`标签
+```
+
+```
+
+4\. 在这个标签后或者这个文档的尾部下面的代码:
+
+```
+
+```
+
+其中,`#screen`是标签`
`的`id`,你想在它里面显示温度。它会每隔1000毫秒加载一次`temperature.php`文件。
+
+我使用了bootstrap框架来制作一个漂亮的面板来显示温度,你还可以加入多个icons和 glyphicons让网页更有吸引力。
+
+这只是一个控制继电器板并显示温度的基础的系统,你可以通过创建基于定时和从恒温器读数等基于事件触发来进一步地对系统进行开发。
+
+--------------------------------------------------------------------------------
+
+
+作者简介:
+
+Abdul Hannan Mustajab: 我17岁,生活在印度。我正在追求科学,数学和计算机科学方面的教育。我在spunkytechnology.com上发表关于我的项目的博客。我一直在对使用不同的微控制器和电路板的基于物联网的AI进行研究。
+
+
+via: https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi
+
+作者:[ Abdul Hannan Mustajab][a]
+译者:[译者ID](https://github.com/zhousiyu325)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/mustajabhannan
+[1]:http://www.php.net/system
+[2]:http://www.php.net/system
+[3]:http://www.php.net/system
+[4]:http://www.php.net/system
+[5]:http://www.php.net/system
+[6]:http://www.php.net/file
+[7]:http://www.php.net/explode
+[8]:http://www.php.net/number_format
+[9]:https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi?rate=RX8QqLzmUb_wEeLw0Ee0UYdp1ehVokKZ-JbbJK_Cn5M
+[10]:https://opensource.com/user/123336/feed
+[11]:https://opensource.com/users/mustajabhannan
+
+
diff --git a/translated/tech/20170502 How to Find Difference Between Two Directories Using Diff and Meld Tools.md b/translated/tech/20170502 How to Find Difference Between Two Directories Using Diff and Meld Tools.md
new file mode 100644
index 0000000000..878b00998a
--- /dev/null
+++ b/translated/tech/20170502 How to Find Difference Between Two Directories Using Diff and Meld Tools.md
@@ -0,0 +1,99 @@
+怎么使用 Diff 和 Meld 工具发现两个目录间的不同之处
+============================================================
+
+在之前的一篇文章里,我们回顾了[ Linux 下 9 个最好的文件比较工具][1],本篇文章中,我们将会描述在 Linux 下怎样找到两个目录之间的不同。
+
+一般情况下,要在 Linux 下比较两个文件,我们会使用 **diff** (一个简单的源自 Unix 的命令行工具 )来显示两个计算机文件的不同;它一行一行的去比较文件,而且很方便使用,在几乎全部的 Linux 发行版都预装了。
+
+问题是在 Linux 下我们怎么才能比较两个目录?现在,我们想知道两个目录中哪些文件/子目录是共有的,哪些只存在一个于目录。
+
+运行 diff 常规的语法如下:
+
+```
+$ diff [OPTION]… FILES
+$ diff options dir1 dir2
+```
+
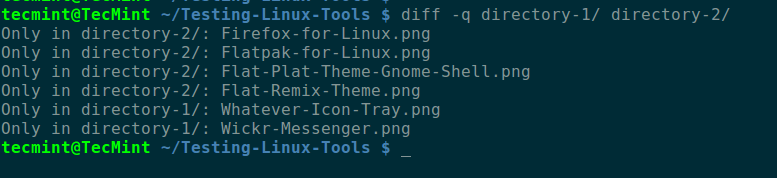
+默认情况下,输出是按文件/子文件夹的文件名的字母排序的,如下面截图所示,在命令中, `-q` 开关是告诉 diif 只有在文件有差异时报告。
+
+```
+$ diff -q directory-1/ directory-2/
+```
+[
+ 
+][3]
+
+*两个文件夹之间的差异*
+
+再次运行 diff 并不能进入子文件夹,但是我们可以使用 `-r` 开关来读子文件夹,如下所示。
+
+```
+$ diff -qr directory-1/ directory-2/
+```
+
+### 使用 Meld 可视化比较和合并工具
+
+meld 是一个很酷的图形化工具(一个 GNOME 桌面下的可视化的比较和合并工具),可供那些喜欢使用鼠标的人使用,可按如下来安装。
+
+```
+$ sudo apt install meld [Debian/Ubuntu systems]
+$ sudo yum install meld [RHEL/CentOS systems]
+$ sudo dnf install meld [Fedora 22+]
+```
+
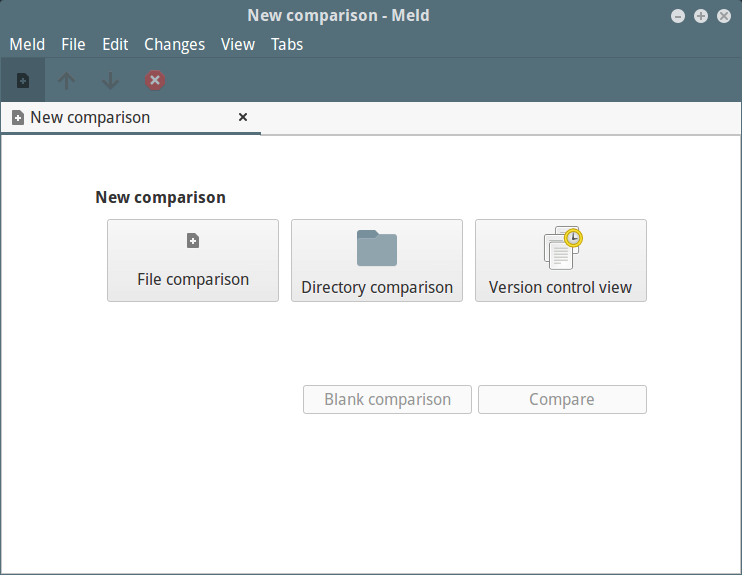
+一旦你安装了它之后,在 **Ubuntu Dash** 或者 **Linux Mint** 菜单搜索 “**meld**” ,或者 Fedora 或 CentOS 桌面的 Activities Overview,然后启动它。
+
+你可以看到如下的 Meld 界面,可以选择文件或者文件夹来比较,此外还有版本控制视图。点击目录比较并移动到下个界面。
+[
+ 
+][4]
+
+*Meld 比较工具*
+
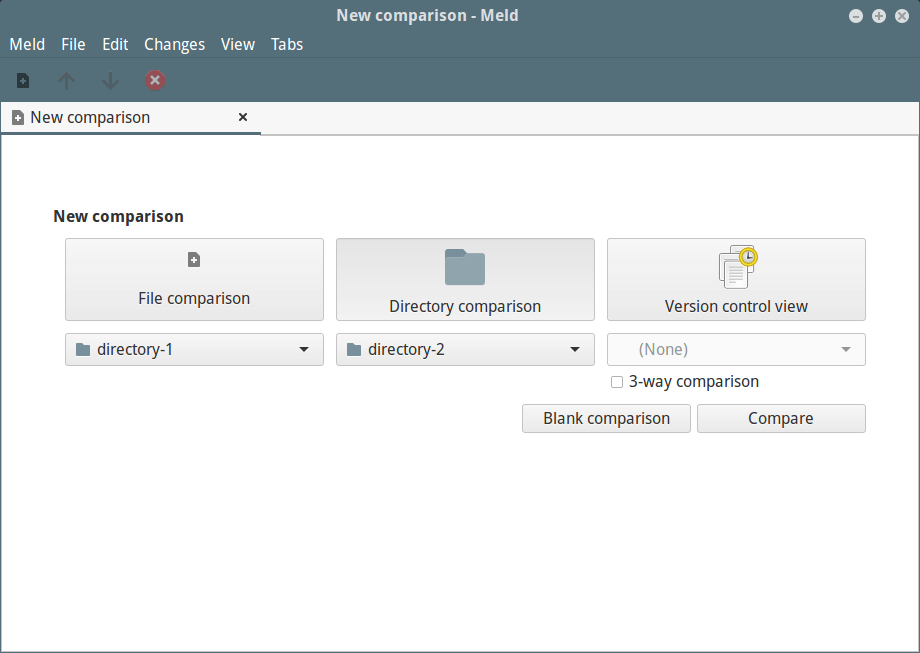
+选择你想要比较的文件夹,注意你可以勾选 “**3-way Comparison**” 选项,添加第三个文件夹。
+[
+ 
+][5]
+
+*选择比较的文件夹*
+
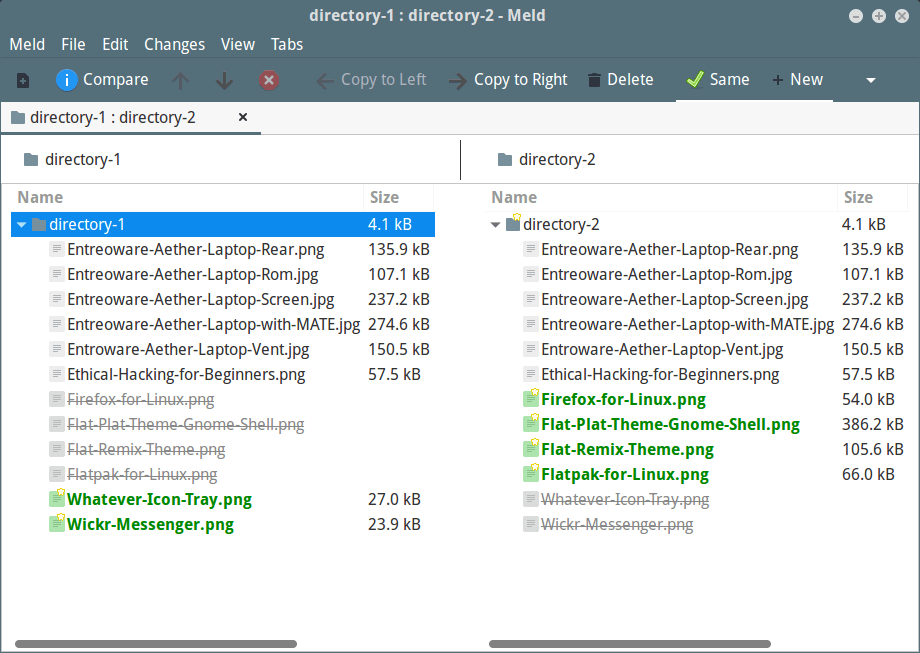
+选择好要比较的文件夹后,点击 “Compare”。
+[
+ 
+][6]
+
+*文件夹不同列表*
+
+在这篇文章中,我们描述了怎么在 Linux 下找到两个文件夹的不同。如果你知道其他的命令或者图形界面工具,不要忘记在下方评论分享你们的想法。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者,即将成为 Linux 系统管理员,Web 开发者,目前是 TecMint 的内容创建者,他喜欢使用电脑工作,并且非常相信分享知识。
+
+-------------------
+
+via: http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/
+
+作者:[Aaron Kili ][a]
+译者:[hkurj](https://github.com/hkurj)
+校对:[jasminepeng](https://github.com/jasminepeng)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/aaronkili/
+[1]:http://www.tecmint.com/best-linux-file-diff-tools-comparison/
+[2]:http://www.tecmint.com/freefilesync-compare-synchronize-files-in-ubuntu/
+[3]:http://www.tecmint.com/wp-content/uploads/2017/05/Difference-Between-Two-Directories.png
+[4]:http://www.tecmint.com/wp-content/uploads/2017/05/Meld-Comparison-Tool.png
+[5]:http://www.tecmint.com/wp-content/uploads/2017/05/Select-Comparison-Directories.png
+[6]:http://www.tecmint.com/wp-content/uploads/2017/05/Listing-Difference-Between-Directories.png
+[7]:http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/#
+[8]:http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/#
+[9]:http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/#
+[10]:http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/#
+[11]:http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/#comments
+[12]:http://www.tecmint.com/author/aaronkili/
+[13]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
+[14]:http://www.tecmint.com/free-linux-shell-scripting-books/
diff --git a/translated/tech/20170504 A beginner s guide to Linux syscalls.md b/translated/tech/20170504 A beginner s guide to Linux syscalls.md
new file mode 100644
index 0000000000..025ec78798
--- /dev/null
+++ b/translated/tech/20170504 A beginner s guide to Linux syscalls.md
@@ -0,0 +1,59 @@
+Linux 系统调用的初学者指南
+============================================================
+
+
+>图片提供: opensource.com
+
+在过去的几年中,我一直在做大量容器相关的工作。先前,我看到 [Julien Friedman][7] 的一个很棒的演讲,它用几行 Go 语言写了一个容器框架。这让我突然了解到容器只是一个受限的 Linux 进程中的机器。
+
+构建这个受限视图涉及到[ Golang 系统调用包][8]中的很多调用。最初,我只是用到了表面的那些,但过了一段时间,我想剥下洋葱的下一层,看看这些系统调用是什么,以及它们的工作原理。我将在 OSCON 的演讲中分享我所学到的东西。
+
+
+顾名思义,[syscalls][9]是系统调用,它们是你从用户空间请求进入 Linux 内核的方式。内核为你做一些工作,例如创建一个进程,然后再回到用户空间。
+
+有一个常见的机制使所有的系统调用转换到内核,它由 **libc** 库处理。 用户空间代码设置一些寄存器,包括其想要的系统调用的 ID 以及需要传递给系统调用的所有参数。它触发一个 “陷阱” 将控制转换到内核。
+
+这是用户空间代码如何向内核请求的,但是 Linux 也有伪文件系统,它允许内核将信息传递给用户空间。内容看起来像普通的目录和文件。
+
+**/proc** 目录是一个很好的例子。看看里面,你会发现有关机器上运行的进程的各种有趣的信息。在某些情况,像 **cgroups**(控制组)那样,用户空间可以通过写入这些伪文件系统下的文件来配置参数。
+
+当你在使用容器时,特别有趣的是,主机的 **/proc** 包含了所有有关容器化进程的信息。这包括环境变量,它们也保存在 **/proc** 伪文件系统中,这意味着你的主机可以访问所有正在运行的容器的环境。如果你通过环境变量将诸如证书或数据库密码这类秘密传递到容器中,则可能会产生安全性后果。
+
+许多编写常规程序的程序员可能不觉得他们经常使用系统调用。但实际上他们会经常调用,因为每天的活动比如制作文件或者更改目录都涉及 Linux 的系统调用。
+
+你不必是一位系统程序元来享受系统调用的乐趣!
+
+
+_如果你想要了解更多_,Liz 会在 Austin,Texas 举办的 OSCON 2017 上演讲 [_Linux 系统调用的初学者指南_][10]。如果你对参加会议感兴趣,_[当你在注册时][11]_,使用这个折扣码:_**PCOS**_。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Liz Rice - Liz Rice 是一位技术传播者,也是 Aqua Security 的容器安全专家。此前,她共同创立了 Microscaling Systems,并开发了其实时伸缩引擎,以及流行的图像元数据网站 MicroBadger.com。她拥有丰富的从网络协议和分布式系统,以及数字技术领域,如 VOD,音乐和 VoIP 软件的开发、团队和产品管理经验。
+
+----------
+
+
+via: https://opensource.com/article/17/5/beginners-guide-syscalls
+
+作者:[Liz Rice ][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/lizrice
+[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
+[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
+[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
+[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
+[5]:https://opensource.com/tags/linux?src=linux_resource_menu
+[6]:https://opensource.com/article/17/5/beginners-guide-syscalls?rate=BT-vq0qMILAvJVxPFqug17N1RfhoAb_vkwNqRZFAqLQ
+[7]:https://twitter.com/doctor_julz
+[8]:https://golang.org/pkg/syscall/
+[9]:http://man7.org/linux/man-pages/man2/syscalls.2.html
+[10]:https://conferences.oreilly.com/oscon/oscon-tx/public/schedule/detail/56840
+[11]:http://www.oreilly.com/pub/cpc/44407?sc_cid=701600000012BzSAAU%20target=%22_blank%22
+[12]:https://opensource.com/user/129431/feed
+[13]:https://opensource.com/users/lizrice
diff --git a/translated/tech/20170505 WPSeku – A Vulnerability Scanner to Find Security Issues in WordPress.md b/translated/tech/20170505 WPSeku – A Vulnerability Scanner to Find Security Issues in WordPress.md
new file mode 100644
index 0000000000..ddfc1d8eaf
--- /dev/null
+++ b/translated/tech/20170505 WPSeku – A Vulnerability Scanner to Find Security Issues in WordPress.md
@@ -0,0 +1,91 @@
+WPSeku - 一个找出 WordPress 安全问题的漏洞扫描器
+============================================================
+
+by [Aaron Kili][9] | Published: May 5, 2017 | Last Updated: May 5, 2017
+
+立即下载你的免费电子书 - [10 本给管理员的免费 Linux 电子书][10] | [4 本免费的 Shell 脚本电子书][11]
+
+WordPress 是一个免费开源、高度可自定义的内容管理系统(CMS),它被全世界数以百万计的人来运行博客和完整的网站。因为它是被用的最多的 CMS,因此有许多潜在的 WordPress 安全问题/漏洞需要考虑。
+
+然而,如果我们遵循通常的 WordPress 最佳实践,这些安全问题可以被处理。在本篇中,我们会向你展示如何使用 WPSeku,一个 Linux 中的 WordPress 漏洞扫描器,它可以被用来找出你的 WordPress 安装的安全漏洞,并阻止潜在的威胁。
+
+WPSeku 是一个用 Python 写的简单 WordPress 漏洞扫描器,它可以被用来扫描本地以及远程的 WordPress 安装来找出安全问题。
+
+### 如何安装 WPSeku - Linux 中的 WordPress 漏洞扫描器
+
+要在 Linux 中安装 WPSeku,你需要如下从 Github clone 最新版本的 WPSeku。
+
+```
+$ cd ~
+$ git clone https://github.com/m4ll0k/WPSeku
+```
+
+完成之后,进入 WPSeku 目录,并如下运行。
+
+```
+$ cd WPSeku
+```
+
+使用 `-u` 选项指定 WordPress 的安装 URL,如下运行 WPSeku:
+
+```
+$ ./wpseku.py -u http://yourdomain.com
+```
+ [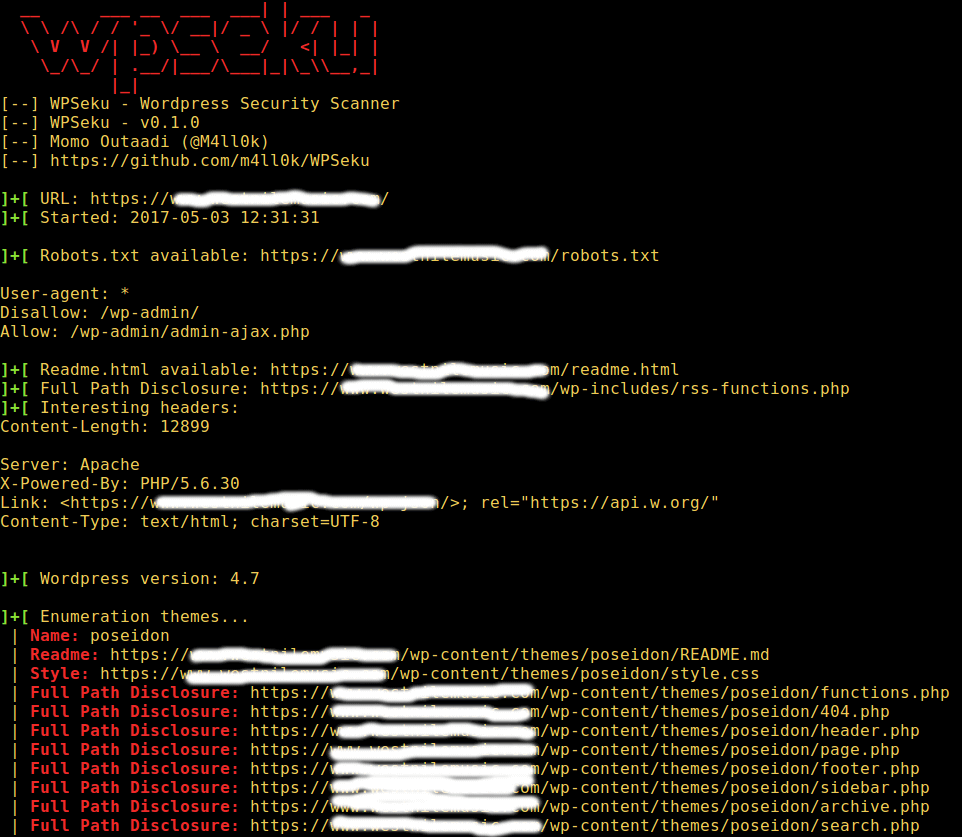][1]
+
+WordPress 漏洞扫描器
+
+以下命令使用 `-p` 选项搜索 WordPress 插件中的跨站脚本、本地文件夹入和 SQL 注入漏洞,你需要在 URL 中指定插件的位置:
+
+```
+$ ./wpseku.py -u http://yourdomain.com/wp-content/plugins/wp/wp.php?id= -p [x,l,s]
+```
+
+以下命令将使用 `-b` 选项通过 XML-RPC 执行暴力密码登录。另外,你可以使用 `--user` 和 `--wordlist` 选项分别设置用户名和单词列表,如下所示。
+
+```
+$ ./wpseku.py -u http://yourdomian.com --user username --wordlist wordlist.txt -b [l,x]
+```
+
+要浏览所有 WPSeku 使用选项,输入:
+
+```
+$ ./wpseku.py --help
+```
+ [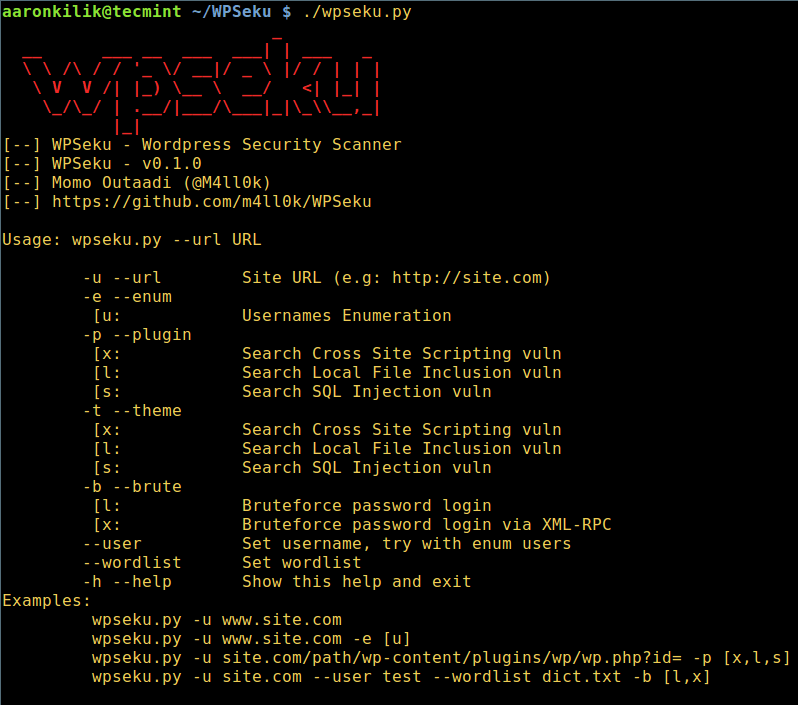][2]
+
+WPSeku WordPress 漏洞扫描帮助
+
+WPSeku Github 仓库:[https://github.com/m4ll0k/WPSeku][3]
+
+就是这样了!在本篇中,我们向你展示了如何在 Linux 中获取并使用 WPSeku 用于 WordPress 漏洞扫描。WordPress 是安全的,但仅在如果我们遵循 WordPress 安全最佳实践的情况下。你有要分享的想法么?如果有,请在评论区留言。
+
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Aaron Kili 是一个 Linux 及 F.O.S.S 热衷者,即将成为 Linux 系统管理员、web 开发者,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
+
+------------------
+
+via: https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/
+
+作者:[Aaron Kili ][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.tecmint.com/author/aaronkili/
+[1]:https://www.tecmint.com/wp-content/uploads/2017/05/WordPress-Vulnerability-Scanner.png
+[2]:https://www.tecmint.com/wp-content/uploads/2017/05/WPSeku-WordPress-Vulnerability-Scanner-Help.png
+[3]:https://github.com/m4ll0k/WPSeku
+[4]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
+[5]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
+[6]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
+[7]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
+[8]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#comments
+[9]:https://www.tecmint.com/author/aaronkili/
+[10]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
+[11]:https://www.tecmint.com/free-linux-shell-scripting-books/
diff --git a/translated/tech/20170506 ttyload – Shows a Color-coded Graph of Linux Load Average in Terminal.md b/translated/tech/20170506 ttyload – Shows a Color-coded Graph of Linux Load Average in Terminal.md
new file mode 100644
index 0000000000..957ddcf44d
--- /dev/null
+++ b/translated/tech/20170506 ttyload – Shows a Color-coded Graph of Linux Load Average in Terminal.md
@@ -0,0 +1,109 @@
+ttyload - 在终端中用彩色显示 Linux 的平均负载
+============================================================
+
+立即下载你的免费电子书 - [10 本给管理员的免费 Linux 电子书][12] | [4 本免费的 Shell 脚本电子书][13]
+
