通讯。
|
||||
|
||||
@ -22,12 +22,13 @@ VirtualBox 和 KVM 是测试路由的好工具,在本文中的所有示例都
|
||||
一个广播域需要一台路由器才可以与其它广播域通讯。我们使用两台计算机和 `ip` 命令来解释这些。我们的两台计算机是 192.168.110.125 和 192.168.110.126,它们都插入到同一台以太网交换机上。在 VirtualBox 或 KVM 中,当你配置一个新网络的时候会自动创建一个虚拟交换机,因此,当你分配一个网络到虚拟虚拟机上时,就像是插入一个交换机一样。使用 `ip addr show` 去查看你的地址和网络接口名字。现在,这两台主机可以互 ping 成功。
|
||||
|
||||
现在,给其中一台主机添加一个不同网络的地址:
|
||||
|
||||
```
|
||||
# ip addr add 192.168.120.125/24 dev ens3
|
||||
|
||||
```
|
||||
|
||||
你可以指定一个网络接口名字,在示例中它的名字是 ens3。这不需要去添加一个网络前缀,在本案例中,它是 /24,但是显式地添加它并没有什么坏处。你可以使用 `ip` 命令去检查你的配置。下面的示例输出为了清晰其见进行了删减:
|
||||
你可以指定一个网络接口名字,在示例中它的名字是 `ens3`。这不需要去添加一个网络前缀,在本案例中,它是 `/24`,但是显式地添加它并没有什么坏处。你可以使用 `ip` 命令去检查你的配置。下面的示例输出为了清晰其见进行了删减:
|
||||
|
||||
```
|
||||
$ ip addr show
|
||||
ens3:
|
||||
@ -35,7 +36,6 @@ ens3:
|
||||
valid_lft 875sec preferred_lft 875sec
|
||||
inet 192.168.120.125/24 scope global ens3
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
```
|
||||
|
||||
主机在 192.168.120.125 上可以 ping 它自己(`ping 192.168.120.125`),这是对你的配置是否正确的一个基本校验,这个时候第二台计算机就已经不能 ping 通那个地址了。
|
||||
@ -45,30 +45,27 @@ ens3:
|
||||
* 第一个网络:192.168.110.0/24
|
||||
* 第二个网络:192.168.120.0/24
|
||||
|
||||
|
||||
|
||||
接下来你的路由器必须配置去转发数据包。数据包转发默认是禁用的,你可以使用 `sysctl` 命令去检查它的配置:
|
||||
|
||||
```
|
||||
$ sysctl net.ipv4.ip_forward
|
||||
net.ipv4.ip_forward = 0
|
||||
|
||||
```
|
||||
|
||||
0 意味着禁用,使用如下的命令去启用它:
|
||||
`0` 意味着禁用,使用如下的命令去启用它:
|
||||
|
||||
```
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
```
|
||||
|
||||
接下来配置你的另一台主机做为第二个网络的一部分,你可以通过将原来在 192.168.110.0/24 的网络中的一台主机分配到 192.168.120.0/24 虚拟网络中,然后重新启动两个 “网络” 主机,注意不是路由器。(或者重启动网络;我年龄大了还有点懒,我记不住那些重启服务的奇怪命令,还不如重启网络来得干脆。)重启后各台机器的地址应该如下所示:
|
||||
|
||||
* 主机 1: 192.168.110.125
|
||||
* 主机 2: 192.168.120.135
|
||||
* 路由器: 192.168.110.126 and 192.168.120.136
|
||||
|
||||
接下来配置你的另一台主机做为第二个网络的一部分,你可以通过将原来在 192.168.110.0/24 的网络中的一台主机分配到 192.168.120.0/24 虚拟网络中,然后重新启动两个 “连网的” 主机,注意不是路由器。(或者重启动主机上的网络服务;我年龄大了还有点懒,我记不住那些重启服务的奇怪命令,还不如重启主机来得干脆。)重启后各台机器的地址应该如下所示:
|
||||
|
||||
* 主机 1: 192.168.110.125
|
||||
* 主机 2: 192.168.120.135
|
||||
* 路由器: 192.168.110.126 和 192.168.120.136
|
||||
|
||||
现在可以去随意 ping 它们,可以从任何一台计算机上 ping 到任何一台其它计算机上。使用虚拟机和各种 Linux 发行版做这些事时,可能会产生一些意想不到的问题,因此,有时候 ping 的通,有时候 ping 不通。不成功也是一件好事,这意味着你需要动手去创建一条静态路由。首先,查看已经存在的路由表。主机 1 和主机 2 的路由表如下所示:
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
@ -82,26 +79,25 @@ default via 192.168.120.1 dev ens3 proto static metric 101
|
||||
src 192.168.110.126 metric 100
|
||||
192.168.120.0/24 dev ens9 proto kernel scope link
|
||||
src 192.168.120.136 metric 100
|
||||
|
||||
```
|
||||
|
||||
这显示了我们使用的由 KVM 分配的缺省路由。169.* 地址是自动链接的本地地址,我们不去管它。接下来我们看两条路由,这两条路由指向到我们的路由器。你可以有多条路由,在这个示例中我们将展示如何在主机 1 上添加一个非默认路由:
|
||||
|
||||
```
|
||||
# ip route add 192.168.120.0/24 via 192.168.110.126 dev ens3
|
||||
|
||||
```
|
||||
|
||||
这意味着主机1 可以通过路由器接口 192.168.110.126 去访问 192.168.110.0/24 网络。看一下它们是如何工作的?主机1 和路由器需要连接到相同的地址空间,然后路由器转发到其它的网络。
|
||||
这意味着主机 1 可以通过路由器接口 192.168.110.126 去访问 192.168.110.0/24 网络。看一下它们是如何工作的?主机 1 和路由器需要连接到相同的地址空间,然后路由器转发到其它的网络。
|
||||
|
||||
以下的命令去删除一条路由:
|
||||
|
||||
```
|
||||
# ip route del 192.168.120.0/24
|
||||
|
||||
```
|
||||
|
||||
在真实的案例中,你不需要像这样手动配置一台路由器,而是使用一个路由器守护程序,并通过 DHCP 做路由器通告,但是理解基本原理很重要。接下来我们将学习如何去配置一个易于使用的路由器守护程序来为你做这些事情。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][2] 来学习更多 Linux 的知识。
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][2] 来学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -109,10 +105,10 @@ via: https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginne
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
[1]:https://linux.cn/article-9657-1.html
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -2,7 +2,8 @@
|
||||
======
|
||||
|
||||

|
||||
**Font Finder** 是旧的 [**Typecatcher**][1] 的 Rust 实现,用于从[**Google 的字体存档**][2]中轻松搜索和安装 Google Web 字体。它可以帮助你在 Linux 桌面上安装数百种免费和开源字体。如果你正在为你的 Web 项目和应用以及其他任何地方寻找好看的字体,Font Finder 可以轻松地为你提供。它是用 Rust 编程语言编写的免费开源 GTK3 应用程序。与使用 Python 编写的 Typecatcher 不同,Font Finder 可以按类别过滤字体,没有 Python 运行时依赖关系,并且有更好的性能和资源消耗。
|
||||
|
||||
Font Finder 是旧的 [Typecatcher][1] 的 Rust 实现,用于从 [Google 的字体存档][2]中轻松搜索和安装 Google Web 字体。它可以帮助你在 Linux 桌面上安装数百种免费和开源字体。如果你正在为你的 Web 项目和应用以及其他任何地方寻找好看的字体,Font Finder 可以轻松地为你提供。它是用 Rust 编程语言编写的自由、开源的 GTK3 应用程序。与使用 Python 编写的 Typecatcher 不同,Font Finder 可以按类别过滤字体,没有 Python 运行时依赖关系,并且有更好的性能和更低的资源消耗。
|
||||
|
||||
在这个简短的教程中,我们将看到如何在 Linux 中安装和使用 Font Finder。
|
||||
|
||||
@ -11,25 +12,25 @@
|
||||
由于 Fond Finder 是使用 Rust 语言编写的,因此你需要向下面描述的那样在系统中安装 Rust。
|
||||
|
||||
安装 Rust 后,运行以下命令安装 Font Finder:
|
||||
|
||||
```
|
||||
$ cargo install fontfinder
|
||||
|
||||
```
|
||||
|
||||
Font Finder 也可以从 [**flatpak app**][3] 安装。首先在你的系统中安装 Flatpak,如下面的链接所述。
|
||||
Font Finder 也可以从 [flatpak app][3] 安装。首先在你的系统中安装 Flatpak,如下面的链接所述。
|
||||
|
||||
然后,使用命令安装 Font Finder:
|
||||
|
||||
```
|
||||
$ flatpak install flathub io.github.mmstick.FontFinder
|
||||
|
||||
```
|
||||
|
||||
### 在 Linux 中使用 Font Finder 搜索和安装 Google Web 字体
|
||||
|
||||
你可以从程序启动器启动 Font Finder,也可以运行以下命令启动它。
|
||||
|
||||
```
|
||||
$ flatpak run io.github.mmstick.FontFinder
|
||||
|
||||
```
|
||||
|
||||
这是 Font Finder 默认界面的样子。
|
||||
@ -42,7 +43,7 @@ $ flatpak run io.github.mmstick.FontFinder
|
||||
|
||||
![][6]
|
||||
|
||||
要安装字体,只需选择它并点击顶部的 **Install** 按钮即可。
|
||||
要安装字体,只需选择它并点击顶部的 “Install” 按钮即可。
|
||||
|
||||
![][7]
|
||||
|
||||
@ -50,7 +51,7 @@ $ flatpak run io.github.mmstick.FontFinder
|
||||
|
||||
![][8]
|
||||
|
||||
同样,要删除字体,只需从 Font Finder 面板中选择它并单击 **Uninstall** 按钮。就这么简单!
|
||||
同样,要删除字体,只需从 Font Finder 面板中选择它并单击 “Uninstall” 按钮。就这么简单!
|
||||
|
||||
左上角的设置按钮(齿轮按钮)提供了切换到暗色预览的选项。
|
||||
|
||||
@ -62,8 +63,6 @@ $ flatpak run io.github.mmstick.FontFinder
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/font-finder-easily-search-and-install-google-web-fonts-in-linux/
|
||||
@ -71,7 +70,7 @@ via: https://www.ostechnix.com/font-finder-easily-search-and-install-google-web-
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
LikeCoin,一种给开放式许可的内容创作者的加密货币
|
||||
======
|
||||
|
||||
> 在共创协议下授权作品和挣钱这二者不再是一种争议。
|
||||
|
||||

|
||||
|
||||
传统观点认为,作家、摄影师、艺术家和其他创作者在<ruby>共创协议<rt>Creative Commons</rt></ruby>和其他开放许可下免费共享内容的不会得到报酬。这意味着大多数独立创作者无法通过在互联网上发布他们的作品来赚钱。而现在有了 [LikeCoin][1]:一个新的开源项目,旨在使这个让艺术家们经常为了贡献而不得不妥协或牺牲的常识成为过去。
|
||||
|
||||
LikeCoin 协议旨在通过创意内容获利,以便创作者可以专注于创造出色的内容而不是出售它。
|
||||
|
||||
该协议同样基于去中心化技术,它可以跟踪何时使用内容,并使用 LikeCoin 这种 [以太坊 ERC-20][2] 加密货币通证来奖励其创作者。它通过“<ruby>创造性共识<rt>Proof of Creativity</rt></ruby>”算法进行操作,该算法一部分根据作品收到多少个“喜欢”,一部分根据有多少作品衍生自它而分配 LikeCoin。由于开放式授权的内容有更多机会被重复使用并获得 LikeCoin 令牌,因此系统鼓励内容创作者在<ruby>共创协议<rt>Creative Commons</rt></ruby>许可下发布。
|
||||
|
||||
### 如何运作的
|
||||
|
||||
当通过 LikeCoin 协议上传创意片段时,内容创作者也将包括作品的元数据,包括作者信息及其 InterPlanetary 关联数据([IPLD][3])。这些数据构成了衍生作品的家族图谱;我们称作品与其衍生品之间的关系为“内容足迹”。这种结构使得内容的继承树可以很容易地追溯到原始作品。
|
||||
|
||||
LikeCoin 通证会使用作品的衍生历史记录的信息来将其分发给创作者。由于所有创意作品都包含作者钱包的元数据,因此相应的 LikeCoin 份额可以通过算法计算并分发。
|
||||
|
||||
LikeCoin 可以通过两种方式获得奖励:要么由想要通过支付给内容创建者来表示赞赏的个人直接给予,或通过 Creators Pool 收集观众的“赞”的并根据内容的 LikeRank 分配 LikeCoin。基于在 LikeCoin 协议中的内容追踪,LikeRank 衡量作品重要性(或者我们在这个场景下定义的创造性)。一般来说,一副作品有越多的衍生作品,创意内容的创新就越多,内容就会有更高的 LikeRank。 LikeRank 是内容创新性的量化者。
|
||||
|
||||
### 如何参与?
|
||||
|
||||
LikeCoin 仍然非常新,我们期望在 2018 年晚些时候推出我们的第一个去中心化程序来奖励<ruby>共创协议<rt>Creative Commons</rt></ruby>的内容,并与更大的社区无缝连接。
|
||||
|
||||
LikeCoin 的大部分代码都可以在 [LikeCoin GitHub][4] 仓库中通过 [GPL 3.0 许可证][5]访问。由于它仍处于积极开发阶段,一些实验代码尚未公开,但我们会尽快完成。
|
||||
|
||||
我们欢迎功能请求、拉取请求、复刻和星标。请参与我们在 Github 上的开发,并加入我们在 [Telegram][6] 的讨论组。我们同样在 [Medium][7]、[Facebook][8]、[Twitter][9] 和我们的网站 [like.co][1] 发布关于我们进展的最新消息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/likecoin
|
||||
|
||||
作者:[Kin Ko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ckxpress
|
||||
[1]:https://like.co/
|
||||
[2]:https://en.wikipedia.org/wiki/ERC20
|
||||
[3]:https://ipld.io/
|
||||
[4]:https://github.com/likecoin
|
||||
[5]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[6]:https://t.me/likecoin
|
||||
[7]:http://medium.com/likecoin
|
||||
[8]:http://fb.com/likecoin.foundation
|
||||
[9]:https://twitter.com/likecoin_fdn
|
||||
@ -0,0 +1,75 @@
|
||||
Linux vs. Unix: What's the difference?
|
||||
======
|
||||

|
||||
|
||||
If you are a software developer in your 20s or 30s, you've grown up in a world dominated by Linux. It has been a significant player in the data center for decades, and while it's hard to find definitive operating system market share reports, Linux's share of data center operating systems could be as high as 70%, with Windows variants carrying nearly all the remaining percentage. Developers using any major public cloud can expect the target system will run Linux. Evidence that Linux is everywhere has grown in recent years when you add in Android and Linux-based embedded systems in smartphones, TVs, automobiles, and many other devices.
|
||||
|
||||
Even so, most software developers, even those who have grown up during this venerable "Linux revolution" have at least heard of Unix. It sounds similar to Linux, and you've probably heard people use these terms interchangeably. Or maybe you've heard Linux called a "Unix-like" operating system.
|
||||
|
||||
So, what is this Unix? The caricatures speak of wizard-like "graybeards" sitting behind glowing green screens, writing C code and shell scripts, powered by old-fashioned, drip-brewed coffee. But Unix has a much richer history beyond those bearded C programmers from the 1970s. While articles detailing the history of Unix and "Unix vs. Linux" comparisons abound, this article will offer a high-level background and a list of major differences between these complementary worlds.
|
||||
|
||||
### Unix's beginnings
|
||||
|
||||
The history of Unix begins at AT&T Bell Labs in the late 1960s with a small team of programmers looking to write a multi-tasking, multi-user operating system for the PDP-7. Two of the most notable members of this team at the Bell Labs research facility were Ken Thompson and Dennis Ritchie. While many of Unix's concepts were derivative of its predecessor ([Multics][1]), the Unix team's decision early in the 1970s to rewrite this small operating system in the C language is what separated Unix from all others. At the time, operating systems were rarely, if ever, portable. Instead, by nature of their design and low-level source language, operating systems were tightly linked to the hardware platform for which they had been authored. By refactoring Unix on the C programming language, Unix could now be ported to many hardware architectures.
|
||||
|
||||
In addition to this new portability, which allowed Unix to quickly expand beyond Bell Labs to other research, academic, and even commercial uses, several key of the operating system's design tenets were attractive to users and programmers. For one, Ken Thompson's [Unix philosophy][2] became a powerful model of modular software design and computing. The Unix philosophy recommended utilizing small, purpose-built programs in combination to do complex overall tasks. Since Unix was designed around files and pipes, this model of "piping" inputs and outputs of programs together into a linear set of operations on the input is still in vogue today. In fact, the current cloud functions-as-a-service (FaaS)/serverless computing model owes much of its heritage to the Unix philosophy.
|
||||
|
||||
### Rapid growth and competition
|
||||
|
||||
Through the late 1970s and 80s, Unix became the root of a family tree that expanded across research, academia, and a growing commercial Unix operating system business. Unix was not open source software, and the Unix source code was licensable via agreements with its owner, AT&T. The first known software license was sold to the University of Illinois in 1975.
|
||||
|
||||
Unix grew quickly in academia, with Berkeley becoming a significant center of activity, given Ken Thompson's sabbatical there in the '70s. With all the activity around Unix at Berkeley, a new delivery of Unix software was born: the Berkeley Software Distribution, or BSD. Initially, BSD was not an alternative to AT&T's Unix, but an add-on with additional software and capabilities. By the time 2BSD (the Second Berkeley Software Distribution) arrived in 1979, Bill Joy, a Berkeley grad student, had added now-famous programs such as `vi` and the C shell (/bin/csh).
|
||||
|
||||
In addition to BSD, which became one of the most popular branches of the Unix family, Unix's commercial offerings exploded through the 1980s and into the '90s with names like HP-UX, IBM's AIX, Sun's Solaris, Sequent, and Xenix. As the branches grew from the original root, the "[Unix wars][3]" began, and standardization became a new focus for the community. The POSIX standard was born in 1988, as well as other standardization follow-ons via The Open Group into the 1990s.
|
||||
|
||||
Around this time AT&T and Sun released System V Release 4 (SVR4), which was adopted by many commercial vendors. Separately, the BSD family of operating systems had grown over the years, leading to some open source variations that were released under the now-familiar [BSD license][4] . This included FreeBSD, OpenBSD, and NetBSD, each with a slightly different target market in the Unix server industry. These Unix variants continue to have some usage today, although many have seen their server market share dwindle into the single digits (or lower). BSD may have the largest install base of any modern Unix system today. Also, every Apple Mac hardware unit shipped in recent history can be claimed by BSD, as its OS X (now macOS) operating system is a BSD-derivative.
|
||||
|
||||
While the full history of Unix and its academic and commercial variants could take many more pages, for the sake of our article focus, let's move on to the rise of Linux.
|
||||
|
||||
### Enter Linux
|
||||
|
||||
What we call the Linux operating system today is really the combination of two efforts from the early 1990s. Richard Stallman was looking to create a truly free and open source alternative to the proprietary Unix system. He was working on the utilities and programs under the name GNU, a recursive algorithm meaning "GNU's not Unix!" Although there was a kernel project underway, it turned out to be difficult going, and without a kernel, the free and open source operating system dream could not be realized. It was Linus Torvald's work—producing a working and viable kernel that he called Linux—that brought the complete operating system to life. Given that Linus was using several GNU tools (e.g., the GNU Compiler Collection, or [GCC][5]), the marriage of the GNU tools and the Linux kernel was a perfect match.
|
||||
|
||||
Linux distributions came to life with the components of GNU, the Linux kernel, MIT's X-Windows GUI, and other BSD components that could be used under the open source BSD license. The early popularity of distributions like Slackware and then Red Hat gave the "common PC user" of the 1990s access to the Linux operating system and, with it, many of the proprietary Unix system capabilities and utilities they used in their work or academic lives.
|
||||
|
||||
Because of the free and open source standing of all the Linux components, anyone could create a Linux distribution with a bit of effort, and soon the total number of distros reached into the hundreds. Today, [distrowatch.com][6] lists 312 unique Linux distributions available in some form. Of course, many developers utilize Linux either via cloud providers or by using popular free distributions like Fedora, Canonical's Ubuntu, Debian, Arch Linux, Gentoo, and many other variants. Commercial Linux offerings, which provide support on top of the free and open source components, became viable as many enterprises, including IBM, migrated from proprietary Unix to offering middleware and software solutions atop Linux. Red Hat built a model of commercial support around Red Hat Enterprise Linux, as did German provider SUSE with SUSE Linux Enterprise Server (SLES).
|
||||
|
||||
### Comparing Unix and Linux
|
||||
|
||||
So far, we've looked at the history of Unix and the rise of Linux and the GNU/Free Software Foundation underpinnings of a free and open source alternative to Unix. Let's examine the differences between these two operating systems that share much of the same heritage and many of the same goals.
|
||||
|
||||
From a user experience perspective, not very much is different! Much of the attraction of Linux was the operating system's availability across many hardware architectures (including the modern PC) and ability to use tools familiar to Unix system administrators and users.
|
||||
|
||||
Because of POSIX standards and compliance, software written on Unix could be compiled for a Linux operating system with a usually limited amount of porting effort. Shell scripts could be used directly on Linux in many cases. While some tools had slightly different flag/command-line options between Unix and Linux, many operated the same on both.
|
||||
|
||||
One side note is that the popularity of the macOS hardware and operating system as a platform for development that mainly targets Linux may be attributed to the BSD-like macOS operating system. Many tools and scripts meant for a Linux system work easily within the macOS terminal. Many open source software components available on Linux are easily available through tools like [Homebrew][7].
|
||||
|
||||
The remaining differences between Linux and Unix are mainly related to the licensing model: open source vs. proprietary, licensed software. Also, the lack of a common kernel within Unix distributions has implications for software and hardware vendors. For Linux, a vendor can create a device driver for a specific hardware device and expect that, within reason, it will operate across most distributions. Because of the commercial and academic branches of the Unix tree, a vendor might have to write different drivers for variants of Unix and have licensing and other concerns related to access to an SDK or a distribution model for the software as a binary device driver across many Unix variants.
|
||||
|
||||
As both communities have matured over the past decade, many of the advancements in Linux have been adopted in the Unix world. Many GNU utilities were made available as add-ons for Unix systems where developers wanted features from GNU programs that aren't part of Unix. For example, IBM's AIX offered an AIX Toolbox for Linux Applications with hundreds of GNU software packages (like Bash, GCC, OpenLDAP, and many others) that could be added to an AIX installation to ease the transition between Linux and Unix-based AIX systems.
|
||||
|
||||
Proprietary Unix is still alive and well and, with many major vendors promising support for their current releases well into the 2020s, it goes without saying that Unix will be around for the foreseeable future. Also, the BSD branch of the Unix tree is open source, and NetBSD, OpenBSD, and FreeBSD all have strong user bases and open source communities that may not be as visible or active as Linux, but are holding their own in recent server share reports, with well above the proprietary Unix numbers in areas like web serving.
|
||||
|
||||
Where Linux has shown a significant advantage over proprietary Unix is in its availability across a vast number of hardware platforms and devices. The Raspberry Pi, popular with hobbyists and enthusiasts, is Linux-driven and has opened the door for an entire spectrum of IoT devices running Linux. We've already mentioned Android devices, autos (with Automotive Grade Linux), and smart TVs, where Linux has large market share. Every cloud provider on the planet offers virtual servers running Linux, and many of today's most popular cloud-native stacks are Linux-based, whether you're talking about container runtimes or Kubernetes or many of the serverless platforms that are gaining popularity.
|
||||
|
||||
One of the most revealing representations of Linux's ascendancy is Microsoft's transformation in recent years. If you told software developers a decade ago that the Windows operating system would "run Linux" in 2016, most of them would have laughed hysterically. But the existence and popularity of the Windows Subsystem for Linux (WSL), as well as more recently announced capabilities like the Windows port of Docker, including LCOW (Linux containers on Windows) support, are evidence of the impact that Linux has had—and clearly will continue to have—across the software world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/differences-between-linux-and-unix
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Multics
|
||||
[2]:https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
[3]:https://en.wikipedia.org/wiki/Unix_wars
|
||||
[4]:https://en.wikipedia.org/wiki/BSD_licenses
|
||||
[5]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[6]:https://distrowatch.com/
|
||||
[7]:https://brew.sh/
|
||||
@ -0,0 +1,175 @@
|
||||
The Best Linux Tools for Teachers and Students
|
||||
======
|
||||
Linux is a platform ready for everyone. If you have a niche, Linux is ready to meet or exceed the needs of said niche. One such niche is education. If you are a teacher or a student, Linux is ready to help you navigate the waters of nearly any level of the educational system. From study aids, to writing papers, to managing classes, to running an entire institution, Linux has you covered.
|
||||
|
||||
If you’re unsure how, let me introduce you to a few tools Linux has at the ready. Some of these tools require little to no learning curve, whereas others require a full blown system administrator to install, setup, and manage. We’ll start with the simple and make our way to the complex.
|
||||
|
||||
### Study aids
|
||||
|
||||
Everyone studies a bit differently and every class requires a different type and level of studying. Fortunately, Linux has plenty of study aids. Let’s take a look at a few examples:
|
||||
|
||||
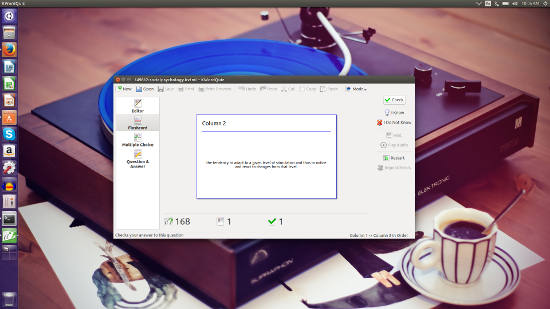
Flash Cards ─ [KWordQuiz][1] (Figure 1) is one of the many flashcard applications available for the Linux platform. KWordQuiz uses the kvtml file format and you can download plenty of pre-made, contributed files to use [here][2]. KWordQuiz is part of the KDE desktop environment, but can be installed on other desktops (KDE dependencies will be installed alongside the flashcard app).
