mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
Translated by cposture
This commit is contained in:
commit
156bef4209
@ -0,0 +1,104 @@
|
||||
在 Linux 上管理加密密钥的最佳体验
|
||||
=============================================
|
||||
|
||||
存储 SSH 的加密秘钥和记住密码一直是一个让人头疼的问题。但是不幸的是,在当前这个充满了恶意黑客和攻击的世界中,基本的安全预防是必不可少的。对于许多普通用户来说,大多数人只能是记住密码,也可能寻找到一个好程序去存储密码,正如我们提醒这些用户不要在每个网站采用相同的密码。但是对于在各个 IT 领域的人们,我们需要将这个事情提高一个层面。我们需要使用像 SSH 密钥这样的加密秘钥,而不只是密码。
|
||||
|
||||
设想一个场景:我有一个运行在云上的服务器,用作我的主 git 库。我有很多台工作电脑,所有这些电脑都需要登录到这个中央服务器去做 push 与 pull 操作。这里我设置 git 使用 SSH。当 git 使用 SSH 时,git 实际上是以 SSH 的方式登录到服务器,就好像你通过 SSH 命令打开一个服务器的命令行一样。为了把这些配置好,我在我的 .ssh 目录下创建一个配置文件,其中包含一个有服务器名字、主机名、登录用户、密钥文件路径等信息的主机项。之后我可以通过输入如下命令来测试这个配置是否正确。
|
||||
|
||||
ssh gitserver
|
||||
|
||||
很快我就可以访问到服务器的 bash shell。现在我可以配置 git 使用相同配置项以及存储的密钥来登录服务器。这很简单,只是有一个问题:对于每一个我要用它登录服务器的电脑,我都需要有一个密钥文件,那意味着需要密钥文件会放在很多地方。我会在当前这台电脑上存储这些密钥文件,我的其他电脑也都需要存储这些。就像那些有特别多的密码的用户一样,我们这些 IT 人员也被这些特别多的密钥文件淹没。怎么办呢?
|
||||
|
||||
### 清理
|
||||
|
||||
在我们开始帮助你管理密钥之前,你需要有一些密钥应该怎么使用的基础知识,以及明白我们下面的提问的意义所在。同时,有个前提,也是最重要的,你应该知道你的公钥和私钥该放在哪里。然后假设你应该知道:
|
||||
|
||||
1. 公钥和私钥之间的差异;
|
||||
2. 为什么你不可以从公钥生成私钥,但是反之则可以?
|
||||
3. `authorized_keys` 文件的目的以及里面包含什么内容;
|
||||
4. 如何使用私钥去登录一个你的对应公钥存储在其上的 `authorized_keys` 文件中的服务器。
|
||||
|
||||

|
||||
|
||||
这里有一个例子。当你在亚马逊的网络服务上创建一个云服务器,你必须提供一个用于连接你的服务器的 SSH 密钥。每个密钥都有一个公开的部分(公钥)和私密的部分(私钥)。你要想让你的服务器安全,乍看之下你可能应该将你的私钥放到服务器上,同时你自己带着公钥。毕竟,你不想你的服务器被公开访问,对吗?但是实际上的做法正好是相反的。
|
||||
|
||||
你应该把自己的公钥放到 AWS 服务器,同时你持有用于登录服务器的私钥。你需要保护好私钥,并让它处于你的控制之中,而不是放在一些远程服务器上,正如上图中所示。
|
||||
|
||||
原因如下:如果公钥被其他人知道了,它们不能用于登录服务器,因为他们没有私钥。进一步说,如果有人成功攻入你的服务器,他们所能找到的只是公钥,他们不可以从公钥生成私钥。同时,如果你在其他的服务器上使用了相同的公钥,他们不可以使用它去登录别的电脑。
|
||||
|
||||
这就是为什么你要把你自己的公钥放到你的服务器上以便通过 SSH 登录这些服务器。你持有这些私钥,不要让这些私钥脱离你的控制。
|
||||
|
||||
但是还有一点麻烦。试想一下我 git 服务器的例子。我需要做一些抉择。有时我登录架设在别的地方的开发服务器,而在开发服务器上,我需要连接我的 git 服务器。如何使我的开发服务器连接 git 服务器?显然是通过使用私钥,但这样就会有问题。在该场景中,需要我把私钥放置到一个架设在别的地方的服务器上,这相当危险。
|
||||
|
||||
一个进一步的场景:如果我要使用一个密钥去登录许多的服务器,怎么办?如果一个入侵者得到这个私钥,这个人就能用这个私钥得到整个服务器网络的权限,这可能带来一些严重的破坏,这非常糟糕。
|
||||
|
||||
同时,这也带来了另外一个问题,我真的应该在这些其他服务器上使用相同的密钥吗?因为我刚才描述的,那会非常危险的。
|
||||
|
||||
最后,这听起来有些混乱,但是确实有一些简单的解决方案。让我们有条理地组织一下。
|
||||
|
||||
(注意,除了登录服务器,还有很多地方需要私钥密钥,但是我提出的这个场景可以向你展示当你使用密钥时你所面对的问题。)
|
||||
|
||||
### 常规口令
|
||||
|
||||
当你创建你的密钥时,你可以选择是否包含一个密钥使用时的口令。有了这个口令,私钥文件本身就会被口令所加密。例如,如果你有一个公钥存储在服务器上,同时你使用私钥去登录服务器的时候,你会被提示输入该口令。没有口令,这个密钥是无法使用的。或者你也可以配置你的密钥不需要口令,然后只需要密钥文件就可以登录服务器了。
|
||||
|
||||
一般来说,不使用口令对于用户来说是更方便的,但是在很多情况下我强烈建议使用口令,原因是,如果私钥文件被偷了,偷密钥的人仍然不可以使用它,除非他或者她可以找到口令。在理论上,这个将节省你很多时间,因为你可以在攻击者发现口令之前,从服务器上删除公钥文件,从而保护你的系统。当然还有一些使用口令的其它原因,但是在很多场合这个原因对我来说更有价值。(举一个例子,我的 Android 平板上有 VNC 软件。平板上有我的密钥。如果我的平板被偷了之后,我会马上从服务器上删除公钥,使得它的私钥没有作用,无论有没有口令。)但是在一些情况下我不使用口令,是因为我正在登录的服务器上没有什么有价值的数据,这取决于情境。
|
||||
|
||||
### 服务器基础设施
|
||||
|
||||
你如何设计自己服务器的基础设施将会影响到你如何管理你的密钥。例如,如果你有很多用户登录,你将需要决定每个用户是否需要一个单独的密钥。(一般来说,应该如此;你不会想在用户之间共享私钥。那样当一个用户离开组织或者失去信任时,你可以删除那个用户的公钥,而不需要必须给其他人生成新的密钥。相似地,通过共享密钥,他们能以其他人的身份登录,这就更糟糕了。)但是另外一个问题是你如何配置你的服务器。举例来说,你是否使用像 Puppet 这样工具配置大量的服务器?你是否基于你自己的镜像创建大量的服务器?当你复制你的服务器,是否每一个的密钥都一样?不同的云服务器软件允许你配置如何选择;你可以让这些服务器使用相同的密钥,也可以给每一个服务器生成一个新的密钥。
|
||||
|
||||
如果你在操作这些复制的服务器,如果用户需要使用不同的密钥登录两个不同但是大部分都一样的系统,它可能导致混淆。但是另一方面,服务器共享相同的密钥会有安全风险。或者,第三,如果你的密钥有除了登录之外的需要(比如挂载加密的驱动),那么你会在很多地方需要相同的密钥。正如你所看到的,你是否需要在不同的服务器上使用相同的密钥不是我能为你做的决定;这其中有权衡,你需要自己去决定什么是最好的。
|
||||
|
||||
最终,你可能会有:
|
||||
|
||||
- 需要登录的多个服务器
|
||||
- 多个用户登录到不同的服务器,每个都有自己的密钥
|
||||
- 每个用户使用多个密钥登录到不同的服务器
|
||||
|
||||
(如果你正在别的情况下使用密钥,这个同样的普适理论也能应用于如何使用密钥,需要多少密钥,它们是否共享,你如何处理公私钥等方面。)
|
||||
|
||||
### 安全方法
|
||||
|
||||
了解你的基础设施和特有的情况,你需要组合一个密钥管理方案,它会指导你如何去分发和存储你的密钥。比如,正如我之前提到的,如果我的平板被偷了,我会从我服务器上删除公钥,我希望这在平板在用于访问服务器之前完成。同样的,我会在我的整体计划中考虑以下内容:
|
||||
|
||||
1. 私钥可以放在移动设备上,但是必须包含口令;
|
||||
2. 必须有一个可以快速地从服务器上删除公钥的方法。
|
||||
|
||||
在你的情况中,你可能决定你不想在自己经常登录的系统上使用口令;比如,这个系统可能是一个开发者一天登录多次的测试机器。这没有问题,但是你需要调整一点你的规则。你可以添加一条规则:不可以通过移动设备登录该机器。换句话说,你需要根据自己的状况构建你的准则,不要假设某个方案放之四海而皆准。
|
||||
|
||||
### 软件
|
||||
|
||||
至于软件,令人吃惊的是,现实世界中并没有很多好的、可靠的存储和管理私钥的软件解决方案。但是应该有吗?考虑下这个,如果你有一个程序存储你所有服务器的全部密钥,并且这个程序被一个快捷的密钥锁住,那么你的密钥就真的安全了吗?或者类似的,如果你的密钥被放置在你的硬盘上,用于 SSH 程序快速访问,密钥管理软件是否真正提供了任何保护吗?
|
||||
|
||||
但是对于整体基础设施和创建/管理公钥来说,有许多的解决方案。我已经提到了 Puppet,在 Puppet 的世界中,你可以创建模块以不同的方式管理你的服务器。这个想法是服务器是动态的,而且不需要精确地复制彼此。[这里有一个聪明的方法](http://manuel.kiessling.net/2014/03/26/building-manageable-server-infrastructures-with-puppet-part-4/),在不同的服务器上使用相同的密钥,但是对于每一个用户使用不同的 Puppet 模块。这个方案可能适合你,也可能不适合你。
|
||||
|
||||
或者,另一个选择就是完全换个不同的档位。在 Docker 的世界中,你可以采取一个不同的方式,正如[关于 SSH 和 Docker 博客](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)所描述的那样。
|
||||
|
||||
但是怎么样管理私钥?如果你搜索过的话,你无法找到很多可以选择的软件,原因我之前提到过;私钥存放在你的硬盘上,一个管理软件可能无法提到更多额外的安全。但是我使用这种方法来管理我的密钥:
|
||||
|
||||
首先,我的 `.ssh/config` 文件中有很多的主机项。我要登录的都有一个主机项,但是有时我对于一个单独的主机有不止一项。如果我有很多登录方式,就会出现这种情况。对于放置我的 git 库的服务器来说,我有两个不同的登录项;一个限制于 git,另一个用于一般用途的 bash 访问。这个为 git 设置的登录选项在机器上有极大的限制。还记得我之前说的我存储在远程开发机器上的 git 密钥吗?好了。虽然这些密钥可以登录到我其中一个服务器,但是使用的账号是被严格限制的。
|
||||
|
||||
其次,大部分的私钥都包含口令。(对于需要多次输入口令的情况,考虑使用 [ssh-agent](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)。)
|
||||
|
||||
再次,我有一些我想要更加小心地保护的服务器,我不会把这些主机项放在我的 host 文件中。这更加接近于社会工程方面,密钥文件还在,但是可能需要攻击者花费更长的时间去找到这个密钥文件,分析出来它们对应的机器。在这种情况下,我就需要手动打出来一条长长的 SSH 命令。(没那么可怕。)
|
||||
|
||||
同时你可以看出来我没有使用任何特别的软件去管理这些私钥。
|
||||
|
||||
## 无放之四海而皆准的方案
|
||||
|
||||
我们偶尔会在 linux.com 收到一些问题,询问管理密钥的好软件的建议。但是退一步看,这个问题事实上需要重新思考,因为没有一个普适的解决方案。你问的问题应该基于你自己的状况。你是否简单地尝试找到一个位置去存储你的密钥文件?你是否寻找一个方法去管理多用户问题,其中每个人都需要将他们自己的公钥插入到 `authorized_keys` 文件中?
|
||||
|
||||
通过这篇文章,我已经囊括了这方面的基础知识,希望到此你明白如何管理你的密钥,并且,只有当你问出了正确的问题,无论你寻找任何软件(甚至你需要另外的软件),它都会出现。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/838235-how-to-best-manage-encryption-keys-on-linux
|
||||
|
||||
作者:[Jeff Cogswell][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/62256
|
||||
51
published/20160629 USE TASK MANAGER EQUIVALENT IN LINUX.md
Normal file
51
published/20160629 USE TASK MANAGER EQUIVALENT IN LINUX.md
Normal file
@ -0,0 +1,51 @@
|
||||
在 Linux 下使用任务管理器
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
有很多 Linux 初学者经常问起的问题,“**Linux 有任务管理器吗?**”,“**怎样在 Linux 上打开任务管理器呢?**”
|
||||
|
||||
来自 Windows 的用户都知道任务管理器非常有用。你可以在 Windows 中按下 `Ctrl+Alt+Del` 打开任务管理器。这个任务管理器向你展示了所有的正在运行的进程和它们消耗的内存,你可以从任务管理器程序中选择并杀死一个进程。
|
||||
|
||||
当你刚使用 Linux 的时候,你也会寻找一个**在 Linux 相当于任务管理器**的一个东西。一个 Linux 使用专家更喜欢使用命令行的方式查找进程和消耗的内存等等,但是你不用必须使用这种方式,至少在你初学 Linux 的时候。
|
||||
|
||||
所有主流的 Linux 发行版都有一个类似于任务管理器的东西。大部分情况下,它叫系统监视器(System Monitor),不过实际上它依赖于你的 Linux 的发行版及其使用的[桌面环境][1]。
|
||||
|
||||
在这篇文章中,我们将会看到如何在以 GNOME 为[桌面环境][2]的 Linux 上找到并使用任务管理器。
|
||||
|
||||
### 在使用 GNOME 桌面环境的 Linux 上的任务管理器等价物
|
||||
|
||||
使用 GNOME 时,按下 super 键(Windows 键)来查找任务管理器:
|
||||
|
||||

|
||||
|
||||
当你启动系统监视器的时候,它会向你展示所有正在运行的进程及其消耗的内存。
|
||||
|
||||

|
||||
|
||||
你可以选择一个进程并且点击“终止进程(End Process)”来杀掉它。
|
||||
|
||||

|
||||
|
||||
你也可以在资源(Resources)标签里面看到关于一些统计数据,例如 CPU 的每个核心的占用,内存用量、网络用量等。
|
||||
|
||||

|
||||
|
||||
这是图形化的方式。如果你想使用命令行,在终端里运行“top”命令然后你就可以看到所有运行的进程及其消耗的内存。你也可以很容易地使用命令行[杀死进程][3]。
|
||||
|
||||
这就是关于在 Fedora Linux 上任务管理器的知识。我希望这个教程帮你学到了知识,如果你有什么问题,请尽管问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/task-manager-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://wiki.archlinux.org/index.php/desktop_environment
|
||||
[2]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[3]: https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/
|
||||
@ -1,77 +0,0 @@
|
||||
How bad a boss is Linus Torvalds?
|
||||
================================================================================
|
||||

|
||||
|
||||
*Linus Torvalds addressed a packed auditorium of Linux enthusiasts during his speech at the LinuxWorld show in San Jose, California, on August 10, 1999. Credit: James Niccolai*
|
||||
|
||||
**It depends on context. In the world of software development, he’s what passes for normal. The question is whether that situation should be allowed to continue.**
|
||||
|
||||
I've known Linus Torvalds, Linux's inventor, for over 20 years. We're not chums, but we like each other.
|
||||
|
||||
Lately, Torvalds has been getting a lot of flack for his management style. Linus doesn't suffer fools gladly. He has one way of judging people in his business of developing the Linux kernel: How good is your code?
|
||||
|
||||
Nothing else matters. As Torvalds said earlier this year at the Linux.conf.au Conference, "I'm not a nice person, and I don't care about you. [I care about the technology and the kernel][1] -- that's what's important to me."
|
||||
|
||||
Now, I can deal with that kind of person. If you can't, you should avoid the Linux kernel community, where you'll find a lot of this kind of meritocratic thinking. Which is not to say that I think everything in Linuxland is hunky-dory and should be impervious to calls for change. A meritocracy I can live with; a bastion of male dominance where women are subjected to scorn and disrespect is a problem.
|
||||
|
||||
That's why I see the recent brouhaha about Torvalds' management style -- or more accurately, his total indifference to the personal side of management -- as nothing more than standard operating procedure in the world of software development. And at the same time, I see another instance that has come to light as evidence of a need for things to really change.
|
||||
|
||||
The first situation arose with the [release of Linux 4.3][2], when Torvalds used the Linux Kernel Mailing List to tear into a developer who had inserted some networking code that Torvalds thought was -- well, let's say "crappy." "[[A]nd it generates [crappy] code.][3] It looks bad, and there's no reason for it." He goes on in this vein for quite a while. Besides the word "crap" and its earthier synonym, he uses the word "idiotic" pretty often.
|
||||
|
||||
Here's the thing, though. He's right. I read the code. It's badly written and it does indeed seem to have been designed to use the new "overflow_usub()" function just for the sake of using it.
|
||||
|
||||
Now, some people see this diatribe as evidence that Torvalds is a bad-tempered bully. I see a perfectionist who, within his field, doesn't put up with crap.
|
||||
|
||||
Many people have told me that this is not how professional programmers should act. People, have you ever worked with top developers? That's exactly how they act, at Apple, Microsoft, Oracle and everywhere else I've known them.
|
||||
|
||||
I've heard Steve Jobs rip a developer to pieces. I've cringed while a senior Oracle developer lead tore into a room of new programmers like a piranha through goldfish.
|
||||
|
||||
In Accidental Empires, his classic book on the rise of PCs, Robert X. Cringely described Microsoft's software management style when Bill Gates was in charge as a system where "Each level, from Gates on down, screams at the next, goading and humiliating them." Ah, yes, that's the Microsoft I knew and hated.
|
||||
|
||||
The difference between the leaders at big proprietary software companies and Torvalds is that he says everything in the open for the whole world to see. The others do it in private conference rooms. I've heard people claim that Torvalds would be fired in their company. Nope. He'd be right where he is now: on top of his programming world.
|
||||
|
||||
Oh, and there's another difference. If you get, say, Larry Ellison mad at you, you can kiss your job goodbye. When you get Torvalds angry at your work, you'll get yelled at in an email. That's it.
|
||||
|
||||
You see, Torvalds isn't anyone's boss. He's the guy in charge of a project with about 10,000 contributors, but he has zero hiring and firing authority. He can hurt your feelings, but that's about it.
|
||||
|
||||
That said, there is a serious problem within both open-source and proprietary software development circles. No matter how good a programmer you are, if you're a woman, the cards are stacked against you.
|
||||
|
||||
No case shows this better than that of Sarah Sharp, an Intel developer and formerly a top Linux programmer. [In a post on her blog in October][4], she explained why she had stopped contributing to the Linux kernel more than a year earlier: "I finally realized that I could no longer contribute to a community where I was technically respected, but I could not ask for personal respect.... I did not want to work professionally with people who were allowed to get away with subtle sexist or homophobic jokes."
|
||||
|
||||
Who can blame her? I can't. Torvalds, like almost every software manager I've ever known, I'm sorry to say, has permitted a hostile work environment.
|
||||
|
||||
He would probably say that it's not his job to ensure that Linux contributors behave with professionalism and mutual respect. He's concerned with the code and nothing but the code.
|
||||
|
||||
As Sharp wrote:
|
||||
|
||||
> I have the utmost respect for the technical efforts of the Linux kernel community. They have scaled and grown a project that is focused on maintaining some of the highest coding standards out there. The focus on technical excellence, in combination with overloaded maintainers, and people with different cultural and social norms, means that Linux kernel maintainers are often blunt, rude, or brutal to get their job done. Top Linux kernel developers often yell at each other in order to correct each other's behavior.
|
||||
>
|
||||
> That's not a communication style that works for me. …
|
||||
>
|
||||
> Many senior Linux kernel developers stand by the right of maintainers to be technically and personally brutal. Even if they are very nice people in person, they do not want to see the Linux kernel communication style change.
|
||||
|
||||
She's right.
|
||||
|
||||
Where I differ from other observers is that I don't think that this problem is in any way unique to Linux or open-source communities. With five years of work in the technology business and 25 years as a technology journalist, I've seen this kind of immature boy behavior everywhere.
|
||||
|
||||
It's not Torvalds' fault. He's a technical leader with a vision, not a manager. The real problem is that there seems to be no one in the software development universe who can set a supportive tone for teams and communities.
|
||||
|
||||
Looking ahead, I hope that companies and organizations, such as the Linux Foundation, can find a way to empower community managers or other managers to encourage and enforce civil behavior.
|
||||
|
||||
We won't, unfortunately, find that kind of managerial finesse in our pure technical or business leaders. It's not in their DNA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
@ -1,49 +0,0 @@
|
||||
Growing a career alongside Linux
|
||||
==================================
|
||||
|
||||

|
||||
|
||||
My Linux story started in 1998 and continues today. Back then, I worked for The Gap managing thousands of desktops running [OS/2][1] (and a few years later, [Warp 3.0][2]). As an OS/2 guy, I was really happy then. The desktops hummed along and it was quite easy to support thousands of users with the tools the GAP had built. Changes were coming, though.
|
||||
|
||||
In November of 1998, I received an invitation to join a brand new startup which would focus on Linux in the enterprise. This startup became quite famous as [Linuxcare][2].
|
||||
|
||||
### My time at Linuxcare
|
||||
|
||||
I had played with Linux a bit, but had never considered delivering it to enterprise customers. Mere months later (which is a turn of the corner in startup time and space), I was managing a line of business that let enterprises get their hardware, software, and even books certified on a few flavors of Linux that were popular back then.
|
||||
|
||||
I supported customers like IBM, Dell, and HP in ensuring their hardware ran Linux successfully. You hear a lot now about preloading Linux on hardware today, but way back then I was invited to Dell to discuss getting a laptop certified to run Linux for an upcoming trade show. Very exciting times! We also supported IBM and HP on a number of certification efforts that spanned a few years.
|
||||
|
||||
Linux was changing fast, much like it always has. It gained hardware support for more key devices like sound, network, graphics. At around that time, I shifted from RPM-based systems to [Debian][3] for my personal use.
|
||||
|
||||
### Using Linux through the years
|
||||
|
||||
Fast forward some years and I worked at a number of companies that did Linux as hardened appliances, Linux as custom software, and Linux in the data center. By the mid 2000s, I was busy doing consulting for that rather large software company in Redmond around some analysis and verification of Linux compared to their own solutions. My personal use had not changed though—I would still run Debian testing systems on anything I could.
|
||||
|
||||
I really appreciated the flexibility of a distribution that floated and was forever updated. Debian is one of the most fun and well supported distributions and has the best community I've ever been a part of.
|
||||
|
||||
When I look back at my own adoption of Linux, I remember with fondness the numerous Linux Expo trade shows in San Jose, San Francisco, Boston, and New York in the early and mid 2000's. At Linuxcare we always did fun and funky booths, and walking the show floor always resulted in getting re-acquainted with old friends. Rumors of work were always traded, and the entire thing underscored the fun of using Linux in real endeavors.
|
||||
|
||||
The rise of virtualization and cloud has really made the use of Linux even more interesting. When I was with Linuxcare, we partnered with a small 30-person company in Palo Alto. We would drive to their offices and get things ready for a trade show that they would attend with us. Who would have ever known that little startup would become VMware?
|
||||
|
||||
I have so many stories, and there were so many people I was so fortunate to meet and work with. Linux has evolved in so many ways and has become so important. And even with its increasing importance, Linux is still fun to use. I think its openness and the ability to modify it has contributed to a legion of new users, which always astounds me.
|
||||
|
||||
### Today
|
||||
|
||||
I've moved away from doing mainstream Linux things over the past five years. I manage large scale infrastructure projects that include a variety of OSs (both proprietary and open), but my heart has always been with Linux.
|
||||
|
||||
The constant evolution and fun of using Linux has been a driving force for me for over the past 18 years. I started with the 2.0 Linux kernel and have watched it become what it is now. It's a remarkable thing. An organic thing. A cool thing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-michael-perry
|
||||
|
||||
作者:[Michael Perry][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/mpmilestogo
|
||||
[1]: https://en.wikipedia.org/wiki/OS/2
|
||||
[2]: https://archive.org/details/IBMOS2Warp3Collection
|
||||
[3]: https://en.wikipedia.org/wiki/Linuxcare
|
||||
[4]: https://www.debian.org/
|
||||
[5]:
|
||||
@ -0,0 +1,73 @@
|
||||
xinglianfly translate
|
||||
Writing online multiplayer game with python and asyncio - part 1
|
||||
===================================================================
|
||||
|
||||
Have you ever combined async with Python? Here I’ll tell you how to do it and show it on a [working example][1] - a popular Snake game, designed for multiple players.
|
||||
|
||||
[Play gmae][2]
|
||||
|
||||
### 1. Introduction
|
||||
|
||||
Massive multiplayer online games are undoubtedly one of the main trends of our century, in both tech and cultural domains. And while for a long time writing a server for a MMO game was associated with massive budgets and complex low-level programming techniques, things are rapidly changing in the recent years. Modern frameworks based on dynamic languages allow handling thousands of parallel user connections on moderate hardware. At the same time, HTML 5 and WebSockets standards enabled the creation of real-time graphics-based game clients that run directly in web browser, without any extensions.
|
||||
|
||||
Python may be not the most popular tool for creating scalable non-blocking servers, especially comparing to node.js popularity in this area. But the latest versions of Python are aimed to change this. The introduction of [asyncio][3] library and a special [async/await][4] syntax makes asynchronous code look as straightforward as regular blocking code, which now makes Python a worthy choice for asynchronous programming. So I will try to utilize these new features to demonstrate a way to create an online multiplayer game.
|
||||
|
||||
### 2. Getting asynchronous
|
||||
|
||||
A game server should handle a maximum possible number of parallel users' connections and process them all in real time. And a typical solution - creating threads, doesn't solve a problem in this case. Running thousands of threads requires CPU to switch between them all the time (it is called context switching), which creates big overhead, making it very ineffective. Even worse with processes, because, in addition, they do occupy too much memory. In Python there is even one more problem - regular Python interpreter (CPython) is not designed to be multithreaded, it aims to achieve maximum performance for single-threaded apps instead. That's why it uses GIL (global interpreter lock), a mechanism which doesn't allow multiple threads to run Python code at the same time, to prevent uncontrolled usage of the same shared objects. Normally the interpreter switches to another thread when currently running thread is waiting for something, usually a response from I/O (like a response from web server for example). This allows having non-blocking I/O operations in your app, because every operation blocks only one thread instead of blocking the whole server. However, it also makes general multithreading idea nearly useless, because it doesn't allow you to execute python code in parallel, even on multi-core CPU. While at the same time it is completely possible to have non-blocking I/O in one single thread, thus eliminating the need of heavy context-switching.
|
||||
|
||||
Actually, a single-threaded non-blocking I/O is a thing you can do in pure python. All you need is a standard [select][5] module which allows you to write an event loop waiting for I/O from non-blocking sockets. However, this approach requires you to define all the app logic in one place, and soon your app becomes a very complex state-machine. There are frameworks that simplify this task, most popular are [tornado][6] and [twisted][7]. They are utilized to implement complex protocols using callback methods (and this is similar to node.js). The framework runs its own event loop invoking your callbacks on the defined events. And while this may be a way to go for some, it still requires programming in callback style, what makes your code fragmented. Compare this to just writing synchronous code and running multiple copies concurrently, like we would do with normal threads. Why wouldn't this be possible in one thread?
|
||||
|
||||
And this is where the concept of microthreads come in. The idea is to have concurrently running tasks in one thread. When you call a blocking function in one task, behind the scenes it calls a "manager" (or "scheduler") that runs an event loop. And when there is some event ready to process, a manager passes execution to a task waiting for it. That task will also run until it reaches a blocking call, and then it will return execution to a manager again.
|
||||
|
||||
>Microthreads are also called lightweight threads or green threads (a term which came from Java world). Tasks which are running concurrently in pseudo-threads are called tasklets, greenlets or coroutines.
|
||||
|
||||
One of the first implementations of microthreads in Python was [Stackless Python][8]. It got famous because it is used in a very successful online game [EVE online][9]. This MMO game boasts about a persistent universe, where thousands of players are involved in different activities, all happening in the real time. Stackless is a standalone Python interpreter which replaces standard function calling stack and controls the flow directly to allow minimum possible context-switching expenses. Though very effective, this solution remained less popular than "soft" libraries that work with a standard interpreter. Packages like [eventlet][10] and [gevent][11] come with patching of a standard I/O library in the way that I/O function pass execution to their internal event loop. This allows turning normal blocking code into non-blocking in a very simple way. The downside of this approach is that it is not obvious from the code, which calls are non-blocking. A newer version of Python introduced native coroutines as an advanced form of generators. Later in Python 3.4 they included asyncio library which relies on native coroutines to provide single-thread concurrency. But only in python 3.5 coroutines became an integral part of python language, described with the new keywords async and await. Here is a simple example, which illustrates using asyncio to run concurrent tasks:
|
||||
|
||||
```
|
||||
import asyncio
|
||||
|
||||
async def my_task(seconds):
|
||||
print("start sleeping for {} seconds".format(seconds))
|
||||
await asyncio.sleep(seconds)
|
||||
print("end sleeping for {} seconds".format(seconds))
|
||||
|
||||
all_tasks = asyncio.gather(my_task(1), my_task(2))
|
||||
loop = asyncio.get_event_loop()
|
||||
loop.run_until_complete(all_tasks)
|
||||
loop.close()
|
||||
```
|
||||
|
||||
We launch two tasks, one sleeps for 1 second, the other - for 2 seconds. The output is:
|
||||
|
||||
```
|
||||
start sleeping for 1 seconds
|
||||
start sleeping for 2 seconds
|
||||
end sleeping for 1 seconds
|
||||
end sleeping for 2 seconds
|
||||
```
|
||||
|
||||
As you can see, coroutines do not block each other - the second task starts before the first is finished. This is happening because asyncio.sleep is a coroutine which returns execution to a scheduler until the time will pass. In the next section, we will use coroutine-based tasks to create a game loop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: http://snakepit-game.com/
|
||||
[3]: https://docs.python.org/3/library/asyncio.html
|
||||
[4]: https://docs.python.org/3/whatsnew/3.5.html#whatsnew-pep-492
|
||||
[5]: https://docs.python.org/2/library/select.html
|
||||
[6]: http://www.tornadoweb.org/
|
||||
[7]: http://twistedmatrix.com/
|
||||
[8]: http://www.stackless.com/
|
||||
[9]: http://www.eveonline.com/
|
||||
[10]: http://eventlet.net/
|
||||
[11]: http://www.gevent.org/
|
||||
@ -0,0 +1,234 @@
|
||||
chunyang-wen translating
|
||||
Writing online multiplayer game with python and asyncio - Part 2
|
||||
==================================================================
|
||||
|
||||

