mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-10 22:21:11 +08:00
commit
139aa1903c
0
published/201407/Encrypting Your Cat Photos.md
Executable file → Normal file
0
published/201407/Encrypting Your Cat Photos.md
Executable file → Normal file
0
published/201505/20150326 How to set up server monitoring system with Monit.md
Executable file → Normal file
0
published/201505/20150326 How to set up server monitoring system with Monit.md
Executable file → Normal file
@ -1,42 +1,43 @@
|
||||
|
||||
开源代码开发的十四点教学技巧
|
||||
在大学培养学生们参与开源代码开发的十四个技巧
|
||||
================================================================================
|
||||
|
||||
对于培养和塑造开源代码开发者,Academia就是一个很好的平台。研究中发现,我们偶尔会开源自己编写的软件。这样做有两个理由,一是为了提升自己编写的工具使用率,二是为了了解人们使用这些工具时会遇到哪些问题。在这样一个编写研究软件的背景下,我的任务就是为 Bradford 大学重新设计二年级的软件工程课程。
|
||||

|
||||
|
||||
这是一个巨大的挑战,因为我所面对的 80 个学生是来自不同专业的,包括 IT、商务计算和软件工程,这些学生将要在一起上课。最有难度的是,需要和这些编程经验差距很大的学生一起编写代码。按照传统,该课程允许学生选择自己的小组,然后给他们布置构建一个存储数据库系统构的任务,最后提交报告作为评估的一部分。
|
||||
学术界是培养和塑造未来的开源开发者的最佳平台。研究中发现,我们偶尔会开源自己编写的软件。这样做有两个理由,一是为了推广自己编写的工具的使用,二是为了了解人们使用这些工具时会遇到哪些问题。在这样一个编写研究软件的背景下,我的任务就是为 Bradford 大学重新设计二年级的本科软件工程课程。
|
||||
|
||||
而我决定重新设计课程,让学生了解现实中的软件团队是如何协作的过程。根据学生的专业和编程技能,我将他们分为五六个人一组。这是为了确保每个小组的整体水平相当,避免小组之间的不公平。
|
||||
这是一个挑战,因为我所面对的 80 个学生是来自不同专业的,包括 IT、商务计算和软件工程,这些学生将要在一起上课。最有难度的是,需要和这些编程经验差距很大的学生一起编写代码。按照传统,该课程允许学生选择自己的小组,然后给他们布置构建一个加油站数据库系统的任务,最后提交报告作为评估的一部分。
|
||||
|
||||
而我决定重新设计课程,让学生了解现实中的软件团队是如何协作的过程。根据学生的专业和编程技能,我将他们分为五、六个人一组。这是为了确保每个小组的整体水平相当,避免小组之间的不等。
|
||||
|
||||
### 核心课程 ###
|
||||
|
||||
课程的形式升级为文化课和实践课两项结合在一起。然而实践部分只是充当辅助,主要是老师监督各个小组的实践进度以及他们如何处理客户和产品之间的关系。传统的教学方式由项目管理、软件测试、工程需求分析以及类似主题的讲座组成,再辅以实践和导师会议。这些会议可以很好的考核学生的水平以及检测出他们是否可以跟得上我们在讲座部分中的软件工程方法。本年的教学主题包括以下内容:
|
||||
课程的形式改为讲座和实践课两项结合在一起。然而实践课作为指导过程,主要是老师监督各个小组的实践进度以及他们如何处理客户和产品之间的关系。而传统的教学方式由项目管理、软件测试、工程需求分析以及类似主题的讲座组成,再辅以实践和导师会议。这些会议可以很好的考核学生的水平以及检测出他们是否可以跟得上我们在讲座部分中的软件工程方法。本年的教学主题包括以下内容:
|
||||
|
||||
- 工程需求分析
|
||||
- 如何与客户及其他团队成员互动
|
||||
- 程序设计方法,如敏捷和极限编程方法
|
||||
- 如何通过学习不同的软件工程方法进行短期的水平提高
|
||||
- 小组会议及文档编写
|
||||
- 项目管理及项目进展图表
|
||||
- 项目管理及项目进展图表(甘特图)
|
||||
- UML 图表及系统描述
|
||||
- 使用 Git 来进行代码的版本控制
|
||||
- 软件测试及 BUG 跟踪
|
||||
- 使用开源库
|
||||
- 开源代码许可及其选择
|
||||
- 软件分发
|
||||
- 软件交付
|
||||
|
||||
在这些讲座之后,会有一些来自世界各地的嘉宾为我们说说他们在软件分发过程中的经验。我们也设法请来大学里知识产权律师谈关于软件在英国的知识产权问题,以及如何处理软件的知识产权问题。
|
||||
在这些讲座之后,会有一些来自世界各地的嘉宾为我们说说他们在软件交付过程中的经验。我们也设法请来大学里知识产权律师谈关于软件在英国的知识产权问题,以及如何处理软件的知识产权问题。
|
||||
|
||||
### 协作工具 ###
|
||||
|
||||
为了让上述教学内容的顺利进行,我们将会介绍一些工具,并训练学生在他们的项目中使用这些工具。如下:
|
||||
为了让上述教学内容的顺利进行,我们将会引入一些工具,并训练学生在他们的项目中使用这些工具。如下:
|
||||
|
||||
- Google Drive:团队与导师之间进行共享的工具,暂时存储用于描述项目的文档和图表、需求收集、会议纪要以及项目时间跟踪等信息。采取这样一个方式来监控并提供直接反馈到每个团队,是非常有效的。
|
||||
- [Basecamp][1]:同样是用于分享文档,在随后的课程中,我们可能会考虑用它取代 Google Drive。
|
||||
- BUG 报告工具,如 [Mantis][2]:只能让有限的用户自由提交 BUG。稍后我们提到的 Git 可以让小组内的所有人员用做 BUG 提交。
|
||||
- BUG 报告工具,如 [Mantis][2]:只能让有限的用户免费提交 BUG。稍后我们提到的 Git 可以让小组内的所有人员用做 BUG 提交。
|
||||
- 远程视频会议工具:在人员不在校内,甚至去了其他城市的情况下使用。学生们可以定期通过 Skype 来交流并记录会议内容或则进行录音作为今后其他用处。
|
||||
- 同时,学生们的项目中还会用到大量的开源工具包。他们可以根据自己小组的项目需求来选择自己使用的工具包和编程语言。唯一的条件是,这些项目必须开源,最后成果可以安装到大学里的实验室,并且大多的研究人员都支持这个条件。