|
||||
|
||||
|
||||
|
||||
### Language tools
|
||||
|
||||
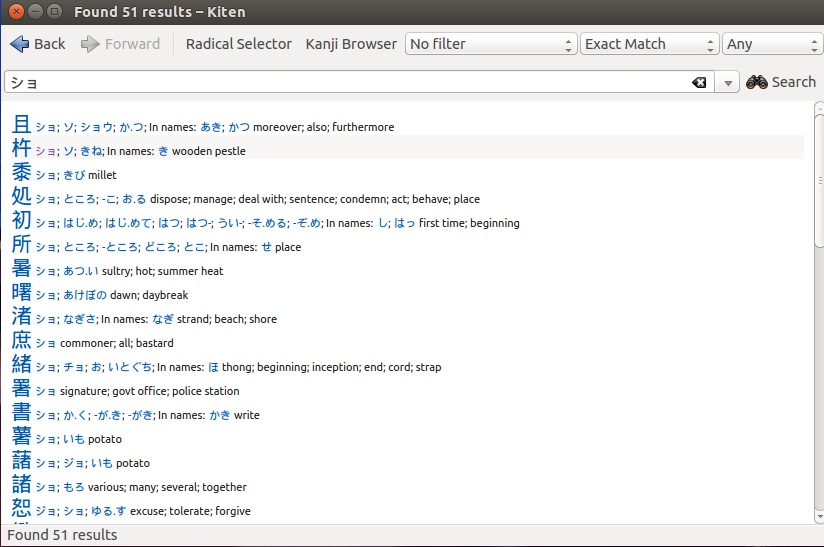
Thanks to an ever-shrinking world, foreign language has become a crucial element of education. You’ll find plenty of language tools, including [Kiten][3] (Figure 2) the kanji browser for the KDE desktop.
|
||||
|
||||
|
||||
|
||||
If Japanese isn’t your language, you could try [Jargon Informatique][4]. This dictionary is entirely in French and, so if you’re new to the language, you might want to stick with something like [Google Translate][5].
|
||||
|
||||
### Writing Aids/ Note Taking
|
||||
|
||||
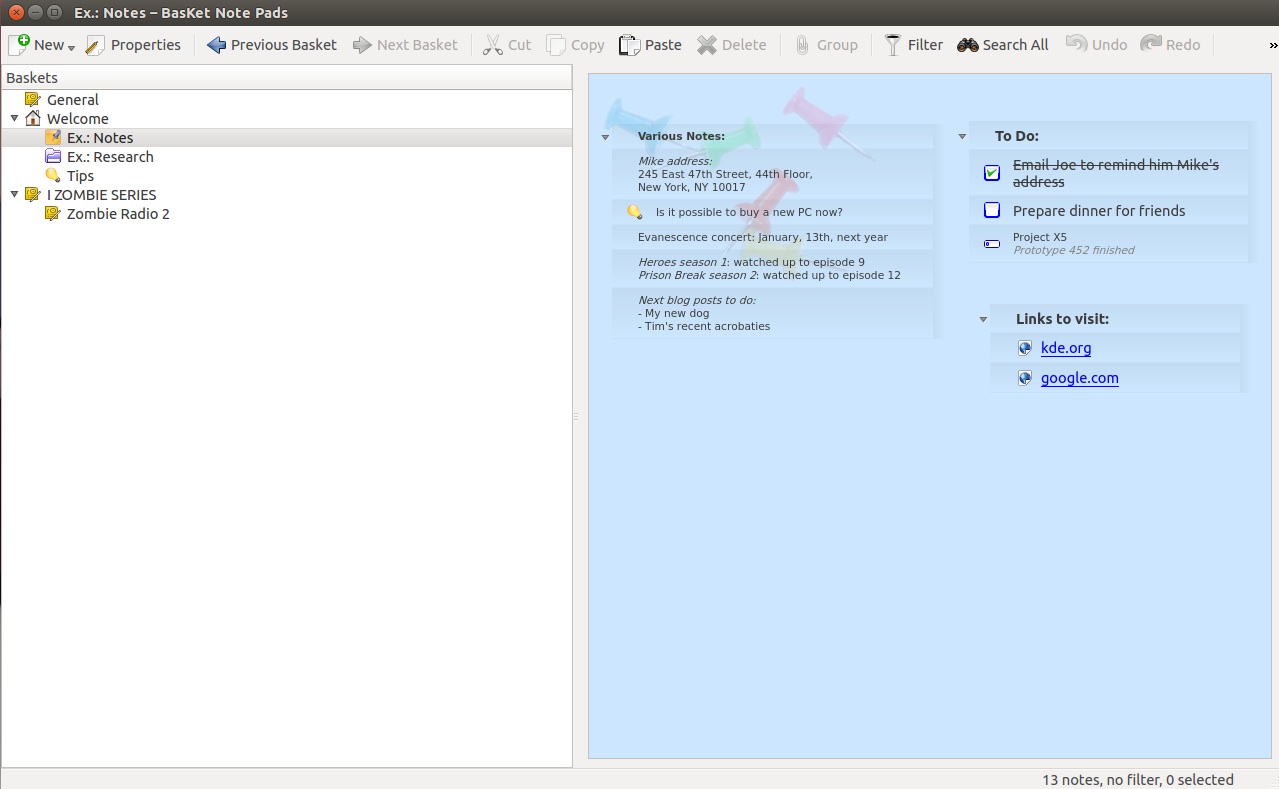
Linux has everything you need to keep notes on a subject and write those term papers. Let’s start with taking notes. If you’re familiar with Microsoft OneNote, you'll love [BasKet Note Pads][6]. With this app, you can create baskets for subjects and add just about anything ─ notes, links, images, cross references (to other baskets ─ Figure 3), app launchers, load from file, and more.
|
||||
|
||||
|
||||
|
||||
You can create baskets that are free-form, so elements can be moved around to suit your need. If you prefer a more ordered feel, create a columned basket to retain those notes walled in.
|
||||
|
||||
Of course, the mother of all writing aids for Linux would be [LibreOffice][7]. The default office suite on most Linux distributions, LibreOffice has your text documents, spreadsheets, presentations, databases, formula, and drawing covered.
|
||||
|
||||
The one caveat to using LibreOffice in an educational environment, is that you will most likely have to save your documents in the MS Office format.
|
||||
|
||||
### Education-specific distribution
|
||||
|
||||
With all of this said about Linux applications geared toward the student in mind, it might behoove you to take a look at one of the distributions created specifically for education. The best in breed is [Edubuntu][8]. This grassroots Linux distribution aims at getting Linux into schools, homes, and communities. Edubuntu uses the default Ubuntu desktop (the Unity shell) and adds the following software:
|
||||
|
||||
|
||||
+ KDE Education Suite
|
||||
|
||||
+ GCompris
|
||||
|
||||
+ Celestia
|
||||
|
||||
+ Tux4Kids
|
||||
|
||||
+ Epoptes
|
||||
|
||||
+ LTSP
|
||||
|
||||
+ GBrainy
|
||||
|
||||
+ and much more.
|
||||
|
||||
Edubuntu isn’t the only game in town. If you’d rather test other education-specific Linux distributions, here’s the short list:
|
||||
|
||||
|
||||
+ Debian-Edu
|
||||
|
||||
+ Fedora Education Spin
|
||||
|
||||
+ Guadalinux-Edu
|
||||
|
||||
+ OpenSuse-Edu
|
||||
|
||||
+ Qimo for Kids
|
||||
|
||||
+ Uberstudent.
|
||||
|
||||
### Classroom/institutional administration
|
||||
|
||||
This is where the Linux platform really shines. There are a number of tools geared specifically for administering. Let’s first look at tools specific to the classroom.
|
||||
|
||||
[iTalc][9] is a powerful didactical environment for the classroom. With this tool, teachers can view and control students desktops (supporting Linux and Windows). The iTalc system allows teachers to view what’s happening on a student's desktop, take control of their desktop, lock their desktop, show demonstrations to desktops, power on/off desktops, send text messages to students' desktops, and much more.
|
||||
|
||||
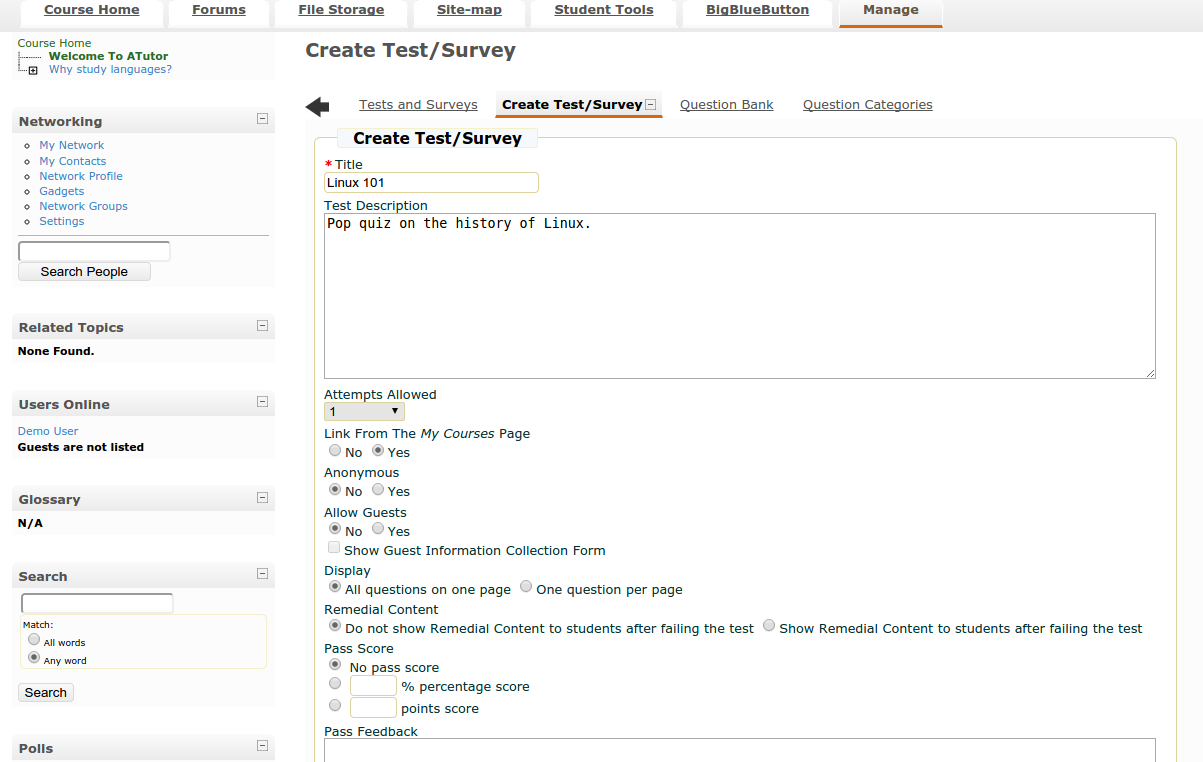
[aTutor][10] (Figure 4) is an open source Learning Management System (LMS) focused on developing online courses and e-learning content. Where aTutor really shines is the creation and management of online tests and quizzes. Of course, aTutor is not limited to testing purposes. With this powerful software, students and teachers can enjoy:
|
||||
|
||||
* Social networking
|
||||
|
||||
* Profiles
|
||||
|
||||
* Messaging
|
||||
|
||||
* Adaptive navigation
|
||||
|
||||
* Work groups
|
||||
|
||||
* File storage
|
||||
|
||||
* Group blogs
|
||||
|
||||
* and much more.
|
||||
|
||||
|
||||
|
||||
|
||||
Course material is easy to create and deploy (you can even assign tests/quizzes to specific study groups).
|
||||
|
||||
[Moodle][11] is one of the most widely used educational management software titles available. With Moodle you can manage, teach, learn, and even participate in your child’s education. This powerhouse software offers collaborative tools for teachers and students, exams, calendars, forums, file management, course management (Figure 5), notifications, progress tracking, mass enrollment, bulk course creation, attendance, and much more.
|
||||
|
||||
|
||||
|
||||
[OpenSIS][12] stands for Open Source Student Information System and does a great job of managing your educational institution. There is a free community edition, but even with the paid version you can look forward to reducing ownership costs for a school district by up to 75 percent (when compared to proprietary solutions).
|
||||
|
||||
OpenSIS includes the following features/modules:
|
||||
|
||||
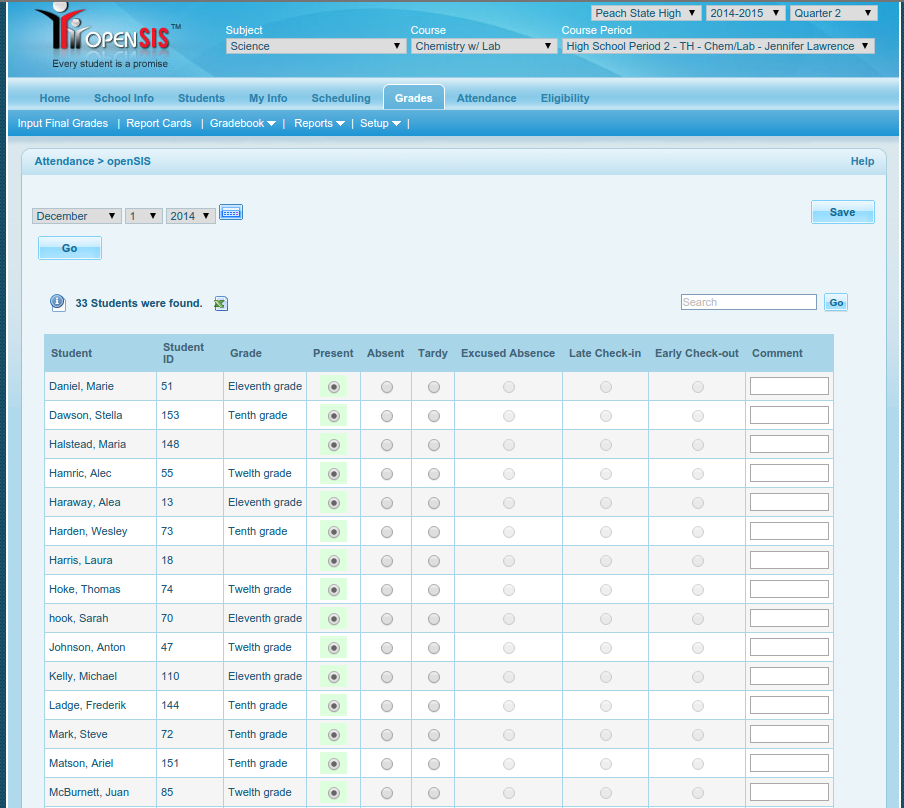
* Attendance (Figure 6)
|
||||
|
||||
* Contact information
|
||||
|
||||
* Student demographics
|
||||
|
||||
* Gradebook
|
||||
|
||||
* Scheduling
|
||||
|
||||
* Health records
|
||||
|
||||
* Report cards.
|
||||
|
||||
|
||||
|
||||
|
||||
There are four editions of OpenSIS. Check out the feature comparison matrix [here][13].
|
||||
|
||||
[vufind][14] is an outstanding library management system that allows students and teachers to easily browse for library resources such as:
|
||||
|
||||
* Catalog Records
|
||||
|
||||
* Locally Cached Journals
|
||||
|
||||
* Digital Library Items
|
||||
|
||||
* Institutional Repository
|
||||
|
||||
* Institutional Bibliography
|
||||
|
||||
* Other Library Collections and Resources.
|
||||
|
||||
|
||||
|
||||
|
||||
The vufind system allows user login where authenticated users can save resources for quick recall and enjoy “more like this” results.
|
||||
|
||||
This list just barely scratches the surface of what is available for Linux in the educational arena. And, as you might expect, each tool is highly customizable and open source ─ so if the software doesn’t precisely meet your needs, you are free (in most cases) to modify the source and change it.
|
||||
|
||||
Linux and education go hand in hand. Whether you are a teacher, a student, or an administrator, you’ll find plenty of tools to help make the institution of education open, flexible, and powerful.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/best-linux-tools-teachers-and-students
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://edu.kde.org/kwordquiz/
|
||||
[2]:http://kde-files.org/index.php?xcontentmode=694
|
||||
[3]:https://edu.kde.org/kiten/
|
||||
[4]:http://jargon.asher256.com/index.php
|
||||
[5]:https://translate.google.com/
|
||||
[6]:http://basket.kde.org/
|
||||
[7]:http://www.libreoffice.com
|
||||
[8]:http://www.edubuntu.org/
|
||||
[9]:http://italc.sourceforge.net/
|
||||
[10]:http://www.atutor.ca/
|
||||
[11]:https://moodle.org/
|
||||
[12]:http://www.opensis.com/
|
||||
[13]:http://www.opensis.com/compare_edition.php
|
||||
[14]:http://vufind-org.github.io/vufind/
|
||||
@ -1,198 +0,0 @@
|
||||
transalting by wyxplus
|
||||
4 Tools for Network Snooping on Linux
|
||||
======
|
||||
Computer networking data has to be exposed, because packets can't travel blindfolded, so join us as we use `whois`, `dig`, `nmcli`, and `nmap` to snoop networks.
|
||||
|
||||
Do be polite and don't run `nmap` on any network but your own, because probing other people's networks can be interpreted as a hostile act.
|
||||
|
||||
### Thin and Thick whois
|
||||
|
||||
You may have noticed that our beloved old `whois` command doesn't seem to give the level of detail that it used to. Check out this example for Linux.com:
|
||||
```
|
||||
$ whois linux.com
|
||||
Domain Name: LINUX.COM
|
||||
Registry Domain ID: 4245540_DOMAIN_COM-VRSN
|
||||
Registrar WHOIS Server: whois.namecheap.com
|
||||
Registrar URL: http://www.namecheap.com
|
||||
Updated Date: 2018-01-10T12:26:50Z
|
||||
Creation Date: 1994-06-02T04:00:00Z
|
||||
Registry Expiry Date: 2018-06-01T04:00:00Z
|
||||
Registrar: NameCheap Inc.
|
||||
Registrar IANA ID: 1068
|
||||
Registrar Abuse Contact Email: abuse@namecheap.com
|
||||
Registrar Abuse Contact Phone: +1.6613102107
|
||||
Domain Status: ok https://icann.org/epp#ok
|
||||
Name Server: NS5.DNSMADEEASY.COM
|
||||
Name Server: NS6.DNSMADEEASY.COM
|
||||
Name Server: NS7.DNSMADEEASY.COM
|
||||
DNSSEC: unsigned
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
There is quite a bit more, mainly annoying legalese. But where is the contact information? It is sitting on whois.namecheap.com (see the third line of output above):
|
||||
```
|
||||
$ whois -h whois.namecheap.com linux.com
|
||||
|
||||
```
|
||||
|
||||
I won't print the output here, as it is very long, containing the Registrant, Admin, and Tech contact information. So what's the deal, Lucille? Some registries, such as .com and .net are "thin" registries, storing a limited subset of domain data. To get complete information use the `-h`, or `--host` option, to get the complete dump from the domain's `Registrar WHOIS Server`.
|
||||
|
||||
Most of the other top-level domains are thick registries, such as .info. Try `whois blockchain.info` to see an example.
|
||||
|
||||
Want to get rid of the obnoxious legalese? Use the `-H` option.
|
||||
|
||||
### Digging DNS
|
||||
|
||||
Use the `dig` command to compare the results from different name servers to check for stale entries. DNS records are cached all over the place, and different servers have different refresh intervals. This is the simplest usage:
|
||||
```
|
||||
$ dig linux.com
|
||||
<<>> DiG 9.10.3-P4-Ubuntu <<>> linux.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<<- opcode: QUERY, status: NOERROR, id: 13694
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 1440
|
||||
;; QUESTION SECTION:
|
||||
;linux.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
linux.com. 10800 IN A 151.101.129.5
|
||||
linux.com. 10800 IN A 151.101.65.5
|
||||
linux.com. 10800 IN A 151.101.1.5
|
||||
linux.com. 10800 IN A 151.101.193.5
|
||||
|
||||
;; Query time: 92 msec
|
||||
;; SERVER: 127.0.1.1#53(127.0.1.1)
|
||||
;; WHEN: Tue Jan 16 15:17:04 PST 2018
|
||||
;; MSG SIZE rcvd: 102
|
||||
|
||||
```
|
||||
|
||||
Take notice of the SERVER: 127.0.1.1#53(127.0.1.1) line near the end of the output. This is your default caching resolver. When the address is localhost, that means there is a DNS server installed on your machine. In my case that is Dnsmasq, which is being used by Network Manager:
|
||||
```
|
||||
$ ps ax|grep dnsmasq
|
||||
2842 ? S 0:00 /usr/sbin/dnsmasq --no-resolv --keep-in-foreground
|
||||
--no-hosts --bind-interfaces --pid-file=/var/run/NetworkManager/dnsmasq.pid
|
||||
--listen-address=127.0.1.1
|
||||
|
||||
```
|
||||
|
||||
The `dig` default is to return A records, which define the domain name. IPv6 has AAAA records:
|
||||
```
|
||||
$ $ dig linux.com AAAA
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:4105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:8105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:c105
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
Checkitout, Linux.com has IPv6 addresses. Very good! If your Internet service provider supports IPv6 then you can connect over IPv6. (Sadly, my overpriced mobile broadband does not.)
|
||||
|
||||
Suppose you make some DNS changes to your domain, or you're seeing `dig` results that don't look right. Try querying with a public DNS service, like OpenNIC:
|
||||
```
|
||||
$ dig @69.195.152.204 linux.com
|
||||
[...]
|
||||
;; Query time: 231 msec
|
||||
;; SERVER: 69.195.152.204#53(69.195.152.204)
|
||||
|
||||
```
|
||||
|
||||
`dig` confirms that you're getting your lookup from 69.195.152.204. You can query all kinds of servers and compare results.
|
||||
|
||||
### Upstream Name Servers
|
||||
|
||||
I want to know what my upstream name servers are. To find this, I first look in `/etc/resolv/conf`:
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.1.1
|
||||
|
||||
```
|
||||
|
||||
Thanks, but I already knew that. Your Linux distribution may be configured differently, and you'll see your upstream servers. Let's try `nmcli`, the Network Manager command-line tool:
|
||||
```
|
||||
$ nmcli dev show | grep DNS
|
||||
IP4.DNS[1]: 192.168.1.1
|
||||
|
||||
```
|
||||
|
||||
Now we're getting somewhere, as that is the address of my mobile hotspot, and I should have thought of that myself. I can log in to its weird little Web admin panel to see its upstream servers. A lot of consumer Internet gateways don't let you view or change these settings, so try an external service such as [What's my DNS server?][1]
|
||||
|
||||
### List IPv4 Addresses on your Network
|
||||
|
||||
Which IPv4 addresses are up and in use on your network?
|
||||
```
|
||||
$ nmap -sn 192.168.1.0/24
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 14:03 PST
|
||||
Nmap scan report for Mobile.Hotspot (192.168.1.1)
|
||||
Host is up (0.011s latency).
|
||||
Nmap scan report for studio (192.168.1.2)
|
||||
Host is up (0.000071s latency).
|
||||
Nmap scan report for nellybly (192.168.1.3)
|
||||
Host is up (0.015s latency)
|
||||
Nmap done: 256 IP addresses (2 hosts up) scanned in 2.23 seconds
|
||||
|
||||
```
|
||||
|
||||
Everyone wants to scan their network for open ports. This example looks for services and their versions:
|
||||
```
|
||||
$ nmap -sV 192.168.1.1/24
|
||||
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 16:46 PST
|
||||
Nmap scan report for Mobile.Hotspot (192.168.1.1)
|
||||
Host is up (0.0071s latency).
|
||||
Not shown: 997 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
22/tcp filtered ssh
|
||||
53/tcp open domain dnsmasq 2.55
|
||||
80/tcp open http GoAhead WebServer 2.5.0
|
||||
|
||||
Nmap scan report for studio (192.168.1.102)
|
||||
Host is up (0.000087s latency).
|
||||
Not shown: 998 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
22/tcp open ssh OpenSSH 7.2p2 Ubuntu 4ubuntu2.2 (Ubuntu Linux; protocol 2.0)
|
||||
631/tcp open ipp CUPS 2.1
|
||||
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
|
||||
|
||||
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
|
||||
Nmap done: 256 IP addresses (2 hosts up) scanned in 11.65 seconds
|
||||
|
||||
```
|
||||
|
||||
These are interesting results. Let's try the same run from a different Internet account, to see if any of these services are exposed to big bad Internet. You have a second network if you have a smartphone. There are probably apps you can download, or use your phone as a hotspot to your faithful Linux computer. Fetch the WAN IP address from the hotspot control panel and try again:
|
||||
```
|
||||
$ nmap -sV 12.34.56.78
|
||||
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 17:05 PST
|
||||
Nmap scan report for 12.34.56.78
|
||||
Host is up (0.0061s latency).
|
||||
All 1000 scanned ports on 12.34.56.78 are closed
|
||||
|
||||
```
|
||||
|
||||
That's what I like to see. Consult the fine man pages for these commands to learn more fun snooping techniques.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/4-tools-network-snooping-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:http://www.whatsmydnsserver.com/
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,166 @@
|
||||
Token ERC Comparison for Fungible Tokens – Blockchainers
|
||||
======
|
||||
“The good thing about standards is that there are so many to choose from.” [_Andrew S. Tanenbaum_][1]
|
||||
|
||||
### Current State of Token Standards
|
||||
|
||||
The current state of Token standards on the Ethereum platform is surprisingly simple: ERC-20 Token Standard is the only accepted and adopted (as [EIP-20][2]) standard for a Token interface.
|
||||
|
||||
Proposed in 2015, it has finally been accepted at the end of 2017.
|
||||
|
||||
In the meantime, many Ethereum Requests for Comments (ERC) have been proposed which address shortcomings of the ERC-20, which partly were caused by changes in the Ethereum platform itself, eg. the fix for the re-entrancy bug with [EIP-150][3]. Other ERC propose enhancements to the ERC-20 Token model. These enhancements were identified by experiences gathered due to the broad adoption of the Ethereum blockchain and the ERC-20 Token standard. The actual usage of the ERC-20 Token interface resulted in new demands and requirements to address non-functional requirements like permissioning and operations.
|
||||
|
||||
This blogpost should give a superficial, but complete, overview of all proposals for Token(-like) standards on the Ethereum platform. This comparison tries to be objective but most certainly will fail in doing so.
|
||||
|
||||
### The Mother of all Token Standards: ERC-20
|
||||
|
||||
There are dozens of [very good][4] and detailed description of the ERC-20, which will not be repeated here. Just the core concepts relevant for comparing the proposals are mentioned in this post.
|
||||
|
||||
#### The Withdraw Pattern
|
||||
|
||||
Users trying to understand the ERC-20 interface and especially the usage pattern for _transfer_ ing Tokens _from_ one externally owned account (EOA), ie. an end-user (“Alice”), to a smart contract, have a hard time getting the approve/transferFrom pattern right.
|
||||
|
||||
![][5]
|
||||
|
||||
From a software engineering perspective, this withdraw pattern is very similar to the [Hollywood principle][6] (“Don’t call us, we’ll call you!”). The idea is that the call chain is reversed: during the ERC-20 Token transfer, the Token doesn’t call the contract, but the contract does the call transferFrom on the Token.
