mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
10c5bec125
3
.gitmodules
vendored
Normal file
3
.gitmodules
vendored
Normal file
@ -0,0 +1,3 @@
|
||||
[submodule "comic"]
|
||||
path = comic
|
||||
url = https://wxy@github.com/LCTT/comic.git
|
||||
1
comic
Submodule
1
comic
Submodule
@ -0,0 +1 @@
|
||||
Subproject commit e5db5b880dac1302ee0571ecaaa1f8ea7cf61901
|
||||
@ -1,17 +1,17 @@
|
||||
在 Linux 如何用 ‘bash-support’ 插件将 Vim 编辑器打造成一个 Bash-IDE
|
||||
在 Linux 如何用 bash-support 插件将 Vim 编辑器打造成一个 Bash-IDE
|
||||
============================================================
|
||||
|
||||
IDE([集成开发环境][1])就是一个软件,它为了最大化程序员生产效率,提供了很多编程所需的设施和组件。 IDE 将所有开发集中到一个程序中,使得程序员可以编写、修改、编译、部署以及调试程序。
|
||||
IDE([集成开发环境][1])就是这样一个软件,它为了最大化程序员生产效率,提供了很多编程所需的设施和组件。 IDE 将所有开发工作集中到一个程序中,使得程序员可以编写、修改、编译、部署以及调试程序。
|
||||
|
||||
在这篇文章中,我们会介绍如何通过使用 bash-support vim 插件将[Vim 编辑器安装和配置][2] 为一个 Bash-IDE。
|
||||
在这篇文章中,我们会介绍如何通过使用 bash-support vim 插件将 [Vim 编辑器安装和配置][2] 为一个 Bash-IDE。
|
||||
|
||||
#### 什么是 bash-support.vim 插件?
|
||||
|
||||
bash-support 是一个高度定制化的 vim 插件,它允许你插入:文件头、补全语句、注释、函数、以及代码块。它也使你可以进行语法检查、使脚本可执行、通过一次按键启动调试器;完成所有的这些而不需要关闭编辑器。
|
||||
bash-support 是一个高度定制化的 vim 插件,它允许你插入:文件头、补全语句、注释、函数、以及代码块。它也使你可以进行语法检查、使脚本可执行、一键启动调试器;而完成所有的这些而不需要关闭编辑器。
|
||||
|
||||
它使用快捷键(映射),通过有组织、一致的文件内容编写/插入,使得 bash 脚本变得有趣和愉快。
|
||||
它使用快捷键(映射),通过有组织地、一致的文件内容编写/插入,使得 bash 脚本变得有趣和愉快。
|
||||
|
||||
插件当前版本是 4.3,版本 4.0 重写了版本 3.12.1,4.0 及之后的版本基于一个全新的、更强大的、和之前版本模板语法不同的模板系统。
|
||||
插件当前版本是 4.3,4.0 版本 重写了之前的 3.12.1 版本,4.0 及之后的版本基于一个全新的、更强大的、和之前版本模板语法不同的模板系统。
|
||||
|
||||
### 如何在 Linux 中安装 Bash-support 插件
|
||||
|
||||
@ -36,64 +36,65 @@ $ unzip ~/Downloads/bash-support.zip
|
||||
$ vi ~/.vimrc
|
||||
```
|
||||
|
||||
通过插入下面一行:
|
||||
并插入下面一行:
|
||||
|
||||
```
|
||||
filetype plug-in on
|
||||
set number #optionally add this to show line numbers in vim
|
||||
set number # 可选,增加这行以在 vim 中显示行号
|
||||
```
|
||||
|
||||
### 如何在 Vim 编辑器中使用 Bash-support 插件
|
||||
|
||||
为了简化使用,通常使用的结构和特定操作可以分别通过键映射插入/执行。 ~/.vim/doc/bashsupport.txt 和 ~/.vim/bash-support/doc/bash-hotkeys.pdf 或者 ~/.vim/bash-support/doc/bash-hotkeys.tex 文件中介绍了映射。
|
||||
为了简化使用,通常使用的结构和特定操作可以分别通过键映射来插入/执行。 `~/.vim/doc/bashsupport.txt` 和 `~/.vim/bash-support/doc/bash-hotkeys.pdf` 或者 `~/.vim/bash-support/doc/bash-hotkeys.tex` 文件中介绍了映射。
|
||||
|
||||
##### 重要:
|
||||
**重要:**
|
||||
|
||||
1. 所有映射(`(\)+charater(s)` 组合)都是针对特定文件类型的:为了避免和其它插件的映射冲突,它们只适用于 ‘sh’ 文件。
|
||||
1. 所有映射(`(\)+charater(s)` 组合)都是针对特定文件类型的:为了避免和其它插件的映射冲突,它们只适用于 `sh` 文件。
|
||||
2. 使用键映射的时候打字速度也有关系,引导符 `('\')` 和后面字符的组合要在特定短时间内才能识别出来(很可能少于 3 秒 - 基于假设)。
|
||||
|
||||
下面我们会介绍和学习使用这个插件一些显著的功能:
|
||||
|
||||
#### 如何为新脚本自动生成文件头
|
||||
|
||||
看下面的事例文件头,为了要在你所有的新脚本中自动创建该文件头,请按照以下步骤操作。
|
||||
看下面的示例文件头,为了要在你所有的新脚本中自动创建该文件头,请按照以下步骤操作。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][3]
|
||||
|
||||
脚本事例文件头选项
|
||||
*脚本示例文件头选项*
|
||||
|
||||
首先设置你的个人信息(作者名称、作者参考、组织、公司等)。在一个 Bash 缓冲区(像下面这样打开一个测试脚本)中使用映射 `\ntw` 启动模板设置向导。
|
||||
|
||||
选中选项(1)设置个性化文件,然后按回车键。
|
||||
选中选项 1 设置个性化文件,然后按回车键。
|
||||
|
||||
```
|
||||
$ vi test.sh
|
||||
```
|
||||
|
||||
[
|
||||

|
||||

|
||||
][4]
|
||||
|
||||
在脚本文件中设置个性化信息
|
||||
*在脚本文件中设置个性化信息*
|
||||
|
||||
之后,再次输入回车键。然后再一次选中选项(1)设置个性化文件的路径并输入回车。
|
||||
之后,再次输入回车键。然后再一次选中选项 1 设置个性化文件的路径并输入回车。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][5]
|
||||
|
||||
设置个性化文件路径
|
||||
*设置个性化文件路径*
|
||||
|
||||
设置向导会把目标文件 .vim/bash-support/rc/personal.templates 拷贝到 .vim/templates/personal.templates,打开并编辑它,在这里你可以输入你的信息。
|
||||
设置向导会把目标文件 `.vim/bash-support/rc/personal.templates` 拷贝到 `.vim/templates/personal.templates`,打开并编辑它,在这里你可以输入你的信息。
|
||||
|
||||
按 `i` 键像截图那样在一个单引号中插入合适的值。
|
||||
按 `i` 键像截图那样在单引号中插入合适的值。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][6]
|
||||
|
||||
在脚本文件头添加信息
|
||||
*在脚本文件头添加信息*
|
||||
|
||||
一旦你设置了正确的值,输入 `:wq` 保存并退出文件。关闭 Bash 测试脚本,打开另一个脚本来测试新的配置。现在文件头中应该有和下面截图类似的你的个人信息:
|
||||
|
||||
@ -101,108 +102,109 @@ $ vi test.sh
|
||||
$ test2.sh
|
||||
```
|
||||
[
|
||||

|
||||

|
||||
][7]
|
||||
|
||||
自动添加文件头到脚本
|
||||
*自动添加文件头到脚本*
|
||||
|
||||
#### 使 Bash-support 插件帮助信息可访问
|
||||
#### 添加 Bash-support 插件帮助信息
|
||||
|
||||
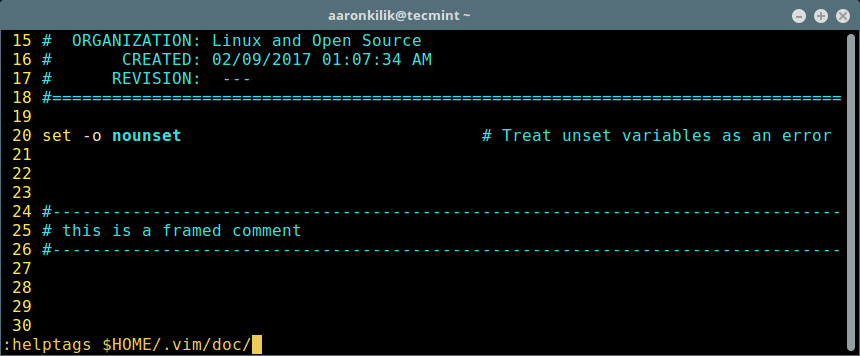
为此,在 Vim 命令行输入下面的命令并按回车键,它会创建 .vim/doc/tags 文件:
|
||||
为此,在 Vim 命令行输入下面的命令并按回车键,它会创建 `.vim/doc/tags` 文件:
|
||||
|
||||
```
|
||||
:helptags $HOME/.vim/doc/
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
|
||||
][8]
|
||||
|
||||
在 Vi 编辑器添加插件帮助
|
||||
*在 Vi 编辑器添加插件帮助*
|
||||
|
||||
#### 如何在 Shell 脚本中插入注释
|
||||
|
||||
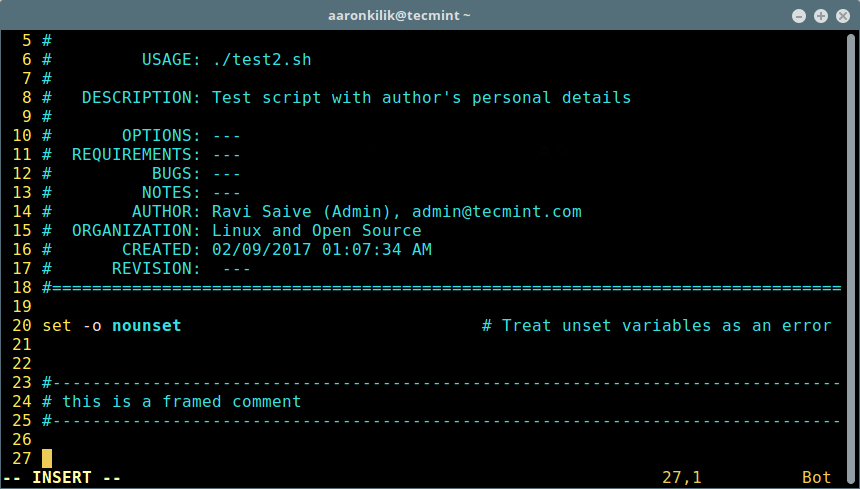
要插入一个块注释,在普通模式下输入 `\cfr`:
|
||||
|
||||
[
|
||||

|
||||
|
||||
][9]
|
||||
|
||||
添加注释到脚本
|
||||
*添加注释到脚本*
|
||||
|
||||
#### 如何在 Shell 脚本中插入语句
|
||||
|
||||
下面是一些用于插入语句的键映射(`n` – 普通模式, `i` – 插入模式):
|
||||
下面是一些用于插入语句的键映射(`n` – 普通模式, `i` – 插入模式,`v` 可视模式):
|
||||
|
||||
1. `\sc` – case in … esac (n, I)
|
||||
2. `\sei` – elif then (n, I)
|
||||
3. `\sf` – for in do done (n, i, v)
|
||||
4. `\sfo` – for ((…)) do done (n, i, v)
|
||||
5. `\si` – if then fi (n, i, v)
|
||||
6. `\sie` – if then else fi (n, i, v)
|
||||
7. `\ss` – select in do done (n, i, v)
|
||||
8. `\su` – until do done (n, i, v)
|
||||
9. `\sw` – while do done (n, i, v)
|
||||
10. `\sfu` – function (n, i, v)
|
||||
11. `\se` – echo -e “…” (n, i, v)
|
||||
12. `\sp` – printf “…” (n, i, v)
|
||||
13. `\sa` – 数组元素, ${.[.]} (n, i, v) 和其它更多的数组功能。
|
||||
1. `\sc` – `case in … esac` (n, i)
|
||||
2. `\sei` – `elif then` (n, i)
|
||||
3. `\sf` – `for in do done` (n, i, v)
|
||||
4. `\sfo` – `for ((…)) do done` (n, i, v)
|
||||
5. `\si` – `if then fi` (n, i, v)
|
||||
6. `\sie` – `if then else fi` (n, i, v)
|
||||
7. `\ss` – `select in do done` (n, i, v)
|
||||
8. `\su` – `until do done` (n, i, v)
|
||||
9. `\sw` – `while do done` (n, i, v)
|
||||
10. `\sfu` – `function` (n, i, v)
|
||||
11. `\se` – `echo -e "…"` (n, i, v)
|
||||
12. `\sp` – `printf "…"` (n, i, v)
|
||||
13. `\sa` – 数组元素, `${.[.]}` (n, i, v) 和其它更多的数组功能。
|
||||
|
||||
#### 插入一个函数和函数头
|
||||
|
||||
输入 `\sfu` 添加一个新的空函数,然后添加函数名并按回车键创建它。之后,添加你的函数代码。
|
||||
|
||||
[
|
||||

|
||||

|
||||
][10]
|
||||
|
||||
在脚本中插入新函数
|
||||
*在脚本中插入新函数*
|
||||
|
||||
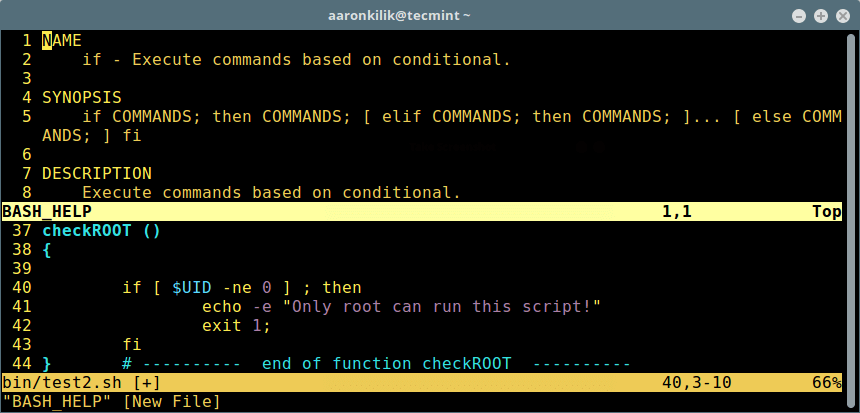
为了给上面的函数创建函数头,输入 `\cfu`,输入函数名称,按回车键并填入合适的值(名称、介绍、参数、返回值):
|
||||
|
||||
[
|
||||

|
||||

|
||||
][11]
|
||||
|
||||
在脚本中创建函数头
|
||||
*在脚本中创建函数头*
|
||||
|
||||
#### 更多关于添加 Bash 语句的例子
|
||||
|
||||
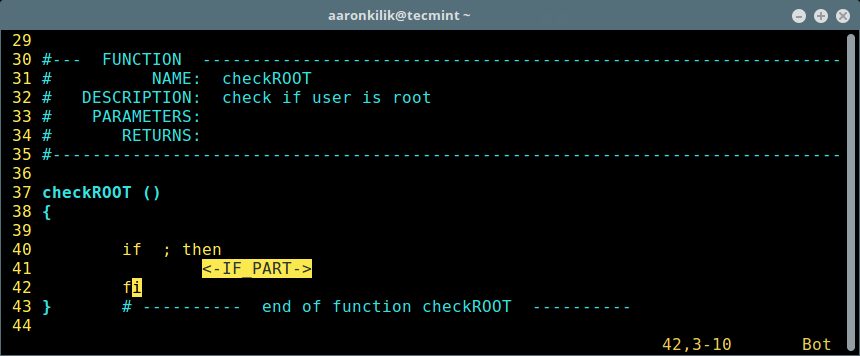
下面是一个使用 `\si` 插入一条 if 语句的例子:
|
||||
下面是一个使用 `\si` 插入一条 `if` 语句的例子:
|
||||
|
||||
[
|
||||

|
||||
|
||||
][12]
|
||||
|
||||
在脚本中插入语句
|
||||
*在脚本中插入语句*
|
||||
|
||||
下面的例子显示使用 `\se` 添加一条 echo 语句:
|
||||
下面的例子显示使用 `\se` 添加一条 `echo` 语句:
|
||||
|
||||
[
|
||||

|
||||

|
||||
][13]
|
||||
|
||||
在脚本中添加 echo 语句
|
||||
*在脚本中添加 echo 语句*
|
||||
|
||||
#### 如何在 Vi 编辑器中使用运行操作
|
||||
|
||||
下面是一些运行操作键映射的列表:
|
||||
|
||||
1. `\rr` – 更新文件,运行脚本 (n, I)
|
||||
2. `\ra` – 设置脚本命令行参数 (n, I)
|
||||
3. `\rc` – 更新文件,检查语法 (n, I)
|
||||
4. `\rco` – 语法检查选项 (n, I)
|
||||
5. `\rd` – 启动调试器 (n, I)
|
||||
6. `\re` – 使脚本可/不可执行(*) (in)
|
||||
1. `\rr` – 更新文件,运行脚本(n, i)
|
||||
2. `\ra` – 设置脚本命令行参数 (n, i)
|
||||
3. `\rc` – 更新文件,检查语法 (n, i)
|
||||
4. `\rco` – 语法检查选项 (n, i)
|
||||
5. `\rd` – 启动调试器(n, i)
|
||||
6. `\re` – 使脚本可/不可执行(*) (n, i)
|
||||
|
||||
#### 使脚本可执行
|
||||
|
||||
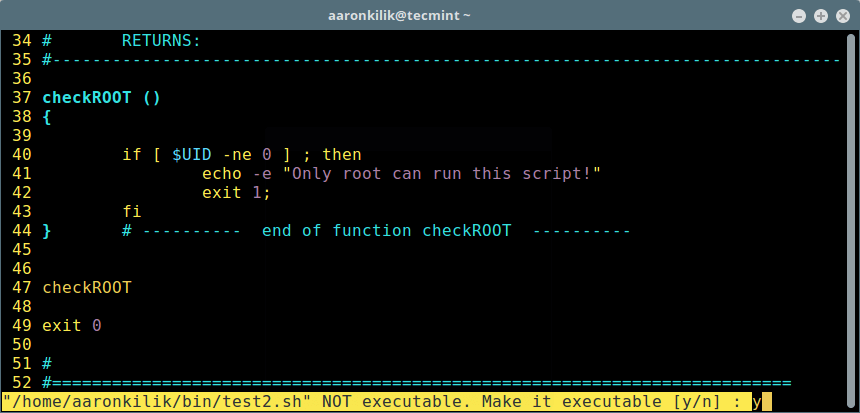
编写完脚本后,保存它然后输入 `\re` 和回车键使它可执行。
|
||||
|
||||
[
|
||||

|
||||
|
||||
][14]
|
||||
|
||||
使脚本可执行
|
||||
*使脚本可执行*
|
||||
|
||||
#### 如何在 Bash 脚本中使用预定义代码片段
|
||||
|
||||
@ -211,23 +213,24 @@ $ test2.sh
|
||||
```
|
||||
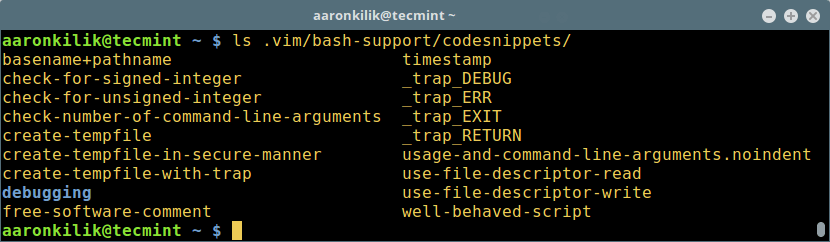
$ .vim/bash-support/codesnippets/
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
|
||||
][15]
|
||||
|
||||
代码段列表
|
||||
*代码段列表*
|
||||
|
||||
为了使用代码段,例如 free-software-comment,输入 `\nr` 并使用自动补全功能选择它的名称,然后输入回车键:
|
||||
|
||||
[
|
||||