+ttyload 是一个轻量级的实用程序,它为 Linux 和其他类 Unix 系统上提供随着时间变化的彩色平均负载。它实现了在终端中图形跟踪系统的平均负载(“tty”)。
+
+它已知可以在诸如 Linux、IRIX、Solaris、FreeBSD、MacOS X (Darwin) 和 Isilon OneFS 等系统上运行。它被设计为可以容易地移植到其他平台,但这也带来了一些艰苦的工作。
+
+它的一些值得注意功能是:它使用相当标准但硬编码的 ANSI 转义序列进行屏幕操作和着色。如果你想要在一个没有负载的系统中查看工作的情况,也可以使用(默认不会安装,甚至不会构建)一个相对独立的负载炸弹。
+
+**建议阅读:**[GoTTY - 将你的 Linux 终端(TTY)作为 Web 程序共享][1]
+
+在本篇中,我们会向你展示如何在 Linux 安装及使用 ttyload,以在终端中用彩色图形查看系统的平均负载。
+
+### 如何在 Linux 中安装 ttyload
+
+在基于 Debian/Ubuntu 的发行版中,你可以输入下面的[ apt 命令][2]来从默认的系统仓库中安装 ttyload。
+
+```
+$ sudo apt-get install ttyload
+```
+
+在其他发型版中,你可以如下从 ttyload 的源码安装。
+
+```
+$ git clone https://github.com/lindes/ttyload.git
+$ cd ttyload
+$ make
+$ ./ttyload
+$ sudo make install
+```
+
+安装完成后,你可以输入下面的命令启动。
+
+```
+$ ttyload
+```
+ [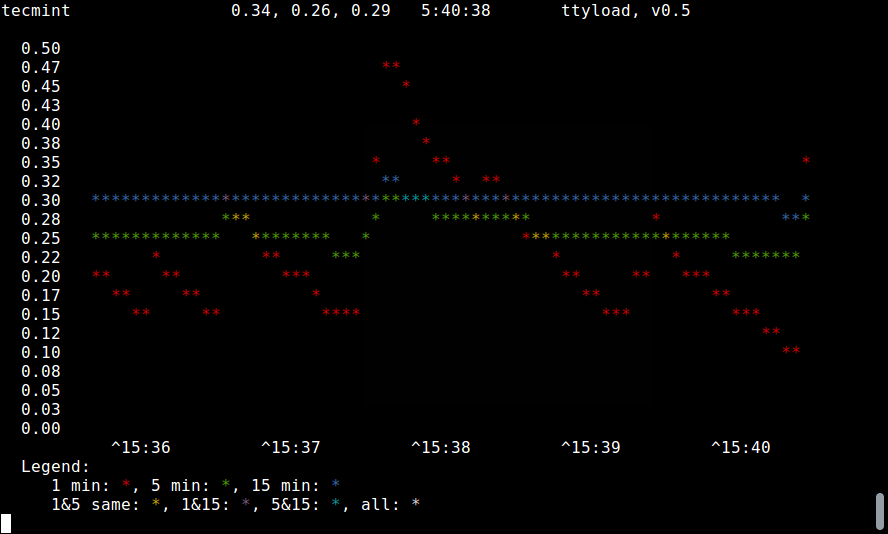][3]
+
+ttyload - 图形浏览 Linux 的平均负载
+
+注意:要关闭程序,只需按下 `[Ctrl+C]` 键。
+
+你也可以定义两次刷新之间间隔的秒数。默认是 4 秒,最小是 1 秒。
+
+```
+$ ttyload -i 5
+$ ttyload -i 1
+```
+
+要以单色模式运行,即它会关闭 ANSI 转义,如下使用 `-m`:
+
+```
+$ ttyload -m
+```
+ [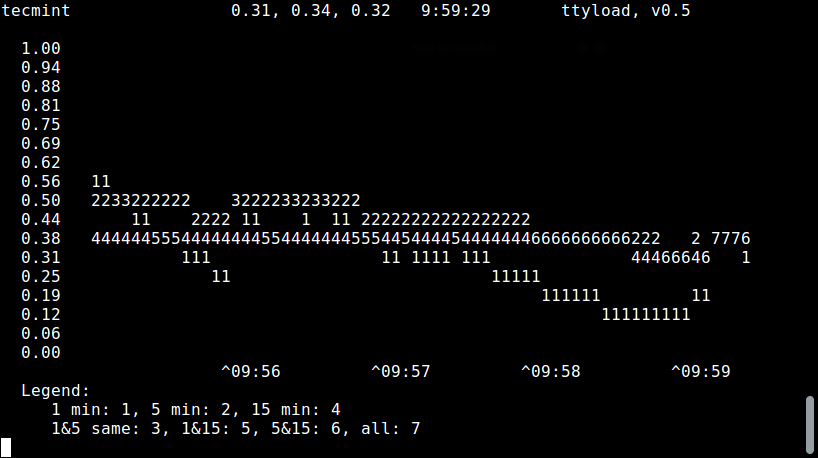][4]
+
+ttyload – 单色模式
+
+要获取 ttyload 的使用信息以及帮助,输入:
+
+```
+$ ttyload -h
+```
+
+下面是一些尚未添加的重要功能:
+
+* 支持任意大小调整。
+
+* 使用相同的基本引擎制作 X 前端,具有 “3xload”。
+
+* 面向日志的模式。
+
+要获得更多信息,访问 ttyload 的主页:[http://www.daveltd.com/src/util/ttyload/][5]
+
+就是这样了!在本文中,我们向你展示了如何在 Linux 中安装及使用 ttyload。通过下面的评论栏给我们回馈。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Aaron Kili 是一个 Linux 和 F.O.S.S 的爱好者,即将推出的 Linux SysAdmin 网络开发人员,目前也是 TecMint 的内容创作者,他喜欢和电脑一起工作,并且坚信共享知识。
+
+
+-------------------
+
+via: https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/
+
+作者:[Aaron Kili ][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.tecmint.com/author/aaronkili/
+[1]:https://www.tecmint.com/gotty-share-linux-terminal-in-web-browser/
+[2]:https://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
+[3]:https://www.tecmint.com/wp-content/uploads/2017/05/ttyload-Graphical-View-of-Linux-Load-Average-.png
+[4]:https://www.tecmint.com/wp-content/uploads/2017/05/ttyload-monochrome-mode.png
+[5]:http://www.daveltd.com/src/util/ttyload/
+[6]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
+[7]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
+[8]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
+[9]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#
+[10]:https://www.tecmint.com/ttyload-shows-color-coded-graph-of-linux-load-average/#comments
+[11]:https://www.tecmint.com/author/aaronkili/
+[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
+[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
diff --git a/translated/tech/20170509 4 Python libraries for building great command-line user interfaces.md b/translated/tech/20170509 4 Python libraries for building great command-line user interfaces.md
new file mode 100644
index 0000000000..23d4c4a107
--- /dev/null
+++ b/translated/tech/20170509 4 Python libraries for building great command-line user interfaces.md
@@ -0,0 +1,304 @@
+4 个用于构建优秀的命令行用户界面的 Python 库
+============================================================
+
+### 在一个分为两部分的关于具有优秀命令行用户界面的应用的系列文章的第二篇安装教程中,我们将讨论 Prompt、Toolkit、Click、Pygments 和 Fuzzy Finder 。
+
+
+
+>图片来自 : [美国 Mennonite 教堂档案][16] 。 Opensource.com. [CC BY-SA 4.0][17]
+
+这是我的一个分为两部分的关于具有优秀命令行用户界面的应用的系列文章的第二篇安装教程。在[第一篇文章][18]中,我们讨论了一些能够使命令行应用用起来令人感到高兴的特性。在第二篇文章中,我们来看看如何用 Python 的一些库来实现这些特性。
+
+我打算用少于 20 行 Python 代码来实现。让我们开始吧。
+
+编程和开发的一些资源
+
+* [最新的 Python 内容][1]
+
+* [我们最新的 JavaScript 文章][2]
+
+* [近期 Perl 文章][3]
+
+* [Red Hat 开发者博客][4]
+
+### Python Prompt Toolkit
+
+我习惯于把这个库称为命令行应用的瑞士军刀,它可以作为 **[readline][5]** 、**[cursed][6]** 等的替代品。让我们首先安装这个库,然后开始该教程:
+
+```
+pip install prompt_toolkit
+```
+
+我们以一个简单的 REPL 开始。一个典型的 REPL 会接收用户的输入,进行一个操作,然后输出结果。比如在我们的例子中,我们将要实现一个和 “echo” 功能一样的 REPL 。它仅仅是打印出用户的输入:
+
+#### REPL
+
+```
+from prompt_toolkit import prompt
+
+while 1:
+ user_input = prompt('>')
+ print(user_input)
+```
+
+这就是实现 REPL 的全部代码。它可以读取用户的输入,然后打印出用户的输入内容。在这段代码中使用的 `prompt` 函数来自 `prompt_toolkit` 库,它是 `readline` 库的一个替代品。
+
+#### 历史命令
+
+为了提高我们的 REPL,我们可以添加历史命令:
+
+```
+from prompt_toolkit import prompt
+from prompt_toolkit.history import FileHistory
+
+while 1:
+ user_input = prompt('>',
+ history=FileHistory('history.txt'),
+ )
+ print(user_input)
+```
+
+我们刚刚给 REPL 添加了持续的**历史命令**。现在,我们可以使用上/下箭头来浏览**历史命令**,并使用 **Ctrl+R** 来搜索**历史命令**。它满足命令行的基本准则。
+
+#### 自动推荐
+
+在第一篇教程中,我讲到的一个已发现技巧是自动推荐**历史命令**。(我首先在 **fish** shell 中看到这一特性。)让我们把这一特性加入到我们的 REPL 中:
+
+```
+from prompt_toolkit import prompt
+from prompt_toolkit.history import FileHistory
+from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
+
+while 1:
+ user_input = prompt('>',
+ history=FileHistory('history.txt'),
+ auto_suggest=AutoSuggestFromHistory(),
+ )
+ print(user_input)
+```
+
+我们只需要给 `prompt()` API 调用添加一个新的参数。现在,我们有了一个具有 **fish shell** 风格的 REPL,它可以自动推荐**历史命令**。
+
+#### 自动补全
+
+现在,让我们通过**自动补全**来加强 Tab-补全。它能够在用户开始输入的时候弹出可能的命令推荐。
+
+REPL 如何来进行推荐呢?我们使用一个字典来进行可能项的推荐。
+
+我们实现一个针对 SQL 的 REPL 。我们可以把自动补全字典和 SQL 存到一起。让我们看一看这是如何实现的:
+
+```
+from prompt_toolkit import prompt
+from prompt_toolkit.history import FileHistory
+from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
+from prompt_toolkit.contrib.completers import WordCompleter
+
+SQLCompleter = WordCompleter(['select', 'from', 'insert', 'update', 'delete', 'drop'],
+ ignore_case=True)
+
+while 1:
+ user_input = prompt('SQL>',
+ history=FileHistory('history.txt'),
+ auto_suggest=AutoSuggestFromHistory(),
+ completer=SQLCompleter,
+ )
+ print(user_input)
+```
+
+再次说明,我们只是简单的使用了 `prompt-toolkit` 内建的一个叫做 `WordCompleter` 的补全特性,它能够把用户输入和可能推荐的字典进行匹配,然后提供一个列表。
+
+现在,我们有了一个能够自动补全、`fish shell` 风格的历史命令推荐以及上/下浏览历史的 REPL 。实现这些特性只用了不到 10 行的实际代码。
+
+### Click
+
+`Click` 是一个命令行创建工具包,使用它能够更容易的为程序解析命令行选项的参数和常量。在这儿我们不讨论如何使用 `Click` 来作为参数解析器。相反,我们将会看到 `Click` 的一些实际功能。
+
+安装 `Click`:
+
+```
+pip install click
+```
+
+#### Pager
+
+`Paper` 是 Unix 系统上的实用工具,它们能够一次性在一页上显示很长的输出。`Pager` 的一些例子包括 `less`、`more`、`most` 等。通过 `pager` 来显示一个命令的输出不仅仅是一个友好的设计,同时也是需要正确做的事。
+
+让我们进一步改进前面的例子。我们不再使用默认的 `print()` 语句,取而代之的是 `click.echo_via_pager()` 。它将会把输出通过 `pager` 发送到标准输出。这是平台无关的,因此在 Unix 系统或 Windows 系统上均能工作。如果必要的话,`click_via_pager` 会尝试使用一个合适的默认 `pager` 来输出,从而能够显示代码高亮。
+
+```
+from prompt_toolkit import prompt
+from prompt_toolkit.history import FileHistory
+from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
+from prompt_toolkit.contrib.completers import WordCompleter
+import click
+
+SQLCompleter = WordCompleter(['select', 'from', 'insert', 'update', 'delete', 'drop'],
+ ignore_case=True)
+
+while 1:
+ user_input = prompt(u'SQL>',
+ history=FileHistory('history.txt'),
+ auto_suggest=AutoSuggestFromHistory(),
+ completer=SQLCompleter,
+ )
+ click.echo_via_pager(user_input)
+```
+
+#### 编辑器
+
+在我以前的文章中,一个值得一提的细节是,当命令过于复杂的时候进入编辑器来编辑。`Click` 有一个[简单的 API][24] 能够打开编辑器,然后把在编辑器中输入的文本返回给应用。
+
+```
+import click
+message = click.edit()
+```
+
+### Fuzzy Finder
+
+`Fuzzy Finder` 是一种通过极小输入来为用户减少推荐的方法。幸运的是,有一个库可以实现 `Fuzzy Finder` 。让我们首先安装这个库:
+
+```
+pip install fuzzyfinder
+```
+
+`Fuzzy Finder` 的 API 很简单。用户向它传递部分字符串和一系列可能的选择,然后,`Fuzzy Finder` 将会返回一个与部分字符串匹配的列表,这一列表是通过模糊算法根据相关性排序得出的。比如:
+
+```
+>>> from fuzzyfinder import fuzzyfinder
+
+>>> suggestions = fuzzyfinder('abc', ['abcd', 'defabca', 'aagbec', 'xyz', 'qux'])
+
+>>> list(suggestions)
+['abcd', 'defabca', 'aagbec']
+```
+
+现在我们有了 `fuzzyfinder`,让我们把它加入到我们的 SQL REPL 中。方法是我们自定义一个 `completer` 而不是使用来自 `prompt-toolkit` 库的 `WordCompleter` 。比如:
+
+```
+from prompt_toolkit import prompt
+from prompt_toolkit.history import FileHistory
+from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
+from prompt_toolkit.completion import Completer, Completion
+import click
+from fuzzyfinder import fuzzyfinder
+
+SQLKeywords = ['select', 'from', 'insert', 'update', 'delete', 'drop']
+
+class SQLCompleter(Completer):
+ def get_completions(self, document, complete_event):
+ word_before_cursor = document.get_word_before_cursor(WORD=True)
+ matches = fuzzyfinder(word_before_cursor, SQLKeywords)
+ for m in matches:
+ yield Completion(m, start_position=-len(word_before_cursor))
+
+while 1:
+ user_input = prompt(u'SQL>',
+ history=FileHistory('history.txt'),
+ auto_suggest=AutoSuggestFromHistory(),
+ completer=SQLCompleter(),
+ )
+ click.echo_via_pager(user_input)
+```
+
+### Pygments
+
+现在,让我们给用户输入添加语法高亮。我们搭建一个 SQL REPL,并且具有丰富多彩的 SQL 语句,这会很棒。
+
+`Pygments` 是一个提供语法高亮的库,内建支持超过 300 种语言。添加语法高亮能够使应用变得丰富多彩,从而能够帮助用户在执行程序前发现 SQL 中存在的错误,比如拼写错误、引号不匹配或括号不匹配。
+
+首先,安装 `Pygments` :
+
+```
+pip install pygments
+```
+
+让我们使用 `Pygments` 来为 SQL REPL 添加颜色:
+
+```
+from prompt_toolkit import prompt
+from prompt_toolkit.history import FileHistory
+from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
+from prompt_toolkit.completion import Completer, Completion
+import click
+from fuzzyfinder import fuzzyfinder
+from pygments.lexers.sql import SqlLexer
+
+SQLKeywords = ['select', 'from', 'insert', 'update', 'delete', 'drop']
+
+class SQLCompleter(Completer):
+ def get_completions(self, document, complete_event):
+ word_before_cursor = document.get_word_before_cursor(WORD=True)
+ matches = fuzzyfinder(word_before_cursor, SQLKeywords)
+ for m in matches:
+ yield Completion(m, start_position=-len(word_before_cursor))
+
+while 1:
+ user_input = prompt(u'SQL>',
+ history=FileHistory('history.txt'),
+ auto_suggest=AutoSuggestFromHistory(),
+ completer=SQLCompleter(),
+ lexer=SqlLexer,
+ )
+ click.echo_via_pager(user_input)
+```
+
+`Prompt Toolkit` 能够和 `Pygments` 一同很好的工作。我们把 `Pygments` 提供的 `SqlLexer` 加入到来自 `prompt-toolkit` 的 `prompt` 中。现在,所有的用户输入都会被当作 SQL 语句,并进行适当着色。
+
+### 结论
+
+我们的“旅途”通过创建一个强大的 REPL 结束,这个 REPL 具有常见的 shell 的全部特性,比如历史命令,键位绑定,用户友好性比如自动补全、模糊查找、`pager` 支持、编辑器支持和语法高亮。我们仅用少于 20 行 Python 代码实现了这个 REPL 。
+
+不是很简单吗?现在,你没有理由不会写一个自己的命令行应用了。下面这些资源可能有帮助:
+
+* [Click][7] (命令行界面创建工具)
+* [Fuzzy Finder][8]
+* [Prompt Toolkit][9]
+* 在 `prompt-toolkit` 的仓库中查看 [Prompt Toolkit 教程][10] 和[例子][11]
+* [Pygments][12]
+
+你也可以在我在 [PyCon US 2017][13] 的演讲[优秀的命令行工具][14]中学到更多东西,该会议是 5 月 20 日在波特兰,俄勒冈举行的。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Amjith Ramanujam - Amjith Ramanujam 是 `pgcli` 和 `mycli` 的作者。人们认为它们很酷,但是他不同意。他喜欢用 Python、JavaScript 和 C 编程。他喜欢写一些简单、易于理解的代码,有时候这样做是成功的。
+
+----------------------------
+
+via: https://opensource.com/article/17/5/4-practical-python-libraries
+
+作者:[ Amjith Ramanujam][a]
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/amjith
+[1]:https://opensource.com/tags/python?src=programming_resource_menu
+[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
+[3]:https://opensource.com/tags/perl?src=programming_resource_menu
+[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
+[5]:https://docs.python.org/2/library/readline.html
+[6]:https://docs.python.org/2/library/curses.html
+[7]:http://click.pocoo.org/5/
+[8]:https://pypi.python.org/pypi/fuzzyfinder
+[9]:https://python-prompt-toolkit.readthedocs.io/en/latest/
