mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-19 00:30:12 +08:00
commit
1163ab4fbf
@ -1,12 +1,12 @@
|
||||
从命令行访问Linux命令小抄
|
||||
================================================================================
|
||||
Linux命令行的强大在于其灵活及多样化,各个Linux命令都带有它自己那部分命令行选项和参数。混合并匹配它们,甚至还可以通过管道和重定向来联结不同的命令。理论上讲,你可以借助几个基本的命令来产生数以百计的使用案例。甚至对于浸淫多年的管理员而言,也难以完全使用它们。那正是命令行小抄成为我们救命稻草的一刻。
|
||||
Linux命令行的强大在于其灵活及多样化,各个Linux命令都带有它自己专属的命令行选项和参数。混合并匹配这些命令,甚至还可以通过管道和重定向来联结不同的命令。理论上讲,你可以借助几个基本的命令来产生数以百计的使用案例。甚至对于浸淫多年的管理员而言,也难以完全使用它们。那正是命令行小抄成为我们救命稻草的一刻。
|
||||
|
||||
[][1]
|
||||
|
||||
我知道联机手册页仍然是我们的良师益友,但我们想通过我们能自行支配的快速参考卡让这一切更为高效和有目的性。最终极的小抄可能被自豪地挂在你的办公室里,也可能作为PDF文件隐秘地存储在你的硬盘上,或者甚至设置成了你的桌面背景图。
|
||||
我知道联机手册页(man)仍然是我们的良师益友,但我们想通过我们能自行支配的快速参考卡让这一切更为高效和有目的性。最终极的小抄可能被自豪地挂在你的办公室里,也可能作为PDF文件隐秘地存储在你的硬盘上,或者甚至设置成了你的桌面背景图。
|
||||
|
||||
最为一个选择,也可以通过另外一个命令来访问你最爱的命令行小抄。那就是,使用[cheat][2]。这是一个命令行工具,它可以让你从命令行读取、创建或更新小抄。这个想法很简单,不过cheat经证明是十分有用的。本教程主要介绍Linux下cheat命令的使用方法。你不需要为cheat命令做个小抄了,它真的很简单。
|
||||
做为一个选择,也可以通过另外一个命令来访问你最爱的命令行小抄。那就是,使用[cheat][2]。这是一个命令行工具,它可以让你从命令行读取、创建或更新小抄。这个想法很简单,不过cheat经证明是十分有用的。本教程主要介绍Linux下cheat命令的使用方法。你不需要为cheat命令做个小抄了,它真的很简单。
|
||||
|
||||
### 安装Cheat到Linux ###
|
||||
|
||||
@ -59,9 +59,9 @@ cheat命令一个很酷的事是,它自带有超过90个的常用Linux命令
|
||||
|
||||
$ cheat -s <keyword>
|
||||
|
||||
在许多情况下,小抄适用于那些正派的人,而对其他某些人却没什么帮助。要想让内建的小抄更具个性化,cheat命令也允许你创建新的小抄,或者更新现存的那些。要这么做的话,cheat命令也会帮你在本地~/.cheat目录中保存一份小抄的副本。
|
||||
在许多情况下,小抄适用于某些人,而对另外一些人却没什么帮助。要想让内建的小抄更具个性化,cheat命令也允许你创建新的小抄,或者更新现存的那些。要这么做的话,cheat命令也会帮你在本地~/.cheat目录中保存一份小抄的副本。
|
||||
|
||||
要使用cheat的编辑功能,首先确保EDITOR环境变量设置为了你默认编辑器所在位置的完整路径。然后,复制(不可编辑)内建小抄到~/.cheat目录。你可以通过下面的命令找到内建小抄所在的位置。一旦你找到了它们的位置,只不过是将它们拷贝到~/.cheat目录。
|
||||
要使用cheat的编辑功能,首先确保EDITOR环境变量设置为你默认编辑器所在位置的完整路径。然后,复制(不可编辑)内建小抄到~/.cheat目录。你可以通过下面的命令找到内建小抄所在的位置。一旦你找到了它们的位置,只不过是将它们拷贝到~/.cheat目录。
|
||||
|
||||
$ cheat -d
|
||||
|
||||
@ -85,7 +85,7 @@ via: http://xmodulo.com/2014/07/access-linux-command-cheat-sheets-command-line.h
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
在哪儿以及怎么写代码:选择最好的免费代码编辑器
|
||||
何处写,如何写:选择最好的免费在线代码编辑器
|
||||
================================================================================
|
||||
深入了解一下Cloud9,Koding和Nitrous.IO。
|
||||
> 深入了解一下Cloud9,Koding和Nitrous.IO。
|
||||
|
||||

|
||||
|
||||
**已经准备好开始你的第一个编程项目了吗?很好!只要配置一下**终端或命令行,学习如何使用并安装所有要用到的编程语言,插件库和API函数库。当最终准备好一切以后,再安装好[Visual Studio][1]就可以开始了,然后才可以预览自己的工作。
|
||||
已经准备好开始你的第一个编程项目了吗?很好!只要配置一下终端或命令行,学习如何使用它,然后安装所有要用到的编程语言,插件库和API函数库。当最终准备好一切以后,再安装好[Visual Studio][1]就可以开始了,然后才可以预览自己的工作。
|
||||
|
||||
至少这是大家过去已经熟悉的方式。
|
||||
|
||||
也难怪初学程序员们逐渐喜欢上在线集成开发环境(IDE)了。IDE是一个代码编辑器,不过已经准备好编程语言以及所有需要的依赖,可以让你避免把它们一一安装到电脑上的麻烦。
|
||||
也难怪初学程序员们逐渐喜欢上在线的集成开发环境(IDE)了。IDE是一个代码编辑器,不过已经准备好编程语言以及所有需要的依赖,可以让你避免把它们一一安装到电脑上的麻烦。
|
||||
|
||||
我想搞清楚到底是哪些因素能组成一个典型的IDE,所以我试用了一下免费级别的时下最受欢迎的三款集成开发环境:[Cloud9][2],[Koding][3]和[Nitrous.IO][4]。在这个过程中,我了解了许多程序员应该或不应该使用IDE的各种情形。
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
假如有一个像Microsoft Word那样的文字编辑器,想想类似Google Drive那样的IDE吧。你可以拥有类似的功能,但是它还能支持从任意电脑上访问,还能随时共享。因为因特网在项目工作流中的影响已经越来越重要,IDE也让生活更轻松。
|
||||
|
||||
在我最近的一篇ReadWrite教程中我使用了Nitrous.IO,这是在文章[创建一个你自己的像Yo那样的极端简单的聊天应用][5]里的一个Python应用。当使用IDE的时候,你只要选择你要用的编程语言,然后通过IDE特别设计用来运行这种语言程序的虚拟机(VM),你就可以测试和预览你的应用了。
|
||||
在我最近的一篇ReadWrite教程中我使用了Nitrous.IO,这是在文章“[创建一个你自己的像Yo那样的极端简单的聊天应用][5]”里的一个Python应用。当使用IDE的时候,你只要选择你要用的编程语言,然后通过IDE特别为运行这种语言程序而设计的虚拟机(VM),你就可以测试和预览你的应用了。
|
||||
|
||||
如果你读过那篇教程,就会知道我的那个应用只用到了两个API库-信息服务Twilio和Python微框架Flask。在我的电脑上就算是使用文字编辑器和终端来做也是很简单的,不过我选择使用IDE还有一个方便的地方:如果大家都使用同样的开发环境,跟着教程一步步走下去就更简单了。
|
||||
|
||||
@ -28,7 +28,7 @@
|
||||
|
||||
但是不能用IDE来永久存储你的整个项目。把帖子保存在Google Drive文件中不会让你的博客丢失。类似Google Drive,IDE可以让你创建链接用于共享内容,但是任何一个都还不足以替代真正的托管服务器。
|
||||
|
||||
还有,IDE并不是设计成方便广泛共享。尽管各种IDE都在不断改善大多数文字编辑器的预览功能,还只能用来给你的朋友或同事展示一下应用预览,而不是,比如说,类似Hacker News的主页。那样的话,占用太多带宽的IDE也许会让你崩溃。
|
||||
还有,IDE并不是设计成方便广泛共享。尽管各种IDE都在不断改善大多数文字编辑器的预览功能,还只能用来给你的朋友或同事展示一下应用的预览,而不是像Hacker News一样的主页。那样的话,占用太多带宽的IDE也许会让你崩溃。
|
||||
|
||||
这样说吧:IDE只是构建和测试你的应用的地方,托管服务器才是它们生存的地方。所以一旦完成了你的应用,你会希望把它布置到能长期托管的云服务器上,最好是能免费托管的那种,例如[Heroku][6]。
|
||||
|
||||
@ -44,7 +44,7 @@
|
||||
|
||||
当我完成了Cloud9的注册后,它提示的第一件事情就是添加我的GitHub和BitBucket账号。马上,所有我的GitHub项目,个人的和协作的,都可以直接克隆到本地并使用Cloud9的开发工具开始工作。其他的IDE在和GitHub集成的方面都没有达到这种水准。
|
||||
|
||||
在我测试的这三款IDE中,Cloud9看起来更加侧重于一个可以让协同工作的人们无缝衔接工作的环境。在这里,它并不是角落里放个聊天窗口。实际上,按照CEO Ruben Daniels说的,试用Cloud9的协作者可以互相看到其他人实时的编码情况,就像Google Drive上的合作者那样。
|
||||
在我测试的这三款IDE中,Cloud9看起来更加侧重于一个可以让协同工作的人们无缝衔接工作的环境。在这里,它并不是角落里放个聊天窗口。实际上,按照其CEO Ruben Daniels说的,试用Cloud9的协作者可以互相看到其他人实时的编码情况,就像Google Drive上的合作者那样。
|
||||
|
||||
“大多数IDE服务的协同功能只能操作单一文件”,Daniels说,“而我们的产品可以支持整个项目中的不同文件。协同功能被完美集成到了我们的IDE中。”
|
||||
|
||||
@ -58,15 +58,15 @@ IDE可以提供你所需的工具来构建和测试所有开源编程语言的
|
||||
|
||||
### Nitrous.IO: An IDE Wherever You Want ###
|
||||
|
||||
相对于自己的桌面环境,使用IDE的最大优势是它是自包含的。你不需要安装任何其他的就可以使用。而另一方面,使用自己的桌面环境的最大优势就是你可以在本地工作,甚至在没有互联网的情况下。
|
||||
相对于自己的桌面环境,使用IDE的最大优势是它是自足的。你不需要安装任何其他的东西就可以使用。而另一方面,使用自己的桌面环境的最大优势就是你可以在本地工作,甚至在没有互联网的情况下。
|
||||
|
||||
Nitrous.IO结合了这两个优势。你可以在网站上在线使用这个IDE,你也可以把它下载到自己的饿电脑上,共同创始人AJ Solimine这样说。优点是你可以结合Nitrous的集成性和你最喜欢的文字编辑器的熟悉。
|
||||
Nitrous.IO结合了这两个优势。“你可以在网站上在线使用这个IDE,你也可以把它下载到自己的电脑上”,其共同创始人AJ Solimine这样说。优点是你可以结合Nitrous的集成性和你最喜欢的文字编辑器的熟悉。
|
||||
|
||||
他说:“你可以使用任意当代浏览器访问Nitrous.IO的在线IDE网站,但我们仍然提供了方便的Windows和Mac桌面应用,可以让你使用你最喜欢的编辑器来写代码。”
|
||||
他说:“你可以使用任意现代浏览器访问Nitrous.IO的在线IDE网站,但我们仍然提供了方便的Windows和Mac桌面应用,可以让你使用你最喜欢的编辑器来写代码。”
|
||||
|
||||
### 底线 ###
|
||||
|
||||
这一个星期的[使用][7]三个不同IDE的最让我意外的收获?它们是如此相似。[当用来做最基本的代码编辑的时候][8],它们都一样的好用。
|
||||
这一个星期[使用][7]三个不同IDE的最让我意外的收获是什么?它们是如此相似。[当用来做最基本的代码编辑的时候][8],它们都一样的好用。
|
||||
|
||||
Cloud9,Koding,[和Nitrous.IO都支持][9]所有主流的开源编程语言,从Ruby到Python到PHP到HTML5。你可以选择任何一种VM。
|
||||
|
||||
@ -76,7 +76,7 @@ Cloud9和Nitrous.IO都实现了GitHub的一键集成。Koding需要[多几个步
|
||||
|
||||
不好的一面,它们都有相同的缺陷,不过考虑到它们都是免费的也还合理。你每次只能同时运行一个VM来测试特定编程语言写出的程序。而当你一段时间没有使用VM之后,IDE会把VM切换成休眠模式以节省带宽,而下次要用的时候就得等它重新加载(Cloud9在这一点上更加费力)。它们中也没有任何一个为已完成的项目提供像样的永久托管服务。
|
||||
|
||||
所以,对咨询我是否有一个完美的免费IDE的人,答案是可能没有。但是这也要看你侧重的地方,对你的某个项目来说也许有一个完美的IDE。
|
||||
所以,对咨询我是否有一个完美的免费IDE的人来说,答案是可能没有。但是这也要看你侧重的地方,对你的某个项目来说也许有一个完美的IDE。
|
||||
|
||||
图片由[Shutterstock][11]友情提供
|
||||
|
||||
@ -86,7 +86,7 @@ via: http://readwrite.com/2014/08/14/cloud9-koding-nitrousio-integrated-developm
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -190,7 +190,7 @@
|
||||
|
||||
<blockquote>CommanderX:那么请大家阅读信件并给予 Topiary 帮助...</blockquote>
|
||||
|
||||
<blockquote>Toad:你真是和【哔~】一样消息灵通。</blockquote>
|
||||
<blockquote>Toad:你真是为了抓人眼球什么都做啊!</blockquote>
|
||||
|
||||
<blockquote>Toad:这么说你得到 Topiary 的消息了?</blockquote>
|
||||
|
||||
@ -200,13 +200,13 @@
|
||||
|
||||
<p>Doyon 越来越大胆。在佛罗里达州当局逮捕了支持流浪者的激进分子后,他就攻击 了奥兰多商务部商会网站。他使用个人笔记本电脑通过公用无线网络实施了攻击,并且没有花费太多精力来隐藏自己的网络行踪。“这种做法很勇敢,但也很愚蠢,”一位自称 Kalli 的 PLF 的资深成员告诉我。“他看起来并不在乎是否会被抓。他完全是一名自杀式黑客。”</p>
|
||||
|
||||
<p>两个月后,Doyon 参与了针对旧金山湾区快速交通系统(Bay Area Rapid Transit)的 DDoS 攻击,以此抗议一名 BART 的警官杀害一名叫做 Charles Hill 的流浪者的事件。随后 Doyon 现身“CBS 晚间新闻”为这次行动辩护,当然,他处理了自己的声音,把自己的脸用香蕉进行替代。他把 DDoS 攻击比作为公民的抗议行为。“与占用 Woolworth 午餐柜台的座位相比,这真的没什么不同,真的,”他说道。CBS 的主播 Bob Schieffer 笑称:“就我所见,它并不完全是一项民权运动。”</p>
|
||||
<p>两个月后,Doyon 参与了针对旧金山湾区快速交通系统(Bay Area Rapid Transit)的 DDoS 攻击,以此抗议一名 BART 的警官杀害一名叫做 Charles Hill 的流浪者的事件。随后 Doyon 现身“CBS 晚间新闻”为这次行动辩护,当然,他处理了自己的声音,用印花大手帕盖住了脸。他把 DDoS 攻击比作为公民的抗议行为。“与占用 Woolworth 午餐柜台的座位相比,这真的没什么不同,真的,”他说道。CBS 的主播 Bob Schieffer 笑称:“就我所见,它并不完全是一项民权运动。”</p>
|
||||
|
||||
<p>2011 年 9 月 22 日,在加利福尼亚州的一家名为 Mountain View 的咖啡店里,Doyon 被捕,同时面临着“使用互联网非法破坏受保护的计算机”罪名指控。他被拘留了一个星期的时间,接着在签署协议之后获得假释。两天后,他不顾律师的反对,宣布将在圣克鲁斯郡法院召开新闻发布会。他梳起了马尾辫,戴着一副墨镜、一顶黑色海盗帽,同时还在脖子上围了一条五彩手帕。</p>
|
||||
<p>2011 年 9 月 22 日,在加利福尼亚州的一家名为 Mountain View 的咖啡店里,Doyon 被捕,同时面临着“使用互联网非法破坏受保护的计算机”的罪名指控。他被拘留了一个星期的时间,接着在签署协议之后获得假释。两天后,他不顾律师的反对,宣布将在圣克鲁斯郡法院召开会议。他梳起了马尾辫,戴着一副墨镜、一顶黑色海盗帽,同时还在脖子上围了一条五彩手帕。</p>
|
||||
|
||||
<p>Doyon 通过非常夸大的方式披露了自己的身份。“我就是 Commander X,”他告诉蜂拥的记者。他举起了拳头。“作为‘匿名者’组织的一员,作为一名核心成员,我感到非常的骄傲。”他在接受一名记者的采访时说,“想要成为一名顶尖黑客的话,你只需要准备一台电脑以及一副墨镜。任何一台电脑都行。”</p>
|
||||
<p>Doyon 通过非常夸大的方式揭露了自己的身份。“我就是 Commander X,”他告诉蜂拥的记者。他举起了拳头。“作为‘匿名者’组织的一员,作为一名核心成员,我感到非常的骄傲。”他在接受一名记者的采访时说,“想要成为一名顶尖黑客的话,你只需要准备一台电脑以及一副墨镜。任何一台电脑都行。”</p>
|
||||
|
||||
<p>Kalli 非常担心 Doyon 会不小心泄露组织机密或者其他匿名者的信息。“这是所有环节中最薄弱的地方,如果这里出问题了,那么组织就完了,”他告诉我。曾在“和平阵营行动”中给予 Doyon 大力帮助的匿名者 Josh Covelli 告诉我,当他在网上看见 Doyon 的新闻发布会视频的时候,他感觉瞬间“下巴掉地下了”。“他的所作所为变得越来越不可捉摸,” Covelli 评价道。</p>