|
||||
|
||||
Have you ever made an asynchronous Python app? Here I’ll tell you how to do it and in the next part, show it on a [working example][1] - a popular Snake game, designed for multiple players.
|
||||
|
||||
see the intro and theory about how to [Get Asynchronous [part 1]][2]
|
||||
|
||||
[Play the game][3]
|
||||
|
||||
### 3. Writing game loop
|
||||
|
||||
The game loop is a heart of every game. It runs continuously to get player's input, update state of the game and render the result on the screen. In online games the loop is divided into client and server parts, so basically there are two loops which communicate over the network. Usually, client role is to get player's input, such as keypress or mouse movement, pass this data to a server and get back the data to render. The server side is processing all the data coming from players, updating game's state, doing necessary calculations to render next frame and passes back the result, such as new placement of game objects. It is very important not to mix client and server roles without a solid reason. If you start doing game logic calculations on the client side, you can easily go out of sync with other clients, and your game can also be created by simply passing any data from the client side.
|
||||
|
||||
A game loop iteration is often called a tick. Tick is an event meaning that current game loop iteration is over and the data for the next frame(s) is ready.
|
||||
In the next examples we will use the same client, which connects to a server from a web page using WebSocket. It runs a simple loop which passes pressed keys' codes to the server and displays all messages that come from the server. [Client source code is located here][4].
|
||||
|
||||
#### Example 3.1: Basic game loop
|
||||
|
||||
[Example 3.1 source code][5]
|
||||
|
||||
We will use [aiohttp][6] library to create a game server. It allows creating web servers and clients based on asyncio. A good thing about this library is that it supports normal http requests and websockets at the same time. So we don't need other web servers to render game's html page.
|
||||
|
||||
Here is how we run the server:
|
||||
|
||||
```
|
||||
app = web.Application()
|
||||
app["sockets"] = []
|
||||
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
|
||||
app.router.add_route('GET', '/connect', wshandler)
|
||||
app.router.add_route('GET', '/', handle)
|
||||
|
||||
web.run_app(app)
|
||||
```
|
||||
|
||||
web.run_app is a handy shortcut to create server's main task and to run asyncio event loop with it's run_forever() method. I suggest you check the source code of this method to see how the server is actually created and terminated.
|
||||
|
||||
An app is a dict-like object which can be used to share data between connected clients. We will use it to store a list of connected sockets. This list is then used to send notification messages to all connected clients. A call to asyncio.ensure_future() will schedule our main game_loop task which sends 'tick' message to clients every 2 seconds. This task will run concurrently in the same asyncio event loop along with our web server.
|
||||
|
||||
There are 2 web request handlers: handle just serves a html page and wshandler is our main websocket server's task which handles interaction with game clients. With every connected client a new wshandler task is launched in the event loop. This task adds client's socket to the list, so that game_loop task may send messages to all the clients. Then it echoes every keypress back to the client with a message.
|
||||
|
||||
In the launched tasks we are running worker loops over the main event loop of asyncio. A switch between tasks happens when one of them uses await statement to wait for a coroutine to finish. For instance, asyncio.sleep just passes execution back to a scheduler for a given amount of time, and ws.receive() is waiting for a message from websocket, while the scheduler may switch to some other task.
|
||||
|
||||
After you open the main page in a browser and connect to the server, just try to press some keys. Their codes will be echoed back from the server and every 2 seconds this message will be overwritten by game loop's 'tick' message which is sent to all clients.
|
||||
|
||||
So we have just created a server which is processing client's keypresses, while the main game loop is doing some work in the background and updates all clients periodically.
|
||||
|
||||
#### Example 3.2: Starting game loop by request
|
||||
|
||||
[Example 3.2 source code][7]
|
||||
|
||||
In the previous example a game loop was running continuously all the time during the life of the server. But in practice, there is usually no sense to run game loop when no one is connected. Also, there may be different game "rooms" running on one server. In this concept one player "creates" a game session (a match in a multiplayer game or a raid in MMO for example) so other players may join it. Then a game loop runs while the game session continues.
|
||||
|
||||
In this example we use a global flag to check if a game loop is running, and we start it when the first player connects. In the beginning, a game loop is not running, so the flag is set to False. A game loop is launched from the client's handler:
|
||||
|
||||
```
|
||||
if app["game_is_running"] == False:
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
This flag is then set to True at the start of game loop() and then back to False in the end, when all clients are disconnected.
|
||||
|
||||
#### Example 3.3: Managing tasks
|
||||
|
||||
[Example 3.3 source code][8]
|
||||
|
||||
This example illustrates working with task objects. Instead of storing a flag, we store game loop's task directly in our application's global dict. This may be not an optimal thing to do in a simple case like this, but sometimes you may need to control already launched tasks.
|
||||
```
|
||||
if app["game_loop"] is None or \
|
||||
app["game_loop"].cancelled():
|
||||
app["game_loop"] = asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
Here ensure_future() returns a task object that we store in a global dict; and when all users disconnect, we cancel it with
|
||||
|
||||
```
|
||||
app["game_loop"].cancel()
|
||||
```
|
||||
|
||||
This cancel() call tells scheduler not to pass execution to this coroutine anymore and sets its state to cancelled which then can be checked by cancelled() method. And here is one caveat worth to mention: when you have external references to a task object and exception happens in this task, this exception will not be raised. Instead, an exception is set to this task and may be checked by exception() method. Such silent fails are not useful when debugging a code. Thus, you may want to raise all exceptions instead. To do so you need to call result() method of unfinished task explicitly. This can be done in a callback:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result())
|
||||
```
|
||||
|
||||
Also if we are going to cancel this task in our code and we don't want to have CancelledError exception, it has a point checking its "cancelled" state:
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result()
|
||||
if not t.cancelled() else None)
|
||||
```
|
||||
|
||||
Note that this is required only if you store a reference to your task objects. In the previous examples all exceptions are raised directly without additional callbacks.
|
||||
|
||||
#### Example 3.4: Waiting for multiple events
|
||||
|
||||
[Example 3.4 source code][9]
|
||||
|
||||
In many cases, you need to wait for multiple events inside client's handler. Beside a message from a client, you may need to wait for different types of things to happen. For instance, if your game's time is limited, you may wait for a signal from timer. Or, you may wait for a message from other process using pipes. Or, for a message from a different server in the network, using a distributed messaging system.
|
||||
|
||||
This example is based on example 3.1 for simplicity. But in this case we use Condition object to synchronize game loop with connected clients. We do not keep a global list of sockets here as we are using sockets only within the handler. When game loop iteration ends, we notify all clients using Condition.notify_all() method. This method allows implementing publish/subscribe pattern within asyncio event loop.
|
||||
|
||||
To wait for two events in the handler, first, we wrap awaitable objects in a task using ensure_future()
|
||||
|
||||
```
|
||||
if not recv_task:
|
||||
recv_task = asyncio.ensure_future(ws.receive())
|
||||
if not tick_task:
|
||||
await tick.acquire()
|
||||
tick_task = asyncio.ensure_future(tick.wait())
|
||||
```
|
||||
|
||||
Before we can call Condition.wait(), we need to acquire a lock behind it. That is why, we call tick.acquire() first. This lock is then released after calling tick.wait(), so other coroutines may use it too. But when we get a notification, a lock will be acquired again, so we need to release it calling tick.release() after received notification.
|
||||
|
||||
We are using asyncio.wait() coroutine to wait for two tasks.
|
||||
|
||||
```
|
||||
done, pending = await asyncio.wait(
|
||||
[recv_task,
|
||||
tick_task],
|
||||
return_when=asyncio.FIRST_COMPLETED)
|
||||
```
|
||||
|
||||
It blocks until either of tasks from the list is completed. Then it returns 2 lists: tasks which are done and tasks which are still running. If the task is done, we set it to None so it may be created again on the next iteration.
|
||||
|
||||
#### Example 3.5: Combining with threads
|
||||
|
||||
[Example 3.5 source code][10]
|
||||
|
||||
In this example we combine asyncio loop with threads by running the main game loop in a separate thread. As I mentioned before, it's not possible to perform real parallel execution of python code with threads because of GIL. So it is not a good idea to use other thread to do heavy calculations. However, there is one reason to use threads with asyncio: this is the case when you need to use other libraries which do not support asyncio. Using these libraries in the main thread will simply block execution of the loop, so the only way to use them asynchronously is to run in a different thread.
|
||||
|
||||
We run game loop using run_in_executor() method of asyncio loop and ThreadPoolExecutor. Note that game_loop() is not a coroutine anymore. It is a function that is executed in another thread. However, we need to interact with the main thread to notify clients on the game events. And while asyncio itself is not threadsafe, it has methods which allow running your code from another thread. These are call_soon_threadsafe() for normal functions and run_coroutine_threadsafe() for coroutines. We will put a code which notifies clients about game's tick to notify() coroutine and runs it in the main event loop from another thread.
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
print("Game loop thread id {}".format(threading.get_ident()))
|
||||
async def notify():
|
||||
print("Notify thread id {}".format(threading.get_ident()))
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
while 1:
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
# blocking the thread
|
||||
sleep(1)
|
||||
# make sure the task has finished
|
||||
task.result()
|
||||
```
|
||||
|
||||
When you launch this example, you will see that "Notify thread id" is equal to "Main thread id", this is because notify() coroutine is executed in the main thread. While sleep(1) call is executed in another thread, and, as a result, it will not block the main event loop.
|
||||
|
||||
#### Example 3.6: Multiple processes and scaling up
|
||||
|
||||
[Example 3.6 source code][11]
|
||||
|
||||
One threaded server may work well, but it is limited to one CPU core. To scale the server beyond one core, we need to run multiple processes containing their own event loops. So we need a way for processes to interact with each other by exchanging messages or sharing game's data. Also in games, it is often required to perform heavy calculations, such as path finding and alike. These tasks are sometimes not possible to complete quickly within one game tick. It is not recommended to perform time-consuming calculations in coroutines, as it will block event processing, so in this case, it may be reasonable to pass the heavy task to other process running in parallel.
|
||||
|
||||
The easiest way to utilize multiple cores is to launch multiple single core servers, like in the previous examples, each on a different port. You can do this with supervisord or similar process-controller system. Then, you may use a load balancer, such as HAProxy, to distribute connecting clients between the processes. There are different ways for processes to interact wich each other. One is to use network-based systems, which allows you to scale to multiple servers as well. There are already existing adapters to use popular messaging and storage systems with asyncio. Here are some examples:
|
||||
|
||||
- [aiomcache][12] for memcached client
|
||||
- [aiozmq][13] for zeroMQ
|
||||
- [aioredis][14] for Redis storage and pub/sub
|
||||
|
||||
You can find many other packages like this on github and pypi, most of them have "aio" prefix.
|
||||
|
||||
Using network services may be effective to store persistent data and exchange some kind of messages. But its performance may be not enough if you need to perform real-time data processing that involves inter-process communications. In this case, a more appropriate way may be using standard unix pipes. asyncio has support for pipes and there is a [very low-level example of the server which uses pipes][15] in aiohttp repository.
|
||||
|
||||
In the current example, we will use python's high-level [multiprocessing][16] library to instantiate new process to perform heavy calculations on a different core and to exchange messages with this process using multiprocessing.Queue. Unfortunately, the current implementation of multiprocessing is not compatible with asyncio. So every blocking call will block the event loop. But this is exactly the case where threads will be helpful because if we run multiprocessing code in a different thread, it will not block our main thread. All we need is to put all inter-process communications to another thread. This example illustrates this technique. It is very similar to multi-threading example above, but we create a new process from a thread.
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
# coroutine to run in main thread
|
||||
async def notify():
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
queue = Queue()
|
||||
|
||||
# function to run in a different process
|
||||
def worker():
|
||||
while 1:
|
||||
print("doing heavy calculation in process {}".format(os.getpid()))
|
||||
sleep(1)
|
||||
queue.put("calculation result")
|
||||
|
||||
Process(target=worker).start()
|
||||
|
||||
while 1:
|
||||
# blocks this thread but not main thread with event loop
|
||||
result = queue.get()
|
||||
print("getting {} in process {}".format(result, os.getpid()))
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
task.result()
|
||||
```
|
||||
|
||||
Here we run worker() function in another process. It contains a loop doing heavy calculations and putting results to the queue, which is an instance of multiprocessing.Queue. Then we get the results and notify clients in the main event loop from a different thread, exactly as in the example 3.5. This example is very simplified, it doesn't have a proper termination of the process. Also, in a real game, we would probably use the second queue to pass data to the worker.
|
||||
|
||||
There is a project called [aioprocessing][17], which is a wrapper around multiprocessing that makes it compatible with asyncio. However, it uses exactly the same approach as described in this example - creating processes from threads. It will not give you any advantage, other than hiding these tricks behind a simple interface. Hopefully, in the next versions of Python, we will get a multiprocessing library based on coroutines and supports asyncio.
|
||||
|
||||
>Important! If you are going to run another asyncio event loop in a different thread or sub-process created from main thread/process, you need to create a loop explicitly, using asyncio.new_event_loop(), otherwise, it will not work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[3]: http://snakepit-game.com/
|
||||
[4]: https://github.com/7WebPages/snakepit-game/blob/master/simple/index.html
|
||||
[5]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_basic.py
|
||||
[6]: http://aiohttp.readthedocs.org/
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_handler.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_global.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_wait.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_thread.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_process.py
|
||||
[12]: https://github.com/aio-libs/aiomcache
|
||||
[13]: https://github.com/aio-libs/aiozmq
|
||||
[14]: https://github.com/aio-libs/aioredis
|
||||
[15]: https://github.com/KeepSafe/aiohttp/blob/master/examples/mpsrv.py
|
||||
[16]: https://docs.python.org/3.5/library/multiprocessing.html
|
||||
[17]: https://github.com/dano/aioprocessing
|
||||
@ -0,0 +1,320 @@
|
||||
wyangsun translating
|
||||
How to build and deploy a Facebook Messenger bot with Python and Flask, a tutorial
|
||||
==========================================================================
|
||||
|
||||
This is my log of how I built a simple Facebook Messenger bot. The functionality is really simple, it’s an echo bot that will just print back to the user what they write.
|
||||
|
||||
This is something akin to the Hello World example for servers, the echo server.
|
||||
|
||||
The goal of the project is not to build the best Messenger bot, but rather to get a feel for what it takes to build a minimal bot and how everything comes together.
|
||||
|
||||
- [Tech Stack][1]
|
||||
- [Bot Architecture][2]
|
||||
- [The Bot Server][3]
|
||||
- [Deploying to Heroku][4]
|
||||
- [Creating the Facebook App][5]
|
||||
- [Conclusion][6]
|
||||
|
||||
### Tech Stack
|
||||
|
||||
The tech stack that was used is:
|
||||
|
||||
- [Heroku][7] for back end hosting. The free-tier is more than enough for a tutorial of this level. The echo bot does not require any sort of data persistence so a database was not used.
|
||||
- [Python][8] was the language of choice. The version that was used is 2.7 however it can easily be ported to Python 3 with minor alterations.
|
||||
- [Flask][9] as the web development framework. It’s a very lightweight framework that’s perfect for small scale projects/microservices.
|
||||
- Finally the [Git][10] version control system was used for code maintenance and to deploy to Heroku.
|
||||
- Worth mentioning: [Virtualenv][11]. This python tool is used to create “environments” clean of python libraries so you can only install the necessary requirements and minimize the app footprint.
|
||||
|
||||
### Bot Architecture
|
||||
|
||||
Messenger bots are constituted by a server that responds to two types of requests:
|
||||
|
||||
- GET requests are being used for authentication. They are sent by Messenger with an authentication code that you register on FB.
|
||||
- POST requests are being used for the actual communication. The typical workflow is that the bot will initiate the communication by sending the POST request with the data of the message sent by the user, we will handle it, send a POST request of our own back. If that one is completed successfully (a 200 OK status is returned) we also respond with a 200 OK code to the initial Messenger request.
|
||||
For this tutorial the app will be hosted on Heroku, which provides a nice and easy interface to deploy apps. As mentioned the free tier will suffice for this tutorial.
|
||||
|
||||
After the app has been deployed and is running, we’ll create a Facebook app and link it to our app so that messenger knows where to send the requests that are meant for our bot.
|
||||
|
||||
### The Bot Server
|
||||
The basic server code was taken from the following [Chatbot][12] project by Github user [hult (Magnus Hult)][13], with a few modifications to the code to only echo messages and a couple bugfixes I came across. This is the final version of the server code:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
|
||||
app = Flask(__name__)
|
||||
|
||||
# This needs to be filled with the Page Access Token that will be provided
|
||||
# by the Facebook App that will be created.
|
||||
PAT = ''
|
||||
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
|
||||
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run()
|
||||
```
|
||||
|
||||
Let’s break down the code. The first part is the imports that will be needed:
|
||||
|
||||
```
|
||||
from flask import Flask, request
|
||||
import json
|
||||
import requests
|
||||
```
|
||||
|
||||
Next we define the two functions (using the Flask specific app.route decorators) that will handle the GET and POST requests to our bot.
|
||||
|
||||
```
|
||||
@app.route('/', methods=['GET'])
|
||||
def handle_verification():
|
||||
print "Handling Verification."
|
||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||
print "Verification successful!"
|
||||
return request.args.get('hub.challenge', '')
|
||||
else:
|
||||
print "Verification failed!"
|
||||
return 'Error, wrong validation token'
|
||||
```
|
||||
|
||||
The verify_token object that is being sent by Messenger will be declared by us when we create the Facebook app. We have to validate the one we are being have against itself. Finally we return the “hub.challenge” back to Messenger.
|
||||
|
||||
The function that handles the POST requests is a bit more interesting.
|
||||
|
||||
```
|
||||
@app.route('/', methods=['POST'])
|
||||
def handle_messages():
|
||||
print "Handling Messages"
|
||||
payload = request.get_data()
|
||||
print payload
|
||||
for sender, message in messaging_events(payload):
|
||||
print "Incoming from %s: %s" % (sender, message)
|
||||
send_message(PAT, sender, message)
|
||||
return "ok"
|
||||
```
|
||||
|
||||
When called we grab the massage payload, use function messaging_events to break it down and extract the sender user id and the actual message sent, generating a python iterator that we can loop over. Notice that in each request sent by Messenger it is possible to have more than one messages.
|
||||
|
||||
```
|
||||
def messaging_events(payload):
|
||||
"""Generate tuples of (sender_id, message_text) from the
|
||||
provided payload.
|
||||
"""
|
||||
data = json.loads(payload)
|
||||
messaging_events = data["entry"][0]["messaging"]
|
||||
for event in messaging_events:
|
||||
if "message" in event and "text" in event["message"]:
|
||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||
else:
|
||||
yield event["sender"]["id"], "I can't echo this"
|
||||
```
|
||||
|
||||
While iterating over each message we call the send_message function and we perform the POST request back to Messnger using the Facebook Graph messages API. During this time we still have not responded to the original Messenger request which we are blocking. This can lead to timeouts and 5XX errors.
|
||||
|
||||
The above was spotted during an outage due to a bug I came across, which was occurred when the user was sending emojis which are actual unicode ids, however Python was miss-encoding. We ended up sending back garbage.
|
||||
|
||||
This POST request back to Messenger would never finish, and that in turn would cause 5XX status codes to be returned to the original request, rendering the service unusable.
|
||||
|
||||
This was fixed by escaping the messages with `encode('unicode_escape')` and then just before we sent back the message decode it with `decode('unicode_escape')`.
|
||||
|
||||
```
|
||||
def send_message(token, recipient, text):
|
||||
"""Send the message text to recipient with id recipient.
|
||||
"""
|
||||
|
||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||
params={"access_token": token},
|
||||
data=json.dumps({
|
||||
"recipient": {"id": recipient},
|
||||
"message": {"text": text.decode('unicode_escape')}
|
||||
}),
|
||||
headers={'Content-type': 'application/json'})
|
||||
if r.status_code != requests.codes.ok:
|
||||
print r.text
|
||||
```
|
||||
|
||||
### Deploying to Heroku
|
||||
|
||||
Once the code was built to my liking it was time for the next step.
|
||||
Deploy the app.
|
||||
|
||||
Sure, but how?
|
||||
|
||||
I have deployed apps before to Heroku (mainly Rails) however I was always following a tutorial of some sort, so the configuration has already been created. In this case though I had to start from scratch.
|
||||
|
||||
Fortunately it was the official [Heroku documentation][14] to the rescue. The article explains nicely the bare minimum required for running an app.
|
||||
|
||||
Long story short, what we need besides our code are two files. The first file is the “requirements.txt” file which is a list of of the library dependencies required to run the application.
|
||||
|
||||
The second file required is the “Procfile”. This file is there to inform the Heroku how to run our service. Again the bare minimum needed for this file is the following:
|
||||
|
||||
>web: gunicorn echoserver:app
|
||||
|
||||
The way this will be interpreted by heroku is that our app is started by running the echoserver.py file and the app will be using gunicorn as the web server. The reason we are using an additional webserver is performance related and is explained in the above Heroku documentation:
|
||||
|
||||
>Web applications that process incoming HTTP requests concurrently make much more efficient use of dyno resources than web applications that only process one request at a time. Because of this, we recommend using web servers that support concurrent request processing whenever developing and running production services.
|
||||
|
||||
>The Django and Flask web frameworks feature convenient built-in web servers, but these blocking servers only process a single request at a time. If you deploy with one of these servers on Heroku, your dyno resources will be underutilized and your application will feel unresponsive.
|
||||
|
||||
>Gunicorn is a pure-Python HTTP server for WSGI applications. It allows you to run any Python application concurrently by running multiple Python processes within a single dyno. It provides a perfect balance of performance, flexibility, and configuration simplicity.
|
||||
|
||||
Going back to our “requirements.txt” file let’s see how it binds with the Virtualenv tool that was mentioned.
|
||||
|
||||
At anytime, your developement machine may have a number of python libraries installed. When deploying applications you don’t want to have these libraries loaded as it makes it hard to make out which ones you actually use.
|
||||
|
||||
What Virtualenv does is create a new blank virtual enviroment so that you can only install the libraries that your app requires.
|
||||
|
||||
You can check which libraries are currently installed by running the following command:
|
||||
|
||||
```
|
||||
kostis@KostisMBP ~ $ pip freeze
|
||||
cycler==0.10.0
|
||||
Flask==0.10.1
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
matplotlib==1.5.1
|
||||
numpy==1.10.4
|
||||
pyparsing==2.1.0
|
||||
python-dateutil==2.5.0
|
||||
pytz==2015.7
|
||||
requests==2.10.0
|
||||
scipy==0.17.0
|
||||
six==1.10.0
|
||||
virtualenv==15.0.1
|
||||
Werkzeug==0.11.10
|
||||
```
|
||||
|
||||
Note: The pip tool should already be installed on your machine along with Python.
|
||||
|
||||
If not check the [official site][15] for how to install it.
|
||||
|
||||
Now let’s use Virtualenv to create a new blank enviroment. First we create a new folder for our project, and change dir into it:
|
||||
|
||||
```
|
||||
kostis@KostisMBP projects $ mkdir echoserver
|
||||
kostis@KostisMBP projects $ cd echoserver/
|
||||
kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
Now let’s create a new enviroment called echobot. To activate it you run the following source command, and checking with pip freeze we can see that it’s now empty.
|
||||
|
||||
```
|
||||
kostis@KostisMBP echoserver $ virtualenv echobot
|
||||
kostis@KostisMBP echoserver $ source echobot/bin/activate
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
(echobot) kostis@KostisMBP echoserver $
|
||||
```
|
||||
|
||||
We can start installing the libraries required. The ones we’ll need are flask, gunicorn, and requests and with them installed we create the requirements.txt file:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install flask
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
|
||||
(echobot) kostis@KostisMBP echoserver $ pip install requests
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||
click==6.6
|
||||
Flask==0.11
|
||||
gunicorn==19.6.0
|
||||
itsdangerous==0.24
|
||||
Jinja2==2.8
|
||||
MarkupSafe==0.23
|
||||
requests==2.10.0
|
||||
Werkzeug==0.11.10
|
||||
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
|
||||
```
|
||||
|
||||
After all the above have been run, we create the echoserver.py file with the python code and the Procfile with the command that was mentioned, and we should end up with the following files/folders:
|
||||
|
||||
```
|
||||
(echobot) kostis@KostisMBP echoserver $ ls
|
||||
Procfile echobot echoserver.py requirements.txt
|
||||
```
|
||||
|
||||
We are now ready to upload to Heroku. We need to do two things. The first is to install the Heroku toolbet if it’s not already installed on your system (go to [Heroku][16] for details). The second is to create a new Heroku app through the [web interface][17].
|
||||
|
||||
Click on the big plus sign on the top right and select “Create new app”.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
|
||||
|
||||
作者:[Konstantinos Tsaprailis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/kostistsaprailis
|
||||
[1]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#tech-stack
|
||||
[2]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#bot-architecture
|
||||
[3]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#the-bot-server
|
||||
[4]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#deploying-to-heroku
|
||||
[5]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#creating-the-facebook-app
|
||||
[6]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#conclusion
|
||||
[7]: https://www.heroku.com
|
||||
[8]: https://www.python.org
|
||||
[9]: http://flask.pocoo.org
|
||||
[10]: https://git-scm.com
|
||||
[11]: https://virtualenv.pypa.io/en/stable
|
||||
[12]: https://github.com/hult/facebook-chatbot-python
|
||||
[13]: https://github.com/hult
|
||||
[14]: https://devcenter.heroku.com/articles/python-gunicorn
|
||||
[15]: https://pip.pypa.io/en/stable/installing
|
||||
[16]: https://toolbelt.heroku.com
|
||||
[17]: https://dashboard.heroku.com/apps
|
||||
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
chunyang-wen translating
|
||||
Writing online multiplayer game with python and asyncio - Part 3
|
||||
=================================================================
|
||||
|
||||

|
||||
|
||||
In this series, we are making an asynchronous Python app on the example of a multiplayer [Snake game][1]. The previous article focused on [Writing Game Loop][2] and Part 1 was covering how to [Get Asynchronous][3].
|
||||
|
||||
You can find the code [here][4].
|
||||
|
||||
### 4. Making a complete game
|
||||
|
||||

|
||||
|
||||
#### 4.1 Project's overview
|
||||
|
||||
In this part, we will review a design of a complete online game. It is a classic snake game with added multiplayer. You can try it yourself at (<http://snakepit-game.com>). A source code is located [in github repository][5]. The game consists of the following files:
|
||||
|
||||
- [server.py][6] - a server handling main game loop and connections.
|
||||
- [game.py][7] - a main Game class, which implements game's logic and most of the game's network protocol.
|
||||
- [player.py][8] - Player class, containing individual player's data and snake's representation. This one is responsible for getting player's input and moving the snake accordingly.
|
||||
- [datatypes.py][9] - basic data structures.
|
||||
- [settings.py][10] - game settings, and it has descriptions in commentaries.
|
||||
- [index.html][11] - all html and javascript client part in one file.
|
||||
|
||||
#### 4.2 Inside a game loop
|
||||
|
||||
Multiplayer snake game is a good example to learn because of its simplicity. All snakes move to one position every single frame, and frames are changing at a very slow rate, allowing you to watch how game engine is working actually. There is no instant reaction to player's keypresses because of the slow speed. A pressed key is remembered and then taken into account while calculating the next frame at the end of game loop's iteration.
|
||||
|
||||
> Modern action games are running at much higher frame rates and often frame rates of server and client are not equal. Client frame rate usually depends on the client hardware performance, while server frame rate is fixed. A client may render several frames after getting the data corresponding to one "game tick". This allows to create smooth animations, which are only limited by client's performance. In this case, a server should pass not only current positions of the objects but also their moving directions, speeds and velocities. And while client frame rate is called FPS (frames per second), sever frame rate is called TPS (ticks per second). In this snake game example both values are equal, and one frame displayed by a client is calculated within one server's tick.
|
||||
|
||||
We will use textmode-like play field, which is, in fact, a html table with one-char cells. All objects of the game are displayed with characters of different colors placed in table's cells. Most of the time client passes pressed keys' codes to the server and gets back play field updates with every "tick". An update from server consists of messages representing characters to render along with their coordinates and colors. So we are keeping all game logic on the server and we are sending to client only rendering data. In addition, we minimize the possibilities to hack the game by substituting its information sent over the network.
|
||||
|
||||
#### 4.3 How does it work?
|
||||
|
||||
The server in this game is close to Example 3.2 for simplicity. But instead of having a global list of connected websockets, we have one server-wide Game object. A Game instance contains a list of Player objects (inside self._players attribute) which represents players connected to this game, their personal data and websocket objects. Having all game-related data in a Game object also allows us to have multiple game rooms if we want to add such feature. In this case, we need to maintain multiple Game objects, one per game started.
|
||||
|
||||
All interactions between server and clients are done with messages encoded in json. Message from the client containing only a number is interpreted as a code of the key pressed by the player. Other messages from client are sent in the following format:
|
||||
|
||||
```
|
||||
[command, arg1, arg2, ... argN ]
|
||||
```
|
||||
|
||||
Messages from server are sent as a list because there is often a bunch of messages to send at once (rendering data mostly):
|
||||
|
||||
```
|
||||
[[command, arg1, arg2, ... argN ], ... ]
|
||||
```
|
||||
|
||||
At the end of every game loop iteration, the next frame is calculated and sent to all the clients. Of course, we are not sending complete frame every time, but only a list of changes for the next frame.
|
||||
|
||||
Note that players are not joining the game immediately after connecting to the server. The connection starts in "spectator" mode, so one can watch how others are playing. if the game is already started, or a "game over" screen from the previous game session. Then a player may press "Join" button to join the existing game or to create a new game if the game is not currently running (no other active players). In the later case, the play field is cleared before the start.
|
||||
|
||||
The play field is stored in Game._world attribute, which is a 2d array made of nested lists. It is used to keep game field's state internally. Each element of an array represents a field's cell which is then rendered to a html table cell. It has a type of Char, which is a namedtuple consisting of a character and color. It is important to keep play field in sync with all the connected clients, so all updates to the play field should be made only along with sending corresponding messages to the clients. This is performed by Game.apply_render() method. It receives a list of Draw objects, which is then used to update play field internally and also to send render message to clients.
|
||||
|
||||
We are using namedtuple not only because it is a good way to represent simple data structures, but also because it takes less space comparing to dict when sending in a json message. If you are sending complex data structures in a real game app, it is recommended to serialize them into a plain and shorter format or even pack in a binary format (such as bson instead of json) to minimize network traffic.
|
||||
|
||||
ThePlayer object contains snake's representation in a deque object. This data type is similar to a list but is more effective for adding and removing elements on its sides, so it is ideal to represent a moving snake. The main method of the class is Player.render_move(), it returns rendering data to move player's snake to the next position. Basically, it renders snake's head in the new position and removes the last element where the tail was in the previous frame. In case the snake has eaten a digit and has to grow, a tail is not moving for a corresponding number of frames. The snake rendering data is used in Game.next_frame() method of the main class, which implements all game logic. This method renders all snake moves and checks for obstacles in front of every snake and also spawns digits and "stones". It is called directly from game_loop() to generate the next frame at every "tick".
|
||||
|
||||
In case there is an obstacle in front of snake's head, a Game.game_over() method is called from Game.next_frame(). It notifies all connected clients about the dead snake (which is turned into stones by player.render_game_over() method) and updates top scores table. Player object's alive flag is set to False, so this player will be skipped when rendering the next frames, until joining the game once again. In case there are no more snakes alive, a "game over" message is rendered at the game field. Also, the main game loop will stop and set game.running flag to False, which will cause a game field to be cleared when some player will press "Join" button next time.
|
||||
|
||||
Spawning of digits and stones is also happening while rendering every next frame, and it is determined by random values. A chance to spawn a digit or a stone can be changed in settings.py along with some other values. Note that digit spawning is happening for every live snake in the play field, so the more snakes are there, the more digits will appear, and they all will have enough food to consume.
|
||||
|
||||
#### 4.4 Network protocol
|
||||
List of messages sent from client
|
||||
|
||||
Command | Parameters |Description
|
||||
:-- |:-- |:--
|
||||
new_player | [name] |Setting player's nickname
|
||||
join | |Player is joining the game
|
||||
|
||||
|
||||
List of messages sent from server
|
||||
|
||||
Command | Parameters |Description
|
||||
:-- |:-- |:--
|
||||
handshake |[id] |Assign id to a player
|
||||
world |[[(char, color), ...], ...] |Initial play field (world) map
|
||||
reset_world | |Clean up world map, replacing all characters with spaces
|
||||
render |[x, y, char, color] |Display character at position
|
||||
p_joined |[id, name, color, score] |New player joined the game
|
||||
p_gameover |[id] |Game ended for a player
|
||||
p_score |[id, score] |Setting score for a player
|
||||
top_scores |[[name, score, color], ...] |Update top scores table
|
||||
|
||||
Typical messages exchange order
|
||||
|
||||
Client -> Server |Server -> Client |Server -> All clients |Commentaries
|
||||
:-- |:-- |:-- |:--
|
||||
new_player | | |Name passed to server
|
||||
|handshake | |ID assigned
|
||||
|world | |Initial world map passed
|
||||
|top_scores | |Recent top scores table passed
|
||||
join | | |Player pressed "Join", game loop started
|
||||
| |reset_world |Command clients to clean up play field
|
||||
| |render, render, ... |First game tick, first frame rendered
|
||||
(key code) | | |Player pressed a key
|
||||
| |render, render, ... |Second frame rendered
|
||||
| |p_score |Snake has eaten a digit
|
||||
| |render, render, ... |Third frame rendered
|
||||
| | |... Repeat for a number of frames ...
|
||||
| |p_gameover |Snake died when trying to eat an obstacle
|
||||
| |top_scores |Updated top scores table (if updated)
|
||||
|
||||
### 5. Conclusion
|
||||
|
||||
To tell the truth, I really enjoy using the latest asynchronous capabilities of Python. The new syntax really makes a difference, so async code is now easily readable. It is obvious which calls are non-blocking and when the green thread switching is happening. So now I can claim with confidence that Python is a good tool for asynchronous programming.
|
||||
|
||||
SnakePit has become very popular at 7WebPages team, and if you decide to take a break at your company, please, don’t forget to leave a feedback for us, say, on [Twitter][12] or [Facebook][13] .
|
||||
|
||||
Get to know more from:
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-part-3/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[3]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[4]: https://github.com/7WebPages/snakepit-game
|
||||
[5]: https://github.com/7WebPages/snakepit-game
|
||||
[6]: https://github.com/7WebPages/snakepit-game/blob/master/server.py
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/game.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/player.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/datatypes.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/settings.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/index.html
|
||||
[12]: https://twitter.com/7WebPages
|
||||
[13]: https://www.facebook.com/7WebPages/
|
||||
490
sources/tech/20160618 An Introduction to Mocking in Python.md
Normal file
490
sources/tech/20160618 An Introduction to Mocking in Python.md
Normal file
@ -0,0 +1,490 @@
|
||||
An Introduction to Mocking in Python
|
||||
=====================================
|
||||
|
||||
This article is about mocking in python,
|
||||
|
||||
**How to Run Unit Tests Without Testing Your Patience**
|
||||
|
||||
More often than not, the software we write directly interacts with what we would label as “dirty” services. In layman’s terms: services that are crucial to our application, but whose interactions have intended but undesired side-effects—that is, undesired in the context of an autonomous test run.For example: perhaps we’re writing a social app and want to test out our new ‘Post to Facebook feature’, but don’t want to actually post to Facebook every time we run our test suite.
|
||||
|
||||
The Python unittest library includes a subpackage named unittest.mock—or if you declare it as a dependency, simply mock—which provides extremely powerful and useful means by which to mock and stub out these undesired side-effects.
|
||||
|
||||
>Source | <http://www.toptal.com/python/an-introduction-to-mocking-in-python>
|
||||
|
||||
Note: mock is [newly included][1] in the standard library as of Python 3.3; prior distributions will have to use the Mock library downloadable via [PyPI][2].
|
||||
|
||||
### Fear System Calls
|
||||
|
||||
To give you another example, and one that we’ll run with for the rest of the article, consider system calls. It’s not difficult to see that these are prime candidates for mocking: whether you’re writing a script to eject a CD drive, a web server which removes antiquated cache files from /tmp, or a socket server which binds to a TCP port, these calls all feature undesired side-effects in the context of your unit-tests.
|
||||
|
||||
>As a developer, you care more that your library successfully called the system function for ejecting a CD as opposed to experiencing your CD tray open every time a test is run.
|
||||
|
||||
As a developer, you care more that your library successfully called the system function for ejecting a CD (with the correct arguments, etc.) as opposed to actually experiencing your CD tray open every time a test is run. (Or worse, multiple times, as multiple tests reference the eject code during a single unit-test run!)
|
||||
|
||||
Likewise, keeping your unit-tests efficient and performant means keeping as much “slow code” out of the automated test runs, namely filesystem and network access.
|
||||
|
||||
For our first example, we’ll refactor a standard Python test case from original form to one using mock. We’ll demonstrate how writing a test case with mocks will make our tests smarter, faster, and able to reveal more about how the software works.
|
||||
|
||||
### A Simple Delete Function
|
||||
|
||||
We all need to delete files from our filesystem from time to time, so let’s write a function in Python which will make it a bit easier for our scripts to do so.
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
|
||||
def rm(filename):
|
||||
os.remove(filename)
|
||||
```
|
||||
|
||||
Obviously, our rm method at this point in time doesn’t provide much more than the underlying os.remove method, but our codebase will improve, allowing us to add more functionality here.
|
||||
|
||||
Let’s write a traditional test case, i.e., without mocks:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import rm
|
||||
|
||||
import os.path
|
||||
import tempfile
|
||||
import unittest
|
||||
|
||||
class RmTestCase(unittest.TestCase):
|
||||
|
||||
tmpfilepath = os.path.join(tempfile.gettempdir(), "tmp-testfile")
|
||||
|
||||
def setUp(self):
|
||||
with open(self.tmpfilepath, "wb") as f:
|
||||
f.write("Delete me!")
|
||||
|
||||
def test_rm(self):
|
||||
# remove the file
|
||||
rm(self.tmpfilepath)
|
||||
# test that it was actually removed
|
||||
self.assertFalse(os.path.isfile(self.tmpfilepath), "Failed to remove the file.")
|
||||
```
|
||||
|
||||
Our test case is pretty simple, but every time it is run, a temporary file is created and then deleted. Additionally, we have no way of testing whether our rm method properly passes the argument down to the os.remove call. We can assume that it does based on the test above, but much is left to be desired.
|
||||
|
||||
Refactoring with MocksLet’s refactor our test case using mock:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import rm
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RmTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os):
|
||||
rm("any path")
|
||||
# test that rm called os.remove with the right parameters
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
With these refactors, we have fundamentally changed the way that the test operates. Now, we have an insider, an object we can use to verify the functionality of another.
|
||||
|
||||
### Potential Pitfalls
|
||||
|
||||
One of the first things that should stick out is that we’re using the mock.patch method decorator to mock an object located at mymodule.os, and injecting that mock into our test case method. Wouldn’t it make more sense to just mock os itself, rather than the reference to it at mymodule.os?
|
||||
|
||||
Well, Python is somewhat of a sneaky snake when it comes to imports and managing modules. At runtime, the mymodule module has its own os which is imported into its own local scope in the module. Thus, if we mock os, we won’t see the effects of the mock in the mymodule module.
|
||||
|
||||
The mantra to keep repeating is this:
|
||||
|
||||
> Mock an item where it is used, not where it came from.
|
||||
|
||||
If you need to mock the tempfile module for myproject.app.MyElaborateClass, you probably need to apply the mock to myproject.app.tempfile, as each module keeps its own imports.
|
||||
|
||||
With that pitfall out of the way, let’s keep mocking.
|
||||
|
||||
### Adding Validation to ‘rm’
|
||||
|
||||
The rm method defined earlier is quite oversimplified. We’d like to have it validate that a path exists and is a file before just blindly attempting to remove it. Let’s refactor rm to be a bit smarter:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
import os.path
|
||||
|
||||
def rm(filename):
|
||||
if os.path.isfile(filename):
|
||||
os.remove(filename)
|
||||
```
|
||||
|
||||
Great. Now, let’s adjust our test case to keep coverage up.
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import rm
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RmTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
Our testing paradigm has completely changed. We now can verify and validate internal functionality of methods without any side-effects.
|
||||
|
||||
### File-Removal as a Service
|
||||
|
||||
So far, we’ve only been working with supplying mocks for functions, but not for methods on objects or cases where mocking is necessary for sending parameters. Let’s cover object methods first.
|
||||
|
||||
We’ll begin with a refactor of the rm method into a service class. There really isn’t a justifiable need, per se, to encapsulate such a simple function into an object, but it will at the very least help us demonstrate key concepts in mock. Let’s refactor:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
import os.path
|
||||
|
||||
class RemovalService(object):
|
||||
"""A service for removing objects from the filesystem."""
|
||||
|
||||
def rm(filename):
|
||||
if os.path.isfile(filename):
|
||||
os.remove(filename)
|
||||
```
|
||||
|
||||
### You’ll notice that not much has changed in our test case:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import RemovalService
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RemovalServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# instantiate our service
|
||||
reference = RemovalService()
|
||||
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
```
|
||||
|
||||
Great, so we now know that the RemovalService works as planned. Let’s create another service which declares it as a dependency:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import os
|
||||
import os.path
|
||||
|
||||
class RemovalService(object):
|
||||
"""A service for removing objects from the filesystem."""
|
||||
|
||||
def rm(self, filename):
|
||||
if os.path.isfile(filename):
|
||||
os.remove(filename)
|
||||
|
||||
|
||||
class UploadService(object):
|
||||
|
||||
def __init__(self, removal_service):
|
||||
self.removal_service = removal_service
|
||||
|
||||
def upload_complete(self, filename):
|
||||
self.removal_service.rm(filename)
|
||||
```
|
||||
|
||||
Since we already have test coverage on the RemovalService, we’re not going to validate internal functionality of the rm method in our tests of UploadService. Rather, we’ll simply test (without side-effects, of course) that UploadService calls the RemovalService.rm method, which we know “just works™” from our previous test case.
|
||||
|
||||
There are two ways to go about this:
|
||||
|
||||
1. Mock out the RemovalService.rm method itself.
|
||||
2. Supply a mocked instance in the constructor of UploadService.
|
||||
|
||||
As both methods are often important in unit-testing, we’ll review both.
|
||||
|
||||
### Option 1: Mocking Instance Methods
|
||||
|
||||
The mock library has a special method decorator for mocking object instance methods and properties, the @mock.patch.object decorator:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import RemovalService, UploadService
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RemovalServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# instantiate our service
|
||||
reference = RemovalService()
|
||||
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
|
||||
|
||||
class UploadServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch.object(RemovalService, 'rm')
|
||||
def test_upload_complete(self, mock_rm):
|
||||
# build our dependencies
|
||||
removal_service = RemovalService()
|
||||
reference = UploadService(removal_service)
|
||||
|
||||
# call upload_complete, which should, in turn, call `rm`:
|
||||
reference.upload_complete("my uploaded file")
|
||||
|
||||
# check that it called the rm method of any RemovalService
|
||||
mock_rm.assert_called_with("my uploaded file")
|
||||
|
||||
# check that it called the rm method of _our_ removal_service
|
||||
removal_service.rm.assert_called_with("my uploaded file")
|
||||
```
|
||||
|
||||
Great! We’ve validated that the UploadService successfully calls our instance’s rm method. Notice anything interesting in there? The patching mechanism actually replaced the rm method of all RemovalService instances in our test method. That means that we can actually inspect the instances themselves. If you want to see more, try dropping in a breakpoint in your mocking code to get a good feel for how the patching mechanism works.
|
||||
|
||||
### Pitfall: Decorator Order
|
||||
|
||||
When using multiple decorators on your test methods, order is important, and it’s kind of confusing. Basically, when mapping decorators to method parameters, [work backwards][3]. Consider this example:
|
||||
|
||||
```
|
||||
@mock.patch('mymodule.sys')
|
||||
@mock.patch('mymodule.os')
|
||||
@mock.patch('mymodule.os.path')
|
||||
def test_something(self, mock_os_path, mock_os, mock_sys):
|
||||
pass
|
||||
```
|
||||
|
||||
Notice how our parameters are matched to the reverse order of the decorators? That’s partly because of [the way that Python works][4]. With multiple method decorators, here’s the order of execution in pseudocode:
|
||||
|
||||
```
|
||||
patch_sys(patch_os(patch_os_path(test_something)))
|
||||
```
|
||||
|
||||
Since the patch to sys is the outermost patch, it will be executed last, making it the last parameter in the actual test method arguments. Take note of this well and use a debugger when running your tests to make sure that the right parameters are being injected in the right order.
|
||||
|
||||
### Option 2: Creating Mock Instances
|
||||
|
||||
Instead of mocking the specific instance method, we could instead just supply a mocked instance to UploadService with its constructor. I prefer option 1 above, as it’s a lot more precise, but there are many cases where option 2 might be efficient or necessary. Let’s refactor our test again:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from mymodule import RemovalService, UploadService
|
||||
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class RemovalServiceTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch('mymodule.os.path')
|
||||
@mock.patch('mymodule.os')
|
||||
def test_rm(self, mock_os, mock_path):
|
||||
# instantiate our service
|
||||
reference = RemovalService()
|
||||
|
||||
# set up the mock
|
||||
mock_path.isfile.return_value = False
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
# test that the remove call was NOT called.
|
||||
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
|
||||
|
||||
# make the file 'exist'
|
||||
mock_path.isfile.return_value = True
|
||||
|
||||
reference.rm("any path")
|
||||
|
||||
mock_os.remove.assert_called_with("any path")
|
||||
|
||||
|
||||
class UploadServiceTestCase(unittest.TestCase):
|
||||
|
||||
def test_upload_complete(self, mock_rm):
|
||||
# build our dependencies
|
||||
mock_removal_service = mock.create_autospec(RemovalService)
|
||||
reference = UploadService(mock_removal_service)
|
||||
|
||||
# call upload_complete, which should, in turn, call `rm`:
|
||||
reference.upload_complete("my uploaded file")
|
||||
|
||||
# test that it called the rm method
|
||||
mock_removal_service.rm.assert_called_with("my uploaded file")
|
||||
```
|
||||
|
||||
In this example, we haven’t even had to patch any functionality, we simply create an auto-spec for the RemovalService class, and then inject this instance into our UploadService to validate the functionality.
|
||||
|
||||
The [mock.create_autospec][5] method creates a functionally equivalent instance to the provided class. What this means, practically speaking, is that when the returned instance is interacted with, it will raise exceptions if used in illegal ways. More specifically, if a method is called with the wrong number of arguments, an exception will be raised. This is extremely important as refactors happen. As a library changes, tests break and that is expected. Without using an auto-spec, our tests will still pass even though the underlying implementation is broken.
|
||||
|
||||
### Pitfall: The mock.Mock and mock.MagicMock Classes
|
||||
|
||||
The mock library also includes two important classes upon which most of the internal functionality is built upon: [mock.Mock][6] and mock.MagicMock. When given a choice to use a mock.Mock instance, a mock.MagicMock instance, or an auto-spec, always favor using an auto-spec, as it helps keep your tests sane for future changes. This is because mock.Mock and mock.MagicMock accept all method calls and property assignments regardless of the underlying API. Consider the following use case:
|
||||
|
||||
```
|
||||
class Target(object):
|
||||
def apply(value):
|
||||
return value
|
||||
|
||||
def method(target, value):
|
||||
return target.apply(value)
|
||||
```
|
||||
|
||||
We can test this with a mock.Mock instance like this:
|
||||
|
||||
```
|
||||
class MethodTestCase(unittest.TestCase):
|
||||
|
||||
def test_method(self):
|
||||
target = mock.Mock()
|
||||
|
||||
method(target, "value")
|
||||
|
||||
target.apply.assert_called_with("value")
|
||||
```
|
||||
|
||||
This logic seems sane, but let’s modify the Target.apply method to take more parameters:
|
||||
|
||||
```
|
||||
class Target(object):
|
||||
def apply(value, are_you_sure):
|
||||
if are_you_sure:
|
||||
return value
|
||||
else:
|
||||
return None
|
||||
```
|
||||
|
||||
Re-run your test, and you’ll find that it still passes. That’s because it isn’t built against your actual API. This is why you should always use the create_autospec method and the autospec parameter with the @patch and @patch.object decorators.
|
||||
|
||||
### Real-World Example: Mocking a Facebook API Call
|
||||
|
||||
To finish up, let’s write a more applicable real-world example, one which we mentioned in the introduction: posting a message to Facebook. We’ll write a nice wrapper class and a corresponding test case.
|
||||
|
||||
```
|
||||
import facebook
|
||||
|
||||
class SimpleFacebook(object):
|
||||
|
||||
def __init__(self, oauth_token):
|
||||
self.graph = facebook.GraphAPI(oauth_token)
|
||||
|
||||
def post_message(self, message):
|
||||
"""Posts a message to the Facebook wall."""
|
||||
self.graph.put_object("me", "feed", message=message)
|
||||
```
|
||||
|
||||
Here’s our test case, which checks that we post the message without actually posting the message:
|
||||
|
||||
```
|
||||
import facebook
|
||||
import simple_facebook
|
||||
import mock
|
||||
import unittest
|
||||
|
||||
class SimpleFacebookTestCase(unittest.TestCase):
|
||||
|
||||
@mock.patch.object(facebook.GraphAPI, 'put_object', autospec=True)
|
||||
def test_post_message(self, mock_put_object):
|
||||
sf = simple_facebook.SimpleFacebook("fake oauth token")
|
||||
sf.post_message("Hello World!")
|
||||
|
||||
# verify
|
||||
mock_put_object.assert_called_with(message="Hello World!")
|
||||
```
|
||||
|
||||
As we’ve seen so far, it’s really simple to start writing smarter tests with mock in Python.
|
||||
|
||||
### Mocking in python Conclusion
|
||||
|
||||
Python’s mock library, if a little confusing to work with, is a game-changer for [unit-testing][7]. We’ve demonstrated common use-cases for getting started using mock in unit-testing, and hopefully this article will help [Python developers][8] overcome the initial hurdles and write excellent, tested code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://slviki.com/index.php/2016/06/18/introduction-to-mocking-in-python/
|
||||
|
||||
作者:[Dasun Sucharith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.slviki.com/
|
||||
[1]: http://www.python.org/dev/peps/pep-0417/
|
||||
[2]: https://pypi.python.org/pypi/mock
|
||||
[3]: http://www.voidspace.org.uk/python/mock/patch.html#nesting-patch-decorators
|
||||
[4]: http://docs.python.org/2/reference/compound_stmts.html#function-definitions
|
||||
[5]: http://www.voidspace.org.uk/python/mock/helpers.html#autospeccing
|
||||
[6]: http://www.voidspace.org.uk/python/mock/mock.html
|
||||
[7]: http://www.toptal.com/qa/how-to-write-testable-code-and-why-it-matters
|
||||
[8]: http://www.toptal.com/python
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,231 +0,0 @@
|
||||
Detecting cats in images with OpenCV
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
Did you know that OpenCV can detect cat faces in images…right out-of-the-box with no extras?
|
||||
|
||||
I didn’t either.
|
||||
|
||||
But after [Kendrick Tan broke the story][1], I had to check it out for myself…and do a little investigative work to see how this cat detector seemed to sneak its way into the OpenCV repository without me noticing (much like a cat sliding into an empty cereal box, just waiting to be discovered).
|
||||
|
||||
In the remainder of this blog post, I’ll demonstrate how to use OpenCV’s cat detector to detect cat faces in images. This same technique can be applied to video streams as well.
|
||||
|
||||
>Looking for the source code to this post? [Jump right to the downloads section][2].
|
||||
|
||||
|
||||
### Detecting cats in images with OpenCV
|
||||
|
||||
If you take a look at the [OpenCV repository][3], specifically within the [haarcascades directory][4] (where OpenCV stores all its pre-trained Haar classifiers to detect various objects, body parts, etc.), you’ll notice two files:
|
||||
|
||||
- haarcascade_frontalcatface.xml
|
||||
- haarcascade_frontalcatface_extended.xml
|
||||
|
||||
Both of these Haar cascades can be used detecting “cat faces” in images. In fact, I used these very same cascades to generate the example image at the top of this blog post.
|
||||
|
||||
Doing a little investigative work, I found that the cascades were trained and contributed to the OpenCV repository by the legendary [Joseph Howse][5] who’s authored a good many tutorials, books, and talks on computer vision.
|
||||
|
||||
In the remainder of this blog post, I’ll show you how to utilize Howse’s Haar cascades to detect cats in images.
|
||||
|
||||
Cat detection code
|
||||
|
||||
Let’s get started detecting cats in images with OpenCV. Open up a new file, name it cat_detector.py , and insert the following code:
|
||||
|
||||
### Detecting cats in images with OpenCVPython
|
||||
|
||||
```
|
||||
# import the necessary packages
|
||||
import argparse
|
||||
import cv2
|
||||
|
||||
# construct the argument parse and parse the arguments
|
||||
ap = argparse.ArgumentParser()
|
||||
ap.add_argument("-i", "--image", required=True,
|
||||
help="path to the input image")
|
||||
ap.add_argument("-c", "--cascade",
|
||||
default="haarcascade_frontalcatface.xml",
|
||||
help="path to cat detector haar cascade")
|
||||
args = vars(ap.parse_args())
|
||||
```
|
||||
|
||||
Lines 2 and 3 import our necessary Python packages while Lines 6-12 parse our command line arguments. We only require a single argument here, the input `--image` that we want to detect cat faces in using OpenCV.
|
||||
|
||||
We can also (optionally) supply a path our Haar cascade via the `--cascade` switch. We’ll default this path to `haarcascade_frontalcatface.xml` and assume you have the `haarcascade_frontalcatface.xml` file in the same directory as your cat_detector.py script.
|
||||
|
||||
Note: I’ve conveniently included the code, cat detector Haar cascade, and example images used in this tutorial in the “Downloads” section of this blog post. If you’re new to working with Python + OpenCV (or Haar cascades), I would suggest downloading the provided .zip file to make it easier to follow along.
|
||||
|
||||
Next, let’s detect the cats in our input image:
|
||||
|
||||
```
|
||||
# load the input image and convert it to grayscale
|
||||
image = cv2.imread(args["image"])
|
||||
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
# load the cat detector Haar cascade, then detect cat faces
|
||||
# in the input image
|
||||
detector = cv2.CascadeClassifier(args["cascade"])
|
||||
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
|
||||
minNeighbors=10, minSize=(75, 75))
|
||||
```
|
||||
|
||||
On Lines 15 and 16 we load our input image from disk and convert it to grayscale (a normal pre-processing step before passing the image to a Haar cascade classifier, although not strictly required).
|
||||
|
||||
Line 20 loads our Haar cascade from disk (in this case, the cat detector) and instantiates the cv2.CascadeClassifier object.
|
||||
|
||||
Detecting cat faces in images with OpenCV is accomplished on Lines 21 and 22 by calling the detectMultiScale method of the detector object. We pass four parameters to the detectMultiScale method, including:
|
||||
|
||||
1. Our image, gray , that we want to detect cat faces in.
|
||||
2.A scaleFactor of our [image pyramid][6] used when detecting cat faces. A larger scale factor will increase the speed of the detector, but could harm our true-positive detection accuracy. Conversely, a smaller scale will slow down the detection process, but increase true-positive detections. However, this smaller scale can also increase the false-positive detection rate as well. See the “A note on Haar cascades” section of this blog post for more information.
|
||||
3. The minNeighbors parameter controls the minimum number of detected bounding boxes in a given area for the region to be considered a “cat face”. This parameter is very helpful in pruning false-positive detections.
|
||||
4. Finally, the minSize parameter is pretty self-explanatory. This value ensures that each detected bounding box is at least width x height pixels (in this case, 75 x 75).
|
||||
|
||||
The detectMultiScale function returns rects , a list of 4-tuples. These tuples contain the (x, y)-coordinates and width and height of each detected cat face.
|
||||
|
||||
Finally, let’s draw a rectangle surround each cat face in the image:
|
||||
|
||||
```
|
||||
# loop over the cat faces and draw a rectangle surrounding each
|
||||
for (i, (x, y, w, h)) in enumerate(rects):
|
||||
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
|
||||
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
|
||||
|
||||
# show the detected cat faces
|
||||
cv2.imshow("Cat Faces", image)
|
||||
cv2.waitKey(0)
|
||||
```
|
||||
|
||||
Given our bounding boxes (i.e., rects ), we loop over each of them individually on Line 25.
|
||||
|
||||
We then draw a rectangle surrounding each cat face on Line 26, while Lines 27 and 28 displays an integer, counting the number of cats in the image.
|
||||
|
||||
Finally, Lines 31 and 32 display the output image to our screen.
|
||||
|
||||
### Cat detection results
|
||||
|
||||
To test our OpenCV cat detector, be sure to download the source code to this tutorial using the “Downloads” section at the bottom of this post.
|
||||
|
||||
Then, after you have unzipped the archive, you should have the following three files/directories:
|
||||
|
||||
1. cat_detector.py : Our Python + OpenCV script used to detect cats in images.
|
||||
2. haarcascade_frontalcatface.xml : The cat detector Haar cascade.
|
||||
3. images : A directory of testing images that we’re going to apply the cat detector cascade to.
|
||||
|
||||
From there, execute the following command:
|
||||
|
||||
Detecting cats in images with OpenCVShell
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_01.jpg
|
||||
```
|
||||
|
||||
|
||||
>Figure 1: Detecting a cat face in an image, even with parts of the cat occluded
|
||||
|
||||
Notice that we have been able to detect the cat face in the image, even though the rest of its body is obscured.
|
||||
|
||||
Let’s try another image:
|
||||
|
||||
```
|
||||
python cat_detector.py --image images/cat_02.jpg
|
||||
```
|
||||
|
||||

