mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
16c1cd93e2
published
20180118 Securing the Linux filesystem with Tripwire.md20180125 BUILDING A FULL-TEXT SEARCH APP USING DOCKER AND ELASTICSEARCH.md20180208 Become a Hollywood movie hacker with these three command line tools.md20180321 The Command line Personal Assistant For Your Linux System.md
translated/tech
@ -1,54 +1,50 @@
|
||||
使用 Tripwire 保护 Linux 文件系统
|
||||
======
|
||||
|
||||
> 如果恶意软件或其情况改变了你的文件系统,Linux 完整性检查工具会提示你。
|
||||
|
||||

|
||||
|
||||
尽管 Linux 被认为是最安全的操作系统(在 Windows 和 MacOS 之前),但它仍然容易受到 rootkit 和其他恶意软件的影响。因此,Linux 用户需要知道如何保护他们的服务器或个人电脑免遭破坏,他们需要采取的第一步就是保护文件系统。
|
||||
尽管 Linux 被认为是最安全的操作系统(排在 Windows 和 MacOS 之前),但它仍然容易受到 rootkit 和其他恶意软件的影响。因此,Linux 用户需要知道如何保护他们的服务器或个人电脑免遭破坏,他们需要采取的第一步就是保护文件系统。
|
||||
|
||||
在本文中,我们将看看 [Tripwire][1],这是保护 Linux 文件系统的绝佳工具。Tripwire 是一个完整性检查工具,使系统管理员、安全工程师和其他人能够检测系统文件的变更。虽然它不是唯一的选择([AIDE][2] 和 [Samhain][3] 提供类似功能),但 Tripwire 可以说是 Linux 系统文件中最常用的完整性检查程序,并在 GPLv2 许可证下开源。
|
||||
在本文中,我们将看看 [Tripwire][1],这是保护 Linux 文件系统的绝佳工具。Tripwire 是一个完整性检查工具,使得系统管理员、安全工程师和其他人能够检测系统文件的变更。虽然它不是唯一的选择([AIDE][2] 和 [Samhain][3] 提供类似功能),但 Tripwire 可以说是 Linux 系统文件中最常用的完整性检查程序,并在 GPLv2 许可证下开源。
|
||||
|
||||
### Tripwire 如何工作
|
||||
|
||||
了解 Tripwire 如何运行对了解 Tripwire 在安装后会做什么有所帮助。Tripwire 主要由两个部分组成:策略和数据库。策略列出了完整性检查器应该生成快照的所有文件和目录,还创建了用于识别对目录和文件更改违规的规则。数据库由 Tripwire 生成的快照组成。
|
||||
|
||||
Tripwire 还有一个配置文件,它指定数据库、策略文件和 Tripwire 可执行文件的位置。它还提供两个加密密钥 - 站点密钥和本地密钥 - 以保护重要文件免遭篡改。站点密钥保护策略和配置文件,而本地密钥保护数据库和生成的报告。
|
||||
Tripwire 还有一个配置文件,它指定数据库、策略文件和 Tripwire 可执行文件的位置。它还提供两个加密密钥 —— 站点密钥和本地密钥 —— 以保护重要文件免遭篡改。站点密钥保护策略和配置文件,而本地密钥保护数据库和生成的报告。
|
||||
|
||||
Tripwire 定期将目录和文件与数据库中的快照进行比较并报告所有的更改。
|
||||
Tripwire 会定期将目录和文件与数据库中的快照进行比较并报告所有的更改。
|
||||
|
||||
### 安装 Tripwire
|
||||
|
||||
要 Tripwire,我们需要先下载并安装它。Tripwire 适用于几乎所有的 Linux 发行版。你可以从 [Sourceforge][4] 下载一个开源版本,并如下根据你的 Linux 版本进行安装。
|
||||
|
||||
Debian 和 Ubuntu 用户可以使用 `apt-get` 直接从仓库安装 Tripwire。非 root 用户应该输入 `sudo` 命令通过 `apt-get` 安装 Tripwire。
|
||||
|
||||
```
|
||||
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install tripwire
|
||||
```
|
||||
|
||||
CentOS 和其他基于 rpm 的发行版使用类似的过程。为了最佳实践,请在安装新软件包(如 Tripwire)之前更新仓库。命令 `yum install epel-release` 意思是我们想要安装额外的存储库。 (`epel` 代表 Extra Packages for Enterprise Linux。)
|
||||
CentOS 和其他基于 RPM 的发行版使用类似的过程。为了最佳实践,请在安装新软件包(如 Tripwire)之前更新仓库。命令 `yum install epel-release` 意思是我们想要安装额外的存储库。 (`epel` 代表 Extra Packages for Enterprise Linux。)
|
||||
|
||||
```
|
||||
|
||||
|
||||
yum update
|
||||
|
||||
yum install epel-release
|
||||
|
||||
yum install tripwire
|
||||
```
|
||||
|
||||
此命令会在安装中运行让 Tripwire 有效运行所需的配置。另外,它会在安装过程中询问你是否使用密码。你可以两个选择都选择 “Yes”。
|
||||
|
||||
另外,如果需要构建配置文件,请选择 “Yes”。选择并确认站点密钥和本地密钥的密码。(建议使用复杂的密码,例如 `Il0ve0pens0urce`。)
|
||||
另外,如果需要构建配置文件,请选择 “Yes”。选择并确认站点密钥和本地密钥的密码。(建议使用复杂的密码,例如 `Il0ve0pens0urce` 这样的。)
|
||||
|
||||
### 建立并初始化 Tripwire 数据库
|
||||
|
||||
接下来,按照以下步骤初始化 Tripwire 数据库:
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --init
|
||||
```
|
||||
|
||||
@ -57,39 +53,34 @@ tripwire --init
|
||||
### 使用 Tripwire 进行基本的完整性检查
|
||||
|
||||
你可以使用以下命令让 Tripwire 检查你的文件或目录是否已被修改。Tripwire 将文件和目录与数据库中的初始快照进行比较的能力依赖于你在活动策略中创建的规则。
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --check
|
||||
```
|
||||
|
||||
你还可以将 `-check` 命令限制为特定的文件或目录,如下所示:
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --check /usr/tmp
|
||||
```
|
||||
|
||||
另外,如果你需要使用 Tripwire 的 `-check` 命令的更多帮助,该命令能够查阅 Tripwire 的手册:
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --check --help
|
||||
```
|
||||
|
||||
### 使用 Tripwire 生成报告
|
||||
|
||||
要轻松生成每日系统完整性报告,请使用以下命令创建一个 “crontab”:
|
||||
要轻松生成每日系统完整性报告,请使用以下命令创建一个 crontab 任务:
|
||||
|
||||
```
|
||||
|
||||
|
||||
crontab -e
|
||||
```
|
||||
|
||||
之后,你可以编辑此文件(使用你选择的文本编辑器)来引入由 cron 运行的任务。例如,你可以使用以下命令设置一个 cron 作业,在每天的 5:40 将 Tripwire 的报告发送到你的邮箱:
|
||||
之后,你可以编辑此文件(使用你选择的文本编辑器)来引入由 cron 运行的任务。例如,你可以使用以下命令设置一个 cron 任务,在每天的 5:40 将 Tripwire 的报告发送到你的邮箱:
|
||||
|
||||
```
|
||||
|
||||
|
||||
40 5 * * * usr/sbin/tripwire --check
|
||||
```
|
||||
|
||||
@ -101,7 +92,7 @@ via: https://opensource.com/article/18/1/securing-linux-filesystem-tripwire
|
||||
|
||||
作者:[Michael Kwaku Aboagye][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,59 +1,55 @@
|
||||
使用 DOCKER 和 ELASTICSEARCH 构建一个全文搜索应用程序
|
||||
使用 Docker 和 Elasticsearch 构建一个全文搜索应用程序
|
||||
============================================================
|
||||
|
||||
_如何在超过 500 万篇文章的 Wikipedia 上找到与你研究相关的文章?_
|
||||

|
||||
|
||||
_如何在超过 20 亿用户的 Facebook 中找到你的朋友(并且还拼错了名字)?_
|
||||
_如何在超过 500 万篇文章的 Wikipedia 上找到与你研究相关的文章?_
|
||||
|
||||
_谷歌如何在整个因特网上搜索你的模糊的、充满拼写错误的查询?_
|
||||
_如何在超过 20 亿用户的 Facebook 中找到你的朋友(并且还拼错了名字)?_
|
||||
|
||||
在本教程中,我们将带你探索如何配置我们自己的全文探索应用程序(与上述问题中的系统相比,它的复杂度要小很多)。我们的示例应用程序将提供一个 UI 和 API 去从 100 部经典文学(比如,_Peter Pan_ , _Frankenstein_ , 和 _Treasure Island_ )中搜索完整的文本。
|
||||
_谷歌如何在整个因特网上搜索你的模糊的、充满拼写错误的查询?_
|
||||
|
||||
你可以在这里([https://search.patricktriest.com][6])预览教程中应用程序的完整版本。
|
||||
在本教程中,我们将带你探索如何配置我们自己的全文搜索应用程序(与上述问题中的系统相比,它的复杂度要小很多)。我们的示例应用程序将提供一个 UI 和 API 去从 100 部经典文学(比如,《彼得·潘》 、 《弗兰肯斯坦》 和 《金银岛》)中搜索完整的文本。
|
||||
|
||||
你可以在这里([https://search.patricktriest.com][6])预览该教程应用的完整版本。
|
||||
|
||||

|
||||
|
||||
这个应用程序的源代码是 100% 公开的,可以在 GitHub 仓库上找到它们 —— [https://github.com/triestpa/guttenberg-search][7]
|
||||
这个应用程序的源代码是 100% 开源的,可以在 GitHub 仓库上找到它们 —— [https://github.com/triestpa/guttenberg-search][7] 。
|
||||
|
||||
在应用程序中添加一个快速灵活的全文搜索可能是个挑战。大多数的主流数据库,比如,[PostgreSQL][8] 和 [MongoDB][9],在它们的查询和索引结构中都提供一个有限的、基础的、文本搜索的功能。为实现高质量的全文搜索,通常的最佳选择是单独数据存储。[Elasticsearch][10] 是一个开源数据存储的领导者,它专门为执行灵活而快速的全文搜索进行了优化。
|
||||
在应用程序中添加一个快速灵活的全文搜索可能是个挑战。大多数的主流数据库,比如,[PostgreSQL][8] 和 [MongoDB][9],由于受其查询和索引结构的限制只能提供一个非常基础的文本搜索功能。为实现高质量的全文搜索,通常的最佳选择是单独的数据存储。[Elasticsearch][10] 是一个开源数据存储的领导者,它专门为执行灵活而快速的全文搜索进行了优化。
|
||||
|
||||
我们将使用 [Docker][11] 去配置我们自己的项目环境和依赖。Docker 是一个容器化引擎,它被 [Uber][12]、[Spotify][13]、[ADP][14]、以及 [Paypal][15] 使用。构建容器化应用的一个主要优势是,项目的设置在 Windows、macOS、以及 Linux 上都是相同的 —— 这使我写这个教程快速又简单。如果你还没有使用过 Docker,不用担心,我们接下来将经历完整的项目配置。
|
||||
我们将使用 [Docker][11] 去配置我们自己的项目环境和依赖。Docker 是一个容器化引擎,它被 [Uber][12]、[Spotify][13]、[ADP][14] 以及 [Paypal][15] 使用。构建容器化应用的一个主要优势是,项目的设置在 Windows、macOS、以及 Linux 上都是相同的 —— 这使我写这个教程快速又简单。如果你还没有使用过 Docker,不用担心,我们接下来将经历完整的项目配置。
|
||||
|
||||
我也会使用 [Node.js][16] (使用 [Koa][17] 框架)、和 [Vue.js][18],用它们分别去构建我们自己的搜索 API 和前端 Web 应用程序。
|
||||
我也会使用 [Node.js][16] (使用 [Koa][17] 框架)和 [Vue.js][18],用它们分别去构建我们自己的搜索 API 和前端 Web 应用程序。