|
||||
<p>Kalli 非常担心 Doyon 会不小心泄露组织机密或者其他匿名者的信息。“这是所有环节中最薄弱的地方,如果这里出问题了,那么组织就完了,”他告诉我。曾在“和平阵营行动”中给予 Doyon 大力帮助的匿名者 Josh Covelli 告诉我,当他在网上看见 Doyon 的新闻发布会视频的时候,他感觉瞬间“下巴掉地上了”。“他的所作所为变得越来越不可捉摸,” Covelli 评价道。</p>
|
||||
|
||||
<p>三个月后,Doyon 的指定律师 Jay Leiderman 出席了圣荷西联邦法庭的辩护。Leiderman 已经好几个星期没有得到 Doyon 的消息了。“我需要得知被告无法出席的具体原因,”法官说。Leiderman 无法回答。Doyon 再次缺席了两星期后的另一场听证会。检控方表示:“很明显,看来被告已经逃跑了。”</p>
|
||||
|
||||
@ -214,7 +214,7 @@
|
||||
|
||||
<p>“Xport 行动”是“匿名者”组织进行的所有同类行动中的第一个行动。这次行动的目标是协助如今已经背负两项罪名的通缉犯 Doyon 潜逃出国。负责调度的人是 Kalli 以及另一位曾在八十年代剑桥的迷幻药派对上和 Doyon 见过面的匿名者老兵。这位老兵是一位已经退休的软件主管,在组织内部威望很高。</p>
|
||||
|
||||
<p>Doyon 的终点站是这位软件主管的家,位于加拿大的偏远乡村。2011 年 12 月,他搭便车前往旧金山,并辗转来到了市区组织大本营。他找到了他的指定联系人,后者带领他到达了奥克兰的一家披萨店。凌晨 2 点,Doyon 通过披萨店的无线网络,接收了一条加密聊天消息。</p>
|
||||
<p>Doyon 的目的地是这位软件主管家,位于加拿大的偏远乡村。2011 年 12 月,他搭便车前往旧金山,并辗转来到了市区组织大本营。他找到了他的指定联系人,后者带领他到达了奥克兰的一家披萨店。凌晨 2 点,Doyon 通过披萨店的无线网络,接收了一条加密聊天消息。</p>
|
||||
|
||||
<p>“你现在靠近窗户吗?”那条消息问道。</p>
|
||||
|
||||
@ -222,13 +222,13 @@
|
||||
|
||||
<p>“往大街对面看。看见一个绿色的邮箱了吗?十五分钟后,你去站到那个邮箱旁边,把你的背包取下来,然后把你的面具放在上面。”</p>
|
||||
|
||||
<p>一连几个星期的时间,Doyon 穿梭于海湾地区的安全屋之间,按照加密聊天那头的指示不断行动。最后,他搭上了前往西雅图的长途公交车,软件主管的一个朋友在那里接待了他。这个朋友是一名非常富有的退休人员,他花费了通过谷歌地球来帮助 Doyon 规划前往加拿大的路线。他们共同前往了一家野外用品供应商店,这位朋友为 Doyon 购置了价值 1500 美元的商品,包括登山鞋以及一个全新的背包。接着他又开车载着 Doyon 北上,两小时后到达距离国界只有几百英里的偏僻地区。随后 Doyon 见到了 Amber Lyon。</p>
|
||||
<p>一连几个星期的时间,Doyon 穿梭于海湾地区的安全屋之间,按照加密聊天那头的指示不断行动。最后,他搭上了前往西雅图的长途公交车,软件主管的一个朋友在那里接待了他。这个朋友是一名非常富有的退休人员,他花费了几小时的时间通过谷歌地球来帮助 Doyon 规划前往加拿大的路线。他们共同前往了一家野外用品供应商店,这位朋友为 Doyon 购置了价值 1500 美元的商品,包括登山鞋以及一个全新的背包。接着他又开车载着 Doyon 北上,两小时后到达距离国界只有几百英里的偏僻地区。随后 Doyon 见到了 Amber Lyon。</p>
|
||||
|
||||
<p>几个月前,广播新闻记者 Lyon 曾在 CNN 的关于“匿名者”组织的节目里采访过 Doyon。Doyon 很欣赏她的报道,他们一直保持着联络。Lyon 要求加入 Doyon 的逃亡行程,为一部可能会发行的纪录片拍摄素材。软件主管认为这样太过冒险,但 Doyon 还是接受了她的请求。“我觉得他是想让自己出名,” Lyon 告诉我。四天的时间里,她用影像记录下了 Doyon 徒步北上,在林间露宿的行程。“那一切看起来不太像是仔细规划过的,” Lyon 回忆说。“他实在是无家可归了,所以他才会想要逃到国外去。”</p>
|
||||
|
||||
<center><img src="http://www.newyorker.com/wp-content/uploads/2014/09/140908_a18506-600.jpg" /></center>
|
||||
|
||||
<center><small>“这里是我们存放各种感觉的仓库。如果你发现了某种感觉,把它带到这里然后锁起来。”</small></center>
|
||||
<center><small>“这里是我们存放各种情感的仓库。如果你产生了某种情感,把它带到这里然后锁起来。”</small></center>
|
||||
|
||||
<p>2012 年 2 月 11 日,Pastebin 上出现了一条消息。“PLF 很高兴的宣布‘ Commander X’,也就是 Christopher Mark Doyon,已经离开了美国的司法管辖区,抵达了加拿大一个比较安全的地方,”上面写着,“PLF 呼吁美国政府,希望政府能够醒悟过来并停止无谓的骚扰与监视行为——不要仅仅逮捕‘匿名者’组织的成员,对所有的激进组织应该一视同仁。”</p>
|
||||
|
||||
@ -236,13 +236,13 @@
|
||||
|
||||
Doyon 和软件主管在加拿大的小木屋里呆了几天。在一次同 Barrett Brown 的聊天中,Doyon 难掩内心的喜悦之情。
|
||||
|
||||
<blockquote>BarrettBrown:你现在应该足够安全了吧,其他的呢?...</blockquote>
|
||||
<blockquote>BarrettBrown:你现在足够多安全的藏身之处等等吧?</blockquote>
|
||||
|
||||
<blockquote>CommanderX:是的,我现在很安全,现在加拿大既不缺钱也不缺藏身的地方。</blockquote>
|
||||
|
||||
<blockquote>CommanderX:Amber Lyon 想要你的一张照片。</blockquote>
|
||||
|
||||
<blockquote>CommanderX:去他【哔~】的怪人,Barrett,相信你会喜欢我告诉她应该怎样评价你的。</blockquote>
|
||||
<blockquote>CommanderX:去你【哔~】的怪人,Barrett,相信你会喜欢我的回复。我一直爱你,永远爱你。</blockquote>
|
||||
|
||||
<blockquote>CommanderX::-)</blockquote>
|
||||
|
||||
@ -258,13 +258,13 @@ Doyon 和软件主管在加拿大的小木屋里呆了几天。在一次同 Barr
|
||||
|
||||
<blockquote>BarrettBrown:当然,估计我们不久后也得这样了</blockquote>
|
||||
|
||||
<p>在 Doyon 出逃十天后,《华尔街日报》上刊登了关于不久后升职为美国国家安全局及网络指挥部主任的 Keith Alexander 的报道,他在白宫举行的秘密会晤以及其他场合下,表达了对“匿名者”组织的高度关注。Alexander 发出警告,两年内,该组织必将会是国家电网改造的大患。参谋长联席会议的主席 General Martin Dempsey 告诉记者,这群人是国家的敌人。“他们有能力把这些使用恶意软件造成破坏的技术扩散到其他的边缘组织去,”随后又补充道,“我们必须防范这种情况发生。”</p>
|
||||
<p>在 Doyon 出逃十天后,《华尔街日报》上刊登了关于不久后升职为美国国家安全局及网络指挥部主任的 Keith Alexander 的报道,他在白宫以及其他场合举行的秘密会晤,表达了对“匿名者”组织的高度关注。Alexander 发出警告,两年内,该组织必将会是国家电网改造的大患。参谋长联席会议的主席 General Martin Dempsey 告诉记者,这群人是国家的敌人。“他们有能力把这些使用恶意软件造成破坏的技术扩散到其他的边缘组织去,”随后又补充道,“我们必须防范这种情况发生。”</p>
|
||||
|
||||
<p>3 月 8 日,国会议员们在国会大厦附近的一个敏感信息隔离设施附近举行了关于网络安全的会议。包括 Alexander、Dempsey、美国联邦调查局局长 Robert Mueller,以及美国国土安全部部长 Janet Napolitano 在内的多名美国安全方面的高级官员出席了这次会议。会议上,通过计算机向与会者模拟了东部沿海地区电力设施可能会遭受到的网络攻击时的情境。“匿名者”组织目前应该还不具备发动此种规模攻击的能力,但安全方面的官员担心他们会联合其他更加危险的组织来共同发动攻击。“在我们着手于不断增加的网络风险事故时,政府仍在就具体的处理细节进行不断协商讨论,” Napolitano 告诉我。当谈及潜在的网络安全隐患时,她补充道,“我们通常会把‘匿名者’组织的行动当做 A 级威胁来应对。”</p>
|
||||
|
||||
<p>“匿名者”也许是当今世界上最强大的无政府主义黑客组织。即使如此,它却从未表现出过任何的会对公共基础设施造成破坏的迹象或意愿。一些网络安全专家称,那些关于“匿名者”组织的谣传太过危言耸听。“在奥兰多发布战前宣言和实际发动 Stuxnet 蠕虫病毒攻击之间是有很大的差距的,” Internet 研究与战略中心的一位职员 James Andrew Lewis 告诉我,这和 2007 年美国与以色列对伊朗原子能网站发动的黑客袭击有关。哈佛大学法学院的教授 Yochai Benkler 告诉我,“我们所看见的只是以主要防御为理由而进行的开销,否则,将很难自圆其说。”</p>
|
||||
|
||||
<p>Keith Alexander 最近刚从政府部门退休,他拒绝就此事发表评论,因为他并不能代表国家安全局、联邦调查局、中央情报局以及国土安全部。尽管匿名者们从未真正盯上过政府部门的计算机网络,但他们对于那些激怒他们的人有着强烈的报复心理。前国土安全部国家网络安全部门负责人 Andy Purdy 告诉我他们“害怕被报复,”无论机构还是个人,都不同意政府公然反对“匿名者”组织。“每个人都非常脆弱,”他说。</p>
|
||||
<p>Keith Alexander 最近刚从政府部门退休,他拒绝就此事发表评论,因为他并不能代表国家安全局、联邦调查局、中央情报局以及国土安全部。尽管匿名者们从未真正盯上过政府部门的计算机网络,但他们对于那些激怒他们的人有着强烈的报复心理。前国土安全部国家网络安全部门负责人 Andy Purdy 告诉我他们“害怕被报复,”无论机构还是个人,都不同意政府公然反对“匿名者”组织。“每个人都容易成为被攻击对象,”他说。</p>
|
||||
|
||||
<h2>9</h2>
|
||||
|
||||
@ -272,7 +272,7 @@ Doyon 和软件主管在加拿大的小木屋里呆了几天。在一次同 Barr
|
||||
|
||||
<p>Doyon 感到很烦躁,但他还是继续扮演着一名黑客——以此吸引关注。他在多伦多上映的纪录片上以戴着面具的匿名者形象出现。在接受《National Post》的采访时,他向记者大肆吹嘘未经证实的消息,“我们已经入侵了美国政府的所有机密数据库。现在的问题是我们该何时泄露这些机密数据,而不是我们是否会泄露。”</p>
|
||||
|
||||
<p>2013 年 1 月,在另一名匿名者介入俄亥俄州<a href="https://gist.githubusercontent.com/SteveArcher/cdffc917a507f875b956/raw/c7b49cc11ae1e790d30c87f7b8de95482c18ec74/%E6%96%AF%E6%89%98%E6%9C%AC%E7%BB%B4%E5%B0%94%E8%BD%AE%E5%A5%B8%E6%A1%88%E5%86%8D%E8%B5%B7%E9%A3%8E%E6%B3%A2%20%E9%BB%91%E5%AE%A2%E7%BB%84%E7%BB%87%E4%BB%8B%E5%85%A5">斯托本维尔未成年少女轮奸案</a>,发起抗议行动之后,Doyon 重新启用了他两年前创办的网站 LocalLeaks,作为那起轮奸事件的信息汇总处理中心。如同许多其他“匿名者”组织的所作所为一样,LocalLeaks 网站非常具有影响力,但却也不承担任何责任。LocalLeaks 网站是第一家公布 12 分钟斯托本维尔高中毕业生猥亵视频的网站,这激起了众多当事人的愤怒。LocalLeaks 网站上同时披露了几份未被法庭收录的关于案件的材料,并且由此不小心透漏出了案件受害人的名字。Doyon向我承认他公开这些未经证实的信息的策略是存在争议的,但他同时回忆起自己当时的想法,“我们可以选择去除这些斯托本维尔案件的材料...也可以选择公开所有我们搜集的信息,基本上,给公众以提醒,不过,前提是你们得相信我们。”</p>
|
||||
<p>2013 年 1 月,在另一名匿名者介入俄亥俄州<a href="https://gist.githubusercontent.com/SteveArcher/cdffc917a507f875b956/raw/c7b49cc11ae1e790d30c87f7b8de95482c18ec74/%E6%96%AF%E6%89%98%E6%9C%AC%E7%BB%B4%E5%B0%94%E8%BD%AE%E5%A5%B8%E6%A1%88%E5%86%8D%E8%B5%B7%E9%A3%8E%E6%B3%A2%20%E9%BB%91%E5%AE%A2%E7%BB%84%E7%BB%87%E4%BB%8B%E5%85%A5">斯托本维尔未成年少女强奸案</a>,发起抗议行动之后,Doyon 重新启用了他两年前创办的网站 LocalLeaks,作为那起强奸事件的信息汇总处理中心。如同许多其他“匿名者”组织的所作所为一样,LocalLeaks 网站非常具有影响力,但却也不承担任何责任。LocalLeaks 网站是第一家公布 12 分钟斯托本维尔高中毕业生猥亵视频的网站,这激起了众多当事人的愤怒。LocalLeaks 网站上同时披露了几份未被法庭收录的关于案件的材料,并且由此不小心透漏出了案件受害人的名字。Doyon向我承认他公开这些未经证实的信息的策略是存在争议的,但他同时回忆起自己当时的想法,“我们可以选择销毁这些斯托本维尔案件的材料...也可以选择公开所有我们搜集的信息,基本上,给公众以提醒,不过,前提是你们得相信我们。”</p>
|
||||
|
||||
<p>2013 年 3 月,一个名为 Rustle League 的组织入侵了 Doyon 的 Twitter 账户,该组织此前经常挑衅“匿名者”组织。Rustle League 的领导者之一 Shm00p 告诉我,“我们的本意并不是伤害那些家伙,只不过,哦,那些家伙说的话你就当是在放屁好了——我会这么做只是因为我感到很好笑。” Rustle League 组织使用 Doyon 的账户发布了含有如 www.jewsdid911.org 链接这样的,种族主义和反犹太主义的信息。</p>
|
||||
|
||||
@ -290,37 +290,37 @@ Doyon 和软件主管在加拿大的小木屋里呆了几天。在一次同 Barr
|
||||
|
||||
<p>我们约定了一次面谈。Doyon 坚持让我通过加密聊天把面谈的详细情况提前告诉他。我坐了几个小时的飞机,租车来到了加拿大的一个偏远小镇,并且禁用了我的电话。</p>
|
||||
|
||||
<p>最后,我在一个狭小安静的住宅区公寓里见到了 Doyon。他穿了一件绿色的军人夹克衫以及印有“匿名者”组织 logo 的 T 恤衫:一个脸被问号所替代的黑衣人形象。公寓里基本上没有什么家具,充满了一股烟味。他谈论起了美国政治(“我基本没怎么在众多的选举中投票——它们不过是暗箱操作的游戏罢了”),好战的伊斯兰教(“我相信,尼日利亚政府的人不过是相互勾结,以创建一个名为‘博科圣地’的基地组织的下属机构罢了”),以及他对“匿名者”组织的小小看法(“那些自称为怪人的人是真的是烂透了,意思是,邪恶的人”)。</p>
|
||||
<p>最后,我在一个狭小安静的住宅区公寓里见到了 Doyon。他穿了一件绿色的军人夹克衫以及印有“匿名者”组织 logo 的 T 恤衫:一个脸被问号所替代的黑衣人形象。公寓里基本上没有什么家具,充满了一股烟味。他谈论起了美国政治(“我基本没怎么在众多的选举中投票——它们不过是暗箱操作的游戏罢了”),好战的伊斯兰教(“我相信,尼日利亚政府的人不过是相互勾结,以创建一个名为‘博科圣地’的基地组织的下属机构罢了”),以及他对“匿名者”组织的小小看法(“那些自称为怪人的人是真的是烂透了,其实是邪恶的人”)。</p>
|
||||
|
||||
<p>Doyon 剃去了他的胡须,但他却显得更加憔悴了。他说那是因为他病了的原因,他几乎很少出去。很小的写字台上有两台笔记本电脑、一摞关于佛教的书,还有一个堆满烟灰的烟灰缸。另一面裸露的泛黄墙壁上挂着盖伊·福克斯面具。他告诉我,“所谓‘Commander X’不过是一个处于极度痛苦中的小老头罢了。”</p>
|
||||
|
||||
<p>在刚过去的圣诞节里,匿名者的新网站 AnonInsiders 的创建者拜访了 Doyon,并给他带来了馅饼和香烟。Doyon 询问来访的朋友是否可以继承自己的衣钵成为 PLF 的最高指挥官,同时希望能够递交出自己手里的“王国钥匙”——手里的所有密码,以及几份关于“匿名者”组织的机密文件。这位朋友委婉的拒绝了。“我有自己的生活,”他告诉了我拒绝的理由。</p>
|
||||
<p>在刚过去的圣诞节里,匿名者的新网站 AnonInsiders 的创建者拜访了 Doyon,并给他带来了馅饼和香烟。Doyon 询问来访的朋友是否可以接替自己成为 PLF 的最高指挥官,同时希望能够递交出自己手里的“王国钥匙”——手里的所有密码,以及几份关于“匿名者”组织的机密文件。这位朋友委婉的拒绝了。“我有自己的生活,”他告诉了我拒绝的理由。</p>
|
||||
|
||||
<h2>11</h2>
|
||||
|
||||
