mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of git@github.com:LCTT/TranslateProject.git
This commit is contained in:
commit
10d78d7662
@ -1,5 +1,4 @@
|
||||
|
||||
Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
Linux 有问必答:如何在 Linux 中统计一个进程的线程数
|
||||
================================================================================
|
||||
> **问题**: 我正在运行一个程序,它在运行时会派生出多个线程。我想知道程序在运行时会有多少线程。在 Linux 中检查进程的线程数最简单的方法是什么?
|
||||
|
||||
@ -7,11 +6,11 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
### 方法一: /proc ###
|
||||
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU, interrupts, memory, disk, 等等.
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU、中断、内存、磁盘等等.
|
||||
|
||||
$ cat /proc/<pid>/status
|
||||
|
||||
上面的命令将显示进程 <pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
上面的命令将显示进程 \<pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
|
||||
Threads: <N>
|
||||
|
||||
@ -23,11 +22,11 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
输出表明该进程有28个线程。
|
||||
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计目录的数量,如下所示。
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计子目录的数量,如下所示。
|
||||
|
||||
$ ls /proc/<pid>/task | wc
|
||||
|
||||
这是因为,对于一个进程中创建的每个线程,在 /proc/<pid>/task 中会创建一个相应的目录,命名为其线程 ID。由此在 /proc/<pid>/task 中目录的总数表示在进程中线程的数目。
|
||||
这是因为,对于一个进程中创建的每个线程,在 `/proc/<pid>/task` 中会创建一个相应的目录,命名为其线程 ID。由此在 `/proc/<pid>/task` 中目录的总数表示在进程中线程的数目。
|
||||
|
||||
### 方法二: ps ###
|
||||
|
||||
@ -35,7 +34,7 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
$ ps hH p <pid> | wc -l
|
||||
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。(注:此文我们翻译过)
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,9 +42,9 @@ via: http://ask.xmodulo.com/number-of-threads-process-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/view-threads-process-linux.html
|
||||
[1]:https://linux.cn/article-5633-1.html
|
||||
@ -1,14 +1,15 @@
|
||||
网络管理命令行工具基础,Nmcli
|
||||
Nmcli 网络管理命令行工具基础
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
### 介绍 ###
|
||||
|
||||
在本教程中,我们会在CentOS / RHEL 7中讨论网络管理工具,也叫**nmcli**。那些使用**ifconfig**的用户应该在CentOS 7中避免使用这个命令。
|
||||
在本教程中,我们会在CentOS / RHEL 7中讨论网络管理工具(NetworkManager command line tool),也叫**nmcli**。那些使用**ifconfig**的用户应该在CentOS 7中避免使用**ifconfig** 了。
|
||||
|
||||
让我们用nmcli工具配置一些网络设置。
|
||||
|
||||
### 要得到系统中所有接口的地址信息 ###
|
||||
#### 要得到系统中所有接口的地址信息 ####
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||
@ -27,13 +28,13 @@
|
||||
inet6 fe80::20c:29ff:fe67:2f4c/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
#### 检索与连接的接口相关的数据包统计 ####
|
||||
#### 检索与已连接的接口相关的数据包统计 ####
|
||||
|
||||
[root@localhost ~]# ip -s link show eno16777736
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到路由配置 ####
|
||||
|
||||
@ -50,11 +51,11 @@
|
||||
|
||||
输出像traceroute,但是更加完整。
|
||||
|
||||

|
||||

|
||||
|
||||
### nmcli 工具 ###
|
||||
|
||||
**Nmcli** 是一个非常丰富和灵活的命令行工具。nmcli使用的情况有:
|
||||
**nmcli** 是一个非常丰富和灵活的命令行工具。nmcli使用的情况有:
|
||||
|
||||
- **设备** – 正在使用的网络接口
|
||||
- **连接** – 一组配置设置,对于一个单一的设备可以有多个连接,可以在连接之间切换。
|
||||
@ -63,7 +64,7 @@
|
||||
|
||||
[root@localhost ~]# nmcli connection show
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到特定连接的详情 ####
|
||||
|
||||
@ -71,7 +72,7 @@
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到网络设备状态 ####
|
||||
|
||||
@ -89,7 +90,7 @@
|
||||
|
||||
这里,
|
||||
|
||||
- **Connection add** – 添加新的连接
|
||||
- **connection add** – 添加新的连接
|
||||
- **con-name** – 连接名
|
||||
- **type** – 设备类型
|
||||
- **ifname** – 接口名
|
||||
@ -100,7 +101,7 @@
|
||||
|
||||
Connection 'dhcp' (163a6822-cd50-4d23-bb42-8b774aeab9cb) successfully added.
|
||||
|
||||
#### 不同过dhcp分配IP,使用“static”添加地址 ####
|
||||
#### 不通过dhcp分配IP,使用“static”添加地址 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection add con-name "static" ifname eno16777736 autoconnect no type ethernet ip4 192.168.1.240 gw4 192.168.1.1
|
||||
|
||||
@ -112,25 +113,23 @@
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||
Again Check, whether ip address is changed or not.
|
||||
再检查一遍,ip地址是否已经改变
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||

|
||||

|
||||
|
||||
#### 添加DNS设置到静态连接中 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" ipv4.dns 202.131.124.4
|
||||
|
||||
#### 添加额外的DNS值 ####
|
||||
#### 添加更多的DNS ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.dns 8.8.8.8
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.dns 8.8.8.8
|
||||
|
||||
**注意**:要使用额外的**+**符号,并且要是**+ipv4.dns**,而不是**ip4.dns**。
|
||||
|
||||
|
||||
添加一个额外的ip地址:
|
||||
####添加一个额外的ip地址####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.addresses 192.168.200.1/24
|
||||
|
||||
@ -138,11 +137,11 @@ Again Check, whether ip address is changed or not.
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||

|
||||

|
||||
|
||||
你会看见,设置生效了。
|
||||
|
||||
完结
|
||||
完结。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -150,6 +149,6 @@ via: http://www.unixmen.com/basics-networkmanager-command-line-tool-nmcli/
|
||||
|
||||
作者:Rajneesh Upadhyay
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -18,9 +18,9 @@ Elementary OS 它自己本身借鉴了 OS X,也就不奇怪它的很多第三
|
||||
|
||||
### 在 Ubuntu、Elementary OS 和 Mint 上安装 NaSC ###
|
||||
|
||||
安装 NaSC 有一个可用的 PPA。PPA 中说 ‘每日’,意味着所有构建(包括不稳定),但作为我的快速测试,并没什么影响。
|
||||
安装 NaSC 有一个可用的 PPA。PPA 是 ‘每日’,意味着每日构建(意即,不稳定),但作为我的快速测试,并没什么影响。
|
||||
|
||||
打卡一个终端并运行下面的命令:
|
||||
打开一个终端并运行下面的命令:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
sudo apt-get update
|
||||
@ -35,7 +35,7 @@ Elementary OS 它自己本身借鉴了 OS X,也就不奇怪它的很多第三
|
||||
sudo apt-get remove nasc
|
||||
sudo apt-add-repository --remove ppa:nasc-team/daily
|
||||
|
||||
如果你试用了这个软件,要分享你的经验哦。除此之外,你也可以在第三方 Elementary OS 应用中体验[Vocal podcast app for Linux][3]。
|
||||
如果你试用了这个软件,要分享你的经验哦。除此之外,你也可以在第三方 Elementary OS 应用中体验 [Vocal podcast app for Linux][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,7 +43,7 @@ via: http://itsfoss.com/math-ubuntu-nasc/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Linux有问必答--如何删除Ubuntu上不再使用的老内核
|
||||
Linux有问必答:如何删除Ubuntu上不再使用的旧内核
|
||||
================================================================================
|
||||
> **提问**:过去我已经在我的Ubuntu上升级了几次内核。现在我想要删除这些旧的内核镜像来节省我的磁盘空间。如何用最简单的方法删除Ubuntu上先前版本的内核?
|
||||
|
||||
在Ubuntu上,有几个方法来升级内核。在Ubuntu桌面中,软件更新允许你每天检查并更新到最新的内核上。在Ubuntu服务器上,一个无人值守的包会自动更新内核最为一项最要的安全更新。然而,你可以手动用apt-get或者aptitude命令来更新。
|
||||
在Ubuntu上,有几个方法来升级内核。在Ubuntu桌面中,软件更新允许你每天检查并更新到最新的内核上。在Ubuntu服务器上,最为重要的安全更新项目之一就是 unattended-upgrades 软件包会自动更新内核。然而,你也可以手动用apt-get或者aptitude命令来更新。
|
||||
|
||||
随着时间的流逝,持续的内核更新会在系统中积聚大量的不再使用的内核,浪费你的磁盘空间。每个内核镜像和其相关联的模块/头文件会占用200-400MB的磁盘空间,因此由不再使用的内核而浪费的磁盘空间会快速地增加。
|
||||
|
||||
|
||||
|
||||
GRUB管理器为每个旧内核都维护了一个GRUB入口,防止你想要进入它们。
|
||||
GRUB管理器为每个旧内核都维护了一个GRUB入口,以备你想要使用它们。
|
||||
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@ GRUB管理器为每个旧内核都维护了一个GRUB入口,防止你想要进
|
||||
|
||||
在删除旧内核之前,记住最好留有2个最近的内核(最新的和上一个版本),以防主要的版本出错。现在就让我们看看如何在Ubuntu上清理旧内核。
|
||||
|
||||
在Ubuntu内核镜像包哈了以下的包。
|
||||
在Ubuntu内核镜像包含了以下的包。
|
||||
|
||||
- **linux-image-<VERSION-NUMBER>**: 内核镜像
|
||||
- **linux-image-extra-<VERSION-NUMBER>**: 额外的内核模块
|
||||
@ -36,7 +36,6 @@ GRUB管理器为每个旧内核都维护了一个GRUB入口,防止你想要进
|
||||
|
||||
上面的命令会删除内核镜像和它相关联的内核模块和头文件。
|
||||
|
||||
updated to remove the corresponding GRUB entry from GRUB menu.
|
||||
注意如果你还没有升级内核那么删除旧内核会自动触发安装新内核。这样在删除旧内核之后,GRUB配置会自动升级来移除GRUB菜单中相关GRUB入口。
|
||||
|
||||
如果你有很多没用的内核,你可以用shell表达式来一次性地删除多个内核。注意这个括号表达式只在bash或者兼容的shell中才有效。
|
||||
@ -52,7 +51,7 @@ updated to remove the corresponding GRUB entry from GRUB menu.
|
||||
|
||||
$ sudo update-grub2
|
||||
|
||||
现在就重启来验证GRUB菜单已经正确清理了。
|
||||
现在就重启来验证GRUB菜单是否已经正确清理了。
|
||||
|
||||
|
||||
|
||||
@ -62,7 +61,7 @@ via: http://ask.xmodulo.com/remove-kernel-images-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,152 @@
|
||||
RHCSA 系列(五): RHEL7 中的进程管理:开机,关机
|
||||
================================================================================
|
||||
我们将概括和简要地复习从你按开机按钮来打开你的 RHEL 7 服务器到呈现出命令行界面的登录屏幕之间所发生的所有事情,以此来作为这篇文章的开始。
|
||||
|
||||

|
||||
|
||||
*Linux 开机过程*
|
||||
|
||||
**请注意:**
|
||||
|
||||
1. 相同的基本原则也可以应用到其他的 Linux 发行版本中,但可能需要较小的更改,并且
|
||||
2. 下面的描述并不是旨在给出开机过程的一个详尽的解释,而只是介绍一些基础的东西
|
||||
|
||||
### Linux 开机过程 ###
|
||||
|
||||
1. 初始化 POST(加电自检)并执行硬件检查;
|
||||
|
||||
2. 当 POST 完成后,系统的控制权将移交给启动管理器的第一阶段(first stage),它存储在一个硬盘的引导扇区(对于使用 BIOS 和 MBR 的旧式的系统而言)或存储在一个专门的 (U)EFI 分区上。
|
||||
|
||||
3. 启动管理器的第一阶段完成后,接着进入启动管理器的第二阶段(second stage),通常大多数使用的是 GRUB(GRand Unified Boot Loader 的简称),它驻留在 `/boot` 中,然后开始加载内核和驻留在 RAM 中的初始化文件系统(被称为 initramfs,它包含执行必要操作所需要的程序和二进制文件,以此来最终挂载真实的根文件系统)。
|
||||
|
||||
4. 接着展示了闪屏(splash)过后,呈现在我们眼前的是类似下图的画面,它允许我们选择一个操作系统和内核来启动:
|
||||
|
||||

|
||||
|
||||
*启动菜单屏幕*
|
||||
|
||||
5. 内核会对接入到系统的硬件进行设置,当根文件系统被挂载后,接着便启动 PID 为 1 的进程,这个进程将开始初始化其他的进程并最终呈现给我们一个登录提示符界面。
|
||||
|
||||
注意:假如我们想在启动后查看这些信息,我们可以使用 [dmesg 命令][1],并使用这个系列里的上一篇文章中介绍过的工具(注:即 grep)来过滤它的输出。
|
||||
|
||||

|
||||
|
||||
*登录屏幕和进程的 PID*
|
||||
|
||||
在上面的例子中,我们使用了大家熟知的 `ps` 命令来显示在系统启动过程中的一系列当前进程的信息,它们的父进程(或者换句话说,就是那个开启这些进程的进程)为 systemd(大多数现代的 Linux 发行版本已经切换到的系统和服务管理器):
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
记住 `-o`(为 -format 的简写)选项允许你以一个自定义的格式来显示 ps 的输出,以此来满足你的需求;这个自定义格式使用 `man ps` 里 STANDARD FORMAT SPECIFIERS 一节中的特定关键词。
|
||||
|
||||
另一个你想自定义 ps 的输出而不是使用其默认输出的情形是:当你需要找到引起 CPU 或内存消耗过多的那些进程,并按照下列方式来对它们进行排序时:
|
||||
|
||||
# ps aux --sort=+pcpu # 以 %CPU 来排序(增序)
|
||||
# ps aux --sort=-pcpu # 以 %CPU 来排序(降序)
|
||||
# ps aux --sort=+pmem # 以 %MEM 来排序(增序)
|
||||
# ps aux --sort=-pmem # 以 %MEM 来排序(降序)
|
||||
# ps aux --sort=+pcpu,-pmem # 结合 %CPU (增序) 和 %MEM (降序)来排列
|
||||
|
||||