|
||||
- 最后,所有团队必须向客户交付他们的项目,包括完整的工作版本的软件、文档和他们自己选择的开放源码许可。大多数的团队选择了 GPLv3 许可证。
|
||||
- 同时,学生们的项目中还会用到大量的开源工具包。他们可以根据自己小组的项目需求来选择自己使用的工具包和编程语言。唯一的条件是,这些项目必须开源,最后成果可以安装到大学里的实验室,并且大多的研究人员都非常支持这个条件。
|
||||
- 最后,所有团队必须向客户交付他们的项目,包括完整的可以工作的软件版本、文档和他们自己选择的开放源码许可。大多数的团队选择了 GPLv3 许可证。
|
||||
|
||||
### 技巧和经验教训 ###
|
||||
|
||||
@ -48,29 +49,29 @@
|
||||
|
||||
3. 学生更加愿意与校外的客户一起协作。他们期待着与外部公司代表或校外人员协作,不过是为了获得新体验而已。与导师进行交流时,他们都能够表现得很专业,这样使得老师非常放心。
|
||||
|
||||
4. 很多团队版开发单元测试的部分放到项目结束之后,从极限编程方法的角度来说,这是一个严重的禁忌。也许测试应包括在不同阶段的评估中,来提醒他们需要与并行开展软件开发和单元测试。
|
||||
4. 很多团队版将开发单元测试的部分放到项目结束之后,从极限编程方法的角度来说,这是一个严重的禁忌。也许测试应包括在不同阶段的评估中,来提醒他们需要并行开展软件开发和单元测试。
|
||||
|
||||
5. 在这个班的 80 个人里边,仅有 4 个女生,每个女都分在不同的小组里边。我观察到,男生们总是充分准备好来承担起领队角色,并将最有趣的代码分配给他们自己来编写,女生则多大遵循安排或者是编写文档。出于某种原因,女生选择不显示权威,即使在女性辅导员鼓励下,她们也不愿编写代码。这仍然是一个需要解决的主要问题。
|
||||
5. 在这个班的 80 个人里边,仅有 4 个女生,每个女生都分在不同的小组里边。我观察到,男生们总是充分准备好来承担起领队角色,并将最有趣的代码部分留给他们自己来编写,女生则多大遵循安排或者是编写文档。出于某种原因,女生选择不出头,即使在女性辅导员鼓励下,她们也不愿编写代码。这仍然是一个需要解决的主要问题。
|
||||
|
||||
6. 允许不同风格项目文档,比方说,UML 图表、状态图或其他形式的。让学生学习这些并与其他课程融汇贯通来提高他们的学习经验。
|
||||
|
||||
7. 学生里边,有些是很好的开发人员,有些做商务计算的则没有多少编程经验。我们要鼓励团队共同努力,避免开发人员做得比那些只做会议记录或文档的其他成员更好的错误认知。我们常在辅导课程中鼓励角色转换,让每个人都有机会学习如何编程。
|
||||
|
||||
8. 小组进行与导师每周见面沟通是非常重要的,可以有效监督各个小组进展情况,还可以了解是谁做了大部分工作。通常,没来参加会议的小组成员基本就是没有参与到他们的团队工作中去的,并且通过其他成员提交的工作报告也可以确定哪些人不活跃。
|
||||
8. 小组与导师每周见面沟通是非常重要的,可以有效监督各个小组进展情况,还可以了解是谁做了大部分工作。通常,没来参加会议的小组成员基本就是没有参与到他们的团队工作中去的,并且通过其他成员所提交的工作报告也可以确定哪些人不活跃。
|
||||
|
||||
9. 我们鼓励学生们把许可证附加到项目中去,使用外部库以及和客户协作的时候要表明确切知识产权问题。 这样可让打破陈规,开拓思维,并了解真实的软件交付问题。
|
||||
|
||||
10. 给学生们自己选择技术空间。
|
||||
10. 给学生们自己选择所用技术的空间。
|
||||
|
||||
11. 助教是关键。同时管理 80 个学生显然很有难度,特别是需要对他们进行评估的那几周。明年我一定会找个助教来帮我一起管理各个小组。
|
||||
|
||||
12. 实验室的技术支持是非常重要的。大学里的技术支持对于本课程是非常赞同的。他们正在考虑明年将虚拟机分配给每个团队,这样没个团队可以根据需要自行在虚拟机中安装任何软件。
|
||||
12. 实验室的技术支持是非常重要的。大学里的技术支持人员对于本课程是非常赞同的。他们正在考虑明年将虚拟机分配给每个团队,这样没个团队可以根据需要自行在虚拟机中安装任何软件。
|
||||
|
||||
13. 团队合作,相互帮助。大多数团队自然而然的支持其他团队成员,同时指导员在中间也帮助了不少。
|
||||
|
||||
14. 来自其他技术人员的帮助会锦上添花。作为一名新的大学导师,我需要从经验中学习,如果我想了解如何管理某些学生和团队,或者对如何让学生适应课程感到困惑时,我会通过多个方面来寻求建议。来自高级技术人员的支持对我来说是一种极大的鼓励。
|
||||
14. 来自其他同事的帮助会锦上添花。作为一名新的大学导师,我需要从经验中学习,如果我想了解如何管理某些学生和团队,或者对如何让学生适应课程感到困惑时,我会通过多个方面来寻求建议。来自资深同事的支持对我来说是一种极大的鼓励。
|
||||
|
||||
最后,对于作为导师的我以及所有的学生来说,这都是个有趣的课程。在学习目标和传统的分级方案上还有有一些问题需解决,以减少教师的工作量。明年,我计划会保留这种教学模式,并希望能够提出更好的分级方案以及介绍更多的软件来帮助监督项目和控制代码版本。
|
||||
最后,对于作为导师的我以及所有的学生来说,这都是个有趣的课程。在学习目标和传统评分方案上还有有一些问题需解决,以减少教师的工作量。明年,我计划会保留这种教学模式,并希望能够提出更好的评分方案以及引入更多的软件来帮助监督项目和控制代码版本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
sed 和 awk,所有的 Linux 管理员都应该会的技能!
|
||||
==========================
|
||||
|
||||

|
||||
|
||||
*图片来源: Shutterstock*
|
||||
|
||||
**我们不要让下一代 Linux 和 Unix 的管理员忘记初始化脚本和基本工具的好处**
|
||||
|
||||
我曾经有一次在 Reddit 看到一个帖子,“[请问如何操作文本文件][1]”。这是一个很简单的需求,就像我们常用 Unix 的人每天遇到的一样。他的问题是,如何删除文件中的重复行,只保留不重复的。 这听起来似乎很简单,但是当文件足够大时,就会有些复杂。
|
||||
|
||||
这个问题有很多种不同的答案。你可以使用几乎任何一种语言来写这样的一个脚本,只是时间的投入和代码的复杂性不同罢了。根据你的个人水平,它大概会花费20-60分钟。但是如果你使用了 Perl、Python、Ruby 中的一种,你可能很快实现它。
|
||||
|
||||
或者你可以使用下面的一个方法,让你无比暖心的: 只用 awk。
|
||||
|
||||
这个答案是迄今为止最简明、最简单的解决问题的方法。它只要一行!