+[10]:https://github.com/jonathanslenders/python-prompt-toolkit/tree/master/examples/tutorial
+[11]:https://github.com/jonathanslenders/python-prompt-toolkit/tree/master/examples/
+[12]:http://pygments.org/
+[13]:https://us.pycon.org/2017/
+[14]:https://us.pycon.org/2017/schedule/presentation/518/
+[15]:https://opensource.com/article/17/5/4-practical-python-libraries?rate=SEw4SQN1U2QSXM7aUHJZb2ZsPwyFylPIbgcVLgC_RBg
+[16]:https://www.flickr.com/photos/mennonitechurchusa-archives/6987770030/in/photolist-bDu9zC-ovJ8gx-aecxqE-oeZerP-orVJHj-oubnD1-odmmg1-ouBNHR-otUoui-occFe4-ot7LTD-oundj9-odj4iX-9QSskz-ouaoMo-ous5V6-odJKBW-otnxbj-osXERb-iqdyJ8-ovgmPu-bDukCS-sdk9QB-5JQauY-fteJ53-ownm41-ov9Ynr-odxW52-rgqPBV-osyhxE-6QLRz9-i7ki3F-odbLQd-ownZP1-osDU6d-owrTXy-osLLXS-out7Dp-hNHsya-wPbFkS-od7yfD-ouA53c-otnzf9-ormX8L-ouTj6h-e8kAze-oya2zR-hn3B2i-aDNNqk-aDNNmR
+[17]:https://creativecommons.org/licenses/by-sa/4.0/
+[18]:https://opensource.com/article/17/4/4-terminal-apps
+[19]:https://python-prompt-toolkit.readthedocs.io/en/latest/
+[20]:http://click.pocoo.org/5/
+[21]:http://pygments.org/
+[22]:https://pypi.python.org/pypi/fuzzyfinder
+[23]:https://en.wikipedia.org/wiki/Read%E2%80%93eval%E2%80%93print_loop
+[24]:http://click.pocoo.org/5/utils/#launching-editors
+[25]:https://opensource.com/user/125521/feed
+[26]:https://opensource.com/article/17/5/4-practical-python-libraries#comments
+[27]:https://opensource.com/users/amjith
diff --git a/translated/tech/20170509 How to Password Protect a Vim File in Linux.md b/translated/tech/20170509 How to Password Protect a Vim File in Linux.md
new file mode 100644
index 0000000000..21ae3a5113
--- /dev/null
+++ b/translated/tech/20170509 How to Password Protect a Vim File in Linux.md
@@ -0,0 +1,155 @@
+怎样在 Linux 中对 Vim 文件进行密码保护
+============================================================
+
+ 现在下载你的免费电子书籍 - [给管理员的 10 本免费的 Linux 电子书籍][16] | [4 本免费的 Shell 脚本电子书籍][17]
+
+[Vim][5] 是一种流行的、功能丰富的和高度可扩展的 [Linux 文本编辑器][6],它的重要功能之一便是支持用各种带密码的加密方法来加密文本文件。
+
+本文中,我们将向你介绍一种简单的 Vim 使用技巧;在 Linux 中使用 Vim 对文件进行密码保护。我们将向你展示如何让一个文件在它创建的时侯以及为了修改目的而被打开了之后获得安全防护。
+
+**建议阅读:** [你应该在 Linux 中使用 Vim 编辑器的 10 个原因][7]
+
+要安装 Vim 完整版,只需运行这些命令:
+
+```
+$ sudo apt install vim #Debian/Ubuntu 系统
+$ sudo yum install vim #RHEL/CentOS 系统
+$ sudo dnf install vim #Fedora 22+
+```
+参阅: [十年后 Vim 8.0 发布了– 在 Linux 上安装][8]
+
+### 怎样在 Linux 中对 Vim 文件进行密码保护
+
+Vim 有个 `-x` 选项,这个选项能让你在创建文件时用它来加密。一旦你运行下面的 [vim 命令][9],你会被提示输入一个密钥:
+
+```
+$ vim -x file.txt
+警告:正在使用弱加密方法;参见 :help 'cm'
+输入加密密钥:*******
+再次输入相同密钥:*******
+```
+
+如果第二次输入的密钥无误,你就能进去修改此文件了。
+
+ [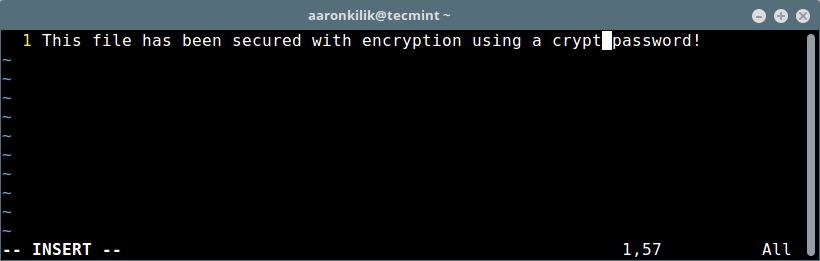][10]
+
+被密码保护的 Vim 文件
+
+等你修改好之后,摁 `[Esc]` 和键入 `:wq` 来保存及关闭文件。下次你想打开它编辑一下,你就必须像这样去输入密钥:
+
+```
+$ vim file.txt
+需要 "file.txt" 的加密密钥
+警告:正在使用弱加密方法;参见 :help 'cm'
+输入密钥:*******
+```
+
+假设你输了一个错误的密码(或者没输密码),你会看到一些垃圾字符。
+
+ [][11]
+
+Vim 中的加密内容
+
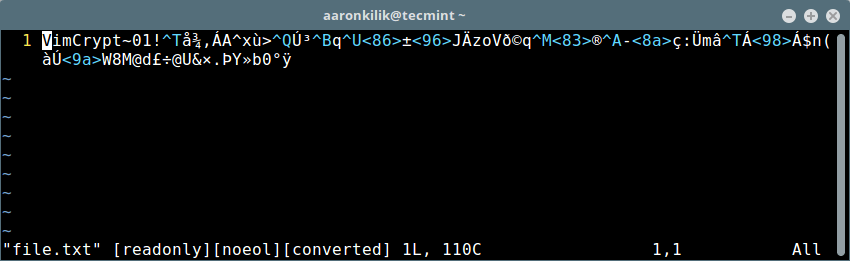
+#### 在 Vim 中设置一种强加密方法
+
+注意:有条告警信息暗示一种弱加密方法已被用于保护文件。那么接下来,我们来看看怎么在 Vim 中设置一种强加密方法。
+
+ [][12]
+
+Vim 中文件弱加密
+
+为了查看 crytmethod(cm) 集,键入(向下滚动可查看所有可用的方法):
+
+```
+:help 'cm'
+```
+
+##### 输出样例
+
+```
+ *'cryptmethod'* *'cm'*
+'cryptmethod' 'cm' string (默认 "zip")
+global or local to buffer |global-local|
+{not in Vi}
+当缓冲区写进文件中所用的方法:
+*pkzip*
+zip PkZip 兼容法。 一种弱加密方法。
+与 Vim 7.2 及更老版本后向兼容。
+*blowfish*
+blowfish 河豚法。 中级强度加密方法但有实现上
+的瑕疵。需要 Vim 7.3 及以上版本,用它加密的文件不
+能被 Vim 7.2 及更老版本读取。它会添加一个 “种子”,
+每次你对这个文件写操作时……
+options.txt [帮助][只读]
+```
+
+你可以像如下所示的那样给一个 Vim 文件设置个新的 cryptomethod(加密方法)(本例中我们用 blowfish2 加密方法)
+
+```
+:setlocal cm=blowfish2
+```
+
+然后键入 `[Enter]` 和 `:wq` 保存下文件。
+
+ [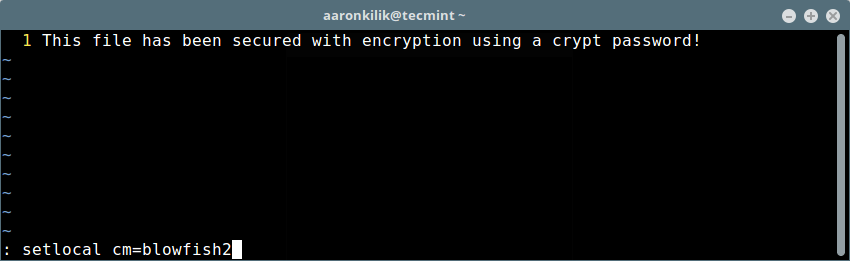][13]
+
+对 Vim 文件设置强加密
+
+现在你再打开下示的文件时应该就看不到那条警告信息了。
+
+```
+$ vim file.txt
+需要 "file.txt" 的加密密钥
+输入加密密钥:*******
+```
+
+你也可以在打开 Vim 文件之后来设置密码,用 `:X` 命令就能像上面所示的那样去设置一个密码关卡。
+
+可以看看我们其他的关于 Vim 编辑器的有用的文章。
+
+1. [在 Linux 中学习有用的 Vim 编辑器的旅行与技巧][1]
+
+2. [给每个 Linux 用户的 8 种有用的 Vim 编辑器技巧][2]
+
+3. [spf13-vim – Vim 编辑器的顶级发行版][3]
+
+4. [怎样在 Linux 种把 Vim 编辑当作 Bash IDE 来用][4]
+
+本文到这里就结束了!文章中我们介绍了怎么通过 Linux 下的 Vim 文本编辑器来给一个文件做加密防护。
+
+永远记住要用强加密方式及密码来适当的保护那些可能包含了诸如用户名及密码、财务账户信息等等机密信息的文本文件。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software,自由及开放源代码软件)爱好者,未来的 Linux 系统管理员、web 开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,且崇尚分享知识。
+
+------------------
+
+via: https://www.tecmint.com/password-protect-vim-file-in-linux/
+
+作者:[Aaron Kili ][a]
+译者:[ch-cn](https://github.com/ch-cn)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.tecmint.com/author/aaronkili/
+[1]:https://www.tecmint.com/learn-vi-and-vim-editor-tips-and-tricks-in-linux/
+[2]:https://www.tecmint.com/how-to-use-vi-and-vim-editor-in-linux/
+[3]:https://www.tecmint.com/spf13-vim-offers-vim-plugins-vim-editor/
+[4]:https://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
+[5]:https://www.tecmint.com/vi-editor-usage/
+[6]:https://www.tecmint.com/best-open-source-linux-text-editors/
+[7]:https://www.tecmint.com/reasons-to-learn-vi-vim-editor-in-linux/
+[8]:https://www.tecmint.com/vim-8-0-install-in-ubuntu-linux-systems/
+[9]:https://www.tecmint.com/linux-command-line-editors/
+[10]:https://www.tecmint.com/wp-content/uploads/2017/05/Vim-File-Password-Protected-File.png
+[11]:https://www.tecmint.com/wp-content/uploads/2017/05/Vim-Content-Encrypted.png
+[12]:https://www.tecmint.com/wp-content/uploads/2017/05/Weak-Encryption-on-Vim-File.png
+[13]:https://www.tecmint.com/wp-content/uploads/2017/05/Set-Strong-Encryption-on-Vim-File.png
+[14]:https://www.tecmint.com/vi-editor-usage/
+[15]:https://www.tecmint.com/author/aaronkili/
+[16]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
+[17]:https://www.tecmint.com/free-linux-shell-scripting-books/
diff --git a/translated/tech/20170515 Show a Custom Message to Users Before Linux Server Shutdown.md b/translated/tech/20170515 Show a Custom Message to Users Before Linux Server Shutdown.md
new file mode 100644
index 0000000000..fc65f547e0
--- /dev/null
+++ b/translated/tech/20170515 Show a Custom Message to Users Before Linux Server Shutdown.md
@@ -0,0 +1,79 @@
+在 Linux 服务器关机前向用户显示一条自定义消息
+============================================================
+
+
+在先前的文章中,我们解释了 Linux 中[ shutdown、poweroff、halt、reboot 命令的不同之处][3],并揭示了在用不同的选项执行这些命令时它们实际做了什么。
+
+本篇将会向你展示如何在系统关机时向所有的系统用户发送一条自定义的消息。
+
+**建议阅读:**[tuptime - 显示 Linux 系统的历史和统计运行时间][4]
+
+作为一名系统管理员,在你关闭服务器之前,你也许想要发送一条消息来警告他们系统将要关闭。默认上,shutdown 命令会如下所示给其他系统用户广播这条信息:
+
+```
+# shutdown 13:25
+```
+Linux Shutdown Broadcast Message
+```
+Shutdown scheduled for Fri 2017-05-12 13:25:00 EAT, use 'shutdown -c' to cancel.
+Broadcast message for root@tecmint (Fri 2017-05-12 13:23:34 EAT):
+The system is going down for power-off at Fri 2017-05-12 13:25:00 EAT!
+```
+
+要在 shutdown 那行发送一条自定义的消息给其他系统用户,运行下面的命令。在本例中,关闭会在命令执行后的两分钟之后发生。
+
+```
+# shutdown 2 The system is going down for required maintenance. Please save any important work you are doing now!
+```
+ [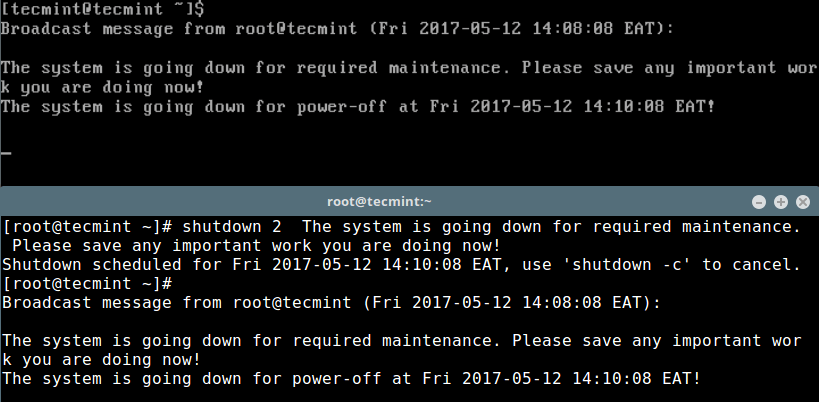][5]
+
+Linux 系统关闭消息
+
+假设你有一些关键的系统操作,如计划系统备份或更新会在系统关闭的时候进行,如下所示,你可以使用 `-c` 选项取消关机,并在执行玩这些操作后继续执行:
+
+```
+# shutdown -c
+```
+Linux Shutdown Cancel Message
+```
+Shutdown scheduled for Fri 2017-05-12 14:10:22 EAT, use 'shutdown -c' to cancel.
+Broadcast message for root@tecmint (Fri 2017-05-14 :10:27 EAT):
+The system shutdown has been cancelled at Fri 2017-05-12 14:11:27 EAT!
+```
+
+另外,学习如何在 Linux 中使用简单和传统的方法[在重启或者开机时自动执行命令/脚本][6]。
+
+不要错过:
+
+1. [关系系统启动进程和服务(SysVinit、Systemd 和 Upstart)][1]
+
+2. [11 个 Linux 中 cron 计划任务示例][2]
+
+现在你知道了如何在系统关闭前向其他系统用户发送自定义消息了。你有其他关于这个主题想要分享的想法么?何不使用下面的评论栏?
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网络开发人员,现在也是 TecMint 的内容创作者,他喜欢和电脑一起工作,坚信共享知识。
+
+------------------
+
+via: https://www.tecmint.com/show-linux-server-shutdown-message/
+
+作者:[Aaron Kili ][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.tecmint.com/author/aaronkili/
+[1]:https://www.tecmint.com/linux-boot-process-and-manage-services/
+[2]:https://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
+[3]:https://www.tecmint.com/shutdown-poweroff-halt-and-reboot-commands-in-linux/
+[4]:https://www.tecmint.com/find-linux-uptime-shutdown-and-reboot-time-with-tuptime/
+[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-System-Shutdown-Message.png
+[6]:https://www.tecmint.com/auto-execute-linux-scripts-during-reboot-or-startup/
+[7]:https://www.tecmint.com/author/aaronkili/
+[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
+[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
diff --git a/translated/tech/20170518 Linfo – Shows Linux Server Health Status in Real-Time.md b/translated/tech/20170518 Linfo – Shows Linux Server Health Status in Real-Time.md
new file mode 100644
index 0000000000..077086073e
--- /dev/null
+++ b/translated/tech/20170518 Linfo – Shows Linux Server Health Status in Real-Time.md
@@ -0,0 +1,131 @@
+Linfo — 实时显示你的 Linux 服务器运行状况
+============================================================
+
+
+Linfo 是一个免费且开源的跨平台服务器统计 UI/库,它可以显示大量的系统信息。Linfo 是可扩展的,通过 `composer`,很容易使用 PHP5 库以程序化方式获取来自 PHP 应用的扩展系统统计。它是 `Web UI` 的一个 `Ncurses CLI view`,在 Linux、Windows、BSD、Darwin/Mac OSX、Solaris 和 Minix 系统上均可用。
+
+Linfo 显示的系统信息包括 [CPU 类型/速度][2]、服务器的体系结构、挂载点使用量、硬盘/光纤/flash 驱动器、硬件设备、网络设备和统计信息、运行时间/启动日期、主机名、内存使用量(RAM 和 swap)、温度/电压/风扇速度和 RAID 阵列等。
+
+#### 环境要求:
+
+* PHP 5.3
+
+* pcre 扩展
+
+* Linux – /proc 和 /sys 已挂载且可对 `PHP` 可读,已经在 2.6.x/3.x 内核中测试过
+
+### 如何在 Linux 中安装服务器统计 UI/库 Info
+
+首先,在 `Apache` 或 `Nginx` 的 Web 根目录下创建一个 `Linfo` 目录,然后,克隆仓库文件并使用下面展示的 [rsync 命令][3]将其移动到目录 `/var/www/html/linfo` 下:
+
+```
+$ sudo mkdir -p /var/www/html/linfo
+$ git clone git://github.com/jrgp/linfo.git
+$ sudo rsync -av linfo/ /var/www/html/linfo/
+```
+
+接下来,将 `sample.config.inc.php` 重命名为 `config.inc.php`。这是 Linfo 的配置文件,你可以在里面定义你想要的值:
+
+```
+$ sudo mv sample.config.inc.php config.inc.php
+```
+
+现在,在 Web 浏览器中打开链接 `http://SERVER_IP/linfo` 来查看这个 Web UI,正如下面的截图所展示的。
+
+从截图中可以看到, Linfo 显示了系统内核信息、硬件组成、RAM 统计、网络设备、驱动器以及文件系统挂载点。
+
+ [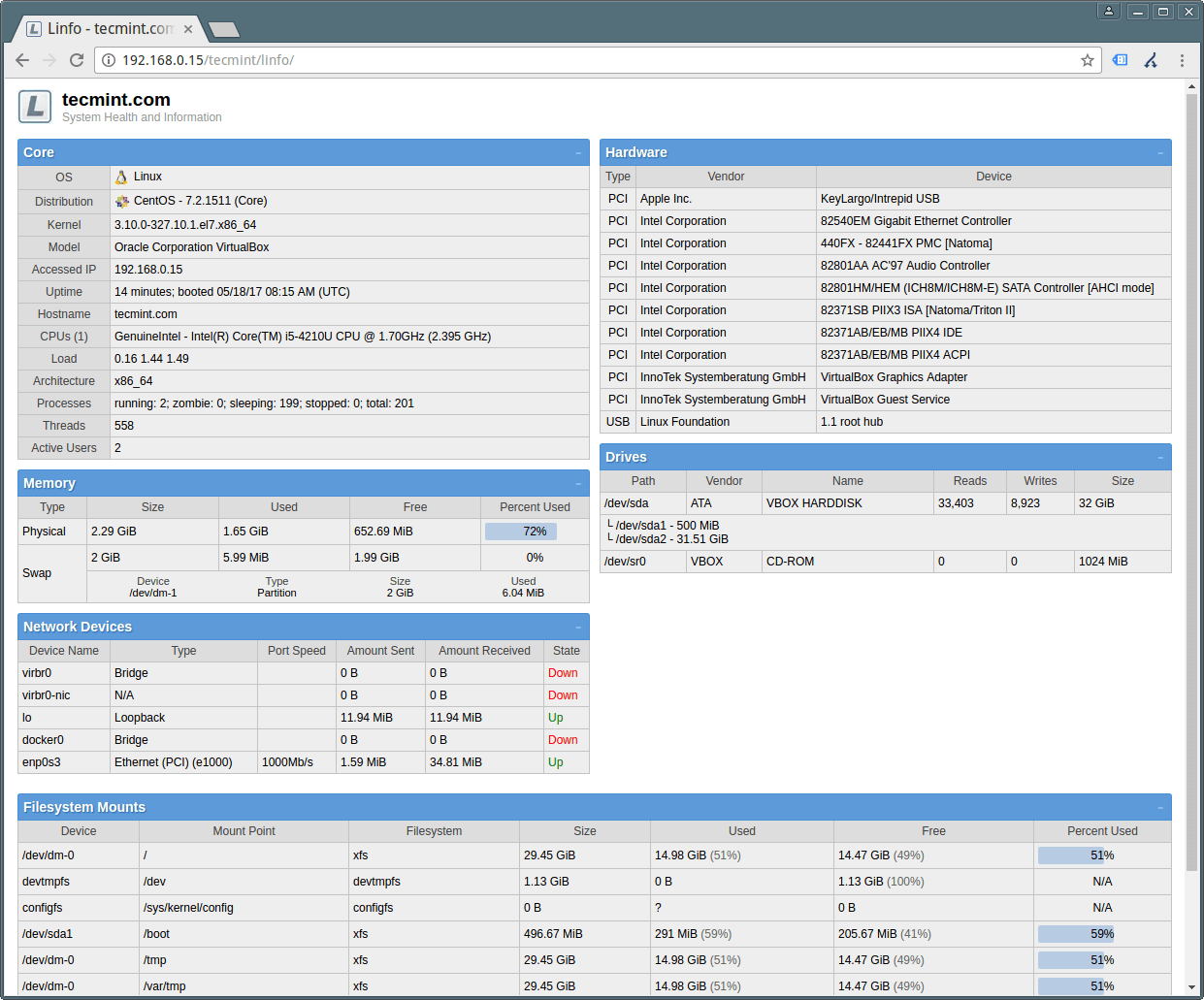][4]
+
+*Linux 服务器运行信息*
+
+你可以将下面一行内容加入配置文件 `config.inc.php` 中,从而可以产生错误信息,以便进行故障排查。
+
+```
+$settings['show_errors'] = true;
+```
+
+### 以 Ncurses 模式运行 Linfo
+
+Linfo 有一个基于 `ncurses` 的简单界面,它依赖于 `php` 的 `ncurses` 扩展。
+
+```
+# yum install php-pecl-ncurses [在 CentOS/RHEL 上]
+# dnf install php-pecl-ncurses [在 Fedora 上]
+$ sudo apt-get install php5-dev libncurses5-dev [在 Debian/Ubuntu 上]
+```
+
+现在,像下面这样编译这个 `php` 扩展:
+
+```
+$ wget http://pecl.php.net/get/ncurses-1.0.2.tgz
+$ tar xzvf ncurses-1.0.2.tgz
+$ cd ncurses-1.0.2
+$ phpize # generate configure script
+$ ./configure
+$ make
+$ sudo make install
+```
+
+接下来,如果编译成功并安装好了该 `php` 扩展,运行下面的命令:
+
+```
+$ sudo echo extension=ncurses.so > /etc/php5/cli/conf.d/ncurses.ini
+```
+
+验证 ncurse:
+
+```
+$ php -m | grep ncurses
+```
+
+Now run the Linfo.