|
||||

|
||||
][16]
|
||||
|
||||
添加代码段到脚本
|
||||
*添加代码段到脚本*
|
||||
|
||||
#### 创建自定义预定义代码段
|
||||
|
||||
可以在 ~/.vim/bash-support/codesnippets/ 目录下编写你自己的代码段。另外,你还可以从你正常的脚本代码中创建你自己的代码段:
|
||||
可以在 `~/.vim/bash-support/codesnippets/` 目录下编写你自己的代码段。另外,你还可以从你正常的脚本代码中创建你自己的代码段:
|
||||
|
||||
1. 选择你想作为代码段的部分代码,然后输入 `\nw` 并给它一个相近的文件名。
|
||||
2. 要读入它,只需要输入 `\nr` 然后使用文件名就可以添加你自定义的代码段。
|
||||
@ -243,17 +246,17 @@ $ .vim/bash-support/codesnippets/
|
||||
|
||||
][17]
|
||||
|
||||
查看内建命令帮助
|
||||
*查看内建命令帮助*
|
||||
|
||||
更多参考资料,可以查看文件:
|
||||
|
||||
```
|
||||
~/.vim/doc/bashsupport.txt #copy of online documentation
|
||||
~/.vim/doc/bashsupport.txt #在线文档的副本
|
||||
~/.vim/doc/tags
|
||||
```
|
||||
|
||||
访问 Bash-support 插件 GitHub 仓库:[https://github.com/WolfgangMehner/bash-support][18]
|
||||
在 Vim 网站访问 Bash-support 插件:[http://www.vim.org/scripts/script.php?script_id=365][19]
|
||||
- 访问 Bash-support 插件 GitHub 仓库:[https://github.com/WolfgangMehner/bash-support][18]
|
||||
- 在 Vim 网站访问 Bash-support 插件:[http://www.vim.org/scripts/script.php?script_id=365][19]
|
||||
|
||||
就是这些啦,在这篇文章中,我们介绍了在 Linux 中使用 Bash-support 插件安装和配置 Vim 为一个 Bash-IDE 的步骤。快去发现这个插件其它令人兴奋的功能吧,一定要在评论中和我们分享哦。
|
||||
|
||||
@ -269,7 +272,7 @@ via: http://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,21 @@
|
||||
[调试器的工作原理:第一篇-基础][21]
|
||||
调试器的工作原理(一):基础篇
|
||||
============================================================
|
||||
|
||||
这是调试器工作原理系列文章的第一篇,我不确定这个系列会有多少篇文章,会涉及多少话题,但我仍会从这篇基础开始。
|
||||
|
||||
### 这一篇会讲什么
|
||||
|
||||
我将为大家展示 Linux 中调试器的主要构成模块 - ptrace 系统调用。这篇文章所有代码都是基于 32 位 Ubuntu 操作系统.值得注意的是,尽管这些代码是平台相关的,将他们移植到其他平台应该并不困难。
|
||||
我将为大家展示 Linux 中调试器的主要构成模块 - `ptrace` 系统调用。这篇文章所有代码都是基于 32 位 Ubuntu 操作系统。值得注意的是,尽管这些代码是平台相关的,将它们移植到其它平台应该并不困难。
|
||||
|
||||
### 缘由
|
||||
|
||||
为了理解我们要做什么,让我们先考虑下调试器为了完成调试都需要什么资源。调试器可以开始一个进程并调试这个进程,又或者将自己同某个已经存在的进程关联起来。调试器能够单步执行代码,设定断点并且将程序执行到断点,检查变量的值并追踪堆栈。许多调试器有着更高级的特性,例如在调试器的地址空间内执行表达式或者调用函数,甚至可以在进程执行过程中改变代码并观察效果。
|
||||
为了理解我们要做什么,让我们先考虑下调试器为了完成调试都需要什么资源。调试器可以开始一个进程并调试这个进程,又或者将自己同某个已经存在的进程关联起来。调试器能够单步执行代码,设定断点并且将程序执行到断点,检查变量的值并追踪堆栈。许多调试器有着更高级的特性,例如在调试器的地址空间内执行表达式或者调用函数,甚至可以在进程执行过程中改变代码并观察效果。
|
||||
|
||||
尽管现代的调试器都十分的复杂 [[1]][13],但他们的工作的原理却是十分的简单。调试器的基础是操作系统与编译器 / 链接器提供的一些基础服务,其余的部分只是[简单的编程][14]。
|
||||
尽管现代的调试器都十分的复杂(我没有检查,但我确信 gdb 的代码行数至少有六位数),但它们的工作的原理却是十分的简单。调试器的基础是操作系统与编译器 / 链接器提供的一些基础服务,其余的部分只是[简单的编程][14]而已。
|
||||
|
||||
### Linux 的调试 - ptrace
|
||||
|
||||
Linux 调试器中的瑞士军刀便是 ptrace 系统调用 [[2]][15]。这是一种复杂却强大的工具,可以允许一个进程控制另外一个进程并从内部替换被控制进程的内核镜像的值[[3]][16].。
|
||||
Linux 调试器中的瑞士军刀便是 `ptrace` 系统调用(使用 man 2 ptrace 命令可以了解更多)。这是一种复杂却强大的工具,可以允许一个进程控制另外一个进程并从<ruby>内部替换<rt>Peek and poke</rt></ruby>被控制进程的内核镜像的值(Peek and poke 在系统编程中是很知名的叫法,指的是直接读写内存内容)。
|
||||
|
||||
接下来会深入分析。
|
||||
|
||||
@ -49,7 +49,7 @@ int main(int argc, char** argv)
|
||||
}
|
||||
```
|
||||
|
||||
看起来相当的简单:我们用 fork 命令创建了一个新的子进程。if 语句的分支执行子进程(这里称之为“target”),else if 的分支执行父进程(这里称之为“debugger”)。
|
||||
看起来相当的简单:我们用 `fork` 创建了一个新的子进程(这篇文章假定读者有一定的 Unix/Linux 编程经验。我假定你知道或至少了解 fork、exec 族函数与 Unix 信号)。if 语句的分支执行子进程(这里称之为 “target”),`else if` 的分支执行父进程(这里称之为 “debugger”)。
|
||||
|
||||
下面是 target 进程的代码:
|
||||
|
||||
@ -69,18 +69,18 @@ void run_target(const char* programname)
|
||||
}
|
||||
```
|
||||
|
||||
这段代码中最值得注意的是 ptrace 调用。在 "sys/ptrace.h" 中,ptrace 是如下定义的:
|
||||
这段代码中最值得注意的是 `ptrace` 调用。在 `sys/ptrace.h` 中,`ptrace` 是如下定义的:
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
第一个参数是 _request_,这是许多预定义的 PTRACE_* 常量中的一个。第二个参数为请求分配进程 ID。第三个与第四个参数是地址与数据指针,用于操作内存。上面代码段中的ptrace调用发起了 PTRACE_TRACEME 请求,这意味着该子进程请求系统内核让其父进程跟踪自己。帮助页面上对于 request 的描述很清楚:
|
||||
第一个参数是 `_request_`,这是许多预定义的 `PTRACE_*` 常量中的一个。第二个参数为请求分配进程 ID。第三个与第四个参数是地址与数据指针,用于操作内存。上面代码段中的 `ptrace` 调用发起了 `PTRACE_TRACEME` 请求,这意味着该子进程请求系统内核让其父进程跟踪自己。帮助页面上对于 request 的描述很清楚:
|
||||
|
||||
> 意味着该进程被其父进程跟踪。任何传递给该进程的信号(除了 SIGKILL)都将通过 wait() 方法阻塞该进程并通知其父进程。**此外,该进程的之后所有调用 exec() 动作都将导致 SIGTRAP 信号发送到此进程上,使得父进程在新的程序执行前得到取得控制权的机会**。如果一个进程并不需要它的的父进程跟踪它,那么这个进程不应该发送这个请求。(pid,addr 与 data 暂且不提)
|
||||
> 意味着该进程被其父进程跟踪。任何传递给该进程的信号(除了 `SIGKILL`)都将通过 `wait()` 方法阻塞该进程并通知其父进程。**此外,该进程的之后所有调用 `exec()` 动作都将导致 `SIGTRAP` 信号发送到此进程上,使得父进程在新的程序执行前得到取得控制权的机会**。如果一个进程并不需要它的的父进程跟踪它,那么这个进程不应该发送这个请求。(pid、addr 与 data 暂且不提)
|
||||
|
||||
我高亮了这个例子中我们需要注意的部分。在 ptrace 调用后,run_target 接下来要做的就是通过 execl 传参并调用。如同高亮部分所说明,这将导致系统内核在 execl 创建进程前暂时停止,并向父进程发送信号。
|
||||
我高亮了这个例子中我们需要注意的部分。在 `ptrace` 调用后,`run_target` 接下来要做的就是通过 `execl` 传参并调用。如同高亮部分所说明,这将导致系统内核在 `execl` 创建进程前暂时停止,并向父进程发送信号。
|
||||
|
||||
是时候看看父进程做什么了。
|
||||
|
||||
@ -110,11 +110,11 @@ void run_debugger(pid_t child_pid)
|
||||
}
|
||||
```
|
||||
|
||||
如前文所述,一旦子进程调用了 exec,子进程会停止并被发送 SIGTRAP 信号。父进程会等待该过程的发生并在第一个 wait() 处等待。一旦上述事件发生了,wait() 便会返回,由于子进程停止了父进程便会收到信号(如果子进程由于信号的发送停止了,WIFSTOPPED 就会返回 true)。
|
||||
如前文所述,一旦子进程调用了 `exec`,子进程会停止并被发送 `SIGTRAP` 信号。父进程会等待该过程的发生并在第一个 `wait()` 处等待。一旦上述事件发生了,`wait()` 便会返回,由于子进程停止了父进程便会收到信号(如果子进程由于信号的发送停止了,`WIFSTOPPED` 就会返回 `true`)。
|
||||
|
||||
父进程接下来的动作就是整篇文章最需要关注的部分了。父进程会将 PTRACE_SINGLESTEP 与子进程ID作为参数调用 ptrace 方法。这就会告诉操作系统,“请恢复子进程,但在它执行下一条指令前阻塞”。周而复始地,父进程等待子进程阻塞,循环继续。当 wait() 中传出的信号不再是子进程的停止信号时,循环终止。在跟踪器(父进程)运行期间,这将会是被跟踪进程(子进程)传递给跟踪器的终止信号(如果子进程终止 WIFEXITED 将返回 true)。
|
||||
父进程接下来的动作就是整篇文章最需要关注的部分了。父进程会将 `PTRACE_SINGLESTEP` 与子进程 ID 作为参数调用 `ptrace` 方法。这就会告诉操作系统,“请恢复子进程,但在它执行下一条指令前阻塞”。周而复始地,父进程等待子进程阻塞,循环继续。当 `wait()` 中传出的信号不再是子进程的停止信号时,循环终止。在跟踪器(父进程)运行期间,这将会是被跟踪进程(子进程)传递给跟踪器的终止信号(如果子进程终止 `WIFEXITED` 将返回 `true`)。
|
||||
|
||||
icounter 存储了子进程执行指令的次数。这么看来我们小小的例子也完成了些有用的事情 - 在命令行中指定程序,它将执行该程序并记录它从开始到结束所需要的 cpu 指令数量。接下来就让我们这么做吧。
|
||||
`icounter` 存储了子进程执行指令的次数。这么看来我们小小的例子也完成了些有用的事情 - 在命令行中指定程序,它将执行该程序并记录它从开始到结束所需要的 cpu 指令数量。接下来就让我们这么做吧。
|
||||
|
||||
### 测试
|
||||
|
||||
@ -131,11 +131,11 @@ int main()
|
||||
|
||||
```
|
||||
|
||||
令我惊讶的是,跟踪器花了相当长的时间,并报告整个执行过程共有超过 100,000 条指令执行。仅仅是一条输出语句?什么造成了这种情况?答案很有趣[[5]][18]。Linux 的 gcc 默认会动态的将程序与 c 的运行时库动态地链接。这就意味着任何程序运行前的第一件事是需要动态库加载器去查找程序运行所需要的共享库。这些代码的数量很大 - 别忘了我们的跟踪器要跟踪每一条指令,不仅仅是主函数的,而是“整个过程中的指令”。
|
||||
令我惊讶的是,跟踪器花了相当长的时间,并报告整个执行过程共有超过 100,000 条指令执行。仅仅是一条输出语句?什么造成了这种情况?答案很有趣(至少你同我一样痴迷与机器/汇编语言)。Linux 的 gcc 默认会动态的将程序与 c 的运行时库动态地链接。这就意味着任何程序运行前的第一件事是需要动态库加载器去查找程序运行所需要的共享库。这些代码的数量很大 - 别忘了我们的跟踪器要跟踪每一条指令,不仅仅是主函数的,而是“整个进程中的指令”。
|
||||
|
||||
所以当我将测试程序使用静态编译时(通过比较,可执行文件会多出 500 KB 左右的大小,这部分是 C 运行时库的静态链接),跟踪器提示只有大概 7000 条指令被执行。这个数目仍然不小,但是考虑到在主函数执行前 libc 的初始化以及主函数执行后的清除代码,这个数目已经是相当不错了。此外,printf 也是一个复杂的函数。
|
||||
所以当我将测试程序使用静态编译时(通过比较,可执行文件会多出 500 KB 左右的大小,这部分是 C 运行时库的静态链接),跟踪器提示只有大概 7000 条指令被执行。这个数目仍然不小,但是考虑到在主函数执行前 libc 的初始化以及主函数执行后的清除代码,这个数目已经是相当不错了。此外,`printf` 也是一个复杂的函数。
|
||||
|
||||
仍然不满意的话,我需要的是“可以测试”的东西 - 例如可以完整记录每一个指令运行的程序执行过程。这当然可以通过汇编代码完成。所以我找到了这个版本的“Hello, world!”并编译了它。
|
||||
仍然不满意的话,我需要的是“可以测试”的东西 - 例如可以完整记录每一个指令运行的程序执行过程。这当然可以通过汇编代码完成。所以我找到了这个版本的 “Hello, world!” 并编译了它。
|
||||
|
||||
|
||||
```
|
||||
@ -168,13 +168,11 @@ len equ $ - msg
|
||||
```
|
||||
|
||||
|
||||
当然,现在跟踪器提示 7 条指令被执行了,这样一来很容易区分他们。
|
||||
|
||||
当然,现在跟踪器提示 7 条指令被执行了,这样一来很容易区分它们。
|
||||
|
||||
### 深入指令流
|
||||
|
||||
|
||||
上面那个汇编语言编写的程序使得我可以向你介绍 ptrace 的另外一个强大的用途 - 详细显示被跟踪进程的状态。下面是 run_debugger 函数的另一个版本:
|
||||
上面那个汇编语言编写的程序使得我可以向你介绍 `ptrace` 的另外一个强大的用途 - 详细显示被跟踪进程的状态。下面是 `run_debugger` 函数的另一个版本:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
@ -209,24 +207,16 @@ void run_debugger(pid_t child_pid)
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
不同仅仅存在于 while 循环的开始几行。这个版本里增加了两个新的 ptrace 调用。第一条将进程的寄存器值读取进了一个结构体中。 sys/user.h 定义有 user_regs_struct。如果你查看头文件,头部的注释这么写到:
|
||||
不同仅仅存在于 `while` 循环的开始几行。这个版本里增加了两个新的 `ptrace` 调用。第一条将进程的寄存器值读取进了一个结构体中。 `sys/user.h` 定义有 `user_regs_struct`。如果你查看头文件,头部的注释这么写到:
|
||||
|
||||
```
|
||||
/* The whole purpose of this file is for GDB and GDB only.
|
||||
Don't read too much into it. Don't use it for
|
||||
anything other than GDB unless know what you are
|
||||
doing. */
|
||||
```
|
||||
|
||||
```
|
||||
/* 这个文件只为了GDB而创建
|
||||
/* 这个文件只为了 GDB 而创建
|
||||
不用详细的阅读.如果你不知道你在干嘛,
|
||||
不要在除了 GDB 以外的任何地方使用此文件 */
|
||||
```
|
||||
|
||||
|
||||
不知道你做何感想,但这让我觉得我们找对地方了。回到例子中,一旦我们在 regs 变量中取得了寄存器的值,我们就可以通过将 PTRACE_PEEKTEXT 作为参数、 regs.eip(x86 上的扩展指令指针)作为地址,调用 ptrace ,读取当前进程的当前指令。下面是新跟踪器所展示出的调试效果:
|
||||
不知道你做何感想,但这让我觉得我们找对地方了。回到例子中,一旦我们在 `regs` 变量中取得了寄存器的值,我们就可以通过将 `PTRACE_PEEKTEXT` 作为参数、 `regs.eip`(x86 上的扩展指令指针)作为地址,调用 `ptrace` ,读取当前进程的当前指令(警告:如同我上面所说,文章很大程度上是平台相关的。我简化了一些设定 - 例如,x86 指令集不需要调整到 4 字节,我的32位 Ubuntu unsigned int 是 4 字节。事实上,许多平台都不需要。从内存中读取指令需要预先安装完整的反汇编器。我们这里没有,但实际的调试器是有的)。下面是新跟踪器所展示出的调试效果:
|
||||
|
||||
```
|
||||
$ simple_tracer traced_helloworld
|
||||
@ -244,7 +234,7 @@ Hello, world!
|
||||
```
|
||||
|
||||
|
||||
现在,除了 icounter,我们也可以观察到指令指针与它每一步所指向的指令。怎么来判断这个结果对不对呢?使用 objdump -d 处理可执行文件:
|
||||
现在,除了 `icounter`,我们也可以观察到指令指针与它每一步所指向的指令。怎么来判断这个结果对不对呢?使用 `objdump -d` 处理可执行文件:
|
||||
|
||||
```
|
||||
$ objdump -d traced_helloworld
|
||||
@ -263,62 +253,36 @@ Disassembly of section .text:
|
||||
804809b: cd 80 int $0x80
|
||||
```
|
||||
|
||||
|
||||
这个结果和我们跟踪器的结果就很容易比较了。
|
||||
|
||||
|
||||
### 将跟踪器关联到正在运行的进程
|
||||
|
||||
|
||||
如你所知,调试器也能关联到已经运行的进程。现在你应该不会惊讶,ptrace 通过 以PTRACE_ATTACH 为参数调用也可以完成这个过程。这里我不会展示示例代码,通过上文的示例代码应该很容易实现这个过程。出于学习目的,这里使用的方法更简便(因为我们在子进程刚开始就可以让它停止)。
|
||||
|
||||
如你所知,调试器也能关联到已经运行的进程。现在你应该不会惊讶,`ptrace` 通过以 `PTRACE_ATTACH` 为参数调用也可以完成这个过程。这里我不会展示示例代码,通过上文的示例代码应该很容易实现这个过程。出于学习目的,这里使用的方法更简便(因为我们在子进程刚开始就可以让它停止)。
|
||||
|
||||
### 代码
|
||||
|
||||
|
||||
上文中的简单的跟踪器(更高级的,可以打印指令的版本)的完整c源代码可以在[这里][20]找到。它是通过 4.4 版本的 gcc 以 -Wall -pedantic --std=c99 编译的。
|
||||
|
||||
上文中的简单的跟踪器(更高级的,可以打印指令的版本)的完整c源代码可以在[这里][20]找到。它是通过 4.4 版本的 gcc 以 `-Wall -pedantic --std=c99` 编译的。
|
||||
|
||||
### 结论与计划
|
||||
|
||||
诚然,这篇文章并没有涉及很多内容 - 我们距离亲手完成一个实际的调试器还有很长的路要走。但我希望这篇文章至少可以使得调试这件事少一些神秘感。`ptrace` 是功能多样的系统调用,我们目前只展示了其中的一小部分。
|
||||
|
||||
诚然,这篇文章并没有涉及很多内容 - 我们距离亲手完成一个实际的调试器还有很长的路要走。但我希望这篇文章至少可以使得调试这件事少一些神秘感。ptrace 是功能多样的系统调用,我们目前只展示了其中的一小部分。
|
||||
|
||||
|
||||
单步调试代码很有用,但也只是在一定程度上有用。上面我通过c的“Hello World!”做了示例。为了执行主函数,可能需要上万行代码来初始化c的运行环境。这并不是很方便。最理想的是在main函数入口处放置断点并从断点处开始分步执行。为此,在这个系列的下一篇,我打算展示怎么实现断点。
|
||||
|
||||
|
||||
单步调试代码很有用,但也只是在一定程度上有用。上面我通过 C 的 “Hello World!” 做了示例。为了执行主函数,可能需要上万行代码来初始化 C 的运行环境。这并不是很方便。最理想的是在 `main` 函数入口处放置断点并从断点处开始分步执行。为此,在这个系列的下一篇,我打算展示怎么实现断点。
|
||||
|
||||
### 参考
|
||||
|
||||
|
||||
撰写此文时参考了如下文章
|
||||
|
||||
* [Playing with ptrace, Part I][11]
|
||||
* [How debugger works][12]
|
||||
|
||||
|
||||
|
||||
[1] 我没有检查,但我确信 gdb 的代码行数至少有六位数。
|
||||
|
||||
[2] 使用 man 2 ptrace 命令可以了解更多。
|
||||
|
||||
[3] Peek and poke 在系统编程中是很知名的叫法,指的是直接读写内存内容。
|
||||
|
||||
[4] 这篇文章假定读者有一定的 Unix/Linux 编程经验。我假定你知道(至少了解概念)fork,exec 族函数与 Unix 信号。
|
||||
|
||||
[5] 至少你同我一样痴迷与机器/汇编语言。
|
||||
|
||||
[6] 警告:如同我上面所说,文章很大程度上是平台相关的。我简化了一些设定 - 例如,x86指令集不需要调整到 4 字节(我的32位 Ubuntu unsigned int 是 4 字节)。事实上,许多平台都不需要。从内存中读取指令需要预先安装完整的反汇编器。我们这里没有,但实际的调试器是有的。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[译者ID](https://github.com/YYforymj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[YYforymj](https://github.com/YYforymj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
165
published/201704/20150112 Data-Oriented Hash Table.md
Normal file
165
published/201704/20150112 Data-Oriented Hash Table.md
Normal file
@ -0,0 +1,165 @@
|
||||
深入解析面向数据的哈希表性能
|
||||
============================================================
|
||||
|
||||
最近几年中,面向数据的设计已经受到了很多的关注 —— 一种强调内存中数据布局的编程风格,包括如何访问以及将会引发多少的 cache 缺失。由于在内存读取操作中缺失所占的数量级要大于命中的数量级,所以缺失的数量通常是优化的关键标准。这不仅仅关乎那些对性能有要求的 code-data 结构设计的软件,由于缺乏对内存效益的重视而成为软件运行缓慢、膨胀的一个很大因素。
|
||||
|
||||
|
||||
高效缓存数据结构的中心原则是将事情变得平滑和线性。比如,在大部分情况下,存储一个序列元素更倾向于使用普通数组而不是链表 —— 每一次通过指针来查找数据都会为 cache 缺失增加一份风险;而普通数组则可以预先获取,并使得内存系统以最大的效率运行
|
||||
|
||||
如果你知道一点内存层级如何运作的知识,下面的内容会是想当然的结果——但是有时候即便它们相当明显,测试一下任不失为一个好主意。几年前 [Baptiste Wicht 测试过了 `std::vector` vs `std::list` vs `std::deque`][4],(后者通常使用分块数组来实现,比如:一个数组的数组)。结果大部分会和你预期的保持一致,但是会存在一些违反直觉的东西。作为实例:在序列链表的中间位置做插入或者移除操作被认为会比数组快,但如果该元素是一个 POD 类型,并且不大于 64 字节或者在 64 字节左右(在一个 cache 流水线内),通过对要操作的元素周围的数组元素进行移位操作要比从头遍历链表来的快。这是由于在遍历链表以及通过指针插入/删除元素的时候可能会导致不少的 cache 缺失,相对而言,数组移位则很少会发生。(对于更大的元素,非 POD 类型,或者你已经有了指向链表元素的指针,此时和预期的一样,链表胜出)
|
||||
|
||||
|
||||
多亏了类似 Baptiste 这样的数据,我们知道了内存布局如何影响序列容器。但是关联容器,比如 hash 表会怎么样呢?已经有了些权威推荐:[Chandler Carruth 推荐的带局部探测的开放寻址][5](此时,我们没必要追踪指针),以及[Mike Acton 推荐的在内存中将 value 和 key 隔离][6](这种情况下,我们可以在每一个 cache 流水线中得到更多的 key), 这可以在我们必须查找多个 key 时提高局部性能。这些想法很有意义,但再一次的说明:测试永远是好习惯,但由于我找不到任何数据,所以只好自己收集了。
|
||||
|
||||
### 测试
|
||||
|
||||
我测试了四个不同的 quick-and-dirty 哈希表实现,另外还包括 `std::unordered_map` 。这五个哈希表都使用了同一个哈希函数 —— Bob Jenkins 的 [SpookyHash][8](64 位哈希值)。(由于哈希函数在这里不是重点,所以我没有测试不同的哈希函数;我同样也没有检测我的分析中的总内存消耗。)实现会通过简短的代码在测试结果表中标注出来。
|
||||
|
||||
* **UM**: `std::unordered_map` 。在 VS2012 和 libstdc++-v3 (libstdc++-v3: gcc 和 clang 都会用到这东西)中,UM 是以链表的形式实现,所有的元素都在链表中,bucket 数组中存储了链表的迭代器。VS2012 中,则是一个双链表,每一个 bucket 存储了起始迭代器和结束迭代器;libstdc++ 中,是一个单链表,每一个 bucket 只存储了一个起始迭代器。这两种情况里,链表节点是独立申请和释放的。最大负载因子是 1 。
|
||||
* **Ch**:分离的、链状 buket 指向一个元素节点的单链表。为了避免分开申请每一个节点,元素节点存储在普通数组池中。未使用的节点保存在一个空闲链表中。最大负载因子是 1。
|
||||
* **OL**:开地址线性探测 —— 每一个 bucket 存储一个 62 bit 的 hash 值,一个 2 bit 的状态值(包括 empty,filled,removed 三个状态),key 和 vale 。最大负载因子是 2/3。
|
||||
* **DO1**:“data-oriented 1” —— 和 OL 相似,但是哈希值、状态值和 key、values 分离在两个隔离的平滑数组中。
|
||||
* **DO2**:“data-oriented 2” —— 与 OL 类似,但是哈希/状态,keys 和 values 被分离在 3 个相隔离的平滑数组中。
|
||||
|
||||
|
||||
在我的所有实现中,包括 VS2012 的 UM 实现,默认使用尺寸为 2 的 n 次方。如果超出了最大负载因子,则扩展两倍。在 libstdc++ 中,UM 默认尺寸是一个素数。如果超出了最大负载因子,则扩展为下一个素数大小。但是我不认为这些细节对性能很重要。素数是一种对低 bit 位上没有足够熵的低劣 hash 函数的挽救手段,但是我们正在用的是一个很好的 hash 函数。
|
||||
|
||||
OL,DO1 和 DO2 的实现将共同的被称为 OA(open addressing)——稍后我们将发现它们在性能特性上非常相似。在每一个实现中,单元数从 100 K 到 1 M,有效负载(比如:总的 key + value 大小)从 8 到 4 k 字节我为几个不同的操作记了时间。 keys 和 values 永远是 POD 类型,keys 永远是 8 个字节(除了 8 字节的有效负载,此时 key 和 value 都是 4 字节)因为我的目的是为了测试内存影响而不是哈希函数性能,所以我将 key 放在连续的尺寸空间中。每一个测试都会重复 5 遍,然后记录最小的耗时。
|
||||
|
||||
测试的操作在这里:
|
||||
|
||||
* **Fill**:将一个随机的 key 序列插入到表中(key 在序列中是唯一的)。
|
||||
* **Presized fill**:和 Fill 相似,但是在插入之间我们先为所有的 key 保留足够的内存空间,以防止在 fill 过程中 rehash 或者重申请。
|
||||
* **Lookup**:执行 100 k 次随机 key 查找,所有的 key 都在 table 中。
|
||||
* **Failed lookup**: 执行 100 k 次随机 key 查找,所有的 key 都不在 table 中。
|
||||
* **Remove**:从 table 中移除随机选择的半数元素。
|
||||
* **Destruct**:销毁 table 并释放内存。
|
||||
|
||||
你可以[在这里下载我的测试代码][9]。这些代码只能在 64 机器上编译(包括Windows和Linux)。在 `main()` 函数顶部附近有一些开关,你可把它们打开或者关掉——如果全开,可能会需要一两个小时才能结束运行。我收集的结果也放在了那个打包文件里的 Excel 表中。(注意: Windows 和 Linux 在不同的 CPU 上跑的,所以时间不具备可比较性)代码也跑了一些单元测试,用来验证所有的 hash 表实现都能运行正确。
|
||||
|
||||
我还顺带尝试了附加的两个实现:Ch 中第一个节点存放在 bucket 中而不是 pool 里,二次探测的开放寻址。
|
||||
这两个都不足以好到可以放在最终的数据里,但是它们的代码仍放在了打包文件里面。
|
||||
|
||||
### 结果
|
||||
|
||||
这里有成吨的数据!!
|
||||
这一节我将详细的讨论一下结果,但是如果你对此不感兴趣,可以直接跳到下一节的总结。
|
||||
|
||||
#### Windows
|
||||
|
||||
这是所有的测试的图表结果,使用 Visual Studio 2012 编译,运行于 Windows 8.1 和 Core i7-4710HQ 机器上。(点击可以放大。)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
从左至右是不同的有效负载大小,从上往下是不同的操作(注意:不是所有的Y轴都是相同的比例!)我将为每一个操作总结一下主要趋向。
|
||||
|
||||
**Fill**:
|
||||
|
||||
在我的 hash 表中,Ch 稍比任何的 OA 变种要好。随着哈希表大小和有效负载的加大,差距也随之变大。我猜测这是由于 Ch 只需要从一个空闲链表中拉取一个元素,然后把它放在 bucket 前面,而 OA 不得不搜索一部分 bucket 来找到一个空位置。所有的 OA 变种的性能表现基本都很相似,当然 DO1 稍微有点优势。
|
||||
|
||||
在小负载的情况,UM 几乎是所有 hash 表中表现最差的 —— 因为 UM 为每一次的插入申请(内存)付出了沉重的代价。但是在 128 字节的时候,这些 hash 表基本相当,大负载的时候 UM 还赢了点。因为,我所有的实现都需要重新调整元素池的大小,并需要移动大量的元素到新池里面,这一点我几乎无能为力;而 UM 一旦为元素申请了内存后便不需要移动了。注意大负载中图表上夸张的跳步!这更确认了重新调整大小带来的问题。相反,UM 只是线性上升 —— 只需要重新调整 bucket 数组大小。由于没有太多隆起的地方,所以相对有效率。
|
||||
|
||||
**Presized fill**:
|
||||
|
||||
大致和 Fill 相似,但是图示结果更加的线性光滑,没有太大的跳步(因为不需要 rehash ),所有的实现差距在这一测试中要缩小了些。大负载时 UM 依然稍快于 Ch,问题还是在于重新调整大小上。Ch 仍是稳步少快于 OA 变种,但是 DO1 比其它的 OA 稍有优势。
|
||||
|
||||
**Lookup**:
|
||||
|
||||
所有的实现都相当的集中。除了最小负载时,DO1 和 OL 稍快,其余情况下 UM 和 DO2 都跑在了前面。(LCTT 译注: 你确定?)真的,我无法描述 UM 在这一步做的多么好。尽管需要遍历链表,但是 UM 还是坚守了面向数据的本性。
|
||||
|
||||
顺带一提,查找时间和 hash 表的大小有着很弱的关联,这真的很有意思。
|
||||
哈希表查找时间期望上是一个常量时间,所以在的渐进视图中,性能不应该依赖于表的大小。但是那是在忽视了 cache 影响的情况下!作为具体的例子,当我们在具有 10 k 条目的表中做 100 k 次查找时,速度会便变快,因为在第一次 10 k - 20 k 次查找后,大部分的表会处在 L3 中。
|
||||
|
||||
**Failed lookup**:
|
||||
|
||||
相对于成功查找,这里就有点更分散一些。DO1 和 DO2 跑在了前面,但 UM 并没有落下,OL 则是捉襟见肘啊。我猜测,这可能是因为 OL 整体上具有更长的搜索路径,尤其是在失败查询时;内存中,hash 值在 key 和 value 之飘来荡去的找不着出路,我也很受伤啊。DO1 和 DO2 具有相同的搜索长度,但是它们将所有的 hash 值打包在内存中,这使得问题有所缓解。
|
||||
|
||||
**Remove**:
|
||||
|
||||
DO2 很显然是赢家,但 DO1 也未落下。Ch 则落后,UM 则是差的不是一丁半点(主要是因为每次移除都要释放内存);差距随着负载的增加而拉大。移除操作是唯一不需要接触数据的操作,只需要 hash 值和 key 的帮助,这也是为什么 DO1 和 DO2 在移除操作中的表现大相径庭,而其它测试中却保持一致。(如果你的值不是 POD 类型的,并需要析构,这种差异应该是会消失的。)
|
||||
|
||||
**Destruct**:
|
||||
|
||||
Ch 除了最小负载,其它的情况都是最快的(最小负载时,约等于 OA 变种)。所有的 OA 变种基本都是相等的。注意,在我的 hash 表中所做的所有析构操作都是释放少量的内存 buffer 。但是 [在Windows中,释放内存的消耗和大小成比例关系][13]。(而且,这是一个很显著的开支 —— 申请 ~1 GB 的内存需要 ~100 ms 的时间去释放!)
|
||||
|
||||
UM 在析构时是最慢的一个(小负载时,慢的程度可以用数量级来衡量),大负载时依旧是稍慢些。对于 UM 来讲,释放每一个元素而不是释放一组数组真的是一个硬伤。
|
||||
|
||||
#### Linux
|
||||
|
||||
我还在装有 Linux Mint 17.1 的 Core i5-4570S 机器上使用 gcc 4.8 和 clang 3.5 来运行了测试。gcc 和 clang 的结果很相像,因此我只展示了 gcc 的;完整的结果集合包含在了代码下载打包文件中,链接在上面。(点击图来缩放)
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
大部分结果和 Windows 很相似,因此我只高亮了一些有趣的不同点。
|
||||
|
||||
**Lookup**:
|
||||
|
||||
这里 DO1 跑在前头,而在 Windows 中 DO2 更快些。(LCTT 译注: 这里原文写错了吧?)同样,UM 和 Ch 落后于其它所有的实现——过多的指针追踪,然而 OA 只需要在内存中线性的移动即可。至于 Windows 和 Linux 结果为何不同,则不是很清楚。UM 同样比 Ch 慢了不少,特别是大负载时,这很奇怪;我期望的是它们可以基本相同。
|
||||
|
||||
**Failed lookup**:
|
||||
|
||||
UM 再一次落后于其它实现,甚至比 OL 还要慢。我再一次无法理解为何 UM 比 Ch 慢这么多,Linux 和 Windows 的结果为何有着如此大的差距。
|
||||
|
||||
|
||||
**Destruct**:
|
||||
|
||||
在我的实现中,小负载的时候,析构的消耗太少了,以至于无法测量;在大负载中,线性增加的比例和创建的虚拟内存页数量相关,而不是申请到的数量?同样,要比 Windows 中的析构快上几个数量级。但是并不是所有的都和 hash 表有关;我们在这里可以看出不同系统和运行时内存系统的表现。貌似,Linux 释放大内存块是要比 Windows 快上不少(或者 Linux 很好的隐藏了开支,或许将释放工作推迟到了进程退出,又或者将工作推给了其它线程或者进程)。
|
||||
|
||||
UM 由于要释放每一个元素,所以在所有的负载中都比其它慢上几个数量级。事实上,我将图片做了剪裁,因为 UM 太慢了,以至于破坏了 Y 轴的比例。
|
||||
|
||||
### 总结
|
||||
|
||||
好,当我们凝视各种情况下的数据和矛盾的结果时,我们可以得出什么结果呢?我想直接了当的告诉你这些 hash 表变种中有一个打败了其它所有的 hash 表,但是这显然不那么简单。不过我们仍然可以学到一些东西。
|
||||
|
||||
首先,在大多数情况下我们“很容易”做的比 `std::unordered_map` 还要好。我为这些测试所写的所有实现(它们并不复杂;我只花了一两个小时就写完了)要么是符合 `unordered_map` 要么是在其基础上做的提高,除了大负载(超过128字节)中的插入性能, `unordered_map` 为每一个节点独立申请存储占了优势。(尽管我没有测试,我同样期望 `unordered_map` 能在非 POD 类型的负载上取得胜利。)具有指导意义的是,如果你非常关心性能,不要假设你的标准库中的数据结构是高度优化的。它们可能只是在 C++ 标准的一致性上做了优化,但不是性能。:P
|
||||
|
||||
其次,如果不管在小负载还是超负载中,若都只用 DO1 (开放寻址,线性探测,hashes/states 和 key/vaules分别处在隔离的普通数组中),那可能不会有啥好表现。这不是最快的插入,但也不坏(还比 `unordered_map` 快),并且在查找,移除,析构中也很快。你所知道的 —— “面向数据设计”完成了!
|
||||
|
||||
注意,我的为这些哈希表做的测试代码远未能用于生产环境——它们只支持 POD 类型,没有拷贝构造函数以及类似的东西,也未检测重复的 key,等等。我将可能尽快的构建一些实际的 hash 表,用于我的实用库中。为了覆盖基础部分,我想我将有两个变种:一个基于 DO1,用于小的,移动时不需要太大开支的负载;另一个用于链接并且避免重新申请和移动元素(就像 `unordered_map` ),用于大负载或者移动起来需要大开支的负载情况。这应该会给我带来最好的两个世界。
|
||||
|
||||
与此同时,我希望你们会有所启迪。最后记住,如果 Chandler Carruth 和 Mike Acton 在数据结构上给你提出些建议,你一定要听。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我是一名图形程序员,目前在西雅图做自由职业者。之前我在 NVIDIA 的 DevTech 软件团队中工作,并在美少女特工队工作室中为 PS3 和 PS4 的 Infamous 系列游戏开发渲染技术。
|
||||
|
||||
自 2002 年起,我对图形非常感兴趣,并且已经完成了一系列的工作,包括:雾、大气雾霾、体积照明、水、视觉效果、粒子系统、皮肤和头发阴影、后处理、镜面模型、线性空间渲染、和 GPU 性能测量和优化。
|
||||
|
||||
你可以在我的博客了解更多和我有关的事,处理图形,我还对理论物理和程序设计感兴趣。
|
||||
|
||||
你可以在 nathaniel.reed@gmail.com 或者在 Twitter(@Reedbeta)/Google+ 上关注我。我也会经常在 StackExchange 上回答计算机图形的问题。
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[sanfusu](https://github.com/sanfusu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
@ -0,0 +1,314 @@
|
||||
2016 年度顶级开源创作工具
|
||||
============================================================
|
||||
|
||||
> 无论你是想修改图片、编译音频,还是制作动画,这里的自由而开源的工具都能帮你做到。
|
||||
|
||||