|
||||
|
||||
```
|
||||
awk '!seen[$0]++' <filename>
|
||||
```
|
||||
|
||||
让我们来看看发生了什么:
|
||||
|
||||
在这个命令中,其实隐藏了很多代码。awk 是一种文本处理语言,并且它内部有很多预设。首先,你看到的实际上是一个 for 循环的结果。awk 假定你想通过循环处理输入文件的每一行,所以你不需要明确的去指定它。awk 还假定了你需要打印输出处理后的数据,所以你也不需要去指定它。最后,awk 假定循环在最后一句指令执行完结束,这一块也不再需要你去指定它。
|
||||
|
||||
这个例子中的字符串 seen 是一个关联数组的名字。$0 是一个变量,表示整个当前行。所以,这个命令翻译成人类语言就是“对这个文件的每一行进行检查,如果你之前没有见过它,就打印出来。” 如果该关联数组的键名还不存在就添加到数组,并增加其取值,这样 awk 下次遇到同样的行时就会不匹配(条件判断为“假”),从而不打印出来。
|
||||
|
||||
一些人认为这样是优雅的,另外的人认为这可能会造成混淆。任何在日常工作上使用 awk 的都是第一类人。awk 就是设计用来做这个的。在 awk 中,你可以写多行代码。你甚至可以[用 awk 写一些让人不安的复杂功能][2]。但终究来说,awk 还是一个进行文本处理的程序,一般是通过管道。去掉(没必要的)循环定义是很常见的快捷用法,不过如果你乐意,你也可以用下面的代码做同样的事情:
|
||||
|
||||
|
||||
```
|
||||
awk '{ if (!seen[$0]) print $0; seen[$0]++ }’
|
||||
```
|
||||
|
||||
这会产生相同的结果。
|
||||
|
||||
awk 是完成这项工作的完美工具。不过,我相信很多管理员--特别是新管理员会转而使用 [Bash][3] 或 Python 来完成这一任务,因为对 awk 的知识和对它的能力的了解看起来随着时间而慢慢被人淡忘。我认为这是标志着一个问题,由于对之前的解决方案缺乏了解,那些已经解决了几十年的问题又突然出现了。
|
||||
|
||||
shell、grep、sed 和 awk 是 Unix 的基础。如果你不能非常轻松的使用它们,你将会被自己束缚住,因为它们构成了通过命令行和脚本与 Unix 系统交互的基础。学习这些工具如何工作最好的方法之一就是观察真实的例子和实验,你可以在各种 Unix 衍生系统的初始化系统中找到很多,但在 Linux 发行版中它们已经被 [systemd][4] 取代了。
|
||||
|
||||
数以百万计的 Unix 管理员了解 Shell 脚本和 Unix 工具如何读、写、修改和用在初始化脚本上。不同系统的初始化脚本有很大不同,甚至是不同的 Linux 发行版也不同。但是它们都源自 sh,而且它们都用像 sed、awk 还有 grep 这样的核心的命令行工具。
|
||||
|
||||
我每天都会听到很多人抱怨初始化脚本太“古老”而且很“难”。但是实际上,初始化脚本和 Unix 管理员每天使用的工具一样,还提供了一个非常好的方式来更加熟悉和习惯这些工具。说初始化脚本难于阅读和难于使用实际上是承认你缺乏对 Unix 基础工具的熟悉。
|
||||
|
||||
说起在 Reddit 上看到的内容,我也碰到过这个问题,来自一个新入行的 Linux 系统管理员, “[问他是否应该还要去学老式的初始化系统 sysvinit][5]”。 这个帖子的大多数的答案都是正面的——是的,应该学习 sysvinit 和 systemd 两个。一位评论者甚至指出,初始化脚本是学习 Bash 的好方法。而另一个消息是,Fortune 50 强的公司还没有计划迁移到以 systemd 为基础的发行版上。
|
||||
|
||||
但是,这提醒了我这确实是一个问题。如果我们继续沿着消除脚本和脱离操作系统核心组件的方式发展下去,由于疏于接触,我们将会不经意间使新管理员难于学习基本的 Unix 工具。
|
||||
|
||||
我不知道为什么有些人想在一层又一层的抽象化来掩盖 Unix 内部,但是这样发展下去可能会让新一代的系统管理员们变成只会按下按钮的工人。我觉得这不是一件好事情。
|
||||
|
||||
------
|
||||
|
||||
via: http://www.infoworld.com/article/2985804/linux/remember-sed-awk-linux-admins-should.html
|
||||
|
||||
作者:[Paul Venezia][a]
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.infoworld.com/author/Paul-Venezia/
|
||||
[1]: https://www.reddit.com/r/linuxadmin/comments/3lwyko/how_do_i_remove_every_occurence_of_duplicate_line/
|
||||
[2]: http://intro-to-awk.blogspot.com/2008/08/awk-more-complex-examples.html
|
||||
[3]: http://www.infoworld.com/article/2613338/linux/linux-how-to-script-a-bash-crash-course.html
|
||||
[4]: http://www.infoworld.com/article/2608798/data-center/systemd--harbinger-of-the-linux-apocalypse.html
|
||||
[5]: https://www.reddit.com/r/linuxadmin/comments/3ltq2y/when_i_start_learning_about_linux_administration/
|
||||
@ -0,0 +1,111 @@
|
||||
如何在 Linux 中根据国家位置来阻断网络流量
|
||||
================================================================================
|
||||
|
||||
作为一名维护 Linux 生产服务器的系统管理员,你可能会遇到这样一些情形:你需要**根据地理位置,选择性地阻断或允许网络流量通过。** 例如你正经历一次由注册在某个特定国家的 IP 发起的 DoS 攻击;或者基于安全考虑,你想阻止来自未知国家的 SSH 登录请求;又或者你的公司对某些在线视频有分销权,它要求只能在特定的国家内合法发行;抑或是由于公司的政策,你需要阻止某个本地主机将文件上传至任意一个非美国的远程云端存储。
