mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
commit
150114e44a
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10458-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 1 OK01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
@ -196,15 +196,15 @@ b loop$
|
||||
|
||||
将这个 SD 卡插入到树莓派,并打开它的电源。这个 OK 的 LED 灯将亮起来。如果不是这样,请查看故障排除页面。如果一切如愿,恭喜你,你已经写出了你的第一个操作系统。[课程 2 OK02][12] 将指导你让 LED 灯闪烁和关闭闪烁。
|
||||
|
||||
[^1]: OK, I'm lying it tells the linker, which is another program used to link several assembled files together. It doesn't really matter.
|
||||
[^2]: Clearly they're important to you. Since the GNU toolchain is mainly used for creating programs, it expects there to be an entry point labelled `_start`. As we're making an operating system, the `_start` is always whatever comes first, which we set up with the `.section .init` command. However, if we don't say where the entry point is, the toolchain gets upset. Thus, the first line says that we are going to define a symbol called `_start` for all to see (globally), and the second line says to make the symbol `_start` the address of the next line. We will come onto addresses shortly.
|
||||
[^3]: This tutorial is designed to spare you the pain of reading it, but, if you must, it can be found here [SoC-Peripherals.pdf](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/SoC-Peripherals.pdf). For added confusion, the manual uses a different addressing system. An address listed as 0x7E200000 would be 0x20200000 in our OS.
|
||||
[^4]: Only values which have a binary representation which only has 1s in the first 8 bits of the representation. In other words, 8 1s or 0s followed by only 0s.
|
||||
[^5]: A hardware engineer was kind enough to explain this to me as follows:
|
||||
[^1]: 是的,我说错了,它告诉的是链接器,它是另一个程序,用于将汇编器转换过的几个代码文件链接到一起。直接说是汇编器也没有大问题。
|
||||
[^2]: 其实它们对你很重要。由于 GNU 工具链主要用于开发操作系统,它要求入口点必须是名为 `_start` 的地方。由于我们是开发一个操作系统,无论什么时候,它总是从 `_start` 开时的,而我们可以使用 `.section .init` 命令去设置它。因此,如果我们没有告诉它入口点在哪里,就会使工具链困惑而产生警告消息。所以,我们先定义一个名为 `_start` 的符号,它是所有人可见的(全局的),紧接着在下一行生成符号 `_start` 的地址。我们很快就讲到这个地址了。
|
||||
[^3]: 本教程的设计减少了你阅读树莓派开发手册的难度,但是,如果你必须要阅读它,你可以在这里 [SoC-Peripherals.pdf](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/SoC-Peripherals.pdf) 找到它。由于添加了混淆,手册中 GPIO 使用了不同的地址系统。我们的操作系统中的地址 0x20200000 对应到手册中是 0x7E200000。
|
||||
[^4]: `mov` 能够加载的值只有前 8 位是 `1` 的二进制表示的值。换句话说就是一个 0 后面紧跟着 8 个 `1` 或 `0`。
|
||||
[^5]: 一个很友好的硬件工程师是这样向我解释这个问题的:
|
||||
|
||||
原因是现在的芯片都是用一种称为 CMOS 的技术来制成的,它是互补金属氧化物半导体的简称。互补的意思是每个信号都连接到两个晶体管上,一个是使用 N 型半导体的材料制成,它用于将电压拉低,而另一个使用 P 型半导体材料制成,它用于将电压升高。在任何时刻,仅有一个半导体是打开的,否则将会短路。P 型材料的导电性能不如 N 型材料。这意味着三倍大的 P 型半导体材料才能提供与 N 型半导体材料相同的电流。这就是为什么 LED 总是通过降低为低电压来打开它,因为 N 型半导体拉低电压比 P 型半导体拉高电压的性能更强。
|
||||
|
||||
The reason is that modern chips are made of a technology called CMOS, which stands for Complementary Metal Oxide Semiconductor. The Complementary part means each signal is connected to two transistors, one made of material called N-type semiconductor which is used to pull it to a low voltage and another made of P-type material to pull it to a high voltage. Only one transistor of the pair turns on at any time, otherwise we'd get a short circuit. P-type isn't as conductive as N-type, which means the P-type transistor has to be about 3 times as big to provide the same current. This is why LEDs are often wired to turn on by pulling them low, because the N-type is stronger at pulling low than the P-type is in pulling high.
|
||||
|
||||
There's another reason. Back in the 1970s chips were made out of entirely out of N-type material ('NMOS'), with the P-type replaced by a resistor. That means that when a signal is pulled low the chip is consuming power (and getting hot) even while it isn't doing anything. Your phone getting hot and flattening the battery when it's in your pocket doing nothing wouldn't be good. So signals were designed to be 'active low' so that they're high when inactive and so don't take any power. Even though we don't use NMOS any more, it's still often quicker to pull a signal low with the N-type than to pull it high with the P-type. Often a signal that's 'active low' is marked with a bar over the top of the name, or written as SIGNAL_n or /SIGNAL. But it can still be confusing, even for hardware engineers!
|
||||
还有一个原因。早在上世纪七十年代,芯片完全是由 N 型材料制成的(NMOS),P 型材料部分使用了一个电阻来代替。这意味着当信号为低电压时,即便它什么事都没有做,芯片仍然在消耗能量(并发热)。你的电话装在口袋里什么事都不做,它仍然会发热并消耗你的电池电量,这不是好的设计。因此,信号设计成 “活动时低”,而不活动时为高电压,这样就不会消耗能源了。虽然我们现在已经不使用 NMOS 了,但由于 N 型材料的低电压信号比 P 型材料的高电压信号要快,所以仍然使用了这种设计。通常在一个 “活动时低” 信号名字上方会有一个条型标记,或者写作 `SIGNAL_n` 或 `/SIGNAL`。但是即便这样,仍然很让人困惑,那怕是硬件工程师,也不可避免这种困惑!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,8 +1,10 @@
|
||||
开始使用 Turtl 这个 Evernote 的开源替代品
|
||||
Turtl:Evernote 的开源替代品
|
||||
======
|
||||
> 如果你正在寻找一个 Evernote 和 Google Keep 的替代品,那么 Turtl 是一个可靠的记笔记工具。
|
||||
|
||||

|
||||
|
||||
我认识的每个人都会记笔记,许多人使用在线笔记应用,如 Evernote、Simplenote 或 Google Keep。这些都是很好的工具,但你不得不担忧信息的安全性和隐私性 - 特别是考虑到 [Evernote 2016 年的隐私策略变更][1]。如果你想要更好地控制笔记和数据,你需要转向开源工具。
|
||||
我认识的每个人都会记笔记,许多人使用在线笔记应用,如 Evernote、Simplenote 或 Google Keep。这些都是很好的工具,但你不得不担忧信息的安全性和隐私性 —— 特别是考虑到 [Evernote 2016 年的隐私策略变更][1]。如果你想要更好地控制笔记和数据,你需要转向开源工具。
|
||||
|
||||
无论你离开 Evernote 的原因是什么,都有开源替代品。让我们来看看其中一个选择:Turtl。
|
||||
|
||||
@ -10,30 +12,25 @@
|
||||
|
||||
[Turtl][2] 背后的开发人员希望你将其视为“具有绝对隐私的 Evernote”。说实话,我不能保证 Turtl 提供的隐私级别,但它是一个非常好的笔记工具。
|
||||
|
||||
要开始使用 Turtl,[下载][3]适用于 Linux、Mac OS 或 Windows 的桌面客户端,或者获取 [Android 应用][4]。安装它,然后启动客户端或应用。系统会要求你输入用户名和密码。Turtl 使用密码来生成加密密钥,根据开发人员的说法,加密密钥会在将笔记存储在设备或服务器上之前对其进行加密。
|
||||
要开始使用 Turtl,[下载][3]适用于 Linux、Mac OS 或 Windows 的桌面客户端,或者获取它的 [Android 应用][4]。安装它,然后启动客户端或应用。系统会要求你输入用户名和密码。Turtl 使用密码来生成加密密钥,根据开发人员的说法,加密密钥会在将笔记存储在设备或服务器上之前对其进行加密。
|
||||
|
||||
### 使用 Turtl
|
||||
|
||||
你可以使用 Turtl 创建以下类型的笔记:
|
||||
|
||||
* 密码
|
||||
|
||||
* 档案
|
||||
|
||||
* 图片
|
||||
|
||||
* 书签
|
||||
|
||||
* 文字笔记
|
||||
|
||||
无论你选择何种类型的笔记,你都可以在类似的窗口中创建:
|
||||
|
||||
|
||||
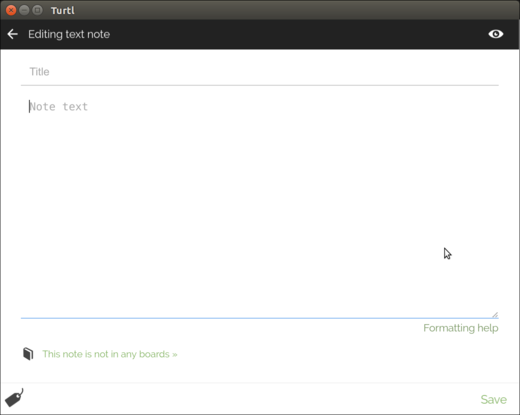
|
||||
|
||||
在 Turtl 中创建新笔记
|
||||
*在 Turtl 中创建新笔记*
|
||||
|
||||
添加笔记标题,文字并(如果你正在创建文件或图像笔记)附加文件或图像等信息。然后单击“保存”。
|
||||
添加笔记标题、文字并(如果你正在创建文件或图像笔记)附加文件或图像等信息。然后单击“保存”。
|
||||
|
||||
你可以通过 [Markdown][6] 为你的笔记添加格式。因为没有工具栏快捷方式,所以你需要手动添加格式。
|
||||
|
||||
@ -41,9 +38,9 @@
|
||||
|
||||
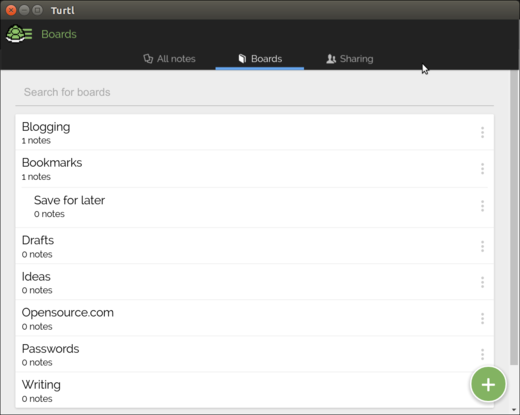
|
||||
|
||||
在 Turtl 中创建新的白板
|
||||
*在 Turtl 中创建新的白板*
|
||||
|
||||
要向白板添加笔记,请创建或编辑笔记,然后单击笔记底部的“此笔记不在任何白板”的链接。选择一个或多个白板,然后单击“完成”。
|
||||
要向白板中添加笔记,请创建或编辑笔记,然后单击笔记底部的“此笔记不在任何白板”的链接。选择一个或多个白板,然后单击“完成”。
|
||||
|
||||
要为笔记添加标记,请单击记事本底部的“标记”图标,输入一个或多个以逗号分隔的关键字,然后单击“完成”。
|
||||
|
||||
@ -57,14 +54,13 @@
|
||||
|
||||
Turtl 以平铺视图显示笔记,让人想起 Google Keep:
|
||||
|
||||
|
||||
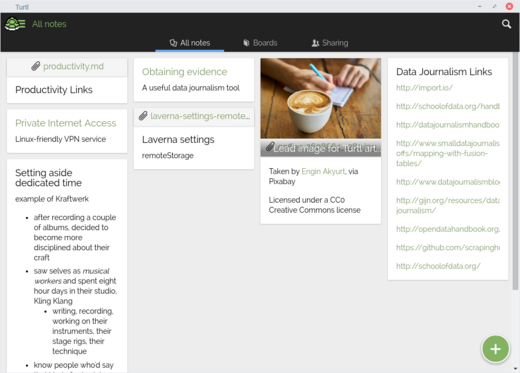
|
||||
|
||||
Turtl 中的一系列笔记
|
||||
*Turtl 中的一系列笔记*
|
||||
|
||||
无法在桌面或 Android 应用上将其更改为列表视图。这对我来说不是问题,但我听说有些人因为它没有列表视图而不喜欢 Turtl。
|
||||
|
||||
说到 Android 应用,它并不坏。但是,它没有与 Android 共享菜单集成。如果你想把在其他应用中看到或阅读的内容添加到 Turtl 笔记中,则需要手动复制并粘贴。
|
||||
说到 Android 应用,它并不差。但是,它没有与 Android 共享菜单集成。如果你想把在其他应用中看到或阅读的内容添加到 Turtl 笔记中,则需要手动复制并粘贴。
|
||||
|
||||
我已经在我的 Linux 笔记本,[运行 GalliumOS 的 Chromebook][10],还有一台 Android 手机上使用 Turtl 几个月了。对所有这些设备来说这都是一种非常无缝的体验。虽然它不是我最喜欢的开源笔记工具,但 Turtl 做得非常好。试试看它,它可能是你正在寻找的简单的笔记工具。
|
||||
|
||||
@ -74,7 +70,7 @@ via: https://opensource.com/article/17/12/using-turtl-open-source-alternative-ev
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,157 @@
|
||||
设计微服务架构前应该了解的 5 项指导原则
|
||||
======
|
||||
> 顶级 CTO 基于五个简单的原则为精心设计的微服务提供建议。
|
||||
|
||||

|
||||
|
||||
对于从微服务开始的团队来说,最大的挑战之一就是坚持<ruby>金发女孩原则<rt>The Goldilocks principle</rt></ruby>(该典故来自于童话《金发姑娘和三只熊》):不要太大,不要太小,不能太紧密耦合。之所以是挑战的部分原因是会对究竟什么是设计良好的微服务感到疑惑。
|
||||
|
||||
数十位 CTO 通过采访分享了他们的经验,这些对话说明了设计良好的微服务的五个特点。本文将帮助指导团队设计微服务。(有关详细信息,请查看即将出版的书籍 [Microservices for Startups][1],LCTT 译注:已可免费下载完整的电子版)。本文将简要介绍微服务的边界和主观的 “规则”,以避免在深入了解五个特征之前就开始指导您的微服务设计。
|
||||
|
||||
### 微服务边界
|
||||
|
||||
[使用微服务开发新系统的核心优势][2]之一是该体系结构允许开发人员独立构建和修改各个组件,但在最大限度地减少每个 API 之间的回调数量方面可能会出现问题。根据 [SparkPost][3] 工程副总裁 Chris McFadden 所说,解决方案是应用适当的服务边界。
|
||||
|
||||
关于边界,与有时难以理解和抽象的领域驱动设计(DDD,一种微服务框架)形成鲜明对比,本文重点介绍了和我们行业的一些顶级 CTO 一同建立的明确定义的微服务边界的实用原则。
|
||||
|
||||
### 避免主观的 “规则”
|
||||
|
||||
如果您阅读了足够多的关于设计和创建微服务的建议,您一定会遇到下面的一些 “规则”。 尽管将它们用作创建微服务的指南很有吸引力,但加入这些主观规则并不是思考确定微服务的边界的原则性方式。
|
||||
|
||||
#### “微服务应该有 X 行代码”
|
||||
|
||||
让我们直说:微服务中有多少行代码没有限制。微服务不会因为您写了几行额外的代码而突然变成一个独石应用。关键是要确保服务中的代码具有很高的内聚性(稍后将对此进行更多介绍)。
|
||||
|
||||
#### “将每个功能转换为微服务”
|
||||
|
||||
如果函数基于三个输入值计算某些内容并返回结果,它是否是微服务的理想候选项?它是否应该是单独可部署应用程序?这确实取决于该函数是什么以及它是如何服务于整个系统。将每个函数转换为微服务在您的情景中可能根本没有意义。
|
||||
|
||||
其他主观规则包括不考虑整个情景的规则,例如团队的经验、DevOps 能力、服务正在执行的操作以及数据的可用性需求。
|
||||
|
||||
### 精心设计的服务的 5 个特点
|
||||
|
||||
如果您读过关于微服务的文章,您无疑会遇到有关设计良好的服务的建议。简单地说,高内聚和低耦合。如果您不熟悉这些概念,有[许多][4][文章][4]关于这些概念的文章。虽然它们提供了合理的建议,但这些概念是相当抽象的。基于与经验丰富的 CTO 们的对话,下面是在创建设计良好的微服务时需要牢记的关键特征。
|
||||
|
||||
#### #1:不与其他服务共享数据库表
|
||||
|
||||
在 SparkPost 的早期,Chris McFadden 和他的团队必须解决每个 SaaS 业务需要面对的问题:它们需要提供基本服务,如身份验证、帐户管理和计费。
|
||||
|
||||
为了解决这个问题,他们创建了两个微服务:用户 API 和帐户 API。用户 API 将处理用户帐户、API 密钥和身份验证,而帐户 API 将处理所有与计费相关的逻辑。这是一个非常合乎逻辑的分离 —— 但没过多久,他们发现了一个问题。
|
||||
|
||||
McFadden 解释说,“我们有一个名为‘用户 API’的服务,还有一个名为‘帐户 API’的服务。问题是,他们之间实际上有几个来回的调用。因此,您会在帐户服务中执行一些操作,然后调用并终止于用户服务,反之亦然”
|
||||
|
||||
这两个服务的耦合太紧密了。
|
||||
|
||||
在设计微服务时,如果您有多个服务引用同一个表,则它是一个危险的信号,因为这可能意味着您的数据库是耦合的源头。
|
||||
|
||||
这确实是关于服务与数据的关系,这正是 [Swiftype SRE,Elastic][6] 的负责人 Oleksiy Kovrin 告诉我。他说,“我们在开发新服务时使用的主要基本原则之一是,它们不应跨越数据库边界。每个服务都应依赖于自己的一组底层数据存储。这使我们能够集中访问控制、审计日志记录、缓存逻辑等。”
|
||||
|
||||
Kovrin 接着解释说,如果数据库表的某个子集“与数据集的其余部分没有或很少连接,则这是一个强烈的信号,表明该组件可以被隔离到单独的 API 或单独的服务中”。
|
||||
|
||||
[Lead Honestly][7] 的联合创始人 Darby Frey 与此的观点相呼应:“每个服务都应该有自己的表并且永远不应该共享数据库表。”
|
||||
|
||||
#### #2:数据库表数量最小化
|
||||
|
||||
微服务的理想尺寸应该足够小,但不能太小。每个服务的数据库表的数量也是如此。
|
||||
|
||||
[Scaylr][8] 的工程主管 Steven Czerwinski 在接受采访时解释说 Scaylr 的最佳选择是“一个或两个服务的数据库表。”
|
||||
|
||||
SparkPost 的 Chris McFadden 表示同意:“我们有一个 suppression 微服务,它处理、跟踪数以百万计和数十亿围绕 suppression 的条目,但它们都非常专注于围绕 suppression,所以实际上只有一个或两个表。其他服务也是如此,比如 webhooks。
|
||||
|
||||
#### #3:考虑有状态和无状态
|
||||
|
||||
在设计微服务时,您需要问问自己它是否需要访问数据库,或者它是否是处理 TB 级数据 (如电子邮件或日志) 的无状态服务。
|
||||
|
||||
[Algolia][9] 的 CTO Julien Lemoine 解释说:“我们通过定义服务的输入和输出来定义服务的边界。有时服务是网络 API,但它也可能是使用文件并在数据库中生成记录的进程 (这就是我们的日志处理服务)。”
|
||||
|
||||
事先要明确是否有状态,这将引导一个更好的服务设计。
|
||||
|
||||
#### #4:考虑数据可用性需求
|
||||
|
||||
在设计微服务时,请记住哪些服务将依赖于此新服务,以及在该数据不可用时的整个系统的影响。考虑到这一点,您可以正确地设计此服务的数据备份和恢复系统。
|
||||
|
||||
Steven Czerwinski 提到,在 Scaylr 由于关键客户行空间映射数据的重要性,它将以不同的方式复制和分离。
|
||||
|
||||
相比之下,他补充说,“每个分片信息,都在自己的小分区里。如果部分客户群体因为没有可用日志而停止服务那很糟糕,但它只影响 5% 的客户,而不是100% 的客户。”
|
||||
|
||||
#### #5:单一的真实来源
|
||||
|
||||
设计服务,使其成为系统中某些内容的唯一真实来源。
|
||||
|
||||
例如,当您从电子商务网站订购内容时,则会生成订单 ID,其他服务可以使用此订单 ID 来查询订单服务,以获取有关订单的完整信息。使用 [发布/订阅模式][10],在服务之间传递的数据应该是订单 ID ,而不是订单本身的属性信息。只有订单服务具有订单的完整信息,并且是给定订单信息的唯一真实来源。
|
||||
|
||||
### 大型团队的注意事项
|
||||
|
||||
考虑到上面列出的五个注意事项,较大的团队应了解其组织结构对微服务边界的影响。
|
||||
|
||||
对于较大的组织,整个团队可以专门拥有服务,在确定服务边界时,组织性就会发挥作用。还有两个需要考虑的因素:**独立的发布计划**和**不同的正常运行时间**的重要性。
|
||||
|
||||
[Cloud66.][11] 的 CEO Khash Sajadi 说:“我们所看到的微服务最成功的实现要么基于类似领域驱动设计这样的软件设计原则 (如面向服务的体系结构),要么基于反映组织方法的设计原则。”
|
||||
|
||||
“所以 (对于) 支付团队” Sajadi 说,“他们有支付服务或信用卡验证服务,这就是他们向外界提供的服务。所以这不一定是关于软件的。这主要是关于为外界提供更多服务的业务单位。”
|
||||
|
||||
### 双披萨原理
|
||||
|
||||
Amazon 是一个拥有多个团队的大型组织的完美示例。正如在一篇发表于 [API Evangelist][12] 的文章中所提到的,Jeff Bezos 向所有员工发布一项要求,告知他们公司内的每个团队都必须通过 API 进行沟通。任何不这样做的人都会被解雇。
|
||||
|
||||
这样,所有数据和功能都通过该接口公开。Bezos 还设法让每个团队解耦,定义他们的资源,并通过 API 提供。Amazon 正在从头建立一个系统。这使得公司内的每一支团队都能成为彼此的合作伙伴。
|
||||
|
||||
我与 [Iron.io][13] 的 CTO Travis Reeder 谈到了 Bezos 的内部倡议。
|
||||
|
||||
“Jeff Bezos 规定所有团队都必须构建 API 才能与其他团队进行沟通,” Reeder 说。“他也是提出‘双披萨’规则的人:一支团队不应该比两个比萨饼能养活的大。”
