mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-04-14 03:30:29 +08:00
translated wi-cuckoo
This commit is contained in:
parent
27c692c632
commit
127cb0b703
89
sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
Normal file → Executable file
89
sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
Normal file → Executable file
@ -1,33 +1,32 @@
|
||||
translating wi-cuckoo
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
一个涵盖 Unix 44 年进化史的仓库
|
||||
=============================================================================
|
||||
### 摘要 ###
|
||||
|
||||
The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
|
||||
Unix 操作系统的进化历史,可以从一个版本控制的仓库中窥见,时间跨越从 1972 年以 5000 行内核代码的出现,到 2015 年成为一个含有 26,000,000 行代码的被广泛使用的系统。该仓库包含 659,000 条提交,和 2306 次合并。仓库部署被普遍采用的 Git 系统储存其代码,并且在时下流行的 GitHub 上建立了档案。它综合了系统定制软件的 24 个快照,都是开发自贝尔实验室,伯克利大学,386BSD 团队,两个传统的仓库 和 开源 FreeBSD 系统的仓库。总的来说,850 位个人贡献者已经确认,更早些时候的一批人主要做基础研究。这些数据可以用于一些经验性的研究,在软件工程,信息系统和软件考古学领域。
|
||||
|
||||
### 1 Introduction ###
|
||||
### 1 介绍 ###
|
||||
|
||||
The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
|
||||
Unix 操作系统作为一个主要的工程上的突破而脱颖而出,得益于其模范的设计,大量的技术贡献,它的开发模型和广泛的使用。Unix 编程环境的设计已经被标榜为一个能提供非常简洁,功能强大并且优雅的设计[[1][1]]。在技术方面,许多对 Unix 有直接贡献的,或者因 Unix 而流行的特性就包括[[2][2]]:用高级语言编写的可移植部署的内核;一个分层式设计的文件系统;兼容的文件,设备,网络和进程间 I/O;管道和过滤架构;虚拟文件系统;和用户可选的 shell。很早的时候,就有一个庞大的社区为 Unix 贡献软件[[3][3]],[[4][4]],pp. 65-72]。随时间流走,这个社区不断壮大,并且以现在称为开源软件开发的方式在工作着[[5][5],pp. 440-442]。Unix 和其睿智的晚辈们也将 C 和 C++ 编程语言,分析程序和词法分析生成器(*yacc,lex*),发扬光大了,文档编制工具(*troff,eqn,tbl*),脚本语言(*awk,sed,Perl*),TCP/IP 网络,和配置管理系统(*SCSS,RCS,Subversion,Git*)发扬广大了,同时也形成了大部分的现代互联网基础设施和网络。
|
||||
|
||||
Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
|
||||
幸运的是,一些重要的具有历史意义的 Unix 材料已经保存下来了,现在保持对外开放。尽管 Unix 最初是由相对严格的协议发行,但在早期的开发中,很多重要的部分是通过 Unix 的某个版权拥有者以一个自由的协议发行。然后将这些部分再结合开发的软件或者以开源发行的软件,Berkeley,Californai 大学和 FreeBSD 项目组从 1972 年六月二十日开始到现在,提供了涵盖整个系统的开发。
|
||||
|
||||
Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
|
||||
|
||||
### 2 Data Overview ###
|
||||
### 2. 数据概览 ###
|
||||
|
||||
The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
|
||||
