mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge remote-tracking branch 'lcct/master'
This commit is contained in:
commit
18284e15ef
@ -0,0 +1,222 @@
|
||||
适合于远程编辑以及更多环境的简洁文本编辑器
|
||||
================================================================================
|
||||
文本编辑器是用来编辑纯文本的软件。这种软件有许多用处,包括修改配置文件,编写程序源代码,记下一些想法或者甚至写一份购物列表。由于这种编辑器能都用于许多不同的方面,因此值得花些时间找一个最适合您喜好的编辑器。
|
||||
|
||||
不论编辑器有多么复杂,它们通常有一个共同的功能集,包括查找/替换文本,格式化文本,导入文件以及在文件中移动文本。
|
||||
|
||||
所有这些文本编辑器都是基于终端的应用,因此他们很适合在远程主机上编辑文件。文本编辑器通常也会提供一个图形化的用户界面,但依旧会保证快速和精简。
|
||||
|
||||
基于终端的应用程序在系统资源方面也是轻量级的(在低配置机器上很有用),比起它的图形化版本来也会更快、更高效,由于它们在X需要重启时也不会停止工作,因此非常适合编写脚本。
|
||||
|
||||
我选择了一些我最喜欢的开源文本编辑器,他们在使用系统资源方面都非常节俭。
|
||||
|
||||
|
||||
|
||||
### Textadept ###
|
||||
|
||||

|
||||
|
||||
Textadept是一款适合程序员的,快速、精简、可扩展、跨平台的开源文本编辑器。这个开源程序由C和Lua写就,并且于这些年间在速度和精简方面进行了优化。
|
||||
|
||||
Textadept是那些想要无限的扩展性且不愿牺牲速度或屈服于代码膨胀的程序员们的理想编辑器。
|
||||
|
||||
它也有一个用于终端的版本,仅仅依赖ncurses,适合在远程主机上进行编辑。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 轻量级
|
||||
- 精简设计以最大化利用屏幕
|
||||
- 自包含的执行文件 - 无需安装
|
||||
- 全键盘驱动
|
||||
- 无限制的分割视图(GUI版本),以您所好任意水平或垂直的分割编辑器窗口。请注意Textadep不是一个选项卡式的编辑器。
|
||||
- 支持多达80种的编程语言
|
||||
- 强大的代码片段和快捷键命令
|
||||
- 代码自动补全和API查询
|
||||
- 无与伦比的扩展性
|
||||
- 书签
|
||||
- 查找和替换
|
||||
- 在文件中查找
|
||||
- 基于缓存的单词补全
|
||||
- 成熟的编程语言符号自动补全,以及显示API文档的功能
|
||||
- 主题:亮色、暗色、终端
|
||||
- 使用词法分析器将名称放到缓冲中,如评论、字符串、关键词
|
||||
- 支持会话
|
||||
- 快速打开
|
||||
- 许多可用的模块,包括对Java、Python、Ruby和近期打开文件列表的支持
|
||||
- 符合Gnome HIG用户接口的指导
|
||||
- 支持编辑Lua代码。许多Textadept对象和Lua的标准库支持语法自动补全和LuaDoc。
|
||||
|
||||
---
|
||||
|
||||
- 网址: [foicica.com/textadept][1]
|
||||
- 开发者: Mitchell and contributors
|
||||
- 许可证: MIT License
|
||||
- 版本号: 7.7
|
||||
|
||||
|
||||
### Vim ###
|
||||
|
||||

|
||||
|
||||
vim是一个高级的文本编辑器,它在'vi'强大的基础上,并拥有更全面的功能集。
|
||||
|
||||
这个编辑器对编程和编辑其他纯ASCII的文件十分有用。所有的命令都由普通的键盘按键提供,能够使用十指来输入,因而十分快捷。另外,功能键可以由用户来定义,并且可也以使用鼠标。
|
||||
|
||||
Vim通常被称作"程序员的编辑器",它十分适合于编程,并被认为可以作为完整的集成开发环境。然而,这个软件并不是仅仅面向程序员。Vim适合于各种文本编辑,从编写email到修改配置文件。
|
||||
|
||||
Vim的界面基于文本界面下的命令行。尽管它的图形化版本gVim为常用的命令添加了菜单和工具栏,但这个软件的整个功能依旧依赖于它的命令行模式。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 3 种模式:
|
||||
- 命令模式
|
||||
- 插入模式
|
||||
- 命令行模式
|
||||
- 无限制的撤销
|
||||
- 多个窗口和缓冲区
|
||||
- 平滑的插入模式
|
||||
- 根据所编辑的文件的类型使用不同的颜色或风格进行语法高亮
|
||||
- 交互命令
|
||||
- 标记一行
|
||||
- vi 行缓冲
|
||||
- 移动代码块
|
||||
- 块操作
|
||||
- 命令行历史
|
||||
- 扩展的正则表达式
|
||||
- 可编辑压缩/打包文件 (gzip, bzip2, zip, tar)
|
||||
- 文件名补全
|
||||
- 标记跳转
|
||||
- 折叠文本
|
||||
- 缩进
|
||||
- ctags和cscope整合
|
||||
- 100%与vi的模式兼容
|
||||
- 插件用于添加/扩展功能
|
||||
- 宏
|
||||
- vimscript, Vim的内部脚本
|
||||
- Unicode支持
|
||||
- 多语言支持
|
||||
- 在线帮助支持
|
||||
|
||||
---
|
||||
|
||||
- 网址: [www.vim.org][2]
|
||||
- 开发者: Bram Moolenaar
|
||||
- 许可证: GNU GPL compatible (charityware)
|
||||
- 版本号: 7.4
|
||||
|
||||
|
||||
|
||||
### ne ###
|
||||
|
||||

|
||||
|
||||
ne是一款全屏幕的开源文本编辑器。它像是一个比vi更容易学习的vi替代物,并且可以在POSIX-兼容的系统中便携使用。
|
||||
|
||||
ne对于新手来说易于使用,但也非常强大并有完全可配置的引导程序,并且在资源使用上十分节约。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 三种用户界面: 控制键,命令行、菜单;按键和菜单都可配置
|
||||
- 语法高亮
|
||||
- 对于UTF-8文件的完全支持,包括占据多列的字符(宽字符)
|
||||
- 文档,剪切块,显示的维度和文件/行号长度都有编号,并且仅受制于机器的整型字长
|
||||
- 简单的脚本语言,脚本可以用简单易理解的录制/播放的方式制作
|
||||
- 无限制的撤销/重做功能(可以通过命令禁用)
|
||||
- 基于被编辑的文件扩展名的自动个性化配置系统
|
||||
- 使用您文档中的词语做字典来进行自动前缀补全
|
||||
- 易用的文件存取功能
|
||||
- 扩展的正则表达式可用于查找和替换,类似emacs和vi
|
||||
- 非常紧凑的内存模型,在加载和修改大型文件时十分快速
|
||||
- 可编辑二进制文件
|
||||
|
||||
---
|
||||
|
||||
- 网址: [ne.di.unimi.it][3]
|
||||
- 开发者: Sebastiano Vigna (original developer). Additional features added by Todd M. Lewis
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 2.5
|
||||
|
||||
----------
|
||||
|
||||
### Zile ###
|
||||
|
||||

|
||||
|
||||
Zile(Zile Is Lossy Emacs,Emacs精简版),它是一个小型的Emacs的克隆版。Zile是一个可定制的,自文档化,实时显示的编辑器,Zile被开发的尽可能像Emacs一样,每个Emacs用户都会对Zile感到亲切。
|
||||
|
||||
Zile以它极小的RAM用量,大约130KB,以及快速开始编辑而闻名。它是支持8比特字符集的,允许用于编写任何种类的文件。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 小型但快速、强大
|
||||
- 多个缓冲区,允许多级的撤销
|
||||
- 多窗口
|
||||
- 以最小的缓冲区完成补全
|
||||
- 自动填充 (自动换行)
|
||||
- Registers
|
||||
- 看起来像Emacs,键序列、功能和变量名都与Emacs相同
|
||||
- Killing
|
||||
- Yanking
|
||||
- 自动行末检测
|
||||
|
||||
---
|
||||
|
||||
- 网址: [www.gnu.org/software/zile][4]
|
||||
- 开发者: Reuben Thomas, Sandro Sigala, David A. Capello
|
||||
- 许可证: GNU GPL v2
|
||||
- 版本号: 2.4.11
|
||||
|
||||
|
||||
|
||||
### nano ###
|
||||
|
||||

|
||||
|
||||
nano是基于curses库的文本编辑器。它是Pico(Pine电子邮件客户端编辑器)的一个复刻版。
|
||||
|
||||
由于Pine套件的许可证问题诉讼案(Pine并未以开源许可证发布),并且也因为Pine缺少一些重要的功能,nano项目于1999年发起。
|
||||
|
||||
nano致力于赶上Pico的功能和其易用性,与此同时提供更多的功能,但不集成Pine/Pico的邮件客户端。
|
||||
|
||||
nano像Pico一样是以键盘为导向的设计,可以用控制键来控制。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 交互式的查找和替换
|
||||
- 彩色语法高亮
|
||||
- 转到行号和列号处
|
||||
- 自动缩进
|
||||
- 功能开关
|
||||
- 支持UTF-8
|
||||
- 混合型的文件类型自动转换
|
||||
- 逐字输入模式
|
||||
- 多个文件缓冲区
|
||||
- 平滑滚动
|
||||
- 括号匹配
|
||||
- 自定义引用字符串
|
||||
- 备份文件
|
||||
- 国际化支持
|
||||
- tab补全文件名
|
||||
|
||||
---
|
||||
|
||||
- 网址: [nano-editor.org][5]
|
||||
- 开发者: Chris Allegretta, David Lawrence, Jordi Mallach, Adam Rogoyski, Robert Siemborski, Rocco Corsi, David Benbennick, Mike Frysinger
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 2.2.6
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://foicica.com/textadept/
|
||||
[2]:http://www.vim.org/
|
||||
[3]:http://ne.di.unimi.it/
|
||||
[4]:http://www.gnu.org/software/zile/
|
||||
[5]:http://nano-editor.org/
|
||||
@ -0,0 +1,67 @@
|
||||
Linux下优秀的音频编辑软件
|
||||
================================================================================
|
||||
|
||||
不论您是一个音乐爱好者或只是一个要记录您导师的讲话的学生,您都需要录制音频和编辑音频。长久以来这样的工作都要靠Macintosh,如今那个时代已经过去,现在Linux也可以胜任这些工作了。简而言之,这里有一份不完全的音频编辑器软件列表,适用于不同的任务和需求。
|
||||
|
||||
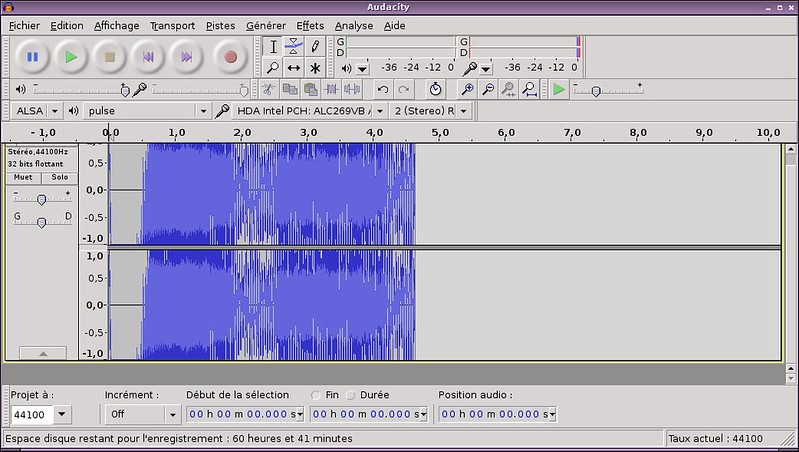
### 1. Audacity ###
|
||||
|
||||
|
||||
|
||||
让我们从我个人最喜欢的软件开始。[Audacity][1]可以运行在Windows、Mac和Linux上。它是开源的,且易于使用。你会觉得:Audacity几乎是完美的。它可以让您在干净的界面上操作音频波形。简单地说,您可以覆盖音轨、剪切和修改音轨、增加特效、执行高级的声音分析,然后将它们导出到一大堆可用的格式。我喜欢它的原因是它将基本的功能和复杂的功能结合在一起并且保持一个简单的学习曲线。然而,它并不是一个完全最优化的软件,尤其是对于音乐家和专业人员。
|
||||
|
||||
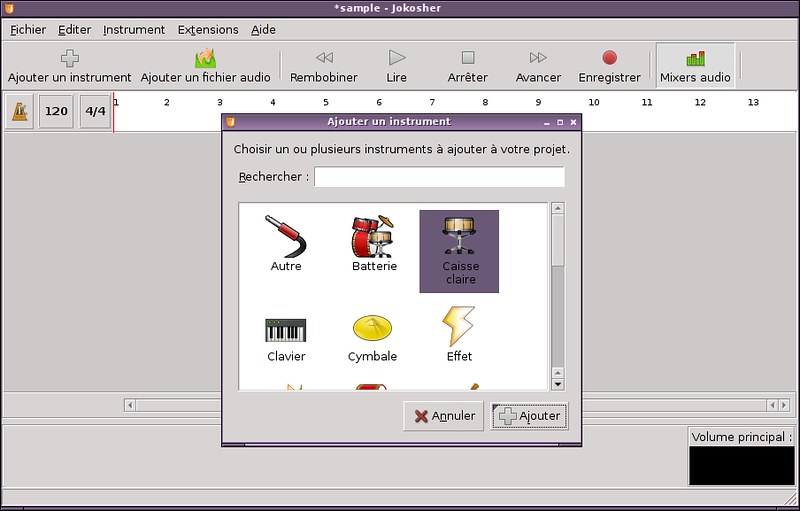
### 2. Jokosher ###
|
||||
|
||||
|
||||
|
||||
在不同的层次上,[Jokosher][2]更多的聚焦在多音轨方面。它使用Python和GTK+作为前端界面,并使用GStreamer作为音频后端。Jokosher那易用的界面和它的扩展性给我留下了深刻的印象。也许编辑的功能并不是最先进的,但它的提示十分清晰,适合音乐家。例如,我十分喜欢音轨和乐器的组合。简而言之,如果您是一个音乐家,那么它是在您转移到下一个软件前进行实践的好机会。
|
||||
|
||||
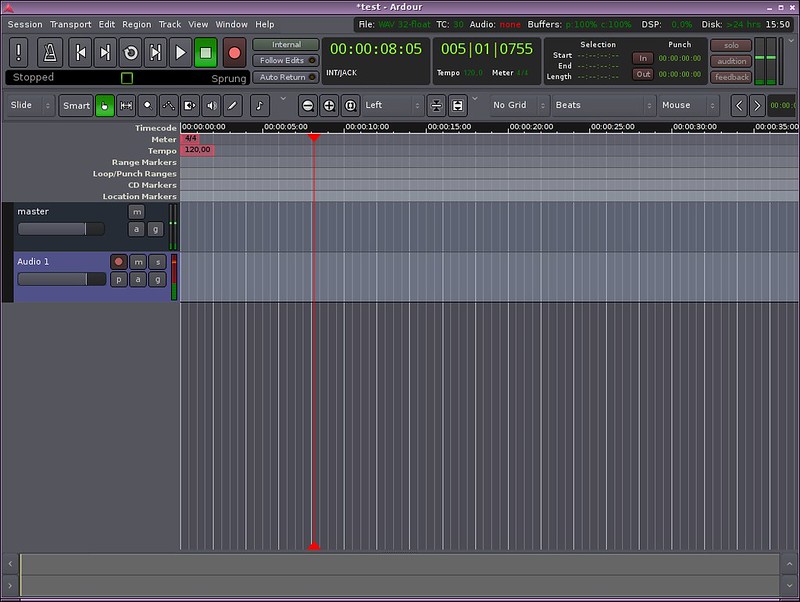
### 3. Ardour ###
|
||||
|
||||
|
||||
|
||||
接下来谈论一些复杂的工具,[Ardour][3]是一套完整的可以录制、编辑和混音的软件。这个设计吸引了所有的专业人员,Ardour在声音和插件方面超出我的想象。如果您在寻找一头野兽并且不惧怕驯服它,那么Ardour或许是一个不错的选择。再次,它的界面和丰富的文档,尤其是它首次启动时的配置工具都是它迷人魅力的一部分。
|
||||
|
||||
### 4. Kwave ###
|
||||
|
||||

|
||||
|
||||
对于所有KDE的热爱者,[KWave][4]绝对符合您对于设计和功能的想象。它有丰富的快捷键以及很多有趣的选项,例如内存管理。尽管很多特效很不错,但我们更应该关注那些用于音频剪切/粘贴的工具。可惜的是它无法与Audacity相比,而更重要的是,它的界面并没有那么吸引我。
|
||||
|
||||
### 5. Qtractor ###
|
||||
|
||||

|
||||
|
||||
如果Kwave对您来说过于简单,但基于Qt的程序却有些吸引力,那么对您来说,也许[Qtractor][5]是一个选项。它致力于做一个“对于家庭用户来说足够简单,并且对专业人员来说足够强大的软件。”实际上它功能和选项的数量几乎是压倒性的。我最喜欢的当然是可定制的快捷键。除此之外,Qtractor可能是我最喜欢的一个处理MIDI文件的工具。
|
||||
|
||||
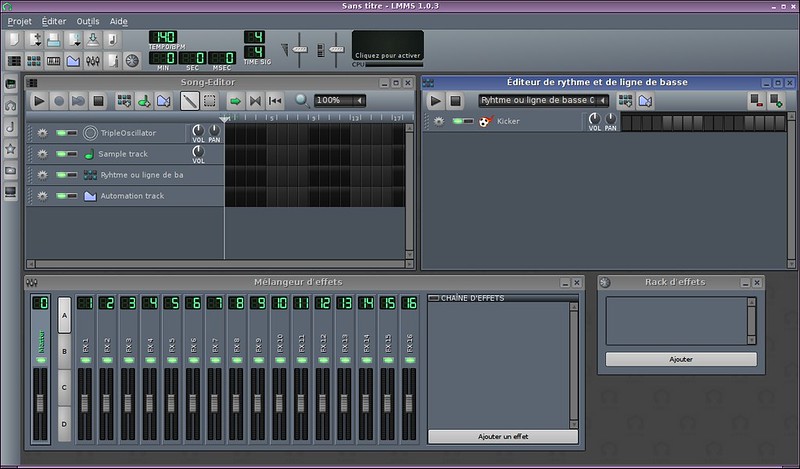
### 6. LMMS ###
|
||||
|
||||
|
||||
|
||||
作为Linux多媒体工作室,LMMS的直接目标是音乐制作。如果您之前没有什么经验并且不想浪费太多的时间,那么请去别处吧。LMMS是其中一个复杂但强大的软件,只有少数的人真正的掌握了它。它有太多的功能和特效以至于无法一一列出,但如果我必须找一个,我会说用来模拟Game Boy声音系统的Freeboy插件简直像魔术一样。然后,去看看它那惊人的文档吧。
|
||||
|
||||
### 7. Traverso ###
|
||||
|
||||
|
||||
|
||||
最后站在我面前的是Traverso,它支持无限制的音轨计数,并直接整合了CD烧录的功能。另外,它对我来说是介于简单的软件和专业的软件之间的程序。它的界面是KDE样式的,其键盘配置很简单。更有趣的是,Traverso会监视您的系统资源以确定不会超过您的CPU或者硬件的能力。
|
||||
|
||||
总而言之,能在Linux系统上看到这么多不同的应用程序是一件开心的事。它使得您永远可以找到最适合自己的那一款。虽然我最喜欢的应用是Audacity,但我非常震惊于LMMS和Jokosher的设计。
|
||||
|
||||
我们有漏掉什么么?您在Linux下使用哪一款软件呢?原因是什么呢?请留言让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-audio-editing-software-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://audacity.sourceforge.net/
|
||||
[2]:https://launchpad.net/jokosher/
|
||||
[3]:http://ardour.org/
|
||||
[4]:http://kwave.sourceforge.net/
|
||||
[5]:http://qtractor.sourceforge.net/qtractor-index.html
|
||||
154
published/20150128 The top 10 rookie open source projects.md
Normal file
154
published/20150128 The top 10 rookie open source projects.md
Normal file
@ -0,0 +1,154 @@
|
||||
2015 年度开源项目新秀榜
|
||||
================================================================================
|
||||
黑鸭(Black Duck)软件公布了一份名叫“年度开源项目新秀”的报告,介绍了由全球开源协会发起的10个最有趣、最活跃的新项目。
|
||||
|
||||

|
||||
|
||||
### 年度开源项目新秀 ###
|
||||
|
||||
每年都有上千新的开源项目问世,但只有少数能够真正的吸引我们的关注。一些项目因为利用了当前比较流行的技术而发展壮大,有一些则真正地开启了一个新的领域。很多开源项目建立的初衷是为了解决一些生产上的问题,还有一些项目则是世界各地志同道合的开发者们共同发起的一个宏伟项目。
|
||||
|
||||
从2009年起,开源软件管理公司黑鸭便发起了[年度开源项目新秀][1]这一活动,它的评选根据[Open Hub][2]网站(即以前的Ohloh)上的活跃度。今年,我们很荣幸能够报道2015年10大开源项目新秀的得主和2名荣誉奖得主,它们是从上千个开源项目中脱颖而出的。评选采用了加权评分系统,得分标准基于项目的活跃度,交付速度和几个其它因数。
|
||||
|
||||
开源俨然成为了产业创新的引擎,就拿今年来说,和Docker容器相关的开源项目在全球各地兴起,这也不恰巧反映了企业最感兴趣的技术领域吗?最后,我们接下来介绍的项目,将会让你了解到全球开源项目的开发者们的在思考什么,这很快将会成为一个指引我们发展的领头羊。
|
||||
|
||||
### 2015年度开源项目新秀: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3]收集打包了一套[Ansible][4]方案和规则(Ansible是一种自动化运维工具),可以从1个容器扩展到一个完整的数据中心。它的创始人Maciej Delmanowski将DebOps开源来保证项目长久进行,从而更好的通过外部贡献者的帮助发展下去。
|
||||
|
||||
DebOps始创于波兰的一个不起眼大学校园里,他们运营自己的数据中心,一切工作都采用手工配置。有时系统崩溃而导致几天的宕机,这时Delmanowski意识到一个配置管理系统是很有必要的。以Debian作为基础开始,DebOps是一组配置一整个数据基础设施的Ansible方案。此项目已经在许多不同的工作环境下实现,而创始者们则打算继续支持和改进这个项目。
|
||||
|
||||
###2015年度开源项目新秀: Code Combat ###
|
||||
|
||||

|
||||
|
||||
传统的纸笔学习方法已近不能满足技术学科了。然而游戏却有很多人都爱玩,这也就是为什么[CodeCombat][5]的创始人会去开发一款多人协同编程游戏来教人们如何编码。
|
||||
|
||||
刚开始CodeCombat是一个创业想法,但其创始人决定取而代之创建一个开源项目。此想法在社区传播开来,很快不少贡献者加入到项目中来。项目发起仅仅两个月后,这款游戏就被接纳到Google’s Summer of Code活动中。这款游戏吸引了大量玩家,并被翻译成45种语言。CodeCombat希望成为那些想要一边学习代码同时获得乐趣的同学的风向标。
|
||||
|
||||
### 2015年度开源项目新秀: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6]是一个点对点的云存储网络,可实现端到端加密,保证用户不用依赖第三方即可传输和共享数据。基于比特币block chain技术和点对点协议,Storj提供安全、私密、加密的云存储。
|
||||
|
||||
云数据存储的反对者担心成本开销和漏洞攻击。针对这两个担忧,Storj提供了一个私有云存储市场,用户可以通过Storjcoin X(SJCX) 购买交易存储空间。上传到Storj的文件会被粉碎、加密和存储到整个社区。只有文件所有者拥有密钥加密的信息。
|
||||
|
||||
在2014年举办的Texas Bitcoin Conference Hackathon会议上,去中心化的云存储市场概念首次被提出并证明可行。在第一次赢得黑客马拉松活动后,项目创始人们和领导团队利用开放论坛、Reddit、比特币论坛和社交媒体增长成了一个活跃的社区,如今,它们已成为影响Storj发展方向的一个重要组成部分。
|
||||
|
||||
### 2015年度开源项目新秀: Neovim ###
|
||||
|
||||

|
||||
|
||||
自1991年出现以来,Vim已经成为数以百万计软件开发人员所钟爱的文本编辑器。 而[Neovim][6]就是它的下一个版本。
|
||||
|
||||
在过去的23年里,软件开发生态系统经历了无数增长和创新。Neovim创始人Thiago de Arruda认为Vim缺乏当代元素,跟不上时代的发展。在保留Vim的招牌功能的前提下,Neovim团队同样在寻求改进和发展这个最受欢迎的文本编辑器的技术。早期众筹让Thiago de Arruda可以连续6个月时间投入到此项目。他相信Neovim社区会支持这个项目,激励他继续开发Neovim。
|
||||
|
||||
### 2015年度开源项目新秀: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
前谷歌员工开发了一个开源的大型企业数据存储项目[CockroachDB][8],它是一个可扩展的、跨地域复制且支持事务的数据存储的解决方案。
|
||||
|
||||
为了保证在线的百万兆字节流量业务的质量,Google开发了Spanner系统,这是一个可扩展的,稳定的,支持事务的系统。许多参与开发CockroachDB的团队现在都服务于开源社区。就像真正的蟑螂(cockroach)一样,CockroachDB可以在没有数据头、任意节点失效的情况下正常运行。这个开源项目有很多富有经验的贡献者,创始人们通过社交媒体、Github、网络、会议和聚会结识他们并鼓励他们参与其中。
|
||||
|
||||
### 2015年度开源项目新秀: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
在将容器化软件到引入开源社区发展时,[Docker][9]是一匹黑马,它创新了一套技术和工具。去年6月谷歌推出了[Kubernetes][10],这是一款开源的容器管理工具,用来加快开发和简化操作。
|
||||
|
||||
谷歌在它的内部运营上使用容器技术多年了。在2014年夏天的DockerCon上大会上,谷歌这个互联网巨头开源了Kubernetes,Kubernetes的开发是为了满足迅速增长的Docker生态系统的需要。通过和其它的组织、项目合作,比如Red Hat和CoreOS,Kubernetes项目的管理者们推动它登上了Docker Hub的工具下载榜榜首。Kubernetes的开发团队希望扩大这个项目,发展它的社区,这样的话软件开发者就能花更少的时间在管理基础设施上,而更多的去开发他们自己的APP。
|
||||
|
||||
### 2015年度开源项目新秀: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
OpenBazaar是一个使用比特币与其他人交易的去中心化的市场。OpenBazaar这一概念最早在编程马拉松(hackathon)活动中被提出,它的创始人结合了BitTorent、比特币和传统的金融服务方式,创造了一个不受审查的交易平台。OpenBazaar的开发团队在寻求新的成员,而且不久以后他们将极度扩大Open Bazaar社区。Open Bazaar的核心是透明度,其创始人和贡献者的共同目标是在商务交易中掀起一场革命,让他们向着一个真实的、一个无控制的,去中心化的市场奋进。
|
||||
|
||||
### 2015年度开源项目新秀: IPFS ###
|
||||
|
||||

|
||||
|
||||
IPFS 是一个面向全球的、点对点的分布式版本文件系统。它综合了Git,BitTorrent,HTTP的思想,开启了一个新的数据和数据结构传输协议。
|
||||
|
||||
人们所知的开源,它的本意用简单的方法解决复杂的问题,这样产生许多新颖的想法,但是那些强大的项目仅仅是开源社区的冰山一角。IFPS有一个非常激进的团队,这个概念的提出是大胆的,令人惊讶的,有点甚至高不可攀。看起来,一个点对点的分布式文件系统是在寻求将所有的计算设备连在一起。这个可能的 HTTP 替换品通过多种渠道维护着一个社区,包括Git社区和超过100名贡献者的IRC。这个疯狂的想法将在2015年进行软件内部测试。
|
||||
|
||||
### 2015年度开源项目新秀: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] 是一个针对在运行中的容器进行收集,统计,处理和输出信息的工具,它可以给容器的使用者提供资源的使用情况和工作特性。对于每一个容器,cAdvisor记录着资源的隔离参数,资源使用历史,资源使用历史对比框图,网络状态。这些从容器输出的数据跨越主机传递。
|
||||
|
||||
cAdvisor可以在绝大多数的Linux发行版上运行,并且支持包括Docker在内的多种容器类型。事实上它成为了一种容器的代理,并被集成在了很多系统中。cAdvisor在DockerHub下载量也是位居前茅。cAdvisor的开发团队希望把cAdvisor改进到能够更深入地理解应用性能,并且集成到集群系统。
|
||||
|
||||
### 2015年度开源项目新秀: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14]提供了一些常见设置来创建一个基础设施,从物理机到虚拟机,以及email服务器、DNS服务器等。这个想法包括从家庭个人机解决方案到公共云平台提供的服务。一旦建立好了以后,Terraform可以让运维人员安全又高效地改变你的基础设施,就如同配置一样。
|
||||
|
||||
Terraform.io的创始者工作在一个Devops模式的公司,他找到了一个窍门把建立一个完整的数据中心所需的知识结合在一起,可以从添加服务器到支持网络服务的功能齐备的数据中心。基础设施的描述采用高级的配置语法,允许你把数据中心的蓝图按版本管理,并且转换成多种代码。著名开源公司HashiCorp赞助开发这个项目。
|
||||
|
||||
### 荣誉奖: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15]为[Docker][16]的使用提供了一个快速的,分离的开发环境。Docker的移植只需要将配置信息放到一个简单的 fig.yml文件里。它会处理所有工作,包括构建、运行,端口转发,分享磁盘和容器链接。
|
||||
|
||||
Orchard去年发起了Fig,来创造一个使Docker工作起来的系统工具。它的开发像是为Docker设置开发环境,为了确保用户能够为他们的APP准确定义环境,在Docker中会运行数据库和缓存。Fig解决了开发者的一个难题。Docker全面支持这个开源项目,最近[将买下][17]Orchard来扩张这个项目。
|
||||
|
||||
### 荣誉奖: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18]是一个基于Docker的持续集成平台,而且它是用Go语言写的。Drone项目不满于现存的设置开发环境的技术和流程。
|
||||
|
||||
Drone提供了一个简单的自动测试和持续交付的方法:简单选择一个Docker镜像来满足你的需求,连接并提交至GitHub即可。Drone使用Docker容器来提供隔离的测试环境,让每个项目完全自主控制它的环境,没有传统的服务器管理的负担。Drone背后的100位社区贡献者强烈希望把这个项目带到企业和移动应用程序开发中。
|
||||
|
||||
### 开源新秀 ###
|
||||
|
||||

|
||||
|
||||
参见:
|
||||
|
||||
- [InfoWorld2015年年度技术奖][21]
|
||||
- [Bossies: 开源软件最高荣誉][22]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
|
||||
@ -194,7 +194,7 @@ mod\_evasive被配置为使用/etc/httpd/conf.d/mod\_evasive.conf中的指令。
|
||||
|
||||
DOSSystemCommand "sudo /usr/local/bin/scripts-tecmint/ban_ip.sh %s"
|
||||
|
||||
上面一行的%s代表了由mod\_evasive检测到的攻击IP地址。
|
||||
上面一行的%s代表了由mod_evasive检测到的攻击IP地址。
|
||||
|
||||
#####将apache用户添加到sudoers文件#####
|
||||
|
||||
@ -233,7 +233,7 @@ mod\_evasive被配置为使用/etc/httpd/conf.d/mod\_evasive.conf中的指令。
|
||||
我们的测试环境由一个CentOS 7服务器[IP 192.168.0.17]和一个Windows组成,在Windows[IP 192.168.0.103]上我们发起攻击:
|
||||
|
||||

|
||||
|
||||
I
|
||||
*确认主机IP地址*
|
||||
|
||||
请播放下面的视频(YT 视频,请自备梯子: https://www.youtube.com/-U_mdet06Jk ),并跟从列出的步骤来模拟一个Dos攻击:
|
||||
@ -257,7 +257,7 @@ mod\_evasive被配置为使用/etc/httpd/conf.d/mod\_evasive.conf中的指令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/protect-apache-using-mod\_security-and-mod\_evasive-on-rhel-centos-fedora/
|
||||
via: http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
如何在 Linux 上使用 x2go 设置远程桌面
|
||||
================================================================================
|
||||
由于一切都迁移到了云上,作为提高职员生产力的一种方式,虚拟远程桌面在工业中越来越流行。尤其对于那些需要在多个地方和设备之间不停漫游的人,远程桌面可以让他们和工作环境保持无缝连接。远程桌面对于雇主同样有吸引力,可以在工作环境中提高敏捷性和灵活性,由于硬件整合、桌面安全加固等原因降低 IT 花费。
|
||||
|
||||
在 Linux 世界中,理所当然设置远程桌面有很多选择,支持许多协议(例如 RDP、RFB、NX) 和服务器/客户端实现(例如 [TigerVNC][1]、RealVNC、FreeNX、x2go、X11vnc、TeamViewer 等等)。
|
||||
|
||||
这当中有个出色的产品叫做 [X2Go][2],它是一个基于 NX(译者注:通过计算机网络显示远程桌面环境的一种技术,可参考 [Wiki][9])的远程桌面服务器和客户端的开源(GPLv2)实现。在这个教程中,我会介绍 **如何为 Linux VPS 使用 X2Go 设置远程桌面环境**。
|
||||
|
||||
### X2Go 是什么? ###
|
||||
|
||||
X2Go 的历史要追溯到 NoMachine 的 NX 技术。NX 远程桌面协议的设计目的是通过利用主动压缩和缓存解决低带宽和高延迟的网络连接问题。后来,NX 转为闭源,但 NX 库还是采用 GPL 协议。这导致出现了多种基于 NX 的远程桌面解决方案开源实现,X2Go 就是其中之一。
|
||||
|
||||
和其它解决方案例如 VNC 相比,X2Go 有哪些好处呢? X2Go 继承了 NX 技术的所有高级功能,很自然能在慢速网络连接上良好工作。另外,由于它内置的基于 SSH 的加密技术,X2Go 保持了确保安全的良好业绩记录。不再需要[手动设置 SSH 隧道][4] 。X2Go 默认支持音频,这意味着远程桌面的音乐播放可以通过网络传送,并进入本地扬声器。在易用性方面,远程桌面上运行的应用程序可以在你的本地桌面中以一个独立窗口无缝呈现,会给你造成一种应用程序实际上在你本地桌面运行的错觉。正如你看到的,这些都是一些基于 VNC 的解决方案所缺少的[强大功能][5]。
|
||||
|
||||
### X2GO 的桌面环境兼容性 ###
|
||||
|
||||
和其它远程桌面服务器一样,X2Go 服务器也有一些[已知的兼容性问题][6]。像 KDE 3/4、Xfce、MATE 和 LXDE 是对 X2Go 服务器最友好的桌面环境。但是,用其它桌面管理器效果可能有所不同。例如,已知 GNOME 3 之后的版本、KDE 5、Unity 和 X2Go 并不兼容。如果你的远程主机的桌面管理器和 X2Go 兼容,你可以继续以下的教程。
|
||||
|
||||
### 在 Linux 上安装 X2Go 服务器 ###
|
||||
|
||||
X2Go 由远程桌面服务器和客户端组件组成。让我们首先安装 X2Go 服务器。我假设你已经有一个和 X2Go 兼容的桌面管理器并且在远程主机上运行,我们会安装 X2Go 服务器到该远程主机。
|
||||
|
||||
注意系统启动后 X2Go 服务器组件没有需要单独启动的服务。你只需要保证开启了 SSH 服务并在正常运行。
|
||||
|
||||
#### Ubuntu 或 Linux Mint: ####
|
||||
|
||||
配置 X2Go PPA 库。对于 Ubuntu 14.04 以及更高版本,有可用的 X2Go PPA。
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Debian (Wheezy): ####
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
#### CentOS/RHEL: ####
|
||||
|
||||
首先启用 [EPEL 库][7] 然后运行:
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
### 在 Linux 上安装 X2Go 客户端 ###
|
||||
|
||||
在将会连接到远程桌面的本地主机上,安装以下命令安装 X2Go 客户端。
|
||||
|
||||
#### Ubuntu 或 Linux Mint: ####
|
||||
|
||||
配置 X2Go PPA 库。对于 Ubuntu 14.04 以及更高版本,有可用的 X2Go PPA。
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
Debian (Wheezy):
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
CentOS/RHEL:
|
||||
|
||||
首先启用 [EPEL 库][7] ,然后运行:
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
### 用 X2Go 客户端连接到远程桌面 ###
|
||||
|
||||
现在可以连接到远程桌面了。在本地主机上,只需运行以下命令或者使用桌面启动器启动 X2Go 客户端。
|
||||
|
||||
$ x2goclient
|
||||
|
||||
输入远程主机的 IP 地址和 SSH 用户名称。同时,指定会话类型(例如,远程主机的桌面管理器)。
|
||||
|
||||
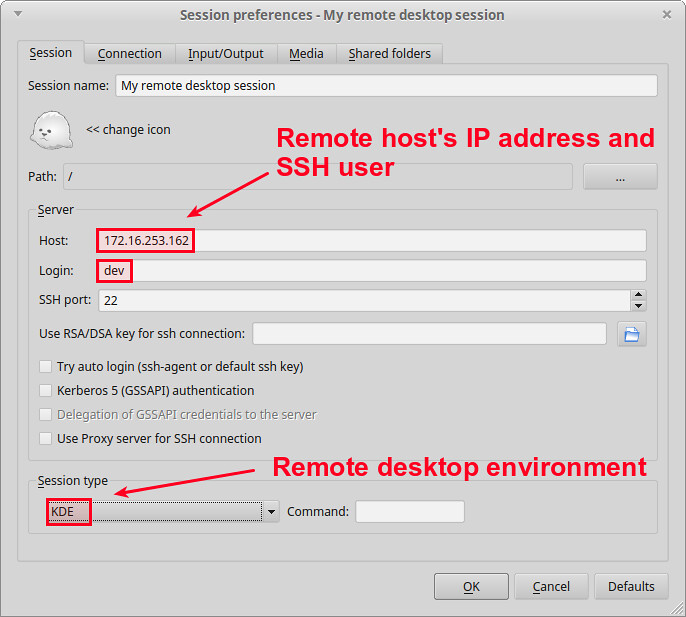
|
||||
|
||||
如果需要的话,你可以自定义其它东西(通过点击其它的标签),例如连接速度、压缩、屏幕分辨率等等。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
当你初始化一个远程桌面连接的时候,会要求你登录。输入你的 SSH 登录名和密码。
|
||||
|
||||
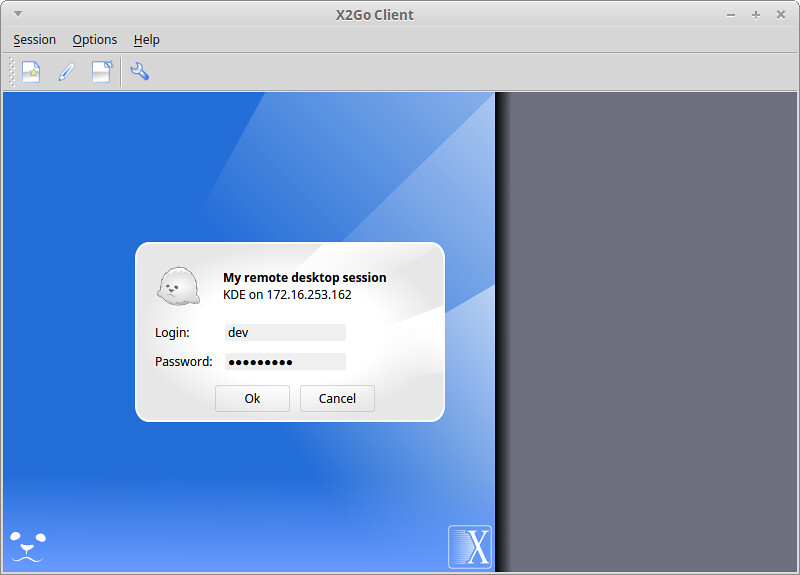
|
||||
|
||||
成功登陆后,你会看到远程桌面屏幕。
|
||||
|
||||

|
||||
|
||||
如果你想测试 X2Go 的无缝窗口功能,选择 "Single application" 会话类型,然后指定远处主机上可执行文件的路径。在该例子中,我选择远程 KDE 主机上的 Dolphin 文件管理器。
|
||||
|
||||

|
||||
|
||||
你成功连接后,你会在本地桌面上看到一个远程应用窗口,而不是完整的远程桌面屏幕。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇教程中,我介绍了如何在 [Linux VPS][8] 实例上设置 X2Go 远程桌面。正如你所看到的,整个设置过程都非常简单(如果你使用一个合适的桌面环境的话)。尽管对于特定桌面仍有问题,X2Go 是一个安全、功能丰富、快速并且免费的远程桌面解决方案。
|
||||
|
||||
X2Go 的什么功能最吸引你?欢迎分享你的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/x2go-remote-desktop-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/centos-remote-desktop-vps.html
|
||||
[2]:http://wiki.x2go.org/
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
[4]:http://xmodulo.com/how-to-set-up-vnc-over-ssh.html
|
||||
[5]:http://wiki.x2go.org/doku.php/doc:newtox2go
|
||||
[6]:http://wiki.x2go.org/doku.php/doc:de-compat
|
||||
[7]:https://linux.cn/article-2324-1.html
|
||||
[8]:http://xmodulo.com/go/digitalocean
|
||||
[9]:https://en.wikipedia.org/wiki/NX_technology
|
||||
111
published/20150429 What are good command line HTTP clients.md
Normal file
111
published/20150429 What are good command line HTTP clients.md
Normal file
@ -0,0 +1,111 @@
|
||||
有哪些不错的命令行HTTP客户端?
|
||||
==============================================================================
|
||||
|
||||
“整体大于它的各部分之和”,这是引自希腊哲学家和科学家的亚里士多德的名言。这句话特别切中Linux。在我看来,Linux最强大的地方之一就是它的协作性。Linux的实用性并不仅仅源自大量的开源程序(命令行)。相反,其协作性来自于这些程序的综合利用,有时是结合成更大型的应用。
|
||||
|
||||
Unix哲学引发了一场“软件工具”的运动,关注开发简洁,基础,干净,模块化和扩展性好的代码,并可以运用于其他的项目。这种哲学成为了许多的Linux项目的一个重要的元素。
|
||||
|
||||
好的开源开发者写程序为了确保该程序尽可能运行得好,并且同时能与其他程序很好地协作。目标就是使用者拥有一堆方便的工具,每一个力求干好一件事。许多程序能独立工作得很好。
|
||||
|
||||
这篇文章讨论3个开源命令行HTTP客户端。这些客户端可以让你使用命令行从互联网上下载文件。但同时,他们也可以用于许多有意思的地方,如测试,调式和与HTTP服务器或web应用交互。对于HTTP架构师和API设计人员来说,使用命令行操作HTTP是一个值得花时间学习的技能。如果你需要经常使用API,HTTPie和cURL就非常有价值。
|
||||
|
||||
###HTTPie###
|
||||
|
||||

|
||||
|
||||
HTTPie(发音 aych-tee-tee-pie)是一款开源的命令行HTTP客户端。它是一个命令行界面,便于手工操作的类cURL工具。
|
||||
|
||||
该软件的目标是使得与Web服务器的交互尽可能的人性化。其提供了一个简单的http命令,允许使用简单且自然的语句发送任意的HTTP请求,并显示不同颜色的输出。HTTPie可以用于测试,调试,以及与HTTP服务器的常规交互。
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 生动而直观的语法格式
|
||||
- 经过格式化的彩色终端输出
|
||||
- 内建JSON支持
|
||||
- 支持表单和文件上传
|
||||
- 支持HTTPS,代理和认证
|
||||
- 任意数据请求
|
||||
- 自定义请求头
|
||||
- 持久会话
|
||||
- 类Wget的下载
|
||||
- 支持Python 2.6,2.7和3.x
|
||||
- 支持Linux,Mac OS X 和 Windows
|
||||
- 支持插件
|
||||
- 文档
|
||||
- 单元测试覆盖
|
||||
|
||||
---
|
||||
|
||||
- 网站:[httpie.org][1]
|
||||
- 开发者: Jakub Roztočil
|
||||
- 证书: 开源
|
||||
- 版本号: 0.9.2
|
||||
|
||||
###cURL###
|
||||
|
||||

|
||||
|
||||
cURL是一个开源的命令行工具,用于使用URL语句传输数据,支持DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS,IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET和TFTP等协议。
|
||||
|
||||
cURL支持SSL证书,HTTP POST,HTTP PUT,FTP上传,基于表单的HTTP上传,代理,缓存,用户名+密码的认证方式(Basic, Digest, NTLM, Negotiate, kerberos...),文件续传,代理通道和一些其他的有用功能。
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 支持配置文件
|
||||
- 一个单独命令行请求多个URL
|
||||
- 支持匹配: [0-13],{one, two, three}
|
||||
- 一个命令上传多个文件
|
||||
- 自定义最大传输速度
|
||||
- 重定向了标准错误输出
|
||||
- 支持Metalink
|
||||
|
||||
---
|
||||
|
||||
- 网站: [curl.haxx.se][2]
|
||||
- 开发者: Daniel Stenberg
|
||||
- 证书: MIT/X derivate license
|
||||
- 版本号: 7.42.0
|
||||
|
||||
###Wget###
|
||||
|
||||

|
||||
|
||||
Wget是一个从网络服务器获取信息的开源软件。其名字源于World Wide Web 和 get。Wget支持HTTP,HTTPS和FTP协议,同时也可以通过HTTP代理获取信息。
|
||||
|
||||
Wget可以根据HTML页面的链接,创建远程网络站点的本地副本,完全重造源站点的目录结构。这种方式被称作“递归下载”。
|
||||
|
||||
Wget设计上增强了低速或者不稳定的网络连接。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 使用REST和RANGE恢复中断的下载
|
||||
- 使用文件名通配符,支持递归地对目录镜像
|
||||
- 基于NLS的消息文件支持多语言
|
||||
- 可选的转换下载文档里地绝对链接为相对链接,使得下载文档可以在本地相互链接
|
||||
- 可以在大多数类UNIX操作系统和微软Windows上运行
|
||||
- 支持HTTP代理
|
||||
- 支持HTTP cookie
|
||||
- 支持HTTP持久连接
|
||||
- 无人照管/后台操作
|
||||
- 当对远程镜像时,使用本地文件时间戳来决定是否需要重新下载文档
|
||||
|
||||
---
|
||||
|
||||
- 站点: [www.gnu.org/software/wget/][3]
|
||||
- 开发者: Hrvoje Niksic, Gordon Matzigkeit, Junio Hamano, Dan Harkless, and many others
|
||||
- 证书: GNU GPL v3
|
||||
- 版本号: 1.16.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150425174537249/HTTPclients.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://httpie.org/
|
||||
[2]:http://curl.haxx.se/
|
||||
[3]:https://www.gnu.org/software/wget/
|
||||
@ -1,37 +1,37 @@
|
||||
在 Debian, Ubuntu, Linux Mint 及 Fedora 中安装 uGet 下载管理器 2.0
|
||||
================================================================================
|
||||
在经历了一段漫长的开发期后,期间发布了超过 11 个开发版本,最终 uGet 项目小组高兴地宣布 uGet 的最新稳定版本 uGet 2.0 已经可以下载使用了。最新版本包含许多吸引人的特点,例如一个新的设定对话框,改进了 aria2 插件对 BitTorrent 和 Metalink 协议的支持,同时对位于横栏中的 uGet RSS 信息提供了更好的支持,其他特点包括:
|
||||
在经历了一段漫长的开发期后,并发布了超过 11 个开发版本,最终 uGet 项目小组高兴地宣布 uGet 的最新稳定版本 uGet 2.0 已经可以下载使用了。最新版本包含许多吸引人的特点,例如一个新的设定对话框,改进了 aria2 插件对 BitTorrent 和 Metalink 协议的支持,同时对位于横幅中的 uGet RSS 信息提供了更好的支持,其他特点包括:
|
||||
|
||||
- 一个新的 “检查更新” 按钮,提醒您有关新的发行版本的信息;
|
||||
- 新增一个 “检查更新” 按钮,提醒您有关新的发行版本的信息;
|
||||
- 增添新的语言支持并升级了现有的语言;
|
||||
- 增加了一个新的 “信息横栏” ,允许开发者轻松地向所有的用户提供有关 uGet 的信息;
|
||||
- 通过对文档、提交反馈和错误报告等内容的链接,增强了帮助菜单;
|
||||
- 新增一个 “信息横幅” ,可以让开发者轻松地向所有的用户提供有关 uGet 的信息;
|
||||
- 增强了帮助菜单,包括文档、提交反馈和错误报告等内容的链接;
|
||||
- 将 uGet 下载管理器集成到了 Linux 平台下的两个主要的浏览器 Firefox 和 Google Chrome 中;
|
||||
- 改进了对 Firefox 插件 ‘FlashGot’ 的支持;
|
||||
|
||||
### 何为 uGet ###
|
||||
|
||||
uGet (先前名为 UrlGfe) 是一个开源,免费,且极其强大的基于 GTK 的多平台下载管理器应用程序,它用 C 语言写就,在 GPL 协议下发布。它提供了一大类的功能,如恢复先前的下载任务,支持多重下载,使用一个独立的配置来支持分类,剪贴板监视,下载队列,从 HTML 文件中导出 URL 地址,集成在 Firefox 中的 Flashgot 插件中,使用集成在 uGet 中的 aria2(一个命令行下载管理器) 来下载 torrent 和 metalink 文件。
|
||||
uGet (先前名为 UrlGfe) 是一个开源,免费,且极其强大的基于 GTK 的多平台下载管理器应用程序,它用 C 语言写就,在 GPL 协议下发布。它提供了大量功能,如恢复先前的下载任务,支持多点下载,使用一个独立的配置来支持分类,剪贴板监视,下载队列,从 HTML 文件中导出 URL 地址,集成在 Firefox 中的 Flashgot 插件中,使用集成在 uGet 中的 aria2(一个命令行下载管理器) 来下载 torrent 和 metalink 文件。
|
||||
|
||||
我已经在下面罗列出了 uGet 下载管理器的所有关键特点,并附带了详细的解释。
|
||||
|
||||
#### uGet 下载管理器的关键特点 ####
|
||||
|
||||
- 下载队列: 可以将你的下载任务放入一个队列中。当某些下载任务完成后,将会自动开始下载队列中余下的文件;
|
||||
- 下载队列: 将你的下载任务放入一个队列中。当某些下载任务完成后,将会自动开始下载队列中余下的文件;
|
||||
- 恢复下载: 假如在某些情况下,你的网络中断了,不要担心,你可以从先前停止的地方继续下载或重新开始;
|
||||
- 下载分类: 支持多种分类来管理下载;
|
||||
- 剪贴板监视: 将要下载的文件类型复制到剪贴板中,便会自动弹出下载提示框以下载刚才复制的文件;
|
||||
- 批量下载: 允许你轻松地一次性下载多个文件;
|
||||
- 支持多种协议: 允许你轻松地使用 aria2 命令行插件通过 HTTP, HTTPS, FTP, BitTorrent 及 Metalink 等协议下载文件;
|
||||
- 多连接: 使用 aria2 插件,每个下载同时支持多达 20 个连接;
|
||||
- 支持 FTP 登录或匿名 FTP 登录: 同时支持使用用户名和密码来登录 FTP 或匿名 FTP ;
|
||||
- 支持 FTP 登录或 FTP 匿名登录: 同时支持使用用户名和密码来登录 FTP 或匿名 FTP ;
|
||||
- 队列下载: 新增队列下载,现在你可以对你的所有下载进行安排调度;
|
||||
- 通过 FlashGot 与 FireFox 集成: 与作为一个独立支持的 Firefox 插件的 FlashGot 集成,从而可以处理单个或大量的下载任务;
|
||||
- CLI 界面或虚拟终端支持: 提供命令行或虚拟终端选项来下载文件;
|
||||
- 自动创建目录: 假如你提供了一个先前并不存在的保存路径,uGet 将会自动创建这个目录;
|
||||
- 下载历史管理: 跟踪记录已下载和已删除的下载任务的条目,每个列表支持 9999 个条目,比当前默认支持条目数目更早的条目将会被自动删除;
|
||||
- 多语言支持: uGet 默认使用英语,但它可支持多达 23 种语言;
|
||||
- Aria2 插件: uGet 集成了 Aria2 插件,来为 aria2 提供更友好的 GUI 界面;
|
||||
- Aria2 插件: uGet 集成了 Aria2 插件,来为你提供更友好的 GUI 界面;
|
||||
|
||||
如若你想了解更加完整的特点描述,请访问 uGet 官方的 [特点页面][1].
|
||||
|
||||
@ -43,7 +43,7 @@ uGet 开发者在 Linux 平台下的各种软件仓库中添加了 uGet 的最
|
||||
|
||||
#### 在 Debian 下 ####
|
||||
|
||||
在 Debian 的测试版本 (Jessie) 和不稳定版本 (Sid) 中,你可以在一个可信赖的基础上,使用官方的软件仓库轻易地安装和升级 uGet 。
|
||||
在 Debian Jessie 和Sid 中,你可以使用官方软件仓库轻易地安装和升级可靠的 uGet 软件包。
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install uget
|
||||
@ -58,7 +58,7 @@ uGet 开发者在 Linux 平台下的各种软件仓库中添加了 uGet 的最
|
||||
|
||||
#### 在 Fedora 下 ####
|
||||
|
||||
在 Fedora 20 – 21 下,最新版本的 uGet(2.0) 可以从官方软件仓库中获得,从这些软件仓库中安装是非常值得信赖的。
|
||||
在 Fedora 20 – 21 下,最新版本的 uGet(2.0) 可以从官方软件仓库中获得可靠的软件包。
|
||||
|
||||
$ sudo yum install uget
|
||||
|
||||
@ -70,7 +70,7 @@ uGet 开发者在 Linux 平台下的各种软件仓库中添加了 uGet 的最
|
||||
|
||||
默认情况下,uGet 在当今大多数的 Linux 系统中使用 `curl` 来作为后端,但 aria2 插件将 curl 替换为 aria2 来作为 uGet 的后端。
|
||||
|
||||
aria2 是一个单独的软件包,需要独立安装。你可以在你的 Linux 发行版本下,使用受支持的软件仓库来轻易地安装 aria2 的最新版本,或根据 [下载 aria2 页面][4] 来安装它,该页面详细解释了在各个发行版本中如何安装 aria2 。
|
||||
aria2 是一个单独的软件包,需要独立安装。你可以在你的 Linux 发行版下,使用受支持的软件仓库来轻易地安装 aria2 的最新版本,或根据 [下载 aria2 页面][4] 来安装它,该页面详细解释了在各个发行版本中如何安装 aria2 。
|
||||
|
||||
#### 在 Debian, Ubuntu 和 Linux Mint 下 ####
|
||||
|
||||
@ -91,28 +91,34 @@ Fedora 的官方软件仓库中已经添加了 aria2 软件包,所以你可以
|
||||
为了启动 uGet,从桌面菜单的搜索栏中键入 "uGet"。可参考如下的截图:
|
||||
|
||||

|
||||
开启 uGet 下载管理器
|
||||
|
||||
*开启 uGet 下载管理器*
|
||||
|
||||

|
||||
uGet 版本: 2.0
|
||||
|
||||
*uGet 版本: 2.0*
|
||||
|
||||
#### 在 uGet 中激活 aria2 插件 ####
|
||||
|
||||
为了激活 aria2 插件, 从 uGet 菜单接着到 `编辑 –> 设置 –> 插件` , 从下拉菜单中选择 "aria2"。
|
||||
|
||||

|
||||
为 uGet 启用 Aria2 插件
|
||||
|
||||
*为 uGet 启用 Aria2 插件*
|
||||
|
||||
### uGet 2.0 截图赏析 ###
|
||||
|
||||

|
||||
使用 Aria2 下载文件
|
||||
|
||||
*使用 Aria2 下载文件*
|
||||
|
||||

|
||||
使用 uGet 下载 Torrent 文件
|
||||
|
||||
*使用 uGet 下载 Torrent 文件*
|
||||
|
||||

|
||||
使用 uGet 进行批量下载
|
||||
|
||||
*使用 uGet 进行批量下载*
|
||||
|
||||
针对其他 Linux 发行版本和 Windows 平台的 RPM 包和 uGet 的源文件都可以在 uGet 的[下载页面][5] 下找到。
|
||||
|
||||
@ -122,7 +128,7 @@ via: http://www.tecmint.com/install-uget-download-manager-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,6 @@
|
||||
translated by strugglingyouth
|
||||
在linux上使用交换文件扩展交换空间
|
||||
================================================================================
|
||||
想像一种情景,当我们的Linux系统用尽交换空间时,在这种情况下,
|
||||
我们想要使用swap分区扩展交换空间,但在某些情况下磁盘上的空闲分区是不可用的,
|
||||
致使我们不能把它扩大。
|
||||
想像一种情景,当我们的Linux系统用尽交换空间时,在这种情况下,我们想要使用swap分区扩展交换空间,但在某些情况下磁盘上已经没有可用的空闲分区了,致使我们不能把它扩大。
|
||||
|
||||
因此,在这种情况下,我们可以使用交换文件增加swap空间。
|
||||
|
||||
@ -16,7 +13,7 @@ free-output-with-swap
|
||||
|
||||
我的交换分区大小是2 GB,我们将把交换空间扩展1GB。
|
||||
|
||||
#### 第一步:使用下面的dd命令创建大小为1GB交换文件d ####
|
||||
#### 第一步:使用下面的dd命令创建大小为1GB交换文件 ####
|
||||
|
||||
[root@linuxtechi ~]# dd if=/dev/zero of=/swap_file bs=1G count=1
|
||||
1+0 records in
|
||||
@ -26,7 +23,7 @@ free-output-with-swap
|
||||
|
||||
根据你的需要替换 ‘**bs**‘ 和 ‘**count**‘ 的大小.
|
||||
|
||||
####第二步:设置交换文件权限为644. ####
|
||||
#### 第二步:设置交换文件权限为600 ####
|
||||
|
||||
[root@linuxtechi ~]# chmod 600 /swap_file
|
||||
|
||||
@ -56,21 +53,20 @@ free-output-with-swap
|
||||
|
||||
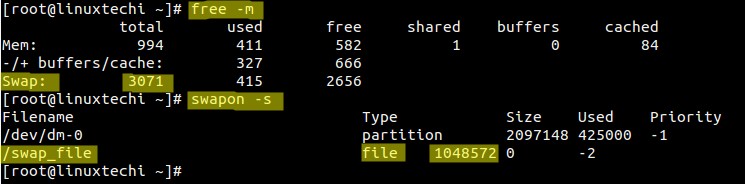
|
||||
|
||||
**Note**: 为了避免出现意外的情况,如下所示使用swapoff命令关闭它,
|
||||
仅在需要使用时,使用步骤5所示的swapon命令,重新启用交换文件。.
|
||||
**Note**: 为了避免出现意外的情况,如下所示使用swapoff命令关闭它,仅在需要使用时,使用步骤5所示的swapon命令,重新启用交换文件。
|
||||
|
||||
[root@linuxtechi ~]# swapoff /swap_file
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
请分享您的宝贵意见或者评论此文章.
|
||||
请分享您的宝贵意见或者评论此文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/extend-swap-space-using-swap-file-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,133 +1,99 @@
|
||||
|
||||
如何在CentOS 7上安装Percona Server
|
||||
|
||||
如何在 CentOS 7 上安装 Percona服务器
|
||||
================================================================================
|
||||
在这篇文章中我们将了解关于Percona Server,一个开源简易的MySQL,MariaDB的替代。InnoDB的数据库引擎使得Percona Server非常有吸引力,如果你需要的高性能,高可靠性和高性价比的解决方案,它将是一个很好的选择。
|
||||
|
||||
在下文中将介绍在CentOS 7上Percona的服务器的安装,以及备份当前数据,配置的步骤和如何恢复备份。
|
||||
|
||||
|
||||
###目录###
|
||||
|
||||
|
||||
1.什么是Percona,为什么使用它
|
||||
2.备份你的数据库
|
||||
3.删除之前的SQL服务器
|
||||
4.使用二进制包安装Percona
|
||||
5.配置Percona
|
||||
6.保护你的数据
|
||||
7.恢复你的备份
|
||||
在这篇文章中我们将了解关于 Percona 服务器,一个开源的MySQL,MariaDB的替代品。InnoDB的数据库引擎使得Percona 服务器非常有吸引力,如果你需要的高性能,高可靠性和高性价比的解决方案,它将是一个很好的选择。
|
||||
|
||||
在下文中将介绍在CentOS 7上Percona 服务器的安装,以及备份当前数据,配置的步骤和如何恢复备份。
|
||||
|
||||
### 1.什么是Percona,为什么使用它 ###
|
||||
|
||||
|
||||
Percona是一个开源简易的MySQL,MariaDB数据库的替代,它是MYSQL的一个分支,相当多的改进和独特的功能使得它比MYSQL更可靠,性能更强,速度更快,它与MYSQL完全兼容,你甚至可以在Oracle的MYSQL与Percona之间使用复制命令。
|
||||
Percona是一个MySQL,MariaDB数据库的开源替代品,它是MySQL的一个分支,相当多的改进和独特的功能使得它比MYSQL更可靠,性能更强,速度更快,它与MYSQL完全兼容,你甚至可以在Oracle的MySQL与Percona之间使用复制。
|
||||
|
||||
#### 在Percona中独具特色的功能 ####
|
||||
|
||||
- 分区适应哈希搜索
|
||||
- 快速校验算法
|
||||
- 缓冲池预加载
|
||||
- 支持FlashCache
|
||||
|
||||
-分段自适应哈希搜索
|
||||
-快速校验算法
|
||||
-缓冲池预加载
|
||||
-支持FlashCache
|
||||
#### MySQL企业版和Percona中的特有功能 ####
|
||||
|
||||
#### MySQL企业版和Percona的特定功能 ####
|
||||
- 从不同的服务器导入表
|
||||
- PAM认证
|
||||
- 审计日志
|
||||
- 线程池
|
||||
|
||||
-从不同的服务器导入表
|
||||
-PAM认证
|
||||
-审计日志
|
||||
-线程池
|
||||
|
||||
|
||||
现在,你肯定很兴奋地看到这些好的东西整理在一起,我们将告诉你如何安装和做些的Percona Server的基本配置。
|
||||
现在,你肯定很兴奋地看到这些好的东西整合在一起,我们将告诉你如何安装和对Percona Server做基本配置。
|
||||
|
||||
### 2. 备份你的数据库 ###
|
||||
|
||||
|
||||
接下来,在命令行下使用SQL命令创建一个mydatabases.sql文件来重建/恢复salesdb和employeedb数据库,重命名数据库以便反映你的设置,如果没有安装MYSQL跳过此步
|
||||
接下来,在命令行下使用SQL命令创建一个mydatabases.sql文件,来重建或恢复salesdb和employeedb数据库,根据你的设置替换数据库名称,如果没有安装MySQL则跳过此步:
|
||||
|
||||
mysqldump -u root -p --databases employeedb salesdb > mydatabases.sql
|
||||
|
||||
复制当前的配置文件,如果你没有安装MYSQL也可跳过
|
||||
|
||||
复制当前的配置文件,如果你没有安装MYSQL也可跳过:
|
||||
|
||||
cp my.cnf my.cnf.bkp
|
||||
|
||||
### 3.删除之前的SQL服务器 ###
|
||||
|
||||
|
||||
停止MYSQL/MariaDB如果它们还在运行
|
||||
|
||||
停止MYSQL/MariaDB,如果它们还在运行:
|
||||
|
||||
systemctl stop mysql.service
|
||||
|
||||
卸载MariaDB和MYSQL
|
||||
|
||||
卸载MariaDB和MYSQL:
|
||||
|
||||
yum remove MariaDB-server MariaDB-client MariaDB-shared mysql mysql-server
|
||||
|
||||
移动重命名在/var/lib/mysql当中的MariaDB文件,这比仅仅只是移除更为安全快速,这就像2级即时备份。:)
|
||||
|
||||
移动重命名放在/var/lib/mysql当中的MariaDB文件。这比仅仅只是移除更为安全快速,这就像2级即时备份。:)
|
||||
|
||||
mv /var/lib/mysql /var/lib/mysql_mariadb
|
||||
|
||||
### 4.使用二进制包安装Percona ###
|
||||
|
||||
|
||||
你可以在众多Percona安装方法中选择,在CentOS中使用Yum或者RPM包安装通常是更好的主意,所以这些是本文介绍的方式,下载源文件编译后安装在本文中并没有介绍。
|
||||
|
||||
从Yum仓库中安装:
|
||||
|
||||
从Yum仓库中安装:
|
||||
|
||||
|
||||
首先,你需要设置的Percona的Yum库:
|
||||
|
||||
首先,你需要设置Percona的Yum库:
|
||||
|
||||
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm
|
||||
|
||||
接下来安装Percona:
|
||||
|
||||
|
||||
yum install Percona-Server-client-56 Percona-Server-server-56
|
||||
|
||||
上面的命令安装Percona的服务器和客户端,共享库,可能需要Perl和Perl模块,以及其他依赖的需要。如DBI::MySQL的,如果这些尚未安装,
|
||||
|
||||
使用RPM包安装:
|
||||
上面的命令安装Percona的服务器和客户端、共享库,可能需要Perl和Perl模块,以及其他依赖的需要,如DBI::MySQL。如果这些尚未安装,可能需要安装更多的依赖包。
|
||||
|
||||
使用RPM包安装:
|
||||
|
||||
我们可以使用wget命令下载所有的rpm包:
|
||||
|
||||
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \ http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \
|
||||
http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
|
||||
使用rpm工具,一次性安装所有的rpm包:
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \
|
||||
Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \
|
||||
Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
注意在上面命令语句中最后的反斜杠'\',如果您安装单独的软件包,记住要解决依赖关系,在安装客户端之前要先安装共享包,在安装服务器之前请先安装客户端。
|
||||
注意在上面命令语句中最后的反斜杠'\'(只是为了换行方便)。如果您安装单独的软件包,记住要解决依赖关系,在安装客户端之前要先安装共享包,在安装服务器之前请先安装客户端。
|
||||
|
||||
### 5.配置Percona服务器 ###
|
||||
|
||||
|
||||
|
||||
#### 恢复之前的配置 ####
|
||||
|
||||
|
||||
当我们从MariaDB迁移过来时,你可以将之前的my.cnf的备份文件恢复回来。
|
||||
|
||||
|
||||
cp /etc/my.cnf.bkp /etc/my.cnf
|
||||
|
||||
#### 创建一个新的my.cnf文件 ####
|
||||
|
||||
|
||||
如果你需要一个适合你需求的新的配置文件或者你并没有备份配置文件,你可以使用以下方法,通过简单的几步生成新的配置文件。
|
||||
|
||||
下面是Percona-server软件包自带的my.cnf文件
|
||||
|
||||
|
||||
# Percona Server template configuration
|
||||
|
||||
[mysqld]
|
||||
@ -158,33 +124,29 @@ Percona是一个开源简易的MySQL,MariaDB数据库的替代,它是MYSQL
|
||||
|
||||
根据你的需要配置好my.cnf后,就可以启动该服务了:
|
||||
|
||||
|
||||
systemctl restart mysql.service
|
||||
|
||||
如果一切顺利的话,它已经准备好执行SQL命令了,你可以用以下命令检查它是否已经正常启动:
|
||||
|
||||
|
||||
mysql -u root -p -e 'SHOW VARIABLES LIKE "version_comment"'
|
||||
|
||||
如果你不能够正常启动它,你可以在**/var/log/mysql/mysqld.log**中查找原因,该文件可在my.cnf的[mysql_safe]的log-error中设置。
|
||||
|
||||
tail /var/log/mysql/mysqld.log
|
||||
|
||||
你也可以在/var/lib/mysql/文件夹下查找格式为[hostname].err的文件,就像下面这个例子样:
|
||||
|
||||
你也可以在/var/lib/mysql/文件夹下查找格式为[主机名].err的文件,就像下面这个例子:
|
||||
|
||||
tail /var/lib/mysql/centos7.err
|
||||
|
||||
如果还是没找出原因,你可以试试strace:
|
||||
|
||||
|
||||
yum install strace && systemctl stop mysql.service && strace -f -f mysqld_safe
|
||||
|
||||
上面的命令挺长的,输出的结果也相对简单,但绝大多数时候你都能找到无法启动的原因。
|
||||
|
||||
### 6.保护你的数据 ###
|
||||
|
||||
好了,你的关系数据库管理系统已经准备好接收SQL查询,但是把你宝贵的数据放在没有最起码安全保护的服务器上并不可取,为了更为安全最好使用mysql_secure_instalation,这个工具可以帮助删除未使用的默认功能,还设置root的密码,并限制使用此用户进行访问。
|
||||
只需要在shell中执行,并参照屏幕上的说明。
|
||||
好了,你的关系数据库管理系统已经准备好接收SQL查询,但是把你宝贵的数据放在没有最起码安全保护的服务器上并不可取,为了更为安全最好使用mysql_secure_install来安装,这个工具可以帮助你删除未使用的默认功能,并设置root的密码,限制使用此用户进行访问。只需要在shell中执行该命令,并参照屏幕上的说明操作。
|
||||
|
||||
mysql_secure_install
|
||||
|
||||
@ -192,28 +154,27 @@ Percona是一个开源简易的MySQL,MariaDB数据库的替代,它是MYSQL
|
||||
|
||||
如果您参照之前的设置,现在你可以恢复数据库,只需再用mysqldump一次。
|
||||
|
||||
|
||||
mysqldump -u root -p < mydatabases.sql
|
||||
恭喜你,你刚刚已经在你的CentOS上成功安装了Percona,你的服务器已经可以正式投入使用;你可以像使用MYSQL一样使用它,你的服务器与他完全兼容。
|
||||
|
||||
恭喜你,你刚刚已经在你的CentOS上成功安装了Percona,你的服务器已经可以正式投入使用;你可以像使用MySQL一样使用它,你的服务器与它完全兼容。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
为了获得更强的性能你需要对配置文件做大量的修改,但这里也有一些简单的选项来提高机器的性能。当使用InnoDB引擎时,将innodb_file_per_table设置为on,它将在一个文件中为每个表创建索引表,这意味着每个表都有它自己的索引文件,它使系统更强大和更容易维修。
|
||||
为了获得更强的性能你需要对配置文件做大量的修改,但这里也有一些简单的选项来提高机器的性能。当使用InnoDB引擎时,将innodb_file_per_table设置为on,它将在一个文件中为每个表创建索引表,这意味着每个表都有它自己的索引文件,它使系统更强大和更容易维修。
|
||||
|
||||
可以修改innodb_buffer_pool_size选项,InnoDB应该有足够的缓存池来应对你的数据集,大小应该为当前可用内存的70%到80%。
|
||||
|
||||
过将innodb-flush-method设置为O_DIRECT,关闭写入高速缓存,如果你使用了RAID,这可以提升性能因为在底层已经完成了缓存操作。
|
||||
将innodb-flush-method设置为O_DIRECT,关闭写入高速缓存,如果你使用了RAID,这可以提升性能,因为在底层已经完成了缓存操作。
|
||||
|
||||
如果你的数据并不是十分关键并且并不需要对数据库事务正确执行的四个基本要素完全兼容,可以将innodb_flush_log_at_trx_commit设置为2,这也能提升系统的性能。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/percona-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[FatJoe123](https://github.com/FatJoe123)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,41 +1,41 @@
|
||||
安装 Tails 1.4 Linux 操作系统来保护隐私和保持匿名
|
||||
用 Tails 1.4 Linux 系统来保护隐私和保持匿名
|
||||
================================================================================
|
||||
在这个互联网世界和互联网的世界中,我们在线执行我们的大多数任务,无论是订票,汇款,研究,商务,娱乐,社交网络,还是其他。每天我们花费大部分时间在网络上。在每个逝去的日子里,在网络中保持匿名变得越来越难,尤其是在被某些机构例如 NSA (National Security Agency,国安局) 植入后门的情况下,这些机构嗅探着我们在网络中的所有动作。在网络中,我们有着极少,或者说根本就没有隐私。基于用户浏览网络的活动和机器的活动的搜索都被记录了下来。
|
||||
在这个互联网世界和互联网的世界中,我们在线执行我们的大多数任务,无论是订票,汇款,研究,商务,娱乐,社交网络,还是其它。每天我们花费大部分时间在网络上。在过去这些的日子里,在网络中保持匿名变得越来越难,尤其是在被某些机构例如 NSA (National Security Agency) 植入后门的情况下,他们嗅探着我们在网络中的所有动作。在网络中,我们有着极少的,或者说根本就没有隐私。基于用户浏览网络的活动和机器的活动的搜索都被记录了下来。
|
||||
|
||||
一个来自于 Tor 项目的绝妙浏览器正被上百万人使用,它帮助我们匿名地浏览网络,即使这样,跟踪你的浏览习惯也并不难,所以只使用 Tor 并不能保证你的网络安全。你可以从下面的链接中查看 Tor 的特点及安装指南。
|
||||
一款来自于 Tor 项目的绝妙浏览器正被上百万人使用,它帮助我们匿名地浏览网络,即使这样,跟踪你的浏览习惯也并不难,所以只使用 Tor 并不能保证你的网络安全。你可以从下面的链接中查看 Tor 的特点及安装指南。
|
||||
|
||||
- [使用 Tor 来进行匿名网络浏览][1]
|
||||
|
||||
Tor 项目中有一个名为 Tails 的操作系统。Tails (The Amnesic Incognito Live System) 是一个 live 操作系统,基于 Debian Linux 发行版本,主要着眼于在浏览网络时在网络中保护隐私和匿名,这意味着所有的外向连接都强制通过 Tor 来连接,直接的(非匿名的) 连接请求都会被阻挡。该系统被设计为可在任何可启动介质上运行,例如 USB 或 DVD。
|
||||
Tor 项目中有一个名为 Tails 的操作系统。Tails (The Amnesic Incognito Live System) 是一个 live 操作系统,基于 Debian Linux 发行版本,主要着眼于在浏览网络时在网络中保护隐私和匿名,这意味着所有的外向连接都强制通过 Tor 来连接,直接的(非匿名的) 连接请求都会被阻挡。该系统被设计为可在任何可启动介质上运行,例如 USB 棒或 DVD。
|
||||
|
||||
Tails OS 的最新稳定发行版本为 1.4 , 于 2015 年 5 月 12 日发行。Tails 由开源单片 Linux 内核支持,构建在 Debian GNU/Linux 之上,着眼于个人电脑市场, 使用 GNOME 3 作为其默认的用户界面。
|
||||
Tails OS 的最新稳定发行版本为 1.4 , 于 2015 年 5 月 12 日发行。Tails 由开源的 Linux 宏内核所驱动,构建在 Debian GNU/Linux 之上,着眼于个人电脑市场, 使用 GNOME 3 作为其默认的用户界面。
|
||||
|
||||
#### Tails OS 1.4 的特点 ####
|
||||
|
||||
- Tails 是一个 free 的操作系统, free 的意义正如 免费(free)啤酒和言论自由(free) 中的 free
|
||||
- Tails 是一个 free 的操作系统, free 的意义不仅是免费(free)啤酒的免费,也是言论自由(free) 中的自由
|
||||
- 构建在 Debian/GNU Linux 操作系统之上, Debian 是使用最广泛的通用操作系统
|
||||
- 着眼于安全的发行版本
|
||||
- 有 Windows 8 外观作为其伪装
|
||||
- 伪装成 Windows 8 外观
|
||||
- 不必安装就可以使用 Live Tails CD/DVD 来匿名浏览网络
|
||||
- 当 Tails 运行时,不留下任何痕迹
|
||||
- 当 Tails 运行时,不会在计算机上留下任何痕迹
|
||||
- 使用先进的加密工具来加密任何相关文件,邮件等内容
|
||||
- 通过 Tor 网络来发送和接收流量
|
||||
- 在真正意义上为任何人在任何地方保护隐私
|
||||
- 在 Live 环境中带有一些可用的应用
|
||||
- 真正意义地无论何时何处保护隐私
|
||||
- 在 Live 环境中带有一些立即可用的应用
|
||||
- 系统自带的所有软件都预先配置好只通过 Tor 网络来连接到互联网
|
||||
- 任何不通过 Tor 网络而尝试连接网络的应用都将被自动阻拦。
|
||||
- 任何不通过 Tor 网络而尝试连接网络的应用都将被自动阻拦
|
||||
- 限制那些想查看你正在浏览什么网站的人的行动,并限制网站获取你的地理位置
|
||||
- 连接到那些被墙或被审查的网站
|
||||
- 特别设计不使用主操作系统的空间,即使在 swap 空间还有空余的情况下
|
||||
- 整个操作系统加载在 RAM 中,在每次重启或关机后会自动擦除掉,所以不会留下任何运行的痕迹。
|
||||
- 特别设计不使用主操作系统的空间,即便是 swap 空间也不用
|
||||
- 整个操作系统加载在内存中,在每次重启或关机后会自动擦除掉,所以不会留下任何运行的痕迹。
|
||||
- 先进的安全实现,通过加密 USB 磁盘, HTTPS 应答加密和对邮件,文档进行签名。
|
||||
|
||||
#### 在 Tails 1.4 中可期待的东西 ####
|
||||
#### 在 Tails 1.4 中所期待的东西 ####
|
||||
|
||||
- 带有安全滑块的 Tor 浏览器 4.5
|
||||
- Tor 被升级到版本 0.2.6.7
|
||||
- 修补了几个安全漏洞
|
||||
- 针对诸如 curl, OpenJDK 7, tor Network, openldap 等应用, 许多漏洞被修复并打上了补丁
|
||||
- 针对诸如 curl、 OpenJDK 7、 tor Network、 openldap 等应用, 许多漏洞被修复并打上了补丁
|
||||
|
||||
要得到完整的更改记录,你需要访问 [这里][2]
|
||||
|
||||
@ -43,7 +43,7 @@ Tails OS 的最新稳定发行版本为 1.4 , 于 2015 年 5 月 12 日发行
|
||||
|
||||
#### 为什么我应该使用 Tails 操作系统 ####
|
||||
|
||||
你需要 Tails 因为你想:
|
||||
你需要 Tails 因为你想:
|
||||
|
||||
- 在网络监控下保持自由
|
||||
- 捍卫自由,隐私和秘密
|
||||
@ -62,85 +62,96 @@ Tails OS 的最新稳定发行版本为 1.4 , 于 2015 年 5 月 12 日发行
|
||||
- [tails-i386-1.4.iso][3]
|
||||
- [tails-i386-1.4.torrent][4]
|
||||
|
||||
2. 下载后,可使用 SHA256SUM 来获取 ISO 文件的哈希值并与官方提供的值相比较,以核实 ISO 文件的完整性
|
||||
2. 下载后,可使用 sha256sum 来获取 ISO 文件的哈希值并与官方提供的值相比较,以核实 ISO 文件的完整性
|
||||
|
||||
$ sha256sum tails-i386-1.4.iso
|
||||
|
||||
339c8712768c831e59c4b1523002b83ccb98a4fe62f6a221fee3a15e779ca65d
|
||||
|
||||
假如你熟悉 OpenPGP ,将 Tails 的签名密钥与 Debian 的 keyring 相比较以验证其签名,若想了解任何有关 Tails 的加密签名,请将浏览器指向 [这里][5]
|
||||
假如你熟悉 OpenPGP ,将 Tails 的签名密钥与 Debian 的 keyring 相比较以验证其签名,若想了解任何有关 Tails 的加密签名,请用浏览器访问 [这里][5]
|
||||
|
||||
3. 下一步,你需要将镜像写入 USB 或 DVD ROM 中。或许你需要看看这篇文章 [如何创建一个 Live 可启动的 USB][6] 以了解如何使得一个闪存驱动器变得可启动并向它写入 ISO 镜像文件。
|
||||
3. 下一步,你需要将镜像写入 USB 棒或 DVD ROM 中。或许你需要看看这篇文章 “[如何创建一个 Live 可启动的 USB棒][6] ”以了解如何使得一个闪存盘变得可启动并向它写入 ISO 镜像文件。
|
||||
|
||||
4. 插入 Tails OS 可启动闪存驱动器或 DVD ROM,并从那里启动 (在 BIOS 中选择该介质来启动)。第一个屏幕中会有两个选项 'Live' 和 'Live (failsafe)' 让你选择。选择 'Live' 并确定。
|
||||
4. 插入 Tails OS 的可启动闪存盘或 DVD ROM,并从那里启动 (在 BIOS 中选择该介质来启动)。第一个屏幕中会有两个选项 'Live' 和 'Live (failsafe)' 让你选择。选择 'Live' 并确定。
|
||||
|
||||

|
||||
Tails 启动菜单
|
||||
|
||||
*Tails 启动菜单*
|
||||
|
||||
5. 在登录之前,你有两个选项, 假如你想配置并设定高级选项,点击 '更多选项' 否则点击 'NO'。
|
||||
|
||||

|
||||
Tails 欢迎界面
|
||||
|
||||
6. 在点击高级选项后,你需要设置 root 密码。假如你想升级它,这是非常重要的。这个 root 密码将会一直有效,知道你关机或重启。
|
||||
*Tails 欢迎界面*
|
||||
|
||||
另外,若你想开启 Windows 伪装,假如你想在一个公共场所运行这个操作系统,这将使得看起来你正在运行 Windows 8 操作系统。这真是一个好的选项!不是吗?另外,你还有一个选项来配置 网络和 Mac 地址,当一切准备完毕后,点击 '登录' !
|
||||
6. 在点击高级选项后,你需要设置 root 密码。假如你想升级它,这是非常重要的。这个 root 密码的有效期将持续到你关机或重启。
|
||||
|
||||
另外,若你想开启 Windows 伪装,假如你想在一个公共场所运行这个操作系统,这将使得看起来你正在运行 Windows 8 操作系统。这真是一个好的选项!不是吗?另外,你还有一个选项来配置网络和 Mac 地址,当一切准备完毕后,点击 '登录' !
|
||||
|
||||

|
||||
Tails OS 的配置
|
||||
|
||||
*Tails OS 的配置*
|
||||
|
||||
7. 这是使用 Windows 皮肤伪装的 Tails GNU/Linux OS:
|
||||
|
||||

|
||||
Tails 的 Windows 伪装
|
||||
|
||||
8. 系统将在后台启动 Tor 网络。在屏幕的右上角查看通知 – Tor 已经准备好了 或现在你已经连接上了互联网。
|
||||
*Tails 的 Windows 伪装*
|
||||
|
||||
你也可以在 Internet 菜单下查看它包含了哪些东西。 注意 – 它包含有 Tor 浏览器(安全的) 和 不安全的网络浏览器(其中的向内和向外数据不通过 Tor 网络) 和其他应用。
|
||||
8. 系统将在后台启动 Tor 网络。在屏幕的右上角查看通知 :“Tor 已经准备好了,现在你已经连接上了互联网”。
|
||||
|
||||
你也可以在 Internet 菜单下查看它包含了哪些东西。 注意 :它包含有 Tor 浏览器(安全的) 和 不安全的网络浏览器(其中的向内和向外数据不通过 Tor 网络) 和其他应用。
|
||||
|
||||
|
||||
Tails 菜单和工具
|
||||
|
||||
*Tails 菜单和工具*
|
||||
|
||||
9. 点击 Tor 并检查你的 IP 地址。 它确认我的物理位置没有被分享以及我的隐私未被触动。
|
||||
|
||||

|
||||
在 Tails 上检查隐私
|
||||
|
||||
10. 你还可以激活 Tails 安装器来从 ISO 镜像文件中 克隆和安装, 克隆和升级以及升级系统。
|
||||
*在 Tails 上检查隐私*
|
||||
|
||||
10. 你还可以激活 Tails 安装器来“克隆和安装”, “克隆和升级”以及“从 ISO 镜像文件中升级系统”。
|
||||
|
||||

|
||||
Tails 安装器选项
|
||||
|
||||
11. 其他选项为选择 Tor 不带有高级选项,就在登录之前。(查看上面的第 5 步).
|
||||
*Tails 安装器选项*
|
||||
|
||||

|
||||
Tails 未带有高级选项
|
||||
11. 如果选择另外的那个不带有高级选项的方式,那就直接登录。(查看上面的第 5 步).
|
||||
|
||||
12. 你将登录到 Gnome3 桌面环境。
|
||||

|
||||
|
||||
*不设置高级选项的 Tails*
|
||||
|
||||
12. 这将登录到 Gnome3 桌面环境。
|
||||
|
||||

|
||||
Tails Gnome 桌面
|
||||
|
||||
13. 假如你点击启动不安全的浏览器,无论在带有伪装,还是没有带有伪装的情况下,你都将会收到弹窗通知。
|
||||
*Tails Gnome 桌面*
|
||||
|
||||
13. 假如你点击启动不安全的浏览器,无论是否带有地址伪装,你都将会收到弹窗通知。
|
||||
|
||||

|
||||
Tails 浏览通知
|
||||
|
||||
*Tails 浏览通知*
|
||||
|
||||
假如你仍启动不安全的浏览器,你将在浏览器中看到如下网页:
|
||||
|
||||