|
||||
|
||||
>图片来源 : opensource.com
|
||||
|
||||
几年前,我在 Red Hat 总结会上做了一个简单的演讲,给与会者展示了 [2012 年度开源创作工具][12]。开源软件在过去几年里发展迅速,现在我们来看看 2016 年的相关领域的软件。
|
||||
|
||||
### 核心应用
|
||||
|
||||
这六款应用是开源的设计软件中的最强王者。它们做的很棒,拥有完善的功能特征集、稳定发行版以及活跃的开发者社区,是很成熟的项目。这六款应用都是跨平台的,每一个都能在 Linux、OS X 和 Windows 上使用,不过大多数情况下 Linux 版本一般都是最先更新的。这些应用广为人知,我已经把最新特性的重要部分写进来了,如果你不是非常了解它们的开发情况,你有可能会忽视这些特性。
|
||||
|
||||
如果你想要对这些软件做更深层次的了解,或许你可以帮助测试这四个软件 —— GIMP、Inkscape、Scribus,以及 MyPaint 的最新版本,在 Linux 机器上你可以用 [Flatpak][13] 软件轻松地安装它们。这些应用的每日构建版本可以[按照指令][14] 通过 Flatpak 的“每日构建的绘图应用(Nightly Graphics Apps)”得到。有一件事要注意:如果你要给每个应用的 Flatpak 版本安装笔刷或者其它扩展,用于移除这些扩展的目录将会位于相应应用的目录 **~/.var/app** 下。
|
||||
|
||||
#### GIMP
|
||||
|
||||
[GIMP][15] [在 2015 年迎来了它的 20 周岁][16],使得它成为这里资历最久的开源创造型应用之一。GIMP 是一款强大的应用,可以处理图片,创作简单的绘画,以及插图。你可以通过简单的任务来尝试 GIMP,比如裁剪、缩放图片,然后循序渐进使用它的其它功能。GIMP 可以在 Linux、Mac OS X 以及 Windows 上使用,是一款跨平台的应用,而且能够打开、导出一系列格式的文件,包括在与之相似的软件 Photoshop 上广为应用的那些格式。
|
||||
|
||||
GIMP 开发团队正在忙着 2.10 发行版的工作;[2.8.18][17] 是最新的稳定版本。更振奋人心的是非稳定版,[2.9.4][18],拥有全新的用户界面,旨在节省空间的符号式图标和黑色主题,改进了颜色管理,更多的基于 GEGL 的支持分离预览的过滤器,支持 MyPaint 笔刷(如下图所示),对称绘图,以及命令行批次处理。想了解更多信息,请关注 [完整的发行版注记][19]。
|
||||
|
||||

|
||||
|
||||
#### Inkscape
|
||||
|
||||
[Inkscape][20] 是一款富有特色的矢量绘图设计软件。可以用它来创作简单的图形、图表、布局或者图标。
|
||||
|
||||
最新的稳定版是 [0.91][21] 版本;与 GIMP 相似,能在预发布版 0.92pre3 版本中找到更多有趣的东西,其发布于 2016 年 11 月。最新推出的预发布版的突出特点是 [梯度网格特性(gradient mesh feature)][22](如下图所示);0.91 发行版里介绍的新特性包括:[强力笔触(power stroke)][23] 用于完全可配置的书法笔画(下图的 “opensource.com” 中的 “open” 用的就是强力笔触技术),画布测量工具,以及 [全新的符号对话框][24](如下图右侧所示)。(很多符号库可以从 GitHub 上获得;[Xaviju's inkscape-open-symbols set][25] 就很不错。)_对象_对话框是在改进版或每日构建中可用的新特性,整合了一个文档中的所有对象,提供工具来管理这些对象。
|
||||
|
||||

|
||||
|
||||
#### Scribus
|
||||
|
||||
[Scribus][26] 是一款强大的桌面出版和页面布局工具。Scribus 让你能够创造精致美丽的物品,包括信封、书籍、杂志以及其它印刷品。Scribus 的颜色管理工具可以处理和输出 CMYK 格式,还能给文件配色,可靠地用于印刷车间的重印。
|
||||
|
||||
[1.4.6][27] 是 Scribus 的最新稳定版本;[1.5.x][28] 系列的发行版更令人期待,因为它们是即将到来的 1.6.0 发行版的预览。1.5.3 版本包含了 Krita 文件(*.KRA)导入工具; 1.5.x 系列中其它的改进包括了表格工具、文本框对齐、脚注、导出可选 PDF 格式、改进的字典、可驻留边框的调色盘、符号工具,和丰富的文件格式支持。
|
||||
|
||||

|
||||
|
||||
#### MyPaint
|
||||
|
||||
[MyPaint][29] 是一款用于数位屏的快速绘图和插画工具。它很轻巧,界面虽小,但快捷键丰富,因此你能够不用放下数位笔而专心于绘图。
|
||||
|
||||
[MyPaint 1.2.0][30] 是其最新的稳定版本,包含了一些新特性,诸如 [直观上墨工具][31] 用来跟踪铅笔绘图的轨迹,新的填充工具,层分组,笔刷和颜色的历史面板,用户界面的改进包括暗色主题和小型符号图标,以及可编辑的矢量层。想要尝试 MyPaint 里的最新改进,我建议安装每日构建版的 Flatpak 构建,尽管自从 1.2.0 版本没有添加重要的特性。
|
||||
|
||||

|
||||
|
||||
#### Blender
|
||||
|
||||
[Blender][32] 最初发布于 1995 年 1 月,像 GIMP 一样,已经有 20 多年的历史了。Blender 是一款功能强大的开源 3D 制作套件,包含建模、雕刻、渲染、真实材质、套索、动画、影像合成、视频编辑、游戏创作以及模拟。
|
||||
|
||||
Blender 最新的稳定版是 [2.78a][33]。2.78 版本很庞大,包含的特性有:改进的 2D 蜡笔(Grease Pencil) 动画工具;针对球面立体图片的 VR 渲染支持;以及新的手绘曲线的绘图工具。
|
||||
|
||||

|
||||
|
||||
要尝试最新的 Blender 开发工具,有很多种选择,包括:
|
||||
|
||||
* Blender 基金会在官方网址提供 [非稳定版的每日构建版][2]。
|
||||
* 如果你在寻找特殊的开发中特性,[graphicall.org][3] 是一个适合社区的网站,能够提供特殊版本的 Blender(偶尔还有其它的创造型开源应用),让艺术家能够尝试体验最新的代码。
|
||||
* Mathieu Bridon 通过 Flatpak 做了 Blender 的一个开发版本。查看它的博客以了解详情:[Flatpak 上每日构建版的 Blender][4]
|
||||
|
||||
#### Krita
|
||||
|
||||
[Krita][34] 是一款拥有强大功能的数字绘图应用。这款应用贴合插画师、印象艺术家以及漫画家的需求,有很多附件,比如笔刷、调色板、图案以及模版。
|
||||
|
||||
最新的稳定版是 [Krita 3.0.1][35],于 2016 年 9 月发布。3.0.x 系列的新特性包括 2D 逐帧动画;改进的层管理器和功能;丰富的常用快捷键;改进了网格、向导和图形捕捉;还有软打样。
|
||||
|
||||

|
||||
|
||||
### 视频处理工具
|
||||
|
||||
关于开源的视频编辑工具则有很多很多。这这些工具之中,[Flowblade][36] 是新推出的,而 Kdenlive 则是构建完善、对新手友好、功能最全的竞争者。对你排除某些备选品有所帮助的主要标准是它们所支持的平台,其中一些只支持 Linux 平台。它们的软件上游都很活跃,最新的稳定版都于近期发布,发布时间相差不到一周。
|
||||
|
||||
#### Kdenlive
|
||||
|
||||
[Kdenlive][37],最初于 2002 年发布,是一款强大的非线性视频编辑器,有 Linux 和 OS X 版本(但是 OS X 版本已经过时了)。Kdenlive 有用户友好的、基于拖拽的用户界面,适合初学者,又有专业人员需要的深层次功能。
|
||||
|
||||
可以看看 Seth Kenlon 写的 [Kdenlive 系列教程][38],了解如何使用 Kdenlive。
|
||||
|
||||
* 最新稳定版: 16.08.2 (2016 年 10 月)
|
||||
|
||||