|
||||
|
||||
### 1 - ELASTICSEARCH 是什么?
|
||||
### 1 - Elasticsearch 是什么?
|
||||
|
||||
全文搜索在现代应用程序中是一个有大量需求的特性。搜索也可能是最难的一项特性 —— 许多流行的网站的搜索功能都不合格,要么返回结果太慢,要么找不到精确的结果。通常,这种情况是被底层的数据库所局限:大多数标准的关系型数据库在基本的 `CONTAINS` 或 `LIKE` SQL 查询上有局限性,它仅提供大多数基本的字符串匹配功能。
|
||||
全文搜索在现代应用程序中是一个有大量需求的特性。搜索也可能是最难的一项特性 —— 许多流行的网站的搜索功能都不合格,要么返回结果太慢,要么找不到精确的结果。通常,这种情况是被底层的数据库所局限:大多数标准的关系型数据库局限于基本的 `CONTAINS` 或 `LIKE` SQL 查询上,它仅提供最基本的字符串匹配功能。
|
||||
|
||||
我们的搜索应用程序将具备:
|
||||
|
||||
1. **快速** - 搜索结果将快速返回,为用户提供一个良好的体验。
|
||||
|
||||
2. **灵活** - 我们希望能够去修改搜索如何执行,这是为了便于在不同的数据库和用户场景下进行优化。
|
||||
|
||||
3. **容错** - 如果搜索内容有拼写错误,我们将仍然会返回相关的结果,而这个结果可能正是用户希望去搜索的结果。
|
||||
|
||||
4. **全文** - 我们不想限制我们的搜索只能与指定的关键字或者标签相匹配 —— 我们希望它可以搜索在我们的数据存储中的任何东西(包括大的文本域)。
|
||||
2. **灵活** - 我们希望能够去修改搜索如何执行的方式,这是为了便于在不同的数据库和用户场景下进行优化。
|
||||
3. **容错** - 如果所搜索的内容有拼写错误,我们将仍然会返回相关的结果,而这个结果可能正是用户希望去搜索的结果。
|
||||
4. **全文** - 我们不想限制我们的搜索只能与指定的关键字或者标签相匹配 —— 我们希望它可以搜索在我们的数据存储中的任何东西(包括大的文本字段)。
|
||||
|
||||

|
||||
|
||||
为了构建一个功能强大的搜索功能,通常最理想的方法是使用一个为全文搜索任务优化过的用户数据存储。在这里我们使用 [Elasticsearch][19],Elasticsearch 是一个开源的内存中的数据存储,它是用 Java 写的,最初是在 [Apache Lucene][20] 库上构建的。
|
||||
为了构建一个功能强大的搜索功能,通常最理想的方法是使用一个为全文搜索任务优化过的数据存储。在这里我们使用 [Elasticsearch][19],Elasticsearch 是一个开源的内存中的数据存储,它是用 Java 写的,最初是在 [Apache Lucene][20] 库上构建的。
|
||||
|
||||
这里有一些来自 [Elastic 官方网站][21] 上的 Elasticsearch 真实使用案例。
|
||||
|
||||
* Wikipedia 使用 Elasticsearch 去提供带高亮搜索片断的全文搜索功能,并且提供按类型搜索和 “did-you-mean” 建议。
|
||||
|
||||
* Guardian 使用 Elasticsearch 把社交网络数据和访客日志相结合,为编辑去提供大家对新文章的实时的反馈。
|
||||
|
||||
* Guardian 使用 Elasticsearch 把社交网络数据和访客日志相结合,为编辑去提供新文章的公众意见的实时反馈。
|
||||
* Stack Overflow 将全文搜索和地理查询相结合,并使用 “类似” 的方法去找到相关的查询和回答。
|
||||
|
||||
* GitHub 使用 Elasticsearch 对 1300 亿行代码进行查询。
|
||||
|
||||
### 与 “普通的” 数据库相比,Elasticsearch 有什么不一样的地方?
|
||||
|
||||
Elasticsearch 之所以能够提供快速灵活的全文搜索,秘密在于它使用 _反转索引_ 。
|
||||
Elasticsearch 之所以能够提供快速灵活的全文搜索,秘密在于它使用<ruby>反转索引<rt>inverted index</rt></ruby> 。
|
||||
|
||||
“索引” 是数据库中的一种数据结构,它能够以超快的速度进行数据查询和检索操作。数据库通过存储与表中行相关联的字段来生成索引。在一种可搜索的数据结构(一般是 [B树][22])中排序索引,在优化过的查询中,数据库能够达到接近线速的时间(比如,“使用 ID=5 查找行)。
|
||||
“索引” 是数据库中的一种数据结构,它能够以超快的速度进行数据查询和检索操作。数据库通过存储与表中行相关联的字段来生成索引。在一种可搜索的数据结构(一般是 [B 树][22])中排序索引,在优化过的查询中,数据库能够达到接近线性的时间(比如,“使用 ID=5 查找行”)。
|
||||
|
||||
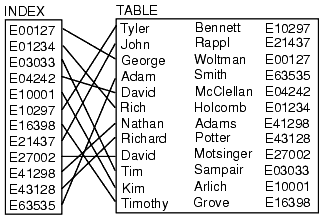
|
||||
|
||||
@ -63,41 +59,38 @@ Elasticsearch 之所以能够提供快速灵活的全文搜索,秘密在于它
|
||||
|
||||
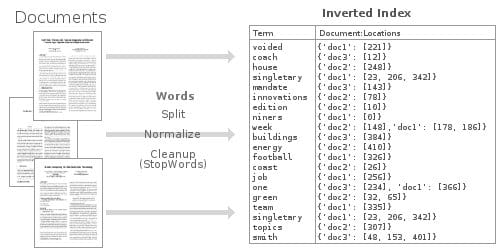
|
||||
|
||||
这种反转索引数据结构可以使我们非常快地查询到,所有出现 ”football" 的文档。通过使用大量优化过的内存中的反转索引,Elasticsearch 可以让我们在存储的数据上,执行一些非常强大的和自定义的全文搜索。
|
||||
这种反转索引数据结构可以使我们非常快地查询到,所有出现 “football” 的文档。通过使用大量优化过的内存中的反转索引,Elasticsearch 可以让我们在存储的数据上,执行一些非常强大的和自定义的全文搜索。
|
||||
|
||||
### 2 - 项目设置
|
||||
|
||||
### 2.0 - Docker
|
||||
#### 2.0 - Docker
|
||||
|
||||
我们在这个项目上使用 [Docker][23] 管理环境和依赖。Docker 是个容器引擎,它允许应用程序运行在一个独立的环境中,不会受到来自主机操作系统和本地开发环境的影响。现在,许多公司将它们的大规模 Web 应用程序主要运行在容器架构上。这样将提升灵活性和容器化应用程序组件的可组构性。
|
||||
|
||||

|
||||
|
||||
对我们来说,使用 Docker 的优势是,它对本教程非常友好,它的本地环境设置量最小,并且跨 Windows、macOS、和 Linux 系统的一致性很好。我们只需要在 Docker 配置文件中定义这些依赖关系,而不是按安装说明分别去安装 Node.js、Elasticsearch、和 Nginx,然后,就可以使用这个配置文件在任何其它地方运行我们的应用程序。而且,因为每个应用程序组件都运行在它自己的独立容器中,它们受本地机器上的其它 “垃圾” 干扰的可能性非常小,因此,在调试问题时,像 "But it works on my machine!" 这类的问题将非常少。
|
||||
对我来说,使用 Docker 的优势是,它对本教程的作者非常方便,它的本地环境设置量最小,并且跨 Windows、macOS 和 Linux 系统的一致性很好。我们只需要在 Docker 配置文件中定义这些依赖关系,而不是按安装说明分别去安装 Node.js、Elasticsearch 和 Nginx,然后,就可以使用这个配置文件在任何其它地方运行我们的应用程序。而且,因为每个应用程序组件都运行在它自己的独立容器中,它们受本地机器上的其它 “垃圾” 干扰的可能性非常小,因此,在调试问题时,像“它在我这里可以工作!”这类的问题将非常少。
|
||||
|
||||
### 2.1 - 安装 Docker & Docker-Compose
|
||||
#### 2.1 - 安装 Docker & Docker-Compose
|
||||
|
||||
这个项目只依赖 [Docker][24] 和 [docker-compose][25],docker-compose 是 Docker 官方支持的一个工具,它用来将定义的多个容器配置 _组装_ 成单一的应用程序栈。
|
||||
|
||||
安装 Docker - [https://docs.docker.com/engine/installation/][26]
|
||||
安装 Docker Compose - [https://docs.docker.com/compose/install/][27]
|
||||
- 安装 Docker - [https://docs.docker.com/engine/installation/][26]
|
||||
- 安装 Docker Compose - [https://docs.docker.com/compose/install/][27]
|
||||
|
||||
### 2.2 - 设置项目主目录
|
||||
#### 2.2 - 设置项目主目录
|
||||
|
||||
为项目创建一个主目录(名为 `guttenberg_search`)。我们的项目将工作在主目录的以下两个子目录中。
|
||||
|
||||
* `/public` - 保存前端 Vue.js Web 应用程序。
|
||||
|
||||
* `/server` - 服务器端 Node.js 源代码。
|
||||
|
||||
### 2.3 - 添加 Docker-Compose 配置
|
||||
#### 2.3 - 添加 Docker-Compose 配置
|
||||
|
||||
接下来,我们将创建一个 `docker-compose.yml` 文件来定义我们的应用程序栈中的每个容器。
|
||||
|
||||
1. `gs-api` - 后端应用程序逻辑使用的 Node.js 容器
|
||||
|
||||
2. `gs-frontend` - 前端 Web 应用程序使用的 Ngnix 容器。
|
||||
|
||||
3. `gs-search` - 保存和搜索数据的 Elasticsearch 容器。
|
||||
|
||||
```
|
||||
@ -140,12 +133,11 @@ services:
|
||||
|
||||
volumes: # Define seperate volume for Elasticsearch data
|
||||
esdata:
|
||||
|
||||
```
|
||||
|
||||
这个文件定义了我们全部的应用程序栈 —— 不需要在你的本地系统上安装 Elasticsearch、Node、和 Nginx。每个容器都将端口转发到宿主机系统(`localhost`)上,以便于我们在宿主机上去访问和调试 Node API、Elasticsearch instance、和前端 Web 应用程序。
|
||||
这个文件定义了我们全部的应用程序栈 —— 不需要在你的本地系统上安装 Elasticsearch、Node 和 Nginx。每个容器都将端口转发到宿主机系统(`localhost`)上,以便于我们在宿主机上去访问和调试 Node API、Elasticsearch 实例和前端 Web 应用程序。
|
||||
|
||||
### 2.4 - 添加 Dockerfile
|
||||
#### 2.4 - 添加 Dockerfile
|
||||
|
||||
对于 Nginx 和 Elasticsearch,我们使用了官方预构建的镜像,而 Node.js 应用程序需要我们自己去构建。
|
||||
|
||||
@ -169,7 +161,6 @@ COPY . .