|
||||
|
||||
While the Hollywood Principle is often used to implement Separation-of-Concerns (SoC), in Ethereum it is a security pattern to avoid having the Token contract to call an unknown function on an external contract. This behaviour was necessary due to the [Call Depth Attack][7] until [EIP-150][3] was activated. After this hard fork, the re-entrancy bug was not possible anymore and the withdraw pattern did not provide any more security than calling the Token directly.
|
||||
|
||||
But why should it be a problem now, the usage might be somehow clumsy, but we can fix this in the DApp frontend, right?
|
||||
|
||||
So, let’s see what happens if a user used transfer to send Tokens to a smart contract. Alice calls transfer on the Token contract with the contract address
|
||||
|
||||
**….aaaaand it’s gone!**
|
||||
|
||||
That’s right, the Tokens are gone. Most likely, nobody will ever get the Tokens back. But Alice is not alone, as Dexaran, inventor of ERC-223, found out, about $400.000 in tokens (let’s just say _a lot_ due to the high volatility of ETH) are irretrievably lost for all of us due to users accidentally sending Tokens to smart contracts.
|
||||
|
||||
Even if the contract developer was extremely user friendly and altruistic, he couldn’t create the contract so that it could react to getting Tokens transferred to it and eg. return them, as the contract will never be notified of this transfer and the event is only emitted on the Token contract.
|
||||
|
||||
From a software engineering perspective that’s a severe shortcoming of ERC-20. If an event occurs (and for the sake of simplicity, we are now assuming Ethereum transactions are actually events), there should be a notification to the parties involved. However, there is an event, but it’s triggered in the Token smart contract which the receiving contract cannot know.
|
||||
|
||||
Currently, it’s not possible to prevent users sending Tokens to smart contracts and losing them forever using the unintuitive transfer on the ERC-20 Token contract.
|
||||
|
||||
### The Empire Strikes Back: ERC-223
|
||||
|
||||
The first attempt at fixing the problems of ERC-20 was proposed by [Dexaran][8]. The main issue solved by this proposal is the different handling of EOA and smart contract accounts.
|
||||
|
||||
The compelling strategy is to reverse the calling chain (and with [EIP-150][3] solved this is now possible) and use a pre-defined callback (tokenFallback) on the receiving smart contract. If this callback is not implemented, the transfer will fail (costing all gas for the sender, a common criticism for ERC-223).
|
||||
|
||||
![][9]
|
||||
|
||||
#### Pros:
|
||||
|
||||
* Establishes a new interface, intentionally being not compliant to ERC-20 with respect to the deprecated functions
|
||||
|
||||
* Allows contract developers to handle incoming tokens (eg. accept/reject) since event pattern is followed
|
||||
|
||||
* Uses one transaction instead of two (transfer vs. approve/transferFrom) and thus saves gas and Blockchain storage
|
||||
|
||||
|
||||
|
||||
|
||||
#### Cons:
|
||||
|
||||
* If tokenFallback doesn’t exist then the contract fallback function is executed, this might have unintended side-effects
|
||||
|
||||
* If contracts assume that transfer works with Tokens, eg. for sending Tokens to specific contracts like multi-sig wallets, this would fail with ERC-223 Tokens, making it impossible to move them (ie. they are lost)
|
||||
|
||||
|
||||
### The Pragmatic Programmer: ERC-677
|
||||
|
||||
The [ERC-667 transferAndCall Token Standard][10] tries to marriage the ERC-20 and ERC-223. The idea is to introduce a transferAndCall function to the ERC-20, but keep the standard as is. ERC-223 intentionally is not completely backwards compatible, since the approve/allowance pattern is not needed anymore and was therefore removed.
|
||||
|
||||
The main goal of ERC-667 is backward compatibility, providing a safe way for new contracts to transfer tokens to external contracts.
|
||||
|
||||
![][11]
|
||||
|
||||
#### Pros:
|
||||
|
||||
* Easy to adapt for new Tokens
|
||||
|
||||
* Compatible to ERC-20
|
||||
|
||||
* Adapter for ERC-20 to use ERC-20 safely
|
||||
|
||||
#### Cons:
|
||||
|
||||
* No real innovations. A compromise of ERC-20 and ERC-223
|
||||
|
||||
* Current implementation [is not finished][12]
|
||||
|
||||
|
||||
### The Reunion: ERC-777
|
||||
|
||||
[ERC-777 A New Advanced Token Standard][13] was introduced to establish an evolved Token standard which learned from misconceptions like approve() with a value and the aforementioned send-tokens-to-contract-issue.
|
||||
|
||||
Additionally, the ERC-777 uses the new standard [ERC-820: Pseudo-introspection using a registry contract][14] which allows for registering meta-data for contracts to provide a simple type of introspection. This allows for backwards compatibility and other functionality extensions, depending on the ITokenRecipient returned by a EIP-820 lookup on the to address, and the functions implemented by the target contract.
|
||||
|
||||
ERC-777 adds a lot of learnings from using ERC-20 Tokens, eg. white-listed operators, providing Ether-compliant interfaces with send(…), using the ERC-820 to override and adapt functionality for backwards compatibility.
|
||||
|
||||
![][15]
|
||||
|
||||
#### Pros:
|
||||
|
||||
* Well thought and evolved interface for tokens, learnings from ERC-20 usage
|
||||
|
||||
* Uses the new standard request ERC-820 for introspection, allowing for added functionality
|
||||
|
||||
* White-listed operators are very useful and are more necessary than approve/allowance , which was often left infinite
|
||||
|
||||
|
||||
#### Cons:
|
||||
|
||||
* Is just starting, complex construction with dependent contract calls
|
||||
|
||||
* Dependencies raise the probability of security issues: first security issues have been [identified (and solved)][16] not in the ERC-777, but in the even newer ERC-820
|
||||
|
||||
|
||||
|
||||
|
||||
### (Pure Subjective) Conclusion
|
||||
|
||||
For now, if you want to go with the “industry standard” you have to choose ERC-20. It is widely supported and well understood. However, it has its flaws, the biggest one being the risk of non-professional users actually losing money due to design and specification issues. ERC-223 is a very good and theoretically founded answer for the issues in ERC-20 and should be considered a good alternative standard. Implementing both interfaces in a new token is not complicated and allows for reduced gas usage.
|
||||
|
||||
A pragmatic solution to the event and money loss problem is ERC-677, however it doesn’t offer enough innovation to establish itself as a standard. It could however be a good candidate for an ERC-20 2.0.
|
||||
|
||||
ERC-777 is an advanced token standard which should be the legitimate successor to ERC-20, it offers great concepts which are needed on the matured Ethereum platform, like white-listed operators, and allows for extension in an elegant way. Due to its complexity and dependency on other new standards, it will take time till the first ERC-777 tokens will be on the Mainnet.
|
||||
|
||||
### Links
|
||||
|
||||
[1] Security Issues with approve/transferFrom-Pattern in ERC-20: <https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view>
|
||||
|
||||
[2] No Event Handling in ERC-20: <https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4>
|
||||
|
||||
[3] Statement for ERC-20 failures and history: <https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258>
|
||||
|
||||
[4] List of differences ERC-20/223: <https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences>
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blockchainers.org/index.php/2018/02/08/token-erc-comparison-for-fungible-tokens/
|
||||
|
||||
作者:[Alexander Culum][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://blockchainers.org/index.php/author/alex/
|
||||
[1]:https://www.goodreads.com/quotes/589703-the-good-thing-about-standards-is-that-there-are-so
|
||||
[2]:https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20.md
|
||||
[3]:https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md
|
||||
[4]:https://medium.com/@jgm.orinoco/understanding-erc-20-token-contracts-a809a7310aa5
|
||||
[5]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-20-Token-Transfer-2.png
|
||||
[6]:http://matthewtmead.com/blog/hollywood-principle-dont-call-us-well-call-you-4/
|
||||
[7]:https://consensys.github.io/smart-contract-best-practices/known_attacks/
|
||||
[8]:https://github.com/Dexaran
|
||||
[9]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-223-Token-Transfer-1.png
|
||||
[10]:https://github.com/ethereum/EIPs/issues/677
|
||||
[11]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-677-Token-Transfer.png
|
||||
[12]:https://github.com/ethereum/EIPs/issues/677#issuecomment-353871138
|
||||
[13]:https://github.com/ethereum/EIPs/issues/777
|
||||
[14]:https://github.com/ethereum/EIPs/issues/820
|
||||
[15]:http://blockchainers.org/wp-content/uploads/2018/02/ERC-777-Token-Transfer.png
|
||||
[16]:https://github.com/ethereum/EIPs/issues/820#issuecomment-362049573
|
||||
72
sources/tech/20180301 Best Websites For Programmers.md
Normal file
72
sources/tech/20180301 Best Websites For Programmers.md
Normal file
@ -0,0 +1,72 @@
|
||||
Best Websites For Programmers
|
||||
======
|
||||
![][1]
|
||||
|
||||
As a programmer, you will often find yourself as a permanent visitor of some websites. These can be tutorial, reference or forums websites. So here in this article let us have a look at the best websites for programmers.
|
||||
|
||||
### W3Schools
|
||||
W3Schools is one of the best websites for beginners as well as experienced web developers to learn various programming languages. You can learn HTML5, CSS3, PHP. JavaScript, ASP etc.
|
||||
|
||||
More importantly, the website holds a lot of resources and references for web developers.
|
||||
|
||||
[![w3schools logo][2]][3]
|
||||
|
||||
You can quickly see various keywords and what they do. The website is very interactive and it allows you to try and practice the code in an embedded editor on the website itself. The website is one of those few that you will frequently visit as a web developer.
|
||||
|
||||
### GeeksforGeeks
|
||||
GeeksforGeeks is a website mostly focused on computer science. It has a huge collection of algorithms, solutions and programming questions.
|
||||
|
||||
[![geeksforgeeks programming support][4]][5]
|
||||
|
||||
The website also has a good stock of most frequently asked questions in interviews. Since the website is more about computer science in general, you will find a solution to all programming solutions in most famous languages.
|
||||
|
||||
### TutorialsPoint
|
||||
The de facto place for learning anything. Tutorials point has some of the finest and easiest tutorials that can teach you any programming language. What I really love about this website is that it is not just limited to generic programming languages.
|
||||
|
||||

|
||||
|
||||
You can find tutorials for almost all frameworks of all languages on the planet.
|
||||
|
||||
### StackOverflow
|
||||
You probably already know this that stack is the place where programmers meet. You ever get stuck solving some of your code, just ask a question on stack and programmers from all over the internet will be there to help you.
|
||||
|
||||
[![stackoverflow linux programming website][6]][7]
|
||||
|
||||
The best part about stack overflow is that almost all questions get answered. You might as well receive answers from several different points of views of other programmers.
|
||||
|
||||
### HackerRank
|
||||
Hacker rank is a website where you can participate in various coding competitions and check your competitive abilities.
|
||||
|
||||
[![hackerrank programming forums][8]][9]There are various contests organized in various programming languages and winning in them increases your score. This score can get you in the top ranks and increase your chance of getting noticed by some software company.
|
||||
|
||||
### Codebeautify
|
||||
Since we are programmers, beauty isn’t something we look after. Many a time our code can be difficult to read by someone else. Codebeautify can make your code easy to read.
|
||||
|
||||

|
||||
|
||||
The website has most languages that it can beautify. Alternatively, if you wish to make your code not readable by someone you can also do that.
|
||||
|
||||
So these were some of my picks for the best websites for programmers. If you frequently visit a site that I haven’t mentioned, do let me know in the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/best-websites-programmers
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/12/best-websites-for-programmers.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/12/w3schools-logo-550x110.png
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/12/w3schools-logo.png
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/12/geeksforgeeks-programming-support-550x152.png
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/12/geeksforgeeks-programming-support.png
|
||||
[6]:http://www.theitstuff.com/wp-content/uploads/2017/12/stackoverflow-linux-programming-website-550x178.png
|
||||
[7]:http://www.theitstuff.com/wp-content/uploads/2017/12/stackoverflow-linux-programming-website.png
|
||||
[8]:http://www.theitstuff.com/wp-content/uploads/2017/12/hackerrank-programming-forums-550x118.png
|
||||
[9]:http://www.theitstuff.com/wp-content/uploads/2017/12/hackerrank-programming-forums.png
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wyxplus
|
||||
Things You Should Know About Ubuntu 18.04
|
||||
======
|
||||
[Ubuntu 18.04 release][1] is just around the corner. I can see lots of questions from Ubuntu users in various Facebook groups and forums. I also organized Q&A sessions on Facebook and Instagram to know what Ubuntu users are wondering about Ubuntu 18.04.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
A reading list for Linux and open source fans
|
||||
======
|
||||
|
||||
|
||||
@ -1,123 +0,0 @@
|
||||
apply for translation.
|
||||
|
||||
How to kill a process or stop a program in Linux
|
||||
======
|
||||
|
||||

|
||||
When a process misbehaves, you might sometimes want to terminate or kill it. In this post, we'll explore a few ways to terminate a process or an application from the command line as well as from a graphical interface, using [gedit][1] as a sample application.
|
||||
|
||||
### Using the command line/termination characters
|
||||
|
||||
#### Ctrl + C
|
||||
|
||||
One problem invoking `gedit` from the command line (if you are not using `gedit &`) is that it will not free up the prompt, so that shell session is blocked. In such cases, Ctrl+C (the Control key in combination with 'C') comes in handy. That will terminate `gedit` and all work will be lost (unless the file was saved). Ctrl+C sends the `SIGINT` signal to `gedit`. This is a stop signal whose default action is to terminate the process. It instructs the shell to stop `gedit` and return to the main loop, and you'll get the prompt back.
|
||||
```
|
||||
$ gedit
|
||||
|
||||
^C
|
||||
|
||||
```
|
||||
|
||||
#### Ctrl + Z
|
||||
|
||||
This is called a suspend character. It sends a `SIGTSTP` signal to process. This is also a stop signal, but the default action is not to kill but to suspend the process.
|
||||
|
||||
It will stop (kill/terminate) `gedit` and return the shell prompt.
|
||||
```
|
||||
$ gedit
|
||||
|
||||
^Z
|
||||
|
||||
[1]+ Stopped gedit
|
||||
|
||||
$
|
||||
|
||||
```
|
||||
|
||||
Once the process is suspended (in this case, `gedit`), it is not possible to write or do anything in `gedit`. In the background, the process becomes a job. This can be verified by the `jobs` command.
|
||||
```
|
||||
$ jobs
|
||||
|
||||
[1]+ Stopped gedit
|
||||
|
||||
```
|
||||
|
||||
`jobs` allows you to control multiple processes within a single shell session. You can stop, resume, and move jobs to the background or foreground as needed.
|
||||
|
||||
Let's resume `gedit` in the background and free up a prompt to run other commands. You can do this using the `bg` command, followed by job ID (notice `[1]` from the output of `jobs` above. `[1]` is the job ID).
|
||||
```
|
||||
$ bg 1
|
||||
|
||||
[1]+ gedit &
|
||||
|
||||
```
|
||||
|
||||
This is similar to starting `gedit` with `&,`:
|
||||
```
|
||||
$ gedit &
|
||||
|
||||
```
|
||||
|
||||
### Using kill
|
||||
|
||||
`kill` allows fine control over signals, enabling you to signal a process by specifying either a signal name or a signal number, followed by a process ID, or PID.
|
||||
|
||||
What I like about `kill` is that it can also work with job IDs. Let's start `gedit` in the background using `gedit &`. Assuming I have a job ID of `gedit` from the `jobs` command, let's send `SIGINT` to `gedit`:
|
||||
```
|
||||
$ kill -s SIGINT %1
|
||||
|
||||
```
|
||||
|
||||
Note that the job ID should be prefixed with `%`, or `kill` will consider it a PID.
|
||||
|
||||
`kill` can work without specifying a signal explicitly. In that case, the default action is to send `SIGTERM`, which will terminate the process. Execute `kill -l` to list all signal names, and use the `man kill` command to read the man page.
|
||||
|
||||
### Using killall
|
||||
|
||||
If you don't want to specify a job ID or PID, `killall` lets you specify a process by name. The simplest way to terminate `gedit` using `killall` is:
|
||||
```
|
||||
$ killall gedit
|
||||
|
||||
```
|
||||
|
||||
This will kill all the processes with the name `gedit`. Like `kill`, the default signal is `SIGTERM`. It has the option to ignore case using `-I`:
|
||||
```
|
||||
$ gedit &
|
||||
|
||||
[1] 14852
|
||||
|
||||
|
||||
|
||||
$ killall -I GEDIT
|
||||
|
||||
[1]+ Terminated gedit
|
||||
|
||||
```
|
||||
|
||||
To learn more about various flags provided by `killall` (such as `-u`, which allows you to kill user-owned processes) check the man page (`man killall`)
|
||||
|
||||
### Using xkill
|
||||
|
||||
Have you ever encountered an issue where a media player, such as [VLC][2], grayed out or hung? Now you can find the PID and kill the application using one of the commands listed above or use `xkill`.
|
||||
|
||||
![Using xkill][3]
|
||||
|
||||
`xkill` allows you to kill a window using a mouse. Simply execute `xkill` in a terminal, which should change the mouse cursor to an **x** or a tiny skull icon. Click **x** on the window you want to close. Be careful using `xkill`, though—as its man page explains, it can be dangerous. You have been warned!
|
||||
|
||||
Refer to the man page of each command for more information. You can also explore commands like `pkill` and `pgrep`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/how-kill-process-stop-program-linux
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://wiki.gnome.org/Apps/Gedit
|
||||
[2]:https://www.videolan.org/vlc/index.html
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/xkill_gedit.png?itok=TBvMw0TN (Using xkill)
|
||||
@ -1,100 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
Creating small containers with Buildah
|
||||
======
|
||||

|
||||
I recently joined Red Hat after many years working for another tech company. In my previous job, I developed a number of different software products that were successful but proprietary. Not only were we legally compelled to not share the software outside of the company, we often didn’t even share it within the company. At the time, that made complete sense to me: The company spent time, energy, and budget developing the software, so they should protect and claim the rewards it garnered.
|
||||
|
||||
Fast-forward to a year ago, when I joined Red Hat and developed a completely different mindset. One of the first things I jumped into was the [Buildah project][1]. It facilitates building Open Container Initiative (OCI) images, and it is especially good at allowing you to tailor the size of the image that is created. At that time Buildah was in its very early stages, and there were some warts here and there that weren’t quite production-ready.
|
||||
|
||||
Being new to the project, I made a few minor changes, then asked where the company’s internal git repository was so that I could push my changes. The answer: Nothing internal, just push your changes to GitHub. I was baffled—sending my changes out to GitHub would mean anyone could look at that code and use it for their own projects. Plus, the code still had a few warts, so that just seemed so counterintuitive. But being the new guy, I shook my head in wonder and pushed the changes out.
|
||||
|
||||
A year later, I’m now convinced of the power and value of open source software. I’m still working on Buildah, and we recently had an issue that illustrates that power and value. The issue, titled [Buildah images not so small?][2] , was raised by Tim Dudgeon (@tdudgeon). To summarize, he noted that images created by Buildah were bigger than those created by Docker, even though the Buildah images didn’t contain the extra "fluff" he saw in the Docker images.
|
||||
|
||||
For comparison he first did:
|
||||
```
|
||||
$ docker pull centos:7
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
docker.io/centos 7 2d194b392dd1 2 weeks ago 195 MB
|
||||
```
|
||||
|
||||
He noted that the size of the Docker image was 195MB. Tim then created a minimal (scratch) image using Buildah, with only the `coreutils` and `bash` packages added to the image, using the following script:
|
||||
```
|
||||
$ cat ./buildah-base.sh
|
||||
#!/bin/bash
|
||||
|
||||
set -x
|
||||
|
||||
# build a minimal image
|
||||
newcontainer=$(buildah from scratch)
|
||||
scratchmnt=$(buildah mount $newcontainer)
|
||||
|
||||
# install the packages
|
||||
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt install_weak_deps=false -y
|
||||
yum clean all -y --installroot $scratchmnt --releasever 7
|
||||
|
||||
sudo buildah config --cmd /bin/bash $newcontainer
|
||||
|
||||
# set some config info
|
||||
buildah config --label name=centos-base $newcontainer
|
||||
|
||||
# commit the image
|
||||
buildah unmount $newcontainer
|
||||
buildah commit $newcontainer centos-base
|
||||
|
||||
$ sudo ./buildah-base.sh
|
||||
|
||||
$ sudo buildah images
|
||||
IMAGE ID IMAGE NAME CREATED AT SIZE
|
||||
8379315d3e3e docker.io/library/centos-base:latest Mar 25, 2018 17:08 212.1 MB
|
||||
```
|
||||
|
||||
Tim wondered why the image was 17MB larger, because `python` and `yum` were not installed in the Buildah image, whereas they were installed in the Docker image. This set off quite the discussion in the GitHub issue, as it was not at all an expected result.
|
||||
|
||||
What was great about the discussion was that not only were Red Hat folks involved, but several others from outside as well. In particular, a lot of great discussion and investigation was led by GitHub user @pixdrift, who noted that the documentation and locale-archive were chewing up a little more than 100MB of space in the Buildah image. Pixdrift suggested forcing locale in the yum installer and provided this updated `buildah-bash.sh` script with those changes:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
set -x
|
||||
|
||||
# build a minimal image
|
||||
newcontainer=$(buildah from scratch)
|
||||
scratchmnt=$(buildah mount $newcontainer)
|
||||
|
||||
# install the packages
|
||||
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt=install_weak_deps=false --setopt=tsflags=nodocs --setopt=override_install_langs=en_US.utf8 -y
|
||||
yum clean all -y --installroot $scratchmnt --releasever 7
|
||||
|
||||
sudo buildah config --cmd /bin/bash $newcontainer
|
||||
|
||||
# set some config info
|
||||
buildah config --label name=centos-base $newcontainer
|
||||
|
||||
# commit the image
|
||||
buildah unmount $newcontainer
|
||||
buildah commit $newcontainer centos-base
|
||||
```
|
||||
|
||||
When Tim ran this new script, the image size shrank to 92MB, shedding 120MB from the original Buildah image size and getting closer to the expected size; however, engineers being engineers, a size savings of 56% wasn’t enough. The discussion went further, involving how to remove individual locale packages to save even more space. To see more details of the discussion, click the [Buildah images not so small?][2] link. Who knows—maybe you’ll have a helpful tip, or better yet, become a contributor for Buildah. On a side note, this solution illustrates how the Buildah software can be used to quickly and easily create a minimally sized container that's loaded only with the software that you need to do your job efficiently. As a bonus, it doesn’t require a daemon to be running.
|
||||
|
||||
This image-sizing issue drove home the power of open source software for me. A number of people from different companies all collaborated to solve a problem through open discussion in a little over a day. Although no code changes were created to address this particular issue, there have been many code contributions to Buildah from contributors outside of Red Hat, and this has helped to make the project even better. These contributions have served to get a wider variety of talented people to look at the code than ever would have if it were a proprietary piece of software stuck in a private git repository. It’s taken only a year to convert me to the [open source way][3], and I don’t think I could ever go back.
|
||||
|
||||
This article was originally posted at [Project Atomic][4]. Reposted with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/containers-buildah
|
||||
|
||||
作者:[Tom Sweeney][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomsweeneyredhat
|
||||
[1]:https://github.com/projectatomic/buildah
|
||||
[2]:https://github.com/projectatomic/buildah/issues/532
|
||||
[3]:https://twitter.com/opensourceway
|
||||
[4]:http://www.projectatomic.io/blog/2018/04/open-source-what-a-concept/
|
||||
@ -1,262 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
Get more done at the Linux command line with GNU Parallel
|
||||
======
|
||||
|
||||

|
||||
|
||||
Do you ever get the funny feeling that your computer isn't quite as fast as it should be? I used to feel that way, and then I found GNU Parallel.
|
||||
|
||||
GNU Parallel is a shell utility for executing jobs in parallel. It can parse multiple inputs, thereby running your script or command against sets of data at the same time. You can use all your CPU at last!
|
||||
|
||||
If you've ever used `xargs`, you already know how to use Parallel. If you don't, then this article teaches you, along with many other use cases.
|
||||
|
||||
### Installing GNU Parallel
|
||||
|
||||
GNU Parallel may not come pre-installed on your Linux or BSD computer. Install it from your repository or ports collection. For example, on Fedora:
|
||||
```
|
||||
$ sudo dnf install parallel
|
||||
|
||||
```
|
||||
|
||||
Or on NetBSD:
|
||||
```
|
||||
# pkg_add parallel
|
||||
|
||||
```
|
||||
|
||||
If all else fails, refer to the [project homepage][1].
|
||||
|
||||
### From serial to parallel
|
||||
|
||||
As its name suggests, Parallel's strength is that it runs jobs in parallel rather than, as many of us still do, sequentially.
|
||||
|
||||
When you run one command against many objects, you're inherently creating a queue. Some number of objects can be processed by the command, and all the other objects just stand around and wait their turn. It's inefficient. Given enough data, there's always going to be a queue, but instead of having just one queue, why not have lots of small queues?
|
||||
|
||||
Imagine you have a folder full of images you want to convert from JPEG to PNG. There are many ways to do this. There's the manual way of opening each image in GIMP and exporting it to the new format. That's usually the worst possible way. It's not only time-intensive, it's labor-intensive.
|
||||
|
||||
A pretty neat variation on this theme is the shell-based solution:
|
||||
```
|
||||
$ convert 001.jpeg 001.png
|
||||
|
||||
$ convert 002.jpeg 002.png
|
||||
|
||||
$ convert 003.jpeg 003.png
|
||||
|
||||
... and so on ...
|
||||
|
||||
```
|
||||
|
||||
It's a great trick when you first learn it, and at first it's a vast improvement. No need for a GUI and constant clicking. But it's still labor-intensive.
|
||||
|
||||
Better still:
|
||||
```
|
||||
$ for i in *jpeg; do convert $i $i.png ; done
|
||||
|
||||
```
|
||||
|
||||
This, at least, sets the job(s) in motion and frees you up to do more productive things. The problem is, it's still a serial process. One image gets converted, and then the next one in the queue steps up for conversion, and so on until the queue has been emptied.
|
||||
|
||||
With Parallel:
|
||||
```
|
||||
$ find . -name "*jpeg" | parallel -I% --max-args 1 convert % %.png
|
||||
|
||||
```
|
||||
|
||||
This is a combination of two commands: the `find` command, which gathers the objects you want to operate on, and the `parallel` command, which sorts through the objects and makes sure everything gets processed as required.
|
||||
|
||||
* `find . -name "*jpeg"` finds all files in the current directory that end in `jpeg`.
|
||||
* `parallel` invokes GNU Parallel.
|
||||
* `-I%` creates a placeholder, called `%`, to stand in for whatever `find` hands over to Parallel. You use this because otherwise you'd have to manually write a new command for each result of `find`, and that's exactly what you're trying to avoid.