|
||||
|
||||
“我认为这里也可以适用同样的方法:无论一个小型团队是否能够开发、管理和富有成效。如果它开始变得笨重或开始变慢,它可能变得太大了。” Reeder 告诉我。
|
||||
|
||||
### 最后注意事项: 您的服务是否具有合适的大小和正确的定义?
|
||||
|
||||
在微服务系统的测试和实施阶段,有一些指标需要记住。
|
||||
|
||||
#### 指标 #1: 服务之间是否存在过度依赖?
|
||||
|
||||
如果两个服务不断地相互回调,那么这就是强烈的耦合信号,也是它们可能更好地合并为一个服务的信号。
|
||||
|
||||
回到 Chris McFadden 的例子, 他有两个 API 服务,帐户服务和用户服务不断地相互通信, McFadden 提出了一个合并服务的想法,并决定将其称为 “账户用户 API”。事实证明,这是一项富有成效的战略。
|
||||
|
||||
“我们开始做的是消除这些内部 API 之间调用的链接,” McFadden 告诉我。“这有助于简化代码。”
|
||||
|
||||
#### 指标 #2: 设置服务的开销是否超过了服务独立的好处?
|
||||
|
||||
Darby Frey 解释说,“每个应用都需要将其日志聚合到某个位置,并需要进行监视。你需要设置它的警报。你需要有标准的操作程序,和在出现问题时的操作手册。您必须管理 SSH 对它的访问。只是为了让一个应用运行起来,就有大量的基础性工作必须存在。”
|
||||
|
||||
### 关键要点
|
||||
|
||||
设计微服务往往会让人感觉更像是一门艺术,而不是一门科学。对工程师来说,这可能并不顺利。有很多一般性的建议,但有时可能有点太抽象了。让我们回顾一下在设计下一组微服务时要注意的五个具体特征:
|
||||
|
||||
1. 不与其他服务共享数据库表
|
||||
2. 数据库表数量最小化
|
||||
3. 考虑有状态和无状态
|
||||
4. 考虑数据可用性需求
|
||||
5. 单一的真实来源
|
||||
|
||||
下次设计一组微服务并确定服务边界时,回顾这些原则应该会使任务变得更容易。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/guide-design-microservices
|
||||
|
||||
作者:[Jake Lumetta][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://buttercms.com/books/microservices-for-startups/
|
||||
[2]:https://buttercms.com/books/microservices-for-startups/should-you-always-start-with-a-monolith
|
||||
[3]:https://www.sparkpost.com/
|
||||
[4]:https://thebojan.ninja/2015/04/08/high-cohesion-loose-coupling/
|
||||
[5]:https://en.wikipedia.org/wiki/Single_responsibility_principle
|
||||
[6]:https://www.elastic.co/solutions/site-search
|
||||
[7]:https://leadhonestly.com/
|
||||
[8]:https://www.scalyr.com/
|
||||
[9]:https://www.algolia.com/
|
||||
[10]:https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
|
||||
[11]:https://www.cloud66.com/
|
||||
[12]:https://apievangelist.com/2012/01/12/the-secret-to-amazons-success-internal-apis/
|
||||
[13]:https://www.iron.io/
|
||||
@ -1,17 +1,18 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "jlztan"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: subject: "What is PPA? Everything You Need to Know About PPA in Linux"
|
||||
[#]: via: "https://itsfoss.com/ppa-guide/"
|
||||
[#]: author: "Abhishek Prakash https://itsfoss.com/author/abhishek/"
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (jlztan)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10456-1.html)
|
||||
[#]: subject: (What is PPA? Everything You Need to Know About PPA in Linux)
|
||||
[#]: via: (https://itsfoss.com/ppa-guide/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
# 什么是 PPA?你需要知道的关于 Linux 中 PPA 的一切
|
||||
Ubuntu PPA 使用指南
|
||||
======
|
||||
|
||||
**简介:一篇涵盖了在 Ubuntu 和其他 Linux 发行版中使用 PPA 的几乎所有问题的深入的文章。**
|
||||
> 一篇涵盖了在 Ubuntu 和其他 Linux 发行版中使用 PPA 的几乎所有问题的深入的文章。
|
||||
|
||||
如果你一直在使用 Ubuntu 或基于 Ubuntu 的其他 Linux 发行版,例如 Linux Mint、Linux Lite、Zorin OS 等,你可能会遇到以下三行神奇的命令:
|
||||
如果你一直在使用 Ubuntu 或基于 Ubuntu 的其他 Linux 发行版,例如 Linux Mint、Linux Lite、Zorin OS 等,你可能会遇到以下三种神奇的命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:dr-akulavich/lighttable
|
||||
@ -21,17 +22,17 @@ sudo apt-get install lighttable-installer
|
||||
|
||||
许多网站推荐使用类似于以上几行的形式 [在 Ubuntu 中安装应用程序][1]。这就是所谓的使用 PPA 安装应用程序。
|
||||
|
||||
但什么是 PPA?为什么用它?使用 PPA 安全吗?如何正确使用 PPA?如何删除 PPA?
|
||||
但什么是 PPA?为什么要用它?使用 PPA 安全吗?如何正确使用 PPA?如何删除 PPA?
|
||||
|
||||
我将在这个详细的指南中回答上述所有问题。即使你已经了解了一些关于 PPA 的事情,我相信这篇文章仍然会让你了解这方面的更多知识。
|
||||
|
||||
请注意我正在使用 Ubuntu 撰写本文。因此,我几乎可以在任何地方使用 Ubuntu 这个术语,但文中的说明和步骤也适用于其他基于 Debian/Ubuntu 的发行版。
|
||||
请注意我正在使用 Ubuntu 撰写本文。因此,我几乎在各个地方都使用了 Ubuntu 这个术语,但文中的说明和步骤也适用于其他基于 Debian/Ubuntu 的发行版。
|
||||
|
||||
### 什么是 PPA?为什么要使用 PPA?
|
||||
|
||||
![Everything you need to know about PPA in Ubuntu Linux][2]
|
||||
|
||||
PPA 表示 个人软件包存档Personal Package Archive<ruby>个人软件包存档<rt>Personal Package Archive</rt></ruby>。
|
||||
PPA 表示<ruby>个人软件包存档<rt>Personal Package Archive</rt></ruby>。
|
||||
|
||||
这样说容易理解吗?可能不是很容易。
|
||||
|
||||
@ -41,12 +42,12 @@ PPA 表示 个人软件包存档Personal Package Archive<ruby>个人软件包存
|
||||
|
||||
软件仓库是一组文件,其中包含各种软件及其版本的信息,以及校验和等其他一些详细信息。每个版本的 Ubuntu 都有自己的四个官方软件仓库:
|
||||
|
||||
- Main - Canonical 支持的免费和开源软件。
|
||||
- Universe - 社区维护的免费和开源软件。
|
||||
- Main - Canonical 支持的自由开源软件。
|
||||
- Universe - 社区维护的自由开源软件。
|
||||
- Restricted - 设备的专有驱动程序。
|
||||
- Multiverse - 受版权或法律问题限制的软件。
|
||||
|
||||
你可以在 [这里][3] 看到所有版本的 Ubuntu 的软件仓库。你可以浏览并转到各个仓库。例如,可以在 [这里][4] 找到 Ubuntu 16.04 的主存储库。
|
||||
你可以在 [这里][3] 看到所有版本的 Ubuntu 的软件仓库。你可以浏览并转到各个仓库。例如,可以在 [这里][4] 找到 Ubuntu 16.04 的主存储库(Main)。
|
||||
|
||||
所以,PPA 基本上是一个包含软件信息的网址。那你的系统又是如何知道这些仓库的位置的呢?
|
||||
|
||||
@ -80,19 +81,21 @@ Ubuntu 不会立即提供该新版本的软件。需要一个步骤来检查此
|
||||
|
||||
### 如何使用 PPA?PPA 是怎样工作的?
|
||||
|
||||
正如我已经告诉过你的那样,[PPA][7] 代表个人软件包存档Personal Package Archive<ruby>个人软件包存档<rt>Personal Package Archive</rt></ruby>。在这里注意 “个人” 这个词,它暗示了这是开发人员独有的东西,并没有得到分发的正式许可。
|
||||
正如我已经告诉过你的那样,[PPA][7] 代表<ruby>个人软件包存档<rt>Personal Package Archive</rt></ruby>。在这里注意 “个人” 这个词,它暗示了这是开发人员独有的东西,并没有得到分发的正式许可。
|
||||
|
||||
Ubuntu 提供了一个名为 Launchpad 的平台,使软件开发人员能够创建自己的软件仓库。 终端用户,也就是你,可以将 PPA 仓库添加到 `sources.list` 文件中,当你更新系统时,你的系统会知道这个新软件的可用性,然后你可以使用标准的 `sudo apt install` 命令安装它。
|
||||
Ubuntu 提供了一个名为 Launchpad 的平台,使软件开发人员能够创建自己的软件仓库。终端用户,也就是你,可以将 PPA 仓库添加到 `sources.list` 文件中,当你更新系统时,你的系统会知道这个新软件的可用性,然后你可以使用标准的 `sudo apt install` 命令安装它。
|
||||
|
||||
`sudo add-apt-repository ppa:dr-akulavich/lighttable`
|
||||
`sudo apt-get update`
|
||||
`sudo apt-get install lighttable-installer`
|
||||
```
|
||||
sudo add-apt-repository ppa:dr-akulavich/lighttable
|
||||
sudo apt-get update
|
||||
sudo apt-get install lighttable-installer
|
||||
```
|
||||
|
||||
概括一下上面三个命令:
|
||||
|
||||
- `sudo add-apt-repository <PPA_info>` < - 此命令将 PPA 仓库添加到列表中。
|
||||
- `sudo apt-get update` < - 此命令更新可以在当前系统上安装的软件包列表。
|
||||
- `sudo apt-get install <package_in_PPA>` < - 此命令安装软件包。
|
||||
- `sudo add-apt-repository <PPA_info>` <- 此命令将 PPA 仓库添加到列表中。
|
||||
- `sudo apt-get update` <- 此命令更新可以在当前系统上安装的软件包列表。
|
||||
- `sudo apt-get install <package_in_PPA>` <- 此命令安装软件包。
|
||||
|
||||
你会发现使用 `sudo apt update` 命令非常重要,否则你的系统将无法知道新软件包何时可用。
|
||||
|
||||
@ -115,17 +118,17 @@ deb-src http://ppa.launchpad.net/dr-akulavich/lighttable/ubuntu YOUR_UBUNTU_VERS
|
||||
|
||||
以上两行是将任何软件仓库添加到你系统的 `sources.list` 文件的传统方法。但 PPA 会自动为你完成这些工作,无需考虑确切的软件仓库 URL 和操作系统版本。
|
||||
|
||||
此处不那么重要的一点是,当你使用 PPA 时,它不会更改原始的 `sources.list` 文件。相反,它在 `/etc/apt/sources.d` 目录中创建了两个文件,一个 “list” 文件和一个带有 “save” 后缀的备份文件。
|
||||
此处不那么重要的一点是,当你使用 PPA 时,它不会更改原始的 `sources.list` 文件。相反,它在 `/etc/apt/sources.d` 目录中创建了两个文件,一个 `.list` 文件和一个带有 `.save` 后缀的备份文件。
|
||||
|
||||
![Using a PPA in Ubuntu][8]
|
||||
|
||||
PPA 创建了单独的 `sources.list` 文件
|
||||
*PPA 创建了单独的 `sources.list` 文件*
|
||||
|
||||
带有后缀 “list” 的文件含有添加软件仓库的信息的命令。
|
||||
带有后缀 `.list` 的文件含有添加软件仓库的信息的命令。
|
||||
|
||||
![PPA add repository information][9]
|
||||
|
||||
一个 PPA 的 `source.list` 文件的内容
|
||||
*一个 PPA 的 `source.list` 文件的内容*
|
||||
|
||||
这是一种安全措施,可以确保添加的 PPA 不会和原始的 `sources.list` 文件弄混,它还有助于移除 PPA。
|
||||
|
||||
@ -135,11 +138,11 @@ PPA 创建了单独的 `sources.list` 文件
|
||||
|
||||
答案在于更新的过程。如果使用 DEB 包安装软件,将无法保证在运行 `sudo apt update` 和 `sudo apt upgrade` 命令时,已安装的软件会被更新为较新的版本。
|
||||
|
||||
这是因为 apt 的升级过程依赖于 `sources.list` 文件。如果文件中没有相应的软件条目,则不会通过标准软件更新程序获得更新。
|
||||
这是因为 `apt` 的升级过程依赖于 `sources.list` 文件。如果文件中没有相应的软件条目,则不会通过标准软件更新程序获得更新。
|
||||
|
||||
那么这是否意味着使用 DEB 安装的软件永远不会得到更新?不是的。这取决于 DEB 包的创建方式。
|
||||
|
||||
一些开发人员会自动在 `sources.list ` 中添加一个条目,这样软件就可以像普通软件一样更新。谷歌 Chrome 浏览器就是这样一个例子。
|
||||
一些开发人员会自动在 `sources.list` 中添加一个条目,这样软件就可以像普通软件一样更新。谷歌 Chrome 浏览器就是这样一个例子。
|
||||
|
||||
某些软件会在运行时通知你有新版本可用。你必须下载新的 DEB 包并再次运行,来将当前软件更新为较新版本。Oracle Virtual Box 就是这样一个例子。
|
||||
|
||||
@ -163,11 +166,11 @@ PPA 创建了单独的 `sources.list` 文件
|
||||
|
||||
并非每个 PPA 都适用于你的特定版本。你应该知道正在使用 [哪个版本的 Ubuntu][11]。版本的开发代号很重要,因为当你访问某个 PPA 的页面时,你可以看到该 PPA 都支持哪些版本的 Ubuntu。
|
||||
|
||||
对于其他基于 Ubuntu 的发行版,你可以查看 `/etc/os-release` 的内容来 [找出 Ubuntu 版本][11] 的信息。
|
||||
对于其他基于 Ubuntu 的发行版,你可以查看 `/etc/os-release` 的内容来 [找出 Ubuntu 版本][11] 的信息。
|
||||
|
||||
![Verify PPA availability for Ubuntu version][12]
|
||||
|
||||
检查 PPA 是否适用于你的 Ubuntu 版本
|
||||
*检查 PPA 是否适用于你的 Ubuntu 版本*
|
||||
|
||||
如何知道 PPA 的网址呢?只需在网上搜索 PPA 的名称,如 `ppa:dr-akulavich/lighttable`,第一个搜索结果来自 [Launchpad][13],这是托管 PPA 的官方平台。你也可以转到 Launchpad 并直接在那里搜索所需的 PPA。
|
||||
|
||||
@ -188,9 +191,9 @@ W: Failed to fetch http://ppa.launchpad.net/venerix/pkg/ubuntu/dists/raring/main
|
||||
E: Some index files failed to download. They have been ignored, or old ones used instead.
|
||||
```
|
||||
|
||||
上面的错误提示说的很明白,是因为系统找不到当前版本对应的仓库。还记得我们之前看到的仓库结构吗?APT 将尝试在 <http://ppa.launchpad.net/\><PPA_NAME>/ubuntu/dists/Ubuntu_Version 中寻找软件信息。
|
||||
上面的错误提示说的很明白,是因为系统找不到当前版本对应的仓库。还记得我们之前看到的仓库结构吗?APT 将尝试在 `http://ppa.launchpad.net/<PPA_NAME>/ubuntu/dists/<Ubuntu_Version>` 中寻找软件信息。
|
||||
|
||||
如果特定版本的 PPA 不可用,它将永远无法打开 URL,你会看到著名的404错误。
|
||||
如果特定版本的 PPA 不可用,它将永远无法打开 URL,你会看到著名的 404 错误。
|
||||
|
||||
#### 为什么 PPA 不适用于所有 Ubuntu 发行版?
|
||||
|
||||
@ -202,7 +205,7 @@ E: Some index files failed to download. They have been ignored, or old ones used
|
||||
|
||||
比如说,你访问 Light Table 的 PPA 页面,使用刚刚学到的有关 PPA 的知识,你会发现 PPA 不适用于你的特定 Ubuntu 版本。
|
||||
|
||||
你可以点击 `查看软件包详细信息`。
|
||||
你可以点击 “查看软件包详细信息”。
|
||||
|
||||
![Get DEB file from PPA][16]
|
||||
|
||||
@ -234,11 +237,11 @@ Ubuntu 软件中心无法移除 PPA 安装的软件包,你必须使用具有
|
||||
sudo apt install synaptic
|
||||
```
|
||||
|
||||
安装后,启动 Synaptic 包管理器并选择 Origin。你会看到添加到系统的各种软件仓库。 PPA 条目将以前缀 PPA 进行标识,单击以查看 PPA 可用的包。已安装的软件前面会有恰当的符号进行标识。
|
||||
安装后,启动 Synaptic 包管理器并选择 “Origin”。你会看到添加到系统的各种软件仓库。PPA 条目将以前缀 PPA 进行标识,单击以查看 PPA 可用的包。已安装的软件前面会有恰当的符号进行标识。
|
||||
|
||||
![Managing PPA with Synaptic package manager][20]
|
||||
|
||||
查找通过 PPA 安装的软件包
|
||||
*查找通过 PPA 安装的软件包*
|
||||
|
||||
找到包后,你可以从 Synaptic 删除它们。此外,也始终可以选择使用命令行进行移除:
|
||||
|
||||
@ -264,7 +267,7 @@ sudo apt remove package_name
|
||||
|
||||
这是一个主观问题。纯粹主义者厌恶 PPA,因为大多数时候 PPA 来自第三方开发者。但与此同时,PPA 在 Debian/Ubuntu 世界中很受欢迎,因为它们提供了更简单的安装选项。
|
||||
|
||||
就安全性而言,使用 PPA 之后,你的 Linux 系统被黑客攻击或注入恶意软件的可能性较小。到目前为止,我不记得发生过这样的事件。
|
||||
就安全性而言,很少见到因为使用 PPA 之后你的 Linux 系统被黑客攻击或注入恶意软件。到目前为止,我不记得发生过这样的事件。
|
||||
|
||||
官方 PPA 可以不加考虑的使用,使用非官方 PPA 完全是你自己的决定。
|
||||
|
||||
@ -285,7 +288,7 @@ via: https://itsfoss.com/ppa-guide/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -300,7 +303,7 @@ via: https://itsfoss.com/ppa-guide/
|
||||
[7]: https://launchpad.net/ubuntu/+ppas
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/01/ppa-sources-list-files.png?resize=800%2C259&ssl=1
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/01/content-of-ppa-list.png?ssl=1
|
||||
[10]: https://itsfoss.com/install-software-from-source-code/
|
||||
[10]: https://linux.cn/article-9172-1.html
|
||||
[11]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/12/verify-ppa-availibility-version.jpg?resize=800%2C481&ssl=1
|
||||
[13]: https://launchpad.net/
|
||||
@ -1,78 +0,0 @@
|
||||
translating by hopefully2333
|
||||
|
||||
5 ways DevSecOps changes security
|
||||
======
|
||||
|
||||

|
||||
|
||||
There’s been an ongoing kerfuffle over whether we need to expand [DevOps][1] to explicitly bring in security. After all, the thinking goes, [DevOps][2] has always been something of a shorthand for a broad set of new practices, using new tools (often open source) and built on more collaborative cultures. Why not [DevBizOps][3] for better aligning with business needs? Or DevChatOps to emphasize better and faster communications?