+现在,运行 Info:
+
+```
+$ cd /var/www/html/linfo/
+$ ./linfo-curses
+```
+ [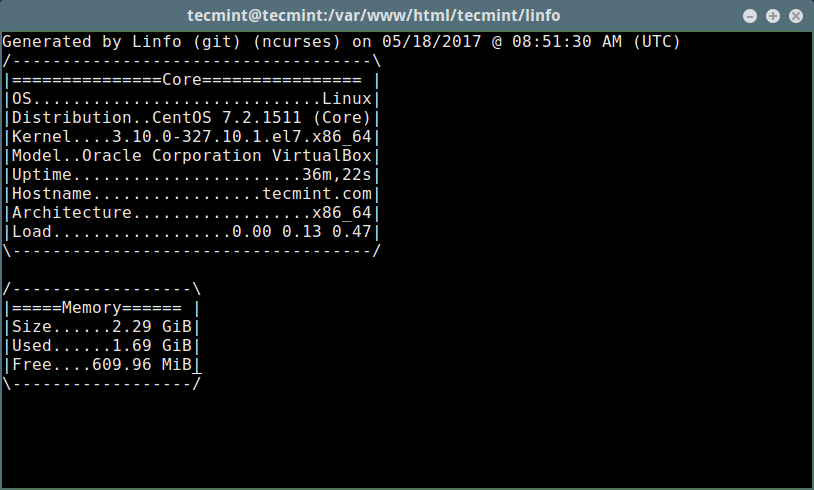][5]
+
+*Linux 服务器信息*
+
+Info 中尚未加入下面这些功能:
+
+1. 支持更多 Unix 操作系统(比如 Hurd、IRIX、AIX 和 HP UX 等)
+
+2. 支持不太出名的操作系统 Haiku/BeOS
+
+3. 额外功能/扩展
+
+5. 在 ncurses 模式中支持 [htop-like][1] 特性
+
+如果想了解更多信息,请访问 Info 的 GitHub 仓库: [https://github.com/jrgp/linfo][6]
+
+这就是本文的全部内容了。从现在起,你可以使用 Info 在 Web 浏览器中查看 Linux 系统的信息。尝试一下,并在评论中和我们分享你的想法。另外,你是否还知道与之类似的有用工具/库?如果有,请给我们提供一些相关信息。
+
+--------------------------------------------------------------------------------
+
+作者简介:
+
+Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识
+
+---------------
+
+via: https://www.tecmint.com/linfo-shows-linux-server-health-status-in-real-time/
+
+作者:[ Aaron Kili][a]
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.tecmint.com/author/aaronkili/
+[1]:https://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
+[2]:https://www.tecmint.com/corefreq-linux-cpu-monitoring-tool/
+[3]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
+[4]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Health-Information.png
+[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Information.png
+[6]:https://github.com/jrgp/linfo
+[7]:https://www.tecmint.com/author/aaronkili/
+[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
+[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
diff --git a/translated/tech/20170518 Maintaining a Git Repository.md b/translated/tech/20170518 Maintaining a Git Repository.md
new file mode 100644
index 0000000000..c86da78795
--- /dev/null
+++ b/translated/tech/20170518 Maintaining a Git Repository.md
@@ -0,0 +1,227 @@
+维护一个Git仓库
+============================================================
+
+维护Git仓库通常包括减少仓库的大小。如果你从另外一个版本控制系统导入了一个仓库,你可能需要在导入后清除掉不必要的文件。本文着重于从一个Git仓库中删除大文件,并且包含下列主题:
+
+* [理解从Git的历史记录中删除文件][1]
+
+* [使用BFG重写历史记录][2]
+
+* [可选,使用git filter-branch重写历史记录][3]
+
+* [垃圾回收][4]
+
+请格外小心.....
+
+本文中的步骤和工具使用的高级技术涉及破坏性操作。确保您在开始之前仔细读过**备份你的仓库**,创建一个备份的方式是使用[--mirror][5]标志对你的仓库克隆,然后对整个克隆的文件进行打包压缩。如果在维护期间意外损坏了您的仓库的关键元素,那么你可以通过备份的仓库来恢复。
+
+请记住,仓库维护对仓库的用户可能会是毁灭性的。与你的团队或者仓库的关注者进行沟通会是一个不错的主意。确保每个人都已经检查了他们的代码,并且同意在仓库维护期间停止开发。
+
+### 理解从Git的历史记录中删除文件
+
+回想一下,克隆存储库会克隆整个历史记录——包括每个源代码文件的所有版本。如果一个用户提交了一个较大的文件,比如一个JAR,则随后的每次克隆都会包含这个文件。即使用户最终在后面的某次提交中删除了这个文件,但是这个文件仍然存在于这个仓库的历史记录中。要想完全的从你的仓库中删除这个文件,你必须:
+
+* 从你的项目的*当前的*文件树中删除该文件;
+
+* 从仓库的历史记录中删除文件——*重写*Git历史记录,从包含该文件的*所有的*提交中删除这个文件;
+
+* 删除指向*旧的*提交历史记录的所有[reflog][6]历史记录;
+
+* 重新整理仓库,使用[git gc][7]对现在没有使用的数据进行垃圾回收。
+
+Git的'gc'(垃圾回收)通过任何一个你的分支或者标签来删除仓库中所有的实际没用的或者用某种方式引用的数据。为了使其有用,我们需要重写包含不需要的文件的所有Git仓库历史记录,仓库将不再引用它——git gc将会丢弃所有没用的数据。
+
+重写存储库历史是一个棘手的事情,因为每次提交都依赖它的父提交,所以任何一个很小的改变都会改变它的每一个子拼音的提交ID。有两个自动化的工具可以做到这:
+
+1. [BFG Repo Cleaner][8] 快速、简单且易于使用,需要Java 6或者更高版本的运行环境。
+
+2. [git filter-branch][9] 功能强大、配置麻烦,用于大于仓库时速度较慢,是核心Git套件的一部分。
+
+切记,当你重写历史记录后,无论你是使用BFG还是使用filter-branch,你都需要删除撒向指向旧的历史记录的`reflog`条目,最后运行垃圾回收器来删除旧的数据。
+
+### 使用BFG重写历史记录
+
+[BFG][11]是为将像大文件或者密码这些不想要的数据从Git仓库中删除而专门设计的,所以它有一一个简单的标志用来删除那些大的历史文件(不是当前提交的文件):`'--strip-blobs-bigger-than'`
+
+```
+$ java -jar bfg.jar --strip-blobs-than 100M
+
+```
+大小超过100MB的任何文件(不在你*最近的*提交中——因为BFG[默认会保护你的最新提交的内容][12])将会从你的Git仓库的历史记录中删除。如果你想用名字来指明具体的文件,你也可以这样做:
+
+```
+$ java -jar bfg.jar --delete-files *.mp4
+
+```
+
+BFG的速度要比git filter-branch快[10-1000x][13],而且通常更容易使用——查看完整的[使用说明][14]和[示例][15]获取更多细节。
+
+### 或者,使用git filter-branch来重写历史记录
+
+`filter-branch`命令可以对Git仓库的历史记录重写,就像BFG一样,但是过程更慢和更手动化。如果你不知道这些大文件在_哪里_,那么你第一步就需要找到它们:
+
+### 手动查看你Git仓库中的大文件
+
+[Antony Stubbs][16]写了一个可以很好地完成这个功能的BASH脚本。该脚本可以检查你的包文件的内容并列出大文件。在你开始删除文件之前,请执行以下操作获取并安装此脚本:
+
+1\. [下载脚本][10]到你的本地的系统。
+
+2\. 将它放在一个可以访问你的Git仓库的易于找到的位置。
+
+3\. 让脚本成为可执行文件:
+
+```
+ $ chmod 777 git_find_big.sh
+
+```
+4\. 克隆仓库到你本地系统。
+
+5\. 改变当前目录到你的仓库根目录。
+
+6\. 手动运行Git垃圾回收器:
+
+```
+ git gc --auto
+```
+
+7\. 找出.git文件夹的大小
+
+```
+$ du -hs .git/objects
+```
+```
+45M .git/objects
+```
+注意文件大小,以便随后参考。
+
+8\. 运行`git_find_big.sh`脚本来列出你的仓库中的大文件。
+
+```
+$ git_find_big.sh
+
+```
+所有文件大小都用kb表示,pack列是在pack文件内压缩后的大小。
+
+```
+size pack SHA location
+```
+```
+592 580 e3117f48bc305dd1f5ae0df3419a0ce2d9617336 media/img/emojis.jar
+```
+```
+550 169 b594a7f59ba7ba9daebb20447a87ea4357874f43 media/js/aui/aui-dependencies.jar
+```
+
+```
+518 514 22f7f9a84905aaec019dae9ea1279a9450277130 media/images/screenshots/issue-tracker-wiki.jar
+```
+```
+337 92 1fd8ac97c9fecf74ba6246eacef8288e89b4bff5 media/js/lib/bundle.js
+```
+```
+240 239 e0c26d9959bd583e5ef32b6206fc8abe5fea8624 media/img/featuretour/heroshot.png
+```
+大文件都是JAR文件,包的大小列是最相关的。`aui-dependencies.jar` 被压缩到169kb,但是`emojis.jar`只压缩到500kb。`emojis.jar`就是一个待删除的对象。
+
+
+### 运行filter-branch
+
+
+你可以给这个命令传递一个用于重写Git索引的过滤器。例如,一个过滤器可以可以将每个检索的提交删除。这个用法如下:
+
+```
+git filter-branch --index-filter 'git rm --cached --ignore-unmatch _pathname_ ' commitHASH
+
+```
+`--index-filter`选项可以修改仓库的索引,`--cached ` 选项从不是磁盘的索引中删除文件。这样会更快,因为你不需要在运行这个过滤器前检查每个修订版。`git rm`中的`ignore-unmatch`选项可以防止当 _pathname_ 正在尝试不在那的文件的时候这个命令失败。通过明确一个提交HASH值,你可以从每个以这个HASH值开始的提交中删除`pathname`。为了从开始处删除,你可以省略这个或者明确HEAD。
+
+如果所有你的大文件在不同的分支,你将需要通过名字来删除每个文件。如果所有大文件在一个单独的分支,你可以直接删除这个分支本身。
+
+### 选项1:通过文件名删除文件
+
+使用下面的步骤来删除大文件:
+
+1\. 使用下面的命令来删除你找到的第一个大文件:
+
+```
+git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
+
+```
+
+2\. 对于剩下的每个大文件,重复步骤1。
+
+3\. 在你的仓库里更新引用。 `filter-branch`会为你原先的引用创建一个以`refs/original/`命名的备份。一旦你确信已经删除了正确的文件,你可以运行下面的命令来删除备份文件,同时可以让垃圾回收器回收大的对象:
+
+```
+ git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
+
+```
+
+### 选项2:直接删除分支
+
+如果你所有的大文件都在一个单独的分支上,你可以直接删除这个分支。删除这个分支会自动删除所有的引用。
+
+1\. 删除分支。
+
+```
+ $ git branch -D PROJ567bugfix
+
+```
+
+2\. 从后面的分支中删除所有的reflog引用。
+
+
+### 对不用的数据垃圾回收
+
+1\. 删除从现在到后面的所有reflog引用(除非你明确地只在一个分支上操作)。
+
+```
+$ git reflog expire --expire=now --all
+
+```
+
+2\. 通过运行垃圾回收器和删除旧的对象重新打包仓库。
+
+```
+ $ git gc --prune=now
+
+```
+
+3\. 把你所有的修改推送回Bitbucket仓库。
+
+```
+$ git push --all --force
+```
+
+4\. 确保你所有的tags也是当前最新的:
+
+```
+ $ git push --tags --force
+
+```
+
+via: https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
+
+作者:[atlassian.com][a]
+译者:[zhousiyu325](https://github.com/zhousiyu325)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
+[1]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UnderstandingfileremovalfromGithistory
+[2]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UsingtheBFGtorewritehistory
+[3]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Alternatively,usinggitfilter-branchtorewritehistory
+[4]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Garbagecollectingdeaddata
+[5]:http://stackoverflow.com/questions/3959924/whats-the-difference-between-git-clone-mirror-and-git-clone-bare
+[6]:http://git-scm.com/docs/git-reflog
+[7]:http://git-scm.com/docs/git-gc
+[8]:http://rtyley.github.io/bfg-repo-cleaner/
+[9]:http://git-scm.com/docs/git-filter-branch
+[10]:https://confluence.atlassian.com/bitbucket/files/321848291/321979854/1/1360604134990/git_find_big.sh
+[11]:http://rtyley.github.io/bfg-repo-cleaner/
+[12]:http://rtyley.github.io/bfg-repo-cleaner/#protected-commits
+[13]:https://www.youtube.com/watch?v=Ir4IHzPhJuI
+[14]:http://rtyley.github.io/bfg-repo-cleaner/#usage
+[15]:http://rtyley.github.io/bfg-repo-cleaner/#examples
+[16]:https://stubbisms.wordpress.com/2009/07/10/git-script-to-show-largest-pack-objects-and-trim-your-waist-line/
\ No newline at end of file
diff --git a/translated/tech/GDB-common-commands.md b/translated/tech/GDB-common-commands.md
deleted file mode 100644
index 4ba6de54ef..0000000000
--- a/translated/tech/GDB-common-commands.md
+++ /dev/null
@@ -1,259 +0,0 @@
-# 常用的 GDB 命令中文释义
-
-## 目录
-
- - [break](#break) -- 缩写 `b`,在指定的行或函数处设置断点
- - [info breakpoints](#info-breakpoints) -- 简写 `i b`,打印未删除的所有断点,观察点和捕获点的列表
- - [disable](#disable) -- 禁用断点,可以缩写为 `dis`
- - [enable](#enable) -- 启用断点
- - [clear](#clear) -- 清除指定行或函数处的断点
- - [delete](#delete) -- 缩写 `d`,删除断点
- - [tbreak](#tbreak) -- 设置临时断点,参数同 `break`,但在程序第一次停住后会被自动删除
- - [watch](#watch) -- 为表达式(或变量)设置观察点,当表达式(或变量)的值有变化时,停住程序
-
- - [step](#step) -- 缩写 `s`,单步跟踪,如果有函数调用,会进入该函数
- - [reverse-step](#reverse-step) -- 反向单步跟踪,如果有函数调用,会进入该函数
- - [next](#next) -- 缩写 `n`,单步跟踪,如果有函数调用,不会进入该函数
- - [reverse-next](#reverse-next) -- 反向单步跟踪,如果有函数调用,不会进入该函数
- - [return](#return) -- 使选定的栈帧返回到其调用者
- - [finish](#finish) -- 缩写 `fin`,执行直到选择的栈帧返回
- - [until](#until) -- 缩写 `u`,执行直到...(用于跳过循环、递归函数调用)
- - [continue](#continue) -- 同义词 `c`,恢复程序执行
-
- - [print](#print) -- 缩写 `p`,打印表达式 EXP 的值
- - [x](#x) -- 查看内存
-
- - [display](#display) -- 每次程序停止时打印表达式 EXP 的值(自动显示)
- - [info display](#info-display) -- 打印早先设置为自动显示的表达式列表
- - [disable display](#disable-display) -- 禁用自动显示
- - [enable display](#enable-display) -- 启用自动显示
- - [undisplay](#undisplay) -- 删除自动显示项
-
- - [help](#help) -- 缩写 `h`,打印命令列表(带参数时查找命令的帮助)
-
- - [attach](#attach) -- 挂接到已在运行的进程来调试
- - [run](#run) -- 缩写 `r`,启动被调试的程序
-
- - [backtrace](#backtrace) -- 缩写 `bt`,查看程序调用栈的信息
-
-
-************
-
-## break
-使用 `break` 命令(缩写 `b`)来设置断点。 参见[官方文档][1]。
-
- - `break` 当不带参数时,在所选栈帧中执行的下一条指令处设置断点。
- - `break ` 在函数体入口处打断点,在 C++ 中可以使用 `class::function` 或 `function(type, ...)` 格式来指定函数名。
- - `break ` 在当前源码文件指定行的开始处打断点。
- - `break -N` `break +N` 在当前源码行前面或后面的 `N` 行开始处打断点,`N` 为正整数。
- - `break ` 在源码文件 `filename` 的 `linenum` 行处打断点。
- - `break ` 在源码文件 `filename` 的 `function` 函数入口处打断点。
- - `break ` 在程序指令的地址处打断点。
- - `break ... if ` 设置条件断点,`...` 代表上述参数之一(或无参数),`cond` 为条件表达式,仅在 `cond` 值非零时停住程序。
-
-## info breakpoints
-查看断点,观察点和捕获点的列表。用法:
-`info breakpoints [list…]`
-`info break [list…]`
-`list…` 用来指定若干个断点的编号(可省略),可以是 `2`, `1-3`, `2 5` 等。
-
-## disable
-禁用一些断点。 参见[官方文档][2]。
-参数是用空格分隔的断点编号。
-要禁用所有断点,不加参数。
-禁用的断点不会被忘记,但直到重新启用才有效。
-用法: `disable [breakpoints] [list…]`
-`breakpoints` 是 `disable` 的子命令(可省略),`list…` 同 `info breakpoints` 中的描述。
-
-## enable
-启用一些断点。 参见[官方文档][2]。
-给出断点编号(以空格分隔)作为参数。
-没有参数时,所有断点被启用。
-
- - `enable [breakpoints] [list…]` 启用指定的断点(或所有定义的断点)。
- - `enable [breakpoints] once list…` 临时启用指定的断点。GDB 在停止您的程序后立即禁用这些断点。
- - `enable [breakpoints] delete list…` 使指定的断点启用一次,然后删除。一旦您的程序停止,GDB 就会删除这些断点。等效于用 `tbreak` 设置的断点。
-
-`breakpoints` 同 `disable` 中的描述。
-
-## clear
-在指定行或函数处清除断点。 参见[官方文档][3]。
-参数可以是行号,函数名称或 "*" 跟一个地址。
-
- - `clear` 当不带参数时,清除所选栈帧在执行的源码行中的所有断点。
- - `clear `, `clear ` 删除在命名函数的入口处设置的任何断点。
- - `clear `, `clear ` 删除在指定的文件指定的行号的代码中设置的任何断点。
- - `clear ` 清除指定程序指令的地址处的断点。
-
-## delete
-删除一些断点或自动显示表达式。 参见[官方文档][3]。
-参数是用空格分隔的断点编号。
-要删除所有断点,不加参数。
-用法: `delete [breakpoints] [list…]`
-
-## tbreak
-设置临时断点。参数形式同 `break` 一样。 参见[官方文档][1]。
-除了断点是临时的之外像 `break` 一样,所以在命中时会被删除。
-
-## watch
-为表达式设置观察点。 参见[官方文档][4]。
-用法: `watch [-l|-location] `
-每当一个表达式的值改变时,观察点就会停止执行您的程序。
-如果给出了 `-l` 或者 `-location`,则它会对 `expr` 求值并观察它所指向的内存。
-例如,`watch *(int *)0x12345678` 将在指定的地址处观察一个 4 字节的区域(假设 int 占用 4 个字节)。
-
-## step
-单步执行程序,直到到达不同的源码行。 参见[官方文档][5]。
-用法: `step [N]`
-参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
-警告:如果当控制在没有调试信息的情况下编译的函数中使用 `step` 命令,则执行将继续进行,
-直到控制到达具有调试信息的函数。 同样,它不会进入没有调试信息编译的函数。
-要执行没有调试信息的函数,请使用 `stepi` 命令,后文再述。
-
-## reverse-step
-反向步进程序,直到到达另一个源码行的开头。 参见[官方文档][6]。
-用法: `reverse-step [N]`
-参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
-
-## next
-单步执行程序,执行完子程序调用。 参见[官方文档][5]。
-用法: `next [N]`
-与 `step` 不同,如果当前的源代码行调用子程序,则此命令不会进入子程序,而是继续执行,将其视为单个源代码行。
-
-## reverse-next
-反向步进程序,执行完子程序调用。 参见[官方文档][6]。
-用法: `reverse-next [N]`
-如果要执行的源代码行调用子程序,则此命令不会进入子程序,调用被视为一个指令。
-参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
-
-## return
-您可以使用 `return` 命令取消函数调用的执行。 参见[官方文档][7]。
-如果你给出一个表达式参数,它的值被用作函数的返回值。
-`return ` 将 `expression` 的值作为函数的返回值并使函数直接返回。
-
-## finish
-执行直到选定的栈帧返回。 参见[官方文档][5]。
-用法: `finish`
-返回后,返回的值将被打印并放入到值历史记录中。
-
-## until
-执行直到程序到达大于当前栈帧或当前栈帧中的指定位置(与 [break](#break) 命令相同的参数)的源码行。 参见[官方文档][5]。
-此命令用于通过一个多次的循环,以避免单步执行。
-`until ` 或 `u ` 继续运行程序,直到达到指定的位置,或者当前栈帧返回。
-
-## continue
-在信号或断点之后,继续运行被调试的程序。 参见[官方文档][5]。
-用法: `continue [N]`
-如果从断点开始,可以使用数字 `N` 作为参数,这意味着将该断点的忽略计数设置为 `N - 1`(以便断点在第 N 次到达之前不会中断)。
-如果启用了非停止模式(使用 `show non-stop` 查看),则仅继续当前线程,否则程序中的所有线程都将继续。
-
-## print
-求值并打印表达式 EXP 的值。 参见[官方文档][8]。
-可访问的变量是所选栈帧的词法环境,以及范围为全局或整个文件的所有变量。
-用法: `print [expr]` 或 `print /f [expr]`
-`expr` 是一个(在源代码语言中的)表达式。
-默认情况下,`expr` 的值以适合其数据类型的格式打印;您可以通过指定 `/f` 来选择不同的格式,其中 `f` 是一个指定格式的字母;参见[输出格式][9]。
-如果省略 `expr`,GDB 再次显示最后一个值。
-
-## x
-检查内存。 参见[官方文档][10]。
-用法: `x/nfu ` 或 `x `
-`n`, `f`, 和 `u` 都是可选参数,用于指定要显示的内存以及如何格式化。
-`addr` 是要开始显示内存的地址的表达式。
-`n` 重复次数(默认值是 1),指定要显示多少个单位(由 `u` 指定)的内存值。
-`f` 显示格式(初始默认值是 `x`),显示格式是 `print('x','d','u','o','t','a','c','f','s')` 使用的格式之一,再加 `i`(机器指令)。
-`u` 单位大小,`b` 表示单字节,`h` 表示双字节,`w` 表示四字节,`g` 表示八字节。
-例如,`x/3uh 0x54320` 表示从地址 0x54320 开始以无符号十进制整数的方式,双字节为单位显示 3 个内存值。
-
-## display
-每次程序停止时打印表达式 EXP 的值。 参见[官方文档][11]。
-用法: `display `, `display/fmt ` 或 `display/fmt `
-`fmt` 用于指定显示格式。像 [print](#print) 命令里的 `/f` 一样。
-对于格式 `i` 或 `s`,或者包括单位大小或单位数量,将表达式 `addr` 添加为每次程序停止时要检查的内存地址。
-
-## info display
-打印自动显示的表达式列表,每个表达式都带有项目编号,但不显示其值。
-包括被禁用的表达式和不能立即显示的表达式(当前不可用的自动变量)。
-
-## undisplay
-取消某些表达式在程序停止时自动显示。
-参数是表达式的编号(使用 `info display` 查询编号)。
-不带参数表示取消所有自动显示表达式。
-`delete display` 具有与此命令相同的效果。
-
-## disable display
-禁用某些表达式在程序停止时自动显示。
-禁用的显示项目不会被自动打印,但不会被忘记。 它可能稍后再次被启用。
-参数是表达式的编号(使用 `info display` 查询编号)。
-不带参数表示禁用所有自动显示表达式。
-
-## enable display
-启用某些表达式在程序停止时自动显示。
-参数是重新显示的表达式的编号(使用 `info display` 查询编号)。
-不带参数表示启用所有自动显示表达式。
-
-## help
-打印命令列表。 参见[官方文档][12]。
-您可以使用不带参数的 `help`(缩写为 `h`)来显示命令的类别名的简短列表。
-使用 `help ` 您可以获取该类中各个命令的列表。
-使用 `help ` 显示如何使用该命令的简述。
-
-## attach
-挂接到 GDB 之外的进程或文件。 参见[官方文档][13]。
-该命令可以将进程 ID 或设备文件作为参数。
-对于进程 ID,您必须具有向进程发送信号的权限,并且必须具有与调试器相同的有效的 uid。
-用法: `attach `
-GDB 在安排调试指定的进程之后做的第一件事是停住它。
-您可以使用所有通过 `run` 命令启动进程时可以使用的 GDB 命令来检查和修改挂接的进程。
-
-## run
-启动被调试的程序。 参见[官方文档][14]。
-可以直接指定参数,也可以用 [set args][15] 设置(启动所需的)参数。
-例如: `run arg1 arg2 ...` 等效于
-```
-set args arg1 arg2 ...
