mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
commit
16a6d0b928
@ -1,8 +1,8 @@
|
||||
[#]: collector: (oska874)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12747-1.html)
|
||||
[#]: subject: (Go on very small hardware Part 2)
|
||||
[#]: via: (https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html)
|
||||
[#]: author: (Michał Derkacz https://ziutek.github.io/)
|
||||
@ -10,17 +10,17 @@
|
||||
Go 语言在极小硬件上的运用(二)
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
[][1]
|
||||
在本文的 [第一部分][2] 的结尾,我承诺要写关于接口的内容。我不想在这里写有关接口或完整或简短的讲义。相反,我将展示一个简单的示例,来说明如何定义和使用接口,以及如何利用无处不在的 `io.Writer` 接口。还有一些关于<ruby>反射<rt>reflection</rt></ruby>和<ruby>半主机<rt>semihosting</rt></ruby>的内容。
|
||||
|
||||

|
||||
|
||||
在本文的 [第一部分][2] 的结尾,我承诺要写关于 _interfaces_ 的内容。我不想在这里写有关接口的完整甚至简短的讲义。相反,我将展示一个简单的示例,来说明如何定义和使用接口,以及如何利用无处不在的 _io.Writer_ 接口。还有一些关于 _reflection_ 和 _semihosting_ 的内容。
|
||||
|
||||
接口是 Go 语言的重要组成部分。如果您想了解更多有关它们的信息,我建议您阅读 [Effective Go][3] 和 [Russ Cox 的文章][4]。
|
||||
接口是 Go 语言的重要组成部分。如果你想了解更多有关它们的信息,我建议你阅读《[高效的 Go 编程][3]》 和 [Russ Cox 的文章][4]。
|
||||
|
||||
### 并发 Blinky – 回顾
|
||||
|
||||
当您阅读前面示例的代码时,您可能会注意到一个违反直觉的方式来打开或关闭 LED。 _Set_ 方法用于关闭 LED,_Clear_ 方法用于打开 LED。这是由于在 <ruby>漏极开路配置<rt>open-drain configuration</rt></ruby> 下驱动了 LED。我们可以做些什么来减少代码的混乱? 让我们用 _On_ 和 _Off_ 方法来定义 _LED_ 类型:
|
||||
当你阅读前面示例的代码时,你可能会注意到一中打开或关闭 LED 的反直觉方式。 `Set` 方法用于关闭 LED,`Clear` 方法用于打开 LED。这是由于在 <ruby>漏极开路配置<rt>open-drain configuration</rt></ruby> 下驱动了 LED。我们可以做些什么来减少代码的混乱?让我们用 `On` 和 `Off` 方法来定义 `LED` 类型:
|
||||
|
||||
```
|
||||
type LED struct {
|
||||
@ -34,15 +34,13 @@ func (led LED) On() {
|
||||
func (led LED) Off() {
|
||||
led.pin.Set()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
现在我们可以简单地调用 `led.On()` 和 `led.Off()`,这不会再引起任何疑惑了。
|
||||
|
||||
在前面的所有示例中,我都尝试使用相同的 <ruby>漏极开路配置<rt>open-drain configuration</rt></ruby>来避免代码复杂化。但是在最后一个示例中,对于我来说,将第三个 LED 连接到 GND 和 PA3 引脚之间并将 PA3 配置为<ruby>推挽模式<rt>push-pull mode</rt></ruby>会更容易。下一个示例将使用以此方式连接的 LED。
|
||||
|
||||
在前面的所有示例中,我都尝试使用相同的 <ruby>漏极开路配置<rt>open-drain configuration</rt></ruby>来 避免代码复杂化。但是在最后一个示例中,对于我来说,将第三个 LED 连接到 GND 和 PA3 引脚之间并将 PA3 配置为<ruby>推挽模式<rt>push-pull mode</rt></ruby>会更容易。下一个示例将使用以此方式连接的 LED。
|
||||
|
||||
但是我们的新 _LED_ 类型不支持推挽配置。实际上,我们应该将其称为 _OpenDrainLED_,并定义另一个类型 _PushPullLED_:
|
||||
但是我们的新 `LED` 类型不支持推挽配置,实际上,我们应该将其称为 `OpenDrainLED`,并定义另一个类型 `PushPullLED`:
|
||||
|
||||
```
|
||||
type PushPullLED struct {
|
||||
@ -56,10 +54,9 @@ func (led PushPullLED) On() {
|
||||
func (led PushPullLED) Off() {
|
||||
led.pin.Clear()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
请注意,这两种类型都具有相同的方法,它们的工作方式也相同。如果在 LED 上运行的代码可以同时使用这两种类型,而不必注意当前使用的是哪种类型,那就太好了。 _interface type_ 可以提供帮助:
|
||||
请注意,这两种类型都具有相同的方法,它们的工作方式也相同。如果在 LED 上运行的代码可以同时使用这两种类型,而不必注意当前使用的是哪种类型,那就太好了。 接口类型可以提供帮助:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -134,21 +131,20 @@ func main() {
|
||||
|
||||
```
|
||||
|
||||
我们定义了 _LED_ 接口,它有两个方法: _On_ 和 _Off_。 _PushPullLED_ 和 _OpenDrainLED_ 类型代表两种驱动 LED 的方式。我们还定义了两个用作构造函数的 _Make_ _*LED_ 函数。这两种类型都实现了 _LED_ 接口,因此可以将这些类型的值赋给 _LED_ 类型的变量:
|
||||
我们定义了 `LED` 接口,它有两个方法: `On` 和 `Off`。 `PushPullLED` 和 `OpenDrainLED` 类型代表两种驱动 LED 的方式。我们还定义了两个用作构造函数的 `Make*LED` 函数。这两种类型都实现了 `LED` 接口,因此可以将这些类型的值赋给 `LED` 类型的变量:
|
||||
|
||||
```
|
||||
led1 = MakeOpenDrainLED(gpio.A.Pin(4))
|
||||
led2 = MakePushPullLED(gpio.A.Pin(3))
|
||||
```
|
||||
|
||||
在这种情况下,可赋值性在编译时检查。赋值后,_led1_ 变量包含一个 `OpenDrainLED{gpio.A.Pin(4)}`,以及一个指向 _OpenDainLED_ 类型的方法集的指针。 `led1.On()` 调用大致对应于以下 C 代码:
|
||||
在这种情况下,<ruby>可赋值性<rt>assignability</rt></ruby>在编译时检查。赋值后,`led1` 变量包含一个 `OpenDrainLED{gpio.A.Pin(4)}`,以及一个指向 `OpenDrainLED` 类型的方法集的指针。 `led1.On()` 调用大致对应于以下 C 代码:
|
||||
|
||||
```
|
||||
led1.methods->On(led1.value)
|
||||
```
|
||||
|
||||
如您所见,如果仅考虑函数调用的开销,这是相当便宜的抽象。
|
||||
|
||||
如你所见,如果仅考虑函数调用的开销,这是相当廉价的抽象。
|
||||
|
||||
但是,对接口的任何赋值都会导致包含有关已赋值类型的大量信息。对于由许多其他类型组成的复杂类型,可能会有很多信息:
|
||||
|
||||
@ -168,7 +164,7 @@ $ arm-none-eabi-size cortexm0.elf
|
||||
10312 196 212 10720 29e0 cortexm0.elf
|
||||
```
|
||||
|
||||
生成的二进制文件仍然包含一些有关类型的必要信息和关于所有导出方法(带有名称)的完整信息。在运行时,主要是当您将存储在接口变量中的一个值赋值给任何其他变量时,需要此信息来检查可赋值性。
|
||||
生成的二进制文件仍然包含一些有关类型的必要信息和关于所有导出方法(带有名称)的完整信息。在运行时,主要是当你将存储在接口变量中的一个值赋值给任何其他变量时,需要此信息来检查可赋值性。
|
||||
|
||||
我们还可以通过重新编译所导入的包来删除它们的类型和字段名称:
|
||||
|
||||
@ -203,28 +199,23 @@ Flash page at addr: 0x08002800 erased
|
||||
|
||||
```
|
||||
|
||||
我没有将 NRST 信号连接到编程器,因此无法使用 _-reset_ 选项,必须按下 reset 按钮才能运行程序。
|
||||
我没有将 NRST 信号连接到编程器,因此无法使用 `-reset` 选项,必须按下复位按钮才能运行程序。
|
||||
|
||||

|
||||
|
||||
看来,_st-flash_ 与此板配合使用有点不可靠 (通常需要重置 ST-LINK 加密狗)。此外,当前版本不会通过 SWD 发出 reset 命令 (仅使用 NRST 信号)。 软件重置是不现实的,但是它通常是有效的,缺少它会将会带来不便。对于<ruby>电路板-程序员<rt>board-programmer</rt></ruby> 组合 _OpenOCD_ 工作得更好。
|
||||
看来,`st-flash` 与此板配合使用有点不可靠(通常需要复位 ST-LINK 加密狗)。此外,当前版本不会通过 SWD 发出复位命令(仅使用 NRST 信号)。软件复位是不现实的,但是它通常是有效的,缺少它会将会带来不便。对于<ruby>板卡程序员<rt>board-programmer</rt></ruby> 来说 OpenOCD 工作得更好。
|
||||
|
||||
### UART
|
||||
|
||||
UART(<ruby>通用异步收发传输器<rt>Universal Aynchronous Receiver-Transmitter</rt></ruby>)仍然是当今微控制器最重要的外设之一。它的优点是以下属性的独特组合:
|
||||
|
||||
* 相对较高的速度,
|
||||
|
||||
* 仅两条信号线(在 <ruby>半双工<rt>half-duplex</rt></ruby> 通信的情况下甚至一条),
|
||||
|
||||
* 角色对称,
|
||||
|
||||
* 关于新数据的 <ruby>同步带内信令<rt>synchronous in-band signaling</rt></ruby>(起始位),
|
||||
|
||||
* 在传输 <ruby>字<rt>words</rt></ruby> 内的精确计时。
|
||||
|
||||
|
||||
这使得最初用于传输由 7-9 位 words 组成的异步消息的 UART,也被用于有效地实现各种其他物理协议,例如被 [WS28xx LEDs][7] 或 [1-wire][8] 设备使用的协议。
|
||||
这使得最初用于传输由 7-9 位的字组成的异步消息的 UART,也被用于有效地实现各种其他物理协议,例如被 [WS28xx LEDs][7] 或 [1-wire][8] 设备使用的协议。
|
||||
|
||||
但是,我们将以其通常的角色使用 UART:从程序中打印文本消息。
|
||||
|
||||
@ -286,7 +277,7 @@ var ISRs = [...]func(){
|
||||
|
||||
```
|
||||
|
||||
您会发现此代码可能有些复杂,但目前 STM32 HAL 中没有更简单的 UART 驱动程序(在某些情况下,简单的轮询驱动程序可能会很有用)。 _usart.Driver_ 是使用 DMA 和中断来卸载 CPU 的高效驱动程序。
|
||||
你会发现此代码可能有些复杂,但目前 STM32 HAL 中没有更简单的 UART 驱动程序(在某些情况下,简单的轮询驱动程序可能会很有用)。 `usart.Driver` 是使用 DMA 和中断来减轻 CPU 负担的高效驱动程序。
|
||||
|
||||
STM32 USART 外设提供传统的 UART 及其同步版本。要将其用作输出,我们必须将其 Tx 信号连接到正确的 GPIO 引脚:
|
||||
|
||||
@ -295,13 +286,13 @@ tx.Setup(&gpio.Config{Mode: gpio.Alt})
|
||||
tx.SetAltFunc(gpio.USART1_AF1)
|
||||
```
|
||||
|
||||
在 Tx-only 模式下配置 _usart.Driver_ (rxdma 和 rxbuf 设置为 nil):
|
||||
在 Tx-only 模式下配置 `usart.Driver` (rxdma 和 rxbuf 设置为 nil):
|
||||
|
||||
```
|
||||
tts = usart.NewDriver(usart.USART1, d.Channel(2, 0), nil, nil)
|
||||
```
|
||||
|
||||
我们使用它的 _WriteString_ 方法来打印这句名句。让我们清理所有内容并编译该程序:
|
||||
我们使用它的 `WriteString` 方法来打印这句名言。让我们清理所有内容并编译该程序:
|
||||
|
||||
```
|
||||
$ cd $HOME/emgo
|
||||
@ -313,15 +304,15 @@ $ arm-none-eabi-size cortexm0.elf
|
||||
12728 236 176 13140 3354 cortexm0.elf
|
||||
```
|
||||
|
||||
要查看某些内容,您需要在 PC 中使用 UART 外设。
|
||||
要查看某些内容,你需要在 PC 中使用 UART 外设。
|
||||
|
||||
**请勿使用 RS232 端口或 USB 转 RS232 转换器!**
|
||||
|
||||
STM32 系列使用 3.3V 逻辑,但是 RS232 可以产生 -15 V ~ +15 V 的电压,这可能会损坏您的 MCU。您需要使用 3.3 V 逻辑的 USB 转 UART 转换器。流行的转换器基于 FT232 或 CP2102 芯片。
|
||||
STM32 系列使用 3.3V 逻辑,但是 RS232 可以产生 -15 V ~ +15 V 的电压,这可能会损坏你的 MCU。你需要使用 3.3V 逻辑的 USB 转 UART 转换器。流行的转换器基于 FT232 或 CP2102 芯片。
|
||||
|
||||

|
||||
|
||||
您还需要一些终端仿真程序 (我更喜欢 [picocom][9])。刷新新图像,运行终端仿真器,然后按几次 reset 按钮:
|
||||
你还需要一些终端仿真程序(我更喜欢 [picocom][9])。刷新新图像,运行终端仿真器,然后按几次复位按钮:
|
||||
|
||||
```
|
||||
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; reset run; exit'
|
||||
@ -377,13 +368,13 @@ Hello, World!
|
||||
Hello, World!
|
||||
```
|
||||
|
||||
每次按下 reset 按钮都会产生新的 “Hello,World!”行。一切都在按预期进行。
|
||||
每次按下复位按钮都会产生新的 “Hello,World!”行。一切都在按预期进行。
|
||||
|
||||
要查看此 MCU 的 <ruby>双向<rt>bi-directional</rt></ruby> UART 代码,请查看 [此示例][10]。
|
||||
|
||||
### io.Writer 接口
|
||||
|
||||
_io.Writer_ 接口可能是 Go 中第二种最常用的接口类型,紧接在 _error_ 接口之后。其定义如下所示:
|
||||
`io.Writer` 接口可能是 Go 中第二种最常用的接口类型,仅次于 `error` 接口。其定义如下所示:
|
||||
|
||||
```
|
||||
type Writer interface {
|
||||
@ -391,7 +382,7 @@ type Writer interface {
|
||||
}
|
||||
```
|
||||
|
||||
_usart.Driver_ 实现了 _io.Writer_ ,因此我们可以替换:
|
||||
`usart.Driver` 实现了 `io.Writer`,因此我们可以替换:
|
||||
|
||||
```
|
||||
tts.WriteString("Hello, World!\r\n")
|
||||
@ -403,15 +394,15 @@ tts.WriteString("Hello, World!\r\n")
|
||||
io.WriteString(tts, "Hello, World!\r\n")
|
||||
```
|
||||
|
||||
此外,您需要将 _io_ 包添加到 _import_ 部分。
|
||||
此外,你需要将 `io` 包添加到 `import` 部分。
|
||||
|
||||
_io.WriteString_ 函数的声明如下所示:
|
||||
`io.WriteString` 函数的声明如下所示:
|
||||
|
||||
```
|
||||
func WriteString(w Writer, s string) (n int, err error)
|
||||
```
|
||||
|
||||
如您所见,_io.WriteString_ 允许使用实现了 _io.Writer_ 接口的任何类型来编写字符串。在内部,它检查基础类型是否具有 _WriteString_ 方法,并使用该方法代替 _Write_ (如果可用)。
|
||||
如你所见,`io.WriteString` 允许使用实现了 `io.Writer` 接口的任何类型来编写字符串。在内部,它检查基础类型是否具有 `WriteString` 方法,并使用该方法代替 `Write`(如果可用)。
|
||||
|
||||
让我们编译修改后的程序:
|
||||
|
||||
@ -422,7 +413,7 @@ $ arm-none-eabi-size cortexm0.elf
|
||||
15456 320 248 16024 3e98 cortexm0.elf
|
||||
```
|
||||
|
||||
如您所见,_io.WriteString_ 导致二进制文件的大小显着增加:15776-12964 = 2812字节。 Flash 上没有太多空间了。是什么引起了这么大规模的增长?
|
||||
如你所见,`io.WriteString` 导致二进制文件的大小显着增加:15776-12964 = 2812 字节。 Flash 上没有太多空间了。是什么引起了这么大规模的增长?
|
||||
|
||||
使用这个命令:
|
||||
|
||||
@ -430,7 +421,7 @@ $ arm-none-eabi-size cortexm0.elf
|
||||
arm-none-eabi-nm --print-size --size-sort --radix=d cortexm0.elf
|
||||
```
|
||||
|
||||
我们可以打印两种情况下按其大小排序的所有符号。通过过滤和分析获得的数据(awk,diff),我们可以找到大约 80 个新符号。最大的十个如下所示:
|
||||
我们可以打印两种情况下按其大小排序的所有符号。通过过滤和分析获得的数据(`awk`,`diff`),我们可以找到大约 80 个新符号。最大的十个如下所示:
|
||||
|
||||
```
|
||||
> 00000062 T stm32$hal$usart$Driver$DisableRx
|
||||
@ -444,9 +435,9 @@ arm-none-eabi-nm --print-size --size-sort --radix=d cortexm0.elf
|
||||
> 00000660 T stm32$hal$usart$Driver$Read
|
||||
```
|
||||
|
||||
因此,即使我们不使用 _usart.Driver.Read_ 方法进行编译,也与 _DisableRx_、_RxDMAISR_、_EnableRx_ 以及上面未提及的其他方法相同。不幸的是,如果您为接口赋值了一些内容,那么它的完整方法集是必需的(包含所有依赖项)。对于使用大多数方法的大型程序来说,这不是问题。但是对于我们这种极简的情况而言,这是一个巨大的负担。
|
||||
因此,即使我们不使用 `usart.Driver.Read` 方法,但它被编译进来了,与 `DisableRx`、`RxDMAISR`、`EnableRx` 以及上面未提及的其他方法一样。不幸的是,如果你为接口赋值了一些内容,就需要它的完整方法集(包含所有依赖项)。对于使用大多数方法的大型程序来说,这不是问题。但是对于我们这种极简的情况而言,这是一个巨大的负担。
|
||||
|
||||
我们已经接近 MCU 的极限,但让我们尝试打印一些数字(您需要在 _import_ 部分中用 _strconv_ 替换 _io_ 包):
|
||||
我们已经接近 MCU 的极限,但让我们尝试打印一些数字(你需要在 `import` 部分中用 `strconv` 替换 `io` 包):
|
||||
|
||||
```
|
||||
func main() {
|
||||
@ -469,8 +460,7 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
与使用 _io.WriteString_ 函数的情况一样,_strconv.WriteInt_ 的第一个参数的类型为 _io.Writer_ 。
|
||||
|
||||
与使用 `io.WriteString` 函数的情况一样,`strconv.WriteInt` 的第一个参数的类型为 `io.Writer`。
|
||||
|
||||
```
|
||||
$ egc
|
||||
@ -479,7 +469,7 @@ $ egc
|
||||
exit status 1
|
||||
```
|
||||
|
||||
这一次我们的空间用完了。让我们试着精简一下有关类型的信息:
|
||||
这一次我们的空间超出的不多。让我们试着精简一下有关类型的信息:
|
||||
|
||||
```
|
||||
$ cd $HOME/emgo
|
||||
@ -500,7 +490,7 @@ hex(a) = c
|
||||
hex(b) = -7b
|
||||
```
|
||||
|
||||
Emgo 中的 _strconv_ 包与 Go 中的原型有很大的不同。 它旨在直接用于写入格式化的数字,并且在许多情况下可以替换繁重的 _fmt_ 包。 这就是为什么函数名称以 _Write_ 而不是 _Format_ 开头,并具有额外的两个参数的原因。 以下是其用法示例:
|
||||
Emgo 中的 `strconv` 包与 Go 中的原型有很大的不同。它旨在直接用于写入格式化的数字,并且在许多情况下可以替换沉重的 `fmt` 包。 这就是为什么函数名称以 `Write` 而不是 `Format` 开头,并具有额外的两个参数的原因。 以下是其用法示例:
|
||||
|
||||
```
|
||||
func main() {
|
||||
@ -536,7 +526,7 @@ func main() {
|
||||
|
||||
### Unix 流 和 <ruby>莫尔斯电码<rt>Morse code</rt></ruby>
|
||||
|
||||
得益于事实上大多数写入功能的函数都使用 _io.Writer_ 而不是具体类型(例如 C 中的 _FILE_ ),因此我们获得了类似于 _Unix stream_ 的功能。在 Unix 中,我们可以轻松地组合简单的命令来执行更大的任务。例如,我们可以通过以下方式将文本写入文件:
|
||||
由于大多数写入的函数都使用 `io.Writer` 而不是具体类型(例如 C 中的 `FILE` ),因此我们获得了类似于 Unix <ruby>流<rt>stream</rt></ruby> 的功能。在 Unix 中,我们可以轻松地组合简单的命令来执行更大的任务。例如,我们可以通过以下方式将文本写入文件:
|
||||
|
||||
```
|
||||
echo "Hello, World!" > file.txt
|
||||
@ -544,13 +534,13 @@ echo "Hello, World!" > file.txt
|
||||
|
||||
`>` 操作符将前面命令的输出流写入文件。还有 `|` 操作符,用于连接相邻命令的输出流和输入流。
|
||||
|
||||
多亏了流,我们可以轻松地转换/过滤任何命令的输出。例如,要将所有字母转换为大写,我们可以通过 `tr` 命令过滤 `echo` 的输出:
|
||||
|
||||
多亏了流,我们可以轻松地转换/过滤任何命令的输出。例如,要将所有字母转换为大写,我们可以通过 _tr_ 命令过滤 echo 的输出:
|
||||
```
|
||||
echo "Hello, World!" | tr a-z A-Z > file.txt
|
||||
```
|
||||
|
||||
为了显示 _io.Writer_ 和 Unix 流之间的类比,让我们编写以下代码:
|
||||
为了显示 `io.Writer` 和 Unix 流之间的类比,让我们编写以下代码:
|
||||
|
||||
```
|
||||
io.WriteString(tts, "Hello, World!\r\n")
|
||||
@ -628,7 +618,7 @@ var morseSymbols = [...]morseSymbol{
|
||||
}
|
||||
```
|
||||
|
||||
您可以在 [这里][11] 找到完整的 _morseSymbols_ 数组。 `//emgo:const` 指令确保 _morseSymbols_ 数组不会被复制到 RAM 中。
|
||||
你可以在 [这里][11] 找到完整的 `morseSymbols` 数组。 `//emgo:const` 指令确保 `morseSymbols` 数组不会被复制到 RAM 中。
|
||||
|
||||
现在我们可以通过两种方式打印句子:
|
||||
|
||||
@ -642,10 +632,9 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
我们使用指向 _MorseWriter_ `&MorseWriter{tts}` 的指针而不是简单的 `MorseWriter{tts}` 值,因为 _MorseWriter_ 太大,不适合接口变量。
|
||||
我们使用指向 `MorseWriter` `&MorseWriter{tts}` 的指针而不是简单的 `MorseWriter{tts}` 值,因为 `MorseWriter` 太大,不适合接口变量。
|
||||
|
||||
|
||||
与 Go 不同,Emgo 不会为存储在接口变量中的值动态分配内存。接口类型的大小受限制,等于三个指针(适合 _slice_ )或两个 _float64_(适合 _complex128_ )的大小,以较大者为准。它可以直接存储所有基本类型和小型 “结构体/数组” 的值,但是对于较大的值,您必须使用指针。
|
||||
与 Go 不同,Emgo 不会为存储在接口变量中的值动态分配内存。接口类型的大小受限制,相当于三个指针(适合 `slice` )或两个 `float64`(适合 `complex128`)的大小,以较大者为准。它可以直接存储所有基本类型和小型 “结构体/数组” 的值,但是对于较大的值,你必须使用指针。
|
||||
|
||||
让我们编译此代码并查看其输出:
|
||||
|
||||
@ -661,9 +650,9 @@ Hello, World!
|
||||
.... . .-.. .-.. --- --..-- .-- --- .-. .-.. -.. ---.
|
||||
```
|
||||
|
||||
### 终极 Blinky
|
||||
### 终极闪烁
|
||||
|
||||
_Blinky_ 等效于 _Hello,World!_ 程序的硬件。一旦有了 Morse 编码器,我们就可以轻松地将两者结合起来以获得 _Ultimate Blinky_ 程序:
|
||||
Blinky 是等效于 “Hello,World!” 程序的硬件。一旦有了摩尔斯编码器,我们就可以轻松地将两者结合起来以获得终极闪烁程序:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -726,7 +715,7 @@ func main() {
|
||||
|
||||
```
|
||||
|
||||
在上面的示例中,我省略了 _MorseWriter_ 类型的定义,因为它已在前面展示过。完整版可通过 [这里][12] 获取。让我们编译它并运行:
|
||||
在上面的示例中,我省略了 `MorseWriter` 类型的定义,因为它已在前面展示过。完整版可通过 [这里][12] 获取。让我们编译它并运行:
|
||||
|
||||
```
|
||||
$ egc
|
||||
@ -739,9 +728,9 @@ $ arm-none-eabi-size cortexm0.elf
|
||||
|
||||
### 反射
|
||||
|
||||
是的,Emgo 支持 [反射][13]。 _reflect_ 包尚未完成,但是已完成的部分足以实现 _fmt.Print_ 函数族了。来看看我们可以在小型 MCU 上做什么。
|
||||
是的,Emgo 支持 [反射][13]。`reflect` 包尚未完成,但是已完成的部分足以实现 `fmt.Print` 函数族了。来看看我们可以在小型 MCU 上做什么。
|
||||
|
||||
为了减少内存使用,我们将使用 [semihosting][14] 作为标准输出。为了方便起见,我们还编写了简单的 _println_ 函数,它在某种程度上类似于 _fmt.Println_。
|
||||
为了减少内存使用,我们将使用 <ruby>[半主机][14]<rt>semihosting</rt></ruby> 作为标准输出。为了方便起见,我们还编写了简单的 `println` 函数,它在某种程度上类似于 `fmt.Println`。
|
||||
|
||||
```
|
||||
package main
|
||||
@ -819,15 +808,15 @@ func main() {
|
||||
|
||||
```
|
||||
|
||||
_semihosting.OpenFile_ 函数允许在主机端 打开/创建 文件。特殊路径 _:tt_ 对应于主机的标准输出。
|
||||
`semihosting.OpenFile` 函数允许在主机端打开/创建文件。特殊路径 `:tt` 对应于主机的标准输出。
|
||||
|
||||
_println_ 函数接受任意数量的参数,每个参数的类型都是任意的:
|
||||
`println` 函数接受任意数量的参数,每个参数的类型都是任意的:
|
||||
|
||||
```
|
||||
func println(args ...interface{})
|
||||
```
|
||||
|
||||
可能是因为任何类型都实现了空接口 _interface{}_。 _println_ 使用 [类型开关][15] 打印字符串,整数和布尔值:
|
||||
可能是因为任何类型都实现了空接口 `interface{}`。 `println` 使用 [类型开关][15] 打印字符串,整数和布尔值:
|
||||
|
||||
```
|
||||
switch v := a.(type) {
|
||||
@ -844,12 +833,11 @@ default:
|
||||
}
|
||||
```
|
||||
|
||||
此外,它还支持任何实现了 _stringer_ 接口的类型,即任何具有 _String()_ 方法的类型。在任何 _case_ 子句中,_v_ 变量具有正确的类型,与 _case_ 关键字后列出的类型相同。
|
||||
此外,它还支持任何实现了 `stringer` 接口的类型,即任何具有 `String()` 方法的类型。在任何 `case` 子句中,`v` 变量具有正确的类型,与 `case` 关键字后列出的类型相同。
|
||||
|
||||
`reflect.ValueOf(p)` 函数通过允许以编程的方式分析其类型和内容的形式返回 `p`。如你所见,我们甚至可以使用 `v.Elem()` 取消引用指针,并打印所有结构体及其名称。
|
||||
|
||||
reflect.ValueOf(p) 函数以允许以编程方式分析其类型和内容的形式返回 _p_。如您所见,我们甚至可以使用 `v.Elem()` 取消引用指针,并打印所有结构体及其名称。
|
||||
|
||||
让我们尝试编译这段代码。现在,让我们看看如果不使用类型和字段名进行编译会产生什么结果:
|
||||
让我们尝试编译这段代码。现在让我们看看如果编译时没有类型和字段名,会有什么结果:
|
||||
|
||||
```
|
||||
$ egc -nt -nf
|
||||
@ -858,7 +846,7 @@ $ arm-none-eabi-size cortexm0.elf
|
||||
16028 216 312 16556 40ac cortexm0.elf
|
||||
```
|
||||
|
||||
闪存上只剩下 140 个可用字节。让我们使用启用了 semihosting 的 OpenOCD 加载它:
|
||||
闪存上只剩下 140 个可用字节。让我们使用启用了半主机的 OpenOCD 加载它:
|
||||
|
||||
```
|
||||
$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; arm semihosting enable; reset run'
|
||||
@ -891,9 +879,9 @@ type(*p) =
|
||||
}
|
||||
```
|
||||
|
||||
如果您实际运行过此代码,则会注意到 semihosting 运行缓慢,尤其是在逐字节写入时(缓冲很有用)。
|
||||
如果你实际运行此代码,则会注意到半主机运行缓慢,尤其是在逐字节写入时(缓冲很有用)。
|
||||
|
||||
如您所见,`*p` 没有类型名称,并且所有结构字段都具有相同的 _X._ 名称。让我们再次编译该程序,这次不带 _-nt -nf_ 选项:
|
||||
如你所见,`*p` 没有类型名称,并且所有结构字段都具有相同的 `X.` 名称。让我们再次编译该程序,这次不带 `-nt -nf` 选项:
|
||||
|
||||
```
|
||||
$ egc
|
||||
@ -902,7 +890,7 @@ $ arm-none-eabi-size cortexm0.elf
|
||||
16052 216 312 16580 40c4 cortexm0.elf
|
||||
```
|
||||
|
||||
现在已经包括了类型和字段名称,但仅在 ~~_main.go_ 文件中~~ _main_ 包中定义了它们。该程序的输出如下所示:
|
||||
现在已经包括了类型和字段名称,但仅在 ~~_main.go_ 文件中~~ `main` 包中定义了它们。该程序的输出如下所示:
|
||||
|
||||
```
|
||||
kind(p) = ptr
|
||||
@ -922,15 +910,15 @@ type(*p) = S
|
||||
|
||||
via: https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html
|
||||
|
||||
作者:[Michał Derkacz ][a]
|
||||
作者:[Michał Derkacz][a]
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ziutek.github.io/
|
||||
[1]:https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html
|
||||
[2]:https://ziutek.github.io/2018/03/30/go_on_very_small_hardware.html
|
||||
[2]:https://linux.cn/article-11383-1.html
|
||||
[3]:https://golang.org/doc/effective_go.html#interfaces
|
||||
[4]:https://research.swtch.com/interfaces
|
||||
[5]:https://blog.golang.org/laws-of-reflection
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12737-1.html)
|
||||
[#]: subject: (Using Yarn on Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/install-yarn-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,15 +10,15 @@
|
||||
在 Ubuntu 和其他 Linux 发行版上使用 Yarn
|
||||
======
|
||||
|
||||
***本速成教程向您展示了在 Ubuntu 和 Debian Linux 上安装 Yarn 包管理器的官方方法。您还将学习到一些基本的 Yarn 命令以及彻底删除 Yarn 的步骤。***
|
||||
> 本速成教程向你展示了在 Ubuntu 和 Debian Linux 上安装 Yarn 包管理器的官方方法。你还将学习到一些基本的 Yarn 命令以及彻底删除 Yarn 的步骤。
|
||||
|
||||
[Yarn][1] 是 Facebook 开发的开源 JavaScript 包管理器。它是流行的 npm 包管理器的一个替代品,或者应该说是改进。 [Facebook 开发团队][2] 创建 Yarn 是为了克服 [npm][3] 的缺点。 Facebook 声称 Yarn 比 npm 更快、更可靠、更安全。
|
||||
|
||||
与 npm 一样,Yarn 为您提供一种自动安装、更新、配置和删除从全局注册表中检索到的程序包的方法。
|
||||
与 npm 一样,Yarn 为你提供一种自动安装、更新、配置和删除从全局注册库中检索到的程序包的方法。
|
||||
|
||||
Yarn 的优点是它更快,因为它缓存了已下载的每个包,所以无需再次下载。它还将操作并行化,以最大化资源利用率。在执行每个已安装的包代码之前,Yarn 还使用 [校验和来验证完整性][4]。 Yarn 还保证在一个系统上运行的安装,在任何其他系统上都会以完全相同地方式工作。
|
||||
Yarn 的优点是它更快,因为它可以缓存已下载的每个包,所以无需再次下载。它还将操作并行化,以最大化资源利用率。在执行每个已安装的包代码之前,Yarn 还使用 [校验和来验证完整性][4]。 Yarn 还保证可以在一个系统上运行的安装,在任何其他系统上都会以完全相同地方式工作。
|
||||
|
||||
如果您正 [在 Ubuntu 上使用 nodejs][5],那么您的系统上可能已经安装了 npm。在这种情况下,您可以通过以下方式使用 npm 全局安装 Yarn:
|
||||
如果你正 [在 Ubuntu 上使用 node.js][5],那么你的系统上可能已经安装了 npm。在这种情况下,你可以使用 npm 通过以下方式全局安装 Yarn:
|
||||
|
||||
```
|
||||
sudo npm install yarn -g
|
||||
@ -30,15 +30,15 @@ sudo npm install yarn -g
|
||||
|
||||
![Yarn JS][6]
|
||||
|
||||
这里提到的指令应该适用于所有版本的 Ubuntu,例如 Ubuntu 18.04、16.04 等。同样的指令集也适用于 Debian 和其他基于 Debian 的发行版。
|
||||
这里提到的说明应该适用于所有版本的 Ubuntu,例如 Ubuntu 18.04、16.04 等。同样的一组说明也适用于 Debian 和其他基于 Debian 的发行版。
|
||||
|
||||
由于本教程使用 curl 来添加 Yarn 项目的 GPG 密钥,所以最好验证一下您是否已经安装了 curl。
|
||||
由于本教程使用 `curl` 来添加 Yarn 项目的 GPG 密钥,所以最好验证一下你是否已经安装了 `curl`。
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
```
|
||||
|
||||
如果 curl 尚未安装,则上面的命令将安装它。既然有了 curl,您就可以使用它以如下方式添加 Yarn 项目的 GPG 密钥:
|
||||
如果 `curl` 尚未安装,则上面的命令将安装它。既然有了 `curl`,你就可以使用它以如下方式添加 Yarn 项目的 GPG 密钥:
|
||||
|
||||
```
|
||||
curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
|
||||
@ -50,14 +50,14 @@ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
|
||||
sudo sh -c 'echo "deb https://dl.yarnpkg.com/debian/ stable main" >> /etc/apt/sources.list.d/yarn.list'
|
||||
```
|
||||
|
||||
您现在可以继续了。[更新 Ubuntu][7] 或 Debian 系统,以刷新可用软件包列表,然后安装 Yarn:
|
||||
你现在可以继续了。[更新 Ubuntu][7] 或 Debian 系统,以刷新可用软件包列表,然后安装 Yarn:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install yarn
|
||||
```
|
||||
|
||||
这将一起安装 Yarn 和 nodejs。该过程完成后,请验证是否已成功安装 Yarn。 您可以通过检查 Yarn 版本来做到这一点。
|
||||
这将一起安装 Yarn 和 node.js。该过程完成后,请验证是否已成功安装 Yarn。 你可以通过检查 Yarn 版本来做到这一点。
|
||||
|
||||
```
|
||||
yarn --version
|
||||
@ -74,15 +74,15 @@ yarn --version
|
||||
|
||||
### 使用 Yarn
|
||||
|
||||
我假设您对 JavaScript 编程以及依赖项的工作原理有一些基本的了解。我在这里不做详细介绍。我将向您展示一些基本的 Yarn 命令,这些命令将帮助您入门。
|
||||
我假设你对 JavaScript 编程以及依赖项的工作原理有一些基本的了解。我在这里不做详细介绍。我将向你展示一些基本的 Yarn 命令,这些命令将帮助你入门。
|
||||
|
||||
#### 使用 Yarn 创建一个新项目
|
||||
|
||||
与 npm 一样,Yarn 也可以使用 package.json 文件。在这里添加依赖项。所有依赖包都缓存在项目根目录下的 node_modules 目录中。
|
||||
与 `npm` 一样,Yarn 也可以使用 `package.json` 文件。在这里添加依赖项。所有依赖包都缓存在项目根目录下的 `node_modules` 目录中。
|
||||
|
||||
在项目的根目录中,运行以下命令以生成新的 package.json 文件:
|
||||
在项目的根目录中,运行以下命令以生成新的 `package.json` 文件:
|
||||
|
||||
它会问您一些问题。您可以按 Enter 跳过或使用默认值。
|
||||
它会问你一些问题。你可以按回车键跳过或使用默认值。
|
||||
|
||||
```
|
||||
yarn init
|
||||
@ -99,7 +99,7 @@ success Saved package.json
|
||||
Done in 82.42s.
|
||||
```
|
||||
|
||||
这样,您就得到了一个如下的 package.json 文件:
|
||||
这样,你就得到了一个如下的 `package.json` 文件:
|
||||
|
||||
```
|
||||
{
|
||||
@ -112,17 +112,17 @@ Done in 82.42s.
|
||||
}
|
||||
```
|
||||
|
||||
现在您有了 package.json,您可以手动编辑它以添加或删除包依赖项,也可以使用 Yarn 命令(首选)。
|
||||
现在你有了 `package.json`,你可以手动编辑它以添加或删除包依赖项,也可以使用 Yarn 命令(首选)。
|
||||
|
||||
#### 使用 Yarn 添加依赖项
|
||||
|
||||
您可以通过以下方式添加对特定包的依赖关系:
|
||||
你可以通过以下方式添加对特定包的依赖关系:
|
||||
|
||||
```
|
||||
yarn add <package_name>
|
||||
yarn add <包名>
|
||||
```
|
||||
|
||||
例如,如果您想在项目中使用 [Lodash][8],则可以使用 Yarn 添加它,如下所示:
|
||||
例如,如果你想在项目中使用 [Lodash][8],则可以使用 Yarn 添加它,如下所示:
|
||||
|
||||
```
|
||||
yarn add lodash
|
||||
@ -141,7 +141,7 @@ info All dependencies
|
||||
Done in 2.67s.
|
||||
```
|
||||
|
||||
您可以看到,此依赖项已自动添加到 package.json 文件中:
|
||||
你可以看到,此依赖项已自动添加到 `package.json` 文件中:
|
||||
|
||||
```
|
||||
{
|
||||
@ -163,25 +163,25 @@ Done in 2.67s.
|
||||
yarn add package@version-or-tag
|
||||
```
|
||||
|
||||
像往常一样,您也可以手动更新 package.json 文件。
|
||||
像往常一样,你也可以手动更新 `package.json` 文件。
|
||||
|
||||
#### 使用 Yarn 升级依赖项
|
||||
|
||||
您可以使用以下命令将特定依赖项升级到其最新版本:
|
||||
你可以使用以下命令将特定依赖项升级到其最新版本:
|
||||
|
||||
```
|
||||
yarn upgrade <package_name>
|
||||
yarn upgrade <包名>
|
||||
```
|
||||
|
||||
它将查看所涉及的包是否具有较新的版本,并且会相应地对其进行更新。
|
||||
|
||||
您还可以通过以下方式更改已添加的依赖项的版本:
|
||||
你还可以通过以下方式更改已添加的依赖项的版本:
|
||||
|
||||
```
|
||||
yarn upgrade package_name@version_or_tag
|
||||
```
|
||||
|
||||
您还可以使用一个命令将项目的所有依赖项升级到它们的最新版本:
|
||||
你还可以使用一个命令将项目的所有依赖项升级到它们的最新版本:
|
||||
|
||||
```
|
||||
yarn upgrade
|
||||
@ -191,21 +191,21 @@ yarn upgrade
|
||||
|
||||
#### 使用 Yarn 删除依赖项
|
||||
|
||||
您可以通过以下方式从项目的依赖项中删除包:
|
||||
你可以通过以下方式从项目的依赖项中删除包:
|
||||
|
||||
```
|
||||
yarn remove <package_name>
|
||||
yarn remove <包名>
|
||||
```
|
||||
|
||||
#### 安装所有项目依赖项
|
||||
|
||||
如果对您 project.json 文件进行了任何更改,则应该运行
|
||||
如果对你 `project.json` 文件进行了任何更改,则应该运行:
|
||||
|
||||
```
|
||||
yarn
|
||||
```
|
||||
|
||||
或者
|
||||
或者,
|
||||
|
||||
```
|
||||
yarn install
|
||||
@ -215,7 +215,7 @@ yarn install
|
||||
|
||||
### 如何从 Ubuntu 或 Debian 中删除 Yarn
|
||||
|
||||
我将通过介绍从系统中删除 Yarn 的步骤来完成本教程,如果您使用上述步骤安装 Yarn 的话。如果您意识到不再需要 Yarn 了,则可以将它删除。
|
||||
我将通过介绍从系统中删除 Yarn 的步骤来完成本教程,如果你使用上述步骤安装 Yarn 的话。如果你意识到不再需要 Yarn 了,则可以将它删除。
|
||||
|
||||
使用以下命令删除 Yarn 及其依赖项。
|
||||
|
||||
@ -223,19 +223,19 @@ yarn install
|
||||
sudo apt purge yarn
|
||||
```
|
||||
|
||||
您也应该从源列表中把存储库信息一并删除掉:
|
||||
你也应该从源列表中把存储库信息一并删除掉:
|
||||
|
||||
```
|
||||
sudo rm /etc/apt/sources.list.d/yarn.list
|
||||
```
|
||||
|
||||
下一步删除已添加到受信任密钥的 GPG 密钥是可选的。但要做到这一点,您需要知道密钥。您可以使用 `apt-key` 命令获得它:
|
||||
下一步删除已添加到受信任密钥的 GPG 密钥是可选的。但要做到这一点,你需要知道密钥。你可以使用 `apt-key` 命令获得它:
|
||||
|
||||
```
|
||||
Warning: apt-key output should not be parsed (stdout is not a terminal) pub rsa4096 2016-10-05 [SC] 72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310 uid [ unknown] Yarn Packaging yarn@dan.cx sub rsa4096 2016-10-05 [E] sub rsa4096 2019-01-02 [S] [expires: 2020-02-02]
|
||||
Warning: apt-key output should not be parsed (stdout is not a terminal) pub rsa4096 2016-10-05 [SC] 72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310 uid [ unknown] Yarn Packaging yarn@dan.cx sub rsa4096 2016-10-05 [E] sub rsa4096 2019-01-02 [S] [expires: 2020-02-02]
|
||||
```
|
||||
|
||||
这里的密钥是以 pub 开始的行中 GPG 密钥指纹的最后 8 个字符。
|
||||
这里的密钥是以 `pub` 开始的行中 GPG 密钥指纹的最后 8 个字符。
|
||||
|
||||
因此,对于我来说,密钥是 `86E50310`,我将使用以下命令将其删除:
|
||||
|
||||
@ -243,11 +243,11 @@ Warning: apt-key output should not be parsed (stdout is not a terminal) pub rsa4
|
||||
sudo apt-key del 86E50310
|
||||
```
|
||||
|
||||
您会在输出中看到 OK,并且 Yarn 包的 GPG 密钥将从系统信任的 GPG 密钥列表中删除。
|
||||
你会在输出中看到 `OK`,并且 Yarn 包的 GPG 密钥将从系统信任的 GPG 密钥列表中删除。
|
||||
|
||||
我希望本教程可以帮助您在 Ubuntu、Debian、Linux Mint、 elementary OS 等操作系统上安装 Yarn。 我提供了一些基本的 Yarn 命令,以帮助您入门,并完成了从系统中删除 Yarn 的完整步骤。
|
||||
我希望本教程可以帮助你在 Ubuntu、Debian、Linux Mint、 elementary OS 等操作系统上安装 Yarn。 我提供了一些基本的 Yarn 命令,以帮助你入门,并完成了从系统中删除 Yarn 的完整步骤。
|
||||
|
||||
希望您喜欢本教程,如果有任何疑问或建议,请随时在下面留言。
|
||||
希望你喜欢本教程,如果有任何疑问或建议,请随时在下面留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -257,7 +257,7 @@ via: https://itsfoss.com/install-yarn-ubuntu
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chenmu-kk)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12768-1.html)
|
||||
[#]: subject: (My first contribution to open source: Making a decision)
|
||||
[#]: via: (https://opensource.com/article/19/11/my-first-open-source-contribution-mistake-decisions)
|
||||
[#]: author: (Galen Corey https://opensource.com/users/galenemco)
|
||||
|
||||
我的第一次开源贡献:做出决定
|
||||
======
|
||||
|
||||
> 一位新的开源贡献者告诉你如何加入到开源项目中。
|
||||
|
||||

|
||||
|
||||
先前,我把我的第一次开源贡献的拖延归咎于[冒牌综合症][2]。但还有一个我无法忽视的因素:我做出决定太艰难了。在[成千上百万][3]的开源项目中选择时,选择一个要做贡献的项目是难以抉择的。如此重负,以至于我常常不得不关掉我的笔记本去思考:“或许我改天再做吧”。
|
||||
|
||||
错误之二是让我对做出决定的恐惧妨碍了我做出第一次贡献。在理想世界里,也许开始我的开源之旅时,心中就已经有了一个真正关心和想去做的具体项目,但我有的只是总得为开源项目做出贡献的模糊目标。对于那些处于同一处境的人来说,这儿有一些帮助我挑选出合适的项目(或者至少是一个好的项目)来做贡献的策略。
|
||||
|
||||
### 经常使用的工具
|
||||
|
||||
一开始,我不认为有必要将自己局限于已经熟悉的工具或项目。有一些项目我之前从未使用过,但由于它们的社区很活跃,或者它们解决的问题很有趣,因此看起来很有吸引力。
|
||||
|
||||
但是,考虑我投入到这个项目中的时间有限,我决定继续投入到我了解的工具上去。要了解工具需求,你需要熟悉它的工作方式。如果你想为自己不熟悉的项目做贡献,则需要完成一个额外的步骤来了解代码的功能和目标。这个额外的工作量可能是有趣且值得的,但也会使你的工作时间加倍。因为我的目标主要是贡献,投入到我了解的工具上是缩小范围的很好方式。回馈一个你认为有用的项目也是有意义的。
|
||||
|
||||
### 活跃而友好的社区
|
||||
|
||||
在选择项目的时候,我希望在那里有人会审查我写的代码才会觉得有信心。当然,我也希望审核我代码的人是个和善的人。毕竟,把你的作品放在那里接受公众监督是很可怕的。虽然我对建设性的反馈持开放态度,但开发者社区中的一些有毒角落是我希望避免的。
|
||||
|
||||
为了评估我将要加入的社区,我查看了我正在考虑加入的仓库的<ruby>议题<rt>issue</rt></ruby>部分。我要查看核心团队中是否有人定期回复。更重要的是,我试着确保没有人在评论中互相诋毁(这在议题讨论中是很常见的)。我还留意了那些有行为准则的项目,概述了什么是适当的和不适当的在线互动行为。
|
||||
|
||||
### 明确的贡献准则
|
||||
|
||||
因为这是我第一次为开源项目做出贡献,在此过程中我有很多问题。一些项目社区在流程的文档记录方面做的很好,可以用来指导挑选其中的议题并发起拉取请求。 [Gatsby][4] 是这种做法的典范,尽管那时我没有选择它们,因为在此之前我从未使用过该产品。
|
||||
|
||||
这种清晰的文档帮助我们缓解了一些不知如何去做的不安全感。它也给了我希望:项目对新的贡献者是开放的,并且会花时间来查看我的工作。除了贡献准则外,我还查看了议题部分,看看这个项目是否使用了“<ruby>第一个好议题<rt>good first issue</rt></ruby>”标志。这是该项目对初学者开放的另一个迹象(并可以帮助你学会要做什么)。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你还没有计划好选择一个项目,那么选择合适的领域进行你的第一个开源贡献更加可行。列出一系列标准可以帮助自己缩减选择范围,并为自己的第一个拉取请求找到一个好的项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/my-first-open-source-contribution-mistake-decisions
|
||||
|
||||
作者:[Galen Corey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chenmu-kk](https://github.com/chenmu-kk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/galenemco
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lightbulb-idea-think-yearbook-lead.png?itok=5ZpCm0Jh (Lightbulb)
|
||||
[2]: https://opensource.com/article/19/10/my-first-open-source-contribution-mistakes
|
||||
[3]: https://github.blog/2018-02-08-open-source-project-trends-for-2018/
|
||||
[4]: https://www.gatsbyjs.org/contributing/
|
||||
@ -1,36 +1,35 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12766-1.html)
|
||||
[#]: subject: (Automate your container orchestration with Ansible modules for Kubernetes)
|
||||
[#]: via: (https://opensource.com/article/20/9/ansible-modules-kubernetes)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
|
||||
使用 Ansible Kubernetes 模块实现容器编排自动化
|
||||
使用 Ansible 的 Kubernetes 模块实现容器编排自动化
|
||||
======
|
||||
> 在云上的 Kubernetes 中结合 Ansible 实现自动化的同时,还可以参照我们的速记表熟悉 Ansible 的 k8s 模块。
|
||||
|
||||
![Ship captain sailing the Kubernetes seas][1]
|
||||
> 将 Kubernetes 与 Ansible 结合实现云端自动化。此外,还可以参照我们的 Ansible 的 k8s 模块速查表。
|
||||
|
||||

|
||||
|
||||
[Ansible][2] 是实现自动化工作的优秀工具,而 [Kubernetes][3] 则是容器编排方面的利器,要是把两者结合起来,会有怎样的效果呢?正如你所猜测的,Ansible + Kubernetes 的确可以实现容器编排自动化。
|
||||
|
||||
### Ansible 模块
|
||||
|
||||
实际上,Ansible 本身只是一个用于解释 YAML 文件的框架。它真正强大之处在于它[丰富的模块][4],所谓<ruby>模块<rt>module</rt></ruby>,就是在 Ansible playbook 中让你得以通过简单配置就能调用外部应用程序的一些工具。
|
||||
实际上,Ansible 本身只是一个用于解释 YAML 文件的框架。它真正强大之处在于它[丰富的模块][4],所谓<ruby>模块<rt>module</rt></ruby>,就是在 Ansible <ruby>剧本<rt>playbook</rt></ruby> 中让你得以通过简单配置就能调用外部应用程序的一些工具。
|
||||
|
||||
Ansible 中有模块可以直接操作 Kubernetes,也有对一些相关组件(例如 [Docker][5] 和 [Podman][6])实现操作的模块。学习使用一个新模块的过程和学习新的终端命令、API 一样,可以先从文档中了解这个模块在调用的时候需要接受哪些参数,以及这些参数在外部应用程序中产生的具体作用。
|
||||
|
||||
### 访问 Kubernetes 集群
|
||||
|
||||
在使用 Ansible Kubernetes 模块之前,先要有能够访问 Kubernetes 集群的权限。在没有权限的情况下,可以尝试使用一个短期账号,但我们更推荐的是按照 Kubernetes 官网上的指引,或是参考 Braynt Son 《[入门 Kubernetes][8]》的教程安装 [Minikube][7]。Minikube 提供了一个单节点 Kubernetes 实例的安装过程,你可以像使用一个完整集群一样对其进行配置和交互。
|
||||
在使用 Ansible Kubernetes 模块之前,先要有能够访问 Kubernetes 集群的权限。在没有权限的情况下,可以尝试使用一个短期在线试用账号,但我们更推荐的是按照 Kubernetes 官网上的指引,或是参考 Braynt Son 《[入门 Kubernetes][8]》的教程安装 [Minikube][7]。Minikube 提供了一个单节点 Kubernetes 实例的安装过程,你可以像使用一个完整集群一样对其进行配置和交互。
|
||||
|
||||
**[下载 [Ansible k8s 速记表][9]]**
|
||||
- 下载 [Ansible k8s 速记表][9](需注册)
|
||||
|
||||
在安装 Minikube 之前,你需要确保你的环境支持虚拟化并安装 `libvirt`,然后对 `libvirt` 用户组授权:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install libvirt
|
||||
$ sudo systemctl start libvirtd
|
||||
@ -42,7 +41,6 @@ $ newgrp libvirt
|
||||
|
||||
为了能够在 Ansible 中使用 Kubernetes 相关的模块,你需要安装以下这些 Python 模块:
|
||||
|
||||
|
||||
```
|
||||
$ pip3.6 install kubernetes --user
|
||||
$ pip3.6 install openshift --user
|
||||
@ -52,9 +50,8 @@ $ pip3.6 install openshift --user
|
||||
|
||||
如果你使用的是 Minikube 而不是完整的 Kubernetes 集群,请使用 `minikube` 命令在本地创建一个最精简化的 Kubernetes 实例:
|
||||
|
||||
|
||||
```
|
||||
`$ minikube start --driver=kvm2 --kvm-network default`
|
||||
$ minikube start --driver=kvm2 --kvm-network default
|
||||
```
|
||||
|
||||
然后等待 Minikube 完成初始化,这个过程所需的时间会因实际情况而异。
|
||||
@ -63,29 +60,26 @@ $ pip3.6 install openshift --user
|
||||
|
||||
集群启动以后,通过 `cluster-info` 选项就可以获取到集群相关信息了:
|
||||
|
||||
|
||||
```
|
||||
$ kubectl cluster-info
|
||||
Kubernetes master is running at <https://192.168.39.190:8443>
|
||||
KubeDNS is running at <https://192.168.39.190:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy>
|
||||
Kubernetes master is running at https://192.168.39.190:8443
|
||||
KubeDNS is running at https://192.168.39.190:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
|
||||
|
||||
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
|
||||
```
|
||||
|
||||
### 使用 `k8s` 模块
|
||||
|
||||
Ansible 使用 `k8s` 这个模块来实现对 Kubernetes 的操作,在 playbook 中使用 `k8s` 模块就可以对 Kuvernetes 对象进行管理。这个模块描述了 `kubectl` 命令的最终状态,例如对于以下这个使用 `kubectl` 创建新的[命名空间][10]的操作:
|
||||
### 使用 k8s 模块
|
||||
|
||||
Ansible 使用 `k8s` 这个模块来实现对 Kubernetes 的操作,在剧本中使用 `k8s` 模块就可以对 Kuvernetes 对象进行管理。这个模块描述了 `kubectl` 命令的最终状态,例如对于以下这个使用 `kubectl` 创建新的[命名空间][10]的操作:
|
||||
|
||||
```
|
||||
`$ kubectl create namespace my-namespace`
|
||||
$ kubectl create namespace my-namespace
|
||||
```
|
||||
|
||||
这是一个很简单的操作,而对这个操作的最终状态用 YAML 文件来描述是这样的:
|
||||
|
||||
|
||||
```
|
||||
\- hosts: localhost
|
||||
- hosts: localhost
|
||||
tasks:
|
||||
- name: create namespace
|
||||
k8s:
|
||||
@ -95,25 +89,22 @@ Ansible 使用 `k8s` 这个模块来实现对 Kubernetes 的操作,在 playboo
|
||||
state: present
|
||||
```
|
||||
|
||||
如果你使用的是 Minikube,那么主机名应该定义为 `localhost`。需要注意的是,模块中对其它可用参数也定义了对应的语法(例如 `api_version` 和 `kind` 参数)。
|
||||
|
||||
在运行这个 playbook 之前,先通过 `yamllint` 命令验证是否有错误:
|
||||
如果你使用的是 Minikube,那么主机名(`hosts`)应该定义为 `localhost`。需要注意的是,所使用的模块也定义了可用参数的语法(例如 `api_version` 和 `kind` 参数)。
|
||||
|
||||
在运行这个剧本之前,先通过 `yamllint` 命令验证是否有错误:
|
||||
|
||||
```
|
||||
`$ yamllint example.yaml`
|
||||
$ yamllint example.yaml
|
||||
```
|
||||
|
||||
确保没有错误之后,运行 playbook:
|
||||
|
||||
确保没有错误之后,运行剧本:
|
||||
|
||||
```
|
||||
`$ ansible-playbook ./example.yaml`
|
||||
$ ansible-playbook ./example.yaml
|
||||
```
|
||||
|
||||
可以验证新的命名空间是否已经被创建出来:
|
||||
|
||||
|
||||
```
|
||||
$ kubectl get namespaces
|
||||
NAME STATUS AGE
|
||||
@ -127,10 +118,9 @@ my-namespace Active 3s
|
||||
|
||||
### 使用 Podman 拉取容器镜像
|
||||
|
||||
容器是受 Kubernetes 管理的最小单位 Linux 系统,因此 [LXC 项目][11]和 Docker 对容器定义了很多规范。Podman 是一个最新的容器操作工具集,它不需要守护进程就可以运行,为此受到了很多用户的欢迎。
|
||||
|
||||
通过 Podman 可以从 Docker Hub 或者 Quay.io 拉取到容器镜像。这一操作对应的 Ansible 语法也很简单,只需要将存储库网站提供的镜像路径写在 playbook 中的相应位置就可以了:
|
||||
容器是个 Linux 系统,几乎是最小化的,可以由 Kubernetes 管理。[LXC 项目][11]和 Docker 定义了大部分的容器规范。最近加入容器工具集的是 Podman,它不需要守护进程就可以运行,为此受到了很多用户的欢迎。
|
||||
|
||||
通过 Podman 可以从 Docker Hub 或者 Quay.io 等存储库拉取容器镜像。这一操作对应的 Ansible 语法也很简单,只需要将存储库网站提供的镜像路径写在剧本中的相应位置就可以了:
|
||||
|
||||
```
|
||||
- name: pull an image
|
||||
@ -140,13 +130,11 @@ my-namespace Active 3s
|
||||
|
||||
使用 `yamllint` 验证:
|
||||
|
||||
|
||||
```
|
||||
`$ yamllint example.yaml`
|
||||
$ yamllint example.yaml
|
||||
```
|
||||
|
||||
运行 playbook:
|
||||
|
||||
运行剧本:
|
||||
|
||||
```
|
||||
$ ansible-playbook ./example.yaml
|
||||
@ -171,8 +159,7 @@ localhost: ok=3 changed=1 unreachable=0 failed=0
|
||||
|
||||
### 使用 Ansible 实现部署
|
||||
|
||||
Ansible 除了可以执行小型维护任务以外,还可以通过 playbook 实现其它由 `kubectl` 实现的功能,因为两者的 YAML 文件之间只有少量的差异。 在 Kubernetes 中使用的 YAML 文件只需要稍加改动,就可以在 Ansible playbook 中使用。例如下面这个用于使用 `kubectl` 命令部署 Web 服务器的 YAML 文件:
|
||||
|
||||
Ansible 除了可以执行小型维护任务以外,还可以通过剧本实现其它由 `kubectl` 实现的功能,因为两者的 YAML 文件之间只有少量的差异。在 Kubernetes 中使用的 YAML 文件只需要稍加改动,就可以在 Ansible 剧本中使用。例如下面这个用于使用 `kubectl` 命令部署 Web 服务器的 YAML 文件:
|
||||
|
||||
```
|
||||
apiVersion: apps/v1
|
||||
@ -196,8 +183,7 @@ spec:
|
||||
- containerPort: 80
|
||||
```
|
||||
|
||||
如果你对其中的参数比较熟悉,你只要把 YAML 文件中的大部分内容放到 playbook 中的 `definition` 部分,就可以在 Ansible 中使用了:
|
||||
|
||||
如果你对其中的参数比较熟悉,你只要把 YAML 文件中的大部分内容放到剧本中的 `definition` 部分,就可以在 Ansible 中使用了:
|
||||
|
||||
```
|
||||
- name: deploy a web server
|
||||
@ -230,7 +216,6 @@ spec:
|
||||
|
||||
执行完成后,使用 `kubectl` 命令可以看到预期中的的<ruby>部署<rt>deployment</rt></ruby>:
|
||||
|
||||
|
||||
```
|
||||
$ kubectl -n my-namespace get pods
|
||||
NAME READY STATUS
|
||||
@ -248,7 +233,7 @@ via: https://opensource.com/article/20/9/ansible-modules-kubernetes
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,169 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12740-1.html)
|
||||
[#]: subject: (How to Reduce/Shrink LVM’s \(Logical Volume Resize\) in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 中减少/缩小 LVM 大小(逻辑卷调整)
|
||||
======
|
||||
|
||||

|
||||
|
||||
减少/缩小逻辑卷是数据损坏的最高风险。
|
||||
|
||||
所以,如果可能的话,尽量避免这种情况,但如果没有其他选择的话,那就继续。
|
||||
|
||||
缩减 LVM 之前,建议先做一个备份。
|
||||
|
||||
当你在 LVM 中的磁盘空间耗尽时,你可以通过缩小现有的没有使用全部空间的 LVM,而不是增加一个新的物理磁盘,在卷组上腾出一些空闲空间。
|
||||
|
||||
**需要注意的是:** 在 GFS2 或者 XFS 文件系统上不支持缩小。
|
||||
|
||||
如果你是逻辑卷管理 (LVM) 的新手,我建议你从我们之前的文章开始学习。
|
||||
|
||||
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)][1]**
|
||||
* **第二部分:[如何在 Linux 中扩展/增加 LVM(逻辑卷调整)][2]**
|
||||
|
||||
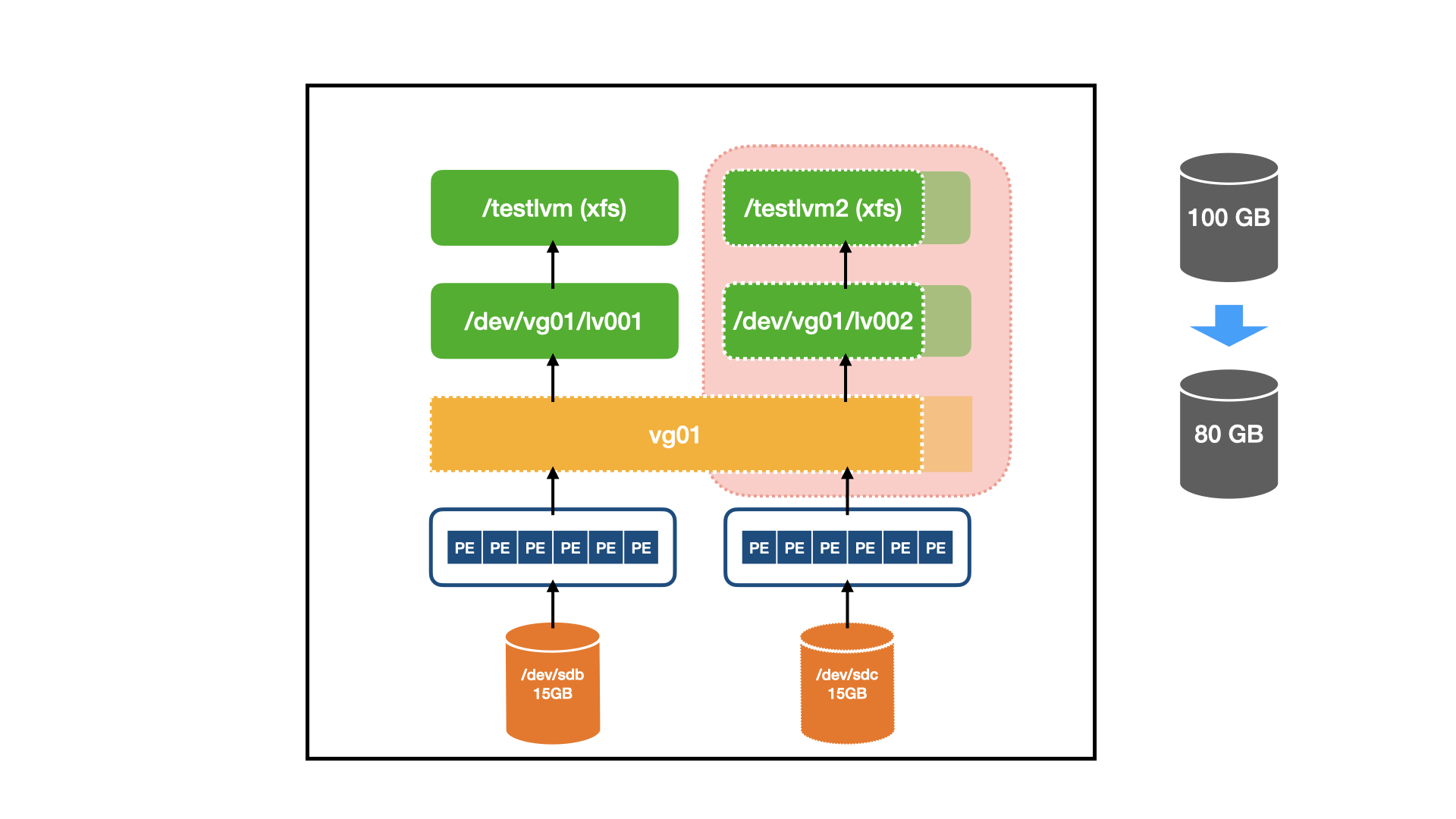
|
||||
|
||||
减少逻辑卷涉及以下步骤:
|
||||
|
||||
* 卸载文件系统
|
||||
* 检查文件系统是否有任何错误
|
||||
* 缩小文件系统的大小
|
||||
* 缩小逻辑卷的大小
|
||||
* 重新检查文件系统是否存在错误(可选)
|
||||
* 挂载文件系统
|
||||
* 检查减少后的文件系统大小
|
||||
|
||||
**比如:** 你有一个 **100GB** 的没有使用全部空间的 LVM,你想把它减少到 **80GB**,这样 **20GB** 可以用于其他用途。
|
||||
|
||||
```
|
||||
# df -h /testlvm1
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg01-lv002 100G 15G 85G 12% /testlvm1
|
||||
```
|
||||
|
||||
### 卸载文件系统
|
||||
|
||||
使用 `umount` 命令卸载文件系统:
|
||||
|
||||
```
|
||||
# umount /testlvm1
|
||||
```
|
||||
|
||||
### 检查文件系统是否有任何错误
|
||||
|
||||
使用 `e2fsck` 命令检查文件系统是否有错误:
|
||||
|
||||
```
|
||||
# e2fsck -f /dev/mapper/vg01-lv002
|
||||
|
||||
e2fsck 1.42.9 (28-Dec-2013)
|
||||
Pass 1: Checking inodes, blocks, and sizes
|
||||
Pass 2: Checking directory structure
|
||||
Pass 3: Checking directory connectivity
|
||||
Pass 4: Checking reference counts
|
||||
Pass 5: Checking group summary information
|
||||
/dev/mapper/vg01-lv002: 13/6553600 files (0.0% non-contiguous), 12231854/26212352 blocks
|
||||
```
|
||||
|
||||
### 缩小文件系统
|
||||
|
||||
下面的命令将把 `testlvm1` 文件系统从 **100GB** 缩小到 **80GB**。
|
||||
|
||||
**文件系统大小调整的常用语法(`resize2fs`)**:
|
||||
|
||||
```
|
||||
resize2fs [现有逻辑卷名] [新的文件系统大小]
|
||||
```
|
||||
|
||||
实际命令如下:
|
||||
|
||||
```
|
||||
# resize2fs /dev/mapper/vg01-lv002 80G
|
||||
|
||||
resize2fs 1.42.9 (28-Dec-2013)
|
||||
Resizing the filesystem on /dev/mapper/vg01-lv002 to 28321400 (4k) blocks.