这 1GB 的 Unix 仓库可以从 [GitHub][9] 克隆。[1][10]如今[2][11],这个仓库包含来自 850 个贡献者的 659,000 个提交和 2306 个合并。贡献者有来自 Bell 实验室的 23 个员工,Berkeley 计算机系统研究组(CSRG)的 158 个人,和 FreeBSD 项目的 660 个成员。
|
||||
|
||||
The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
|
||||
这个仓库的生命始于一个 *Epoch* 的标签,这里面只包含了证书信息和现在的 README 文件。其后各种各样的标签和分支记录了很多重要的时刻。
|
||||
|
||||
- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
|
||||
- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
|
||||
- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
|
||||
- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
|
||||
- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
|
||||
- *Research-VX* 标签对应来自 Bell 实验室六次的研究版本。从 *Research-V1* (PDP-11 4768 行汇编代码)开始,到以 *Research-V7* (大约 324,000 行代码,1820 个 C 文件)结束。
|
||||
- *Bell-32V* 是 DEC/VAX 架构的 Unix 第七个版本的一部分。
|
||||
- *BSD-X* 标签对应 Berkeley 释出的 15 个快照。
|
||||
- *386BSD-X* 标签对应系统的两个开源版本,主要是 Lynne 和 William Jolitz 写的 适用于 Intel 386 架构的内核代码。
|
||||
- *FreeBSD-release/X* 标签和分支标记了来自 FreeBSD 项目的 116 个发行版。
|
||||
|
||||
In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
|
||||
另外,以 *-Snapshot-Development* 为后缀的分支,表示一个被综合的以时间排序的快照文件序列的一些提交,而以一个 *-VCS-Development* 为后缀的标签,标记了有特别发行版出现的历史分支的时刻。
|
||||
|
||||
The repository's history includes commits from the earliest days of the system's development, such as the following.
|
||||
仓库的历史包含从系统开发早期的一些提交,比如下面这些。
|
||||
|
||||
commit c9f643f59434f14f774d61ee3856972b8c3905b1
|
||||
Author: Dennis Ritchie <research!dmr>
|
||||
@ -35,69 +34,69 @@ The repository's history includes commits from the earliest days of the system's
|
||||
Research V5 development
|
||||
Work on file usr/sys/dmr/kl.c
|
||||
|
||||
Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
|
||||
释出间隙的合并随着系统进化而发生,比如 从 BSD 2 到 BSD 3 的开发,Unix 32/V 也是正确地代表了 Git 仓库里带两个父节点的图形节点。(这太莫名其妙了)
|
||||
|
||||
More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
|
||||
更为重要的是,该仓库的构造方式允许 **git blame**,就是可以给源代码加上注释,如版本,日期和它们第一次出现相关联的作者,这样可以知道任何代码的起源。比如说 **BSD-4** 这个标签,在内核的 *pipe.c* 文件上运行一下 git blame,就会显示代码行由 Ken Thompson 写于 1974,1975 和 1979年,Bill Joy 写于 1980 年。这就可以自动(尽管计算上比较费事)检测出任何时刻出现的代码。
|
||||
|
||||
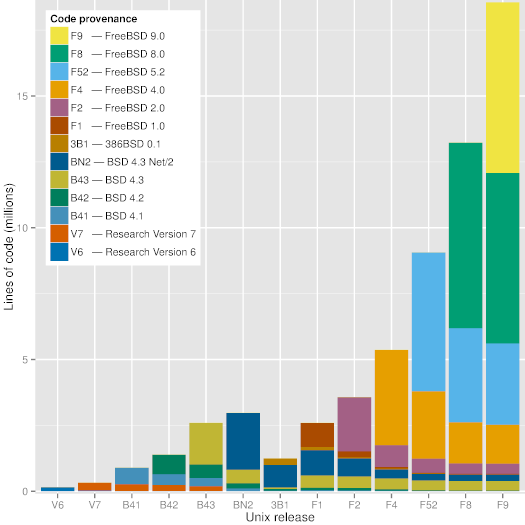
|
||||
|
||||
Figure 1: Code provenance across significant Unix releases.
