mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
15705a0bd3
@ -0,0 +1,188 @@
|
||||
Linux 上查看系统/服务器运行时间的 11 种方法
|
||||
======
|
||||
|
||||
你是否想知道自己的 Linux 系统正常运行了多长时间而没有宕机?系统是什么时候启动的?
|
||||
|
||||
Linux 上有多个查看服务器/系统运行时间的命令,大多数用户喜欢使用标准并且很有名的 `uptime` 命令获取这些具体的信息。
|
||||
|
||||
服务器的运行时间对一些用户来说不那么重要,但是当服务器运行诸如在线商城<ruby>门户<rt>portal</rt></ruby>、网上银行门户等<ruby>关键任务应用<rt>mission-critical applications</rt></ruby>时,它对于<ruby>服务器管理员<rt>server adminstrators</rt></ruby>来说就至关重要。
|
||||
|
||||
它必须做到零宕机,因为一旦停机就会影响到数百万用户。
|
||||
|
||||
正如我所说,许多命令都可以让用户看到 Linux 服务器的运行时间。在这篇教程里我会教你如何使用下面 11 种方式来查看。
|
||||
|
||||
<ruby>正常运行时间<rt>uptime</rt></ruby>指的是服务器自从上次关闭或重启以来经过的时间。
|
||||
|
||||
`uptime` 命令获取 `/proc` 文件中的详细信息并输出正常运行时间,而 `/proc` 文件并不适合人直接看。
|
||||
|
||||
以下这些命令会输出系统运行和启动的时间。也会显示一些额外的信息。
|
||||
|
||||
### 方法 1:使用 uptime 命令
|
||||
|
||||
`uptime` 命令会告诉你系统运行了多长时间。它会用一行显示以下信息。
|
||||
|
||||
当前时间、系统运行时间、当前登录用户的数量、过去 1 分钟/5 分钟/15 分钟系统负载的均值。
|
||||
|
||||
```
|
||||
# uptime
|
||||
|
||||
08:34:29 up 21 days, 5:46, 1 user, load average: 0.06, 0.04, 0.00
|
||||
```
|
||||
|
||||
### 方法 2:使用 w 命令
|
||||
|
||||
`w` 命令为每个登录进系统的用户,每个用户当前所做的事情,所有活动的负载对计算机的影响提供了一个快速的概要。这个单一命令结合了多个 Unix 程序:`who`、`uptime`,和 `ps -a` 的结果。
|
||||
|
||||
```
|
||||
# w
|
||||
|
||||
08:35:14 up 21 days, 5:47, 1 user, load average: 0.26, 0.09, 0.02
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
root pts/1 103.5.134.167 08:34 0.00s 0.01s 0.00s w
|
||||
```
|
||||
|
||||
### 方法 3:使用 top 命令
|
||||
|
||||
`top` 命令是 Linux 上监视实时系统进程的基础命令之一。它显示系统信息和运行进程的信息,例如正常运行时间、平均负载、运行的任务、登录用户数量、CPU 数量 & CPU 利用率、内存 & 交换空间信息。
|
||||
|
||||
**推荐阅读:**[TOP 命令监视服务器性能的例子][1]
|
||||
|
||||
```
|
||||
# top -c
|
||||
|
||||
top - 08:36:01 up 21 days, 5:48, 1 user, load average: 0.12, 0.08, 0.02
|
||||
Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie
|
||||
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Mem: 1872888k total, 1454644k used, 418244k free, 175804k buffers
|
||||
Swap: 2097148k total, 0k used, 2097148k free, 1098140k cached
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
1 root 20 0 19340 1492 1172 S 0.0 0.1 0:01.04 /sbin/init
|
||||
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kthreadd]
|
||||
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 [migration/0]
|
||||
4 root 20 0 0 0 0 S 0.0 0.0 0:34.32 [ksoftirqd/0]
|
||||
5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 [stopper/0]
|
||||
```
|
||||
|
||||
### 方法 4:使用 who 命令
|
||||
|
||||
`who` 命令列出当前登录进计算机的用户。`who` 命令与 `w` 命令类似,但后者还包含额外的数据和统计信息。
|
||||
|
||||
```
|
||||
# who -b
|
||||
system boot 2018-04-12 02:48
|
||||
```
|
||||
|
||||
### 方法 5:使用 last 命令
|
||||
|
||||
`last` 命令列出最近登录过的用户。`last` 回溯 `/var/log/wtmp` 文件并显示自从文件创建后登录进(出)的用户。
|
||||
|
||||
```
|
||||
# last reboot -F | head -1 | awk '{print $5,$6,$7,$8,$9}'
|
||||
Thu Apr 12 02:48:04 2018
|
||||
```
|
||||
|
||||
### 方法 6:使用 /proc/uptime 文件
|
||||
|
||||
这个文件中包含系统上次启动后运行时间的详细信息。`/proc/uptime` 的输出相当精简。
|
||||
|
||||
第一个数字是系统自从启动的总秒数。第二个数字是总时间中系统空闲所花费的时间,以秒为单位。
|
||||
|
||||
```
|
||||
# cat /proc/uptime
|
||||
1835457.68 1809207.16
|
||||
```
|
||||
|
||||
### 方法 7:使用 tuptime 命令
|
||||
|
||||
`tuptime` 是一个汇报系统运行时间的工具,输出历史信息并作以统计,保留重启之间的数据。和 `uptime` 命令很像,但输出更有意思一些。
|
||||
|
||||
```
|
||||
$ tuptime
|
||||
```
|
||||
|
||||
### 方法 8:使用 htop 命令
|
||||
|
||||
`htop` 是运行在 Linux 上的一个交互式进程查看器,是 Hisham 使用 ncurses 库开发的。`htop` 比起 `top` 有很多的特性和选项。
|
||||
|
||||
**推荐阅读:** [使用 Htop 命令监控系统资源][2]
|
||||
|
||||
```
|
||||
# htop
|
||||
|
||||
CPU[| 0.5%] Tasks: 48, 5 thr; 1 running
|
||||
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||| 165/1828MB] Load average: 0.10 0.05 0.01
|
||||
Swp[ 0/2047MB] Uptime: 21 days, 05:52:35
|
||||
|
||||
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
|
||||
29166 root 20 0 110M 2484 1240 R 0.0 0.1 0:00.03 htop
|
||||
29580 root 20 0 11464 3500 1032 S 0.0 0.2 55:15.97 /bin/sh ./OSWatcher.sh 10 1
|
||||
1 root 20 0 19340 1492 1172 S 0.0 0.1 0:01.04 /sbin/init
|
||||
486 root 16 -4 10780 900 348 S 0.0 0.0 0:00.07 /sbin/udevd -d
|
||||
748 root 18 -2 10780 932 360 S 0.0 0.0 0:00.00 /sbin/udevd -d
|
||||
```
|
||||
|
||||
### 方法 9:使用 glances 命令
|
||||
|
||||
`glances` 是一个跨平台的基于 curses 库的监控工具,它是使用 python 编写的。可以说它非常强大,仅用一点空间就能获得很多信息。它使用 psutil 库从系统中获取信息。
|
||||
|
||||
`glances` 可以监控 CPU、内存、负载、进程、网络接口、磁盘 I/O、<ruby>磁盘阵列<rt>RAID</rt></ruby>、传感器、文件系统(与文件夹)、容器、监视器、Alert 日志、系统信息、运行时间、<ruby>快速查看<rt>Quicklook</rt></ruby>(CPU,内存、负载)等。
|
||||
|
||||
**推荐阅读:** [Glances (集大成)– Linux 上高级的实时系统运行监控工具][3]
|
||||
|
||||
```
|
||||
glances
|
||||
|
||||
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 21 days, 05:55:15
|
||||
|
||||
CPU [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
|
||||
MEM [||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
|
||||
SWAP [|||| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
|
||||
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
|
||||
|
||||
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
|
||||
docker0 0b 232b
|
||||
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
|
||||
lo 616b 616b
|
||||
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
|
||||
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
|
||||
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
|
||||
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
```
|
||||
|
||||
### 方法 10:使用 stat 命令
|
||||
|
||||
`stat` 命令显示指定文件或文件系统的详细状态。
|
||||
|
||||
```
|
||||
# stat /var/log/dmesg | grep Modify
|
||||
Modify: 2018-04-12 02:48:04.027999943 -0400
|
||||
```
|
||||
|
||||
### 方法 11:使用 procinfo 命令
|
||||
|
||||
`procinfo` 从 `/proc` 文件夹下收集一些系统数据并将其很好的格式化输出在标准输出设备上。
|
||||
|
||||
```
|
||||
# procinfo | grep Bootup
|
||||
Bootup: Fri Apr 20 19:40:14 2018 Load average: 0.16 0.05 0.06 1/138 16615
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
|
||||
[2]:https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/
|
||||
[3]:https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/
|
||||
107
sources/talk/20150513 XML vs JSON.md
Normal file
107
sources/talk/20150513 XML vs JSON.md
Normal file
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (XML vs JSON)
|
||||
[#]: via: (https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#xml-advantages)
|
||||
[#]: author: (TOM STRASSNER tomstrassner@gmail.com)
|
||||
|
||||
XML vs JSON
|
||||
======
|
||||
|
||||
### Introduction
|
||||
|
||||
XML and JSON are the two most common formats for data interchange in the Web today. XML was created by the W3C in 1996, and JSON was publicly specified by Douglas Crockford in 2002. Although their purposes are not identical, they are frequently used to accomplish the same task, which is data interchange. Both have well-documented open standards on the Web ([RFC 7159][1], [RFC 4825][2]), and both are human and machine-readable. Neither one is absolutely superior to the other, as each is better suited for different use cases.
|
||||
|
||||
### XML Advantages
|
||||
|
||||
There are several advantages that XML has over JSON. One of the biggest differences between the two is that in XML you can put metadata into the tags in the form of attributes. With JSON, the programmer could accomplish the same goal that metadata achieves by making the entity an object and adding the attributes as members of the object. However, the way XML does it may often be preferable, given the slightly misleading nature of turning something into an object that is not one in the client program. For example, if your C++ program sends an int via JSON and needs metadata to be sent along with it, you would have to make it an object, with one name/value pair for the actual value of the int, and more name/value pairs for each attribute. The program that receives the JSON would read it as an object, when in fact it is not one. While this is a viable solution, it defies one of JSON’s key advantages: “JSON's structures look like conventional programming language structures. No restructuring is necessary.”[2]
|
||||
|
||||
Although I will argue later that this can also be a drawback of XML, its mechanism to resolve name conflicts, prefixes, gives it power that JSON does not have. With prefixes, the programmer has the ability to name two different kinds of entities the same thing.[1] This would be advantageous in situations where the different entities should have the same name in the client program, perhaps if they are used in entirely different scopes.
|
||||
|
||||
Another advantage of XML is that most browsers render it in a highly readable and organized way. The tree structure of XML lends itself well to this formatting, and allows for browsers to let users to naturally collapse individual tree elements. This feature would be particularly useful in debugging.
|
||||
|
||||
One of the most significant advantages that XML has over JSON is its ability to communicate mixed content, i.e. strings that contain structured markup. In order to handle this with XML, the programmer need only put the marked-up text within a child tag of the parent in which it belongs. Similar to the metadata situation, since JSON only contains data, there is no such simple way to indicate markup. It would again require storing metadata as data, which could be considered an abuse of the format.
|
||||
|
||||
### JSON Advantages
|
||||
|
||||
JSON has several advantages as well. One of the most obvious of these is that JSON is significantly less verbose than XML, because XML necessitates opening and closing tags (or in some cases less verbose self-closing tags), and JSON uses name/value pairs, concisely delineated by “{“ and “}” for objects, “[“ and “]” for arrays, “,” to separate pairs, and “:” to separate name from value. Even when zipped (using gzip), JSON is still smaller and it takes less time to zip it.[6] As determined by Sumaray and Makki as well as Nurseitov, Paulson, Reynolds, and Izurieta in their experimental findings, JSON outperforms XML in a number of ways. First, naturally following from its conciseness, JSON files that contain the same information as their XML counterparts are almost always significantly smaller, which leads to faster transmission and processing. Second, difference in size aside, both groups found that JSON was serialized and deserialized drastically faster than XML.[3][4] Third, the latter study determined that JSON processing outdoes XML in CPU resource utilization. They found that JSON used less total resources, more user CPU, and less system CPU. The experiment used RedHat machines, and RedHat claims that higher user CPU usage is preferable.[3] Unsurprisingly, the Sumaray and Makki study determined that JSON performance is superior to XML on mobile devices too.[4] This makes sense, given that JSON uses less resources, and mobile devices are less powerful than desktop machines.
|
||||
|
||||
Yet another advantage that JSON has over XML is that its representation of objects and arrays allows for direct mapping onto the corresponding data structures in the host language, such as objects, records, structs, dictionaries, hash tables, keyed lists, and associative arrays for objects, and arrays, vectors, lists, and sequences for arrays.[2] Although it is perfectly possible to represent these structures in XML, it is only as a function of the parsing, and it takes more code to serialize and deserialize properly. It also would not always be obvious to the reader of arbitrary XML what tags represent an object and what tags represent an array, especially because nested tags can just as easily be structured markup instead. The curly braces and brackets of JSON definitively show the structure of the data. However, this advantage does come with the caveat explained above, that the JSON can inaccurately represent the data if the need arises to send metadata.
|
||||
|
||||
Although XML supports namespaces and prefixes, JSON’s handling of name collisions is less verbose than prefixes, and arguably feels more natural with the program using it; in JSON, each object is its own namespace, so names may be repeated as long as they are in different scopes. This may be preferable, as in most programming languages members of different objects can have the same name, because they are distinguished by the names of the objects to which they belong.
|
||||
|
||||
Perhaps the most significant advantage that JSON has over XML is that JSON is a subset of JavaScript, so code to parse and package it fits very naturally into JavaScript code. This seems highly beneficial for JavaScript programs, but does not directly benefit any programs that use languages other than JavaScript. However, this drawback has been largely overcome, as currently the JSON website lists over 175 tools for 64 different programming languages that exist to integrate JSON processing. While I cannot speak to the quality of most of these tools, it is clear that the developer community has embraced JSON and has made it simple to use in many different platforms.
|
||||
|
||||
### Purposes
|
||||
|
||||
Simply put, XML’s purpose is document markup. This is decidedly not a purpose of JSON, so XML should be used whenever this is what needs to be done. It accomplishes this purpose by giving semantic meaning to text through its tree-like structure and ability to represent mixed content. Data structures can be represented in XML, but that is not its purpose.
|
||||
|
||||
JSON’s purpose is structured data interchange. It serves this purpose by directly representing objects, arrays, numbers, strings, and booleans. Its purpose is distinctly not document markup. As described above, JSON does not have a natural way to represent mixed content.
|
||||
|
||||
### Software
|
||||
|
||||
The following major public APIs uses XML only: Amazon Product Advertising API.
|
||||
|
||||
The following major APIs use JSON only: Facebook Graph API, Google Maps API, Twitter API, AccuWeather API, Pinterest API, Reddit API, Foursquare API.
|
||||
|
||||
The following major APIs use both XML and JSON: Google Cloud Storage, Linkedin API, Flickr API
|
||||
|
||||
Of the top 10 most popular APIs according to Programmable Web[9], along with a couple more popular ones, only one supports XML and not JSON. Several support both, and several support only JSON. Among developer APIs for modern and popular websites, JSON clearly seems to be preferred. This also indicates that more app developers that use these APIs prefer JSON. This is likely a result of its reputation as the faster and leaner of the two. Furthermore, most of these APIs communicate data rather than documents, so JSON would be more appropriate. For example, Facebook is mainly concerned with communicating data about users and posts, Google Maps deals in coordinates and information about entities on their maps, and AccuWeather just sends weather data. Overall, it is impossible to say whether JSON or XML is currently used more in APIs, but the trend is certainly swinging towards JSON.[10][11]
|
||||
|
||||
The following major desktop software uses XML only: Microsoft Word, Apache OpenOffice, LibreOffice.
|
||||
|
||||
It makes sense for software that is mainly concerned with document creation, manipulation, and storage to use XML rather than JSON. Also, all three of these programs support mixed content, which JSON does not do well. For example, if a user is typing up an essay in Microsoft Word, they may put different font, size, color, positioning, and styling on different blocks of text. XML naturally represents these properties with nested tags and attributes.
|
||||
|
||||
The following major databases support XML: IBM DB2, Microsoft SQL Server, Oracle Database, PostgresSQL, BaseX, eXistDB, MarkLogic, MySQL.
|
||||
|
||||
The following major databases support JSON: MongoDB, CouchDB, eXistDB, Elastisearch, BaseX, MarkLogic, OrientDB, Oracle Database, PostgresSQL, Riak.
|
||||
|
||||
For a long time, SQL and the relational database model dominated the market. Corporate giants like Oracle and Microsoft have always marketed such databases. However, in the last decade, there has been a major rise in popularity of NoSQL databases. As this has coincided with the rise of JSON, most NoSQL databases support JSON, and some, such as MongoDB, CouchDB, and Riak use JSON to store their data. These databases have two important qualities that make them better suited for modern websites: they are generally more scalable than relational SQL databases, and they are designed to the core to run in the Web.[10] Since JSON is more lightweight and a subset of JavaScript, it suits NoSQL databases well, and helps facilitate these two qualities. In addition, many older databases have added support for JSON, such as Oracle Database and PostgresSQL. Conversion between XML and JSON is a hassle, so naturally, as more developers use JSON for their apps, more database companies have incentive to support it.[7]
|
||||
|
||||
### Future
|
||||
|
||||
One of the most heavily anticipated changes in the Internet is the “Internet of Things”, i.e. the addition to the Internet of non-computer devices such as watches, thermostats, televisions, refrigerators, etc. This movement is well underway, and is expected to explode in the near future, as predictions for the number of devices in the Internet of Things in 2020 range from about 26 billion to 200 billion.[12][13][13] Almost all of these devices are smaller and less powerful than laptop and desktop computers. Many of them only run embedded systems. Thus, when they have the need to exchange data with other entities in the Web, the lighter and faster JSON would naturally be preferable to XML.[10] Also, with the recent rapid rise of JSON use in the Web relative to XML, new devices may benefit more from speaking JSON. This highlights an example of Metcalf’s Law; whether XML or JSON or something entirely new becomes the most popular format in the Web, newly added devices and all existing devices will benefit much more if the newly added devices speak the most popular language.
|
||||
|
||||
With the creation and recent rapid increase in popularity of Node.js, a server-side JavaScript framework, along with NoSQL databases like MongoDB, full-stack JavaScript development has become a reality. This bodes well for the future of JSON, as with these new apps, JSON is spoken at every level of the stack, which generally makes the apps very fast and lightweight. This is a desirable trait for any app, so this trend towards full-stack JavaScript is not likely to die out anytime soon.[10]
|
||||
|
||||
Another existing trend in the world of app development is toward REST and away from SOAP.[11][15][16] Both XML and JSON can be used with REST, but SOAP exclusively uses XML.
|
||||
|
||||
The given trends indicate that JSON will continue to dominate the Web, and XML use will continue to decrease. This should not be overblown, however, because XML is still very heavily used in the Web, and it is the only option for apps that use SOAP. Given the widespread migration from SOAP to REST, the rise of NoSQL databases and full-stack JavaScript, and the far superior performance of JSON, I believe that JSON will soon be much more widely used than XML in the Web. There seem to be very few applications where XML is the better choice.
|
||||
|
||||
### References
|
||||
|
||||
1. [XML Tutorial](http://www.w3schools.com/xml/default.asp)
|
||||
2. [Introducing JSON](http://www.json.org/)
|
||||
3. [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf)
|
||||
4. [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810)
|
||||
5. [JSON vs. XML: The Debate](http://ajaxian.com/archives/json-vs-xml-the-debate)
|
||||
6. [JSON vs. XML: Some hard numbers about verbosity](http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity)
|
||||
7. [How JSON sparked NoSQL -- and will return to the RDBMS fold](http://www.infoworld.com/article/2608293/nosql/how-json-sparked-nosql----and-will-return-to-the-rdbms-fold.html)
|
||||
8. [Did You Say "JSON Support" in Oracle 12.1.0.2?](https://blogs.oracle.com/OTN-DBA-DEV-Watercooler/entry/did_you_say_json_support)
|
||||
9. [Most Popular APIs: At Least One Will Surprise You](http://www.programmableweb.com/news/most-popular-apis-least-one-will-surprise-you/2014/01/23)
|
||||
10. [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
11. [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/)
|
||||
12. [A Simple Explanation Of 'The Internet Of Things’](http://www.forbes.com/sites/jacobmorgan/2014/05/13/simple-explanation-internet-things-that-anyone-can-understand/)
|
||||
13. [Proofpoint Uncovers Internet of Things (IoT) Cyberattack](http://www.proofpoint.com/about-us/press-releases/01162014.php)
|
||||
14. [The Internet of Things: New Threats Emerge in a Connected World](http://www.symantec.com/connect/blogs/internet-things-new-threats-emerge-connected-world)
|
||||
15. [3,000 Web APIs: Trends From A Quickly Growing Directory](http://www.programmableweb.com/news/3000-web-apis-trends-quickly-growing-directory/2011/03/08)
|
||||
16. [How REST replaced SOAP on the Web: What it means to you](http://www.infoq.com/articles/rest-soap)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#xml-advantages
|
||||
|
||||
作者:[TOM STRASSNER][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: tomstrassner@gmail.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://tools.ietf.org/html/rfc7159
|
||||
[2]: https://tools.ietf.org/html/rfc4825
|
||||
@ -1,3 +1,5 @@
|
||||
translating by hopefully2333
|
||||
|
||||
5 ways DevSecOps changes security
|
||||
======
|
||||
|
||||
|
||||
@ -1,64 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 resolutions for open source project maintainers)
|
||||
[#]: via: (https://opensource.com/article/18/12/resolutions-open-source-project-maintainers)
|
||||
[#]: author: (Ben Cotton https://opensource.com/users/bcotton)
|
||||
|
||||
5 resolutions for open source project maintainers
|
||||
======
|
||||
No matter how you say it, good communication is essential to strong open source communities.
|
||||

|
||||
|
||||
I'm generally not big on New Year's resolutions. I have no problem with self-improvement, of course, but I tend to anchor around other parts of the calendar. Even so, there's something about taking down this year's free calendar and replacing it with next year's that inspires some introspection.
|
||||
|
||||
In 2017, I resolved to not share articles on social media until I'd read them. I've kept to that pretty well, and I'd like to think it has made me a better citizen of the internet. For 2019, I'm thinking about resolutions to make me a better open source software maintainer.
|
||||
|
||||
Here are some resolutions I'll try to stick to on the projects where I'm a maintainer or co-maintainer.
|
||||
|
||||
### 1\. Include a code of conduct
|
||||
|
||||
Jono Bacon included "not enforcing the code of conduct" in his article "[7 mistakes you're probably making][1]." Of course, to enforce a code of conduct, you must first have a code of conduct. I plan on defaulting to the [Contributor Covenant][2], but you can use whatever you like. As with licenses, it's probably best to use one that's already written instead of writing your own. But the important thing is to find something that defines how you want your community to behave, whatever that looks like. Once it's written down and enforced, people can decide for themselves if it looks like the kind of community they want to be a part of.
|
||||
|
||||
### 2\. Make the license clear and specific
|
||||
|
||||
You know what really stinks? Unclear licenses. "This software is licensed under the GPL" with no further text doesn't tell me much. Which version of the [GPL][3]? Do I get to pick? For non-code portions of a project, "licensed under a Creative Commons license" is even worse. I love the [Creative Commons licenses][4], but there are several different licenses with significantly different rights and obligations. So, I will make it very clear which variant and version of a license applies to my projects. I will include the full text of the license in the repo and a concise note in the other files.
|
||||
|
||||
Sort of related to this is using an [OSI][5]-approved license. It's tempting to come up with a new license that says exactly what you want it to say, but good luck if you ever need to enforce it. Will it hold up? Will the people using your project understand it?
|
||||
|
||||
### 3\. Triage bug reports and questions quickly
|
||||
|
||||
Few things in technology scale as poorly as open source maintainers. Even on small projects, it can be hard to find the time to answer every question and fix every bug. But that doesn't mean I can't at least acknowledge the person. It doesn't have to be a multi-paragraph reply. Even just labeling the GitHub issue shows that I saw it. Maybe I'll get to it right away. Maybe I'll get to it a year later. But it's important for the community to see that, yes, there is still someone here.
|
||||
|
||||
### 4\. Don't push features or bug fixes without accompanying documentation
|
||||
|
||||
For as much as my open source contributions over the years have revolved around documentation, my projects don't reflect the importance I put on it. There aren't many commits I can push that don't require some form of documentation. New features should obviously be documented at (or before!) the time they're committed. But even bug fixes should get an entry in the release notes. If nothing else, a push is a good opportunity to also make a commit to improving the docs.
|
||||
|
||||
### 5\. Make it clear when I'm abandoning a project
|
||||
|
||||
I'm really bad at saying "no" to things. I told the editors I'd write one or two articles for [Opensource.com][6] and here I am almost 60 articles later. Oops. But at some point, the things that once held my interests no longer do. Maybe the project is unnecessary because its functionality got absorbed into a larger project. Maybe I'm just tired of it. But it's unfair to the community (and potentially dangerous, as the recent [event-stream malware injection][7] showed) to leave a project in limbo. Maintainers have the right to walk away whenever and for whatever reason, but it should be clear that they have.
|
||||
|
||||
Whether you're an open source maintainer or contributor, if you know other resolutions project maintainers should make, please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/resolutions-open-source-project-maintainers
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/8/mistakes-open-source-avoid
|
||||
[2]: https://www.contributor-covenant.org/
|
||||
[3]: https://opensource.org/licenses/gpl-license
|
||||
[4]: https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[5]: https://opensource.org/
|
||||
[6]: http://Opensource.com
|
||||
[7]: https://arstechnica.com/information-technology/2018/11/hacker-backdoors-widely-used-open-source-software-to-steal-bitcoin/
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (NSA to Open Source its Reverse Engineering Tool GHIDRA)
|
||||
[#]: via: (https://itsfoss.com/nsa-ghidra-open-source)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
NSA to Open Source its Reverse Engineering Tool GHIDRA
|
||||
======
|
||||
|
||||
GHIDRA – NSA’s reverse engineering tool is getting ready for a free public release this March at the [RSA Conference 2019][1] to be held in San Francisco.
|
||||
|
||||
The National Security Agency (NSA) did not officially announce this – however – a senior NSA advisor, Robert Joyce’s [session description][2] on the official RSA conference website revealed about it before any official statement or announcement.
|
||||
|
||||
Here’s what it mentioned:
|
||||
|
||||
![][3]
|
||||
Image Credits: [Twitter][4]
|
||||
|
||||
In case the text in the image isn’t properly visible, let me quote the description here:
|
||||
|
||||
> NSA has developed a software reverse engineering framework known as GHIDRA, which will be demonstrated for the first time at RSAC 2019. An interactive GUI capability enables reverse engineers to leverage an integrated set of features that run on a variety of platforms including Windows, Mac OS, and Linux and supports a variety of processor instruction sets. The GHISDRA platform includes all the features expected in high-end commercial tools, with new and expanded functionality NSA uniquely developed. and will be released for free public use at RSA.
|
||||
|
||||
### What is GHIDRA?
|
||||
|
||||
GHIDRA is a software reverse engineering framework developed by [NSA][5] that is in use by the agency for more than a decade.
|
||||
|
||||
Basically, a software reverse engineering tool helps to dig up the source code of a proprietary program which further gives you the ability to detect virus threats or potential bugs. You should read how [reverse engineering][6] works to know more.
|
||||
|
||||
The tool is is written in Java and quite a few people compared it to high-end commercial reverse engineering tools available like [IDA][7].
|
||||
|
||||
A [Reddit thread][8] involves more detailed discussion where you will find some ex-employees giving good amount of details before the availability of the tool.
|
||||
|
||||
![NSA open source][9]
|
||||
|
||||
### GHIDRA was a secret tool, how do we know about it?
|
||||
|
||||
The existence of the tool was uncovered in a series of leaks by [WikiLeaks][10] as part of [Vault 7 documents of CIA][11].
|
||||
|
||||
### Is it going to be open source?
|
||||
|
||||
We do think that the reverse engineering tool to be released could be made open source. Even though there is no official confirmation mentioning “open source” – but a lot of people do believe that NSA is definitely targeting the open source community to help improve their tool while also reducing their effort to maintain this tool.