|
||||
|
||||
# Start app
|
||||
CMD [ "npm", "start" ]
|
||||
|
||||
```
|
||||
|
||||
这个 Docker 配置扩展了官方的 Node.js 镜像、拷贝我们的应用程序源代码、以及在容器内安装 NPM 依赖。
|
||||
@ -181,12 +172,11 @@ node_modules/
|
||||
npm-debug.log
|
||||
books/
|
||||
public/
|
||||
|
||||
```
|
||||
|
||||
> 请注意:我们之所以不拷贝 `node_modules` 目录到我们的容器中 —— 是因为我们要在容器中运行 `npm install` 来构建这个进程。从宿主机系统拷贝 `node_modules` 可能会引起错误,因为一些包需要在某些操作系统上专门构建。比如说,在 macOS 上安装 `bcrypt` 包,然后尝试将这个模块直接拷贝到一个 Ubuntu 容器上将不能工作,因为 `bcyrpt` 需要为每个操作系统构建一个特定的二进制文件。
|
||||
> 请注意:我们之所以不拷贝 `node_modules` 目录到我们的容器中 —— 是因为我们要在容器构建过程里面运行 `npm install`。从宿主机系统拷贝 `node_modules` 到容器里面可能会引起错误,因为一些包需要为某些操作系统专门构建。比如说,在 macOS 上安装 `bcrypt` 包,然后尝试将这个模块直接拷贝到一个 Ubuntu 容器上将不能工作,因为 `bcyrpt` 需要为每个操作系统构建一个特定的二进制文件。
|
||||
|
||||
### 2.5 - 添加基本文件
|
||||
#### 2.5 - 添加基本文件
|
||||
|
||||
为了测试我们的配置,我们需要添加一些占位符文件到应用程序目录中。
|
||||
|
||||
@ -194,7 +184,6 @@ public/
|
||||
|
||||
```
|
||||
<html><body>Hello World From The Frontend Container</body></html>
|
||||
|
||||
```
|
||||
|
||||
接下来,在 `server/app.js` 中添加 Node.js 占位符文件。
|
||||
@ -213,10 +202,9 @@ app.listen(port, err => {
|
||||
if (err) console.error(err)
|
||||
console.log(`App Listening on Port ${port}`)
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
最后,添加我们的 `package.json` 节点应用配置。
|
||||
最后,添加我们的 `package.json` Node 应用配置。
|
||||
|
||||
```
|
||||
{
|
||||
@ -244,14 +232,13 @@ app.listen(port, err => {
|
||||
"koa-router": "7.2.1"
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个文件定义了应用程序启动命令和 Node.js 包依赖。
|
||||
|
||||
> 注意:不要运行 `npm install` —— 当它构建时,这个依赖将在容器内安装。
|
||||
> 注意:不要运行 `npm install` —— 当它构建时,依赖会在容器内安装。
|
||||
|
||||
### 2.6 - 测试它的输出
|
||||
#### 2.6 - 测试它的输出
|
||||
|
||||
现在一切新绪,我们来测试应用程序的每个组件的输出。从应用程序的主目录运行 `docker-compose build`,它将构建我们的 Node.js 应用程序容器。
|
||||
|
||||
@ -261,13 +248,13 @@ app.listen(port, err => {
|
||||
|
||||
|
||||
|
||||
> 这一步可能需要几分钟时间,因为 Docker 要为每个容器去下载基础镜像,接着再去运行,启动应用程序非常快,因为所需要的镜像已经下载完成了。
|
||||
> 这一步可能需要几分钟时间,因为 Docker 要为每个容器去下载基础镜像。以后再次运行,启动应用程序会非常快,因为所需要的镜像已经下载完成了。
|
||||
|
||||
在你的浏览器中尝试访问 `localhost:8080` —— 你将看到简单的 “Hello World" Web 页面。
|
||||
在你的浏览器中尝试访问 `localhost:8080` —— 你将看到简单的 “Hello World” Web 页面。
|
||||
|
||||
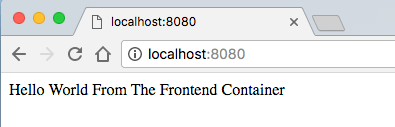
|
||||
|
||||
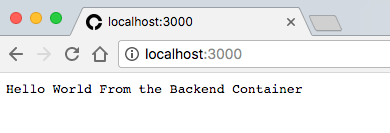
访问 `localhost:3000` 去验证我们的 Node 服务器,它将返回 "Hello World" 信息。
|
||||
访问 `localhost:3000` 去验证我们的 Node 服务器,它将返回 “Hello World” 信息。
|
||||
|
||||
|
||||
|
||||
@ -289,16 +276,15 @@ app.listen(port, err => {
|
||||
},
|
||||
"tagline" : "You Know, for Search"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
如果三个 URLs 都显示成功,祝贺你!整个容器栈已经正常运行了,接下来我们进入最有趣的部分。
|
||||
如果三个 URL 都显示成功,祝贺你!整个容器栈已经正常运行了,接下来我们进入最有趣的部分。
|
||||
|
||||
### 3 - 连接到 ELASTICSEARCH
|
||||
### 3 - 连接到 Elasticsearch
|
||||
|
||||
我们要做的第一件事情是,让我们的应用程序连接到我们本地的 Elasticsearch 实例上。
|
||||
|
||||
### 3.0 - 添加 ES 连接模块
|
||||
#### 3.0 - 添加 ES 连接模块
|
||||
|
||||
在新文件 `server/connection.js` 中添加如下的 Elasticsearch 初始化代码。
|
||||
|
||||
@ -328,7 +314,6 @@ async function checkConnection () {
|
||||
}
|
||||
|
||||
checkConnection()
|
||||
|
||||
```
|
||||
|
||||
现在,我们重新构建我们的 Node 应用程序,我们将使用 `docker-compose build` 来做一些改变。接下来,运行 `docker-compose up -d` 去启动应用程序栈,它将以守护进程的方式在后台运行。
|
||||
@ -351,12 +336,11 @@ checkConnection()
|
||||
number_of_in_flight_fetch: 0,
|
||||
task_max_waiting_in_queue_millis: 0,
|
||||
active_shards_percent_as_number: 50 }
|
||||
|
||||
```
|
||||
|
||||
继续之前,我们先删除最下面的 `checkConnection()` 调用,因为,我们最终的应用程序将调用外部的连接模块。
|
||||
|
||||
### 3.1 - 添加函数去重置索引
|
||||
#### 3.1 - 添加函数去重置索引
|
||||
|
||||
在 `server/connection.js` 中的 `checkConnection` 下面添加如下的函数,以便于重置 Elasticsearch 索引。
|
||||
|
||||
@ -370,12 +354,11 @@ async function resetIndex (index) {
|
||||
await client.indices.create({ index })
|
||||
await putBookMapping()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 3.2 - 添加图书模式
|
||||
#### 3.2 - 添加图书模式
|
||||
|
||||
接下来,我们将为图书的数据模式添加一个 "mapping"。在 `server/connection.js` 中的 `resetIndex` 函数下面添加如下的函数。
|
||||
接下来,我们将为图书的数据模式添加一个 “映射”。在 `server/connection.js` 中的 `resetIndex` 函数下面添加如下的函数。
|
||||
|
||||
```
|
||||
/** Add book section schema mapping to ES */
|
||||
@ -389,12 +372,11 @@ async function putBookMapping () {
|
||||
|
||||
return client.indices.putMapping({ index, type, body: { properties: schema } })
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这是为 `book` 索引定义了一个 mapping。一个 Elasticsearch 的 `index` 大概类似于 SQL 的 `table` 或者 MongoDB 的 `collection`。我们通过添加 mapping 来为存储的文档指定每个字段和它的数据类型。Elasticsearch 是无模式的,因此,从技术角度来看,我们是不需要添加 mapping 的,但是,这样做,我们可以更好地控制如何处理数据。
|
||||
这是为 `book` 索引定义了一个映射。Elasticsearch 中的 `index` 大概类似于 SQL 的 `table` 或者 MongoDB 的 `collection`。我们通过添加映射来为存储的文档指定每个字段和它的数据类型。Elasticsearch 是无模式的,因此,从技术角度来看,我们是不需要添加映射的,但是,这样做,我们可以更好地控制如何处理数据。
|
||||
|
||||
比如,我们给 "title" 和 ”author" 字段分配 `keyword` 类型,给 “text" 字段分配 `text` 类型。之所以这样做的原因是,搜索引擎可以区别处理这些字符串字段 —— 在搜索的时候,搜索引擎将在 `text` 字段中搜索可能的匹配项,而对于 `keyword` 类型字段,将对它们进行全文匹配。这看上去差别很小,但是它们对在不同的搜索上的速度和行为的影响非常大。
|
||||
比如,我们给 `title` 和 `author` 字段分配 `keyword` 类型,给 `text` 字段分配 `text` 类型。之所以这样做的原因是,搜索引擎可以区别处理这些字符串字段 —— 在搜索的时候,搜索引擎将在 `text` 字段中搜索可能的匹配项,而对于 `keyword` 类型字段,将对它们进行全文匹配。这看上去差别很小,但是它们对在不同的搜索上的速度和行为的影响非常大。
|
||||
|
||||
在文件的底部,导出对外发布的属性和函数,这样我们的应用程序中的其它模块就可以访问它们了。
|
||||
|
||||
@ -402,31 +384,29 @@ async function putBookMapping () {
|
||||
module.exports = {
|
||||
client, index, type, checkConnection, resetIndex
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 4 - 加载原始数据
|
||||
|
||||
我们将使用来自 [Gutenberg 项目][28] 的数据 —— 它致力于为公共提供免费的线上电子书。在这个项目中,我们将使用 100 本经典图书来充实我们的图书馆,包括_《The Adventures of Sherlock Holmes》_、_《Treasure Island》_、_《The Count of Monte Cristo》_、_《Around the World in 80 Days》_、_《Romeo and Juliet》_ 、和_《The Odyssey》_。
