mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
125175bc57
published
sources
talk
tech
20180128 Get started with Org mode without Emacs.md20180926 HTTP- Brief History of HTTP.md20190217 How to Change User Password in Ubuntu -Beginner-s Tutorial.md20190218 SPEED TEST- x86 vs. ARM for Web Crawling in Python.md20190219 3 tools for viewing files at the command line.md20190219 5 Good Open Source Speech Recognition-Speech-to-Text Systems.md20190219 How to List Installed Packages on Ubuntu and Debian -Quick Tip.md20190219 Logical - in Bash.md
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhs852)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10552-1.html)
|
||||
[#]: subject: (How To Install And Use PuTTY On Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
@ -12,7 +12,7 @@
|
||||
|
||||

|
||||
|
||||
PuTTY 是一个免费、开源且支持包括 SSH、Telnet 和 Rlogin 在内的多种协议的 GUI 客户端。一般来说,Windows 管理员们会把 PuTTY 当成 SSH 或 Telnet 客户端来在本地 Windows 系统和远程 Linux 服务器之间建立连接。不过,PuTTY 可不是 Windows 的独占软件。它在 Linux 用户之中也是很流行的。本篇文章将会告诉你如何在 Linux 中安装并使用 PuTTY。
|
||||
PuTTY 是一个自由开源且支持包括 SSH、Telnet 和 Rlogin 在内的多种协议的 GUI 客户端。一般来说,Windows 管理员们会把 PuTTY 当成 SSH 或 Telnet 客户端来在本地 Windows 系统和远程 Linux 服务器之间建立连接。不过,PuTTY 可不是 Windows 的独占软件。它在 Linux 用户之中也是很流行的。本篇文章将会告诉你如何在 Linux 中安装并使用 PuTTY。
|
||||
|
||||
### 在 Linux 中安装 PuTTY
|
||||
|
||||
@ -60,11 +60,11 @@ PuTTY 的默认界面长这个样子:
|
||||
|
||||
### 使用 PuTTY 访问远程 Linux 服务器
|
||||
|
||||
请在左侧面板点击 **会话** 选项卡,输入远程主机名(或 IP 地址)。然后,请选择连接类型(比如 Telnet、Rlogin 以及 SSH 等)。根据你选择的连接类型,PuTTY 会自动选择对应连接类型的默认端口号(比如 SSH 是 22、Telnet 是 23),如果你修改了默认端口号,别忘了手动把它输入到 **端口** 里。在这里,我用 SSH 连接到远程主机。在输入所有信息后,请点击 **打开**。
|
||||
请在左侧面板点击 “Session” 选项卡,输入远程主机名(或 IP 地址)。然后,请选择连接类型(比如 Telnet、Rlogin 以及 SSH 等)。根据你选择的连接类型,PuTTY 会自动选择对应连接类型的默认端口号(比如 SSH 是 22、Telnet 是 23),如果你修改了默认端口号,别忘了手动把它输入到 “Port” 里。在这里,我用 SSH 连接到远程主机。在输入所有信息后,请点击 “Open”。
|
||||
|
||||
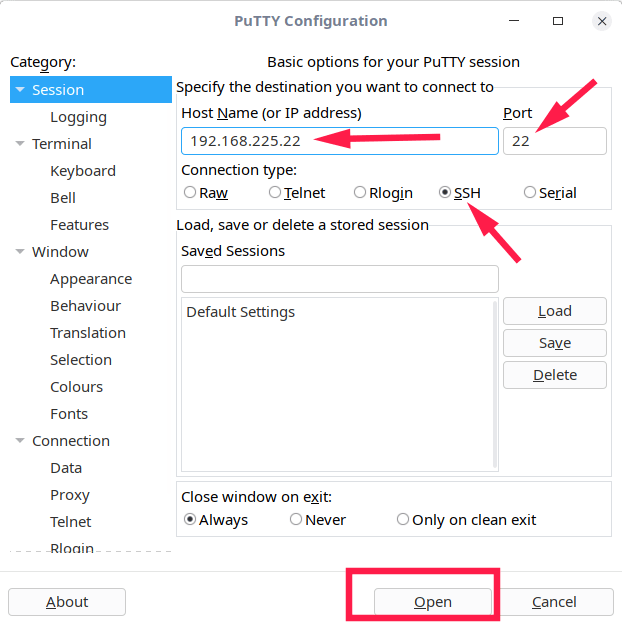
|
||||
|
||||
如果这是你首次连接到这个远程主机,PuTTY 会显示一个安全警告,问你是否信任你连接到的远程主机。点击 **接受** 即可将远程主机的密钥加入 PuTTY 的储存当中:
|
||||
如果这是你首次连接到这个远程主机,PuTTY 会显示一个安全警告,问你是否信任你连接到的远程主机。点击 “Accept” 即可将远程主机的密钥加入 PuTTY 的缓存当中:
|
||||
|
||||
![PuTTY 安全警告][2]
|
||||
|
||||
@ -74,63 +74,60 @@ PuTTY 的默认界面长这个样子:
|
||||
|
||||
#### 使用密钥验证访问远程主机
|
||||
|
||||
一些 Linux 管理员可能在服务器上配置了密钥认证。举个例子,在用 PuTTY 访问 AMS instances 的时候,你需要指定密钥文件的位置。PuTTY 可以使用它自己的格式(**.ppk** 文件)来进行公钥验证。
|
||||
一些 Linux 管理员可能在服务器上配置了密钥认证。举个例子,在用 PuTTY 访问 AMS 实例的时候,你需要指定密钥文件的位置。PuTTY 可以使用它自己的格式(`.ppk` 文件)来进行公钥验证。
|
||||
|
||||
首先输入主机名或 IP。之后,在 **分类** 选项卡中,展开 **连接**,再展开 **SSH**,然后选择 **认证**,之后便可选择 **.ppk** 密钥文件了。
|
||||
首先输入主机名或 IP。之后,在 “Category” 选项卡中,展开 “Connection”,再展开 “SSH”,然后选择 “Auth”,之后便可选择 `.ppk` 密钥文件了。
|
||||
|
||||
![][3]
|
||||
|
||||
点击接受来关闭安全提示。然后,输入远程主机的密码片段(如果密钥被密码片段保护)来建立连接。
|
||||
点击 “Accept” 来关闭安全提示。然后,输入远程主机的密码(如果密钥被密码保护)来建立连接。
|
||||
|
||||
#### 保存 PuTTY 会话
|
||||
|
||||
有些时候,你可能需要多次连接到同一个远程主机,你可以保存这些会话并在之后不输入信息访问他们。
|
||||
|
||||
请输入主机名(或 IP 地址),并提供一个会话名称,然后点击 **保存**。如果你有密钥文件,请确保你在点击保存按钮之前指定它们。
|
||||
请输入主机名(或 IP 地址),并提供一个会话名称,然后点击 “Save”。如果你有密钥文件,请确保你在点击 “Save” 按钮之前指定它们。
|
||||
|
||||
![][4]
|
||||
|
||||
现在,你可以通过选择 **已保存的会话**,然后点击 **Load**,再点击 **打开** 来启动连接。
|
||||
现在,你可以通过选择 “Saved sessions”,然后点击 “Load”,再点击 “Open” 来启动连接。
|
||||
|
||||
#### 使用 <ruby>pscp<rt>PuTTY Secure Copy Client</rt></ruby> 来将文件传输到远程主机中
|
||||
#### 使用 PuTTY 安全复制客户端(pscp)来将文件传输到远程主机中
|
||||
|
||||
通常来说,Linux 用户和管理员会使用 **scp** 这个命令行工具来从本地往远程主机传输文件。不过 PuTTY 给我们提供了一个叫做 <ruby>PuTTY 安全拷贝客户端<rt>PuTTY Secure Copy Client</rt></ruby>(简写为 **PSCP**)的工具来干这个事情。如果你的本地主机运行的是 Windows,你可能需要这个工具。PSCP 在 Windows 和 Linux 下都是可用的。
|
||||
通常来说,Linux 用户和管理员会使用 `scp` 这个命令行工具来从本地往远程主机传输文件。不过 PuTTY 给我们提供了一个叫做 <ruby>PuTTY 安全复制客户端<rt>PuTTY Secure Copy Client</rt></ruby>(简写为 `pscp`)的工具来干这个事情。如果你的本地主机运行的是 Windows,你可能需要这个工具。PSCP 在 Windows 和 Linux 下都是可用的。
|
||||
|
||||
使用这个命令来将 **file.txt** 从本地的 Arch Linux 拷贝到远程的 Ubuntu 上:
|
||||
使用这个命令来将 `file.txt` 从本地的 Arch Linux 拷贝到远程的 Ubuntu 上:
|
||||
|
||||
```shell
|
||||
pscp -i test.ppk file.txt sk@192.168.225.22:/home/sk/
|
||||
```
|
||||
|
||||
让我们来拆分这个命令:
|
||||
让我们来分析这个命令:
|
||||
|
||||
* **-i test.ppk** : 访问远程主机的密钥文件;
|
||||
* **file.txt** : 要拷贝到远程主机的文件;
|
||||
* **sk@192.168.225.22** : 远程主机的用户名与 IP;
|
||||
* **/home/sk/** : 目标路径。
|
||||
* `-i test.ppk`:访问远程主机所用的密钥文件;
|
||||
* `file.txt`:要拷贝到远程主机的文件;
|
||||
* `sk@192.168.225.22`:远程主机的用户名与 IP;
|
||||
* `/home/sk/`:目标路径。
|
||||
|
||||
|
||||
|
||||
要拷贝一个目录,请使用 <ruby>**-r**<rt>Recursive</rt></ruby> 参数:
|
||||
要拷贝一个目录,请使用 `-r`(<ruby>递归<rt>Recursive</rt></ruby>)参数:
|
||||
|
||||
```shell
|
||||
pscp -i test.ppk -r dir/ sk@192.168.225.22:/home/sk/
|
||||
```
|
||||
|
||||
要使用 pscp 传输文件,请执行以下命令:
|
||||
要使用 `pscp` 传输文件,请执行以下命令:
|
||||
|
||||
```shell
|
||||
pscp -i test.ppk c:\documents\file.txt.txt sk@192.168.225.22:/home/sk/
|
||||
```
|
||||
|
||||
你现在应该了解了 PuTTY 是什么,知道了如何安装它和如何使用它。同时,你也学习到了如何使用 pscp 程序在本地和远程主机上传输文件。
|
||||
你现在应该了解了 PuTTY 是什么,知道了如何安装它和如何使用它。同时,你也学习到了如何使用 `pscp` 程序在本地和远程主机上传输文件。
|
||||
|
||||
以上便是所有了,希望这篇文章对你有帮助。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/
|
||||
@ -138,7 +135,7 @@ via: https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zhs852](https://github.com/zhs852)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How our non-profit works openly to make education accessible)
|
||||
[#]: via: (https://opensource.com/open-organization/19/2/building-curriculahub)
|
||||
[#]: author: (Tanner Johnson https://opensource.com/users/johnsontanner3)
|
||||
|
||||
How our non-profit works openly to make education accessible
|
||||
======
|
||||
To build an open access education hub, our team practiced the same open methods we teach our students.
|
||||

|
||||
|
||||
I'm lucky to work with a team of impressive students at Duke University who are leaders in their classrooms and beyond. As members of [CSbyUs][1], a non-profit and student-run organization based at Duke, we connect university students to middle school students, mostly from [title I schools][2] across North Carolina's Research Triangle Park. Our mission is to fuel future change agents from under-resourced learning environments by fostering critical technology skills for thriving in the digital age.
|
||||
|
||||
The CSbyUs Tech R&D team (TRD for short) recently set an ambitious goal to build and deploy a powerful web application over the course of one fall semester. Our team of six knew we had to do something about our workflow to ship a product by winter break. In our middle school classrooms, we teach our learners to use agile methodologies and design thinking to create mobile applications. On the TRD team, we realized we needed to practice what we preach in those classrooms to ship a quality product by semester's end.
|
||||
|
||||
This is the story of how and why we utilized the principles we teach our students in order to deploy technology that will scale our mission and make our teaching resources open and accessible.
|
||||
|
||||
### Setting the scene
|
||||
|
||||
For the past two years, CSbyUs has operated "on the ground," connecting Duke undergraduates to Durham middle schools via after-school programming. After teaching and evaluating several iterations of our unique, student-centered mobile app development curriculum, we saw promising results. Our middle schoolers were creating functional mobile apps, connecting to their mentors, and leaving the class more confident in their computer science skills. Naturally, we wondered how to expand our programming.
|
||||
|
||||
We knew we should take our own advice and lean into web-based technologies to share our work, but we weren't immediately sure what problem we needed to solve. Ultimately, we decided to create a web app that serves as a centralized hub for open source and open access digital education curricula. "CurriculaHub" (name inspired by GitHub) would be the defining pillar of CSbyUs's new website, where educators could share and adapt resources.