-run
-```
-还允许使用 ">", "<", 或 ">>" 进行输入和输出重定向。
-
-## backtrace
-打印整个栈的回溯。 参见[官方文档][16]。
-
- - `bt` 打印整个栈的回溯,每个栈帧一行。
- - `bt n` 类似于上,但只打印最内层的 n 个栈帧。
- - `bt -n` 类似于上,但只打印最外层的 n 个栈帧。
- - `bt full n` 类似于 `bt n`,还打印局部变量的值。
-
-`where` 和 `info stack`(缩写 `info s`) 是 `backtrace` 的别名。
-
-************
-
-## 参考资料
-
- - [Debugging with GDB](https://sourceware.org/gdb/current/onlinedocs/gdb/)
- - [用 GDB 调试程序(二)](http://blog.csdn.net/haoel/article/details/2880)
-
---------------------------------------------------------------------------------
-
-编译者:[robot527](https://github.com/robot527)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[1]:https://sourceware.org/gdb/current/onlinedocs/gdb/Set-Breaks.html
-[2]:https://sourceware.org/gdb/current/onlinedocs/gdb/Disabling.html
-[3]:https://sourceware.org/gdb/current/onlinedocs/gdb/Delete-Breaks.html
-[4]:https://sourceware.org/gdb/current/onlinedocs/gdb/Set-Watchpoints.html
-[5]:https://sourceware.org/gdb/current/onlinedocs/gdb/Continuing-and-Stepping.html
-[6]:https://sourceware.org/gdb/current/onlinedocs/gdb/Reverse-Execution.html
-[7]:https://sourceware.org/gdb/current/onlinedocs/gdb/Returning.html
-[8]:https://sourceware.org/gdb/current/onlinedocs/gdb/Data.html
-[9]:https://sourceware.org/gdb/current/onlinedocs/gdb/Output-Formats.html
-[10]:https://sourceware.org/gdb/current/onlinedocs/gdb/Memory.html
-[11]:https://sourceware.org/gdb/current/onlinedocs/gdb/Auto-Display.html
-[12]:https://sourceware.org/gdb/current/onlinedocs/gdb/Help.html
-[13]:https://sourceware.org/gdb/current/onlinedocs/gdb/Attach.html
-[14]:https://sourceware.org/gdb/current/onlinedocs/gdb/Starting.html
-[15]:https://sourceware.org/gdb/current/onlinedocs/gdb/Arguments.html
-[16]:https://sourceware.org/gdb/current/onlinedocs/gdb/Backtrace.html
-
diff --git a/translated/tech/Tmux_doc_cn.md b/translated/tech/Tmux_doc_cn.md
deleted file mode 100644
index 4d94302414..0000000000
--- a/translated/tech/Tmux_doc_cn.md
+++ /dev/null
@@ -1,1648 +0,0 @@
-校对中
-
-- [名称](#名称)
-- [用法](#用法)
-- [描述](#描述)
-- [键绑定](#键绑定)
-- [命令](#命令)
-- [客户端和会话](#客户端和会话)
-- [窗口和面板](#窗口和面板)
- - [窗口和面板命令](#窗口和面板命令)
-- [键绑定2](#键绑定2)
- - [键绑定命令](#键绑定命令)
-- [选项](#选项)
- - [选项设置](#选项设置)
- - [服务器选项](#服务器选项)
- - [会话选项](#会话选项)
- - [窗口选项](#窗口选项)
-- [鼠标支持](#鼠标支持)
-- [格式](#格式)
-- [名称和标题](#名称和标题)
-- [环境](#环境)
-- [状态行](#状态行)
-- [缓冲区](#缓冲区)
-- [杂项](#杂项)
-- [TERMINFO EXTENSIONS](#TERMINFO EXTENSIONS)
-- [控制模式](#控制模式)
-- [文件](#文件)
-- [样例](#样例)
-
-
-##名称
-tmux — terminal multiplexer(终端复用器)
-
-##用法:
-
- tmux [-2lCuv] [-c shell-command] [-f file] [-L socket-name] [-S socket-path] [command [flags]]
-
-##描述
-
-tmux是一个终端复用器:它可以在单个屏幕中创建、访问以及控制多个终端。
-tmux也可以从窗口中脱离附着并且继续在后台运行,以便在之后再回到会话。
-当开启tmux之后,它会创建带有一个单独窗口的会话并且在屏幕中进行显示。
-在屏幕底部的状态行显示当前会话的信息并且用来进入交互式命令。
-一个会话是一个在tmux管理下的伪终端集合,每个会话具有一个或多个窗口与其链接。
-一个窗口占用了整个屏幕,并且可以被分割成长方形的面板,每个面板分别为一个伪终端。
-多个tmux实例可能连接到同一个会话,并且任何的窗口可能在一个会话中表示。
-当所有的会话被终止之后,tmux就会退出。
-
-每个会话都是持久的并且可能在意外失联或故意脱离附着之后生存下来,tmux可以使用下面的命令来恢复原来的会话:
-
- $ tmux attach
-
-在tmux中,一个会话由一个客户端在整个屏幕中显示,并且所有的会话都是由一个单独的服务器进行管理的。
-这个服务器以及每个客户端是通过一个在/tmp中的socket进行交流的。
-
-*选项描述*:
-
- '-2'
- 强制tmux假设终端支持256颜色。
-
- '-C'
- 以控制模式开启,使用-CC来让echo失效
-
- '-c shell-command'
- 使用默认的shell来执行shell命令。
- 如果有必要的话,tmux服务器会开启来检索默认的shell选项。
- 这个选项用来当tmux作为一个登录shell时与sh进行兼容的。
-
- '-f file'
- 指定一个可选的配置文件,默认情况下,tmux会从/etc/tmux.conf中加载系统配置文件-如果这个文件存在的话。
- 然后会尝试查找用户的配置文件 ~/.tmux.conf。
- 配置文件是一个tmux命令集合,其中的命令在服务器第一次启动时按顺序执行的。
- tmux会在服务器进程启动之后加载一次配置文件。
- "source-file"命令可以用来在稍后加载一个文件。
- tmux在第一次会话创建时会显示配置文件中的命令出现的任何错误,但是会继续处理配置文件的余下部分。
-
- '-L socket-name'
- tmurx 将服务器*socsket*存储在*TMUX_TMPDIR*目录下,如果这个变量没有设置的话就会使用*TMPDIR*替换,
- 或者当两者都不存在时,就会存储在 /tmp 目录下。默认的*socket*的名称为*default*。
- 这个选项允许指定一个不同的socket名称,允许多个独立的tmux服务器运行。
- 与-S不同的是,不需要使用全路经:所有的sockets文件会创建在一个相同的目录下。
- 如果socket被意外地删除了,那么SIGUSR1信号会发送给tmux服务器进程来重新创建socket文件(注意如果当之前描述的任何
- 父目录不存在的话会出错)。
-
- '-l'
- 当作一个登录shell使用,当前这个标记没有什么效果是当tmux被用来作为登录shell时与其他shell进行兼容的。
-
- '-S socket-path'
- 为服务器的socket指定一个可选的全路经,当这个选项指定之后,那么默认的目录不会被使用,并且-L选项会被忽略。
-
- '-u'
- tmux尝试通过第一个LC_ALL,LC_CTYPE和LANG环境变量来猜测终端是否可能支持UTF-8,这可能不会总是正确。
- -u 选项显式地告知tmux UTF-8是支持的。
- 如果服务器通过客户端传递-u或者检测到UTF-8进行启动的,那么utf8和status-utf8选项会分别在全局窗口和会话选项中生效。
-
- '-v'
- 请求详细登录,这个选项可能由于不断增长的修饰词被多次指定。登录消息会被存储在当前目录下的tmux-clientPID.log
- 和tmux-serverPID.log文件中。其中的PID代表服务器或客户端进程ID。
-
- 'command [flags]'
- 这个用来指定命令集合中的一个来控制tmux,如果没有指定任何命令那么假设一个新建会话命令。
-
-##键绑定
-
-tmux可以通过一个前缀键与跟随的命令键进行结合的方式从一个附着的客户端进行控制,前缀键默认为'C-b'
-
-默认的命令键绑定为:
-
- 结合键 |含义
--------------------------------------|---------------------
- C-b |给应用发送一个前缀键 C-b
- C-o |将当前窗口中的面板向前切换。
- C-z |将tmux客户端挂起
- ! |将当前面板在窗口中突出显示
- " |将当前的面板分割为上下两个面板
- # |列出所有的粘贴缓存
- $ |重命名当前会话
- % |将当前面板分割为左右两个面板
- & |终止当前窗口
- ' |显示一个窗口索引来进行选择
- ( |将当前附着的客户端转换到前一个会话
- ) |将附着的客户端转换到下一个会话
- , |重命名当前窗口
- - |删除最近的复制文本缓存
- . |提示一个索引来移动当前窗口
- 0-9 |选择0-9个窗口
- : |输入tmux命令提示
- ; |移动到前面的活动面板
- = |从一个列表中选择一个缓存来交互式粘贴。
- ? |列出所有的键绑定
- D |选择一个客户端来脱离其附着
- L |将附着的客户端切换到最后一个会话中
- [ |输入赋值模式来复制文本或查看历史
- ] |粘贴最近复制的文本缓存
- c |创建一个新的窗口
- d |脱离当前的客户端
- f |提示在打开的窗口中搜索文本
- i |显示关于当前窗口的一些信息
- l |移动到之前选择的窗口
- n |移动到下一个窗口
- o |移动到当前窗口的下一个面板
- p |移动到之前的窗口
- q |简单地显示面板索引
- r |强制重绘附着的客户端
- s |为当前附着的客户端交互式地选择一个新的会话
- t |显示时间
- w |交互式地选择当前的窗口
- x |终止当前的面板
- z |切换当前面板的放大状态
- { |使用之前的面板来替换当前的面板
- } |使用下一个面板来替换当前的面板
- ~ |显示tmux之前的消息如果存在的话。
- PageUp |进入复制模式并且将页面向上滚动一页。
- Up,Down,Left,Right |转换到当前面板的上, 下,左,右
- M-1到M-5(M=Alt) |将面板按照预设的1-5个布局进行安排:偶数水平,偶数垂直,主水平,主垂直或平铺
- Space |将当前窗口按照下一个预设布局进行安排
- M-n |移动到下一个窗口并且带有一个响铃或者活动标记
- M-o |将当前窗口中的面板从前向后反转
- M-p |移动到前一个窗口并且带有响铃或者活动标记
- C-Up, C-Down C-Left, C-Right |以一个单格的步调调整当前面板的大小
- M-Up, M-Down M-Left, M-Right |以五个单格的步调调整当前面板的大小
-
-键绑定可以通过bind-key和unbind-key命令来改变。
-
-
-##命令
-
-这部分包含了tmux支持的命令列表,大部分的命令接收可选的-t参数与一个目标客户端,目标会话,目标窗口或者目标面板。
-它们指定了受命令影响的客户端,会话,窗口或面板
-
-目标客户端应该为客户端链接的pty文件的名称,例如对于附着在/dev/ttyp1的客户端可能为 /dev/ttyp1或
-ttyp1。如果没有指定客户端,tmux会尝试当前使用的客户端;
-如果失败的话,就会报告一个错误。客户端可以通过list-clients命令列出。
-
-目标会话会按照以下顺序进行尝试:
-
- 1. 一个以$作为前缀的会话ID。
- 2. 一个精确的会话名称(会在list-sessions命令中列出)。
- 3. 会话名称的开始部分,例如“mysess”会匹配一个名为"mysession"的会话。
- 4. 一个与会话名称匹配的fnmatch 模式
-
-如果找到了一个单独的会话,就会将其作为目标会话;如果匹配多个会话就会产生错误。
-如果忽略一个会话的话,那么就会使用当前的会话-如果可用的话;如果当前会话不可用,那么最近使用的会话就会被选择。
-
-目标窗口通过session:window的格式来指定一个窗口。 会话按照target-session的规则,而窗口会按照以下的顺序来查找:
-
- 1. 一个下面列表中的特殊标记。
- 2. 一个窗口索引,例如'mysession:1'表示会话'mysession'中的第一个窗口。
- 3. 一个窗口ID,例如@1。
- 4. 一个精确的窗口名称,例如'mysession:mywindow'。
- 5. 一个窗口名称的开始部分,例如'mysession:mywin'。
- 6. 一个于窗口名称相匹配的fnmatch模式。
- 7. 一个空窗口名称制定了下一个未使用的索引如果合适的话(例如new-window或link-window命令),
- 否则会话中的当前窗口就被选择。
-
-下面的特殊标记可用来指定一个特定的窗口。每个都具有一个可选的单字符格式。
-
- 符号 | 别名 | 含义
---------------|------|---------------
- {start} | ^ | 最小数值的窗口
- {end} | $ | 最大数值的窗口
- {last} | ! | 最后一个窗口
- {next} | + | 按照数字的下一个窗口
- {previous}| - | 按照数字的上一个窗口
- {mouse} | = | 鼠标事件发生的窗口
-
-目标面板可以是一个面板ID或者是一个与目标窗口相似的形式,但是带有一个额外可选的跟随面板索引或面板ID的点号“.”。
-如果忽略面板索引的话,那么指定窗口当前的活动面板就会被使用,下面的特殊符号可以作为面板索引使用:
-
- 符号 |别名 | 含义
--------------------|------|-------------
- {last} | ! | 最后一个面板
- {next} | + | 数字指定的下一个面板
- {previous} | - | 数字指定的前一个面板
- {top} | | 顶端面板
- {bottom} | | 底端面板
- {left} | | 最左端面板
- {right} | | 最右端面板
- {top-left} | | 左顶端面板
- {top-right} | | 右顶端面板
- {bottom-left} | | 左底端面板
- {bottom-right} | | 右底端面板
- {up} | | 活动面板上面的面板
- {down} | | 活动面板下面的面板
- {left} | | 活动面板左边的面板
- {right} | | 活动面板右边的面板
- {mouse} | = | 鼠标事件发生的面板
-
-符号'+'和'-'可能跟随一个位移,例如:
-
- select-window -t:+2
-
-会话,窗口和面板都通过一个唯一的ID来进行数字编码;
-会话ID带有一个*$*前缀,窗口ID带有一个*@*前缀,面板ID带有一个*%*前缀。
-这些在tmux服务器中的会话,窗口或面板生命周期中都是唯一不变的。
-面板ID通过TMUX_PANE环境变量传递给面板的子进程,
-ID可能使用'session_id','window_id'或'pane_id'何display-message,list-sesions,list-windows或list-panes命令的格式进行显示。
-
-shell-command 参数是sh命令,这可能是一个传递给shell的参数,例如:
-
- new-window 'vi /etc/passwd'
-
-会运行:
- /bin/sh -c 'vi /etc/passwd'
-
-此外,new-window,new-session,split-window, respawn-window以及respawn-pane命令允许 shell-command
-作为多参数给定并且可以直接执行(不需要 'sh -C')。 者可以避免shell引用问题,例如:
-
- $ tmux new-window vi /etc/passwd
-
-会直接运行vi,而不需要调用shell。
-
-命令 [参数] 指向一个tmux命令,命令和参数分别进行传递,例如:
-
- bind-key F1 set-window-option force-width 81
-
-或者,如果使用sh的话:
-
- $ tmux bind-key F1 set-window-option force-width 81
-
-多个命令可以作为命令序列的一部分一起指定,每个命令需要使用空格和分号来分隔;
-命令按照从左至右的顺序执行,并且以反斜线结束的行会继续到下一行,除非被另外一个反斜线转义。
-一个字面量分号可以通过一个反斜线进行转义包含进来(例如,当需要制定一个命令行序列给键绑定时)
-
-tmux命令包含样例:
-
- refresh-client -t/dev/ttyp2
- rename-session -tfirst newname
- set-window-option -t:0 monitor-activity on
- new-window ; split-window -d
- bind-key R source-file ~/.tmux.conf \; \
- display-message "source-file done"
-
-或者从sh中:
-
- $ tmux kill-window -t :1
- $ tmux new-window \; split-window -d
- $ tmux new-session -d 'vi /etc/passwd' \; split-window -d \; attach
-
-##客户端和会话:
-
-tmux服务器管理客户端,会话,窗口和面板。
-客户端是附着在会话上来与他们交互的,不论他们是通过new-session命令或者之后的attach-session命令创建的会话。
-每个会话具有一个或多个窗口与其链接。
-窗口可以连接到多个会话上,窗口又是有一个或多个面板组成的,每个面板包含了一个伪终端。
-对于创建、链接或其他窗口操作的命令会在 [窗口和面板](#窗口和面板)部分详解。
-
-下面的命令可以用来管理客户端和会话:
-
- attach-session [-dr] [-c working-directory] [-t target-session]
- (别名: attach)
-
-如果在tmux外部来运行,会在当前终端中创建一个新的客户端并且将其附着在一个目标会话上。如果这个命令是在tmux中运行的,就会切换当前的客户端。
--d 使附着在这个会话上的其他客户端就会脱离,
--r表示这个客户端时只读的(只有键绑定到detach-client或switch-client命令时具有效果)。
-如果没有启动服务器, attach-session 会尝试启动服务器;除非在配置文件中创建了会话否则就会失败。
-对于attach-session命令的目标会话规则稍微有一点调整:如果tmux需要选择最近使用的会话,会偏好选择最近使用的脱离附着的会话。
--c 设置会话的工作目录(为新窗口所使用)为working-directory
-
- detach-client [-P] [-a] [-s target-session] [-t target-client]
- (别名: detach)
-
-如果绑定了一个键时会脱离当前客户端,由-t来指定客户端,或者所有附着在由-s指定的会话中的客户端。
--a选项会终止除-t指定的目标客户端之外的所有客户端。
--P发送一个SIGHUP信号给当前客户端的父进程,一般是导致其触发退出动作。
-
- has-session [-t target-session]
- (别名: has)
-
-如果指定的会话不存在的话,就会报告一个错误并且退出,返回值为1. 如果存在的话,就会退出,返回值为0.