|
||||
|
||||
所有的上述情形都需要设置防火墙,使之具有**基于国家位置过滤流量**的功能。有几个方法可以做到这一点,其中之一是你可以使用 TCP wrappers 来为某个应用(例如 SSH,NFS, httpd)设置条件阻塞。但其缺点是你想要保护的那个应用必须以支持 TCP wrappers 的方式构建。另外,TCP wrappers 并不总是能够在各个平台中获取到(例如,Arch Linux [放弃了][2]对它的支持)。另一种方式是结合基于国家的 GeoIP 信息,设置 [ipset][3],并将它应用到 iptables 的规则中。后一种方式看起来更有希望一些,因为基于 iptables 的过滤器是与应用无关的,且容易设置。
|
||||
|
||||
在本教程中,我将展示 **另一个基于 iptables 的 GeoIP 过滤器,它由 xtables-addons 来实现**。对于那些不熟悉它的人来说, xtables-addons 是用于 netfilter/iptables 的一系列扩展。一个包含在 xtables-addons 中的名为 xt\_geoip 的模块扩展了 netfilter/iptables 的功能,使得它可以根据流量来自或流向的国家来进行过滤,IP 掩蔽(NAT)或丢包。若你想使用 xt\_geoip,你不必重新编译内核或 iptables,你只需要使用当前的内核构建环境(/lib/modules/\`uname -r`/build)以模块的形式构建 xtables-addons。同时也不需要进行重启。只要你构建并安装了 xtables-addons , xt\_geoip 便能够配合 iptables 使用。
|
||||
|
||||
至于 xt\_geoip 和 ipset 之间的比较,[xtables-addons 的官方网站][3] 上是这么说的: 相比于 ipset,xt\_geoip 在内存占用上更胜一筹,但对于匹配速度,基于哈希的 ipset 可能更有优势。
|
||||
|
||||
在教程的余下部分,我将展示**如何使用 iptables/xt\_geoip 来根据流量的来源地或流入的国家阻断网络流量**。
|
||||
|
||||
### 在 Linux 中安装 xtables-addons ###
|
||||
|
||||
下面介绍如何在各种 Linux 平台中编译和安装 xtables-addons。
|
||||
|
||||
为了编译 xtables-addons,首先你需要安装一些依赖软件包。
|
||||
|
||||
#### 在 Debian,Ubuntu 或 Linux Mint 中安装依赖 ####
|
||||
|
||||
$ sudo apt-get install iptables-dev xtables-addons-common libtext-csv-xs-perl pkg-config
|
||||
|
||||
#### 在 CentOS,RHEL 或 Fedora 中安装依赖 ####
|
||||
|
||||
CentOS/RHEL 6 需要事先设置好 EPEL 仓库(为 perl-Text-CSV\_XS 所需要)。
|
||||
|
||||
$ sudo yum install gcc-c++ make automake kernel-devel-`uname -r` wget unzip iptables-devel perl-Text-CSV_XS
|
||||
|
||||
#### 编译并安装 xtables-addons ####
|
||||
|
||||
从 `xtables-addons` 的[官方网站][4] 下载源码包,然后按照下面的指令编译安装它。
|
||||
|
||||
$ wget http://downloads.sourceforge.net/project/xtables-addons/Xtables-addons/xtables-addons-2.10.tar.xz
|
||||
$ tar xf xtables-addons-2.10.tar.xz
|
||||
$ cd xtables-addons-2.10
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
需要注意的是,对于基于红帽的系统(CentOS、RHEL、Fedora),它们默认开启了 SELinux,所以有必要像下面这样调整 SELinux 的策略。否则,SELinux 将阻止 iptables 加载 xt\_geoip 模块。
|
||||
|
||||
$ sudo chcon -vR --user=system_u /lib/modules/$(uname -r)/extra/*.ko
|
||||
$ sudo chcon -vR --type=lib_t /lib64/xtables/*.so
|
||||
|
||||
### 为 xtables-addons 安装 GeoIP 数据库 ###
|
||||
|
||||
下一步是安装 GeoIP 数据库,它将被 xt\_geoip 用来查询 IP 地址与国家地区之间的对应关系。方便的是,`xtables-addons` 的源码包中带有两个帮助脚本,它们被用来从 MaxMind 下载 GeoIP 数据库并将它转化为 xt\_geoip 可识别的二进制形式文件;它们可以在源码包中的 geoip 目录下找到。请遵循下面的指导来在你的系统中构建和安装 GeoIP 数据库。
|
||||
|
||||
$ cd geoip
|
||||
$ ./xt_geoip_dl
|
||||
$ ./xt_geoip_build GeoIPCountryWhois.csv
|
||||
$ sudo mkdir -p /usr/share/xt_geoip
|
||||
$ sudo cp -r {BE,LE} /usr/share/xt_geoip
|
||||
|
||||
根据 [MaxMind][5] 的说明,他们的 GeoIP 数据库能够以 99.8% 的准确率识别出 ip 所对应的国家,并且每月这个数据库将进行更新。为了使得本地安装的 GeoIP 数据是最新的,或许你需要设置一个按月执行的 [cron job][6] 来时常更新你本地的 GeoIP 数据库。
|
||||
|
||||
### 阻断来自或流向某个国家的网络流量 ###
|
||||
|
||||
一旦 xt\_geoip 模块和 GeoIP 数据库安装好后,你就可以在 iptabels 命令中使用 geoip 的匹配选项。
|
||||
|
||||
$ sudo iptables -m geoip --src-cc country[,country...] --dst-cc country[,country...]