|
||||
|
||||
But the vision and implementation didn't happen overnight.
|
||||
|
||||
Given our sense of urgency and the potential of "CurriculaHub," we wanted to start this project with a well defined plan. The stakes were (and are) high, so planning, albeit occasionally tedious, was critical to our success. Like the curriculum we teach, we scaffolded our workflow process with design thinking and agile methodology, two critical 21st century frameworks we often fail to practice in higher ed.
|
||||
|
||||
What follows is a step-wise explanation of our design thinking process, starting from inspiration and ending in a shipped prototype.
|
||||
|
||||
```
|
||||
This is the story of how and why we utilized the principles we teach our students in order to deploy technology that will scale our mission and make our teaching resources open and accessible.
|
||||
```
|
||||
|
||||
### Our Process
|
||||
|
||||
#### **Step 1: Pre-Work**
|
||||
|
||||
In order to understand the why to our what, you have to know who our team is.
|
||||
|
||||
The members of this team are busy. All of us contribute to CSbyUs beyond our TRD-related responsibilities. As an organization with lofty goals beyond creating a web-based platform, we have to reconcile our "on the ground" commitments (i.e., curriculum curation, research and evaluation, mentorship training and practice, presentations at conferences, etc.) with our "in the cloud" technological goals.
|
||||
|
||||
In addition to balancing time across our organization, we have to be flexible in the ways we communicate. As a remote member of the team, I'm writing this post from Spain, but the rest of our team is based in North Carolina, adding collaboration challenges.
|
||||
|
||||
Before diving into development (or even problem identification), we knew we had to set some clear expectations for how we'd operate as a team. We took a note from our curriculum team's book and started with some [rules of engagement][3]. This is actually [a well-documented approach][4] to setting up a team's [social contract][5] used by teams across the tech space. During a summer internship at IBM, I remember pre-project meetings where my manager and team spent more than an hour clarifying principles of interaction. Whenever we faced uncertainty in our team operations, we'd pull out the rules of engagement and clear things up almost immediately. (An aside: I've found this strategy to be wildly effective not only in my teams, but in all relationships).
|
||||
|
||||
Considering the remote nature of our team, one of our favorite tools is Slack. We use it for almost everything. We can't have sticky-note brainstorms, so we create Slack brainstorm threads. In fact, that's exactly what we did to generate our rules of engagement. One [open source principle we take to heart is transparency][6]; Slack allows us to archive and openly share our thought processes and decision-making steps with the rest of our team.
|
||||
|
||||
#### **Step 2: Empathy Research**
|
||||
|
||||
We're all here for unique reasons, but we find a common intersection: the desire to broaden equity in access to quality digital era education.
|
||||
|
||||
Each member of our team has been lucky enough to study at Duke. We know how it feels to have limitless opportunities and the support of talented peers and renowned professors. But we're mindful that this isn't normal. Across the country and beyond, these opportunities are few and far between. Where they do exist, they're confined within the guarded walls of higher institutes of learning or come with a lofty price tag.
|
||||
|
||||
While our team members' common desire to broaden access is clear, we work hard to root our decisions in research. So our team begins each semester [reviewing][7] [research][8] that justifies our existence. TRD works with CRD (curriculum research and development) and TT (teaching team), our two other CSbyUs sub-teams, to discuss current trends in digital education access, their systemic roots, and novel approaches to broaden access and make materials relevant to learners. We not only perform research collaboratively at the beginning of the semester but also implement weekly stand-up research meetings with the sub-teams. During these, CRD often presents new findings we've gleaned from interviewing current teachers and digging into the current state of access in our local community. They are our constant source of data-driven, empathy-fueling research.
|
||||
|
||||
Through this type of empathy-based research, we have found that educators interested in student-centered teaching and digital era education lack a centralized space for proven and adaptable curricula and lesson plans. The bureaucracy and rigid structures that shape classroom learning in the United States makes reshaping curricula around the personal needs of students daunting and seemingly impossible. As students, educators, and technologists, we wondered how we might unleash the creativity and agency of others by sharing our own resources and creating an online ecosystem of support.
|
||||
|
||||
#### **Step 3: Defining the Problem**
|
||||
|
||||
We wanted to avoid [scope creep][9] caused by a poorly defined mission and vision (something that happens too often in some organizations). We needed structures to define our goals and maintain clarity in scope. Before imagining our application features, we knew we'd have to start with defining our north star. We would generate a clear problem statement to which we could refer throughout development.
|
||||
|
||||
Before imagining our application features, we knew we'd have to start with defining our north star.
|
||||
|
||||
This is common practice for us. Before committing to new programming, new partnerships, or new changes, the CSbyUs team always refers back to our mission and vision and asks, "Does this make sense?" (in fact, we post our mission and vision to the top of every meeting minutes document). If it fits and we have capacity to pursue it, we go for it. And if we don't, then we don't. In the case of a "no," we are always sure to document what and why because, as engineers know, [detailed logs are almost always a good decision][10]. TRD gleaned that big-picture wisdom and implemented a group-defined problem statement to guide our sub-team mission and future development decisions.
|
||||
|
||||
To formulate a single, succinct problem statement, we each began by posting our own takes on the problem. Then, during one of our weekly [30-minute-no-more-no-less stand-up meetings][11], we identified commonalities and differences, ultimately [merging all our ideas into one][12]. Boiled down, we identified that there exist massive barriers for educators, parents, and students to share, modify, and discuss open source and accessible curricula. And of course, our mission would be to break down those barriers with user-centered technology. This "north star" lives as a highly visible document in our Google Drive, which has influenced our feature prioritization and future directions.
|
||||
|
||||
#### **Step 4: Ideating a Solution**
|
||||
|
||||
With our problem defined and our rules of engagement established, we were ready to imagine a solution.
|
||||
|
||||
We believe that effective structures can ensure meritocracy and community. Sometimes, certain personalities dominate team decision-making and leave little space for collaborative input. To avoid that pitfall and maximize our equality of voice, we tend to use "offline" individual brainstorms and merge collective ideas online. It's the same process we used to create our rules of engagement and problem statement. In the case of ideating a solution, we started with "offline" brainstorms of three [S.M.A.R.T. goals][13]. Those goals would be ones we could achieve as a software development team (specifically because the CRD and TT teams offer different skill sets) and address our problem statement. Finally, we wrote these goals in a meeting minutes document, clustering common goals and ultimately identifying themes that describe our application features. In the end, we identified three: support, feedback, and open source curricula.
|
||||
|
||||
From here, we divided ourselves into sub-teams, repeating the goal-setting process with those teams—but in a way that was specific to our features. And if it's not obvious by now, we realized a web-based platform would be the most optimal and scalable solution for supporting students, educators, and parents by providing a hub for sharing and adapting proven curricula.
|
||||
|
||||
To work efficiently, we needed to be adaptive, reinforcing structures that worked and eliminating those that didn't. For example, we put a lot of effort in crafting meeting agendas. We strive to include only those subjects we must discuss in-person and table everything else for offline discussions on Slack or individually organized calls. We practice this in real time, too. During our regular meetings on Google Hangouts, if someone brings up a topic that isn't highly relevant or urgent, the current stand-up lead (a role that rotates weekly) "parking lots" it until the end of the meeting. If we have space at the end, we pull from the parking lot, and if not, we reserve that discussion for a Slack thread.
|
||||
|
||||
This prioritization structure has led to massive gains in meeting efficiency and a focus on progress updates, shared technical hurdle discussions, collective decision-making, and assigning actionable tasks (the next-steps a person has committed to taking, documented with their name attached for everyone to view).
|
||||
|
||||
#### **Step 5: Prototyping**
|
||||
|
||||
This is where the fun starts.
|
||||
|
||||
Our team was only able to unite new people with highly varied experience through the power of open principles and methodologies.
|
||||
|
||||
Given our requirements—like an interactive user experience, the ability to collaborate on blogs and curricula, and the ability to receive feedback from our users—we began identifying the best technologies. Ultimately, we decided to build our web app with a ReactJS frontend and a Ruby on Rails backend. We chose these due to the extensive documentation and active community for both, and the well-maintained libraries that bridge the relationship between the two (e.g., react-on-rails). Since we chose Rails for our backend, it was obvious from the start that we'd work within a Model-View-Controller framework.
|
||||
|
||||
Most of us didn't have previous experience with web development, neither on the frontend nor the backend. So, getting up and running with either technology independently presented a steep learning curve, and gluing the two together only steepened it. To centralize our work, we use an open-access GitHub repository. Given our relatively novice experience in web development, our success hinged on extremely efficient and open collaborations.
|
||||
|
||||
And to explain that, we need to revisit the idea of structures. Some of ours include peer code reviews—where we can exchange best-practices and reusable solutions, maintaining up-to-date tech and user documentation so we can look back and understand design decisions—and (my personal favorite) our questions bot on Slack, which gently reminds us to post and answer questions in a separate Slack #questions channel.
|
||||
|
||||
We've also dabbled with other strategies, like instructional videos for generating basic React components and rendering them in Rails Views. I tried this and in my first video, [I covered a basic introduction to our repository structure][14] and best practices for generating React components. While this proved useful, our team has since realized the wealth of online resources that document various implementations of these technologies robustly. Also, we simply haven't had enough time (but we might revisit them in the future—stay tuned).
|
||||
|
||||
We're also excited about our cloud-based implementation. We use Heroku to host our application and manage data storage. In next iterations, we plan to both expand upon our current features and configure a continuous iteration/continuous development pipeline using services like Jenkins integrated with GitHub.
|
||||
|
||||
#### **Step 6: Testing**
|
||||
|
||||
Since we've [just deployed][1], we are now in a testing stage. Our goals are to collect user feedback across our feature domains and our application experience as a whole, especially as they interact with our specific audiences. Given our original constraints (namely, time and people power), this iteration is the first of many to come. For example, future iterations will allow for individual users to register accounts and post external curricula directly on our site without going through the extra steps of email. We want to scale and maximize our efficiency, and that's part of the recipe we'll deploy in future iterations. As for user testing: We collect user feedback via our contact form, via informal testing within our team, and via structured focus groups. [We welcome your constructive feedback and collaboration][15].
|
||||
|
||||
Our team was only able to unite new people with highly varied experience through the power of open principles and methodologies. Luckily enough, each one I described in this post is adaptable to virtually every team.
|
||||
|
||||
Regardless of whether you work—on a software development team, in a classroom, or, heck, [even in your family][16]—principles like transparency and community are almost always the best foundation for a successful organization.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/2/building-curriculahub
|
||||
|
||||
作者:[Tanner Johnson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/johnsontanner3
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://csbyus.org
|
||||
[2]: https://www2.ed.gov/programs/titleiparta/index.html
|
||||
[3]: https://docs.google.com/document/d/1tqV6B6Uk-QB7Psj1rX9tfCyW3E64_v6xDlhRZ-L2rq0/edit
|
||||
[4]: https://www.atlassian.com/team-playbook/plays/rules-of-engagement
|
||||
[5]: https://openpracticelibrary.com/practice/social-contract/
|
||||
[6]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[7]: https://services.google.com/fh/files/misc/images-of-computer-science-report.pdf
|
||||
[8]: https://drive.google.com/file/d/1_iK0ZRAXVwGX9owtjUUjNz3_2kbyYZ79/view?usp=sharing
|
||||
[9]: https://www.pmi.org/learning/library/top-five-causes-scope-creep-6675
|
||||
[10]: https://www.codeproject.com/Articles/42354/The-Art-of-Logging#what
|
||||
[11]: https://opensource.com/open-organization/16/2/6-steps-running-perfect-30-minute-meeting
|
||||
[12]: https://docs.google.com/document/d/1wdPRvFhMKPCrwOG2CGp7kP4rKOXrJKI77CgjMfaaXnk/edit?usp=sharing
|
||||
[13]: https://www.projectmanager.com/blog/how-to-create-smart-goals
|
||||
[14]: https://www.youtube.com/watch?v=52kvV0plW1E
|
||||
[15]: http://csbyus.org/
|
||||
[16]: https://opensource.com/open-organization/15/11/what-our-families-teach-us-about-organizational-life
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -62,7 +62,7 @@ via: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
286
sources/tech/20180926 HTTP- Brief History of HTTP.md
Normal file
286
sources/tech/20180926 HTTP- Brief History of HTTP.md
Normal file
@ -0,0 +1,286 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HTTP: Brief History of HTTP)
|
||||
[#]: via: (https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol)
|
||||
[#]: author: (Ilya Grigorik https://www.igvita.com/)
|
||||
|
||||
HTTP: Brief History of HTTP
|
||||
======
|
||||
|
||||
### Introduction
|
||||
|
||||
The Hypertext Transfer Protocol (HTTP) is one of the most ubiquitous and widely adopted application protocols on the Internet: it is the common language between clients and servers, enabling the modern web. From its simple beginnings as a single keyword and document path, it has become the protocol of choice not just for browsers, but for virtually every Internet-connected software and hardware application.