|
||||
|
||||
This way the tool can remain free and the open source community can help improve GHIDRA as well.
|
||||
|
||||
You can also check out the existing [Vault 7 document at WikiLeaks][12] to come up with your prediction.
|
||||
|
||||
### Is NSA doing a good job here?
|
||||
|
||||
The reverse engineering tool is going to be available for Windows, Linux, and Mac OS for free.
|
||||
|
||||
Of course, we care about the Linux platform here – which could be a very good option for people who do not want to or cannot afford a thousand dollar license for a reverse engineering tool with the best-in-class features.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
If GHIDRA becomes open source and is available for free, it would definitely help a lot of researchers and students and on the other side – the competitors will be forced to adjust their pricing.
|
||||
|
||||
What are your thoughts about it? Is it a good thing? What do you think about the tool going open sources Let us know what you think in the comments below.
|
||||
|
||||
![][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/nsa-ghidra-open-source
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.rsaconference.com/events/us19
|
||||
[2]: https://www.rsaconference.com/events/us19/agenda/sessions/16608-come-get-your-free-nsa-reverse-engineering-tool
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/come-get-your-free-nsa.jpg?fit=800%2C337&ssl=1
|
||||
[4]: https://twitter.com/0xffff0800/status/1080909700701405184
|
||||
[5]: http://nsa.gov
|
||||
[6]: https://en.wikipedia.org/wiki/Reverse_engineering
|
||||
[7]: https://en.wikipedia.org/wiki/Interactive_Disassembler
|
||||
[8]: https://www.reddit.com/r/ReverseEngineering/comments/ace2m3/come_get_your_free_nsa_reverse_engineering_tool/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/nsa-open-source.jpeg?resize=800%2C450&ssl=1
|
||||
[10]: https://www.wikileaks.org/
|
||||
[11]: https://en.wikipedia.org/wiki/Vault_7
|
||||
[12]: https://wikileaks.org/ciav7p1/cms/page_9536070.html
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/nsa-open-source.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What metrics matter: A guide for open source projects)
|
||||
[#]: via: (https://opensource.com/article/19/1/metrics-guide-open-source-projects)
|
||||
[#]: author: (Gordon Haff https://opensource.com/users/ghaff)
|
||||
|
||||
What metrics matter: A guide for open source projects
|
||||
======
|
||||
5 principles for deciding what to measure.
|
||||

|
||||
|
||||
"Without data, you're just a person with an opinion."
|
||||
|
||||
Those are the words of W. Edwards Deming, the champion of statistical process control, who was credited as one of the inspirations for what became known as the Japanese post-war economic miracle of 1950 to 1960. Ironically, Japanese manufacturers like Toyota were far more receptive to Deming’s ideas than General Motors and Ford were.
|
||||
|
||||
Community management is certainly an art. It’s about mentoring. It’s about having difficult conversations with people who are hurting the community. It’s about negotiation and compromise. It’s about interacting with other communities. It’s about making connections. In the words of Red Hat’s Diane Mueller, it’s about "nurturing conversations."
|
||||
|
||||
However, it’s also about metrics and data.
|
||||
|
||||
Some have much in common with software development projects more broadly. Others are more specific to the management of the community itself. I think of deciding what to measure and how as adhering to five principles.
|
||||
|
||||
### 1. Recognize that behaviors aren't independent of the measurements you choose to highlight.
|
||||
|
||||
In 2008, Daniel Ariely published Predictably Irrational, one of a number of books written around that time that introduced behavioral psychology and behavioral economics to the general public. One memorable quote from that book is the following: “Human beings adjust behavior based on the metrics they’re held against. Anything you measure will impel a person to optimize his score on that metric. What you measure is what you’ll get. Period.”
|
||||
|
||||
This shouldn’t be surprising. It’s a finding that’s been repeatedly confirmed by research. It should also be familiar to just about anyone with business experience. It’s certainly not news to anyone in sales management, for example. Base sales reps’ (or their managers’) bonuses solely on revenue, and they’ll try to discount whatever it takes to maximize revenue, even if it puts margin in the toilet. Conversely, want the sales force to push a new product line—which will probably take extra effort—but skip the spiffs? Probably not happening.
|
||||
|
||||
And lest you think I’m unfairly picking on sales, this behavior is pervasive, all the way up to the CEO, as Ariely describes in a 2010 Harvard Business Review article: “CEOs care about stock value because that’s how we measure them. If we want to change what they care about, we should change what we measure.”
|
||||
|
||||
Developers and other community members are not immune.
|
||||
|
||||
### 2. You need to choose relevant metrics.
|
||||
|
||||
There’s a lot of folk wisdom floating around about what’s relevant and important that’s not necessarily true. My colleague [Dave Neary offers an example from baseball][1]: “In the late '90s, the key measurements that were used to measure batter skill were RBI (runs batted in) and batting average (how often a player got on base with a hit, divided by the number of at-bats). The Oakland A’s were the first major league team to recruit based on a different measurement of player performance: on-base percentage. This measures how often they get to first base, regardless of how it happens.”
|
||||
|
||||
Indeed, the whole revolution of sabermetrics in baseball and elsewhere, which was popularized in Michael Lewis’ Moneyball, often gets talked about in terms of introducing data in a field that historically was more about gut feel and personal experience. But it was also about taking a game that had actually always been fairly numbers-obsessed and coming up with new metrics based on mostly existing data to better measure player value. (The data revolution going on in sports today is more about collecting much more data through video and other means than was previously available.)
|
||||
|
||||
### 3. Quantity may not lead to quality.
|
||||
|
||||
As a corollary, collecting lots of tangential but easy-to-capture data isn’t better than just selecting a few measurements you’ve determined are genuinely useful. In a world where online behavior can be tracked with great granularity and displayed in colorful dashboards, it’s tempting to be distracted by sheer data volume, even when it doesn’t deliver any great insight into community health and trajectory.
|
||||
|
||||
This may seem like an obvious point: Why measure something that isn’t relevant? In practice, metrics often get chosen because they’re easy to measure, not because they’re particularly useful. They tend to be more about inputs than outputs: The number of developers. The number of forum posts. The number of commits. Collectively, measures like this often get called vanity metrics. They’re ubiquitous, but most people involved with community management don’t think much of them.
|
||||
|
||||
Number of downloads may be the worst of the bunch. It’s true that, at some level, they’re an indication of interest in a project. That’s something. But it’s sufficiently distant from actively using the project, much less engaging with the project deeply, that it’s hard to view downloads as a very useful number.
|
||||
|
||||
Is there any harm in these vanity metrics? Yes, to the degree that you start thinking that they’re something to base action on. Probably more seriously, stakeholders like company management or industry observers can come to see them as meaningful indicators of project health.
|
||||
|
||||
### 4. Understand what measurements really mean and how they relate to each other.
|
||||
|
||||
Neary makes this point to caution against myopia. “In one project I worked on,” he says, ”some people were concerned about a recent spike in the number of bug reports coming in because it seemed like the project must have serious quality issues to resolve. However, when we looked at the numbers, it turned out that many of the bugs were coming in because a large company had recently started using the project. The increase in bug reports was actually a proxy for a big influx of new users, which was a good thing.”
|
||||
|
||||
In practice, you often have to measure through proxies. This isn’t an inherent problem, but the further you get between what you want to measure and what you’re actually measuring, the harder it is to connect the dots. It’s fine to track progress in closing bugs, writing code, and adding new features. However, those don’t necessarily correlate with how happy users are or whether the project is doing a good job of working towards its long-term objectives, whatever those may be.
|
||||
|
||||
### 5. Different measurements serve different purposes.
|
||||
|
||||
Some measurements may be non-obvious but useful for tracking the success of a project and community relative to internal goals. Others may be better suited for a press release or other external consumption. For example, as a community manager, you may really care about the number of meetups, mentoring sessions, and virtual briefings your community has held over the past three months. But it’s the number of contributions and contributors that are more likely to grab the headlines. You probably care about those too. But maybe not as much, depending upon your current priorities.
|
||||
|
||||
Still, other measurements may relate to the goals of any sponsoring organizations. The measurements most relevant for projects tied to commercial products are likely to be different from pure community efforts.
|
||||
|
||||
Because communities differ and goals differ, it’s not possible to simply compile a metrics checklist, but here are some ideas to think about:
|
||||
|
||||
Consider qualitative metrics in addition to quantitative ones. Conducting surveys and other studies can be time-consuming, especially if they’re rigorous enough to yield better-than-anecdotal data. It also requires rigor to construct studies so that they can be used to track changes over time. In other words, it’s a lot easier to measure quantitative contributor activity than it is to suss out if the community members are happier about their participation today than they were a year ago. However, given the importance of culture to the health of a community, measuring it in a systematic way can be a worthwhile exercise.
|
||||
|
||||
Breadth of community, including how many are unaffiliated with commercial entities, is important for many projects. The greater the breadth, the greater the potential leverage of the open source development process. It can also be instructive to see how companies and individuals are contributing. Projects can be explicitly designed to better accommodate casual contributors.
|
||||
|
||||
Are new contributors able to have an impact, or are they ignored? How long does it take for code contributions to get committed? How long does it take for a reported bug to be fixed or otherwise responded to? If they asked a question in a forum, did anyone answer them? In other words, are you letting contributors contribute?
|
||||
|
||||
Advancement within the project is also an important metric. [Mikeal Rogers of the Node.js community][2] explains: “The shift that we made was to create a support system and an education system to take a user and turn them into a contributor, first at a very low level, and educate them to bring them into the committer pool and eventually into the maintainer pool. The end result of this is that we have a wide range of skill sets. Rather than trying to attract phenomenal developers, we’re creating new phenomenal developers.”
|
||||
|
||||
Whatever metrics you choose, don’t forget why you made them metrics in the first place. I find a helpful question to ask is: “What am I going to do with this number?” If the answer is to just put it in a report or in a press release, that’s not a great answer. Metrics should be measurements that tell you either that you’re on the right path or that you need to take specific actions to course-correct.
|
||||
|
||||
For this reason, Stormy Peters, who handles community leads at Red Hat, [argues for keeping it simple][3]. She writes, “It’s much better to have one or two key metrics than to worry about all the possible metrics. You can capture all the possible metrics, but as a project, you should focus on moving one. It’s also better to have a simple metric that correlates directly to something in the real world than a metric that is a complicated formula or ration between multiple things. As project members make decisions, you want them to be able to intuitively feel whether or not it will affect the project’s key metric in the right direction.”
|
||||
|
||||
The article is adapted from [How Open Source Ate Software][4] by Gordon Haff (Apress 2018).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/metrics-guide-open-source-projects
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ghaff
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://community.redhat.com/blog/2014/07/when-metrics-go-wrong/
|
||||
[2]: https://opensource.com/article/17/3/nodejs-community-casual-contributors
|
||||
[3]: https://medium.com/open-source-communities/3-important-things-to-consider-when-measuring-your-success-50e21ad82858
|
||||
[4]: https://www.apress.com/us/book/9781484238936
|
||||
@ -0,0 +1,76 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (You (probably) don't need Kubernetes)
|
||||
[#]: via: (https://arp242.net/weblog/dont-need-k8s.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
You (probably) don't need Kubernetes
|
||||
======
|
||||
|
||||
This may perhaps be an unpopular opinion, but the overwhelming majority of companies are probably better off not using k8s.
|
||||
|
||||
You know those old “Hello world according to programmer skill” jokes that start with `printf("hello, world\n")` for a junior programmer and end with some convoluted Java OOP design pattern solution for senior software architect engineer? This is kind of like that.
|
||||
|
||||
* Junior sysops
|
||||
`./binary`
|
||||
* Experienced sysops
|
||||
`./binary` on EC2.
|
||||
* devops
|
||||
Self-deployed CI pipeline to run `./binary` on EC2.
|
||||
* Senior cloud orchestration engineer
|
||||
k8s orchestrated self-deployed CI pipeline to run `./binary` on E2C platform.
|
||||
|
||||
|
||||
|
||||
¯\\_(ツ)_/¯
|
||||
|
||||
That doesn’t mean that Kubernetes or any of these things are bad per se, just as Java or OOP aren’t bad per se, but rather that they’re horribly misapplied in many cases, just as using several Java OOP design patterns are horribly misapplied to a hello world program. For most companies the sysops requirements are fundamentally not very complex, and applying k8s to them makes litle sense.
|
||||
|
||||
Complexity creates work by its very nature, and I’m skeptical that using k8s is a time-saver for most users. It’s like spending a day on a script to automate some 10-minute task that you do once a month. That’s not a good time investment (especially since the chances are you’ll have to invest further time in the future by expanding or debugging that script at some point).
|
||||
|
||||
Your deployments probably should be automated – lest you [end up like Knightmare][1] – but k8s can often be replaced by a simple shell script.
|
||||
|
||||
In our own company the sysops team spent a lot of time setting up k8s. They also had to spend a lot of time on updating to a newer version a while ago (1.6 ➙ 1.8). And the result is something no one really understands without really diving in to k8s, and even then it’s hard (those YAML files, yikes!)
|
||||
|
||||
Before I could debug and fix deploy issues myself. Now that’s a lot harder. I understand the basic concepts, but that’s not all that useful when actually debugging practical issues. I don’t deal with k8s often enough to justify learning this.
|
||||
|
||||
That k8s is really hard is not a novel insight, which is why there are a host of “k8s made easy” solutions out there. The idea of adding another layer on top of k8s to “make it easier” strikes me as, ehh, unwise. It’s not like that complexity disappears; you’ve just hidden it.
|
||||
|
||||
I have said this many times before: when determining if something is “easy” then my prime concern is not how easy something is to write, but how easy something is to debug when things fail. Wrapping k8s will not make things easier to debug, quite the opposite: it will make it even harder.
|
||||
|
||||
There is a famous Blaise Pascal quote:
|
||||
|
||||
> All human evil comes from a single cause, man’s inability to sit still in a room.
|
||||
|
||||
k8s – and to lesser extent, Docker – seem to be an example of that. A lot of people seem lost in the excitement of the moment and are “k8s al the things!”, just as some people were lost in the excitement when Java OOP was new, so everything has to be converted from the “old” way to the “new” ones, even though the “old” ways still worked fine.
|
||||
|
||||
Sometimes the IT industry is pretty silly.
|
||||
|
||||
Or to summarize this post [with a Tweet][2]:
|
||||
|
||||
> 2014 - We must adopt #microservices to solve all problems with monoliths
|
||||
> 2016 - We must adopt #docker to solve all problems with microservices
|
||||
> 2018 - We must adopt #kubernetes to solve all problems with docker
|
||||
|
||||
You can mail me at [martin@arp242.net][3] or [create a GitHub issue][4] for feedback, questions, etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/dont-need-k8s.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://dougseven.com/2014/04/17/knightmare-a-devops-cautionary-tale/
|
||||
[2]: https://twitter.com/sahrizv/status/1018184792611827712
|
||||
[3]: mailto:martin@arp242.net
|
||||
[4]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Getting started with Turtl, an open source alternative to Evernote
|
||||
======
|
||||

|
||||
|
||||
@ -1,52 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Powers of two, powers of Linux: 2048 at the command line)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-2048)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Powers of two, powers of Linux: 2048 at the command line
|
||||
======
|
||||
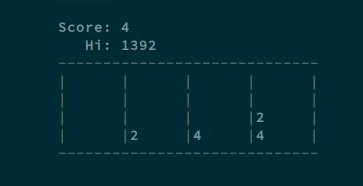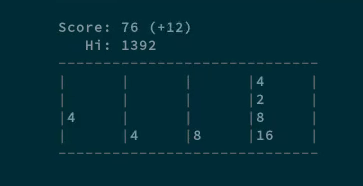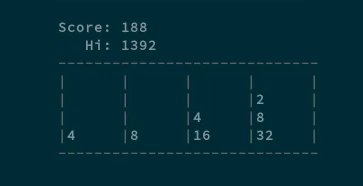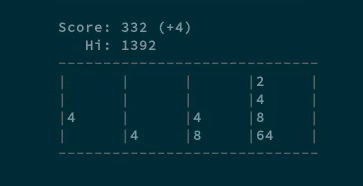
Looking for a terminal-based game to pass the time? Look no further than 2048-cli.
|
||||
|
||||
|
||||
Hello and welcome to today's installment of the Linux command-line toys advent calendar. Every day, we look at a different toy for your terminal: it could be a game or any simple diversion that helps you have fun.
|
||||
|
||||
Maybe you have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
|
||||
Today's toy is a [command-line version][1] of one of my all-time favorite casual games, [2048][2] (which itself is a clone of another clone).
|
||||
|
||||
To play, you just slide blocks up, down, left, and right to combine matching pairs and increment numbers, until you've made a block that is 2048 in size. The catch (and the challenge), is that you can't just move one block; instead, you move every block on the screen.
|
||||
|
||||
It's simple, fun, and easy to get lost in it for hours. This 2048 clone, [2048-][1][cli][1], is by Marc Tiehuis and written in C, and made available as open source under an MIT license. You can find the source code [on GitHub][1], where you can also get installation instructions for your platform. Since it was packaged for Fedora, for me, installing it was as simple as:
|
||||
|
||||
```
|
||||
$ sudo dnf install 2048-cli
|
||||
```
|
||||
|
||||
That's it, have fun!
|
||||
|
||||
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [Play Tetris at your Linux terminal][3], and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-2048
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tiehuis/2048-cli
|
||||
[2]: https://github.com/gabrielecirulli/2048
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-tetris
|
||||
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (s-tui: A Terminal Tool To Monitor CPU Temperature, Frequency, Power And Utilization In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
|
||||
s-tui: A Terminal Tool To Monitor CPU Temperature, Frequency, Power And Utilization In Linux
|
||||
======
|
||||
|
||||
By default every Linux administrator would go with **[lm_sensors to monitor CPU temperature][1]**.
|
||||
|
||||
lm_sensors (Linux monitoring sensors) is a free and open-source application that provides tools and drivers for monitoring temperatures, voltage, and fans.
|
||||
|
||||
It’s a CLI utility and if you are looking for alternative tools.
|
||||
|
||||
I would suggest you to go for s-tui.
|
||||
|
||||
It’s a Stress Terminal UI which helps administrator to view CPU temperature with colors.
|
||||
|
||||
### What is s-tui
|
||||
|
||||
s-tui is a terminal UI for monitoring your computer. s-tui allows to monitor CPU temperature, frequency, power and utilization in a graphical way from the terminal.
|
||||
|
||||
Also, shows performance dips caused by thermal throttling, it requires minimal resources and doesn’t requires X-server. It was written in Python and requires root privilege to use this.
|
||||
|
||||
s-tui is a self-contained application which can run out-of-the-box and doesn’t need config files to drive its core features.
|
||||
|
||||
s-tui uses psutil to probe some of your hardware information. If your hardware is not supported, you might not see all the information.
|
||||
|
||||
Running s-tui as root gives access to the maximum Turbo Boost frequency available to your CPU when stressing all cores.
|
||||
|
||||
It uses Stress utility in the background to check the temperature of its components do not exceed their acceptable range by imposes certain types of compute stress on your system.
|
||||
|
||||
Running an overclocked PC is fine as long as it is stable and that the temperature of its components do not exceed their acceptable range.
|
||||
|
||||
There are several programs available to assess system stability through stress testing the system and thereby the overclock level.
|
||||
|
||||
### How to Install s-tui In Linux
|
||||
|
||||
It was written in Python and pip installation is a recommended method to install s-tui on Linux. Make sure you should have installed python-pip package on your system. If no, use the following command to install it.
|
||||
|
||||
For Debian/Ubuntu users, use **[Apt Command][2]** or **[Apt-Get Command][3]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo apt install python-pip stress
|
||||
```
|
||||
|
||||
For Archlinux users, use **[Pacman Command][4]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo pacman -S python-pip stress
|
||||
```
|
||||
|
||||
For Fedora users, use **[DNF Command][5]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo dnf install python-pip stress
|
||||
```
|
||||
|
||||
For CentOS/RHEL users, use **[YUM Command][6]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo yum install python-pip stress
|
||||
```
|
||||
|
||||
For openSUSE users, use **[Zypper Command][7]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo zypper install python-pip stress
|
||||
```
|
||||
|
||||
Finally run the following **[pip command][8]** to install s-tui tool in Linux.
|
||||
|
||||
For Python 2.x:
|
||||
|
||||
```
|
||||
$ sudo pip install s-tui
|
||||
```
|
||||
|
||||
For Python 3.x:
|
||||
|
||||
```
|
||||
$ sudo pip3 install s-tui
|
||||
```
|
||||
|
||||
### How to Access s-tui
|
||||
|
||||
As i told in the beginning of the article. It requires root privilege to get all the information from your system. Just run the following command to launch s-tui.
|
||||
|
||||
```
|
||||
$ sudo s-tui
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
By default it enable hardware monitoring and select the “Stress” option to do the stress test on your system.
|
||||
![][11]
|
||||
|
||||
To check other options, navigate to help page.
|
||||
|
||||
```
|
||||
$ s-tui --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/view-check-cpu-hard-disk-temperature-linux/
|
||||
[2]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[8]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
|
||||
[9]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/12/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency-1.jpg
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/12/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency-2.jpg
|
||||
116
sources/tech/20190104 Managing dotfiles with rcm.md
Normal file
116
sources/tech/20190104 Managing dotfiles with rcm.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing dotfiles with rcm)
|
||||
[#]: via: (https://fedoramagazine.org/managing-dotfiles-rcm/)
|
||||
[#]: author: (Link Dupont https://fedoramagazine.org/author/linkdupont/)
|
||||
|
||||
Managing dotfiles with rcm
|
||||
======
|
||||
|
||||

|
||||
|
||||
A hallmark feature of many GNU/Linux programs is the easy-to-edit configuration file. Nearly all common free software programs store configuration settings inside a plain text file, often in a structured format like JSON, YAML or [“INI-like”][1]. These configuration files are frequently found hidden inside a user’s home directory. However, a basic ls won’t reveal them. UNIX standards require that any file or directory name that begins with a period (or “dot”) is considered “hidden” and will not be listed in directory listings unless requested by the user. For example, to list all files using the ls program, pass the -a command-line option.
|
||||
|
||||
Over time, these configuration files become highly customized, and managing them becomes increasingly more challenging as time goes on. Not only that, but keeping them synchronized between multiple computers is a common challenge in large organizations. Finally, many users find a sense of pride in their unique configuration settings and want an easy way to share them with friends. That’s where **rcm** steps in.
|
||||
|
||||
**rcm** is a “rc” file management suite (“rc” is another convention for naming configuration files that has been adopted by some GNU/Linux programs like screen or bash). **rcm** provides a suite of commands to manage and list files it tracks. Install **rcm** using **dnf**.
|
||||
|
||||
### Getting started
|
||||
|
||||
By default, **rcm** uses ~/.dotfiles for storing all the dotfiles it manages. A managed dotfile is actually stored inside ~/.dotfiles, and a symlink is placed in the expected file’s location. For example, if ~/.bashrc is tracked by **rcm** , a long listing would look like this.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ ls -l ~/.bashrc
|
||||
lrwxrwxrwx. 1 link link 27 Dec 16 05:19 .bashrc -> /home/link/.dotfiles/bashrc
|
||||
[link@localhost ~]$
|
||||
```
|
||||
|
||||
**rcm** consists of 4 commands:
|
||||
|
||||
* mkrc – convert a file into a dotfile managed by rcm
|
||||
* lsrc – list files managed by rcm
|
||||
* rcup – synchronize dotfiles managed by rcm
|
||||
* rcdn – remove all the symlinks managed by rcm
|
||||
|
||||
|
||||
|
||||
### Share bashrc across two computers
|
||||
|
||||
It is not uncommon today for a user to have shell accounts on more than one computer. Keeping dotfiles synchronized between those computers can be a challenge. This scenario will present one possible solution, using only **rcm** and **git**.
|
||||
|
||||
First, convert (or “bless”) a file into a dotfile managed by **rcm** with mkrc.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ mkrc -v ~/.bashrc
|
||||
Moving...
|
||||
'/home/link/.bashrc' -> '/home/link/.dotfiles/bashrc'
|
||||
Linking...
|
||||
'/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc'
|
||||
[link@localhost ~]$
|
||||
```
|
||||
|
||||
Next, verify the listings are correct with lsrc.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ lsrc
|
||||
/home/link/.bashrc:/home/link/.dotfiles/bashrc
|
||||
[link@localhost ~]$
|
||||
```
|
||||
|
||||
Now create a git repository inside ~/.dotfiles and set up an accessible remote repository using your choice of hosted git repositories. Commit the bashrc file and push a new branch.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ cd ~/.dotfiles
|
||||
[link@localhost .dotfiles]$ git init
|
||||
Initialized empty Git repository in /home/link/.dotfiles/.git/
|
||||
[link@localhost .dotfiles]$ git remote add origin git@github.com:linkdupont/dotfiles.git
|
||||
[link@localhost .dotfiles]$ git add bashrc
|
||||
[link@localhost .dotfiles]$ git commit -m "initial commit"
|
||||
[master (root-commit) b54406b] initial commit
|
||||
1 file changed, 15 insertions(+)
|
||||
create mode 100644 bashrc
|
||||
[link@localhost .dotfiles]$ git push -u origin master
|
||||
...
|
||||
[link@localhost .dotfiles]$
|
||||
```
|
||||
|
||||
On the second machine, clone this repository into ~/.dotfiles.
|
||||
|
||||
```
|
||||
[link@remotehost ~]$ git clone git@github.com:linkdupont/dotfiles.git ~/.dotfiles
|
||||
...
|
||||
[link@remotehost ~]$
|
||||
```
|
||||
|
||||
Now update the symlinks managed by **rcm** with rcup.
|
||||
|
||||
```
|
||||
[link@remotehost ~]$ rcup -v
|
||||
replacing identical but unlinked /home/link/.bashrc
|
||||
removed '/home/link/.bashrc'
|
||||
'/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc'
|
||||
[link@remotehost ~]$
|
||||
```
|
||||
|
||||
Overwrite the existing ~/.bashrc (if it exists) and restart the shell.
|
||||
|
||||
That’s it! The host-specific option (-o) is a useful addition to the scenario above. And as always, be sure to read the manpages; they contain a wealth of example commands.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-dotfiles-rcm/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/linkdupont/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/INI_file
|
||||
@ -0,0 +1,223 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Search, Study And Practice Linux Commands On The Fly!)
|
||||
[#]: via: (https://www.ostechnix.com/search-study-and-practice-linux-commands-on-the-fly/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Search, Study And Practice Linux Commands On The Fly!
|
||||
======
|
||||
|
||||

|
||||
|
||||
The title may look like sketchy and click bait. Allow me to explain what I am about to explain in this tutorial. Let us say you want to download an archive file, extract it and move the file from one location to another from command line. As per the above scenario, we may need at least three Linux commands, one for downloading the file, one for extracting the downloaded file and one for moving the file. If you’re intermediate or advanced Linux user, you could do this easily with an one-liner command or a script in few seconds/minutes. But, if you are a noob who don’t know much about Linux commands, you might need little help.
|
||||
|
||||
Of course, a quick google search may yield many results. Or, you could use [**man pages**][1]. But some man pages are really long, comprehensive and lack in useful example. You might need to scroll down for quite a long time when you’re looking for a particular information on the specific flags/options. Thankfully, there are some [**good alternatives to man pages**][2], which are focused on mostly practical commands. One such good alternative is **TLDR pages**. Using TLDR pages, we can quickly and easily learn a Linux command with practical examples. To access the TLDR pages, we require a TLDR client. There are many clients available. Today, we are going to learn about one such client named **“Tldr++”**.
|
||||
|
||||
Tldr++ is a fast and interactive tldr client written with **Go** programming language. Unlike the other Tldr clients, it is fully interactive. That means, you can pick a command, read all examples , and immediately run any command without having to retype or copy/paste each command in the Terminal. Still don’t get it? No problem. Read on to learn and practice Linux commands on the fly.
|
||||
|
||||
### Install Tldr++
|
||||
|
||||
Installing Tldr++ is very simple. Download tldr++ latest version from the [**releases page**][3]. Extract it and move the tldr++ binary to your $PATH.