<p>2014 年 8 月 9 日,当地时间下午 5 时 09 分,来自密苏里州圣路易斯郊区德尔伍德的一位说唱歌手同时也是激进分子的 Kareem (Tef Poe) Jackson,在 Twitter 上谈起了邻近城镇的一系列令人担忧的举措。“基本可以断定弗格森已经实施了戒严,任何人都无法出入,”他在 Twitter 上写道。“国内的朋友还有因特网上的朋友请帮助我们!!!”五个小时前,弗格森,一位十八岁的手无寸铁的非裔美国人 Michael Brown,被一位白人警察射杀。射杀警察声称自己这么做的原因是 Brown 意图伸手抢夺自己的枪支。而事发当时和 Brown 在一起的朋友 Dorian Johnson 却说,Brown 唯一做得不对的地方在于他当时拒绝离开街道中间。</p>
|
||||
<p>2014 年 8 月 9 日,当地时间下午 5 时 09 分,来自密苏里州圣路易斯郊区德尔伍德的一位说唱歌手同时也是激进分子的 Kareem (Tef Poe) Jackson,在 Twitter 上谈起了邻近城镇的一系列令人担忧的举措。“基本可以断定弗格森已经实施了戒严,任何人都无法出入,”他在 Twitter 上写道。“国内外的朋友们请帮助我们!!!”五个小时前,弗格森,一位十八岁的手无寸铁的非裔美国人 Michael Brown,被一位白人警察射杀。射杀警察声称自己这么做的原因是 Brown 意图伸手抢夺自己的枪支。而事发当时和 Brown 在一起的朋友 Dorian Johnson 却说,Brown 唯一做得不对的地方在于他当时拒绝离开街道中间。</p>
|
||||
|
||||
<p>不到两小时,Jackson 就收到了一位名为 CommanderXanon 的 Twitter 用户的回复。“你完全可以相信我们,”回复信息里写道。“你是否可以给我们详细描述一下现场情况,那样会对我们很有帮助。”近几周的时间里,仍然呆在加拿大的 Doyon 复出了。六月,他在还有两个月满 50 岁的时候,成功戒烟(“#戒瘾成功 #电子香烟功不可没 #老了,”他在戒烟成功后在 Twitter 上写道)。七月,在加沙地带爆发武装对抗之后,Doyon 发表 Twiter 支持“匿名者”组织的“拯救加沙行动”,并发动了一系列针对以色列网站的 DDoS 攻击。Doyon 认为弗格森枪击事件更加令人关注。抛开他本人的个性,他有在事件发展到引人注目之前的早期,就迅速注意该事件的能力。</p>
|
||||
<p>不到两小时,Jackson 就收到了一位名为 CommanderXanon 的 Twitter 用户的回复。“你完全可以相信我们,”回复信息里写道。“你是否可以给我们详细描述一下现场情况,那样会对我们很有帮助。”近几周的时间里,仍然呆在加拿大的 Doyon 复出了。六月,他在还有两个月满 50 岁的时候,成功戒烟(“#戒瘾成功 #电子香烟功不可没 #老了,”他在戒烟成功后在 Twitter 上写道)。七月,在加沙地带爆发武装对抗之后,Doyon 发表 Twiter 支持“匿名者”组织的“拯救加沙行动”,并发动了一系列针对以色列网站的 DDoS 攻击。Doyon 认为弗格森枪击事件更加令人关注。抛开他本人的个性,他有能力在事件发展到引人注目之前,就迅速注意该事件。</p>
|
||||
|
||||
<p>“正在网上搜索关于那名警察以及当地政府的信息,” Doyon 发 Twitter 道。不到十分钟,他就为此专门在 IRC 聊天室里创建了一个频道。“‘匿名者’组织‘弗格森’行动正式启动,”他又发了一条 Twitter。但只有两个人转推了此消息。</p>
|
||||
|
||||
<p>次日早晨,Doyon 发布了一条链接,链接指向的是一个初具雏形的网站,网站首页有一条致弗格森市民的信息——“你们并不孤单,我们将尽一切努力支持你们”——以及致当地警察的警告:“如果你们对对弗格森的抗议者们滥用职权、骚扰,或者伤害了他们,我们绝对会让你们所有政府部门的网站瘫痪。这不是威胁,这是承诺。”同时 Doyon 呼吁有 130 万粉丝的“匿名者”组织的 Twitter 账号 YourAnonNews 给与支持。“请支持‘弗格森’行动”,他发送了消息。一分钟后,YourAnonNews 回复表示同意。当天,包含话题 #OpFerguson 的 Twitter 发表/转推了超过六千次。</p>
|
||||
<p>次日早晨,Doyon 发布了一条链接,链接指向的是一个初具雏形的网站,网站首页有一条致弗格森市民的信息——“你们并不孤单,我们将尽一切努力支持你们”——以及致当地警察的警告:“如果你们对弗格森的抗议者们滥用职权、骚扰,或者伤害了他们,我们绝对会让你们所有政府部门的网站瘫痪。这不是威胁,这是承诺。”同时 Doyon 呼吁有 130 万粉丝的“匿名者”组织的 Twitter 账号 YourAnonNews 给与支持。“请支持‘弗格森’行动”,他发送了消息。一分钟后,YourAnonNews 回复表示同意。当天,包含话题 #OpFerguson 的 Twitter 被转发了超过六千次。</p>
|
||||
|
||||
<p>这个事件迅速成为头条新闻,同时匿名者们在弗格森周围进行了大集会。与“阿拉伯之春行动”类似,“匿名者”组织向抗议者们发送了电子关怀包,包括抗暴指导(“把瓦斯弹捡起来回丢给警察”)与可打印的盖伊·福克斯面具。Jackson 和其他示威者在弗格森进行示威游行时,警察企图通过橡皮子弹和催泪瓦斯来驱散他们。“当时的情景真像是布鲁斯·威利斯的电影里的情节,” Jackson 后来告诉我。“不过巴拉克·奥巴马应该并不会支持‘匿名者’组织传授给我们的这些知识,”他笑称道。“让那些警察赶到束手无策真的是太爽了。”</p>
|
||||
<p>这个事件迅速成为头条新闻,同时匿名者们在弗格森周围进行了大集会。与“阿拉伯之春行动”类似,“匿名者”组织向抗议者们发送了电子关怀包,包括抗暴指导(“把瓦斯弹捡起来回丢给警察”)与可打印的盖伊·福克斯面具。Jackson 和其他示威者在弗格森进行示威游行时,警察企图通过橡皮子弹和催泪瓦斯来驱散他们。“当时的情景真像是布鲁斯·威利斯的电影里的情节,” Jackson 后来告诉我。“不过巴拉克·奥巴马应该并不会支持‘匿名者’组织传授给我们的这些知识,”他说道。“知道有人在你的背后支持你,真是感觉欣慰。”</p>
|
||||
|
||||
<p>有个域名是 www.opferguson.com 的网站,后来发现不过是一个骗局——一个用来收集访问者 ip 地址的陷阱,随后这些地址会被移交给执法机构。有些人怀疑 Commander X 是政府的线人。在 IRC 聊天室 #OpFerguson 频道,一个名叫 Sherlock 写道,“现在频道里每个人说的已经让我害怕去点击任何陌生的链接了。除非是一个我非常熟悉的网址,否则我绝对不会去点击。”</p>
|
||||
<p>有个网址是 www.opferguson.com 的网站,后来发现不过是一个骗局——一个用来收集访问者 ip 地址的陷阱,随后这些地址会被移交给执法机构。有些人怀疑 Commander X 是政府的线人。在 IRC 聊天室 #OpFerguson 频道,一个名叫 Sherlock 写道,“现在频道里每个人说的已经让我害怕去点击任何陌生的链接了。除非是一个我非常熟悉的网址,否则我绝对不会去点击。”</p>
|
||||
|
||||
<p>弗格森的抗议者要求当局公布射杀 Brown 的警察的名字。几天后,匿名者们附和了抗议者们的请求。有人在 Twitter 上写道,“弗格森警察局最好公布肇事警察的名字,否则‘匿名者’组织将会替他们公布。”8 月 12 的新闻发布会上,圣路易斯警察局的局长 Jon Belmar 拒绝了这个请求。“我们不会这样做,除非他们被某个罪名所指控,”他说道。</p>
|
||||
|
||||
<p>作为报复,一名黑客使用名为 TheAnonMessage 的 Twitter 账户公布了一条链接,该链接指向一段来自警察的无线电设备所记录的音频文件,文件记录时间是 Brown 被枪杀的两小时左右。TheAnonMessage 同时也把矛头指向了 Belmar,在 Twitter 上公布了这位警察局长的家庭住址、电话号码以及他的家庭照片——一张是他的儿子在长椅上睡觉,另一张则是 Belmar 和他的妻子的合影。“不错的照片,Jon,” TheAnonMessage 在 Twitter 上写道。“你的妻子在她这个年龄算是一个美人了。你已经爱她爱得不耐烦了吗?”一个小时后,TheAnonMessage 又以 Belmar 的女儿为把柄进行了恐吓。</p>
|
||||
|
||||
<p>Richard Stallman,来自 MIT 的初代黑客,告诉我虽然他在很多地方赞同“匿名者”组织的行为,但他认为这些泄露私人信息的攻击行为是要受到谴责的。即使是在国内,TheAnonMessage 的行为也受到了谴责。“为何要泄露无辜的人的信息到网上?”一位匿名者通过 IRC 发问,并且表示威胁 Belmar 的家人实在是“相当愚蠢的行为”。但是 TheAnonMessage 和其他的一些匿名者仍然进行着不断搜寻,并企图在将来再次进行泄露信息的攻击。在互联网上可以得到所有弗格森警察局警员的名字,匿名者们不断地搜索着信息,企图找出具体是哪一个警察找出杀害了 Brown。</p>
|
||||
<p>Richard Stallman,来自 MIT 的初代黑客,告诉我虽然他在很多地方赞同“匿名者”组织的行为,但他认为这些泄露私人信息的攻击行为是要受到谴责的。即使是组织内部,TheAnonMessage 的行为也受到了谴责。“为何要泄露无辜的人的信息到网上?”一位匿名者通过 IRC 发问,并且表示威胁 Belmar 的家人实在是“相当愚蠢的行为”。但是 TheAnonMessage 和其他的一些匿名者仍然进行着不断搜寻,并企图在将来再次进行泄露信息的攻击。在互联网上可以得到所有弗格森警察局警员的名字,匿名者们不断地搜索着信息,企图找出具体是哪一个警察找出杀害了 Brown。</p>
|
||||
|
||||
<center><img src="http://www.newyorker.com/wp-content/uploads/2014/09/140908_steig-1999-04-12-600.jpg" /></center>
|
||||
|
||||
<center><small></small>1999 年 4 月 12 日 “我应该把镜头对向谁?”</center>
|
||||
|
||||
<p>8 月 14 日清晨,及位匿名者基于 Facebook 上的照片还有其他的证据,确定了射杀 Brown 的凶手是一位名叫 Bryan Willman 的 32 岁男子。根据一份 IRC 聊天记录,一位匿名者贴出了 Willman 的浮夸面孔的照片;另一位匿名者提醒道,“凶手声称自己的脸没有被任何人看到。”另一位昵称为 Anonymous|11057 的匿名者承认他对 Willman 的怀疑确实是“跳跃性的可能错误的逻辑过程推导出来的。”不过他还是写道,“我只是无法动摇自己的想法。虽然我没有任何证据,但我非常非常地确信就是他。”</p>
|
||||
<p>8 月 14 日清晨,几位匿名者基于 Facebook 上的照片还有其他的证据,确定了射杀 Brown 的凶手是一位名叫 Bryan Willman 的 32 岁男子。根据一份 IRC 聊天记录,一位匿名者贴出了 Willman 的肿胀面孔的照片;另一位匿名者提醒道,“凶手声称自己的脸没有被任何人看到。”另一位昵称为 Anonymous|11057 的匿名者承认他对 Willman 的怀疑确实是“跳跃性的可能错误的逻辑过程推导出来的。”不过他还是写道,“我只是无法动摇自己的想法。虽然我没有任何证据,但我非常非常地确信就是他。”</p>
|
||||
|
||||
<p>TheAnonMessage 看起来被这次对话逗乐了,写道,“#愿逝者安息,凶手是 BryanWillman。”另一位匿名者发出了强烈警告。“请务必确认,” Anonymous|2252 写道。“这不仅仅关乎到一个人的性命,我们可以不负责任地向公众公布我们的结果,但却很可能有无辜的人会因此受到不应受到的对待。”</p>
|
||||
|
||||
@ -356,15 +356,15 @@ Doyon 和软件主管在加拿大的小木屋里呆了几天。在一次同 Barr
|
||||
|
||||
<blockquote>anondepp:lol</blockquote>
|
||||
|
||||
<p>早晨 9 时 45 分,圣路易斯警察局对 TheAnonMessage 进行了答复。“Bryan Willman 从来没有在弗格森警察局或者圣路易斯警察局任过职,” 他们在 Twitter 上写道。“请不要再公布这位无辜市民的信息了。”(随后 FBI 对弗格森警察的电脑遭黑客入侵的事情展开了调查。)Twitter 管理员迅速封禁了 TheAnonMessage 的账户,但 Willman 的名字和家庭住址仍然被广泛传开。</p>
|
||||
<p>早晨 9 时 45 分,圣路易斯警察局对 TheAnonMessage 进行了答复。“Bryan Willman 从来没有在 警察局或者圣路易斯警察局任过职,” 他们在 Twitter 上写道。“请不要再公布这位无辜市民的信息了。”(随后 FBI 对弗格森警察的电脑遭黑客入侵的事情展开了调查。)Twitter 管理员迅速封禁了 TheAnonMessage 的账户,但 Willman 的名字和家庭住址仍然被广泛传开。</p>
|
||||
|
||||
<p>实际上,Willman 是弗格森西郊圣安区的警察外勤负责人。当圣路易斯警察局的情报处打电话告诉 Willman,他已经被“确认”为凶手时,他告诉我,“我以为不过是个奇怪的笑话。”几小时后,他的社交账号上就收到了数百条要杀死他的威胁。他在警察的保护下,独自一人在家里呆了将近一个星期。“我只希望这一切都尽快过去,”他告诉我他的感受。他认为“匿名者”组织已经不可挽回地损害了他的名誉。“我不知道他们怎么会以为自己可以被再次信任的,”他说。</p>
|
||||
<p>实际上,Willman 是弗格森西郊圣安区的警察外勤负责人。当圣路易斯警察局的情报处打电话告诉 Willman,他已经被“确认”为凶手时,他告诉我,“我以为不过是个奇怪的笑话。”几小时后,他的社交账号上就收到了成百上千条死亡恐吓。他在警察的保护下,独自一人在家里呆了将近一个星期。“我只希望这一切都尽快过去,”他告诉我他的感受。他认为“匿名者”组织已经不可挽回地损害了他的名誉。“我不知道他们怎么会以为自己可以被再次信任的,”他说。</p>
|
||||
|
||||
<p>“我们并不完美,” OpFerguson 在 Twitter 上说道。“‘匿名者’组织确实犯错了,过去的几天我们制造一些混乱。为此,我们道歉。”尽管 Doyon 并不应该为这次错误的信息泄露攻击负责,但其他的匿名者却因为他发起了一次无法控制的行动,而归咎他。YourAnonNews 在 Pastebin 上发表了一则消息,上面写道,“你们也许注意到了组织不同的 Twitter 账户发表的话题 #Ferguson 和 #OpFerguson,这两个话题下的 Twitter 与信息是相互矛盾的。为什么会在这些关键话题上出现分歧,部分原因是因为 CommanderX 是一个‘想让自己出名的疯子/想让公众认识自己的疯子’——这种人喜欢,或者至少不回避媒体的宣传——并且显而易见的,组织内大部分成员并不喜欢这样。”</p>
|
||||
|
||||
<p>在个人 Twitter 上,Doyon 否认了所有关于“弗格森行动”的职责,他写道,“我讨厌这样。我不希望这样的情况发生,我也不希望和我认为是朋友的人战斗。”沉寂了几天后,他又再度获吹响了战斗的号角。他最近在 Twitter 上写道,“你们称他们是暴民,我们却称他们是压迫下的反抗之声”以及“解放西藏”。</p>
|
||||
|
||||
<p>Doyon 仍然处于藏匿状态。甚至连他的律师 Jay Leiderman 也不知道他在哪里。Leiderman 表示,除了在圣克鲁斯受到的指控,Doyon 很有可能因为攻击了 PayPal 和奥兰多而面临新的指控。一旦他被捕,所有的刑期加起来,他的余生就要在监狱里度过了。借鉴 Edward Snowden 的先例,他希望申请去俄罗斯避难。我们谈话时,他用一支点燃的香烟在他的公寓里比划着。“这里比他【哔~】的牢房强多了吧?我绝对不会出去,”他愤愤道。“我不会再联系我的家人了....这是相当高的代价,但我必须这么做,我会尽我的努力让所有人活得自由、明白。”</p>
|
||||
<p>Doyon 仍然处于藏匿状态。甚至连他的律师 Jay Leiderman 也不知道他在哪里。Leiderman 表示,除了在圣克鲁斯受到的指控,Doyon 很有可能因为攻击了 PayPal 和奥兰多而面临新的指控。一旦他被捕,所有的刑期加起来,他的余生就要在监狱里度过了。借鉴 Edward Snowden 的先例,他希望申请去俄罗斯避难。我们谈话时,他用一支点燃的香烟在他的公寓里比划着。“这里比【哔~】的牢房强多了吧?我绝对不会出去,”他愤愤道。“我不会再联系我的家人了....这是相当高的代价,但我必须这么做,我会尽我的努力让所有人活得自由、明白。”</p>
|
||||
|
||||
|
||||
|
||||
@ -372,6 +372,6 @@ Doyon 和软件主管在加拿大的小木屋里呆了几天。在一次同 Barr
|
||||
|
||||
<p>作者:<a href="http://www.newyorker.com/contributors/david-kushner">David Kushner</a></p>
|
||||
<p>译者:<a href="https://github.com/SteveArcher">SteveArcher</a></p>
|
||||
<p>校对:<a href="https://github.com/校对者ID">校对者ID</a></p>
|
||||
<p>校对:<a href="https://github.com/carolinewuyan">Caroline</a></p>
|
||||
|
||||
<p>本文由 <a href="https://github.com/LCTT/TranslateProject">LCTT</a> 原创翻译,<a href="http://linux.cn/">Linux中国</a>荣誉推出</p>
|
||||
@ -1,87 +0,0 @@
|
||||
[bazz2 is here]
|
||||
What’s wrong with IPv4 and Why we are moving to IPv6
|
||||
================================================================================
|
||||
For the past 10 years or so, this has been the year that IPv6 will become wide spread. It hasn’t happened yet. Consequently, there is little widespread knowledge of what IPv6 is, how to use it, or why it is inevitable.