|
||||
Tails 浏览警告
|
||||
|
||||
*Tails 浏览警告*
|
||||
|
||||
#### Tails 适合我吗?####
|
||||
|
||||
要想得到上面问题的答案,首先回答如下的问题:
|
||||
|
||||
- 在上网时,你想你的隐私未被触动吗?
|
||||
- 你想在身份信息窃取者的眼皮底下保持隐身吗?
|
||||
- 在上网时,你想你的隐私不被触动吗?
|
||||
- 你想在窃取身份信息的人的眼皮底下保持隐身吗?
|
||||
- 你想在你的网上私人聊天过程中被他人嗅探吗?
|
||||
- 你真的想向任何人展示你的地理位置吗?
|
||||
- 你开展银行网上交易吗?
|
||||
- 你愿意受政府和 ISP(注:网络提供商) 的审查吗?
|
||||
- 你愿意受政府和 ISP的审查吗?
|
||||
|
||||
假如以上问题中,任意一个问题的答案为 'YES',则你最好需要 Tails。假如上面所有的问题的答案都是 'NO',则或许你不需要它。
|
||||
|
||||
@ -150,27 +161,28 @@ Tails 浏览警告
|
||||
|
||||
### 总结 ###
|
||||
|
||||
对于那些工作在不安全环境中的人来说,Tails 是一个必需的操作系统。Tails 还是一个着眼于安全的操作系统,现在为止,包含一大批应用 – Gnome 桌面, Tor, Firefox (Iceweasel), Network Manager, Pidgin, Claws mail, Liferea feed addregator, Gobby, Aircrack-ng, I2P。
|
||||
对于那些工作在不安全环境中的人来说,Tails 是一个必需的操作系统。Tails 还是一个着眼于安全的操作系统,现在为止,包含了一大批应用 – Gnome 桌面、Tor、 Firefox (Iceweasel)、 Network Manager、 Pidgin、 Claws mail、 Liferea feed addregator、 Gobby、 Aircrack-ng、 I2P。
|
||||
|
||||
同时,它含有一些有关加密和隐私的工具,即 UKS, GNUPG, PWGen, Shamir’s Secret Sharing, Virtual Keyboard (against Hardware Keylogging), MAT, KeePassX Password Manager 等。
|
||||
同时,它含有一些有关加密和隐私的工具,即 UKS、 GnuPG、 PWGen、 Shamir's Secret Sharing、 Virtual Keyboard (对付硬件的键盘记录器)、 MAT、 KeePassX Password Manager 等。
|
||||
|
||||
这就是全部了。关注 Tecmint。请分享你的有关 Tails GNU/Linux 操作系统的想法。对于这个项目的未来,你怎么看?同时在实际中测试它,并让我们获知你的体验感受。
|
||||
这就是全部了。关注我们。请分享你的有关 Tails GNU/Linux 操作系统的想法。对于这个项目的未来,你怎么看?同时在实际中测试它,并让我们获知你的体验感受。
|
||||
|
||||
你也可以在 [Virtualbox][8] 中运行它。 Tails 在 RAM 中加载整个操作系统,所以在 VM 中你需要给定足够的 RAM 来运行 Tails。
|
||||
你也可以在 [Virtualbox][8] 中运行它。 Tails 在内存中加载整个操作系统,所以在虚拟机中你需要给定足够的内存来运行 Tails。
|
||||
|
||||
我在 1GB 内存的环境中测试了 Tails,它工作起来毫无滞后感。谢谢我们的所有用户的支持。使我们成为一个包含所有 Linux 相关信息的地方,你的支持是必需的。 Kudos!
|
||||
|
||||
我在 1GB 的环境中测试了 Tails,它工作起来毫无滞后感。谢谢我们的所有用户的支持。使 Tecmint 成为一个包含所有 Linux 相关信息的地方,你的合作是必需的。 Kudos!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-tails-1-4-linux-operating-system-to-preserve-privacy-and-anonymity/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
[1]:https://linux.cn/article-3566-1.html
|
||||
[2]:https://tails.boum.org/news/version_1.4/index.en.html
|
||||
[3]:http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
[4]:https://tails.boum.org/torrents/files/tails-i386-1.4.torrent
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答——Linux上Apache错误日志的位置在哪里?
|
||||
Linux有问必答:Linux上Apache错误日志的位置在哪里?
|
||||
================================================================================
|
||||
> **问题**: 我尝试着解决我 Linux 系统上的 Apache 网络服务器的错误,Apache的错误日志文件放在[你的 Linux 版本]的哪个位置呢?
|
||||
> **问题**: 我尝试着解决我 Linux 系统上的 Apache Web 服务器的错误,Apache的错误日志文件放在[XX Linux 版本]的哪个位置呢?
|
||||
|
||||
错误日志和访问日志文件为系统管理员提供了有用的信息,比如,为网络服务器排障,[保护][1]系统不受各种各样的恶意活动侵犯,或者只是进行[各种各样的][2][分析][3]以监控 HTTP 服务器。根据你网络服务器配置的不同,其错误/访问日志可能放在你系统中不同位置。
|
||||
错误日志和访问日志文件为系统管理员提供了有用的信息,比如,为 Web 服务器排障,[保护][1]系统不受各种各样的恶意活动侵犯,或者只是进行[各种各样的][2][分析][3]以监控 HTTP 服务器。根据你 Web 服务器配置的不同,其错误/访问日志可能放在你系统中不同位置。
|
||||
|
||||
本文可以帮助你**找到Linux上的Apache错误日志**。
|
||||
|
||||
@ -28,7 +28,7 @@ Linux有问必答——Linux上Apache错误日志的位置在哪里?
|
||||
|
||||
#### 使用虚拟主机自定义的错误日志 ####
|
||||
|
||||
如果在 Apache 网络服务器中使用了虚拟主机, ErrorLog 指令可能会在虚拟主机容器内指定,在这种情况下,上面所说的系统范围的错误日志位置将被忽略。
|
||||
如果在 Apache Web 服务器中使用了虚拟主机, ErrorLog 指令可能会在虚拟主机容器内指定,在这种情况下,上面所说的系统范围的错误日志位置将被忽略。
|
||||
|
||||
启用了虚拟主机后,各个虚拟主机可以定义其自身的自定义错误日志位置。要找出某个特定虚拟主机的错误日志位置,你可以打开 /etc/apache2/sites-enabled/<your-site>.conf,然后查找 ErrorLog 指令,该指令会显示站点指定的错误日志文件。
|
||||
|
||||
@ -40,11 +40,11 @@ Linux有问必答——Linux上Apache错误日志的位置在哪里?
|
||||
|
||||
#### 自定义的错误日志 ####
|
||||
|
||||
要找出 Apache 错误日志的自定义位置,请用文本编辑器打开 /etc/httpd/conf/httpd.conf,然后查找 ServerRoot,该参数显示了 Apache 服务器目录树的顶层,日志文件和配置都位于该目录树中。例如:
|
||||
要找出 Apache 错误日志的自定义位置,请用文本编辑器打开 /etc/httpd/conf/httpd.conf,然后查找 ServerRoot,该参数显示了 Apache Web 服务器目录树的顶层,日志文件和配置都位于该目录树中。例如:
|
||||
|
||||
ServerRoot "/etc/httpd"
|
||||
|
||||
现在,查找 ErrorLog 开头的行,该行指出了 Apache 网络服务器将错误日志写到了哪里去。注意,指定的位置是 ServerRoot 值的相对位置。例如:
|
||||
现在,查找 ErrorLog 开头的行,该行指出了 Apache Web 服务器将错误日志写到了哪里去。注意,指定的位置是 ServerRoot 值的相对位置。例如:
|
||||
|
||||
ErrorLog "log/error_log"
|
||||
|
||||
@ -71,11 +71,11 @@ via: http://ask.xmodulo.com/apache-error-log-location-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
[2]:http://xmodulo.com/interactive-apache-web-server-log-analyzer-linux.html
|
||||
[3]:http://xmodulo.com/sql-queries-apache-log-files-linux.html
|
||||
[1]:https://linux.cn/article-5068-1.html
|
||||
[2]:https://linux.cn/article-5352-1.html
|
||||
[3]:https://linux.cn/article-4405-1.html
|
||||
@ -1,7 +1,7 @@
|
||||
如何在云服务提供商的机器使用Docker Machine
|
||||
如何在云服务提供商的平台上使用Docker Machine
|
||||
================================================================================
|
||||
大家好,今天我们来学习如何使用Docker Machine在各种云服务提供商的平台部署Docker。Docker Machine是一个可以帮助我们在自己的电脑、云服务提供商的机器以及我们数据中心的机器上创建Docker机器的应用程序。它为创建服务器、在服务器中安装Docker、根据用户需求配置Docker客户端提供了简单的解决方案。驱动API对本地机器、数据中心的虚拟机或者公用云机器都适用。Docker Machine支持Windows、OSX和Linux,并且提供一个独立的二进制文件,可以直接使用。它让我们可以充分利用支持Docker的基础设施的生态环境合作伙伴,并且使用相同的接口进行访问。它让人们可以使用一个命令来简单而迅速地在不同的云平台部署Docker容器。
|
||||
|
||||
|
||||
大家好,今天我们来了解如何使用Docker Machine在各种云服务提供商的平台上部署Docker。Docker Machine是一个可以帮助我们在自己的电脑、云服务提供商的平台以及我们数据中心的机器上创建Docker机器的应用程序。它为创建服务器、在服务器中安装Docker、根据用户需求配置Docker客户端提供了简单的解决方案。驱动API对本地机器、数据中心的虚拟机或者公用云机器都适用。Docker Machine支持Windows、OSX和Linux,并且提供一个独立的二进制文件,可以直接使用。它让我们可以充分利用支持Docker的基础设施的生态环境合作伙伴,并且使用相同的接口进行访问。它让人们可以使用一个命令来简单而迅速地在不同的云平台部署Docker容器。
|
||||
|
||||
### 1. 安装Docker Machine ###
|
||||
|
||||
@ -25,14 +25,14 @@ Docker Machine可以很好地支持每一种Linux发行版。首先,我们需
|
||||
|
||||

|
||||
|
||||
另外机器上需要有docker命令,可以使用如下命令安装:
|
||||
要在我们的机器上启用docker命令,需要使用如下命令安装Docker客户端:
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建机器 ###
|
||||
|
||||
在自己的Linux机器上安装好了Docker Machine之后,我们想要将一个docker虚拟机部署到云服务器上。Docker Machine支持几个流行的云平台,如igital Ocean、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Computing等等,所以我们可以在不同的平台使用相同的接口来部署Docker。本文中我们会使用digitalocean驱动在Digital Ocean的服务器上部署Docker,--driver选项指定digitalocean驱动,--digitalocean-access-token选项指定[Digital Ocean Control Panel][1]提供的API Token,命令最后的是我们创建的Docker虚拟机的机器名。运行如下命令:
|
||||
在自己的Linux机器上安装好了Docker Machine之后,我们想要将一个docker虚拟机部署到云服务器上。Docker Machine支持几个流行的云平台,如igital Ocean、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Computing及其它等等,所以我们可以在不同的平台使用相同的接口来部署Docker。本文中我们会使用digitalocean驱动在Digital Ocean的服务器上部署Docker,--driver选项指定digitalocean驱动,--digitalocean-access-token选项指定[Digital Ocean Control Panel][1]提供的API Token,命令最后的是我们创建的Docker虚拟机的机器名。运行如下命令:
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
@ -40,7 +40,7 @@ Docker Machine可以很好地支持每一种Linux发行版。首先,我们需
|
||||
|
||||

|
||||
|
||||
**注意**: 这里linux-dev是我们将要创建的机器的名称。`<API-Token>`是一个安全key,可以在Digtal Ocean Control Panel生成。要找到这个key,我们只需要登录到我们的Digital Ocean Control Panel,然后点击API,再点击Generate New Token,填写一个名称,选上Read和Write。然后我们就会得到一串十六进制的key,那就是`<API-Token>`,简单地替换到上边的命令中即可。
|
||||
**注意**: 这里linux-dev是我们将要创建的机器的名称。`<API-Token>`是一个安全key,可以在Digtal Ocean Control Panel生成。要找到这个key,我们只需要登录到我们的Digital Ocean Control Panel,然后点击API,再点击 Generate New Token,填写一个名称,选上Read和Write。然后我们就会得到一串十六进制的key,那就是`<API-Token>`,简单地替换到上边的命令中即可。
|
||||
|
||||
运行如上命令后,我们可以在Digital Ocean Droplet Panel中看到一个具有默认配置的droplet已经被创建出来了。
|
||||
|
||||
@ -48,35 +48,35 @@ Docker Machine可以很好地支持每一种Linux发行版。首先,我们需
|
||||
|
||||
简便起见,docker-machine会使用默认配置来部署Droplet。我们可以通过增加选项来定制我们的Droplet。这里是一些digitalocean相关的选项,我们可以使用它们来覆盖Docker Machine所使用的默认配置。
|
||||
|
||||
--digitalocean-image "ubuntu-14-04-x64" 是选择Droplet的镜像
|
||||
--digitalocean-ipv6 enable 是启用IPv6网络支持
|
||||
--digitalocean-private-networking enable 是启用专用网络
|
||||
--digitalocean-region "nyc3" 是选择部署Droplet的区域
|
||||
--digitalocean-size "512mb" 是选择内存大小和部署的类型
|
||||
- --digitalocean-image "ubuntu-14-04-x64" 用于选择Droplet的镜像
|
||||
- --digitalocean-ipv6 enable 启用IPv6网络支持
|
||||
- --digitalocean-private-networking enable 启用专用网络
|
||||
- --digitalocean-region "nyc3" 选择部署Droplet的区域
|
||||
- --digitalocean-size "512mb" 选择内存大小和部署的类型
|
||||
|
||||
如果你想在其他云服务使用docker-machine,并且想覆盖默认的配置,可以运行如下命令来获取Docker Mackine默认支持的对每种平台适用的参数。
|
||||
|
||||
# docker-machine create -h
|
||||
|
||||
### 3. 选择活跃机器 ###
|
||||
### 3. 选择活跃主机 ###
|
||||
|
||||
部署Droplet后,我们想马上运行一个Docker容器,但在那之前,我们需要检查下活跃机器是否是我们需要的机器。可以运行如下命令查看。
|
||||
部署Droplet后,我们想马上运行一个Docker容器,但在那之前,我们需要检查下活跃主机是否是我们需要的机器。可以运行如下命令查看。
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
ACTIVE一列有“*”标记的是活跃机器。
|
||||
ACTIVE一列有“*”标记的是活跃主机。
|
||||
|
||||
现在,如果我们想将活跃机器切换到需要的机器,运行如下命令:
|
||||
现在,如果我们想将活跃主机切换到需要的主机,运行如下命令:
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
**注意**:这里,linux-dev是机器名,我们打算激活这个机器,并且在其中运行Docker容器。
|
||||
**注意**:这里,linux-dev是机器名,我们打算激活这个机器,并且在其上运行Docker容器。
|
||||
|
||||
### 4. 运行一个Docker容器 ###
|
||||
|
||||
现在,我们已经选择了活跃机器,就可以运行Docker容器了。可以测试一下,运行一个busybox容器来执行`echo hello word`命令,这样就可以得到输出:
|
||||
现在,我们已经选择了活跃主机,就可以运行Docker容器了。可以测试一下,运行一个busybox容器来执行`echo hello word`命令,这样就可以得到输出:
|
||||
|
||||
# docker run busybox echo hello world
|
||||
|
||||
@ -98,9 +98,9 @@ SSH到机器上之后,我们可以在上边运行任何Docker容器。这里
|
||||
|
||||
# exit
|
||||
|
||||
### 5. 删除机器 ###
|
||||
### 5. 删除主机 ###
|
||||
|
||||
删除在运行的机器以及它的所有镜像和容器,我们可以使用docker-machine rm命令:
|
||||
删除在运行的主机以及它的所有镜像和容器,我们可以使用docker-machine rm命令:
|
||||
|
||||
# docker-machine rm linux-dev
|
||||
|
||||
@ -112,15 +112,15 @@ SSH到机器上之后,我们可以在上边运行任何Docker容器。这里
|
||||
|
||||

|
||||
|
||||
### 6. 在不使用驱动的情况新增一个机器 ###
|
||||
### 6. 在不使用驱动的情况新增一个主机 ###
|
||||
|
||||
我们可以在不使用驱动的情况往Docker增加一台机器,只需要一个URL。它可以使用一个已有机器的别名,所以我们就不需要每次在运行docker命令时输入完整的URL了。
|
||||
我们可以在不使用驱动的情况往Docker增加一台主机,只需要一个URL。它可以使用一个已有机器的别名,所以我们就不需要每次在运行docker命令时输入完整的URL了。
|
||||
|
||||
$ docker-machine create --url=tcp://104.131.50.36:2376 custombox
|
||||
|
||||
### 7. 管理机器 ###
|
||||
### 7. 管理主机 ###
|
||||
|
||||
如果你已经让Docker运行起来了,可以使用简单的**docker-machine stop**命令来停止所有正在运行的机器,如果需要再启动的话可以运行**docker-machine start**:
|
||||
如果你已经让Docker运行起来了,可以使用简单的**docker-machine stop**命令来停止所有正在运行的主机,如果需要再启动的话可以运行**docker-machine start**:
|
||||
|
||||
# docker-machine stop
|
||||
# docker-machine start
|
||||
@ -140,7 +140,7 @@ via: http://linoxide.com/linux-how-to/use-docker-machine-cloud-provider/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,13 @@
|
||||
如何在Ubuntu/Debian/Linux Mint中编译和安装wxWidgets
|
||||
================================================================================
|
||||
|
||||
### wxWidgets ###
|
||||
|
||||
wxWidgets是一个程序开发框架/库, 允许你在Windows、Mac、Linux中使用相同的代码跨平台开发。
|
||||
|
||||
它主要用C++写成,但也可以与其他语言绑定比如Python、Perl、Ruby。
|
||||
wxWidgets是一个程序开发框架/库, 允许你在Windows、Mac、Linux中使用相同的代码跨平台开发。它主要用C++写成,但也可以与其他语言绑定比如Python、Perl、Ruby。
|
||||
|
||||
本教程中我将向你展示如何在基于Debian的linux中如Ubuntu和Linux Mint中编译wxwidgets 3.0+。
|
||||
|
||||
从源码编译wxWidgets并不困难,仅仅需要几分钟。
|
||||
|
||||
库可以按不同的方式来编译,比如静态或者动态库。
|
||||
从源码编译wxWidgets并不困难,仅仅需要几分钟。库可以按不同的方式来编译,比如静态或者动态库。
|
||||
|
||||
### 1. 下载 wxWidgets ###
|
||||
|
||||
@ -20,13 +17,13 @@ wxWidgets是一个程序开发框架/库, 允许你在Windows、Mac、Linux中
|
||||
|
||||
### 2. 设置编译环境 ###
|
||||
|
||||
要编译wxwidgets,我们需要一些工具包括C++编译器, 在Linux上是g++。所有这些可以通过apt-get工具从仓库中安装。
|
||||
要编译wxwidgets,我们需要一些工具包括C++编译器,在Linux上是g++。所有这些可以通过apt-get工具从仓库中安装。
|
||||
|
||||
我们还需要wxWidgets依赖的GTK开发库。
|
||||
|
||||
$ sudo apt-get install libgtk-3-dev build-essential checkinstall
|
||||
|
||||
>checkinstall工具允许我们为wxwidgets创建一个安装包,这样之后就可以轻松的使用包管理器来卸载。
|
||||
> 这个叫做checkinstall的工具允许我们为wxwidgets创建一个安装包,这样之后就可以轻松的使用包管理器来卸载。
|
||||
|
||||
### 3. 编译 wxWidgets ###
|
||||
|
||||
@ -42,7 +39,7 @@ wxWidgets是一个程序开发框架/库, 允许你在Windows、Mac、Linux中
|
||||
|
||||
"--disable-shared"选项将会编译静态库而不是动态库。
|
||||
|
||||
make命令完成后,编译也成功了。是时候安装wxWidgets到正确的目录。
|
||||
make命令完成后,编译就成功了。是时候安装wxWidgets到正确的目录。
|
||||
|
||||
更多信息请参考install.txt和readme.txt,这可在wxwidgets中的/docs/gtk/目录下找到。
|
||||
|
||||
@ -58,7 +55,7 @@ checkinstall会询问几个问题,请保证在提问后提供一个版本号
|
||||
|
||||
### 5. 追踪安装的文件 ###
|
||||
|
||||
如果你想要检查文件安装的位置,使用dpkg命令后面跟上checkinstall提供的报名。
|
||||
如果你想要检查文件安装的位置,使用dpkg命令后面跟上checkinstall提供的包名。
|
||||
|
||||
$ dpkg -L package_name
|
||||
/.
|
||||
@ -85,17 +82,17 @@ checkinstall会询问几个问题,请保证在提问后提供一个版本号
|
||||
$ cd samples/
|
||||
$ make
|
||||
|
||||
make命令完成后,进入sampl子目录,这里就有一个可以马上运行的Demo程序了。
|
||||
make命令完成后,进入sample 子目录,这里就有一个可以马上运行的Demo程序了。
|
||||
|
||||
### 7. 编译你的第一个程序 ###
|
||||
|
||||
你完成编译demo程序后,可以写你自己的程序来编译了。这个也很简单。
|
||||
|
||||
假设你用的是C++这样你可以使用编辑器的高亮特性。比如gedit、kate、kwrite等等。或者用全功能的IDE像Geany、Codelite、Codeblocks等等。
|
||||
假设你用的是C++,这样的话你还可以使用编辑器的高亮特性。比如gedit、kate、kwrite等等。或者用全功能的IDE像Geany、Codelite、Codeblocks等等。
|
||||
|
||||
然而你的第一个程序只需要用一个文本编辑器来快速完成。
|
||||
|
||||
这里就是
|
||||
如下:
|
||||
|
||||
#include <wx/wx.h>
|
||||
|
||||
@ -155,7 +152,7 @@ via: http://www.binarytides.com/install-wxwidgets-ubuntu/
|
||||
|
||||
作者:[Silver Moon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Shell脚本:使用rsync备份文件/目录
|
||||
================================================================================
|
||||
本文,我们带来了shell脚本,用来使用rsync命令将你本地Linux机器上的文件/目录备份到远程Linux服务器上。使用该脚本实施备份会是一个交互的方式,你需要提供远程备份服务器的主机名/ip地址和文件夹位置。我们保留了一个独立文件,在这个文件中你需要提供需要备份的文件/目录。我们添加了两个脚本,**第一个脚本**在每次拷贝完一个文件后询问密码(如果你启用了ssh验证密钥,那么就不会询问密码),而第二个脚本中,则只会提示一次输入密码。
|
||||
本文我们介绍一个shell脚本,用来使用rsync命令将你本地Linux机器上的文件/目录备份到远程Linux服务器上。使用该脚本会以交互的方式实施备份,你需要提供远程备份服务器的主机名/ip地址和文件夹位置。我们使用一个单独的列表文件,在这个文件中你需要列出要备份的文件/目录。我们添加了两个脚本,**第一个脚本**在每次拷贝完一个文件后询问密码(如果你启用了ssh密钥验证,那么就不会询问密码),而第二个脚本中,则只会提示一次输入密码。
|
||||
|
||||
我们打算备份bckup.txt,dataconfig.txt,docs和orcledb。
|
||||
|
||||
@ -12,7 +12,7 @@ Shell脚本:使用rsync备份文件/目录
|
||||
drwxr-xr-x. 2 root root 4096 May 15 10:45 docs
|
||||
drwxr-xr-x. 2 root root 4096 May 15 10:44 oracledb
|
||||
|
||||
该文件包含了备份文件/目录的详情
|
||||
bckup.txt文件包含了需要备份的文件/目录的详情
|
||||
|
||||
[root@Fedora21 tmp]# cat /tmp/bckup.txt
|
||||
/tmp/oracledb
|
||||
@ -24,46 +24,46 @@ Shell脚本:使用rsync备份文件/目录
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#We will save path to backup file in variable
|
||||
# 将备份列表文件的路径保存到变量中
|
||||
backupf='/tmp/bckup.txt'
|
||||
|
||||
#Next line just prints message
|
||||
# 输入一个提示信息
|
||||
echo "Shell Script Backup Your Files / Directories Using rsync"
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Server
|
||||
# 检查是否输入了目标服务器,如果为空就再次提示用户输入
|
||||
while [ x$desthost = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name desthost
|
||||
# 提示用户输入目标服务器地址并保存到变量
|
||||
read -p "Destination backup Server : " desthost
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Path
|
||||
# 检查是否输入了目标文件夹,如果为空就再次提示用户输入
|
||||
while [ x$destpath = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name destpath
|
||||
# 提示用户输入目标文件夹并保存到变量
|
||||
read -p "Destination Folder : " destpath
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#Next line will start reading backup file line by line
|
||||
# 逐行读取备份列表文件
|
||||
for line in `cat $backupf`
|
||||
|
||||
#and on each line will execute next
|
||||
# 对每一行都进行处理
|
||||
do
|
||||
|
||||
#print message that file/dir will be copied
|
||||
# 显示要被复制的文件/文件夹名称
|
||||
echo "Copying $line ... "
|
||||
#copy via rsync file/dir to destination
|
||||
# 通过 rsync 复制文件/文件夹到目标位置
|
||||
|
||||
rsync -ar "$line" "$desthost":"$destpath"
|
||||
|
||||
#this line just print done
|
||||
# 显示完成
|
||||
echo "DONE"
|
||||
|
||||
#end of reading backup file
|
||||
# 结束
|
||||
done
|
||||
|
||||
#### 运行带有输出结果的脚本 ####
|
||||
@ -91,64 +91,65 @@ Shell脚本:使用rsync备份文件/目录
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#We will save path to backup file in variable
|
||||
# 将备份列表文件的路径保存到变量中
|
||||
backupf='/tmp/bckup.txt'
|
||||
|
||||
#Next line just prints message
|
||||
# 输入一个提示信息
|
||||
echo "Shell Script Backup Your Files / Directories Using rsync"
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Server
|
||||
# 检查是否输入了目标服务器,如果为空就再次提示用户输入
|
||||
while [ x$desthost = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name desthost
|
||||
# 提示用户输入目标服务器地址并保存到变量
|
||||
read -p "Destination backup Server : " desthost
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter Destination Path
|
||||
# 检查是否输入了目标文件夹,如果为空就再次提示用户输入
|
||||
while [ x$destpath = "x" ]; do
|
||||
|
||||
#next line prints what userd should enter, and stores entered value to variable with name destpath
|
||||
# 提示用户输入目标文件夹并保存到变量
|
||||
read -p "Destination Folder : " destpath
|
||||
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#next line check if entered value is not null, and if null it will reask user to enter password
|
||||
# 检查是否输入了目标服务器密码,如果为空就再次提示用户输入
|
||||
while [ x$password = "x" ]; do
|
||||
#next line prints what userd should enter, and stores entered value to variable with name password. #To hide password we are using -s key
|
||||
# 提示用户输入密码并保存到变量
|
||||
# 使用 -s 选项不回显输入的密码
|
||||
read -sp "Password : " password
|
||||
#next line finishes while loop
|
||||
# 结束循环
|
||||
done
|
||||
|
||||
#Next line will start reading backup file line by line
|
||||
# 逐行读取备份列表文件
|
||||
for line in `cat $backupf`
|
||||
|
||||
#and on each line will execute next
|
||||
# 对每一行都进行处理
|
||||
do
|
||||
|
||||
#print message that file/dir will be copied
|
||||
# 显示要被复制的文件/文件夹名称
|
||||
echo "Copying $line ... "
|
||||
#we will use expect tool to enter password inside script
|
||||
# 使用 expect 来在脚本中输入密码
|
||||
/usr/bin/expect << EOD
|
||||
#next line set timeout to -1, recommended to use
|
||||
# 推荐设置超时为 -1
|
||||
set timeout -1
|
||||
#copy via rsync file/dir to destination, using part of expect — spawn command
|
||||
# 通过 rsync 复制文件/文件夹到目标位置,使用 expect 的组成部分 spawn 命令
|
||||
|
||||
spawn rsync -ar ${line} ${desthost}:${destpath}
|
||||
#as result of previous command we expect “password” promtp
|
||||
# 上一行命令会等待 “password” 提示
|
||||
expect "*?assword:*"
|
||||
#next command enters password from script
|
||||
# 在脚本中提供密码
|
||||
send "${password}\r"
|
||||
#next command tells that we expect end of file (everything finished on remote server)
|
||||
# 等待文件结束符(远程服务器处理完了所有事情)
|
||||
expect eof
|
||||
#end of expect pard
|
||||
# 结束 expect 脚本
|
||||
EOD
|
||||
#this line just print done
|
||||
# 显示结束
|
||||
echo "DONE"
|
||||
|
||||
#end of reading backup file
|
||||
# 完成
|
||||
done
|
||||
|
||||
#### 运行第二个带有输出结果的脚本的屏幕截图 ####
|
||||
@ -163,7 +164,7 @@ via: http://linoxide.com/linux-shell-script/shell-script-backup-files-directorie
|
||||
|
||||
作者:[Yevhen Duma][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Linux 有问必答--如何在桌面版 Ubuntu 中用命令行更改系统代理设置
|
||||
Linux 有问必答:如何在桌面版 Ubuntu 中用命令行更改系统代理设置
|
||||
================================================================================
|
||||
> **问题**: 我经常需要在桌面版 Ubuntu 中更改系统代理设置,但我不想通过繁琐的 GUI 菜单链:"系统设置" -> "网络" -> "网络代理"。在命令行中有更方便的方法更改桌面版的代理设置吗?
|
||||
> **问题**: 我经常需要在桌面版 Ubuntu 中更改系统代理设置,但我不想通过繁琐的 GUI 菜单点击:"系统设置" -> "网络" -> "网络代理"。在命令行中有更方便的方法更改桌面版的代理设置吗?
|
||||
|
||||
在桌面版 Ubuntu 中,它的桌面环境设置,包括系统代理设置,都存储在 DConf 数据库,这是简单的键值对存储。如果你想通过系统设置菜单修改桌面属性,更改会持久保存在后端的 DConf 数据库。在 Ubuntu 中更改 DConf 数据库有基于图像用户界面和非图形用户界面的两种方式。系统设置或者 dconf-editor 是访问 DConf 数据库的图形方法,而 gsettings 或 dconf 就是能更改数据库的命令行工具。
|
||||
在桌面版 Ubuntu 中,它的桌面环境设置,包括系统代理设置,都存储在 DConf 数据库,这是简单的键值对存储。如果你想通过系统设置菜单修改桌面属性,更改会持久保存在后端的 DConf 数据库。在 Ubuntu 中更改 DConf 数据库有基于图像用户界面和非图形用户界面的两种方式。系统设置或者 `dconf-editor` 是访问 DConf 数据库的图形方法,而 `gsettings` 或 `dconf` 就是能更改数据库的命令行工具。
|
||||
|
||||
下面介绍如何用 gsettings 从命令行更改系统代理设置。
|
||||
下面介绍如何用 `gsettings` 从命令行更改系统代理设置。
|
||||
|
||||
|
||||
|
||||
gsetting 读写特定 Dconf 设置的基本用法如下:
|
||||
`gsettings` 读写特定 Dconf 设置的基本用法如下:
|
||||
|
||||
更改 DConf 设置:
|
||||
|
||||
@ -53,7 +53,7 @@ gsetting 读写特定 Dconf 设置的基本用法如下:
|
||||
|
||||
### 在命令行中清除系统代理设置 ###
|
||||
|
||||
最后,清除所有 手动/自动 代理设置,还原为无代理设置:
|
||||
最后,清除所有“手动/自动”代理设置,还原为无代理设置:
|
||||
|
||||
$ gsettings set org.gnome.system.proxy mode 'none'
|
||||
|
||||
@ -63,7 +63,7 @@ via: http://ask.xmodulo.com/change-system-proxy-settings-command-line-ubuntu-des
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux ntopng——网络监控工具的安装(附截图)
|
||||
Linux 上网络监控工具 ntopng 的安装
|
||||
================================================================================
|
||||
当今世界,人们的计算机都相互连接,互联互通。小到你的家庭局域网(LAN),大到最大的一个被我们称为的——互联网。当你管理一台联网的计算机时,你就是在管理最关键的组件之一。由于大多数开发出的应用程序都基于网络,网络就连接起了这些关键点。
|
||||
当今世界,人们的计算机都相互连接,互联互通。小到你的家庭局域网(LAN),大到最大的一个被我们称为互联网。当你管理一台联网的计算机时,你就是在管理最关键的组件之一。由于大多数开发出的应用程序都基于网络,网络就连接起了这些关键点。
|
||||
|
||||
这就是为什么我们需要网络监控工具。最好的网络监控工具之一,它叫作ntop。来自[维基百科][1]的知识“ntop是一个网络探测器,它以与top显示进程般类似的方式显示网络使用率。在交互模式中,它显示了用户终端上的网络状态。在网页模式中,它作为网络服务器,创建网络状态的HTML转储文件。它支持NetFlow/sFlowemitter/collector,这是一个基于HTTP的客户端界面,用于创建ntop为中心的监控应用和RRD用于持续地存储通信数据”
|
||||
这就是为什么我们需要网络监控工具。ntop 是最好的网络监控工具之一。来自[维基百科][1]的知识“ntop是一个网络探测器,它以与top显示进程般类似的方式显示网络使用率。在交互模式中,它显示了用户终端上的网络状态。在网页模式中,它作为网络服务器,创建网络状态的HTML转储文件。它支持NetFlow/sFlowemitter/collector,这是一个基于HTTP的客户端界面,用于创建ntop为中心的监控应用,并使用RRD来持续存储通信数据”。
|
||||
|
||||
15年后的今天,你将见到ntopng——下一代ntop。
|
||||
|
||||
@ -15,7 +15,7 @@ Ntopng是一个基于网页的高速通信分析器和流量收集器。Ntopng
|
||||
从[ntopng网站][2]上,我们可以看到他们说它有众多的特性。这里列出了其中一些:
|
||||
|
||||
- 按各种协议对网络通信排序
|
||||
- 显示网络通信和IPv4/v6激活的主机
|
||||
- 显示网络通信和IPv4/v6的激活主机
|
||||
- 持续不断以RRD格式存储定位主机的通信数据到磁盘
|
||||
- 通过nDPI,ntop的DPI框架,发现应用协议
|
||||
- 显示各种协议间的IP通信分布
|
||||
@ -24,11 +24,9 @@ Ntopng是一个基于网页的高速通信分析器和流量收集器。Ntopng
|
||||
- 报告按协议类型排序的IP协议使用率
|
||||
- 生成HTML5/AJAX网络通信数据
|
||||
|
||||
### 安装 ###
|
||||
### 安装的先决条件 ###
|
||||
|
||||
Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的下载页面][3]找到这些包。对于32位操作系统,你必须从源代码编译。本文在**CentOS 6.4 32位**版本上**测试过**。但是,它也可以在其它基于CentOS/RedHat的Linux版本上工作。让我们开始吧。
|
||||
|
||||
#### 先决条件 ####
|
||||
Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[它们的下载页面][3]找到这些包。对于32位操作系统,你必须从源代码编译。本文在**CentOS 6.4 32位**版本上**测试过**。但是,它也可以在其它基于CentOS/RedHat的Linux版本上工作。让我们开始吧。
|
||||
|
||||
#### 开发工具 ####
|
||||
|
||||
@ -78,7 +76,7 @@ Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的
|
||||
# make
|
||||
# make install
|
||||
|
||||
*由于ntopng是一个基于网页的应用,你的系统必须安装有工作良好的网络服务器*
|
||||
*由于ntopng是一个基于网页的应用,你的系统必须安装有工作良好的 Web 服务器*
|
||||
|
||||
### 为ntopng创建配置文件 ###
|
||||
|
||||
@ -89,13 +87,16 @@ Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的
|
||||
# cd ntopng
|
||||
# vi ntopng.start
|
||||
|
||||
放入这些行:
|
||||
--local-network “10.0.2.0/24”
|
||||
放入这些行:
|
||||
|
||||
--local-network "10.0.2.0/24"
|
||||
--interface 1
|
||||
|
||||
---
|
||||
# vi ntopng.pid
|
||||
|
||||
放入该行:
|
||||
放入该行:
|
||||
|
||||
-G=/var/run/ntopng.pid
|
||||
|
||||
保存这些文件,然后继续下一步。
|
||||
@ -128,7 +129,7 @@ Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的
|
||||
|
||||

|
||||
|
||||
在**主机菜单**上,你可以看到连接到流的所有主机
|
||||
在**主机菜单**上,你可以看到连接到流的所有主机。
|
||||
|
||||

|
||||
|
||||
@ -146,8 +147,7 @@ Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的
|
||||
|
||||

|
||||
|
||||
**界面菜单**将引领你进入更多内部菜单。
|
||||
包菜单将给你显示包的分布大小。
|
||||
**界面菜单**将引领你进入更多内部菜单。包菜单将给你显示包的大小分布。
|
||||
|
||||

|
||||
|
||||
@ -157,7 +157,7 @@ Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的
|
||||
|
||||

|
||||
|
||||
你也可以通过使用**历史活跃度菜单**查看活跃度
|
||||
你也可以通过使用**历史活跃度菜单**查看活跃度。
|
||||
|
||||

|
||||
|
||||
@ -167,7 +167,7 @@ Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的
|
||||
|
||||

|
||||
|
||||
Ntopng为你提供了一个范围宽广的时间线,从5分钟到1年都可以。你只需要点击你想要现实的时间线。图标本身是可以点击的,你可以点击它来进行缩放。
|
||||
Ntopng为你提供了一个范围宽广的时间线,从5分钟到1年都可以。你只需要点击你想要显示的时间线。图表本身是可以点击的,你可以点击它来进行缩放。
|
||||
|
||||
当然,ntopng能做的事比上面图片中展示的还要多得多。你也可以将定位和电子地图服务整合进来。在ntopng自己的网站上,有已付费的模块可供使用,如nprobe可以扩展ntopng可以提供给你的信息。更多关于ntopng的信息,你可以访问[ntopng网站][5]。
|
||||
|
||||
@ -177,7 +177,7 @@ via: http://linoxide.com/monitoring-2/ntopng-network-monitoring-tool/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
102
published/20150527 3 Open Source Python Shells.md
Normal file
102
published/20150527 3 Open Source Python Shells.md
Normal file
@ -0,0 +1,102 @@
|
||||
3个开源的Python Shell
|
||||
=========================================================================
|
||||
|
||||
Python是一个高级、通用、结构化且强大的开源编程语言,广泛用于各种编程工作。它拥有一个全动态类型系统和自动内存管理,与Scheme,Ruby,Perl和Tcl的十分相似,避免编译型语言的许多复杂地方和难以理解。Python于1991年由Guido van Rossum创造,然后逐渐成长,流行。
|
||||
|
||||
Python是一个非常实用,而且流行的计算机编程语言。使用一个如Python这样的解释型语言的好处之一就是,可以借助其交互的shell探索式地编程。你可以试着代码,而不必专门写一个脚本。但是Python shell也有一些局限性。基本来说,有许多很漂亮的Python shell可选择,都是在基础shell上扩展的。他们每一个都提供了一个极好的交互性的Python 体验。
|
||||
|
||||
### bpython ###
|
||||
|
||||

|
||||
|
||||
对于Linux,BSD,OS X和Windows来说,bpython是一个不错的Python解释器的界面。
|
||||
|
||||
其想法是提供给用户所有的内置功能,很像现在的IDE(集成开发环境),但是是在一个简单,轻量级的包里,可以在终端窗口里面运行。
|
||||
|
||||
bpython并不追求创造任何新的或者开创性的东西。相反,它聚集了一些简洁的理念,关注于实用性和操作性。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 内置的语法高亮 - 使用Pygments排版你敲出的代码,并合理配色
|
||||
- 根据你的行为,显示自动补全的建议
|
||||
- 为任何Python函数列出所期望的参数 - 可以显示你调用的任何函数的参数列表
|
||||
- “Rewind”功能会调出内存里的最后一行代码并重新执行
|
||||
- 可以将你输入的代码送到pastebin
|
||||
- 可以将你输入的代码保存到一个文件
|
||||
- 自动缩进
|
||||
- 支持Python 3
|
||||
|
||||
---
|
||||
|
||||
- 网址: [www.bpython-interpreter.org][1]
|
||||
- 开发者: Bob Farrell and contributors
|
||||
- 证书: MIT License
|
||||
- 版本号: 0.14.1
|
||||
|
||||
### IPython ###
|
||||
|
||||

|
||||
|
||||
IPython是Python shell的一个交互加强版。她提供了一个丰富的工具集合,帮助你交互式地充分利用Python。
|
||||
|
||||
IPython可以用来取代标准的Python shell,也可以与标准Python科学和数值处理工具配合,用做一个科学计算(如Matlab或者Mathematical)的完整工作环境。她支持动态对象内省,有限的输入/输出提示,一个宏系统,会话日志,会话恢复,访问完整的系统外壳,详尽且彩色的追踪报告,自动圆括号补全,自动引号补全和可嵌入其他Python程序。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 强大的交互Shell(基于终端或者Qt)
|
||||
- 一个基于浏览器的记事本,支持代码,富文本,数学表达式,内置图表和其他富媒介。
|
||||
- 支持交互式的数据可视化和使用GUI工具箱
|
||||
- 灵活,嵌入式的解释器可以加载进你自己的项目里
|
||||
- 易于使用,高效的并行运算工具
|
||||
|
||||
---
|
||||
|
||||
- 网址: [ipython.org][2]
|
||||
- 开发者: The IPython Development Team
|
||||
- 证书: BSD
|
||||
- 版本号: 3.1
|
||||
|
||||
### DreamPie ###
|
||||
|
||||

|
||||
|
||||
DreamPie是一个为可靠性和趣味性设计的Python shell。
|
||||
|
||||
DreamPie可以用于任何Python解释器(Jython,IronPython,PyPy)。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 一个新式的交互shell:窗口被分成历史区域和代码区域,历史区域可以让你看到之前的命令及其输出,代码区域是里敲代码的地方。这样,你可以编辑任意多的代码,就好像在你最喜欢的编辑器里一样,并且适当时候可以执行它。你也可以从其他地方复制代码,编辑并马上运行它
|
||||
- “只复制代码”命令可以复制你想要的代码,以便你可以把它存入一个文件。代码已经用四个空格缩进进行格式化
|
||||
- 自动补全属性和文件名字
|
||||
- 自动显示函数参数和文档
|
||||
- 在结果历史中保存你最近的结果,备以后用
|
||||
- 可以自动折叠很长的输出,以便你可以专注于重要的地方
|
||||
- 保存会话的历史记录为一个HTML文件,备以后查询。你可以加载历史文件到DreamPie里,并且快速重复之前的命令。
|
||||
- 自动添加圆括号与可选的引号,当你在函数与方法后按下空格键。例如,键入execfile后按下空格会提示execfile("fn")
|
||||
- 支持交互的matplotlib绘图
|
||||
- 支持Python 2.5,Python 2.6,Python 3.1,Jython 2.5,IronPython 2.6和PyPy
|
||||
- 难以置信的快速反应
|
||||
|
||||
---
|
||||
|
||||
- 网址: [www.dreampie.org][3]
|
||||
- 开发者: Noam Yorav-Raphael
|
||||
- 证书: GNU GPL v3
|
||||
- 版本号: 1.2.1
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150523032756576/PythonShells.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.bpython-interpreter.org/
|
||||
[2]:http://ipython.org/
|
||||
[3]:http://www.dreampie.org/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
笔记本过热是最近一个常见的问题。监控硬件温度或许可以帮助你诊断笔记本为什么会过热。本篇中,我们会**了解如何在Ubuntu中检查CPU的温度**。
|
||||
夏天到了,笔记本过热是最近一个常见的问题。监控硬件温度或许可以帮助你诊断笔记本为什么会过热。本篇中,我们会**了解如何在Ubuntu中检查CPU的温度**。
|
||||
|
||||
我们将使用一个GUI工具[Psensor][1],它允许你在Linux中监控硬件温度。用Psensor你可以:
|
||||
我们将使用一个GUI工具[Psensor][1],它允许你在Linux中监控硬件温度。用Psensor你可以:
|
||||
|
||||
- 监控cpu和主板的温度
|
||||
- 监控NVidia GPU的文档
|
||||
@ -17,7 +17,7 @@ Psensor最新的版本同样提供了Ubuntu中的指示小程序,这样使得
|
||||
|
||||
### 如何在Ubuntu 15.04 和 14.04中安装Psensor ###
|
||||
|
||||
在安装Psensor前,你需要安装和配置[lm-sensors][2],一个用于硬件监控的命令行工具。如果你想要测量磁盘温度,你还需要安装[hddtemp][3]。要安装这些工具,运行下面的这些命令:
|
||||
在安装Psensor前,你需要安装和配置[lm-sensors][2],这是一个用于硬件监控的命令行工具。如果你想要测量磁盘温度,你还需要安装[hddtemp][3]。要安装这些工具,运行下面的这些命令:
|
||||
|
||||
sudo apt-get install lm-sensors hddtemp
|
||||
|
||||
@ -45,7 +45,7 @@ Psensor最新的版本同样提供了Ubuntu中的指示小程序,这样使得
|
||||
|
||||
sudo apt-get install psensor
|
||||
|
||||
安装完成后,在Unity Dash中运行程序。第一次运行时,你应该配置Psensor该监控什么状态。
|
||||
安装完成后,在Unity Dash中运行程序。第一次运行时,你应该配置Psensor该监控什么状态。
|
||||
|
||||

|
||||
|
||||
@ -73,7 +73,7 @@ via: http://itsfoss.com/check-laptop-cpu-temperature-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
Linux有问必答 -- 如何在Linux中挂载LVM分区
|
||||
Linux有问必答:如何在Linux中直接挂载LVM分区
|
||||
================================================================================
|
||||
> **提问**: 我有一个USB盘包含了LVM分区。 我想要在Linux中访问这些LVM分区。我该如何在Linux中挂载LVM分区?
|
||||
|
||||
】LVM是逻辑卷管理工具,它允许你使用逻辑卷和卷组的概念来管理磁盘空间。使用LVM相比传统分区最大的好处是弹性地位用户和程序分配空间而不用考虑每个物理磁盘的大小。
|
||||
LVM是逻辑卷管理工具,它允许你使用逻辑卷和卷组的概念来管理磁盘空间。使用LVM相比传统分区最大的好处是弹性地为用户和程序分配空间而不用考虑每个物理磁盘的大小。
|
||||
|
||||
在LVM中,那些创建了逻辑分区的物理存储是传统的分区(比如:/dev/sda2,/dev/sdb1)。这些分区必须被初始化位“物理卷”并被标签(如,“Linux LVM”)来使它们可以在LVM中使用。一旦分区被标记被LVM分区,你不能直接用mount命令挂载。
|
||||
在LVM中,那些创建了逻辑分区的物理存储是传统的分区(比如:/dev/sda2,/dev/sdb1)。这些分区必须被初始化为“物理卷 PV”并加上卷标(如,“Linux LVM”)来使它们可以在LVM中使用。一旦分区被标记被LVM分区,你不能直接用mount命令挂载。
|
||||
|
||||
如果你尝试挂载一个LVM分区(比如/dev/sdb2), 你会得到下面的错误。
|
||||
|
||||
@ -16,9 +16,9 @@ Linux有问必答 -- 如何在Linux中挂载LVM分区
|
||||
|
||||
|
||||
|
||||
要正确地挂载LVM分区,你必须挂载分区创建的“逻辑分区”。下面就是如何做的。
|
||||
要正确地挂载LVM分区,你必须挂载分区中创建的“逻辑卷”。下面就是如何做的。
|
||||
|
||||
=首先,用下面的命令检查可用的卷组:
|
||||
首先,用下面的命令检查可用的卷组:
|
||||
|
||||
$ sudo pvs
|
||||
|
||||
@ -60,7 +60,9 @@ Linux有问必答 -- 如何在Linux中挂载LVM分区
|
||||
|
||||
|
||||
|
||||
如果你想要挂载一个特定的逻辑卷,使用“LV Path”下面的设备名(如:/dev/vg_ezsetupsystem40a8f02fadd0/lv_home)。
|
||||
*上图可以看到两个逻辑卷的名字:lv_root和lv_home*
|
||||
|
||||
如果你想要挂载一个特定的逻辑卷,使用如下的“LV Path”的设备名(如:/dev/vg_ezsetupsystem40a8f02fadd0/lv_home)。
|
||||
|
||||
$ sudo mount /dev/vg_ezsetupsystem40a8f02fadd0/lv_home /mnt
|
||||
|
||||
@ -82,7 +84,7 @@ via: http://ask.xmodulo.com/mount-lvm-partition-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
11个让人惊叹的Linux终端彩蛋
|
||||
11个无用而有趣的Linux终端彩蛋
|
||||
================================================================================
|
||||
这里有一些很酷的Linux终端彩蛋,其中的每一个看上去并没有实际用途,但很精彩。
|
||||
这里有一些很酷的Linux终端彩蛋,其中的每一个看上去并没有实际用途,但很有趣。
|
||||
|
||||

|
||||
|
||||
@ -8,7 +8,7 @@
|
||||
|
||||
当我们使用命令行工作时,Linux是功能和实用性最好的操作系统之一。想要执行一个特殊任务?可能一个程序或者脚本就可以帮你搞定。但就像一本书中说到的,只工作不玩耍聪明的孩子也会变傻。下边是我最喜欢的可以在终端做的没有实际用途的、傻傻的、恼人的、可笑的事情。
|
||||
|
||||
### 给终端一个态度 ###
|
||||
### 让终端成为一个有态度的人 ###
|
||||
|
||||
* 第一步)敲入`sudo visudo`
|
||||
* 第二步)在“Defaults”末尾(文件的前半部分)添加一行“Defaults insults”。
|
||||
@ -20,13 +20,13 @@
|
||||
|
||||
### apt-get moo ###
|
||||
|
||||
你看过这张截图?那就是运行`apt-get moo`(在基于Debian的系统)的结果。对,就是它了。不要对它抱太多幻想,你会失望的,我不骗你。但是这是Linux世界最被人熟知的彩蛋之一。所以我把它包含进来,并且放在前排,然后我也就不会收到5千封邮件,指责我把它遗漏了。
|
||||
|
||||
|
||||
|
||||
你看过这张截图?那就是运行`apt-get moo`(在基于Debian的系统)的结果。对,就是它了。不要对它抱太多幻想,你会失望的,我不骗你。但是这是Linux世界最被人熟知的彩蛋之一。所以我把它包含进来,并且放在前排,然后我也就不会收到5千封邮件,指责我把它遗漏了。
|
||||
|
||||
### aptitude moo ###
|
||||
|
||||
更有趣的是将moo应用到aptitude上。敲入`aptitude moo`(在Ubuntu及其衍生版),你对`moo`可以做什么事情的看法会有所变化。你还还会知道更多事情,尝试重新输入这条命令,但这次添加一个`-v`参数。这还没有结束,试着添加更多`v`,一次添加一个,直到aptitude给了你想要的东西。
|
||||
更有趣的是将moo应用到aptitude上。敲入`aptitude moo`(在Ubuntu及其衍生版),你对`moo`可以做什么事情的看法会有所变化。你还还会知道更多事情,尝试重新输入这条命令,但这次添加一个`-v`参数。这还没有结束,试着添加更多`v`,一次添加一个,直到抓狂的aptitude给了你想要的东西。
|
||||
|
||||
|
||||
|
||||
@ -38,25 +38,25 @@
|
||||
* 第二步)在“# Misc options”部分,去掉“Color”前的“#”。
|
||||
* 第三步)添加“ILoveCandy”。
|
||||
|
||||
现在我们使用pacman安装新软件包时,进度条里会出现一个小吃豆人。真应该默认就是这样的。
|
||||
现在我们使用pacman安装新软件包时,进度条里会出现一个小吃豆人。真应该默认就这样的。
|
||||
|
||||
|
||||
|
||||
### Cowsay! ###
|
||||
|
||||
`aptitude moo`的输出格式很漂亮,但我想你苦于不能自由自在地使用。输入`cowsay`,它会做到你想做的事情。你可以让牛说任何你喜欢的东西。而且不只可以用牛,还可以用Calvin、Beavis和Ghostbusters的ASCII logo——输入`cowsay -l`可以得到所有可用的logo。它是Linux世界的强大工具。像很多其他命令一样,你可以使用管道把其他程序的输出输送给它,比如`fortune | cowsay`。
|
||||
`aptitude moo`的输出格式很漂亮,但我想你苦于不能自由自在地使用。输入`cowsay`,它会做到你想做的事情。你可以让牛说任何你喜欢的东西。而且不只可以用牛,还可以用Calvin、Beavis和Ghostbusters logo的ASCII的艺术,输入`cowsay -l`可以得到所有可用的参数。它是Linux世界的强大工具。像很多其他命令一样,你可以使用管道把其他程序的输出输送给它,比如`fortune | cowsay`,让这头牛变成哲学家。
|
||||
|
||||
|
||||
|
||||
### 变成3l33t h@x0r ###
|
||||
|
||||
`nmap`并不是我们平时经常使用的基本命令。但如果你想蹂躏`nmap`的话,可能想在它的输出中看到l33t。在任何`nmap`命令(比如`nmap -oS - google.com`)后添加`-oS`。现在你的`nmap`已经处于官方名称是“[Script Kiddie Mode][1]”的模式了。Angelina Jolie和Keanu Reeves会为此骄傲的。
|
||||
`nmap`并不是我们平时经常使用的基本命令。但如果你想蹂躏`nmap`的话,比如像人一样看起来像l33t。在任何`nmap`命令后添加`-oS`(比如`nmap -oS - google.com`)。现在你的`nmap`已经处于标准叫法是“[脚本玩具模式][1]”的模式了。Angelina Jolie和Keanu Reeves会为此骄傲的。
|
||||
|
||||
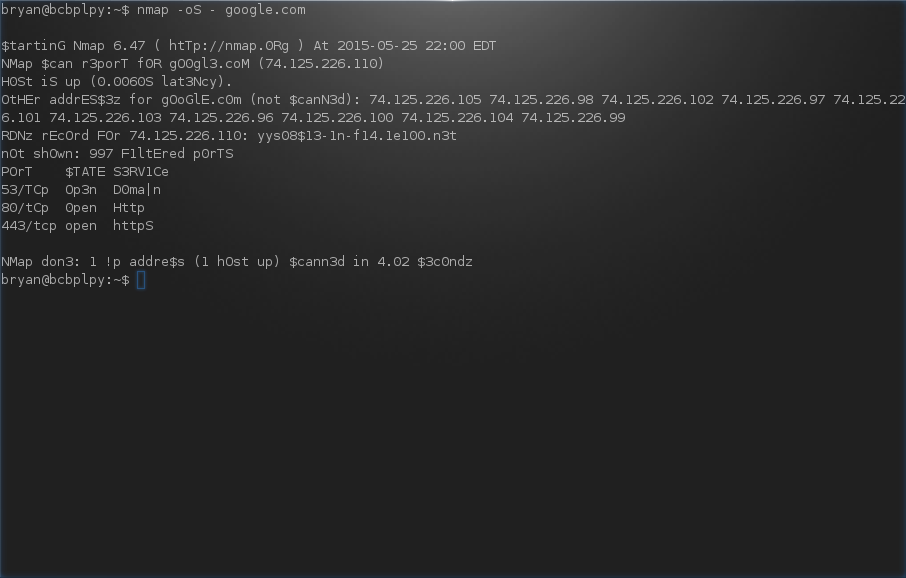
|
||||
|
||||
### 获得所有的Discordian日期 ###
|
||||
|
||||
如果你们曾经坐在一起思考,“嗨!我想使用无用但异想天开的方式来书写今天的日期……”试试运行`ddate`。结果类似于“Today is Setting Orange, the 72nd day of Discord in the YOLD 3181”,这会让你的服务树日志平添不少香料。
|
||||
如果你们曾经坐在一起思考,“嗨!我想使用无用但异想天开的方式来书写今天的日期……”试试运行`ddate`。结果类似于“Today is Setting Orange, the 72nd day of Discord in the YOLD 3181”,这会让你的服务树日志平添不少趣味。
|
||||
|
||||
注意:在技术层面,确实有一个[Discordian Calendar][2],理论上被[Discordianism][3]追随者所使用。这意味着我可能得罪某些人。或者不会,我不确定。不管怎样,`ddate`是一个方便的工具。
|
||||
|
||||
@ -76,7 +76,7 @@
|
||||
|
||||
### 将任何文本逆序输出 ###
|
||||
|
||||
将任何文本使用管道输送给`rev`命令,它就会将文本内容逆序输出。`fortune | rev`会给你好运。当然,这不意味着rev会将幸运转换成不幸。
|
||||
将任何文本使用管道输送给`rev`命令,它就会将文本内容逆序输出。`fortune | rev`会给你好运。当然,这不意味着rev会将幸运(fortune)转换成不幸。
|
||||
|
||||
|
||||
|
||||
@ -94,7 +94,7 @@ via: http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,287 @@
|
||||
27 个 Linux 下软件包管理工具 DNF 命令例子
|
||||
================================================================================
|
||||
DNF即Dandified YUM,是基于RPM的Linux发行版的下一代软件包管理工具。它首先在Fedora 18中出现,并且在最近发行的Fedora 22中替代了[YUM工具集][1]。
|
||||
|
||||

|
||||
|
||||
DNF致力于改善YUM的瓶颈,即性能、内存占用、依赖解决、速度和许多其他方面。DNF使用RPM、libsolv和hawkey库进行包管理。尽管它并未预装在CentOS和RHEL 7中,但您可以通过yum安装,并同时使用二者。
|
||||
|
||||
您也许想阅读更多关于DNF的信息:
|
||||
|
||||
- [使用DNF取代Yum背后的原因][2]
|
||||
|
||||
最新的DNF稳定版本是2015年5月11日发布的1.0(在写这篇文章之前)。它(以及所有DNF之前版本)主要由Python编写,并以GPL v2许可证发布。
|
||||
|
||||
### 安装DNF ###
|
||||
|
||||
尽管Fedora 22官方已经过渡到了DNF,但DNF并不在RHEL/CentOS 7的默认仓库中。
|
||||
|
||||
为了在RHEL/CentOS系统中安装DNF,您需要首先安装和开启epel-release仓库。
|
||||
|
||||
# yum install epel-release
|
||||
或
|
||||
# yum install epel-release -y
|
||||
|
||||
尽管并不建议在使用yum时添上'-y'选项,因为最好还是看看什么将安装在您的系统中。但如果您对此并不在意,则您可以使用'-y'选项以自动化的安装而无需用户干预。
|
||||
|
||||
接下来,使用yum命令从epel-realease仓库安装DNF包。
|
||||
|
||||
# yum install dnf
|
||||
|
||||
在您装完dnf后,我会向您展示27个实用的dnf命令和例子,以便帮您更容易和高效的管理基于RPM包的发行版。
|
||||
|
||||
### 1. 检查DNF版本 ###
|
||||
|
||||
检查您的系统上安装的DNF版本。
|
||||
|
||||
# dnf --version
|
||||
|
||||
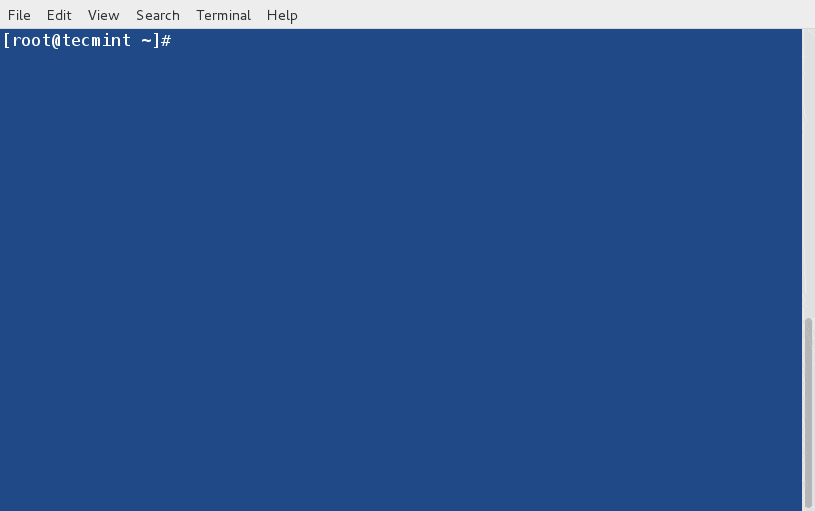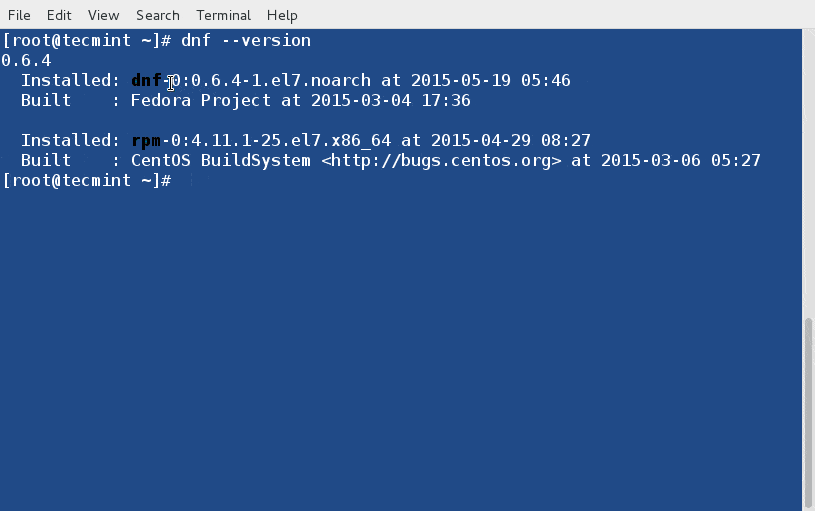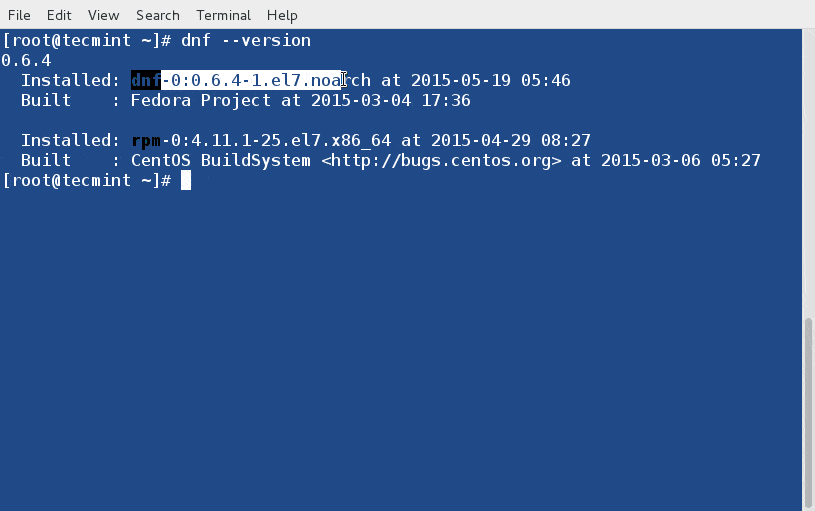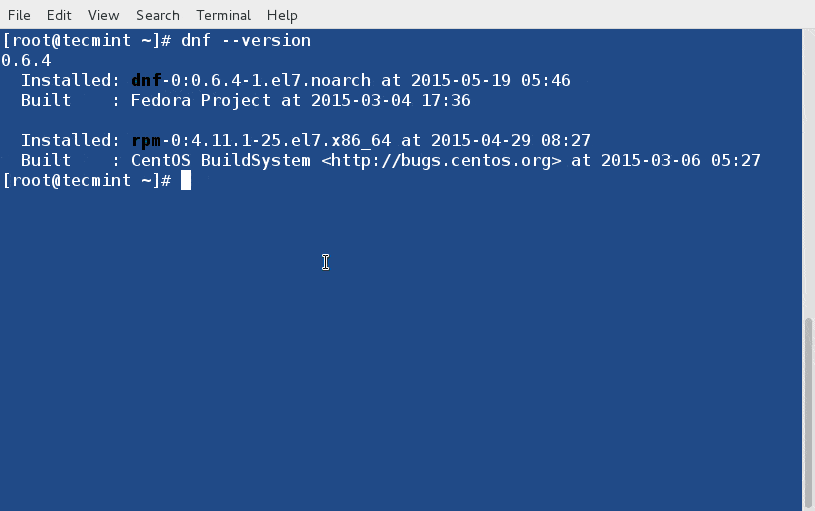
|
||||
|
||||
### 2. 列出启用的DNF仓库 ###
|
||||
|
||||
dnf命令中的'repolist'选项将显示您系统中所有启用的仓库。
|
||||
|
||||
# dnf repolist
|
||||
|
||||

|
||||
|
||||
### 3. 列出所有启用和禁用的DNF仓库 ###
|
||||
|
||||
'repolist all'选项将显示您系统中所有启用/禁用的仓库。
|
||||
|
||||
# dnf repolist all
|
||||
|
||||
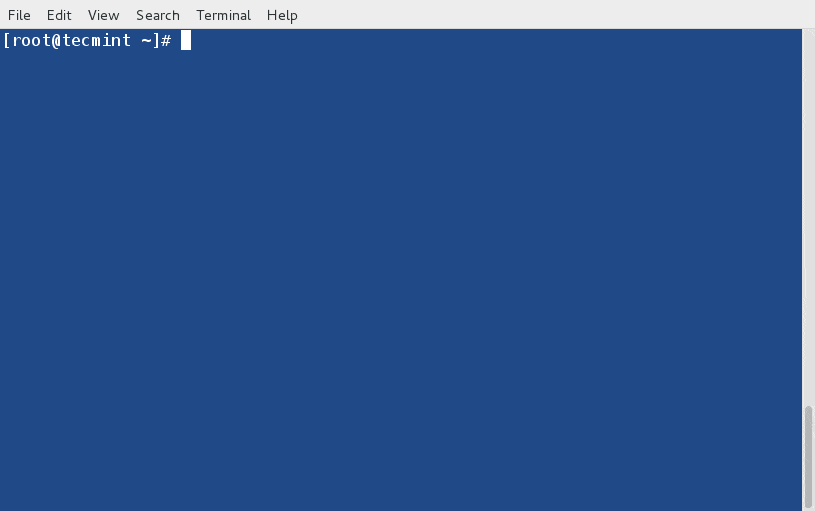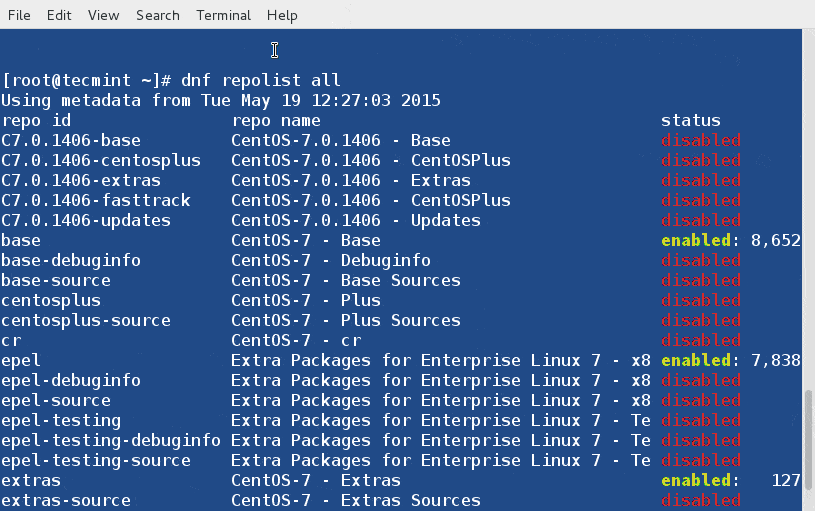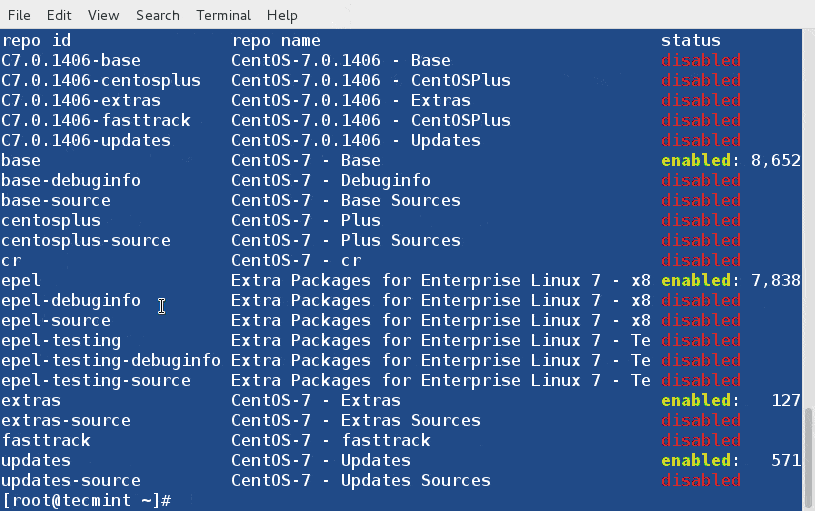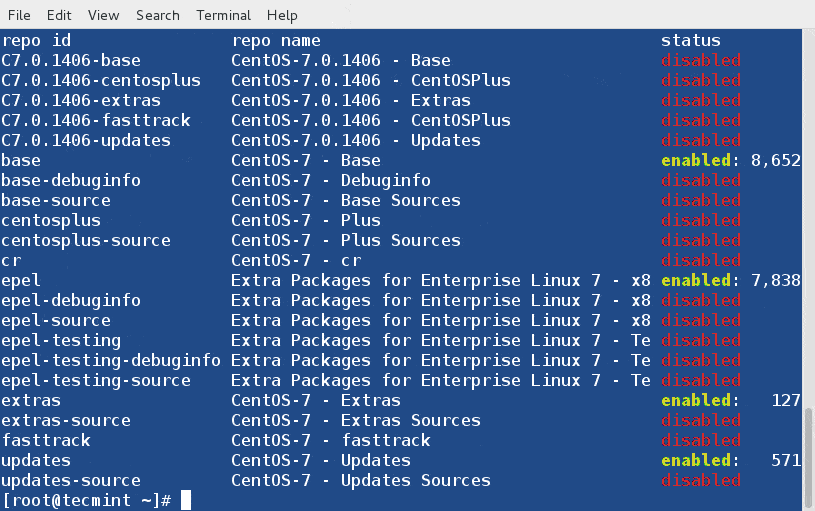
|
||||
|
||||
### 4. 用DNF列出所有可用的且已安装的软件包 ###
|
||||
|
||||
'dnf list'命令将列出所有仓库中所有可用的软件包和您Linux系统中已安装的软件包。
|
||||
|
||||
# dnf list
|
||||
|
||||

|
||||
|
||||
### 5. 用DNF列出所有已安装的软件包 ###
|
||||
|
||||
尽管'dnf list'命令将列出所有仓库中所有可用的软件包和已安装的软件包。然而像下面一样使用'list installed'选项将只列出已安装的软件包。
|
||||
|
||||
# dnf list installed
|
||||
|
||||

|
||||
|
||||
### 6. 用DNF列出所有可用的软件包 ###
|
||||
|
||||
类似的,可以用'list available'选项列出所有开启的仓库中所有可用的软件包。
|
||||
|
||||
# dnf list available
|
||||
|
||||
|
||||
|
||||
### 7. 使用DNF查找软件包 ###
|
||||
|
||||
如果您不太清楚您想安装的软件包的名字,这种情况下,您可以使用'search'选项来搜索匹配该字符(例如,nano)和字符串的软件包。
|
||||
|
||||
# dnf search nano
|
||||
|
||||

|
||||
|
||||
### 8. 查看哪个软件包提供了某个文件/子软件包? ###
|
||||
|
||||
dnf的选项'provides'能查找提供了某个文件/子软件包的软件包名。例如,如果您想找找哪个软件包提供了您系统中的'/bin/bash'文件,可以使用下面的命令
|
||||
|
||||
# dnf provides /bin/bash
|
||||
|
||||
|
||||
|
||||
### 9. 使用DNF获得一个软件包的详细信息 ###
|
||||
|
||||
如果您想在安装一个软件包前知道它的详细信息,您可以使用'info'来获得一个软件包的详细信息,例如:
|
||||
|
||||
# dnf info nano
|
||||
|
||||
|
||||
|
||||
### 10. 使用DNF安装软件包 ###
|
||||
|
||||
想安装一个叫nano的软件包,只需运行下面的命令,它会为nano自动的解决和安装所有的依赖。
|
||||
|
||||
# dnf install nano
|
||||
|
||||

|
||||
|
||||
### 11. 使用DNF更新一个软件包 ###
|
||||
|
||||
您可能只想更新一个特定的包(例如,systemd)并且保留系统内剩余软件包不变。
|
||||
|
||||
# dnf update systemd
|
||||
|
||||

|
||||
|
||||
### 12. 使用DNF检查系统更新 ###
|
||||
|
||||
检查系统中安装的所有软件包的更新可以简单的使用如下命令:
|
||||
|
||||
# dnf check-update
|
||||
|
||||
|
||||
|
||||
### 13. 使用DNF更新系统中所有的软件包 ###
|
||||
|
||||
您可以使用下面的命令来更新整个系统中所有已安装的软件包。
|
||||
|
||||
# dnf update
|
||||
或
|
||||
# dnf upgrade
|
||||
|
||||

|
||||
|
||||
### 14. 使用DNF来移除/删除一个软件包 ###
|
||||
|
||||
您可以在dnf命令中使用'remove'或'erase'选项来移除任何不想要的软件包。
|
||||
|
||||
# dnf remove nano
|
||||
或
|
||||
# dnf erase nano
|
||||
|
||||
|
||||
|
||||
### 15. 使用DNF移除于依赖无用的软件包(Orphan Packages) ###
|
||||
|
||||
这些为了满足依赖安装的软件包在相应的程序删除后便不再需要了。可以用过下面的命令来将它们删除。
|
||||
|
||||
# dnf autoremove
|
||||
|
||||

|
||||
|
||||
### 16. 使用DNF移除缓存的软件包 ###
|
||||
|
||||
我们在使用dnf时经常会碰到过期的头部信息和不完整的事务,它们会导致错误。我们可以使用下面的语句清理缓存的软件包和包含远程包信息的头部信息。
|
||||
|
||||
# dnf clean all
|
||||
|
||||
|
||||
|
||||
### 17. 获得特定DNF命令的帮助 ###
|
||||
|
||||
您可能需要特定的DNF命令的帮助(例如,clean),可以通过下面的命令来得到:
|
||||
|
||||
# dnf help clean
|
||||
|
||||
|
||||
|
||||
### 18. 列出所有DNF的命令和选项 ###
|
||||
|
||||
要显示所有dnf的命令和选项,只需要:
|
||||
|
||||
# dnf help
|
||||
|
||||

|
||||
|
||||
### 19. 查看DNF的历史记录 ###
|
||||
|
||||
您可以调用'dnf history'来查看已经执行过的dnf命令的列表。这样您便可以知道什么被安装/移除及其时间戳。
|
||||
|
||||
# dnf history
|
||||
|
||||
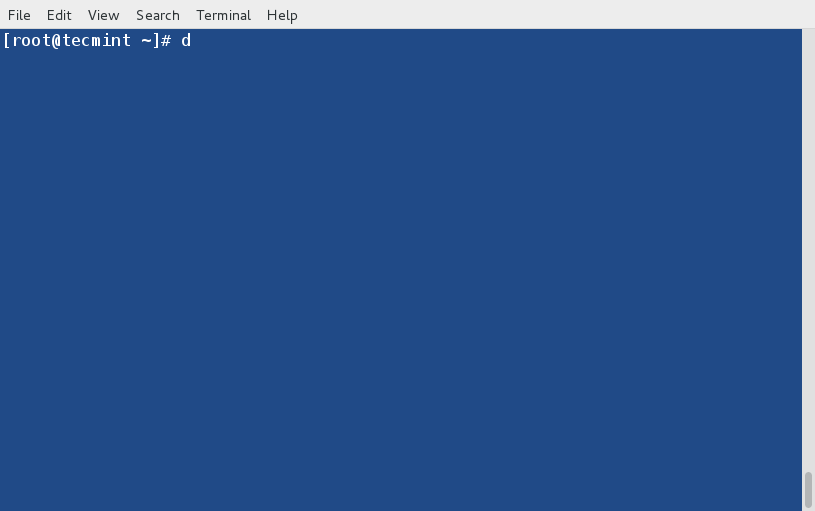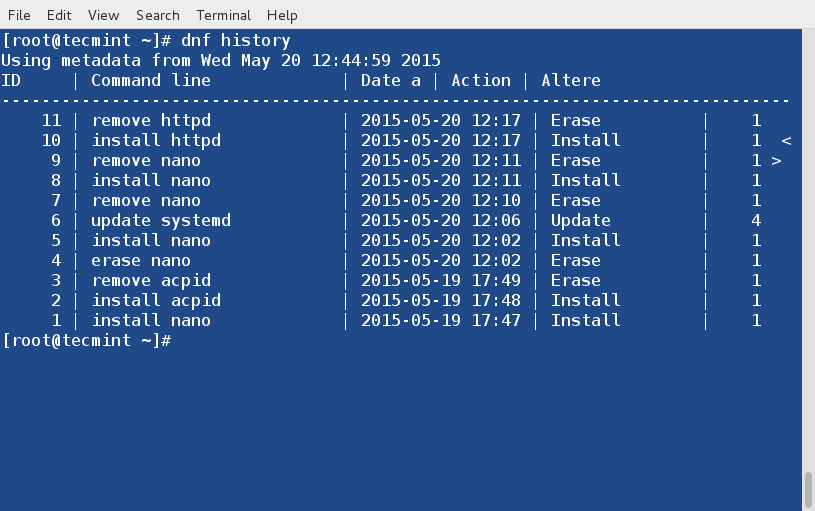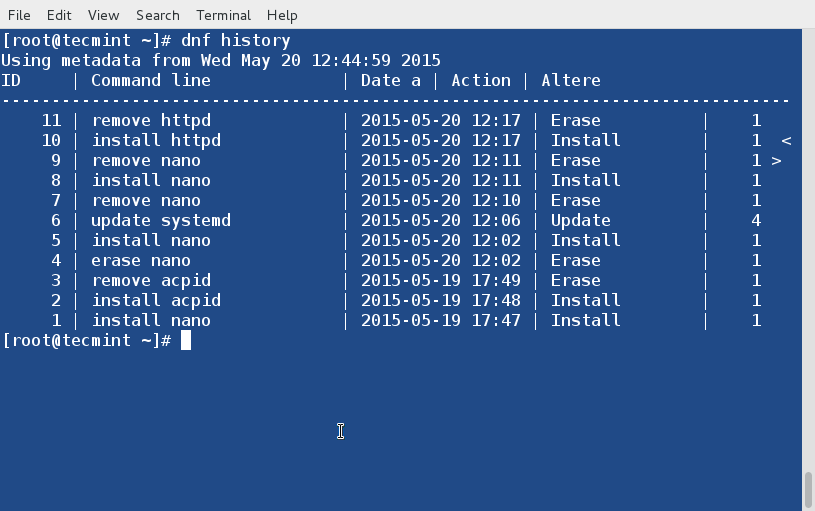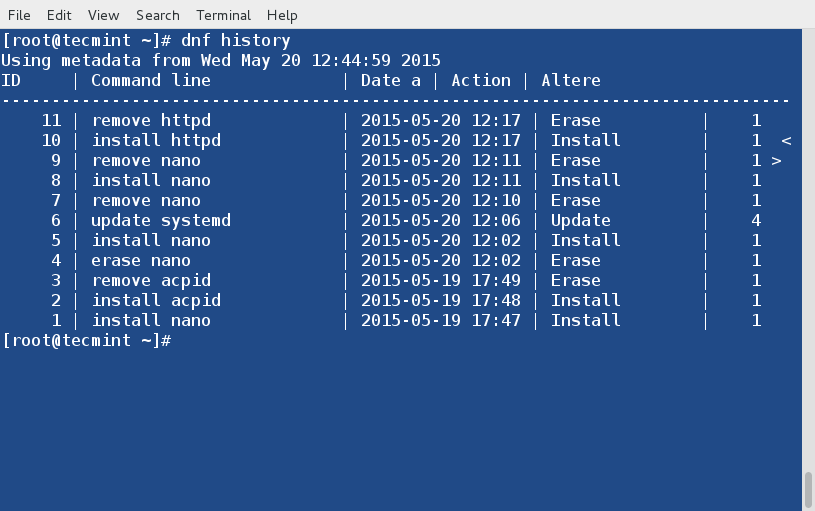
|
||||
|
||||
### 20. 显示所有软件包组 ###
|
||||
|
||||
'dnf grouplist'命令可以显示所有可用的或已安装的软件包,如果没有什么输出,则它会列出所有已知的软件包组。
|
||||
|
||||
# dnf grouplist
|
||||
|
||||

|
||||
|
||||
### 21. 使用DNF安装一个软件包组 ###
|
||||
|
||||
要安装一组由许多软件打包在一起的软件包组(例如,Educational Softaware),只需要执行:
|
||||
|
||||
# dnf groupinstall 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 22. 更新一个软件包组 ###
|
||||
|
||||
可以通过下面的命令来更新一个软件包组(例如,Educational Software):
|
||||
|
||||
# dnf groupupdate 'Educational Software'
|
||||
|
||||
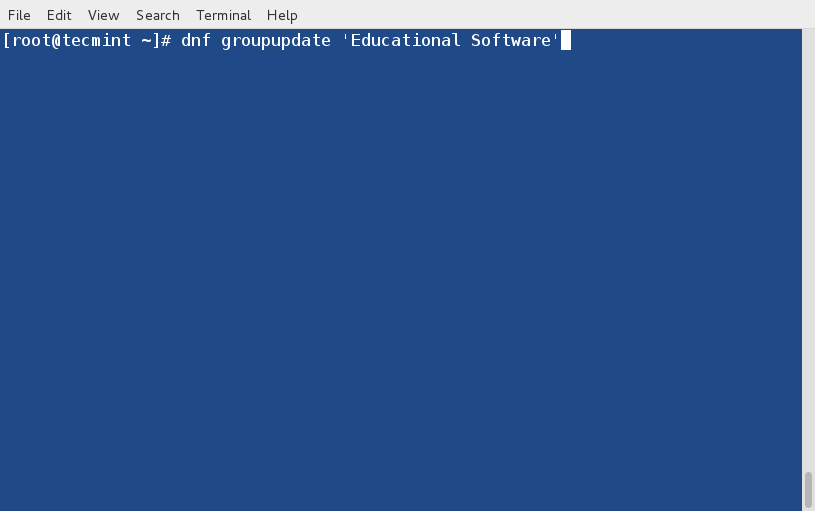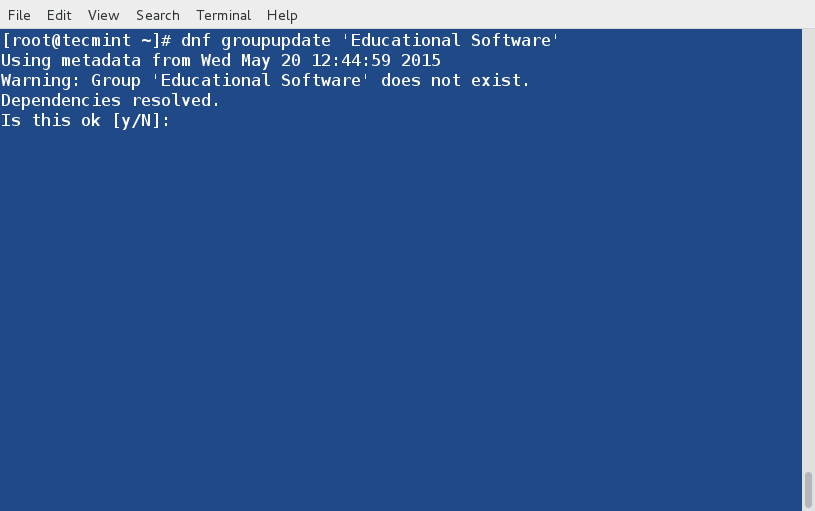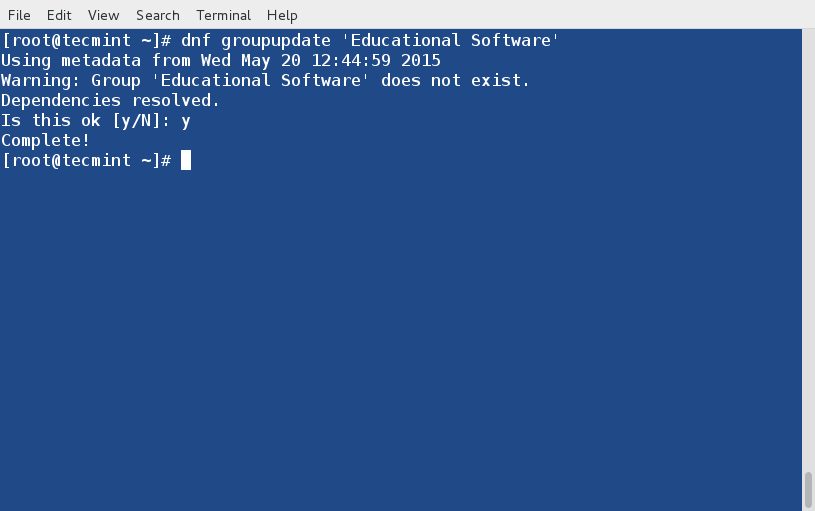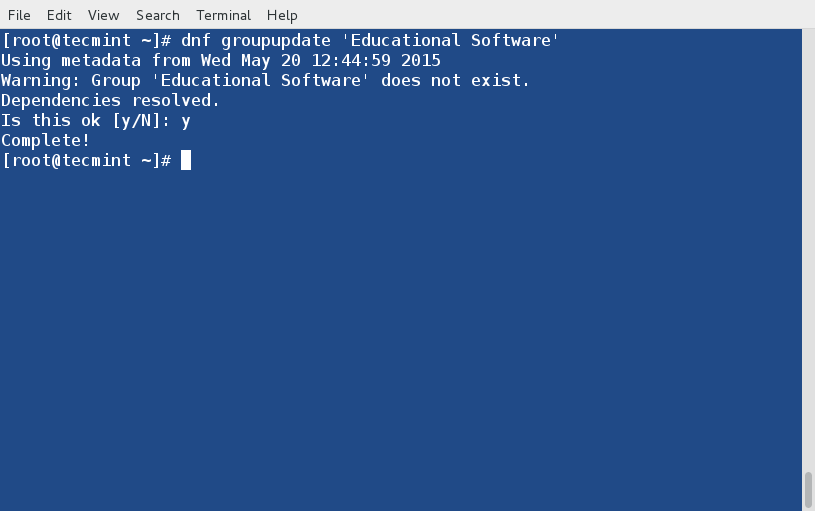
|
||||
|
||||
### 23. 移除一个软件包组 ###
|
||||
|
||||
可以使用下面的命令来移除一个软件包组(例如,Educational Software):
|
||||
|
||||
# dnf groupremove 'Educational Software'
|
||||
|
||||
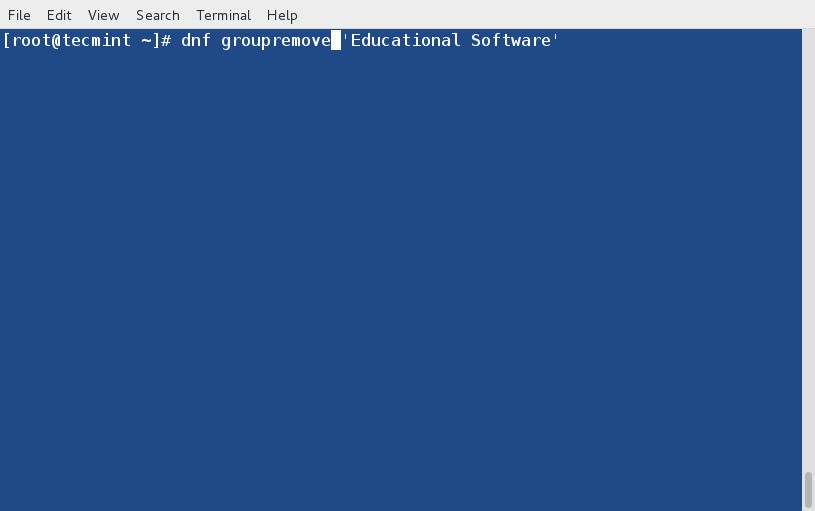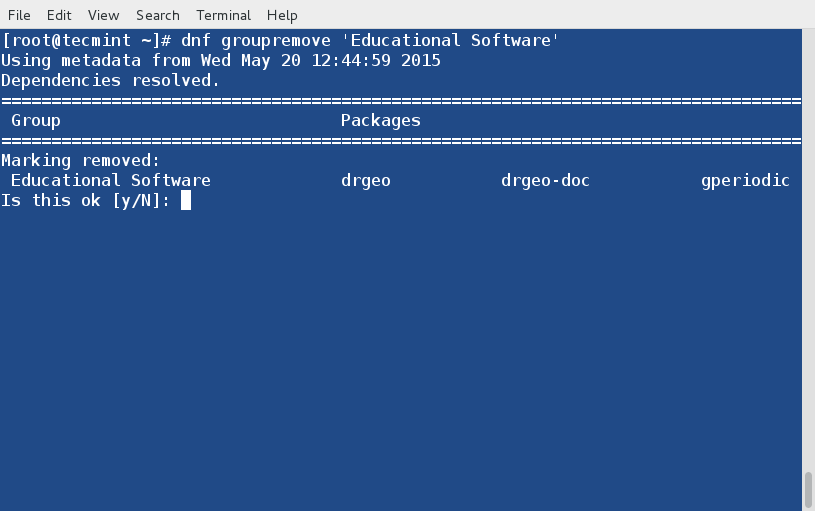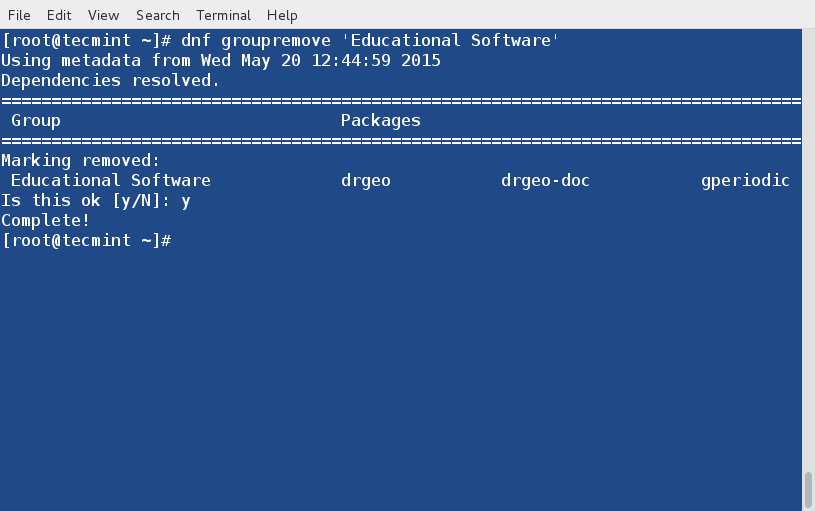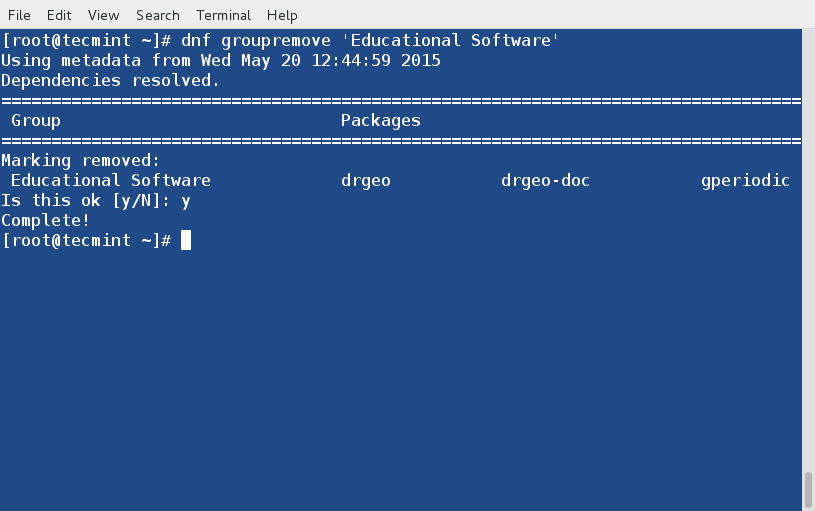
|
||||
|
||||
### 24. 从某个特定的仓库安装一个软件包 ###
|
||||
|
||||
DNF可以从任何特定的仓库(比如 epel)安装一个软件包(例如,phpmyadmin):
|
||||
|
||||
# dnf --enablerepo=epel install phpmyadmin
|
||||
|
||||