|
||||
The filesystem on /dev/mapper/vg01-lv002 is now 28321400 blocks long.
|
||||
```
|
||||
|
||||
### 减少逻辑卷 (LVM) 容量
|
||||
|
||||
现在使用 `lvreduce` 命令缩小逻辑卷(LVM) 的大小。通过下面的命令, `/dev/mapper/vg01-lv002` 将把逻辑卷 (LVM) 从 100GB 缩小到 80GB。
|
||||
|
||||
**LVM 缩减 (`lvreduce`) 的常用语法**:
|
||||
|
||||
```
|
||||
lvreduce [新的 LVM 大小] [现有逻辑卷名称]
|
||||
```
|
||||
|
||||
实际命令如下:
|
||||
|
||||
```
|
||||
# lvreduce -L 80G /dev/mapper/vg01-lv002
|
||||
|
||||
WARNING: Reducing active logical volume to 80.00 GiB
|
||||
THIS MAY DESTROY YOUR DATA (filesystem etc.)
|
||||
Do you really want to reduce lv002? [y/n]: y
|
||||
Reducing logical volume lv002 to 80.00 GiB
|
||||
Logical volume lv002 successfully resized
|
||||
```
|
||||
|
||||
### 可选:检查文件系统是否有错误
|
||||
|
||||
缩减 LVM 后再次检查文件系统是否有错误:
|
||||
|
||||
```
|
||||
# e2fsck -f /dev/mapper/vg01-lv002
|
||||
|
||||
e2fsck 1.42.9 (28-Dec-2013)
|
||||
Pass 1: Checking inodes, blocks, and sizes
|
||||
Pass 2: Checking directory structure
|
||||
Pass 3: Checking directory connectivity
|
||||
Pass 4: Checking reference counts
|
||||
Pass 5: Checking group summary information
|
||||
/dev/mapper/vg01-lv002: 13/4853600 files (0.0% non-contiguous), 1023185/2021235 blocks
|
||||
```
|
||||
|
||||
### 挂载文件系统并检查缩小后的大小
|
||||
|
||||
最后挂载文件系统,并检查缩小后的文件系统大小。
|
||||
|
||||
使用 `mount` 命令[挂载逻辑卷][4]:
|
||||
|
||||
```
|
||||
# mount /testlvm1
|
||||
```
|
||||
|
||||
使用 [df 命令][5]检查挂载的卷。
|
||||
|
||||
```
|
||||
# df -h /testlvm1
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg01-lv002 80G 15G 65G 18% /testlvm1
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-12670-1.html
|
||||
[2]: https://linux.cn/article-12673-1.html
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2020/09/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux-1.png
|
||||
[4]: https://www.2daygeek.com/mount-unmount-file-system-partition-in-linux/
|
||||
[5]: https://www.2daygeek.com/linux-check-disk-space-usage-df-command/
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12748-1.html)
|
||||
[#]: subject: (Linux Jargon Buster: What is FOSS \(Free and Open Source Software\)? What is Open Source?)
|
||||
[#]: via: (https://itsfoss.com/what-is-foss/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -47,26 +47,26 @@ FOSS 是指<ruby>自由和开放源码软件<rt>Free and Open Source Software</r
|
||||
|
||||
![][4]
|
||||
|
||||
你可能已经注意到了,自由和开源软件中的 “Free” 并不意味着它是免费的,它意味着运行、修改和分发软件的自由。
|
||||
你可能已经注意到了,自由和开源软件中的 “Free” 并不意味着它是免费的,它意味着运行、修改和分发软件的“自由”。
|
||||
|
||||
人们经常错误地认为,FOSS 或开源软件不能有价格标签。这是不正确的。
|
||||
|
||||
大多数 FOSS 都是免费提供的,原因有很多:
|
||||
|
||||
* 源代码已经向公众开放,所以一些开发者认为没有必要在下载上贴上价格标签。
|
||||
* 源代码已经向公众开放,所以一些开发者认为没有必要在下载软件时贴上价格标签。
|
||||
* 有些项目是由一些志愿者免费提供的。因此,主要的开发者认为对这么多人免费贡献的东西收费是不道德的。
|
||||
* 有些项目是由较大的企业或非营利组织支持和/或开发的,这些组织会雇佣开发人员在他们的开源项目上工作。
|
||||
* 有些开发者创建开源项目是出于兴趣,或者出于他们对用代码为世界做贡献的热情。对他们来说,下载量、贡献和感谢的话比金钱更重要。
|
||||
|
||||
为了避免强调 “免费”,有些人使用了 FLOSS 这个词。FLOSS 是<ruby>自由和开源软件<rt>Free/Libre Open Source Software</rt></ruby>的缩写。单词 Libre(意为自由)与 gartuit/gratis(免费)不同。
|
||||
为了避免强调 “免费”,有些人使用了 FLOSS 这个词(LCTT 译注:有时候也写作 F/LOSS)。FLOSS 是<ruby>自由和开源软件<rt>Free/Libre Open Source Software</rt></ruby>的缩写。单词 Libre(意为自由)与 gartuit/gratis(免费)不同。
|
||||
|
||||
> “Free”是言论自由的自由,而不是如免费啤酒的免费。
|
||||
> “Free” 是言论自由的自由,而不是免费啤酒的免费。
|
||||
|
||||
### FOSS 项目如何赚钱?
|
||||
|
||||
开源项目不赚钱是一个神话。红帽是第一个达到 10 亿美元大关的开源公司。[IBM 以 340 亿美元收购了红帽][5]。这样的例子有很多。
|
||||
|
||||
许多开源项目,特别是企业领域的项目,都会提供收费的支持和面向企业的功能。这是R红帽、SUSE Linux 和更多此类项目的主要商业模式。
|
||||
许多开源项目,特别是企业领域的项目,都会提供收费的支持和面向企业的功能。这是红帽、SUSE Linux 和更多此类项目的主要商业模式。
|
||||
|
||||
一些开源项目,如 Discourse、WordPress 等,则提供其软件的托管实例,并收取一定的费用。
|
||||
|
||||
@ -86,13 +86,13 @@ FOSS 是指<ruby>自由和开放源码软件<rt>Free and Open Source Software</r
|
||||
|
||||
### FOSS 与开源之间的区别是什么?
|
||||
|
||||
你会经常遇到 FOSS 和开源的术语。它们经常被互换使用。
|
||||
你会经常遇到 FOSS 和<ruby>开源<rt>Open Source</rt></ruby>的术语。它们经常被互换使用。
|
||||
|
||||
它们是同一件事吗?这很难用“是”和“不是”来回答。
|
||||
|
||||
你看,FOSS 中的“Free”一词让很多人感到困惑,因为人们错误地认为它是免费的。企业高管、高层和决策者往往会关注自由和开源中的“免费”。由于他们是商业人士,专注于为他们的公司赚钱,“自由”一词在采用 FOSS 原则时起到了威慑作用。
|
||||
|
||||
这就是为什么在上世纪 90 年代中期创建出了一个名为<ruby>[开源促进会][8]<rt>Open Source Initiative</rt></ruby>的新组织。他们从自由和开放源码软件中去掉了“自由”一词,并创建了自己的[开放源码的定义][9],以及自己的一套许可证。
|
||||
这就是为什么在上世纪 90 年代中期创立了一个名为<ruby>[开源促进会][8]<rt>Open Source Initiative</rt></ruby>的新组织。他们从自由和开放源码软件中去掉了“自由”一词,并创建了自己的[开放源码的定义][9],以及自己的一套许可证。
|
||||
|
||||
“<ruby>开源<rt>Open Source</rt></ruby>”一词在软件行业特别流行。高管们对开源更加适应。开源软件的采用迅速增长,我相信 “免费”一词的删除确实起到了作用。
|
||||
|
||||
@ -111,7 +111,7 @@ via: https://itsfoss.com/what-is-foss/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,51 +1,50 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12738-1.html)
|
||||
[#]: subject: (Simplify your web experience with this internet protocol alternative)
|
||||
[#]: via: (https://opensource.com/article/20/10/gemini-internet-protocol)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用此互联网协议替代方案简化你的 Web 体验
|
||||
使用互联网协议替代方案 Gemini 简化你的 Web 体验
|
||||
======
|
||||
用 Gemini 协议发现更安静、更简单的互联网新角落。
|
||||
![Person typing on a 1980's computer][1]
|
||||
|
||||
如果你已经上网了很长时间,或者只是了解很多,你可能还记得一个早期的文本共享协议,叫做 [Gopher][2]。Gopher 最终被 HTTP 协议所取代,当然,HTTP 协议是现代万维网的基础。对于很多人来说,”互联网“和”万维网“是一回事,因为很多人并不会有意识地做_不_在 www 子域下的事情。
|
||||
> 用 Gemini 协议发现更安静、更简单的互联网新角落。
|
||||
|
||||
但一直以来,都有各种网络协议在互联网络上共享信息。Telnet、FTP、SSH、Torrent、GNUnet 等等。最近,在这一系列的替代品中又多了一个,它叫 [Gemini][3]。
|
||||

|
||||
|
||||
Gemini 协议,以”水星计划“和”阿波罗计划“的基础实验之间的太空任务命名,旨在和平地处在 Gopher 和 HTTP 之间。无论如何,它的目的并不是要取代现代 Web,但它确实试图创造一个简化的网络和一个现代化的 Gopher。
|
||||
如果你很久以前就已经上网了,或者是知识非常丰富,你可能还记得一个早期的文本共享协议,叫做 [Gopher][2]。Gopher 最终被 HTTP 协议所取代,当然,HTTP 协议是现代万维网的基础。对于很多人来说,“<ruby>互联网<rt>internet</rt></ruby>”和“<ruby>万维网<rt>World Wide Web</rt></ruby>”是一回事,因为很多人没有意识到在网上进行了*非* www 子域下的任何操作。
|
||||
|
||||
它的发展虽然可能很年轻,但意义重大,原因有很多。当然,人们会因为技术和哲学上的原因而对现代 Web 表示质疑,但它只是一般的臃肿。当你真正想要的是一个非常具体的问题的可靠答案时,那么无数次点击谷歌搜索的结果让人感觉过头了。
|
||||
但一直以来,都有各种网络协议在互联网络上共享信息:Telnet、FTP、SSH、Torrent、GNUnet 等等。最近,在这一系列的替代品中又多了一个,它叫 [Gemini][3]。
|
||||
|
||||
Gemini(双子座)协议,以“水星计划”和“阿波罗计划”的基础实验之间的太空任务命名,旨在和平地处在 Gopher 和 HTTP 之间。无论如何,它的目的并不是要取代现代 Web,但它确实试图创造一个简化的网络和一个现代化的 Gopher。
|
||||
|
||||
它的发展历史虽然可能很年轻,但意义重大,原因有很多。当然,人们会因为技术和哲学上的原因而对现代 Web 表示质疑,但它只是一般的臃肿。当你真正想要的是一个非常具体的问题的可靠答案时,那么无数次点击谷歌搜索的结果让人感觉过头了。
|
||||
|
||||
许多人使用 Gopher 就是因为这个原因:它的规模小到可以让小众的兴趣很容易找到。然而,Gopher 是一个旧的协议,它对编程、网络和浏览做出了一些假设,但这些假设已经不再适用了。 Gemini 的目标是将最好的网络带入一种类似于 Gopher 但易于编程的格式。一个简单的 Gemini 浏览器可以用几百行代码写成,并且有一个非常好的浏览器用 1600 行左右写成。这对于程序员、学生和极简主义者来说都是一个强大的功能。
|
||||
|
||||
### 如何浏览 Gemini
|
||||
|
||||
就像早期的网络一样,Gemini 的规模很小,有一个运行 Gemini 网站的已知服务器列表。就像浏览 HTTP 站点需要一个网页浏览器一样,访问 Gemini 站点也需要一个 Gemini 浏览器。已经有几个可用的,在 [Gemini 网站][4]上列出。
|
||||
就像早期的网络一样,Gemini 的规模很小,所以有一个列表列出了运行 Gemini 网站的已知服务器。就像浏览 HTTP 站点需要一个网页浏览器一样,访问 Gemini 站点也需要一个 Gemini 浏览器。在 [Gemini 网站][4]上列出了有几个可用的浏览器。
|
||||
|
||||
最简单的一个是 [AV-98][5] 客户端。它是用 Python 编写的,在终端中运行。要想试试的话,请下载它:
|
||||
|
||||
|
||||
```
|
||||
`$ git clone https://tildegit.org/solderpunk/AV-98.git`
|
||||
$ git clone https://tildegit.org/solderpunk/AV-98.git
|
||||
```
|
||||
|
||||
进入下载目录,运行 AV-98:
|
||||
|
||||
|
||||
```
|
||||
$ cd AV-98.git
|
||||
$ python3 ./main.py
|
||||
```
|
||||
|
||||
客户端是一个交互式的提示。它有有限的几个命令,主要的命令是简单的 `go`,后面跟着一个 Gemini 服务器地址。进入已知的 [Gemini 服务器][6]列表,选择一个看起来很有趣的服务器,然后尝试访问它:
|
||||
|
||||
客户端是一个交互式的提示符。它有有限的几个命令,主要的命令是简单的 `go`,后面跟着一个 Gemini 服务器地址。在已知的 [Gemini 服务器][6]列表中选择一个看起来很有趣的服务器,然后尝试访问它:
|
||||
|
||||
```
|
||||
AV-98> go gemini://example.club
|
||||
AV-98> go gemini://example.club
|
||||
|
||||
Welcome to the example.club Gemini server!
|
||||
|
||||
@ -56,11 +55,11 @@ Here are some folders of ASCII art:
|
||||
[3] Demons
|
||||
```
|
||||
|
||||
导航是按照编号的链接来进行的。例如,要进入 Penguins 目录,输入 `1` 然后按回车键:
|
||||
导航是按照编号的链接来进行的。例如,要进入 `Penguins` 目录,输入 `1` 然后按回车键:
|
||||
|
||||
|
||||
```
|
||||
AV-98> 1
|
||||
AV-98> 1
|
||||
|
||||
[1] Gentoo
|
||||
[2] Emperor
|
||||
@ -69,14 +68,13 @@ AV-98> 1
|
||||
|
||||
要返回,输入 `back` 并按回车键:
|
||||
|
||||
|
||||
```
|
||||
`AV-98> back`
|
||||
AV-98> back
|
||||
```
|
||||
|
||||
更多命令,请输入 `help`。
|
||||
|
||||
### Gemini 作为你的 web 替代
|
||||
### 用 Gemini 作为你的 web 替代
|
||||
|
||||
Gemini 协议非常简单,初级和中级程序员都可以为其编写客户端,而且它是在互联网上分享内容的一种简单快捷的方式。虽然万维网的无处不在对广泛传播是有利的,但总有替代方案的空间。看看 Gemini,发现更安静、更简单的互联网的新角落。
|
||||
|
||||
@ -87,7 +85,7 @@ via: https://opensource.com/article/20/10/gemini-internet-protocol
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,181 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12750-1.html)
|
||||
[#]: subject: (How to Remove Physical Volume from a Volume Group in LVM)
|
||||
[#]: via: (https://www.2daygeek.com/linux-remove-delete-physical-volume-pv-from-volume-group-vg-in-lvm/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何从 LVM 的卷组中删除物理卷?
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你的 LVM 不再需要使用某个设备,你可以使用 `vgreduce` 命令从卷组中删除物理卷。
|
||||
|
||||
`vgreduce` 命令可以通过删除物理卷来缩小卷组的容量。但要确保该物理卷没有被任何逻辑卷使用,请使用 `pvdisplay` 命令查看。如果物理卷仍在使用,你必须使用 `pvmove` 命令将数据转移到另一个物理卷。
|
||||
|
||||
数据转移后,它就可以从卷组中删除。
|
||||
|
||||
最后使用 `pvremove` 命令删除空物理卷上的 LVM 标签和 LVM 元数据。
|
||||
|
||||
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)][1]**
|
||||
* **第二部分:[如何在 Linux 中扩展/增加 LVM 大小(逻辑卷调整)][2]**
|
||||
* **第三部分:[如何在 Linux 中减少/缩小 LVM 大小(逻辑卷调整)][3]**
|
||||
|
||||
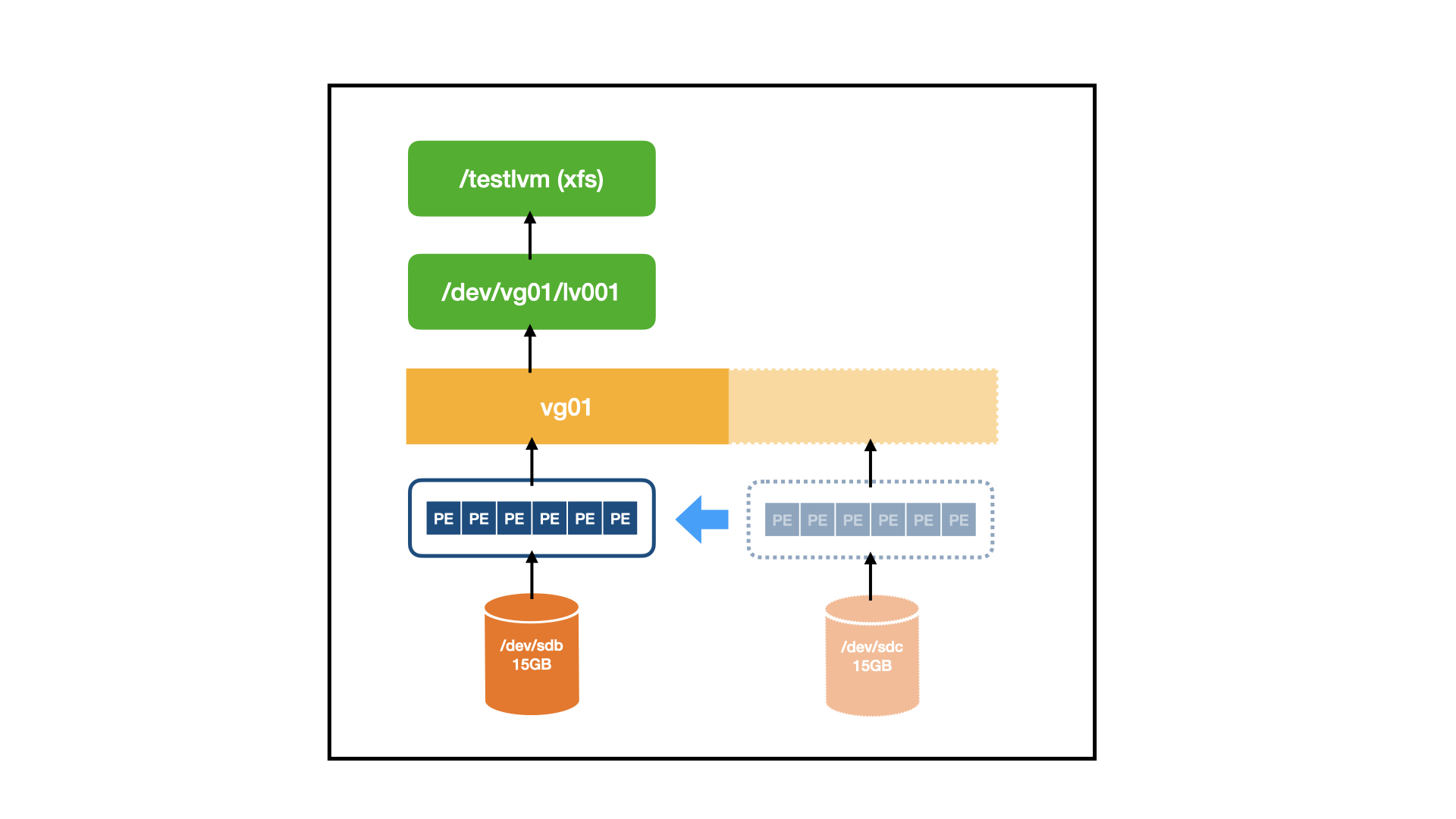
|
||||
|
||||
### 将扩展块移动到现有物理卷上
|
||||
|
||||
使用 `pvs` 命令检查是否使用了所需的物理卷(我们计划删除 LVM 中的 `/dev/sdc` 磁盘)。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda myvg lvm2 a- 75.00G 14.00G 61.00G
|
||||
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
|
||||
/dev/sdc myvg lvm2 a- 17.15G 12.15G 5.00G
|
||||
```
|
||||
|
||||
如果使用了,请检查卷组中的其他物理卷是否有足够的空闲<ruby>扩展块<rt>extent</rt></ruby>。
|
||||
|
||||
如果有的话,你可以在需要删除的设备上运行 `pvmove` 命令。扩展块将被分配到其他设备上。
|
||||
|
||||
```
|
||||
# pvmove /dev/sdc
|
||||
|
||||
/dev/sdc: Moved: 2.0%
|
||||
…
|
||||
/dev/sdc: Moved: 79.2%
|
||||
…
|
||||
/dev/sdc: Moved: 100.0%
|
||||
```
|
||||
|
||||
当 `pvmove` 命令完成后。再次使用 `pvs` 命令检查物理卷是否有空闲。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda myvg lvm2 a- 75.00G 1.85G 73.15G
|
||||
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
|
||||
/dev/sdc myvg lvm2 a- 17.15G 17.15G 0
|
||||
```
|
||||
|
||||
如果它是空闲的,使用 `vgreduce` 命令从卷组中删除物理卷 `/dev/sdc`。
|
||||
|
||||
```
|
||||
# vgreduce myvg /dev/sdc
|
||||
Removed "/dev/sdc" from volume group "vg01"
|
||||
```
|
||||
|
||||
最后,运行 `pvremove` 命令从 LVM 配置中删除磁盘。现在,磁盘已经完全从 LVM 中移除,可以用于其他用途。
|
||||
|
||||
```
|
||||
# pvremove /dev/sdc
|
||||
Labels on physical volume "/dev/sdc" successfully wiped.
|
||||
```
|
||||
|
||||
### 移动扩展块到新磁盘
|
||||
|
||||
如果你在卷组中的其他物理卷上没有足够的可用扩展。使用以下步骤添加新的物理卷。
|
||||
|
||||
向存储组申请新的 LUN。分配完毕后,运行以下命令来[在 Linux 中发现新添加的 LUN 或磁盘][5]。
|
||||
|
||||
```
|
||||
# ls /sys/class/scsi_host
|
||||
host0
|
||||
```
|
||||
|
||||
```
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
```
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
操作系统中检测到磁盘后,使用 `pvcreate` 命令创建物理卷。
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdd
|
||||
Physical volume "/dev/sdd" successfully created
|
||||
```
|
||||
|
||||
使用以下命令将新的物理卷 `/dev/sdd` 添加到现有卷组 `vg01` 中。
|
||||
|
||||
```
|
||||
# vgextend vg01 /dev/sdd
|
||||
Volume group "vg01" successfully extended
|
||||
```
|
||||
|
||||
现在,使用 `pvs` 命令查看你添加的新磁盘 `/dev/sdd`。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda myvg lvm2 a- 75.00G 14.00G 61.00G
|
||||
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
|
||||
/dev/sdc myvg lvm2 a- 17.15G 12.15G 5.00G
|
||||
/dev/sdd myvg lvm2 a- 60.00G 60.00G 0
|
||||
```
|
||||
|
||||
使用 `pvmove` 命令将数据从 `/dev/sdc` 移动到 `/dev/sdd`。
|
||||
|
||||
```
|
||||
# pvmove /dev/sdc /dev/sdd
|
||||
|
||||
/dev/sdc: Moved: 10.0%
|
||||
…
|
||||
/dev/sdc: Moved: 79.7%
|
||||
…
|
||||
/dev/sdc: Moved: 100.0%
|
||||
```
|
||||
|
||||
数据移动到新磁盘后。再次使用 `pvs` 命令检查物理卷是否空闲。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda myvg lvm2 a- 75.00G 14.00G 61.00G
|
||||
/dev/sdb myvg lvm2 a- 50.00G 45.00G 5.00G
|
||||
/dev/sdc myvg lvm2 a- 17.15G 17.15G 0
|
||||
/dev/sdd myvg lvm2 a- 60.00G 47.85G 12.15G
|
||||
```
|
||||
|
||||
如果空闲,使用 `vgreduce` 命令从卷组中删除物理卷 `/dev/sdc`。
|
||||
|
||||
```
|
||||
# vgreduce myvg /dev/sdc
|
||||
Removed "/dev/sdc" from volume group "vg01"
|
||||
```
|
||||
|
||||
最后,运行 `pvremove` 命令从 LVM 配置中删除磁盘。现在,磁盘已经完全从 LVM 中移除,可以用于其他用途。
|
||||
|
||||
```
|
||||
# pvremove /dev/sdc
|
||||
Labels on physical volume "/dev/sdc" successfully wiped.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-remove-delete-physical-volume-pv-from-volume-group-vg-in-lvm/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-12670-1.html
|
||||
[2]: https://linux.cn/article-12673-1.html
|
||||
[3]: https://linux.cn/article-12740-1.html
|
||||
[4]: https://www.2daygeek.com/wp-content/uploads/2020/10/remove-delete-physical-volume-pv-from-volume-group-vg-lvm-linux-2.png
|
||||
[5]: https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/
|
||||
@ -1,55 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12743-1.html)
|
||||
[#]: subject: (Install MariaDB or MySQL on Linux)
|
||||
[#]: via: (https://opensource.com/article/20/10/mariadb-mysql-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 Linux 上安装 MariaDB 或 MySQL
|
||||
======
|
||||
开始在 Linux 系统上使用开源的 SQL 数据库。
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
[MariaDB][2] 和 [MySQL][3] 都是使用 SQL 的开源数据库,并且共享相同的原始代码库。MariaDB 是 MySQL 的替代品,因此你可以使用相同的命令 (`mysql`) 与 MySQL 和 MariaDB 数据库进行交互。因此,本文同时适用于 MariaDB 和 MySQL。
|
||||
> 开始在 Linux 系统上使用开源的 SQL 数据库吧。
|
||||
|
||||

|
||||
|
||||
[MariaDB][2] 和 [MySQL][3] 都是使用 SQL 的开源数据库,并且共享相同的初始代码库。MariaDB 是 MySQL 的替代品,你可以使用相同的命令(`mysql`)与 MySQL 和 MariaDB 数据库进行交互。因此,本文同时适用于 MariaDB 和 MySQL。
|
||||
|
||||
### 安装 MariaDB
|
||||
|
||||
你可以使用你的 Linux 发行版的包管理器安装 MariaDB。在大多数发行版上,MariaDB 分为服务器包和客户端包。服务器包提供了数据库”引擎“,即 MariaDB 在后台运行(通常在物理服务器上)的部分,它监听数据输入或数据输出请求。客户端包提供了 `mysql` 命令,你可以用它来与服务器通信。
|
||||
你可以使用你的 Linux 发行版的包管理器安装 MariaDB。在大多数发行版上,MariaDB 分为服务器包和客户端包。服务器包提供了数据库“引擎”,即 MariaDB 在后台运行(通常在物理服务器上)的部分,它监听数据输入或数据输出请求。客户端包提供了 `mysql` 命令,你可以用它来与服务器通信。
|
||||
|
||||
在 RHEL、Fedora、CentOS 或类似的发行版上:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install mariadb mariadb-server`
|
||||
$ sudo dnf install mariadb mariadb-server
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Elementary 或类似的发行版上:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install mariadb-client mariadb-server`
|
||||
$ sudo apt install mariadb-client mariadb-server
|
||||
```
|
||||
|
||||
其他系统可能会以不同的系统打包 MariaDB,所以你可能需要搜索你的软件仓库来了解你的发行版的维护者是如何提供它的。
|
||||
其他操作系统可能会以不同的打包系统封装 MariaDB,所以你可能需要搜索你的软件仓库来了解你的发行版的维护者是如何提供它的。
|
||||
|
||||
### 启动 MariaDB
|
||||
|
||||
因为 MariaDB 被设计成一部分作为数据库服务器的功能,它可以在一台计算机上运行,并从另一台计算机上进行管理。只要你能访问运行它的计算机,你就可以使用 `mysql` 命令来管理数据库。在写这篇文章时,我在本地计算机上运行了 MariaDB,但你同样可能会与远程系统上托管的 MariaDB 数据库进行交互。
|
||||
因为 MariaDB 被设计为部分作为数据库服务器,它可以在一台计算机上运行,并从另一台计算机上进行管理。只要你能访问运行它的计算机,你就可以使用 `mysql` 命令来管理数据库。在写这篇文章时,我在本地计算机上运行了 MariaDB,但你同样可与远程系统上托管的 MariaDB 数据库进行交互。
|
||||
|
||||
在启动 MariaDB 之前,你必须创建一个初始数据库。在初始化其文件结构时,你应该定义你希望 MariaDB 使用的用户。默认情况下,MariaDB 使用当前用户,但你可能希望它使用一个专用的用户帐户。你的包管理器可能为你配置了一个系统用户和组。使用 `grep` 查找是否有一个 `mysql` 组:
|
||||
|
||||
```
|
||||
$ grep mysql /etc/group
|
||||
mysql❌27:
|
||||
mysql:x:27:
|
||||
```
|
||||
|
||||
你也可以在 `/etc/passwd` 中寻找这个专门的用户,但通常情况下,有组的地方就有用户。如果没有专门的 `mysql` 用户和组,可以在 `/etc/group` 中寻找一个明显的替代(比如 `mariadb`)。如果没有,请阅读你的发行版文档来了解 MariaDB 是如何运行的。
|
||||
你也可以在 `/etc/passwd` 中寻找这个专门的用户,但通常情况下,有组就会有用户。如果没有专门的 `mysql` 用户和组,可以在 `/etc/group` 中寻找一个明显的替代品(比如 `mariadb`)。如果没有,请阅读你的发行版文档来了解 MariaDB 是如何运行的。
|
||||
|
||||
假设你的安装使用 `mysql`,初始化数据库环境:
|
||||
|
||||
|
||||
```
|
||||
$ sudo mysql_install_db --user=mysql
|
||||
Installing MariaDB/MySQL system tables in '/var/lib/mysql'...
|
||||
@ -59,7 +58,6 @@ OK
|
||||
|
||||
这一步的结果显示了接下来你必须执行的配置 MariaDB 的任务:
|
||||
|
||||
|
||||
```
|
||||
PLEASE REMEMBER TO SET A PASSWORD FOR THE MariaDB root USER !
|
||||
To do so, start the server, then issue the following commands:
|
||||
@ -75,23 +73,20 @@ databases and anonymous user created by default. This is
|
||||
strongly recommended for production servers.
|
||||
```
|
||||
|
||||
使用你的发行版的 init 系统启动 MariaDB:
|
||||
|
||||
使用你的发行版的初始化系统启动 MariaDB:
|
||||
|
||||
```
|
||||
`$ sudo systemctl start mariadb`
|
||||
$ sudo systemctl start mariadb
|
||||
```
|
||||
|
||||
在启动时启用 MariaDB 服务器:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo systemctl enable --now mariadb`
|
||||
$ sudo systemctl enable --now mariadb
|
||||
```
|
||||
|
||||
现在你已经有了一个 MariaDB 服务器,为它设置一个密码:
|
||||
|
||||
|
||||
```
|
||||
mysqladmin -u root password 'myreallysecurepassphrase'
|
||||
mysqladmin -u root -h $(hostname) password 'myreallysecurepassphrase'
|
||||
@ -106,7 +101,7 @@ via: https://opensource.com/article/20/10/mariadb-mysql-linux
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12752-1.html)
|
||||
[#]: subject: (2 Ways to Download Files From Linux Terminal)
|
||||
[#]: via: (https://itsfoss.com/download-files-from-linux-terminal/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -12,7 +12,7 @@
|
||||
|
||||
如果你被困在 Linux 终端,比如说在服务器上,如何从终端下载文件?
|
||||
|
||||
在 Linux 中是没有下载命令的,但是有几个 Linux 命令可用于下载文件。
|
||||
在 Linux 中是没有 `download` 命令的,但是有几个 Linux 命令可用于下载文件。
|
||||
|
||||
在这篇终端技巧中,你将学习两种在 Linux 中使用命令行下载文件的方法。
|
||||
|
||||
@ -22,15 +22,15 @@
|
||||
|
||||
![][1]
|
||||
|
||||
[wget][2] 也许是 Linux 和类 UNIX 系统中使用最多的命令行下载管理器。你可以使用 wget 下载一个文件、多个文件、整个目录甚至整个网站。
|
||||
[wget][2] 也许是 Linux 和类 UNIX 系统中使用最多的命令行下载管理器。你可以使用 `wget` 下载一个文件、多个文件、整个目录甚至整个网站。
|
||||
|
||||
wget 是非交互式的,可以轻松地在后台工作。这意味着你可以很容易地在脚本中使用它,甚至构建像 [uGet 下载管理器][3]这样的工具。
|
||||
`wget` 是非交互式的,可以轻松地在后台工作。这意味着你可以很容易地在脚本中使用它,甚至构建像 [uGet 下载管理器][3]这样的工具。
|
||||
|
||||
让我们看看如何使用 wget 从终端下载文件。
|
||||
让我们看看如何使用 `wget` 从终端下载文件。
|
||||
|
||||
#### 安装 wget
|
||||
|
||||
大多数 Linux 发行版都预装了 wget。它也可以在大多数发行版的仓库中找到,你可以使用发行版的包管理器轻松安装它。
|
||||
大多数 Linux 发行版都预装了 `wget`。它也可以在大多数发行版的仓库中找到,你可以使用发行版的包管理器轻松安装它。
|
||||
|
||||
在基于 Ubuntu 和 Debian 的发行版上,你可以使用 [apt 包管理器][4]命令:
|
||||
|
||||
@ -48,7 +48,7 @@ wget URL
|
||||
|
||||
![][5]
|
||||
|
||||
要下载多个文件,你必须将它们的 URL 保存在一个文本文件中,并将该文件作为输入提供给 wget,就像这样:
|
||||
要下载多个文件,你必须将它们的 URL 保存在一个文本文件中,并将该文件作为输入提供给 `wget`,就像这样:
|
||||
|
||||
```
|
||||
wget -i download_files.txt
|
||||
@ -56,9 +56,9 @@ wget -i download_files.txt
|
||||
|
||||
#### 用 wget 下载不同名字的文件
|
||||
|
||||
你会注意到,一个网页在 wget 中几乎总是以 index.html 的形式保存。为下载的文件提供自定义名称是个好主意。
|
||||
你会注意到,网页在 `wget` 中几乎总是以 `index.html` 的形式保存。为下载的文件提供自定义名称是个好主意。
|
||||
|
||||
你可以在下载时使用 -O (大写字母 O) 选项来提供输出文件名。
|
||||
你可以在下载时使用 `-O` (大写字母 `O`) 选项来提供输出文件名:
|
||||
|
||||
```
|
||||
wget -O filename URL
|
||||
@ -68,7 +68,7 @@ wget -O filename URL
|
||||
|
||||
#### 用 wget 下载一个文件夹
|
||||
|
||||
假设你正在浏览一个 FTP 服务器,你需要下载整个目录,你可以使用递归选项:
|
||||
假设你正在浏览一个 FTP 服务器,你需要下载整个目录,你可以使用递归选项 `-r`:
|
||||
|
||||
```
|
||||
wget -r ftp://server-address.com/directory
|
||||
@ -76,14 +76,12 @@ wget -r ftp://server-address.com/directory
|
||||
|
||||
#### 使用 wget 下载整个网站
|
||||
|
||||
是的,你完全可以做到这一点。你可以用 wget 镜像整个网站。我说的下载整个网站是指整个面向公众的网站结构。
|
||||
|
||||
虽然你可以直接使用镜像选项 -m,但最好加上:
|
||||
|
||||
* –convert-links :链接将被转换,使内部链接指向下载的资源,而不是网站。
|
||||
* –page-requisites:下载额外的东西,如样式表,使页面在离线状态下看起来更好。
|
||||
是的,你完全可以做到这一点。你可以用 `wget` 镜像整个网站。我说的下载整个网站是指整个面向公众的网站结构。
|
||||
|
||||
虽然你可以直接使用镜像选项 `-m`,但最好加上:
|
||||
|
||||
* `–convert-links`:链接将被转换,使内部链接指向下载的资源,而不是网站。
|
||||
* `–page-requisites`:下载额外的东西,如样式表,使页面在离线状态下看起来更好。
|
||||
|
||||
```
|
||||
wget -m --convert-links --page-requisites website_address
|
||||
@ -93,7 +91,7 @@ wget -m --convert-links --page-requisites website_address
|
||||
|
||||
#### 额外提示:恢复未完成的下载
|
||||
|
||||
如果你因为某些原因按 C 键中止了下载,你可以用选项 -c 恢复之前的下载:
|
||||
如果你因为某些原因按 `CTRL-C` 键中止了下载,你可以用选项 `-c` 恢复之前的下载:
|
||||
|
||||
```
|
||||
wget -c
|
||||
@ -101,13 +99,13 @@ wget -c
|
||||
|
||||
### 使用 curl 在 Linux 命令行中下载文件
|
||||
|
||||
和 wget 一样,[curl][8] 也是 Linux 终端中最常用的下载文件的命令之一。[使用 curl][9] 的方法有很多,但我在这里只关注简单的下载。
|
||||
和 `wget` 一样,[curl][8] 也是 Linux 终端中最常用的下载文件的命令之一。[使用 curl][9] 的方法有很多,但我在这里只关注简单的下载。
|
||||
|
||||
#### 安装 curl
|
||||
|
||||
虽然 curl 并不是预装的,但在大多数发行版的官方仓库中都有。你可以使用你的发行版的包管理器来安装它。
|
||||
虽然 `curl` 并不是预装的,但在大多数发行版的官方仓库中都有。你可以使用你的发行版的包管理器来安装它。
|
||||
|
||||
要[在 Ubuntu][10] 和其他基于 Debian 的发行版上安装 curl,请使用以下命令:
|
||||
要[在 Ubuntu][10] 和其他基于 Debian 的发行版上安装 `curl`,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
@ -115,9 +113,9 @@ sudo apt install curl
|
||||
|
||||
#### 使用 curl 下载文件或网页
|
||||
|
||||
如果你在使用 curl 命令时没有在 URL 中带任何选项,它就会读取文件并打印在终端上。
|
||||
如果你在使用 `curl` 命令时没有在 URL 中带任何选项,它就会读取文件并打印在终端上。
|
||||
|
||||
要在 Linux 终端中使用 curl 命令下载文件,你必须使用 -O(大写字母 O)选项:
|
||||
要在 Linux 终端中使用 `curl` 命令下载文件,你必须使用 `-O`(大写字母 `O`)选项:
|
||||
|
||||
```
|
||||
curl -O URL
|
||||
@ -125,17 +123,17 @@ curl -O URL
|
||||
|
||||
![][11]
|
||||
|
||||
在 Linux 中,用 curl 下载多个文件是比较简单的。你只需要指定多个 URL 即可:
|
||||
在 Linux 中,用 `curl` 下载多个文件是比较简单的。你只需要指定多个 URL 即可:
|
||||
|
||||
```
|
||||
curl -O URL1 URL2 URL3
|
||||
```
|
||||
|
||||
请记住,curl 不像 wget 那么简单。当 wget 将网页保存为 index.html 时,curl 会抱怨远程文件没有网页的名字。你必须按照下一节的描述用一个自定义的名字来保存它。
|
||||
请记住,`curl` 不像 `wget` 那么简单。`wget` 可以将网页保存为 `index.html`,`curl` 却会抱怨远程文件没有网页的名字。你必须按照下一节的描述用一个自定义的名字来保存它。
|
||||
|
||||
#### 用不同的名字下载文件
|
||||
|
||||
这可能会让人感到困惑,但如果要为下载的文件提供一个自定义的名称(而不是原始名称),你必须使用 -o(小写 O)选项:
|
||||
这可能会让人感到困惑,但如果要为下载的文件提供一个自定义的名称(而不是原始名称),你必须使用 `-o`(小写 `O`)选项:
|
||||
|
||||
```
|
||||
curl -o filename URL
|
||||
@ -143,23 +141,23 @@ curl -o filename URL
|
||||
|
||||
![][12]
|
||||
|
||||
有些时候,curl 并不能像你期望的那样下载文件,你必须使用选项 -L(代表位置)来正确下载。这是因为有些时候,链接会重定向到其他链接,而使用选项 -L,它就会跟随最终的链接。
|
||||
有些时候,`curl` 并不能像你期望的那样下载文件,你必须使用选项 `-L`(代表位置)来正确下载。这是因为有些时候,链接会重定向到其他链接,而使用选项 `-L`,它就会跟随最终的链接。
|
||||
|
||||
#### 用 curl 暂停和恢复下载
|
||||
|
||||
和 wget 一样,你也可以用 curl 的 -c 选项恢复暂停的下载:
|
||||
和 `wget` 一样,你也可以用 `curl` 的 `-c` 选项恢复暂停的下载:
|
||||
|
||||
```
|
||||
curl -c URL
|
||||
```
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
和以往一样,在 Linux 中做同一件事有多种方法。从终端下载文件也不例外。
|
||||
|
||||
wget 和 curl 只是 Linux 中最流行的两个下载文件的命令。还有更多这样的命令行工具。基于终端的网络浏览器,如 [elinks][13]、[w3m][14] 等也可以用于在命令行下载文件。
|
||||
`wget` 和 `curl` 只是 Linux 中最流行的两个下载文件的命令。还有更多这样的命令行工具。基于终端的网络浏览器,如 [elinks][13]、[w3m][14] 等也可以用于在命令行下载文件。
|
||||
|
||||
就个人而言,对于一个简单的下载,我更喜欢使用 wget 而不是 curl。它更简单,也不会让你感到困惑,因为你可能很难理解为什么 curl 不能以预期的格式下载文件。
|
||||
就个人而言,对于一个简单的下载,我更喜欢使用 `wget` 而不是 `curl`。它更简单,也不会让你感到困惑,因为你可能很难理解为什么 `curl` 不能以预期的格式下载文件。
|
||||
|
||||
欢迎你的反馈和建议。
|
||||
|
||||
@ -170,7 +168,7 @@ via: https://itsfoss.com/download-files-from-linux-terminal/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,32 +1,34 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12759-1.html)
|
||||
[#]: subject: (MellowPlayer is a Desktop App for Various Streaming Music Services)
|
||||
[#]: via: (https://itsfoss.com/mellow-player/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
MellowPlayer 是一款用于各种流媒体音乐服务的桌面应用
|
||||
MellowPlayer:一款用于各种流媒体音乐服务的桌面应用
|
||||
======
|
||||
|
||||
_**简介:MellowPlayer 是一个免费开源的桌面应用,可以让你在 Linux 和 Windows 上整合基于网络的音乐流媒体服务。**_
|
||||
> MellowPlayer 是一个自由开源的桌面应用,可以让你在 Linux 和 Windows 上整合基于网络的音乐流媒体服务。
|
||||
|
||||
![][8]
|
||||
|
||||
毋庸置疑,很多用户都喜欢使用流媒体服务来收听自己喜欢的音乐,而不是从商店购买单首音乐或者下载收藏。
|
||||
|
||||
当然,流媒体服务可以让你探索新的音乐,帮助艺术家轻松接触到更多的听众。但是,由于有许多的音乐流媒体服务([Soundcloud][1]、[Spotify][2]、[YouTube Music][3]、[Amazon Music][4] 等),因此当在使用电脑时,要有效地使用它们往往会变得很麻烦。
|
||||
当然,流媒体服务可以让你探索新的音乐,帮助艺术家轻松传播到更多的听众。但是,由于有许多的音乐流媒体服务([Soundcloud][1]、[Spotify][2]、[YouTube Music][3]、[Amazon Music][4] 等),因此当在使用电脑时,要有效地使用它们往往会变得很麻烦。
|
||||
|
||||
你可以[在 Linux 上安装 Spotify][5],但没有 Amazon Music 的桌面应用。所以,有可能你无法从单一门户管理流媒体服务。
|
||||
你可以[在 Linux 上安装 Spotify][5],但没有 Amazon Music 的桌面应用,所以,有可能你无法从单一门户管理流媒体服务。
|
||||
|
||||
如果一个桌面应用可以让你同时在 Windows 和 Linux 上免费整合流媒体服务呢?在本文中,我将介绍这样一款应用:“[MellowPlayer][6]”。
|
||||
如果一个桌面应用可以让你同时在 Windows 和 Linux 上免费整合流媒体服务呢?在本文中,我将介绍这样一款应用:[MellowPlayer][6]。
|
||||
|
||||
### MellowPlayer: 集成各种流媒体音乐服务的开源应用
|
||||
|
||||
![][7]
|
||||
|
||||
MellowPlayer 是一款免费开源的跨平台桌面应用,它可以让你整合多个流媒体服务,并在一个界面上管理它们。
|
||||
MellowPlayer 是一款自由开源的跨平台桌面应用,它可以让你整合多个流媒体服务,并在一个界面上管理它们。
|
||||
|
||||
你可以整合多个支持的流媒体服务。你还可以从每个单独的服务中获得一定程度的控制权来调整你的体验。例如,你可以设置自动跳过广告或在 YouTube 上静音。
|
||||
你可以整合多个支持的流媒体服务。你还可以从每个服务中获得一定程度的控制权,来调整你的体验。例如,你可以设置在 YouTube 上自动跳过或静音广告。
|
||||
|
||||
对 Windows 和 Linux 的跨平台支持绝对是一个加分项。
|
||||
|
||||
@ -36,25 +38,21 @@ MellowPlayer 是一款免费开源的跨平台桌面应用,它可以让你整
|
||||
|
||||
### MellowPlayer 的特点
|
||||
|
||||
![][8]
|
||||
|
||||
* 跨平台 (Windows 和 Linux)
|
||||
* 免费且开源
|
||||
* 基于插件的应用,让你通过创建一个插件来添加新的服务
|
||||
* 自由且开源
|
||||
* 基于插件的应用,让你可以通过创建一个插件来添加新的服务
|
||||
* 将服务作为本地桌面应用与系统托盘整合
|
||||
* 支持热键
|
||||
* 支持通知
|
||||
* 收听历史
|
||||
|
||||
|
||||
|
||||
### 在 Linux 上安装 MellowPlayer
|
||||
|
||||
![][9]
|
||||
|
||||
MellowPlayer 是以 [Flatpak 包][10]的形式提供的。我知道这让一些人很失望,但它在 Linux 中只有 Flaptak,WIndows 中只有一个可执行文件。如果你不知道,请按照我们的[在 Linux 上使用 Flatpak][11] 指南来开始使用。
|
||||
MellowPlayer 是以 [Flatpak 包][10]的形式提供的。我知道这让一些人很失望,但它在 Linux 中只有 Flaptak,Windows 中只有一个可执行文件。如果你不知道,请按照我们的[在 Linux 上使用 Flatpak][11] 指南来开始使用。
|
||||
|
||||
[下载 MellowPlayer][12]
|
||||
- [下载 MellowPlayer][12]
|
||||
|
||||
### 总结
|
||||
|
||||
@ -71,7 +69,7 @@ via: https://itsfoss.com/mellow-player/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12769-1.html)
|
||||
[#]: subject: (Try Linux on any computer with this bootable USB tool)
|
||||
[#]: via: (https://opensource.com/article/20/10/fedora-media-writer)
|
||||
[#]: author: (Sumantro Mukherjee https://opensource.com/users/sumantro)
|
||||
|
||||
用这个创建可引导 USB 的工具在电脑上尝试 Linux
|
||||
======
|
||||
|
||||
> Fedora Media Writer 是创建临场版 USB 以尝试 Linux 的方便方法。
|
||||
|
||||

|
||||
|
||||
[Fedora Media Writer][2] 是一个小巧、轻量、全面的工具,它简化了 Linux 的入门体验。它可以下载 Fedora 的 Workstation 或 Server 版本并写入到一个可以在任何系统上引导的 USB 驱动器上,使你无需将其安装到硬盘上就可以试用 Fedora Linux。
|
||||
|
||||
Media Writer 工具可以用来创建一个<ruby>临场体验的<rt>Live</rt></ruby>、可引导的 USB 驱动器。在你的平台上安装 Fedora Media Writer 应用后,你可以下载并烧录最新的 Fedora Workstation 或 Server 稳定版,也可以选择烧录你下载的任何其他镜像。而且它并不局限于英特尔 64 位设备。它还可以用于 ARM 设备,如[树莓派][3],这些设备日益变得更加强大和有用。
|
||||
|
||||
![Fedora Media Writer main screen][4]
|
||||
|
||||
### 安装 Fedora Media Writer
|
||||
|
||||
[安装 Fedora Media Writer][6] 有几种方式。你可以通过 GitHub [从源码编译][7]、下载 MacOS 或 Windows 版本、使用 `dnf` 或 `yum` 安装 RPM 包,或者以 Flatpak 的形式获得。
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install mediawriter
|
||||
```
|
||||
|
||||
最新版本请参见 GitHub 仓库的[发布][8]部分。
|
||||
|
||||
### 准备好你的媒体介质
|
||||
|
||||
首先,你需要一个 USB 驱动器来安装你的 Linux 操作系统。这就是 Fedora Media Writer 要烧录的设备。这个驱动器必须是空白或可擦除的,因为 **该 USB 驱动器上的所有数据都会被删除**。如果有任何数据,哪怕只是一个文件,如果你不想丢失,那么你必须在继续之前备份它!
|
||||
|
||||
确认你的 USB 驱动器是可擦除的之后,将它插入你的电脑并启动 Fedora Media Writer。
|
||||
|
||||
### 使用 Fedora Media Writer
|
||||
|
||||
当你启动 Fedora Media Writer 时,你会看到一个页面,提示你从互联网上获取一个可引导的镜像,或者从你的硬盘上加载一个自定义镜像。第一个选择是 Fedora 的最新版本。Workstation 版本适用于台式机和笔记本电脑,Server 版本适用于虚拟化、机架服务器或任何你想作为服务器运行的情况。
|
||||
|
||||
如果你选择了 Fedora 镜像,Media Writer 会下载一个光盘镜像(通常称为 “iso”,文件扩展名为 .iso),并将其保存到你的下载文件夹中,这样你就可以重复使用它来烧录另一个驱动器。
|
||||
|
||||
![Select your image][9]
|
||||
|
||||
另外还有 Fedora Spins,这是来自 Fedora 社区的镜像,它旨在满足小众的兴趣。例如,如果你是 [MATE 桌面][10]的粉丝,那么你会很高兴地发现 Media Writer 提供了 MATE spin。它有很多,所以请滚动查看所有的选择。如果你是 Linux 的新手,不要被吓到或感到困惑:这些额外的选项是为老用户准备的,这些用户除了默认的选项外,还发展出了自己的偏好,所以对你来说,只使用 Workstation 或 Server 选项就行,这取决于你是想把 Fedora 作为一个桌面还是作为一个服务器操作系统来运行。
|
||||
|
||||
如果你需要一个与你当前使用的 CPU 不同架构的镜像,从窗口右上角的下拉菜单中选择 CPU 架构。
|
||||
|
||||
如果你已经将镜像保存在硬盘上,请选择“Custom Image”选项,并选择你要烧录到 USB 的发行版的 .iso 文件。
|
||||
|
||||
### 写入 USB 驱动器
|
||||
|
||||
当你下载或选择了一个镜像,你必须确认你要将该镜像写入驱动器。
|
||||
|
||||
驱动器选择下拉菜单只显示了外部驱动器,所以你不会意外地覆盖自己的硬盘驱动器。这是 Fedora Media Writer 的一个重要功能,它比你在网上看到的许多手动说明要安全得多。然而,如果你的计算机上连接了多个外部驱动器,除了你想覆盖的那个,你应该将它们全部移除,以增加安全性。
|
||||
|
||||
选择你要安装镜像的驱动器,然后单击“Write to Disk”按钮。
|
||||
|
||||
![Media write][11]
|
||||
|
||||
稍等一会儿,镜像就会被写入到你的驱动器,然后可以看看 Don Watkins 对[如何从 USB 驱动器启动到 Linux][12]的出色介绍。
|
||||
|
||||
### 开始使用 Linux
|
||||
|
||||
Fedora Media Writer 是一种将 Fedora Workstation 或 Server,或任何 Linux 发行版烧录到 USB 驱动器的方法,因此你可以在安装它到设备上之前试用它。试试吧,并在评论中分享你的经验和问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/fedora-media-writer
|
||||
|
||||
作者:[Sumantro Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sumantro
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/usb-hardware.png?itok=ROPtNZ5V (Multiple USB plugs in different colors)
|
||||
[2]: https://github.com/FedoraQt/MediaWriter
|
||||
[3]: https://fedoraproject.org/wiki/Architectures/ARM/Raspberry_Pi
|
||||
[4]: https://opensource.com/sites/default/files/uploads/fmw_mainscreen.png (Fedora Media Writer main screen)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://docs.fedoraproject.org/en-US/fedora/f32/install-guide/install/Preparing_for_Installation/#_fedora_media_writer
|
||||
[7]: https://github.com/FedoraQt/MediaWriter#building
|
||||
[8]: https://github.com/FedoraQt/MediaWriter/releases
|
||||
[9]: https://opensource.com/sites/default/files/mediawriter-image.png
|
||||
[10]: https://opensource.com/article/19/12/mate-linux-desktop
|
||||
[11]: https://opensource.com/sites/default/files/mediawriter-write.png (Media write)
|
||||
[12]: https://opensource.com/article/20/4/first-linux-computer
|
||||
122
published/20201016 Set up ZFS on Linux with yum.md
Normal file
122
published/20201016 Set up ZFS on Linux with yum.md
Normal file
@ -0,0 +1,122 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12754-1.html)
|
||||
[#]: subject: (Set up ZFS on Linux with yum)
|
||||
[#]: via: (https://opensource.com/article/20/10/zfs-dnf)
|
||||
[#]: author: (Sheng Mao https://opensource.com/users/ivzhh)
|
||||
|
||||
在 Linux 上使用 yum 设置 ZFS
|
||||
======
|
||||
|
||||
> 在 Fedora 上使用 yum 仓库来获取最新的 ZFS 特性。
|
||||
|
||||

|
||||
|
||||
我是一名 Fedora Linux 用户,我每天都会运行 `yum upgrade`。虽然这个习惯使我能够运行所有最新的软件([Fedora 的四个基础][2]之一的 “First” ,它也做到了),但它也会提醒 [ZFS][3] 存储平台和新内核之间的不兼容性。
|
||||
|
||||
作为一名开发者,有时我需要最新的 ZFS 分支的新特性。例如,ZFS 2.0.0 包含了一个令人兴奋的新功能,它大大[提高了 ZVOL 同步性能][4],这对我这个 KVM 用户来说至关重要。但这意味着,如果我想使用 2.0.0 分支,我必须自己构建 ZFS。
|
||||
|
||||
起初,我只是在每次内核更新后从它的 Git 仓库中手动编译 ZFS。如果我忘记了,ZFS 就会在下次启动时无法被识别。幸运的是,我很快就学会了如何为 ZFS 设置动态内核模块支持 ([DKMS][5])。然而,这个解决方案并不完美。首先,它没有利用强大的 [yum][6] 系统,而这个系统可以帮助解决依赖关系和升级。此外,使用 `yum` 在你自己的包和上游包之间进行切换是非常容易的。
|
||||
|
||||
在本文中,我将演示如何设置 `yum` 仓库来打包 ZFS。这个方案有两个步骤:
|
||||
|
||||
1. 从 ZFS 的 Git 仓库中创建 RPM 包。
|
||||
2. 建立一个 `yum` 仓库来托管这些包。
|
||||
|
||||
### 创建 RPM 包
|
||||
|
||||
要创建 RPM 包,你需要安装 RPM 工具链。`yum` 提供了一个组来捆绑安装这些工具:
|
||||
|
||||
```
|
||||
sudo dnf group install 'C Development Tools and Libraries' 'RPM Development Tools'
|
||||
```
|
||||
|
||||
安装完这些之后,你必须从 ZFS Git 仓库中安装构建 ZFS 所需的所有包。这些包属于三个组:
|
||||
|
||||
1. [Autotools][7],用于从平台配置中生成构建文件。
|
||||
2. 用于构建 ZFS 内核和用户态工具的库。
|
||||
3. 构建 RPM 包的库。
|
||||
|
||||
```
|
||||
sudo dnf install libtool autoconf automake gettext createrepo \
|
||||
libuuid-devel libblkid-devel openssl-devel libtirpc-devel \
|
||||
lz4-devel libzstd-devel zlib-devel \
|
||||
kernel-devel elfutils-libelf-devel \
|
||||
libaio-devel libattr-devel libudev-devel \
|
||||
python3-devel libffi-devel
|
||||
```
|
||||
|
||||
现在你已经准备好创建你自己的包了。
|
||||
|
||||
### 构建 OpenZFS
|
||||
|
||||
[OpenZFS][8] 提供了优秀的基础设施。要构建它:
|
||||
|
||||
1. 用 `git` 克隆仓库,并切换到你希望使用的分支/标签。
|
||||
2. 运行 Autotools 生成一个 makefile。
|
||||
3. 运行 `make rpm`,如果一切正常,RPM 文件将被放置在 `build` 文件夹中。
|
||||
|
||||
```
|
||||
$ git clone --branch=zfs-2.0.0-rc3 <https://github.com/openzfs/zfs.git> zfs
|
||||
$ cd zfs
|
||||
$ ./autogen.sh
|
||||
$ ./configure
|
||||
$ make rpm
|
||||
```
|
||||
|
||||
### 建立一个 yum 仓库
|
||||
|
||||
在 `yum` 中,仓库是一个服务器或本地路径,包括元数据和 RPM 文件。用户设置一个 INI 配置文件,`yum` 命令会自动解析元数据并下载相应的软件包。
|
||||
|
||||
Fedora 提供了 `createrepo` 工具来设置 `yum` 仓库。首先,创建仓库,并将 ZFS 文件夹中的所有 RPM 文件复制到仓库中。然后运行 `createrepo --update` 将所有的包加入到元数据中。
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /var/lib/zfs.repo
|
||||
$ sudo createrepo /var/lib/zfs.repo
|
||||
$ sudo cp *.rpm /var/lib/zfs.repo/
|
||||
$ sudo createrepo --update /var/lib/zfs.repo
|
||||
```
|
||||
|
||||
在 `/etc/yum.repos.d` 中创建一个新的配置文件来包含仓库路径:
|
||||
|
||||
```
|
||||
$ echo \
|
||||
"[zfs-local]\\nname=ZFS Local\\nbaseurl=file:///var/lib/zfs.repo\\nenabled=1\\ngpgcheck=0" |\
|
||||
sudo tee /etc/yum.repos.d/zfs-local.repo
|
||||
|
||||
$ sudo dnf --repo=zfs-local list available --refresh
|
||||
```
|
||||
|
||||
终于完成了!你已经有了一个可以使用的 `yum` 仓库和 ZFS 包。现在你只需要安装它们。
|
||||
|
||||
```
|
||||
$ sudo dnf install zfs
|
||||
$ sudo /sbin/modprobe zfs
|
||||
```
|
||||
|
||||
运行 `sudo zfs version` 来查看你的用户态和内核工具的版本。恭喜!你拥有了 [Fedora 中的 ZFS][9]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/zfs-dnf
|
||||
|
||||
作者:[Sheng Mao][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ivzhh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://docs.fedoraproject.org/en-US/project/#_what_is_fedora_all_about
|
||||
[3]: https://zfsonlinux.org/
|
||||
[4]: https://www.phoronix.com/scan.php?page=news_item&px=OpenZFS-3x-Boost-Sync-ZVOL
|
||||
[5]: https://www.linuxjournal.com/article/6896
|
||||
[6]: https://en.wikipedia.org/wiki/Yum_%28software%29
|
||||
[7]: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
[8]: https://openzfs.org/wiki/Main_Page
|
||||
[9]: https://openzfs.github.io/openzfs-docs/Getting%20Started/Fedora.html
|
||||
93
published/20201027 Fedora 33 is officially here.md
Normal file
93
published/20201027 Fedora 33 is officially here.md
Normal file
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12764-1.html)
|
||||
[#]: subject: (Fedora 33 is officially here!)
|
||||
[#]: via: (https://fedoramagazine.org/announcing-fedora-33/)
|
||||
[#]: author: (Matthew Miller https://fedoramagazine.org/author/mattdm/)
|
||||
|
||||
Fedora 33 正式发布了
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
> 本文译自 Fedora 官方发布公告。
|
||||
|
||||
今天,我很兴奋地与大家分享数千名 Fedora 项目贡献者辛勤工作的成果:我们的最新版本 Fedora 33 来了! 这是一个有着很多变化的大版本,但我相信所有这些工作也会让您感到舒适,实现我们的目标:即为您带来最新的稳定、强大、健壮的自由和开源软件,并提供许多易于使用的产品。
|
||||
|
||||
如果您不想耽误时间,直接体验,现在就去 <https://getfedora.org/> 下载吧,欲了解详情请继续阅读!
|
||||
|
||||
### 找到适合您的 Fedora 风味!
|
||||
|
||||
Fedora Edition 是针对桌面、服务器和云环境中各种“体现”特定用途的目标产品,现在它也适用于物联网。
|
||||
|
||||
Fedora Workstation 专注于桌面,尤其是面向那些想要“只管去用”的 Linux 操作系统体验的软件开发者。这个版本的特点是 [GNOME 3.38][2],它一如既往地有很多很棒的改进。新增的 Tour 应用可以帮助新用户学习它们的操作方式。和我们所有其他面向桌面的变体一样,Fedora Workstation 现在使用 [BTRFS 作为默认文件系统][3]。这些发布的版本中带来了很多伟大的增强功能,这个先进的文件系统为之奠定了基础。为了您的视觉享受,Fedora 33 Workstation 现在默认提供了一个动画背景(它会基于一天中的时间变化)。
|
||||
|
||||
Fedora CoreOS 是一个新兴的 Fedora 版本。它是一个自动更新的、最小化的操作系统,用于安全地、大规模地运行容器化工作负载。它提供了几个[更新流][4],可以遵循大致每两周一次的自动更新。目前 **next** 流是基于 Fedora 33 的,**testing** 和 **stable** 流后继也会跟进。您可以从[下载页面][5]中找到关于跟随 **next** 流发布的工件的信息,并在 [Fedora CoreOS 文档][6]中找到关于如何使用这些工件的信息。
|
||||
|
||||
新晋升为 Edition 状态的 [Fedora IoT][7],为物联网生态系统和边缘计算用例提供了坚实的基础。在许多功能之外,Fedora 33 IoT 还引入了<ruby>平台抽象安全<rt>Platform AbstRaction for SECurity</rt></ruby>(PARSEC),这是一个开源倡议,以平台无关的方式为硬件安全和加密服务提供了通用 API。
|
||||
|
||||
当然,我们制作的不仅仅是“官方版本”,还有 [Fedora Spin][8]和 [Lab][9]。[Fedora Spin][8] 和 [Lab][9] 针对不同的受众和用例,包括 [Fedora CompNeuro][10],它为神经科学带来了大量的开源计算建模工具,以及 [KDE Plasma][11] 和 [Xfce][12]等桌面环境。
|
||||
|
||||
此外,别忘了我们还有备用架构:[ARM AArch64、Power 和 S390x][13]。在 Fedora 33 中提供的新功能,AArch64 用户可以使用 .NET Core 语言进行跨平台开发。我们改进了对 Pine64 设备、NVidia Jetson 64 位平台以及 Rockchip 片上系统(SoC)设备的支持,包括 Rock960、RockPro64 和 Rock64。(不过,有个最新的说明:在其中一些设备上可能会出现启动问题。从现有的 Fedora 32 升级是没问题的。更多信息将在[常见错误][14]页面上公布。)
|
||||
|
||||
我们也很高兴地宣布,Fedora 云镜像和 Fedora CoreOS 将首次与 Fedora 33 一起在亚马逊的 [AWS 市场][15] 中提供。Fedora 云镜像在亚马逊云中已经存在了十多年,您可以通过 AMI ID 或[点击一下][16]来启动我们的官方镜像。该市场提供了获得同样东西的另一种方式,显著扩大了 Fedora 的知名度。这也将使我们的云镜像可以更快地在新的 AWS 区域中可用。特别感谢 David Duncan 让这一切成为现实!