|
||||
|
||||
However, [as John Willis wrote earlier this year][4] on his coming around to the [DevSecOps][5] terminology, “Hopefully, someday we will have a world where we no longer have to use the word DevSecOps and security will be an inherent part of all service delivery discussions. Until that day, and at this point, my general conclusion is that it’s just three new characters. More importantly, the name really differentiates the problem statement in a world where we as an industry are not doing a great job on information security.”
|
||||
|
||||
So why aren’t we doing a great job on [information security][6], and what does it mean to do a great job in a DevSecOps context?
|
||||
|
||||
We’ve arguably never done a great job of information security in spite of (or maybe because of) the vast industry of complex point products addressing narrow problems. But we also arguably did a good enough job during the era when defending against threats focused on securing the perimeter, network connections were limited, and most users were employees using company-provided devices.
|
||||
|
||||
Those circumstances haven’t accurately described most organizations’ reality for a number of years now. But the current era, which brings in not only DevSecOps but new application architectural patterns, development practices, and an increasing number of threats, defines a stark new normal that requires a faster pace of change. It’s not so much that DevSecOps in isolation changes security, but that infosec circa 2018 requires new approaches.
|
||||
|
||||
Consider these five areas.
|
||||
|
||||
### Automation
|
||||
|
||||
Lots of automation is a hallmark of DevOps generally. It’s partly about speed. If you’re going to move fast (and not break things), you need to have repeatable processes that execute without a lot of human intervention. Indeed, automation is one of the best entry points for DevOps, even in organizations that are still mostly working on monolithic legacy apps. Automating routine processes associated with configurations or testing with easy-to-use tools such as [Ansible][7] is a common quick hit for starting down the path to DevOps.
|
||||
|
||||
DevSecOps is no different. Security today is a continuous process rather than a discrete checkpoint in the application lifecycle, or even a weekly or monthly check. When vulnerabilities are found and fixes issued by a vendor, it’s important they be applied quickly given that exploits taking advantage of those vulnerabilities will be out soon.
|
||||
|
||||
### "Shift left"
|
||||
|
||||
Traditional security is often viewed as a gatekeeper at the end of the development process. Check all the boxes and your app goes into production. Otherwise, try again. Security teams have a reputation for saying no a lot.
|
||||
|
||||
Therefore, the thinking goes, why not move security earlier (left in a typical left-to-right drawing of a development pipeline)? Security may still say no, but the consequences of rework in early-stage development are a lot less than they are when the app is complete and ready to ship.
|
||||
|
||||
I don’t like the “shift left” term, though. It implies that security is still a one-time event that’s just been moved earlier. Security needs to be a largely automated process everywhere in the application lifecycle, from the supply chain to the development and test process all the way through deployment.
|
||||
|
||||
### Manage dependencies
|
||||
|
||||
One of the big changes we see with modern app development is that you often don’t write most of the code. Using open source libraries and frameworks is one obvious case in point. But you may also just use external services from public cloud providers or other sources. In many cases, this external code and services will dwarf what you write yourself.
|
||||
|
||||
As a result, DevSecOps needs to include a serious focus on your [software supply chain][8]. Are you getting your software from trusted sources? Is it up to date? Is it integrated into the security processes that you use for your own code? What policies do you have in place for which code and APIs you can use? Is commercial support available for the components that you are using for your own production code?
|
||||
|
||||
No set of answers are going to be appropriate in all cases. They may be different for a proof-of-concept versus an at-scale production workload. But, as has been the case in manufacturing for a long time (and DevSecOps has many analogs in how manufacturing has evolved), the integrity of the supply chain is critical.
|
||||
|
||||
### Visibility
|
||||
|
||||
I’ve talked a lot about the need for automation throughout all the stages of the application lifecycle. That makes the assumption that we can see what’s going on in each of those stages.
|
||||
|
||||
Effective DevSecOps requires effective instrumentation so that automation knows what to do. This instrumentation falls into a number of categories. There are long-term and high-level metrics that help tell us if the overall DevSecOps process is working well. There are critical alerts that require immediate human intervention (the security scanning system is down!). There are alerts, such as for a failed scan, that require remediation. And there are logs of the many parameters we capture for later analysis (what’s changing over time? What caused that failure?).
|
||||
|
||||
### Services vs. monoliths
|
||||
|
||||
While DevSecOps practices can be applied across many types of application architectures, they’re most effective with small and loosely coupled components that can be updated and reused without potentially forcing changes elsewhere in the app. In their purest form, these components can be [microservices][9] or functions, but the general principles apply wherever you have loosely coupled services communicating over a network.
|
||||
|
||||
This pattern does introduce some new security challenges. The interactions between components can be complex and the total attack surface can be larger because there are now more entry points to the application across the network.
|
||||
|
||||
On the other hand, this type of architecture also means that automated security and monitoring also has more granular visibility into the application components because they’re no longer buried deep within a monolithic application.
|
||||
|
||||
Don’t get too wrapped up in the DevSecOps term, but take it as a reminder that security is evolving because the way that we write and deploy applications is evolving.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/devsecops-changes-security
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ghaff
|
||||
[1]: https://opensource.com/resources/devops
|
||||
[2]: https://opensource.com/tags/devops
|
||||
[3]: https://opensource.com/article/18/5/steps-apply-devops-culture-beyond-it
|
||||
[4]: https://www.devsecopsdays.com/articles/its-just-a-name
|
||||
[5]: https://opensource.com/article/18/4/devsecops
|
||||
[6]: https://opensource.com/article/18/6/where-cycle-security-devops
|
||||
[7]: https://opensource.com/tags/ansible
|
||||
[8]: https://opensource.com/article/17/1/be-open-source-supply-chain
|
||||
[9]: https://opensource.com/tags/microservices
|
||||
@ -1,68 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 2 OK02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 2 OK02
|
||||
======
|
||||
|
||||
The OK02 lesson builds on OK01, by causing the 'OK' or 'ACT' LED to turn on and off repeatedly. It is assumed you have the code for the [Lesson 1: OK01][1] operating system as a basis.
|
||||
|
||||
### 1 Waiting
|
||||
|
||||
Waiting is a surprisingly useful part of Operating System development. Often Operating Systems find themselves with nothing to do, and must delay. In this example, we wish to do so in order to allow the LED flashing off and on to be visible. If you just turned it off and on, it would not be visible, as the computer would be able to turn it off and on many thousands of times per second. In later lessons we will look at accurate waiting, but for now it is sufficient to simply waste time.
|
||||
|
||||
```
|
||||
mov r2,#0x3F0000
|
||||
wait1$:
|
||||
sub r2,#1
|
||||
cmp r2,#0
|
||||
bne wait1$
|
||||
```
|
||||
|
||||
```
|
||||
sub reg,#val subtracts the number val from the value in reg.
|
||||
|
||||
cmp reg,#val compares the value in reg with the number val.
|
||||
|
||||
Suffix ne causes the command to be executed only if the last comparison determined that the numbers were not equal.
|
||||
```
|
||||
|
||||
The code above is a generic piece of code that creates a delay, which thanks to every Raspberry Pi being basically the same, is roughly the same time. How it does this is using a mov command to put the value 3F000016 into r2, and then subtracting 1 from this value until it is 0. The new commands here are sub, cmp, and bne.
|
||||
|
||||
sub is the subtract command, and simply subtracts the second argument from the first.
|
||||
|
||||
cmp is a more interesting command. It compares the first argument with the second, and remembers the result of the comparison in a special register called the current processor status register. You don't really need to worry about this, suffice to say it remembers, among other things, which of the two numbers was bigger or smaller, or if they were equal.[1]
|
||||
|
||||
bne is actually just a branch command in disguise. In the ARM assembly language family, any instruction can be executed conditionally. This means that the instruction is only run if the last comparison had a certain result. We will use this extensively later for interesting tricks, but in this case we use the ne suffix on the b command to mean 'only branch if the last comparison's result was that the values were not equal'. The ne suffix can be used on any command, as can several other (16 in all) conditions such as eq for equal and lt for less than.
|
||||
|
||||
### 2 The All Together
|
||||
|
||||
I mentioned briefly last time that the status LED can be turned off again by writing to an offset of 28 from the GPIO controller instead of 40 (i.e. str r1,[r0,#28]). Thus, you need to modify the code from OK01 to turn the LED on, run the wait code, turn it off, run the wait code again, and then include a branch back to the beginning. Note, it is not necessary to re-enable the output to GPIO 16, we need only do that once. If you're being efficient, which I strongly encourage, you should be able to reuse the value of r1. As with all lessons, a full solution to this can be found on the [download page][2]. Be careful to make sure all of your labels are unique. When you write wait1$: you cannot label another line wait1$.
|
||||
|
||||
On my Raspberry Pi it flashes about twice a second. this could easily be altered by changing the value we set r2 to. However, unfortunately we can't precisely predict the speed this runs at. If you didn't manage to get this working see our trouble shooting page, otherwise, congratulations.
|
||||
|
||||
In this lesson we've learnt two more assembly commands, sub and cmp, as well as learning about conditional execution in ARM.
|
||||
|
||||
In the next lesson, [Lesson 3: OK03][3] we will evaluate how we're coding, and establish some standards so that we can reuse code, and if necessary, work with C or C++ code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html
|
||||
@ -1,590 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (An introduction to the Tornado Python web app framework)
|
||||
[#]: via: (https://opensource.com/article/18/6/tornado-framework)
|
||||
[#]: author: (Nicholas Hunt-Walker https://opensource.com/users/nhuntwalker)
|
||||
[#]: url: ( )
|
||||
|
||||
An introduction to the Tornado Python web app framework
|
||||
======
|
||||
In the third part in a series comparing Python frameworks, learn about Tornado, built to handle asynchronous processes.
|
||||

|
||||
|
||||
In the first two articles in this four-part series comparing different Python web frameworks, we've covered the [Pyramid][1] and [Flask][2] web frameworks. We've built the same app twice and seen the similarities and differences between a complete DIY framework and a framework with a few more batteries included.
|
||||
|
||||
Now let's look at a somewhat different option: [the Tornado framework][3]. Tornado is, for the most part, as bare-bones as Flask, but with a major difference: Tornado is built specifically to handle asynchronous processes. That special sauce isn't terribly useful in the app we're building in this series, but we'll see where we can use it and how it works in a more general situation.
|
||||
|
||||
Let's continue the pattern we set in the first two articles and start by tackling the setup and config.
|
||||
|
||||
### Tornado startup and configuration
|
||||
|
||||
If you've been following along with this series, what we do first shouldn't come as much of a surprise.
|
||||
|
||||
```
|
||||
$ mkdir tornado_todo
|
||||
$ cd tornado_todo
|
||||
$ pipenv install --python 3.6
|
||||
$ pipenv shell
|
||||
(tornado-someHash) $ pipenv install tornado
|
||||
```
|
||||
|
||||
Create a `setup.py` for installing our application:
|
||||
|
||||
```
|
||||
(tornado-someHash) $ touch setup.py
|
||||
# setup.py
|
||||
from setuptools import setup, find_packages
|
||||
|
||||
requires = [
|
||||
'tornado',
|
||||
'tornado-sqlalchemy',
|
||||
'psycopg2',
|
||||
]
|
||||
|
||||
setup(
|
||||
name='tornado_todo',
|
||||
version='0.0',
|
||||
description='A To-Do List built with Tornado',
|
||||
author='<Your name>',
|
||||
author_email='<Your email>',
|
||||
keywords='web tornado',
|
||||
packages=find_packages(),
|
||||
install_requires=requires,
|
||||
entry_points={
|
||||
'console_scripts': [
|
||||
'serve_app = todo:main',
|
||||
],
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
Because Tornado doesn't require any external configuration, we can dive right into writing the Python code that'll run our application. Let's make our inner `todo` directory and fill it with the first few files we'll need.
|
||||
|
||||
```
|
||||
todo/
|
||||
__init__.py
|
||||
models.py
|
||||
views.py
|
||||
```
|
||||
|
||||
Like Flask and Pyramid, Tornado has some central configuration that will go in `__init__.py`. From `tornado.web`, we'll import the `Application` object. This will handle the hookups for routing and views, including our database (when we get there) and any extra settings needed to run our Tornado app.
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
```
|
||||
|
||||
When we use the `define` function, we end up creating attributes on the `options` object. Anything that goes in the position of the first argument will be the attribute's name, and what's assigned to the `default` keyword argument will be the value of that attribute.
|
||||
|
||||
As an example, if we name the attribute `potato` instead of `port`, we can access its value via `options.potato`.
|
||||
|
||||
Calling `listen` on the `HTTPServer` doesn't start the server yet. We must do one more step to have a working application that can listen for requests and return responses. We need an input-output loop. Thankfully, Tornado comes with that out of the box in the form of `tornado.ioloop.IOLoop`.
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
I like some kind of a `print` statement somewhere that tells me when I'm serving my application, but that's me. You could do without the `print` line if you so chose.
|
||||
|
||||
We begin our I/O loop with `IOLoop.current().start()`. Let's talk a little more about input, output, and asynchronicity.
|
||||
|
||||
### The basics of async in Python and the I/O loop
|
||||
|
||||
Allow me to preface by saying that I am absolutely, positively, surely, and securely not an expert in asynchronous programming. As with all things I write, what follows stems from the limits of my understanding of the concept. As I am human, it may be deeply, deeply flawed.
|
||||
|
||||
The main concerns of an asynchronous program are:
|
||||
|
||||
* How is data coming in?
|
||||
* How is data going out?
|
||||
* When can some procedure be left to run without consuming my full attention?
|
||||
|
||||
|
||||
|
||||
Due to the [global interpreter lock][4] (GIL), Python is—by design—a [single-threaded][5] language. For every task a Python program must execute, the full attention of its thread of execution is on that task for the duration of that task. Our HTTP server is written in Python. Thus, when data (e.g., an HTTP request) is received, the server's sole focus is that incoming data. This means that, in most cases, whatever procedures need to run in handling and processing that data will completely consume your server's thread of execution, blocking other potential data from being received until your server finishes whatever it needed to do.
|
||||
|
||||
In many cases this isn't too problematic; a typical web request-response cycle will take only fractions of a second. Along with that, the sockets that HTTP servers are built from can maintain a backlog of incoming requests to be handled. So, if a request comes in while that socket is handling something else, chances are it'll just wait in line a bit before being addressed. For a low to intermediate traffic site, a fraction of a second isn't that big of a deal, and you can use multiple deployed instances along with a load-balancer like [NGINX][6] to distribute traffic for the larger request loads.
|
||||
|
||||
What if, however, your average response time takes more than a fraction of a second? What if you use data from the incoming request to start some long-running process like a machine-learning algorithm or some massive database query? Now, your single-threaded web server starts to accumulate an unaddressable backlog of requests, some of which will get dropped due to simply timing out. This is not an option, especially if you want your service to be seen as reliable on a regular basis.
|
||||
|
||||
In comes the asynchronous Python program. It's important to keep in mind that because it's written in Python, the program is still a single-threaded process. Anything that would block execution in a synchronous program, unless specifically flagged, will still block execution in an asynchronous one.
|
||||
|
||||
When it's structured correctly, however, your asynchronous Python program can "shelve" long-running tasks whenever you designate that a certain function should have the ability to do so. Your async controller can then be alerted when the shelved tasks are complete and ready to resume, managing their execution only when needed without completely blocking the handling of new input.
|
||||
|
||||
That was somewhat jargony, so let's demonstrate with a human example.
|
||||
|
||||
#### Bringing it home
|
||||
|
||||
I often find myself trying to get multiple chores done at home with little time to do them. On a given day, that backlog of chores may look like:
|
||||
|
||||
* Cook a meal (20 min. prep, 40 min. cook)
|
||||
* Wash dishes (60 min.)
|
||||
* Wash and dry laundry (30 min. wash, 90 min. dry per load)
|
||||
* Vacuum floors (30 min.)
|
||||
|
||||
|
||||
|
||||
If I were acting as a traditional, synchronous program, I'd be doing each task myself, by hand. Each task would require my full attention to complete before I could consider handling anything else, as nothing would get done without my active attention. So my sequence of execution might look like:
|
||||
|
||||
1. Focus fully on preparing and cooking the meal, including waiting around for food to just… cook (60 min.).
|
||||
2. Transfer dirty dishes to sink (65 min. elapsed).
|
||||
3. Wash all the dishes (125 min. elapsed).
|
||||
4. Start laundry with my full focus on that, including waiting around for the washing machine to finish, then transferring laundry to the dryer, and waiting for the dryer to finish (250 min. elapsed).
|
||||
5. Vacuum the floors (280 min. elapsed).
|
||||
|
||||
|
||||
|
||||
That's 4 hours and 40 minutes to complete my chores from end-to-end.
|
||||
|
||||
Instead of working hard, I should work smart like an asynchronous program. My home is full of machines that can do my work for me without my continuous effort. Meanwhile, I can switch my attention to what may actively need it right now.
|
||||
|
||||
My execution sequence might instead look like:
|
||||
|
||||
1. Load clothes into and start the washing machine (5 min.).
|
||||
2. While the washing machine is running, prep food (25 min. elapsed).
|
||||
3. After prepping food, start cooking food (30 min. elapsed).
|
||||
4. While the food is cooking, move clothes from the washing machine into the dryer and start dryer (35 min. elapsed).
|
||||
5. While dryer is running and food is still cooking, vacuum the floors (65 min. elapsed).
|
||||
6. After vacuuming the floors, take food off the stove and load the dishwasher (70 min. elapsed).
|
||||
7. Run the dishwasher (130 min. when done).
|
||||
|
||||
|
||||
|
||||
Now I'm down to 2 hours and 10 minutes. Even if I allow more time for switching between jobs (10-20 more minutes total), I'm still down to about half the time I would've spent if I'd waited to perform each task in sequential order. This is the power of structuring your program to be asynchronous.
|
||||
|
||||
#### So where does the I/O loop come in?
|
||||
|
||||
An asynchronous Python program works by taking in data from some external source (input) and, should the process require it, offloading that data to some external worker (output) for processing. When that external process finishes, the main Python program is alerted. The program then picks up the result of that external processing (input) and continues on its merry way.
|
||||
|
||||
Whenever that data isn't actively in the hands of the main Python program, that main program is freed to work on just about anything else. This includes awaiting completely new inputs (e.g., HTTP requests) and handling the results of long-running processes (e.g., results of machine-learning algorithms, long-running database queries). The main program, while still single-threaded, becomes event-driven, triggered into action for specific occurrences handled by the program. The main worker that listens for those events and dictates how they should be handled is the I/O loop.
|
||||
|
||||
We traveled a long road to get to this nugget of an explanation, I know, but what I'm hoping to communicate here is that it's not magic, nor is it some type of complex parallel processing or multi-threaded work. The global interpreter lock is still in place; any long-running process within the main program will still block anything else from happening. The program is also still single-threaded; however, by externalizing tedious work, we conserve the attention of that thread to only what it needs to be attentive to.
|
||||
|
||||
This is kind of like my asynchronous chores above. When my attention is fully necessary for prepping food, that's all I'm doing. However, when I can get the stove to do work for me by cooking my food, and the dishwasher to wash my dishes, and the washing machine and dryer to handle my laundry, my attention is freed to work on other things. When I am alerted that one of my long-running tasks is finished and ready to be handled once again, if my attention is free, I can pick up the results of that task and do whatever needs to be done with it next.
|
||||
|
||||
### Tornado routes and views
|
||||
|
||||
Despite having gone through all the trouble of talking about async in Python, we're going to hold off on using it for a bit and first write a basic Tornado view.
|
||||
|
||||
Unlike the function-based views we've seen in the Flask and Pyramid implementations, Tornado's views are all class-based. This means we'll no longer use individual, standalone functions to dictate how requests are handled. Instead, the incoming HTTP request will be caught and assigned to be an attribute of our defined class. Its methods will then handle the corresponding request types.
|
||||
|
||||
Let's start with a basic view that prints "Hello, World" to the screen. Every class-based view we construct for our Tornado app must inherit from the `RequestHandler` object found in `tornado.web`. This will set up all the ground-level logic that we'll need (but don't want to write) to take in a request and construct a properly formatted HTTP response.
|
||||
|
||||
```
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class HelloWorld(RequestHandler):
|
||||
"""Print 'Hello, world!' as the response body."""
|
||||
|
||||
def get(self):
|
||||
"""Handle a GET request for saying Hello World!."""
|
||||
self.write("Hello, world!")
|
||||
```
|
||||
|
||||
Because we're looking to handle a `GET` request, we declare (really override) the `get` method. Instead of returning anything, we provide text or a JSON-serializable object to be written to the response body with `self.write`. After that, we let the `RequestHandler` take on the rest of the work that must be done before a response can be sent.
|
||||
|
||||
As it stands, this view has no actual connection to the Tornado application itself. We have to go back into `__init__.py` and update the `main` function a bit. Here's the new hotness:
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import HelloWorld
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', HelloWorld)
|
||||
])
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
#### What'd we do?
|
||||
|
||||
We imported the `HelloWorld` view from the `views.py` file into `__init__.py` at the top of the script. Then we added a list of route-view pairs as the first argument to the instantiation to `Application`. Whenever we want to declare a route in our application, it must be tied to a view. You can use the same view for multiple routes if you want, but there must always be a view for every route.
|
||||
|
||||
We can make sure this all works by running our app with the `serve_app` command we enabled in the `setup.py`. Check `http://localhost:8888/` and see that it says "Hello, world!"
|
||||
|
||||
Of course, there's more we can and will do in this space, but let's move on to models.
|
||||
|
||||
### Connecting the database
|
||||
|
||||
If we want to hold onto data, we need to connect a database. Like with Flask, we'll be using a framework-specific variant of SQLAlchemy called [tornado-sqlalchemy][7].
|
||||
|
||||
Why use this instead of just the bare [SQLAlchemy][8]? Well, `tornado-sqlalchemy` has all the goodness of straightforward SQLAlchemy, so we can still declare models with a common `Base` as well as use all the column data types and relationships to which we've grown accustomed. Alongside what we already know from habit, `tornado-sqlalchemy` provides an accessible async pattern for its database-querying functionality specifically to work with Tornado's existing I/O loop.
|
||||
|
||||
We set the stage by adding `tornado-sqlalchemy` and `psycopg2` to `setup.py` to the list of required packages and reinstall the package. In `models.py`, we declare our models. This step looks pretty much exactly like what we've already seen in Flask and Pyramid, so I'll skip the full-class declarations and just put up the necessaries of the `Task` model.
|
||||
|
||||
```
|
||||
# this is not the complete models.py, but enough to see the differences
|
||||
from tornado_sqlalchemy import declarative_base
|
||||
|
||||
Base = declarative_base
|
||||
|
||||
class Task(Base):
|
||||
# and so on, because literally everything's the same...
|
||||
```
|
||||
|
||||
We still have to connect `tornado-sqlalchemy` to the actual application. In `__init__.py`, we'll be defining the database and integrating it into the application.