|
||||
|
||||
```
|
||||
$ wget https://github.com/isacikgoz/tldr/releases/download/v0.5.0/tldr_0.5.0_linux_amd64.tar.gz
|
||||
|
||||
$ tar xzf tldr_0.5.0_linux_amd64.tar.gz
|
||||
|
||||
$ sudo mv tldr /usr/local/bin
|
||||
|
||||
$ sudo chmod +x /usr/local/bin/tldr
|
||||
```
|
||||
|
||||
Now, run ‘tldr’ binary to populate the tldr pages in your local system.
|
||||
|
||||
```
|
||||
$ tldr
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Enumerating objects: 6, done.
|
||||
Counting objects: 100% (6/6), done.
|
||||
Compressing objects: 100% (6/6), done.
|
||||
Total 18157 (delta 0), reused 3 (delta 0), pack-reused 18151
|
||||
Successfully cloned into: /home/sk/.local/share/tldr
|
||||
```
|
||||
|
||||
|
||||
|
||||
Tldr++ is available in AUR. If you’re on Arch Linux, you can install it using any AUR helper, for example [**YaY**][4]. Make sure you have removed any existing tldr client from your system and run the following command to install tldr++.
|
||||
|
||||
```
|
||||
$ yay -S tldr++
|
||||
```
|
||||
|
||||
Alternatively, you can build from source as described below. Since Tldr++ is written using Go language, make sure you have installed it on your Linux box. If it isn’t installed yet, refer the following guide.
|
||||
|
||||
+ [How To Install Go Language In Linux](https://www.ostechnix.com/install-go-language-linux/)
|
||||
|
||||
After installing Go, run the following command to install Tldr++.
|
||||
|
||||
```
|
||||
$ go get -u github.com/isacikgoz/tldr
|
||||
```
|
||||
|
||||
This command will download the contents of tldr repository in a folder named **‘go’** in the current working directory.
|
||||
|
||||
Now run the ‘tldr’ binary to populate all tldr pages in your local system using command:
|
||||
|
||||
```
|
||||
$ go/bin/tldr
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][6]
|
||||
|
||||
Finally, copy the tldr binary to your PATH.
|
||||
|
||||
```
|
||||
$ sudo mv tldr /usr/local/bin
|
||||
```
|
||||
|
||||
It is time to see some examples.
|
||||
|
||||
### Tldr++ Usage
|
||||
|
||||
Type ‘tldr’ command without any options to display all command examples in alphabetical order.
|
||||
|
||||
![][7]
|
||||
|
||||
Use the **UP/DOWN arrows** to navigate through the commands, type any letters to search or type a command name to view the examples of that respective command. Press **?** for more and **Ctrl+c** to return/exit.
|
||||
|
||||
To display the example commands of a specific command, for example **apt** , simply do:
|
||||
|
||||
```
|
||||
$ tldr apt
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
Choose any example command from the list and hit ENTER. You will see a *** symbol** before the selected command. For example, I choose the first command i.e ‘sudo apt update’. Now, it will ask you whether to continue or not. If the command is correct, just type ‘y’ to continue and type your sudo password to run the selected command.
|
||||
|
||||
![][9]
|
||||
|
||||
See? You don’t need to copy/paste or type the actual command in the Terminal. Just choose it from the list and run on the fly!
|
||||
|
||||
There are hundreds of Linux command examples are available in Tldr pages. You can choose one or two commands per day and learn them thoroughly. And keep this practice everyday to learn as much as you can.
|
||||
|
||||
### Learn And Practice Linux Commands On The Fly Using Tldr++
|
||||
|
||||
Now think of the scenario that I mentioned in the first paragraph. You want to download a file, extract it and move it to different location and make it executable. Let us see how to do it interactively using Tldr++ client.
|
||||
|
||||
**Step 1 – Download a file from Internet**
|
||||
|
||||
To download a file from command line, we mostly use **‘curl’** or **‘wget’** commands. Let me use ‘wget’ to download the file. To open tldr page of wget command, just run:
|
||||
|
||||
```
|
||||
$ tldr wget
|
||||
```
|
||||
|
||||
Here is the examples of wget command.
|
||||
|
||||

|
||||
|
||||
You can use **UP/DOWN** arrows to go through the list of commands. Once you choose the command of your choice, press ENTER. Here I chose the first command.
|
||||
|
||||
Now, enter the path of the file to download.
|
||||
|
||||

|
||||
|
||||
You will then be asked to confirm if it is the correct command or not. If the command is correct, simply type ‘yes’ or ‘y’ to start downloading the file.
|
||||
|
||||
![][10]
|
||||
|
||||
We have downloaded the file. Let us go ahead and extract this file.
|
||||
|
||||
**Step 2 – Extract downloaded archive**
|
||||
|
||||
We downloaded the **tar.gz** file. So I am going to open the ‘tar’ tldr page.
|
||||
|
||||
```
|
||||
$ tldr tar
|
||||
```
|
||||
|
||||
You will see the list of example commands. Go through the examples and find which command is suitable to extract tar.gz(gzipped archive) file and hit ENTER key. In our case, it is the third command.
|
||||
|
||||
![][11]
|
||||
|
||||
Now, you will be prompted to enter the path of the tar.gz file. Just type the path and hit ENTER key. Tldr++ supports smart file suggestions. That means it will suggest the file name automatically as you type. Just press TAB key for auto-completion.
|
||||
|
||||
![][12]
|
||||
|
||||
If you downloaded the file to some other location, just type the full path, for example **/home/sk/Downloads/tldr_0.5.0_linux_amd64.tar.gz.**
|
||||
|
||||
Once you enter the path of the file to extract, press ENTER and then, type ‘y’ to confirm.
|
||||
|
||||
![][13]
|
||||
|
||||
**Step 3 – Move file from one location to another**
|
||||
|
||||
We extracted the archive. Now we need to move the file to another location. To move the files from one location to another, we use ‘mv’ command. So, let me open the tldr page for mv command.
|
||||
|
||||
```
|
||||
$ tldr mv
|
||||
```
|
||||
|
||||
Choose the correct command to move the files from one location to another. In our case, the first command will work, so let me choose it.
|
||||
|
||||
![][14]
|
||||
|
||||
Type the path of the file that you want to move and enter the destination path and hit ENTER key.
|
||||
|
||||
![][15]
|
||||
|
||||
**Note:** Type **y!** or **yes!** to run command with **sudo** privileges.
|
||||
|
||||
As you see in the above screenshot, I moved the file named **‘tldr’** to **‘/usr/local/bin/’** location.
|
||||
|
||||
For more details, refer the project’s GitHub page given at the end.
|
||||
|
||||
|
||||
### Conclusion
|
||||
|
||||
Don’t get me wrong. **Man pages are great!** There is no doubt about it. But, as I already said, many man pages are comprehensive and doesn’t have useful examples. There is no way I could memorize all lengthy commands with tricky flags. Some times I spent much time on man pages and remained clueless. The Tldr pages helped me to find what I need within few minutes. Also, we use some commands once in a while and then we forget them completely. Tldr pages on the other hand actually helps when it comes to using commands we rarely use. Tldr++ client makes this task much easier with smart user interaction. Give it a go and let us know what you think about this tool in the comment section below.
|
||||
|
||||
And, that’s all. More good stuffs to come. Stay tuned!
|
||||
|
||||
Good luck!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/search-study-and-practice-linux-commands-on-the-fly/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/learn-use-man-pages-efficiently/
|
||||
[2]: https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
[3]: https://github.com/isacikgoz/tldr/releases
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-1.png
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-11.png
|
||||
[8]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-12.png
|
||||
[9]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-13.png
|
||||
[10]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-4.png
|
||||
[11]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-6.png
|
||||
[12]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-7.png
|
||||
[13]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-8.png
|
||||
[14]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-9.png
|
||||
[15]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-10.png
|
||||
@ -0,0 +1,224 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Setting up an email server, part 1: The Forwarder)
|
||||
[#]: via: (https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/)
|
||||
[#]: author: (Julian Andres Klode https://blog.jak-linux.org/)
|
||||
|
||||
Setting up an email server, part 1: The Forwarder
|
||||
======
|
||||
|
||||
This week, I’ve been working on rolling out mail services on my server. I started working on a mail server setup at the end of November, while the server was not yet in use, but only for about two days, and then let it rest.
|
||||
|
||||
As my old shared hosting account expired on January 1, I had to move mail forwarding duties over to the new server. Yes forwarding - I do plan to move hosting the actual email too, but at the moment it’s “just” forwarding to gmail.
|
||||
|
||||
### The Software
|
||||
|
||||
As you might know from the web server story, my server runs on Ubuntu 18.04. I set up a mail server on this system using
|
||||
|
||||
* [Postfix][1] for SMTP duties (warning, they oddly do not have an https page)
|
||||
* [rspamd][2] for spam filtering, and signing DKIM / ARC
|
||||
* [bind9][3] for DNS resolving
|
||||
* [postsrsd][4] for SRS
|
||||
|
||||
|
||||
|
||||
You might wonder why bind9 is in there. It turns out that DNS blacklists used by spam filters block the caching DNS servers you usually use, so you have to use your own recursive DNS server. Ubuntu offers you the choice between bind9 and dnsmasq in main, and it seems like bind9 is more appropriate here than dnsmasq.
|
||||
|
||||
### Setting up postfix
|
||||
|
||||
Most of the postfix configuration is fairly standard. So, let’s skip TLS configuration and outbound SMTP setups (this is email, and while they support TLS, it’s all optional, so let’s not bother that much here).
|
||||
|
||||
The most important part is restrictions in `main.cf`.
|
||||
|
||||
First of all, relay restrictions prevent us from relaying emails to weird domains:
|
||||
|
||||
```
|
||||
# Relay Restrictions
|
||||
smtpd_relay_restrictions = reject_non_fqdn_recipient reject_unknown_recipient_domain permit_mynetworks permit_sasl_authenticated defer_unauth_destination
|
||||
```
|
||||
|
||||
We also only accept mails from hosts that know their own full qualified name:
|
||||
|
||||
```
|
||||
# Helo restrictions (hosts not having a proper fqdn)
|
||||
smtpd_helo_required = yes
|
||||
smtpd_helo_restrictions = permit_mynetworks reject_invalid_helo_hostname reject_non_fqdn_helo_hostname reject_unknown_helo_hostname
|
||||
```
|
||||
|
||||
We also don’t like clients (other servers) that send data too early, or have an unknown hostname:
|
||||
|
||||
```
|
||||
smtpd_data_restrictions = reject_unauth_pipelining
|
||||
smtpd_client_restrictions = permit_mynetworks reject_unknown_client_hostname
|
||||
```
|
||||
|
||||
I also set up a custom apparmor profile that’s pretty lose, I plan to migrate to the one in the apparmor git eventually but it needs more testing and some cleanup.
|
||||
|
||||
### Sender rewriting scheme
|
||||
|
||||
For SRS using postsrsd, we define the `SRS_DOMAIN` in `/etc/default/postsrsd` and then configure postfix to talk to it:
|
||||
|
||||
```
|
||||
# Handle SRS for forwarding
|
||||
recipient_canonical_maps = tcp:localhost:10002
|
||||
recipient_canonical_classes= envelope_recipient,header_recipient
|
||||
|
||||
sender_canonical_maps = tcp:localhost:10001
|
||||
sender_canonical_classes = envelope_sender
|
||||
```
|
||||
|
||||
This has a minor issue that it also rewrites the `Return-Path` when it delivers emails locally, but as I am only forwarding, I’m worrying about that later.
|
||||
|
||||
### rspamd basics
|
||||
|
||||
rspamd is a great spam filtering system. It uses a small core written in C and a bunch of Lua plugins, such as:
|
||||
|
||||
* IP score, which keeps track of how good a specific server was in the past
|
||||
* Replies, which can check whether an email is a reply to another one
|
||||
* DNS blacklisting
|
||||
* DKIM and ARC validation and signing
|
||||
* DMARC validation
|
||||
* SPF validation
|
||||
|
||||
|
||||
|
||||
It also has a nice web UI:
|
||||
|
||||
![rspamd web ui status][5]
|
||||
|
||||
rspamd web ui status
|
||||
|
||||
![rspamd web ui investigating a spam message][6]
|
||||
|
||||
rspamd web ui investigating a spam message
|
||||
|
||||
Setting up rspamd is quite easy. You basically just drop a bunch of configuration overrides into `/etc/rspamd/local.d` and you’re done. Heck, it mostly works out of the box. There’s a fancy `rspamadm configwizard` too.
|
||||
|
||||
What you do want for rspamd is a redis server. redis is needed in [many places][7], such as rate limiting, greylisting, dmarc, reply tracking, ip scoring, neural networks.
|
||||
|
||||
I made a few changes to the defaults:
|
||||
|
||||
* I enabled subject rewriting instead of adding headers, so spam mail subjects get `[SPAM]` prepended, in `local.d/actions.conf`:
|
||||
|
||||
```
|
||||
reject = 15;
|
||||
rewrite_subject = 6;
|
||||
add_header = 6;
|
||||
greylist = 4;
|
||||
subject = "[SPAM] %s";
|
||||
```
|
||||
|
||||
* I set `autolearn = true;` in `local.d/classifier-bayes.conf` to make it learn that an email that has a score of at least 15 (those that are rejected) is spam, and emails with negative scores are ham.
|
||||
|
||||
* I set `extended_spam_headers = true;` in `local.d/milter_headers.conf` to get a report from rspamd in the header seeing the score and how the score came to be.
|
||||
|
||||
|
||||
|
||||
|
||||
### ARC setup
|
||||
|
||||
[ARC][8] is the ‘Authenticated Received Chain’ and is currently a DMARC working group work item. It allows forwarders / mailing lists to authenticate their forwarding of the emails and the checks they have performed.
|
||||
|
||||
rspamd is capable of validating and signing emails with ARC, but I’m not sure how much influence ARC has on gmail at the moment, for example.
|
||||
|
||||
There are three parts to setting up ARC:
|
||||
|
||||
1. Generate a DKIM key pair (use `rspamadm dkim_keygen`)
|
||||
2. Setup rspamd to sign incoming emails using the private key
|
||||
3. Add a DKIM `TXT` record for the public key. `rspamadm` helpfully tells you how it looks like.
|
||||
|
||||
|
||||
|
||||
For step two, what we need to do is configure `local.d/arc.conf`. You can basically use the example configuration from the [rspamd page][9], the key point for signing incoming email is to specifiy `sign_incoming = true;` and `use_domain_sign_inbound = "recipient";` (FWIW, none of these options are documented, they are fairly new, and nobody updated the documentation for them).
|
||||
|
||||
My configuration looks like this at the moment:
|
||||
|
||||
```
|
||||
# If false, messages with empty envelope from are not signed
|
||||
allow_envfrom_empty = true;
|
||||
# If true, envelope/header domain mismatch is ignored
|
||||
allow_hdrfrom_mismatch = true;
|
||||
# If true, multiple from headers are allowed (but only first is used)
|
||||
allow_hdrfrom_multiple = false;
|
||||
# If true, username does not need to contain matching domain
|
||||
allow_username_mismatch = false;
|
||||
# If false, messages from authenticated users are not selected for signing
|
||||
auth_only = true;
|
||||
# Default path to key, can include '$domain' and '$selector' variables
|
||||
path = "${DBDIR}/arc/$domain.$selector.key";
|
||||
# Default selector to use
|
||||
selector = "arc";
|
||||
# If false, messages from local networks are not selected for signing
|
||||
sign_local = true;
|
||||
#
|
||||
sign_inbound = true;
|
||||
# Symbol to add when message is signed
|
||||
symbol_signed = "ARC_SIGNED";
|
||||
# Whether to fallback to global config
|
||||
try_fallback = true;
|
||||
# Domain to use for ARC signing: can be "header" or "envelope"
|
||||
use_domain = "header";
|
||||
use_domain_sign_inbound = "recipient";
|
||||
# Whether to normalise domains to eSLD
|
||||
use_esld = true;
|
||||
# Whether to get keys from Redis
|
||||
use_redis = false;
|
||||
# Hash for ARC keys in Redis
|
||||
key_prefix = "ARC_KEYS";
|
||||
```
|
||||
|
||||
This would also sign any outgoing email, but I’m not sure that’s necessary - my understanding is that we only care about ARC when forwarding/receiving incoming emails, not when sending them (at least that’s what gmail does).
|
||||
|
||||
### Other Issues
|
||||
|
||||
There are few other things to keep in mind when running your own mail server. I probably don’t know them all yet, but here we go:
|
||||
|
||||
* You must have a fully qualified hostname resolving to a public IP address
|
||||
|
||||
* Your public IP address must resolve back to the fully qualified host name
|
||||
|
||||
* Again, you should run a recursive DNS resolver so your DNS blacklists work (thanks waldi for pointing that out)
|
||||
|
||||
* Setup an SPF record. Mine looks like this:
|
||||
|
||||
`jak-linux.org. 3600 IN TXT "v=spf1 +mx ~all"`
|
||||
|
||||
this states that all my mail servers may send email, but others probably should not (a softfail). Not having an SPF record can punish you; for example, rspamd gives missing SPF and DKIM a score of 1.
|
||||
|
||||
* All of that software is sandboxed using AppArmor. Makes you question its security a bit less!
|
||||
|
||||
|
||||
|
||||
|
||||
### Source code, outlook
|
||||
|
||||
As always, you can find the Ansible roles on [GitHub][10]. Feel free to point out bugs! 😉
|
||||
|
||||
In the next installment of this series, we will be looking at setting up Dovecot, and configuring DKIM. We probably also want to figure out how to run notmuch on the server, keep messages in matching maildirs, and have my laptop synchronize the maildir and notmuch state with the server. Ugh, sounds like a lot of work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/
|
||||
|
||||
作者:[Julian Andres Klode][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.jak-linux.org/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.postfix.org/
|
||||
[2]: https://rspamd.com/
|
||||
[3]: https://www.isc.org/downloads/bind/
|
||||
[4]: https://github.com/roehling/postsrsd
|
||||
[5]: https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/rspamd-status.png
|
||||
[6]: https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/rspamd-spam.png
|
||||
[7]: https://rspamd.com/doc/configuration/redis.html
|
||||
[8]: http://arc-spec.org/
|
||||
[9]: https://rspamd.com/doc/modules/arc.html
|
||||
[10]: https://github.com/julian-klode/ansible.jak-linux.org
|
||||
176
sources/tech/20190107 Aliases- To Protect and Serve.md
Normal file
176
sources/tech/20190107 Aliases- To Protect and Serve.md
Normal file
@ -0,0 +1,176 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Aliases: To Protect and Serve)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Aliases: To Protect and Serve
|
||||
======
|
||||
|
||||

|
||||
|
||||
Happy 2019! Here in the new year, we’re continuing our series on aliases. By now, you’ve probably read our [first article on aliases][1], and it should be quite clear how they are the easiest way to save yourself a lot of trouble. You already saw, for example, that they helped with muscle-memory, but let's see several other cases in which aliases come in handy.
|
||||
|
||||
### Aliases as Shortcuts
|
||||
|
||||
One of the most beautiful things about Linux's shells is how you can use zillions of options and chain commands together to carry out really sophisticated operations in one fell swoop. All right, maybe beauty is in the eye of the beholder, but let's agree that this feature published practical.
|
||||
|
||||
The downside is that you often come up with recipes that are often hard to remember or cumbersome to type. Say space on your hard disk is at a premium and you want to do some New Year's cleaning. Your first step may be to look for stuff to get rid off in you home directory. One criteria you could apply is to look for stuff you don't use anymore. `ls` can help with that:
|
||||
|
||||
```
|
||||
ls -lct
|
||||
```
|
||||
|
||||
The instruction above shows the details of each file and directory (`-l`) and also shows when each item was last accessed (`-c`). It then orders the list from most recently accessed to least recently accessed (`-t`).
|
||||
|
||||
Is this hard to remember? You probably don’t use the `-c` and `-t` options every day, so perhaps. In any case, defining an alias like
|
||||
|
||||
```
|
||||
alias lt='ls -lct'
|
||||
```
|
||||
|
||||
will make it easier.
|
||||
|
||||
Then again, you may want to have the list show the oldest files first:
|
||||
|
||||
```
|
||||
alias lo='lt -F | tac'
|
||||
```
|
||||
|
||||
![aliases][3]
|
||||
|
||||
Figure 1: The lt and lo aliases in action.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
There are a few interesting things going here. First, we are using an alias (`lt`) to create another alias -- which is perfectly okay. Second, we are passing a new parameter to `lt` (which, in turn gets passed to `ls` through the definition of the `lt` alias).
|
||||
|
||||
The `-F` option appends special symbols to the names of items to better differentiate regular files (that get no symbol) from executable files (that get an `*`), files from directories (end in `/`), and all of the above from links, symbolic and otherwise (that end in an `@` symbol). The `-F` option is throwback to the days when terminals where monochrome and there was no other way to easily see the difference between items. You use it here because, when you pipe the output from `lt` through to `tac` you lose the colors from `ls`.
|
||||
|
||||
The third thing to pay attention to is the use of piping. Piping happens when you pass the output from an instruction to another instruction. The second instruction can then use that output as its own input. In many shells (including Bash), you pipe something using the pipe symbol (`|`).
|
||||
|
||||
In this case, you are piping the output from `lt -F` into `tac`. `tac`'s name is a bit of a joke. You may have heard of `cat`, the instruction that was nominally created to con _cat_ enate files together, but that in practice is used to print out the contents of a file to the terminal. `tac` does the same, but prints out the contents it receives in reverse order. Get it? `cat` and `tac`. Developers, you so funny!
|
||||
|
||||
The thing is both `cat` and `tac` can also print out stuff piped over from another instruction, in this case, a list of files ordered chronologically.
|
||||
|
||||
So... after that digression, what comes out of the other end is the list of files and directories of the current directory in inverse order of freshness.
|
||||
|
||||
The final thing you have to bear in mind is that, while `lt` will work the current directory and any other directory...
|
||||
|
||||
```
|
||||
# This will work:
|
||||
lt
|
||||
# And so will this:
|
||||
lt /some/other/directory
|
||||
```
|
||||
|
||||
... `lo` will only work with the current directory:
|
||||
|
||||
```
|
||||
# This will work:
|
||||
lo
|
||||
# But this won't:
|
||||
lo /some/other/directory
|
||||
```
|
||||
|
||||
This is because Bash expands aliases into their components. When you type this:
|
||||
|
||||
```
|
||||
lt /some/other/directory
|
||||
```
|
||||
|
||||
Bash REALLY runs this:
|
||||
|
||||
```
|
||||
ls -lct /some/other/directory
|
||||
```
|
||||
|
||||
which is a valid Bash command.
|
||||
|
||||
However, if you type this:
|
||||
|
||||
```
|
||||
lo /some/other/directory
|
||||
```
|
||||
|
||||
Bash tries to run this:
|
||||
|
||||
```
|
||||
ls -lct -F | tac /some/other/directory
|
||||
```
|
||||
|
||||
which is not a valid instruction, because `tac` mainly because _/some/other/directory_ is a directory, and `cat` and `tac` don't do directories.
|
||||
|
||||
### More Alias Shortcuts
|
||||
|
||||
* `alias lll='ls -R'` prints out the contents of a directory and then drills down and prints out the contents of its subdirectories and the subdirectories of the subdirectories, and so on and so forth. It is a way of seeing everything you have under a directory.
|
||||
|
||||
* `mkdir='mkdir -pv'` let's you make directories within directories all in one go. With the base form of `mkdir`, to make a new directory containing a subdirectory you have to do this:
|
||||
|
||||
```
|
||||
mkdir newdir
|
||||
mkdir newdir/subdir
|
||||
```
|
||||
|
||||
Or this:
|
||||
|
||||
```
|
||||
mkdir -p newdir/subdir
|
||||
```
|
||||
|
||||
while with the alias you would only have to do this:
|
||||
|
||||
```
|
||||
mkdir newdir/subdir
|
||||
```
|
||||
|
||||
Your new `mkdir` will also tell you what it is doing while is creating new directories.
|
||||
|
||||
|
||||
|
||||
|
||||
### Aliases as Safeguards
|
||||
|
||||
The other thing aliases are good for is as safeguards against erasing or overwriting your files accidentally. At this stage you have probably heard the legendary story about the new Linux user who ran:
|
||||
|
||||
```
|
||||
rm -rf /
|
||||
```
|
||||
|
||||
as root, and nuked the whole system. Then there's the user who decided that:
|
||||
|
||||
```
|
||||
rm -rf /some/directory/ *
|
||||
```
|
||||
|
||||
was a good idea and erased the complete contents of their home directory. Notice how easy it is to overlook that space separating the directory path and the `*`.
|
||||
|
||||
Both things can be avoided with the `alias rm='rm -i'` alias. The `-i` option makes `rm` ask the user whether that is what they really want to do and gives you a second chance before wreaking havoc in your file system.
|
||||
|
||||
The same goes for `cp`, which can overwrite a file without telling you anything. Create an alias like `alias cp='cp -i'` and stay safe!
|
||||
|
||||
### Next Time
|
||||
|
||||
We are moving more and more into scripting territory. Next time, we'll take the next logical step and see how combining instructions on the command line gives you really interesting and sophisticated solutions to everyday admin problems.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve
|
||||
[2]: https://www.linux.com/files/images/fig01png-0
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fig01_0.png?itok=crqTm_va (aliases)
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
@ -0,0 +1,232 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Different Ways To Update Linux Kernel For Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/different-ways-to-update-linux-kernel-for-ubuntu/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Different Ways To Update Linux Kernel For Ubuntu
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this guide, we have given 7 different ways to update Linux kernel for Ubuntu. Among the 7 methods, five methods requires system reboot to apply the new Kernel and two methods don’t. Before updating Linux Kernel, it is **highly recommended to backup your important data!** All methods mentioned here are tested on Ubuntu OS only. We are not sure if they will work on other Ubuntu flavors (Eg. Xubuntu) and Ubuntu derivatives (Eg. Linux Mint).
|
||||
|
||||
### Part A – Kernel Updates with reboot
|
||||
|
||||
The following methods requires you to reboot your system to apply the new Linux Kernel. All of the following methods are recommended for personal or testing systems. Again, please backup your important data, configuration files and any other important stuff from your Ubuntu system.
|
||||
|
||||
#### Method 1 – Update the Linux Kernel with dpkg (The manual way)
|
||||
|
||||
This method helps you to manually download and install the latest available Linux kernel from **[kernel.ubuntu.com][1]** website. If you want to install most recent version (either stable or release candidate), this method will help. Download the Linux kernel version from the above link. As of writing this guide, the latest available version was **5.0-rc1** and latest stable version was **v4.20**.
|
||||
|
||||
![][3]
|
||||
|
||||
Click on the Linux Kernel version link of your choice and find the section for your architecture (‘Build for XXX’). In that section, download the two files with these patterns (where X.Y.Z is the highest version):
|
||||
|
||||
1. linux-image-*X.Y.Z*-generic-*.deb
|
||||
2. linux-modules-X.Y.Z*-generic-*.deb
|
||||
|
||||
|
||||
|
||||
In a terminal, change directory to where the files are and run this command to manually install the kernel:
|
||||
|
||||
```
|
||||
$ sudo dpkg --install *.deb
|
||||
```
|
||||
|
||||
Reboot to use the new kernel:
|
||||
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
Check the kernel is as expected:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
```
|
||||
|
||||
For step by step instructions, please check the section titled under “Install Linux Kernel 4.15 LTS On DEB based systems” in the following guide.
|
||||
|
||||
+ [Install Linux Kernel 4.15 In RPM And DEB Based Systems](https://www.ostechnix.com/install-linux-kernel-4-15-rpm-deb-based-systems/)
|
||||
|
||||
The above guide is specifically written for 4.15 version. However, all the steps are same for installing latest versions too.
|
||||
|
||||
**Pros:** No internet needed (You can download the Linux Kernel from any system).
|
||||
|
||||
**Cons:** Manual update. Reboot necessary.
|
||||
|
||||
#### Method 2 – Update the Linux Kernel with apt-get (The recommended method)
|
||||
|
||||
This is the recommended way to install latest Linux kernel on Ubuntu-like systems. Unlike the previous method, this method will download and install latest Kernel version from Ubuntu official repositories instead of **kernel.ubuntu.com** website..
|
||||
|
||||
To update the whole system including the Kernel, just do:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get upgrade
|
||||
```
|
||||
|
||||
If you want to update the Kernel only, run:
|
||||
|
||||
```
|
||||
$ sudo apt-get upgrade linux-image-generic
|
||||
```
|
||||
|
||||
**Pros:** Simple. Recommended method.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
Updating Kernel from official repositories will mostly work out of the box without any problems. If it is the production system, this is the recommended way to update the Kernel.