|
||||
|
||||
As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
|
||||
如上图[12]所示,现代版本的 Unix(FreeBSD 9)依然有来自 BSD 4.3,BSD 4.3 Net/2 和 BSD 2.0 的代码块。有趣的是,这图片显示有部分代码好像没有保留下来,当时激进地要创造一个脱离于 Berkeyel(386BSD 和 FreeBSD 1.0)释出代码的开源操作系统,其所开发的代码。FreeBSD 9 中最古老的代码是一个 18 行的队列,在 C 库里面的 timezone.c 文件里,该文件也可以在第七版的 Unix 文件里找到,同样的名字,时间戳是 1979 年一月十日 - 36 年前。
|
||||
|
||||
### 3 Data Collection and Processing ###
|
||||
### 数据收集和处理 ###
|
||||
|
||||
The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
|
||||
这个项目的目的是以某种方式巩固从数据方面说明 Unix 的进化,通过将其并入一个现代的修订仓库,帮助人们对系统进化的研究。项目工作包括收录数据,分类并综合到一个单独的 Git 仓库里。
|
||||
|
||||
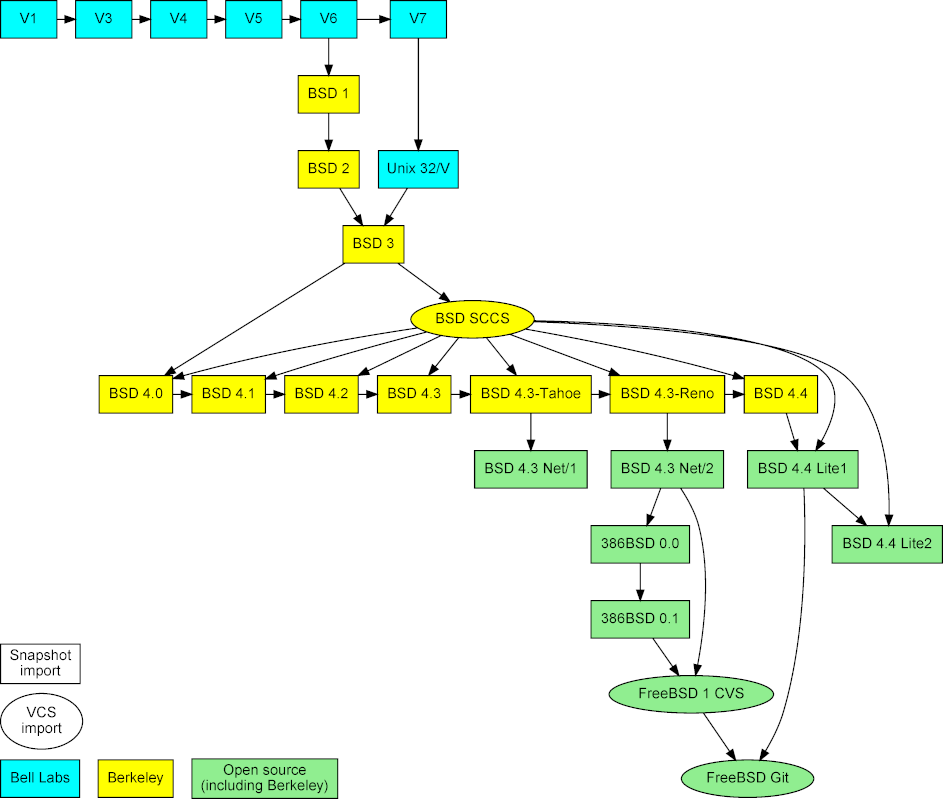
|
||||
|
||||
Figure 2: Imported Unix snapshots, repositories, and their mergers.