|
||||
|
||||
*自定义 ps 命令的输出*
|
||||
|
||||
### systemd 的一个介绍 ###
|
||||
|
||||
在 Linux 世界中,很少有能比在主流的 Linux 发行版本中采用 systemd 引起更多的争论的决定。systemd 的倡导者根据以下事实来表明其主要的优势:
|
||||
|
||||
1. 在系统启动期间,systemd 允许并发地启动更多的进程(相比于先前的 SysVinit,SysVinit 似乎总是表现得更慢,因为它一个接一个地启动进程,检查一个进程是否依赖于另一个进程,然后等待守护进程启动才可以启动的更多的服务),并且
|
||||
2. 在一个运行着的系统中,它用作一个动态的资源管理器。这样在启动期间,当一个服务被需要时,才启动它(以此来避免消耗系统资源)而不是在没有一个合理的原因的情况下启动额外的服务。
|
||||
3. 向后兼容 sysvinit 的脚本。
|
||||
|
||||
另外请阅读: ['init' 和 'systemd' 背后的故事][2]
|
||||
|
||||
systemd 由 systemctl 工具控制,假如你了解 SysVinit,你将会对以下的内容感到熟悉:
|
||||
|
||||
- service 工具,在旧一点的系统中,它被用来管理 SysVinit 脚本,以及
|
||||
- chkconfig 工具,为系统服务升级和查询运行级别信息
|
||||
- shutdown 你一定使用过几次来重启或关闭一个运行的系统。
|
||||
|
||||
下面的表格展示了使用传统的工具和 systemctl 之间的相似之处:
|
||||
|
||||
|
||||
| 旧式工具 | Systemctl 等价命令 | 描述 |
|
||||
|-------------|----------------------|-------------|
|
||||
| service name start | systemctl start name | 启动 name (这里 name 是一个服务) |
|
||||
| service name stop | systemctl stop name | 停止 name |
|
||||
| service name condrestart | systemctl try-restart name | 重启 name (如果它已经运行了) |
|
||||
| service name restart | systemctl restart name | 重启 name |
|
||||
| service name reload | systemctl reload name | 重载 name 的配置 |
|
||||
| service name status | systemctl status name | 显示 name 的当前状态 |
|
||||
| service - status-all | systemctl | 显示当前所有服务的状态 |
|
||||
| chkconfig name on | systemctl enable name | 通过一个特定的单元文件,让 name 可以在系统启动时运行(这个文件是一个符号链接)。启用或禁用一个启动时的进程,实际上是增加或移除一个到 /etc/systemd/system 目录中的符号链接。 |
|
||||
| chkconfig name off | systemctl disable name | 通过一个特定的单元文件,让 name 可以在系统启动时禁止运行(这个文件是一个符号链接)。 |
|
||||
| chkconfig -list name | systemctl is-enabled name | 确定 name (一个特定的服务)当前是否启用。|
|
||||
| chkconfig - list | systemctl - type=service | 显示所有的服务及其是否启用或禁用。 |
|
||||
| shutdown -h now | systemctl poweroff | 关机 |
|
||||
| shutdown -r now | systemctl reboot | 重启系统 |
|
||||
|
||||
systemd 也引进了单元(unit)(它可能是一个服务,一个挂载点,一个设备或者一个网络套接字)和目标(target)(它们定义了 systemd 如何去管理和同时开启几个相关的进程,可以认为它们与在基于 SysVinit 的系统中的运行级别等价,尽管事实上它们并不等价)的概念。
|
||||
|
||||
### 总结归纳 ###
|
||||
|
||||
其他与进程管理相关,但并不仅限于下面所列的功能的任务有:
|
||||
|
||||
**1. 在考虑到系统资源的使用上,调整一个进程的执行优先级:**
|
||||
|
||||
这是通过 `renice` 工具来完成的,它可以改变一个或多个正在运行着的进程的调度优先级。简单来说,调度优先级是一个允许内核(当前只支持 >= 2.6 的版本)根据某个给定进程被分配的执行优先级(即友善度(niceness),从 -20 到 19)来为其分配系统资源的功能。
|
||||
|
||||
`renice` 的基本语法如下:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
在上面的通用命令中,第一个参数是将要使用的优先级数值,而另一个参数可以是进程 ID(这是默认的设定),进程组 ID,用户 ID 或者用户名。一个常规的用户(即除 root 以外的用户)只可以更改他或她所拥有的进程的调度优先级,并且只能增加友善度的层次(这意味着占用更少的系统资源)。
|
||||
|
||||

|
||||
|
||||
*进程调度优先级*
|
||||
|
||||
**2. 按照需要杀死一个进程(或终止其正常执行):**
|
||||
|
||||
更精确地说,杀死一个进程指的是通过 [kill 或 pkill][3] 命令给该进程发送一个信号,让它优雅地(SIGTERM=15)或立即(SIGKILL=9)结束它的执行。
|
||||
|
||||
这两个工具的不同之处在于前一个被用来终止一个特定的进程或一个进程组,而后一个则允许你通过进程的名称和其他属性,执行相同的动作。
|
||||
|
||||
另外, pkill 与 pgrep 相捆绑,pgrep 提供将受符合的进程的 PID 给 pkill 来使用。例如,在运行下面的命令之前:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
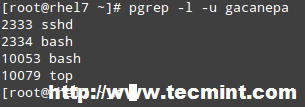
查看一眼由 gacanepa 所拥有的 PID 或许会带来点帮助:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||
|
||||
|
||||
*找到用户拥有的 PID*
|
||||
|
||||
默认情况下,kill 和 pkiill 都发送 SIGTERM 信号给进程,如我们上面提到的那样,这个信号可以被忽略(即该进程可能会终止其自身的执行,也可能不终止),所以当你因一个合理的理由要真正地停止一个运行着的进程,则你将需要在命令行中带上特定的 SIGKILL 信号:
|
||||
|
||||
# kill -9 identifier # 杀死一个进程或一个进程组
|
||||
# kill -s SIGNAL identifier # 同上
|
||||
# pkill -s SIGNAL identifier # 通过名称或其他属性来杀死一个进程
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们解释了在 RHEL 7 系统中,有关开机启动过程的基本知识,并分析了一些可用的工具来帮助你通过使用一般的程序和 systemd 特有的命令来管理进程。
|
||||
|
||||
请注意,这个列表并不旨在涵盖有关这个话题的所有花哨的工具,请随意使用下面的评论栏来添加你自已钟爱的工具和命令。同时欢迎你的提问和其他的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-3587-1.html
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:https://linux.cn/article-2116-1.html
|
||||
@ -1,63 +0,0 @@
|
||||
Is Linux Right For You?
|
||||
================================================================================
|
||||
> Not everyone should opt for Linux -- for many users, remaining with Windows or OSX is the better choice.
|
||||
|
||||
I enjoy using Linux on the desktop. Not because of software politics or because I despise other operating systems. I simply like Linux because it just works.
|
||||
|
||||
It's been my experience that not everyone is cut out for the Linux lifestyle. In this article, I'll help you run through the pros and cons of making the switch to Linux so you can determine if switching is right for you.
|
||||
|
||||
### When to make the switch ###
|
||||
|
||||
Switching to Linux makes sense when there is a decisive reason to do so. The same can be said about moving from Windows to OS X or vice versa. In order to have success with switching, you must be able to identify your reason for jumping ship in the first place.
|
||||
|
||||
For some people, the reason for switching is frustration with their current platform. Maybe the latest upgrade left them with a lousy experience and they're ready to chart new horizons. In other instances, perhaps it's simply a matter of curiosity. Whatever the motivation, you must have a good reason for switching operating systems. If you're pushing yourself in this direction without a good reason, then no one wins.
|
||||
|
||||
However, there are exceptions to every rule. And if you're really interested in trying Linux on the desktop, then maybe coming to terms with a workable compromise is the way to go.
|
||||
|
||||
### Starting off slow ###
|
||||
|
||||
After trying Linux for the first time, I've seen people blast their Windows installation to bits because they had a good experience with Ubuntu on a flash drive for 20 minutes. Folks, this isn't a test. Instead I'd suggest the following:
|
||||
|
||||
- Run the [Linux distro in a virtual machine][1] for a week. This means you are committing to running that distro for all browser work, email and other tasks you might otherwise do on that machine.
|
||||
- If running a VM for a week is too resource intensive, try doing the same with a USB drive running Linux that offers [some persistent storage][2]. This will allow you to leave your main OS alone and intact. At the same time, you'll still be able to "live inside" of your Linux distribution for a week.
|
||||
- If you find that everything is successful after a week of running Linux, the next step is to examine how many times you booted into Windows that week. If only occasionally, then the next step is to look into [dual-booting Windows][3] and Linux. For those of you that only found themselves using their Linux distro, it might be worth considering making the switch full time.
|
||||
- Before you hose your Windows partition completely, it might make more sense to purchase a second hard drive to install Linux onto instead. This allows you to dual-boot, but to do so with ample hard drive space. It also makes Windows available to you if something should come up.
|
||||
|
||||
### What do you gain adopting Linux? ###
|
||||
|
||||
So what does one gain by switching to Linux? Generally it comes down to personal freedom for most people. With Linux, if something isn't to your liking, you're free to change it. Using Linux also saves users oodles of money in avoiding hardware upgrades and unnecessary software expenses. Additionally, you're not burdened with tracking down lost license keys for software. And if you dislike the direction a particular distribution is headed, you can switch to another distribution with minimal hassle.
|
||||
|
||||
The sheer volume of desktop choice on the Linux desktop is staggering. This level of choice might even seem overwhelming to the newcomer. But if you find a distro base (Debian, Fedora, Arch, etc) that you like, the hard work is already done. All you need to do now is find a variation of the distro and the desktop environment you prefer.
|
||||
|
||||
Now one of the most common complaints I hear is that there isn't much in the way of software for Linux. However, this isn't accurate at all. While other operating systems may have more of it, today's Linux desktop has applications to do just about anything you can think of. Video editing (home and pro-level), photography, office management, remote access, music (listening and creation), plus much, much more.
|
||||
|
||||
### What you lose adopting Linux? ###
|
||||
|
||||
As much as I enjoy using Linux, my wife's home office relies on OS X. She's perfectly content using Linux for some tasks, however she relies on OS X for specific software not available for Linux. This is a common problem that many people face when first looking at making the switch. You must decide whether or not you're going to be losing out on critical software if you make the switch.
|
||||
|
||||
Sometimes the issue is because the software has content locked down with it. In other cases, it's a workflow and functionality that was found with the legacy applications and not with the software available for Linux. I myself have never experienced this type of challenge, but I know those who have. Many of the software titles available for Linux are also available for other operating systems. So if there is a concern about such things, I encourage you to try out comparable apps on your native OS first.
|
||||
|
||||
Another thing you might lose by switching to Linux is the luxury of local support when you need it. People scoff at this, but I know of countless instances where a newcomer to Linux was dismayed to find their only recourse for solving Linux challenges was from strangers on the Web. This is especially problematic if their only PC is the one having issues. Windows and OS X users are spoiled in that there are endless support techs in cities all over the world that support their platform(s).
|
||||
|
||||
### How to proceed from here ###
|
||||
|
||||
Perhaps the single biggest piece of advice to remember is always have a fallback plan. Remember, once you wipe that copy of Windows 10 from your hard drive, you may find yourself spending money to get it reinstalled. This is especially true for those of you who upgrade from other Windows releases. Accepting this, persistent flash drives with Linux or dual-booting Windows and Linux is always a preferable way forward for newcomers. Odds are that you may be just fine and take to Linux like a fish to water. But having that fallback plan in place just means you'll sleep better at night.
|
||||
|
||||
If instead you've been relying on a dual-boot installation for weeks and feel ready to take the plunge, then by all means do it. Wipe your drive and start off with a clean installation of your favorite Linux distribution. I've been a full time Linux enthusiast for years and I can tell you for certain, it's a great feeling. How long? Let's just say my first Linux experience was with early Red Hat. I finally installed a dedicated installation on my laptop by 2003.
|
||||
|
||||
Existing Linux enthusiasts, where did you first get started? Was your switch an exciting one or was it filled with angst? Hit the Comments and share your experiences.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/is-linux-right-for-you.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://www.psychocats.net/ubuntu/virtualbox
|
||||
[2]:http://www.howtogeek.com/howto/14912/create-a-persistent-bootable-ubuntu-usb-flash-drive/
|
||||
[3]:http://www.linuxandubuntu.com/home/dual-boot-ubuntu-15-04-14-10-and-windows-10-8-1-8-step-by-step-tutorial-with-screenshots
|
||||
@ -1,41 +0,0 @@
|
||||
Ubuntu Linux-Based Open Source OS Runs 42 Percent of Dell PCs in China
|
||||
================================================================================
|
||||
> Dell says that 42 percent of the PCs it sells in the Chinese market run Kylin, an open source operating system based on Ubuntu Linux that Canonical helped to create.
|
||||
|
||||
Open source fans, rejoice: The Year of the Linux Desktop has arrived. Or something close to it is on the horizon in China, at least, where [Dell][1] has reported that more than 40 percent of the PCs it sells run a variant of [Ubuntu Linux][2] that [Canonical][3] helped develop.
|
||||
|
||||
Specifically, Dell said that 42 percent of computers in China run NeoKylin, an operating system that originated as an effort in China to build a home-grown alternative to [Microsoft][4] (MSFT) Windows. Also known simply Kylin, the OS has been based on Ubuntu since 2013, when Canonical began collaborating with the Chinese government to create an Ubuntu variant tailored for the Chinese market.
|
||||
|
||||
Earlier versions of Kylin, which has been around since 2001, were based on other operating systems, including FreeBSD, an open source Unix-like operating system that is distinct from Linux.
|
||||
|
||||
Ubuntu Kylin looks and feels a lot like modern versions of Ubuntu proper. It sports the [Unity][5] interface and runs the standard suite of open source apps, as well as specialized ones such as Youker Assistant, a graphical front end that helps users manage basic computing tasks. Kylin's default theme makes it look just a little more like Windows than stock Ubuntu, however.
|
||||
|
||||
Given the relative stagnation of the market for desktop Linux PCs in most of the world, Dell's announcement is striking. And in light of China's [hostility][6] toward modern editions of Windows, the news does not bode well for Microsoft's prospects in the Chinese market.
|
||||
|
||||
Dell's comment on Linux PC sales in China—which appeared in the form of a statement by an executive to the Wall Street Journal—comes on the heels of the company's [announcement][7] of $125 million of new investment in China.
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/091515/ubuntu-linux-based-open-source-os-runs-42-percent-dell-pc
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://dell.com/
|
||||
[2]:http://ubuntu.com/
|
||||
[3]:http://canonical.com/
|
||||
[4]:http://microsoft.com/
|
||||
[5]:http://unity.ubuntu.com/
|
||||
[6]:http://www.wsj.com/articles/windows-8-faces-new-criticism-in-china-1401882772
|
||||
[7]:http://thevarguy.com/business-technology-solution-sales/091415/dell-125-million-directed-china-jobs-new-business-and-innovation
|
||||
@ -0,0 +1,30 @@
|
||||
Italy's Ministry of Defense to Drop Microsoft Office in Favor of LibreOffice
|
||||
================================================================================
|
||||
>**LibreItalia's Italo Vignoli [reports][1] that the Italian Ministry of Defense is about to migrate to the LibreOffice open-source software for productivity and adopt the Open Document Format (ODF), while moving away from proprietary software products.**
|
||||
|
||||
The movement comes in the form of a [collaboration][1] between Italy's Ministry of Defense and the LibreItalia Association. Sonia Montegiove, President of the LibreItalia Association, and Ruggiero Di Biase, Rear Admiral and General Executive Manager of Automated Information Systems of the Ministry of Defense in Italy signed an agreement for a collaboration to adopt the LibreOffice office suite in all of the Ministry's offices.
|
||||
|
||||
While the LibreItalia non-profit organization promises to help the Italian Ministry of Defense with trainers for their offices across the country, the Ministry will start the implementation of the LibreOffice software on October 2015 with online training courses for their staff. The entire transition process is expected to be completed by the end of year 2016\. An Italian law lets officials find open source software alternatives to well-known commercial software.
|
||||
|
||||
"Under the agreement, the Italian Ministry of Defense will develop educational content for a series of online training courses on LibreOffice, which will be released to the community under Creative Commons, while the partners, LibreItalia, will manage voluntarily the communication and training of trainers in the Ministry," says Italo Vignoli, Honorary President of LibreItalia.
|
||||
|
||||
### The Ministry of Defense will adopt the Open Document Format (ODF)
|
||||
|
||||
The initiative will allow the Italian Ministry of Defense to be independent from proprietary software applications, which are aimed at individual productivity, and adopt open source document format standards like Open Document Format (ODF), which is used by default in the LibreOffice office suite. The project follows similar movements already made by governments of other European countries, including United Kingdom, France, Spain, Germany, and Holland.
|
||||
|
||||
It would appear that numerous other public institutions all over Italy are using open source alternatives, including the Italian Region Emilia Romagna, Galliera Hospital in Genoa, Macerata, Cremona, Trento and Bolzano, Perugia, the municipalities of Bologna, ASL 5 of Veneto, Piacenza and Reggio Emilia, and many others. AGID (Agency for Digital Italy) welcomes this project and hopes that other public institutions will do the same.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/italy-s-ministry-of-defense-to-drop-microsoft-office-in-favor-of-libreoffice-491850.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://www.libreitalia.it/accordo-di-collaborazione-tra-associazione-libreitalia-onlus-e-difesa-per-ladozione-del-prodotto-libreoffice-quale-pacchetto-di-produttivita-open-source-per-loffice-automation/
|
||||
[2]:http://www.libreitalia.it/chi-siamo/
|
||||
@ -1,84 +0,0 @@
|
||||
ictlyh Translating
|
||||
Best command line tools for linux performance monitoring
|
||||
================================================================================
|
||||
Sometimes a system can be slow and many reasons can be the root cause. To identify the process that is consuming memory, disk I/O or processor capacity you need to use tools to see what is happening in an operation system.
|
||||
|
||||
There are many tools to monitor a GNU/Linux server. In this article, I am providing 7 monitoring tools and i hope it will help you.
|
||||
|
||||
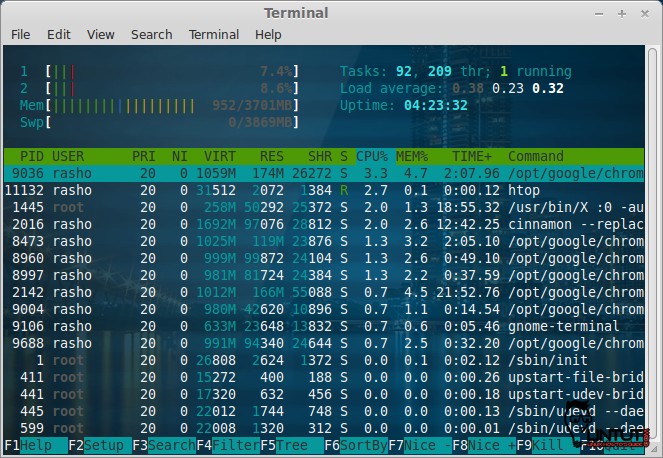
###Htop
|
||||
Htop is an alternative of top command but it provides interactive system-monitor process-viewer and more user friendly output than top.
|
||||
|
||||
htop also provides a better way to navigate to any process using keyboard Up/Down keys as well as we can also operate it using mouse.
|
||||
|
||||
For Check our previous post:[How to install and use htop on RHEL/Centos and Fedora linux][1]
|
||||
|
||||
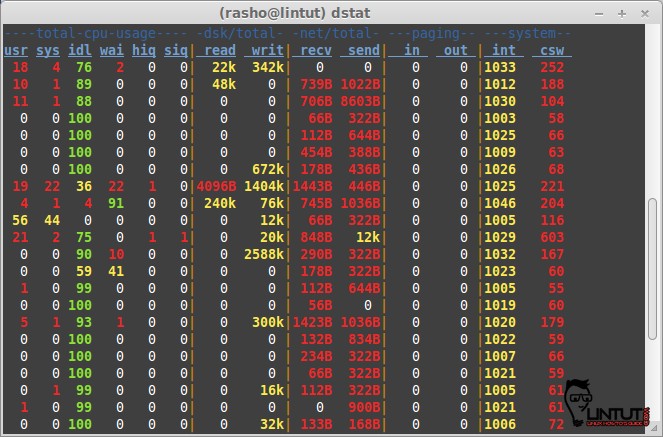
###dstat
|
||||
Dstat is a versatile replacement for vmstat, iostat, netstat and ifstat. Dstat overcomes some of their limitations and adds some extra features, more counters and flexibility. Dstat is handy for monitoring systems during performance tuning tests, benchmarks or troubleshooting.
|
||||
|
||||
Dstat allows you to view all of your system resources in real-time, you can eg. compare disk utilization in combination with interrupts from your IDE controller, or compare the network bandwidth numbers directly with the disk throughput (in the same interval).
|
||||
Dstat gives you detailed selective information in columns and clearly indicates in what magnitude and unit the output is displayed. Less confusion, less mistakes. And most importantly, it makes it very easy to write plugins to collect your own counters and extend in ways you never expected.
|
||||
|
||||
Dstat’s output by default is designed for being interpreted by humans in real-time, however you can export details to CSV output to a file to be imported later into Gnumeric or Excel to generate graphs.
|
||||
Check our previous post:[How to install and use dstat on RHEL/CentOS,Fedora and Debian/Ubuntu based distribution][2]
|
||||
|
||||
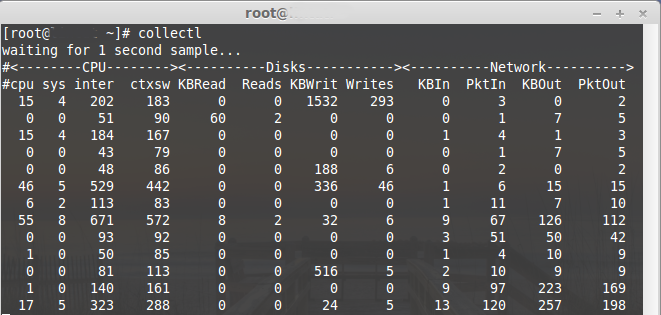
###Collectl
|
||||
Collectl is a light-weight performance monitoring tool capable of reporting interactively as well as logging to disk. It reports statistics on cpu, disk, infiniband, lustre, memory, network, nfs, process, quadrics, slabs and more in easy to read format.
|
||||
In this article i will show you how to install and sample usage Collectl on Debian/Ubuntu and RHEL/Centos and Fedora linux.
|
||||
|
||||
Check our previous post:[Collectl-Monitoring system resources][3]
|
||||
|
||||
|
||||
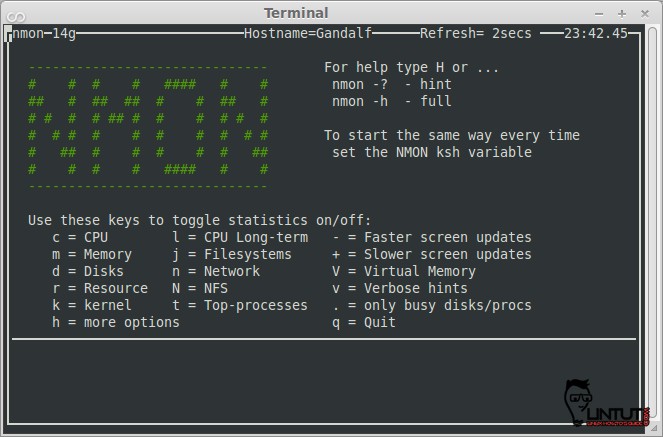
###Nmon
|
||||
nmon is a beutiful tool to monitor linux system performance. It works on Linux, IBM AIX Unix, Power,x86, amd64 and ARM based system such as Raspberry Pi. The nmon command displays and recordslocal system information. The command can run either in interactive or recording mode.
|
||||
|
||||
Check our previous post: [Nmon – linux monitoring tools][4]
|
||||
|
||||
###Saidar
|
||||
Saidar is a curses-based application to display system statistics. It use the libstatgrab library, which provides cross platform access to statistics about the system on which it’s run. Reported statistics includeCPU, load, processes, memory, swap, network input and output and disks activities along with their free space.
|
||||
|
||||
Check our previous post:[Saidar – system monitoring tool][5]
|
||||
|
||||
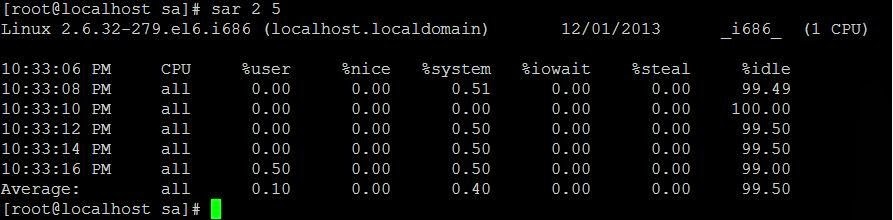
###Sar
|
||||
The sar utility, which is part of the systat package, can be used to review history performance data on your server. System resource utilization can be seen for given time frames to help troubleshoot performance issues, or to optimize performance.
|
||||
|
||||
Check our previous post:[Using Sar To Monitor System Performance][6]
|
||||
|
||||
|
||||
###Glances
|
||||
Glances is a cross-platform curses-based command line monitoring tool writen in Python which use the psutil library to grab informations from the system. Glance monitoring CPU, Load Average, Memory, Network Interfaces, Disk I/O, Processesand File System spaces utilization.
|
||||
|
||||
Glances can adapt dynamically the displayed information depending on the terminal siwrize. It can also work in a client/server mode for remote monitoring.
|
||||
|
||||
Check our previous post: [Glances – Real Time System Monitoring Tool for Linux][7]
|
||||
|
||||
|
||||
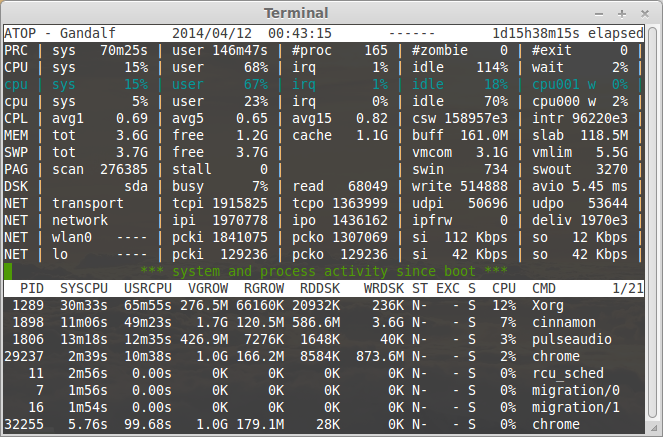
###Atop
|
||||
[Atop](http://www.atoptool.nl/) is an interactive monitor to view the load on a Linux system. It shows the occupation of the most critical hardware resources on system level, i.e. cpu, memory, disk and network. It also shows which processes are responsible for the indicated load with respect to cpu- and memory load on process level. Disk load is shown if per process “storage accounting” is active in the kernel or if the kernel patch ‘cnt’ has been installed. Network load is only shown per process if the kernel patch ‘cnt’ has been installed.
|
||||
|
||||
For more about Atop check next post:[Atop - monitor system resources in linux][8]
|
||||
So, if you come across any other similar tool then let us know in the comment box below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://lintut.com/best-command-line-tools-for-linux-performance-monitring/
|
||||
|
||||
作者:[rasho][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:http://lintut.com/install-htop-in-rhel-centos-fedora-linux/
|
||||
[2]:http://lintut.com/dstat-linux-monitoring-tools/
|
||||
[3]:http://lintut.com/collectl-monitoring-system-resources/
|
||||
[4]:http://lintut.com/nmon-linux-monitoring-tools/
|
||||
[5]:http://lintut.com/saidar-system-monitoring-tool/
|
||||
[6]:http://lintut.com/using-sar-to-monitor-system-performance/
|
||||
[7]:http://lintut.com/glances-an-eye-on-your-system/
|
||||
[8]:http://lintut.com/atop-linux-system-resource-monitor/
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
5 Useful Commands to Manage File Types and System Time in Linux – Part 3
|
||||
================================================================================
|
||||
Adapting to using the command line or terminal can be very hard for beginners who want to learn Linux. Because the terminal gives more control over a Linux system than GUIs programs, one has to get a used to running commands on the terminal. Therefore to memorize different commands in Linux, you should use the terminal on a daily basis to understand how commands are used with different options and arguments.
|
||||
|
||||
@ -1,105 +0,0 @@
|
||||
|
||||
translating by ezio
|
||||
|
||||
How to Setup Node JS v4.0.0 on Ubuntu 14.04 / 15.04
|
||||
================================================================================
|
||||
Hi everyone, Node.JS Version 4.0.0 has been out, the popular server-side JavaScript platform has combines the Node.js and io.js code bases. This release represents the combined efforts encapsulated in both the Node.js project and the io.js project that are now combined in a single codebase. The most important change is this Node.js is ships with version 4.5 of Google's V8 JavaScript engine, which is the same version that ships with the current Chrome browser. So, being able to more closely track V8’s releases means Node.js runs JavaScript faster, more securely, and with the ability to use many desirable ES6 language features.
|
||||
|
||||