|
||||
|
||||
#### Flowblade
|
||||
|
||||
2012 年发布, [Flowblade][39],只有 Linux 版本的视频编辑器,是个相当不错的后起之秀。
|
||||
|
||||
* 最新稳定版: 1.8 (2016 年 9 月)
|
||||
|
||||
#### Pitivi
|
||||
|
||||
[Pitivi][40] 是用户友好型的自由开源视频编辑器。Pitivi 是用 [Python][41] 编写的(“Pitivi” 中的 “Pi”来源于此),使用了 [GStreamer][42] 多媒体框架,社区活跃。
|
||||
|
||||
* 最新稳定版: 0.97 (2016 年 8 月)
|
||||
* 通过 Flatpak 获取 [最新版本][5]
|
||||
|
||||
#### Shotcut
|
||||
|
||||
[Shotcut][43] 是一款自由开源的跨平台视频编辑器,[早在 2004 年]就发布了,之后由现在的主要开发者 [Dan Dennedy][45] 重写。
|
||||
|
||||
* 最新稳定版: 16.11 (2016 年 11 月)
|
||||
* 支持 4K 分辨率
|
||||
* 仅以 tar 包方式发布
|
||||
|
||||
#### OpenShot Video Editor
|
||||
|
||||
始于 2008 年,[OpenShot Video Editor][46] 是一款自由、开源、易于使用、跨平台的视频编辑器。
|
||||
|
||||
* 最新稳定版: [2.1][6] (2016 年 8 月)
|
||||
|
||||
|
||||
### 其它工具
|
||||
|
||||
#### SwatchBooker
|
||||
|
||||
[SwatchBooker][47] 是一款很方便的工具,尽管它近几年都没有更新了,但它还是很有用。SwatchBooler 能帮助用户从各大制造商那里合法地获取色卡,你可以用其它自由开源的工具处理它导出的格式,包括 Scribus。
|
||||
|
||||
#### GNOME Color Manager
|
||||
|
||||
[GNOME Color Manager][48] 是 GNOME 桌面环境内建的颜色管理器,而 GNOME 是某些 Linux 发行版的默认桌面。这个工具让你能够用色度计为自己的显示设备创建属性文件,还可以为这些设备加载/管理 ICC 颜色属性文件。
|
||||
|
||||
#### GNOME Wacom Control
|
||||
|
||||
[The GNOME Wacom controls][49] 允许你在 GNOME 桌面环境中配置自己的 Wacom 手写板;你可以修改手写板交互的很多选项,包括自定义手写板灵敏度,以及手写板映射到哪块屏幕上。
|
||||
|
||||
#### Xournal
|
||||
|
||||
[Xournal][50] 是一款简单但可靠的应用,可以让你通过手写板手写或者在笔记上涂鸦。Xournal 是一款有用的工具,可以让你签名或注解 PDF 文档。
|
||||
|
||||
#### PDF Mod
|
||||
|
||||
[PDF Mod][51] 是一款编辑 PDF 文件很方便的工具。PDF Mod 让用户可以移除页面、添加页面,将多个 PDF 文档合并成一个单独的 PDF 文件,重新排列页面,旋转页面等。
|
||||
|
||||
#### SparkleShare
|
||||
|
||||
[SparkleShare][52] 是一款基于 git 的文件分享工具,艺术家用来协作和分享资源。它会挂载在 GitLab 仓库上,你能够采用一个精妙的开源架构来进行资源管理。SparkleShare 的前端通过在顶部提供一个类似下拉框界面,避免了使用 git 的复杂性。
|
||||
|
||||
### 摄影
|
||||
|
||||
#### Darktable
|
||||
|
||||
[Darktable][53] 是一款能让你开发数位 RAW 文件的应用,有一系列工具,可以管理工作流、无损编辑图片。Darktable 支持许多流行的相机和镜头。
|
||||
|
||||