|
||||
|
||||
Method 1 and 2 requires user intervention to update Linux Kernels. The following methods (3, 4 & 5) are mostly automated.
|
||||
|
||||
#### Method 3 – Update the Linux Kernel with Ukuu
|
||||
|
||||
**Ukuu** is a Gtk GUI and command line tool that downloads the latest main line Linux kernel from **kernel.ubuntu.com** , and install it automatically in your Ubuntu desktop and server editions. Ukku is not only simplifies the process of manually downloading and installing new Kernels, but also helps you to safely remove the old and unnecessary Kernels. For more details, refer the following guide.
|
||||
|
||||
+ [Ukuu – An Easy Way To Install And Upgrade Linux Kernel In Ubuntu-based Systems](https://www.ostechnix.com/ukuu-an-easy-way-to-install-and-upgrade-linux-kernel-in-ubuntu-based-systems/)
|
||||
|
||||
**Pros:** Easy to install and use. Automatically installs main line Kernel.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
#### Method 4 – Update the Linux Kernel with UKTools
|
||||
|
||||
Just like Ukuu, the **UKTools** also fetches the latest stable Kernel from from **kernel.ubuntu.com** site and installs it automatically on Ubuntu and its derivatives like Linux Mint. More details about UKTools can be found in the link given below.
|
||||
|
||||
+ [UKTools – Upgrade Latest Linux Kernel In Ubuntu And Derivatives](https://www.ostechnix.com/uktools-upgrade-latest-linux-kernel-in-ubuntu-and-derivatives/)
|
||||
|
||||
**Pros:** Simple. Automated.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
#### Method 5 – Update the Linux Kernel with Linux Kernel Utilities
|
||||
|
||||
**Linux Kernel Utilities** is yet another program that makes the process of updating Linux kernel easy in Ubuntu-like systems. It is actually a set of BASH shell scripts used to compile and/or update latest Linux kernels for Debian and derivatives. It consists of three utilities, one for manually compiling and installing Kernel from source from [**http://www.kernel.org**][4] website, another for downloading and installing pre-compiled Kernels from from **<https://kernel.ubuntu.com>** website. and third script is for removing the old kernels. For more details, please have a look at the following link.
|
||||
|
||||
+ [Linux Kernel Utilities – Scripts To Compile And Update Latest Linux Kernel For Debian And Derivatives](https://www.ostechnix.com/linux-kernel-utilities-scripts-compile-update-latest-linux-kernel-debian-derivatives/)
|
||||
|
||||
**Pros:** Simple. Automated.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
|
||||
### Part B – Kernel Updates without reboot
|
||||
|
||||
As I already said, all of above methods need you to reboot the server before the new kernel is active. If they are personal systems or testing machines, you could simply reboot and start using the new Kernel. But, what if they are production systems that requires zero downtime? No problem. This is where **Livepatching** comes in handy!
|
||||
|
||||
The **livepatching** (or hot patching) allows you to install Linux updates or patches without rebooting, keeping your server at the latest security level, without any downtime. This is attractive for ‘always-on’ servers, such as web hosts, gaming servers, in fact, any situation where the server needs to stay on all the time. Linux vendors maintain patches only for security fixes, so this approach is best when security is your main concern.
|
||||
|
||||
The following two methods doesn’t require system reboot and useful for updating Linux Kernel on production and mission-critical Ubuntu servers.
|
||||
|
||||
#### Method 6 – Update the Linux Kernel Canonical Livepatch Service
|
||||
|
||||
![][5]
|
||||
|
||||
[**Canonical Livepatch Service**][6] applies Kernel updates, patches and security hotfixes automatically without rebooting the Ubuntu systems. It reduces the Ubuntu systems downtime and keep them secure. Canonical Livepatch Service can be set up either during or after installation. If you are using desktop Ubuntu, the Software Updater will automatically check for kernel patches and notify you. In a console-based system, it is up to you to run apt-get update regularly. It will install kernel security patches only when you run the command “apt-get upgrade”, hence is semi-automatic.
|
||||
|
||||
Livepatch is free for three systems. If you have more than three, you need to upgrade to enterprise support solution named **Ubuntu Advantage** suite. This suite includes **Kernel Livepatching** and other services such as,
|
||||
|
||||
* Extended Security Maintenance – critical security updates after Ubuntu end-of-life.
|
||||
* Landscape – the systems management tool for using Ubuntu at scale.
|
||||
* Knowledge Base – A private collection of articles and tutorials written by Ubuntu experts.
|
||||
* Phone and web-based support.
|
||||
|
||||
|
||||
|
||||
**Cost**
|
||||
|
||||
Ubuntu Advantage includes three paid plans namely, Essential, Standard and Advanced. The basic plan (Essential plan) starts from **225 USD per year for one physical node** and **75 USD per year for one VPS**. It seems there is no monthly subscription for Ubuntu servers and desktops. You can view detailed information on all plans [**here**][7].
|
||||
|
||||
**Pros:** Simple. Semi-automatic. No reboot necessary. Free for 3 systems.
|
||||
|
||||
**Cons:** Expensive for 4 or more hosts. No patch rollback.
|
||||
|
||||
**Enable Canonical Livepatch Service**
|
||||
|
||||
If you want to setup Livepatch service after installation, just do the following steps.
|
||||
|
||||
Get a key at [**https://auth.livepatch.canonical.com/**][8].
|
||||
|
||||
```
|
||||
$ sudo snap install canonical-livepatch
|
||||
|
||||
$ sudo canonical-livepatch enable your-key
|
||||
```
|
||||
|
||||
#### Method 7 – Update the Linux Kernel with KernelCare
|
||||
|
||||
![][9]
|
||||
|
||||
[**KernelCare**][10] is the newest of all the live patching solutions. It is the product of [CloudLinux][11]. KernelCare runs on Ubuntu and other flavors of Linux. It checks for patch releases every 4 hours and will install them without confirmation. Patches can be rolled back if there are problems.
|
||||
|
||||
**Cost**
|
||||
|
||||
Fees, per server: **4 USD per month** , **45 USD per year**.
|
||||
|
||||
Compared to Ubuntu Livepatch, kernelCare seems very cheap and affordable. Good thing is **monthly subscriptions are also available**. Another notable feature is it supports other Linux distributions, such as Red Hat, CentOS, Debian, Oracle Linux, Amazon Linux and virtualization platforms like OpenVZ, Proxmox etc.
|
||||
|
||||
You can read all the features and benefits of KernelCare [**here**][12] and check all available plan details [**here**][13].
|
||||
|
||||
**Pros:** Simple. Fully automated. Wide OS coverage. Patch rollback. No reboot necessary. Free license for non-profit organizations. Low cost.
|
||||
|
||||
**Cons:** Not free (except for 30 day trial).
|
||||
|
||||
**Enable KernelCare Service**
|
||||
|
||||
Get a 30-day trial key at [**https://cloudlinux.com/kernelcare-free-trial5**][14].
|
||||
|
||||
Run the following commands to enable KernelCare and register the key.
|
||||
|
||||
```
|
||||
$ sudo wget -qq -O - https://repo.cloudlinux.com/kernelcare/kernelcare_install.sh | bash
|
||||
|
||||
$ sudo /usr/bin/kcarectl --register KEY
|
||||
```
|
||||
|
||||
If you’re looking for an affordable and reliable commercial service to keep the Linux Kernel updated on your Linux servers, KernelCare is good to go.
|
||||
|
||||
*with inputs from **Paul A. Jacobs** , a Technical Evangelist and Content Writer from Cloud Linux.*
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
And, that’s all for now. Hope this was useful. If you believe any other tools/methods should include in this list, feel free to let us know in the comment section below. I will check and update this guide accordingly.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/different-ways-to-update-linux-kernel-for-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/01/Ubuntu-mainline-kernel.png
|
||||
[4]: http://www.kernel.org
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2019/01/Livepatch.png
|
||||
[6]: https://www.ubuntu.com/livepatch
|
||||
[7]: https://www.ubuntu.com/support/plans-and-pricing
|
||||
[8]: https://auth.livepatch.canonical.com/
|
||||
[9]: http://www.ostechnix.com/wp-content/uploads/2019/01/KernelCare.png
|
||||
[10]: https://www.kernelcare.com/
|
||||
[11]: https://www.cloudlinux.com/
|
||||
[12]: https://www.kernelcare.com/update-kernel-linux/
|
||||
[13]: https://www.kernelcare.com/pricing/
|
||||
[14]: https://cloudlinux.com/kernelcare-free-trial5
|
||||
@ -0,0 +1,239 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (DriveSync – Easy Way to Sync Files Between Local And Google Drive from Linux CLI)
|
||||
[#]: via: (https://www.2daygeek.com/drivesync-google-drive-sync-client-for-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
DriveSync – Easy Way to Sync Files Between Local And Google Drive from Linux CLI
|
||||
======
|
||||
|
||||
Google Drive is an one of the best cloud storage compared with other cloud storage.
|
||||
|
||||
It’s one of the application which is used by millions of users in daily basics.
|
||||
|
||||
It allow users to access the application anywhere irrespective of devices.
|
||||
|
||||
We can upload, download & share documents, photo, files, docs, spreadsheet, etc to anyone with securely.
|
||||
|
||||
We had already written few articles in 2daygeek website about google drive mapping with Linux.
|
||||
|
||||
If you would like to check those, navigate to the following link.
|
||||
|
||||
GNOME desktop offers easy way to **[Integrate Google Drive Using Gnome Nautilus File Manager in Linux][1]** without headache.
|
||||
|
||||
Also, you can give a try with **[Google Drive Ocamlfuse Client][2]**.
|
||||
|
||||
### What’s DriveSync?
|
||||
|
||||
[DriveSync][3] is a command line utility that synchronizes your files between local system and Google Drive via command line.
|
||||
|
||||
Downloads new remote files, uploads new local files to your Drive and deletes or updates files both locally and on Drive if they have changed in one place.
|
||||
|
||||
Allows blacklisting or whitelisting of files and folders that should not / should be synced.
|
||||
|
||||
It was written in Ruby scripting language so, make sure your system should have ruby installed. If it’s not installed then install it as a prerequisites for DriveSync.
|
||||
|
||||
### DriveSync Features
|
||||
|
||||
* Downloads new remote files
|
||||
* Uploads new local files
|
||||
* Delete or Update files in both locally and Drive
|
||||
* Allow blacklist to disable sync for files and folders
|
||||
* Automate the sync using cronjob
|
||||
* Allow us to set file upload/download size (Defautl 512MB)
|
||||
* Allow us to modify Timeout threshold
|
||||
|
||||
|
||||
|
||||
### How to Install Ruby Scripting Language in Linux?
|
||||
|
||||
Ruby is an interpreted scripting language for quick and easy object-oriented programming. It has many features to process text files and to do system management tasks (like in Perl). It is simple, straight-forward, and extensible.
|
||||
|
||||
It’s available in all the Linux distribution official repository. Hence we can easily install it with help of distribution official **[Package Manager][4]**.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][5]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo dnf install ruby rubygem-bundler
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][6]** or **[APT Command][7]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo apt install ruby ruby-bundler
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][8]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo pacman -S ruby ruby-bundler
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][9]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo yum install ruby ruby-bundler
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][10]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo zypper install ruby ruby-bundler
|
||||
```
|
||||
|
||||
### How to Install DriveSync in Linux?
|
||||
|
||||
DriveSync installation also easy to do it. Follow the below procedure to get it done.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/MStadlmeier/drivesync.git
|
||||
$ cd drivesync/
|
||||
$ bundle install
|
||||
```
|
||||
|
||||
### How to Set Up DriveSync in Linux?
|
||||
|
||||
As of now, we had successfully installed DriveSync and still we need to perform few steps to use this.
|
||||
|
||||
Run the following command to set up this and Sync the files.
|
||||
|
||||
```
|
||||
$ ruby drivesync.rb
|
||||
```
|
||||
|
||||
When you ran the above command you will be getting the below url.
|
||||
![][12]
|
||||
|
||||
Navigate to the given URL in your preferred Web Browser and follow the instruction. It will open a google sign-in page in default web browser. Enter your credentials then hit Sign in button.
|
||||
![][13]
|
||||
|
||||
Input your password.
|
||||
![][14]
|
||||
|
||||
Hit **`Allow`** button to allow DriveSync to access your Google Drive.
|
||||
![][15]
|
||||
|
||||
Finally, it will give you an authorization code.
|
||||
![][16]
|
||||
|
||||
Just copy and past it on the terminal and hit **`Enter`** button to start the sync.
|
||||
![][17]
|
||||
|
||||
Yes, it’s syncing the files from Google Drive to my local folder.
|
||||
|
||||
```
|
||||
$ ruby drivesync.rb
|
||||
Warning: Could not find config file at /home/daygeek/.drivesync/config.yml . Creating default config...
|
||||
Open the following URL in the browser and enter the resulting code after authorization
|
||||
https://accounts.google.com/o/oauth2/auth?access_type=offline&approval_prompt=force&client_id=xxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com&include_granted_scopes=true&redirect_uri=urn:ietf:wg:oauth:2.0:oob&response_type=code&scope=https://www.googleapis.com/auth/drive
|
||||
4/ygAxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
Local folder is 1437 files behind and 0 files ahead of remote
|
||||
Starting sync at 2019-01-06 19:48:49 +0530
|
||||
Downloading file 2018-07-31-17-48-54-635_1533039534635_XXXPM0534X_ITRV.zip ...
|
||||
Downloading file 5459XXXXXXXXXX25_11-03-2018.PDF ...
|
||||
Downloading file 2g-image-design/new-design-28-Mar-2018/new-base-format-icon-theme.svg ...
|
||||
Downloading file 2g-image-design/new-design-28-Mar-2018/2g-banner-format.svg ...
|
||||
Downloading file 2g-image-design/new-design-28-Mar-2018/new-base-format.svg ...
|
||||
Downloading file documents/Magesh_Resume_Updated_26_Mar_2018.doc ...
|
||||
Downloading file documents/Magesh_Resume_updated-new.doc ...
|
||||
Downloading file documents/Aadhaar-Thanu.PNG ...
|
||||
Downloading file documents/Aadhaar-Magesh.PNG ...
|
||||
Downloading file documents/Copy of PP-docs.pdf ...
|
||||
Downloading file EAadhaar_2189821080299520170807121602_25082017123052_172991.pdf ...
|
||||
Downloading file Tanisha/VID_20170223_113925.mp4 ...
|
||||
Downloading file Tanisha/VID_20170224_073234.mp4 ...
|
||||
Downloading file Tanisha/VID_20170304_170457.mp4 ...
|
||||
Downloading file Tanisha/IMG_20170225_203243.jpg ...
|
||||
Downloading file Tanisha/IMG_20170226_123949.jpg ...
|
||||
Downloading file Tanisha/IMG_20170226_123953.jpg ...
|
||||
Downloading file Tanisha/IMG_20170304_184227.jpg ...
|
||||
.
|
||||
.
|
||||
.
|
||||
Sync complete.
|
||||
```
|
||||
|
||||
It will create the **`drive`** folder under **`/home/user/Documents/`** and sync all the files in it.
|
||||
![][18]
|
||||
|
||||
DriveSync configuration files are located in the following location **`/home/user/.drivesync/`** if you had installed it on your **home** directory.
|
||||
|
||||
```
|
||||
$ ls -lh ~/.drivesync/
|
||||
total 176K
|
||||
-rw-r--r-- 1 daygeek daygeek 1.9K Jan 6 19:42 config.yml
|
||||
-rw-r--r-- 1 daygeek daygeek 170K Jan 6 21:31 manifest
|
||||
```
|
||||
|
||||
You can make your changes by modifying the **`config.yml`** file.
|
||||
|
||||
### How to Verify Whether Sync is Working Fine or Not?
|
||||
|
||||
To test this, we are going to create a new folder called **`2g-docs-2019`**. Also, adding an image file in it. Once it’s done, run the **`drivesync.rb`** command again.
|
||||
|
||||
```
|
||||
$ ruby drivesync.rb
|
||||
Local folder is 0 files behind and 1 files ahead of remote
|
||||
Starting sync at 2019-01-06 21:59:32 +0530
|
||||
Uploading file 2g-docs-2019/Asciinema - Record And Share Your Terminal Activity On The Web.png ...
|
||||
```
|
||||
|
||||
Yes, it has been synced to Google Drive. The same has been verified through Web Browser.
|
||||
![][19]
|
||||
|
||||
Create the below **CronJob** to enable an auto sync. The following “CronJob” will be running an every mins.
|
||||
|
||||
```
|
||||
$ vi crontab
|
||||
*/1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated ruby ~/drivesync/drivesync.rb
|
||||
```
|
||||
|
||||
I have added one more file to test this. Yes, it got success.
|
||||
|
||||
```
|
||||
Jan 07 09:36:01 daygeek-Y700 crond[590]: (daygeek) RELOAD (/var/spool/cron/daygeek)
|
||||
Jan 07 09:36:01 daygeek-Y700 crond[20942]: pam_unix(crond:session): session opened for user daygeek by (uid=0)
|
||||
Jan 07 09:36:01 daygeek-Y700 CROND[20943]: (daygeek) CMD (ruby ~/drivesync/drivesync.rb)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Local folder is 0 files behind and 1 files ahead of remote)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Starting sync at 2019-01-07 09:36:26 +0530)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Uploading file 2g-docs-2019/Check CPU And HDD Temperature In Linux.png ...)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT ()
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Sync complete.)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: pam_unix(crond:session): session closed for user daygeek
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/drivesync-google-drive-sync-client-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/mount-access-setup-google-drive-in-linux/
|
||||
[2]: https://www.2daygeek.com/mount-access-google-drive-on-linux-with-google-drive-ocamlfuse-client/
|
||||
[3]: https://github.com/MStadlmeier/drivesync
|
||||
[4]: https://www.2daygeek.com/category/package-management/
|
||||
[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[6]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[7]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[9]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-1.jpg
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-2.png
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-3.png
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-4.png
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-5.png
|
||||
[17]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-6.jpg
|
||||
[18]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-7.jpg
|
||||
[19]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-8.png
|
||||
303
sources/tech/20190107 How to manage your media with Kodi.md
Normal file
303
sources/tech/20190107 How to manage your media with Kodi.md
Normal file
@ -0,0 +1,303 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to manage your media with Kodi)
|
||||
[#]: via: (https://opensource.com/article/19/1/manage-your-media-kodi)
|
||||
[#]: author: (Steve Ovens https://opensource.com/users/stratusss)
|
||||
|
||||
How to manage your media with Kodi
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you, like me, like to own your own data, chances are you also like to purchase movies and TV shows on Blu-Ray or DVD discs. And you may also like to make [ISOs][1] of the videos to keep exact digital copies, as I do.
|
||||
|
||||
For a little while, it might be manageable to have a bunch of files stored in some sort of directory structure. However, as your collection grows, you may want features like resuming from a specific spot; keeping track of where you left off watching a video (i.e., its watched status); storing episode or movie summaries and movie trailers; buying media in multiple languages; or just having a sane way to play all those ISOs you ripped.
|
||||
|
||||
This is where Kodi comes in.
|
||||
|
||||
### What is Kodi?
|
||||
|
||||
Modern [Kodi][2] is the successor to Xbox Media Player, which was discontinued way back in 2003. In June 2004, Xbox Media Center (XBMC) was born. For over three years, XBMC remained on the Xbox. Then in 2007, work began in earnest to port the media player over to Linux.
|
||||
|
||||
|
||||
|
||||
Aside from some uninteresting technical history, things remained fairly stable, and XBMC grew in prominence. By 2014, XBMC had a thriving community, and its core functionality grew to include playing games, streaming content from the web, and connecting to mobile devices. This, combined with legal issues involving Xbox in the name, lead the team behind XBMC to rename it Kodi. Kodi is now branded as an "entertainment hub that brings all your digital media together into a beautiful and user-friendly package."
|
||||
|
||||
Today, Kodi has an extensible interface that has allowed the open source community to build new functionality using plugins. Note that, as with all open source software, Kodi's developers are not responsible for the ecosystem's plugins.
|
||||
|
||||
### How do I start?
|
||||
|
||||
For Ubuntu-based distributions, Kodi is just a few short commands away:
|
||||
|
||||
```
|
||||
sudo apt install software-properties-common
|
||||
sudo add-apt-repository ppa:team-xbmc/ppa
|
||||
sudo apt update
|
||||
sudo apt install kodi
|
||||
```
|
||||
|
||||
In Arch Linux, you can install the latest version from the community repo:
|
||||
|
||||
```
|
||||
sudo pacman -S kodi
|
||||
```
|
||||
|
||||
Packages were maintained for Fedora 26 by RPM Fusion (referenced in the [Kodi documentation][3]). I tried it on Fedora 29, and it was quite unstable. I'm sure that this will improve over time, but my experience is that Fedora 29 is not the ideal platform for Kodi.
|
||||
|
||||
### OK, it's installed… now what?
|
||||
|
||||
Before we proceed, note that I am making two assumptions about your media content:
|
||||
|
||||
1. You have your own local, legally attained content.
|
||||
2. You have already transferred this content from your DVDs, Blu-Rays, or another digital distribution source to your local directory or network.
|
||||
|
||||
|
||||
|
||||
Kodi uses a scraping service to pull down TV and movie metadata. For Kodi to match things appropriately, I recommend adopting a directory and file-naming structure similar to this:
|
||||
|
||||
```
|
||||
Utopia
|
||||
├── Utopia.S01.dvd_rip.x264
|
||||
│ ├── Utopia.S01E01.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E02.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E03.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E04.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E05.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E06.dvd_rip.x264.mkv
|
||||
└── Utopia.S02.dvd_rip.x264
|
||||
├── Utopia.S02E01.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E02.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E03.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E04.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E05.dvd_rip.x264.mkv
|
||||
└── Utopia.S02E06.dvd_rip.x264.mkv
|
||||
```
|
||||
|
||||
I put the source (my DVD) and the codec (x264) in the title, but these are optional. For a TV series, you can include the episode title in the filename if you like. The important part is **SxxExx** , which stands for Season and Episode. This is how Kodi (and by extension the scrapers) can identify your media.
|
||||
|
||||
Assuming you have organized your media like this, let's do some basic Kodi configuration.
|
||||
|
||||
### Add video sources
|
||||
|
||||
Adding video sources is a simple, six-step process:
|
||||
|
||||
1. Enter the files section
|
||||
2. Select **Files**
|
||||
3. Click **Add source**
|
||||
4. Browse to your source
|
||||
5. Define the video content type
|
||||
6. Refresh the metadata
|
||||
|
||||
|
||||
|
||||
If you're impatient, feel free to navigate these steps on your own. But if you want details, keep reading.
|
||||
|
||||
When you first launch Kodi, you'll see the home screen below. Click **Enter files section**. It doesn't matter whether you do this under Movies (as shown here) or TV shows.
|
||||
|
||||
|
||||
|
||||
Next, select the **Videos** folder, click **Files** , and choose **Add videos**.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Either click on **None** and start typing the path to your files or click **Browse** and use the file navigation.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
As you can see in this screenshot, I added my local **Videos** directory. You can set some default options through **Browse** , such as specifying your home folder and any drives you have mounted—maybe on a network file system (NFS), universal plug and play (UPnP) device, Windows Network ([SMB/CIFS][4]), or [zeroconf][5]. I won't cover most of these, as they are outside the scope of this article, but we will use NFS later for one of Kodi's advanced features.
|
||||
|
||||
After you select your path and click OK, identify the type of content you're working with.
|
||||
|
||||
|
||||
|
||||
Next, Kodi prompts you to refresh the metadata for the content in the selected directory. This is how Kodi knows what videos you have and their synopsis, cast information, thumbnails, fan art, etc. Select **Yes** , and you can watch the video-scanning progress in the top right-hand corner.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
When the scan completes, you'll see lots of useful information, such as video overviews and season and episode descriptions for TV shows.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
You can use the same process for other types of content, such as music or music videos.
|
||||
|
||||
### Increase functionality with add-ons
|
||||
|
||||
One of the most interesting things about open source projects is that the community often extends them well beyond their initial scope. Kodi has a very robust add-on infrastructure. Most of them are produced by Kodi fans who want to extend its default functionality, and sometimes companies (such as the [Plex][6] content streaming service) release official plugins. Be very careful about adding plugins from untrusted sources. Just because you find an add-on on the internet does not mean it is safe!
|
||||
|
||||
**Be warned:** Add-ons are not supported by Kodi's core team!
|
||||
|
||||
Having said that, there are many useful add-ons that are worth your consideration. In my house, we use Kodi for local playback and Plex when we want to access our content outside the house—with one exception. One of our rooms has a poor WiFi signal. I rip my Blu-Rays to very large MKV files (usually 20–40GB each), and the WiFi (and therefore Kodi) can't handle the files without stuttering. Although you can (and we have) dug into some of the advanced buffering options, even those tweaks have proved insufficient with very large files. Since we already have a Plex server that can transcode content, we solved our problem with a Kodi add-on.
|
||||
|
||||
To show how to install an add-on, I'll use Plex as an example. First, click on **Add-ons** in the side panel and select **Enter add-on browser**. Either use the search function or scroll down until you find Plex.
|
||||
|
||||
|
||||
|
||||
Select the Plex add-on and click the **Install** button in the lower right-hand corner.
|
||||
|
||||
|
||||
|
||||
Once the download completes, you can access Plex on the main Kodi screen under **Add-ons**.
|
||||
|
||||
|
||||
|
||||
There are several ways to configure an add-on. Some add-ons, such as NHL TV, are configured via a menu accessed by right-clicking the add-on and selecting Configure. Others, such as Plex, display a configuration walk-through when they launch. If an add-on doesn't seem to be configured when you first launch it, try right-clicking its menu and see if a settings option is available there.
|
||||
|
||||
### Coordinating metadata across Kodi devices
|
||||
|
||||
In our house, we have multiple machines that run Kodi. By default, Kodi tracks metadata, such as a video's watched status and show information, locally. Therefore, content updates on one machine won't appear on any other machine—unless you configure all your Kodi devices to store metadata inside an SQL database (which is a feature Kodi supports). This technique is not particularly difficult, but it is more advanced. If you're willing to put in the effort, here's how to do it.
|
||||
|
||||
#### Before you begin
|
||||
|
||||
There are a few things you need to know before configuring shared status for Kodi.
|
||||
|
||||
1. All content must be on a network share ([Samba][7], NFS, etc.).
|
||||
2. All content must be mounted via the network protocol, even if the disks are local to the machine. That means that no matter where the content is physically located, each client must be configured to use a network fileshare source.
|
||||
3. You need to be running an SQL-style database. Kodi's official guide walks through MySQL, but I chose MariaDB.
|
||||
4. All clients need to have the database port open (port 3306 in the case of MySQL/MariaDB) or the firewalls disabled.
|
||||
5. All clients must be running the same version of Kodi
|
||||
|
||||
|
||||
|
||||
#### Install and configure the database
|
||||
|
||||
If you're running Ubuntu, you can install MariaDB with the following commands:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install mariadb-server -y
|
||||
```
|
||||
|
||||
I am running MariaDB on an Arch Linux machine. The [Arch Wiki][8] documents the initial setup process well, but I'll summarize it here.
|
||||
|
||||
To install, issue the following command:
|
||||
|
||||
```
|
||||
sudo pacman -S mariadb
|
||||
```
|
||||
|
||||
Most distributions of MariaDB will have the same setup commands. I recommend that you understand what the commands do, but you can safely take the defaults if you're in a home environment.
|
||||
|
||||
```
|
||||
sudo systemctl start mariadb
|
||||
sudo mysql_install_db --user=mysql --basedir=/usr --datadir=/var/lib/mysql
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
Next, edit the MariaDB config file. This file is different depending on your distribution. On Ubuntu, you want to edit **/etc/mysql/mariadb.conf.d/50-server.cnf**. On Arch, the file is either **/etc/my.cnf** or **/etc/mysql/my.cnf**. Locate the line that says **bind-address = 127.0.0.1** and change it to your desired Ethernet port's IP address or to **bind-address = 0.0.0.0** if you want it to listen on all interfaces.
|
||||
|
||||
Restart the service so the change will take effect:
|
||||
|
||||
```
|
||||
sudo systemctl restart mariadb
|
||||
```
|
||||
|
||||
#### Configure Kodi and MariaDB/MySQL
|
||||
|
||||
To enable Kodi to write to the database, one of two things needs to happen: You can create the database yourself, or you can let Kodi do it for you. In this case, since the only database on this system is for Kodi, I'll create a user with the rights to create any databases that Kodi requires. Do NOT do this if the machine runs more than one database.