|
||||
|
||||
### 常规改进
|
||||
|
||||
无论您使用的是哪种版本的 Fedora,您都会得到开源世界提供的最新版本。遵循我们的 [First][17] 原则,我们更新了关键的编程语言和系统库包,包括 Python 3.9、Ruby on Rails 6.0 和 Perl 5.32。在 Fedora KDE 中,我们沿用了 Fedora 32 Workstation 中的工作,默认启用了 EarlyOOM 服务,以改善低内存情况下的用户体验。
|
||||
|
||||
为了让 Fedora 的默认体验更好,我们将 nano 设置为默认编辑器。nano 是一个对新用户友好的编辑器。当然,那些想要像 vi 这样强大的编辑器的用户可以自己设置默认编辑器。
|
||||
|
||||
我们很高兴您能试用新版本! 前往 <https://getfedora.org/> 并立即下载它。或者如果您已经在运行 Fedora 操作系统,请按照这个简单的[升级说明][18]进行升级。关于 Fedora 33 新特性的更多信息,请参见[发布说明][19]。
|
||||
|
||||
### 关于安全启动的说明
|
||||
|
||||
<ruby>安全启动<rt>Secure Boot</rt></ruby>是一种安全标准,它确保只有官方签署的操作系统软件才能加载到您的计算机上。这对于防止持久恶意软件非常重要,因为这些恶意软件可能会隐藏在您的计算机固件中,甚至在重新安装操作系统时也能存活。然而,在 [Boot Hole][20] 漏洞发生后,用于签署 Fedora <ruby>引导加载器<rt>Bootloader</rt></ruby>软件的加密证书将被撤销,并被新的证书取代。由于这将产生大范围的影响,撤销应该要到 2021 年第二季度或更晚才会广泛推行。
|
||||
|
||||
然而,一些用户可能已经从其他操作系统或固件更新中收到了这种撤销。在这种情况下,Fedora 将不能在启用了安全启动时进行安装。要说明的是,这不会影响大多数用户。如果它确实影响到了您,您可以暂时禁用安全启动。我们会在大范围的证书撤销之前发布一个用新证书签署的更新,在所有支持的版本上都可以使用,到那时,安全启动应该可以重新启用。
|
||||
|
||||
### 万一出现问题时……
|
||||
|
||||
如果您遇到问题,请查看 [Fedora 33 常见错误][14]页面;如果您有疑问,请访问我们的 [Ask Fedora][21] 用户支持平台。
|
||||
|
||||
### 谢谢大家
|
||||
|
||||
感谢在这个发布周期中为 Fedora 项目做出贡献的成千上万的人,尤其是那些在疫情大流行期间为使这个版本准时发布而付出额外努力的人。Fedora 是一个社区,很高兴看到我们如此互相支持。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/announcing-fedora-33/
|
||||
|
||||
作者:[Matthew Miller][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/mattdm/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/10/f33-final-816x345.jpg
|
||||
[2]: https://www.gnome.org/news/2020/09/gnome-3-38-released/
|
||||
[3]: https://fedoramagazine.org/btrfs-coming-to-fedora-33/
|
||||
[4]: https://docs.fedoraproject.org/en-US/fedora-coreos/update-streams/
|
||||
[5]: https://getfedora.org/en/coreos/download?stream=next
|
||||
[6]: https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/
|
||||
[7]: https://getfedora.org/iot
|
||||
[8]: https://spins.fedoraproject.org/
|
||||
[9]: https://labs.fedoraproject.org/
|
||||
[10]: https://labs.fedoraproject.org/en/comp-neuro/
|
||||
[11]: https://spins.fedoraproject.org/en/kde/
|
||||
[12]: https://spins.fedoraproject.org/en/xfce/
|
||||
[13]: https://alt.fedoraproject.org/alt/
|
||||
[14]: https://fedoraproject.org/wiki/Common_F33_bugs
|
||||
[15]: https://aws.amazon.com/marketplace
|
||||
[16]: https://getfedora.org/en/coreos/download?tab=cloud_launchable&stream=stable
|
||||
[17]: https://docs.fedoraproject.org/en-US/project/#_first
|
||||
[18]: https://docs.fedoraproject.org/en-US/quick-docs/upgrading/
|
||||
[19]: https://docs.fedoraproject.org/en-US/fedora/f33/release-notes/
|
||||
[20]: https://access.redhat.com/security/vulnerabilities/grub2bootloader
|
||||
[21]: http://ask.fedoraproject.org
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How anyone can contribute to open source software in their job)
|
||||
[#]: via: (https://opensource.com/article/20/10/open-your-job)
|
||||
[#]: author: (Catherine Robson https://opensource.com/users/crobson)
|
||||
|
||||
How anyone can contribute to open source software in their job
|
||||
======
|
||||
Open your job, and you'll open opportunities for software developers to
|
||||
build applications that meet your needs.
|
||||
![Active listening in a meeting is a skill][1]
|
||||
|
||||
Imagine a world where your software works perfectly for you. It meets your needs, does things your way, and is the ideal tool to achieve great things toward your goals.
|
||||
|
||||
Open source software stems from these roots. Many projects are built by engineers that have a problem and build a solution to solve it. Then they openly share their solution with others to use and improve.
|
||||
|
||||
Unfortunately, building software is hard. Not everyone has the expertise to build software that works perfectly for their needs. And if the software developers building applications don't fully understand users' needs and how they do their job, the solutions they build may not meet the users' needs and may accidentally create a lot of gaps.
|
||||
|
||||
I recently encountered an example of this at my dentist's office. As I was waiting in the chair, I couldn't help but notice how long the dental hygienist was taking to punch around in the software to get ready for the dentist's examination. So I asked her, "Do you feel like this software meets your needs?" She replied, "No! It's so complex, and what I actually need is never where I need it!"
|
||||
|
||||
Part of the problem is that the people who built this software are probably not dentists, dental hygienists, or have any experience with a dentist other than as a patient in the chair. Many software companies have roles to help fill those gaps—product managers, product and market analysts, researchers, and others are meant to help gather requirements that tell development teams what to build.
|
||||
|
||||
But we all know about learning a new domain. There's learning it from the outside, casually understanding it; then there's learning it from the inside, living it day-to-day, and really knowing it as an expert. The closer the development team can get to the real, "living it" experience, the better decisions they will make when they build software for specific users and domains.
|
||||
|
||||
Open source has an ethos of sharing the work being done. Now I think it is time to evolve open source to the next level: sharing work that _needs to be_ done. Domain experts (i.e., the eventual users) need to share information about what they need to do their job so that open source developers can build software to meet their needs.
|
||||
|
||||
This might sound overwhelming if you're not a software developer. Contributing to open source means that you need to write code, understand [Git][2], or cross other technical hurdles, right? Not necessarily; contributing your domain expertise is an important part of open source development.
|
||||
|
||||
And you can use the tools you already have. You're already on social media. You probably have access to a word processor of some kind. And you have a work environment that can be shared openly (even in COVID times, thanks to technology).
|
||||
|
||||
### Three steps to opening your job
|
||||
|
||||
The following steps can help you open your job so software developers can learn your domain, understand your job and pain points, and build software that works better for you.
|
||||
|
||||
#### 1\. Invite software builders into your work environment
|
||||
|
||||
An ethnographic study is where parts of the software team shadow you in your job. You'll be asked to do everything you normally do on a workday, just as you always do it. Like a "fly on the wall," the software team is there to observe and understand how you do what you do. They might debrief with you throughout the day to get more insights into why you did certain things. Overall, this is meant to be non-invasive for you but very informative for the team.
|
||||
|
||||
#### 2\. Share writeups about your job with software builders
|
||||
|
||||
Far too often in the software industry, we focus on the software, not its use. As an example, a software requirement may come in as: "Show the history of dental work done to a tooth." This assumes that the software is required to do this job and that this history is useful no matter where it's shown in the software.
|
||||
|
||||
Instead, developers need to back up and make sure they understand the job functions thoroughly. For example, a requirement could say: "A patient has a tooth with a cavity that was found during routine cleaning. While the patient is still there, the dentist needs to know what else has been done to the tooth to be able to prescribe a solution to the patient." By knowing the job that needs to be done, the software developer can build software that enables easy selection of the tooth in question, mid-exam, with gloves on. Therefore, this information should be available while in the "routine cleaning" view.
|
||||
|
||||
Writing up your intent and context while you're using the software, rather than the tasks you do, can help software developers build to meet your true needs.
|
||||
|
||||
If you want to go deeper, look at the [Jobs To Be Done][3] (JTBD) framework as a way to convey your expertise to software teams.
|
||||
|
||||
#### 3\. Use social media to share videos, explanations, and more about your job
|
||||
|
||||
Use the social media platform of your choice (e.g., YouTube, Reddit, etc.) to share information about your job. Recording and sharing a "day in the life" video openly could greatly help development teams really understand what you do and how you do it so that they can create software that serves your needs.
|
||||
|
||||
### Open opportunities
|
||||
|
||||
Open your job, and you'll open opportunities for software developers to build better software! Let's bring open source to the next level together by sharing more about what you need.
|
||||
|
||||
You don't need to be a master coder to contribute to open source. Jade Wang shares 8 ways you can...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/open-your-job
|
||||
|
||||
作者:[Catherine Robson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/crobson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/team-discussion-mac-laptop-stickers.png?itok=AThobsFH (Active listening in a meeting is a skill)
|
||||
[2]: https://opensource.com/resources/what-is-git
|
||||
[3]: https://www.google.com/books/edition/The_Jobs_To_Be_Done_Playbook/1vHRDwAAQBAJ?hl=en&gbpv=1&printsec=frontcover
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to influence people to join open source)
|
||||
[#]: via: (https://opensource.com/article/20/10/influence-open-source)
|
||||
[#]: author: (Joshua Pearce https://opensource.com/users/jmpearce)
|
||||
|
||||
How to influence people to join open source
|
||||
======
|
||||
Giving people what they want is the most effective way to introduce
|
||||
people to open source.
|
||||
![pipe in a building][1]
|
||||
|
||||
If you are reading Opensource.com, you might be able to code, and you are probably reading this on an open source browser on some elusive [Linux distro][2]. You probably have not seen a browser ad in years because you are running an [open source ad blocker][3]. You feel warm and fuzzy when you think about penguins.
|
||||
|
||||
Simply, you know the power of the force of open source and have made it part of your life. Sadly, not everyone has found the open source way yet. Their computers are painfully slow; they see more ads than content when they surf the web; they spend their money on patented and copyrighted junk. Some of these people may even be related to you—take your nieces and nephews, for example.
|
||||
|
||||
### Knowledge is wealth
|
||||
|
||||
So, how do you introduce your nieces and nephews (and everyone else) to open source?
|
||||
|
||||
I tried to answer this question and being a professor, a profession well known for being long-winded, I ended up with a book: [_Create, Share, and Save Money Using Open Source Projects_][4], published by McGraw-Hill
|
||||
|
||||
The trick, I think, is finding something that your niece or nephew wants but doesn't have the money to buy, then showing them how open source knowledge can get them what they want.
|
||||
|
||||
![Lift Standing Desk][5]
|
||||
|
||||
[Lift Standing Desk][6] (Joni Steiner and Nick Ierodiaconou, [CC-BY-SA-NC][7])
|
||||
|
||||
Knowledge has a unique property among commodities. Unlike gold or wheat, it not only retains value when it is shared, but it can rapidly increase in value. The internet enables unlimited scaling of this process, as the price of information-sharing approaches zero. Everyone with internet access has historically unprecedented access to this wealth. For example, I provide [free links to repositories][4] with books, education, movies, how-tos, maps, music, photographs, art, software, and recipes.
|
||||
|
||||
### Don't buy it, make it
|
||||
|
||||
Free and open source is expanding further into the physical world, and we all have the opportunity to radically reduce the cost of just about everything you can buy at Walmart or Amazon, including [toys][8], [electronics][9], [household goods][10], and clothing. The combination of open source sharing and digital manufacturing—using 3D printers and similar tools—enables individuals to make their own complex, valuable products.
|
||||
|
||||
![3D printed household items][11]
|
||||
|
||||
[3D-printed household items][12] (Joshua M. Pearce, [CC BY-SA 3.0][13])
|
||||
|
||||
For years, scientists have been doing this [in their labs][14]. But now, anyone can easily customize products to fit their exact needs. There are already millions of free designs available.
|
||||
|
||||
![Recyclebot][15]
|
||||
|
||||
[Recyclebot][16] (Joshua M. Pearce, [GPLv3][17])
|
||||
|
||||
The way to really knock the bottom out of a product's price is to [source the raw materials from trash][18]. This is possible for a dizzying array of products because of recent improvements in small-scale recycling processes (like [Recyclebots][19], which I use in my lab) that enable people to make valuable products from waste. Best of all, anyone can get these green, custom creations for a small fraction of the cost of a proprietary system. We can normally produce a custom product for [less than the sales tax][20] on a conventional product—with the same functionality, a better, customized form, and almost no cost.
|
||||
|
||||
### Learn more
|
||||
|
||||
In _[Create, Share, and Save Money Using Open Source Projects][4],_ I share the potential in at-home manufacturing and recycling and even how to score free big-ticket items, including housing and electricity, with open source. You can also learn more about this on a webinar I recorded with Megan Krieger and Janet Callahan for Michigan Tech's [Husky Bites][21].
|
||||
|
||||
Hopefully, this knowledge is motivating enough to pull in a niece or nephew or two over to the open source way!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/influence-open-source
|
||||
|
||||
作者:[Joshua Pearce][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jmpearce
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/open_pipe_red_hat_tower_building.png?itok=8ho3yi7L (pipe in a building)
|
||||
[2]: https://distrowatch.com/
|
||||
[3]: https://opensource.com/article/20/4/ad-blockers
|
||||
[4]: https://www.appropedia.org/Create,_Share,_and_Save_Money_Using_Open-Source_Projects
|
||||
[5]: https://opensource.com/sites/default/files/uploads/opendesk_furniture_lift-standing-desk.jpg (Lift Standing Desk)
|
||||
[6]: https://www.appropedia.org/File:Opendesk_furniture_lift-standing-desk.jpg
|
||||
[7]: https://creativecommons.org/licenses/by-nc-sa/2.0/
|
||||
[8]: http://www.mdpi.com/2227-7080/5/3/45
|
||||
[9]: https://doi.org/10.3390/inventions3030064
|
||||
[10]: https://www.mdpi.com/2227-7080/5/1/7
|
||||
[11]: https://opensource.com/sites/default/files/uploads/3dprinted_household.jpg (3D printed household items)
|
||||
[12]: https://www.appropedia.org/File:3dprinted_household.JPG
|
||||
[13]: https://creativecommons.org/licenses/by-sa/3.0/
|
||||
[14]: https://opensource.com/article/20/10/open-source-hardware-savings
|
||||
[15]: https://opensource.com/sites/default/files/uploads/recyclebotrep.png (Recyclebot)
|
||||
[16]: https://www.appropedia.org/File:Recyclebotrep.png
|
||||
[17]: https://www.gnu.org/licenses/gpl-3.0.html
|
||||
[18]: https://www.academia.edu/34738483/Tightening_the_Loop_on_the_Circular_Economy_Coupled_Distributed_Recycling_and_Manufacturing_with_Recyclebot_and_RepRap_3-D_Printing
|
||||
[19]: https://www.appropedia.org/Recyclebot
|
||||
[20]: https://opensource.com/article/17/3/how-to-create-consumer-goods-open-hardware
|
||||
[21]: https://www.facebook.com/Michigan-Tech-College-of-Engineering-109353424030003/videos/husky-bites-presents-special-guest-joshua-m-pearce/2669023713361207/
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why it's important to keep the cloud open)
|
||||
[#]: via: (https://opensource.com/article/20/10/keep-cloud-open)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Why it's important to keep the cloud open
|
||||
======
|
||||
An open cloud helps developers maintain autonomy and security while
|
||||
taking advantage of the power and reach of the cloud.
|
||||
![Sky with clouds and grass][1]
|
||||
|
||||
There's a famous sticker featured on many laptop lids; it goes something like this: "the 'cloud' is just somebody else's computer."
|
||||
|
||||
There's a lot of truth to that sentiment, but it's not exactly technically accurate. In fact, cloud computing isn't just somebody else's computer; it's somebody else's _hundreds and thousands_ of computers.
|
||||
|
||||
Years ago, "the cloud" did indeed just refer to the simplified graphic in a flowchart, so the illustrator didn't have to try to accurately depict the multiple networks that comprise the World Wide Web. Now, however, the cloud isn't just describing traffic or small-time remote file storage offers. The cloud of today is a _platform_ of interconnected computational nodes working together to keep containerized Linux images, each running a distinct service (or "microservice" in developer lingo), functioning as applications distributed over the whole world.
|
||||
|
||||
The cloud is a computer, no different in theory than the device you're reading this article on, but very different in construction. For instance, you don't own the cloud. You might wonder how such a concept can possibly be compatible with the idea of open source and free software, methods of computing in which the user famously owns the software they run. Surely you can't own software when you don't even own the device it's installed on?
|
||||
|
||||
### Open source and the cloud
|
||||
|
||||
For several years now, the Internet has been something of a software neutral zone. The model of the Internet isn't the same as "traditional" software in which there's a one-to-one, or maybe a one-per-family, relationship between the app and the user. The Internet is built of servers, which run services intended for multiple users. You sign up for an account on a site, and, in the best-case scenario, you more or less "own" your user account and data, but you don't own the site. You can't stop your Internet service and bring up the website on your computer. The software "lives" on a server somewhere. Even when the software is open source, such as WordPress or Drupal, and even if you download it and install it locally on your own computer, you still don't possess the instance you created an account on.
|
||||
|
||||
For this reason, even users very conscious of the threat of non-open software tend to overlook the question of software on the Internet. It can be increasingly difficult to recognize the importance of open source when even popular open source projects are hosted on Github (which uses a non-open web stack), Slack, or Discord instead of [Mattermost][2] or [Matrix][3] for chat; Google Docs instead of [Etherpad][4] for collaboration; Trello instead of [Phabricator][5] for [project management][6]; Jira for bug tracking; Gmail for communication, and so on. For as much as open source has won within software development and server hosting, it seems to willingly lock itself inside proprietary infrastructure.
|
||||
|
||||
### Why the cloud is so powerful
|
||||
|
||||
The problem doesn't end with infrastructure. The reason open source projects are locking themselves into proprietary systems for support is that the cloud itself is the computer, and the computer powered by the cloud is a lot more powerful than any developer's workstation. Not only does it have more processing power, but it also has a greater reach. An application you develop to run on the cloud can serve millions of users without even one of them having to figure out how to download and install anything. Your users just launch a browser and use your app, on any device, without even worrying about whether their device is powerful enough for the task they need to be done.
|
||||
|
||||
The cloud just makes sense, for computation, for delivery, and even for marketing. The problem is, it doesn't make any sense for open source. And that's why the cloud is no longer enough. The cloud needs to be upgraded to an open hybrid cloud.
|
||||
|
||||
### What is an open hybrid cloud?
|
||||
|
||||
When people talked about "the cloud" many years ago, it referred to the network serving as the computer. It was even then an old idea, but it was only just being realized. But because the network was the computer, the natural and correct assumption was that most users wouldn't own the computer; they'd only log in with client machines. And that's exactly the form it has taken—you own a device that browses to a cloud owned by Google, Microsoft, or Amazon.
|
||||
|
||||
This came to be known as the public cloud because the infrastructure running the cloud is available to the general public. You can buy time on several public clouds, interact with it through Kubernetes, and develop apps for Linux containers.
|
||||
|
||||
It didn't take long for individual companies to build private clouds—an infrastructure available only to their employees and clients. This ensured that important data remained under their control, and it often cost less than buying time on someone else's infrastructure.
|
||||
|
||||
A hybrid cloud combines these two concepts—you maintain a private cloud for your own use, and you use a public cloud to provide services you can't run only privately. An open hybrid cloud is a hybrid cloud built on open source, whether it's OKD, OpenShift, Kubernetes, RHEL, Debian, Alpine, Podman, Docker, Ansible, or custom scripts.
|
||||
|
||||
### Getting an open hybrid cloud
|
||||
|
||||
The cloud is powerful, so it stands to reason that it can actually help solve a little problem like ensuring user independence. It doesn't happen overnight, though, and the proprietary cloud is already entrenched in services used by millions. So, as an open source enthusiast, what can you do to promote the open hybrid cloud?
|
||||
|
||||
### Don't settle for closed clouds
|
||||
|
||||
If you're a developer, seek out an open hybrid cloud when you're looking for a platform to build upon. If you can't find one within your price range and you can't build a small one, then support open stacks. Look at the services your project relies upon and make sure you can reimplement the stack, should you need to.
|
||||
|
||||
### Use open source online
|
||||
|
||||
As a user, look for [federated systems][7] for social media, and look for open source platforms like WordPress, Drupal, Nextcloud, Etherpad, EtherCalc, and others, for online collaboration. You're not running the instance you're using, but at least you know that the code is auditable and that you're not supporting an environment that forces developers to contribute to proprietary software.
|
||||
|
||||
### Data liberation
|
||||
|
||||
Whether or not the environment is open source, ensure that important data is secure and can be exported. We're well into the 21st century, so there's no excuse for a website to gather data about without proper encryption and no excuse to withhold your data from you. You should be able to export anything you put _into_ a site for your own backups.
|
||||
|
||||
### Be open
|
||||
|
||||
In an open hybrid cloud, you own your development environment and your data, and you maintain your autonomy the same way you do with a laptop running [Linux][8] or [BSD][9]. Cloud computing is the future. Let's work together to make sure the future is open.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/keep-cloud-open
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus-cloud.png?itok=vz0PIDDS (Sky with clouds and grass)
|
||||
[2]: http://mattermost.com
|
||||
[3]: http://matrix.org
|
||||
[4]: http://etherpad.org
|
||||
[5]: https://www.phacility.com/phabricator/
|
||||
[6]: https://opensource.com/alternatives/trello
|
||||
[7]: https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[8]: https://opensource.com/resources/linux
|
||||
[9]: https://opensource.com/article/20/5/furybsd-linux
|
||||
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to define a product in the open source software supply chain)
|
||||
[#]: via: (https://opensource.com/article/20/10/defining-product-open-source)
|
||||
[#]: author: (Scott McCarty https://opensource.com/users/fatherlinux)
|
||||
|
||||
How to define a product in the open source software supply chain
|
||||
======
|
||||
Differentiation is what makes a product successful. Learn more in part
|
||||
two of this series on open source in the software supply chain.
|
||||
![Gift box opens with colors coming out][1]
|
||||
|
||||
In the first article in this series, "[Is open source a development model, business model, or something else?][2]" I introduced the concept that open source is part of the supply chain for software products. But to truly understand open source as a supply chain, you must have a decent understanding of what a product is. A product can be thought of as a business, and as legendary business guru [Peter Drucker][3] said, "The purpose of business is to create and keep a customer." Drucker's statement means a business or product must be useful enough to pay for, or it will fail. Product differentiation is the thing that creates and retains customers.
|
||||
|
||||
### What's in a software product?
|
||||
|
||||
Even in the stone age of 1999, when I started my career, the concept of software products existed—you could go to a store and purchase boxed copies of Red Hat Linux on compact discs (though floppies were still very much in use). The idea of software products existing might sound like a joke, and it is, but in the 1940s and 1950s (when computers, as we know them, were created), software was not a component of value that was bought and sold. There was no market for software. You couldn't buy it, sell it, or access it online.
|
||||
|
||||
Instead of buying software, the choice was to build or buy a physical computer; with either option, you wrote the software yourself for that specific computer.
|
||||
|
||||
> _That… specific… computer…_
|
||||
|
||||
No joke. In the early days of computers, software couldn't run anywhere except for the computer you wrote it on. In fact, in the early days, you couldn't even use the same programming language on two different computers. But, as computers evolved, system software, such as operating systems, assemblers, and compilers, were created. And with the advent of this system software, application code became more reusable and portable.
|
||||
|
||||
In the 1960s, cross-platform compilers and operating systems led to the concept of reusable code, such as macros and eventually libraries. At the beginning of every project, you built your own reusable functions and libraries. (Computer science courses still force you to do this so that you learn what's going on behind the scenes.) Concurrently, processors and operating systems standardized, enabling portability between computers.
|
||||
|
||||
In the early days, these components were used within single organizations (e.g., a government, university, company, etc.), but the desire to share software among organizations emerged quickly. If you're interested in understanding the history of code portability from the first computers to containers, see "Fatherlinux's" [Container portability][4] series or the [History of compiler construction][5] Wikipedia page. Suffice to say, code had to be portable before anyone could have software products, open source or even containers.
|
||||
|
||||
### Reusable and portable software
|
||||
|
||||
Once code became portable and shareable between organizations, the next logical step was to sell it. In these early days, having software that did _something useful_ was differentiating in the marketplace. This was a breakthrough because if you needed a calculator, a compiler, or a piece of word processing software, it became cheaper and easier to buy it than to write it. So software products were born.
|
||||
|
||||
This model really only worked to tackle general-purpose problems that a lot of people share—things like calculating numbers, writing documents, or compiling software; these are business problems. General-purpose software is great, but it doesn't elegantly solve specific problems related to business rules within a single industry or organization, although you can abuse Excel or Google Sheets pretty hard. For specific business problems, it's more efficient to write custom code. This need led to the rise of middleware, things like Java, service buses, and databases. Middleware was bought and sold to assist with custom software development.
|
||||
|
||||
Code portability led to a marketplace for software applications and middleware. Software companies began to provide competing solutions with differentiated value. You picked the compiler or the calculator that you wanted based on features. The existence of competing solutions was great for consumers because it drove software companies to create more specialized solutions, each with unique value. Whether a product is built on open source or not, it must provide unique value in the marketplace.
|
||||
|
||||
### Understanding differentiated value
|
||||
|
||||
To explain differentiated value, I'll use an analogy about automobiles. Families need cars, sport utility vehicles (SUVs), or minivans. They might want comfortable seats, infotainment systems, or safety features. They often have a preference on color. Each family is different and has specific needs, so the perfect automobile would be one that the family built together as a project.
|
||||
|
||||
Most families don't have the time, desire, money, or credit to buy all of the components necessary to build the perfect car from scratch, much less the time to maintain it over a given lifecycle. It wouldn't be an economical investment of time or money for a family. It would cost them way more, and take a long time to build. Instead, families buy automobiles from existing vendors, as a built solution to their transportation problem. Although the bought car will be imperfect, it will approximately meet their needs with much less time and money invested.
|
||||
|
||||
Automobile vendors put a solution together with undifferentiated and differentiated components. This includes everything from the motor, fuel injectors, tires, and seats in the car, to the buying experience at the dealership, the financing, and the service program while the car is owned. All of these features and experiences are a component of the solution that families buy when looking for an automobile. The combination of all these things is what produces something that is different and, hopefully, better in the marketplace. We call this _differentiation_. The more competing solutions, the more differentiation in the marketplace, and the better the chance that a family can find a car that matches their needs more approximately.
|
||||
|
||||
### Differentiation in open source
|
||||
|
||||
In a traditional manufactured product or service, there is a distinction between the value provided by the supplier and the value provided by the company selling directly to the consumer. You could make a further distinction between business-to-consumer (B2C) or business-to-business (B2B) products and services, but that's beyond the scope of this series.
|
||||
|
||||
The astute reader may already be thinking, "yeah, but with traditional products, the suppliers are also companies selling products with differentiation." This is completely true, and in this way, open source projects are no different. Community-driven, open source projects don't have the advantage of expensive marketing campaigns, focus groups, and sales teams to educate customers, but they must also differentiate themselves in the marketplace.
|
||||
|
||||
Differentiation is an important concept for product managers, developers, and even systems administrators. Even in a broader context, the output of any sort of knowledge work—code, writing, music, or art—differentiation is what brings value and meaning to our work. Differentiation is what creates value, whether it's a software product or service, labor, or even music.
|
||||
|
||||
In the next article, I'll dive deeper into how software product teams differentiate their solutions from the open source components provided by their suppliers. We'll even cover software as a service (SaaS).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/defining-product-open-source
|
||||
|
||||
作者:[Scott McCarty][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/fatherlinux
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_gift_giveaway_box_520x292.png?itok=w1YQhNH1 (Gift box opens with colors coming out)
|
||||
[2]: https://opensource.com/article/20/10/open-source-supply-chain
|
||||
[3]: https://en.wikipedia.org/wiki/Peter_Drucker
|
||||
[4]: http://crunchtools.com/container-portability-part-1/
|
||||
[5]: https://en.wikipedia.org/wiki/History_of_compiler_construction
|
||||
@ -0,0 +1,139 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A few things I've learned about email marketing)
|
||||
[#]: via: (https://jvns.ca/blog/2020/10/28/a-few-things-i-ve-learned-about-email-marketing/)
|
||||
[#]: author: (Julia Evans https://jvns.ca/)
|
||||
|
||||
A few things I've learned about email marketing
|
||||
======
|
||||
|
||||
Hello! I’ve been learning a lot about business over the last few years (it’s possible to make a living by helping people learn! it’s amazing!). One of the things I’ve found hardest to get my head around was email marketing.
|
||||
|
||||
Like a lot of people, I get a lot of unwanted email, and at first I was really opposed to doing any kind of email marketing because I was worried I’d be the _source_ of that unwanted email. But I’ve learned how to do it in a way that feels good to me, and where the replies to my marketing emails are usually along the lines of “wow, I love this, thank you so much!”. ([literally: here are excerpts from the last 20 or so replies I’ve gotten][1])
|
||||
|
||||
I’m going to structure this as a series of beliefs I had about email marketing that turned out not to be universally true.
|
||||
|
||||
### myth 1: selling things is an adversarial relationship
|
||||
|
||||
I used to think that selling things was a sort of adversarial relationship: the person selling the product wants to convince the buyer (by any means necessary) to spend as much money as possible, and that people buying things are usually kind of resentful of anyone asking them to spend money.
|
||||
|
||||
I’ve learned that actually a lot of people are happy (or even actively **want**) to spend money on something that will help them solve a problem they have.
|
||||
|
||||
Here’s a silly example of something illustrating this: 2 years ago, we’d hired someone to paint our new apartment. We decided to paint a lot of the walls white, and we were stuck with the impossible problem of deciding which of the 10 billion possible shades of white to paint the walls. I found a $27 ebook called [white is complicated][2], and (long story short, this blog post is not about painting) it really helped me confidently choose a shade of white!! We spent thousands of dollars on painting, so $30 was a really good investment in making sure we’d be happy with the result.
|
||||
|
||||
So even though $27 for an ebook on how to choose a white seems silly at first, I was really happy to spend the money, and my guess is a lot of other people who bought that ebook are as well.
|
||||
|
||||
The bigger idea here is that it’s easier to run a business when you’re selling to people who are happy to buy things based on the value they’re getting from the product. In my case, I’ve found that there are lots of programmers who are happy to pay for clear, short, friendly explanations of concepts they need to understand for their jobs.
|
||||
|
||||
### a quick note on how I learned these things: 30x500
|
||||
|
||||
I originally wrote this blog post about all these things I learned, and it kind of read like I figured out all of these things naturally over the course of running a business. But that’s not how it went at all! I’ve actually found it very hard to debug business problems on my own. A lot of the attitudes I had when I started out running a business were counterproductive (like thinking of selling something as an adversarial process), and I don’t know that many people who run similar businesses who I can get advice from.
|
||||
|
||||
I learned how to think about selling things as a non-adversarial process (and everything else in this blog post, and a lot more) from [30x500][3], a business class by Amy Hoy ([her writing is here][4]) and [Alex Hillman][5] that I bought a couple of years ago. 30x500 is about running a specific kind of business (very briefly: sell to people who buy based on value, decide what to build by researching your audience, market by teaching people helpful things), which happens to be the exact kind of business that I run. It’s been a really great way to learn how to run my business better.
|
||||
|
||||
Okay, back to my misconceptions about email marketing!
|
||||
|
||||
### myth 2: sending email is inherently bad
|
||||
|
||||
The next thing I believed was that sending email from a business was somehow inherently bad and that all marketing email was unwanted.
|
||||
|
||||
I now realize this is untrue even for normal marketing emails – for example, lots of people subscribe to marketing newsletters for brands they like because they want to hear about new products when they come out & sales.
|
||||
|
||||
But marketing emails aren’t just “not inherently bad”, they can actually be really useful!
|
||||
|
||||
### marketing is about building trust
|
||||
|
||||
When I started sending out business emails, I based them on the emails I was used to receiving – I’d announce new zines I’d written, and explain why the zine was useful.
|
||||
|
||||
But what I’ve learned is that (at least for me) marketing isn’t about describing your product to the audience, **marketing is about building trust by helping people**.
|
||||
|
||||
So, instead of just periodically emailing out “hey, here’s a new zine, here’s why it’s good”, my main marketing email list is called [saturday comics][6], and it sends you 1 email a week with a programming comic.
|
||||
|
||||
What I like about this approach to marketing (“just help people learn things for free”) is that it’s literally just what I love doing anyway – I wrote this blog to help people learn things for free for years just because I think it’s fun to help people learn.
|
||||
|
||||
And people love the Saturday Comics! And it makes money – I announce new zines to that list as well, and lots of people buy them. It’s really simple and nice!
|
||||
|
||||
### myth 3: you have to trick people into signing up for your email marketing list
|
||||
|
||||
One pattern I see a lot is that I sign up for some free service, and then I start getting deluged with marketing emails trying to convince me to upgrade to the paid tier or whatever. I used to think that this was how marketing emails **had** to work – you somehow get people’s email and then send them email, and hope that for some reason (???) they decide to buy things from you.
|
||||
|
||||
But, of course, this isn’t true! If your marketing list is actually just full of genuinely helpful emails, and you can describe who it’s intended for clearly (give people a link to the archive to see if they like what they see!), then a lot of people will be happy to sign up and receive the emails!
|
||||
|
||||
If you clearly communicate who your mailing list will help, then people can easily filter themselves in, and the only people on the list will be happy to be on the list. And then you don’t have to send any unwanted email at all! Hooray!
|
||||
|
||||
Here’s one story that influenced how I think about this: once I sent an email to everyone who had bought a past zine saying “hey, I just released this other zine, maybe you want to buy it!”. And I got an angry reply from someone saying something like “why are you emailing me, I just bought that one thing from you, I don’t want you to keep emailing me about other things”. I decided that I agreed with that, and now I’m more careful about being clear about what kinds of emails people are opting into.
|
||||
|
||||
### marketing is about communicating clearly & honestly
|
||||
|
||||
One insight (from Alex Hillman) that helped me a lot recently was – when someone is dissatisfied with something they bought, it doesn’t always mean that the product is “bad”. Maybe the product is helpful to many other people!
|
||||
|
||||
But it definitely means that the person’s expectations weren’t met. A tiny example: one of the few refund requests I’ve gotten for a zine was from someone from who expected there to be more information about sed in the zine, and they were disappointed there was only 1 page about sed.
|
||||
|
||||
So if I communicate clearly & accurately what problems a product solves, who it’s for, and how it solves those problems, people are much more likely to be delighted when they buy it and be happy to buy from me again in the future!. For my zines specifically, I like to make the table of contents very easy to find so that people can see that there’s [1 page about sed][7] :)
|
||||
|
||||
### myth 4: you have to constantly produce new emails
|
||||
|
||||
I’ve tried and failed to start a lot of mailing lists. the pattern I kept getting stuck in was:
|
||||
|
||||
I have an idea for a weekly mailing list I send 2 emails I give up forever
|
||||
|
||||
This was partly because I thought that to have a weekly/biweekly mailing list, you have to write new emails every week. And some people definitely do mailing lists this way, like [Austin Kleon][8].
|
||||
|
||||
But I learned that there’s a different way to write a mailing list! Instead, you:
|
||||
|
||||
put together a list of your best articles / comics / whatever when someone subscribes to that list, send them 1 email a week (or every 2 weeks, or whatever) with one article from the List Of Your Best Articles
|
||||
|
||||
The point is most people in the world probably haven’t already read your best articles, and so if you just send them one article a week from that list, it’ll probably actually be MORE helpful to them than if you were writing a new article every week. And you don’t need to write any emails every week!
|
||||
|
||||
I think this is called a “drip marketing campaign”, but when I search for that term I don’t find the results super helpful – there’s a lot out there about tools to do this, but as with anything I think the actual content of the emails is the most important thing.
|
||||
|
||||
### myth 5: unsubscribes are the end of the world
|
||||
|
||||
Another email marketing thing I used to get stressed out about was unsubscribes. It always feels a little sad to send an email about something I’m excited about and see 20 people unsubscribe immediately, even if it’s only 0.3% of people on the mailing list.
|
||||
|
||||
But I know that I subscribe to mailing lists very liberally, even on topics that I’m not that interested in, and 70% of the time I decide that I’m not that interested in the topic and unsubscribe eventually. A small percentage of people unsubscribing really just isn’t that big of a deal.
|
||||
|
||||
### myth 6: you need to optimize your open rates
|
||||
|
||||
There are all kinds of analytics you can do with email marketing, like open rates. I love numbers and analyzing things, but so far I really haven’t found trying to A/B test or optimize my numbers to be that productive or healthy. I’d rather spend my energy on just writing more helpful things for people to read.
|
||||
|
||||
The most important thing I’ve learned about website analytics is that it’s unproductive to look at random statistics like “the open rate on this email is 43% but the last one was 47%” and wonder what they mean. What _has_ been helpful has been coming up with a few specific questions that are important to me (“are people visiting this page from links on other sites, or only from my links?”) and keeping very rough track of the answers over time.
|
||||
|
||||
So far I’ve really never used any of the tracking features of my email marketing software. The only thing I’ve done that I’ve found helpful is: sometimes when I release a new zine I’ll send out a discount code to people on the list, and I can tell if people bought the thing from the mailing list because they used the discount code.
|
||||
|
||||
### it’s important to remember there are people on the other side
|
||||
|
||||
The last thing that’s helped me is to remember that even though emailing thousands of people sometimes feels like a weird anonymous thing, there are a lot of very delightful people on the other side! So when I write emails, I usually try to imagine that I’m writing to some very nice person I met at a conference one time who told me that they like my blog. We’re not best friends, but they know my work to some extent, and they’re interested to hear what I have to say.
|
||||
|
||||
I often like to remind people why they’re getting the email, especially if I haven’t emailed that list for a long time – “you signed up to get announcements when I release a new zine, so here’s an announcement!”. I think the technical email marketing term for this is a list being “cold” and “warm”, like if you don’t email a list for too long it’s “cold” and your subscribers might have forgotten that they’re on it.
|
||||
|
||||
### that’s all!
|
||||
|
||||
When I started, I was really convinced that email marketing was this terrible, awful thing that I could not do that mostly involved tricking people into getting emails they don’t want (ok, I’m exaggerating a bit, but I really struggled with it). But it’s possible to do it in a transparent way where I’m mostly just sending people helpful emails that they do want!
|
||||
|
||||
The big surprise for me was that email marketing is not a monolithic thing. I have a lot of choices about how to do it, and if I don’t like the way someone else does email marketing, I can just make different choices when doing it myself!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2020/10/28/a-few-things-i-ve-learned-about-email-marketing/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://jvns.ca/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://gist.github.com/jvns/c2aaecbbbf60b7f3adf3e0be18d54a7b
|
||||
[2]: https://mariakillam.com/product/white-is-complicated/
|
||||
[3]: https://30x500.com/academy/
|
||||
[4]: https://stackingthebricks.com/
|
||||
[5]: https://dangerouslyawesome.com
|
||||
[6]: https://wizardzines.com/saturday-comics
|
||||
[7]: https://wizardzines.com/zines/bite-size-command-line/
|
||||
[8]: https://austinkleon.com/
|
||||
@ -1,186 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use the internet from the command line with curl)
|
||||
[#]: via: (https://opensource.com/article/20/5/curl-cheat-sheet)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Use the internet from the command line with curl
|
||||
======
|
||||
Download our new curl cheat sheet. Curl is a fast and efficient way to
|
||||
pull the information you need from the internet without using a
|
||||
graphical interface.
|
||||
![Cheat Sheet cover image][1]
|
||||
|
||||
Curl is commonly considered a non-interactive web browser. That means it's able to pull information from the internet and display it in your terminal or save it to a file. This is literally what web browsers, such as Firefox or Chromium, do except they _render_ the information by default, while curl downloads and displays raw information. In reality, the curl command does much more and has the ability to transfer data to or from a server using one of many supported protocols, including HTTP, FTP, SFTP, IMAP, POP3, LDAP, SMB, SMTP, and many more. It's a useful tool for the average terminal user, a vital convenience for the sysadmin, and a quality assurance tool for microservices and cloud developers.
|
||||
|
||||
Curl is designed to work without user interaction, so unlike Firefox, you must think about your interaction with online data from start to finish. For instance, if you want to view a web page in Firefox, you launch a Firefox window. After Firefox is open, you type the website you want to visit into the URL field or a search engine. Then you navigate to the site and click on the page you want to see.
|
||||
|
||||
The same concepts apply to curl, except you do it all at once: you launch curl at the same time you feed it the internet location you want and tell it whether you want to the data to be saved in your terminal or to a file. The complexity increases when you have to interact with a site that requires authentication or with an API, but once you learn the **curl** command syntax, it becomes second nature. To help you get the hang of it, we collected the pertinent syntax information in a handy [cheat sheet][2].
|
||||
|
||||
### Download a file with curl
|
||||
|
||||
You can download a file with the **curl** command by providing a link to a specific URL. If you provide a URL that defaults to **index.html**, then the index page is downloaded, and the file you downloaded is displayed on your terminal screen. You can pipe the output to less or tail or any other command:
|
||||
|
||||
|
||||
```
|
||||
$ curl "<http://example.com>" | tail -n 4
|
||||
<h1>Example Domain</h1>
|
||||
<p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p>
|
||||
<p><a href="[https://www.iana.org/domains/example"\>More][3] information...</a></p>
|
||||
</div></body></html>
|
||||
```
|
||||
|
||||
Because some URLs contain special characters that your shell normally interprets, it's safest to surround your URL in quotation marks.
|
||||
|
||||
Some files don't translate well to being displayed in a terminal. You can use the **\--remote-name** option to cause the file to be saved according to what it's called on the server:
|
||||
|
||||
|
||||
```
|
||||
$ curl --remote-name "<https://example.com/linux-distro.iso>"
|
||||
$ ls
|
||||
linux-distro.iso
|
||||
```
|
||||
|
||||
Alternatively, you can use the **\--output** option to name your download whatever you want:
|
||||
|
||||
|
||||
```
|
||||
`curl "http://example.com/foo.html" --output bar.html`
|
||||
```
|
||||
|
||||
### List contents of a remote directory with curl
|
||||
|
||||
Because curl is non-interactive, it's difficult to browse a page for downloadable elements. Provided that the remote server you're connecting to allows it, you can use **curl** to list the contents of a directory:
|
||||
|
||||
|
||||
```
|
||||
`$ curl --list-only "https://example.com/foo/"`
|
||||
```
|
||||
|
||||
### Continue a partial download
|
||||
|
||||
If you're downloading a very large file, you might find that you have to interrupt the download. Curl is intelligent enough to determine where you left off and continue the download. That means the next time you're downloading a 4GB Linux distribution ISO and something goes wrong, you never have to go back to the start. The syntax for **\--continue-at** is a little unusual: if you know the byte count where your download was interrupted, you can provide it; otherwise, you can use a lone dash (**-**) to tell curl to detect it automatically:
|
||||
|
||||
|
||||
```
|
||||
`$ curl --remote-name --continue-at - "https://example.com/linux-distro.iso"`
|
||||
```
|
||||
|
||||
### Download a sequence of files
|
||||
|
||||
If you need to download several files—rather than just one big file—curl can help with that. Assuming you know the location and file-name pattern of the files you want to download, you can use curl's sequencing notation: the start and end point between a range of integers, in brackets. For the output filename, use **#1** to indicate the first variable:
|
||||
|
||||
|
||||
```
|
||||
`$ curl "https://example.com/file_[1-4].webp" --output "file_#1.webp"`
|
||||
```
|
||||
|
||||
If you need to use another variable to represent another sequence, denote each variable in the order it appears in the command. For example, in this command, **#1** refers to the directories **images_000** through **images_009**, while **#2** refers to the files **file_1.webp** through **file_4.webp**:
|
||||
|
||||
|
||||
```
|
||||
$ curl "<https://example.com/images\_00\[0-9\]/file\_\[1-4\].webp>" \
|
||||
\--output "file_#1-#2.webp"
|
||||
```
|
||||
|
||||
### Download all PNG files from a site
|
||||
|
||||
You can do some rudimentary web scraping to find what you want to download, too, using only **curl** and **grep**. For instance, say you need to download all images associated with a web page you're archiving. First, download the page referencing the images. Pipe the page to grep with a search for the image type you're targeting (PNG in this example). Finally, create a **while** loop to construct a download URL and to save the files to your computer:
|
||||
|
||||
|
||||
```
|
||||
$ curl <https://example.com> |\
|
||||
grep --only-matching 'src="[^"]*.[png]"' |\
|
||||
cut -d\" -f2 |\
|
||||
while read i; do \
|
||||
curl <https://example.com/"${i}>" -o "${i##*/}"; \
|
||||
done
|
||||
```
|
||||
|
||||
This is just an example, but it demonstrates how flexible curl can be when combined with a Unix pipe and some clever, but basic, parsing.
|
||||
|
||||
### Fetch HTML headers
|
||||
|
||||
Protocols used for data exchange have a lot of metadata embedded in the packets that computers send to communicate. HTTP headers are components of the initial portion of data. It can be helpful to view these headers (especially the response code) when troubleshooting your connection to a site:
|
||||
|
||||
|
||||
```
|
||||
curl --head "<https://example.com>"
|
||||
HTTP/2 200
|
||||
accept-ranges: bytes
|
||||
age: 485487
|
||||
cache-control: max-age=604800
|
||||
content-type: text/html; charset=UTF-8
|
||||
date: Sun, 26 Apr 2020 09:02:09 GMT
|
||||
etag: "3147526947"
|
||||
expires: Sun, 03 May 2020 09:02:09 GMT
|
||||
last-modified: Thu, 17 Oct 2019 07:18:26 GMT
|
||||
server: ECS (sjc/4E76)
|
||||
x-cache: HIT
|
||||
content-length: 1256
|
||||
```
|
||||
|
||||
### Fail quickly
|
||||
|
||||
A 200 response is the usual HTTP indicator of success, so it's what you usually expect when you contact a server. The famous 404 response indicates that a page can't be found, and 500 means there was a server error.
|
||||
|
||||
To see what errors are happening during negotiation, add the **\--show-error** flag:
|
||||
|
||||
|
||||
```
|
||||
`$ curl --head --show-error "http://opensource.ga"`
|
||||
```
|
||||
|
||||
These can be difficult for you to fix unless you have access to the server you're contacting, but curl generally tries its best to resolve the location you point it to. Sometimes when testing things over a network, seemingly endless retries just waste time, so you can force curl to exit upon failure quickly with the **\--fail-early** option:
|
||||
|
||||
|
||||
```
|
||||
`curl --fail-early "http://opensource.ga"`
|
||||
```
|
||||
|
||||
### Redirect query as specified by a 3xx response
|
||||
|
||||
The 300 series of responses, however, are more flexible. Specifically, the 301 response means that a URL has been moved permanently to a different location. It's a common way for a website admin to relocate content while leaving a "trail" so people visiting the old location can still find it. Curl doesn't follow a 301 redirect by default, but you can make it continue on to a 301 destination by using the **\--location** option:
|
||||
|
||||
|
||||
```
|
||||
$ curl "<https://iana.org>" | grep title
|
||||
<title>301 Moved Permanently</title>
|
||||
$ curl --location "<https://iana.org>"
|
||||
<title>Internet Assigned Numbers Authority</title>
|
||||
```
|
||||
|
||||
### Expand a shortened URL
|
||||
|
||||
The **\--location** option is useful when you want to look at shortened URLs before visiting them. Shortened URLs can be useful for social networks with character limits (of course, this may not be an issue if you use a [modern and open source social network][4]) or for print media in which users can't just copy and paste a long URL. However, they can also be a little dangerous because their destination is, by nature, concealed. By combining the **\--head** option to view just the HTTP headers and the **\--location** option to unravel the final destination of a URL, you can peek into a shortened URL without loading the full resource:
|
||||
|
||||
|
||||
```
|
||||
$ curl --head --location \
|
||||
"<https://bit.ly/2yDyS4T>"
|
||||
```
|
||||
|
||||
### [Download our curl cheat sheet][2]
|
||||
|
||||
Once you practice thinking about the process of exploring the web as a single command, curl becomes a fast and efficient way to pull the information you need from the internet without bothering with a graphical interface. To help you build it into your usual workflow, we've created a [curl cheat sheet][2] with common curl uses and syntax, including an overview of using it to query an API.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/curl-cheat-sheet
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coverimage_cheat_sheet.png?itok=lYkNKieP (Cheat Sheet cover image)
|
||||
[2]: https://opensource.com/downloads/curl-command-cheat-sheet
|
||||
[3]: https://www.iana.org/domains/example"\>More
|
||||
[4]: https://opensource.com/article/17/4/guide-to-mastodon
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,210 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install Ubuntu Server on a Raspberry Pi)
|
||||
[#]: via: (https://itsfoss.com/install-ubuntu-server-raspberry-pi/)
|
||||
[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
|
||||
|
||||
How to Install Ubuntu Server on a Raspberry Pi
|
||||
======
|
||||
|
||||
The [Raspberry Pi][1] is the best-known [single-board computer][2]. Initially, the scope of the Raspberry Pi project was targeted to the promotion of teaching of basic computer science in schools and in developing countries.
|
||||
|
||||
Its low cost, portability and very low power consumption, made the models far more popular than anticipated. From weather station to home automation, tinkerers built so many [cool projects using Raspberry Pi][3].
|
||||
|
||||
The [4th generation of the Raspberry Pi][4], is equipped with features and processing power of a regular desktop computer. But this article is not about using RPi as desktop. Instead, I’ll show you how to install Ubuntu server on Raspberry Pi.
|
||||
|
||||
In this tutorial I will use a Raspberry Pi 4 and I will cover the following:
|
||||
|
||||
* Installing Ubuntu Server on a microSD card
|
||||
* Setting up a wireless network connection on the Raspberry Pi
|
||||
* Accessing your Raspberry Pi via SSH
|
||||
|
||||
|
||||
|
||||
![][5]
|
||||
|
||||
**You’ll need the following things for this tutorial**:
|
||||
|
||||
* A micro SD card (8 GB or greater recommended)
|
||||
* A computer (running Linux, Windows or macOS) with a micro SD card reader
|
||||
* A Raspberry Pi 2, 3 or 4
|
||||
* Good internet connection
|
||||
* An HDMI cable for the Pi 2 & 3 and a micro HDMI cable for the Pi 4 (optional)
|
||||
* A USB keyboard set (optional)
|
||||
|
||||
|
||||
|
||||
### Installing Ubuntu Server on a Raspberry Pi
|
||||
|
||||
![][6]
|
||||
|
||||
I have used Ubuntu for creating Raspberry Pi SD card in this tutorial but you may follow it on other Linux distributions, macOS and Windows as well. This is because the steps for preparing the SD card is the same with Raspberry Pi Imager tool.
|
||||
|
||||
The Raspberry Pi Imager tool downloads the image of your [choice of Raspberry Pi OS][7] automatically. This means that you need a good internet connection for downloading data around 1 GB.
|
||||
|
||||
#### Step 1: Prepare the SD Card with Raspberry Pi Imager
|
||||
|
||||
Make sure you have inserted the microSD card into your computer, and install the Raspberry Pi Imager at your computer.
|
||||
|
||||
You can download the Imager tool for your operating system from these links:
|
||||
|
||||
* [Raspberry Pi Imager for Ubuntu/Debian][8]
|
||||
* [Raspberry Pi Imager for Windows][9]
|
||||
* [Raspberry Pi Imager for MacOS][10]
|
||||
|
||||
|
||||
|
||||
Despite I use Ubuntu, I won’t use the Debian package that is listed above, but I will install the snap package using the command line. This method can be applied to wider range of Linux distributions.
|
||||
|
||||
```
|
||||
sudo snap install rpi-imager
|
||||
```
|
||||
|
||||
Once you have installed Raspberry Pi Imager tool, find and open it and click on the “CHOOSE OS” menu.
|
||||
|
||||
![][11]
|
||||
|
||||
Scroll across the menu and click on “Ubuntu” (Core and Server Images).
|
||||
|
||||
![][12]
|
||||
|
||||
From the available images, I choose the Ubuntu 20.04 LTS 64 bit. If you have a Raspberry Pi 2, you are limited to the 32bit image.
|
||||
|
||||
**Important Note: If you use the latest Raspberry Pi 4 – 8 GB RAM model, you should choose the 64bit OS, otherwise you will be able to use 4 GB RAM only.**
|
||||
|
||||
![][13]
|
||||
|
||||
Select your microSD card from the “SD Card” menu, and click on “WRITE”after.
|
||||
|
||||
![][14]
|
||||
|
||||
If it shows some error, try writing it again. It will now download the Ubuntu server image and write it to the micro SD card.
|
||||
|
||||
It will notify you when the process is completed.
|
||||
|
||||
![][15]
|
||||
|
||||
#### Step 2: Add WiFi support to Ubuntu server
|
||||
|
||||
Once the micro SD card flashing is done, you are almost ready to use it. There is one thng that you may want to do before using it and that is to add Wi-Fi support.
|
||||
|
||||
With the SD card still inserted in the card reader, open the file manager and locate the “system-boot” partition on the card.
|
||||
|
||||
The file that you are looking for and need to edit is named `network-config`.
|
||||
|
||||
![][16]
|
||||
|
||||
This process can be done on Windows and MacOS too. Edit the **`network-config`** file as already mentioned to add your Wi-Fi credentials.
|
||||
|
||||
Firstly, uncomment (remove the hashtag “#” at the beginning) from lines that are included in the rectangular box.
|
||||
|
||||
After that, replace myhomewifi with your Wi-Fi network name enclosed in quotation marks, such as “itsfoss” and the “S3kr1t” with the Wi-Fi password enclosed in quotation marks, such as “12345679”.
|
||||
|
||||
![][17]
|
||||
|
||||
It may look like this:
|
||||
|
||||
```
|
||||
wifis:
|
||||
wlan0:
|
||||
dhcp4: true
|
||||
optional: true
|
||||
access-points:
|
||||
"your wifi name":
|
||||
password: "your_wifi_password"
|
||||
```
|
||||
|
||||
Save the file and insert the micro SD card into your Raspberry Pi. During the first boot, if your Raspberry Pi fails connect to the Wi-Fi network, simply reboot your device.
|
||||
|
||||
#### Step 3: Use Ubuntu server on Raspberry Pi (if you have dedicated monitor, keyboard and mouse for Raspberry Pi)
|
||||
|
||||
If you have got an additional set of mouse, keyboard and a monitor for the Raspberry Pi, you can use easily use it like any other computer (but without GUI).
|
||||
|
||||
Simply insert the micro SD card to the Raspberry Pi, plug in the monitor, keyboard and mouse. Now [turn on your Raspberry Pi][18]. It will present TTY login screen (black terminal screen) and aks for username and password.
|
||||
|
||||
* Default username: ubuntu
|
||||
* Default password: ubuntu
|
||||
|
||||
|
||||
|
||||
When prompted, use “**ubuntu**” for the password. Right after a successful login, [Ubuntu will ask you to change the default password][19].
|
||||
|
||||
Enjoy your Ubuntu Server!
|
||||
|
||||
#### Step 3: Connect remotely to your Raspberry Pi via SSH (if you don’t have monitor, keyboard and mouse for Raspberry Pi)
|
||||
|
||||
It is okay if you don’t have a dedicated monitor to be used with Raspberry Pi. Who needs a monitor with a server when you can just SSH into it and use it the way you want?
|
||||
|
||||
**On Ubuntu and Mac OS**, an SSH client is usually already installed. To connect remotely to your Raspberry Pi, you need to discover its IP address. Check the [devices connected to your network][20] and see which one is the Raspberry Pi.
|
||||
|
||||
Since I don’t have access to a Windows machine, you can access a comprehensive guide provided by [Microsoft][21].
|
||||
|
||||
Open a terminal and run the following command:
|
||||
|
||||
```
|
||||
ssh [email protected]_pi_ip_address
|
||||
```
|
||||
|
||||
You will be asked to confirm the connection with the message:
|
||||
|
||||
```
|
||||
Are you sure you want to continue connecting (yes/no/[fingerprint])?
|
||||
```
|
||||
|
||||
Type “yes” and click the enter key.
|
||||
|
||||
![][22]
|
||||
|
||||
When prompted, use “ubuntu” for the password as mentioned earlier. You’ll be asked to change the password of course.
|
||||
|
||||
Once done, you will be automatically logged out and you have to reconnect, using your new password.
|
||||
|
||||
Your Ubuntu server is up and running on a Raspberry Pi!
|
||||
|
||||
**Conclusion**
|
||||
|
||||
Installing Ubuntu Server on a Raspberry Pi is an easy process and it comes pre-configured at a great degree which the use a pleasant experience.
|
||||
|
||||
I have to say that among all the [operating systems that I tried on my Raspberry Pi][7], Ubuntu Server was the easiest to install. I am not exaggerating. Check my guide on [installing Arch Linux on Raspberry Pi][23] for reference.
|
||||
|
||||
I hope this guide helped you in installing Ubuntu server on your Raspberry Pi as well. If you have questions or suggestions, please let me know in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-ubuntu-server-raspberry-pi/
|
||||
|
||||
作者:[Dimitrios Savvopoulos][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/dimitrios/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[2]: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
[3]: https://itsfoss.com/raspberry-pi-projects/
|
||||
[4]: https://itsfoss.com/raspberry-pi-4/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/Ubuntu-Server-20.04.1-LTS-aarch64.png?resize=800%2C600&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-raspberry-pi.png?resize=800%2C450&ssl=1
|
||||
[7]: https://itsfoss.com/raspberry-pi-os/
|
||||
[8]: https://downloads.raspberrypi.org/imager/imager_amd64.deb
|
||||
[9]: https://downloads.raspberrypi.org/imager/imager.exe
|
||||
[10]: https://downloads.raspberrypi.org/imager/imager.dmg
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager.png?resize=800%2C600&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager-choose-ubuntu.png?resize=800%2C600&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager-ubuntu-server.png?resize=800%2C600&ssl=1
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager-sd-card.png?resize=800%2C600&ssl=1
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-installed-raspberry-pi.png?resize=799%2C506&ssl=1
|
||||
[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-pi-network-config.png?resize=800%2C565&ssl=1
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/Ubuntu-server-wifi.png?resize=800%2C600&ssl=1
|
||||
[18]: https://itsfoss.com/turn-on-raspberry-pi/
|
||||
[19]: https://itsfoss.com/change-password-ubuntu/
|
||||
[20]: https://itsfoss.com/how-to-find-what-devices-are-connected-to-network-in-ubuntu/
|
||||
[21]: https://docs.microsoft.com/en-us/windows-server/administration/openssh/openssh_install_firstuse
|
||||
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-change-password.png?resize=800%2C600&ssl=1
|
||||
[23]: https://itsfoss.com/install-arch-raspberry-pi/
|
||||
@ -1,171 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Reduce/Shrink LVM’s (Logical Volume Resize) in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How to Reduce/Shrink LVM’s (Logical Volume Resize) in Linux
|
||||
======
|
||||
|
||||
Reducing/Shrinking the logical volume is the highest risk of data corruption.
|
||||
|
||||
So try to avoid this kind of situation if possible, but go ahead if you have no other options.
|
||||
|
||||
It is always recommended to make a backup before shrinking an LVM.
|
||||
|
||||
When you are running out of disk space in LVM, you can make some free space on the volume group by reducing the exsisting LVM that no longer uses the full size, instead of adding a new physical disk.
|
||||
|
||||
**Make a note:** Shrinking is not supported on a `GFS2` or `XFS` file system.
|
||||
|
||||
If you are new to Logical Volume Management (LVM), I suggest you start with our previous article.
|
||||
|
||||
* **Part-1: [How to Create/Configure LVM (Logical Volume Management) in Linux][1]**
|
||||
* **Part-2: [How to Extend/Increase LVM’s (Logical Volume Resize) in Linux][2]**
|
||||
|
||||
|
||||
|
||||
![][3]
|
||||
|
||||
Reducing the logical volume involves the below steps.
|
||||
|
||||
* Unmount the file system.
|
||||
* Check the file system for any errors.
|
||||
* Shrink the file system size.
|
||||
* Reduce the logical volume size.
|
||||
* Re-check the file system for errors (Optional).
|
||||
* Mount the file system
|
||||
* Check the reduced file system size
|
||||
|
||||
|
||||
|
||||
**For instance;** You have a **100GB** LVM that no longer uses the full size, you want to reduce it to **80GB** so **20GB** can be used for other purposes.
|
||||
|
||||
```
|
||||
# df -h /testlvm1
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg01-lv002 100G 15G 85G 12% /testlvm1
|
||||
```
|
||||
|
||||
### 1) Unmount the file system
|
||||
|
||||
Use the umount command to unmount the file system.
|
||||
|
||||
```
|
||||
# umount /testlvm1
|
||||
```
|
||||
|
||||
### 2) Check the file system for any Errors
|
||||
|
||||
Check the file system for any errors using the e2fsck command.
|
||||
|
||||
```
|
||||
# e2fsck -f /dev/mapper/vg01-lv002
|
||||
|
||||
e2fsck 1.42.9 (28-Dec-2013)
|
||||
Pass 1: Checking inodes, blocks, and sizes
|
||||
Pass 2: Checking directory structure
|
||||
Pass 3: Checking directory connectivity
|
||||
Pass 4: Checking reference counts
|
||||
Pass 5: Checking group summary information
|
||||
/dev/mapper/vg01-lv002: 13/6553600 files (0.0% non-contiguous), 12231854/26212352 blocks
|
||||
```
|
||||
|
||||
### 3) Shrink the file system.
|
||||
|
||||
The below command will reduce the **“testlvm1”** file system from **100GB** to **80GB**.
|
||||
|
||||
**Common syntax for file system resize (resize2fs).**
|
||||
|
||||
```
|
||||
resize2fs [Existing Logical Volume Name] [New Size of File System]
|
||||
```
|
||||
|
||||
The actual command is as follows.
|
||||
|
||||
```
|
||||
# resize2fs /dev/mapper/vg01-lv002 80G
|
||||
|
||||
resize2fs 1.42.9 (28-Dec-2013)
|
||||
Resizing the filesystem on /dev/mapper/vg01-lv002 to 28321400 (4k) blocks.
|
||||
The filesystem on /dev/mapper/vg01-lv002 is now 28321400 blocks long.
|
||||
```
|
||||
|
||||
### 4) Reduce the Logical Volume (LVM)
|
||||
|
||||
Now reduce the logical volume (LVM) size using the lvreduce command. The below command **“/dev/mapper/vg01-lv002”** will shrink the Logical volume (LVM) from 100GB to 80GB.
|
||||
|
||||
**Common syntax for LVM Reduce (lvreduce)**
|
||||
|
||||
```
|
||||
lvreduce [New Size of LVM] [Existing Logical Volume Name]
|
||||
```
|
||||
|
||||
The actual command is as follows.
|
||||
|
||||
```
|
||||
# lvreduce -L 80G /dev/mapper/vg01-lv002
|
||||
|
||||
WARNING: Reducing active logical volume to 80.00 GiB
|
||||
THIS MAY DESTROY YOUR DATA (filesystem etc.)
|
||||
Do you really want to reduce lv002? [y/n]: y
|
||||
Reducing logical volume lv002 to 80.00 GiB
|
||||
Logical volume lv002 successfully resized
|
||||
```
|
||||
|
||||
### 5) Optional: Check the file system for any Errors
|
||||
|
||||
Check the file system again if there are any errors after LVM has been reduced.
|
||||
|
||||
```
|
||||
# e2fsck -f /dev/mapper/vg01-lv002
|
||||
|
||||
e2fsck 1.42.9 (28-Dec-2013)
|
||||
Pass 1: Checking inodes, blocks, and sizes
|
||||
Pass 2: Checking directory structure
|
||||
Pass 3: Checking directory connectivity
|
||||
Pass 4: Checking reference counts
|
||||
Pass 5: Checking group summary information
|
||||
/dev/mapper/vg01-lv002: 13/4853600 files (0.0% non-contiguous), 1023185/2021235 blocks
|
||||
```
|
||||
|
||||
### 6) Mount the file system and check the reduced size
|
||||
|
||||
Finally mount the file system and check the reduced file system size.
|
||||
|
||||
Use the mount command to **[mount the logical volume][4]**.
|
||||
|
||||
```
|
||||
# mount /testlvm1
|
||||
```
|
||||
|
||||
Check the newly mounted volume using the **[df command][5]**.
|
||||
|
||||
```
|
||||
# df -h /testlvm1
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg01-lv002 80G 15G 65G 18% /testlvm1
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/
|
||||
[2]: https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux/
|
||||
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]: https://www.2daygeek.com/mount-unmount-file-system-partition-in-linux/
|
||||
[5]: https://www.2daygeek.com/linux-check-disk-space-usage-df-command/
|
||||
@ -1,89 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How open source underpins blockchain technology)
|
||||
[#]: via: (https://opensource.com/article/20/10/open-source-blockchain)
|
||||
[#]: author: (Matt Shealy https://opensource.com/users/mshealy)
|
||||
|
||||
How open source underpins blockchain technology
|
||||
======
|
||||
Openness, not regulation, is what creates blockchain's security and
|
||||
reliability.