|
||||
|
||||
In this chapter, we will take a brief historical tour of the evolution of the HTTP protocol. A full discussion of the varying HTTP semantics is outside the scope of this book, but an understanding of the key design changes of HTTP, and the motivations behind each, will give us the necessary background for our discussions on HTTP performance, especially in the context of the many upcoming improvements in HTTP/2.
|
||||
|
||||
### §HTTP 0.9: The One-Line Protocol
|
||||
|
||||
The original HTTP proposal by Tim Berners-Lee was designed with simplicity in mind as to help with the adoption of his other nascent idea: the World Wide Web. The strategy appears to have worked: aspiring protocol designers, take note.
|
||||
|
||||
In 1991, Berners-Lee outlined the motivation for the new protocol and listed several high-level design goals: file transfer functionality, ability to request an index search of a hypertext archive, format negotiation, and an ability to refer the client to another server. To prove the theory in action, a simple prototype was built, which implemented a small subset of the proposed functionality:
|
||||
|
||||
* Client request is a single ASCII character string.
|
||||
|
||||
* Client request is terminated by a carriage return (CRLF).
|
||||
|
||||
* Server response is an ASCII character stream.
|
||||
|
||||
|
||||
|
||||
* Server response is a hypertext markup language (HTML).
|
||||
|
||||
* Connection is terminated after the document transfer is complete.
|
||||
|
||||
|
||||
|
||||
|
||||
However, even that sounds a lot more complicated than it really is. What these rules enable is an extremely simple, Telnet-friendly protocol, which some web servers support to this very day:
|
||||
|
||||
```
|
||||
$> telnet google.com 80
|
||||
|
||||
Connected to 74.125.xxx.xxx
|
||||
|
||||
GET /about/
|
||||
|
||||
(hypertext response)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
The request consists of a single line: `GET` method and the path of the requested document. The response is a single hypertext document—no headers or any other metadata, just the HTML. It really couldn’t get any simpler. Further, since the previous interaction is a subset of the intended protocol, it unofficially acquired the HTTP 0.9 label. The rest, as they say, is history.
|
||||
|
||||
From these humble beginnings in 1991, HTTP took on a life of its own and evolved rapidly over the coming years. Let us quickly recap the features of HTTP 0.9:
|
||||
|
||||
* Client-server, request-response protocol.
|
||||
|
||||
* ASCII protocol, running over a TCP/IP link.
|
||||
|
||||
* Designed to transfer hypertext documents (HTML).
|
||||
|
||||
* The connection between server and client is closed after every request.
|
||||
|
||||
|
||||
```
|
||||
Popular web servers, such as Apache and Nginx, still support the HTTP 0.9 protocol—in part, because there is not much to it! If you are curious, open up a Telnet session and try accessing google.com, or your own favorite site, via HTTP 0.9 and inspect the behavior and the limitations of this early protocol.
|
||||
```
|
||||
|
||||
### §HTTP/1.0: Rapid Growth and Informational RFC
|
||||
|
||||
The period from 1991 to 1995 is one of rapid coevolution of the HTML specification, a new breed of software known as a "web browser," and the emergence and quick growth of the consumer-oriented public Internet infrastructure.
|
||||
|
||||
```
|
||||
##### §The Perfect Storm: Internet Boom of the Early 1990s
|
||||
|
||||
Building on Tim Berner-Lee’s initial browser prototype, a team at the National Center of Supercomputing Applications (NCSA) decided to implement their own version. With that, the first popular browser was born: NCSA Mosaic. One of the programmers on the NCSA team, Marc Andreessen, partnered with Jim Clark to found Mosaic Communications in October 1994. The company was later renamed Netscape, and it shipped Netscape Navigator 1.0 in December 1994. By this point, it was already clear that the World Wide Web was bound to be much more than just an academic curiosity.
|
||||
|
||||
In fact, that same year the first World Wide Web conference was organized in Geneva, Switzerland, which led to the creation of the World Wide Web Consortium (W3C) to help guide the evolution of HTML. Similarly, a parallel HTTP Working Group (HTTP-WG) was established within the IETF to focus on improving the HTTP protocol. Both of these groups continue to be instrumental to the evolution of the Web.
|
||||
|
||||
Finally, to create the perfect storm, CompuServe, AOL, and Prodigy began providing dial-up Internet access to the public within the same 1994–1995 time frame. Riding on this wave of rapid adoption, Netscape made history with a wildly successful IPO on August 9, 1995—the Internet boom had arrived, and everyone wanted a piece of it!
|
||||
```
|
||||
|
||||
The growing list of desired capabilities of the nascent Web and their use cases on the public Web quickly exposed many of the fundamental limitations of HTTP 0.9: we needed a protocol that could serve more than just hypertext documents, provide richer metadata about the request and the response, enable content negotiation, and more. In turn, the nascent community of web developers responded by producing a large number of experimental HTTP server and client implementations through an ad hoc process: implement, deploy, and see if other people adopt it.
|
||||
|
||||
From this period of rapid experimentation, a set of best practices and common patterns began to emerge, and in May 1996 the HTTP Working Group (HTTP-WG) published RFC 1945, which documented the "common usage" of the many HTTP/1.0 implementations found in the wild. Note that this was only an informational RFC: HTTP/1.0 as we know it is not a formal specification or an Internet standard!
|
||||
|
||||
Having said that, an example HTTP/1.0 request should look very familiar:
|
||||
|
||||
```
|
||||
$> telnet website.org 80
|
||||
|
||||
Connected to xxx.xxx.xxx.xxx
|
||||
|
||||
GET /rfc/rfc1945.txt HTTP/1.0
|
||||
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
|
||||
Accept: */*
|
||||
|
||||
HTTP/1.0 200 OK
|
||||
Content-Type: text/plain
|
||||
Content-Length: 137582
|
||||
Expires: Thu, 01 Dec 1997 16:00:00 GMT
|
||||
Last-Modified: Wed, 1 May 1996 12:45:26 GMT
|
||||
Server: Apache 0.84
|
||||
|
||||
(plain-text response)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
1. Request line with HTTP version number, followed by request headers
|
||||
|
||||
2. Response status, followed by response headers
|
||||
|
||||
|
||||
|
||||
|
||||
The preceding exchange is not an exhaustive list of HTTP/1.0 capabilities, but it does illustrate some of the key protocol changes:
|
||||
|
||||
* Request may consist of multiple newline separated header fields.
|
||||
|
||||
* Response object is prefixed with a response status line.
|
||||
|
||||
* Response object has its own set of newline separated header fields.
|
||||
|
||||
* Response object is not limited to hypertext.
|
||||
|
||||
* The connection between server and client is closed after every request.
|
||||
|
||||
|
||||
|
||||
|
||||
Both the request and response headers were kept as ASCII encoded, but the response object itself could be of any type: an HTML file, a plain text file, an image, or any other content type. Hence, the "hypertext transfer" part of HTTP became a misnomer not long after its introduction. In reality, HTTP has quickly evolved to become a hypermedia transport, but the original name stuck.
|
||||
|
||||
In addition to media type negotiation, the RFC also documented a number of other commonly implemented capabilities: content encoding, character set support, multi-part types, authorization, caching, proxy behaviors, date formats, and more.
|
||||
|
||||
```
|
||||
Almost every server on the Web today can and will still speak HTTP/1.0. Except that, by now, you should know better! Requiring a new TCP connection per request imposes a significant performance penalty on HTTP/1.0; see [Three-Way Handshake][1], followed by [Slow-Start][2].
|
||||
```
|
||||
|
||||
### §HTTP/1.1: Internet Standard
|
||||
|
||||
The work on turning HTTP into an official IETF Internet standard proceeded in parallel with the documentation effort around HTTP/1.0 and happened over a period of roughly four years: between 1995 and 1999. In fact, the first official HTTP/1.1 standard is defined in RFC 2068, which was officially released in January 1997, roughly six months after the publication of HTTP/1.0. Then, two and a half years later, in June of 1999, a number of improvements and updates were incorporated into the standard and were released as RFC 2616.
|
||||
|
||||
The HTTP/1.1 standard resolved a lot of the protocol ambiguities found in earlier versions and introduced a number of critical performance optimizations: keepalive connections, chunked encoding transfers, byte-range requests, additional caching mechanisms, transfer encodings, and request pipelining.
|
||||
|
||||
With these capabilities in place, we can now inspect a typical HTTP/1.1 session as performed by any modern HTTP browser and client:
|
||||
|
||||
```
|
||||
$> telnet website.org 80
|
||||
Connected to xxx.xxx.xxx.xxx
|
||||
|
||||
GET /index.html HTTP/1.1
|
||||
Host: website.org
|
||||
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
|
||||
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
|
||||
Accept-Encoding: gzip,deflate,sdch
|
||||
Accept-Language: en-US,en;q=0.8
|
||||
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
|
||||
Cookie: __qca=P0-800083390... (snip)
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Server: nginx/1.0.11
|
||||
Connection: keep-alive
|
||||
Content-Type: text/html; charset=utf-8
|
||||
Via: HTTP/1.1 GWA
|
||||
Date: Wed, 25 Jul 2012 20:23:35 GMT
|
||||
Expires: Wed, 25 Jul 2012 20:23:35 GMT
|
||||
Cache-Control: max-age=0, no-cache
|
||||
Transfer-Encoding: chunked
|
||||
|
||||
100
|
||||
<!doctype html>
|
||||
(snip)
|
||||
|
||||
100
|
||||
(snip)
|
||||
|
||||
0
|
||||
|
||||
GET /favicon.ico HTTP/1.1
|
||||
Host: www.website.org
|
||||
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4)... (snip)
|
||||
Accept: */*
|
||||
Referer: http://website.org/
|
||||
Connection: close
|
||||
Accept-Encoding: gzip,deflate,sdch
|
||||
Accept-Language: en-US,en;q=0.8
|
||||
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
|
||||
Cookie: __qca=P0-800083390... (snip)
|
||||
|
||||
HTTP/1.1 200 OK
|
||||
Server: nginx/1.0.11
|
||||
Content-Type: image/x-icon
|
||||
Content-Length: 3638
|
||||
Connection: close
|
||||
Last-Modified: Thu, 19 Jul 2012 17:51:44 GMT
|
||||
Cache-Control: max-age=315360000
|
||||
Accept-Ranges: bytes
|
||||
Via: HTTP/1.1 GWA
|
||||
Date: Sat, 21 Jul 2012 21:35:22 GMT
|
||||
Expires: Thu, 31 Dec 2037 23:55:55 GMT
|
||||
Etag: W/PSA-GAu26oXbDi
|
||||
|
||||
(icon data)
|
||||
(connection closed)
|
||||
```
|
||||
|
||||
1. Request for HTML file, with encoding, charset, and cookie metadata
|
||||
|
||||
2. Chunked response for original HTML request
|
||||
|
||||
3. Number of octets in the chunk expressed as an ASCII hexadecimal number (256 bytes)
|
||||
|
||||
4. End of chunked stream response
|
||||
|
||||
5. Request for an icon file made on same TCP connection
|
||||
|
||||
6. Inform server that the connection will not be reused
|
||||
|
||||
7. Icon response, followed by connection close
|
||||
|
||||
|
||||
|
||||
|
||||
Phew, there is a lot going on in there! The first and most obvious difference is that we have two object requests, one for an HTML page and one for an image, both delivered over a single connection. This is connection keepalive in action, which allows us to reuse the existing TCP connection for multiple requests to the same host and deliver a much faster end-user experience; see [Optimizing for TCP][3].
|
||||
|
||||
To terminate the persistent connection, notice that the second client request sends an explicit `close` token to the server via the `Connection` header. Similarly, the server can notify the client of the intent to close the current TCP connection once the response is transferred. Technically, either side can terminate the TCP connection without such signal at any point, but clients and servers should provide it whenever possible to enable better connection reuse strategies on both sides.
|
||||
|
||||
```
|
||||
HTTP/1.1 changed the semantics of the HTTP protocol to use connection keepalive by default. Meaning, unless told otherwise (via `Connection: close` header), the server should keep the connection open by default.
|
||||
|
||||
However, this same functionality was also backported to HTTP/1.0 and enabled via the `Connection: Keep-Alive` header. Hence, if you are using HTTP/1.1, technically you don’t need the `Connection: Keep-Alive` header, but many clients choose to provide it nonetheless.
|
||||
```
|
||||
|
||||
Additionally, the HTTP/1.1 protocol added content, encoding, character set, and even language negotiation, transfer encoding, caching directives, client cookies, plus a dozen other capabilities that can be negotiated on each request.