|
||||
|
||||

|
||||
|
||||
IPv4 and IPv6 Comparison
|
||||
|
||||
### What’s wrong with IPv4? ###
|
||||
|
||||
We’ve been using **IPv4** ever since RFC 791 was published in 1981. At the time, computers were big, expensive, and rare. IPv4 had provision for **4 billion IP** addresses, which seemed like an enormous number compared to the number of computers. Unfortunately, IP addresses are not use consequently. There are gaps in the addressing. For example, a company might have an address space of **254 (2^8-2)** addresses, and only use 25 of them. The remaining 229 are reserved for future expansion. Those addresses cannot be used by anybody else, because of the way networks route traffic. Consequently, what seemed like a large number in 1981 is actually a small number in 2014.
|
||||
|
||||
The Internet Engineering Task Force (**IETF**) recognized this problem in the early 1990s and came up with two solutions: Classless Internet Domain Router (**CIDR**) and private IP addresses. Prior to the invention of CIDR, you could get one of three network sizes: **24 bits** (16,777,214 addresses), **20 bits** (1,048,574 addresses) and **16 bits** (65,534 addresses). Once CIDR was invented, it was possible to split networks into subnetworks.
|
||||
|
||||
So, for example, if you needed **5 IP** addresses, your ISP would give you a network with a size of 3 bits which would give you **6 IP** addresses. So that would allow your ISP to use addresses more efficiently. Private IP addresses allow you to create a network where each machine on the network can easily connect to another machine on the internet, but where it is very difficult for a machine on the internet to connect back to your machine. Your network is private, hidden. Your network could be very large, 16,777,214 addresses, and you could subnet your private network into smaller networks, so that you could manage your own addresses easily.
|
||||
|
||||
You are probably using a private address right now. Check your own IP address: if it is in the range of **10.0.0.0 – 10.255.255.255** or **172.16.0.0 – 172.31.255.255** or **192.168.0.0 – 192.168.255.255**, then you are using a private IP address. These two solutions helped forestall disaster, but they were stopgap measures and now the time of reckoning is upon us.
|
||||
|
||||
Another problem with **IPv4** is that the IPv4 header was variable length. That was acceptable when routing was done by software. But now routers are built with hardware, and processing the variable length headers in hardware is hard. The large routers that allow packets to go all over the world are having problems coping with the load. Clearly, a new scheme was needed with fixed length headers.
|
||||
|
||||
Still another problem with **IPv4** is that, when the addresses were allocated, the internet was an American invention. IP addresses for the rest of the world are fragmented. A scheme was needed to allow addresses to be aggregated somewhat by geography so that the routing tables could be made smaller.
|
||||
|
||||
Yet another problem with IPv4, and this may sound surprising, is that it is hard to configure, and hard to change. This might not be apparent to you, because your router takes care of all of these details for you. But the problems for your ISP drives them nuts.
|
||||
|
||||
All of these problems went into the consideration of the next version of the Internet.
|
||||
|
||||
### About IPv6 and its Features ###
|
||||
|
||||
The **IETF** unveiled the next generation of IP in December 1995. The new version was called IPv6 because the number 5 had been allocated to something else by mistake. Some of the features of IPv6 included.
|
||||
|
||||
- 128 bit addresses (3.402823669×10³⁸ addresses)
|
||||
- A scheme for logically aggregating addresses
|
||||
- Fixed length headers
|
||||
- A protocol for automatically configuring and reconfiguring your network.
|
||||
|
||||
Let’s look at these features one by one:
|
||||
|
||||
#### Addresses ####
|
||||
|
||||
The first thing everybody notices about **IPv6** is that the number of addresses is enormous. Why so many? The answer is that the designers were concerned about the inefficient organization of addresses, so there are so many available addresses that we could allocate inefficiently in order to achieve other goals. So, if you want to build your own IPv6 network, chances are that your ISP will give you a network of **64 bits** (1.844674407×10¹⁹ addresses) and let you subnet that space to your heart’s content.
|
||||
|
||||
#### Aggregation ####
|
||||
|
||||
With so many addresses to use, the address space can be allocated sparsely in order to route packets efficiently. So, your ISP gets a network space of **80 bits**. Of those 80 bits, 16 of them are for the ISPs subnetworks, and 64 bits are for the customer’s networks. So, the ISP can have 65,534 networks.
|
||||
|
||||
However, that address allocation isn’t cast in stone, and if the ISP wants more smaller networks, it can do that (although probably the ISP would probably simply ask for another space of 80 bits). The upper 48 bits is further divided, so that ISPs that are “**close**” to one another have similar network addresses ranges, to allow the networks to be aggregated in the routing tables.
|
||||
|
||||
#### Fixed length Headers ####
|
||||
|
||||
An **IPv4** header has a variable length. An **IPv6** header always has a fixed length of 40 bytes. In IPv4, extra options caused the header to increase in size. In IPv6, if additional information is needed, that additional information is stored in extension headers, which follow the IPv6 header and are generally not processed by the routers, but rather by the software at the destination.
|
||||
|
||||
One of the fields in the IPv6 header is the flow. A flow is a **20 bit** number which is created pseudo-randomly, and it makes it easier for the routers to route packets. If a packet has a flow, then the router can use that flow number as an index into a table, which is fast, rather than a table lookup, which is slow. This feature makes **IPv6** very easy to route.
|
||||
|
||||
#### Automatic Configuration ####
|
||||
|
||||
In **IPv6**, when a machine first starts up, it checks the local network to see if any other machine is using its address. If the address is unused, then the machine next looks for an IPv6 router on the local network. If it finds the router, then it asks the router for an IPv6 address to use. Now, the machine is set and ready to communicate on the internet – it has an IP address for itself and it has a default router.
|
||||
|
||||
If the router should go down, then the machines on the network will detect the problem and repeat the process of looking for an IPv6 router, to find the backup router. That’s actually hard to do in IPv4. Similarly, if the router wants to change the addressing scheme on its network, it can. The machines will query the router from time to time and change their addresses automatically. The router will support both the old and new addresses until all of the machines have switched over to the new configuration.
|
||||
|
||||
IPv6 automatic configuration is not a complete solution. There are some other things that a machine needs in order to use the internet effectively: the name servers, a time server, perhaps a file server. So there is **dhcp6** which does the same thing as dhcp, only because the machine boots in a routable state, one dhcp daemon can service a large number of networks.
|
||||
|
||||
#### There’s one big problem ####
|
||||
|
||||
So if IPv6 is so much better than IPv4, why hasn’t adoption been more widespread (as of **May 2014**, Google estimates that its IPv6 traffic is about **4%** of its total traffic)? The basic problem is which comes first, the **chicken or the egg**? Somebody running a server wants the server to be as widely available as possible, which means it must have an **IPv4** address.
|
||||
|
||||
It could also have an IPv6 address, but few people would use it and you do have to change your software a little to accommodate IPv6. Furthermore, a lot of home networking routers do not support IPv6. A lot of ISPs do not support IPv6. I asked my ISP about it, and I was told that they will provide it when customers ask for it. So I asked how many customers had asked for it. One, including me.
|
||||
|
||||
By way of contrast, all of the major operating systems, Windows, OS X, and Linux support IPv6 “**out of the box**” and have for years. The operating systems even have software that will allow IPv6 packets to “**tunnel**” within IPv4 to a point where the IPv6 packets can be removed from the surrounding IPv4 packet and sent on their way.
|
||||
|
||||
#### Conclusion ####
|
||||
|
||||
IPv4 has served us well for a long time. IPv4 has some limitations which are going to present insurmountable problems in the near future. IPv6 will solve those problems by changing the strategy for allocating addresses, making improvements to ease the routing of packets, and making it easier to configure a machine when it first joins the network.
|
||||
|
||||
However, acceptance and usage of IPv6 has been slow, because change is hard and expensive. The good news is that all operating systems support IPv6, so when you are ready to make the change, your computer will need little effort to convert to the new scheme.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/ipv4-and-ipv6-comparison/
|
||||
|
||||
作者:[Jeff Silverman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/jeffsilverm/
|
||||
@ -0,0 +1,100 @@
|
||||
Shellshock: How to protect your Unix, Linux and Mac servers
|
||||
================================================================================
|
||||
> **Summary**: The Unix/Linux Bash security hole can be deadly to your servers. Here's what you need to worry about, how to see if you can be attacked, and what to do if your shields are down.
|
||||
|
||||
The only thing you have to fear with [Shellshock, the Unix/Linux Bash security hole][1], is fear itself. Yes, Shellshock can serve as a highway for worms and malware to hit your Unix, Linux, and Mac servers, but you can defend against it.
|
||||
|
||||

|
||||
|
||||
If you don't patch and defend yourself against Shellshock today, you may have lost control of your servers by tomorrow.
|
||||
|
||||
However, Shellshock is not as bad as [HeartBleed][2]. Not yet, anyway.
|
||||
|
||||
While it's true that the [Bash shell][3] is the default command interpreter on most Unix and Linux systems and all Macs — the majority of Web servers — for an attacker to get to your system, there has to be a way for him or her to actually get to the shell remotely. So, if you're running a PC without [ssh][4], [rlogin][5], or another remote desktop program, you're probably safe enough.
|
||||
|
||||
A more serious problem is faced by devices that use embedded Linux — such as routers, switches, and appliances. If you're running an older, no longer supported model, it may be close to impossible to patch it and will likely be vulnerable to attacks. If that's the case, you should replace as soon as possible.
|
||||
|
||||
The real and present danger is for servers. According to the National Institute of Standards (NIST), [Shellshock scores a perfect 10][6] for potential impact and exploitability. [Red Hat][7] reports that the most common attack vectors are:
|
||||
|
||||
- **httpd (Your Web server)**: CGI [Common-Gateway Interface] scripts are likely affected by this issue: when a CGI script is run by the web server, it uses environment variables to pass data to the script. These environment variables can be controlled by the attacker. If the CGI script calls Bash, the script could execute arbitrary code as the httpd user. mod_php, mod_perl, and mod_python do not use environment variables and we believe they are not affected.
|
||||
- **Secure Shell (SSH)**: It is not uncommon to restrict remote commands that a user can run via SSH, such as rsync or git. In these instances, this issue can be used to execute any command, not just the restricted command.
|
||||
- **dhclient**: The [Dynamic Host Configuration Protocol Client (dhclient)][8] is used to automatically obtain network configuration information via DHCP. This client uses various environment variables and runs Bash to configure the network interface. Connecting to a malicious DHCP server could allow an attacker to run arbitrary code on the client machine.
|
||||
- **[CUPS][9] (Linux, Unix and Mac OS X's print server)**: It is believed that CUPS is affected by this issue. Various user-supplied values are stored in environment variables when cups filters are executed.
|
||||
- **sudo**: Commands run via sudo are not affected by this issue. Sudo specifically looks for environment variables that are also functions. It could still be possible for the running command to set an environment variable that could cause a Bash child process to execute arbitrary code.
|
||||
- **Firefox**: We do not believe Firefox can be forced to set an environment variable in a manner that would allow Bash to run arbitrary commands. It is still advisable to upgrade Bash as it is common to install various plug-ins and extensions that could allow this behavior.
|
||||
- **Postfix**: The Postfix [mail] server will replace various characters with a ?. While the Postfix server does call Bash in a variety of ways, we do not believe an arbitrary environment variable can be set by the server. It is however possible that a filter could set environment variables.
|
||||
|
||||
So much for Red Hat's thoughts. Of these, the Web servers and SSH are the ones that worry me the most. The DHCP client is also troublesome, especially if, as it the case with small businesses, your external router doubles as your Internet gateway and DHCP server.
|
||||
|
||||
Of these, Web server attacks seem to be the most common by far. As Florian Weimer, a Red Hat security engineer, wrote: "[HTTP requests to CGI scripts][10] have been identified as the major attack vector." Attacks are being made against systems [running both Linux and Mac OS X][11].
|
||||
|
||||
Jaime Blasco, labs director at [AlienVault][12], a security management services company, ran a [honeypot][13] looking for attackers and found "[several machines trying to exploit the Bash vulnerability][14]. The majority of them are only probing to check if systems are vulnerable. On the other hand, we found two worms that are actively exploiting the vulnerability and installing a piece of malware on the system."
|
||||
|
||||
Other security researchers have found that the malware is the usual sort. They typically try to plant distributed denial of service (DDoS) IRC bots and attempt to guess system logins and passwords using a list of poor passwords such as 'root', 'admin', 'user', 'login', and '123456.'
|
||||
|
||||
So, how do you know if your servers can be attacked? First, you need to check to see if you're running a vulnerable version of Bash. To do that, run the following command from a Bash shell:
|
||||
|
||||
env x='() { :;}; echo vulnerable' bash -c "echo this is a test"
|
||||
|
||||
If you get the result:
|
||||
|
||||
*vulnerable this is a test*
|
||||
|
||||
Bad news, your version of Bash can be hacked. If you see:
|
||||
|
||||
*bash: warning: x: ignoring function definition attempt bash: error importing function definition for `x' this is a test*
|
||||
|
||||
You're good. Well, to be more exact, you're as protected as you can be at the moment.
|
||||
|
||||
While all major Linux distributors have released patches that stop most attacks — [Apple has not released a patch yet][15] — it has been discovered that "[patches shipped for this issue are incomplete][16]. An attacker can provide specially-crafted environment variables containing arbitrary commands that will be executed on vulnerable systems under certain conditions." While it's unclear if these attacks can be used to hack into a system, it is clear that they can be used to crash them, thanks to a null-pointer exception.
|
||||
|
||||
Patches to fill-in the [last of the Shellshock security hole][17] are being worked on now. In the meantime, you should update your servers as soon as possible with the available patches and keep an eye open for the next, fuller ones.