|
||||
|
||||
#### Entangle
|
||||
|
||||
[Entangle][54] 允许你将数字相机连接到电脑上,让你能从电脑上完全控制相机。
|
||||
|
||||
#### Hugin
|
||||
|
||||
[Hugin][55] 是一款工具,让你可以拼接照片,从而制作全景照片。
|
||||
|
||||
### 2D 动画
|
||||
|
||||
#### Synfig Studio
|
||||
|
||||
[Synfig Studio][56] 是基于矢量的二维动画套件,支持位图原图,在平板上用起来方便。
|
||||
|
||||
#### Blender Grease Pencil
|
||||
|
||||
我在前面讲过了 Blender,但值得注意的是,最近的发行版里[重构的蜡笔特性][57],添加了创作二维动画的功能。
|
||||
|
||||
#### Krita
|
||||
|
||||
[Krita][58] 现在同样提供了二维动画功能。
|
||||
|
||||
### 音频编辑
|
||||
|
||||
#### Audacity
|
||||
|
||||
[Audacity][59] 在编辑音频文件、记录声音方面很有名,是用户友好型的工具。
|
||||
|
||||
#### Ardour
|
||||
|
||||
[Ardour][60] 是一款数字音频工作软件,界面中间是录音,编辑和混音工作流。使用上它比 Audacity 要稍微难一点,但它允许自动操作,并且更高端。(有 Linux、Mac OS X 和 Windows 版本)
|
||||
|
||||
#### Hydrogen
|
||||
|
||||
[Hydrogen][61] 是一款开源的电子鼓,界面直观。它可以用合成的乐器创作、整理各种乐谱。
|
||||
|
||||
#### Mixxx
|
||||
|
||||
[Mixxx][62] 是四仓 DJ 套件,让你能够以强大操控来 DJ 和混音歌曲,包含节拍循环、时间延长、音高变化,还可以用 DJ 硬件控制器直播混音和衔接。
|
||||
|
||||
### Rosegarden
|
||||
|
||||
[Rosegarden][63] 是一款作曲软件,有乐谱编写和音乐作曲或编辑的功能,提供音频和 MIDI 音序器。(LCTT 译注:MIDI 即 Musical Instrument Digital Interface 乐器数字接口)
|
||||
|
||||
#### MuseScore
|
||||
|
||||
[MuseScore][64] 是乐谱创作、记谱和编辑的软件,它还有个乐谱贡献者社区。
|
||||
|
||||
### 其它具有创造力的工具
|
||||
|
||||
#### MakeHuman
|
||||
|
||||
[MakeHuman][65] 是一款三维绘图工具,可以创造人型的真实模型。
|
||||
|
||||
#### Natron
|
||||
|
||||
[Natron][66] 是基于节点的合成工具,用于视频后期制作、动态图象和设计特效。
|
||||
|
||||
#### FontForge
|
||||
|
||||
[FontForge][67] 是创作和编辑字体的工具。允许你编辑某个字体中的字形,也能够使用这些字形生成字体。
|
||||
|
||||
#### Valentina
|
||||
|
||||
[Valentina][68] 是用来设计缝纫图案的应用。
|
||||
|
||||
#### Calligra Flow
|
||||
|
||||
[Calligra Flow][69] 是一款图表工具,类似 Visio(有 Linux,Mac OS X 和 Windows 版本)。
|
||||
|
||||
### 资源
|
||||
|
||||
这里有很多小玩意和彩蛋值得尝试。需要一点灵感来探索?这些网站和论坛有很多教程和精美的成品能够激发你开始创作:
|
||||
|
||||
1、 [pixls.us][7]: 摄影师 Pat David 管理的博客,他专注于专业摄影师使用的自由开源的软件和工作流。
|
||||
2、 [David Revoy 's Blog][8]: David Revoy 的博客,热爱自由开源,非常有天赋的插画师,概念派画师和开源倡议者,对 Blender 基金会电影有很大贡献。
|
||||
3、 [The Open Source Creative Podcast][9]: 由 Opensource.com 社区版主和专栏作家 [Jason van Gumster][10] 管理,他是 Blender 和 GIMP 的专家, [《Blender for Dummies》][1] 的作者,该文章正好是面向我们这些热爱开源创作工具和这些工具周边的文化的人。
|
||||
4、 [Libre Graphics Meeting][11]: 自由开源创作软件的开发者和使用这些软件的创作者的年度会议。这是个好地方,你可以通过它找到你喜爱的开源创作软件将会推出哪些有意思的特性,还可以了解到这些软件的用户用它们在做什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Máirín Duffy - Máirín 是 Red Hat 的首席交互设计师。她热衷于自由软件和开源工具,尤其是在创作领域:她最喜欢的应用是 [Inkscape](http://inkscape.org)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/16/12/yearbook-top-open-source-creative-tools-2016
|
||||
|
||||
作者:[Máirín Duffy][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mairin
|
||||
[1]:http://www.blenderbasics.com/
|
||||
[2]:https://builder.blender.org/download/
|
||||
[3]:http://graphicall.org/
|
||||
[4]:https://mathieu.daitauha.fr/blog/2016/09/23/blender-nightly-in-flatpak/
|
||||
[5]:https://pitivi.wordpress.com/2016/07/18/get-pitivi-directly-from-us-with-flatpak/
|
||||
[6]:http://www.openshotvideo.com/2016/08/openshot-21-released.html
|
||||
[7]:http://pixls.us/
|
||||
[8]:http://davidrevoy.com/
|
||||
[9]:http://monsterjavaguns.com/podcast/
|
||||
[10]:https://opensource.com/users/jason-van-gumster
|
||||
[11]:http://libregraphicsmeeting.org/2016/
|
||||
[12]:https://opensource.com/life/12/9/tour-through-open-source-creative-tools
|
||||
[13]:https://opensource.com/business/16/8/flatpak
|
||||
[14]:http://flatpak.org/apps.html
|
||||
[15]:https://opensource.com/tags/gimp
|
||||
[16]:https://linux.cn/article-7131-1.html
|
||||
[17]:https://www.gimp.org/news/2016/07/14/gimp-2-8-18-released/
|
||||
[18]:https://www.gimp.org/news/2016/07/13/gimp-2-9-4-released/
|
||||
[19]:https://www.gimp.org/news/2016/07/13/gimp-2-9-4-released/
|
||||
[20]:https://opensource.com/tags/inkscape
|
||||
[21]:http://wiki.inkscape.org/wiki/index.php/Release_notes/0.91
|
||||
[22]:http://wiki.inkscape.org/wiki/index.php/Mesh_Gradients
|
||||
[23]:https://www.youtube.com/watch?v=IztyV-Dy4CE
|
||||
[24]:https://inkscape.org/cs/~doctormo/%E2%98%85symbols-dialog
|
||||
[25]:https://github.com/Xaviju/inkscape-open-symbols
|
||||
[26]:https://opensource.com/tags/scribus
|
||||
[27]:https://www.scribus.net/scribus-1-4-6-released/
|
||||
[28]:https://www.scribus.net/scribus-1-5-2-released/
|
||||
[29]:http://mypaint.org/
|
||||
[30]:http://mypaint.org/blog/2016/01/15/mypaint-1.2.0-released/
|
||||
[31]:https://github.com/mypaint/mypaint/wiki/v1.2-Inking-Tool
|
||||
[32]:https://opensource.com/tags/blender
|
||||
[33]:http://www.blender.org/features/2-78/
|
||||
[34]:https://opensource.com/tags/krita
|
||||
[35]:https://krita.org/en/item/krita-3-0-1-update-brings-numerous-fixes/
|
||||
[36]:https://opensource.com/life/16/9/10-reasons-flowblade-linux-video-editor
|
||||
[37]:https://opensource.com/tags/kdenlive
|
||||
[38]:https://opensource.com/life/11/11/introduction-kdenlive
|
||||
[39]:http://jliljebl.github.io/flowblade/
|
||||
[40]:http://pitivi.org/
|
||||
[41]:http://wiki.pitivi.org/wiki/Why_Python%3F
|
||||
[42]:https://gstreamer.freedesktop.org/
|
||||
[43]:http://shotcut.org/
|
||||
[44]:http://permalink.gmane.org/gmane.comp.lib.fltk.general/2397
|
||||
[45]:http://www.dennedy.org/
|
||||
[46]:http://openshot.org/
|
||||
[47]:http://www.selapa.net/swatchbooker/
|
||||
[48]:https://help.gnome.org/users/gnome-help/stable/color.html.en
|
||||
[49]:https://help.gnome.org/users/gnome-help/stable/wacom.html.en
|
||||
[50]:http://xournal.sourceforge.net/
|
||||
[51]:https://wiki.gnome.org/Apps/PdfMod
|
||||
[52]:https://www.sparkleshare.org/
|
||||
[53]:https://opensource.com/life/16/4/how-use-darktable-digital-darkroom
|
||||
[54]:https://entangle-photo.org/
|
||||
[55]:http://hugin.sourceforge.net/
|
||||
[56]:https://opensource.com/article/16/12/synfig-studio-animation-software-tutorial
|
||||
[57]:https://wiki.blender.org/index.php/Dev:Ref/Release_Notes/2.78/GPencil
|
||||
[58]:https://opensource.com/tags/krita
|
||||
[59]:https://opensource.com/tags/audacity
|
||||
[60]:https://ardour.org/
|
||||
[61]:http://www.hydrogen-music.org/
|
||||
[62]:http://mixxx.org/
|
||||
[63]:http://www.rosegardenmusic.com/
|
||||
[64]:https://opensource.com/life/16/03/musescore-tutorial
|
||||
[65]:http://makehuman.org/
|
||||
[66]:https://natron.fr/
|
||||
[67]:http://fontforge.github.io/en-US/
|
||||
[68]:http://valentina-project.org/
|
||||
[69]:https://www.calligra.org/flow/
|
||||
@ -1,74 +1,59 @@
|
||||
|
||||
2016 Git 新视界
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
2016 年 Git 发生了 _惊天动地_ 地变化,发布了五大新特性[¹][57] (从 _v2.7_ 到 _v2.11_ )和十六个补丁[²][58]。189 位作者[³][59]贡献了 3676 个提交[⁴][60]到 `master` 分支,比 2015 年多了 15%[⁵][61]!总计有 1545 个文件被修改,其中增加了 276799 行并移除了 100973 行。
|
||||
|
||||
但是,通过统计提交的数量和代码行数来衡量生产力是一种十分愚蠢的方法。除了深度研究过的开发者可以做到凭直觉来判断代码质量的地步,我们普通人来作仲裁难免会因我们常人的判断有失偏颇。
|
||||
|
||||
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾 。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
|
||||
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
|
||||
|
||||
* [完成][41]`[git worktree][25]`[命令][42]
|
||||
* [更多方便的][43]`[git rebase][26]`[选项][44]
|
||||
* `[git lfs][27]`[梦幻的性能加速][45]
|
||||
* `[git diff][28]`[实验性的算法和更好的默认结果][46]
|
||||
* `[git submodules][29]`[差强人意][47]
|
||||
* `[git stash][30]`的[90 个增强][48]
|
||||
* [完成][41] [`git worktree`][25] [命令][42]
|
||||
* [更多方便的][43] [`git rebase`][26] [选项][44]
|
||||
* [`git lfs`][27] [梦幻的性能加速][45]
|
||||
* [`git diff`][28] [实验性的算法和更好的默认结果][46]
|
||||
* [`git submodules`][29] [差强人意][47]
|
||||
* [`git stash`][30] 的[90 个增强][48]
|
||||
|
||||
在我们开始之前,请注意在大多数操作系统上都自带有 Git 的旧版本,所以你需要检查你是否在使用最新并且最棒的版本。如果在终端运行 `git --version` 返回的结果小于 Git `v2.11.0`,请立刻跳转到 Atlassian 的快速指南 [更新或安装 Git][63] 并根据你的平台做出选择。
|
||||
|
||||
###[所需的“引用”]
|
||||
|
||||
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档生成统计信息(以及开篇的封面图片)的。你也可以使用下面的命令来对你自己的仓库做一个快速的 *年度回顾*!
|
||||
|
||||
###[`引用` 是需要的]
|
||||
|
||||
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档(以及开篇的封面图片)生成统计信息的。你也可以使用下面的命令来对你自己的仓库做一个快速的 *年度回顾*!
|
||||
|
||||
```
|
||||
¹ Tags from 2016 matching the form vX.Y.0
|
||||
```
|
||||
>¹ Tags from 2016 matching the form vX.Y.0
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format \
|
||||
'%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.0 .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
² Tags from 2016 matching the form vX.Y.Z
|
||||
```
|
||||
> ² Tags from 2016 matching the form vX.Y.Z
|
||||
|
||||
```
|
||||
$ git for-each-ref --sort=-taggerdate --format '%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.[^0] .* 2016"
|
||||
```
|
||||
|
||||
```
|
||||
³ Commits by author in 2016
|
||||
```
|
||||
> ³ Commits by author in 2016
|
||||
|
||||
```
|
||||
$ git shortlog -s -n --since=2016-01-01 --until=2017-01-01
|
||||
```
|
||||
|
||||
```
|
||||
⁴ Count commits in 2016
|
||||
```
|
||||
> ⁴ Count commits in 2016
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2016-01-01 --until=2017-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁵ ... and in 2015
|
||||
```
|
||||
> ⁵ ... and in 2015
|
||||
|
||||
```
|
||||
$ git log --oneline --since=2015-01-01 --until=2016-01-01 | wc -l
|
||||
```
|
||||
|
||||
```
|
||||
⁶ Net LOC added/removed in 2016
|
||||
```
|
||||
> ⁶ Net LOC added/removed in 2016
|
||||
|
||||
```
|
||||
$ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
@ -79,39 +64,36 @@ $ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
|
||||
|
||||
现在,让我们开始说好的回顾……
|
||||
|
||||
### 完成 Git worktress
|
||||
`git worktree` 命令首次出现于 Git v2.5 但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入—— `list` 子命令,和为二分搜索增加了命令空间的 refs——而 `lock`/`unlock` 子命令则是在 v2.10被引入。
|
||||
### 完成 Git 工作树(worktree)
|
||||
|
||||
`git worktree` 命令首次出现于 Git v2.5 ,但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入:`list` 子命令,和为二分搜索增加了命令空间的 refs。而 `lock`/`unlock` 子命令则是在 v2.10 被引入。
|
||||
|
||||
#### 什么是工作树呢?
|
||||
|
||||
[`git worktree`][49] 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支:
|
||||
|
||||
#### 什么是 worktree 呢?
|
||||
`[git worktree][49]` 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支
|
||||
```
|
||||
$ git worktree add -b hotfix/BB-1234 ../hotfix/BB-1234
|
||||
Preparing ../hotfix/BB-1234 (identifier BB-1234)
|
||||
HEAD is now at 886e0ba Merged in bedwards/BB-13430-api-merge-pr (pull request #7822)
|
||||
```
|
||||
|
||||
Worktree 不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
|
||||
工作树不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.6.0 v2.6.0
|
||||
Preparing ../git-v2.6.0 (identifier git-v2.6.0)
|
||||
HEAD is now at be08dee Git 2.6
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree add ../git-v2.7.0 v2.7.0
|
||||
Preparing ../git-v2.7.0 (identifier git-v2.7.0)
|
||||
HEAD is now at 7548842 Git 2.7
|
||||
```
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