|
||||
|
||||
### 25. 将已安装的软件包同步到稳定发行版 ###
|
||||
|
||||
'dnf distro-sync'将同步所有已安装的软件包到所有开启的仓库中最近的稳定版本。如果没有选择软件包,则会同步所有已安装的软件包。
|
||||
|
||||
# dnf distro-sync
|
||||
|
||||

|
||||
|
||||
### 26. 重新安装一个软件包 ###
|
||||
|
||||
'dnf reinstall nano'命令将重新安装一个已经安装的软件包(例如,nano):
|
||||
|
||||
# dnf reinstall nano
|
||||
|
||||

|
||||
|
||||
### 27. 降级一个软件包 ###
|
||||
|
||||
选项'downgrade'将会使一个软件包(例如,acpid)回退到低版本。
|
||||
|
||||
# dnf downgrade acpid
|
||||
|
||||
示例输出
|
||||
|
||||
Using metadata from Wed May 20 12:44:59 2015
|
||||
No match for available package: acpid-2.0.19-5.el7.x86_64
|
||||
Error: Nothing to do.
|
||||
|
||||
**我观察到**:dnf不会按预想的那样降级一个软件包。这已做为一个bug被提交。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
DNF是YUM管理器的优秀替代品。它试着自动做许多甚至不推荐有经验的Linux系统管理员做的工作。例如:
|
||||
|
||||
- `--skip-broken`不被DNF识别,并且DNF中没有其替代命令。
|
||||
- 尽管您可能会运行dnf provides,但再也没有'resolvedep'命令了。
|
||||
- 没有'deplist'命令用来发现软件包依赖。
|
||||
- 您排除一个仓库意味着在所有操作上排除该仓库,而在yum中,排除一个仓库只在安装和升级等时刻排除他们。
|
||||
|
||||
许多Linux用户对于Linux生态系统的走向不甚满意。首先[Systemd替换了init系统][3]v,现在DNF将于不久后替换YUM,首先是Fedora 22,接下来是RHEL和CentOS。
|
||||
|
||||
您怎么看呢?是不是发行版和整个Linux生态系统并不注重用户并且在朝着与用户愿望相悖的方向前进呢?IT行业里有这样一句话 - “如果没有坏,为什么要修呢?”,System V和YUM都没有坏。
|
||||
|
||||
上面便是这篇文章的全部了。请在下方留言以让我了解您的宝贵想法。点赞和分享以帮助我们传播。谢谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
|
||||
[3]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
@ -1,10 +1,15 @@
|
||||
如何在Linux中安装漂亮的扁平化Arc GTK+主题
|
||||
如何在 Linux 中安装漂亮的 GTK+ 扁平化主题 Arc
|
||||
================================================================================
|
||||
> 易于理解的分步教程
|
||||
|
||||
**今天我们将向你介绍最新发布的GTK+主题,它拥有透明和扁平元素,并且与多个桌面环境和Linux发行版兼容。[这个主题叫Arc][1]。**
|
||||
|
||||
开始讲细节之前,我建议你快速浏览一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该知道它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME栈。
|
||||
开始讲细节之前,我建议你快速浏览一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该知道它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME 体系。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
同样、Arc主题的开发者告诉我们它已经成功地在Ubuntu 15.04(Vivid Vervet)、 Arch Linux、 elementary OS 0.3 Freya、 Fedora 21、 Fedora 22、 Debian GNU/Linux 8.0 (Jessie)、 Debian Testing、 Debian Unstable、 openSUSE 13.2、 openSUSE Tumbleweed和Gentoo测试过了。
|
||||
|
||||
@ -12,7 +17,7 @@
|
||||
|
||||
要构建Arc主题,你需要先安装一些包,比如autoconf、 automake、 pkg-config (对于Fedora则是pkgconfig)、基于Debian/Ubuntu-based发行版的libgtk-3-dev或者基于RPM的gtk3-devel、 git、 gtk2-engines-pixbuf和gtk-engine-murrine (对于Fedora则是gtk-murrine-engine)。
|
||||
|
||||
Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地,并在每行的末尾按下回车键并等待上一步完成来继续下一步。
|
||||
Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地输入,并在每行的末尾按下回车键并等待上一步完成来继续下一步。
|
||||
|
||||
git clone https://github.com/horst3180/arc-theme --depth 1 && cd arc-theme
|
||||
git fetch --tags
|
||||
@ -22,11 +27,7 @@ Arc主题还没有二进制包,因此你需要从git仓库中取下最新的
|
||||
|
||||
就是这样!此时你已经在你的GNU/Linux发行版中安装了Arc主题,如果你使用GNOME可以使用GONME Tweak工具,如果你使用Ubuntu的Unity可以使用Unity Tweak工具来激活主题。玩得开心但不要忘了在下面的评论栏里留下你的截图。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,14 +1,12 @@
|
||||
sevenot translated
|
||||
下载年度报告,了解The Document Foundation2014年的成果
|
||||
================================================================================
|
||||

|
||||
|
||||
|
||||
TDF ReportThe Document Foundation (TDF)郑重地发布了2014年度报告,你可以点击这里下载: [http://tdf.io/report2014][1] (3.2 MB PDF)。高清质量的可以点击这里下载 [http://tdf.io/report2014hq][2] (15.9 MB PDF)。
|
||||
The Document Foundation (TDF)郑重地发布了2014年度报告,你可以点击这里下载: [http://tdf.io/report2014][1] (3.2 MB PDF)。高清质量的可以点击这里下载 [http://tdf.io/report2014hq][2] (15.9 MB PDF)。
|
||||
|
||||
TDF年度报告中,以回顾2014年开始了这篇报告,其中包括了TDF和LibreOffice的精彩集锦,并且总结了财务情况和预算。
|
||||
|
||||
该报告涉及到项目和活动的会议包括:2014年在伯尔尼的LibreOffice大会,在布鲁塞尔、大加那利岛、巴黎、波士顿和土鲁斯的认证项目,网站与质量保证,Hackfests项目,本土语言项目,基础设施,文档项目,市场设计与营销。
|
||||
该报告涉及到项目和活动的会议包括:2014年在伯尔尼的LibreOffice大会,在布鲁塞尔、大加那利岛、巴黎、波士顿和土鲁斯的认证项目、网站与质量保证、Hackfests项目等,本土语言项目,基础设施,文档项目,市场设计与营销。
|
||||
|
||||
该报告涉及到的软件开发活动和代码包括:工程指导委员会的活动,LibreOffice的开发,文档解放项目,LibreOffice的安卓移植。
|
||||
|
||||
@ -17,8 +15,7 @@ TDF年度报告中,以回顾2014年开始了这篇报告,其中包括了TDF
|
||||
TDF 2014年度报告的编辑工作由Sophie Gautier, Alexander Werner, Christian Lohmaier, Florian Effenberger, Italo Vignoli 和 Robinson Tryon完成,由Barak Paz设计样式,Libreoffice社区协助完成。
|
||||
|
||||
|
||||
为了使该文档分布达到最大程度的分布,采用了CC3 认证发布,除非特殊标注,TDF成员和自由软件基金会拥有其所有权。
|
||||
[德语版年度报告下载请点击[http://tdf.io/bericht2014][3]].
|
||||
为了最大程度的传播该文档,采用了CC3 认证发布,除非特殊标注,TDF成员和自由软件基金会拥有其所有权。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -26,7 +23,7 @@ via: http://blog.documentfoundation.org/2015/06/03/read-about-the-document-found
|
||||
|
||||
作者:italovignoli
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,37 +1,36 @@
|
||||
如何在Ubuntu 15.04(Vivid Vervet)中安装nginx和google pagespeed
|
||||
如何在 Ubuntu 15.04 中安装 nginx 和 google pagespeed
|
||||
================================================================================
|
||||
Nginx (engine-x)是一个开源高性能http、反向代理和IMAP/POP3代理服务器。nginx杰出的功能有:稳定、丰富的功能集、简单的配置和低资源消耗。nginx被用于一些高性能网站并在站长之间变得越来越流行。本教程会从源码构建一个带有google paespeed模块用于Ubuntu 15.04中的.deb包。
|
||||
Nginx (engine-x)是一个开源的高性能 HTTP 服务器、反向代理和 IMAP/POP3 代理服务器。nginx 杰出的功能有:稳定、丰富的功能集、简单的配置和低资源消耗。nginx 被用于一些高性能网站并在站长之间变得越来越流行。本教程会从源码构建一个带有 google paespeed 模块的用于 Ubuntu 15.04 的 nginx .deb 安装包。
|
||||
|
||||
pagespeed 是一个由 google 开发的 web 服务器模块来加速网站响应时间、优化 html 和减少页面加载时间。ngx_pagespeed 的功能如下:
|
||||
|
||||
pagespeed是一个由google开发的web服务器模块来加速网站响应时间、优化html和减少页面加载时间。ngx_pagespeed的功能如下:
|
||||
|
||||
- 图像优化:去除meta数据、动态剪裁、重压缩。
|
||||
- CSS与JavaScript 放大、串联、内联、外联。
|
||||
- 图像优化:去除元数据、动态缩放、重压缩。
|
||||
- CSS 与 JavaScript 压缩、串联、内联、外联。
|
||||
- 小资源内联
|
||||
- 延迟图像与JavaScript加载
|
||||
- HTML重写。
|
||||
- 图像与 JavaScript 延迟加载
|
||||
- HTML 重写
|
||||
- 缓存生命期插件
|
||||
|
||||
更多请见 [https://developers.google.com/speed/pagespeed/module/][1].
|
||||
更多请见 [https://developers.google.com/speed/pagespeed/module/][1]。
|
||||
|
||||
### 预备要求 ###
|
||||
### 前置要求 ###
|
||||
|
||||
Ubuntu Server 15.04 64位
|
||||
root 权限
|
||||
- Ubuntu Server 15.04 64位
|
||||
- root 权限
|
||||
|
||||
本篇我们将要:
|
||||
|
||||
- 安装必备包
|
||||
- 安装带ngx_pagespeed的nginx
|
||||
- 安装必备软件包
|
||||
- 安装带 ngx_pagespeed 的 nginx
|
||||
- 测试
|
||||
|
||||
#### 安装必备包 ####
|
||||
|
||||
sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
|
||||
#### 安装带ngx_pagespeed的nginx ####
|
||||
### 安装带 ngx_pagespeed 的 nginx ###
|
||||
|
||||
**第一步 - 添加nginx仓库**
|
||||
#### 第一步 - 添加nginx仓库####
|
||||
|
||||
vim /etc/apt/sources.list.d/nginx.list
|
||||
|
||||
@ -51,7 +50,7 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
sudo sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys KEYNUMBER
|
||||
sudo apt-get update
|
||||
|
||||
**第二步 - 从仓库下载nginx 1.8**
|
||||
####第二步 - 从仓库下载 nginx 1.8####
|
||||
|
||||
sudo su
|
||||
cd ~
|
||||
@ -60,7 +59,7 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
apt-get source nginx
|
||||
apt-get build-dep nginx
|
||||
|
||||
**第三步 - 下载Pagespeed**
|
||||
#### 第三步 - 下载 Pagespeed####
|
||||
|
||||
cd ~
|
||||
mkdir -p ~/new/ngx_pagespeed/
|
||||
@ -73,12 +72,12 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
wget https://dl.google.com/dl/page-speed/psol/${ngx_version}.tar.gz
|
||||
tar -xzf 1.9.32.3.tar.gz
|
||||
|
||||
**第三步 - 配置nginx来编译Pagespeed**
|
||||
####第四步 - 配置 nginx 来编译 Pagespeed####
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/debin/
|
||||
vim rules
|
||||
|
||||
在CFLAGS `.configure`下添加模块:
|
||||
在两处 CFLAGS `.configure` 下添加模块:
|
||||
|
||||
--add-module=../../ngx_pagespeed/ngx_pagespeed-release-1.9.32.3-beta \
|
||||
|
||||
@ -86,27 +85,27 @@ sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
|
||||

|
||||
|
||||
**第五步 - 打包nginx包并安装**
|
||||
####第五步 - 打包 nginx 软件包并安装####
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/
|
||||
dpkg-buildpackage -b
|
||||
|
||||
dpkg-buildpackage会编译 ~/new/ngix_source/成nginx.deb。打包完成后,看一下目录:
|
||||
dpkg-buildpackage 会编译 ~/new/ngix_source/ 为 nginx.deb。打包完成后,看一下目录:
|
||||
|
||||
cd ~/new/ngix_source/
|
||||
ls
|
||||
|
||||
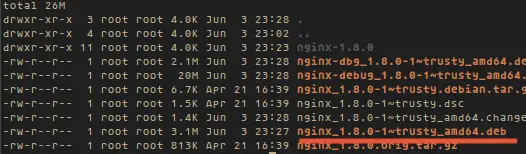
|
||||
|
||||
接着安装nginx。
|
||||
接着安装 nginx。
|
||||
|
||||
dpkg -i nginx_1.8.0-1~trusty_amd64.deb
|
||||
|
||||
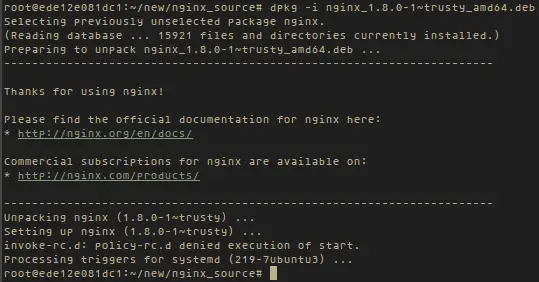
|
||||
|
||||
#### 测试 ####
|
||||
### 测试 ###
|
||||
|
||||
运行nginx -V测试nginx是否已经自带ngx_pagespeed。
|
||||
运行 nginx -V 测试 nginx 是否已经自带 ngx_pagespeed。
|
||||
|
||||
nginx -V
|
||||
|
||||
@ -114,15 +113,15 @@ dpkg-buildpackage会编译 ~/new/ngix_source/成nginx.deb。打包完成后,
|
||||
|
||||
### 总结 ###
|
||||
|
||||
稳定、快速、开源的nginx支持许多不同的优化模块。这其中之一是google开发的‘pagespeed’。不像apache,nginx模块不是动态加载的,因此你必须在编译之前就选择完需要的模块。
|
||||
稳定、快速、开源的 nginx 支持许多不同的优化模块。这其中之一是 google 开发的‘pagespeed’。不像 apache,nginx 模块不是动态加载的,因此你必须在编译之前就选择好需要的模块。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-nginx-and-google-pagespeed-on-ubuntu-15-04/#step-build-nginx-package-and-install
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-nginx-and-google-pagespeed-on-ubuntu-15-04/
|
||||
|
||||
作者:Muhammad Arul
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,27 @@
|
||||
|
||||
在Ubuntu 15.04下安装Android Studio
|
||||
PS 原MD文件有大段重复并且排版错误,译者已修复
|
||||
================================================================================
|
||||
|
||||
Android Studio是官方为了Android应用开发者而发布的IDE,它基于IntelliJ的IDEA。
|
||||

|
||||
|
||||
Android Studio是官方为了Android应用开发者而发布的IDE,它基于IntelliJ的IDEA。
|
||||
|
||||
### Android Studio的功能 ###
|
||||
|
||||
灵活的基于Gradle的建构系统
|
||||
- 灵活的基于Gradle的建构系统
|
||||
|
||||
针对不同手机编译多个版本的apk
|
||||
- 针对不同手机编译多个版本的apk
|
||||
|
||||
代码模板功能构建出各种常用的应用
|
||||
- 代码模板功能构建出各种常用的应用
|
||||
|
||||
支持拖动编辑主题的富布局编辑器
|
||||
- 支持拖动编辑主题的富布局编辑器
|
||||
|
||||
lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他问题
|
||||
- lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他问题
|
||||
|
||||
代码混淆和应用签名功能
|
||||
|
||||
内置 Google Cloud Platform 的支持,可以轻易的融入Google Cloud Messaging 和 App Engine支持
|
||||
|
||||
还有更多
|
||||
- 代码混淆和应用签名功能
|
||||
|
||||
- 内置 Google Cloud Platform 的支持,可以轻易的融入Google Cloud Messaging 和 App Engine支持
|
||||
|
||||
- 还有更多
|
||||
|
||||
### 在 Ubuntu 15.04 上安装 Android Studio ###
|
||||
|
||||
@ -33,7 +31,6 @@ lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他
|
||||
sudo apt-get update
|
||||
sudo apt-get install android-studio
|
||||
|
||||
|
||||
如果要把Android Studio添加到启动栏,你需要如下操作
|
||||
|
||||
打开Android Studio,点击Configure选择Create Desktop Entry,这样Android Studio应该在dash中创建快捷方式了。
|
||||
@ -42,8 +39,6 @@ lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
@ -60,7 +55,7 @@ via: http://www.ubuntugeek.com/install-android-studio-on-ubuntu-15-04.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,175 @@
|
||||
深入 NGINX: 我们如何设计性能和扩展
|
||||
================================================================================
|
||||
|
||||
NGINX 能在 web 性能中取得领先地位,这是由于其软件设计所决定的。许多 web 服务器和应用程序服务器使用一个简单的线程或基于流程的架构,NGINX 立足于一个复杂的事件驱动的体系结构,使它能够在现代硬件上扩展到成千上万的并发连接。
|
||||
|
||||
这张[深入 NGINX][1] 的信息图从高层次的流程架构深度挖掘说明了 NGINX 如何在单一进程里保持多个连接。这篇博客进一步详细地解释了这一切是如何工作的。
|
||||
|
||||
### 知识 – NGINX进程模型 ###
|
||||
|
||||
|
||||
|
||||
为了更好的理解这个设计,你需要理解 NGINX 如何运行的。NGINX 有一个主进程(它执行特权操作,如读取配置和绑定端口)和一些工作进程与辅助进程。
|
||||
|
||||
# service nginx restart
|
||||
* Restarting nginx
|
||||
# ps -ef --forest | grep nginx
|
||||
root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx \
|
||||
-c /etc/nginx/nginx.conf
|
||||
nginx 32476 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32477 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32479 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32480 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32481 32475 0 13:36 ? 00:00:00 \_ nginx: cache manager process
|
||||
nginx 32482 32475 0 13:36 ? 00:00:00 \_ nginx: cache loader process
|
||||
|
||||
在四核服务器,NGINX 主进程创建了4个工作进程和两个管理磁盘内容缓存的缓存辅助进程。
|
||||
|
||||
### 为什么架构很重要? ###
|
||||
|
||||
任何 Unix 应用程序的根本基础是线程或进程。(从 Linux 操作系统的角度来看,线程和进程大多是相同的,主要的区别是他们共享内存的程度。)一个线程或进程是一个自包含的指令集,操作系统可以在一个 CPU 核心上调度运行它们。大多数复杂的应用程序并行运行多个线程或进程有两个原因:
|
||||
|
||||
- 它们可以同时使用更多的计算核心。
|
||||
- 线程或进程可以轻松实现并行操作。(例如,在同一时刻保持多连接)。
|
||||
|
||||
进程和线程消耗资源。他们每个都使用内存和其他系统资源,他们会在 CPU 核心中换入和换出(一个操作可以叫做上下文切换)。大多数现代服务器可以并行保持上百个小型的、活动的线程或进程,但是一旦内存耗尽或高 I/O 压力引起大量的上下文切换会导致性能严重下降。
|
||||
|
||||
网络应用程序设计的常用方法是为每个连接分配一个线程或进程。此体系结构简单、容易实现,但是当应用程序需要处理成千上万的并发连接时这种结构就不具备扩展性。
|
||||
|
||||
### NGINX 如何工作? ###
|
||||
|
||||
NGINX 使用一种可预测的进程模式来分配可使用的硬件资源:
|
||||
|
||||
- 主进程(master)执行特权操作,如读取配置和绑定端口,然后创建少量的子进程(如下的三种类型)。
|
||||
- 缓存加载器进程(cache loader)在加载磁盘缓存到内存中时开始运行,然后退出。适当的调度,所以其资源需求很低。
|
||||
- 缓存管理器进程(cache manager)定期裁剪磁盘缓存中的记录来保持他们在配置的大小之内。
|
||||
- 工作进程(worker)做所有的工作!他们保持网络连接、读写内容到磁盘,与上游服务器通信。
|
||||
|
||||
在大多数情况下 NGINX 的配置建议:每个 CPU 核心运行一个工作进程,这样最有效地利用硬件资源。你可以在配置中包含 [worker_processes auto][2]指令配置:
|
||||
|
||||
worker_processes auto;
|
||||
|
||||
当一个 NGINX 服务处于活动状态,只有工作进程在忙碌。每个工作进程以非阻塞方式保持多连接,以减少上下文交换。
|
||||
|
||||
每个工作进程是一个单一线程并且独立运行,它们会获取新连接并处理之。这些进程可以使用共享内存通信来共享缓存数据、会话持久性数据及其它共享资源。(在 NGINX 1.7.11 及其以后版本,还有一个可选的线程池,工作进程可以转让阻塞的操作给它。更多的细节,参见“[NGINX 线程池可以爆增9倍性能!][16]”。对于 NGINX Plus 用户,该功能计划在今年晚些时候加入到 R7 版本中。)
|
||||
|
||||
### NGINX 工作进程内部 ###
|
||||
|
||||
|
||||
|
||||
每个 NGINX 工作进程按照 NGINX 配置初始化,并由主进程提供一组监听端口。
|
||||
|
||||
NGINX 工作进程首先在监听套接字上等待事件([accept_mutex][3] 和[内核套接字分片][4])。事件被新进来的连接初始化。这些连接被分配到一个状态机 – HTTP 状态机是最常用的,但 NGINX 也实现了流式(原始 TCP )状态机和几种邮件协议(SMTP、IMAP和POP3)的状态机。
|
||||
|
||||
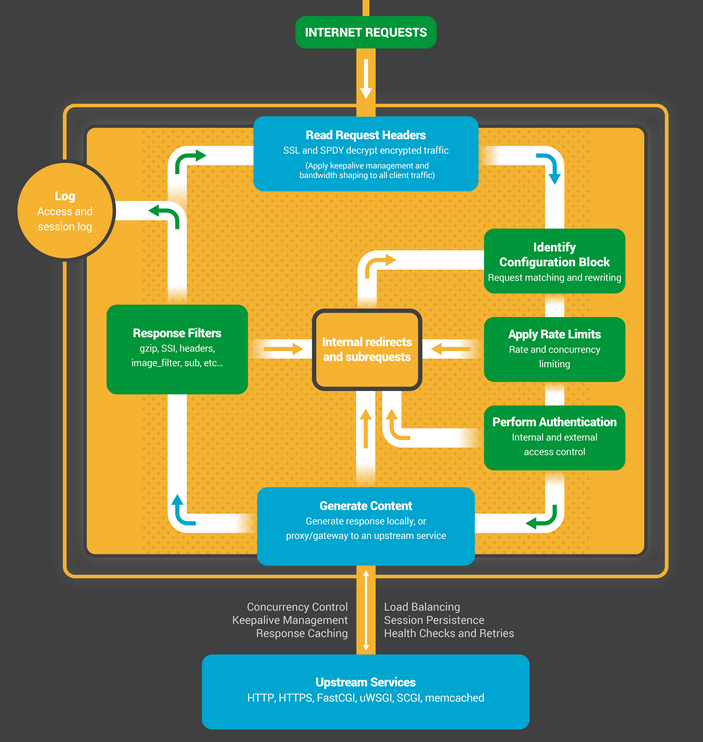
|
||||
|
||||
状态机本质上是一组指令,告诉 NGINX 如何处理一个请求。大多数 web 服务器像 NGINX 一样使用类似的状态机来实现相同的功能 - 区别在于实现。
|
||||
|
||||
### 调度状态机 ###
|
||||
|
||||
把状态机想象成国际象棋的规则。每个 HTTP 事务是一个象棋游戏。一方面棋盘是 web 服务器 —— 一位大师可以非常迅速地做出决定。另一方面是远程客户端 —— 在一个相对较慢的网络下 web 浏览器访问网站或应用程序。
|
||||
|
||||
不管怎样,这个游戏规则很复杂。例如,web 服务器可能需要与各方沟通(代理一个上游的应用程序)或与身份验证服务器对话。web 服务器的第三方模块甚至可以扩展游戏规则。
|
||||
|
||||
#### 一个阻塞状态机 ####
|
||||
|
||||
回忆我们之前的描述,一个进程或线程就像一套独立的指令集,操作系统可以在一个 CPU 核心上调度运行它。大多数 web 服务器和 web 应用使用每个连接一个进程或者每个连接一个线程的模式来玩这个“象棋游戏”。每个进程或线程都包含玩完“一个游戏”的指令。在服务器运行该进程的期间,其大部分的时间都是“阻塞的” —— 等待客户端完成它的下一步行动。
|
||||
|
||||

|
||||
|
||||
1. web 服务器进程在监听套接字上监听新连接(客户端发起新“游戏”)
|
||||
1. 当它获得一个新游戏,就玩这个游戏,每走一步去等待客户端响应时就阻塞了。
|
||||
1. 游戏完成后,web 服务器进程可能会等待是否有客户机想要开始一个新游戏(这里指的是一个“保持的”连接)。如果这个连接关闭了(客户端断开或者发生超时),web 服务器进程会返回并监听一个新“游戏”。
|
||||
|
||||
要记住最重要的一点是每个活动的 HTTP 连接(每局棋)需要一个专用的进程或线程(象棋高手)。这个结构简单容并且易扩展第三方模块(“新规则”)。然而,还是有巨大的不平衡:尤其是轻量级 HTTP 连接其实就是一个文件描述符和小块内存,映射到一个单独的线程或进程,这是一个非常重量级的系统对象。这种方式易于编程,但太过浪费。
|
||||
|
||||
#### NGINX是一个真正的象棋大师 ####
|
||||
|
||||
也许你听过[同时表演赛][5]游戏,有一个象棋大师同时对战许多对手?
|
||||
|
||||

|
||||
|
||||
*[列夫·吉奥吉夫在保加利亚的索非亚同时对阵360人][6]。他的最终成绩是284胜70平6负。*
|
||||
|
||||
这就是 NGINX 工作进程如何“下棋”的。每个工作进程(记住 - 通常每个CPU核心上有一个工作进程)是一个可同时对战上百人(事实是,成百上千)的象棋大师。
|
||||
|
||||
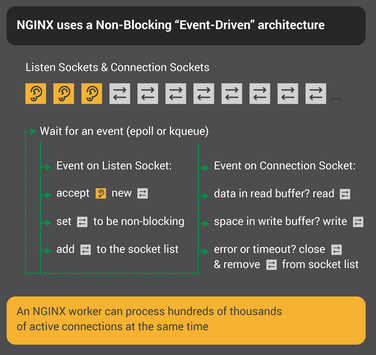
|
||||
|
||||
1. 工作进程在监听和连接套接字上等待事件。
|
||||
1. 事件发生在套接字上,并且由工作进程处理它们:
|
||||
- 在监听套接字的事件意味着一个客户端已经开始了一局新棋局。工作进程创建了一个新连接套接字。
|
||||
- 在连接套接字的事件意味着客户端已经下了一步棋。工作进程及时响应。
|
||||
|
||||
一个工作进程在网络流量上从不阻塞,等待它的“对手”(客户端)做出反应。当它下了一步,工作进程立即继续其他的游戏,在那里工作进程正在处理下一步,或者在门口欢迎一个新玩家。
|
||||
|
||||
#### 为什么这个比阻塞式多进程架构更快? ####
|
||||
|
||||
NGINX 每个工作进程很好的扩展支撑了成百上千的连接。每个连接在工作进程中创建另外一个文件描述符和消耗一小部分额外内存。每个连接有很少的额外开销。NGINX 进程可以固定在某个 CPU 上。上下文交换非常罕见,一般只发生在没有工作要做时。
|
||||
|
||||
在阻塞方式,每个进程一个连接的方法中,每个连接需要大量额外的资源和开销,并且上下文切换(从一个进程切换到另一个)非常频繁。
|
||||
|
||||
更详细的解释,看看这篇关于 NGINX 架构的[文章][7],它由NGINX公司开发副总裁及共同创始人 Andrew Alexeev 写的。
|
||||
|
||||
通过适当的[系统优化][8],NGINX 的每个工作进程可以扩展来处理成千上万的并发 HTTP 连接,并能脸不红心不跳的承受峰值流量(大量涌入的新“游戏”)。
|
||||
|
||||
### 更新配置和升级 NGINX ###
|
||||
|
||||
NGINX 的进程体系架构使用少量的工作进程,有助于有效的更新配置文件甚至 NGINX 程序本身。
|
||||
|
||||
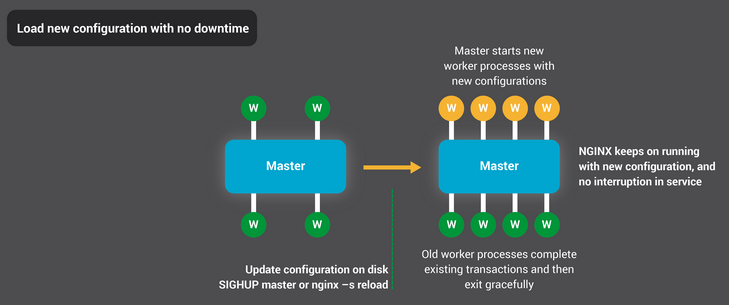
|
||||
|
||||
更新 NGINX 配置文件是非常简单、轻量、可靠的操作。典型的就是运行命令 `nginx –s reload`,所做的就是检查磁盘上的配置并发送 SIGHUP 信号给主进程。
|
||||
|
||||
当主进程接收到一个 SIGHUP 信号,它会做两件事:
|
||||
|
||||
- 重载配置文件和分支出一组新的工作进程。这些新的工作进程立即开始接受连接和处理流量(使用新的配置设置)
|
||||
- 通知旧的工作进程优雅的退出。工作进程停止接受新的连接。当前的 http 请求一旦完成,工作进程就彻底关闭这个连接(那就是,没有残存的“保持”连接)。一旦所有连接关闭,这个工作进程就退出。
|
||||
|
||||
这个重载过程能引发一个 CPU 和内存使用的小峰值,但是跟活动连接加载的资源相比它一般不易察觉。每秒钟你可以多次重载配置(很多 NGINX 用户都这么做)。非常罕见的情况下,有很多世代的工作进程等待关闭连接时会发生问题,但即使是那样也很快被解决了。
|
||||
|
||||
NGINX 的程序升级过程中拿到了高可用性圣杯 —— 你可以随随时更新这个软件,不会丢失连接,停机,或者中断服务。
|
||||
|
||||
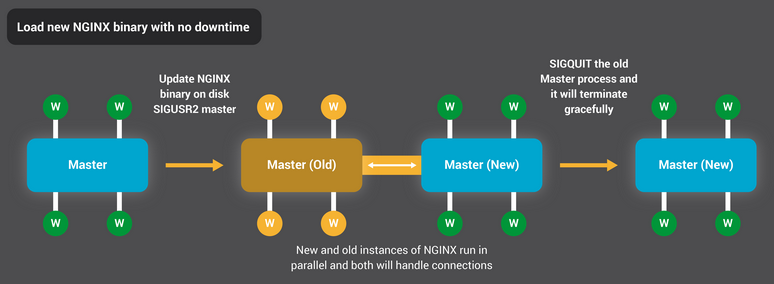
|
||||
|
||||
程序升级过程类似于平滑重载配置的方法。一个新的 NGINX 主进程与原主进程并行运行,然后他们共享监听套接字。两个进程都是活动的,并且各自的工作进程处理流量。然后你可以通知旧的主进程和它的工作进程优雅的退出。
|
||||
|
||||
整个过程的详细描述在 [NGINX 管理][9]。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
[深入 NGINX 信息图][10] 提供一个 NGINX 功能实现的高层面概览,但在这简单的解释的背后是超过十年的创新和优化,使得 NGINX 在广泛的硬件上提供尽可能最好的性能同时保持了现代 Web 应用程序所需要的安全性和可靠性。
|
||||
|
||||
如果你想阅读更多关于NGINX的优化,查看这些优秀的资源:
|
||||
|
||||
- [安装和 NGINX 性能调优][11] (webinar; Speaker Deck 上的[讲义][12])
|
||||
- [NGINX 性能调优][13]
|
||||
- [开源应用架构: NGINX 篇][14]
|
||||
- [NGINX 1.9.1 中的套接字分片][15] (使用 SO_REUSEPORT 套接字选项)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/
|
||||
|
||||
作者:[Owen Garrett][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nginx.com/author/owen/
|
||||
[1]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[2]:http://nginx.org/en/docs/ngx_core_module.html#worker_processes
|
||||
[3]:http://nginx.org/en/docs/ngx_core_module.html#accept_mutex
|
||||
[4]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[5]:http://en.wikipedia.org/wiki/Simultaneous_exhibition
|
||||
[6]:http://gambit.blogs.nytimes.com/2009/03/03/in-chess-records-were-made-to-be-broken/
|
||||
[7]:http://www.aosabook.org/en/nginx.html
|
||||
[8]:http://nginx.com/blog/tuning-nginx/
|
||||
[9]:http://nginx.org/en/docs/control.html
|
||||
[10]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[11]:http://nginx.com/resources/webinars/installing-tuning-nginx/
|
||||
[12]:https://speakerdeck.com/nginx/nginx-installation-and-tuning
|
||||
[13]:http://nginx.com/blog/tuning-nginx/
|
||||
[14]:http://www.aosabook.org/en/nginx.html
|
||||
[15]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[16]:http://nginx.com/blog/thread-pools-boost-performance-9x/
|
||||
@ -0,0 +1,84 @@
|
||||
PHP 20岁了:从玩具到巨头
|
||||
=============================================================================
|
||||
|
||||
> 曾经的‘丑小鸭工程’已经转变为一个互联网巨头,感谢灵活、务实和充满活力的开发者社区。
|
||||
|
||||
当Rasmus Lerdorf发布“[一个用C写的小型紧凑的CGI可执行程序集合][2]”时, 他没有想到他的创造会对网络发展产生多大的影响。今年在Miami举行的SunshinePHP大会上,Lerdorf做了开场演讲,他自嘲到,“在1995年的时候,我以为我已经在 Web 上解除了C API的束缚。显然,事情并非那样,我们全成了C程序员了。”
|
||||
|
||||