|
||||
我们将使用来自 [古登堡项目][28] 的数据 —— 它致力于为公共提供免费的线上电子书。在这个项目中,我们将使用 100 本经典图书来充实我们的图书馆,包括《福尔摩斯探案集》、《金银岛》、《基督山复仇记》、《环游世界八十天》、《罗密欧与朱丽叶》 和《奥德赛》。
|
||||
|
||||

|
||||
|
||||
### 4.1 - 下载图书文件
|
||||
#### 4.1 - 下载图书文件
|
||||
|
||||
我将这 100 本书打包成一个文件,你可以从这里下载它 ——
|
||||
[https://cdn.patricktriest.com/data/books.zip][29]
|
||||
|
||||
将这个文件解压到你的项目的 `books/` 目录中。
|
||||
|
||||
你可以使用以下的命令来完成(需要在命令行下使用 [wget][30] 和 ["The Unarchiver"][31])。
|
||||
你可以使用以下的命令来完成(需要在命令行下使用 [wget][30] 和 [The Unarchiver][31])。
|
||||
|
||||
```
|
||||
wget https://cdn.patricktriest.com/data/books.zip
|
||||
unar books.zip
|
||||
|
||||
```
|
||||
|
||||
### 4.2 - 预览一本书
|
||||
#### 4.2 - 预览一本书
|
||||
|
||||
尝试打开其中的一本书的文件,假设打开的是 `219-0.txt`。你将注意到它开头是一个公开访问的协议,接下来是一些标识这本书的书名、作者、发行日期、语言和字符编码的行。
|
||||
|
||||
@ -441,7 +421,6 @@ Last Updated: September 7, 2016
|
||||
Language: English
|
||||
|
||||
Character set encoding: UTF-8
|
||||
|
||||
```
|
||||
|
||||
在 `*** START OF THIS PROJECT GUTENBERG EBOOK HEART OF DARKNESS ***` 这些行后面,是这本书的正式内容。
|
||||
@ -450,7 +429,7 @@ Character set encoding: UTF-8
|
||||
|
||||
下一步,我们将使用程序从文件头部来解析书的元数据,提取 `*** START OF` 和 `***END OF` 之间的内容。
|
||||
|
||||
### 4.3 - 读取数据目录
|
||||
#### 4.3 - 读取数据目录
|
||||
|
||||
我们将写一个脚本来读取每本书的内容,并将这些数据添加到 Elasticsearch。我们将定义一个新的 Javascript 文件 `server/load_data.js` 来执行这些操作。
|
||||
|
||||
@ -486,7 +465,6 @@ async function readAndInsertBooks () {
|
||||
}
|
||||
|
||||
readAndInsertBooks()
|
||||
|
||||
```
|
||||
|
||||
我们将使用一个快捷命令来重构我们的 Node.js 应用程序,并更新运行的容器。
|
||||
@ -501,7 +479,7 @@ readAndInsertBooks()
|
||||
|
||||
|
||||
|
||||
### 4.4 - 读取数据文件
|
||||
#### 4.4 - 读取数据文件
|
||||
|
||||
接下来,我们读取元数据和每本书的内容。
|
||||
|
||||
@ -536,32 +514,26 @@ function parseBookFile (filePath) {
|
||||
console.log(`Parsed ${paragraphs.length} Paragraphs\n`)
|
||||
return { title, author, paragraphs }
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个函数执行几个重要的任务。
|
||||
|
||||
1. 从文件系统中读取书的文本。
|
||||
|
||||
2. 使用正则表达式(关于正则表达式,请参阅 [这篇文章][1] )解析书名和作者。
|
||||
|
||||
3. 通过匹配 ”Guttenberg 项目“ 头部和尾部,识别书的正文内容。
|
||||
|
||||
3. 通过匹配 “古登堡项目” 的头部和尾部,识别书的正文内容。
|
||||
4. 提取书的内容文本。
|
||||
|
||||
5. 分割每个段落到它的数组中。
|
||||
|
||||
6. 清理文本并删除空白行。
|
||||
|
||||
它的返回值,我们将构建一个对象,这个对象包含书名、作者、以及书中各段落的数据。
|
||||
它的返回值,我们将构建一个对象,这个对象包含书名、作者、以及书中各段落的数组。
|
||||
|
||||
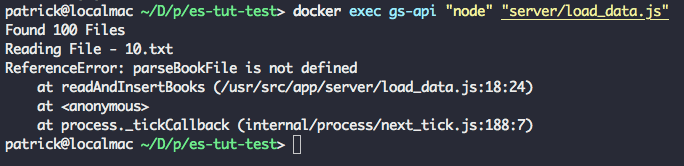
再次运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"`,你将看到如下的输出,在输出的末尾有三个额外的行。
|
||||
再次运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"`,你将看到输出同之前一样,在输出的末尾有三个额外的行。
|
||||
|
||||
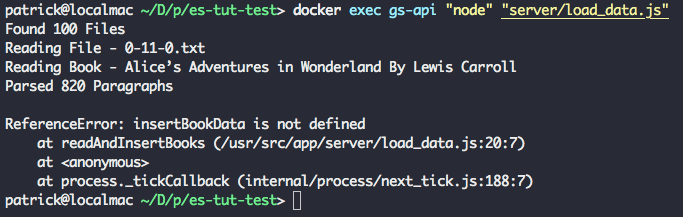
|
||||
|
||||
成功!我们的脚本从文本文件中成功解析出了书名和作者。脚本再次以错误结束,因为到现在为止,我们还没有定义辅助函数。
|
||||
|
||||
### 4.5 - 在 ES 中索引数据文件
|
||||
#### 4.5 - 在 ES 中索引数据文件
|
||||
|
||||
最后一步,我们将批量上传每个段落的数组到 Elasticsearch 索引中。
|
||||
|
||||
@ -596,12 +568,11 @@ async function insertBookData (title, author, paragraphs) {
|
||||
await esConnection.client.bulk({ body: bulkOps })
|
||||
console.log(`Indexed Paragraphs ${paragraphs.length - (bulkOps.length / 2)} - ${paragraphs.length}\n\n\n`)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个函数将使用书名、作者、和附加元数据的段落位置来索引书中的每个段落。我们通过批量操作来插入段落,它比逐个段落插入要快的多。
|
||||
这个函数将使用书名、作者和附加元数据的段落位置来索引书中的每个段落。我们通过批量操作来插入段落,它比逐个段落插入要快的多。
|
||||
|
||||
> 我们分批索引段落,而不是一次性插入全部,是为运行这个应用程序的、内存稍有点小(1.7 GB)的服务器 `search.patricktriest.com` 上做的一个重要优化。如果你的机器内存还行(4 GB 以上),你或许不用分批上传。
|
||||
> 我们分批索引段落,而不是一次性插入全部,是为运行这个应用程序的内存稍有点小(1.7 GB)的服务器 `search.patricktriest.com` 上做的一个重要优化。如果你的机器内存还行(4 GB 以上),你或许不用分批上传。
|
||||
|
||||
运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"` 一次或多次 —— 现在你将看到前面解析的 100 本书的完整输出,并插入到了 Elasticsearch。这可能需要几分钟时间,甚至更长。
|
||||
|
||||
@ -611,13 +582,13 @@ async function insertBookData (title, author, paragraphs) {
|
||||
|
||||
现在,Elasticsearch 中已经有了 100 本书了(大约有 230000 个段落),现在我们尝试搜索查询。
|
||||
|
||||
### 5.0 - 简单的 HTTP 查询
|
||||
#### 5.0 - 简单的 HTTP 查询
|
||||
|
||||
首先,我们使用 Elasticsearch 的 HTTP API 对它进行直接查询。
|
||||
|
||||
在你的浏览器上访问这个 URL - `http://localhost:9200/library/_search?q=text:Java&pretty`
|
||||
|
||||
在这里,我们将执行一个极简的全文搜索,在我们的图书馆的书中查找 ”Java" 这个词。
|
||||
在这里,我们将执行一个极简的全文搜索,在我们的图书馆的书中查找 “Java” 这个词。
|
||||
|
||||
你将看到类似于下面的一个 JSON 格式的响应。
|
||||
|
||||
@ -663,12 +634,11 @@ async function insertBookData (title, author, paragraphs) {
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
用 Elasticseach 的 HTTP 接口可以测试我们插入的数据是否成功,但是如果直接将这个 API 暴露给 Web 应用程序将有极大的风险。这个 API 将会暴露管理功能(比如直接添加和删除文档),最理想的情况是完全不要对外暴露它。而是写一个简单的 Node.js API 去接收来自客户端的请求,然后(在我们的本地网络中)生成一个正确的查询发送给 Elasticsearch。
|
||||
|
||||
### 5.1 - 查询脚本
|
||||
#### 5.1 - 查询脚本
|
||||
|
||||
我们现在尝试从我们写的 Node.js 脚本中查询 Elasticsearch。
|
||||
|
||||
@ -694,7 +664,6 @@ module.exports = {
|
||||
return client.search({ index, type, body })
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我们的搜索模块定义一个简单的 `search` 函数,它将使用输入的词 `match` 查询。
|
||||
@ -702,13 +671,9 @@ module.exports = {
|
||||
这是查询的字段分解 -
|
||||
|
||||
* `from` - 允许我们分页查询结果。默认每个查询返回 10 个结果,因此,指定 `from: 10` 将允许我们取回 10-20 的结果。
|
||||
|
||||
* `query` - 这里我们指定要查询的词。
|
||||
|
||||
* `operator` - 我们可以修改搜索行为;在本案例中,我们使用 "and" 操作去对查询中包含所有 tokens(要查询的词)的结果来确定优先顺序。
|
||||
|
||||
* `operator` - 我们可以修改搜索行为;在本案例中,我们使用 `and` 操作去对查询中包含所有字元(要查询的词)的结果来确定优先顺序。
|
||||
* `fuzziness` - 对拼写错误的容错调整,`auto` 的默认为 `fuzziness: 2`。模糊值越高,结果越需要更多校正。比如,`fuzziness: 1` 将允许以 `Patricc` 为关键字的查询中返回与 `Patrick` 匹配的结果。
|
||||
|
||||
* `highlights` - 为结果返回一个额外的字段,这个字段包含 HTML,以显示精确的文本字集和查询中匹配的关键词。
|
||||
|
||||
你可以去浏览 [Elastic Full-Text Query DSL][32],学习如何随意调整这些参数,以进一步自定义搜索查询。
|
||||
@ -717,7 +682,7 @@ module.exports = {
|
||||
|
||||
为了能够从前端应用程序中访问我们的搜索功能,我们来写一个快速的 HTTP API。