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
CREATE USER 'kodi' IDENTIFIED BY 'kodi';
|
||||
GRANT ALL ON core.md Dict.md lctt2014.md lctt2016.md lctt2018.md README.md TO 'kodi';
|
||||
flush privileges;
|
||||
\q
|
||||
```
|
||||
|
||||
This grants the user all rights—essentially enabling it to act as a root user. For my purposes, this is fine.
|
||||
|
||||
Next, on each Kodi device where you want to share metadata, create the following file: **/home/ <USER>/.kodi/userdata/advancedsettings.xml**. This file can contain a lot of very advanced, tweakable settings. My devices have these settings:
|
||||
|
||||
```
|
||||
<advancedsettings>
|
||||
<videodatabase>
|
||||
<type>mysql</type>
|
||||
<host>mysql-arch.example.com</host>
|
||||
<port>3306</port>
|
||||
<user>kodi</user>
|
||||
<pass>kodi</pass>
|
||||
</videodatabase>
|
||||
<videolibrary>
|
||||
<importwatchedstate>true</importwatchedstate>
|
||||
<importresumepoint>true</importresumepoint>
|
||||
</videolibrary>
|
||||
<cache>
|
||||
<!--- The three settings will go in this space, between the two network tags. --->
|
||||
<buffermode>1</buffermode>
|
||||
<memorysize>322122547</memorysize>
|
||||
<readfactor>20</readfactor>
|
||||
</cache>
|
||||
</advancedsettings>
|
||||
```
|
||||
|
||||
The **< cache>** section—which sets how much of a file Kodi will buffer over the network— is optional in this scenario. See the [Kodi wiki][9] for a full breakdown of this file and its options.
|
||||
|
||||
Once the configuration is complete, it's a good idea to close and reopen Kodi to make sure the settings are applied.
|
||||
|
||||
The final step is configuring all the Kodi clients to use the same network share for all their content. Only one client needs to scrap/refresh the metadata if everything is created successfully. When data is collected, you should see that Kodi creates a new database on your SQL server:
|
||||
|
||||
```
|
||||
[kodi@kodi-mysql ~]$ mysql -u root -p
|
||||
Enter password:
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MariaDB connection id is 180
|
||||
Server version: 10.1.37-MariaDB MariaDB Server
|
||||
|
||||
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
|
||||
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
|
||||
MariaDB [(none)]> show databases;
|
||||
+--------------------+
|
||||
| Database |
|
||||
+--------------------+
|
||||
| MyVideos107 |
|
||||
| information_schema |
|
||||
| mysql |
|
||||
| performance_schema |
|
||||
+--------------------+
|
||||
4 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
This article walked through how to get up and running with the basic functionality of Kodi. You should be able to add content and pull down metadata to make browsing your media more convenient.
|
||||
|
||||
You also know how to search for, install, and potentially configure add-ons for additional features. Be extra careful when downloading add-ons, as they are provided by the community at large and not the core developers. It's best to use add-ons only from organizations or companies you trust.
|
||||
|
||||
And you know a bit about sharing metadata across multiple devices. You've been introduced to **advancedsettings.xml** ; hopefully it has piqued your interest. Kodi has a lot of dials and knobs to turn, and you can squeeze a lot of performance and functionality out of the platform with enough experimentation.
|
||||
|
||||
Are you interested in doing more tweaking? What are some of your favorite add-ons or settings? Do you want to know how to change the user interface? What are some of your favorite skins? Let me know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/manage-your-media-kodi
|
||||
|
||||
作者:[Steve Ovens][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stratusss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/ISO_image
|
||||
[2]: https://kodi.tv/
|
||||
[3]: https://kodi.wiki/view/HOW-TO:Install_Kodi_for_Linux#Fedora
|
||||
[4]: https://en.wikipedia.org/wiki/Server_Message_Block
|
||||
[5]: https://en.wikipedia.org/wiki/Zero-configuration_networking
|
||||
[6]: https://www.plex.tv
|
||||
[7]: https://www.samba.org/
|
||||
[8]: https://wiki.archlinux.org/index.php/MySQL
|
||||
[9]: https://kodi.wiki/view/Advancedsettings.xml
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How ASLR protects Linux systems from buffer overflow attacks)
|
||||
[#]: via: (https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How ASLR protects Linux systems from buffer overflow attacks
|
||||
======
|
||||
|
||||

|
||||
|
||||
Address Space Layout Randomization (ASLR) is a memory-protection process for operating systems that guards against buffer-overflow attacks. It helps to ensure that the memory addresses associated with running processes on systems are not predictable, thus flaws or vulnerabilities associated with these processes will be more difficult to exploit.
|
||||
|
||||
ASLR is used today on Linux, Windows, and MacOS systems. It was first implemented on Linux in 2005. In 2007, the technique was deployed on Microsoft Windows and MacOS. While ASLR provides the same function on each of these operating systems, it is implemented differently on each one.
|
||||
|
||||
The effectiveness of ASLR is dependent on the entirety of the address space layout remaining unknown to the attacker. In addition, only executables that are compiled as Position Independent Executable (PIE) programs will be able to claim the maximum protection from ASLR technique because all sections of the code will be loaded at random locations. PIE machine code will execute properly regardless of its absolute address.
|
||||
|
||||
**[ Also see:[Invaluable tips and tricks for troubleshooting Linux][1] ]**
|
||||
|
||||
### ASLR limitations
|
||||
|
||||
In spite of ASLR making exploitation of system vulnerabilities more difficult, its role in protecting systems is limited. It's important to understand that ASLR:
|
||||
|
||||
* Doesn't _resolve_ vulnerabilities, but makes exploiting them more of a challenge
|
||||
* Doesn't track or report vulnerabilities
|
||||
* Doesn't offer any protection for binaries that are not built with ASLR support
|
||||
* Isn't immune to circumvention
|
||||
|
||||
|
||||
|
||||
### How ASLR works
|
||||
|
||||
ASLR increases the control-flow integrity of a system by making it more difficult for an attacker to execute a successful buffer-overflow attack by randomizing the offsets it uses in memory layouts.
|
||||
|
||||
ASLR works considerably better on 64-bit systems, as these systems provide much greater entropy (randomization potential).
|
||||
|
||||
### Is ASLR working on your Linux system?
|
||||
|
||||
Either of the two commands shown below will tell you whether ASLR is enabled on your system.
|
||||
|
||||
```
|
||||
$ cat /proc/sys/kernel/randomize_va_space
|
||||
2
|
||||
$ sysctl -a --pattern randomize
|
||||
kernel.randomize_va_space = 2
|
||||
```
|
||||
|
||||
The value (2) shown in the commands above indicates that ASLR is working in full randomization mode. The value shown will be one of the following:
|
||||
|
||||
```
|
||||
0 = Disabled
|
||||
1 = Conservative Randomization
|
||||
2 = Full Randomization
|
||||
```
|
||||
|
||||
If you disable ASLR and run the commands below, you should notice that the addresses shown in the **ldd** output below are all the same in the successive **ldd** commands. The **ldd** command works by loading the shared objects and showing where they end up in memory.
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=0 <== disable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 0
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
```
|
||||
|
||||
If the value is set back to **2** to enable ASLR, you will see that the addresses will change each time you run the command.
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=2 <== enable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 2
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007fff47d0e000) <== first set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007f1cb7ce0000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f1cb7cda000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1cb7af0000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007f1cb8045000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffe1cbd7000) <== second set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007fed59742000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fed5973c000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fed59552000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007fed59aa7000)
|
||||
```
|
||||
|
||||
### Attempting to bypass ASLR
|
||||
|
||||
In spite of its advantages, attempts to bypass ASLR are not uncommon and seem to fall into several categories:
|
||||
|
||||
* Using address leaks
|
||||
* Gaining access to data relative to particular addresses
|
||||
* Exploiting implementation weaknesses that allow attackers to guess addresses when entropy is low or when the ASLR implementation is faulty
|
||||
* Using side channels of hardware operation
|
||||
|
||||
|
||||
|
||||
### Wrap-up
|
||||
|
||||
ASLR is of great value, especially when run on 64 bit systems and implemented properly. While not immune from circumvention attempts, it does make exploitation of system vulnerabilities considerably more difficult. Here is a reference that can provide a lot more detail [on the Effectiveness of Full-ASLR on 64-bit Linux][2], and here is a paper on one circumvention effort to [bypass ASLR][3] using branch predictors.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[2]: https://cybersecurity.upv.es/attacks/offset2lib/offset2lib-paper.pdf
|
||||
[3]: http://www.cs.ucr.edu/~nael/pubs/micro16.pdf
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,152 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automating deployment strategies with Ansible)
|
||||
[#]: via: (https://opensource.com/article/19/1/automating-deployment-strategies-ansible)
|
||||
[#]: author: (Jario da Silva Junior https://opensource.com/users/jairojunior)
|
||||
|
||||
Automating deployment strategies with Ansible
|
||||
======
|
||||
Use automation to eliminate time sinkholes due to repetitive tasks and unplanned work.
|
||||

|
||||
|
||||
When you examine your technology stack from the bottom layer to the top—hardware, operating system (OS), middleware, and application—with their respective configurations, it's clear that changes are far more frequent as you go up in the stack. Your hardware will hardly change, your OS has a long lifecycle, and your middleware will keep up with the application's needs, but even if your release cycle is long (weeks or months), your applications will be the most volatile.
|
||||
|
||||
|
||||
|
||||
In [The Practice of System and Network Administration][1], the authors categorize the biggest "time sinkholes" in IT as manual/non-standard provisioning of OSes and application deployments. These time sinkholes will consume you with repetitive tasks or unplanned work.
|
||||
|
||||
How so? Let's say you provision a new server without Network Time Protocol (NTP) properly configured, and a small percentage of your requests—in a cluster of dozens of servers—start to behave strangely because an application uses some sort of scheduler that relies on correct time. When you look at it like this, it is an easy problem to fix, but how long it would it take your team figure it out? Incidents or unplanned work consume a lot of your time and, even worse, your greatest talents. Should you really be wasting time investigating production systems like this? Wouldn't it be better to set this server aside and automatically provision a new one from scratch?
|
||||
|
||||
What about manual deployment? Imagine 20 binaries deployed across a farm or nodes with their respective configuration files? How error-prone is this? Inevitably, it will eventually end up in unplanned work.
|
||||
|
||||
The [State of DevOps Report 2018][2] introduces the stages of DevOps adoption, and it's no surprise that Stage 0 includes deployment automation and reuse of deployment patterns, while Stage 1 and 2 focus on standardization of your infrastructure stack to reduce inconsistencies across your environment.
|
||||
|
||||
Note that, more than once, I have seen an ops team using this "standardization" as an excuse to limit a development team's ability to deliver, forcing them to use a hammer on something that is definitely not a nail. Don't do it; the price is extremely high.
|
||||
|
||||
The lesson to be learned here is that lack of automation not only increases your lead time but also the rate of problems in your process and the amount of unplanned work you face. If you've read [The Phoenix Project][3], you know this is the root of all evil in any value stream, and if you don't get rid of it, it will eventually kill your business.
|
||||
|
||||
When trying to fill the biggest time sinkholes, why not start with automating operating system installation? We could, but the results would take longer to appear since new virtual machines are not created as frequently as applications are deployed. In other words, this may not free up the time we need to power our initiative, so it could die prematurely.
|
||||
|
||||
Still not convinced? Smaller and more frequent releases are also extremely positive from the development side. Let's explain a little further…
|
||||
|
||||
### Deploy ≠ Release
|
||||
|
||||
The first thing to understand is that, although they're used interchangeably, deployment and release do **NOT** mean the same thing. Release refers to providing the user a new version, while deployment is the technical process of deploying the new version. Let's focus on the technical process of deployment.
|
||||
|
||||
### Tasks, groups, and Ansible
|
||||
|
||||
We need to understand the deployment process from the beginning to the end, including everything in the middle—the tasks, which servers are involved in the process, and which steps are executed—to avoid falling into the pitfalls described by Mattias Geniar in [Automating the unknown][4].
|
||||
|
||||
#### Tasks
|
||||
|
||||
The steps commonly executed in a regular deployment process include:
|
||||
|
||||
* Deploy application(s)/database(s) or database(s) change(s)
|
||||
* Stop/start services and monitoring
|
||||
* Add/remove the server from our load balancers
|
||||
* Verify application state—is it ready to serve requests?
|
||||
* Manual approval—is it necessary?
|
||||
|
||||
|
||||
|
||||
For some people, automating the deployment process but leaving a manual approval step is like riding a bike with training wheels. As someone once told me: "It's better to ride with training wheels than not ride at all."
|
||||
|
||||
What if a tool doesn't include an API or a command-line interface (CLI) to enable task automation? Well, maybe it's time to think about changing tools. There are many open source application servers, databases, monitoring systems, and load balancers that are easily automated—thanks in large part to the [Unix way][5]. When adopting a new technology, eliminate options that are not automated and use your creativity to support your legacy technologies. For example, I've seen people versioning network appliance configuration files and updating them using FTP.
|
||||
|
||||
And guess what? It's a wonderful time to adopt open source tools. The recent [Accelerate: State of DevOps][6] report found that open source technologies are in predominant use in high-performance organizations. The logic is pretty simple: open source projects function in a "Darwinist" model, where those that do not adapt and evolve will die for lack of a user base or contributions. Feedback is paramount to software evolution.
|
||||
|
||||
#### Groups
|
||||
|
||||
To identify groups of servers to target for automation, think about the most tasks you want to automate, such as those that:
|
||||
|
||||
* Deploy application(s)/database(s) or database change(s)
|
||||
* Stop/start services and monitoring
|
||||
* Add/remove server(s) from load balancer(s)
|
||||
* Verify application state—is it ready to serve requests?
|
||||
|
||||
|
||||
|
||||
#### The playbook
|
||||
|
||||
A high-level deployment process could be:
|
||||
|
||||
1. Stop monitoring (to avoid false-positives)
|
||||
2. Remove server from the load balancer (to prevent the user from receiving an error code)
|
||||
3. Stop the service (to enable a graceful shutdown)
|
||||
4. Deploy the new version of the application
|
||||
5. Wait for the application to be ready to receive new requests
|
||||
6. Execute steps 3, 2, and 1.
|
||||
7. Do the same for the next N servers.
|
||||
|
||||
|
||||
|
||||
Having documentation of your process is nice, but having an executable documenting your deployment is better! Here's what steps 1–5 would look like in Ansible for a fully open source stack:
|
||||
|
||||
```
|
||||
- name: Disable alerts
|
||||
nagios:
|
||||
action: disable_alerts
|
||||
host: "{{ inventory_hostname }}"
|
||||
services: webserver
|
||||
delegate_to: "{{ item }}"
|
||||
loop: "{{ groups.monitoring }}"
|
||||
|
||||
- name: Disable servers in the LB
|
||||
haproxy:
|
||||
host: "{{ inventory_hostname }}"
|
||||
state: disabled
|
||||
backend: app
|
||||
delegate_to: "{{ item }}"
|
||||
loop: " {{ groups.lbserver }}"
|
||||
|
||||
- name: Stop the service
|
||||
service: name=httpd state=stopped
|
||||
|
||||
- name: Deploy a new version
|
||||
unarchive: src=app.tar.gz dest=/var/www/app
|
||||
|
||||
- name: Verify application state
|
||||
uri:
|
||||
url: "http://{{ inventory_hostname }}/app/healthz"
|
||||
status_code: 200
|
||||
retries: 5
|
||||
```
|
||||
|
||||
### Why Ansible?
|
||||
|
||||
There are other alternatives for application deployment, but the things that make Ansible an excellent choice include:
|
||||
|
||||
* Multi-tier orchestration (i.e., **delegate_to** ) allowing you to orderly target different groups of servers: monitoring, load balancer, application server, database, etc.
|
||||
* Rolling upgrade (i.e., serial) to control how changes are made (e.g., 1 by 1, N by N, X% at a time, etc.)
|
||||
* Error control, **max_fail_percentage** and **any_errors_fatal** , is my process all-in or will it tolerate fails?
|
||||
* A vast library of modules for:
|
||||
* Monitoring (e.g., Nagios, Zabbix, etc.)
|
||||
* Load balancers (e.g., HAProxy, F5, Netscaler, Cisco, etc.)
|
||||
* Services (e.g., service, command, file)
|
||||
* Deployment (e.g., copy, unarchive)
|
||||
* Programmatic verifications (e.g., command, Uniform Resource Identifier)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
|
||||
|
||||
作者:[Jario da Silva Junior][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jairojunior
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.amazon.com/Practice-System-Network-Administration-Enterprise/dp/0321919165/ref=dp_ob_title_bk
|
||||
[2]: https://puppet.com/resources/whitepaper/state-of-devops-report
|
||||
[3]: https://www.amazon.com/Phoenix-Project-DevOps-Helping-Business/dp/0988262592
|
||||
[4]: https://ma.ttias.be/automating-unknown/
|
||||
[5]: https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
[6]: https://cloudplatformonline.com/2018-state-of-devops.html
|
||||
@ -0,0 +1,76 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding /etc/services file in Linux)
|
||||
[#]: via: (https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/)
|
||||
[#]: author: (kerneltalks https://kerneltalks.com)
|
||||
|
||||
Understanding /etc/services file in Linux
|
||||
======
|
||||
|
||||
Article which helps you to understand /etc/services file in Linux. Learn about content, format & importance of this file.
|
||||
|
||||
![/etc/services file in Linux][1]
|
||||
/etc/services file in Linux
|
||||
|
||||
Internet daemon is important service in Linux world. It takes care of all network services with the help of `/etc/services` file. In this article we will walk you through content, format of this file and what it means to a Linux system.
|
||||
|
||||
`/etc/services` file contains list of network services and ports mapped to them. `inetd` or `xinetd` looks at these details so that it can call particular program when packet hits respective port and demand for service.
|
||||
|
||||
As a normal user you can view this file since file is world readable. To edit this file you need to have root privileges.
|
||||
|
||||
```
|
||||
$ ll /etc/services
|
||||
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
|
||||
```
|
||||
|
||||
### `/etc/services` file format
|
||||
|
||||
```
|
||||
service-name port/protocol [aliases..] [#comment]
|
||||
```
|
||||
|
||||
Last two fields are optional hence denoted in `[` `]`
|
||||
|
||||
where –
|
||||
|
||||
* service-name is name of the network service. e.g. [telnet][2], [ftp][3] etc.
|
||||
* port/protocol is port being used by that network service (numerical value) and protocol (TCP/UDP) used for communication by service.
|
||||
* alias is alternate name for service.
|
||||
* comment is note or description you can add to service. Starts with `#` mark
|
||||
|
||||
|
||||
|
||||
### Sample` /etc/services` file
|
||||
|
||||
```
|
||||
# Each line describes one service, and is of the form:
|
||||
#
|
||||
# service-name port/protocol [aliases ...] [# comment]
|
||||
|
||||
tcpmux 1/tcp # TCP port service multiplexer
|
||||
rje 5/tcp # Remote Job Entry
|
||||
echo 7/udp
|
||||
discard 9/udp sink null
|
||||
```
|
||||
|
||||
Here, you can see use of optional last two fields as well. `discard` service has alternate name as `sink` or `null`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kerneltalks.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/kerneltalks.com/wp-content/uploads/2019/01/undestanding-etc-service-file-in-linux.png?ssl=1
|
||||
[2]: https://kerneltalks.com/config/configure-telnet-server-linux/
|
||||
[3]: https://kerneltalks.com/config/ftp-server-configuration-steps-rhel-6/
|
||||
369
sources/tech/20190110 5 useful Vim plugins for developers.md
Normal file
369
sources/tech/20190110 5 useful Vim plugins for developers.md
Normal file
@ -0,0 +1,369 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 useful Vim plugins for developers)
|
||||
[#]: via: (https://opensource.com/article/19/1/vim-plugins-developers)
|
||||
[#]: author: (Ricardo Gerardi https://opensource.com/users/rgerardi)
|
||||
|
||||
5 useful Vim plugins for developers
|
||||
======
|
||||
Expand Vim's capabilities and improve your workflow with these five plugins for writing code.
|
||||

|
||||
|
||||
I have used [Vim][1] as a text editor for over 20 years, but about two years ago I decided to make it my primary text editor. I use Vim to write code, configuration files, blog articles, and pretty much everything I can do in plaintext. Vim has many great features and, once you get used to it, you become very productive.
|
||||
|
||||
I tend to use Vim's robust native capabilities for most of what I do, but there are a number of plugins developed by the open source community that extend Vim's capabilities, improve your workflow, and make you even more productive.
|
||||
|
||||
Following are five plugins that are useful when using Vim to write code in any programming language.
|
||||
|
||||
### 1. Auto Pairs
|
||||
|
||||
The [Auto Pairs][2] plugin helps insert and delete pairs of characters, such as brackets, parentheses, or quotation marks. This is very useful for writing code, since most programming languages use pairs of characters in their syntax—such as parentheses for function calls or quotation marks for string definitions.
|
||||
|
||||
In its most basic functionality, Auto Pairs inserts the corresponding closing character when you type an opening character. For example, if you enter a bracket **[** , Auto-Pairs automatically inserts the closing bracket **]**. Conversely, if you use the Backspace key to delete the opening bracket, Auto Pairs deletes the corresponding closing bracket.
|
||||
|
||||
If you have automatic indentation on, Auto Pairs inserts the paired character in the proper indented position when you press Return/Enter, saving you from finding the correct position and typing the required spaces or tabs.
|
||||
|
||||
Consider this Go code block for instance:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Inserting an opening curly brace **{** after **items** and pressing Return/Enter produces this result:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items {
|
||||
| (cursor here)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Auto Pairs offers many other options (which you can read about on [GitHub][3]), but even these basic features will save time.
|
||||
|
||||
### 2. NERD Commenter
|
||||
|
||||
The [NERD Commenter][4] plugin adds code-commenting functions to Vim, similar to the ones found in an integrated development environment (IDE). With this plugin installed, you can select one or several lines of code and change them to comments with the press of a button.
|
||||
|
||||
NERD Commenter integrates with the standard Vim [filetype][5] plugin, so it understands several programming languages and uses the appropriate commenting characters for single or multi-line comments.
|
||||
|
||||
The easiest way to get started is by pressing **Leader+Space** to toggle the current line between commented and uncommented. The standard Vim Leader key is the **\** character.
|
||||
|
||||
In Visual mode, you can select multiple lines and toggle their status at the same time. NERD Commenter also understands counts, so you can provide a count n followed by the command to change n lines together.
|
||||
|
||||
Other useful features are the "Sexy Comment," triggered by **Leader+cs** , which creates a fancy comment block using the multi-line comment character. For example, consider this block of code:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items {
|
||||
fmt.Println(i)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Selecting all the lines in **function main** and pressing **Leader+cs** results in the following comment block:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
/*
|
||||
* x := true
|
||||
* items := []string{"tv", "pc", "tablet"}
|
||||
*
|
||||
* if x {
|
||||
* for _, i := range items {
|
||||
* fmt.Println(i)
|
||||
* }
|
||||
* }
|
||||
*/
|
||||
}
|
||||
```
|
||||
|
||||
Since all the lines are commented in one block, you can uncomment the entire block by toggling any of the lines of the block with **Leader+Space**.
|
||||
|
||||
NERD Commenter is a must-have for any developer using Vim to write code.
|
||||
|
||||
### 3. VIM Surround
|
||||
|
||||
The [Vim Surround][6] plugin helps you "surround" existing text with pairs of characters (such as parentheses or quotation marks) or tags (such as HTML or XML tags). It's similar to Auto Pairs but, instead of working while you're inserting text, it's more useful when you're editing text.
|
||||
|
||||
For example, if you have the following sentence:
|
||||
|
||||
```
|
||||
"Vim plugins are awesome !"
|
||||
```
|
||||
|
||||
You can remove the quotation marks around the sentence by pressing the combination **ds"** while your cursor is anywhere between the quotation marks:
|
||||
|
||||
```
|
||||
Vim plugins are awesome !
|
||||
```
|
||||
|
||||
You can also change the double quotation marks to single quotation marks with the command **cs"'** :
|
||||
|
||||
```
|
||||
'Vim plugins are awesome !'
|
||||
```
|
||||
|
||||
Or replace them with brackets by pressing **cs'[**
|
||||
|
||||
```
|
||||
[ Vim plugins are awesome ! ]
|
||||
```
|
||||
|
||||
While it's a great help for text objects, this plugin really shines when working with HTML or XML tags. Consider the following HTML line:
|
||||
|
||||
```
|
||||
<p>Vim plugins are awesome !</p>
|
||||
```
|
||||
|
||||
You can emphasize the word "awesome" by pressing the combination **ysiw <em>** while the cursor is anywhere on that word:
|
||||
|
||||
```
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
```
|
||||
|
||||
Notice that the plugin is smart enough to use the proper closing tag **< /em>**.
|
||||
|
||||
Vim Surround can also indent text and add tags in their own lines using **ySS**. For example, if you have:
|
||||
|
||||
```
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
```
|
||||
|
||||
Add a **div** tag with this combination: **ySS <div class="normal">**, and notice that the paragraph line is indented automatically.
|
||||
|
||||
```
|
||||
<div class="normal">
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
Vim Surround has many other options. Give it a try—and consult [GitHub][7] for additional information.
|
||||
|
||||
### 4\. Vim Gitgutter
|
||||
|
||||
The [Vim Gitgutter][8] plugin is useful for anyone using Git for version control. It shows the output of **Git diff** as symbols in the "gutter"—the sign column where Vim presents additional information, such as line numbers. For example, consider the following as the committed version in Git:
|
||||
|
||||
```
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
5 func main() {
|
||||
6 x := true
|
||||
7 items := []string{"tv", "pc", "tablet"}
|
||||
8
|
||||
9 if x {
|
||||
10 for _, i := range items {
|
||||
11 fmt.Println(i)
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
After making some changes, Vim Gitgutter displays the following symbols in the gutter:
|
||||
|
||||
```
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
The **-** symbol shows that a line was deleted between lines 5 and 6. The **~** symbol shows that line 8 was modified, and the symbol **+** shows that line 11 was added.
|
||||
|
||||
In addition, Vim Gitgutter allows you to navigate between "hunks"—individual changes made in the file—with **[c** and **]c** , or even stage individual hunks for commit by pressing **Leader+hs**.
|
||||
|
||||
This plugin gives you immediate visual feedback of changes, and it's a great addition to your toolbox if you use Git.
|
||||
|
||||
### 5\. VIM Fugitive
|
||||
|
||||
[Vim Fugitive][9] is another great plugin for anyone incorporating Git into the Vim workflow. It's a Git wrapper that allows you to execute Git commands directly from Vim and integrates with Vim's interface. This plugin has many features—check its [GitHub][10] page for more information.
|
||||
|
||||
Here's a basic Git workflow example using Vim Fugitive. Considering the changes we've made to the Go code block on section 4, you can use **git blame** by typing the command **:Gblame** :
|
||||
|
||||
```
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
|
||||
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
|
||||
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
|
||||
```
|
||||
|
||||
You can see that lines 8 and 11 have not been committed. Check the repository status by typing **:Gstatus** :
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is up to date with 'origin/master'.
|
||||
3 #
|
||||
4 # Changes not staged for commit:
|
||||
5 # (use "git add <file>..." to update what will be committed)
|
||||
6 # (use "git checkout -- <file>..." to discard changes in working directory)
|
||||
7 #
|
||||
8 # modified: vim-5plugins/examples/test1.go
|
||||
9 #
|
||||
10 no changes added to commit (use "git add" and/or "git commit -a")
|
||||
--------------------------------------------------------------------------------------------------------
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
Vim Fugitive opens a split window with the result of **git status**. You can stage a file for commit by pressing the **-** key on the line with the name of the file. You can reset the status by pressing **-** again. The message updates to reflect the new status:
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is up to date with 'origin/master'.
|
||||
3 #
|
||||
4 # Changes to be committed:
|
||||
5 # (use "git reset HEAD <file>..." to unstage)
|
||||
6 #
|
||||
7 # modified: vim-5plugins/examples/test1.go
|
||||
8 #
|
||||
--------------------------------------------------------------------------------------------------------
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
Now you can use the command **:Gcommit** to commit the changes. Vim Fugitive opens another split that allows you to enter a commit message:
|
||||
|
||||
```
|
||||
1 vim-5plugins: Updated test1.go example file
|
||||
2 # Please enter the commit message for your changes. Lines starting
|
||||
3 # with '#' will be ignored, and an empty message aborts the commit.
|
||||
4 #
|
||||
5 # On branch master
|
||||
6 # Your branch is up to date with 'origin/master'.
|
||||
7 #
|
||||
8 # Changes to be committed:
|
||||
9 # modified: vim-5plugins/examples/test1.go
|
||||
10 #
|
||||
```
|
||||
|
||||
Save the file with **:wq** to complete the commit:
|
||||
|
||||
```
|
||||
[master c3bf80f] vim-5plugins: Updated test1.go example file
|
||||
1 file changed, 2 insertions(+), 2 deletions(-)
|
||||
Press ENTER or type command to continue
|
||||
```
|
||||
|
||||
You can use **:Gstatus** again to see the result and **:Gpush** to update the remote repository with the new commit.