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import HelloWorld
|
||||
|
||||
# add these
|
||||
import os
|
||||
from tornado_sqlalchemy import make_session_factory
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', HelloWorld)
|
||||
],
|
||||
session_factory=factory
|
||||
)
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
Much like the session factory we passed around in Pyramid, we can use `make_session_factory` to take in a database URL and produce an object whose sole purpose is to provide connections to the database for our views. We then tie it into our application by passing the newly created `factory` into the `Application` object with the `session_factory` keyword argument.
|
||||
|
||||
Finally, initializing and managing the database will look the same as it did for Flask and Pyramid (i.e., separate DB management script, working with respect to the `Base` object, etc.). It'll look so similar that I'm not going to reproduce it here.
|
||||
|
||||
### Revisiting views
|
||||
|
||||
Hello, World is always nice for learning the basics, but we need some real, application-specific views.
|
||||
|
||||
Let's start with the info view.
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class InfoView(RequestHandler):
|
||||
"""Only allow GET requests."""
|
||||
SUPPORTED_METHODS = ["GET"]
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def get(self):
|
||||
"""List of routes for this API."""
|
||||
routes = {
|
||||
'info': 'GET /api/v1',
|
||||
'register': 'POST /api/v1/accounts',
|
||||
'single profile detail': 'GET /api/v1/accounts/<username>',
|
||||
'edit profile': 'PUT /api/v1/accounts/<username>',
|
||||
'delete profile': 'DELETE /api/v1/accounts/<username>',
|
||||
'login': 'POST /api/v1/accounts/login',
|
||||
'logout': 'GET /api/v1/accounts/logout',
|
||||
"user's tasks": 'GET /api/v1/accounts/<username>/tasks',
|
||||
"create task": 'POST /api/v1/accounts/<username>/tasks',
|
||||
"task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
|
||||
"task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
|
||||
"delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
|
||||
}
|
||||
self.write(json.dumps(routes))
|
||||
```
|
||||
|
||||
So what changed? Let's go from the top down.
|
||||
|
||||
The `SUPPORTED_METHODS` class attribute was added. This will be an iterable of only the request methods that are accepted by this view. Any other method will return a [405][9] status code. When we made the `HelloWorld` view, we didn't specify this, mostly out of laziness. Without this class attribute, this view would respond to any request trying to access the route tied to the view.
|
||||
|
||||
The `set_default_headers` method is declared, which sets the default headers of the outgoing HTTP response. We declare this here to ensure that any response we send back has a `"Content-Type"` of `"application/json"`.
|
||||
|
||||
We added `json.dumps(some_object)` to the argument of `self.write` because it makes it easy to construct the content for the body of the outgoing response.
|
||||
|
||||
Now that's done, and we can go ahead and connect it to the home route in `__init__.py`.
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import InfoView
|
||||
|
||||
# add these
|
||||
import os
|
||||
from tornado_sqlalchemy import make_session_factory
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', InfoView)
|
||||
],
|
||||
session_factory=factory
|
||||
)
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
As we know, more views and routes will need to be written. Each one will get dropped into the `Application` route listing as needed. Each will also need a `set_default_headers` method. On top of that, we'll create our `send_response`method, whose job it will be to package our response along with any custom status codes we want to set for a given response. Since each one will need both methods, we can create a base class containing them that each of our views can inherit from. That way, we have to write them only once.
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler):
|
||||
"""Base view for this application."""
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
For a view like the `TaskListView` we'll soon write, we'll also need a connection to the database. We'll need `tornado_sqlalchemy`'s `SessionMixin` to add a database session within every view class. We can fold that into the `BaseView` so that, by default, every view inheriting from it has access to a database session.
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado_sqlalchemy import SessionMixin
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler, SessionMixin):
|
||||
"""Base view for this application."""
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
As long as we're modifying this `BaseView` object, we should address a quirk that will come up when we consider data being posted to this API.
|
||||
|
||||
When Tornado (as of v.4.5) consumes data from a client and organizes it for use in the application, it keeps all the incoming data as bytestrings. However, all the code here assumes Python 3, so the only strings that we want to work with are Unicode strings. We can add another method to this `BaseView` class whose job it will be to convert the incoming data to Unicode before using it anywhere else in the view.
|
||||
|
||||
If we want to convert this data before we use it in a proper view method, we can override the view class's native `prepare` method. Its job is to run before the view method runs. If we override the `prepare` method, we can set some logic to run that'll do the bytestring-to-Unicode conversion whenever a request is received.
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado_sqlalchemy import SessionMixin
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler, SessionMixin):
|
||||
"""Base view for this application."""
|
||||
|
||||
def prepare(self):
|
||||
self.form_data = {
|
||||
key: [val.decode('utf8') for val in val_list]
|
||||
for key, val_list in self.request.arguments.items()
|
||||
}
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
If there's any data coming in, it'll be found within the `self.request.arguments` dictionary. We can access that data by key and convert its contents (always a list) to Unicode. Because this is a class-based view instead of a function-based view, we can store the modified data as an instance attribute to be used later. I called it `form_data` here, but it can just as easily be called `potato`. The point is that we can store data that has been submitted to the application.
|
||||
|
||||
### Asynchronous view methods
|
||||
|
||||
Now that we've built our `BaseView`, we can build the `TaskListView` that will inherit from it.
|
||||
|
||||
As you can probably tell from the section heading, this is where all that talk about asynchronicity comes in. The `TaskListView` will handle `GET` requests for returning a list of tasks and `POST` requests for creating new tasks given some form data. Let's first look at the code to handle the `GET` request.
|
||||
|
||||
```
|
||||
# all the previous imports
|
||||
import datetime
|
||||
from tornado.gen import coroutine
|
||||
from tornado_sqlalchemy import as_future
|
||||
from todo.models import Profile, Task
|
||||
|
||||
# the BaseView is above here
|
||||
class TaskListView(BaseView):
|
||||
"""View for reading and adding new tasks."""
|
||||
SUPPORTED_METHODS = ("GET", "POST",)
|
||||
|
||||
@coroutine
|
||||
def get(self, username):
|
||||
"""Get all tasks for an existing user."""
|
||||
with self.make_session() as session:
|
||||
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
|
||||
if profile:
|
||||
tasks = [task.to_dict() for task in profile.tasks]
|
||||
self.send_response({
|
||||
'username': profile.username,
|
||||
'tasks': tasks
|
||||
})
|
||||
```
|
||||
|
||||
The first major piece here is the `@coroutine` decorator, imported from `tornado.gen`. Any Python callable that has a portion that acts out of sync with the normal flow of the call stack is effectively a "co-routine"; a routine that can run alongside other routines. In the example of my household chores, pretty much every chore was a co-routine. Some were blocking routines (e.g., vacuuming the floor), but that routine simply blocked my ability to start or attend to anything else. It didn't block any of the other routines that were already set in motion from continuing.
|
||||
|
||||
Tornado offers a number of ways to build an app that take advantage of co-routines, including allowing us to set locks on function calls, conditions for synchronizing asynchronous routines, and a system for manually modifying the events that control the I/O loop.
|
||||
|
||||
The only way the `@coroutine` decorator is used here is to allow the `get` method to farm out the SQL query as a background process and resume once the query is complete, while not blocking the Tornado I/O loop from handling other sources of incoming data. That is all that's "asynchronous" about this implementation: out-of-band database queries. Clearly if we wanted to showcase the magic and wonder of an async web app, a To-Do List isn't the way.
|
||||
|
||||
But hey, that's what we're building, so let's see how our method takes advantage of that `@coroutine` decorator. The `SessionMixin` that was, well, mixed into the `BaseView` declaration added two handy, database-aware attributes to our view class: `session` and `make_session`. They're similarly named and accomplish fairly similar goals.
|
||||
|
||||
The `self.session` attribute is a session with an eye on the database. At the end of the request-response cycle, just before the view sends a response back to the client, any changes that have been made to the database are committed, and the session is closed.
|
||||
|
||||
`self.make_session` is a context manager and generator, building and returning a brand new session object on the fly. That first `self.session` object still exists; `make_session` creates a new one anyway. The `make_session` generator also has baked into itself the logic for committing and closing the session it creates as soon as its context (i.e., indentation level) ends.
|
||||
|
||||
If you inspect the source code, there is no difference between the type of object assigned to `self.session` and the type of object generated by `self.make_session`. The difference is in how they're managed.
|
||||
|
||||
With the `make_session` context manager, the generated session belongs only to the context, beginning and ending within that context. You can open, modify, commit, and close multiple database sessions within the same view with the `make_session` context manager.
|
||||
|
||||
`self.session` is much simpler, with the session already opened by the time you get to your view method and committing before the response is sent back to the client.
|
||||
|
||||
Although the [read the docs snippet][10] and the [the PyPI example][11] both specify the use of the context manager, there's nothing about either the `self.session` object or the `session` generated by `self.make_session` that is inherently asynchronous. The point where we start thinking about the async behavior built into `tornado-sqlalchemy` comes when we initiate a query.
|
||||
|
||||
The `tornado-sqlalchemy` package provides us with the `as_future` function. The job of `as_future` is to wrap the query constructed by the `tornado-sqlalchemy` session and yield its return value. If the view method is decorated with `@coroutine`, then using this `yield as_future(query)` pattern will now make your wrapped query an asynchronous background process. The I/O loop takes over, awaiting the return value of the query and the resolution of the `future` object created by `as_future`.
|
||||
|
||||
To have access to the result from `as_future(query)`, you must `yield` from it. Otherwise, you get only an unresolved generator object and can do nothing with the query.
|
||||
|
||||
Everything else in this view method is pretty much par for the course, mirroring what we've already seen in Flask and Pyramid.
|
||||
|
||||
The `post` method will look fairly similar. For the sake of consistency, let's see how the `post` method looks and how it handles the `self.form_data` that was constructed with the `BaseView`.
|
||||
|
||||
```
|
||||
@coroutine
|
||||
def post(self, username):
|
||||
"""Create a new task."""
|
||||
with self.make_session() as session:
|
||||
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
|
||||
if profile:
|
||||
due_date = self.form_data['due_date'][0]
|
||||
task = Task(
|
||||
name=self.form_data['name'][0],
|
||||
note=self.form_data['note'][0],
|
||||
creation_date=datetime.now(),
|
||||
due_date=datetime.strptime(due_date, '%d/%m/%Y %H:%M:%S') if due_date else None,
|
||||
completed=self.form_data['completed'][0],
|
||||
profile_id=profile.id,
|
||||
profile=profile
|
||||
)
|
||||
session.add(task)
|
||||
self.send_response({'msg': 'posted'}, status=201)
|
||||
```
|
||||
|
||||
As I said, it's about what we'd expect:
|
||||
|
||||
* The same query pattern as we saw with the `get` method
|
||||
* The construction of an instance of a new `Task` object, populated with data from `form_data`
|
||||
* The adding (but not committing because it's handled by the context manager!) of the new `Task` object to the database session
|
||||
* The sending of a response back to the client
|
||||
|
||||
|
||||
|
||||
And thus we have the basis for our Tornado web app. Everything else (e.g., database management and more views for a more complete app) is effectively the same as what we've already seen in the Flask and Pyramid apps.
|
||||
|
||||
### Thoughts about using the right tool for the right job
|
||||
|
||||
What we're starting to see as we continue to move through these web frameworks is that they can all effectively handle the same problems. For something like this To-Do List, any framework can do the job. However, some web frameworks are more appropriate for certain jobs than other ones, depending on what "more appropriate" means for you and your needs.
|
||||
|
||||
While Tornado is clearly capable of handling the same job that Pyramid or Flask can handle, to use it for an app like this is effectively a waste. It's like using a car to travel one block from home. Yes it can do the job of "travel," but short trips aren't why you choose to use a car over a bike or just your feet.
|
||||
|
||||
Per the documentation, Tornado is billed as "a Python web framework and asynchronous networking library." There are few like it in the Python web framework ecosystem. If the job you're trying to accomplish requires (or would benefit significantly from) asynchronicity in any way, shape, or form, use Tornado. If your application needs to handle multiple, long-lived connections while not sacrificing much in performance, choose Tornado. If your application is many applications in one and needs to be thread-aware for the accurate handling of data, reach for Tornado. That's where it works best.
|
||||
|
||||
Use your car to do "car things." Use other modes of transportation to do everything else.
|
||||
|
||||
### Going forward and a little perspective check
|
||||
|
||||
Speaking of using the right tool for the right job, keep in mind the scope and scale, both present and future, of your application when choosing your framework. Up to this point we've only looked at frameworks meant for small to midsized web applications. The next and final installment of this series will cover one of the most popular Python frameworks, Django, meant for big applications that might grow bigger. Again, while it technically can and will handle the To-Do List problem, keep in mind that it's not really what the framework is for. We'll still put it through its paces to show how an application can be built with it, but we have to keep in mind the intent of the framework and how that's reflected in its architecture:
|
||||
|
||||
* **Flask:** Meant for small, simple projects; makes it easy for us to construct views and connect them to routes quickly; can be encapsulated in a single file without much fuss
|
||||
* **Pyramid:** Meant for projects that may grow; contains a fair bit of configuration to get up and running; separate realms of application components can easily be divided and built out to arbitrary depth without losing sight of the central application
|
||||
* **Tornado:** Meant for projects benefiting from precise and deliberate I/O control; allows for co-routines and easily exposes methods that can control how requests are received/responses are sent and when those operations occur
|
||||
* **Django:** (As we'll see) meant for big things that may get bigger; large ecosystem of add-ons and mods; very opinionated in its configuration and management in order to keep all the disparate parts in line
|
||||
|
||||
|
||||
|
||||
Whether you've been reading since the first post in this series or joined a little later, thanks for reading! Please feel free to leave questions or comments. I'll see you next time with hands full of Django.
|
||||
|
||||
### Huge shout-out to the Python BDFL
|
||||
|
||||
I must give credit where credit is due. Massive thanks are owed to [Guido van Rossum][12] for more than just creating my favorite programming language.
|
||||
|
||||
During [PyCascades 2018][13], I was fortunate not only to give the talk this article series is based on, but also to be invited to the speakers' dinner. I got to sit next to Guido the whole night and pepper him with questions. One of those questions was how in the world async worked in Python, and he, without a bit of fuss, spent time explaining it to me in a way that I could start to grasp the concept. He later [tweeted to me][14] a spectacular resource for learning async with Python that I subsequently read three times over three months, then wrote this post. You're an awesome guy, Guido!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/tornado-framework
|
||||
|
||||
作者:[Nicholas Hunt-Walker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nhuntwalker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/5/pyramid-framework
|
||||
[2]: https://opensource.com/article/18/4/flask
|
||||
[3]: https://tornado.readthedocs.io/en/stable/
|
||||
[4]: https://realpython.com/python-gil/
|
||||
[5]: https://en.wikipedia.org/wiki/Thread_(computing)
|
||||
[6]: https://www.nginx.com/
|
||||
[7]: https://tornado-sqlalchemy.readthedocs.io/en/latest/
|
||||
[8]: https://www.sqlalchemy.org/
|
||||
[9]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_errors
|
||||
[10]: https://tornado-sqlalchemy.readthedocs.io/en/latest/#usage
|
||||
[11]: https://pypi.org/project/tornado-sqlalchemy/#description
|
||||
[12]: https://www.twitter.com/gvanrossum
|
||||
[13]: https://www.pycascades.com
|
||||
[14]: https://twitter.com/gvanrossum/status/956186585493458944
|
||||
@ -1,76 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding /etc/services file in Linux)
|
||||
[#]: via: (https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/)
|
||||
[#]: author: (kerneltalks https://kerneltalks.com)
|
||||
|
||||
Understanding /etc/services file in Linux
|
||||
======
|
||||
|
||||
Article which helps you to understand /etc/services file in Linux. Learn about content, format & importance of this file.
|
||||
|
||||
![/etc/services file in Linux][1]
|
||||
/etc/services file in Linux
|
||||
|
||||
Internet daemon is important service in Linux world. It takes care of all network services with the help of `/etc/services` file. In this article we will walk you through content, format of this file and what it means to a Linux system.
|
||||
|
||||
`/etc/services` file contains list of network services and ports mapped to them. `inetd` or `xinetd` looks at these details so that it can call particular program when packet hits respective port and demand for service.
|
||||
|
||||
As a normal user you can view this file since file is world readable. To edit this file you need to have root privileges.
|
||||
|
||||
```
|
||||
$ ll /etc/services
|
||||
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
|
||||
```
|
||||
|
||||
### `/etc/services` file format
|
||||
|
||||
```
|
||||
service-name port/protocol [aliases..] [#comment]
|
||||
```
|
||||
|
||||
Last two fields are optional hence denoted in `[` `]`
|
||||
|
||||
where –
|
||||
|
||||
* service-name is name of the network service. e.g. [telnet][2], [ftp][3] etc.
|
||||
* port/protocol is port being used by that network service (numerical value) and protocol (TCP/UDP) used for communication by service.
|
||||
* alias is alternate name for service.