|
||||
* `--max-args 1` limits the rate at which Parallel requests a new object from the queue. Since the command Parallel is running requires only one file, you limit the rate to 1. Were you doing a more complex command that required two files (such as `cat 001.txt 002.txt > new.txt`), you would limit the rate to 2.
|
||||
* `convert % %.png` is the command you want to run in Parallel.
|
||||
|
||||
|
||||
|
||||
The result of this command is that `find` gathers all relevant files and hands them over to `parallel`, which launches a job and immediately requests the next in line. Parallel continues to do this for as long as it is safe to launch new jobs without crippling your computer. As old jobs are completed, it replaces them with new ones, until all the data provided to it has been processed. What took 10 minutes before might take only 5 or 3 with Parallel.
|
||||
|
||||
### Multiple inputs
|
||||
|
||||
The `find` command is an excellent gateway to Parallel as long as you're familiar with `find` and `xargs` (collectively called GNU Find Utilities, or `findutils`). It provides a flexible interface that many Linux users are already comfortable with and is pretty easy to learn if you're a newcomer.
|
||||
|
||||
The `find` command is fairly straightforward: you provide `find` with a path to a directory you want to search and some portion of the file name you want to search for. Use wildcard characters to cast your net wider; in this example, the asterisk indicates anything, so `find` locates all files that end with the string `searchterm`:
|
||||
```
|
||||
$ find /path/to/directory -name "*searchterm"
|
||||
|
||||
```
|
||||
|
||||
By default, `find` returns the results of its search one item at a time, with one item per line:
|
||||
```
|
||||
$ find ~/graphics -name "*jpg"
|
||||
|
||||
/home/seth/graphics/001.jpg
|
||||
|
||||
/home/seth/graphics/cat.jpg
|
||||
|
||||
/home/seth/graphics/penguin.jpg
|
||||
|
||||
/home/seth/graphics/IMG_0135.jpg
|
||||
|
||||
```
|
||||
|
||||
When you pipe the results of `find` to `parallel`, each item on each line is treated as one argument to the command that `parallel` is arbitrating. If, on the other hand, you need to process more than one argument in one command, you can split up the way the data in the queue is handed over to `parallel`.
|
||||
|
||||
Here's a simple, unrealistic example, which I'll later turn into something more useful. You can follow along with this example, as long as you have GNU Parallel installed.
|
||||
|
||||
Assume you have four files. List them, one per line, to see exactly what you have:
|
||||
```
|
||||
$ echo ada > ada ; echo lovelace > lovelace
|
||||
|
||||
$ echo richard > richard ; echo stallman > stallman
|
||||
|
||||
$ ls -1
|
||||
|
||||
ada
|
||||
|
||||
lovelace
|
||||
|
||||
richard
|
||||
|
||||
stallman
|
||||
|
||||
```
|
||||
|
||||
You want to combine two files into a third that contains the contents of both files. This requires that Parallel has access to two files, so the `-I%` variable won't work in this case.
|
||||
|
||||
Parallel's default behavior is basically invisible:
|
||||
```
|
||||
$ ls -1 | parallel echo
|
||||
|
||||
ada
|
||||
|
||||
lovelace
|
||||
|
||||
richard
|
||||
|
||||
stallman
|
||||
|
||||
```
|
||||
|
||||
Now tell Parallel you want to get two objects per job:
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 echo
|
||||
|
||||
ada lovelace
|
||||
|
||||
richard stallman
|
||||
|
||||
```
|
||||
|
||||
Now the lines have been combined. Specifically, two results from `ls -1` are passed to Parallel all at once. That's the right number of arguments for this task, but they're effectively one argument right now: "ada lovelace" and "richard stallman." What you actually want is two distinct arguments per job.
|
||||
|
||||
Luckily, that technicality is parsed by Parallel itself. If you set `--max-args` to `2`, you get two variables, `{1}` and `{2}`, representing the first and second parts of the argument:
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 cat {1} {2} ">" {1}_{2}.person
|
||||
|
||||
```
|
||||
|
||||
In this command, the variable `{1}` is ada or richard (depending on which job you look at) and `{2}` is either `lovelace` or `stallman`. The contents of the files are redirected with a redirect symbol in quotes (the quotes grab the redirect symbol from Bash so Parallel can use it) and placed into new files called `ada_lovelace.person` and `richard_stallman.person`.
|
||||
```
|
||||
$ ls -1
|
||||
|
||||
ada
|
||||
|
||||
ada_lovelace.person
|
||||
|
||||
lovelace
|
||||
|
||||
richard
|
||||
|
||||
richard_stallman.person
|
||||
|
||||
stallman
|
||||
|
||||
|
||||
|
||||
$ cat ada_*person
|
||||
|
||||
ada lovelace
|
||||
|
||||
$ cat ri*person
|
||||
|
||||
richard stallman
|
||||
|
||||
```
|
||||
|
||||
If you spend all day parsing log files that are hundreds of megabytes in size, you might see how parallelized text parsing could be useful to you; otherwise, this is mostly a demonstrative exercise.
|
||||
|
||||
However, this kind of processing is invaluable for more than just text parsing. Here's a real-life example from the film world. Consider a directory of video files and audio files that need to be joined together.
|
||||
```
|
||||
$ ls -1
|
||||
|
||||
12_LS_establishing-manor.avi
|
||||
|
||||
12_wildsound.flac
|
||||
|
||||
14_butler-dialogue-mixed.flac
|
||||
|
||||
14_MS_butler.avi
|
||||
|
||||
...and so on...
|
||||
|
||||
```
|
||||
|
||||
Using the same principles, a simple command can be created so that the files are combined in parallel:
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 ffmpeg -i {1} -i {2} -vcodec copy -acodec copy {1}.mkv
|
||||
|
||||
```
|
||||
|
||||
### Brute. Force.
|
||||
|
||||
All this fancy input and output parsing isn't to everyone's taste. If you prefer a more direct approach, you can throw commands at Parallel and walk away.
|
||||
|
||||
First, create a text file with one command on each line:
|
||||
```
|
||||
$ cat jobs2run
|
||||
|
||||
bzip2 oldstuff.tar
|
||||
|
||||
oggenc music.flac
|
||||
|
||||
opusenc ambiance.wav
|
||||
|
||||
convert bigfile.tiff small.jpeg
|
||||
|
||||
ffmepg -i foo.avi -v:b 12000k foo.mp4
|
||||
|
||||
xsltproc --output build/tmp.fo style/dm.xsl src/tmp.xml
|
||||
|
||||
bzip2 archive.tar
|
||||
|
||||
```
|
||||
|
||||
Then hand the file over to Parallel:
|
||||
```
|
||||
$ parallel --jobs 6 < jobs2run
|
||||
|
||||
```
|
||||
|
||||
And now all jobs in your file are run in Parallel. If more jobs exist than jobs allowed, a queue is formed and maintained by Parallel until all jobs have run.
|
||||
|
||||
### Much, much more
|
||||
|
||||
GNU Parallel is a powerful and flexible tool, with far more use cases than can fit into this article. Its man page provides examples of really cool things you can do with it, from remote execution over SSH to incorporating Bash functions into your Parallel commands. There's even an extensive demonstration series on [YouTube][2], so you can learn from the GNU Parallel team directly. The GNU Parallel lead maintainer has also just released the command's official guide, available from [Lulu.com][3].
|
||||
|
||||
GNU Parallel has the power to change the way you compute, and if doesn't do that, it will at the very least change the time your computer spends computing. Try it today!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/gnu-parallel
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:https://www.gnu.org/software/parallel
|
||||
[2]:https://www.youtube.com/watch?v=OpaiGYxkSuQ&list=PL284C9FF2488BC6D1
|
||||
[3]:http://www.lulu.com/shop/ole-tange/gnu-parallel-2018/paperback/product-23558902.html
|
||||
133
sources/tech/20180514 A CLI Game To Learn Vim Commands.md
Normal file
133
sources/tech/20180514 A CLI Game To Learn Vim Commands.md
Normal file
@ -0,0 +1,133 @@
|
||||
A CLI Game To Learn Vim Commands
|
||||
======
|
||||
|
||||

|
||||
|
||||
Howdy, Vim users! Today, I stumbled upon a cool utility to sharpen your Vim usage skills. Vim is a great editor to write and edit code. However, some of you (including me) are still struggling with the steep learning curve. Not anymore! Meet **PacVim** , a CLI game that helps you to learn Vim commands. PacVim is inspired by the classic game [**PacMan**][1] and it gives you plenty of practice with Vim commands in a fun and interesting way. Simply put, PacVim is a fun, free way to learn about the vim commands in-depth. Please do not confuse PacMan with [**pacman**][2] (the arch Linux package manager). PacMan is a classic, popular arcade game released in the 1980s.
|
||||
|
||||
In this brief guide, we will see how to install and use PacVim in Linux.
|
||||
|
||||
### Install PacVim
|
||||
|
||||
First, install **Ncurses** library and **development tools** as described in the following links.
|
||||
|
||||
Please note that this game may not compile and install properly without gcc version 4.8.X or higher. I tested PacVim on Ubuntu 18.04 LTS and it worked perfectly.
|
||||
|
||||
Once Ncurses and gcc are installed, run the following commands to install PacVim.
|
||||
```
|
||||
$ git clone https://github.com/jmoon018/PacVim.git
|
||||
$ cd PacVim
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
## Learn Vim Commands Using PacVim
|
||||
|
||||
### Start PacVim game
|
||||
|
||||
To play this game, just run:
|
||||
```
|
||||
$ pacvim [LEVEL_NUMER] [MODE]
|
||||
|
||||
```
|
||||
|
||||
For example, the following command starts the game in 5th level with normal mode.
|
||||
```
|
||||
$ pacvim 5 n
|
||||
|
||||
```
|
||||
|
||||
Here, **“5”** represents the level and **“n”** represents the mode. There are two modes
|
||||
|
||||
* **n** – normal mode.
|
||||
* **h** – hard mode.
|
||||
|
||||
|
||||
|
||||
The default mode is h, which is hard:
|
||||
|
||||
To start from the beginning (0 level), just run:
|
||||
```
|
||||
$ pacvim
|
||||
|
||||
```
|
||||
|
||||
Here is the sample output from my Ubuntu 18.04 LTS system.
|
||||
|
||||
![][4]
|
||||
|
||||
To begin the game, just press **ENTER**.
|
||||
|
||||
![][5]
|
||||
|
||||
Now start playing the game. Read the next chapter to know how to play.
|
||||
|
||||
To quit, press **ESC** or **q**.
|
||||
|
||||
The following command starts the game in 5th level with hard mode.
|
||||
```
|
||||
$ pacvim 5 h
|
||||
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ pacvim 5
|
||||
|
||||
```
|
||||
|
||||
### How to play PacVim?
|
||||
|
||||
The usage of PacVim is very similar to PacMan.
|
||||
|
||||
You must run over all the characters on the screen while avoiding the ghosts (the red color characters).
|
||||
|
||||
PacVim has two special obstacles:
|
||||
|
||||
1. You cannot move into the walls (yellow color). You must use vim motions to jump over them.
|
||||
2. If you step on a tilde character (cyan `~`), you lose!
|
||||
|
||||
|
||||
|
||||
You are given three lives. You gain a life each time you beat level 0, 3, 6, 9, etc. There are 10 levels in total, starting from 0 to 9. After beating the 9th level, the game is reset to the 0th level, but the ghosts move faster.
|
||||
|
||||
**Winning conditions**
|
||||
|
||||
Use vim commands to move the cursor over the letters and highlight them. After all letters are highlighted, you win and proceed to the next level.
|
||||
|
||||
**Losing conditions**
|
||||
|
||||
If you touch a ghost (indicated by a **red G** ) or a **tilde** character, you lose a life. If you have less than 0 lives, you will lose the entire game.
|
||||
|
||||
Here is the list of Implemented Commands:-
|
||||
|
||||
key what it does q quit the game h move left j move down k move up l move right w move forward to next word beginning W move forward to next WORD beginning e move forward to next word ending E move forward to next WORD ending b move backward to next word beginning B move backward to next WORD beginning $ move to the end of the line 0 move to the beginning of the line gg/1G move to the beginning of the first line numberG move to the beginning of the line given by number G move to the beginning of the last line ^ move to the first word at the current line & 1337 cheatz (beat current level)
|
||||
|
||||
After playing couple levels, you may notice there is a slight improvement in Vim usage. Keep playing this game once in a while until you mastering the Vim usage.
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
And, that’s all for now. Hope this was useful. Playing PacVim is fun, interesting and keep you occupied. At the same time, you should be able to thoroughly learn the enough Vim commands. Give it a try, you won’t be disappointed.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pacvim-a-cli-game-to-learn-vim-commands/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://en.wikipedia.org/wiki/Pac-Man
|
||||
[2]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/05/pacvim-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/05/pacvim-2.png
|
||||
@ -0,0 +1,216 @@
|
||||
MapTool: A robust, flexible virtual tabletop for RPGs
|
||||
======
|
||||
|
||||
|
||||
|
||||
When I was looking for a virtual tabletop for role-playing games (RPGs), either for local play or for playing on a network with family and friends around the world, I had several criteria. First, I wanted a platform I could use offline while I prepped a campaign. Second, I didn't want something that came with the burden of being a social network. I wanted the equivalent of a [Sword Coast][1] campaign-setting [boxed set][2] that I could put on my digital "shelf" and use when I wanted, how I wanted.
|
||||
|
||||
I looked at it this way: I purchased [AD&D 2nd edition][3] as a hardcover book, so even though there have since been many great releases, I can still play AD&D 2nd edition today. The same goes for my digital life. When I want to use my digital maps and tokens or go back to an old campaign, I want access to them regardless of circumstance.
|
||||
|
||||
|
||||
|
||||
### Virtual tabletop
|
||||
|
||||
[MapTool][4] is the flagship product of the RPTools software suite. It's a Java application, so it runs on any operating system that can run Java, which is basically every computer. It's also open source and costs nothing to use, although RPTools accepts [donations][5] if you're so inclined.
|
||||
|
||||
### Installing MapTool
|
||||
|
||||
Download MapTool from [rptools.net][6].
|
||||
|
||||
It's likely that you already have Java installed; if not, download and install it from [java.net][7]. If you're not sure whether you have it installed or not, you can download MapTool first, try to run it, and install Java if it fails to run.
|
||||
|
||||
### Using MapTool
|
||||
|
||||
If you're a game master (GM), MapTool is a great way to provide strategic maps for battles and exploration without investing in physical maps, tokens, or miniatures.
|
||||
|
||||
MapTool is a full-featured virtual tabletop. You can load maps into it, import custom tokens, track initiative order and health, and save campaigns. You can use it locally at your game table, or you can share your session with remote gamers so they can follow along. There are other virtual tabletops out there, but MapTool is the only one you own, part and parcel.
|
||||
|
||||
To load a map into MapTool, all you need is a PNG or JPEG version of a map.
|
||||
|
||||
1. Launch MapTool, then go to the **Map** menu and select **New Map**.
|
||||
2. In the **Map Properties** window that appears, click the **Map** button.
|
||||
3. Click the **Filesystem** button in the bottom-left corner to locate your map graphic on your hard drive.
|
||||
|
||||
|
||||
|
||||
If you have no digital maps yet, there are dozens of map packs available from [Open Gaming Store][8], so you're sure to find a map regardless of where your adventure path may take you.
|
||||
|
||||
MapTool, like most virtual tabletops, expects a PNG or JPEG. I maintain a simple [Image Magick][9] script to convert maps from PDF to PNG. The script runs on Linux, BSD, or Mac and is probably also easily adapted to PowerShell.
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
#GNU All-Permissive http://www.gnu.org/licenses
|
||||
|
||||
|
||||
|
||||
CMD=`which convert` || echo "Image Magick not found in PATH."
|
||||
|
||||
ARG=("${@}")
|
||||
|
||||
ARRAYSIZE=${#ARG[*]}
|
||||
|
||||
|
||||
|
||||
while [ True ]; do
|
||||
|
||||
for item in "${ARG[@]}"; do
|
||||
|
||||
$CMD "${item}" `basename "${item}" .pdf`.jpg || \
|
||||
|
||||
$CMD "${item}" `basename "${item}" .PDF`.jpg
|
||||
|
||||
done
|
||||
|
||||
done
|
||||
|
||||
exit
|
||||
|
||||
```
|
||||
|
||||
If running code like that scares you, there are plenty of PDF-to-image converters, like [GIMP][10], for manually converting a PDF to PNG or JPEG on an as-needed basis.
|
||||
|
||||
#### Adding tokens
|
||||
|
||||
Now that you have a map loaded, it's time to add player characters (PCs) and non-player characters (NPCs). MapTool ships with a modest selection of token graphics, but you can always create and use your own or download more from the internet. In fact, the RPTools website recently linked to [ImmortalNights][11], a website by artist Devin Night, with over 100 tokens for free and purchase.
|
||||
|
||||
1. Click the **Tokens** folder icon in the MapTool **Resource Library** panel.
|
||||
2. In the panel just beneath the **Resource Library** panel, the default tokens appear. You can add your own tokens using the **Add resources to library** option in the **File** menu.
|
||||
3. In the **New token** pop-up dialogue box, give the token a name and PC or NPC designation.
|
||||
|
||||
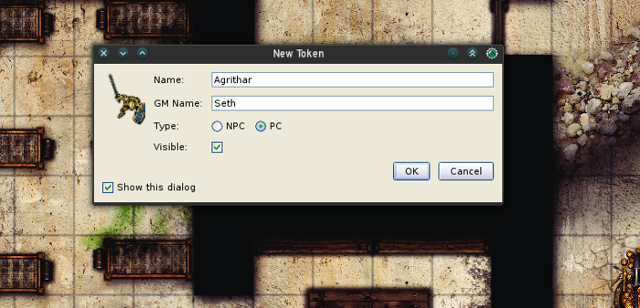
|
||||
|
||||
4. Once the token is on the map, it should align perfectly with the map grid. If it doesn't, you can adjust the grid.
|
||||
5. Right-click on the token to adjust its rotation, size, and other attributes.
|
||||
|
||||
|
||||
|
||||
#### Adjusting the grid
|
||||
|
||||
By default, MapTool provides an invisible 50x50 square grid over any map. If your map graphic already has a grid on it, you can adjust MapTool's grid to match your graphic.
|
||||
|
||||
1. Select **Adjust grid** in the **Map** menu. A grid overlay appears over your map.
|
||||
2. Click and drag the overlay grid so one overlay square sits inside one of your map graphic's grid squares.
|
||||
3. Adjust the **Grid Size** pixel value in the property box in the top-right corner of the MapTool window.
|
||||
4. When finished, click the property box's **Close** button.
|
||||
|
||||
|
||||
|
||||
You can set the default grid size using the **Preferences** selection in the **Edit** menu. For instance, I do this for [Paizo][12] maps on my 96dpi screen.
|
||||
|
||||
MapTool's default assumes each grid block is a five-foot square, but you can adjust that if you're using a wide area representing long-distance travel or if you've drawn a custom map to your own scale.
|
||||
|
||||
### Sharing the screen locally
|
||||
|
||||
While you can use MapTool solely as a GM tool to help keep track of character positions, you can also share it with your players.
|
||||
|
||||
If you're using MapTool as a digital replacement for physical maps at your game table, you can just plug your computer into your TV. That's the simplest way to share the map with everyone at your table.
|
||||
|
||||
Another alternative is to use MapTool's built-in server. If your players are physically sitting in the same room and on the same network, select **Start server** from the **File** menu.
|
||||
|
||||
The only required field is a name for the GM. The default port is 51234. If you don't know what that means, that's OK; a port is just a flag identifying where a service like MapTool is running.
|
||||
|
||||
Once your MapTool server is started, players can connect by selecting **Connect to server** in the **File** menu.
|
||||
|
||||
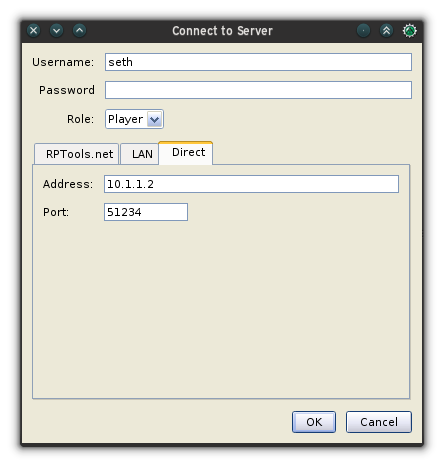
|
||||
|
||||
A name is required, but no password is needed unless the GM has set one when starting the server.
|
||||
|
||||
The IP address is your local IP address, so it starts with either 192.168 or 10. If you don't know your local IP address, you can check it from your computer's networking control panel. On Linux, you can also find it by typing:
|
||||
```
|
||||
$ ip -4 -ts a
|
||||
|
||||
```
|
||||
|
||||
And on BSD or Mac:
|
||||
```
|
||||
$ ifconfig
|
||||
|
||||
```
|
||||
|
||||
On Windows, open PowerShell from your **Start** menu and type:
|
||||
```
|
||||
ipconfig
|
||||
|
||||
```
|
||||
|
||||
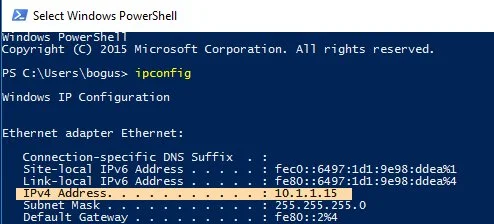
|
||||
|
||||
If your players have trouble connecting, there are two likely causes:
|
||||
|
||||
* You forgot to start the server. Start it and have your players try again.
|
||||
* You have a firewall running on your computer. If you're on your home network, it's safe to deactivate your firewall or to tell it to permit traffic on port 51234. If you're in a public gaming space, you should not lower your firewall, but it's safe to permit traffic on port 51234 as long as you have set a password for your MapTool server.
|
||||
|
||||

|
||||
|
||||
### Sharing the screen worldwide
|
||||
|
||||
If you're playing remotely with people all over the world, letting them into your private MapTool server is a little more complex to set up, but you only have to do it once and then you're set.
|
||||
|
||||
#### Router
|
||||
|
||||
The first device that needs to be adjusted is your home router. This is the box you got from your internet service provider. You might also call it your modem.
|
||||
|
||||
Every device is different, so there's no way for me to definitively tell you what you need to click on to adjust your settings. Generally, you access your home router through a web browser. Your router's address is often printed on the bottom of the router and begins with either 192.168 or 10.
|
||||
|
||||
Navigate to the router address and log in with the credentials you were provided when you got your internet service. It's often as simple as `admin` with a numeric password (sometimes this password is printed on the router, too). If you don't know the login, call your internet provider and ask for details.
|
||||
|
||||
Different routers use different terms for the same thing; keywords to look for are **Port forwarding** , **Virtual server** , and **Firewall**. Whatever your router calls it, you want to accept traffic coming to port 51234 of your router and forward that traffic to the same port of your personal computer's IP address.
|
||||
|
||||
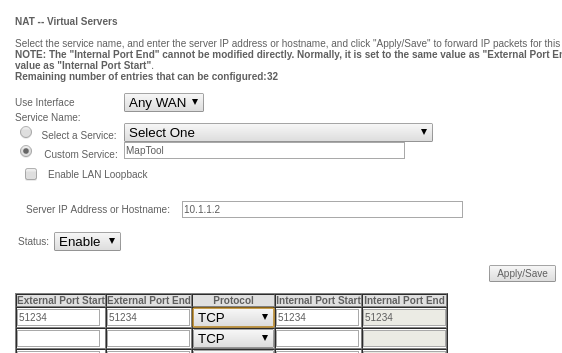
|
||||
|
||||
If you're confused, search the internet for the term "port forwarding" and your router's brand name. This isn't an uncommon task for PC gamers, so instructions are out there.
|
||||
|
||||
#### Finding your external IP address
|
||||
|
||||
Now you're allowing traffic through the MapTool port, so you need to tell your players where to go.
|
||||
|
||||
1. Get your worldwide IP address at [icanhazip.com][13].
|
||||
2. Start the MapTool server from the **File** menu. Set a password for safety.
|
||||
3. Have players select **Connect to server** from the **File** menu.
|
||||
4. In the **Connect to server** window, have players click the **Direct** tab and enter a username, password, and your IP address.
|
||||
|
||||
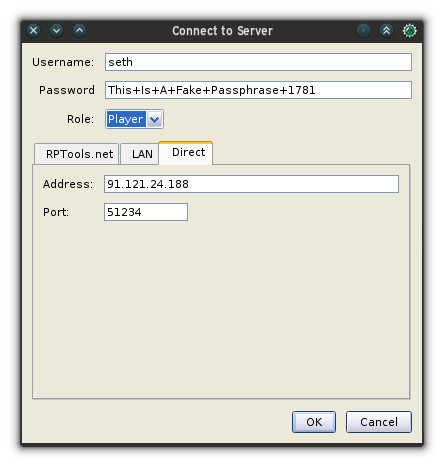
|
||||
|
||||
### Features a-plenty
|
||||
|
||||
This has been a brief overview of things you can do with MapTool. It has many other features, including an initiative tracker, adjustable tokens visibility (hide treasure and monsters from your players!), impersonation, line-of-sight (conceal hidden doors behind statues or other structures!), and fog of war.
|
||||
|
||||
It can serve just as a digital battle map, or it can be the centerpiece of your tabletop game.
|
||||
|
||||

|
||||
|
||||
### Why MapTool?
|
||||
|
||||
Before you comment about them: Yes, there are a few virtual tabletop services online, and some of them are very good. They provide a good supply of games looking for players and players looking for games. If you can't find your fellow gamers locally, online tabletops are a great solution.
|
||||
|
||||
By contrast, some people are not fans of social networking, so we shy away from sites that excitedly "bring people together." I've got friends to game with, and we're happy to build and set up our own infrastructure. We don't need to sign up for yet another site; we don't need to throw our hats into a great big online bucket and register when and how we game.
|
||||
|
||||
Ultimately, I like MapTool because I have it with me whether or not I'm online. I can plan a campaign, populate it with graphics, and set up all my maps in advance without depending on having internet access. It's almost like doing the frontend programming for a video game, knowing that the backend "technology" will all happen in the player's minds on game night.