|
||||
|
||||
We are not going to dwell on the semantics of every HTTP/1.1 feature. This is a subject for a dedicated book, and many great ones have been written already. Instead, the previous example serves as a good illustration of both the quick progress and evolution of HTTP, as well as the intricate and complicated dance of every client-server exchange. There is a lot going on in there!
|
||||
|
||||
```
|
||||
For a good reference on all the inner workings of the HTTP protocol, check out O’Reilly’s HTTP: The Definitive Guide by David Gourley and Brian Totty.
|
||||
```
|
||||
|
||||
### §HTTP/2: Improving Transport Performance
|
||||
|
||||
Since its publication, RFC 2616 has served as a foundation for the unprecedented growth of the Internet: billions of devices of all shapes and sizes, from desktop computers to the tiny web devices in our pockets, speak HTTP every day to deliver news, video, and millions of other web applications we have all come to depend on in our lives.
|
||||
|
||||
What began as a simple, one-line protocol for retrieving hypertext quickly evolved into a generic hypermedia transport, and now a decade later can be used to power just about any use case you can imagine. Both the ubiquity of servers that can speak the protocol and the wide availability of clients to consume it means that many applications are now designed and deployed exclusively on top of HTTP.
|
||||
|
||||
Need a protocol to control your coffee pot? RFC 2324 has you covered with the Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0)—originally an April Fools’ Day joke by IETF, and increasingly anything but a joke in our new hyper-connected world.
|
||||
|
||||
> The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. It is a generic, stateless, protocol that can be used for many tasks beyond its use for hypertext, such as name servers and distributed object management systems, through extension of its request methods, error codes and headers. A feature of HTTP is the typing and negotiation of data representation, allowing systems to be built independently of the data being transferred.
|
||||
>
|
||||
> RFC 2616: HTTP/1.1, June 1999
|
||||
|
||||
The simplicity of the HTTP protocol is what enabled its original adoption and rapid growth. In fact, it is now not unusual to find embedded devices—sensors, actuators, and coffee pots alike—using HTTP as their primary control and data protocols. But under the weight of its own success and as we increasingly continue to migrate our everyday interactions to the Web—social, email, news, and video, and increasingly our entire personal and job workspaces—it has also begun to show signs of stress. Users and web developers alike are now demanding near real-time responsiveness and protocol performance from HTTP/1.1, which it simply cannot meet without some modifications.
|
||||
|
||||
To meet these new challenges, HTTP must continue to evolve, and hence the HTTPbis working group announced a new initiative for HTTP/2 in early 2012:
|
||||
|
||||
> There is emerging implementation experience and interest in a protocol that retains the semantics of HTTP without the legacy of HTTP/1.x message framing and syntax, which have been identified as hampering performance and encouraging misuse of the underlying transport.
|
||||
>
|
||||
> The working group will produce a specification of a new expression of HTTP’s current semantics in ordered, bi-directional streams. As with HTTP/1.x, the primary target transport is TCP, but it should be possible to use other transports.
|
||||
>
|
||||
> HTTP/2 charter, January 2012
|
||||
|
||||
The primary focus of HTTP/2 is on improving transport performance and enabling both lower latency and higher throughput. The major version increment sounds like a big step, which it is and will be as far as performance is concerned, but it is important to note that none of the high-level protocol semantics are affected: all HTTP headers, values, and use cases are the same.
|
||||
|
||||
Any existing website or application can and will be delivered over HTTP/2 without modification: you do not need to modify your application markup to take advantage of HTTP/2. The HTTP servers will have to speak HTTP/2, but that should be a transparent upgrade for the majority of users. The only difference if the working group meets its goal, should be that our applications are delivered with lower latency and better utilization of the network link!
|
||||
|
||||
Having said that, let’s not get ahead of ourselves. Before we get to the new HTTP/2 protocol features, it is worth taking a step back and examining our existing deployment and performance best practices for HTTP/1.1. The HTTP/2 working group is making fast progress on the new specification, but even if the final standard was already done and ready, we would still have to support older HTTP/1.1 clients for the foreseeable future—realistically, a decade or more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hpbn.co/brief-history-of-http/#http-09-the-one-line-protocol
|
||||
|
||||
作者:[Ilya Grigorik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.igvita.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://hpbn.co/building-blocks-of-tcp/#three-way-handshake
|
||||
[2]: https://hpbn.co/building-blocks-of-tcp/#slow-start
|
||||
[3]: https://hpbn.co/building-blocks-of-tcp/#optimizing-for-tcp
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (An-DJ )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,533 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (SPEED TEST: x86 vs. ARM for Web Crawling in Python)
|
||||
[#]: via: (https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/)
|
||||
[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
|
||||
|
||||
SPEED TEST: x86 vs. ARM for Web Crawling in Python
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Can you imagine if your job was to trawl competitor websites and jot prices down by hand, again and again and again? You’d burn your whole office down by lunchtime.
|
||||
|
||||
So, little wonder web crawlers are huge these days. They can keep track of customer sentiment and trending topics, monitor job openings, real estate transactions, UFC results, all sorts of stuff.
|
||||
|
||||
For those of a certain bent, this is fascinating stuff. Which is how I found myself playing around with [Scrapy][2], an open source web crawling framework written in Python.
|
||||
|
||||
Being wary of the potential to do something catastrophic to my computer while poking with things I didn’t understand, I decided to install it on my main machine but a Raspberry Pi.
|
||||
|
||||
And wouldn’t you know it? It actually didn’t run too shabby on the little tacker. Maybe this is a good use case for an ARM server?
|
||||
|
||||
Google had no solid answer. The nearest thing I found was [this Drupal hosting drag race][3], which showed an ARM server outperforming a much more expensive x86 based account.
|
||||
|
||||
That was definitely interesting. I mean, isn’t a web server kind of like a crawler in reverse? But with one operating on a LAMP stack and the other on a Python interpreter, it’s hardly the exact same thing.
|
||||
|
||||
So what could I do? Only one thing. Get some VPS accounts and make them race each other.
|
||||
|
||||
### What’s the Deal With ARM Processors?
|
||||
|
||||
ARM is now the most popular CPU architecture in the world.
|
||||
|
||||
But it’s generally seen as something you’d opt for to save money and battery life, rather than a serious workhorse.
|
||||
|
||||
It wasn’t always that way: this CPU was designed in Cambridge, England to power the fiendishly expensive [Acorn Archimedes][4]. This was the most powerful desktop computer in the world, and by a long way too: it was multiple times the speed of the fastest 386.
|
||||
|
||||
Acorn, like Commodore and Atari, somewhat ignorantly believed that the making of a great computer company was in the making of great computers. Bill Gates had a better idea. He got DOS on as many x86 machines – of the most widely varying quality and expense – as he could.
|
||||
|
||||
Having the best user base made you the obvious platform for third party developers to write software for; having all the software support made yours the most useful computer.
|
||||
|
||||
Even Apple nearly bit the dust. All the $$$$ were in building a better x86 chip, this was the architecture that ended up being developed for serious computing.
|
||||
|
||||
That wasn’t the end for ARM though. Their chips weren’t just fast, they could run well without drawing much power or emitting much heat. That made them a preferred technology in set top boxes, PDAs, digital cameras, MP3 players, and basically anything that either used a battery or where you’d just rather avoid the noise of a large fan.
|
||||
|
||||
So it was that Acorn spun off ARM, who began an idiosyncratic business model that continues to today: ARM doesn’t actually manufacture any chips, they license their intellectual property to others who do.
|
||||
|
||||
Which is more or less how they ended up in so many phones and tablets. When Linux was ported to the architecture, the door opened to other open source technologies, which is how we can run a web crawler on these chips today.
|
||||
|
||||
#### ARM in the Server Room
|
||||
|
||||
Some big names, like [Microsoft][5] and [Cloudflare][6], have placed heavy bets on the British Bulldog for their infrastructure. But for those of us with more modest budgets, the options are fairly sparse.
|
||||
|
||||
In fact, when it comes to cheap and cheerful VPS accounts that you can stick on the credit card for a few bucks a month, for years the only option was [Scaleway][7].
|
||||
|
||||
This changed a few months ago when public cloud heavyweight [AWS][8] launched its own ARM processor: the [AWS Graviton][9].
|
||||
|
||||
I decided to grab one of each, and race them against the most similar Intel offering from the same provider.
|
||||
|
||||
### Looking Under the Hood
|
||||
|
||||
So what are we actually racing here? Let’s jump right in.
|
||||
|
||||
#### Scaleway
|
||||
|
||||
Scaleway positions itself as “designed for developers”. And you know what? I think that’s fair enough: it’s definitely been a good little sandbox for developing and prototyping.
|
||||
|
||||
The dirt simple product offering and clean, easy dashboard guides you from home page to bash shell in minutes. That makes it a strong option for small businesses, freelancers and consultants who just want to get straight into a good VPS at a great price to run some crawls.
|
||||
|
||||
The ARM account we will be using is their [ARM64-2GB][10], which costs 3 euros a month and has 4 Cavium ThunderX cores. This launched in 2014 as the first server-class ARMv8 processor, but is now looking a bit middle-aged, having been superseded by the younger, prettier ThunderX2.
|
||||
|
||||
The x86 account we will be comparing it to is the [1-S][11], which costs a more princely 4 euros a month and has 2 Intel Atom C3995 cores. Intel’s Atom range is a low power single-threaded system on chip design, first built for laptops and then adapted for server use.
|
||||
|
||||
These accounts are otherwise fairly similar: they each have 2 gigabytes of memory, 50 gigabytes of SSD storage and 200 Mbit/s bandwidth. The disk drives possibly differ, but with the crawls we’re going to run here, this won’t come into play, we’re going to be doing everything in memory.
|
||||
|
||||
When I can’t use a package manager I’m familiar with, I become angry and confused, a bit like an autistic toddler without his security blanket, entirely beyond reasoning or consolation, it’s quite horrendous really, so both of these accounts will use Debian Stretch.
|
||||
|
||||
#### Amazon Web Services
|
||||
|
||||
In the same length of time as it takes you to give Scaleway your credit card details, launch a VPS, add a sudo user and start installing dependencies, you won’t even have gotten as far as registering your AWS account. You’ll still be reading through the product pages trying to figure out what’s going on.
|
||||
|
||||
There’s a serious breadth and depth here aimed at enterprises and others with complicated or specialised needs.
|
||||
|
||||
The AWS Graviton we wanna drag race is part of AWS’s “Elastic Compute Cloud” or EC2 range. I’ll be running it as an on-demand instance, which is the most convenient and expensive way to use EC2. AWS also operates a [spot market][12], where you get the server much cheaper if you can be flexible about when it runs. There’s also a [mid-priced option][13] if you want to run it 24/7.
|
||||
|
||||
Did I mention that AWS is complicated? Anyhoo..
|
||||
|
||||
The two accounts we’re comparing are [a1.medium][14] and [t2.small][15]. They both offer 2GB of RAM. Which begs the question: WTF is a vCPU? Confusingly, it’s a different thing on each account.
|
||||
|
||||
On the a1.medium account, a vCPU is a single core of the new AWS Graviton chip. This was built by Annapurna Labs, an Israeli chip maker bought by Amazon in 2015. This is a single-threaded 64-bit ARMv8 core exclusive to AWS. This has an on-demand price of 0.0255 US dollars per hour.
|
||||
|
||||
Our t2.small account runs on an Intel Xeon – though exactly which Xeon chip it is, I couldn’t really figure out. This has two threads per core – though we’re not really getting the whole core, or even the whole thread.
|
||||
|
||||
Instead we’re getting a “baseline performance of 20%, with the ability to burst above that baseline using CPU credits”. Which makes sense in principle, though it’s completely unclear to me what to actually expect from this. The on-demand price for this account is 0.023 US dollars per hour.
|
||||
|
||||
I couldn’t find Debian in the image library here, so both of these accounts will run Ubuntu 18.04.
|
||||
|
||||
### Beavis and Butthead Do Moz’s Top 500
|
||||
|
||||
To test these VPS accounts, I need a crawler to run – one that will let the CPU stretch its legs a bit. One way to do this would be to just hammer a few websites with as many requests as fast as possible, but that’s not very polite. What we’ll do instead is a broad crawl of many websites at once.
|
||||
|
||||
So it’s in tribute to my favourite physicist turned filmmaker, Mike Judge, that I wrote beavis.py. This crawls Moz’s Top 500 Websites to a depth of 3 pages to count how many times the words “wood” and “ass” occur anywhere within the HTML source.
|
||||
|
||||
Not all 500 websites will actually get crawled here – some will be excluded by robots.txt and others will require javascript to follow links and so on. But it’s a wide enough crawl to keep the CPU busy.
|
||||
|
||||
Python’s [global interpreter lock][16] means that beavis.py can only make use of a single CPU thread. To test multi-threaded we’re going to have to launch multiple spiders as seperate processes.