|
||||
|
||||
In the meantime, if, as is likely, you're running the Apache Web server, there are some [Mod_Security][18] rules that can stop attempts to exploit Shellshock. These rules, created by Red Hat, are:
|
||||
|
||||
Request Header values:
|
||||
SecRule REQUEST_HEADERS "^\(\) {" "phase:1,deny,id:1000000,t:urlDecode,status:400,log,msg:'CVE-2014-6271 - Bash Attack'"
|
||||
|
||||
SERVER_PROTOCOL values:
|
||||
SecRule REQUEST_LINE "\(\) {" "phase:1,deny,id:1000001,status:400,log,msg:'CVE-2014-6271 - Bash Attack'"
|
||||
|
||||
GET/POST names:
|
||||
SecRule ARGS_NAMES "^\(\) {" "phase:2,deny,id:1000002,t:urlDecode,t:urlDecodeUni,status:400,log,msg:'CVE-2014-6271 - Bash Attack'"
|
||||
|
||||
GET/POST values:
|
||||
SecRule ARGS "^\(\) {" "phase:2,deny,id:1000003,t:urlDecode,t:urlDecodeUni,status:400,log,msg:'CVE-2014-6271 - Bash Attack'"
|
||||
|
||||
File names for uploads:
|
||||
SecRule FILES_NAMES "^\(\) {" "phase:2,deny,id:1000004,t:urlDecode,t:urlDecodeUni,status:400,log,msg:'CVE-2014-6271 - Bash Attack'"
|
||||
|
||||
It is vital that you patch your servers as soon as possible, even with the current, incomplete ones, and to set up defenses around your Web servers. If you don't, you could come to work tomorrow to find your computers completely compromised. So get out there and start patching!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/shellshock-how-to-protect-your-unix-linux-and-mac-servers-7000034072/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://www.zdnet.com/unixlinux-bash-critical-security-hole-uncovered-7000034021/
|
||||
[2]:http://www.zdnet.com/heartbleed-serious-openssl-zero-day-vulnerability-revealed-7000028166
|
||||
[3]:http://www.gnu.org/software/bash/
|
||||
[4]:http://www.openbsd.org/cgi-bin/man.cgi?query=ssh&sektion=1
|
||||
[5]:http://unixhelp.ed.ac.uk/CGI/man-cgi?rlogin
|
||||
[6]:http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-7169
|
||||
[7]:http://www.redhat.com/
|
||||
[8]:http://www.isc.org/downloads/dhcp/
|
||||
[9]:https://www.cups.org/
|
||||
[10]:http://seclists.org/oss-sec/2014/q3/650
|
||||
[11]:http://www.zdnet.com/first-attacks-using-shellshock-bash-bug-discovered-7000034044/
|
||||
[12]:http://www.alienvault.com/
|
||||
[13]:http://www.sans.org/security-resources/idfaq/honeypot3.php
|
||||
[14]:http://www.alienvault.com/open-threat-exchange/blog/attackers-exploiting-shell-shock-cve-2014-6721-in-the-wild
|
||||
[15]:http://apple.stackexchange.com/questions/146849/how-do-i-recompile-bash-to-avoid-the-remote-exploit-cve-2014-6271-and-cve-2014-7
|
||||
[16]:https://bugzilla.redhat.com/show_bug.cgi?id=1141597#c27
|
||||
[17]:http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2014-7169
|
||||
[18]:http://www.inmotionhosting.com/support/website/modsecurity/what-is-modsecurity-and-why-is-it-important
|
||||
@ -0,0 +1,65 @@
|
||||
What Linux Users Should Know About Open Hardware
|
||||
================================================================================
|
||||
> What Linux users don't know about manufacturing open hardware can lead them to disappointment.
|
||||
|
||||
Business and free software have been intertwined for years, but the two often misunderstand one another. That's not surprising -- what is just a business to one is way of life for the other. But the misunderstanding can be painful, which is why debunking it is a worth the effort.
|
||||
|
||||
An increasingly common case in point: the growing attempts at open hardware, whether from Canonical, Jolla, MakePlayLive, or any of half a dozen others. Whether pundit or end-user, the average free software user reacts with exaggerated enthusiasm when a new piece of hardware is announced, then retreats into disillusionment as delay follows delay, often ending in the cancellation of the entire product.
|
||||
|
||||
It's a cycle that does no one any good, and often breeds distrust – and all because the average Linux user has no idea what's happening behind the news.
|
||||
|
||||
My own experience with bringing products to market is long behind me. However, nothing I have heard suggests that anything has changed. Bringing open hardware or any other product to market remains not just a brutal business, but one heavily stacked against newcomers.
|
||||
|
||||
### Searching for Partners ###
|
||||
|
||||
Both the manufacturing and distribution of digital products is controlled by a relatively small number of companies, whose time can sometimes be booked months in advance. Profit margins can be tight, so like movie studios that buy the rights to an ancient sit-com, the manufacturers usually hope to clone the success of the latest hot product. As Aaron Seigo told me when talking about his efforts to develop the Vivaldi tablet, the manufacturers would much rather prefer someone else take the risk of doing anything new.
|
||||
|
||||
Not only that, but they would prefer to deal with someone with an existing sales record who is likely to bring repeat business.
|
||||
|
||||
Besides, the average newcomer is looking at a product run of a few thousand units. A chip manufacturer would much rather deal with Apple or Samsung, whose order is more likely in the hundreds of thousands.
|
||||
|
||||
Faced with this situation, the makers of open hardware are likely to find themselves cascading down into the list of manufacturers until they can find a second or third tier manufacturer that is willing to take a chance on a small run of something new.
|
||||
|
||||
They might be reduced to buying off-the-shelf components and assembling units themselves, as Seigo tried with Vivaldi. Alternatively, they might do as Canonical did, and find established partners that encourage the industry to take a gamble. Even if they succeed, they have usually taken months longer than they expected in their initial naivety.
|
||||
|
||||
### Staggering to Market ###
|
||||
|
||||
However, finding a manufacturer is only the first obstacle. As Raspberry Pi found out, even if the open hardware producers want only free software in their product, the manufacturers will probably insist that firmware or drivers stay proprietary in the name of protecting trade secrets.
|
||||
|
||||
This situation is guaranteed to set off criticism from potential users, but the open hardware producers have no choice except to compromise their vision. Looking for another manufacturer is not a solution, partly because to do so means more delays, but largely because completely free-licensed hardware does not exist. The industry giants like Samsung have no interest in free hardware, and, being new, the open hardware producers have no clout to demand any.
|
||||
|
||||
Besides, even if free hardware was available, manufacturers could probably not guarantee that it would be used in the next production run. The producers might easily find themselves re-fighting the same battle every time they needed more units.
|
||||
|
||||
As if all this is not enough, at this point the open hardware producer has probably spent 6-12 months haggling. The chances are, the industry standards have shifted, and they may have to start from the beginning again by upgrading specs.
|
||||
|
||||
### A Short and Brutal Shelf Life ###
|
||||
|
||||
Despite these obstacles, hardware with some degree of openness does sometimes get released. But remember the challenges of finding a manufacturer? They have to be repeated all over again with the distributors -- and not just once, but region by region.
|
||||
|
||||
Typically, the distributors are just as conservative as the manufacturers, and just as cautious about dealing with newcomers and new ideas. Even if they agree to add a product to their catalog, the distributors can easily decide not to encourage their representatives to promote it, which means that in a few months they have effectively removed it from the shelves.
|
||||
|
||||
Of course, online sales are a possibility. But meanwhile, the hardware has to be stored somewhere, adding to the cost. Production runs on demand are expensive even in the unlikely event that they are available, and even unassembled units need storage.
|
||||
|
||||
### Weighing the Odds ###
|
||||
|
||||
I have been generalizing wildly here, but anyone who has ever been involved in producing anything will recognize what I am describing as the norm. And just to make matters worse, open hardware producers typically discover the situation as they are going through it. Inevitably, they make mistakes, which adds still more delays.
|
||||
|
||||
But the point is, if you have any sense of the process at all, your knowledge is going to change how you react to news of another attempt at hardware. The process means that, unless a company has been in serious stealth mode, an announcement that a product will be out in six months will rapidly prove to be an outdate guestimate. 12-18 months is more likely, and the obstacles I describe may mean that the product will never actually be released.
|
||||
|
||||
For example, as I write, people are waiting for the emergence of the first Steam Machines, the Linux-based gaming consoles. They are convinced that the Steam Machines will utterly transform both Linux and gaming.
|
||||
|
||||
As a market category, Steam Machines may do better than other new products, because those who are developing them at least have experience developing software products. However, none of the dozen or so Steam Machines in development have produced more than a prototype after almost a year, and none are likely to be available for buying until halfway through 2015. Given the realities of hardware manufacturing, we will be lucky if half of them see daylight. In fact, a release of 2-4 might be more realistic.
|
||||
|
||||
I make that prediction with next to no knowledge of any of the individual efforts. But, having some sense of how hardware manufacturing works, I suspect that it is likely to be closer to what happens next year than all the predictions of a new Golden Age for Linux and gaming. I would be entirely happy being wrong, but the fact remains: what is surprising is not that so many Linux-associated hardware products fail, but that any succeed even briefly.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/what-linux-users-should-know-about-open-hardware-1.html
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
@ -1,238 +0,0 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
How to set up Nagios Remote Plugin Executor (NRPE) in Linux
|
||||
================================================================================
|
||||
As far as network management is concerned, Nagios is one of the most powerful tools. Nagios can monitor the reachability of remote hosts, as well as the state of services running on them. However, what if we want to monitor something other than network services for a remote host? For example, we may want to monitor the disk utilization or [CPU processor load][1] of a remote host. Nagios Remote Plugin Executor (NRPE) is a tool that can help with doing that. NRPE allows one to execute Nagios plugins installed on remote hosts, and integrate them with an [existing Nagios server][2].
|
||||
|
||||
This tutorial will cover how to set up NRPE on an existing Nagios deployment. The tutorial is primarily divided into two parts:
|
||||
|
||||
- Configure remote hosts.
|
||||
- Configure a Nagios monitoring server.
|
||||
|
||||
We will then finish off by defining some custom commands that can be used with NRPE.
|
||||
|
||||
### Configure Remote Hosts for NRPE ###
|
||||
|
||||
#### Step One: Installing NRPE Service ####
|
||||
|
||||
You need to install NRPE service on every remote host that you want to monitor using NRPE. NRPE service daemon on each remote host will then communicate with a Nagios monitoring server.
|
||||
|
||||
Necessary packages for NRPE service can easily be installed using apt-get or yum, subject to the platform. In case of CentOS, we will need to [add Repoforge repository][3] as NRPE is not available in CentOS repositories.
|
||||
|
||||
**On Debian, Ubuntu or Linux Mint:**
|
||||
|
||||
# apt-get install nagios-nrpe-server
|
||||
|
||||
**On CentOS, Fedora or RHEL:**
|
||||
|
||||
# yum install nagios-nrpe
|
||||
|
||||
#### Step Two: Preparing Configuration File ####
|
||||
|
||||
The configuration file /etc/nagios/nrpe.cfg is similar for Debian-based and RedHat-based systems. The configuration file is backed up, and then updated as follows.
|
||||
|
||||
# vim /etc/nagios/nrpe.cfg
|
||||
|
||||
----------
|
||||
|
||||
## NRPE service port can be customized ##
|
||||
server_port=5666
|
||||
|
||||
## the nagios monitoring server is permitted ##
|
||||
## NOTE: There is no space after the comma ##
|
||||
allowed_hosts=127.0.0.1,X.X.X.X-IP_v4_of_Nagios_server
|
||||
|
||||
## The following examples use hard-coded command arguments.
|
||||
## These parameters can be modified as needed.
|
||||
|
||||
## NOTE: For CentOS 64 bit, use /usr/lib64 instead of /usr/lib ##
|
||||
|
||||
command[check_users]=/usr/lib/nagios/plugins/check_users -w 5 -c 10
|
||||
command[check_load]=/usr/lib/nagios/plugins/check_load -w 15,10,5 -c 30,25,20
|
||||
command[check_hda1]=/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -p /dev/hda1
|
||||
command[check_zombie_procs]=/usr/lib/nagios/plugins/check_procs -w 5 -c 10 -s Z
|
||||
command[check_total_procs]=/usr/lib/nagios/plugins/check_procs -w 150 -c 200
|
||||
|
||||
Now that the configuration file is ready, NRPE service is ready to be fired up.
|
||||
|
||||
#### Step Three: Initiating NRPE Service ####
|
||||
|
||||
For RedHat-based systems, the NRPE service needs to be added as a startup service.
|
||||
|
||||
**On Debian, Ubuntu, Linux Mint:**
|
||||
|
||||
# service nagios-nrpe-server restart
|
||||
|
||||
**On CentOS, Fedora or RHEL:**
|
||||
|
||||
# service nrpe restart
|
||||
# chkconfig nrpe on
|
||||
|
||||
#### Step Four: Verifying NRPE Service Status ####
|
||||
|
||||
Information about NRPE daemon status can be found in the system log. For a Debian-based system, the log file will be /var/log/syslog. The log file for a RedHat-based system will be /var/log/messages. A sample log is provided below for reference.
|
||||
|
||||
nrpe[19723]: Starting up daemon
|
||||
nrpe[19723]: Listening for connections on port 5666
|
||||
nrpe[19723]: Allowing connections from: 127.0.0.1,X.X.X.X
|
||||
|
||||
In case firewall is running, TCP port 5666 should be open, which is used by NRPE daemon.
|
||||
|
||||
# netstat -tpln | grep 5666
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 0.0.0.0:5666 0.0.0.0:* LISTEN 19885/nrpe
|
||||
|
||||
### Configure Nagios Monitoring Server for NRPE ###
|
||||
|
||||
The first step in configuring an existing Nagios monitoring server for NRPE is to install NRPE plugin on the server.
|
||||
|
||||
#### Step One: Installing NRPE Plugin ####
|
||||
|
||||
In case the Nagios server is running on a Debian-based system (Debian, Ubuntu or Linux Mint), a necessary package can be installed using apt-get.
|
||||
|
||||
# apt-get install nagios-nrpe-plugin
|
||||
|
||||
After the plugin is installed, the check_nrpe command, which comes with the plugin, is modified a bit.
|
||||
|
||||
# vim /etc/nagios-plugins/config/check_nrpe.cfg
|
||||
|
||||
----------
|
||||
|
||||
## the default command is overwritten ##
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
In case the Nagios server is running on a RedHat-based system (CentOS, Fedora or RHEL), you can install NRPE plugin using yum. On CentOS, [adding Repoforge repository][4] is necessary.
|
||||
|
||||
# yum install nagios-plugins-nrpe
|
||||
|
||||
Now that the NRPE plugin is installed, proceed to configure a Nagios server following the rest of the steps.
|
||||
|
||||
#### Step Two: Defining Nagios Command for NRPE Plugin ####
|
||||
|
||||
First, we need to define a command in Nagios for using NRPE.
|
||||
|
||||
# vim /etc/nagios/objects/commands.cfg
|
||||
|
||||
----------
|
||||
|
||||
## NOTE: For CentOS 64 bit, use /usr/lib64 instead of /usr/lib ##
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
#### Step Three: Adding Host and Command Definition ####
|
||||
|
||||
Next, define remote host(s) and commands to execute remotely on them.
|
||||
|
||||
The following shows sample definitions of a remote host a command to execute on the host. Naturally, your configuration will be adjusted based on your requirements. The path to the file is slightly different for Debian-based and RedHat-based systems. But the content of the files are identical.
|
||||
|
||||
**On Debian, Ubuntu or Linux Mint:**
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe.cfg
|
||||
|
||||
**On CentOS, Fedora or RHEL:**
|
||||
|
||||
# vim /etc/nagios/objects/nrpe.cfg
|
||||
|
||||
----------
|
||||
|
||||
define host{
|
||||
use linux-server
|
||||
host_name server-1
|
||||
alias server-1
|
||||
address X.X.X.X-IPv4_address_of_remote_host
|
||||
}
|
||||
|
||||
define service {
|
||||
host_name server-1
|
||||
service_description Check Load
|
||||
check_command check_nrpe!check_load
|
||||
check_interval 1
|
||||
use generic-service
|
||||
}
|
||||
|
||||
#### Step Four: Restarting Nagios Service ####
|
||||
|
||||
Before restarting Nagios, updated configuration is verified with a dry run.
|
||||
|
||||
**On Ubuntu, Debian, or Linux Mint:**
|
||||
|
||||
# nagios3 -v /etc/nagios3/nagios.cfg
|
||||
|
||||
**On CentOS, Fedora or RHEL:**
|
||||
|
||||
# nagios -v /etc/nagios/nagios.cfg
|
||||
|
||||
If everything goes well, Nagios service can be restarted.
|
||||
|
||||
# service nagios restart
|
||||
|
||||
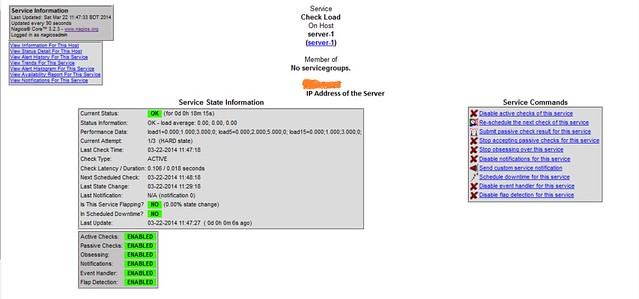
|
||||
|
||||
### Configuring Custom Commands with NRPE ###
|
||||
|
||||
#### Setup on Remote Servers ####
|
||||
|
||||
The following is a list of custom commands that can be used with NRPE. These commands are defined in the file /etc/nagios/nrpe.cfg located at the remote servers.