|
||||
>Figure 2: A second example of detecting a cat in an image with OpenCV, this time the cat face is slightly different
|
||||
|
||||
This cat’s face is clearly different from the other one, as it’s in the middle of a “meow”. In either case, the cat detector cascade is able to correctly find the cat face in the image.
|
||||
|
||||
The same is true for this image as well:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_03.jpg
|
||||
```
|
||||
|
||||
|
||||
>Figure 3: Cat detection with OpenCV and Python
|
||||
|
||||
Our final example demonstrates detecting multiple cats in an image using OpenCV and Python:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_04.jpg
|
||||
```
|
||||
|
||||

|
||||
>Figure 4: Detecting multiple cats in the same image with OpenCV
|
||||
|
||||
Note that the Haar cascade can return bounding boxes in an order that you may not like. In this case, the middle cat is actually labeled as the third cat. You can resolve this “issue” by sorting the bounding boxes according to their (x, y)-coordinates for a consistent ordering.
|
||||
|
||||
#### A quick note on accuracy
|
||||
|
||||
It’s important to note that in the comments section of the .xml files, Joseph Howe details that the cat detector Haar cascades can report cat faces where there are actually human faces.
|
||||
|
||||
In this case, he recommends performing both face detection and cat detection, then discarding any cat bounding boxes that overlap with the face bounding boxes.
|
||||
|
||||
#### A note on Haar cascades
|
||||
|
||||
First published in 2001 by Paul Viola and Michael Jones, [Rapid Object Detection using a Boosted Cascade of Simple Features][7], this original work has become one of the most cited papers in computer vision.
|
||||
|
||||
This algorithm is capable of detecting objects in images, regardless of their location and scale. And perhaps most intriguing, the detector can run in real-time on modern hardware.
|
||||
|
||||
In their paper, Viola and Jones focused on training a face detector; however, the framework can also be used to train detectors for arbitrary “objects”, such as cars, bananas, road signs, etc.
|
||||
|
||||
#### The problem?
|
||||
|
||||
The biggest problem with Haar cascades is getting the detectMultiScale parameters right, specifically scaleFactor and minNeighbors . You can easily run into situations where you need to tune both of these parameters on an image-by-image basis, which is far from ideal when utilizing an object detector.
|
||||
|
||||
The scaleFactor variable controls your [image pyramid][8] used to detect objects at various scales of an image. If your scaleFactor is too large, then you’ll only evaluate a few layers of the image pyramid, potentially leading to you missing objects at scales that fall in between the pyramid layers.
|
||||
|
||||
On the other hand, if you set scaleFactor too low, then you evaluate many pyramid layers. This will help you detect more objects in your image, but it (1) makes the detection process slower and (2) substantially increases the false-positive detection rate, something that Haar cascades are known for.
|
||||
|
||||
To remember this, we often apply [Histogram of Oriented Gradients + Linear SVM detection][9] instead.
|
||||
|
||||
The HOG + Linear SVM framework parameters are normally much easier to tune — and best of all, HOG + Linear SVM enjoys a much smaller false-positive detection rate. The only downside is that it’s harder to get HOG + Linear SVM to run in real-time.
|
||||
|
||||
### Interested in learning more about object detection?
|
||||
|
||||

|
||||
>Figure 5: Learn how to build custom object detectors inside the PyImageSearch Gurus course.
|
||||
|
||||
If you’re interested in learning how to train your own custom object detectors, be sure to take a look at the PyImageSearch Gurus course.
|
||||
|
||||
Inside the course, I have 15 lessons covering 168 pages of tutorials dedicated to teaching you how to build custom object detectors from scratch. You’ll discover how to detect road signs, faces, cars (and nearly any other object) in images by applying the HOG + Linear SVM framework for object detection.
|
||||
|
||||
To learn more about the PyImageSearch Gurus course (and grab 10 FREE sample lessons), just click the button below:
|
||||
|
||||
### Summary
|
||||
|
||||
In this blog post, we learned how to detect cats in images using the default Haar cascades shipped with OpenCV. These Haar cascades were trained and contributed to the OpenCV project by [Joseph Howse][9], and were originally brought to my attention [in this post][10] by Kendrick Tan.
|
||||
|
||||
While Haar cascades are quite useful, we often use HOG + Linear SVM instead, as it’s a bit easier to tune the detector parameters, and more importantly, we can enjoy a much lower false-positive detection rate.
|
||||
|
||||
I detail how to build custom HOG + Linear SVM object detectors to recognize various objects in images, including cars, road signs, and much more [inside the PyImageSearch Gurus course][11].
|
||||
|
||||
Anyway, I hope you enjoyed this blog post!
|
||||
|
||||
Before you go, be sure to signup for the PyImageSearch Newsletter using the form below to be notified when new blog posts are published.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/
|
||||
|
||||
作者:[Adrian Rosebrock][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.pyimagesearch.com/author/adrian/
|
||||
[1]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[2]: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/#
|
||||
[3]: https://github.com/Itseez/opencv
|
||||
[4]: https://github.com/Itseez/opencv/tree/master/data/haarcascades
|
||||
[5]: http://nummist.com/
|
||||
[6]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[7]: https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
|
||||
[8]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[9]: http://www.pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/
|
||||
[10]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[11]: https://www.pyimagesearch.com/pyimagesearch-gurus/
|
||||
|
||||
|
||||
|
||||
@ -1,115 +0,0 @@
|
||||
Translating by GitFuture
|
||||
|
||||
Monitor Linux With Netdata
|
||||
===
|
||||
|
||||
Netdata is a real-time resource monitoring tool with a friendly web front-end developed and maintained by [FireHOL][1]. With this tool, you can read charts representing resource utilization of things like CPUs, RAM, disks, network, Apache, Postfix and more. It is similar to other monitoring software like Nagios; however, Netdata is only for real-time monitoring via a web interface.
|
||||
|
||||
|
||||
### Understanding Netdata
|
||||
|
||||
There’s currently no authentication, so if you’re concerned about someone getting information about the applications you’re running on your system, you should restrict who has access via a firewall policy. The UI is simplified in a way anyone could look at the graphs and understand what they’re seeing, or at least be impressed by your flashy setup.
|
||||
|
||||
The web front-end is very responsive and requires no Flash plugin. The UI doesn’t clutter things up with unneeded features, but sticks to what it does. At first glance, it may seem a bit much with the hundreds of charts you have access to, but luckily the most commonly needed charts (i.e. CPU, RAM, network, and disk) are at the top. If you wish to drill deeper into the graphical data, all you have to do is scroll down or click on the item in the menu to the right. Netdata even allows you to control the chart with play, reset, zoom and resize with the controls on the bottom right of each chart.
|
||||
|
||||
|
||||
>Netdata chart control
|
||||
|
||||
When it comes down to system resources, the software doesn’t need too much either. The creators choose to write the software in C. Netdata doesn’t use much more than ~40MB of RAM.
|
||||
|
||||
|
||||
>Netdata memory usage
|
||||
|
||||
### Download Netdata
|
||||
|
||||
To download this software, you can head over to [Netdata GitHub page][2]. Then click the “Clone or download” green button on the left of the page. You should then be presented with two options.
|
||||
|
||||
#### Via the ZIP file
|
||||
|
||||
One option is to download the ZIP file. This will include everything in the repository; however, if the repository is updated then you will need to download the ZIP file again. Once you download the ZIP file, you can use the `unzip` tool in the command line to extract the contents. Running the following command will extract the contents of the ZIP file into a “`netdata`” folder.
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
$ unzip netdata-master.zip
|
||||
```
|
||||
|
||||
|
||||
>Netdata unzipped
|
||||
|
||||
ou don’t need to add the `-d` option in unzip because their content is inside a folder at the root of the ZIP file. If they didn’t have that folder at the root, unzip would have extracted the contents in the current directory (which can be messy).
|
||||
|
||||
#### Via git
|
||||
|
||||
The next option is to download the repository via git. You will, of course, need git installed on your system. This is usually installed by default on Fedora. If not, you can install git from the command line with the following command.
|
||||
|
||||
```
|
||||
$ sudo dnf install git
|
||||
```
|
||||
|
||||
After installing git, you will need to “clone” the repository to your system. To do this, run the following command.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/firehol/netdata.git
|
||||
```
|
||||
|
||||
This will then clone (or make a copy of) the repository in the current working directory.
|
||||
|
||||
### Install Netdata
|
||||
|
||||
There are some packages you will need to build Netdata successfully. Luckily, it’s a single line to install the things you need ([as stated in their installation guide][3]). Running the following command in the terminal will install all of the dependencies you need to use Netdata.
|
||||
|
||||
```
|
||||
$ dnf install zlib-devel libuuid-devel libmnl-devel gcc make git autoconf autogen automake pkgconfig
|
||||
```
|
||||
|
||||
Once the required packages are installed, you will need to cd into the netdata/ directory and run the netdata-installer.sh script.
|
||||
|
||||
```
|
||||
$ sudo ./netdata-installer.sh
|
||||
```
|
||||
|
||||
You will then be prompted to press enter to build and install the program. If you wish to continue, press enter to be on your way!
|
||||
|
||||
|
||||
>Netdata install.
|
||||
|
||||
If all goes well, you will have Netdata built, installed, and running on your system. The installer will also add an uninstall script in the same folder as the installer called `netdata-uninstaller.sh`. If you change your mind later, running this script will remove it from your system.
|
||||
|
||||
You can see it running by checking its status via systemctl.
|
||||
|
||||
```
|
||||
$ sudo systemctl status netdata
|
||||
```
|
||||
|
||||
### Accessing Netdata
|
||||
|
||||
Now that we have Netdata installed and running, you can access the web interface via port 19999. I have it running on a test machine, as shown in the screenshot below.
|
||||
|
||||
|
||||
>An overview of what Netdata running on your system looks like
|
||||
|
||||
Congratulations! You now have successfully installed and have access to beautiful displays, graphs, and advanced statistics on the performance of your machine. Whether it’s for a personal machine so you can show it off to your friends or for getting deeper insight into the performance of your server, Netdata delivers on performance reporting for any system you choose.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/monitor-linux-netdata/
|
||||
|
||||
作者:[Martino Jones][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/monitor-linux-netdata/
|
||||
[1]: https://firehol.org/
|
||||
[2]: https://github.com/firehol/netdata
|
||||
[3]: https://github.com/firehol/netdata/wiki/Installation
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,88 @@
|
||||
Translating by Flowsnow!
|
||||
72% Of The People I Follow On Twitter Are Men
|
||||
===============================================
|
||||
|
||||

|
||||
|
||||
At least, that's my estimate. Twitter does not ask users their gender, so I [have written a program that guesses][1] based on their names. Among those who follow me, the distribution is even worse: 83% are men. None are gender-nonbinary as far as I can tell.
|
||||
|
||||
The way to fix the first number is not mysterious: I should notice and seek more women experts tweeting about my interests, and follow them.
|
||||
|
||||
The second number, on the other hand, I can merely influence, but I intend to improve it as well. My network on Twitter should represent of the software industry's diverse future, not its unfair present.
|
||||
|
||||
### How Did I Measure It?
|
||||
|
||||
I set out to estimate the gender distribution of the people I follow—my "friends" in Twitter's jargon—and found it surprisingly hard. [Twitter analytics][2] readily shows me the converse, an estimate of my followers' gender:
|
||||
|
||||
|
||||
|
||||
So, Twitter analytics divides my followers' accounts among male, female, and unknown, and tells me the ratio of the first two groups. (Gender-nonbinary folk are absent here—they're lumped in with the Twitter accounts of organizations, and those whose gender is simply unknown.) But Twitter doesn't tell me the ratio of my friends. That [which is measured improves][3], so I searched for a service that would measure this number for me, and found [FollowerWonk][4].
|
||||
|
||||
FollowerWonk guesses my friends are 71% men. Is this a good guess? For the sake of validation, I compare FollowerWonk's estimate of my followers to Twitter's estimate:
|
||||
|
||||
**Twitter analytics**
|
||||
|
||||
|men |women
|
||||
:-- |:-- |:--
|
||||
Followers |83% |17%
|
||||
|
||||
**FollowerWonk**
|
||||
|
||||
|men |women
|
||||
:-- |:-- |:--
|
||||
Followers |81% |19%
|
||||
Friends I follow |72% |28%
|
||||
|
||||
My followers show up 81% male here, close to the Twitter analytics number. So far so good. If FollowerWonk and Twitter agree on the gender ratio of my followers, that suggests FollowerWonk's estimate of the people I follow (which Twitter doesn't analyze) is reasonably good. With it, I can make a habit of measuring my numbers, and improve them.
|
||||
|
||||
At $30 a month, however, checking my friends' gender distribution with FollowerWonk is a pricey habit. I don't need all its features anyhow. Can I solve only the gender-distribution problem economically?
|
||||
|
||||
Since FollowerWonk's numbers seem reasonable, I tried to reproduce them. Using Python and [some nice Philadelphians' Twitter][5] API wrapper, I began downloading the profiles of all my friends and followers. I immediately found that Twitter's rate limits are miserly, so I randomly sampled only a subset of users instead.
|
||||
|
||||
I wrote a rudimentary program that searches for a pronoun announcement in each of my friends' profiles. For example, a profile description that includes "she/her" probably belongs to a woman, a description with "they/them" is probably nonbinary. But most don't state their pronouns: for these, the best gender-correlated information is the "name" field: for example, @gvanrossum's name field is "Guido van Rossum", and the first name "Guido" suggests that @gvanrossum is male. Where pronouns were not announced, I decided to use first names to estimate my numbers.
|
||||
|
||||
My script passes parts of each name to the SexMachine library to guess gender. [SexMachine][6] has predictable downfalls, like mistaking "Brooklyn Zen Center" for a woman named "Brooklyn", but its estimates are as good as FollowerWonk's and Twitter's:
|
||||
|
||||
|
||||
|
||||
|nonbinary |men |women |no gender,unknown
|
||||
:-- |:-- |:-- |:-- |:--
|
||||
Friends I follow |1 |168 |66 |173
|
||||
|0% |72% |28% |
|
||||
Followers |0 |459 |108 |433
|
||||
|0% |81% |19% |
|
||||
|
||||
(Based on all 408 friends and a sample of 1000 followers.)
|
||||
|
||||
### Know Your Number
|
||||
|
||||
I want you to check your Twitter network's gender distribution, too. So I've deployed "Proportional" to PythonAnywhere's handy service for $10 a month:
|
||||
|
||||
><www.proporti.onl>
|
||||
|
||||
The application may rate-limit you or otherwise fail, so use it gently. The [code is on GitHub][7]. It includes a command-line tool, as well.
|
||||
|
||||
Who is represented in your network on Twitter? Are you speaking and listening to the same unfairly distributed group who have been talking about software for the last few decades, or does your network look like the software industry of the future? Let's know our numbers and improve them.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://emptysqua.re/blog/gender-of-twitter-users-i-follow/
|
||||
|
||||
作者:[A. Jesse Jiryu Davis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/AJesseJiryuDavis/
|
||||
[1]: https://www.proporti.onl/
|
||||
[2]: https://analytics.twitter.com/
|
||||
[3]: http://english.stackexchange.com/questions/14952/that-which-is-measured-improves
|
||||
[4]: https://moz.com/followerwonk/
|
||||
[5]: https://github.com/bear/python-twitter/graphs/contributors
|
||||
[6]: https://pypi.python.org/pypi/SexMachine/
|
||||
[7]: https://github.com/ajdavis/twitter-gender-distribution
|
||||
@ -0,0 +1,46 @@
|
||||
DAISY : A Linux-compatible text format for the visually impaired
|
||||
=================================================================
|
||||
|
||||
|
||||