|
||||
|
||||
If you're looking for a robust and flexible virtual tabletop, try MapTool!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/maptool
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:https://en.wikibooks.org/wiki/Dungeons_%26_Dragons/Commercial_settings/Forgotten_Realms/Sword_Coast
|
||||
[2]:https://en.wikipedia.org/wiki/Dungeons_%26_Dragons_campaign_settings
|
||||
[3]:https://en.wikipedia.org/wiki/Editions_of_Dungeons_%26_Dragons#Advanced_Dungeons_&_Dragons_2nd_edition
|
||||
[4]:http://www.rptools.net/toolbox/maptool/
|
||||
[5]:http://www.rptools.net/donate/
|
||||
[6]:http://www.rptools.net/downloadsw/
|
||||
[7]:http://jdk.java.net/8
|
||||
[8]:https://www.opengamingstore.com/search?q=map
|
||||
[9]:http://www.imagemagick.org/script/index.php
|
||||
[10]:http://gimp.org
|
||||
[11]:http://immortalnights.com/tokenpage.html
|
||||
[12]:http://paizo.com/
|
||||
[13]:http://icanhazip.com/
|
||||
@ -1,74 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Protect your Fedora system against this DHCP flaw
|
||||
======
|
||||

|
||||
|
||||
A critical security vulnerability was discovered and disclosed earlier today in dhcp-client. This DHCP flaw carries a high risk to your system and data, especially if you use untrusted networks such as a WiFi access point you don’t own. Read more here for how to protect your Fedora system.
|
||||
|
||||
Dynamic Host Control Protocol (DHCP) allows your system to get configuration from a network it joins. Your system will make a request for DHCP data, and typically a server such as a router answers. The server provides the necessary data for your system to configure itself. This is how, for instance, your system configures itself properly for networking when it joins a wireless network.
|
||||
|
||||
However, an attacker on the local network may be able to exploit this vulnerability. Using a flaw in a dhcp-client script that runs under NetworkManager, the attacker may be able to run arbitrary commands with root privileges on your system. This DHCP flaw puts your system and your data at high risk. The flaw has been assigned CVE-2018-1111 and has a [Bugzilla tracking bug][1].
|
||||
|
||||
### Guarding against this DHCP flaw
|
||||
|
||||
New dhcp packages contain fixes for Fedora 26, 27, and 28, as well as Rawhide. The maintainers have submitted these updates to the updates-testing repositories. They should show up in stable repos within a day or so of this post for most users. The desired packages are:
|
||||
|
||||
* Fedora 26: dhcp-4.3.5-11.fc26
|
||||
* Fedora 27: dhcp-4.3.6-10.fc27
|
||||
* Fedora 28: dhcp-4.3.6-20.fc28
|
||||
* Rawhide: dhcp-4.3.6-21.fc29
|
||||
|
||||
|
||||
|
||||
#### Updating a stable Fedora system
|
||||
|
||||
To update immediately on a stable Fedora release, use this command [with sudo][2]. Type your password at the prompt, if necessary:
|
||||
```
|
||||
sudo dnf --refresh --enablerepo=updates-testing update dhcp-client
|
||||
|
||||
```
|
||||
|
||||
Later, use the standard stable repos to update. To update your Fedora system from the stable repos, use this command:
|
||||
```
|
||||
sudo dnf --refresh update dhcp-client
|
||||
|
||||
```
|
||||
|
||||
#### Updating a Rawhide system
|
||||
|
||||
If your system is on Rawhide, use these commands to download and update the packages immediately:
|
||||
```
|
||||
mkdir dhcp && cd dhcp
|
||||
koji download-build --arch={x86_64,noarch} dhcp-4.3.6-21.fc29
|
||||
sudo dnf update ./dhcp-*.rpm
|
||||
|
||||
```
|
||||
|
||||
After the nightly Rawhide compose, simply run sudo dnf update to get the update.
|
||||
|
||||
### Fedora Atomic Host
|
||||
|
||||
The fixes for Fedora Atomic Host are in ostree version 28.20180515.1. To get the update, run this command:
|
||||
```
|
||||
atomic host upgrade -r
|
||||
|
||||
```
|
||||
|
||||
This command reboots your system to apply the upgrade.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/protect-fedora-system-dhcp-flaw/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://bugzilla.redhat.com/show_bug.cgi?id=1567974
|
||||
[2]:https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
A guide to Git branching
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,107 @@
|
||||
What You Need to Know About Cryptocurrency ‘Malware’ Found on Ubuntu’s Snap Store
|
||||
======
|
||||
Recently, it was discovered that a couple of apps in the Ubuntu Snaps store contained cryptocurrency mining software. Canonical swiftly removed the offending apps, but several questions are left unanswered.
|
||||
|
||||
### Discovery of Crypto Miner on Snap Store
|
||||
|
||||
![Crypto Miner Malware on Ubuntu Snap Store][1]
|
||||
|
||||
On May 11, a user named [tarwirdur][2] opened a new issue on the [snapcraft.io repository][3]. In the issue, he noted that a snap entitled 2048buntu created by Nicolas Tomb contained a cryptocurrency miner. He asked how he could “complain about the application” for security reasons. tarwirdur later posted to say that all the others snaps created by Nicolas Tomb also contained cryptocurrency miners.
|
||||
|
||||
It appears that the snaps used systemd to automatically launch the code at boot and run it in the background with the user none the wiser.
|
||||
|
||||
{For those unfamiliar with the terminology, a cryptocurrency miner is a piece of software that uses a computer’s main processor or graphics processor to “mine” digital currency. “Mining” usually involves solving a mathematical equation. In this case, if you were running the 2048buntu game, the game used additional processing power for cryptocurrency mining.}
|
||||
|
||||
The Snapcraft team responded by quickly removing all apps created by the offender. They also started an investigation.
|
||||
|
||||
### The Man Behind the Mask Speaks
|
||||
|
||||
On May 13, a Disqus user named Nicolas Tomb [posted a comment][4] on OMGUbuntu’s coverage of the news. In this comment, he stated that he added the cryptocurrency miner to monetize the snaps. He apologized for his actions and promised to send any funds that had been mined to the Ubuntu foundation.
|
||||
|
||||
We can’t say for sure if this comment was posted by the same Nicolas Tomb since the Disqus account was just recently created and only has one comment associated with it. For now, we’ll assume that it is.
|
||||
|
||||
### Canonical Makes a Statement
|
||||
|
||||
On May 15, Canonical issued a statement on the situation. Entitled [“Trust and security in the Snap Store”][5], the post starts out by restating the situation. They add that the snaps have been [reissued with the cryptocurrency mining code removed][6].
|
||||
|
||||
Canonical then attempts to examine the motives of Nicolas Tomb. They note that he told them he did it in an attempt to monetize the apps (as stated above) and stopped doing it when confronted. They also note that “mining cryptocurrency is not illegal or unethical by itself”. They are however unhappy about the fact that he did not disclose the cryptocurrency miner in the snap description.
|
||||
|
||||
From there Canonical moves to the subject of reviewing software. According to the post, the Snap Store uses a quality control system similar to iOS, Android, and Windows: “automated checkpoints that packages must go through before they are accepted, and manual reviews by a human when specific issues are flagged”.
|
||||
|
||||
However, Canonical says “it’s impossible for a large scale repository to only accept software after every individual file has been reviewed in detail”. Therefore, they need to trust the source, not the content. After all, that is what the current Ubuntu repo system is based on.
|
||||
|
||||
Canonical follows this up by talking about the future of snaps. They acknowledge that the current system is not perfect. They are continually working to improve it. They have “very interesting security features in the works that will improve the safety of the system and also the experience of people handling software deployments in servers and desktops”.
|
||||
|
||||
One of the features they are working on is the ability to see if a publisher is verified. Other improvements include: “upstreaming of all the AppArmor kernel patches” and other under-the-hood fixes.
|
||||
|
||||
### Thoughts on the ‘Snap store malware’
|
||||
|
||||
Based on all that I’ve read, I’ve got a few thoughts and questions of my own.
|
||||
|
||||
#### How Long Was This Running?
|
||||
|
||||
First of all, how long have these mining snaps been available on the Snap Store? Since they have all been removed, we don’t have that data. I was able to grab an image of the 2048buntu page from the Google cache, but it doesn’t show much of anything. Depending on how long it ran, how many systems it got installed on, and what cryptocurrency was being mined, we could either be talks about a little bit of money or a pile. A further question is: would Canonical have been able to catch this in the future?
|
||||
|
||||
#### Was it Really a Malware?
|
||||
|
||||
A lot of news sites are reporting this as a malware infection. I think I might have even seen this incident referred to as Linux’s first malware. I’m not sure that term is accurate. Dictionary.com defines [malware][7] as: “software intended to damage a computer, mobile device, computer system, or computer network, or to take partial control over its operation”.
|
||||
|
||||
The snaps in question did not damage or take control of the computers involved. it also did not infect other computers. It couldn’t have because all snaps are sandboxed. At the most, they leached processor power, that’s about it. So, I wouldn’t call it malware.
|
||||
|
||||
#### Nothing Like a Loophole
|
||||
|
||||
The one defense that Nicolas Tomb uses is that the Snap Store didn’t have any rules against cryptocurrency mining when he uploaded the snaps. {I can bet you that they are rectifying that problem right now.} They didn’t have that rule for the simple reason that no one had done it before. If Tomb was trying to do things correctly, he should have asked if this kind of behavior was allowed. The fact that he didn’t seems to point to the fact that he knew they would probably say no. At the very least, they would have told him to put it in the description.
|
||||
|
||||
![][8]
|
||||
|
||||
#### Something Looks Hinkey
|
||||
|
||||
As I said before, I got a screenshot of the 2048buntu page from Google cache. Just looking at it raises several red flags. First, there is almost no real description. This is all it says “Game like 2048. This game is clone popular game – 2048 with ubuntu colors.” Wow. {That’ll bring in the suckers.} When I read something as empty as that, I get nervous.
|
||||
|
||||
Another thing to notice is the size of it. Version 1.0 of the 2048buntu snap weighs almost 140 MB. Why would a game this simple need that much space? There are browser versions written in Javascript that probably use less than a quarter of that. There other snaps of 2048 games on the Snap Store and none of them has half the file size.
|
||||
|
||||
Then, you have the license. This is a clone of a popular game using Ubuntu colors. How can it be considered proprietary? I’m sure that legit devs in the audience would have uploaded it with a FOSS (Free and Open Source Software) license just because of the content.
|
||||
|
||||
These factors alone should have made this snap, in particular, stand out and call for a review.
|
||||
|
||||
#### Who is Nicolas Tomb?
|
||||
|
||||
After first reading about this, I decided to see what I could find out about the guy who started this mess. When I searched for Nicolas Tomb, I found nothing, zip, nada, zilch. All I found were a bunch of news articles about the cryptocurrency mining snaps and information about taking a trip to the tomb of St. Nicolas. There is no sign of Nicolas Tomb on Twitter or Github either. This seems like a name created just to upload these snaps.
|
||||
|
||||
This also leads to a point in the Canonical blog post about verifying publishers. The last time I looked, quite a few snaps were not published by the maintainers of the applications. This makes me nervous. I would be more willing to trust a snap of say Firefox if it was published by Mozilla, instead of Leonard Borsch. If it’s too much work for the application maintainer to also take care of the snap, there should be a way for the maintainer to put their stamp of approval on the snap for their program. Something like Firefox snap published by Fredrick Ham, approved by Mozilla Foundation. Just something to give the user more confidence in what they are downloading.
|
||||
|
||||
#### Snap Store Definitely has Room to Improve
|
||||
|
||||
It seems to me that one of the first features that the Snap Store team should have implemented was a way to report suspicious snaps. tarwirdur had to find the site’s Github page. The average user would not have thought of that. If the Snap Store can’t review every line of code, enabling the users to reports problems is the next best thing. Even rating system would not be a bad addition. I’m sure there would have been a couple people who would have given 2048buntu a low rating for using too many system resources.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
From all the I have seen, I think that someone created a number of simple apps, embedded a cryptocurrency miner in each, and uploaded them to the Snap Store with the goal of raking in piles of money. Once they got caught, they claimed it was only to monetize the snaps. If that was true, they would have mentioned it in the snap description. Hidden crypto miners are nothing [new][9]. They are generally a method of computing power theft.
|
||||
|
||||
I wish that Canonical already have features in place to combat this problem and I hope they appear quickly.
|
||||
|
||||
What do you think of the Snap Store ‘malware episode’? What would you do to improve it? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/snapstore-cryptocurrency-saga/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/ubuntu-snap-malware-800x450.jpeg
|
||||
[2]:https://github.com/tarwirdur
|
||||
[3]:https://github.com/canonical-websites/snapcraft.io/issues/651
|
||||
[4]:https://disqus.com/home/discussion/omgubuntu/malware_found_on_the_ubuntu_snap_store/#comment-3899153046
|
||||
[5]:https://blog.ubuntu.com/2018/05/15/trust-and-security-in-the-snap-store
|
||||
[6]:https://forum.snapcraft.io/t/action-against-snap-store-malware/5417/8
|
||||
[7]:http://www.dictionary.com/browse/malware?s=t
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/2048buntu.png
|
||||
[9]:https://krebsonsecurity.com/2018/03/who-and-what-is-coinhive/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Install Ncurses Library In Linux
|
||||
======
|
||||

|
||||
|
||||
@ -0,0 +1,106 @@
|
||||
An introduction to cryptography and public key infrastructure
|
||||
======
|
||||

|
||||
|
||||
Secure communication is quickly becoming the norm for today's web. In July 2018, Google Chrome plans to [start showing "not secure" notifications][1] for **all** sites transmitted over HTTP (instead of HTTPS). Mozilla has a [similar plan][2]. While cryptography is becoming more commonplace, it has not become easier to understand. [Let's Encrypt][3] designed and built a wonderful solution to provide and periodically renew free security certificates, but if you don't understand the underlying concepts and pitfalls, you're just another member of a large group of [cargo cult][4] programmers.
|
||||
|
||||
### Attributes of secure communication
|
||||
|
||||
The intuitively obvious purpose of cryptography is confidentiality: a message can be transmitted without prying eyes learning its contents. For confidentiality, we encrypt a message: given a message, we pair it with a key and produce a meaningless jumble that can only be made useful again by reversing the process using the same key (thereby decrypting it). Suppose we have two friends, [Alice and Bob][5], and their nosy neighbor, Eve. Alice can encrypt a message like "Eve is annoying", send it to Bob, and never have to worry about Eve snooping on her.
|
||||
|
||||
For truly secure communication, we need more than confidentiality. Suppose Eve gathered enough of Alice and Bob's messages to figure out that the word "Eve" is encrypted as "Xyzzy". Furthermore, Eve knows Alice and Bob are planning a party and Alice will be sending Bob the guest list. If Eve intercepts the message and adds "Xyzzy" to the end of the list, she's managed to crash the party. Therefore, Alice and Bob need their communication to provide integrity: a message should be immune to tampering.
|
||||
|
||||
We have another problem though. Suppose Eve watches Bob open an envelope marked "From Alice" with a message inside from Alice reading "Buy another gallon of ice cream." Eve sees Bob go out and come back with ice cream, so she has a general idea of the message's contents even if the exact wording is unknown to her. Bob throws the message away, Eve recovers it, and then every day for the next week drops an envelope marked "From Alice" with a copy of the message in Bob's mailbox. Now the party has too much ice cream and Eve goes home with free ice cream when Bob gives it away at the end of the night. The extra messages are confidential, and their integrity is intact, but Bob has been misled as to the true identity of the sender. Authentication is the property of knowing that the person you are communicating with is in fact who they claim to be.
|
||||
|
||||
Information security has [other attributes][6], but confidentiality, integrity, and authentication are the three traits you must know.
|
||||
|
||||
### Encryption and ciphers
|
||||
|
||||
What are the components of encryption? We need a message which we'll call the plaintext. We may need to do some initial formatting to the message to make it suitable for the encryption process (padding it to a certain length if we're using a block cipher, for example). Then we take a secret sequence of bits called the key. A cipher then takes the key and transforms the plaintext into ciphertext. The ciphertext should look like random noise and only by using the same cipher and the same key (or as we will see later in the case of asymmetric ciphers, a mathematically related key) can the plaintext be restored.
|
||||
|
||||
The cipher transforms the plaintext's bits using the key's bits. Since we want to be able to decrypt the ciphertext, our cipher needs to be reversible too. We can use [XOR][7] as a simple example. It is reversible and is [its own inverse][8] (P ^ K = C; C ^ K = P) so it can both encrypt plaintext and decrypt ciphertext. A trivial use of an XOR can be used for encryption in a one-time pad, but it is generally not [practical][9]. However, it is possible to combine XOR with a function that generates an arbitrary stream of random data from a single key. Modern ciphers like AES and Chacha20 do exactly that.
|
||||
|
||||
We call any cipher that uses the same key to both encrypt and decrypt a symmetric cipher. Symmetric ciphers are divided into stream ciphers and block ciphers. A stream cipher runs through the message one bit or byte at a time. Our XOR cipher is a stream cipher, for example. Stream ciphers are useful if the length of the plaintext is unknown (such as data coming in from a pipe or socket). [RC4][10] is the best-known stream cipher but it is vulnerable to several different attacks, and the newest version (1.3) of the TLS protocol (the "S" in "HTTPS") does not even support it. [Efforts][11] are underway to create new stream ciphers with some candidates like [ChaCha20][12] already supported in TLS.
|
||||
|
||||
A block cipher takes a fix-sized block and encrypts it with a fixed-sized key. The current king of the hill in the block cipher world is the [Advanced Encryption Standard][13] (AES), and it has a block size of 128 bits. That's not very much data, so block ciphers have a [mode][14] that describes how to apply the cipher's block operation across a message of arbitrary size. The simplest mode is [Electronic Code Book][15] (ECB) which takes the message, splits it into blocks (padding the message's final block if necessary), and then encrypts each block with the key independently.
|
||||
|
||||

|
||||
|
||||
You may spot a problem here: if the same block appears multiple times in the message (a phrase like "GET / HTTP/1.1" in web traffic, for example) and we encrypt it using the same key, we'll get the same result. The appearance of a pattern in our encrypted communication makes it vulnerable to attack.
|
||||
|
||||
Thus there are more advanced modes such as [Cipher Block Chaining][16] (CBC) where the result of each block's encryption is XORed with the next block's plaintext. The very first block's plaintext is XORed with an initialization vector of random numbers. There are many other modes each with different advantages and disadvantages in security and speed. There are even modes, such as Counter (CTR), that can turn a block cipher into a stream cipher.
|
||||
|
||||
|
||||
|
||||
In contrast to symmetric ciphers, there are asymmetric ciphers (also called public-key cryptography). These ciphers use two keys: a public key and a private key. The keys are mathematically related but still distinct. Anything encrypted with the public key can only be decrypted with the private key and data encrypted with the private key can be decrypted with the public key. The public key is widely distributed while the private key is kept secret. If you want to communicate with a given person, you use their public key to encrypt your message and only their private key can decrypt it. [RSA][17] is the current heavyweight champion of asymmetric ciphers.
|
||||
|
||||
A major downside to asymmetric ciphers is that they are computationally expensive. Can we get authentication with symmetric ciphers to speed things up? If you only share a key with one other person, yes. But that breaks down quickly. Suppose a group of people want to communicate with one another using a symmetric cipher. The group members could establish keys for each unique pairing of members and encrypt messages based on the recipient, but a group of 20 people works out to 190 pairs of members total and 19 keys for each individual to manage and secure. By using an asymmetric cipher, each person only needs to guard their own private key and have access to a listing of public keys.
|
||||
|
||||
Asymmetric ciphers are also limited in the [amount of data][18] they can encrypt. Like block ciphers, you have to split a longer message into pieces. In practice then, asymmetric ciphers are often used to establish a confidential, authenticated channel which is then used to exchange a shared key for a symmetric cipher. The symmetric cipher is used for subsequent communications since it is much faster. TLS can operate in exactly this fashion.
|
||||
|
||||
### At the foundation
|
||||
|
||||
At the heart of secure communication are random numbers. Random numbers are used to generate keys and to provide unpredictability for otherwise deterministic processes. If the keys we use are predictable, then we're susceptible to attack right from the very start. Random numbers are difficult to generate on a computer which is meant to behave in a consistent manner. Computers can gather random data from things like mouse movement or keyboard timings. But gathering that randomness (called entropy) takes significant time and involve additional processing to ensure uniform distributions. It can even involve the use of dedicated hardware (such as [a wall of lava lamps][19]). Generally, once we have a truly random value, we use that as a seed to put into a [cryptographically secure pseudorandom number generator][20] Beginning with the same seed will always lead to the same stream of numbers, but what's important is that the stream of numbers descended from the seed don't exhibit any pattern. In the Linux kernel, [/dev/random and /dev/urandom][21], operate in this fashion: they gather entropy from multiple sources, process it to remove biases, create a seed, and can then provide the random numbers used to generate an RSA key for example.
|
||||
|
||||
### Other cryptographic building blocks
|
||||
|
||||
We've covered confidentiality, but I haven't mentioned integrity or authentication yet. For that, we'll need some new tools in our toolbox.
|
||||
|
||||
The first is the cryptographic hash function. A cryptographic hash function is meant to take an input of arbitrary size and produce a fixed size output (often called a digest). If we can find any two messages that create the same digest, that's a collision and makes the hash function unsuitable for cryptography. Note the emphasis on "find"; if we have an infinite world of messages and a fixed sized output, there are bound to be collisions, but if we can find any two messages that collide without a monumental investment of computational resources, that's a deal-breaker. Worse still would be if we could take a specific message and could then find another message that results in a collision.
|
||||
|
||||
As well, the hash function should be one-way: given a digest, it should be computationally infeasible to determine what the message is. Respectively, these [requirements][22] are called collision resistance, second preimage resistance, and preimage resistance. If we meet these requirements, our digest acts as a kind of fingerprint for a message. No two people ([in theory][23]) have the same fingerprints, and you can't take a fingerprint and turn it back into a person.
|
||||
|
||||
If we send a message and a digest, the recipient can use the same hash function to generate an independent digest. If the two digests match, they know the message hasn't been altered. [SHA-256][24] is the most popular cryptographic hash function currently since [SHA-1][25] is starting to [show its age][26].
|
||||
|
||||
Hashes sound great, but what good is sending a digest with a message if someone can tamper with your message and then tamper with the digest too? We need to mix hashing in with the ciphers we have. For symmetric ciphers, we have message authentication codes (MACs). MACs come in different forms, but an HMAC is based on hashing. An [HMAC][27] takes the key K and the message M and blends them together using a hashing function H with the formula H(K + H(K + M)) where "+" is concatenation. Why this formula specifically? That's beyond this article, but it has to do with protecting the integrity of the HMAC itself. The MAC is sent along with an encrypted message. Eve could blindly manipulate the message, but as soon as Bob independently calculates the MAC and compares it to the MAC he received, he'll realize the message has been tampered with.
|
||||
|
||||
For asymmetric ciphers, we have digital signatures. In RSA, encryption with a public key makes something only the private key can decrypt, but the inverse is true as well and can create a type of signature. If only I have the private key and encrypt a document, then only my public key will decrypt the document, and others can implicitly trust that I wrote it: authentication. In fact, we don't even need to encrypt the entire document. If we create a digest of the document, we can then encrypt just the fingerprint. Signing the digest instead of the whole document is faster and solves some problems around the size of a message that can be encrypted using asymmetric encryption. Recipients decrypt the digest, independently calculate the digest for the message, and then compare the two to ensure integrity. The method for digital signatures varies for other asymmetric ciphers, but the concept of using the public key to verify a signature remains.
|
||||
|
||||
### Putting it all together
|
||||
|
||||
Now that we have all the major pieces, we can implement a [system][28] that has all three of the attributes we're looking for. Alice picks a secret symmetric key and encrypts it with Bob's public key. Then she hashes the resulting ciphertext and uses her private key to sign the digest. Bob receives the ciphertext and the signature, computes the ciphertext's digest and compares it to the digest in the signature he verified using Alice's public key. If the two digests are identical, he knows the symmetric key has integrity and is authenticated. He decrypts the ciphertext with his private key and uses the symmetric key Alice sent him to communicate with her confidentially using HMACs with each message to ensure integrity. There's no protection here against a message being replayed (as seen in the ice cream disaster Eve caused). To handle that issue, we would need some sort of "handshake" that could be used to establish a random, short-lived session identifier.
|
||||
|
||||
The cryptographic world is vast and complex, but I hope this article gives you a basic mental model of the core goals and components it uses. With a solid foundation in the concepts, you'll be able to continue learning more.
|
||||
|
||||
Thank you to Hubert Kario, Florian Weimer, and Mike Bursell for their help with this article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/cryptography-pki
|
||||
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://security.googleblog.com/2018/02/a-secure-web-is-here-to-stay.html
|
||||
[2]:https://blog.mozilla.org/security/2017/01/20/communicating-the-dangers-of-non-secure-http/
|
||||
[3]:https://letsencrypt.org/
|
||||
[4]:https://en.wikipedia.org/wiki/Cargo_cult_programming
|
||||
[5]:https://en.wikipedia.org/wiki/Alice_and_Bob
|
||||
[6]:https://en.wikipedia.org/wiki/Information_security#Availability
|
||||
[7]:https://en.wikipedia.org/wiki/XOR_cipher
|
||||
[8]:https://en.wikipedia.org/wiki/Involution_(mathematics)#Computer_science
|
||||
[9]:https://en.wikipedia.org/wiki/One-time_pad#Problems
|
||||
[10]:https://en.wikipedia.org/wiki/RC4
|
||||
[11]:https://en.wikipedia.org/wiki/ESTREAM
|
||||
[12]:https://en.wikipedia.org/wiki/Salsa20
|
||||
[13]:https://en.wikipedia.org/wiki/Advanced_Encryption_Standard
|
||||
[14]:https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
[15]:https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#/media/File:ECB_encryption.svg
|
||||
[16]:https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#/media/File:CBC_encryption.svg
|
||||
[17]:https://en.wikipedia.org/wiki/RSA_(cryptosystem)
|
||||
[18]:https://security.stackexchange.com/questions/33434/rsa-maximum-bytes-to-encrypt-comparison-to-aes-in-terms-of-security
|
||||
[19]:https://www.youtube.com/watch?v=1cUUfMeOijg
|
||||
[20]:https://en.wikipedia.org/wiki/Cryptographically_secure_pseudorandom_number_generator
|
||||
[21]:https://www.2uo.de/myths-about-urandom/
|
||||
[22]:https://crypto.stackexchange.com/a/1174
|
||||
[23]:https://www.telegraph.co.uk/science/2016/03/14/why-your-fingerprints-may-not-be-unique/
|
||||
[24]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[25]:https://en.wikipedia.org/wiki/SHA-1
|
||||
[26]:https://security.googleblog.com/2017/02/announcing-first-sha1-collision.html
|
||||
[27]:https://en.wikipedia.org/wiki/HMAC
|
||||
[28]:https://en.wikipedia.org/wiki/Hybrid_cryptosystem
|
||||
@ -0,0 +1,53 @@
|
||||
Audacity quick tip: quickly remove background noise
|
||||
======
|
||||
|
||||

|
||||
When recording sounds on a laptop — say for a simple first screencast — many users typically use the built-in microphone. However, these small microphones also capture a lot of background noise. In this quick tip, learn how to use [Audacity][1] in Fedora to quickly remove the background noise from audio files.