|
||||
|
||||
题图来自: [Steve Jurvetson via Flickr][1]
|
||||
|
||||
实际上,当Lerdorf发布个人主页工具(Personal Home Page Tools,即 PHP 名字的来源)的1.0版本时,那时的网络还是如此的年轻。直到那年的十一月份HTML 2.0还没有公布,而且HTTP/1.0也是次年的五月份才出现。那时,NCSA HTTPd是使用最广泛的网络服务器,而网景的Navigator则是最流行的网络浏览器,八月份的时候,IE1.0才刚刚出现。换句话说,PHP的开端刚好撞上了浏览器战争的前夜。
|
||||
|
||||
早些时候,我们谈论了一大堆关于PHP对网络发展的影响。回到那时候,当说到用于网络应用的服务器端处理,我们的选择是有限的。PHP满足了我们对于一种工具的需求,这就是可以使得我们在网络上做一些动态的事情。它的实用的灵活性只受限于我们的想像力,PHP从那时起便与网络共同成长。现在,PHP占据了网络语言的超过80%的份额,已经是成熟的脚本语言,特别适合解决网络问题。她独一无二的血统讲述了一个故事,实用高于理论,解决问题高于纯正。
|
||||
|
||||
### 把我们钩住的网络魔力 ###
|
||||
|
||||
PHP一开始并不是一门编程语言,从她的设计就很明显不是 -- 或者她本来就缺乏相关特性,正如那些贬低者指出的那样。最初,她是作为一种API帮助网络开发者能够接入底层的C语言封装库。第一个版本是一组小的CGI可执行程序,提供表单处理功能,可以访问查询参数和mSQL数据库。而且她可以如此容易地处理一个网络应用的数据库,证明了其在激发我们对于PHP的兴趣和PHP后来的支配地位的关键作用。
|
||||
|
||||
到了第二版 -- 即 PHP/FI -- 数据库的支持已经扩展到包括PostgreSQL、MySQL、Oracle、Sybase等等。她通过封装他们的C语言库来支持各种数据库,将他们作为PHP库的一部分。PHP/FI也封装了GD库,可以创建并管理GIF图像。她可以作为一个Apache模块运行,或者编译进FastCGI支持,并且她引入的 PHP 编程语言支持变量、数组、语言结构和函数。对于那个时候大多数在网络这块工作的人来说,PHP是我们一直在寻求的那款“胶水”。
|
||||
|
||||
当PHP吸纳越来越多的编程语言功能,演变为第三版和之后的版本时,她从来没有失去这种黏合的特性。通过仓库如PECL(PHP Extension Community Library),PHP可以把各种库都连在一起,将他们的函数引入到PHP层面。这种将组件结合在一起的能力,成为PHP之美的一个重要方面,使之不会受限于其源代码上。
|
||||
|
||||
### 网络,一个码农们的社区 ###
|
||||
|
||||
PHP在网络发展上的持续影响并不局限于能用这种语言干什么。PHP如何完成工作,谁参与进来 -- 这些都是PHP传奇中很重要的部分。
|
||||
|
||||
早在1997年,PHP的用户群体开始形成。其中最早的是美国中西部PHP用户组(后来叫做 Chiago PHP),并[1997年二月份的时候举行了第一次聚会][4]。这是一个充满生气、饱含激情的开发者社区形成的开端,聚合成一种吸引力 -- 在网络上的一个小工具就可以帮助他们解决问题。PHP这种普遍存在的特性使得她成为网络开发一个很自然的选择。在分享主导的世界里,她开始盛行,而且低入的门槛对于许多早期的网络开发者来说是十分有吸引力的。
|
||||
|
||||
伴随着社区的成长,为开发者带来了一堆工具和资源。这一年是2000年,出现了PHP的一个转折点,它见证了第一次PHP开发者大会,聚集了编程语言的核心开发者,他们在Tel Aviv见面,讨论即将到来的4.0版本的发布。PHP扩展和应用仓库(PEAR)也于2000年发起,它提供了高质量的用户代码包,依据标准和最佳操作。第一届PHP大会PHP Kongress不久之后在德国举行。[PHPDeveloper.org][5]也随后上线,直到今天,这都是PHP社区里最权威的新闻资源。
|
||||
|
||||
这个社区的势头表明了接下来几年里PHP成长的关键所在。随着网络开发产业的爆发,PHP也获得发展。PHP开始为更多、更大的网站提供动力。越来越多的用户群在世界各地开花。邮件列表、在线论坛、IRC、大会,以及如php[architect]、德国PHP杂志、国际PHP杂志等商业杂志 -- PHP社区的活力在完成网络工作的方式上有极其重要的影响:共同地,开放地,倡导代码共享。
|
||||
|
||||
然后,在10年前,PHP 5发布后不久,在网络发展史上一个有趣地事情发生了,它导致了PHP社区如何构建库和应用的转变:Ruby on Rails发布了。
|
||||
|
||||
### 框架的异军突起 ###
|
||||
|
||||
用于Ruby编程语言的Ruby on Rails框架在MVC(模型-视图-控制)架构模型上获得了不断增长的焦点与关注。Mojavi PHP框架几年前已经使用MVC模型了,但是Ruby on Rails的高明之处在于巩固了MVC。框架引爆了PHP社区,并且框架已经改变了开发者构建PHP应用程序的方式。
|
||||
|
||||
许多重要的项目和发展已经发端,这归功于PHP社区框架的生长。[PHP框架互用性组织][6]成立于2009年,致力于在框架间建立编码标准,命名约定与最佳操作。编纂这些标准和操作帮助为开发者在使用成员项目的代码时提供了越来越多的互用性软件。互用性意味着每个框架可以拆分为组块和独立的库,也可以作为整体的框架在一起使用。互用性带来了另一个重要的里程碑:Composer项目于2011年诞生了。
|
||||
|
||||
从Node.js的NPM和Ruby的Bundler获得灵感,Composer开辟了PHP应用开发的新纪元,创造了一次PHP“文艺复兴”。它激发了包互用性、标准命名约定、编码标准的采用、覆盖测试的提升。它是任何现代PHP应用中的一个基本工具。
|
||||
|
||||
### 加速和创新的需要 ###
|
||||
|
||||
如今,PHP社区有一个生机勃勃应用和库的生态系统,有一些被广泛安装的PHP应用包括WordPress,Drupal,Joomla和MediaWiki。从小型的夫妻店站点到whitehouse.gov和Wikipeida,这些应用支撑了各种不同规模的业务的网站。在Alexa前十的站点中,有6个使用PHP,在一天内为数十亿的页面访问提供服务。因此,PHP应用已成为需要加速的首选,并且许多创新也加入到PHP的核心来提升性能。
|
||||
|
||||
在2010年,Facebook公开了其用作PHP源对源的编译器的HipHop,可以翻译PHP代码为C++代码,并且编译为一个单独的可执行二进制应用。Facebook的规模和成长需要从标准互用的PHP代码迁移到更快、最佳的可执行的代码。尽管如此,由于PHP的易用和快速开发周期,Facebook还想继续使用PHP。HipHop后来进化为HHVM,这是一个针对PHP的JIT(just-in-time)编译基础的执行引擎,其包含一个基于PHP的新的语言:[Hack][7]。
|
||||
|
||||
Facebook的创新以及其他的VM项目是在引擎水平上的比较,其引起了关于Zend引擎未来的讨论。Zend引擎依然是PHP的内核和语言规范。在2014年,它创建了一个语言规范项目,“提供一个完整的,简明的语句定义,和PHP语言的语义学”,使得对编译器项目来说,创建互用的PHP实现成为可能。
|
||||
|
||||
下一个PHP的主要版本成为了激烈争论的话题,他们提出了一个叫做phpng(下一代)的项目,来清理,重构,优化和改进PHP代码基础,这也展示了对实际应用的性能的实质提升。由于之前有一个未发布的PHP 6.0版本,因此在决定命名下一个主要版本叫做“PHP 7”后,就合并了phpng分支,并制定了开发PHP 7的计划,以增加很多语言中拥有的功能,如scalar和返回类型提示。
|
||||
|
||||
随着[今天第一版PHP 7 alpha发布][8],基准检测程序显示她在许多方面[与HHVM的一样好或者拥有更好的性能][9],PHP正与现代网络开发需求保持一致的步伐。同样地,PHP-FIG继续创新和推动框架与库的协作 -- 最近由于[PSR-7][10]的采纳,这将会改变PHP项目处理HTTP的方式。用户组、会议、公众和如[PHPMentoring.org][11]这样的布道者继续在PHP开发者社区提倡最好的操作、编码标准和测试。
|
||||
|
||||
PHP从各个方面见证了网络的成熟,而且PHP自己也成熟了。曾经一个简单的低级C语言库的API封装,PHP以她自己的方式,已经成为一个羽翼丰满的编程语言。她的开发者社区是一个充满生气、乐于助人、在实用方面引以为傲,并且欢迎新人的地方。PHP已经经受了20年的考验,而且目前在语言与社区里的活跃性,会保证她在接下来的几年里将会是一个密切相关的、积极有用的的语言。
|
||||
|
||||
在Rasmus Lerdorf的SunshinePHP的演讲中,他回忆到,“我会想到我会在20年之后讨论当初做的这个愚蠢的小项目吗?没有。”
|
||||
|
||||
这里向Lerdorf和PHP社区的其他人致敬,感谢他们把这个“愚蠢的小项目”变成了一个如今网络上持久、强大的组件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2933858/php/php-at-20-from-pet-project-to-powerhouse.html
|
||||
|
||||
作者:[Ben Ramsey][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Ben-Ramsey/
|
||||
[1]:https://www.flickr.com/photos/jurvetson/13049862325
|
||||
[2]:https://groups.google.com/d/msg/comp.infosystems.www.authoring.cgi/PyJ25gZ6z7A/M9FkTUVDfcwJ
|
||||
[3]:http://w3techs.com/technologies/overview/programming_language/all
|
||||
[4]:http://web.archive.org/web/20061215165756/http://chiphpug.php.net/mpug.htm
|
||||
[5]:http://www.phpdeveloper.org/
|
||||
[6]:http://www.php-fig.org/
|
||||
[7]:http://www.infoworld.com/article/2610885/facebook-q-a--hack-brings-static-typing-to-php-world.html
|
||||
[8]:https://wiki.php.net/todo/php70#timetable
|
||||
[9]:http://talks.php.net/velocity15
|
||||
[10]:http://www.php-fig.org/psr/psr-7/
|
||||
[11]:http://phpmentoring.org/
|
||||
|
||||
433
published/20150617 The Art of Command Line.md
Normal file
433
published/20150617 The Art of Command Line.md
Normal file
@ -0,0 +1,433 @@
|
||||
命令行艺术
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
流畅地使用命令行是一个常被忽略的技能,或被认为是神秘的奥义。但是,它会以明显而微妙的方式改善你作为工程师的灵活度和生产力。这是我在 Linux 上工作时发现的有用的命令行使用小窍门和笔记的精粹。有些小窍门是很基础的,而有些是相当地特别、复杂、或者晦涩难懂。这篇文章不长,但是如果你可以使用并记得这里的所有内容,那么你就懂得很多了。
|
||||
|
||||
其中大部分[最初](http://www.quora.com/What-are-some-lesser-known-but-useful-Unix-commands)[出现](http://www.quora.com/What-are-the-most-useful-Swiss-army-knife-one-liners-on-Unix)在[Quora](http://www.quora.com/What-are-some-time-saving-tips-that-every-Linux-user-should-know)上,但是考虑到兴趣所在,似乎更应该放到 Github 上,这里的人比我更能提出改进建议。如果你看到一个错误,或者更好的某种东西,请提交问题或 PR!(当然,提交前请看看必读小节和已有的 PR/Issue。)
|
||||
|
||||
## 必读
|
||||
|
||||
范围:
|
||||
|
||||
- 本文是针对初学者和专业人员的,选题目标是覆盖面广(全都很重要)、有针对性(大多数情况下都给出具体实例)而简洁(避免不必要内容以及你能在其它地方轻松找到的离题的内容)。每个小窍门在某种情形下都很必需的,或者能比替代品大大节省时间。
|
||||
- 这是为 Linux 写的。绝大部分条目都可以同样应用到 MacOS(或者甚至 Cygwin)。
|
||||
- 主要针对交互式 Bash,尽管大多数小窍门也可以应用到其它 shell,以及常规 Bash 脚本。
|
||||
- 包括了“标准的”UNIX 命令以及那些需要安装的软件包(它们很重要,值得安装)。
|
||||
|
||||
注意:
|
||||
|
||||
- 为了能在一篇文章内展示尽量多的东西,一些具体的信息会被放到引用页里。你可以使用 Google 来获得进一步的内容。(如果需要的话,)你可以使用 `apt-get`/`yum`/`dnf`/`pacman`/`pip`/`brew` 来安装这些新的程序。
|
||||
- 使用 [Explainshell][1] 来获取命令、参数、管道等内容的解释。
|
||||
|
||||
## 基础
|
||||
|
||||
- 学习基本 Bash 技能。实际上,键入`man bash`,然后至少浏览一遍所有内容;它很容易理解,没那么长。其它 shell 也不错,但是 Bash 很强大,而且到处都可以找到(如果在你自己的笔记本上*只*学习 zsh、fish 之类,会在很多情形下受到限制,比如使用现存的服务器时)。
|
||||
|
||||
- 至少学好一种基于文本的编辑器。理想的一个是 Vim(`vi`),因为在终端中编辑时随时都能找到它(即使大多数时候你在使用 Emacs、一个大型的 IDE、或一个现代的时髦编辑器)。
|
||||
|
||||
- 学习怎样使用 `man` 来阅读文档(好奇的话,用 `man man` 来列出分区号,比如 1 是常规命令,5 是文件描述,8 用于管理员)。用 `apropos` 找到帮助页。了解哪些命令不是可执行程序,而是 Bash 内置的,你可以用 `help` 和 `help -d` 得到帮助。
|
||||
|
||||
- 学习使用 `>` 和 `<` 来进行输出和输入重定向,以及使用 `|` 来管道重定向,学习关于 stdout 和 stderr 的东西。
|
||||
|
||||
- 学习 `*`(也许还有 `?` 和 `{`...`}` )文件通配扩展和应用,以及双引号 `"` 和单引号 `'` 之间的区别。(更多内容请参看下面关于变量扩展部分)。
|
||||
|
||||
- 熟悉 Bash 作业管理:`&`, **ctrl-z**, **ctrl-c**, `jobs`, `fg`, `bg`, `kill` 等等。
|
||||
|
||||
- 掌握`ssh`,以及通过 `ssh-agent`,`ssh-add` 等进行无密码验证的基础技能。
|
||||
|
||||
- 基本的文件管理:`ls` 和 `ls -l`(特别是,知道`ls -l`各个列的意义),`less`, `head`, `tail` 和 `tail -f`(或者更好的`less +F`),`ln` 和 `ln -s`(知道硬链接和软链接的区别,以及硬链接相对于软链接的优势),`chown`,`chmod`,`du`(用于查看磁盘使用率的快速摘要:`du -sk *`)。文件系统管理:`df`, `mount`,`fdisk`,`mkfs`,`lsblk`。
|
||||
|
||||
- 基本的网络管理: `ip` 或 `ifconfig`,`dig`。
|
||||
|
||||
- 熟知正则表达式,以及各种使用`grep`/`egrep`的选项。`-i`,`-o`,`-A` 和 `-B` 选项值得掌握。
|
||||
|
||||
- 学会使用 `apt-get`,`yum` ,`dnf` 或 `pacman`(这取决于你的发行版)来查找并安装软件包。确保你可以用 `pip` 来安装基于 Python 的命令行工具(下面的一些东西可以很容易地通过 `pip` 安装)。
|
||||
|
||||
|
||||
## 日常使用
|
||||
|
||||
- 在Bash中,使用 **tab** 补完参数,使用 **ctrl-r** 来搜索命令历史。
|
||||
|
||||
- 在Bash中,使用 **ctrl-w** 来删除最后的单词,使用 **ctrl-u** 来删除整行,返回行首。使用 **alt-b** 和 **alt-f** 来逐词移动,使用 **ctrl-k** 来清除到行尾的内容,以及使用 **ctrl-l** 清屏。参见 `man readline` 来查看 Bash 中所有默认的键盘绑定,有很多。例如,**alt-.** 可以循环显示先前的参数,而**alt-** 扩展通配。(LCTT 译注:关于 Bash 下的快捷键,可以参阅: https://linux.cn/article-5660-1.html )
|
||||
|
||||
- 另外,如果你喜欢 vi 风格的键盘绑定,可以使用 `set -o vi`。
|
||||
|
||||
- 要查看最近用过的命令,请使用 `history` 。 有许多缩写形式,比如 `!$`(上次的参数)和`!!`(上次的命令),虽然使用 `ctrl-r` 和 `alt-.` 更容易些。(LCTT 译注:关于历史扩展功能,可以参阅: https://linux.cn/article-5658-1.html )
|
||||
|
||||
- 返回先前的工作目录: `cd -`
|
||||
|
||||
- 如果你命令输入到一半,但是改变主意了,可以敲 **alt-#** 来添加一个 `#` 到开头,然后将该命令作为注释输入(或者使用快捷键 **ctrl-a**, **#**,**enter** 输入)。然后,你可以在后面通过命令历史来回到该命令。
|
||||
|
||||
- 使用 `xargs`(或 `parallel`),它很强大。注意,你可以控制每行(`-L`)执行多少个项目,以及并行执行(`-P`)。如果你不确定它是否会做正确的事情,可以首先使用 `xargs echo`。同时,使用 `-I{}` 也很方便。样例:
|
||||
```bash
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- `pstree -p` 对于显示进程树很有帮助。
|
||||
|
||||
- 使用 `pgrep` 和 `pkill` 来按名称查找进程或给指定名称的进程发送信号(`-f` 很有帮助)。
|
||||
|
||||
- 掌握各种可以发送给进程的信号。例如,要挂起进程,可以使用 `kill -STOP [pid]`。完整的列表可以查阅 `man 7 signal`。
|
||||
|
||||
- 如果你想要一个后台进程一直保持运行,使用 `nohup` 或 `disown`。
|
||||
|
||||
- 通过 `netstat -lntp` 或 `ss -plat` 检查哪些进程在监听(用于 TCP,对 UDP 使用 `-u` 替代 `-t`)。
|
||||
|
||||
- `lsof`来查看打开的套接字和文件。
|
||||
|
||||
- 在 Bash 脚本中,使用 `set -x` 调试脚本输出。尽可能使用严格模式。使用 `set -e` 在遇到错误时退出。也可以使用 `set -o pipefail`,对错误进行严格处理(虽然该话题有点微妙)。对于更复杂的脚本,也可以使用 `trap`。
|
||||
|
||||
- 在 Bash 脚本中,子 shell(写在括号中的)是组合命令的便利的方式。一个常见的例子是临时移动到一个不同的工作目录,如:
|
||||
```bash
|
||||
# 在当前目录做些事
|
||||
(cd /some/other/dir; other-command)
|
||||
# 继续回到原目录
|
||||
```
|
||||
|
||||
- 注意,在 Bash 中有大量的各种各样的变量扩展。检查一个变量是否存在:`${name:?error message}`。例如,如果一个Bash脚本要求一个单一参数,只需写 `input_file=${1:?usage: $0 input_file}`。算术扩展:`i=$(( (i + 1) % 5 ))`。序列: `{1..10}`。修剪字符串:`${var%suffix}` 和 `${var#prefix}`。例如,if `var=foo.pdf` ,那么 `echo ${var%.pdf}.txt` 会输出 `foo.txt`。
|
||||
|
||||
- 命令的输出可以通过 `<(some command)` 作为一个文件来处理。例如,将本地的 `/etc/hosts` 和远程的比较:
|
||||
```sh
|
||||
diff /etc/hosts <(ssh somehost cat /etc/hosts)
|
||||
```
|
||||
|
||||
- 了解 Bash 中的“嵌入文档”,就像在 `cat <<EOF ...` 中。
|
||||
|
||||
- 在 Bash 中,通过:`some-command >logfile 2>&1` 同时重定向标准输出和标准错误。通常,要确保某个命令不再为标准输入打开文件句柄,而是将它捆绑到你所在的终端,添加 `</dev/null` 是个不错的做法。
|
||||
|
||||
- `man ascii` 可以得到一个不错的ASCII表,带有十六进制和十进制值两种格式。对于常规编码信息,`man unicode`,`man utf-8` 和 `man latin1` 将很有帮助。
|
||||
|
||||
- 使用 `screen` 或 `tmux` 来复用屏幕,这对于远程 ssh 会话尤为有用,使用它们来分离并重连到会话。另一个只用于保持会话的最小可选方案是 `dtach`。
|
||||
|
||||
- 在 ssh 中,知道如何使用 `-L` 或 `-D`(偶尔也用`-R`)来打开端口通道是很有用的,如从一台远程服务器访问网站时。
|
||||
|
||||
- 为你的 ssh 配置进行优化很有用;例如,这个 `~/.ssh/config` 包含了可以避免在特定网络环境中连接被断掉的情况的设置、使用压缩(这对于通过低带宽连接使用 scp 很有用),以及使用一个本地控制文件来开启到同一台服务器的多通道:
|
||||
```
|
||||
TCPKeepAlive=yes
|
||||
ServerAliveInterval=15
|
||||
ServerAliveCountMax=6
|
||||
Compression=yes
|
||||
ControlMaster auto
|
||||
ControlPath /tmp/%r@%h:%p
|
||||
ControlPersist yes
|
||||
```
|
||||
|
||||
- 其它一些与 ssh 相关的选项对会影响到安全,请小心开启,如各个子网或主机,或者在信任的网络中:`StrictHostKeyChecking=no`, `ForwardAgent=yes`
|
||||
|
||||
- 要获得八进制格式的文件的权限,这对于系统配置很有用而用 `ls` 又没法查看,而且也很容易搞得一团糟,可以使用像这样的东西:
|
||||
```sh
|
||||
stat -c '%A %a %n' /etc/timezone
|
||||
```
|
||||
|
||||
- 对于从另一个命令的输出结果中交互选择值,可以使用[`percol`](https://github.com/mooz/percol)。
|
||||
|
||||
- 对于基于另一个命令(如`git`)输出的文件交互,可以使用`fpp` ([路径选择器](https://github.com/facebook/PathPicker))。
|
||||
|
||||
- 要为当前目录(及子目录)中的所有文件构建一个简单的 Web 服务器,让网络中的任何人都可以获取,可以使用:
|
||||
`python -m SimpleHTTPServer 7777` (使用端口 7777 和 Python 2)。
|
||||
|
||||
|
||||
## 处理文件和数据
|
||||
|
||||
- 要在当前目录中按名称定位文件,`find . -iname '*something*'`(或者相类似的)。要按名称查找任何地方的文件,使用 `locate something`(但请记住,`updatedb` 可能还没有索引最近创建的文件)。
|
||||
|
||||
- 对于源代码或数据文件进行的常规搜索(要比 `grep -r` 更高级),使用 [`ag`](https://github.com/ggreer/the_silver_searcher)。
|
||||
|
||||
- 要将 HTML 转成文本:`lynx -dump -stdin`。
|
||||
|
||||
- 对于 Markdown、HTML,以及各种类型的文档转换,可以试试 [`pandoc`](http://pandoc.org/)。
|
||||
|
||||
- 如果你必须处理 XML,`xmlstarlet` 虽然有点老旧,但是很好用。
|
||||
|
||||
- 对于 JSON,使用`jq`。
|
||||
|
||||
- 对于 Excel 或 CSV 文件,[csvkit](https://github.com/onyxfish/csvkit) 提供了 `in2csv`,`csvcut`,`csvjoin`,`csvgrep` 等工具。
|
||||
|
||||
- 对于亚马逊 S3 ,[`s3cmd`](https://github.com/s3tools/s3cmd) 会很方便,而 [`s4cmd`](https://github.com/bloomreach/s4cmd) 则更快速。亚马逊的 [`aws`](https://github.com/aws/aws-cli) 则是其它 AWS 相关任务的必备。
|
||||
|
||||
- 掌握 `sort` 和 `uniq`,包括 uniq 的 `-u` 和 `-d` 选项——参见下面的单行程序。
|
||||
|
||||
- 掌握 `cut`,`paste` 和 `join`,它们用于处理文本文件。很多人会使用 `cut`,但常常忘了 `join`。
|
||||
|
||||
- 了解 `tee`,它会将 stdin 同时复制到一个文件和 stdout,如 `ls -al | tee file.txt`。
|
||||
|
||||
- 知道 locale 会以微妙的方式对命令行工具产生大量的影响,包括排序的顺序(整理)以及性能。大多数安装好的 Linux 会设置 `LANG` 或其它 locale 环境变量为本地设置,比如像 US English。但是,你要明白,如果改变了本地环境,那么排序也将改变。而且 i18n 过程会让排序或其它命令的运行慢*好多倍*。在某些情形中(如像下面那样的设置操作或唯一性操作),你可以安全地整个忽略缓慢的 i18n 过程,然后使用传统的基于字节的排序顺序 `export LC_ALL=C`。
|
||||
|
||||
- 了解基本的改动数据的 `awk` 和 `sed` 技能。例如,计算某个文本文件第三列所有数字的和:`awk '{ x += $3 } END { print x }'`。这可能比 Python 的同等操作要快3倍,而且要短3倍。
|
||||
|
||||
- 在一个或多个文件中,替换所有出现在特定地方的某个字符串:
|
||||
```sh
|
||||
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
|
||||
```
|
||||
|
||||
- 要立即根据某个模式对大量文件重命名,使用 `rename`。对于复杂的重命名,[`repren`](https://github.com/jlevy/repren) 可以帮助你达成。
|
||||
```sh
|
||||
# 恢复备份的文件名 foo.bak -> foo:
|
||||
rename 's/\.bak$//' *.bak
|
||||
# 文件和目录的全名 foo -> bar:
|
||||
repren --full --preserve-case --from foo --to bar .
|
||||
```
|
||||
|
||||
- 使用 `shuf` 来从某个文件中打乱或随机选择行。
|
||||
|
||||
- 了解 `sort` 的选项。知道这些键是怎么工作的(`-t`和`-k`)。特别是,注意你需要写`-k1,1`来只通过第一个字段排序;`-k1`意味着根据整行排序。
|
||||
|
||||
- 稳定排序(`sort -s`)会很有用。例如,要首先按字段2排序,然后再按字段1排序,你可以使用 `sort -k1,1 | sort -s -k2,2`
|
||||
|
||||
- 如果你曾经需要在 Bash 命令行中写一个水平制表符(如,用于 -t 参数的排序),按**ctrl-v** **[Tab]**,或者写`$'\t'`(后面的更好,因为你可以复制/粘贴)。
|
||||
|
||||
- 对源代码进行补丁的标准工具是 `diff` 和 `patch`。 用 `diffstat` 来统计 diff 情况。注意 `diff -r` 可以用于整个目录,所以可以用 `diff -r tree1 tree2 | diffstat` 来统计(两个目录的)差异。
|
||||
|
||||
- 对于二进制文件,使用 `hd` 进行简单十六进制转储,以及 `bvi` 用于二进制编辑。
|
||||
|
||||
- 还是用于二进制文件,`strings`(加上 `grep` 等)可以让你找出一点文本。
|
||||
|
||||
- 对于二进制文件的差异(delta 压缩),可以使用 `xdelta3`。
|
||||
|
||||
- 要转换文本编码,试试 `iconv` 吧,或者对于更高级的用途使用 `uconv`;它支持一些高级的 Unicode 的东西。例如,这个命令可以转换为小写并移除所有重音符号(通过扩展和丢弃):
|
||||
```sh
|
||||
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
|
||||
```
|
||||
|
||||
- 要将文件分割成几个部分,来看看 `split`(按大小分割)和 `csplit`(按格式分割)吧。
|
||||
|
||||
- 使用 `zless`,`zmore`,`zcat` 和 `zgrep` 来操作压缩文件。
|
||||
|
||||
## 系统调试
|
||||
|
||||
- 对于 Web 调试,`curl` 和 `curl -I` 很方便灵活,或者也可以使用它们的同行 `wget`,或者更现代的 [`httpie`](https://github.com/jakubroztocil/httpie)。
|
||||
|
||||
- 要了解磁盘、CPU、网络的状态,使用 `iostat`,`netstat`,`top`(或更好的 `htop`)和(特别是)`dstat`。它们对于快速获知系统中发生的状况很好用。
|
||||
|
||||
- 对于更深层次的系统总览,可以使用 [`glances`](https://github.com/nicolargo/glances)。它会在一个终端窗口中为你呈现几个系统层次的统计数据,对于快速检查各个子系统很有帮助。
|
||||
|
||||
- 要了解内存状态,可以运行 `free` 和 `vmstat`,看懂它们的输出结果吧。特别是,要知道“cached”值是Linux内核为文件缓存所占有的内存,因此,要有效地统计“free”值。
|
||||
|
||||
- Java 系统调试是一件截然不同的事,但是对于 Oracle 系统以及其它一些 JVM 而言,不过是一个简单的小把戏,你可以运行 `kill -3 <pid>`,然后一个完整的堆栈追踪和内存堆的摘要(包括常规的垃圾收集细节,这很有用)将被转储到stderr/logs。
|
||||
|
||||
- 使用 `mtr` 作路由追踪更好,可以识别网络问题。
|
||||
|
||||
- 对于查看磁盘满载的原因,`ncdu` 会比常规命令如 `du -sh *` 更节省时间。
|
||||
|
||||
- 要查找占用带宽的套接字和进程,试试 `iftop` 或 `nethogs` 吧。
|
||||
|
||||
- (Apache附带的)`ab`工具对于临时应急检查网络服务器性能很有帮助。对于更复杂的负载测试,可以试试 `siege`。
|
||||
|
||||
- 对于更仔细的网络调试,可以用 `wireshark`,`tshark` 或 `ngrep`。
|
||||
|
||||
- 掌握 `strace` 和 `ltrace`。如果某个程序失败、挂起或崩溃,而你又不知道原因,或者如果你想要获得性能的大概信息,这些工具会很有帮助。注意,分析选项(`-c`)和使用 `-p` 关联运行进程。
|
||||
|
||||
- 掌握 `ldd` 来查看共享库等。
|
||||
|
||||
- 知道如何使用 `gdb` 来连接到一个运行着的进程并获取其堆栈追踪信息。
|
||||
|
||||
- 使用 `/proc`。当调试当前的问题时,它有时候出奇地有帮助。样例:`/proc/cpuinfo`,`/proc/xxx/cwd`,`/proc/xxx/exe`,`/proc/xxx/fd/`,`/proc/xxx/smaps`。
|
||||
|
||||
- 当调试过去某个东西为何出错时,`sar` 会非常有帮助。它显示了 CPU、内存、网络等的历史统计数据。
|
||||
|
||||
- 对于更深层的系统和性能分析,看看 `stap` ([SystemTap](https://sourceware.org/systemtap/wiki)),[`perf`](http://en.wikipedia.org/wiki/Perf_(Linux)) 和 [`sysdig`](https://github.com/draios/sysdig) 吧。
|
||||
|
||||
- 确认是正在使用的 Linux 发行版版本(支持大多数发行版):`lsb_release -a`。
|
||||
|
||||
- 每当某个东西的行为异常时(可能是硬件或者驱动器问题),使用`dmesg`。
|
||||
|
||||
## 单行程序
|
||||
|
||||
这是将命令连成一行的一些样例:
|
||||
|
||||
- 有时候通过 `sort`/`uniq` 对文本文件做交集、并集和差集运算时,这个例子会相当有帮助。假定 `a` 和 `b` 是已经进行了唯一性处理的文本文件。这会很快,而且可以处理任意大小的文件,总计可达数千兆字节。(Sort不受内存限制,不过如果 `/tmp` 放在一个很小的根分区的话,你可能需要使用 `-T` 选项。)也可参见上面关于`LC_ALL`的注解和 `-u` 选项(参见下面例子更清晰)。
|
||||
|
||||
```bash
|
||||
cat a b | sort | uniq > c # c 是 a 和 b 的并集
|
||||
cat a b | sort | uniq -d > c # c 是 a 和 b 的交集
|
||||
cat a b b | sort | uniq -u > c # c 是 a 减去 b 的差集
|
||||
```
|
||||
- 使用 `grep . *` 来可视化查看一个目录中的所有文件的所有内容,例如,对于放满配置文件的目录: `/sys`, `/proc`, `/etc`。
|
||||
|
||||
- 对某个文本文件的第三列中所有数据进行求和(该例子可能比同等功能的Python要快3倍,而且代码也少于其3倍):
|
||||
```sh
|
||||
awk '{ x += $3 } END { print x }' myfile
|
||||
```
|
||||
|
||||
- 如果想要查看某个文件树的大小/日期,该例子就像一个递归`ls -l`,但是比`ls -lR`要更容易读懂:
|
||||
```sh
|
||||
find . -type f -ls
|
||||
```
|
||||
|
||||
- 只要可以,请使用 `xargs` 或 `parallel`。注意,你可以控制每行(`-L`)执行多少个项目,以及并行执行(`-P`)。如果你不确定它是否会做正确的事情,可以首先使用 `xargs echo`。同时,使用 `-I{}` 也很方便。样例:
|
||||
```sh
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- 比如说,你有一个文本文件,如 Web 服务器的日志,在某些行中出现了某个特定的值,如 URL 中出现的 `acct_id` 参数。如果你想要统计有多少个 `acct_id` 的请求:
|
||||
```sh
|
||||
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
|
||||
```
|
||||
|
||||
- 运行该函数来获得来自本文的随机提示(解析Markdown并从中提取某个项目):
|
||||
```sh
|
||||
function taocl() {
|
||||
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README.md |
|
||||
pandoc -f markdown -t html |
|
||||
xmlstarlet fo --html --dropdtd |
|
||||
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
|
||||
xmlstarlet unesc | fmt -80
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 晦涩难懂,但却有用
|
||||
|
||||
- `expr`:实施算术或布林操作,或者求正则表达式的值
|
||||
|
||||
- `m4`:简单的宏处理器
|
||||
|
||||
- `yes`:大量打印一个字符串
|
||||
|
||||
- `cal`:漂亮的日历
|
||||
|
||||
- `env`:(以特定的环境变量设置)运行一个命令(脚本中很有用)
|
||||
|
||||
- `look`:查找以某个字符串开头的英文单词(或文件中的行)
|
||||
|
||||
- `cut ` 和 `paste` 以及 `join`:数据处理
|
||||
|
||||
- `fmt`:格式化文本段落
|
||||
|
||||
- `pr`:格式化文本为页/列
|
||||
|
||||
- `fold`:文本折行
|
||||
|
||||
- `column`:格式化文本为列或表
|
||||
|
||||
- `expand` 和 `unexpand`:在制表符和空格间转换
|
||||
|
||||
- `nl`:添加行号
|
||||
|
||||
- `seq`:打印数字
|
||||
|
||||
- `bc`:计算器
|
||||
|
||||
- `factor`:分解质因子
|
||||
|
||||
- `gpg`:加密并为文件签名
|
||||
|
||||
- `toe`:terminfo 条目表
|
||||
|
||||
- `nc`:网络调试和数据传输
|
||||
|
||||
- `socat`:套接字中继和 tcp 端口转发(类似 `netcat`)
|
||||
|
||||
- `slurm`:网络流量可视化
|
||||
|
||||
- `dd`:在文件或设备间移动数据
|
||||
|
||||
- `file`:识别文件类型
|
||||
|
||||
- `tree`:以树形显示目录及子目录;类似 `ls`,但是是递归的。
|
||||
|
||||
- `stat`:文件信息
|
||||
|
||||
- `tac`:逆序打印文件
|
||||
|
||||
- `shuf`:从文件中随机选择行
|
||||
|
||||
- `comm`:逐行对比分类排序的文件
|
||||
|
||||
- `hd`和`bvi`:转储或编辑二进制文件
|
||||
|
||||
- `strings`:从二进制文件提取文本
|
||||
|
||||
- `tr`:字符转译或处理
|
||||
|
||||
- `iconv `或`uconv`:文本编码转换
|
||||
|
||||
- `split `和`csplit`:分割文件
|
||||
|
||||
- `units`:单位转换和计算;将每双周(fortnigh)一浪(浪,furlong,长度单位,约201米)转换为每瞬(blink)一缇(缇,twip,一种和屏幕无关的长度单位)(参见: /usr/share/units/definitions.units)(LCTT 译注:这都是神马单位啊!)
|
||||
|
||||
- `7z`:高比率文件压缩
|
||||
|
||||
- `ldd`:动态库信息
|
||||
|
||||
- `nm`:目标文件的符号
|
||||
|
||||
- `ab`:Web 服务器基准测试
|
||||
|
||||
- `strace`:系统调用调试
|
||||
|
||||
- `mtr`:用于网络调试的更好的路由追踪软件
|
||||
|
||||
- `cssh`:可视化并发 shell
|
||||
|
||||
- `rsync`:通过 SSH 同步文件和文件夹
|
||||
|
||||
- `wireshark` 和 `tshark`:抓包和网络调试
|
||||
|
||||
- `ngrep`:从网络层摘取信息
|
||||
|
||||
- `host` 和 `dig`:DNS查询
|
||||
|
||||
- `lsof`:处理文件描述符和套接字信息
|
||||
|
||||
- `dstat`:有用的系统统计数据
|
||||
|
||||
- [`glances`](https://github.com/nicolargo/glances):高级,多个子系统概览
|
||||
|
||||
- `iostat`:CPU和磁盘使用率统计
|
||||
|
||||
- `htop`:top的改进版
|
||||
|
||||
- `last`:登录历史
|
||||
|
||||
- `w`:谁登录进来了
|
||||
|
||||
- `id`:用户/组身份信息
|
||||
|
||||
- `sar`:历史系统统计数据
|
||||
|
||||
- `iftop`或`nethogs`:按套接口或进程的网络使用率
|
||||
|
||||
- `ss`:套接口统计数据
|
||||
|
||||
- `dmesg`:启动和系统错误信息
|
||||
|
||||
- `hdparm`:SATA/ATA 磁盘操作/改善性能
|
||||
|
||||
- `lsb_release`:Linux 发行版信息
|
||||
|
||||
- `lsblk`:列出块设备,以树形展示你的磁盘和分区
|
||||
|
||||
- `lshw`:硬件信息
|
||||
|
||||
- `fortune`,`ddate` 和 `sl`:嗯,好吧,它取决于你是否认为蒸汽机车和 Zippy 引用“有用”
|
||||
|
||||
|
||||
## 更多资源
|
||||
|
||||
- [超棒的shell](https://github.com/alebcay/awesome-shell): 一个shell工具和资源一览表。
|
||||
- [严格模式](http://redsymbol.net/articles/unofficial-bash-strict-mode/) 用于写出更佳的shell脚本。
|
||||
|
||||
|
||||
## 免责声明
|
||||
|
||||
除了非常小的任务外,其它都写出了代码供大家阅读。伴随力量而来的是责任。事实是,你*能*在Bash中做的,并不意味着是你所应该做的!;)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/jlevy/the-art-of-command-line
|
||||
|
||||
作者:[jlevy][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jlevy
|
||||
[1]:http://explainshell.com/
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
Linux 4.1 带来了什么新东西?
|
||||
================================================================================
|
||||
**一个新的Linux内核已经发布了 - 全世界为之心跳(我们想把它说的诗意一些)**
|
||||
|
||||
Linus Torvalds(除了他不会有谁了)在Linux邮件列表(当然不会在别的地方)中[宣布][1],在大概两个月后迎来了[第一个4.x系列的Linux内核的发布][2]。
|
||||
|
||||
像每次发布前那样,Linux 4.1带来了很多的改变。它们包括了硬件兼容性、电源管理、文件系统性能、以及你从没听说过的处理器的技术修复。
|
||||
|
||||
Linux 4.1 已经进入将在10月发布的 Ubuntu 15.10 。
|
||||
|
||||
### Linux 4.1 有哪些新东西 ###
|
||||
|
||||

|
||||
|
||||
*Tux 收到了邮件*
|
||||
|
||||
这个标题只是说说而已,我们不是简单地将发布公告贴到这里。
|
||||
|
||||
我们会从(大量、冗长以及那些不明觉厉的的技术的)更改日志去挑选一些对桌面用户而言,不见得夸张但或许有用的亮点。
|
||||
|
||||
#### 电源管理 ####
|
||||
|
||||
你可以在Linux 4.1中找到的面向用户的一大特性是对 Intel 的 Cherry Trail 和 Bay Trai 芯片、Soc及Intel计算棒等设备的性能及能效的提升。
|
||||
|
||||
传闻建议是Linux 4.1给出了新的Intel硬件组合,和更长电池寿命。这么多的进步自然不可能针对所有芯片,它只对特定芯片和系统(和高端的)有用,但仍旧是一个令人兴奋的消息。
|
||||
|
||||
**Linux 4.1 亮点包括:**
|
||||
|
||||
- ext4 有了文件系统层面的加密(感谢Google)
|
||||
- 罗技游戏手柄lg4ff驱动改进了‘力反馈’
|
||||
- 东芝笔记本驱动进行了USB睡眠充电和背光改进
|
||||
- Xbox One控制器支持Rumble
|
||||
- Wacom平板驱动改进了电源报告
|
||||
- 各种针对arm和x86设备电源管理改进
|
||||
- Samsung Exynos 3250 电源管理改进
|
||||
- 支持Bamboo平板
|
||||
- 联想OneLink Pro Dock获得USB支持
|
||||
- 支持Realtek 8723A、 8723B、 8761A、 8821 Wi-Fi网卡
|
||||
|
||||
### Ubuntu中安装Linux 4.1 ###
|
||||
|
||||
虽然这次发布的内核被标记为稳定,但是Ubuntu用户并不需要迫切地安装它。
|
||||
|
||||
但如果你等不及了并且技术足够熟练,你可以从[Canonical的主干内核归档][3]中下载合适的软件包来安装Linux 4.1(或者冒着风险使用第三方PPA)。
|
||||
|
||||
10月发布的Ubuntu 15.10 Wily Werewolf将会基于Ubuntu Kernel 4.1.x(Ubuntu内核是基于Linux内核加上Ubuntu没被上流接受的独有补丁)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/linux-4-1-kernel-new-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://lkml.org/lkml/2015/6/22/8
|
||||
[2]:http://www.omgubuntu.co.uk/2015/04/linux-kernel-4-0-new-features
|
||||
[3]:http://kernel.ubuntu.com/~kernel-ppa/mainline/?C=N;O=D
|
||||
@ -1,127 +0,0 @@
|
||||
Linux Humor on the Command-line
|
||||
================================================================================
|
||||
The desktop is full of eye candy. It enhances the visual experience and, in some cases, can also increase functionality of software. But it also makes software fun. Working on the command-line does not have to be always serious. If you want some fun on the command-line, there are lots of commands to raise a smile.
|
||||
|
||||
Linux is a fun operating system. Linux offers a vast collection of small open source utilities that perform functions ranging from the obvious to the bizarre. It is the quality and selection of these tools that help Linux stand out. Check out these 7 small utilities.
|
||||
|
||||
### lolcat ###
|
||||
|
||||

|
||||
|
||||
lolcat is a program that concatenates files, or standard input, to standard output (like the generic cat), and adds rainbow coloring to it.
|
||||
|
||||
lolcat is often combined with other tools such as toilet or figlet to generate text. This software should not be confused with a lolcat; an image macro of one or more cats.
|
||||
|
||||
lolcat was written by Moe.
|
||||
|
||||
Website: [github.com][1]
|
||||
|
||||
### cowsay ###
|
||||
|
||||

|
||||
|
||||
cowsay is a configurable open source program which generates ASCII pictures of a cow with a message in a speech bubble. cowsay is written in Perl.
|
||||
|
||||
cowsay is not limited to generating pictures of cows. It can generate pre-made images of other animals including a duck, elephant, koala, moose, pony, sheep, stegosaurus, and turkey, as well as cheese, snowman, and a skeleton.
|
||||
|
||||
There is a related program called cowthink, which generates cows with thought bubbles, as opposed to speech bubbles.
|
||||
|
||||
Features include:
|
||||
|
||||
- Make scripts more interesting
|
||||
- Borg mode
|
||||
- Ways to alter the way the cow looks, for example making the cow look greedy, paranoid, stoned, tired, wired, youthful and more
|
||||
- xcowsay variant available
|
||||
|
||||
Website: [nog.net][2]
|
||||
|
||||
### doge ###
|
||||
|
||||

|
||||
|
||||
doge is a simple motd script based on the slightly stupid but very funny doge meme. It prints random grammatically incorrect statements that are sometimes based on things from your computer.
|
||||
|
||||
Doge is an Internet meme that became popular in 2013. The meme typically consists of a picture of a Shiba Inu accompanied by multicolored text in Comic Sans font in the foreground. The text, representing a kind of internal monologue, is deliberately written in a form of broken English.
|
||||
|
||||
- Randomly placed and colored random strings, complete with broken english
|
||||
- Awesome Shibe in the terminal
|
||||
- Fetching of system data, such as hostname, running processes, current user and $EDITOR
|
||||
- If you have lolcat, you can do this gem: while true; do doge | lolcat -a -d 100 -s 100 -p 1; done
|
||||
- stdin support: ls /usr/bin | doge will doge-print some of the executables found in /usr/bin. wow. There are also multiple command line switches that control filtering and statistical frequency of words
|
||||
|
||||
Website: [github.com/thiderman/doge][3]
|
||||
|
||||
### ASCIIQuarium ###
|
||||
|
||||

|
||||
|
||||
ASCIIQuarium is an aquarium/sea animation in ASCII art. Enjoy the fascinating creatures that live in the water from your computer.
|
||||
|
||||
To run ASCIIQuarium you need to have installed Perl's curses package, and the Term::Animation module. To install the former, type sudo apt-get install libcurses-perl. To install the latter, type sudo cpan Term::Animation, both at the command line.
|
||||
|
||||
Features include:
|
||||
|
||||
- Multicolored fish
|
||||
- Amusing animations, including a fish hook
|
||||
- There are swans, ducks, dolphins, and ships too
|
||||
|
||||
Website: [www.robobunny.com][4]
|
||||
|
||||
### sl - Steam Locomotive ###
|
||||
|
||||

|
||||
|
||||
sl is an amusing command line tool that displays animations to correct users who accidentally type sl instead of ls.
|
||||
|
||||
I'm rather sloppy at typing, preferring speed to accuracy. But typos can be a tad dangerous on the command line. So sl can serve as a practical reminder of curing a bad habit of mistyping. It always raises a chuckle too.
|
||||
|
||||
Features include:
|
||||
|
||||
- With -F, train flies
|
||||
- With -l, it shows a small train
|
||||
- With -a, an accident seems to happen
|
||||
|
||||
Website: [github.com/mtoyoda/sl][5]
|
||||
|
||||
### aafire ###
|
||||
|
||||

|
||||
|
||||
aafire displays burning ASCII art flames in the terminal. It demonstrates the the capabilities of the aalib library, an ascii art library.
|
||||
|
||||
Website: [aa-project.sourceforge.net/aalib][6]
|
||||
|
||||
### CMatrix ###
|
||||
|
||||

|
||||
|
||||
CMatrix is an ncurses program that simulates the display from "The Matrix". If you have been living in a cave for the past 15 years, you might not know The Matrix is a 1999 American science fiction acting film starring Keanu Reeves, Laurence Fishburne, Carrie-Anne Moss, Hugo Weaving, and Joe Pantoliano.
|
||||
|
||||
It works with terminal settings up to 132x300 and can scroll lines all at the same rate or asynchronously and at a user-defined speed.
|
||||
|
||||
Features include:
|
||||
|
||||
- Change the text colour
|
||||
- Turn on bold characters
|
||||
- Asynchronous scroll
|
||||
- Use old-style scrolling
|
||||
- "Screensaver" mode
|
||||
|
||||
Website: [www.asty.org/cmatrix][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150614112018846/Humor.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://github.com/busyloop/lolcat
|
||||
[2]:https://web.archive.org/web/20120225123719/http://www.nog.net/%7Etony/warez/cowsay.shtml
|
||||
[3]:https://github.com/thiderman/doge
|
||||
[4]:http://www.robobunny.com/projects/asciiquarium/html/
|
||||
[5]:https://github.com/mtoyoda/sl
|
||||
[6]:http://aa-project.sourceforge.net/aalib/
|
||||
[7]:http://www.asty.org/cmatrix/
|
||||
@ -0,0 +1,153 @@
|
||||
translating by ZTinoZ
|
||||
Screen Capture Made Easy with these Dedicated Tools
|
||||
================================================================================
|
||||
"A picture is worth a thousand words", a phrase which emerged in the USA in the early part of the 20th century, refers to the notion that a single still image can present as much information as a large amount of descriptive text. Essentially, pictures convey information more effectively and efficiently than words can.
|
||||
|
||||
A screenshot (or screengrab) is a snapshot or picture captured by a computer to record the output of a visual device. Screen capture software enable screenshots to be taken on a computer. This type of software has lots of uses. As an image can illustrate the operation of computer software well, screenshots play an important role in software development and documentation. Alternatively, if you have a technical problem with your computer, a screenshot allows a technical support department to understand the problems you are facing. Writing computer-related articles, documentation and tutorials is nigh on impossible without a good tool for creating screenshots. Screenshots are also useful to save snippets of anything you have on your screen, particularly when it can not be easily printed.
|
||||
|
||||
Linux has a good selection of open source dedicated screenshot programs, both graphical and console based. For a feature-rich dedicated screenshot utility, look no further than Shutter. This tool is a superb example of a small open source tool. But there are some great alternatives too.
|
||||
|
||||
Screen capture functionality is not only provided by dedicated applications. GIMP and ImageMagick, two programs which are primarily image manipulation tools, also offer competent screen capturing functionality.
|
||||
|
||||
----------
|
||||
|
||||
### Shutter ###
|
||||
|
||||

|
||||
|
||||
Shutter is a feature-rich screenshot application. You can take a screenshot of a specific area, window, your whole screen, or even of a website - apply different effects to it, draw on it to highlight points, and then upload to an image hosting site, all within one window.
|
||||
|
||||
Features include:
|
||||
|
||||
|
||||
- Take a screenshot of:
|
||||
- a specific area
|
||||
- window
|
||||
- the complete desktop
|
||||
- web pages from a script
|
||||
- Apply different effects to the screenshot
|
||||
- Hotkeys
|
||||
- Print
|
||||
- Take screenshot directly or with a specified delay time
|
||||
- Save the screenshots to a specified directory and name them in a convenient way (using special wild-cards)
|
||||
- Fully integrated into the GNOME Desktop (TrayIcon etc)
|
||||
- Generate thumbnails directly when you are taking a screenshot and set a size level in %
|
||||
- Shutter session collection:
|
||||
- Keep track of all screenshots during session
|
||||
- Copy screeners to clipboard
|
||||
- Print screenshots
|
||||
- Delete screenshots
|
||||
- Rename your file
|
||||
- Upload your files directly to Image-Hosters (e.g. http://ubuntu-pics.de), retrieve all the needed links and share them with others
|
||||
- Edit screenshots directly using the embedded drawing tool
|
||||
|
||||
- Website: [shutter-project.org][1]
|
||||
- Developer: Mario Kemper and Shutter Team
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 0.93.1
|
||||
|
||||
----------
|
||||
|
||||
### HotShots ###
|
||||
|
||||

|
||||
|
||||
HotShots is an application for capturing screens and saving them in a variety of image formats as well as adding annotations and graphical data (arrows, lines, texts, ...).
|
||||
|
||||
You can also upload your creations to the web (FTP/some web services). HotShots is written with Qt.
|
||||
|
||||
HotShots is not available in Ubuntu's Software Center. But it's easy to install by typing at the command line:
|
||||
|
||||
sudo add-apt-repository ppa:ubuntuhandbook1/apps
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install hotshots
|
||||
|
||||
Features include:
|
||||
|
||||
- Simple to use
|
||||
- Full featured
|
||||
- Built-in editor
|
||||
- Hotkeys
|
||||
- Built-in magnification
|
||||
- Freehand and multi-screen capture
|
||||
- Supported Output Formats: Black & Whte (bw), Encapsulated PostScript (eps, epsf), Encapsulated PostScript Interchange (epsi), OpenEXR (exr), PC Paintbrush Exchange (pcx), Photoshop Document (psd), ras, rgb, rgba, Irix RGB (sgi), Truevision Targa (tga), eXperimental Computing Facility (xcf), Windows Bitmap (bmp), DirectDraw Surface (dds), Graphic Interchange Format (gif), Icon Image (ico), Joint Photographic Experts Group 2000 (jp2), Joint Photographic Experts Group (jpeg, jpg), Multiple-image Network Graphics (mng), Portable Pixmap (ppm), Scalable Vector Graphics (svg), svgz, Tagged Image File Format (tif, tiff), webp, X11 Bitmap (xbm), X11 Pixmap (xpm), and Khoros Visualization (xv)
|
||||
- Internationalization support: Basque, Chinese, Czech, French, Galician, German, Greek, Italian, Japanese, Lithuanian, Polish, Portuguese, Romanian, Russian, Serbian, Singhalese, Slovak, Spanish, Turkish, Ukrainian, and Vietnamese
|
||||
|
||||
- Website: [thehive.xbee.net][2]
|
||||
- Developer: xbee
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 2.2.0
|
||||
|
||||
----------
|
||||
|
||||
### ScreenCloud ###
|
||||
|
||||

|
||||
|
||||
ScreenCloud is an easy to use open source screenshot tool.
|
||||
|
||||
With this software, users can take a screenshot using one of the 3 hotkeys or simply click the ScreenCloud tray icon. Users can choose where you want to save the screenshot.
|
||||
|
||||
If you choose to upload your screenshot to the screencloud website, a link will automatically be copied to your clipboard. This can be shared with friends or colleagues via email or in an IM conversation. All they have to do is click the link and look at your screenshot.
|
||||
|
||||
Features include:
|
||||
|
||||
- Capture full screen, window or selection
|
||||
- Fast and easy: Snap a photo, paste the link, done
|
||||
- Free hosting of your screenshots
|
||||
- Hotkeys
|
||||
- Set timer delay
|
||||
- Enable 'Capture window borders'
|
||||
- Enable/Disable Notifications
|
||||
- Set app to run on start up
|
||||
- Adjust account/upload/filename/shortcut settings
|
||||
- Cross platform tool
|
||||
- Plugin support, save to Dropbox, Imgur, and more
|
||||
- Supports uploading to FTP and SFTP servers
|
||||
|
||||
- Website: [screencloud.net][3]
|
||||
- Developer: Olav S Thoresen
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.2.1
|
||||
|
||||
----------
|
||||
|
||||
### KSnapshot ###
|
||||
|
||||

|
||||
|
||||
KSnapshot is a simple utility for taking screenshots. It can capture images of the whole desktop, a single window, a section of a window or a selected region. Images can then be saved in a variety of different formats.
|
||||
|
||||
KSnapshot also allows users to use hotkeys to take a screenshot. Besides saving the screenshot, it can be copied to the clipboard or opened with any program that is associated with image files.
|
||||
|
||||
KSnapshot is part of the KDE 4 graphics module.
|
||||
|
||||
Features include:
|
||||
|
||||
- Save snapshot in multiple formats
|
||||
- Snapshot delay
|
||||
- Exclude window decorations
|
||||
- Copy the snapshot to the clipboard
|
||||
- Hotkeys
|
||||
- Can be scripted using its D-Bus interface
|
||||
|
||||
- Website: [www.kde.org][4]
|
||||
- Developer: KDE, Richard J. Moore, Aaron J. Seigo, Matthias Ettrich
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 0.8.2
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/2015062316235249/ScreenCapture.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://shutter-project.org/
|
||||
[2]:http://thehive.xbee.net/
|
||||
[3]:https://screencloud.net/
|
||||
[4]:https://www.kde.org/applications/graphics/ksnapshot/
|
||||
@ -0,0 +1,158 @@
|
||||
Backup with these DeDuplicating Encryption Tools
|
||||
================================================================================
|
||||
Data is growing both in volume and value. It is becoming increasingly important to be able to back up and restore this information quickly and reliably. As society has adapted to technology and learned how to depend on computers and mobile devices, there are few that can deal with the reality of losing important data. Of firms that suffer the loss of data, 30% fold within a year, 70% cease trading within five years. This highlights the value of data.
|
||||
|
||||
With data growing in volume, improving storage utilization is pretty important. In computing, data deduplication is a specialized data compression technique for eliminating duplicate copies of repeating data. This technique therefore improves storage utilization.
|
||||
|
||||
Data is not only of interest to its creator. Governments, competitors, criminals, snoopers may be very keen to access your data. They might want to steal your data, extort money from you, or see what you are up to. Enryption is essential to protect your data.
|
||||
|
||||
So the solution is a deduplicating encrypting backup software.
|
||||
|
||||
Making file backups is an essential activity for all users, yet many users do not take adequate steps to protect their data. Whether a computer is being used in a corporate environment, or for private use, the machine's hard disk may fail without any warning signs. Alternatively, some data loss occurs as a result of human error. Without regular backups being made, data will inevitably be lost even if the services of a specialist recovery organisation are used.
|
||||
|
||||
This article provides a quick roundup of 6 deduplicating encryption backup tools.
|
||||
|
||||
----------
|
||||
|
||||
### Attic ###
|
||||
|
||||
Attic is a deduplicating, encrypted, authenticated and compressed backup program written in Python. The main goal of Attic is to provide an efficient and secure way to backup data. The data deduplication technique used makes Attic suitable for daily backups since only the changes are stored.
|
||||
|
||||
Features include:
|
||||
|
||||
- Easy to use
|
||||
- Space efficient storage variable block size deduplication is used to reduce the number of bytes stored by detecting redundant data
|
||||
- Optional data encryption using 256-bit AES encryption. Data integrity and authenticity is verified using HMAC-SHA256
|
||||
- Off-site backups with SDSH
|
||||
- Backups mountable as filesystems
|
||||
|
||||
Website: [attic-backup.org][1]
|
||||
|
||||
----------
|
||||
|
||||
### Borg ###
|
||||
|
||||
Borg is a fork of Attic. It is a secure open source backup program designed for efficient data storage where only new or modified data is stored.
|
||||
|
||||
The main goal of Borg is to provide an efficient and secure way to backup data. The data deduplication technique used makes Borg suitable for daily backups since only the changes are stored. The authenticated encryption makes it suitable for backups to not fully trusted targets.
|
||||
|
||||
Borg is written in Python. Borg was created in May 2015 in response to the difficulty of getting new code or larger changes incorporated into Attic.
|
||||
|
||||
Features include:
|
||||
|
||||
- Easy to use
|
||||
- Space efficient storage variable block size deduplication is used to reduce the number of bytes stored by detecting redundant data
|
||||
- Optional data encryption using 256-bit AES encryption. Data integrity and authenticity is verified using HMAC-SHA256
|
||||
- Off-site backups with SDSH
|
||||
- Backups mountable as filesystems
|
||||
|
||||
Borg is not compatible with Attic.
|
||||
|
||||
Website: [borgbackup.github.io/borgbackup][2]
|
||||
|
||||
----------
|
||||
|
||||
### Obnam ###
|
||||
|
||||
Obnam (OBligatory NAMe) is an easy to use, secure Python based backup program. Backups can be stored on local hard disks, or online via the SSH SFTP protocol. The backup server, if used, does not require any special software, on top of SSH.
|
||||
|
||||
Obnam performs de-duplication by splitting up file data into chunks, and storing those individually. Generations are incremental backups; Every backup generation looks like a fresh snapshot, but is really incremental. Obnam is developed by Lars Wirzenius.
|
||||
|
||||
Features include:
|
||||
|
||||
- Easy to use
|
||||
- Snapshot backups
|
||||
- Data de-duplication, across files, and backup generations
|
||||
- Encrypted backups, using GnuPG
|
||||
- Backup multiple clients to a single repository
|
||||
- Backup checkpoints (creates a "save" every 100MBs or so)
|
||||
- Number of options for performance tuning including lru-size and/or upload-queue-size
|
||||
- MD5 checksum algorithm for recognising duplicate data chunks
|
||||
- Store backups to a server via SFTP
|
||||
- Supports both push (i.e. Run on the client) and pull (i.e. Run on the server) methods
|
||||
|
||||
Website: [obnam.org][3]
|
||||
|
||||
----------
|
||||
|
||||
### Duplicity ###
|
||||
|
||||
Duplicity incrementally backs up files and directory by encrypting tar-format volumes with GnuPG and uploading them to a remote (or local) file server. To transmit data it can use ssh/scp, local file access, rsync, ftp, and Amazon S3.
|
||||
|
||||
Because duplicity uses librsync, the incremental archives are space efficient and only record the parts of files that have changed since the last backup. As the software uses GnuPG to encrypt and/or sign these archives, they will be safe from spying and/or modification by the server.
|
||||
|
||||
Currently duplicity supports deleted files, full unix permissions, directories, symbolic links, fifos, etc.
|
||||
|
||||
The duplicity package also includes the rdiffdir utility. Rdiffdir is an extension of librsync's rdiff to directories; it can be used to produce signatures and deltas of directories as well as regular files.
|
||||
|
||||
Features include:
|
||||
|
||||
- Simple to use
|
||||
- Encrypted and signed archives (using GnuPG)
|
||||
- Bandwidth and space efficient, using the rsync algorithm
|
||||
- Standard file format
|
||||
- Choice of remote protocol
|
||||
- Local storage
|
||||
- scp/ssh
|
||||
- ftp
|
||||
- rsync
|
||||
- HSI
|
||||
- WebDAV
|
||||
- Amazon S3
|
||||
|
||||
Website: [duplicity.nongnu.org][4]
|
||||
|
||||
----------
|
||||
|
||||
### ZBackup ###
|
||||
|
||||
ZBackup is a versatile globally-deduplicating backup tool.
|
||||
|
||||
Features include:
|
||||
|
||||
- Parallel LZMA or LZO compression of the stored data. You can mix LZMA and LZO in a repository
|
||||
- Built-in AES encryption of the stored data
|
||||
- Possibility to delete old backup data
|
||||
- Use of a 64-bit rolling hash, keeping the amount of soft collisions to zero
|
||||
- Repository consists of immutable files. No existing files are ever modified
|
||||
- Written in C++ only with only modest library dependencies
|
||||
- Safe to use in production
|
||||
- Possibility to exchange data between repos without recompression
|
||||
- Uses a 64-bit modified Rabin-Karp rolling hash
|
||||
|
||||
Website: [zbackup.org][5]
|
||||
|
||||
----------
|
||||
|
||||
### bup ###
|
||||
|
||||
bup is a program written in Python that backs things up. It's short for "backup". It provides an efficient way to backup a system based on the git packfile format, providing fast incremental saves and global deduplication (among and within files, including virtual machine images).
|
||||
|
||||
bup is released under the LGPL version 2 license.
|
||||
|
||||
Features include:
|
||||
|
||||
- Global deduplication (among and within files, including virtual machine images)
|
||||
- Uses a rolling checksum algorithm (similar to rsync) to split large files into chunks
|
||||
- Uses the packfile format from git
|
||||
- Writes packfiles directly offering fast incremental saves
|
||||
- Can use "par2" redundancy to recover corrupted backups
|
||||
- Mount your bup repository as a FUSE filesystem
|
||||
|
||||
Website: [bup.github.io][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150628060000607/BackupTools.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://attic-backup.org/
|
||||
[2]:https://borgbackup.github.io/borgbackup/
|
||||
[3]:http://obnam.org/
|
||||
[4]:http://duplicity.nongnu.org/
|
||||
[5]:http://zbackup.org/
|
||||
[6]:https://bup.github.io/
|
||||
@ -0,0 +1,69 @@
|
||||
sevenot translating
|
||||
First Stable Version Of Atom Code Editor Has Been Released
|
||||
================================================================================
|
||||

|
||||
|
||||
[Atom 1.0][1] is here. One of the [best open source code editors][2], [Atom][3] was available for public uses for almost a year but this is the first stable version of the most talked about text/code editor of recent times. Promoted as the “hackable text editor for 21st century”, this project of [Github][4] has already been downloaded 1.5 million times in the past and currently it has over 350,000 monthly active users.
|
||||
|
||||
### It’s been a long time ###
|
||||
|
||||
Rome was not built in a day and neither was Atom. Since it was first conceptualized in 2008 till the first stable release this month, it has taken several years and hundreds of contributors from across the globe, along with main developers working on Atom core. A quick look at the journey of Atom can be seen in the picture below:
|
||||
|
||||

|
||||
Image credit: Atom
|
||||
|
||||
### Back to the future ###
|
||||
|
||||
This launch of Atom 1.0 is announced with a retro video showing the capabilities of the editor. Resembling to 70’s science fiction TV series, this will be the coolest video you are going to watch today :)
|
||||
|
||||
注:youtube视频,不行做个链接吧
|
||||
<iframe width="640" height="390" frameborder="0" allowfullscreen="true" src="http://www.youtube.com/embed/Y7aEiVwBAdk?version=3&rel=1&fs=1&showsearch=0&showinfo=1&iv_load_policy=1&wmode=transparent" type="text/html" class="youtube-player"></iframe>
|
||||
|
||||
### Features of Atom text editor ###
|
||||
|
||||
- Cross-platform editing
|
||||
- Built-in package manager
|
||||
- Smart autocompletion
|
||||
- File system browser
|
||||
- Multiple panes
|
||||
- Find and replace
|
||||
- Highly customizable
|
||||
- Modern look
|
||||
|
||||
### Get Atom 1.0 ###
|
||||
|
||||
Atom 1.0 is available for Linux, Windows and Mac OS X. For Debian based Linux distributions such as Ubuntu and Linux Mint, Atom provides .deb binaries. For Fedora, it also has .rpm binaries. You can also get the source code, if you like. The links below will let you download the latest stable version.
|
||||
|
||||
- [Atom .deb][5]
|
||||
- [Atom .rpm][6]
|
||||
- [Atom Source Code][7]
|
||||
|
||||
If you prefer, you can [install Atom in Ubuntu using PPA][8]. The PPA is not official though.
|
||||
|
||||
注:下面是一个调查,可以发布的时候在文章内发布个调查
|
||||
|
||||
#### Are you excited about Atom? ####
|
||||
|
||||
- Oh Yes! This is the best thing that could happen to programmers.
|
||||
- Not really. I have seen better editors.
|
||||
- Don't care. My default text editor does the job just fine.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/atom-stable-released/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://blog.atom.io/2015/06/25/atom-1-0.html
|
||||
[2]:http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[3]:https://atom.io/
|
||||
[4]:https://github.com/
|
||||
[5]:https://atom.io/download/deb
|
||||
[6]:https://atom.io/download/rpm
|
||||
[7]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[8]:http://itsfoss.com/install-atom-text-editor-ubuntu-1404-linux-mint-17/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Comparative Introduction To FreeBSD For Linux Users
|
||||
================================================================================
|
||||

|
||||
@ -95,4 +97,4 @@ via: https://www.unixmen.com/comparative-introduction-freebsd-linux-users/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
|
||||
@ -1,83 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
PHP at 20: From pet project to powerhouse
|
||||
================================================================================
|
||||

|
||||
|
||||
Credit: [Steve Jurvetson via Flickr][1]
|
||||
|
||||
> The one-time ‘silly little project’ has transformed into a Web powerhouse, thanks to flexibility, pragmatism, and a vibrant community of Web devs
|
||||
|
||||
When Rasmus Lerdorf released “[a set of small tight CGI binaries written in C][2],” he had no idea how much his creation would impact Web development. Delivering the opening keynote at this year’s SunshinePHP conference in Miami, Lerdorf quipped, “In 1995, I thought I had unleashed a C API upon the Web. Obviously, that’s not what happened, or we’d all be C programmers.”
|
||||
|
||||
In fact, when Lerdorf released version 1.0 of Personal Home Page Tools -- as PHP was then known -- the Web was very young. HTML 2.0 would not be published until November of that year, and HTTP/1.0 not until May the following year. NCSA HTTPd was the most widely deployed Web server, and Netscape Navigator was the most popular Web browser, with Internet Explorer 1.0 to arrive in August. In other words, PHP’s beginnings coincided with the eve of the browser wars.
|
||||
|
||||
Those early days speak volumes about PHP’s impact on Web development. Back then, our options were limited when it came to server-side processing for Web apps. PHP stepped in to fill our need for a tool that would enable us to do dynamic things on the Web. That practical flexibility captured our imaginations, and PHP has since grown up with the Web. Now powering [more than 80 percent of the Web][3], PHP has matured into a scripting language that is especially suited to solve the Web problem. Its unique pedigree tells a story of pragmatism over theory and problem solving over purity.
|
||||
|
||||
### The Web glue we got hooked on ###
|
||||
|
||||
PHP didn’t start out as a language, and this is clear from its design -- or lack thereof, as detractors point out. It began as an API to help Web developers access lower-level C libraries. The first version was a small CGI binary that provided form-processing functionality with access to request parameters and the mSQL database. And its facility with a Web app’s database would prove key in sparking our interest in PHP and PHP’s subsequent ascendancy.
|
||||
|
||||
By version 2 -- aka PHP/FI -- database support had expanded to include PostgreSQL, MySQL, Oracle, Sybase, and more. It supported these databases by wrapping their C libraries, making them a part of the PHP binary. PHP/FI could also wrap the GD library to create and manipulate GIF images. It could be run as an Apache module or compiled with FastCGI support, and it introduced the PHP script language with support for variables, arrays, language constructs, and functions. For many of us working on the Web at that time, PHP was the kind of glue we'd been looking for.
|
||||
|
||||
As PHP folded in more and more programming language features, morphing into version 3 and onward, it never lost this gluelike aspect. Through repositories like PECL (PHP Extension Community Library), PHP could tie together libraries and expose their functionality to the PHP layer. This capacity to bring together components became a significant facet of the beauty of PHP, though it was not limited to its source code.
|
||||
|
||||
### The Web as a community of coders ###
|
||||
|
||||
PHP’s lasting impact on Web development isn’t limited to what can be done with the language itself. How PHP work is done and who participates -- these too are important parts of PHP’s legacy.
|
||||
|
||||
As early as 1997, PHP user groups began forming. One of the earliest was the Midwest PHP User’s Group (later known as Chicago PHP), which held its [first meeting in February 1997][4]. This was the beginning of what would become a vibrant, energetic community of developers assembled over an affinity for a little tool that helped them solve problems on the Web. The ubiquity of PHP made it a natural choice for Web development. It became especially popular in the shared hosting world, and its low barrier to entry was attractive to many early Web developers.
|
||||
|
||||
With a growing community came an assortment of tools and resources for PHP developers. The year 2000 -- a watershed moment for PHP -- witnessed the first PHP Developers’ Meeting, a gathering of the core developers of the programming language, who met in Tel Aviv to discuss the forthcoming 4.0 release. PHP Extension and Application Repository (PEAR) also launched in 2000 to provide high-quality userland code packages following standards and best practices. The first PHP conference, PHP Kongress, was held in Germany soon after. [PHPDeveloper.org][5] came online, and to this day, it is the most authoritative news source in the PHP community.
|
||||
|
||||
This communal momentum proved vital to PHP’s growth in subsequent years, and as the Web development industry erupted, so did PHP. PHP began powering more and larger websites. More user groups formed around the world. Mailing lists; online forums; IRC; conferences; trade journals such as php[architect], the German PHP Magazin, and International PHP Magazine -- the vibrancy of the PHP community had a significant impact on the way Web work would be done: collectively and openly, with an emphasis on code sharing.
|
||||
|
||||
Then, 10 years ago, shortly after the release of PHP 5, an interesting thing happened in Web development that created a general shift in how the PHP community built libraries and applications: Ruby on Rails was released.
|
||||
|
||||
### The rise of frameworks ###
|
||||
|
||||
The Ruby on Rails framework for the Ruby programming language created an increased focus and attention on the MVC (model-view-controller) architectural pattern. The Mojavi PHP framework a few years prior had used this pattern, but the hype around Ruby on Rails is what firmly cemented MVC in the PHP frameworks that followed. Frameworks exploded in the PHP community, and frameworks have changed the way developers build PHP applications.
|
||||
|
||||
Many important projects and developments have arisen, thanks to the proliferation of frameworks in the PHP community. The PHP [Framework Interoperability Group][6] formed in 2009 to aid in establishing coding standards, naming conventions, and best practices among frameworks. Codifying these standards and practices helped provide more interoperable software for developers using member projects’ code. This interoperability meant that each framework could be split into components and stand-alone libraries could be used together with monolithic frameworks. With interoperability came another important milestone: The Composer project was born in 2011.
|
||||
|
||||
Inspired by Node.js’s NPM and Ruby’s Bundler, Composer has ushered in a new era of PHP application development, creating a PHP renaissance of sorts. It has encouraged interoperability between packages, standard naming conventions, adoption of coding standards, and increased test coverage. It is an essential tool in any modern PHP application.
|
||||
|
||||
### The need for speed and innovation ###
|
||||
|
||||
Today, the PHP community has a thriving ecosystem of applications and libraries. Some of the most widely installed PHP applications include WordPress, Drupal, Joomla, and MediaWiki. These applications power the Web presence of businesses of all sizes, from small mom-and-pop shops to sites like whitehouse.gov and Wikipedia. Six of the Alexa top 10 sites use PHP to serve billions of pages a day. As a result, PHP applications have been optimized for speed -- and much innovation has gone into PHP core to improve performance.
|
||||
|
||||
In 2010, Facebook unveiled its HipHop for PHP source-to-source compiler, which translates PHP code into C++ code and compiles it into a single executable binary application. Facebook’s size and growth necessitated the move away from standard interpreted PHP code to a faster, optimized executable. However, Facebook wanted to continue using PHP for its ease of use and rapid development cycles. HipHop for PHP evolved into HHVM, a JIT (just-in-time) compilation-based execution engine for PHP, which included a new language based on PHP: [Hack][7].
|
||||
|
||||
Facebook’s innovations, as well as other VM projects, created competition at the engine level, leading to discussions about the future of the Zend Engine that still powers PHP’s core, as well as the question of a language specification. In 2014, a language specification project was created “to provide a complete and concise definition of the syntax and semantics of the PHP language,” making it possible for compiler projects to create interoperable PHP implementations.
|
||||
|
||||
The next major version of PHP became a topic of intense debate, and a project known as phpng (next generation) was offered as an option to clean up, refactor, optimize, and improve the PHP code base, which also showed substantial improvements to the performance of real-world applications. After deciding to name the next major version “PHP 7,” due to a previous, unreleased PHP 6.0 version, the phpng branch was merged in, and plans were made to proceed with PHP 7, working in many of the language features offered by Hack, such as scalar and return type hinting.
|
||||
|
||||
With the [first PHP 7 alpha release due out today][8] and benchmarks showing [performance as good as or better than that of HHVM][9] in many cases, PHP is keeping up with the pace of modern Web development needs. Likewise, the PHP-FIG continues to innovate and push frameworks and libraries to collaborate and cooperate -- most recently with the adoption of [PSR-7][10], which will change the way PHP projects handle HTTP. User groups, conferences, publications, and initiatives like [PHPMentoring.org][11] continue to advocate best practices, coding standards, and testing to the PHP developer community.
|
||||
|
||||
PHP has seen the Web mature through various stages, and PHP has matured. Once a simple API wrapper around lower-level C libraries, PHP has become a full-fledged programming language in its own right. Its developer community is vibrant and helpful, priding themselves in pragmatism and welcoming newcomers. PHP has stood the test of time for 20 years, and current activity in the language and community is ensuring it will be a relevant and useful language for years to come.
|
||||
|
||||
During his SunshinePHP keynote, Rasmus Lerdorf reflected, “Did I think I’d be here 20 years later talking about this silly little project I did? No, I didn’t.”
|
||||
|
||||
Here’s to Lerdorf and the rest of the PHP community for transforming this “silly little project” into a lasting, powerful component of the Web today.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2933858/php/php-at-20-from-pet-project-to-powerhouse.html
|
||||
|
||||
作者:[Ben Ramsey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Ben-Ramsey/
|
||||
[1]:https://www.flickr.com/photos/jurvetson/13049862325
|
||||
[2]:https://groups.google.com/d/msg/comp.infosystems.www.authoring.cgi/PyJ25gZ6z7A/M9FkTUVDfcwJ
|
||||
[3]:http://w3techs.com/technologies/overview/programming_language/all
|
||||
[4]:http://web.archive.org/web/20061215165756/http://chiphpug.php.net/mpug.htm
|
||||
[5]:http://www.phpdeveloper.org/
|
||||
[6]:http://www.php-fig.org/
|
||||
[7]:http://www.infoworld.com/article/2610885/facebook-q-a--hack-brings-static-typing-to-php-world.html
|
||||
[8]:https://wiki.php.net/todo/php70#timetable
|
||||
[9]:http://talks.php.net/velocity15
|
||||
[10]:http://www.php-fig.org/psr/psr-7/
|
||||
[11]:http://phpmentoring.org/
|
||||
@ -1,84 +0,0 @@
|
||||
translating by wwy-hust
|
||||
|
||||
What is good audio editing software on Linux
|
||||
================================================================================
|
||||
|
||||
Whether you are an amateur musician or just a student recording his professor, you need to edit and work with audio recordings. If for a long time such task was exclusively attributed to Macintosh, this time is over, and Linux now has what it takes to do the job. In short, here is a non-exhaustive list of good audio editing software, fit for different tasks and needs.
|
||||
|
||||
### 1. Audacity ###
|
||||
|
||||

|
||||
|
||||
Let's get started head on with my personal favorite. [Audacity][1] works on Windows, Mac, and Linux. It is open source. It is easy to use. You get it: Audacity is almost perfect. This program lets you manipulate the audio waveform from a clean interface. In short, you can overlay tracks, cut and edit them easily, apply effects, perform advanced sound analysis, and finally export to a plethora of format. The reason I like it so much is that it combines both basic features with more complicated ones, but maintain an easy leaning curve. However, it is not a fully optimized software for hardcore musicians, or people with professional knowledge.
|
||||
|
||||
### 2. Jokosher ###
|
||||
|
||||

|
||||
|
||||
On a different level, [Jokosher][2] focuses more on the multi-track aspect for musical artists. Developed in Python and using the GTK+ interface with GStreamer for audio back-end, Jokosher really impressed me with its slick interface and its extensions. If the editing features are not the most advanced, the language is clear and directed to musicians. And I really like the association between tracks and instruments for example. In short, if you are starting as a musician, it might be a good place to get some experience before moving on to more complex suites.
|
||||
|
||||
### 3. Ardour ###
|
||||
|
||||

|
||||
|
||||
And talking about compex suites, [Ardour][3] is complete software for recording, editing, and mixing. Designed this time to appeal to all professionals, Ardour features in term of sound routing and plugins go way beyond my comprehension. So if you are looking for a beast and are not afraid to tame it, Ardour is probably a good pick. Again, the interface contributes to its charm, as well as its extensive documentation. I particularly appreciated the first-launch configuration tool.
|
||||
|
||||
### 4. Kwave ###
|
||||
|
||||

|
||||
|
||||
For all KDE lovers, [KWave][4] corresponds to your idea of design and features. There are plenty of shortcuts and interesting options, like memory management. Even if the few effects are nice, we are more dealing with a simple tool to cut/paste audio together. It becomes shard not to compare it with Audacity unfortunately. And on top of that, the interface did not appeal to me that much.
|
||||
|
||||
### 5. Qtractor ###
|
||||
|
||||

|
||||
|
||||
If Kwave is too simplistic for you but a Qt-based program really has some appeal, then [Qtractor][5] might be your option. It aims to be "simple enough for the average home user, and yet powerful enough for the professional user." Indeed the quantity of features and options is almost overwhelming. My favorite being of course customizable shortcuts. Apart from that, Qtractor is probably one of my favorite tools to deal with MIDI files.
|
||||
|
||||
### 6. LMMS ###
|
||||
|
||||

|
||||
|
||||
Standing for Linux MultiMedia Studio, LMMS is directly targeted for music production. If you do not have prior experience and do not want to spend too much time getting some, go elsewhere. LMMS is one of those complex but powerful software that only a few will truly master. The number of features and effects is simply too long to list, but if I had to pick one, I would say that the Freeboy plugin to emulate Game Boy sound system is just magical. Past that, go see their amazing documentation.
|
||||
|
||||
### 7. Traverso ###
|
||||
|
||||

|
||||
|
||||
Finally, Traverso stood out to me for its unlimited track count and its direct integration with CD burning capacities. Aside from that, it appeared to me as a middle man between a simplistic software and a professional program. The interface is very KDE-like, and the keyboard configuration is always welcome. And cherry on the cake, Traverso monitors your resources and make sure that your CPU or hard drive does not go overboard.
|
||||
|
||||
To conclude, it is always a pleasure to see such a large diversity of applications on Linux. It makes finding the software that best fits your needs always possible. While my personal favorite stays Audacity, I was very surprised by the design of programs like LMMS or Jokosher.
|
||||
|
||||
Did we miss one? What do you use for audio editing on Linux? And why? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-audio-editing-software-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://audacity.sourceforge.net/
|
||||
[2]:https://launchpad.net/jokosher/
|
||||
[3]:http://ardour.org/
|
||||
[4]:http://kwave.sourceforge.net/
|
||||
[5]:http://qtractor.sourceforge.net/qtractor-index.html
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,422 +0,0 @@
|
||||
25 Useful Apache ‘.htaccess’ Tricks to Secure and Customize Websites
|
||||
================================================================================
|
||||
Websites are important parts of our lives. They serve the means to expand businesses, share knowledge and lots more. Earlier restricted to providing only static contents, with introduction of dynamic client and server side scripting languages and continued advancement of existing static language like html to html5, adding every bit of dynamicity is possible to the websites and what left is expected to follow soon in near future.
|
||||
|
||||
With websites, comes the need of a unit that can display these websites to a huge set of audience all over the globe. This need is fulfilled by the servers that provide means to host a website. This includes a list of servers like: Apache HTTP Server, Joomla, and WordPress that allow one to host their websites.
|
||||
|
||||

|
||||
25 htaccess Tricks
|
||||
|
||||
One who wants to host a website can create a local server of his own or can contact any of above mentioned or any another server administrator to host his website. But the actual issue starts from this point. Performance of a website depends mainly on following factors:
|
||||
|
||||
- Bandwidth consumed by the website.
|
||||
- How secure is the website against hackers.
|
||||
- Optimism when it comes to data search through the database
|
||||
- User-friendliness when it comes to displaying navigation menus and providing more UI features.
|
||||
|
||||
Alongside this, various factors that govern success of servers in hosting websites are:
|
||||
|
||||
- Amount of data compression achieved for a particular website.
|
||||
- Ability to simultaneously serve multiple clients asking for a same or different website.
|
||||
- Securing the confidential data entered on the websites like: emails, credit card details and so on.
|
||||
- Allowing more and more options to enhance dynamicity to a website.
|
||||
|
||||
This article deals with one such feature provided by the servers that help enhance performance of websites along with securing them from bad bots, hotlinks etc. i.e. ‘.htaccess‘ file.
|
||||
|
||||
### What is .htaccess? ###
|
||||
|
||||
htaccess (or hypertext access) are the files that provide options for website owners to control the server environment variables and other parameters to enhance functionality of their websites. These files can reside in any and every directory in the directory tree of the website and provide features to the directory and the files and folders inside it.
|
||||
|
||||
What are these features? Well these are the server directives i.e. the lines that instruct server to perform a specific task, and these directives apply only to the files and folders inside the folder in which this file is placed. These files are hidden by default as all Operating System and the web servers are configured to ignore them by default but making the hidden files visible can make you see this very special file. What type of parameters can be controlled is the topic of discussion of subsequent sections.
|
||||
|
||||
Note: If .htaccess file is placed in /apache/home/www/Gunjit/ directory then it will provide directives for all the files and folders in that directory, but if this directory contains another folder namely: /Gunjit/images/ which again has another .htaccess file then the directives in this folder will override those provided by the master .htaccess file (or file in the folder up in hierarchy).
|
||||
|
||||
### Apache Server and .htaccess files ###
|
||||
|
||||
Apache HTTP Server colloquially called Apache was named after a Native American Tribe Apache to respect its superior skills in warfare strategy. Build on C/C++ and XML it is cross-platform web server which is based on NCSA HTTPd server and has a key role in growth and advancement of World Wide Web.
|
||||
|
||||
Most commonly used on UNIX, Apache is available for wide variety of platforms including FreeBSD, Linux, Windows, Mac OS, Novel Netware etc. In 2009, Apache became the first server to serve more than 100 million websites.
|
||||
|
||||
Apache server has one .htaccess file per user in www/ directory. Although these files are hidden but can be made visible if required. In www/ directory there are a number of folders each pertaining to a website named on user’s or owner’s name. Apart from this you can have one .htaccess file in each folder which configured files in that folder as stated above.
|
||||
|
||||
How to configure htaccess file on Apache server is as follows…
|
||||
|
||||
### Configuration on Apache Server ###
|
||||
|
||||
There can be two cases:
|
||||
|
||||
#### Hosting website on own server ####
|
||||
|
||||
In this case, if .htaccess files are not enabled, you can enable .htaccess files by simply going to httpd.conf (Default configuration file for Apache HTTP Daemon) and finding the <Directories> section.
|
||||
|
||||
<Directory "/var/www/htdocs">
|
||||
|
||||
And locate the line that says…
|
||||
|
||||
AllowOverride None
|
||||
|
||||
And correct it to.
|
||||
|
||||
AllowOverride All
|
||||
|
||||
Now, on restarting Apache, .htaccess will work.
|
||||
|
||||
#### Hosting website on different hosting provider server ####
|
||||
|
||||
In this case it is better to consult the hosting admin, if they allow access to .htaccess files.
|
||||
|
||||
### 25 ‘.htaccess’ Tricks of Apache Web Server for Websites ###
|
||||
|
||||
#### 1. How to enable mod_rewrite in .htaccess file ####
|
||||
|
||||
mod_rewrite option allows you to use redirections and hiding your true URL with redirecting to some other URL. This option can prove very useful allowing you to replace the lengthy and long URL’s to short and easy to remember ones.
|
||||
|
||||
To allow mod_rewrite just have a practice to add the following line as the first line of your .htaccess file.
|
||||
|
||||
Options +FollowSymLinks
|
||||
|
||||
This option allows you to follow symbolic links and thus enable the mod_rewrite option on the website. Replacing the URL with short and crispy one is presented later on.
|
||||
|
||||
#### 2. How to Allow or Deny Access to Websites ####
|
||||
|
||||
htaccess file can allow or deny access of website or a folder or files in the directory in which it is placed by using order, allow and deny keywords.
|
||||
|
||||
**Allowing access to only 192.168.3.1 IP**
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
Allow from 192.168.3.1
|
||||
|
||||
OR
|
||||
|
||||
Order Allow, Deny
|
||||
Allow from 192.168.3.1
|
||||
|
||||
Order keyword here specifies the order in which allow, deny access would be processed. For the above ‘Order’ statement, the Allow statements would be processed first and then the deny statements would be processed.
|
||||
|
||||
**Denying access to only one IP Address**
|
||||
|
||||
The below lines provide the means to allow access of the website to all the users accept one with IP Address: 192.168.3.1.
|
||||
|
||||
rder Allow, Deny
|
||||
Deny from 192.168.3.1
|
||||
Allow from All
|
||||
|
||||
OR
|
||||
|
||||
|
||||
Order Deny, Allow
|
||||
Deny from 192.168.3.1
|
||||
|
||||
#### 3. Generate Apache Error documents for different error codes. ####
|
||||
|
||||
Using some simple lines, we can fix the error document that run on different error codes generated by the server when user/client requests a page not available on the website like most of us would have seen the ‘404 Page not found’ page in their web browser. ‘.htaccess’ files specify what action to take in case of such error conditions.
|
||||
|
||||
To do this, the following lines are needed to be added to the ‘.htaccess’ files:
|
||||
|
||||
ErrorDocument <error-code> <path-of-document/string-representing-html-file-content>
|
||||
|
||||
‘ErrorDocument’ is a keyword, error-code can be any of 401, 403, 404, 500 or any valid error representing code and lastly, ‘path-of-document’ represents the path on the local machine (in case you are using your own local server) or on the server (in case you are using any other’s server to host your website).
|
||||
|
||||
**Example:**
|
||||
|
||||
ErrorDocument 404 /error-docs/error-404.html
|
||||
|
||||
The above line sets the document ‘error-404.html’ placed in error-docs folder to be displayed in case the 404 error is reported by the server for any invalid request for a page by the client.
|
||||
|
||||
rrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
|
||||
The above representation is also correct which places the string representing a usual html file.
|
||||
|
||||
#### 4. Setting/Unsetting Apache server environment variables ####
|
||||
|
||||
In .htaccess file you can set or unset the global environment variables that server allow to be modified by the hosters of the websites. For setting or unsetting the environment variables you need to add the following lines to your .htaccess files.
|
||||
|
||||
**Setting the Environment variables**
|
||||
|
||||
SetEnv OWNER “Gunjit Khera”
|
||||
|
||||
Unsetting the Environment variables
|
||||
|
||||
UnsetEnv OWNER
|
||||
|
||||
#### 5. Defining different MIME types for files ####
|
||||
|
||||
MIME (Multipurpose Internet Multimedia Extensions) are the types that are recognized by the browser by default when running any web page. You can define MIME types for your website in .htaccess files, so that different types of files as defined by you can be recognized and run by the server.
|
||||
|
||||
<IfModule mod_mime.c>
|
||||
AddType application/javascript js
|
||||
AddType application/x-font-ttf ttf ttc
|
||||
</IfModule>
|
||||
|
||||
Here, mod_mime.c is the module for controlling definitions of different MIME types and if you have this module installed on your system then you can use this module to define different MIME types for different extensions used in your website so that server can understand them.
|
||||
|
||||
#### 6. How to Limit the size of Uploads and Downloads in Apache ####
|
||||
|
||||
.htaccess files allow you the feature to control the amount of data being uploaded or downloaded by a particular client from your website. For this you just need to append the following lines to your .htaccess file:
|
||||
|
||||
php_value upload_max_filesize 20M
|
||||
php_value post_max_size 20M
|
||||
php_value max_execution_time 200
|
||||
php_value max_input_time 200
|
||||
|
||||
The above lines set maximum upload size, maximum size of data being posted, maximum execution time i.e. the maximum time the a user is allowed to execute a website on his local machine, maximum time constrain within on the input time.
|
||||
|
||||
#### 7. Making Users to download .mp3 and other files before playing on your website. ####
|
||||
|
||||
Mostly, people play songs on websites before downloading them to check the song quality etc. Being a smart seller you can add a feature that can come in very handy for you which will not let any user play songs or videos online and users have to download them for playing. This is very useful as online playing of songs and videos consumes a lot of bandwidth.
|
||||
|
||||
Following lines are needed to be added to be added to your .htaccess file:
|
||||
|
||||
AddType application/octet-stream .mp3 .zip
|
||||
|
||||
#### 8. Setting Directory Index for Website ####
|
||||
|
||||
Most of website developers would already know that the first page that is displayed i.e. the home page of a website is named as ‘index.html’ .Many of us would have seen this also. But how is this set?
|
||||
|
||||
.htaccess file provides a way to list a set of pages which would be scanned in order when a client requests to visit home page of the website and accordingly any one of the listed set of pages if found would be listed as the home page of the website and displayed to the user.
|
||||
|
||||
Following line is needed to be added to produce the desired effect.
|
||||
|
||||
DirectoryIndex index.html index.php yourpage.php
|
||||
|
||||
The above line specifies that if any request for visiting the home page comes by any visitor then the above listed pages will be searched in order in the directory firstly: index.html which if found will be displayed as the sites home page, otherwise list will proceed to the next page i.e. index.php and so on till the last page you have entered in the list.
|
||||
|
||||
#### 9. How to enable GZip compression for Files to save site’s bandwidth. ####
|
||||
|
||||
This is a common observation that heavy sites generally run bit slowly than light weight sites that take less amount of space. This is just because for a heavy site it takes time to load the huge script files and images before displaying them on the client’s web browser.
|
||||
|
||||
This is a common mechanism that when a browser requests a web page, server provides the browser with that webpage and now to locally display that web page, the browser has to download that page and then run the script inside that page.
|
||||
|
||||
What GZip compression does here is saving the time required to serve a single customer thus increasing the bandwidth. The source files of the website on the server are kept in compressed form and when the request comes from a user then these files are transferred in compressed form which are then uncompressed and executed on the server. This improves the bandwidth constrain.
|
||||
|
||||
Following lines can allow you to compress the source files of your website but this requires mod_deflate.c module to be installed on your server.
|
||||
|
||||
<IfModule mod_deflate.c>
|
||||
AddOutputFilterByType DEFLATE text/plain
|
||||
AddOutputFilterByType DEFLATE text/html
|
||||
AddOutputFilterByType DEFLATE text/xml
|
||||
AddOutputFilterByType DEFLATE application/html
|
||||
AddOutputFilterByType DEFLATE application/javascript
|
||||
AddOutputFilterByType DEFLATE application/x-javascript
|
||||
</IfModule>
|
||||
|
||||
#### 10. Playing with the File types. ####
|
||||
|
||||
There are certain conditions that the server assumes by default. Like: .php files are run on the server, similarly .txt files say for example are meant to be displayed. Like this we can make some executable cgi-scripts or files to be simply displayed as the source code on our website instead of being executed.
|
||||
|
||||
To do this observe the following lines from a .htaccess file.
|
||||
|
||||
RemoveHandler cgi-script .php .pl .py
|
||||
AddType text/plain .php .pl .py
|
||||
|
||||
These lines tell the server that .pl (perl script), .php (PHP file) and .py (Python file) are meant to just be displayed and not executed as cgi-scripts.
|
||||
|
||||
#### 11. Setting the Time Zone for Apache server ####
|
||||
|
||||
The power and importance of .htaccess files can be seen by the fact that this can be used to set the Time Zone of the server accordingly. This can be done by setting a global Environment variable ‘TZ’ of the list of global environment variables that are provided by the server to each of the hosted website for modification.
|
||||
|
||||
Due to this reason only, we can see time on the websites (that display it) according to our time zone. May be some other person hosting his website on the server would have the timezone set according to the location where he lives.
|
||||
|
||||
Following lines set the Time Zone of the Server.
|
||||
|
||||
SetEnv TZ India/Kolkata
|
||||
|
||||
#### 12. How to enable Cache Control on Website ####
|
||||
|
||||
A very interesting feature of browser, most have observed is that on opening one website simultaneously more than one time, the latter one opens fast as compared to the first time. But how is this possible? Well in this case, the browser stores some frequently visited pages in its cache for faster access later on.
|
||||
|
||||
But for how long? Well this answer depends on you i.e. on the time you set in your .htaccess file for Cache control. The .htaccess file can specify the amount of time for which the pages of website can stay in the browser’s cache and after expiration of time, it must revalidate i.e. pages would be deleted from the Cache and recreated the next time user visits the site.
|
||||
|
||||
Following lines implement Cache Control for your website.
|
||||
|
||||
<FilesMatch "\.(ico|png|jpeg|svg|ttf)$">
|
||||
Header Set Cache-Control "max-age=3600, public"
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.(js|css)$">
|
||||
Header Set Cache-Control "public"
|
||||
Header Set Expires "Sat, 24 Jan 2015 16:00:00 GMT"
|
||||
</FilesMatch>
|
||||
|
||||
The above lines allow caching of the pages which are inside the directory in which .htaccess files are placed for 1 hour.
|
||||
|
||||
#### 13. Configuring a single file, the <files> option. ####
|
||||
|
||||
Usually the content in .htaccess files apply to all the files and folders inside the directory in which the file is placed, but you can also provide some special permissions to a special file, like denying access to that file only or so on.
|
||||
|
||||
For this you need to add <File> tag to your file in a way like this:
|
||||
|
||||
<files conf.html="">
|
||||
Order allow, deny
|
||||
Deny from 188.100.100.0
|
||||
</files>
|
||||
|
||||
This is a simple case of denying a file ‘conf.html’ from access by IP 188.100.100.0, but you can add any or every feature described for .htaccess file till now including the features yet to be described to the file like: Cache-control, GZip compression.
|
||||
|
||||
This feature is used by most of the servers to secure .htaccess files which is the reason why we are not able to see the .htaccess files on the browsers. How the files are authenticated is demonstrated in subsequent heading.
|
||||
|
||||
#### 14. Enabling CGI scripts to run outside of cgi-bin folder. ####
|
||||
|
||||
Usually servers run CGI scripts that are located inside the cgi-bin folder but, you can enable running of CGI scripts located in your desired folder but just adding following lines to .htaccess file located in the desired folder and if not, then creating one, appending following lines:
|
||||
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
|
||||
#### 15. How to enable SSI on Website with .htaccess ####
|
||||
|
||||
Server side includes as the name suggests would be related to something included at the server side. But what? Generally when we have many pages in our website and we have a navigation menu on our home page that displays links to other pages then, we can enable SSI (Server Size Includes) option that allows all the pages displayed in the navigation menu to be included with the home page completely.
|
||||
|
||||
The SSI allows inclusion of multiple pages as if content they contain is a part of a single page so that any editing needed to be done is done in one file only which saves a lot of disk space. This option is by default enabled on servers but for .shtml files.
|
||||
|
||||
In case you want to enable it for .html files you need to add following lines:
|
||||
|
||||
AddHandler server-parsed .html
|
||||
|
||||
After this following in the html file would lead to SSI.
|
||||
|
||||
<!--#inlcude virtual= “gk/document.html”-->
|
||||
|
||||
#### 16. How to Prevent website Directory Listing ####
|
||||
|
||||
To prevent any client being able to list the directories of the website on the server at his local machine add following lines to the file inside the directory you don’t want to get listed.
|
||||
|
||||
Options -Indexes
|
||||
|
||||
#### 17. Changing Default charset and language headers. ####
|
||||
|
||||
.htaccess files allow you to modify the character set used i.e. ASCII or UNICODE, UTF-8 etc. for your website along with the default language used for the display of content.
|
||||
|
||||
Following server’s global environment variables allow you to achieve above feature.
|
||||
|
||||
AddDefaultCharset UTF-8
|
||||
DefaultLanguage en-US
|
||||
|
||||
**Re-writing URL’s: Redirection Rules**
|
||||
|
||||
Re-writing feature simply means replacing the long and un-rememberable URL’s with short and easy to remember ones. But, before going into this topic there are some rules and some conventions for special symbols used later on in this article.
|
||||
|
||||
**Special Symbols:**
|
||||
|
||||
Symbol Meaning
|
||||
^ - Start of the string
|
||||
$ - End of the String
|
||||
| - Or [a|b] – a or b
|
||||
[a-z] - Any of the letter between a to z
|
||||
+ - One or more occurrence of previous letter
|
||||
* - Zero or more occurrence of previous letter
|
||||
? - Zero or one occurrence of previous letter
|
||||
|
||||
**Constants and their meaning:**
|
||||
|
||||
Constant Meaning
|
||||
NC - No-case or case sensitive
|
||||
L - Last rule – stop processing further rules
|
||||
R - Temporary redirect to new URL
|
||||
R=301 - Permanent redirect to new URL
|
||||
F - Forbidden, send 403 header to the user
|
||||
P - Proxy – grab remote content in substitution section and return it
|
||||
G - Gone, no longer exists
|
||||
S=x - Skip next x rules
|
||||
T=mime-type - Force specified MIME type
|
||||
E=var:value - Set environment variable var to value
|
||||
H=handler - Set handler
|
||||
PT - Pass through – in case of URL’s with additional headers.
|
||||
QSA - Append query string from requested to substituted URL
|
||||
|
||||
#### 18. Redirecting a non-www URL to a www URL. ####
|
||||
|
||||
Before starting with the explanation, lets first see the lines that are needed to be added to .htaccess file to enable this feature.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
The above lines enable the Rewrite Engine and then in second line check all those URL’s that pertain to host abc.net or have the HTTP_HOST environment variable set to “abc.net”.
|
||||
|
||||
For all such URL’s the code permanently redirects them (as R=301 rule is enabled) to the new URL http://www.abc.net/$1 where $1 is the non-www URL having host as abc.net. The non-www URL is the one in bracket and is referred by $1.
|
||||
|
||||
#### 19. Redirecting entire website to https. ####
|
||||
|
||||
Following lines will help you transfer entire website to https:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTPS} !on
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
The above lines enable the re-write engine and then check the value of HTTPS environment variable. If it is on then re-write the entire pages of the website to https.
|
||||
|
||||
#### 20. A custom redirection example ####
|
||||
|
||||
For example, redirect url ‘http://www.abc.net?p=100&q=20 ‘ to ‘http://www.abc.net/10020pq’.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteRule ^http://www.abc.net/([0-9]+)([0-9]+)pq$ ^http://www.abc.net?p=$1&q=$2
|
||||
|
||||
In above lines, $1 represents the first bracket and $2 represents the second bracket.
|
||||
|
||||
#### 21. Renaming the htaccess file ####
|
||||
|
||||
For preventing the .htaccess file from the intruders and other people from viewing those files you can rename that file so that it is not accessed by client’s browser. The line that does this is:
|
||||
|
||||
AccessFileName htac.cess
|
||||
|
||||
#### 22. How to Prevent Image Hotlinking for your Website ####
|
||||
|
||||
Another problem that is major factor of large bandwidth consumption by the websites is the problem of hot links which are links to your websites by other websites for display of images mostly of your website which consumes your bandwidth. This problem is also called as ‘bandwidth theft’.
|
||||
|
||||
A common observation is when a site displays the image contained in some other site due to this hot-linking your site needs to be loaded and at the stake of your site’s bandwidth, the other site’s images are displayed. To prevent this for like: images such as: .gif, .jpeg etc. following lines of code would help:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_REFERER} !^$
|
||||
RewriteCond %{HTTP_REFERERER} !^http://(www\.)?mydomain.com/.*$ [NC]
|
||||
RewriteRule \.(gif|jpeg|png)$ - [F].
|
||||
|
||||
The above lines check if the HTTP_REFERER is not set to blank or not set to any of the links in your websites. If this is happening then all the images in your page are replaced by 403 forbidden.
|
||||
|
||||
#### 23. How to Redirect Users to Maintenance Page. ####
|
||||
|
||||
In case your website is down for maintenance and you want to notify all your clients that need to access your websites about this then for such cases you can add following lines to your .htaccess websites that allow only admin access and replace the site pages having links to any .jpg, .css, .gif, .js etc.
|
||||
|
||||
RewriteCond %{REQUEST_URI} !^/admin/ [NC]
|
||||
RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
|
||||
[NC,L,U,QSA]
|
||||
|
||||
These lines check if the Requested URL contains any request for any admin page i.e. one starting with ‘/admin/’ or any request to ‘.png, .jpg, .js, .css’ pages and for any such requests it replaces that page to ‘ErrorDocs/Maintainence_Page.html’.
|
||||
|
||||
#### 24. Mapping IP Address to Domain Name ####
|
||||
|
||||
Name servers are the servers that convert a specific IP Address to a domain name. This mapping can also be specified in the .htaccess files in the following manner.
|
||||
|
||||
For Mapping L.M.N.O address to a domain name www.hellovisit.com
|
||||
RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
|
||||
RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
|
||||
|
||||
The above lines check if the host for any page is having the IP Address as: L.M.N.O and if so the page is mapped to the domain name http://www.hellovisit.com by the third line by permanent redirection.
|
||||
|
||||
#### 25. FilesMatch Tag ####
|
||||
|
||||
Like <files> tag that is used to apply conditions to a single file, <FilesMatch> can be used to match to a group of files and apply some conditions to the group of files as below:
|
||||
|
||||
<FilesMatch “\.(png|jpg)$”>
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
</FilesMatch>
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The list of tricks that can be done with .htaccess files is much more. Thus, this gives us an idea how powerful this file is and how much security and dynamicity and other features it can give to your website.
|
||||
|
||||
We’ve tried our best to cover as much as htaccess tricks in this article, but incase if we’ve missed any important trick, or you most welcome to post your htaccess ideas and tricks that you know via comments section below – we will include those in our article too…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
|
||||
作者:[Gunjit Khera][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gunjitk94/
|
||||
@ -1,268 +0,0 @@
|
||||
How to Manage and Use LVM (Logical Volume Management) in Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
In our [previous article we told you what LVM is and what you may want to use it for][1], and today we are going to walk you through some of the key management tools of LVM so you will be confident when setting up or expanding your installation.
|
||||
|
||||
As stated before, LVM is a abstraction layer between your operating system and physical hard drives. What that means is your physical hard drives and partitions are no longer tied to the hard drives and partitions they reside on. Rather, the hard drives and partitions that your operating system sees can be any number of separate hard drives pooled together or in a software RAID.
|
||||
|
||||
To manage LVM there are GUI tools available but to really understand what is happening with your LVM configuration it is probably best to know what the command line tools are. This will be especially useful if you are managing LVM on a server or distribution that does not offer GUI tools.
|
||||
|
||||
Most of the commands in LVM are very similar to each other. Each valid command is preceded by one of the following:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
|
||||
The physical volume commands are for adding or removing hard drives in volume groups. Volume group commands are for changing what abstracted set of physical partitions are presented to your operating in logical volumes. Logical volume commands will present the volume groups as partitions so that your operating system can use the designated space.
|
||||
|
||||
### Downloadable LVM Cheat Sheet ###
|
||||
|
||||
To help you understand what commands are available for each prefix we made a LVM cheat sheet. We will cover some of the commands in this article, but there is still a lot you can do that won’t be covered here.
|
||||
|
||||
All commands on this list will need to be run as root because you are changing system wide settings that will affect the entire machine.
|
||||
|
||||

|
||||
|
||||
### How to View Current LVM Information ###
|
||||
|
||||
The first thing you may need to do is check how your LVM is set up. The s and display commands work with physical volumes (pv), volume groups (vg), and logical volumes (lv) so it is a good place to start when trying to figure out the current settings.
|
||||
|
||||
The display command will format the information so it’s easier to understand than the s command. For each command you will see the name and path of the pv/vg and it should also give information about free and used space.
|
||||
|
||||

|
||||
|
||||
The most important information will be the PV name and VG name. With those two pieces of information we can continue working on the LVM setup.
|
||||
|
||||
### Creating a Logical Volume ###
|
||||
|
||||
Logical volumes are the partitions that your operating system uses in LVM. To create a logical volume we first need to have a physical volume and volume group. Here are all of the steps necessary to create a new logical volume.
|
||||
|
||||
#### Create physical volume ####
|
||||
|
||||
We will start from scratch with a brand new hard drive with no partitions or information on it. Start by finding which disk you will be working with. (/dev/sda, sdb, etc.)
|
||||
|
||||
> Note: Remember all of the commands will need to be run as root or by adding ‘sudo’ to the beginning of the command.
|
||||
|
||||
fdisk -l
|
||||
|
||||
If your hard drive has never been formatted or partitioned before you will probably see something like this in the fdisk output. This is completely fine because we are going to create the needed partitions in the next steps.
|
||||
|
||||

|
||||
|
||||
Our new disk is located at /dev/sdb so lets use fdisk to create a new partition on the drive.
|
||||
|
||||
There are a plethora of tools that can create a new partition with a GUI, [including Gparted][2], but since we have the terminal open already, we will use fdisk to create the needed partition.
|
||||
|
||||
From a terminal type the following commands:
|
||||
|
||||
fdisk /dev/sdb
|
||||
|
||||
This will put you in a special fdisk prompt.
|
||||
|
||||

|
||||
|
||||
Enter the commands in the order given to create a new primary partition that uses 100% of the new hard drive and is ready for LVM. If you need to change the partition size or want multiple partions I suggest using GParted or reading about fdisk on your own.
|
||||
|
||||
**Warning: The following steps will format your hard drive. Make sure you don’t have any information on this hard drive before following these steps.**
|
||||
|
||||
- n = create new partition
|
||||
- p = creates primary partition
|
||||
- 1 = makes partition the first on the disk
|
||||
|
||||
Push enter twice to accept the default first cylinder and last cylinder.
|
||||
|
||||

|
||||
|
||||
To prepare the partition to be used by LVM use the following two commands.
|
||||
|
||||
- t = change partition type
|
||||
- 8e = changes to LVM partition type
|
||||
|
||||
Verify and write the information to the hard drive.
|
||||
|
||||
- p = view partition setup so we can review before writing changes to disk
|
||||
- w = write changes to disk
|
||||
|
||||

|
||||
|
||||
After those commands, the fdisk prompt should exit and you will be back to the bash prompt of your terminal.
|
||||
|
||||
Enter pvcreate /dev/sdb1 to create a LVM physical volume on the partition we just created.
|
||||
|
||||
You may be asking why we didn’t format the partition with a file system but don’t worry, that step comes later.
|
||||
|
||||

|
||||
|
||||
#### Create volume Group ####
|
||||
|
||||
Now that we have a partition designated and physical volume created we need to create the volume group. Luckily this only takes one command.
|
||||
|
||||
vgcreate vgpool /dev/sdb1
|
||||
|
||||

|
||||
|
||||
Vgpool is the name of the new volume group we created. You can name it whatever you’d like but it is recommended to put vg at the front of the label so if you reference it later you will know it is a volume group.
|
||||
|
||||
#### Create logical volume ####
|
||||
|
||||
To create the logical volume that LVM will use:
|
||||
|
||||
lvcreate -L 3G -n lvstuff vgpool
|
||||
|
||||

|
||||
|
||||
The -L command designates the size of the logical volume, in this case 3 GB, and the -n command names the volume. Vgpool is referenced so that the lvcreate command knows what volume to get the space from.
|
||||
|
||||
#### Format and Mount the Logical Volume ####
|
||||
|
||||
One final step is to format the new logical volume with a file system. If you want help choosing a Linux file system, read our [how to that can help you choose the best file system for your needs][3].
|
||||
|
||||
mkfs -t ext3 /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
Create a mount point and then mount the volume somewhere you can use it.
|
||||
|
||||
mkdir /mnt/stuff
|
||||
mount -t ext3 /dev/vgpool/lvstuff /mnt/stuff
|
||||
|
||||

|
||||
|
||||
#### Resizing a Logical Volume ####
|
||||
|
||||
One of the benefits of logical volumes is you can make your shares physically bigger or smaller without having to move everything to a bigger hard drive. Instead, you can add a new hard drive and extend your volume group on the fly. Or if you have a hard drive that isn’t used you can remove it from the volume group to shrink your logical volume.
|
||||
|
||||
There are three basic tools for making physical volumes, volume groups, and logical volumes bigger or smaller.
|
||||
|
||||
Note: Each of these commands will need to be preceded by pv, vg, or lv depending on what you are working with.
|
||||
|
||||
- resize – can shrink or expand physical volumes and logical volumes but not volume groups
|
||||
- extend – can make volume groups and logical volumes bigger but not smaller
|
||||
- reduce – can make volume groups and logical volumes smaller but not bigger
|
||||
|
||||
Let’s walk through an example of how to add a new hard drive to the logical volume “lvstuff” we just created.
|
||||
|
||||
#### Install and Format new Hard Drive ####
|
||||
|
||||
To install a new hard drive follow the steps above to create a new partition and add change it’s partition type to LVM (8e). Then use pvcreate to create a physical volume that LVM can recognize.
|
||||
|
||||
#### Add New Hard Drive to Volume Group ####
|
||||
|
||||
To add the new hard drive to a volume group you just need to know what your new partition is, /dev/sdc1 in our case, and the name of the volume group you want to add it to.
|
||||
|
||||
This will add the new physical volume to the existing volume group.
|
||||
|
||||
vgextend vgpool /dev/sdc1
|
||||
|
||||

|
||||
|
||||
#### Extend Logical Volume ####
|
||||
|
||||
To resize the logical volume we need to say how much we want to extend by size instead of by device. In our example we just added a 8 GB hard drive to our 3 GB vgpool. To make that space usable we can use lvextend or lvresize.
|
||||
|
||||
lvextend -L8G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
While this command will work you will see that it will actually resize our logical volume to 8 GB instead of adding 8 GB to the existing volume like we wanted. To add the last 3 available gigabytes you need to use the following command.
|
||||
|
||||
lvextend -L+3G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
Now our logical volume is 11 GB in size.
|
||||
|
||||
#### Extend File System ####
|
||||
|
||||
The logical volume is 11 GB but the file system on that volume is still only 3 GB. To make the file system use the entire 11 GB available you have to use the command resize2fs. Just point resize2fs to the 11 GB logical volume and it will do the magic for you.
|
||||
|
||||
resize2fs /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
**Note: If you are using a different file system besides ext3/4 please see your file systems resize tools.**
|
||||
|
||||
#### Shrink Logical Volume ####
|
||||
|
||||
If you wanted to remove a hard drive from a volume group you would need to follow the above steps in reverse order and use lvreduce and vgreduce instead.
|
||||
|
||||
1. resize file system (make sure to move files to a safe area of the hard drive before resizing)
|
||||
1. reduce logical volume (instead of + to extend you can also use – to reduce by size)
|
||||
1. remove hard drive from volume group with vgreduce
|
||||
|
||||
#### Backing up a Logical Volume ####
|
||||
|
||||
Snapshots is a feature that some newer advanced file systems come with but ext3/4 lacks the ability to do snapshots on the fly. One of the coolest things about LVM snapshots is your file system is never taken offline and you can have as many as you want without taking up extra hard drive space.
|
||||
|
||||

|
||||
|
||||
When LVM takes a snapshot, a picture is taken of exactly how the logical volume looks and that picture can be used to make a copy on a different hard drive. While a copy is being made, any new information that needs to be added to the logical volume is written to the disk just like normal, but changes are tracked so that the original picture never gets destroyed.
|
||||
|
||||
To create a snapshot we need to create a new logical volume with enough free space to hold any new information that will be written to the logical volume while we make a backup. If the drive is not actively being written to you can use a very small amount of storage. Once we are done with our backup we just remove the temporary logical volume and the original logical volume will continue on as normal.
|
||||
|
||||
#### Create New Snapshot ####
|
||||
|
||||
To create a snapshot of lvstuff use the lvcreate command like before but use the -s flag.
|
||||
|
||||
lvcreate -L512M -s -n lvstuffbackup /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
Here we created a logical volume with only 512 MB because the drive isn’t being actively used. The 512 MB will store any new writes while we make our backup.
|
||||
|
||||
#### Mount New Snapshot ####
|
||||
|
||||
Just like before we need to create a mount point and mount the new snapshot so we can copy files from it.
|
||||
|
||||
mkdir /mnt/lvstuffbackup
|
||||
mount /dev/vgpool/lvstuffbackup /mnt/lvstuffbackup
|
||||
|
||||

|
||||
|
||||
#### Copy Snapshot and Delete Logical Volume ####
|
||||
|
||||
All you have left to do is copy all of the files from /mnt/lvstuffbackup/ to an external hard drive or tar it up so it is all in one file.
|
||||
|
||||
**Note: tar -c will create an archive and -f will say the location and file name of the archive. For help with the tar command use man tar in the terminal.**
|
||||
|
||||
tar -cf /home/rothgar/Backup/lvstuff-ss /mnt/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
Remember that while the backup is taking place all of the files that would be written to lvstuff are being tracked in the temporary logical volume we created earlier. Make sure you have enough free space while the backup is happening.
|
||||
|
||||
Once the backup finishes, unmount the volume and remove the temporary snapshot.
|
||||
|
||||
umount /mnt/lvstuffbackup
|
||||
lvremove /dev/vgpool/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
#### Deleting a Logical Volume ####
|
||||
|
||||
To delete a logical volume you need to first make sure the volume is unmounted, and then you can use lvremove to delete it. You can also remove a volume group once the logical volumes have been deleted and a physical volume after the volume group is deleted.
|
||||
|
||||
Here are all the commands using the volumes and groups we’ve created.
|
||||
|
||||
umount /mnt/lvstuff
|
||||
lvremove /dev/vgpool/lvstuff
|
||||
vgremove vgpool
|
||||
pvremove /dev/sdb1 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
That should cover most of what you need to know to use LVM. If you’ve got some experience on the topic, be sure to share your wisdom in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -1,137 +0,0 @@
|
||||
How to set up remote desktop on Linux VPS using x2go
|
||||
================================================================================
|
||||
As everything is moved to the cloud, virtualized remote desktop becomes increasingly popular in the industry as a way to enhance employee's productivity. Especially for those who need to roam constantly across multiple locations and devices, remote desktop allows them to stay connected seamlessly to their work environment. Remote desktop is attractive for employers as well, achieving increased agility and flexibility in work environments, lower IT cost due to hardware consolidation, desktop security hardening, and so on.
|
||||
|
||||
In the world of Linux, of course there is no shortage of choices for settings up remote desktop environment, with many protocols (e.g., RDP, RFB, NX) and server/client implementations (e.g., [TigerVNC][1], RealVNC, FreeNX, x2go, X11vnc, TeamViewer) available.
|
||||
|
||||
Standing out from the pack is [X2Go][2], an open-source (GPLv2) implementation of NX-based remote desktop server and client. In this tutorial, I am going to demonstrate **how to set up remote desktop environment for [Linux VPS][3] using X2Go**.
|
||||
|
||||
### What is X2Go? ###
|
||||
|
||||
The history of X2Go goes back to NoMachine's NX technology. The NX remote desktop protocol was designed to deal with low bandwidth and high latency network connections by leveraging aggressive compression and caching. Later, NX was turned into closed-source while NX libraries were made GPL-ed. This has led to open-source implementation of several NX-based remote desktop solutions, and one of them is X2Go.
|
||||
|
||||
What benefits does X2Go bring to the table, compared to other solutions such as VNC? X2Go inherits all the advanced features of NX technology, so naturally it works well over slow network connections. Besides, X2Go boasts of an excellent track record of ensuring security with its built-in SSH-based encryption. No longer need to set up an SSH tunnel [manually][4]. X2Go comes with audio support out of box, which means that music playback at the remote desktop is delivered (via PulseAudio) over network, and fed into local speakers. On usability front, an application that you run on remote desktop can be seamlessly rendered as a separate window on your local desktop, giving you an illusion that the application is actually running on the local desktop. As you can see, these are some of [its powerful features][5] lacking in VNC based solutions.
|
||||
|
||||
### X2GO's Desktop Environment Compatibility ###
|
||||
|
||||
As with other remote desktop servers, there are [known compatibility issues][6] for X2Go server. Desktop environments like KDE3/4, Xfce, MATE and LXDE are the most friendly to X2Go server. However, your mileage may vary with other desktop managers. For example, the later versions of GNOME 3, KDE5, Unity are known to be not compatible with X2Go. If the desktop manager of your remote host is compatible with X2Go, you can follow the rest of the tutorial.
|
||||
|
||||
### Install X2Go Server on Linux ###
|
||||
|
||||
X2Go consists of remote desktop server and client components. Let's start with X2Go server installation. I assume that you already have an X2Go-compatible desktop manager up and running on a remote host, where we will be installing X2Go server.
|
||||
|
||||
Note that X2Go server component does not have a separate service that needs to be started upon boot. You just need to make sure that SSH service is up and running.
|
||||
|
||||
#### Ubuntu or Linux Mint: ####
|
||||
|
||||
Configure X2Go PPA repository. X2Go PPA is available for Ubuntu 14.04 and higher.
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Debian (Wheezy): ####
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goserver x2goserver-xsession
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
#### CentOS/RHEL: ####
|
||||
|
||||
Enable [EPEL respository][7] first, and then run:
|
||||
|
||||
$ sudo yum install x2goserver x2goserver-xsession
|
||||
|
||||
### Install X2Go Client on Linux ###
|
||||
|
||||
On a local host where you will be connecting to remote desktop, install X2GO client as follows.
|
||||
|
||||
#### Ubuntu or Linux Mint: ####
|
||||
|
||||
Configure X2Go PPA repository. X2Go PPA is available for Ubuntu 14.04 and higher.
|
||||
|
||||
$ sudo add-apt-repository ppa:x2go/stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
Debian (Wheezy):
|
||||
|
||||
$ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
|
||||
$ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install x2goclient
|
||||
|
||||
#### Fedora: ####
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
CentOS/RHEL:
|
||||
|
||||
Enable EPEL respository first, and then run:
|
||||
|
||||
$ sudo yum install x2goclient
|
||||
|
||||
### Connect to Remote Desktop with X2Go Client ###
|
||||
|
||||
Now it's time to connect to your remote desktop. On the local host, simply run the following command or use desktop launcher to start X2Go client.
|
||||
|
||||
$ x2goclient
|
||||
|
||||
Enter the remote host's IP address and SSH user name. Also, specify session type (i.e., desktop manager of a remote host).
|
||||
|
||||

|
||||
|
||||
If you want, you can customize other things (by pressing other tabs), like connection speed, compression, screen resolution, and so on.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
When you initiate a remote desktop connection, you will be asked to log in. Type your SSH login and password.
|
||||
|
||||

|
||||
|
||||
Upon successful login, you will see the remote desktop screen.
|
||||
|
||||

|
||||
|
||||
If you want to test X2Go's seamless window feature, choose "Single application" as session type, and specify the path to an executable on the remote host. In this example, I choose Dolphin file manager on a remote KDE host.
|
||||
|
||||

|
||||
|
||||
Once you are successfully connected, you will see a remote application window open on your local desktop, not the entire remote desktop screen.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I demonstrated how to set up X2Go remote desktop on [Linux VPS][8] instance. As you can see, the whole setup process is pretty much painless (if you are using a right desktop environment). While there are some desktop-specific quirkiness, X2Go is a solid remote desktop solution which is secure, feature-rich, fast, and free.
|
||||
|
||||
What feature is the most appealing to you in X2Go? Please share your thought.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/x2go-remote-desktop-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/centos-remote-desktop-vps.html
|
||||
[2]:http://wiki.x2go.org/
|
||||
[3]:http://xmodulo.com/go/digitalocean
|
||||
[4]:http://xmodulo.com/how-to-set-up-vnc-over-ssh.html
|
||||
[5]:http://wiki.x2go.org/doku.php/doc:newtox2go
|
||||
[6]:http://wiki.x2go.org/doku.php/doc:de-compat
|
||||
[7]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[8]:http://xmodulo.com/go/digitalocean
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
Lolcat – A Command Line Tool to Output Rainbow Of Colors in Linux Terminal
|
||||
================================================================================
|
||||
For those who believe that Linux Command Line is boring and there isn’t any fun, then you’re wrong here are the articles on Linux, that shows how funny and naughty is Linux..
|
||||
@ -173,4 +175,4 @@ via: http://www.tecmint.com/lolcat-command-to-output-rainbow-of-colors-in-linux-
|
||||
[1]:http://www.tecmint.com/20-funny-commands-of-linux-or-linux-is-fun-in-terminal/
|
||||
[2]:http://www.tecmint.com/linux-funny-commands/
|
||||
[3]:http://www.tecmint.com/play-with-word-and-character-counts-in-linux/
|
||||
[4]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
|
||||
@ -1,301 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
20 Useful Terminal Emulators for Linux
|
||||
================================================================================
|
||||
A Terminal emulator is a computer program that reproduces a video terminal within some other display structure. In other words the Terminal emulator has an ability to make a dumb machine appear like a client computer networked to the server. The terminal emulator allows an end user to access console as well as its applications such as text user interface and command line interface.
|
||||
|
||||

|
||||
|
||||
20 Linux Terminal Emulators
|
||||
|
||||
You may find huge number of terminal emulators to choose from this open source world. Some of them offers large range of features while others offers less features. To give a better understanding to the quality of software that are available, we have gathered a list of marvelous terminal emulator for Linux. Each title provides its description and feature along with screenshot of the software with relevant download link.
|
||||
|
||||
### 1. Terminator ###
|
||||
|
||||
Terminator is an advanced and powerful terminal emulator which supports multiple terminals windows. This emulator is fully customizable. You can change the size, colour, give different shapes to the terminal. Its very user friendly and fun to use.
|
||||
|
||||
#### Features of Terminator ####
|
||||
|
||||
- Customize your profiles and colour schemes, set the size to fit your needs.
|
||||
- Use plugins to get even more functionality.
|
||||
- Several key-shortcuts are available to speed up common activities.
|
||||
- Split the terminal window into several virtual terminals and re-size them as needed.
|
||||
|
||||
|
||||
|
||||
Terminator Terminal
|
||||
|
||||
- [Terminator Homepage][1]
|
||||
- [Download and Installation Instructions][2]
|
||||
|
||||
### 2. Tilda ###
|
||||
|
||||
Tilda is a stylish drop-down terminal based on GTK+. With the help of a single key press you can launch a new or hide Tilda window. However, you can add colors of your choice to change the look of the text and Terminal background.
|
||||
|
||||
#### Features of Tilda ####
|
||||
|
||||
Interface with Highly customization option.
|
||||
You can set the transparency level for Tilda window.
|
||||
Excellent built-in colour schemes.
|
||||
|
||||

|
||||
|
||||
Tilda Terminal
|
||||
|
||||
- [Tilda Homepage][3]
|
||||
|
||||
### 3. Guake ###
|
||||
|
||||
Guake is a python based drop-down terminal created for the GNOME Desktop Environment. It is invoked by pressing a single keystroke, and can make it hidden by pressing same keystroke again. Its design was determined from FPS (First Person Shooter) games such as Quake and one of its main target is be easy to reach.
|
||||
|
||||
Guake is very much similar to Yakuaka and Tilda, but it’s an experiment to mix the best of them into a single GTK-based program. Guake has been written in python from scratch using a little piece in C (global hotkeys stuff).
|
||||
|
||||

|
||||
|
||||
Guake Terminal
|
||||
|
||||
- [Guake Homepage][4]
|
||||
|
||||
### 4. Yakuake ###
|
||||
|
||||
Yakuake (Yet Another Kuake) is a KDE based drop-down terminal emulator very much similar to Guake terminal emulator in functionality. It’s design was inspired from fps consoles games such as Quake.
|
||||
|
||||
Yakuake is basically a KDE application, which can be easily installed on KDE desktop, but if you try to install Yakuake in GNOME desktop, it will prompt you to install huge number of dependency packages.
|
||||
|
||||
#### Yakuake Features ####
|
||||
|
||||
- Fluently turn down from the top of your screen
|
||||
- Tabbed interface
|
||||
- Configurable dimensions and animation speed
|
||||
- Customizable
|
||||
|
||||

|
||||
|
||||
Yakuake Terminal
|
||||
|
||||
- [Yakuake Homepage][5]
|
||||
|
||||
### 5. ROXTerm ###
|
||||
|
||||
ROXterm is yet another lightweight terminal emulator designed to provide similar features to gnome-terminal. It was originally constructed to have lesser footprints and faster start-up time by not using the Gnome libraries and by using a independent applet to bring the configuration interface (GUI), but over the time it’s role has shifted to bringing a higher range of features for power users.
|
||||
|
||||
However, it is more customizable than gnome-terminal and anticipated more at “power” users who make excessive use of terminals. It is easily integrated with GNOME desktop environment and provides features like drag & drop of items into terminal.
|
||||
|
||||

|
||||
|
||||
Roxterm Terminal
|
||||
|
||||
- [ROXTerm Homepage][6]
|
||||
|
||||
### 6. Eterm ###
|
||||
|
||||
Eterm is a lightest color terminal emulator designed as a replacement for xterm. It is developed with a Freedom of Choice ideology, leaving as much power, flexibility, and freedom as workable in the hands of the user.
|
||||
|
||||

|
||||
|
||||
Eterm Terminal
|
||||
|
||||
- [Eterm Homepage][7]
|
||||
|
||||
### 7. Rxvt ###
|
||||
|
||||
Rxvt stands for extended virtual terminal is a color terminal emulator application for Linux intended as an xterm replacement for power users who don’t need to have a feature such as Tektronix 4014 emulation and toolkit-style configurability.
|
||||
|
||||

|
||||
|
||||
Rxvt Terminal
|
||||
|
||||
- [Rxvt Homepage][8]
|
||||
|
||||
### 8. Wterm ###
|
||||
|
||||
Wterm is a another light weight color terminal emulator based on rxvt project. It includes features such as background images, transparency, reverse transparency and an considerable set or runtime options are accessible resulting in a very high customizable terminal emulator.
|
||||
|
||||

|
||||
|
||||
wterm Terminal
|
||||
|
||||
- [Wterm Homepage][9]
|
||||
|
||||
### 9. LXTerminal ###
|
||||
|
||||
LXTerminal is a default VTE-based terminal emulator for LXDE (Lightweight X Desktop Environment) without any unnecessary dependency. The terminal has got some nice features such as.
|
||||
LXTerminal Features
|
||||
|
||||
- Multiple tabs support
|
||||
- Supports common commands like cp, cd, dir, mkdir, mvdir.
|
||||
- Feature to hide the menu bar for saving space
|
||||
- Change the color scheme.
|
||||
|
||||

|
||||
|
||||
lxterminal Terminal
|
||||
|
||||
- [LXTerminal Homepage][10]
|
||||
|
||||
### 10. Konsole ###
|
||||
|
||||
Konsole is yet another powerful KDE based free terminal emulator was originally created by Lars Doelle.
|
||||
Konsole Features
|
||||
|
||||
- Multiple Tabbed terminals.
|
||||
- Translucent backgrounds.
|
||||
- Support for Split-view mode.
|
||||
- Directory and SSH bookmarking.
|
||||
- Customizable color schemes.
|
||||
- Customizable key bindings.
|
||||
- Notification alerts about activity in a terminal.
|
||||
- Incremental search
|
||||
- Support for Dolphin file manager
|
||||
- Export of output in plain text or HTML format.
|
||||
|
||||

|
||||
|
||||
Konsole Terminal
|
||||
|
||||
- [Konsole Homepage][11]
|
||||
|
||||
### 11. TermKit ###
|
||||
|
||||
TermKit is a elegant terminal that aims to construct aspects of the GUI with the command line based application using WebKit rendering engine mostly used in web browsers like Google Chrome and Chromium. TermKit is originally designed for Mac and Windows, but due to TermKit fork by Floby which you can now able to install it under Linux based distributions and experience the power of TermKit.
|
||||
|
||||
|
||||
|
||||
TermKit Terminal
|
||||
|
||||
- [TermKit Homepage][12]
|
||||
|
||||
12. st
|
||||
|
||||
st is a simple terminal implementation for X Window.
|
||||
|
||||

|
||||
|
||||
st terminal
|
||||
|
||||
- [st Homepage][13]
|
||||
|
||||
### 13. Gnome-Terminal ###
|
||||
|
||||
GNOME terminal is a built-in terminal emulator for GNOME desktop environment developed by Havoc Pennington and others. It allow users to run commands using a real Linux shell while remaining on the on the GNOME environment. GNOME Terminal emulates the xterm terminal emulator and brings a few similar features.
|
||||
|
||||
The Gnome terminal supports multiple profiles, where users can able to create multiple profiles for his/her account and can customize configuration options such as fonts, colors, background image, behavior, etc. per account and define a name to each profile. It also supports mouse events, url detection, multiple tabs, etc.
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
|
||||
- [Gnome Terminal][14]
|
||||
|
||||
### 14. Final Term ###
|
||||
|
||||
Final Term is a open source stylish terminal emulator that has some exciting capabilities and handy features into one single beautiful interface. It is still under development, but provides significant features such as Semantic text menus, Smart command completion, GUI terminal controls, Omnipotent keybindings, Color support and many more. The following animated screen grab demonstrates some of their features. Please click on image to view demo.
|
||||
|
||||

|
||||
|
||||
FinalTerm Terminal
|
||||
|
||||
- [Final Term][15]
|
||||
|
||||
### 15. Terminology ###
|
||||
|
||||
Terminology is yet another new modern terminal emulator created for the Enlightenment desktop, but also can be used in different desktop environments. It has some awesome unique features, which do not have in any other terminal emulator.
|
||||
|
||||
Apart features, terminology offers even more things that you wouldn’t assume from a other terminal emulators, like preview thumbnails of images, videos and documents, it also allows you to see those files directly from Terminology.
|
||||
|
||||
You can watch a following demonstrations video created by the Terminology developer (the video quality isn’t clear, but still it’s enough to get the idea about Terminology).
|
||||
|
||||
<iframe width="630" height="480" frameborder="0" allowfullscreen="" src="//www.youtube.com/embed/ibPziLRGvkg"></iframe>
|
||||
|
||||
- [Terminology][16]
|
||||
|
||||
### 16. Xfce4 terminal ###
|
||||
|
||||
Xfce terminal is a lightweight modern and easy to use terminal emulator specially designed for Xfce desktop environment. The latest release of xfce terminal has some new cool features such as search dialog, tab color changer, drop-down console like Guake or Yakuake and many more.
|
||||
|
||||

|
||||
|
||||
Xfce Terminal
|
||||
|
||||
- [Xfce4 Terminal][17]
|
||||
|
||||
### 17. xterm ###
|
||||
|
||||
The xterm application is a standard terminal emulator for the X Window System. It maintain DEC VT102 and Tektronix 4014 compatible terminals for applications that can’t use the window system directly.
|
||||
|
||||

|
||||
|
||||
xterm Terminal
|
||||
|
||||
- [xterm][18]
|
||||
|
||||
### 18. LilyTerm ###
|
||||
|
||||
The LilyTerm is a another less known open source terminal emulator based off of libvte that desire to be fast and lightweight. LilyTerm also include some key features such as:
|
||||
|
||||
- Support for tabbing, coloring and reordering tabs
|
||||
- Ability to manage tabs through keybindings
|
||||
- Support for background transparency and saturation.
|
||||
- Support for user specific profile creation.
|
||||
- Several customization options for profiles.
|
||||
- Extensive UTF-8 support.
|
||||
|
||||

|
||||
|
||||
Lilyterm Terminal
|
||||
|
||||
- [LilyTerm][19]
|
||||
|
||||
### 19. Sakura ###
|
||||
|
||||
The sakura is a another less known Unix style terminal emulator developed for command line purpose as well as text-based terminal programs. Sakura is based on GTK and livte and provides not more advanced features but some customization options such as multiple tab support, custom text color, font and background images, speedy command processing and few more.
|
||||
|
||||

|
||||
|
||||
Sakura Terminal
|
||||
|
||||
- [Sakura][20]
|
||||
|
||||
### 20. rxvt-unicode ###
|
||||
|
||||
The rxvt-unicode (also known as urxvt) is a yet another highly customizable, lightweight and fast terminal emulator with xft and unicode support was developed by Marc Lehmann. It got some outstanding features such as support for international language via Unicode, the ability to display multiple font types and support for Perl extensions.
|
||||
|
||||

|
||||
|
||||
rxvt unicode
|
||||
|
||||
- [rxvt-unicode][21]
|
||||
|
||||
If you know any other capable Linux terminal emulators that I’ve not included in the above list, please do share with me using our comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-terminal-emulators/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:https://launchpad.net/terminator
|
||||
[2]:http://www.tecmint.com/terminator-a-linux-terminal-emulator-to-manage-multiple-terminal-windows/
|
||||
[3]:http://tilda.sourceforge.net/tildaabout.php
|
||||
[4]:https://github.com/Guake/guake
|
||||
[5]:http://extragear.kde.org/apps/yakuake/
|
||||
[6]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
|
||||
[7]:http://www.eterm.org/
|
||||
[8]:http://sourceforge.net/projects/rxvt/
|
||||
[9]:http://sourceforge.net/projects/wterm/
|
||||
[10]:http://wiki.lxde.org/en/LXTerminal
|
||||
[11]:http://konsole.kde.org/
|
||||
[12]:https://github.com/unconed/TermKit
|
||||
[13]:http://st.suckless.org/
|
||||
[14]:https://help.gnome.org/users/gnome-terminal/stable/
|
||||
[15]:http://finalterm.org/
|
||||
[16]:http://www.enlightenment.org/p.php?p=about/terminology
|
||||
[17]:http://docs.xfce.org/apps/terminal/start
|
||||
[18]:http://invisible-island.net/xterm/
|
||||
[19]:http://lilyterm.luna.com.tw/
|
||||
[20]:https://launchpad.net/sakura
|
||||
[21]:http://software.schmorp.de/pkg/rxvt-unicode
|
||||
@ -1,122 +0,0 @@
|
||||
How to edit your documents collaboratively on Linux
|
||||
================================================================================
|
||||
> "Developed many years before by some high-strung, compulsive assistant, the Bulletin was simply a Word document that lived in a shared folder both Emily and I could access. Only one of us could open it at a time and add a new message, thought, or question to the itemized list. Then we'd print out the updated version and place it on the clipboard that sat on the shelf over my desk, removing the old ones as we went." ("The Devil Wears Prada" by Lauren Weisberger)
|
||||
|
||||
Even today such a "collaborative editing" is in use where only one person can open a shared file, make changes to it, and then inform others about what and when was modified.
|
||||
|
||||
ONLYOFFICE is an open source online office suite integrated with different management tools for documents, emails, events, tasks and client relations.
|
||||
|
||||
Using ONLYOFFICE office suite, a group of people can edit text, spreadsheet or presentation within a browser simultaneously. Leave comments directly in their document and interact with each other using the integrated chat. And, finally, save the document as a PDF file for further printing. As an added bonus, it gives the possibility to view the document history and restore the previous revision/version if needed.
|
||||
|
||||
In this tutorial, I will describe how to deploy your own online office suite using [ONLYOFFICE Free Edition][1], an ONLYOFFICE self-hosted version distributed under GNU AGPL v3.
|
||||
|
||||
### Installing ONLYOFFICE on Linux ###
|
||||
|
||||
ONLYOFFICE installation requires the presence of mono (version 4.0.0 or later), nodejs, libstdc++6, nginx and mysql-server in your Linux system. To simplify the installation process and avoid dependency errors, I install ONLYOFFICE using Docker. In this case there is only one dependency to be installed - [Docker][2].
|
||||
|
||||
Just to remind, Docker is an open-source project that automates the deployment of applications inside software containers. If Docker is not available on your Linux system, install it first by referring to Docker installation instructions for [Debian-based][3] or [Red-Hat based][4] systems.
|
||||
|
||||
Note that you will need Docker 1.4.1 or later. To check the installed Docker version, use the following command.
|
||||
|
||||
$ docker version
|
||||
|
||||
To try ONLYOFFICE inside a Docker container, simply execute the following commands:
|
||||
|
||||
$ sudo docker run -i -t -d --name onlyoffice-document-server onlyoffice/documentserver
|
||||
$ sudo docker run -i -t -d -p 80:80 -p 443:443 --link onlyoffice-document-server:document_server onlyoffice/communityserver
|
||||
|
||||
These commands will download the [official ONLYOFFICE Docker image][5] with all dependencies needed for its correct work.
|
||||
|
||||
It's also possible to install [ONLYOFFICE Online Editors][6] separately on a Linux server, and easily integrate it into your website or cloud application via API provided.
|
||||
|
||||
### Running a Self-Hosted Online Office ###
|
||||
|
||||
To open your online office, enter localhost (http://IP-Address/) in the address bar of your browser. The Welcome page will open:
|
||||
|
||||

|
||||
|
||||
Enter a password and specify the email address you will use to access your office the next time.
|
||||
|
||||
### Editing Your Documents Online ###
|
||||
|
||||
First, click the Documents link to open **the My Documents** folder.
|
||||
|
||||
|
||||
|
||||
#### STEP 1. Select a Document to Edit ####
|
||||
|
||||
To create a new document right there, click on the **Create** button in the upper left corner, and choose the file type from the drop-down list. To edit a file stored on your hard disk drive, upload it to **Documents** clicking the **Upload** button next to **Create** button.
|
||||
|
||||
|
||||
|
||||
#### STEP 2. Share your Document ####
|
||||
|
||||
Use the **Share** button to the right side if you are in the **My Documents** folder, or follow **File >> Document Info ... >> Change Access Rights** if you are inside your document.
|
||||
|
||||
In the opened **Sharing Settings** window, click on the **People outside portal** link on the left, open the access to the document, and give full access to it by enabling the **Full Access** radio button.
|
||||
|
||||
Finally, choose a way to share the link to your document, send it via email or one of the available social networks: Google+, Facebook, or Twitter.
|
||||
|
||||
|
||||
|
||||
#### STEP 3. Start the Collaborative Editing ####
|
||||
|
||||
To start co-editing the document, the invited person just needs to follow the provided link.
|
||||
|
||||
The text passages edited by your co-editors will be automatically marked with dashed lines of different colors.
|
||||
|
||||
|
||||
|
||||
As soon as one of your collaborators saves his/her changes, you will see a note appearing in the left upper corner of the top toolbar, indicating that there areupdates.
|
||||
|
||||
|
||||
|
||||
To save your changes and get updates, click on the **Save** icon. All the updates will then be highlighted.
|
||||
|
||||
|
||||
|
||||
#### STEP 4. Interact with your Co-editors ####
|
||||
|
||||
To leave some comments, select a text passage with the mouse, right-click on it and, and choose the **Add comment** option from the context menu.
|
||||
|
||||

|
||||
|
||||
To interact with co-editors in real time, use the integrated chat instead. All the users who currently edit the document will be listed on the **Chat** panel. To open it, click on the **Chat** icon at the left-side bar. To start a discussion, enter your message into an appropriate field on the **Chat** panel.
|
||||
|
||||
|
||||
|
||||
### Useful Tips ###
|
||||
|
||||
As final notes, here are some useful tips for you to take full advantage of ONLYOFFICE.
|
||||
|
||||
#### Tip #1. Editing your Docs from Cloud Storage Services, Like ownCloud ####
|
||||
|
||||
If you store your documents in other web resources like Box, Dropbox, Google Drive, OneDrive, SharePoint or ownCloud, you can easily synchronize them with the ONLYOFFICE.
|
||||
|
||||
In the opened 'Documents' module, click one of the icons under the **Add the account** caption: Google, Box, DropBox, OneDrive, ownCloud or 'Add account', and enter the requested data.
|
||||
|
||||
#### Tip #2. Editing Your Docs on iPad ####
|
||||
|
||||
To add some changes to your document on the go, I use ONLYOFFICE Documents app for iPad. You can download and install it from [iTune][7], then you need to enter your ONLYOFFICE portal address, email and password to access your documents. The feature set is almost the same.
|
||||
|
||||
To evaluate ONLYOFFICE Online Editors features, you can use the [cloud version][8] for personal use.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/edit-documents-collaboratively-linux.html
|
||||
|
||||
作者:[Tatiana Kochedykova][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/tatiana
|
||||
[1]:http://www.onlyoffice.org/
|
||||
[2]:http://xmodulo.com/recommend/dockerbook
|
||||
[3]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
|
||||
[4]:http://xmodulo.com/docker-containers-centos-fedora.html
|
||||
[5]:https://registry.hub.docker.com/u/onlyoffice/communityserver/
|
||||
[6]:http://onlyoffice.org/sources#document
|
||||
[7]:https://itunes.apple.com/us/app/onlyoffice-documents/id944896972
|
||||
[8]:https://personal.onlyoffice.com/
|
||||
@ -1,436 +0,0 @@
|
||||
zpl1025
|
||||
How to Manipulate Filenames Having Spaces and Special Characters in Linux
|
||||
================================================================================
|
||||
We come across files and folders name very regularly. In most of the cases file/folder name are related to the content of the file/folder and starts with number and characters. Alpha-Numeric file name are pretty common and very widely used, but this is not the case when we have to deal with file/folder name that has special characters in them.
|
||||
|
||||
**Note**: We can have files of any type but for simplicity and easy implementation we will be dealing with Text file (.txt), throughout the article.
|
||||
|
||||
Example of most common file names are:
|
||||
|
||||
abc.txt
|
||||
avi.txt
|
||||
debian.txt
|
||||
...
|
||||
|
||||
Example of numeric file names are:
|
||||
|
||||
121.txt
|
||||
3221.txt
|
||||
674659.txt
|
||||
...
|
||||
|
||||
Example of Alpha-Numeric file names are:
|
||||
|
||||
eg84235.txt
|
||||
3kf43nl2.txt
|
||||
2323ddw.txt
|
||||
...
|
||||
|
||||
Examples of file names that has special character and is not very common:
|
||||
|
||||
#232.txt
|
||||
#bkf.txt
|
||||
#bjsd3469.txt
|
||||
#121nkfd.txt
|
||||
-2232.txt
|
||||
-fbjdew.txt
|
||||
-gi32kj.txt
|
||||
--321.txt
|
||||
--bk34.txt
|
||||
...
|
||||
|
||||
One of the most obvious question here is – who on earth create/deal with files/folders name having a Hash `(#)`, a semi-colon `(;)`, a dash `(-)` or any other special character.
|
||||
|
||||
I Agree to you, that such file names are not common still your shell should not break/give up when you have to deal with any such file names. Also speaking technically every thing be it folder, driver or anything else is treated as file in Linux.
|
||||
|
||||
### Dealing with file that has dash (-) in it’s name ###
|
||||
|
||||
Create a file that starts with a dash `(-)`, say -abx.txt.
|
||||
|
||||
$ touch -abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: invalid option -- 'b'
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
The reason for above error, that shell interprets anything after a dash `(-)`, as option, and obviously there is no such option, hence is the error.
|
||||
|
||||
To resolve such error, we have to tell the Bash shell (yup this and most of the other examples in the article is for BASH) not to interpret anything after special character (here dash), as option.
|
||||
|
||||
There are two ways to resolve this error as:
|
||||
|
||||
$ touch -- -abc.txt [Option #1]
|
||||
$ touch ./-abc.txt [Option #2]
|
||||
|
||||
You may verify the file thus created by both the above ways by running commands ls or [ls -l][1] for long listing.
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 11:05 -abc.txt
|
||||
|
||||
To edit the above file you may do:
|
||||
|
||||
$ nano -- -abc.txt
|
||||
or
|
||||
$ nano ./-abc.txt
|
||||
|
||||
**Note**: You may replace nano with any other editor of your choice say vim as:
|
||||
|
||||
$ vim -- -abc.txt
|
||||
or
|
||||
$ vim ./-abc.txt
|
||||
|
||||
Similarly to move such file you have to do:
|
||||
|
||||
$ mv -- -abc.txt -a.txt
|
||||
or
|
||||
$ mv -- -a.txt -abc.txt
|
||||
|
||||
and to Delete this file, you have to do:
|
||||
|
||||
$ rm -- -abc.txt
|
||||
or
|
||||
$ rm ./-abc.txt
|
||||
|
||||
If you have lots of files in a folder the name of which contains dash, and you want to delete all of them at once, do as:
|
||||
|
||||
$ rm ./-*
|
||||
|
||||
**Important to Note:**
|
||||
|
||||
1. The same rule as discussed above follows for any number of hypen in the name of the file and their occurrence. Viz., -a-b-c.txt, ab-c.txt, abc-.txt, etc.
|
||||
|
||||
2. The same rule as discussed above follows for the name of the folder having any number of hypen and their occurrence, except the fact that for deleting the folder you have to use ‘rm -rf‘ as:
|
||||
|
||||
$ rm -rf -- -abc
|
||||
or
|
||||
$ rm -rf ./-abc
|
||||
|
||||
### Dealing with files having HASH (#) in the name ###
|
||||
|
||||
The symbol `#` has a very different meaning in BASH. Anything after a `#` is interpreted as comment and hence neglected by BASH.
|
||||
|
||||
**Understand it using examples:**
|
||||
|
||||
create a file #abc.txt.
|
||||
|
||||
$ touch #abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
The reason for above error, that Bash is interpreting #abc.txt a comment and hence ignoring. So the [command touch][2] has been passed without any file Operand, and hence is the error.
|
||||
|
||||
To resolve such error, you may ask BASH not to interpret # as comment.
|
||||
|
||||
$ touch ./#abc.txt
|
||||
or
|
||||
$ touch '#abc.txt'
|
||||
|
||||
and verify the file just created as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:14 #abc.txt
|
||||
|
||||
Now create a file the name of which contains # anywhere except at the begging.
|
||||
|
||||
$ touch ./a#bc.txt
|
||||
$ touch ./abc#.txt
|
||||
|
||||
or
|
||||
$ touch 'a#bc.txt'
|
||||
$ touch 'abc#.txt'
|
||||
|
||||
Run ‘ls -l‘ to verify it:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 a#bc.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 abc#.txt
|
||||
|
||||
What happens when you create two files (say a and #bc) at once:
|
||||
|
||||
$ touch a.txt #bc.txt
|
||||
|
||||
Verify the file just created:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:18 a.txt
|
||||
|
||||
Obvious from the above example it only created file ‘a‘ and file ‘#bc‘ has been ignored. To execute the above situation successfully we can do,
|
||||
|
||||
$ touch a.txt ./#bc.txt
|
||||
or
|
||||
$ touch a.txt '#bc.txt'
|
||||
|
||||
and verify it as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 a.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 #bc.txt
|
||||
|
||||
You can move the file as:
|
||||
|
||||
$ mv ./#bc.txt ./#cd.txt
|
||||
or
|
||||
$ mv '#bc.txt' '#cd.txt'
|
||||
|
||||
Copy it as:
|
||||
|
||||
$ cp ./#cd.txt ./#de.txt
|
||||
or
|
||||
$ cp '#cd.txt' '#de.txt'
|
||||
|
||||
You may edit it as using your choice of editor as:
|
||||
|
||||
$ vi ./#cd.txt
|
||||
or
|
||||
$ vi '#cd.txt'
|
||||
|
||||
----------
|
||||
|
||||
$ nano ./#cd.txt
|
||||
or
|
||||
$ nano '#cd.txt'
|
||||
|
||||
And Delete it as:
|
||||
|
||||
$ rm ./#bc.txt
|
||||
or
|
||||
$ rm '#bc.txt'
|
||||
|
||||
To delete all the files that has hash (#) in the file name, you may use:
|
||||
|
||||
# rm ./#*
|
||||
|
||||
### Dealing with files having semicolon (;) in its name ###
|
||||
|
||||
In case you are not aware, semicolon acts as a command separator in BASH and perhaps other shell as well. Semicolon lets you execute several command in one go and acts as separator. Have you ever deal with any file name having semicolon in it? If not here you will.
|
||||
|
||||
Create a file having semi-colon in it.
|
||||
|
||||
$ touch ;abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
bash: abc.txt: command not found
|
||||
|
||||
The reason for above error, that when you run the above command BASH interpret touch as a command but could not find any file operand before semicolon and hence it reports error. It also reports another error that ‘abc.txt‘ command not found, only because after semicolon BASH was expecting another command and ‘abc.txt‘, is not a command.
|
||||
|
||||
To resolve such error, tell BASH not to interpret semicolon as command separator, as:
|
||||
|
||||
$ touch ./';abc.txt'
|
||||
or
|
||||
$ touch ';abc.txt'
|
||||
|
||||
**Note**: We have enclosed the file name with single quote ''. It tells BASH that ; is a part of file name and not command separator.
|
||||
|
||||
Rest of the action (viz., copy, move, delete) on the file and folder having semicolon in its name can be carried out straight forward by enclosing the name in single quote.
|
||||
|
||||
### Dealing with other special characters in file/folder name ###
|
||||
|
||||
#### Plus Sign (+) in file name ####
|
||||
|
||||
Don’t requires anything extra, just do it normal way, as simple file name as shown below.
|
||||
|
||||
$ touch +12.txt
|
||||
|
||||
#### Dollar sign ($) in file name ####
|
||||
|
||||
You have to enclose file name in single quote, as we did in the case of semicolon. Rest of the things are straight forward..
|
||||
|
||||
$ touch '$12.txt'
|
||||
|
||||
#### Percent (%) in file name ####
|
||||
|
||||
You don’t need to do anything differently, treat it as normal file.
|
||||
|
||||
$ touch %12.txt
|
||||
|
||||
#### Asterisk (*) in file name ####
|
||||
|
||||
Having Asterisk in file name don’t change anything and you can continue using it as normal file.
|
||||
|
||||
$ touch *12.txt
|
||||
|
||||
Note: When you have to delete a file that starts with *, Never use following commands to delete such files.
|
||||
|
||||
$ rm *
|
||||
or
|
||||
$ rm -rf *
|
||||
|
||||
Instead use,
|
||||
|
||||
$ rm ./*.txt
|
||||
|
||||
#### Exclamation mark (!) in file name ####
|
||||
|
||||
Just Enclose the file name in single quote and rest of the things are same.
|
||||
|
||||
$ touch '!12.txt'
|
||||
|
||||
#### At Sign (@) in file name ####
|
||||
|
||||
Nothing extra, treat a filename having At Sign as nonrmal file.
|
||||
|
||||
$ touch '@12.txt'
|
||||
|
||||
#### ^ in file name ####
|
||||
|
||||
No extra attention required. Use a file having ^ in filename as normal file.
|
||||
|
||||
$ touch ^12.txt
|
||||
|
||||
#### Ampersand (&) in file name ####
|
||||
|
||||
Filename should be enclosed in single quotes and you are ready to go.
|
||||
|
||||
$ touch '&12.txt'
|
||||
|
||||
#### Parentheses () in file name ####
|
||||
|
||||
If the file name has Parenthesis, you need to enclose filename with single quotes.
|
||||
|
||||
$ touch '(12.txt)'
|
||||
|
||||
#### Braces {} in file name ####
|
||||
|
||||
No Extra Care needed. Just treat it as just another file.
|
||||
|
||||
$ touch {12.txt}
|
||||
|
||||
#### Chevrons <> in file name ####
|
||||
|
||||
A file name having Chevrons must be enclosed in single quotes.
|
||||
|
||||
$ touch '<12.txt>'
|
||||
|
||||
#### Square Brackets [ ] in file name ####
|
||||
|
||||
Treat file name having Square Brackets as normal files and you need not take extra care of it.
|
||||
|
||||
$ touch [12.txt]
|
||||
|
||||
#### Under score (_) in file name ####
|
||||
|
||||
They are very common and don’t require anything extra. Just do what you would have done with a normal file.
|
||||
|
||||
$ touch _12.txt
|
||||
|
||||
#### Equal-to (=) in File name ####
|
||||
|
||||
Having an Equal-to sign do not change anything, you can use it as normal file.
|
||||
|
||||
$ touch =12.txt
|
||||
|
||||
#### Dealing with back slash (\) ####
|
||||
|
||||
Backslash tells shell to ignore the next character. You have to enclose file name in single quote, as we did in the case of semicolon. Rest of the things are straight forward.
|
||||
|
||||
$ touch '\12.txt'
|
||||
|
||||
#### The Special Case of Forward Slash ####
|
||||
|
||||
You cannot create a file the name of which includes a forward slash (/), until your file system has bug. There is no way to escape a forward slash.
|
||||
|
||||
So if you can create a file such as ‘/12.txt’ or ‘b/c.txt’ then either your File System has bug or you have Unicode support, which lets you create a file with forward slash. In this case the forward slash is not a real forward slash but a Unicode character that looks alike a forward slash.
|
||||
|
||||
#### Question Mark (?) in file name ####
|
||||
|
||||
Again, an example where you don’t need to put any special attempt. A file name having Question mark can be treated in the most general way.
|
||||
|
||||
$ touch ?12.txt
|
||||
|
||||
#### Dot Mark (.) in file name ####
|
||||
|
||||
The files starting with dot `(.)` are very special in Linux and are called dot files. They are hidden files generally a configuration or system files. You have to use switch ‘-a‘ or ‘-A‘ with ls command to view such files.
|
||||
|
||||
Creating, editing, renaming and deleting of such files are straight forward.
|
||||
|
||||
$ touch .12.txt
|
||||
|
||||
Note: In Linux you may have as many dots `(.)` as you need in a file name. Unlike other system dots in file name don’t means to separate name and extension. You can create a file having multiple dots as:
|
||||
|
||||
$ touch 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
and check it as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 14:32 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
#### Comma (,) in file name ####
|
||||
|
||||
You can have comma in a file name, as many as you want and you Don’t requires anything extra. Just do it normal way, as simple file name.
|
||||
|
||||
$ touch ,12.txt
|
||||
or
|
||||
$ touch ,12,.txt
|
||||
|
||||
#### Colon (:) in File name ####
|
||||
|
||||
You can have colon in a file name, as many as you want and you Don’t requires anything extra. Just do it normal way, as simple file name.
|
||||
|
||||
$ touch :12.txt
|
||||
or
|
||||
$ touch :12:.txt
|
||||
|
||||
#### Having Quotes (single and Double) in file name ####
|
||||
|
||||
To have quotes in file name, we have to use the rule of exchange. I.e, if you need to have single quote in file name, enclose the file name with double quotes and if you need to have double quote in file name, enclose it with single quote.
|
||||
|
||||
$ touch "15'.txt"
|
||||
|
||||
and
|
||||
|
||||
$ touch '15”.txt'
|
||||
|
||||
#### Tilde (~) in file name ####
|
||||
|
||||
Some Editors in Linux like emacs create a backup file of the file being edited. The backup file has the name of the original file plus a tilde at the end of the file name. You can have a file that name of which includes tilde, at any location simply as:
|
||||
|
||||
$ touch ~1a.txt
|
||||
or
|
||||
$touch 2b~.txt
|
||||
|
||||
#### White Space in file name ####
|
||||
|
||||
Create a file the name of which has space between character/word, say “hi my name is avishek.txt”.
|
||||
|
||||
It is not a good idea to have file name with spaces and if you have to distinct readable name, you should use, underscore or dash. However if you have to create such a file, you have to use backward slash which ignores the next character to it. To create above file we have to do it this way..
|
||||
|
||||
$ touch hi\ my\ name\ is\ avishek.txt
|
||||
|
||||
hi my name is avishek.txt
|
||||
|
||||
I have tried covering all the scenario you may come across. Most of the above implementation are explicitly for BASH Shell and may not work in other shell.
|
||||
|
||||
If you feel that I missed something (that is very common and human nature), you may include your suggestion in the comments below. Keep Connected, Keep Commenting. Stay Tuned and connected! Like and share us and help us get spread!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
@ -1,175 +0,0 @@
|
||||
wyangsun 申领
|
||||
Inside NGINX: How We Designed for Performance & Scale
|
||||
================================================================================
|
||||
NGINX leads the pack in web performance, and it’s all due to the way the software is designed. Whereas many web servers and application servers use a simple threaded or process-based architecture, NGINX stands out with a sophisticated event-driven architecture that enables it to scale to hundreds of thousands of concurrent connections on modern hardware.
|
||||
|
||||
The [Inside NGINX][1] infographic drills down from the high-level process architecture to illustrate how NGINX handles multiple connections within a single process. This blog explains how it all works in further detail.
|
||||
|
||||
### Setting the Scene – the NGINX Process Model ###
|
||||
|
||||

|
||||
|
||||
To better understand this design, you need to understand how NGINX runs. NGINX has a master process (which performs the privileged operations such as reading configuration and binding to ports) and a number of worker and helper processes.
|
||||
|
||||
# service nginx restart
|
||||
* Restarting nginx
|
||||
# ps -ef --forest | grep nginx
|
||||
root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx \
|
||||
-c /etc/nginx/nginx.conf
|
||||
nginx 32476 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32477 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32479 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32480 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32481 32475 0 13:36 ? 00:00:00 \_ nginx: cache manager process
|
||||
nginx 32482 32475 0 13:36 ? 00:00:00 \_ nginx: cache loader process
|
||||
|
||||
On this 4-core server, the NGINX master process creates 4 worker processes and a couple of cache helper processes which manage the on-disk content cache.
|
||||
|
||||
### Why Is Architecture Important? ###
|
||||
|
||||
The fundamental basis of any Unix application is the thread or process. (From the Linux OS perspective, threads and processes are mostly identical; the major difference is the degree to which they share memory.) A thread or process is a self-contained set of instructions that the operating system can schedule to run on a CPU core. Most complex applications run multiple threads or processes in parallel for two reasons:
|
||||
|
||||
- They can use more compute cores at the same time.
|
||||
- Threads and processes make it very easy to do operations in parallel (for example, to handle multiple connections at the same time).
|
||||
|
||||
Processes and threads consume resources. They each use memory and other OS resources, and they need to be swapped on and off the cores (an operation called a context switch). Most modern servers can handle hundreds of small, active threads or processes simultaneously, but performance degrades seriously once memory is exhausted or when high I/O load causes a large volume of context switches.
|
||||
|
||||
The common way to design network applications is to assign a thread or process to each connection. This architecture is simple and easy to implement, but it does not scale when the application needs to handle thousands of simultaneous connections.
|
||||
|
||||
### How Does NGINX Work? ###
|
||||
|
||||
NGINX uses a predictable process model that is tuned to the available hardware resources:
|
||||
|
||||
- The master process performs the privileged operations such as reading configuration and binding to ports, and then creates a small number of child processes (the next three types).
|
||||
- The cache loader process runs at startup to load the disk-based cache into memory, and then exits. It is scheduled conservatively, so its resource demands are low.
|
||||
- The cache manager process runs periodically and prunes entries from the disk caches to keep them within the configured sizes.
|
||||
- The worker processes do all of the work! They handle network connections, read and write content to disk, and communicate with upstream servers.
|
||||
|
||||
The NGINX configuration recommended in most cases – running one worker process per CPU core – makes the most efficient use of hardware resources. You configure it by including the [worker_processes auto][2] directive in the configuration:
|
||||
|
||||
worker_processes auto;
|
||||
|
||||
When an NGINX server is active, only the worker processes are busy. Each worker process handles multiple connections in a non-blocking fashion, reducing the number of context switches.
|
||||
|
||||
Each worker process is single-threaded and runs independently, grabbing new connections and processing them. The processes can communicate using shared memory for shared cache data, session persistence data, and other shared resources.
|
||||
|
||||
### Inside the NGINX Worker Process ###
|
||||
|
||||

|
||||
|
||||
Each NGINX worker process is initialized with the NGINX configuration and is provided with a set of listen sockets by the master process.
|
||||
|
||||
The NGINX worker processes begin by waiting for events on the listen sockets ([accept_mutex][3] and [kernel socket sharding][4]). Events are initiated by new incoming connections. These connections are assigned to a state machine – the HTTP state machine is the most commonly used, but NGINX also implements state machines for stream (raw TCP) traffic and for a number of mail protocols (SMTP, IMAP, and POP3).
|
||||
|
||||

|
||||
|
||||
The state machine is essentially the set of instructions that tell NGINX how to process a request. Most web servers that perform the same functions as NGINX use a similar state machine – the difference lies in the implementation.
|
||||
|
||||
### Scheduling the State Machine ###
|
||||
|
||||
Think of the state machine like the rules for chess. Each HTTP transaction is a chess game. On one side of the chessboard is the web server – a grandmaster who can make decisions very quickly. On the other side is the remote client – the web browser that is accessing the site or application over a relatively slow network.
|
||||
|
||||
However, the rules of the game can be very complicated. For example, the web server might need to communicate with other parties (proxying to an upstream application) or talk to an authentication server. Third-party modules in the web server can even extend the rules of the game.
|
||||
|
||||
#### A Blocking State Machine ####
|
||||
|
||||
Recall our description of a process or thread as a self-contained set of instructions that the operating system can schedule to run on a CPU core. Most web servers and web applications use a process-per-connection or thread-per-connection model to play the chess game. Each process or thread contains the instructions to play one game through to the end. During the time the process is run by the server, it spends most of its time ‘blocked’ – waiting for the client to complete its next move.
|
||||
|
||||

|
||||
|
||||
1. The web server process listens for new connections (new games initiated by clients) on the listen sockets.
|
||||
1. When it gets a new game, it plays that game, blocking after each move to wait for the client’s response.
|
||||
1. Once the game completes, the web server process might wait to see if the client wants to start a new game (this corresponds to a keepalive connection). If the connection is closed (the client goes away or a timeout occurs), the web server process returns to listening for new games.
|
||||
|
||||
The important point to remember is that every active HTTP connection (every chess game) requires a dedicated process or thread (a grandmaster). This architecture is simple and easy to extend with third-party modules (‘new rules’). However, there’s a huge imbalance: the rather lightweight HTTP connection, represented by a file descriptor and a small amount of memory, maps to a separate thread or process, a very heavyweight operating system object. It’s a programming convenience, but it’s massively wasteful.
|
||||
|
||||
#### NGINX is a True Grandmaster ####
|
||||
|
||||
Perhaps you’ve heard of [simultaneous exhibition][5] games, where one chess grandmaster plays dozens of opponents at the same time?
|
||||
|
||||

|
||||
|
||||
[Kiril Georgiev played 360 people simultaneously in Sofia, Bulgaria][6]. His final score was 284 wins, 70 draws and 6 losses.
|
||||
|
||||
That’s how an NGINX worker process plays “chess.” Each worker (remember – there’s usually one worker for each CPU core) is a grandmaster that can play hundreds (in fact, hundreds of thousands) of games simultaneously.
|
||||
|
||||

|
||||
|
||||
1. The worker waits for events on the listen and connection sockets.
|
||||
1. Events occur on the sockets and the worker handles them:
|
||||
|
||||
- An event on the listen socket means that a client has started a new chess game. The worker creates a new connection socket.
|
||||
- An event on a connection socket means that the client has made a new move. The worker responds promptly.
|
||||
|
||||
A worker never blocks on network traffic, waiting for its “opponent” (the client) to respond. When it has made its move, the worker immediately proceeds to other games where moves are waiting to be processed, or welcomes new players in the door.
|
||||
|
||||
### Why Is This Faster than a Blocking, Multi-Process Architecture? ###
|
||||
|
||||
NGINX scales very well to support hundreds of thousands of connections per worker process. Each new connection creates another file descriptor and consumes a small amount of additional memory in the worker process. There is very little additional overhead per connection. NGINX processes can remain pinned to CPUs. Context switches are relatively infrequent and occur when there is no work to be done.
|
||||
|
||||
In the blocking, connection-per-process approach, each connection requires a large amount of additional resources and overhead, and context switches (swapping from one process to another) are very frequent.
|
||||
|
||||
For a more detailed explanation, check out this [article][7] about NGINX architecture, by Andrew Alexeev, VP of Corporate Development and Co-Founder at NGINX, Inc.
|
||||
|
||||
With appropriate [system tuning][8], NGINX can scale to handle hundreds of thousands of concurrent HTTP connections per worker process, and can absorb traffic spikes (an influx of new games) without missing a beat.
|
||||
|
||||
### Updating Configuration and Upgrading NGINX ###
|
||||
|
||||
NGINX’s process architecture, with a small number of worker processes, makes for very efficient updating of the configuration and even the NGINX binary itself.
|
||||
|
||||

|
||||
|
||||
Updating NGINX configuration is a very simple, lightweight, and reliable operation. It typically just means running the `nginx –s reload` command, which checks the configuration on disk and sends the master process a SIGHUP signal.
|
||||
|
||||
When the master process receives a SIGHUP, it does two things:
|
||||
|
||||
- Reloads the configuration and forks a new set of worker processes. These new worker processes immediately begin accepting connections and processing traffic (using the new configuration settings).
|
||||
- Signals the old worker processes to gracefully exit. The worker processes stop accepting new connections. As soon as each current HTTP request completes, the worker process cleanly shuts down the connection (that is, there are no lingering keepalives). Once all connections are closed, the worker processes exit.
|
||||
|
||||
This reload process can cause a small spike in CPU and memory usage, but it’s generally imperceptible compared to the resource load from active connections. You can reload the configuration multiple times per second (and many NGINX users do exactly that). Very rarely, issues arise when there are many generations of NGINX worker processes waiting for connections to close, but even those are quickly resolved.
|
||||
|
||||
NGINX’s binary upgrade process achieves the holy grail of high-availability – you can upgrade the software on the fly, without any dropped connections, downtime, or interruption in service.
|
||||
|
||||

|
||||
|
||||
The binary upgrade process is similar in approach to the graceful reload of configuration. A new NGINX master process runs in parallel with the original master process, and they share the listening sockets. Both processes are active, and their respective worker processes handle traffic. You can then signal the old master and its workers to gracefully exit.
|
||||
|
||||
The entire process is described in more detail in [Controlling NGINX][9].
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The [Inside NGINX infographic][10] provides a high-level overview of how NGINX functions, but behind this simple explanation is over ten years of innovation and optimization that enable NGINX to deliver the best possible performance on a wide range of hardware while maintaining the security and reliability that modern web applications require.
|
||||
|
||||
If you’d like to read more about the optimizations in NGINX, check out these great resources:
|
||||
|
||||
- [Installing and Tuning NGINX for Performance][11] (webinar; [slides][12] at Speaker Deck)
|
||||
- [Tuning NGINX for Performance][13]
|
||||
- [The Architecture of Open Source Applications – NGINX][14]
|
||||
- [Socket Sharding in NGINX Release 1.9.1][15] (using the SO_REUSEPORT socket option)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/
|
||||
|
||||
作者:[Owen Garrett][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nginx.com/author/owen/
|
||||
[1]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[2]:http://nginx.org/en/docs/ngx_core_module.html#worker_processes
|
||||
[3]:http://nginx.org/en/docs/ngx_core_module.html#accept_mutex
|
||||
[4]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[5]:http://en.wikipedia.org/wiki/Simultaneous_exhibition
|
||||
[6]:http://gambit.blogs.nytimes.com/2009/03/03/in-chess-records-were-made-to-be-broken/
|
||||
[7]:http://www.aosabook.org/en/nginx.html
|
||||
[8]:http://nginx.com/blog/tuning-nginx/
|
||||
[9]:http://nginx.org/en/docs/control.html
|
||||
[10]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[11]:http://nginx.com/resources/webinars/installing-tuning-nginx/
|
||||
[12]:https://speakerdeck.com/nginx/nginx-installation-and-tuning
|
||||
[13]:http://nginx.com/blog/tuning-nginx/
|
||||
[14]:http://www.aosabook.org/en/nginx.html
|
||||
[15]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
@ -1,91 +0,0 @@
|
||||
How to combine two graphs on Cacti
|
||||
================================================================================
|
||||
[Cacti][1] a fantastic open source network monitoring system that is widely used to graph network elements like bandwidth, storage, processor and memory utilization. Using its web based interface, you can create and organize graphs easily. However, some advanced features like merging graphs, creating aggregate graphs using multiple sources, migration of Cacti to another server are not provided by default. You might need some experience with Cacti to pull these off. In this tutorial, we will see how we can merge two Cacti graphs into one.
|
||||
|
||||
Consider this example. Client-A has been connected to port 5 of switch-A for the last six months. Port 5 becomes faulty, and so the client is migrated to Port 6. As Cacti uses different graphs for each interface/element, the bandwidth history of the client would be split into port 5 and port 6. So we end up with two graphs for one client - one with six months' worth of old data, and the other that contains ongoing data.
|
||||
|
||||
In such cases, we can actually combine the two graphs so the old data is appended to the new graph, and we get to keep a single graph containing historic and new data for one customer. This tutorial will explain exactly how we can achieve that.
|
||||
|
||||
Cacti stores the data of each graph in its own RRD (round robin database) file. When a graph is requested, the values stored in a corresponding RRD file are used to generate the graph. RRD files are stored in `/var/lib/cacti/rra` in Ubuntu/Debian systems and in `/var/www/cacti/rra` in CentOS/RHEL systems.
|
||||
|
||||
The idea behind merging graphs is to alter these RRD files so the values from the old RRD file are appended to the new RRD file.
|
||||
|
||||
### Scenario ###
|
||||
|
||||
The services for a client is running on eth0 for over a year. Because of hardware failure, the client has been migrated to eth1 interface of another server. We want to graph the bandwidth of the new interface, while retaining the historic data for over a year. The client would see only one graph.
|
||||
|
||||
### Identifying the RRD for the Graph ###
|
||||
|
||||
The first step during graph merging is to identify the RRD file associated with a graph. We can check the file by opening the graph in debug mode. To do this, go to Cacti's menu: Console > Graph Management > Select Graph > Turn On Graph Debug Mode.
|
||||
|
||||
#### Old graph: ####
|
||||
|
||||
|
||||
|
||||
#### New graph: ####
|
||||
|
||||
|
||||
|
||||
From the example output (which is based on a Debian system), we can identify the RRD files for two graphs:
|
||||
|
||||
- **Old graph**: /var/lib/cacti/rra/old_graph_traffic_in_8.rrd
|
||||
- **New graph**: /var/lib/cacti/rra/new_graph_traffic_in_10.rrd
|
||||
|
||||
### Preparing a Script ###
|
||||
|
||||
We will merge two RRD files using a [RRD splice script][2]. Download this PHP script, and install it as /var/lib/cacti/rra/rrdsplice.php (for Debian/Ubuntu) or /var/www/cacti/rra/rrdsplice.php (for CentOS/RHEL).
|
||||
|
||||
Next, make sure that the file is owned by Apache user.
|
||||
|
||||
On Debian or Ubuntu, run the following command:
|
||||
|
||||
# chown www-data:www-data rrdsplice.php
|
||||
|
||||
and update rrdsplice.php accordingly. Look for the following line:
|
||||
|
||||
chown($finrrd, "apache");
|
||||
|
||||
and replace it with:
|
||||
|
||||
chown($finrrd, "www-data");
|
||||
|
||||
On CentOS or RHEL, run the following command:
|
||||
|
||||
# chown apache:apache rrdsplice.php
|
||||
|
||||
### Merging Two Graphs ###
|
||||
|
||||
The syntax usage of the script can easily be found by running it without any parameters.
|
||||
|
||||
# cd /path/to/rrdsplice.php
|
||||
# php rrdsplice.php
|
||||
|
||||
----------
|
||||
|
||||
USAGE: rrdsplice.php --oldrrd=file --newrrd=file --finrrd=file
|
||||
|
||||
Now we are ready to merge two RRD files. Simply supply the names of an old RRD file and a new RRD file. We will overwrite the merged result back to the new RRD file.
|
||||
|
||||
# php rrdsplice.php --oldrrd=old_graph_traffic_in_8.rrd --newrrd=new_graph_traffic_in_10.rrd --finrrd=new_graph_traffic_in_10.rrd
|
||||
|
||||
Now the data from the old RRD file should be appended to the new RRD. Any new data will continue to be written by Cacti to the new RRD file. If we click on the graph, we should be able to verify that the weekly, monthly and yearly records have also been added from the old graph. The second graph in the following diagram shows weekly records from the old graph.
|
||||
|
||||
|
||||
|
||||
To sum up, this tutorial showed how we can easily merge two Cacti graphs into one. This trick is useful when a service is migrated to another device/interface and we want to deal with only one graph instead of two. The script is very handy as it can join graphs regardless of the source device e.g., Cisco 1800 router and Cisco 2960 switch.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/combine-two-graphs-cacti.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/install-configure-cacti-linux.html
|
||||
[2]:http://svn.cacti.net/viewvc/developers/thewitness/rrdsplice/rrdsplice.php
|
||||
@ -1,177 +0,0 @@
|
||||
LINUX 101: POWER UP YOUR SHELL
|
||||
================================================================================
|
||||
> Get a more versatile,featureful and colourful command line interface with our guide to shell basics.
|
||||
|
||||
**WHY DO THIS?**
|
||||
|
||||
- Make life at the shell prompt easier and faster.
|
||||
- Resume sessions after losing a connection.
|
||||
- Stop pushing around that fiddly rodent!
|
||||
|
||||
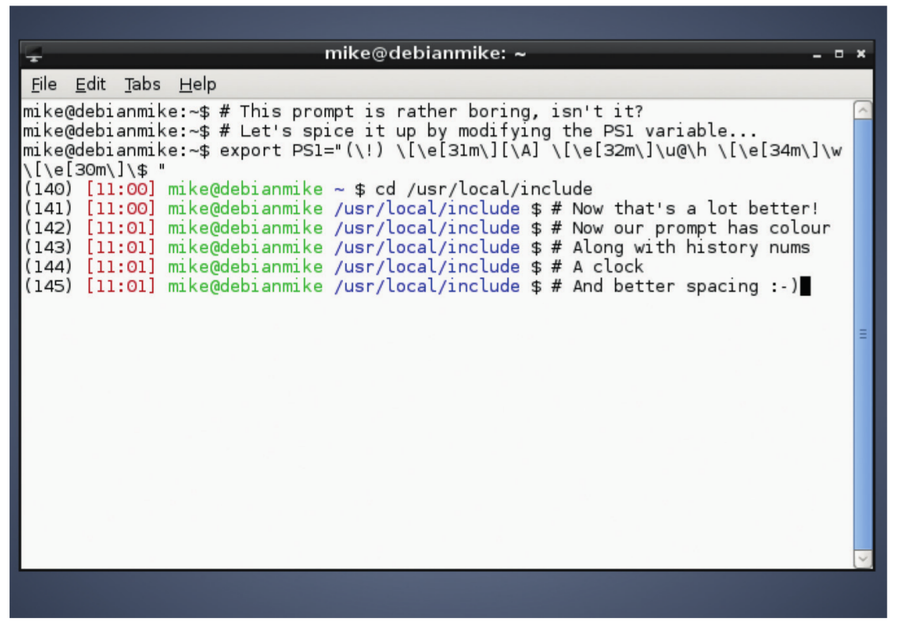
|
||||
|
||||
Here’s our souped-up prompt on steroids. It’s a bit long for this small terminal window, but you can tweak it to your liking.
|
||||
|
||||
As a Linux user, you’re probably familiar with the shell (aka command line). You may pop up the occasional terminal now and then for some essential jobs that you can’t do at the GUI, or perhaps you live in a tiling window manager environment and the shell is your main way of interacting with your Linux box.
|
||||
|
||||
In either case, you’re probably using the stock Bash configuration that came with your distro – and while it’s powerful enough for most jobs, it could still be a lot better. In this tutorial we’ll show you how to pimp up your shell to make it more informative, useful and pleasant to work in. We’ll customise the prompt to make it provide better feedback than the defaults, and we’ll show you how to manage sessions and run multiple programs together with the incredibly cool tmux tool. And for a bit of eye candy, we’ll look at colour schemes as well. So, onwards!
|
||||
|
||||
### Make your prompt sing ###
|
||||
|
||||
Most distributions ship with very plain prompts – they show a bit of information, and generally get you by, but the prompt can do so much more. Take the default prompt on a Debian 7 installation, for instance:
|
||||
|
||||
mike@somebox:~$
|
||||
|
||||
This shows the user, hostname, current directory and account type symbol (if you switch to root, the **$** changes to #). But where is this information stored? The answer is in the **PS1** environment variable. If you enter **echo $PS1** you’ll see this at the end of the text string that appears:
|
||||
|
||||
u@h:w$
|
||||
|
||||
This looks a bit ugly, and at first glance you might start screaming, assuming it to be a dreaded regular expression, but we’re not going to fry our brains with the complexity of those. No, the slashes here are escape sequences, telling the prompt to do special things. The **u** part, for instance, tells the prompt to show the username, while w means the working directory.
|
||||
|
||||
Here’s a list of things you can use in the prompt:
|
||||
|
||||
- d The current date.
|
||||
- h The hostname.
|
||||
- n A newline character.
|
||||
- A The current time (HH:MM).
|
||||
- u The current user.
|
||||
- w (lowercase) The whole working directory.
|
||||
- W (uppercase) The basename of the working directory.
|
||||
- $ A prompt symbol that changes to # for root.
|
||||
- ! The shell history number of this command.
|
||||
|
||||
To clarify the difference in the **w** and **W** options: with the former, you’ll see the whole path for the directory in which you’re working (eg **/usr/local/bin**), whereas for the latter it will just show the **bin** part.
|
||||
|
||||
Now, how do you go about changing the prompt? You need to modify the contents of the **PS1** environment variable. Try this:
|
||||
|
||||
export PS1=”I am u and it is A $”
|
||||
|
||||
Now your prompt will look something like:
|
||||
|
||||
I am mike and it is 11:26 $
|
||||
|
||||
From here you can experiment with the other escape sequences shown above to create the prompt of your dreams. But wait a second – when you log out, all of your hard work will be lost, because the value of the **PS1** environment variable is reset each time you start a terminal. The simplest way to fix this is to open the **.bashrc** configuration file (in your home directory) and add the complete export command to the bottom. This **.bashrc** file will be read by Bash every time you start a new shell session, so your beefed-up prompt will always appear. You can also spruce up your prompt with extra colour. This is a bit tricky at first, as you have to use some rather odd-looking escape sequences, but the results can be great. Add this to a point in your **PS1** string and it will change the text to red:
|
||||
|
||||
[e[31m]
|
||||
|
||||
You can change 31 here to other numbers for different colours:
|
||||
|
||||
- 30 Black
|
||||
- 32 Green
|
||||
- 33 Yellow
|
||||
- 34 Blue
|
||||
- 35 Magenta
|
||||
- 36 Cyan
|
||||
- 37 White
|
||||
|
||||
So, let’s finish off this section by creating the mother of all prompts, using the escape sequences and colours we’ve already looked at. Take a deep breath, flex your fingers, and then type this beast:
|
||||
|
||||
export PS1=”(!) [e[31m][A] [e[32m]u@h [e[34m]w [e[30m]$ “
|
||||
|
||||
This provides a Bash command history number, current time, and colours for the user/hostname combination and working directory. If you’re feeling especially ambitious, you can change the background colours as well as the foreground ones, for really striking combinations. The ever useful Arch wiki has a full list of colour codes: [http://tinyurl.com/3gvz4ec][1].
|
||||
|
||||
> ### Shell essentials ###
|
||||
>
|
||||
> If you’re totally new to Linux and have just picked up this magazine for the first time, you might find the tutorial a bit heavy going. So here are the basics to get you familiar with the shell. It’s usually found as Terminal, XTerm or Konsole in your menus, and when you start it the most useful commands are:
|
||||
>
|
||||
> **ls** (list files); **cp one.txt two.txt** (copy file); **rm file.txt** (remove file); **mv old.txt new.txt** (move or rename);
|
||||
>
|
||||
> **cd /some/directory** (change directory); **cd ..** (change to directory above); **./program** (run program in current directory); **ls > list.txt** (redirect output to a file).
|
||||
>
|
||||
> Almost every command has a manual page explaining options (eg **man ls** – press Q to quit the viewer). There you can learn about command options, so you can see that **ls -la** shows a detailed list including hidden files. Use the up and down cursor keys to cycle through previous commands, and use Tab after entering part of a file or directory name to auto-complete it.
|
||||
|
||||
### Tmux: A window manager for your shell ###
|
||||
|
||||
A window manager inside a text mode environment – it sounds crazy, right? Well, do you remember when web browsers first implemented tabbed browsing? It was a major step forward in usability at the time, and reduced clutter in desktop taskbars and window lists enormously. Instead of having taskbar or pager icons for every single site you had open, you just had the one button for your browser, and then the ability to switch sites inside the browser itself. It made an awful lot of sense.
|
||||
|
||||
If you end up running several terminals at the same time, a similar situation occurs; you might find it annoying to keep jumping between them, and finding the right one in your taskbar or window list each time. With a text-mode window manager you can not only run multiple shell sessions simultaneously inside the same terminal window, but you can even arrange them side-by-side.
|
||||
|
||||
And there’s another benefit too: detaching and reattaching. The best way to see how this works is to try it yourself. In a terminal window, enter **screen** (it’s installed by default on most distros, or will be available in your package repositories). Some welcome text appears – just hit Enter to dismiss it. Now run an interactive text mode program, such as **nano**, and close the terminal window.
|
||||
|
||||
In a normal shell session, the act of closing the window would terminate every process running inside it – so your Nano editing session would be a goner. But not with screen. Open a new terminal and enter:
|
||||
|
||||
screen -r
|
||||
|
||||
And voilà: the Nano session you started before is back!
|
||||
|
||||
When you originally ran **screen**, it created a new shell session that was independent and not tied to a specific terminal window, so it could be detached and reattached (hence the **-r** option) later.
|
||||
|
||||
This is especially useful if you’re using SSH to connect to another machine, doing some work, and don’t want a flaky connection to ruin all your progress. If you do your work inside a **screen** session and your connection goes down (or your laptop battery dies, or your computer explodes), you can simply reconnect/recharge/buy a new computer, then SSH back in to the remote box, run **screen -r** to reattach and carry on from where you left off.
|
||||
|
||||
Now, we’ve been talking about GNU **screen** here, but the title of this section mentions tmux. Essentially, **tmux** (terminal multiplexer) is like a beefed up version of **screen** with lots of useful extra features, so we’re going to focus on it here. Some distros include **tmux** by default; in others it’s usually just an **apt-get, yum install** or **pacman -S** command away.
|
||||
|
||||
Once you have it installed, enter **tmux** to start it. You’ll notice right away that there’s a green line of information along the bottom. This is very much like a taskbar from a traditional window manager: there’s a list of running programs, the hostname of the machine, a clock and the date. Now run a program, eg Nano again, and hit Ctrl+B followed by C. This creates a new window inside the tmux session, and you can see this in the taskbar at the bottom:
|
||||
|
||||
0:nano- 1:bash*
|
||||
|
||||
Each window has a number, and the currently displayed program is marked with an asterisk symbol. Ctrl+B is the standard way of interacting with tmux, so if you hit that key combo followed by a window number, you’ll switch to that window. You can also use Ctrl+B followed by N and P to switch to the next and previous windows respectively – or use Ctrl+B followed by L to switch between the two most recently used windows (a bit like the classic Alt+Tab behaviour on the desktop). To get a window list, use Ctrl+B followed by W.
|
||||
|
||||
So far, so good: you can now have multiple programs running inside a single terminal window, reducing clutter (especially if you often have multiple SSH logins active on the same remote machine). But what about seeing two programs at the same time?
|
||||
|
||||
For this, tmux uses “panes”. Hit Ctrl+B followed by % and the current window will be split into two sections, one on the left and one on the right. You can switch between them Using Ctrl+B followed by O. This is especially useful if you want to see two things at the same time – eg a manual page in one pane, and an editor with a configuration file in another.
|
||||
|
||||
Sometimes you’ll want to resize the individual panes, and this is a bit trickier. First you have to hit Ctrl+B followed by : (colon), which turns the tmux bar along the bottom into a dark orange colour. You’re now in command mode, where you can type in commands to operate tmux. Enter **resize-pane -R** to resize the current pane one character to the right, or use **-L** to resize in a leftward direction. These may seem like long commands for a relatively simple operation, but note that the tmux command mode (started with the aforementioned colon) has tab completion. So you don’t have to type the whole command – just enter “**resi**” and hit Tab to complete. Also note that the **tmux** command mode also has a history, so if you want to repeat the resize operation, hit Ctrl+B followed by colon and then use the up cursor key to retrieve the command that you entered previously.
|
||||
|
||||
Finally, let’s look at detaching and reattaching – the awesome feature of screen we demonstrated earlier. Inside tmux, hit Ctrl+B followed by D to detach the current tmux session from the terminal window, which leaves everything running in the background. To reattach to the session use **tmux a**. But what happens if you have multiple tmux sessions running? Use this command to list them:
|
||||
|
||||
tmux ls
|
||||
|
||||
This shows a number for each session; if you want to reattach to session 1, use tmux a -t 1. tmux is hugely configurable, with the ability to add custom keybindings and change colour schemes, so once you’re comfortable with the main features, delve into the manual page to learn more.
|
||||
|
||||
tmux: a window manager for your shell
|
||||
|
||||
|
||||
|
||||
Here’s tmux with two panes open: the left has Vim editing a configuration file, while the right shows a manual page
|
||||
|
||||
> ### Zsh: an alternative shell ###
|
||||
>
|
||||
> Choice is good, but standardisation is also important as well. So it makes sense that almost every mainstream Linux distribution uses the Bash shell by default – although there are others. Bash provides pretty much everything you need from a shell, including command history, filename completion and lots of scripting ability. It’s mature, reliable and well documented – but it’s not the only shell in town.
|
||||
>
|
||||
> Many advanced users swear by Zsh, the Z Shell. This is a replacement for Bash that offers almost all of the same functionality, with some extra features on top. For instance, in Zsh you can enter **ls** - and hit Tab to get quick descriptions of the various options available for **ls**. No need to open the manual page!
|
||||
>
|
||||
> Zsh sports other great auto-completion features: type **cd /u/lo/bi** and hit Tab, for instance, and the full path of **/usr/local/bin** will appear (providing there aren’t other paths containing **u**, **lo** and **bi**). Or try **cd** on its own followed by Tab, and you’ll see nicely coloured directory listings – much better than the plain ones used by Bash.
|
||||
>
|
||||
> Zsh is available in the package repositories of all major distros; install it and enter **zsh** to start it. To change your default shell from Bash to Zsh, use the **chsh** command. And for more information visit [www.zsh.org][2].
|
||||
|
||||
### The terminals of the Future ###
|
||||
|
||||
You might be wondering why the application that contains your command prompt is called a terminal. Back in the early days of Unix, people tended to work on multi-user machines, with a giant mainframe computer occupying a room somewhere in a building, and people connected to it using screen and keyboard combinations at the end of some wires. These terminal machines were often called “dumb”, because they didn’t do any important processing themselves – they just displayed whatever was sent down the wire from the mainframe, and sent keyboard presses back to it.
|
||||
|
||||
Today, almost all of us do the actual processing on our own machines, so our computers are not terminals in a traditional sense. This is why programs like **XTerm**, Gnome Terminal, Konsole etc. are called “terminal emulators” – they provide the same facilities as the physical terminals of yesteryear. And indeed, in many respects they haven’t moved on much. Sure, we have anti-aliased fonts now, better colours and the ability to click on URLs, but by and large they’ve been working in the same way for decades.
|
||||
|
||||
Some programmers are trying to change this though. **Terminology** ([http://tinyurl.com/osopjv9][3]), from the team behind the ultra-snazzy Enlightenment window manager, aims to bring terminals into the 21st century with features such as inline media display. You can enter **ls** in a directory full of images and see thumbnails, or even play videos from directly inside your terminal. This makes the terminal work a bit more like a file manager, and means that you can quickly check the contents of media files without having to open them in a separate application.
|
||||
|
||||
Then there’s Xiki ([www.xiki.org][4]), which describes itself as “the command revolution”. It’s like a cross between a traditional shell, a GUI and a wiki; you can type commands anywhere, store their output as notes for reference later, and create very powerful custom commands. It’s hard to describe it in mere words, so the authors have made a video (see the Screencasts section of the **Xiki** site) which shows how much potential it has.
|
||||
|
||||
And Xiki is definitely not a flash in the pan project that will die of bitrot in a few months. The authors ran a successful Kickstarter campaign to fund its development, netting over $84,000 at the end of July. Yes, you read that correctly – $84K for a terminal emulator. It might be the most unusual crowdfunding campaign since some crazy guys decided to start their own Linux magazine…
|
||||
|
||||
### Next-gen terminals ###
|
||||
|
||||
Many command line and text-based programs match their GUI equivalents for feature parity, and are often much faster and more efficient to use. Our recommendations: **Irssi** (IRC client); **Mutt** (mail client); **rTorrent** (BitTorrent); **Ranger** (file manager); **htop** (process monitor). ELinks does a decent job for web browsing, given the limitations of the terminal, and it’s useful for reading text-heavy websites such as Wikipedia.
|
||||
|
||||
> ### Fine-tune your colour scheme ###
|
||||
>
|
||||
> We’re not obsessed with eye-candy at Linux Voice, but we do recognise the importance of aesthetics when you’re staring at something for several hours every day. Many of us love to tweak our desktops and window managers to perfection, crafting pixel-perfect drop shadows and fiddling with colour schemes until we’re 100% happy. (And then fiddling some more out of habit.)
|
||||
>
|
||||
> But then we tend to ignore the terminal window. Well, that deserves some love too, and at [http://ciembor.github.io/4bit][5] you’ll find a highly awesome colour scheme designer that can export settings for all of the popular terminal emulators (**XTerm, Gnome Terminal, Konsole and Xfce4 Terminal are among the apps supported.**) Move the sliders until you attain colour scheme nirvana, then click on the Get Scheme button at the top-right of the page.
|
||||
>
|
||||
> Similarly, if you spend a lot of time in a text editor such as Vim or Emacs, it’s worth using a well-crafted palette there as well. **Solarized at** [http://ethanschoonover.com/solarized][6] is an excellent scheme that’s not just pretty, but designed for maximum usability, with plenty of research and testing behind it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://tinyurl.com/3gvz4ec
|
||||
[2]:http://www.zsh.org/
|
||||
[3]:http://tinyurl.com/osopjv9
|
||||
[4]:http://www.xiki.org/
|
||||
[5]:http://ciembor.github.io/4bit
|
||||
[6]:http://ethanschoonover.com/solarized
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
XBMC: build a remote control
|
||||
================================================================================
|
||||
**Take control of your home media player with a custom remote control running on your Android phone.**
|
||||
@ -261,4 +262,4 @@ via: http://www.linuxvoice.com/xbmc-build-a-remote-control/
|
||||
[2]:http://wiki.xbmc.org/?title=JSON-RPC_API/v6
|
||||
[3]:https://github.com/ben-ev/xbmc-remote
|
||||
[4]:https://github.com/ben-ev/xbmc-remote
|
||||
[5]:https://github.com/features
|
||||
[5]:https://github.com/features
|
||||
|
||||
@ -1,436 +0,0 @@
|
||||
Translating by GOLinux!
|
||||
The Art of Command Line
|
||||
================================================================================
|
||||
- [Basics](#basics)
|
||||
- [Everyday use](#everyday-use)
|
||||
- [Processing files and data](#processing-files-and-data)
|
||||
- [System debugging](#system-debugging)
|
||||
- [One-liners](#one-liners)
|
||||
- [Obscure but useful](#obscure-but-useful)
|
||||
- [More resources](#more-resources)
|
||||
- [Disclaimer](#disclaimer)
|
||||
|
||||
|
||||

|
||||
|
||||
Fluency on the command line is a skill often neglected or considered arcane, but it improves your flexibility and productivity as an engineer in both obvious and subtle ways. This is a selection of notes and tips on using the command-line that I've found useful when working on Linux. Some tips are elementary, and some are fairly specific, sophisticated, or obscure. This page is not long, but if you can use and recall all the items here, you know a lot.
|
||||
|
||||
Much of this
|
||||
[originally](http://www.quora.com/What-are-some-lesser-known-but-useful-Unix-commands)
|
||||
[appeared](http://www.quora.com/What-are-the-most-useful-Swiss-army-knife-one-liners-on-Unix)
|
||||
on [Quora](http://www.quora.com/What-are-some-time-saving-tips-that-every-Linux-user-should-know),
|
||||
but given the interest there, it seems it's worth using Github, where people more talented than I can readily suggest improvements. If you see an error or something that could be better, please submit an issue or PR!
|
||||
|
||||
Scope:
|
||||
|
||||
- The goals are breadth and brevity. Every tip is essential in some situation or significantly saves time over alternatives.
|
||||
- This is written for Linux. Many but not all items apply equally to MacOS (or even Cygwin).
|
||||
- The focus is on interactive Bash, though many tips apply to other shells and to general Bash scripting.
|
||||
- Descriptions are intentionally minimal, with the expectation you'll use `man`, `apt-get`/`yum`/`dnf` to install, and Google for more background.
|
||||
|
||||
|
||||
## Basics
|
||||
|
||||
- Learn basic Bash. Actually, type `man bash` and at least skim the whole thing; it's pretty easy to follow and not that long. Alternate shells can be nice, but Bash is powerful and always available (learning *only* zsh, fish, etc., while tempting on your own laptop, restricts you in many situations, such as using existing servers).
|
||||
|
||||
- Learn at least one text-based editor well. Ideally Vim (`vi`), as there's really no competition for random editing in a terminal (even if you use Emacs, a big IDE, or a modern hipster editor most of the time).
|
||||
|
||||
- Learn about redirection of output and input using `>` and `<` and pipes using `|`. Learn about stdout and stderr.
|
||||
|
||||
- Learn about file glob expansion with `*` (and perhaps `?` and `{`...`}`) and quoting and the difference between double `"` and single `'` quotes. (See more on variable expansion below.)
|
||||
|
||||
- Be familiar with Bash job management: `&`, **ctrl-z**, **ctrl-c**, `jobs`, `fg`, `bg`, `kill`, etc.
|
||||
|
||||
- Know `ssh`, and the basics of passwordless authentication, via `ssh-agent`, `ssh-add`, etc.
|
||||
|
||||
- Basic file management: `ls` and `ls -l` (in particular, learn what every column in `ls -l` means), `less`, `head`, `tail` and `tail -f` (or even better, `less +F`), `ln` and `ln -s` (learn the differences and advantages of hard versus soft links), `chown`, `chmod`, `du` (for a quick summary of disk usage: `du -sk *`), `df`, `mount`.
|
||||
|
||||
- Basic network management: `ip` or `ifconfig`, `dig`.
|
||||
|
||||
- Know regular expressions well, and the various flags to `grep`/`egrep`. The `-i`, `-o`, `-A`, and `-B` options are worth knowing.
|
||||
|
||||
- Learn to use `apt-get`, `yum`, or `dnf` (depending on distro) to find and install packages. And make sure you have `pip` to install Python-based command-line tools (a few below are easiest to install via `pip`).
|
||||
|
||||
|
||||
## Everyday use
|
||||
|
||||
- In Bash, use **ctrl-r** to search through command history.
|
||||
|
||||
- In Bash, use **ctrl-w** to delete the last word, and **ctrl-u** to delete the whole line. Use **alt-b** and **alt-f** to move by word, and **ctrl-k** to kill to the end of the line. See `man readline` for all the default keybindings in Bash. There are a lot. For example **alt-.** cycles through previous arguments, and **alt-*** expands a glob.
|
||||
|
||||
- To go back to the previous working directory: `cd -`
|
||||
|
||||
- If you are halfway through typing a command but change your mind, hit **alt-#** to add a `#` at the beginning and enter it as a comment (or use **ctrl-a**, **#**, **enter**). You can then return to it later via command history.
|
||||
|
||||
- Use `xargs` (or `parallel`). It's very powerful. Note you can control how many items execute per line (`-L`) as well as parallelism (`-P`). If you're not sure if it'll do the right thing, use `xargs echo` first. Also, `-I{}` is handy. Examples:
|
||||
```bash
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- `pstree -p` is a helpful display of the process tree.
|
||||
|
||||
- Use `pgrep` and `pkill` to find or signal processes by name (`-f` is helpful).
|
||||
|
||||
- Know the various signals you can send processes. For example, to suspend a process, use `kill -STOP [pid]`. For the full list, see `man 7 signal`
|
||||
|
||||
- Use `nohup` or `disown` if you want a background process to keep running forever.
|
||||
|
||||
- Check what processes are listening via `netstat -lntp`.
|
||||
|
||||
- See also `lsof` for open sockets and files.
|
||||
|
||||
- In Bash scripts, use `set -x` for debugging output. Use strict modes whenever possible. Use `set -e` to abort on errors. Use `set -o pipefail` as well, to be strict about errors (though this topic is a bit subtle). For more involved scripts, also use `trap`.
|
||||
|
||||
- In Bash scripts, subshells (written with parentheses) are convenient ways to group commands. A common example is to temporarily move to a different working directory, e.g.
|
||||
```bash
|
||||
# do something in current dir
|
||||
(cd /some/other/dir; other-command)
|
||||
# continue in original dir
|
||||
```
|
||||
|
||||
- In Bash, note there are lots of kinds of variable expansion. Checking a variable exists: `${name:?error message}`. For example, if a Bash script requires a single argument, just write `input_file=${1:?usage: $0 input_file}`. Arithmetic expansion: `i=$(( (i + 1) % 5 ))`. Sequences: `{1..10}`. Trimming of strings: `${var%suffix}` and `${var#prefix}`. For example if `var=foo.pdf`, then `echo ${var%.pdf}.txt` prints `foo.txt`.
|
||||
|
||||
- The output of a command can be treated like a file via `<(some command)`. For example, compare local `/etc/hosts` with a remote one:
|
||||
```sh
|
||||
diff /etc/hosts <(ssh somehost cat /etc/hosts)
|
||||
```
|
||||
|
||||
- Know about "here documents" in Bash, as in `cat <<EOF ...`.
|
||||
|
||||
- In Bash, redirect both standard output and standard error via: `some-command >logfile 2>&1`. Often, to ensure a command does not leave an open file handle to standard input, tying it to the terminal you are in, it is also good practice to add `</dev/null`.
|
||||
|
||||
- Use `man ascii` for a good ASCII table, with hex and decimal values. For general encoding info, `man unicode`, `man utf-8`, and `man latin1` are helpful.
|
||||
|
||||
- Use `screen` or `tmux` to multiplex the screen, especially useful on remote ssh sessions and to detach and re-attach to a session. A more minimal alternative for session persistence only is `dtach`.
|
||||
|
||||
- In ssh, knowing how to port tunnel with `-L` or `-D` (and occasionally `-R`) is useful, e.g. to access web sites from a remote server.
|
||||
|
||||
- It can be useful to make a few optimizations to your ssh configuration; for example, this `~/.ssh/config` contains settings to avoid dropped connections in certain network environments, use compression (which is helpful with scp over low-bandwidth connections), and multiplex channels to the same server with a local control file:
|
||||
```
|
||||
TCPKeepAlive=yes
|
||||
ServerAliveInterval=15
|
||||
ServerAliveCountMax=6
|
||||
Compression=yes
|
||||
ControlMaster auto
|
||||
ControlPath /tmp/%r@%h:%p
|
||||
ControlPersist yes
|
||||
```
|
||||
|
||||
- A few other options relevant to ssh are security sensitive and should be enabled with care, e.g. per subnet or host or in trusted networks: `StrictHostKeyChecking=no`, `ForwardAgent=yes`
|
||||
|
||||
- To get the permissions on a file in octal form, which is useful for system configuration but not available in `ls` and easy to bungle, use something like
|
||||
```sh
|
||||
stat -c '%A %a %n' /etc/timezone
|
||||
```
|
||||
|
||||
- For interactive selection of values from the output of another command, use [`percol`](https://github.com/mooz/percol).
|
||||
|
||||
- For interaction with files based on the output of another command (like `git`), use `fpp` ([PathPicker](https://github.com/facebook/PathPicker)).
|
||||
|
||||
- For a simple web server for all files in the current directory (and subdirs), available to anyone on your network, use:
|
||||
`python -m SimpleHTTPServer 7777` (for port 7777 and Python 2).
|
||||
|
||||
|
||||
## Processing files and data
|
||||
|
||||
- To locate a file by name in the current directory, `find . -iname '*something*'` (or similar). To find a file anywhere by name, use `locate something` (but bear in mind `updatedb` may not have indexed recently created files).
|
||||
|
||||
- For general searching through source or data files (more advanced than `grep -r`), use [`ag`](https://github.com/ggreer/the_silver_searcher).
|
||||
|
||||
- To convert HTML to text: `lynx -dump -stdin`
|
||||
|
||||
- For Markdown, HTML, and all kinds of document conversion, try [`pandoc`](http://pandoc.org/).
|
||||
|
||||
- If you must handle XML, `xmlstarlet` is old but good.
|
||||
|
||||
- For JSON, use `jq`.
|
||||
|
||||
- For Excel or CSV files, [csvkit](https://github.com/onyxfish/csvkit) provides `in2csv`, `csvcut`, `csvjoin`, `csvgrep`, etc.
|
||||
|
||||
- For Amazon S3, [`s3cmd`](https://github.com/s3tools/s3cmd) is convenient and [`s4cmd`](https://github.com/bloomreach/s4cmd) is faster. Amazon's [`aws`](https://github.com/aws/aws-cli) is essential for other AWS-related tasks.
|
||||
|
||||
- Know about `sort` and `uniq`, including uniq's `-u` and `-d` options -- see one-liners below.
|
||||
|
||||
- Know about `cut`, `paste`, and `join` to manipulate text files. Many people use `cut` but forget about `join`.
|
||||
|
||||
- Know that locale affects a lot of command line tools in subtle ways, including sorting order (collation) and performance. Most Linux installations will set `LANG` or other locale variables to a local setting like US English. But be aware sorting will change if you change locale. And know i18n routines can make sort or other commands run *many times* slower. In some situations (such as the set operations or uniqueness operations below) you can safely ignore slow i18n routines entirely and use traditional byte-based sort order, using `export LC_ALL=C`.
|
||||
|
||||
- Know basic `awk` and `sed` for simple data munging. For example, summing all numbers in the third column of a text file: `awk '{ x += $3 } END { print x }'`. This is probably 3X faster and 3X shorter than equivalent Python.
|
||||
|
||||
- To replace all occurrences of a string in place, in one or more files:
|
||||
```sh
|
||||
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
|
||||
```
|
||||
|
||||
- To rename many files at once according to a pattern, use `rename`. For complex renames, [`repren`](https://github.com/jlevy/repren) may help.
|
||||
```sh
|
||||
# Recover backup files foo.bak -> foo:
|
||||
rename 's/\.bak$//' *.bak
|
||||
# Full rename of filenames, directories, and contents foo -> bar:
|
||||
repren --full --preserve-case --from foo --to bar .
|
||||
```
|
||||
|
||||
- Use `shuf` to shuffle or select random lines from a file.
|
||||
|
||||
- Know `sort`'s options. Know how keys work (`-t` and `-k`). In particular, watch out that you need to write `-k1,1` to sort by only the first field; `-k1` means sort according to the whole line.
|
||||
|
||||
- Stable sort (`sort -s`) can be useful. For example, to sort first by field 2, then secondarily by field 1, you can use `sort -k1,1 | sort -s -k2,2`
|
||||
|
||||
- If you ever need to write a tab literal in a command line in Bash (e.g. for the -t argument to sort), press **ctrl-v** **[Tab]** or write `$'\t'` (the latter is better as you can copy/paste it).
|
||||
|
||||
- For binary files, use `hd` for simple hex dumps and `bvi` for binary editing.
|
||||
|
||||
- Also for binary files, `strings` (plus `grep`, etc.) lets you find bits of text.
|
||||
|
||||
- To convert text encodings, try `iconv`. Or `uconv` for more advanced use; it supports some advanced Unicode things. For example, this command lowercases and removes all accents (by expanding and dropping them):
|
||||
```sh
|
||||
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
|
||||
```
|
||||
|
||||
- To split files into pieces, see `split` (to split by size) and `csplit` (to split by a pattern).
|
||||
|
||||
- Use `zless`, `zmore`, `zcat`, and `zgrep` to operate on compressed files.
|
||||
|
||||
|
||||
## System debugging
|
||||
|
||||
- For web debugging, `curl` and `curl -I` are handy, or their `wget` equivalents, or the more modern [`httpie`](https://github.com/jakubroztocil/httpie).
|
||||
|
||||
- To know disk/cpu/network status, use `iostat`, `netstat`, `top` (or the better `htop`), and (especially) `dstat`. Good for getting a quick idea of what's happening on a system.
|
||||
|
||||
- For a more in-depth system overview, use [`glances`](https://github.com/nicolargo/glances). It presents you with several system level statistics in one terminal window. Very helpful for quickly checking on various subsystems.
|
||||
|
||||
- To know memory status, run and understand the output of `free` and `vmstat`. In particular, be aware the "cached" value is memory held by the Linux kernel as file cache, so effectively counts toward the "free" value.
|
||||
|
||||
- Java system debugging is a different kettle of fish, but a simple trick on Oracle's and some other JVMs is that you can run `kill -3 <pid>` and a full stack trace and heap summary (including generational garbage collection details, which can be highly informative) will be dumped to stderr/logs.
|
||||
|
||||
- Use `mtr` as a better traceroute, to identify network issues.
|
||||
|
||||
- For looking at why a disk is full, `ncdu` saves time over the usual commands like `du -sh *`.
|
||||
|
||||
- To find which socket or process is using bandwidth, try `iftop` or `nethogs`.
|
||||
|
||||
- The `ab` tool (comes with Apache) is helpful for quick-and-dirty checking of web server performance. For more complex load testing, try `siege`.
|
||||
|
||||
- For more serious network debugging, `wireshark`, `tshark`, or `ngrep`.
|
||||
|
||||
- Know about `strace` and `ltrace`. These can be helpful if a program is failing, hanging, or crashing, and you don't know why, or if you want to get a general idea of performance. Note the profiling option (`-c`), and the ability to attach to a running process (`-p`).
|
||||
|
||||
- Know about `ldd` to check shared libraries etc.
|
||||
|
||||
- Know how to connect to a running process with `gdb` and get its stack traces.
|
||||
|
||||
- Use `/proc`. It's amazingly helpful sometimes when debugging live problems. Examples: `/proc/cpuinfo`, `/proc/xxx/cwd`, `/proc/xxx/exe`, `/proc/xxx/fd/`, `/proc/xxx/smaps`.
|
||||
|
||||
- When debugging why something went wrong in the past, `sar` can be very helpful. It shows historic statistics on CPU, memory, network, etc.
|
||||
|
||||
- For deeper systems and performance analyses, look at `stap` ([SystemTap](https://sourceware.org/systemtap/wiki)), [`perf`](http://en.wikipedia.org/wiki/Perf_(Linux)), and [`sysdig`](https://github.com/draios/sysdig).
|
||||
|
||||
- Confirm what Linux distribution you're using (works on most distros): `lsb_release -a`
|
||||
|
||||
- Use `dmesg` whenever something's acting really funny (it could be hardware or driver issues).
|
||||
|
||||
|
||||
## One-liners
|
||||
|
||||
A few examples of piecing together commands:
|
||||
|
||||
- It is remarkably helpful sometimes that you can do set intersection, union, and difference of text files via `sort`/`uniq`. Suppose `a` and `b` are text files that are already uniqued. This is fast, and works on files of arbitrary size, up to many gigabytes. (Sort is not limited by memory, though you may need to use the `-T` option if `/tmp` is on a small root partition.) See also the note about `LC_ALL` above.
|
||||
```sh
|
||||
cat a b | sort | uniq > c # c is a union b
|
||||
cat a b | sort | uniq -d > c # c is a intersect b
|
||||
cat a b b | sort | uniq -u > c # c is set difference a - b
|
||||
```
|
||||
|
||||
- Summing all numbers in the third column of a text file (this is probably 3X faster and 3X less code than equivalent Python):
|
||||
```sh
|
||||
awk '{ x += $3 } END { print x }' myfile
|
||||
```
|
||||
|
||||
- If want to see sizes/dates on a tree of files, this is like a recursive `ls -l` but is easier to read than `ls -lR`:
|
||||
```sh
|
||||
find . -type f -ls
|
||||
```
|
||||
|
||||
- Use `xargs` or `parallel` whenever you can. Note you can control how many items execute per line (`-L`) as well as parallelism (`-P`). If you're not sure if it'll do the right thing, use xargs echo first. Also, `-I{}` is handy. Examples:
|
||||
```sh
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- Say you have a text file, like a web server log, and a certain value that appears on some lines, such as an `acct_id` parameter that is present in the URL. If you want a tally of how many requests for each `acct_id`:
|
||||
```sh
|
||||
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
|
||||
```
|
||||
|
||||
- Run this function to get a random tip from this document (parses Markdown and extracts an item):
|
||||
```sh
|
||||
function taocl() {
|
||||
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README.md |
|
||||
pandoc -f markdown -t html |
|
||||
xmlstarlet fo --html --dropdtd |
|
||||
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
|
||||
xmlstarlet unesc | fmt -80
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## Obscure but useful
|
||||
|
||||
- `expr`: perform arithmetic or boolean operations or evaluate regular expressions
|
||||
|
||||
- `m4`: simple macro processor
|
||||
|
||||
- `screen`: powerful terminal multiplexing and session persistence
|
||||
|
||||
- `yes`: print a string a lot
|
||||
|
||||
- `cal`: nice calendar
|
||||
|
||||
- `env`: run a command (useful in scripts)
|
||||
|
||||
- `look`: find English words (or lines in a file) beginning with a string
|
||||
|
||||
- `cut `and `paste` and `join`: data manipulation
|
||||
|
||||
- `fmt`: format text paragraphs
|
||||
|
||||
- `pr`: format text into pages/columns
|
||||
|
||||
- `fold`: wrap lines of text
|
||||
|
||||
- `column`: format text into columns or tables
|
||||
|
||||
- `expand` and `unexpand`: convert between tabs and spaces
|
||||
|
||||
- `nl`: add line numbers
|
||||
|
||||
- `seq`: print numbers
|
||||
|
||||
- `bc`: calculator
|
||||
|
||||
- `factor`: factor integers
|
||||
|
||||
- `gpg`: encrypt and sign files
|
||||
|
||||
- `toe`: table of terminfo entries
|
||||
|
||||
- `nc`: network debugging and data transfer
|
||||
|
||||
- `ngrep`: grep for the network layer
|
||||
|
||||
- `dd`: moving data between files or devices
|
||||
|
||||
- `file`: identify type of a file
|
||||
|
||||
- `stat`: file info
|
||||
|
||||
- `tac`: print files in reverse
|
||||
|
||||
- `shuf`: random selection of lines from a file
|
||||
|
||||
- `comm`: compare sorted files line by line
|
||||
|
||||
- `hd` and `bvi`: dump or edit binary files
|
||||
|
||||
- `strings`: extract text from binary files
|
||||
|
||||
- `tr`: character translation or manipulation
|
||||
|
||||
- `iconv `or uconv: conversion for text encodings
|
||||
|
||||
- `split `and `csplit`: splitting files
|
||||
|
||||
- `7z`: high-ratio file compression
|
||||
|
||||
- `ldd`: dynamic library info
|
||||
|
||||
- `nm`: symbols from object files
|
||||
|
||||
- `ab`: benchmarking web servers
|
||||
|
||||
- `strace`: system call debugging
|
||||
|
||||
- `mtr`: better traceroute for network debugging
|
||||
|
||||
- `cssh`: visual concurrent shell
|
||||
|
||||
- `wireshark` and `tshark`: packet capture and network debugging
|
||||
|
||||
- `host` and `dig`: DNS lookups
|
||||
|
||||
- `lsof`: process file descriptor and socket info
|
||||
|
||||
- `dstat`: useful system stats
|
||||
|
||||
- [`glances`](https://github.com/nicolargo/glances): high level, multi-subsystem overview
|
||||
|
||||
- `iostat`: CPU and disk usage stats
|
||||
|
||||
- `htop`: improved version of top
|
||||
|
||||
- `last`: login history
|
||||
|
||||
- `w`: who's logged on
|
||||
|
||||
- `id`: user/group identity info
|
||||
|
||||
- `sar`: historic system stats
|
||||
|
||||
- `iftop` or `nethogs`: network utilization by socket or process
|
||||
|
||||
- `ss`: socket statistics
|
||||
|
||||
- `dmesg`: boot and system error messages
|
||||
|
||||
- `hdparm`: SATA/ATA disk manipulation/performance
|
||||
|
||||
- `lsb_release`: Linux distribution info
|
||||
|
||||
- `lshw`: hardware information
|
||||
|
||||
- `fortune`, `ddate`, and `sl`: um, well, it depends on whether you consider steam locomotives and Zippy quotations "useful"
|
||||
|
||||
|
||||
## More resources
|
||||
|
||||
- [awesome-shell](https://github.com/alebcay/awesome-shell): A curated list of shell tools and resources.
|
||||
- [Strict mode](http://redsymbol.net/articles/unofficial-bash-strict-mode/) for writing better shell scripts.
|
||||
|
||||
|
||||
## Disclaimer
|
||||
|
||||
With the exception of very small tasks, code is written so others can read it. With power comes responsibility. The fact you *can* do something in Bash doesn't necessarily mean you should! ;)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/jlevy/the-art-of-command-line
|
||||
|
||||
作者:[jlevy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jlevy
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,206 +0,0 @@
|
||||
Tor Browser: An Ultimate Web Browser for Anonymous Web Browsing in Linux
|
||||
================================================================================
|
||||
Most of us give a considerable time of ours to Internet. The primary Application we require to perform our internet activity is a browser, a web browser to be more perfect. Over Internet most of our’s activity is logged to Server/Client machine which includes IP address, Geographical Location, search/activity trends and a whole lots of Information which can potentially be very harmful, if used intentionally the other way.
|
||||
|
||||