|
||||
|
||||
Node.js 4.0.0 aims to provide an easy update path for current users of io.js and node as there are no major API changes. Let’s see how you can easily get it installed and setup on Ubuntu server by following this simple article.
|
||||
|
||||
### Basic System Setup ###
|
||||
|
||||
Node works perfectly on Linux, Macintosh, and Solaris operating systems and among the Linux operating systems it has the best results using Ubuntu OS. That's why we are to setup it Ubuntu 15.04 while the same steps can be followed using Ubuntu 14.04.
|
||||
|
||||
#### 1) System Resources ####
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
#### 2) System Update ####
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) Installing Dependencies ####
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### Download Latest Node JS v4.0.0 ###
|
||||
|
||||
Let's download the latest Node JS version 4.0.0 by following this link of [Node JS Download Page][1].
|
||||
|
||||

|
||||
|
||||
We will copy the link location of its latest package and download it using 'wget' command as shown.
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
Once download completes, unpack using 'tar' command as shown.
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### Installing Node JS v4.0.0 ###
|
||||
|
||||
Now we have to start the installation of Node JS from its downloaded source code. So, change your directory and configure the source code by running its configuration script before compiling it on your ubuntu server.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
Now run the 'make install' command to compile the Node JS installation package as shown.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
The make command will take a couple of minutes while compiling its binaries so after executinf above command, wait for a while and keep calm.
|
||||
|
||||
### Testing Node JS Installation ###
|
||||
|
||||
Once the compilation process is complete, we will test it if every thing went fine. Let's run the following command to confirm the installed version of Node JS.
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
By executing 'node' without any arguments from the command-line you will be dropped into the REPL (Read-Eval-Print-Loop) that has simplistic emacs line-editing where you can interactively run JavaScript and see the results.
|
||||
|
||||

|
||||
|
||||
### Writing Test Program ###
|
||||
|
||||
We can also try out a very simple console program to test the successful installation and proper working of Node JS. To do so we will create a file named "test.js" and write the following code into it and save the changes made in the file as shown.
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
Now in order to run the above program, from the command prompt run the below command.
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
So, upon successful installation we will get the output as shown in the screen, where as in the above program it loads the "util" class into a variable "util" and then uses the "util" object to perform the console tasks. While the console.log is a command similar to the cout in C++.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -1,78 +0,0 @@
|
||||
translating by ezio
|
||||
|
||||
Linux FAQs with Answers--How to check weather forecasts from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: I often check local weather forecasts on the Linux desktop. However, is there an easy way to access weather forecast information in the terminal environment, where I don't have access to desktop widgets or web browser?
|
||||
|
||||
For Linux desktop users, there are many ways to access weather forecasts, e.g., using standalone weather apps, desktop widgets, or panel applets. If your work environment is terminal-based, there are also several ways to access weather forecasts from the command line.
|
||||
|
||||
Among them is [wego][1], **a cute little weather app for the terminal**. Using an ncurses-based fancy interface, this command-line app allows you to see current weather conditions and forecasts at a glance. It retrieves the weather forecasts for the next 5 days via a weather forecast API.
|
||||
|
||||
### Install Wego on Linux ###
|
||||
|
||||
Installation of wego is pretty simple. wego is written in Go language, thus the first step is to [install Go language][2]. After installing Go, proceed to install wego as follows.
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
The wego tool will be installed under $GOPATH/bin. So add $GOPATH/bin to your $PATH variable.
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
Now go ahead and invoke wego from the command line.
|
||||
|
||||
$ wego
|
||||
|
||||
The first time you run wego, it will generate a config file (~/.wegorc), where you need to specify a weather API key.
|
||||
|
||||
You can obtain a free API key from [worldweatheronline.com][3]. Free sign-up is quick and easy. You only need a valid email address.
|
||||
|
||||

|
||||
|
||||
Your .wegorc will look like the following.
|
||||
|
||||

|
||||
|
||||
Other than API key, you can specify in ~/.wegorc your preferred location, use of metric/imperial units, and language.
|
||||
|
||||
Note that the weather API is rate-limited; 5 queries per second, and 250 queries per day.
|
||||
|
||||
When you invoke wego command again, you will see the latest weather forecast (of your preferred location), shown as follows.
|
||||
|
||||