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
People are often surprised when they find out that blockchain technology, which is known for its security, is built on open source software code. In fact, this openness is what creates its security and reliability.
|
||||
|
||||
One of the core values of building anything as open source is gaining efficiency. Creating a community of developers with different perspectives and skillsets, all working on the same code base, can exponentially increase the number and complexity of applications built.
|
||||
|
||||
### Open source: more common than people think
|
||||
|
||||
One of the more popular operating systems, Linux, is open source. Linux powers the servers for many of the services we feel comfortable sharing personal information on every day. This includes Google, Facebook, and thousands of major websites. When you're interacting with these services, you're doing so on computer networks that are running Linux. Chromebooks are using Linux. Android phones use an operating system based on Linux.
|
||||
|
||||
Linux is not owned by a corporation. It's free to use and created by collaborative efforts. More than 20,000 developers from more than 1,700 companies [have contributed to the code][2] since its origins in 2005.
|
||||
|
||||
That's how open source software works. Tons of people contribute and constantly add, modify, or build off the open source codebase to create new apps and platforms. Much of the software code for blockchain and cryptocurrency has been developed using open source software. Open source software is built by passionate users that are constantly on guard for bugs, glitches, or flaws. When a problem is discovered, a community of developers works separately and together on the fix.
|
||||
|
||||
### Blockchain and open source
|
||||
|
||||
An entire community of open source blockchain developers is constantly adding to and refining the codebase.
|
||||
|
||||
Here are the fundamental ways blockchain performs:
|
||||
|
||||
* Blockchain platforms have a transactional database that allows peers to transact with each other at any time.
|
||||
* User-identification labels are attached that facilitate the transactions.
|
||||
* The platforms must have a secure way to verify transactions before they become approved.
|
||||
* Transactions that cannot be verified will not take place.
|
||||
|
||||
|
||||
|
||||
Open source software allows developers to create these platforms in a [decentralized application (Dapp)][3], which is key to the safety, security, and variability of transactions in the blockchain.
|
||||
|
||||
This decentralized approach means there is no central authority to mediate transactions. That means no one person controls what happens. Direct peer-to-peer interactions can happen quickly and securely. As transactions are recorded in the ledger, they are distributed across the ecosystem.
|
||||
|
||||
Blockchain uses cryptography to keep things secure. Each transaction carries information connecting it with previous transactions to verify its authenticity. This prevents threat actors from tampering with the data because once it's added to the public ledger, it can't be changed by other users.
|
||||
|
||||
### Is blockchain open source?
|
||||
|
||||
Although blockchain itself may not technically be open source, blockchain _systems_ are typically implemented with open source software using a concept that embodies an open culture because no government authority regulates it. Proprietary software developed by a private company to handle financial transactions is likely regulated by [government agencies][4]. In the US, that might include the Securities and Exchange Commission (SEC), the Federal Reserve Board, and the Federal Deposit Insurance Corporation (FDIC). Blockchain technology doesn't require government oversight when it's used in an open environment. In effect, the community of users is what verifies transactions.
|
||||
|
||||
You might call it an extreme form of crowdsourcing, both for developing the open source software that's used to build the blockchain platforms and for verifying transactions. That's one of the reasons blockchain has gotten so much attention: It has the potential to disrupt entire industries because it acts as an authoritative intermediary to handle and verify transactions.
|
||||
|
||||
### Bitcoin, Ethereum, and other cryptocurrencies
|
||||
|
||||
As of June 2020, more than [50 million people have blockchain wallets][5]. Most are used for financial transactions, such as trading Bitcoin, Ethereum, and other cryptocurrencies. It's become mainstream for many to [check cryptocurrency prices][6] the same way traders watch stock prices.
|
||||
|
||||
Cryptocurrency platforms also use open source software. The [Ethereum project][7] developed free and open source software that anyone can use, and a large community of developers contributes to the code. The Bitcoin reference client was developed by more than 450 developers and engineers that have made more than 150,000 contributions to the code-writing effort.
|
||||
|
||||
A cryptocurrency blockchain is a continuously growing record. Each record is linked together in a sequence, and the records are called blocks. When linked together, they form a chain. Each block has its own [unique marker called a hash][8]. A block contains its hash and a cryptographic hash from a previous block. In essence, each block is linked to the previous block, forming long chains that are impossible to break, with each containing information about other blocks that are used to verify transactions.
|
||||
|
||||
There's no central bank in financial or cryptocurrency blockchains. The blocks are distributed throughout the internet, creating a robust audit trail that can be tracked. Anyone with access to the chain can verify a transaction but cannot change the records.
|
||||
|
||||
### An unbreakable chain
|
||||
|
||||
While blockchains are not regulated by any government or agency, the distributed network keeps them secure. As chains grow, each transaction makes it more difficult to fake. Blocks are distributed all over the world in networks using trust markers that can't be changed. The chain becomes virtually unbreakable.
|
||||
|
||||
The code behind this decentralized network is open source and is one of the reasons users trust each other in transactions rather than having to use an intermediary such as a bank or broker. The software underpinning cryptocurrency platforms is open to anyone and free to use, created by consortiums of developers that are independent of each other. This has created one of the world's largest check-and-balance systems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/open-source-blockchain
|
||||
|
||||
作者:[Matt Shealy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mshealy
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
|
||||
[2]: https://www.linuxfoundation.org/wp-content/uploads/2020/08/2020_kernel_history_report_082720.pdf
|
||||
[3]: https://www.freecodecamp.org/news/what-is-a-dapp-a-guide-to-ethereum-dapps/
|
||||
[4]: https://www.investopedia.com/ask/answers/063015/what-are-some-major-regulatory-agencies-responsible-overseeing-financial-institutions-us.asp
|
||||
[5]: https://www.statista.com/statistics/647374/worldwide-blockchain-wallet-users/
|
||||
[6]: https://www.okex.com/markets
|
||||
[7]: https://ethereum.org/en/
|
||||
[8]: https://opensource.com/article/18/7/bitcoin-blockchain-and-open-source
|
||||
@ -1,173 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Free Up Space in /boot Partition on Ubuntu Linux?)
|
||||
[#]: via: (https://itsfoss.com/free-boot-partition-ubuntu/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
How to Free Up Space in /boot Partition on Ubuntu Linux?
|
||||
======
|
||||
|
||||
The other day, I got a warning that boot partition is almost full or has no space left. Yes, I have a separate boot partition, not many people do that these days, I believe.
|
||||
|
||||
This was the first time I saw such an error and it left me confused. Now, there are several [ways to free up space on Ubuntu][1] (or Ubuntu-based distros) but not all of them are useful in this case.
|
||||
|
||||
This is why I decided to write about the steps I followed to free some space in the /boot partition.
|
||||
|
||||
### Free up space in /boot partition on Ubuntu (if your boot partition is running out of space)
|
||||
|
||||
![][2]
|
||||
|
||||
I’d advise you to carefully read through the solutions and follow the one best suited for your situation. It’s easy but you need to be cautious about performing some of these on your production systems.
|
||||
|
||||
#### Method 1: Using apt autoremove
|
||||
|
||||
You don’t have to be a terminal expert to do this, it’s just one command and you will be removing unused kernels to free up space in the /boot partition.
|
||||
|
||||
All you have to do is, type in:
|
||||
|
||||
```
|
||||
sudo apt autoremove
|
||||
```
|
||||
|
||||
This will not just remove unused kernels but also get rid of the dependencies that you don’t need or isn’t needed by any of the tools installed.
|
||||
|
||||
Once you enter the command, it will list the things that will be removed and you just have to confirm the action. If you’re curious, you can go through it carefully and see what it actually removes.
|
||||
|
||||
Here’s how it will look like:
|
||||
|
||||
![][3]
|
||||
|
||||
You have to press **Y** to proceed.
|
||||
|
||||
_**It’s worth noting that this method will only work if you’ve a tiny bit of space left and you get the warning. But, if your /boot partition is full, APT may not even work.**_
|
||||
|
||||
In the next method, I’ll highlight two different ways by which you can remove old kernels to free up space using a GUI and also the terminal.
|
||||
|
||||
#### Method 2: Remove Unused Kernel Manually (if apt autoremove didn’t work)
|
||||
|
||||
Before you try to [remove any older kernels][4] to free up space, you need to identify the current active kernel and make sure that you don’t delete that.
|
||||
|
||||
To [check your kernel version][5], type in the following command in the terminal:
|
||||
|
||||
```
|
||||
uname -r
|
||||
```
|
||||
|
||||
The [uname command is generally used to get Linux system information][6]. Here, this command displays the current Linux kernel being used. It should look like this:
|
||||
|
||||
![][7]
|
||||
|
||||
Now, that you know what your current Linux Kernel is, you just have to remove the ones that do not match this version. You should note it down somewhere so that you ensure you do not remove it accidentally.
|
||||
|
||||
Next, to remove it, you can either utilize the terminal or the GUI.
|
||||
|
||||
Warning!
|
||||
|
||||
Be extra careful while deleting kernels. Identify and delete old kernels only, not the current one you are using otherwise you’ll have a broken system.
|
||||
|
||||
##### Using a GUI tool to remove old Linux kernels
|
||||
|
||||
You can use the [Synaptic Package Manager][8] or a tool like [Stacer][9] to get started. Personally, when I encountered a full /boot partition with apt broken, I used [Stacer][6] to get rid of older kernels. So, let me show you how that looks.
|
||||
|
||||
First, you need to launch “**Stacer**” and then navigate your way to the package uninstaller as shown in the screenshot below.
|
||||
|
||||
![][10]
|
||||
|
||||
Here, search for “**image**” and you will find the images for the Linux Kernels you have. You just have to delete the old kernel versions and not your current kernel image.
|
||||
|
||||
I’ve pointed out my current kernel and old kernels in my case in the screenshot above, so you have to be careful with your kernel version on your system.
|
||||
|
||||
You don’t have to delete anything else, just the ones that are the older kernel versions.
|
||||
|
||||
Similarly, just search for “**headers**” in the list of packages and delete the old ones as shown below.
|
||||
|
||||
![][11]
|
||||
|
||||
Just to warn you, you **don’t want to remove “linux-headers-generic”**. Only focus on the ones that have version numbers with them.
|
||||
|
||||
And, that’s it, you’ll be done and apt will be working again and you have successfully freed up some space from your /boot partition. Similarly, you can do this using any other package manager you’re comfortable with.
|
||||
|
||||
#### Using the command-line to remove old kernels
|
||||
|
||||
It’s the same thing but just using the terminal. So, if you don’t have the option to use a GUI (if it’s a remote machine/server) or if you’re just comfortable with the terminal, you can follow the steps below.
|
||||
|
||||
First, list all your kernels installed using the command below:
|
||||
|
||||
```
|
||||
ls -l /boot
|
||||
```
|
||||
|
||||
It should look something like this:
|
||||
|
||||
![][12]
|
||||
|
||||
The ones that are mentioned as “**old**” or the ones that do not match your current kernel version are the unused kernels that you can delete.
|
||||
|
||||
Now, you can use the **rm** command to remove the specific kernels from the boot partition using the command below (a single command for each):
|
||||
|
||||
```
|
||||
sudo rm /boot/vmlinuz-5.4.0-7634-generic
|
||||
```
|
||||
|
||||
Make sure to check the version for your system — it may be different for your system.
|
||||
|
||||
If you have a lot of unused kernels, this will take time. So, you can also get rid of multiple kernels using the following command:
|
||||
|
||||
```
|
||||
sudo rm /boot/*-5.4.0-{7634}-*
|
||||
```
|
||||
|
||||
To clarify, you need to write the last part/code of the Kernel versions separated by commas to delete them all at once.
|
||||
|
||||
Suppose, I have two old kernels 5.4.0-7634-generic and 5.4.0-7624, the command will be:
|
||||
|
||||
```
|
||||
sudo rm /boot/*-5.4.0-{7634,7624}-*
|
||||
```
|
||||
|
||||
If you don’t want to see the old kernel version in the grub boot menu, you can simply [update grub][13] using the following command:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
That’s it. You’re done. You’ve freed up space and also potentially fixed the broken APT if it was an issue after your /boot partition filled up.
|
||||
|
||||
In some cases, you may need to enter these commands to fix the broken apt (as I’ve noticed in the forums):
|
||||
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
sudo apt install -f
|
||||
```
|
||||
|
||||
Do note that you don’t need to enter the above commands unless you find APT broken. Personally, I didn’t need these commands but I found them handy for some on the forums.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/free-boot-partition-ubuntu/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/free-boot-space-ubuntu-linux.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/apt-autoremove-screenshot.jpg?resize=800%2C415&ssl=1
|
||||
[4]: https://itsfoss.com/remove-old-kernels-ubuntu/
|
||||
[5]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[6]: https://linuxhandbook.com/uname/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/uname-r-screenshot.jpg?resize=800%2C198&ssl=1
|
||||
[8]: https://itsfoss.com/synaptic-package-manager/
|
||||
[9]: https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/stacer-remove-kernel.jpg?resize=800%2C562&ssl=1
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/stacer-remove-kernel-header.png?resize=800%2C576&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/command-kernel-list.png?resize=800%2C432&ssl=1
|
||||
[13]: https://itsfoss.com/update-grub/
|
||||
@ -1,63 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Start using virtual tables in Apache Cassandra 4.0)
|
||||
[#]: via: (https://opensource.com/article/20/10/virtual-tables-apache-cassandra)
|
||||
[#]: author: (Ben Bromhead https://opensource.com/users/ben-bromhead)
|
||||
|
||||
Start using virtual tables in Apache Cassandra 4.0
|
||||
======
|
||||
What they are and how to use them.
|
||||
![Computer laptop in space][1]
|
||||
|
||||
Among the [many additions][2] in the recent [Apache Cassandra 4.0 beta release][3], virtual tables is one that deserves some attention.
|
||||
|
||||
In previous versions of Cassandra, users needed access to Java Management Extensions ([JMX][4]) to examine Cassandra details such as running compactions, clients, metrics, and a variety of configuration settings. Virtual tables removes these challenges. Cassandra 4.0 beta enables users to query those details and data as Cassandra Query Language (CQL) rows from a read-only system table.
|
||||
|
||||
Here is how the JMX-based mechanism in previous Cassandra versions worked. Imagine a user wants to check on the compaction status of a particular node in a cluster. The user first has to establish a JMX connection to run `nodetool compactionstats` on the node. This requirement immediately presents the user with a few complications. Is the user's client configured for JMX access? Are the Cassandra nodes and firewall configured to allow JMX access? Are the proper measures for security and auditing prepared and in place? These are only some of the concerns users had to contend with when dealing with in previous versions of Cassandra.
|
||||
|
||||
With Cassandra 4.0, virtual tables make it possible for users to query the information they need by utilizing their previously configured driver. This change removes all overhead associated with implementing and maintaining JMX access.
|
||||
|
||||
Cassandra 4.0 creates two new keyspaces to help users leverage virtual tables: `system_views` and `system_virtual_schema`. The `system_views` keyspace contains all the valuable information that users seek, usefully stored in a number of tables. The `system_virtual_schema` keyspace, as the name implies, stores all necessary schema information for those virtual tables.
|
||||
|
||||
![system_views and system_virtual_schema keyspaces and tables][5]
|
||||
|
||||
(Ben Bromhead, [CC BY-SA 4.0][6])
|
||||
|
||||
It's important to understand that the scope of each virtual table is restricted to its node. Any query of virtual tables will return data that is valid only for the node that acts as its coordinator, regardless of consistency. To simplify for this requirement, support has been added to several drivers to specify the coordinator node in these queries (the Python, DataStax Java, and other drivers now offer this support).
|
||||
|
||||
To illustrate, examine this `sstable_tasks` virtual table. This virtual table displays all operations on [SSTables][7], including compactions, cleanups, upgrades, and more.
|
||||
|
||||
![Querying the sstable_tasks virtual table][8]
|
||||
|
||||
(Ben Bromhead, [CC BY-SA 4.0][6])
|
||||
|
||||
If a user were to run `nodetool compactionstats` in a previous Cassandra version, this is the same type of information that would be displayed. Here, the query finds that the node currently has one active compaction. It also displays its progress and its keyspace and table. Thanks to the virtual table, a user can gather this information quickly, and just as efficiently gain the insight needed to correctly diagnose the cluster's health.
|
||||
|
||||
To be clear, Cassandra 4.0 doesn't eliminate the need for JMX access: JMX is still the only option for querying some metrics. That said, users will welcome the ability to pull key cluster metrics simply by using CQL. Thanks to the convenience afforded by virtual tables, users may be able to reinvest time and resources previously devoted to JMX tools into Cassandra itself. Client-side tooling should also begin to leverage the advantages offered by virtual tables.
|
||||
|
||||
If you are interested in the Cassandra 4.0 beta release and its virtual tables feature, [try it out][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/virtual-tables-apache-cassandra
|
||||
|
||||
作者:[Ben Bromhead][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ben-bromhead
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_space_graphic_cosmic.png?itok=wu493YbB (Computer laptop in space)
|
||||
[2]: https://www.instaclustr.com/apache-cassandra-4-0-beta-released/
|
||||
[3]: https://cassandra.apache.org/download/
|
||||
[4]: https://en.wikipedia.org/wiki/Java_Management_Extensions
|
||||
[5]: https://opensource.com/sites/default/files/uploads/cassandra_virtual-tables.png (system_views and system_virtual_schema keyspaces and tables)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://cassandra.apache.org/doc/latest/architecture/storage_engine.html#sstables
|
||||
[8]: https://opensource.com/sites/default/files/uploads/cassandra_virtual-tables_sstable_tasks.png (Querying the sstable_tasks virtual table)
|
||||
@ -1,123 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Clear Apt Cache and Reclaim Precious Disk Space)
|
||||
[#]: via: (https://itsfoss.com/clear-apt-cache/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Clear Apt Cache and Reclaim Precious Disk Space
|
||||
======
|
||||
|
||||
How do you clear the apt cache? You simply use this [apt-get command][1] option:
|
||||
|
||||
```
|
||||
sudo apt-get clean
|
||||
```
|
||||
|
||||
But there is more to cleaning apt cache than just running the above command.
|
||||
|
||||
In this tutorial, I’ll explain what is apt cache, why is it used, why you would want to clean it and what other things you should know about purging apt cache.
|
||||
|
||||
I am going to use Ubuntu here for reference but since this is about apt, it is applicable to [Debian][2] and other Debian and Ubuntu-based distributions like Linux Mint, Deepin and more.
|
||||
|
||||
### What is apt cache? Why is it used?
|
||||
|
||||
When you install a package using apt-get or [apt command][3] (or DEB packages in the software center), the apt [package manager][4] downloads the package and its dependencies in .deb format and keeps it in /var/cache/apt/archives folder.
|
||||
|
||||
![][5]
|
||||
|
||||
While downloading, apt keeps the deb package in /var/cache/apt/archives/partial directory. When the deb package is downloaded completely, it is moved out to /var/cache/apt/archives directory.
|
||||
|
||||
Once the deb files for the package and its dependencies are downloaded, your system [installs the package from these deb files][6].
|
||||
|
||||
Now you see the use of cache? The system needs a place to keep the package files somewhere before installing them. If you are aware of the [Linux directory structure][7], you would understand that /var/cache is the appropriate here.
|
||||
|
||||
#### Why keep the cache after installing the package?
|
||||
|
||||
The downloaded deb files are not removed from the directory immediately after the installation is completed. If you remove a package and reinstall it, your system will look for the package in the cache and get it from here instead of downloading it again (as long as the package version in the cache is the same as the version in remote repository).
|
||||
|
||||
This is much quicker. You can try this on your own and see how long a program takes to install the first time, remove it and install it again. You can [use the time command to find out how long does it take to complete a command][8]: _**time sudo apt install package_name**_.
|
||||
|
||||
I couldn’t find anything concrete on the cache retention policy so I cannot say how long does Ubuntu keep the downloaded packages in the cache.
|
||||
|
||||
#### Should you clean apt cache?
|
||||
|
||||
It depends on you. If you are running out of disk space on root, you could clean apt cache and reclaim the disk space. It is one of the [several ways to free up disk space on Ubuntu][9].
|
||||
|
||||
Check how much space the cache takes with the [du command][10]:
|
||||
|
||||
![][11]
|
||||
|
||||
Sometime this could go in 100s of MB and this space could be crucial if you are running a server.
|
||||
|
||||
#### How to clean apt cache?
|
||||
|
||||
If you want to clear the apt cache, there is a dedicated command to do that. So don’t go about manually deleting the cache directory. Simply use this command:
|
||||
|
||||
```
|
||||
sudo apt-get clean
|
||||
```
|
||||
|
||||
This will remove the content of the /var/cache/apt/archives directory (except the lock file). Here’s a dry run (simulation) of what the apt-get clean command deletes:
|
||||
|
||||
![][12]
|
||||
|
||||
There is another command that deals with cleaning the apt cache:
|
||||
|
||||
```
|
||||
sudo apt-get autoclean
|
||||
```
|
||||
|
||||
Unlike clean, autoclean only removes the packages that are not possible to download from the repositories.
|
||||
|
||||
Suppose you installed package xyz. Its deb files remain in the cache. If there is now a new version of xyz package available in the repository, this existing xyz package in the cache is now outdated and useless. The autoclean option will delete such useless packages that cannot be downloaded anymore.
|
||||
|
||||
#### Is it safe to delete apt cache?
|
||||
|
||||
![][13]
|
||||
|
||||
Yes. It is completely safe to clear the cache created by apt. It won’t negatively impact the performance of the system. Maybe if you reinstall the package it will take a bit longer to download but that’s about it.
|
||||
|
||||
Again, use the apt-get clean command. It is quicker and easier than manually deleting cache directory.
|
||||
|
||||
You may also use graphical tools like [Stacer][14] or [Bleachbit][15] for this purpose.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
At the time of writing this article, there is no built-in option with the newer apt command. However, keeping backward compatibility, _**apt clean**_ can still be run (which should be running apt-get clean underneath it). Please refer to this article to [know the difference between apt and apt-get][16].
|
||||
|
||||
I hope you find this explanation about apt cache interesting. It is not something essential but knowing this little things make you more knowledgeable about your Linux system.
|
||||
|
||||
I welcome your feedback and suggestions in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/clear-apt-cache/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/apt-get-linux-guide/
|
||||
[2]: https://www.debian.org/
|
||||
[3]: https://itsfoss.com/apt-command-guide/
|
||||
[4]: https://itsfoss.com/package-manager/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-get-clean-cache.png?resize=800%2C470&ssl=1
|
||||
[6]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[7]: https://linuxhandbook.com/linux-directory-structure/
|
||||
[8]: https://linuxhandbook.com/time-command/
|
||||
[9]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[10]: https://linuxhandbook.com/find-directory-size-du-command/
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-archive-size.png?resize=800%2C233&ssl=1
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-get-clean-ubuntu.png?resize=800%2C339&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/Clear-Apt-Cache.png?resize=800%2C450&ssl=1
|
||||
[14]: https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[15]: https://itsfoss.com/use-bleachbit-ubuntu/
|
||||
[16]: https://itsfoss.com/apt-vs-apt-get-difference/
|
||||
@ -1,81 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (LibreOffice Wants Apache to Drop the Ailing OpenOffice and Support LibreOffice Instead)
|
||||
[#]: via: (https://itsfoss.com/libreoffice-letter-openoffice/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
LibreOffice Wants Apache to Drop the Ailing OpenOffice and Support LibreOffice Instead
|
||||
======
|
||||
|
||||
It is a no-brainer that Apache OpenOffice is still a relevant recommendation when we think about [open source alternatives to Microsoft Office][1] for Linux users. However, for the past several years, the development of OpenOffice is pretty much stale.
|
||||
|
||||
Of course, it is not a shocker, considering Abhishek wrote about the [possibility of Apache OpenOffice shutting down][2] back in 2016.
|
||||
|
||||
Now, in an [open letter from The Document Foundation][3], they appeal Apache OpenOffice to recommend users to start using better alternatives like LibreOffice. In this article, I shall mention some highlights from the blog post by The Document Foundation and what it means to Apache OpenOffice.
|
||||
|
||||
![][4]
|
||||
|
||||
### Apache OpenOffice is History, LibreOffice is the Future?
|
||||
|
||||
Even though I didn’t use OpenOffice back in the day, it is safe to say that it is definitely not a modern open-source alternative to Microsoft Office. Not anymore, at least.
|
||||
|
||||
Yes, Apache OpenOffice is still something important for legacy users and was a great alternative a few years back.
|
||||
|
||||
Here’s the timeline of major releases for OpenOffice and LibreOffice:
|
||||
|
||||
![][5]
|
||||
|
||||
Now that there’s no significant development taking place for OpenOffice, what’s the future of Apache OpenOffice? A fairly active project with no major releases by the largest open source foundation?
|
||||
|
||||
It does not sound promising and that is exactly what The Document Foundation highlights in their open letter:
|
||||
|
||||
> OpenOffice(.org) – the “father project” of LibreOffice – was a great office suite, and changed the world. It has a fascinating history, but **since 2014, Apache OpenOffice (its current home) hasn’t had a single major release**. That’s right – no significant new features or major updates have arrived in over six years. Very few minor releases have been made, and there have been issues with timely security updates too.
|
||||
|
||||
For an average user, if they don’t know about [LibreOffice][6], I would definitely want them to know. But, should the Apache Foundation suggest OpenOffice users to try LibreOffice to experience a better or advanced office suite?
|
||||
|
||||
I don’t know, maybe yes, or no?
|
||||
|
||||
> …many users don’t know that LibreOffice exists. The OpenOffice brand is still so strong, even though the software hasn’t had a significant release for over six years, and is barely being developed or supported
|
||||
|
||||
As mentioned in the open letter, The Document Foundation highlights the advantages/improvements of LibreOffice over OpenOffice and appeals to Apache OpenOffice that they start recommending their users to try something better (i.e. LibreOffice):
|
||||
|
||||
> We appeal to Apache OpenOffice to do the right thing. Our goal should be to **get powerful, up-to-date and well-maintained productivity tools into the hands of as many people as possible**. Let’s work together on that!
|
||||
|
||||
### What Should Apache OpenOffice Do?
|
||||
|
||||
If OpenOffice does the work, users may not need the effort to look for alternatives. So, is it a good idea to call out another project about their slow development and suggest them to embrace the future tools and recommend them instead?
|
||||
|
||||
In an argument, one might say it is only fair to promote your competition if you’re done and have no interest in improving OpenOffice. And, there’s nothing wrong in that, the open-source community should always work together to ensure that new users get the best options available.
|
||||
|
||||
On another side, one might say that The Document Foundation is frustrated about OpenOffice still being something relevant in 2020, even without any significant improvements.
|
||||
|
||||
I won’t judge, but I think these conflicting thoughts come to my mind when I take a look at the open letter.
|
||||
|
||||
### Do you think it is time to put OpenOffice to rest and rely on LibreOffice?
|
||||
|
||||
Even though LibreOffice seems to be a superior choice and definitely deserves the limelight, what do you think should be done? Should Apache discontinue OpenOffice and redirect users to LibreOffice?
|
||||
|
||||
Your opinion is welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/libreoffice-letter-openoffice/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[2]: https://itsfoss.com/openoffice-shutdown/
|
||||
[3]: https://blog.documentfoundation.org/blog/2020/10/12/open-letter-to-apache-openoffice/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/libre-office-open-office.png?resize=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/libre-office-open-office-derivatives.jpg?resize=800%2C166&ssl=1
|
||||
[6]: https://itsfoss.com/libreoffice-tips/
|
||||
@ -1,99 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Try Linux on any computer with this bootable USB tool)
|
||||
[#]: via: (https://opensource.com/article/20/10/fedora-media-writer)
|
||||
[#]: author: (Sumantro Mukherjee https://opensource.com/users/sumantro)
|
||||
|
||||
Try Linux on any computer with this bootable USB tool
|
||||
======
|
||||
Fedora Media Writer is a hassle-free way to create a live USB to give
|
||||
Linux a try.
|
||||
![Multiple USB plugs in different colors][1]
|
||||
|
||||
[Fedora Media Writer][2] is a small, lightweight, comprehensive tool that simplifies the Linux getting-started experience. It downloads and writes Fedora Workstation or Server onto a USB drive that can boot up on any system, making it accessible for you to try Fedora Linux without having to install it to your hard drive.
|
||||
|
||||
The Media Writer tool can be used to create a live, bootable USB. After installing the Fedora Media Writer application on your platform, you can download and flash the latest stable version of Fedora Workstation or Server, or you can choose any other image you've downloaded. And it isn't limited to Intel 64-bit devices. It's also available for ARM devices, [such as the Raspberry Pi][3], which are becoming more powerful and useful every day.
|
||||
|
||||
![Fedora Media Writer main screen][4]
|
||||
|
||||
(Sumantro Mukherjee, [CC BY-SA 4.0][5])
|
||||
|
||||
### Install Fedora Media Writer
|
||||
|
||||
You have several options for [installing Fedora Media Writer][6]. You can [build it from source][7] on GitHub, download it for macOS or Windows, use an RPM with **dnf** or **yum**, or get it as a Flatpak.
|
||||
|
||||
On Fedora:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install mediawriter`
|
||||
```
|
||||
|
||||
See the [Releases][8] section of the GitHub repo for the latest version.
|
||||
|
||||
### Prepare your media
|
||||
|
||||
The first thing you need is a USB drive for your Linux OS to be installed onto. This is what Fedora Media Writer will flash. This drive must be either blank or expendable because **all data on the USB drive will be erased.** If there's any data—even just one file—that you don't want to lose, then you must back it up before continuing!
|
||||
|
||||
Once you've got a USB drive that you've confirmed is expendable, plug it into your computer and launch Fedora Media Writer.
|
||||
|
||||
### Use Fedora Media Writer
|
||||
|
||||
When you launch Fedora Media Writer, you're presented with a screen that prompts you to acquire a bootable image from the Internet, or to load a custom image from your hard drive. The first selections are the latest releases of Fedora: Workstation for desktops and laptops, and Server for virtualization, rack servers, or anything you want to run as a server.
|
||||
|
||||
Should you select one of the Fedora images, Media Writer downloads a disc image (usually called an "iso", after its filename extension of **.iso**) and saves it to your `Downloads` folder so you can reuse it to flash another drive if you want.
|
||||
|
||||
![Select your image][9]
|
||||
|
||||
Also available are Fedora Spins, which are images from the Fedora community meant to satisfy niche interests. For instance, if you're a fan of the [MATE desktop][10], then you'll be pleased to find a MATE "spin" available from Media Writer. There are many to choose from, so scroll through to see them all. If you're new to Linux, don't be overwhelmed or confused: the extra options are intended for longtime users who have developed preferences aside from the defaults, so it's safe for you to just use the Workstation or Server option depending on whether you want to run Fedora as a desktop or as a server OS.
|
||||
|
||||
If you need an image for a different CPU than the one you're currently using, select the CPU architecture from the drop-down menu in the upper-right corner of the window.
|
||||
|
||||
If you have an image saved to your hard drive already, select the **Custom Image** option and select the **.iso** file of the distribution you want to flash to USB.
|
||||
|
||||
### Writing to a USB drive
|
||||
|
||||
Once you've downloaded or selected an image, you must confirm that you want to write the image to your drive.
|
||||
|
||||
The drive selection drop-down menu only shows external drives, so there's no chance of you accidentally overwriting your own hard drive. This is an important feature of Fedora Media Writer, and one that makes it much safer than many manual instructions you might see elsewhere online. However, if you have more than one external drive attached to your computer, you should remove them all except the one you want to overwrite, just for added safety.
|
||||
|
||||
Select the drive you want the image to be installed onto, and click the **Write to Disk** button.
|
||||
|
||||
![Media write][11]
|
||||
|
||||
|
||||
|
||||
Wait a while for the image to be written to your drive, and then check out Don Watkins' excellent overview of [how to boot to Linux from a USB drive][12] .
|
||||
|
||||
### Get started with Linux
|
||||
|
||||
Fedora Media Writer is a way to flash Fedora Workstation or Server, or any Linux distribution, to a USB drive so you can try it out before you install it on your device. Give it a try, and share your experience and questions in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/fedora-media-writer
|
||||
|
||||
作者:[Sumantro Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sumantro
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/usb-hardware.png?itok=ROPtNZ5V (Multiple USB plugs in different colors)
|
||||
[2]: https://github.com/FedoraQt/MediaWriter
|
||||
[3]: https://fedoraproject.org/wiki/Architectures/ARM/Raspberry_Pi
|
||||
[4]: https://opensource.com/sites/default/files/uploads/fmw_mainscreen.png (Fedora Media Writer main screen)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://docs.fedoraproject.org/en-US/fedora/f32/install-guide/install/Preparing_for_Installation/#_fedora_media_writer
|
||||
[7]: https://github.com/FedoraQt/MediaWriter#building
|
||||
[8]: https://github.com/FedoraQt/MediaWriter/releases
|
||||
[9]: https://opensource.com/sites/default/files/mediawriter-image.png
|
||||
[10]: https://opensource.com/article/19/12/mate-linux-desktop
|
||||
[11]: https://opensource.com/sites/default/files/mediawriter-write.png (Media write)
|
||||
[12]: https://opensource.com/article/20/4/first-linux-computer
|
||||
@ -1,132 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Set up ZFS on Linux with yum)
|
||||
[#]: via: (https://opensource.com/article/20/10/zfs-dnf)
|
||||
[#]: author: (Sheng Mao https://opensource.com/users/ivzhh)
|
||||
|
||||
Set up ZFS on Linux with yum
|
||||
======
|
||||
Use a yum repo to take advantage of the latest ZFS features on Fedora.
|
||||
![Puzzle pieces coming together to form a computer screen][1]
|
||||
|
||||
I am a Fedora Linux user who runs `yum upgrade` daily. While this habit enables me to run all the latest software (one of [Fedora's four foundations][2] is "first," and it lives up to that), it also highlights any incompatibilities between the [ZFS][3] storage platform and a new kernel.
|
||||
|
||||
As a developer, sometimes I need new features from the latest ZFS branch. For example, ZFS 2.0.0 contains an exciting new feature greatly [improving ZVOL sync performance][4], which is critical to me as a KVM user. But this means that if I want to use the 2.0.0 branch, I have to build ZFS myself.
|
||||
|
||||
At first, I just compiled ZFS manually from its Git repo after every kernel update. If I forgot, ZFS would fail to be recognized on the next boot. Luckily, I quickly learned how to set up dynamic kernel module support ([DKMS][5]) for ZFS. However, this solution isn't perfect. For one thing, it doesn't utilize the powerful [yum][6] system, which can help with resolving dependencies and upgrading. In addition, switching between your own package and an upstream package is pretty easy with yum.
|
||||
|
||||
In this article, I will demonstrate how to set up a yum repo for packaging ZFS. The solution has two steps:
|
||||
|
||||
1. Create RPM packages from the ZFS Git repository
|
||||
2. Set up a yum repo to host the packages
|
||||
|
||||
|
||||
|
||||
### Create RPM packages
|
||||
|
||||
To create RPM packages, you need to install the RPM toolchain. Yum provides groups to bundle installing the tools:
|
||||
|
||||
|
||||
```
|
||||
`sudo dnf group install 'C Development Tools and Libraries' 'RPM Development Tools'`
|
||||
```
|
||||
|
||||
After these have been installed, you must install all the packages necessary to build ZFS from the ZFS Git repo. The packages belong to three groups:
|
||||
|
||||
1. [Autotools][7] to generate build files from platform configurations
|
||||
2. Libraries for building ZFS kernel and userland tools
|
||||
3. Libraries for building RPM packages
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
sudo dnf install libtool autoconf automake gettext createrepo \
|
||||
libuuid-devel libblkid-devel openssl-devel libtirpc-devel \
|
||||
lz4-devel libzstd-devel zlib-devel \
|
||||
kernel-devel elfutils-libelf-devel \
|
||||
libaio-devel libattr-devel libudev-devel \
|
||||
python3-devel libffi-devel
|
||||
```
|
||||
|
||||
Now you are ready to create your own packages.
|
||||
|
||||
### Build OpenZFS
|
||||
|
||||
[OpenZFS][8] provides excellent infrastructure. To build it:
|
||||
|
||||
1. Clone the repository with `git` and switch to the branch/tag that you hope to use.
|
||||
2. Run Autotools to generate a makefile.
|
||||
3. Run `make rpm` and, if everything works, RPM files will be placed in the build folder.
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ git clone --branch=zfs-2.0.0-rc3 <https://github.com/openzfs/zfs.git> zfs
|
||||
$ cd zfs
|
||||
$ ./autogen.sh
|
||||
$ ./configure
|
||||
$ make rpm
|
||||
```
|
||||
|
||||
### Set up a yum repo
|
||||
|
||||
In yum, a repo is a server or local path that includes metadata and RPM files. A consumer sets up an INI configuration file, and the `yum` command automatically resolves the metadata and downloads the corresponding packages.
|
||||
|
||||
Fedora provides the `createrepo` tool to set up a yum repo. First, create the repo and copy all RPM files from the ZFS folder to the repo. Then run `createrepo --update` to include all packages in the metadata:
|
||||
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /var/lib/zfs.repo
|
||||
$ sudo createrepo /var/lib/zfs.repo
|
||||
$ sudo cp *.rpm /var/lib/zfs.repo/
|
||||
$ sudo createrepo --update /var/lib/zfs.repo
|
||||
```
|
||||
|
||||
Create a new configuration file in `/etc/yum.repos.d` to include the repo path:
|
||||
|
||||
|
||||
```
|
||||
$ echo \
|
||||
"[zfs-local]\\\nname=ZFS Local\\\nbaseurl=file:///var/lib/zfs.repo\\\nenabled=1\\\ngpgcheck=0" |\
|
||||
sudo tee /etc/yum.repos.d/zfs-local.repo
|
||||
|
||||
$ sudo dnf --repo=zfs-local list available --refresh
|
||||
```
|
||||
|
||||
Finally, you have reached the end of the journey! You have a working yum repo and ZFS packages. Now you just need to install them:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install zfs
|
||||
$ sudo /sbin/modprobe zfs
|
||||
```
|
||||
|
||||
Run `sudo zfs version` to see the version of your userland and kernel tools. Congratulations! You have [ZFS for Fedora][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/zfs-dnf
|
||||
|
||||
作者:[Sheng Mao][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ivzhh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://docs.fedoraproject.org/en-US/project/#_what_is_fedora_all_about
|
||||
[3]: https://zfsonlinux.org/
|
||||
[4]: https://www.phoronix.com/scan.php?page=news_item&px=OpenZFS-3x-Boost-Sync-ZVOL
|
||||
[5]: https://www.linuxjournal.com/article/6896
|
||||
[6]: https://en.wikipedia.org/wiki/Yum_%28software%29
|
||||
[7]: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
[8]: https://openzfs.org/wiki/Main_Page
|
||||
[9]: https://openzfs.github.io/openzfs-docs/Getting%20Started/Fedora.html
|
||||
198
sources/tech/20201019 Web of Trust, Part 2- Tutorial.md
Normal file
198
sources/tech/20201019 Web of Trust, Part 2- Tutorial.md
Normal file
@ -0,0 +1,198 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Web of Trust, Part 2: Tutorial)
|
||||
[#]: via: (https://fedoramagazine.org/web-of-trust-part-2-tutorial/)
|
||||
[#]: author: (Kevin "Eonfge" Degeling https://fedoramagazine.org/author/eonfge/)
|
||||
|
||||
Web of Trust, Part 2: Tutorial
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
["The spider web"][2] by [bluesbby][3] is licensed under [CC BY 2.0][4][][4]
|
||||
|
||||
The [previous article][5] looked at how the Web of Trust works in concept, and how the Web of Trust is implemented at Fedora. In this article, you’ll learn how to do it yourself. The power of this system lies in everybody being able to validate the actions of others—if you know how to validate somebody’s work, you’re contributing to the strength of our shared security.
|
||||
|
||||
### Choosing a project
|
||||
|
||||
[Remmina][6] is a remote desktop client written in GTK+. It aims to be useful for system administrators and travelers who need to work with lots of remote computers in front of either large monitors or tiny netbooks. In the current age, where many people must work remotely or at least manage remote servers, the security of a program like Remmina is critical. Even if you do not use it yourself, you can contribute to the Web of Trust by checking it for others.
|
||||
|
||||
The question is: how do you know that a given version of Remmina is good, and that the original developer—or distribution server—has not been compromised?
|
||||
|
||||
For this tutorial, you’ll use [Flatpak][7] and the [Flathub][8] repository. Flatpak is intentionally well-suited for making verifiable rebuilds, which is one of the tenets of the Web of Trust. It’s easier to work with since it doesn’t require users to download independent development packages. Flatpak also uses techniques to prevent in‑flight tampering, using hashes to validate its read‑only state. As far as the Web of Trust is concerned, Flatpak is the future.
|
||||
|
||||
For this guide, you use Remmina, but this guide generally applies to every application you use. It’s also not exclusive to Flatpak, and the general steps also apply to Fedora’s repositories. In fact, if you’re currently reading this article on Debian or Arch, you can still follow the instructions. If you want to follow along using traditional RPM repositories, make sure to check out [this article][9].
|
||||
|
||||
### Installing and checking
|
||||
|
||||
To install Remmina, use the Software Center or run the following from a terminal:
|
||||
|
||||
```
|
||||
flatpak install flathub org.remmina.Remmina -y
|
||||
```
|
||||
|
||||
After installation, you’ll find the files in:
|
||||
|
||||
```
|
||||
/var/lib/flatpak/app/org.remmina.Remmina/current/active/files/
|
||||
```
|
||||
|
||||
Open a terminal here and find the following directories using _ls -la_:
|
||||
|
||||
```
|
||||
total 44
|
||||
drwxr-xr-x. 2 root root 4096 Jan 1 1970 bin
|
||||
drwxr-xr-x. 3 root root 4096 Jan 1 1970 etc
|
||||
drwxr-xr-x. 8 root root 4096 Jan 1 1970 lib
|
||||
drwxr-xr-x. 2 root root 4096 Jan 1 1970 libexec
|
||||
-rw-r--r--. 2 root root 18644 Aug 25 14:37 manifest.json
|
||||
drwxr-xr-x. 2 root root 4096 Jan 1 1970 sbin
|
||||
drwxr-xr-x. 15 root root 4096 Jan 1 1970 share
|
||||
```
|
||||
|
||||
#### Getting the hashes
|
||||
|
||||
In the _bin_ directory you will find the main binaries of the application, and in _lib_ you find all dependencies that Remmina uses. Now calculate a hash for _./bin/remmina_:
|
||||
|
||||
```
|
||||
sha256sum ./bin/*
|
||||
```
|
||||
|
||||
This will give you a list of numbers: checksums. Copy them to a temporary file, as this is the current version of Remmina that Flathub is distributing. These numbers have something special: only an exact copy of Remmina can give you the same numbers. Any change in the code—no matter how minor—will produce different numbers.
|
||||
|
||||
Like Fedora’s Koji and Bodhi build and update services, Flathub has all its build servers in plain view. In the case of Flathub, look at [Buildbot][10] to see who is responsible for the official binaries of a package. Here you will find all of the logs, including all the failed builds and their paper trail.
|
||||
|
||||
![][11]
|
||||
|
||||
#### Getting the source
|
||||
|
||||
The main Flathub project is hosted on GitHub, where the exact compile instructions (“manifest” in Flatpak terms) are visible for all to see. Open a new terminal in your Home folder. Clone the instructions, and possible submodules, using one command:
|
||||
|
||||
```
|
||||
git clone --recurse-submodules https://github.com/flathub/org.remmina.Remmina
|
||||
```
|
||||
|
||||
#### Developer tools
|
||||
|
||||
Start off by installing the Flatpak Builder:
|
||||
|
||||
```
|
||||
sudo dnf install flatpak-builder
|
||||
```
|
||||
|
||||
After that, you’ll need to get the right SDK to rebuild Remmina. In the manifest, you’ll find the current SDK is.
|
||||
|
||||
```
|
||||
"runtime": "org.gnome.Platform",
|
||||
"runtime-version": "3.38",
|
||||
"sdk": "org.gnome.Sdk",
|
||||
"command": "remmina",
|
||||
```
|
||||
|
||||
This indicates that you need the GNOME SDK, which you can install with:
|
||||
|
||||
```
|
||||
flatpak install org.gnome.Sdk//3.38
|
||||
```
|
||||
|
||||
This provides the latest versions of the Free Desktop and GNOME SDK. There are also additional SDK’s for additional options, but those are beyond the scope of this tutorial.
|
||||
|
||||
#### Generating your **own hashes**
|
||||
|
||||
Now that everything is set up, compile your version of Remmina by running:
|
||||
|
||||
```
|
||||
flatpak-builder build-dir org.remmina.Remmina.json --force-clean
|
||||
```
|
||||
|
||||
After this, your terminal will print a lot of text, your fans will start spinning, and you’re compiling Remmina. If things do not go so smoothly, refer to the [Flatpak Documentation][12]; troubleshooting is beyond the scope of this tutorial.
|
||||
|
||||
Once complete, you should have the directory ._/build-dir/files/_, which should contain the same layout as above. Now the moment of truth: it’s time to generate the hashes for the built project:
|
||||
|
||||
```
|
||||
sha256sum ./bin/*
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
You should get exactly the same numbers. This proves that the version on Flathub is indeed the version that the Remmina developers and maintainers intended for you to run. This is great, because this shows that Flathub has not been compromised. The web of trust is strong, and you just made it a bit better.
|
||||
|
||||
### Going deeper
|
||||
|
||||
But what about the _./lib/_ directory? And what version of Remmina did you actually compile? This is where the Web of Trust starts to branch. First, you can also double-check the hashes of the _./lib/_ directory. Repeat the _sha256sum_ command using a different directory.
|
||||
|
||||
But what version of Remmina did you compile? Well, that’s in the Manifest. In the text file you’ll find (usually at the bottom) the git repository and branch that you just used. At the time of this writing, that is:
|
||||
|
||||
```
|
||||
"type": "git",
|
||||
"url": "https://gitlab.com/Remmina/Remmina.git",
|
||||
"tag": "v1.4.8",
|
||||
"commit": "7ebc497062de66881b71bbe7f54dabfda0129ac2"
|
||||
```
|
||||
|
||||
Here, you can decide to look at the Remmina code itself:
|
||||
|
||||
```
|
||||
git clone --recurse-submodules https://gitlab.com/Remmina/Remmina.git
|
||||
cd ./Remmina
|
||||
git checkout tags/v1.4.8
|
||||
```
|
||||
|
||||
The last two commands are important, since they ensure that you are looking at the right version of Remmina. Make sure you use the corresponding tag of the Manifest file. you can see everything that you just built.
|
||||
|
||||
### What if…?
|
||||
|
||||
The question on some minds is: what if the hashes don’t match? Quoting a famous novel: “Don’t Panic.” There are multiple legitimate reasons as to why the hashes do not match.
|
||||
|
||||
It might be that you are not looking at the same version. If you followed this guide to a T, it should give matching results, but minor errors will cause vastly different results. Repeat the process, and ask for help if you’re unsure if you’re making errors. Perhaps Remmina is in the process of updating.
|
||||
|
||||
But if that still doesn’t justify the mismatch in hashes, go to the [maintainers of Remmina][14] on Flathub and open an issue. Assume good intentions, but you might be onto something that isn’t totally right.
|
||||
|
||||
The most obvious upstream issue is that Remmina does not properly support reproducible builds yet. The code of Remmina needs to be written in such a way that repeating the same action twice, gives the same result. For developers, there is an [entire guide][15] on how to do that. If this is the case, there should be an issue on the upstream bug-tracker, and if it is not there, make sure that you create one by explaining your steps and the impact.
|
||||
|
||||
If all else fails, and you’ve informed upstream about the discrepancies and they to don’t know what is happening, then it’s time to send an email to the Administrators of Flathub and the developer in question.
|
||||
|
||||
### Conclusion
|
||||
|
||||
At this point, you’ve gone through the entire process of validating a single piece of a bigger picture. Here, you can branch off in different directions:
|
||||
|
||||
* Try another Flatpak application you like or use regularly
|
||||
* Try the RPM version of Remmina
|
||||
* Do a deep dive into the C code of Remmina
|
||||
* Relax for a day, knowing that the Web of Trust is a collective effort
|
||||
|
||||
|
||||
|
||||
In the grand scheme of things, we can all carry a small part of responsibility in the Web of Trust. By taking free/libre open source software (FLOSS) concepts and applying them in the real world, you can protect yourself and others. Last but not least, by understanding how the Web of Trust works you can see how FLOSS software provides unique protections.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/web-of-trust-part-2-tutorial/
|
||||
|
||||
作者:[Kevin "Eonfge" Degeling][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/eonfge/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/09/weboftrust2-816x345.jpg
|
||||
[2]: https://www.flickr.com/photos/17367470@N05/21329974875
|
||||
[3]: https://www.flickr.com/photos/17367470@N05
|
||||
[4]: https://creativecommons.org/licenses/by/2.0/?ref=ccsearch&atype=html
|
||||
[5]: https://fedoramagazine.org/web-of-trust-part-1-concept/
|
||||
[6]: https://remmina.org/
|
||||
[7]: https://flatpak.org/
|
||||
[8]: https://flathub.org/home
|
||||
[9]: https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/
|
||||
[10]: https://flathub.org/builds/#/
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2020/09/Screenshot_2020-09-24-Flathub-builds-1024x434.png
|
||||
[12]: https://docs.flatpak.org/en/latest/building.html
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2020/09/Screenshot-from-2020-09-22-21-49-47.png
|
||||
[14]: https://github.com/flathub/org.remmina.Remmina
|
||||
[15]: https://reproducible-builds.org/
|
||||
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 open source tools I can't live without)
|
||||
[#]: via: (https://opensource.com/article/20/10/open-source-tools)
|
||||
[#]: author: (Victoria Martinez de la Cruz https://opensource.com/users/vkmc)
|
||||
|
||||
5 open source tools I can't live without
|
||||
======
|
||||
Increase your productivity inside and outside the terminal by keeping
|
||||
these tools in your own bag of tricks.
|
||||
![woman on laptop sitting at the window][1]
|
||||
|
||||
Some time ago, I engaged with a Twitter thread that went viral among techies. The challenge? Pick only five tools that you cannot live without. I started to think about this in relation to my everyday life, and picking just five tools was not easy. I use many tools that I consider essential, such as my [IRC][2] client to connect with my colleagues and friends (yes, I still use IRC), a good text editor to hack on things, a calendar app to keep organized, and a videoconferencing platform when more direct interaction is needed.
|
||||
|
||||
So let me put a twist on this challenge: Pick just five open source tools that boost your productivity. Here's my list; please share yours in the comments.
|
||||
|
||||
### tmate
|
||||
|
||||
![tmate screenshot][3]
|
||||
|
||||
(Victoria Marinez de la Cruz, [CC BY-SA 4.0][4])
|
||||
|
||||
Oh, I love this tool. tmate is a fork of the well-known [tmux][5] terminal multiplexer that allows you to start a tmux session and share it over SSH. You can use it for [pair programming][6] (which is my primary use case) or for remote control.
|
||||
|
||||
If you collaborate often with your team members, and you want an easy, distro-agnostic, open source way to program with them (and sharing terminal access is enough for you), this is definitely a must-add to your list.
|
||||
|
||||
Get more info on [tmate's website][7], or check out the code on [GitHub][8].
|
||||
|
||||
### ix
|
||||
|
||||
ix is a command-line pastebin. You don't need to install anything; you can create new pastes just by `curl`ing to the [ix.io][9] site. For example, `echo Hello world. | curl -F 'f:1=<-' ix.io` will give you a link to ix.io where the message "Hello world" is pasted. This is very convenient when you want to share logs for debugging purposes or to save config files in servers where you don't have a desktop environment.
|
||||
|
||||
One downside is that the source code is not yet published, even though it is intended to be free and open source. If you are the author and are reading this post, please post the code so that we can contribute to the polishing process.
|
||||
|
||||
### asciinema
|
||||
|
||||
Yes, this is another terminal tool. asciinema allows you to record your terminal. There are many ways to use it, but I generally use it to make demos for presentations. It's very easy to use, and there are packages available for many Linux distributions and other platforms.
|
||||
|
||||
To see how it works, check out this [cool demo][10]. Isn't it great?
|
||||
|
||||
Get more information on [asciinema's website][11] and access its source code on [GitHub][12].
|
||||
|
||||
### GNOME Pomodoro
|
||||
|
||||
![pomodoro timer gnome][13]
|
||||
|
||||
(Victoria Martinez de la Cruz, [CC BY-SA 4.0][4])
|
||||
|
||||
OK, that's enough with the terminal tools. Now I want to share this simple gem for getting and staying organized. Have you heard about the [Pomodoro Technique][14]? Pomodoro is basically a time-management tool. It uses a tomato-shaped timer that helps you split your time into work chunks and breaks (by default, 25 minutes of work followed by five-minute breaks). And, after every four pomodoros, you take a longer break (15 minutes by default). The idea is that you stay focused during the work time, and you stretch and relax on the breaks.
|
||||
|
||||
This sounds very, very simple, and you might be hesitant to allow a tomato-shaped clock to control your life, but it definitely helped me get better organized and avoid exhaustion when trying to focus on many things at the same time.
|
||||
|
||||
Whatever your role, I highly recommend this practice. And among the many different tools that implement it, I recommend the GNOME Pomodoro app. It's available for major GNU/Linux distros, so it requires that you use the GNOME desktop environment (this might be its downside).
|
||||
|
||||
Check out more information on [GNOME Pomodoro's website][15], and access its [GitHub][16] repo to get the source code and learn how you can contribute.
|
||||
|
||||
### Jitsi
|
||||
|
||||
Last but not least is Jitsi. When you're working on a remote, globally distributed team, you need a way to connect with people. Instant messaging is good, but sometimes it's better to have a quick meeting to discuss things face to face (well, seeing each other faces). There are a lot of [videoconferencing tools][17] available, but I like Jitsi a lot. Not only because it's free and open source, but also because it provides a clean, functional interface. You can set up your own Jitsi server (for business purposes), but you can also try out a public Jitsi instance by going to the [Jitsi Meet][18] website.
|
||||
|
||||
A good practice for setting up this kind of meeting: use it only when you have a clear agenda in mind. And always ask yourself, can this meeting be an email instead? Follow these guidelines and use Jitsi with caution, and your workday will be extremely productive!
|
||||
|
||||
Learn more on [Jitsi's website][19] and start contributing by accessing its [GitHub][20] repository.
|
||||
|
||||
* * *
|
||||
|
||||
I hope my list helps you reach the next level in productivity. What are your five, can't-do-without-them, open source productivity tools? Let me know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/open-source-tools
|
||||
|
||||
作者:[Victoria Martinez de la Cruz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/vkmc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-window-focus.png?itok=g0xPm2kD (young woman working on a laptop)
|
||||
[2]: https://en.wikipedia.org/wiki/Internet_Relay_Chat
|
||||
[3]: https://opensource.com/sites/default/files/pictures/tmate-opensource.jpg (tmate screenshot)
|
||||
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[5]: https://opensource.com/article/20/7/tmux-cheat-sheet
|
||||
[6]: https://en.wikipedia.org/wiki/Pair_programming
|
||||
[7]: https://tmate.io/
|
||||
[8]: https://github.com/tmate-io/tmate
|
||||
[9]: http://ix.io/
|
||||
[10]: https://asciinema.org/a/239367
|
||||
[11]: https://asciinema.org/
|
||||
[12]: https://github.com/asciinema/asciinema
|
||||
[13]: https://opensource.com/sites/default/files/pictures/pomodoro_timer_gnome.jpg (pomodoro timer gnome)
|
||||
[14]: https://en.wikipedia.org/wiki/Pomodoro_Technique
|
||||
[15]: https://gnomepomodoro.org/
|
||||
[16]: https://github.com/codito/gnome-pomodoro
|
||||
[17]: https://opensource.com/article/20/5/open-source-video-conferencing
|
||||
[18]: https://meet.jit.si/
|
||||
[19]: https://jitsi.org/
|
||||
[20]: https://github.com/jitsi
|
||||
@ -0,0 +1,290 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Incremental backup with Butterfly Backup)
|
||||
[#]: via: (https://fedoramagazine.org/butterfly-backup/)
|
||||
[#]: author: (Matteo Guadrini https://fedoramagazine.org/author/matteoguadrini/)
|
||||
|
||||
Incremental backup with Butterfly Backup
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
### Introduction
|
||||
|
||||
This article explains how to make incremental or differential backups, with a catalog available to restore (or export) at the point you want, with [Butterfly Backup][2].
|
||||
|
||||
#### Requirements
|
||||
|
||||
Butterfly Backup is a simple wrapper of rsync written in python; the first requirement is **[python3.3][3]** or higher (plus module [cryptography][4] for _init_ action). Other requirements are **[openssh][5]** and **[rsync][6]** (version 2.5 or higher). Ok, let’s go!
|
||||
|
||||
[Editors note: rsync version 3.2.3 is already installed on Fedora 33 systems]
|
||||
|
||||
```
|
||||
$ sudo dnf install python3 openssh rsync git
|
||||
$ sudo pip3 install cryptography
|
||||
```
|
||||
|
||||
### Installation
|
||||
|
||||
After that, installing Butterfly Backup is very simple by using the following commands to clone the repository locally, and set up Butterfly Backup for use:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/MatteoGuadrini/Butterfly-Backup.git
|
||||
$ cd Butterfly-Backup
|
||||
$ sudo python3 setup.py
|
||||
$ bb --help
|
||||
$ man bb
|
||||
```
|
||||
|
||||
To upgrade, you would use the same commands too.
|
||||
|
||||
### Example
|
||||
|
||||
Butterfly Backup is a server to client tool and is installed on a server (or workstation). The restore process restores the files into the specified client. This process shares some of the options available to the backup process.
|
||||
|
||||
Backups are organized accord to precise catalog; this is an example:
|
||||
|
||||
```
|
||||
$ tree destination/of/backup
|
||||
.
|
||||
├── destination
|
||||
│ ├── hostname or ip of the PC under backup
|
||||
│ │ ├── timestamp folder
|
||||
│ │ │ ├── backup folders
|
||||
│ │ │ ├── backup.log
|
||||
│ │ │ └── restore.log
|
||||
│ │ ├─── general.log
|
||||
│ │ └─── symlink of last backup
|
||||
│
|
||||
├── export.log
|
||||
├── backup.list
|
||||
└── .catalog.cfg
|
||||
```
|
||||
|
||||
Butterfly Backup has six main operations, referred to as **actions**, you can get information about them with the _–help_ command.
|
||||
|
||||
```
|
||||
$ bb --help
|
||||
usage: bb [-h] [--verbose] [--log] [--dry-run] [--version]
|
||||
{config,backup,restore,archive,list,export} ...
|
||||
|
||||
Butterfly Backup
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
--verbose, -v Enable verbosity
|
||||
--log, -l Create a log
|
||||
--dry-run, -N Dry run mode
|
||||
--version, -V Print version
|
||||
|
||||
action:
|
||||
Valid action
|
||||
|
||||
{config,backup,restore,archive,list,export}
|
||||
Available actions
|
||||
config Configuration options
|
||||
backup Backup options
|
||||
restore Restore options
|
||||
archive Archive options
|
||||
list List options
|
||||
export Export options
|
||||
```
|
||||
|
||||
#### Configuration
|
||||
|
||||
Configuration mode is straight forward; If you’re already familiar with the exchange keys and OpenSSH, you probably won’t need it. First, you must create a configuration (rsa keys), for instance:
|
||||
|
||||
```
|
||||
$ bb config --new
|
||||
SUCCESS: New configuration successfully created!
|
||||
```
|
||||
|
||||
After creating the configuration, the keys will be installed (copied) on the hosts you want to backup:
|
||||
|
||||
```
|
||||
$ bb config --deploy host1
|
||||
Copying configuration to host1; write the password:
|
||||
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/arthur/.ssh/id_rsa.pub"
|
||||
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
|
||||
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
|
||||
arthur@host1's password:
|
||||
|
||||
Number of key(s) added: 1
|
||||
|
||||
Now try logging into the machine, with: "ssh 'arthur@host1'"
|
||||
and check to make sure that only the key(s) you wanted were added.
|
||||
|
||||
SUCCESS: Configuration copied successfully on host1!
|
||||
```
|
||||
|
||||
#### Backup
|
||||
|
||||
There are two backup modes: _single_ and _bulk_.
|
||||
The most relevant features of the two backup modes are the parallelism and retention of old backups. See the two parameters _–parallel_ and _–retention_ in the [documentation][7].
|
||||
|
||||
##### Single backup
|
||||
|
||||
The backup of a single machine consists in taking the files and folders indicated in the command line, and putting them into the cataloging structure indicated above. In other words, copy all file and folders of a machine into a path.
|
||||
|
||||
This is an examples:
|
||||
|
||||
```
|
||||
$ bb backup --computer host1 --destination /mnt/backup --data User Config --type Unix
|
||||
Start backup on host1
|
||||
SUCCESS: Command rsync -ah --no-links arthur@host1:/home :/etc /mnt/backup/host1/2020_09_19__10_28
|
||||
```
|
||||
|
||||
##### Bulk backup
|
||||
|
||||
Above all, bulk mode backups share the same options as single mode, with the difference that they accept a file containing a list of hostnames or ips. In this mode backups will performed in parallel (by default 5 machines at a time). Above all, if you want to run fewer or more machines in parallel, specify the _–parallel_ parameter.
|
||||
|
||||
Incremental of the previous backup, for instance:
|
||||
|
||||
```
|
||||
$ cat /home/arthur/pclist.txt
|
||||
host1
|
||||
host2
|
||||
host3
|
||||
$ bb backup --list /home/arthur/pclist.txt --destination /mnt/backup --data User Config --type Unix
|
||||
ERROR: The port 22 on host2 is closed!
|
||||
ERROR: The port 22 on host3 is closed!
|
||||
Start backup on host1
|
||||
SUCCESS: Command rsync -ahu --no-links --link-dest=/mnt/backup/host1/2020_09_19__10_28 arthur@host1:/home :/etc /mnt/backup/host1/2020_09_19__10_50
|
||||
```
|
||||
|
||||
There are four backup modes, which you specify with the _–mode_ flag: **Full** (backup all files) , **Mirror** (backup all files in mirror mode), **Differential** (is based on the latest _Full_ backup) and **Incremental** (is based on the latest backup).
|
||||
The default mode is _Incremental_; _Full_ mode is set by default when the flag is not specified.
|
||||
|
||||
#### Listing catalog
|
||||
|
||||
The first time you run backup commands, the catalog is created. The catalog is used for future backups and all the restores that are made through Butterfly Backup. To query this catalog use the list command.
|
||||
First, let’s query the catalog in our example:
|
||||
|
||||
```
|
||||
$ bb list --catalog /mnt/backup
|
||||
|
||||
BUTTERFLY BACKUP CATALOG
|
||||
|
||||
Backup id: aba860b0-9944-11e8-a93f-005056a664e0
|
||||
Hostname or ip: host1
|
||||
Timestamp: 2020-09-19 10:28:12
|
||||
|
||||
Backup id: dd6de2f2-9a1e-11e8-82b0-005056a664e0
|
||||
Hostname or ip: host1
|
||||
Timestamp: 2020-09-19 10:50:59
|
||||
```
|
||||
|
||||
Press _q_ for exit and select a backup-id:
|
||||
|
||||
```
|
||||
$ bb list --catalog /mnt/backup --backup-id dd6de2f2-9a1e-11e8-82b0-005056a664e0
|
||||
Backup id: dd6de2f2-9a1e-11e8-82b0-005056a664e0
|
||||
Hostname or ip: host1
|
||||
Type: Incremental
|
||||
Timestamp: 2020-09-19 10:50:59
|
||||
Start: 2020-09-19 10:50:59
|
||||
Finish: 2020-09-19 11:43:51
|
||||
OS: Unix
|
||||
ExitCode: 0
|
||||
Path: /mnt/backup/host1/2020_09_19__10_50
|
||||
List: backup.log
|
||||
etc
|
||||
home
|
||||
```
|
||||
|
||||
To export the catalog list use it with an external tool like _cat_, include the _–_–_log_ flag:
|
||||
|
||||
```
|
||||
$ bb list --catalog /mnt/backup --log
|
||||
$ cat /mnt/backup/backup.list
|
||||
```
|
||||
|
||||
#### Restore
|
||||
|
||||
The restore process is the exact opposite of the backup process. It takes the files from a specific backup and push it to the destination computer.
|
||||
This command perform a restore on the same machine of the backup, for instance:
|
||||
|
||||
```
|
||||
$ bb restore --catalog /mnt/backup --backup-id dd6de2f2-9a1e-11e8-82b0-005056a664e0 --computer host1 --log
|
||||
Want to do restore path /mnt/backup/host1/2020_09_19__10_50/etc? To continue [Y/N]? y
|
||||
Want to do restore path /mnt/backup/host1/2020_09_19__10_50/home? To continue [Y/N]? y
|
||||
SUCCESS: Command rsync -ahu -vP --log-file=/mnt/backup/host1/2020_09_19__10_50/restore.log /mnt/backup/host1/2020_09_19__10_50/etc arthur@host1:/restore_2020_09_19__10_50
|
||||
SUCCESS: Command rsync -ahu -vP --log-file=/mnt/backup/host1/2020_09_19__10_50/restore.log /mnt/backup/host1/2020_09_19__10_50/home/* arthur@host1:/home
|
||||
```
|
||||
|
||||
> Without specifying the “_type_” flag that indicates the operating system on which the data are being retrieved, Butterfly Backup will select it directly from the catalog via the backup-id.