|
||||
|
||||
Tor Browser: Anonymous Browsing
|
||||
|
||||
Moreover the National Security Agency (NSA) aka International Spying Agency keeps tracks of ours digital footprints. Not to mention a restricted proxy server which again can be used as data ripping server is not the answer. And most of the corporates and companies wont allow you to access a proxy server.
|
||||
|
||||
So, what we need here is an application, preferably small in size and let it be standalone, portable and which servers the purpose. Here comes an application – the Tor Browser, which has all the above discussed features and even beyond that.
|
||||
|
||||
In this article we will be discussing Tor browser, its features, its usages and Area of Application, Installation and other important aspects of The Tor Browser Application.
|
||||
|
||||
#### What is Tor Browser? ####
|
||||
|
||||
Tor is a Freely distributed Application Software, released under BSD style Licensing which allows to surf Internet anonymously, through its safe and reliable onion like structure. Tor previously was called as ‘The Onion Router‘ because of its structure and functioning mechanism. This Application is written in C programming Language.
|
||||
|
||||
#### Features of Tor Browser ####
|
||||
|
||||
- Cross Platform Availability. i.e., this application is available for Linux, Windows as well as Mac.
|
||||
- Complex Data encryption before it it sent over Internet.
|
||||
- Automatic data decryption at client side.
|
||||
- It is a combination of Firefox Browser + Tor Project.
|
||||
- Provides anonymity to servers and websites.
|
||||
- Makes it possible to visit locked websites.
|
||||
- Performs task without revealing IP of Source.
|
||||
- Capable of routing data to/from hidden services and application behind firewall.
|
||||
- Portable – Run a preconfigured web browser directly from the USB storage Device. No need to install it locally.
|
||||
- Available for architectures x86 and x86_64.
|
||||
- Easy to set FTP with Tor using configuration as “socks4a” proxy on “localhost” port “9050”
|
||||
- Tor is capable of handling thousands of relay and millions of users.
|
||||
|
||||
#### How Tor Browser Works? ####
|
||||
|
||||
Tor works on the concept of Onion routing. Onion routing resemble to onion in structure. In onion routing the layers are nested one over the other similar to the layers of onion. This nested layer is responsible for encrypting data several times and sends it through virtual circuits. On the client side each layer decrypt the data before passing it to the next level. The last layer decrypts the innermost layer of encrypted data before passing the original data to the destination.
|
||||
|
||||
In this process of decryption all the layers function so intelligently that there is no need to reveal IP and Geographical location of User thus limiting any chance of anybody watching your internet connection or the sites you are visiting.
|
||||
|
||||
All these working seems a bit complex, but the end user execution and working of Tor browser is nothing to worry about. In-fact Tor browser resembles any other browser (Especially Mozilla Firefox) in functioning.
|
||||
|
||||
### Installation of Tor Browser in Linux ###
|
||||
|
||||
As discussed above, Tor browser is available for Linux, Windows and Mac. The user need to download the latest version (i.e. Tor Browser 4.0.4) application from the link below as per their system and architecture.
|
||||
|
||||
- [https://www.torproject.org/download/download-easy.html.en][1]
|
||||
|
||||
After downloading the Tor browser, we need to install it. But the good thing with ‘Tor’ is that we don’t need to install it. It can run directly from a Pen Drive and the browser can be preconfigured. That means plug and Run Feature in perfect sense of Portability.
|
||||
|
||||
After downloading the Tar-ball (*.tar.xz) we need to Extract it.
|
||||
|
||||
**On 32-Bit System**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
$ tar xpvf tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
|
||||
**On 64-Bit System**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
$ tar -xpvf tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
|
||||
**Note** : In the above command we used ‘$‘ which means that the package is extracted as user and not root. It is strictly suggested to extract and run tor browser not as root.
|
||||
|
||||
After successful extraction, we can move the extracted browser to anywhere/USB Mass Storage device. And run the application from the extracted folder and run ‘start-tor-browser’ strictly not as root.
|
||||
|
||||
$ cd tor-browser_en-US
|
||||
$ ./start-tor-browser
|
||||
|
||||
|
||||
|
||||
Starting Tor Browser
|
||||
|
||||
**1. Trying to connect to the Tor Network. Click “Connect” and Tor will do rest of the settings for you.**
|
||||
|
||||

|
||||
|
||||
Connecting to Tor Network
|
||||
|
||||
**2. The welcome Window/Tab.**
|
||||
|
||||
|
||||
|
||||
Tor Welcome Screen
|
||||
|
||||
**3. Tor Browser Running a Video from Youtube.**
|
||||
|
||||

|
||||
|
||||
Watching Video on Youtube
|
||||
|
||||
**4. Opening a banking site for online Purchasing/Transaction.**
|
||||
|
||||

|
||||
|
||||
Browsing a Banking Site
|
||||
|
||||
**5. The browser showing my current proxy IP. Note that the text that reads “Proxy Server detected”.**
|
||||
|
||||
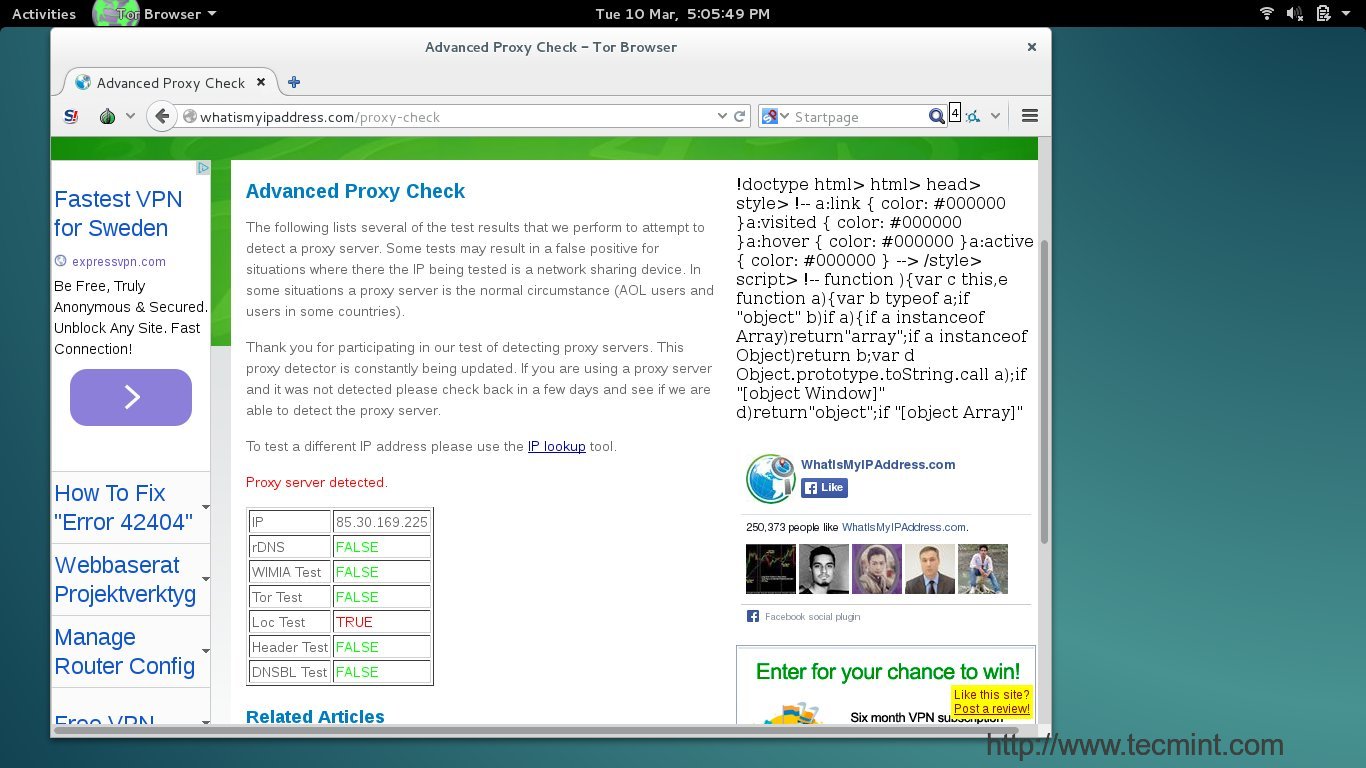
|
||||
|
||||
Checking IP Address
|
||||
|
||||
**Note**: That you need to point to the Tor startup script using text session, everytime you want to run Tor. Moreover a terminal will be busy all the time till you are running tor. How to overcome this and create a desktop/dock-bar Icon?
|
||||
|
||||
6. We need to create `tor.desktop` file inside the directory where extracted files resides.
|
||||
|
||||
$ touch tor.desktop
|
||||
|
||||
Now edit the file using your favourite editor with the text below. Save and exit. I used nano.
|
||||
|
||||
$ nano tor.desktop
|
||||
|
||||
----------
|
||||
|
||||
#!/usr/bin/env xdg-open
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=Tor
|
||||
Comment=Anonymous Browse
|
||||
Type=Application
|
||||
Terminal=false
|
||||
Exec=/home/avi/Downloads/tor-browser_en-US/start-tor-browser
|
||||
Icon=/home/avi/Downloads/tor-browser_en-US/Browser/browser/icons/mozicon128.png
|
||||
StartupNotify=true
|
||||
Categories=Network;WebBrowser;
|
||||
|
||||
**Note**: Make sure to replace the path with the location of your tor browser in the above.
|
||||
|
||||
**7. Once done! Double click the file `tor.desktop` to fire Tor browser. You may need to trust it for the first time.**
|
||||
|
||||

|
||||
|
||||
Tor Application Launcher
|
||||
|
||||
**8. Once you trust you might note that the icon of `tor.desktop` changed.**
|
||||
|
||||

|
||||
|
||||
Tor icon Changed
|
||||
|
||||
9. You may drag and drop the `tor.desktop` icon to create shortcut on Desktop and Dock Bar.
|
||||
|
||||

|
||||
|
||||
Add Tor Shortcut on Desktop
|
||||
|
||||
**10. About Tor Browser.**
|
||||
|
||||