|
||||
|
||||
## Warning status when load average exceeds 1, 2 and 1 for 1, 5, 15 minute interval, respectively.
|
||||
## Critical status when load average exceeds 3, 5 and 3 for 1, 5, 15 minute interval, respectively.
|
||||
command[check_load]=/usr/lib/nagios/plugins/check_load -w 1,2,1 -c 3,5,3
|
||||
|
||||
## Warning level 25% and critical level 10% for free space of /home.
|
||||
## Could be customized to monitor any partition (e.g. /dev/sdb1, /, /var, /home)
|
||||
command[check_disk]=/usr/lib/nagios/plugins/check_disk -w 25% -c 10% -p /home
|
||||
|
||||
## Warn if number of instances for process_ABC exceeds 10. Critical for 20 ##
|
||||
command[check_process_ABC]=/usr/lib/nagios/plugins/check_procs -w 1:10 -c 1:20 -C process_ABC
|
||||
|
||||
## Critical if the number of instances for process_XYZ drops below 1 ##
|
||||
command[check_process_XYZ]=/usr/lib/nagios/plugins/check_procs -w 1: -c 1: -C process_XYZ
|
||||
|
||||
#### Setup on Nagios Monitoring Server ####
|
||||
|
||||
To apply the custom commands defined above, we modify the service definition at Nagios monitoring server as follows. The service definition could go to the file where all the services are defined (e.g., /etc/nagios/objects/nrpe.cfg or /etc/nagios3/conf.d/nrpe.cfg)
|
||||
|
||||
## example 1: check process XYZ ##
|
||||
define service {
|
||||
host_name server-1
|
||||
service_description Check Process XYZ
|
||||
check_command check_nrpe!check_process_XYZ
|
||||
check_interval 1
|
||||
use generic-service
|
||||
}
|
||||
|
||||
## example 2: check disk state ##
|
||||
define service {
|
||||
host_name server-1
|
||||
service_description Check Process XYZ
|
||||
check_command check_nrpe!check_disk
|
||||
check_interval 1
|
||||
use generic-service
|
||||
}
|
||||
|
||||
To sum up, NRPE is a powerful add-on to Nagios as it provides provision for monitoring a remote server in a highly configurable fashion. Using NRPE, we can monitor server load, running processes, logged in users, disk states and other parameters.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/03/nagios-remote-plugin-executor-nrpe-linux.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/2012/08/how-to-measure-average-cpu-utilization.html
|
||||
[2]:http://xmodulo.com/2013/12/install-configure-nagios-linux.html
|
||||
[3]:http://xmodulo.com/2013/01/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
[4]:http://xmodulo.com/2013/01/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
@ -0,0 +1,108 @@
|
||||
Git Rebase Tutorial: Going Back in Time with Git Rebase
|
||||
================================================================================
|
||||

|
||||
|
||||
A programmer since the tender age of 10, Christoph Burgdorf is the the founder of the HannoverJS meetup, and he has been an active member in the AngularJS community since its very beginning. He is also very knowledgeable about the ins and outs of git, where he hosts workshops at [thoughtram][1] to help beginners master the technology.
|
||||
|
||||
The following tutorial was originally posted on his [blog][2].
|
||||
|
||||
----------
|
||||
|
||||
### Tutorial: Git Rebase ###
|
||||
|
||||
Imagine you are working on that radical new feature. It’s going to be brilliant but it takes a while. You’ve been working on that for a couple of days now, maybe weeks.
|
||||
|
||||
Your feature branch is already six commits ahead of master. You’ve been a good developer and have crafted meaningful semantical commits. But there’s the thing: you are slowly realizing that this beast will still take some more time before it’s really ready to be merged back into master.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
|
||||
What you also realize is that some parts are actually less coupled to the new feature. They could land in master earlier. Unfortunately, the part that you want to port back into master earlier is in a commit somewhere in the middle of your six commits. Even worse, it also contains a change that relies on a previous commits of your feature branch. One could argue that you should have made that two commits in the first place, but then nobody is perfect.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
^
|
||||
|
|
||||
mixed commit
|
||||
|
||||
At the time that you crafted the commit, you didn’t foresee that you might come into a situation where you want to gradually bring the feature into master. Heck! You wouldn’t have guessed that this whole thing could take us so long.
|
||||
|
||||
What you need is a way to go back in history, open up the commit and split it into two commits so that you can separate out all the things that are safe to be ported back into master by now.
|
||||
|
||||
Speaking in terms of a graph, we want to have it like this.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3a-f3b-f4-f5-f6(feature)
|
||||
|
||||
With the work split into two commits, we could just cherry-pick the precious bits into master.
|
||||
|
||||
Turns out, git comes with a powerful command git rebase -i which lets us do exactly that. It lets us change the history. Changing the history can be problematic and as a rule of thumb should be avoided as soon as the history is shared with others. In our case though, we are just changing history of our local feature branch. Nobody will get hurt. Promised!
|
||||
|
||||
Ok, let’s take a closer look at what exactly happened in commit f3. Turns out we modified two files: userService.js and wishlistService.js. Let’s say that the changes to userService.js could go straight back into master whereas the changes to wishlistService.js could not. Because wishlistService.js does not even exist in master. It was introduced in commit f1.
|
||||
|
||||
> Pro Tip: even if the changes would have been in one file, git could handle that. We keep things simple for this blog post though.
|
||||
|
||||
We’ve set up a [public demo repository][3] that we will use for this exercise. To make it easier to follow, each commit message is prefixed with the pseudo SHAs used in the graphs above. What follows is the branch graph as printed by git before we start to split the commit f3.
|
||||
|
||||

|
||||
|
||||
Now the first thing we want to do is to checkout our feature branch with git checkout feature. To get started with the rebase we run git rebase -i master.
|
||||
|
||||
Now what follows is that git opens a temporary file in the configured editor (defaults to Vim).
|
||||
|
||||

|
||||
|
||||
This file is meant to provide you some options for the rebase and it comes with a little cheat sheet (the blue text). For each commit we could choose between the actions pick, reword, edit, squash, fixup and exec. Each action can also be referred to by its short form p, r, e, s, f and e. It’s out of the scope of this article to describe each and every option so let’s focus on our specific task.
|
||||
|
||||
We want to choose the edit option for our f3 commit hence we change the contents to look like that.
|
||||
|
||||
Now we save the file (in Vim <ESC> followed by :wq, followed by <RETURN>). The next thing we notice is that git stops the rebase at the commit for which we choose the edit option.
|
||||
|
||||
What this means is that git started to apply f1, f2 and f3 as if it was a regular rebase but then stopped **after** applying f3. In fact, we can prove that if we just look at the log at the point where we stopped.
|
||||
|
||||
To split our commit f3 into two commits, all we have to do at this point is to reset gits pointer to the previous commit (f2) while keeping the working directory the same as it is right now. This is exactly what the mixed mode of git reset does. Since mixed is the default mode of git reset we can just write git reset head~1. Let’s do that and also run git status right after it to see what happened.
|
||||
|
||||
The git status tells us that both our userService.js and our wishlistService.js are modified. If we run git diff we can see that those are exactly the changes of our f3 commit.
|
||||
|
||||
If we look at the log again at this point we see that the f3 is gone though.
|
||||
|
||||
We are now at the point that we have the changes of our previous f3 commit ready to be committed whereas the original f3 commit itself is gone. Keep in mind though that we are still in the middle of a rebase. Our f4, f5 and f6 commits are not lost, they’ll be back in a moment.
|
||||
|
||||
Let’s make two new commits: Let’s start with the commit for the changes made to the userService.js which are fine to get picked into master. Run git add userService.js followed by git commit -m "f3a: add updateUser method".
|
||||
|
||||
Great! Let’s create another commit for the changes made to wishlistService.js. Run git add wishlistService.js followed by git commit -m "f3b: add addItems method".
|
||||
|
||||
Let’s take a look at the log again.
|
||||
|
||||
This is exactly what we wanted except our commits f4, f5 and f6 are still missing. This is because we are still in the middle of the interactive rebase and we need to tell git to continue with the rebase. This is done with the command git rebase --continue.
|
||||
|
||||
Let’s check out the log again.
|
||||
|
||||
And that’s it. We now have the history we wanted. The previous f3 commit is now split into two commits f3a and f3b. The only thing left to do is to cherry-pick the f3a commit over to the master branch.
|
||||
|
||||
To finish the last step we first switch to the master branch. We do this with git checkout master. Now we can pick the f3a commit with the cherry-pick command. We can refer to the commit by its SHA key which is bd47ee1 in this case.
|
||||
|
||||
We now have the f3a commit sitting on top of latest master. Exactly what we wanted!
|
||||
|
||||
Given the length of the post this may seem like a lot of effort but it’s really only a matter of seconds for an advanced git user.
|
||||
|
||||
> Note: Christoph is currently writing a book on [rebasing with Git][4] together with Pascal Precht, and you can subscribe to it at leanpub to get notified when it’s ready.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/git-tutorial/git-rebase-split-old-commit-master
|
||||
|
||||
作者:[cburgdorf][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/cburgdorf
|
||||
[1]:http://thoughtram.io/
|
||||
[2]:http://blog.thoughtram.io/posts/going-back-in-time-to-split-older-commits/
|
||||
[3]:https://github.com/thoughtram/interactive-rebase-demo
|
||||
[4]:https://leanpub.com/rebase-the-complete-guide-on-rebasing-in-git
|
||||
@ -0,0 +1,89 @@
|
||||
Learning Vim in 2014: Working with Files
|
||||
================================================================================
|
||||
As a software developer, you shouldn't have to spend time thinking about how to get to the code you want to edit. One of the messiest parts of my transition to using Vim full time was its way of dealing with files. Coming to Vim after primarily using Eclipse and Sublime Text, it frustrated me that Vim doesn't bundle a persistent file system viewer, and the built-in ways of opening and switching files always felt extremely painful.
|
||||
|
||||
At this point I appreciate the depth of Vim's file management features. I've put together a system that works for me even better than more visual editors once did. Because it's purely keyboard based, it allows me to move through my code much faster. That took some time though, and involves several plugins. But the first step was me understanding Vim's built in options for dealing with files. This post will be looking at the most important structures Vim provides you for file management, with a quick peek at some of the more advanced features you can get through plugins.
|
||||
|
||||
### The Basics: Opening a new file ###
|
||||
|
||||
One of the biggest obstacles to learning Vim is its lack of visual affordances. Unlike modern GUI based editors, there is no obvious way to do anything when you open a new instance of Vim in the terminal. Everything is done through keyboard commands, and while that ends up being more efficient for experienced users, new Vim users will find themselves looking up even basic commands routinely. So lets start with the basics.
|
||||
|
||||
The command to open a new file in Vim is **:e <filename>. :e** opens up a new buffer with the contents of the file inside. If the file doesn't exist yet it opens up an empty buffer and will write to the file location you specify once you make changes and save. Buffers are Vim's term for a "block of text stored in memory". That text can be associated with an existing file or not, but there will be one buffer for each file you have open.
|
||||
|
||||
After you open a file and make changes, you can save the contents of the buffer back to the file with the write command **:w**. If the buffer is not yet associated with a file or you want to save to a different location, you can save to a specific file with **:w <filename>**. You may need to add a ! and use **:w! <filename>** if you're overwriting an existing file.
|
||||
|
||||
This is the survival level knowledge for dealing with Vim files. Plenty of developers get by with just these commands, and its technically all you need. But Vim offers a lot more for those who dig a bit deeper.
|
||||
|
||||
### Buffer Management ###
|
||||
|
||||
Moving beyond the basics, let's talk some more about buffers. Vim handles open files a bit differently than other editors. Rather than leaving all open files visible as tabs, or only allowing you to have one file open at a time, Vim allows you to have multiple buffers open. Some of these may be visible while others are not. You can view a list of all open buffers at any time with **:ls**. This shows each open buffer, along with their buffer number. You can then switch to a specific buffer with the **:b <buffer-number>** command, or move in order along the list with the **:bnext** and **:bprevious** commands. (these can be shortened to **:bn** and **:bp** respectively).
|
||||
|
||||
While these commands are the fundamental Vim solutions for managing buffers, I've found that they don't map well to my own way of thinking about files. I don't want to care about the order of buffers, I just want to go to the file I'm thinking about, or maybe to the file I was just in before the current one. So while its important to understand Vim's underlying buffer model, I wouldn't necessarily recommend its builtin commands as your main file management strategy. There are more powerful options available.
|
||||
|
||||

|
||||
|
||||
### Splits ###
|
||||
|
||||
One of the best parts of managing files in Vim is its splits. With Vim, you can split your current window into 2 windows at any time, and then resize and arrange them into any configuration you like. Its not unusual for me to have 6 files open at a given time, each with its own small split of the window.
|
||||
|
||||
You can open a new split with **:sp <filename>** or **:vs <filename>**, for horizontal and vertical splits respectively. There are keyword commands you can use to then resize the windows the way you want them, but to be honest this is the one Vim task I prefer to do with my mouse. A mouse gives me more precision without having to guess the number of columns I want or fiddle back and forth between 2 widths.
|
||||
|
||||
After you create some splits, you can switch back and forth between them with **ctrl-w [h|j|k|l]**. This is a bit clunky though, and it's important for common operations to be efficient and easy. If you use splits heavily, I would personally recommend aliasing these commands to **ctrl-h** **ctrl-j** etc in your .vimrc using this snippet.
|
||||
|
||||
nnoremap <C-J> <C-W><C-J> "Ctrl-j to move down a split
|
||||
nnoremap <C-K> <C-W><C-K> "Ctrl-k to move up a split
|
||||
nnoremap <C-L> <C-W><C-L> "Ctrl-l to move right a split
|
||||
nnoremap <C-H> <C-W><C-H> "Ctrl-h to move left a split
|
||||
|
||||
### The jumplist ###
|
||||
|
||||
Splits solve the problem of viewing multiple related files at a time, but we still haven't seen a satisfactory solution for moving quickly between open and hidden files. The jumplist is one tool you can use for that.
|
||||
|
||||
The jumplist is one of those Vim features that can appear weird or even useless at first. Vim keeps track of every motion command and file switch you make as you're editing files. Every time you "jump" from one place to another in a split, Vim adds an entry to the jumplist. While this may initially seem like a small thing, it becomes powerful when you're switching files a lot, or moving around in a large file. Instead of having to remember your place, or worry about what file you were in, you can instead retrace your footsteps quickly using some quick key commands. **Ctrl-o** allows you to jump back to your last jump location. Repeating it multiple times allows you to quickly jump back to the last file or code chunk you were working on, without having to keep the details of where that code is in your head. You can then move back up the chain with **ctrl-i**. This turns out to be immensely powerful when you're moving around in code quickly, debugging a problem in multiple files or flipping back and forth between 2 files. Instead of typing file names or remembering buffer numbers, you can just move up and down the existing path. It's not the answer to everything, but like other Vim concepts, it's a small focused tool that adds to the overall power of the editor without trying to do everything.
|
||||
|
||||
### Plugins ###
|
||||
|
||||
So let's be real, if you're coming to Vim from something like Sublime Text or Atom, there's a good chance all of this looks a bit arcane, scary, and inefficient. "Why would I want to type the full path to open a file when Sublime has fuzzy finding?" "How can I get a view of a project's structure without a sidebar to show the directory tree?" Legitimate questions. The good news is that Vim has solutions. They're just not baked into the Vim core. I'll touch more on Vim configuration and plugins in later posts, but for now here's a pointer to 3 helpful plugins that you can use to get Sublime-like file management.
|
||||
|
||||
- [CtrlP][1] is a fuzzy finding file search similar to Sublime's "Go to Anything" bar. It's lightning fast and pretty configurable. I use it as my main way of opening new files. With it I only need to know part of the file name and don't need to memorize my project's directory structure.
|
||||
- [The NERDTree][2] is a "file navigation drawer" plugin that replicates the side file navigation that many editors have. I actually rarely use it, as fuzzy search always seems faster to me. But it can be useful coming into a project, when you're trying to learn the project structure and see what's available. NERDTree is immensely configurable, and also replaces Vim's built in directory tools when installed.
|
||||
- [Ack.vim][3] is a code search plugin for Vim that allows you to search across your project for text expressions. It acts as a light wrapper around Ack or Ag, [2 great code search tools][4], and allows you to quickly jump to any occurrence of a search term in your project.
|
||||
|
||||
Between it's core and its plugin ecosystem, Vim offers enough tools to allow you to craft your workflow anyway you want. File management is a key part of a good software development system, and it's worth experimenting to get it right.
|
||||
|
||||
Start with the basics for long enough to understand them, and then start adding tools on top until you find a comfortable workflow. It will all be worth it when you're able to seamlessly move to the code you want to work on without the mental overhead of figuring out how to get there.
|
||||
|
||||
### More Resources ###
|
||||
|
||||
- [Seamlessly Navigate Vim & Tmux Splits][5] This is a must read for anyone who wants to use vim with [tmux][6]. It presents an easy system for treating Vim and Tmux splits as equals, and moving between them easily.
|
||||
- [Using Tab Pages][7] One file management feature I didn't cover, since it's poorly named and a bit confusing to use, is Vim's "tab" feature. This post on the Vim wiki gives a good overview of how you can use "tab pages" to have multiple views of your current workspace
|
||||
- [Vimcasts: The edit command][8] Vimcasts in general is a great resource for anyone learning Vim, but this screenshot does a good job of covering the file opening basics mentioned above, with some suggestions on improving the builtin workflow
|
||||
|
||||
### Subscribe ###
|
||||
|
||||
This was the third in a series of posts on learning Vim in a modern way. If you enjoyed the post consider subscribing to the [feed][8] or joining my [mailing list][10]. I'll be continuing with [a post on Vim configuration next week][11] after a brief JavaScript interlude later this week. You should also checkout the first 2 posts in this series, on [the basics of using Vim][12], and [the language of Vim and Vi][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
|
||||
作者:[Ben McCormick][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
[1]:https://github.com/kien/ctrlp.vim
|
||||
[2]:https://github.com/scrooloose/nerdtree
|
||||
[3]:https://github.com/mileszs/ack.vim
|
||||
[4]:http://benmccormick.org/2013/11/25/a-look-at-ack/
|
||||
[5]:http://robots.thoughtbot.com/seamlessly-navigate-vim-and-tmux-splits
|
||||
[6]:http://tmux.sourceforge.net/
|
||||
[7]:http://vim.wikia.com/wiki/Using_tab_pages
|
||||
[8]:http://vimcasts.org/episodes/the-edit-command/
|
||||
[9]:http://feedpress.me/benmccormick
|
||||
[10]:http://eepurl.com/WFYon
|
||||
[11]:http://benmccormick.org/2014/07/14/learning-vim-in-2014-configuring-vim/
|
||||
[12]:http://benmccormick.org/2014/06/30/learning-vim-in-2014-the-basics/
|
||||
[13]:http://benmccormick.org/2014/07/02/learning-vim-in-2014-vim-as-language/
|
||||
@ -0,0 +1,121 @@
|
||||
wangjiezhe translating
|
||||
|
||||
Using GIT to backup your website files on linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Well not exactly Git but a software based on Git known as BUP. I generally use rsync to backup my files and that has worked fine so far. The only problem or drawback is that you cannot restore your files to a particular point in time. Hence, I started looking for an alternative and found BUP a git based software which stores your data in repositories and gives you the option to restore data to a particular point in time.