|
||||
|
||||
The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
|
||||
项目以三种数据类型为基础(见 Figure [2][13])。首先,早些发布的版本快照,是从 [Unix Heritage Society archive][14] 中获得,[2][15] 在 [CD-ROM 镜像][16] 中包括 CSRG 全部的源包,[4][17] [Oldlinux site],[5][19] 和 [FreeBSD 包][20]。[6][21] 其次,以前的,现在的仓库,也就是 CSRG SCCS [[6][22]] 仓库,FreeBSD 1 CVS 仓库,和[现代 FreeBSD 开发的 Git 镜像][23]。[7][24]前两个都是从相同的源获得而作为对应的快照。
|
||||
|
||||
The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
|
||||
最后,也是最费力的数据源是 **primary research**。释出的快照并没有提供关于它们的源头和每个文件贡献者的信息。因此,这些信息片段需要通过 primary research 验证。至于作者信息主要通过作者的自传,研究论文,内部备忘录和旧文档扫描;通过阅读并且自动处理源代码和帮助页面补充;通过与那个年代的人用电子邮件交流;在 *StackExchange* 网站上贴出疑问;查看文件的位置(在早期的内核源代码版本中,分为 `usr/sys/dmr` 和 `/usr/sys/ken`);从研究论文和帮助手册到源代码,从一个发行版到另一个发行版地宣传中获取。(有趣的是,第一和第二的研究版帮助页面都有一个 “owner” 部分,列出了作者(比如,*Ken*)与对应的系统命令,文件,系统调用,或者功能库。在第四版中这个部分就没了,而在 BSD 发行版中又浮现了 “Author” 部分。)关于作者信息更为详细地写在了项目的文件中,这些文件被用于匹配源代码文件和它们的作者和对应的提交信息。最后,information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26](不好组织这个语言)
|
||||
|
||||
The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
|
||||
作为该项目的一部分而开发的软件和数据文件,现在可以[在线获取][27],[9][28],并且,如果有合适的网络环境,CPU 和磁盘资源,可以用来从头构建这样一个仓库。关于主要发行版的所有者信息,都存储在该项目 `author-path` 目录下的文件里。These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author.(这句单词都认识,但是不理解具体意思)也可以制定多个作者。正则表达式是按线性处理的,所以一个文件末尾的匹配一切的表达式可以指定一个发行版的默认作者。为避免重复,一个以 `.au` 后缀的独立文件专门用于映射作者身份到他们的名字和 email。这样一个文件为每个社区建立了一个,以关联系统的进化:Bell 实验室,Berkeley,386BSD 和 FreeBSD。为了真实性的需要,早期 Bell 实验室发行版的 emails 都以 UUCP 注释列出了(e.g. `research!ken`)。FreeBSD 作者的鉴定人图谱,需要导入早期的 CVS 仓库,通过从如今项目的 Git 仓库里解压对应的数据构建。总的来说,注释作者信息的文件(828 rules)包含 1107 行,并且另外 640 映射作者鉴定人到名字。
|
||||
|
||||
The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
|
||||
现在项目的数据源被编码成了一个 168 行的 `Makefile`。它包括下面的步骤。
|
||||
|
||||
**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
|
||||
**Fetching** 从远程站点复制和克隆大约 11GB 的镜像,档案和仓库。
|
||||
|
||||
**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
|
||||
**Tooling** 从 2.9 BSD 中为旧的 PDP-11 档案获取一个归档器,并作出调整来在现代的 Unix 版本下编译;编译 4.3 BSD *compress* 程序来解压 386BSD 发行版,这个程序不再是现代 Unix 系统的组成部分了。
|
||||
|
||||
**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
|
||||
**Organizing** 用 tar 和 *cpio* 解压缩包;结合第六版的三个目录;用旧的 PDP-11 归档器解压所有的 1 BSD 档案;挂载 CD-ROM 镜像,这样可以作为文件系统处理;组合 8 和 62 386BSD 散乱的磁盘镜像为两个独立的文件。
|
||||
|
||||
**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
|
||||