|
||||
|
||||
The displayed weather information includes: (1) temperature, (2) wind direction and speed, (3) viewing distance, and (4) precipitation amount and probability.
|
||||
|
||||
By default, it will show 3-day weather forecast. To change this behavior, you can supply the number of days (upto five) as an argument. For example, to see 5-day forecast:
|
||||
|
||||
$ wego 5
|
||||
|
||||
If you want to check the weather of any other location, you can specify the city name.
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. You encounter the following error while running wego.
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
This error can happen when you run wego on a platform which is not supported by the native Go compiler gc (e.g., Fedora). In that case, you can compile the program using gccgo, a compiler-frontend for Go language. This can be done as follows.
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -1,48 +0,0 @@
|
||||
Enable Automatic System Updates In Ubuntu
|
||||
================================================================================
|
||||
Before seeing **how to enable automatic system updates in Ubuntu**, first let’s see why should we do it in the first place.
|
||||
|
||||
By default Ubuntu checks for updates daily. When there are security updates, it shows immediately but for other updates (i.e. regular software updates) it pop ups once a week. So, if you have been using Ubuntu for a while, this may be a familiar sight for you:
|
||||
|
||||

|
||||
|
||||
Now if you are a normal desktop user, you don’t really care about what kind of updates are these. And this is not entirely a bad thing. You trust Ubuntu to provide you good updates, right? So, you just select ‘Install Now’ most of the time, don’t you?
|
||||
|
||||
And all you do is to click on Install Now, why not enable the automatic system updates? Enabling automatic system updates means all the latest updates will be automatically downloaded and installed without requiring any actions from you. Isn’t it convenient?
|
||||
|
||||
### Enable automatic updates in Ubuntu ###
|
||||
|
||||
I am using Ubuntu 15.04 in this tutorial but the steps are the same for Ubuntu 14.04 as well.
|
||||
|
||||
Go to Unity Dash and look for Software & Updates:
|
||||
|
||||

|
||||
|
||||
This will open the Software sources settings for you. Click on Updates tab here:
|
||||
|
||||

|
||||
|
||||
In here, you’ll see the default settings which is daily check for updates and immediate notification for security updates.
|
||||
|
||||

|
||||
|
||||
All you need to do is to change the action which reads “When there are” to “Download and install automatically”. This will download all the available updates and install them automatically.
|
||||
|
||||

|
||||
|
||||
That’s it. Close it and you have automatic updates enabled in Ubuntu. In fact this tutorial is pretty similar to [changing update notification frequency in Ubuntu][1].
|
||||
|
||||
Do you use automatic updates installation or you prefer to install them manually?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/automatic-system-updates-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/ubuntu-notify-updates-frequently/
|
||||
@ -1,82 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
Linux FAQs with Answers--How to find out which CPU core a process is running on
|
||||
================================================================================
|
||||
> Question: I have a Linux process running on my multi-core processor system. How can I find out which CPU core the process is running on?
|
||||
|
||||
When you run performance-critical HPC applications or network-heavy workload on [multi-core NUMA processors][1], CPU/memory affinity is one important factor to consider to maximize their performance. Scheduling closely related processes on the same NUMA node can reduce slow remote memory access. On processors like Intel's Sandy Bridge processor which has an integrated PCIe controller, you want to schedule network I/O workload on the same NUMA node as the NIC card to exploit PCI-to-CPU affinity.
|
||||
|
||||
As part of performance tuning or troubleshooting, you may want to know on which CPU core (or NUMA node) a particular process is currently scheduled.
|
||||
|
||||
Here are several ways to **find out which CPU core is a given Linux process or a thread is scheduled on**.
|
||||
|
||||
### Method One ###
|
||||
|
||||
If a process is explicitly pinned to a particular CPU core using commands like [taskset][2], you can find out the pinned CPU using the following taskset command:
|
||||
|
||||
$ taskset -c -p <pid>
|
||||
|
||||
For example, if the process you are interested in has PID 5357:
|
||||
|
||||
$ taskset -c -p 5357
|
||||
|
||||
----------
|
||||
|
||||
pid 5357's current affinity list: 5
|
||||
|
||||
The output says the process is pinned to CPU core 5.
|
||||
|
||||
However, if you haven't explicitly pinned the process to any CPU core, you will get something like the following as the affinity list.
|
||||
|
||||
pid 5357's current affinity list: 0-11
|
||||
|
||||
The output indicates that the process can potentially be scheduled on any CPU core from 0 to 11. So in this case, taskset is not useful in identifying which CPU core the process is currently assigned to, and you should use other methods as described below.
|
||||
|
||||
### Method Two ###
|
||||
|
||||
The ps command can tell you the CPU ID each process/thread is currently assigned to (under "PSR" column).
|
||||
|
||||
$ ps -o pid,psr,comm -p <pid>
|
||||
|
||||
----------
|
||||
|
||||
PID PSR COMMAND
|
||||
5357 10 prog
|
||||
|
||||
The output says the process with PID 5357 (named "prog") is currently running on CPU core 10. If the process is not pinned, the PSR column can keep changing over time depending on where the kernel scheduler assigns the process.
|
||||
|
||||
### Method Three ###
|
||||
|
||||
The top command can also show the CPU assigned to a given process. First, launch top command with "p" option. Then press 'f' key, and add "Last used CPU" column to the display. The currently used CPU core will appear under "P" (or "PSR") column.
|
||||
|
||||
$ top -p 5357
|
||||
|
||||

|
||||
|
||||
Compared to ps command, the advantage of using top command is that you can continuously monitor how the assigned CPU changes over time.
|
||||
|
||||
### Method Four ###
|
||||
|
||||
Yet another method to check the currently used CPU of a process/thread is to use [htop command][3].
|
||||
|
||||
Launch htop from the command line. Press <F2> key, go to "Columns", and add PROCESSOR under "Available Columns".
|
||||
|
||||
The currently used CPU ID of each process will appear under "CPU" column.
|
||||
|
||||

|
||||
|
||||
Note that all previous commands taskset, ps and top assign CPU core IDs 0, 1, 2, ..., N-1. However, htop assigns CPU core IDs starting from 1 (upto N).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/cpu-core-process-is-running.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[2]:http://xmodulo.com/run-program-process-specific-cpu-cores-linux.html
|
||||
[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html
|
||||
@ -0,0 +1,202 @@
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
|
||||
The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
|
||||
|
||||
### 1 Introduction ###
|
||||
|
||||
The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
|
||||
|
||||
Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
|
||||
|
||||
Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
|
||||
|
||||
### 2 Data Overview ###
|
||||
|
||||
The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
|
||||
|
||||
The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
|
||||
|
||||
- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
|
||||
- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
|
||||
- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
|
||||
- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
|
||||
- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
|
||||
|
||||
In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
|
||||
|
||||
The repository's history includes commits from the earliest days of the system's development, such as the following.
|
||||
|
||||
commit c9f643f59434f14f774d61ee3856972b8c3905b1
|
||||
Author: Dennis Ritchie <research!dmr>
|
||||
Date: Mon Dec 2 18:18:02 1974 -0500
|
||||
Research V5 development
|
||||
Work on file usr/sys/dmr/kl.c
|
||||
|
||||
Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
|
||||
|
||||
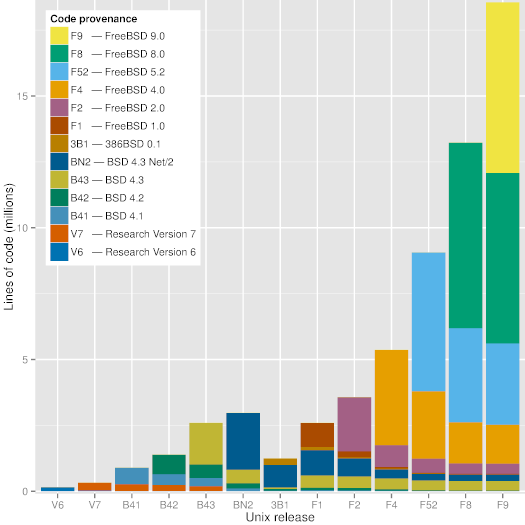
More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
|
||||
|
||||
|
||||
|
||||
Figure 1: Code provenance across significant Unix releases.
|
||||
|
||||
As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
|
||||
|
||||
### 3 Data Collection and Processing ###
|
||||
|
||||
The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
|
||||
|
||||
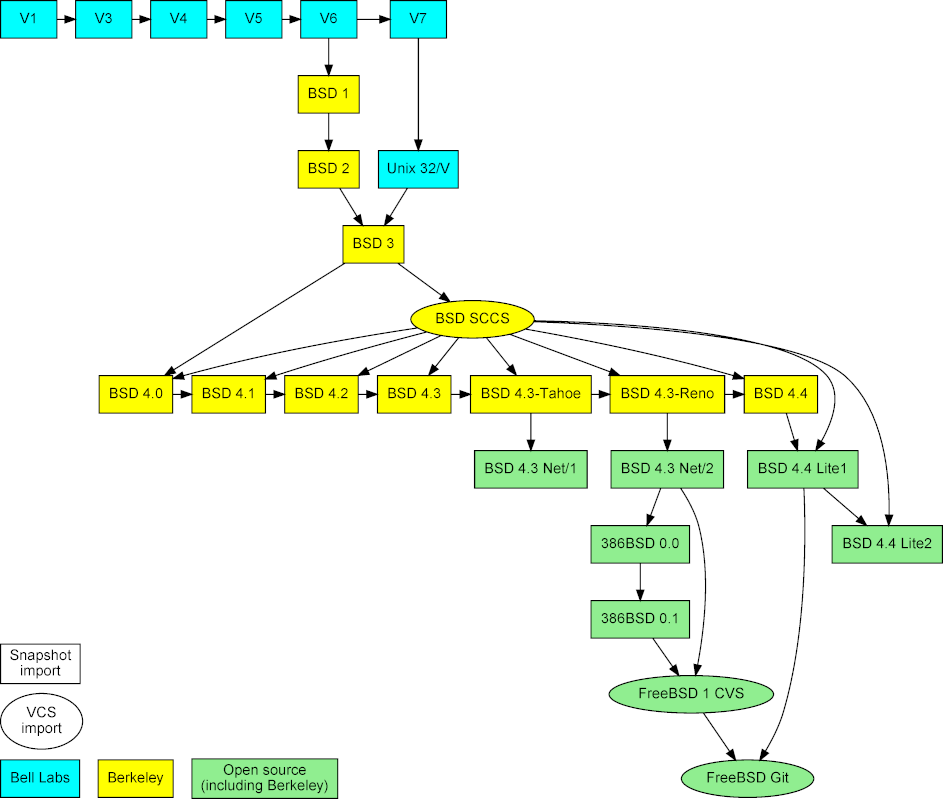
|
||||
|
||||
Figure 2: Imported Unix snapshots, repositories, and their mergers.
|
||||
|
||||
The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
|
||||
|
||||
The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
|
||||
|
||||
The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
|
||||
|
||||
The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
|
||||
|
||||
**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
|
||||
|
||||
**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
|
||||
|
||||
**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
|
||||
|
||||
**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
|
||||
|
||||
An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
|
||||
|
||||
Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
|
||||
|
||||
For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
|
||||
|
||||
The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
|
||||
|
||||
### 4 Data Uses ###
|
||||
|
||||
The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
|
||||
|
||||
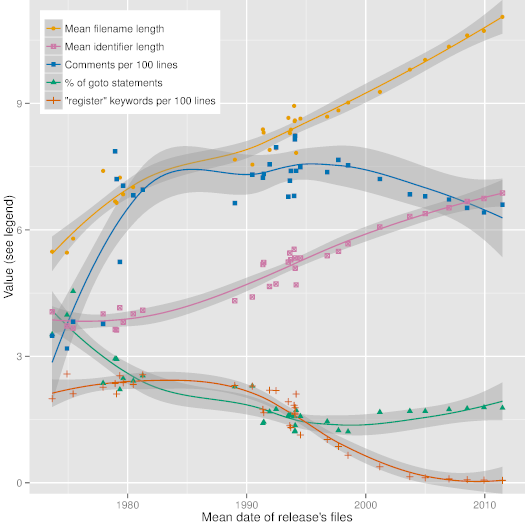
|
||||
|
||||
Figure 3: Code style evolution along Unix releases.
|
||||
|
||||
Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
|
||||
|
||||
### 5 Further Work ###
|
||||
|
||||
Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
|
||||
|
||||
#### Acknowledgements ####
|
||||
|
||||
The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
|
||||
|
||||
This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
|
||||
|
||||
### References ###
|
||||
|
||||
[[1]][31]
|
||||
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
|
||||
|
||||
[[2]][32]
|
||||
D. M. Ritchie and K. Thompson, "The UNIX time-sharing system," *Bell System Technical Journal*, vol. 57, no. 6, pp. 1905-1929, July-August 1978.
|
||||
|
||||
[[3]][33]
|
||||
D. M. Ritchie, "The evolution of the UNIX time-sharing system," *AT&T Bell Laboratories Technical Journal*, vol. 63, no. 8, pp. 1577-1593, Oct. 1984.
|
||||
|
||||
[[4]][34]
|
||||
P. H. Salus, *A Quarter Century of UNIX*. Boston, MA: Addison-Wesley, 1994.
|
||||
|
||||
[[5]][35]
|
||||
E. S. Raymond, *The Art of Unix Programming*. Addison-Wesley, 2003.
|
||||
|
||||
[[6]][36]
|
||||
M. J. Rochkind, "The source code control system," *IEEE Transactions on Software Engineering*, vol. SE-1, no. 4, pp. 255-265, 1975.
|
||||
|
||||
----------
|
||||
|
||||
#### Footnotes: ####
|
||||
|
||||
[1][37] - [https://github.com/dspinellis/unix-history-repo][38]
|
||||
|
||||
[2][39] - Updates may add or modify material. To ensure replicability the repository's users are encouraged to fork it or archive it.
|
||||
|
||||
[3][40] - [http://www.tuhs.org/archive_sites.html][41]
|
||||
|
||||
[4][42] - [https://www.mckusick.com/csrg/][43]
|
||||
|
||||
[5][44] - [http://www.oldlinux.org/Linux.old/distributions/386BSD][45]
|
||||
|
||||
[6][46] - [http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/][47]
|
||||
|
||||
[7][48] - [https://github.com/freebsd/freebsd][49]
|
||||
|
||||
[8][50] - [http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree][51]
|
||||
|
||||
[9][52] - [https://github.com/dspinellis/unix-history-make][53]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#MPT78
|
||||
[2]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#RT78
|
||||
[3]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Rit84
|
||||
[4]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Sal94
|
||||
[5]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Ray03
|
||||
[6]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:data
|
||||
[7]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:dev
|
||||
[8]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:use
|
||||
[9]:https://github.com/dspinellis/unix-history-repo
|
||||
[10]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAB
|
||||
[11]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAC
|
||||
[12]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:provenance
|
||||
[13]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[14]:http://www.tuhs.org/archive_sites.html
|
||||
[15]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAD
|
||||
[16]:https://www.mckusick.com/csrg/
|
||||
[17]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAE
|
||||
[18]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[19]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAF
|
||||
[20]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[21]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAG
|
||||
[22]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#SCCS
|
||||
[23]:https://github.com/freebsd/freebsd
|
||||
[24]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAH
|
||||
[25]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[26]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAI
|
||||
[27]:https://github.com/dspinellis/unix-history-make
|
||||
[28]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAJ
|
||||
[29]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[30]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:metrics
|
||||
[31]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITEMPT78
|
||||
[32]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERT78
|
||||
[33]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERit84
|
||||
[34]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESal94
|
||||
[35]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERay03
|
||||
[36]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESCCS
|
||||
[37]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAB
|
||||
[38]:https://github.com/dspinellis/unix-history-repo
|
||||
[39]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAC
|
||||
[40]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAD
|
||||
[41]:http://www.tuhs.org/archive_sites.html
|
||||
[42]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAE
|
||||
[43]:https://www.mckusick.com/csrg/
|
||||
[44]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAF
|
||||
[45]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[46]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAG
|
||||
[47]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[48]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAH
|
||||
[49]:https://github.com/freebsd/freebsd
|
||||
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
|
||||
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by KnightJoker
|
||||
|
||||
Learn with Linux: Master Your Math with These Linux Apps
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,212 +0,0 @@
|
||||
ictlyh Translating
|
||||
RHCE Series: Implementing HTTPS through TLS using Network Security Service (NSS) for Apache
|
||||
================================================================================
|
||||
If you are a system administrator who is in charge of maintaining and securing a web server, you can’t afford to not devote your very best efforts to ensure that data served by or going through your server is protected at all times.
|
||||
|
||||