-
- kill-server
-
-终止tmux服务器和客户端并且销毁所有的会话。
-
- kill-session [-a] [-t target-session]
-
-销毁指定的会话,关闭连接到会话的任何窗口,并且让所有附着在其上的客户端脱离。
-如果给定了-a选项的话,除了指定的会话之外的会话都被终止。
-
- list-clients [-F format] [-t target-session]
- (别名: lsc)
-
-列出附着在服务器上的所有客户端。 对于-F标记,可以参考 [FORMATS](#格式)部分。
-如果给定了目标会话的话,只列出连接到该会话上的客户端。
-
- list-commands
- (别名: lscm)
-
-列出所有tmux支持的所有命令语法。
-
- list-sessions [-F format]
- (别名: ls)
-
-列出服务器管理的所有会话,对于-F标记,参考 [FORMATS](#格式)部分。
-
- lock-client [-t target-client]
- (别名: lockc)
-
-锁定目标客户端, 可以参考 lock-server 命令。
-
- lock-session [-t target-session]
- (别名: locks)
-
-锁定附着在目标会话上的所有客户端。
-
- new-session [-AdDP] [-c start-directory] [-F format] [-n window-name] [-s session-name] [-t target-session] [-x width] [-y height] [shell-command]
- (别名:new)
-
-使用session-name 来创建一个新的会话。
-
-除非给定-d选项,否则新的会话就会附着在当前的终端上。 window-name和shell-comand
-是在初始化窗口中执行的窗口和shell命令名称。
-如果使用了-d选项, -x和-y用来指定初始窗口的大小(默认为80x24)。
-如果从终端中运行,任何的termios特殊字符都被保存并且在新会话中的新窗口中使用。
--A 标记使得新会话与一个附着会话具有相同的行为,如果会话名称已经存在的话;这种情况下,对于attach-session来说-D具有与-d相同的行为。
-如果给定了-t选项,新的会话被分组到目标会话中。
-这就意味着他们共享相同的窗口集合--目标会话中的所有窗口都会连接到新的会话上,并且任何后续的新建窗口或关闭窗口都会被应用在两个会话上。
-当前的窗口和之前的窗口以及任何会话选项保持独立,并且每个会话都会在不影响其他会话的情况下被终止。
--n或 shell-command只有在使用-t选项时合法。
--P选项会在新会话创建之后来打印新会话相关信息。默认情况下,会使用'#{session_name}:'格式,但是可以通过-F来指定一个不同的格式。
-
- refresh-client [-S] [-t target-client]
- (别名:refresh)
-
-如果绑定了一个键的话会刷新当前客户端,如果使用-t指定了一个客户端的话会刷新单独的客户端。
--S 只会更新客户端的状态条。
-
- rename-session [-t target-session] new-name
- (别名:rename)
-
-重命名会话为一个新名称。
-
- show-messages [-IJT] [-t target-client]
- (别名:showmsgs)
-
-显示客户端消息或服务器信息。
-所有显示在状态行的消息都存储在一个客户端独立的消息日志中,具有一个由message-limit选项设置的最大限制。
--t 显示目标客户端的日志。
--I,-J 和-T分别显示运行服务器,任务和终端的调试信息。
-
- source-file path
- (别名:source)
-
-从路径中来执行命令
-
- start-server
- (别名:start)
-
-开启tmux服务器,如果还没有运行,不会创建任何会话。
-
- suspend-client [-t target-client]
- (别名:suspendc)
-
-通过发送一个SIGTSTP(tty stop)信号来挂起一个客户端。
-
- switch-client [-lnpr] [-c target-client] [-t target-session] [-T key-table]
- (别名:switchc)
-
-将目标客户端所在的当前会话切换到目标会话中,
-如果-l, -n或者-p被使用的话,客户端会被分别移动到最后,下一个或上一个会话中。
--r 转换一个客户端的只读(可以参考attach-session命令)
--T 设置客户端的键表;来自客户端的下一个键会被解释为来自键表。
-这可能会被用在配置多个前缀键时或者绑定命令到一序列键值时使用。
-
-例如,让键入'abc'来运行 list-keys命令:
-
- bind-key -Ttable2 c list-keys
- bind-key -Ttable1 b switch-client -Ttable2
- bind-key -Troot a switch-client -Ttable1
-
-##窗口和面板
-
-一个tmux窗口可能会在处在多个模式中的某一个模式。
-默认的模式时直接访问附着在窗口上的终端。
-另外一个是复制模式,允许一个窗口的一部分或者其历史能够被复制到一个粘贴缓存中,以便稍候插入到另外的窗口中。
-这个模式时使用 copy-mode命令来进入的,默认绑定到'\['上。也会在一个命令产生输出时进入,例如通过键绑定执行的list-keys。
-可用的键依赖于是选择emacs还是vi模式(参考 mode-keys 选项)。 下面的键对于不同的模式具有合适的支持。
-
- 函数 |vi模式 |emacs模式
--------------------------------|-----------|----------------
- Append selection |A |
- Back to indentation |^ |M-m
- Bottom of history |G |M-<
- Clear selection Escape |C-g |
- Copy selection Enter |M-w |
- Copy to named buffer |" |
- Cursor down |j |Down
- Cursor left |h |Left
- Cursor right |l |Right
- Cursor to bottom line |L |
- Cursor to middle line |M |M-r
- Cursor to top line |H |M-R
- Cursor up |k |Up
- Delete entire line |d |C-u
- Delete/Copy to end of line |D |C-k
- End of line |$ |C-e
- Go to line |: |g
- Half page down |C-d |M-Down
- Half page up |C-u |M-Up
- Jump again |; |;
- Jump again in reverse |, |,
- Jump backward |F |F
- Jump forward |f |f
- Jump to backward |T |
- Jump to forward |t |
- Next page |C-f |Page down
- Next space |W |
- Next space, end of word |E |
- Next word |w |
- Next word end |e |M-f
- Other end of selection |o |
- Paste buffer |p |C-y
- Previous page |C-b |Page up
- Previous space |B |
- Previous word |b |M-b
- Quit mode |q |Escape
- Rectangle toggle |v |R
- Scroll down |C-Down/C-e |C-Down
- Scroll up |C-Up/C-y |C-Up
- Search again |n |n
- Search again in reverse |N |N
- Search backward |? |C-r
- Search forward |/ |C-s
- Select line |V |
- Start of line |0 |C-a
- Start selection |Space |C-Space
- Top of history |g |M->
- Transpose characters |C-t |
-
-下一个和上一个单词简默认使用空格和'-','_'以及'@'字符作为单词分隔符,但是可以通过设置会话的word-separators选项进行调整。
-下一个单词会移动到下一个单词的开始位置,下一个单词的末尾会移动到下一个单词的末尾位置,
-前一个单词移动到前一个单词的开始位置。 三个下一个和前一个空格键具有相似的作用但是单独使用一个空格作为单词分隔符。
-
-跳转命令允许在一个行中快速移动,例如,输入'f'跟随一个'/'会将光标移动到当前行的下一个'/'字符处。
-一个';'之后会移动到字符下一次出现的地方。
-
-复制模式中的命令可能由一个可选的重复计数器作为前导,在vi键绑定下,通过数字键来输入前导;
-使用emacs时,使用Alt(meta)+数字作为前导实体。例如,为了将光标向前移动10个单词使用'M-1 0 M-f'-对于emacs模式,'10w'-对于vi模式。
-
-模式键绑定是通过一个命名表集合定义的:在命令提示的行编辑时使用vi-edit和emacs-edit键,
-当从列表中选择时使用vi-choice和emacs-coice键,在复制模式中时使用vi-copy和emacs-copy键。
-这些表可以通过list-keys命令来查看,另外可以通过bind-key和unbund-key命令来修改或移除键。
-如果append-selection,copy-selection或者start-named-buffer给定-x标记,tmux将不会在复制之后退出复制模式。
-copy-pipe复制所选内容并且将其管道到一个命令。
-
-例如下面的命令会绑定'C-w'在复制之后不会退出, 'C-q'将所选内容复制到/tmp和粘贴缓冲中。
-
- bind-key -temacs-copy C-w copy-selection -x
- bind-key -temacs-copy C-q copy-pipe "cat >/tmp/out"
-
-粘贴缓存键会从栈中顶端的粘贴缓存中粘贴第一行。
-copy-mode命令的简介为:
-
- copy-mode [-Mu] [-t target-pane]
-
-进入复制模式。-u选项向上滚动一页。 -M 开始一个鼠标拖拽(只有在绑定鼠标键绑定时有效,参考MOUSE SUPPORT)
-
-tmux显示的每个窗口可能会被分割为一个或多个面板;每个面板占用一个特定的区域进行显示并且具有一个单独的终端。
-一个窗口可以通过split-window名令分割为多个面板。窗口可以被水平分割(使用-h标记)或者垂直分割。
-面板可以通过resize-pane命令改变大小(默认绑定为'C-up','C-down','C-left','C-right'),
-当前的面板可能会通过select-panel命令改变,而rotate-window和swap-panel命令可以在不改变面板位置的情况下切换面板。
-面板被从0开始的数字按顺序计数。
-
-有一些默认的预设布局可用,这可以通过select-layout命令来选择或者使用next-layout命令循环选择(默认绑定为'Space'布局);
-一旦布局被选定,其中的面板会被移动以及重新改变大小。
-
-支持以下的布局:
-
-even-horizontal: 面板按照偶数地从左到右来分布在窗口中。
-even-vertical: 面板按照偶数地从上到下来分布在窗口中
-main-horizontal: 在窗口的顶端会显示一个大的面板,其余的面板按照从左到右的方式在底部左端的空间分布,
-可以使用main-pane-height窗口选项来指定顶部面板的高度。
-main-vertical: 类似于main-horizontal,但是最大的面板会放置在窗口左边而其他的面板按照从上往下的方式在右边进行分布。
-可以参考main-pane-width窗口选项。
-tiled: 面板会尽量将面板在窗口中在行列上以偶数地方式分布。
-
-此外,select-layout可以用来应用一个之前使用的布局,list-windows命令会以一个合适的格式显示每个窗口的布局来于select-layout命令结合使用,例如:
-
- $ tmux list-windows
-
- 0: ksh [159x48] layout: bb62,159x48,0,0{79x48,0,0,79x48,80,0}
- $ tmux select-layout bb62,159x48,0,0{79x48,0,0,79x48,80,0}
-
-tmux自动地调整当前窗口大小中的布局大小。 注意,一个布局不能应用在多于布局默认定义的面板数量。
-
-###窗口和面板命令
-与窗口和面板相关的命令如下:
-
- break-pane [-dP] [-F format] [-t target-pane]
- (别名:breakp)
-
-将目标面板从其所在的窗口中终止,并将其作为一个新窗口中的唯一的面板。 如果指定-d,新的窗口不会称为当前的窗口。
--P选项会在新窗口创建之后显示其信息。 默认会使用
-'#{session_name}:#{window_index}'的显示格式,但是可以通过-f来指定一个不同的格式。
-
- capture-pane [-aepPq] [-b buffer-name] [-E end-line] [-S start-line] [-t target-pane]
- (别名:capturep)
-捕获一个面板的内容,如果指定-p,那么输出会到达stdou,否则会到达有-b指定的缓冲区(如果没有指定-b缓冲区的话就会指定一个新的缓冲区)。
-如果指定-a, 会使用备用屏幕,并且历史是不可以访问的。如果没有备用的屏幕,在没有指定-q的情况下会返回一个错误。
-如果指定-e,那么输出会包含文本转义序列和后台属性。 -C 也会转义非打印字符为八进制 \\xxx。 -J
-会链接包裹的多行并且保留每行末尾尾随的空格。 -P 只会面板接受到的捕获开头是一个非完整转义序列的任意输出。
--S 和 -E 指定开始和结束行的行数,0是可视面板的第一行,而负数时历史行。 '-'到 -S是历史的开始,而
-'-'到-E是可视面板的结尾。 默认情况下只会捕获面板的可视内容。
-
- choose-client [-F format] [-t target-window] [template]
-将一个窗口置于客户端选择模式,允许从一个列表中交互地选择一个客户端。
-在一个客户端被选择之后'%%'会由模板中的客户端pty路径替换,之后的结果会作为一个命令被执行。
-如果模板没有给定,会使用"detach-client -t '%%'"。
-对于-F标记,可以参考[FORMATS](#格式)部分。 这个命令只有在至少一个客户端被附着之后才工作。
-
- choose-session [-F format] [-t target-window] [template]
-将一个窗口置于会话选择模式中,可以从一个列表中交互式地选择一个会话。
-当一个会话被选择时,'%%'会由模板中的会话名称替换,之后的结果会作为一个命令被执行。
-如果模板没有给定,会使用"switch-client -t '%%'"。
-对于-F标记,可以参考[FORMATS](#格式)部分。这个命令只有在至少有一个客户端附着时工作。
-
- choose-tree [-suw] [-b session-template] [-c window-template] [-S format] [-W format] [-t target-window]
-将窗口置于一个树选择模式,其中的会话或窗口可能是从一个列表中交互地选择的。
-默认情况下,窗口属于一个会话主要为了显示他们与一个会话的关系。
-注意choose-window和choose-session命令被包裹在choose-tree中。
-如果给定-s会显示会话,如果给定-w会显示窗口。
-默认情形下,树是被折叠起来的,会话必须通过右箭头简将其展开为窗口。 -u选项会将所有的会话展开。
-如果给定-b,会重载默认的会话命令。 注意 '%%'可以被使用而且会被会话名称替换。如果没有指定的话,默认为"switch-client -t
-'%%'"。 如果给定-c,会重载默认的窗口命令,与-b类似,'%%'可以被使用而且会被会话名与窗口索引替换。
-当一个窗口从列表中被选择时,会话命令会在窗口命令运行之前运行。
-如果给定-S,会显示指定的格式而不是默认的会话格式。如果给定-W,会显示指定的格式而不是默认的窗口格式。
-对于-s和-w选项的含义可以参考[FORMATS](#格式)部分。
-这个命令只有当至少有一个客户端附着时工作。
-
- choose-window [-F format] [-t target-window] [template]
-将一个窗口置于一个选择模式,其中的窗口可以从一个列表中交互地选择。
-当选择一个窗口之后,'%%'会被模板中的会话名称和窗括索引替换,之后的结果作为一个命令被执行。
-如果没有给定模板,"select-window -t '%%'"被使用。
-对于-F的含义可以参考[FORMATS](#格式)部分。 这个命令只有在至少一个客户端附着之后才会工作。
-
- display-panes [-t target-client]
- (别名:displayp)
-由一个客户端来显示每个面板的可视化指示器,可以参考 display-panes-time, display-panes-colour和
-display-panes-active-colour会话选项。由于指示器在屏幕上,一个面板可以通过'0-9'键来选择。
-
- find-window [-CNT] [-F format] [-t target-window] match-string
- (别名:findw)
-在窗口名称,标题和可见的内容中搜索fnmatch模式的匹配字符串。标记被用来控制匹配行为: -C只匹配可见窗口内容,
--N只匹配窗口名称,-T匹配窗口标题。
-默认为-CNT。如果只有一个窗口匹配,就会被自动选择,否则就会显示一个选项列表。
-对于-F标记可以参考[FORMATS](#格式)部分。这个命令只有在至少一个客户端被附着时会工作。
-
- join-pane [-bdhv] [-l size | -p percentage] [-s src-pane] [-t dst-pane]
- (别名:joinp)
-与split-window相似,但是取代分割dst-panel并创建一个新面板而代之的是,将其分割并将src-panel移动到空间中。
-这个可以用来逆转break-pane动作。-b选项使得src-pane被联接到dst-pane的左边或上边。
-
- kill-pane [-a] [-t target-pane]
- (别名:killp)
-销毁给定的pane。如果所在窗口中没有剩余的面板,该窗口也会被销毁。 -a选项会销毁除由-t指定面板之外的所有面板。
-
- kill-window [-a] [-t target-window]
- (别名:killw)
-终止当前窗口或目标窗口,将其从所链接的任意会话中移除。 -a选项终止除-t指定窗口之外的所有窗口。
-
- last-pane [-de] [-t target-window]
- (别名:lastp)
-选择最后一个面板,-e 使得输入到面板生效,-d使得输入到面板失效。
-
- last-window [-t target-session]
- (别名:last)
-选择最后一个窗口,如果没有目标窗口指定,选择当前会话中的最后一个窗口。
-
- link-window [-dk] [-s src-window] [-t dst-window]
- (别名:linkw)
-将在src-window的窗口链接到指定的dst-window。如果dst-window被指定但是不存在的话,那么src-window会被链接导那儿。
-如果给定-k并且dst-window存在,那么就会将其终止,否则就会生成一个错误。如果给定-d,新链接的窗口不会被选择。
-
- list-panes [-as] [-F format] [-t target]
- (别名:lsp)
-如果给定-a, 会湖绿target并且会列出服务器上的所有面板。
-如果给定-s,target就是一个会话(或者当前会话)。如果都没有指定,target就是一个窗口(或者当前窗口)。对于-F标记可以参考[FORMATS](#格式)部分。
-
- list-windows [-a] [-F format] [-t target-session]
- (别名:lsw)
-如果给定-a,会列出服务器上的所有窗口。 否则会列出当前会话或target-session中的窗口。对于-F标记可以参考[FORMATS](#格式)部分。
-
- move-pane [-bdhv] [-l size | -p percentage] [-s src-pane] [-t dst-pane]
- (别名:movep)
-与join-pane类似,但是src-pane和dst-pane可以属于相同的窗口。
-
- move-window [-rdk] [-s src-window] [-t dst-window]
- (别名: movew)
-这个于link-window相似,除了src-window中的窗口被移动到dst-window。给定-r会话中的所有窗口都会在遵照base-index选项下按照序列顺序重新编号。
-
- new-window [-adkP] [-c start-directory] [-F format] [-n window-name] [-t target-window] [shell-command]
- (别名:neww)
-创建一个新的窗口,给定-a,新建的窗口会被插入到指定target-window的下一个索引上,必要的话会将窗口向上移,否则target-window就是这个新建的窗口。
-
-如果给定-d, 会话不会将新建窗口作为当前窗口。target-window表示将会创建的窗口;如果目标窗口已经存在会显示一个错误,如果使用-k标记就会销毁。
-shell-command是将要执行的命令。如果没有指定shell-command,
-default-command选项的值被默认使用。-c选项指定了新窗口创建的工作目录。
-当shell命令完成时,窗口关闭。 参考remain-on-exit选项来改变这个行为。
-对于运行在tmux中的所有程序需要将TERM环境变量设置为"screen"。
-新的窗口会自动将"TERM=screen"加到他们的环境中,但是必须注意不要在shell启动文件中重置这个变量。
--P 选项在新窗口创建后会打印与之相关的信息。
-默认情况下,使用'#{session_name}:#{window_index}'的格式,但是可以通过使用-F来指定一个不同的格式。
-
- next-layout [-t target-window]
- (别名:nextl)
-将窗口移动到下一个布局模式并且重新安排面板来使之适应。
-
- next-window [-a] [-t target-session]
- (别名:next)
-移动到会话中的下一个窗口,如果-a指定,在移动到下一个窗口时带有警告。
-
- pipe-pane [-o] [-t target-pane] [shell-command]
- (别名:pipep)
-将target-pane中程序的输出通过管道传递给一个shell命令。一个面板可能一次只能管道给一个命令,在shell-command命令执行之前任何存在的管道都会关闭。
-shell-command字符串可能会包含status-left选项所支持的特殊字符序列。 如果没有指定shell-command,那么当前的管道就会被关闭。
--o选项只有在没有之前的管道存在时打开一个新管道,允许一个管道通过一个单键进行切换,例如:
-
- bind-key C-p pipe-pane -o 'cat >>~/output.#I-#P'
-
-
- previous-layout [-t target-window]
- (别名:prevl )
-移动到会话之前的布局。
-
- previous-window [-a] [-t target-session]
- (别名:prev)
-移动到会话之前的窗口,使用-a选项会带有一个警告。
-
- rename-window [-t target-window] new-name
- (别名: renamew)
-重命名当前窗口或者由-t指定的target-window窗口为new-name
-
- resize-pane [-DLMRUZ] [-t target-pane] [-x width] [-y height] [adjustment]
- (别名:resizep)
-重新定义面板的大小,通过-U, -D, -L或-R来调整上下左右,或者通过-x/-y指定绝对值大小。
-调整是通过行或单元格来给定的(默认为1)。
-使用-Z时,活动面板会在放大(占用整个窗口)或未放大(在布局中的正常位置)之间进行切换。
--M 开始鼠标重定义大小(只有在鼠标键绑定时有效,参考MOUSE SUPPORT部分)
-
- respawn-pane [-k] [-t target-pane] [shell-command]
- (别名:respawnp)
-在shell-comman退出之后重新激活面板(可以参考remain-on-exit 窗口选项)。如果没有给定shell-comman,
-那么面板创建时所使用的命令会被执行。面板必须是已经激活的状态,如果给定-k,任何存在的命令都会被终止。
-
- respawn-window [-k] [-t target-window] [shell-command]
- (别名:respawnw)
-在shell-command退出之后重新激活窗口(可以参考remain-on-exit窗口选项)。 如果没有指定shell-comman,
-那么窗口创建时所使用的命令会被执行。 窗口必须是已经激活的状态,如果指定-k任何存在的命令都会被终止。
-
- rotate-window [-DU] [-t target-window]
- (别名:rotatew)
-轮换窗口中面板的位置,或者通过-U向前或者向后。
-
- select-layout [-nop] [-t target-window] [layout-name]
- (别名:selectl)
-为窗口选择一个特定的布局,如果没有指定布局名称,就会使用最后使用的预设布局并且重新布局。
-
- select-pane [-DdegLlRU] [-P style] [-t target-pane]
- (别名:selectp)
-将target-pane面板作为target-window窗口中的活动面板,或者设置其风格(使用-P)。
-如果使用了-D,-L,-R或者-U的话,就会分别使用target-pane面板的下面,左边,右边或上面的面板。
--l与使用last-pane命令效果一样。 -e使得输入到面板生效,-d使得输入到面板失效。
-
-每个面板具有一个风格:默认使用window-style和window-active-style选项。select-pane -P 为单个面板设置风格。
-例如将第一个面板的北京设置为红色red:
-
- select-pane -t:.1 -P 'bg=red'
-
--g 显示当前面板的样式。
-
- select-window [-lnpT] [-t target-window]
- (别名:selectw)
-选择目标窗口。-l,-n和-p等价于last-window,next-window和previous-window命令。
-如果给定-T,而且选择的窗口已经是当前窗口,那么命令表现为last-windown命令。
-
- split-window [-bdhvP] [-c start-directory] [-l size | -p percentage] [-t target-pane] [shell-command] [-F format]
- (别名:splitw)
-通过分割target-pane窗口来创建一个新面板: -h为水平分割,-v为垂直分割; 默认为垂直分割。
--l和-p选项指定新面板的行(对于垂直分割)或单元格(水平分割),或者作为百分比。-b选项使得新建面板在target-pane的左边或上边。
-其他的任何选项的含义于new-window命令一样。
-
- swap-pane [-dDU] [-s src-pane] [-t dst-pane]
- (别名:swapp)
-转换两个面板。如果使用-U并且没有通过-s来指定源面板的话,dst-pane会与之前的面板进行转换;-D与下一个面板进行转换。
--d用来指示tmux不要改变活动面板。
-
- swap-window [-d] [-s src-window] [-t dst-window]
- (别名:swapw)
-这个与link-window类似,除了源面板与目标面板相互转换之外。如果在src-window没有窗口的话会出错。
-
- unlink-window [-k] [-t target-window]
- (别名:unlinkw)
-取消target-window的链接。除非给定-k选项,否则只有当一个窗口链接到多个会话时才会被取消链接-窗口不能链接到空会话;
-如果指定-k选项,而且窗口只有与一个会话相关联,那么窗口会被取消该链接并且被销毁。
-
-##键绑定2
-
- tmux允许一个命令被绑定到大多数键上-无论是否带有前导键。当指定键时,大部分键代表其本身字面量含义(例如'A-Z')。
-Control键可能表示为'C-'或'^'前导,而Alt(meta)表示为'M-'。此外,特殊的键名称也是被接受的:Up,Down, Left, Right,
-BSpace, BTab, DC(delete), End, Enter, Escape, F1-F12, Home, IC(insert), NPage/PageDown/PgDn, PPage/PageUp/PgUp, Space和Tab。
-注意为了绑定双引号或单引号键,引号标记是必需的,例如:
-
- bind-key '"' split-window
- bind-key "'" new-window
-
-###键绑定命令
-与键绑定相关的命令如下:
-
- bind-key [-cnr] [-t mode-table] [-T key-table] key command [arguments]
- (别名:bind)
-将键绑定到命令。键被绑定到一个键表中。
-默认情况(没有'-T')时,键被绑定到前导键表中。这个表被用在前导键键入之后再键入的键(例如,'c'默认绑定为前导键表中的新建窗口命令,
-所以'C-b c'会创建一个新窗口)。
-根键表被用在不需要前导键的键输入:将'c'在根键表中绑定为新建窗口命令时意味着一个普通的'c'键就会创建一个新窗口。
-'-n' 是 '-T root' 的别名。键同样可以绑定到客制化的键表中,'switch-client -T command' 用来从一个键绑定中切换到相应的键。
-'-r' 标记指定这个键可以重复,参考'repeat-time'选项。
-
-如果出现-t选项,那么键会绑定到一个mode-table(模式表): 使用-c来绑定到命令模式,缺省时绑定为普通模式。
-可以参考WINDOWS AND PANES部分,并且 list-keys命令可以查看模式键绑定。
-
-为了查看默认的绑定和可用的命令可以参考list-keys 命令:
-
- list-keys [-t mode-table] [-T key-table]
- (别名:lsk)
-列出所有的键绑定。 没有指定-T时会打印所有的键表,指定-T时只会打印key-table.