|
||||
|
||||
This is why I wrote butthead.py. Any true fan of the show knows that, as crude as Butthead was, he was always slightly more sophisticated than Beavis.
|
||||
|
||||
Splitting the crawl into multiple lists of start pages and allowed domains might slightly impact what gets crawled – fewer external links to other websites in the top 500 will get followed. But every crawl will be different anyway, so we will count how many pages are scraped as well as how long they take.
|
||||
|
||||
### Installing Scrapy on an ARM Server
|
||||
|
||||
Installing Scrapy is basically the same on each architecture. You install pip and various other dependencies, then install Scrapy from pip.
|
||||
|
||||
Installing Scrapy from pip to an ARM device does take noticeably longer though. I’m guessing this is because it has to compile the binary parts from source.
|
||||
|
||||
Once Scrapy is installed, I ran it from the shell to check that it’s fetching pages.
|
||||
|
||||
On Scaleway’s ARM account, there seemed to be a hitch with the service_identity module: it was installed but not working. This issue had come up on the Raspberry Pi as well, but not the AWS Graviton.
|
||||
|
||||
Not to worry, this was easily fixed with the following command:
|
||||
|
||||
```
|
||||
sudo pip3 install service_identity --force --upgrade
|
||||
```
|
||||
|
||||
Then we were off and racing!
|
||||
|
||||
### Single Threaded Crawls
|
||||
|
||||
The Scrapy docs say to try to [keep your crawls running between 80-90% CPU usage][17]. In practice, it’s hard – at least it is with the script I’ve written. What tends to happen is that the CPU gets very busy early in the crawl, drops a little bit and then rallies again.
|
||||
|
||||
The last part of the crawl, where most of the domains have been finished, can go on for quite a few minutes, which is frustrating, because at that point it feels like more a measure of how big the last website is than anything to do with the processor.
|
||||
|
||||
So please take this for what it is: not a state of the art benchmarking tool, but a short and slightly balding Australian in his underpants running some scripts and watching what happens.
|
||||
|
||||
So let’s get down to brass tacks. We’ll start with the Scaleway crawls.
|
||||
|
||||
| VPS | Account | Time | Pages | Scraped | Pages/Hour | €/million | pages |
|
||||
| --------- | ------- | ------- | ------ | ---------- | ---------- | --------- | ----- |
|
||||
| Scaleway | | | | | | | |
|
||||
| ARM64-2GB | 108m | 59.27s | 38,205 | 21,032.623 | 0.28527 | | |
|
||||
| --------- | ------- | ------- | ------ | ---------- | ---------- | --------- | ----- |
|
||||
| Scaleway | | | | | | | |
|
||||
| 1-S | 97m | 44.067s | 39,476 | 24,324.648 | 0.33011 | | |
|
||||
|
||||
I kept an eye on the CPU use of both of these crawls using [top][18]. Both crawls hit 100% CPU use at the beginning, but the ThunderX chip was definitely redlining a lot more. That means these figures understate how much faster the Atom core crawls than the ThunderX.
|
||||
|
||||
While I was watching CPU use in top, I could also see how much RAM was in use – this increased as the crawl continued. The ARM account used 14.7% at the end of the crawl, while the x86 was at 15%.
|
||||
|
||||
Watching the logs of these crawls, I also noticed a lot more pages timing out and going missing when the processor was maxed out. That makes sense – if the CPU’s too busy to respond to everything then something’s gonna go missing.
|
||||
|
||||
That’s not such a big deal when you’re just racing the things to see which is fastest. But in a real-world situation, with business outcomes at stake in the quality of your data, it’s probably worth having a little bit of headroom.
|
||||
|
||||
And what about AWS?
|
||||
|
||||
| VPS Account | Time | Pages Scraped | Pages / Hour | $ / Million Pages |
|
||||
| ----------- | ---- | ------------- | ------------ | ----------------- |
|
||||
| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
|
||||
| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
|
||||
|
||||
I’ve included these results for sake of comparison with the Scaleway crawls, but these crawls were kind of a bust. Monitoring the CPU use – this time through the AWS dashboard rather than through top – showed that the script wasn’t making good use of the available processing power on either account.
|
||||
|
||||
This was clearest with the a1.medium account – it hardly even got out of bed. It peaked at about 45% near the beginning and then bounced around between 20% and 30% for the rest.
|
||||
|
||||
What’s intriguing to me about this is that the exact same script ran much slower on the ARM processor – and that’s not because it hit a limit of the Graviton’s CPU power. It had oodles of headroom left. Even the Intel Atom core managed to finish, and that was maxing out for some of the crawl. The settings were the same in the code, the way they were being handled differently on the different architecture.
|
||||
|
||||
It’s a bit of a black box to me whether that’s something inherent to the processor itself, the way the binaries were compiled, or some interaction between the two. I’m going to speculate that we might have seen the same thing on the Scaleway ARM VPS, if we hadn’t hit the limit of the CPU core’s processing power first.
|
||||
|
||||
It was harder to know how the t2.small account was doing. The crawl sat at about 20%, sometimes going as high as 35%. Was that it meant by “baseline performance of 20%, with the ability to burst to a higher level”? I had no idea. But I could see on the dashboard I wasn’t burning through any CPU credits.
|
||||
|
||||
Just to make extra sure, I installed [stress][19] and ran it for a few minutes; sure enough, this thing could do 100% if you pushed it.
|
||||
|
||||
Clearly, I was going to need to crank the settings up on both these processors to make them sweat a bit, so I set CONCURRENT_REQUESTS to 5000 and REACTOR_THREADPOOL_MAXSIZE to 120 and ran some more crawls.
|
||||
|
||||
| VPS Account | Time | Pages Scraped | Pages/hr | $/10000 Pages |
|
||||
| ----------- | ---- | ------------- | -------- | ------------- |
|
||||
| a1.medium | 46m 13.619s | 40,283 | 52,285.047 | 0.48771 |
|
||||
| t2.small | 41m7.619s | 36,241 | 52,871.857 | 0.43501 |
|
||||
| t2.small (No CPU credits) | 73m 8.133s | 34,298 | 28,137.8891 | 0.81740 |
|
||||
|
||||
The a1 instance hit 100% usage about 5 minutes into the crawl, before dropping back to 80% use for another 20 minutes, climbing up to 96% again and then dropping down again as it was wrapping things up. That was probably about as well-tuned as I was going to get it.
|
||||
|
||||
The t2 instance hit 50% early in the crawl and stayed there for until it was nearly done. With 2 threads per core, 50% CPU use is one thread maxed out.
|
||||
|
||||
Here we see both accounts produce similar speeds. But the Xeon thread was redlining for most of the crawl, and the Graviton was not. I’m going to chalk this up as a slight win for the Graviton.
|
||||
|
||||
But what about once you’ve burnt through all your CPU credits? That’s probably the fairer comparison – to only use them as you earn them. I wanted to test that as well. So I ran stress until all the CPU credits were exhausted and ran the crawl again.
|
||||
|
||||
With no credits in the bank, the CPU usage maxed out at 27% and stayed there. So many pages ended up going missing that it actually performed worse than when on the lower settings.
|
||||
|
||||
### Multi Threaded Crawls
|
||||
|
||||
Dividing our crawl up between multiple spiders in separate processes offers a few more options to make use of the available cores.
|
||||
|
||||
I first tried dividing everything up between 10 processes and launching them all at once. This turned out to be slower than just dividing them up into 1 process per core.
|
||||
|
||||
I got the best result by combining these methods – dividing the crawl up into 10 processes and then launching 1 process per core at the start and then the rest as these crawls began to wind down.
|
||||
|
||||
To make this even better, you could try to minimise the problem of the last lingering crawler by making sure the longest crawls start first. I actually attempted to do this.
|
||||
|
||||
Figuring that the number of links on the home page might be a rough proxy for how large the crawl would be, I built a second spider to count them and then sort them in descending order of number of outgoing links. This preprocessing worked well and added a little over a minute.
|
||||
|
||||
It turned out though that blew the crawling time out beyond two hours! Putting all the most link heavy websites together in the same process wasn’t a great idea after all.
|
||||
|
||||
You might effectively deal with this by tweaking the number of domains per process as well – or by shuffling the list after it’s ordered. That’s a bit much for Beavis and Butthead though.
|
||||
|
||||
So I went back to my earlier method that had worked somewhat well:
|
||||
|
||||
| VPS Account | Time | Pages Scraped | Pages/hr | €/10,000 pages |
|
||||
| ----------- | ---- | ------------- | -------- | -------------- |
|
||||
| Scaleway ARM64-2GB | 62m 10.078s | 36,158 | 34,897.0719 | 0.17193 |
|
||||
| Scaleway 1-S | 60m 56.902s | 36,725 | 36,153.5529 | 0.22128 |
|
||||
|
||||
After all that, using more cores did speed up the crawl. But it’s hardly a matter of just halving or quartering the time taken.
|
||||
|
||||
I’m certain that a more experienced coder could better optimise this to take advantage of all the cores. But, as far as “out of the box” Scrapy performance goes, it seems to be a lot easier to speed up a crawl by using faster threads rather than by throwing more cores at it.
|
||||
|
||||
As it is, the Atom has scraped slightly more pages in slightly less time. On a value for money metric, you could possibly say that the ThunderX is ahead. Either way, there’s not a lot of difference here.
|
||||
|
||||
### Everything You Always Wanted to Know About Ass and Wood (But Were Afraid to Ask)
|
||||
|
||||
After scraping 38,205 pages, our crawler found 24,170,435 mentions of ass and 54,368 mentions of wood.
|
||||
|
||||
![][20]
|
||||
|
||||
Considered on its own, this is a respectable amount of wood.
|
||||
|
||||
But when you set it against the sheer quantity of ass we’re dealing with here, the wood looks miniscule.
|
||||
|
||||
### The Verdict
|
||||
|
||||
From what’s visible to me at the moment, it looks like the CPU architecture you use is actually less important than how old the processor is. The AWS Graviton from 2018 was the winner here in single-threaded performance.
|
||||
|
||||
You could of course argue that the Xeon still wins, core for core. But then you’re not really going dollar for dollar anymore, or even thread for thread.
|
||||
|
||||
The Atom from 2017, on the other hand, comfortably bested the ThunderX from 2014. Though, on the value for money metric, the ThunderX might be the clear winner. Then again, if you can run your crawls on Amazon’s spot market, the Graviton is still ahead.
|
||||
|
||||
All in all, I think this shows that, yes, you can crawl the web with an ARM device, and it can compete on both performance and price.
|
||||
|
||||
Whether the difference is significant enough for you to turn what you’re doing upside down is a whole other question of course. Certainly, if you’re already on the AWS cloud – and your code is portable enough – then it might be worthwhile testing out their a1 instances.
|
||||
|
||||
Hopefully we will see more ARM options on the public cloud in near future.
|
||||
|
||||
### The Scripts
|
||||
|
||||
This is my first real go at doing anything in either Python or Scrapy. So this might not be great code to learn from. Some of what I’ve done here – such as using global variables – is definitely a bit kludgey.
|
||||
|
||||
Still, I want to be transparent about my methods, so here are my scripts.
|
||||
|
||||
To run them, you’ll need Scrapy installed and you will need the CSV file of [Moz’s top 500 domains][21]. To run butthead.py you will also need [psutil][22].