|
||||
|
||||
RHCE Series: Implementing HTTPS through TLS using Network Security Service (NSS) for Apache – Part 8
|
||||
|
||||
In order to provide more secure communications between web clients and servers, the HTTPS protocol was born as a combination of HTTP and SSL (Secure Sockets Layer) or more recently, TLS (Transport Layer Security).
|
||||
|
||||
Due to some serious security breaches, SSL has been deprecated in favor of the more robust TLS. For that reason, in this article we will explain how to secure connections between your web server and clients using TLS.
|
||||
|
||||
This tutorial assumes that you have already installed and configured your Apache web server. If not, please refer to following article in this site before proceeding further.
|
||||
|
||||
- [Install LAMP (Linux, MySQL/MariaDB, Apache and PHP) on RHEL/CentOS 7][1]
|
||||
|
||||
### Installation of OpenSSL and Utilities ###
|
||||
|
||||
First off, make sure that Apache is running and that both http and https are allowed through the firewall:
|
||||
|
||||
# systemctl start http
|
||||
# systemctl enable http
|
||||
# firewall-cmd --permanent –-add-service=http
|
||||
# firewall-cmd --permanent –-add-service=https
|
||||
|
||||
Then install the necessary packages:
|
||||
|
||||
# yum update && yum install openssl mod_nss crypto-utils
|
||||
|
||||
**Important**: Please note that you can replace mod_nss with mod_ssl in the command above if you want to use OpenSSL libraries instead of NSS (Network Security Service) to implement TLS (which one to use is left entirely up to you, but we will use NSS in this article as it is more robust; for example, it supports recent cryptography standards such as PKCS #11).
|
||||
|
||||
Finally, uninstall mod_ssl if you chose to use mod_nss, or viceversa.
|
||||
|
||||
# yum remove mod_ssl
|
||||
|
||||
### Configuring NSS (Network Security Service) ###
|
||||
|
||||
After mod_nss is installed, its default configuration file is created as /etc/httpd/conf.d/nss.conf. You should then make sure that all of the Listen and VirtualHost directives point to port 443 (default port for HTTPS):
|
||||
|
||||
nss.conf – Configuration File
|
||||
|
||||
----------
|
||||
|
||||
Listen 443
|
||||
VirtualHost _default_:443
|
||||
|
||||
Then restart Apache and check whether the mod_nss module has been loaded:
|
||||
|
||||
# apachectl restart
|
||||
# httpd -M | grep nss
|
||||
|
||||

|
||||
|
||||
Check Mod_NSS Module Loaded in Apache
|
||||
|
||||
Next, the following edits should be made in `/etc/httpd/conf.d/nss.conf` configuration file:
|
||||
|
||||
1. Indicate NSS database directory. You can use the default directory or create a new one. In this tutorial we will use the default:
|
||||
|
||||
NSSCertificateDatabase /etc/httpd/alias
|
||||
|
||||
2. Avoid manual passphrase entry on each system start by saving the password to the database directory in /etc/httpd/nss-db-password.conf:
|
||||
|
||||
NSSPassPhraseDialog file:/etc/httpd/nss-db-password.conf
|
||||
|
||||
Where /etc/httpd/nss-db-password.conf contains ONLY the following line and mypassword is the password that you will set later for the NSS database:
|
||||
|
||||
internal:mypassword
|
||||
|
||||
In addition, its permissions and ownership should be set to 0640 and root:apache, respectively:
|
||||
|
||||
# chmod 640 /etc/httpd/nss-db-password.conf
|
||||
# chgrp apache /etc/httpd/nss-db-password.conf
|
||||
|
||||
3. Red Hat recommends disabling SSL and all versions of TLS previous to TLSv1.0 due to the POODLE SSLv3 vulnerability (more information [here][2]).
|
||||
|
||||
Make sure that every instance of the NSSProtocol directive reads as follows (you are likely to find only one if you are not hosting other virtual hosts):
|
||||
|
||||
NSSProtocol TLSv1.0,TLSv1.1
|
||||
|
||||
4. Apache will refuse to restart as this is a self-signed certificate and will not recognize the issuer as valid. For this reason, in this particular case you will have to add:
|
||||
|
||||
NSSEnforceValidCerts off
|
||||
|
||||
5. Though not strictly required, it is important to set a password for the NSS database:
|
||||
|
||||
# certutil -W -d /etc/httpd/alias
|
||||
|
||||
|
||||
|
||||
Set Password for NSS Database
|
||||
|
||||
### Creating a Apache SSL Self-Signed Certificate ###
|
||||
|
||||
Next, we will create a self-signed certificate that will identify the server to our clients (please note that this method is not the best option for production environments; for such use you may want to consider buying a certificate verified by a 3rd trusted certificate authority, such as DigiCert).
|
||||
|
||||
To create a new NSS-compliant certificate for box1 which will be valid for 365 days, we will use the genkey command. When this process completes:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||
Choose Next:
|
||||
|
||||

|
||||
|
||||
Create Apache SSL Key
|
||||
|
||||
You can leave the default choice for the key size (2048), then choose Next again:
|
||||
|
||||

|
||||
|
||||
Select Apache SSL Key Size
|
||||
|
||||
Wait while the system generates random bits:
|
||||
|
||||

|
||||
|
||||
Generating Random Key Bits
|
||||
|
||||
To speed up the process, you will be prompted to enter random text in your console, as shown in the following screencast. Please note how the progress bar stops when no input from the keyboard is received. Then, you will be asked to:
|
||||
|
||||
1. Whether to send the Certificate Sign Request (CSR) to a Certificate Authority (CA): Choose No, as this is a self-signed certificate.
|
||||
|
||||
2. to enter the information for the certificate.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" src="//www.youtube.com/embed/mgsfeNfuurA" allowfullscreen="allowfullscreen"></iframe>
|
||||
|
||||
Finally, you will be prompted to enter the password to the NSS certificate that you set earlier:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||

|
||||
|
||||
Apache NSS Certificate Password
|
||||
|
||||
At anytime, you can list the existing certificates with:
|
||||
|
||||
# certutil –L –d /etc/httpd/alias
|
||||
|
||||

|
||||
|
||||
List Apache NSS Certificates
|
||||
|
||||
And delete them by name (only if strictly required, replacing box1 by your own certificate name) with:
|
||||
|
||||
# certutil -d /etc/httpd/alias -D -n "box1"
|
||||
|
||||
if you need to.c
|
||||
|
||||
### Testing Apache SSL HTTPS Connections ###
|
||||
|
||||
Finally, it’s time to test the secure connection to our web server. When you point your browser to https://<web server IP or hostname>, you will get the well-known message “This connection is untrusted“:
|
||||
|
||||

|
||||
|
||||
Check Apache SSL Connection
|
||||
|
||||
In the above situation, you can click on Add Exception and then Confirm Security Exception – but don’t do it yet. Let’s first examine the certificate to see if its details match the information that we entered earlier (as shown in the screencast).
|
||||
|
||||
To do so, click on View… –> Details tab above and you should see this when you select Issuer from the list:
|
||||
|
||||

|
||||
|
||||
Confirm Apache SSL Certificate Details
|
||||
|
||||
Now you can go ahead, confirm the exception (either for this time or permanently) and you will be taken to your web server’s DocumentRoot directory via https, where you can inspect the connection details using your browser’s builtin developer tools:
|
||||
|
||||
In Firefox you can launch it by right clicking on the screen, and choosing Inspect Element from the context menu, specifically through the Network tab:
|
||||
|
||||

|
||||
|
||||
Inspect Apache HTTPS Connection
|
||||
|
||||
Please note that this is the same information as displayed before, which was entered during the certificate previously. There’s also a way to test the connection using command line tools:
|
||||
|
||||
On the left (testing SSLv3):
|
||||
|
||||
# openssl s_client -connect localhost:443 -ssl3
|
||||
|
||||
On the right (testing TLS):
|
||||
|
||||
# openssl s_client -connect localhost:443 -tls1
|
||||
|
||||

|
||||
|
||||
Testing Apache SSL and TLS Connections
|
||||
|
||||
Refer to the screenshot above for more details.
|
||||
|
||||
### Summary ###
|
||||
|
||||
As I’m sure you already know, the presence of HTTPS inspires trust in visitors who may have to enter personal information in your site (from user names and passwords all the way to financial / bank account information).
|
||||
|
||||
In that case, you will want to get a certificate signed by a trusted Certificate Authority as we explained earlier (the steps to set it up are identical with the exception that you will need to send the CSR to a CA, and you will get the signed certificate back); otherwise, a self-signed certificate as the one used in this tutorial will do.
|
||||
|
||||
For more details on the use of NSS, please refer to the online help about [mod-nss][3]. And don’t hesitate to let us know if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-apache-https-self-signed-certificate-using-nss/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[1]:http://www.tecmint.com/author/gacanepa/
|
||||
[2]:https://access.redhat.com/articles/1232123
|
||||
[3]:https://git.fedorahosted.org/cgit/mod_nss.git/plain/docs/mod_nss.html
|
||||
63
translated/talk/20150901 Is Linux Right For You.md
Normal file
63
translated/talk/20150901 Is Linux Right For You.md
Normal file
@ -0,0 +1,63 @@
|
||||
Linux系统是否适合于您?
|
||||
================================================================================
|
||||
> 并非人人都适合使用Linux--对许多用户来说,Windows或OSX会是更好的选择。
|
||||
|
||||
我喜欢使用Linux系统,并不是因为软件的政治性质,也不是不喜欢其他操作系统。我喜欢Linux系统因为它能满足我的需求并且确实适合使用。
|
||||
|
||||
我的经验是,并非人人都适合切换至“Linux的生活方式”。本文将帮助您通过分析使用Linux系统的利弊来供您自行判断使用Linux是否真正适合您。
|
||||
|
||||
### 什么时候更换系统? ###
|
||||
|
||||
当有充分的理由时,将系统切换到Linux系统是很有意义的。这对Windows用户将系统更换到OSX或类似的情况都同样适用。为让您的系统转变成功,您必须首先确定为什么要做这种转换。
|
||||
|
||||
对某些人来说,更换系统通常意味着他们不满于当前的系统操作平台。也许是最新的升级给了他们糟糕的用户体验,他们已准备好更换到别的系统,也许仅仅是因为对某个系统好奇。不管动机是什么,必须要有充分的理由支撑您做出更换操作系统的决定。如果没有一个充足的原因让您这样做,往往不会成功。
|
||||
|
||||
然而事事都有例外。如果您确实对Linux非常感兴趣,或许可以选择一种折衷的方式。
|
||||
|
||||
### 放慢起步的脚步 ###
|
||||
|
||||
第一次尝试运行Linux系统后,我看到就有人开始批判Windows安装过程的费时,完全是因为他们20分钟就用闪存安装好Ubuntu的良好体验。但是伙伴们,这并不只是一次测验。相反,我有如下建议:
|
||||
|
||||
- 一周的时间尝试在[虚拟机上运行Linux系统][1]。这意味着您将在该系统上运行所有的浏览器工作、邮箱操作和其它想要完成的任务。
|
||||
- 如果运行虚拟机资源消耗太大,您可以尝试通过[存储持久性][2]的USB驱动器来运行Linux,您的主操作系统将不受任何影响。与此同时,您仍可以运行Linux系统。
|
||||
- 运行Linux系统一周后,如果一切进展顺利,下一步您可以计算一下这周内登入Windows的次数。如果只是偶尔登陆Windows系统,下一步就可以尝试运行Windows和Linux[双系统][3]。对那些只运行Linux系统的用户,可以考虑尝试将系统真正更换为Linux系统。
|
||||
- 在管理Windows分区前,有必要购买一个新硬盘来安装Linux系统。这样只要有充足的硬盘空间,您就可以使用双系统。如果想到必须要要启动Windows系统做些事情,Windows系统也是可以运行的。
|
||||
|
||||
### 使用Linux系统的好处是什么? ###
|
||||
|
||||
将系统更换到Linux有什么好处呢?一般而言,这种好处对大多数人来说可以归结到释放个性化自由。在使用Linux系统的时候,如果您不喜欢某些设置,可以自行更改它们。同时使用Linux可以为用户节省大量的硬件升级开支和不必要的软件开支。另外,您不需再费力找寻已丢失的软件许可证密钥,而且如果您不喜欢即将发布的系统版本,大可轻松地更换到别的版本。
|
||||
|
||||
台式机首选Linux系统是令人吃惊的,看起来对新手来说做这种选择非常困难。但是如果您发现了喜欢的一款Linux版本(Debian,Fedora,Arch等),最困难的工作其实已经完成了,您需要做的就是找到各版本并选择出您最喜欢的系统版本环境。
|
||||
|
||||
如今我听到的最常见的抱怨之一是用户发现没有太多的软件格式能适用于Linux系统。然而,这并不是事实。尽管别的操作系统可能会提供更多软件,但是如今的Linux也已经提供了足够多应用程序满足您的各种需求,包括视频剪辑(家庭版和专业版),摄影,办公管理软件,远程访问,音乐软件,还有很多别的各类软件。
|
||||
|
||||
### 使用Linux系统您会失去些什么? ###
|
||||
|
||||
虽然我喜欢使用Linux,但我妻子的家庭办公系统依然依赖于OS X。对于用Linux系统完成一些特定的任务她心满意足,但是她仍习惯于使用提供Linux不支持的一些软件的OS X系统。这是许多想要更换系统的用户会遇到的一个常见的问题。如果要更换系统,您需要考虑是否愿意失去一些关键的软件工具。
|
||||
|
||||
有时在Linux系统上遇到问题是因为软件会内容锁定。别的情况下,是在Linux系统上可运行的软件并不适用于传统应用程序的工作流和功能。我自己并没有遇到过这类问题,但是我知道确实存在这些问题。许多Linux上的软件在其他操作系统上也都可以用。所以如果担心这类软件兼容问题,建议您先尝试在已有的系统上操作一下几款类似的应用程序。
|
||||
|
||||
更换成Linux系统后,另一件您可能会失去的是本地系统支持服务。人们通常会嘲笑这种愚蠢行径,但我知道,无数的新手在使用Linux时会发现解决Linux上各种问题的唯一资源就是来自网络另一端的陌生人提供的帮助。如果只是他们的PC遇到了一些问题,这将会比较麻烦。Windows和OS X的用户已经习惯各城市遍布了支持他们操作系统的各项技术服务。
|
||||
|
||||
### 如何开启新旅程? ###
|
||||
|
||||
这里建议大家要记住最重要的就是经常做备份。如果您将Windows 10从硬盘中擦除,您会发现重新安装它又会花费金钱。对那些从其他Windows发布版本升级的用户来说尤其会遇到这种情况。接受这个建议,那就是对新手来说使用闪存安装Linux或使用Windows和Linux双系统都是更值得提倡的做法。您也许会如鱼得水般使用Linux系统,但是有了一份备份计划,您将高枕无忧。
|
||||
|
||||
相反,如果数周以来您一直依赖于使用双操作系统,但是已经准备好冒险去尝试一下单操作系统,那么就去做吧。格式化您的驱动器,重新安装您喜爱的Linux distribution。数年来我一直都是"全职"Linux使用爱好者,这里可以确定地告诉您,使用Linux系统感觉棒极了。这种感觉会持续多久?我第一次的Linux系统使用经验还是来自早期的Red Hat系统,2003年我已经决定在自己的笔记本上安装专用的Linux系统并一直使用至今。
|
||||
|
||||
Linux爱好者们,你们什么时候开始使用Linux的?您在最初更换成Linux系统时是兴奋还是焦虑呢?欢迎点击评论分享你们的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/is-linux-right-for-you.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[icybreaker](https://github.com/icybreaker)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://www.psychocats.net/ubuntu/virtualbox
|
||||
[2]:http://www.howtogeek.com/howto/14912/create-a-persistent-bootable-ubuntu-usb-flash-drive/
|
||||
[3]:http://www.linuxandubuntu.com/home/dual-boot-ubuntu-15-04-14-10-and-windows-10-8-1-8-step-by-step-tutorial-with-screenshots
|
||||
@ -0,0 +1,41 @@
|
||||
基于Linux的Ubuntu开源操作系统在中国42%的Dell PC上运行
|
||||
================================================================================
|
||||
> Dell称它在中国市场出售的42%的PC运行的是Kylin,一款Canonical帮助创建的基于Ubuntu的操作系统。
|
||||
|
||||
让开源粉丝欢喜的是:Linux桌面年来了。或者说中国正在接近这个目标,[Dell][1]报告称超过40%售卖的PC机运行的是 [Canonical][3]帮助开发的[Ubuntu Linux][2]。
|
||||
|
||||
特别地,Dell称42%的中国电脑运行NeoKylin,一款中国本土倾力打造的用于替代[Microsoft][4] (MSFT) Windows的操作系统。它也简称麒麟,一款从2013年出来的基于Ubuntu的操作系统,也是这年开始Canonical公司与中国政府合作来建立一个专为中国市场Ubuntu变种。
|
||||
|
||||
2001年左右早期版本的麒麟,都是基于其他操作系统,包括FreeBSD,一个开放源码的区别于Linux的类Unix操作系统。
|
||||
|
||||
Ubuntu的麒麟的外观和感觉很像Ubuntu的现代版本。它拥有的[Unity][5]界面,并运行标准开源套件,以及专门的如Youker助理程序,它是一个图形化的前端,帮助用户管理的基本计算任务。但是麒麟的默认主题使得它看起来有点像Windows而不是Ubuntu。
|
||||
|
||||
鉴于桌面Linux PC市场在世界上大多数国家的相对停滞,戴尔的宣布是惊人的。并结合中国对现代windows的轻微[敌意][6],这个消息并不预示着微软在中国市场的前景。
|
||||
|
||||
在Dell公司[宣布][7]在华投资1.25亿美元很快之后一位行政官给华尔街杂志的评论中提到了Dell在中国市场上PC的销售。
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/091515/ubuntu-linux-based-open-source-os-runs-42-percent-dell-pc
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[geekpi](https://github.com/geeekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://dell.com/
|
||||
[2]:http://ubuntu.com/
|
||||
[3]:http://canonical.com/
|
||||
[4]:http://microsoft.com/
|
||||
[5]:http://unity.ubuntu.com/
|
||||
[6]:http://www.wsj.com/articles/windows-8-faces-new-criticism-in-china-1401882772
|
||||
[7]:http://thevarguy.com/business-technology-solution-sales/091415/dell-125-million-directed-china-jobs-new-business-and-innovation
|
||||
@ -1,62 +0,0 @@
|
||||
在 Ubuntu 和 Elementary 上使用 NaSC 做简单数学运算
|
||||
================================================================================
|
||||