|
||||
|
||||
你想要阻断流量的那些国家是使用[2个字母的 ISO3166 代码][7] 来特别指定的(例如 US(美国)、CN(中国)、IN(印度)、FR(法国))。
|
||||
|
||||
例如,假如你想阻断来自也门(YE) 和 赞比亚(ZM)的流量,下面的 iptabels 命令便可以达到此目的。
|
||||
|
||||
$ sudo iptables -I INPUT -m geoip --src-cc YE,ZM -j DROP
|
||||
|
||||
假如你想阻断流向中国(CN) 的流量,可以运行下面的命令:
|
||||
|
||||
$ sudo iptables -A OUTPUT -m geoip --dst-cc CN -j DROP
|
||||
|
||||
匹配条件也可以通过在 `--src-cc` 或 `--dst-cc` 选项前加 `!` 来达到相反的目的:
|
||||
|
||||
假如你想在你的服务器上阻断来自所有非美国的流量,可以运行:
|
||||
|
||||
$ sudo iptables -I INPUT -m geoip ! --src-cc US -j DROP
|
||||
|
||||
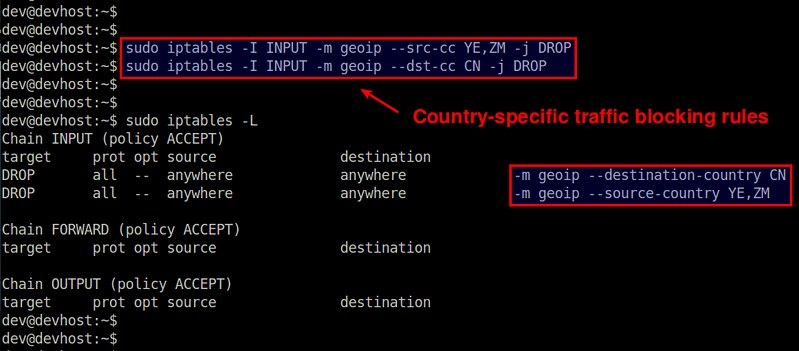
|
||||
|
||||
#### 对于使用 Firewall-cmd 的用户 ####
|
||||
|
||||
某些发行版本例如 CentOS/RHEL7 或 Fedora 已经用 firewalld 替代了 iptables 来作为默认的防火墙服务。在这些系统中,你可以类似使用 xt\_geoip 那样,使用 firewall-cmd 来阻断流量。利用 firewall-cmd 命令,上面的三个例子可被重新写为:
|
||||
|
||||
$ sudo firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -m geoip --src-cc YE,ZM -j DROP
|
||||
$ sudo firewall-cmd --direct --add-rule ipv4 filter OUTPUT 0 -m geoip --dst-cc CN -j DROP
|
||||
$ sudo firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -m geoip ! --src-cc US -j DROP
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本教程中,我展示了使用 iptables/xt\_geoip 来根据流量的来源地或流入的国家轻松地阻断网络流量。假如你有这方面的需求,把它部署到你的防火墙系统中可以使之成为一个实用的办法。作为最后的警告,我应该提醒你的是:在你的服务器上通过基于 GeoIP 的流量过滤来禁止特定国家的流量并不总是万无一失的。GeoIP 数据库本身就不是很准确或齐全,且流量的来源或目的地可以轻易地通过使用 VPN、Tor 或其他任意易受攻击的中继主机来达到欺骗的目的。基于地理位置的过滤器甚至可能会阻止本不该阻止的合法网络流量。在你决定把它部署到你的生产环境之前请仔细考虑这个限制。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/block-network-traffic-by-country-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://www.archlinux.org/news/dropping-tcp_wrappers-support/
|
||||
[2]:http://xmodulo.com/block-unwanted-ip-addresses-linux.html
|
||||
[3]:http://xtables-addons.sourceforge.net/geoip.php
|
||||
[4]:http://xtables-addons.sourceforge.net/
|
||||
[5]:https://support.maxmind.com/geoip-faq/geoip2-and-geoip-legacy-databases/how-accurate-are-your-geoip2-and-geoip-legacy-databases/
|
||||
[6]:http://ask.xmodulo.com/add-cron-job-linux.html
|
||||
[7]:https://en.wikipedia.org/wiki/ISO_3166-1
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||

|
||||
|
||||
Glances 是一个跨平台、基于命令行、文本模式的系统监控工具。它是用 Python 编写的,使用 `psutil` 库从系统获取信息。你可以用它来监控 CPU、平均负载、内存、网络接口、磁盘 I/O,文件系统空间利用率、挂载的设备、所有活动进程以及消耗资源最多的进程。Glances 有很多有趣的选项。它的主要特性之一是可以在配置文件中设置阀值(careful[小心]、warning[警告]、critical[致命]),然后它会用不同颜色显示信息以表明系统的瓶颈。
|
||||
Glances 是一个用于监控系统的跨平台、基于文本模式的命令行工具。它是用 Python 编写的,使用 `psutil` 库从系统获取信息。你可以用它来监控 CPU、平均负载、内存、网络接口、磁盘 I/O,文件系统空间利用率、挂载的设备、所有活动进程以及消耗资源最多的进程。Glances 有很多有趣的选项。它的主要特性之一是可以在配置文件中设置阀值(careful[小心]、warning[警告]、critical[致命]),然后它会用不同颜色显示信息以表明系统的瓶颈。
|
||||
|
||||
### Glances 的功能
|
||||
|
||||
@ -18,11 +18,11 @@ Glances 是一个跨平台、基于命令行、文本模式的系统监控工具
|
||||
|
||||
### 安装 Glances
|
||||
|
||||
Glances 在 Ubuntu 的软件源中,所以安装很简单。执行下面的命令安装 Glances:
|
||||
Glances 在 Ubuntu 的软件仓库中,所以安装很简单。执行下面的命令安装 Glances:
|
||||
|
||||
sudo apt-get install glances
|
||||
|
||||
(LCTT 译注:若安装后无法正常使用,可考虑使用 pip 安装/升级glances:`sudo pip install --upgrade glances`)
|
||||
(LCTT 译注:若安装后无法正常使用,可考虑使用 pip 安装/升级 glances:`sudo pip install --upgrade glances`)
|
||||
|
||||
### Glances 使用方法
|
||||
|
||||
@ -34,7 +34,7 @@ Glances 在 Ubuntu 的软件源中,所以安装很简单。执行下面的命
|
||||
|
||||

|
||||
|
||||
要退出 Glances 终端,按 ESC 键或 “Ctrl + C”。
|
||||
要退出 Glances 终端,按 ESC 键或 `Ctrl + C`。
|
||||
|
||||
默认情况下,时间间隔(LCTT 译注:显示数据刷新的时间间隔)是 1s,不过你可以在从终端启动 Glances 时自定义时间间隔。
|
||||
|
||||
@ -46,10 +46,10 @@ Glances 在 Ubuntu 的软件源中,所以安装很简单。执行下面的命
|
||||
|
||||
Glances 中不同颜色的含义:
|
||||
|
||||
- `绿色`:正常
|
||||
- `蓝色`:需要注意
|
||||
- `紫色`:警告
|
||||
- `红色`:严重
|
||||
- `绿色`:正常(OK)
|
||||
- `蓝色`:小心(careful)
|
||||
- `紫色`:警告(warning)
|
||||
- `红色`:致命(critical)
|
||||
|
||||
默认设置下,Glances 的阀值设置是:careful=50,warning=70,critical=90。你可以通过 “/etc/glances/” 目录下的默认配置文件 glances.conf 来自定义这些阀值。
|
||||
|
||||
@ -101,7 +101,7 @@ via: https://www.maketecheasier.com/glances-monitor-system-ubuntu/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[bianjp](https://github.com/bianjp)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,16 @@
|
||||
使用Nmon监控Linux的系统性能
|
||||
使用 Nmon 监控 Linux 的系统性能
|
||||
================================================================================