|
||||
|
||||
With BUP you will first need to initialize an empty repository, then take a backup of all your files. When BUP takes a backup it creates a restore point which you can later restore to. It also creates an index of all your files, this index contains file attributes and checksum. When another backup is scheduled BUP compares the files with this attribute and only saves data if anything has changed. This saves you a lot of space.
|
||||
|
||||
### Installing BUP (Tested on Centos 6 & 7) ###
|
||||
|
||||
Ensure you have RPMFORGE and EPEL repos installed.
|
||||
|
||||
[techarena51@vps ~]$sudo yum groupinstall "Development Tools"
|
||||
[techarena51@vps ~]$ sudo yum install python python-devel
|
||||
[techarena51@vps ~]$ sudo yum install fuse-python pyxattr pylibacl
|
||||
[techarena51@vps ~]$ sudo yum install perl-Time-HiRes
|
||||
[techarena51@vps ~]$ git clone git://github.com/bup/bup
|
||||
[techarena51@vps ~]$cd bup
|
||||
[techarena51@vps ~]$ make
|
||||
[techarena51@vps ~]$ make test
|
||||
[techarena51@vps ~]$sudo make install
|
||||
|
||||
For debian/ubuntu users you can do “apt-get build-dep bup” on recent versions for more information check out https://github.com/bup/bup
|
||||
You may get errors on CentOS 7 at “make test”, but you can continue to run make install.
|
||||
|
||||
The first step like git is to initialize an empty repository.
|
||||
|
||||
[techarena51@vps ~]$bup init
|
||||
|
||||
By default, bup will store it’s repository under “~/.bup” but you can change that by setting the “export BUP_DIR=/mnt/user/bup” environment variable
|
||||
|
||||
Next you create an index of all files. The index, as I mentioned earlier stores a listing of files, their attributes, and their git object ids (sha1 hashes). ( Attributes include soft links, permissions as well as the immutable bit
|
||||
|
||||
bup index /path/to/file
|
||||
bup save -n nameofbackup /path/to/file
|
||||
|
||||
#Example
|
||||
[techarena51@vps ~]$ bup index /var/www/html
|
||||
Indexing: 7973, done (4398 paths/s).
|
||||
bup: merging indexes (7980/7980), done.
|
||||
|
||||
[techarena51@vps ~]$ bup save -n techarena51 /var/www/html
|
||||
|
||||
Reading index: 28, done.
|
||||
Saving: 100.00% (4/4k, 28/28 files), done.
|
||||
bloom: adding 1 file (7 objects).
|
||||
Receiving index from server: 1268/1268, done.
|
||||
bloom: adding 1 file (7 objects).
|
||||
|
||||
“BUP save” will split all the contents of the file into chunks and store them as objects. The “-n” option takes the name of backup.
|
||||
|
||||
You can check a list of backups as well as a list of backed up files.
|
||||
|
||||
[techarena51@vps ~]$ bup ls
|
||||
local-etc techarena51 test
|
||||
#Check for a list of backups available for my site
|
||||
[techarena51@vps ~]$ bup ls techarena51
|
||||
2014-09-24-064416 2014-09-24-071814 latest
|
||||
#Check for the files available in these backups
|
||||
[techarena51@vps ~]$ bup ls techarena51/2014-09-24-064416/var/www/html
|
||||
apc.php techarena51.com wp-config-sample.php wp-load.php
|
||||
|
||||
Backing up files on the same server is never a good option. BUP allows you to remotely backup your website files, you however need to ensure that your SSH keys and BUP are installed on the remote server.
|
||||
|
||||
bup index path/to/dir
|
||||
bup save-r remote-vps.com -n backupname path/to/dir
|
||||
|
||||
### Example: Backing up the “/var/www/html” directory ###
|
||||
|
||||
[techarena51@vps ~]$bup index /var/www/html
|
||||
[techarena51@vps ~]$ bup save -r user@remotelinuxvps.com: -n techarena51 /var/www/html
|
||||
Reading index: 28, done.
|
||||
Saving: 100.00% (4/4k, 28/28 files), done.
|
||||
bloom: adding 1 file (7 objects).
|
||||
Receiving index from server: 1268/1268, done.
|
||||
bloom: adding 1 file (7 objects).
|
||||
|
||||
### Restoring your Backup ###
|
||||
|
||||
Log into the remote server and type the following
|
||||
|
||||
[techarena51@vps ~]$bup restore -C ./backup techarena51/latest
|
||||
|
||||
#Restore an older version of the entire working dir elsewhere
|
||||
[techarena51@vps ~]$bup restore -C /tmp/bup-out /testrepo/2013-09-29-195827
|
||||
#Restore one individual file from an old backup
|
||||
[techarena51@vps ~]$bup restore -C /tmp/bup-out /testrepo/2013-09-29-201328/root/testbup/binfile1.bin
|
||||
|
||||
The only drawback is you cannot restore files to another server, you have to manually copy the files via SCP or even rsync.
|
||||
|
||||
View your backups via an integrated web server
|
||||
|
||||
bup web
|
||||
#specific port
|
||||
bup web :8181
|
||||
|
||||
You can run bup along with a shell script and a cron job once everyday.
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
bup index /var/www/html
|
||||
bup save -r user@remote-vps.com: -n techarena51 /var/www/html
|
||||
|
||||
BUP may not be perfect, but it get’s the job done pretty well. I would definitely like to see more development on this project and hopefully a remote restore as well.
|
||||
|
||||
You may also like to read using [inotify-tools][1] for real time file syncing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://techarena51.com/index.php/using-git-backup-website-files-on-linux/
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://techarena51.com/
|
||||
[1]:http://techarena51.com/index.php/inotify-tools-example/
|
||||
@ -0,0 +1,88 @@
|
||||
IPv6:IPv4犯的罪,为什么要我来弥补
|
||||
================================================================================
|
||||
(LCTT:标题党了一把,哈哈哈好过瘾,求不拍砖)
|
||||
|
||||
在过去的十年间,IPv6 本来应该得到很大的发展,但事实上这种好事并没有降临。由此导致了一个结果,那就是大部分人都不了解 IPv6 的一些知识:它是什么,怎么使用,以及,为什么它会存在?(LCTT:这是要回答蒙田的“我是谁”哲学思考题吗?)
|
||||
|
||||

|
||||
|
||||
IPv4 和 IPv6 的区别
|
||||
|
||||
### IPv4 做错了什么? ###
|
||||
|
||||
自从1981年发布了 RFC 791 标准以来我们就一直在使用 **IPv4**。在那个时候,电脑又大又贵还不多见,而 IPv4 号称能提供**40亿条 IP 地址**,在当时看来,这个数字好大好大。不幸的是,这么多的 IP 地址并没有被充分利用起来,地址与地址之间存在间隙。举个例子,一家公司可能有**254(2^8-2)**条地址,但只使用其中的25条,剩下的229条被空占着,以备将来之需。于是这些空闲着的地址不能服务于真正需要它们的用户,原因就是网络路由规则的限制。最终的结果是在1981年看起来那个好大好大的数字,在2014年看起来变得好小好小。
|
||||
|
||||
互联网工程任务组(**IETF**)在90年代指出了这个问题,并提供了两套解决方案:无类型域间选路(**CIDR**)以及私有地址。在 CIDR 出现之前,你只能选择三种网络地址长度:**24 位** (共可用16,777,214个地址), **20位** (共可用1,048,574个地址)以及**16位** (共可用65,534个地址)。CIDR 出现之后,你可以将一个网络再划分成多个子网。
|
||||
|
||||
举个例子,如果你需要**5个 IP 地址**,你的 ISP 会为你提供一个子网,里面的主机地址长度为3位,也就是说你最多能得到**6个地址**(LCTT:抛开子网的网络号,3位主机地址长度可以表示0~7共8个地址,但第0个和第7个有特殊用途,不能被用户使用,所以你最多能得到6个地址)。这种方法让 ISP 能尽最大效率分配 IP 地址。“私有地址”这套解决方案的效果是,你可以自己创建一个网络,里面的主机可以访问外网的主机,但外网的主机很难访问到你创建的那个网络上的主机,因为你的网络是私有的、别人不可见的。你可以创建一个非常大的网络,因为你可以使用16,777,214个主机地址,并且你可以将这个网络分割成更小的子网,方便自己管理。
|
||||
|
||||
也许你现在正在使用私有地址。看看你自己的 IP 地址,如果这个地址在这些范围内:**10.0.0.0 – 10.255.255.255**、**172.16.0.0 – 172.31.255.255**或**192.168.0.0 – 192.168.255.255**,就说明你在使用私有地址。这两套方案有效地将“IP 地址用尽”这个灾难延迟了好长时间,但这毕竟只是权宜之计,现在我们正面临最终的审判。
|
||||
|
||||
**IPv4** 还有另外一个问题,那就是这个协议的消息头长度可变。如果数据通过软件来路由,这个问题还好说。但现在路由器功能都是由硬件提供的,处理变长消息头对硬件来说是一件困难的事情。一个大的路由器需要处理来自世界各地的大量数据包,这个时候路由器的负载是非常大的。所以很明显,我们需要固定消息头的长度。
|
||||
|
||||
还有一个问题,在分配 IP 地址的时候,美国人发了因特网(LCTT:这个万恶的资本主义国家占用了大量 IP 地址)。其他国家只得到了 IP 地址的碎片。我们需要重新定制一个架构,让连续的 IP 地址能在地理位置上集中分布,这样一来路由表可以做的更小(LCTT:想想吧,网速肯定更快)。
|
||||
|
||||
还有一个问题,这个问题你听起来可能还不大相信,就是 IPv4 配置起来比较困难,而且还不好改变。你可能不会碰到这个问题,因为你的路由器为你做了这些事情,不用你去操心。但是你的 ISP 对此一直是很头疼的。
|
||||
|
||||
下一代因特网需要考虑上述的所有问题。
|
||||
|
||||
### IPv6 和它的优点 ###
|
||||
|
||||
**IETF** 在1995年12月公布了下一代 IP 地址标准,名字叫 IPv6,为什么不是 IPv5?因为某个错误原因,“版本5”这个编号被其他项目用去了。IPv6 的优点如下:
|
||||
|
||||
- 128位地址长度(共有3.402823669×10³⁸个地址)
|
||||
- 这个架构下的地址在逻辑上聚合
|
||||
- 消息头长度固定
|
||||
- 支持自动配置和修改你的网络。
|
||||
|
||||
我们一项一项地分析这些特点:
|
||||
|
||||
#### 地址 ####
|
||||
|
||||
人们谈到 **IPv6** 时,第一件注意到的事情就是它的地址好多好多。为什么要这么多?因为设计者考虑到地址不能被充分利用起来,我们必须提供足够多的地址,让用户去挥霍,从而达到一些特殊目的。所以如果你想架设自己的 IPv6 网络,你的 ISP 可以给你分配拥有**64位**主机地址长度的网络(可以分配1.844674407×10¹⁹台主机),你想怎么玩就怎么玩。
|
||||
|
||||
#### 聚合 ####
|
||||
|
||||
有这么多的地址,这个地址可以被稀稀拉拉地分配给主机,从而更高效地路由数据包。算一笔帐啊,你的 ISP 拿到一个**80位**地址长度的网络空间,其中16位是 ISP 的子网地址,剩下64位分给你作为主机地址。这样一来,你的 ISP 可以分配65,534个子网。
|
||||
|
||||
然而,这些地址分配不是一成不变地,如果 ISP 想拥有更多的小子网,完全可以做到(当然,土豪 ISP 可能会要求再来一个80位网络空间)。最高的48位地址是相互独立地,也就是说 ISP 与 ISP 之间虽然可能分到相同地80位网络空间,但是这两个空间是相互隔离的,好处就是一个网络空间里面的地址会聚合在一起。
|
||||
|
||||
#### 固定的消息头长度 ####
|
||||
|
||||
**IPv4** 消息头长度可变,但 **IPv6** 消息头长度被固定为40字节。IPv4 会由于额外的参数导致消息头变长,IPv6 中,如果有额外参数,这些信息会被放到一个紧挨着消息头的地方,不会被路由器处理,当消息到达目的地时,这些额外参数会被软件提取出来。
|
||||
|
||||
IPv6 消息头有一个部分叫“flow”,是一个20位伪随机数,用于简化路由器对数据包地路由过程。如果一个数据包存在“flow”,路由器就可以根据这个值作为索引查找路由表,不必慢吞吞地遍历整张路由表来查询路由路径。这个优点使 **IPv6** 更容易被路由。
|
||||
|
||||
#### 自动配置 ####
|
||||
|
||||
**IPv6** 中,当主机开机时,会检查本地网络,看看有没有其他主机使用了自己的 IP 地址。如果地址没有被使用,就接着查询本地的 IPv6 路由器,找到后就向它请求一个 IPv6 地址。然后这台主机就可以连上互联网了 —— 它有自己的 IP 地址,和自己的默认路由器。
|
||||
|
||||
如果这台默认路由器当机,主机就会接着找其他路由器,作为备用路由器。这个功能在 IPv4 协议里实现起来非常困难。同样地,假如路由器想改变自己的地址,自己改掉就好了。主机会自动搜索路由器,并自动更新路由器地址。路由器会同时保存新老地址,直到所有主机都把自己地路由器地址更新成新地址。
|
||||
|
||||
IPv6 自动配置还不是一个完整地解决方案。想要有效地使用互联网,一台主机还需要另外的东西:域名服务器、时间同步服务器、或者还需要一台文件服务器。于是 **dhcp6** 出现了,提供与 dhcp 一样的服务,唯一的区别是 dhcp6 的机器可以在可路由的状态下启动,一个 dhcp 进程可以为大量网络提供服务。
|
||||
|
||||
#### 唯一的大问题 ####
|
||||
|
||||
如果 IPv6 真的比 IPv4 好那么多,为什么它还没有被广泛使用起来(Google 在**2014年5月份**估计 IPv6 的市场占有率为**4%**)?一个最基本的原因是“先有鸡还是先有蛋”问题,用户需要让自己的服务器能为尽可能多的客户提供服务,这就意味着他们必须部署一个 **IPv4** 地址。
|
||||
|
||||
当然,他们可以同时使用 IPv4 和 IPv6 两套地址,但很少有客户会用到 IPv6,并且你还需要对你的软件做一些小修改来适应 IPv6。另外比较头疼的一点是,很多家庭的路由器压根不支持 IPv6。还有就是 ISP 也不愿意支持 IPv6,我问过我的 ISP 这个问题,得到的回答是:只有客户明确指出要部署这个时,他们才会用 IPv6。然后我问了现在有多少人有这个需求,答案是:包括我在内,共有1个。
|
||||
|
||||
与这种现实状况呈明显对比的是,所有主流操作系统:Windows、OS X、Linux 都默认支持 IPv6 好多年了。这些操作系统甚至提供软件让 IPv6 的数据包披上 IPv4 的皮来骗过那些会丢弃 IPv6 数据包的主机,从而达到传输数据的目的(LCTT:呃,这是高科技偷渡?)。
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
IPv4 已经为我们服务了好长时间。但是它的缺陷会在不远的将来遭遇不可克服的困难。IPv6 通过改变地址分配规则、简化数据包路由过程、简化首次加入网络时的配置过程等策略,可以完美解决这个问题。
|
||||
|
||||
问题是,大众在接受和使用 IPv6 的过程中进展缓慢,因为改变代价太大了。好消息是所有操作系统都支持 IPv6,所以当你有一天想做出改变,你的电脑只需要改变一点点东西,就能转到全新的架构体系中去。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/ipv4-and-ipv6-comparison/
|
||||
|
||||
作者:[Jeff Silverman][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/jeffsilverm/
|
||||
@ -0,0 +1,236 @@
|
||||
如何在 Linux 环境下配置 Nagios Remote Plugin Executor (NRPE)
|
||||
================================================================================
|
||||
就网络管理而言,Nagios 是最强大的工具之一。Nagios 可以监控远程主机的可访问性,以及其中正在运行的服务的状态。不过,如果我们想要监控远程主机中网络服务以外的东西呢?比方说,我们可能想要监控远程主机上的磁盘利用率或者 [CPU 处理器负载][1]。Nagios Remote Plugin Executor(NRPE)便是一个可以帮助你完成这些操作的工具。NRPE 允许你执行在远程主机上安装的 Nagios 插件,并且将它们集成到一个[已经存在的 Nagios 服务器][2]里。
|
||||
|
||||
本教程将会介绍如何在一个已经部署好的 Nagios 中配置 NRPE。本教程主要分为两部分:
|
||||
|
||||
- 配置远程主机。
|
||||
- 配置 Nagios 监控服务器。
|
||||
|
||||
之后我们会以定义一些可以被 NRPE 使用的自定义命令来结束本教程。
|
||||
|
||||
### 为 NRPE 配置远程主机 ###
|
||||
|
||||
#### 第一步:安装 NRPE 服务 ####
|
||||
|
||||
你需要在你想要使用 NRPE 监控的每一台远程主机上安装 NRPE 服务。每一台远程主机上的 NRPE 服务守护进程将会与一台 Nagios 监控服务器进行通信。
|
||||
|
||||
取决于所在的平台, NRPE 服务所需要的软件包可以很容易地用 apt-get 或者 yum 来安装。对于 CentOS 来说,由于 NRPE 并不在 CentOS 的仓库中,我们需要[添加 Repoforge 仓库][3]。
|
||||
|
||||
**对于 Debian、Ubuntu 或者 Linux Mint:**
|
||||
|
||||
# apt-get install nagios-nrpe-server
|
||||
|
||||
**对于 CentOS、Fedora 或者 RHEL:**
|
||||
|
||||
# yum install nagios-nrpe
|
||||
|
||||
#### 第二步:准备配置文件 ####
|
||||
|
||||
配置文件 /etc/nagios/nrpe.cfg 在基于 Debian 或者 RedHat 的系统中比较相近。让我们备份并修改配置文件:
|
||||
|
||||
# vim /etc/nagios/nrpe.cfg
|
||||
|
||||
----------
|
||||
|
||||
## NRPE 服务端口是可以自定义的 ##
|
||||
server_port=5666
|
||||
|
||||
## 允许 Nagios 监控服务器访问 ##
|
||||
## 注意:逗号后面没有空格 ##
|
||||
allowed_hosts=127.0.0.1,X.X.X.X-IP_v4_of_Nagios_server
|
||||
|
||||
## 下面的例子中我们硬编码了参数。
|
||||
## 这些参数可以按需修改。
|
||||
|
||||
## 注意:对于 CentOS 64 位用户,请使用 /usr/lib64 替代 /usr/lib ##
|