|
||||
* comment is note or description you can add to service. Starts with `#` mark
|
||||
|
||||
|
||||
|
||||
### Sample` /etc/services` file
|
||||
|
||||
```
|
||||
# Each line describes one service, and is of the form:
|
||||
#
|
||||
# service-name port/protocol [aliases ...] [# comment]
|
||||
|
||||
tcpmux 1/tcp # TCP port service multiplexer
|
||||
rje 5/tcp # Remote Job Entry
|
||||
echo 7/udp
|
||||
discard 9/udp sink null
|
||||
```
|
||||
|
||||
Here, you can see use of optional last two fields as well. `discard` service has alternate name as `sink` or `null`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kerneltalks.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/kerneltalks.com/wp-content/uploads/2019/01/undestanding-etc-service-file-in-linux.png?ssl=1
|
||||
[2]: https://kerneltalks.com/config/configure-telnet-server-linux/
|
||||
[3]: https://kerneltalks.com/config/ftp-server-configuration-steps-rhel-6/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
The Ruby Story
|
||||
红宝石(Ruby)史话
|
||||
======
|
||||
尽管我很难说清楚为什么,但 Ruby 一直是我最喜爱的一门编程语言。如果用音乐来类比的话,Python 给我的感觉像是<ruby>朋克摇滚<rt>punk rock</rt></ruby>,简单、直接,但略显单调,而 Ruby 则像是爵士乐,赋予了程序员<ruby>灵活的表达<rt>freedom to express</rt></ruby>,虽然这可能会让代码变复杂、程序不直观。
|
||||
|
||||
Ruby 社区一直将<ruby>灵活表达<rt>freedom of expression</rt></ruby>视为其核心价值。可我不认同这对于 Ruby 的开发和普及是最重要的。一个人创建一门编程语言也许是为了更高的性能,也许是为了在抽象上节省更多的时间,可 Ruby 就有趣在它并不关心这些,从它诞生之初,它的目标就是让程序员更快乐。
|
||||
尽管我很难说清楚为什么,但 Ruby 一直是我最喜爱的一门编程语言。如果用音乐来类比的话,Python 给我的感觉像是<ruby>朋克摇滚<rt>punk rock</rt></ruby>,简单、直接,但略显单调,而 Ruby 则像是爵士乐,赋予了程序员表达自我的根本自由,虽然这可能会让代码变复杂,编写出来的程序对其他人来说不直观。
|
||||
|
||||
### 松本 行弘
|
||||
Ruby 社区一直将<ruby>灵活表达<rt>freedom of expression</rt></ruby>视为其核心价值。可我不认同这对于 Ruby 的开发和普及是最重要的。创建一门编程语言也许是为了更高的性能,也许是为了在抽象上节省更多的时间,可 Ruby 就有趣在它并不关心这些,从它诞生之初,它的目标就是让程序员更快乐。
|
||||
|
||||
<ruby>松本行弘<rt>Yukihiro Matsumoto</rt></ruby>,也叫 “Matz”,于 1990 年毕业于筑波大学。筑波是东京东北方向上的一个小城市,是科学研究与技术开发的中心之一。那里的筑波大学以其 STEM 计划广为流传。松本行弘就在筑波大学的信息科学专业学习过,且专攻编程语言。他也在 Ikuo Nakata 的编程语言实验室工作过。
|
||||
(LCTT译注:STEM是科学(Science),技术(Technology),工程(Engineering),数学(Mathematics)四门学科英文首字母的缩写。)
|
||||
### 松本·行弘
|
||||
|
||||
<ruby>松本·行弘<rt>Yukihiro Matsumoto</rt></ruby>,亦称为 “Matz”,于 1990 年毕业于筑波大学。筑波是东京东北方向上的一个小城市,是科学研究与技术开发的中心之一。筑波大学以其 STEM 计划广为流传。松本·行弘在筑波大学的信息科学专业学习过,且专攻编程语言。他也在 Ikuo Nakata 的编程语言实验室工作过。(LCTT 译注:STEM 是<ruby>科学<rt>Science</rt></ruby>、<ruby>技术<rt>Technology</rt></ruby>、<ruby>工程<rt>Engineering</rt></ruby>、<ruby>数学<rt>Mathematics</rt></ruby>四门学科英文首字母的缩写。)
|
||||
|
||||
松本从 1993 年开始制作 Ruby,那时他才刚毕业几年。他制作 Ruby 的起因是觉得那时的脚本语言缺乏一些特性。他在使用 Perl 的时候觉得这门语言过于“玩具”,此外 Python 也有点弱,用他自己的话说:
|
||||
|
||||
> 我那时就知道 Python 了,但我不喜欢它,因为我认为这不是一门真正的面向对象的语言。面向对象就像是 Python 的一个附件。作为一个编程语言狂热者,我在 15 年里一直是面向对象的忠实粉丝。我真的想要一门生来就面向对象而且易用的脚本语言。我为此特地寻找过,可事实并不如愿。
|
||||
> 我那时就知道 Python 了,但我不喜欢它,因为我认为它不是一门真正的面向对象的语言。面向对象就像是 Python 的一个附件。作为一个编程语言狂热者,我在 15 年里一直是面向对象的忠实粉丝。我真的想要一门生来就面向对象而且易用的脚本语言。我为此特地寻找过,可事实并不如愿。[^1]
|
||||
|
||||
所以一种解释松本创造 Ruby 的动机就是他想要创造一门更好的,而且面向对象的 Perl 版本。
|
||||
所以一种解释松本创造 Ruby 的动机就是他想要创造一门更好的,而且面向对象版的 Perl。
|
||||
|
||||
但在其他场合,松本说他创造 Ruby 主要是为了让他自己和别人更快乐。2008 年,松本在谷歌技术讲座结束时放映了这张幻灯片:
|
||||
|
||||
@ -21,50 +21,53 @@ Ruby 社区一直将<ruby>灵活表达<rt>freedom of expression</rt></ruby>视
|
||||
|
||||
他对听众说到,
|
||||
|
||||
> 我希望 Ruby 能帮助世界上的每一个程序员更有效率地工作,享受编程并感到快乐。这也是制作 Ruby 语言的主要意图。
|
||||
> 我希望 Ruby 能帮助世界上的每一个程序员更有效率地工作,享受编程并感到快乐。这也是制作 Ruby 语言的主要意图。[^2]
|
||||
|
||||
松本开玩笑的说他制作 Ruby 的原因很自私,因为他觉得其他的语言乏味,所以需要创造一点让自己开心的东西。
|
||||
松本开玩笑的说他制作 Ruby 的原因很自私,因为他觉得其它的语言乏味,所以需要创造一点让自己开心的东西。
|
||||
|
||||
这张幻灯片展现了松本谦虚的一面。其实,松本是一位摩门教徒,因此我很好奇他传奇般的友善有多少归功于他的宗教信仰。无论如何,他的友善在 Ruby 社区广为流传,甚至有一条称为 MINASWAN 的原则,即“<ruby>松本人很好,我们也一样<rt>Matz Is Nice And So We Are Nice</rt></ruby>”。我想那张幻灯片一定震惊了来自 Google 的观众。我想谷歌技术讲座上的每张幻灯片都充满着代码和运行效率的指标,来说明一个方案比另一个更快更有效,可仅仅放映崇高的目标的幻灯片却寥寥无几。
|
||||
这张幻灯片展现了松本谦虚的一面。其实,松本是一位摩门教徒践行者,因此我很好奇他传奇般的友善有多少归功于他的宗教信仰。无论如何,他的友善在 Ruby 社区广为流传,甚至有一条称为 MINASWAN 的原则,即“<ruby>松本人很好,我们也一样<rt>Matz Is Nice And So We Are Nice</rt></ruby>”。我想那张幻灯片一定震惊了来自 Google 的观众。我想谷歌技术讲座上的每张幻灯片都充满着代码和运行效率的指标,来说明一个方案比另一个更快更有效,可仅仅放映崇高的目标的幻灯片却寥寥无几。
|
||||
|
||||
Ruby 主要受到 Perl 的印象。Perl 则是由 Larry Wall 与 20 世纪 80 年代晚期创造的语言,主要用于处理和转换基于文本的数据。Perl 因其文本处理和正则表达式而闻名于世。对于 Ruby 程序员,Perl 程序中的很多语法元素都不陌生,例如符号`$`、符号`@`、`elsif`等等。虽然我觉得,这些不是 Ruby 应该具有的特征。除了这些符号外,Ruby 还借鉴了 Perl 中的正则表达式和标准库。
|
||||
Ruby 主要受到 Perl 的影响。Perl 则是由 Larry Wall 于 20 世纪 80 年代晚期创造的语言,主要用于处理和转换基于文本的数据。Perl 因其文本处理和正则表达式而闻名于世。对于 Ruby 程序员,Perl 程序中的很多语法元素都不陌生,例如符号 `$`、符号 `@`、`elsif` 等等。虽然我觉得,这些不是 Ruby 应该具有的特征。除了这些符号外,Ruby 还借鉴了 Perl 中的正则表达式的处理和标准库。
|
||||
|
||||
但影响了 Ruby 的不仅仅只有 Perl 。在 Ruby 之前松本使用过运行在 Emacs Lisp 上的邮件客户端。这一经历让他对 Emacs 和 Lisp 语言运行的内部原理有了更多的认识。松本说 Ruby 的对象模型也受其启发。在那之上,松本添加了一个 Smalltalk 风格的信息传递系统,这一系统随后成为了 Ruby 中任何依赖 `#method_missing` 的操作的基石。松本说 Ada 和 Eiffel 也影响了 Ruby 的设计。
|
||||
但影响了 Ruby 的不仅仅只有 Perl 。在 Ruby 之前松本就完全用 Emacs Lisp 写过一个邮件客户端。这一经历让他对 Emacs 和 Lisp 语言运行的内部原理有了更多的认识。松本说 Ruby 底层的对象模型也受其启发。在那之上,松本添加了一个 Smalltalk 风格的信息传递系统,这一系统随后成为了 Ruby 中任何依赖 `#method_missing` 的操作的基石。松本也表示过 Ada 和 Eiffel 也影响了 Ruby 的设计。
|
||||
|
||||
当时间来到了给这门新语言命名的时候,松本和它的同事 Keiju Ishitsuka 挑选了很多个名字。他们希望名字能够体现新语言和 Perl、shell 脚本间的联系。在[这一段聊天记录][2]中,Ishitsuka 和 松本也许花了太多的时间来思考 <ruby>shell<rt>贝壳</rt></ruby>、<ruby>clam<rt>蛤蛎</rt></ruby>、<ruby>oyster<rt>牡蛎</rt></ruby>和<ruby>pearl<rt>珍珠</rt></ruby>之间的关系了,以至于差点把 Ruby 命名为“<ruby>Coral<rt>珊瑚虫</rt></ruby>”或“<ruby>Bisque<rt>贝类浓汤</rt></ruby>”。幸好,他们决定使用 Ruby ,因为他就像 pearl 一样,是一种珍贵的宝石。此外,<ruby>Ruby<rt>红宝石</rt></ruby> 还是 7 月的诞生石,而 <ruby>Peral<rt>珍珠</rt></ruby> 则是 6 月的诞生石,采用了类似 C++ 和 C# 的隐喻,暗示着她们是改进自前辈的编程语言。
|
||||
(LCTT译注:Perl 和 Pearl 发音相同;shell 是操作系统提供的用户界面,这里指的是命令行界面;更多有关诞生石的[信息](https://zh.wikipedia.org/zh-hans/%E8%AA%95%E7%94%9F%E7%9F%B3)。)
|
||||
当时间来到了给这门新语言命名的时候,松本和他的同事 Keiju Ishitsuka 挑选了很多个名字。他们希望名字能够体现新语言和 Perl、shell 脚本间的联系。在[这一段非常值得一读的即时消息记录][2]中,Ishitsuka 和 松本也许花了太多的时间来思考 <ruby>shell<rt>贝壳</rt></ruby>、<ruby>clam<rt>蛤蛎</rt></ruby>、<ruby>oyster<rt>牡蛎</rt></ruby>和<ruby>pearl<rt>珍珠</rt></ruby>之间的关系了,以至于差点把 Ruby 命名为“<ruby>Coral<rt>珊瑚虫</rt></ruby>”或“<ruby>Bisque<rt>贝类浓汤</rt></ruby>”。幸好,他们决定使用 Ruby,因为它就像 pearl 一样,是一种珍贵的宝石。此外,<ruby>Ruby<rt>红宝石</rt></ruby> 还是 7 月的生辰石,而 <ruby>Pearl<rt>珍珠</rt></ruby> 则是 6 月的生辰石,采用了类似 C++ 和 C# 的隐喻,暗示着她们是改进自前辈的编程语言。(LCTT 译注:Perl 和 Pearl 发音相同,所以也常以“珍珠”来借喻 Perl;shell 是操作系统提供的用户界面,这里指的是命令行界面;更多有关生辰石的[信息](https://zh.wikipedia.org/zh-hans/%E8%AA%95%E7%94%9F%E7%9F%B3)。)
|
||||
|
||||
### Ruby 走向西方
|
||||
### Ruby 西渐
|
||||
|
||||
Ruby 在日本的普及很快。1995 年 Ruby 刚刚发布后不久后,松本就被一家名为 Netlab 的日本软件咨询基团(全名 Network Applied Communication Laboratory)雇用,并全职为 Ruby 工作。到 2000 年时,仅仅在 Ruby 发布 5 年后,Ruby 在日本的流行度就超过了 Python。可这是的 Ruby 从刚刚进入英语国家。虽然从 Ruby 的诞生之初就存在日语邮件的列表,但是英语邮件的列表直到 1998 年才建立起来。而且起初在英语邮件的列表里交流的大多是日本的 Ruby 狂热者,但这一问题随着 Ruby 在西方国家的普及而逐渐得以改善。
|
||||
Ruby 在日本的普及很快。1995 年 Ruby 刚刚发布后不久后,松本就被一家名为 Netlab 的日本软件咨询财团(全名 Network Applied Communication Laboratory)雇用,并全职为 Ruby 工作。到 2000 年时,在 Ruby 发布仅仅 5 年后,Ruby 在日本的流行度就超过了 Python。可这时的 Ruby 才刚刚进入英语国家。虽然从 Ruby 的诞生之初就存在讨论它的日语邮件列表,但是英语的邮件列表直到 1998 年才建立起来。而且起初英语的邮件列表是用于日本的 Ruby 狂热者用英语交流的,但这一情况随着 Ruby 的普及而逐渐得以改变。
|
||||
|
||||
在 2000 年,Dave Thomas 出版了第一本涵盖 Ruby 的英文书籍《Programming Ruby》。因为它的封面上画着一把锄头,所以这本书也被称为锄头书。是它第一次向身处西方的程序员们介绍了 Ruby。就像在日本那样,Ruby 的普及很快,到 2002 年时,英语邮件列表的流量超过了日语邮件列表。
|
||||
在 2000 年,Dave Thomas 出版了第一本涵盖 Ruby 的英文书籍《Programming Ruby》。因为它的封面上画着一把锄头,所以这本书也被称为锄头书。这是第一次向身处西方的程序员们介绍了 Ruby。就像在日本那样,Ruby 的普及很快,到 2002 年时,英语的 Ruby 邮件列表的通信超过了原来的日语邮件列表。
|
||||
|
||||
时间来到了 2005 年,Ruby 更流行了,但它任然不是主流的编程语言。然而,Ruby on Rails 的发布让一切都不一样了。Ruby on Rails 是 Ruby 的“杀手应用”,没有别的什么项目比它更能推动 Ruby 的普及了。在 Ruby on Rails 发布后,人们对 Ruby 的兴趣爆发式的增长,看看 TIOBE 监测的语言排行:
|
||||
时间来到了 2005 年,Ruby 更流行了,但它仍然不是主流的编程语言。然而,Ruby on Rails 的发布让一切都不一样了。Ruby on Rails 是 Ruby 的“杀手级应用”,没有别的什么项目能比它更推动 Ruby 的普及了。在 Ruby on Rails 发布后,人们对 Ruby 的兴趣爆发式的增长,看看 TIOBE 监测的语言排行:
|
||||
|
||||
![][3]
|
||||
|
||||
有时人们开玩笑的说,Ruby 程序全是基于 Ruby-on-Rails 的网站。虽然这听起来就像是 Ruby on Rails 占领了整个 Ruby 社区,但在一定程度上,这是事实。因为 Rails 开发需要 Ruby,Ruby 在西方是随着 Rails 的发布才普及开的。Rails 欠 Ruby 的和 Ruby 欠 Rails 的一样多。
|
||||
有时人们开玩笑的说,Ruby 程序全是基于 Ruby-on-Rails 的网站。虽然这听起来就像是 Ruby on Rails 占领了整个 Ruby 社区,但在一定程度上,这是事实。因为 Ruby 被人所熟知是因为它是人们写 Rails 应用时用的语言。Rails 欠 Ruby 的和 Ruby 欠 Rails 的一样多。
|
||||
|
||||
Ruby 的设计哲学也深深地影响了 Rails 的设计与开发。Rails 之父 David Heinemeier Hansson 常常提起他第一次与 Ruby 的接触的情形,那简直就是一次传教。他说,那经历简直太有感召力了,让他感到要为松本的杰作(指 Ruby)“传教”的使命。对于 Hansson 来说,Ruby 的灵活性简直就是对 Python 或 Java 语言中自上而下的设计哲学的反抗。他很欣赏 Ruby 这门能够信任自己的语言,Ruby 赋予了他自由选择<ruby>程序表达方式<rt>express his programs</rt></ruby>的权力。
|
||||
Ruby 的设计哲学也深深地影响了 Rails 的设计与开发。Rails 之父 David Heinemeier Hansson 常常提起他第一次与 Ruby 的接触的情形,那简直就是一次传教。他说,那种经历简直太有感召力了,让他感受到要为松本的杰作(指 Ruby)“传教”的使命。[^3] 对于 Hansson 来说,Ruby 的灵活性简直就是对 Python 或 Java 语言中自上而下的设计哲学的反抗。他很欣赏 Ruby 这门能够信任自己的语言,Ruby 赋予了他自由选择<ruby>程序表达方式<rt>express his programs</rt></ruby>的权力。
|
||||
|
||||
就像松本那样,Hansson 声称他创造 Rails 时因为对现状的不满并想让自己能更开心。他也认同让程序员更快乐高于一切的观点,所以检验 Rails 是否需要添加一项新特性的标准是“<ruby>更灿烂的笑容标准<rt>The Principle of The Bigger Smile</rt></ruby>”。什么功能能让 Hansson 更开心就给 Rails 添加什么。因此,Rails 中包括了很多非传统的功能,例如“Inflector”类和 `Time` 扩展("Inflector"类试图将单个类的名字映射到多个数据库表的名字;`Time` 扩展允许程序员使用 `2.days.ago` 这样的表达式)。可能会有人觉得这些功能太奇怪了,但 Rails 的成功表明它的确能让很多人的生活得更快乐。
|
||||
就像松本那样,Hansson 声称他创造 Rails 时因为对现状的不满并想让自己能更开心。他也认同让程序员更快乐高于一切的观点,所以检验 Rails 是否需要添加一项新特性的标准是“<ruby>更灿烂的笑容标准<rt>The Principle of The Bigger Smile</rt></ruby>”。什么功能能让 Hansson 更开心就给 Rails 添加什么。因此,Rails 中包括了很多非正统的功能,例如 “Inflector” 类和 `Time` 扩展(“Inflector”类试图将单个类的名字映射到多个数据库表的名字;`Time` 扩展允许程序员使用 `2.days.ago` 这样的表达式)。可能会有人觉得这些功能太奇怪了,但 Rails 的成功表明它的确能让很多人的生活得更快乐。
|
||||
|
||||
因此,Rails 不但是 Ruby 的一个普及度很高的应用,而且体现了 Ruby 的很多核心准则。此外,很难看到使用其他语言开发的 Rails 的替代品,因为 Rails 的实现依赖于 Ruby 中<ruby>类似于宏的类方法<rt>macro-like class method</rt></ruby>来实现模型关联的功能这样的功能。一些人认为这么多的 Ruby 开发需要基于 Ruby on Rails 是 Ruby 生态不健康的表现,但 Ruby 和 Ruby on Rails 结合的如此紧密并不是没有道理的。
|
||||
因此,虽然 Rails 看起来是一个偶然使 Ruby 更流行的应用,但事实上它体现了 Ruby 的很多核心准则。此外,很难看到使用其他语言开发的 Rails,因为 Rails 的实现依赖于 Ruby 中<ruby>类似于宏的类方法调用<rt>macro-like class method calls</rt></ruby>来实现模型关联这样的功能。一些人认为这么多的 Ruby 开发需要基于 Ruby on Rails 是 Ruby 生态不健康的表现,但 Ruby 和 Ruby on Rails 结合的如此紧密并不是没有道理的。
|
||||
|
||||
### Ruby 的未来
|
||||
### Ruby 之未来
|
||||
|
||||
人们似乎对 Ruby 是否正在灭亡有着异常的兴趣。早在 2011 年,Stack Overflow 和 Quora 上就有程序员在咨询“如果几年后不在使用 Ruby 那么现在是否有必要学它”。这些担忧对 Ruby 并不合理,虽然在 TIOBE 指数和 Stack Overflow 趋势上,Ruby 和 Ruby on Rails 的人气在萎缩,可它也曾是新兴的、热门的技术,但在更新更热的框架面前,排名自然会有所下降。
|
||||
人们似乎对 Ruby(及 Ruby on Rails)是否正在消亡有着异常的兴趣。早在 2011 年,Stack Overflow 和 Quora 上就充斥着程序员在咨询“如果几年后不再使用 Ruby 那么现在是否有必要学它”的话题。这些担忧对 Ruby 并非没有道理,根据 TIOBE 指数和 Stack Overflow 趋势,Ruby 和 Ruby on Rails 的人气一直在萎缩,虽然它也曾是热门新事物,但在更新更热的框架面前它已经黯然失色。