-带-t时,在模式表中的键绑定会被列出来; 模式可能为以下之一:vi-edit,emacs-edit,vi-choice,emacs-choice,
-vi-copy或emcas-copy。
-
- send-keys [-lMR] [-t target-pane] key ...
- (别名:send)
-发送一个或多个键到一个窗口中,其中的每个参数key是发送的键的名称(例如'C-a'或者'npage');
-如果字符串不能作为键来识别,就会作为一系列字符串发送。
--l标记让键名查找失效并且发送键的字面量值。所有的参数被按照先后顺序序列地发送。
--R标记导致终端状态被重置。
--M 通过一个鼠标时间传递(只有当绑定一个鼠标键绑定时有效,参考MOUSE SUPPORT)。
-
- send-prefix [-2] [-t target-pane]
-发送前导键-或者发送二级前导键如果与-2一起使用时-到一个窗口就像该键被按下一样。
-
- unbind-key [-acn] [-t mode-table] [-T key-table] key
- (别名:unbind)
-取消命令到键的绑定,-c,-n,-T 和-t与bind-key命令的含义一样。 如果-a存在,所有的键绑定都会被移除。
-
-##选项
-tmux的外观和行为可以通过修改各个选项的值来进行改变,具有三种选项:服务器选项,会话选项和窗口选项。
-tmux服务器具有一个全局选项集合--这个选项集合不会应用到任何特定的窗口或会话中。
-这些选项通过'set-option -s'命令进行修改,或者通过'show-options -s' 命令进行显示。
-此外,每个单独的会话可能具有一个会话选项集合,同时具有一个分开全局会话选项集合。
-没有特定选项配置的会话会从全局会话选项中继承其值。会话选项可以通过set-option命令进行设置或重置,
-可以通过show-options命令来列出会话选项。可用的服务器和会话选项会在set-option命令下列出。
-类似地,每个窗口都附着了一个窗口选项集合,并且具有一个全局窗口集合来继承所有的重置选项。
-窗口选项使用set-window-option命令来进行修改,并且可以通过show-window-options命令来列出。
-所有的窗口选项使用set-window-option命令归档。
-
-tmux也支持以'@'作为前导的用户选项, 用户选项可以具有任何名称,可以被设置为任何字符串,只要具有'@'作为前导,例如:
-
- $ tmux setw -q @foo "abc123"
- $ tmux showw -v @foo
- abc123
-
-###选项设置
-
-设置选项的命令如下:
-
- set-option [-agoqsuw] [-t target-session | target-window] option value
- (别名:set)
-通过-w来设置窗口选项(与set-window-option命令等价),-s设置服务器选项,否则设置会话选项。
-如果指定-g,那么全局会话或窗口选项就会被设置。
--u标记用来重置选项,所以一个会话从全局选项中来继承,不能重置一个全局选项。
--o标记阻止设置一个已经存在的选项。
--q标记会取消位置选项发生的错误。
-带有-a时,如果选项期待一个字符串或者一个样式,那么只会被附加在已经设置的值后面,例如:
-
- set -g status-left "foo"
- set -ag status-left "bar"
-
-会得到'foobar'结果,而:
-
- set -g status-style "bg=red"
- set -ag status-style "fg=blue"
-
-会得到一个红色背景和蓝色前景的结果。
-没有-a时,这个值会使用默认的背景和一个蓝色前景。
-可用的窗口选项在set-window-option下列出。
-选项的值依赖于选项类型,可以为数字,字符串,或者一个标记(on/off/省略)。
-
-
-
-
-###服务器选项
-可选的服务器选项有:
-
- buffer-limit number
-设置缓冲器数量; 新的缓冲器被放置在栈顶端,旧的缓冲器在维护最大长度时有必要时从栈底端移除。
-
- default-terminal terminal
-为会话中新创键的窗口设置一个默认的终端-默认值为TERM环境变量。为了让tmux正确工作,这个值必须设置为'screen','tmux'或者来自他们的一个派生值。
-
- escape-time time
-设置一个tmux用来在接受到一个转义字符输入时的等待毫秒数,以此让tmux来判断该字符时函数的一部分还是一个meta键序列的一部分。
-默认为500毫秒。
-设置一个tmux用来在接受到一个转义字符输入时的等待毫秒数,以此让tmux来判断该字符时函数的一部分还是一个meta键序列的一部分。
-默认为500毫秒。
-
- exit-unattached [on | off]
-如果生效,服务器会在没有任何附着的客户端时退出。
-
-
- focus-events [on | off]
-如果生效,在终端支持的情况下会从终端获取聚焦事件请求,然后通过tmux中运行的应用来传递。
-附着的客户端应该被脱离附着状态然后在选项修改之后重新进行附着。
-
- message-limit number
-设置每个客户端保存到消息日志中的错误或信息消息的数量,默认为100。
-
- set-clipboard [on | off]
-尝试使用\e]52;...\007 xterm转义序列来设置终端的剪切版。
-如果在客户终端的terminfo描述中存在一个Ms实体,那么这个选项默认为on. 注意在xterm中需要设置以下资源来让这个特性生效:
-
- disallowedWindowOps: 20,21,SetXprop
-
-或者在需要的时候从xterm交互中改变这个属性值。
-
- terminal-overrides string
-包含了一个个实体列表来重载使用terminfo读取的终端描述信息。
-字符串是一个"逗号"分割的项目列表,每个项目是一个':'分割的字符串来组成终端类型模式以及一个name=value实体集合。
-
-例如,为了给所有的终端类型设置terminfo实体'clear'为'\e[H\e[J',以及将'rxvt'终端类型的实体'dch1'的值设置为'\e[P',
-那么这个选项会按照以下字符串进行设置:
-
- "*:clear=\e[H\e[2J,rxvt:dch1=\e[P"
-
-终端实体值会在解释之前通过strunvis传递,默认的值会强制地更新支持256colors的终端的'colors'实体:
-
- "*256col*:colors=256,xterm*:XT"
-
-
-
-###会话选项
-
-可用的会话选项有:
-
- assume-paste-time milliseconds
-如果被键入的键快于用毫秒指定的值,那么这些键会被假设为粘贴而不是键入,而且tmux键绑定不会被执行。默认为一毫秒,0用来让选项失效。
-
- base-index index
-设置在创建一个新窗口时应该搜索的未使用索引的基索引,默认为0。
-
- bell-action [any | none | current]
-窗口响铃动作,any表示连接到一个会话的任何窗口中的响铃会导致这个会话中的当前窗口中的一个响铃,none表示所有的响铃被忽略,
-current表示除了当前窗口之外的窗口中的响铃将会被忽略。
-
- bell-on-alert [on | off]
-如果为on,在出现一个警告时,终端会响铃。
-
- default-command shell-command
-设置新窗口所使用的命令(如果没有指定就是窗口创建时的命令)为shell-command, 可能为任何sh命令。
-默认是一个空字符串,用来指示tmux使用默认shell选项来创建一个登录shell。
-
- default-shell path
-指定默认的shell, 当default-command为空时,这个会作为新建窗口的登录shell,这个path值必须为完整的路径名。
-在启动之后,tmux会尝试从第一个合适的SHELL环境变量中来设置为默认值,shell由'getpwuid'或者 '/bin/sh'。
-这个选项在将tmux作为一个登录shell使用时应该被配置。
-
- destroy-unattached [on | off]
-如果生效的话,当会话不再附着在任何客户端时就会被销毁。
-
- detach-on-destroy [on | off]
-如果为on(默认值), 当附着的会话被销毁时,客户端会脱离附着。 如果off,客户端会被切换为剩余会话中的最近活动的会话。
-
- display-panes-active-colour colour
-设置为活动面板显示指令的display-panes命令所使用的colour。
-
- display-panes-colour colour
-设置为不活动面板显示指令的display-panes命令所使用的colour。
-
- display-panes-time time
-以毫秒为淡灰来设置display-panes命令显示指令出现的时间。
-
- display-time time
-设置状态行消息和其他屏幕指令显示的时间总和,时间是以毫秒指定的。
-
- history-limit lines
-设置窗口历史持有的最大行数,这个设置只会应用在新窗口上--退出时窗口历史不会重写大小并且会保留在其创建时段的限制。
-
- lock-after-time number
-在number秒时间不活动后会锁定会话(与lock-session命令类似),如果lock-server选项被设置的话,
-那么整个服务器(所有会话)都会被锁定。默认为不锁定(number为0)。
-
- lock-command shell-command
-锁定每个客户端时运行的命令,默认为lock -np 命令。
-
- lock-server [on | off]
-如果选项为on(默认值), 与每个会话单独锁定不同的是,整个服务器会在所有会话被锁定时锁定。
-作为一个会话选项这个没有什么影响,这个必须时一个全局选项。
-
- message-command-style style
-设置状态行命令样式,样式是一个由逗号分割的字符列表来指定的。
-这些样式可能时'bg=colour'来设置背景颜色,'fg=colour'来设置前景颜色,另外有下面指定的属性列表:
-
-颜色值可以为这些颜色中的一个:black,red,green, yellow, blue, magenta,cyan,white,aixterm bright
-variants(如果支持的话,会有:brightred,breightgreen,等)。
-256-colour集合中从colour0到colour255为默认值,或者一个十六进制的RGB字符串,例如'#ffffff'-会从默认的256-colour集合中选择最匹配的颜色。
-属性既可以为none或者一个逗号分割一个或多个包含(bright(或bold),dim,underscore,blink,reverse, hidden或者italics)的列表来开启属性,
-或者带有'no'前缀的属性来关闭属性。
-
-样例:
-
- fg=yellow,bold,underscore,blink
- bg=black,fg=default,noreverse
-
-如果set-option命令具有一个 '-a' 标记的话,新的样式会添加进来,否则已经存在的样式被替换。
-
- message-style style
-设置状态行消息样式,对于如何指定样式,可以参考message-command-style选项。
-
- mouse [on | off]
-如果为on,tmux会捕获鼠标并且允许鼠标时间作为键绑定进行结合。 可以参考MOUSE SUPPORT 部分详解。
-
- mouse-utf8 [on | off]
-如果生效,在UTF-8终端请求鼠标输入作为UTF-8。
-
- prefix key
-设置接收到的key作为前导键
-
- prefix2 key
-设置接收到的键作为二级前导键。
-
- renumber-windows [on | off]
-如果为on, 当一个窗口在会话中关闭时,自动地将其他窗口按照数字顺序重新编序。
-这回参考base-index选项如果设置了这个选项的话。如果为off,不会对窗口进行重新排序。
-
- repeat-time time
-允许指定的时间内(默认为500毫秒)在不重新输入前导键时输入多个命令。
-一个键是否可以重复可以在使用bind-key命令结合时使用-r选项进行设置。
-对于与resize-pane命令结合的默认键的重复是开启的。
-
- set-remain-on-exit [on | off]
-为在这个会话中任何第一次创建的窗口设置remain-on-exit窗口选项。
-当这个选项为true时,运行程序所在的窗口在程序退出时不会关闭,而是保持打开但是不活动。
-可以使用respawn-window命令来重新激活这个窗口,或者使用kill-window来销毁窗口。
-
-如果tsl和fslterminfo实体存在的话,会尝试用其来设置客户终端的标题。
-如果终端显示为一个xterm的话tmux自动将其设置为\e]2;...\007序列。
-这个选项默认为off。注意elinks只会在设置了STY环境变量时才尝试设置窗口标题。
-
- set-titles-string string
-如果set-titles为on,那么字符串string就会用来设置窗口标题。 格式被扩展,参考[FORMATS](#格式)部分。
-
- status [on | off]
-显示或隐藏状态行。
-
- status-interval interval
-在每个间隔时间段更新状态栏。 默认时没15秒更新。如果为0会让时间间隔重绘状态失效。
-
- status-justify [left | centre | right]
-设置状态行窗口列表组件的位置:left,center,或者right对齐。
-
- status-keys [vi | emacs]
-在状态栏使用vi或者emacs-样式的键绑定,例如在命令提示时。默认为emacs, 除非VISUAL
-或者EDITOR环境变量被设置并且包含字符串'vi'。
-
- status-left string
-将字符串(默认为会话名称)显示在状态栏的左边。字符串会通过strftime传递并且格式会被扩展,也可能会包含下面特殊字符序列的任意字符:
-
- 字符对 | 替换值
----------------------------|---------------------------------
- #(shell-command) | 命令输出的首行。
- #[attributes] | 颜色或属性改变
- ## | 一个'#'字面量值。
-
-'\#(shell-command)'形式执行'shell-command'然后插入其输出的首行。
-注意shell命令只会在由status-interval选项指定的时间间隔内执行一次:如果同时重绘状态的话,会使用之前输出结果。
-shell命令的执行会带有tmux的全局变量集合(参考 ENVIRONMENT部分)。
-对于如何设置名字和标题的细节可以参考NAMES AND TITLES 部分。 对于允许设定的属性可以参考message-command-style选项。
-
-样例有:
-
- #(sysctl vm.loadavg)
- #[fg=yellow,bold]#(apm -l)%%#[default] [#S]
-
-默认字符串中的UTF-8不会被解释,需要使用status-utf8选项来开启UTF-8。
-默认值为'[#s]'。
-
- status-left-length length
-设置状态栏左边组件的最大长度,默认为10。
-
- status-left-style style
-设置状态行左边部分的样式,参考message-style-style选项来指定样式。
-
- status-position [top | bottom]
-设置状态行的位置。
-
- status-right string
-显示字符串在状态栏的右边,默认为带双引号的当前窗口标题以及日期时间会被显示。
-与status-left类似,字符串也会传递给strftime,字符对会被替换而且UTF-8也依赖于status-utf8选项。
-
- status-right-length length
-设置状态栏右边组件的最大长度,默认为10。
-
- status-right-style style
-设置状态行右边部分的样式,参考message-command-style选项设置样式。
-
- status-style style
-设置状态行样式,参考message-command-style选项设置样式。
-
- status-utf8 [on | off]
-指示tmux将status-left和status-right中的字符串中的top-bit-set当作UTF-8处理;值得注意的时,这对于宽字符很重要。默认为off。
-
- update-environment variables
-设置一个包含由空格分开的环境变量列表字符串--这些环境变量会在新会话创建时或一个已存在的会话被附着时复制到会话环境中。
-任何在源环境中不存在的变量会从会话环境中设置为移除(类似于将-r传递给set-environment命令)。
-默认值为"DISPLAY SSH_ASKPASS SSH_AUTH_SOCK SSH_AGENT_PID SSH_CONNECTION WINDOWID XAUTHORITY"。
-
- visual-activity [on | off]
-如果为on, 当活动出现在一个由monitor-activity窗口选项生效的窗口中时显示一个状态行。
-
- visual-bell [on | off]
-如果为on,响铃时会显示一个消息而不是将其传递到终端(会产生一个声音)。可以参考bell-action选项。
-
- visual-silence [on | off]
-如果monitor-silence生效的话,那么当时间间隔在一个指定窗口中过期时会打印一个消息。
-
- word-separators string
-设置会话关于单词分隔符字符的概念,主要是为了复制模式中的下一个或前一个单词命令的目的。默认为'-_@'。
-
- set-window-option [-agoqu] [-t target-window] option value
- (别名:setw)
-Set a window option. The -a, -g, -o, -q and -u flags work similarly to the set-option command.