|
||||
|
||||
About Tor Browser
|
||||
|
||||
**Note**: If you are using older version of Tor, you may update it from the above window.
|
||||
|
||||
#### Usability/Area of Application ####
|
||||
|
||||
- Anonymous communication over web.
|
||||
- Surf to Blocked web Pages.
|
||||
- Link other Application Viz (FTP) to this secure Internet Browsing Application.
|
||||
|
||||
#### Controversies of Tor-browser ####
|
||||
|
||||
- No security at the boundary of Tor Application i.e., Data Entry and Exit Points.
|
||||
- A study in 2011 reveals that a specific way of attacking Tor will reveal IP address of BitTorrent Users.
|
||||
- Some protocols shows the tendency of leaking IP address, revealed in a study.
|
||||
- Earlier version of Tor bundled with older versions of Firefox browser were found to be JavaScript Attack Vulnerable.
|
||||
- Tor Browser Seems to Work slow.
|
||||
|
||||
#### Real world Implementation of Tor-browser ####
|
||||
|
||||
- Vuze BitTorrent Client
|
||||
- Anonymous Os
|
||||
- Os’es from Scratch
|
||||
- whonix, etc.
|
||||
|
||||
#### Future of Tor Browser ####
|
||||
|
||||
Tor browser is promising. Perhaps the first application of its kind is implemented very brilliantly. Tor browser must invest for Support, Scalability and research for securing the data from latest attacks. This application is need of the future.
|
||||
|
||||
#### Download Free eBook ####
|
||||
|
||||
Unofficial Guide to Tor Private Browsing
|
||||
|
||||
[][2]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Tor bowser is a must tool in the present time where the organization you are working for don’t allow you to access certain websites or if you don’t want others to look into your private business or you don’t want to provide your digital footprints to NSA.
|
||||
|
||||
**Note**: Tor Browser don’t provide any safety from Viruses, Trojans or other threats of this kind. Moreover by writing an article of this we never mean to indulge into illegal activity by hiding our identity over Internet. This Post is totally for educational Purpose and for any illegal use of it neither the author of the post nor Tecmint will be responsible. It is the sole responsibility of user.
|
||||
|
||||
Tor-browser is a wonderful application and you must give it a try. That’s all for now. I’ll be here again with another interesting article you people will love to read. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your value-able feedback in our comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.torproject.org/download/download-easy.html.en
|
||||
[2]:http://tecmint.tradepub.com/free/w_make129/prgm.cgi
|
||||
@ -0,0 +1,348 @@
|
||||
Shilpa Nair Shares Her Interview Experience on RedHat Linux Package Management
|
||||
================================================================================
|
||||
**Shilpa Nair has just graduated in the year 2015. She went to apply for Trainee position in a National News Television located in Noida, Delhi. When she was in the last year of graduation and searching for help on her assignments she came across Tecmint. Since then she has been visiting Tecmint regularly.**
|
||||
|
||||

|
||||
|
||||
Linux Interview Questions on RPM
|
||||
|
||||
All the questions and answers are rewritten based upon the memory of Shilpa Nair.
|
||||
|
||||
> “Hi friends! I am Shilpa Nair from Delhi. I have completed my graduation very recently and was hunting for a Trainee role soon after my degree. I have developed a passion for UNIX since my early days in the collage and I was looking for a role that suits me and satisfies my soul. I was asked a lots of questions and most of them were basic questions related to RedHat Package Management.”
|
||||
|
||||
Here are the questions, that I was asked and their corresponding answers. I am posting only those questions that are related to RedHat GNU/Linux Package Management, as they were mainly asked.
|
||||
|
||||
### 1. How will you find if a package is installed or not? Say you have to find if ‘nano’ is installed or not, what will you do? ###
|
||||
|
||||
> **Answer** : To find the package nano, weather installed or not, we can use rpm command with the option -q is for query and -a stands for all the installed packages.
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> Also the package name must be complete, an incomplete package name will return the prompt without printing anything which means that package (incomplete package name) is not installed. It can be understood easily by the example below:
|
||||
>
|
||||
> We generally substitute vim command with vi. But if we find package vi/vim we will get no result on the standard output.
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> However we can clearly see that the package is installed by firing vi/vim command. Here is culprit is incomplete file name. If we are not sure of the exact file-name we can use wildcard as:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> This way we can find information about any package, if installed or not.
|
||||
|
||||
### 2. How will you install a package XYZ using rpm? ###
|
||||
|
||||
> **Answer** : We can install any package (*.rpm) using rpm command a shown below, here options -i (install), -v (verbose or display additional information) and -h (print hash mark during package installation).
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> If upgrading a package from earlier version -U switch should be used, option -v and -h follows to make sure we get a verbose output along with hash Mark, that makes it readable.
|
||||
|
||||
### 3. You have installed a package (say httpd) and now you want to see all the files and directories installed and created by the above package. What will you do? ###
|
||||
|
||||
> **Answer** : We can list all the files (Linux treat everything as file including directories) installed by the package httpd using options -l (List all the files) and -q (is for query).
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. You are supposed to remove a package say postfix. What will you do? ###
|
||||
|
||||
> **Answer** : First we need to know postfix was installed by what package. Find the package name that installed postfix using options -e erase/uninstall a package) and –v (verbose output).
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> and then remove postfix as:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. Get detailed information about an installed package, means information like Version, Release, Install Date, Size, Summary and a brief description. ###
|
||||
|
||||
> **Answer** : We can get detailed information about an installed package by using option -qa with rpm followed by package name.
|
||||
>
|
||||
> For example to find details of package openssh, all I need to do is:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. You are not sure about what are the configuration files provided by a specific package say httpd. How will you find list of all the configuration files provided by httpd and their location. ###
|
||||
|
||||
> **Answer** : We need to run option -c followed by package name with rpm command and it will list the name of all the configuration file and their location.
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> Similarly we can list all the associated document files as:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> also, we can list the associated License file as:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> Not to mention that the option -d and option -L in the above command stands for ‘documents‘ and ‘License‘, respectively.
|
||||
|
||||
### 7. You came across a configuration file located at ‘/usr/share/alsa/cards/AACI.conf’ and you are not sure this configuration file is associated with what package. How will you find out the parent package name? ###
|
||||
|
||||
> **Answer** : When a package is installed, the relevant information gets stored in the database. So it is easy to trace what provides the above package using option -qf (-f query packages owning files).
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> Similarly we can find (what provides) information about any sub-packge, document files and License files.
|
||||
|
||||
### 8. How will you find list of recently installed software’s using rpm? ###
|
||||
|
||||
> **Answer** : As said earlier, everything being installed is logged in database. So it is not difficult to query the rpm database and find the list of recently installed software’s.
|
||||
>
|
||||
> We can do this by running the below commands using option –last (prints the most recent installed software’s).
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> The above command will print all the packages installed in a order such that, the last installed software appears at the top.
|
||||
>
|
||||
> If our concern is to find out specific package, we can grep that package (say sqlite) from the list, simply as:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> We can also get a list of 10 most recently installed software simply as:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> We can refine the result to output a more custom result simply as:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> In the above command -n represents number followed by a numeric value. The above command prints a list of 2 most recent installed software.
|
||||
|
||||
### 9. Before installing a package, you are supposed to check its dependencies. What will you do? ###
|
||||
|
||||
> **Answer** : To check the dependencies of a rpm package (XYZ.rpm), we can use switches -q (query package), -p (query a package file) and -R (Requires / List packages on which this package depends i.e., dependencies).
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. Is rpm a front-end Package Management Tool? ###
|
||||
|
||||
> **Answer** : No! rpm is a back-end package management for RPM based Linux Distribution.
|
||||
>
|
||||
> [YUM][1] which stands for Yellowdog Updater Modified is the front-end for rpm. YUM automates the overall process of resolving dependencies and everything else.
|
||||
>
|
||||
> Very recently [DNF][2] (Dandified YUM) replaced YUM in Fedora 22. Though YUM is still available to be used in RHEL and CentOS, we can install dnf and use it alongside of YUM. DNF is said to have a lots of improvement over YUM.
|
||||
>
|
||||
> Good to know, you keep yourself updated. Lets move to the front-end part.
|
||||
|
||||
### 11. How will you list all the enabled repolist on a system. ###
|
||||
|
||||
> **Answer** : We can list all the enabled repos on a system simply using following commands.
|
||||
>
|
||||
> # yum repolist
|
||||
> or
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> The above command will only list those repos that are enabled. If we need to list all the repos, enabled or not, we can do.
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. How will you list all the available and installed packages on a system? ###
|
||||
|
||||
> **Answer** : To list all the available packages on a system, we can do:
|
||||
>
|
||||
> # yum list available
|
||||
> or
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> To list all the installed Packages on a system, we can do.
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> To list all the available and installed packages on a system, we can do.
|
||||
>
|
||||
> # yum list
|
||||
> or
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. How will you install and update a package and a group of packages separately on a system using YUM/DNF? ###
|
||||
|
||||
> Answer : To Install a package (say nano), we can do,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> To Install a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> To update a package (say nano), we can do.
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> To update a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. How will you SYNC all the installed packages on a system to stable release? ###
|
||||
|
||||
> **Answer** : We can sync all the packages on a system (say CentOS or Fedora) to stable release as,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/RHEL]
|
||||
> or
|
||||
> # dnf distro-sync [On Fedora 20 Onwards]
|
||||
|
||||
Seems you have done a good homework before coming for the interview,Good!. Before proceeding further I just want to ask one more question.
|
||||
|
||||
### 15. Are you familiar with YUM local repository? Have you tried making a Local YUM repository? Let me know in brief what you will do to create a local YUM repo. ###
|
||||
|
||||
> **Answer** : First I would like to Thank you Sir for appreciation. Coming to question, I must admit that I am quiet familiar with Local YUM repositories and I have already implemented it for testing purpose in my local machine.
|
||||
>
|
||||
> 1. To set up Local YUM repository, we need to install the below three packages as:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. Create a directory (say /home/$USER/rpm) and copy all the RPMs from RedHat/CentOS DVD to that folder.
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. Create base repository headers as.
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. Create the .repo file (say abc.repo) at the location /etc/yum.repos.d simply as:
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**Important**: Make sure to remove $USER with user_name.
|
||||
|
||||
That’s all we need to do to create a Local YUM repository. We can now install applications from here, that is relatively fast, secure and most important don’t need an Internet connection.
|
||||
|
||||
Okay! It was nice interviewing you. I am done. I am going to suggest your name to HR. You are a young and brilliant candidate we would like to have in our organization. If you have any question you may ask me.
|
||||
|
||||
**Me**: Sir, it was really a very nice interview and I feel very lucky today, to have cracked the interview..
|
||||
|
||||
Obviously it didn’t end here. I asked a lots of questions like the project they are handling. What would be my role and responsibility and blah..blah..blah
|
||||
|
||||
Friends, by the time all these were documented I have been called for HR round which is 3 days from now. Hope I do my best there as well. All your blessings will count.
|
||||
|
||||
Thankyou friends and Tecmint for taking time and documenting my experience. Mates I believe Tecmint is doing some really extra-ordinary which must be praised. When we share ours experience with other, other get to know many things from us and we get to know our mistakes.
|
||||
|
||||
It enhances our confidence level. If you have given any such interview recently, don’t keep it to yourself. Spread it! Let all of us know that. You may use the below form to share your experience with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -0,0 +1,125 @@
|
||||
How to Provision Swarm Clusters using Docker Machine
|
||||
================================================================================
|
||||
Hi all, today we'll learn how we can deploy Swarm Clusters using Docker Machine. It serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Docker Machine is an application that helps to create Docker hosts on our computer, on cloud providers and inside our own data center. It provides easy solution for creating servers, installing Docker on them and then configuring the Docker client according the users configuration and requirements. We can provision swarm clusters with any driver we need and is highly secured with TLS Encryption.
|
||||
|
||||
Here are some quick and easy steps on how to provision swarm clusters with Docker Machine.
|
||||
|
||||
### 1. Installing Docker Machine ###
|
||||
|
||||
Docker Machine supports awesome on every Linux Operating System. First of all, we'll need to download the latest version of Docker Machine from the Github site . Here, we'll use curl to download the latest version of Docker Machine ie 0.2.0 .
|
||||
|
||||
For 64 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
For 32 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
After downloading the latest release of Docker Machine, we'll make the file named docker-machine under /usr/local/bin/ executable using the command below.
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
After doing the above, we'll wanna ensure that we have successfully installed docker-machine. To check it, we can run the docker-machine -v which will give output of the version of docker-machine installed in our system.
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
To enable Docker commands on our machines, make sure to install the Docker client as well by running the command below.
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. Creating Machine ###
|
||||
|
||||
After installing Machine into our working PC or device, we'll wanna go forward to create a machine using Docker Machine. Here, in this tutorial we'll gonna deploy a machine in the Digital Ocean Platform so we'll gonna use "digitalocean" as its Driver API then, docker swarm will be running into that Droplet which will be further configured as Swarm Master and another droplet will be created which will be configured as Swarm Node Agent.
|
||||
|
||||
So, to create the machine, we'll need to run the following command.
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**Note**: Here, linux-dev is the name of the machine we are wanting to create. <API-Token> is a security key which can be generated from the Digital Ocean Control Panel of the account holder of Digital Ocean Cloud Platform. To retrieve that key, we simply need to login to our Digital Ocean Control Panel then click on API, then click on Generate New Token and give it a name tick on both Read and Write. Then we'll get a long hex key, thats the <API-Token> now, simply replace it into the command above.
|
||||
|
||||
Now, to load the Machine configuration into the shell we are running the comamands, run the following command.
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
Then, we'll mark our machine as ACTIVE by running the below command.
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
Now, we'll check whether its been marked as ACTIVE "*" or not.
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. Running Swarm Docker Image ###
|
||||
|
||||
Now, after we finish creating the required machine. We'll gonna deploy swarm docker image in our active machine. This machine will run the docker image and will control over the Swarm master and node. To run the image, we can simply run the below command.
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
If you are trying to run swarm docker image using **32 bit Operating System** in the computer where Docker Machine is running, we'll need to SSH into the Droplet.
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. Creating Swarm Master ###
|
||||
|
||||
Now, after our machine and swarm image is running into the machine, we'll now create a Swarm Master. This will also add the master as a node. To do so, here's the command below.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. Creating Swarm Nodes ###
|
||||
|
||||
Now, we'll create a swarm node which will get connected with the Swarm Master. The command below will create a new droplet which will be named as swarm-node and will get connected with the Swarm Master as node. This will create a Swarm cluster across the two nodes.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. Connecting to the Swarm Master ###
|
||||
|
||||
We, now connect to the Swarm Master so that we can deploy Docker containers across the nodes as per the requirement and configuration. To load the Swarm Master's Machine configuration into our environment, we can run the below command.
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
After that, we can run the required containers of our choice across the nodes. Here, we'll check if everything went fine or not. So, we'll run **docker info** to check the information about the Swarm Clusters.
|
||||
|
||||
# docker info
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We can pretty easily create Swarm Cluster with Docker Machine. This method is a lot productive because it reduces a lot of time of a system admin or users. In this article, we successfully provisioned clusters by creating a master and a node using a machine with Digital Ocean as driver. It can be created using any driver like VirtualBox, Google Cloud Computing, Amazon Web Service, Microsoft Azure and more according to the need and requirement of the user and the connection is highly secured with TLS Encryption. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,206 @@
|
||||
4 Useful Tips on mkdir, tar and kill Commands in Linux
|
||||
================================================================================
|
||||
We keep on accomplishing a task conventionally until we come to know that it can be done in a much better way the other way. In continuation of our [Linux Tips and Trick Series][1], I am here with the below four tips that will going to help you in lots of ways. Here we go!
|
||||
|
||||

|
||||
|
||||
4 Linux Useful Tips and Hacks
|
||||
|
||||
### 1. You are supposed to create a long/complex directory tree similar to given below. What is the most effective way to achieve this? ###
|
||||
|
||||
Directory tree structure to achieve as suggested below.
|
||||
|
||||
$ cd /home/$USER/Desktop
|
||||
$ mkdir tecmint
|
||||
$ mkdir tecmint/etc
|
||||
$ mkdir tecmint/lib
|
||||
$ mkdir tecmint/usr
|
||||
$ mkdir tecmint/bin
|
||||
$ mkdir tecmint/tmp
|
||||
$ mkdir tecmint/opt
|
||||
$ mkdir tecmint/var
|
||||
$ mkdir tecmint/etc/x1
|
||||
$ mkdir tecmint/usr/x2
|
||||
$ mkdir tecmint/usr/x3
|
||||
$ mkdir tecmint/tmp/Y1
|
||||
$ mkdir tecmint/tmp/Y2
|
||||
$ mkdir tecmint/tmp/Y3
|
||||
$ mkdir tecmint/tmp/Y3/z
|
||||
|
||||
The above scenario can simply be achieved by running the below 1-liner command.
|
||||
|
||||
$ mkdir -p /home/$USER/Desktop/tecmint/{etc/x1,lib,usr/{x2,x3},bin,tmp/{Y1,Y2,Y3/z},opt,var}
|
||||
|
||||
To verify you may use tree command. If not installed you may apt or yum the package ‘tree‘.
|
||||
|
||||
$ tree tecmint
|
||||
|
||||

|
||||
|
||||
Check Directory Structure
|
||||
|
||||
We can create directory tree structure of any complexity using the above way. Notice it is nothing other than a normal command but its using `{}` to create hierarchy of directories. This may prove very helpful if used from inside of a shell script when required and in general.
|
||||
|
||||
### 2. Create a file (say test) on your Desktop (/home/$USER/Desktop) and populate it with the below contents. ###
|
||||
|
||||
ABC
|
||||
DEF
|
||||
GHI
|
||||
JKL
|
||||
MNO
|
||||
PQR
|
||||
STU
|
||||
VWX
|
||||
Y
|
||||
Z
|
||||
|
||||
What a normal user would do in this scenario?
|
||||
|
||||
a. He will create the file first, preferably using [touch command][2], as:
|
||||
|
||||
$ touch /home/$USER/Desktop/test
|
||||
|
||||
b. He will use a text editor to open the file, which may be nano, vim, or any other editor.
|
||||
|
||||
$ nano /home/$USER/Desktop/test
|
||||
|
||||
c. He will then place the above text into this file, save and exit.
|
||||
|
||||
So regardless of time taken by him/her, he need at-least 3 steps to execute the above scenario.
|
||||
|
||||
What a smart experienced Linux-er will do? He will just type the below text in one-go on terminal and all done. He need not do each action separately.
|
||||
|
||||
cat << EOF > /home/$USER/Desktop/test
|
||||
ABC
|
||||
DEF
|
||||
GHI
|
||||
JKL
|
||||
MNO
|
||||
PQR
|
||||
STU
|
||||
VWX
|
||||
Y
|
||||
Z
|
||||
EOF
|
||||
|
||||
You may use ‘cat‘ command to check if the file and its content were created successfully or not.
|
||||
|
||||
$ cat /home/avi/Desktop/test
|
||||
|
||||
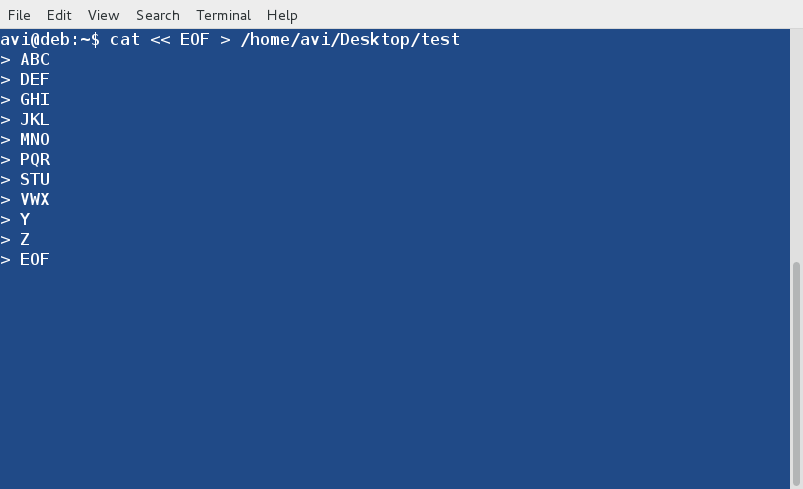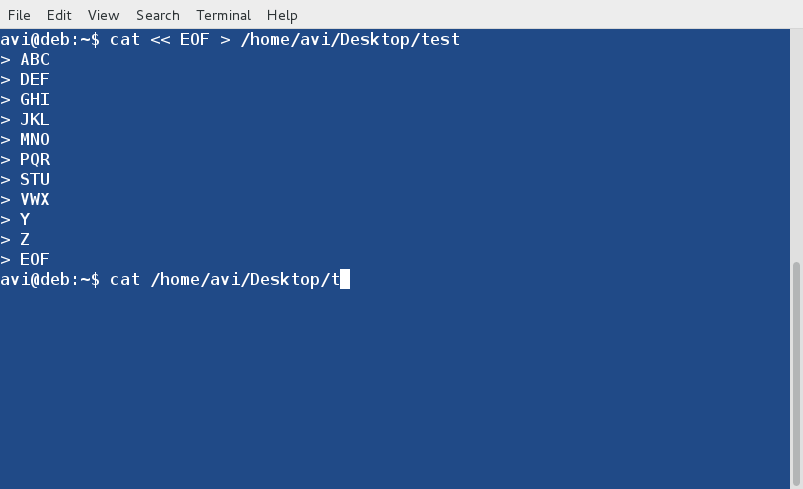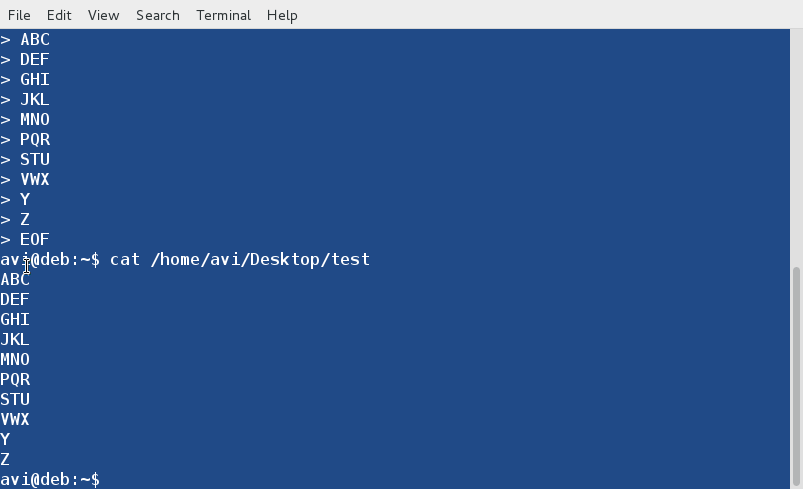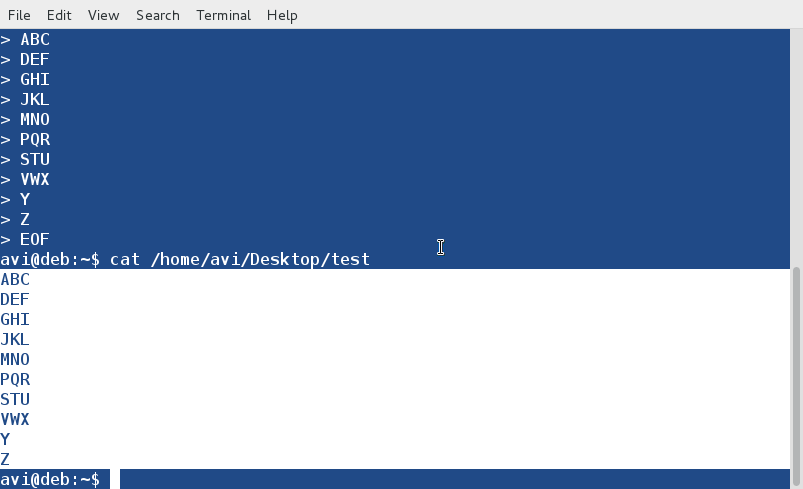
|
||||
|
||||
### 3. We deal with archives (specially TAR balls) very often on Linux. In many cases we have to use that TAR ball on some location other than Downloads folder. What we do in this scenario? ###
|
||||
|
||||
We normally do two things in this scenario.
|
||||
|
||||
a. Copy/Move the tar ball and extract it at destination, as:
|
||||
|
||||
$ cp firefox-37.0.2.tar.bz2 /opt/
|
||||
or
|
||||
$ mv firefox-37.0.2.tar.bz2 /opt/
|
||||
|
||||
b. cd to /opt/ directory.
|
||||
|
||||
$ cd /opt/
|
||||
|
||||
c. Extract the Tarball.
|
||||
|
||||
# tar -jxvf firefox-37.0.2.tar.bz2
|
||||
|
||||
We can do this the other way around.
|
||||
|
||||
We will extract the Tarball where it is and Copy/Move the extracted archive to the required destination as:
|
||||
|
||||
$ tar -jxvf firefox-37.0.2.tar.bz2
|
||||
$ cp -R firefox/ /opt/
|
||||
or
|
||||
$ mv firefox/ /opt/
|
||||
|
||||
In either case the work is taking two or steps to complete. The professional can complete this task in one step as:
|
||||
|
||||
$ tar -jxvf firefox-37.0.2.tar.bz2 -C /opt/
|
||||
|
||||
The option -C makes tar extract the archive in the specified folder (here /opt/).
|
||||
|
||||
No it is not about an option (-C) but it is about habits. Make a habit of using option -C with tar. It will ease your life. From now don’t move the archive or copy/move the extracted file, just leave the TAR-ball in the Downloads folder and extract it anywhere you want.
|
||||
|
||||
### 4. How we kill a process in a traditional way? ###
|
||||
|
||||
In most general way, we first list all the process using command `ps -A` and pipeline it with grep to find a process/service (say apache2), simply as:
|
||||
|
||||
$ ps -A | grep -i apache2
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
1006 ? 00:00:00 apache2
|
||||
2702 ? 00:00:00 apache2
|
||||
2703 ? 00:00:00 apache2
|
||||
2704 ? 00:00:00 apache2
|
||||
2705 ? 00:00:00 apache2
|
||||
2706 ? 00:00:00 apache2
|
||||
2707 ? 00:00:00 apache2
|
||||
|
||||
The above output shows all currently running apache2 processes with their PID’s, you can then use these PID’s to kill apache2 with the help of following command.
|
||||
|
||||
# kill 1006 2702 2703 2704 2705 2706 2707
|
||||
|
||||
and then cross check if any process/service with the name ‘apache2‘ is running or not, as:
|
||||
|
||||
$ ps -A | grep -i apache2
|
||||
|
||||
However we can do it in a more understandable format using utilities like pgrep and pkill. You may find relevant information about a process just by using pgrep. Say you have to find the process information for apache2, you may simply do:
|
||||
|
||||
$ pgrep apache2
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
15396
|
||||
15400
|
||||
15401
|
||||
15402
|
||||
15403
|
||||
15404
|
||||
15405
|
||||
|
||||
You may also list process name against pid by running.
|
||||
|
||||
$ pgrep -l apache2
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
15396 apache2
|
||||
15400 apache2
|
||||
15401 apache2
|
||||
15402 apache2
|
||||
15403 apache2
|
||||
15404 apache2
|
||||
15405 apache2
|
||||
|
||||
To kill a process using pkill is very simple. You just type the name of resource to kill and you are done. I have written a post on pkill which you may like to refer here : [http://www.tecmint.com/how-to-kill-a-process-in-linux/][3].
|
||||
|
||||
To kill a process (say apache2) using pkill, all you need to do is:
|
||||
|
||||
# pkill apache2
|
||||
|
||||
You may verify if apache2 has been killed or not by running the below command.
|
||||
|
||||
$ pgrep -l apache2
|
||||
|
||||
It returns the prompt and prints nothing means there is no process running by the name of apache2.
|
||||
|
||||
That’s all for now, from me. All the above discussed point are not enough but will surely help. We not only mean to produce tutorials to make you learn something new every-time but also want to show ‘How to be more productive in the same frame‘. Provide us with your valuable feedback in the comments below. Keep connected. Keep Commenting.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mkdir-tar-and-kill-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -0,0 +1,222 @@
|
||||
Autojump – An Advanced ‘cd’ Command to Quickly Navigate Linux Filesystem
|
||||
================================================================================
|
||||
Those Linux users who mainly work with Linux command Line via console/terminal feels the real power of Linux. However it may sometimes be painful to navigate inside Linux Hierarchical file system, specially for the newbies.
|
||||
|
||||
There is a Linux Command-line utility called ‘autojump‘ written in Python, which is an advanced version of Linux ‘[cd][1]‘ command.
|
||||
|
||||

|
||||
|
||||
Autojump – A Fastest Way to Navigate Linux File System
|
||||
|
||||
This application was originally written by Joël Schaerer and now maintained by +William Ting.
|
||||
|
||||
Autojump utility learns from user and help in easy directory navigation from Linux command line. Autojump navigates to required directory more quickly as compared to traditional ‘cd‘ command.
|
||||
|
||||
#### Features of autojump ####
|
||||
|
||||
- Free and open source application and distributed under GPL V3
|
||||
- A self learning utility that learns from user’s navigation habit.
|
||||
- Faster navigation. No need to include sub-directories name.
|
||||
- Available in repository to be downloaded for most of the standard Linux distributions including Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat and Fedora.
|
||||
- Available for other platform as well, like OS X(Using Homebrew) and Windows (enabled by clink)
|
||||
- Using autojump you may jump to any specific directory or to a child directory. Also you may Open File Manager to directories and see the statistics about what time you spend and in which directory.
|
||||
|
||||
#### Prerequisites ####
|
||||
|
||||
- Python Version 2.6+
|
||||
|
||||
### Step 1: Do a Full System Update ###
|
||||
|
||||
1. Do a system Update/Upgrade as a **root** user to ensure you have the latest version of Python installed.
|
||||
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [APT based systems]
|
||||
# yum update && yum upgrade [YUM based systems]
|
||||
# dnf update && dnf upgrade [DNF based systems]
|
||||
|
||||
**Note** : It is important to note here that, on YUM or DNF based systems, update and upgrade performs the same things and most of the time interchangeable unlike APT based system.
|
||||
|
||||
### Step 2: Download and Install Autojump ###
|
||||
|
||||
2. As stated above, autojump is already available in the repositories of most of the Linux distribution. You may just install it using the Package Manager. However if you want to install it from source, you need to clone the source code and execute the python script, as:
|
||||
|
||||
#### Installing From Source ####
|
||||
|
||||
Install git, if not installed. It is required to clone git.
|
||||
|
||||
# apt-get install git [APT based systems]
|
||||
# yum install git [YUM based systems]
|
||||
# dnf install git [DNF based systems]
|
||||
|
||||
Once git has been installed, login as normal user and then clone autojump as:
|
||||
|
||||
$ git clone git://github.com/joelthelion/autojump.git
|
||||
|
||||
Next, switch to the downloaded directory using cd command.
|
||||
|
||||
$ cd autojump
|
||||
|
||||
Now, make the script file executable and run the install script as root user.
|
||||
|
||||
# chmod 755 install.py
|
||||
# ./install.py
|
||||
|
||||
#### Installing from Repositories ####
|
||||
|
||||
3. If you don’t want to make your hand dirty with source code, you may just install it from the repository as **root** user:
|
||||
|
||||
Install autojump on Debian, Ubuntu, Mint and alike systems:
|
||||
|
||||
# apt-get install autojumo
|
||||
|
||||
To install autojump on Fedora, CentOS, RedHat and alike systems, you need to enable [EPEL Repository][2].
|
||||
|
||||
# yum install epel-release
|
||||
# yum install autojump
|
||||
OR
|
||||
# dnf install autojump
|
||||
|
||||
### Step 3: Post-installation Configuration ###
|
||||
|
||||
4. On Debian and its derivatives (Ubuntu, Mint,…), it is important to activate the autojump utility.
|
||||
|
||||
To activate autojump utility temporarily, i.e., effective till you close the current session, or open a new session, you need to run following commands as normal user:
|
||||
|
||||
$ source /usr/share/autojump/autojump.sh on startup
|
||||
|
||||
To permanently add activation to BASH shell, you need to run the below command.
|
||||
|
||||
$ echo '. /usr/share/autojump/autojump.sh' >> ~/.bashrc
|
||||
|
||||
### Step 4: Autojump Pretesting and Usage ###
|
||||
|
||||
5. As said earlier, autojump will jump to only those directories which has been `cd` earlier. So before we start testing we are going to ‘cd‘ a few directories and create a few as well. Here is what I did.
|
||||
|
||||
$ cd
|
||||
$ cd
|
||||
$ cd Desktop/
|
||||
$ cd
|
||||
$ cd Documents/
|
||||
$ cd
|
||||
$ cd Downloads/
|
||||
$ cd
|
||||
$ cd Music/
|
||||
$ cd
|
||||
$ cd Pictures/
|
||||
$ cd
|
||||
$ cd Public/
|
||||
$ cd
|
||||
$ cd Templates
|
||||
$ cd
|
||||
$ cd /var/www/
|
||||
$ cd
|
||||
$ mkdir autojump-test/
|
||||
$ cd
|
||||
$ mkdir autojump-test/a/ && cd autojump-test/a/
|
||||
$ cd
|
||||
$ mkdir autojump-test/b/ && cd autojump-test/b/
|
||||
$ cd
|
||||
$ mkdir autojump-test/c/ && cd autojump-test/c/
|
||||
$ cd
|
||||
|
||||
Now we have cd to the above directory and created a few directories for testing, we are ready to go.
|
||||
|
||||
**Point to Remember** : The usage of j is a wrapper around autojump. You may use j in place of autojump command and vice versa.
|
||||
|
||||
6. Check the version of installed autojump using -v option.
|
||||
|
||||
$ j -v
|
||||
or
|
||||
$ autojump -v
|
||||
|
||||

|
||||
|
||||
Check Autojump Version
|
||||
|
||||
7. Jump to a previously visited directory ‘/var/www‘.
|
||||
|
||||
$ j www
|
||||
|
||||
|
||||
|
||||
Jump To Directory
|
||||
|
||||
8. Jump to previously visited child directory ‘/home/avi/autojump-test/b‘ without typing sub-directory name.
|
||||
|
||||
$ jc b
|
||||
|
||||

|
||||
|
||||
Jump to Child Directory
|
||||
|
||||
9. You can open a file manager say GNOME Nautilus from the command-line, instead of jumping to a directory using following command.
|
||||
|
||||
$ jo www
|
||||
|
||||
|
||||
|
||||
Jump to Directory
|
||||
|
||||

|
||||
|
||||
Open Directory in File Browser
|
||||
|
||||
You can also open a child directory in a file manager.
|
||||
|
||||
$ jco c
|
||||
|
||||

|
||||
|
||||
Open Child Directory
|
||||
|
||||

|
||||
|
||||
Open Child Directory in File Browser
|
||||
|
||||
10. Check stats of each folder key weight and overall key weight along with total directory weight. Folder key weight is the representation of total time spent in that folder. Directory weight if the number of directory in list.
|
||||
|
||||
$ j --stat
|
||||
|
||||

|
||||
|
||||
Check Directory Statistics
|
||||
|
||||
**Tips** : The file where autojump stores run log and error log files in the folder `~/.local/share/autojump/`. Don’t overwrite these files, else you may loose all your stats.
|
||||
|
||||
$ ls -l ~/.local/share/autojump/
|
||||
|
||||
|
||||
|
||||
Autojump Logs
|
||||
|
||||
11. You may seek help, if required simply as:
|
||||
|
||||
$ j --help
|
||||
|
||||

|
||||
|
||||
Autojump Help and Options
|
||||
|
||||
### Functionality Requirements and Known Conflicts ###
|
||||
|
||||
- autojump lets you jump to only those directories to which you have already cd. Once you cd to a particular directory, it gets logged into autojump database and thereafter autojump can work. You can not jump to a directory to which you have not cd, after setting up autojump, no matter what.
|
||||
- You can not jump to a directory, the name of which begins with a dash (-). You may consider to read my post on [Manipulation of files and directories][3] that start with ‘-‘ or other special characters”
|
||||
- In BASH Shell autojump keeps track of directories by modifying $PROMPT_COMMAND. It is strictly recommended not to overwrite $PROMPT_COMMAND. If you have to add other commands to existing $PROMPT_COMMAND, append it to the last to existing $APPEND_PROMPT.
|
||||
|
||||
### Conclusion: ###
|
||||
|
||||
autojump is a must utility if you are a command-line user. It eases a lots of things. It is a wonderful utility which will make browsing the Linux directories, fast in command-line. Try it yourself and let me know your valuable feedback in the comments below. Keep Connected, Keep Sharing. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
@ -0,0 +1,188 @@
|
||||
RHCSA Series: Essentials of Virtualization and Guest Administration with KVM – Part 15
|
||||
================================================================================
|
||||
If you look up the word virtualize in a dictionary, you will find that it means “to create a virtual (rather than actual) version of something”. In computing, the term virtualization refers to the possibility of running multiple operating systems simultaneously and isolated one from another, on top of the same physical (hardware) system, known in the virtualization schema as host.
|
||||
|
||||

|
||||
|
||||
RHCSA Series: Essentials of Virtualization and Guest Administration with KVM – Part 15
|
||||
|
||||
Through the use of the virtual machine monitor (also known as hypervisor), virtual machines (referred to as guests) are provided virtual resources (i.e. CPU, RAM, storage, network interfaces, to name a few) from the underlying hardware.
|
||||
|
||||
With that in mind, it is plain to see that one of the main advantages of virtualization is cost savings (in equipment and network infrastructure and in terms of maintenance effort) and a substantial reduction in the physical space required to accommodate all the necessary hardware.
|
||||
|
||||
Since this brief how-to cannot cover all virtualization methods, I encourage you to refer to the documentation listed in the summary for further details on the subject.
|
||||
|
||||
Please keep in mind that the present article is intended to be a starting point to learn the basics of virtualization in RHEL 7 using [KVM][1] (Kernel-based Virtual Machine) with command-line utilities, and not an in-depth discussion of the topic.
|
||||
|
||||
### Verifying Hardware Requirements and Installing Packages ###
|
||||
|
||||
In order to set up virtualization, your CPU must support it. You can verify whether your system meets the requirements with the following command:
|
||||
|
||||
# grep -E 'svm|vmx' /proc/cpuinfo
|
||||
|
||||
In the following screenshot we can see that the current system (with an AMD microprocessor) supports virtualization, as indicated by svm. If we had an Intel-based processor, we would see vmx instead in the results of the above command.
|
||||
|
||||

|
||||
|
||||
Check KVM Support
|
||||
|
||||
In addition, you will need to have virtualization capabilities enabled in the firmware of your host (BIOS or UEFI).
|
||||
|
||||
Now install the necessary packages:
|
||||
|
||||
- qemu-kvm is an open source virtualizer that provides hardware emulation for the KVM hypervisor whereas qemu-img provides a command line tool for manipulating disk images.
|
||||
- libvirt includes the tools to interact with the virtualization capabilities of the operating system.
|
||||
- libvirt-python contains a module that permits applications written in Python to use the interface supplied by libvirt.
|
||||
- libguestfs-tools: miscellaneous system administrator command line tools for virtual machines.
|
||||
- virt-install: other command-line utilities for virtual machine administration.
|
||||
|
||||
# yum update && yum install qemu-kvm qemu-img libvirt libvirt-python libguestfs-tools virt-install
|
||||
|
||||
Once the installation completes, make sure you start and enable the libvirtd service:
|
||||
|
||||
# systemctl start libvirtd.service
|
||||
# systemctl enable libvirtd.service
|
||||
|
||||
By default, each virtual machine will only be able to communicate with the rest in the same physical server and with the host itself. To allow the guests to reach other machines inside our LAN and also the Internet, we need to set up a bridge interface in our host (say br0, for example) by,
|
||||
|
||||
1. adding the following line to our main NIC configuration (most likely `/etc/sysconfig/network-scripts/ifcfg-enp0s3`):
|
||||
|
||||
BRIDGE=br0
|
||||
|
||||
2. creating the configuration file for br0 (/etc/sysconfig/network-scripts/ifcfg-br0) with these contents (note that you may have to change the IP address, gateway address, and DNS information):
|
||||
|
||||
DEVICE=br0
|
||||
TYPE=Bridge
|
||||
BOOTPROTO=static
|
||||
IPADDR=192.168.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NM_CONTROLLED=no
|
||||
DEFROUTE=yes
|
||||
PEERDNS=yes
|
||||
PEERROUTES=yes
|
||||
IPV4_FAILURE_FATAL=no
|
||||
IPV6INIT=yes
|
||||
IPV6_AUTOCONF=yes
|
||||
IPV6_DEFROUTE=yes
|
||||
IPV6_PEERDNS=yes
|
||||
IPV6_PEERROUTES=yes
|
||||
IPV6_FAILURE_FATAL=no
|
||||
NAME=br0
|
||||
ONBOOT=yes
|
||||
DNS1=8.8.8.8
|
||||
DNS2=8.8.4.4
|
||||
|
||||
3. finally, enabling packet forwarding by making, in `/etc/sysctl.conf`,
|
||||
|
||||
net.ipv4.ip_forward = 1
|
||||
|
||||
and loading the changes to the current kernel configuration:
|
||||
|
||||
# sysctl -p
|
||||
|
||||
Note that you may also need to tell firewalld that this kind of traffic should be allowed. Remember that you can refer to the article on that topic in this same series ([Part 11: Network Traffic Control Using FirewallD and Iptables][2]) if you need help to do that.
|
||||
|
||||
### Creating VM Images ###
|
||||
|
||||
By default, VM images will be created to `/var/lib/libvirt/images` and you are strongly advised to not change this unless you really need to, know what you’re doing, and want to handle SELinux settings yourself (such topic is out of the scope of this tutorial but you can refer to Part 13 of the RHCSA series: [Mandatory Access Control Essentials with SELinux][3] if you want to refresh your memory).
|
||||
|
||||
This means that you need to make sure that you have allocated the necessary space in that filesystem to accommodate your virtual machines.
|
||||
|
||||
The following command will create a virtual machine named `tecmint-virt01` with 1 virtual CPU, 1 GB (=1024 MB) of RAM, and 20 GB of disk space (represented by `/var/lib/libvirt/images/tecmint-virt01.img`) using the rhel-server-7.0-x86_64-dvd.iso image located inside /home/gacanepa/ISOs as installation media and the br0 as network bridge:
|
||||
|
||||
# virt-install \
|
||||
--network bridge=br0
|
||||
--name tecmint-virt01 \
|
||||
--ram=1024 \
|
||||
--vcpus=1 \
|
||||
--disk path=/var/lib/libvirt/images/tecmint-virt01.img,size=20 \
|
||||
--graphics none \
|
||||
--cdrom /home/gacanepa/ISOs/rhel-server-7.0-x86_64-dvd.iso
|
||||
--extra-args="console=tty0 console=ttyS0,115200"
|
||||
|
||||
If the installation file was located in a HTTP server instead of an image stored in your disk, you will have to replace the –cdrom flag with –location and indicate the address of the online repository.
|
||||
|
||||
As for the –graphics none option, it tells the installer to perform the installation in text-mode exclusively. You can omit that flag if you are using a GUI interface and a VNC window to access the main VM console. Finally, with –extra-args we are passing kernel boot parameters to the installer that set up a serial VM console.
|
||||
|
||||
The installation should now proceed as a regular (real) server now. If not, please review the steps listed above.
|
||||
|
||||
### Managing Virtual Machines ###
|
||||
|
||||
These are some typical administration tasks that you, as a system administrator, will need to perform on your virtual machines. Note that all of the following commands need to be run from your host:
|
||||
|
||||
**1. List all VMs:**
|
||||
|
||||
# virsh list --all
|
||||
|
||||
From the output of the above command you will have to note the Id for the virtual machine (although it will also return its name and current status) because you will need it for most administration tasks related to a particular VM.
|
||||
|
||||
**2. Display information about a guest:**
|
||||
|
||||
# virsh dominfo [VM Id]
|
||||
|
||||
**3. Start, restart, or stop a guest operating system:**
|
||||
|
||||
# virsh start | reboot | shutdown [VM Id]
|
||||
|
||||
**4. Access a VM’s serial console if networking is not available and no X server is running on the host:**
|
||||
|
||||
# virsh console [VM Id]
|
||||
|
||||
**Note** that this will require that you add the serial console configuration information to the `/etc/grub.conf` file (refer to the argument passed to the –extra-args option when the VM was created).
|
||||
|
||||
**5. Modify assigned memory or virtual CPUs:**
|
||||
|
||||
First, shutdown the guest:
|
||||
|
||||
# virsh shutdown [VM Id]
|
||||
|
||||
Edit the VM configuration for RAM:
|
||||
|
||||
# virsh edit [VM Id]
|
||||
|
||||
Then modify
|
||||
|
||||
<memory>[Memory size here without brackets]</memory>
|
||||
|
||||
Restart the VM with the new settings:
|
||||
|
||||
# virsh create /etc/libvirt/qemu/tecmint-virt01.xml
|
||||
|
||||
Finally, change the memory dynamically:
|
||||
|
||||
# virsh setmem [VM Id] [Memory size here without brackets]
|
||||
|
||||
For CPU:
|
||||
|
||||
# virsh edit [VM Id]
|
||||
|
||||
Then modify
|
||||
|
||||
<cpu>[Number of CPUs here without brackets]</cpu>
|
||||
|
||||
For further commands and details, please refer to table 26.1 in Chapter 26 of the RHEL 5 Virtualization guide (that guide, though a bit old, includes an exhaustive list of virsh commands used for guest administration).
|
||||
|
||||
### SUMMARY ###
|
||||
|
||||
In this article we have covered some basic aspects of virtualization with KVM in RHEL 7, which is both a vast and a fascinating topic, and I hope it will be helpful as a starting guide for you to later explore more advanced subjects found in the official [RHEL virtualization][4] getting started and [deployment / administration guides][5].
|
||||
|
||||
In addition, you can refer to the preceding articles in [this KVM series][6] in order to clarify or expand some of the concepts explained here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/kvm-virtualization-basics-and-guest-administration/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.linux-kvm.org/page/Main_Page
|
||||
[2]:http://www.tecmint.com/firewalld-vs-iptables-and-control-network-traffic-in-firewall/
|
||||
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[4]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Getting_Started_Guide/index.html
|
||||
[5]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Deployment_and_Administration_Guide/index.html
|
||||
[6]:http://www.tecmint.com/install-and-configure-kvm-in-linux/
|
||||
@ -1,214 +0,0 @@
|
||||
适合于远程编辑以及更多环境的简洁文本编辑器
|
||||
================================================================================
|
||||
文本编辑器是用来编辑纯文本的软件。这种软件有许多用处,包括修改配置文件,编写程序源代码,记下一些想法或者甚至写一份购物列表。由于这种编辑器能都用于许多不同的活动,因此值得花些时间找一个最适合您喜好的编辑器。
|
||||
|
||||
不论编辑器有多么复杂,它们通常有一个共同的功能集,包括查找/替换文本,格式化文本,导入文件以及在文件中移动文本。
|
||||
|
||||
所有这些文本编辑器都是基于终端的应用,因此他们很适合在远程主机上编辑文件。文本编辑器通常也会提供一个图形化的用户界面,但依旧会保证快速和最小化。
|
||||
|
||||
基于终端的应用程序在系统资源方面也是轻量级的(在低配置机器上很有用),比起它的图形化版本来也会更快、更高效,由于它们在X需要重启时也不会停止工作,因此非常适合编写脚本。
|
||||
|
||||
我选择了一些我最喜欢的开源文本编辑器,他们在使用系统资源方面都非常节俭。
|
||||
|
||||
----------
|
||||
|
||||
### Textadept ###
|
||||
|
||||

|
||||
|
||||
Textadept是一款适合程序员的,快速、最小化、可扩展、跨平台的开源文本编辑器。这个开源程序由C和Lua写就,并且于这些年间在速度和最小化方面进行了优化。
|
||||
|
||||
Textadept是那些想要无限的扩展性且不愿牺牲速度或屈服于代码膨胀的程序员们的理想编辑器。
|
||||
|
||||
它也有一个用于终端的版本,仅仅依赖ncurses,适合在远程主机上进行编辑。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 轻量级
|
||||
- 最小化设计以最大化屏幕
|
||||
- 自包含的执行文件 - 无需安装
|
||||
- 全键盘驱动
|
||||
- 无限制的分割视图(GUI版本),以您所好任意水平或垂直的分割编辑器窗口。请注意Textadept没有打开文件标签。
|
||||
- 支持多于80种的编程语言
|
||||
- 强大的片段快捷命令
|
||||
- 代码自动补全和API查询
|
||||
- 无与伦比的扩展性
|
||||
- 书签
|
||||
- 查找和替换
|
||||
- 在文件中查找
|
||||
- 基于缓存的单词补全
|
||||
- 成熟的编程语言符号自动补全,以及显示API文档的功能
|
||||
- 主题:明亮、黑暗、终端
|
||||
- 使用词法分析器将名称分配给缓冲元素,如评论、字符串、关键词
|
||||
- 远程会话
|
||||
- 快速打开
|
||||
- 许多可用的模块,包括对Java、Python、Ruby和近期打开文件列表的支持
|
||||
- 符合Gnome HIG用户接口的指导
|
||||
- 支持编辑Lua代码。语法自动补全,LuaDoc,许多Textadept对象和Lua的标准库。
|
||||
|
||||
- 网址: [foicica.com/textadept][1]
|
||||
- 开发者: Mitchell and contributors
|
||||
- 许可证: MIT License
|
||||
- 版本号: 7.7
|
||||
|
||||
----------
|
||||
|
||||
### Vim ###
|
||||
|
||||

|
||||
|
||||
vim是一个高级的文本编辑器,它基于'vi'的强大,并拥有更全面的功能集。
|
||||
|
||||
这个编辑器对编程和编辑其他纯ASCII的文件十分有用。所有的命令都由普通的键盘字符提供,能够使用十指来输入,因而十分快捷。另外,功能键可以由用户来定义,并且可也以使用鼠标。
|
||||
|
||||
Vim通常被称作"程序员的编辑器",它十分适合于编程,并被认为可以作为完整的集成开发环境。然而,这个软件并不是仅仅面向程序员。Vim高度重视各种文本编辑,从编写email到修改配置文件。
|
||||
|
||||
Vim的接口基于文本界面下的命令行。尽管它的图形化版本gVim为常用的命令添加了菜单和工具栏,但这个软件的整个功能依旧依赖于它的命令行模式。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 3 种模式:
|
||||
- - Command 模式
|
||||
- - Insert 模式
|
||||
- - Command line 模式
|
||||
- 无限制的撤销
|
||||
- 多个窗口和缓冲区
|
||||
- 平滑的输入模式
|
||||
- 根据所编辑的文件的类型使用不同的颜色或风格进行语法高亮
|
||||
- 交互命令
|
||||
- - 标记一行
|
||||
- - vi 行缓冲
|
||||
- - 移动代码块
|
||||
- 块操作
|
||||
- 命令历史
|
||||
- 扩展的正则表达式
|
||||
- 编辑压缩/打包文件 (gzip, bzip2, zip, tar)
|
||||
- 文件名补全
|
||||
- 标记跳转
|
||||
- 折叠文本
|
||||
- 缩进
|
||||
- ctags和cscope整合
|
||||
- 100%与vi的模式兼容
|
||||
- 插件用于添加/扩展功能
|
||||
- 宏
|
||||
- vimscript, Vim的内部脚本
|
||||
- Unicode支持
|
||||
- 多语言支持
|
||||
- 在线帮助支持
|
||||
|
||||
- 网址: [www.vim.org][2]
|
||||
- 开发者: Bram Moolenaar
|
||||
- 许可证: GNU GPL compatible (charityware)
|
||||
- 版本号: 7.4
|
||||
|
||||
----------
|
||||
|
||||
### ne ###
|
||||
|
||||

|
||||
|
||||
ne是一款全屏幕的开源文本编辑器。它像是一个比vi更容易学习的vi替代物,并且可以在POSIX-兼容的系统中便携使用。
|
||||
|
||||
ne对于新手来说易于使用,但也非常强大并有完全可配置的引导程序,并且在资源使用上十分节约。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 三种用户接口: 控制击键,命令行和菜单;击键和菜单都可配置
|
||||
- 语法高亮
|
||||
- 对于UTF-8文件的完全支持,包括多列字符
|
||||
- 文档,剪切,显示的维度和文件/行号长度都有编号,并且仅受制于机器的整型字长
|
||||
- 简单的脚本语言,脚本可以用简单易理解的录制/播放的方式制作
|
||||
- 无限制的撤销/重做功能(可以通过命令禁用)
|
||||
- 基于被编辑的文件扩展的自动个性化配置系统
|
||||
- 使用您文档中的词语做字典来进行自动前缀补全
|
||||
- 易用的文件存取功能
|
||||
- 扩展的正则表达式可用于查找和替换,类似emacs和vi
|
||||
- 非常紧凑的内存模型,在加载和修改大型文件时十分快速
|
||||
- 可编辑二进制文件
|
||||
|
||||
- 网址: [ne.di.unimi.it][3]
|
||||
- 开发者: Sebastiano Vigna (original developer). Additional features added by Todd M. Lewis
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 2.5
|
||||
|
||||
----------
|
||||
|
||||
### Zile ###
|
||||
|
||||

|
||||
|
||||
Zile是Lossy Emacs(Emacs精简版),它是一个小型的Emacs的克隆版。Zile是一个可定制的,自文档化,实时显示的编辑器,在编写Zile时像Emacs一样尽可能的小,每个Emacs用户都会对Zile感到亲切。
|
||||
|
||||
Zile以它极小的RAM用量,大约130KB,以及快速开始编辑而闻名。它是8比特清洁的,允许用于编写任何种类的文件。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 小型但快速、强大
|
||||
- 多个缓冲区,允许多级的撤销
|
||||
- 多窗口
|
||||
- 好用,有力【不太清楚怎么翻译】
|
||||
- 以最小的缓冲区完成补全
|
||||
- 自动填充 (自动换行)
|
||||
- 寄存器视图
|
||||
- 看起来像Emacs,键序列、功能和变量名都与Emacs相同
|
||||
- Killing
|
||||
- Yanking
|
||||
- 自动行末检测
|
||||
|
||||
- 网址: [www.gnu.org/software/zile][4]
|
||||
- 开发者: Reuben Thomas, Sandro Sigala, David A. Capello
|
||||
- 许可证: GNU GPL v2
|
||||
- 版本号: 2.4.11
|
||||
|
||||
----------
|
||||
|
||||
### nano ###
|
||||
|
||||

|
||||
|
||||
nano是基于curses库的文本编辑器。它是Pico(Pine电子邮件客户端编辑器)的一个复刻版。
|
||||
|
||||
由于Pine的许可证问题诉讼案(Pine并未以开源许可证发布),并且也因为Pine缺少一些重要的功能,nano项目于1999年开始。
|
||||
|
||||
nano致力于赶上Pico的功能和其易用性,与此同时提供更多的功能,但不集成Pine/Pico的邮件客户端。
|
||||
|
||||
nano像Pico一样是以键盘为导向的设计,可以用控制键来控制。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 交互式的查找和替换
|
||||
- 彩色语法高亮
|
||||
- 转到行号和列号处
|
||||
- 自动缩进
|
||||
- 功能开关
|
||||
- 支持UTF-8
|
||||
- 混合型的文件类型自动转换
|
||||
- 逐字输入模式
|
||||
- 多个文件缓冲区
|
||||
- 平滑滚动
|
||||
- 括号匹配
|
||||
- 自定义引用字符串
|
||||
- 备份文件
|
||||
- 国际化支持
|
||||
- tab补全文件名
|
||||
|
||||
- 网址: [nano-editor.org][5]
|
||||
- 开发者: Chris Allegretta, David Lawrence, Jordi Mallach, Adam Rogoyski, Robert Siemborski, Rocco Corsi, David Benbennick, Mike Frysinger
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 2.2.6
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://foicica.com/textadept/
|
||||
[2]:http://www.vim.org/
|
||||
[3]:http://ne.di.unimi.it/
|
||||
[4]:http://www.gnu.org/software/zile/
|
||||
[5]:http://nano-editor.org/
|
||||
@ -1,110 +0,0 @@
|
||||
什么是好的命令行HTTP客户端?
|
||||
==============================================================================
|
||||
整体大于各部分之和,这是引自希腊哲学家和科学家的亚里士多德的名言。这句话特别切中Linux。在我看来,Linux最强大的地方之一就是它的协作性。Linux的实用性并不仅仅源自大量的开源程序(命令行)。相反,其协作性来自于这些程序的综合利用,有时是结合更大型的应用。
|
||||
|
||||
Unix哲学引发了一场“软件工具”的运动,关注开发简洁,基础,干净,模块化和扩展性好的代码,并可以运用于其他的项目。这种哲学为许多的Linux项目留下了一个重要的元素。
|
||||
|
||||
好的开源开发者写程序为了确保该程序尽可能运行正确,同时能与其他程序很好地协作。目标就是使用者拥有一堆方便的工具,每一个力求干不止一件事。许多程序能独立工作得很好。
|
||||
|
||||
这篇文章讨论3个开源命令行HTTP客户端。这些客户端可以让你使用命令行从互联网上下载文件。但同时,他们也可以用于许多有意思的地方,如测试,调式和与HTTP服务器或网络应用互动。对于HTTP架构师和API设计人员来说,使用命令行操作HTTP是一个值得花时间学习的技能。如果你需要来回使用API,HTTPie和cURL,这没什么价值。
|
||||
|
||||
-------------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
HTTPie(发音 aych-tee-tee-pie)是一款开源命令行HTTP客户端。它是一个命令行界面,类cURL的工具。
|
||||
|
||||
该软件的目标是使得与网络服务器的交互尽可能的人性化。其提供了一个简单的http命令,允许使用简单且自然的语句发送任意的HTTP请求,并显示不同颜色的输出。HTTPie可以用于测试,调式和与HTTP服务器的一般交互。
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 可表达,直观的语句
|
||||
- 格式化,颜色区分的终端输出
|
||||
- 内建JSON支持
|
||||
- 表单和文件上传
|
||||
- HTTPS,代理和认证
|
||||
- 任意数据请求
|
||||
- 自定义标题 (此处header不确定是否特别意义)
|
||||
- 持久会话
|
||||
- 类Wget下载
|
||||
- Python 2.6,2.7和3.x支持
|
||||
- Linux,Mac OS X 和 Windows支持
|
||||
- 支持插件
|
||||
- 帮助文档
|
||||
- 测试覆盖 (直译有点别扭)
|
||||
|
||||
- 网站:[httpie.org][1]
|
||||
- 开发者: Jakub Roztočil
|
||||
- 证书: 开源
|
||||
- 版本号: 0.9.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
cURL是一个开源命令行工具,用于使用URL语句传输数据,支持DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS,IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET和TFTP。
|
||||
|
||||
cURL支持SSL证书,HTTP POST,HTTP PUT,FTP上传,HTTP基于表单上传,代理,缓存,用户名+密码认证(Basic, Digest, NTLM, Negotiate, kerberos...),文件传输恢复, 代理通道和一些其他实用窍门的总线负载。(这里的名词我不明白其专业意思)
|
||||
|
||||
#### 功能包括:####
|
||||
|
||||
- 配置文件支持
|
||||
- 一个单独命令行多个URL
|
||||
- “globbing”漫游支持: [0-13],{one, two, three}
|
||||
- 一个命令上传多个文件
|
||||
- 自定义最大传输速度
|
||||
- 重定向标准错误输出
|
||||
- Metalink支持
|
||||
|
||||
- 网站: [curl.haxx.se][2]
|
||||
- 开发者: Daniel Stenberg
|
||||
- 证书: MIT/X derivate license
|
||||
- 版本号: 7.42.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Wget是一个从网络服务器获取信息的开源软件。其名字源于World Wide Web 和 get。Wget支持HTTP,HTTPS和FTP协议,同时也通过HTTP代理获取信息。
|
||||
|
||||
Wget可以根据HTML页面的链接,创建远程网络站点的本地版本,是完全重造源站点的目录结构。这种方式被冠名“recursive downloading。”
|
||||
|
||||
Wget已经设计可以加快低速或者不稳定的网络连接。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 使用REST和RANGE恢复中断的下载
|
||||
- 使用文件名
|
||||
- 多语言的基于NLS的消息文件
|
||||
- 选择性地转换下载文档里地绝对链接为相对链接,使得下载文档可以本地相互链接
|
||||
- 在大多数类UNIX操作系统和微软Windows上运行
|
||||
- 支持HTTP代理
|
||||
- 支持HTTP数据缓存
|
||||
- 支持持续地HTTP连接
|
||||
- 无人照管/后台操作
|
||||
- 当远程对比时,使用本地文件时间戳来决定是否需要重新下载文档 (mirroring没想出合适的表达)
|
||||
|
||||
- 站点: [www.gnu.org/software/wget/][3]
|
||||
- 开发者: Hrvoje Niksic, Gordon Matzigkeit, Junio Hamano, Dan Harkless, and many others
|
||||
- 证书: GNU GPL v3
|
||||
- 版本号: 1.16.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150425174537249/HTTPclients.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://httpie.org/
|
||||
[2]:http://curl.haxx.se/
|
||||
[3]:https://www.gnu.org/software/wget/
|
||||
@ -1,100 +0,0 @@
|
||||
3个开源的Python Shell
|
||||
=========================================================================
|
||||
Python是一个高级,通用,结构化且强大的开源编程语言,用于广泛的编程工作。它拥有一个完全的动态类型系统和自动内存管理,与Scheme,Ruby,Perl和Tcl的十分相似,避免编译型语言的许多复杂地方和难以理解。Python于1991年由Guido van Rossum创造,然后逐渐成长,流行。
|
||||
|
||||
Python是一个非常实用,而且流行的计算机编程语言。使用一个如Python这样的解释型语言的好处之一就是,可以借助其交互的shell考察式地编程。你可以试用代码,而不必写一个脚本。但是Python shell也有一些局限性。基本来说,有许多很nice的Python shell可选择,都是在基础shell上扩展的。他们每一个都提供了一个极好的交互性的Python 体验。
|
||||
|
||||
--------------
|
||||
|
||||
### bpython ###
|
||||
|
||||

|
||||
|
||||
对于Linux,BSD,OS X和Windows来说,bpython是Python解释器一个受欢迎的接口。
|
||||
|
||||
想法是提供给用户所有的内置功能,很像现在的IDEs(集成开发环境),但是是在一个简单,轻量级的包里,可以在终端窗口里面运行。
|
||||
|
||||
bpython并不追求创造任何新的或者开创性的东西。相反,她聚集了一些简洁的理念,关注于实用性和操作性。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 内置的语法高亮 - 使用Pygments排版你敲出的代码,并合理地上色
|
||||
- 根据你的行为,显示自动补全的建议。
|
||||
- 为任何Python函数列出期望的参数 - 力求显示一列参数,为你调用的任何函数
|
||||
- “Rewind”功能,弹出内存里的最后一行代码并重新评定
|
||||
- 发送你已经解除占用的代码到粘贴缓存
|
||||
- 保存你已经输入到一个文件里的代码
|
||||
- 自动缩进
|
||||
- 支持Python 3
|
||||
|
||||
- 网址: [www.bpython-interpreter.org][1]
|
||||
- 开发者: Bob Farrell and contributors
|
||||
- 证书: MIT License
|
||||
- 版本号: 0.14.1
|
||||
|
||||
----------
|
||||
|
||||
### IPython ###
|
||||
|
||||

|
||||
|
||||
IPython是Python shell的一个交互加强版。她提供了一个丰富的工具集合,帮助你交互式地充分利用Python。
|
||||
|
||||
IPython可以用来取代标准的Python shell,或者当与标准Python 科学和数值处理工具配合,用做一个科学计算(如Matlab或者Mathematical)的完整工作环境。她支持动态对象内省,有限的输入/输出提示,一个宏观系统,会话登录,会话恢复,完整的系统接入,详尽且彩色的追踪报告,自动圆括号,自动应用和可嵌入其他Python程序。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 强大的交互Shell(终端或者基于Qt)
|
||||
- 一个基于浏览器的记事本,支持代码,多样文本,数学表达式,内置飞行图表和其他丰富媒介。
|
||||
- 支持交互式的数据虚拟化和GUI工具箱使用
|
||||
- 灵活,嵌入式的解释器可以加载进你自己的项目里
|
||||
- 易于使用,高效的并行运算工具
|
||||
|
||||
- 网址: [ipython.org][2]
|
||||
- 开发者: The IPython Development Team
|
||||
- 证书: BSD
|
||||
- 版本号: 3.1
|
||||
|
||||
----------
|
||||
|
||||
### DreamPie ###
|
||||
|
||||

|
||||
|
||||
DreamPie是一个为可靠性和兴趣设计的Python shell。
|
||||
|
||||
DreamPie可以用于任何Python解释器(Jython,IronPython,PyPy)。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 一个交互shell的新概念:窗口被分成历史区域和代码区域,历史区域可以让你看到之前的命令及其输出,代码区域是里敲代码的地方。这样,你可以编辑任意数量的代码,就好像在你最喜欢的编辑器里一样,并且适当时候可以执行它。你也可以从其他地方复制你想保存的代码,所以你可以把它存入一个文件。代码可以很好地格式化为四级缩进。
|
||||
- 自动补全属性和文件名字
|
||||
- 自动显示函数参数和文档
|
||||
- 在结果历史中保存你最近的结果,备以后用
|
||||
- 可以自动展开很长的输出,所以你可以专注于重要的地方
|
||||
- 保存会话的历史记录为一个HTML文件,备以后查询。你可以加载历史文件到DreamPie里,并且快速回退到之前的命令。
|
||||
- 自动添加圆括号与可选的引用,当你在函数与方法后按下空格键。例如,键入execfile fn并且获得execfile("fn")
|
||||
- 支持交互的matplotlib绘图
|
||||
- 支持Python 2.5,Python 2.6,Python 3.1,Jython 2.5,IronPython 2.6和PyPy
|
||||
- 难以置信的快速反应
|
||||
|
||||
- 网址: [www.dreampie.org][3]
|
||||
- 开发者: Noam Yorav-Raphael
|
||||
- 证书: GNU GPL v3
|
||||
- 版本号: 1.2.1
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150523032756576/PythonShells.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.bpython-interpreter.org/
|
||||
[2]:http://ipython.org/
|
||||
[3]:http://www.dreampie.org/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
127
translated/share/20150616 Linux Humor on the Command-line.md
Normal file
127
translated/share/20150616 Linux Humor on the Command-line.md
Normal file
@ -0,0 +1,127 @@
|
||||
Linux命令行中的幽默
|
||||
================================================================================
|
||||
桌面通常是非常养眼的,它增强了可视化的体验,有时也能够增强某些软件的功能,以及让软件变得更有趣。在命令行下工作也不需要总是很严肃,如果您想在命令行下找些乐子,那么有很多命令可以让您展露微笑。
|
||||
|
||||
Linux是个有趣的操作系统。它提供大量的小型开源工具,从平淡无奇的软件到稀奇古怪的应用。这些工具的质量和可选择性帮助Linux脱颖而出。让我们一起来看看下面这七个小工具吧。
|
||||
|
||||
### lolcat ###
|
||||
|
||||

|
||||
|
||||
lolcat是一个连接文件或标准输入到标准输出(类似一般的cat)的程序,他会为输出添加七彩的颜色。
|
||||
|
||||
lolcat通常和其他诸如toilet或figlet等生成文本的应用结合使用。这个软件不应被误认为一个或多个猫的图像的宏。
|
||||
|
||||
lolcat由Moe编写。
|
||||
|
||||
网址: [github.com][1]
|
||||
|
||||
### cowsay ###
|
||||
|
||||

|
||||
|
||||
cowsay是一个可配置的开源软件,它用ASCII码生成奶牛的图片,并可以在对话气泡中显示消息。cowsay是用Perl写的。
|
||||
|
||||
cowsay并不仅仅只能显示奶牛。它能生成预先制作的图片或者其他动物,包括鸭子、考拉、麋鹿、小马、绵羊、剑龙和火鸡,以及奶酪、雪人和骨架。
|
||||
|
||||
有一个叫cowthink的应用,与对话的气泡不同,它能在生成奶牛的同时能生成思考的气泡。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 让脚本变得更有趣
|
||||
- Borg模式
|
||||
- 可以更改奶牛看起来的样子,比如让奶牛看起来贪婪、偏执、固执、疲倦、古怪、年轻等
|
||||
- 奶牛说话的内容可以修改
|
||||
|
||||
网址: [nog.net][2]
|
||||
|
||||
### doge ###
|
||||
|
||||

|
||||
|
||||
doge是一个基于有些愚蠢但很有趣的doge的梗的简单的每日信息脚本。它随机的打印一些在语法上有误的句子,有时这些句子基于您电脑中的东西。
|
||||
|
||||
doge是一个在2013年非常流行的互联网潮流元素(梗)。这个梗通常由一幅日本柴犬的图片和彩色的文字组成。这些文字故意用一种蹩脚的语气写成了一些互联网的独白。
|
||||
|
||||
- 随机的用不同的颜色和蹩脚的英语写下随机的句子
|
||||
- 终端中的柴犬效果非常棒
|
||||
- 获得系统数据,比如主机名、运行中的程序、当前用户、$EDITOR
|
||||
- 如果您安装了lolcat,您可以用它作为点缀: while true; do doge | lolcat -a -d 100 -s 100 -p 1; done
|
||||
- 标准输入支持: ls /usr/bin | doge 将打印一些/usr/bin下的可执行文件。哇噢。还有许多命令行的开关可以过滤词语以及控制词语的频率。
|
||||
|
||||
网址: [github.com/thiderman/doge][3]
|
||||
|
||||
### ASCIIQuarium ###
|
||||
|
||||

|
||||
|
||||
ASCIIQuarium是一个以ASCII码方式画出的水族馆/海洋动画。享受生活在您电脑中水底的奇妙生物吧。
|
||||
|
||||
想运行ASCIIQuarium,您需要安装Perl的curses包以及Term::Animation模块。请使用sudo apt-get install libcurses-perl来安装前者,使用sudo cpan Term::Animation来安装后者。两个命令都需要在终端中运行。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 五彩的鱼儿
|
||||
- 有趣的动画,包括钓鱼钩
|
||||
- 还有许多的天鹅、鸭子、海豚和船只
|
||||
|
||||
网址: [www.robobunny.com][4]
|
||||
|
||||
### sl - 蒸汽机车 ###
|
||||
|
||||

|
||||
|
||||
sl是一个有趣的终端应用,它为那些意外的错将ls输成sl的用户显示一个动画。
|
||||
|
||||
我打字通常非常草率,更喜欢速度而不是准确性。但错别字在命令行中是非常危险的。因此sl作为一个实际的提醒者,提醒我们注意错误输入的这种坏习惯。它总是会让人咯咯的笑。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 使用 -F, 火车在飞翔
|
||||
- 使用 -l, 显示一个小型的火车
|
||||
- 使用 -a, 看上去发生了意外
|
||||
|
||||
网址: [github.com/mtoyoda/sl][5]
|
||||
|
||||
### aafire ###
|
||||
|
||||

|
||||
|
||||
aafire在终端中显示燃烧的ASCII火焰。它展示了一个ascii艺术库 - aalib库的强大能力。
|
||||
|
||||
网址: [aa-project.sourceforge.net/aalib][6]
|
||||
|
||||
### CMatrix ###
|
||||
|
||||

|
||||
|
||||
CMatrix是一个基于ncurses的程序,它模拟《黑客帝国》(一部电影)中的画面。如果您在一个山洞里度过了上个15年,那么您可能不知道黑客帝国是1999年的美国科幻电影,主角为 Keanu Reeves, Laurence Fishburne, Carrie-Anne Moss, Hugo Weaving和 Joe Pantoliano。
|
||||
|
||||
它可以在终端设置为132x300的情况下工作,并且可以以同样的速率进行滚动或者以用户定义的速度进行异步的滚动。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 修改文本颜色
|
||||
- 使用粗体字符
|
||||
- 异步滚动
|
||||
- 使用老式的滚动效果
|
||||
- 屏幕保护程序模式
|
||||
|
||||
网址: [www.asty.org/cmatrix][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150614112018846/Humor.html
|
||||
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://github.com/busyloop/lolcat
|
||||
[2]:https://web.archive.org/web/20120225123719/http://www.nog.net/%7Etony/warez/cowsay.shtml
|
||||
[3]:https://github.com/thiderman/doge
|
||||
[4]:http://www.robobunny.com/projects/asciiquarium/html/
|
||||
[5]:https://github.com/mtoyoda/sl
|
||||
[6]:http://aa-project.sourceforge.net/aalib/
|
||||
[7]:http://www.asty.org/cmatrix/
|
||||
@ -1,153 +0,0 @@
|
||||
sevenot translated
|
||||
排名前十的年度开源项目新秀
|
||||
================================================================================
|
||||
黑鸭(Black Duck)软件公布了一份名叫“年度开源项目新秀”的报告,介绍了由全球开源协会发起的10个最有趣、最活跃的新项目。
|
||||
|
||||

|
||||
|
||||
### 年度开源项目新秀 ###
|
||||
|
||||
每年都有上千新的开源项目问世,但只有少数能够真正的吸引我们的关注。一些项目因为利用了当前比较流行的技术而发展壮大,有一些则真正地开启了一个新的邻域。很多开源项目建立的初衷是为了解决一些生产上的问题,还有一些项目则是世界各地志同道合的开发者们共同发起的一个宏伟项目。
|
||||
|
||||
从2009年起,开源软件公司黑鸭便发起了[年度开源项目新秀][1]这一活动,它的评选根据[Open Hub][2] 网站(即以前的Ohloh)。今年,我们很荣幸能够报道2015年10大开源项目新秀的得主和2名荣誉奖得主,它们是从上千个开源项目中脱颖而出的。评选采用了加权评分系统,得分标准基于项目的活跃度,交付速度,和几个其它因数。
|
||||
|
||||
开源俨然成为了产业创新的引擎,就拿今年来说,和Docker容器相关的开源项目在全球各地新起,这也不恰巧反映了企业最感兴趣的技术邻域吗?最后,我们接下来介绍的项目,将会让你了解到全球开源项目的开发者们的在思考什么,这很快将会成为一个指引我们发展的领头羊。
|
||||
|
||||
### 2015年度开源项目新秀: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3]收集打包了一套[Ansible][4] (Ansible是一种自动化运维工具)方案和规则,可以从1个容器扩展到一个完整的数据中心。它的创始人Maciej Delmanowski将DebOps开源来保证项目长久进行,从而更好的利用外部贡献者来发展下去
|
||||
|
||||
DebOps始创于波兰的一个不起眼大学校园里,在自己的数据中心上运行,一切都是手工配置的。有时系统崩溃而导致几天的宕机,这时Delmanowski意识到一个配置管理系统是很有必要的。从Debian的基础做起,DebOps是一组配置一整个数据基础设施Ansible方案。此项目已经在许多不同的工作环境下实现,而创始者们则打算继续支持和开发这个项目。
|
||||
|
||||
###2015年度开源项目新秀: Code Combat ###
|
||||
|
||||

|
||||
|
||||
传统的纸笔学习方法已近不能满足技术学科了。然而游戏都是关于参与者,这也就是为什么[CodeCombat][5] 的创始人会去开发一款多人协同编程游戏来教人们如何编码。
|
||||
|
||||
刚开始CodeCombat是一个创业想法,但其创始人决定创建一个开源项目将其取代。此想法在社区传播开来,很快不少贡献者加入到项目中来。项目发起仅仅两个月后,这款游戏就被收入Google’s Summer of Code。这款游戏吸引了大量玩家,并被翻译成45种语言。CodeCombat希望成为那些想要一边学习代码同时获得乐趣的同学的风向标。
|
||||
|
||||
### 2015年度开源项目新秀: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6]是一个点对点的云存储网络,可实现端到端加密,保证用户不用依赖第三方即可传输、共享数据。基于比特币block chain技术和点对点协议,Storj提供安全、私密、加密的云存储。
|
||||
|
||||
云数据存储的反对者担心成本开销和漏洞攻击。为了做到没有死角,Storj是一个私有云存储市场,用户可以通过Storjcoin X(SJCX) 购买交易存储空间。上传到Storj的文件会被粉碎、加密和存储到整个社区。只有文件所有者拥有密钥加密的信息
|
||||
|
||||
在2014年举办的Texas Bitcoin Conference Hackathon会议上,云存储市场概念首次被提出并证明可行。在第一次赢得黑客马拉松活动后,项目创始人们和领导团队利用开源论坛Reddit、比特币论坛和社交媒体推广此项目。如今,它们已成为Storj决策过程的一个重要组成部分。
|
||||
|
||||
### 2015年度开源项目新秀: Neovim ###
|
||||
|
||||

|
||||
|
||||
自1991年提出概念以来,Vim已经成为数以百万计软件开发人员所钟爱的文本编辑器。 [Neovim][6] 是它的下一个版本。
|
||||
|
||||
在过去的23年里,软件开发生态系统经历了无数增长和创新。Neovim创始人Thiago de Arruda知道Vim缺少当代元素,跟不上时代的发展。在保留Vim的签名功能的前提下,Neovim团队同样在寻求最受欢迎的文本编辑器改善和发展技术。集资初期,Thiago de Arruda连续6个月时间关注推出此项目。他相信他的团队和支持他激励他继续发展Neovim。
|
||||
|
||||
### 2015年度开源项目新秀: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
前谷歌员工开发了一个开源的企业数据存储项目[CockroachDB][8],它是一个可扩展的、跨地域复制且支持事务的数据存储的解决方案。
|
||||
|
||||
为了保证在线百万兆字节流量业务的质量,Google公开了他们的Spanner系统,这是一个可扩展的,稳定的,支持事务的系统。许多参与开发CockroachDB的团队现在都服务与开源社区。就像真正的蟑螂一样,CockroachDB可以在没有数据头、没有任何节点的情况下正常运行。这个开源项目有很多富有经验的贡献者,创始人们通过社会媒体、Github、网络、会议和聚会结识他们并鼓励他们参与其中。
|
||||
|
||||
### 2015年度开源项目新秀: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
在介绍集装箱化的软件对开源社区的发展时,[Docker][9]是一匹黑马,它在技术和工具的设置上做了创新。去年6月谷歌推出了[Kubernetes][10],这是一款开源的容器管理工具,用来加快开发和简化操作。
|
||||
|
||||
谷歌在它的网络系统上使用容器技术多年了。在2014年夏天的DockerCon上大会上,谷歌这个互联网巨头开源了Kubernetes,Kubernetes的开发是为了满足迅速增长的Docker生态系统的需要。通过和其它的组织、项目合作,比如 Red Hat和CoreOS,Kubernetes的管理者们促使它登上了Docker Hub的工具下载榜榜首。Kubernetes的开发团队希望扩大这个项目,发展它的社区,这样的话软件开发者就能花更少的时间在管理基础设施上,而更多的去开发他们自己的APP。
|
||||
|
||||
### 2015年度开源项目新秀: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
OpenBazaar是一个使用比特币和其他人交易的市场。OpenBazaar这一概念最早在编程马拉松(hackathon)活动中被提出,它的创始人结合了BitTorent,比特币和传统的金融服务方式,创造了一个不受审查的交易平台。OpenBazaar的开发团队在寻求新的成员,而且不久以后他们将无限扩大Open Bazaar的社区。Open Bazaar旨在透明度和同一个目标去在商务交易中掀起一场革命,这会帮助创始人和贡献者向着一个真实的世界奋斗,一个没有控制,分散的市场。
|
||||
|
||||
### 2015年度开源项目新秀: IPFS ###
|
||||
|
||||

|
||||
|
||||
IPFS 是一个全球的点对点式的分布式版本文件系统。它综合了Git,BitTorrent,HTTP的思想,开启了一个新的数据和数据结构传输协议。
|
||||
|
||||
开源被人们所知晓的原因,是它本意用简单的方法解决复杂的问题,这样产生许多新颖的想法,但是着些强大的项目仅仅是开源社区的冰山一角。IFPS有一个积极的团队,这个概念的提出是大胆的,令人惊讶的,有点甚至高不可攀。这样来看,一个点对点的分布是文件系统是在寻找所有连在一起的计算设备。也许HTTP的更换可以靠着通过多种手段继续保持一个社区,包括Git社区和超过100名贡献者的IRC。这个疯狂的想法将在2015年进行软件内部测试。
|
||||
|
||||
### 2015年度开源项目新秀: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] 是一个针对在运行中的容器进行收集,合计,处理和输出信息的工具,它可以给容器的使用者提供资源的使用情况和工作特性。对于每一个容器,cAdvisor记录着资源的分离参数,资源使用历史,资源使用历史对比框图,网络状态。这些从容器输出的数据在机器中传递。
|
||||
|
||||
cAdvisor可以在绝大多数的Linux上运行,并且支持包括Docker在内的多种容器类型。事实上它成为了一种容器的代理,并被集成在了很多系统中。cAdvisor在DockerHub下载量也是位居前茅。cAdvisor的开发团队希望把cAdvisor发展到能够更深入地理解应用并且集成到集群系统。
|
||||
|
||||
### 2015年度开源项目新秀: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14]提供了一些列的设置来创建一个基础设施,从物理机到虚拟机再到email服务器、DNS服务器。这个概念包括从家庭个人机解决方案到公共云平台提供的服务。一旦建立好了以后,Terraform便进行一系列的操作来改变你的基础设施,安全又高效,就如同配置一样。
|
||||
|
||||
如果你在Devops模式下的公司里工作,Terraform.io的创始者找到了一个窍门把建立一个完整的数据中心所需的知识结合在一起,从插入服务器到整个网络和功能齐备的数据中心。基础设施的描述采用高级的配置语法,允许你把数据中心的蓝图做成多版本并且可以使用多种代码。著名开源公司HashiCorp赞助开发这个项目。
|
||||
|
||||
### 荣誉奖: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15] 为[Docker][16]的使用提供了一个快速的,分离的开发环境。Docker的移植只需要将配置信息放到一个简单的 fig.yml文件里。它会处理所有工作,包括建立、运行,端口转发,分享磁盘和容器链接。
|
||||
Fig solved a major pain point for developers. Docker fully supports this open source project and [recently purchased Orchard][17] to expand the reach of Fig.
|
||||
Orchard去年发起了Fig,来创造一个使Docker工作的系统工具。它的开发像是为Docker设置开发环境,为了确保用户能够为他们的APP准确定义环境,在Docker中会运行数据库和缓存。Fig解决了开发者的一个难题。Docker全面支持这个开源项目,最近将买下Orchard来扩张这个项目。
|
||||
|
||||
### 荣誉奖: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18]是一个基于Docker的持续集成平台,而且它是用Go语言写的。Drone项目不满于现存的技术和流程,它旨在开发环境。
|
||||
|
||||
Drone提供了一个简单的自动测试和持续交付的方法:简单选择一个Docker形象来满足你的需求,连接并提交至GitHub即可。Drone使用Docker容器来提供隔离的测试环境,让每个项目完全自主控制堆栈,没有传统的服务器管理的负担。Drone背后的100位社区贡献者强烈希望把这个项目带到企业和移动应用程序开发中
|
||||
### 开源新秀 ###
|
||||
|
||||

|
||||
|
||||
- [2014年度开源项目新秀][20]
|
||||
- [InfoWorld2015年年度技术奖][21]
|
||||
- [Bossies: 开源软件最高荣誉][22]
|
||||
- [ Windows管理员15个必不可少的开源工具][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
@ -0,0 +1,116 @@
|
||||
没有Linus,Linux的未来是什么样子?
|
||||
==============================================================================
|
||||