|
||||
|
||||
### Installing Audacity
|
||||
|
||||
Audacity is an application in Fedora for mixing, cutting, and editing audio files. It supports a wide range of formats out of the box on Fedora — including MP3 and OGG. Install Audacity from the Software application.
|
||||
|
||||
![][2]
|
||||
|
||||
If the terminal is more your speed, use the command:
|
||||
```
|
||||
sudo dnf install audacity
|
||||
|
||||
```
|
||||
|
||||
### Import your Audio, sample background noise
|
||||
|
||||
After installing Audacity, open the application, and import your sound using the **File > Import** menu item. This example uses a [sound bite from freesound.org][3] to which noise was added:
|
||||
|
||||
Next, take a sample of the background noise to be filtered out. With the tracks imported, select an area of the track that contains only the background noise. Then choose **Effect > Noise Reduction** from the menu, and press the **Get Noise Profile** button.
|
||||
|
||||
![][4]
|
||||
|
||||
### Filter the Noise
|
||||
|
||||
Next, select the area of the track you want to filter the noise from. Do this either by selecting with the mouse, or **Ctrl + a** to select the entire track. Finally, open the **Effect > Noise Reduction** dialog again, and click OK to apply the filter.
|
||||
|
||||
![][5]
|
||||
|
||||
Additionally, play around with the settings until your tracks sound better. Here is the original file again, followed by the noise reduced track for comparison (using the default settings):
|
||||
|
||||
https://ryanlerch.fedorapeople.org/sidebyside.ogg?_=2
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/audacity-quick-tip-quickly-remove-background-noise/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]:https://www.audacityteam.org/
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/03/audacity-software.jpg
|
||||
[3]:https://freesound.org/people/levinj/sounds/8323/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/03/select-noise-profile.gif
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/03/apply-filter.gif
|
||||
@ -0,0 +1,209 @@
|
||||
How to Install and Configure KVM on Ubuntu 18.04 LTS Server
|
||||
======
|
||||
**KVM** (Kernel-based Virtual Machine) is an open source full virtualization solution for Linux like systems, KVM provides virtualization functionality using the virtualization extensions like **Intel VT** or **AMD-V**. Whenever we install KVM on any linux box then it turns it into the hyervisor by loading the kernel modules like **kvm-intel.ko** ( for intel based machines) and **kvm-amd.ko** ( for amd based machines).
|
||||
|
||||
KVM allows us to install and run multiple virtual machines (Windows & Linux). We can create and manage KVM based virtual machines either via **virt-manager** graphical user interface or **virt-install** & **virsh** cli commands.
|
||||
|
||||
In this article we will discuss how to install and configure **KVM hypervisor** on Ubuntu 18.04 LTS server. I am assuming you have already installed Ubuntu 18.04 LTS server on your system. Login to your server and perform the following steps.
|
||||
|
||||
### Step:1 Verify Whether your system support hardware virtualization
|
||||
|
||||
Execute below egrep command to verify whether your system supports hardware virtualization or not,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ egrep -c '(vmx|svm)' /proc/cpuinfo
|
||||
1
|
||||
linuxtechi@kvm-ubuntu18-04:~$
|
||||
|
||||
```
|
||||
|
||||
If the output is greater than 0 then it means your system supports Virtualization else reboot your system, then go to BIOS settings and enable VT technology.
|
||||
|
||||
Now Install “ **kvm-ok** ” utility using below command, it is used to determine if your server is capable of running hardware accelerated KVM virtual machines
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo apt install cpu-checker
|
||||
|
||||
```
|
||||
|
||||
Run kvm-ok command and verify the output,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo kvm-ok
|
||||
INFO: /dev/kvm exists
|
||||
KVM acceleration can be used
|
||||
linuxtechi@kvm-ubuntu18-04:~$
|
||||
|
||||
```
|
||||
|
||||
### Step:2 Install KVM and its required packages
|
||||
|
||||
Run the below apt commands to install KVM and its dependencies
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo apt update
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo apt install qemu qemu-kvm libvirt-bin bridge-utils virt-manager
|
||||
|
||||
```
|
||||
|
||||
Once the above packages are installed successfully, then your local user (In my case linuxtechi) will be added to the group libvirtd automatically.
|
||||
|
||||
### Step:3 Start & enable libvirtd service
|
||||
|
||||
Whenever we install qemu & libvirtd packages in Ubuntu 18.04 Server then it will automatically start and enable libvirtd service, In case libvirtd service is not started and enabled then run beneath commands,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo service libvirtd start
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo update-rc.d libvirtd enable
|
||||
|
||||
```
|
||||
|
||||
Now verify the status of libvirtd service using below command,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ service libvirtd status
|
||||
|
||||
```
|
||||
|
||||
Output would be something like below:
|
||||
|
||||
[![libvirtd-command-ubuntu18-04][1]![libvirtd-command-ubuntu18-04][2]][3]
|
||||
|
||||
### Step:4 Configure Network Bridge for KVM virtual Machines
|
||||
|
||||
Network bridge is required to access the KVM based virtual machines outside the KVM hypervisor or host. In Ubuntu 18.04, network is managed by netplan utility, whenever we freshly installed Ubuntu 18.04 server then a file with name “ **/etc/netplan/50-cloud-init.yaml** ” is created automatically, to configure static IP and bridge, netplan utility will refer this file.
|
||||
|
||||
As of now I have already configured the static IP via this file and content of this file is below:
|
||||
```
|
||||
network:
|
||||
ethernets:
|
||||
ens33:
|
||||
addresses: [192.168.0.51/24]
|
||||
gateway4: 192.168.0.1
|
||||
nameservers:
|
||||
addresses: [192.168.0.1]
|
||||
dhcp4: no
|
||||
optional: true
|
||||
version: 2
|
||||
|
||||
```
|
||||
|
||||
Let’s add the network bridge definition in this file,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo vi /etc/netplan/50-cloud-init.yaml
|
||||
|
||||
network:
|
||||
version: 2
|
||||
ethernets:
|
||||
ens33:
|
||||
dhcp4: no
|
||||
dhcp6: no
|
||||
|
||||
bridges:
|
||||
br0:
|
||||
interfaces: [ens33]
|
||||
dhcp4: no
|
||||
addresses: [192.168.0.51/24]
|
||||
gateway4: 192.168.0.1
|
||||
nameservers:
|
||||
addresses: [192.168.0.1]
|
||||
|
||||
```
|
||||
|
||||
As you can see we have removed the IP address from interface(ens33) and add the same IP to the bridge ‘ **br0** ‘ and also added interface (ens33) to the bridge br0. Apply these changes using below netplan command,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo netplan apply
|
||||
linuxtechi@kvm-ubuntu18-04:~$
|
||||
|
||||
```
|
||||
|
||||
If you want to see the debug logs then use the below command,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo netplan --debug apply
|
||||
|
||||
```
|
||||
|
||||
Now Verify the bridge status using following methods:
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo networkctl status -a
|
||||
|
||||
```
|
||||
|
||||
[![networkctl-command-output-ubuntu18-04][1]![networkctl-command-output-ubuntu18-04][4]][4]
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ ifconfig
|
||||
|
||||
```
|
||||
|
||||
[![ifconfig-command-output-ubuntu18-04][1]![ifconfig-command-output-ubuntu18-04][5]][5]
|
||||
|
||||
### Start:5 Creating Virtual machine (virt-manager or virt-install command )
|
||||
|
||||
There are two ways to create virtual machine:
|
||||
|
||||
* virt-manager (GUI utility)
|
||||
* virt-install command (cli utility)
|
||||
|
||||
|
||||
|
||||
**Creating Virtual machine using virt-manager:**
|
||||
|
||||
Start the virt-manager by executing the beneath command,
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo virt-manager
|
||||
|
||||
```
|
||||
|
||||
[![Start-Virt-Manager-Ubuntu18-04][1]![Start-Virt-Manager-Ubuntu18-04][6]][6]
|
||||
|
||||
Create a new virtual machine
|
||||
|
||||
[![ISO-file-Virt-Manager][1]![ISO-file-Virt-Manager][7]][7]
|
||||
|
||||
Click on forward and select the ISO file, in my case I am using RHEL 7.3 iso file.
|
||||
|
||||
[![Select-ISO-file-virt-manager-Ubuntu18-04-Server][1]![Select-ISO-file-virt-manager-Ubuntu18-04-Server][8]][8]
|
||||
|
||||
Click on Forward
|
||||
|
||||
In the next couple of windows, you will be prompted to specify the RAM, CPU and disk for the VM.
|
||||
|
||||
Now Specify the Name of the Virtual Machine and network,
|
||||
|
||||
[![VM-Name-Network-Virt-Manager-Ubuntu18-04][1]![VM-Name-Network-Virt-Manager-Ubuntu18-04][9]][9]
|
||||
|
||||
Click on Finish
|
||||
|
||||
[![RHEL7-3-Installation-Virt-Manager][1]![RHEL7-3-Installation-Virt-Manager][10]][10]
|
||||
|
||||
Now follow the screen instruction and complete the installation,
|
||||
|
||||
**Creating Virtual machine from CLI using virt-install command,**
|
||||
|
||||
Use the below virt-install command to create a VM from terminal, it will start the installation in CLI, replace the name of the VM, description, location of ISO file and network bridge as per your setup.
|
||||
```
|
||||
linuxtechi@kvm-ubuntu18-04:~$ sudo virt-install -n DB-Server --description "Test VM for Database" --os-type=Linux --os-variant=rhel7 --ram=1096 --vcpus=1 --disk path=/var/lib/libvirt/images/dbserver.img,bus=virtio,size=10 --network bridge:br0 --graphics none --location /home/linuxtechi/rhel-server-7.3-x86_64-dvd.iso --extra-args console=ttyS0
|
||||
|
||||
```
|
||||
|
||||
That’s conclude the article, I hope this article help you to install KVM on your Ubuntu 18.04 Server. Apart from this, KVM is the default hypervisor for Openstack.
|
||||
|
||||
Read More On : “[ **How to Create, Revert and Delete KVM Virtual machine (domain) snapshot with virsh command**][11]“
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/install-configure-kvm-ubuntu-18-04-server/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/plugins/lazy-load/images/1x1.trans.gif
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2018/05/libvirtd-command-ubuntu18-04-1024x339.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2018/05/libvirtd-command-ubuntu18-04.jpg
|
||||
[4]:https://www.linuxtechi.com/wp-content/uploads/2018/05/networkctl-command-output-ubuntu18-04.jpg
|
||||
[5]:https://www.linuxtechi.com/wp-content/uploads/2018/05/ifconfig-command-output-ubuntu18-04.jpg
|
||||
[6]:https://www.linuxtechi.com/wp-content/uploads/2018/05/Start-Virt-Manager-Ubuntu18-04.jpg
|
||||
[7]:https://www.linuxtechi.com/wp-content/uploads/2018/05/ISO-file-Virt-Manager.jpg
|
||||
[8]:https://www.linuxtechi.com/wp-content/uploads/2018/05/Select-ISO-file-virt-manager-Ubuntu18-04-Server.jpg
|
||||
[9]:https://www.linuxtechi.com/wp-content/uploads/2018/05/VM-Name-Network-Virt-Manager-Ubuntu18-04.jpg
|
||||
[10]:https://www.linuxtechi.com/wp-content/uploads/2018/05/RHEL7-3-Installation-Virt-Manager.jpg
|
||||
[11]:https://www.linuxtechi.com/create-revert-delete-kvm-virtual-machine-snapshot-virsh-command/
|
||||
@ -0,0 +1,117 @@
|
||||
Advanced use of the less text file viewer in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
I recently read Scott Nesbitt's article "[Using less to view text files at the Linux command line][1]" and was inspired to share additional tips and tricks I use with `less`.
|
||||
|
||||
### LESS env var
|
||||
|
||||
If you have an environment variable `LESS` defined (e.g., in your `.bashrc`), `less` treats it as a list of options, as if passed on the command line.
|
||||
|
||||
I use this:
|
||||
```
|
||||
LESS='-C -M -I -j 10 -# 4'
|
||||
|
||||
```
|
||||
|
||||
These mean:
|
||||
|
||||
* `-C` – Make full-screen reprints faster by not scrolling from the bottom.
|
||||
* `-M` – Show more information from the last (status) line. You can customize the information shown with `-PM`, but I usually do not bother.
|
||||
* `-I` – Ignore letter case (upper/lower) in searches.
|
||||
* `-j 10` – Show search results in line 10 of the terminal, instead of the first line. This way you have 10 lines of context each time you press `n` (or `N`) to jump to the next (or previous) match.
|
||||
* `-# 4` – Jump four characters to the right or left when pressing the Right or Left arrow key. The default is to jump half of the screen, which I usually find to be too much. Generally speaking, `less` seems to be (at least partially) optimized to the environment it was initially developed in, with slow modems and low-bandwidth internet connections, when it made sense to jump half a screen.
|
||||
|
||||
|
||||
|
||||
### PAGER env var
|
||||
|
||||
Many programs show information using the command set in the `PAGER` environment variable (if it's set). So, you can set `PAGER=less` in your `.bashrc` and have your program run `less`. Check the man page environ(7) (`man 7 environ`) for other such variables.
|
||||
|
||||
### -S
|
||||
|
||||
`-S` tells `less` to chop long lines instead of wrapping them. I rarely find a need for this unless (and until) I've started viewing a file. Fortunately, you can type all command-line options inside `less` as if they were keyboard commands. So, if I want to chop long lines while I'm already in a file, I can simply type `-S`.
|
||||
|
||||
The command-line optiontellsto chop long lines instead of wrapping them. I rarely find a need for this unless (and until) I've started viewing a file. Fortunately, you can type all command-line options insideas if they were keyboard commands. So, if I want to chop long lines while I'm already in a file, I can simply type
|
||||
|
||||
Here's an example I use a lot:
|
||||
```
|
||||
su - postgres
|
||||
|
||||
export PAGER=less # Because I didn't bother editing postgres' .bashrc on all the machines I use it on
|
||||
|
||||
psql
|
||||
|
||||
```
|
||||
|
||||
Sometimes when I later view the output of a `SELECT` command with a very wide output, I type `-S` so it will be formatted nicely. If it jumps too far when I press the Right arrow to see more (because I didn't set `-#`), I can type `-#8`, then each Right arrow press will move eight characters to the right.
|
||||
|
||||
Sometimes after typing `-S` too many times, I exit psql and run it again after entering:
|
||||
```
|
||||
export LESS=-S
|
||||
|
||||
```
|
||||
|
||||
### F
|
||||
|
||||
The command `F` makes `less` work like `tail -f`—waiting until more data is added to the file before showing it. One advantage this has over `tail -f` is that highlighting search matches still works. So you can enter `less /var/log/logfile`, search for something—which will highlight all occurrences of it (unless you used `-g`)—and then press `F`. When more data is written to the log, `less` will show it and highlight the new matches.
|
||||
|
||||
After you press `F`, you can press `Ctrl+C` to stop it from looking for new data (this will not kill it); go back into the file to see older stuff, search for other things, etc.; and then press `F` again to look at more new data.
|
||||
|
||||
### Searching
|
||||
|
||||
Searches use the system's regexp library, and this usually means you can use extended regular expressions. In particular, searching for `one|two|three` will find and highlight all occurrences of one, two, or three.
|
||||
|
||||
Another pattern I use a lot, especially with wide log lines (e.g., ones that span more than one terminal line), is `.*something.*`, which highlights the entire line. This pattern makes it much easier to see where a line starts and finishes. I also combine these, such as: `.*one thing.*|.*another thing.*`, or `key: .*|.*marker.*` to see the contents of `key` (e.g., in a log file with a dump of some dictionary/hash) and highlight relevant marker lines (so I have a context), or even, if I know the value is surrounded by quotes:
|
||||
```
|
||||
key: '[^']*'|.*marker.*
|
||||
|
||||
```
|
||||
|
||||
`less` maintains a history of your search items and saves them to disk for future invocations. When you press `/` (or `?`), you can go through this history with the Up or Down arrow (as well as do basic line editing).
|
||||
|
||||
I stumbled upon what seems to be a very useful feature when skimming through the `less` man page while writing this article: skipping uninteresting lines with `&!pattern`. For example, while looking for something in `/var/log/messages`, I used to iterate through this list of commands:
|
||||
```
|
||||
cat /var/log/messages | egrep -v 'systemd: Started Session' | less
|
||||
|
||||
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session' | less
|
||||
|
||||
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session|User Slice' | less
|
||||
|
||||
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session|User Slice|dbus' | less
|
||||
|
||||
cat /var/log/messages | egrep -v 'systemd: Started Session|systemd: Starting Session|User Slice|dbus|PackageKit Daemon' | less
|
||||
|
||||
```
|
||||
|
||||
But now I know how to do the same thing within `less`. For example, I can type `&!systemd: Started Session`, then decide I want to get rid of `systemd: Starting Session`, so I add it by typing `&!` and use the Up arrow to get the previous search from the history. Then I type `|systemd: Starting Session` and press `Enter`, continuing to add more items the same way until I filter out enough to see the more interesting stuff.
|
||||
|
||||
### =
|
||||
|
||||
The command `=` shows more information about the file and location, even more than `-M`. If the file is very long, and calculating `=` takes too long, you can press `Ctrl+C` and it will stop trying.
|
||||
|
||||
If the content you're viewing is from a pipe rather than a file, `=` (and `-M`) will not show what it does not know, including the number of lines and bytes in the file. To see that data, if you know that `command` will finish quickly, you can jump to the end with `G`, and then `less` will start showing that information.
|
||||
|
||||
If you press `G` and the command writing to the pipe takes longer than expected, you can press `Ctrl+C`, and the command will be killed. Pressing `Ctrl+C` will kill it even if you didn't press `G`, so be careful not to press `Ctrl+C` accidentally if you don't intend to kill it. For this reason, if the command does something (that is, it's not only showing information), it's usually safer to write its output to a file and view the file in a separate terminal, instead of using a pipe.
|
||||
|
||||
### Why you need less
|
||||
|
||||
`less` is a very powerful program, and contrary to newer contenders in this space, such as `most` and `moar`, you are likely to find it on almost all the systems you use, just like `vi`. So, even if you use GUI viewers or editors, it's worth investing some time going through the `less` man page, at least to get a feeling of what's available. This way, when you need to do something that might be covered by existing functionality, you'll know to search the manual page or the internet to find what you need.
|
||||
|
||||
For more information, visit the [less home page][2]. The site has a nice FAQ with more tips and tricks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/advanced-use-less-text-file-viewer
|
||||
|
||||
作者:[Yedidyah Bar David][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/didib
|
||||
[1]:http://opensource.com/article/18/4/using-less-view-text-files-command-line
|
||||
[2]:http://www.greenwoodsoftware.com/less/
|
||||
@ -0,0 +1,83 @@
|
||||
Free Resources for Securing Your Open Source Code
|
||||
======
|
||||
|
||||

|
||||
|
||||
While the widespread adoption of open source continues at a healthy rate, the recent [2018 Open Source Security and Risk Analysis Report][1] from Black Duck and Synopsys reveals some common concerns and highlights the need for sound security practices. The report examines findings from the anonymized data of over 1,100 commercial codebases with represented Industries from automotive, Big Data, enterprise software, financial services, healthcare, IoT, manufacturing, and more.
|
||||
|
||||
The report highlights a massive uptick in open source adoption, with 96 percent of the applications scanned containing open source components. However, the report also includes warnings about existing vulnerabilities. Among the [findings][2]:
|
||||
|
||||
* “What is worrisome is that 78 percent of the codebases examined contained at least one open source vulnerability, with an average 64 vulnerabilities per codebase.”
|
||||
|
||||
* “Over 54 percent of the vulnerabilities found in audited codebases are considered high-risk vulnerabilities.”
|
||||
|
||||
* Seventeen percent of the codebases contained a highly publicized vulnerability such as Heartbleed, Logjam, Freak, Drown, or Poodle.
|
||||
|
||||
|
||||
|
||||
|
||||
"The report clearly demonstrates that with the growth in open source use, organizations need to ensure they have the tools to detect vulnerabilities in open source components and manage whatever license compliance their use of open source may require," said Tim Mackey, technical evangelist at Black Duck by Synopsys.
|
||||
|
||||
Indeed, with ever more impactful security threats emerging,the need for fluency with security tools and practices has never been more pronounced. Most organizations are aware that network administrators and sysadmins need to have strong security skills, and, in many cases security certifications. [In this article,][3] we explored some of the tools, certifications and practices that many of them wisely embrace.
|
||||
|
||||
The Linux Foundation has also made available many informational and educational resources on security. Likewise, the Linux community offers many free resources for specific platforms and tools. For example, The Linux Foundation has published a [Linux workstation security checklist][4] that covers a lot of good ground. Online publications ranging from the [Fedora security guide][5] to the[Securing Debian Manual][6] can also help users protect against vulnerabilities within specific platforms.
|
||||
|
||||
The widespread use of cloud platforms such as OpenStack is also stepping up the need for cloud-centric security smarts. According to The Linux Foundation’s[Guide to the Open Cloud][7]: “Security is still a top concern among companies considering moving workloads to the public cloud, according to Gartner, despite a strong track record of security and increased transparency from cloud providers. Rather, security is still an issue largely due to companies’ inexperience and improper use of cloud services.”
|
||||
|
||||
For both organizations and individuals, the smallest holes in implementation of routers, firewalls, VPNs, and virtual machines can leave room for big security problems. Here is a collection of free tools that can plug these kinds of holes:
|
||||
|
||||
* [Wireshark][8], a packet analyzer
|
||||
|
||||
* [KeePass Password Safe][9], a free open source password manager
|
||||
|
||||
* [Malwarebytes][10], a free anti-malware and antivirus tool
|
||||
|
||||
* [NMAP][11], a powerful security scanner
|
||||
|
||||
* [NIKTO][12], an open source web server scanner
|
||||
|
||||
* [Ansible][13], a tool for automating secure IT provisioning
|
||||
|
||||
* [Metasploit][14], a tool for understanding attack vectors and doing penetration testing
|
||||
|
||||
|
||||
|
||||
|
||||
Instructional videos abound for these tools. You’ll find a whole[tutorial series][15] for Metasploit, and [video tutorials][16] for Wireshark. Quite a few free ebooks provide good guidance on security as well. For example, one of the common ways for security threats to invade open source platforms occurs in M&A scenarios, where technology platforms are merged—often without proper open source audits. In an ebook titled [Open Source Audits in Merger and Acquisition Transactions][17], from Ibrahim Haddad and The Linux Foundation, you’ll find an overview of the open source audit process and important considerations for code compliance, preparation, and documentation.
|
||||
|
||||
Meanwhile, we’ve[previously covered][18] a free ebook from the editors at[The New Stack][19] called Networking, Security & Storage with Docker & Containers. It covers the latest approaches to secure container networking, as well as native efforts by Docker to create efficient and secure networking practices. The ebook is loaded with best practices for locking down security at scale.
|
||||
|
||||
All of these tools and resources, and many more, can go a long way toward preventing security problems, and an ounce of prevention is, as they say, worth a pound of cure. With security breaches continuing, now is an excellent time to look into the many security and compliance resources for open source tools and platforms available. Learn more about security, compliance, and open source project health [here][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/5/free-resources-securing-your-open-source-code
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.blackducksoftware.com/open-source-security-risk-analysis-2018
|
||||
[2]:https://www.prnewswire.com/news-releases/synopsys-report-finds-majority-of-software-plagued-by-known-vulnerabilities-and-license-conflicts-as-open-source-adoption-soars-300648367.html
|
||||
[3]:https://www.linux.com/blog/sysadmin-ebook/2017/8/future-proof-your-sysadmin-career-locking-down-security
|
||||
[4]:http://go.linuxfoundation.org/ebook_workstation_security
|
||||
[5]:https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html
|
||||
[6]:https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html
|
||||
[7]:https://www.linux.com/publications/2016-guide-open-cloud
|
||||
[8]:https://www.wireshark.org/
|
||||
[9]:http://keepass.info/
|
||||
[10]:https://www.malwarebytes.com/
|
||||
[11]:http://searchsecurity.techtarget.co.uk/tip/Nmap-tutorial-Nmap-scan-examples-for-vulnerability-discovery
|
||||
[12]:https://cirt.net/Nikto2
|
||||
[13]:https://www.ansible.com/
|
||||
[14]:https://www.metasploit.com/
|
||||
[15]:http://www.computerweekly.com/tutorial/The-Metasploit-Framework-Tutorial-PDF-compendium-Your-ready-reckoner
|
||||
[16]:https://www.youtube.com/watch?v=TkCSr30UojM
|
||||
[17]:https://www.linuxfoundation.org/resources/open-source-audits-merger-acquisition-transactions/
|
||||
[18]:https://www.linux.com/news/networking-security-storage-docker-containers-free-ebook-covers-essentials
|
||||
[19]:http://thenewstack.io/ebookseries/
|
||||
[20]:https://www.linuxfoundation.org/projects/security-compliance/
|
||||
232
sources/tech/20180522 How to Run Your Own Git Server.md
Normal file
232
sources/tech/20180522 How to Run Your Own Git Server.md
Normal file
@ -0,0 +1,232 @@
|
||||
How to Run Your Own Git Server
|
||||
======
|
||||
**Learn how to set up your own Git server in this tutorial from our archives.**
|
||||
|
||||
[Git ][1]is a versioning system [developed by Linus Torvalds][2], that is used by millions of users around the globe. Companies like GitHub offer code hosting services based on Git. [According to reports, GitHub, a code hosting site, is the world's largest code hosting service.][3] The company claims that there are 9.2M people collaborating right now across 21.8M repositories on GitHub. Big companies are now moving to GitHub. [Even Google, the search engine giant, is shutting it's own Google Code and moving to GitHub.][4]
|
||||
|
||||
### Run your own Git server
|
||||
|
||||
GitHub is a great service, however there are some limitations and restrictions, especially if you are an individual or a small player. One of the limitations of GitHub is that the free service doesn’t allow private hosting of the code. [You have to pay a monthly fee of $7 to host 5 private repositories][5], and the expenses go up with more repos.
|
||||
|
||||
In cases like these or when you want more control, the best path is to run Git on your own server. Not only do you save costs, you also have more control over your server. In most cases a majority of advanced Linux users already have their own servers and pushing Git on those servers is like ‘free as in beer’.
|
||||
|
||||
In this tutorial we are going to talk about two methods of managing your code on your own server. One is running a bare, basic Git server and and the second one is via a GUI tool called [GitLab][6]. For this tutorial I used a fully patched Ubuntu 14.04 LTS server running on a VPS.
|
||||
|
||||
### Install Git on your server
|
||||
|
||||
In this tutorial we are considering a use-case where we have a remote server and a local server and we will work between these machines. For the sake of simplicity we will call them remote-server and local-server.