|
||||
|
||||
### 6.0 - API 服务器
|
||||
#### 6.0 - API 服务器
|
||||
|
||||
用以下的内容替换现有的 `server/app.js` 文件。
|
||||
|
||||
@ -761,7 +726,6 @@ app
|
||||
if (err) throw err
|
||||
console.log(`App Listening on Port ${port}`)
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
这些代码将为 [Koa.js][33] Node API 服务器导入服务器依赖,设置简单的日志,以及错误处理。
|
||||
@ -782,10 +746,9 @@ router.get('/search', async (ctx, next) => {
|
||||
ctx.body = await search.queryTerm(term, offset)
|
||||
}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
使用 `docker-compose up -d --build` 重启动应用程序。之后在你的浏览器中尝试调用这个搜索端点。比如,`http://localhost:3000/search?term=java` 这个请求将搜索整个图书馆中提到 “Jave" 的内容。
|
||||
使用 `docker-compose up -d --build` 重启动应用程序。之后在你的浏览器中尝试调用这个搜索端点。比如,`http://localhost:3000/search?term=java` 这个请求将搜索整个图书馆中提到 “Java” 的内容。
|
||||
|
||||
结果与前面直接调用 Elasticsearch HTTP 界面的结果非常类似。
|
||||
|
||||
@ -835,7 +798,6 @@ router.get('/search', async (ctx, next) => {
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 6.2 - 输入校验
|
||||
@ -864,7 +826,6 @@ router.get('/search',
|
||||
ctx.body = await search.queryTerm(term, offset)
|
||||
}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
现在,重启服务器,如果你使用一个没有搜索关键字的请求(`http://localhost:3000/search`),你将返回一个带相关消息的 HTTP 400 错误,比如像 `Invalid URL Query - child "term" fails because ["term" is required]`。
|
||||
@ -875,7 +836,7 @@ router.get('/search',
|
||||
|
||||
现在我们的 `/search` 端点已经就绪,我们来连接到一个简单的 Web 应用程序来测试这个 API。
|
||||
|
||||
### 7.0 - Vue.js 应用程序
|
||||
#### 7.0 - Vue.js 应用程序
|
||||
|
||||
我们将使用 Vue.js 去协调我们的前端。
|
||||
|
||||
@ -934,14 +895,13 @@ const vm = new Vue ({
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
这个应用程序非常简单 —— 我们只定义了一些共享的数据属性,以及添加了检索和分页搜索结果的方法。为防止每按键一次都调用 API,搜索输入有一个 100 毫秒的除颤功能。
|
||||
这个应用程序非常简单 —— 我们只定义了一些共享的数据属性,以及添加了检索和分页搜索结果的方法。为防止每次按键一次都调用 API,搜索输入有一个 100 毫秒的除颤功能。
|
||||
|
||||
解释 Vue.js 是如何工作的已经超出了本教程的范围,如果你使用过 Angular 或者 React,其实一些也不可怕。如果你完全不熟悉 Vue,想快速了解它的功能,我建议你从官方的快速指南入手 —— [https://vuejs.org/v2/guide/][36]
|
||||
|
||||
### 7.1 - HTML
|
||||
#### 7.1 - HTML
|
||||
|
||||
使用以下的内容替换 `/public/index.html` 文件中的占位符,以便于加载我们的 Vue.js 应用程序和设计一个基本的搜索界面。
|
||||
|
||||
@ -1004,10 +964,9 @@ const vm = new Vue ({
|
||||
<script src="app.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
### 7.2 - CSS
|
||||
#### 7.2 - CSS
|
||||
|
||||
添加一个新文件 `/public/styles.css`,使用一些自定义的 UI 样式。
|
||||
|
||||
@ -1098,10 +1057,9 @@ body { font-family: 'EB Garamond', serif; }
|
||||
justify-content: space-around;
|
||||
background: white;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 7.3 - 尝试输出
|
||||
#### 7.3 - 尝试输出
|
||||
|
||||
在你的浏览器中打开 `localhost:8080`,你将看到一个简单的带结果分页功能的搜索界面。在顶部的搜索框中尝试输入不同的关键字来查看它们的搜索情况。
|
||||
|
||||
@ -1113,7 +1071,7 @@ body { font-family: 'EB Garamond', serif; }
|
||||
|
||||
### 8 - 分页预览
|
||||
|
||||
如果点击每个搜索结果,然后查看到来自书中的内容,那将是非常棒的体验。
|
||||
如果能点击每个搜索结果,然后查看到来自书中的内容,那将是非常棒的体验。
|
||||
|
||||
### 8.0 - 添加 Elasticsearch 查询
|
||||
|
||||
@ -1137,12 +1095,11 @@ getParagraphs (bookTitle, startLocation, endLocation) {
|
||||
|
||||
return client.search({ index, type, body })
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个新函数将返回给定的书的开始位置和结束位置之间的一个排序后的段落数组。
|
||||
|
||||
### 8.1 - 添加 API 端点
|
||||
#### 8.1 - 添加 API 端点
|
||||
|
||||
现在,我们将这个函数链接到 API 端点。
|
||||
|
||||
@ -1170,10 +1127,9 @@ router.get('/paragraphs',
|
||||
ctx.body = await search.getParagraphs(bookTitle, start, end)
|
||||
}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
### 8.2 - 添加 UI 功能
|
||||
#### 8.2 - 添加 UI 功能
|
||||
|
||||
现在,我们的新端点已经就绪,我们为应用程序添加一些从书中查询和显示全部页面的前端功能。
|
||||
|
||||
@ -1217,10 +1173,9 @@ router.get('/paragraphs',
|
||||
document.body.style.overflow = 'auto'
|
||||
this.selectedParagraph = null
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这五个函数了提供了通过页码从书中下载和分页(每次十个段落)的逻辑。
|
||||
这五个函数提供了通过页码从书中下载和分页(每次十个段落)的逻辑。
|
||||
|
||||
现在,我们需要添加一个 UI 去显示书的页面。在 `/public/index.html` 的 `<!-- INSERT BOOK MODAL HERE -->` 注释下面添加如下的内容。
|
||||
|
||||
@ -1258,7 +1213,6 @@ router.get('/paragraphs',
|
||||
<button class="mui-btn mui-btn--flat" v-on:click="nextBookPage()">Next Page</button>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
```
|
||||
|
||||
再次重启应用程序服务器(`docker-compose up -d --build`),然后打开 `localhost:8080`。当你再次点击搜索结果时,你将能看到关键字附近的段落。如果你感兴趣,你现在甚至可以看这本书的剩余部分。
|
||||
@ -1269,42 +1223,38 @@ router.get('/paragraphs',
|
||||
|
||||
你可以去比较你的本地结果与托管在这里的完整示例 —— [https://search.patricktriest.com/][37]
|
||||
|
||||
### 9 - ELASTICSEARCH 的缺点
|
||||
### 9 - Elasticsearch 的缺点
|
||||
|
||||
### 9.0 - 耗费资源
|
||||
#### 9.0 - 耗费资源
|
||||
|
||||
Elasticsearch 是计算密集型的。[官方建议][38] 运行 ES 的机器最好有 64 GB 的内存,强烈反对在低于 8 GB 内存的机器上运行它。Elasticsearch 是一个 _内存中_ 数据库,这样使它的查询速度非常快,但这也非常占用系统内存。在生产系统中使用时,[他们强烈建议在一个集群中运行多个 Elasticsearch 节点][39],以实现高可用、自动分区、和一个节点失败时的数据冗余。
|
||||
Elasticsearch 是计算密集型的。[官方建议][38] 运行 ES 的机器最好有 64 GB 的内存,强烈反对在低于 8 GB 内存的机器上运行它。Elasticsearch 是一个 _内存中_ 数据库,这样使它的查询速度非常快,但这也非常占用系统内存。在生产系统中使用时,[他们强烈建议在一个集群中运行多个 Elasticsearch 节点][39],以实现高可用、自动分区和一个节点失败时的数据冗余。
|
||||
|
||||
我们的这个教程中的应用程序运行在一个 $15/月 的 GCP 计算实例中( [search.patricktriest.com][40]),它只有 1.7 GB 的内存,它勉强能运行这个 Elasticsearch 节点;有时候在进行初始的数据加载过程中,整个机器就 ”假死机“ 了。在我的经验中,Elasticsearch 比传统的那些数据库,比如,PostgreSQL 和 MongoDB 耗费的资源要多很多,这样会使托管主机的成本增加很多。
|
||||
|
||||
### 9.1 - 与数据库的同步
|
||||
|
||||
在大多数应用程序,将数据全部保存在 Elasticsearch 并不是个好的选择。最好是使用 ES 作为应用程序的主要事务数据库,但是一般不推荐这样做,因为在 Elasticsearch 中缺少 ACID,如果在处理数据的时候发生伸缩行为,它将丢失写操作。在许多案例中,ES 服务器更多是一个特定的角色,比如做应用程序中的一个文本搜索功能。这种特定的用途,要求它从主数据库中复制数据到 Elasticsearch 实例中。
|
||||
对于大多数应用程序,将数据全部保存在 Elasticsearch 并不是个好的选择。可以使用 ES 作为应用程序的主要事务数据库,但是一般不推荐这样做,因为在 Elasticsearch 中缺少 ACID,如果大量读取数据的时候,它能导致写操作丢失。在许多案例中,ES 服务器更多是一个特定的角色,比如做应用程序中的一个文本搜索功能。这种特定的用途,要求它从主数据库中复制数据到 Elasticsearch 实例中。