|
||||
>Image by :
|
||||
Image by Kate Ter Haar. Modified by opensource.com. CC BY-SA 2.0.
|
||||
|
||||
If you're blind or visually impaired like I am, you usually require various levels of hardware or software to do things that people who can see take for granted. One among these is specialized formats for reading print books: Braille (if you know how to read it) or specialized text formats such as DAISY.
|
||||
|
||||
### What is DAISY?
|
||||
|
||||
DAISY stands for Digital Accessible Information System. It's an open standard used almost exclusively by the blind to read textbooks, periodicals, newspapers, fiction, you name it. It was founded in the mid '90s by [The DAISY Consortium][1], a group of organizations dedicated to producing a set of standards that would allow text to be marked up in a way that would make it easy to read, skip around in, annotate, and otherwise manipulate text in much the same way a sighted user would.
|
||||
|
||||
The current version of DAISY 3.0, was released in mid-2005 and is a complete rewrite of the standard. It was created with the goal of making it much easier to write books complying with it. It's worth noting that DAISY can support plain text only, audio recordings (in PCM Wave or MPEG Layer III format) only, or a combination of text and audio. Specialized software can read these books and allow users to set bookmarks and navigate a book as easily as a sighted person would with a print book.
|
||||
|
||||
### How does DAISY work?
|
||||
|
||||
DAISY, regardless of the specific version, works a bit like this: You have your main navigation file (ncc.html in DAISY 2.02) that contains metadata about the book, such as author's name, copyright date, how many pages the book has, etc. This file is a valid XML document in the case of DAISY 3.0, with DTD (document type definition) files being highly recommended to be included with each book.
|
||||
|
||||
In the navigation control file is markup describing precise positions—either text caret offsets in the case of text navigation or time down to the millisecond in the case of audio recordings—that allows the software to skip to that exact point in the book much as a sighted person would turn to a chapter page. It's worth noting that this navigation control file only contains positions for the main, and largest, elements of a book.
|
||||
|
||||
The smaller elements are handled by SMIL (synchronized multimedia integration language) files. These files contain position points for each chapter in the book. The level of navigation depends heavily on how well the book was marked up. Think of it like this: If a print book has no chapter headings, you will have a hard time figuring out which chapter you're in. If a DAISY book is badly marked up, you might only be able to navigate to the start of the book, or possibly only to the table of contents. If a book is marked up badly enough (or missing markup entirely), your DAISY reading software is likely to simply ignore it.
|
||||
|
||||
### Why the need for specialized software?
|
||||
|
||||
You may be wondering why, if DAISY is little more than HTML, XML, and audio files, you would need specialized software to read and manipulate it. Technically speaking, you don't. The specialized software is mostly for convenience. In Linux, for example, a simple web browser can be used to open the books and read them. If you click on the XML file in a DAISY 3 book, all the software will generally do is read the spines of the books you give it access to and create a list of them that you click on to open. If a book is badly marked up, it won't show up in this list.
|
||||
|
||||
Producing DAISY is another matter entirely, and usually requires either specialized software or enough knowledge of the specifications to modify general-purpose software to parse it.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Fortunately, DAISY is a dying standard. While it is very good at what it does, the need for specialized software to produce it has set us apart from the normal sighted world, where readers use a variety of formats to read their books electronically. This is why the DAISY consortium has succeeded DAISY with EPUB, version 3, which supports what are called media overlays. This is basically an EPUB book with optional audio or video. Since EPUB shares a lot of DAISY's XML markup, some software that can read DAISY can see EPUB books but usually cannot read them. This means that once the websites that provide books for us switch over to this open format, we will have a much larger selection of software to read our books.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/5/daisy-linux-compatible-text-format-visually-impaired
|
||||
|
||||
作者:[Kendell Clark][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kendell-clark
|
||||
[1]: http://www.daisy.org
|
||||
@ -1,72 +0,0 @@
|
||||
zpl1025
|
||||
Industrial SBC builds on Raspberry Pi Compute Module
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
On Kickstarter, a “MyPi” industrial SBC using the RPi Compute Module offers a mini-PCIe slot, serial port, wide-range power, and modular expansion.
|
||||
|
||||
You might wonder why in 2016 someone would introduce a sandwich-style single board computer built around the aging, ARM11 based COM version of the original Raspberry Pi, the [Raspberry Pi Compute Module][1]. First off, there are still plenty of industrial applications that don’t need much CPU horsepower, and second, the Compute Module is still the only COM based on Raspberry Pi hardware, although the cheaper, somewhat COM-like [Raspberry Pi Zero][2], which has the same 700MHz processor, comes close.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
>MyPi with COM and I/O add-ons (left), and in its optional industrial enclosure
|
||||
|
||||
In addition, Embedded Micro Technology says its SBC is also designed to support a swap-in for a promised Raspberry Pi Compute Module upgrade built around the Raspberry Pi 3’s quad-core, Cortex-A53 Broadcom BCM2837 SoC. Since this product could arrive any week now, it’s unclear how that all sorts out for Kickstarter backers. Still, it’s nice to know you’re somewhat futureproof, even if you have to pay for the upgrade.
|
||||
|
||||
The MyPi is not the only new commercial embedded device based on the Raspberry Pi Compute Module. Pigeon Computers launched a [Pigeon RB100][3] industrial automation controller based on the COM in May. Most such devices arrived in 2014, however, shortly after the COM arrived, including the [Techbase Modberry][4].
|
||||
|
||||
The MyPi is over a third of the way toward its $21,696 funding goal with 30 days to go. An early bird package starts at $119, with shipments in September. Other kit options include a $187 version that includes the $30 Raspberry Pi Compute Module, as well as various cables. Kits are also available with add-on boards and an industrial enclosure.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
>MyPi baseboard without COM or add-ons (left) and its port details
|
||||
|
||||
The Raspberry Pi Compute Module starts the MyPi off with the Broadcom BCM2835 SoC, 512MB RAM, and 4GB eMMC flash. The MyPi adds to this with a microSD card slot, an HDMI port, two USB 2.0 ports, a 10/100 Ethernet port, and a similarly coastline RS232 port (via USB).
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
>Two views of the MyPi board with RPi and mini-PCIe modules installed
|
||||
|
||||
The MyPi is further equipped with a mini-PCIe socket, which is said to be “USB only and intended for use of modems available in the mPCIe form factor.” A SIM card slot is also available. Dual standard Raspberry Pi camera connectors are onboard along with an audio out interface, a battery-backed RTC, and LEDs. The SBC has a wide-range, 9-23V DC input.
|
||||
|
||||
The MyPi is designed for Raspberry Pi hackers who have stacked so many HAT add-on boards, they can no longer work with them effectively or stuff them inside and industrial enclosure, says Embedded Micro. The MyPi supports HATs, but also offers the company’s own “ASIO” (Application Specific I/O) add-on modules, which route their I/O back to the carrier board, which, in turn, connects it to the 8-pin, green, Phoenix-style, industrial I/O connector (labeled “ASIO Out”) on the board’s edge, as illustrated in the diagram below.
|
||||
|
||||

|
||||
>MyPi’s modular expansion interface
|
||||
|
||||
As the Kickstarter page explains it: “Rather than have a plug in HAT card with IO signal connectors poking out on all sides, instead we take these same IO signals back down a second output connector which is directly connected to the green industrial connector.” Additionally, “by simply using extended length interface pins on the card (raising it up) you can expand the IO set further — all without using any cable assemblies!” says Embedded Micro.
|
||||
|
||||

|
||||
>MyPi and its optional I/O add-on cards
|
||||
|
||||
The company offers a line of hardened ASIO plug-in cards for the MyPi, as shown above. These initially include CAN-Bus, 4-20mA transducer signals, RS485, Narrow Band RF, and more.
|
||||
|
||||
### Further information
|
||||
|
||||
The MyPi is available on Kickstarter starting at a 79-Pound ($119) early bird package (without the Raspberry Pi Compute Module) through July 23, with shipments due in September. More information may be found on the [MyPi Kickstarter page][5] and the [Embedded Micro Technology website][6].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/industrial-sbc-builds-on-rpi-compute-module/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://hackerboards.com/industrial-sbc-builds-on-rpi-compute-module/
|
||||
[1]: http://hackerboards.com/raspberry-pi-morphs-into-30-dollar-com/
|
||||
[2]: http://hackerboards.com/pi-zero-tweak-adds-camera-connector-keeps-5-price/
|
||||
[3]: http://hackerboards.com/automation-controller-runs-linux-on-raspberry-pi-com/
|
||||
[4]: http://hackerboards.com/automation-controller-taps-raspberry-pi-compute-module/
|
||||
[5]: https://www.kickstarter.com/projects/410598173/mypi-industrial-strength-raspberry-pi-for-iot-proj
|
||||
[6]: http://www.embeddedpi.com/
|
||||
@ -1,125 +0,0 @@
|
||||
chunyang-wen translating
|
||||
How to Hide Linux Command Line History by Going Incognito
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
If you’re a Linux command line user, you’ll agree that there are times when you do not want certain commands you run to be recorded in the command line history. There could be many reasons for this. For example, you’re at a certain position in your company, and you have some privileges that you don’t want others to abuse. Or, there are some critical commands that you don’t want to run accidentally while you’re browsing the history list.
|
||||
|
||||
But is there a way to control what goes into the history list and what doesn’t? Or, in other words, can we turn on a web browser-like incognito mode in the Linux command line? The answer is yes, and there are many ways to achieve this, depending on what exactly you want. In this article we will discuss some of the popular solutions available.
|
||||
|
||||
Note: all the commands presented in this article have been tested on Ubuntu.
|
||||
|
||||
### Different ways available
|
||||
|
||||
The first two ways we’ll describe here have already been covered in [one of our previous articles][1]. If you are already aware of them, you can skip over these. However, if you aren’t aware, you’re advised to go through them carefully.
|
||||
|
||||
#### 1. Insert space before command
|
||||
|
||||
Yes, you read it correctly. Insert a space in the beginning of a command, and it will be ignored by the shell, meaning the command won’t be recorded in history. However, there’s a dependency – the said solution will only work if the HISTCONTROL environment variable is set to “ignorespace” or “ignoreboth,” which is by default in most cases.
|
||||
|
||||
So, a command like the following:
|
||||
|
||||
```
|
||||
[space]echo "this is a top secret"
|
||||
```
|
||||
|
||||
Won’t appear in the history if you’ve already done this command:
|
||||
|
||||
```
|
||||
export HISTCONTROL = ignorespace
|
||||
```
|
||||
|
||||
The below screenshot is an example of this behavior.
|
||||
|
||||

|
||||
|
||||
The fourth “echo” command was not recorded in the history as it was run with a space in the beginning.
|
||||
|
||||
#### 2. Disable the entire history for the current session
|
||||
|
||||
If you want to disable the entire history for a session, you can easily do that by unsetting the HISTSIZE environment variable before you start with your command line work. To unset the variable run the following command:
|
||||
|
||||
```
|
||||
export HISTFILE=0
|
||||
```
|
||||
|
||||
HISTFILE is the number of lines (or commands) that can be stored in the history list for an ongoing bash session. By default, this variable has a set value – for example, 1000 in my case.
|
||||
|
||||
So, the command mentioned above will set the environment variable’s value to zero, and consequently nothing will be stored in the history list until you close the terminal. Keep in mind that you’ll also not be able to see the previously run commands by pressing the up arrow key or running the history command.
|
||||
|
||||
#### 3. Erase the entire history after you’re done
|
||||
|
||||
This can be seen as an alternative to the solution mentioned in the previous section. The only difference is that in this case you run a command AFTER you’re done with all your work. Thh following is the command in question:
|
||||
|
||||
```
|
||||
history -cw
|
||||
```
|
||||
|
||||
As already mentioned, this will have the same effect as the HISTFILE solution mentioned above.
|
||||
|
||||
#### 4. Turn off history only for the work you do
|
||||
|
||||
While the solutions (2 and 3) described above do the trick, they erase the entire history, something which might be undesired in many situations. There might be cases in which you want to retain the history list up until the point you start your command line work. For situations like these you need to run the following command before starting with your work:
|
||||
|
||||
```
|
||||
[space]set +o history
|
||||
```
|
||||
|
||||
Note: [space] represents a blank space.
|
||||
|
||||
The above command will disable the history temporarily, meaning whatever you do after running this command will not be recorded in history, although all the stuff executed prior to the above command will be there as it is in the history list.
|
||||
|
||||
To re-enable the history, run the following command:
|
||||
|
||||
```
|
||||
[Space]set -o history
|
||||
```
|
||||
|
||||
This brings things back to normal again, meaning any command line work done after the above command will show up in the history.
|
||||
|
||||
#### 5. Delete specific commands from history
|
||||
|
||||
Now suppose the history list already contains some commands that you didn’t want to be recorded. What can be done in this case? It’s simple. You can go ahead and remove them. The following is how to accomplish this:
|
||||
|
||||
```
|
||||
[space]history | grep "part of command you want to remove"
|
||||
```
|
||||
|
||||
The above command will output a list of matching commands (that are there in the history list) with a number [num] preceding each of them.
|
||||
|
||||
Once you’ve identified the command you want to remove, just run the following command to remove that particular entry from the history list:
|
||||
|
||||
```
|
||||
history -d [num]
|
||||
```
|
||||
|
||||
The following screenshot is an example of this.
|
||||
|
||||

|
||||
|
||||
The second ‘echo’ command was removed successfully.
|
||||
|
||||
Alternatively, you can just press the up arrow key to take a walk back through the history list, and once the command of your interest appears on the terminal, just press “Ctrl + U” to totally blank the line, effectively removing it from the list.
|
||||
|
||||
### Conclusion
|
||||
|
||||
There are multiple ways in which you can manipulate the Linux command line history to suit your needs. Keep in mind, however, that it’s usually not a good practice to hide or remove a command from history, although it’s also not wrong, per se, but you should be aware of what you’re doing and what effects it might have.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-command-line-history-incognito/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/himanshu/
|
||||
[1]: https://www.maketecheasier.com/command-line-history-linux/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,407 @@
|
||||
Backup Photos While Traveling With an Ipad Pro and a Raspberry Pi
|
||||
===================================================================
|
||||
|
||||

|
||||
>Backup Photos While Traveling - Gear.
|
||||
|
||||
### Introduction
|
||||
|
||||
I’ve been on a quest to finding the ideal travel photo backup solution for a long time. Relying on just tossing your SD cards in your camera bag after they are full during a trip is a risky move that leaves you too exposed: SD cards can be lost or stolen, data can get corrupted or cards can get damaged in transit. Backing up to another medium - even if it’s just another SD card - and leaving that in a safe(r) place while traveling is the best practice. Ideally, backing up to a remote location would be the way to go, but that may not be practical depending on where you are traveling to and Internet availability in the region.
|
||||
|
||||
My requirements for the ideal backup procedure are:
|
||||
|
||||
1. Use an iPad to manage the process instead of a laptop. I like to travel light and since most of my trips are business related (i.e. non-photography related), I’d hate to bring my personal laptop along with my business laptop. My iPad, however; is always with me, so using it as a tool just makes sense.
|
||||
2. Use as few hardware devices as practically possible.
|
||||
3. Connection between devices should be secure. I’ll be using this setup in hotels and airports, so closed and encrypted connection between devices is ideal.
|
||||
4. The whole process should be sturdy and reliable. I’ve tried other options using router/combo devices and [it didn’t end up well][1].
|
||||
|
||||
### The Setup
|
||||
|
||||
I came up with a setup that meets the above criteria and is also flexible enough to expand on it in the future. It involves the use of the following gear:
|
||||
|
||||
1. [iPad Pro 9.7][2] inches. It’s the most powerful, small and lightweight iOS device at the time of writing. Apple pencil is not really needed, but it’s part of my gear as I so some editing on the iPad Pro while on the road. All the heavy lifting will be done by the Raspberry Pi, so any other device capable of connecting through SSH would fit the bill.
|
||||
2. [Raspberry Pi 3][3] with Raspbian installed.
|
||||
3. [Micro SD card][4] for Raspberry Pi and a Raspberry Pi [box/case][5].
|
||||
5. [128 GB Pen Drive][6]. You can go bigger, but 128 GB is enough for my user case. You can also get a portable external hard drive like [this one][7], but the Raspberry Pi may not provide enough power through its USB port, which means you would have to get a [powered USB hub][8], along with the needed cables, defeating the purpose of having a lightweight and minimalistic setup.
|
||||
6. [SD card reader][9]
|
||||
7. [SD Cards][10]. I use several as I don’t wait for one to fill up before using a different one. That allows me to spread photos I take on a single trip amongst several cards.
|
||||
|
||||
The following diagram shows how these devices will be interacting with each other.
|
||||
|
||||

|
||||
>Backup Photos While Traveling - Process Diagram.
|
||||
|
||||
The Raspberry Pi will be configured to act as a secured Hot Spot. It will create its own WPA2-encrypted WiFi network to which the iPad Pro will connect. Although there are many online tutorials to create an Ad Hoc (i.e. computer-to-computer) connection with the Raspberry Pi, which is easier to setup; that connection is not encrypted and it’s relatively easy for other devices near you to connect to it. Therefore, I decided to go with the WiFi option.
|
||||
|
||||
The camera’s SD card will be connected to one of the Raspberry Pi’s USB ports through an SD card reader. Additionally, a high capacity Pen Drive (128 GB in my case) will be permanently inserted in one of the USB ports on the Raspberry Pi. I picked the [Sandisk Ultra Fit][11] because of its tiny size. The main idea is to have the Raspberry Pi backup the photos from the SD Card to the Pen Drive with the help of a Python script. The backup process will be incremental, meaning that only changes (i.e. new photos taken) will be added to the backup folder each time the script runs, making the process really fast. This is a huge advantage if you take a lot of photos or if you shoot in RAW format. The iPad will be used to trigger the Python script and to browse the SD Card and Pen Drive as needed.
|
||||
|
||||
As an added benefit, if the Raspberry Pi is connected to Internet through a wired connection (i.e. through the Ethernet port), it will be able to share the Internet connection with the devices connected to its WiFi network.
|
||||
|
||||
### 1. Raspberry Pi Configuration
|
||||
|
||||
This is the part where we roll up our sleeves and get busy as we’ll be using Raspbian’s command-line interface (CLI) . I’ll try to be as descriptive as possible so it’s easy to go through the process.
|
||||
|
||||
#### Install and Configure Raspbian
|
||||
|
||||
Connect a keyboard, mouse and an LCD monitor to the Raspberry Pi. Insert the Micro SD in the Raspberry Pi’s slot and proceed to install Raspbian per the instructions in the [official site][12].
|
||||
|
||||
After the installation is done, go to the CLI (Terminal in Raspbian) and type:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
```
|
||||
|
||||
This will upgrade all software on the machine. I configured the Raspberry Pi to connect to the local network and changed the default password as a safety measure.
|
||||
|
||||
By default SSH is enabled on Raspbian, so all sections below can be done from a remote machine. I also configured RSA authentication, but that’s optional. More info about it [here][13].
|
||||
|
||||
This is a screenshot of the SSH connection to the Raspberry Pi from [iTerm][14] on Mac:
|
||||
|
||||
##### Creating Encrypted (WPA2) Access Point
|
||||
|
||||
The installation was made based on [this][15] article, it was optimized for my user case.
|
||||
|
||||
##### 1. Install Packages
|
||||
|
||||
We need to type the following to install the required packages:
|
||||
|
||||
```
|
||||
sudo apt-get install hostapd
|
||||
sudo apt-get install dnsmasq
|
||||
```
|
||||
|
||||
hostapd allows to use the built-in WiFi as an access point. dnsmasq is a combined DHCP and DNS server that’s easy to configure.
|
||||
|
||||
##### 2. Edit dhcpcd.conf
|
||||
|
||||
Connect to the Raspberry Pi through Ethernet. Interface configuration on the Raspbery Pi is handled by dhcpcd, so first we tell it to ignore wlan0 as it will be configured with a static IP address.
|
||||
|
||||
Open up the dhcpcd configuration file with sudo nano `/etc/dhcpcd.conf` and add the following line to the bottom of the file:
|
||||
|
||||
```
|
||||
denyinterfaces wlan0
|
||||
```
|
||||
|
||||
Note: This must be above any interface lines that may have been added.
|
||||
|
||||
##### 3. Edit interfaces
|
||||
|
||||
Now we need to configure our static IP. To do this, open up the interface configuration file with sudo nano `/etc/network/interfaces` and edit the wlan0 section so that it looks like this:
|
||||
|
||||
```
|
||||
allow-hotplug wlan0
|
||||
iface wlan0 inet static
|
||||
address 192.168.1.1
|
||||
netmask 255.255.255.0
|
||||
network 192.168.1.0
|
||||
broadcast 192.168.1.255
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
Also, the wlan1 section was edited to be:
|
||||
|
||||
```
|
||||
#allow-hotplug wlan1
|
||||
#iface wlan1 inet manual
|
||||
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
```
|
||||
|
||||
Important: Restart dhcpcd with sudo service dhcpcd restart and then reload the configuration for wlan0 with `sudo ifdown eth0; sudo ifup wlan0`.
|
||||
|
||||
##### 4. Configure Hostapd
|
||||
|
||||
Next, we need to configure hostapd. Create a new configuration file with `sudo nano /etc/hostapd/hostapd.conf with the following contents:
|
||||
|
||||
```
|
||||
interface=wlan0
|
||||
|
||||
# Use the nl80211 driver with the brcmfmac driver
|
||||
driver=nl80211
|
||||
|
||||
# This is the name of the network
|
||||
ssid=YOUR_NETWORK_NAME_HERE
|
||||
|
||||
# Use the 2.4GHz band
|
||||
hw_mode=g
|
||||
|
||||
# Use channel 6
|
||||
channel=6
|
||||
|
||||
# Enable 802.11n
|
||||
ieee80211n=1
|
||||
|
||||
# Enable QoS Support
|
||||
wmm_enabled=1
|
||||
|
||||
# Enable 40MHz channels with 20ns guard interval
|
||||
ht_capab=[HT40][SHORT-GI-20][DSSS_CCK-40]
|
||||
|
||||
# Accept all MAC addresses
|
||||
macaddr_acl=0
|
||||
|
||||
# Use WPA authentication
|
||||
auth_algs=1
|
||||
|
||||
# Require clients to know the network name
|
||||
ignore_broadcast_ssid=0
|
||||
|
||||
# Use WPA2
|
||||
wpa=2
|
||||
|
||||
# Use a pre-shared key
|
||||
wpa_key_mgmt=WPA-PSK
|
||||
|
||||
# The network passphrase
|
||||
wpa_passphrase=YOUR_NEW_WIFI_PASSWORD_HERE
|
||||
|
||||
# Use AES, instead of TKIP
|
||||
rsn_pairwise=CCMP
|
||||
```
|
||||
|
||||
Now, we also need to tell hostapd where to look for the config file when it starts up on boot. Open up the default configuration file with `sudo nano /etc/default/hostapd` and find the line `#DAEMON_CONF=""` and replace it with `DAEMON_CONF="/etc/hostapd/hostapd.conf"`.
|
||||
|
||||
##### 5. Configure Dnsmasq
|
||||
|
||||
The shipped dnsmasq config file contains tons of information on how to use it, but we won’t be using all the options. I’d recommend moving it (rather than deleting it), and creating a new one with
|
||||
|
||||
```
|
||||
sudo mv /etc/dnsmasq.conf /etc/dnsmasq.conf.orig
|
||||
sudo nano /etc/dnsmasq.conf
|
||||
```
|
||||
|
||||
Paste the following into the new file:
|
||||
|
||||
```
|
||||
interface=wlan0 # Use interface wlan0
|
||||
listen-address=192.168.1.1 # Explicitly specify the address to listen on
|
||||
bind-interfaces # Bind to the interface to make sure we aren't sending things elsewhere
|
||||
server=8.8.8.8 # Forward DNS requests to Google DNS
|
||||
domain-needed # Don't forward short names
|
||||
bogus-priv # Never forward addresses in the non-routed address spaces.
|
||||
dhcp-range=192.168.1.50,192.168.1.100,12h # Assign IP addresses in that range with a 12 hour lease time
|
||||
```
|
||||
|
||||
##### 6. Set up IPV4 forwarding
|
||||
|
||||
One of the last things that we need to do is to enable packet forwarding. To do this, open up the sysctl.conf file with `sudo nano /etc/sysctl.conf`, and remove the # from the beginning of the line containing `net.ipv4.ip_forward=1`. This will enable it on the next reboot.
|
||||
|
||||
We also need to share our Raspberry Pi’s internet connection to our devices connected over WiFi by the configuring a NAT between our wlan0 interface and our eth0 interface. We can do this by writing a script with the following lines.
|
||||
|
||||
```
|
||||
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
|
||||
sudo iptables -A FORWARD -i eth0 -o wlan0 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
sudo iptables -A FORWARD -i wlan0 -o eth0 -j ACCEPT
|
||||
```
|
||||
|
||||
I named the script hotspot-boot.sh and made it executable with:
|
||||
|
||||
```
|
||||
sudo chmod 755 hotspot-boot.sh
|
||||
```
|
||||
|
||||
The script should be executed when the Raspberry Pi boots. There are many ways to accomplish this, and this is the way I went with:
|
||||
|
||||
1. Put the file in `/home/pi/scripts`.
|
||||
2. Edit the rc.local file by typing `sudo nano /etc/rc.local` and place the call to the script before the line that reads exit 0 (more information [here][16]).
|
||||
|
||||
This is how the rc.local file looks like after editing it.
|
||||
|
||||
```
|
||||
#!/bin/sh -e
|
||||
#
|
||||
# rc.local
|
||||
#
|
||||
# This script is executed at the end of each multiuser runlevel.
|
||||
# Make sure that the script will "exit 0" on success or any other
|
||||
# value on error.
|
||||
#
|
||||
# In order to enable or disable this script just change the execution
|
||||
# bits.
|
||||
#
|
||||
# By default this script does nothing.
|
||||
|
||||
# Print the IP address
|
||||
_IP=$(hostname -I) || true
|
||||
if [ "$_IP" ]; then
|
||||
printf "My IP address is %s\n" "$_IP"
|
||||
fi
|
||||
|
||||
sudo /home/pi/scripts/hotspot-boot.sh &
|
||||
|
||||
exit 0
|
||||
|
||||
```
|
||||
|
||||
#### Installing Samba and NTFS Compatibility.
|
||||
|
||||
We also need to install the following packages to enable the Samba protocol and allow the File Browser App to see the connected devices to the Raspberry Pi as shared folders. Also, ntfs-3g provides NTFS compatibility in case we decide to connect a portable hard drive to the Raspberry Pi.
|
||||
|
||||
```
|
||||
sudo apt-get install ntfs-3g
|
||||
sudo apt-get install samba samba-common-bin
|
||||
```
|
||||
|
||||
You can follow [this][17] article for details on how to configure Samba.
|
||||
|
||||
Important Note: The referenced article also goes through the process of mounting external hard drives on the Raspberry Pi. We won’t be doing that because, at the time of writing, the current version of Raspbian (Jessie) auto-mounts both the SD Card and the Pendrive to `/media/pi/` when the device is turned on. The article also goes over some redundancy features that we won’t be using.
|
||||
|
||||
### 2. Python Script
|
||||
|
||||
Now that the Raspberry Pi has been configured, we need to work on the script that will actually backup/copy our photos. Note that this script just provides certain degree of automation to the backup process. If you have a basic knowledge of using the Linux/Raspbian CLI, you can just SSH into the Raspberry Pi and copy yourself all photos from one device to the other by creating the needed folders and using either the cp or the rsync command. We’ll be using the rsync method on the script as it’s very reliable and allows for incremental backups.
|
||||
|
||||
This process relies on two files: the script itself and the configuration file `backup_photos.conf`. The latter just have a couple of lines indicating where the destination drive (Pendrive) is mounted and what folder has been mounted to. This is what it looks like:
|
||||
|
||||
```
|
||||
mount folder=/media/pi/
|
||||
destination folder=PDRIVE128GB
|
||||
```
|
||||
|
||||
Important: Do not add any additional spaces between the `=` symbol and the words to both sides of it as the script will break (definitely an opportunity for improvement).
|
||||
|
||||
Below is the Python script, which I named `backup_photos.py` and placed in `/home/pi/scripts/`. I included comments in between the lines of code to make it easier to follow.
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
|
||||
import os
|
||||
import sys
|
||||
from sh import rsync
|
||||
|
||||
'''
|
||||
The script copies an SD Card mounted on /media/pi/ to a folder with the same name
|
||||
created in the destination drive. The destination drive's name is defined in
|
||||
the .conf file.
|
||||
|
||||
|
||||
Argument: label/name of the mounted SD Card.
|
||||
'''
|
||||
|
||||
CONFIG_FILE = '/home/pi/scripts/backup_photos.conf'
|
||||
ORIGIN_DEV = sys.argv[1]
|
||||
|
||||
def create_folder(path):
|
||||
|
||||
print ('attempting to create destination folder: ',path)
|
||||
if not os.path.exists(path):
|
||||
try:
|
||||
os.mkdir(path)
|
||||
print ('Folder created.')
|
||||
except:
|
||||
print ('Folder could not be created. Stopping.')
|
||||
return
|
||||
else:
|
||||
print ('Folder already in path. Using that instead.')
|
||||
|
||||
|
||||
|
||||
confFile = open(CONFIG_FILE,'rU')
|
||||
#IMPORTANT: rU Opens the file with Universal Newline Support,
|
||||
#so \n and/or \r is recognized as a new line.
|
||||
|
||||
confList = confFile.readlines()
|
||||
confFile.close()
|
||||
|
||||
|
||||
for line in confList:
|
||||
line = line.strip('\n')
|
||||
|
||||
try:
|
||||
name , value = line.split('=')
|
||||
|
||||
if name == 'mount folder':
|
||||
mountFolder = value
|
||||
elif name == 'destination folder':
|
||||
destDevice = value
|
||||
|
||||
|
||||
except ValueError:
|
||||
print ('Incorrect line format. Passing.')
|
||||
pass
|
||||
|
||||
|
||||
destFolder = mountFolder+destDevice+'/'+ORIGIN_DEV
|
||||
create_folder(destFolder)
|
||||
|
||||
print ('Copying files...')
|
||||
|
||||
# Comment out to delete files that are not in the origin:
|
||||
# rsync("-av", "--delete", mountFolder+ORIGIN_DEV, destFolder)
|
||||
rsync("-av", mountFolder+ORIGIN_DEV+'/', destFolder)
|
||||
|
||||
print ('Done.')
|
||||
```
|
||||
|
||||
### 3. iPad Pro Configuration
|
||||
|
||||
Since all the heavy-lifting will be done on the Raspberry Pi and no files will be transferred through the iPad Pro, which was a huge disadvantage in [one of the workflows I tried before][18]; we just need to install [Prompt 2][19] on the iPad to access the Raspeberry Pi through SSH. Once connected, you can either run the Python script or copy the files manually.
|
||||
|
||||

|
||||
>SSH Connection to Raspberry Pi From iPad Using Prompt.
|
||||
|
||||
Since we installed Samba, we can access USB devices connected to the Raspberry Pi in a more graphical way. You can stream videos, copy and move files between devices. [File Browser][20] is perfect for that.
|
||||
|
||||
### 4. Putting it All Together
|
||||
|
||||
Let’s suppose that `SD32GB-03` is the label of an SD card connected to one of the USB ports on the Raspberry Pi. Also, let’s suppose that `PDRIVE128GB` is the label of the Pendrive, also connected to the device and defined on the `.conf` file as indicated above. If we wanted to backup the photos on the SD Card, we would need to go through the following steps:
|
||||
|
||||
1. Turn on Raspberry Pi so that drives are mounted automatically.
|
||||
2. Connect to the WiFi network generated by the Raspberry Pi.
|
||||
3. Connect to the Raspberry Pi through SSH using the [Prompt][21] App.
|
||||
4. Type the following once you are connected:
|
||||
|
||||
```
|
||||
python3 backup_photos.py SD32GB-03
|
||||
```
|
||||
|
||||
The first backup my take some minutes depending on how much of the card is used. That means you need to keep the connection alive to the Raspberry Pi from the iPad. You can get around this by using the [nohup][22] command before running the script.
|
||||
|
||||
```
|
||||
nohup python3 backup_photos.py SD32GB-03 &
|
||||
```
|
||||
|
||||

|
||||
>iTerm Screenshot After Running Python Script.
|
||||
|
||||
### Further Customization
|
||||
|
||||
I installed a VNC server to access Raspbian’s graphical interface from another computer or the iPad through [Remoter App][23]. I’m looking into installing [BitTorrent Sync][24] for backing up photos to a remote location while on the road, which would be the ideal setup. I’ll expand this post once I have a workable solution.
|
||||
|
||||
Feel free to either include your comments/questions below or reach out to me. My contact info is at the footer of this page.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
|
||||
作者:[Editor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
|
||||
[1]: http://bit.ly/1MVVtZi
|
||||
[2]: http://www.amazon.com/dp/B01D3NZIMA/?tag=movinelect0e-20
|
||||
[3]: http://www.amazon.com/dp/B01CD5VC92/?tag=movinelect0e-20
|
||||
[4]: http://www.amazon.com/dp/B010Q57T02/?tag=movinelect0e-20
|
||||
[5]: http://www.amazon.com/dp/B01F1PSFY6/?tag=movinelect0e-20
|
||||
[6]: http://amzn.to/293kPqX
|
||||
[7]: http://amzn.to/290syFY
|
||||
[8]: http://amzn.to/290syFY
|
||||
[9]: http://amzn.to/290syFY
|
||||
[10]: http://amzn.to/290syFY
|
||||
[11]: http://amzn.to/293kPqX
|
||||
[12]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[13]: https://www.raspberrypi.org/documentation/remote-access/ssh/passwordless.md
|
||||
[14]: https://www.iterm2.com/
|
||||
[15]: https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
|
||||
[16]: https://www.raspberrypi.org/documentation/linux/usage/rc-local.md
|
||||
[17]: http://www.howtogeek.com/139433/how-to-turn-a-raspberry-pi-into-a-low-power-network-storage-device/
|
||||
[18]: http://bit.ly/1MVVtZi
|
||||
[19]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[20]: https://itunes.apple.com/us/app/filebrowser-access-files-on/id364738545?mt=8&uo=4&at=11lqkH
|
||||
[21]: https://itunes.apple.com/us/app/prompt-2/id917437289?mt=8&uo=4&at=11lqkH
|
||||
[22]: https://en.m.wikipedia.org/wiki/Nohup
|
||||
[23]: https://itunes.apple.com/us/app/remoter-pro-vnc-ssh-rdp/id519768191?mt=8&uo=4&at=11lqkH
|
||||
[24]: https://getsync.com/
|
||||
33
sources/tech/20160630 What makes up the Fedora kernel.md
Normal file
33
sources/tech/20160630 What makes up the Fedora kernel.md
Normal file
@ -0,0 +1,33 @@
|
||||
What makes up the Fedora kernel?
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
Every Fedora system runs a kernel. Many pieces of code come together to make this a reality.
|
||||
|
||||
Each release of the Fedora kernel starts with a baseline release from the [upstream community][1]. This is often called a ‘vanilla’ kernel. The upstream kernel is the standard. The goal is to have as much code upstream as possible. This makes it easier for bug fixes and API updates to happen as well as having more people review the code. In an ideal world, Fedora would be able to to take the kernel straight from kernel.org and send that out to all users.
|
||||
|
||||
Realistically, using the vanilla kernel isn’t complete enough for Fedora. Some features Fedora users want may not be available. The [Fedora kernel][2] that users actually receive contains a number of patches on top of the vanilla kernel. These patches are considered ‘out of tree’. Many of these patches will not exist out of tree patches very long. If patches are available to fix an issue, the patches may be pulled in to the Fedora tree so the fix can go out to users faster. When the kernel is rebased to a new version, the patches will be removed if they are in the new version.
|
||||
|
||||
Some patches remain in the Fedora kernel tree for an extended period of time. A good example of patches that fall into this category are the secure boot patches. These patches provide a feature Fedora wants to support even though the upstream community has not yet accepted them. It takes effort to keep these patches up to date so Fedora tries to minimize the number of patches that are carried without being accepted by an upstream kernel maintainer.
|
||||
|
||||
Generally, the best way to get a patch included in the Fedora kernel is to send it to the ]Linux Kernel Mailing List (LKML)][3] first and then ask for it to be included in Fedora. If a patch has been accepted by a maintainer it stands a very high chance of being included in the Fedora kernel tree. Patches that come from places like github which have not been submitted to LKML are unlikely to be taken into the tree. It’s important to send the patches to LKML first to ensure Fedora is carrying the correct patches in its tree. Without the community review, Fedora could end up carrying patches which are buggy and cause problems.
|
||||
|
||||
The Fedora kernel contains code from many places. All of it is necessary to give the best experience possible.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
|
||||
作者:[Laura Abbott][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/makes-fedora-kernel/
|
||||
[1]: http://www.kernel.org/
|
||||
[2]: http://pkgs.fedoraproject.org/cgit/rpms/kernel.git/
|
||||
[3]: http://www.labbott.name/blog/2015/10/02/the-art-of-communicating-with-lkml/
|
||||
@ -0,0 +1,143 @@
|
||||
How To Setup Bridge (br0) Network on Ubuntu Linux 14.04 and 16.04 LTS
|
||||
=======================================================================
|
||||
|
||||
> am a new Ubuntu Linux 16.04 LTS user. How do I setup a network bridge on the host server powered by Ubuntu 14.04 LTS or 16.04 LTS operating system?
|
||||
|
||||

|
||||
|
||||
A Bridged networking is nothing but a simple technique to connect to the outside network through the physical interface. It is useful for LXC/KVM/Xen/Containers virtualization and other virtual interfaces. The virtual interfaces appear as regular hosts to the rest of the network. In this tutorial I will explain how to configure a Linux bridge with bridge-utils (brctl) command line utility on Ubuntu server.
|
||||
|
||||
### Our sample bridged networking
|
||||
|
||||
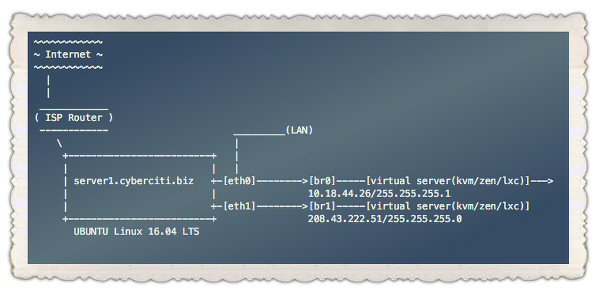
|
||||
>Fig.01: Sample Ubuntu Bridged Networking Setup For Kvm/Xen/LXC Containers (br0)
|
||||
|
||||
In this example eth0 and eth1 is the physical network interface. eth0 connected to the LAN and eth1 is attached to the upstream ISP router/Internet.
|
||||
|
||||
### Install bridge-utils
|
||||
|
||||
Type the following [apt-get command][1] to install the bridge-utils:
|
||||
|
||||
```
|
||||
$ sudo apt-get install bridge-utils
|
||||
```
|
||||
|
||||
OR
|
||||
|
||||
````
|
||||
$ sudo apt install bridge-utils
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
|
||||
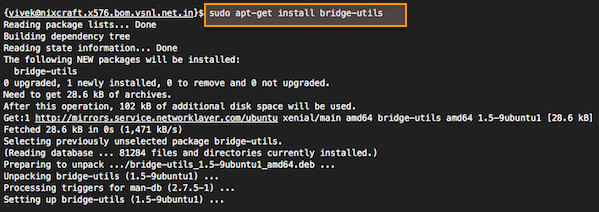
|
||||
>Fig.02: Ubuntu Linux install bridge-utils package
|
||||
|
||||
### Creating a network bridge on the Ubuntu server
|
||||
|
||||
Edit `/etc/network/interfaces` using a text editor such as nano or vi, enter:
|
||||
|
||||
```
|
||||
$ sudo cp /etc/network/interfaces /etc/network/interfaces.bakup-1-july-2016
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
Let us setup eth1 and map it to br1, enter (delete or comment out all eth1 entries):
|
||||
|
||||
```
|
||||
# br1 setup with static wan IPv4 with ISP router as gateway
|
||||
auto br1
|
||||
iface br1 inet static
|
||||
address 208.43.222.51
|
||||
network 255.255.255.248
|
||||
netmask 255.255.255.0
|
||||
broadcast 208.43.222.55
|
||||
gateway 208.43.222.49
|
||||
bridge_ports eth1
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
To setup eth0 and map it to br0, enter (delete or comment out all eth1 entries):
|
||||
|
||||
```
|
||||
auto br0
|
||||
iface br0 inet static
|
||||
address 10.18.44.26
|
||||
netmask 255.255.255.192
|
||||
broadcast 10.18.44.63
|
||||
dns-nameservers 10.0.80.11 10.0.80.12
|
||||
# set static route for LAN
|
||||
post-up route add -net 10.0.0.0 netmask 255.0.0.0 gw 10.18.44.1
|
||||
post-up route add -net 161.26.0.0 netmask 255.255.0.0 gw 10.18.44.1
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
### A note about br0 and DHCP
|
||||
|
||||
DHCP config options:
|
||||
|
||||
```
|
||||
auto br0
|
||||
iface br0 inet dhcp
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
### Restart the server or networking service
|
||||
|
||||
You need to reboot the server or type the following command to restart the networking service (this may not work on SSH based session):
|
||||
|
||||
```
|
||||
$ sudo systemctl restart networking
|
||||
```
|
||||
|
||||
If you are using Ubuntu 14.04 LTS or older not systemd based system, enter:
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/restart networking
|
||||
```
|
||||
|
||||
### Verify connectivity
|
||||
|
||||
Use the ping/ip commands to verify that both LAN and WAN interfaces are reachable:
|
||||
```
|
||||
# See br0 and br1
|
||||
ip a show
|
||||
# See routing info
|
||||
ip r
|
||||
# ping public site
|
||||
ping -c 2 cyberciti.biz
|
||||
# ping lan server
|
||||
ping -c 2 10.0.80.12
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
|
||||
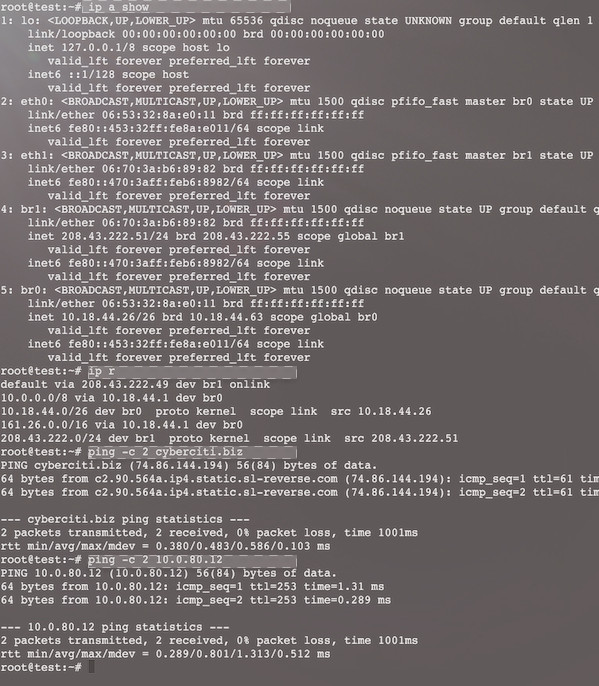
|
||||
>Fig.03: Verify Bridging Ethernet Connections
|
||||
|
||||
Now, you can configure XEN/KVM/LXC containers to use br0 and br1 to reach directly to the internet or private lan. No need to setup special routing or iptables SNAT rules.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/how-to-create-bridge-interface-ubuntu-linux/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/nixcraft
|
||||
[1]: http://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
|
||||
@ -0,0 +1,100 @@
|
||||
How to Encrypt a Flash Drive Using VeraCrypt
|
||||
============================================
|
||||
|
||||
Many security experts prefer open source software like VeraCrypt, which can be used to encrypt flash drives, because of its readily available source code.
|
||||
|
||||
Encryption is a smart idea for protecting data on a USB flash drive, as we covered in our piece that described ]how to encrypt a flash drive][1] using Microsoft BitLocker.
|
||||
|
||||
But what if you do not want to use BitLocker?
|
||||
|
||||
You may be concerned that because Microsoft's source code is not available for inspection, it could be susceptible to security "backdoors" used by the government or others. Because source code for open source software is widely shared, many security experts feel open source software is far less likely to have any backdoors.
|
||||
|
||||
Fortunately, there are several open source encryption alternatives to BitLocker.
|
||||
|
||||
If you need to be able to encrypt and access files on any Windows machine, as well as computers running Apple OS X or Linux, the open source [VeraCrypt][2] offers an excellent alternative.
|
||||
|
||||
VeraCrypt is derived from TrueCrypt, a well-regarded open source encryption software product that has now been discontinued. But the code for TrueCrypt was audited and no major security flaws were found. In addition, it has since been improved in VeraCrypt.
|
||||
|
||||
Versions exist for Windows, OS X and Linux.
|
||||
|
||||
Encrypting a USB flash drive with VeraCrypt is not as straightforward as it is with BitLocker, but it still only takes a few minutes.
|
||||
|
||||
### Encrypting Flash Drive with VeraCrypt in 8 Steps
|
||||
|
||||
After [downloading VeraCrypt][3] for your operating system:
|
||||
|
||||
Start VeraCrypt, and click on Create Volume to start the VeraCrypt Volume Creation Wizard.
|
||||
|
||||