|
||||
|
||||
First, install Git on both machines. You can install Git from the packages already available via the repos or your distros, or you can do it manually. In this article we will use the simpler method:
|
||||
```
|
||||
sudo apt-get install git-core
|
||||
|
||||
```
|
||||
|
||||
Then add a user for Git.
|
||||
```
|
||||
sudo useradd git
|
||||
passwd git
|
||||
|
||||
```
|
||||
|
||||
In order to ease access to the server let's set-up a password-less ssh login. First create ssh keys on your local machine:
|
||||
```
|
||||
ssh-keygen -t rsa
|
||||
|
||||
```
|
||||
|
||||
It will ask you to provide the location for storing the key, just hit Enter to use the default location. The second question will be to provide it with a pass phrase which will be needed to access the remote server. It generates two keys - a public key and a private key. Note down the location of the public key which you will need in the next step.
|
||||
|
||||
Now you have to copy these keys to the server so that the two machines can talk to each other. Run the following command on your local machine:
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
|
||||
|
||||
```
|
||||
|
||||
Now ssh into the server and create a project directory for Git. You can use the desired path for the repo.
|
||||
|
||||
Then change to this directory:
|
||||
```
|
||||
cd /home/swapnil/project-1.git
|
||||
|
||||
```
|
||||
|
||||
Then create an empty repo:
|
||||
```
|
||||
git init --bare
|
||||
Initialized empty Git repository in /home/swapnil/project-1.git
|
||||
|
||||
```
|
||||
|
||||
We now need to create a Git repo on the local machine.
|
||||
```
|
||||
mkdir -p /home/swapnil/git/project
|
||||
|
||||
```
|
||||
|
||||
And change to this directory:
|
||||
```
|
||||
cd /home/swapnil/git/project
|
||||
|
||||
```
|
||||
|
||||
Now create the files that you need for the project in this directory. Stay in this directory and initiate git:
|
||||
```
|
||||
git init
|
||||
Initialized empty Git repository in /home/swapnil/git/project
|
||||
|
||||
```
|
||||
|
||||
Now add files to the repo:
|
||||
```
|
||||
git add .
|
||||
|
||||
```
|
||||
|
||||
Now every time you add a file or make changes you have to run the add command above. You also need to write a commit message with every change in a file. The commit message basically tells what changes were made.
|
||||
```
|
||||
git commit -m "message" -a
|
||||
[master (root-commit) 57331ee] message
|
||||
2 files changed, 2 insertions(+)
|
||||
create mode 100644 GoT.txt
|
||||
create mode 100644 writing.txt
|
||||
|
||||
```
|
||||
|
||||
In this case I had a file called GoT (Game of Thrones review) and I made some changes, so when I ran the command it specified that changes were made to the file. In the above command '-a' option means commits for all files in the repo. If you made changes to only one you can specify the name of that file instead of using '-a'.
|
||||
|
||||
An example:
|
||||
```
|
||||
git commit -m "message" GoT.txt
|
||||
[master e517b10] message
|
||||
1 file changed, 1 insertion(+)
|
||||
|
||||
```
|
||||
|
||||
Until now we have been working on the local server. Now we have to push these changes to the server so the work is accessible over the Internet and you can collaborate with other team members.
|
||||
```
|
||||
git remote add origin ssh://git@remote-server/repo-<wbr< a="">>path-on-server..git
|
||||
|
||||
```
|
||||
|
||||
Now you can push or pull changes between the server and local machine using the 'push' or 'pull' option:
|
||||
```
|
||||
git push origin master
|
||||
|
||||
```
|
||||
|
||||
If there are other team members who want to work with the project they need to clone the repo on the server to their local machine:
|
||||
```
|
||||
git clone git@remote-server:/home/swapnil/project.git
|
||||
|
||||
```
|
||||
|
||||
Here /home/swapnil/project.git is the project path on the remote server, exchange the values for your own server.
|
||||
|
||||
Then change directory on the local machine (exchange project with the name of project on your server):
|
||||
```
|
||||
cd /project
|
||||
|
||||
```
|
||||
|
||||
Now they can edit files, write commit change messages and then push them to the server:
|
||||
```
|
||||
git commit -m 'corrections in GoT.txt story' -a
|
||||
And then push changes:
|
||||
|
||||
git push origin master
|
||||
|
||||
```
|
||||
|
||||
I assume this is enough for a new user to get started with Git on their own servers. If you are looking for some GUI tools to manage changes on local machines, you can use GUI tools such as QGit or GitK for Linux.
|
||||
|
||||
### Using GitLab
|
||||
|
||||
This was a pure command line solution for project owner and collaborator. It's certainly not as easy as using GitHub. Unfortunately, while GitHub is the world's largest code hosting service; its own software is not available for others to use. It's not open source so you can't grab the source code and compile your own GitHub. Unlike WordPress or Drupal you can't download GitHub and run it on your own servers.
|
||||
|
||||
As usual in the open source world there is no end to the options. GitLab is a nifty project which does exactly that. It's an open source project which allows users to run a project management system similar to GitHub on their own servers.
|
||||
|
||||
You can use GitLab to run a service similar to GitHub for your team members or your company. You can use GitLab to work on private projects before releasing them for public contributions.
|
||||
|
||||
GitLab employs the traditional Open Source business model. They have two products: free of cost open source software, which users can install on their own servers, and a hosted service similar to GitHub.
|
||||
|
||||
The downloadable version has two editions - the free of cost community edition and the paid enterprise edition. The enterprise edition is based on the community edition but comes with additional features targeted at enterprise customers. It’s more or less similar to what WordPress.org or Wordpress.com offer.
|
||||
|
||||
The community edition is highly scalable and can support 25,000 users on a single server or cluster. Some of the features of GitLab include: Git repository management, code reviews, issue tracking, activity feeds, and wikis. It comes with GitLab CI for continuous integration and delivery.
|
||||
|
||||
Many VPS providers such as Digital Ocean offer GitLab droplets for users. If you want to run it on your own server, you can install it manually. GitLab offers an Omnibus package for different operating systems. Before we install GitLab, you may want to configure an SMTP email server so that GitLab can push emails as and when needed. They recommend Postfix. So, install Postfix on your server:
|
||||
```
|
||||
sudo apt-get install postfix
|
||||
|
||||
```
|
||||
|
||||
During installation of Postfix it will ask you some questions; don't skip them. If you did miss it you can always re-configure it using this command:
|
||||
```
|
||||
sudo dpkg-reconfigure postfix
|
||||
|
||||
```
|
||||
|
||||
When you run this command choose "Internet Site" and provide the email ID for the domain which will be used by Gitlab.
|
||||
|
||||
In my case I provided it with:
|
||||
```
|
||||
This e-mail address is being protected from spambots. You need JavaScript enabled to view it
|
||||
|
||||
|
||||
```
|
||||
|
||||
Use Tab and create a username for postfix. The Next page will ask you to provide a destination for mail.
|
||||
|
||||
In the rest of the steps, use the default options. Once Postfix is installed and configured, let's move on to install GitLab.
|
||||
|
||||
Download the packages using wget (replace the download link with the [latest packages from here][7]) :
|
||||
```
|
||||
wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
Then install the package:
|
||||
```
|
||||
sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
Now it's time to configure and start GitLabs.
|
||||
```
|
||||
sudo gitlab-ctl reconfigure
|
||||
|
||||
```
|
||||
|
||||
You now need to configure the domain name in the configuration file so you can access GitLab. Open the file.
|
||||
```
|
||||
nano /etc/gitlab/gitlab.rb
|
||||
|
||||
```
|
||||
|
||||
In this file edit the 'external_url' and give the server domain. Save the file and then open the newly created GitLab site from a web browser.
|
||||
|
||||
By default it creates 'root' as the system admin and uses '5iveL!fe' as the password. Log into the GitLab site and then change the password.
|
||||
|
||||
Once the password is changed, log into the site and start managing your project.
|
||||
|
||||
GitLab is overflowing with features and options. I will borrow popular lines from the movie, The Matrix: "Unfortunately, no one can be told what all GitLab can do. You have to try it for yourself."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/how-run-your-own-git-server
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://github.com/git/git
|
||||
[2]:https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/
|
||||
[3]:https://github.com/about/press
|
||||
[4]:http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html
|
||||
[5]:https://github.com/pricing
|
||||
[6]:https://about.gitlab.com/
|
||||
[7]:https://about.gitlab.com/downloads/
|
||||
@ -0,0 +1,134 @@
|
||||
Using Stratis to manage Linux storage from the command line
|
||||
======
|
||||
|
||||

|
||||
|
||||
As discussed in [Part 1][1] and [Part 2][2] of this series, Stratis is a volume-managing filesystem with functionality similar to that of [ZFS][3] and [Btrfs][4]. In this article, we'll walk through how to use Stratis on the command line.
|
||||
|
||||
### Getting Stratis
|
||||
|
||||
For non-developers, the easiest way to try Stratis now is in [Fedora 28][5].
|
||||
|
||||
Once you're running this, you can install the Stratis daemon and the Stratis command-line tool with:
|
||||
```
|
||||
# dnf install stratis-cli stratisd
|
||||
|
||||
```
|
||||
|
||||
### Creating a pool
|
||||
|
||||
Stratis has three concepts: blockdevs, pools, and filesystems. Blockdevs are the block devices, such as a disk or a disk partition, that make up a pool. Once a pool is created, filesystems can be created from it.
|
||||
|
||||
Assuming you have a block device called `vdg` on your system that is not currently in use or mounted, you can create a Stratis pool on it with:
|
||||
```
|
||||
# stratis pool create mypool /dev/vdg
|
||||
|
||||
```
|
||||
|
||||
This assumes `vdg` is completely zeroed and empty. If it is not in use but has old data on it, it may be necessary to use `pool create`'s `- force` option. If it is in use, don't use it for Stratis.
|
||||
|
||||
If you want to create a pool from more than one block device, just list them all on the `pool create` command line. You can also add more blockdevs later using the `blockdev add-data` command. Note that Stratis requires blockdevs to be at least 1 GiB in size.
|
||||
|
||||
### Creating filesystems
|
||||
|
||||
Once you've created a pool called `mypool`, you can create filesystems from it:
|
||||
```
|
||||
# stratis fs create mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
After creating a filesystem called `myfs1` from pool `mypool`, you can mount and use it, using the entries Stratis has created within /dev/stratis:
|
||||
```
|
||||
# mkdir myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
The filesystem is now mounted on `myfs1` and ready to use.
|
||||
|
||||
### Snapshots
|
||||
|
||||
In addition to creating empty filesystems, you can also create a filesystem as a snapshot of an existing filesystem:
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1 myfs1-experiment
|
||||
|
||||
```
|
||||
|
||||
After doing so, you could mount the new `myfs1-experiment`, which will initially contain the same file contents as `myfs1`, but could change as the filesystem is modified. Whatever changes you made to `myfs1-experiment` would not be reflected in `myfs1` unless you unmounted `myfs1` and destroyed it with:
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
```
|
||||
|
||||
and then snapshotted the snapshot to recreate it and remounted it:
|
||||
```
|
||||
# stratis fs snapshot mypool myfs1-experiment myfs1
|
||||
|
||||
# mount /dev/stratis/mypool/myfs1 myfs1
|
||||
|
||||
```
|
||||
|
||||
### Getting information
|
||||
|
||||
Stratis can list pools on the system:
|
||||
```
|
||||
# stratis pool list
|
||||
|
||||
```
|
||||
|
||||
As filesystems have more data written to them, you will see the "Total Physical Used" value increase. Be careful when this approaches "Total Physical Size"; we're still working on handling this correctly.
|
||||
|
||||
To list filesystems within a pool:
|
||||
```
|
||||
# stratis fs list mypool
|
||||
|
||||
```
|
||||
|
||||
To list the blockdevs that make up a pool:
|
||||
```
|
||||
# stratis blockdev list mypool
|
||||
|
||||
```
|
||||
|
||||
These give only minimal information currently, but they will provide more in the future.
|
||||
|
||||
#### Destroying a pool
|
||||
|
||||
Once you have an idea of what Stratis can do, to destroy the pool, first make sure all filesystems created from it are unmounted and destroyed, then use the `pool destroy` command:
|
||||
```
|
||||
# umount myfs1
|
||||
|
||||
# umount myfs1-experiment (if you created it)
|
||||
|
||||
# stratis fs destroy mypool myfs1
|
||||
|
||||
# stratis fs destroy mypool myfs1-experiment
|
||||
|
||||
# stratis pool destroy mypool
|
||||
|
||||
```
|
||||
|
||||
`stratis pool list` should now show no pools.
|
||||
|
||||
That's it! For more information, please see the manpage: `man stratis`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/stratis-storage-linux-command-line
|
||||
|
||||
作者:[Andy Grover][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/agrover
|
||||
[1]:https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux
|
||||
[2]:https://opensource.com/article/18/4/stratis-lessons-learned
|
||||
[3]:https://en.wikipedia.org/wiki/ZFS
|
||||
[4]:https://en.wikipedia.org/wiki/Btrfs
|
||||
[5]:https://fedoraproject.org/wiki/Releases/28/Schedule
|
||||
@ -0,0 +1,206 @@
|
||||
四个Linux网络嗅探工具
|
||||
======
|
||||
|
||||
在计算机网络中,数据是暴露的,因为数据包传输是无法隐藏的,所以让我们来使用 `whois`,`dig`,`nmcli` 和 `nmap` 这四个工具来嗅探网络吧。
|
||||
|
||||
请注意,不要运行 `nmap` 在不属于自己的网络上,因为这有可能会被其他人解读成为恶意攻击。
|
||||
|
||||
### 精简和详细域名信息查询
|
||||
|
||||
您可能已经注意到,之前我们用心爱的 `whois` 命令查询域名信息,但现如今似乎没有提供同过去一样的详细程度。我们使用该命令查询 Linux.com 域名描述信息:
|
||||
|
||||
```
|
||||
$ whois linux.com
|
||||
Domain Name: LINUX.COM
|
||||
Registry Domain ID: 4245540_DOMAIN_COM-VRSN
|
||||
Registrar WHOIS Server: whois.namecheap.com
|
||||
Registrar URL: http://www.namecheap.com
|
||||
Updated Date: 2018-01-10T12:26:50Z
|
||||
Creation Date: 1994-06-02T04:00:00Z
|
||||
Registry Expiry Date: 2018-06-01T04:00:00Z
|
||||
Registrar: NameCheap Inc.
|
||||
Registrar IANA ID: 1068
|
||||
Registrar Abuse Contact Email: abuse@namecheap.com
|
||||
Registrar Abuse Contact Phone: +1.6613102107
|
||||
Domain Status: ok https://icann.org/epp#ok
|
||||
Name Server: NS5.DNSMADEEASY.COM
|
||||
Name Server: NS6.DNSMADEEASY.COM
|
||||
Name Server: NS7.DNSMADEEASY.COM
|
||||
DNSSEC: unsigned
|
||||
[...]
|
||||
|
||||
```
|
||||
有很多令人讨厌的法律声明。但在哪有联系信息呢?该网站位于 whois.namecheap.com 站点上(见上面输出的第三行):
|
||||
|
||||
```
|
||||
$ whois -h whois.namecheap.com linux.com
|
||||
|
||||
```
|
||||
我就不复制出来,因为这实在太长了,包含了注册人,管理员和技术人员的联系信息。怎么回事啊,露西尔?(LCTT 译注:《行尸走肉》中尼根的棒子)有一些注册表,比如.com和.net是精简注册表,保存了一部分有限的域名信息。为了获取完整信息请使用 `-h` 或 `--host` 参数,该参数便会从域名的 `注册服务机构` 中获取。
|
||||
|
||||
大部分顶级域名是需要详细的注册信息,如.info。试着使用`whois blockchain.info`命令来查看。
|
||||
|
||||
想要摆脱这些烦人的法律声明?使用 `-H` 参数。
|
||||
|
||||
### DNS解析
|
||||
|
||||
使用 `dig` 命令比较从不同的域名服务器返回的查询结果,去除陈旧的信息。域名服务器记录缓存各地的解析信息,并且不同的域名服务器有不同的刷新间隔。以下是一个简单的用法:
|
||||
|
||||
```
|
||||
$ dig linux.com
|
||||
<<>> DiG 9.10.3-P4-Ubuntu <<>> linux.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<<- opcode: QUERY, status: NOERROR, id: 13694
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 1440
|
||||
;; QUESTION SECTION:
|
||||
;linux.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
linux.com. 10800 IN A 151.101.129.5
|
||||
linux.com. 10800 IN A 151.101.65.5
|
||||
linux.com. 10800 IN A 151.101.1.5
|
||||
linux.com. 10800 IN A 151.101.193.5
|
||||
|
||||
;; Query time: 92 msec
|
||||
;; SERVER: 127.0.1.1#53(127.0.1.1)
|
||||
;; WHEN: Tue Jan 16 15:17:04 PST 2018
|
||||
;; MSG SIZE rcvd: 102
|
||||
|
||||
```
|
||||
注意下靠近末尾的这行信息:SERVER: 127.0.1.1#53(127.0.1.1),这是您默认的缓存解析器。当地址是本地时,就相当于在您的电脑上安装DNS服务。在我看来这就是一个Dnsmasq工具(LCTT 译注:是一个小巧且方便地用于配置DNS和DHCP的工具),该工具被用作网络管理:
|
||||
|
||||
```
|
||||
$ ps ax|grep dnsmasq
|
||||
2842 ? S 0:00 /usr/sbin/dnsmasq --no-resolv --keep-in-foreground
|
||||
--no-hosts --bind-interfaces --pid-file=/var/run/NetworkManager/dnsmasq.pid
|
||||
--listen-address=127.0.1.1
|
||||
|
||||
```
|
||||
|
||||
`dig` 命令默认是返回A记录,也就是域名。IPv6则有AAAA记录:
|
||||
|
||||
```
|
||||
$ $ dig linux.com AAAA
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:4105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:8105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:c105
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
仔细检查下,发现Linux.com有IPv6地址。很好!如果您的网络服务支持IPv6那么您就可以用IPv6连接。(令人难过的是,我的移动宽带则没提供IPv6)
|
||||
|
||||
|
||||
假设您能使DNS改变您的域名,又或是您使用 `dig` 查询的结果有误。试着用一个公共DNS,如OpenNIC:
|
||||
|
||||
```
|
||||
$ dig @69.195.152.204 linux.com
|
||||
[...]
|
||||
;; Query time: 231 msec
|
||||
;; SERVER: 69.195.152.204#53(69.195.152.204)
|
||||
|
||||
```
|
||||
`dig` 回应您正在的查询是来自 69.195.152.204。您可以查询各种服务并且比较结果。
|
||||
|
||||
### 上游域名服务器
|
||||
|
||||
我想知道我的上游域名服务器是谁。为了查询,我首先看下`/etc/resolv/conf` 的配置信息:
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.1.1
|
||||
|
||||
```
|
||||
|
||||
很幸运,不过我是已经知道。您的Linux发行版可能配置不同,您会看到您的上游服务器。接下来我们来试试网络管理器命令行工具 `nmcli`:
|
||||
|
||||
```
|
||||
$ nmcli dev show | grep DNS
|
||||
IP4.DNS[1]: 192.168.1.1
|
||||
|
||||
```
|
||||
|
||||
很好,现在我们已经知道了,其实那是我的移动热点,并且我已经确认那是我的热点。我能够登录到简易管理面板,来查询上游服务器。然而许多消费者互联网网关不会让您看到或改变这些设置,因此只能尝试其他的方法,如 [我的域名服务器是什么?][1]
|
||||
|
||||
### 查找在您的网络中IPv4地址
|
||||
|
||||
您的网络上有哪些IPv4地址已启用并正在使用中?
|
||||
|
||||
```
|
||||
$ nmap -sn 192.168.1.0/24
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 14:03 PST
|
||||
Nmap scan report for Mobile.Hotspot (192.168.1.1)
|
||||
Host is up (0.011s latency).
|
||||
Nmap scan report for studio (192.168.1.2)
|
||||
Host is up (0.000071s latency).
|
||||
Nmap scan report for nellybly (192.168.1.3)
|
||||
Host is up (0.015s latency)
|
||||
Nmap done: 256 IP addresses (2 hosts up) scanned in 2.23 seconds
|
||||
|
||||
```
|
||||
每个人都想去扫描自己的局域网中开放的端口。下面的例子是寻找服务和他们的版本号:
|
||||
|
||||
```
|
||||
$ nmap -sV 192.168.1.1/24
|
||||
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 16:46 PST
|
||||
Nmap scan report for Mobile.Hotspot (192.168.1.1)
|
||||
Host is up (0.0071s latency).
|
||||
Not shown: 997 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
22/tcp filtered ssh
|
||||
53/tcp open domain dnsmasq 2.55
|
||||
80/tcp open http GoAhead WebServer 2.5.0
|
||||
|
||||
Nmap scan report for studio (192.168.1.102)
|
||||
Host is up (0.000087s latency).
|
||||
Not shown: 998 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
22/tcp open ssh OpenSSH 7.2p2 Ubuntu 4ubuntu2.2 (Ubuntu Linux; protocol 2.0)
|
||||
631/tcp open ipp CUPS 2.1
|
||||
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
|
||||
|
||||
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
|
||||
Nmap done: 256 IP addresses (2 hosts up) scanned in 11.65 seconds
|
||||
|
||||
```
|
||||
|
||||
这些是有趣的结果。让我们尝试从不同的网络帐户进行相同的操作,以查看这些服务是否暴露于互联网中。如果您有智能手机,相当于您有第二个网络。您可以下载应用程序,还可以为您的Linux电脑提供热点。从热点控制面板获取广域网IP地址,然后重试:
|
||||
|
||||
```
|
||||
$ nmap -sV 12.34.56.78
|
||||
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 17:05 PST
|
||||
Nmap scan report for 12.34.56.78
|
||||
Host is up (0.0061s latency).
|
||||
All 1000 scanned ports on 12.34.56.78 are closed
|
||||
|
||||
```
|
||||
果然不出所料,结果和我想象的一样。可以用手册来查询这些命令,以便了解更多有趣的嗅探技术。
|
||||
|
||||
|
||||
了解更多Linux的相关知识可以从Linux基金会和edX(LCTT译者注:edX是麻省理工和哈佛大学于2012年4月联手创建的大规模开放在线课堂平台)中获取免费的 ["介绍Linux" ][2]课程。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/4-tools-network-snooping-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:http://www.whatsmydnsserver.com/
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,106 @@
|
||||
如何在 Linux 系统中结束结束进程或是中止程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
进程出错的时候,您可能会想要中止或是中断这个进程。本文,我们将在命令行和图形界面中探索进程或是应用程序的中断,这里我们使用 [gedit][1] 作为样例程序。
|
||||
|
||||
### 使用命令行、终端字符
|
||||
|
||||
#### Ctrl + C
|
||||
|
||||
在命令行中调用 `gedit` (如果您没有使用 `gedit &` 命令)程序发生错误时,shell 会话被阻塞,将不会释放出相应的错误提示,此下,`Ctrl + C` (Ctrl 和 C 的组合键) 会很管用。`gedit` 会被中断,由于 `Ctrl + C` 给 `gedit` 发送了 `SIGINT` 信号,之前的所有工作都将丢失(除非文件已经被保存)。`SIGINT` 是一个会默认执行进程中断的终止信号,它将指示 shell 终止 `gedit` 的运行,并返回到主函数的循环中,此时,您将得到提示语。
|
||||
|
||||
```
|
||||
$ gedit
|
||||
^C
|
||||
```
|
||||
|
||||
#### Ctrl + Z
|
||||
|
||||
它被称为挂起字符,能够为进程发送 `SIGTSTP` 信号。它也是一个中止信号,但是默认行为不是杀死进程,而是挂起进程。
|
||||
|
||||
下面的命令将会停止(杀死/中断) `gedit` 的运行,并返回 shell 提示。
|
||||
```
|
||||
$ gedit
|
||||
^Z
|
||||
[1]+ Stopped gedit
|
||||
$
|
||||
```
|
||||
|
||||
一旦进程被挂起(以 `gedit` 为例),将不能在 `gedit` 中做任何事情。而在后台,该进程任然是一个作业,可以使用 `jsbs` 命令验证。
|
||||
```
|
||||
$ jobs
|
||||
[1]+ Stopped gedit
|
||||
```
|
||||
|
||||
`jobs` 允许您在单个 shell 会话中控制多个进程。您可以在前台或是后台终止,恢复或是移动作业。
|
||||
|
||||
让我们在后台恢复 `gedit`,释放提示并运行其它命令吧。您可以根据作业 ID(注意,`jobs` 命令显示出来的 `[1]` 就是作业 ID)使用 `bg` 命令恢复进程。
|
||||
```
|
||||
$ bg 1
|
||||
[1]+ gedit &
|
||||
```
|
||||
|
||||
这和直接使用 `gedit &` 启动程序效果差不多:
|
||||
```
|
||||
$ gedit &
|
||||
```
|
||||
|
||||
### 使用 kill
|
||||
|
||||
`kill` 命令提供信号的精确控制,允许您通过进程 ID 或是 PID,根据特定的信号名或是信号数字为进程发送信号。
|
||||
|
||||
`kill` 命令能够根据作业 ID 控制进程,这一点是我喜欢的。让我们使用 `gedit &` 命令在后台开启 `gedit` 服务。假设通过 `jobs` 命令我得到了一个 `gedit` 的作业 ID,让我们为 `gedit` 发送 `SIGINT` 信号吧:
|
||||
```
|
||||
$ kill -s SIGINT %1
|
||||
```
|
||||
|
||||
作业 ID 需要使用 `%` 前缀,不然 `kill` 会将其视作 PID。
|
||||
|
||||
不明确指定的信号,`kill` 仍然可以工作。此时,默认会发送能中断进程的 `SIGTERM` 信号。执行 `kill -l` 查看信号名列表,使用 `man kill` 命令阅读手册。
|
||||
|
||||
### 使用 killall
|
||||
|
||||
如果您不想使用特定的工作 ID 或者 PID,`killall` 允许您使用特定的进程名。中断 `gedit` 最简单的 `killall` 使用方式是:
|
||||
```
|
||||
$ killall gedit
|
||||
```
|
||||
|
||||
它将终止所有名为 `gedit` 的进程。和 `kill` 想死,默认发送的信号时 `SIGTERM`。
|
||||
This will kill all the processes with the name `gedit`. Like `kill`, the default signal is `SIGTERM`. 使用 `-I` 选项忽略大小写。
|
||||
```
|
||||
$ gedit &
|
||||
[1] 14852
|
||||
|
||||
$ killall -I GEDIT
|
||||
[1]+ Terminated gedit
|
||||
```
|
||||
|
||||
查看手册学习更多 `killall` 命令选项(如 `-u`)。
|
||||
|
||||
### 使用 xkill
|
||||
|
||||
您是否遇见过播放器崩溃,比如 [VLC][2] 灰屏或挂起?现在,获得程序 PID 之后,您就可以使用 `xkill` 命令终止应用程序。
|
||||
|
||||
![Using xkill][3]
|
||||
|
||||
`xkill` 允许您使用鼠标关闭窗口。仅需在终端执行 `xkill` 命令,它将会改变鼠标光标为一个 **X** 或是一个骷髅图标。点击您想关闭的进程窗口上的 **X**。小心使用 `xkill`,如手册描述的一致,它很危险。我已经提醒过您了!