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is ahead of 'origin/master' by 1 commit.
|
||||
3 # (use "git push" to publish your local commits)
|
||||
4 #
|
||||
5 nothing to commit, working tree clean
|
||||
```
|
||||
|
||||
If you like Vim Fugitive and want to learn more, the GitHub repository has links to screencasts showing additional functionality and workflows. Check it out!
|
||||
|
||||
### What's next?
|
||||
|
||||
These Vim plugins help developers write code in any programming language. There are two other categories of plugins to help developers: code-completion plugins and syntax-checker plugins. They are usually related to specific programming languages, so I will cover them in a follow-up article.
|
||||
|
||||
Do you have another Vim plugin you use when writing code? Please share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/vim-plugins-developers
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgerardi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.vim.org/
|
||||
[2]: https://www.vim.org/scripts/script.php?script_id=3599
|
||||
[3]: https://github.com/jiangmiao/auto-pairs
|
||||
[4]: https://github.com/scrooloose/nerdcommenter
|
||||
[5]: http://vim.wikia.com/wiki/Filetype.vim
|
||||
[6]: https://www.vim.org/scripts/script.php?script_id=1697
|
||||
[7]: https://github.com/tpope/vim-surround
|
||||
[8]: https://github.com/airblade/vim-gitgutter
|
||||
[9]: https://www.vim.org/scripts/script.php?script_id=2975
|
||||
[10]: https://github.com/tpope/vim-fugitive
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Build a retro gaming console with RetroPie)
|
||||
[#]: via: (https://opensource.com/article/19/1/retropie)
|
||||
[#]: author: (Jay LaCroix https://opensource.com/users/jlacroix)
|
||||
|
||||
Build a retro gaming console with RetroPie
|
||||
======
|
||||
Play your favorite classic Nintendo, Sega, and Sony console games on Linux.
|
||||

|
||||
|
||||
The most common question I get on [my YouTube channel][1] and in person is what my favorite Linux distribution is. If I limit the answer to what I run on my desktops and laptops, my answer will typically be some form of an Ubuntu-based Linux distro. My honest answer to this question may surprise many. My favorite Linux distribution is actually [RetroPie][2].
|
||||
|
||||
As passionate as I am about Linux and open source software, I'm equally passionate about classic gaming, specifically video games produced in the '90s and earlier. I spend most of my surplus income on older games, and I now have a collection of close to a thousand games for over 20 gaming consoles. In my spare time, I raid flea markets, yard sales, estate sales, and eBay buying games for various consoles, including almost every iteration made by Nintendo, Sega, and Sony. There's something about classic games that I adore, a charm that seems lost in games released nowadays.
|
||||
|
||||
Unfortunately, collecting retro games has its fair share of challenges. Cartridges with memory for save files will lose their charge over time, requiring the battery to be replaced. While it's not hard to replace save batteries (if you know how), it's still time-consuming. Games on CD-ROMs are subject to disc rot, which means that even if you take good care of them, they'll still lose data over time and become unplayable. Also, sometimes it's difficult to find replacement parts for some consoles. This wouldn't be so much of an issue if the majority of classic games were available digitally, but the vast majority are never re-released on a digital platform.
|
||||
|
||||
### Gaming on RetroPie
|
||||
|
||||
RetroPie is a great project and an asset to retro gaming enthusiasts like me. RetroPie is a Raspbian-based distribution designed for use on the Raspberry Pi (though it is possible to get it working on other platforms, such as a PC). RetroPie boots into a graphical interface that is completely controllable via a gamepad or joystick and allows you to easily manage digital copies (ROMs) of your favorite games. You can scrape information from the internet to organize your collection better and manage lists of favorite games, and the entire interface is very user-friendly and efficient. From the interface, you can launch directly into a game, then exit the game by pressing a combination of buttons on your gamepad. You rarely need a keyboard, unless you have to enter your WiFi password or manually edit configuration files.
|
||||
|
||||
I use RetroPie to host a digital copy of every physical game I own in my collection. When I purchase a game from a local store or eBay, I also download the ROM. As a collector, this is very convenient. If I don't have a particular physical console within arms reach, I can boot up RetroPie and enjoy a game quickly without having to connect cables or clean cartridge contacts. There's still something to be said about playing a game on the original hardware, but if I'm pressed for time, RetroPie is very convenient. I also don't have to worry about dead save batteries, dirty cartridge contacts, disc rot, or any of the other issues collectors like me have to regularly deal with. I simply play the game.
|
||||
|
||||
Also, RetroPie allows me to be very clever and utilize my technical know-how to achieve additional functionality that's not normally available. For example, I have three RetroPies set up, each of them synchronizing their files between each other by leveraging [Syncthing][3], a popular open source file synchronization tool. The synchronization happens automatically, and it means I can start a game on one television and continue in the same place on another unit since the save files are included in the synchronization. To take it a step further, I also back up my save and configuration files to [Backblaze B2][4], so I'm protected if an SD card becomes defective.
|
||||
|
||||
### Setting up RetroPie
|
||||
|
||||
Setting up RetroPie is very easy, and if you've ever set up a Raspberry Pi Linux distribution before (such as Raspbian) the process is essentially the same—you simply download the IMG file and flash it to your SD card by utilizing another tool, such as [Etcher][5], and insert it into your RetroPie. Then plug in an AC adapter and gamepad and hook it up to your television via HDMI. Optionally, you can buy a case to protect your RetroPie from outside elements and add visual appeal. Here is a listing of things you'll need to get started:
|
||||
|
||||
* Raspberry Pi board (Model 3B+ or higher recommended)
|
||||
* SD card (16GB or larger recommended)
|
||||
* A USB gamepad
|
||||
* UL-listed micro USB power adapter, at least 2.5 amp
|
||||
|
||||
|
||||
|
||||
If you choose to add the optional Raspberry Pi case, I recommend the Super NES and Super Famicom themed cases from [RetroFlag][6]. Not only do these cases look cool, but they also have fully functioning power and reset buttons. This means you can configure the reset and power buttons to directly trigger the operating system's halt process, rather than abruptly terminating power. This definitely makes for a more professional experience, but it does require the installation of a special script. The instructions are on [RetroFlag's GitHub page][7]. Be wary: there are many cases available on Amazon and eBay of varying quality. Some of them are cheap knock-offs of RetroFlag cases, and others are just a lower quality overall. In fact, even cases by RetroFlag vary in quality—I had some power-distribution issues with the NES-themed case that made for an unstable experience. If in doubt, I've found that RetroFlag's Super NES and Super Famicom themed cases work very well.
|
||||
|
||||
### Adding games
|
||||
|
||||
When you boot RetroPie for the first time, it will resize the filesystem to ensure you have full access to the available space on your SD card and allow you to set up your gamepad. I can't give you links for game ROMs, so I'll leave that part up to you to figure out. When you've found them, simply add them to the RetroPie SD card in the designated folder, which would be located under **/home/pi/RetroPie/roms/ <console_name>**. You can use your favorite tool for transferring the ROMs to the Pi, such as [SCP][8] in a terminal, [WinSCP][9], [Samba][10], etc. Once you've added the games, you can rescan them by pressing start and choosing the option to restart EmulationStation. When it restarts, it should automatically add menu entries for the ROMs you've added. That's basically all there is to it.
|
||||
|
||||
(The rescan updates EmulationStation’s game inventory. If you don’t do that, it won’t list any newly added games you copy over.)
|
||||
|
||||
Regarding the games' performance, your mileage will vary depending on which consoles you're emulating. For example, I've noticed that Sega Dreamcast games barely run at all, and most Nintendo 64 games will run sluggishly with a bad framerate. Many PlayStation Portable (PSP) games also perform inconsistently. However, all of the 8-bit and 16-bit consoles emulate seemingly perfectly—I haven't run into a single 8-bit or 16-bit game that doesn't run well. Surprisingly, games designed for the original PlayStation run great for me, which is a great feat considering the lower-performance potential of the Raspberry Pi.
|
||||
|
||||
Overall, RetroPie's performance is great, but the Raspberry Pi is not as powerful as a gaming PC, so adjust your expectations accordingly.
|
||||
|
||||
### Conclusion
|
||||
|
||||
RetroPie is a fantastic open source project dedicated to preserving classic games and an asset to game collectors everywhere. Having a digital copy of my physical game collection is extremely convenient. If I were to tell my childhood self that one day I could have an entire game collection on one device, I probably wouldn't believe it. But RetroPie has become a staple in my household and provides hours of fun and enjoyment.
|
||||
|
||||
If you want to see the parts I mentioned as well as a quick installation overview, I have [a video][11] on [my YouTube channel][12] that goes over the process and shows off some gameplay at the end.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/retropie
|
||||
|
||||
作者:[Jay LaCroix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jlacroix
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/channel/UCxQKHvKbmSzGMvUrVtJYnUA
|
||||
[2]: https://retropie.org.uk/
|
||||
[3]: https://syncthing.net/
|
||||
[4]: https://www.backblaze.com/b2/cloud-storage.html
|
||||
[5]: https://www.balena.io/etcher/
|
||||
[6]: https://www.amazon.com/shop/learnlinux.tv?listId=1N9V89LEH5S8K
|
||||
[7]: https://github.com/RetroFlag/retroflag-picase
|
||||
[8]: https://en.wikipedia.org/wiki/Secure_copy
|
||||
[9]: https://winscp.net/eng/index.php
|
||||
[10]: https://www.samba.org/
|
||||
[11]: https://www.youtube.com/watch?v=D8V-KaQzsWM
|
||||
[12]: http://www.youtube.com/c/LearnLinuxtv
|
||||
@ -0,0 +1,61 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Joplin, a note-taking app)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-joplin)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Joplin, a note-taking app
|
||||
======
|
||||
Learn how open source tools can help you be more productive in 2019. First up, Joplin.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the first of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Joplin
|
||||
|
||||
In the realm of productivity tools, note-taking apps are VERY handy. Yes, you can use the open source [NixNote][1] to access [Evernote][2] notes, but it's still linked to the Evernote servers and still relies on a third party for security. And while you CAN export your Evernote notes from NixNote, the only format options are NixNote XML or PDF files.
|
||||
|
||||
|
||||
|
||||
Enter [Joplin][3]. Joplin is a NodeJS application that runs and stores notes locally, allows you to encrypt your notes and supports multiple sync methods. Joplin can run as a console or graphical application on Windows, Mac, and Linux. Joplin also has mobile apps for Android and iOS, meaning you can take your notes with you without a major hassle. Joplin even allows you to format notes with Markdown, HTML, or plain text.
|
||||
|
||||
|
||||
|
||||
One really nice thing about Joplin is it supports two kinds of notes: plain notes and to-do notes. Plain notes are what you expect—documents containing text. To-do notes, on the other hand, have a checkbox in the notes list that allows you to mark them "done." And since the to-do note is still a note, you can include lists, documentation, and additional to-do items in a to-do note.
|
||||
|
||||
When using the GUI, you can toggle editor views between plain text, WYSIWYG, and a split screen showing both the source text and the rendered view. You can also specify an external editor in the GUI, making it easy to update notes with Vim, Emacs, or any other editor capable of handling text documents.
|
||||
|
||||
![Joplin console version][5]
|
||||
|
||||
Joplin in the console.
|
||||
|
||||
The console interface is absolutely fantastic. While it lacks a WYSIWYG editor, it defaults to the text editor for your login. It also has a powerful command mode that allows you to do almost everything you can do in the GUI version. And it renders Markdown correctly in the viewer.
|
||||
|
||||
You can group notes in notebooks and tag notes for easy grouping across your notebooks. And it even has built-in search, so you can find things if you forget where you put them.
|
||||
|
||||
Overall, Joplin is a first-class note-taking app ([and a great alternative to Evernote][6]) that will help you be organized and more productive over the next year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-joplin
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://nixnote.org/NixNote-Home/
|
||||
[2]: https://evernote.com/
|
||||
[3]: https://joplin.cozic.net/
|
||||
[4]: https://opensource.com/article/19/1/file/419776
|
||||
[5]: https://opensource.com/sites/default/files/uploads/joplin-2_0.png (Joplin console version)
|
||||
[6]: https://opensource.com/article/17/12/joplin-open-source-evernote-alternative
|
||||
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Move Multiple File Types Simultaneously From Commandline)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-move-multiple-file-types-simultaneously-from-commandline/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Move Multiple File Types Simultaneously From Commandline
|
||||
======
|
||||
|
||||

|
||||
|
||||
The other day I was wondering how can I move (not copy) multiple file types from directory to another. I already knew how to [**find and copy certain type of files from one directory to another**][1]. But, I don’t know how to move multiple file types simultaneously. If you’re ever in a situation like this, I know a easy way to do it from commandline in Unix-like systems.
|
||||
|
||||
### Move Multiple File Types Simultaneously
|
||||
|
||||
Picture this scenario.You have multiple type of files, for example .pdf, .doc, .mp3, .mp4, .txt etc., on a directory named **‘dir1’**. Let us take a look at the dir1 contents:
|
||||
|
||||
```
|
||||
$ ls dir1
|
||||
file.txt image.jpg mydoc.doc personal.pdf song.mp3 video.mp4
|
||||
```
|
||||
|
||||
You want to move some of the file types (not all of them) to different location. For example, let us say you want to move doc, pdf and txt files only to another directory named **‘dir2’** in one go.
|
||||
|
||||
To copy .doc, .pdf and .txt files from dir1 to dir2 simultaneously, the command would be:
|
||||
|
||||
```
|
||||
$ mv dir1/*.{doc,pdf,txt} dir2/
|
||||
```
|
||||
|
||||
It’s easy, isn’t it?
|
||||
|
||||
Now, let us check the contents of dir2:
|
||||
|
||||
```
|
||||
$ ls dir2/
|
||||
file.txt mydoc.doc personal.pdf
|
||||
```
|
||||
|
||||
See? Only the file types .doc, .pdf and .txt from dir1 have been moved to dir2.
|
||||
|
||||
![][3]
|
||||
|
||||
You can add as many file types as you want to inside curly braces in the above command to move them across different directories. The above command just works fine for me on Bash.
|
||||
|
||||
Another way to move multiple file types is go to the source directory i.e dir1 in our case:
|
||||
|
||||
```
|
||||
$ cd ~/dir1
|
||||
```
|
||||
|
||||
And, move file types of your choice to the destination (E.g dir2) as shown below.
|
||||
|
||||
```
|
||||
$ mv *.doc *.txt *.pdf /home/sk/dir2/
|
||||
```
|
||||
|
||||
To move all files having a particular extension, for example **.doc** only, run:
|
||||
|
||||
```
|
||||
$ mv dir1/*.doc dir2/
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
|
||||
```
|
||||
$ man mv
|
||||
```
|
||||
|
||||
Moving a few number of same or different file types is easy! You could do this with couple mouse clicks in GUI mode or use a one-liner command in CLI mode. However, If you have thousands of different file types in a directory and wanted to move multiple file types to different directory in one go, it would be a cumbersome task. To me, the above method did the job easily! If you know any other one-liner commands to move multiple file types at a time, please share it in the comment section below. I will check and update the guide accordingly.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-move-multiple-file-types-simultaneously-from-commandline/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/find-copy-certain-type-files-one-directory-another-linux/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/01/mv-command.gif
|
||||
632
sources/tech/20190114 How to Build a Netboot Server, Part 4.md
Normal file
632
sources/tech/20190114 How to Build a Netboot Server, Part 4.md
Normal file
@ -0,0 +1,632 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Build a Netboot Server, Part 4)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-build-a-netboot-server-part-4/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
How to Build a Netboot Server, Part 4
|
||||
======
|
||||

|
||||
|
||||
One significant limitation of the netboot server built in this series is the operating system image being served is read-only. Some use cases may require the end user to modify the image. For example, an instructor may want to have the students install and configure software packages like MariaDB and Node.js as part of their course walk-through.
|
||||
|
||||
An added benefit of writable netboot images is the end user’s “personalized” operating system can follow them to different workstations they may use at later times.
|
||||
|
||||
### Change the Bootmenu Application to use HTTPS
|
||||
|
||||
Create a self-signed certificate for the bootmenu application:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# MY_NAME=$(</etc/hostname)
|
||||
# MY_TLSD=/opt/bootmenu/tls
|
||||
# mkdir $MY_TLSD
|
||||
# openssl req -newkey rsa:2048 -nodes -keyout $MY_TLSD/$MY_NAME.key -x509 -days 3650 -out $MY_TLSD/$MY_NAME.pem
|
||||
```
|
||||
|
||||
Verify your certificate’s values. Make sure the “CN” value in the “Subject” line matches the DNS name that your iPXE clients use to connect to your bootmenu server:
|
||||
|
||||
```
|
||||
# openssl x509 -text -noout -in $MY_TLSD/$MY_NAME.pem
|
||||
```
|
||||
|
||||
Next, update the bootmenu application’s listen directive to use the HTTPS port and the newly created certificate and key:
|
||||
|
||||
```
|
||||
# sed -i "s#listen => .*#listen => ['https://$MY_NAME:443?cert=$MY_TLSD/$MY_NAME.pem\&key=$MY_TLSD/$MY_NAME.key\&ciphers=AES256-SHA256:AES128-SHA256:AES256-SHA:AES128-SHA'],#" /opt/bootmenu/bootmenu.conf
|
||||
```
|
||||
|
||||
Note the ciphers have been restricted to [those currently supported by iPXE][1].
|
||||
|
||||
GnuTLS requires the “CAP_DAC_READ_SEARCH” capability, so add it to the bootmenu application’s systemd service:
|
||||
|
||||
```
|
||||
# sed -i '/^AmbientCapabilities=/ s/$/ CAP_DAC_READ_SEARCH/' /etc/systemd/system/bootmenu.service
|
||||
# sed -i 's/Serves iPXE Menus over HTTP/Serves iPXE Menus over HTTPS/' /etc/systemd/system/bootmenu.service
|
||||
# systemctl daemon-reload
|
||||
```
|
||||
|
||||
Now, add an exception for the bootmenu service to the firewall and restart the service:
|
||||
|
||||
```
|
||||
# MY_SUBNET=192.0.2.0
|
||||
# MY_PREFIX=24
|
||||
# firewall-cmd --add-rich-rule="rule family='ipv4' source address='$MY_SUBNET/$MY_PREFIX' service name='https' accept"
|
||||
# firewall-cmd --runtime-to-permanent
|
||||
# systemctl restart bootmenu.service
|
||||
```
|
||||
|
||||
Use wget to verify it’s working:
|
||||
|
||||
```
|
||||
$ MY_NAME=server-01.example.edu
|
||||
$ MY_TLSD=/opt/bootmenu/tls
|
||||
$ wget -q --ca-certificate=$MY_TLSD/$MY_NAME.pem -O - https://$MY_NAME/menu
|
||||
```
|
||||
|
||||
### Add HTTPS to iPXE
|
||||
|
||||
Update init.ipxe to use HTTPS. Then recompile the ipxe bootloader with options to embed and trust the self-signed certificate you created for the bootmenu application:
|
||||
|
||||
```
|
||||
$ echo '#define DOWNLOAD_PROTO_HTTPS' >> $HOME/ipxe/src/config/local/general.h
|
||||
$ sed -i 's/^chain http:/chain https:/' $HOME/ipxe/init.ipxe
|
||||
$ cp $MY_TLSD/$MY_NAME.pem $HOME/ipxe
|
||||
$ cd $HOME/ipxe/src
|
||||
$ make clean
|
||||
$ make bin-x86_64-efi/ipxe.efi EMBED=../init.ipxe CERT="../$MY_NAME.pem" TRUST="../$MY_NAME.pem"
|
||||
```
|
||||
|
||||
You can now copy the HTTPS-enabled iPXE bootloader out to your clients and test that everything is working correctly:
|
||||
|
||||
```
|
||||
$ cp $HOME/ipxe/src/bin-x86_64-efi/ipxe.efi $HOME/esp/efi/boot/bootx64.efi
|
||||
```
|
||||
|
||||
### Add User Authentication to Mojolicious
|
||||
|
||||
Create a PAM service definition for the bootmenu application:
|
||||
|
||||
```
|
||||
# dnf install -y pam_krb5
|
||||
# echo 'auth required pam_krb5.so' > /etc/pam.d/bootmenu
|
||||
```
|
||||
|
||||
Add a library to the bootmenu application that uses the Authen-PAM perl module to perform user authentication:
|
||||
|
||||
```
|
||||
# dnf install -y perl-Authen-PAM;
|
||||
# MY_MOJO=/opt/bootmenu
|
||||
# mkdir $MY_MOJO/lib
|
||||
# cat << 'END' > $MY_MOJO/lib/PAM.pm
|
||||
package PAM;
|
||||
|
||||
use Authen::PAM;
|
||||
|
||||
sub auth {
|
||||
my $success = 0;
|
||||
|
||||
my $username = shift;
|
||||
my $password = shift;
|
||||
|
||||
my $callback = sub {
|
||||
my @res;
|
||||
while (@_) {
|
||||
my $code = shift;
|
||||
my $msg = shift;
|
||||
my $ans = "";
|
||||
|
||||
$ans = $username if ($code == PAM_PROMPT_ECHO_ON());
|
||||
$ans = $password if ($code == PAM_PROMPT_ECHO_OFF());
|
||||
|
||||
push @res, (PAM_SUCCESS(), $ans);
|
||||
}
|
||||
push @res, PAM_SUCCESS();
|
||||
|
||||
return @res;
|
||||
};
|
||||
|
||||
my $pamh = new Authen::PAM('bootmenu', $username, $callback);
|
||||
|
||||
{
|
||||
last unless ref $pamh;
|
||||
last unless $pamh->pam_authenticate() == PAM_SUCCESS;
|
||||
$success = 1;
|
||||
}
|
||||
|
||||
return $success;
|
||||
}
|
||||
|
||||
return 1;
|
||||
END
|
||||
```
|
||||
|
||||
The above code is taken almost verbatim from the Authen::PAM::FAQ man page.
|
||||
|
||||
Redefine the bootmenu application so it returns a netboot template only if a valid username and password are supplied:
|
||||
|
||||
```
|
||||
# cat << 'END' > $MY_MOJO/bootmenu.pl
|
||||
#!/usr/bin/env perl
|
||||
|
||||
use lib 'lib';
|
||||
|
||||
use PAM;
|
||||
use Mojolicious::Lite;
|
||||
use Mojolicious::Plugins;
|
||||
use Mojo::Util ('url_unescape');
|
||||
|
||||
plugin 'Config';
|
||||
|
||||
get '/menu';
|
||||
get '/boot' => sub {
|
||||
my $c = shift;
|
||||
|
||||
my $instance = $c->param('instance');
|
||||
my $username = $c->param('username');
|
||||
my $password = $c->param('password');
|
||||
|
||||
my $template = 'menu';
|
||||
|
||||
{
|
||||
last unless $instance =~ /^fc[[:digit:]]{2}$/;
|
||||
last unless $username =~ /^[[:alnum:]]+$/;
|
||||
last unless PAM::auth($username, url_unescape($password));
|
||||
$template = $instance;
|
||||
}
|
||||
|
||||
return $c->render(template => $template);
|
||||
};
|
||||
|
||||
app->start;
|
||||
END
|
||||
```
|
||||
|
||||
The bootmenu application now looks for the lib directory relative to its WorkingDirectory. However, by default the working directory is set to the root directory of the server for systemd units. Therefore, you must update the systemd unit to set WorkingDirectory to the root of the bootmenu application instead:
|
||||
|
||||
```
|
||||
# sed -i "/^RuntimeDirectory=/ a WorkingDirectory=$MY_MOJO" /etc/systemd/system/bootmenu.service
|
||||
# systemctl daemon-reload
|
||||
```
|
||||
|
||||
Update the templates to work with the redefined bootmenu application:
|
||||
|
||||
```
|
||||
# cd $MY_MOJO/templates
|
||||
# MY_BOOTMENU_SERVER=$(</etc/hostname)
|
||||
# MY_FEDORA_RELEASES="28 29"
|
||||
# for i in $MY_FEDORA_RELEASES; do echo '#!ipxe' > fc$i.html.ep; grep "^kernel\|initrd" menu.html.ep | grep "fc$i" >> fc$i.html.ep; echo "boot || chain https://$MY_BOOTMENU_SERVER/menu" >> fc$i.html.ep; sed -i "/^:f$i$/,/^boot /c :f$i\nlogin\nchain https://$MY_BOOTMENU_SERVER/boot?instance=fc$i\&username=\${username}\&password=\${password:uristring} || goto failed" menu.html.ep; done
|
||||
```
|
||||
|
||||
The result of the last command above should be three files similar to the following:
|
||||
|
||||
**menu.html.ep** :
|
||||
|
||||
```
|
||||
#!ipxe
|
||||
|
||||
set timeout 5000
|
||||
|
||||
:menu
|
||||
menu iPXE Boot Menu
|
||||
item --key 1 lcl 1. Microsoft Windows 10
|
||||
item --key 2 f29 2. RedHat Fedora 29
|
||||
item --key 3 f28 3. RedHat Fedora 28
|
||||
choose --timeout ${timeout} --default lcl selected || goto shell
|
||||
set timeout 0
|
||||
goto ${selected}
|
||||
|
||||
:failed
|
||||
echo boot failed, dropping to shell...
|
||||
goto shell
|
||||
|
||||
:shell
|
||||
echo type 'exit' to get the back to the menu
|
||||
set timeout 0
|
||||
shell
|
||||
goto menu
|
||||
|
||||
:lcl
|
||||
exit
|
||||
|
||||
:f29
|
||||
login
|
||||
chain https://server-01.example.edu/boot?instance=fc29&username=${username}&password=${password:uristring} || goto failed
|
||||
|
||||
:f28
|
||||
login
|
||||
chain https://server-01.example.edu/boot?instance=fc28&username=${username}&password=${password:uristring} || goto failed
|
||||
```
|
||||
|
||||
**fc29.html.ep** :
|
||||
|
||||
```
|
||||
#!ipxe
|
||||
kernel --name kernel.efi ${prefix}/vmlinuz-4.19.5-300.fc29.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc29 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
|
||||
initrd --name initrd.img ${prefix}/initramfs-4.19.5-300.fc29.x86_64.img
|
||||
boot || chain https://server-01.example.edu/menu
|
||||
```
|
||||
|
||||
**fc28.html.ep** :
|
||||
|
||||
```
|
||||
#!ipxe
|
||||
kernel --name kernel.efi ${prefix}/vmlinuz-4.19.3-200.fc28.x86_64 initrd=initrd.img ro ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc28-lun-1 netroot=iscsi:192.0.2.158::::iqn.edu.example.server-01:fc28 console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
|
||||
initrd --name initrd.img ${prefix}/initramfs-4.19.3-200.fc28.x86_64.img
|
||||
boot || chain https://server-01.example.edu/menu
|
||||
```
|
||||
|
||||
Now, restart the bootmenu application and verify authentication is working:
|
||||
|
||||
```
|
||||
# systemctl restart bootmenu.service
|
||||
```
|
||||
|
||||
### Make the iSCSI Target Writeable
|
||||
|
||||
Now that user authentication works through iPXE, you can create per-user, writeable overlays on top of the read-only image on demand when users connect. Using a [copy-on-write][2] overlay has three advantages over simply copying the original image file for each user:
|
||||
|
||||
1. The copy can be created very quickly. This allows creation on-demand.
|
||||
2. The copy does not increase the disk usage on the server. Only what the user writes to their personal copy of the image is stored in addition to the original image.