|
||||
|
||||
The VeraCrypt Volume Creation Wizard allows you to create an encrypted file container on the flash drive which sits along with other unencrypted files, or you can choose to encrypt the entire flash drive. For the moment, we will choose to encrypt the entire flash drive.
|
||||
|
||||

|
||||
|
||||
On the next screen, choose Standard VeraCrypt Volume.
|
||||
|
||||

|
||||
|
||||
Select the drive letter of the flash drive you want to encrypt (in this case O:).
|
||||
|
||||

|
||||
|
||||
Choose the Volume Creation Mode. If your flash drive is empty or you want to delete everything it contains, choose the first option. If you want to keep any existing files, choose the second option.
|
||||
|
||||

|
||||
|
||||
This screen allows you to choose your encryption options. If you are unsure of which to choose, leave the default settings of AES and SHA-512.
|
||||
|
||||

|
||||
|
||||
After confirming the Volume Size screen, enter and re-enter the password you want to use to encrypt your data.
|
||||
|
||||

|
||||
|
||||
To work effectively, VeraCrypt must draw from a pool of entropy or "randomness." To generate this pool, you'll be asked to move your mouse around in a random fashion for about a minute. Once the bar has turned green, or preferably when it reaches the far right of the screen, click Format to finish creating your encrypted drive.
|
||||
|
||||

|
||||
|
||||
### Using a Flash Drive Encrypted with VeraCrypt
|
||||
|
||||
When you want to use an encrypted flash drive, first insert the drive in the computer and start VeraCrypt.
|
||||
|
||||
Then select an unused drive letter (such as z:) and click Auto-Mount Devices.
|
||||
|
||||

|
||||
|
||||
Enter your password and click OK.
|
||||
|
||||

|
||||
|
||||
The mounting process may take a few minutes, after which your unencrypted drive will become available with the drive letter you selected previously.
|
||||
|
||||
### VeraCrypt Traveler Disk Setup
|
||||
|
||||
If you set up a flash drive with an encrypted container rather than encrypting the whole drive, you also have the option to create what VeraCrypt calls a traveler disk. This installs a copy of VeraCrypt on the USB flash drive itself, so when you insert the drive in another Windows computer you can run VeraCrypt automatically from the flash drive; there is no need to install it on the computer.
|
||||
|
||||
You can set up a flash drive to be a Traveler Disk by choosing Traveler Disk SetUp from the Tools menu of VeraCrypt.
|
||||
|
||||

|
||||
|
||||
It is worth noting that in order to run VeraCrypt from a Traveler Disk on a computer, you must have administrator privileges on that computer. While that may seem to be a limitation, no confidential files can be opened safely on a computer that you do not control, such as one in a business center.
|
||||
|
||||
>Paul Rubens has been covering enterprise technology for over 20 years. In that time he has written for leading UK and international publications including The Economist, The Times, Financial Times, the BBC, Computing and ServerWatch.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.esecurityplanet.com/open-source-security/how-to-encrypt-flash-drive-using-veracrypt.html
|
||||
|
||||
作者:[Paul Rubens ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.esecurityplanet.com/author/3700/Paul-Rubens
|
||||
[1]: http://www.esecurityplanet.com/views/article.php/3880616/How-to-Encrypt-a-USB-Flash-Drive.htm
|
||||
[2]: http://www.esecurityplanet.com/open-source-security/veracrypt-a-worthy-truecrypt-alternative.html
|
||||
[3]: https://veracrypt.codeplex.com/releases/view/619351
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,70 @@
|
||||
Using Vagrant to control your DigitalOcean cloud instances
|
||||
=========================================================
|
||||
|
||||

|
||||
|
||||
[Vagrant][1] is an application to create and support virtual development environments using virtual machines. Fedora has [official support for Vagrant][2] with libvirt on your local system. [DigitalOcean][3] is a cloud provider that provides a one-click deployment of a Fedora Cloud instance to an all-SSD server in under a minute. During the [recent Cloud FAD][4] in Raleigh, the Fedora Cloud team packaged a new plugin for Vagrant which enables Fedora users to keep up cloud instances in DigitalOcean using local Vagrantfiles.
|
||||
|
||||
### How to use this plugin
|
||||
|
||||
First step is to install the package in the command line.
|
||||
|
||||
```
|
||||
$ sudo dnf install -y vagrant-digitalocean
|
||||
```
|
||||
|
||||
After installing the plugin, the next task is to create the local Vagrantfile. An example is provided below.
|
||||
|
||||
```
|
||||
$ mkdir digitalocean
|
||||
$ cd digitalocean
|
||||
$ cat Vagrantfile
|
||||
Vagrant.configure('2') do |config|
|
||||
config.vm.hostname = 'dropletname.kushaldas.in'
|
||||
# Alternatively, use provider.name below to set the Droplet name. config.vm.hostname takes precedence.
|
||||
|
||||
config.vm.provider :digital_ocean do |provider, override|
|
||||
override.ssh.private_key_path = '/home/kdas/.ssh/id_rsa'
|
||||
override.vm.box = 'digital_ocean'
|
||||
override.vm.box_url = "https://github.com/devopsgroup-io/vagrant- digitalocean/raw/master/box/digital_ocean.box"
|
||||
|
||||
provider.token = 'Your AUTH Token'
|
||||
provider.image = 'fedora-23-x64'
|
||||
provider.region = 'nyc2'
|
||||
provider.size = '512mb'
|
||||
provider.ssh_key_name = 'Kushal'
|
||||
end
|
||||
end
|
||||
```
|
||||
|
||||
### Notes about Vagrant DigitalOcean plugin
|
||||
|
||||
A few points to remember about the SSH key naming scheme: if you already have the key uploaded to DigitalOcean, make sure that the provider.ssh_key_name matches the name of the existing key in their server. The provider.image details are found at the [DigitalOcean documentation][5]. The AUTH token is created on the control panel within the Apps & API section.
|
||||
|
||||
You can then get the instance up with the following command.
|
||||
|
||||
```
|
||||
$ vagrant up --provider=digital_ocean
|
||||
```
|
||||
|
||||
This command will fire up the instance in the DigitalOcean server. You can then SSH into the box by using vagrant ssh command. Run vagrant destroy to destroy the instance.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-vagrant-digitalocean-cloud/
|
||||
|
||||
作者:[Kushal Das][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://kushal.id.fedoraproject.org/
|
||||
[1]: https://www.vagrantup.com/
|
||||
[2]: https://fedoramagazine.org/running-vagrant-fedora-22/
|
||||
[3]: https://www.digitalocean.com/
|
||||
[4]: https://communityblog.fedoraproject.org/fedora-cloud-fad-2016/
|
||||
[5]: https://developers.digitalocean.com/documentation/v2/#create-a-new-droplet
|
||||
139
sources/tech/20160711 Getting started with Git.md
Normal file
139
sources/tech/20160711 Getting started with Git.md
Normal file
@ -0,0 +1,139 @@
|
||||
Getting started with Git
|
||||
=========================
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
|
||||
In the introduction to this series we learned who should use Git, and what it is for. Today we will learn how to clone public Git repositories, and how to extract individual files without cloning the whole works.
|
||||
|
||||
Since Git is so popular, it makes life a lot easier if you're at least familiar with it at a basic level. If you can grasp the basics (and you can, I promise!), then you'll be able to download whatever you need, and maybe even contribute stuff back. And that, after all, is what open source is all about: having access to the code that makes up the software you run, the freedom to share it with others, and the right to change it as you please. Git makes this whole process easy, as long as you're comfortable with Git.
|
||||
|
||||
So let's get comfortable with Git.
|
||||
|
||||
### Read and write
|
||||
|
||||
Broadly speaking, there are two ways to interact with a Git repository: you can read from it, or you can write to it. It's just like a file: sometimes you open a document just to read it, and other times you open a document because you need to make changes.
|
||||
|
||||
In this article, we'll cover reading from a Git repository. We'll tackle the subject of writing back to a Git repository in a later article.
|
||||
|
||||
### Git or GitHub?
|
||||
|
||||
A word of clarification: Git is not the same as GitHub (or GitLab, or Bitbucket). Git is a command-line program, so it looks like this:
|
||||
|
||||
```
|
||||
$ git
|
||||
usage: Git [--version] [--help] [-C <path>]
|
||||
[-p | --paginate | --no-pager] [--bare]
|
||||
[--Git-dir=<path>] <command> [<args>]
|
||||
|
||||
```
|
||||
|
||||
As Git is open source, lots of smart people have built infrastructures around it which, in themselves, have become very popular.
|
||||
|
||||
My articles about Git teach pure Git first, because if you understand what Git is doing then you can maintain an indifference to what front end you are using. However, my articles also include common ways of accomplishing each task through popular Git services, since that's probably what you'll encounter first.
|
||||
|
||||
### Installing Git
|
||||
|
||||
To install Git on Linux, grab it from your distribution's software repository. BSD users should find Git in the Ports tree, in the devel section.
|
||||
|
||||
For non-open source operating systems, go to the [project site][1] and follow the instructions. Once installed, there should be no difference between Linux, BSD, and Mac OS X commands. Windows users will have to adapt Git commands to match the Windows file system, or install Cygwin to run Git natively, without getting tripped up by Windows file system conventions.
|
||||
|
||||
### Afternoon tea with Git
|
||||
|
||||
Not every one of us needs to adopt Git into our daily lives right away. Sometimes, the most interaction you have with Git is to visit a repository of code, download a file or two, and then leave. On the spectrum of getting to know Git, this is more like afternoon tea than a proper dinner party. You make some polite conversation, you get the information you need, and then you part ways without the intention of speaking again for at least another three months.
|
||||
|
||||
And that's OK.
|
||||
|
||||
Generally speaking, there are two ways to access Git: via command line, or by any one of the fancy Internet technologies providing quick and easy access through the web browser.
|
||||
|
||||
Say you want to install a trash bin for use in your terminal because you've been burned one too many times by the rm command. You've heard about Trashy, which calls itself "a sane intermediary to the rm command", and you want to look over its documentation before you install it. Lucky for you, [Trashy is hosted publicly on GitLab.com][2].
|
||||
|
||||
### Landgrab
|
||||
|
||||
The first way we'll work with this Git repository is a sort of landgrab method: we'll clone the entire thing, and then sort through the contents later. Since the repository is hosted with a public Git service, there are two ways to do this: on the command line, or through a web interface.
|
||||
|
||||
To grab an entire repository with Git, use the git clone command with the URL of the Git repository. If you're not clear on what the right URL is, the repository should tell you. GitLab gives you a copy-and-paste repository URL [for Trashy][3].
|
||||
|
||||
|
||||
|
||||
You might notice that on some services, both SSH and HTTPS links are provided. You can use SSH only if you have write permissions to the repository. Otherwise, you must use the HTTPS URL.
|
||||
|
||||
Once you have the right URL, cloning the repository is pretty simple. Just git clone the URL, and optionally name the directory to clone it into. The default behaviour is to clone the git directory to your current directory; for example, 'trashy.git' gets put in your current location as 'trashy'. I use the .clone extension as a shorthand for repositories that are read-only, and the .git extension as shorthand for repositories I can read and write, but that's not by any means an official mandate.
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/trashy/trashy.git trashy.clone
|
||||
Cloning into 'trashy.clone'...
|
||||
remote: Counting objects: 142, done.
|
||||
remote: Compressing objects: 100% (91/91), done.
|
||||
remote: Total 142 (delta 70), reused 103 (delta 47)
|
||||
Receiving objects: 100% (142/142), 25.99 KiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (70/70), done.
|
||||
Checking connectivity... done.
|
||||
```
|
||||
|
||||
Once the repository has been cloned successfully, you can browse files in it just as you would any other directory on your computer.
|
||||
|
||||
The other way to get a copy of the repository is through the web interface. Both GitLab and GitHub provide a snapshot of any repository in a .zip file. GitHub has a big green download button, but on GitLab, look for an inconspicuous download button on the far right of your browser window:
|
||||
|
||||
|
||||
|
||||
### Pick and choose
|
||||
|
||||
An alternate method of obtaining a file from a Git repository is to find the file you're after and pluck it right out of the repository. This method is only supported via web interfaces, which is essentially you looking at someone else's clone of a repository; you can think of it as a sort of HTTP shared directory.
|
||||
|
||||
The problem with using this method is that you might find that certain files don't actually exist in a raw Git repository, as a file might only exist in its complete form after a make command builds the file, which won't happen until you download the repository, read the README or INSTALL file, and run the command. Assuming, however, that you are sure a file does exist and you just want to go into the repository, grab it, and walk away, you can do that.
|
||||
|
||||
In GitLab and GitHub, click the Files link for a file view, view the file in Raw mode, and use your web browser's save function, e.g. in Firefox, File > Save Page As. In a GitWeb repository (a web view of personal git repositories used some who prefer to host git themselves), the Raw view link is in the file listing view.
|
||||
|
||||
|
||||
|
||||
### Best practices
|
||||
|
||||
Generally, cloning an entire Git repository is considered the right way of interacting with Git. There are a few reasons for this. Firstly, a clone is easy to keep updated with the git pull command, so you won't have to keep going back to some web site for a new copy of a file each time an improvement has been made. Secondly, should you happen to make an improvement yourself, then it is easier to submit those changes to the original author if it is all nice and tidy in a Git repository.
|
||||
|
||||
For now, it's probably enough to just practice going out and finding interesting Git repositories and cloning them to your drive. As long as you know the basics of using a terminal, then it's not hard to do. Don't know the basics of terminal usage? Give me five more minutes of your time.
|
||||
|
||||
### Terminal basics
|
||||
|
||||
The first thing to understand is that all files have a path. That makes sense; if I told you to open a file for me on a regular non-terminal day, you'd have to get to where that file is on your drive, and you'd do that by navigating a bunch of computer windows until you reached that file. For example, maybe you'd click your home directory > Pictures > InktoberSketches > monkey.kra.
|
||||
|
||||
In that scenario, we could say that the file monkeysketch.kra has the path $HOME/Pictures/InktoberSketches/monkey.kra.
|
||||
|
||||
In the terminal, unless you're doing special sysadmin work, your file paths are generally going to start with $HOME (or, if you're lazy, just the ~ character) followed by a list of folders up to the filename itself. This is analogous to whatever icons you click in your GUI to reach the file or folder.
|
||||
|
||||
If you want to clone a Git repository into your Documents directory, then you could open a terminal and run this command:
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/foo/bar.git
|
||||
$HOME/Documents/bar.clone
|
||||
```
|
||||
|
||||
Once that is complete, you can open a file manager window, navigate to your Documents folder, and you'll find the bar.clone directory waiting for you.
|
||||
|
||||
If you want to get a little more advanced, you might revisit that repository at some later date, and try a git pull to see if there have been updates to the project:
|
||||
|
||||
```
|
||||
$ cd $HOME/Documents/bar.clone
|
||||
$ pwd
|
||||
bar.clone
|
||||
$ git pull
|
||||
```
|
||||
|
||||
For now, that's all the terminal commands you need to get started, so go out and explore. The more you do it, the better you get at it, and that is, at least give or take a vowel, the name of the game.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/stumbling-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]: https://git-scm.com/download
|
||||
[2]: https://gitlab.com/trashy/trashy
|
||||
[3]: https://gitlab.com/trashy/trashy.git
|
||||
|
||||
@ -1,208 +0,0 @@
|
||||
martin
|
||||
|
||||
Part 11 - How to Manage and Create LVM Using vgcreate, lvcreate and lvextend Commands
|
||||
============================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>LFCS: Manage LVM and Create LVM Partition – Part 11
|
||||
|
||||
One of the most important decisions while installing a Linux system is the amount of storage space to be allocated for system files, home directories, and others. If you make a mistake at that point, growing a partition that has run out of space can be burdensome and somewhat risky.
|
||||
|
||||
**Logical Volumes Management** (also known as **LVM**), which have become a default for the installation of most (if not all) Linux distributions, have numerous advantages over traditional partitioning management. Perhaps the most distinguishing feature of LVM is that it allows logical divisions to be resized (reduced or increased) at will without much hassle.
|
||||
|
||||
The structure of the LVM consists of:
|
||||
|
||||
* One or more entire hard disks or partitions are configured as physical volumes (PVs).
|
||||
* A volume group (**VG**) is created using one or more physical volumes. You can think of a volume group as a single storage unit.
|
||||
* Multiple logical volumes can then be created in a volume group. Each logical volume is somewhat equivalent to a traditional partition – with the advantage that it can be resized at will as we mentioned earlier.
|
||||
|
||||
In this article we will use three disks of **8 GB** each (**/dev/sdb**, **/dev/sdc**, and **/dev/sdd**) to create three physical volumes. You can either create the PVs directly on top of the device, or partition it first.
|
||||
|
||||
Although we have chosen to go with the first method, if you decide to go with the second (as explained in [Part 4 – Create Partitions and File Systems in Linux][3] of this series) make sure to configure each partition as type `8e`.
|
||||
|
||||
### Creating Physical Volumes, Volume Groups, and Logical Volumes
|
||||
|
||||
To create physical volumes on top of **/dev/sdb**, **/dev/sdc**, and **/dev/sdd**, do:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
You can list the newly created PVs with:
|
||||
|
||||
```
|
||||
# pvs
|
||||
```
|
||||
|
||||
and get detailed information about each PV with:
|
||||
|
||||
```
|
||||
# pvdisplay /dev/sdX
|
||||
```
|
||||
|
||||
(where **X** is b, c, or d)
|
||||
|
||||
If you omit `/dev/sdX` as parameter, you will get information about all the PVs.
|
||||
|
||||
To create a volume group named `vg00` using `/dev/sdb` and `/dev/sdc` (we will save `/dev/sdd` for later to illustrate the possibility of adding other devices to expand storage capacity when needed):
|
||||
|
||||
```
|
||||
# vgcreate vg00 /dev/sdb /dev/sdc
|
||||
```
|
||||
|
||||
As it was the case with physical volumes, you can also view information about this volume group by issuing:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
Since `vg00` is formed with two **8 GB** disks, it will appear as a single **16 GB** drive:
|
||||
|
||||

|
||||
>List LVM Volume Groups
|
||||
|
||||
When it comes to creating logical volumes, the distribution of space must take into consideration both current and future needs. It is considered good practice to name each logical volume according to its intended use.
|
||||
|
||||
For example, let’s create two LVs named `vol_projects` (**10 GB**) and `vol_backups` (remaining space), which we can use later to store project documentation and system backups, respectively.
|
||||
|
||||
The `-n` option is used to indicate a name for the LV, whereas `-L` sets a fixed size and `-l` (lowercase L) is used to indicate a percentage of the remaining space in the container VG.
|
||||
|
||||
```
|
||||
# lvcreate -n vol_projects -L 10G vg00
|
||||
# lvcreate -n vol_backups -l 100%FREE vg00
|
||||
```
|
||||
|
||||
As before, you can view the list of LVs and basic information with:
|
||||
|
||||
```
|
||||
# lvs
|
||||
```
|
||||
|
||||
and detailed information with
|
||||
|
||||
```
|
||||
# lvdisplay
|
||||
```
|
||||
|
||||
To view information about a single **LV**, use **lvdisplay** with the **VG** and **LV** as parameters, as follows:
|
||||
|
||||
```
|
||||
# lvdisplay vg00/vol_projects
|
||||
```
|
||||
|
||||

|
||||
>List Logical Volume
|
||||
|
||||
In the image above we can see that the LVs were created as storage devices (refer to the LV Path line). Before each logical volume can be used, we need to create a filesystem on top of it.
|
||||
|
||||
We’ll use ext4 as an example here since it allows us both to increase and reduce the size of each LV (as opposed to xfs that only allows to increase the size):
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/vg00/vol_projects
|
||||
# mkfs.ext4 /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||
In the next section we will explain how to resize logical volumes and add extra physical storage space when the need arises to do so.
|
||||
|
||||
### Resizing Logical Volumes and Extending Volume Groups
|
||||
|
||||
Now picture the following scenario. You are starting to run out of space in `vol_backups`, while you have plenty of space available in `vol_projects`. Due to the nature of LVM, we can easily reduce the size of the latter (say **2.5 GB**) and allocate it for the former, while resizing each filesystem at the same time.
|
||||
|
||||
Fortunately, this is as easy as doing:
|
||||
|
||||
```
|
||||
# lvreduce -L -2.5G -r /dev/vg00/vol_projects
|
||||
# lvextend -l +100%FREE -r /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>Resize Reduce Logical Volume and Volume Group
|
||||
|
||||
It is important to include the minus `(-)` or plus `(+)` signs while resizing a logical volume. Otherwise, you’re setting a fixed size for the LV instead of resizing it.
|
||||
|
||||
It can happen that you arrive at a point when resizing logical volumes cannot solve your storage needs anymore and you need to buy an extra storage device. Keeping it simple, you will need another disk. We are going to simulate this situation by adding the remaining PV from our initial setup (`/dev/sdd`).
|
||||
|
||||
To add `/dev/sdd` to `vg00`, do
|
||||
|
||||
```
|
||||
# vgextend vg00 /dev/sdd
|
||||
```
|
||||
|
||||
If you run vgdisplay `vg00` before and after the previous command, you will see the increase in the size of the VG:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
|
||||
>Check Volume Group Disk Size
|
||||
|
||||
Now you can use the newly added space to resize the existing LVs according to your needs, or to create additional ones as needed.
|
||||
|
||||
### Mounting Logical Volumes on Boot and on Demand
|
||||
|
||||
Of course there would be no point in creating logical volumes if we are not going to actually use them! To better identify a logical volume we will need to find out what its `UUID` (a non-changing attribute that uniquely identifies a formatted storage device) is.
|
||||
|
||||
To do that, use blkid followed by the path to each device:
|
||||
|
||||
```
|
||||
# blkid /dev/vg00/vol_projects
|
||||
# blkid /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>Find Logical Volume UUID
|
||||
|
||||
Create mount points for each LV:
|
||||
|
||||
```
|
||||
# mkdir /home/projects
|
||||
# mkdir /home/backups
|
||||
```
|
||||
|
||||
and insert the corresponding entries in `/etc/fstab` (make sure to use the UUIDs obtained before):
|
||||
|
||||
```
|
||||
UUID=b85df913-580f-461c-844f-546d8cde4646 /home/projects ext4 defaults 0 0
|
||||
UUID=e1929239-5087-44b1-9396-53e09db6eb9e /home/backups ext4 defaults 0 0
|
||||
```
|
||||
|
||||
Then save the changes and mount the LVs:
|
||||
|
||||
```
|
||||
# mount -a
|
||||
# mount | grep home
|
||||
```
|
||||
|
||||

|
||||
>Find Logical Volume UUID
|
||||
|
||||
When it comes to actually using the LVs, you will need to assign proper `ugo+rwx` permissions as explained in [Part 8 – Manage Users and Groups in Linux][4] of this series.
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have introduced [Logical Volume Management][5], a versatile tool to manage storage devices that provides scalability. When combined with RAID (which we explained in [Part 6 – Create and Manage RAID in Linux][6] of this series), you can enjoy not only scalability (provided by LVM) but also redundancy (offered by RAID).
|
||||
|
||||
In this type of setup, you will typically find `LVM` on top of `RAID`, that is, configure RAID first and then configure LVM on top of it.
|
||||
|
||||
If you have questions about this article, or suggestions to improve it, feel free to reach us using the comment form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
|
||||
[4]: http://www.tecmint.com/manage-users-and-groups-in-linux/
|
||||
[5]: http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
[6]: http://www.tecmint.com/creating-and-managing-raid-backups-in-linux/
|
||||
80
translated/talk/20151117 How bad a boss is Linus Torvalds.md
Normal file
80
translated/talk/20151117 How bad a boss is Linus Torvalds.md
Normal file
@ -0,0 +1,80 @@
|
||||
Translated by FrankXinqi
|
||||
|
||||
Linus Torvalds作为一个老板有多么糟糕?
|
||||
================================================================================
|
||||

|
||||
|
||||
*1999 年 8 月 10 日,加利福尼亚州圣何塞市,在 LinuxWorld Show 上 Linus Torvalds 在一个坐满 Linux 爱好者的礼堂中发表了一篇演讲。作者:James Niccolai*
|
||||
|
||||
**这取决于所处的领域。在软件开发的世界中,他变得更加平庸。问题是,这种情况是否应该被允许继续?**
|
||||
|
||||
Linus Torvalds 是 Linux 的发明者,我认识他超过 20 年了。我们不是密友,但是我们欣赏彼此。
|
||||
|
||||
最近,因为 Linus Torvalds 的管理风格,他正遭到严厉的炮轰。Linus 无法忍受胡来的人。「代码的质量有多好?」是他在 Linux 内核的开发过程中评判人的一种方式。
|
||||
|
||||
没有什么比这个更重要了。正如 Linus 今年(1999年)早些时候在 Linux.conf.au 会议上说的那样,「我不是一个友好的人,并且我不关心你。对我重要的是『[我所关心的技术和内核][1]』。」
|
||||
|
||||
现在我也可以和这只关心技术的这一类人打交道了。如果你不能,你应当避免参加 Linux 内核会议,因为在那里你会遇到许多有这种精英思想的人。这不代表我认为在 Linux 领域所有东西都是极好的,并且应该不受其他影响的来激起改变。我能够一起生活的一个精英;在一个男性做主导的大城堡中遇到的问题是,女性经常受到蔑视和无礼的对待。
|
||||
|
||||
这就是我看到的最近关于 Linus 管理风格所引发社会争吵的原因 -- 或者更准确的说,他对于个人管理方面是完全冷漠的 -- 就像不过是在软件开发世界的标准操作流程一样。与此同时,我看到了另外一个非常需要被改变的事实,它必须作为证据公开。
|
||||
|
||||
第一次是在 [Linux 4.3 发布][2]的时候出现的这个情况,Linus 使用 Linux 内核邮件列表来狠狠的攻击一个插入了非常糟糕并且没有价值的网络代码的开发者。「[这段代码导致了非常糟糕并且没有价值的代码。][3]这看起来太糟糕了,并且完全没有理由这样做。」当他说到这里的时候,他沉默了很长时间。除了使用「非常糟糕并且没有价值」这个词,他在早期使用「愚蠢的」这个同义词是相对较好的。
|
||||
|
||||
但是,事情就是这样。Linus 是对的。我读了代码后,发现代码确实很烂并且开发者是为了使用新的「overflow_usub()」 函数而使用的。
|
||||
|
||||
现在,一些人把 Linus 的这种谩骂的行为看作他脾气不好而且恃强凌弱的证据。我见过一个完美主义者,在他的领域中,他无法忍受这种糟糕。
|
||||
|
||||
许多人告诉我,这不是一个专业的程序员应当有的行为。人们,你曾经和最优秀的开发者一起工作过吗?据我所知道的,在 Apple,Microsoft,Oracle 这就是他们的行为。
|
||||
|
||||
我曾经听过 Steve Jobs 攻击一个开发者,像把他撕成碎片那样。我大为不快,当一个 Oracle 的高级开发者攻击一屋子的新开发者的时候就像食人鱼穿过一群金鱼那样。
|
||||
|
||||
在意外的电脑帝国,在 Robert X. Cringely 关于 PCs 崛起的经典书籍中,他这样描述 Bill Gates 的微软软件管理风格,Bill Gates 像计算机系统一样管理他们,『比尔盖茨是最高等级,从他开始每一个等级依次递减,上级会向下级叫嚷,刺激他们,甚至羞辱他们。』
|
||||
|
||||
Linus 和所有大型的私有软件公司的领导人不同的是,Linus 说在这里所有的东西是向全世界公开的。而其他人是在私有的会议室中做东西的。我听有人说 Linus 在那种公司中可能会被开除。这是不可能的。他会在正确的地方就像现在这样,他在编程世界的最顶端。
|
||||
|
||||
但是,这里有另外一个不同。如果 Larry Ellison (Oracle的首席执行官)向你发火,你就别想在这里干了。如果 Linus 向你发火,你会在邮件中收到他的责骂。这就是差别。
|
||||
|
||||
你知道的,Linus 不是任何人的老板。他完全没有雇佣和解聘的权利,他只是负责着有 10,000 个贡献者的一个项目而已。他仅仅能做的就是从心理上伤害你。
|
||||
|
||||
这说明,在开源软件开发圈和私有软件开发圈中同时存在一个非常严重的问题。不管你是一个多么好的编程者,如果你是一个女性,你的这个身份就是对你不利的。
|
||||
|
||||
这种情况并没有在 Sarah Sharp 的身上有任何好转,她现在是一个Intel的开发者,以前是一个顶尖的Linux程序员。[在她博客10月份的一个帖子中][4],她解释道:『我最终发现,我不能够再为Linux社区做出贡献了。因为在在那里,我虽然能够得到技术上的尊重,却得不到个人的尊重……我不想专职于同那些轻微的性别歧视者或开同性恋玩笑的人一起工作。』
|
||||
|
||||
谁能责怪她呢?我不能。我非常伤心的说,Linus 就像所有我见过的软件经理一样,是他造成了这种不利的工作环境。
|
||||
|
||||
他可能会说,确保 Linux 的贡献者都表现出专业精神和相互尊重不应该是他的工作。除了代码以外,他不关系任何其他事情。
|
||||
|
||||
就像Sarah Sharp写的那样:
|
||||
|
||||
|
||||
> 我对于 Linux 内核社区做出的技术努力表现出非常的尊重。他们在那维护一些最高标准的代码,以此来平衡并且发展一个项目。他们专注于优秀的技术,却带有过量的维护人员,他们有不同的文化背景和社会规范,这些意味着这些 Linux 内核维护者说话非常直率,粗鲁或者为了完成他们的任务而不讲道理。顶尖的 Linux 内核开发者经常为了使别人改正行为而向他们大喊大叫。
|
||||
>
|
||||
> 这种事情发生在我身上,但它不是一种有效的沟通方式。
|
||||
>
|
||||
> 许多高级的 Linux 内核开发者支持那些技术上和人性上不讲道理的维护者的权利。即使他们是非常友好的人,他们不想看到 Linux 内核交流方式改变。
|
||||
|
||||
她是对的。
|
||||
|
||||
我和其他调查者不同的是,我不认为这个问题对于 Linux 或开源社区在任何方面有特殊之处。作为一个从事技术商业工作超过五年和有着 25 年技术工作经历的记者,我随处可见这种不成熟的男孩的行为。
|
||||
|
||||
这不是 Linus 的错误。他不是一个经理,他是一个有想象力的技术领导者。看起来真正的问题是,在软件开发领域没有人能够用一种支持的语气来对待团队和社区。
|
||||
|
||||
展望未来,我希望像 Linux Foundation 这样的公司和组织,能够找到一种方式去授权社区经理或其他经理来鼓励并且强制实施民主的行为。
|
||||
|
||||
非常遗憾的是,我们不能够在我们这种纯技术或纯商业的领导人中找到这种管理策略。它不存在于这些人的基因中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[FrankXinqi](https://github.com/FrankXinqi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html
|
||||
[2]:http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/
|
||||
[3]:http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html
|
||||
[4]:http://sarah.thesharps.us/2015/10/05/closing-a-door/
|
||||
@ -0,0 +1,49 @@
|
||||
培养一个 Linux 职业生涯
|
||||
==================================
|
||||
|
||||