|
||||
|
||||
一种解释这种趋势的理论是程序员们正在舍弃动态类型的语言转而选择静态类的。TIOBE 指数的趋势中可以看出对软件质量的需求在上升,这使出现在运行时的异常变得难以接受。他们引用 TypeScript 来说明这一趋势,TypeScript 是 JavaScript 的全新版本,而它创造的目的正是为了保证客户端运行的代码能收益于编译所提供的安全保障。
|
||||
一种解释这种趋势的理论是程序员们正在舍弃动态类型的语言转而选择静态类型的。TIOBE 指数的趋势中可以看出对软件质量的需求在上升,这使得出现在运行时的异常变得难以接受。他们引用 TypeScript 来说明这一趋势,TypeScript 是 JavaScript 的全新版本,而创造它的目的正是为了保证客户端运行的代码能受益于编译所提供的安全保障。
|
||||
|
||||
我认为另一个原因可能是比起 Ruby on Rails 推出的时候,现在存在着更多有竞争力的框架。2005 年它刚刚发布的时候,还没有那么多用于创建 Web 程序的框架,其主要的替代者还是 Java。可在今天,你可以用 Go、Javascript 或者 Python 上的各种优秀的框架,而这还仅仅是主流的选择。 Web 的世界似乎正走向更加分布式的结构,与其使用一个代码仓库来完成从数据库读取到页面渲染所有事务,不如将事务拆分到多个组建,其中每个组件专注于一项事务并将其做到最好。在这种趋势下,Rails 相较于那些专攻与 JavaScript 前端通信的 JSON API 就显得过于宽泛和臃肿。
|
||||
我认为另一个更可能的原因是比起 Ruby on Rails 推出的时候,现在存在着更多有竞争力的框架。2005 年它刚刚发布的时候,还没有那么多用于创建 Web 程序的框架,其主要的替代者还是 Java。可在今天,你可以使用为 Go、Javascript 或者 Python 开发的各种优秀的框架,而这还仅仅是主流的选择。Web 的世界似乎正走向更加分布式的结构,与其使用一块代码来完成从数据库读取到页面渲染所有事务,不如将事务拆分到多个组件,其中每个组件专注于一项事务并将其做到最好。在这种趋势下,Rails 相较于那些专攻于 JavaScript 前端通信的 JSON API 就显得过于宽泛和臃肿。
|
||||
|
||||
总而言之,我们有理由对 Ruby 的未来持乐观态度。因为不管是 Ruby 还是 Rails 的开发都还很活跃。松本和其他的贡献者们都在努力开发 Ruby 的第三个主要版本。新的版本将比现在的版本快上 3 倍,以减轻制约着 Ruby 发展的性能问题。虽然从 2005 年起,越来越多的 Web 框架被开发出来,但这并不意味着 Ruby on Rails 就失去了其生存空间。Rails 是一个富有大量功能的成熟的工具,对于一些特定类型的应用开发一直是非常好的选择。
|
||||
|
||||
但就算 Ruby 和 Rails 走上了灭亡的道路,Ruby 让程序员更快乐的信条一定会存活下来。Ruby 已经深远的影响了许多新的编程语言的设计,这些语言的设计中能够看到来自 Ruby 的很多理念。而其他的新生语言则试着变成 Ruby 更现代的实现,例如 Elixir 是一个强调函数式编程的语言,仍在开发中的 Crystal 目标是成为使用静态类型的 Ruby 。世界上许多程序员都喜欢上了 Ruby,因此它的影响必将会在未来持续很长一段时间。
|
||||
但就算 Ruby 和 Rails 走上了消亡的道路,Ruby 让程序员更快乐的信条一定会存活下来。Ruby 已经深远的影响了许多新的编程语言的设计,这些语言的设计中能够看到来自 Ruby 的很多理念。而其他的新生语言则试着变成 Ruby 更现代的实现,例如 Elixir 是一个强调函数式编程范例的语言,仍在开发中的 Crystal 目标是成为使用静态类型的 Ruby 。世界上许多程序员都喜欢上了 Ruby 及其语法,因此它的影响必将会在未来持续很长一段时间。
|
||||
|
||||
喜欢吗?这里每两周都会发表一篇这样的文章。请在推特上关注我们 [@TwoBitHistory][4] 或者订阅我们的 [RSS][5],这样新文章发布的第一时间你就能得到通知。
|
||||
喜欢这篇文章吗?这里每两周都会发表一篇这样的文章。请在推特上关注我们 [@TwoBitHistory][4] 或者订阅我们的 [RSS][5],这样新文章发布的第一时间你就能得到通知。
|
||||
|
||||
[^1]: http://ruby-doc.org/docs/ruby-doc-bundle/FAQ/FAQ.html
|
||||
[^2]: https://www.youtube.com/watch?v=oEkJvvGEtB4?t=30m55s
|
||||
[^3]: http://rubyonrails.org/doctrine/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -73,7 +76,7 @@ via: https://twobithistory.org/2017/11/19/the-ruby-story.html
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wwhio](https://github.com/wwhio)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,155 +0,0 @@
|
||||
设计微服务架构前,您应该了解的5项指导原则
|
||||
======
|
||||
|
||||

|
||||
对于从微服务开始的团队来说,最大的挑战之一就是坚持金发姑娘原则(The *Goldilocks principle*):不要太大, 不要太小,不能太紧密耦合。之所以是挑战的原因是会对究竟什么是设计良好的微服务感到疑惑。
|
||||
|
||||
数十家 CTOs 通过采访分享了他们的经验, 这些对话说明了设计良好的微服务的五个特点。本文将帮助指导团队设计微服务。(有关详细信息, 请查看即将出版的书籍 [Microservices for Startups][1])。本文将简要介绍微服务的边界和主观的 ”规则“,以避免在深入了解五个特征之前就开始指导您的微服务设计。
|
||||
|
||||
### 微服务边界
|
||||
|
||||
[core benefits of developing new systems with microservices][2] (开发具有微服务的新系统的核心优势)其中之一是该体系结构允许开发人员独立构建和修改单个组件, 但在最大限度地减少每个 API 之间的回调数量方面可能会出现问题。 根据 Chris McFadden 的解决方法,[SparkPost ][3] 的工程副总裁,应用适当的服务边界去解决问题。
|
||||
|
||||
关于边界, 与 domain-driven design (DDD)—a framework for microservices (域驱动设计--微服务框架)有时难以理解和抽象的概念形成鲜明对比,本文重点介绍了与我们行业的一些顶级 CTOs 建立明确定义的微服务边界的实用原则。
|
||||
|
||||
### 避免主观的 ”规则“
|
||||
|
||||
如果您阅读了足够多的关于设计和创建微服务的建议,您一定会遇到下面的一些 ”规则“。 尽管将它们用作创建微服务的指南很有吸引力, 但加入这些主观规则并不是思考确定微服务的边界的原则性方式。
|
||||
|
||||
#### ”微服务应该有 X 行代码“
|
||||
|
||||
让我们直说:微服务中有多少行代码没有限制。微服务不会因为您写了几行额外的代码而突然变成一个巨无霸。关键是要确保服务中的代码具有很高的内聚性 (稍后将对此进行更多介绍)。
|
||||
|
||||
#### “将每个功能转换为微服务”
|
||||
|
||||
如果函数基于三个输入值计算某些内容并返回结果,它是否是微服务的理想候选项?它是否应该是单独可部署应用程序?这确实取决于函数是什么以及它是如何服务于整个系统。将每个函数转换为微服务在您的内容中可能根本没有意义。
|
||||
|
||||
其他主观规则包括不考虑整个内容的规则, 例如团队的经验、 DevOps (Development和Operations的组合词)容量、服务正在执行的操作以及数据的可用性需求。
|
||||
|
||||
### 精心设计的服务的5个特点
|
||||
|
||||
如果您读过关于微服务的文章, 您无疑会遇到关于什么是设计良好的服务的建议。简单地说, 高内聚和低耦合。如果您不熟悉这些概念, 有许多文章需要查看 [many][4] [articles][5] 。虽然他们提供了合理的建议,但这些概念是相当抽象的。下面, 基于与经验丰富的 CTOs 的对话, 在创建设计良好的微服务时需要牢记的关键特征。
|
||||
|
||||
#### #1: 不与其他服务共享数据库表
|
||||
|
||||
在 SparkPost 的早期, Chris McFadden 和他的团队必须解决一个问题,,每个 SaaS 生意(Software-as-a-Service,软件即服务)都要面对的:他们需要提供基本服务,如身份验证、帐户管理和计费。
|
||||
|
||||
为了解决这个问题,他们创建了两个微服务:用户 API 和帐户 API。用户 API 将处理用户帐户、API 密钥和身份验证,而帐户 API 将处理所有与计费相关的逻辑。一个非常符合逻辑的分离--但没过多久,他们发现了一个问题。
|
||||
|
||||
McFadden 解释说,“我们有一个名为 ”用户 API “的服务,还有一个名为”帐户 API “的服务。问题是,他们之间实际上有几个来回的电话。因此, 您会在帐户中执行一些操作,并在用户中具有调用和终结点,反之亦然”
|
||||
|
||||
这两个服务的耦合太紧密了。
|
||||
|
||||
在设计微服务时, 如果您有多个服务引用同一个表, 则它是一个危险的信号,因为这可能意味着您的数据库是耦合的源头。
|
||||
|
||||
这确实是关于服务与数据的关系, 这正是Oleksiy Kovrin,[Swiftype SRE, Elastic][6] 的领导者, 告诉我。“我们在开发新服务时使用的主要基本原则之一是, 它们不应跨越数据库边界。每个服务都应依赖于自己的一组基础数据存储。这使我们能够集中访问控制、审计日志记录、缓存逻辑等。”
|
||||
|
||||
Kovrin 接着解释说,如果数据库表的子集 “与数据集的其余部分没有或很少连接,则这是一个强烈的信号, 表明组件可以被隔离到单独的 API 或单独的服务中”。
|
||||
|
||||
Darby Frey , [Lead Honestly][7] 的联合创始人,与此的观点相呼应:”每个服务都应该有自己的表 [并且] 永远不应该共享数据库表。“
|
||||
|
||||
#### #2: 数据库表数量最小化
|
||||
|
||||
微服务的理想尺寸足够小,但不会更小。每个服务的数据库表的数量也是如此。
|
||||
|
||||
Steven Czerwinski,[Scaylr][8] 的工程主管, 在接受采访时解释说 Scaylr 的最佳选择是 ”一个或两个服务的数据库表“。
|
||||
|
||||
SparkPost's Chris McFadden 同意:”我们有一个(suppression)限制微服务,它处理, 跟踪, 数以百万计和数十亿的条目周围的限制,但它都非常集中只是围绕限制,所以实际上只有一个或两个表。其他服务也是如此,比如 *webhooks* 。
|
||||
|
||||
#### #3: 考虑有状态和无状态
|
||||
|
||||
在设计微服务时,您需要问问自己它是否需要访问数据库,或者它是否会是处理 TB 级数据 (如电子邮件或日志) 的无状态服务。
|
||||
|
||||
Julien Lemoine, [Algolia][9] 的 CTO,解释说::“我们通过定义服务的输入和输出来定义服务的边界。有时服务是网络 API ,但它也可能是在数据库中使用文件和生成记录的进程 (这就是我们的日志处理服务)。
|
||||
|
||||
事先要清楚状态,这将引导一个更好的服务设计。
|
||||
|
||||
#### #4: 考虑数据可用性需求
|
||||
|
||||
在设计微服务时,请记住哪些服务将依赖于此新服务, 以及在该数据不可用时的全系统影响。考虑到这一点,您可以正确地设计此服务的数据备份和恢复系统。
|
||||
|
||||
Steven Czerwinski 在 Scaylr 提到,由于关键客户行空间映射数据的重要性,它将以不同的方式复制和分离。
|
||||
|
||||
他补充说,”每个分片信息,在自己的小分区里。如果因为这部分客户群体不会有他们的可用日志而下降,那很糟糕,但它只影响5% 的客户,而不是100% 的客户。
|
||||
|
||||
#### #5: 真理的唯一来源
|
||||
|
||||
设计服务,使其成为系统中某些内容的唯一实际来源
|
||||
|
||||
例如,当您从电子商务网站订购内容时, 则会生成订单 ID ,其他服务可以使用此订单 ID 来查询订单服务,以获取有关订单的完整信息。使用 [publish/subscribe pattern][10] ,在服务之间传递的数据应该是订单 ID , 而不是订单本身的属性信息。只有订单服务具有完整的信息,并且是给定订单的唯一实际来源。
|
||||
|
||||
### 大型团队的注意事项
|
||||
|
||||
考虑到上面列出的五个注意事项,较大的团队应了解其组织结构对微服务边界的影响。
|
||||
|
||||
对于大型组织,整个团队可以专门拥有服务,在确定服务边界时, 有组织性的考虑因素就会发挥作用。还有两个需要考虑的因素: **独立的发布计划**和**不同的正常运行时间**的重要性。
|
||||
|
||||
Khash Sajadi , [Cloud66.][11] 的 CEO 说:”我们所看到的微服务最成功的实现要么基于软件设计原则 (例如域驱动设计和面向服务的体系结构), 要么基于反映组织方法的设计原则“
|
||||
|
||||
”所以 (对于) 支付团队“ Sajadi 继续说,,”他们有支付服务或信用卡验证服务, 这就是他们向外界提供的服务。所以这不一定是关于软件的。这主要是关于为外界提供更多服务的业务单位 “
|
||||
|
||||
### 双披萨原理
|
||||
|
||||
Amazon 是一个拥有多个团队的大型组织的完美示例。正如在一篇文章中所提到的, [API Evangelist][12] ,Jeff Bezos向所有员工发出授权,告知他们公司内的每个团队都必须通过 API 进行沟通。任何没有被解雇的人都会被解雇。
|
||||
|
||||
这样,所有数据和功能都通过接口公开。Bezos 还设法让每个团队分离,定义他们的资源是什么, 并通过 API 使它们可用。亚马逊正在从地面上建立一个系统。这使得公司内的每一支团队都能成为彼此的合作伙伴。
|
||||
|
||||
Travis Reeder , [Iron.io][13] 的CTO,谈论关于 Bezos 的内部提议。
|
||||
|
||||
”Jeff Bezos 规定所有团队都必须构建 API 才能与其他团队进行沟通,“ Reeder 说。”他也是提出‘双披萨’规则的人:一支球队不应该比两个比萨饼能养活的大。
|
||||
|
||||
“我认为这里也可以适用同样的方法:无论一个小型团队是否能够开发、管理和富有成效。如果它开始变得笨重或开始后退。可能会变得太大” Reeder 告诉我。
|
||||
|
||||
### 最后注意事项: 您的服务是否具有正确的大小和正确定义?
|
||||
|
||||
在微服务系统的测试和实施阶段,有一些指标需要记住。
|
||||
|
||||
#### 指标 #1: 服务之间是否存在过度依赖?
|
||||
|
||||
如果两个服务不断地相互回调,那么这就是耦合的强烈信号,也是它们可能更好地合并为一个服务的信号。
|
||||
|
||||
回到 Chris McFadden 的例子, 他有两个 API 服务、帐户和用户不断地相互通信, McFadden 提出了一个合并服务的想法, 并决定将其称为 “原告 API”。事实证明, 这是一项富有成效的战略。”我们开始做的是消除这些链接 [这是] 内部 API 调用投注他们之间“ McFadden 告诉我。这有助于简化代码。
|
||||
|
||||
#### 指标 #2: 设置服务的开销是否超过了服务独立的好处?
|
||||
|
||||
Darby Frey 解释说,“每个应用都需要将其日志聚合到某个位置,并需要进行监视。你需要设置它的警报。你需要有标准的作业程序,并在事情发生时运行书籍。您必须管理 SSH 对该事物的访问。为了让一个应用单纯运行, 必须存在一个巨大的基础。
|
||||
|
||||
### 主要外包
|
||||
|
||||
设计微服务往往会让人感觉更像是一门艺术, 而不是一门科学。对工程师来说, 这可能不是很好。外面有很多一般性的建议, 但有时可能有点太抽象了。让我们回顾一下在设计下一组微服务时要注意的五个具体特征:
|
||||
|
||||
1. 不与其他服务共享数据库表
|
||||
2. 数据库表数量最小化
|
||||
3. 考虑有状态和无状态
|
||||
4. 考虑数据可用性需求
|
||||
5. 真理的唯一来源
|
||||
|
||||
|
||||
|
||||
下次设计一组微服务并确定服务边界时,回顾这些原则应该会使任务变得更容易。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/guide-design-microservices
|
||||
|
||||
作者:[Jake Lumetta][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://buttercms.com/books/microservices-for-startups/
|
||||
[2]:https://buttercms.com/books/microservices-for-startups/should-you-always-start-with-a-monolith
|
||||
[3]:https://www.sparkpost.com/
|
||||
[4]:https://thebojan.ninja/2015/04/08/high-cohesion-loose-coupling/
|
||||
[5]:https://en.wikipedia.org/wiki/Single_responsibility_principle
|
||||
[6]:https://www.elastic.co/solutions/site-search
|
||||
[7]:https://leadhonestly.com/
|
||||
[8]:https://www.scalyr.com/
|
||||
[9]:https://www.algolia.com/
|
||||
[10]:https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
|
||||
[11]:https://www.cloud66.com/
|
||||
[12]:https://apievangelist.com/2012/01/12/the-secret-to-amazons-success-internal-apis/
|
||||
[13]:https://www.iron.io/
|
||||
@ -0,0 +1,77 @@
|
||||
|
||||
五种 DevSecOps 提升安全性
|
||||
======
|
||||
|
||||

|
||||
|
||||
对于我们是否需要扩展 DevOps 以确实提升安全性,我们一直都有争议。毕竟,我们的想法是,DevOps 一直是一系列的新实践的简写,使用新工具(通常是开源的)并且在这之上构建更多的协作文化。为什么 DevBizOps 不能更好地满足商业的需求?或者说 DevChatOps 强调的是更快更好的沟通?
|
||||
|
||||
在今年(译者注:此处是2018年)的早些时候写的关于他理解的 DevSecOps 术语,“我希望,有一天在世界范围内,我们能不再使用 DevSecOps 这个词,安全会是所有的服务交付讨论中理所应当的部分。直到那一天到来为止,在这一点上,我的一般性结论是,这个词只有三个新的特性。更重要的是,我们作为一个产业,在信息安全方面并没有做的很好,而这个名称切实地区分出了问题的状况”
|
||||
|
||||
所以,为什么我们在信息安全方面做的不好,在 DevSecOps 的语境下安全做的好又是什么意思呢?
|
||||
|
||||
我们大概从未做好过信息安全,尽管(也可能是因为)复杂的工业点产品地址拥挤问题。我们仍然可以在这个时代把工作做得足够好,以此来防范威胁,这些威胁主要集中在一个范围内,网络的连接是有限的,而且大多数的用户都是公司的员工,使用的是公司提供的设备。
|
||||
|
||||
这些年来,这些情况并没有能准确地描述出大多数组织的真实现状。但在现在这个时代,不止引入了 DevSecOps,也同时引入了新的应用架构模型,开发实践,和越来越多的安全威胁,这些一起定义了一个需要更快迭代的新常态。还没有应用得很多的 DevSecOps 在独立改变安全,但是 2018 年的信息安全需要新的方法。
|
||||
|
||||
请仔细思考下面这五个领域。
|
||||
|
||||
### 自动化
|
||||
|
||||
大量的自动化通常是 DevOps 的标志,这部分是关于速度的,如果你要快速移动(并且不会打坏东西),你需要有可重复的过程,而且这个过程不需要太多的人工干预。实际上,自动化是 DevOps 最好的切入点之一,甚至是在仍然主要工作在单片机电路程序的组织里也是如此。使用像 Ansible 这样易于使用的工具来自动化地处理相关的配置或者是测试,这是快速开始 DevOps 之路的常用方法。
|
||||
|
||||
DevSecOps 也不例外,在今天,安全已经变成了一个持续性的过程,而不是在应用的生命周期里进行不定期的检查,甚至是每周、每月的检查。当漏洞被厂商发现并修复的时候,这些漏洞能被快速地应用是很重要的,因为利用这些漏洞的利用程序很快就会被淘汰。
|
||||
|
||||
### "左转"
|
||||
|
||||
在开发流程结束时,传统安全通常被视作一个守门人。检查所有的部分确保没有问题,然后这个应用程序就可以投入生产了。否则,就要再来一次。所以安全团队的声誉并不高。
|
||||
|
||||
因此,我们想的是,没什么不把安全这个部分提到前面呢(左边是一个典型的从左到右的开发流程图)?安全性可能仍然不行,但在开发的早期进行重构的影响要远远小于开发已经完成并且准备上线时进行重构的影响。
|
||||
|
||||
不过,我不喜欢“左移”这个词,这意味着安全仍然是一个只不过提前进行的一次性工作。在应用程序的整个生命周期里,从供应链到开发,再到测试,直到上线部署,安全都需要进行大量的自动化处理。
|
||||
|
||||
### 管理依赖
|
||||
|
||||
我们在现代应用程序开发过程中看到的一个最大的改变,就是你通常不需要去编写这个程序的大部分代码。使用开源的函数库和框架就是一个明显的例子。但是你也可以从公共的云服务商或其他来源那里获得额外的服务。在许多情况下,这些额外的代码和服务比你给自己写的要好得多。
|
||||
|
||||
因此,DevSecOps 需要你把重点放在你的软件供应链上,你是从可信的来源那里获取你的软件的吗?这些软件是最新的吗?它们已经集成到了你为自己的代码使用的安全流程中了吗?对于这些你能使用的代码和 API 你有哪些策略?你为自己的产品代码使用的组件是否有可用的商业支持?