/Users/kannonboy/src/git 7548842 [master]
|
||||
/Users/kannonboy/src/git-v2.6.0 be08dee (detached HEAD)
|
||||
/Users/kannonboy/src/git-v2.7.0 7548842 (detached HEAD)
|
||||
```
|
||||
|
||||
```
|
||||
$ cd ../git-v2.7.0 && make
|
||||
```
|
||||
|
||||
@ -119,7 +101,7 @@ $ cd ../git-v2.7.0 && make
|
||||
|
||||
#### 列出工作树
|
||||
|
||||
`git worktree list` 子命令(于 Git v2.7引入)显示所有与当前仓库有关的工作树。
|
||||
`git worktree list` 子命令(于 Git v2.7 引入)显示所有与当前仓库有关的工作树。
|
||||
|
||||
```
|
||||
$ git worktree list
|
||||
@ -130,43 +112,41 @@ $ git worktree list
|
||||
|
||||
#### 二分查找工作树
|
||||
|
||||
`[gitbisect][50]` 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 `master` 分支最后的提交上有一个测试没有通过,我可以使用 `git bisect` 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
|
||||
[`gitbisect`][50] 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 `master` 分支最后的提交上有一个测试没有通过,我可以使用 `git bisect` 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
|
||||
|
||||
```
|
||||
$ git bisect start
|
||||
```
|
||||
|
||||
```
|
||||
# indicate the last commit known to be passing the tests
|
||||
# (e.g. the latest release tag)
|
||||
# 找到已知通过测试的最后提交
|
||||
# (例如最新的发布里程碑)
|
||||
$ git bisect good v2.0.0
|
||||
```
|
||||
|
||||
```
|
||||
# indicate a known broken commit (e.g. the tip of master)
|
||||
# 找到已知的出问题的提交
|
||||
# (例如在 `master` 上的提示)
|
||||
$ git bisect bad master
|
||||
```
|
||||
|
||||
```
|
||||
# tell git bisect a script/command to run; git bisect will
|
||||
# find the oldest commit between "good" and "bad" that causes
|
||||
# this script to exit with a non-zero status
|
||||
# 告诉 git bisect 要运行的脚本/命令;
|
||||
# git bisect 会在 “good” 和 “bad”范围内
|
||||
# 找到导致脚本以非 0 状态退出的最旧的提交
|
||||
$ git bisect run npm test
|
||||
```
|
||||
|
||||
在后台,bisect 使用 refs 来跟踪 好 与 坏 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 `.git/refs/bisect` 命名空间,意味着 `git bisect` 操作如果运行在不同的工作树下可能会互相干扰。
|
||||
在后台,bisect 使用 refs 来跟踪 “good” 与 “bad” 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 `.git/refs/bisect` 命名空间,意味着 `git bisect` 操作如果运行在不同的工作树下可能会互相干扰。
|
||||
|
||||
到了 v2.7 版本,bisect 的 refs 移到了 `.git/worktrees/$worktree_name/refs/bisect`, 所以你可以并行运行 bisect 操作于多个工作树中。
|
||||
|
||||
#### 锁定工作树
|
||||
|
||||
当你完成了一颗工作树的工作,你可以直接删除它,然后通过运行 `git worktree prune` 等它被当做垃圾自动回收。但是,如果你在网络共享或者可移除媒介上存储了一颗工作树,如果工作树目录在删除期间不可访问,工作树会被完全清除——不管你喜不喜欢!Git v2.10 引入了 `git worktree lock` 和 `unlock` 子命令来防止这种情况发生。
|
||||
|
||||
```
|
||||
# to lock the git-v2.7 worktree on my USB drive
|
||||
# 在我的 USB 盘上锁定 git-v2.7 工作树
|
||||
$ git worktree lock /Volumes/Flash_Gordon/git-v2.7 --reason \
|
||||
"In case I remove my removable media"
|
||||
```
|
||||
|
||||
```
|
||||
# to unlock (and delete) the worktree when I'm finished with it
|
||||
# 当我完成时,解锁(并删除)该工作树
|
||||
$ git worktree unlock /Volumes/Flash_Gordon/git-v2.7
|
||||
$ rm -rf /Volumes/Flash_Gordon/git-v2.7
|
||||
$ git worktree prune
|
||||
@ -175,32 +155,33 @@ $ git worktree prune
|
||||
`--reason` 标签允许为未来的你留一个记号,描述为什么当初工作树被锁定。`git worktree unlock` 和 `lock` 都要求你指定工作树的路径。或者,你可以 `cd` 到工作树目录然后运行 `git worktree lock .` 来达到同样的效果。
|
||||
|
||||
|
||||
### 更多 Git 变基(rebase)选项
|
||||
|
||||
### 更多 Git `reabse` 选项
|
||||
2016 年三月,Git v2.8 增加了在拉取过程中交互进行 rebase 的命令 `git pull --rebase=interactive` 。对应地,六月份 Git v2.9 发布了通过 `git rebase -x` 命令对执行变基操作而不需要进入交互模式的支持。
|
||||
2016 年三月,Git v2.8 增加了在拉取过程中交互进行变基的命令 `git pull --rebase=interactive` 。对应地,六月份 Git v2.9 发布了通过 `git rebase -x` 命令对执行变基操作而不需要进入交互模式的支持。
|
||||
|
||||
#### Re-啥?
|
||||
|
||||
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是 rebase。
|
||||
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是变基(rebase)。
|
||||
|
||||
变基操作意味着将一个或多个提交在一个指定分支上重写。`git rebase` 命令是被深度重载了,但是 rebase 名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
|
||||
变基操作意味着将一个或多个提交在一个指定分支上重写。`git rebase` 命令是被深度重载了,但是 rebase 这个名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
|
||||
|
||||
从概念上说,rebase 通过将你的分支上的提交存储为一系列补丁包临时释放了它们,接着将这些补丁包按顺序依次打在目标提交之上。
|
||||
从概念上说,rebase 通过将你的分支上的提交临时存储为一系列补丁包,接着将这些补丁包按顺序依次打在目标提交之上。
|
||||
|
||||
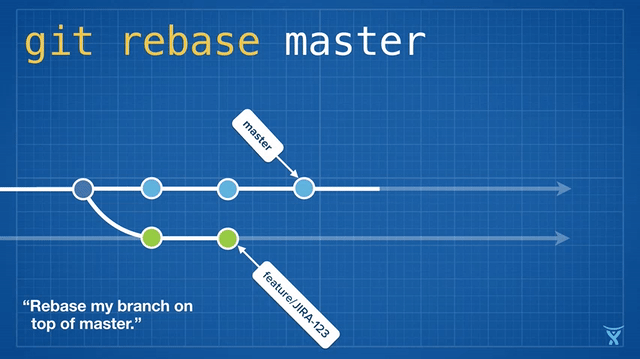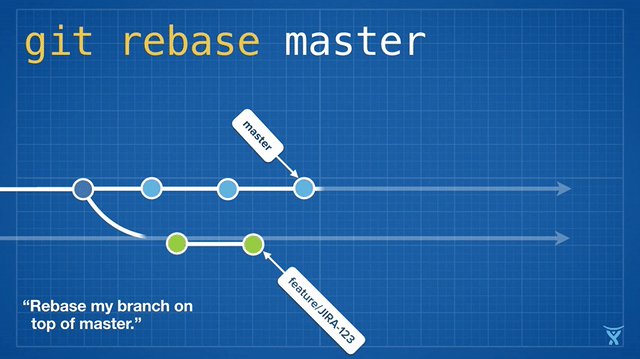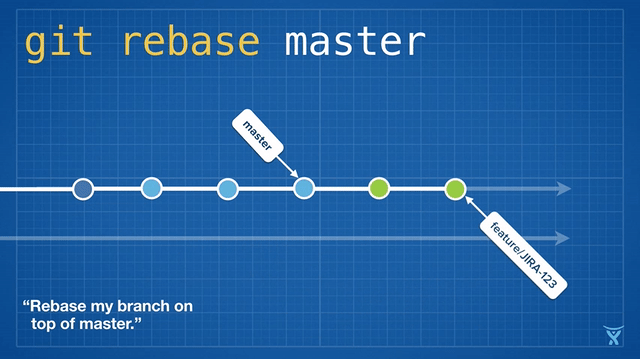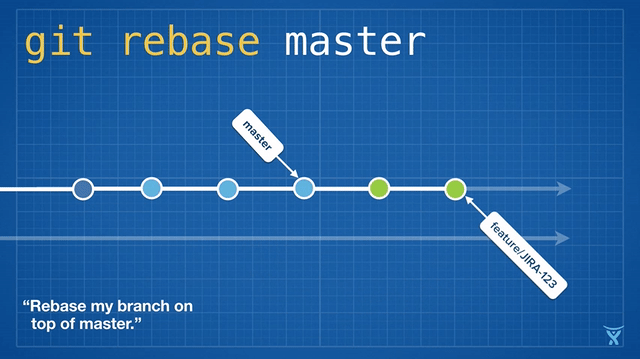
|
||||

|
||||
|
||||
对 master 分支的一个功能分支执行变基操作 (`git reabse master`)是一种通过将 master 分支上最新的改变合并到功能分支的“保鲜法”。对于长期存在的功能分支,规律的变基操作能够最大程度的减少开发过程中出现冲突的可能性和严重性。
|
||||
|
||||
有些团队会选择在合并他们的改动到 master 前立即执行变基操作以实现一次快速合并 (`git merge --ff <feature>`)。对 master 分支快速合并你的提交是通过简单的将 master ref 指向你的重写分支的顶点而不需要创建一个合并提交。
|
||||
|
||||

|
||||

|
||||
|
||||
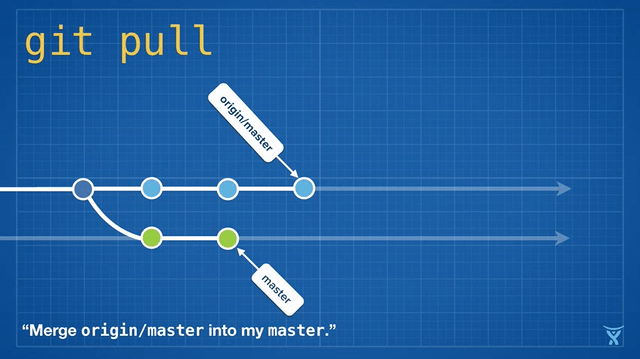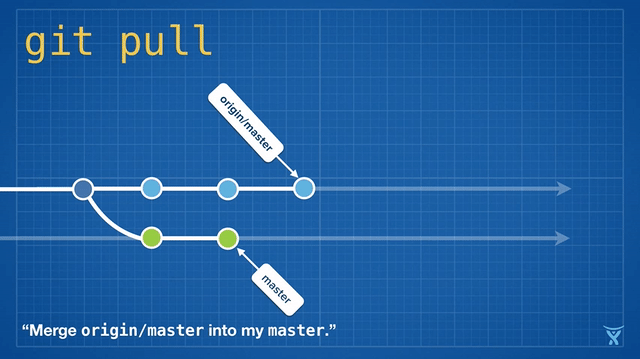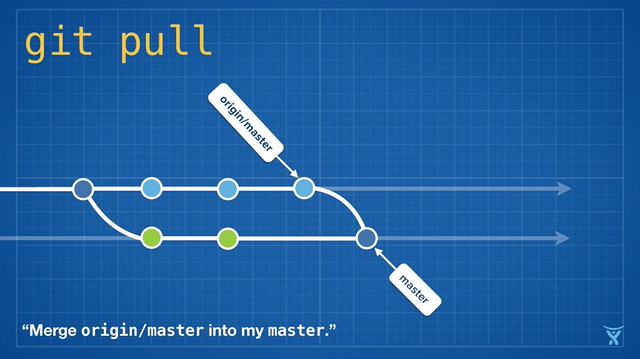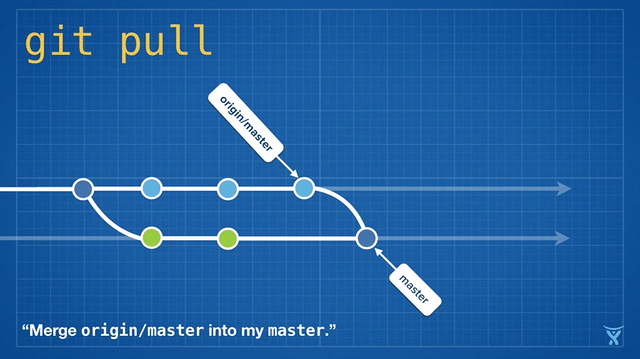
变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如 `git pull`。如果你在本地 master 分支有未推送的提交,运行 `git pull` 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
|
||||
变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如拉取操作 `git pull` 。如果你在本地 master 分支有未推送的提交,运行 `git pull` 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
|
||||
|
||||
|
||||

|
||||
|
||||
这有点混乱,而且在繁忙的团队,你会获得成堆的不必要的合并提交。`git pull --rebase` 将你本地的提交在你队友的提交上执行变基而不产生一个合并提交。
|
||||
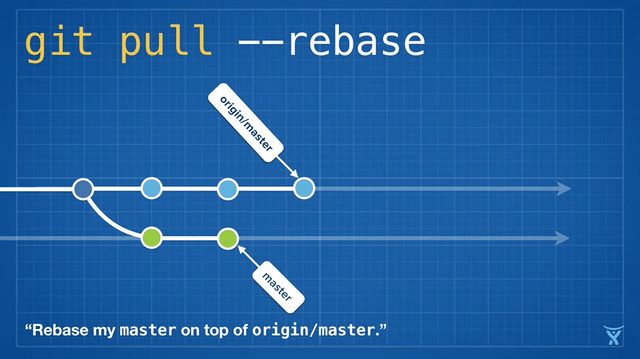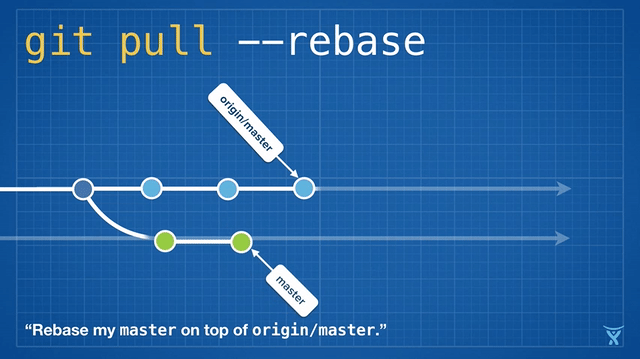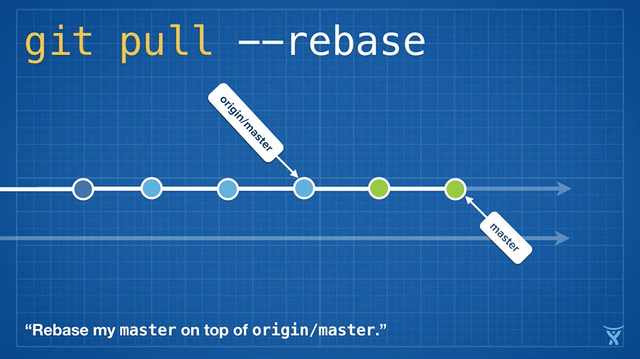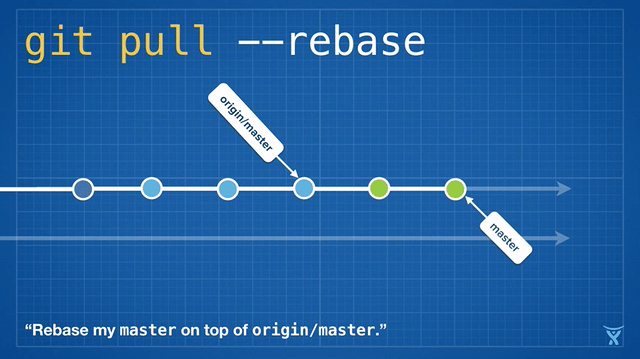
|
||||
|
||||

|
||||
|
||||
这很整洁吧!甚至更酷,Git v2.8 引入了一个新特性,允许你在拉取时 _交互地_ 变基。
|
||||
|
||||
@ -209,18 +190,15 @@ $ git worktree prune
|
||||
交互式变基是变基操作的一种更强大的形态。和标准变基操作相似,它可以重写提交,但它也可以向你提供一个机会让你能够交互式地修改这些将被重新运用在新基准上的提交。
|
||||
|
||||
当你运行 `git rebase --interactive` (或 `git pull --rebase=interactive`)时,你会在你的文本编辑器中得到一个可供选择的提交列表视图。
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
```
|
||||
|
||||
```
|
||||
$ git rebase master --interactive
|
||||
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
pick ed93626 ACE-1294: removed pull request service from test
|
||||
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 commands)
|
||||
#
|
||||
# Commands:
|
||||
@ -238,27 +216,30 @@ pick e68f710 ACE-1294: added testing data to batch email file
|
||||
# If you remove a line here THAT COMMIT WILL BE LOST.
|
||||
```
|
||||
|
||||
注意到每一条提交旁都有一个 `pick`。这是对 rebase 而言,"照原样留下这个提交"。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 `pick` 改为 `edit` 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
|
||||
* `reword`: 编辑提交信息。
|
||||
* `edit`: 编辑提交了的文件。
|
||||
* `squash`: 将提交与之前的提交(同在文件中)合并,并将提交信息拼接。
|
||||
* `fixup`: 将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。
|
||||
* `exec`: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。
|
||||
注意到每一条提交旁都有一个 `pick`。这是对 rebase 而言,“照原样留下这个提交”。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 `pick` 改为 `edit` 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
|
||||
|
||||
* `reword`:编辑提交信息。
|
||||
* `edit`:编辑提交了的文件。
|
||||
* `squash`:将提交与之前的提交(同在文件中)合并,并将提交信息拼接。
|
||||
* `fixup`:将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。
|
||||
* `exec`: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。
|
||||
* `drop`: 这将丢弃这条提交。
|
||||
|
||||
你也可以在文件内重新整理提交,这样会改变他们被重新运用的顺序。这会很顺手当你对不同的主题创建了交错的提交时,你可以使用 `squash` 或者 `fixup` 来将其合并成符合逻辑的原子提交。
|
||||
你也可以在文件内重新整理提交,这样会改变它们被重新应用的顺序。当你对不同的主题创建了交错的提交时这会很顺手,你可以使用 `squash` 或者 `fixup` 来将其合并成符合逻辑的原子提交。
|
||||
|
||||
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 `reword` 和 `edit` 命令处为你暂停来执行你设计好的改变并且自动运行 `squash`, `fixup`,`exec` 和 `drop`命令。
|
||||
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 `reword` 和 `edit` 命令处为你暂停来执行你设计好的改变,并且自动运行 `squash`, `fixup`,`exec` 和 `drop` 命令。
|
||||
|
||||
####非交互性式执行
|
||||
|
||||
当你执行变基操作时,本质上你是在通过将你每一条新提交应用于指定基址的头部来重写历史。`git pull --rebase` 可能会有一点危险,因为根据上游分支改动的事实,你的新建历史可能会由于特定的提交遭遇测试失败甚至编译问题。如果这些改动引起了合并冲突,变基过程将会暂停并且允许你来解决它们。但是,整洁的合并改动仍然有可能打断编译或测试过程,留下破败的提交弄乱你的提交历史。
|
||||
|
||||
但是,你可以指导 Git 为每一个重写的提交来运行你的项目测试套件。在 Git v2.9 之前,你可以通过绑定 `git rebase --interactive` 和 `exec` 命令来实现。例如这样:
|
||||
|
||||
```
|
||||
$ git rebase master −−interactive −−exec=”npm test”
|
||||
```
|
||||
|
||||
...会生成在重写每条提交后执行 `npm test` 这样的一个交互式变基计划,保证你的测试仍然会通过:
|
||||
……这会生成一个交互式变基计划,在重写每条提交后执行 `npm test` ,保证你的测试仍然会通过:
|
||||
|
||||
```
|
||||
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
|
||||
@ -269,20 +250,17 @@ pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
|
||||
exec npm test
|
||||
pick e68f710 ACE-1294: added testing data to batch email file
|
||||
exec npm test
|
||||
```
|
||||
|
||||
```
|
||||
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 command(s))
|
||||
```
|
||||
|
||||
如果出现了测试失败的情况,变基会暂停并让你修复这些测试(并且将你的修改应用于相应提交):
|
||||
|
||||
```
|
||||
291 passing
|
||||
1 failing
|
||||
```
|
||||
|
||||
```
|
||||
1) Host request “after all” hook:
|
||||
1) Host request "after all" hook:
|
||||
Uncaught Error: connect ECONNRESET 127.0.0.1:3001
|
||||
…
|
||||
npm ERR! Test failed.
|
||||
@ -292,91 +270,96 @@ You can fix the problem, and then run
|
||||
```
|
||||
|
||||
这很方便,但是使用交互式变基有一点臃肿。到了 Git v2.9,你可以这样来实现非交互式变基:
|
||||
|
||||
```
|
||||
$ git rebase master -x “npm test”
|
||||
$ git rebase master -x "npm test"
|
||||
```
|
||||
|
||||
简单替换 `npm test` 为 `make`,`rake`,`mvn clean install`,或者任何你用来构建或测试你的项目的命令。
|
||||
可以简单替换 `npm test` 为 `make`,`rake`,`mvn clean install`,或者任何你用来构建或测试你的项目的命令。
|
||||
|
||||
#### 小小警告
|
||||
|
||||
####小小警告
|
||||
就像电影里一样,重写历史可是一个危险的行当。任何提交被重写为变基操作的一部分都将改变它的 SHA-1 ID,这意味着 Git 会把它当作一个全新的提交对待。如果重写的历史和原来的历史混杂,你将获得重复的提交,而这可能在你的团队中引起不少的疑惑。
|
||||
|
||||
为了避免这个问题,你仅仅需要遵照一条简单的规则:
|
||||
|
||||
> _永远不要变基一条你已经推送的提交!_
|
||||
|
||||
坚持这一点你会没事的。
|
||||
|
||||
### Git LFS 的性能提升
|
||||
|
||||
[Git 是一个分布式版本控制系统][64],意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。[Git LFS(Large File Storage 大文件存储)][65] 是一个 Git 拓展包,由 Atlassian、GitHub 和其他一些开源贡献者开发,通过需要时才下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
|
||||
|
||||
### `Git LFS` 的性能提升
|
||||
[Git 是一个分布式版本控制系统][64],意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。[Git LFS(Large File Storage 大文件存储)][65] 是一个 Git 拓展包,由 Atlassian,GitHub 和其他一些开源贡献者开发,通过消极地下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
|
||||
|
||||
在 Git 2016 年的五大发布中,Git LFS 自身有四个功能丰富的发布:v1.2 到 v1.5。你可以凭 Git LFS 自身来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
|
||||
在 Git 2016 年的五大发布中,Git LFS 自身就有四个功能版本的发布:v1.2 到 v1.5。你可以仅对 Git LFS 这一项来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
|
||||
|
||||
#### 长期过滤进程
|
||||
|
||||
当你 `git add` 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储前转化文件的内容。Git LFS 通过使用净化过滤器将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
|
||||
当你 `git add` 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储之前转化文件的内容。Git LFS 通过使用净化过滤器(clean filter)将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
|
||||
|
||||
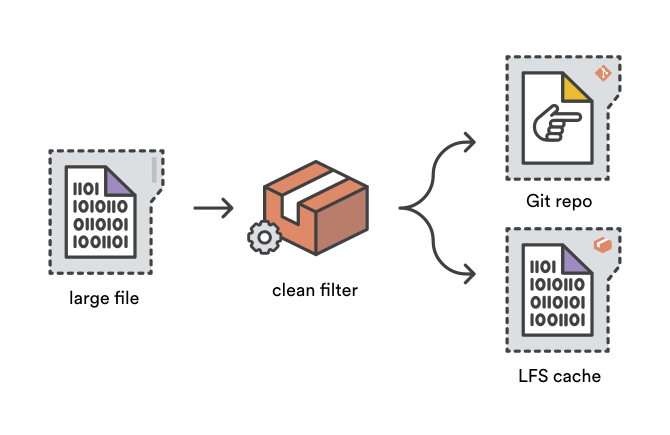
|
||||
|
||||