|
||||
|
||||
##### beavis.py
|
||||
|
||||
```
|
||||
import scrapy
|
||||
from scrapy.spiders import CrawlSpider, Rule
|
||||
from scrapy.linkextractors import LinkExtractor
|
||||
from scrapy.crawler import CrawlerProcess
|
||||
|
||||
ass = 0
|
||||
wood = 0
|
||||
totalpages = 0
|
||||
|
||||
def getdomains():
|
||||
|
||||
moz500file = open('top500.domains.05.18.csv')
|
||||
|
||||
domains = []
|
||||
moz500csv = moz500file.readlines()
|
||||
|
||||
del moz500csv[0]
|
||||
|
||||
for csvline in moz500csv:
|
||||
leftquote = csvline.find('"')
|
||||
rightquote = leftquote + csvline[leftquote + 1:].find('"')
|
||||
domains.append(csvline[leftquote + 1:rightquote])
|
||||
|
||||
return domains
|
||||
|
||||
def getstartpages(domains):
|
||||
|
||||
startpages = []
|
||||
|
||||
for domain in domains:
|
||||
startpages.append('http://' + domain)
|
||||
|
||||
return startpages
|
||||
|
||||
class AssWoodItem(scrapy.Item):
|
||||
ass = scrapy.Field()
|
||||
wood = scrapy.Field()
|
||||
url = scrapy.Field()
|
||||
|
||||
class AssWoodPipeline(object):
|
||||
def __init__(self):
|
||||
self.asswoodstats = []
|
||||
|
||||
def process_item(self, item, spider):
|
||||
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
|
||||
|
||||
def close_spider(self, spider):
|
||||
asstally, woodtally = 0, 0
|
||||
|
||||
for asswoodcount in self.asswoodstats:
|
||||
asstally += asswoodcount[1]
|
||||
woodtally += asswoodcount[2]
|
||||
|
||||
global ass, wood, totalpages
|
||||
ass = asstally
|
||||
wood = woodtally
|
||||
totalpages = len(self.asswoodstats)
|
||||
|
||||
class BeavisSpider(CrawlSpider):
|
||||
name = "Beavis"
|
||||
allowed_domains = getdomains()
|
||||
start_urls = getstartpages(allowed_domains)
|
||||
#start_urls = [ 'http://medium.com' ]
|
||||
custom_settings = {
|
||||
'DEPTH_LIMIT': 3,
|
||||
'DOWNLOAD_DELAY': 3,
|
||||
'CONCURRENT_REQUESTS': 1500,
|
||||
'REACTOR_THREADPOOL_MAXSIZE': 60,
|
||||
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
|
||||
'LOG_LEVEL': 'INFO',
|
||||
'RETRY_ENABLED': False,
|
||||
'DOWNLOAD_TIMEOUT': 30,
|
||||
'COOKIES_ENABLED': False,
|
||||
'AJAXCRAWL_ENABLED': True
|
||||
}
|
||||
|
||||
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
|
||||
|
||||
def parse_asswood(self, response):
|
||||
if isinstance(response, scrapy.http.TextResponse):
|
||||
item = AssWoodItem()
|
||||
item['ass'] = response.text.casefold().count('ass')
|
||||
item['wood'] = response.text.casefold().count('wood')
|
||||
item['url'] = response.url
|
||||
yield item
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
process = CrawlerProcess({
|
||||
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
|
||||
})
|
||||
|
||||
process.crawl(BeavisSpider)
|
||||
process.start()
|
||||
|
||||
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
|
||||
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
|
||||
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
|
||||
```
|
||||
|
||||
##### butthead.py
|
||||
|
||||
```
|
||||
import scrapy, time, psutil
|
||||
from scrapy.spiders import CrawlSpider, Rule, Spider
|
||||
from scrapy.linkextractors import LinkExtractor
|
||||
from scrapy.crawler import CrawlerProcess
|
||||
from multiprocessing import Process, Queue, cpu_count
|
||||
|
||||
ass = 0
|
||||
wood = 0
|
||||
totalpages = 0
|
||||
linkcounttuples =[]
|
||||
|
||||
def getdomains():
|
||||
|
||||
moz500file = open('top500.domains.05.18.csv')
|
||||
|
||||
domains = []
|
||||
moz500csv = moz500file.readlines()
|
||||
|
||||
del moz500csv[0]
|
||||
|
||||
for csvline in moz500csv:
|
||||
leftquote = csvline.find('"')
|
||||
rightquote = leftquote + csvline[leftquote + 1:].find('"')
|
||||
domains.append(csvline[leftquote + 1:rightquote])
|
||||
|
||||
return domains
|
||||
|
||||
def getstartpages(domains):
|
||||
|
||||
startpages = []
|
||||
|
||||
for domain in domains:
|
||||
startpages.append('http://' + domain)
|
||||
|
||||
return startpages
|
||||
|
||||
class AssWoodItem(scrapy.Item):
|
||||
ass = scrapy.Field()
|
||||
wood = scrapy.Field()
|
||||
url = scrapy.Field()
|
||||
|
||||
class AssWoodPipeline(object):
|
||||
def __init__(self):
|
||||
self.asswoodstats = []
|
||||
|
||||
def process_item(self, item, spider):
|
||||
self.asswoodstats.append((item.get('url'), item.get('ass'), item.get('wood')))
|
||||
|
||||
def close_spider(self, spider):
|
||||
asstally, woodtally = 0, 0
|
||||
|
||||
for asswoodcount in self.asswoodstats:
|
||||
asstally += asswoodcount[1]
|
||||
woodtally += asswoodcount[2]
|
||||
|
||||
global ass, wood, totalpages
|
||||
ass = asstally
|
||||
wood = woodtally
|
||||
totalpages = len(self.asswoodstats)
|
||||
|
||||
|
||||
class ButtheadSpider(CrawlSpider):
|
||||
name = "Butthead"
|
||||
custom_settings = {
|
||||
'DEPTH_LIMIT': 3,
|
||||
'DOWNLOAD_DELAY': 3,
|
||||
'CONCURRENT_REQUESTS': 250,
|
||||
'REACTOR_THREADPOOL_MAXSIZE': 30,
|
||||
'ITEM_PIPELINES': { '__main__.AssWoodPipeline': 10 },
|
||||
'LOG_LEVEL': 'INFO',
|
||||
'RETRY_ENABLED': False,
|
||||
'DOWNLOAD_TIMEOUT': 30,
|
||||
'COOKIES_ENABLED': False,
|
||||
'AJAXCRAWL_ENABLED': True
|
||||
}
|
||||
|
||||
rules = ( Rule(LinkExtractor(), callback='parse_asswood'), )
|
||||
|
||||
|
||||
def parse_asswood(self, response):
|
||||
if isinstance(response, scrapy.http.TextResponse):
|
||||
item = AssWoodItem()
|
||||
item['ass'] = response.text.casefold().count('ass')
|
||||
item['wood'] = response.text.casefold().count('wood')
|
||||
item['url'] = response.url
|
||||
yield item
|
||||
|
||||
def startButthead(domainslist, urlslist, asswoodqueue):
|
||||
crawlprocess = CrawlerProcess({
|
||||
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)'
|
||||
})
|
||||
|
||||
crawlprocess.crawl(ButtheadSpider, allowed_domains = domainslist, start_urls = urlslist)
|
||||
crawlprocess.start()
|
||||
asswoodqueue.put( (ass, wood, totalpages) )
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
asswoodqueue = Queue()
|
||||
domains=getdomains()
|
||||
startpages=getstartpages(domains)
|
||||
processlist =[]
|
||||
cores = cpu_count()
|
||||
|
||||
for i in range(10):
|
||||
domainsublist = domains[i * 50:(i + 1) * 50]
|
||||
pagesublist = startpages[i * 50:(i + 1) * 50]
|
||||
p = Process(target = startButthead, args = (domainsublist, pagesublist, asswoodqueue))
|
||||
processlist.append(p)
|
||||
|
||||
for i in range(cores):
|
||||
processlist[i].start()
|
||||
|
||||
time.sleep(180)
|
||||
|
||||
i = cores
|
||||
|
||||
while i != 10:
|
||||
time.sleep(60)
|
||||
if psutil.cpu_percent() < 66.7:
|
||||
processlist[i].start()
|
||||
i += 1
|
||||
|
||||
for i in range(10):
|
||||
processlist[i].join()
|
||||
|
||||
for i in range(10):
|
||||
asswoodtuple = asswoodqueue.get()
|
||||
ass += asswoodtuple[0]
|
||||
wood += asswoodtuple[1]
|
||||
totalpages += asswoodtuple[2]
|
||||
|
||||
print('Uhh, that was, like, ' + str(totalpages) + ' pages crawled.')
|
||||
print('Uh huhuhuhuh. It said ass ' + str(ass) + ' times.')
|
||||
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/quadbike-1024x683.jpg
|
||||
[2]: https://scrapy.org/
|
||||
[3]: https://www.info2007.net/blog/2018/review-scaleway-arm-based-cloud-server.html
|
||||
[4]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
|
||||
[5]: https://www.computerworld.com/article/3178544/microsoft-windows/microsoft-and-arm-look-to-topple-intel-in-servers.html
|
||||
[6]: https://www.datacenterknowledge.com/design/cloudflare-bets-arm-servers-it-expands-its-data-center-network
|
||||
[7]: https://www.scaleway.com/
|
||||
[8]: https://aws.amazon.com/
|
||||
[9]: https://www.theregister.co.uk/2018/11/27/amazon_aws_graviton_specs/
|
||||
[10]: https://www.scaleway.com/virtual-cloud-servers/#anchor_arm
|
||||
[11]: https://www.scaleway.com/virtual-cloud-servers/#anchor_starter
|
||||
[12]: https://aws.amazon.com/ec2/spot/pricing/
|
||||
[13]: https://aws.amazon.com/ec2/pricing/reserved-instances/
|
||||
[14]: https://aws.amazon.com/ec2/instance-types/a1/
|
||||
[15]: https://aws.amazon.com/ec2/instance-types/t2/
|
||||
[16]: https://wiki.python.org/moin/GlobalInterpreterLock
|
||||
[17]: https://docs.scrapy.org/en/latest/topics/broad-crawls.html
|
||||
[18]: https://linux.die.net/man/1/top
|
||||
[19]: https://linux.die.net/man/1/stress
|
||||
[20]: https://blog.dxmtechsupport.com.au/wp-content/uploads/2019/02/Screenshot-from-2019-02-16-17-01-08.png
|
||||
[21]: https://moz.com/top500
|
||||
[22]: https://pypi.org/project/psutil/
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 tools for viewing files at the command line)
|
||||
[#]: via: (https://opensource.com/article/19/2/view-files-command-line)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
3 tools for viewing files at the command line
|
||||
======
|
||||
Take a look at less, Antiword, and odt2txt, three utilities for viewing files in the terminal.
|
||||

|
||||
|
||||
I always say you don't need to use the command line to use Linux effectively—I know many Linux users who never crack open a terminal window and are quite happy. However, even though I don't consider myself a techie, I spend about 20% of my computing time at the command line, manipulating files, processing text, and using utilities.
|
||||
|
||||
One thing I often do in a terminal window is viewing files, whether text or word processor files. Sometimes it's just easier to use a command line utility than to fire up a text editor or a word processor.
|
||||
|
||||
Here are three of the utilities I use to view files at the command line.
|
||||
|
||||
### less
|
||||
|
||||
The beauty of [less][1] is that it's easy to use and it breaks the files you're viewing down into discrete chunks (or pages), which makes them easier to read. You use it to view text files at the command line, such as a README, an HTML file, a LaTeX file, or anything else in plaintext. I took a look at less in a [previous article][2].
|
||||
|
||||
To use less, just type:
|
||||
|
||||
```
|
||||
less file_name
|
||||
```
|
||||
|
||||
|
||||
|
||||
Scroll down through the file by pressing the spacebar or PgDn key on your keyboard. You can move up through a file by pressing the PgUp key. To stop viewing the file, press the Q key on your keyboard.
|
||||
|
||||
### Antiword
|
||||
|
||||
[Antiword][3] is great little utility that you can use to that can convert Word documents to plaintext. If you want, you can also convert them to [PostScript][4] or [PDF][5]. For this article, let's just stick with the conversion to text.
|
||||
|
||||
Antiword can read and convert files created with versions of Word from 2.0 to 2003. It doesn't read DOCX files—if you try, Antiword displays an error message that what you're trying to read is a ZIP file. That's technically correct, but it's still frustrating.
|
||||
|
||||
To view a Word document using Antiword, type the following command:
|
||||
|
||||
```
|
||||
antiword file_name.doc
|
||||
```
|
||||
|
||||
Antiword converts the document to text and displays it in the terminal window. Unfortunately, it doesn't break the document into pages in the terminal. You can, though, redirect Antiword's output to a utility like less or [more][6] to paginate it. Do that by typing the following command:
|
||||
|
||||
```
|
||||
antiword file_name.doc | less
|
||||
```
|
||||
|
||||
If you're new to the command line, the | is called a pipe. That's what does the redirection.
|
||||
|
||||
|
||||
|
||||
### odt2txt
|
||||
|
||||
Being a good open source citizen, you'll want to use as many open formats as possible. For your word processing needs, you might deal with [ODT][7] files (used by such word processors as LibreOffice Writer and AbiWord) instead of Word files. Even if you don't, you might run into ODT files. And they're easy to view at the command line, even if you don't have Writer or AbiWord installed on your computer.