|
||||
|
||||
#### Archive old backup
|
||||
|
||||
Archive operations are used to store backups by saving disk space.
|
||||
|
||||
```
|
||||
$ bb archive --catalog /mnt/backup/ --days 1 --destination /mnt/archive/ --verbose --log
|
||||
INFO: Check archive this backup f65e5afe-9734-11e8-b0bb-005056a664e0. Folder /mnt/backup/host1/2020_09_18__17_50
|
||||
INFO: Check archive this backup 4f2b5f6e-9939-11e8-9ab6-005056a664e0. Folder /mnt/backup/host1/2020_09_15__07_26
|
||||
SUCCESS: Delete /mnt/backup/host1/2020_09_15__07_26 successfully.
|
||||
SUCCESS: Archive /mnt/backup/host1/2020_09_15__07_26 successfully.
|
||||
$ ls /mnt/archive
|
||||
host1
|
||||
$ ls /mnt/archive/host1
|
||||
2020_09_15__07_26.zip
|
||||
```
|
||||
|
||||
After that, look in the catalog and see that the backup was actually archived:
|
||||
|
||||
```
|
||||
$ bb list --catalog /mnt/backup/ -i 4f2b5f6e-9939-11e8-9ab6-005056a664e0
|
||||
Backup id: 4f2b5f6e-9939-11e8-9ab6-005056a664e0
|
||||
Hostname or ip: host1
|
||||
Type: Incremental
|
||||
Timestamp: 2020-09-15 07:26:46
|
||||
Start: 2020-09-15 07:26:46
|
||||
Finish: 2020-09-15 08:43:45
|
||||
OS: Unix
|
||||
ExitCode: 0
|
||||
Path: /mnt/backup/host1/2020_09_15__07_26
|
||||
Archived: True
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
Butterfly Backup was born from a very complex need; this tool provides superpowers to rsync, automates the backup and restore process. In addition, the catalog allows you to have a system similar to a “time machine”.
|
||||
|
||||
In conclusion, Butterfly Backup is a lightweight, versatile, simple and scriptable backup tool.
|
||||
|
||||
One more thing; Easter egg: _**bb** -Vv_
|
||||
|
||||
Thank you for reading my post.
|
||||
|
||||
Full documentation: [https://butterfly-backup.readthedocs.io/][7]
|
||||
Github: <https://github.com/MatteoGuadrini/Butterfly-Backup>
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by [Manu M][8] on [Unsplash][9]_.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/butterfly-backup/
|
||||
|
||||
作者:[Matteo Guadrini][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/matteoguadrini/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/09/butterfly-backup-816x345.jpg
|
||||
[2]: https://matteoguadrini.github.io/Butterfly-Backup/
|
||||
[3]: https://fedoramagazine.org/help-port-python-packages-python-3/
|
||||
[4]: https://cryptography.io/en/latest/
|
||||
[5]: https://fedoramagazine.org/open-source-ssh-clients/
|
||||
[6]: https://fedoramagazine.org/scp-users-migration-guide-to-rsync/
|
||||
[7]: https://butterfly-backup.readthedocs.io/en/latest/
|
||||
[8]: https://unsplash.com/@leocub?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[9]: https://unsplash.com/s/photos/butterfly?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,199 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 steps to learn any programming language)
|
||||
[#]: via: (https://opensource.com/article/20/10/learn-any-programming-language)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
5 steps to learn any programming language
|
||||
======
|
||||
With just a little programming experience, you can learn a new language
|
||||
in just a few days (sometimes less).
|
||||
![Learning to program][1]
|
||||
|
||||
Some people love learning new programming languages. Other people can't imagine having to learn even one. In this article, I'm going to show you how to think like a coder so that you can confidently learn any programming language you want.
|
||||
|
||||
The truth is, once you've learned how to program, the language you use becomes less of a hurdle and more of a formality. In fact, that's just one of the many reasons educators say to [teach kids to code early][2]. Regardless of how simple their introductory language may be, the logic remains the same across everything else children (or adult learners) are likely to encounter later.
|
||||
|
||||
With just a little programming experience, which you can gain from any one of several introductory articles here on Opensource.com, you can go on to learn _any_ programming language in just a few days (sometimes less). Now, this isn't magic, and you do have to put some effort into it. And admittedly, it takes a lot longer than just a few days to learn every library available to a language or to learn the nuances of packaging your code for delivery. But getting started is easier than you might think, and the rest comes naturally with practice.
|
||||
|
||||
When experienced programmers sit down to learn a new language, they're looking for five things. Once you know those five things, you're ready to start coding.
|
||||
|
||||
### 1\. Syntax
|
||||
|
||||
![Syntax][3]
|
||||
|
||||
(Seth Kenlon, [CC BY-SA 4.0][4])
|
||||
|
||||
The syntax of a language describes the structure of code. This encompasses both how the code is written on a line-by-line basis as well as the actual words used to construct code statements.
|
||||
|
||||
[Python][5], for instance, is known for using indentation to indicate where one block ends and another one starts:
|
||||
|
||||
|
||||
```
|
||||
while j < rows:
|
||||
while k < columns:
|
||||
tile = Tile(k * w)
|
||||
board.add(tile)
|
||||
k += 1
|
||||
j += 1
|
||||
k = 0
|
||||
```
|
||||
|
||||
[Lua][6] just uses the keyword `end`:
|
||||
|
||||
|
||||
```
|
||||
for i,obj in ipairs(hit) do
|
||||
if obj.moving == 1 then
|
||||
obj.x,obj.y = v.mouse.getPosition()
|
||||
end
|
||||
end
|
||||
```
|
||||
|
||||
[Java][7], [C][8], C++, and similar languages use braces:
|
||||
|
||||
|
||||
```
|
||||
while (std::getline(e,r)) {
|
||||
wc++;
|
||||
}
|
||||
```
|
||||
|
||||
A language's syntax also involves things like including libraries, setting variables, and terminating lines. With practice, you'll learn to recognize syntactical requirements (and conventions) almost subliminally as you read sample code.
|
||||
|
||||
#### Take action
|
||||
|
||||
When learning a new programming language, strive to understand its syntax. You don't have to memorize it, just know where to look, should you forget. It also helps to use a good [IDE][9], because many of them alert you of syntax errors as they occur.
|
||||
|
||||
### 2\. Built-ins and conditionals
|
||||
|
||||
![built-in words][10]
|
||||
|
||||
(Seth Kenlon, [CC BY-SA 4.0][4])
|
||||
|
||||
A programming language, just like a natural language, has a finite number of words it recognizes as valid. This vocabulary can be expanded with additional libraries, but the core language knows a specific set of keywords. Most languages don't have as many keywords as you probably think. Even in a very low-level language like C, there are only 32 words, such as `for`, `do`, `while`, `int`, `float`, `char`, `break`, and so on.
|
||||
|
||||
Knowing these keywords gives you the ability to write basic expressions, the building blocks of a program. Many of the built-in words help you construct conditional statements, which influence the flow of your program. For instance, if you want to write a program that lets you click and drag an icon, then your code must detect when the user's mouse cursor is positioned over an icon. The code that causes the mouse to grab the icon must execute only _if_ the mouse cursor is within the same coordinates as the icon's outer edges. That's a classic if/then statement, but different languages can express that differently.
|
||||
|
||||
Python uses a combination of `if`, `elif`, and `else` but doesn't explicitly close the statement:
|
||||
|
||||
|
||||
```
|
||||
if var == 1:
|
||||
# action
|
||||
elif var == 2:
|
||||
# some action
|
||||
else:
|
||||
# some other action
|
||||
```
|
||||
|
||||
[Bash][11] uses `if`, `elif`, `else`, and uses `fi` to end the statement:
|
||||
|
||||
|
||||
```
|
||||
if [ "$var" = "foo" ]; then
|
||||
# action
|
||||
elif [ "$var" = "bar" ]; then
|
||||
# some action
|
||||
else
|
||||
# some other action
|
||||
fi
|
||||
```
|
||||
|
||||
C and Java, however, use `if`, `else`, and `else if`, enclosed by braces:
|
||||
|
||||
|
||||
```
|
||||
if (boolean) {
|
||||
// action
|
||||
} else if (boolean) {
|
||||
// some action
|
||||
} else {
|
||||
// some other action
|
||||
}
|
||||
```
|
||||
|
||||
While there are small variations in word choice and syntax, the basics are always the same. Learn the ways to define conditions in the programming language you're learning, including `if/then`, `do...while`, and `case` statements.
|
||||
|
||||
#### Take action
|
||||
|
||||
Get familiar with the core set of keywords a programming language understands. In practice, your code will contain more than just a language's core words, because there are almost certainly libraries containing lots of simple functions to help you do things like print output to the screen or display a window. The logic that drives those libraries, however, starts with a language's built-in keywords.
|
||||
|
||||
### 3\. Data types
|
||||
|
||||
![Data types][12]
|
||||
|
||||
(Seth Kenlon, [CC BY-SA 4.0][4])
|
||||
|
||||
Code deals with data, so you must learn how a programming language recognizes different kinds of data. All languages understand integers and most understand decimals and individual characters (a, b, c, and so on). These are often denoted as `int`, `float` and `double`, and `char`, but of course, the language's built-in vocabulary informs you of how to refer to these entities.
|
||||
|
||||
Sometimes a language has extra data types built into it, and other times complex data types are enabled with libraries. For instance, Python recognizes a string of characters with the keyword `str`, but C code must include the `string.h` header file for string features.
|
||||
|
||||
#### Take action
|
||||
|
||||
Libraries can unlock all manner of data types for your code, but learning the basic ones included with a language is a sensible starting point.
|
||||
|
||||
### 4\. Operators and parsers
|
||||
|
||||
![Operators][13]
|
||||
|
||||
(Seth Kenlon, [CC BY-SA 4.0][4])
|
||||
|
||||
Once you understand the types of data a programming language deals in, you can learn how to analyze that data. Luckily, the discipline of mathematics is pretty stable, so math operators are often the same (or at least very similar) across many languages. For instance, adding two integers is usually done with a `+` symbol, and testing whether one integer is greater than another is usually done with the `>` symbol. Testing for equality is usually done with `==` (yes, that's two equal symbols, because a single equal symbol is usually reserved to _set_ a value).
|
||||
|
||||
There are notable exceptions to the obvious in languages like Lisp and Bash, but as with everything else, it's just a matter of mental transliteration. Once you know _how_ the expression is different, it's trivial for you to adapt. A quick review of a language's math operators is usually enough to get a feel for how math is done.
|
||||
|
||||
You also need to know how to compare and operate on non-numerical data, such as characters and strings. These are often done with a language's core libraries. For instance, Python features the `split()` method, while C requires `string.h` to provide the `strtok()` function.
|
||||
|
||||
#### Take action
|
||||
|
||||
Learn the basic functions and keywords for manipulating basic data types, and look for core libraries that help you accomplish complex actions.
|
||||
|
||||
### 5\. Functions
|
||||
|
||||
![Class][14]
|
||||
|
||||
(Seth Kenlon, [CC BY-SA 4.0][4])
|
||||
|
||||
Code usually isn't just a to-do list for a computer. Typically when you write code, you're looking to present a computer with a set of theoretical conditions and a set of instructions for actions that must be taken when each condition is met. While flow control with conditional statements and math and logic operators can do a lot, code is a lot more efficient once functions and classes are introduced because they let you define subroutines. For instance, should an application require a confirmation dialogue box very frequently, it's a lot easier to write that box _once_ as an instance of a class rather than re-writing it each time you need it to appear throughout your code.
|
||||
|
||||
You need to learn how classes and functions are defined in the programming language you're learning. More precisely, first, you need to learn whether classes and functions are available in the programming language. Most modern languages do support functions, but classes are specialized constructs common to object-oriented languages.
|
||||
|
||||
#### Take action
|
||||
|
||||
Learn the constructs available in a language that help you write and use code efficiently.
|
||||
|
||||
### You can learn anything
|
||||
|
||||
Learning a programming language is, in itself, a sort of subroutine of the coding process. Once you understand the theory behind how code works, the language you use is just a medium for delivering logic. The process of learning a new language is almost always the same: learn syntax through simple exercises, learn vocabulary so you can build up to performing complex actions, and then practice, practice, practice.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/learn-any-programming-language
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/learn-programming-code-keyboard.png?itok=xaLyptT4 (Learning to program)
|
||||
[2]: https://opensource.com/article/20/9/scratch
|
||||
[3]: https://opensource.com/sites/default/files/uploads/syntax_0.png (Syntax)
|
||||
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[5]: https://opensource.com/downloads/cheat-sheet-python-37-beginners
|
||||
[6]: https://opensource.com/article/20/2/lua-cheat-sheet
|
||||
[7]: https://opensource.com/downloads/java-cheat-sheet
|
||||
[8]: https://opensource.com/downloads/c-programming-cheat-sheet
|
||||
[9]: https://opensource.com/resources/what-ide
|
||||
[10]: https://opensource.com/sites/default/files/uploads/builtin.png (built-in words)
|
||||
[11]: https://opensource.com/downloads/bash-cheat-sheet
|
||||
[12]: https://opensource.com/sites/default/files/uploads/type.png (Data types)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/operator.png (Operators)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/class.png (Class)
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (New open source project crowdsources internet security)
|
||||
[#]: via: (https://opensource.com/article/20/10/crowdsec)
|
||||
[#]: author: (Philippe Humeau https://opensource.com/users/philippe-humeau)
|
||||
|
||||
New open source project crowdsources internet security
|
||||
======
|
||||
CrowdSec aims to leverage the power of the crowd to create a very
|
||||
accurate IP reputation database
|
||||
![Lots of people in a crowd.][1]
|
||||
|
||||
[CrowdSec][2] is a new security project designed to protect servers, services, containers, or virtual machines exposed on the internet with a server-side agent. It was inspired by [Fail2Ban][3] and aims to be a modernized, collaborative version of that intrusion-prevention framework.
|
||||
|
||||
CrowdSec is free and open source (under an MIT License), with the source code available on [GitHub][4]. It is currently is available for Linux, with ports to macOS and Windows on the roadmap.
|
||||
|
||||
### How CrowdSec works
|
||||
|
||||
CrowdSec is written in Golang and was designed to run on modern, complex architectures such as clouds, lambdas, and containers. To achieve this, it's "decoupled," meaning you can "detect here" (e.g., in your database logs) and "remedy there" (e.g., in your firewall or rproxy).
|
||||
|
||||
The tool uses [leaky buckets][5] internally to allow for tight event control. Scenarios are written in YAML to make them as simple and readable as possible without sacrificing granularity. The inference engine lets you get insights from chain buckets or meta-buckets, meaning if several buckets (e.g., web scan, port scan, and login attempt failed) overflow into a "meta-bucket," you can trigger a "targeted attack" remediation.
|
||||
|
||||
Aggressive Internet Protocols (IPs) are dealt with using bouncers. The [CrowdSec Hub][6] offers ready-to-use data connectors, bouncers (e.g., Nginx, PHP, Cloudflare, Netfilter), and scenarios to deter various attack classes. Bouncers can remedy threats in various ways.
|
||||
|
||||
It works on bouncers such as Captcha, limiting applicative rights, multi-factor authentication, throttling queries, or activating Cloudflare attack mode just when needed. You can get a sense of what's happening locally (and where it's occurring) with a lightweight visualization interface and strong [Prometheus][7] observability.
|
||||
|
||||
![CrowdSec's operation][8]
|
||||
|
||||
(CrowdSec, [CC BY-SA 4.0][9])
|
||||
|
||||
### Crowdsourcing security
|
||||
|
||||
While the software currently looks like a spruced up Fail2Ban, the goal is to leverage the power of the crowd to create a very accurate IP reputation database. When CrowdSec bounces a specific IP, the triggered scenario and the timestamp are sent to our API to be checked and integrated into the global consensus of bad IPs.
|
||||
|
||||
While we are already redistributing a blocklist to our community (you can see it by entering `cscli ban list --api` on the command line), we plan to really improve this part as soon as we have dealt with other prerequisite code lines. The network already has sightings of 100,000+ IPs (refreshed daily) and is able to redistribute ~10% (10,000) of those to our community members. The project has also been designed to be [GDPR][10] compliant and privacy respectful, both in technical and legal terms.
|
||||
|
||||
Our vision is that once the CrowdSec community is large enough, we will all generate, in real time, the most accurate IP reputation database available. This global reputation engine, coupled with local behavior assessment and remediation, should allow many businesses to achieve tighter security at a very low cost.
|
||||
|
||||
### Case studies
|
||||
|
||||
Here are two examples of what CrowdSec does.
|
||||
|
||||
> A company protecting its customers from DDoS attacks set up a DDoS mitigation strategy relying on Fail2Ban. When one of its customers was attacked by a 7,000-machine botnet, CrowdSec was able to ingest all the logs and successfully banned more than 95% of the botnet, efficiently mitigating the attack, in less than five minutes. For the sake of comparison, Fail2Ban would have needed to process several thousand logs per minute, which is quite challenging and would have taken nearly 50 minutes to deal with this attack.
|
||||
|
||||
> An e-commerce business was going through a massive credit card stuffing attack. The attacker was spamming the payment gateway, testing thousands of different credit card details using a sole IP address. Instead of having to amend all of its apps to try to detect the attack, by installing CrowdSec, the company could scan all the logs and block the intrusion within minutes.
|
||||
|
||||
### Business model
|
||||
|
||||
A common stress in open source projects is setting up a viable monetization model. So, in full transparency, we'll offer premium subscriptions to businesses that want to leverage the IP reputation database without contributing to it or sharing their banned IP data. This will allow anyone to query the IP reputation database upon receiving the first packet from an unknown IP before accepting it.
|
||||
|
||||
### Getting started and getting involved
|
||||
|
||||
CrowdSec's setup is quick and easy (taking just five minutes, tops). It's heavily assisted by a wizard to allow as many people and organizations as possible to use it. The project is production-grade and already runs in many places, including hosting companies, although it's still in beta.
|
||||
|
||||
Currently, our community members come from 28 countries across five different continents. We are looking for more users, contributors, and ambassadors to take the project to the next level.
|
||||
|
||||
![User map][11]
|
||||
|
||||
We would love to hear your feedback and engage in further discussions, so please don't hesitate to comment, reach out through our [website][2], [GitHub][4], or [Discourse][12], or give us a shout on [Gitter][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/crowdsec
|
||||
|
||||
作者:[Philippe Humeau][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/philippe-humeau
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_community_1.png?itok=rT7EdN2m (Lots of people in a crowd.)
|
||||
[2]: https://crowdsec.net/
|
||||
[3]: https://www.fail2ban.org/
|
||||
[4]: https://github.com/CrowdSecurity/crowdsec
|
||||
[5]: https://en.wikipedia.org/wiki/Leaky_bucket
|
||||
[6]: https://hub.crowdsec.net/
|
||||
[7]: https://opensource.com/article/19/11/introduction-monitoring-prometheus
|
||||
[8]: https://opensource.com/sites/default/files/uploads/crowdsec_operation.jpg (CrowdSec's operation)
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]: https://en.wikipedia.org/wiki/General_Data_Protection_Regulation
|
||||
[11]: https://opensource.com/sites/default/files/cs_user_map.png (User map)
|
||||
[12]: https://discourse.crowdsec.net/
|
||||
[13]: https://gitter.im/crowdsec-project/community
|
||||
171
sources/tech/20201023 Secure NTP with NTS.md
Normal file
171
sources/tech/20201023 Secure NTP with NTS.md
Normal file
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Secure NTP with NTS)
|
||||
[#]: via: (https://fedoramagazine.org/secure-ntp-with-nts/)
|
||||
[#]: author: (Miroslav Lichvar https://fedoramagazine.org/author/mlichvar/)
|
||||
|
||||
Secure NTP with NTS
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Many computers use the Network Time Protocol (NTP) to synchronize their system clocks over the internet. NTP is one of the few unsecured internet protocols still in common use. An attacker that can observe network traffic between a client and server can feed the client with bogus data and, depending on the client’s implementation and configuration, force it to set its system clock to any time and date. Some programs and services might not work if the client’s system clock is not accurate. For example, a web browser will not work correctly if the web servers’ certificates appear to be expired according to the client’s system clock. Use Network Time Security (NTS) to secure NTP.
|
||||
|
||||
Fedora 33[1][2] is the first Fedora release to support NTS. NTS is a new authentication mechanism for NTP. It enables clients to verify that the packets they receive from the server have not been modified while in transit. The only thing an attacker can do when NTS is enabled is drop or delay packets. See [RFC8915][3] for further details about NTS.
|
||||
|
||||
NTP can be secured well with symmetric keys. Unfortunately, the server has to have a different key for each client and the keys have to be securely distributed. That might be practical with a private server on a local network, but it does not scale to a public server with millions of clients.
|
||||
|
||||
NTS includes a Key Establishment (NTS-KE) protocol that automatically creates the encryption keys used between the server and its clients. It uses Transport Layer Security (TLS) on TCP port 4460. It is designed to scale to very large numbers of clients with a minimal impact on accuracy. The server does not need to keep any client-specific state. It provides clients with cookies, which are encrypted and contain the keys needed to authenticate the NTP packets. Privacy is one of the goals of NTS. The client gets a new cookie with each server response, so it doesn’t have to reuse cookies. This prevents passive observers from tracking clients migrating between networks.
|
||||
|
||||
The default NTP client in Fedora is _chrony_. Chrony added NTS support in version 4.0. The default configuration hasn’t changed. Chrony still uses public servers from the [pool.ntp.org][4] project and NTS is not enabled by default.
|
||||
|
||||
Currently, there are very few public NTP servers that support NTS. The two major providers are Cloudflare and Netnod. The [Cloudflare servers][5] are in various places around the world. They use anycast addresses that should allow most clients to reach a close server. The [Netnod servers][6] are located in Sweden. In the future we will probably see more public NTP servers with NTS support.
|
||||
|
||||
A general recommendation for configuring NTP clients for best reliability is to have at least three working servers. For best accuracy, it is recommended to select close servers to minimize network latency and asymmetry caused by asymmetric network routing. If you are not concerned about fine-grained accuracy, you can ignore this recommendation and use any NTS servers you trust, no matter where they are located.
|
||||
|
||||
If you do want high accuracy, but you don’t have a close NTS server, you can mix distant NTS servers with closer non-NTS servers. However, such a configuration is less secure than a configuration using NTS servers only. The attackers still cannot force the client to accept arbitrary time, but they do have a greater control over the client’s clock and its estimate of accuracy, which may be unacceptable in some environments.
|
||||
|
||||
### Enable client NTS in the installer
|
||||
|
||||
When installing Fedora 33, you can enable NTS in the _Time & Date_ dialog in the _Network Time_ configuration. Enter the name of the server and check the NTS support before clicking the **+** (Add) button. You can add one or more servers or pools with NTS. To remove the default pool of servers (_2.fedora.pool.ntp.org_), uncheck the corresponding mark in the _Use_ column.
|
||||
|
||||
![Network Time configuration in Fedora installer][7]
|
||||
|
||||
### Enable client NTS in the configuration file
|
||||
|
||||
If you upgraded from a previous Fedora release, or you didn’t enable NTS in the installer, you can enable NTS directly in _/etc/chrony.conf_. Specify the server with the _nts_ option in addition to the recommended _iburst_ option. For example:
|
||||
|
||||
```
|
||||
server time.cloudflare.com iburst nts
|
||||
server nts.sth1.ntp.se iburst nts
|
||||
server nts.sth2.ntp.se iburst nts
|
||||
```
|
||||
|
||||
You should also allow the client to save the NTS keys and cookies to disk, so it doesn’t have to repeat the NTS-KE session on each start. Add the following line to _chrony.conf_, if it is not already present:
|
||||
|
||||
```
|
||||
ntsdumpdir /var/lib/chrony
|
||||
```
|
||||
|
||||
If you don’t want NTP servers provided by DHCP to be mixed with the servers you have specified, remove or comment out the following line in _chrony.conf_:
|
||||
|
||||
```
|
||||
sourcedir /run/chrony-dhcp
|
||||
```
|
||||
|
||||
After you have finished editing _chrony.conf_, save your changes and restart the _chronyd_ service:
|
||||
|
||||
```
|
||||
systemctl restart chronyd
|
||||
```
|
||||
|
||||
### Check client status
|
||||
|
||||
Run the following command under the root user to check whether the NTS key establishment was successful:
|
||||
|
||||
```
|
||||
# chronyc -N authdata
|
||||
Name/IP address Mode KeyID Type KLen Last Atmp NAK Cook CLen
|
||||
=========================================================================
|
||||
time.cloudflare.com NTS 1 15 256 33m 0 0 8 100
|
||||
nts.sth1.ntp.se NTS 1 15 256 33m 0 0 8 100
|
||||
nts.sth2.ntp.se NTS 1 15 256 33m 0 0 8 100
|
||||
```
|
||||
|
||||
The _KeyID_, _Type_, and _KLen_ columns should have non-zero values. If they are zero, check the system log for error messages from _chronyd_. One possible cause of failure is a firewall is blocking the client’s connection to the server’s TCP port ( port 4460).
|
||||
|
||||
Another possible cause of failure is a certificate that is failing to verify because the client’s clock is wrong. This is a chicken-or-the-egg type problem with NTS. You may need to manually correct the date or temporarily disable NTS in order to get NTS working. If your computer has a real-time clock, as almost all computers do, and it’s backed up by a good battery, this operation should be needed only once.
|
||||
|
||||
If the computer doesn’t have a real-time clock or battery, as is common with some small ARM computers like the Raspberry Pi, you can add the _-s_ option to _/etc/sysconfig/chronyd_ to restore time saved on the last shutdown or reboot. The clock will be behind the true time, but if the computer wasn’t shut down for too long and the server’s certificates were not renewed too close to their expiration, it should be sufficient for the time checks to succeed. As a last resort, you can disable the time checks with the _nocerttimecheck_ directive. See the _chrony.conf(5)_ man page for details.
|
||||
|
||||
Run the following command to confirm that the client is making NTP measurements:
|
||||
|
||||
```
|
||||
# chronyc -N sources
|
||||
MS Name/IP address Stratum Poll Reach LastRx Last sample
|
||||
===============================================================================
|
||||
^* time.cloudflare.com 3 6 377 45 +355us[ +375us] +/- 11ms
|
||||
^+ nts.sth1.ntp.se 1 6 377 44 +237us[ +237us] +/- 23ms
|
||||
^+ nts.sth2.ntp.se 1 6 377 44 -170us[ -170us] +/- 22ms
|
||||
```
|
||||
|
||||
The _Reach_ column should have a non-zero value; ideally 377. The value 377 shown above is an octal number. It indicates that the last eight requests all had a valid response. The validation check will include NTS authentication if enabled. If the value only rarely or never gets to 377, it indicates that NTP requests or responses are getting lost in the network. Some major network operators are known to have middleboxes that block or limit rate of large NTP packets as a mitigation for amplification attacks that exploit the monitoring protocol of _ntpd_. Unfortunately, this impacts NTS-protected NTP packets, even though they don’t cause any amplification. The NTP working group is considering an alternative port for NTP as a workaround for this issue.
|
||||
|
||||
### Enable NTS on the server
|
||||
|
||||
If you have your own NTP server running _chronyd_, you can enable server NTS support to allow its clients to be synchronized securely. If the server is a client of other servers, it should use NTS or a symmetric key for its own synchronization. The clients assume the synchronization chain is secured between all servers up to the primary time servers.
|
||||
|
||||
Enabling server NTS is similar to enabling HTTPS on a web server. You just need a private key and certificate. The certificate could be signed by the Let’s Encrypt authority using the _certbot_ tool, for example. When you have the key and certificate file (including intermediate certificates), specify them in _chrony.conf_ with the following directives:
|
||||
|
||||
```
|
||||
ntsserverkey /etc/pki/tls/private/foo.example.net.key
|
||||
ntsservercert /etc/pki/tls/certs/foo.example.net.crt
|
||||
```
|
||||
|
||||
Make sure the _ntsdumpdir_ directive mentioned previously in the client configuration is present in _chrony.conf_. It allows the server to save its keys to disk, so the clients of the server don’t have to get new keys and cookies when the server is restarted.
|
||||
|
||||
Restart the _chronyd_ service:
|
||||
|
||||
```
|
||||
systemctl restart chronyd
|
||||
```
|
||||
|
||||
If there are no error messages in the system log from _chronyd_, it should be accepting client connections. If the server has a firewall, it needs to allow both the UDP 123 and TCP 4460 ports for NTP and NTS-KE respectively.
|
||||
|
||||
You can perform a quick test from a client machine with the following command:
|
||||
|
||||
```
|
||||
$ chronyd -Q -t 3 'server foo.example.net iburst nts maxsamples 1'
|
||||
2020-10-13T12:00:52Z chronyd version 4.0 starting (+CMDMON +NTP +REFCLOCK +RTC +PRIVDROP +SCFILTER +SIGND +ASYNCDNS +NTS +SECHASH +IPV6 +DEBUG)
|
||||
2020-10-13T12:00:52Z Disabled control of system clock
|
||||
2020-10-13T12:00:55Z System clock wrong by -0.001032 seconds (ignored)
|
||||
2020-10-13T12:00:55Z chronyd exiting
|
||||
```
|
||||
|
||||
If you see a _System clock wrong_ message, it’s working correctly.
|
||||
|
||||
On the server, you can use the following command to check how many NTS-KE connections and authenticated NTP packets it has handled:
|
||||
|
||||
```
|
||||
# chronyc serverstats
|
||||
NTP packets received : 2143106240
|
||||
NTP packets dropped : 117180834
|
||||
Command packets received : 16819527
|
||||
Command packets dropped : 0
|
||||
Client log records dropped : 574257223
|
||||
NTS-KE connections accepted: 104
|
||||
NTS-KE connections dropped : 0
|
||||
Authenticated NTP packets : 52139
|
||||
```
|
||||
|
||||
If you see non-zero _NTS-KE connections accepted_ and _Authenticated NTP packets_, it means at least some clients were able to connect to the NTS-KE port and send an authenticated NTP request.
|
||||
|
||||
_— Cover photo by Louis. K on Unsplash —_
|
||||
|
||||
* * *
|
||||
|
||||
1\. The Fedora 33 _Beta_ installer contains an older chrony prerelease which doesn’t work with current NTS servers because the NTS-KE port has changed. Consequently, in the Network Time configuration in the installer, the servers will always appear as not working. After installation, the chrony package needs to be updated before it will work with current servers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/secure-ntp-with-nts/
|
||||
|
||||
作者:[Miroslav Lichvar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/mlichvar/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/10/secure-ntp-with-nts-816x345.jpg
|
||||
[2]: tmp.rl0XC1HIGm#footnote1
|
||||
[3]: https://tools.ietf.org/html/rfc8915
|
||||
[4]: https://www.pool.ntp.org
|
||||
[5]: https://developers.cloudflare.com/time-services/nts/usage
|
||||
[6]: https://www.netnod.se/time-and-frequency/how-to-use-nts
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2020/10/anaconda-nts.png
|
||||
173
sources/tech/20201026 Manage content using Pulp Debian.md
Normal file
173
sources/tech/20201026 Manage content using Pulp Debian.md
Normal file
@ -0,0 +1,173 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage content using Pulp Debian)
|
||||
[#]: via: (https://opensource.com/article/20/10/pulp-debian)
|
||||
[#]: author: (Maximilian Kolb https://opensource.com/users/kolb)
|
||||
|
||||
Manage content using Pulp Debian
|
||||
======
|
||||
Mirror, sync, upload, and publish Debian software packages with the
|
||||
pulp_deb plugin.
|
||||
![Gift box opens with colors coming out][1]
|
||||
|
||||
Pulp is an open source repository management tool that helps you fetch, mirror, upload, and publish content within your organization. It can be used to [manage various types of content][2] such as software packages (from RPM packages to Ruby gems), as well as Ansible collections, container images, and even arbitrary files.
|
||||
|
||||
A typical workflow starts with fetching software packages from an existing repository (for example, <http://mirror.centos.org/centos/7/os/x86_64/>) or adding packages manually (for private packages built within your organization). Then Pulp helps you make arbitrary collections of software packages that are consumable by clients. With it, you:
|
||||
|
||||
* Gain control over what content is available for consumers
|
||||
* Can use version control
|
||||
* Reduce bandwidth and storage needs by providing a local, deduplicated source
|
||||
|
||||
|
||||
|
||||
If you're new to Pulp, read Melanie Corr's introductory article on [how to manage your software repositories with Pulp][3].
|
||||
|
||||
### Manage Debian packages with Pulp
|
||||
|
||||
Pulp relies on plugins to adequately handle different types of content. For example, the [Pulp RPM][4] plugin enables you to manage .rpm packages. With the [Pulp Debian][5] plugin, you can mirror, sync, upload, and publish .deb packages within APT repositories. The pulp_deb plugin is essential if you want to manage and provide consumable software packages for Linux distributions such as Debian and Ubuntu, and it's free and open source software provided and maintained by the Pulp community.
|
||||
|
||||
With the Pulp Debian plugin, you can manage Debian content by synchronizing remote repositories, providing an interface to upload your own content, and publishing content to repositories.
|
||||
|
||||
Pulp supports several different [Debian content types][6], including packages, package indices, Release Files, and more. "Content type" refers to either a specific artifact or metadata. For example, a content unit of type `package` refers to a .deb package.
|
||||
|
||||
Synchronizing a remote repository is one of Pulp Debian plugin's main features, and it's one of the ways to obtain content. The synchronization process uses a [remote][7] definition that contains a URL, [distribution][8], components, and architectures:
|
||||
|
||||
* The **URL** is the path to the remote APT repository.
|
||||
* The **distribution** is the path between the `dists/` directory of the APT repository and the relevant `Release` file. This is usually (but not always) the codename or suite of the Debian-based Linux distribution (`buster` for Debian 10, `stretch` for Debian 9, `focal` for Ubuntu 20.04, and so on). Running `lsb_release -cs` on any Debian or Ubuntu host shows the distribution's codename.
|
||||
* **Components** describe arbitrary subsets of repositories (`main`, `contrib`, or `non-free` for Debian, or `main`, `restricted`, `universe`, and `multiverse` for Ubuntu). You can use this to filter and categorize packages within an APT repository.
|
||||
* The **architecture** refers to the processor architecture a software package can run on, most commonly `i386`, `amd64`, or `arm64`. If a software package does not depend on a specific processor architecture, the architecture may be set to `all`.
|
||||
|
||||
|
||||
|
||||
Specifying a distribution is mandatory, whereas defining components and architectures is optional. If undefined, Pulp automatically syncs all packages without filtering for components or architectures. Pulp automatically verifies the [GNU Privacy Guard][9] signature of the `Release` File, should the corresponding GPG public key be assigned to the remote.
|
||||
|
||||
### An example workflow
|
||||
|
||||
It's easy to go from a remote repository to a verbatim publication with Pulp's [REST API][10]. The following API calls assume you're using [HTTPie][11].
|
||||
|
||||
Imagine you want to provide .deb packages to hosts within your organization. The following basic workflow guides your first steps in using Pulp and the Pulp Debian plugin.
|
||||
|
||||
![Pulp Debian workflow][12]
|
||||
|
||||
Image by Maximilian Kolb
|
||||
|
||||
#### 1\. Create a local repository
|
||||
|
||||
Start by creating a local repository in Pulp with a single API call. You can do this with HTTPie or the [curl command][13]:
|
||||
|
||||
|
||||
```
|
||||
`http post http://<hostname>:24817/pulp/api/v3/repositories/deb/apt/ name=<name_of_your_repository>`
|
||||
```
|
||||
|
||||
#### 2\. Create a remote
|
||||
|
||||
Next, create a remote. This API call requires a URL and an arbitrary `name` value. Defining a distribution and architecture is optional:
|
||||
|
||||
|
||||
```
|
||||
`http post http://<hostname>:24817/pulp/api/v3/remotes/deb/apt/ name="nginx.org" url="http://nginx.org/packages/debian" distributions="buster"`
|
||||
```
|
||||
|
||||
Whether you define only one or multiple distributions, Pulp will later sync packages for all architectures, as they are undefined for this remote.
|
||||
|
||||
#### 3\. Synchronize
|
||||
|
||||
The third and final step to fetch remote content to Pulp is to sync the remote to your local repository. You do this by making a call to the sync API endpoint of your repository:
|
||||
|
||||
|
||||
```
|
||||
`http post http://<hostname>:24817/pulp/api/v3/repositories/deb/apt/<uuid_repository>/sync/ remote=http://<hostname>:24817/pulp/api/v3/remotes/deb/apt/<uuid_remote>/`
|
||||
```
|
||||
|
||||
In this sample command, each of the UUIDs refers to Pulp's internal references, displayed as `pulp_href` by the API. This step may take some time, depending on your environment, the size of the repository, and the available bandwidth.
|
||||
|
||||
### Make your Pulp content consumable
|
||||
|
||||
After acquiring content for Pulp through synchronization, it becomes consumable by clients.
|
||||
|
||||
#### 1\. Create a publication
|
||||
|
||||
Publications are always based on a Pulp repository. They contain extra settings on how to publish content. You can use the `APT` publisher on any repository of the APT type containing .deb packages.
|
||||
|
||||
The following API call creates a publication in verbatim mode. That is, it provides the exact same structure and content of the remote repository:
|
||||
|
||||
|
||||
```
|
||||
`http post http://<hostname>:24817/pulp/api/v3/publications/deb/verbatim/ repository=/pulp/api/v3/repositories/deb/apt/<uuid_repository>/`
|
||||
```
|
||||
|
||||
Replace the UUID with the repository you want to publish. This step may take some time, depending on the size of the repository.
|
||||
|
||||
#### 2\. Create a distribution
|
||||
|
||||
A distribution takes the finished publication and serves it through the Pulp content app, which makes it available (or "consumable") by your users. In the context of a Debian system, this means that the repository can be added to `/etc/apt/sources.list` and used as a way to install software.
|
||||
|
||||
The following API call requires the UUID of the publication created in the first step:
|
||||
|
||||
|
||||
```
|
||||
`http post http://<hostname>:24817/pulp/api/v3/distributions/deb/apt/ name="name_of_the_distribution" base_path="base_path_of_the_distribution" publication=http://<hostname>:24817/pulp/api/v3/publications/deb/verbatim/<uuid_publication>/`
|
||||
```
|
||||
|
||||
The `base_path` value is part of the URL used by clients when referring to the APT repository, and the name can be arbitrary. Calling the distribution's API endpoint on a specific published distribution returns the URL of the Pulp repository:
|
||||
|
||||
|
||||
```
|
||||
`http get http://<hostname>:24817/pulp/api/v3/distributions/deb/apt/<uuid_distribution>/`
|
||||
```
|
||||
|
||||
This URL is directly consumable by APT clients. It can now be added to `/etc/apt/sources.list` as a valid repository.
|
||||
|
||||
### Pulp API
|
||||
|
||||
Using these API calls lets you sync an APT repository to your own Pulp instance and republish it verbatim, without touching the packages, any metadata, or signatures. Refer to the [API documentation][6] and [feature overview][14] for further information and other modes of publication.
|
||||
|
||||
### Open source flexibility
|
||||
|
||||
One important aspect of Pulp and its plugin structure is that it's extremely flexible, in no small part due to its open source nature. You can run Pulp as a standalone service, but you don't have to. It can be integrated into something bigger.
|
||||
|
||||
I work at [ATIX][15], where we've started using Pulp and the Pulp Debian plugin in a project called [orcharhino][16]. It's based on [Foreman][17] and includes the powerful [Katello][18] plugin for additional content-management capabilities, which itself relies on Pulp for repository management. With this, we've been able to manage our data center with automated system deployment, configuration management, and patch management.
|
||||
|
||||
In other words, ATIX develops the Pulp Debian plugin primarily with a Katello use case in mind. Whether you need Katello or Pulp or just a specific Pulp plugin, you can rest assured that this modularity is by design.
|
||||
|
||||
Using Pulp, you can mirror remote software repositories, host private software packages, and manage different types of content on one platform.
|
||||
|
||||
Try [Pulp][19] and the [Pulp Debian][5] plugin today, and don't be afraid to join and ask the [community][20] for help. We welcome any and all feedback.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/pulp-debian
|
||||
|
||||
作者:[Maximilian Kolb][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kolb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_gift_giveaway_box_520x292.png?itok=w1YQhNH1 (Gift box opens with colors coming out)
|
||||
[2]: https://pulpproject.org/content-plugins/#pulp-3-content-plugins-information
|
||||
[3]: https://opensource.com/article/20/8/manage-repositories-pulp
|
||||
[4]: https://github.com/pulp/pulp_rpm
|
||||
[5]: https://github.com/pulp/pulp_deb
|
||||
[6]: https://pulp-deb.readthedocs.io/en/latest/restapi.html
|
||||
[7]: https://docs.pulpproject.org/pulpcore/glossary.html#term-Remote
|
||||
[8]: https://docs.pulpproject.org/pulpcore/glossary.html#term-Distribution
|
||||
[9]: https://gnupg.org/
|
||||
[10]: https://docs.pulpproject.org/pulpcore/restapi.html
|
||||
[11]: https://httpie.org/
|
||||
[12]: https://opensource.com/sites/default/files/pulp-debian-workflow_0.jpg (Pulp Debian workflow)
|
||||
[13]: https://www.redhat.com/sysadmin/use-curl-api
|
||||
[14]: https://pulp-deb.readthedocs.io/en/latest/feature_overview.html
|
||||
[15]: https://atix.de/en/
|
||||
[16]: https://orcharhino.com/
|
||||
[17]: https://theforeman.org/
|
||||
[18]: https://theforeman.org/plugins/katello
|
||||
[19]: https://pulpproject.org/
|
||||
[20]: https://pulpproject.org/get_involved/
|
||||
155
sources/tech/20201026 Pi from High School Maths.md
Normal file
155
sources/tech/20201026 Pi from High School Maths.md
Normal file
@ -0,0 +1,155 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Pi from High School Maths)
|
||||
[#]: via: (https://theartofmachinery.com/2020/10/26/pi_from_high_school_maths.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
|
||||
Pi from High School Maths
|
||||
======
|
||||
|
||||
Warning: I don’t think the stuff in this post has any direct practical application by itself (unless you’re a nuclear war survivor and need to reconstruct maths from scratch or something). Sometimes I like to go back to basics, though. Here’s a look at (\pi) and areas of curved shapes without any calculus or transcendental functions.
|
||||
|
||||
### A simple algorithm for calculating (\pi)
|
||||
|
||||
This algorithm starts with simple number theoretic musing. Some whole numbers form neat Pythagorean triples ((x,y,z)) where (x^{2} + y^{2} = z^{2}). E.g., (3^{2} + 4^{2} = 5^{2}). It’s easy to find all the solutions to (x^{2} + y^{2} = 5^{2}) through brute-force search because we know that (x) and (y) can’t be bigger than (5). Here they are:
|
||||
|
||||
[\begin{matrix} {0^{2} + 5^{2}} & {= 5^{2}} \ {3^{2} + 4^{2}} & {= 5^{2}} \ {4^{2} + 3^{2}} & {= 5^{2}} \ {5^{2} + 0^{2}} & {= 5^{2}} \ \end{matrix}]
|
||||
|
||||
(Plus all the negative-number combinations, but let’s stick with non-negative integers and just count 4 solutions.) If we relax the equation, and count solutions to (x^{2} + y^{2} \leq 5^{2}), the answer turns out to be 26. Why care? Well, if (t) is the total number of solutions to (x^{2} + y^{2} \leq n^{2}), then
|
||||
|
||||
[\lim\limits_{n\rightarrow\infty}\frac{4t}{(n + 1)^{2}} = \pi]
|
||||
|
||||
Or, in code, here’s a simple program that estimates (\pi), getting more accurate for bigger values of the `n` variable:
|
||||
|
||||
```
|
||||
import std;
|
||||
|
||||
ulong sq(ulong x) pure
|
||||
{
|
||||
return x * x;
|
||||
}
|
||||
|
||||
void main(string[] args)
|
||||
{
|
||||
const n = args.length > 1 ? args[1].to!ulong : 20;
|
||||
|
||||
ulong total;
|
||||
foreach (x; 0..n+1)
|
||||
{
|
||||
foreach (y; 0..n+1)
|
||||
{
|
||||
if (sq(x) + sq(y) <= sq(n)) total++;
|
||||
}
|
||||
}
|
||||
|
||||
/*
|
||||
// Alternatively, for functional programming fans:
|
||||
const total =
|
||||
cartesianProduct(iota(n+1), iota(n+1))
|
||||
.filter!(p => sq(p[0]) + sq(p[1]) <= sq(n))
|
||||
.walkLength;
|
||||
*/
|
||||
|
||||
writef("%.12f\n", 4.0 * total / sq(n+1));
|
||||
}
|
||||
|
||||
$ ./pi_calc
|
||||
3.038548752834
|
||||
$ ./pi_calc 10000
|
||||
3.141362256135
|
||||
```
|
||||
|
||||
Okay, that’s a little bit more accurate than (\frac{22}{7}). Unlike most formulae for (\pi), though, there’s a simple diagram that shows how it works. Imagine we lay out the ((x,y)) integer pairs (where (x) and (y) range from (0) to (n)) on a 2D grid the obvious way. The figure below shows an example for (n = 10), with the arrow (r) pointing from the origin to ((6,8)). (r) and the (x) and (y) components make a right-angled triangle, so [Pythagoras’s theorem][1] says that (x^{2} + y^{2} = r^{2}). For ((6,8)), (r = 10 = n), so ((6,8)) is on the boundary as a solution to (x^{2} + y^{2} \leq 10^{2}). That boundary (the set of real-valued points a constant distance (n = 10) from the origin) makes a quarter circle.
|
||||
|
||||
![][2]
|
||||
|
||||
A circle is a simple, convex shape, and the grid points are evenly spaced, so the number of points inside the quarter circle will be roughly proportional to the area. More specifically, the fraction of all the grid points inside the quarter circle will be roughly the area of the quarter circle divided by the area of square around all points. The quarter circle area is (\pi r^{2} \div 4), inside the square of area (r^{2}) (remember, (n = r)), so (\frac{\pi}{4}) of all points represent solutions. The (x) and (y) values count from (0) to (n), so there are ((n + 1)^{2}) grid points. Rearrange the equations and you get a formula for estimating (\pi) from a solution count. The grid points keep drawing an arbitrarily more accurate circle as (n) gets bigger (just like a higher-resolution computer monitor does) so the estimate is exact in the limit.
|
||||
|
||||
### A faster implementation
|
||||
|
||||
The code above is simple but slow because it brute-force scans over all ((n + 1) \times (n + 1))possible (x) and (y) values. But we obviously don’t need to scan _all_ values. If we know that (x^{2} + y^{2} \leq n^{2}), then making (x) or (y) smaller will only give us another solution. We don’t need to keep testing smaller values after we find a solution. Ultimately, we only need to find the integral points around the boundary. Here’s a faster algorithm based on that idea.
|
||||
|
||||
Imagine we scan along the integral (x) values and find the maximum integral (y) value that still gives us a solution. This gives us a border line marked in red in the figure below. If (y = 8) for a given (x) value, we instantly know there are (8 + 1 = 9) solutions with that given (x) value ((+ 1) to count the (y = 0) solution).
|
||||
|
||||
![][3]
|
||||
|
||||
Note that as (x) scans from (0) to (n), (y) starts at (n) and decreases to (0). Importantly, it _only_ decreases — it’s monotonic. So if we scan (x) from (0) to (n), we can find the next boundary (y) point by starting from the previous boundary point and searching downwards. Here’s some code:
|
||||
|
||||
```
|
||||
ulong y = n, total;
|
||||
foreach (x; 0..n+1)
|
||||
{
|
||||
while (sq(x) + sq(y) > sq(n)) y--;
|
||||
total += y + 1;
|
||||
}
|
||||
```
|
||||
|
||||
This version still has nested loops, so it might look like it’s still (O(n^{2})). However, the inner `while` loop executes a varying number of times for each (x) value. Often the `y--` doesn’t trigger at all. In fact, because `y` starts from `n` and monotonically decreases to 0, we know the `y--` will be executed exactly `n` times in total. There’s no instruction in that code that executes more than (O(n)) times, total, so the whole algorithm is (O(n)).
|
||||
|
||||
With 64b `ulong` integers, the largest value of `n` that works before overflow is 4294967294:
|
||||
|
||||
```
|
||||
$ ./pi_calc 4294967294
|
||||
3.141592653058
|
||||
```
|
||||
|
||||
There are ways to get faster convergence using numerical integration tricks, but I like the way this algorithm only uses integer arithmetic (up until the final division), and can be understood directly from simple diagrams.
|
||||
|
||||
### Area of a circle without calculus
|
||||
|
||||
Perhaps you feel a bit cheated because that algorithm assumes the (\pi r^{2}) formula for the area of a circle. Sure, that’s arguably included in “high school maths”, but it’s something students just get told to remember, unless they study integral calculus and derive it that way. But if we’re going to assume (\pi r^{2}), why not assume the theory of trigonometric functions as well, and just use (\pi = 4\operatorname{atan}(1))?
|
||||
|
||||
The great ancient Greek mathematician Archimedes figured out the circle area over two thousand years ago without integral calculus (or trigonometric functions for that matter). He started with an elegant insight about regular (i.e., equal-sided) polygons.
|
||||
|
||||
The famous [“half base times height” formula for the area of a triangle already had a well-known proof in the first book of Euclid’s Elements of Geometry][4] (easily derived from [a theorem about parallelograms][5]). Conveniently, any regular polygon can be split into equal triangles joined to the centre. For example, a regular hexagon splits into six triangles, as in the figure below. We can take any one of the triangles (they’re all the same) and call the “base” the side that’s also a side of the polygon. Then the “height” is the line from the centre of the base to the centre of the polygon.
|
||||
|
||||
![][6]
|
||||
|
||||
Now here’s Archimedes’s neat insight: The ratio of the triangle area to the base is (\frac{h}{2}). If you add up all the areas, you get the area of the polygon. Likewise, if you add up all the bases, you get the perimeter of the polygon. Because the triangle area/base ratio is a constant (\frac{h}{2}) for all triangles, the area/perimeter ratio for the whole polygon is the same (\frac{h}{2}). As a formula, the area of _any_ regular polygon is (P \times \frac{h}{2}) (where (P) is the perimeter).
|
||||
|
||||
If you think of a circle as a regular polygon with infinitely many sides (so that (h) becomes the radius of the circle), and use the circle circumference ((2\pi r)) as your basic definition of (\pi), then that implies the area of a circle is (2\pi r \times \frac{r}{2} = \pi r^{2}).
|
||||
|
||||
Of course, Archimedes was a respected mathematician who couldn’t get away with just assuming that anything true of a polygon is true of a circle (counterexample: all polygons have bumpy corners, but circles don’t). He used the kind of geometric proof by contradiction that was popular in his day. (He even took it further and analysed spheres, cylinders, parabolas and other curved objects, almost inventing something like modern real analysis a couple of millenia early.) Sadly, not all of his mathemetical work has survived, but [the key part of his Measurement of a Circle][7] has.
|
||||
|
||||
Here’s the high-level version. Archimedes claimed that the area of a circle is (2\pi r \times \frac{r}{2}). Suppose you think his value is too small, and the circle is really bigger than (2\pi r \times \frac{r}{2}). That means there’s enough room inside the circle to fit a regular polygon that’s also bigger than (2\pi r \times \frac{r}{2}). But Archimedes said that’s contradictory because for any such polygon, (h < r), and (P < 2\pi r) (because each side of the polygon is a straight line that’s shorter than the circle arc that connects the same points), so the area (A = P \times \frac{h}{2} < 2\pi r \times \frac{r}{2}). The polygon’s area can’t be both bigger and smaller than (2\pi r \times \frac{r}{2}).
|
||||
|
||||
![][8]
|
||||
|
||||
Archimedes argued that there’s a similar contradiction if you think (2\pi r \times \frac{r}{2}) is too big, and the circle area is smaller than that. In that case he could make a polygon that’s also smaller than (2\pi r \times \frac{r}{2}), yet still wraps around the circle. For this polygon, (h = r), but he said the perimeter of the polygon must be greater than (2\pi r)[1][9], so that the polygon’s area must be bigger than (2\pi r \times \frac{r}{2}), even though it’s also meant to be smaller.
|
||||
|
||||
![][10]
|
||||
|
||||
If both of those cases lead to contradiction, we’re left with the only alternative that the circle area is (\pi r^{2}).
|
||||
|
||||
1. I don’t actually know how he argued this. [↩︎][11]
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://theartofmachinery.com/2020/10/26/pi_from_high_school_maths.html
|
||||
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://theartofmachinery.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cut-the-knot.org/pythagoras/
|
||||
[2]: https://theartofmachinery.com/images/pi_from_high_school_maths/pi_calc_grid.svg
|
||||
[3]: https://theartofmachinery.com/images/pi_from_high_school_maths/pi_fast_calc_grid.svg
|
||||
[4]: https://mathcs.clarku.edu/~djoyce/java/elements/bookI/propI37.html
|
||||
[5]: https://mathcs.clarku.edu/~djoyce/java/elements/bookI/propI35.html
|
||||
[6]: https://theartofmachinery.com/images/pi_from_high_school_maths/polygon.svg
|
||||
[7]: https://flashman.neocities.org/ARCHCI1set.htm
|
||||
[8]: https://theartofmachinery.com/images/pi_from_high_school_maths/polygon_inner.svg
|
||||
[9]: tmp.gJlezpSbZb#fn:1
|
||||
[10]: https://theartofmachinery.com/images/pi_from_high_school_maths/polygon_outer.svg
|
||||
[11]: tmp.gJlezpSbZb#fnref:1
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bring old hardware back to life with OpenBSD)
|
||||
[#]: via: (https://opensource.com/article/20/10/old-hardware-openbsd)
|
||||
[#]: author: (Jonathan Garrido https://opensource.com/users/jgarrido)
|
||||
|
||||
Bring old hardware back to life with OpenBSD
|
||||
======
|
||||
Install OpenBSD and the Xfce desktop to give a new spin to an old
|
||||
machine—for free.
|
||||
![Old UNIX computer][1]
|
||||
|
||||
Almost everyone has (or knows someone who has) old hardware sitting around gathering dust because they believe that no modern operating system (OS) supports such a relic. I know this is wrong because I am one of those geeks who likes to use every piece of equipment as long as it is possibly functional.
|
||||
|
||||
Although most modern OSes do run better on modern hardware, it is also true that there are alternatives for up-to-date 32-bit OSes to run all types of machines, including very old ones. Thanks to a bunch of people with enough determination and skills, there are different types of Linux and BSD distros that you can use, free of charge, to give a new spin to an old machine.
|
||||
|
||||
## What can you do with a new OS on old hardware?
|
||||
|
||||
Besides the obvious benefit of bringing back a piece of equipment that has been idle for a price that is equal to nothing, using an open source 32-bit distro to revive "antique" hardware has several benefits and purposes, including:
|
||||
|
||||
* **Create single-purpose equipment:** Today's networks are complex, and there are a lot of services that interact with one another. After bringing an old machine back to life, you can set it up to fulfill one of those unique services within your infrastructure, such as DHCP, DNS, or SFTP.
|
||||
* **Learn how the OS works:** I always want to know how things work under the hood. Tinkering with old hardware and tiny OSes gives you the chance to understand the interactions between hardware and software, learn how to tune the installation's default settings to make the most of a system, and much, much more.
|
||||
* **Teach others about open source:** Finally, 32-bit OSes and old hardware can teach the next generation about OSes and the open source world. One of the main features of these types of OSes is their simplicity of use with fewer options to overwhelm the user. This makes them an excellent tool to teach and explore the essential components of any operating system.
|
||||
|
||||
|
||||
|
||||
## Distributions to try
|
||||
|
||||
To encourage you, here is a list of distros that I have tried on old hardware with very good results. These are not the only options available, but these are the ones I have used the most:
|
||||
|
||||
* [Linux Lite][2]
|
||||
* [FreeBSD][3]
|
||||
* [OpenBSD][4]
|
||||
* [Lubuntu][5]
|
||||
* [Debian][6]
|
||||
* [Tiny Core Linux][7]
|
||||
* [Slax Linux][8]
|
||||
|
||||
|
||||
|
||||
## Give it a try with OpenBSD
|
||||
|
||||
OpenBSD is one of the main [BSD][9] distros. It is well-known because it is made with security in mind, with almost no security bugs in the default installation and a lot of cryptography tools available to users. Another cool feature, at least for me, is the fact that you can run it on a huge variety of hardware, from new computers to very old machines.
|
||||
|
||||
For this installation, my hardware was a 2005 MacBook with the following specs:
|
||||
|
||||
* A 32-bit, dual-core processor
|
||||
* 2GB of RAM (with no possibility of expansion)
|
||||
* A 32GB hard drive
|
||||
* Two network cards
|
||||
* A CD-ROM (reads only CDs)
|
||||
* A few USB ports
|
||||
|
||||
|
||||
|
||||
### Install OpenBSD
|
||||
|
||||
The installation was very straightforward. I [downloaded][10] the most recent version of OpenBSD and created a boot CD (because there is no other way to boot my old laptop besides the internal drive). The installation went flawlessly. It recognized my hardware, network (including my access point), and time zone; let me choose the layout of my hard drive and manage my users; and asked some questions about the system's security setup. Also, even though the installation has a very small footprint, OpenBSD let me choose what to install and from where.
|
||||
|
||||
I ended up with a brand-new, up-to-date operating system and a screen like this.
|
||||
|
||||
![OpenBSD][11]
|
||||
|
||||
(Jonathan Garrido, [CC BY-SA 4.0][12])
|
||||
|
||||
### Add a graphical desktop
|
||||
|
||||
If you want your desktop to use graphical applications, a black terminal with white letters is not enough. So follow these steps to install the [Xfce desktop][13]:
|
||||
|
||||
1. As root, run: [code]`pkg_add xcfe xfce-extras slim slim-themes consolekit2 polkit`[/code] to install the Xfce environment and the login greeter. In the above, `pkg_add` is the utility to use when you want to d
|
||||
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (KDE Neon vs Kubuntu: What’s the Difference Between the Two KDE Distribution?)
|
||||
[#]: via: (https://itsfoss.com/kde-neon-vs-kubuntu/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
KDE Neon vs Kubuntu: What’s the Difference Between the Two KDE Distribution?
|
||||
======
|
||||
|
||||
When you find two Linux distributions based on [Ubuntu][1] and powered up by [KDE][2], which one do you choose?
|
||||
|
||||
* [Kubuntu][3] is the official KDE flavor from Ubuntu.
|
||||
* [KDE Neon][4] is the Ubuntu-based distribution by KDE itself.
|
||||
|
||||
|
||||
|
||||
I know it is often confusing especially if you have never used either of them but got them as recommendations for usage. Hence, to help you make a decision, I thought of compiling a list of differences (and similarities) between KDE Neon and Kubuntu.
|
||||
|
||||
Let’s start with getting to know the similarities and then proceed with the differences.
|
||||
|
||||
**Note:** _Depending on your system, your experience with the distributions might differ. So, take this article as a reference and not a “what’s better” comparison._
|
||||
|
||||
### KDE Neon vs Kubuntu: Feature wise comparison
|
||||
|
||||
![][5]
|
||||
|
||||
It’s always good to compare distribution based on their similarities. So, theoretically, I’ve tried to put down the most important differences.
|
||||
|
||||
However, it is worth noting that the compatibility, performance, and the stability of the distros will vary depending on your hardware and hence, that has not been accounted here.
|
||||
|
||||
#### Ubuntu as the Base
|
||||
|
||||
![][6]
|
||||
|
||||
Yes, both the Linux distributions are based on Ubuntu. However, KDE Neon is based only on the latest Ubuntu LTS release while Kubuntu offers an Ubuntu LTS based edition and a non-LTS edition as well.
|
||||
|
||||
So, with KDE Neon, you would expect to get your hands on the latest Ubuntu features right after a few months of the next Ubuntu LTS release (2 years). But, with Kubuntu, you have got the option to opt for a non-LTS release and try on the latest Ubuntu releases with 6 months of software updates.
|
||||
|
||||
KDE Neon does offer testing editions and developer editions but those are meant to test pre-release KDE software.
|
||||
|
||||
#### KDE Plasma Desktop
|
||||
|
||||
![][7]
|
||||
|
||||
Even though both of the distros feature KDE plasma desktop and you can get the same level of customization, KDE Neon gets the latest KDE Plasma desktop release first.
|
||||
|
||||
If you did not know already, KDE Neon is developed by the official KDE team and was announced by Jonathan Riddell (Founder of Kubuntu) after he was [forced out of Kubuntu by Canonical][8].
|
||||
|
||||
So, not just limited to the latest Plasma desktop, but if you want the latest and greatest of KDE as soon as possible, KDE Neon is the perfect choice for that.
|
||||
|
||||
Kubuntu will eventually get the update for newer KDE software — but it will take time. If you’re not too sure about the latest KDE software/desktop and all you need is a stable KDE-powered system, you should go with Kubuntu LTS releases.
|
||||
|
||||
#### Pre-installed Software
|
||||
|
||||
Out of the box, you will find Kubuntu to have several essential tools and applications pre-installed. But, with KDE Neon, you would need to find and install several applications and tools.
|
||||
|
||||
To give you some perspective, KDE Neon might turn out to be a lightweight distro when compared to Kubuntu. However, for new Linux users, they might find Kubuntu as an easy-to-use experience with more essential software and tools pre-installed.
|
||||
|
||||
**Recommended Read:**
|
||||
|
||||
![][9]
|
||||
|
||||
#### [KDE Neon: KDE’s Very Own Linux Distribution Provides the Latest and Greatest of KDE With the Simplicity of Ubuntu][10]
|
||||
|
||||
#### Software Updates
|
||||
|
||||
If you are not using a metered connection, this may not matter at all. But, just for the sake of it, I should mention that KDE Neon gets more software updates considering the regular Ubuntu LTS fixes/updates along with KDE software updates.
|
||||
|
||||
With Kubuntu, you just get the Ubuntu LTS updates (unless you’re using the non-LTS edition). So, technically, you can expect less number of updates.
|
||||
|
||||
#### Ubuntu with KDE vs Plasma Experience
|
||||
|
||||
![][11]
|
||||
|
||||
I know if you haven’t tried both of them, you might think of them as pretty similar. But, Kubuntu is an official flavour of Ubuntu that focused more on the experience with Ubuntu on a KDE desktop environment.
|
||||
|
||||
While KDE Neon is technically the same thing, but it is all about getting the best-in-class Plasma desktop experience with the latest stuff on board.
|
||||
|
||||
Even though both the distributions work amazing out of the box, they have a different vision and the development proceeds on both them accordingly. You just have to decide what you want for yourself and choose one of them.
|
||||
|
||||
#### Hardware Compatibility
|
||||
|
||||
![Kubuntu Focus Laptop][12]
|
||||
|
||||
As I mentioned earlier, this is not a fact-based point here. But, as per my quick look on the feedback or experiences shared by the users online, it seems that Kubuntu works with a wide range of old hardware along with new hardware (potentially dating back to 2012) while KDE Neon may not.
|
||||
|
||||
It’s just a thing to keep in mind if you try KDE Neon and it doesn’t work for some reason. You know what to do.