|
||||
|
||||
污化过滤器是净化过滤器的对立面——正如其名。在 `git checkout` 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
|
||||
污化过滤器(smudge filter)是净化过滤器的对立面——正如其名。在 `git checkout` 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
|
||||
|
||||
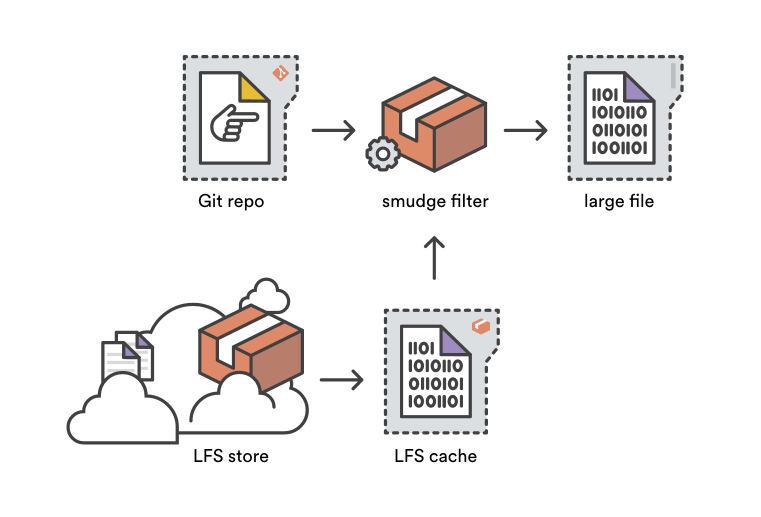
|
||||
|
||||
传统上,污化和净化过滤进程在每个文件被增加和检出时只能被唤起一次。所以,一个项目如果有 1000 个文件在被 Git LFS 追踪 ,做一次全新的检出需要唤起 `git-lfs-smudge` 命令 1000 次。尽管单次操作相对很迅速,但是经常执行 1000 次独立的污化进程总耗费惊人。、
|
||||
|
||||
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。[Lars Schneider][66],Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
|
||||
> 使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
|
||||
> 这真是一个让人印象深刻的性能增强!
|
||||
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。[Lars Schneider][66],Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
|
||||
|
||||
> 使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了 80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
|
||||
|
||||
这真是一个让人印象深刻的性能增强!
|
||||
|
||||
#### LFS 专有克隆
|
||||
|
||||
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两个 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 `git clone` 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
|
||||
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两次 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 `git clone` 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
|
||||
|
||||
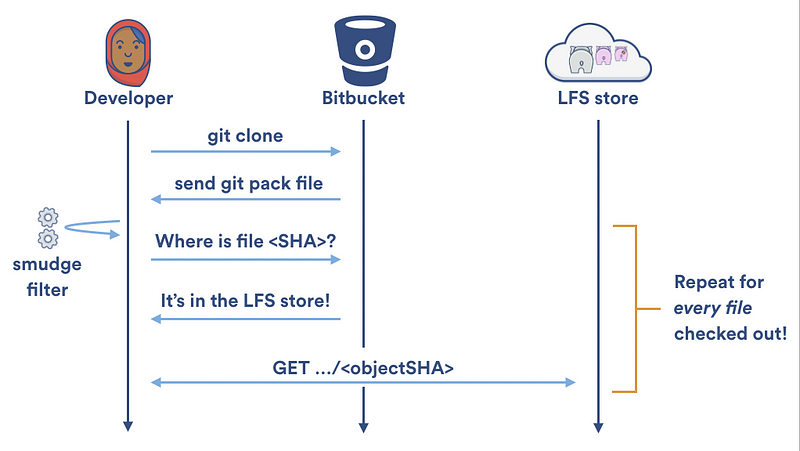
|
||||

|
||||
|
||||
幸运的是,Git LFS v1.2 提供了专门的 `[git lfs clone][51]` 命令。不再是一次下载一个文件; `git lfs clone` 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
|
||||
幸运的是,Git LFS v1.2 提供了专门的 [`git lfs clone`][51] 命令。不再是一次下载一个文件; `git lfs clone` 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
|
||||
|
||||
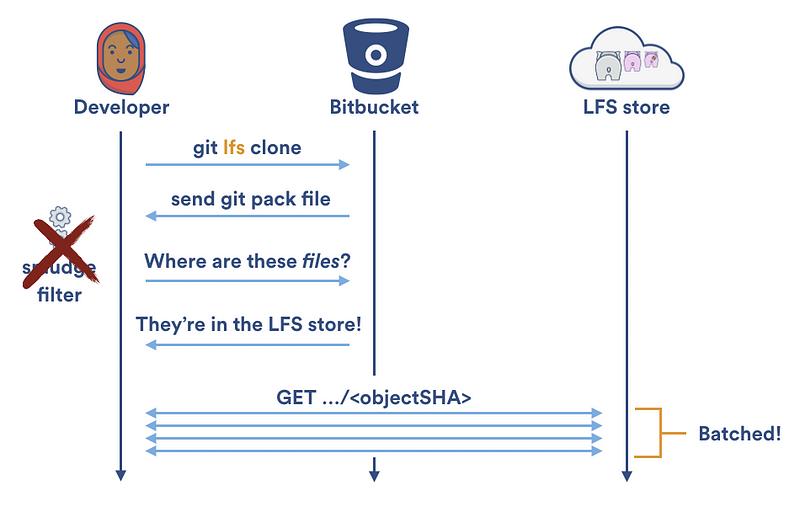
|
||||

|
||||
|
||||
###自定义传输路由器
|
||||
### 自定义传输路由器(Transfer Adapter)
|
||||
|
||||
正如之前讨论过的,Git LFS 在 v1.5 中 发起了对长期过滤进程的支持。不过,对另外一种可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
|
||||
正如之前讨论过的,Git LFS 在 v1.5 中提供对长期过滤进程的支持。不过,对另外一种类型的可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器(pluggable transfer adapter)的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
|
||||
|
||||
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 [Bitbucket LFS Media Adapter][67] 的托管服务商。这是为了从 Bitbucket 的一个独特的被称为 chunking 的 LFS 存储 API 特性中获利。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。
|
||||

|
||||
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 [Bitbucket LFS Media Adapter][67] 的托管服务商。这是为了从 Bitbucket 的一个被称为 chunking 的 LFS 存储 API 独特特性中获益。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。
|
||||
|
||||

|
||||
|
||||
分块给予了 Bitbucket 支持的 Git LFS 三大优势:
|
||||
1. 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够梦幻地提升传输速度。
|
||||
2. 可恢复文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
|
||||
3. 免重复。Git LFS,正如 Git 本身,是内容索位;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下Git LFS 在追踪一个 41M 的电子游戏精灵表。如果我们增加在此精灵表上增加 2MB 的新层并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送 ~7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新层的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
|
||||
|
||||
可自定义的传输路由器是 Git LFS 一个伟大的特性,它们使得不同服务商在不过载核心项目的前提下体验适合其服务器的优化后的传输协议。
|
||||
1. 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够神奇地提升传输速度。
|
||||
2. 可续传的文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
|
||||
3. 免重复。Git LFS,正如 Git 本身,是一种可定位的内容;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下 Git LFS 在追踪一个 41M 的精灵表格(spritesheet)。如果我们增加在此精灵表格上增加 2MB 的新的部分并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送大约 7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新的部分的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
|
||||
|
||||
### 更佳的 `git diff` 算法与默认值
|
||||
可自定义的传输路由器是 Git LFS 的一个伟大的特性,它们使得不同服务商在不重载核心项目的前提下体验适合其服务器的优化后的传输协议。
|
||||
|
||||
### 更佳的 git diff 算法与默认值
|
||||
|
||||
不像其他的版本控制系统,Git 不会明确地存储文件被重命名了的事实。例如,如果我编辑了一个简单的 Node.js 应用并且将 `index.js` 重命名为 `app.js`,然后运行 `git diff`,我会得到一个看起来像一个文件被删除另一个文件被新建的结果。
|
||||
|
||||

|
||||

|
||||
|
||||
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟一次新建,但这不是对人类最友好的方式来诉说它。其实,你可以使用 `-M` 标志来指示 Git 在计算差异时抽空尝试检测重命名文件。对之前的例子,`git diff -M` 给我们如下结果:
|
||||