|
||||
|
||||
比如,假设我们将用户信息保存在一个 PostgreSQL 表中,但是用 Elasticsearch 去驱动我们的用户搜索功能。如果一个用户,比如,"Albert",决定将他的名字改成 "Al",我们将需要把这个变化同时反映到我们主要的 PostgreSQL 数据库和辅助的 Elasticsearch 集群中。
|
||||
比如,假设我们将用户信息保存在一个 PostgreSQL 表中,但是用 Elasticsearch 去提供我们的用户搜索功能。如果一个用户,比如,“Albert”,决定将他的名字改成 “Al”,我们将需要把这个变化同时反映到我们主要的 PostgreSQL 数据库和辅助的 Elasticsearch 集群中。
|
||||
|
||||
正确地集成它们可能比较棘手,最好的答案将取决于你现有的应用程序栈。这有多种开源方案可选,从 [用一个进程去关注 MongoDB 操作日志][41] 并自动同步检测到的变化到 ES,到使用一个 [PostgresSQL 插件][42] 去创建一个定制的、基于 PSQL 的索引来与 Elasticsearch 进行自动沟通。
|
||||
|
||||
如果没有有效的预构建选项可用,你可能需要在你的服务器代码中增加一些钩子,这样可以基于数据库的变化来手动更新 Elasticsearch 索引。最后一招,我认为是一个最后的选择,因为,使用定制的业务逻辑去保持 ES 的同步可能很复杂,这将会给应用程序引入很多的 bugs。
|
||||
如果没有有效的预构建选项可用,你可能需要在你的服务器代码中增加一些钩子,这样可以基于数据库的变化来手动更新 Elasticsearch 索引。最后一招,我认为是一个最后的选择,因为,使用定制的业务逻辑去保持 ES 的同步可能很复杂,这将会给应用程序引入很多的 bug。
|
||||
|
||||
让 Elasticsearch 与一个主数据库同步,将使它的架构更加复杂,其复杂性已经超越了 ES 的相关缺点,但是当在你的应用程序中考虑添加一个专用的搜索引擎的利弊得失时,这个问题是值的好好考虑的。
|
||||
|
||||
### 总结
|
||||
|
||||
在很多现在流行的应用程序中,全文搜索是一个非常重要的功能 —— 而且是很难实现的一个功能。对于在你的应用程序中添加一个快速而又可定制的文本搜索,Elasticsearch 是一个非常好的选择,但是,在这里也有一个替代者。[Apache Solr][43] 是一个类似的开源搜索平台,它是基于 Apache Lucene 构建的,它与 Elasticsearch 的核心库是相同的。[Algolia][44] 是一个搜索即服务的 Web 平台,它已经很快流行了起来,并且它对新手非常友好,很易于上手(但是作为折衷,它的可定制性较小,并且使用成本较高)。
|
||||
在很多现在流行的应用程序中,全文搜索是一个非常重要的功能 —— 而且是很难实现的一个功能。对于在你的应用程序中添加一个快速而又可定制的文本搜索,Elasticsearch 是一个非常好的选择,但是,在这里也有一个替代者。[Apache Solr][43] 是一个类似的开源搜索平台,它是基于 Apache Lucene 构建的,与 Elasticsearch 的核心库是相同的。[Algolia][44] 是一个搜索即服务的 Web 平台,它已经很快流行了起来,并且它对新手非常友好,很易于上手(但是作为折衷,它的可定制性较小,并且使用成本较高)。
|
||||
|
||||
“搜索” 特性并不是 Elasticsearch 唯一功能。ES 也是日志存储和分析的常用工具,在一个 ELK(Elasticsearch、Logstash、Kibana)栈配置中通常会使用它。灵活的全文搜索功能使得 Elasticsearch 在数据量非常大的科学任务中用处很大 —— 比如,在一个数据集中正确的/标准化的条目拼写,或者为了类似的词组搜索一个文本数据集。
|
||||
“搜索” 特性并不是 Elasticsearch 唯一功能。ES 也是日志存储和分析的常用工具,在一个 ELK(Elasticsearch、Logstash、Kibana)架构配置中通常会使用它。灵活的全文搜索功能使得 Elasticsearch 在数据量非常大的科学任务中用处很大 —— 比如,在一个数据集中正确的/标准化的条目拼写,或者为了类似的词组搜索一个文本数据集。
|
||||
|
||||
对于你自己的项目,这里有一些创意。
|
||||
|
||||
* 添加更多你喜欢的书到教程的应用程序中,然后创建你自己的私人图书馆搜索引擎。
|
||||
|
||||
* 利用来自 [Google Scholar][2] 的论文索引,创建一个学术抄袭检测引擎。
|
||||
|
||||
* 通过将字典中的每个词索引到 Elasticsearch,创建一个拼写检查应用程序。
|
||||
|
||||
* 通过将 [Common Crawl Corpus][3] 加载到 Elasticsearch 中,构建你自己的与谷歌竞争的因特网搜索引擎(注意,它可能会超过 50 亿个页面,这是一个成本极高的数据集)。
|
||||
|
||||
* 在 journalism 上使用 Elasticsearch:在最近的大规模泄露的文档中搜索特定的名字和关键词,比如, [Panama Papers][4] 和 [Paradise Papers][5]。
|
||||
|
||||
本教程中应用程序的源代码是 100% 公开的,你可以在 GitHub 仓库上找到它们 —— [https://github.com/triestpa/guttenberg-search][45]
|
||||
@ -1324,7 +1274,7 @@ via: https://blog.patricktriest.com/text-search-docker-elasticsearch/
|
||||
|
||||
作者:[Patrick Triest][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
假装很忙的三个命令行工具
|
||||
======
|
||||
|
||||
> 有时候你很忙。而有时候你只是需要看起来很忙,就像电影中的黑客一样。有一些开源工具就是干这个的。
|
||||
|
||||

|
||||
|
||||
如果在你在消磨时光时看过谍战片、动作片或犯罪片,那么你就会清晰地在脑海中勾勒出黑客的电脑屏幕的样子。就像是在《黑客帝国》电影中,[代码雨][1] 一样的十六进制数字流,又或是一排排快速移动的代码。
|
||||
|
||||
也许电影中出现一幅世界地图,其中布满了闪烁的光点和一些快速更新的图表。不可或缺的,也可能有 3D 旋转的几何形状。甚至,这一切都会显示在一些完全不符合人类习惯的数量荒谬的显示屏上。 在《剑鱼行动》电影中黑客就使用了七个显示屏。
|
||||
|
||||
当然,我们这些从事计算机行业的人一下子就明白这完全是胡说八道。虽然在我们中,许多人都有双显示器(或更多),但一个闪烁的数据仪表盘、刷新的数据通常和专注工作是相互矛盾的。编写代码、项目管理和系统管理与日常工作不同。我们遇到的大多数情况,为了解决问题,都需要大量的思考,与客户沟通所得到一些研究和组织的资料,然后才是少许的 [敲代码][7]。
|
||||
|
||||
然而,这与我们想追求电影中的效果并不矛盾,也许,我们只是想要看起来“忙于工作”而已。
|
||||
|
||||
**注:当然,我仅仅是在此胡诌。**如果您公司实际上是根据您繁忙程度来评估您的工作时,无论您是蓝领还是白领,都需要亟待解决这样的工作文化。假装工作很忙是一种有毒的文化,对公司和员工都有害无益。
|
||||
|
||||
这就是说,让我们找些乐子,用一些老式的、毫无意义的数据和代码片段填充我们的屏幕。(当然,数据或许有意义,但不是在这种没有上下文的环境中。)当然有一些用于此用途的有趣的图形界面程序,如 [hackertyper.net][8] 或是 [GEEKtyper.com][9] 网站(LCTT 译注:是在线假装黑客操作的网站),为什么不使用标准的 Linux 终端程序呢?对于更老派的外观,可以考虑使用 [酷炫复古终端][10],这听起来确实如此:一个酷炫的复古终端程序。我将在下面的屏幕截图中使用酷炫复古终端,因为它看起来的确很酷。
|
||||
|
||||
### Genact
|
||||
|
||||
我们来看下第一个工具——Genact。Genact 的原理很简单,就是慢慢地无尽循环播放您选择的一个序列,让您的代码在您外出休息时“编译”。由您来决定播放顺序,但是其中默认包含数字货币挖矿模拟器、Composer PHP 依赖关系管理工具、内核编译器、下载器、内存转储等工具。其中我最喜欢的是其中类似《模拟城市》加载显示。所以只要没有人仔细检查,你可以花一整个下午等待您的电脑完成进度条。
|
||||
|
||||
Genact [发布了][11] 支持 Linux、OS X 和 Windows 的版本。并且其 Rust [源代码][12] 在 GitHub 上开源(遵循 [MIT 许可证][13])。
|
||||
|
||||
|
||||
|
||||
### Hollywood
|
||||
|
||||
Hollywood 采取更直接的方法。它本质上是在终端中创建一个随机的数量和配置的分屏,并启动那些看起来很繁忙的应用程序,如 htop、目录树、源代码文件等,并每隔几秒将其切换。它被组织成一个 shell 脚本,所以可以非常容易地根据需求进行修改。
|
||||
|
||||
Hollywood的 [源代码][14] 在 GitHub 上开源(遵循 [Apache 2.0 许可证][15])。
|
||||
|
||||
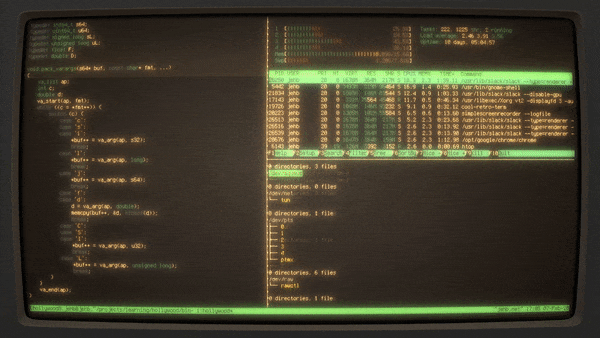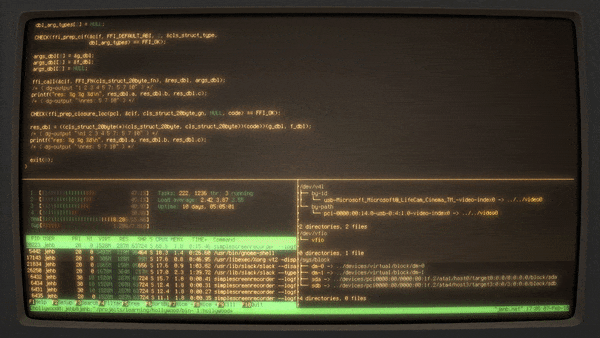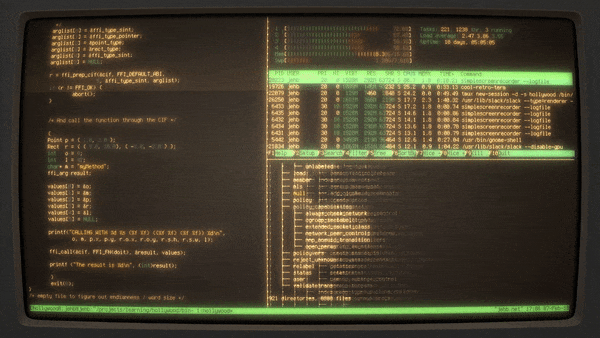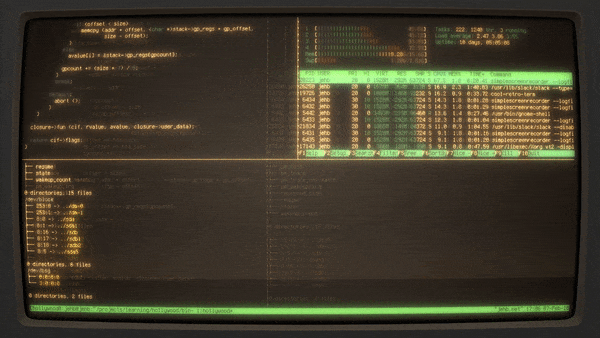
|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
Blessed-contrib 是我个人最喜欢的应用,实际上并不是为了这种表演而专门设计的应用。相反地,它是一个基于 Node.js 的终端仪表盘的构建库的演示文件。与其他两个不同,实际上我已经在工作中使用 Blessed-contrib 的库,而不是用于假装忙于工作。因为它是一个相当有用的库,并且可以使用一组在命令行显示信息的小部件。与此同时填充虚拟数据也很容易,所以可以很容易实现你在计算机上模拟《战争游戏》的想法。
|
||||
|
||||
Blessed-contrib 的[源代码][16]在 GitHub 上(遵循 [MIT 许可证][17])。
|
||||
|
||||
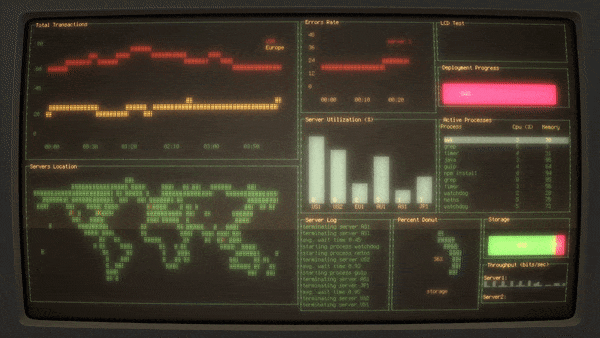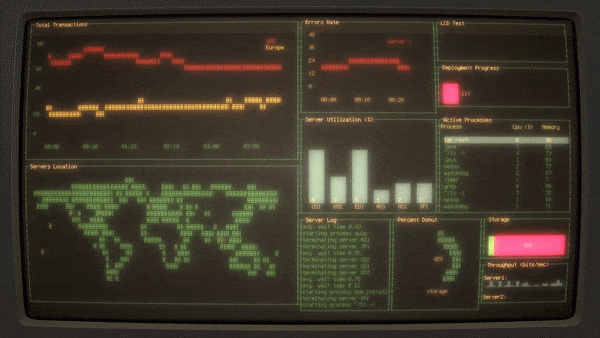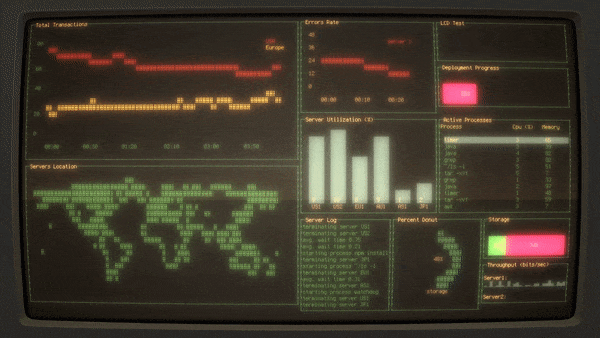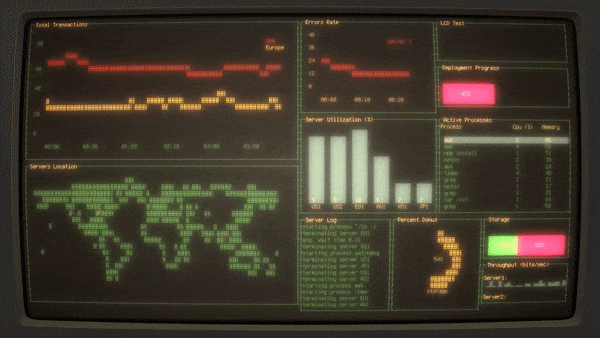
|
||||
|
||||
当然,尽管这些工具很容易使用,但也有很多其他的方式使你的屏幕丰富。在你看到电影中最常用的工具之一就是Nmap,这是一个开源的网络安全扫描工具。实际上,它被广泛用作展示好莱坞电影中,黑客电脑屏幕上的工具。因此 Nmap 的开发者创建了一个 [页面][18],列出了它出现在其中的一些电影,从《黑客帝国 2:重装上阵》到《谍影重重3》、《龙纹身的女孩》,甚至《虎胆龙威 4》。
|
||||
|
||||
当然,您可以创建自己的组合,使用终端多路复用器(如 `screen` 或 `tmux`)启动您希望使用的任何数据切分程序。
|
||||
|
||||
那么,您是如何使用您的屏幕的呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
@ -1,37 +1,37 @@
|
||||
# 您的 Linux 系统命令行个人助理
|
||||
Yoda:您的 Linux 系统命令行个人助理
|
||||
===========
|
||||
|
||||

|
||||
|
||||
不久前,我们写了一个名为 [**“Betty”**][1] 的命令行虚拟助手。今天,我偶然发现了一个类似的实用程序,叫做 **“Yoda”**。Yoda 是一个命令行个人助理,可以帮助您在 Linux 中完成一些琐碎的任务。它是用 Python 编写的一个免费的开源应用程序。在本指南中,我们将了解如何在 GNU/Linux 中安装和使用 Yoda。