|
||||
|
||||
How? With a little utility called [odt2txt][8]. As you've probably guessed, odt2txt converts an ODT file to plaintext. To use it, run the command:
|
||||
|
||||
```
|
||||
odt2txt file_name.odt
|
||||
```
|
||||
|
||||
Like Antiword, odt2txt converts the document to text and displays it in the terminal window. And, like Antiword, it doesn't page the document. Once again, though, you can pipe the output from odt2txt to a utility like less or more using the following command:
|
||||
|
||||
```
|
||||
odt2txt file_name.odt | more
|
||||
```
|
||||
|
||||
|
||||
|
||||
Do you have a favorite utility for viewing files at the command line? Feel free to share it with the community by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/view-files-command-line
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnu.org/software/less/
|
||||
[2]: https://opensource.com/article/18/4/using-less-view-text-files-command-line
|
||||
[3]: http://www.winfield.demon.nl/
|
||||
[4]: http://en.wikipedia.org/wiki/PostScript
|
||||
[5]: http://en.wikipedia.org/wiki/Portable_Document_Format
|
||||
[6]: https://opensource.com/article/19/1/more-text-files-linux
|
||||
[7]: http://en.wikipedia.org/wiki/OpenDocument
|
||||
[8]: https://github.com/dstosberg/odt2txt
|
||||
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 Good Open Source Speech Recognition/Speech-to-Text Systems)
|
||||
[#]: via: (https://fosspost.org/lists/open-source-speech-recognition-speech-to-text)
|
||||
[#]: author: (Simon James https://fosspost.org/author/simonjames)
|
||||
|
||||
5 Good Open Source Speech Recognition/Speech-to-Text Systems
|
||||
======
|
||||
|
||||

|
||||
|
||||
A speech-to-text (STT) system is as its name implies; A way of transforming the spoken words via sound into textual files that can be used later for any purpose.
|
||||
|
||||
Speech-to-text technology is extremely useful. It can be used for a lot of applications such as a automation of transcription, writing books/texts using your own sound only, enabling complicated analyses on information using the generated textual files and a lot of other things.
|
||||
|
||||
In the past, the speech-to-text technology was dominated by proprietary software and libraries; Open source alternatives didn’t exist or existed with extreme limitations and no community around. This is changing, today there are a lot of open source speech-to-text tools and libraries that you can use right now.
|
||||
|
||||
Here we list 5 of them.
|
||||
|
||||
### Open Source Speech Recognition Libraries
|
||||
|
||||
#### Project DeepSpeech
|
||||
|
||||
![5 Good Open Source Speech Recognition/Speech-to-Text Systems 15 open source speech recognition][1]
|
||||
|
||||
This project is made by Mozilla; The organization behind the Firefox browser. It’s a 100% free and open source speech-to-text library that also implies the machine learning technology using TensorFlow framework to fulfill its mission.
|
||||
|
||||
In other words, you can use it to build training models yourself to enhance the underlying speech-to-text technology and get better results, or even to bring it to other languages if you want. You can also easily integrate it to your other machine learning projects that you are having on TensorFlow. Sadly it sounds like the project is currently only supporting English by default.
|
||||
|
||||
It’s also available in many languages such as Python (3.6); Which allows you to have it working in seconds:
|
||||
|
||||
```
|
||||
pip3 install deepspeech
|
||||
deepspeech --model models/output_graph.pbmm --alphabet models/alphabet.txt --lm models/lm.binary --trie models/trie --audio my_audio_file.wav
|
||||
```
|
||||
|
||||
You can also install it using npm:
|
||||
|
||||
```
|
||||
npm install deepspeech
|
||||
```
|
||||
|
||||
For more information, refer to the [project’s homepage][2].
|
||||
|
||||
#### Kaldi
|
||||
|
||||
![5 Good Open Source Speech Recognition/Speech-to-Text Systems 17 open source speech recognition][3]
|
||||
|
||||
Kaldi is an open source speech recognition software written in C++, and is released under the Apache public license. It works on Windows, macOS and Linux. Its development started back in 2009.
|
||||
|
||||
Kaldi’s main features over some other speech recognition software is that it’s extendable and modular; The community is providing tons of 3rd-party modules that you can use for your tasks. Kaldi also supports deep neural networks, and offers an [excellent documentation on its website][4].
|
||||
|
||||
While the code is mainly written in C++, it’s “wrapped” by Bash and Python scripts. So if you are looking just for the basic usage of converting speech to text, then you’ll find it easy to accomplish that via either Python or Bash.
|
||||
|
||||
[Project’s homepage][5].
|
||||
|
||||
#### Julius
|
||||
|
||||
![5 Good Open Source Speech Recognition/Speech-to-Text Systems 19 open source speech recognition][6]
|
||||
|
||||
Probably one of the oldest speech recognition software ever; It’s development started in 1991 at the University of Kyoto, and then its ownership was transferred to an independent project team in 2005.
|
||||
|
||||
Julius main features include its ability to perform real-time STT processes, low memory usage (Less than 64MB for 20000 words), ability to produce N-best/Word-graph output, ability to work as a server unit and a lot more. This software was mainly built for academic and research purposes. It is written in C, and works on Linux, Windows, macOS and even Android (on smartphones).
|
||||
|
||||
Currently it supports both English and Japanese languages only. The software is probably availbale to install easily in your Linux distribution’s repository; Just search for julius package in your package manager. The latest version was [released][7] around one and half months ago.
|
||||
|
||||
[Project’s homepage][8].
|
||||
|
||||
#### Wav2Letter++
|
||||
|
||||
![5 Good Open Source Speech Recognition/Speech-to-Text Systems 21 open source speech recognition][9]
|
||||
|
||||
If you are looking for something modern, then this one is for you. Wav2Letter++ is an open source speech recognition software that was released by Facebook’s AI Research Team just 2 months ago. The code is released under the BSD license.
|
||||
|
||||
Facebook is [describing][10] its library as “the fastest state-of-the-art speech recognition system available”. The concepts on which this tool is built makes it optimized for performance by default; Facebook’s also-new machine learning library [FlashLight][11] is used as the underlying core of Wav2Letter++.
|
||||
|
||||
Wav2Letter++ needs you first to build a training model for the language you desire by yourself in order to train the algorithms on it. No pre-built support of any language (including English) is available; It’s just a machine-learning-driven tool to convert speech to text. It was written in C++, hence the name (Wav2Letter++).
|
||||
|
||||
[Project’s homepage][12].
|
||||
|
||||
#### DeepSpeech2
|
||||
|
||||
![5 Good Open Source Speech Recognition/Speech-to-Text Systems 23 open source speech recognition][13]
|
||||
|
||||
Researchers at the Chinese giant Baidu are also working on their own speech-to-text engine, called DeepSpeech2. It’s an end-to-end open source engine that uses the “PaddlePaddle” deep learning framework for converting both English & Mandarin Chinese languages speeches into text. The code is released under BSD license.
|
||||
|
||||
The engine can be trained on any model and for any language you desire. The models are not released with the code; You’ll have to build them yourself, just like the other software. DeepSpeech2’s source code is written in Python; So it should be easy for you to get familiar with it if that’s the language you use.
|
||||
|
||||
[Project’s homepage][14].
|
||||
|
||||
### Conclusion
|
||||
|
||||
The speech recognition category is still mainly dominated by proprietary software giants like Google and IBM (which do provide their own closed-source commercial services for this), but the open source alternatives are promising. Those 5 open source speech recognition engines should get you going in building your application, all of them are still under heavy development by time. In few years, we expect open source to become the norm for those technologies just like in the other industries.
|
||||
|
||||
If you have any other recommendations for this list, or comments in general, we’d love to hear them below!
|
||||
|
||||
**
|
||||
|
||||
Shares
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/lists/open-source-speech-recognition-speech-to-text
|
||||
|
||||
作者:[Simon James][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/simonjames
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/hero_speech-machine-learning2.png?resize=820%2C280&ssl=1 (5 Good Open Source Speech Recognition/Speech-to-Text Systems 16 open source speech recognition)
|
||||
[2]: https://github.com/mozilla/DeepSpeech
|
||||
[3]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-19-1134.png?resize=591%2C138&ssl=1 (5 Good Open Source Speech Recognition/Speech-to-Text Systems 18 open source speech recognition)
|
||||
[4]: http://kaldi-asr.org/doc/index.html
|
||||
[5]: http://kaldi-asr.org
|
||||
[6]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/mic_web.png?resize=385%2C100&ssl=1 (5 Good Open Source Speech Recognition/Speech-to-Text Systems 20 open source speech recognition)
|
||||
[7]: https://github.com/julius-speech/julius/releases
|
||||
[8]: https://github.com/julius-speech/julius
|
||||
[9]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/fully_convolutional_ASR.png?resize=850%2C177&ssl=1 (5 Good Open Source Speech Recognition/Speech-to-Text Systems 22 open source speech recognition)
|
||||
[10]: https://code.fb.com/ai-research/wav2letter/
|
||||
[11]: https://github.com/facebookresearch/flashlight
|
||||
[12]: https://github.com/facebookresearch/wav2letter
|
||||
[13]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/ds2.png?resize=850%2C313&ssl=1 (5 Good Open Source Speech Recognition/Speech-to-Text Systems 24 open source speech recognition)
|
||||
[14]: https://github.com/PaddlePaddle/DeepSpeech
|
||||
@ -0,0 +1,184 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to List Installed Packages on Ubuntu and Debian [Quick Tip])
|
||||
[#]: via: (https://itsfoss.com/list-installed-packages-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to List Installed Packages on Ubuntu and Debian [Quick Tip]
|
||||
======
|
||||
|
||||
So you [installed Ubuntu and started using][1] it extensively. Somewhere down the line, you are bound to lose the track of the software that you had installed over the time.
|
||||
|
||||
That’s perfectly normal. No one expects you to remember all the packages installed on your system. But the question arises, how to know what packages have been installed? How to see the installed packages?
|
||||
|
||||
### List installed packages in Ubuntu and Debian
|
||||
|
||||
![List installed Packages][2]
|
||||
|
||||
If you use [apt command][3] extensively, you would probably expect a command like apt list installed packages. You are not entirely wrong here.
|
||||
|
||||
While [apt-get command][4] doesn’t have a straightforward option like apt-get list installed packages, apt has a command for this.
|
||||
|
||||
```
|
||||
apt list --installed
|
||||
```
|
||||
|
||||
This will list all the packages that have been installed using apt. It will also list the packages that were installed as a dependency. Which means that not only you’ll have the applications you installed, you’ll also have a huge list of libraries and other packages that you didn’t install directly.
|
||||
|
||||
![List installed packages in Ubuntu with apt command][5]Listing installed packages with apt command
|
||||
|
||||
Since the list of installed packages is a huge one, it would be a better idea to use grep and filter the output for a certain package.
|
||||
|
||||
```
|
||||
apt list --installed | grep program_name
|
||||
```
|
||||
|
||||
Note that the above method also lists the [applications installed with .deb files][6]. That’s cool, isn’t it?
|
||||
|
||||
If you have read my [apt vs apt-get comparison][7] article, you probably already know that both apt and apt-get basically use [dpkg][8]. This means you can use dpkg command to list all the installed packages in Debian.
|
||||
|
||||
```
|
||||
dpkg-query -l
|
||||
```
|
||||
|
||||
You can filter the output with grep again to search for a specific package.
|
||||
|
||||
![Listing installed packages with dpkg command][9]![Listing installed packages with dpkg command][9]Listing installed packages with dpkg
|
||||
|
||||
So far, you have dealt with applications installed with Debian’s package manager. What about Snap and Flatpak applications? How to list them because they are not accessible with apt and dpkg?
|
||||
|
||||
To show all the [Snap packages][10] installed on your system, use this command:
|
||||
|
||||
```
|
||||
snap list
|
||||
```
|
||||
|
||||
Snap list also indicates which applications are from a verified publisher with a green tick.
|
||||
|
||||
![List installed packages with snap][11]Listing installed Snap packages
|
||||
|
||||
To list all the [Flatpak packages][12] installed on your system, use this:
|
||||
|
||||
```
|
||||
flatpak list
|
||||
```
|
||||
|
||||
Let me summarize it for you.
|
||||
|
||||
Summary
|
||||
|
||||
To list packages using apt command:
|
||||
|
||||
**apt** **list –installed**
|
||||
|
||||
To list packages using dpkg command:
|
||||
|
||||
**dpkg-query -l**
|
||||
|
||||
To list Snap packages installed on your system:
|
||||
|
||||
**snap list**
|
||||
|
||||
To list Flatpak packages installed on your system:
|
||||
|
||||
**flatpak list**
|
||||
|
||||
### List the recently installed packages
|
||||
|
||||
So far you saw the list of installed packages in alphabetical order. What if you want to see the packages that have been installed recently?
|
||||
|
||||
Thankfully, a Linux system keeps a log of everything that happens in your system. You can refer to the logs to see the recently installed packages.
|
||||
|
||||
There are a couple of ways to do this. You can either use the dpkg command’s log or the apt command’s log.
|
||||
|
||||
You’ll have to use grep command to filter the result to list the installed packages only.
|
||||
|
||||
```
|
||||
grep " install " /var/log/dpkg.log
|
||||
```
|
||||
|
||||
This will list all the packages including the dependencies that were installed recently on your system along with the time of installation.