**Cleaning** 重新存储第一版的内核源代码文件,这个可以通过合适的字符识别从打印输出用获取;给第七版的源代码文件打补丁;移除一个发行版后被添加进来的元数据和其他文件,为避免得到错误的时间戳信息;修复毁坏的 SCCS 文件;通过移除 CVS symbols assigned to multiple revisions with a custom Perl script,删除 CVS *Attr* 文件和用 *cvs2svn* 将 CVS 仓库转换为 Git 仓库,来处理早期的 FreeBSD CVS 仓库。
|
||||
|
||||
An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
|
||||
在仓库表述中有一个很有意思的部分就是,如何导入那些快照,并以一种方式联系起来,使得 *git blame* 可以发挥它的魔力。快照导入到仓库是作为一系列的提交实现的,根据每个文件的时间戳。当所有文件导入后,就被用对应发行版的名字给标记了。在这点上,一个人可以删除那些文件,并开始导入下一个快照。注意 *git blame* 命令是通过回溯一个仓库的历史来工作的,并使用启发法来检测文件之间或内部的代码移动和复制。因此,删除掉的快照间会产生中断,防止它们之间的代码被追踪。
|
||||
|
||||
Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
|
||||
相反,在下一个快照导入之前,之前快照的所有文件都被移动到了一个隐藏的后备目录里,叫做 `.ref`(引用)。它们保存在那,直到下个快照的所有文件都被导入了,这时候它们就会被删掉。因为 `.ref` 目录下的每个文件都完全配对一个原始文件,*git blame* 可以知道多少源代码通过 `.ref` 文件从一个版本移到了下一个,而不用显示出 `.ref` 文件。为了更进一步帮助检测代码起源,同时增加表述的真实性,每个发行版都被表述成了一个合并,介于有增加文件的分支(*-Development*)与之前发行版之间的合并。
|
||||
|
||||
For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
|
||||
上世纪 80 年代这个时期,只有 Berkeley 开发文件的一个子集是用 SCCS 版本控制的。整个时期内,我们统一的仓库里包含了来自 SCCS 的提交和快照增加的文件。在每个发行版的时间点上,可以发现 SCCS 最近的提交,被标记成一个发行版中增加的导入分支的合并。这些合并可以在 Figure [2][29] 中间看到。
|
||||
|
||||
The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
|
||||
将各种数据资源综合到一个仓库的工作,主要是用两个脚本来完成的。一个 780 行的 Perl 脚本(`import-dir.pl`)可以从一个单独的数据源(快照目录,SCCS 仓库,或者 Git 仓库)中,以 *Git fast export* 格式导出(真实的或者综合的)提交历史。输出是一个简单的文本格式,Git 工具用这个来导入和导出提交。其他方面,这个脚本以一些东西为参数,如文件到贡献者的映射,贡献者登录名和他们的全名间的映射,导入的提交会被合并,哪些文件要处理,哪些文件要忽略,和“引用”文件的处理。一个 450 行的 Shell 脚本创建 Git 仓库,并调用带适当参数的 Perl 脚本,导入 27 个可用的历史数据资源。Shell 脚本也会跑 30 遍测试,比较特定标签的仓库和对应的数据源,确认出现的和没出现的备用目录,并查看分支树和合并的数量,*git blame* 和 *git log* 的输出中的退化。最后,*git* 被调用来作垃圾收集和压缩仓库,从最初的 6GB 降到发行的 1GB。
|
||||
|
||||
### 4 Data Uses ###
|
||||
### 4 数据使用 ###
|
||||
|
||||
The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
|
||||
数据可以用于软件工程,信息系统和软件考古学领域的经验性研究。鉴于它从不间断而独一无二的存在了超过了 40 年,可以供软件的进化和代代更迭参考。伴随那个时代以来在处理速度千倍地增长,存储容量百万倍的扩大,数据同样可以用于软件和硬件技术交叉进化的研究。软件开发从研究中心到大学,到开源社区的转移,可以用来研究组织文化对于软件开发的影响。仓库也可以用于学习开发者编程的影响力,比如 Turing 奖获得者(Dennis Ritchie 和 Ken Thompson)和 IT 产业的大佬(Bill Joy 和 Eric Schmidt)。另一个值得学习的现象是代码的长寿,无论是单行的水平,或是作为那个时代随 Unix 发行的完整的系统(Ingres, Lisp, Pascal, Ratfor, Snobol, TMP),和导致代码存活或消亡的因素。最后,因为数据使 Git 底层软件仓库存储技术感到压力,到了它的限度,这会加速修正管理系统领域的工程进度。
|
||||
|
||||
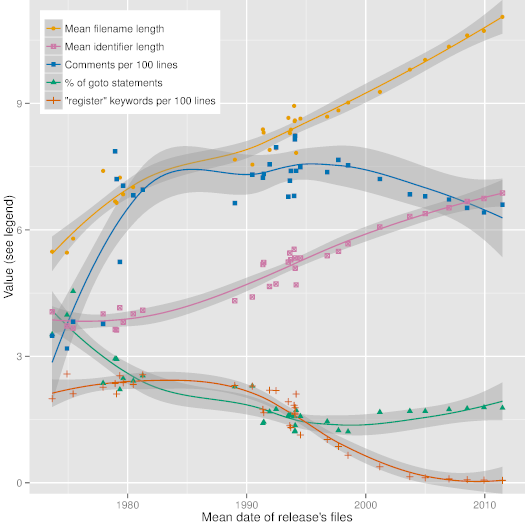
|
||||
|
||||
Figure 3: Code style evolution along Unix releases.