|
||||
不久前,我们介绍了一个名为 [“Betty”][1] 的命令行虚拟助手。今天,我偶然发现了一个类似的实用程序,叫做 “Yoda”。Yoda 是一个命令行个人助理,可以帮助您在 Linux 中完成一些琐碎的任务。它是用 Python 编写的一个自由开源应用程序。在本指南中,我们将了解如何在 GNU/Linux 中安装和使用 Yoda。
|
||||
|
||||
### 安装 Yoda,命令行私人助理。
|
||||
|
||||
Yoda 需要 **Python 2** 和 PIP 。如果在您的 Linux 中没有安装 PIP,请参考下面的指南来安装它。只要确保已经安装了 **python2-pip** 。Yoda 可能不支持 Python 3。
|
||||
Yoda 需要 Python 2 和 PIP 。如果在您的 Linux 中没有安装 PIP,请参考下面的指南来安装它。只要确保已经安装了 python2-pip 。Yoda 可能不支持 Python 3。
|
||||
|
||||
**注意**:我建议你在虚拟环境下试用 Yoda。 不仅仅是 Yoda,总是在虚拟环境中尝试任何 Python 应用程序,让它们不会干扰全局安装的软件包。 您可以按照上文链接中标题为“创建虚拟环境”一节中所述设置虚拟环境。
|
||||
- [如何使用 pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
在您的系统上安装了 pip 之后,使用下面的命令克隆 Yoda 库。
|
||||
注意:我建议你在 Python 虚拟环境下试用 Yoda。 不仅仅是 Yoda,应该总在虚拟环境中尝试任何 Python 应用程序,让它们不会干扰全局安装的软件包。 您可以按照上文链接中标题为“创建虚拟环境”一节中所述设置虚拟环境。
|
||||
|
||||
在您的系统上安装了 `pip` 之后,使用下面的命令克隆 Yoda 库。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/yoda-pa/yoda
|
||||
|
||||
```
|
||||
|
||||
上面的命令将在当前工作目录中创建一个名为 “yoda” 的目录,并在其中克隆所有内容。转到 Yoda 目录:
|
||||
上面的命令将在当前工作目录中创建一个名为 `yoda` 的目录,并在其中克隆所有内容。转到 `yoda` 目录:
|
||||
|
||||
```
|
||||
$ cd yoda/
|
||||
|
||||
```
|
||||
|
||||
运行以下命令安装Yoda应用程序。
|
||||
运行以下命令安装 Yoda 应用程序。
|
||||
|
||||
```
|
||||
$ pip install .
|
||||
|
||||
```
|
||||
|
||||
请注意最后的点(.)。 现在,所有必需的软件包将被下载并安装。
|
||||
请注意最后的点(`.`)。 现在,所有必需的软件包将被下载并安装。
|
||||
|
||||
### 配置 Yoda
|
||||
|
||||
@ -41,7 +41,6 @@ $ pip install .
|
||||
|
||||
```
|
||||
$ yoda setup new
|
||||
|
||||
```
|
||||
|
||||
填写下列的问题:
|
||||
@ -59,7 +58,6 @@ Where shall your config be stored? (Default: ~/.yoda/)
|
||||
|
||||
A configuration file already exists. Are you sure you want to overwrite it? (y/n)
|
||||
y
|
||||
|
||||
```
|
||||
|
||||
你的密码在加密后保存在配置文件中,所以不用担心。
|
||||
@ -68,25 +66,22 @@ y
|
||||
|
||||
```
|
||||
$ yoda setup check
|
||||
|
||||
```
|
||||
|
||||
你会看到如下的输出。
|
||||
|
||||
```
|
||||
Name: Senthil Kumar
|
||||
Email: [email protected]
|
||||
Email: sk@senthilkumar.com
|
||||
Github username: sk
|
||||
|
||||
```
|
||||
|
||||
默认情况下,您的信息存储在 **~/.yoda** 目录中。
|
||||
默认情况下,您的信息存储在 `~/.yoda` 目录中。
|
||||
|
||||
要删除现有配置,请执行以下操作:
|
||||
|
||||
```
|
||||
$ yoda setup delete
|
||||
|
||||
```
|
||||
|
||||
### 用法
|
||||
@ -95,7 +90,6 @@ Yoda 包含一个简单的聊天机器人。您可以使用下面的聊天命令
|
||||
|
||||
```
|
||||
$ yoda chat who are you
|
||||
|
||||
```
|
||||
|
||||
样例输出:
|
||||
@ -107,14 +101,13 @@ I'm a virtual agent
|
||||
$ yoda chat how are you
|
||||
Yoda speaks:
|
||||
I'm doing very well. Thanks!
|
||||
|
||||
```
|
||||
|
||||
以下是我们可以用 Yoda 做的事情:
|
||||
以下是我们可以用 Yoda 做的事情:
|
||||
|
||||
**测试网络速度**
|
||||
#### 测试网络速度
|
||||
|
||||
让我们问一下 Yoda 关于互联网速度的问题。运行:
|
||||
让我们问一下 Yoda 关于互联网速度的问题。运行:
|
||||
|
||||
```
|
||||
$ yoda speedtest
|
||||
@ -122,18 +115,16 @@ Speed test results:
|
||||
Ping: 108.45 ms
|
||||
Download: 0.75 Mb/s
|
||||
Upload: 1.95 Mb/s
|
||||
|
||||
```
|
||||
|
||||
**缩短并展开网址**
|
||||
#### 缩短和展开网址
|
||||
|
||||
Yoda 还有助于缩短任何网址。
|
||||
Yoda 还有助于缩短任何网址:
|
||||
|
||||
```
|
||||
$ yoda url shorten https://www.ostechnix.com/
|
||||
Here's your shortened URL:
|
||||
https://goo.gl/hVW6U0
|
||||
|
||||
```
|
||||
|
||||
要展开缩短的网址:
|
||||
@ -142,11 +133,9 @@ https://goo.gl/hVW6U0
|
||||
$ yoda url expand https://goo.gl/hVW6U0
|
||||
Here's your original URL:
|
||||
https://www.ostechnix.com/
|
||||
|
||||
```
|
||||
|
||||
|
||||
**阅读黑客新闻**
|
||||
#### 阅读 Hacker News
|
||||
|
||||
我是 Hacker News 网站的常客。 如果你像我一样,你可以使用 Yoda 从下面的 Hacker News 网站阅读新闻。
|
||||
|
||||
@ -159,12 +148,11 @@ Description-- I came up with this idea "a Yelp for developers" when talking with
|
||||
url-- https://news.ycombinator.com/item?id=16636071
|
||||
|
||||
Continue? [press-"y"]
|
||||
|
||||
```
|
||||
|
||||
Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 “y” 并按下 ENTER。
|
||||
Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 `y` 并按下回车。
|
||||
|
||||
**管理个人日记**
|
||||
#### 管理个人日记
|
||||
|
||||
我们也可以保留个人日记以记录重要事件。
|
||||
|
||||
@ -174,7 +162,6 @@ Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 “y
|
||||
$ yoda diary nn
|
||||
Input your entry for note:
|
||||
Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
要创建新笔记,请再次运行上述命令。
|
||||
@ -188,7 +175,6 @@ Today's notes:
|
||||
Time | Note
|
||||
--------|-----
|
||||
16:41:41| Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
不仅仅是笔记,Yoda 还可以帮助你创建任务。
|
||||
@ -199,7 +185,6 @@ Today's notes:
|
||||
$ yoda diary nt
|
||||
Input your entry for task:
|
||||
Write an article about Yoda and publish it on OSTechNix
|
||||
|
||||
```
|
||||
|
||||
要查看任务列表,请运行:
|
||||
@ -217,10 +202,9 @@ Summary:
|
||||
----------------
|
||||
Incomplete tasks: 1
|
||||
Completed tasks: 0
|
||||
|
||||
```
|
||||
|
||||
正如你在上面看到的,我有一个未完成的任务。 要将其标记为已完成,请运行以下命令并输入已完成的任务序列号并按下 ENTER 键:
|
||||
正如你在上面看到的,我有一个未完成的任务。 要将其标记为已完成,请运行以下命令并输入已完成的任务序列号并按下回车键:
|
||||
|
||||
```
|
||||
$ yoda diary ct
|
||||
@ -231,7 +215,6 @@ Number | Time | Task
|
||||
1 | 16:44:03: Write an article about Yoda and publish it on OSTechNix
|
||||
Enter the task number that you would like to set as completed
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
您可以随时使用命令分析当前月份的任务:
|
||||
@ -241,18 +224,16 @@ $ yoda diary analyze
|
||||
Percentage of incomplete task : 0
|
||||
Percentage of complete task : 100
|
||||
Frequency of adding task (Task/Day) : 3
|
||||
|
||||
```
|
||||
|
||||
有时候,你可能想要记录一个关于你爱的或者敬佩的人的个人资料。
|
||||
|
||||
**记录关于爱人的笔记**
|
||||
#### 记录关于爱人的笔记
|
||||
|
||||
首先,您需要设置配置来存储朋友的详细信息。 请运行:
|
||||
|
||||
```
|
||||
$ yoda love setup
|
||||
|
||||
```
|
||||
|
||||
输入你的朋友的详细信息:
|
||||
@ -264,7 +245,6 @@ Enter sex(M/F):
|
||||
M
|
||||
Where do they live?