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
So, what would it be? KDE Neon or Kubuntu? That’s really is your choice.
|
||||
|
||||
Both are good choices for a [beginner-friendly Linux distribution][13] but if you want the latest KDE Plasma desktop, KDE Neon gets the edge here. You can read more about it in our [review of KDE Neon][10].
|
||||
|
||||
Feel free to let me know your thoughts in the comments down below and what do you find good/bad on either of them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/kde-neon-vs-kubuntu/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://ubuntu.com/
|
||||
[2]: https://kde.org/
|
||||
[3]: https://kubuntu.org
|
||||
[4]: https://neon.kde.org
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/kde-neon-vs-kubuntu.png?resize=800%2C450&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/01/install_ubuntu_8.jpg?resize=796%2C611&ssl=1
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/kde-plasma-5-20-feat.png?resize=800%2C394&ssl=1
|
||||
[8]: https://lwn.net/Articles/645973/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/08/kde-neon-review.jpg?fit=800%2C450&ssl=1
|
||||
[10]: https://itsfoss.com/kde-neon-review/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/kubuntu-kde.jpg?resize=800%2C450&ssl=1
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/kubuntu-focus-laptop.jpg?resize=800%2C600&ssl=1
|
||||
[13]: https://itsfoss.com/best-linux-beginners/
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Map Your Gamepad Buttons With Keyboard, Mouse, or Macros/Scripts Using AntiMicroX in Linux)
|
||||
[#]: via: (https://itsfoss.com/antimicrox/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Map Your Gamepad Buttons With Keyboard, Mouse, or Macros/Scripts Using AntiMicroX in Linux
|
||||
======
|
||||
|
||||
_**Brief: AntiMicroX is a GUI tool to map your gamepad with your keyboard, mouse, or custom macros/scripts in Linux. Let’s take a closer look at it.**_
|
||||
|
||||
Gaming peripherals on Linux do not have a great reputation, but we do have some interesting open source tools that can make things easier for you. For instance, I’ve previously covered a tool [Piper which lets you configure your gaming mouse][1].
|
||||
|
||||
This time, let me introduce you to an exciting open source tool that lets you utilize your game pad by mapping it to your keyboard, mouse, scripts, or macros.
|
||||
|
||||
![][2]
|
||||
|
||||
In this article, I’ll mention why you might need it and its key features to help you know more about it.
|
||||
|
||||
### AntiMicroX: An open source tool to map your gamepad
|
||||
|
||||
Of course, this isn’t for everyone but an open source GUI tool for something useful, why not?
|
||||
|
||||
Maybe you have a system that you utilize for media consumption (or as a [media server on Linux][3]). Or, maybe you want to use a desktop application using your gamepad.
|
||||
|
||||
Also, you may want to use it to play a game that does not offer gamepad support.
|
||||
|
||||
For such cases, AntiMicroX is a tool that you would want to explore (even if that’s just for fun).
|
||||
|
||||
### Features of AntiMicroX
|
||||
|
||||
![][4]
|
||||
|
||||
* Map with keyboard buttons
|
||||
* Controller mapping to make sure the host detects the correct triggers
|
||||
* Multiple controller profile
|
||||
* Ability to launch an executable using the gamepad
|
||||
* Map with mouse buttons
|
||||
* Gamepad calibration option
|
||||
* Tweak Gamepad poll rate (if needed)
|
||||
* Auto profile support
|
||||
|
||||
|
||||
|
||||
### Installing AntiMicroX on Linux
|
||||
|
||||
![][5]
|
||||
|
||||
AntiMicroX offers a wide range of options to get it installed on a Linux distribution. You will find a DEB package, [Flatpak package][6], and an AppImage file.
|
||||
|
||||
It is easy to [install it using the deb package][7]. In addition to that, you may refer to our [Flatpak guide][8] or [AppImage guide][9] to get started installing AntiMicroX as well.
|
||||
|
||||
You can also build it from source if needed. Nevertheless, you should find all the necessary instructions in its [GitHub page][10] along with the packages in its [releases section][11].
|
||||
|
||||
[AntiMicroX][12]
|
||||
|
||||
**Recommended Read:**
|
||||
|
||||
![][13]
|
||||
|
||||
#### [How to Configure Gaming Mouse on Linux Using Piper GUI Tool][1]
|
||||
|
||||
Love gaming on Linux? Take your gaming to the next level by configuring your gaming mouse in Linux using Piper GUI application.
|
||||
|
||||
### My Thoughts on Using AntiMicroX on Linux
|
||||
|
||||
Surprisingly, mapping the game pad buttons was easier than you would expect. I was able to map the buttons with my keyboard and assign custom macros/scripts as well.
|
||||
|
||||
Mapping the buttons with the mouse isn’t that simple and may not work well if you already have the mouse buttons assigned for different macros (like in my case). For gaming, it would be nice to calibrate and map the gamepad buttons properly before pairing it up with the keyboard buttons.
|
||||
|
||||
It worked just fine with my generic controller. You can definitely try it out.
|
||||
|
||||
Did you know about this? Have you tried it yet? Now that we’re looking for interesting open-source tools, do you know about anything else similar to this for [gaming on Linux][14]?
|
||||
|
||||
Let me know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/antimicrox/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/piper-configure-gaming-mouse-linux/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/10/antimicrox-mapping.png?resize=800%2C557&ssl=1
|
||||
[3]: https://itsfoss.com/best-linux-media-server/
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/10/antimicrox-gamepad.jpg?resize=800%2C631&ssl=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/10/antimicrox-calibration.jpg?resize=800%2C637&ssl=1
|
||||
[6]: https://itsfoss.com/what-is-flatpak/
|
||||
[7]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[8]: https://itsfoss.com/flatpak-guide/
|
||||
[9]: https://itsfoss.com/use-appimage-linux/
|
||||
[10]: https://github.com/AntiMicroX/antimicrox
|
||||
[11]: https://github.com/AntiMicroX/antimicrox/releases
|
||||
[12]: https://github.com/AntiMicroX/antimicrox/
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/06/configuring-gaming-mouse-linux.png?fit=800%2C450&ssl=1
|
||||
[14]: https://itsfoss.com/linux-gaming-guide/
|
||||
@ -0,0 +1,170 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (You can Surf Internet in Linux Terminal With These Command Line Browsers)
|
||||
[#]: via: (https://itsfoss.com/terminal-web-browsers/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
You can Surf Internet in Linux Terminal With These Command Line Browsers
|
||||
======
|
||||
|
||||
I’m guessing that you are probably using Firefox or a Chrome-based browser like [Brave][1] to read this article. Or, maybe, Google Chrome or [Chromium][2].
|
||||
|
||||
In other words, you are utilizing a GUI-based approach to browse the web. However, back in the days, people used the terminal to fetch resources and browse the web because everything was mostly text-based information.
|
||||
|
||||
Even though you cannot get every information from a terminal now, you can still try the command line browsers for some text-based information and open a web page from the Linux terminal.
|
||||
|
||||
Not just limited to that, but if you are accessing a remote server or stuck in a terminal without a GUI, a terminal web browser can prove to be useful as well.
|
||||
|
||||
So, in this article, I will be mentioning some terminal based web browsers that you can try on Linux.
|
||||
|
||||
### Best Terminal-based Web Browsers for Linux Users
|
||||
|
||||
_**Note:** The list is in no particular order of ranking._
|
||||
|
||||
#### 1\. W3M
|
||||
|
||||
![][3]
|
||||
|
||||
w3m is a popular open-source text-based web browser for the terminal. Even though the original project is no longer active, an active version of it is being maintained by a different developer Tatsuya Kinoshita.
|
||||
|
||||
w3m is quite simple, supports SSL connections, colors, and in-line images as well. Of course, depending on what resource you are trying to access, things might look different on your end. As per my quick test, it didn’t seem to load up [DuckDuckGo][4] but I could [use Google in terminal][5] just fine.
|
||||
|
||||
You can simply type **w3m** in the terminal to get help after installation. If you’re curious, you can also check out the repository at [GitHub][6].
|
||||
|
||||
##### How to install and use w3m?
|
||||
|
||||
W3M is available on most of the default repositories for any Debian-based Linux distribution. If you have an Arch-based distro, you might want to check [AUR][7] if it’s not available directly.
|
||||
|
||||
For Ubuntu, you can install it by typing in:
|
||||
|
||||
```
|
||||
sudo apt install w3m w3m-img
|
||||
```
|
||||
|
||||
Here, we are installing the w3m package along with image extension for in-line image support. Next, to get started, you have to simply follow the command below:
|
||||
|
||||
```
|
||||
w3m xyz.com
|
||||
```
|
||||
|
||||
Of course, you need to replace xyz.com to any website that you want to browse/test. Finally, you should know that you can use the keyboard arrow keys to navigate and press enter when you want to take an action.
|
||||
|
||||
To quit, you can press **SHIFT+Q**, and to go back to the previous page — **SHIFT+B**. Additional shortcuts include **SHIFT + T** to open a new tab and **SHIFT + U** to open a new URL.
|
||||
|
||||
You can explore more about it by heading to its man page as well.
|
||||
|
||||
#### 2\. Lynx
|
||||
|
||||
![][8]
|
||||
|
||||
Lynx is yet another open source command line browser which you can try. Fortunately, more websites tend to work when using Lynx, so I’d say it is definitely better in that aspect. I was able to load up DuckDuckGo and make it work.
|
||||
|
||||
In addition to that, I also noticed that it lets you accept/deny cookies when visiting various web resources. You can set it to always accept or deny as well. So, that’s a good thing.
|
||||
|
||||
On the other hand, the window does not re-size well while using it from the terminal. I haven’t looked for any solutions to that, so if you’re trying this out, you might want to do that. In either case, it works great and you get all the instructions for the keyboard shortcuts right when you launch it in the terminal.
|
||||
|
||||
Note that it does not match the system terminal theme, so it will look different no matter how your terminal looks like.
|
||||
|
||||
##### How to install Lynx?
|
||||
|
||||
Unlike w3m, you do get some Win32 installers if you’re interested to try. But, on Linux, it is available on the most of the default repositories.
|
||||
|
||||
For Ubuntu, you just need to type in:
|
||||
|
||||
```
|
||||
sudo apt install lynx
|
||||
```
|
||||
|
||||
To get started, you just have to follow the command below:
|
||||
|
||||
```
|
||||
lynx examplewebsite.com
|
||||
```
|
||||
|
||||
Here, you just need to replace the example website with the resource you want to visit.
|
||||
|
||||
If you want to explore the packages for other Linux distros, you can check out their [official website resources][9].
|
||||
|
||||
#### 3\. Links2
|
||||
|
||||
![][10]
|
||||
|
||||
Links2 is an interesting text-based browser that you can easily utilize on your terminal with a good user experience. It gives you a nice interface to type in the URL and then proceed as soon as you launch it.
|
||||
|
||||
![][11]
|
||||
|
||||
It is worth noting that the theme will depend on your terminal settings, I have it set as “black-green”, hence this is what you see. Once you launch it as a command line browser, you just need to press any key to bring the URL prompt or Q to quit it. It works good enough and renders text from most of the sites.
|
||||
|
||||
Unlike Lynx, you do not get the ability to accept/reject cookies. Other than that, it seems to work just fine.
|
||||
|
||||
##### How to install Links2?
|
||||
|
||||
As you’d expect, you will find it available in the most of the default repositories. For Ubuntu, you can install it by typing the following command in the terminal:
|
||||
|
||||
```
|
||||
sudo apt install links2
|
||||
```
|
||||
|
||||
You can refer to its [official][12] [][12][website][12] for packages or documentations if you want to install it on any other Linux distribution.
|
||||
|
||||
#### 4\. eLinks
|
||||
|
||||
![][13]
|
||||
|
||||
eLinks is similar to Links2 — but it is no longer maintained. You will still find it in the default repositories of various distributions, hence, I kept it in this list.
|
||||
|
||||
It does not blend in with your system terminal theme. So, this may not be a pretty experience as a text-based browser without a “dark” mode if you needed that.
|
||||
|
||||
##### How to install eLinks?
|
||||
|
||||
On Ubuntu, it is easy to install it. You just have to type in the following in the terminal:
|
||||
|
||||
```
|
||||
sudo apt install elinks
|
||||
```
|
||||
|
||||
For other Linux distributions, you should find it available on the standard repositories. But, you can refer to the [official installation instructions][14] if you do not find it in the repository.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
It’s no surprise that there aren’t a lot of text-based web browsers to run on the terminal. Some projects like [Browsh][15] have tried to present a modern Linux command-line browser but it did not work in my case.
|
||||
|
||||
While tools like curl and wget allow you to [download files from the Linux command line][16], these terminal-based web browsers provide additional features.
|
||||
|
||||
In addition to command-line browsers, you may also like to try some [command line games for Linux][17], if you want to play around in the terminal.
|
||||
|
||||
What do you think about the text-based web browsers for Linux terminal? Feel free to let me know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/terminal-web-browsers/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/brave-web-browser/
|
||||
[2]: https://itsfoss.com/install-chromium-ubuntu/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/10/w3m-google.jpg?resize=800%2C463&ssl=1
|
||||
[4]: https://duckduckgo.com/
|
||||
[5]: https://itsfoss.com/review-googler-linux/
|
||||
[6]: https://github.com/tats/w3m
|
||||
[7]: https://itsfoss.com/aur-arch-linux/
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/10/lynx-terminal.jpg?resize=800%2C497&ssl=1
|
||||
[9]: https://lynx.invisible-island.net/lynx-resources.html
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/links2-terminal.jpg?resize=800%2C472&ssl=1
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/links2-terminal-welcome.jpg?resize=800%2C541&ssl=1
|
||||
[12]: http://links.twibright.com/download.php
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/elinks-terminal.jpg?resize=800%2C465&ssl=1
|
||||
[14]: http://elinks.or.cz/documentation/installation.html
|
||||
[15]: https://www.brow.sh/
|
||||
[16]: https://itsfoss.com/download-files-from-linux-terminal/
|
||||
[17]: https://itsfoss.com/best-command-line-games-linux/
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 new sudo features you need to know in 2020)
|
||||
[#]: via: (https://opensource.com/article/20/10/sudo-19)
|
||||
[#]: author: (Peter Czanik https://opensource.com/users/czanik)
|
||||
|
||||
5 new sudo features you need to know in 2020
|
||||
======
|
||||
From central session recording through chroot support to Python API,
|
||||
sudo 1.9 offers many new features.
|
||||
![Wratchet set tools][1]
|
||||
|
||||
When you want to perform an action on a [POSIX system][2], one of the safest ways to do so is to use the sudo command. Unlike logging in as the root user and performing what could be a dangerous action, sudo grants any user [designated as a "sudoer"][3] by the sysadmin temporary permission to perform a normally restricted activity.
|
||||
|
||||
This system has helped keep Linux, Unix, and macOS systems safe from silly mistakes and malicious attacks for decades, and it is the default administrative mechanism on all major Linux distributions today.
|
||||
|
||||
When it was released in May 2020, sudo 1.9 brought many new features, including central collection of session recordings, support for chroot within sudo, and a Python API. If you are surprised by any of these, read my article about some [lesser-known features of sudo][4].
|
||||
|
||||
Sudo is a lot more than just a prefix for administrative commands. You can fine-tune permissions, record what is happening on the terminal, extend sudo using plugins, store configurations in LDAP, do extensive logging, and much more.
|
||||
|
||||
Version 1.9.0 and subsequent minor releases added a variety of new features (which I'll describe below), including:
|
||||
|
||||
* A recording service to collect sudo session recordings centrally
|
||||
* Audit plugin API
|
||||
* Approval plugin API
|
||||
* Python support for plugins
|
||||
* Chroot and CWD support built into sudo (starting with 1.9.3)
|
||||
|
||||
|
||||
|
||||
### Where to get sudo 1.9
|
||||
|
||||
Most Linux distributions still package the previous generation of sudo (version 1.8), and it will stay that way in long-term support (LTS) releases for several years. The most complete sudo 1.9 package I am aware of in a Linux distribution is openSUSE [Tumbleweed][5], which is a rolling distro, and the sudo package has Python support available in a subpackage. Recent [Fedora][6] releases include sudo 1.9 but without Python. [FreeBSD Ports][7] has the latest sudo version available, and you can enable Python support if you build sudo yourself instead of using the package.
|
||||
|
||||
If your favorite Linux distribution does not yet include sudo 1.9, check the [sudo binaries page][8] to see if a ready-to-use package is available for your system. This page also has packages for several commercial Unix variants.
|
||||
|
||||
As usual, before you start experimenting with sudo settings, _make sure you know the root password_. Yes, even on Ubuntu. Having a temporary "backdoor" is important; without it, you would have to hack your own system if something goes wrong. And remember: a syntactically correct configuration does not mean that anybody can do anything through sudo on that system!
|
||||
|
||||
### Recording service
|
||||
|
||||
The recording service collects session recordings centrally. This offers many advantages compared to local session log storage:
|
||||
|
||||
* It is more convenient to search in one place instead of visiting individual machines for recordings
|
||||
* Recordings are available even if the sending machine is down
|
||||
* Recordings cannot be deleted by local users who want to cover their tracks
|
||||
|
||||
|
||||
|
||||
For a quick test, you can send sessions through non-encrypted connections to the recording service. My blog contains [instructions][9] for setting it up in just a few minutes. For a production setup, I recommend using encryption. There are many possibilities, so read the [documentation][10] that best suits your environment.
|
||||
|
||||
### Audit plugin API
|
||||
|
||||
The new audit plugin API is not a user-visible feature. In other words, you cannot configure it from the sudoers file. It is an API, meaning that you can access audit information from plugins, including ones written in Python. You can use it in many different ways, like sending events from sudo directly to Elasticsearch or Logging-as-a-Service (LaaS) when something interesting happens. You can also use it for debugging and print otherwise difficult-to-access information to the screen in whatever format you like.
|
||||
|
||||
Depending on how you want to use it, you can find its documentation in the sudo plugin manual page (for C) and the sudo Python plugin manual. [Sample Python code][11] is available in the sudo source code, and there is also a [simplified example][12] on my blog.
|
||||
|
||||
### Approval plugin API
|
||||
|
||||
The approval plugin API makes it possible to include extra restrictions before a command will execute. These will run only after the policy plugin succeeds, so you can effectively add additional policy layers without replacing the policy plugin and thus sudoers. Multiple approval plugins may be defined, and all must succeed for the command to execute.
|
||||
|
||||
As with the audit plugin API, you can use it both from C and Python. The [sample Python code][13] documented on my blog is a good introduction to the API. Once you understand how it works, you can extend it to connect sudo to ticketing systems and approve sessions only with a related open ticket. You can also connect to an HR database so that only the engineer on duty can gain administrative privileges.
|
||||
|
||||
### Python support for plugins
|
||||
|
||||
Even though I am not a programmer, my favorite new sudo 1.9 feature is Python support for plugins. You can use most of the APIs available from C with Python as well. Luckily, sudo is not performance-sensitive, so the relatively slow speed of running Python code is not a problem for sudo. Using Python for extending sudo has many advantages:
|
||||
|
||||
* Easier, faster development
|
||||
* No need to compile; code might even be distributed by configuration management
|
||||
* Many APIs do not have ready-to-use C clients, but Python code is available
|
||||
|
||||
|
||||
|
||||
In addition to the audit and approval plugin APIs, there are a few others available, and you can do very interesting things with them.
|
||||
|
||||
By using the policy plugin API, you can replace the sudo policy engine. Note you will lose most sudo features, and there is no more sudoers-based configuration. This can still be useful in niche cases, but most of the time, it is better to keep using sudoers and create additional policies using the approval plugin API. If you want to give it a try, my [introduction to the Python plugin][14] provides a very simple policy: allowing only the `id` command. Once again, make sure you know the root password, as once this policy is enabled, it prevents any practical use of sudo.
|
||||
|
||||
Using the I/O logs API, you can access input and output from user sessions. This means you can analyze what is happening in a session and even terminate it if you find something suspicious. This API has many possible uses, such as data-leak prevention. You can monitor the screen for keywords and, if any of them appear in the data stream, you can break the connection before the keyword can appear on the user's screen. Another possibility is checking what the user is typing and using that data to reconstruct the command line the user is entering. For example, if a user enters `rm -fr /`, you can disconnect the user even before Enter is hit.
|
||||
|
||||
The group plugin API allows non-Unix group lookups. In a way, this is similar to the approval plugin API as it also extends the policy plugin. You can check if a user is part of a given group and act based on this in later parts of the configuration.
|
||||
|
||||
### Chroot and CWD support
|
||||
|
||||
The latest additions to sudo are chroot and change working directory (CWD) support. Neither option is enabled by default—you need to explicitly enable them in the sudoers file. When they're enabled, you can fine-tune target directories or allow users to specify which directory to use. The logs reflect when these settings were used.
|
||||
|
||||
On most systems, chroot is available only to root. If one of your users needs chroot, you need to give them root access, which gives them a lot more power than just chroot. Alternately, you can allow access to the chroot command through sudo, but it still allows loopholes where they can gain full access. When you use sudo's built-in chroot support, you can easily restrict access to a single directory. You can also give users the flexibility to specify the root directory. Of course, this might lead to disasters (e.g., `sudo --chroot / -s`), but at least the event is logged.
|
||||
|
||||
When you run a command through sudo, it sets the working directory to the current directory. This is the expected behavior, but there may be cases when the command needs to be run in a different directory. For example, I recall using an application that checked my privileges by checking whether my working directory was `/root`.
|
||||
|
||||
### Try the new features
|
||||
|
||||
I hope that this article inspires you to take a closer look at sudo 1.9. Central session recording is both more convenient and secure than storing session logs locally. Chroot and CWD support give you additional security and flexibility. And using Python to extend sudo makes it easy to custom-tailor sudo to your environment. You can try the new features by using one of the latest Linux distributions or the ready-to-use packages from the sudo website.
|
||||
|
||||
If you want to learn more about sudo, here are a few resources:
|
||||
|
||||
* [Sudo website][15]
|
||||
* [Sudo blog][16]
|
||||
* [Sudo on Twitter][17]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/sudo-19
|
||||
|
||||
作者:[Peter Czanik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/czanik
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tools_osyearbook2016_sysadmin_cc.png?itok=Y1AHCKI4 (Wratchet set tools)
|
||||
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[3]: https://opensource.com/article/17/12/using-sudo-delegate
|
||||
[4]: https://opensource.com/article/19/10/know-about-sudo
|
||||
[5]: https://software.opensuse.org/distributions/tumbleweed
|
||||
[6]: https://getfedora.org/
|
||||
[7]: https://www.freebsd.org/ports/
|
||||
[8]: https://www.sudo.ws/download.html#binary
|
||||
[9]: https://blog.sudo.ws/posts/2020/03/whats-new-in-sudo-1.9-recording-service/
|
||||
[10]: https://www.sudo.ws/man/sudo_logsrvd.man.html#EXAMPLES
|
||||
[11]: https://github.com/sudo-project/sudo/blob/master/plugins/python/example_audit_plugin.py
|
||||
[12]: https://blog.sudo.ws/posts/2020/06/sudo-1.9-using-the-new-audit-api-from-python/
|
||||
[13]: https://blog.sudo.ws/posts/2020/08/sudo-1.9-using-the-new-approval-api-from-python/
|
||||
[14]: https://blog.sudo.ws/posts/2020/01/whats-new-in-sudo-1.9-python/
|
||||
[15]: https://www.sudo.ws/
|
||||
[16]: https://blog.sudo.ws/
|
||||
[17]: https://twitter.com/sudoproject
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How JavaScript became a serious programming language)
|
||||
[#]: via: (https://opensource.com/article/20/10/history-javascript)
|
||||
[#]: author: (Nimisha Mukherjee https://opensource.com/users/nimisha)
|
||||
|
||||
How JavaScript became a serious programming language
|
||||
======
|
||||
From humble beginnings as a way to make websites pretty, JavaScript has
|
||||
been transformed into a serious programming language.
|
||||
![Javascript code close-up with neon graphic overlay][1]
|
||||
|
||||
JavaScript's humble start began in 1995, when it was [created in just 10 days][2] by Brendan Eich, then an employee with Netscape Communications Corporation. JavaScript has come a long way since then, from a tool to make websites pretty to a serious programming language.
|
||||
|
||||
In its early days, JavaScript was considered a visual tool that made websites a little more fun and attractive. Languages like [Jakarta Server Pages][3] (JSP; formerly JavaServer Pages) used to do all the heavy lifting on rendered web pages, and JavaScript was used to create basic interactions, visual enhancements, and animations.
|
||||
|
||||
For a long time, the demarcations between HTML, CSS, and JavaScript were not clear. Frontend development primarily consists of HTML, CSS, and JavaScript, forming a "[layer cake][4]" of standard web technologies.
|
||||
|
||||
![Layer cake of standard web technologies][5]
|
||||
|
||||
The "[layer cake][4]" of standard web technologies (Mozilla Developers Network, [CC BY-SA 4.0][6])
|
||||
|
||||
HTML and CSS provide structure, format, and style to content. JavaScript comes into play once a web page does something beyond displaying static content. Ecma International develops JavaScript specifications, and the World Wide Web Consortium (W3C) develops HTML and CSS specifications.
|
||||
|
||||
### How JavaScript gained prominence
|
||||
|
||||
There is a long [history][7] behind how JavaScript came to be the [most popular][8] programming language. Back in the 1990s, Java was king, and comparisons to it were inevitable. Many engineers thought JavaScript was not a good programming language due to lack of support for object-oriented programming. Even though it was not evident, JavaScript's object-model and functional features were already present in its first version.
|
||||
|
||||
After JavaScript's rushed release in 1995, Netscape submitted it to the European Computer Manufacturers Association (ECMA) International for standardization. This led to [ECMAScript][9], a JavaScript standard meant to ensure interoperability of web pages across different web browsers. ECMAScript 1 came out in June 1997 and helped to advance the standardization of JavaScript.
|
||||
|
||||
During this time, PHP and JSP became popular server-side language choices. JSP had gained prominence as the preferred alternative to Common Gateway Interface ([CGI][10]) because it enabled embedding Java code in HTML. While it was popular, developers found it unnatural to have Java inside HTML. In addition, even for the simplest text change on HTML, JSP had to undergo a time-consuming lifecycle. In today's microservice world, JSP-oriented pages are considered technical debt.
|
||||
|
||||
[PHP][11] works similarly to JSP but the PHP code is processed as a Common Gateway Interface ([CGI][10]) executable. PHP-based web applications are easier to deploy than those based on JSP. Overall, it is easier to get up and running with PHP. Today, PHP and JavaScript are one of the most popular combinations for creating dynamic websites. PHP serves as the server-side scripting and JavaScript as the client-side scripting.
|
||||
|
||||
JavaScript's adoption grew with the release of [jQuery][12], a multi-purpose JavaScript library that simplifies tedious Document Object Model (DOM) management, event handling, and [Ajax][13], in 2006.
|
||||
|
||||
The turning point for JavaScript came in 2009 when [Node.js][14] was released. Developers could now write server-side scripting with JavaScript. Closely following were frameworks like [Backbone.js][15] and [AngularJS][16], both released in 2010. This led to the concept of full-stack development using a single language.
|
||||
|
||||
In 2015, Ecma International released ECMAScript 6 (ES6), which added significant new syntax for writing complex applications, including class declarations. Other new features included iterators, arrow function expressions, let and const keywords, typed arrays, new collections (maps, sets, and WeakMap), promises, template literals for strings, and many other cool features. Later editions have gone on to add more features that have made JavaScript more robust, streamlined, and reliable.
|
||||
|
||||
### Conclusion
|
||||
|
||||
JavaScript has advanced significantly over the past two decades. Most browsers now compete to meet compliance, so the latest specifications are rolled out faster.
|
||||
|
||||
There are a host of stable JavaScript frameworks to choose from, depending on your project requirements, including the most popular ones: [React][17], [Angular][18], and [Vue.js][19]. In the next article in this series, I'll dive into why JavaScript is so popular.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/history-javascript
|
||||
|
||||
作者:[Nimisha Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nimisha
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_javascript.jpg?itok=60evKmGl (Javascript code close-up with neon graphic overlay)
|
||||
[2]: https://en.wikipedia.org/wiki/JavaScript
|
||||
[3]: https://en.wikipedia.org/wiki/Jakarta_Server_Pages
|
||||
[4]: https://developer.mozilla.org/en-US/docs/Learn/JavaScript/First_steps/What_is_JavaScript
|
||||
[5]: https://opensource.com/sites/default/files/uploads/layercakewebtech.png (Layer cake of standard web technologies)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://blog.logrocket.com/history-of-frontend-frameworks/
|
||||
[8]: https://octoverse.github.com/
|
||||
[9]: https://en.wikipedia.org/wiki/ECMAScript
|
||||
[10]: https://en.wikipedia.org/wiki/Common_Gateway_Interface
|
||||
[11]: https://en.wikipedia.org/wiki/PHP#:~:text=PHP%20development%20began%20in%201994,Interpreter%22%20or%20PHP%2FFI.
|
||||
[12]: https://en.wikipedia.org/wiki/JQuery
|
||||
[13]: https://en.wikipedia.org/wiki/Ajax_(programming)
|
||||
[14]: https://en.wikipedia.org/wiki/Node.js
|
||||
[15]: https://en.wikipedia.org/wiki/Backbone.js
|
||||
[16]: https://en.wikipedia.org/wiki/AngularJS
|
||||
[17]: https://reactjs.org/
|
||||
[18]: https://angular.io/
|
||||
[19]: https://vuejs.org/
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Clear Terminal Screen in Ubuntu and Other Linux Distributions [Beginner’s Tip])
|
||||
[#]: via: (https://itsfoss.com/clear-terminal-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Clear Terminal Screen in Ubuntu and Other Linux Distributions [Beginner’s Tip]
|
||||
======
|
||||
|
||||
When you are working in the terminal, often you’ll find that your terminal screen is filled up with too many commands and their outputs.
|
||||
|
||||
You may want to clear the terminal to declutter the screen and focus on the next task you are going to perform. Clearing the Linux terminal screen helps a lot, trust me.
|
||||
|
||||
### Clear Linux terminal with clear command
|
||||
|
||||
So, how do you clear terminal in Linux? The simplest and the most common way is to use the clear command:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
You need no option with the clear command. It’s that simple but there are some additional things you need to know about it.
|
||||
|
||||
![][1]
|
||||
|
||||
_**The clear command and other methods of clearing screen may depend on the terminal emulator you are using.**_ Terminal emulator is the terminal application that you use for accessing the Linux shell (command line).
|
||||
|
||||
If you use clear command on Ubuntu with GNOME Terminal, it will clear the screen and you won’t be able to see what else you had on the screen previously.
|
||||
|
||||
In many other terminal emulators or Putty, it may just clear the screen for one page. If you scroll with mouse or PageUp and PageDown keys, you can still access the old screen outputs.
|
||||
|
||||
Frankly, it depends on your need. If you suddenly realize that you need to refer to the output of a previously run command, perhaps having that option available will be helpful.
|
||||
|
||||
### Other ways to clear terminal screen in Linux
|
||||
|
||||
![][2]
|
||||
|
||||
Clear command is not the only way to clear the terminal screen.
|
||||
|
||||
You can use Ctrl+L [keyboard shortcut in Linux][3] to clear the screen. It works in most terminal emulators.
|
||||
|
||||
```
|
||||
Ctrl+L
|
||||
```
|
||||
|
||||
If you use Ctrl+L and clear command in GNOME terminal (default in Ubuntu), you’ll notice the difference between their impact. Ctrl+L moves the screen one page down giving the illusion of a clean screen but you can still access the command output history by scrolling up.
|
||||
|
||||
**Some other terminal emulators have this keyboard shortcut set at Ctrl+Shift+K.**
|
||||
|
||||
You can also use reset command for clearing the terminal screen. Actually, this command performs a complete terminal re-initialization. It could take a bit longer than clear command, though.
|
||||
|
||||
```
|
||||
reset
|
||||
```
|
||||
|
||||
There are a couple of other complicated ways to clear the screen when you want to clear the screen completely. But since the command is a bit complicated, it’s better to use it as [alias in Linux][4]:
|
||||
|
||||
```
|
||||
alias cls='printf "\033c"'
|
||||
```
|
||||
|
||||
You can add this alias to your bash profile so that it is available as command.
|
||||
|
||||
I know this was a pretty basic topic and most Linux users probably already knew it but it doesn’t harm in covering the elementary topics for the new Linux users. Isn’t it?
|
||||
|
||||
Got some secretive tip on clearing terminal screen? Why not share it with us?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/clear-terminal-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/clear-command-linux.gif?resize=800%2C432&ssl=1
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/clear-terminal-screen-linux.png?resize=800%2C450&ssl=1
|
||||
[3]: https://linuxhandbook.com/linux-shortcuts/
|
||||
[4]: https://linuxhandbook.com/linux-alias-command/
|
||||
@ -0,0 +1,629 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Program in Arm6 assembly language on a Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/20/10/arm6-assembly-language)
|
||||
[#]: author: (Marty Kalin https://opensource.com/users/mkalindepauledu)
|
||||
|
||||
Program in Arm6 assembly language on a Raspberry Pi
|
||||
======
|
||||
Assembly language offers special insights into how machines work and how
|
||||
they can be programmed.
|
||||
![An intersection of pipes.][1]
|
||||
|
||||
The [Arm website][2] touts the processor's underlying architecture as "the keystone of the world's largest compute ecosystem," which is plausible given the number of handheld and embedded devices with Arm processors. Arm processors are prevalent in the Internet of Things (IoT), but they are also used in desktop machines, servers, and even high-performance computers, such as the Fugaku HPC. But why look at Arm machines through the lens of assembly language?
|
||||
|
||||
Assembly language is the symbolic language immediately above machine code and thereby offers special insights into how machines work and how they can be programmed efficiently. In this article, I hope to illustrate this point with the Arm6 architecture using a Raspberry Pi 4 mini-desktop machine running Debian.
|
||||
|
||||
The Arm6 family of processors supports two instruction sets:
|
||||
|
||||
* The Arm set, with 32-bit instructions throughout.
|
||||
* The Thumb set, with a mix of 16-bit and 32-bit instructions.
|
||||
|
||||
|
||||
|
||||
The examples in this article use the Arm instruction set. The Arm assembly code is in lowercase, and, for contrast, pseudo-assembly code is in uppercase.
|
||||
|
||||
### Load-store machines
|
||||
|
||||
The RISC/CISC distinction is often seen when comparing the Arm family and the Intel x86 family of processors, both of which are commercial products competing on the market. The terms RISC (reduced instruction set computer) and CISC (complex instruction set computer) date from the middle 1980s. Even then the terms were misleading, in that both RISC (e.g., MIPS) and CISC (e.g., Intel) processors had about 300 instructions in their instruction sets; today the counts for core instructions in Arm and Intel machines are close, although both types of machines have extended their instruction sets. A sharper distinction between Arm and Intel machines draws on an architectural feature other than instruction count.
|
||||
|
||||
An instruction set architecture (ISA) is an abstract model of a computing machine. Processors from Arm and Intel implement different ISAs: Arm processors implement a load-store ISA, whereas their Intel counterparts implement a register-memory ISA. The difference in ISAs can be described as:
|
||||
|
||||
* In a load-store machine, only two instructions move data between a CPU and the memory subsystem:
|
||||
* A load instruction copies bits from memory into a CPU register.
|
||||
* A store instruction copies bits from a CPU register into memory.
|
||||
* Other instructions—in particular, the ones for arithmetic-logic operations—use only CPU registers as source and destination operands. For example, here is pseudo-assembly code on a load-store machine to add two numbers originally in memory, storing their sum back in memory (comments start with `##`): [code] ## R0 is a CPU register, RAM[32] is a memory location
|
||||
LOAD R0, RAM[32] ## R0 = RAM[32]
|
||||
LOAD R1, RAM[64] ## R1 = RAM[64]
|
||||
ADD R2, R0, R1 ## R2 = R0 + R1
|
||||
STORE R2, RAM[32] ## RAM[32] = R2 [/code] The task requires four instructions: two LOADs, one ADD, and one STORE.
|
||||
* By contrast, a register-memory machine allows the operands for arithmetic-logic instructions to be registers or memory locations, usually in any combination. For example, here is pseudo-assembly code on a register-memory machine to add two numbers in memory: [code]`ADD RAM[32], RAM[32], RAM[64] ## RAM[32] += RAM[64]`[/code] The task can be accomplished with a single instruction, although the bits to be added must still be fetched from memory to a CPU, and the sum then must be copied back to memory location RAM[32].
|
||||
|
||||
|
||||
|
||||
Any ISA comes with tradeoffs. As the example above illustrates, a load-store ISA has what architects call "low instruction density": relatively many instructions may be required to perform a task. A register-memory machine has high instruction density, which is an upside. There are upsides, as well, to the load-store ISA.
|
||||
|
||||
Load-store design is an effort to simplify an architecture. For instance, consider the case in which a register-memory machine has an instruction with mixed operands:
|
||||
|
||||
|
||||
```
|
||||
COPY R2, RAM[64] ## R2 = RAM[64]
|
||||
ADD RAM[32], RAM[32], R2 ## RAM[32] = RAM[32] + R2
|
||||
```
|
||||
|
||||
Executing the ADD instruction is tricky in that the access times for the numbers to be added differs—perhaps significantly if the memory operand happens to be only in main memory rather than also in a cache thereof. Load-store machines avoid the problem of mixed access times in arithmetic-logic operations: all operands, as registers, have the same access time.
|
||||
|
||||
Furthermore, load-store architectures emphasize fixed-sized instructions (e.g., 32-bits apiece), limited formats (e.g., one, two, or three fields per instruction), and relatively few addressing modes. These design constraints mean that the processor's control unit (CU) and arithmetic-logic unit (ALU) can be simplified: fewer transistors and wires, less required power and generated heat, and so on. Load-store machines are designed to be architecturally sparse.
|
||||
|
||||
My aim is not to step into the debate over load-store versus register-memory machines but rather to set up a code example in the load-store Arm6 architecture. This first look at load-store helps to explain the code that follows. The two programs (one in C, one in Arm6 assembly) are available on [my website][3].
|
||||
|
||||
### The hstone program in C
|
||||
|
||||
Among my favorite short code examples is the hailstone function, which takes a positive integer as an argument. (I used this example in an [earlier article on WebAssembly][4].) This function is rich enough to highlight important assembly-language details. The function is defined as:
|
||||
|
||||
|
||||
```
|
||||
3N+1 if N is odd
|
||||
hstone(N) =
|
||||
N/2 if N is even
|
||||
```
|
||||
|
||||
For example, hstone(12) evaluates to 6, whereas hstone(11) evaluates to 34. If N is odd, then 3N+1 is even; but if N is even, then N/2 could be either even (e.g., 4/2 = 2) or odd (e.g., 6/2 = 3).
|
||||
|
||||
The hstone function can be used iteratively by passing the returned value as the next argument. The result is a _hailstone sequence_, such as this one, which starts with 24 as the original argument, the returned value 12 as the next argument, and so on:
|
||||
|
||||
|
||||
```
|
||||
`24,12,6,3,10,5,16,8,4,2,1,4,2,1,...`
|
||||
```
|
||||
|
||||
It takes 10 steps for the sequence to converge to 1, at which point the sequence of 4,2,1 repeats indefinitely: (3x1)+1 is 4, which is halved to yield 2, which is halved to yield 1, and so on. For an explanation of why "hailstone" seems an appropriate name for such sequences, see "[Mathematical mysteries: Hailstone sequences][5]."
|
||||
|
||||
Note that powers of 2 converge quickly: 2N requires just N divisions by 2 to reach 1. For example, 32 = 25 has a convergence length of 5, and 512 = 29 has a convergence length of 9. If the hailstone function returns any power of 2, then the sequence converges to 1. Of interest here is the sequence length from the initial argument to the first occurrence of 1.
|
||||
|
||||
The [Collatz conjecture][6] is that a hailstone sequence converges to 1 no matter what the initial argument N > 0 happens to be. Neither a counterexample nor a proof has been found. The conjecture, simple as it is to illustrate with a program, remains a profoundly challenging problem in number theory.
|
||||
|
||||
Below is the C source code for the hstoneC program, which computes the length of the hailstone sequence whose starting value is given as user input. The assembly-language version of the program (hstoneS) is provided after an overview of Arm6 basics. For clarity, the two programs are structurally similar.
|
||||
|
||||
Here is the C source code:
|
||||
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
/* Compute steps from n to 1.
|
||||
-- update an odd n to (3 * n) + 1
|
||||
-- update an even n to (n / 2) */
|
||||
unsigned hstone(unsigned n) {
|
||||
unsigned len = 0; /* counter */
|
||||
while (1) {
|
||||
if (1 == n) break;
|
||||
n = (0 == (n & 1)) ? n / 2 : (3 * n) + 1;
|
||||
len++;
|
||||
}
|
||||
return len;
|
||||
}
|
||||
|
||||
int main() {
|
||||
[printf][7]("Integer > 0: ");
|
||||
unsigned num;
|
||||
[scanf][8]("%u", &num);
|
||||
[printf][7]("Steps from %u to 1: %u\n", num, hstone(num));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
When the program is run with an input of 9, the output is:
|
||||
|
||||
|
||||
```
|
||||
`Steps from 9 to 1: 19`
|
||||
```
|
||||
|
||||
The hstoneC program has a simple structure. The `main` function prompts the user for an input N (an integer > 0) and then calls the `hstone` function with this input as an argument. The `hstone` function loops until the sequence from N reaches the first 1, returning the number of steps required.
|
||||
|
||||
The most complicated statement in the program involves C's conditional operator, which is used to update N:
|
||||
|
||||
|
||||
```
|
||||
`n = (0 == (n & 1)) ? n / 2 : (3 * n) + 1;`
|
||||
```
|
||||
|
||||
This is a terse form of an if-then construct. The test `(0 == (n & 1))` checks whether the C variable `n` (representing N) is even or odd depending on whether the bitwise AND of N and 1 is zero: an integer value is even just in case its least-significant (rightmost) bit is zero. If N is even, N/2 becomes the new value; otherwise, 3N+1 becomes the new value. The assembly-language version of the program (hstoneS) likewise avoids an explicit if-else construct in updating its implementation of N.
|
||||
|
||||
My Arm6 mini-desktop machine includes the GNU C toolset, which can generate the corresponding code in assembly language. With `%` as the command-line prompt, the command is:
|
||||
|
||||
|
||||
```
|
||||
`% gcc -S hstoneC.c ## -S flag produces and saves assembly code`
|
||||
```
|
||||
|
||||
This produces the file hstoneC.s, which is about 120 lines of assembly-language source code, including a `nop` ("no operation") instruction. Compiler-generated assembly tends to be hard to read and may have inefficiencies such as the `nop`. A hand-crafted version, such as `hstoneS.s` (below), can be easier to follow and even significantly shorter (e.g., `hstoneS.s` has about 50 lines of code).
|
||||
|
||||
### Assembly language basics
|
||||
|
||||
Arm6, like most modern architectures, is byte-addressable: a memory address is of a byte, even if the addressed item (e.g., a 32-bit instruction) consists of multiple bytes. Instructions are addressed in little-[endian][9] fashion: the address is of the low-order byte. Data items are addressed in little-endian fashion by default, but this can be changed to big-endian so that the address of a multi-byte data item points to the high-order byte. By tradition, the low-order byte is depicted as the rightmost one and the high-order byte as the leftmost one:
|
||||
|
||||
|
||||
```
|
||||
high-order low-order
|
||||
/ /
|
||||
+----+----+----+----+
|
||||
| b1 | b2 | b3 | b4 | ## 4 bytes = 32 bits
|
||||
+----+----+----+----+
|
||||
```
|
||||
|
||||
Addresses are 32-bits in size, and data items come in three standard sizes:
|
||||
|
||||
* A _byte_ is 8 bits in size.
|
||||
* A _halfword_ is 16 bits in size.
|
||||
* A _word_ is 32 bits in size.
|
||||
|
||||
|
||||
|
||||
Aggregates of bytes, halfwords, and words (e.g., arrays and structures) are supported. CPU registers are 32-bits in size.
|
||||
|
||||
Assembly languages, in general, have three key features with a syntax that is close and, at times, identical:
|
||||
|
||||
* Directives in both Arm6 and Intel assembly start with a period. Here are two Arm6 examples, which happen to work in Intel as well:
|
||||
|
||||
|
||||
```
|
||||
.data
|
||||
.align 4
|
||||
```
|
||||
|
||||
The first directive indicates that the following section holds data items rather than code. The `.align 4` directive specifies that data items should be laid out, in memory, on 4-byte boundaries, which is common in modern architectures. As the name suggests, a directive gives direction to the translator (the "assembler") as this does its work.
|
||||
|
||||
By contrast, this directive indicates a code rather than a data section:
|
||||
|
||||
|
||||
```
|
||||
`.text`
|
||||
```
|
||||
|
||||
The term "text" is traditional, and its meaning, in this context, is "read-only": during program execution, code is read-only, whereas data can be read and written.
|
||||
|
||||
* Labels in both recent Arm and Intel assembly end with colons. A label is a memory address for either data items (e.g., variables) or code blocks (e.g., functions). Assembly languages, in general, rely heavily on addresses, which means that manipulating pointers—in particular, dereferencing them to get the values to which they point—takes front stage in assembly-language programming. Here are two labels in the hstoneS program:
|
||||
|
||||
|
||||
```
|
||||
collatz: /* label */
|
||||
mov r0, #0 /* instruction */
|
||||
loop_start: /* label */
|
||||
...
|
||||
```
|
||||
|
||||
The first label marks the start of the `collatz` function, whose first instruction copies the value zero (`#0`) into the register `r0`. (The `mov` for "move" opcode occurs across assembly languages but really means "copy.") The second label, `loop_start:`, is the address of the loop that computes the length of the hailstone sequence. The register `r0` serves as the sequence counter.
|
||||
|
||||
* Instructions, which assembly-sensitive editors usually indent along with directives, specify the operations to be performed (e.g., `mov`) together with operands (in this case, `r0` and `#0`). There are instructions with no operands and others with several.
|
||||
|
||||
|
||||
|
||||
|
||||
The `mov` instruction above does not violate the load-store principle about memory access. In general, a load instruction (`ldr` in Arm6) loads memory contents into a register. By contrast, a `mov` instruction can be used to copy an "immediate value," such as an integer constant, into a register:
|
||||
|
||||
|
||||
```
|
||||
`mov r0, #0 /* copy zero into r0 */`
|
||||
```
|
||||
|
||||
A `mov` instruction also can be used to copy the contents of one register into another:
|
||||
|
||||
|
||||
```
|
||||
`mov r1, r0 /* r1 = r0 */`
|
||||
```
|
||||
|
||||
The load opcode `ldr` would be inappropriate in both cases because a memory location is not in play. Examples of Arm6 `ldr` ("load register") and `str` ("store register") instructions are forthcoming.
|
||||
|
||||
The Arm6 architecture has 16 primary CPU registers (each 32-bits in size), a mix of general-purpose and special-purpose. Table 1 gives a summary, listing special features and uses beyond scratchpad:
|
||||
|
||||
#### Table 1. Primary CPU registers
|
||||
|
||||
Register | Special features
|
||||
---|---
|
||||
r0 | 1st arg to library function, retval
|
||||
r1 | 2nd arg to library function
|
||||
r2 | 3rd arg to library function
|
||||
r3 | 4th arg to library function
|
||||
r4 | callee-saved
|
||||
r5 | callee-saved
|
||||
r6 | callee-saved
|
||||
r7 | callee-saved, system calls
|
||||
r8 | callee-saved
|
||||
r9 | callee-saved
|
||||
r10 | callee-saved
|
||||
r11 | callee-saved, frame pointer
|
||||
r12 | intra-procedure
|
||||
r13 | stack pointer
|
||||
r14 | link register
|
||||
r15 | program counter
|
||||
|
||||
In general, CPU registers serve as a backup for the stack, the area of main memory that provides reusable scratchpad storage for the arguments passed to functions and the local variables used in functions and other code blocks (e.g., the body of a loop). Given that CPU registers reside on the same chip as the CPU, access time is fast. Access to the stack is significantly slower, with the details depending on the particularities of a system. However, registers are scarce. In the case of Arm6, there are only 16 primary CPU registers, and some of these have special uses beyond scratchpad.
|
||||
|
||||
The first four registers, `r0` through `r3`, are used for scratchpad but also to pass arguments along to library functions. For example, calling a library function such as `printf` (used in both the hstoneC and hstoneS programs) requires that the expected arguments be in the expected registers. The `printf` function takes at least one argument (a format string) but usually takes others, as well (the values to be formatted). The address of the format string has to be in register `r0` for the call to succeed. A programmer-defined function can implement its own register strategy, of course, but using the first four registers for function arguments is common in Arm6 programming.
|
||||
|
||||
Register `r0` also has special uses. For example, it typically holds the value returned from a function, as in the `collatz` function of the hstoneS program. If a program calls the `syscall` function, which is used to invoke system functions such as `read` and `write`, register `r0` holds the integer identifier of the system function to be called (e.g., function `write` has 4 as its identifier). In this respect, register `r0` is similar in purpose to register `r7`, which holds such an identifier when function `svc` ("supervisor call") is used instead of `syscall`.
|
||||
|
||||
Registers `r4` through `r11` are general-purpose and "callee saved" (aka "non-volatile" or "call-preserved"). Consider the case in which function F1 calls function F2 using registers to pass arguments to F2. The registers `r0` through `r3` are "caller saved" (aka "volatile" or "call-clobbered") in that, for example, the called function F2 might call some other function F3 by using the very same registers that F1 did—but with new values therein:
|
||||
|
||||
|
||||
```
|
||||
27 13 191 437
|
||||
\ \ \ \
|
||||
r0, r1 r0, r1
|
||||
F1-------->F2-------->F3
|
||||
```
|
||||
|
||||
After F1 calls F2, the contents of registers `r0` and `r1` get changed for F2's call to F3. Accordingly, F1 must not assume that its values in `r0` and `r1` (27 and 13, respectively) have been preserved; instead, these values have been overwritten—clobbered by the new values 191 and 437. Because the first four registers are not "callee saved," called function F2 is not responsible for preserving and later restoring the values in the registers set by F1.
|
||||
|
||||
Callee-saved registers bring responsibility to a called function. For example, if F1 used callee-saved registers `r4` and `r5` in its call to F2, then F2 would be responsible for saving the contents of these registers (typically on the stack) and then restoring the values before returning to F1. F2's code then might start and end as follows:
|
||||
|
||||
|
||||
```
|
||||
push {r4, r5} /* save r4 and r5 values on the stack */
|
||||
... /* reuse r4 and r5 for some other task */
|
||||
pop {r4, r5} /* restore r4 and r5 values */
|
||||
```
|
||||
|
||||
The `push` operation saves the values in `r4` and `r5` to the stack. The matching `pop` operation then recovers these values from the stack and puts them into `r4` and `r5`.
|
||||
|
||||
Other registers in Table 1 can be used as scratchpad, but some have a special use, as well. As noted earlier, register `r7` can be used to make system calls (e.g., to function `write`), which a later example shows in detail. In an `svc` instruction, the integer identifier for a particular system function must be in register `r7` (e.g., 4 to identify the `write` function).
|
||||
|
||||
Register `r11` is aliased as `fp` for "frame pointer," which points to the start of the current call frame. When one function calls another, the called function gets its own area of the stack (a call frame) for use as scratchpad. A frame pointer, unlike the stack pointer described below, typically remains fixed until a called function returns.
|
||||
|
||||
Register `r12`, also known as `ip` ("intra-procedure"), is used by the dynamic linker. Between calls to dynamically linked library functions, however, a program can use this register as scratchpad.
|
||||
|
||||
Register `r13`, which has `sp` ("stack pointer") as an alias, points to the top of the stack and is updated automatically through `push` and `pop` operations. The stack pointer also can be used as a base address with an offset; for example, `sp - #4` points 4 bytes below where the `sp` points. The Arm6 stack, like its Intel counterpart, grows from high to low addresses. (Some authors accordingly describe the stack pointer as pointing to the bottom rather than the top of the stack.)
|
||||
|
||||
Register `r14`, with `lr` as an alias, serves as the "link register" that holds a return address for a function. However, a called function can call another with a `bl` ("branch with link") or `bx` ("branch with exchange") instruction, thereby clobbering the contents of the `lr` register. For example, in the hstoneS program, the function `main` calls four others. Accordingly, function `main` saves the `lr` of its caller on the stack and later restores this value. The pattern occurs regularly in Arm6 assembly language:
|
||||
|
||||
|
||||
```
|
||||
push {lr} /* save caller's lr */
|
||||
... /* call some functions */
|
||||
pop {lr} /* restore caller's lr */
|
||||
```
|
||||
|
||||
Register `r15` is also the `pc` ("program counter"). In most architectures, the program counter points to the "next" instruction to be executed. For historical reasons, the Arm6 `pc` points to _two_ instructions beyond the current one. The `pc` can be manipulated directly (for example, to call a function), but the recommended approach is to use instructions such as `bl` that manipulate the link register.
|
||||
|
||||
Arm6 has the usual assortment of instructions for arithmetic (e.g., add, subtract, multiply, divide), logic (e.g., compare, shift), control (e.g., branch, exit), and input/output (e.g., read, write). The results of comparisons and other operations are saved in the special-purpose register `cpsr` ("current processor status register"). For example, this register records whether an addition caused an overflow or whether two compared integer values are equal.
|
||||
|
||||
It is worth repeating that the Arm6 has exactly two basic data movement instructions: `ldr` to load memory contents into a register and `str` to store register contents in memory. Arm6 includes variations of the basic `ldr` and `str` instructions, but the load-store pattern of moving data between registers and memory remains the same.
|
||||
|
||||
A code example brings these architectural details to life. The next section introduces the hailstone program in assembly language.
|
||||
|
||||
### The hstone program in Arm6 assembly
|
||||
|
||||
The above overview of Arm6 assembly is enough to introduce the full code example for hstoneS. For clarity, the assembly-language program hstoneS has essentially the same structure as the C program hstoneC: two functions, `main` and `collatz`, and mostly straight-line code execution in each function. The behavior of the two programs is the same.
|
||||
|
||||
Here is the source code for hstoneS:
|
||||
|
||||
|
||||
```
|
||||
.data /* data versus code */
|
||||
.balign 4 /* alignment on 4-byte boundaries */
|
||||
|
||||
/* labels (addresses) for user input, formatters, etc. */
|
||||
num: .int 0 /* 4-byte integer */
|
||||
steps: .int 0 /* another for the result */
|
||||
prompt: .asciz "Integer > 0: " /* zero-terminated ASCII string */
|
||||
format: .asciz "%u" /* %u for "unsigned" */
|
||||
report: .asciz "From %u to 1 takes %u steps.\n"
|
||||
|
||||
.text /* code: 'text' in the sense of 'read only' */
|
||||
.global main /* program's entry point must be global */
|
||||
.extern [printf][7] /* library function */
|
||||
.extern [scanf][8] /* ditto */
|
||||
|
||||
collatz: /** collatz function **/
|
||||
mov r0, #0 /* r0 is the step counter */
|
||||
loop_start: /** collatz loop **/
|
||||
cmp r1, #1 /* are we done? (num == 1?) */
|
||||
beq collatz_end /* if so, return to main */
|
||||
|
||||
and r2, r1, #1 /* odd-even test for r1 (num) */
|
||||
cmp r2, #0 /* even? */
|
||||
moveq r1, r1, LSR #1 /* even: divide by 2 via a 1-bit right shift */
|
||||
addne r1, r1, r1, LSL #1 /* odd: multiply by adding and 1-bit left shift */
|
||||
addne r1, #1 /* odd: add the 1 for (3 * num) + 1 */
|
||||
|
||||
add r0, r0, #1 /* increment counter by 1 */
|
||||
b loop_start /* loop again */
|
||||
collatz_end:
|
||||
bx lr /* return to caller (main) */
|
||||
|
||||
main:
|
||||
push {lr} /* save link register to stack */
|
||||
|
||||
/* prompt for and read user input */
|
||||
ldr r0, =prompt /* format string's address into r0 */
|
||||
bl [printf][7] /* call printf, with r0 as only argument */
|
||||
|
||||
ldr r0, =format /* format string for scanf */
|
||||
ldr r1, =num /* address of num into r1 */
|
||||
bl [scanf][8] /* call scanf */
|
||||
|
||||
ldr r1, =num /* address of num into r1 */
|
||||
ldr r1, [r1] /* value at the address into r1 */
|
||||
bl collatz /* call collatz with r1 as the argument */
|
||||
|
||||
/* demo a store */
|
||||
ldr r3, =steps /* load memory address into r3 */
|
||||
str r0, [r3] /* store hailstone steps at mem[r3] */
|
||||
|
||||
/* setup report */
|
||||
mov r2, r0 /* r0 holds hailstone steps: copy into r2 */
|
||||
ldr r1, =num /* get user's input again */
|
||||
ldr r1, [r1] /* dereference address to get value */
|
||||
ldr r0, =report /* format string for report into r0 */
|
||||
bl [printf][7] /* print report */
|
||||
|
||||
pop {lr} /* return to caller */
|
||||
```
|
||||
|
||||
Arm6 assembly supports documentation in either C style (the slash-star and star-slash syntax used here) or one-line comments introduced by the @ sign. The hstoneS program, like its C counterpart, has two functions:
|
||||
|
||||
* The program's entry point is the `main` function, which is identified by the label `main:`; this label marks where the function's first instruction is found. In Arm6 assembly, the entry point must be declared as global:
|
||||
|
||||
|
||||
```
|
||||
`.global main`
|
||||
```
|
||||
|
||||
In C, a function's _name_ is the address of the code block that makes up the function's body, and a C function is `extern` (global) by default. It is unsurprising how much C and assembly language resemble one another; indeed, C is portable assembly language.
|
||||
|
||||
* The `collatz` function expects one argument, which is implemented by the register `r1` to hold the user's input of an unsigned integer value (e.g., 9). This function updates register `r1` until it equals 1, keeping count of the steps involved with register `r0`, which thereby serves as the function's return value.
|
||||
|
||||
|
||||
|
||||
|
||||
An early and interesting code segment in `main` involves the call to the library function `scanf`, a high-level input function that scans a value from the standard input (by default, the keyboard) and converts this value to the desired data type, in this case, a 4-byte unsigned integer. Here is the code segment in full:
|
||||
|
||||
|
||||
```
|
||||
ldr r0, =format /* address of format string into r0 */
|
||||
ldr r1, =num /* address of num into r1 */
|
||||
bl [scanf][8] /* call scanf (bl = branch with link) */
|
||||
|
||||
ldr r1, =num /* address of num into r1 */
|
||||
ldr r1, [r1] /* value at the address into r1 */
|
||||
bl collatz /* call collatz with r1 as the argument */
|
||||
```
|
||||
|
||||
Two labels (addresses) are in play: `format` and `num`, both of which are defined in the `.data` section at the top of the program:
|
||||
|
||||
|
||||
```
|
||||
num: .int 0
|
||||
format: .asciz "%u"
|
||||
```
|
||||
|
||||
The label `num:` is the memory address of a 4-byte integer value, initialized to zero; the label `format:` points to a null-terminated (the "z" in "asciz" for zero) string `"%u"`, which specifies that the scanned input should be converted to an unsigned integer. Accordingly, the first two instructions in the code segment load the address of the format string (`=format`) into register `r0` and the address for the scanned number (`=num`) into register `r1`. Note that each label now starts with an equals sign ("assign address") and that the colon is dropped at the end of each label. The library function `scanf` can take an arbitrary number of arguments, but the first (which `scanf` expects in register `r0`) should be the "address" of a format string. In this example, the second argument to `scanf` is the "address" at which to save the scanned integer.
|
||||
|
||||
The last three instructions in the code segment highlight important assembly details. The first `ldr` instruction loads the _address_ of the memory-based integer (`=num`) into register `r1`. However, the `collatz` function expects the _value_ stored at this address, not the address itself; hence, the address is dereferenced to get the value:
|
||||
|
||||
|
||||
```
|
||||
ldr r1, =num /* load address into r1 */
|
||||
ldr r1, [r1] /* dereference to get value */
|
||||
```
|
||||
|
||||
The square brackets specify memory and `r1` holds a memory address. The expression `[r1]` thus evaluates to the _value_ stored in memory at address `r1`. The example underscores that registers can hold addresses and values stored at addresses: register `r1` first holds an address and then the value stored at this address.
|
||||
|
||||
When the `collatz` function returns to `main`, this function first performs a store operation:
|
||||
|
||||
|
||||
```
|
||||
ldr r3, =steps /* steps is a memory address */
|
||||
str r0, [r3] /* store r0 value at mem[r3] */
|
||||
```
|
||||
|
||||
The label `steps:` is from the `.data` section and register `r0` holds the steps computed in the `collatz` function. The `str` instruction thus saves to memory the length of the hailstone sequence. In a `ldr` instruction, the first operand (a register) is the _target_ for the load; but in a `str` operation, the first operand (also a register) is the _source_ for the store. In both cases, the second operand is a memory location.
|
||||
|
||||
Some additional work in `main` sets up the final report:
|
||||
|
||||
|
||||
```
|
||||
mov r2, r0 /* save count in r2 */
|
||||
ldr r1, =num /* recover user input */
|
||||
ldr r1, [r1] /* dereference r1 */
|
||||
ldr r0, =report /* r0 points to format string */
|
||||
bl [printf][7] /* print report */
|
||||
```
|
||||
|
||||
In the `collatz` function, register `r0` tracks how many steps are needed to reach 1 from the user's input, but the library function `printf` expects its first argument (the address of a format string) to be stored in register `r0`. The return value in register `r0` is therefore copied into register `r2` with the `mov` instruction. The address of the format string for `printf` is then stored in register `r0`.
|
||||
|
||||
The argument to the `collatz` function is the scanned input, which is stored in register `r1`; but this register is updated in the `collatz` loop unless the value happens to be 1 at the start. Accordingly, the address `num:` is again copied into `r1` and then dereferenced to get the user's original input. This value becomes the second argument to `printf`, the starting value of the hailstone sequence. With this setup in place, `main` calls `printf` with the `bl` ("branch with link") instruction.
|
||||
|
||||
At the very start of the `collatz` loop, the program checks whether the sequence has hit a 1:
|
||||
|
||||
|
||||
```
|
||||
cmp r1, #1
|
||||
beq collatz_end
|
||||
```
|
||||
|
||||
If register `r1` has 1 as its value, there is a branch (`beq` for "branch if equal") to the end of the `collatz` function, which means a return to its caller `main` with register `r0` as the return value—the number of steps in the hailstone sequence.
|
||||
|
||||
The `collatz` function introduces new features and opcodes, which illustrate how efficient assembly code can be. The assembly code, like the C code, checks for N's parity, with register `r1` as N:
|
||||
|
||||
|
||||
```
|
||||
and r2, r1, #1 /* r2 = r1 & 1 */
|
||||
cmp r2, #0 /* is the result even? */
|
||||
```
|
||||
|
||||
The result of the bitwise AND operation on register `r1` and 1 is stored in register `r2`. If the least-significant (rightmost) bit of register `r2` is a 1, then N (register `r1`) is odd, and otherwise, it is even. The result of this comparison (saved in the special-purpose register `cpsr`) is used automatically in forthcoming instructions such as `moveq` ("move if equal") and `addne` ("add if not equal").
|
||||
|
||||
The assembly code, like the C code, now avoids an explicit if-else construct. This code segment has the same effect as an if-else test, but the code is more efficient in that no branching is involved—the code executes in straight-line fashion because the conditional tests are built into the instruction opcodes:
|
||||
|
||||
|
||||
```
|
||||
moveq r1, r1, LSR #1 /* right-shift 1 bit if even */
|
||||
addne r1, r1, r1, LSL #1 /* left-shift 1 bit and add otherwise */
|
||||
addne r1, #1 /* add 1 for the + 1 in N = 3N + 1 */
|
||||
```
|
||||
|
||||
The `moveq` (`eq` for "if equal") instruction checks the outcome of the earlier `cmp` test, which determines whether the current value of register `r1` (N) is even or odd. If the value in register `r1` is even, this value must be updated to its half, which is done by a 1-bit right-shift (`LSR #1`). In general, right-shifting an integer is more efficient than explicitly dividing it by two. For example, suppose that register `r1` currently holds 4, whose least significant four bits are:
|
||||
|
||||
|
||||
```
|
||||
`...0100 ## 4 in binary`
|
||||
```
|
||||
|
||||
Shifting right by 1 bit yields:
|
||||
|
||||
|
||||
```
|
||||
`...0010 ## 2 in binary`
|
||||
```
|
||||
|
||||
The `LSR` stands for "logical shift right" and contrasts with `ASR` for "arithmetic shift right." An arithmetic shift is sign-preserving (most significant bit of 1 for negative and 0 for non-negative), whereas a logical shift is not, but the hailstone programs deal exclusively with _unsigned_ (hence, non-negative) values. In a logical shift, the shifted bits are replaced by zeros.
|
||||
|
||||
If register `r1` holds a value with odd parity, similar straight-line code occurs:
|
||||
|
||||
|
||||
```
|
||||
addne r1, r1, r1, LSL #1 /* r1 = r1 * 3 */
|
||||
addne r1, #1 /* r1 = r1 + 1 */
|
||||
```
|
||||
|
||||
The two `addne` instructions (`ne` for "if not equal") execute only if the earlier check for parity indicates an odd value. The first `addne` instruction does multiplication through a 1-bit left-shift and addition. In general, shifting and adding are more efficient than explicitly multiplying. The second `addne` then adds 1 to register `r1` so that the update is from N to 3N+1.
|
||||
|
||||
### Assembling the hstoneS program
|
||||
|
||||
The assembly source code for the hstoneS program needs to be translated ("assembled") into a binary _object module_, which is then linked with appropriate libraries to become executable. The simplest approach is to use the GNU C compiler in the same way as it is used to compile a C program such as hstoneC:
|
||||
|
||||
|
||||
```
|
||||
`% gcc -o hstoneS hstoneS.s`
|
||||
```
|
||||
|
||||
This command does the assembling and linking.
|
||||
|
||||
A slightly more efficient approach is to use the _as_ utility that ships with the GNU toolset. This approach separates the assembling and the linking. Here is the assembling step:
|
||||
|
||||
|
||||
```
|
||||
`% as -o hstoneS.o hstoneS.s ## assemble`
|
||||
```
|
||||
|
||||
The extension `.o` is traditional for object modules. The system utility _ld_ then could be used for the linking, but an easier and equally efficient approach is to revert to the _gcc_ command:
|
||||
|
||||
|
||||
```
|
||||
`% gcc -o hstoneS hstoneS.o ## link`
|
||||
```
|
||||
|
||||
This approach highlights again that the C compiler handles any mix of C and assembly, whether source files or object modules.
|
||||
|
||||
### Wrapping up with an explicit system call
|
||||
|
||||
The two hailstone programs use the high-level input/output functions `scanf` and `printf`. These functions are high-level in that they deal with formatted types (in this case, unsigned integers) rather than with raw bytes. In an embedded system, however, these functions might not be available; the low-level input/output functions `read` and `write`, which ultimately implement their high-level counterparts, then would be used instead. These two system functions are low-level in that they work with raw bytes.
|
||||
|
||||
In Arm6 assembly, a program explicitly calls a system function such as `write` in an indirect manner—by invoking one of the aforementioned functions `svc` or `syscall`, for example:
|
||||
|
||||
|
||||
```
|
||||
calls calls
|
||||
program------->svc------->write
|
||||
```
|
||||
|
||||
The integer identifier for a particular system function (e.g., 4 identifies `write`) goes into the appropriate register (register `r7` for `svc` and register `r0` for `syscall`). The code segments below illustrate, first with `svc` and then with `syscall`.