|
||||
3. Since most sectors for each copy are the same sectors on the server’s storage, they’ll likely already be loaded in RAM when subsequent users access their copies of the operating system. This improves the server’s performance because RAM is faster than disk I/O.
|
||||
|
||||
|
||||
|
||||
One potential pitfall of using copy-on-write is that once overlays are created, the images on which they are overlayed must not be changed. If they are changed, all the overlays will be corrupted. Then the overlays must be deleted and replaced with new, blank overlays. Even simply mounting the image file in read-write mode can cause sufficient filesystem updates to corrupt the overlays.
|
||||
|
||||
Due to the potential for the overlays to be corrupted if the original image is modified, mark the original image as immutable by running:
|
||||
|
||||
```
|
||||
# chattr +i </path/to/file>
|
||||
```
|
||||
|
||||
You can use lsattr </path/to/file> to view the status of the immutable flag and use to chattr -i </path/to/file> unset the immutable flag. While the immutable flag is set, even the root user or a system process running as root cannot modify or delete the file.
|
||||
|
||||
Begin by stopping the tgtd.service so you can change the image files:
|
||||
|
||||
```
|
||||
# systemctl stop tgtd.service
|
||||
```
|
||||
|
||||
It’s normal for this command to take a minute or so to stop when there are connections still open.
|
||||
|
||||
Now, remove the read-only iSCSI export. Then update the readonly-root configuration file in the template so the image is no longer read-only:
|
||||
|
||||
```
|
||||
# MY_FC=fc29
|
||||
# rm -f /etc/tgt/conf.d/$MY_FC.conf
|
||||
# TEMP_MNT=$(mktemp -d)
|
||||
# mount /$MY_FC.img $TEMP_MNT
|
||||
# sed -i 's/^READONLY=yes$/READONLY=no/' $TEMP_MNT/etc/sysconfig/readonly-root
|
||||
# sed -i 's/^Storage=volatile$/#Storage=auto/' $TEMP_MNT/etc/systemd/journald.conf
|
||||
# umount $TEMP_MNT
|
||||
```
|
||||
|
||||
Journald was changed from logging to volatile memory back to its default (log to disk if /var/log/journal exists) because a user reported his clients would freeze with an out-of-memory error due to an application generating excessive system logs. The downside to setting logging to disk is that extra write traffic is generated by the clients, and might burden your netboot server with unnecessary I/O. You should decide which option — log to memory or log to disk — is preferable depending on your environment.
|
||||
|
||||
Since you won’t make any further changes to the template image, set the immutable flag on it and restart the tgtd.service:
|
||||
|
||||
```
|
||||
# chattr +i /$MY_FC.img
|
||||
# systemctl start tgtd.service
|
||||
```
|
||||
|
||||
Now, update the bootmenu application:
|
||||
|
||||
```
|
||||
# cat << 'END' > $MY_MOJO/bootmenu.pl
|
||||
#!/usr/bin/env perl
|
||||
|
||||
use lib 'lib';
|
||||
|
||||
use PAM;
|
||||
use Mojolicious::Lite;
|
||||
use Mojolicious::Plugins;
|
||||
use Mojo::Util ('url_unescape');
|
||||
|
||||
plugin 'Config';
|
||||
|
||||
get '/menu';
|
||||
get '/boot' => sub {
|
||||
my $c = shift;
|
||||
|
||||
my $instance = $c->param('instance');
|
||||
my $username = $c->param('username');
|
||||
my $password = $c->param('password');
|
||||
|
||||
my $chapscrt;
|
||||
my $template = 'menu';
|
||||
|
||||
{
|
||||
last unless $instance =~ /^fc[[:digit:]]{2}$/;
|
||||
last unless $username =~ /^[[:alnum:]]+$/;
|
||||
last unless PAM::auth($username, url_unescape($password));
|
||||
last unless $chapscrt = `sudo scripts/mktgt $instance $username`;
|
||||
$template = $instance;
|
||||
}
|
||||
|
||||
return $c->render(template => $template, username => $username, chapscrt => $chapscrt);
|
||||
};
|
||||
|
||||
app->start;
|
||||
END
|
||||
```
|
||||
|
||||
This new version of the bootmenu application calls a custom mktgt script which, on success, returns a random [CHAP][3] password for each new iSCSI target that it creates. The CHAP password prevents one user from mounting another user’s iSCSI target by indirect means. The app only returns the correct iSCSI target password to a user who has successfully authenticated.
|
||||
|
||||
The mktgt script is prefixed with sudo because it needs root privileges to create the target.
|
||||
|
||||
The $username and $chapscrt variables also pass to the render command so they can be incorporated into the templates returned to the user when necessary.
|
||||
|
||||
Next, update our boot templates so they can read the username and chapscrt variables and pass them along to the end user. Also update the templates to mount the root filesystem in rw (read-write) mode:
|
||||
|
||||
```
|
||||
# cd $MY_MOJO/templates
|
||||
# sed -i "s/:$MY_FC/:$MY_FC-<%= \$username %>/g" $MY_FC.html.ep
|
||||
# sed -i "s/ netroot=iscsi:/ netroot=iscsi:<%= \$username %>:<%= \$chapscrt %>@/" $MY_FC.html.ep
|
||||
# sed -i "s/ ro / rw /" $MY_FC.html.ep
|
||||
```
|
||||
|
||||
After running the above commands, you should have boot templates like the following:
|
||||
|
||||
```
|
||||
#!ipxe
|
||||
kernel --name kernel.efi ${prefix}/vmlinuz-4.19.5-300.fc29.x86_64 initrd=initrd.img rw ip=dhcp rd.peerdns=0 nameserver=192.0.2.91 nameserver=192.0.2.92 root=/dev/disk/by-path/ip-192.0.2.158:3260-iscsi-iqn.edu.example.server-01:fc29-<%= $username %>-lun-1 netroot=iscsi:<%= $username %>:<%= $chapscrt %>@192.0.2.158::::iqn.edu.example.server-01:fc29-<%= $username %> console=tty0 console=ttyS0,115200n8 audit=0 selinux=0 quiet
|
||||
initrd --name initrd.img ${prefix}/initramfs-4.19.5-300.fc29.x86_64.img
|
||||
boot || chain https://server-01.example.edu/menu
|
||||
```
|
||||
|
||||
NOTE: If you need to view the boot template after the variables have been [interpolated][4], you can insert the “shell” command on its own line just before the “boot” command. Then, when you netboot your client, iPXE gives you an interactive shell where you can enter “imgstat” to view the parameters being passed to the kernel. If everything looks correct, you can type “exit” to leave the shell and continue the boot process.
|
||||
|
||||
Now allow the bootmenu user to run the mktgt script (and only that script) as root via sudo:
|
||||
|
||||
```
|
||||
# echo "bootmenu ALL = NOPASSWD: $MY_MOJO/scripts/mktgt *" > /etc/sudoers.d/bootmenu
|
||||
```
|
||||
|
||||
The bootmenu user should not have write access to the mktgt script or any other files under its home directory. All the files under /opt/bootmenu should be owned by root, and should not be writable by any user other than root.
|
||||
|
||||
Sudo does not work well with systemd’s DynamicUser option, so create a normal user account and set the systemd service to run as that user:
|
||||
|
||||
```
|
||||
# useradd -r -c 'iPXE Boot Menu Service' -d /opt/bootmenu -s /sbin/nologin bootmenu
|
||||
# sed -i 's/^DynamicUser=true$/User=bootmenu/' /etc/systemd/system/bootmenu.service
|
||||
# systemctl daemon-reload
|
||||
```
|
||||
|
||||
Finally, create a directory for the copy-on-write overlays and create the mktgt script that manages the iSCSI targets and their overlayed backing stores:
|
||||
|
||||
```
|
||||
# mkdir /$MY_FC.cow
|
||||
# mkdir $MY_MOJO/scripts
|
||||
# cat << 'END' > $MY_MOJO/scripts/mktgt
|
||||
#!/usr/bin/env perl
|
||||
|
||||
# if another instance of this script is running, wait for it to finish
|
||||
"$ENV{FLOCKER}" eq 'MKTGT' or exec "env FLOCKER=MKTGT flock /tmp $0 @ARGV";
|
||||
|
||||
# use "RETURN" to print to STDOUT; everything else goes to STDERR by default
|
||||
open(RETURN, '>&', STDOUT);
|
||||
open(STDOUT, '>&', STDERR);
|
||||
|
||||
my $instance = shift or die "instance not provided";
|
||||
my $username = shift or die "username not provided";
|
||||
|
||||
my $img = "/$instance.img";
|
||||
my $dir = "/$instance.cow";
|
||||
my $top = "$dir/$username";
|
||||
|
||||
-f "$img" or die "'$img' is not a file";
|
||||
-d "$dir" or die "'$dir' is not a directory";
|
||||
|
||||
my $base;
|
||||
die unless $base = `losetup --show --read-only --nooverlap --find $img`;
|
||||
chomp $base;
|
||||
|
||||
my $size;
|
||||
die unless $size = `blockdev --getsz $base`;
|
||||
chomp $size;
|
||||
|
||||
# create the per-user sparse file if it does not exist
|
||||
if (! -e "$top") {
|
||||
die unless system("dd if=/dev/zero of=$top status=none bs=512 count=0 seek=$size") == 0;
|
||||
}
|
||||
|
||||
# create the copy-on-write overlay if it does not exist
|
||||
my $cow="$instance-$username";
|
||||
my $dev="/dev/mapper/$cow";
|
||||
if (! -e "$dev") {
|
||||
my $over;
|
||||
die unless $over = `losetup --show --nooverlap --find $top`;
|
||||
chomp $over;
|
||||
die unless system("echo 0 $size snapshot $base $over p 8 | dmsetup create $cow") == 0;
|
||||
}
|
||||
|
||||
my $tgtadm = '/usr/sbin/tgtadm --lld iscsi';
|
||||
|
||||
# get textual representations of the iscsi targets
|
||||
my $text = `$tgtadm --op show --mode target`;
|
||||
my @targets = $text =~ /(?:^T.*\n)(?:^ .*\n)*/mg;
|
||||
|
||||
# convert the textual representations into a hash table
|
||||
my $targets = {};
|
||||
foreach (@targets) {
|
||||
my $tgt;
|
||||
my $sid;
|
||||
|
||||
foreach (split /\n/) {
|
||||
/^Target (\d+)(?{ $tgt = $targets->{$^N} = [] })/;
|
||||
/I_T nexus: (\d+)(?{ $sid = $^N })/;
|
||||
/Connection: (\d+)(?{ push @{$tgt}, [ $sid, $^N ] })/;
|
||||
}
|
||||
}
|
||||
|
||||
my $hostname;
|
||||
die unless $hostname = `hostname`;
|
||||
chomp $hostname;
|
||||
|
||||
my $target = 'iqn.' . join('.', reverse split('\.', $hostname)) . ":$cow";
|
||||
|
||||
# find the target id corresponding to the provided target name and
|
||||
# close any existing connections to it
|
||||
my $tid = 0;
|
||||
foreach (@targets) {
|
||||
next unless /^Target (\d+)(?{ $tid = $^N }): $target$/m;
|
||||
foreach (@{$targets->{$tid}}) {
|
||||
die unless system("$tgtadm --op delete --mode conn --tid $tid --sid $_->[0] --cid $_->[1]") == 0;
|
||||
}
|
||||
}
|
||||
|
||||
# create a new target if an existing one was not found
|
||||
if ($tid == 0) {
|
||||
# find an available target id
|
||||
my @ids = (0, sort keys %{$targets});
|
||||
$tid = 1; while ($ids[$tid]==$tid) { $tid++ }
|
||||
|
||||
# create the target
|
||||
die unless -e "$dev";
|
||||
die unless system("$tgtadm --op new --mode target --tid $tid --targetname $target") == 0;
|
||||
die unless system("$tgtadm --op new --mode logicalunit --tid $tid --lun 1 --backing-store $dev") == 0;
|
||||
die unless system("$tgtadm --op bind --mode target --tid $tid --initiator-address ALL") == 0;
|
||||
}
|
||||
|
||||
# (re)set the provided target's chap password
|
||||
my $password = join('', map(chr(int(rand(26))+65), 1..8));
|
||||
my $accounts = `$tgtadm --op show --mode account`;
|
||||
if ($accounts =~ / $username$/m) {
|
||||
die unless system("$tgtadm --op delete --mode account --user $username") == 0;
|
||||
}
|
||||
die unless system("$tgtadm --op new --mode account --user $username --password $password") == 0;
|
||||
die unless system("$tgtadm --op bind --mode account --tid $tid --user $username") == 0;
|
||||
|
||||
# return the new password to the iscsi target on stdout
|
||||
print RETURN $password;
|
||||
END
|
||||
# chmod +x $MY_MOJO/scripts/mktgt
|
||||
```
|
||||
|
||||
The above script does five things:
|
||||
|
||||
1. It creates the /<instance>.cow/<username> sparse file if it does not already exist.
|
||||
2. It creates the /dev/mapper/<instance>-<username> device node that serves as the copy-on-write backing store for the iSCSI target if it does not already exist.
|
||||
3. It creates the iqn.<reverse-hostname>:<instance>-<username> iSCSI target if it does not exist. Or, if the target does exist, it closes any existing connections to it because the image can only be opened in read-write mode from one place at a time.
|
||||
4. It (re)sets the chap password on the iqn.<reverse-hostname>:<instance>-<username> iSCSI target to a new random value.
|
||||
5. It prints the new chap password on [standard output][5] if all of the previous tasks compeleted successfully.
|
||||
|
||||
|
||||
|
||||
You should be able to test the mktgt script from the command line by running it with valid test parameters. For example:
|
||||
|
||||
```
|
||||
# echo `$MY_MOJO/scripts/mktgt fc29 jsmith`
|
||||
```
|
||||
|
||||
When run from the command line, the mktgt script should print out either the eight-character random password for the iSCSI target if it succeeded or the line number on which something went wrong if it failed.
|
||||
|
||||
On occasion, you may want to delete an iSCSI target without having to stop the entire service. For example, a user might inadvertently corrupt their personal image, in which case you would need to systematically undo everything that the above mktgt script does so that the next time they log in they will get a copy of the original image.
|
||||
|
||||
Below is an rmtgt script that undoes, in reverse order, what the above mktgt script did:
|
||||
|
||||
```
|
||||
# mkdir $HOME/bin
|
||||
# cat << 'END' > $HOME/bin/rmtgt
|
||||
#!/usr/bin/env perl
|
||||
|
||||
@ARGV >= 2 or die "usage: $0 <instance> <username> [+d|+f]\n";
|
||||
|
||||
my $instance = shift;
|
||||
my $username = shift;
|
||||
|
||||
my $rmd = ($ARGV[0] eq '+d'); #remove device node if +d flag is set
|
||||
my $rmf = ($ARGV[0] eq '+f'); #remove sparse file if +f flag is set
|
||||
my $cow = "$instance-$username";
|
||||
|
||||
my $hostname;
|
||||
die unless $hostname = `hostname`;
|
||||
chomp $hostname;
|
||||
|
||||
my $tgtadm = '/usr/sbin/tgtadm';
|
||||
my $target = 'iqn.' . join('.', reverse split('\.', $hostname)) . ":$cow";
|
||||
|
||||
my $text = `$tgtadm --op show --mode target`;
|
||||
my @targets = $text =~ /(?:^T.*\n)(?:^ .*\n)*/mg;
|
||||
|
||||
my $targets = {};
|
||||
foreach (@targets) {
|
||||
my $tgt;
|
||||
my $sid;
|
||||
|
||||
foreach (split /\n/) {
|
||||
/^Target (\d+)(?{ $tgt = $targets->{$^N} = [] })/;
|
||||
/I_T nexus: (\d+)(?{ $sid = $^N })/;
|
||||
/Connection: (\d+)(?{ push @{$tgt}, [ $sid, $^N ] })/;
|
||||
}
|
||||
}
|
||||
|
||||
my $tid = 0;
|
||||
foreach (@targets) {
|
||||
next unless /^Target (\d+)(?{ $tid = $^N }): $target$/m;
|
||||
foreach (@{$targets->{$tid}}) {
|
||||
die unless system("$tgtadm --op delete --mode conn --tid $tid --sid $_->[0] --cid $_->[1]") == 0;
|
||||
}
|
||||
die unless system("$tgtadm --op delete --mode target --tid $tid") == 0;
|
||||
print "target $tid deleted\n";
|
||||
sleep 1;
|
||||
}
|
||||
|
||||
my $dev = "/dev/mapper/$cow";
|
||||
if ($rmd or ($rmf and -e $dev)) {
|
||||
die unless system("dmsetup remove $cow") == 0;
|
||||
print "device node $dev deleted\n";
|
||||
}
|
||||
|
||||
if ($rmf) {
|
||||
my $sf = "/$instance.cow/$username";
|
||||
die "sparse file $sf not found" unless -e "$sf";
|
||||
die unless system("rm -f $sf") == 0;
|
||||
die unless not -e "$sf";
|
||||
print "sparse file $sf deleted\n";
|
||||
}
|
||||
END
|
||||
# chmod +x $HOME/bin/rmtgt
|
||||
```
|
||||
|
||||
For example, to use the above script to completely remove the fc29-jsmith target including its backing store device node and its sparse file, run the following:
|
||||
|
||||
```
|
||||
# rmtgt fc29 jsmith +f
|
||||
```
|
||||
|
||||
Once you’ve verified that the mktgt script is working properly, you can restart the bootmenu service. The next time someone netboots, they should receive a personal copy of the the netboot image they can write to:
|
||||
|
||||
```
|
||||
# systemctl restart bootmenu.service
|
||||
```
|
||||
|
||||
Users should now be able to modify the root filesystem as demonstrated in the below screenshot:
|
||||
|
||||
![][6]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-build-a-netboot-server-part-4/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://ipxe.org/crypto
|
||||
[2]: https://en.wikipedia.org/wiki/Copy-on-write
|
||||
[3]: https://en.wikipedia.org/wiki/Challenge-Handshake_Authentication_Protocol
|
||||
[4]: https://en.wikipedia.org/wiki/String_interpolation
|
||||
[5]: https://en.wikipedia.org/wiki/Standard_streams
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/11/netboot-fix-pam_mount-1024x819.png
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Turn a Raspberry Pi 3B+ into a PriTunl VPN)
|
||||
[#]: via: (https://opensource.com/article/19/1/pritunl-vpn-raspberry-pi)
|
||||
[#]: author: (Stephen Bancroft https://opensource.com/users/stevereaver)
|
||||
|
||||
Turn a Raspberry Pi 3B+ into a PriTunl VPN
|
||||
======
|
||||
PriTunl is a VPN solution for small businesses and individuals who want private access to their network.
|
||||
|
||||

|
||||
|
||||
[PriTunl][1] is a fantastic VPN terminator solution that's perfect for small businesses and individuals who want a quick and simple way to access their network privately. It's open source, and the basic free version is more than enough to get you started and cover most simple use cases. There is also a paid enterprise version with advanced features like Active Directory integration.
|
||||
|
||||
### Special considerations on Raspberry Pi 3B+
|
||||
|
||||
PriTunl is generally simple to install, but this project—turning a Raspberry Pi 3B+ into a PriTunl VPN appliance—adds some complexity. For one thing, PriTunl is supplied only as AMD64 and i386 binaries, but the 3B+ uses ARM architecture. This means you must compile your own binaries from source. That's nothing to be afraid of; it can be as simple as copying and pasting a few commands and watching the terminal for a short while.
|
||||
|
||||
Another problem: PriTunl seems to require 64-bit architecture. I found this out when I got errors when I tried to compile PriTunl on my Raspberry Pi's 32-bit operating system. Fortunately, Ubuntu's beta version of 18.04 for ARM64 boots on the Raspberry Pi 3B+.
|
||||
|
||||
Also, the Raspberry Pi 3B+ uses a different bootloader from other Raspberry Pi models. This required a complicated set of steps to install and update the necessary files to get a Raspberry Pi 3B+ to boot.
|
||||
|
||||
### Installing PriTunl
|
||||
|
||||
You can overcome these problems by installing a 64-bit operating system on the Raspberry Pi 3B+ before installing PriTunl. I'll assume you have basic knowledge of how to get around the Linux command line and a Raspberry Pi.
|
||||
|
||||
Start by opening a terminal and downloading the Ubuntu 18.04 ARM64 beta release by entering:
|
||||
|
||||
```
|
||||
$ wget http://cdimage.ubuntu.com/releases/18.04/beta/ubuntu-18.04-beta-preinstalled-server-arm64+raspi3.img.xz
|
||||
```
|
||||
|
||||
Unpack the download:
|
||||
|
||||
```
|
||||
$ xz -d ubuntu-18.04-beta-preinstalled-server-arm64+raspi3.xz
|
||||
```
|
||||
|
||||
Insert the SD card you'll use with your Raspberry Pi into your desktop or laptop computer. Your computer will assign the SD card a drive letter—something like **/dev/sda** or **/dev/sdb**. Enter the **dmesg** command and examine the last lines of the output to find out the card's drive assignment.
|
||||
|
||||
**Be VERY CAREFUL with the next step! I can't stress that enough; if you get the drive assignment wrong, you could destroy your system.**
|
||||
|
||||
Write the image to your SD card with the following command, changing **< DRIVE>** to your SD card's drive assignment (obtained in the previous step):
|
||||
|
||||
```
|
||||
$ dd if=ubuntu-18.04-beta-preinstalled-server-arm64+raspi3.img of=<DRIVE> bs=8M
|
||||
```
|
||||
|
||||
After it finishes, insert the SD card into your Pi and power it up. Make sure the Pi is connected to your network, then log in with username/password combination ubuntu/ubuntu.
|
||||
|
||||
Enter the following commands on your Pi to install a few things to prepare to compile PriTunl:
|
||||
|
||||
```
|
||||
$ sudo apt-get -y install build-essential git bzr python python-dev python-pip net-tools openvpn bridge-utils psmisc golang-go libffi-dev mongodb
|
||||
```
|
||||
|
||||
There are a few changes from the standard PriTunl source [installation instructions on GitHub][2]. Make sure you are logged into your Pi and **sudo** to root:
|
||||
|
||||
```
|
||||
$ sudo su -
|
||||
```
|
||||
|
||||
This should leave you in root's home directory. To install PriTunl version 1.29.1914.98, enter (per GitHub):
|
||||
|
||||
```
|
||||
export VERSION=1.29.1914.98
|
||||
tee -a ~/.bashrc << EOF
|
||||
export GOPATH=\$HOME/go
|
||||
export PATH=/usr/local/go/bin:\$PATH
|
||||
EOF
|
||||
source ~/.bashrc
|
||||
mkdir pritunl && cd pritunl
|
||||
go get -u github.com/pritunl/pritunl-dns
|
||||
go get -u github.com/pritunl/pritunl-web
|
||||
sudo ln -s ~/go/bin/pritunl-dns /usr/bin/pritunl-dns
|
||||
sudo ln -s ~/go/bin/pritunl-web /usr/bin/pritunl-web
|
||||
wget https://github.com/pritunl/pritunl/archive/$VERSION.tar.gz
|
||||
tar -xf $VERSION.tar.gz
|
||||
cd pritunl-$VERSION
|
||||
python2 setup.py build
|
||||
pip install -r requirements.txt
|
||||
python2 setup.py install --prefix=/usr/local
|
||||
```
|
||||
|
||||
Now the MongoDB and PriTunl systemd units should be ready to start up. Assuming you're still logged in as root, enter:
|
||||
|
||||
```
|
||||
systemctl daemon-reload
|
||||
systemctl start mongodb pritunl
|
||||
systemctl enable mongodb pritunl
|
||||
```
|
||||
|
||||
That's it! You're ready to hit PriTunl's browser user interface and configure it by following PriTunl's [installation and configuration instructions][3] on its website.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/pritunl-vpn-raspberry-pi
|
||||
|
||||
作者:[Stephen Bancroft][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stevereaver
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pritunl.com/
|
||||
[2]: https://github.com/pritunl/pritunl
|
||||
[3]: https://docs.pritunl.com/docs/configuration-5
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 resolutions for open source project maintainers)
|
||||
[#]: via: (https://opensource.com/article/18/12/resolutions-open-source-project-maintainers)
|
||||
[#]: author: (Ben Cotton https://opensource.com/users/bcotton)
|
||||
|
||||
5个为开源项目维护者而生的解决方案
|
||||
======
|
||||
|
||||
不管你怎么说,好的交流是一个活跃的开源社区的必备品。
|
||||
|
||||

|
||||
|
||||
我不会给你一个大而全的新年的解决方案。关于自我提升,我没有任何问题,这篇文章我希望锚定这个日历中的另外一部分。不过即使是这样,这里也有一些关于取消今年的免费日历并将其替换为新的日历的内容,以激发自省。
|
||||
|
||||
在 2017 年,我从不在社交媒体上分享我从未阅读过的文章。我一直保持这样的状态,我也认为它让我成为了一个更好的互联网公民。对于 2019 年,我正在考虑让我成为更好的开源软件维护者的解决方案。
|
||||
|
||||
|
||||
下面是一些我在一些项目中担任维护者或共同维护者时坚持的决议:
|
||||
|
||||
### 1\. 包含行为准则
|
||||
|
||||
Jono Bacon 在他的文章“[7个你可能犯的错误][1]”中包含了“不强制执行行为准则”。当然,去强制执行行为准则,你首先需要有一个行为准则。我设计了一个默认的[贡献者契约][2],但是你可以使用其他你喜欢的。关于这个 License ,最好的方法是使用别人已经写好的,而不是你自己写的。但是重要的是,要找到一些能够定义你希望你的社区执行的,无论他们是什么样子。一旦这些被记录下来并强制执行,人们就能自行决定是否成为他们想象中社区的一份子。
|
||||
|
||||
|
||||
### 2\. 使许可证清晰且明确
|
||||
|
||||
你知道什么真的很烦么?不清晰的许可证。"这个软件基于 GPL 授权",如果没有进一步提供更多信息的文字,我无法知道更多信息。基于哪个版本的[GPL][3]?对于项目的非代码部分,“根据知识共享许可证授权”更糟糕。我喜欢[知识共享许可证][4],但其中有几个不同的许可证包含着不同的权利和义务。因此,我将清楚的说明许可证的版本适用于我的项目。我将会在 repo 中包含许可的全文,并在其他文件中包含简明的注释。
|
||||
|
||||
与此相关的一类是使用 [OSI][5]批准的许可证。想出一个新的准确的说明了你想要表达什么的许可证是有可能的,但是如果你需要强制执行它,祝你好运。会坚持使用它么?使用您项目的人会理解么?
|
||||
|
||||
|
||||
|
||||
### 3\. 快速分类错误报告和问题
|
||||
|
||||
技术的规模很难会和开源维护者一样差。即使在小型项目中,也很难找到时间去回答每个问题并修复每个错误。但这并不意味着我至少不能去回应这个人,它没必要是多段的回复。即使只是标记了 Github Issue 也表明了我看见它了。也许我马上就会处理它,也许一年后我会处理它。但是让社区看到它很重要。是的,这里还有其他人。
|
||||
|
||||
### 4\. 如果没有伴随的文档,请不要推送新特性或 Bugfix
|
||||
|
||||
尽管多年来我的开源贡献都围绕着文档,但我的项目并没有反映出我对他们的重视。我很少有不需要某种形式文档的推送。新的特性显然应该在他们被提交甚至是之前编写文档。但即使是错误修复,也应该在发行说明中有一个条目。如果没有什么其他的,一个 push 也是很好的改善文档的机会。
|
||||
|
||||
### 5\. 放弃一个项目时,要说清楚
|
||||
|
||||
我很擅长对事情说“不”,我告诉编辑我会为 [Opensource.com][6] 写一到两篇文章,现在我有了将近 60 篇文章。Oops。但在某些时候,曾经符合我利益的事情不再有用。也许该项目是不必要的,因为它的功能被吸收到更大的项目中,也许只是我厌倦了它。但这对社区是不公平的(并且存在潜在的危险,正如最近的[event-stream 恶意软件注入][7]所示),会让项目陷入困境。维护者有权随时离开,但他们离开时应该清清楚楚。
|
||||
|
||||
无论你是开源维护者还是贡献者,如果你知道项目维护者应该作出的其他决议,请在评论中分享!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/resolutions-open-source-project-maintainers
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/8/mistakes-open-source-avoid
|
||||
[2]: https://www.contributor-covenant.org/
|
||||
[3]: https://opensource.org/licenses/gpl-license
|
||||
[4]: https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[5]: https://opensource.org/
|
||||
[6]: http://Opensource.com
|
||||
[7]: https://arstechnica.com/information-technology/2018/11/hacker-backdoors-widely-used-open-source-software-to-steal-bitcoin/
|
||||
@ -1,200 +0,0 @@
|
||||
Linux 上查看系统/服务器运行时间的 11 种方法
|
||||
======
|
||||
你是否想知道自己的 Linux 系统除宕机外正常运行了多长时间?系统什么时候启动以及现在的日期?