|
||||
|
||||
NaSC(Not a Soulver Clone,并非 Soulver 的克隆品)是为 Elementary 操作系统进行数学计算而设计的一款开源软件。类似于 Mac 上的 [Soulver][1]。
|
||||
|
||||
> 它能使你像平常那样进行计算。它允许你输入任何你想输入的,智能识别其中的数学部分并在右边面板打印出结果。然后你可以在后面的等式中使用这些结果,如果结果发生了改变,等式中使用的也会同样变化。
|
||||
|
||||
用 NaSC,你可以:
|
||||
|
||||
- 自己定义复杂的计算
|
||||
- 改变单位和值(英尺、米、厘米,美元、欧元等)
|
||||
- 了解行星的表面积
|
||||
- 解二次多项式
|
||||
- 以及其它
|
||||
|
||||
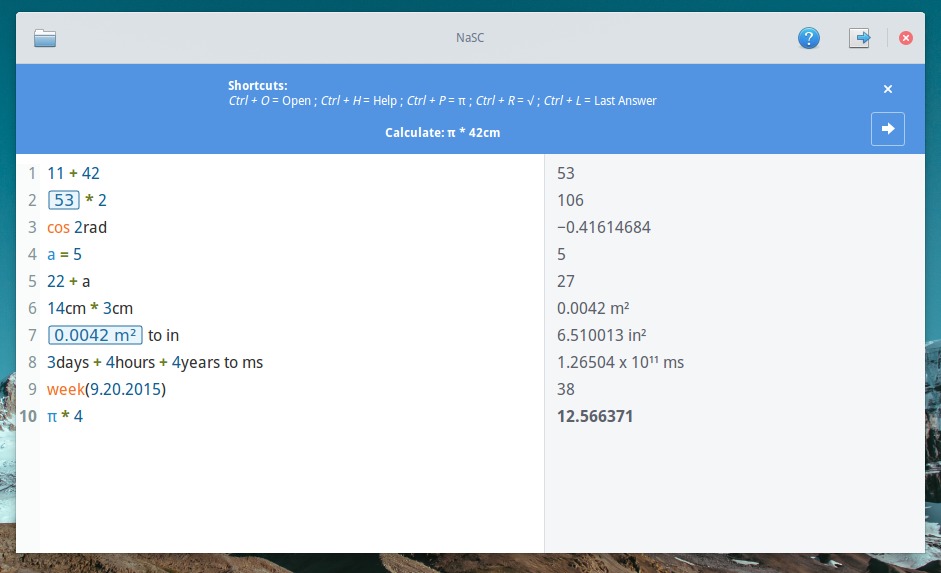
|
||||
|
||||
第一次启动时,NaSC 提供了一个关于现有功能的教程。以后你还可以通过点击标题栏上的帮助图标再次查看。
|
||||
|
||||
|
||||
|
||||
另外,这个软件还允许你保存文件以便以后继续工作。还可以在一定时间内通过粘贴板共用。
|
||||
|
||||
### 在 Ubuntu 或 Elementary OS Freya 上安装 NaSC: ###
|
||||
|
||||
对于 Ubuntu 15.04,Ubuntu 15.10,Elementary OS Freya,从 Dash 或应用启动器中打开终端,逐条运行下面的命令:
|
||||
|
||||
1. 通过命令添加 [NaSC PPA][2]:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
|
||||
|
||||
|
||||
2. 如果安装了 Synaptic 软件包管理器,点击 ‘Reload’ 后搜索并安装 ‘nasc’。
|
||||
|
||||
或者运行下面的命令更新系统缓存并安装软件:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install nasc
|
||||
|
||||
3. **(可选)** 要卸载软件以及 NaSC,运行:
|
||||
|
||||
sudo apt-get remove nasc && sudo add-apt-repository -r ppa:nasc-team/daily
|
||||
|
||||
对于不想添加 PPA 的人,可以直接从[该网页][3]获取 .deb 安装包。、
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/make-math-simple-in-ubuntu-elementary-os-via-nasc/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://www.acqualia.com/soulver/
|
||||
[2]:https://launchpad.net/~nasc-team/+archive/ubuntu/daily/
|
||||
[3]:http://ppa.launchpad.net/nasc-team/daily/ubuntu/pool/main/n/nasc/
|
||||
@ -0,0 +1,102 @@
|
||||
|
||||
在ubunt 14.04/15.04 上配置Node JS v4.0.0
|
||||
================================================================================
|
||||
大家好,Node.JS 4.0 发布了,主流的服务器端JS 平台已经将Node.js 和io.js 结合到一起。4.0 版就是两者结合的产物——共用一个代码库。这次最主要的变化是Node.js 封装了Google V8 4.5 JS 引擎,而这一版与当前的Chrome 一致。所以,紧跟V8 的版本号可以让Node.js 运行的更快、更安全,同时更好的利用ES6 的很多语言特性。
|
||||
|
||||

|
||||
|
||||
Node.js 4.0 的目标是为io.js 当前用户提供一个简单的升级途径,所以这次并没有太多重要的API 变更。剩下的内容会让我们看到如何轻松的在ubuntu server 上安装、配置Node.js。
|
||||
|
||||
### 基础系统安装 ###
|
||||
|
||||
Node 在Linux,Macintosh,Solaris 这几个系统上都可以完美的运行,同时linux 的发行版本当中Ubuntu 是最合适的。这也是我们为什么要尝试在ubuntu 15.04 上安装Node,当然了在14.04 上也可以使用相同的步骤安装。
|
||||
#### 1) 系统资源 ####
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
#### 2) 系统更新 ####
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) 安装依赖 ####
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### 下载最新版的Node JS v4.0.0 ###
|
||||
|
||||
使用链接 [Node JS Download Page][1] 下载源代码.
|
||||
|
||||

|
||||
|
||||
我们会复制最新源代码的链接,然后用`wget` 下载,命令如下:
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
下载完成后使用命令`tar` 解压缩:
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### 安装 Node JS v4.0.0 ###
|
||||
|
||||
现在可以开始使用下载好的源代码编译Nod JS。你需要在ubuntu serve 上开始编译前运行配置脚本来修改你要使用目录和配置参数。
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
现在运行命令'make install' 编译安装Node JS:
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
make 命令会花费几分钟完成编译,冷静的等待一会。
|
||||
|
||||
### 验证Node 安装 ###
|
||||
|
||||
一旦编译任务完成,我们就可以开始验证安装工作是否OK。我们运行下列命令来确认Node JS 的版本。
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
在命令行下不带参数的运行`node` 就会进入REPL(Read-Eval-Print-Loop,读-执行-输出-循环)模式,它有一个简化版的emacs 行编辑器,通过它你可以交互式的运行JS和查看运行结果。
|
||||

|
||||
|
||||
### 写测试程序 ###
|
||||
|
||||
我们也可以写一个很简单的终端程序来测试安装是否成功,并且工作正常。要完成这一点,我们将会创建一个“tes.js” 文件,包含一下代码,操作如下:
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
现在为了运行上面的程序,在命令行运行下面的命令。
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
在一个成功安装了Node JS 的环境下运行上面的程序就会在屏幕上得到上图所示的输出,这个程序加载类 “util” 到变量“util” 中,接着用对象“util” 运行终端任务,console.log 这个命令作用类似C++ 里的cout
|
||||
|
||||
### 结论 ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
希望本文能够通过在ubuntu 上安装、运行Node.JS让你了解一下Node JS 的大概,如果你是刚刚开始使用Node.JS 开发应用程序。最后我们可以说我们能够通过Node JS v4.0.0 获取显著的性能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/osk874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -0,0 +1,70 @@
|
||||
Linux 问与答:如何在Linux 命令行下浏览天气预报
|
||||
================================================================================
|
||||
> **Q**: 我经常在Linux 桌面查看天气预报。然而,是否有一种在终端环境下,不通过桌面小插件或者网络查询天气预报的方法?
|
||||
|
||||
对于Linux 桌面用户来说,有很多办法获取天气预报,比如使用专门的天气应用,桌面小插件,或者面板小程序。但是如果你的工作环境实际与终端的,这里也有一些在命令行下获取天气的手段。
|
||||
|
||||
其中有一个就是 [wego][1],**一个终端下的小巧程序**。使用基于ncurses 的接口,这个命令行程序允许你查看当前的天气情况和之后的预报。它也会通过一个天气预报的API 收集接下来5 天的天气预报。
|
||||
|
||||
### 在Linux 下安装Wego ###
|
||||
安装wego 相当简单。wego 是用Go 编写的,引起第一个步骤就是安装[Go 语言][2]。然后再安装wego。
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
wego 会被安装到$GOPATH/bin,所以要将$GOPATH/bin 添加到$PATH 环境变量。
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
现在就可与直接从命令行启动wego 了。
|
||||
|
||||
$ wego
|
||||
|
||||
第一次运行weg 会生成一个配置文件(~/.wegorc),你需要指定一个天气API key。
|
||||
你可以从[worldweatheronline.com][3] 获取一个免费的API key。免费注册和使用。你只需要提供一个有效的邮箱地址。
|
||||
|
||||

|
||||
|
||||
你的 .wegorc 配置文件看起来会这样:
|
||||
|
||||

|
||||
|
||||
除了API key,你还可以把你想要查询天气的地方、使用的城市/国家名称、语言配置在~/.wegorc 中。
|
||||
注意,这个天气API 的使用有限制:每秒最多5 次查询,每天最多250 次查询。
|
||||
当你重新执行wego 命令,你将会看到最新的天气预报(当然是你的指定地方),如下显示。
|
||||
|
||||

|
||||
|
||||
显示出来的天气信息包括:(1)温度,(2)风速和风向,(3)可视距离,(4)降水量和降水概率
|
||||
默认情况下会显示3 天的天气预报。如果要进行修改,可以通过参数改变天气范围(最多5天),比如要查看5 天的天气预报:
|
||||
|
||||
$ wego 5
|
||||
|
||||
如果你想检查另一个地方的天气,只需要提供城市名即可:
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### 问题解决 ###
|
||||
1. 可能会遇到下面的错误:
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
当你在一个不支持原生Go 编译器的环境下运行wego 时就会出现这个错误。在这种情况下你只需要使用gccgo ——一个Go 的编译器前端来编译程序即可。这一步可以通过下面的命令完成。
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -0,0 +1,48 @@
|
||||
开启Ubuntu系统自动升级
|
||||
================================================================================
|
||||
在学习如何开启Ubuntu系统自动升级之前,先解释下为什么需要自动升级。
|
||||
|
||||
默认情况下,ubuntu每天一次检查更新。但是一周只会弹出一次软件升级提醒,除非当有安全性升级时,才会立即弹出。所以,如果你已经使用Ubuntu一段时间,你肯定很熟悉这个画面:
|
||||
|
||||

|
||||
|
||||
但是做为一个正常桌面用户,根本不会去关心有什么更新细节。而且这个提醒完全就是浪费时间,你肯定信任Ubuntu提供的升级补丁,对不对?所以,大部分情况你肯定会选择“现在安装”,对不对?
|
||||
|
||||
所以,你需要做的就只是点一下升级按钮。现在,明白为什么需要自动系统升级了吧?开启自动系统升级意味着所有最新的更新都会自动下载并安装,并且没有请求确认。是不是很方便?
|
||||
|
||||
### 开启Ubuntu自动升级 ###
|
||||
|
||||
演示使用Ubuntu15.04,Ubuntu 14.04步骤类似。
|
||||
|
||||
打开Unity Dash ,找到软件&更新:
|
||||
|
||||