|
||||
|
||||
没有一套标准答案可以应对所有的情况。对于概念验证和大规模的生产,它们可能会有所不同。但是,正如制造业长期存在的情况(DevSecOps 和制造业的发展方面有许多相似之处),供应链的可信是至关重要的。
|
||||
|
||||
### 可见性
|
||||
|
||||
关于贯穿应用程序整个生命周期里所有阶段的自动化的需求,我已经谈过很多了。这里假设我们能看见每个阶段里发生的情况。
|
||||
|
||||
有效的 DevSecOps 需要有效的检测,以便于自动化程序知道要做什么。这个检测分了很多类别。一些长期的和高级别的指标能帮助我们了解整个 DevSecOps 流程是否工作良好。严重威胁级别的警报需要立刻有人进行处理(安全扫描系统已经关闭!)。有一些警报,比如扫描失败,需要进行修复。我们记录了大量的参数来生成日志,以便事后进行分析(随着时间的推移,哪些发生了改变?导致失败的原因是什么?)。
|
||||
|
||||
### 分散服务 vs 一体化解决方案
|
||||
|
||||
虽然 DevSecOps 实践可以应用于多种类型的应用架构,但它们对小型且松散耦合的组件最有效,这些组件可以进行更新和复用,而且不会在应用程序的其他地方进行强制更改。在纯净版的形式里,这些组件可以是微服务或者函数,但是这个一般性原则适用于通过网络进行通信的松散耦合服务的任何地方。
|
||||
|
||||
这种方法确实带来了一些新的安全挑战,组件之间的交互可能会很复杂,总的攻击面会更大,因为现在应用程序通过网络有了更多的切入点。
|
||||
|
||||
另一方面,这种类型的架构还意味着自动化的安全和监视可以更加精细地查看应用程序的组件,因为它们不再深埋在一整个应用程序之中。
|
||||
|
||||
不要过多地关注 DevSecOps 这个术语,但要提醒一下,安全正在不断地演变,因为我们编写和部署程序的方式也在不断地演变。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/devsecops-changes-security
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ghaff
|
||||
[1]: https://opensource.com/resources/devops
|
||||
[2]: https://opensource.com/tags/devops
|
||||
[3]: https://opensource.com/article/18/5/steps-apply-devops-culture-beyond-it
|
||||
[4]: https://www.devsecopsdays.com/articles/its-just-a-name
|
||||
[5]: https://opensource.com/article/18/4/devsecops
|
||||
[6]: https://opensource.com/article/18/6/where-cycle-security-devops
|
||||
[7]: https://opensource.com/tags/ansible
|
||||
[8]: https://opensource.com/article/17/1/be-open-source-supply-chain
|
||||
[9]: https://opensource.com/tags/microservices
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ()
|
||||
[#]: publisher: ()
|
||||
[#]: url: ()
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 2 OK02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室 – 树莓派:课程 2 OK02
|
||||
======
|
||||
|
||||
OK02 课程是在 OK01 课程的基础上构建,通过不停地打开和关闭 `OK` 或 `ACT` LED 指示灯来实现闪烁。假设你已经有了 [课程 1:OK01][1] 操作系统的代码,它将是这一节课的基础。
|
||||
|
||||
### 1、等待
|
||||
|
||||
等待是操作系统开发中非常有用的部分。操作系统经常发现自己无事可做,以及必须要延迟。在这个例子中,我们想去做等待,为了能够让这种等待可以看得见,让 LED 灯打开关闭闪烁起来。如果你只是打开和关闭它,你什么都看不到,因为计算机每秒种可以打开和关闭它好几千次。在后面的课程中,我们将看到精确的等待,但是现在,我们只要简单地去消耗时间就足够了。
|
||||
|
||||
```
|
||||
mov r2,#0x3F0000
|
||||
wait1$:
|
||||
sub r2,#1
|
||||
cmp r2,#0
|
||||
bne wait1$
|
||||
```
|
||||
|
||||
```
|
||||
sub reg,#val 从寄存器 reg 中的值上减去数字 val
|
||||
|
||||
cmp reg,#val 将寄存器中的值与数字 val 进行比较。
|
||||
|
||||
如果最后的比较结果是不相等,那么执行后面的 ne 命令。
|
||||
```
|
||||
|
||||
上面是一个很常见的产生延迟的代码片段,由于每个树莓派基本上是相同的,所以产生的延迟大致也是相同的。它的工作原理是,使用一个 `mov` 命令将值 3F0000<sub>16</sub> 推入到寄存器 r2 中,然后将这个值减 1,直到这个值减到 0 为止。在这里使用了三个新命令 `sub`、 `cmp` 和 `bne`。
|
||||
|
||||
`sub` 是减法命令,它只是简单地从第一个参数中的值减去第二个参数中的值。
|
||||
|
||||
`cmp` 是个很有趣的命令。它将第一个参数与第二个参数进行比较,然后将比较结果记录到一个称为当前处理器状态寄存器的专用寄存器中。你其实不用担心它,它记住的只是两个数谁大或谁小,或是相等而已。[^1]
|
||||
|
||||
`bne` 其实是一个伪装的分支命令。在 ARM 汇编语言家族中,任何指令都可以有条件运行。这意味着如果上一个比较结果是某个确定的结果,那个指令才会运行。这是个非常有意思的技巧,我们在后面将大量使用到它,但在本案例中,我们在 `b` 命令后面的 ne 后缀意思是 “只有在上一个比较的结果是值不相等,才去运行分支”。`ne` 后缀可以使用在任何命令上,其它几个(总共 16 个)条件也是如此,比如 `eq` 表示等于,而 `lt` 表示小于。
|
||||
|
||||
### 2、组合到一起
|
||||
|
||||
上一节讲我提到过,通过将 GPIO 地址偏移量设置为 28(即:str r1,[r0,#28])而不是 40 即可实现 LED 的关闭。因此,你需要去修改课程 OK01 的代码,在打开 LED 后,运行等待代码,然后再关闭 LED,再次运行等待代码,并包含一个回到开始位置的分支。注意,不需要重新启用 GPIO 的 16 号针脚的输出功能,这个操作只需要做一次就可以了。如果你想更高效,我建议你复用 r1 寄存器的值。所有课程都一样,你可以在 [下载页面][2] 找到所有的解决方案。需要注意的是,必须保证你的所有标签都是唯一的。当你写了 wait1\$: 你其它行上的标签就不能再使用 wait1\$ 了。
|
||||
|
||||
在我的树莓派上,它大约是每秒闪两次。通过改变我们所设置的 r2 寄存器中的值,可以很轻松地修改它。但是,不幸的是,我不能够精确地预测它的运行速度。如果你的树莓派未按预期正常工作,请查看我们的故障排除页面,如果它正常工作,恭喜你。
|
||||
|
||||
在这个课程中,我们学习了另外两个汇编命令:`sub` 和 `cmp`,同时学习了 ARM 中如何实现有条件运行。
|
||||
|
||||
在下一个课程,[课程 3:OK03][3] 中我们将学习如何编写代码,以及建立一些代码复用的标准,并且如果需要的话,可能会使用 C 或 C++ 来写代码。
|
||||
|
||||
[^1]:如果你点了这个链接,说明你一定想知道它的具体内容。CPSR 是一个由许多独立的比特位组成的 32 比特寄存器。它有一个位用于表示正数、零和负数。当一个 cmp 指令运行后,它从第一个参数上减去第二个参数,然后用这个位记下它的结果是正数、零还是负数。如果是零意味着它们相等(a-b=0 暗示着 a=b)如果为正数意味着 a 大于 b(a-b>0 暗示着 a>b),如果为负数意味着小于。还有其它比较指令,但 cmp 指令最直观。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html
|
||||
@ -0,0 +1,580 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (An introduction to the Tornado Python web app framework)
|
||||
[#]: via: (https://opensource.com/article/18/6/tornado-framework)
|
||||
[#]: author: (Nicholas Hunt-Walker https://opensource.com/users/nhuntwalker)
|
||||
[#]: url: ( )
|
||||
|
||||
Python Web 框架 Tornado 简介
|
||||
======
|
||||
|
||||
在比较 Python 框架的系列文章的第三部分中,我们来了解 Tornado,它是为处理异步进程而构建的。
|
||||
|
||||

|
||||
|
||||
在这个由四部分组成的系列文章的前两篇中,我们介绍了 [Pyramid][1] 和 [Flask][2] Web 框架。我们已经构建了两次相同的应用程序,看到了一个完全的 DIY 框架和包含更多电池的框架之间的异同。
|
||||
|
||||
现在让我们来看看另一个稍微不同的选项:[Tornado 框架][3]。Tornado 在很大程度上与 Flask 一样简单,但有一个主要区别:Tornado 是专门为处理异步进程而构建的。在我们本系列所构建的应用程序中,这种特殊的酱料(译者注:这里意思是 Tornado 的异步功能)并不是非常有用,但我们将看到在哪里可以使用它,以及它在更一般的情况下是如何工作的。
|
||||
|
||||
让我们继续前两篇文章中设置的流程,首先从处理设置和配置。
|
||||
|
||||
### Tornado 启动和配置
|
||||
|
||||
如果你一直关注这个系列,那么第一步应该对你来说习以为常。
|
||||
```
|
||||
$ mkdir tornado_todo
|
||||
$ cd tornado_todo
|
||||
$ pipenv install --python 3.6
|
||||
$ pipenv shell
|
||||
(tornado-someHash) $ pipenv install tornado
|
||||
```
|
||||
|
||||
创建一个 `setup.py` 文件来安装我们的应用程序相关的东西:
|
||||
```
|
||||
(tornado-someHash) $ touch setup.py
|
||||
# setup.py
|
||||
from setuptools import setup, find_packages
|
||||
|
||||
requires = [
|
||||
'tornado',
|
||||
'tornado-sqlalchemy',
|
||||
'psycopg2',
|
||||
]
|
||||
|
||||
setup(
|
||||
name='tornado_todo',
|
||||
version='0.0',
|
||||
description='A To-Do List built with Tornado',
|
||||
author='<Your name>',
|
||||
author_email='<Your email>',
|
||||
keywords='web tornado',
|
||||
packages=find_packages(),
|
||||
install_requires=requires,
|
||||
entry_points={
|
||||
'console_scripts': [
|
||||
'serve_app = todo:main',
|
||||
],
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
因为 Tornado 不需要任何外部配置,所以我们可以直接编写 Python 代码来让程序运行。让我们创建 `todo` 目录,并用需要的前几个文件填充它。
|
||||
```
|
||||
todo/
|
||||
__init__.py
|
||||
models.py
|
||||
views.py
|
||||
```
|
||||
|
||||
就像 Flask 和 Pyramid 一样,Tornado 也有一些基本配置,将放在 `__init__.py` 中。从 `tornado.web` 中,我们将导入 `Application` 对象,它将处理路由和视图的连接,包括数据库(当我们谈到那里时再说)以及运行 Tornado 应用程序所需的其它额外设置。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
```
|
||||
|
||||
当我们使用 `define` 函数时,我们最终会在 `options` 对象上创建属性。第一个参数位置的任何内容都将是属性的名称,分配给 `default` 关键字参数的内容将是该属性的值。
|
||||
|
||||
例如,如果我们将属性命名为 `potato` 而不是 `port`,我们可以通过 `options.potato` 访问它的值。
|
||||
|
||||
在 `HTTPServer` 上调用 `listen` 并不会启动服务器。我们必须再做一步,找一个可以监听请求并返回响应的工作应用程序,我们需要一个输入输出循环。幸运的是,Tornado 以 `tornado.ioloop.IOLoop` 的形式提供了开箱即用的功能。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
我喜欢某种形式的 `print` 声明,告诉我什么时候应用程序正在提供服务,我就是这样子。如果你愿意,可以不使用 `print`。
|
||||
|
||||
我们以 `IOLoop.current().start()` 开始我们的 I/O 循环。让我们进一步讨论输入,输出和异步性。
|
||||
|
||||
### Python 中的异步和 I/O 循环的基础知识
|
||||
|
||||
请允许我提前说明,我绝对,肯定,肯定并且安心地说不是异步编程方面的专家。就像我写的所有内容一样,接下来的内容源于我对这个概念的理解的局限性。因为我是人,可能有很深很深的缺陷。
|
||||
|
||||
异步程序的主要问题是:
|
||||
|
||||
* 数据如何进来?
|
||||
* 数据如何出去?
|
||||
* 什么时候可以在不占用我全部注意力情况下运行某个过程?
|
||||
|
||||
由于[全局解释器锁][4](GIL),Python 被设计为一种单线程语言。对于 Python 程序必须执行的每个任务,其线程执行的全部注意力都集中在该任务的持续时间内。我们的 HTTP 服务器是用 Python 编写的,因此,当接收到数据(如 HTTP 请求)时,服务器的唯一关心的是传入的数据。这意味着,在大多数情况下,无论是程序需要运行还是处理数据,程序都将完全消耗服务器的执行线程,阻止接收其它可能的数据,直到服务器完成它需要做的事情。
|
||||
|
||||
在许多情况下,这不是太成问题。典型的 Web 请求,响应周期只需要几分之一秒。除此之外,构建 HTTP 服务器的套接字可以维护待处理的传入请求的积压。因此,如果请求在该套接字处理其它内容时进入,则它很可能只是在处理之前稍微排队等待一会。对于低到中等流量的站点,几分之一秒的时间并不是什么大问题,你可以使用多个部署的实例以及 [NGINX][6] 等负载均衡器来为更大的请求负载分配流量。
|
||||
|
||||
但是,如果你的平均响应时间超过一秒钟,该怎么办?如果你使用来自传入请求的数据来启动一些长时间的过程(如机器学习算法或某些海量数据库查询),该怎么办?现在,你的单线程 Web 服务器开始累积一个无法寻址的积压请求,其中一些请求会因为超时而被丢弃。这不是一种选择,特别是如果你希望你的服务在一段时间内是可靠的。
|
||||
|
||||
异步 Python 程序登场。重要的是要记住因为它是用 Python 编写的,所以程序仍然是一个单线程进程。除非特别标记,否则在异步程序中仍然会阻塞执行。
|
||||
|
||||
但是,当异步程序结构正确时,只要你指定某个函数应该具有这样的能力,你的异步 Python 程序就可以“搁置”长时间运行的任务。然后,当搁置的任务完成并准备好恢复时,异步控制器会收到报告,只要在需要时管理它们的执行,而不会完全阻塞对新输入的处理。
|
||||
|
||||
这有点夸张,所以让我们用一个人类的例子来证明。
|
||||
|
||||
### 带回家吧
|
||||
|
||||
我经常发现自己在家里试图完成很多家务,但没有多少时间来做它们。在某一天,积压的家务可能看起来像:
|
||||
|
||||
* 做饭(20 分钟准备,40 分钟烹饪)
|
||||
* 洗碗(60 分钟)
|
||||
* 洗涤并擦干衣物(30 分钟洗涤,每次干燥 90 分钟)
|
||||
* 真空清洗地板(30 分钟)
|
||||
|
||||
如果我是一个传统的同步程序,我会亲自完成每项任务。在我考虑处理任何其他事情之前,每项任务都需要我全神贯注地完成。因为如果没有我的全力关注,什么事情都完成不了。所以我的执行顺序可能如下:
|
||||
|
||||
1. 完全专注于准备和烹饪食物,包括等待食物烹饪(60 分钟)
|
||||
2. 将脏盘子移到水槽中(65 分钟过去了)
|
||||
3. 清洗所有盘子(125 分钟过去了)
|
||||
4. 开始完全专注于洗衣服,包括等待洗衣机洗完,然后将衣物转移到烘干机,再等烘干机完成( 250 分钟过去了)
|
||||
5. 对地板进行真空吸尘(280 分钟了)
|
||||
|
||||
从头到尾完成所有事情花费了 4 小时 40 分钟。
|
||||
|
||||
我应该像异步程序一样聪明地工作,而不是努力工作。我的家里到处都是可以为我工作的机器,而不用我一直努力工作。同时,现在我可以将注意力转移真正需要的东西上。
|
||||
|
||||
我的执行顺序可能看起来像:
|
||||
|
||||
1. 将衣物放入洗衣机并启动它(5 分钟)
|
||||
2. 在洗衣机运行时,准备食物(25 分钟过去了)
|
||||
3. 准备好食物后,开始烹饪食物(30 分钟过去了)
|
||||
4. 在烹饪食物时,将衣物从洗衣机移到烘干机机中开始烘干(35 分钟过去了)
|
||||
5. 当烘干机运行中,且食物仍在烹饪时,对地板进行真空吸尘(65 分钟过去了)
|
||||
6. 吸尘后,将食物从炉子中取出并装盘子入洗碗机(70 分钟过去了)
|
||||
7. 运行洗碗机(130 分钟完成)
|
||||
|
||||
现在花费的时间下降到 2 小时 10 分钟。即使我允许在作业之间切换花费更多时间(总共 10-20 分钟)。如果我等待着按顺序执行每项任务,我花费的时间仍然只有一半左右。这就是将程序构造为异步的强大功能。
|
||||
|
||||
#### 那么 I/O 循环在哪里?
|
||||
|
||||
一个异步 Python 程序的工作方式是从某个外部源(输入)获取数据,如果某个进程需要,则将该数据转移到某个外部工作者(输出)进行处理。当外部进程完成时,Python 主程序会收到提醒,然后程序获取外部处理(输入)的结果,并继续这样其乐融融的方式。
|
||||
|
||||
当数据不在 Python 主程序手中时,主程序就会被释放来处理其它任何事情。包括等待全新的输入(如 HTTP 请求)和处理长时间运行的进程的结果(如机器学习算法的结果,长时间运行的数据库查询)。主程序虽仍然是单线程的,但成了事件驱动的,它对程序处理的特定事件会触发动作。监听这些事件并指示应如何处理它们的主要是 I/O 循环在工作。
|
||||
|
||||
我知道,我们走了很长的路才得到这个重要的解释,但我希望在这里传达的是,它不是魔术,也不是某种复杂的并行处理或多线程工作。全局解释器锁仍然存在,主程序中任何长时间运行的进程仍然会阻塞其它任何事情的进行,该程序仍然是单线程的。然而,通过将繁琐的工作外部化,我们可以将线程的注意力集中在它需要注意的地方。
|
||||
|
||||
这有点像我上面的异步任务。当我的注意力完全集中在准备食物上时,它就是我所能做的一切。然而,当我能让炉子帮我做饭,洗碗机帮我洗碗,洗衣机和烘干机帮我洗衣服时,我的注意力就会被释放出来,去做其它事情。当我被提醒,我的一个长时间运行的任务已经完成并准备再次处理时,如果我的注意力是空闲的,我可以获取该任务的结果,并对其做下一步需要做的任何事情。
|
||||
|
||||
### Tornado 路由和视图
|
||||
|
||||
尽管经历了在 Python 中讨论异步的所有麻烦,我们还是决定暂不使用它。先来编写一个基本的 Tornado 视图。
|
||||
|
||||
与我们在 Flask 和 Pyramid 实现中看到的基于函数的视图不同,Tornado 的视图都是基于类的。这意味着我们将不在使用单独的,独立的函数来规定如何处理请求。相反,传入的 HTTP 请求将被捕获并将其分配为我们定义的类的一个属性。然后,它的方法将处理相应的请求类型。
|
||||
|
||||
让我们从一个基本的视图开始,即在屏幕上打印 "Hello, World"。我们为 Tornado 应用程序构造的每个基于类的视图都必须继承 `tornado.web` 中的 `RequestHandler` 对象。这将设置我们需要(但不想写)的所有底层逻辑来接收请求,同时构造正确格式的 HTTP 响应。
|
||||
|
||||
```
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class HelloWorld(RequestHandler):
|
||||
"""Print 'Hello, world!' as the response body."""
|
||||
|
||||
def get(self):
|
||||
"""Handle a GET request for saying Hello World!."""
|
||||
self.write("Hello, world!")