|
||||
|
||||
Linux 上有多个查看服务器/系统运行时间的命令,大多数用户喜欢使用标准并且很有名的 `uptime` 命令获取这些具体的信息。
|
||||
|
||||
服务器的运行时间对一些用户来说不那么重要,但是当服务器运行诸如在线商城<ruby>门户<rt>portal</rt></ruby>、网上银行门户等<ruby>关键任务应用<rt>mission-critical applications</rt></ruby>时,它对于<ruby>服务器管理员<rt>server adminstrators</rt></ruby>来说就至关重要。
|
||||
|
||||
它必须做到 0 宕机,因为一旦停机就会影响到数百万用户。
|
||||
|
||||
正如我所说,许多命令都可以让用户看到 Linux 服务器的运行时间。在这篇教程里我会教你如何使用下面 11 种方式来查看。
|
||||
|
||||
<ruby>正常运行时间<rt>uptime</rt></ruby>指的是服务器自从上次关闭或重启以来经过的时间。
|
||||
|
||||
`uptime` 命令获取 `/proc` 文件中的详细信息并输出正常运行时间,`/proc` 文件不能直接读取。
|
||||
|
||||
以下这些命令会输出系统运行和启动的时间。也会显示一些额外的信息。
|
||||
|
||||
### 方法 1:使用 uptime 命令
|
||||
|
||||
`uptime` 命令会告诉你系统运行了多长时间。它会用一行显示以下信息。
|
||||
|
||||
当前时间,系统运行时间,当前登录用户的数量,过去 1 分钟、5 分钟、15 分钟系统负载的均值。
|
||||
|
||||
```
|
||||
# uptime
|
||||
|
||||
08:34:29 up 21 days, 5:46, 1 user, load average: 0.06, 0.04, 0.00
|
||||
|
||||
```
|
||||
|
||||
### 方法 2:使用 w 命令
|
||||
|
||||
`w` 命令为每个登录进系统的用户,每个用户当前所做的事情,所有活动的负载对计算机的影响提供了一个快速的概要。这个单一命令结合了多个 Unix 程序:who,uptime,和 ps -a。
|
||||
```
|
||||
# w
|
||||
|
||||
08:35:14 up 21 days, 5:47, 1 user, load average: 0.26, 0.09, 0.02
|
||||
USER TTY FROM [email protected] IDLE JCPU PCPU WHAT
|
||||
root pts/1 103.5.134.167 08:34 0.00s 0.01s 0.00s w
|
||||
|
||||
```
|
||||
|
||||
### 方法 3:使用 top 命令
|
||||
|
||||
`top` 命令是 Linux 上监视实时系统进程的基础命令之一。它显示系统信息和运行进程的信息,例如正常运行时间,平均负载,运行的任务,登录用户数量,CPU 数量 & CPU 利用率,内存 & 交换空间信息。
|
||||
|
||||
**推荐阅读:**[TOP 命令监视服务器性能的例子][1]
|
||||
```
|
||||
# top -c
|
||||
|
||||
top - 08:36:01 up 21 days, 5:48, 1 user, load average: 0.12, 0.08, 0.02
|
||||
Tasks: 98 total, 1 running, 97 sleeping, 0 stopped, 0 zombie
|
||||
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
|
||||
Mem: 1872888k total, 1454644k used, 418244k free, 175804k buffers
|
||||
Swap: 2097148k total, 0k used, 2097148k free, 1098140k cached
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
1 root 20 0 19340 1492 1172 S 0.0 0.1 0:01.04 /sbin/init
|
||||
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kthreadd]
|
||||
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 [migration/0]
|
||||
4 root 20 0 0 0 0 S 0.0 0.0 0:34.32 [ksoftirqd/0]
|
||||
5 root RT 0 0 0 0 S 0.0 0.0 0:00.00 [stopper/0]
|
||||
|
||||
```
|
||||
|
||||
### 方法 4:使用 who 命令
|
||||
|
||||
`who` 命令列出当前登录进计算机的用户。`who` 命令与 `w` 命令类似,但后者还包含额外的数据和统计信息。
|
||||
|
||||
```
|
||||
# who -b
|
||||
|
||||
system boot 2018-04-12 02:48
|
||||
|
||||
```
|
||||
|
||||
### 方法 5:使用 last 命令
|
||||
|
||||
`last` 命令列出最近登录过的用户。`last` 往回查找 `/var/log/wtmp` 文件并显示自从文件创建后登录进(出)的用户。
|
||||
|
||||
```
|
||||
# last reboot -F | head -1 | awk '{print $5,$6,$7,$8,$9}'
|
||||
|
||||
Thu Apr 12 02:48:04 2018
|
||||
|
||||
```
|
||||
|
||||
### 方法 6:使用 /proc/uptime 文件
|
||||
|
||||
这个文件中包含系统上次启动后运行时间的详细信息。`/proc/uptime` 的输出相当精简。
|
||||
|
||||
第一个数字是系统自从启动的总秒数。第二个数字是总时间中系统空闲所花费的时间,以秒为单位。
|
||||
|
||||
```
|
||||
# cat /proc/uptime
|
||||
|
||||
1835457.68 1809207.16
|
||||
|
||||
```
|
||||
|
||||
### 方法 7:使用 tuptime 命令
|
||||
|
||||
`tuptime` 是一个汇报系统运行时间的工具,输出历史信息并作以统计,保留重启之间的数据。和 `uptime` 命令很像,但输出更有意思一些。
|
||||
|
||||
```
|
||||
$ tuptime
|
||||
|
||||
```
|
||||
|
||||
### 方法 8:使用 htop 命令
|
||||
|
||||
`htop` 是运行在 Linux 上一个由 Hisham 使用 ncurses 库开发的交互式进程查看器。`htop` 比起 `top` 有很多的特性和选项。
|
||||
|
||||
**推荐阅读:** [使用 Htop 命令监控系统资源][2]
|
||||
|
||||
```
|
||||
# htop
|
||||
|
||||
CPU[| 0.5%] Tasks: 48, 5 thr; 1 running
|
||||
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||| 165/1828MB] Load average: 0.10 0.05 0.01
|
||||
Swp[ 0/2047MB] Uptime: 21 days, 05:52:35
|
||||
|
||||
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
|
||||
29166 root 20 0 110M 2484 1240 R 0.0 0.1 0:00.03 htop
|
||||
29580 root 20 0 11464 3500 1032 S 0.0 0.2 55:15.97 /bin/sh ./OSWatcher.sh 10 1
|
||||
1 root 20 0 19340 1492 1172 S 0.0 0.1 0:01.04 /sbin/init
|
||||
486 root 16 -4 10780 900 348 S 0.0 0.0 0:00.07 /sbin/udevd -d
|
||||
748 root 18 -2 10780 932 360 S 0.0 0.0 0:00.00 /sbin/udevd -d
|
||||
|
||||
```
|
||||
|
||||
### 方法 9:使用 glances 命令
|
||||
|
||||
`glances` 是一个跨平台基于 curses 使用 python 写的监控工具。我们可以说它非常强大,仅用一点空间就能获得很多信息。它使用 psutil 库从系统中获取信息。
|
||||
|
||||
`glances` 可以监控 CPU,内存,负载,进程,网络接口,磁盘 I/O,<ruby>磁盘阵列<rt>RAID</rt></ruby>,传感器,文件系统(与文件夹),容器,显示器,Alert 日志,系统信息,运行时间,<ruby>快速查看<rt>Quicklook</rt></ruby>(CPU,内存等)。
|
||||
|
||||
**推荐阅读:** [Glances (集大成)– Linux 上高级的实时系统运行监控工具][3]
|
||||
```
|
||||
glances
|
||||
|
||||
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 21 days, 05:55:15
|
||||
|
||||
CPU [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
|
||||
MEM [||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
|
||||
SWAP [|||| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
|
||||
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
|
||||
|
||||
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
|
||||
docker0 0b 232b
|
||||
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
|
||||
lo 616b 616b
|
||||
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
|
||||
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
|
||||
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
|
||||
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
|
||||
```
|
||||
|
||||
### 方法 10:使用 stat 命令
|
||||
|
||||
`stat` 命令显示指定文件或文件系统的详细状态。
|
||||
|
||||
```
|
||||
# stat /var/log/dmesg | grep Modify
|
||||
|
||||
Modify: 2018-04-12 02:48:04.027999943 -0400
|
||||
|
||||
```
|
||||
|
||||
### 方法 11:使用 procinfo 命令
|
||||
|
||||
`procinfo` 从 `/proc` 文件夹下收集一些系统数据并将其很好的格式化输出在标准输出设备上。
|
||||
|
||||
```
|
||||
# procinfo | grep Bootup
|
||||
|
||||
Bootup: Fri Apr 20 19:40:14 2018 Load average: 0.16 0.05 0.06 1/138 16615
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
|
||||
[2]:https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/
|
||||
[3]:https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/
|
||||
@ -0,0 +1,52 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Powers of two, powers of Linux: 2048 at the command line)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-2048)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
2 的力量,Linux 的力量:终端中的 2048
|
||||
======
|
||||
正在寻找基于终端的游戏来打发时间么?来看看 2048-cli 吧。
|
||||

|
||||
|
||||
你好,欢迎来到今天的 Linux 命令行玩具日历。每天,我们会为你的终端带来一个不同的玩具:它可能是一个游戏或任何简单的消遣,可以帮助你获得乐趣。
|
||||
|
||||
很可能你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新事物。
|
||||
|
||||
今天的玩具是我最喜欢的休闲游戏之一 [2048][2] (它本身就是另外一个克隆的克隆)的[命令行版本][1]。
|
||||
|
||||
要进行游戏,你只需将滑块向上、向下、向左、向右移动,组合成对的数字,并增加数字,直到你得到数字 2048 的块。吸引人的地方(以及挑战)是你不能只移动一个滑块,而是需要移动屏幕上的每一块。
|
||||
|
||||
它简单、有趣,很容易在里面沉迷几个小时。这个 2048 的克隆 [2048-cli][1] 是 Marc Tiehuis 用 C 编写的,并在 MIT 许可下开源。你可以在 [GitHub][1] 上找到源代码,你也可在这找到适用于你的平台的安装说明。由于它已为 Fedora 打包,因此我来说,安装就像下面那样简单:
|
||||
|
||||
```
|
||||
$ sudo dnf install 2048-cli
|
||||
```
|
||||
|
||||
这是这样,玩得开心!
|
||||
|
||||

|
||||
|
||||
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
|
||||
|
||||
查看昨天的玩具,[在 Linux 终端中玩俄罗斯方块][3],记得明天再来!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-2048
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tiehuis/2048-cli
|
||||
[2]: https://github.com/gabrielecirulli/2048
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-tetris
|
||||
@ -7,20 +7,20 @@
|
||||
[#]: via: (https://www.ostechnix.com/how-to-install-microsoft-net-core-sdk-on-linux/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Install Microsoft .NET Core SDK On Linux
|
||||
如何在 Linux 中安装微软的 .NET Core SDK
|
||||
======
|
||||
|
||||

|
||||
|
||||
The **.NET Core** is a free, cross platform and open source framework developed by Microsoft to build desktop applications, mobile apps, web apps, IoT apps and gaming apps etc. If you’re dotnet developer coming from Windows platform, .NET core helps you to setup your development environment easily on any Linux and Unix-like operating systems. This step by step guide explains how to install Microsoft .NET Core SDK on Linux and how to write your first app using .Net.
|
||||
**.NET Core** 是微软提供的免费、跨平台和开源的开发框架,可以构建桌面应用程序、移动端应用程序、网络应用程序、物联网应用程序和游戏应用程序等。如果你是 Windows 平台下的 dotnet 开发人员的话,使用 .NET core 可以很轻松就设置好任何 Linux 和类 Unix 操作系统下的开发环境。本分步操作指南文章解释了如何在 Linux 中安装 .NET Core SDK 以及如何使用 .NET 开发出第一个应用程序。
|
||||
|
||||
### Install Microsoft .NET Core SDK On Linux
|
||||
### Linux 中安装 .NET Core SDK
|
||||
|
||||
The .NET core supports GNU/Linux, Mac OS and Windows. .Net core can be installed on popular GNU/Linux operating systems including Debian, Fedora, CentOS, Oracle Linux, RHEL, SUSE/openSUSE, and Ubuntu. As of writing this guide, the latest .NET core version was **2.2**.
|
||||
.NET Core 支持 GNU/Linux、Mac OS 和 Windows 系统,可以在主流的 GNU/Linux 操作系统上安装运行,包括 Debian、Fedora、CentOS、Oracle Linux、RHEL、SUSE/openSUSE 和 Ubuntu 。在撰写这篇教程时,其最新版本为 **2.2**。
|
||||
|
||||
On **Debian 9** , you can install .NET Core SDK as shown below.
|
||||
**Debian 9** 系统上安装 .NET Core SDK,请按如下步骤进行。
|
||||
|
||||
First of all, you need to register Microsoft key and add .NET repository by running the following commands:
|
||||
首先,需要注册微软的密钥,接着把 .NET 源仓库地址添加进来,运行的命令如下:
|
||||
|
||||
```
|
||||
$ wget -qO- https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > microsoft.asc.gpg
|
||||
@ -31,16 +31,16 @@ $ sudo chown root:root /etc/apt/trusted.gpg.d/microsoft.asc.gpg
|
||||
$ sudo chown root:root /etc/apt/sources.list.d/microsoft-prod.list
|
||||
```
|
||||
|
||||
After registering the key and adding the repository, install .NET SDK using commands:
|
||||
注册好密钥及添加完仓库源后,就可以安装 .NET SDK 了,命令如下:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**On Debian 8:**
|
||||
**Debian 8 系统上安装:**
|
||||
|
||||
Add Microsoft key and enable .NET repository:
|
||||
增加微软密钥,添加 .NET 仓库源:
|
||||
|
||||
```
|
||||
$ wget -qO- https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > microsoft.asc.gpg
|
||||
@ -51,16 +51,16 @@ $ sudo chown root:root /etc/apt/trusted.gpg.d/microsoft.asc.gpg
|
||||
$ sudo chown root:root /etc/apt/sources.list.d/microsoft-prod.list
|
||||
```
|
||||
|
||||
Install .NET SDK:
|
||||
安装 .NET SDK:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**On Fedora 28:**
|
||||
**Fedora 28 系统上安装:**
|
||||
|
||||
Add Microsoft key and enable .NET repository:
|
||||
增加微软密钥,添加 .NET 仓库源:
|
||||
|
||||
```
|
||||
$ sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
|
||||
@ -69,14 +69,16 @@ $ sudo mv prod.repo /etc/yum.repos.d/microsoft-prod.repo
|
||||
$ sudo chown root:root /etc/yum.repos.d/microsoft-prod.repo
|
||||
```
|
||||
|
||||
Now, Install .NET SDK:
|
||||
现在, 可以安装 .NET SDK 了:
|
||||
|
||||
```
|
||||
$ sudo dnf update
|
||||
$ sudo dnf install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
On **Fedora 27** , add the key and repository using commands:
|
||||
**Fedora 27 系统下:**
|
||||
|
||||
增加微软密钥,添加 .NET 仓库源,命令如下:
|
||||
|
||||
```
|
||||
$ sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
|
||||
@ -85,31 +87,31 @@ $ sudo mv prod.repo /etc/yum.repos.d/microsoft-prod.repo
|
||||
$ sudo chown root:root /etc/yum.repos.d/microsoft-prod.repo
|
||||
```
|
||||
|
||||
And install .NET SDK using commands:
|
||||
接着安装 .NET SDK ,命令如下:
|
||||
|
||||
```
|
||||
$ sudo dnf update
|
||||
$ sudo dnf install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**On CentOS/Oracle Linux:**
|
||||
**CentOS/Oracle 版本的 Linux 系统上:**
|
||||
|
||||
Add Microsoft key and enable .NET core repository:
|
||||
增加微软密钥,添加 .NET 仓库源,使其可用
|
||||
|
||||
```
|
||||
$ sudo rpm -Uvh https://packages.microsoft.com/config/rhel/7/packages-microsoft-prod.rpm
|
||||
```
|
||||
|
||||
Update the repositories and install .NET SDK:
|
||||
更新源仓库,安装 .NET SDK:
|
||||
|
||||
```
|
||||
$ sudo yum update
|
||||
$ sudo yum install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**On openSUSE Leap:**
|
||||
**openSUSE Leap 版本的系统上:**
|
||||
|
||||
Add key, enable repository and install necessary dependencies using the following commands:
|
||||
添加密钥,使仓库源可用,安装必需的依赖包,其命令如下:
|
||||
|
||||
```
|
||||
$ sudo zypper install libicu
|
||||
@ -119,29 +121,29 @@ $ sudo mv prod.repo /etc/zypp/repos.d/microsoft-prod.repo
|
||||
$ sudo chown root:root /etc/zypp/repos.d/microsoft-prod.repo
|
||||
```
|
||||
|
||||
Update the repositories and Install .NET SDK using commands:
|
||||
更新源仓库,安装 .NET SDK,命令如下:
|
||||
|
||||
```
|
||||
$ sudo zypper update
|
||||
$ sudo zypper install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**On Ubuntu 18.04 LTS:**
|
||||
**Ubuntu 18.04 LTS 版本的系统上:**
|
||||
|
||||
Register the Microsoft key and .NET core repository using commands:
|
||||
注册微软的密钥和 .NET Core 仓库源,命令如下:
|
||||
|
||||
```
|
||||
$ wget -q https://packages.microsoft.com/config/ubuntu/18.04/packages-microsoft-prod.deb
|
||||
$ sudo dpkg -i packages-microsoft-prod.deb
|
||||
```
|
||||
|
||||
Enable ‘Universe’ repository using:
|
||||
使 ‘Universe’ 仓库可用:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository universe
|
||||
```
|
||||
|
||||
Then, install .NET Core SDK using command:
|
||||
然后,安装 .NET Core SDK ,命令如下:
|
||||
|
||||
```
|
||||
$ sudo apt-get install apt-transport-https
|
||||
@ -149,16 +151,16 @@ $sudo apt-get update
|
||||
$ sudo apt-get install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
**On Ubuntu 16.04 LTS:**
|
||||
**Ubuntu 16.04 LTS 版本的系统上:**
|
||||
|
||||
Register Microsoft key and .NET repository using commands:
|
||||
注册微软的密钥和 .NET Core 仓库源,命令如下:
|
||||
|
||||
```
|
||||
$ wget -q https://packages.microsoft.com/config/ubuntu/16.04/packages-microsoft-prod.deb
|
||||
$ sudo dpkg -i packages-microsoft-prod.deb
|
||||
```
|
||||
|
||||
And then, Install .NET core SDK:
|
||||
然后安装 .NET core SDK:
|
||||
|
||||
```
|
||||
$ sudo apt-get install apt-transport-https
|
||||
@ -166,17 +168,17 @@ $ sudo apt-get update
|
||||
$ sudo apt-get install dotnet-sdk-2.2
|
||||
```
|
||||
|
||||
### Create Your First App
|
||||
### 创建你的第一个应用程序
|
||||
|
||||
We have successfully installed .Net Core SDK in our Linux box. It is time to create our first app using dotnet.
|
||||
我们已经成功的在 Linux 机器中安装了 .NET Core SDK。是时候使用 dotnet 创建第一个应用程序了。
|
||||
|
||||
For the purpose of this guide, I am going to create a new app called **“ostechnixApp”**. To do so, simply run the following command:
|
||||
接下来的目的,我们会创建一个名为 **“ostechnixApp”** 的应用程序。为此,可以简单的运行如下命令:
|
||||
|
||||
```
|
||||
$ dotnet new console -o ostechnixApp
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
**简单的输出:**
|
||||
|
||||
```
|
||||
Welcome to .NET Core!
|
||||
@ -208,9 +210,9 @@ Restore completed in 894.27 ms for /home/sk/ostechnixApp/ostechnixApp.csproj.
|
||||
Restore succeeded.
|
||||
```
|
||||
|
||||
As you can see in the above output, .Net has created a new application of type console. The parameter -o creates a directory named “ostechnixApp” where you store your app data with all necessary files.
|
||||
正如上面的输出所示的,.NET 已经为我们创建一个控制台类型的应用程序。`-o` 参数创建了一个名为 “ostechnixApp” 的目录,其包含有存储此应用程序数据所必需的文件。
|
||||
|
||||
Let us switch to ostechnixApp directory and see what’s in there.
|
||||
让我们切换到 ostechnixApp 目录,看看里面有些什么。
|
||||
|
||||
```
|
||||
$ cd ostechnixApp/
|
||||
@ -218,7 +220,7 @@ $ ls
|
||||
obj ostechnixApp.csproj Program.cs
|
||||
```
|
||||
|
||||
As you there are three files named **ostechnixApp.csproj** and **Program.cs** and one directory named **obj**. By default, the Program.cs file will contain the code to run the ‘Hello World’ program in the console. Let us have a look at the code.
|
||||
可以看到有两个名为 **ostechnixApp.csproj** 和 **Program.cs** 的文件,以及一个名为 **ojb** 的目录。默认情况下, `Program.cs` 文件包含有可以在控制台中运行的 'Hello World' 程序代码。可以看看此代码:
|
||||
|
||||
```
|
||||
$ cat Program.cs
|
||||
@ -236,7 +238,7 @@ namespace ostechnixApp
|
||||
}
|
||||
```
|
||||
|
||||
To run the newly created app, simply run the following command:
|
||||
要运行此应用程序,可以简单的使用如下命令:
|
||||
|
||||
```
|
||||
$ dotnet run
|
||||
@ -245,9 +247,9 @@ Hello World!
|
||||
|
||||

|
||||
|
||||
Simple, isn’t it? Yes, it is! Now, you can write your code in the **Program.cs** file and run it as shown above.
|
||||
很简单,对吧?是的,就是如此简单。现在你可以在 **Program.cs** 这文件中写上自己的代码,然后像上面所示的执行。
|
||||
|
||||
Alternatively, you can create a new directory, for example mycode, using commands:
|
||||
或者,你可以创建一个新的目录,如例子所示的 `mycode` 目录,命令如下:
|
||||
|
||||
```
|
||||
$ mkdir ~/.mycode
|
||||
@ -255,13 +257,13 @@ $ mkdir ~/.mycode
|
||||
$ cd mycode/
|
||||
```
|
||||
|
||||
…and make that as your new development environment by running the following command:
|
||||
然后运行如下命令,使其成为你的新开发环境目录:
|
||||
|
||||
```
|
||||
$ dotnet new console
|
||||
```
|
||||
|
||||
Sample output:
|
||||
简单的输出:
|
||||
|
||||
```
|
||||
The template "Console Application" was created successfully.
|
||||
@ -276,46 +278,46 @@ Restore completed in 331.87 ms for /home/sk/mycode/mycode.csproj.
|
||||
Restore succeeded.
|
||||
```
|
||||
|
||||
The above command will create two files named **mycode.csproj** and **Program.cs** and one directory named **obj**. Open the Program.cs file in your favorite editor, delete or modify the existing ‘hello world’ code with your own code.
|
||||
上的命令会创建两个名叫 **mycode.csproj** 和 **Program.cs** 的文件及一个名为 **obj** 的目录。用你喜欢的编辑器打开 `Program.cs` 文件, 删除或修改原来的 'hello world' 代码段,然后编写自己的代码。
|
||||
|
||||
Once the code is written, save and close the Program.cs file and run the app using command:
|
||||
写完代码,保存,关闭 Program.cs 文件,然后运行此应用程序,命令如下:
|
||||
|
||||
```
|
||||
$ dotnet run
|
||||
```
|
||||
|
||||
To check the installed .NET core SDK version, simply run:
|
||||
想要查看安装的 .NET core SDK 的版本的话,可以简单的运行:
|
||||
|
||||
```
|
||||
$ dotnet --version
|
||||
2.2.101
|
||||
```
|
||||
|
||||
To get help, run:
|
||||
要获得帮助,请运行:
|
||||
|
||||
```
|
||||
$ dotnet --help
|
||||
```
|
||||
|
||||
### Get Microsoft Visual Studio Code Editor
|
||||
### 使用微软的 Visual Studio Code 编辑器
|
||||
|
||||
To write the code, you can use your favorite editors of your choice. Microsoft has also its own editor named “ **Microsoft Visual Studio Code** ” with support for .NET. It is an open source, lightweight and powerful source code editor. It comes with built-in support for JavaScript, TypeScript and Node.js and has a rich ecosystem of extensions for other languages (such as C++, C#, Python, PHP, Go) and runtimes (such as .NET and Unity). It is a cross-platform code editor, so you can use it in Microsoft Windows, GNU/Linux, and Mac OS X. You can use it if you’re interested.
|
||||
要编写代码,你可以任选自己喜欢的编辑器。同时微软自己也有一款支持 .NET 的编辑器,其名为 “ **Microsoft Visual Studio Code** ”。它是一款开源、轻量级、功能强大的源代码编辑器。其内置了对 JavaScript、TypeScript 和 Node.js 的支持,并为其它语言(如 C++、C#、Python、PHP、Go)和运行时态(如 .NET 和 Unity)提供了丰富的扩展,已经形成一个完整的生态系统。它是一款跨平台的代码编辑器,所以在微软的 Windows 系统、GNU/Linux 系统和 Mac OS X 系统都可以使用。如果对其感兴趣,就可以使用。
|
||||
|
||||
To know how to install and use it on Linux, please refer the following guide.
|
||||
To know how to install and use it on Linux, please refer the following guide.想了解如何在 Linux 上安装和使用,请参阅以下指南。
|
||||
|
||||
[Install Microsoft Visual Studio Code In Linux][3]
|
||||
[Linux 中安装 Microsoft Visual Studio Code][3]
|
||||
|
||||
[**This page**][1] has some basic tutorials to learn .NET Core and .NET Core SDK tools using Visual Studio Code editor. Go and check them to learn more.
|
||||
关于 Visual Studio Code editor 中 .NET Core 和 .NET Core SDK 工具的使用,[**此网页**][1]有一些基础的教程。想了解更多就去看看吧。
|
||||
|
||||
### Telemetry
|
||||
|
||||
By default, the .NET core SDK will collect the usage data using a feature called **‘Telemetry’**. The collected data is anonymous and shared to the development team and community under the [Creative Commons Attribution License][2]. So the .NET team will understand how the tools are used and decide how they can be improved over time. If you don’t want to share your usage information, you can simply opt-out of telemetry by setting the **DOTNET_CLI_TELEMETRY_OPTOUT** environment variable to **‘1’** or **‘true’** using your favorite shell.
|
||||
默认情况下,.NET core SDK 会采集用户使用情况数据,此功能被称为 **‘Telemetry’**。采集数据是匿名的,并根据[知识共享署名许可][2]分享给其开发团队和社区。因此 .NET 团队会知道这些工具的使用状况,然后根据统计做出决策,改进产品。如果你不想分享自己的使用信息的话,可以使用顺手的 shell 工具把名为 **DOTNET_CLI_TELEMETRY_OPTOUT** 的环境变量参数设置为 **‘1’** 或 **‘true’**,这样就简单的关闭此功能了。
|
||||
|
||||
And, that’s all. You know how to install .NET Core SDK on various Linux platforms and how to create a basic app using it. TO learn more about .NET usage, refer the links given at the end of this guide.
|
||||
就这样。你已经知道如何在各 Linux 平台上安装 .NET Core SDK 以及知道如何创建基本的应用程序了。想了解更多 .NET 使用知识的话,请参阅此文章末尾给出的链接。
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
会爆出更多干货的。敬请关注!
|
||||
|
||||
Cheers!
|
||||
祝贺下!
|
||||
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user