|
||||
|
||||
打开软件资源设置,切换到升级标签:
|
||||
|
||||

|
||||
|
||||
可以发现,默认设置就是每日检查并立即提醒安全升级。
|
||||
|
||||

|
||||
|
||||
改变 ‘当有安全升级’和‘当有其他升级’的选项为:下载并自动安装。
|
||||
|
||||

|
||||
|
||||
关闭对话框完成设定。这样每次Ubuntu检查更新后就会自动升级。事实上,这篇文章十分类似[改变Ubuntu升级提醒频率][1]。
|
||||
|
||||
你喜欢自动升级还是手动安装升级呢?欢迎评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/automatic-system-updates-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/ubuntu-notify-updates-frequently/
|
||||
@ -0,0 +1,82 @@
|
||||
Linux 有问必答--如何找出哪个 CPU 内核正在运行进程
|
||||
================================================================================
|
||||
>问题:我有个 Linux 进程运行在多核处理器系统上。怎样才能找出哪个 CPU 内核正在运行该进程?
|
||||
|
||||
当你运行需要较高性能的 HPC 程序或非常消耗网络资源的程序在 [多核 NUMA 处理器上][1],CPU/memory 的亲和力是限度其发挥最大性能的重要因素之一。在同一 NUMA 节点上调整程序的亲和力可以减少远程内存访问。像英特尔 Sandy Bridge 处理器,该处理器有一个集成的 PCIe 控制器,要调整同一 NUMA 节点的网络 I/O 负载可以使用 网卡控制 PCI 和 CPU 亲和力。
|
||||
|
||||
由于性能优化和故障排除只是一部分,你可能想知道哪个 CPU 内核(或 NUMA 节点)被调度运行特定的进程。
|
||||
|
||||
这里有几种方法可以 **找出哪个 CPU 内核被调度来运行 给定的 Linux 进程或线程**。
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
如果一个进程明确的被固定到 CPU 的特定内核,如使用 [taskset][2] 命令,你可以使用 taskset 命令找出被固定的 CPU 内核:
|
||||
|
||||
$ taskset -c -p <pid>
|
||||
|
||||
例如, 如果你对 PID 5357 这个进程有兴趣:
|
||||
|
||||
$ taskset -c -p 5357
|
||||
|
||||
----------
|
||||
|
||||
pid 5357's current affinity list: 5
|
||||
|
||||
输出显示这个过程被固定在 CPU 内核 5。
|
||||
|
||||
但是,如果你没有明确固定进程到任何 CPU 内核,你会得到类似下面的亲和力列表。
|
||||
|
||||
pid 5357's current affinity list: 0-11
|
||||
|
||||
输出表明,该进程可能会被安排在从0到11中的任何一个 CPU 内核。在这种情况下,taskset 不会识别该进程当前被分配给哪个 CPU 内核,你应该使用如下所述的方法。
|
||||
|
||||
### 方法二 ###
|
||||
|
||||
ps 命令可以告诉你每个进程/线程目前分配到的 (在“PSR”列)CPU ID。
|
||||
|
||||
|
||||
$ ps -o pid,psr,comm -p <pid>
|
||||
|
||||
----------
|
||||
|
||||
PID PSR COMMAND
|
||||
5357 10 prog
|
||||
|
||||
输出表示进程的 PID 为 5357(名为"prog")目前在CPU 内核 10 上运行着。如果该过程没有被固定,PSR 列可以保持随着时间变化,内核可能调度该进程到不同位置。
|
||||
|
||||
### 方法三 ###
|
||||
|
||||
top 命令也可以显示 CPU 被分配给哪个进程。首先,在top 命令中使用“P”选项。然后按“f”键,显示中会出现 "Last used CPU" 列。目前使用的 CPU 内核将出现在 “P”(或“PSR”)列下。
|
||||
|
||||
$ top -p 5357
|
||||
|
||||

|
||||
|
||||
相比于 ps 命令,使用 top 命令的好处是,你可以连续监视随着时间的改变, CPU 是如何分配的。
|
||||
|
||||
### 方法四 ###
|
||||
|
||||
另一种来检查一个进程/线程当前使用的是哪个 CPU 内核的方法是使用 [htop 命令][3]。
|
||||
|
||||
从命令行启动 htop。按 <F2> 键,进入"Columns",在"Available Columns"下会添加 PROCESSOR。
|
||||
|
||||
每个进程当前使用的 CPU ID 将出现在“CPU”列中。
|
||||
|
||||

|
||||
|
||||
请注意,所有以前使用的命令 taskset,ps 和 top 分配CPU 内核的 IDs 为 0,1,2,...,N-1。然而,htop 分配 CPU 内核 IDs 从 1开始(直到 N)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/cpu-core-process-is-running.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[2]:http://xmodulo.com/run-program-process-specific-cpu-cores-linux.html
|
||||
[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html
|
||||
@ -0,0 +1,60 @@
|
||||
在 Ubuntu 和 Linux Mint 上安装 Terminator 0.98
|
||||
================================================================================
|
||||
[Terminator][1],在一个窗口中有多个终端。该项目的目标之一是为管理终端提供一个有用的工具。它的灵感来自于类似 gnome-multi-term,quankonsole 等程序,这些程序关注于在窗格中管理终端。 Terminator 0.98 带来了更完美的标签功能,更好的布局保存/恢复,改进了偏好用户界面和多出 bug 修复。
|
||||
|
||||

|
||||
|
||||
###TERMINATOR 0.98 的更改和新特性
|
||||
- 添加了一个布局启动器,允许在不用布局之间简单切换(用 Alt + L 打开一个新的布局切换器);
|
||||
- 添加了一个新的手册(使用 F1 打开);
|
||||
- 保存的时候,布局现在会记住:
|
||||
- * 最大化和全屏状态
|
||||
- * 窗口标题
|
||||
- * 激活的标签
|
||||
- * 激活的终端
|
||||
- * 每个终端的工作目录
|
||||
- 添加选项用于启用/停用非同质标签和滚动箭头;
|
||||
- 添加快捷键用于按行/半页/一页向上/下滚动;
|
||||
- 添加使用 Ctrl+鼠标滚轮放大/缩小,Shift+鼠标滚轮向上/下滚动页面;
|
||||
- 为下一个/上一个 profile 添加快捷键
|
||||
- 改进自定义命令菜单的一致性
|
||||
- 新增快捷方式/代码来切换所有/标签分组;
|
||||
- 改进监视插件
|
||||
- 增加搜索栏切换;
|
||||
- 清理和重新组织窗口偏好,包括一个完整的全局便签更新
|
||||
- 添加选项用于设置 ActivityWatcher 插件静默时间
|
||||
- 其它一些改进和 bug 修复
|
||||
- [点击此处查看完整更新日志][2]
|
||||
|
||||
### 安装 Terminator 0.98:
|
||||
|
||||
Terminator 0.98 有可用的 PPA,首先我们需要在 Ubuntu/Linux Mint 上添加库。在终端里运行下面的命令来安装 Terminator 0.98。
|
||||
|
||||
$ sudo add-apt-repository ppa:gnome-terminator/nightly
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install terminator
|
||||
|
||||
如果你想要移除 Terminator,只需要在终端中运行下面的命令(可选)
|
||||
|
||||
$ sudo apt-get remove terminator
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ewikitech.com/articles/linux/terminator-install-ubuntu-linux-mint/
|
||||
|
||||
作者:[admin][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ewikitech.com/author/admin/
|
||||
[1]:https://launchpad.net/terminator
|
||||
[2]:http://bazaar.launchpad.net/~gnome-terminator/terminator/trunk/view/head:/ChangeLog
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,48 @@
|
||||
如何在Ubuntu中添加和删除书签[新手技巧]
|
||||
================================================================================
|
||||

|
||||
|
||||
这是一篇对完全是新手的一篇技巧,我将向你展示如何在Ubuntu文件管理器中添加书签。
|
||||
|
||||
现在如果你想知道为什么要这么做,答案很简单。它可以让你可以快速地在左边栏中访问。比如。我[在Ubuntu中安装了Copy][1]。现在它创建了/Home/Copy。先进入Home目录再进入Copy目录并不是一件大事,但是我想要更快地访问它。因此我添加了一个书签这样我就可以直接从侧边栏访问了。
|
||||
|
||||
### 在Ubuntu中添加书签 ###
|
||||
|
||||
打开Files。进入你想要保存快速访问的目录。你需要在标记书签的目录里面。
|
||||
|
||||
现在,你有两种方法。
|
||||
|
||||
#### 方法1: ####
|
||||
|
||||
当你在Files中时(Ubuntu中的文件管理器),查看顶部菜单。你会看到书签按钮。点击它你会看到将当前路径保存为书签的选项。
|
||||
|
||||

|
||||
|
||||
#### 方法 2: ####
|
||||
|
||||
你可以直接按下Ctrl+D就可以将当前位置保存位书签。
|
||||
|
||||
如你所见,这里左边栏就有一个新添加的Copy目录:
|
||||
|
||||

|
||||
|
||||
### 管理书签 ###
|
||||
|
||||
如果你不想要太多的书签或者你错误地添加了一个书签,你可以很简单地删除它。按下Ctrl+B查看所有的书签。现在选择想要删除的书签并点击删除。
|
||||
|
||||

|
||||
|
||||
这就是在Ubuntu中管理书签需要做的。我知道这对于大多数用户而言很贱,但是这也许多Ubuntu的新手而言或许还有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/add-remove-bookmarks-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/install-copy-in-ubuntu-14-04/
|
||||
151
translated/tech/20150918 Install Justniffer In Ubuntu 15.04.md
Normal file
151
translated/tech/20150918 Install Justniffer In Ubuntu 15.04.md
Normal file
@ -0,0 +1,151 @@
|
||||
在 Ubuntu 15.04 上安装 Justniffer
|
||||
================================================================================
|
||||
### 简介 ###
|
||||
|
||||
[Justniffer][1] 是一个可用于替换 Snort 的网络协议分析器。它非常流行,可交互式地跟踪/探测一个网络连接。它能从实时环境中抓取流量,支持 “lipcap” 和 “tcpdump” 文件格式。它可以帮助用户分析一个用 wireshark 难以抓包的复杂网络。尤其是它可以有效的帮助分析应用层流量,能提取类似图像、脚本、HTML 等 http 内容。Justniffer 有助于理解不同组件之间是如何通信的。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
Justniffer 收集一个复杂网络的所有流量而不影响系统性能,这是 Justniffer 的一个优势,它还可以保存日志用于之后的分析,Justniffer 其它一些重要功能包括:
|
||||
|
||||
#### 1. 可靠的 TCP 流重建 ####
|
||||
|
||||
它可以使用主机 Linux 内核的一部分用于记录并重现 TCP 片段和 IP 片段。
|
||||
|
||||
#### 2. 日志 ####
|
||||
|
||||
保存日志用于之后的分析,并能自定义保存内容和时间。
|
||||
|
||||
#### 3. 可扩展 ####
|
||||
|
||||
可以通过外部 python、 perl 和 bash 脚本扩展来从分析报告中获取一些额外的结果。
|
||||
|
||||
#### 4. 性能管理 ####
|
||||
|
||||
基于连接时间、关闭时间、响应时间或请求时间等提取信息。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
Justniffer 可以通过 PPA 安装:
|
||||
|
||||
运行下面命令添加库:
|
||||
|
||||
$ sudo add-apt-repository ppa:oreste-notelli/ppa
|
||||
|
||||
更新系统:
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
安装 Justniffer 工具:
|
||||
|
||||
$ sudo apt-get install justniffer
|
||||
|
||||
make 的时候失败了,然后我运行下面的命令并尝试重新安装服务
|
||||
|
||||
$ sudo apt-get -f install
|
||||
|
||||
### 事例 ###
|
||||
|
||||
首先用 -v 选项验证安装的 Justniffer 版本,你需要用超级用户权限来使用这个工具。
|
||||
|
||||
$ sudo justniffer -V
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**1. 为 eth1 接口导出 apache 中的流量到终端**
|
||||
|
||||
$ sudo justniffer -i eth1
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**2. 可以永恒下面的选项跟踪正在运行的 tcp 流**
|
||||
|
||||
$ sudo justniffer -i eth1 -r
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**3. 获取 web 服务器的响应时间**
|
||||
|
||||
$ sudo justniffer -i eth1 -a " %response.time"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**4. 使用 Justniffer 读取一个 tcpdump 抓取的文件**
|
||||
|
||||
首先,用 tcpdump 抓取流量。
|
||||
|
||||
$ sudo tcpdump -w /tmp/file.cap -s0 -i eth0
|
||||
|
||||
然后用 Justniffer 访问数据
|
||||
|
||||
$ justniffer -f file.cap
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**5. 只抓取 http 数据**
|
||||
|
||||
$ sudo justniffer -i eth1 -r -p "port 80 or port 8080"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**6. 从一个指定主机获取 http 数据**
|
||||
|
||||
$ justniffer -i eth1 -r -p "host 192.168.1.250 and tcp port 80"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**7. 以更精确的格式抓取数据**
|
||||
|
||||
当你输入 **justniffer -h** 的时候你可以看到很多用于以更精确的方式获取数据的格式关键字
|
||||
|
||||
$ justniffer -h
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
让我们用 Justniffer 根据预先定义的参数提取数据
|
||||
|
||||
$ justniffer -i eth1 -l "%request.timestamp %request.header.host %request.url %response.time"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
其中还有很多你可以探索的选项
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Justniffer 是用于网络测试一个很好的工具。在我看来对于那些用 Snort 来进行网络探测的用户来说,Justniffer 是一个更简单的工具。它提供了很多 **格式关键字** 用于按照你的需要精确地提取数据。你可以用 .cap 文件格式记录网络信息,之后用于分析监视网络服务性能。
|
||||
|
||||
**参考资料:**
|
||||
|
||||
- [Justniffer 官网][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-justniffer-ubuntu-15-04/
|
||||
|
||||
作者:[Rajneesh Upadhyay][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/rajneesh/
|
||||
[1]:http://sourceforge.net/projects/justniffer/?source=directory
|
||||
[2]:http://justniffer.sourceforge.net/
|
||||
@ -0,0 +1,210 @@
|
||||
RHCE 系列: 使用网络安全服务(NSS)为 Apache 通过 TLS 实现 HTTPS
|
||||
================================================================================
|
||||
如果你是一个负责维护和确保 web 服务器安全的系统管理员,你不能不花费最大的精力确保服务器中处理和通过的数据任何时候都受到保护。
|
||||

|
||||
|
||||
RHCE 系列:第八部分 - 使用网络安全服务(NSS)为 Apache 通过 TLS 实现 HTTPS
|
||||
|
||||
为了在客户端和服务器之间提供更安全的连接,作为 HTTP 和 SSL(安全套接层)或者最近称为 TLS(传输层安全)的组合,产生了 HTTPS 协议。
|
||||
|
||||
由于一些严重的安全漏洞,SSL 已经被更健壮的 TLS 替代。由于这个原因,在这篇文章中我们会解析如何通过 TLS 实现你 web 服务器和客户端之间的安全连接。
|
||||
|
||||
这里假设你已经安装并配置好了 Apache web 服务器。如果还没有,在进入下一步之前请阅读下面站点中的文章。
|
||||
|
||||
- [在 RHEL/CentOS 7 上安装 LAMP(Linux,MySQL/MariaDB,Apache 和 PHP)][1]
|
||||
|
||||
### 安装 OpenSSL 和一些工具包 ###
|
||||
|
||||
首先,确保正在运行 Apache 并且允许 http 和 https 通过防火墙:
|
||||
|
||||
# systemctl start http
|
||||
# systemctl enable http
|
||||
# firewall-cmd --permanent –-add-service=http
|
||||
# firewall-cmd --permanent –-add-service=https
|
||||
|
||||
然后安装一些必须软件包:
|
||||
|
||||
# yum update && yum install openssl mod_nss crypto-utils
|
||||
|
||||
**重要**:请注意如果你想使用 OpenSSL 库而不是 NSS(网络安全服务)实现 TLS,你可以在上面的命令中用 mod\_ssl 替换 mod\_nss(使用哪一个取决于你,但在这篇文章中由于更加健壮我们会使用 NSS;例如,它支持最新的加密标准,比如 PKCS #11)。
|
||||
|
||||
如果你使用 mod\_nss,首先要卸载 mod\_ssl,反之如此。
|
||||
|
||||
# yum remove mod_ssl
|
||||
|
||||
### 配置 NSS(网络安全服务)###
|
||||
|
||||
安装完 mod\_nss 之后,会创建默认的配置文件 /etc/httpd/conf.d/nss.conf。你应该确保所有 Listen 和 VirualHost 指令都指向 443 号端口(HTTPS 默认端口):
|
||||
|
||||
nss.conf – 配置文件
|
||||
|
||||
----------
|
||||
|
||||
Listen 443
|
||||
VirtualHost _default_:443
|
||||
|
||||
然后重启 Apache 并检查是否加载了 mod\_nss 模块:
|
||||
|
||||
# apachectl restart
|
||||
# httpd -M | grep nss
|
||||
|
||||