|
||||
|
||||
参阅手册,了解上述命令更多信息。您还可以接续探索 `pkill` 和 `pgrep` 命令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/how-kill-process-stop-program-linux
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://wiki.gnome.org/Apps/Gedit
|
||||
[2]:https://www.videolan.org/vlc/index.html
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/uploads/xkill_gedit.png?itok=TBvMw0TN (Using xkill)
|
||||
@ -0,0 +1,98 @@
|
||||
使用 Buildah 创建小体积的容器
|
||||
======
|
||||

|
||||
我最近加入了 Red Hat,在这之前我在另外一家科技公司工作了很多年。在我的上一份工作岗位上,我开发了不少不同类型的软件产品,这些产品是成功的,但都有版权保护。不仅法规限制了我们不能在公司外将软件共享,而且我们在公司内部也基本不进行共享。在那时,我觉得这很有道理:公司花费了时间、精力和预算用于开发软件,理应保护并要求软件涉及的利益。
|
||||
|
||||
时间如梭,去年我加入 Red Hat 并培养出一种完全不同的理念。[Buildah 项目][1]是我最早加入的项目之一,该项目用于构建 OCI (Open Container Initiative) 标准的镜像,特别擅长让你精简已创建镜像的体积。那时 Buildah 还处于非常早期的阶段,包含一些瑕疵,不适合用于生产环境。
|
||||
|
||||
刚接触项目不久,我做了一些小变更,然后询问公司内部 git 仓库地址,以便提交我做的变更。收到的回答是:没有内部仓库,直接将变更提交到 GitHub 上。这让我感到困惑,将我的变更提交到 GitHub 意味着:任何人都可以查看这部分代码并在他们自己的项目中使用。况且代码还有一些瑕疵,这样做简直有悖常理。但作为一个新人,我只是惊讶地摇了摇头并提交了变更。
|
||||
|
||||
一年后,我终于相信了开源软件的力量和价值。我仍为 Buildah 项目工作,我们最近遇到的一个主题很形象地说明了这种力量和价值。标题为 [Buildah 镜像体积并不小?][2] 的主题由 Tim Dudgeon (@tdudgeon) 提出。简而言之,他发现使用 Buildah 创建的镜像比使用 Docker 创建的镜像体积更大,而且 Buildah 镜像中并不包含一些额外应用,但 Docker 镜像中却包含它们。
|
||||
|
||||
为了比较,他首先操作如下:
|
||||
```
|
||||
$ docker pull centos:7
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
docker.io/centos 7 2d194b392dd1 2 weeks ago 195 MB
|
||||
```
|
||||
|
||||
他发现 Docker 镜像的体积为 195MB。Tim 接着使用 Buildah 创建了一个(基于 scratch 的)最小化镜像,仅仅将 `coreutils` 和 `bash` 软件包加入到镜像中,使用的脚本如下:
|
||||
```
|
||||
$ cat ./buildah-base.sh
|
||||
#!/bin/bash
|
||||
|
||||
set -x
|
||||
|
||||
# build a minimal image
|
||||
newcontainer=$(buildah from scratch)
|
||||
scratchmnt=$(buildah mount $newcontainer)
|
||||
|
||||
# install the packages
|
||||
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt install_weak_deps=false -y
|
||||
yum clean all -y --installroot $scratchmnt --releasever 7
|
||||
|
||||
sudo buildah config --cmd /bin/bash $newcontainer
|
||||
|
||||
# set some config info
|
||||
buildah config --label name=centos-base $newcontainer
|
||||
|
||||
# commit the image
|
||||
buildah unmount $newcontainer
|
||||
buildah commit $newcontainer centos-base
|
||||
|
||||
$ sudo ./buildah-base.sh
|
||||
|
||||
$ sudo buildah images
|
||||
IMAGE ID IMAGE NAME CREATED AT SIZE
|
||||
8379315d3e3e docker.io/library/centos-base:latest Mar 25, 2018 17:08 212.1 MB
|
||||
```
|
||||
|
||||
Tim 想知道为何 Buildah 镜像体积反而大 17MB,毕竟 `python` 和 `yum` 软件包都没有安装到 Buildah 镜像中,而这些软件已经安装到 Docker 镜像中。这个结果并不符合预期,在 Github 的相关主题中引发了广泛的讨论。
|
||||
|
||||
不仅 Red Hat 的员工参与了讨论,还有不少公司外人士也加入了讨论,这很有意义。值得一提的是,GitHub 用户 @pixdrift 主导了很多重要的讨论并提出很多发现,他指出在 Buildah 镜像中文档和语言包就占据了比 100MB 略多一点的空间。Pixdrift 建议在 yum 安装器中强制指定语言,据此提出如下修改过的 `buildah-bash.sh` 脚本:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
set -x
|
||||
|
||||
# build a minimal image
|
||||
newcontainer=$(buildah from scratch)
|
||||
scratchmnt=$(buildah mount $newcontainer)
|
||||
|
||||
# install the packages
|
||||
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt=install_weak_deps=false --setopt=tsflags=nodocs --setopt=override_install_langs=en_US.utf8 -y
|
||||
yum clean all -y --installroot $scratchmnt --releasever 7
|
||||
|
||||
sudo buildah config --cmd /bin/bash $newcontainer
|
||||
|
||||
# set some config info
|
||||
buildah config --label name=centos-base $newcontainer
|
||||
|
||||
# commit the image
|
||||
buildah unmount $newcontainer
|
||||
buildah commit $newcontainer centos-base
|
||||
```
|
||||
|
||||
Tim 运行这个新脚本,得到的镜像体积缩减至 92MB,相比之前的 Buildah 镜像体积减少了 120MB,这比较接近我们的预期;然而,c出于工程师的天性,56% 的体积缩减不能让他们满足。讨论继续深入下去,涉及如何移除个人语言包以节省更多空间。如果想了解讨论细节,点击 [Buildah 镜像体积并不小?][2] 链接。说不定你也能给出有帮助的点子,甚至更进一步成为 Buildah 项目的贡献者。这个主题的解决从一个侧面告诉我们,Buildah 软件可以多么快速和容易地创建体积最小化的容器,该容器仅包含你高效运行任务所需的软件。额外的好处是,你无需运行一个守护进程。
|
||||
|
||||
这个镜像体积缩减的主题让我意识到开源软件的力量。来自不同公司的大量开发者,在一天多的时间内,以开放讨论的形式进行合作解决问题。虽然解决这个具体问题并没有修改已有代码,但 Red Hat 公司外开发者对 Buildah 做了很多代码贡献,进而帮助项目变得更好。这些贡献也吸引了更多人才关注项目代码;如果像之前那样,代码作为版权保护软件的一部分放置在私有 git 仓库中,不会获得上述好处。我只用了一年的时间就转向拥抱 [开源方式][3],而且可能不会再转回去了。
|
||||
|
||||
文章最初发表于 [Project Atomic][4],已获得转载许可。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/containers-buildah
|
||||
|
||||
作者:[Tom Sweeney][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomsweeneyredhat
|
||||
[1]:https://github.com/projectatomic/buildah
|
||||
[2]:https://github.com/projectatomic/buildah/issues/532
|
||||
[3]:https://twitter.com/opensourceway
|
||||
[4]:http://www.projectatomic.io/blog/2018/04/open-source-what-a-concept/
|
||||
@ -0,0 +1,216 @@
|
||||
使用 GNU Parallel 提高 Linux 命令行执行效率
|
||||
======
|
||||
|
||||

|
||||
|
||||
你是否有过这种感觉,你的主机运行速度没有预期的那么快?我也曾经有过这种感觉,直到我发现了 GNU Parallel。
|
||||
|
||||
GNU Parallel 是一个 shell 工具,可以并行执行任务。它可以解析多种输入,让你可以同时在多份数据上运行脚本或命令。你终于可以使用全部的 CPU 了!
|
||||
|
||||
如果你用过 `xargs`,上手 Parallel 几乎没有难度。如果没有用过,这篇教程会告诉你如何使用,同时给出一些其它的用例。
|
||||
|
||||
### 安装 GNU Parallel
|
||||
|
||||
GNU Parallel 很可能没有预装在你的 Linux 或 BSD 主机上,你可以从软件源(Linux 对应 repository,BSD 对应 ports collection)中安装。以 Fedora 为例:
|
||||
```
|
||||
$ sudo dnf install parallel
|
||||
|
||||
```
|
||||
|
||||
对于 NetBSD:
|
||||
```
|
||||
# pkg_add parallel
|
||||
|
||||
```
|
||||
|
||||
如果各种方式都不成功,请参考[项目主页][1]。
|
||||
|
||||
### 从串行到并行
|
||||
|
||||
正如其名称所示,Parallel 的强大之处是以并行方式执行任务;而我们中不少人平时仍然以串行方式运行任务。
|
||||
|
||||
当你对多个对象执行某个命令时,你实际上创建了一个任务队列。一部分对象可以被命令处理,剩余的对象需要等待,直到命令处理它们。这种方式是低效的。只要数据够多,总会形成任务队列;但与其只使用一个任务队列,为何不使用多个更小规模的任务队列呢?
|
||||
|
||||
假设你有一个图片目录,你希望将目录中的图片从 JEEG 格式转换为 PNG 格式。有多种方法可以完成这个任务。可以手动用 GIMP 打开每个图片,输出成新格式,但这基本是最差的选择,费时费力。
|
||||
|
||||
上述方法有一个漂亮且简洁的变种,即基于 shell 的方案:
|
||||
```
|
||||
$ convert 001.jpeg 001.png
|
||||
$ convert 002.jpeg 002.png
|
||||
$ convert 003.jpeg 003.png
|
||||
... 略 ...
|
||||
|
||||
```
|
||||
|
||||
对于初学者而言,这是一个不小的转变,而且看起来是个不小的改进。不再需要图像界面和不断的鼠标点击,但仍然是费力的。
|
||||
|
||||
进一步改进:
|
||||
```
|
||||
$ for i in *jpeg; do convert $i $i.png ; done
|
||||
|
||||
```
|
||||
|
||||
至少,这一步设置好任务执行,让你节省时间去做更有价值的事情。但问题来了,这仍然是串行操作;一张图片转换完成后,队列中的下一张进行转换,依此类推直到全部完成。
|
||||
|
||||
使用 Parallel:
|
||||
```
|
||||
$ find . -name "*jpeg" | parallel -I% --max-args 1 convert % %.png
|
||||
|
||||
```
|
||||
|
||||
这是两条命令的组合:`find` 命令,用于收集需要操作的对象;`parallel` 命令,用于对象排序并确保每个对象按需处理。
|
||||
|
||||
* `find . -name "*jpeg"` 查找当前目录下以 `jpeg` 结尾的所有文件。
|
||||
* `parallel` 调用 GNU Parallel。
|
||||
* `-I%` 创建了一个占位符 `%`,代表 `find` 传递给 Parallel 的内容。如果不使用占位符,你需要对 `find` 命令的每一个结果手动编写一个命令,而这恰恰是你想要避免的。
|
||||
* `--max-args 1` 给出 Parallel 从队列获取新对象的速率限制。考虑到 Parallel 运行的命令只需要一个文件输入,这里将速率限制设置为 1。假如你需要执行更复杂的命令,需要两个文件输入(例如 `cat 001.txt 002.txt > new.txt`),你需要将速率限制设置为 2。
|
||||
* `convert % %.png` 是你希望 Parallel 执行的命令。
|
||||
|
||||
|
||||
组合命令的执行效果如下:`find` 命令收集所有相关的文件信息并传递给 `parallel`,后者(使用当前参数)启动一个任务,(无需等待任务完成)立即获取参数行中的下一个参数(注:管道输出的每一行对应 `parallel` 的一个参数,所有参数构成参数行);只要你的主机没有瘫痪,Parallel 会不断做这样的操作。旧任务完成后,Parallel 会为分配新任务,直到所有数据都处理完成。不使用 Parallel 完成任务大约需要 10 分钟,使用后仅需 3 至 5 分钟。
|
||||
|
||||
### 多个输入
|
||||
|
||||
只要你熟悉 `find` 和 `xargs` (整体被称为 GNU 查找工具,或 `findutils`),`find` 命令是一个完美的 Parallel 数据提供者。它提供了灵活的接口,大多数 Linux 用户已经很习惯使用,即使对于初学者也很容易学习。
|
||||
|
||||
`find` 命令十分直截了当:你向 `find` 提供搜索路径和待查找文件的一部分信息。可以使用通配符完成模糊搜索;在下面的例子中,星号匹配任何字符,故 `find` 定位(文件名)以字符 `searchterm` 结尾的全部文件:
|
||||
```
|
||||
$ find /path/to/directory -name "*searchterm"
|
||||
|
||||
```
|
||||
|
||||
默认情况下,`find` 逐行返回搜索结果,每个结果对应 1 行:
|
||||
```
|
||||
$ find ~/graphics -name "*jpg"
|
||||
/home/seth/graphics/001.jpg
|
||||
/home/seth/graphics/cat.jpg
|
||||
/home/seth/graphics/penguin.jpg
|
||||
/home/seth/graphics/IMG_0135.jpg
|
||||
|
||||
```
|
||||
|
||||
当使用管道将 `find` 的结果传递给 `parallel` 时,每一行中的文件路径被视为 `parallel` 命令的一个参数。另一方面,如果你需要使用命令处理多个参数,你可以改变队列数据传递给 `parallel` 的方式。
|
||||
|
||||
下面先给出一个不那么真实的例子,后续会做一些修改使其更加有意义。如果你安装了 GNU Parallel,你可以跟着这个例子操作。
|
||||
|
||||
假设你有 4 个文件,按照每行一个文件的方式列出,具体如下:
|
||||
```
|
||||
$ echo ada > ada ; echo lovelace > lovelace
|
||||
$ echo richard > richard ; echo stallman > stallman
|
||||
$ ls -1
|
||||
ada
|
||||
lovelace
|
||||
richard
|
||||
stallman
|
||||
|
||||
```
|
||||
|
||||
你需要将两个文件合并成第三个文件,后者同时包含前两个文件的内容。这种情况下,Parallel 需要访问两个文件,使用 `-I%` 变量的方式不符合本例的预期。
|
||||
|
||||
Parallel 默认情况下读取 1 个队列对象:
|
||||
```
|
||||
$ ls -1 | parallel echo
|
||||
ada
|
||||
lovelace
|
||||
richard
|
||||
stallman
|
||||
|
||||
```
|
||||
现在让 Parallel 每个任务使用 2 个队列对象:
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 echo
|
||||
ada lovelace
|
||||
richard stallman
|
||||
|
||||
```
|
||||
|
||||
现在,我们看到行已经并合并;具体而言,`ls -1` 的两个查询结果会被同时传送给 Parallel。传送给 Parallel 的参数涉及了任务所需的 2 个文件,但目前还只是 1 个有效参数:(对于两个任务分别为)"ada lovelace" 和 "richard stallman"。你真正需要的是每个任务对应 2 个独立的参数。
|
||||
|
||||
值得庆幸的是,Parallel 本身提供了上述所需的解析功能。如果你将 `--max-args` 设置为 `2`,那么 `{1}` 和 `{2}` 这两个变量分别代表传入参数的第一和第二部分:
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 cat {1} {2} ">" {1}_{2}.person
|
||||
|
||||
```
|
||||
|
||||
在上面的命令中,变量 `{1}` 值为 `ada` 或 `richard` (取决于你选取的任务),变量 `{2}` 值为 `lovelace` 或 `stallman`。通过使用重定向符号(放到引号中,防止被 Bash 识别,以便 Parallel 使用),(两个)文件的内容被分别重定向至新文件 `ada_lovelace.person` 和 `richard_stallman.person`。
|
||||
```
|
||||
$ ls -1
|
||||
ada
|
||||
ada_lovelace.person
|
||||
lovelace
|
||||
richard
|
||||
richard_stallman.person
|
||||
stallman
|
||||
|
||||
$ cat ada_*person
|
||||
ada lovelace
|
||||
$ cat ri*person
|
||||
richard stallman
|
||||
|
||||
```
|
||||
|
||||
如果你整天处理大量几百 MB 大小的日志文件,那么(上述)并行处理文本的方法对你帮忙很大;否则,上述例子只是个用于上手的示例。
|
||||
|
||||
然而,这种处理方法对于很多文本处理之外的操作也有很大帮助。下面是来自电影产业的真实案例,其中需要将一个目录中的视频文件和(对应的)音频文件进行合并。
|
||||
```
|
||||
$ ls -1
|
||||
12_LS_establishing-manor.avi
|
||||
12_wildsound.flac
|
||||
14_butler-dialogue-mixed.flac
|
||||
14_MS_butler.avi
|
||||
...略...
|
||||
|
||||
```
|
||||
|
||||
使用同样的方法,使用下面这个简单命令即可并行地合并文件:
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 ffmpeg -i {1} -i {2} -vcodec copy -acodec copy {1}.mkv
|
||||
|
||||
```
|
||||
|
||||
### 简单粗暴的方式
|
||||
|
||||
上述花哨的输入输出处理不一定对所有人的口味。如果你希望更直接一些,可以将一堆命令甩给 Parallel,然后去干些其它事情。
|
||||
|
||||
首先,需要创建一个文本文件,每行包含一个命令:
|
||||
```
|
||||
$ cat jobs2run
|
||||
bzip2 oldstuff.tar
|
||||
oggenc music.flac
|
||||
opusenc ambiance.wav
|
||||
convert bigfile.tiff small.jpeg
|
||||
ffmepg -i foo.avi -v:b 12000k foo.mp4
|
||||
xsltproc --output build/tmp.fo style/dm.xsl src/tmp.xml
|
||||
bzip2 archive.tar
|
||||
|
||||
```
|
||||
|
||||
接着,将文件传递给 Parallel:
|
||||
```
|
||||
$ parallel --jobs 6 < jobs2run
|
||||
|
||||
```
|
||||
|
||||
现在文件中对应的全部任务都在被 Parallel 执行。如果任务数量超过允许的数目(译者注:应该是 --jobs 指定的数目或默认值),Parallel 会创建并维护一个队列,直到任务全部完成。
|
||||
|
||||
### 更多内容
|
||||
|
||||
GNU Parallel 是个强大而灵活的工具,还有很多很多用例无法在本文中讲述。工具的 man 页面提供很多非常酷的例子可供你参考,包括通过 SSH 远程执行和在 Parallel 命令中使用 Bash 函数等。[YouTube][2] 上甚至有一个系列,包含大量操作演示,让你可以直接从 GNU Parallel 团队学习。GNU Paralle 的主要维护者还发布了官方使用指导手册,可以从 [Lulu.com][3] 获取。
|
||||
|
||||
GNU Parallel 有可能改变你完成计算的方式;即使没有,也会至少改变你主机花在计算上的时间。马上上手试试吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/gnu-parallel
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:https://www.gnu.org/software/parallel
|
||||
[2]:https://www.youtube.com/watch?v=OpaiGYxkSuQ&list=PL284C9FF2488BC6D1
|
||||
[3]:http://www.lulu.com/shop/ole-tange/gnu-parallel-2018/paperback/product-23558902.html
|
||||
@ -1,47 +0,0 @@
|
||||
LikeCoin,一种给创作者的开放内容许可的加密货币
|
||||
======
|
||||

|
||||
|
||||
传统观点表明,作家、摄影师、艺术家和其他创作者在 Creative Commons 和其他开放许可下免费共享内容的不会得到报酬。这意味着大多数独立创作者无法通过在互联网上发布他们的作品来赚钱。输入 [LikeCoin][1]:一个新的开源项目,旨在制定这个惯例,艺术家经常为了分发而不得不妥协或牺牲,这是过去的事情。
|
||||
|
||||
LikeCoin 协议旨在通过创意内容获利,因此创作者可以专注于创造出色的内容而不是出售。
|
||||
|
||||
协议同样基于去中心化技术,它可以跟踪何时使用内容,并使用 LikeCoin,一种 [Ethereum ERC-20][2] 加密货币令牌奖励其创作者。它通过“创造性证明”算法进行操作,该算法一部分根据作品收到多少个“喜欢”,一部分根据有多少作品衍生自它而分配 LikeCoin。由于开放授权内容有更多机会被重复使用并获得 LikeCoin 令牌,因此系统鼓励内容创作者在 Creative Commons 许可下发布。
|
||||
|
||||
### 如何运行
|
||||
|
||||
当通过 LikeCoin 协议上传创意片段时,内容创作者将包括作品的元数据,包括作者信息及其 InterPlanetary 关联数据([IPLD][3])。这些数据构成了衍生作品的家族图表;我们称作品与其衍生品之间的关系为“内容足迹”。这种结构使得内容的继承树可以很容易地追溯到原始作品。
|
||||
|
||||
LikeCoin 令牌将作品衍生历史记录的信息分发给创作者。由于所有创意作品都包含作者钱包的元数据,因此相应的 LikeCoin 份额可以通过算法计算并分发。
|
||||
|
||||
LikeCoin 可以通过两种方式获得奖励:直接由想要通过支付内容创建者来表示赞赏的个人或通过 Creators Pool 收集观众的“赞”的并根据内容的 LikeRank 分配 LikeCoin。基于在 LikeCoin 协议中的内容追踪,LikeRank 衡量作品重要性(或者我们在这定义的创造性)。一般来说,一副作品有越多的衍生作品,创意内容的创新越多,内容就会有更高的 LikeRank。 LikeRank 是内容创新性的量化者。
|
||||
|
||||
### 如何参与?
|
||||
|
||||
LikeCoin 仍然非常新,我们期望在 2018 年晚些时候推出我们的第一个去中心化程序来奖励 Creative Commons 的内容,并与更大的社区无缝连接。
|
||||
|
||||
LikeCoin 的大部分代码都可以在 [LikeCoin GitHub][4] 仓库中通过[ GPL 3.0 许可证][5]访问。由于它仍处于积极开发阶段,一些实验代码尚未公开,但我们会尽快完成。
|
||||
|
||||
我们欢迎功能请求,pull request,fork 和 star。请参与我们在 Github 上的开发,并加入我们在 [Telegram][6] 的讨论组。我们同样在 [Medium][7]、[Facebook][8]、[Twitter][9] 和我们的网站 [like.co][1] 发布关于我们进展的最新消息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/likecoin
|
||||
|
||||
作者:[Kin Ko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ckxpress
|
||||
[1]:https://like.co/
|
||||
[2]:https://en.wikipedia.org/wiki/ERC20
|
||||
[3]:https://ipld.io/
|
||||
[4]:https://github.com/likecoin
|
||||
[5]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[6]:https://t.me/likecoin
|
||||
[7]:http://medium.com/likecoin
|
||||
[8]:http://fb.com/likecoin.foundation
|
||||
[9]:https://twitter.com/likecoin_fdn
|
||||
@ -0,0 +1,72 @@
|
||||
保护你的 Fedora 系统免受这个 DHCP 漏洞
|
||||
======
|
||||

|
||||
|
||||
今天早些时候在 dhcp-client 中发现并披露了一个严重的安全漏洞。此 DHCP 漏洞会对你的系统和数据造成高风险,尤其是在使用不受信任的网络如非你拥有的 WiFi 接入点时。阅读更多关于如何保护你的 Fedora 系统。
|
||||
|
||||
动态主机控制协议(DHCP)能让你的系统从其加入的网络获取配置。你的系统将请求 DHCP 数据,并且通常是路由器等服务器应答。服务器为你的系统提供必要的数据以进行自我配置。例如,你的系统如何在加入无线网络时正确进行网络配置。
|
||||
|
||||
但是,本地网络上的攻击者可能会利用此漏洞。使用在 NetworkManager 下运行的 dhcp-client 脚本中的漏洞,攻击者可能能够在系统上以 root 权限运行任意命令。这个 DHCP 漏洞使你的系统和数据处于高风险状态。该漏洞已分配 CVE-2018-1111,并且有[ Bugzilla 来跟踪 bug][1]。
|
||||
|
||||
### 防范这个 DHCP 漏洞
|
||||
|
||||
新的 dhcp 软件包包含 Fedora 26、27 和 28 以及 Rawhide 的修复程序。维护人员已将这些更新提交到 updates-testing 仓库。对于大多数用户而言,它们应该在这篇文章的大约一天左右的时间内在稳定仓库出现。所需的软件包是:
|
||||
|
||||
* Fedora 26: dhcp-4.3.5-11.fc26
|
||||
* Fedora 27: dhcp-4.3.6-10.fc27
|
||||
* Fedora 28: dhcp-4.3.6-20.fc28
|
||||
* Rawhide: dhcp-4.3.6-21.fc29
|
||||
|
||||
|
||||
|
||||
#### 更新稳定的 Fedora 系统
|
||||
|
||||
要在稳定的 Fedora 版本上立即更新,请[使用 sudo ][2]运行此命令。如有必要,请在提示时输入你的密码:
|
||||
```
|
||||
sudo dnf --refresh --enablerepo=updates-testing update dhcp-client
|
||||
|
||||
```
|
||||
|
||||
之后,使用标准稳定仓库进行更新。要从稳定的仓库更新 Fedora 系统,请使用以下命令:
|
||||
```
|
||||
sudo dnf --refresh update dhcp-client
|
||||
|
||||
```
|
||||
|
||||
#### 更新 Rawhide 系统
|
||||
|
||||
如果你的系统是 Rawhide,请使用以下命令立即下载和更新软件包:
|
||||
```
|
||||
mkdir dhcp && cd dhcp
|
||||
koji download-build --arch={x86_64,noarch} dhcp-4.3.6-21.fc29
|
||||
sudo dnf update ./dhcp-*.rpm
|
||||
|
||||
```
|
||||
|
||||
在每日的 Rawhide compose 后,只需运行 sudo dnf update 即可获取更新。
|
||||
|
||||
### Fedora Atomic Host
|
||||
|
||||
针对 Fedora Atomic Host 的修复程序版本为 28.20180515.1。要获得更新,请运行以下命令:
|
||||
```
|
||||
atomic host upgrade -r
|
||||
|
||||
```
|
||||
|
||||
此命令将重启系统以应用升级。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/protect-fedora-system-dhcp-flaw/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://bugzilla.redhat.com/show_bug.cgi?id=1567974
|
||||
[2]:https://fedoramagazine.org/howto-use-sudo/
|
||||
Loading…
Reference in New Issue
Block a user