|
||||
Rameswaram
|
||||
|
||||
```
|
||||
|
||||
要查看此人的详细信息,请运行:
|
||||
@ -272,7 +252,6 @@ Rameswaram
|
||||
```
|
||||
$ yoda love status
|
||||
{'place': 'Rameswaram', 'name': 'Abdul Kalam', 'sex': 'M'}
|
||||
|
||||
```
|
||||
|
||||
要添加你的爱人的生日:
|
||||
@ -281,7 +260,6 @@ $ yoda love status
|
||||
$ yoda love addbirth
|
||||
Enter birthday
|
||||
15-10-1931
|
||||
|
||||
```
|
||||
|
||||
查看生日:
|
||||
@ -289,7 +267,6 @@ Enter birthday
|
||||
```
|
||||
$ yoda love showbirth
|
||||
Birthday is 15-10-1931
|
||||
|
||||
```
|
||||
|
||||
你甚至可以添加关于该人的笔记:
|
||||
@ -297,7 +274,6 @@ Birthday is 15-10-1931
|
||||
```
|
||||
$ yoda love note
|
||||
Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
您可以使用命令查看笔记:
|
||||
@ -306,7 +282,6 @@ Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was th
|
||||
$ yoda love notes
|
||||
Notes:
|
||||
1: Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
你也可以写下这个人喜欢的东西:
|
||||
@ -317,7 +292,6 @@ Add things they like
|
||||
Physics, Aerospace
|
||||
Want to add more things they like? [y/n]
|
||||
n
|
||||
|
||||
```
|
||||
|
||||
要查看他们喜欢的东西,请运行:
|
||||
@ -326,12 +300,9 @@ n
|
||||
$ yoda love likes
|
||||
Likes:
|
||||
1: Physics, Aerospace
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
|
||||
**跟踪资金费用**
|
||||
#### 跟踪资金费用
|
||||
|
||||
您不需要单独的工具来维护您的财务支出。 Yoda 会替您处理好。
|
||||
|
||||
@ -339,7 +310,6 @@ Likes:
|
||||
|
||||
```
|
||||
$ yoda money setup
|
||||
|
||||
```
|
||||
|
||||
输入您的货币代码和初始金额:
|
||||
@ -360,7 +330,6 @@ Enter initial amount:
|
||||
```
|
||||
$ yoda money status
|
||||
{'initial_money': 10000, 'currency_code': 'INR'}
|
||||
|
||||
```
|
||||
|
||||
让我们假设你买了一本价值 250 卢比的书。 要添加此费用,请运行:
|
||||
@ -369,7 +338,6 @@ $ yoda money status
|
||||
$ yoda money exp
|
||||
Spend 250 INR on books
|
||||
output:
|
||||
|
||||
```
|
||||
|
||||
要查看花费,请运行:
|
||||
@ -377,44 +345,35 @@ output:
|
||||
```
|
||||
$ yoda money exps
|
||||
2018-03-21 17:12:31 INR 250 books
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
#### 创建想法列表
|
||||
|
||||
**创建想法列表**
|
||||
|
||||
创建一个新的想法:
|
||||
创建一个新的想法:
|
||||
|
||||
```
|
||||
$ yoda ideas add --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
列出想法:
|
||||
列出想法:
|
||||
|
||||
```
|
||||
$ yoda ideas show
|
||||
|
||||
```
|
||||
|
||||
从任务中移除一个想法:
|
||||
从任务中移除一个想法:
|
||||
|
||||
```
|
||||
$ yoda ideas remove --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
要完全删除这个想法,请运行:
|
||||
要完全删除这个想法,请运行:
|
||||
|
||||
```
|
||||
$ yoda ideas remove --project <project_name>
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
|
||||
**学习英语词汇**
|
||||
#### 学习英语词汇
|
||||
|
||||
Yoda 帮助你学习随机英语单词并追踪你的学习进度。
|
||||
|
||||
@ -422,36 +381,31 @@ Yoda 帮助你学习随机英语单词并追踪你的学习进度。
|
||||
|
||||
```
|
||||
$ yoda vocabulary word
|
||||
|
||||
```
|
||||
|
||||
它会随机显示一个单词。 按 ENTER 键显示单词的含义。 再一次,Yoda 问你是否已经知道这个词的意思。 如果您已经知道,请输入“是”。 如果您不知道,请输入“否”。 这可以帮助你跟踪你的进度。 使用以下命令来了解您的进度。
|
||||
它会随机显示一个单词。 按回车键显示单词的含义。 再一次,Yoda 问你是否已经知道这个词的意思。 如果您已经知道,请输入“是”。 如果您不知道,请输入“否”。 这可以帮助你跟踪你的进度。 使用以下命令来了解您的进度。
|
||||
|
||||
```
|
||||
$ yoda vocabulary accuracy
|
||||
|
||||
```
|
||||
|
||||
此外,Yoda 可以帮助您做其他一些事情,比如找到单词的定义和创建插卡以轻松学习任何内容。 有关更多详细信息和可用选项列表,请参阅帮助部分。
|
||||
|
||||
```
|
||||
$ yoda --help
|
||||
|
||||
```
|
||||
|
||||
更多好的东西来了。请继续关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/yoda-the-command-line-personal-assistant-for-your-linux-system/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,82 +0,0 @@
|
||||
用这三个命令行工具成为好莱坞电影中的黑客
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果在你成长过程中有看过谍战片、动作片或犯罪片,那么你就会清楚地了解黑客的电脑屏幕是什么样子。就像是在《黑客帝国》电影中,[代码雨][1] 一样的十六进制数字流,又或是一排排快速移动的代码 。
|
||||
|
||||
也许电影中出现一幅世界地图,其中布满了闪烁的光点除和一些快速更新的字符。 而且是3D旋转的几何图像,为什么不可能出现在现实中呢? 如果可能的话,那么就会出现数量多得不可思议的显示屏,以及不符合人体工学的电脑椅或其他配件。 在《剑鱼行动》电影中黑客就使用了七个显示屏。
|
||||
|
||||
当然,我们这些从事计算机行业的人一下子就明白这完全是胡说八道。虽然在我们中,许多人都有双显示器(或更多),但一个闪烁的数据仪表盘通常和专注工作是相互矛盾的。编写代码、项目管理和系统管理与日常工作不同。我们遇到的大多数情况,为了解决问题,都需要大量的思考,与客户沟通所得到一些研究和组织的资料,然后才是少许的 [敲代码][7]。
|
||||
|
||||
然而,这与我们想追求电影中的效果并不矛盾,也许,我们只是想要看起来“忙于工作”而已。
|
||||
|
||||
**注:当然,我仅仅是在此胡诌。**如果实际上您公司是根据您繁忙程度来评估您的工作时,无论您是蓝领还是白领,都需要亟待解决这样的工作文化。假装工作很忙是一种有毒的文化,对公司和员工都有害无益。
|
||||
|
||||
这就是说,让我们找些乐子,用一些老式的、毫无意义的数据和代码片段填充我们的屏幕。(当然,数据或许有意义,而不是没有上下文。)当然有许多有趣的图形界面,如 [hackertyper.net][8] 或是 [GEEKtyper.com][9] 网站(译者注:是在线模拟黑客网站),为什么不使用Linux终端程序呢?对于更老派的外观,可以考虑使用 [酷炫复古终端][10],这听起来确实如此:一个酷炫的复古终端程序。我将在下面的屏幕截图中使用酷炫复古终端,因为它看起来的确很酷。
|
||||
|
||||
|
||||
### Genact
|
||||
|
||||
我们来看下第一个工具——Genact。Genact的原理很简单,就是慢慢地循环播放您选择的一个序列,让您的代码在您外出休息时“编译”。由您来决定播放顺序,但是其中默认包含数字货币挖矿模拟器、PHP管理依赖关系工具、内核编译器、下载器、内存转储等工具。其中我最喜欢的是其中类似《模拟城市》加载显示。所以只要没有人仔细检查,你可以花一整个下午等待您的电脑完成进度条。
|
||||
|
||||
Genact[发行版][11]支持Linux、OS X和Windows。并且用Rust编写。[源代码][12] 在GitHub上开源(遵循[MIT许可证][13])
|
||||
|
||||

|
||||
|
||||
### Hollywood
|
||||
|
||||
|
||||
Hollywood采取更直接的方法。它本质上是在终端中创建一个随机数字和配置分屏,并启动跑个不停的应用程序,如htop,目录树,源代码文件等,并每隔几秒将其切换。它被放在一起作为一个shell脚本,所以可以非常容易地根据需求进行修改。
|
||||
|
||||
|
||||
Hollywood的 [源代码][14] 在GitHub上开源(遵循[Apache 2.0许可证][15])。
|
||||
|
||||

|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
Blessed-contrib是我个人最喜欢的应用,实际上并不是为了表演而专门设计的应用。相反地,它是一个基于Node.js的后台终端构建库的演示文件。与其他两个不同,实际上我已经在工作中使用Blessed-contrib的库,而不是用于假装忙于工作。因为它是一个相当有用的库,并且可以使用一组在命令行显示信息的小部件。与此同时填充虚拟数据也很容易,所以可以很容易实现模拟《战争游戏》的想法。
|
||||
|
||||
|
||||
Blessed-contrib的[源代码][16]在GitHub上(遵循[MIT许可证][17])。
|
||||
|
||||
|
||||

|
||||
|
||||
当然,尽管这些工具很容易使用,但也有很多其他的方式使你的屏幕丰富。在你看到电影中最常用的工具之一就是Nmap,一个开源的网络安全扫描工具。实际上,它被广泛用作展示好莱坞电影中,黑客电脑屏幕上的工具。因此Nmap的开发者创建了一个 [页面][18],列出了它出现在其中的一些电影,从《黑客帝国2:重装上阵》到《谍影重重3》、《龙纹身的女孩》,甚至《虎胆龙威4》。
|
||||
|
||||
当然,您可以创建自己的组合,使用终端多路复用器(如屏幕或tmux)启动您希望的任何数据分散应用程序。
|
||||
|
||||
|
||||
那么,您是如何使用您的屏幕的呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
Loading…
Reference in New Issue
Block a user