|
||||
|
||||
我与 Linux 的故事开始于 1998 年,一直延续到今天。 当时我在 Gap 公司工作,管理着成千台运行着 [OS/2][1] 系统的台式机 ( 并且在随后的几年里是 [Warp 3.0][2])。 作为一个 OS/2 的使用者,那时我非常高兴。 随着这些台式机的嗡鸣,我们使用 Gap 开发的工具轻而易举地就能支撑起对成千的用户的服务支持。 然而,一切都将改变了。
|
||||
|
||||
在 1998 年的 11 月, 我收到邀请加入一个新成立的公司,这家公司将专注于 Linux 上。 这就是后来非常出名的 [Linuxcare][2].
|
||||
|
||||
### 我在 Linuxcare 的时光
|
||||
|
||||
我曾经有接触过一些 Linux , 但我从未想过要把它提供给企业客户。仅仅几个月后 ( 从这里开始成为了空间和时间上的转折点 ), 我就在管理一整条线的业务,让企业获得他们的软件,硬件,甚至是证书认证等不同风格且在当时非常盛行的的 Linux 服务。
|
||||
|
||||
我向我的客户提供像 IBM ,Dell ,HP 等产品以确保他们的硬件能够成功的运行 Linux 。 今天你们应该都听过许多关于在硬件上预载 Linux 的事, 但当时我被邀请到 Dell 去讨论有关于为即将到来的贸易展在笔记本电脑上运行 Linux 的相关事宜。 这是多么激动人心的时刻 !同时我们也在有效期的几年内支持 IBM 和 HP 等多项认证工作。
|
||||
|
||||
Linux 变化得非常快,并且它总是这样。 它也获得了更多的关键设备的支持,比如声音,网络和图形。在这段时间, 我把个人使用的系统从基于 RPM 的系统换成了 [Debian][3] 。
|
||||
|
||||
### 使用 Linux 的这些年
|
||||
|
||||
几年前我在一些以 Linux 为硬设备,客户软件以及数据中心的公司工作。而在二十世纪中期的时候,那时我正在忙着做咨询,而那些在 Redmond 的大型软件公司正围绕着 Linux 做一些分析和验证以和自己的解决方案做对比。 我个人使用的系统一直改变,我仍会在任何能做到的时候运行 Debian 测试系统。
|
||||
|
||||
我真的非常欣赏其发行版本的灵活性和永久更新状态。 Debian 是我所使用过的最有趣且拥有良好支持的发行版本且拥有最好的社区的版本之一。
|
||||
|
||||
当我回首我使用 Linux 的这几年,我仍记得大约在二十世纪前期和中期的时候在圣何塞,旧金山,波士顿和纽约的那些 Linux 的展览会。在 Linuxcare 时我们总是会做一些有趣而且时髦的展览位,在那边逛的时候总会碰到一些老朋友。这一切工作都是需要付出代价的,所有的这一切都是在努力地强调使用 Linux 的乐趣。
|
||||
|
||||
同时,虚拟化和云的崛起也让 Linux 变得更加有趣。 当我在 Linuxcare 的时候, 我们常和 Palo Alto 的一个约 30 人左右的小公司在一块。我们会开车到他们的办公处然后准备一个展览并且他们也会参与进来。 谁会想得到这个小小的开端会成就后来的 VMware ?
|
||||
|
||||
我还有许多的故事,能认识这些人并和他们一起工作我感到很幸运。 Linux 在各方面都不断发展且变得尤为重要。 并且甚至随着它重要性的提升,它使用起来仍然非常有趣。 我认为它的开放性和可定制能力给它带来了大量的新用户,这也是让我感到非常震惊的一点。
|
||||
|
||||
### 现在
|
||||
|
||||
在过去的五年里我逐渐离开 Linux 的主流事物。 我所管理的大规模基础设施项目中包含着许多不同的操作系统 ( 包括非开源的和开源的 ), 但我的心一直以来都是和 Linux 在一起的。
|
||||
|
||||
在使用 Linux 过程中的乐趣和不断进步是在过去的 18 年里一直驱动我的动力。我从 Linux 2.0 内核开始看着它变成现在的这样。 Linux 是一个卓越,有机且非常酷的东西。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-michael-perry
|
||||
|
||||
作者:[Michael Perry][a]
|
||||
译者:[译者ID](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/mpmilestogo
|
||||
[1]: https://en.wikipedia.org/wiki/OS/2
|
||||
[2]: https://archive.org/details/IBMOS2Warp3Collection
|
||||
[3]: https://en.wikipedia.org/wiki/Linuxcare
|
||||
[4]: https://www.debian.org/
|
||||
[5]:
|
||||
@ -1,110 +0,0 @@
|
||||
Linux 如何最好地管理加密密钥
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
存储 SSH 的加密秘钥以及记住密码一直是一个让人头疼的问题。但是不幸的是,在当前充满了恶意黑客和攻击的世界中,基本的安全预警是必不可少的。对于大量的普通用户,它相当于简单地记住密码,也可能寻找一个好程序去存储密码,正如我们提醒这些用户不要在每个网站都有相同的密码。但是对于在各个 IT 领域的我们,我们需要将这个提高一个层次。我们不得不处理加密秘钥,比如 SSH 密钥,而不只是密码。
|
||||
|
||||
设想一个场景:我有一个运行在云上的服务器,用于我的主 git 库。我有很多台工作电脑。所有电脑都需要登陆中央服务器去 push 与 pull。我设置 git 使用 SSH。当 git 使用 SSH, git 实际上以相同的方式登陆服务器,就好像你通过 SSH 命令打开一个服务器的命令行。为了配置所有内容,我在我的 .ssh 目录下创建一个配置文件,其中包含一个有服务器名字,主机名,登陆用户,密钥文件的路径的主机项。之后我可以通过输入命令来测试这个配置。
|
||||
|
||||
>ssh gitserver
|
||||
|
||||
很快我得到了服务器的 bash shell。现在我可以配置 git 使用相同项与存储的密钥来登陆服务器。很简单,除了一个问题,对于每一个我用于登陆服务器的电脑,我需要有一个密钥文件。那意味着需要不止一个密钥文件。当前这台电脑和我的其他电脑都存储有这些密钥文件。同样的,用户每天有特大量的密码,对于我们 IT人员,很容易结束这特大量的密钥文件。怎么办呢?
|
||||
|
||||
## 清理
|
||||
|
||||
在开始使用程序去帮助你管理你的密钥之前,你不得不在你的密码应该怎么处理和我们问的问题是否有意义这两个方面打下一些基础。同时,这需要第一,也是最重要的,你明白你的公钥和私钥的使用位置。我将设想你知道:
|
||||
|
||||
1. 公钥和私钥之间的差异;
|
||||
|
||||
2. 为什么你不可以从公钥生成私钥,但是你可以逆向生成?
|
||||
|
||||
3. `authorized_keys` 文件的目的以及它的内容;
|
||||
|
||||
4. 你如何使用私钥去登陆服务器,其中服务器上的 `authorized_keys` 文件中存有相应的公钥;
|
||||
|
||||
这里有一个例子。当你在亚马逊的网络服务上创建一个云服务器,你必须提供一个 SSH 密码,用于连接你的服务器。每一个密钥有一个公开的部分,和私密的部分。因为你想保持你的服务器安全,乍看之下你可能要将你的私钥放到服务器上,同时你自己带着公钥。毕竟,你不想你的服务器被公开访问,对吗?但是实际上这是逆向的。
|
||||
|
||||
你把自己的公钥放到 AWS 服务器,同时你持有你自己的私钥用于登陆服务器。你保护私钥,同时保持私钥在自己一方,而不是在一些远程服务器上,正如上图中所示。
|
||||
|
||||
原因如下:如果公钥公之于众,他们不可以登陆服务器,因为他们没有私钥。进一步说,如果有人成功攻入你的服务器,他们所能找到的只是公钥。你不可以从公钥生成私钥。同时如果你在其他的服务器上使用相同的密钥,他们不可以使用它去登陆别的电脑。
|
||||
|
||||
这就是为什么你把你自己的公钥放到你的服务器上以便通过 SSH 登陆这些服务器。你持有这些私钥,不要让这些私钥脱离你的控制。
|
||||
|
||||
但是还有麻烦。试想一下我 git 服务器的例子。我要做一些决定。有时我登陆架设在别的地方的开发服务器。在开发服务器上,我需要连接我的 git 服务器。如何使我的开发服务器连接 git 服务器?通过使用私钥。同时这里面还有麻烦。这个场景需要我把私钥放置到一个架设在别的地方的服务器上。这相当危险。
|
||||
|
||||
一个进一步的场景:如果我要使用一个密钥去登陆许多的服务器,怎么办?如果一个入侵者得到这个私钥,他或她将拥有私钥,并且得到服务器的全部虚拟网络的权限,同时准备做一些严重的破坏。这一点也不好。
|
||||
|
||||
同时那当然会带来一个别的问题,我真的应该在这些其他服务器上使用相同的密钥?因为我刚才描述的,那会非常危险的。
|
||||
|
||||
最后,这听起来有些混乱,但是有一些简单的解决方案。让我们有条理地组织一下:
|
||||
|
||||
(注意你有很多地方需要密钥登陆服务器,但是我提出这个作为一个场景去向你展示当你处理密钥的时候你面对的问题)
|
||||
|
||||
## 关于口令句
|
||||
|
||||
当你创建你的密钥时,你可以选择是否包含一个口令字,这个口令字会在使用私钥的时候是必不可少的。有了这个口令字,私钥文件本身会被口令字加密。例如,如果你有一个公钥存储在服务器上,同时你使用私钥去登陆服务器的时候,你会被提示,输入口令字。没有口令字,这个密钥是无法使用的。或者,你可以配置你的密钥不需要口令字。然后所有你需要的只是用于登陆服务器的密钥文件。
|
||||
|
||||
普遍上,不使用口令字对于用户来说是更容易的,但是我强烈建议在很多情况下使用口令字,原因是,如果私钥文件被偷了,偷密钥的人仍然不可以使用它,除非他或者她可以找到口令字。在理论上,这个将节省你很多时间,因为你可以在攻击者发现口令字之前,从服务器上删除公钥文件,从而保护你的系统。还有一些别的原因去使用口令字,但是这个原因对我来说在很多场合更有价值。(举一个例子,我的 Android 平板上有 VNC 软件。平板上有我的密钥。如果我的平板被偷了之后,我会马上从服务器上删除公钥,使得它的私钥没有作用,无论有没有口令字。)但是在一些情况下我不使用口令字,是因为我正在登陆的服务器上没有什么有价值的数据。它取决于情境。
|
||||
|
||||
## 服务器基础设施
|
||||
|
||||
你如何设置自己服务器的基础设置将会影响到你如何管理你的密钥。例如,如果你有很多用户登陆,你将需要决定每个用户是否需要一个单独的密钥。(普遍来说,他们应该;你不会想要用户之间共享私钥。那样当一个用户离开组织或者失去信任时,你可以删除那个用户的公钥,而不需要必须给其他人生成新的密钥。相似地,通过共享密钥,他们能以其他人的身份登录,这就更坏了。)但是另外一个问题,你如何配置你的服务器。你是否使用工具,比如 Puppet,配置大量的服务器?同时你是否基于你自己的镜像创建大量的服务器?当你复制你的服务器,你是否需要为每个人设置相同的密钥?不同的云服务器软件允许你配置这个;你可以让这些服务器使用相同的密钥,或者给每一个生成一个新的密钥。
|
||||
|
||||
如果你在处理复制的服务器,它可能导致混淆如果用户需要使用不同的密钥登陆两个不同的系统。但是另一方面,服务器共享相同的密钥会有安全风险。或者,第三,如果你的密钥有除了登陆之外的需要(比如挂载加密的驱动),之后你会在很多地方需要相同的密钥。正如你所看到的,你是否需要在不同的服务器上使用相同的密钥不是我为你做的决定;这其中有权衡,而且你需要去决定什么是最好的。
|
||||
|
||||
最终,你可能会有:
|
||||
|
||||
- 需要登录的多个服务器
|
||||
|
||||
- 多个用户登陆不同的服务器,每个都有自己的密钥
|
||||
|
||||
- 每个用户多个密钥当他们登陆不同的服务器的时候
|
||||
|
||||
(如果你正在别的情况下使用密钥,相同的普遍概念会应用于如何使用密钥,需要多少密钥,他们是否共享,你如何处理密钥的私密部分和公开部分。)
|
||||
|
||||
## 安全方法
|
||||
|
||||
知道你的基础设施和独一无二的情况,你需要组合一个密钥管理方案,它会引导你去分发和存储你的密钥。比如,正如我之前提到的,如果我的平板被偷了,我会从我服务器上删除公钥,期望在平板在用于访问服务器。同样的,我会在我的整体计划中考虑以下内容:
|
||||
|
||||
1. 移动设备上的私钥没有问题,但是必须包含口令字;
|
||||
|
||||
2. 必须有一个方法可以快速地从服务器上删除公钥。
|
||||
|
||||
在你的情况中,你可能决定,你不想在自己经常登录的系统上使用口令字;比如,这个系统可能是一个开发者一天登录多次的测试机器。这没有问题,但是你需要调整你的规则。你可能添加一条规则,不可以通过移动设备登录机器。换句话说,你需要根据自己的状况构建你的协议,不要假设某个方案放之四海而皆准。
|
||||
|
||||
## 软件
|
||||
|
||||
至于软件,毫不意外,现实世界中并没有很多好的,可用的软件解决方案去存储和管理你的私钥。但是应该有吗?考虑到这个,如果你有一个程序存储你所有服务器的全部密钥,并且这个程序被一个核心密钥锁住,那么你的密钥就真的安全了吗?或者,同样的,如果你的密钥被放置在你的硬盘上,用于 SSH 程序快速访问,那样一个密钥管理软件是否真正提供了任何保护吗?
|
||||
|
||||
但是对于整体基础设施和创建,管理公钥,有许多的解决方案。我已经提到了 Puppet。在 Puppet 的世界中,你创建模块来以不同的方式管理你的服务器。这个想法是服务器是动态的,而且不必要准确地复制其他机器。[这里有一个聪明的途径](http://manuel.kiessling.net/2014/03/26/building-manageable-server-infrastructures-with-puppet-part-4/),它在不同的服务器上使用相同的密钥,但是对于每一个用户使用不同的 Puppet 模块。这个方案可能适合你,也可能不适合你。
|
||||
|
||||
或者,另一个选项就是完全换挡。在 Docker 的世界中,你可以采取一个不同的方式,正如[关于 SSH 和 Docker 博客](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)所描述的。
|
||||
|
||||
但是怎么样管理私钥?如果你搜索,你无法找到很多的软件选择,原因我之前提到过;密钥存放在你的硬盘上,一个管理软件可能无法提到很多额外的安全。但是我确实使用这种方法来管理我的密钥:
|
||||
|
||||
首先,我的 `.ssh/config` 文件中有很多的主机项。我有一个我登陆的主机项,但是有时我对于一个单独的主机有不止一项。如果我有很多登陆,那种情况就会发生。对于架设我的 git 库的服务器,我有两个不同的登陆项;一个限制于 git,另一个为普遍目的的 bash 访问。这个为 git 设置的登陆选项在机器上有极大的限制。还记得我之前说的关于我存在于远程开发机器上的 git 密钥吗?好了。虽然这些密钥可以登陆到我其中一个服务器,但是使用的账号是被严格限制的。
|
||||
|
||||
其次,大部分的私钥都包含口令字。(对于处理不得不多次输入口令字的情况,考虑使用 [ssh-agent](http://blog.docker.com/2014/06/why-you-dont-need-to-run-sshd-in-docker/)。)
|
||||
|
||||
再次,我确实有许多服务器,我想要更加小心地防御,并且在我 host 文件中并没有这样的项。这更加接近于社交工程方面,因为密钥文件还存在于那里,但是可能需要攻击者花费更长的时间去定位这个密钥文件,分析出来他们攻击的机器。在这些例子中,我只是手动打出来长的 SSH 命令。(这真不怎么坏。)
|
||||
|
||||
同时你可以看出来我没有使用任何特别的软件去管理这些私钥。
|
||||
|
||||
## 无放之四海而皆准的方案
|
||||
|
||||
我们偶然间收到 linux.com 的问题,关于管理密钥的好软件的建议。但是让我们后退一步。这个问题事实上需要重新定制,因为没有一个普适的解决方案。你问的问题基于你自己的状况。你是否简单地尝试找到一个位置去存储你的密钥文件?你是否寻找一个方法去管理多用户问题,其中每个人都需要将他们自己的公钥插入到 `authorized_keys` 文件中?
|
||||
|
||||
通过这篇文章,我已经囊括了基础知识,希望到此你明白如何管理你的密钥,并且,只有当你问了正确的问题,无论你寻找任何软件(甚至你需要另外的软件),它都会出现。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/838235-how-to-best-manage-encryption-keys-on-linux
|
||||
|
||||
作者:[Jeff Cogswell][a]
|
||||
译者:[mudongliang](https://github.com/mudongliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/62256
|
||||
150
translated/tech/20160309 Let’s Build A Web Server. Part 1.md
Normal file
150
translated/tech/20160309 Let’s Build A Web Server. Part 1.md
Normal file
@ -0,0 +1,150 @@
|
||||
Let’s Build A Web Server. Part 1.
|
||||
=====================================
|
||||
|
||||
Out for a walk one day, a woman came across a construction site and saw three men working. She asked the first man, “What are you doing?” Annoyed by the question, the first man barked, “Can’t you see that I’m laying bricks?” Not satisfied with the answer, she asked the second man what he was doing. The second man answered, “I’m building a brick wall.” Then, turning his attention to the first man, he said, “Hey, you just passed the end of the wall. You need to take off that last brick.” Again not satisfied with the answer, she asked the third man what he was doing. And the man said to her while looking up in the sky, “I am building the biggest cathedral this world has ever known.” While he was standing there and looking up in the sky the other two men started arguing about the errant brick. The man turned to the first two men and said, “Hey guys, don’t worry about that brick. It’s an inside wall, it will get plastered over and no one will ever see that brick. Just move on to another layer.”1
|
||||
|
||||
The moral of the story is that when you know the whole system and understand how different pieces fit together (bricks, walls, cathedral), you can identify and fix problems faster (errant brick).
|
||||
|
||||
What does it have to do with creating your own Web server from scratch?
|
||||
|
||||
I believe to become a better developer you MUST get a better understanding of the underlying software systems you use on a daily basis and that includes programming languages, compilers and interpreters, databases and operating systems, web servers and web frameworks. And, to get a better and deeper understanding of those systems you MUST re-build them from scratch, brick by brick, wall by wall.
|
||||
|
||||
Confucius put it this way:
|
||||
|
||||
>“I hear and I forget.”
|
||||
|
||||
|
||||
|
||||
>“I see and I remember.”
|
||||
|
||||
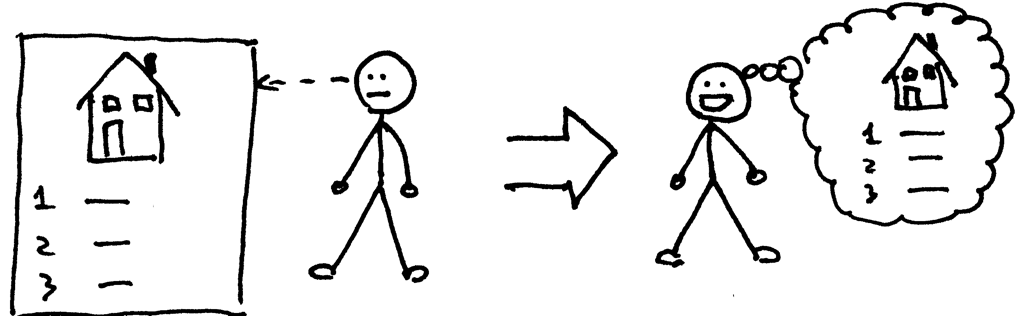
|
||||
|
||||
>“I do and I understand.”
|
||||
|
||||
|
||||
|
||||
I hope at this point you’re convinced that it’s a good idea to start re-building different software systems to learn how they work.
|
||||
|
||||
In this three-part series I will show you how to build your own basic Web server. Let’s get started.
|
||||
|
||||
First things first, what is a Web server?
|
||||
|
||||
|
||||
|
||||
In a nutshell it’s a networking server that sits on a physical server (oops, a server on a server) and waits for a client to send a request. When it receives a request, it generates a response and sends it back to the client. The communication between a client and a server happens using HTTP protocol. A client can be your browser or any other software that speaks HTTP.
|
||||
|
||||
What would a very simple implementation of a Web server look like? Here is my take on it. The example is in Python but even if you don’t know Python (it’s a very easy language to pick up, try it!) you still should be able to understand concepts from the code and explanations below:
|
||||
|
||||
```
|
||||
import socket
|
||||
|
||||
HOST, PORT = '', 8888
|
||||
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
listen_socket.bind((HOST, PORT))
|
||||
listen_socket.listen(1)
|
||||
print 'Serving HTTP on port %s ...' % PORT
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
request = client_connection.recv(1024)
|
||||
print request
|
||||
|
||||
http_response = """\
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
client_connection.close()
|
||||
```
|
||||
|
||||
Save the above code as webserver1.py or download it directly from GitHub and run it on the command line like this
|
||||
|
||||
```
|
||||
$ python webserver1.py
|
||||
Serving HTTP on port 8888 …
|
||||
```
|
||||
|
||||
Now type in the following URL in your Web browser’s address bar http://localhost:8888/hello, hit Enter, and see magic in action. You should see “Hello, World!” displayed in your browser like this:
|
||||
|
||||
|
||||
|
||||
Just do it, seriously. I will wait for you while you’re testing it.
|
||||
|
||||
Done? Great. Now let’s discuss how it all actually works.
|
||||
|
||||
First let’s start with the Web address you’ve entered. It’s called an URL and here is its basic structure:
|
||||
|
||||
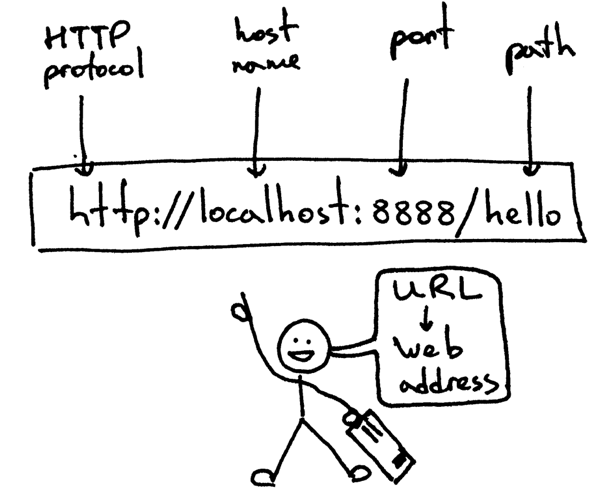
|
||||
|
||||
This is how you tell your browser the address of the Web server it needs to find and connect to and the page (path) on the server to fetch for you. Before your browser can send a HTTP request though, it first needs to establish a TCP connection with the Web server. Then it sends an HTTP request over the TCP connection to the server and waits for the server to send an HTTP response back. And when your browser receives the response it displays it, in this case it displays “Hello, World!”
|
||||
|
||||
Let’s explore in more detail how the client and the server establish a TCP connection before sending HTTP requests and responses. To do that they both use so-called sockets. Instead of using a browser directly you are going to simulate your browser manually by using telnet on the command line.
|
||||
|
||||
On the same computer you’re running the Web server fire up a telnet session on the command line specifying a host to connect to localhost and the port to connect to 8888 and then press Enter:
|
||||
|
||||
```
|
||||
$ telnet localhost 8888
|
||||
Trying 127.0.0.1 …
|
||||
Connected to localhost.
|
||||
```
|
||||
|
||||
At this point you’ve established a TCP connection with the server running on your local host and ready to send and receive HTTP messages. In the picture below you can see a standard procedure a server has to go through to be able to accept new TCP connections.
|
||||
|
||||
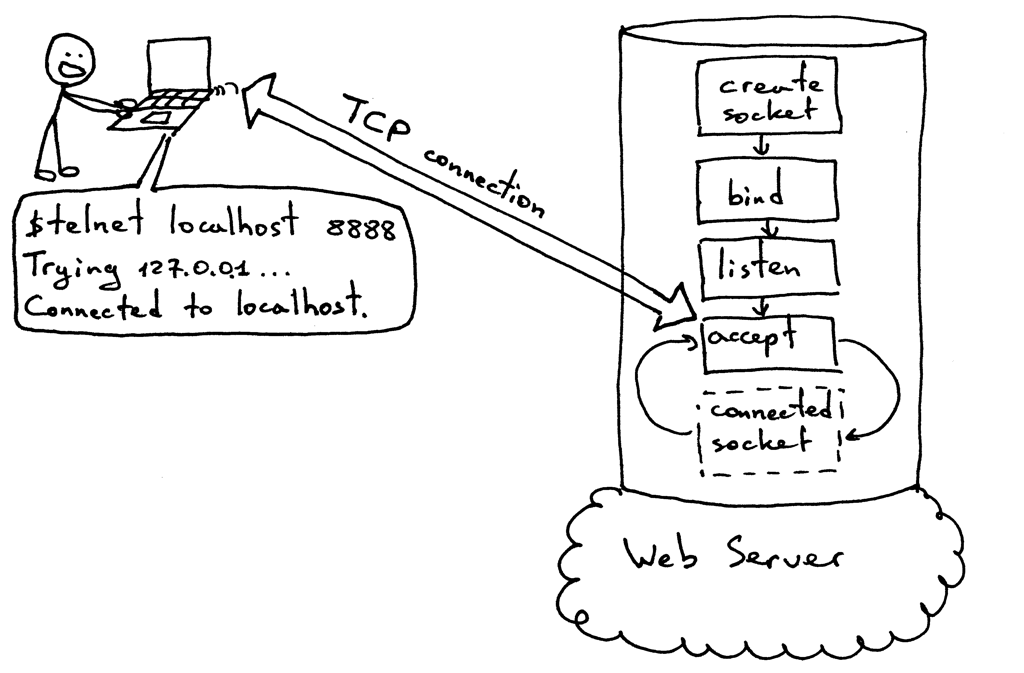
|
||||
|
||||
In the same telnet session type GET /hello HTTP/1.1 and hit Enter:
|
||||
|
||||
```
|
||||
$ telnet localhost 8888
|
||||
Trying 127.0.0.1 …
|
||||
Connected to localhost.
|
||||
GET /hello HTTP/1.1
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
```
|
||||
|
||||
You’ve just manually simulated your browser! You sent an HTTP request and got an HTTP response back. This is the basic structure of an HTTP request:
|
||||
|
||||
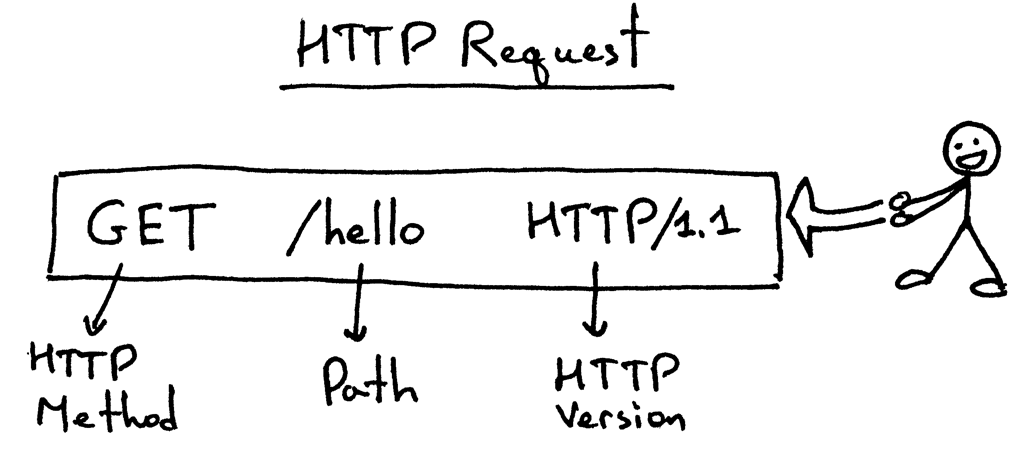
|
||||
|
||||
The HTTP request consists of the line indicating the HTTP method (GET, because we are asking our server to return us something), the path /hello that indicates a “page” on the server we want and the protocol version.
|
||||
|
||||
For simplicity’s sake our Web server at this point completely ignores the above request line. You could just as well type in any garbage instead of “GET /hello HTTP/1.1” and you would still get back a “Hello, World!” response.
|
||||
|
||||
Once you’ve typed the request line and hit Enter the client sends the request to the server, the server reads the request line, prints it and returns the proper HTTP response.
|
||||
|
||||
Here is the HTTP response that the server sends back to your client (telnet in this case):
|
||||
|
||||
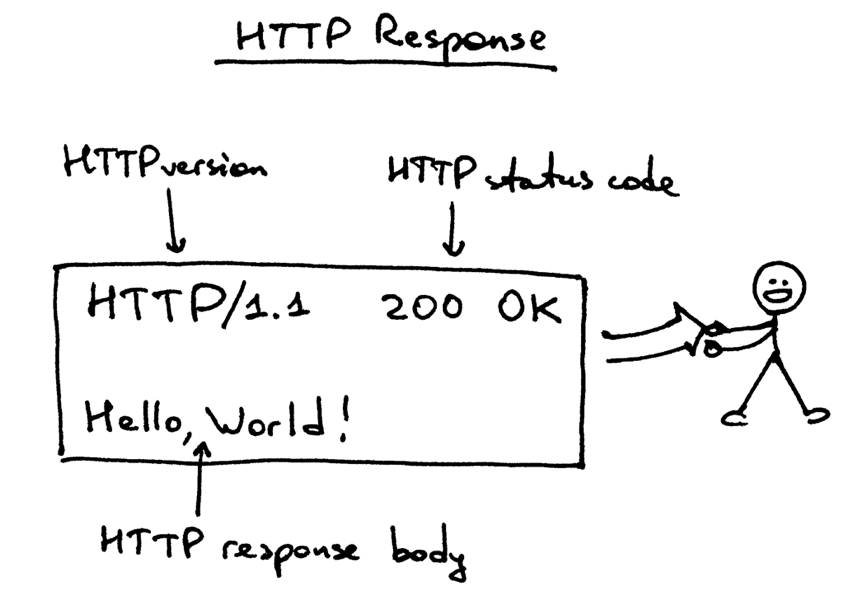
|
||||
|
||||
Let’s dissect it. The response consists of a status line HTTP/1.1 200 OK, followed by a required empty line, and then the HTTP response body.
|
||||
|
||||
The response status line HTTP/1.1 200 OK consists of the HTTP Version, the HTTP status code and the HTTP status code reason phrase OK. When the browser gets the response, it displays the body of the response and that’s why you see “Hello, World!” in your browser.
|
||||
|
||||
And that’s the basic model of how a Web server works. To sum it up: The Web server creates a listening socket and starts accepting new connections in a loop. The client initiates a TCP connection and, after successfully establishing it, the client sends an HTTP request to the server and the server responds with an HTTP response that gets displayed to the user. To establish a TCP connection both clients and servers use sockets.
|
||||
|
||||
Now you have a very basic working Web server that you can test with your browser or some other HTTP client. As you’ve seen and hopefully tried, you can also be a human HTTP client too, by using telnet and typing HTTP requests manually.
|
||||
|
||||
Here’s a question for you: “How do you run a Django application, Flask application, and Pyramid application under your freshly minted Web server without making a single change to the server to accommodate all those different Web frameworks?”
|
||||
|
||||
I will show you exactly how in Part 2 of the series. Stay tuned.
|
||||
|
||||
BTW, I’m writing a book “Let’s Build A Web Server: First Steps” that explains how to write a basic web server from scratch and goes into more detail on topics I just covered. Subscribe to the mailing list to get the latest updates about the book and the release date.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbaws-part1/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://linkedin.com/in/ruslanspivak/
|
||||
|
||||
|
||||
|
||||
427
translated/tech/20160406 Let’s Build A Web Server. Part 2.md
Normal file
427
translated/tech/20160406 Let’s Build A Web Server. Part 2.md
Normal file
@ -0,0 +1,427 @@
|
||||
Let’s Build A Web Server. Part 2.
|
||||
===================================
|
||||
|
||||
Remember, in Part 1 I asked you a question: “How do you run a Django application, Flask application, and Pyramid application under your freshly minted Web server without making a single change to the server to accommodate all those different Web frameworks?” Read on to find out the answer.
|
||||
|
||||
In the past, your choice of a Python Web framework would limit your choice of usable Web servers, and vice versa. If the framework and the server were designed to work together, then you were okay:
|
||||
|
||||
|
||||
|
||||
But you could have been faced (and maybe you were) with the following problem when trying to combine a server and a framework that weren’t designed to work together:
|
||||
|
||||
|
||||
|
||||
Basically you had to use what worked together and not what you might have wanted to use.
|
||||
|
||||
So, how do you then make sure that you can run your Web server with multiple Web frameworks without making code changes either to the Web server or to the Web frameworks? And the answer to that problem became the Python Web Server Gateway Interface (or WSGI for short, pronounced “wizgy”).
|
||||
|
||||