|
||||
|
||||
这次采访是 Linux For You 杂志在2007年进行的,现在我们发表在这里是为了存档的目的。
|
||||
|
||||
**Q:对于Linux内核,未来的计划/道路/强化是怎样的?**
|
||||
|
||||
Linus:我从来没有太多的预见性 — 与其从宏大的计划上看未来,我倾向于从一个相对短的时间框架,比如“几个月之后的事情”。我是一个忠实的‘细节成败论’的信仰者,如果你抓住了细节,大的事情也会大事化小,小事化没。
|
||||
|
||||
所以,对于五年后内核会是什么样,我真的没有任何大眼光 — 仅仅是一个非常普遍的计划,确保我们对其保持关注。实际上,对于我个人来说,我最担心的事情之一甚至不是技术问题,而是确保‘进程’工作,这样人们才可以相互协作好。
|
||||
|
||||
**Q:你怎么看Linux和Solaris之间的关系在未来的发展?它会如何使用户受益?**
|
||||
|
||||
Linus:我并不能看到整个重叠的地方,除了我认为Solaris会开始使用更过Linux用户磁盘工具(显然我自己来说没有太多关注这个 — 我真的只关心内核)。Linux的桌面比起传统Solaris拥有的好多了,而且我希望Solaris移植越来越多的Linux的东西,朝着一个更加类Linux的模型前进。
|
||||
|
||||
从纯内核方面讲,证书的差异意味着没有太多的合作,但是如果看到这种情况改变会很有趣。Sun已经声明在GPL(v2或v3)下授权Solaris,如果这种证书差异消失,那么会导致一些有趣的技术出现。但对此,我持待见态度。
|
||||
|
||||
**Q:现在GPL v3已经完成并发布了,你是否预见有任何情况会激起你开始移植内核到Solaris上去?或者,从你的角度看,它是否很糟糕以至于你从来没考虑过他?**
|
||||
|
||||
Linus:我觉得相比于早先的草稿,v3有了很多提高,并且我也认为它不是一个糟糕的证书。我只是认为它没有GPLv2一般的‘伟大’。
|
||||
|
||||
所以,由于没有了GPLv2,我会看见自己将会使用GPLv3。但是,自从我有了一个更好的选择,我为什么不应该考虑一下呢?
|
||||
|
||||
这就是说,我努力保持实用主义精神,并且我认为GPLv3比起GPLv2不是一个好证书这件事不是一个‘黑与白’的问题。这是一个平衡做法。如果GPLv3有其他的优点,可能那些优点会在很大程度上倾斜喜爱GPLv3的天平。
|
||||
|
||||
恕我直言,我并没有看到任何优点,但是如果Solaris真的在GPLv3下发布,可能避免不必要的不兼容证书这条足够称为一个优点,可能也会值得去尝试重新许可Linux的内核放在GPLv3下。
|
||||
|
||||
不要误解我 — 我认为这是不大可能的。但是我确实想澄清我本质上不是一个证书偏执者。我认为GPLv2是毫无疑问的好证书,但是证书不是一切。
|
||||
|
||||
总的来说,我使用很多其他证书下的程序。我可能没有把我自己做的一个项目放在BSD(或X11—MIT)证书下,但是我认为它是一个伟大的证书,对于其他项目来说,它可能是最佳的选择。
|
||||
|
||||
**Q:目前有没有任何印度人,你想特别提出作为Linux内核的关键贡献者?**
|
||||
|
||||
Linus:我不得不承认,我并没有与实际认识的来自印度的任何人直接工作。那就是说,我应该稍微澄清下:我已经非常有意识地努力建立一个规模庞大的内核开发团队,这样我不用以独自地工作而告终。
|
||||
|
||||
我非常相信大多数人基本上被束缚起来了,只对很少的人十分了解(你最亲近的家人和朋友),我也努力构造这样一个开发模型影响这种状况:通过一个‘开发者网络’,人们可以在此互动,可能是与一批你信任的人,而且那些人反过来与他们信任的一群人互动。
|
||||
|
||||
所以,当我偶然与上百个开发者联系,他们发给我一两个随机的补丁,我已经努力去建立这样一个环境,在这里我做的一堆事,发生在我熟知的人组成的一个较小的集合间,仅仅因为我认为那就是人们工作的方式。当然也是我喜欢工作的方式。
|
||||
|
||||
同时,坦白地说,我甚至不知道许多与我一起工作的人生活在哪里。位置成了十分次要的东西。所以我很确信与我工作最亲密的前10—15个人中,没有印度的,可能这话稍后传到公众耳里,然后被指出确实有一些人来自那里!
|
||||
|
||||
**Q:自从Linux的内核开发对你依赖如此严重以来,你如何计划组织/重组,让它在没有你的情况下继续发展,假设你决定花更多的时间在你自己的生活和家庭上面?**
|
||||
|
||||
Linus:现在Linux比我大得多了,为了这个实现我已经工作了很长时间。是的,我仍然十分亲切地身在其中,而且我对其有着想当大的日常影响,我最终会是这样一个人,在某种程度上,扮演着许多内核开发活跃者的中心点的角色;但是 — 我不会说Linux“严重依赖”于我。
|
||||
|
||||
所以,如果我得了心脏病并且明天就死了(很高兴没这种可能:我显然在任何方面都还健康),人们肯定会注意到,但是有成千上万的人为内核工作,并且不止一两个人能够接替我,还少有困惑。
|
||||
|
||||
**Q:印度是软件工程师的主要产地之一,当然我们没有在Linux领域做太多贡献。你觉得什么是保持印度人在Linux领域变得具有前瞻性的?如果我们鼓励印度人参与并为Linux做很大的贡献,你觉得如何?假如你有一个在印度的粉丝;你会用你的形象来启迪那些爱好者吗?**
|
||||
|
||||
Linus:对我来说,这确实是一个不好回答的问题。进入开源是如此一个底层结构(网络接入,教育,你说的),信息流和简单的文化的复杂组合,我甚至不能去猜测最大的障碍会是什么。
|
||||
|
||||
在很多方面,至少那些在印度含英语文化的地方,应该有一个相对容易的方式参与Linux和其他开源项目,如果仅仅是由于语言门槛的话。当然比起亚洲的许多地方,甚至欧洲的一些地方要容易些。
|
||||
|
||||
当然,有一些人,并不等同于印度的大部分群体,而且我自己关于印度的情况也知道不多,甚至没法做出一点半路聪明猜测最好的前路是什么。我猜一个热情的本地用户社区一直是最好的途径,我认为你们已经拥有这样的社区了。
|
||||
|
||||
至于我的‘形象’,我自己不以为然。我不是一个伟大的公众演讲者,而且我最近些年已经避免出游,因为被看做符号‘形象’让我很不自在。我就是一个工程师而已,而且我仅仅是喜欢我做的事情,并与社会上其他人一起工作。
|
||||
|
||||
**Q:什么样的理由会让你考虑去看看印度?**
|
||||
|
||||
Linus:如第一个回答中提到,我完全地讨厌公开演讲,所以我才想避免开会等等这些事。我更愿意某天去印度度个假,但是如果我这样做,我可能悄悄地干 — 出行之前不告诉任何人,仅仅作为一个游客去游览印度!
|
||||
|
||||
**Q:最近,你好像在抨击Subversion与CVS,质问他们的基础架构。现在你已经从Subversion和CVS社区那里得到回应,你仍然在坚持自己正确,或者没有被说服吗?**
|
||||
|
||||
Linus:因为我发现这个争论很有趣,所以我想做一个强硬的声明。换句话说,我确实‘喜欢’争论。并不是不经思考的,但是我确实想要让争论更热烈些,而不仅仅是完全的柏拉图式的。
|
||||
|
||||
做出强硬的争论有时会导致一个非常合理的反驳,然后我会很高兴地说:“噢,好吧,你是对的。”
|
||||
|
||||
但是话说回来,对SVN/CVS并不会发生这种情况。我怀疑很多人真的不是很喜欢CVS,所以我真的不期望任何人去坚持CVS是一切,而不是一个老旧的系统。当我知道少数人确实这样争论了,我之前就不该那么不礼貌地反对SVN(嘿,这是公平的 — 我真的不是一个非常礼貌的家伙!),我认为不是任何人都可以争论SVN是‘好的’。
|
||||
|
||||
我认为,SVN就是一个‘好过头’的经典案例。人们过去经常使用SVN,并且它也‘很好’,用途广泛,但是它的好过头完全如DOS与Windows也‘好过头’一样。不是什么伟大的技术,只是普遍适用而已,同时它对人们来说运行良好,看着十分熟悉。但是很少有人以此为傲,或者对其有兴奋感。
|
||||
|
||||
Git,从另外方面讲,其身后有一些‘UNIX 哲学’。它不是关于UNIX,实质上,是像原始的UNIX,它身后有一个基础的想法。对UNIX来说,最底层的哲学就是,“所有东西只是一个文件”。对Git来说,“则是每个东西仅仅是内容寻址数据库中的一个对像”。
|
||||
|
||||
**Q:现在如此多的发行是好事还是坏事?选择是很有意思的,但是没有人需要被选择给撑着。相较于这么多的人每天花费数小时去构建成百上千的发行版,如果人们可以一起来支持少数的发行版(可能每一个有一个人),这样进入企业,接受微软的挑战是不是更容易些呢?对此你怎么看?**
|
||||
|
||||
Linus:我认为多发行版是开源不可回避的部分。它会造成困惑吗?当然。它会变得低效率吗?是的。但是我喜欢拿它与政治比较:’民主‘也有那些令人困惑的选择,通常没有选择是必须的,或者你‘真正’想要的。而且有时候,如果你不需要担心选举,不同党派和联合等等方面的困惑的话,你可能喜欢事情更加容易一些,更有效率一些。
|
||||
|
||||
但是最后我想说,选择可能会导致低效率,但是它也让每个人至少保留了‘所谓的’诚信。我们可能都希望我们的政治家比过去更诚信,我们也希望不同的发行版有一天做出其他的选择,但是没有那种选择的话,事情可能会更糟。
|
||||
|
||||
**Q:为什么你觉得CFS比SD更好?**
|
||||
|
||||
Linus:一部分原因是我与Ingo[Molnar]工作你很长一段时间,这就是说,我了解他,并且知道他会对发生的任何事情非常负责。那种品质是非常重要的。
|
||||
|
||||
但是一部分原因就简单的与用户有关。其他地方的大多数人实际上表示CFS比SD好。包括许多3D游戏方面(这是人们声称SD最强的一点)。
|
||||
|
||||
同时,尽管如此,我认为并不是代码的任何一段都十分‘完美’。最好的情况是想成为SD支持者的人会努力提高SD,使得平衡会倾覆其他方面 — 而我们会保持两个阵营都尝试有趣的事情,因为内部的竞争会刺激他们。
|
||||
|
||||
**Q:在Google一次关于Git的访谈中,有人问你如何会停止六个月的商业活动,为git编写了一个目前由一些中心化的东西和交易管理的,特别庞大的代码基础。你对此的回答是什么?**
|
||||
|
||||
Linus:啊哈。那个问题我在现场没有听清楚(在录制结果里,问题会听得更清楚些),当我回头去听录制的音频,注意到了我没有回答他的问题,但是我觉得这问题他问过。
|
||||
|
||||
无论如何,我们确实有很多导入的工具,所以你实际上可以仅仅是从任何其他的早期SCM导入一个大工程到git里,但问题显然不是经常以导入动作本身结束,而是需要‘习惯’这种新模式!
|
||||
|
||||
坦白来说,我认为关于‘习惯它’没有任何其他答案,而只是去开始使用和尝试它。显然,你不想以导入你现有的最大且最中心的项目为开端;那确实会使每件事出现停顿,然后使得每个人都很不高兴。
|
||||
|
||||
所以没有理智健全的人会一夜之间拥护将一切移到git上去,并强迫人们改变他们的环境。是的,你需要以公司里的小项目开始,可能是一些一个组主要控制和维护的项目,然后开始转移其到git。这是你能让人们习惯这种模式的方式,你开始有一个核心的组,知道git如何工作,如何在公司里面使用它。
|
||||
|
||||
接着,你就会铺展开来。并不一次就位。你会导入越来越多的项目 — 如果在你公司里你有‘一个大仓库’;你也会差不多确定将那个仓库作为许多模块的集合,因为让每个人去检查每件事不是一个可执行的工作模型(除非‘每件事’并不非常大)。
|
||||
|
||||
所以,你基本上有一次转移了一个模块,直到你发现你使用git如此舒服的那个点,你可以移植余下的所有(或者‘余下’太传统了,没人会关心)。
|
||||
|
||||
Git最赞的一个功能是,它实际上可以同很多其他SCM相处很好。这就是很多git用户使用它的时候:‘他们’可能只是使用git,但有时候与他们一起工作的人并没有发现,因为他们看到git的结果,联想到一些传统的SCM上去。
|
||||
|
||||
**Q:在Transmeta,他们曾经经历过用另外的架构设置部署吗?[Transmeta Crusoe的芯片看起来像一个非常软的CPU — 提到一台Burroughs B1000的解释机器,这实际上部署了多台虚拟机。有一台是用于系统软件,一台是用于Cobol,一台用于Fortran;如果上述正确,那么一个人可以部署Burroughs 6/7000或者HP3000,如栈结构一样,在芯片上或者一个适合JVM的结构集合等等。]**
|
||||
|
||||
Linus:我们确实有一些备选的结构集合,我仍然不打算谈论这个,我可以说我们已经做了一个混合结构集合的公开证明。我们有一个技术宝箱,在那里你同时可以跑x86结构和Java字节码(实际上,它是一个轻量的扩展pico—java,iirc)。
|
||||
|
||||
(选择DOOM的原因仅仅是其源代码可用,并且游戏的核心部分非常小,足以很容易拿它来做一个验证 — 而且它也显然看起来十分有趣。)
|
||||
|
||||
有更多的事情是在内部运作,但是我不能谈论他们。而且实际上,就我个人而言,对Java不怎么感冒。
|
||||
|
||||
**Q:386BSD衍生了NetBSD,FreeBSD和OpenBSD,在Linux出现之前已经发展不错了,但是Linux传播比386BSD及其衍生者更为广泛。这在多大程度上左右你对证书的选择,和你选择的发展过程?你不认为比起GPLv2来,是GPLv3保护了自由,孕育了Linux比BSD更好,直到现在?**
|
||||
|
||||
Linus:
|
||||
|
||||
@ -0,0 +1,422 @@
|
||||
用于提高网站安全性和自定义网站的 25 个有用 Apache ‘.htaccess’ 小技巧
|
||||
================================================================================
|
||||
网站是我们生活中重要的一部分。它们是实现扩大业务、分享知识以及其它更多功能的方式。之前受制于只能提供静态内容,随着动态客户端和服务器端脚本语言的引入和现有静态语言的持续改进,例如从 html 到 html5,动态网站成为可能,剩下的也许在不久的将来也会实现。
|
||||
|
||||
有了网站,随之而来的是对能向全球大规模用户显示站点的单元的需求。这个需求通过托管网站的服务器实现。这包括一系列的服务器,例如:Apache HTTP Server、Joomla 以及 允许个人拥有自己网站的 WordPress。
|
||||
|
||||

|
||||
25 个 htaccess 小技巧
|
||||
|
||||
想要拥有一个网站,可以创建一个自己的本地服务器,或者联系任何上面提到的或其它服务器管理员来托管他的网站。但实际问题也从这点开始。网站的性能主要取决于以下因素:
|
||||
|
||||
- 网站消耗的带宽。
|
||||
- 针对黑客网站有多安全。
|
||||
- 对数据库进行数据检索时的优化。
|
||||
- 显示导航菜单和提供更多 UI 功能时的用户友好性。
|
||||
|
||||
除此之外,保证托管网站服务器成功的多种因素还包括:
|
||||
|
||||
- 对于一个流行站点的数据压缩量。
|
||||
- 同时为多个请求同一或不同站点的用户服务的能力。
|
||||
- 保证网站上输入的机密数据安全,例如:Email、信用卡信息等等。
|
||||
- 允许更多的选项用于增强站点的动态性。
|
||||
|
||||
这篇文章讨论一个服务器提供的用于增强网站性能和提高针对坏机器人、热链接等的安全性的功能。例如 ‘.htaccess’ 文件。
|
||||
|
||||
### .htaccess 是什么? ###
|
||||
|
||||
htaccess (hypertext access,超文本访问) 是为网站所有者提供用于控制服务器环境变量以及其它参数的选项,从而增强他们网站的功能的文件。这些文件可以在网站目录树的任何一个目录中,并向该目录以及目录中的文件和子目录提供功能。
|
||||
|
||||
这些功能是什么呢?其实这些是服务器的指令,例如命令服务器执行特定任务的行,这些命令只对该文件所在目录中的文件和子目录有效。这些文件默认是隐藏的,因为所有操作系统和网站服务器默认配置为忽略。但让隐藏文件可见可以让你看到这些特殊文件。后续章节的话题将讨论能控制什么类型的参数。
|
||||
|
||||
注意:如果 .htaccess 文件保存在 /apache/home/www/Gunjit/ 目录,那么它会向该目录中的所有文件和子目录提供命令,但如果该目录包含一个名为 /Gunjit/images/ 子目录,且该子目录中也有一个 .htaccess 文件,那么这个子目录中的命令会覆盖父目录中 .htaccess 文件(或者层次结构中更上层文件)提供的命令。
|
||||
|
||||
### Apache Server 和 .htaccess 文件 ###
|
||||
|
||||
Apache HTTP Server 俗称为 Apache,是为了表示对一个有卓越战争策略技能的美洲土著部落的尊敬而命名。它是用 C/C++ 和 XML 建立的基于 [NCSA HTTPd 服务器][1] 的跨平台 Web 服务器,它在万维网的成长和发展中起到了关键作用。
|
||||
|
||||
最常用于 UNIX,Apache 也能用于多种平台,包括 FreeBSD、Linux、Windows、Mac OS、Novel Netware 等。在 2009 年,Apache 成为第一个为超过一亿站点提供服务的服务器。
|
||||
|
||||
Apache 服务器对于 www/ 目录中的每个用户有一个单独的 .htaccess 文件。尽管这些文件是隐藏的,但如果需要的话可以使它们可见。在 www/ 目录中有很多子目录,每个子目录通过用户名或所有者名称命名,包含了一个站点。除此之外你可以在每个子目录中有一个 .htaccess 文件,像之前所述用于配置子目录中的文件。
|
||||
|
||||
下面介绍如果配置 Apache 服务器上的 htaccess 文件。
|
||||
|
||||
### Apache 服务器上的配置 ###
|
||||
|
||||
这里有两种情况:
|
||||
|
||||
#### 在自己的服务器上托管网站 ####
|
||||
|
||||
在这种情况下,如果没有启用 .htaccess 文件,你可以通过在 http.conf(Apache HTTP 守护进程的默认配置文件) 中找到 <Directories> 部分启用。
|
||||
|
||||
<Directory "/var/www/htdocs">
|
||||
|
||||
定位如下行
|
||||
|
||||
AllowOverride None
|
||||
|
||||
更改为
|
||||
|
||||
AllowOverride All
|
||||
|
||||
现在,重启 Apache 后就启用了 .htaccess。
|
||||
|
||||
#### 在不同的托管服务提供商的服务器上托管网站 ####
|
||||
|
||||
在这种情况下最好咨询托管管理员,如果他们允许访问 .htaccess 文件的话。
|
||||
|
||||
### 用于站点的 25 个 Apache Web 服务器 ‘.htaccess’ 小技巧 ###
|
||||
|
||||
#### 1. 如何在 .htaccess 文件中启用 mod_rewrite ####
|
||||
|
||||
mod_rewrite 选项允许你使用重定向并通过重定向到其它 URL 隐藏你真实的 URL。这个选项非常有用,允许你用短的容易记忆的 URL 替换长 URL。
|
||||
|
||||
要允许 mod_rewrite,只需要在你的 .htaccess 文件的第一行添加如下一行。
|
||||
|
||||
Options +FollowSymLinks
|
||||
|
||||
该选项允许你跟踪符号链接从而在站点中启用 mod_rewrite。后面会介绍用短 URL 替换。
|
||||
|
||||
#### 2. 如果允许或禁止对站点的访问 ####
|
||||
|
||||
通过使用 order、allow 和 deny 关键字,htaccess 文件可以允许或者禁止对站点或目录中子目录或文件的访问。
|
||||
|
||||
**只允许 IP 192.168.3.1 的访问**
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
Allow from 192.168.3.1
|
||||
|
||||
或
|
||||
|
||||
Order Allow, Deny
|
||||
Allow from 192.168.3.1
|
||||
|
||||
这里的 Order 关键字指定处理 allow 和 deny 访问的顺序。对于上面的 ‘Order’ 语句,首先会处理 Allow 语句,然后是 deny 语句。
|
||||
|
||||
**只禁止某个 IP 的访问**
|
||||
|
||||
下面一行的意思是除了 IP 地址 192.168.3.1,允许所有用户访问网站。
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from 192.168.3.1
|
||||
Allow from All
|
||||
|
||||
或
|
||||
|
||||
Order Deny, Allow
|
||||
Deny from 192.168.3.1
|
||||
|
||||
#### 3. 为不同错误码生成 Apache 错误文档 ####
|
||||
|
||||
用一些简单行,我们可以解决当用户/客户端请求一个站点上不可用的网页时服务器产生的错误码的错误文档,例如我们大部分人见过的浏览器中显示的 ‘404 Page not found’。‘.htaccess’ 文件指定了发生这些错误情况时采取何种操作。
|
||||
|
||||
要做到这点,需要添加下面的行到 ‘.htaccess’ 文件:
|
||||
|
||||
ErrorDocument <error-code> <path-of-document/string-representing-html-file-content>
|
||||
|
||||
‘ErrorDocument’ 是一个关键字,error-code 可以是 401、403、404、500 或任何有效的表示错误的代码,最后 ‘path-of-document’ 表示本地机器上的路径(如果你使用的是你自己的本地服务器) 或 服务器上的路径(如果你使用任何其它服务器来托管网站)。
|
||||
|
||||
**例子:**
|
||||
|
||||
ErrorDocument 404 /error-docs/error-404.html
|
||||
|
||||
上面一行设置客户请求任何无效页面,服务器报告 404 错误时显示 error-docs 目录下的 ‘error-404.html’ 文档。
|
||||
|
||||
ErrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
|
||||
上面的表示也正确,其中字符串表示一个普通的 html 文件。
|
||||
|
||||
#### 4. 设置/取消 Apache 服务器环境变量 ####
|
||||
|
||||
在 .htaccess 文件中你可以设置或者取消站点所有者用来更改服务器设置的全局环境变量。要设置或取消环境变量,你需要在你的 .htaccess 文件中添加下面的行。
|
||||
|
||||
**设置环境变量**
|
||||
|
||||
SetEnv OWNER “Gunjit Khera”
|
||||
|
||||
**取消环境变量**
|
||||
|
||||
UnsetEnv OWNER
|
||||
|
||||
#### 5. 为文件定义不同 MIME 类型 ####
|
||||
|
||||
MIME(Multipurpose Internet Multimedia Extensions,,多用途 Internet 多媒体扩展) 是浏览器运行任何页面默认能识别的类型。你可以在 .htaccess 文件中为你的站点定义 MIME 类型,然后服务器就可以识别你定义的类型的文件并运行。
|
||||
|
||||
<IfModule mod_mime.c>
|
||||
AddType application/javascript js
|
||||
AddType application/x-font-ttf ttf ttc
|
||||
</IfModule>
|
||||
|
||||
这里,mod_mime.c 是用于控制定义不同 MIME 类型的模块,如果在你的系统中已经安装了这个模块,那么你就可以用该模块去为你站点中不同的扩展定义不同的 MIME 类型,从而服务器可以理解这些文件。
|
||||
|
||||
#### 6. 如何在 Apache 中限制上传和下载的大小 ####
|
||||
|
||||
.htaccess 文件允许你拥有控制一个特定用户从你的站点上传或下载数据量大小的功能。要做到这点你只需要添加下面的行到你的 .htaccess 文件:
|
||||
|
||||
php_value upload_max_filesize 20M
|
||||
php_value post_max_size 20M
|
||||
php_value max_execution_time 200
|
||||
php_value max_input_time 200
|
||||
|
||||
上面的行设置最大上传大小、最大推送数据大小、最大执行时间,例如允许用户在本地机器运行站点的最大时间、限制的最大输入时间。
|
||||
|
||||
#### 7. 让用户在站点上播放 .mp3 和其它文件之前预先下载 ####
|
||||
|
||||
大部分情况下,人们在下载检查音乐质量之前会在网站上播放等等。作为一个聪明的销售者,你可以添加一个简单的功能,不允许任何用户在线播放音乐或视频,而是必须下载后才能播放。这非常有用,因为在线播放音乐和视频会消耗很多带宽。
|
||||
|
||||
要添加下面的行到你的 .htaccess 文件:
|
||||
|
||||
AddType application/octet-stream .mp3 .zip
|
||||
|
||||
#### 8. 为站点设置目录索引 ####
|
||||
|
||||
大部分网站开发者都知道第一个显示的页面,例如一个站点的主页面,被命名为 ‘index.html’。我们大部分也见过这个。但是如何设置呢?
|
||||
|
||||
.htaccess 文件提供了一种方式用于列出一个客户端请求访问网站的主页面时会顺序扫描的一些网页集,相应地如果找到了列出的页面中的任何一个就会作为站点的主页面并显示给用户。
|
||||
|
||||
需要添加下面的行产生所需的效果。
|
||||
|
||||
DirectoryIndex index.html index.php yourpage.php
|
||||
|
||||
上面一行指定如果有任何访问主页面的请求到来,首先会在目录中顺序搜索上面列出的网页:如果发现了 index.html 则显示为主页面,否则会处理下一个页面,例如 index.php,如此直到你在列表中输入的最后一个页面。
|
||||
|
||||
#### 9. 如何为文件启用 GZip 压缩以节省网站带宽 ####
|
||||
|
||||
繁重站点通常比只占少量空间的轻量级站点运行更慢是常见的现象。这是因为对于繁重站点需要时间加载大量的脚本文件和图片用于在客户端的 Web 浏览器上显示。
|
||||
|
||||
当浏览器请求一个 web 页面时,服务器提供给浏览器该页面并局部显示该 web 页面,浏览器需要下载该页面然后在页面内部运行脚本,这是一种常见机制。
|
||||
|
||||
这里 GZip 压缩所做的就是节省单个用户的服务时间从而提高带宽。服务器上站点的源文件以压缩形式保存,当用户请求到来的时候,这些文件以压缩形式传送,然后在服务器上解压并执行。这改进了带宽限制。
|
||||
|
||||
下面的行允许你压缩站点的源文件,但要求在你的服务器上安装 mod_deflate.c 模块。
|
||||
|
||||
<IfModule mod_deflate.c>
|
||||
AddOutputFilterByType DEFLATE text/plain
|
||||
AddOutputFilterByType DEFLATE text/html
|
||||
AddOutputFilterByType DEFLATE text/xml
|
||||
AddOutputFilterByType DEFLATE application/html
|
||||
AddOutputFilterByType DEFLATE application/javascript
|
||||
AddOutputFilterByType DEFLATE application/x-javascript
|
||||
</IfModule>
|
||||
|
||||
#### 10. 处理文件类型 ####
|
||||
|
||||
服务器默认的有一些特定情况。例如:在服务器上运行 .php 文件,显示 .txt 文件。像这些我们可以以源代码形式只显示一些可执行 cgi 脚本或文件而不是执行它们。
|
||||
|
||||
要做到这点在 .htaccess 文件中有如下行。
|
||||
|
||||
RemoveHandler cgi-script .php .pl .py
|
||||
AddType text/plain .php .pl .py
|
||||
|
||||
这些行告诉服务器只显示而不执行 .pl (perl 脚本)、.php (PHP 文件) 和 .py (Python 文件) 。
|
||||
|
||||
#### 11. 为 Apache 服务器设置时区 ####
|
||||
|
||||
.htaccess 文件可用于为服务器设置时区可以看出它的能力和重要性。这可以通过设置一个服务器为每个托管站点提供的一系列全局环境变量中的 ‘TZ’ 完成。
|
||||
|
||||
由于这个原因,我们可以在网站上看到根据我们的时区显示的时间。也许服务器上其他拥有网站的人会根据他居住地点的位置设置时区。
|
||||
|
||||
下面的一行为服务器设置时区。
|
||||
|
||||
SetEnv TZ India/Kolkata
|
||||
|
||||
#### 12. 如果在站点上启用缓存控制 ####
|
||||
|
||||
浏览器很有趣的一个功能是,已经观察到多次同时打开一个网站,和第一次打开相比之后会更快。但为什么会这样呢?事实上,浏览器在它的缓存中保存了一些通常访问的页面用于加快后面的访问。
|
||||
|
||||
但保存多长时间呢?这取决于你自己。例如,你的 .htaccess 文件中设置的缓存控制时间。.htaccess 文件指定了站点的网页可以在浏览器缓存中保存的时间,时间到期后需要重新验证,例如页面会从缓存中删除然后在下次用户访问站点的时候重建。
|
||||
|
||||
下面的行为你的站点实现缓存控制。
|
||||
|
||||
<FilesMatch "\.(ico|png|jpeg|svg|ttf)$">
|
||||
Header Set Cache-Control "max-age=3600, public"
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.(js|css)$">
|
||||
Header Set Cache-Control "public"
|
||||
Header Set Expires "Sat, 24 Jan 2015 16:00:00 GMT"
|
||||
</FilesMatch>
|
||||
|
||||
上面的行允许缓存 .htaccess 文件所在目录中的页面一小时。
|
||||
|
||||
#### 13. <files> 配置单个文件 ####
|
||||
|
||||
通常 .htaccess 文件中的内容会对该文件所在目录中的所有文件和子目录起作用,但是你也可以对特殊文件设置一些特殊权限,例如只禁止对某个文件的访问等等。
|
||||
|
||||
要做到这点,你需要在文件中以类似方式添加 <File> 标记:
|
||||
|
||||
<files conf.html="">
|
||||
Order allow, deny
|
||||
Deny from 188.100.100.0
|
||||
</files>
|
||||
|
||||
这是一个禁止 IP 188.100.100.0 访问 ‘conf.html’ 的简单例子,但是你也可以添加介绍过的 .htaccess 文件的任何功能,包括将要介绍的功能,例如:缓存控制、GZip 压缩。
|
||||
|
||||
大部分服务器会用这个功能增强 .htaccess 文件的安全,这也是我们在浏览器上看不到 .htaccess 文件的原因。在后面的章节中会介绍如何给文件授权。
|
||||
|
||||
#### 14. 启用在 cgi-bin 目录以外运行 CGI 脚本 ####
|
||||
|
||||
通常服务器运行的 CGI 脚本都保存在 cgi-bin 目录中,但是你可以启用在你需要的目录运行 CGI 脚本,只需要在所需的目录中添加下面的行到 .htaccess 文件,如果没有改文件就创建一个,并添加下面的行:
|
||||
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
|
||||
#### 15.如何用 .htaccess 在站点上启用 SSI ####
|
||||
|
||||
服务器端包括顾名思义的和服务器部分相关的东西。但是什么呢?通常当我们在站点上有很多页面的时候,我们在主页面上会有一个显示到其它页面链接的导航菜单,我们可以启用 SSI(Server Size Includes) 选项允许导航菜单中显示的所有页面完全包含在主页面中。
|
||||
|
||||
SSI 允许包含多个页面,好像他们包含的内容就是一个单一页面的一部分,因此任何需要的编辑都只有一个文件,从而可以节省很多磁盘空间。除了 .shtml 文件,服务器默认启用了该选项。
|
||||
|
||||
如果你想要对 .html 启用该选项,你需要添加下面的行:
|
||||
|
||||
AddHandler server-parsed .html
|
||||
|
||||
这之后 html 文件会导向 SSI。
|
||||
|
||||
<!--#inlcude virtual= “gk/document.html”-->
|
||||
|
||||
#### 16. 如何防止网站目录列表 ####
|
||||
|
||||
为防止任何客户端在本地机器罗列服务器上的网站目录列表,添加下面的行到你不想列出的目录的文件中。
|
||||
|
||||
Options -Indexes
|
||||
|
||||
#### 17. 更改默认字符集和语言头 ####
|
||||
|
||||
.htaccess 文件允许你更改网站使用的字符集,例如 ASCII 或 UNICODE,UTF-8 等,以及用于显示内容的默认语言。
|
||||
|
||||
在服务器的全局环境变量之后添加下面语句可以实现上述功能。
|
||||
|
||||
AddDefaultCharset UTF-8
|
||||
DefaultLanguage en-US
|
||||
|
||||
**重写 URL 的重定向规则**
|
||||
|
||||
重写功能仅意味着用短而易记的 URL 替换长而难以记忆的 URL。但是,在开始这个话题之前,这里有一些本文后面会使用的特殊字符的规则和约定。
|
||||
|
||||
**特殊符号:**
|
||||
|
||||
符号 含义
|
||||
^ - 字符串开头
|
||||
$ - 字符串结尾
|
||||
| - 或 [a|b] – a 或 b
|
||||
[a-z] - a 到 z 的任意字母
|
||||
+ - 之前字母的一次或多次出现
|
||||
* - 之前字母的零次或多次出现
|
||||
? - 之前字母的零次或一次出现
|
||||
|
||||
**常量和它们的含义:**
|
||||
|
||||
常量 含义
|
||||
NC - 区分大小写
|
||||
L - 最后的规则 – 停止处理更多规则
|
||||
R - 临时重定向到新 URL
|
||||
R=301 - 永久重定向到新 URL
|
||||
F - 禁止发送 403 头给用户
|
||||
P - 代理 – 获取远程内容代替部分并返回
|
||||
G - Gone, 不再存在
|
||||
S=x - 跳过后面的 x 条规则
|
||||
T=mime-type - 强制指定 MIME 类型
|
||||
E=var:value - 设置环境变量 var 的值为 value
|
||||
H=handler - 设置处理器
|
||||
PT - Pass through – 如果 URL 有额外的头
|
||||
QSA - 从到替换 URL 的请求追加查询字符串
|
||||
|
||||
#### 18. 重定向一个非 www URL 到 www URL ####
|
||||
|
||||
在开始解释之前,首先看看启用该功能需要添加到 .htaccess 文件的行。
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
上面的行启用 Rewrite Engine 然后在第二行检查所有涉及到主机 abc.net 或 环境变量 HTTP_HOST 为 “abc.net” 的 URL。
|
||||
|
||||
对于所有这样的 URL,代码永久重定向它们(如果启用了 R=301 规则)到新 URL http://www.abc.net/$1,其中 $1 是主机为 abc.net 的非 www URL。非 www URL 是大括号内的内容,并通过 $1 引用。
|
||||
|
||||
#### 19. 重定向整个站点到 https ####
|
||||
|
||||
下面的行会帮助你转换整个网站到 https:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTPS} !on
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
上面的行启用 re-write engine 然后检查环境变量 HTTPS 的值。如果设置了那么重写所有网站页面到 https。
|
||||
|
||||
#### 20.一个自定义重写例子 ####
|
||||
|
||||
例如,重定向 url ‘http://www.abc.net?p=100&q=20’ 到 ‘http://www.abc.net/10020pq’。
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteRule ^http://www.abc.net/([0-9]+)([0-9]+)pq$ ^http://www.abc.net?p=$1&q=$2
|
||||
|
||||
在上面的行中,$1 表示第一个括号,$2 表示第二个括号。
|
||||
|
||||
#### 21. 重命名 htaccess 文件 ####
|
||||
|
||||
为了防止入侵者和其他人查看 .htaccess 文件,你可以重命名该文件,这样就不能通过客户端浏览器访问。实现该目标的语句是:
|
||||
|
||||
AccessFileName htac.cess
|
||||
|
||||
#### 22. 如何为你的网站禁用图片链接 ####
|
||||
|
||||
网站大的带宽消耗的另外一个重要问题是热链接问题,这是其它站点用于显示你网站的图片而链接到你的网站的链接,这会消耗你的带宽。这问题也被成为 ‘带宽盗窃’。
|
||||
|
||||
一个常见现象是当一个网站要显示其它网站所包含的图片时,由于该链接你的网站需要被加载,消耗你站点的带宽而显示其它站点的图片。为了防止出现这种情况,例如 .gif、.jpeg 图片等,下面的代码行会有所帮助:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_REFERER} !^$
|
||||
RewriteCond %{HTTP_REFERERER} !^http://(www\.)?mydomain.com/.*$ [NC]
|
||||
RewriteRule \.(gif|jpeg|png)$ - [F].
|
||||
|
||||
上面的行检查 HTTP_REFERER 是否没有设为空或没有设为你站点上的任何链接。如果是这样的话,你网页上的所有图片会用 403 禁止访问代替。
|
||||
|
||||
#### 23. 如何将用户重定向到维护页面 ####
|
||||
|
||||
如果你的网站需要进行维护并且你想向所有需要访问该网站的你的所有客户通知这个消息,对于这种情况,你可以添加下面的行到你的 .htaccess 文件,从而只允许管理员访问并替换所有有 .jpg、.css、.gif、.js 等的页面。
|
||||
|
||||
RewriteCond %{REQUEST_URI} !^/admin/ [NC]
|
||||
RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
|
||||
[NC,L,U,QSA]
|
||||
|
||||
这些行检查请求 URL 是否包含任何例如以 ‘/admin/’ 开头的管理页面的请求,或任何到 ‘.png, .jpg, .js, .css’ 页面的请求,对于任何这样的请求,用 ‘ErrorDocs/Maintainence_Page.html’ 替换那个页面。
|
||||
|
||||
#### 24. 映射 IP 地址到域名 ####
|
||||
|
||||
名称服务器是将特定 IP 地址转换为域名的服务器。该映射也可以在 .htaccess 文件中用以下形式指定。
|
||||
|
||||
为了将地址 L.M.N.O 映射到域名 www.hellovisit.com
|
||||
RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
|
||||
RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
|
||||
|
||||
上面的行检查任何页面的主机是否包含类似 L.M.N.O 的 IP 地址,如果是的话第三行会通过永久重定向将页面映射到域名 http://www.hellovisit.com。
|
||||
|
||||
#### 25. FilesMatch 标签 ####
|
||||
|
||||
类似用于应用条件到单个文件的 <files> 标签,<FilesMatch> 能用于匹配一组文件并对该组文件应用一些条件,如下:
|
||||
|
||||
<FilesMatch “\.(png|jpg)$”>
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
</FilesMatch>
|
||||
|
||||
### 结论 ###
|
||||
|
||||
.htaccess 文件能实现的小技巧还有很多。这告诉了我们这个文件有多么强大,通过该文件能给你的站点添加多少安全性、动态性以及其它功能。
|
||||
|
||||
我们已经在这篇文章中尽最大努力覆盖尽可能多的 htaccess 小技巧,但如果我们缺少了任何重要的技巧,或者你愿意告诉我们你的 htaccess 想法和技巧,你可以在下面的评论框中提交,我们也会在文章中进行介绍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
|
||||
作者:[Gunjit Khera][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gunjitk94/
|
||||
[1]:https://en.wikipedia.org/wiki/NCSA_HTTPd
|
||||
@ -0,0 +1,268 @@
|
||||
如何在 Ubuntu 中管理和使用 LVM(Logical Volume Management,逻辑卷管理)
|
||||
================================================================================
|
||||

|
||||
|
||||
在我们之前的文章中,我们介绍了[什么是 LVM 以及能用 LVM 做什么][1],今天我们会给你介绍一些 LVM 的主要管理工具,使得你在设置和扩展安装时更游刃有余。
|
||||
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是,你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘驱动汇集而成或是一个软件磁盘阵列。
|
||||
|
||||
要管理 LVM,这里有很多可用的 GUI 工具,但要真正理解 LVM 配置发生的事情,最好要知道一些命令行工具。这当你在一个服务器或不提供 GUI 工具的发行版上管理 LVM 时尤为有用。
|
||||
|
||||
LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以下其中之一开头:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组使得你的操作系统能使用指定的空间。
|
||||
|
||||
### 可下载的 LVM 备忘单 ###
|
||||
|
||||
为了帮助你理解每个前缀可用的命令,我们制作了一个备忘单。我们会在该文章中介绍一些命令,但仍有很多你可用但没有介绍到的命令。
|
||||
|
||||
该列表中的所有命令都要以 root 身份运行,因为你更改的是会影响整个机器系统级设置。
|
||||
|
||||

|
||||
|
||||
### 如何查看当前 LVM 信息 ###
|
||||
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置好的开始点。
|
||||
|
||||
display 命令会格式化输出信息,因此比 s 命令更易于理解。对每个命令你会看到名称和 pv/vg 的路径,它还会给出空闲和已使用空间的信息。
|
||||
|
||||

|
||||
|
||||
最重要的信息是 PV 名称和 VG 名称。用这两部分信息我们可以继续进行 LVM 设置。
|
||||
|
||||
### 创建一个逻辑卷 ###
|
||||
|
||||
逻辑卷是你的操作系统在 LVM 中使用的分区。创建一个逻辑卷,首先需要拥有一个物理卷和卷组。下面是创建一个新的逻辑卷所需要的全部命令。
|
||||
|
||||
#### 创建物理卷 ####
|
||||
|
||||
我们会从一个完全新的没有任何分区和信息的硬盘驱动开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
|
||||
> 注意:记住所有的命令都要以 root 身份运行或者在命令前面添加 'sudo' 。
|
||||
|
||||
fdisk -l
|
||||
|
||||
如果之前你的硬盘驱动从没有格式化或分区,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
|
||||

|
||||
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在驱动上创建一个新的分区。
|
||||
|
||||
这里有大量能创建新分区的 GUI 工具,包括 [Gparted][2],但由于我们已经打开了终端,我们将使用 fdisk 命令创建需要的分区。
|
||||
|
||||
在终端中输入以下命令:
|
||||
|
||||
fdisk /dev/sdb
|
||||
|
||||
这会使你进入到一个特殊的 fdisk 提示符中。
|
||||
|
||||

|
||||
|
||||
以指定的顺序输入命令创建一个使用新硬盘驱动 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或相应多个分区,我建议使用 GParted 或自己了解关于 fdisk 命令的使用。
|
||||
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何信息。**
|
||||
|
||||
- n = 创建新分区
|
||||
- p = 创建主分区
|
||||
- 1 = 成为磁盘上的首个分区
|
||||
|
||||
输入 enter 键两次以接受默认的第一个和最后一个柱面。
|
||||
|
||||

|
||||
|
||||
用下面的命令准备 LVM 所使用的分区。
|
||||
|
||||
- t = 更改分区类型
|
||||
- 8e = 更改为 LVM 分区类型
|
||||
|
||||
核实并将信息写入硬盘驱动器。
|
||||
|
||||
- p = 查看分区设置使得写入更改到磁盘之前可以回看
|
||||
- w = 写入更改到磁盘
|
||||
|
||||

|
||||
|
||||
运行这些命令之后,会退出 fdisk 提示符并返回到终端的 bash 提示符中。
|
||||
|
||||
输入 pvcreate /dev/sdb1 在刚创建的分区上新建一个 LVM 物理卷。
|
||||
|
||||
你也许会问为什么我们不用一个文件系统格式化分区,不用担心,该步骤在后面。
|
||||
|
||||

|
||||
|
||||
#### 创建卷组 ####
|
||||
|
||||
现在我们有了一个指定的分区和创建好的物理卷,我们需要创建一个卷组。很幸运这只需要一个命令。
|
||||
|
||||
vgcreate vgpool /dev/sdb1
|
||||
|
||||

|
||||
|
||||
Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
|
||||
#### 创建逻辑卷 ####
|
||||
|
||||
创建 LVM 将使用的逻辑卷:
|
||||
|
||||
lvcreate -L 3G -n lvstuff vgpool
|
||||
|
||||

|
||||
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 所以 lvcreate 命令知道从什么卷获取空间。
|
||||
|
||||
#### 格式化并挂载逻辑卷 ####
|
||||
|
||||
最后一步是用一个文件系统格式化新的逻辑卷。如果你需要选择一个 Linux 文件系统的帮助,请阅读 [如果根据需要选取最合适的文件系统][3]。
|
||||
|
||||
mkfs -t ext3 /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
创建挂载点并将卷挂载到你可以使用的地方。
|
||||
|
||||
mkdir /mnt/stuff
|
||||
mount -t ext3 /dev/vgpool/lvstuff /mnt/stuff
|
||||
|
||||

|
||||
|
||||
#### 重新设置逻辑卷大小 ####
|
||||
|
||||
逻辑卷的一个好处是你能使你的共享物理变大或变小而不需要移动所有东西到一个更大的硬盘驱动。另外,你可以添加新的硬盘驱动并同时扩展你的卷组。或者如果你有一个不使用的硬盘驱动,你可以从卷组中移除它使得逻辑卷变小。
|
||||
|
||||
这里有三个用于使物理卷、卷组和逻辑卷变大或变小的基础工具。
|
||||
|
||||
注意:这些命令中的每个都要以 pv、vg 或 lv 开头,取决于你的工作对象。
|
||||
|
||||
- resize – 能压缩或扩展物理卷和逻辑卷,但卷组不能
|
||||
- extend – 能使卷组和逻辑卷变大但不能变小
|
||||
- reduce – 能使卷组和逻辑卷变小但不能变大
|
||||
|
||||
让我们来看一个如何向刚创建的逻辑卷 "lvstuff" 添加新硬盘驱动的例子。
|
||||
|
||||
#### 安装并格式化新硬盘驱动 ####
|
||||
|
||||
按照上面创建新分区并更改分区类型为 LVM(8e) 的步骤安装一个新硬盘驱动。然后用 pvcreate 命令创建一个 LVM 能识别的物理卷。
|
||||
|
||||
#### 添加新硬盘驱动到卷组 ####
|
||||
|
||||
要添加新的硬盘驱动到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
|
||||
这会添加新物理卷到已存在的卷组中。
|
||||
|
||||
vgextend vgpool /dev/sdc1
|
||||
|
||||

|
||||
|
||||
#### 扩展逻辑卷 ####
|
||||
|
||||
调整逻辑卷的大小,我们需要指出的是通过大小而不是设备来扩展。在我们的例子中,我们会添加一个 8GB 的硬盘驱动到我们的 3GB vgpool。我们可以用 lvextend 或 lvresize 命令使该空间可用。
|
||||
|
||||
lvextend -L8G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
当这个命令工作的时候你会发现它实际上重新设置逻辑卷大小为 8GB 而不是我们期望的将 8GB 添加到已存在的卷上。要添加剩余的可用 3GB 你需要用下面的命令。
|
||||
|
||||
lvextend -L+3G /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
现在我们的逻辑卷已经是 11GB 大小了。
|
||||
|
||||
#### 扩展文件系统 ####
|
||||
|
||||
逻辑卷是 11GB 大小但是上面的文件系统仍然只有 3GB。要使文件系统使用整个的 11GB 可用空间你需要用 resize2fs 命令。你只需要指定 resize2fs 到 11GB 逻辑卷它就会帮你完成其余的工作。
|
||||
|
||||
resize2fs /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
**注意:如果你使用除 ext3/4 之外的文件系统,请查看调整你的文件系统大小的工具。**
|
||||
|
||||
#### 压缩逻辑卷 ####
|
||||
|
||||
如果你想从卷组中移除一个硬盘驱动你可以按照上面的步骤反向操作,并用 lvreduce 或 vgreduce 命令代替。
|
||||
|
||||
1. 调整文件系统大小 (调整之前确保已经移动文件到硬盘驱动安全的地方)
|
||||
1. 减小逻辑卷 (除了 + 可以扩展大小,你也可以用 - 压缩大小)
|
||||
1. 用 vgreduce 从卷组中移除硬盘驱动
|
||||
|
||||
#### 备份逻辑卷 ####
|
||||
|
||||
快照是一些新的高级文件系统提供的功能,但是 ext3/4 文件系统并没有快照的功能。LVM 快照最棒的是你的文件系统永不掉线,你可以拥有你想要的任何大小而不需要额外的硬盘空间。
|
||||
|
||||

|
||||
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该照片可以用于在不同的硬盘驱动上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
|
||||
要创建一个快照,我们需要创建拥有足够空闲空间的逻辑卷,用于保存我们备份的时候会写入该逻辑卷的任何新信息。如果驱动并不是经常写入,你可以使用很小的一个存储空间。备份完成的时候我们只需要移除临时逻辑卷,原始逻辑卷会和往常一样。
|
||||
|
||||
#### 创建新快照 ####
|
||||
|
||||
创建 lvstuff 的快照,用带 -s 标记的 lvcreate 命令。
|
||||
|
||||
lvcreate -L512M -s -n lvstuffbackup /dev/vgpool/lvstuff
|
||||
|
||||

|
||||
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为驱动实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
|
||||
#### 挂载新快照 ####
|
||||
|
||||
和之前一样,我们需要创建一个挂载点并挂载新快照,然后才能从中复制文件。
|
||||
|
||||
mkdir /mnt/lvstuffbackup
|
||||
mount /dev/vgpool/lvstuffbackup /mnt/lvstuffbackup
|
||||
|
||||

|
||||
|
||||
#### 复制快照和删除逻辑卷 ####
|
||||
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘驱动或者打包所有文件到一个文件。
|
||||
|
||||
**注意:tar -c 会创建一个归档文件,-f 要指出归档文件的名称和路径。要获取 tar 命令的帮助信息,可以在终端中输入 man tar。**
|
||||
|
||||
tar -cf /home/rothgar/Backup/lvstuff-ss /mnt/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
记住备份发生的时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
|
||||
备份完成后,卸载卷并移除临时快照。
|
||||
|
||||
umount /mnt/lvstuffbackup
|
||||
lvremove /dev/vgpool/lvstuffbackup/
|
||||
|
||||

|
||||
|
||||
#### 删除逻辑卷 ####
|
||||
|
||||
要删除一个逻辑卷,你首先需要确保卷已经卸载,然后你可以用 lvremove 命令删除它。逻辑卷删除后你可以移除卷组,卷组删除后你可以删除物理卷。
|
||||
|
||||
这是所有移除我们创建的卷和组的命令。
|
||||
|
||||
umount /mnt/lvstuff
|
||||
lvremove /dev/vgpool/lvstuff
|
||||
vgremove vgpool
|
||||
pvremove /dev/sdb1 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
这些已经囊括了关于 LVM 你需要了解的大部分知识。如果你有任何关于这些讨论的经验,请在下面的评论框中和大家分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -0,0 +1,302 @@
|
||||
20款优秀的Linux终端仿真器
|
||||
================================================================================
|
||||
终端仿真器是一款用其它显示结构重现可视终端的计算机程序。换句话说就是终端仿真器能使哑终端看似像一台客户机连接上了服务器。终端仿真器允许最终用户像文本用户界面和命令行界面一样连接控制台和应用程序。
|
||||
|
||||

|
||||
|
||||
20款Linux终端仿真器
|
||||
|
||||
你能从开源世界中找到大量的终端仿真器来使用,有些拥有大量的特性而有些则反之。为了能更好地理解它们所能提供的质量,我们收集了一份不可思议的Linux终端仿真器清单。每一款都列出了它们各自的描述和特性以及软件界面截图和下载链接。
|
||||
|
||||
### 1. Terminator ###
|
||||
|
||||
Terminator是一款先进且强大的终端仿真器,它支持多终端窗口。这款仿真器可以完全自定义。你可以更改它的界面尺寸、颜色,给它设置不同的形状。拥有高用户友好性且使用起来很有乐趣。
|
||||
|
||||
#### Terminator的特性 ####
|
||||
|
||||
- 自定义外形和配色方案,根据你的需要设置尺寸。
|
||||
- 使用插件来获取更多功能。
|
||||
- 快捷键可以加快普通操作。
|
||||
- 可以把终端窗口分裂成几个虚拟终端并把它们重新设置成你需要的尺寸。
|
||||
|
||||

|
||||
|
||||
Terminator Terminal
|
||||
|
||||
- [Terminator Homepage][1]
|
||||
- [Download and Installation Instructions][2]
|
||||
|
||||
### 2. Tilda ###
|
||||
|
||||
Tilda是一款漂亮的基于GTK+的下拉式终端,敲击一个键你就可以呼出一个新的或隐藏着的Tilda窗口。你也可以添加你所选择的颜色来更改文本颜色和终端背景颜色。
|
||||
|
||||
#### Tilda的特性 ####
|
||||
|
||||
- 高度定制的选项界面设置。
|
||||
- 你可以给Tilda设置透明度。
|
||||
- 优秀的嵌入式配色方案。
|
||||
|
||||

|
||||
|
||||
Tilda Terminal
|
||||
|
||||
- [Tilda Homepage][3]
|
||||
|
||||
### 3. Guake ###
|
||||
|
||||
Guake是一款基于python的下拉式终端,诞生于GNOME桌面环境。按一个键就能调出,再按一下就能隐藏。它的设计构思来源于FPS (第一人称射击) 游戏例如Quake,其目标显而易见。
|
||||
|
||||
Guake与Yakuaka和Tilda非常相似,不过它是一个集上述二者的优点于一体的基于GTK的程序。Guake完全是用Python和小片的C写成的(全局热键部分)。
|
||||
|
||||

|
||||
|
||||
Guake Terminal
|
||||
|
||||
- [Guake Homepage][4]
|
||||
|
||||
### 4. Yakuake ###
|
||||
|
||||
Yakuake (Yet Another Kuake) 是一款基于KDE的下拉式终端仿真器,它与Guake再功能上非常相似。它的射击构思也是受FPS游戏的启发例如Quake。
|
||||
|
||||
Yakuake主要是一款KDE应用程序,它能非常轻松地安装在KDE桌面上,但是如果你试着将它安装在GNOME桌面上,你将会安装大量的依赖包。
|
||||
|
||||
#### Yakuake的特性 ####
|
||||
|
||||
- 从屏幕顶端弹回顺畅
|
||||
- 选项卡式界面
|
||||
- 可配置的尺寸和动画速度
|
||||
- 可定制
|
||||
|
||||

|
||||
|
||||
Yakuake Terminal
|
||||
|
||||
- [Yakuake Homepage][5]
|
||||
|
||||
### 5. ROXTerm ###
|
||||
|
||||
ROXterm又是一款轻量级终端仿真器,旨在提供与GNOME终端相似的特性。它原本创造出来是为了通过不使用Gnome库从而拥有更少的占用空间和更快的启动速度并使用独立的小程序来建立配置界面(GUI), 但是随着时间的流逝,它的角色就转变为给那些高级用户带来更高一层的特性。
|
||||
|
||||
然而,它比GNOME终端更加具有可制定性并且对于那些经常使用终端的高级用户更令人期望。它能和GNOME桌面环境完美结合并在终端中提供像拖拽项目那样的特性。
|
||||
|
||||

|
||||
|
||||
Roxterm Terminal
|
||||
|
||||
- [ROXTerm Homepage][6]
|
||||
|
||||
### 6. Eterm ###
|
||||
|
||||
Eterm是最轻量级的一款彩色终端仿真器,是作为xterm的替代品而被设计出来。它是以一种选择自由的思想、避免臃肿、灵活性和自由在用户手中是触手可及的理念而开发出来的。
|
||||
|
||||

|
||||
|
||||
Eterm Terminal
|
||||
|
||||
- [Eterm Homepage][7]
|
||||
|
||||
### 7. Rxvt ###
|
||||
|
||||
代表着扩展虚拟终端的Rxvt是一款彩色终端仿真器,为那些不需要一些特性例如Tektronix 4014仿真和toolkit-style可配置性的高级用户而生的xterm的替代品。
|
||||
|
||||

|
||||
|
||||
Rxvt Terminal
|
||||
|
||||
- [Rxvt Homepage][8]
|
||||
|
||||
### 8. Wterm ###
|
||||
|
||||
Wterm是另一款以rxvt项目为基础的轻量级彩色终端仿真器。它所包含的特性包括设置背景图片、透明度、反向透明度和大量的设置或运行环境选项让它成为一款可高度自定义的终端仿真器。
|
||||
|
||||

|
||||
|
||||
wterm Terminal
|
||||
|
||||
- [Wterm Homepage][9]
|
||||
|
||||
### 9. LXTerminal ###
|
||||
|
||||
LXTerminal是一款基于VTE的终端仿真器,默认运行于没有任何多余依赖的LXDE(轻量级X桌面环境)下。这款终端有很多很棒的特性。
|
||||
|
||||
#### LXTerminal的特性 ####
|
||||
|
||||
- 多标签支持
|
||||
- 支持普通命令如cp, cd, dir, mkdir, mvdir
|
||||
- 隐藏菜单栏以保证足够界面空间
|
||||
- 更改配色方案
|
||||
|
||||

|
||||
|
||||
lxterminal Terminal
|
||||
|
||||
- [LXTerminal Homepage][10]
|
||||
|
||||
### 10. Konsole ###
|
||||
|
||||
Konsole是另一款强大的基于KDE的免费终端仿真器,最初由Lars Doelle创造。
|
||||
|
||||
#### Konsole的特性 ####
|
||||
|
||||
- 多标签式终端
|
||||
- 半透明背景
|
||||
- 支持拆分视图模式
|
||||
- 目录和SSH书签化
|
||||
- 可定制的配色方案
|
||||
- 可定制的按键绑定
|
||||
- 终端中的活动通知警告
|
||||
- 增量搜索
|
||||
- 支持Dolphin文件管理器
|
||||
- 普通文本和HTML格式输出出口
|
||||
|
||||

|
||||
|
||||
Konsole Terminal
|
||||
|
||||
- [Konsole Homepage][11]
|
||||
|
||||
### 11. TermKit ###
|
||||
|
||||
TermKit是一款漂亮简洁的终端,其目标是用在Google Chrome和Chromium中广泛被使用的WebKit渲染引擎在基于应用程序的命令行中构建出GUI视图。TermKit起初是为Mac和Windows设计的,但是由于TermKit被Floby给fork并做了修改,现在你可以将它安装在Linux发行版上并感受TermKit带来的魅力。
|
||||
|
||||

|
||||
|
||||
TermKit Terminal
|
||||
|
||||
- [TermKit Homepage][12]
|
||||
|
||||
### 12. st ###
|
||||
|
||||
st是一款简单的X Window终端实现接口。
|
||||
|
||||

|
||||
|
||||
st terminal
|
||||
|
||||
- [st Homepage][13]
|
||||
|
||||
### 13. Gnome-Terminal ###
|
||||
|
||||
GNOME终端是一款在GNOME桌面环境下的嵌入式终端仿真器,由Havoc Pennington和其他一些人共同开发。它允许用户在GNOME环境下的同时使用一个真实的Linux shell来运行命令。GNOME终端是模拟的xterm终端仿真器并带来了一些相似的特性。
|
||||
|
||||
Gnome终端支持多用户,用户可以为他们的账户创建多个用户,每个用户能自定义配置选项,如字体、颜色、背景图片、行为习惯等等并能分别给它们取名。它也支持鼠标事件、url探测、多标签等。
|
||||
|
||||

|
||||
|
||||
Gnome Terminal
|
||||
|
||||
- [Gnome Terminal][14]
|
||||
|
||||
### 14. Final Term ###
|
||||
|
||||
Final Term是一款漂亮的开源终端仿真器,在这一个界面里蕴藏着一些令人激动的功能和特性。虽然它仍然有待改进,但是它提供了一些重要的特性比如Semantic文本菜单、智能的命令行实现、GUI终端控制、全能的快捷键、彩色支持等等。以下动图抓取并演示了它们的一些特性,点开来看看吧。
|
||||
|
||||

|
||||
|
||||
FinalTerm Terminal
|
||||
|
||||
- [Final Term][15]
|
||||
|
||||
### 15. Terminology ###
|
||||
|
||||
Terminology是一款新的现代化终端仿真器,为Enlightenment桌面创造,但也能用于其它桌面环境。它有一些独一无二的棒极了的特性,这是其它终端仿真器所不具备的。
|
||||
|
||||
抛开这些特性,terminology甚至还提供了你无法从其它仿真器看到的东西,比如图像、视频和文档的缩略图预览,它允许你从Terminology直接就能看到那些文件。
|
||||
|
||||
你可以来看看Terminology的开发人员制作的小视频(视频画质不太清晰,但足以让你了解Terminology了)。
|
||||
|
||||
<iframe width="630" height="480" frameborder="0" allowfullscreen="" src="//www.youtube.com/embed/ibPziLRGvkg"></iframe>
|
||||
|
||||
- [Terminology][16]
|
||||
|
||||
### 16. Xfce4 terminal ###
|
||||
|
||||
Xfce终端是一款轻量级的现代化终端仿真器,它简单易用,为Xfce桌面环境设计。它最新的一个版本有许多新的炫酷特性比如搜索会话、标签颜色转换器、像Guake或Yakuake一样的下拉式控制台等等。
|
||||
|
||||

|
||||
|
||||
Xfce Terminal
|
||||
|
||||
- [Xfce4 Terminal][17]
|
||||
|
||||
### 17. xterm ###
|
||||
|
||||
xterm应用程序是一款标准的在X Window系统上的终端仿真器。它保持了DEC VT102和Tektronix 4014,让应用能直接使用X Window系统。
|
||||
|
||||

|
||||
|
||||
xterm Terminal
|
||||
|
||||
- [xterm][18]
|
||||
|
||||
### 18. LilyTerm ###
|
||||
|
||||
LilyTerm是一款基于libvte的开源终端仿真器,这款不太出名的仿真器追求的是快速和轻量级。LilyTerm也包括一些关键特性:
|
||||
|
||||
- 支持标签移动、着色以及标签重新排序
|
||||
- 通过快捷键管理标签
|
||||
- 支持背景透明化和饱和度调整
|
||||
- 支持为特定用户创建配置文件
|
||||
- 若干个自定义选项
|
||||
- 广泛支持UTF-8
|
||||
|
||||

|
||||
|
||||
Lilyterm Terminal
|
||||
|
||||
- [LilyTerm][19]
|
||||
|
||||
### 19. Sakura ###
|
||||
|
||||
Sakura是另一款不知名的Unix风格终端仿真器,按照命令行模式和基于文本的终端程序开发。Sakura基于GTK和livte,自身特性不多,不过还是有一些自定义选项比如多标签支持、自定义文本颜色、字体和背景图片、快速命令处理等等。
|
||||
|
||||

|
||||
|
||||
Sakura Terminal
|
||||
|
||||
- [Sakura][20]
|
||||
|
||||
### 20. rxvt-unicode ###
|
||||
|
||||
rxvt-unicode (也称为urxvt) 是另一个高度可定制、轻量级和快速的终端仿真器,支持xft和unicode,由Marc Lehmann开发。它有许多显著特性比如支持Unicode上的国际语言,能显示多种字体类型并支持Perl扩展。
|
||||
|
||||

|
||||
|
||||
rxvt unicode
|
||||
|
||||
- [rxvt-unicode][21]
|
||||
|
||||
如果你知道任何其它强大的Linux终端仿真器而上文未提及,欢迎在评论中与我们分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-terminal-emulators/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:https://launchpad.net/terminator
|
||||
[2]:http://www.tecmint.com/terminator-a-linux-terminal-emulator-to-manage-multiple-terminal-windows/
|
||||
[3]:http://tilda.sourceforge.net/tildaabout.php
|
||||
[4]:https://github.com/Guake/guake
|
||||
[5]:http://extragear.kde.org/apps/yakuake/
|
||||
[6]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
|
||||
[7]:http://www.eterm.org/
|
||||
[8]:http://sourceforge.net/projects/rxvt/
|
||||
[9]:http://sourceforge.net/projects/wterm/
|
||||
[10]:http://wiki.lxde.org/en/LXTerminal
|
||||
[11]:http://konsole.kde.org/
|
||||
[12]:https://github.com/unconed/TermKit
|
||||
[13]:http://st.suckless.org/
|
||||
[14]:https://help.gnome.org/users/gnome-terminal/stable/
|
||||
[15]:http://finalterm.org/
|
||||
[16]:http://www.enlightenment.org/p.php?p=about/terminology
|
||||
[17]:http://docs.xfce.org/apps/terminal/start
|
||||
[18]:http://invisible-island.net/xterm/
|
||||
[19]:http://lilyterm.luna.com.tw/
|
||||
[20]:https://launchpad.net/sakura
|
||||
[21]:http://software.schmorp.de/pkg/rxvt-unicode
|
||||
@ -0,0 +1,122 @@
|
||||
如何在 Linux 上协同编辑文档
|
||||
================================================================================
|
||||
> “多年前由一些高度紧张、强迫性助理开发的 Bulletin,只是共享文件夹中只有 Emily 和我可以访问的 Word 文档。同一时间我们只有一个人可以打开它并添加消息、想法,或者提问项目列表。然后我们再打印出更新版本并放到我桌子架上的剪贴板,并在退出时删除旧版本。”(Lauren Weisberger 称之为“穿 Prada 的女魔头”)
|
||||
|
||||
直到今天仍然在使用这样的“协同编辑”,只有一个人可以打开共享文件,对其进行更改,然后告诉其它人什么时候修改了什么。
|
||||
|
||||
ONLYOFFICE 是一款集成了文档、电子邮件、事件、任务和客户关系管理工具的开源在线办公套件。
|
||||
|
||||
使用 ONLYOFFICE 办公套件,一组人可以同时编辑文本、电子表格或者在浏览器上进行展示。直接在他们的文档上留下评论并用集成的聊天工具和其他人沟通。最后,保存文档为 PDF 文件用于之后的打印。作为额外的增强功能,它还能浏览文档历史并在如果需要时恢复到之前的修订/版本。
|
||||
|
||||
在这篇教程中,我会介绍如何使用 [免费版 ONLYOFFICE][1] 部署你自己的在线办公套件,免费版 ONLYOFFICE 是 ONLYOFFICE 在 GNU AGPL v3 协议下发布的自托管版本。
|
||||
|
||||
### 在 Linux 上安装 ONLYOFFICE ###
|
||||
|
||||
安装 ONLYOFFICE 要求在你的 Linux 系统上要有 mono(4.0.0 或更高版本)、nodejs、libstdc++6、nginx 和 mysql-server。为了简化安装过程并避免依赖错误,我使用 Docker 安装 ONLYOFFICE。在这种情况下只需要安装一种依赖 - [Docker][2]。
|
||||
|
||||
提醒一下,Docker 是一个在软件容器中自动部署应用的开源项目。如果在你的 Linux 系统上 Docker 不可用,首先根据 [基于 Debian][3] 或 [基于 Red-Hat][4] 系统的 Docker 安装指令安装它。
|
||||
|
||||
注意,你需要 Docker 1.4.1 或更高版本。要检查安装的 Docker 版本,可以使用下面的命令。
|
||||
|
||||
$ docker version
|
||||
|
||||
在一个 Docker 容器中试用 ONLYOFFICE,只需要执行下面的命令:
|
||||
|
||||
$ sudo docker run -i -t -d --name onlyoffice-document-server onlyoffice/documentserver
|
||||
$ sudo docker run -i -t -d -p 80:80 -p 443:443 --link onlyoffice-document-server:document_server onlyoffice/communityserver
|
||||
|
||||
这些命令会下载为了能正常运行带有所有所需依赖的 [官方 ONLYOFFICE Docker 镜像][5]。
|
||||
|
||||
也可以在 Linux 服务器上单独安装 [ONLYOFFICE 在线编辑器][6],并通过提供的 API 轻松地集成到你的站点或云应用。
|
||||
|
||||
### 运行自托管在线 Office ###
|
||||
|
||||
要打开你的在线 office,在你浏览器的地址栏输入 localhost(http://IP-Address/)。会打开欢迎页面:
|
||||
|
||||

|
||||
|
||||
输入一个密码并指定下次访问你的 office 所使用的电子邮件地址。
|
||||
|
||||
### 在线编辑文档 ###
|
||||
|
||||
首先点击 Document 链接打开 **the My Documents** 文件夹。
|
||||
|
||||

|
||||
|
||||
#### STEP 1. 选择需要编辑的文档 ####
|
||||
|
||||
要在这里新建一个新文档,点击左上角的 “Create” 按钮,从下拉列表中选择文件类型。要编辑保存在你硬盘中的文件,点击 **Create** 按钮旁边的 **Upload** 按钮上传文件到 **Document**。
|
||||
|
||||

|
||||
|
||||
#### STEP 2. 共享文档 ####
|
||||
|
||||
如果你在 **My Documents** 文件夹中,用右边的 **Share** 按钮,或者如果你在文档中,用 **File >> Document Info ... >> Change Access Rights**。
|
||||
|
||||
在打开的 **Sharing Settings** 窗口,点击左边的 **People outside portal** 链接,打开到文档的访问,并通过启用 **Full Access** 单选按钮给予完全访问权限。
|
||||
|
||||
最后,选择一种方式共享到你文档的链接,通过 email 或者你可用的一种社交网络:Google+、Facebook 或 Twitter 发送。
|
||||
|
||||

|
||||
|
||||
#### STEP 3. 开始协同编辑 ####
|
||||
|
||||
邀请的人只需要根据提供的链接就可以开始协同编辑文档。
|
||||
|
||||
会自动用不用颜色的虚线将你的合作者编辑的文本段落标记出来。
|
||||
|
||||

|
||||
|
||||
只要你的其中一个合作者保存了他的/她的更改,你会看到在顶部工具栏左上角出现了一个注意标签,表示这里有更新。
|
||||
|
||||

|
||||
|
||||
点击 **Save** 图标保存更改并更新。然后会高亮所有的更新。
|
||||
|
||||

|
||||
|
||||
#### STEP 4. 和合作者互动 ####
|
||||
|
||||
要写评论,用鼠标选择一个文本段落,右击并从上下文菜单中选择 **Add comment** 选项。
|
||||
|
||||

|
||||
|
||||
要和合作者实时互动,可以使用集成的聊天工具。**Chat** 面板会列出所有正在编辑文档的用户。点击左侧边栏的 **Chat** 图标打开它。在 **Chat** 面板的合适区域输入你的信息开始讨论。
|
||||
|
||||

|
||||
|
||||
### 有用的提示 ###
|
||||
|
||||
最后,这里有一些你充分利用 ONLYOFFICE 的有用提示。
|
||||
|
||||
#### Tip #1. 在云存储服务例如 ownCloud 上编辑文档 ####
|
||||
|
||||
如果你将文档存储在其它网络资源上,例如 Box、Dropbox、Google Drive、OneDrive、SharePoint 或 ownCloud,你可以轻松地和 ONLYOFFICE 同步。
|
||||
|
||||
在打开的 ‘Documents’ 模块,点击 **Add the account** 下面的其中一个图标:Google、Box、DropBox、OneDrive、ownCloud 或 ‘Add account’,并输入所需数据。
|
||||
|
||||
#### Tip #2. 在 iPad 上编辑文档 ####
|
||||
|
||||
为了在任意时刻添加更改到文档,我使用 iPad 的 ONLYOFFICE Documents 应用。你可以从 [iTune][7] 下载并安装它,然后你需要输入你的 ONLYOFFICE 地址、email 和密码来访问你的文档。功能设置几乎一样。
|
||||
|
||||
为了评估 ONLYOFFICE 在线编辑器的功能,你可以使用供个人使用的 [云版本][8]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/edit-documents-collaboratively-linux.html
|
||||
|
||||
作者:[Tatiana Kochedykova][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/tatiana
|
||||
[1]:http://www.onlyoffice.org/
|
||||
[2]:http://xmodulo.com/recommend/dockerbook
|
||||
[3]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
|
||||
[4]:http://xmodulo.com/docker-containers-centos-fedora.html
|
||||
[5]:https://registry.hub.docker.com/u/onlyoffice/communityserver/
|
||||
[6]:http://onlyoffice.org/sources#document
|
||||
[7]:https://itunes.apple.com/us/app/onlyoffice-documents/id944896972
|
||||
[8]:https://personal.onlyoffice.com/
|
||||
@ -1,287 +0,0 @@
|
||||
27个Linux下软件包管理工具‘DNF’(Yum的分支)的命令
|
||||
================================================================================
|
||||
DNF即Dandified YUM是基于RPM的发行版的下一代软件包管理工具。它首先在Fedora 18中出现,并且在最近发行的Fedora 22中替代了[YUM工具集][1]。
|
||||
|
||||

|
||||
|
||||
DNF致力于改善YUM的瓶颈,即性能、内存占用、依赖解决、速度和许多其他方面。DNF使用RPM、libsolv和hawkey库进行包管理。尽管它并未预装在CentOS和RHEL 7中,但您可以通过yum安装,并同时使用二者。
|
||||
|
||||
您也许想阅读更多关于DNF的信息:
|
||||
|
||||
- [使用DNF取代Yum背后的原因][2]
|
||||
|
||||
最新的DNF稳定版本是2015年5月11日发布的1.0(在写这篇文章之前)。它(以及所有DNF之前版本)主要由Python编写,并以GPL v2许可证发布。
|
||||
|
||||
### 安装DNF ###
|
||||
|
||||
尽管Fedora 22官方已经过渡到了DNF,但DNF并不在RHEL/CentOS 7的默认仓库中。
|
||||
|
||||
为了在RHEL/CentOS系统中安装DNF,您需要首先安装和开启epel-release仓库。
|
||||
|
||||
# yum install epel-release
|
||||
或
|
||||
# yum install epel-release -y
|
||||
|
||||
尽管并不建议在使用yum时添上'-y'选项,因为最好还是看看什么将安装在您的系统中。但如果您对此并不在意,则您可以使用'-y'选项以自动化的安装而无需用户干预。
|
||||
|
||||
接下来,使用yum命令从epel-realease仓库安装DNF包。
|
||||
|
||||
# yum install dnf
|
||||
|
||||
在您装完dnf后,我会向您展示27个实用的dnf命令和例子,以便帮您更容易和高效的管理基于RPM包的发行版。
|
||||
|
||||
### 1. 检查DNF版本 ###
|
||||
|
||||
检查您的系统上安装的DNF版本。
|
||||
|
||||
# dnf --version
|
||||
|
||||

|
||||
|
||||
### 2. 列出开启的DNF仓库 ###
|
||||
|
||||
dnf命令中的'repolist'选项将显示您系统中所有开启的仓库。
|
||||
|
||||
# dnf repolist
|
||||
|
||||

|
||||
|
||||
### 3. 列出所有开启和关闭的DNF仓库 ###
|
||||
|
||||
'repolist all'选项将显示您系统中所有开启/关闭的仓库。
|
||||
|
||||
# dnf repolist all
|
||||
|
||||

|
||||
|
||||
### 4. 用DNF列出所有可用的且已安装的软件包 ###
|
||||
|
||||
'dnf list'命令将列出所有仓库中所有可用的软件包和您Linux系统中已安装的软件包。
|
||||
|
||||
# dnf list
|
||||
|
||||

|
||||
|
||||
### 5. 用DNF列出所有已安装的软件包 ###
|
||||
|
||||
尽管'dnf list'命令将列出所有仓库中所有可用的软件包和已安装的软件包。然而像下面一样使用'list installed'选项将只列出已安装的软件包。
|
||||
|
||||
# dnf list installed
|
||||
|
||||

|
||||
|
||||
### 6. 用DNF列出所有可用的软件包 ###
|
||||
|
||||
类似的,可以用'list available'选项列出所有开启的仓库中所有可用的软件包。
|
||||
|
||||
# dnf list available
|
||||
|
||||

|
||||
|
||||
### 7. 使用DNF查找软件包 ###
|
||||
|
||||
如果您不太清楚您想安装的软件包的名字,这种情况下,您可以使用'search'选项来搜索匹配该字符(例如,nano)和字符串的软件包。
|
||||
|
||||
# dnf search nano
|
||||
|
||||

|
||||
|
||||
### 8. 查看哪个软件包提供了某个文件/子软件软件包? ###
|
||||
|
||||
dnf的选项'provides'能查找提供了某个文件/子软件包的软件包名。例如,如果您想找找那个软件包提供了您系统中的'/bin/bash'文件,可以使用下面的命令
|
||||
|
||||
# dnf provides /bin/bash
|
||||
|
||||

|
||||
|
||||
### 9. 使用DNF获得一个软件包的详细信息 ###
|
||||
|
||||
如果您想在安装一个软件包前知道它的详细信息,您可以使用'info'来获得一个软件包的详细信息,例如:
|
||||
|
||||
# dnf info nano
|
||||
|
||||

|
||||
|
||||
### 10. 使用DNF安装软件包 ###
|
||||
|
||||
想安装一个叫nano的软件包,只需运行下面的命令,它会为nano自动的解决和安装所有的依赖。
|
||||
|
||||
# dnf install nano
|
||||
|
||||

|
||||
|
||||
### 11. 使用DNF更新一个软件包 ###
|
||||
|
||||
您可能只想更新一个特定的包(例如,systemd)并且保留系统内剩余软件包不变。
|
||||
|
||||
# dnf update systemd
|
||||
|
||||

|
||||
|
||||
### 12. 使用DNF检查系统更新 ###
|
||||
|
||||
检查系统中安装的所有软件包的更新可以简单的使用dnf进行:
|
||||
|
||||
# dnf check-update
|
||||
|
||||

|
||||
|
||||
### 13. 使用DNF安装系统中所有的软件包 ###
|
||||
|
||||
您可以使用下面的命令来更新整个系统中所有已安装的软件包。
|
||||
|
||||
# dnf update
|
||||
或
|
||||
# dnf upgrade
|
||||
|
||||

|
||||
|
||||
### 14. 使用DNF来移除/删除一个软件包 ###
|
||||
|
||||
您可以在dnf命令中使用'remove'或'erase'选项来移除任何不想要的软件包。
|
||||
|
||||
# dnf remove nano
|
||||
或
|
||||
# dnf erase nano
|
||||
|
||||

|
||||
|
||||
### 15. 使用DNF移除于依赖无用的软件包(Orphan Packages) ###
|
||||
|
||||
这些为了满足依赖安装的软件包在相应的程序删除后便不再需要了。可以用过下面的命令来将它们删除。
|
||||
|
||||
# dnf autoremove
|
||||
|
||||

|
||||
|
||||
### 16. 使用DNF移除缓存的软件包 ###
|
||||
|
||||
我们在使用dnf时经常会碰到过期的头部和不完整的事务,它们会导致错误。我们可以使用下面的语句清理缓存的软件包和包含远程包信息的头部。
|
||||
|
||||
# dnf clean all
|
||||
|
||||

|
||||
|
||||
### 17. 获得特定DNF命令的帮助 ###
|
||||
|
||||
您可能需要特定的DNF命令的帮助(例如,clean),可以通过下面的命令来得到:
|
||||
|
||||
# dnf help clean
|
||||
|
||||

|
||||
|
||||
### 18. 列出所有DNF的命令和选项 ###
|
||||
|
||||
要显示所有dnf的命令和选项,只需要:
|
||||
|
||||
# dnf help
|
||||
|
||||

|
||||
|
||||
### 19. 查看DNF的历史记录 ###
|
||||
|
||||
您可以调用'dnf history'来查看已经执行过的dnf命令的列表。这样您便可以知道什么被安装/移除以及时间戳。
|
||||
|
||||
# dnf history
|
||||
|
||||

|
||||
|
||||
### 20. 显示所有软件包组 ###
|
||||
|
||||
'dnf grouplist'命令可以打印所有可用的或已安装的软件包,如果没有什么输出,则它会列出所有已知的软件包组。
|
||||
|
||||
# dnf grouplist
|
||||
|
||||

|
||||
|
||||
### 21. 使用DNF安装一个软件包组 ###
|
||||
|
||||
要安装一组由许多软件打包在一起的软件包组(例如,Educational Softaware),只需要执行:
|
||||
|
||||
# dnf groupinstall 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 22. 更新一个软件包组 ###
|
||||
|
||||
可以通过下面的命令来更新一个软件包组(例如,Educational Software):
|
||||
|
||||
# dnf groupupdate 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 23. 移除一个软件包组 ###
|
||||
|
||||
可以使用下面的命令来移除一个软件包组(例如,Educational Software):
|
||||
|
||||
# dnf groupremove 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 24. 从某个特定的仓库安装一个软件包 ###
|
||||
|
||||
DNF可以从任何特定的仓库安装一个软件包(例如,phpmyadmin):
|
||||
|
||||
# dnf --enablerepo=epel install phpmyadmin
|
||||
|
||||

|
||||
|
||||
### 25. 将已安装的软件包同步到稳定发行版 ###
|
||||
|
||||
'dnf distro-sync'将同步所有已安装的软件包到所有开启的仓库中最近的稳定版本。如果没有软件包被选择,则会同步所有已安装的软件包。
|
||||
|
||||
# dnf distro-sync
|
||||
|
||||

|
||||
|
||||
### 26. 重新安装一个软件包 ###
|
||||
|
||||
'dnf reinstall nano'命令将重新安装一个已经安装的软件包(例如,nano):
|
||||
|
||||
# dnf reinstall nano
|
||||
|
||||

|
||||
|
||||
### 27. 降级一个软件包 ###
|
||||
|
||||
选项'downgrade'将会使一个软件包(例如,acpid)回退到低版本。
|
||||
|
||||
# dnf downgrade acpid
|
||||
|
||||
示例输出
|
||||
|
||||
Using metadata from Wed May 20 12:44:59 2015
|
||||
No match for available package: acpid-2.0.19-5.el7.x86_64
|
||||
Error: Nothing to do.
|
||||
|
||||
**我的观察**:dnf不会按预想的那样降级一个软件包。这已做为一个bug被提交。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
DNF是YUM管理器的优秀替代品。它倾向于自动做许多有经验的Linux系统管理员不建议做的工作。例如:
|
||||
|
||||
- `--skip-broken`不被DNF识别,并且DNF中没有其替代命令。
|
||||
- 尽管您可能会运行dnf provides,但再也没有'resolvedep'命令了。
|
||||
- 没有'deplist'命令用来发现软件包依赖。
|
||||
- 您排除一个仓库意味着在所有操作上排除该仓库,而在yum中,排除一个仓库只在安装和升级等时刻排除他们。
|
||||
|
||||
许多Linux用户对于Linux生态系统的走向不甚满意。首先[Systemd替换了init system][3]v,现在DNF将于不久后替换YUM,首先是Fedora 22,接下来是RHEL和CentOS。
|
||||
|
||||
您怎么看呢?是不是发行版和整个Linux生态系统并不注重用户并且在朝着与用户愿望相悖的方向前进呢?IT行业里有这样一句话 - “如果没有坏,为什么要修呢?”,System V和YUM都没有坏。
|
||||
|
||||
上面便是这篇文章的全部了。请在下方留言以让我了解您的宝贵想法。点赞和分享以帮助我们传播。谢谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
|
||||
[3]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
@ -1,77 +0,0 @@
|
||||
Ubuntu中安装Unity 8桌面预览版
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你一直关注新闻,那么Ubuntu将会切换到[Mir显示服务器][1],并随同发布[Unity 8][2]桌面。然而,在尚未确定Unity 8是否会在[Ubuntu 15.10 Willy Werewolf][3]中部署到Mir上之前,提供了一个Unity 8的预览版本供你体验和测试。通过官方PPA,可以很容地**安装Unity 8到Ubuntu 14.04,14.10和15.04中**。
|
||||
|
||||
到目前为止,开发者已经可以通过[ISO][4]获得该Unity 8预览来进行测试。但是Canonical已经通过[LXC容器][5]发布了。通过该方法,你可以获取Unity 8桌面会话,让它作为任何一个桌面环境运行在Mir显示服务器上。就像你[在Ubuntu中安装Mate桌面][6],然后从LightDm登录屏幕选择桌面会话一样。
|
||||
|
||||
好奇?想要试试Unity 8?让我们来看怎样安装它吧。
|
||||
|
||||
**注意: 它是一个实验性预览,可能不是所有人都可以让它正确工作的。**
|
||||
|
||||
### 安装Unity 8桌面到Ubuntu ###
|
||||
|
||||
下面是安装并使用Unity 8的步骤:
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 12.04和14.04 ####
|
||||
|
||||
如果你真运行着Ubuntu 12.04和14.04,那么你必须使用官方PPA来安装Unity 8。使用以下命令进行安装:
|
||||
|
||||
sudo apt-add-repository ppa:unity8-desktop-session-team/unity8-preview-lxc
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 14.10和15.04 ####
|
||||
|
||||
如果你真运行着Ubuntu 14.10或15.04,那么Unity 8 LXC已经在源中准备好。你只需要运行以下命令:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 2: 设置Unity 8桌面预览LXC ####
|
||||
|
||||
安装Unity 8 LXC后,该对它进行设置,下面的命令就可达到目的:
|
||||
|
||||
sudo unity8-lxc-setup
|
||||
|
||||
它将花费一些时间来设置,所以,给点耐心吧。它会下载ISO,然后解压缩,接着完整最后一些必要的设置来让它工作。它也会安装一个LightDM的轻度修改版本。这一切都搞定后,需要重启。
|
||||
|
||||
#### 步骤 3: 选择Unity 8 ####
|
||||
|
||||
重启后,在登录屏幕,点击你的登录旁边的Ubuntu图标:
|
||||
|
||||