|
||||
|
||||
The two code segments write the traditional greeting to the standard output, which is the screen by default. The standard output has a _file descriptor_, a non-negative integer value that identifies it. The three predefined descriptors are:
|
||||
|
||||
|
||||
```
|
||||
standard input: 0 (keyboard by default)
|
||||
standard output: 1 (screen by default)
|
||||
standard error: 2 (screen by default)
|
||||
```
|
||||
|
||||
Here is the code segment for a sample system call with `svc`:
|
||||
|
||||
|
||||
```
|
||||
msg: .asciz "Hello, world!\n" /* greeting */
|
||||
...
|
||||
mov r0, #1 /* 1 = standard output */
|
||||
ldr r1, =msg /* address of bytes to write */
|
||||
mov r2, #14 /* message length (in bytes) */
|
||||
mov r7, #4 /* write has 4 as an id */
|
||||
svc #0 /* system call to write */
|
||||
```
|
||||
|
||||
The function `write` takes three arguments and, when called via `svc`, the function's arguments go into the following registers:
|
||||
|
||||
* `r0` holds the target for the write operation, in this case, the standard output (`#1`).
|
||||
* `r1` has the address of the byte(s) to write (`=msg`).
|
||||
* `r2` specifies how many bytes are to be written (`#14`).
|
||||
|
||||
|
||||
|
||||
In the case of the `svc` instruction, register `r7` identifies, with a non-negative integer (in this case, `#4`), which system function to call. The `svc` call returns zero (the `#0`) to signal success but usually a negative value to signal an error.
|
||||
|
||||
The `syscall` and `svc` functions differ in detail, but using either to invoke a system function requires the same two steps:
|
||||
|
||||
* Specify the system function to be called (in `r7` for `svc`, in `r0` for `syscall`).
|
||||
* Put the arguments for the system function in the appropriate registers, which differ between the `svc` and `syscall` variants.
|
||||
|
||||
|
||||
|
||||
Here is the `syscall` example of invoking the `write` function:
|
||||
|
||||
|
||||
```
|
||||
msg: .asciz "Hello, world!\n" /* greeting */
|
||||
...
|
||||
mov r1, #1 /* standard output */
|
||||
ldr r2, =msg /* address of message */
|
||||
mov r3, #14 /* byte count */
|
||||
mov r0, #4 /* identifier for write */
|
||||
syscall
|
||||
```
|
||||
|
||||
C has a thin wrapper not only for the `syscall` function but for the system functions `read` and `write` as well. The C wrapper for `syscall` gives the gist at a high level:
|
||||
|
||||
|
||||
```
|
||||
syscall(SYS_write, /* 4 is the id for write */
|
||||
STDOUT_FILENO, /* 1 is the standard output */
|
||||
"Hello, world!\n", /* message */
|
||||
14); /* byte length */
|
||||
```
|
||||
|
||||
The direct approach in C uses the wrapper for the system `write` function:
|
||||
|
||||
|
||||
```
|
||||
`write(STDOUT_FILENO, "Hello, world!\n", 14);`
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/arm6-assembly-language
|
||||
|
||||
作者:[Marty Kalin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mkalindepauledu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LAW-Internet_construction_9401467_520x292_0512_dc.png?itok=RPkPPtDe (An intersection of pipes.)
|
||||
[2]: https://www.arm.com/
|
||||
[3]: https://condor.depaul.edu/mkalin
|
||||
[4]: https://opensource.com/article/19/8/webassembly-speed-code-reuse
|
||||
[5]: https://plus.maths.org/content/mathematical-mysteries-hailstone-sequences
|
||||
[6]: https://en.wikipedia.org/wiki/Collatz_conjecture
|
||||
[7]: http://www.opengroup.org/onlinepubs/009695399/functions/printf.html
|
||||
[8]: http://www.opengroup.org/onlinepubs/009695399/functions/scanf.html
|
||||
[9]: https://en.wikipedia.org/wiki/Endianness
|
||||
81
sources/tech/20201028 What-s new in Fedora 33 Workstation.md
Normal file
81
sources/tech/20201028 What-s new in Fedora 33 Workstation.md
Normal file
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What’s new in Fedora 33 Workstation)
|
||||
[#]: via: (https://fedoramagazine.org/whats-new-fedora-33-workstation/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
What’s new in Fedora 33 Workstation
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 33 Workstation is the [latest release][2] of our free, leading-edge operating system. You can download it from [the official website here][3] right now. There are several new and noteworthy changes in Fedora 33 Workstation. Read more details below.
|
||||
|
||||
### GNOME 3.38
|
||||
|
||||
Fedora 33 Workstation includes the latest release of GNOME Desktop Environment for users of all types. GNOME 3.38 in Fedora 33 Workstation includes many updates and improvements, including:
|
||||
|
||||
#### A new GNOME Tour app
|
||||
|
||||
New users are now greeted by “a new _Tour_ application, highlighting the main functionality of the desktop and providing first time users a nice welcome to GNOME.”
|
||||
|
||||
![The new GNOME Tour application in Fedora 33][4]
|
||||
|
||||
#### Drag to reorder apps
|
||||
|
||||
GNOME 3.38 replaces the previously split Frequent and All apps views with a single customizable and consistent view that allows you to reorder apps and organize them into custom folders. Simply click and drag to move apps around.
|
||||
|
||||
![GNOME 3.38 Drag to Reorder][5]
|
||||
|
||||
#### Improved screen recording
|
||||
|
||||
The screen recording infrastructure in GNOME Shell has been improved to take advantage of PipeWire and kernel APIs. This will help reduce resource consumption and improve responsiveness.
|
||||
|
||||
GNOME 3.38 also provides many additional features and enhancements. Check out the [GNOME 3.38 Release Notes][6] for further information.
|
||||
|
||||
* * *
|
||||
|
||||
### B-tree file system
|
||||
|
||||
As [announced previously][7], new installations of Fedora 33 will default to using [Btrfs][8]. Features and enhancements are added to Btrfs with each new kernel release. The [change log][9] has a complete summary of the features that each new kernel version brings to Btrfs.
|
||||
|
||||
* * *
|
||||
|
||||
### Swap on ZRAM
|
||||
|
||||
Anaconda and Fedora IoT have been using swap-on-zram by default for years. With Fedora 33, swap-on-zram will be enabled by default instead of a swap partition. Check out [the Fedora wiki page][10] for more details about swap-on-zram.
|
||||
|
||||
* * *
|
||||
|
||||
### Nano by default
|
||||
|
||||
Fresh Fedora 33 installations will set the EDITOR environment variable to [_nano_ by default][11]. This change affects several command line tools that spawn a text editor when they require user input. With earlier releases, this environment variable default was unspecified, leaving it up to the individual application to pick a default editor. Typically, applications would use _[vi][12]_ as their default editor due to it being a small application that is traditionally available on the base installation of most Unix/Linux operating systems. Since Fedora 33 includes nano in its base installation, and since nano is more intuitive for a beginning user to use, Fedora 33 will use nano by default. Users who want vi can, of course, override the value of the EDITOR variable in their own environment. See [the Fedora change request][11] for more details.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/whats-new-fedora-33-workstation/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/10/f33workstation-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/announcing-fedora-33/
|
||||
[3]: https://getfedora.org/workstation
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2020/10/fedora-33-gnome-tour-1.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/10/drag-to-reorder-1.gif
|
||||
[6]: https://help.gnome.org/misc/release-notes/3.38/
|
||||
[7]: https://fedoramagazine.org/btrfs-coming-to-fedora-33/
|
||||
[8]: https://en.wikipedia.org/wiki/Btrfs
|
||||
[9]: https://btrfs.wiki.kernel.org/index.php/Changelog#By_feature
|
||||
[10]: https://fedoraproject.org/wiki/Changes/SwapOnZRAM
|
||||
[11]: https://fedoraproject.org/wiki/Changes/UseNanoByDefault
|
||||
[12]: https://en.wikipedia.org/wiki/Vi
|
||||
@ -0,0 +1,389 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Improve your database knowledge with this MariaDB and MySQL cheat sheet)
|
||||
[#]: via: (https://opensource.com/article/20/10/mariadb-mysql-cheat-sheet)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Improve your database knowledge with this MariaDB and MySQL cheat sheet
|
||||
======
|
||||
Read this article and download our free cheat sheet to get started using
|
||||
an open source database.
|
||||
![Cheat Sheet cover image][1]
|
||||
|
||||
When you're writing an application or configuring one for a server, eventually, you will need to store persistent information. Sometimes, a configuration file, such as an INI or [YAML][2] file will do. Other times, a custom file format designed in XML or JSON or similar is better.
|
||||
|
||||
But sometimes you need something that can validate input, search through information quickly, make connections between related data, and generally handle your users' work adeptly. That's what a database is designed to do, and [MariaDB][3] (a fork of [MySQL][4] by some of its original developers) is a great option. I use MariaDB in this article, but the information applies equally to MySQL.
|
||||
|
||||
It's common to interact with a database through programming languages. For this reason, there are [SQL][5] libraries for Java, Python, Lua, PHP, Ruby, C++, and many others. However, before using these libraries, it helps to have an understanding of what's happening with the database engine and why your choice of database is significant. This article introduces MariaDB and the `mysql` command to familiarize you with the basics of how a database handles data.
|
||||
|
||||
If you don't have MariaDB yet, follow the instructions in my article about [installing MariaDB on Linux][6]. If you're not on Linux, use the instructions provided on the MariaDB [download page][7].
|
||||
|
||||
### Interact with MariaDB
|
||||
|
||||
You can interact with MariaDB using the `mysql` command. First, verify that your server is up and running using the `ping` subcommand, entering your MariaDB password when prompted:
|
||||
|
||||
|
||||
```
|
||||
$ mysqladmin -u root -p ping
|
||||
Enter password:
|
||||
mysqld is alive
|
||||
```
|
||||
|
||||
To make exploring SQL easy, open an interactive MariaDB session:
|
||||
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
Enter password:
|
||||
Welcome to the MariaDB monitor.
|
||||
Commands end with ; or \g.
|
||||
[...]
|
||||
Type 'help;' or '\h' for help.
|
||||
Type '\c' to clear the current input statement.
|
||||
|
||||
MariaDB [(none)]>
|
||||
```
|
||||
|
||||
This places you in a MariaDB subshell, and your prompt is now a MariaDB prompt. Your usual Bash commands don't work here. You must use MariaDB commands. To see a list of MariaDB commands, type `help` (or just `?`). These are administrative commands for your MariaDB shell, so they're useful for customizing your shell, but they aren't part of the SQL language.
|
||||
|
||||
### Learn SQL basics
|
||||
|
||||
The [Structured Query Language (SQL)][8] is named after what it provides: a method to inquire about the contents of a database in a predictable and consistent syntax in order to receive useful results. SQL reads a lot like an ordinary English sentence, if a little robotic. For instance, if you've signed into a database server and you need to understand what you have to work with, type `SHOW DATABASES;` and press Enter for the results.
|
||||
|
||||
SQL commands are terminated with a semicolon. If you forget the semicolon, MariaDB assumes you want to continue your query on the next line, where you can either do so or terminate the query with a semicolon.
|
||||
|
||||
|
||||
```
|
||||
MariaDB [(NONE)]> SHOW DATABASES;
|
||||
+--------------------+
|
||||
| DATABASE |
|
||||
+--------------------+
|
||||
| information_schema |
|
||||
| mysql |
|
||||
| performance_schema |
|
||||
| test |
|
||||
+--------------------+
|
||||
4 ROWS IN SET (0.000 sec)
|
||||
```
|
||||
|
||||
This shows there are four databases present: information_schema, mysql, performance_schema, and test. To issue queries to a database, you must select which database you want MariaDB to use. This is done with the MariaDB command `use`. Once you choose a database, your MariaDB prompt changes to reflect the active database.
|
||||
|
||||
|
||||
```
|
||||
MariaDB [(NONE)]> USE test;
|
||||
MariaDB [(test)]>
|
||||
```
|
||||
|
||||
#### Show database tables
|
||||
|
||||
Databases contain _tables_, which can be visualized in the same way a spreadsheet is: as a series of rows (called _records_ in a database) and columns. The intersection of a row and a column is called a _field_.
|
||||
|
||||
To see the tables available in a database (you can think of them as tabs in a multi-sheet spreadsheet), use the SQL keyword `SHOW` again:
|
||||
|
||||
|
||||
```
|
||||
MariaDB [(test)]> SHOW TABLES;
|
||||
empty SET
|
||||
```
|
||||
|
||||
The `test` database doesn't have much to look at, so use the `use` command to switch to the `mysql` database.
|
||||
|
||||
|
||||
```
|
||||
MariaDB [(test)]> USE mysql;
|
||||
MariaDB [(mysql)]> SHOW TABLES;
|
||||
|
||||
+---------------------------+
|
||||
| Tables_in_mysql |
|
||||
+---------------------------+
|
||||
| column_stats |
|
||||
| columns_priv |
|
||||
| db |
|
||||
[...]
|
||||
| time_zone_transition_type |
|
||||
| transaction_registry |
|
||||
| USER |
|
||||
+---------------------------+
|
||||
31 ROWS IN SET (0.000 sec)
|
||||
```
|
||||
|
||||
There are a lot more tables in this database! The `mysql` database is the system management database for this MariaDB instance. It contains important data, including an entire user structure to manage database privileges. It's an important database, and you don't always have to interact with it directly, but it's not uncommon to manipulate it in SQL scripts. It's also useful to understand the `mysql` database when you're learning MariaDB because it can help demonstrate some basic SQL commands.
|
||||
|
||||
#### Examine a table
|
||||
|
||||
The last table listed in this instance's `mysql` database is titled `user`. This table contains data about users permitted to access the database. Right now, there's only a root user, but you can add other users with varying privileges to control whether each user can view, update, or create data. To get an idea of all the attributes a MariaDB user can have, you can view column headers in a table:
|
||||
|
||||
|
||||
```
|
||||
> SHOW COLUMNS IN USER;
|
||||
MariaDB [mysql]> SHOW COLUMNS IN USER;
|
||||
+-------------+---------------+------+-----+----------+
|
||||
| FIELD | TYPE | NULL | KEY | DEFAULT |
|
||||
+-------------+---------------+------+-----+----------+
|
||||
| Host | CHAR(60) | NO | PRI | |
|
||||
| USER | CHAR(80) | NO | PRI | |
|
||||
| Password | CHAR(41) | NO | | |
|
||||
| Select_priv | enum('N','Y') | NO | | N |
|
||||
| Insert_priv | enum('N','Y') | NO | | N |
|
||||
| Update_priv | enum('N','Y') | NO | | N |
|
||||
| Delete_priv | enum('N','Y') | NO | | N |
|
||||
| Create_priv | enum('N','Y') | NO | | N |
|
||||
| Drop_priv | enum('N','Y') | NO | | N |
|
||||
[...]
|
||||
47 ROWS IN SET (0.001 sec)
|
||||
```
|
||||
|
||||
#### Create a new user
|
||||
|
||||
Whether you need help from a fellow human to administer a database or you're setting up a database for a computer to use (for example, in a WordPress, Drupal, or Joomla installation), it's common to need an extra user account within MariaDB. You can create a MariaDB user either by adding it to the `user` table in the `mysql` database, or you can use the SQL keyword `CREATE` to prompt MariaDB to do it for you. The latter features some helper functions so that you don't have to generate all the information manually:
|
||||
|
||||
|
||||
```
|
||||
`> CREATE USER 'tux'@'localhost' IDENTIFIED BY 'really_secure_password';`
|
||||
```
|
||||
|
||||
#### View table fields
|
||||
|
||||
You can view fields and values in a database table with the `SELECT` keyword. In this example, you created a user called `tux`, so select the columns in the `user` table:
|
||||
|
||||
|
||||
```
|
||||
> SELECT USER,host FROM USER;
|
||||
+------+------------+
|
||||
| USER | host |
|
||||
+------+------------+
|
||||
| root | localhost |
|
||||
[...]
|
||||
| tux | localhost |
|
||||
+------+------------+
|
||||
7 ROWS IN SET (0.000 sec)
|
||||
```
|
||||
|
||||
#### Grant privileges to a user
|
||||
|
||||
By looking at the column listing on the `user` table, you can explore a user's status. For instance, the new user `tux` doesn't have permission to do anything with the database. Using the `WHERE` statement, you can view only the record for `tux`:
|
||||
|
||||
|
||||
```
|
||||
> SELECT USER,select_priv,insert_priv,update_priv FROM USER WHERE USER='tux';
|
||||
+------+-------------+-------------+-------------+
|
||||
| USER | select_priv | insert_priv | update_priv |
|
||||
+------+-------------+-------------+-------------+
|
||||
| tux | N | N | N |
|
||||
+------+-------------+-------------+-------------+
|
||||
```
|
||||
|
||||
Use the `GRANT` command to modify user permissions:
|
||||
|
||||
|
||||
```
|
||||
> GRANT SELECT ON *.* TO 'tux'@'localhost';
|
||||
> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Verify your change:
|
||||
|
||||
|
||||
```
|
||||
> SELECT USER,select_priv,insert_priv,update_priv FROM USER WHERE USER='tux';
|
||||
+------+-------------+-------------+-------------+
|
||||
| USER | select_priv | insert_priv | update_priv |
|
||||
+------+-------------+-------------+-------------+
|
||||
| tux | Y | N | N |
|
||||
+------+-------------+-------------+-------------+
|
||||
```
|
||||
|
||||
User `tux` now has privileges to select records from all tables.
|
||||
|
||||
### Create a custom database
|
||||
|
||||
So far, you've interacted just with the default databases. Most people rarely interact much with the default databases outside of user management. Usually, you create a database and populate it with tables full of custom data.
|
||||
|
||||
#### Create a MariaDB database
|
||||
|
||||
You may already be able to guess how to create a new database in MariaDB. It's a lot like creating a new user:
|
||||
|
||||
|
||||
```
|
||||
> CREATE DATABASE example;
|
||||
Query OK, 1 ROW affected (0.000 sec)
|
||||
> SHOW DATABASES;
|
||||
+--------------------+
|
||||
| DATABASE |
|
||||
+--------------------+
|
||||
| example |
|
||||
[...]
|
||||
```
|
||||
|
||||
Make this new database your active one with the `use` command:
|
||||
|
||||
|
||||
```
|
||||
`> USE example;`
|
||||
```
|
||||
|
||||
#### Create a table
|
||||
|
||||
Creating a table is more complex than creating a database because you must define column headings. MariaDB provides many convenience functions for you to use when creating columns, including data type definitions, automatic incrementing options, constraints to avoid empty values, automated timestamps, and more.
|
||||
|
||||
Here's a simple table to describe a set of users:
|
||||
|
||||
|
||||
```
|
||||
> CREATE TABLE IF NOT EXISTS member (
|
||||
-> id INT AUTO_INCREMENT PRIMARY KEY,
|
||||
-> name VARCHAR(128) NOT NULL,
|
||||
-> startdate TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
|
||||
Query OK, 0 ROWS affected (0.030 sec)
|
||||
```
|
||||
|
||||
This table provides a unique identifier to each row by using an auto-increment function. It contains a field for a user's name, which cannot be empty (or `null`), and generates a timestamp when the record is created.
|
||||
|
||||
Populate this table with some sample data using the `INSERT` SQL keyword:
|
||||
|
||||
|
||||
```
|
||||
> INSERT INTO member (name) VALUES ('Alice');
|
||||
Query OK, 1 ROW affected (0.011 sec)
|
||||
> INSERT INTO member (name) VALUES ('Bob');
|
||||
Query OK, 1 ROW affected (0.011 sec)
|
||||
> INSERT INTO member (name) VALUES ('Carol');
|
||||
Query OK, 1 ROW affected (0.011 sec)
|
||||
> INSERT INTO member (name) VALUES ('David');
|
||||
Query OK, 1 ROW affected (0.011 sec)
|
||||
```
|
||||
|
||||
Verify the data in the table:
|
||||
|
||||
|
||||
```
|
||||
> SELECT * FROM member;
|
||||
+----+-------+---------------------+
|
||||
| id | name | startdate |
|
||||
+----+-------+---------------------+
|
||||
| 1 | Alice | 2020-10-03 15:25:06 |
|
||||
| 2 | Bob | 2020-10-03 15:26:43 |
|
||||
| 3 | Carol | 2020-10-03 15:26:46 |
|
||||
| 4 | David | 2020-10-03 15:26:51 |
|
||||
+----+-------+---------------------+
|
||||
4 ROWS IN SET (0.000 sec)
|
||||
```
|
||||
|
||||
#### Add multiple rows at once
|
||||
|
||||
Now create a second table:
|
||||
|
||||
|
||||
```
|
||||
> CREATE TABLE IF NOT EXISTS linux (
|
||||
-> id INT AUTO_INCREMENT PRIMARY KEY,
|
||||
-> distro VARCHAR(128) NOT NULL,
|
||||
Query OK, 0 ROWS affected (0.030 sec)
|
||||
```
|
||||
|
||||
Populate it with some sample data, this time using a little `VALUES` shortcut so you can add multiple rows in one command. The `VALUES` keyword expects a list in parentheses, but it can take multiple lists separated by commas:
|
||||
|
||||
|
||||
```
|
||||
> INSERT INTO linux (distro)
|
||||
-> VALUES ('Slackware'), ('RHEL'),('Fedora'),('Debian');
|
||||
Query OK, 4 ROWS affected (0.011 sec)
|
||||
Records: 4 Duplicates: 0 Warnings: 0
|
||||
> SELECT * FROM linux;
|
||||
+----+-----------+
|
||||
| id | distro |
|
||||
+----+-----------+
|
||||
| 1 | Slackware |
|
||||
| 2 | RHEL |
|
||||
| 3 | Fedora |
|
||||
| 4 | Debian |
|
||||
+----+-----------+
|
||||
```
|
||||
|
||||
### Create relationships between tables
|
||||
|
||||
You now have two tables, but there's no relationship between them. They each contain independent data, but you might need to associate a member of the first table to a specific item listed in the second.
|
||||
|
||||
To do that, you can create a new column for the first table that corresponds to something in the second. Because both tables were designed with unique identifiers (the auto-incrementing `id` field), the easiest way to connect them is to use the `id` field of one as a selector for the other.
|
||||
|
||||
Create a new column in the first table to represent a value in the second table:
|
||||
|
||||
|
||||
```
|
||||
> ALTER TABLE member ADD COLUMN (os INT);
|
||||
Query OK, 0 ROWS affected (0.012 sec)
|
||||
Records: 0 Duplicates: 0 Warnings: 0
|
||||
> DESCRIBE member;
|
||||
DESCRIBE member;
|
||||
+-----------+--------------+------+-----+---------+------+
|
||||
| FIELD | TYPE | NULL | KEY | DEFAULT | Extra|
|
||||
+-----------+--------------+------+-----+---------+------+
|
||||
| id | INT(11) | NO | PRI | NULL | auto_|
|
||||
| name | VARCHAR(128) | NO | | NULL | |
|
||||
| startdate | TIMESTAMP | NO | | cur[...]| |
|
||||
| os | INT(11) | YES | | NULL | |
|
||||
+-----------+--------------+------+-----+---------+------+
|
||||
```
|
||||
|
||||
Using the unique IDs of the `linux` table, assign a distribution to each member. Because the records already exist, use the `UPDATE` SQL keyword rather than `INSERT`. Specifically, you want to select one row and then update the value of one column. Syntactically, this is expressed a little in reverse, with the update happening first and the selection matching last:
|
||||
|
||||
|
||||
```
|
||||
> UPDATE member SET os=1 WHERE name='Alice';
|
||||
Query OK, 1 ROW affected (0.007 sec)
|
||||
ROWS matched: 1 Changed: 1 Warnings: 0
|
||||
```
|
||||
|
||||
Repeat this process for the other names in the `member` table to populate it with data. For variety, assign three different distributions across the four rows (doubling up on one).
|
||||
|
||||
#### Join tables
|
||||
|
||||
Now that these two tables relate to one another, you can use SQL to display the associated data. There are many kinds of joins in databases, and you can try them all once you know the basics. Here's a basic join to correlate the values found in the `os` field of the `member` table to the `id` field of the `linux` table:
|
||||
|
||||
|
||||
```
|
||||
SELECT * FROM member JOIN linux ON member.os=linux.id;
|
||||
+----+-------+---------------------+------+----+-----------+
|
||||
| id | name | startdate | os | id | distro |
|
||||
+----+-------+---------------------+------+----+-----------+
|
||||
| 1 | Alice | 2020-10-03 15:25:06 | 1 | 1 | Slackware |
|
||||
| 2 | Bob | 2020-10-03 15:26:43 | 3 | 3 | Fedora |
|
||||
| 4 | David | 2020-10-03 15:26:51 | 3 | 3 | Fedora |
|
||||
| 3 | Carol | 2020-10-03 15:26:46 | 4 | 4 | Debian |
|
||||
+----+-------+---------------------+------+----+-----------+
|
||||
4 ROWS IN SET (0.000 sec)
|
||||
```
|
||||
|
||||
The `os` and `id` fields form the join.
|
||||
|
||||
In a graphical application, you can imagine that the `os` field might be set by a drop-down menu, the values for which are drawn from the contents of the `distro` field of the `linux` table. By using separate tables for unique but related sets of data, you ensure the consistency and validity of data, and thanks to SQL, you can associate them dynamically later.
|
||||
|
||||
### [Download the MariaDB and MySQL cheat sheet][9]
|
||||
|
||||
MariaDB is an enterprise-grade database. It's designed and proven to be a robust, powerful, and fast database engine. Learning it is a great step toward using it to do things like managing web applications or programming language libraries. As a quick reference when you're using MariaDB, [download our MariaDB and MySQL cheat sheet][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/mariadb-mysql-cheat-sheet
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coverimage_cheat_sheet.png?itok=lYkNKieP (Cheat Sheet cover image)
|
||||
[2]: https://www.redhat.com/sysadmin/yaml-tips
|
||||
[3]: https://mariadb.org/
|
||||
[4]: https://www.mysql.com/
|
||||
[5]: https://en.wikipedia.org/wiki/SQL
|
||||
[6]: https://opensource.com/article/20/10/install-mariadb-and-mysql-linux
|
||||
[7]: https://mariadb.org/download
|
||||
[8]: https://publications.opengroup.org/c449
|
||||
[9]: https://opensource.com/downloads/mariadb-mysql-cheat-sheet
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Kernel 5.10 Will be the Next LTS Release and it has Some Exciting Improvements Lined Up)
|
||||
[#]: via: (https://itsfoss.com/kernel-5-10/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Linux Kernel 5.10 Will be the Next LTS Release and it has Some Exciting Improvements Lined Up
|
||||
======
|
||||
|
||||
_**Development for Linux Kernel 5.10 is in progress. It’s been confirmed to be a long term support release and it will be bringing newer hardware support among other promised features.**_
|
||||
|
||||
### Linux Kernel 5.10 will be Long Term Support Release
|
||||
|
||||
**Greg Kroah-Hartman**, the key stable kernel maintainer, addressed an “Ask the Expert” session at Linux Foundation’s Open-Source Summit Europe and confirmed that Linux 5.10 will be the next LTS release.
|
||||
|
||||
Even though there were some early speculations of 5.9 being the LTS release, Greg clarified that the last kernel release of the year will always be an LTS release.
|
||||
|
||||
As of now, [Linux Kernel 5.4][1] series happens to be the latest LTS version out there which added a lot of improvements and hardware support. Also, considering the development progress with Linux [Kernel 5.8][2] being the biggest release so far and Linux 5.10’s first release candidate being close to it, there’s a lot of things going on under the hood.
|
||||
|
||||
> Because people keep asking me… <https://t.co/cUcGoXEZtX>
|
||||
>
|
||||
> — Greg K-H (@gregkh) [October 26, 2020][3]
|
||||
|
||||
Let’s take a look at some of the features and improvements that you can expect with Linux Kernel 5.10.
|
||||
|
||||
### Linux kernel 5.10 features
|
||||
|
||||
![][4]
|
||||
|
||||
**Note:** _Linux Kernel 5.10 is still in early development. So, we will be updating the article regularly for the latest additions/feature updates._
|
||||
|
||||
#### AMD Zen 3 Processor Support
|
||||
|
||||
The new [Ryzen 5000][5] lineup is one of the biggest buzzes of 2020. So, with Linux Kernel 5.10 release candidate version, various additions are being made for Zen 3 processors.
|
||||
|
||||
#### Intel Rocket Lake Support
|
||||
|
||||
I do not hope for a lot with Intel’s Rocket Lake chipsets arriving Q1 next year (2021). But, considering that Intel’s constantly squeezing everything out of that 14 nm process, it is definitely a good thing to see work done for Intel Rocket Lake on Linux Kernel 5.10
|
||||
|
||||
#### Open Source Driver for Radeon RX 6000 series
|
||||
|
||||
Even though we’re covering this a day before the Big Navi reveal, the Radeon RX 6000 series is definitely going to be something impressive to compete with NVIDIA RTX 3000 series.
|
||||
|
||||
Of course, unless it suffers from the same issues the Vega series or the 5000 series met with.
|
||||
|
||||
It’s good to see work being already done for an open source driver to support the next-gen Radeon GPUs on Linux Kernel 5.10.
|
||||
|
||||
#### File System Optimizations and Storage Improvements
|
||||
|
||||
[Phoronix][6] reports on file-system optimizations and storage improvements with 5.10 as well. So, judging by that, we should see some performance improvements.
|
||||
|
||||
#### Other Improvements
|
||||
|
||||
Undoubtedly, you should expect a great deal of driver updates and hardware supports with the new kernel.
|
||||
|
||||
For now, the support for SoundBlaster AE-7, early support for NVIDIA Orin (AI processor), and Tiger Lake GPU improvements seem to be the key highlights.
|
||||
|
||||
A stable release for Linux Kernel 5.10 should be expected around the mid-December timeline. It will be supported for at least 2 years but you could end up with security/bug fix updates till 2026. So, we will have to stay tuned to the development for anything exciting on the next Linux Kernel 5.10 LTS release.
|
||||
|
||||
**Recommended Read:**
|
||||
|
||||
![][7]
|
||||
|
||||
#### [Explained! Why Your Distribution Still Using an ‘Outdated’ Linux Kernel?][8]
|
||||
|
||||
A new stable kernel is released every 2-3 months yet your distribution might still be using an old, outdated Linux kernel. But you don’t need to worry and here’s why!
|
||||
|
||||
What do you think about the upcoming Linux Kernel 5.10 release? Let us know your thoughts in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/kernel-5-10/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/linux-kernel-5-4/
|
||||
[2]: https://itsfoss.com/kernel-5-8-release/
|
||||
[3]: https://twitter.com/gregkh/status/1320745076566433793?ref_src=twsrc%5Etfw
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/kernel-5-10-release.png?resize=800%2C450&ssl=1
|
||||
[5]: https://www.tomsguide.com/news/amd-ryzen-5000-revealed-what-it-means-for-pc-gaming
|
||||
[6]: https://www.phoronix.com/scan.php?page=article&item=linux-510-features&num=1
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/12/why_Linux_distro_use_outdated_kernel.jpg?fit=800%2C450&ssl=1
|
||||
[8]: https://itsfoss.com/why-distros-use-old-kernel/
|
||||
@ -0,0 +1,369 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing resources with cgroups in systemd)
|
||||
[#]: via: (https://opensource.com/article/20/10/cgroups)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
Managing resources with cgroups in systemd
|
||||
======
|
||||
Cgroups manage resources per application rather than by the individual
|
||||
processes that make up an application.
|
||||
![Business woman on laptop sitting in front of window][1]
|
||||
|
||||
There is little more frustrating to me as a sysadmin than unexpectedly running out of a computing resource. On more than one occasion, I have filled all available disk space in a partition, run out of RAM, and not had enough CPU time to perform my tasks in a reasonable amount of time. Resource management is one of the most important tasks that sysadmins do.
|
||||
|
||||
The point of resource management is to ensure that all processes have relatively equal access to the system resources they need. Resource management also involves ensuring that RAM, hard drive space, and CPU capacity are added when necessary or rationed when that is not possible. In addition, users who hog system resources, whether intentionally or accidentally, should be prevented from doing so.
|
||||
|
||||
There are tools that enable sysadmins to monitor and manage various system resources. For example, [top][2] and similar tools allow you to monitor the use of memory, I/O, storage (disk, SSD, etc.), network, swap space, CPU usage, and more. These tools, particularly those that are CPU-centric, are mostly based on the paradigm that the running process is the unit of control. At best, they provide a way to adjust the nice number–and through that, the priority—or to kill a running process. (For information about nice numbers, see [_Monitoring Linux and Windows hosts with Glances_][3].)
|
||||
|
||||
Other tools based on traditional resource management in a SystemV environment are managed by the `/etc/security/limits.conf` file and the local configuration files located in the `/etc/security/limits.d` directory. Resources can be limited in a fairly crude but useful manner by user or group. Resources that can be managed include various aspects of RAM, total CPU time per day, total amount of data, priority, nice number, number of concurrent logins, number of processes, maximum file size, and more.
|
||||
|
||||
### Using cgroups for process management
|
||||
|
||||
One major difference between [systemd and SystemV][4] is how they handle processes. SystemV treats each process as an entity unto itself. systemd collects related processes into control groups, called [cgroups][5] (short for control groups), and manages system resources for the cgroup as a whole. This means resources can be managed per application rather than by the individual processes that make up an application.
|
||||
|
||||
The control units for cgroups are called slice units. Slices are a conceptualization that allows systemd to order processes in a tree format for ease of management.
|
||||
|
||||
### Viewing cgroups
|
||||
|
||||
I'll start with some commands that allow you to view various types of information about cgroups. The `systemctl status <service>` command displays slice information about a specified service, including its slice. This example shows the `at` daemon:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl status atd.service
|
||||
● atd.service - Deferred execution scheduler
|
||||
Loaded: loaded (/usr/lib/systemd/system/atd.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Wed 2020-09-23 12:18:24 EDT; 1 day 3h ago
|
||||
Docs: man:atd(8)
|
||||
Main PID: 1010 (atd)
|
||||
Tasks: 1 (limit: 14760)
|
||||
Memory: 440.0K
|
||||
CPU: 5ms
|
||||
CGroup: /system.slice/atd.service
|
||||
└─1010 /usr/sbin/atd -f
|
||||
|
||||
Sep 23 12:18:24 testvm1.both.org systemd[1]: Started Deferred execution scheduler.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
This is an excellent example of one reason that I find systemd more usable than SystemV and the old init program. There is so much more information here than SystemV could provide. The cgroup entry includes the hierarchical structure where the `system.slice` is systemd (PID 1), and the `atd.service` is one level below and part of the `system.slice`. The second line of the cgroup entry also shows the process ID (PID) and the command used to start the daemon.
|
||||
|
||||
The `systemctl` command shows multiple cgroup entries. The `--all` option shows all slices, including those that are not currently active:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemctl -t slice --all
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
-.slice loaded active active Root Slice
|
||||
system-getty.slice loaded active active system-getty.slice
|
||||
system-lvm2\x2dpvscan.slice loaded active active system-lvm2\x2dpvscan.slice
|
||||
system-modprobe.slice loaded active active system-modprobe.slice
|
||||
system-sshd\x2dkeygen.slice loaded active active system-sshd\x2dkeygen.slice
|
||||
system-systemd\x2dcoredump.slice loaded inactive dead system-systemd\x2dcoredump.slice
|
||||
system-systemd\x2dfsck.slice loaded active active system-systemd\x2dfsck.slice
|
||||
system.slice loaded active active System Slice
|
||||
user-0.slice loaded active active User Slice of UID 0
|
||||
user-1000.slice loaded active active User Slice of UID 1000
|
||||
user.slice loaded active active User and Session Slice
|
||||
|
||||
LOAD = Reflects whether the unit definition was properly loaded.
|
||||
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
|
||||
SUB = The low-level unit activation state, values depend on unit type.
|
||||
|
||||
11 loaded units listed.
|
||||
To show all installed unit files use 'systemctl list-unit-files'.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
The first thing to notice about this data is that it shows user slices for UIDs 0 (root) and 1000, which is my user login. This shows only the slices and not the services that are part of each slice. This data shows that a slice is created for each user at the time they log in. This can provide a way to manage all of a user's tasks as a single cgroup entity.
|
||||
|
||||
### Explore the cgroup hierarchy
|
||||
|
||||
All is well and good so far, but cgroups are hierarchical, and all of the service units run as members of one of the cgroups. Viewing that hierarchy is easy and uses one old command and one new one that is part of systemd.
|
||||
|
||||
The `ps` command can be used to map the processes and their locations in the cgroup hierarchy. Note that it is necessary to specify the desired data columns when using the `ps` command. I significantly reduced the volume of output from this command below, but I tried to leave enough so you can get a feel for what you might find on your systems:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# ps xawf -eo pid,user,cgroup,args
|
||||
PID USER CGROUP COMMAND
|
||||
2 root - [kthreadd]
|
||||
3 root - \\_ [rcu_gp]
|
||||
4 root - \\_ [rcu_par_gp]
|
||||
6 root - \\_ [kworker/0:0H-kblockd]
|
||||
9 root - \\_ [mm_percpu_wq]
|
||||
10 root - \\_ [ksoftirqd/0]
|
||||
11 root - \\_ [rcu_sched]
|
||||
12 root - \\_ [migration/0]
|
||||
13 root - \\_ [cpuhp/0]
|
||||
14 root - \\_ [cpuhp/1]
|
||||
<SNIP>
|
||||
625406 root - \\_ [kworker/3:0-ata_sff]
|
||||
625409 root - \\_ [kworker/u8:0-events_unbound]
|
||||
1 root 0::/init.scope /usr/lib/systemd/systemd --switched-root --system --deserialize 30
|
||||
588 root 0::/system.slice/systemd-jo /usr/lib/systemd/systemd-journald
|
||||
599 root 0::/system.slice/systemd-ud /usr/lib/systemd/systemd-udevd
|
||||
741 root 0::/system.slice/auditd.ser /sbin/auditd
|
||||
743 root 0::/system.slice/auditd.ser \\_ /usr/sbin/sedispatch
|
||||
764 root 0::/system.slice/ModemManag /usr/sbin/ModemManager
|
||||
765 root 0::/system.slice/NetworkMan /usr/sbin/NetworkManager --no-daemon
|
||||
767 root 0::/system.slice/irqbalance /usr/sbin/irqbalance --foreground
|
||||
779 root 0::/system.slice/mcelog.ser /usr/sbin/mcelog --ignorenodev --daemon --foreground
|
||||
781 root 0::/system.slice/rngd.servi /sbin/rngd -f
|
||||
782 root 0::/system.slice/rsyslog.se /usr/sbin/rsyslogd -n
|
||||
<SNIP>
|
||||
893 root 0::/system.slice/sshd.servi sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
|
||||
1130 root 0::/user.slice/user-0.slice \\_ sshd: root [priv]
|
||||
1147 root 0::/user.slice/user-0.slice | \\_ sshd: root@pts/0
|
||||
1148 root 0::/user.slice/user-0.slice | \\_ -bash
|
||||
1321 root 0::/user.slice/user-0.slice | \\_ screen
|
||||
1322 root 0::/user.slice/user-0.slice | \\_ SCREEN
|
||||
1323 root 0::/user.slice/user-0.slice | \\_ /bin/bash
|
||||
498801 root 0::/user.slice/user-0.slice | | \\_ man systemd.resource-control
|
||||
498813 root 0::/user.slice/user-0.slice | | \\_ less
|
||||
1351 root 0::/user.slice/user-0.slice | \\_ /bin/bash
|
||||
123293 root 0::/user.slice/user-0.slice | | \\_ man systemd.slice
|
||||
123305 root 0::/user.slice/user-0.slice | | \\_ less
|
||||
1380 root 0::/user.slice/user-0.slice | \\_ /bin/bash
|
||||
625412 root 0::/user.slice/user-0.slice | | \\_ ps xawf -eo pid,user,cgroup,args
|
||||
625413 root 0::/user.slice/user-0.slice | | \\_ less
|
||||
246795 root 0::/user.slice/user-0.slice | \\_ /bin/bash
|
||||
625338 root 0::/user.slice/user-0.slice | \\_ /usr/bin/mc -P /var/tmp/mc-root/mc.pwd.246795
|
||||
625340 root 0::/user.slice/user-0.slice | \\_ bash -rcfile .bashrc
|
||||
1218 root 0::/user.slice/user-1000.sl \\_ sshd: dboth [priv]
|
||||
1233 dboth 0::/user.slice/user-1000.sl \\_ sshd: dboth@pts/1
|
||||
1235 dboth 0::/user.slice/user-1000.sl \\_ -bash
|
||||
<SNIP>
|
||||
1010 root 0::/system.slice/atd.servic /usr/sbin/atd -f
|
||||
1011 root 0::/system.slice/crond.serv /usr/sbin/crond -n
|
||||
1098 root 0::/system.slice/lxdm.servi /usr/sbin/lxdm-binary
|
||||
1106 root 0::/system.slice/lxdm.servi \\_ /usr/libexec/Xorg -background none :0 vt01 -nolisten tcp -novtswitch -auth /var/run/lxdm/lxdm-:0.auth
|
||||
370621 root 0::/user.slice/user-1000.sl \\_ /usr/libexec/lxdm-session
|
||||
370631 dboth 0::/user.slice/user-1000.sl \\_ xfce4-session
|
||||
370841 dboth 0::/user.slice/user-1000.sl \\_ /usr/bin/ssh-agent /bin/sh -c exec -l bash -c "/usr/bin/startxfce4"
|
||||
370911 dboth 0::/user.slice/user-1000.sl \\_ xfwm4 --display :0.0 --sm-client-id 2dead44ab-0b4d-4101-bca4-e6771f4a8ac2
|
||||
370930 dboth 0::/user.slice/user-1000.sl \\_ xfce4-panel --display :0.0 --sm-client-id 2ce38b8ef-86fd-4189-ace5-deec1d0e0952
|
||||
370942 dboth 0::/user.slice/user-1000.sl | \\_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libsystray.so 6 23068680 systr
|
||||
ay Notification Area Area where notification icons appear
|
||||
370943 dboth 0::/user.slice/user-1000.sl | \\_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libpulseaudio-plugin.so 8 2306
|
||||
8681 pulseaudio PulseAudio Plugin Adjust the audio volume of the PulseAudio sound system
|
||||
370944 dboth 0::/user.slice/user-1000.sl | \\_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libxfce4powermanager.so 9 2306
|
||||
8682 power-manager-plugin Power Manager Plugin Display the battery levels of your devices and control the brightness of your display
|
||||
370945 dboth 0::/user.slice/user-1000.sl | \\_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libnotification-plugin.so 10 2
|
||||
3068683 notification-plugin Notification Plugin Notification plugin for the Xfce panel
|
||||
370948 dboth 0::/user.slice/user-1000.sl | \\_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libactions.so 14 23068684 acti
|
||||
ons Action Buttons Log out, lock or other system actions
|
||||
370934 dboth 0::/user.slice/user-1000.sl \\_ Thunar --sm-client-id 2cfc809d8-4e1d-497a-a5c5-6e4fa509c3fb --daemon
|
||||
370939 dboth 0::/user.slice/user-1000.sl \\_ xfdesktop --display :0.0 --sm-client-id 299be0608-4dca-4055-b4d6-55ec6e73a324
|
||||
370962 dboth 0::/user.slice/user-1000.sl \\_ nm-applet
|
||||
<SNIP>
|
||||
```
|
||||
|
||||
You can view the entire hierarchy with the `systemd-cgls` command, which is a bit simpler because it does not require any complex options.
|
||||
|
||||
I have shortened this tree view considerably. as well, but I left enough to give you some idea of the amount of data as well as the types of entries you should see when you do this on your system. I did this on one of my virtual machines, and it is about 200 lines long; the amount of data from my primary workstation is about 250 lines:
|
||||
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# systemd-cgls
|
||||
Control group /:
|
||||
-.slice
|
||||
├─user.slice
|
||||
│ ├─user-0.slice
|
||||
│ │ ├─session-1.scope
|
||||
│ │ │ ├─ 1130 sshd: root [priv]
|
||||
│ │ │ ├─ 1147 sshd: root@pts/0
|
||||
│ │ │ ├─ 1148 -bash
|
||||
│ │ │ ├─ 1321 screen
|
||||
│ │ │ ├─ 1322 SCREEN
|
||||
│ │ │ ├─ 1323 /bin/bash
|
||||
│ │ │ ├─ 1351 /bin/bash
|
||||
│ │ │ ├─ 1380 /bin/bash
|
||||
│ │ │ ├─123293 man systemd.slice
|
||||
│ │ │ ├─123305 less
|
||||
│ │ │ ├─246795 /bin/bash
|
||||
│ │ │ ├─371371 man systemd-cgls
|
||||
│ │ │ ├─371383 less
|
||||
│ │ │ ├─371469 systemd-cgls
|
||||
│ │ │ └─371470 less
|
||||
│ │ └─[user@0.service][6] …
|
||||
│ │ ├─dbus-broker.service
|
||||
│ │ │ ├─1170 /usr/bin/dbus-broker-launch --scope user
|
||||
│ │ │ └─1171 dbus-broker --log 4 --controller 12 --machine-id 3bccd1140fca488187f8a1439c832f07 --max-bytes 100000000000000 --max-fds 25000000000000 --max->
|
||||
│ │ ├─gvfs-daemon.service
|
||||
│ │ │ └─1173 /usr/libexec/gvfsd
|
||||
│ │ └─init.scope
|
||||
│ │ ├─1137 /usr/lib/systemd/systemd --user
|
||||
│ │ └─1138 (sd-pam)
|
||||
│ └─user-1000.slice
|
||||
│ ├─[user@1000.service][7] …
|
||||
│ │ ├─dbus\x2d:1.2\x2dorg.xfce.Xfconf.slice
|
||||
│ │ │ └─dbus-:[1.2-org.xfce.Xfconf@0.service][8]
|
||||
│ │ │ └─370748 /usr/lib64/xfce4/xfconf/xfconfd
|
||||
│ │ ├─dbus\x2d:1.2\x2dca.desrt.dconf.slice
|
||||
│ │ │ └─dbus-:[1.2-ca.desrt.dconf@0.service][9]
|
||||
│ │ │ └─371262 /usr/libexec/dconf-service
|
||||
│ │ ├─dbus-broker.service
|
||||
│ │ │ ├─1260 /usr/bin/dbus-broker-launch --scope user
|
||||
│ │ │ └─1261 dbus-broker --log 4 --controller 11 --machine-id
|
||||
<SNIP>
|
||||
│ │ └─gvfs-mtp-volume-monitor.service
|
||||
│ │ └─370987 /usr/libexec/gvfs-mtp-volume-monitor
|
||||
│ ├─session-3.scope
|
||||
│ │ ├─1218 sshd: dboth [priv]
|
||||
│ │ ├─1233 sshd: dboth@pts/1
|
||||
│ │ └─1235 -bash
|
||||
│ └─session-7.scope
|
||||
│ ├─370621 /usr/libexec/lxdm-session
|
||||
│ ├─370631 xfce4-session
|
||||
│ ├─370805 /usr/bin/VBoxClient --clipboard
|
||||
│ ├─370806 /usr/bin/VBoxClient --clipboard
|
||||
│ ├─370817 /usr/bin/VBoxClient --seamless
|
||||
│ ├─370818 /usr/bin/VBoxClient --seamless
|
||||
│ ├─370824 /usr/bin/VBoxClient --draganddrop
|
||||
│ ├─370825 /usr/bin/VBoxClient --draganddrop
|
||||
│ ├─370841 /usr/bin/ssh-agent /bin/sh -c exec -l bash -c "/usr/bin/startxfce4"
|
||||
│ ├─370910 /bin/gpg-agent --sh --daemon --write-env-file /home/dboth/.cache/gpg-agent-info
|
||||
│ ├─370911 xfwm4 --display :0.0 --sm-client-id 2dead44ab-0b4d-4101-bca4-e6771f4a8ac2
|
||||
│ ├─370923 xfsettingsd --display :0.0 --sm-client-id 261b4a437-3029-461c-9551-68c2c42f4fef
|
||||
│ ├─370930 xfce4-panel --display :0.0 --sm-client-id 2ce38b8ef-86fd-4189-ace5-deec1d0e0952
|
||||
│ ├─370934 Thunar --sm-client-id 2cfc809d8-4e1d-497a-a5c5-6e4fa509c3fb --daemon
|
||||
│ ├─370939 xfdesktop --display :0.0 --sm-client-id 299be0608-4dca-4055-b4d6-55ec6e73a324
|
||||
<SNIP>
|
||||
└─system.slice
|
||||
├─rngd.service
|
||||
│ └─1650 /sbin/rngd -f
|
||||
├─irqbalance.service
|
||||
│ └─1631 /usr/sbin/irqbalance --foreground
|
||||
├─fprintd.service
|
||||
│ └─303383 /usr/libexec/fprintd
|
||||
├─systemd-udevd.service
|
||||
│ └─956 /usr/lib/systemd/systemd-udevd
|
||||
<SNIP>
|
||||
├─systemd-journald.service
|
||||
│ └─588 /usr/lib/systemd/systemd-journald
|
||||
├─atd.service
|
||||
│ └─1010 /usr/sbin/atd -f
|
||||
├─system-dbus\x2d:1.10\x2dorg.freedesktop.problems.slice
|
||||
│ └─dbus-:[1.10-org.freedesktop.problems@0.service][10]
|
||||
│ └─371197 /usr/sbin/abrt-dbus -t133
|
||||
├─sshd.service
|
||||
│ └─893 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
|
||||
├─vboxservice.service
|
||||
│ └─802 /usr/sbin/VBoxService -f
|
||||
├─crond.service
|
||||
│ └─1011 /usr/sbin/crond -n
|
||||
├─NetworkManager.service
|
||||
│ └─765 /usr/sbin/NetworkManager --no-daemon
|
||||
├─switcheroo-control.service
|
||||
│ └─787 /usr/libexec/switcheroo-control
|
||||
<SNIP>
|
||||
```
|
||||
|
||||
This tree view shows all of the user and system slices and the services and programs running in each cgroup. Notice the units called "scopes," which group related programs into a management unit, within the `user-1000.slice` in the listing above. The `user-1000.slice/session-7.scope` cgroup contains the GUI desktop program hierarchy, starting with the LXDM display manager session and all of its subtasks, including things like the Bash shell and the Thunar GUI file manager.
|
||||
|
||||
Scope units are not defined in configuration files but are generated programmatically as the result of starting groups of related programs. Scope units do not create or start the processes running as part of that cgroup. All processes within the scope are equal, and there is no internal hierarchy. The life of a scope begins when the first process is created and ends when the last process is destroyed.
|
||||
|
||||
Open several windows on your desktop, such as terminal emulators, LibreOffice, or whatever you want, then switch to an available virtual console and start something like `top` or [Midnight Commander][11]. Run the `systemd-cgls` command on your host, and take note of the overall hierarchy and the scope units.
|
||||
|
||||
The `systemd-cgls` command provides a more complete representation of the cgroup hierarchy (and details of the units that make it up) than any other command I have found. I prefer its cleaner representation of the tree than what the `ps` command provides.
|
||||
|
||||
### With a little help from my friends
|
||||
|
||||
After covering these basics, I had planned to go into more detail about cgroups and how to use them, but I discovered a series of four excellent articles by Red Hat's [Steve Ovens][12] on Opensource.com's sister site [Enable Sysadmin][13]. Rather then basically rewriting Steve's articles, I decided it would be much better to take advantage of his cgroup expertise by linking to them:
|
||||
|
||||
1. [A Linux sysadmin's introduction to cgroups][14]
|
||||
2. [How to manage cgroups with CPUShares][15]
|
||||
3. [Managing cgroups the hard way—manually][16]
|
||||
4. [Managing cgroups with systemd][17]
|
||||
|
||||
|
||||
|
||||
Enjoy and learn from them, as I did.
|
||||
|
||||
### Other resources
|
||||
|
||||
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup. This list has grown since I started this series of articles to reflect the research I have done.
|
||||
|
||||
* The Fedora Project has a good, practical [guide][18] [to systemd][18]. It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd.
|
||||
* The Fedora Project also has a good [cheat sheet][19] that cross-references the old SystemV commands to comparable systemd ones.
|
||||
* The [systemd.unit(5) manual page][20] contains a nice list of unit file sections and their configuration options along with concise descriptions of each.
|
||||
* Red Hat documentation contains a good description of the [Unit file structure][21] as well as other important information.
|
||||
* For detailed technical information about systemd and the reasons for creating it, check out Freedesktop.org's [description of systemd][22]. This page is one of the best I have found because it contains many links to other important and accurate documentation.
|
||||
* Linux.com's "More systemd fun" offers more advanced systemd [information and tips][23].
|
||||
* See the man page for [systemd.resource-control(5)][24].
|
||||
* In [_The Linux kernel user's and administrator's guide_][25], see the [Control Group v2][26] entry.
|
||||
|
||||
|
||||
|
||||
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
|
||||
|
||||
* [Rethinking PID 1][27]
|
||||
* [systemd for Administrators, Part I][28]
|
||||
* [systemd for Administrators, Part II][29]
|
||||
* [systemd for Administrators, Part III][30]
|
||||
* [systemd for Administrators, Part IV][31]
|
||||
* [systemd for Administrators, Part V][32]
|
||||
* [systemd for Administrators, Part VI][33]
|
||||
* [systemd for Administrators, Part VII][34]
|
||||
* [systemd for Administrators, Part VIII][35]
|
||||
* [systemd for Administrators, Part IX][36]
|
||||
* [systemd for Administrators, Part X][37]
|
||||
* [systemd for Administrators, Part XI][38]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/cgroups
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-concentration-focus-windows-office.png?itok=-8E2ihcF (Woman using laptop concentrating)
|
||||
[2]: https://en.wikipedia.org/wiki/Top_(software)
|
||||
[3]: https://opensource.com/article/19/11/monitoring-linux-glances
|
||||
[4]: https://opensource.com/article/20/4/systemd
|
||||
[5]: https://en.wikipedia.org/wiki/Cgroups
|
||||
[6]: mailto:user@0.service
|
||||
[7]: mailto:user@1000.service
|
||||
[8]: mailto:1.2-org.xfce.Xfconf@0.service
|
||||
[9]: mailto:1.2-ca.desrt.dconf@0.service
|
||||
[10]: mailto:1.10-org.freedesktop.problems@0.service
|
||||
[11]: https://midnight-commander.org/
|
||||
[12]: https://www.redhat.com/sysadmin/users/steve-ovens
|
||||
[13]: https://www.redhat.com/sysadmin/
|
||||
[14]: https://www.redhat.com/sysadmin/cgroups-part-one
|
||||
[15]: https://www.redhat.com/sysadmin/cgroups-part-two
|
||||
[16]: https://www.redhat.com/sysadmin/cgroups-part-three
|
||||
[17]: https://www.redhat.com/sysadmin/cgroups-part-four
|
||||
[18]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html
|
||||
[19]: https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet
|
||||
[20]: https://man7.org/linux/man-pages/man5/systemd.unit.5.html
|
||||
[21]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_basic_system_settings/managing-services-with-systemd_configuring-basic-system-settings#Managing_Services_with_systemd-Unit_File_Structure
|
||||
[22]: https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[23]: https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/
|
||||
[24]: https://man7.org/linux/man-pages/man5/systemd.resource-control.5.html
|
||||
[25]: https://www.kernel.org/doc/html/latest/admin-guide/index.html
|
||||
[26]: https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html
|
||||
[27]: http://0pointer.de/blog/projects/systemd.html
|
||||
[28]: http://0pointer.de/blog/projects/systemd-for-admins-1.html
|
||||
[29]: http://0pointer.de/blog/projects/systemd-for-admins-2.html
|
||||
[30]: http://0pointer.de/blog/projects/systemd-for-admins-3.html
|
||||
[31]: http://0pointer.de/blog/projects/systemd-for-admins-4.html
|
||||
[32]: http://0pointer.de/blog/projects/three-levels-of-off.html
|
||||
[33]: http://0pointer.de/blog/projects/changing-roots
|
||||
[34]: http://0pointer.de/blog/projects/blame-game.html
|
||||
[35]: http://0pointer.de/blog/projects/the-new-configuration-files.html
|
||||
[36]: http://0pointer.de/blog/projects/on-etc-sysinit.html
|
||||
[37]: http://0pointer.de/blog/projects/instances.html
|
||||
[38]: http://0pointer.de/blog/projects/inetd.html
|
||||
@ -0,0 +1,167 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Use apt-cache Command in Debian, Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/apt-cache-command/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Use apt-cache Command in Debian, Ubuntu and Other Linux Distributions
|
||||
======
|
||||
|
||||
_**With apt-cache command, you can search for package details in the local APT cache. Learn to use apt-cache command in this tutorial.**_
|
||||
|
||||
### What is apt-cache command used for?
|
||||
|
||||
The [apt][1] [package manager][2] works on a local cache of package metadata. The metadata usually consists information like package name, version, description, dependencies, its repository and developers. With the apt-cache command, you can query this local APT cache and get relevant information.
|
||||
|
||||
You can search for the availability of a package, its version number, its dependencies among other things. I’ll show you how to use the apt-cache command with examples.
|
||||
|
||||
The **location of APT cache** is /var/lib/apt/lists/ directory. Which repository metadata to cache depends on the repositories added in your source list in the /etc/apt/sources.list file and additional repository files located in ls /etc/apt/sources.list.d directory.
|
||||
|
||||
Surprisingly, apt-cache doesn’t clear the APT cache. For that you’ll have to [use the apt-get clean command][3].
|
||||
|
||||
Needless to say, the APT packaging system is used on Debian and Debian-based Linux distributions like Ubuntu, Linux Mint, elementary OS etc. You cannot use it on Arch or Fedora.
|
||||
|
||||
### Using apt-cache command
|
||||
|
||||
![][4]
|
||||
|
||||
Like any other Linux command, there are several options available with apt-cache and you can always refer to its man page to read about them.
|
||||
|
||||
However, you probably won’t need to use all of them. This is why I am going to show you only the most common and useful examples of the apt-cache command in this tutorial.
|
||||
|
||||
Always update
|
||||
|
||||
It is always a good idea to update the local APT cache to sync it with the remote repositories. How do you do that? You use the command:
|
||||
|
||||
**sudo apt update**
|
||||
|
||||
#### Search for packages
|
||||
|
||||
The most common use of apt-cache command is for finding package. You can use a regex pattern to search for a package in the local APT cache.
|
||||
|
||||
```
|
||||
apt-cache search package_name
|
||||
```
|
||||
|
||||
By default, it looks for the search term in both the name and description of the package. It shows the matching package along with its short description in alphabetical order.
|
||||
|
||||
![][5]
|
||||
|
||||
You can narrow down your search to look for the search term in package names only.
|
||||
|
||||
```
|
||||
apt-cache search --names-only package_name
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
If you want complete details of all the matched packages, you may use the `--full` flag. It can also be used with `--names-only` flag.
|
||||
|
||||
![][7]
|
||||
|
||||
#### Get detailed package information
|
||||
|
||||
If you know the exact package name (or if you have manged to find it with the search), you can get the detailed metadata information on the package.
|
||||
|
||||
```
|
||||
apt-cache show package_name
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
You can see all kind of details in the package metadata like name, version, developer, maintainer, repository, short and long description, package size and even checksum.
|
||||
|
||||
There is another option showpkg that displays information about the package name, version and its forward and reverse dependencies.
|
||||
|
||||
```
|
||||
apt-cache showpkg package_name
|
||||
```
|
||||
|
||||
#### apt-cache policy
|
||||
|
||||
This is one of the rarely used option of apt-cache command. The policy options helps you debug the issue related to the [preference file][9].
|
||||
|
||||
If you specify the package name, it will show whether the package is installed, which version is available from which repository and its priority.
|
||||
|
||||
![][10]
|
||||
|
||||
By default, each installed package version has a priority of 100 and a non-installed package has a priority of 500. The same package may have more than one version with a different priority. APT installs the version with higher priority unless the installed version is newer.
|
||||
|
||||
If this doesn’t make sense, it’s okay. It will be extremely rare for a regular Linux user to dwell this deep into package management.
|
||||
|
||||
#### Check dependencies and reverse dependencies of a package
|
||||
|
||||
You can [check the dependencies of a package][11] before (or even after) installing it. It also shows all the possible packages that can fulfill the dependency.
|
||||
|
||||
```
|
||||
apt-cache depends package
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
You may also check which packages are dependent on a certain package by checking the reverse dependencies with apt-cahce.
|
||||
|
||||
![][13]
|
||||
|
||||
Frankly, I was also surprised to see that a DevOps tool like Ansible has a dependency on a [funny Linux command like Cowsay][14]. I think it’s perhaps because after [installing Ansible][15], it displays some message on the nodes.
|
||||
|
||||
#### Check unmet dependencies
|
||||
|
||||
You may get troubled with [unmet dependencies issue in Ubuntu][16] or other Linux. The apt-cache command provides option to check all the unmet dependencies of various available packages on your system.
|
||||
|
||||
```
|
||||
apt-cache unmet
|
||||
```
|
||||
|
||||
![][17]
|
||||
|
||||
**Conclusion**
|
||||
|
||||
You can list all available packages with the apt-cache command. The output would be huge, so I suggest combining it with [wc command][18] to get a total number of available packages like this:
|
||||
|
||||
```
|
||||
apt-cache pkgnames | wc -l
|
||||
```
|
||||
|
||||
Did you notice that you don’t need to be [root user][19] for using apt-cache command?
|
||||
|
||||
The newer [apt command][20] has a few options available to match the features of apt-cache command. Since apt is new, apt-get and its associated commands like apt-cache are still preferred to be used in scripts.