|
||||
|
||||
WSGI allowed developers to separate choice of a Web framework from choice of a Web server. Now you can actually mix and match Web servers and Web frameworks and choose a pairing that suits your needs. You can run Django, Flask, or Pyramid, for example, with Gunicorn or Nginx/uWSGI or Waitress. Real mix and match, thanks to the WSGI support in both servers and frameworks:
|
||||
|
||||
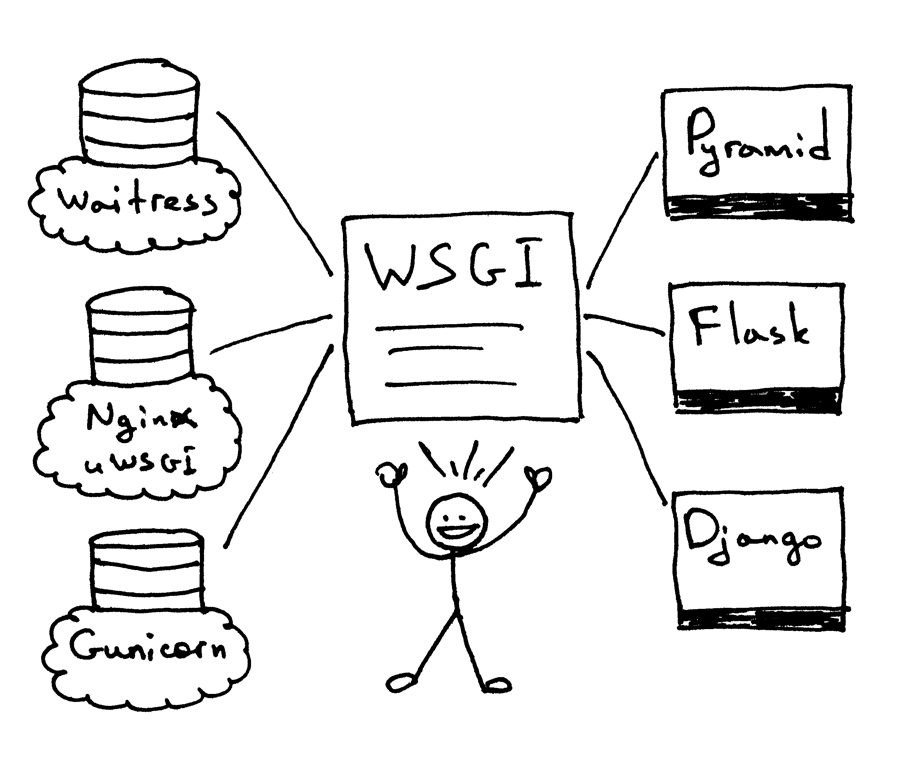
|
||||
|
||||
So, WSGI is the answer to the question I asked you in Part 1 and repeated at the beginning of this article. Your Web server must implement the server portion of a WSGI interface and all modern Python Web Frameworks already implement the framework side of the WSGI interface, which allows you to use them with your Web server without ever modifying your server’s code to accommodate a particular Web framework.
|
||||
|
||||
Now you know that WSGI support by Web servers and Web frameworks allows you to choose a pairing that suits you, but it is also beneficial to server and framework developers because they can focus on their preferred area of specialization and not step on each other’s toes. Other languages have similar interfaces too: Java, for example, has Servlet API and Ruby has Rack.
|
||||
|
||||
It’s all good, but I bet you are saying: “Show me the code!” Okay, take a look at this pretty minimalistic WSGI server implementation:
|
||||
|
||||
```
|
||||
# Tested with Python 2.7.9, Linux & Mac OS X
|
||||
import socket
|
||||
import StringIO
|
||||
import sys
|
||||
|
||||
|
||||
class WSGIServer(object):
|
||||
|
||||
address_family = socket.AF_INET
|
||||
socket_type = socket.SOCK_STREAM
|
||||
request_queue_size = 1
|
||||
|
||||
def __init__(self, server_address):
|
||||
# Create a listening socket
|
||||
self.listen_socket = listen_socket = socket.socket(
|
||||
self.address_family,
|
||||
self.socket_type
|
||||
)
|
||||
# Allow to reuse the same address
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
# Bind
|
||||
listen_socket.bind(server_address)
|
||||
# Activate
|
||||
listen_socket.listen(self.request_queue_size)
|
||||
# Get server host name and port
|
||||
host, port = self.listen_socket.getsockname()[:2]
|
||||
self.server_name = socket.getfqdn(host)
|
||||
self.server_port = port
|
||||
# Return headers set by Web framework/Web application
|
||||
self.headers_set = []
|
||||
|
||||
def set_app(self, application):
|
||||
self.application = application
|
||||
|
||||
def serve_forever(self):
|
||||
listen_socket = self.listen_socket
|
||||
while True:
|
||||
# New client connection
|
||||
self.client_connection, client_address = listen_socket.accept()
|
||||
# Handle one request and close the client connection. Then
|
||||
# loop over to wait for another client connection
|
||||
self.handle_one_request()
|
||||
|
||||
def handle_one_request(self):
|
||||
self.request_data = request_data = self.client_connection.recv(1024)
|
||||
# Print formatted request data a la 'curl -v'
|
||||
print(''.join(
|
||||
'< {line}\n'.format(line=line)
|
||||
for line in request_data.splitlines()
|
||||
))
|
||||
|
||||
self.parse_request(request_data)
|
||||
|
||||
# Construct environment dictionary using request data
|
||||
env = self.get_environ()
|
||||
|
||||
# It's time to call our application callable and get
|
||||
# back a result that will become HTTP response body
|
||||
result = self.application(env, self.start_response)
|
||||
|
||||
# Construct a response and send it back to the client
|
||||
self.finish_response(result)
|
||||
|
||||
def parse_request(self, text):
|
||||
request_line = text.splitlines()[0]
|
||||
request_line = request_line.rstrip('\r\n')
|
||||
# Break down the request line into components
|
||||
(self.request_method, # GET
|
||||
self.path, # /hello
|
||||
self.request_version # HTTP/1.1
|
||||
) = request_line.split()
|
||||
|
||||
def get_environ(self):
|
||||
env = {}
|
||||
# The following code snippet does not follow PEP8 conventions
|
||||
# but it's formatted the way it is for demonstration purposes
|
||||
# to emphasize the required variables and their values
|
||||
#
|
||||
# Required WSGI variables
|
||||
env['wsgi.version'] = (1, 0)
|
||||
env['wsgi.url_scheme'] = 'http'
|
||||
env['wsgi.input'] = StringIO.StringIO(self.request_data)
|
||||
env['wsgi.errors'] = sys.stderr
|
||||
env['wsgi.multithread'] = False
|
||||
env['wsgi.multiprocess'] = False
|
||||
env['wsgi.run_once'] = False
|
||||
# Required CGI variables
|
||||
env['REQUEST_METHOD'] = self.request_method # GET
|
||||
env['PATH_INFO'] = self.path # /hello
|
||||
env['SERVER_NAME'] = self.server_name # localhost
|
||||
env['SERVER_PORT'] = str(self.server_port) # 8888
|
||||
return env
|
||||
|
||||
def start_response(self, status, response_headers, exc_info=None):
|
||||
# Add necessary server headers
|
||||
server_headers = [
|
||||
('Date', 'Tue, 31 Mar 2015 12:54:48 GMT'),
|
||||
('Server', 'WSGIServer 0.2'),
|
||||
]
|
||||
self.headers_set = [status, response_headers + server_headers]
|
||||
# To adhere to WSGI specification the start_response must return
|
||||
# a 'write' callable. We simplicity's sake we'll ignore that detail
|
||||
# for now.
|
||||
# return self.finish_response
|
||||
|
||||
def finish_response(self, result):
|
||||
try:
|
||||
status, response_headers = self.headers_set
|
||||
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
|
||||
for header in response_headers:
|
||||
response += '{0}: {1}\r\n'.format(*header)
|
||||
response += '\r\n'
|
||||
for data in result:
|
||||
response += data
|
||||
# Print formatted response data a la 'curl -v'
|
||||
print(''.join(
|
||||
'> {line}\n'.format(line=line)
|
||||
for line in response.splitlines()
|
||||
))
|
||||
self.client_connection.sendall(response)
|
||||
finally:
|
||||
self.client_connection.close()
|
||||
|
||||
|
||||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||||
|
||||
|
||||
def make_server(server_address, application):
|
||||
server = WSGIServer(server_address)
|
||||
server.set_app(application)
|
||||
return server
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if len(sys.argv) < 2:
|
||||
sys.exit('Provide a WSGI application object as module:callable')
|
||||
app_path = sys.argv[1]
|
||||
module, application = app_path.split(':')
|
||||
module = __import__(module)
|
||||
application = getattr(module, application)
|
||||
httpd = make_server(SERVER_ADDRESS, application)
|
||||
print('WSGIServer: Serving HTTP on port {port} ...\n'.format(port=PORT))
|
||||
httpd.serve_forever()
|
||||
```
|
||||
|
||||
It’s definitely bigger than the server code in Part 1, but it’s also small enough (just under 150 lines) for you to understand without getting bogged down in details. The above server also does more - it can run your basic Web application written with your beloved Web framework, be it Pyramid, Flask, Django, or some other Python WSGI framework.
|
||||
|
||||
Don’t believe me? Try it and see for yourself. Save the above code as webserver2.py or download it directly from GitHub. If you try to run it without any parameters it’s going to complain and exit.
|
||||
|
||||
```
|
||||
$ python webserver2.py
|
||||
Provide a WSGI application object as module:callable
|
||||
```
|
||||
|
||||
It really wants to serve your Web application and that’s where the fun begins. To run the server the only thing you need installed is Python. But to run applications written with Pyramid, Flask, and Django you need to install those frameworks first. Let’s install all three of them. My preferred method is by using virtualenv. Just follow the steps below to create and activate a virtual environment and then install all three Web frameworks.
|
||||
|
||||
```
|
||||
$ [sudo] pip install virtualenv
|
||||
$ mkdir ~/envs
|
||||
$ virtualenv ~/envs/lsbaws/
|
||||
$ cd ~/envs/lsbaws/
|
||||
$ ls
|
||||
bin include lib
|
||||
$ source bin/activate
|
||||
(lsbaws) $ pip install pyramid
|
||||
(lsbaws) $ pip install flask
|
||||
(lsbaws) $ pip install django
|
||||
```
|
||||
|
||||
At this point you need to create a Web application. Let’s start with Pyramid first. Save the following code as pyramidapp.py to the same directory where you saved webserver2.py or download the file directly from GitHub:
|
||||
|
||||
```
|
||||
from pyramid.config import Configurator
|
||||
from pyramid.response import Response
|
||||
|
||||
|
||||
def hello_world(request):
|
||||
return Response(
|
||||
'Hello world from Pyramid!\n',
|
||||
content_type='text/plain',
|
||||
)
|
||||
|
||||
config = Configurator()
|
||||
config.add_route('hello', '/hello')
|
||||
config.add_view(hello_world, route_name='hello')
|
||||
app = config.make_wsgi_app()
|
||||
```
|
||||
|
||||
Now you’re ready to serve your Pyramid application with your very own Web server:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py pyramidapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
You just told your server to load the ‘app’ callable from the python module ‘pyramidapp’ Your server is now ready to take requests and forward them to your Pyramid application. The application only handles one route now: the /hello route. Type http://localhost:8888/hello address into your browser, press Enter, and observe the result:
|
||||
|
||||
|
||||
|
||||
You can also test the server on the command line using the ‘curl’ utility:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Check what the server and curl prints to standard output.
|
||||
|
||||
Now onto Flask. Let’s follow the same steps.
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask import Response
|
||||
flask_app = Flask('flaskapp')
|
||||
|
||||
|
||||
@flask_app.route('/hello')
|
||||
def hello_world():
|
||||
return Response(
|
||||
'Hello world from Flask!\n',
|
||||
mimetype='text/plain'
|
||||
)
|
||||
|
||||
app = flask_app.wsgi_app
|
||||
```
|
||||
|
||||
Save the above code as flaskapp.py or download it from GitHub and run the server as:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py flaskapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
Now type in the http://localhost:8888/hello into your browser and press Enter:
|
||||
|
||||
|
||||
|
||||
Again, try ‘curl’ and see for yourself that the server returns a message generated by the Flask application:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Can the server also handle a Django application? Try it out! It’s a little bit more involved, though, and I would recommend cloning the whole repo and use djangoapp.py, which is part of the GitHub repository. Here is the source code which basically adds the Django ‘helloworld’ project (pre-created using Django’s django-admin.py startproject command) to the current Python path and then imports the project’s WSGI application.
|
||||
|
||||
```
|
||||
import sys
|
||||
sys.path.insert(0, './helloworld')
|
||||
from helloworld import wsgi
|
||||
|
||||
|
||||
app = wsgi.application
|
||||
```
|
||||
|
||||
Save the above code as djangoapp.py and run the Django application with your Web server:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py djangoapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
Type in the following address and press Enter:
|
||||
|
||||
|
||||
|
||||
And as you’ve already done a couple of times before, you can test it on the command line, too, and confirm that it’s the Django application that handles your requests this time around:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Did you try it? Did you make sure the server works with those three frameworks? If not, then please do so. Reading is important, but this series is about rebuilding and that means you need to get your hands dirty. Go and try it. I will wait for you, don’t worry. No seriously, you must try it and, better yet, retype everything yourself and make sure that it works as expected.
|
||||
|
||||
Okay, you’ve experienced the power of WSGI: it allows you to mix and match your Web servers and Web frameworks. WSGI provides a minimal interface between Python Web servers and Python Web Frameworks. It’s very simple and it’s easy to implement on both the server and the framework side. The following code snippet shows the server and the framework side of the interface:
|
||||
|
||||
```
|
||||
def run_application(application):
|
||||
"""Server code."""
|
||||
# This is where an application/framework stores
|
||||
# an HTTP status and HTTP response headers for the server
|
||||
# to transmit to the client
|
||||
headers_set = []
|
||||
# Environment dictionary with WSGI/CGI variables
|
||||
environ = {}
|
||||
|
||||
def start_response(status, response_headers, exc_info=None):
|
||||
headers_set[:] = [status, response_headers]
|
||||
|
||||
# Server invokes the ‘application' callable and gets back the
|
||||
# response body
|
||||
result = application(environ, start_response)
|
||||
# Server builds an HTTP response and transmits it to the client
|
||||
…
|
||||
|
||||
def app(environ, start_response):
|
||||
"""A barebones WSGI app."""
|
||||
start_response('200 OK', [('Content-Type', 'text/plain')])
|
||||
return ['Hello world!']
|
||||
|
||||
run_application(app)
|
||||
```
|
||||
|
||||
Here is how it works:
|
||||
|
||||
1. The framework provides an ‘application’ callable (The WSGI specification doesn’t prescribe how that should be implemented)
|
||||
2. The server invokes the ‘application’ callable for each request it receives from an HTTP client. It passes a dictionary ‘environ’ containing WSGI/CGI variables and a ‘start_response’ callable as arguments to the ‘application’ callable.
|
||||
3. The framework/application generates an HTTP status and HTTP response headers and passes them to the ‘start_response’ callable for the server to store them. The framework/application also returns a response body.
|
||||
4. The server combines the status, the response headers, and the response body into an HTTP response and transmits it to the client (This step is not part of the specification but it’s the next logical step in the flow and I added it for clarity)
|
||||
|
||||
And here is a visual representation of the interface:
|
||||
|
||||
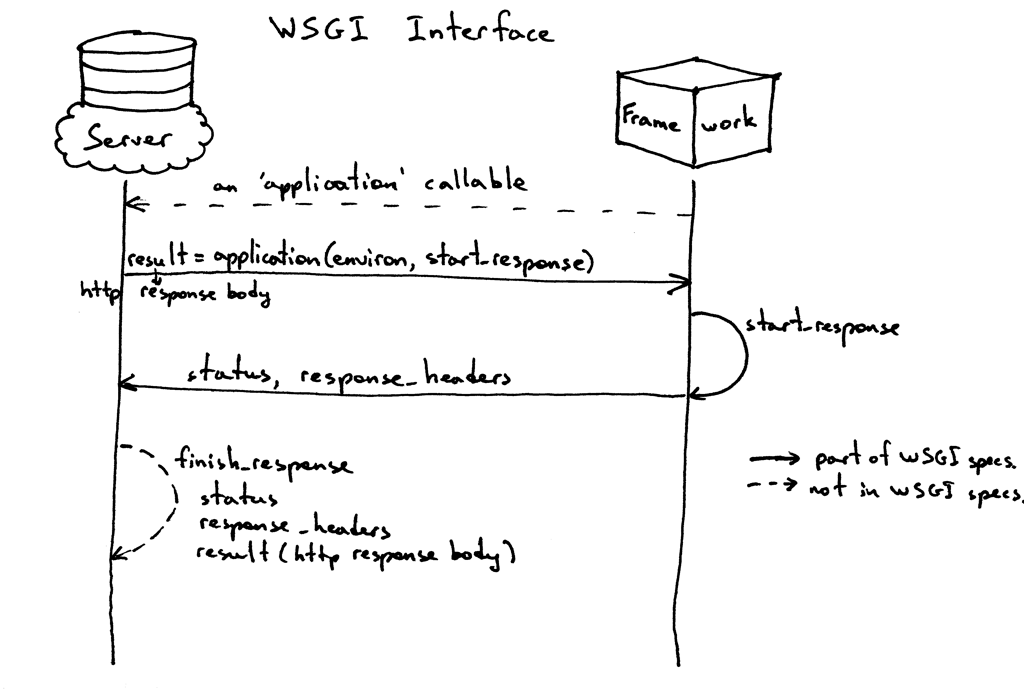
|
||||
|
||||
So far, you’ve seen the Pyramid, Flask, and Django Web applications and you’ve seen the server code that implements the server side of the WSGI specification. You’ve even seen the barebones WSGI application code snippet that doesn’t use any framework.
|
||||
|
||||
The thing is that when you write a Web application using one of those frameworks you work at a higher level and don’t work with WSGI directly, but I know you’re curious about the framework side of the WSGI interface, too because you’re reading this article. So, let’s create a minimalistic WSGI Web application/Web framework without using Pyramid, Flask, or Django and run it with your server:
|
||||
|
||||
```
|
||||
def app(environ, start_response):
|
||||
"""A barebones WSGI application.
|
||||
|
||||
This is a starting point for your own Web framework :)
|
||||
"""
|
||||
status = '200 OK'
|
||||
response_headers = [('Content-Type', 'text/plain')]
|
||||
start_response(status, response_headers)
|
||||
return ['Hello world from a simple WSGI application!\n']
|
||||
```
|
||||
|
||||
Again, save the above code in wsgiapp.py file or download it from GitHub directly and run the application under your Web server as:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py wsgiapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
Type in the following address and press Enter. This is the result you should see:
|
||||
|
||||
|
||||
|
||||
You just wrote your very own minimalistic WSGI Web framework while learning about how to create a Web server! Outrageous.
|
||||
|
||||
Now, let’s get back to what the server transmits to the client. Here is the HTTP response the server generates when you call your Pyramid application using an HTTP client:
|
||||
|
||||

|
||||
|
||||
The response has some familiar parts that you saw in Part 1 but it also has something new. It has, for example, four HTTP headers that you haven’t seen before: Content-Type, Content-Length, Date, and Server. Those are the headers that a response from a Web server generally should have. None of them are strictly required, though. The purpose of the headers is to transmit additional information about the HTTP request/response.
|
||||
|
||||
Now that you know more about the WSGI interface, here is the same HTTP response with some more information about what parts produced it:
|
||||
|
||||
|
||||
|
||||
I haven’t said anything about the ‘environ’ dictionary yet, but basically it’s a Python dictionary that must contain certain WSGI and CGI variables prescribed by the WSGI specification. The server takes the values for the dictionary from the HTTP request after parsing the request. This is what the contents of the dictionary look like:
|
||||
|
||||
|
||||
|
||||
A Web framework uses the information from that dictionary to decide which view to use based on the specified route, request method etc., where to read the request body from and where to write errors, if any.
|
||||
|
||||
By now you’ve created your own WSGI Web server and you’ve made Web applications written with different Web frameworks. And, you’ve also created your barebones Web application/Web framework along the way. It’s been a heck of a journey. Let’s recap what your WSGI Web server has to do to serve requests aimed at a WSGI application:
|
||||
|
||||
- First, the server starts and loads an ‘application’ callable provided by your Web framework/application
|
||||
- Then, the server reads a request
|
||||
- Then, the server parses it
|
||||
- Then, it builds an ‘environ’ dictionary using the request data
|
||||
- Then, it calls the ‘application’ callable with the ‘environ’ dictionary and a ‘start_response’ callable as parameters and gets back a response body.
|
||||
- Then, the server constructs an HTTP response using the data returned by the call to the ‘application’ object and the status and response headers set by the ‘start_response’ callable.
|
||||
- And finally, the server transmits the HTTP response back to the client
|
||||
|
||||
|
||||
|
||||
That’s about all there is to it. You now have a working WSGI server that can serve basic Web applications written with WSGI compliant Web frameworks like Django, Flask, Pyramid, or your very own WSGI framework. The best part is that the server can be used with multiple Web frameworks without any changes to the server code base. Not bad at all.
|
||||
|
||||
Before you go, here is another question for you to think about, “How do you make your server handle more than one request at a time?”
|
||||
|
||||
Stay tuned and I will show you a way to do that in Part 3. Cheers!
|
||||
|
||||
BTW, I’m writing a book “Let’s Build A Web Server: First Steps” that explains how to write a basic web server from scratch and goes into more detail on topics I just covered. Subscribe to the mailing list to get the latest updates about the book and the release date.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbaws-part2/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/rspivak/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
228
translated/tech/20160620 Detecting cats in images with OpenCV.md
Normal file
228
translated/tech/20160620 Detecting cats in images with OpenCV.md
Normal file
@ -0,0 +1,228 @@
|
||||
使用 OpenCV 识别图片中的猫
|
||||
=======================================
|
||||
|
||||

|
||||
|
||||
你知道 OpenCV 可以识别在图片中识别猫脸吗?还是在开箱即用的情况下,无需多余的附件。
|
||||
|
||||
我也不知道。
|
||||
|
||||
但是在看完'[Kendrick Tan broke the story][1]'这个故事之后, 我需要亲自体验一下...去看看到OpenCV 是如何在我没有察觉到的情况下,将这一个功能添加进了他的软件库。
|
||||
|
||||
作为这个博客的大纲,我将会展示如何使用 OpenCV 的猫检测器在图片中识别猫脸。同样的,你也可以在视频流中使用该技术。
|
||||
|
||||
> 想找这篇博客的源码?[请点这][2]。
|
||||
|
||||
|
||||
### 使用 OpenCV 在图片中检测猫
|
||||
|
||||
如果你看一眼[OpenCV 的代码库][3],尤其是在[haarcascades 目录][4](OpenCV 用来保存处理他对多种目标检测的Cascade预先训练的级联图像分类), 你将会注意到这两个文件:
|
||||
|
||||
- haarcascade_frontalcatface.xml
|
||||
- haarcascade_frontalcatface_extended.xml
|
||||
|
||||
这两个 Haar Cascade 文件都将被用来在图片中检测猫脸。实际上,我使用了相同的方式来生成这篇博客顶端的图片。
|
||||
|
||||
在做了一些调查工作之后,我发现训练这些记过并且将其提供给 OpenCV 仓库的是鼎鼎大名的 [Joseph Howse][5],他在计算机视觉领域有着很高的声望。
|
||||
|
||||
在博客的剩余部分,我将会展示给你如何使用 Howse 的 Haar 级联模型来检测猫。
|
||||
|
||||
让我们开工。新建一个叫 cat_detector.py 的文件,并且输入如下的代码:
|
||||
|
||||
### 使用 OpenCVPython 来检测猫
|
||||
|
||||
```
|
||||
# import the necessary packages
|
||||
import argparse
|
||||
import cv2
|
||||
|
||||
# construct the argument parse and parse the arguments
|
||||
ap = argparse.ArgumentParser()
|
||||
ap.add_argument("-i", "--image", required=True,
|
||||
help="path to the input image")
|
||||
ap.add_argument("-c", "--cascade",
|
||||
default="haarcascade_frontalcatface.xml",
|
||||
help="path to cat detector haar cascade")
|
||||
args = vars(ap.parse_args())
|
||||
```
|
||||
|
||||
第2和第3行主要是导入了必要的 python 包。6-12行主要是我们的命令行参数。我们在这只需要使用单独的参数'--image'。
|
||||
|
||||
我们可以指定一个 Haar cascade 的路径通过 `--cascade` 参数。默认使用 `haarcascades_frontalcatface.xml`,同时需要保证这个文件和你的 `cat_detector.py` 在同一目录下。
|
||||
|
||||
注意:我已经打包了猫的检测代码,还有在这个教程里的样本图片。你可以在博客的'Downloads' 部分下载到。如果你是刚刚接触 Python+OpenCV(或者 Haar 级联模型), 我会建议你下载 zip 压缩包,这个会方便你进行操作。
|
||||
|
||||
接下来,就是检测猫的时刻了:
|
||||
|
||||
```
|
||||
# load the input image and convert it to grayscale
|
||||
image = cv2.imread(args["image"])
|
||||
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
# load the cat detector Haar cascade, then detect cat faces
|
||||
# in the input image
|
||||
detector = cv2.CascadeClassifier(args["cascade"])
|
||||
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
|
||||
minNeighbors=10, minSize=(75, 75))
|
||||
```
|
||||
|
||||
在15,16行,我们从硬盘上读取了图片,并且进行灰度化(一个常用的图片预处理,方便 Haar cascade 进行分类,尽管不是必须)
|
||||
|
||||
20行,我们加载了Haar casacade,即猫检测器,并且初始化了 cv2.CascadeClassifier 对象。
|
||||
|
||||
使用 OpenCV 检测猫脸的步骤是21,22行,通过调用 detectMultiScale 方法。我们使用四个参数来调用。包括:
|
||||
|
||||
1. 灰度化的图片,即样本图片。
|
||||
2. scaleFactor 参数,[图片金字塔][6]使用的检测猫脸时的检测粒度。一个更大的粒度将会加快检测的速度,但是会对准确性产生影响。相反的,一个更小的粒度将会影响检测的时间,但是会增加正确性。但是,细粒度也会增加错误的检测数量。你可以看博客的 'Haar 级联模型笔记' 部分来获得更多的信息。
|
||||
3. minNeighbors 参数控制了检测的最小数量,即在给定区域最小的检测猫脸的次数。这个参数很好的可以排除错误的检测结果。
|
||||
4. 最后,minSize 参数很好的自我说明了用途。即最后图片的最小大小,这个例子中就是 75\*75
|
||||
|
||||
detectMultiScale 函数 return rects,这是一个4维数组链表。这些item 中包含了猫脸的(x,y)坐标值,还有宽度,高度。
|
||||
|
||||
最后,让我们在图片上画下这些矩形来标识猫脸:
|
||||
|
||||
```
|
||||
# loop over the cat faces and draw a rectangle surrounding each
|
||||
for (i, (x, y, w, h)) in enumerate(rects):
|
||||
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
|
||||
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
|
||||
|
||||
# show the detected cat faces
|
||||
cv2.imshow("Cat Faces", image)
|
||||
cv2.waitKey(0)
|
||||
```
|
||||
|
||||
给相关的区域(举个例子,rects),我们在25行依次历遍它。
|
||||
|
||||
在26行,我们在每张猫脸的周围画上一个矩形。27,28行展示了一个整数,即图片中猫的数量。
|
||||
|
||||
最后,31,32行在屏幕上展示了输出的图片。
|
||||
|
||||
### 猫检测结果
|
||||
|
||||
为了测试我们的 OpenCV 毛检测器,可以在文章的最后,下载教程的源码。
|
||||
|
||||
然后,在你解压缩之后,你将会得到如下的三个文件/目录:
|
||||
|
||||
1. cat_detector.py:我们的主程序
|
||||
2. haarcascade_frontalcatface.xml: Haar cascade 猫检测资源
|
||||
3. images:我们将会使用的检测图片目录。
|
||||
|
||||
到这一步,执行以下的命令:
|
||||
|
||||
使用 OpenCVShell 检测猫。
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_01.jpg
|
||||
```
|
||||
|
||||

|
||||
>1. 在图片中检测猫脸,甚至是猫的一部分。
|
||||
|
||||
注意,我们已经可以检测猫脸了,即使他的其余部分是被隐藏的。
|
||||
|
||||
试下另外的一张图片:
|
||||
|
||||
```
|
||||
python cat_detector.py --image images/cat_02.jpg
|
||||
```
|
||||
|
||||

|
||||
>2. 第二个例子就是在略微不同的猫脸中检测。
|
||||
|
||||
这次的猫脸和第一次的明显不同,因为它在'Meow'的中央。这种情况下,我们依旧能检测到正确的猫脸。
|
||||
|
||||
这张图片的结果也是正确的:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_03.jpg
|
||||
```
|
||||
|
||||

|
||||
>3. 使用 OpenCV 和 python 检测猫脸
|
||||
|
||||
我们最后的一个样例就是在一张图中检测多张猫脸:
|
||||
|
||||
```
|
||||
$ python cat_detector.py --image images/cat_04.jpg
|
||||
```
|
||||
|
||||

|
||||
>Figure 4: Detecting multiple cats in the same image with OpenCV
|
||||
>4. 在同一张图片中使用 OpenCV 检测多只猫
|
||||
|
||||
注意,Haar cascade 的返回值并不是有序的。这种情况下,中间的那只猫会被标记成第三只。你可以通过判断他们的(x, y)坐标来自己排序。
|
||||
|
||||
#### 精度的 Tips
|
||||
|
||||
xml 文件中的注释,非常重要,Joseph Hower 提到了猫 脸检测器有可能会将人脸识别成猫脸。
|
||||
|
||||
这种情况下,他推荐使用两种检测器(人脸&猫脸),然后将出现在人脸识别结果中的结果剔除掉。
|
||||
|
||||
#### Haar 级联模型注意事项
|
||||
|
||||
这个方法首先出现在 Paul Viola 和 Michael Jones 2001 年发布的 [Rapid Object Detection using a Boosted Cascade of Simple Features] 论文中。现在它已经成为了计算机识别领域引用最多的成果之一。
|
||||
|
||||
这个算法能够识别图片中的对象,无论地点,规模。并且,他也能在现有的硬件条件下实现实时计算。
|
||||
|
||||
在他们的论文中,Viola 和 Jones 关注在训练人脸检测器;但是,这个框架也能用来检测各类事物,如汽车,香蕉,路标等等。
|
||||
|
||||
#### 有问题?
|
||||
|
||||
Haar 级联模型最大的问题就是如何确定 detectMultiScale 方法的参数正确。特别是 scaleFactor 和 minNeighbors 参数。你很容易陷入,一张一张图片调参数的坑,这个就是该模型很难被实用化的原因。
|
||||
|
||||
这个 scaleFactor 变量控制了用来检测图片各种对象的[图像棱锥图][8]。如何参数过大,你就会得到更少的特征值,这会导致你无法在图层中识别一些目标。
|
||||
|
||||
换句话说,如果参数过低,你会检测出过多的图层。这虽然可以能帮助你检测更多的对象。但是他会造成计算速度的降低还会提高错误率。
|
||||
|
||||
为了避免这个,我们通常使用[Histogram of Oriented Gradients + Linear SVM detection][9]。
|
||||
|
||||
HOG + 线性 SVM 框架,它的参数更加容易的进行调优。而且也有更低的错误识别率,但是最大的缺点及时无法实时运算。
|
||||
|
||||
### 对对象识别感兴趣?并且希望了解更多?
|
||||
|
||||

|
||||
>5. 在 PyImageSearch Gurus 课程中学习如何构建自定义的对象识别器。
|
||||
|
||||
如果你对学习如何训练自己的自定义对象识别器,请务必要去学习 PyImageSearch Gurus 的课程。
|
||||
|
||||
在这个课程中,我提供了15节课还有超过168页的教程,来教你如何从0开始构建自定义的对象识别器。你会掌握如何应用 HOG+线性 SVM 计算框架来构建自己的对象识别器。
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇博客里,我们学习了如何使用默认的 Haar 级联模型来识别图片中的猫脸。这些 Haar casacades 是通过[Joseph Howse][9] 贡献给 OpenCV 项目的。我是在[这篇文章][10]中开始注意到这个。
|
||||
|
||||
尽管 Haar 级联模型相当有用,但是我们也经常用 HOG 和 线性 SVM 替代。因为后者相对而言更容易使用,并且可以有效地降低错误的识别概率。
|
||||
|
||||
我也会在[在 PyImageSearch Gurus 的课程中][11]详细的讲述如何使用 HOG 和线性 SVM 对象识别器,来识别包括汽车,路标在内的各种事物。
|
||||
|
||||
不管怎样,我希望你享受这篇博客。
|
||||
|
||||
在你离开之前,确保你会使用这下面的表单注册 PyImageSearch Newsletter。这样你能收到最新的消息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/
|
||||
|
||||
作者:[Adrian Rosebrock][a]
|
||||
译者:[译者ID](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.pyimagesearch.com/author/adrian/
|
||||
[1]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[2]: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/#
|
||||
[3]: https://github.com/Itseez/opencv
|
||||
[4]: https://github.com/Itseez/opencv/tree/master/data/haarcascades
|
||||
[5]: http://nummist.com/
|
||||
[6]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[7]: https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
|
||||
[8]: http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/
|
||||
[9]: http://www.pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/
|
||||
[10]: http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html
|
||||
[11]: https://www.pyimagesearch.com/pyimagesearch-gurus/
|
||||
|
||||
|
||||
|
||||
112
translated/tech/20160620 Monitor Linux With Netdata.md
Normal file
112
translated/tech/20160620 Monitor Linux With Netdata.md
Normal file
@ -0,0 +1,112 @@
|
||||
用 Netdata 监控 Linux
|
||||
=======
|
||||
|
||||
Netdata 是一个实时的资源监控工具,它拥有基于 web 的友好界面,由 [FireHQL][1] 开发和维护。通过这个工具,你可以通过图表来了解 CPU,RAM,硬盘,网络,Apache, Postfix等软硬件的资源使用情况。它很像 Nagios 等别的监控软件;但是,Netdata 仅仅支持通过网络接口进行实时监控。
|
||||
|
||||
### 了解 Netdata
|
||||
|
||||
目前 Netdata 还没有验证机制,如果你担心别人能从你的电脑上获取相关信息的话,你应该设置防火墙规则来限制访问。UI 是简化版的,以便用户查看和理解他们看到的表格数据,至少你能够记住它的快速安装。
|
||||
|
||||
它的 web 前端响应很快,而且不需要 Flash 插件。 UI 很整洁,保持着 Netdata 应有的特性。粗略的看,你能够看到很多图表,幸运的是绝大多数常用的图表数据(像 CPU,RAM,网络和硬盘)都在顶部。如果你想深入了解图形化数据,你只需要下滑滚动条,或者点击在右边菜单的项目。通过每个图表的右下方的按钮, Netdata 还能让你控制图表的显示,重置,缩放。
|
||||
|
||||

|
||||
>Netdata 图表控制
|
||||
|
||||
Netdata 并不会占用多少系统资源,它占用的内存不会超过 40MB。因为这个软件是作者用 C 语言写的。
|
||||
|
||||

|
||||
>Netdata 显示的内存使用情况
|
||||
|
||||
### 下载 Netdata
|
||||
|
||||
要下载这个软件,你可以从访问 [Netdata GitHub page][2]。然后点击页面左边绿色的 "Clone or download" 按钮 。你应该能看到两个选项。
|
||||
|
||||
#### 通过 ZIP 文件下载
|
||||
|
||||
另一种方法是下载 ZIP 文件。它包含在仓库的所有东西。但是如果仓库更新了,你需要重新下载 ZIP 文件。下载完 ZIP 文件后,你要用 `unzip` 命令行工具来解压文件。运行下面的命令能把 ZIP 文件的内容解压到 `netdata` 文件夹。
|
||||
|
||||
```
|
||||
$ cd ~/Downloads
|
||||
$ unzip netdata-master.zip
|
||||
```
|
||||
|
||||

|
||||
>解压 Netdata
|
||||
|
||||
没必要在 unzip 命令后加上 `-d` 选项,因为文件都是是放在 ZIP 文件里的一个文件夹里面。如果没有那个文件夹, unzip 会把所有东西都解压到当前目录下面(这会让文件非常混乱)。
|
||||
|
||||
#### 通过 Git 下载
|
||||
|
||||
还有一种方式是通过 git 下载整个仓库。当然,你的系统需要安装 git。Git 在 Fedora 系统是默认安装的。如果没有安装,你可以用下面的命令在命令行里安装 git。
|
||||
|
||||
```
|
||||
$ sudo dnf install git
|
||||
```
|
||||
|
||||
安装好 git 后,你要把仓库 “clone” 到你的系统里。运行下面的命令。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/firehol/netdata.git
|
||||
```
|
||||
|
||||
这个命令会在当前工作目录克隆(或者说复制一份)仓库。
|
||||
|
||||
### 安装 Netdata
|
||||
|
||||
有些软件包是你成功构造 Netdata 时候需要的。 还好,一行命令就可以安装你所需要的东西([as stated in their installation guide][3])。在命令行运行下面的命令就能满足安装 Netdata 需要的所有依赖关系。
|
||||
|
||||
```
|
||||
$ dnf install zlib-devel libuuid-devel libmnl-devel gcc make git autoconf autogen automake pkgconfig
|
||||
```
|
||||
|
||||
当所有需要的软件包都安装好了,你就 cd 到 netdata/ 目录,运行 netdata-installer.sh 脚本。
|
||||
|
||||
```
|
||||
$ sudo ./netdata-installer.sh
|
||||
```
|
||||
|
||||
然后就会提示你按回车键,开始安装程序。如果要继续的话,就按下回车吧。
|
||||
|
||||