|
||||
```
|
||||
|
||||
因为我们要处理 `GET` 请求,所以我们声明(实际上是重写) `get` 方法。我们提供文本或 JSON 可序列化对象,用 `self.write` 写入响应体。之后,我们让 `RequestHandler` 来做在发送响应之前必须完成的其它工作。
|
||||
|
||||
就目前而言,此视图与 Tornado 应用程序本身并没有实际连接。我们必须回到 `__init__.py`,并稍微更新 `main` 函数。以下是新的内容:
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import HelloWorld
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', HelloWorld)
|
||||
])
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
#### 我们做了什么
|
||||
|
||||
我们将 `views.py` 文件中的 `HelloWorld` 视图导入到脚本 `__init__.py` 的顶部。然后我们添加了一个路由-视图对应的列表,作为 `Application` 实例化的第一个参数。每当我们想要在应用程序中声明一个路由时,它必须绑定到一个视图。如果需要,可以对多个路由使用相同的视图,但每个路由必须有一个视图。
|
||||
|
||||
我们可以通过在 `setup.py` 中启用的 `serve_app` 命令来运行应用程序,从而确保这一切都能正常工作。查看 `http://localhost:8888/` 并看到它显示 "Hello, world!"。
|
||||
|
||||
当然,在这个领域中我们还能做更多,也将做更多,但现在让我们来讨论模型吧。
|
||||
|
||||
### 连接数据库
|
||||
|
||||
如果我们想要保留数据,我们需要连接数据库。与 Flask 一样,我们将使用一个特定于框架的 SQLAchemy 变体,名为 [tornado-sqlalchemy][7]。
|
||||
|
||||
为什么要使用它而不是 [SQLAlchemy][8] 呢?好吧,其实 `tornado-sqlalchemy` 具有简单 SQLAlchemy 的所有优点,因此我们仍然可以使用通用的 `Base` 声明模型,并使用我们习以为常的所有列数据类型和关系。除了我们已经从习惯中了解到的,`tornado-sqlalchemy` 还为其数据库查询功能提供了一种可访问的异步模式,专门用于与 Tornado 现有的 I/O 循环一起工作。
|
||||
|
||||
我们通过将 `tornado-sqlalchemy` 和 `psycopg2` 添加到 `setup.py` 到所需包的列表并重新安装包来创建环境。在 `models.py` 中,我们声明了模型。这一步看起来与我们在 Flask 和 Pyramid 中已经看到的完全一样,所以我将跳过全部声明,只列出了 `Task` 模型的必要部分。
|
||||
|
||||
```
|
||||
# 这不是完整的 models.py, 但是足够看到不同点
|
||||
from tornado_sqlalchemy import declarative_base
|
||||
|
||||
Base = declarative_base
|
||||
|
||||
class Task(Base):
|
||||
# 等等,因为剩下的几乎所有的东西都一样 ...
|
||||
```
|
||||
|
||||
我们仍然需要将 `tornado-sqlalchemy` 连接到实际应用程序。在 `__init__.py` 中,我们将定义数据库并将其集成到应用程序中。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import HelloWorld
|
||||
|
||||
# add these
|
||||
import os
|
||||
from tornado_sqlalchemy import make_session_factory
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', HelloWorld)
|
||||
],
|
||||
session_factory=factory
|
||||
)
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
就像我们在 Pyramid 中传递的会话工厂一样,我们可以使用 `make_session_factory` 来接收数据库 URL 并生成一个对象,这个对象的唯一目的是为视图提供到数据库的连接。然后我们将新创建的 `factory` 传递给 `Application` 对象,并使用 `session_factory` 关键字参数将它绑定到应用程序中。
|
||||
|
||||
最后,初始化和管理数据库与 Flask 和 Pyramid 相同(即,单独的 DB 管理脚本,与 `Base` 对象一起工作等)。它看起来很相似,所以在这里我就不介绍了。
|
||||
|
||||
### 回顾视图
|
||||
|
||||
Hello,World 总是适合学习基础知识,但我们需要一些真实的,特定应用程序的视图。
|
||||
|
||||
让我们从 info 视图开始。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class InfoView(RequestHandler):
|
||||
"""只允许 GET 请求"""
|
||||
SUPPORTED_METHODS = ["GET"]
|
||||
|
||||
def set_default_headers(self):
|
||||
"""设置默认响应头为 json 格式的"""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def get(self):
|
||||
"""列出这个 API 的路由"""
|
||||
routes = {
|
||||
'info': 'GET /api/v1',
|
||||
'register': 'POST /api/v1/accounts',
|
||||
'single profile detail': 'GET /api/v1/accounts/<username>',
|
||||
'edit profile': 'PUT /api/v1/accounts/<username>',
|
||||
'delete profile': 'DELETE /api/v1/accounts/<username>',
|
||||
'login': 'POST /api/v1/accounts/login',
|
||||
'logout': 'GET /api/v1/accounts/logout',
|
||||
"user's tasks": 'GET /api/v1/accounts/<username>/tasks',
|
||||
"create task": 'POST /api/v1/accounts/<username>/tasks',
|
||||
"task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
|
||||
"task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
|
||||
"delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
|
||||
}
|
||||
self.write(json.dumps(routes))
|
||||
```
|
||||
|
||||
有什么改变吗?让我们从上往下看。
|
||||
|
||||
我们添加了 `SUPPORTED_METHODS` 类属性,它是一个可迭代对象,代表这个视图所接受的请求方法,其他任何方法都将返回一个 [405][9] 状态码。当我们创建 `HelloWorld` 视图时,我们没有指定它,主要是当时有点懒。如果没有这个类属性,此视图将响应任何试图绑定到该视图的路由的请求。
|
||||
|
||||
我们声明了 `set_default_headers` 方法,它设置 HTTP 响应的默认头。我们在这里声明它,以确保我们返回的任何响应都有一个 `"Content-Type"` 是 `"application/json"` 类型。
|
||||
|
||||
我们将 `json.dumps(some_object)` 添加到 `self.write` 的参数中,因为它可以很容易地构建响应主体的内容。
|
||||
|
||||
现在已经完成了,我们可以继续将它连接到 `__init__.py` 中的主路由。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import InfoView
|
||||
|
||||
# 添加这些
|
||||
import os
|
||||
from tornado_sqlalchemy import make_session_factory
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', InfoView)
|
||||
],
|
||||
session_factory=factory
|
||||
)
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
我们知道,还需要编写更多的视图和路由。每个都会根据需要放入 `Application` 路由列表中,每个视图还需要一个 `set_default_headers` 方法。在此基础上,我们还将创建 `send_response` 方法,它的作用是将响应与我们想要给响应设置的任何自定义状态码打包在一起。由于每个视图都需要这两个方法,因此我们可以创建一个包含它们的基类,这样每个视图都可以继承基类。这样,我们只需要编写一次。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler):
|
||||
"""Base view for this application."""
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
对于我们即将编写的 `TaskListView` 这样的视图,我们还需要一个到数据库的连接。我们需要 `tornado_sqlalchemy` 中的 `SessionMixin` 在每个视图类中添加一个数据库会话。我们可以将它放在 `BaseView` 中,这样,默认情况下,从它继承的每个视图都可以访问数据库会话。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado_sqlalchemy import SessionMixin
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler, SessionMixin):
|
||||
"""Base view for this application."""
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
只要我们修改 `BaseView` 对象,在将数据发布到这个 API 时,我们就应该定位到这里。
|
||||
|
||||
当 Tornado(从 v.4.5 开始)使用来自客户端的数据并将其组织起来到应用程序中使用时,它会将所有传入数据视为字节串。但是,这里的所有代码都假设使用 Python 3,因此我们希望使用的唯一字符串是 Unicode 字符串。我们可以为这个 `BaseView` 类添加另一个方法,它的工作是将输入数据转换为 Unicode,然后再在视图的其他地方使用。
|
||||
|
||||
如果我们想要在正确的视图方法中使用它之前转换这些数据,我们可以重写视图类的原生 `prepare` 方法。它的工作是在视图方法运行前运行。如果我们重写 `prepare` 方法,我们可以设置一些逻辑来运行,每当收到请求时,这些逻辑就会执行字节串到 Unicode 的转换。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado_sqlalchemy import SessionMixin
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler, SessionMixin):
|
||||
"""Base view for this application."""
|
||||
|
||||
def prepare(self):
|
||||
self.form_data = {
|
||||
key: [val.decode('utf8') for val in val_list]
|
||||
for key, val_list in self.request.arguments.items()
|
||||
}
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
如果有任何数据进入,它将在 `self.request.arguments` 字典中找到。我们可以通过键访问该数据库,并将其内容(始终是列表)转换为 Unicode。因为这是基于类的视图而不是基于函数的,所以我们可以将修改后的数据存储为一个实例属性,以便以后使用。我在这里称它为 `form_data`,但它也可以被称为 `potato`。关键是我们可以存储提交给应用程序的数据。
|
||||
|
||||
### 异步视图方法
|
||||
|
||||
现在我们已经构建了 `BaseaView`,我们可以构建 `TaskListView` 了,它会继承 `BaseaView`。
|
||||
|
||||
正如你可以从章节标题中看到的那样,以下是所有关于异步性的讨论。`TaskListView` 将处理返回任务列表的 `GET` 请求和用户给定一些表单数据来创建新任务的 `POST` 请求。让我们首先来看看处理 `GET` 请求的代码。
|
||||
|
||||
```
|
||||
# all the previous imports
|
||||
import datetime
|
||||
from tornado.gen import coroutine
|
||||
from tornado_sqlalchemy import as_future
|
||||
from todo.models import Profile, Task
|
||||
|
||||
# the BaseView is above here
|
||||
class TaskListView(BaseView):
|
||||
"""View for reading and adding new tasks."""
|
||||
SUPPORTED_METHODS = ("GET", "POST",)
|
||||
|
||||
@coroutine
|
||||
def get(self, username):
|
||||
"""Get all tasks for an existing user."""
|
||||
with self.make_session() as session:
|
||||
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
|
||||
if profile:
|
||||
tasks = [task.to_dict() for task in profile.tasks]
|
||||
self.send_response({
|
||||
'username': profile.username,
|
||||
'tasks': tasks
|
||||
})
|
||||
```
|
||||
|
||||
这里的第一个主要部分是 `@coroutine` 装饰器,它从 `tornado.gen` 导入。任何具有与调用堆栈的正常流程不同步的部分的 Python 可调用实际上是“协程”。一个可以与其它协程一起运行的协程。在我的家务劳动的例子中,几乎所有的家务活都是一个共同的例行协程。有些人阻止了例行协程(例如,给地板吸尘),但这种例行协程只会阻碍我开始或关心其它任何事情的能力。它没有阻止已经启动的任何其他协程继续进行。
|
||||
|
||||
Tornado 提供了许多方法来构建一个利用协程的应用程序,包括允许我们设置函数调用锁,同步异步协程的条件,以及手动修改控制 I/O 循环的事件系统。
|
||||
|
||||
这里使用 `@coroutine` 装饰器的唯一条件是允许 `get` 方法将 SQL 查询作为后台进程,并在查询完成后恢复,同时不阻止 Tornado I/O 循环去处理其他传入的数据源。这就是关于此实现的所有“异步”:带外数据库查询。显然,如果我们想要展示异步 Web 应用程序的魔力和神奇,那么一个任务列表就不是好的展示方式。
|
||||
|
||||
但是,这就是我们正在构建的,所以让我们来看看方法如何利用 `@coroutine` 装饰器。`SessionMixin` 混合到 `BaseView` 声明中,为我们的视图类添加了两个方便的,支持数据库的属性:`session` 和 `make_session`。它们的名字相似,实现的目标也相当相似。
|
||||
|
||||
`self.session` 属性是一个关注数据库的会话。在请求-响应周期结束时,在视图将响应发送回客户端之前,任何对数据库的更改都被提交,并关闭会话。
|
||||
|
||||
`self.make_session` 是一个上下文管理器和生成器,可以动态构建和返回一个全新的会话对象。第一个 `self.session` 对象仍然存在。无论如何,反正 `make_session` 会创建一个新的。`make_session` 生成器还为其自身提供了一个功能,用于在其上下文(即缩进级别)结束时提交和关闭它创建的会话。
|
||||
|
||||
如果你查看源代码,则赋值给 `self.session` 的对象类型与 `self.make_session` 生成的对象类型之间没有区别,不同之处在于它们是如何被管理的。
|
||||
|
||||
使用 `make_session` 上下文管理器,生成的会话仅属于上下文,在该上下文中开始和结束。你可以使用 `make_session` 上下文管理器在同一个视图中打开,修改,提交以及关闭多个数据库会话。
|
||||
|
||||
`self.session` 要简单得多,当你进入视图方法时会话已经打开,在响应被发送回客户端之前会话就已提交。
|
||||
|
||||
虽然[读取文档片段][10]和 [PyPI 示例][11]都说明了上下文管理器的使用,但是没有说明 `self.session` 对象或由 `self.make_session` 生成的 `session` 本质上是不是异步的。当我们启动查询时,我们开始考虑内置于 `tornado-sqlalchemy` 中的异步行为。
|
||||
|
||||
`tornado-sqlalchemy` 包为我们提供了 `as_future` 函数。它的工作是装饰 `tornado-sqlalchemy` 会话构造的查询并 yield 其返回值。如果视图方法用 `@coroutine` 装饰,那么使用 `yield as_future(query)` 模式将使封装的查询成为一个异步后台进程。I/O 循环会接管等待查询的返回值和 `as_future` 创建的 `future` 对象的解析。
|
||||
|
||||
要访问 `as_future(query)` 的结果,你必须从它 `yield`。否则,你只能获得一个未解析的生成器对象,并且无法对查询执行任何操作。
|
||||
|
||||
这个视图方法中的其他所有内容都与之前课堂上的类似,与我们在 Flask 和 Pyramid 中看到的内容类似。
|
||||
|
||||
`post` 方法看起来非常相似。为了保持一致性,让我们看一下 `post` 方法以及它如何处理用 `BaseView` 构造的 `self.form_data`。
|
||||
|
||||
```
|
||||
@coroutine
|
||||
def post(self, username):
|
||||
"""Create a new task."""
|
||||
with self.make_session() as session:
|
||||
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
|
||||
if profile:
|
||||
due_date = self.form_data['due_date'][0]
|
||||
task = Task(
|
||||
name=self.form_data['name'][0],
|
||||
note=self.form_data['note'][0],
|
||||
creation_date=datetime.now(),
|
||||
due_date=datetime.strptime(due_date, '%d/%m/%Y %H:%M:%S') if due_date else None,
|
||||
completed=self.form_data['completed'][0],
|
||||
profile_id=profile.id,
|
||||
profile=profile
|
||||
)
|
||||
session.add(task)
|
||||
self.send_response({'msg': 'posted'}, status=201)
|
||||
```
|
||||
|
||||
正如我所说,这是我们所期望的:
|
||||
|
||||
* 与我们在 `get` 方法中看到的查询模式相同
|
||||
* 构造一个新的 `Task` 对象的实例,用 `form_data` 的数据填充
|
||||
* 添加新的 `Task` 对象(但不提交,因为它由上下文管理器处理!)到数据库会话
|
||||
* 将响应发送给客户端
|
||||
|
||||
这样我们就有了 Tornado web 应用程序的基础。其他内容(例如,数据库管理和更多完整应用程序的视图)实际上与我们在 Flask 和 Pyramid 应用程序中看到的相同。
|
||||
|
||||
### 关于使用合适的工具完成合适的工作的一点想法
|
||||
|
||||
在我们继续浏览这些 Web 框架时,我们开始看到它们都可以有效地处理相同的问题。对于像这样的待办事项列表,任何框架都可以完成这项任务。但是,有些 Web 框架比其它框架更适合某些工作,这具体取决于对你来说什么“更合适”和你的需求。
|
||||
|
||||
虽然 Tornado 显然能够处理 Pyramid 或 Flask 可以处理的相同工作,但将它用于这样的应用程序实际上是一种浪费,这就像开车从家走一个街区(to 校正:这里意思应该是从家开始走一个街区只需步行即可)。是的,它可以完成“旅行”的工作,但短途旅行不是你选择汽车而不是自行车或者使用双脚的原因。
|
||||
|
||||
根据文档,Tornado 被称为 “Python Web 框架和异步网络库”。在 Python Web 框架生态系统中很少有人喜欢它。如果你尝试完成的工作需要(或将从中获益)以任何方式,形状或形式的异步性,使用 Tornado。如果你的应用程序需要处理多个长期连接,同时又不想牺牲太多性能,选择 Tornado。如果你的应用程序是多个应用程序,并且需要线程感知以准确处理数据,使用 Tornado。这是它最有效的地方。
|
||||
|
||||
用你的汽车做“汽车的事情”,使用其他交通工具做其他事情。
|
||||
|
||||
### 向前看,进行一些深度检查
|
||||
|
||||
谈到使用合适的工具来完成合适的工作,在选择框架时,请记住应用程序的范围和规模,包括现在和未来。到目前为止,我们只研究了适用于中小型 Web 应用程序的框架。本系列的下一篇也是最后一篇将介绍最受欢迎的 Python 框架之一 Django,它适用于可能会变得更大的大型应用程序。同样,尽管它在技术上能够并且将会处理待办事项列表问题,但请记住,这不是它的真正用途。我们仍然会通过它来展示如何使用它来构建应用程序,但我们必须牢记框架的意图以及它是如何反映在架构中的:
|
||||
|
||||
* **Flask:** 适用于小型,简单的项目。它可以使我们轻松地构建视图并将它们快速连接到路由,它可以简单地封装在一个文件中。
|
||||
|
||||
* **Pyramid:** 适用于可能增长的项目。它包含一些配置来启动和运行。应用程序组件的独立领域可以很容易地划分并构建到任意深度,而不会忽略中央应用程序。
|
||||
|
||||
* **Tornado:** 适用于受益于精确和有意识的 I/O 控制的项目。它允许协程,并轻松公开可以控制如何接收请求或发送响应以及何时发生这些操作的方法。
|
||||
|
||||
* **Django:**(我们将会看到)意味着可能会变得更大的东西。它有着非常庞大的生态系统,包括大量插件和模块。它非常有主见的配置和管理,以保持所有不同部分在同一条线上。
|
||||
|
||||
无论你是从本系列的第一篇文章开始阅读,还是稍后才加入的,都要感谢阅读!请随意留下问题或意见。下次再见时,我手里会拿着 Django。
|
||||
|
||||
### 感谢 Python BDFL
|
||||
|
||||
我必须把功劳归于它应得的地方,非常感谢 [Guido van Rossum][12],不仅仅是因为他创造了我最喜欢的编程语言。
|
||||
|
||||
在 [PyCascades 2018][13] 期间,我很幸运的不仅给了基于这个文章系列的演讲,而且还被邀请参加了演讲者的晚宴。整个晚上我都坐在 Guido 旁边,不停地问他问题。其中一个问题是,在 Python 中异步到底是如何工作的,但他没有一点大惊小怪,而是花时间向我解释,让我开始理解这个概念。他后来[推特给我][14]发了一条消息:是用于学习异步 Python 的广阔资源。我随后在三个月内阅读了三次,然后写了这篇文章。你真是一个非常棒的人,Guido!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/tornado-framework
|
||||
|
||||
作者:[Nicholas Hunt-Walker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nhuntwalker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/5/pyramid-framework
|
||||
[2]: https://opensource.com/article/18/4/flask
|
||||
[3]: https://tornado.readthedocs.io/en/stable/
|
||||
[4]: https://realpython.com/python-gil/
|
||||
[5]: https://en.wikipedia.org/wiki/Thread_(computing)
|
||||
[6]: https://www.nginx.com/
|
||||
[7]: https://tornado-sqlalchemy.readthedocs.io/en/latest/
|
||||
[8]: https://www.sqlalchemy.org/
|
||||
[9]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_errors
|
||||
[10]: https://tornado-sqlalchemy.readthedocs.io/en/latest/#usage
|
||||
[11]: https://pypi.org/project/tornado-sqlalchemy/#description
|
||||
[12]: https://www.twitter.com/gvanrossum
|
||||
[13]: https://www.pycascades.com
|
||||
[14]: https://twitter.com/gvanrossum/status/956186585493458944
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding /etc/services file in Linux)
|
||||
[#]: via: (https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/)
|
||||
[#]: author: (kerneltalks https://kerneltalks.com)
|
||||
|
||||
理解 Linux 中的 /etc/services 文件
|
||||
======
|
||||
|
||||
这篇文章将帮助你了解 Linux 中 /etc/services 文件,包括它的内容,格式以及重要性。
|
||||
|
||||
![/etc/services file in Linux][1]
|
||||
Linux 中的 /etc/services 文件
|
||||
|
||||
网络守护程序是 Linux 世界中的重要服务。它借助 `/etc/services` 文件来处理所有网络服务。在本文中,我们将向你介绍这个文件的内容,格式以及它对于 Linux 系统的意义。
|
||||
|
||||
`/etc/services` 文件包含网络服务和它们映射端口的列表。`inetd` 或 `xinetd` 会查看这些细节,以便在数据包到达各自的端口或服务有需求时,它会调用特定的程序。
|
||||
|
||||
作为普通用户,你可以查看此文件,因为文件一般都是可读的。要编辑此文件,你需要有 root 权限。
|
||||
|
||||
```
|
||||
$ ll /etc/services
|
||||
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
|
||||
```
|
||||
|
||||
### `/etc/services` 文件格式
|
||||
|
||||
```
|
||||
service-name port/protocol [aliases..] [#comment]
|
||||
```
|
||||
|
||||
最后两个字段是可选的,因此用 `[` `]` 表示。
|
||||
|
||||
其中:
|
||||
|
||||
* service-name 是网络服务的名称。例如 [telnet][2], [ftp][3] 等。
|
||||
* port/protocol 是网络服务使用的端口(一个数值)和服务通信使用的协议(TCP/UDP)。
|
||||
* alias 是服务的别名。
|
||||
* comment 是你可以添加到服务的注释或说明。以 `#` 标记开头。
|
||||
|
||||
### `/etc/services` 文件示例
|
||||
|
||||
```
|
||||
# 每行描述一个服务,形式如下:
|
||||
#
|
||||
# service-name port/protocol [aliases ...] [# comment]
|
||||
|
||||
tcpmux 1/tcp # TCP port service multiplexer
|
||||
rje 5/tcp # Remote Job Entry
|
||||
echo 7/udp
|
||||
discard 9/udp sink null
|
||||
```
|
||||
|
||||
在这里,你可以看到可选的最后两个字段的用处。`discard` 服务的别名为 `sink` 或 `null`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kerneltalks.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/kerneltalks.com/wp-content/uploads/2019/01/undestanding-etc-service-file-in-linux.png?ssl=1
|
||||
[2]: https://kerneltalks.com/config/configure-telnet-server-linux/
|
||||
[3]: https://kerneltalks.com/config/ftp-server-configuration-steps-rhel-6/
|
||||
Loading…
Reference in New Issue
Block a user