|
||||
Nmon(得名于Nigel's的监控器)是IBM的员工Nigel Griffiths为AIX和Linux系统开发的一款计算机性能系统监控工具。Nmon可以把操作系统的统计数据展示在屏幕上或者存储到一份数据文件里,来帮助理解计算机资源的使用情况、调整选项和系统瓶颈。这个系统基准测试工具只需要使用一条命令就能得到大量重要的性能数据。使用Nmon可以很轻松的监控系统的CPU、内存、网络、硬盘、文件系统、NFS、高耗进程、资源和微分区功率的信息。
|
||||
Nmon(得名于 Nigel 的监控器)是IBM的员工 Nigel Griffiths 为 AIX 和 Linux 系统开发的一款计算机性能系统监控工具。Nmon 可以把操作系统的统计数据展示在屏幕上或者存储到一份数据文件里,来帮助了解计算机资源的使用情况、调整方向和系统瓶颈。这个系统基准测试工具只需要使用一条命令就能得到大量重要的性能数据。使用 Nmon 可以很轻松的监控系统的 CPU、内存、网络、硬盘、文件系统、NFS、高耗进程、资源和 IBM Power 系统的微分区的信息。
|
||||
|
||||
### Nmon 安装 ###
|
||||
|
||||
Nmon默认是存在于Ubuntu的仓库中的。你可以通过下面的命令安装Nmon:
|
||||
Nmon 默认是存在于 Ubuntu 的仓库中的。你可以通过下面的命令安装 Nmon:
|
||||
|
||||
sudo apt-get install nmon
|
||||
|
||||
怎么使用Nmon来监控Linux的性能
|
||||
安装完成后,通过在终端输入`nmon` 命令来启动Nmon
|
||||
### 怎么使用Nmon来监控Linux的性能 ###
|
||||
|
||||
安装完成后,通过在终端输入`nmon` 命令来启动 Nmon
|
||||
|
||||
nmon
|
||||
|
||||
@ -17,25 +18,24 @@ Nmon默认是存在于Ubuntu的仓库中的。你可以通过下面的命令安
|
||||
|
||||

|
||||
|
||||
从上面的截图可以看到nmon命令行工具完全是交互式运行的,你可以使用快捷键来轻松查看对应的统计数据。
|
||||
你可以使用下面的nmon快捷键来显示不同的系统统计数据:
|
||||
从上面的截图可以看到 nmon 命令行工具完全是交互式运行的,你可以使用快捷键来轻松查看对应的统计数据。你可以使用下面的 nmon 快捷键来显示不同的系统统计数据:
|
||||
|
||||
- `q` : 停止或编辑Nmon
|
||||
- `q` : 停止并退出 Nmon
|
||||
- `h` : 查看帮助
|
||||
- `c` : 查看CPU统计数据
|
||||
- `c` : 查看 CPU 统计数据
|
||||
- `m` : 查看内存统计数据
|
||||
- `d` : 查看硬盘统计数据
|
||||
- `k` : 查看内核统计数据
|
||||
- `n` : 查看网络统计数据
|
||||
- `N` : 查看NFS统计数据
|
||||
- `N` : 查看 NFS 统计数据
|
||||
- `j` : 查看文件系统统计数据
|
||||
- `t` : 查看高耗进程
|
||||
- `V` : 查看虚拟内存统计数据
|
||||
- `v` : 详细模式
|
||||
|
||||
### 核查CPU处理器 ###
|
||||
### 核查 CPU 处理器 ###
|
||||
|
||||
如果你想收集关于CPU性能相关的统计数据,你应该按下键盘上的`c`键,之后你将会看到下面的输出:
|
||||
如果你想收集关于 CPU 性能相关的统计数据,你应该按下键盘上的`c`键,之后你将会看到下面的输出:
|
||||
|
||||

|
||||
|
||||
@ -47,7 +47,7 @@ Nmon默认是存在于Ubuntu的仓库中的。你可以通过下面的命令安
|
||||
|
||||
### 核查网络统计数据 ###
|
||||
|
||||
如果想收集Linux系统网络统计数据,按下`n`键,你将会看到下面输出:
|
||||
如果想收集 Linux 系统的网络统计数据,按下`n`键,你将会看到下面输出:
|
||||
|
||||

|
||||
|
||||
@ -59,19 +59,19 @@ Nmon默认是存在于Ubuntu的仓库中的。你可以通过下面的命令安
|
||||
|
||||
### 核查内核信息 ###
|
||||
|
||||
Nmon一个非常重要的快捷键是`k`键,用来显示系统内核相关的概要信息。按下`k`键之后,会看到下面输出:
|
||||
Nmon 一个非常重要的快捷键是`k`键,用来显示系统内核相关的概要信息。按下`k`键之后,会看到下面输出:
|
||||
|
||||

|
||||
|
||||
### 获取系统信息 ###
|
||||
|
||||
对每个系统管理员来说一个非常有用的快捷键是`r`键,可以用来显示计算机系统结构、操作系统版本号和CPU等不同资源的信息。按下`r`键之后会看到下面输出:
|
||||
对每个系统管理员来说一个非常有用的快捷键是`r`键,可以用来显示计算机的系统结构、操作系统版本号和 CPU 等不同资源的信息。按下`r`键之后会看到下面输出:
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
还有许多其他的工具实现的功能和Nmon一样,不过Nmon对一个Linux新手来说还是很友好的。如果你有什么问题,尽管评论。
|
||||
还有许多其他的工具做的和 Nmon 同样的工作,不过 Nmon 对一个 Linux 新手来说还是很友好的。如果你有什么问题,尽管评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -79,7 +79,7 @@ via: https://www.maketecheasier.com/monitor-linux-system-performance/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[sonofelice](https://github.com/sonofelice)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -25,7 +25,7 @@ Ubuntu 里的“间谍软件”将在 Ubuntu 16.04 LTS 中被禁用
|
||||
|
||||
[电子前哨基金会 (EFF)][2]也在一系列博文中表达出对此的关注,并且建议 Canonical 将这个功能做成用户自由选择是否开启的功能。Privacy International 比其他的组织走的更远,对于 Ubuntu 的工作,他们给 Ubuntu 的缔造者发了一个“[老大哥奖][3]”。
|
||||
|
||||
[Canonical][4] 坚称] Unity 的在线搜索功能所收集的数据是匿名的以及“不可识别是来自哪个用户的”。
|
||||
[Canonical][4] 坚称 Unity 的在线搜索功能所收集的数据是匿名的以及“不可识别是来自哪个用户的”。
|
||||
|
||||
在[2013年 Canoical 发布的博文中][5]他们解释道:“**(我们)会使用户了解我们收集哪些信息以及哪些第三方服务商将会在他们搜索时从 Dash 栏中给出结果。我们只会收集能够提升用户体验的信息。**”
|
||||
|
||||
|
||||
@ -1,112 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
How to block network traffic by country on Linux
|
||||
================================================================================
|
||||
As a system admin who maintains production Linux servers, there are circumstances where you need to **selectively block or allow network traffic based on geographic locations**. For example, you are experiencing denial-of-service attacks mostly originating from IP addresses registered with a particular country. You want to block SSH logins from unknown foreign countries for security reasons. Your company has a distribution right to online videos, which requires it to legally stream to particular countries only. You need to prevent any local host from uploading documents to any non-US remote cloud storage due to geo-restriction company policies.