|
||||
>Netdata 的安装。
|
||||
|
||||
如果一切顺利,你的系统上就已经安装并且运行了 Netdata。安装脚本还会在相应的文件夹里添加一个卸载脚本,叫做 `netdata-uninstaller.sh`。如果你以后不想使用 Netdata,运行这个脚本可以从你的系统里面卸载掉 Netdata。
|
||||
|
||||
你可以通过 systemctl 查看它的运行状态。
|
||||
|
||||
```
|
||||
$ sudo systemctl status netdata
|
||||
```
|
||||
|
||||
### 使用 Netdata
|
||||
|
||||
既然我们已经安装并且运行了 Netdata,你就能够通过 19999 端口来访问 web 界面。下面的截图是我在一个测试机器上运行的 Netdata。
|
||||
|
||||

|
||||
>关于 Netdata 运行时的概览
|
||||
|
||||
恭喜!你已经成功安装并且能够看到关于你的机器性能的完美显示,图形和高级的统计数据。无论是否是你个人的机器,你都可以向你的朋友们炫耀,因为你能够深入的了解你的服务器性能,Netdata 在任何机器上的性能报告都非常出色。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/monitor-linux-netdata/
|
||||
|
||||
作者:[Martino Jones][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/monitor-linux-netdata/
|
||||
[1]: https://firehol.org/
|
||||
[2]: https://github.com/firehol/netdata
|
||||
[3]: https://github.com/firehol/netdata/wiki/Installation
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,71 @@
|
||||
用树莓派计算模块搭建的工业单板计算机
|
||||
=====================================================
|
||||
|
||||

|
||||
|
||||
在 Kickstarter 众筹网站上,一个叫“MyPi”的项目用 RPi 计算模块制作了一款 SBC(Single Board Computer 单板计算机),提供 mini-PCIe 插槽,串口,宽范围输入电源,以及模块扩展等功能。
|
||||
|
||||
你也许觉得奇怪,都 2016 年了,为什么还会有人发布这样一款长得有点像三明治,用过时的基于 ARM11 的原版树莓派 COM(Compuer on Module,模块化计算机)版本,[树莓派计算模块][1],构建的单板计算机。首先,目前仍然有大量工业应用不需要太多 CPU 处理能力,第二,树莓派计算模块仍是目前仅有的基于树莓派硬件的 COM,虽然更便宜,有点像 COM 并采用 700MHz 处理器的 [零号树莓派][2],快要发布了。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
>安装了 COM 和 I/O 组件的 MyPi(左),装入了可选的工业外壳中
|
||||
|
||||
另外,Embedded Micro Technology 还表示它的 SBC 还设计成支持和承诺的树莓派计算模块升级版互换,采用树莓派 3 的四核,Cortex-A53 博通 BCM2837 SoC。因为这个产品最近很快就会到货,不确定他们怎么能及时为 Kickstarter 赞助者处理好这一切。不过,以后能支持也挺不错,就算要为这个升级付费也可以接受。
|
||||
|
||||
MyPi 并不是唯一一款新的基于树莓派计算模块的商业嵌入式设备。Pigeon Computers 在五月份启动了 [Pigeon RB100][3] 的项目,是一个基于 COM 的工业自动化控制器。不过,包括 [Techbase Modberry][4] 在内的这一类设备大都出现在 2014 年 COM 发布之后的一小段时间内。
|
||||
|
||||
MyPi 的目标是 30 天内筹集 $21,696,目前已经实现了三分之一。早期参与包的价格 $119 起,九月份发货。其他选项有 $187 版本,里面包含了价值 $30 的树莓派计算模块,以及各种线缆。套件里还有各种插件板以及工业外壳可选。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
>不带 COM 和插件板的 MyPi 主板(左)以及它的接口定义
|
||||
|
||||
树莓派计算模块能给 MyPi 带来博通 BCM2835 Soc,512MB 内存,以及 4GB eMMC 存储空间。MyPi 主板扩展了一个 microSD 卡槽,一个 HDMI 接口,两个 USB 2.0 接口,一个 10/100 以太网口,还有一个类似网口的 RS232 端口(通过 USB)。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
>插上树莓派计算模块和 mini-PCIe 模块的 MyPi 的两个视角
|
||||
|
||||
MyPi 还将配备一个 mini-PCIe 插槽,据说“只支持 USB,以及只适用 mPCIe 形式的调制解调器”。还带有一个 SIM 卡插槽。板上还有双标准的树莓派摄像头接口,一个音频输出接口,自带备用电池的 RTC,LED 灯。还支持宽范围的 9-23V 直流输入。
|
||||
|
||||
Embedded Micro 表示,MyPi 是为那些树莓派爱好者们设计的,他们堆积了太多 HAT 外接板,已经不能有效地工作了,或者不能很好地装入工业外壳里。MyPi 支持 HAT,另外还提供了公司自己定义的“ASIO”(特定应用接口)插件模块,它会将自己的 I/O 扩展到主板上,主板再将它们连到主板边上的 8 脚,绿色,工业 I/O 连接器(标记了“ASIO Out”)上,在下面图片里有描述。
|
||||
|
||||

|
||||
>MyPi 的模块扩展接口
|
||||
|
||||
就像 Kickstarter 页面里描述的:“比起在板边插满带 IO 信号接头的 HAT 板,我们有意将同样的 IO 信号接到另一个接头,它直接接到绿色的工业接头上。”另外,“通过简单地延长卡上的插脚长度(抬高),你将来可以直接扩展 IO 集 - 这些都不需要任何排线!”Embedded Micro 表示。
|
||||
|
||||

|
||||
>MyPi 和它的可选 I/O 插件板卡
|
||||
|
||||
公司为 MyPi 提供了一系列可靠的 ASIO 插件板,像上面展示的。这些一开始会包括 CAN 总线,4-20mA 传感器信号,RS485,窄带 RF,等等。
|
||||
|
||||
### 更多信息
|
||||
|
||||
MyPi 在 Kickstarter 上提供了 7 月 23 日到期的 79 英镑($119)早期参与包(不包括树莓派计算模块),预计九月份发货。更多信息请查看 [Kickstarter 上 MyPi 的页面][5] 以及 [Embedded Micro Technology 官网][6]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/industrial-sbc-builds-on-rpi-compute-module/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://hackerboards.com/industrial-sbc-builds-on-rpi-compute-module/
|
||||
[1]: http://hackerboards.com/raspberry-pi-morphs-into-30-dollar-com/
|
||||
[2]: http://hackerboards.com/pi-zero-tweak-adds-camera-connector-keeps-5-price/
|
||||
[3]: http://hackerboards.com/automation-controller-runs-linux-on-raspberry-pi-com/
|
||||
[4]: http://hackerboards.com/automation-controller-taps-raspberry-pi-compute-module/
|
||||
[5]: https://www.kickstarter.com/projects/410598173/mypi-industrial-strength-raspberry-pi-for-iot-proj
|
||||
[6]: http://www.embeddedpi.com/
|
||||
@ -0,0 +1,124 @@
|
||||
如何进入无痕模式进而隐藏 Linux 的命令行历史
|
||||
================================================================
|
||||
|
||||

|
||||
|
||||
如果你是 Linux 命令行的用户,你会同意有的时候你不希望某些命令记录在你的命令行历史中。其中原因可能很多。例如,你在公司处于某个职位,你有一些不希望被其它人滥用的特权。亦或者有些特别重要的命令,你不希望在你浏览历史列表时误执行。
|
||||
|
||||
然而,有方法可以控制哪些命令进入历史列表,哪些不进入吗?或者换句话说,我们在 Linux 终端中可以开启像浏览器一样的无痕模式吗?答案是肯定的,而且根据你想要的具体目标,有很多实现方法。在这篇文章中,我们将讨论一些行之有效的方法。
|
||||
|
||||
注意:文中出现的所有命令都在 Ubuntu 下测试过。
|
||||
|
||||
### 不同的可行方法
|
||||
|
||||
前面两种方法已经在之前[一篇文章][1]中描述了。如果你已经了解,这部分可以略过。然而,如果你不了解,建议仔细阅读。
|
||||
|
||||
#### 1. 在命令前插入空格
|
||||
|
||||
是的,没看错。在命令前面插入空格,这条命令会被终端忽略,也就意味着它不会出现在历史记录中。但是这种方法有个前提,只有在你的环境变量 HISTCONTROL 设置为 "ignorespace" 或者 "ignoreboth" 才会起作用。在大多数情况下,这个是默认值。
|
||||
|
||||
所以,像下面的命令:
|
||||
|
||||
```
|
||||
[space]echo "this is a top secret"
|
||||
```
|
||||
|
||||
你执行后,它不会出现在历史记录中。
|
||||
|
||||
```
|
||||
export HISTCONTROL = ignorespace
|
||||
```
|
||||
|
||||
下面的截图是这种方式的一个例子。
|
||||
|
||||

|
||||
|
||||
第四个 "echo" 命令因为前面有空格,它没有被记录到历史中。
|
||||
|
||||
#### 2. 禁用当前会话的所有历史记录
|
||||
|
||||
如果你想禁用某个会话所有历史,你可以简单地在开始命令行工作前清除环境变量 HISTSIZE 的值。执行下面的命令来清除其值:
|
||||
|
||||
```
|
||||
export HISTFILE=0
|
||||
```
|
||||
|
||||
HISTFILE 表示对于 bash 会话其历史中可以保存命令的个数。默认情况,它设置了一个非零值,例如 在我的电脑上,它的值为 1000。
|
||||
|
||||
所以上面所提到的命令将其值设置为 0,结果就是直到你关闭终端,没有东西会存储在历史记录中。记住同样你也不能通过按向上的箭头按键来执行之前的命令,也不能运行 history 命令。
|
||||
|
||||
#### 3. 工作结束后清除整个历史
|
||||
|
||||
这可以看作是前一部分所提方案的另外一种实现。唯一的区别是在你完成所有工作之后执行这个命令。下面是刚讨论的命令:
|
||||
|
||||
```
|
||||
history -cw
|
||||
```
|
||||
|
||||
刚才已经提到,这个和 HISTFILE 方法有相同效果。
|
||||
|
||||
#### 4. 只针对你的工作关闭历史记录
|
||||
|
||||
虽然前面描述的方法(2 和 3)可以实现目的,它们清除整个历史,在很多情况下,有些可能不是我们所期望的。有时候你可能想保存直到你开始命令行工作之间的历史记录。类似的需求需要在你开始工作前执行下述命令:
|
||||
|
||||
```
|
||||
[space]set +o history
|
||||
```
|
||||
|
||||
备注:[space] 表示空格。
|
||||
|
||||
上面的命令会临时禁用历史功能,这意味着在这命令之后你执行的所有操作都不会记录到历史中,然而这个命令之前的所有东西都会原样记录在历史列表中。
|
||||
|
||||
要重新开启历史功能,执行下面的命令:
|
||||
|
||||
```
|
||||
[Space]set -o history
|
||||
```
|
||||
|
||||
它将环境恢复原状,也就是你完成你的工作,执行上述命令之后的命令都会出现在历史中。
|
||||
|
||||
#### 5. 从历史记录中删除指定的命令
|
||||
|
||||
现在假设历史记录中有一些命令你不希望被记录。这种情况下我们怎么办?很简单。直接动手删除它们。通过下面的命令来删除:
|
||||
|
||||
```
|
||||
[space]history | grep "part of command you want to remove"
|
||||
```
|
||||
|
||||
上面的命令会输出历史记录中匹配的命令,每一条前面会有个数字。
|
||||
|
||||
一旦你找到你想删除的命令,执行下面的命令,从历史记录中删除那个指定的项:
|
||||
|
||||
```
|
||||
history -d [num]
|
||||
```
|
||||
|
||||
下面是这个例子的截图。
|
||||
|
||||

|
||||
|
||||
第二个 ‘echo’命令被成功的删除了。
|
||||
|
||||
同样的,你可以使用向上的箭头一直往回翻看历史记录。当你发现你感兴趣的命令出现在终端上时,按下 “Ctrl + U”清除整行,也会从历史记录中删除它。
|
||||
|
||||
### 总结
|
||||
|
||||
有多种不同的方法可以操作 Linux 命令行历史来满足你的需求。然而请记住,从历史中隐藏或者删除命令通常不是一个好习惯,尽管本质上这并没有错。但是你必须知道你在做什么,以及可能产生的后果。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-command-line-history-incognito/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/himanshu/
|
||||
[1]: https://www.maketecheasier.com/command-line-history-linux/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,52 +0,0 @@
|
||||
在linux下使用任务管理器
|
||||
====================================
|
||||
|
||||

|
||||
|
||||
有很多Linux初学者经常问起的问题,“**Linux有任务管理器吗**”,“**在Linux上面你是怎样打开任务管理器的呢**”?
|
||||
|
||||
来自Windows的用户都知道任务管理器非常有用。你按下Ctrl+Alt+Del来打开任务管理器。这个任务管理器向你展示了所有的正在运行的进程和它们消耗的内存。你可以从任务管理器程序中选择并杀死一个进程。
|
||||
|
||||
当你刚使用Linux的时候,你也会寻找一个**在Linux相当于任务管理器**的一个东西。一个Linux使用专家更喜欢使用命令行的方式查找进程和消耗的内存,但是你不必去使用这种方式,至少在你初学Linux的时候。
|
||||
|
||||
所有主流的Linux发行版都有一个类似于任务管理器的东西。大部分情况下,**它叫System Monitor**。但是它实际上依赖于你的Linux的发行版和它使用的[桌面环境][1]。
|
||||
|
||||
在这篇文章中,我们将会看到如何在使用GNOME的[桌面环境][2]的Linux上查找并使用任务管理器。
|
||||
|
||||
###在使用GNOME的桌面环境的linux上使用任务管理器
|
||||
|
||||
当你使用GNOME的时候,按下super键(Windows 键)来查找任务管理器:
|
||||
|
||||

|
||||
|
||||
当你启动System Monitor的时候,它会向你展示所有正在运行的进程和被它们消耗的内存。
|
||||
|
||||

|
||||
|
||||
你可以选择一个进程并且点击“End Process”来杀掉它。
|
||||
|
||||

|
||||
|
||||
你也可以在Resources标签里面看到关于一些系统的数据,例如每个cpu核心的消耗,内存的使用,网络的使用等。
|
||||
|
||||

|
||||
|
||||
这是图形化的一种方式。如果你想使用命令行,在终端里运行“top”命令然后你就可以看到所有运行的进程和他们消耗的内存。你也可以参考[使用命令行杀死进程][3]这篇文章。
|
||||
|
||||
这就是所有你需要知道的关于在Fedora Linux上任务管理器的知识。我希望这个教程帮你学到了知识,如果你有什么问题,请尽管问。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/task-manager-linux/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[xinglianfly](https://github.com/xinglianfly)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://wiki.archlinux.org/index.php/desktop_environment
|
||||
[2]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[3]: https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/
|
||||
@ -0,0 +1,282 @@
|
||||
教程:开始学习如何使用 Docker Swarm 部署可扩展的 Python3 应用
|
||||
==============
|
||||
|
||||
[Ben Firshman][2]最近在[Dockercon][1]做了一个关于使用 Docker 构建无服务应用的演讲,你可以在[这查看详情][3](可以和视频一起)。之后,我写了[一篇文章][4]关于如何使用[AWS Lambda][5]构建微服务系统。
|
||||
|
||||
今天,我想展示给你的就是如何使用[Docker Swarm][6]然后部署一个简单的 Python Falcon REST 应用。尽管,我不会使用[dockerrun][7]或者是其他无服务特性。你可能会惊讶,使用 Docker Swarm 部署(替换)一个 Python(Java, Go 都一样) 应用是如此的简单。
|
||||
|
||||
注意:这展示的部分步骤是截取自[Swarm Tutorial][8]。我已经修改了部分章节,并且[在 Vagrant 的帮助文档][9]中添加了构建本地测试环境的文档。请确保,你使用的是1.12或以上版本的 Docker 引擎。我写这篇文章的时候,使用的是1.12RC2版本的 Docker。注意的是,这只是一个测试版本,只会可能还会有修改。
|
||||
|
||||
你要做的第一件事,就是你要保证你正确的安装了[Vagrant][10],如果你想本地运行的话。你也可以按如下步骤使用你最喜欢的云服务提供商部署 Docker Swarm 虚拟机系统。
|
||||
|
||||
我们将会使用这三台 VM:一个简单的 Docker Swarm 管理平台和两台 worker。
|
||||
|
||||
安全注意事项:Vagrantfile 代码中包含了部分位于 Docker 测试服务器上的 shell 脚本。这是一个隐藏的安全问题。如果你没有权限的话。请确保你会在运行代码之前[审查这部分的脚本][11]。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/chadlung/vagrant-docker-swarm
|
||||
$ cd vagrant-docker-swarm
|
||||
$ vagrant plugin install vagrant-vbguest
|
||||
$ vagrant up
|
||||
```
|
||||
|
||||
Vagrant up 命令可能会花很长的时间来执行。
|
||||
|
||||
SSH 登陆进入 manager1 虚拟机:
|
||||
|
||||
```
|
||||
$ vagrant ssh manager1
|
||||
```
|
||||
|
||||
在 manager1 的终端中执行如下命令:
|
||||
|
||||
```
|
||||
$ sudo docker swarm init --listen-addr 192.168.99.100:2377
|
||||
```
|
||||
|
||||
现在还没有 worker 注册上来:
|
||||
|
||||
```
|
||||
$ sudo docker node ls
|
||||
```
|
||||
|
||||
Let’s register the two workers. Use two new terminal sessions (leave the manager1 session running):
|
||||
通过两个新的终端会话(退出 manager1 的登陆后),我们注册两个 worker。
|
||||
|
||||
```
|
||||
$ vagrant ssh worker1
|
||||
```
|
||||
|
||||
在 worker1 上执行如下命令:
|
||||
|
||||
```
|
||||
$ sudo docker swarm join 192.168.99.100:2377
|
||||
```
|
||||
|
||||
在 worker2 上重复这些命令。
|
||||
|
||||
在 manager1 上执行这个命令:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
```
|
||||
|
||||
你将会看到:
|
||||
|
||||

|
||||
|
||||
开始在 manager1 的终端里,部署一个简单的服务。
|
||||
|
||||
```
|
||||
sudo docker service create --replicas 1 --name pinger alpine ping google.com
|
||||
```
|
||||
|
||||
这个命令将会部署一个服务,他会从 worker 机器中的一台 ping google.com。(manager 也可以运行服务,不过[这也可以被禁止][12])如果你只是想 worker 运行容器的话)。可以使用如下命令,查看哪些节点正在执行服务:
|
||||
|
||||
```
|
||||
$ sudo docker service tasks pinger
|
||||
```
|
||||
|
||||
结果回合这个比较类似:
|
||||
|
||||

|
||||
|
||||
所以,我们知道了服务正跑在 worker1 上。我们可以回到 worker1 的会话里,然后进入正在运行的容器:
|
||||
|
||||
```
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以看到容器的 id 是: ae56769b9d4d
|
||||
|
||||
在我的例子中,我运行的是如下的代码:
|
||||
|
||||
```
|
||||
$ sudo docker attach ae56769b9d4d
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以仅仅只用 CTRL-C 来停止服务。
|
||||
|
||||
回到 manager1,并且移除 pinger 服务。
|
||||
|
||||
```
|
||||
$ sudo docker service rm pinger
|
||||
```
|
||||
|
||||
现在,我们将会部署可复制的 Python 应用。请记住,为了保持文章的简洁,而且容易复制,所以部署的是一个简单的应用。
|
||||
|
||||
你需要做的第一件事就是将镜像放到[Docker Hub][13]上,或者使用我[已经上传的一个][14]。这是一个简单的 Python 3 Falcon REST 应用。他有一个简单的入口: /hello 带一个 value 参数。
|
||||
|
||||
[chadlung/hello-app][15]的 Python 代码看起来像这样:
|
||||
|
||||
```
|
||||
import json
|
||||
from wsgiref import simple_server
|
||||
|
||||
import falcon
|
||||
|
||||
|
||||
class HelloResource(object):
|
||||
def on_get(self, req, resp):
|
||||
try:
|
||||
value = req.get_param('value')
|
||||
|
||||
resp.content_type = 'application/json'
|
||||
resp.status = falcon.HTTP_200
|
||||
resp.body = json.dumps({'message': str(value)})
|
||||
except Exception as ex:
|
||||
resp.status = falcon.HTTP_500
|
||||
resp.body = str(ex)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
app = falcon.API()
|
||||
hello_resource = HelloResource()
|
||||
app.add_route('/hello', hello_resource)
|
||||
httpd = simple_server.make_server('0.0.0.0', 8080, app)
|
||||
httpd.serve_forever()
|
||||
```
|
||||
|
||||
Dockerfile 很简单:
|
||||
|
||||
```
|
||||
FROM python:3.4.4
|
||||
|
||||
RUN pip install -U pip
|
||||
RUN pip install -U falcon
|
||||
|
||||
EXPOSE 8080
|
||||
|
||||
COPY . /hello-app
|
||||
WORKDIR /hello-app
|
||||
|
||||
CMD ["python", "app.py"]
|
||||
```
|
||||
|
||||
再一次说明,这是非常详细的奖惩,如果你想,你也可以在本地访问这个入口: <http://127.0.0.1:8080/hello?value=Fred>
|
||||
|
||||
这将返回如下结果:
|
||||
|
||||
```
|
||||
{"message": "Fred"}
|
||||
```
|
||||
|
||||
在 Docker Hub 上构建和部署这个 hello-app(修改成你自己的 Docker Hub 仓库或者[这个][15]):
|
||||
|
||||
```
|
||||
$ sudo docker build . -t chadlung/hello-app:2
|
||||
$ sudo docker push chadlung/hello-app:2
|
||||
```
|
||||
|
||||
现在,我们可以将应用部署到之前的 Docker Swarm 了。登陆 manager1 终端,并且执行:
|
||||
|
||||
```
|
||||
$ sudo docker service create -p 8080:8080 --replicas 2 --name hello-app chadlung/hello-app:2
|
||||
$ sudo docker service inspect --pretty hello-app
|
||||
$ sudo docker service tasks hello-app
|
||||
```
|
||||
|
||||
现在,我们已经可以测试了。使用任何一个节点 Swarm 的 IP,来访问/hello 的入口,在本例中,我在 Manager1 的终端里使用 curl 命令:
|
||||
|
||||
注意,在 Swarm 中的所有 IP 都可以工作,即使这个服务只运行在一台或者更多的节点上。
|
||||
|
||||
```
|
||||
$ curl -v -X GET "http://192.168.99.100:8080/hello?value=Chad"
|
||||
$ curl -v -X GET "http://192.168.99.101:8080/hello?value=Test"
|
||||
$ curl -v -X GET "http://192.168.99.102:8080/hello?value=Docker"
|
||||
```
|
||||
|
||||
结果就是:
|
||||
|
||||
```
|
||||
* Hostname was NOT found in DNS cache
|
||||
* Trying 192.168.99.101...
|
||||
* Connected to 192.168.99.101 (192.168.99.101) port 8080 (#0)
|
||||
> GET /hello?value=Chad HTTP/1.1
|
||||
> User-Agent: curl/7.35.0
|
||||
> Host: 192.168.99.101:8080
|
||||
> Accept: */*
|
||||
>
|
||||
* HTTP 1.0, assume close after body
|
||||
< HTTP/1.0 200 OK
|
||||
< Date: Tue, 28 Jun 2016 23:52:55 GMT
|
||||
< Server: WSGIServer/0.2 CPython/3.4.4
|
||||
< content-type: application/json
|
||||
< content-length: 19
|
||||
<
|
||||
{"message": "Chad"}
|
||||
```
|
||||
|
||||
从浏览器中访问其他节点:
|
||||
|
||||

|
||||
|
||||
如果你想看运行的所有服务,你可以在 manager1 节点上运行如下代码:
|
||||
|
||||
```
|
||||
$ sudo docker service ls
|
||||
```
|
||||
|
||||
如果你想添加可视化控制平台,你可以安装[Docker Swarm Visualizer][16](这非常简单上手)。在 manager1 的终端中执行如下代码:
|
||||
|
||||

|
||||
|
||||
打开你的浏览器,并且访问: <http://192.168.99.100:5000/>
|
||||
|
||||
结果(假设已经运行了两个 Docker Swarm 服务):
|
||||
|
||||

|
||||
|
||||
停止运行 hello-app(已经在两个节点上运行了),可以在 manager1 上执行这个代码:
|
||||
|
||||
```
|
||||
$ sudo docker service rm hello-app
|
||||
```
|
||||
|
||||
如果想停止, 那么在 manager1 的终端中执行:
|
||||
|
||||
```
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
获得容器的 ID,这里是: f71fec0d3ce1
|
||||
|
||||
从 manager1 的终端会话中执行这个代码:
|
||||
|
||||
```
|
||||
$ sudo docker stop f71fec0d3ce1
|
||||
```
|
||||
|
||||
祝你使用 Docker Swarm。这篇文章主要是以1.12版本来进行描述的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.giantflyingsaucer.com/blog/?p=5923
|
||||
|
||||
作者:[Chad Lung][a]
|
||||
译者:[译者ID](https://github.com/MikeCoder)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.giantflyingsaucer.com/blog/?author=2
|
||||
[1]: http://dockercon.com/
|
||||
[2]: https://blog.docker.com/author/bfirshman/
|
||||
[3]: https://blog.docker.com/author/bfirshman/
|
||||
[4]: http://www.giantflyingsaucer.com/blog/?p=5730
|
||||
[5]: https://aws.amazon.com/lambda/
|
||||
[6]: https://docs.docker.com/swarm/
|
||||
[7]: https://github.com/bfirsh/dockerrun
|
||||
[8]: https://docs.docker.com/engine/swarm/swarm-tutorial/
|
||||
[9]: https://github.com/chadlung/vagrant-docker-swarm
|
||||
[10]: https://www.vagrantup.com/
|
||||
[11]: https://test.docker.com/
|
||||
[12]: https://docs.docker.com/engine/reference/commandline/swarm_init/
|
||||
[13]: https://hub.docker.com/
|
||||
[14]: https://hub.docker.com/r/chadlung/hello-app/
|
||||
[15]: https://hub.docker.com/r/chadlung/hello-app/
|
||||
[16]: https://github.com/ManoMarks/docker-swarm-visualizer
|
||||
@ -0,0 +1,206 @@
|
||||
LFCS 系列第十一讲:如何使用命令 vgcreate、lvcreate 和 lvextend 管理和创建 LVM
|
||||
============================================================================================
|
||||
|
||||
由于 LFCS 考试中的一些改变已在 2016 年 2 月 2 日生效,我们添加了一些必要的专题到 [LFCS 系列][1]。我们也非常推荐备考的同学,同时阅读 [LFCE 系列][2]。
|
||||
|
||||

|
||||
>LFCS:管理 LVM 和创建 LVM 分区
|
||||
|
||||
在安装 Linux 系统的时候要做的最重要的决定之一便是给系统文件,home 目录等分配空间。在这个地方犯了错,再要增长空间不足的分区,那样既麻烦又有风险。
|
||||
|
||||
**逻辑卷管理** (即 **LVM**)相较于传统的分区管理有许多优点,已经成为大多数(如果不能说全部的话) Linux 发行版安装时的默认选择。LVM 最大的优点应该是能方便的按照你的意愿调整(减小或增大)逻辑分区的大小。
|
||||
|
||||
LVM 的组成结构:
|
||||
|
||||
* 把一块或多块硬盘或者一个或多个分区配置成物理卷(PV)。
|
||||
* 一个用一个或多个物理卷创建出的卷组(**VG**)。可以把一个卷组想象成一个单独的存储单元。
|
||||
* 在一个卷组上可以创建多个逻辑卷。每个逻辑卷相当于一个传统意义上的分区 —— 优点是它的大小可以根据需求重新调整大小,正如之前提到的那样。
|
||||
|
||||
本文,我们将使用三块 **8 GB** 的磁盘(**/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**)分别创建三个物理卷。你既可以直接在设备上创建 PV,也可以先分区在创建。
|
||||
|
||||
在这里我们选择第一种方式,如果你决定使用第二种(可以参考本系列[第四讲:创建分区和文件系统][3])确保每个分区的类型都是 `8e`。
|
||||
|
||||
### 创建物理卷,卷组和逻辑卷
|
||||
|
||||
要在 **/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**上创建物理卷,运行:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
你可以列出新创建的 PV ,通过:
|
||||
|
||||
```
|
||||
# pvs
|
||||
```
|
||||
|
||||
并得到每个 PV 的详细信息,通过:
|
||||
|
||||
```
|
||||
# pvdisplay /dev/sdX
|
||||
```
|
||||
|
||||
(**X** 即 b、c 或 d)
|
||||
|
||||
如果没有输入 `/dev/sdX` ,那么你将得到所有 PV 的信息。
|
||||
|
||||
使用 /dev/sdb` 和 `/dev/sdc` 创建卷组 ,命名为 `vg00` (在需要时是可以通过添加其他设备来扩展空间的,我们等到说明这点的时候再用,所以暂时先保留 `/dev/sdd`):
|
||||
|
||||
```
|
||||
# vgcreate vg00 /dev/sdb /dev/sdc
|
||||
```
|
||||
|
||||
就像物理卷那样,你也可以查看卷组的信息,通过:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
由于 `vg00` 是由两个 **8 GB** 的磁盘组成的,所以它将会显示成一个 **16 GB** 的硬盘:
|
||||
|
||||

|
||||
>LVM 卷组列表
|
||||
|
||||
当谈到创建逻辑卷,空间的分配必须考虑到当下和以后的需求。根据每个逻辑卷的用途来命名是一个好的做法。
|
||||
|
||||
举个例子,让我们创建两个 LV,命名为 `vol_projects` (**10 GB**) 和 `vol_backups` (剩下的空间), 在日后分别用于部署项目文件和系统备份。
|
||||
|
||||
参数 `-n` 用于为 LV 指定名称,而 `-L` 用于设定固定的大小,还有 `-l` (小写的 L)在 VG 的预留空间中用于指定百分比大小的空间。
|
||||
|
||||
```
|
||||
# lvcreate -n vol_projects -L 10G vg00
|
||||
# lvcreate -n vol_backups -l 100%FREE vg00
|
||||
```
|
||||
|
||||
和之前一样,你可以查看 LV 的列表和基础信息,通过:
|
||||
|
||||
```
|
||||
# lvs
|
||||
```
|
||||
|
||||
或是详细信息,通过:
|
||||
|
||||
```
|
||||
# lvdisplay
|
||||
```
|
||||
|
||||
若要查看单个 **LV** 的信息,使用 **lvdisplay** 加上 **VG** 和 **LV** 作为参数,如下:
|
||||
|
||||
```
|
||||
# lvdisplay vg00/vol_projects
|
||||
```
|
||||
|
||||

|
||||
>逻辑卷列表
|
||||
|
||||
如上图,我们看到 LV 已经被创建成存储设备了(参考 LV Path line)。在使用每个逻辑卷之前,需要先在上面创建文件系统。
|
||||
|
||||
这里我们拿 ext4 来做举例,因为对于每个 LV 的大小, ext4 既可以增大又可以减小(相对的 xfs 就只允许增大):
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/vg00/vol_projects
|
||||
# mkfs.ext4 /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||
我们将在下一节向大家说明,如何调整逻辑卷的大小并在需要的时候添加额外的外部存储空间。
|
||||
|
||||
### 调整逻辑卷大小和扩充卷组
|
||||
|
||||
现在设想以下场景。`vol_backups` 中的空间即将用完,而 `vol_projects` 中还有富余的空间。由于 LVM 的特性,我们可以轻易的减小后者的大小(比方说 **2.5 GB**),并将其分配给前者,与此同时调整每个文件系统的大小。
|
||||
|
||||
幸运的是这很简单,只需:
|
||||
|
||||
```
|
||||
# lvreduce -L -2.5G -r /dev/vg00/vol_projects
|
||||
# lvextend -l +100%FREE -r /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>减小逻辑卷和卷组
|
||||
|
||||
在调整逻辑卷的时候,其中包含的减号 `(-)` 或加号 `(+)` 是十分重要的。否则 LV 将会被设置成指定的大小,而非调整指定大小。
|
||||
|
||||
有些时候,你可能会遭遇那种无法仅靠调整逻辑卷的大小就可以解决的问题,那时你就需要购置额外的存储设备了,你可能需要再加一块硬盘。这里我们将通过添加之前配置时预留的 PV (`/dev/sdd`),用以模拟这种情况。
|
||||
|
||||
想把 `/dev/sdd` 加到 `vg00`,执行:
|
||||
|
||||
```
|
||||
# vgextend vg00 /dev/sdd
|
||||
```
|
||||
|
||||
如果你在运行上条命令的前后执行 vgdisplay `vg00` ,你就会看出 VG 的大小增加了。
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||

|
||||
>查看卷组磁盘大小
|
||||
|
||||
现在,你可以使用新加的空间,按照你的需求调整现有 LV 的大小,或者创建一个新的 LV。
|
||||
|
||||
### 在启动和需求时挂载逻辑卷
|
||||
|
||||
当然,如果我们不打算实际的使用逻辑卷,那么创建它们就变得毫无意义了。为了更好的识别逻辑卷,我们需要找出它的 `UUID` (用于识别一个格式化存储设备的唯一且不变的属性)。
|
||||
|
||||
要做到这点,可使用 blkid 加每个设备的路径来实现:
|
||||
|
||||
```
|
||||
# blkid /dev/vg00/vol_projects
|
||||
# blkid /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>寻找逻辑卷的 UUID
|
||||
|
||||
为每个 LV 创建挂载点:
|
||||
|
||||
```
|
||||
# mkdir /home/projects
|
||||
# mkdir /home/backups
|
||||
```
|
||||
|
||||
并在 `/etc/fstab` 插入相应的条目(确保使用之前获得的UUID):
|
||||
|
||||
```
|
||||
UUID=b85df913-580f-461c-844f-546d8cde4646 /home/projects ext4 defaults 0 0
|
||||
UUID=e1929239-5087-44b1-9396-53e09db6eb9e /home/backups ext4 defaults 0 0
|
||||
```
|
||||
|
||||
保存并挂载 LV:
|
||||
|
||||
```
|
||||
# mount -a
|
||||
# mount | grep home
|
||||
```
|
||||
|
||||

|
||||
>挂载逻辑卷
|
||||
|
||||
在涉及到 LV 的实际使用时,你还需要按照曾在本系列[第八讲:管理用户和用户组][4]中讲解的那样,为其设置合适的 `ugo+rwx`。
|
||||
|
||||
### 总结
|
||||
|
||||
本文介绍了 [逻辑卷管理][5],一个用于管理可扩展存储设备的多功能工具。与 RAID(曾在本系列讲解过的 [第六讲:组装分区为RAID设备——创建和管理系统备份][6])结合使用,你将同时体验到(LVM 带来的)可扩展性和(RAID 提供的)冗余。
|
||||
|
||||
在这类的部署中,你通常会在 `RAID` 上发现 `LVM`,这就是说,要先配置好 RAID 然后它在上面配置 LVM。
|
||||
|
||||
如果你对本问有任何的疑问和建议,可以直接在下方的评论区告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-and-create-lvm-parition-using-vgcreate-lvcreate-and-lvextend/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: https://linux.cn/article-7161-1.html
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: https://linux.cn/article-7187-1.html
|
||||
[4]: https://linux.cn/article-7418-1.html
|
||||
[5]: http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
[6]: https://linux.cn/article-7229-1.html
|
||||
Loading…
Reference in New Issue
Block a user