|
||||
|
||||
你应该可以在这看到Unity 8的选项,选择它:
|
||||
|
||||

|
||||
|
||||
### 卸载Unity 8 LXC ###
|
||||
|
||||
如果你发现Unity 8毛病太多,或者你不喜欢它,那么你可以以相同的方式切换会默认Unity版本。此外,你也可以通过下面的命令移除Unity 8:
|
||||
|
||||
sudo apt-get remove unity8-lxc
|
||||
|
||||
该命令会将Unity 8选项从LightDM屏幕移除,但是配置仍然保留着。
|
||||
|
||||
以上就是你在Ubuntu中安装嗲有Mir的Unity 8的全部过程,试玩后请分享你关于Unity 8的想法哦!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-unity-8-desktop-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/Mir_%28software%29
|
||||
[2]:https://wiki.ubuntu.com/Unity8Desktop
|
||||
[3]:http://itsfoss.com/ubuntu-15-10-codename/
|
||||
[4]:https://wiki.ubuntu.com/Unity8DesktopIso
|
||||
[5]:https://wiki.ubuntu.com/Unity8inLXC
|
||||
[6]:http://itsfoss.com/install-mate-desktop-ubuntu-14-04/
|
||||
@ -0,0 +1,435 @@
|
||||
Linux 下如何处理包含空格和特殊字符的文件名
|
||||
================================================================================
|
||||
我们经常会看到文件名和文件夹名。大多数时候文件/文件夹的名字和内容相关并以数字和字母开头。字母-数字文件名最常见,应用也很广泛,但总会需要处理一些包含特殊字符的文件名/文件夹名。
|
||||
|
||||
** 注意 **:我们可能有各种类型的文件,但是为了简单以及方便实现,在本文中我们只处理文本文件(.txt)。
|
||||
|
||||
最常见的文件名例子:
|
||||
|
||||
abc.txt
|
||||
avi.txt
|
||||
debian.txt
|
||||
...
|
||||
|
||||
数字文件名例子:
|
||||
|
||||
121.txt
|
||||
3221.txt
|
||||
674659.txt
|
||||
...
|
||||
|
||||
字母数字文件名例子:
|
||||
|
||||
eg84235.txt
|
||||
3kf43nl2.txt
|
||||
2323ddw.txt
|
||||
...
|
||||
|
||||
包含特殊字符的文件名的例子,并不常见:
|
||||
|
||||
#232.txt
|
||||
#bkf.txt
|
||||
#bjsd3469.txt
|
||||
#121nkfd.txt
|
||||
-2232.txt
|
||||
-fbjdew.txt
|
||||
-gi32kj.txt
|
||||
--321.txt
|
||||
--bk34.txt
|
||||
...
|
||||
|
||||
一个显而易见的问题是 - 在这个星球上有谁会创建/处理包含井号`(#)`,分号`(;)`,破折号`(-)`或其他特殊字符的文件/文件夹啊。
|
||||
|
||||
我和你想的一样,这种文件名确实不常见,不过在你必须得处理这种文件名的时候你的 shell 也不应该出错或罢工。而且技术上来说,Linux 下的一切比如文件夹,驱动器或其他所有的都被当作文件处理。
|
||||
|
||||
### 处理名字包含破折号(-)的文件 ###
|
||||
|
||||
创建以破折号`(-)`开头的文件,比如 -abx.txt。
|
||||
|
||||
$ touch -abc.txt
|
||||
|
||||
#### 测试输出 ####
|
||||
|
||||
touch: invalid option -- 'b'
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
出现上面错误的原因是,shell 把破折号`(-)`之后的内容认作参数了,而很明显没有这样的参数,所以报错。
|
||||
|
||||
要解决这个问题,我们得告诉 Bash shell(是的,这里以及本文后面的大多数例子都是基于 BASH 环境)不要将特殊字符(这里是破折号)后的字符解释为参数。
|
||||
|
||||
有两种方法解决这个错误:
|
||||
|
||||
$ touch -- -abc.txt [方法 #1]
|
||||
$ touch ./-abc.txt [方法 #2]
|
||||
|
||||
你可以通过运行命令 ls 或 [ls -l][1] 列出详细信息来检查通过上面两种方式创建的文件。
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 11:05 -abc.txt
|
||||
|
||||
要编辑上述文件可以这样:
|
||||
|
||||
$ nano -- -abc.txt
|
||||
或者
|
||||
$ nano ./-abc.txt
|
||||
|
||||
**注意**:你可以将 nano 替换为任何其他你喜欢的编辑器比如说 vim:
|
||||
|
||||
$ vim -- -abc.txt
|
||||
或者
|
||||
$ vim ./-abc.txt
|
||||
|
||||
如果只是简单地移动文件可以这样:
|
||||
|
||||
$ mv -- -abc.txt -a.txt
|
||||
或者
|
||||
$ mv -- -a.txt -abc.txt
|
||||
|
||||
删除这种文件,可以这样:
|
||||
|
||||
$ rm -- -abc.txt
|
||||
或者
|
||||
$ rm ./-abc.txt
|
||||
|
||||
如果一个目录下有大量这种名字包含破折号的文件,要一次全部删除的话,可以这样:
|
||||
|
||||
$ rm ./-*
|
||||
|
||||
**重要:**
|
||||
|
||||
1. 上面讨论的规则可以同样应用于名字中包含任意数量以及位置连接符号的文件。就是说,-a-b-c.txt,ab-c.txt,abc-.txt,等等。
|
||||
|
||||
2. 上面讨论的规则可以同样应用于名字中包含任意数量以及位置连接符号的文件夹,除了一种情况,在删除一个文件夹的时候你得这样使用`rm -rf`:
|
||||
|
||||
$ rm -rf -- -abc
|
||||
或者
|
||||
$ rm -rf ./-abc
|
||||
|
||||
### 处理名字包含井号(#)的文件 ###
|
||||
|
||||
符号`#`在 BASH 里有非常特别的含义。`#`之后的一切都会被认为是评论,因此会被 BASH 忽略。
|
||||
|
||||
**通过例子来加深理解:**
|
||||
|
||||
创建一个名字是 #abc.txt 的文件:
|
||||
|
||||
$ touch #abc.txt
|
||||
|
||||
#### 测试输出 ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
出现上面错误的原因是,BASH 将 #abc.txt 解释为评论而忽略了。所以[命令 touch][2]没有收到任何文件作为参数,所以导致这个错误。
|
||||
|
||||
要解决这个问题,你肯能需要告诉 BASH 不要将 # 解释为评论。
|
||||
|
||||
$ touch ./#abc.txt
|
||||
或者
|
||||
$ touch '#abc.txt'
|
||||
|
||||
检查刚创建的文件:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:14 #abc.txt
|
||||
|
||||
现在创建名字中除了开头的其他地方包含 # 的文件。
|
||||
|
||||
$ touch ./a#bc.txt
|
||||
$ touch ./abc#.txt
|
||||
|
||||
或者
|
||||
$ touch 'a#bc.txt'
|
||||
$ touch 'abc#.txt'
|
||||
|
||||
运行 ‘ls -l‘ 来检查:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 a#bc.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 abc#.txt
|
||||
|
||||
如果同时创建两个文件(比如 a 和 #bc)会怎么样:
|
||||
|
||||
$ touch a.txt #bc.txt
|
||||
|
||||
检查刚创建的文件:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:18 a.txt
|
||||
|
||||
很明显上面的例子中只创建了文件 `a` 而文件 `#bc` 被忽略了。对于上面的情况我们可以这样做,
|
||||
|
||||
$ touch a.txt ./#bc.txt
|
||||
或者
|
||||
$ touch a.txt '#bc.txt'
|
||||
|
||||
检查一下:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 a.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 #bc.txt
|
||||
|
||||
可以这样移动文件:
|
||||
|
||||
$ mv ./#bc.txt ./#cd.txt
|
||||
或者
|
||||
$ mv '#bc.txt' '#cd.txt'
|
||||
|
||||
这样拷贝:
|
||||
|
||||
$ cp ./#cd.txt ./#de.txt
|
||||
或者
|
||||
$ cp '#cd.txt' '#de.txt'
|
||||
|
||||
可以使用你喜欢的编辑器来编辑文件:
|
||||
|
||||
$ vi ./#cd.txt
|
||||
或者
|
||||
$ vi '#cd.txt'
|
||||
|
||||
----------
|
||||
|
||||
$ nano ./#cd.txt
|
||||
或者
|
||||
$ nano '#cd.txt'
|
||||
|
||||
这样删除:
|
||||
|
||||
$ rm ./#bc.txt
|
||||
或者
|
||||
$ rm '#bc.txt'
|
||||
|
||||
要删除所有以井号(#)开头的文件,可以这样:
|
||||
|
||||
# rm ./#*
|
||||
|
||||
### 处理名字包含分号(;)的文件 ###
|
||||
|
||||
如果你还不知道的话,分号在 BASH 里起到命令分隔的作用,其他 shell 可能也是一样的。分号作为分隔符可以让你一次执行几个命令。你碰到过名字包含分号的文件吗?如果没有的话,这里有例子。
|
||||
|
||||
创建一个名字包含分号的文件。
|
||||
|
||||
$ touch ;abc.txt
|
||||
|
||||
#### 测试输出 ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
bash: abc.txt: command not found
|
||||
|
||||
出现上面错误的原因是,在运行上面命令的时候 BASH 会把 touch 解释为一个命令但是在分号前没有任何文件参数,所以报告错误。然后报告的另一个错误找不到命令 `abc.txt`,只是因为在分号后 BASH 会期望另一个新的命令,而 `abc.txt` 并不是一个命令。
|
||||
|
||||
要解决这个问题,我们得告诉 BASH 不要将分号解释为命令分隔符,例如:
|
||||
|
||||
$ touch ./';abc.txt'
|
||||
或者
|
||||
$ touch ';abc.txt'
|
||||
|
||||
**注意**:我们将文件名用单引号 '' 包含起来。这样可以告诉 BASH 分号 ; 是文件名的一部分而不是命令分隔符。
|
||||
|
||||
对名字包含分号的文件和文件夹的其他操作(就是,拷贝、移动、删除)可以直接将名字用单引号包含起来就好了。
|
||||
|
||||
### 处理名字包含其他特殊字符的文件/文件夹 ###
|
||||
|
||||
#### 文件名包含加号 (+) ####
|
||||
|
||||
不需要任何特殊处理,按平时的方式做就好了,比如下面测试的文件名。
|
||||
|
||||
$ touch +12.txt
|
||||
|
||||
#### 文件名包含美元符 ($) ####
|
||||
|
||||
你需要将文件名用单引号括起来,像处理分号那样的方式。然后就很简单了。
|
||||
|
||||
$ touch '$12.txt'
|
||||
|
||||
#### 文件名包含百分号 (%) ####
|
||||
|
||||
不需要任何特殊处理,当作一个普通文件就可以了。
|
||||
|
||||
$ touch %12.txt
|
||||
|
||||
#### 文件名包含星号 (*) ####
|
||||
|
||||
名字包含星号的文件没有改变太多,你仍然可以把它当作一个普通文件。(注:星号在 shell 里有特殊意义,用作文件名最好用单引号括起来或使用反斜杠转义)
|
||||
|
||||
$ touch *12.txt
|
||||
|
||||
注意:当你需要删除星号开头的文件时,千万不要用类似下面的命令。
|
||||
|
||||
$ rm *
|
||||
或者
|
||||
$ rm -rf *
|
||||
|
||||
而是用这样的命令,(注:这个命令是删除当前目录所有.txt文件。。。)
|
||||
|
||||
$ rm ./*.txt
|
||||
|
||||
#### 文件名包含叹号 (!) ####
|
||||
|
||||
只要将文件名用单引号括起来,其他的就一样了。
|
||||
|
||||
$ touch '!12.txt'
|
||||
|
||||
#### 文件名包含小老鼠 (@) ####
|
||||
|
||||
没有什么特别的,可以将名字包含小老鼠的文件当作普通文件。
|
||||
|
||||
$ touch '@12.txt'
|
||||
|
||||
#### 文件名包含 ^ ####
|
||||
|
||||
不需要特殊处理。可以将名字包含 ^ 的文件当作普通文件。
|
||||
|
||||
$ touch ^12.txt
|
||||
|
||||
#### 文件名包含 (&) ####
|
||||
|
||||
将文件名用单引号括起来,然后就可以操作了。
|
||||
|
||||
$ touch '&12.txt'
|
||||
|
||||
#### 文件名包含括号 () ####
|
||||
|
||||
如果文件名包含括号,你需要将文件名用单引号括起来。
|
||||
|
||||
$ touch '(12.txt)'
|
||||
|
||||
#### 文件名包含花括号 {} ####
|
||||
|
||||
不需要特别注意。可以当作普通文件处理。(注:花括号在 shell 里有特殊意义,用作文件名最好用单引号括起来或使用反斜杠转义)
|
||||
|
||||
$ touch {12.txt}
|
||||
|
||||
#### 文件名包含尖括号 <> ####
|
||||
|
||||
名字包含尖括号的文件需要用单引号括起来。
|
||||
|
||||
$ touch '<12.txt>'
|
||||
|
||||
#### 文件名包含方括号 [ ] ####
|
||||
|
||||
名字包含方括号的文件可以当作普通文件,不用特别处理。(注:方括号在 shell 里有特殊意义,用作文件名最好用单引号括起来或使用反斜杠转义)
|
||||
|
||||
$ touch [12.txt]
|
||||
|
||||
#### 文件名包含下划线 (_) ####
|
||||
|
||||
这个非常普遍不需要特殊对待。当作普通文件随意处理。
|
||||
|
||||
$ touch _12.txt
|
||||
|
||||
#### 文件名包含等号 (=) ####
|
||||
|
||||
文件名包含等号不会改变任何事情,你可以当作普通文件。(注:等号在 shell 里有特殊意义,用作文件名最好用单引号括起来或使用反斜杠转义)
|
||||
|
||||
$ touch =12.txt
|
||||
|
||||
#### 处理反斜杠 (\) ####
|
||||
|
||||
反斜杠会告诉 shell 忽略后面字符的特殊含义。你必须将文件名用单引号括起来,就像处理分号那样。其他的就没什么了。
|
||||
|
||||
$ touch '\12.txt'
|
||||
|
||||
#### 包含斜杠的特殊情形 ####
|
||||
|
||||
除非你的文件系统有问题,否则你不能创建名字包含斜杠的文件。没办法转义斜杠。
|
||||
|
||||
所以如果你能创建类似 ‘/12.txt’ 或者 ‘b/c.txt’ 这样的文件,那要么你的文件系统有问题,或者支持 Unicode,这样你可以创建包含斜杠的文件。只是这样并不是真的斜杠,而是一个看起来像斜杠的 Unicode 字符。
|
||||
|
||||
#### 文件名包含问号 (?) ####
|
||||
|
||||
再一次,这个也是不需要特别处理的情况。名字包含问号的文件可以和大多数情况一样对待。(注:问号在 shell 里有特殊意义,用作文件名最好用单引号括起来或使用反斜杠转义)
|
||||
|
||||
$ touch ?12.txt
|
||||
|
||||
#### 文件名包含点 (.) ####
|
||||
|
||||
在 Linux 里以点 `(.)` 开头的文件非常特别,被称为点文件。它们通常是隐藏的配置文件或系统文件。你需要使用 ls 命令的 ‘-a‘ 或 ‘-A‘ 开关来查看这种文件。
|
||||
|
||||
创建,编辑,重命名和删除这种文件很直接。
|
||||
|
||||
$ touch .12.txt
|
||||
|
||||
注意:在 Linux 里你可能碰到名字包含许多点 `(.)` 的文件。不像其他操作系统,文件名里的点并不意味着分隔名字和扩展后缀。你可以创建名字包含多个点的文件:
|
||||
|
||||
$ touch 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
检查一下:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 14:32 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
#### 文件名包含逗号 (,) ####
|
||||
|
||||
你可以在文件名中使用逗号,可以有任意多个而不用特殊对待。就像平时普通名字文件那样处理。
|
||||
|
||||
$ touch ,12.txt
|
||||
或者
|
||||
$ touch ,12,.txt
|
||||
|
||||
#### 文件名包含冒号 (:) ####
|
||||
|
||||
你可以在文件名中使用冒号,可以有任意多个而不用特殊对待。就像平时普通名字文件那样处理。(注:冒号在 shell 里有特殊意义,用作文件名最好用单引号括起来或使用反斜杠转义)
|
||||
|
||||
$ touch :12.txt
|
||||
或者
|
||||
$ touch :12:.txt
|
||||
|
||||
#### 文件名包含引号(单引号和双引号) ####
|
||||
|
||||
要在文件名里使用引号,我们需要使用交替规则。例如,如果你需要在文件名里使用单引号,那就用双引号把文件名括起来。而如果你需要在文件名里使用双引号,那就用单引号把文件名括起来。
|
||||
|
||||
$ touch "15'.txt"
|
||||
|
||||
以及
|
||||
|
||||
$ touch '15”.txt'
|
||||
|
||||
#### 文件名包含波浪号 (~) ####
|
||||
|
||||
Linux 下一些像 emacs 这样的文本编辑器在编辑文件的时候会创建备份文件。这个备份文件的名字是在原文件名后面附加一个波浪号。你可以在文件名任意位置使用波浪号,例如:(注:波浪号在 shell 里有特殊意义,用作文件名最好用单引号括起来或使用反斜杠转义)
|
||||
|
||||
$ touch ~1a.txt
|
||||
或者
|
||||
$touch 2b~.txt
|
||||
|
||||
#### 文件名包含空格 ####
|
||||
|
||||
创建名字的字符/单词之间包含空格的文件,比如 “hi my name is avishek.txt”。
|
||||
|
||||
最好不要在文件名里使用空格,如果你必须要分隔可读的名字,可以使用下划线或横杠。不过,你还是需要创建这样的文件的话,你可以用反斜杠来转义下一个字符。要创建上面名字的文件可以这样做。
|
||||
|
||||
$ touch hi\ my\ name\ is\ avishek.txt
|
||||
|
||||
hi my name is avishek.txt
|
||||
|
||||
我已经尝试覆盖你可能碰到的所有情况。上面大多数测试都在 BASH Shell 里完成,可能在其他 shell 下会有差异。
|
||||
|
||||
如果你觉得我遗漏了什么(这很正常也符合人性),请把你的建议发表到下面的评论里。保持联系,多评论。不要走开!求点赞求分享求扩散!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
@ -0,0 +1,91 @@
|
||||
如何在 Cacti 中合并两幅图片
|
||||
================================================================================
|
||||
[Cacti][1] 是一个很棒的开源网络监视系统,它广泛使用于图示网络元素,例如带宽、存储、处理器和内存使用。使用它的基于网络的接口,你可以轻松地创建和组织图。然而,默认并没有提供一些高级功能,例如合并图片、使用多个来源创建聚合图、迁移 Cacti 到另一台服务器。使用 Cacti 的这些功能你还需要一些经验。在该教程中,我们会看到如何在将两幅 Cacti 图片合并为一幅。
|
||||
|
||||
考虑这个例子。在过去的 6 个月中,客户端 A 连接到了交换机 A 的端口 5。端口 5 发生了错误,因此客户端迁移到了端口 6。由于 Cacti 为每个接口/元素使用不同的图,客户端的带宽历史会分成端口 5 和端口 6。结果是对于一个客户端我们有两幅图片 - 一幅是 6 个月的旧数据,另一幅保存了后续的数据。
|
||||
|
||||
在这种情况下,我们实际上可以合并两幅图片将旧数据加到新的图中,使得用一个单独的图为一个用户保存历史的和新数据。该教程将会解释如何做到这一点。
|
||||
|
||||
Cacti 将每幅图片的数据保存在它自己的 RRD(round robin database,循环数据库) 文件中。当请求一幅图片时,根据保存在对应 RRD 文件中的值生成图。在 Ubuntu/Debian 系统中,RRD 文件保存在 `/var/lib/cacti/rra`,在 CentOS/RHEL 系统中则是 `/var/www/cacti/rra`。
|
||||
|
||||
合并图片背后的思想是更改这些 RRD 文件使得旧 RRD 文件中的值能追加到新的 RRD 文件中。
|
||||
|
||||
### 情景 ###
|
||||
|
||||
一个客户端的服务在 eth0 上运行了超过一年。由于硬件损坏,客户端迁移到了另一台服务器的 eth1 接口。我们想图示新接口的带宽,同时保留超过一年的历史数据。只在一幅图中显示客户端。
|
||||
|
||||
### 确定图的 RRD 文件 ###
|
||||
|
||||
图合并的首个步骤是确定和图关联的 RRD 文件。我们可以通过以调试模式打开图检查文件。要做到这点,在 Cacti 的菜单中: 控制台 > 管理图 > 选择图 > 打开图调试模式。
|
||||
|
||||
#### 旧图: ####
|
||||
|
||||

|
||||
|
||||
#### 新图: ####
|
||||
|
||||

|
||||
|
||||
从样例输出(基于 Debian 系统)中,我们可以确定两幅图片的 RRD 文件:
|
||||
|
||||
- **旧图**: /var/lib/cacti/rra/old_graph_traffic_in_8.rrd
|
||||
- **新图**: /var/lib/cacti/rra/new_graph_traffic_in_10.rrd
|
||||
|
||||
### 准备脚本 ###
|
||||
|
||||
我们会用一个 [RRD 剪接脚本][2] 合并两个 RRD 文件。下载该 PHP 脚本,并安装为 /var/lib/cacti/rra/rrdsplice.php (Debian/Ubuntu 系统) 或 /var/www/cacti/rra/rrdsplice.php (CentOS/RHEL 系统)。
|
||||
|
||||
下一步,确认 Apache 用户拥有该文件。
|
||||
|
||||
在 Debian 或 Ubuntu 系统中,运行下面的命令:
|
||||
|
||||
# chown www-data:www-data rrdsplice.php
|
||||
|
||||
并更新 rrdsplice.php。查找下面的行:
|
||||
|
||||
chown($finrrd, "apache");
|
||||
|
||||
用下面的语句替换:
|
||||
|
||||
chown($finrrd, "www-data");
|
||||
|
||||
在 CentOS 或 RHEL 系统中,运行下面的命令:
|
||||
|
||||
# chown apache:apache rrdsplice.php
|
||||
|
||||
### 合并两幅图 ###
|
||||
|
||||
通过不带任何参数运行该脚本可以获得脚本的使用语法。
|
||||
|
||||
# cd /path/to/rrdsplice.php
|
||||
# php rrdsplice.php
|
||||
|
||||
----------
|
||||
|
||||
USAGE: rrdsplice.php --oldrrd=file --newrrd=file --finrrd=file
|
||||
|
||||
现在我们准备好合并两个 RRD 文件了。只需要指定旧 RRD 文件和新 RRD 文件的名称。我们会将合并后的结果重写到新 RRD 文件中。
|
||||
|
||||
# php rrdsplice.php --oldrrd=old_graph_traffic_in_8.rrd --newrrd=new_graph_traffic_in_10.rrd --finrrd=new_graph_traffic_in_10.rrd
|
||||
|
||||
现在旧 RRD 文件中的数据已经追加到了新 RRD 文件中。Cacti 会将任何新数据写到新 RRD 文件中。如果我们点击图,我们可以发现也已经添加了旧图的周、月、年记录。下面图表中的第二幅图显示了旧图的周记录。
|
||||
|
||||

|
||||
|
||||
总之,该教程显示了如何简单地将两幅 Cacti 图片合并为一幅。当服务迁移到另一个设备/接口,我们希望只处理一幅图片而不是两幅时,这个小技巧非常有用。该脚本非常方便,因为它可以不管源设备合并图片,例如 Cisco 1800 路由器和 Cisco 2960 交换机。
|
||||
|
||||
希望这些能对你有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/combine-two-graphs-cacti.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/install-configure-cacti-linux.html
|
||||
[2]:http://svn.cacti.net/viewvc/developers/thewitness/rrdsplice/rrdsplice.php
|
||||
@ -1,64 +1,64 @@
|
||||
Installing LAMP (Linux, Apache, MariaDB, PHP/PhpMyAdmin) in RHEL/CentOS 7.0
|
||||
在RHEL/CentOS 7.0中安装LAMP(Linux、 Apache、 MariaDB、 PHP/PhpMyAdmin)
|
||||
================================================================================
|
||||
Skipping the LAMP introduction, as I’m sure that most of you know what is all about. This tutorial will concentrate on how to install and configure famous LAMP stack – Linux Apache, MariaDB, PHP, PhpMyAdmin – on the last release of Red Hat Enterprise Linux 7.0 and CentOS 7.0, with the mention that both distributions have upgraded httpd daemon to Apache HTTP 2.4.
|
||||
跳过LAMP的介绍因为我认为你们大多数已经知道了。这个教程会集中在如何在升级到Apache 2.4的 Red Hat Enterprise Linux 7.0 和 CentOS 7.0中安装和配置LAMP-Linux Apache、 MariaDB、 PHP、PhpMyAdmin。
|
||||
|
||||

|
||||
|
||||
Install LAMP in RHEL/CentOS 7.0
|
||||
在RHEL/CentOS 7.0中安装LAMP
|
||||
|
||||
#### Requirements ####
|
||||
#### 要求 ####
|
||||
|
||||
Depending on the used distribution, RHEL or CentOS 7.0, use the following links to perform a minimal system installation, using a static IP Address for network configuration.
|
||||
根据使用的发行版,RHEL 或者 CentOS 7.0使用下面的链接来执行最小的系统安装,网络使用静态ip
|
||||
|
||||
**For RHEL 7.0**
|
||||
**对于RHEL 7.0**
|
||||
|
||||
- [RHEL 7.0 Installation Procedure][1]
|
||||
- [Register and Enable Subscriptions/Repositories on RHEL 7.0][2]
|
||||
- [RHEL 7.0安装过程][1]
|
||||
- [在RHEL 7.0中注册和启用订阅仓库][2]
|
||||
|
||||
**For CentOS 7.0**
|
||||
**对于 CentOS 7.0**
|
||||
|
||||
- [CentOS 7.0 Installation Procedure][3]
|
||||
- [CentOS 7.0 安装过程][3]
|
||||
|
||||
### Step 1: Install Apache Server with Basic Configurations ###
|
||||
### 第一步: 使用基本配置安装apache ###
|
||||
|
||||
**1. After performing a minimal system installation and configure your server network interface with a [Static IP Address on RHEL/CentOS 7.0][4], go ahead and install Apache 2.4 httpd service binary package provided form official repositories using the following command.**
|
||||
**1. 在执行最小系统安装并配置[在RHEL/CentOS 7.0中配置静态ip][4]**就可以从使用下面的命令从官方仓库安装最新的Apache 2.4 httpd服务。
|
||||
|
||||
# yum install httpd
|
||||
|
||||
|
||||
|
||||
Install Apache Web Server
|
||||
安装apache服务
|
||||
|
||||
**2. After yum manager finish installation, use the following commands to manage Apache daemon, since RHEL and CentOS 7.0 both migrated their init scripts from SysV to systemd – you can also use SysV and Apache scripts the same time to manage the service.**
|
||||
**2. 安装安城后,使用下面的命令来管理apache守护进程,因为RHEL and CentOS 7.0都将init脚本从SysV升级到了systemd - 你也可以同事使用SysV和Apache脚本来管理服务。**
|
||||
|
||||
# systemctl status|start|stop|restart|reload httpd
|
||||
|
||||
OR
|
||||
或者
|
||||
|
||||
# service httpd status|start|stop|restart|reload
|
||||
|
||||
OR
|
||||
或者
|
||||
|
||||
# apachectl configtest| graceful
|
||||
|
||||

|
||||
|
||||
Start Apache Web Server
|
||||
启动apache服务
|
||||
|
||||
**3. On the next step start Apache service using systemd init script and open RHEL/CentOS 7.0 Firewall rules using firewall-cmd, which is the default command to manage iptables through firewalld daemon.**
|
||||
**3. 下一步使用systemd初始化脚本来启动apache服务并用firewall-cmd打开RHEL/CentOS 7.0防火墙规则, 这是通过firewalld守护进程管理iptables的默认命令。**
|
||||
|
||||
# firewall-cmd --add-service=http
|
||||
|
||||
**NOTE**: Make notice that using this rule will lose its effect after a system reboot or firewalld service restart, because it opens on-fly rules, which are not applied permanently. To apply consistency iptables rules on firewall use –permanent option and restart firewalld service to take effect.
|
||||
**注意**:上面的命令会在系统重启或者firewalld服务重启后失效,因为它是即时的规则,它不会永久生效。要使iptables规则在fiewwall中持久化,使用-permanent选项并重启firewalld服务来生效。
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
# systemctl restart firewalld
|
||||
|
||||

|
||||
|
||||
Enable Firewall in CentOS 7
|
||||
在CentOS 7中启用Firewall
|
||||
|
||||
Other important Firewalld options are presented below:
|
||||
下面是firewalld其他的重要选项:
|
||||
|
||||
# firewall-cmd --state
|
||||
# firewall-cmd --list-all
|
||||
@ -67,37 +67,38 @@ Other important Firewalld options are presented below:
|
||||
# firewall-cmd --query-service service_name
|
||||
# firewall-cmd --add-port=8080/tcp
|
||||
|
||||
**4. To verify Apache functionality open a remote browser and type your server IP Address using HTTP protocol on URL (http://server_IP), and a default page should appear like in the screenshot below.**
|
||||
**4. 要验证apache的功能,打开一个远程浏览器并使用http协议输入你服务器的ip地址(http://server_IP), 应该会显示下图中的默认页面。**
|
||||
|
||||

|
||||
|
||||
Apache Default Page
|
||||
Apache默认页
|
||||
|
||||
**5. For now, Apache DocumentRoot path it’s set to /var/www/html system path, which by default doesn’t provide any index file. If you want to see a directory list of your DocumentRoot path open Apache welcome configuration file and set Indexes statement from – to + on <LocationMach> directive, using the below screenshot as an example.**
|
||||
**5. 现在apache的根地址在/var/www/html,该目录中没有提供任何index文件。如果你想要看见根目录下的文件夹列表,打开apache欢迎配置文件并设置 <LocationMach>下Indexes前的状态从-到+,下面的截图就是一个例子。**
|
||||
|
||||
# nano /etc/httpd/conf.d/welcome.conf
|
||||
|
||||

|
||||
|
||||
Apache Directory Listing
|
||||
Apache目录列出
|
||||
|
||||
**6. Close the file, restart Apache service to reflect changes and reload your browser page to see the final result.**
|
||||
**6. 关闭文件,重启apache服务来使设置生效,重载页面来看最终效果。**
|
||||
|
||||
# systemctl restart httpd
|
||||
|
||||

|
||||
|
||||
Apache Index File
|
||||
Apache Index 文件
|
||||
|
||||
### Step 2: Install PHP5 Support for Apache ###
|
||||
### 第二步: 为Apache安装php5支持 ###
|
||||
|
||||
**7. Before installing PHP5 dynamic language support for Apache, get a full list of available PHP modules and extensions using the following command.**
|
||||
|
||||
**7. 在为apache安装php支持之前,使用下面的命令的得到所有可用的php模块和扩展。**
|
||||
|
||||
# yum search php
|
||||
|
||||

|
||||
|
||||
Install PHP in CentOS 7
|
||||
在
|
||||
|
||||
**8. Depending on what type of applications you want to use, install the required PHP modules from the above list, but for a basic MariaDB support in PHP and PhpMyAdmin you need to install the following modules.**
|
||||
|
||||
@ -140,22 +141,22 @@ Set Timezone in PHP
|
||||
|
||||

|
||||
|
||||
Install MariaDB in CentOS 7
|
||||
在CentOS 7中安装PHP
|
||||
|
||||
**12. After MariaDB package is installed, start database daemon and use mysql_secure_installation script to secure database (set root password, disable remotely logon from root, remove test database and remove anonymous users).**
|
||||
***12. 安装MariaDB后,开启数据库守护进程并使用mysql_secure_installation脚本来保护数据库(设置root密码、禁止远程root登录、移除测试数据库、移除匿名用户)**
|
||||
|
||||
# systemctl start mariadb
|
||||
# mysql_secure_installation
|
||||
|
||||

|
||||
|
||||
Start MariaDB Database
|
||||
启动MariaDB数据库
|
||||
|
||||

|
||||
|
||||
Secure MySQL Installation
|
||||
MySQL安全设置
|
||||
|
||||
**13. To test database functionality login to MariaDB using its root account and exit using quit statement.**
|
||||
**13. 要测试数据库功能,使用root账户登录MariaDB并用quit退出。**
|
||||
|
||||
mysql -u root -p
|
||||
MariaDB > SHOW VARIABLES;
|
||||
@ -163,27 +164,27 @@ Secure MySQL Installation
|
||||
|
||||

|
||||
|
||||
Connect MySQL Database
|
||||
连接MySQL数据库
|
||||
|
||||
### Step 4: Install PhpMyAdmin ###
|
||||
### 第四步: 安装PhpMyAdmin ###
|
||||
|
||||
**14. By default official RHEL 7.0 or CentOS 7.0 repositories doesn’t provide any binary package for PhpMyAdmin Web Interface. If you are uncomfortable using MySQL command line to manage your database you can install PhpMyAdmin package by enabling CentOS 7.0 rpmforge repositories using the following command.**
|
||||
**14. RHEL 7.0 或者 CentOS 7.0仓库默认没有提供PhpMyAdmin二进制安装包。如果你不适应使用MySQL命令行来管理你的数据库,你可以通过下面的命令启用CentOS 7.0 rpmforge仓库来安装PhpMyAdmin。**
|
||||
|
||||
# yum install http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el7.rf.x86_64.rpm
|
||||
|
||||
After enabling rpmforge repository, next install PhpMyAdmin.
|
||||
启用rpmforge仓库后,下面安装PhpMyAdmin。
|
||||
|
||||
# yum install phpmyadmin
|
||||
|
||||

|
||||
|
||||
Enable RPMForge Repository
|
||||
启用RPMForge仓库
|
||||
|
||||
**15. Next configure PhpMyAdmin to allow connections from remote hosts by editing phpmyadmin.conf file, located on Apache conf.d directory, commenting the following lines.**
|
||||
**15. 下面配置PhpMyAdmin的phpmyadmin.conf来允许远程连接,它位于Apache conf.d目录下,并注释掉下面的行。**
|
||||
|
||||
# nano /etc/httpd/conf.d/phpmyadmin.conf
|
||||
|
||||
Use a # and comment this lines.
|
||||
使用#来注释掉行。
|
||||
|
||||
# Order Deny,Allow
|
||||
# Deny from all
|
||||
@ -191,40 +192,40 @@ Use a # and comment this lines.
|
||||
|
||||

|
||||
|
||||
Allow Remote PhpMyAdmin Access
|
||||
允许远程PhpMyAdmin访问
|
||||
|
||||
**16. To be able to login to PhpMyAdmin Web interface using cookie authentication method add a blowfish string to phpmyadmin config.inc.php file like in the screenshot below using the [generate a secret string][6], restart Apache Web service and direct your browser to the URL address http://server_IP/phpmyadmin/.**
|
||||
**16. 要使用cookie验证来登录PhpMyAdmin,像下面的截图那样使用[生成字符串][6]添加一个blowfish字符串到config.inc.php文件下,重启apache服务并打开URL:http://server_IP/phpmyadmin/。**
|
||||
|
||||
# nano /etc/httpd/conf.d/phpmyadmin.conf
|
||||
# systemctl restart httpd
|
||||
|
||||

|
||||
|
||||
Add Blowfish in PhpMyAdmin
|
||||
在PhpMyAdmin中添加Blowfish
|
||||
|
||||

|
||||
|
||||
PhpMyAdmin Dashboard
|
||||
PhpMyAdmin面板
|
||||
|
||||
### Step 5: Enable LAMP System-wide ###
|
||||
### 第五步: 系统范围启用LAMP ###
|
||||
|
||||
**17. If you need MariaDB and Apache services to be automatically started after reboot issue the following commands to enable them system-wide.**
|
||||
**17. 如果你需要在重启后自动运行MariaDB和Apache服务,你需要系统级地启用它们。**
|
||||
|
||||
# systemctl enable mariadb
|
||||
# systemctl enable httpd
|
||||
|
||||

|
||||
|
||||
Enable Services System Wide
|
||||
系统级启用服务
|
||||
|
||||
That’s all it takes for a basic LAMP installation on Red Hat Enterprise 7.0 or CentOS 7.0. The next series of articles related to LAMP stack on CentOS/RHEL 7.0 will discuss how to create Virtual Hosts, generate SSL Certificates and Keys and add SSL transaction support for Apache HTTP Server.
|
||||
这就是在Red Hat Enterprise 7.0或者CentOS 7.0中安装LAMP的过程。CentOS/RHEL 7.0上关于LAMP洗系列文章将会讨论在Apache中创建虚拟主机,生成SSL证书、密钥和添加SSL事物支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -235,4 +236,4 @@ via: http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[3]:http://www.tecmint.com/centos-7-installation/
|
||||
[4]:http://www.tecmint.com/configure-network-interface-in-rhel-centos-7-0/
|
||||
[5]:http://php.net/manual/en/timezones.php
|
||||
[6]:http://www.question-defense.com/tools/phpmyadmin-blowfish-secret-generator
|
||||
[6]:http://www.question-defense.com/tools/phpmyadmin-blowfish-secret-generator
|
||||
177
translated/tech/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
177
translated/tech/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
@ -0,0 +1,177 @@
|
||||
LINUX 101: 让你的 SHELL 更强大
|
||||
================================================================================
|
||||
> 在我们的有关 shell 基础的指导下, 得到一个更灵活,功能更强大且多彩的命令行界面
|
||||
|
||||
**为何要这样做?**
|
||||
|
||||
- 使得在 shell 提示符下过得更轻松,高效
|
||||
- 在失去连接后恢复先前的会话
|
||||
- Stop pushing around that fiddly rodent! (注: 我不知道这句该如何翻译)
|
||||
|
||||

|
||||
|
||||
Here’s our souped-up prompt on steroids.(注: 我不知道该如何翻译这句)对于这个细小的终端窗口来说,这或许有些长.但你可以根据你的喜好来调整它的大小.
|
||||
|
||||
作为一个 Linux 用户, 对 shell (又名为命令行),你可能会熟悉. 或许你需要时不时的打开终端来完成那些不能在 GUI 下处理的必要任务,抑或是因为你处在一个平铺窗口管理器的环境中, 而 shell 是你与你的 linux 机器交互的主要方式.
|
||||
|
||||
在上面的任一情况下,你可能正在使用你所使用的发行版本自带的 Bash 配置. 尽管对于大多数的任务而言,它足够强大,但它可以更加强大. 在本教程中,我们将向你展示如何使得你的 shell 更具信息性,更加实用且更适于在其中工作. 我们将对提示符进行自定义,让它比默认情况下提供更好的反馈,并向你展示如何使用炫酷的 `tmux` 工具来管理会话并同时运行多个程序. 并且,为了让眼睛舒服一点,我们还将关注配色方案. 接着,就让我们向前吧!
|
||||
|
||||
### 让提示符 "唱歌" ###
|
||||
|
||||
大多数的发行版本配置有一个非常简单的提示符 – 它们大多向你展示了一些基本信息, 但提示符可以为你提供更多的内容.例如,在 Debian 7 下,默认的提示符是这样的:
|
||||
|
||||
mike@somebox:~$
|
||||
|
||||
上面的提示符展示出了用户,主机名,当前目录和账户类型符号(假如你切换到 root 账户, **$** 会变为 # ). 那这些信息是在哪里存储的呢? 答案是:在 **PS1** 环境变量中. 假如你键入 **echo $PS1**, 你将会在这个命令的输出字符串的最后有如下的字符:
|
||||
|
||||
\u@\h:\w$ (注:这里没有加上斜杠 \,应该是没有转义 ,下面的有些命令也一样,我把 \ 都加上了,发表的时候也得注意一下)
|
||||
|
||||
这看起来有一些丑陋,并在瞥见它的第一眼时,你可能会开始尖叫,认为它是令人恐惧的正则表达式,但我们不打算用这些复杂的字符来煎熬我们的大脑. 这不是正则表达式, 这里的斜杠是转义序列,它告诉提示符进行一些特别的处理. 例如,上面的 **u** 部分,告诉提示符展示用户名, 而 w 则展示工作路径.
|
||||
|
||||
下面是一些你可以在提示符中用到的字符的列表:
|
||||
|
||||
- d 当前的日期.
|
||||
- h 主机名.
|
||||
- n 代表新的一行的字符.
|
||||
- A 当前的时间 (HH:MM).
|
||||
- u 当前的用户.
|
||||
- w (小写) 整个工作路径的全称.
|
||||
- W (大写) 工作路径的简短名称.
|
||||
- $ 一个提示符号,对于 root 用户为 # 号.
|
||||
- ! 当前命令在 shell 历史记录中的序号.
|
||||
|
||||
下面解释 **w** 和 **W** 选项的区别: 对于前者,你将看到你所在的工作路径的完整地址,(例如 **/usr/local/bin**), 而对于后者, 它则只显示 **bin** 这一部分.
|
||||
|
||||
现在, 我们该怎样改变提示符呢? 你需要更改 **PS1** 环境变量的内容, 试试下面这个:
|
||||
|
||||
export PS1=”I am \u and it is \A $”
|
||||
|
||||
现在, 你的提示符将会像下面这样:
|
||||
|
||||
I am mike and it is 11:26 $
|
||||
|
||||
从这个例子出发, 你就可以按照你的想法来试验一下上面列出的其他转义序列. 但稍等片刻 – 当你登出后,你的这些努力都将消失,因为在你每次打开终端时, **PS1** 环境变量的值都会被重置. 解决这个问题的最简单方式是打开 **.bashrc** 配置文件(在你的家目录下) 并在这个文件的最下方添加上完整的 `export` 命令.在每次你启动一个新的 shell 会话时,这个 **.bashrc** 会被 `Bash` 读取, 所以你的被加强了的提示符就可以一直出现.你还可以使用额外的颜色来装扮提示符.刚开始,这将有点棘手,因为你必须使用一些相当奇怪的转义序列,但结果是非常漂亮的. 将下面的字符添加到你的 **PS1**字符串中的某个位置,最终这将把文本变为红色:
|
||||
|
||||
\[\e[31m\]
|
||||
|
||||
你可以将这里的 31 更改为其他的数字来获得不同的颜色:
|
||||
|
||||
- 30 黑色
|
||||
- 32 绿色
|
||||
- 33 黄色
|
||||
- 34 蓝色
|
||||
- 35 洋红色
|
||||
- 36 青色
|
||||
- 37 白色
|
||||
|
||||
所以,让我们使用先前看到的转义序列和颜色来创造一个提示符,以此来结束这一小节的内容. 深吸一口气,弯曲你的手指,然后键入下面这只"野兽":
|
||||
|
||||
export PS1="(\!) \[\e[31m\] \[\A\] \[\e[32m\]\u@\h \[\e[34m\]\w \[\e[30m\]$"
|
||||
|
||||
上面的命令提供了一个 Bash 命令历史序号, 当前的时间,用户或主机名与颜色之间的组合,以及工作路径.假如你"野心勃勃",利用一些惊人的组合,你还可以更改提示符的背景色和前景色.先前实用的 Arch wiki 有一个关于颜色代码的完整列表:[http://tinyurl.com/3gvz4ec][1].
|
||||
|
||||
> ### Shell 精要 ###
|
||||
>
|
||||
> 假如你是一个彻底的 Linux 新手并第一次阅读这份杂志,或许你会发觉阅读这些教程有些吃力. 所以这里有一些基础知识来让你熟悉一些 shell. 通常在你的菜单中, shell 指的是 Terminal, XTerm 或 Konsole, 但你启动它后, 最为实用的命令有这些:
|
||||
>
|
||||
> **ls** (列出文件名); **cp one.txt two.txt** (复制文件); **rm file.txt** (移除文件); **mv old.txt new.txt** (移动或重命名文件);
|
||||
>
|
||||
> **cd /some/directory** (改变目录); **cd ..** (回到上级目录); **./program** (在当前目录下运行一个程序); **ls > list.txt** (重定向输出到一个文件).
|
||||
>
|
||||
> 几乎每个命令都有一个手册页用来解释其选项(例如 **man ls** – 按 Q 来退出).在那里,你可以知晓命令的选项,这样你就知道 **ls -la** 展示一个详细的列表,其中也列出了隐藏文件, 并且在键入一个文件或目录的名字的一部分后, 可以使用 Tab 键来自动补全.
|
||||
|
||||
### Tmux: 针对 shell 的窗口管理器 ###
|
||||
|
||||
在文本模式的环境中使用一个窗口管理器 – 这听起来有点不可思议, 是吧? 然而,你应该记得当 Web 浏览器第一次实现分页浏览的时候吧? 在当时, 这是在可用性上的一个重大进步,它减少了桌面任务栏的杂乱无章和繁多的窗口列表. 对于你的浏览器来说,你只需要一个按钮便可以在浏览器中切换到你打开的每个单独网站, 而不是针对每个网站都有一个任务栏或导航图标. 这个功能非常有意义.
|
||||
|
||||
若有时你同时运行着几个虚拟终端,你便会遇到相似的情况; 在这些终端之间跳转,或每次在任务栏或窗口列表中找到你所需要的那一个终端,都可能会让你觉得麻烦. 拥有一个文本模式的窗口管理器不仅可以让你像在同一个终端窗口中运行多个 shell 会话,而且你甚至还可以将这些窗口排列在一起.
|
||||
|
||||
另外,这样还有另一个好处:可以将这些窗口进行分离和重新连接.想要看看这是如何运行的最好方式是自己尝试一下. 在一个终端窗口中,输入 **screen** (在大多数发行版本中,它被默认安装了或者可以在软件包仓库中找到). 某些欢迎的文字将会出现 – 只需敲击 Enter 键这些文字就会消失. 现在运行一个交互式的文本模式的程序,例如 **nano**, 并关闭这个终端窗口.
|
||||
|
||||
在一个正常的 shell 对话中, 关闭窗口将会终止所有在该终端中运行的进程 – 所以刚才的 Nano 编辑对话也就被终止了, 但对于 screen 来说,并不是这样的. 打开一个新的终端并输入如下命令:
|
||||
|
||||
screen -r
|
||||
|
||||
瞧, 你刚开打开的 Nano 会话又回来了!
|
||||
|
||||
当刚才你运行 **screen** 时, 它会创建了一个新的独立的 shell 会话, 它不与某个特定的终端窗口绑定在一起,所以可以在后面被分离并重新连接( 即 **-r** 选项).
|
||||
|
||||
当你正使用 SSH 去连接另一台机器并做着某些工作, 但并不想因为一个单独的连接而毁掉你的所有进程时,这个方法尤其有用.假如你在一个 **screen** 会话中做着某些工作,并且你的连接突然中断了(或者你的笔记本没电了,又或者你的电脑报废了),你只需重新连接一个新的电脑或给电脑充电或重新买一台电脑,接着运行 **screen -r** 来重新连接到远程的电脑,并在刚才掉线的地方接着开始.
|
||||
|
||||
现在,我们都一直在讨论 GNU 的 **screen**,但这个小节的标题提到的是 tmux. 实质上, **tmux** (terminal multiplexer) 就像是 **screen** 的一个进阶版本,带有许多有用的额外功能,所以现在我们开始关注 tmux. 某些发行版本默认包含了 **tmux**; 在其他的发行版本上,通常只需要一个 **apt-get, yum install** 或 **pacman -S** 命令便可以安装它.
|
||||
|
||||
一旦你安装了它过后,键入 **tmux** 来启动它.接着你将注意到,在终端窗口的底部有一条绿色的信息栏,它非常像传统的窗口管理器中的任务栏: 上面显示着一个运行着的程序的列表,机器的主机名,当前时间和日期. 现在运行一个程序,又以 Nano 为例, 敲击 Ctrl+B 后接着按 C 键, 这将在 tmux 会话中创建一个新的窗口,你便可以在终端的底部的任务栏中看到如下的信息:
|
||||
|
||||
0:nano- 1:bash*
|
||||
|
||||
每一个窗口都有一个数字,当前呈现的程序被一个星号所标记. Ctrl+B 是与 tmux 交互的标准方式, 所以若你敲击这个按键组合并带上一个窗口序号, 那么就会切换到对应的那个窗口.你也可以使用 Ctrl+B 再加上 N 或 P 来分别切换到下一个或上一个窗口 – 或者使用 Ctrl+B 加上 L 来在最近使用的两个窗口之间来进行切换(有点类似于桌面中的经典的 Alt+Tab 组合键的效果). 若需要知道窗口列表,使用 Ctrl+B 再加上 W.
|
||||
|
||||
目前为止,一切都还好:现在你可以在一个单独的终端窗口中运行多个程序,避免混乱(尤其是当你经常与同一个远程主机保持多个 SSH 连接时.). 当想同时看两个程序又该怎么办呢?
|
||||
|
||||
针对这种情况, 可以使用 tmux 中的窗格. 敲击 Ctrl+B 再加上 % , 则当前窗口将分为两个部分,一个在左一个在右.你可以使用 Ctrl+B 再加上 O 来在这两个部分之间切换. 这尤其在你想同时看两个东西时非常实用, – 例如一个窗格看指导手册,另一个窗格里用编辑器看一个配置文件.
|
||||
|
||||
有时,你想对一个单独的窗格进行缩放,而这需要一定的技巧. 首先你需要敲击 Ctrl+B 再加上一个 :(分号),这将使得位于底部的 tmux 栏变为深橙色. 现在,你进入了命令模式,在这里你可以输入命令来操作 tmux. 输入 **resize-pane -R** 来使当前窗格向右移动一个字符的间距, 或使用 **-L** 来向左移动. 对于一个简单的操作,这些命令似乎有些长,但请注意,在 tmux 的命令模式(以前面提到的一个分号开始的模式)下,可以使用 Tab 键来补全命令. 另外需要提及的是, **tmux** 同样也有一个命令历史记录,所以若你想重复刚才的缩放操作,可以先敲击 Ctrl+B 再跟上一个分号并使用向上的箭头来取回刚才输入的命令.
|
||||
|
||||
最后,让我们看一下分离和重新连接 - 即我们刚才介绍的 screen 的特色功能. 在 tmux 中,敲击 Ctrl+B 再加上 D 来从当前的终端窗口中分离当前的 tmux 会话, 这使得这个会话的一切工作都在后台中运行.使用 **tmux a** 可以再重新连接到刚才的会话. 但若你同时有多个 tmux 会话在运行时,又该怎么办呢? 我们可以使用下面的命令来列出它们:
|
||||
|
||||
tmux ls
|
||||
|
||||
这个命令将为每个会话分配一个序号; 假如你想重新连接到会话 1, 可以使用 `tmux a -t 1`. tmux 是可以高度定制的,你可以自定义按键绑定并更改配色方案, 所以一旦你适应了它的主要功能,请钻研指导手册以了解更多的内容.
|
||||
|
||||
tmux: 一个针对 shell 的窗口管理器
|
||||
|
||||

|
||||
|
||||
上图中, tmux 开启了两个窗格: 左边是 Vim 正在编辑一个配置文件,而右边则展示着指导手册页.
|
||||
|
||||
> ### Zsh: 另一个 shell ###
|
||||
>
|
||||
> 选择是好的,但标准同样重要. 你要知道几乎每个主流的 Linux 发行版本都默认使用 Bash shell – 尽管还存在其他的 shell. Bash 为你提供了一个 shell 能够给你提供的几乎任何功能,包括命令历史记录,文件名补全和许多脚本编程的能力.它成熟,可靠并文档丰富 – 但它不是你唯一的选择.
|
||||
>
|
||||
> 许多高级用户热衷于 Zsh, 即 Z shell. 这是 Bash 的一个替代品并提供了 Bash 的几乎所有功能,令外还提供了一些额外的功能. 例如, 在 Zsh 中,你输入 **ls** - 并敲击 Tab 键可以得到 **ls** 可用的各种不同选项的一个大致描述. 而不需要再打开 man page 了!
|
||||
>
|
||||
> Zsh 还支持其他强大的自动补全功能: 例如,输入 **cd /u/lo/bi** 再敲击 Tab 键, 则完整的路径名 **/usr/local/bin** 就会出现(这里假设没有其他的路径包含 **u**, **lo** 和 **bi** 等字符.). 或者只输入 **cd** 再跟上 Tab 键,则你将看到着色后的路径名的列表 – 这比 Bash 给出的简单的结果好看得多.
|
||||
>
|
||||
> Zsh 在大多数的主要发行版本上都可以得到; 安装它后并输入 **zsh** 便可启动它. 要将你的默认 shell 从 Bash 改为 Zsh, 可以使用 **chsh** 命令. 若需了解更多的信息,请访问 [www.zsh.org][2].
|
||||
|
||||
### "未来" 的终端 ###
|
||||
|
||||
你或许会好奇为什么包含你的命令行提示符的应用被叫做终端. 这需要追溯到 Unix 的早期, 那时人们一般工作在一个多用户的机器上,这个巨大的电脑主机将占据一座建筑中的一个房间, 人们在某些线路的配合下,使用屏幕和键盘来连接到这个主机, 这些终端机通常被称为 "哑终端", 因为它们不能靠自己做任何重要的执行任务 – 它们只展示通过线路从主机传来的信息,并输送回从键盘的敲击中得到的输入信息.
|
||||
|
||||
今天,几乎所有的我们在自己的机器上执行实际的操作,所以我们的电脑不是传统意义下的终端, 这就是为什么诸如 **XTerm**, Gnome Terminal, Konsole 等程序被称为 "终端模拟器" 的原因 – 他们提供了同昔日的物理终端一样的功能.事实上,在许多方面它们并没有改变多少.诚然,现在我们有了反锯齿字体,更好的颜色和点击网址的能力,但总的来说,几十年来我们一直以同样的方式在工作.
|
||||
|
||||
所以某些程序员正尝试改变这个状况. **Terminology** ([http://tinyurl.com/osopjv9][3]), 它来自于超级时髦的 Enlightenment 窗口管理器背后的团队,旨在将终端引入 21 世纪,例如带有在线媒体显示功能.你可以在一个充满图片的目录里输入 **ls** 命令,便可以看到它们的缩略图,或甚至可以直接在你的终端里播放视频. 这使得一个终端有点类似于一个文件管理器,意味着你可以快速地检查媒体文件的内容而不必用另一个应用来打开它们.
|
||||
|
||||
接着还有 Xiki ([www.xiki.org][4]),它自身的描述为 "命令的革新".它就像是一个传统的 shell, 一个 GUI 和一个 wiki 之间的过渡; 你可以在任何地方输入命令,并在后面将它们的输出存储为笔记以作为参考,并可以创建非常强大的自定义命令.用几句话是很能描述它的,所以作者们已经创作了一个视频来展示它的潜力是多么的巨大(请看 **Xiki** 网站的截屏视频部分).
|
||||
|
||||
并且 Xiki 绝不是那种在几个月之内就消亡的昙花一现的项目,作者们成功地进行了一次 Kickstarter 众筹,在七月底已募集到超过 $84,000. 是的,你没有看错 – $84K 来支持一个终端模拟器.这可能是最不寻常的集资活动,因为某些疯狂的家伙已经决定开始创办它们自己的 Linux 杂志 ......
|
||||
|
||||
### 下一代终端 ###
|
||||
|
||||
许多命令行和基于文本的程序在功能上与它们的 GUI 程序是相同的,并且常常更加快速和高效. 我们的推荐有:
|
||||
**Irssi** (IRC 客户端); **Mutt** (mail 客户端); **rTorrent** (BitTorrent); **Ranger** (文件管理器); **htop** (进程监视器). 若给定在终端的限制下来进行 Web 浏览, Elinks 确实做的很好,并且对于阅读那些以文字为主的网站例如 Wikipedia 来说,它非常实用.
|
||||
|
||||
> ### 微调配色方案 ###
|
||||
>
|
||||
> 在 Linux Voice 中,我们并不迷恋养眼的东西,但当你每天花费几个小时盯着屏幕看东西时,我们确实认识到美学的重要性.我们中的许多人都喜欢调整我们的桌面和窗口管理器来达到完美的效果,调整阴影效果,摆弄不同的配色方案,直到我们 100% 的满意.(然后出于习惯,摆弄更多的东西.)
|
||||
>
|
||||
> 但我们倾向于忽视终端窗口,它理应也获得我们的喜爱, 并且在 [http://ciembor.github.io/4bit][5] 你将看到一个极其棒的配色方案设计器,对于所有受欢迎的终端模拟器(**XTerm, Gnome Terminal, Konsole and Xfce4 Terminal are among the apps supported.**),它可以色设定.移动滑动条直到你看到配色方案 norvana, 然后点击位于该页面右上角的 `得到方案` 按钮.
|
||||
>
|
||||
> 相似的,假如你在一个文本编辑器,如 Vim 或 Emacs 上花费很多的时间,使用一个精心设计的调色板也是非常值得的. **Solarized at** [http://ethanschoonover.com/solarized][6] 是一个卓越的方案,它不仅漂亮,而且因追求最大的可用性而设计,在其背后有着大量的研究和测试.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://tinyurl.com/3gvz4ec
|
||||
[2]:http://www.zsh.org/
|
||||
[3]:http://tinyurl.com/osopjv9
|
||||
[4]:http://www.xiki.org/
|
||||
[5]:http://ciembor.github.io/4bit
|
||||
[6]:http://ethanschoonover.com/solarized
|
||||
@ -0,0 +1,206 @@
|
||||
Tor浏览器:Linux下用于匿名Web浏览的终极浏览器
|
||||
================================================================================
|
||||
我们大多数人都在上网方面花费很多时间。上网使用的应用程序主要是浏览器,一个Web浏览器则更加完美。我们网络的活动要以客户端/服务器的方式登录,这个过程会包括IP地址、地理信息、搜索、活动以及许多潜在的信息,这些信息如果以其他方式被故意使用,会存在潜在的危险性。
|
||||
|
||||

|
||||
|
||||
Tor浏览器:匿名浏览器
|
||||
|
||||
此外,美国国家安全局(NSA)即国际间谍机构会记录我们的数字足迹。更不必说某个受限的代理服务器也会被用来做为数据搜集服务器。并且大多数企业和公司不会允许您访问代理服务器(使您能保障自己的隐私)。
|
||||
|
||||
因此,我们需要的最好是一个小型、独立、可携带的应用程序,它能达到匿名的效果。Tor浏览器便是这样的一个应用,它拥有上面提到的所有功能,甚至不止于此。
|
||||
|
||||
这篇文章里我们会讨论Tor浏览器,它的功能、使用方式、领域、安装以及其他关于Tor浏览器的重要方面。
|
||||
|
||||
#### 什么是Tor浏览器? ####
|
||||
|
||||
Tor是一个自由分发的应用软件,以BSD式的许可证发布,通过其安全可靠的洋葱式的结构,允许用户匿名的进行网络浏览。从前,由于它的结构和运作机制,Tor被称为‘洋葱路由器’。这个应用是由C语言写成的。
|
||||
|
||||
#### Tor浏览器的功能 ####
|
||||
|
||||
- 跨平台可用。例如,这个应用程序在Linux、Windows和Mac下都可用。
|
||||
- 在发送数据到因特网前进行复杂的数据加密。
|
||||
- 在客户端进行的数据自动解密。
|
||||
- 它是火狐浏览器和Tor工程的结合。
|
||||
- 对服务器和网站提供匿名性。
|
||||
- 可以访问被锁定的网站。
|
||||
- 无需暴露源IP便可以执行任务。
|
||||
- 可以在防火墙后将数据路由至/从隐藏的服务和应用程序。
|
||||
- 便携性 - 可以直接从USB存储器运行一个预配置的web浏览器。无需本地安装。
|
||||
- 在x86和x86_64平台均可用
|
||||
- 可以通过使用Tor以“socks4a”的方式在“localhost”的“9050”端口上配置代理以设置FTP。
|
||||
- Tor拥有处理上千的转播和上百万用户的能力。
|
||||
|
||||
#### Tor浏览器如何工作? ####
|
||||
|
||||
Tor的工作方式基于洋葱路由的概念。洋葱路由的结构类似洋葱,它的每一层都嵌套在另一层里面,就像洋葱一样。这种嵌套的结构负责多次加密数据并将其通过虚拟电路进行发送。在客户端一边每一层都在将他传递到下一层之前解密数据。最后一层在将原始数据传递到目的地前解密最里面一层的加密数据。
|
||||
|
||||
在这个过程里,这种解密整个层的功能设计的如此高明以至于无法追踪IP以及用户的地理位置,因此可以限制任何人观察您访问站点的网络连接。
|
||||
|
||||
所有这些过程看起来有些复杂,但用户使用Tor浏览器时没有必要担心。实际上,Tor浏览器的功能像其他浏览器一样(尤其是Mozilla的Firefox)。
|
||||
|
||||
### 在Linux中安装Tor浏览器 ###
|
||||
|
||||
就像上面讨论的一样,Tor浏览器在Linux和Windows以及Mac下都可用。用户需要根据系统和架构的不同在下面的链接处下载最新的版本(例如,Tor浏览器4.0.4)。
|
||||
|
||||
- [https://www.torproject.org/download/download-easy.html.en][1]
|
||||
|
||||
在下载Tor浏览器后,我们需要安装它。但好的是我们不需要安装‘Tor’。它能直接从随身设备中运行,并且该浏览器可以被预配置。这意味着插件和运行的特性可以完美的移植。
|
||||
|
||||
下载打包文件(*.tar.xz)后我们需要解压它。
|
||||
|
||||
**32位系统**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
$ tar xpvf tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
|
||||
**64位系统**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
$ tar -xpvf tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
|
||||
**注意** : 在上面的命令中,我们使用‘$‘意味着这个压缩包应以普通用户而不是root用户来解压。我们强烈建议您不要以root用户解压和运行Tor浏览器。
|
||||
|
||||
在成功的解压后,我们便可以将解压后的浏览器移动到任何地方/USB存储设备中。并从解压的文件夹以非root用户直接运行‘start-tor-browser’。
|
||||
|
||||
$ cd tor-browser_en-US
|
||||
$ ./start-tor-browser
|
||||
|
||||

|
||||
|
||||
开始使用Tor浏览器
|
||||
|
||||
**1. 尝试连接到Tor网络。点击“连接”之后Tor将按照设置帮您做剩下的事情。**
|
||||
|
||||

|
||||
|
||||
连接到Tor网络
|
||||
|
||||
**2. 欢迎窗口/标签。**
|
||||
|
||||

|
||||
|
||||
Tor欢迎界面
|
||||
|
||||
**3. Tor浏览器从Youtube处加载视频。**
|
||||
|
||||

|
||||
|
||||
在Youtube上看视频
|
||||
|
||||
**4. 打开银行网址以进行在线购物和交易。**
|
||||
|
||||

|
||||
|
||||
浏览银行站点
|
||||
|
||||
**5. 浏览器显示我当前的代理IP。注意文本为“Proxy Server detected”。**
|
||||
|
||||

|
||||
|
||||
检查IP地址
|
||||
|
||||
**注意**: 每次您想运行Tor时,您需要使用文本模式来指向Tor启动脚本。并且该终端在您运行Tor时会持续保持忙碌状态。如何克服这些,并创建一个桌面/Dock栏图标呢?
|
||||
|
||||
**6. 我们需要在解压的文件夹中创建`tor.desktop`。**
|
||||
|
||||
$ touch tor.desktop
|
||||
|
||||
接着使用您喜欢的编辑器编辑这个文件,加入下面的文本,这里我使用nano。
|
||||
|
||||
$ nano tor.desktop
|
||||
|
||||
----------
|
||||
|
||||
#!/usr/bin/env xdg-open
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=Tor
|
||||
Comment=Anonymous Browse
|
||||
Type=Application
|
||||
Terminal=false
|
||||
Exec=/home/avi/Downloads/tor-browser_en-US/start-tor-browser
|
||||
Icon=/home/avi/Downloads/tor-browser_en-US/Browser/browser/icons/mozicon128.png
|
||||
StartupNotify=true
|
||||
Categories=Network;WebBrowser;
|
||||
|
||||
**注意**: 确保将上面的tor浏览器的路径替换为您的环境中的路径。
|
||||
|
||||
**7. 一旦搞定后,您就可以双击`tor.desktop`文件来运行Tor浏览器了,您可能需要在第一次运行时信任该文件。**
|
||||
|
||||

|
||||
|
||||
Tor应用启动器
|
||||
|
||||
**8. 一旦您选择了信任,请注意`tor.desktop`文件的图标则会改变。**
|
||||
|
||||

|
||||
|
||||
Tor图标已改变
|
||||
|
||||
**9. 您可以通过拖拽`tor.desktop`的图标在桌面和Dock栏中创建快捷方式。**
|
||||
|
||||

|
||||
|
||||
在桌面添加Tor快捷方式
|
||||
|
||||
**10. 关于Tor浏览器。**
|
||||
|
||||

|
||||
|
||||
关于Tor浏览器
|
||||
|
||||
**注意**: 如果您在使用旧版本的Tor,您可以从上面的窗口更新它。
|
||||
|
||||
#### 应用的可用性和领域 ####
|
||||
|
||||
- 匿名使用网络。
|
||||
- 浏览被阻挡的页面。
|
||||
- 连接其他应用,即(FTP)来保证网络安全的访问。
|
||||
|
||||
#### 关于Tor浏览器的争论 ####
|
||||
|
||||
- 在Tor浏览器的周边并没有什么安全措施。比如,数据入口点和出口点。
|
||||
- 一项2011年的研究发现一种特殊的针对Tor浏览器的攻击可以得到BitTorrent用户的IP地址。
|
||||
- 在一些研究中发现某些特定的协议有泄漏IP地址的倾向。
|
||||
- Tor早些的版本绑定了旧版本的Firefox浏览器,这被证明较易受JavaScript攻击。
|
||||
- Tor浏览器工作的比较缓慢。
|
||||
|
||||
#### 真实世界中Tor浏览器的实现 ####
|
||||
|
||||
- Vuze BitTorrent Client
|
||||
- Anonymous Os
|
||||
- Os’es from Scratch
|
||||
- whonix 等
|
||||
|
||||
#### Tor浏览器的未来 ####
|
||||
|
||||
Tor浏览器是前途无量的。也许它实现的第一个应用程序非常出色,但Tor浏览器必须加大对伸缩性的支持以及对近期的攻击进行研究以保证数据安全。这个应用程序是未来的需要。
|
||||
|
||||
#### 下载免费的电子书 ####
|
||||
|
||||
非官方的Tor私密浏览指南
|
||||
|
||||
[][2]
|
||||
|
||||
### 结论 ###
|
||||
|
||||
如果您工作的部门不允许您访问某网站或者如果您不希望别人知道您的私人事务或您不想向NSA提供您的个人数字足迹,那么Tor浏览器在目前是必须的。
|
||||
|
||||
**注意**: Tor浏览器提供的安全性不能抵御病毒、木马或其他类似这样的安全威胁。写这篇文章的目的也不是希望通过在互联网上隐藏我们的身份来放纵非法活动。这篇文章纯粹是为了教学的目的,作者和Tecmint均不会为任何非法的使用负责。这是用户的唯一责任。
|
||||
|
||||
Tor浏览器是一个非常不错的应用,您值得尝试!这就是我要说的全部了,我还会在这里写一些您感兴趣的文章,所以请继续关注Tecmint。别忘了在留言区提供给我们您有价值的反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.torproject.org/download/download-easy.html.en
|
||||
[2]:http://tecmint.tradepub.com/free/w_make129/prgm.cgi
|
||||
@ -0,0 +1,264 @@
|
||||
在Ubuntu下用不同方式安装Node.JS
|
||||
================================================================================
|
||||
|
||||
如果你要在Ubuntu 15.04上安装Node.js的话,这篇教程对你来说肯定很重要。Node.js根本上来说就是一个运行在服务端上的封装好了输入输出流的javascript程序。Node.js巧妙的使用单线程的event loop来处理异步IO。同时它在平台层面上,面向系统拥有非常实用的文件读写,网络操作功能。所以这篇文章将展示在Ubuntu 15.04 server上不同的安装Node.Js的方式。
|
||||
|
||||
### 安装Node.JS 的方法###
|
||||
|
||||
有许多不同的方法安装Node.JS,我们可以选择其一。通过本篇文章我们将手把手带着你在Ubuntu 15.04上安装Node.Js,在此之前请卸载旧版本的包以免发生包冲突。
|
||||
|
||||
- 从源代码安装Node.JS
|
||||
- 用包管理器安装Node.JS
|
||||
- 从Github远程库安装Node.JS
|
||||
- 用NVM安装Node.JS
|
||||
|
||||
### 1) 从源代码安装Node.JS ###
|
||||
|
||||
让我们开始从从源代码安装Node.JS之前,请确认系统上的所有的依赖包都已经更新到最新版本。然后跟着以下步骤来开始安装:
|
||||
|
||||
#### 步骤1: 升级系统 ####
|
||||
|
||||
用以下命令来升级系统,并且安装一些Node.JS必要的包。
|
||||
|
||||
root@ubuntu-15:~# apt-get update
|
||||
|
||||
root@ubuntu-15:~# apt-get install python gcc make g++
|
||||
|
||||
#### 步骤2: 获取Node.JS的源代码 ####
|
||||
|
||||
安装好依赖包之后我们可以从官方网站上下载Node.JS的源代码。下载以及解压的命令如下:
|
||||
|
||||
root@ubuntu-15:~# wget http://nodejs.org/dist/v0.12.4/node-v0.12.4.tar.gz
|
||||
root@ubuntu-15:~# tar zxvf node-v0.12.4.tar.gz
|
||||
|
||||
#### 步骤3: 开始安装 ####
|
||||
|
||||
现在我们进入源代码的目录然后运行.configuration文件
|
||||
|
||||

|
||||
|
||||
root@ubuntu-15:~# ls
|
||||
node-v0.12.4 node-v0.12.4.tar.gz
|
||||
root@ubuntu-15:~# cd node-v0.12.4/
|
||||
root@ubuntu-15:~/node-v0.12.4# ./configure
|
||||
root@ubuntu-15:~/node-v0.12.4# make install
|
||||
|
||||
### 安装后测试 ###
|
||||
|
||||
只要运行一次上面的命令就顺利安装好了Node.JS,现在我们来确认一下版本信息和测试以下Node.JS是否可以运行输出。
|
||||
|
||||
root@ubuntu-15:~/node-v0.12.4# node -v
|
||||
v0.12.4
|
||||
|
||||

|
||||
|
||||
创建一个以.js为扩展名的文件然后用Node的命令运行
|
||||
|
||||
root@ubuntu-15:~/node-v0.12.4# touch helo_test.js
|
||||
root@ubuntu-15:~/node-v0.12.4# vim helo_test.js
|
||||
console.log('Hello World');
|
||||
|
||||
现在我们用Node的命令运行文件
|
||||
|
||||
root@ubuntu-15:~/node-v0.12.4# node helo_test.js
|
||||
Hello World
|
||||
|
||||
输出的结果证明我们已经成功的在Ubuntu 15.04安装好了Node.JS,同时我们也能运行JavaScript文件。
|
||||
|
||||
### 2) 利用包管理器安装Node.JS ###
|
||||
|
||||
在Ubuntu下用包管理器安装Node.JS是非常简单的,只要增加NodeSource的个人软件包档案(PPA)即可。
|
||||
|
||||
我们将下面通过PPA安装Node.JS
|
||||
|
||||
#### 步骤1: 用curl获取源代码 ####
|
||||
|
||||
在我们用curl获取源代码之前,我们必须先升级操作系统然后用curl命令获取NodeSource添加到本地仓库。
|
||||
|
||||
root@ubuntu-15:~#apt-get update
|
||||
root@ubuntu-15:~# curl -sL https://deb.nodesource.com/setup | sudo bash -
|
||||
|
||||
curl将运行以下任务
|
||||
|
||||
## Installing the NodeSource Node.js 0.10 repo...
|
||||
## Populating apt-get cache...
|
||||
## Confirming "vivid" is supported...
|
||||
## Adding the NodeSource signing key to your keyring...
|
||||
## Creating apt sources list file for the NodeSource Node.js 0.10 repo...
|
||||
## Running `apt-get update` for you...
|
||||
Fetched 6,411 B in 5s (1,077 B/s)
|
||||
Reading package lists... Done
|
||||
## Run `apt-get install nodejs` (as root) to install Node.js 0.10 and npm
|
||||
|
||||
#### 步骤2: 安装NodeJS和NPM ####
|
||||
|
||||
运行以上命令之后如果输出如上所示,我们可以用apt-get命令来安装NodeJS和NPM包。
|
||||
|
||||
root@ubuntu-15:~# apt-get install nodejs
|
||||
|
||||

|
||||
|
||||
#### STEP 3: Installing Build Essentials Tool ####
|
||||
#### 步骤3: 安装一些必备的工具 ####
|
||||
|
||||
通过以下命令来安装编译安装一些我们必需的本地插件。
|
||||
|
||||
root@ubuntu-15:~# apt-get install -y build-essential
|
||||
|
||||
### 通过Node.JS Shell来测试 ###
|
||||
|
||||
测试Node.JS的步骤与之前使用源代码安装相似,通过以下node命令来确认Node.JS是否完全安装好:
|
||||
|
||||
root@ubuntu-15:~# node
|
||||
> console.log('Node.js Installed Using Package Manager');
|
||||
Node.js Installed Using Package Manager
|
||||
|
||||
----------
|
||||
|
||||
root@ubuntu-15:~# node
|
||||
> a = [1,2,3,4,5]
|
||||
[ 1, 2, 3, 4, 5 ]
|
||||
> typeof a
|
||||
'object'
|
||||
> 5 + 2
|
||||
7
|
||||
>
|
||||
(^C again to quit)
|
||||
>
|
||||
root@ubuntu-15:~#
|
||||
|
||||
### 使用NodeJS应用进行简单的测试 ###
|
||||
|
||||
REPL是一个Node.js的shell,任何有效的JavaScript代码都能在REPL下运行通过。所以让我们看看在Node.JS下的REPL是什么样子吧。
|
||||
|
||||
root@ubuntu-15:~# node
|
||||
> var repl = require("repl");
|
||||
undefined
|
||||
> repl.start("> ");
|
||||
|
||||
Press Enter and it will show out put like this:
|
||||
> { domain: null,
|
||||
_events: {},
|
||||
_maxListeners: 10,
|
||||
useGlobal: false,
|
||||
ignoreUndefined: false,
|
||||
eval: [Function],
|
||||
inputStream:
|
||||
{ _connecting: false,
|
||||
_handle:
|
||||
{ fd: 0,
|
||||
writeQueueSize: 0,
|
||||
owner: [Circular],
|
||||
onread: [Function: onread],
|
||||
reading: true },
|
||||
_readableState:
|
||||
{ highWaterMark: 0,
|
||||
buffer: [],
|
||||
length: 0,
|
||||
pipes: null,
|
||||
...
|
||||
...
|
||||
|
||||
以下是可以在REPL下使用的命令列表
|
||||
|
||||

|
||||
|
||||
### 使用NodeJS的包管理器 ###
|
||||
|
||||
NPM是一个提供给node脚本连续运行的命令行工具,它能通过package.json来安装和管理依赖包。最开始从初始化命令init开始
|
||||
|
||||
root@ubuntu-15:~# npm init
|
||||
|
||||

|
||||
|
||||
### 3) 从Github远程库安装Node.JS ###
|
||||
|
||||
在这个方法中我们需要一些步骤来把Node.JS从Github的远程的仓库克隆到本地仓库目录
|
||||
|
||||
在开始克隆(clone)包到本地并且配制之前,我们要先安装以下依赖包
|
||||
|
||||
root@ubuntu-15:~# apt-get install g++ curl make libssl-dev apache2-utils git-core
|
||||
|
||||
现在我们开始用git命令克隆到本地并且转到配制目录
|
||||
|
||||
root@ubuntu-15:~# git clone git://github.com/ry/node.git
|
||||
root@ubuntu-15:~# cd node/
|
||||
|
||||

|
||||
|
||||
clone仓库之后,通过运行.config命令来编译生成完整的安装包。
|
||||
|
||||
root@ubuntu-15:~# ./configure
|
||||
|
||||

|
||||
|
||||
运行make install命令之后耐心等待几分钟,程序将会安装好Node.JS
|
||||
|
||||
root@ubuntu-15:~/node# make install
|
||||
|
||||
root@ubuntu-15:~/node# node -v
|
||||
v0.13.0-pre
|
||||
|
||||
### 测试Node.JS ###
|
||||
|
||||
root@ubuntu-15:~/node# node
|
||||
> a = [1,2,3,4,5,6,7]
|
||||
[ 1, 2, 3, 4, 5, 6, 7 ]
|
||||
> typeof a
|
||||
'object'
|
||||
> 6 + 5
|
||||
11
|
||||
>
|
||||
(^C again to quit)
|
||||
>
|
||||
root@ubuntu-15:~/node#
|
||||
|
||||
### 4) 通过NVM安装Node.JS ###
|
||||
|
||||
在最后一种方法中我们我们将用NVM来比较容易安装Node.JS。安装和配制Node.JS,这是最好的方法之一,它可以供我们选择要安装的版本。
|
||||
|
||||
在安装之前,请确认本机以前的安装包已经被卸载
|
||||
|
||||
#### 步骤1: 安装依赖包 ####
|
||||
|
||||
首先升级Ubuntu Server系统,然后安装以下安装Node.JS和使用NVM所要依赖的包。用curl命令从git上下载NVM到本地仓库:
|
||||
|
||||
root@ubuntu-15:~# apt-get install build-essential libssl-dev
|
||||
root@ubuntu-15:~# curl https://raw.githubusercontent.com/creationix/nvm/v0.16.1/install.sh | sh
|
||||
|
||||

|
||||
|
||||
#### 步骤2: 修改Home环境 ####
|
||||
|
||||
用curl从NVM下载必需的包到用户的home目录之后,我们需要修改bash的配制文件添加NVM,之后只要重新登录中断或者用如下命令更新即可
|
||||
|
||||
root@ubuntu-15:~# source ~/.profile
|
||||
|
||||
现在我们可以用NVM来设置默认的NVM的版本或者用如下命令来指定之前版本:
|
||||
|
||||
root@ubuntu-15:~# nvm ls
|
||||
root@ubuntu-15:~# nvm alias default 0.12.4
|
||||
|
||||

|
||||
|
||||
#### 步骤3: 使用NVM ####
|
||||
|
||||
我们已经通过NVM成功的安装了Node.JS,所以我们现在可以使用各种有用的命令。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
现在我们已经准备好了在服务端安装Node.JS,你可以从我们说的四种方式中选择最合适你的方式在最新的Ubuntu 15.04上来安装Node.JS,安装好之后你就可以利用Node.JS来编写你的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-ubuntu-15-04-different-methods/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,309 @@
|
||||
|
||||
15 个有用的 MySQL/MariaDB 性能调整和优化技巧
|
||||
================================================================================
|
||||
MySQL是一个强大的开源关系型数据库管理系统或简称RDBMS。它被发布在1995年(20年前)。它采用的结构化查询语言在数据库管理中可能是最好的选择。最新的MySQL版本是5.6.25,2015年5月29日发行的。
|
||||
|
||||
尽管有许多关于MySQL有趣的传闻,其中一个有趣的事实是,这个名字来自Michael Widenius(MySQL的创始人)的女儿。本文旨在向您展示一些有用的做法,以帮助您管理您的MySQL服务器。
|
||||
|
||||

|
||||
|
||||
MySQL性能优化
|
||||
|
||||
2009年4月,MySQL被Oracle收购。其结果导致一个叫MariaDB的社区成立。创建的主要原因是为了保持MySQL项目的自由。
|
||||
|
||||
今天,MySQL和MariaDB对于Web应用程序像,WordPress, Joomla, Magento和其他的,是使用最广泛的(但不是使用最多的)RDBMS。
|
||||
|
||||
|
||||
这篇文章将告诉你一些基本的,但有用如何优化MySQL / MariaDB性能的技巧。说明,本文假定您已经安装了MySQL或MariaDB。如果你仍然不知道如何在系统上安装它们,你可以按照以下说明去安装:
|
||||
|
||||
- [Installing LAMP on RHEL/CentOS 7][1]
|
||||
- [Installing LAMP on Fedora 22][2]
|
||||
- [Setting Up LAMP on Ubuntu 15.04][3]
|
||||
- [Installing MariaDB on Debian 8][4]
|
||||
- [Install MariaDB on Gentoo Linux][5]
|
||||
- [Install MariaDB on Arch Linux][6]
|
||||
|
||||
**说明**: 在开始之前,不要盲目的接受这些建议。每个MySQL的设置是不同的,在进行任何更改之前需要慎重考虑。
|
||||
|
||||
|
||||
你需要明白这些:
|
||||
|
||||
- MySQL/MariaDB配置文件位于 `/etc/my.cnf`. 每次需改此文件后你需要重新启动MySQL服务,以使新更改生效。
|
||||
- 这篇文章使用MySQL 5.6版本 。
|
||||
|
||||
### 1. 启动 InnoDB 的`file-per-table` ###
|
||||
|
||||
首先,它是非常重要的对于解释InnoDB是一个存储引擎。MySQL和MariaDB使用的默认存储引擎是InnoDB。过去,MySQL使用系统表空间来保存数据库中的表和索引。这意味着服务器唯一的目的就是数据库处理,它的存储盘不用于其他的目的。
|
||||
|
||||
InnoDB提供了更灵活的方式,它把每个数据库的信息保存在一个`.ibd` 数据文件中。像“TRUNCATE”这样的操作可以更快地完成,当删除或截断一个数据库表时,你也可以回收未使用的空间。
|
||||
|
||||
这种结构的另一个好处是,可以保留一些数据库表在一个单独的存储设备。这可以大大提高你磁盘的I/O负载。
|
||||
|
||||
MySQL 5.6及以上的版本默认启用`innodb_file_per_table`。你可以在/etc/my.cnf文件中看到。该指令看起来是这样的:
|
||||
|
||||
innodb_file_per_table=1
|
||||
|
||||
### 2. 将MySQL数据库中的数据放在独立分区上 ###
|
||||
|
||||
**注意**: 此设置只能工作在MySQL上, 而不能在MariaDB上.
|
||||
|
||||
有时OS的读/写操作会减缓你MySQL服务器的性能,尤其是如果位于同一块磁盘上。因此,我建议你使用单独的磁盘(SSD最好)用于MySQL服务。
|
||||
|
||||
要完成这步,你需要将新的磁盘连接到您的计算机/服务器上。对于这篇文章,我会认为磁盘将被识别为/dev/sdb。
|
||||
|
||||
下一步将是准备新的分区:
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
现在按“N”来创建新的分区。接着按“P”,以使其创建为主分区。在此之后,设置分区号为1-4之间。之后,你可以选择分区大小。这里按enter。在接下来的步骤中,你需要配置分区的大小。
|
||||
|
||||
如果你希望使用全部的磁盘,按一次enter。否则,你需要手动设置新分区的大小。准备就绪后按“w”保存。现在,我们需要为我们的新分区创建一个文件系统。这可以很轻松的完成:
|
||||
|
||||
# mkfs.ext4 /dev/sdb1
|
||||
|
||||
现在挂载新分区到文件夹下。在根目录下创建一个名为“ssd”的文件夹:
|
||||
|
||||
# mkdir /ssd/
|
||||
|
||||
挂载新分区到刚才创建的文件夹下:
|
||||
|
||||
# mount /dev/sdb1 /ssd/
|
||||
|
||||
你可以添加如下行在/etc/fstab文件中设置开机自动挂载:
|
||||
|
||||
/dev/sdb1 /ssd ext3 defaults 0 0
|
||||
|
||||
现在我们移动MySQL到新磁盘中。首先停止服务:
|
||||
|
||||
# service mysqld stop
|
||||
|
||||
我建议你停止Apache/nginx,以及以防止任何操作试图在数据库中写入:
|
||||
|
||||
# service httpd stop
|
||||
# service nginx stop
|
||||
|
||||
现在我们复制完整的MySQL目录到新分区中:
|
||||
|
||||
# cp /var/lib/mysql /ssd/ -Rp
|
||||
|
||||
这可能需要一段时间,具体取决于你的MySQL数据库的大小。一旦这个过程完成后重命名MySQL的目录:
|
||||
|
||||
# mv /var/lib/mysql /var/lib/mysql-backup
|
||||
|
||||
然后创建一个链接:
|
||||
|
||||
# ln -s /ssd/mysql /var/lib/mysql
|
||||
|
||||
现在启动你的MySQL和web服务:
|
||||
|
||||
# service mysqld start
|
||||
# service httpd start
|
||||
# service nginx start
|
||||
|
||||
以后你的数据库将使用新的磁盘访问。
|
||||
|
||||
### 3. 优化InnoDB的缓冲区 ###
|
||||
|
||||
InnoDB引擎在内存中有一个缓冲数据和索引的缓冲区。这将有助于你在MySQL/MariaDB中的查询更快的执行。选择合适的内存大小对系统的查询来说是非常重要的,并且使你对系统的内存消耗也会有一个更好的认识。
|
||||
|
||||
下面是你需要考虑的:
|
||||
|
||||
- 其他的进程需要消耗多少内存,包括你的系统进程,表的数量,套接字缓冲区大小。
|
||||
- 你的服务器是否专用于MySQL还是你也运行其他非常消耗内存的服务。
|
||||
|
||||
|
||||
在一个专用的机器上,你可能会使用60-70%的内存分配给`innodb_buffer_pool_size`。如果你打算在一个机器上运行多个服务,你应该重新考虑`innodb_buffer_pool_size`的内存大小。
|
||||
|
||||
你需要设置my.cnf中的此项:
|
||||
|
||||
innodb_buffer_pool_size
|
||||
|
||||
### 4. 在MySQL中避免使用Swappiness ###
|
||||
|
||||
使用交换空间需要一个进程,当系统移动一部分内存到一个空闲的分区中就叫做“swap”。通常当你的系统用完物理内存后就会出现这种情况而不是释放一些RAM,然后将信息写进磁盘中。你可能已经猜测到磁盘比你的内存要慢得多。
|
||||
|
||||
默认情况下该选项已经启用:
|
||||
|
||||
# sysctl vm.swappiness
|
||||
|
||||
vm.swappiness = 60
|
||||
|
||||
使用以下命令关闭swappiness:
|
||||
|
||||
# sysctl -w vm.swappiness=0
|
||||
|
||||
### 5. 设置MySQL的最大连接数 ###
|
||||
|
||||
`max_connections`变量告诉你的服务器当前允许多少并发连接。MySQL/ MariaDB服务器允许的`max_connections` + 1为超级用户给定的值。当连接建立后,执行MySQL查询会有时间的限制 - 之后,它被关闭,新连接可以取代其位置。
|
||||
|
||||
请记住,太多的连接会导致RAM的使用量过高并且会锁定你的MySQL服务器。一般小网站需要100-200的连接数而较大可能需要500-800甚至更多。这里的值很大程度上取决于你的MySQL/MariaDB的使用情况。
|
||||
|
||||
你可以动态的改变`max_connections`的值而无需重启MySQL服务器:
|
||||
|
||||
# mysql -u root -p
|
||||
mysql> set global max_connections := 300;
|
||||
|
||||
### 6. 配置MySQL的`thread_cache_size`变量 ###
|
||||
|
||||
`thread_cache_size`变量用来设置你服务器缓存的线程数量。当客户端断开连接时,如果当前线程数小于`thread_cache_size`,他的线程将被放入缓存中。下一个请求将使用缓存池中的线程来完成。
|
||||
|
||||
要提高服务器的性能,你可以设置`thread_cache_size`的值相对高一些。你可以通过以下方法来查看线程池的使用情况::
|
||||
|
||||
mysql> show status like 'Threads_created';
|
||||
mysql> show status like 'Connections';
|
||||
|
||||
你可以用以下公式来计算线程池的使用率:
|
||||
|
||||
100 - ((Threads_created / Connections) * 100)
|
||||
|
||||
如果你得到一个较低的数字,这意味着大多数mysql连接请求使用新的线程,而不是从缓存加载。在这种情况下,你需要增加`thread_cache_size`。
|
||||
|
||||
但有一个好处是,`thread_cache_size`可以动态的改变而无需重启MySQL服务。你可以通过以下方式来实现:
|
||||
|
||||
mysql> set global thread_cache_size = 16;
|
||||
|
||||
### 7.禁用MySQL的DNS反向查询 ###
|
||||
|
||||
当新的连接出现时,默认情况下MySQL/MariaDB会使用DNS来解析用户的IP地址/主机名,每个新的连接,它的IP都会被解析为主机名。然后,主机名又被反解析为IP来验证这两个是否一致。
|
||||
|
||||
当DNS服务器出现问题或者配置有问题时,解析会变得非常慢,这就是为什么要关闭DNS的反向解析,你可以在你的配置文件中添加以下选项去设定:
|
||||
|
||||
[mysqld]
|
||||
# Skip reverse DNS lookup of clients
|
||||
skip-name-resolve
|
||||
|
||||
更改后需要重新启动你的MySQL服务器.
|
||||
|
||||
### 8. 配置MySQL的`query_cache_size`变量 ###
|
||||
|
||||
如果你有很多重复的查询或者不经常改变的数据 – 请使用缓存查询。 人们常常不理解`query_cache_size`的实际含义而将此值设置为几十兆,这实际上会降低服务器的性能。
|
||||
|
||||
背后的原因是,线程需要在更新过程中锁定缓存。通常设置为200-300 MB应该足够了。如果你的网站比较小的,你可以尝试给64M并在以后及时去增加。
|
||||
|
||||
添加以下选项到你的MySQL配置文件中:
|
||||
|
||||
query_cache_type = 1
|
||||
query_cache_limit = 256K
|
||||
query_cache_min_res_unit = 2k
|
||||
query_cache_size = 80M
|
||||
|
||||
### 9. 配置`tmp_table_size`变量和`max_heap_table_size`变量 ###
|
||||
|
||||
这两个变量的大小相同都将帮助你避免将数据直接写入到磁盘中去。`tmp_table_size` 是内置内存表的最大空间,如果超出限值表的大小将被转换到磁盘上的MyISAM表。
|
||||
|
||||
这将影响数据库的性能。管理员通常建议在服务器上设置这两个值为RAM的每GB为64M。
|
||||
|
||||
[mysqld]
|
||||
tmp_table_size= 64M
|
||||
max_heap_table_size= 64M
|
||||
|
||||
### 10. 开启MySQL慢速查询日志 ###
|
||||
|
||||
慢查询日志可以帮助你定位数据库的问题,并帮助您调试。在你的MySQL配置文件中添加以下选项来启用:
|
||||
|
||||
slow-query-log = 1
|
||||
slow-query-log-file = /var/lib/mysql/mysql-slow.log
|
||||
long_query_time = 1
|
||||
|
||||
第一个变量开启慢查询日志,第二个告诉MySQL实际的日志文件存储在哪。使用`long_query_time`来定义MySQL查询完成时长。
|
||||
|
||||
### 11.检查MySQL的空闲连接 ###
|
||||
|
||||
空闲连接会消耗资源,应中断或者尽可能被刷新。这样的连接都在“sleep”状态并且会保持一段时间。通过以下命令可以查看空闲的连接:
|
||||
|
||||
# mysqladmin processlist -u root -p | grep “Sleep”
|
||||
|
||||
这会显示处于睡眠状态的进程列表。当代码使用到数据库持久连接时会出现以下情况。使用PHP调用mysql_pconnect可以打开这个连接,即执行查询,删除认证最后关闭打开的连接。这会导致每个线程的缓冲区被保存在缓存中,直到该线程死亡。
|
||||
|
||||
首先你要做的就是检查代码并修复它。如果你不能访问正在运行的代码,你可以修改`wait_timeout`变量。默认值是28800秒,而你可以将其降低到60:
|
||||
|
||||
wait_timeout=60
|
||||
|
||||
### 12. 为MySQL选择正确的文件系统 ###
|
||||
|
||||
选择正确的文件系统对数据库至关重要。在这里你需要考虑的最重要的事情是 - 数据的完整性,性能和易管理性。
|
||||
|
||||
按照MariaDB的建议,最好的文件系统是XFS,ext4或者BTRFS。所有这些都可以作为企业用的日志文件系统,它们可以使用非常大的文件和大容量存储。
|
||||
|
||||
关于这三个文件系统你可以在下面看到一些有用的信息:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="179"></colgroup>
|
||||
<colgroup width="85" span="3"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" height="18" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">Filesystems</span></b></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">XFS</span></b></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">Ext4</span></b></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial;">Btrfs</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="center" height="18" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Maximum filesystem size</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">8EB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">1EB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">16EB</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center" height="18" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Maximum file size</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">8EB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">16TB</span></td>
|
||||
<td align="center" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">16EB</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
这篇文章将详细介绍Linux文件系统的利与弊:
|
||||
|
||||
- [Linux Filesystem Explained][7]
|
||||
|
||||
### 13. 设置MySQL的`max_allowed_packet` ###
|
||||
|
||||
MySQL的数据被拆分成包发送。通常,单个报文被认为是一次发送到客户端。`max_allowed_packet`变量可以定义被发送包的大小。
|
||||
|
||||
此值设置得过低可能会导致查询速度变得非常慢,然后你会看到一个错误在MySQL的错误日志中。它建议你将数据包的大小设置成最大。
|
||||
|
||||
### 14. 测试MySQL的性能 ###
|
||||
|
||||
你应该定期检测MySQL/MariaDB的性能。这将帮助你查看资源的使用情况或需要调整某些变量的值。
|
||||
|
||||
有大量的测试工具可用,但我推荐你一个简单易用的。该工具被称为mysqltuner。
|
||||
|
||||
使用下面的命令下载并运行它:
|
||||
|
||||
# wget https://github.com/major/MySQLTuner-perl/tarball/master
|
||||
# tar xf master
|
||||
# cd major-MySQLTuner-perl-993bc18/
|
||||
# ./mysqltuner.pl
|
||||
|
||||
你将收到有关MySQL使用和推荐提示的详细报告。下面是在MariaDB上安装后的默认输出:
|
||||
|
||||

|
||||
|
||||
### 15. 优化和修复MySQL数据库 ###
|
||||
|
||||
有时候MySQL/MariaDB数据库中的表很容易崩溃,尤其是当服务器意外关机时,数据库仍然被访问中或者在执行复制操作,文件系统会突然崩溃。然而,有一个免费的开源工具,被称为'mysqlcheck'的,它会自动检查,修复和优化Linux中数据库的所有表。
|
||||
|
||||
# mysqlcheck -u root -p --auto-repair --check --optimize --all-databases
|
||||
# mysqlcheck -u root -p --auto-repair --check --optimize databasename
|
||||
|
||||
就是这样!我希望你已经发现了上述文章有用的地方,并帮助你优化你的MySQL服务器。一如往常,如果你有任何问题或意见,请在下面的评论部分提交。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mysql-mariadb-performance-tuning-and-optimization/
|
||||
|
||||
作者:[Marin Todorov][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/marintodorov89/
|
||||
[1]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[2]:http://www.tecmint.com/install-lamp-linux-apache-mysql-php-on-fedora-22/
|
||||
[3]:http://www.tecmint.com/install-lamp-on-ubuntu-15-04/
|
||||
[4]:http://www.tecmint.com/install-mariadb-in-debian/
|
||||
[5]:http://www.tecmint.com/install-lemp-in-gentoo-linux/
|
||||
[6]:http://www.tecmint.com/install-lamp-in-arch-linux/
|
||||
[7]:http://www.tecmint.com/linux-file-system-explained/
|
||||
Loading…
Reference in New Issue
Block a user