|
||||
|
||||
Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
|
||||
Figure [3][30] 描述了一些有趣的代码统计,根据 36 个主要 Unix 发行版,验证了代码风格和编程语言的使用在很长的时间尺度上的进化。这种进化是软硬件技术的需求和支持驱动的,软件构筑理论,甚至社会力量。图片中的数据已经计算了在一个所给发行版中出现的文件的平均时间。正如可以从中看到,在过去的 40 年中,验证器和文件名字的长度已经稳定从 4 到 6 个字符增长到 7 到 11 个字符。我们也可以看到在评论数量的少量稳定增加,和 *goto* 表达的使用量减少,同时 *register* 这个类型修改器的消失。
|
||||
|
||||
### 5 Further Work ###
|
||||
### 5 未来的工作 ###
|
||||
|
||||
Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
|
||||
可以做很多事情去提高仓库的正确性和有效性。创建进程作为源代码开源了,通过 GitHub 的拉取请求,可以很容易地贡献更多代码和修复。最有用的社区贡献会使得导入的快照文件的覆盖增长,这曾经是隶属于一个具体的作者。现在,大约 90,000 个文件(在 160,000 总量之外)被指定了作者,根据一个默认的规则。类似地,大约有 250 个作者(最初 FreeBSD 那些)是验证器确认的。两个都列在了 build 仓库无配对的目录里,也欢迎贡献数据。进一步,BSD SCCS 和 FreeBSD CVS 的提交,共享相同的作者和时间戳,这些可以结合成一个单独的 Git 提交。导入 SCCS 文件提交的支持会被添加进来,为了引入仓库对应的元数据。最后,最重要的,开源系统的更多分支会添加进来,比如 NetBSD OpenBSD, DragonFlyBSD 和 *illumos*。理想地,其他重要的历史上的 Unix 发行版,它们的版权拥有者,如 System III, System V, NeXTSTEP 和 SunOS,也会在一个协议下释出他们的系统,允许他们的合作伙伴使用仓库用于研究。
|
||||
|
||||
#### Acknowledgements ####
|
||||
### 鸣谢 ###
|
||||
|
||||
The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
|
||||
本人感谢很多付出努力的人们。 Brian W. Kernighan, Doug McIlroy 和 Arnold D. Robbins 帮助 Bell 实验室开发了登录验证器。 Clem Cole, Era Erikson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze 和 Anatole Shaw 开发了 BSD 的登录验证器。BSD SCCS 导入了 H. Merijn Brand 和 Jonathan Gray 的开发工作的代码。
|
||||
|
||||
This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
|
||||
这次研究通过 National Strategic Reference Framework (NSRF) 的 Operational Program " Education and Lifelong Learning" - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform,由 European Union ( European Social Fund - ESF) 和 Greek national funds 出资赞助。
|
||||
|
||||
### References ###
|
||||
### 引用 ###
|
||||
|
||||
[[1]][31]
|
||||
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
|
||||
@ -143,7 +142,7 @@ This research has been co-financed by the European Union (European Social Fund -
|
||||
|
||||
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Loading…
Reference in New Issue
Block a user