||||
|
||||
command[check_users]=/usr/lib/nagios/plugins/check_users -w 5 -c 10
|
||||
command[check_load]=/usr/lib/nagios/plugins/check_load -w 15,10,5 -c 30,25,20
|
||||
command[check_hda1]=/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -p /dev/hda1
|
||||
command[check_zombie_procs]=/usr/lib/nagios/plugins/check_procs -w 5 -c 10 -s Z
|
||||
command[check_total_procs]=/usr/lib/nagios/plugins/check_procs -w 150 -c 200
|
||||
|
||||
现在配置文件已经准备好了,NRPE 服务已经可以启动了。
|
||||
|
||||
#### 第三步:初始化 NRPE 服务 ####
|
||||
|
||||
对于基于 RedHat 的系统,NRPE 服务需要被添加为启动服务。
|
||||
|
||||
**对于 Debian、Ubuntu、Linux Mint:**
|
||||
|
||||
# service nagios-nrpe-server restart
|
||||
|
||||
**对于 CentOS、Fedora 或者 RHEL:**
|
||||
|
||||
# service nrpe restart
|
||||
# chkconfig nrpe on
|
||||
|
||||
#### 第四步:验证 NRPE 服务状态 ####
|
||||
|
||||
NRPE 守护进程的状态信息可以在系统日志中找到。对于基于 Debian 的系统,日志文件在 /var/log/syslog,而基于 RedHat 的系统的日志文件则是 /var/log/messages。下面提供一段样例日志以供参考:
|
||||
|
||||
nrpe[19723]: Starting up daemon
|
||||
nrpe[19723]: Listening for connections on port 5666
|
||||
nrpe[19723]: Allowing connections from: 127.0.0.1,X.X.X.X
|
||||
|
||||
如果使用了防火墙,被 NRPE 守护进程使用的 TCP 端口 5666 应该被开启。
|
||||
|
||||
# netstat -tpln | grep 5666
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 0.0.0.0:5666 0.0.0.0:* LISTEN 19885/nrpe
|
||||
|
||||
### 为 NRPE 配置 Nagios 监控服务器 ###
|
||||
|
||||
为 NRPE 配置已有的 Nagios 监控服务器的第一步是在服务器上安装 NRPE 插件。
|
||||
|
||||
#### 第一步:安装 NRPE 插件 ####
|
||||
|
||||
当 Nagios 服务器运行在基于 Debian 的系统(Debian、Ubuntu 或者 Linux Mint)上时,需要的软件宝可以通过 apt-get 安装。
|
||||
|
||||
# apt-get install nagios-nrpe-plugin
|
||||
|
||||
插件安装完成后,对随插件安装的 check_nrpe 命令稍作修改。
|
||||
|
||||
# vim /etc/nagios-plugins/config/check_nrpe.cfg
|
||||
|
||||
----------
|
||||
|
||||
## 默认命令会被覆盖 ##
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
如果 Nagios 服务器运行在基于 RedHat 的系统(CentOS、Fedora 或者 RHEL)上,你可以通过 yum 安装 NRPE 插件。对于 CentOS,[添加 Repoforge 仓库][4] 是必要的。
|
||||
|
||||
# yum install nagios-plugins-nrpe
|
||||
|
||||
现在 NRPE 插件已经安装完成,继续下面的步骤以配置一台 Nagios 服务器。
|
||||
|
||||
#### 第二步:为 NRPE 插件定义 Nagios 命令 ####
|
||||
|
||||
我们需要首先在 Nagios 中定义一个命令来使用 NRPE。
|
||||
|
||||
# vim /etc/nagios/objects/commands.cfg
|
||||
|
||||
----------
|
||||
|
||||
## 注意:对于 CentOS 64 位用户,请使用 /usr/lib64 替代 /usr/lib ##
|
||||
define command{
|
||||
command_name check_nrpe
|
||||
command_line /usr/lib/nagios/plugins/check_nrpe -H '$HOSTADDRESS$' -c '$ARG1$'
|
||||
}
|
||||
|
||||
#### 第三步:添加主机与命令定义 ####
|
||||
|
||||
接下来定义远程主机以及我们将要在它们上面运行的命令。
|
||||
|
||||
下面的例子为一台远程主机定义了一个可以在上面执行的命令。一般来说,你的配置需要按照你的需求来改变。配置文件的路径在基于 Debian 和基于 RedHat 的系统上略有不同,不过文件的内容是完全一样的。
|
||||
|
||||
**对于 Debian、Ubuntu 或者 Linux Mint:**
|
||||
|
||||
# vim /etc/nagios3/conf.d/nrpe.cfg
|
||||
|
||||
**对于 CentOS、Fedora 或者 RHEL:**
|
||||
|
||||
# vim /etc/nagios/objects/nrpe.cfg
|
||||
|
||||
----------
|
||||
|
||||
define host{
|
||||
use linux-server
|
||||
host_name server-1
|
||||
alias server-1
|
||||
address X.X.X.X-IPv4_address_of_remote_host
|
||||
}
|
||||
|
||||
define service {
|
||||
host_name server-1
|
||||
service_description Check Load
|
||||
check_command check_nrpe!check_load
|
||||
check_interval 1
|
||||
use generic-service
|
||||
}
|
||||
|
||||
#### 第四步:重启 Nagios 服务 ####
|
||||
|
||||
在重启 Nagios 之前,可以通过测试来验证配置。
|
||||
|
||||
**对于 Ubuntu、Debian 或者 Linux Mint:**
|
||||
|
||||
# nagios3 -v /etc/nagios3/nagios.cfg
|
||||
|
||||
**对于 CentOS、Fedora 或者 RHEL:**
|
||||
|
||||
# nagios -v /etc/nagios/nagios.cfg
|
||||
|
||||
如果一切正常,我们就可以重启 Nagios 服务了。
|
||||
|
||||
# service nagios restart
|
||||
|
||||

|
||||
|
||||
### 为 NRPE 配置自定义命令 ###
|
||||
|
||||
#### 远程服务器上的配置 ####
|
||||
|
||||
下面列出了一些可以用于 NRPE 的自定义命令。这些命令在远程服务器的 /etc/nagios/nrpe.cfg 文件中定义。
|
||||
|
||||
## 当 1、5、15 分钟的平均负载分别超过 1、2、1 时进入警告状态
|
||||
## 当 1、5、15 分钟的平均负载分别超过 3、5、3 时进入严重警告状态
|
||||
command[check_load]=/usr/lib/nagios/plugins/check_load -w 1,2,1 -c 3,5,3
|
||||
|
||||
## 对于 /home 目录的可用空间设置了警告级别为 25%,以及严重警告级别为 10%。
|
||||
## 可以定制为监控任何分区(比如 /dev/sdb1、/、/var、/home)
|
||||
command[check_disk]=/usr/lib/nagios/plugins/check_disk -w 25% -c 10% -p /home
|
||||
|
||||
## 当 process_ABC 的实例数量超过 10 时警告,超过 20 时严重警告 ##
|
||||
command[check_process_ABC]=/usr/lib/nagios/plugins/check_procs -w 1:10 -c 1:20 -C process_ABC
|
||||
|
||||
## 当 process_ABC 的实例数量跌到 1 以下时严重警告 ##
|
||||
command[check_process_XYZ]=/usr/lib/nagios/plugins/check_procs -w 1: -c 1: -C process_XYZ
|
||||
|
||||
#### Nagios 监控服务器上的配置 ####
|
||||
|
||||
我们通过修改 Nagios 监控服务器里的服务定义来应用上面定义的自定义命令。服务定义可以写在所有服务被定义的地方(比如 /etc/nagios/objects/nrpe.cfg 或 /etc/nagios3/conf.d/nrpe.cfg)
|
||||
|
||||
## 示例 1:检查进程 XYZ ##
|
||||
define service {
|
||||
host_name server-1
|
||||
service_description Check Process XYZ
|
||||
check_command check_nrpe!check_process_XYZ
|
||||
check_interval 1
|
||||
use generic-service
|
||||
}
|
||||
|
||||
## 示例 2:检查磁盘状态 ##
|
||||
define service {
|
||||
host_name server-1
|
||||
service_description Check Process XYZ
|
||||
check_command check_nrpe!check_disk
|
||||
check_interval 1
|
||||
use generic-service
|
||||
}
|
||||
|
||||
总而言之,NRPE 是 Nagios 的一个强大的扩展,它提供了高度可定制的远程服务器监控方案。使用 NRPE,我们可以监控系统的负载、运行的进程、已登录的用户、磁盘状态,以及其它的指标。
|
||||
|
||||
希望这些可以帮到你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/03/nagios-remote-plugin-executor-nrpe-linux.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/2012/08/how-to-measure-average-cpu-utilization.html
|
||||
[2]:http://xmodulo.com/2013/12/install-configure-nagios-linux.html
|
||||
[3]:http://xmodulo.com/2013/01/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
[4]:http://xmodulo.com/2013/01/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
|
||||
@ -1,21 +1,19 @@
|
||||
wangjiezhe translating
|
||||
|
||||
Unix: stat -- more than ls
|
||||
Unix: stat -- 获取比 ls 更多的信息
|
||||
================================================================================
|
||||
> Tired of ls and want to see more interesting information on your files? Try stat!
|
||||
> 厌倦了 ls 命令, 并且想查看更多有关你的文件的有趣的信息? 试一试 stat!
|
||||
|
||||

|
||||
|
||||
The ls command is probably one of the first commands that anyone using Unix learns, but it only shows a small portion of the information that is available with the stat command.
|
||||
ls 命令可能是每一个 Unix 使用者第一个学习的命令之一, 但它仅仅显示了 stat 命令能给出的信息的一小部分.
|
||||
|
||||
The stat command pulls information from the file's inode. As you might be aware, there are actually three sets of dates and times that are stored for every file on your system. These include the date the file was last modified (i.e., the date and time that you see when you use the ls -l command), the time the file was last changed (which includes renaming the file), and the time that file was last accessed.
|
||||
stat 命令从文件的索引节点获取信息. 正如你可能已经了解的那样, 每一个系统里的文件都存有三组日期和时间, 它们包括最近修改时间(即使用 ls -l 命令时显示的日期和时间), 最近状态改变时间(包括重命名文件)和最近访问时间.
|
||||
|
||||
View a long listing for a file and you will see something like this:
|
||||
使用长列表模式查看文件信息, 你会看到类似下面的内容:
|
||||
|
||||
$ ls -l trythis
|
||||
-rwx------ 1 shs unixdweebs 109 Nov 11 2013 trythis
|
||||
|
||||
Use the stat command and you see all this:
|
||||
使用 stat 命令, 你会看到下面这些:
|
||||
|
||||
$ stat trythis
|
||||
File: `trythis'
|
||||
@ -26,11 +24,11 @@ Use the stat command and you see all this:
|
||||
Modify: 2013-11-11 08:40:10.000000000 -0500
|
||||
Change: 2013-11-11 08:40:10.000000000 -0500
|
||||
|
||||
The file's change and modify dates/times are the same in this case, while the access time is fairly recent. We can also see that the file is using 8 blocks and we see the permissions in each of the two formats -- the octal (0700) format and the rwx format. The inode number, shown in the third line of the output, is 12731681. There are no additional hard links (Links: 1). And the file is a regular file.
|
||||
在上面的情形中, 文件的状态改变和文件修改的日期/时间是相同的, 而访问时间则是相当近的时间. 我们还可以看到文件使用了 8 个块, 以及两种格式显示的文件权限 -- 八进制(0700)格式和 rwx 格式. 在第三行显示的索引节点是 12731681. 文件没有其它的硬链接(Links: 1). 而且, 这个文件是一个常规文件.
|
||||
|
||||
Rename the file and you will see that the change time will be updated.
|
||||
重命名文件, 你会看到状态改变时间发生变化.
|
||||
|
||||
This, the ctime information, was originally intended to hold the creation date and time for the file, but the field was turned into the change time field somewhere a while back.
|
||||
这里的 ctime 信息, 最早设计用来存储文件的创建日期和时间, 但之前的某个时间变为用来存储状态修改时间.
|
||||
|
||||
$ mv trythis trythat
|
||||
$ stat trythat
|
||||
@ -42,9 +40,9 @@ This, the ctime information, was originally intended to hold the creation date a
|
||||
Modify: 2013-11-11 08:40:10.000000000 -0500
|
||||
Change: 2014-09-21 12:46:22.000000000 -0400
|
||||
|
||||
Changing the file's permissions would also register in the ctime field.
|
||||
改变文件的权限也会改变 ctime 域.
|
||||
|
||||
You can also use wilcards with the stat command and list your files' stats in a group:
|
||||
你也可以配合通配符来使用 stat 命令以列出一组文件的状态:
|
||||
|
||||
$ stat myfile*
|
||||
File: `myfile'
|
||||
@ -69,18 +67,18 @@ You can also use wilcards with the stat command and list your files' stats in a
|
||||
Modify: 2014-08-22 12:03:59.000000000 -0400
|
||||
Change: 2014-08-22 12:03:59.000000000 -0400
|
||||
|
||||
We can get some of this information with other commands if we like.
|
||||
如果我们喜欢的话, 我们也可以通过其他命令来获取这些信息.
|
||||
|
||||
Add the "u" option to a long listing and you'll see something like this. Notice this shows us the last access time while adding "c" shows us the change time (in this example, the time when we renamed the file).
|
||||
向 ls -l 命令添加 "u" 选项, 你会获得下面的结果. 注意这个选项会显示最后访问时间, 而添加 "c" 选项则会显示状态改变时间(在本例中, 是我们重命名文件的时间).
|
||||
|
||||
$ ls -lu trythat
|
||||
-rwx------ 1 shs unixdweebs 109 Sep 9 19:27 trythat
|
||||
$ ls -lc trythat
|
||||
-rwx------ 1 shs unixdweebs 109 Sep 21 12:46 trythat
|
||||
|
||||
The stat command can also work against directories.
|
||||
stat 命令也可应用与文件夹.
|
||||
|
||||
In this case, we see that there are a number of links.
|
||||
在这个例子中, 我们可以看到有许多的链接.
|
||||
|
||||
$ stat bin
|
||||
File: `bin'
|
||||
@ -91,7 +89,7 @@ In this case, we see that there are a number of links.
|
||||
Modify: 2014-09-15 17:54:41.000000000 -0400
|
||||
Change: 2014-09-15 17:54:41.000000000 -0400
|
||||
|
||||
Here, we're looking at a file system.
|
||||
在这里, 我们查看一个文件系统.
|
||||
|
||||
$ stat -f /dev/cciss/c0d0p2
|
||||
File: "/dev/cciss/c0d0p2"
|
||||
@ -100,16 +98,24 @@ Here, we're looking at a file system.
|
||||
Blocks: Total: 259366 Free: 259337 Available: 259337
|
||||
Inodes: Total: 223834 Free: 223531
|
||||
|
||||
Notice the Namelen (name length) field. Good luck if you had your heart set on file names with greater than 255 characters!
|
||||
注意 Namelen (文件名长度)域, 如果文件名长于 255 个字符的话, 你会很幸运地在文件名处看到心形符号!
|
||||
|
||||
The stat command can also display some of its information a field at a time for those times when that's all you want to see, In the example below, we just want to see the file type and then the number of hard links.
|
||||
stat 命令还可以一次显示所有我们想要的信息. 下面的例子中, 我们只想查看文件类型, 然后是硬连接数.
|
||||
|
||||
$ stat --format=%F trythat
|
||||
regular file
|
||||
$ stat --format=%h trythat
|
||||
1
|
||||
|
||||
In the examples below, we look at permissions -- in each of the two available formats -- and then the file's SELinux security context.
|
||||
在下面的例子中, 我们查看了文件权限 -- 分别以两种可用的格式 -- 然后是文件的 SELinux 安全环境.
|
||||
|
||||
译者注: 原文到这里就结束了, 但很明显缺少结尾. 最后一段的例子可以分别用
|
||||
|
||||
$ stat --format=%a trythat
|
||||
$ stat --format=%A trythat
|
||||
$ stat --format=%C trythat
|
||||
|
||||
来实现.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Loading…
Reference in New Issue
Block a user