|
||||
|
||||
All these scenarios require an ability to set up a firewall which does **country-based traffic filtering**. There are a couple of ways to do that. For one, you can use TCP wrappers to set up conditional blocking for individual applications (e.g., SSH, NFS, httpd). The downside is that the application you want to protect must be built with TCP wrappers support. Besides, TCP wrappers are not universally available across different platforms (e.g., Arch Linux [dropped][2] its support). An alternative approach is to set up [ipset][3] with country-based GeoIP information and apply it to iptables rules. The latter approach is more promising as the iptables-based filtering is application-agnostic and easy to set up.
|
||||
|
||||
In this tutorial, I am going to present **another iptables-based GeoIP filtering which is implemented with xtables-addons**. For those unfamiliar with it, xtables-addons is a suite of extensions for netfilter/iptables. Included in xtables-addons is a module called xt_geoip which extends the netfilter/iptables to filter, NAT or mangle packets based on source/destination countries. For you to use xt_geoip, you don't need to recompile the kernel or iptables, but only need to build xtables-addons as modules, using the current kernel build environment (/lib/modules/`uname -r`/build). Reboot is not required either. As soon as you build and install xtables-addons, xt_geoip is immediately usable with iptables.
|
||||
|
||||
As for the comparison between xt_geoip and ipset, the [official source][3] mentions that xt_geoip is superior to ipset in terms of memory foot print. But in terms of matching speed, hash-based ipset might have an edge.
|
||||
|
||||
In the rest of the tutorial, I am going to show **how to use iptables/xt_geoip to block network traffic based on its source/destination countries**.
|
||||
|
||||
### Install Xtables-addons on Linux ###
|
||||
|
||||
Here is how you can compile and install xtables-addons on various Linux platforms.
|
||||
|
||||
To build xtables-addons, you need to install a couple of dependent packages first.
|
||||
|
||||
#### Install Dependencies on Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo apt-get install iptables-dev xtables-addons-common libtext-csv-xs-perl pkg-config
|
||||
|
||||
#### Install Dependencies on CentOS, RHEL or Fedora ####
|
||||
|
||||
CentOS/RHEL 6 requires EPEL repository being set up first (for perl-Text-CSV_XS).
|
||||
|
||||
$ sudo yum install gcc-c++ make automake kernel-devel-`uname -r` wget unzip iptables-devel perl-Text-CSV_XS
|
||||
|
||||
#### Compile and Install Xtables-addons ####
|
||||
|
||||
Download the latest `xtables-addons` source code from the [official site][4], and build/install it as follows.
|
||||
|
||||
$ wget http://downloads.sourceforge.net/project/xtables-addons/Xtables-addons/xtables-addons-2.10.tar.xz
|
||||
$ tar xf xtables-addons-2.10.tar.xz
|
||||
$ cd xtables-addons-2.10
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
Note that for Red Hat based systems (CentOS, RHEL, Fedora) which have SELinux enabled by default, it is necessary to adjust SELinux policy as follows. Otherwise, SELinux will prevent iptables from loading xt_geoip module.
|
||||
|
||||
$ sudo chcon -vR --user=system_u /lib/modules/$(uname -r)/extra/*.ko
|
||||
$ sudo chcon -vR --type=lib_t /lib64/xtables/*.so
|
||||
|
||||
### Install GeoIP Database for Xtables-addons ###
|
||||
|
||||
The next step is to install GeoIP database which will be used by xt_geoip for IP-to-country mapping. Conveniently, the xtables-addons source package comes with two helper scripts for downloading GeoIP database from MaxMind and converting it into a binary form recognized by xt_geoip. These scripts are found in geoip folder inside the source package. Follow the instructions below to build and install GeoIP database on your system.
|
||||
|
||||
$ cd geoip
|
||||
$ ./xt_geoip_dl
|
||||
$ ./xt_geoip_build GeoIPCountryWhois.csv
|
||||
$ sudo mkdir -p /usr/share/xt_geoip
|
||||
$ sudo cp -r {BE,LE} /usr/share/xt_geoip
|
||||
|
||||
According to [MaxMind][5], their GeoIP database is 99.8% accurate on a country-level, and the database is updated every month. To keep the locally installed GeoIP database up-to-date, you want to set up a monthly [cron job][6] to refresh the local GeoIP database as often.
|
||||
|
||||
### Block Network Traffic Originating from or Destined to a Country ###
|
||||
|
||||
Once xt_geoip module and GeoIP database are installed, you can immediately use the geoip match options in iptables command.
|
||||
|
||||
$ sudo iptables -m geoip --src-cc country[,country...] --dst-cc country[,country...]
|
||||
|
||||
Countries you want to block are specified using [two-letter ISO3166 code][7] (e.g., US (United States), CN (China), IN (India), FR (France)).
|
||||
|
||||
For example, if you want to block incoming traffic from Yemen (YE) and Zambia (ZM), the following iptables command will do.
|
||||
|
||||
$ sudo iptables -I INPUT -m geoip --src-cc YE,ZM -j DROP
|
||||
|
||||
If you want to block outgoing traffic destined to China (CN), run the following command.
|
||||
|
||||
$ sudo iptables -A OUTPUT -m geoip --dst-cc CN -j DROP
|
||||
|
||||
The matching condition can also be "negated" by prepending "!" to "--src-cc" or "--dst-cc". For example:
|
||||
|
||||
If you want to block all incoming non-US traffic on your server, run this:
|
||||
|
||||
$ sudo iptables -I INPUT -m geoip ! --src-cc US -j DROP
|
||||
|
||||

|
||||
|
||||
#### For Firewall-cmd Users ####
|
||||
|
||||
Some distros such as CentOS/RHEL 7 or Fedora have replaced iptables with firewalld as the default firewall service. On such systems, you can use firewall-cmd to block traffic using xt_geoip similarly. The above three examples can be rewritten with firewall-cmd as follows.