|
||||
|
||||
检查 Apache 是否加载 mod\_nss 模块
|
||||
|
||||
下一步,在 `/etc/httpd/conf.d/nss.conf` 配置文件中做以下更改:
|
||||
|
||||
1. 指定 NSS 数据库目录。你可以使用默认的目录或者新建一个。本文中我们使用默认的:
|
||||
|
||||
NSSCertificateDatabase /etc/httpd/alias
|
||||
|
||||
2. 通过保存密码到数据库目录中的 /etc/httpd/nss-db-password.conf 文件避免每次系统启动时要手动输入密码:
|
||||
|
||||
NSSPassPhraseDialog file:/etc/httpd/nss-db-password.conf
|
||||
|
||||
其中 /etc/httpd/nss-db-password.conf 只包含以下一行,其中 mypassword 是后面你为 NSS 数据库设置的密码:
|
||||
|
||||
internal:mypassword
|
||||
|
||||
另外,要设置该文件的权限和属主为 0640 和 root:apache:
|
||||
|
||||
# chmod 640 /etc/httpd/nss-db-password.conf
|
||||
# chgrp apache /etc/httpd/nss-db-password.conf
|
||||
|
||||
3. 由于 POODLE SSLv3 漏洞,红帽建议停用 SSL 和 TLSv1.0 之前所有版本的 TLS(更多信息可以查看[这里][2])。
|
||||
|
||||
确保 NSSProtocol 指令的每个实例都类似下面一样(如果你没有托管其它虚拟主机,很可能只有一条):
|
||||
|
||||
NSSProtocol TLSv1.0,TLSv1.1
|
||||
|
||||
4. 由于这是一个自签名证书,Apache 会拒绝重启,并不会识别为有效发行人。由于这个原因,对于这种特殊情况我们还需要添加:
|
||||
|
||||
NSSEnforceValidCerts off
|
||||
|
||||
5. 虽然并不是严格要求,为 NSS 数据库设置一个密码同样很重要:
|
||||
|
||||
# certutil -W -d /etc/httpd/alias
|
||||
|
||||

|
||||
|
||||
为 NSS 数据库设置密码
|
||||
|
||||
### 创建一个 Apache SSL 自签名证书 ###
|
||||
|
||||
下一步,我们会创建一个自签名证书为我们的客户机识别服务器(请注意这个方法对于生产环境并不是最好的选择;对于生产环境你应该考虑购买第三方可信证书机构验证的证书,例如 DigiCert)。
|
||||
|
||||
我们用 genkey 命令为 box1 创建有效期为 365 天的 NSS 兼容证书。完成这一步后:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||
选择 Next:
|
||||
|
||||

|
||||
|
||||
创建 Apache SSL 密钥
|
||||
|
||||
你可以使用默认的密钥大小(2048),然后再次选择 Next:
|
||||
|
||||

|
||||
|
||||
选择 Apache SSL 密钥大小
|
||||
|
||||
等待系统生成随机比特:
|
||||
|
||||

|
||||
|
||||
生成随机密钥比特
|
||||
|
||||
为了加快速度,会提示你在控制台输入随机字符,正如下面的截图所示。请注意当没有从键盘接收到输入时进度条是如何停止的。然后,会让你选择:
|
||||
|
||||
1. 是否发送验证签名请求(CSR)到一个验证机构(CA):选择 No,因为这是一个自签名证书。
|
||||
|
||||
2. 为证书输入信息。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" src="//www.youtube.com/embed/mgsfeNfuurA" allowfullscreen="allowfullscreen"></iframe>
|
||||
|
||||
最后,会提示你输入之前设置的密码到 NSS 证书:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||

|
||||
|
||||
Apache NSS 证书密码
|
||||
|
||||
在任何时候你都可以用以下命令列出现有的证书:
|
||||
|
||||
# certutil –L –d /etc/httpd/alias
|
||||
|
||||

|
||||
|
||||
列出 Apache NSS 证书
|
||||
|
||||
然后通过名字删除(除非严格要求,用你自己的证书名称替换 box1):
|
||||
|
||||
# certutil -d /etc/httpd/alias -D -n "box1"
|
||||
|
||||
如果你需要继续的话:
|
||||
|
||||
### 测试 Apache SSL HTTPS 连接 ###
|
||||
|
||||
最后,是时候测试到我们服务器的安全连接了。当你用浏览器打开 https://<web 服务器 IP 或主机名\>,你会看到著名的信息 “This connection is untrusted”:
|
||||
|
||||

|
||||
|
||||
检查 Apache SSL 连接
|
||||
|
||||
在上面的情况中,你可以点击添加例外(Add Exception) 然后确认安全例外(Confirm Security Exception) - 但先不要这么做。让我们首先来看看证书看它的信息是否和我们之前输入的相符(如截图所示)。
|
||||
|
||||
要做到这点,点击上面的视图(View...)-> 详情(Details)选项卡,当你从列表中选择发行人你应该看到这个:
|
||||
|
||||

|
||||
|
||||
确认 Apache SSL 证书详情
|
||||
|
||||
现在你继续,确认例外(限于此次或永久),然后会通过 https 把你带到你 web 服务器的 DocumentRoot 目录,在这里你可以使用你浏览器自带的开发者工具检查连接详情:
|
||||
|
||||
在火狐浏览器中,你可以通过在屏幕中右击然后从上下文菜单中选择检查元素(Inspect Element)启动,尤其是通过网络选项卡:
|
||||
|
||||

|
||||
|
||||
检查 Apache HTTPS 连接
|
||||
|
||||
请注意这和之前显示的在验证过程中输入的信息一致。还有一种方式通过使用命令行工具测试连接:
|
||||
|
||||
左边(测试 SSLv3):
|
||||
|
||||
# openssl s_client -connect localhost:443 -ssl3
|
||||
|
||||
右边(测试 TLS):
|
||||
|
||||
# openssl s_client -connect localhost:443 -tls1
|
||||
|
||||

|
||||
|
||||
测试 Apache SSL 和 TLS 连接
|
||||
|
||||
参考上面的截图了解更相信信息。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我确信你已经知道,使用 HTTPS 会增加会在你站点中输入个人信息的访客的信任(从用户名和密码到任何商业/银行账户信息)。
|
||||
|
||||
在那种情况下,你会希望获得由可信验证机构签名的证书,正如我们之前解释的(启用的步骤和发送 CSR 到 CA 然后获得签名证书的例子相同);另外的情况,就是像我们的例子中一样使用自签名证书。
|
||||
|
||||
要获取更多关于使用 NSS 的详情,可以参考关于 [mod-nss][3] 的在线帮助。如果你有任何疑问或评论,请告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-apache-https-self-signed-certificate-using-nss/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[1]:http://www.tecmint.com/author/gacanepa/
|
||||
[2]:https://access.redhat.com/articles/1232123
|
||||
[3]:https://git.fedorahosted.org/cgit/mod_nss.git/plain/docs/mod_nss.html
|
||||
@ -1,214 +0,0 @@
|
||||
RHECSA 系列:RHEL7 中的进程管理:开机,关机,以及两者之间的所有其他事项 – Part 5
|
||||
================================================================================
|
||||
我们将概括和简要地复习从你按开机按钮来打开你的 RHEL 7 服务器到呈现出命令行界面的登录屏幕之间所发生的所有事情,以此来作为这篇文章的开始。
|
||||
|
||||

|
||||
|
||||
Linux 开机过程
|
||||
|
||||
**请注意:**
|
||||
|
||||
1. 相同的基本原则也可以应用到其他的 Linux 发行版本中,但可能需要较小的更改,并且
|
||||
2. 下面的描述并不是旨在给出开机过程的一个详尽的解释,而只是介绍一些基础的东西
|
||||
|
||||
### Linux 开机过程 ###
|
||||
|
||||
1.初始化 POST(加电自检)并执行硬件检查;
|
||||
|
||||
2.当 POST 完成后,系统的控制权将移交给启动管理器的第一阶段,它存储在一个硬盘的引导扇区(对于使用 BIOS 和 MBR 的旧式的系统)或存储在一个专门的 (U)EFI 分区上。
|
||||
|
||||
3.启动管理器的第一阶段完成后,接着进入启动管理器的第二阶段,通常大多数使用的是 GRUB(GRand Unified Boot Loader 的简称),它驻留在 `/boot` 中,反过来加载内核和驻留在 RAM 中的初始化文件系统(被称为 initramfs,它包含执行必要操作所需要的程序和二进制文件,以此来最终挂载真实的根文件系统)。
|
||||
|
||||
4.接着经历了闪屏过后,呈现在我们眼前的是类似下图的画面,它允许我们选择一个操作系统和内核来启动:
|
||||
|
||||

|
||||
|
||||
启动菜单屏幕
|
||||
|
||||
5.然后内核对挂载到系统的硬件进行设置,一旦根文件系统被挂载,接着便启动 PID 为 1 的进程,反过来这个进程将初始化其他的进程并最终呈现给我们一个登录提示符界面。
|
||||
|
||||
注意:假如我们想在后面这样做(注:这句话我总感觉不通顺,不明白它的意思,希望改一下),我们可以使用 [dmesg 命令][1](注:这篇文章已经翻译并发表了,链接是 https://linux.cn/article-3587-1.html )并使用这个系列里的上一篇文章中解释过的工具(注:即 grep)来过滤它的输出。
|
||||
|
||||

|
||||
|
||||
登录屏幕和进程的 PID
|
||||
|
||||
在上面的例子中,我们使用了众所周知的 `ps` 命令来显示在系统启动过程中的一系列当前进程的信息,它们的父进程(或者换句话说,就是那个开启这些进程的进程) 为 systemd(大多数现代的 Linux 发行版本已经切换到的系统和服务管理器):
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
记住 `-o`(为 -format 的简写)选项允许你以一个自定义的格式来显示 ps 的输出,以此来满足你的需求;这个自定义格式使用 man ps 里 STANDARD FORMAT SPECIFIERS 一节中的特定关键词。
|
||||
|
||||
另一个你想自定义 ps 的输出而不是使用其默认输出的情形是:当你需要找到引起 CPU 或内存消耗过多的那些进程,并按照下列方式来对它们进行排序时:
|
||||
|
||||
# ps aux --sort=+pcpu # 以 %CPU 来排序(增序)
|
||||
# ps aux --sort=-pcpu # 以 %CPU 来排序(降序)
|
||||
# ps aux --sort=+pmem # 以 %MEM 来排序(增序)
|
||||
# ps aux --sort=-pmem # 以 %MEM 来排序(降序)
|
||||
# ps aux --sort=+pcpu,-pmem # 结合 %CPU (增序) 和 %MEM (降序)来排列
|
||||
|
||||

|
||||
|
||||
自定义 ps 命令的输出
|
||||
|
||||
### systemd 的一个介绍 ###
|
||||
|
||||
在 Linux 世界中,很少有决定能够比在主流的 Linux 发行版本中采用 systemd 引起更多的争论。systemd 的倡导者根据以下事实命名其主要的优势:
|
||||
|
||||
另外请阅读: ['init' 和 'systemd' 背后的故事][2]
|
||||
|
||||
1. 在系统启动期间,systemd 允许并发地启动更多的进程(相比于先前的 SysVinit,SysVinit 似乎总是表现得更慢,因为它一个接一个地启动进程,检查一个进程是否依赖于另一个进程,然后等待守护进程去开启可以开始的更多的服务),并且
|
||||
2. 在一个运行着的系统中,它作为一个动态的资源管理器来工作。这样在开机期间,当一个服务被需要时,才启动它(以此来避免消耗系统资源)而不是在没有一个合理的原因的情况下启动额外的服务。
|
||||
3. 向后兼容 sysvinit 的脚本。
|
||||
|
||||
systemd 由 systemctl 工具控制,假如你带有 SysVinit 背景,你将会对以下的内容感到熟悉:
|
||||
|
||||
- service 工具, 在旧一点的系统中,它被用来管理 SysVinit 脚本,以及
|
||||
- chkconfig 工具, 为系统服务升级和查询运行级别信息
|
||||
- shutdown, 你一定使用过几次来重启或关闭一个运行的系统。
|
||||
|
||||
下面的表格展示了使用传统的工具和 systemctl 之间的相似之处:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="237"></colgroup>
|
||||
<colgroup width="256"></colgroup>
|
||||
<colgroup width="1945"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="left" height="25" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Legacy tool</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Systemctl equivalent</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name start</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl start name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Start name (where name is a service)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name stop</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl stop name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Stop name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name condrestart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl try-restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name (if it’s already running)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name restart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name reload</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reload name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Reloads the configuration for name</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name status</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl status name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Displays the current status of name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service –status-all</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays the status of all current services</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name on</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl enable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name off</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl disable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Disables name to run on startup as specified in the unit file (the file to which the symlink points)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl is-enabled name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Verify whether name (a specific service) is currently enabled</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl –type=service</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays all services and tells whether they are enabled or disabled</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -h now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl poweroff</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Power-off the machine (halt)</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -r now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reboot</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Reboot the system</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
systemd 也引进了单元(它可能是一个服务,一个挂载点,一个设备或者一个网络套接字)和目标(它们定义了 systemd 如何去管理和同时开启几个相关的进程,并可认为它们与在基于 SysVinit 的系统中的运行级别等价,尽管事实上它们并不等价)。
|
||||
|
||||
### 总结归纳 ###
|
||||
|
||||
其他与进程管理相关,但并不仅限于下面所列的功能的任务有:
|
||||
|
||||
**1. 在考虑到系统资源的使用上,调整一个进程的执行优先级:**
|
||||
|
||||
这是通过 `renice` 工具来完成的,它可以改变一个或多个正在运行着的进程的调度优先级。简单来说,调度优先级是一个允许内核(当前只支持 >= 2.6 的版本)根据某个给定进程被分配的执行优先级(即优先级,从 -20 到 19)来为其分配系统资源的功能。
|
||||
|
||||
`renice` 的基本语法如下:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
在上面的通用命令中,第一个参数是将要使用的优先级数值,而另一个参数可以解释为进程 ID(这是默认的设定),进程组 ID,用户 ID 或者用户名。一个常规的用户(即除 root 以外的用户)只可以更改他或她所拥有的进程的调度优先级,并且只能增加优先级的层次(这意味着占用更少的系统资源)。
|
||||
|
||||

|
||||
|
||||
进程调度优先级
|
||||
|
||||
**2. 按照需要杀死一个进程(或终止其正常执行):**
|
||||
|
||||
更精确地说,杀死一个进程指的是通过 [kill 或 pkill][3]命令给该进程发送一个信号,让它优雅地(SIGTERM=15)或立即(SIGKILL=9)结束它的执行。
|
||||
|
||||
这两个工具的不同之处在于前一个被用来终止一个特定的进程或一个进程组,而后一个则允许你在进程的名称和其他属性的基础上,执行相同的动作。
|
||||
|
||||
另外, pkill 与 pgrep 相捆绑,pgrep 提供将受影响的进程的 PID 给 pkill 来使用。例如,在运行下面的命令之前:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
查看一眼由 gacanepa 所拥有的 PID 或许会带来点帮助:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||

|
||||
|
||||
找到用户拥有的 PID
|
||||
|
||||
默认情况下,kill 和 pkiill 都发送 SIGTERM 信号给进程,如我们上面提到的那样,这个信号可以被忽略(即该进程可能会终止其自身的执行或者不终止),所以当你因一个合理的理由要真正地停止一个运行着的进程,则你将需要在命令行中带上特定的 SIGKILL 信号:
|
||||
|
||||
# kill -9 identifier # 杀死一个进程或一个进程组
|
||||
# kill -s SIGNAL identifier # 同上
|
||||
# pkill -s SIGNAL identifier # 通过名称或其他属性来杀死一个进程
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们解释了在 RHEL 7 系统中,有关开机启动过程的基本知识,并分析了一些可用的工具来帮助你通过使用一般的程序和 systemd 特有的命令来管理进程。
|
||||
|
||||
请注意,这个列表并不旨在涵盖有关这个话题的所有花哨的工具,请随意使用下面的评论栏来添加你自已钟爱的工具和命令。同时欢迎你的提问和其他的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user