|
||||
|
||||
```
|
||||
2019-02-12 12:41:42 install ubuntu-make:all 16.11.1ubuntu1
|
||||
2019-02-13 21:03:02 install xdg-desktop-portal:amd64 0.11-1
|
||||
2019-02-13 21:03:02 install libostree-1-1:amd64 2018.8-0ubuntu0.1
|
||||
2019-02-13 21:03:02 install flatpak:amd64 1.0.6-0ubuntu0.1
|
||||
2019-02-13 21:03:02 install xdg-desktop-portal-gtk:amd64 0.11-1
|
||||
2019-02-14 11:49:10 install qml-module-qtquick-window2:amd64 5.9.5-0ubuntu1.1
|
||||
2019-02-14 11:49:10 install qml-module-qtquick2:amd64 5.9.5-0ubuntu1.1
|
||||
2019-02-14 11:49:10 install qml-module-qtgraphicaleffects:amd64 5.9.5-0ubuntu1
|
||||
```
|
||||
|
||||
You can also use the history of apt command. This will show only the programs that you installed using apt command. It won’t show the dependencies installed with it, though the details are present in the logs. Sometimes, you just want to see that, right?
|
||||
|
||||
```
|
||||
grep " install " /var/log/apt/history.log
|
||||
```
|
||||
|
||||
The output should be something like this:
|
||||
|
||||
```
|
||||
Commandline: apt install pinta
|
||||
Commandline: apt install pinta
|
||||
Commandline: apt install tmux
|
||||
Commandline: apt install terminator
|
||||
Commandline: apt install moreutils
|
||||
Commandline: apt install ubuntu-make
|
||||
Commandline: apt install flatpak
|
||||
Commandline: apt install cool-retro-term
|
||||
Commandline: apt install ubuntu-software
|
||||
```
|
||||
|
||||
![List recently installed packages][13]Listing recently installed packages
|
||||
|
||||
The history log of apt is quite useful because it shows the time when the apt command was run, the user who ran the command and the packages that were installed by a command.
|
||||
|
||||
### Bonus Tip: Show installed applications in Software Center
|
||||
|
||||
If you are not comfortable with the terminal and the commands, you still has a way to see the applications installed on your system.
|
||||
|
||||
You can open the Software Center and click on the Installed tab. You’ll see the list of applications that have been installed on your system.
|
||||
|
||||
![List Installed Software in Ubuntu Software Center][14]Showing installed applications in Software Center
|
||||
|
||||
It won’t show the libraries and other command line stuff though but perhaps you don’t want to see that as you are more GUI centric. Otherwise, you can always use the Synaptic Package Manager.
|
||||
|
||||
**That’s it**
|
||||
|
||||
I hope this quick little tutorial helped you to see the list of installed packages on Ubuntu and Debian based distributions.
|
||||
|
||||
If you have questions or suggestions to improve this article, please leave a comment below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/list-installed-packages-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/getting-started-with-ubuntu/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages.png?resize=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/apt-command-guide/
|
||||
[4]: https://itsfoss.com/apt-get-linux-guide/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages-in-ubuntu-with-apt.png?resize=800%2C407&ssl=1
|
||||
[6]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[7]: https://itsfoss.com/apt-vs-apt-get-difference/
|
||||
[8]: https://wiki.debian.org/dpkg
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages-with-dpkg.png?ssl=1
|
||||
[10]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-snap-packages.png?ssl=1
|
||||
[12]: https://itsfoss.com/flatpak-guide/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/apt-list-recently-installed-packages.png?resize=800%2C187&ssl=1
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/installed-software-ubuntu.png?ssl=1
|
||||
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/list-installed-packages.png?fit=800%2C450&ssl=1
|
||||
227
sources/tech/20190219 Logical - in Bash.md
Normal file
227
sources/tech/20190219 Logical - in Bash.md
Normal file
@ -0,0 +1,227 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Logical & in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Logical & in Bash
|
||||
======
|
||||
|
||||

|
||||
|
||||
One would think you could dispatch `&` in two articles. Turns out you can't. While [the first article dealt with using `&` at the end of commands to push them into the background][1] and then diverged into explaining process management, the second article saw [`&` being used as a way to refer to file descriptors][2], which led us to seeing how, combined with `<` and `>`, you can route inputs and outputs from and to different places.
|
||||
|
||||
This means we haven't even touched on `&` as an AND operator, so let's do that now.
|
||||
|
||||
### & is a Bitwise Operator
|
||||
|
||||
If you are at all familiar with binary operations, you will have heard of AND and OR. These are bitwise operations that operate on individual bits of a binary number. In Bash, you use `&` as the AND operator and `|` as the OR operator:
|
||||
|
||||
**AND**
|
||||
|
||||
```
|
||||
0 & 0 = 0
|
||||
|
||||
0 & 1 = 0
|
||||
|
||||
1 & 0 = 0
|
||||
|
||||
1 & 1 = 1
|
||||
```
|
||||
|
||||
**OR**
|
||||
|
||||
```
|
||||
0 | 0 = 0
|
||||
|
||||
0 | 1 = 1
|
||||
|
||||
1 | 0 = 1
|
||||
|
||||
1 | 1 = 1
|
||||
```
|
||||
|
||||
You can test this by ANDing any two numbers and outputting the result with `echo`:
|
||||
|
||||
```
|
||||
$ echo $(( 2 & 3 )) # 00000010 AND 00000011 = 00000010
|
||||
|
||||
2
|
||||
|
||||
$ echo $(( 120 & 97 )) # 01111000 AND 01100001 = 01100000
|
||||
|
||||
96
|
||||
```
|
||||
|
||||
The same goes for OR (`|`):
|
||||
|
||||
```
|
||||
$ echo $(( 2 | 3 )) # 00000010 OR 00000011 = 00000011
|
||||
|
||||
3
|
||||
|
||||
$ echo $(( 120 | 97 )) # 01111000 OR 01100001 = 01111001
|
||||
|
||||
121
|
||||
```
|
||||
|
||||
Three things about this:
|
||||
|
||||
1. You use `(( ... ))` to tell Bash that what goes between the double brackets is some sort of arithmetic or logical operation. `(( 2 + 2 ))`, `(( 5 % 2 ))` (`%` being the [modulo][3] operator) and `((( 5 % 2 ) + 1))` (equals 3) will all work.
|
||||
2. [Like with variables][4], `$` extracts the value so you can use it.
|
||||
3. For once spaces don't matter: `((2+3))` will work the same as `(( 2+3 ))` and `(( 2 + 3 ))`.
|
||||
4. Bash only operates with integers. Trying to do something like this `(( 5 / 2 ))` will give you "2", and trying to do something like this `(( 2.5 & 7 ))` will result in an error. Then again, using anything but integers in a bitwise operation (which is what we are talking about now) is generally something you wouldn't do anyway.
|
||||
|
||||
|
||||
|
||||
**TIP:** If you want to check what your decimal number would look like in binary, you can use _bc_ , the command-line calculator that comes preinstalled with most Linux distros. For example, using:
|
||||
|
||||
```
|
||||
bc <<< "obase=2; 97"
|
||||
```
|
||||
|
||||
will convert `97` to binary (the _o_ in `obase` stands for _output_ ), and ...
|
||||
|
||||
```
|
||||
bc <<< "ibase=2; 11001011"
|
||||
```
|
||||
|
||||
will convert `11001011` to decimal (the _i_ in `ibase` stands for _input_ ).
|
||||
|
||||
### && is a Logical Operator
|
||||
|
||||
Although it uses the same logic principles as its bitwise cousin, Bash's `&&` operator can only render two results: 1 ("true") and 0 ("false"). For Bash, any number not 0 is “true” and anything that equals 0 is “false.” What is also false is anything that is not a number:
|
||||
|
||||
```
|
||||
$ echo $(( 4 && 5 )) # Both non-zero numbers, both true = true
|
||||
|
||||
1
|
||||
|
||||
$ echo $(( 0 && 5 )) # One zero number, one is false = false
|
||||
|
||||
0
|
||||
|
||||
$ echo $(( b && 5 )) # One of them is not number, one is false = false
|
||||
|
||||
0
|
||||
```
|
||||
|
||||
The OR counterpart for `&&` is `||` and works exactly as you would expect.
|
||||
|
||||
All of this is simple enough... until it comes to a command's exit status.
|
||||
|
||||
### && is a Logical Operator for Command Exit Status
|
||||
|
||||
[As we have seen in previous articles][2], as a command runs, it outputs error messages. But, more importantly for today's discussion, it also outputs a number when it ends. This number is called an _exit code_ , and if it is 0, it means the command did not encounter any problem during its execution. If it is any other number, it means something, somewhere, went wrong, even if the command completed.
|
||||
|
||||
So 0 is good, any other number is bad, and, in the context of exit codes, 0/good means "true" and everything else means “false.” Yes, this is **the exact contrary of what you saw in the logical operations above** , but what are you gonna do? Different contexts, different rules. The usefulness of this will become apparent soon enough.
|
||||
|
||||
Moving on.
|
||||
|
||||
Exit codes are stored _temporarily_ in the [special variable][5] `?` \-- yes, I know: another confusing choice. Be that as it may, [remember that in our article about variables][4], and we said that you read the value in a variable using a the `$` symbol. So, if you want to know if a command has run without a hitch, you have to read `?` as soon as the command finishes and before running anything else.
|
||||
|
||||
Try it with:
|
||||
|
||||
```
|
||||
$ find /etc -iname "*.service"
|
||||
|
||||
find: '/etc/audisp/plugins.d': Permission denied
|
||||
|
||||
/etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service
|
||||
|
||||
/etc/systemd/system/dbus-org.freedesktop.ModemManager1.service
|
||||
|
||||
[etcetera]
|
||||
```
|
||||
|
||||
[As you saw in the previous article][2], running `find` over _/etc_ as a regular user will normally throw some errors when it tries to read subdirectories for which you do not have access rights.
|
||||
|
||||
So, if you execute...
|
||||
|
||||
```
|
||||
echo $?
|
||||
```
|
||||
|
||||
... right after `find`, it will print a `1`, indicating that there were some errors.
|
||||
|
||||
(Notice that if you were to run `echo $?` a second time in a row, you'd get a `0`. This is because `$?` would contain the exit code of `echo $?`, which, supposedly, will have executed correctly. So the first lesson when using `$?` is: **use`$?` straight away** or store it somewhere safe -- like in another variable, or you will lose it).
|
||||
|
||||
One immediate use of `?` is to fold it into a list of chained commands and bork the whole thing if anything fails as Bash runs through it. For example, you may be familiar with the process of building and compiling the source code of an application. You can run them on after another by hand like this:
|
||||
|
||||
```
|
||||
$ configure
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
|
||||
$ make
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
|
||||
$ make install
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
|
||||
.
|
||||
```
|
||||
|
||||
You can also put all three on one line...
|
||||
|
||||
```
|
||||
$ configure; make; make install
|
||||
```
|
||||
|
||||
... and hope for the best.
|
||||
|
||||
The disadvantage of this is that if, say, `configure` fails, Bash will still try and run `make` and `sudo make install`, even if there is nothing to make or, indeed, install.
|
||||
|
||||
The smarter way of doing it is like this:
|
||||
|
||||
```
|
||||
$ configure && make && make install
|
||||
```
|
||||
|
||||
This takes the exit code from each command and uses it as an operand in a chained `&&` operation.
|
||||
|
||||
But, and here's the kicker, Bash knows the whole thing is going to fail if `configure` returns a non-zero result. If that happens, it doesn't have to run `make` to check its exit code, since the result is going to be false no matter what. So, it forgoes `make` and just passes a non-zero result onto the next step of the operation. And, as `configure && make` delivers false, Bash doesn't have to run `make install` either. This means that, in a long chain of commands, you can join them with `&&`, and, as soon as one fails, you can save time as the rest of the commands get canceled immediately.
|
||||
|
||||
You can do something similar with `||`, the OR logical operator, and make Bash continue processing chained commands if only one of a pair completes.
|
||||
|
||||
In view of all this (along with the stuff we covered earlier), you should now have a clearer idea of what the command line we set at the beginning of [this article does][1]:
|
||||
|
||||
```
|
||||
mkdir test_dir 2>/dev/null || touch backup/dir/images.txt && find . -iname "*jpg" > backup/dir/images.txt &
|
||||
```
|
||||
|
||||
So, assuming you are running the above from a directory for which you have read and write privileges, what it does it do and how does it do it? How does it avoid unseemly and potentially execution-breaking errors? Next week, apart from giving you the solution, we'll be dealing with brackets: curly, curvy and straight. Don't miss it!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/2/logical-ampersand-bash
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux
|
||||
[2]: https://www.linux.com/blog/learn/2019/2/ampersands-and-file-descriptors-bash
|
||||
[3]: https://en.wikipedia.org/wiki/Modulo_operation
|
||||
[4]: https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise
|
||||
[5]: https://www.gnu.org/software/bash/manual/html_node/Special-Parameters.html
|
||||
Loading…
Reference in New Issue
Block a user