|
||||
|
||||
$ sudo firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -m geoip --src-cc YE,ZM -j DROP
|
||||
$ sudo firewall-cmd --direct --add-rule ipv4 filter OUTPUT 0 -m geoip --dst-cc CN -j DROP
|
||||
$ sudo firewall-cmd --direct --add-rule ipv4 filter INPUT 0 -m geoip ! --src-cc US -j DROP
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I presented iptables/xt_geoip which is an easy way to filter network packets based on their source/destination countries. This can be a useful arsenal to deploy in your firewall system if needed. As a final word of caution, I should mention that GeoIP-based traffic filtering is not a foolproof way to ban certain countries on your server. GeoIP database is by nature inaccurate/incomplete, and source/destination geography can easily be spoofed using VPN, Tor or any compromised relay hosts. Geography-based filtering can even block legitimate traffic that should not be banned. Understand this limitation before you decide to deploy it in your production environment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/block-network-traffic-by-country-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://www.archlinux.org/news/dropping-tcp_wrappers-support/
|
||||
[2]:http://xmodulo.com/block-unwanted-ip-addresses-linux.html
|
||||
[3]:http://xtables-addons.sourceforge.net/geoip.php
|
||||
[4]:http://xtables-addons.sourceforge.net/
|
||||
[5]:https://support.maxmind.com/geoip-faq/geoip2-and-geoip-legacy-databases/how-accurate-are-your-geoip2-and-geoip-legacy-databases/
|
||||
[6]:http://ask.xmodulo.com/add-cron-job-linux.html
|
||||
[7]:https://en.wikipedia.org/wiki/ISO_3166-1
|
||||
@ -1,69 +0,0 @@
|
||||
|
||||
# 学会Sed和Awk? 所有的Linux管理员都应该会的技能
|
||||
|
||||

|
||||
|
||||
图片来源: Shutterstock
|
||||
|
||||
**我们不希望下一代Linux和Unix的管理员忘记任何初始化脚本和基本工具的好处**
|
||||
|
||||
我曾经有一次在Reddit发表文章的机会, [asking about textfile manipulation][1].这是一个很简单请求,就像我们平时常用Unix的人所见到的。他的问题是,如何删除文件中的重复行,并保存在独立的实例里。 这听起来似乎很简单,但是当文件足够大时,就会有些复杂。
|
||||
|
||||
这个问题有很多种不同的答案。我怀疑你可以使用几乎任何一种语言来写这样的一个脚本,只是时间的投入和代码的复杂性不同罢了。根据你的个人水平,它大概会花费20-60分钟。但是如果你使用了Perl,Python,Ruby中的一种,你可能很快实现它。
|
||||
|
||||
或者你可以使用下面的一个方法,让你无比暖心的: 只用 awk.
|
||||
|
||||
这个答案是迄今为止最简明、最简单的解决问题的方法。他只要一行:
|
||||
|
||||
```
|
||||
awk '!seen[$0]++' <filename>.
|
||||
```
|
||||
|
||||
让我们来分析一下
|
||||
|
||||
在这段代码中,其实隐藏了很多代码。AWK是一种文本处理语言,并且他内部做了大量的假设。首先,你看到的实际上是一个循环的结果。Awk假定你想通过循环输入文件的每一行,所以你不需要明确的去设定它。Awk还假定了你需要打印数据的输出,所以你也不需要去指定它。最好,Awk假定循环在最后一句话执行完结束,这一块也不再需要你去指定它
|
||||
|
||||
这个例子中看到的字符串是一个关联的数组的名字。$0是一个变量,表示当前行的全部。所以,这个命令翻译成话就是“对这个文件的每一行进行检查,如果你之前没有见过他,就打印出来。”Awk通过做这些来看这个数组是否早已存在或值不相等的,这样就不匹配参数,下次就不会再打印了。
|
||||
|
||||
一些人认为这样是优雅的,另外的人认为这可能会造成混淆。任何在日常基础事情上使用Awk的都是第一类人。Awk就是被设计做这个的。在Awk中,你可以写多行。甚至是一些复杂的功能。你甚至可以[用awk写一些让人不安的复杂功能][2]。但,最终,Awk还是一个通过管道进行文字处理的程序。去除循环定义的外部缺陷是很常见的用法,你可以用下面的代码做同样的事情
|
||||
|
||||
|
||||
|
||||
```
|
||||
awk '{ if (!seen[$0]) print $0; seen[$0]++ }’
|
||||
```
|
||||
|
||||
这必将导致相同的结果
|
||||
|
||||
Awk是完成这项工作的完美工具。不过,我相信很多管理员--特别是新管理员会跳转到[Bash][ 3 ]或Python来完成这一任务,因为Awk的知识和他所能做的事情总是随着时间而褪色。我认为这是一个标识性的事情。几十年来,以前的解决方案总是缺乏对新的问题的处理方法
|
||||
|
||||
The shell, grep, sed, and awk 是Unix的计算基础.如果你不能非常轻松的使用他们,你将会变得十分脆弱。因为他们通过命令行和脚本的相互作用来实现。学习这些工具如何工作最好的方法之一就是观察和正在运行的范例一起工作,通过Unix系统特有的Init系统,或者在Linux发行版被称为 [systemd][4].
|
||||
|
||||
数以百万计的Unix管理员了解Shell脚本和Unix工具同读、写、修改和研究Init脚本。不同系统的Init脚本有很大不同,甚至是不同的发行版。但是他们都源自sh,而且他他们都用核心命令行工具像sed,awk还有grep
|
||||
|
||||
我每天都会挺到很多抱怨init脚本太“古老”而且很“难”。但是实际上,Init脚本和Unix管理员每天使用的工具一样,而且还提供了一个非常好的方式来更加熟悉和习惯这些工具。说Init脚本难的应该承认,你缺乏对Unix基础工具的熟悉。
|
||||
|
||||
说起在Reddit上的事情,我也碰到过这个问题,从一个初露头角的Linux系统管理员, [问他是否应该去学Sysvinit][5]. 大多数的答案都是好的方向--是的,应该学习sysvinit和systemd.一位评论者甚至指出,Init脚本是学习Bash的好方法。而另一个国家50强的公司不会搬到一个以系统为基础的发行版
|
||||
|
||||
但是,这提醒了我这是一个问题。如果我们继续沿着消除脚本和脱离我们操作系统的系统核心组件。由于出现的太少,我们将会不经意间的使新的管理员学习基本的Unix工具变得更难
|
||||
|
||||
我不知道为什么有些人想掩盖Unix内核抽象化和反抽象化,但是这样的一条路径可以减少一代Unix管理员出事后对服务支持的依赖。我相信这不是一件好事情。
|
||||
|
||||
------
|
||||
|
||||
via: http://www.infoworld.com/article/2985804/linux/remember-sed-awk-linux-admins-should.html
|
||||
|
||||
作者:[Paul Venezia][a]
|
||||
|
||||
译者:[Bestony](https://github.com/Bestony)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.infoworld.com/author/Paul-Venezia/
|
||||
[1]: https://www.reddit.com/r/linuxadmin/comments/3lwyko/how_do_i_remove_every_occurence_of_duplicate_line/
|
||||
[2]: http://intro-to-awk.blogspot.com/2008/08/awk-more-complex-examples.html
|
||||
[3]: http://www.infoworld.com/article/2613338/linux/linux-how-to-script-a-bash-crash-course.html
|
||||
[4]: http://www.infoworld.com/article/2608798/data-center/systemd--harbinger-of-the-linux-apocalypse.html
|
||||
[5]: https://www.reddit.com/r/linuxadmin/comments/3ltq2y/when_i_start_learning_about_linux_administration/
|
||||
Loading…
Reference in New Issue
Block a user