-
-###窗口选项
-支持的窗口选项有:
-
- aggressive-resize [on | off]
-积极地重新调整所选窗口大小。意味着tmux会重新调整窗口的尺寸为当前窗口的最小会话尺寸,而不是其附着的最小的会话。
-在当前窗口改变为另外一个会话时窗口会重新调整大小;这个选项对于支持SIGWINCH的全屏程序有好处而对于交互式程序如shell不是太好。
-
- allow-rename [on | off]
-允许程序通过终端转义序列(\033k...\033\\)改变窗口名称。默认为on。
-
- alternate-screen [on | off]
-这个选项用来配置运行在tmux中的程序是否可以使用终端的被用屏幕特性-允许terminfo的smcup和rmcup能力。
-被用屏幕特性在一个交互式程序开启并且在从退出后恢复之后可以保留窗口的内容,
-这样任何程序开始之前的可视输出会在程序退出之后重新出现。默认为on。
-
- automatic-rename [on | off]
-控制自动化窗口命名。当开启这个设置时,tmux会使用由automatic-rename-format指定的格式来自动地重命名窗口。
-对于由new-window和new-session在创建时,或者之后通过rename-window或者使用终端转义序列指定的窗口名称, 这个标识会自动失效。
-
-可以通过以下方式来将其在全局范围内关闭:
-
- set-window-option -g automatic-rename off
-
-
- automatic-rename-format format
-
-在automatic-rename选项生效时会使用这个格式, 参考 [FORMATS](#格式) 。
-
- c0-change-interval interval
- c0-change-trigger trigger
-这两个选项配置面板改变时间间隔的一个简单格式。如果tmux在1毫秒内查看到除C0序列之外的触发器(例如回车,换行或删除)
-修改屏幕,会立即停止更新面板。否则会在每个时间间隔内重绘整个面板。
-这个可以帮助来阻止快速输出(例如yes)覆盖整个终端。默认为触发器250, 时间间隔100。
-0触发器用来失效速率限制。
-
-
-
- clock-mode-colour colour
-设置时钟颜色。
-
- clock-mode-style [12 | 24]
-设置时钟小时格式
-
- force-height height
- force-width width
-阻止tmux将窗口的大小值超过width或height, 0值会恢复默认无限制设置。
-
- main-pane-height height
- main-pane-width width
-设置main-horizontal 或 main-vertical布局中的主面板的长和宽。
-
-
-mode-keys [vi | emacs]
-在复制或选择模式中使用vi/emacs键绑定。与status-keys选项一样默认为emacs, 除非VISUAL或EDITOR包含了vi。
-
-mode-style style
-设置窗口模式样式, 参考message-command-style选项指定样式。
-
-monitor-activity [on | off]
-监视窗口中的活动。具有活动事件的窗口在状态栏上高亮显示。
-
-monitor-silence [interval]
-在一段时间间隔内对非活动窗口进行监控。时间间隔内沉默的窗口在状态栏高亮。
-0间隔值让其监控失效。
-
-
-other-pane-height height
-设置main-horizontal布局中主面板之外的面板高度。默认为0-没有任何作用。
-如果main-pane-height和other-pane-height选项同时设置,主面板会变得来使得
-其他面板达到指定高度,但是不会反过来作用。
-
-other-pane-width width
-与other-pane-height类似,只是用来设置 main-vertical布局中的其他面板的宽度。
-
-pane-active-border-style style
-设置当前活动面板的边框样式。 参考 message-command-style选项来指定样式,属性被忽视。
-
-pane-base-index index
-与 base-index类似,只是用来设置面板的开始数字。
-
-pane-border-style style
-设置活动面板周围面板的样式。 参考 message-command-style选项来指定样式,属性被忽视。
-
-remain-on-exit [on | off]
-带有该标识设置的窗口在其中程序退出时不会被销毁。
-窗口可能使用respawn-window命令重新激活。
-
-synchronize-panes [on | off]
-将到任意面板的输入复制到相同窗口中的所有其他面板(没有在特殊模式中的面板)。
-
-utf8 [on | off]
-指示tmux期待在窗口中出现 UTF-8序列。
-
-window-active-style style
-设置窗口的活动面板的样式。参考 message-command-style选项来指定样式。
-
-window-status-activity-style style
-设置窗口的状态行样式带有一个活动警告。参考 message-command-style选项来指定样式。
-
-window-status-bell-style style
-设置窗口的状态行样式带有一个响铃警告。参考 message-command-style选项来指定样式。
-
- window-status-current-format string
-与 window-status-format类似,只是这个格式在窗口为当前窗口时使用。
-
- window-status-current-style style
-为当前的活动窗口设置状态行样式。 参考 message-command-style选项来指定样式。
-
- window-status-format string
-设置状态行列表中显示窗口的格式。 参考 status-left选项关于可用的特殊字符序列信息。默认值为'#I:#W#F'。
-
- window-status-last-style style
-为最后一个活动窗口设置状态行样式。参考 message-command-style选项来指定样式。
-
- window-status-separator string
-设置状态行中窗口之间的分隔符,默认为单个空格符。
-
- window-status-style style
-为单个窗口设置状态行样式。参考 message-command-style选项来指定样式。
-
- window-style style
-设置默认窗口样式。参考 message-command-style选项来指定样式。
-
- xterm-keys [on | off]
-设置该选项会使tmux生成xterm-style功能键序列; 这些包含了一个数字来指定修饰符如Shift,Alt或Ctrl。默认为off。
-
- wrap-search [on | off]
-设置这个选项会使得搜索动作包含面板内容的末尾。 默认为on。
-
- show-options [-gqsvw] [-t target-session | target-window] [option]
-(别名:show)
-使用-w来显示窗口选项(可以指定单个窗口),使用-s显示服务器选项,否则显示target-session的会话选项。
--g用来显示全局会话或窗口选项。
--v只显示选项值,不包含名称。
--q指示重置选项不会返回错误。
-
- show-window-options [-gv] [-t target-window] [option]
-(别名:showw)
-列出窗口选项或者target-window指定的单个窗口选项。
--g用来显示全局窗口选项。
--v显示选项值,忽略选项名。
-
-##鼠标支持
-如果鼠标选项开启(默认为关闭),tmux允许将鼠标时间作为键来结合。
-每个键的名称是由鼠标事件(例如'MouseUp1')和一个位置后缀('Pane'表示面板内容,'Border'面板边界
-或者'Status'状态行)组成的。可以使用以下的鼠标事件:
-
- MouseDown1 MouseUp1 MouseDrag1
- MouseDown2 MouseUp2 MouseDrag2
- MouseDown3 MouseUp3 MouseDrag3
- WheelUp WheelDown
-
-每个都需要带有一个位置后缀,例如'MouseDown1Status'
-
-特殊标记'{mouse}'或'='可能在命令中作为target-window或target-pane与鼠标键绑定进行结合。
-会在鼠标事件发生的位置解析为窗口或面板(例如,对于一个'MouseUp1Status'绑定在在状态行上的窗口,
-或者对于'WheelDownPane'绑定面板上的鼠标滚动)。
-
-'send-key -M'标记可以用来将一个鼠标时间转发到一个面板上。
-
-默认的键绑定允许鼠标用来选择和改变面板大小,复制文本或者使用状态行来改变窗口。
-这些动作在开启鼠标选项时发生作用。
-
-
-##格式
-
-有些命令接受由-F标记附带的格式参数。这个参数是一个控制命令输出格式的字符串。
-可替换的变量被包含在'#{'和'}'之间,例如'#{session_name}'。
-可用的变量在下表中列出,或者tmux选项的名称可以一个选项的值。
-有些变量具有一个简短的别名,例如'#s', 而'##'会使用一个单独的'#'来替换。
-
-
-条件可以通过'?'作为前缀,逗号作为分隔符来使用,如果指定的变量存在并且不是0,那么第一个选项被选择,否则选择第二个选项。
-例如'#{?session_attached,attached,not attached}'条件,当会话是附着的就会包含'attached'否则就会包含'not attached'。
-而对于'#{?automatic-rename, yes, no}'如果开启了automatic-rename的话会包含'yes'否则包含'no'。
-可以通过一个前缀'=',一个数字和一个冒号来作为字符串的长度限制,所以'#{=10:pane_title}'最多包含pane标题的前10个字符。
-
-在合适的地方有以下的变量是可用的:
-
- 变量名 | 别名 | 替换值
- -----------------------|--------------|-----------------------------------
- alternate_on | | If pane is in alternate screen
- alternate_saved_x | | Saved cursor X in alternate screen
- alternate_saved_y | | Saved cursor Y in alternate screen
- buffer_sample | | Sample of start of buffer
- buffer_size | | Size of the specified buffer in bytes
- client_activity | | Integer time client last had activity
- client_activity_string | | String time client last had activity
- client_created | | Integer time client created
- client_created_string | | String time client created
- client_height | | Height of client
- client_last_session | | Name of the client's last session
- client_prefix | | 1 if prefix key has been pressed
- client_readonly | | 1 if client is readonly
- client_session | | Name of the client's session
- client_termname | | Terminal name of client
- client_tty | | Pseudo terminal of client
- client_utf8 | | 1 if client supports utf8
- client_width | | Width of client
- cursor_flag | | Pane cursor flag
- cursor_x | | Cursor X position in pane
- cursor_y | | Cursor Y position in pane
- history_bytes | | Number of bytes in window history
- history_limit | | Maximum window history lines
- history_size | | Size of history in bytes
- host | #H | Hostname of local host
- host_short | #h | Hostname of local host (no domain name)
- insert_flag | | Pane insert flag
- keypad_cursor_flag | | Pane keypad cursor flag
- keypad_flag | | Pane keypad flag
- line | | Line number in the list
- mouse_any_flag | | Pane mouse any flag
- mouse_button_flag | | Pane mouse button flag
- mouse_standard_flag | | Pane mouse standard flag
- mouse_utf8_flag | | Pane mouse UTF-8 flag
- pane_active | | 1 if active pane
- pane_bottom | | Bottom of pane
- pane_current_command | | Current command if available
- pane_dead | | 1 if pane is dead
- pane_dead_status | | Exit status of process in dead pane
- pane_height | | Height of pane
- pane_id | #D | Unique pane ID
- pane_in_mode | | If pane is in a mode
- pane_input_off | | If input to pane is disabled
- pane_index | #P | Index of pane
- pane_left | | Left of pane
- pane_pid | | PID of first process in pane
- pane_right | | Right of pane
- pane_start_command | | Command pane started with
- pane_synchronized | | If pane is synchronized
- pane_tabs | | Pane tab positions
- pane_title | #T | Title of pane
- pane_top | | Top of pane
- pane_tty | | Pseudo terminal of pane
- pane_width | | Width of pane
- saved_cursor_x | | Saved cursor X in pane
- saved_cursor_y | | Saved cursor Y in pane
- scroll_region_lower | | Bottom of scroll region in pane
- scroll_region_upper | | Top of scroll region in pane
- session_attached | | Number of clients session is attached to
- session_activity | | Integer time of session last activity
- session_activity_string| | String time of session last activity
- session_created | | Integer time session created
- session_created_string | | String time session created
- session_group | | Number of session group
- session_grouped | | 1 if session in a group
- session_height | | Height of session
- session_id | | Unique session ID
- session_many_attached | | 1 if multiple clients attached
- session_name | #S | Name of session
- session_width | | Width of session
- session_windows | | Number of windows in session
- window_active | | 1 if window active
- window_activity_flag | | 1 if window has activity alert
- window_bell_flag | | 1 if window has bell
- window_find_matches | | Matched data from the find-window
- window_flags | #F | Window flags
- window_height | | Height of window
- window_id | | Unique window ID
- window_index | #I | Index of window
- window_last_flag | | 1 if window is the last used
- window_layout | | Window layout description
- window_name | #W | Name of window
- window_panes | | Number of panes in window
- window_silence_flag | | 1 if window has silence alert
- window_width | | Width of window
- window_zoomed_flag | | 1 if window is zoomed
- wrap_flag | | Pane wrap flag
-
-
-##名称和标题
-
-tmux区分名称和标题,窗口和会话具有名称用来作为目标标识,并且在状态行和不同的列表中显示:
-名称是tmux对于一个窗口或会话的标识符。
-只有pane面板有标题,面板的标题是由在其中运行的程序设置的并且不能由tmux改变。
-与X窗口管理器中的xterm窗口标题的设置所使用的机制相同。
-窗口本身没有标题----一个窗口的标题就是其活动面板的标题。
-tmux本身会设置客户端所在终端的标题,参考set-title选项。
-
-A session's name is set with the new-session and rename-session commands. A window's name is set with one of:
-一个会话的名称通过new-session和rename-session命令来设置的,一个窗口的名称可以通过以下方式设置:
-
- 1. 一个命令的参数(如new-window和new-session的-n参数)
- 2. 一个转义序列: $ printf '\033kWINDOW_NAME\033\\'
-
-自动重命名会将名称设置为窗口活动面板中的活动程序,参考automatic-rename选项。
-
-当一个面板第一次创建时,其标题为主机名hostname。一个面板的标题可以通过OSC标题设置序列进行设置,例如:
- $ printf '\033]2;My Title\033\\'
-
-##环境
-
-当tmux服务器启动时,tmux会将环境复制到全局环境中,此外每个会话具有一个会话环境。
-当一个窗口被创建时,会将会话环境和全局环境合并。
-如果一个变量存在两个环境中,会使用会话环境中的变量。结果就是初始环境传递给新进程。
-
-当一个新会话创建或者一个就会话重新附着时,update-environment会话选项可以用来从一个客户端来更新会话环境。
-tmux也会使用一些内部信息来初始化TMUX变量以便允许命令在内部执行,TERM变量会设置为正确的终端'screen'。
-
-修改和查看环境的命令有:
-
- set-environment [-gru] [-t target-session] name [value]
- (别名:setenv)
-设置或重置一个环境变量,如果使用-g,会在全局变量中进行改变;否则只会改变target-session的会话环境。
--u标记用来重置一个变量。 -r用来指示在开起一个新进程时从环境中移除该变量。
-
- show-environment [-g] [-t target-session] [variable]
- (别名:showenv)
-显示目标会话target-session或者全局环境(使用-g时)变量。
-如果忽略变量,会显示所有的变量。从环境中移除的变量会用'-'作为前导。
-
-##状态行
-tmux包含了一个可选的状态行会显示在每个终端的底端行。
-默认状态行时有效的(可以通过status会话选项失效)并且被包含的,从左到右分别有:
-包含在方括号中的当前会话名称;窗口列表;双引号包含的活动面板;以及时间和日期。
-
-状态行由三部分组成:
-可配置的左边和右边部分(可以包含shell命令输出的动态的内容,例如时间和日期,
-参考status-left,status-left-length,status-right,status-right-length选项), 以及中间的窗口列表。
-默认窗口列表显示当前会话中按照数字升序排列窗口的索引,名称和标记(如果存在的话)。
-可以通过window-status-format和window-status-current-format选项客制化。
-
-附加在窗口名称后面的标记可以是以下符号之一:
-
- 符号 | 含义
----------|-----------
- * | 表示当前窗口
- - | 最有一个选择的窗口。
- # | 窗口被监控并且活动会被检测。
- ! | 会在窗口中出现一个响铃。
- ~ | 窗口会在monitor-silence时间间隔中保持沉默。
- Z | 窗口的活动面板被放大了。
-
-符号#与monitor-activity窗口选项相关。窗口名称会在有警告(响铃,活动或沉默)出现的时候以反转的颜色打印
-
-状态行的颜色和属性是可以配置的,整个状态行使用status-style会话选项,单个的窗口使用window=status-style窗口选项配置。
-
-状态行会自动地刷新如果当其在时间间隔内被改变的话,时间间隔可以通过status-interval会话选项控制。
-
-与状态行相关的命令有:
-
- command-prompt [-I inputs] [-p prompts] [-t target-client] [template]
-在客户端打开一个命令提示,可以在tmux内用用来执行交互式命令。
-
-如果指定了template的话,其会被作为命令使用。
--I是每个提示初始化文本列表-由逗号分割的。
--p 提示是一个按照顺序显示的逗号分割的提示列表;否则只显示一个单独的构造于template(如果提供了的话)提示,否则使用':'。
-inputs和prompts都可能包含由status-left选项支持的特殊字符序列。
-在命令被执行之前,第一个出现的字符串'%%'和出现的所有'%1'都会被第一个提示的响应替换,
-第二个'%%'和所有的'%2'会被第二个提示的响应替换,以此类推, 直到第九个提示可以被替换。
-
- confirm-before [-p prompt] [-t target-client] command
- (别名:confirm)
-在执行命令之前进行确认,如果指定-p, 提示为prompt参数的显示,否则提示会从command来构造。
-可能会包含由status-left选项支持的特殊字符序列。
-这个命令只会在tmux中工作。
-
- display-message [-p] [-c target-client] [-t target-pane] [message]
- (别名:display)
-显示一个消息, 如果没有给定-p,
-那么输出会被打印到标准输出中,否则会显示在target-client的状态行上。
-消息的格式在[FORMTS](#格式)部分描述。
-如果给第-t就会从target-pane中获取信息,否则就会从附着在target-client的会话中的活动窗口中获取。
-
-##缓冲区
-tmux维护了一个命名的粘贴缓冲区集合,每个可能显式地或自动地命名。
-显式地命名的缓冲区是在通过set-buffer或load-buffer命令创建时命名的,
-或者是通过set-buffer -n 来重命名一个自动命名的缓冲区。
-自动命名的缓冲区的名称会类似于'buffer0001','buffer0002'等。
-当达到buffer-limit选项的限制时,最旧的自动命名的缓冲区被删除。
-显示命名的缓冲区不会收到buffer-limit的限制,可以通过delete-buffer命令删除。
-
-缓冲区可以使用copy-mode或set-buffer以及load-buffer命令来添加,并且通过paste-buffer命令来将其粘贴到一个窗口。
-如果一个缓冲区命令没有指定缓冲区时,就会假设使用最近添加的自动命名的缓冲区。
-
-每个窗口也会维护一个可配值的历史缓冲区,默认会保留到2000行;这个可以通过history-limit选项修改(参考set-option命令)。
-
-缓冲区命令有:
- choose-buffer [-F format] [-t target-window] [template]
-将窗口置于缓冲区选择模式,一个缓冲区可以从一个列表中交互地选择。
-在选择一个缓冲区之后,'%%'会被template中的缓冲区名称替换,之后的结果会作为一个命令被执行。
-如果没有给定template,会使用"paste-buffer -b '%%'"来替换。 对于-F标记参考[FORMATS](#格式)部分。
-这个命令只有在至少有一个客户端附着时工作。
-
- clear-history [-t target-pane]
- (别名:clearhist)
-对指定的pane删除并释放history。
-
- delete-buffer [-b buffer-name]
- (别名:deleteb)
-删除名为buffer-name的缓冲区,在没有指定buffer-name时删除最佳男自动命名添加的缓冲区。
-
- list-buffers [-F format]
- (别名:lsb)
-列出全局缓冲区,对于-F可以参考[FORMATS](#格式)部分。
-
- load-buffer [-b buffer-name] path
- (别名:loadb)
-从path中加载指定粘贴缓冲区的内容。
-
- paste-buffer [-dpr] [-b buffer-name] [-s separator] [-t target-pane]
- (别名:pasteb)
-将一个粘贴缓冲却中的内容插入到一个指定的pane中。如果没有指定target-pane,会被粘贴到当前的一个。
--d 同时也会删除粘贴缓冲区。当输出时,任何粘贴缓冲区中的换行符会使用一个分隔符替换(默认为回车符)。
--s 指定客制化分隔符。
--r 标记意味着不做换行符的替换。
--p 当应用程序请求大括号粘贴模式的话,粘贴的大括号控制代码会被插入到缓冲区中。
-
- save-buffer [-a] [-b buffer-name] path
- (别名:saveb)
-将指定的粘贴缓冲区中的内容保存到一个路径path. -a选项用来指示附加模式而不是直接重写文件。
-
- set-buffer [-a] [-b buffer-name] [-n new-buffer-name] data
- (别名:setb)
-将指定缓冲区的内容设置为data.
-使用-a选项来将data附加到缓冲区而不是直接重写缓冲区。-n用来重命名缓冲区到一个new-buffer-name。
-
- show-buffer [-b buffer-name]
- (别名:showb)
-显示指定缓冲区的内容。
-
-##杂项
-其他杂项命令有:
- clock-mode [-t target-pane]
-显示一个大的时钟。
-
- if-shell [-bF] [-t target-pane] shell-command command [command]
- (别名:if)
-如果shell-command返回成功的话执行第一个命令,否则执行第二个命令。
-在执行之前,shell-command会使用[FORMATS](#格式)部分指定的规则进行扩展,包括相关的target-pane。-b指示shell-command在后台运行。
-如果给定-F,shell-command不会被执行而是认为时成功的(如果既不是空的也不是0的话-在格式扩展之后)。
-
- lock-server
- (别名:lock)
-通过运行lock-command选项指定的命令来分别锁定每个客户端。
-
- run-shell [-b] [-t target-pane] shell-command
- (别名:run)
-在不创建一个窗口的前提下在后台中运行一个shell-command。
-执行之前,shell-command使用[FORMATS](#格式)部分指定的规则进行扩展。
--b指示在后台运行。
-在完成之后,任何到标准输出的输出会在copy模式中显示(在由-t指定的pane或当前pane-如果缺省的话)。
-如果命令没有成功返回,退出状态也会被显示。
-
- wait-for [-L | -S | -U] channel
- (别名:wait)
-当不带选项使用时,在使用相同的channel的wait-for -S唤醒之前阻止客户端退出。
--L会锁定channel,任何尝试锁定相同channel的客户端会一直等待直到使用wait-for -U 解锁。 这个命令只有在tmux外部工作。
-
-##TERMINFO EXTENSIONS
-
-tmux可以理解terminfo的一些扩展:
-Cs, Cr
-设置光标颜色,第一个使用一个单个字符串参数来设置颜色;第二个没有参数来恢复默认的光标颜色。
-如果设置的话一系列这样的值会被用来在tmux中改变光标颜色:
-
- $ printf '\033]12;red\033\\'
-
-Ss, Se
-设置或重置光标样式。 如果设置以下的序列可能会用来将光标变为一个下划线:
-
- $ printf '\033[4 q'
-
-如果没有设置Se,Ss和参数0会被用来重新设置光标样式。
-
-Ms
-这个序列可以被tmux用来存储当前缓冲区到主机终端剪贴板中。可以参考set-clipboad选项和xterm的man页面。
-
-##控制模式
-
-tmux提供了一个成为control(控制)模式的文本界面。这使得应用程序可以通过一个简单的文本协议与tmux进行交流。
-在控制模式中,一个客户端发送tmux命令或以新行结束的命令序列到标准输入中。
-每个命令将会在标准输出中产生一个输出块。
-一个输出块包含了一个%begin行与跟随的输出(可能为空)。
-输出块会以一个%end或%error作为结尾。
-%begin和匹配的%end/%error具有两个参数:一个整数时间和命令编号,例如:
-
- %begin 1363006971 2
- 0: ksh* (1 panes) [80x24] [layout b25f,80x24,0,0,2] @2 (active)
- %end 1363006971 2
-
-在控制模式中,tmux输出通知,一个通知不会出现在输出块中。
-
-下面是通知的定义:
-
- %exit [reason]
-
-当tmux客户端没有附着在任何会话中或者出现错误时,tmux客户端会立即退出。如果存在的话,reason描述了客户端退出的原因。
-
- %layout-change window-id window-layout
-
-一个带有window-id的窗口布局被改变,新的布局为window-layout。
-
- %output pane-id value
-
-一个窗口面板产生的输出。 值会转义非打印字符而且饭斜线作为八进制\xxx。
-
- %session-changed session-id name
-客户端现在被附着在ID为session-id的会话上,并且使用name命名。
-
- %session-renamed name
-当前会话被重命名为name。
-
- %sessions-changed
-
-一个会话被创建或销毁。
-
- %unlinked-window-add window-id
-
-ID为window-id的窗口被创建,但是没有连接到当前会话。
-
- %window-add window-id
-ID为window-id的窗口被连接到当前会话。
-
- %window-close window-id
-ID为window-id的窗口被关闭。
-
- %window-renamed window-id name
-ID为window-id的窗口重命名为name。
-
-##文件
-o
- ~/.tmux.conf : 默认的tmux配置文件。
- /etc/tmux.conf : 系统范围的配置文件。
-
-##样例
-
-创建一个运行vi的新的tmux会话:
-
- $ tmux new-session vi
-
-大部分命令具有一个简短形式,也成为别名。例如new-session的别名为new:
- $ tmux new vi
-
-可选地,一个命令最短的不混淆的简短格式是被接受的,如果有多个选项,会被列出:
-
- $ tmux n
- ambiguous command: n, could be: new-session, new-window, next-window
-
-在一个活动会话中,一个新的窗口可以通过键入'C-b c'来创建(ctrl 跟随b 然后跟随c键)。
-
-窗口可以使用'C-b 0-9'来在窗口0-9中导航,也可以通过'C-b n'选择下一个窗口,'C-b p'选择上一个窗口。
-
-一个会话可以通过使用'C-b d'来脱离附着,也可以通过以下命令来重新附着:
- $ tmux attach-session
-
-键入'C-b ?' 列出当前窗口中的当前键绑定; 使用上下箭头可以导航列表,'q'从其中退出。
-
-当tmux启动时运行的命令可能放置在 ~/.tmux.conf配置文件中,常见样例包括:
-
-改变默认的前导键:
-
- set-option -g prefix C-a
- unbind-key C-b
- bind-key C-a send-prefix
-
-关闭状态行或者改变其颜色:
-
- set-option -g status off
- set-option -g status-style bg=blue
-
-设置其他选项,例如默认命令或者在30分钟不活动之后锁定:
-
- set-option -g default-command "exec /bin/ksh"
- set-option -g lock-after-time 1800
-
-创建新的键绑定:
-
- bind-key b set-option status
- bind-key / command-prompt "split-window 'exec man %%'"
- bind-key S command-prompt "new-window -n %1 'ssh %1'"
-
-参考: pty(4)
-
-作者: Nicholas Marriott
-
-译者: Liang Guisheng