|
||||
|
||||
I hope you find this tutorial helpful. If you have questions about any point discussed above or suggestion to improve it, please let me know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/apt-cache-command/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wiki.debian.org/Apt
|
||||
[2]: https://itsfoss.com/package-manager/
|
||||
[3]: https://itsfoss.com/clear-apt-cache/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-command.png?resize=800%2C450&ssl=1
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-search.png?resize=759%2C437&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-search-names-only.png?resize=759%2C209&ssl=1
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-show-full.png?resize=759%2C722&ssl=1
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-show-pkgname.png?resize=800%2C795&ssl=1
|
||||
[9]: https://debian-handbook.info/browse/stable/sect.apt-get.html#sect.apt.priorities
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-policy.png?resize=795%2C456&ssl=1
|
||||
[11]: https://itsfoss.com/check-dependencies-package-ubuntu/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-dependency-check.png?resize=768%2C304&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-reverse-dependency.png?resize=768%2C304&ssl=1
|
||||
[14]: https://itsfoss.com/funny-linux-commands/
|
||||
[15]: https://linuxhandbook.com/install-ansible-linux/
|
||||
[16]: https://itsfoss.com/held-broken-packages-error/
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-unmet.png?resize=759%2C399&ssl=1
|
||||
[18]: https://linuxhandbook.com/wc-command/
|
||||
[19]: https://itsfoss.com/root-user-ubuntu/
|
||||
[20]: https://itsfoss.com/apt-command-guide/
|
||||
@ -1,56 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( chenmu-kk )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (My first contribution to open source: Making a decision)
|
||||
[#]: via: (https://opensource.com/article/19/11/my-first-open-source-contribution-mistake-decisions)
|
||||
[#]: author: (Galen Corey https://opensource.com/users/galenemco)
|
||||
|
||||
我的第一次开源贡献:做出决定
|
||||
======
|
||||
一位新的开源贡献者记录了她加入到开源项目后开始犯得五个错误。
|
||||
|
||||
![Lightbulb][1]
|
||||
|
||||
先前,我将大量的责任归咎于[冒充综合症][2]因为这延迟了我的第一个开源贡献。但还有一个我无法忽视的因素:我无法做决定来拯救我的生活。 在[成千上百万][3]的开源项目中抉择时,选择一个要做贡献的项目势不可挡。如此压迫以至于我常常不得不关掉我的笔记本去思考:“或许我可以改天再做一次”。
|
||||
|
||||
错误二是让我对做决定的恐惧妨碍了我做出第一次贡献。在理想世界里,也许我会带着一个我真正关心和想去做的特定项目开始我的开源之旅,但我有的只是总得为开源项目做出的贡献的模糊目标。对于那些处于同一处境的人来说,这儿有一些策略可以为自己的贡献挑选合适的项目(或者至少是一个好的项目)。
|
||||
|
||||
### 我经常使用的工具
|
||||
|
||||
一开始,我不认为有必要将自己局限于已经熟悉的工具或项目。有一些我之前从未使用过,但由于他们活跃的社区,或者他们解决了有趣的问题,因此看起来很有吸引力。
|
||||
|
||||
但是,考虑我投入到这个项目中的时间有限,我决定继续使用我了解的工具。要了解工具需求,你需要熟悉它的工作方式。如果您想为自己不熟悉的项目做贡献,则需要完成一个额外的步骤来了解代码的功能和目标。这个额外的工作量是有趣且值得的,但也会使你的工作时间加倍。因为我的目标主要是贡献,坚持我所知道的是缩小范围一个很好的方式。回馈一个你认为有用的项目也是一种回报。
|
||||
|
||||
### 我经常使用的工具
|
||||
|
||||
一开始,我不认为有必要将自己局限于已经熟悉的工具或项目。有一些我之前从未使用过,但由于他们活跃的社区,或者他们解决了有趣的问题,因此看起来很有吸引力。
|
||||
|
||||
但是,考虑我投入到这个项目中的时间有限,我决定继续使用我了解的工具。要了解工具需求,你需要熟悉它的工作方式。如果您想为自己不熟悉的项目做贡献,则需要完成一个额外的步骤来了解代码的功能和目标。这个额外的工作量是有趣且值得的,但也会使你的工作时间加倍。因为我的目标主要是贡献,坚持我所知道的是缩小范围一个很好的方式。回馈一个你认为有用的项目也是一种回报。
|
||||
|
||||
因为这是我第一次为开源项目做出贡献,在此过程中我有很多问题。一些项目社区非常擅长记录选择问题和提出请求的程序。一些项目社区在记录流程方面很优秀,可以用来挑选其中的项目并提交请求。尽管那时我没有选择它们,因为在此之前我从未使用过该产品,[Gatsby][4]是该实践的一个范例。
|
||||
|
||||
这种细致的文件帮助我们缓解一些不知如何去做的不安全感。它也给了我希望,项目是开放给新的贡献者,并将花时间来查看我的工作。除了贡献准则外,我还查看了问题部分,看看这个项目是否利用了“好的第一个问题”标志。这是该项目对初学者开放的另一个标志(并帮助你学会如何操作)。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你还没有计划好一个项目,那么选择合适的领域进行您的第一个开源贡献已势不可挡。列出一系列标准可以帮助自己缩减选择范围,并为自己的首次提交找到一个好的项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/my-first-open-source-contribution-mistake-decisions
|
||||
|
||||
作者:[Galen Corey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chenmu-kk](https://github.com/chenmu-kk)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/galenemco
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lightbulb-idea-think-yearbook-lead.png?itok=5ZpCm0Jh (Lightbulb)
|
||||
[2]: https://opensource.com/article/19/10/my-first-open-source-contribution-mistakes
|
||||
[3]: https://github.blog/2018-02-08-open-source-project-trends-for-2018/
|
||||
[4]: https://www.gatsbyjs.org/contributing/
|
||||
@ -0,0 +1,161 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use the internet from the command line with curl)
|
||||
[#]: via: (https://opensource.com/article/20/5/curl-cheat-sheet)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 curl 从命令行访问互联网
|
||||
======
|
||||
下载我们整理的 curl 备忘录。在不使用图形界面的情况下从互联网上获取所需的信息,curl 是一种快速有效的方法。
|
||||
|
||||
![Cheat Sheet cover image][1]
|
||||
|
||||
Curl 通常被认为是非交互式 Web 浏览器,这意味着它能够从互联网上获取信息并在你的终端中显示或将其保存到文件中。从表面看,这是 Web 浏览器,例如 Firefox 或 Chromium 所做的工作,只是它们默认情况下会 _渲染_ 信息,而 curl 会下载并显示原始信息。实际上,curl 命令可以做更多的事情,并且能够使用多种协议与服务器进行双向传输数据,这些协议包括 HTTP、FTP、SFTP、IMAP、POP3、LDAP、SMB、SMTP 等。对于普通终端用户来说,这是一个有用的工具;而对于系统管理员,这非常便捷;对于微服务和云开发人员来说,它是质量保证的工具。
|
||||
|
||||
Curl 被设计为在没有用户交互的情况下工作,因此与 Firefox 不同,你必须从头到尾考虑与在线数据的交互。例如,如果想要在 Firefox 中查看网页,你需要启动 Firefox 窗口。打开 Firefox 后,在地址栏或搜索引擎中输入要访问的网站。然后,导航到网站,然后单击要查看的页面。
|
||||
|
||||
对于 curl 来说也是如此,不同之处在于你需要一次执行所有操作:在启动 curl 的同时提供需要访问的 Internet 位置,并告诉它是否要将数据保存在终端或文件中。当你必须与需要身份验证的网站或 API 进行交互时,会变得有点复杂,但是一旦你学习了 **curl** 命令语法,它就会成为你的第二天性。为了帮助你掌握它,我们在一个方便的[备忘录][2]中收集了相关的语法信息。
|
||||
|
||||
### 使用 curl 下载文件
|
||||
|
||||
你可以通过提供指向特定 URL 的链接来使用 **curl** 命令下载文件。如果你提供的 URL 默认为 **index.html**,那么将下载此页面,并将下载的文件显示在终端屏幕上。你可以将数据通过管道传递到 less、tail 或任何其它命令:
|
||||
```
|
||||
$ curl "http://example.com" | tail -n 4
|
||||
<h1>Example Domain</h1>
|
||||
<p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p>
|
||||
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
|
||||
</div></body></html>
|
||||
```
|
||||
|
||||
由于某些 URL 包含特殊字符,shell 通常会将其解释,因此用引号将 URL 包起来是最安全的。
|
||||
|
||||
某些文件在终端中无法很好的转换显示。你可以使用 **\--remote-name** 选项使文件根据服务器上的命名进行保存:
|
||||
```
|
||||
$ curl --remote-name "<https://example.com/linux-distro.iso>"
|
||||
$ ls
|
||||
linux-distro.iso
|
||||
```
|
||||
|
||||
或者,你可以使用 **\--output** 选项来命名你想要下载的内容:
|
||||
|
||||
```
|
||||
curl "http://example.com/foo.html" --output bar.html
|
||||
```
|
||||
|
||||
### 使用 curl 列出带有远程目录的内容
|
||||
|
||||
因为 curl 不是交互式的,所以很难浏览页面上的可下载元素。如果你要连接的远程服务器允许,可以使用 **curl** 来列出目录的内容:
|
||||
```
|
||||
$ curl --list-only "https://example.com/foo/"
|
||||
```
|
||||
|
||||
### 继续中断下载
|
||||
|
||||
如果你正在下载一个非常大的文件,你可能会发现有时候必须中断下载。Curl 非常智能,可以确定下载从何处中断并继续下载。这意味着,下一次当你下载一个 4GB 的 Linux 发行版 ISO 出现问题时,就不必重新开始了。**\--continue-at** 的语法有点不寻常:如果你知道下载中断时的字节数,你可以提供给 curl;否则,你可以使用单独的一个破折号(**-**)指示 curl 自动检测:
|
||||
```
|
||||
$ curl --remote-name --continue-at - "https://example.com/linux-distro.iso"
|
||||
```
|
||||
|
||||
### 下载文件序列
|
||||
|
||||
如果你需要下载多个文件而不是一个大文件,那么 curl 可以帮助你解决这个问题。假设你知道要下载的文件的位置和文件名模式,则可以使用 curl 的排序标记:中括号中整数范围内的起点和终点。对于输出文件名,使用 **#1** 表示第一个变量:
|
||||
|
||||
```
|
||||
$ curl "https://example.com/file_[1-4].webp" --output "file_#1.webp"
|
||||
```
|
||||
|
||||
如果你需要使用其它变量来表示另一个序列,按照每个变量在命令中出现的顺序表示它们。例如,在这个命令中,**#1** 指目录 **images_000** 到 **images_009**,而 **#2** 指目录 **file_1.webp** 至 **file_4.webp**。
|
||||
```
|
||||
$ curl "<https://example.com/images\_00\[0-9\]/file\_\[1-4\].webp>" \
|
||||
\--output "file_#1-#2.webp"
|
||||
```
|
||||
|
||||
### 从站点下载所有 PNG 文件
|
||||
|
||||
你也可以仅使用 **curl** 和 **grep** 进行一些基本的 Web 抓取操作,以找到想要下载的内容。例如,假设你需要下载与正在归档网页关联的所有图像,首先,下载引用图像的页面。将页面内通过管道传输到 grep,搜索所需的图片类型(在此示例中为 PNG)。最后,创建一个 **while** 循环来构造下载 URL,并将文件保存到你的计算机:
|
||||
```
|
||||
$ curl https://example.com |\
|
||||
grep --only-matching 'src="[^"]*.[png]"' |\
|
||||
cut -d\" -f2 |\
|
||||
while read i; do \
|
||||
curl https://example.com/"${i}" -o "${i##*/}"; \
|
||||
done
|
||||
```
|
||||
|
||||
这只是一个示例,但它展示了 curl 与 Unix 管道和一些基本巧妙的解析结合使用时是多么的灵活。
|
||||
|
||||
### 获取 HTML 头
|
||||
|
||||
用于数据交换的协议在计算机发送通信的数据包中嵌入了大量元数据。HTTP 头是数据初始部分的组件。在连接一个网站出现问题时,查看这些报文头(尤其是响应码)会有所帮助:
|
||||
```
|
||||
curl --head "<https://example.com>"
|
||||
HTTP/2 200
|
||||
accept-ranges: bytes
|
||||
age: 485487
|
||||
cache-control: max-age=604800
|
||||
content-type: text/html; charset=UTF-8
|
||||
date: Sun, 26 Apr 2020 09:02:09 GMT
|
||||
etag: "3147526947"
|
||||
expires: Sun, 03 May 2020 09:02:09 GMT
|
||||
last-modified: Thu, 17 Oct 2019 07:18:26 GMT
|
||||
server: ECS (sjc/4E76)
|
||||
x-cache: HIT
|
||||
content-length: 1256
|
||||
```
|
||||
|
||||
### 快速失败
|
||||
|
||||
响应 200 通常是 HTTP 成功指示符,这是你与服务器连接时通常期望的结果。著名的 404 响应表示找不到页面,而 500 则表示服务器在处理请求时出现了错误。
|
||||
|
||||
要查看协商过程中发生了什么错误,添加 **\--shou-error** 选项:
|
||||
```
|
||||
$ curl --head --show-error "http://opensource.ga"
|
||||
```
|
||||
|
||||
除非你可以访问要连接的服务器,否则这些问题将很难解决,但是 curl 通常会尽力连接你指定的地址。有时在网络上进行测试时,无休止的重试似乎只会浪费时间,因此你可以使用 **\--fail-early** 选项来强制 curl 在失败时迅速退出:
|
||||
```
|
||||
curl --fail-early "http://opensource.ga"
|
||||
```
|
||||
|
||||
### 由 3xx 响应指定的重定向查询
|
||||
|
||||
300 这个系列的响应更加灵活。具体来说,301 响应意味着一个 URL 已被永久移动到其它位置。对于网站管理员来说,重新定位内容并留下“痕迹”是一种常见的方式,这样访问老地址的人们仍然可以找到它。默认情况下,Curl 不会进行 301 重定向,但你可以使用 **\--localtion** 选项使其继续进入 301 响应指向的目标:
|
||||
```
|
||||
$ curl "https://iana.org" | grep title
|
||||
<title>301 Moved Permanently</title>
|
||||
$ curl --location "https://iana.org"
|
||||
<title>Internet Assigned Numbers Authority</title>
|
||||
```
|
||||
|
||||
### 展开短网址
|
||||
|
||||
如果你想要在访问短网址之前先查看它们,那么 **\--location** 选项非常有用。短网址对于有字符限制的社交网络(当然,如果你使用[现代和开源的社交网络][4]的话,这可能不是问题),或者对于用户不能复制粘贴长地址的打印媒体来说是有用处的。但是,它们也可能存在风险,因为其目的地址本质上是隐藏的。通过结合使用 **\--head** 选项仅查看 HTTP 头,**\--location** 选项可以查看一个 URL 的最终地址,你可以查看一个短网址而无需加载其完整的资源:
|
||||
```
|
||||
$ curl --head --location \
|
||||
"<https://bit.ly/2yDyS4T>"
|
||||
```
|
||||
|
||||
### [下载我们的 curl 备忘录][2]
|
||||
|
||||
一旦你开始考虑了将探索 web 由一条命令来完成,那么 curl 就成为一种快速有效的方式,可以从 Internet 上获取所需的信息,而无需麻烦图形界面。为了帮助你适应到工作流中,我们创建了一个 [curl 备忘录][2],它包含常见的 curl 用法和语法,包括使用它查询 API 的概述。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/curl-cheat-sheet
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coverimage_cheat_sheet.png?itok=lYkNKieP (Cheat Sheet cover image)
|
||||
[2]: https://opensource.com/downloads/curl-command-cheat-sheet
|
||||
[3]: https://www.iana.org/domains/example"\>More
|
||||
[4]: https://opensource.com/article/17/4/guide-to-mastodon
|
||||
@ -0,0 +1,211 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install Ubuntu Server on a Raspberry Pi)
|
||||
[#]: via: (https://itsfoss.com/install-ubuntu-server-raspberry-pi/)
|
||||
[#]: author: (Dimitrios Savvopoulos https://itsfoss.com/author/dimitrios/)
|
||||
|
||||
如何在树莓派上安装 Ubuntu 服务器?
|
||||
======
|
||||
|
||||
[树莓派][1]是最著名的[单板计算机][2]。最初,树莓派项目的范围是针对促进学校和发展中国家的计算机基础科学教学。
|
||||
|
||||
它的低成本、便携性和极低的功耗,使得它的受欢迎程度远远超过预期。从气象站到家庭自动化,玩家们用树莓派搭建了许多[酷炫的项目][3]。
|
||||
|
||||
[第四代树莓派][4]具备了普通台式电脑的功能和处理能力。但本文并不是要介绍如何使用树莓派作为桌面。相反,我会告诉你如何在树莓派上安装 Ubuntu 服务器。
|
||||
|
||||
在本教程中,我将使用树莓派 4,以下是我将介绍的内容:
|
||||
|
||||
* 在 microSD 卡上安装 Ubuntu 服务器
|
||||
* 在树莓派上设置无线网络连接
|
||||
* 通过 SSH 访问你的树莓派
|
||||
|
||||
|
||||
|
||||
![][5]
|
||||
|
||||
**本教程需要以下东西**:
|
||||
|
||||
* 一张 micro SD 卡(建议使用 8GB 或更大的卡)
|
||||
* 一台带有 micro SD 卡读卡器的计算机(运行 Linux、Windows 或 macOS)
|
||||
* 树莓派 2、3 或 4
|
||||
* 良好的互联网连接
|
||||
* 用于树莓派 2 和 3 的 HDMI 线和用于树莓派 4的 micro HDMI 线(可选)
|
||||
* 一套 USB 键盘(可选)
|
||||
|
||||
|
||||
|
||||
### 在树莓派上安装 Ubuntu 服务器
|
||||
|
||||
![][6]
|
||||
|
||||
在本教程中,我使用 Ubuntu 来创建树莓派 SD 卡,但你可以在其他 Linux 发行版、macOS 和 Windows 上创建它。这是因为准备 SD 卡的步骤对 Raspberry Pi Imager 工具而言是一样的。
|
||||
|
||||
Raspberry Pi Imager 工具会自动下载你[选择树莓派系统][7]的镜像。这意味着你需要一个良好的网络连接来下载 1GB 左右的数据。
|
||||
|
||||
#### 步骤 1:用 Raspberry Pi Imager 准备 SD 卡
|
||||
|
||||
确保你已将 microSD 卡插入电脑,并在电脑上安装 Raspberry Pi Imager。
|
||||
|
||||
你可以从这些链接中下载适合你操作系统的 Imager 工具:
|
||||
|
||||
* [用于 Ubuntu/Debian 的 Raspberry Pi Imager][8]
|
||||
* [用于 Windows 的 Raspberry Pi Imager][9]
|
||||
* [用于 MacOS 的 Raspberry Pi Imager][10]
|
||||
|
||||
|
||||
|
||||
|
||||
尽管我使用的是 Ubuntu,但我不会使用上面列出的 Debian 软件包,而是使用命令行安装 snap 包。这个方法可以适用于更广泛的 Linux 发行版。
|
||||
|
||||
```
|
||||
sudo snap install rpi-imager
|
||||
```
|
||||
|
||||
安装好 Raspberry Pi Imager 工具后,找到并打开它,点击 ”CHOOSE OS“ 菜单。
|
||||
|
||||
![][11]
|
||||
|
||||
滚动菜单并点击 ”Ubuntu“ (核心和服务器镜像)。
|
||||
|
||||
![][12]
|
||||
|
||||
从可用的镜像中,我选择了 Ubuntu 20.04 LTS 64 位。如果你有一个树莓派 2,那你只能选择 32 位镜像。
|
||||
|
||||
**重要提示:如果你使用的是最新的树莓派 4 - 8 GB 内存型号,你应该选择 64 位操作系统,否则只能使用 4 GB 内存。**
|
||||
|
||||
![][13]
|
||||
|
||||
从 “SD Card” 菜单中选择你的 microSD 卡,然后点击 ”WRITE“。
|
||||
|
||||
![][14]
|
||||
|
||||
如果它显示一些错误,请尝试再次写入它。现在它将下载 Ubuntu 服务器镜像并将其写入 micro SD 卡。
|
||||
|
||||
当这个过程完成时,它将通知你。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 步骤 2:在 Ubuntu 服务器上添加 WiFi 支持
|
||||
|
||||
烧录完 micro SD 卡后,你就差不多可以使用它了。在使用它之前,有一件事情你可能想做,那就是添加 Wi-Fi 支持。
|
||||
|
||||
SD 卡仍然插入读卡器中,打开文件管理器,找到卡上的 ”system-boot” 分区。
|
||||
|
||||
你要找的和需要编辑的文件名为 `network-config`。
|
||||
|
||||
![][16]
|
||||
|
||||
这个过程也可以在 Windows 和 MacOS 上完成。如前所述,编辑 **`network-config`** 文件,添加你的 Wi-Fi 凭证。
|
||||
|
||||
首先,取消矩形框内的行的注释(删除开头的标签 “#”),然后将 myhomewifi 替换为你的 Wi-Fi 网络名称。
|
||||
|
||||
之后,将 myhomewifi 替换为你的 Wi-Fi 网络名,用引号括起来,比如 ”itsfoss“,将 ”S3kr1t“ 替换为 Wi-Fi 密码,用引号括起来,比如 ”12345679“。
|
||||
|
||||
![][17]
|
||||
|
||||
它可能看上去像这样:
|
||||
|
||||
```
|
||||
wifis:
|
||||
wlan0:
|
||||
dhcp4: true
|
||||
optional: true
|
||||
access-points:
|
||||
"your wifi name":
|
||||
password: "your_wifi_password"
|
||||
```
|
||||
|
||||
保存文件并将 micro SD 卡插入到你的树莓派中。在第一次启动时,如果你的树莓派无法连接到 Wi-Fi 网络,只需重启你的设备。
|
||||
|
||||
#### 步骤 3:在树莓派上使用 Ubuntu 服务器(如果你有专门的显示器、键盘和鼠标的话)
|
||||
|
||||
如果你有一套额外的鼠标,键盘和显示器,你可以很容易地像其他电脑一样使用树莓派(但没有 GUI)。
|
||||
|
||||
只需将 micro SD 卡插入树莓派,连接显示器、键盘和鼠标。现在[打开你的树莓派][18]。它将出现 TTY 登录屏幕(黑色终端屏幕)并询问用户名和密码。
|
||||
|
||||
* 默认用户名:ubuntu
|
||||
* 默认密码:ubuntu
|
||||
|
||||
|
||||
|
||||
看到提示时,用 “**ubuntu**” 作为密码。登录成功后,[Ubuntu 会要求你更改默认密码][19]。
|
||||
|
||||
享受你的 Ubuntu 服务器吧!
|
||||
|
||||
#### 步骤 3:通过 SSH 远程连接到你的树莓派(如果你没有树莓派的显示器、键盘和鼠标的话)
|
||||
|
||||
如果你没有专门的显示器与树莓派一起使用也没关系。当你可以直接通过 SSH 进入它并按照你的方式使用它时,谁还需要一个带有显示器的服务器呢?
|
||||
|
||||
**在 Ubuntu 和 Mac OS**上,通常已经安装了一个 SSH 客户端。要远程连接到你的树莓派,你需要发现它的 IP 地址。检查[连接到你的网络的设备][20],看看哪个是树莓派。
|
||||
|
||||
由于我没有 Windows 机器,你可以访问[微软][21]提供的综合指南。
|
||||
|
||||
打开终端,运行以下命令:
|
||||
|
||||
```
|
||||
ssh [email protected]_pi_ip_address
|
||||
```
|
||||
|
||||
你可能会看到以下信息确认连接:
|
||||
|
||||
```
|
||||
Are you sure you want to continue connecting (yes/no/[fingerprint])?
|
||||
```
|
||||
|
||||
输入 ”yes“,然后点击回车键。
|
||||
|
||||
![][22]
|
||||
|
||||
当提示时,用前面提到的 ”ubuntu“ 作为密码。当然,你会被要求更改密码。
|
||||
|
||||
完成后,你将自动注销,你必须使用新密码重新连接。
|
||||
|
||||
你的 Ubuntu 服务器就可以在树莓派上运行了!
|
||||
|
||||
**总结**
|
||||
|
||||
在树莓派上安装 Ubuntu 服务器是一个简单的过程,而且它的预配置程度很高,使用起来很愉快。
|
||||
|
||||
我不得不说,在所有[我在树莓派上尝试的操作系统][7]中,Ubuntu 服务器是最容易安装的。我并没有夸大其词。请查看我的[在树莓派上安装 Arch Linux][23]的指南,以供参考。
|
||||
|
||||
希望这篇指南也能帮助你在树莓派上安装 Ubuntu 服务器。如果你有问题或建议,请在评论区告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-ubuntu-server-raspberry-pi/
|
||||
|
||||
作者:[Dimitrios Savvopoulos][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/dimitrios/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[2]: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
[3]: https://itsfoss.com/raspberry-pi-projects/
|
||||
[4]: https://itsfoss.com/raspberry-pi-4/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/Ubuntu-Server-20.04.1-LTS-aarch64.png?resize=800%2C600&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-raspberry-pi.png?resize=800%2C450&ssl=1
|
||||
[7]: https://itsfoss.com/raspberry-pi-os/
|
||||
[8]: https://downloads.raspberrypi.org/imager/imager_amd64.deb
|
||||
[9]: https://downloads.raspberrypi.org/imager/imager.exe
|
||||
[10]: https://downloads.raspberrypi.org/imager/imager.dmg
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager.png?resize=800%2C600&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager-choose-ubuntu.png?resize=800%2C600&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager-ubuntu-server.png?resize=800%2C600&ssl=1
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/raspberry-pi-imager-sd-card.png?resize=800%2C600&ssl=1
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-installed-raspberry-pi.png?resize=799%2C506&ssl=1
|
||||
[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-pi-network-config.png?resize=800%2C565&ssl=1
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/Ubuntu-server-wifi.png?resize=800%2C600&ssl=1
|
||||
[18]: https://itsfoss.com/turn-on-raspberry-pi/
|
||||
[19]: https://itsfoss.com/change-password-ubuntu/
|
||||
[20]: https://itsfoss.com/how-to-find-what-devices-are-connected-to-network-in-ubuntu/
|
||||
[21]: https://docs.microsoft.com/en-us/windows-server/administration/openssh/openssh_install_firstuse
|
||||
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/ubuntu-server-change-password.png?resize=800%2C600&ssl=1
|
||||
[23]: https://itsfoss.com/install-arch-raspberry-pi/
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "xiao-song-123"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: subject: "How open source underpins blockchain technology"
|
||||
[#]: via: "https://opensource.com/article/20/10/open-source-blockchain"
|
||||
[#]: author: "Matt Shealy https://opensource.com/users/mshealy"
|
||||
|
||||
开源是如何支撑区块链技术发展的
|
||||
======
|
||||
创造出区块链安全性和可靠性的原因:是开放,而非监管。
|
||||
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
|
||||
当人们发现以安全性而闻名的区块链技术居然是建立在开源软件代码之上时,通常会感到非常惊讶。事实上,正是这种开放性才赋予了区块链技术的安全性和可靠性。
|
||||
|
||||
把任何事物构建成开源的,其核心价值之一就是提高效率。建立起一个有着不同观点和技能的开发人员社区,这些开发人员工作在同一个代码库的时候,可以成倍增加构建出来的应用程序数量以及复杂性。
|
||||
|
||||
### 开源比人们想象中的要更加普遍
|
||||
|
||||
开源的 Linux,就是一种比较流行的操作系统。Linux 为服务器提供了许多服务,这些服务让我们可以轻松地共享个人信息。其中包括 Google,Facebook 和数千个主要网站。当我们使用这些服务时,就是在和这些在网络上运行着 Linux 系统的计算机进行交互。Chromebook 也使用 Linux,Android 手机使用的操作系统也是基于 Linux 的。
|
||||
|
||||
Linux 不属于任何一家公司,人们可以免费使用并且可以共同协作来完善创造它。自 2005 年推出以来,已经有来自 1,700 多家公司的 20,000 多名开发人员 [为其中的代码做出了贡献][2] 。
|
||||
|
||||
这就是开源软件的工作原理。大量的人为此贡献,并不断添加、修改或构建开源代码库来创建新的应用程序和平台。区块链和加密货币的大部分代码都是使用开源软件开发的。开源软件是由热情的用户构建的,这些用户对错误、故障或缺陷时刻保持警惕。当发现问题时,开源社区中的开发人员将一起努力来解决问题。
|
||||
|
||||
### 区块链和开源
|
||||
|
||||
整个开源区块链开发者社区都在不断地添加和完善代码库。
|
||||
|
||||
以下是区块链执行的基本方式:
|
||||
|
||||
* 区块链平台具有一个交易数据库,该交易数据库允许对等方在任何时候彼此进行交易。
|
||||
* 附有用户识别标签,以方便交易。
|
||||
* 平台一定有一种安全的方式来在交易批准前对交易进行验证。
|
||||
* 无法被验证的交易不会进行。
|
||||
|
||||
|
||||
|
||||
开源软件允许开发者在 [去中心化应用程序(Dapp)][3]中创建这些平台,这是区块链中交易的安全性、安全性和可变性的关键。
|
||||
|
||||
这种去中心化的方式意味着没有中央权威机构来调解交易,没有人能控制发生的事情。直接点对点的交易可以更快速、安全的进行。随着交易记录在分类账簿中,这条交易记录也会分发到系统各处。
|
||||
|
||||
区块链使用密码学来保证安全。每一笔交易都携带着与前一笔交易相关联的信息,以验证其真实性。这可以防止威胁者篡改数据,因为一旦数据被添加到公共分类账中,其他用户就不能更改。
|
||||
|
||||
### 区块链是开源的吗?
|
||||
|
||||
虽然区块链本身在技术上可能不是开源的,但区块链系统通常是使用开源软件实现的,因为没有政府机构对其进行监管,所以这些开源软件使用的概念体现了一种开放文化。私人公司开发的用于处理金融交易的专有软件很可能受到 [政府机构 ][4] 的监管。在美国,这可能包括美国证券交易委员会 (SEC)、联邦储备委员会和联邦存款保险公司 (FDIC)。区块链技术在开放环境下使用不需要政府监管,实际上,用来验证交易的是用户社区。
|
||||
|
||||
你可以称它为众包的一种极端形式,既用于开发构建区块链平台的开源软件,也用于验证交易。这就是区块链得到如此多关注的原因之一:它有可能颠覆整个行业,因为它可以作为处理和验证交易的权威中介。
|
||||
|
||||
### 比特币,以太坊和其他加密货币
|
||||
|
||||
截至2020年6月,超过 [5000万人拥有区块链钱包][5] 。他们大多数用于金融交易,例如交易比特币,以太坊和其他加密货币。 与交易员观察股票价格一样,[检查加密货币价格][6] 已成为许多人的主流。
|
||||
|
||||
加密货币平台也使用开源软件。[以太坊项目][7] 开发出了任何人都可以免费使用的开源软件,社区中大量的开发者都为此贡献了代码。比特币客户端的参考实现版是由 450 多个开发人员和工程师进行开发的,他们已经贡献了超过 150,000 行代码。
|
||||
|
||||
加密货币区块链是一个持续增长的记录。每个被称作为块的记录按顺序链接在一起,它们互相链接形成一条链。每个块都有其自己的唯一标记,这个标记称为 [哈希][8] 。一个块包含自身的哈希值和前一个块密码的哈希值。从本质上讲,每个块都链接到前一个块,形成了无法中断的长链,每个长链都包含有关用于验证交易的其他块的信息。
|
||||
|
||||
在金融或是加密货币的区块链中没有中央银行。这些分布在整个互联网中的区块,建立了一个性能强大的审计跟踪系统。任何人都能够通过区块链来验证交易,但却不能更改上面的记录。
|
||||
|
||||
### 牢不可破的区块链
|
||||
|
||||
尽管区块链不受任何政府或机构的监管,但分布式的网络保证了它们的安全。随着区块链的发展,每一笔交易都会增加伪造的难度。区块分布在世界各地的网络中,它们使用的信任标记不可被改变,这条链条变得牢不可破。
|
||||
|
||||
这种去中心化的网络,其背后的代码是开源的,也是用户在交易中不必使用诸如银行或经纪人之类的中介就可以相互信任的原因之一。支撑加密货币平台的软件是由相互独立的开发者组建的联盟创建的,并且任何人都可以免费使用。这创造了世界上最大的制衡体系之一。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/open-source-blockchain
|
||||
|
||||
作者:[Matt Shealy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[xiao-song-123](https://github.com/xiao-song-123)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mshealy
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ "cubes coming together to create a larger cube"
|
||||
[2]: https://www.linuxfoundation.org/wp-content/uploads/2020/08/2020_kernel_history_report_082720.pdf
|
||||
[3]: https://www.freecodecamp.org/news/what-is-a-dapp-a-guide-to-ethereum-dapps/
|
||||
[4]: https://www.investopedia.com/ask/answers/063015/what-are-some-major-regulatory-agencies-responsible-overseeing-financial-institutions-us.asp
|
||||
[5]: https://www.statista.com/statistics/647374/worldwide-blockchain-wallet-users/
|
||||
[6]: https://www.okex.com/markets
|
||||
[7]: https://ethereum.org/en/
|
||||
[8]: https://opensource.com/article/18/7/bitcoin-blockchain-and-open-source
|
||||
@ -0,0 +1,173 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Free Up Space in /boot Partition on Ubuntu Linux?)
|
||||
[#]: via: (https://itsfoss.com/free-boot-partition-ubuntu/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
如何在 Ubuntu Linux 上释放 /boot 分区的空间?
|
||||
======
|
||||
|
||||
前几天,我收到一个警告,/boot 分区已经几乎满了或者已经没有剩余空间了。是的,我有一个独立的 /boot 分区,我相信现在很少有人这样做了。
|
||||
|
||||
这是我第一次看到这样一个错误,它让我很迷惑。现在,这里有一些 [方法来释放在 Ubuntu 上的分区][1] (或者基于 Ubuntu 的发行版) ,但是在这种情况下并不是所有的方法都能用。
|
||||
|
||||
这就是为什么我决定写这些我释放 /boot 分区空间的步骤的原因。
|
||||
|
||||
### 如何在 Ubuntu 上释放 /boot 分区的空间(如果你的 /boot 分区空间不足)
|
||||
|
||||
![][2]
|
||||
|
||||
我建议你仔细阅读这些解决方案,并由此得出最适合你情况的解决方案。解决方案的操作很容易,但是你需要在你的生产力系统上小心的执行这些解决方案。
|
||||
|
||||
#### 方法 1: 使用 apt autoremove
|
||||
|
||||
你不必是一名终端专家来做这件事,它只需要一个命令,你将移除未使用的内核来释放 /boot 分区中是空间。
|
||||
|
||||
你所有要做的事情是,输入:
|
||||
|
||||
```
|
||||
sudo apt autoremove
|
||||
```
|
||||
|
||||
这个命令不仅仅可以移除未使用的内核,而且也将摆脱你不需要的或工具安装后所不需要的依赖项。
|
||||
|
||||
在你输入命令后,它将列出将被移除的东西,你只需要确认操作即可。如果你很好奇它将移除什么,你可以仔细检查一下看看它实际移除了什么。
|
||||
|
||||
这里是它应该看起来的样子:
|
||||
|
||||
![][3]
|
||||
|
||||
你必需按 **Y** 按键来继续。
|
||||
|
||||
_**值得注意的是,这种方法只在你仅剩余一点点空间并并且得到警告的情况下才有效。但是,如果你的 /boot 分区已经满了,APT 甚至可能不会工作。**_
|
||||
|
||||
在接下来的方法中,我将重点介绍两种不同的方法,通过这些方法你可以使用 GUI 和终端来移除旧内核来释放空间。
|
||||
|
||||
#### 方法 2: 手动移除未使用的内核(如果 apt autoremove 不工作的话)
|
||||
|
||||
在你尝试 [移除一些旧内核][4] 来释放空间前,你需要识别当前活动的内核,并且确保你不会删除它。
|
||||
|
||||
为 [检查你的内核的版本][5] ,在终端中输入下面的命令:
|
||||
|
||||
```
|
||||
uname -r
|
||||
```
|
||||
|
||||
[uname 命令通常用于获取 Linux 系统信息][6] 。在这里,这个命令显示当前正在被使用的 Linux 内核。它看起来应该是这样:
|
||||
|
||||
![][7]
|
||||
|
||||
现在,你已经知道你当前的 Linux 内核是什么,你必需移除一个不同于这个版本内核的内核。你应该把它记录在某些地方,以便你不会不知不觉地移除它。
|
||||
|
||||
接下来,要移除它,你可以使用终端或 GUI .
|
||||
|
||||
警告!
|
||||
|
||||
在删除内核时一定要额外的小心。只识别和删除旧内核,而不是当前你正在使用的内核,否则你将会拥有一个残缺的系统。
|
||||
|
||||
##### 使用一个 GUI 工具来移除旧的 Linux 内核
|
||||
|
||||
你可以使用 [Synaptic 软件包管理器][8] 或一个类似 [Stacer][9] 的工具来开始。就我个人而言,当我遇到一个满满的 /boot 分区且 apt 损坏是,我使用 [Stacer][6] 来丢弃旧内核。因此,让我向你展示一下它看起的样子。
|
||||
|
||||
首先,你需要启动 “**Stacer**” ,然后导航到软件包卸载器,如下面屏幕截图所示。
|
||||
|
||||
![][10]
|
||||
|
||||
在这里,搜索 “**image**” ,你将找到你所拥有的 Linux 内核。你只需要删除旧内核版本的镜像,而不是当前内核的镜像。
|
||||
|
||||
在上面的屏幕截图中,我已经指出了我系统上的当前内核和旧内核,因此你必需注意你系统上的内核。
|
||||
|
||||
你没有必要删除任何其它东西,只需要删除旧的内核版本。
|
||||
|
||||
同样的,只需要在软件包列表中搜索 “**headers**” ,并删除如下显示的旧的 “**headers**” 版本。
|
||||
|
||||
![][11]
|
||||
|
||||
只是提醒你,你 **不希望移除 “linux-headers-generic”** 。只是关注那些与其相关的有版本号的。
|
||||
|
||||
然后,就这样,你完成了所有的工作,apt 将会再次工作,并且你将成功地释放来自 /boot 分区的一些空间。同样地,你也可以使用任意其它的软件包管理器来完成这些工作。
|
||||
|
||||
#### 使用命令行来移除旧内核
|
||||
|
||||
使用命令行来移除旧内核与使用 GUI 来移除旧内核是一样的。因此,如果你没有选择使用一款 GUI 软件 (如果它是一台远程机器/一项远程服务) 的权利,或者如果你只是对终端情有独钟,你可以仿效下面的步骤。
|
||||
|
||||
首先,使用下面的命令列出所有已安装的内核:
|
||||
|
||||
```
|
||||
ls -l /boot
|
||||
```
|
||||
|
||||
它应该看起来像这样:
|
||||
|
||||
![][12]
|
||||
|
||||
写为 “**old**” 的内核,或者不匹配你当前内核版本,都是未使用的内核,你可以删除它们。
|
||||
|
||||
现在,你可以使用 **rm** 命令来移除具体指定来自 /boot 分区中的内核,使用下面的命令(一个命令对应一个内核):
|
||||
|
||||
```
|
||||
sudo rm /boot/vmlinuz-5.4.0-7634-generic
|
||||
```
|
||||
|
||||
务必检查你发系统的版本 — 它可能与你的系统的版本不同。
|
||||
|
||||
如果你有很多未使用的内核,这将需要一些时间。因此,你也可以下面的命令丢弃多个内核:
|
||||
|
||||
```
|
||||
sudo rm /boot/*-5.4.0-{7634}-*
|
||||
```
|
||||
|
||||
为了澄清这一点,你需要用逗号分隔内核版本号的最后一部分/编码,以便同时删除它们。
|
||||
|
||||
假设,我有两个旧的内核 5.4.0-7634-generic 和 5.4.0-7624 ,那么命令将是:
|
||||
|
||||
```
|
||||
sudo rm /boot/*-5.4.0-{7634,7624}-*
|
||||
```
|
||||
|
||||
如果你不希望在 grub 启动菜单中再看到这些旧的内核版本,你可以使用下面的命令简单地 [更新 grub][13] :
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
就这样,你完成了所有的工作。你已经释放了空间,还修复了可能潜在的破损的 APT 问题,如果它是一个在你的 /boot 分区填满后出现的重要的问题的话。
|
||||
|
||||
在一些情况下,你需要输入这些命令来修复破损的 (正如我在论坛中注意到的):
|
||||
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
sudo apt install -f
|
||||
```
|
||||
|
||||
注意,除非你发现 APT 已破损,否则你不需要输入上面的命令。就我个人而言,我不需要这些命令,但是我发现这些命令对论坛上的一些人很有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/free-boot-partition-ubuntu/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/free-boot-space-ubuntu-linux.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/apt-autoremove-screenshot.jpg?resize=800%2C415&ssl=1
|
||||
[4]: https://itsfoss.com/remove-old-kernels-ubuntu/
|
||||
[5]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[6]: https://linuxhandbook.com/uname/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/uname-r-screenshot.jpg?resize=800%2C198&ssl=1
|
||||
[8]: https://itsfoss.com/synaptic-package-manager/
|
||||
[9]: https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/stacer-remove-kernel.jpg?resize=800%2C562&ssl=1
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/stacer-remove-kernel-header.png?resize=800%2C576&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/command-kernel-list.png?resize=800%2C432&ssl=1
|
||||
[13]: https://itsfoss.com/update-grub/
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Start using virtual tables in Apache Cassandra 4.0)
|
||||
[#]: via: (https://opensource.com/article/20/10/virtual-tables-apache-cassandra)
|
||||
[#]: author: (Ben Bromhead https://opensource.com/users/ben-bromhead)
|
||||
|
||||
开始在 Apache Cassandra 4.0 中使用虚拟表
|
||||
======
|
||||
它们是什么以及如何使用它们。
|
||||
![Computer laptop in space][1]
|
||||
|
||||
在最近的 [Apache Cassandra 4.0 测试版][3]中的[众多新增功能][2]中,虚拟表是一个值得关注的功能。
|
||||
|
||||
在以前的 Cassandra 版本中,用户需要访问 Java 管理扩展 ([JMX][4]) 来检查 Cassandra 的细节,如运行中的压缩、客户端、度量和各种配置设置。虚拟表消除了这些挑战。Cassandra 4.0 测试版使用户能够从一个只读的系统表中以 Cassandra 查询语言 (CQL) 行的形式查询这些细节和数据。
|
||||
|
||||
以下是之前 Cassandra 版本中基于 JMX 的机制是如何工作的。想象一下,一个用户想要检查集群中某个节点的压缩状态。用户首先要建立一个 JMX 连接,在节点上运行 `nodetool compactionstats`。这个要求给用户带来了一些复杂的问题。用户的客户端是否配置了 JMX 访问?Cassandra 节点和防火墙是否配置为允许 JMX 访问?是否准备好了适当的安全和审计措施,并落实到位?这些只是用户在处理 Cassandra 以前版本时不得不面对的一些问题。
|
||||
|
||||
在 Cassandra 4.0 中,虚拟表使得用户可以利用之前配置的驱动来查询所需信息。这一变化消除了与实现和维护 JMX 访问相关的所有开销。
|
||||
|
||||
Cassandra 4.0 创建了两个新的键空间来帮助用户利用虚拟表:`system_views` 和 `system_virtual_schema`。`system_views` 键空间包含了用户查询的所有有价值的信息,有用地存储在一些表中。`system_virtual_schema` 键空间,顾名思义,存储了这些虚拟表的所有必要的模式信息。
|
||||
|
||||
![system_views and system_virtual_schema keyspaces and tables][5]
|
||||
|
||||
(Ben Bromhead, [CC BY-SA 4.0][6])
|
||||
|
||||
重要的是要明白,每个虚拟表的范围仅限于其节点。任何虚拟表查询都将返回只对作为其协调器的节点有效的数据,而不管一致性如何。为了简化这一要求,已经在几个驱动中添加了支持,以便在这些查询中指定协调器节点 (Python、DataStax Java 和其他驱动现在提供了这种支持)。
|
||||
|
||||
为了说明这一点,请检查这个 `sstable_tasks` 虚拟表。这个虚拟表显示了对 [SSTables][7] 的所有操作,包括压缩、清理、升级等。
|
||||
|
||||
![Querying the sstable_tasks virtual table][8]
|
||||
|
||||
(Ben Bromhead, [CC BY-SA 4.0][6])
|
||||
|
||||
如果用户在以前的 Cassandra 版本中运行 `nodetool compactionstats`,则会显示相同类型的信息。 在这里,查询发现该节点当前有一个活动的压缩。它还显示了它的进度以及它的键空间和表。得益于虚拟表,用户可以快速收集这些信息,并同样有效地获得正确诊断集群健康状况所需的能力。
|
||||
|
||||
需要说明的是,Cassandra 4.0 并没有去除对 JMX 访问的需求。JMX 仍然是查询某些指标的唯一选择。尽管如此,用户会欢迎简单地使用 CQL 来获取关键集群指标的能力。由于虚拟表提供的便利,用户可能会将之前投入到 JMX 工具的时间和资源重新投入到 Cassandra 本身。客户端工具也应该开始利用虚拟表提供的优势。
|
||||
|
||||
如果你对 Cassandra 4.0 测试版及其虚拟表功能感兴趣,请[试试试它][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/virtual-tables-apache-cassandra
|
||||
|
||||
作者:[Ben Bromhead][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ben-bromhead
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_space_graphic_cosmic.png?itok=wu493YbB (Computer laptop in space)
|
||||
[2]: https://www.instaclustr.com/apache-cassandra-4-0-beta-released/
|
||||
[3]: https://cassandra.apache.org/download/
|
||||
[4]: https://en.wikipedia.org/wiki/Java_Management_Extensions
|
||||
[5]: https://opensource.com/sites/default/files/uploads/cassandra_virtual-tables.png (system_views and system_virtual_schema keyspaces and tables)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://cassandra.apache.org/doc/latest/architecture/storage_engine.html#sstables
|
||||
[8]: https://opensource.com/sites/default/files/uploads/cassandra_virtual-tables_sstable_tasks.png (Querying the sstable_tasks virtual table)
|
||||
@ -0,0 +1,123 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Clear Apt Cache and Reclaim Precious Disk Space)
|
||||
[#]: via: (https://itsfoss.com/clear-apt-cache/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何清除 apt 缓存来回收宝贵的磁盘空间
|
||||
======
|
||||
|
||||
如何清除 apt 缓存?你只需使用这个 [apt-get 命令][1]选项:
|
||||
|
||||
```
|
||||
sudo apt-get clean
|
||||
```
|
||||
|
||||
但是,清理 apt 缓存不仅仅是运行上面的命令。
|
||||
|
||||
在本教程中,我将解释什么是 apt 缓存、为什么会使用它、为什么你要清理它,以及关于清理 apt 缓存你应该知道的其他事情。
|
||||
|
||||
我将在这里使用 Ubuntu 作为参考,但由于这是关于 apt 的,因此它也适用于 [Debian][2] 和其他基于 Debian 和 Ubuntu 的发行版,比如 Linux Mint、Deepin 等等。
|
||||
|
||||
### 什么是 apt 缓存?为什么要使用它?
|
||||
|
||||
当你使用 apt-get 或 [apt 命令][3]安装一个软件包时(或在软件中心安装 DEB 包),apt [包管理器][4]会以 .deb 格式下载软件包及其依赖关系,并将其保存在 /var/cache/apt/archives 文件夹中。
|
||||
|
||||
![][5]
|
||||
|
||||
下载时,apt 将 deb 包保存在 /var/cache/apt/archives/partial 目录下。当 deb 包完全下载完毕后,它会被移到 /var/cache/apt/archives 目录下。
|
||||
|
||||
下载完包的 deb 文件及其依赖关系后,你的系统就会[从这些 deb 文件中安装包][6]。
|
||||
|
||||
现在你明白缓存的用途了吧?系统在安装软件包之前,需要一个地方把软件包文件存放在某个地方。如果你了解 [Linux 目录结构][7],你就会明白,/var/cache 是合适的地方。
|
||||
|
||||
#### 为什么安装包后要保留缓存?
|
||||
|
||||
下载的 deb 文件在安装完成后并不会立即从目录中删除。如果你删除了一个软件包,然后重新安装,你的系统会在缓存中查找这个软件包,并从这里获取它,而不是重新下载(只要缓存中的软件包版本与远程仓库中的版本相同)。
|
||||
|
||||
这样就快多了。你可以自己尝试一下,看看一个程序第一次安装,删除后再安装需要多长时间。你可以[使用 time 命令来了解完成一个命令需要多长时间][8]:_**time sudo apt install package_name**_
|
||||
|
||||
我找不到任何关于缓存保留策略的内容,所以我无法说明 Ubuntu 会在缓存中保留下载的包多长时间。
|
||||
|
||||
#### 你应该清理 apt 缓存吗?
|
||||
|
||||
这取决于你。如果你的根目录下的磁盘空间用完了,你可以清理 apt cache 来回收磁盘空间。这是 [Ubuntu 上释放磁盘空间的几种方法][9]之一。
|
||||
|
||||
使用 [du 命令][10]检查缓存占用了多少空间:
|
||||
|
||||
![][11]
|
||||
|
||||
有的时候,这可能会占用几百兆,如果你正在运行一个服务器,这些空间可能是至关重要的。
|
||||
|
||||
#### 如何清理 apt 缓存?
|
||||
|
||||
如果你想清除 apt 缓存,有一个专门的命令来做。所以不要去手动删除缓存目录。只要使用这个命令就可以了:
|
||||
|
||||
```
|
||||
sudo apt-get clean
|
||||
```
|
||||
|
||||
这将删除 /var/cache/apt/archives 目录的内容(除了锁文件)。以下是 apt-get clean 命令模拟删除内容:
|
||||
|
||||
![][12]
|
||||
|
||||
还有一个命令是关于清理 apt 缓存的:
|
||||
|
||||
```
|
||||
sudo apt-get autoclean
|
||||
```
|
||||
|
||||
与 clean 不同的是,autoclean 只删除那些无法从仓库中下载的包。
|
||||
|
||||
假设你安装了包 xyz。它的 deb 文件仍然保留在缓存中。如果现在仓库中有新的 xyz 包,那么缓存中现有的这个 xyz 包就已经过时了,没有用了。autoclean 选项会删除这种不能再下载的无用包。
|
||||
|
||||
#### 删除 apt 缓存安全吗?
|
||||
|
||||
![][13]
|
||||
|
||||
是的,清除 apt 创建的缓存是完全安全的。它不会对系统的性能产生负面影响。也许如果你重新安装软件包,下载时间会更长一些,但也仅此而已。
|
||||
|
||||
再说一次,使用 apt-get clean 命令。它比手动删除缓存目录更快、更简单。
|
||||
|
||||
你也可以使用像 [Stacer][14] 或 [Bleachbit][15] 这样的图形工具来实现这个目的。
|
||||
|
||||
#### 总结
|
||||
|
||||
在写这篇文章的时候,新的 apt 命令没有内置选项。不过,为了保持向后的兼容性,仍然可以运行 _**apt clean**_ (内部应该是运行 apt-get clean)。请参考这篇文章来[了解 apt 和 apt-get 的区别][16]。
|
||||
|
||||
我希望你觉得这个关于 apt 缓存的解释很有趣。虽然这不是什么必要的东西,但了解这些小东西会让你对你的 Linux 系统更加了解。
|
||||
|
||||
欢迎你在评论区提出反馈和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/clear-apt-cache/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/apt-get-linux-guide/
|
||||
[2]: https://www.debian.org/
|
||||
[3]: https://itsfoss.com/apt-command-guide/
|
||||
[4]: https://itsfoss.com/package-manager/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-get-clean-cache.png?resize=800%2C470&ssl=1
|
||||
[6]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[7]: https://linuxhandbook.com/linux-directory-structure/
|
||||
[8]: https://linuxhandbook.com/time-command/
|
||||
[9]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[10]: https://linuxhandbook.com/find-directory-size-du-command/
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-archive-size.png?resize=800%2C233&ssl=1
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-get-clean-ubuntu.png?resize=800%2C339&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/Clear-Apt-Cache.png?resize=800%2C450&ssl=1
|
||||
[14]: https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[15]: https://itsfoss.com/use-bleachbit-ubuntu/
|
||||
[16]: https://itsfoss.com/apt-vs-apt-get-difference/
|
||||
@ -1,185 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Remove Physical Volume from a Volume Group in LVM)
|
||||
[#]: via: (https://www.2daygeek.com/linux-remove-delete-physical-volume-pv-from-volume-group-vg-in-lvm/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何从 LVM 的卷组中删除物理卷?
|
||||
======
|
||||
|
||||
如果 LVM 不再需要使用某个设备,你可以使用 vgreduce 命令从卷组中删除物理卷。
|
||||
|
||||
vgreduce 命令通过删除物理卷来缩小卷组的容量。
|
||||
|
||||
但要确保物理卷没有被任何逻辑卷使用,请使用 pvdisplay 命令。
|
||||
|
||||
如果物理卷仍在使用,你必须使用 pvmove 命令将数据转移到另一个物理卷。
|
||||
|
||||
数据转移后,它就可以从卷组中删除。
|
||||
|
||||
最后使用 pvremove 命令删除空物理卷上的 LVM 标签和 LVM 元数据。
|
||||
|
||||
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)][1]**。
|
||||
* **第二部分:[如何在 Linux 中扩展/增加 LVM 大小(逻辑卷调整)][2]**。
|
||||
* **第三部分:[如何在 Linux 中减少/缩小 LVM 大小(逻辑卷调整)][3]**。
|
||||
|
||||
|
||||
|
||||
![][4]
|
||||
|
||||
### 1) 将扩展移动到现有物理卷上
|
||||
|
||||
使用 pvs 命令检查是否使用了所需的物理卷(我们计划删除 LVM 中的 **“/dev/sdb1”** 磁盘)。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda1 myvg lvm2 a- 75.00G 14.00G 61.00G
|
||||
/dev/sdb1 myvg lvm2 a- 50.00G 45.00G 5.00G
|
||||
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G
|
||||
```
|
||||
|
||||
如果使用了,请检查卷组中的其他物理卷是否有足够的空闲空间。
|
||||
|
||||
如果有的话,你可以在需要删除的设备上运行 pvmove 命令。扩展将被分配到其他设备上。
|
||||
|
||||
```
|
||||
# pvmove /dev/sdb1
|
||||
|
||||
/dev/sdb1: Moved: 2.0%
|
||||
…
|
||||
/dev/sdb1: Moved: 79.2%
|
||||
…
|
||||
/dev/sdb1: Moved: 100.0%
|
||||
```
|
||||
|
||||
当 pvmove 命令完成后。再次使用 pvs 命令检查物理卷是否有空闲。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda1 myvg lvm2 a- 75.00G 9.00G 66.00G
|
||||
/dev/sdb1 myvg lvm2 a- 50.00G 50.00G 0
|
||||
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G
|
||||
```
|
||||
|
||||
如果它是空闲的,使用 vgreduce 命令从卷组中删除物理卷 /dev/sdb1。
|
||||
|
||||
```
|
||||
# vgreduce myvg /dev/sdb1
|
||||
Removed "/dev/sdb1" from volume group "myvg"
|
||||
```
|
||||
|
||||
最后,运行 pvremove 命令从 LVM 配置中删除磁盘。现在,磁盘已经完全从 LVM 中移除,可以用于其他用途。
|
||||
|
||||
```
|
||||
# pvremove /dev/sdb1
|
||||
Labels on physical volume "/dev/sdb1" successfully wiped.
|
||||
```
|
||||
|
||||
### 2) 移动扩展到新磁盘
|
||||
|
||||
如果你在卷组中的其他物理卷上没有足够的可用扩展。使用以下步骤添加新的物理卷。
|
||||
|
||||
向存储组申请新的 LUN。分配完毕后,运行以下命令来**[在 Linux 中发现新添加的 LUN 或磁盘][5]**。
|
||||
|
||||
```
|
||||
# ls /sys/class/scsi_host
|
||||
host0
|
||||
```
|
||||
|
||||
```
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
```
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
操作系统中检测到磁盘后,使用 pvcreate 命令创建物理卷。
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdd1
|
||||
Physical volume "/dev/sdd1" successfully created
|
||||
```
|
||||
|
||||
使用以下命令将新的物理卷 /dev/sdd1 添加到现有卷组 vg01 中。
|
||||
|
||||
```
|
||||
# vgextend vg01 /dev/sdd1
|
||||
Volume group "vg01" successfully extended
|
||||
```
|
||||
|
||||
现在,使用 pvs 命令查看你添加的新磁盘 **“/dev/sdd1”**。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda1 myvg lvm2 a- 75.00G 14.00G 61.00G
|
||||
/dev/sdb1 myvg lvm2 a- 50.00G 0 50.00G
|
||||
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G
|
||||
/dev/sdd1 myvg lvm2 a- 60.00G 60.00G 0
|
||||
```
|
||||
|
||||
使用 pvmove 命令将数据从 /dev/sdb1 移动到 /dev/sdd1。
|
||||
|
||||
```
|
||||
# pvmove /dev/sdb1 /dev/sdd1
|
||||
|
||||
/dev/sdb1: Moved: 10.0%
|
||||
…
|
||||
/dev/sdb1: Moved: 79.7%
|
||||
…
|
||||
/dev/sdb1: Moved: 100.0%
|
||||
```
|
||||
|
||||
数据移动到新磁盘后。再次使用 pvs 命令检查物理卷是否空闲。
|
||||
|
||||
```
|
||||
# pvs -o+pv_used
|
||||
|
||||
PV VG Fmt Attr PSize PFree Used
|
||||
/dev/sda1 myvg lvm2 a- 75.00G 14.00G 61.00G
|
||||
/dev/sdb1 myvg lvm2 a- 50.00G 50.00G 0
|
||||
/dev/sdc1 myvg lvm2 a- 17.15G 12.15G 5.00G
|
||||
/dev/sdd1 myvg lvm2 a- 60.00G 10.00G 50.00G
|
||||
```
|
||||
|
||||
如果空闲,使用 vgreduce 命令从卷组中删除物理卷 /dev/sdb1。
|
||||
|
||||
```
|
||||
# vgreduce myvg /dev/sdb1
|
||||
Removed "/dev/sdb1" from volume group "myvg"
|
||||
```
|
||||
|
||||
最后,运行 pvremove 命令从 LVM 配置中删除磁盘。现在,磁盘已经完全从 LVM 中移除,可以用于其他用途。
|
||||
|
||||
```
|
||||
# pvremove /dev/sdb1
|
||||
Labels on physical volume "/dev/sdb1" successfully wiped.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-remove-delete-physical-volume-pv-from-volume-group-vg-in-lvm/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/
|
||||
[2]: https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux/
|
||||
[3]: https://www.2daygeek.com/reduce-shrink-decrease-resize-lvm-logical-volume-in-linux/
|
||||
[4]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]: https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (LibreOffice Wants Apache to Drop the Ailing OpenOffice and Support LibreOffice Instead)
|
||||
[#]: via: (https://itsfoss.com/libreoffice-letter-openoffice/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
LibreOffice 希望 Apache 放弃陷入困境的 OpenOffice,转而支持 LibreOffice
|
||||
======
|
||||
|
||||
对于 Linux 用户来说,当我们想到[微软 Office 的开源替代品][1]时,Apache OpenOffice 仍然是一个相关的推荐,这是不言而喻的。然而,在过去的几年里,OpenOffice 的发展几乎是停滞的。
|
||||
|
||||
当然,考虑到 Abhishek 早在 2016年 就写过 [Apache OpenOffice 关闭的可能性][2],这并不令人震惊。
|
||||
|
||||
现在,在[文档基金会的公开信][3]中,他们呼吁 Apache OpenOffice 推荐用户开始使用更好的替代品,比如 LibreOffice。在本文中,我将提到文档基金会的博文中的一些重点,以及它对 Apache OpenOffice 的意义。
|
||||
|
||||
![][4]
|
||||
|
||||
### Apache OpenOffice 是历史,LibreOffice 是未来?
|
||||
|
||||
尽管我当年没有使用过 OpenOffice,但可以肯定地说,它绝对不是微软 Office 的现代开源替代品。至少现在不是了。
|
||||
|
||||
是的,Apache OpenOffice 对于传统用户来说仍然是很重要的东西,在几年前是一个很好的替代品。
|
||||
|
||||
以下是 OpenOffice 和 LibreOffice 的主要发布时间线:
|
||||
|
||||
![][5]
|
||||
|
||||
现在 OpenOffice 已经没有重大的开发了,Apache OpenOffice 的未来是什么?最大开源基金会一个有些活跃的项目没有重大发布?
|
||||
|
||||
这听起来并不乐观,而这正是文档基金会在他们的公开信中所强调的:
|
||||
|
||||
> OpenOffice(.org),LibreOffice 的”父项目“,是一个伟大的办公套件,它改变了世界。它有着引人入胜的历史,但**自从 2014 年以来,Apache OpenOffice (它现在的家)还没有一个重大的版本**。没错,六年多来,没有重大的新功能或重大更新到来。很少有次要的发布,而且在及时的安全更新方面也存在问题。
|
||||
|
||||
对于一个普通用户来说,如果他们不知道 [LibreOffice][6],我肯定希望他们知道。但是,Apache 基金会是否应该建议 OpenOffice 用户尝试使用 LibreOffice 来体验更好或更高级的办公套件呢?
|
||||
|
||||
我不知道,也许是,或者不是?
|
||||
|
||||
> ...很多用户不知道 LibreOffice 的存在。OpenOffice 的品牌仍然如此强大,尽管该软件已经有六年多没有重大的版本发布,而且几乎没有人开发或支持它。
|
||||
|
||||
正如在公开信中提到的,文档基金会强调了 LibreOffice 相对于 OpenOffice的 优势/改进,并呼吁 Apache OpenOffice 开始推荐他们的用户尝试更好的东西(即 LibreOffice):
|
||||
|
||||
> 我们呼吁 Apache OpenOffice 做正确的事情。我们的目标应该是**把强大的、最新的、维护良好的生产力工具送到尽可能多的人手中**。让我们一起努力吧!
|
||||
|
||||
### Apache OpenOffice 应该做什么?
|
||||
|
||||
如果 OpenOffice 能完成工作,用户可能不需要努力寻找替代品。那么,因为他们的缓慢开发而呼唤另一个项目,建议用户采用未来工具并推荐它是一个好主意么?
|
||||
|
||||
在争论中,有人可能会说,如果你已经完成了,并且对改进 OpenOffice 没有兴趣,那么推广你的竞争对手才是公平的。而且,这并没有错,开源社区应该一直合作,以确保新用户得到最好的选择。
|
||||
|
||||
从另一个侧面来看,我们可以说,文档基金会对于 OpenOffice 在 2020 年即使没有任何重大改进却仍然有重要意义感到沮丧。
|
||||
|
||||
我不会去评判,但当我看了这封公开信时,这些矛盾的想法就浮现在我的脑海里。
|
||||
|
||||
### 你认为是时候把 OpenOffice 搁置起来,依靠 LibreOffice 了吗?
|
||||
|
||||
即使 LibreOffice 似乎是一个更优越的选择,并且绝对值得关注,你认为应该怎么做?Apache 是否应该停止 OpenOffice,并将用户重定向到 LibreOffice?
|
||||
|
||||
欢迎你的意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/libreoffice-letter-openoffice/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[2]: https://itsfoss.com/openoffice-shutdown/
|
||||
[3]: https://blog.documentfoundation.org/blog/2020/10/12/open-letter-to-apache-openoffice/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/libre-office-open-office.png?resize=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/libre-office-open-office-derivatives.jpg?resize=800%2C166&ssl=1
|
||||
[6]: https://itsfoss.com/libreoffice-tips/
|
||||
117
translated/tech/20201026 ninja- a simple way to do builds.md
Normal file
117
translated/tech/20201026 ninja- a simple way to do builds.md
Normal file
@ -0,0 +1,117 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (ninja: a simple way to do builds)
|
||||
[#]: via: (https://jvns.ca/blog/2020/10/26/ninja--a-simple-way-to-do-builds/)
|
||||
[#]: author: (Julia Evans https://jvns.ca/)
|
||||
|
||||
ninja:一个简单的构建方式
|
||||
======
|
||||
|
||||
大家好!每隔一段时间,我就会发现一款我非常喜欢的新软件,今天我想说说我最近喜欢的一款软件:[ninja][1]!
|
||||
|
||||
### 增量构建很有用
|
||||
|
||||
我做了很多小项目,在这些项目中,我想设置增量构建。例如,现在我正在写一本关于 bash 的杂志,杂志的每一页都有一个 `.svg`文件。我需要将 SVG 转换为 PDF,我的做法是这样的:
|
||||
|
||||
```
|
||||
for i in *.svg
|
||||
do
|
||||
svg2pdf $i $i.pdf # or ${i/.svg/.pdf} if you want to get really fancy
|
||||
done
|
||||
```
|
||||
|
||||
这很好用,但是我的 `svg2pdf` 脚本有点慢(它使用 Inkscape),而且当我刚刚只更新了一页的时候,必须等待 90 秒或者其他什么时间来重建所有的 PDF 文件,这很烦人。
|
||||
|
||||
### 构建系统是让人困惑的
|
||||
|
||||
在过去,我对使用 make 或 bazel 这样的构建系统来做我的小项目一直很反感,因为 bazel 是个大而复杂的东西,而 `make` 对我来说感觉有点神秘。我真的不知道如何使用它们中的任何一个。
|
||||
|
||||
所以很长时间以来,我只是写了一个 bash 脚本或者其他的东西来进行构建,然后就认命了,有时候只能等一分钟。
|
||||
|
||||
### ninja 是一个非常简单的构建系统
|
||||
|
||||
但 ninja 并不复杂!以下是我所知道的关于 ninja 构建文件的语法:如何创建一个 `rule `和一个 `build`:
|
||||
|
||||
`rule` 有一个命令和描述(描述只是给人看的,所以你可以知道它在构建你的代码时在做什么)。
|
||||
|
||||
```
|
||||
rule svg2pdf
|
||||
command = inkscape $in --export-text-to-path --export-pdf=$out
|
||||
description = svg2pdf $in $out
|
||||
```
|
||||
|
||||
`build` 的语法是 `build output_file: rule_name input_files`。下面是一个使用 `svg2pdf` 规则的例子。输出在规则中的 `$out` 里,输入在 `$in` 里。
|
||||
|
||||
```
|
||||
build pdfs/variables.pdf: svg2pdf variables.svg
|
||||
```
|
||||
|
||||
这就完成了!如果你把这两个东西放在一个叫 `build.ninja` 的文件里,然后运行 `ninja`,ninja 会运行 `inkscape variables.svg --export-text-to-path --export-pdf=pdfs/variables.pdf`。然后如果你再次运行它,它不会运行任何东西(因为它可以告诉你已经构建了 `pdfs/variables.pdf`,而且是最新的)。
|
||||
|
||||
Ninja 还有一些更多的功能(见[手册][2]),但我还没有用过。它最初是[为 Chromium][3] 构建的,所以即使只有一个小的功能集,它也能支持大型构建。
|
||||
|
||||
### ninja 文件通常是自动生成的
|
||||
|
||||
ninja 的神奇之处在于,你不必使用一些混乱的构建语言,它们很难记住(比如 make),因为你不经常使用它,相反,ninja 语言超级简单,如果你想做一些复杂的事情,那么你只需使用任意编程语言生成你想要的构建文件。
|
||||
|
||||
我喜欢写一个 `build.py` 文件,或者像这样的文件,创建 ninja 的构建文件,然后运行 `ninja`:
|
||||
|
||||
```
|
||||
with open('build.ninja', 'w') as ninja_file:
|
||||
# write some rules
|
||||
ninja_file.write("""
|
||||
rule svg2pdf
|
||||
command = inkscape $in --export-text-to-path --export-pdf=$out
|
||||
description = svg2pdf $in $out
|
||||
""")
|
||||
|
||||
# some for loop with every file I need to build
|
||||
for filename in things_to_convert:
|
||||
ninja_file.write(f"""
|
||||
build {filename.replace('svg', 'pdf')}: svg2pdf {filename}
|
||||
""")
|
||||
|
||||
# run ninja
|
||||
import subprocess
|
||||
subprocess.check_call(['ninja'])
|
||||
```
|
||||
|
||||
我相信有一堆 ninja 的最佳实践,但我不知道。对于我的小项目而言,我发现它很好用。
|
||||
|
||||
### meson 是一个生成 ninja 文件的构建系统
|
||||
|
||||
我对 [Meson][4] 还不太了解,但最近我在构建一个 C 程序 ([plocate][5],一个比 `locate` 更快的替代方案)时,我注意到它有不同的构建说明,而不是通常的 `./configure; make; make install`:
|
||||
|
||||
```
|
||||
meson builddir
|
||||
cd builddir
|
||||
ninja
|
||||
```
|
||||
|
||||
好像 Meson 是一个 C/C++/Java/Rust/Fortran 的构建系统,可以用 ninja 作为后端。
|
||||
|
||||
### 就是这些!
|
||||
|
||||
我使用 ninja 已经有几个月了。我真的很喜欢它,而且它几乎没有给我带来让人头疼的构建问题,这让我感觉非常神奇。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2020/10/26/ninja--a-simple-way-to-do-builds/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://jvns.ca/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://ninja-build.org/
|
||||
[2]: https://ninja-build.org/manual.html
|
||||
[3]: http://neugierig.org/software/chromium/notes/2011/02/ninja.html
|
||||
[4]: https://mesonbuild.com/Tutorial.html
|
||||
[5]: https://blog.sesse.net/blog/tech/2020-09-28-00-37_introducing_plocate
|
||||
Loading…
Reference in New Issue
Block a user