|
||||
我猜测移动或重命名一个文件从技术上来讲是一次删除后跟着一次新建,但这不是对人类最友好的描述方式。其实,你可以使用 `-M` 标志来指示 Git 在计算差异时同时尝试检测是否是文件重命名。对之前的例子,`git diff -M` 给我们如下结果:
|
||||
|
||||
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,`-M` 会考虑任意两个文件都有超过 50% 相似度。这意味着,你需要编辑少于 50% 的行数来确保它们被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,`-M80%`。
|
||||

|
||||
|
||||
到 Git v2.9 版本,如果你使用了 `-M` 标志 `git diff` 和 `git log` 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显示的传递 `--no-renames` 标志来禁用它。
|
||||
第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,`-M` 会处理任意两个超过 50% 相似度的文件。这意味着,你需要编辑少于 50% 的行数来确保它们可以被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,`-M80%`。
|
||||
|
||||
到 Git v2.9 版本,无论你是否使用了 `-M` 标志, `git diff` 和 `git log` 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显式的传递 `--no-renames` 标志来禁用这种行为。
|
||||
|
||||
#### 详细的提交
|
||||
|
||||
你经历过调用 `git commit` 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?verbose 标志就为此而来!
|
||||
你经历过调用 `git commit` 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?`verbose` 标志就为此而来!
|
||||
|
||||
不像这样:
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
```
|
||||
|
||||
```
|
||||
Ah crap, which dependency did I just rev?
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with ‘#’ will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
@ -387,15 +370,16 @@ Ah crap, which dependency did I just rev?
|
||||
#
|
||||
```
|
||||
|
||||
...你可以调用 `git commit --verbose` 来查看你改动造成的内联差异。不用担心,这不会包含在你的提交信息中:
|
||||
……你可以调用 `git commit --verbose` 来查看你改动造成的行内差异。不用担心,这不会包含在你的提交信息中:
|
||||
|
||||
|
||||

|
||||
|
||||
`--verbose` 标志不是最新的,但是直到 Git v2.9 你可以通过 `git config --global commit.verbose true` 永久的启用它。
|
||||
`--verbose` 标志并不是新出现的,但是直到 Git v2.9 你才可以通过 `git config --global commit.verbose true` 永久的启用它。
|
||||
|
||||
#### 实验性的 Diff 改进
|
||||
|
||||
当一个被修改部分前后几行相同时,`git diff` 可能产生一些稍微令人迷惑的输出。如果在一个文件中有两个或者更多相似结构的函数时这可能发生。来看一个有些刻意人为的例子,想象我们有一个 JS 文件包含一个单独的函数:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
@ -403,15 +387,14 @@ function productName() {
|
||||
}
|
||||
```
|
||||
|
||||
现在想象一下我们刚提交的改动包含一个预谋的 _另一个_可以做相似事情的函数:
|
||||
现在想象一下我们刚提交的改动包含一个我们专门做的 _另一个_可以做相似事情的函数:
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productId() {
|
||||
return "Bitbucket";
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/* @return {string} "Bitbucket" */
|
||||
function productName() {
|
||||
return "Bitbucket";
|
||||
@ -420,32 +403,34 @@ function productName() {
|
||||
|
||||
我们希望 `git diff` 显示开头五行被新增,但是实际上它不恰当地将最初提交的第一行也包含进来。
|
||||
|
||||

|
||||

|
||||
|
||||
错误的注释被包含在了 diff 中!这虽不是世界末日,但每次发生这种事情总免不了花费几秒钟的意识去想 _啊?_
|
||||
在十二月,Git v2.11 介绍了一个新的实验性的 diff 选项,`--indent-heuristic`,尝试生成从美学角度来看更赏心悦目的 diff。
|
||||
|
||||

|
||||

|
||||
|
||||
在后台,`--indent-heuristic` 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 "不良" 分数。这是基于试探性的如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲不良)以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
|
||||
在后台,`--indent-heuristic` 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 “不良” 分数。这是基于启发式的,如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲“不良”),以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
|
||||
|
||||
这个特性还是实验性的,但是你可以通过应用 `--indent-heuristic` 选项到任何 `git diff` 命令来专门测试它。如果,如果你喜欢尝鲜,你可以这样将其在你的整个系统内启用:
|
||||
|
||||
这个特性还是实验性的,但是你可以通过应用 `--indent-heuristic` 选项到任何 `git diff` 命令来专门测试它。如果,如果你喜欢在刀口上讨生活,你可以这样将其在你的整个系统内使能:
|
||||
```
|
||||
$ git config --global diff.indentHeuristic true
|
||||
```
|
||||
|
||||
### Submodules 差强人意
|
||||
### 子模块(Submodule)差强人意
|
||||
|
||||
子模块允许你从 Git 仓库内部引用和包含其他 Git 仓库。这通常被用在当一些项目管理的源依赖也在被 Git 跟踪时,或者被某些公司用来作为包含一系列相关项目的 [monorepo][68] 的替代品。
|
||||
|
||||
由于某些用法的复杂性以及使用错误的命令相当容易破坏它们的事实,Submodule 得到了一些坏名声。
|
||||
|
||||
|
||||

|
||||
|
||||
但是,它们还是有着它们的用处,而且,我想,仍然对其他方案有依赖时的最好的选择。 幸运的是,2016 对 submodule 用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
|
||||
但是,它们还是有着它们的用处,而且,我想这仍然是用于需要厂商依赖项的最好选择。 幸运的是,2016 对子模块的用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
|
||||
|
||||
#### 并行抓取
|
||||
当克隆或则抓取一个仓库时,加上 `--recurse-submodules` 选项意味着任何引用的 submodule 也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个 submodule。直到 Git v2.8,你可以附加 `--jobs=n` 选项来使用 _n_ 个并行线程来抓取 submodules。
|
||||
|
||||
当克隆或则抓取一个仓库时,加上 `--recurse-submodules` 选项意味着任何引用的子模块也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个子模块。直到 Git v2.8,你可以附加 `--jobs=n` 选项来使用 _n_ 个并行线程来抓取子模块。
|
||||
|
||||
我推荐永久的配置这个选项:
|
||||
|
||||
@ -453,30 +438,31 @@ $ git config --global diff.indentHeuristic true
|
||||
$ git config --global submodule.fetchJobs 4
|
||||
```
|
||||
|
||||
...或者你可以选择使用任意程度的平行化。
|
||||
……或者你可以选择使用任意程度的平行化。
|
||||
|
||||
#### 浅层子模块
|
||||
Git v2.9 介绍了 `git clone —shallow-submodules` 标志。它允许你抓取你仓库的完整克隆,然后递归的浅层克隆所有引用的子模块的一个提交。如果你不需要项目的依赖的完整记录时会很有用。
|
||||
#### 浅层化子模块
|
||||
|
||||
例如,一个仓库有着一些混合了的子模块,其中包含有其他方案商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层子模块克隆然后深度选择几个你想要与之工作的项目。
|
||||
Git v2.9 介绍了 `git clone —shallow-submodules` 标志。它允许你抓取你仓库的完整克隆,然后递归地以一个提交的深度浅层化克隆所有引用的子模块。如果你不需要项目的依赖的完整记录时会很有用。
|
||||
|
||||
另一种情况可能是配置一次持续性的集成或调度工作。Git 需要超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
|
||||
例如,一个仓库有着一些混合了的子模块,其中包含有其他厂商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层化子模块克隆,然后深度选择几个你想工作与其上的项目。
|
||||
|
||||
另一种情况可能是配置持续集成或部署工作。Git 需要一个包含了子模块的超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
|
||||
|
||||
#### 子模块的替代品
|
||||
|
||||
`--reference` 选项可以和 `git clone` 配合使用来指定另一个本地仓库作为一个目标存储来保存你本地已经存在的又通过网络传输的重复制目标。语法为:
|
||||
`--reference` 选项可以和 `git clone` 配合使用来指定另一个本地仓库作为一个替代的对象存储,来避免跨网络重新复制你本地已经存在的对象。语法为:
|
||||
|
||||
```
|
||||
$ git clone --reference <local repo> <url>
|
||||
```
|
||||
|
||||
直到 Git v2.11,你可以使用 `—reference` 选项与 `—recurse-submodules` 结合来设置子模块替代品从另一个本地仓库指向子模块。其语法为:
|
||||
到 Git v2.11,你可以使用 `—reference` 选项与 `—recurse-submodules` 结合来设置子模块指向一个来自另一个本地仓库的子模块。其语法为:
|
||||
|
||||
```
|
||||
$ git clone --recurse-submodules --reference <local repo> <url>
|
||||
```
|
||||
|
||||
这潜在的可以省下很大数量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你所克隆自的远程仓库所必需的所有子模块时,它可能会失败。。
|
||||
这潜在的可以省下大量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你克隆的远程仓库所必需的所有子模块时,它可能会失败。
|
||||
|
||||
幸运的是,方便的 `—-reference-if-able` 选项将会让它优雅地失败,然后为丢失了的被引用的本地仓库的所有子模块回退为一次普通的克隆。
|
||||
|
||||
@ -487,11 +473,11 @@ $ git clone --recurse-submodules --reference-if-able \
|
||||
|
||||
#### 子模块的 diff
|
||||
|
||||
在 Git v2.11 之前,Git 有两种模式来显示对更新了仓库子模块的提交之间的差异。
|
||||
在 Git v2.11 之前,Git 有两种模式来显示对更新你的仓库子模块的提交之间的差异。
|
||||
|
||||
`git diff —-submodule=short` 显示你的项目引用的子模块中的旧提交和新提交( 这也是如果你整体忽略 `--submodule` 选项的默认结果):
|
||||
`git diff —-submodule=short` 显示你的项目引用的子模块中的旧提交和新提交(这也是如果你整体忽略 `--submodule` 选项的默认结果):
|
||||
|
||||
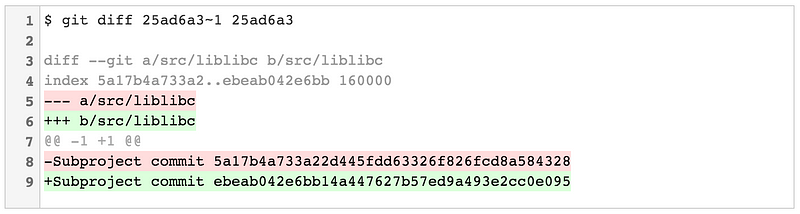
|
||||

|
||||
|
||||
`git diff —submodule=log` 有一点啰嗦,显示更新了的子模块中任意新建或移除的提交的信息中统计行。
|
||||
|
||||
@ -499,15 +485,16 @@ $ git clone --recurse-submodules --reference-if-able \
|
||||
|
||||
Git v2.11 引入了第三个更有用的选项:`—-submodule=diff`。这会显示更新后的子模块所有改动的完整的 diff。
|
||||
|
||||
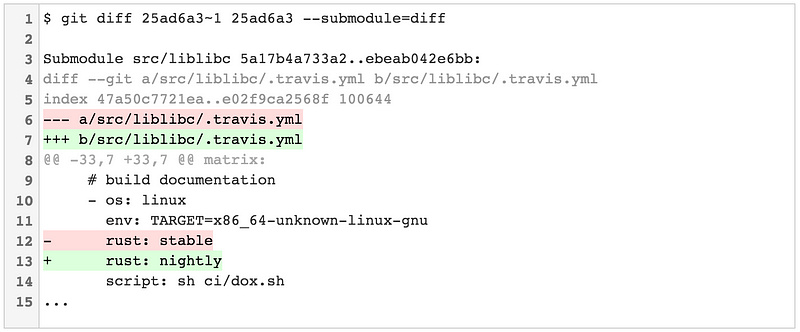
|
||||

|
||||
|
||||
### `git stash` 的 90 个增强
|
||||
### git stash 的 90 个增强
|
||||
|
||||
不像 submodules,几乎没有 Git 用户不钟爱 `[git stash][52]`。 `git stash` 临时搁置(或者 _藏匿_)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
|
||||
不像子模块,几乎没有 Git 用户不钟爱 [`git stash`][52]。 `git stash` 临时搁置(或者 _藏匿_)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
|
||||
|
||||
#### 自动搁置
|
||||
|
||||
如果你是 `git rebase` 的粉丝,你可能很熟悉 `--autostash` 选项。它会在变基之前自动搁置工作区所有本地修改然后等变基结束再将其复用。
|
||||
|
||||
```
|
||||
$ git rebase master --autostash
|
||||
Created autostash: 54f212a
|
||||
@ -516,12 +503,14 @@ First, rewinding head to replay your work on top of it...
|
||||
Applied autostash.
|
||||
```
|
||||
|
||||
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 `rebase.autostash` 可以将这个特性设为默认,你可以这样来全局使能它:
|
||||
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 `rebase.autostash` 可以将这个特性设为默认,你可以这样来全局启用它:
|
||||
|
||||
```
|
||||
$ git config --global rebase.autostash true
|
||||
```
|
||||
|
||||
`rebase.autostash` 实际上自从 [Git v1.8.4][69] 就可用了,但是 v2.7 引入了通过 `--no-autostash` 选项来取消这个标志的功能。如果你对未暂存的改动使用这个选项,变基会被一条工作树被污染的警告禁止:
|
||||
|
||||
```
|
||||
$ git rebase master --no-autostash
|
||||
Cannot rebase: You have unstaged changes.
|
||||
@ -531,31 +520,37 @@ Please commit or stash them.
|
||||
#### 补丁式搁置
|
||||
|
||||
说到配置标签,Git v2.7 也引入了 `stash.showPatch`。`git stash show` 的默认行为是显示你搁置文件的汇总。
|
||||
|
||||
```
|
||||
$ git stash show
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
将 `-p` 标志传入会将 `git stash show` 变为 "补丁模式",这将会显示完整的 diff:
|
||||
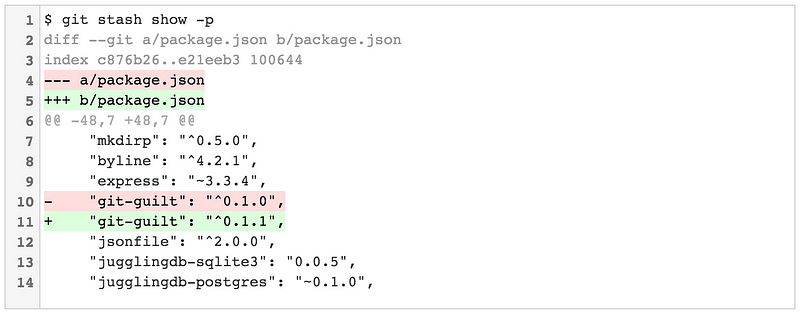
|
||||
将 `-p` 标志传入会将 `git stash show` 变为 “补丁模式”,这将会显示完整的 diff:
|
||||
|
||||

|
||||
|
||||
`stash.showPatch` 将这个行为定为默认。你可以将其全局启用:
|
||||
|
||||
`stash.showPatch` 将这个行为定为默认。你可以将其全局使能:
|
||||
```
|
||||
$ git config --global stash.showPatch true
|
||||
```
|
||||
|
||||
如果你使能 `stash.showPatch` 但却之后决定你仅仅想要查看文件总结,你可以通过传入 `--stat` 选项来重新获得之前的行为。
|
||||
|
||||
```
|
||||
$ git stash show --stat
|
||||
package.json | 2 +-
|
||||
1 file changed, 1 insertion(+), 1 deletion(-)
|
||||
```
|
||||
|
||||
顺便一提:`--no-patch` 是一个有效选项但它不会如你所希望的改写 `stash.showPatch` 的结果。不仅如此,它会传递给用来生成补丁时潜在调用的 `git diff` 命令,然后你会发现完全没有任何输出。
|
||||
顺便一提:`--no-patch` 是一个有效选项但它不会如你所希望的取消 `stash.showPatch`。不仅如此,它会传递给用来生成补丁时潜在调用的 `git diff` 命令,然后你会发现完全没有任何输出。
|
||||
|
||||
#### 简单的搁置标识
|
||||
如果你是 `git stash` 的粉丝,你可能知道你可以搁置多次改动然后通过 `git stash list` 来查看它们:
|
||||
|
||||
如果你惯用 `git stash` ,你可能知道你可以搁置多次改动然后通过 `git stash list` 来查看它们:
|
||||
|
||||
```
|
||||
$ git stash list
|
||||
stash@{0}: On master: crazy idea that might work one day
|
||||
@ -564,11 +559,11 @@ stash@{2}: On master: perf improvement that I forgot I stashed
|
||||
stash@{3}: On master: pop this when we use Docker in production
|
||||
```
|
||||
|
||||
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(`stash@{1}`, `stash@{2}`, 等)也可能将它们勾勒成 "仅仅是 Git 的一个特性吧"。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型一个非常巧妙使用(或者说是滥用了的)的特性。
|
||||
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(`stash@{1}`、`stash@{2}` 等),或许你可能将它们勾勒成 “仅仅是 Git 的癖好吧”。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型的一个非常巧妙使用(或者说是滥用了的)的结果。
|
||||
|
||||
在后台,`git stash` 命令实际创建了一系列特别的提交目标,这些目标对你搁置的改动做了编码并且维护一个 [reglog][70] 来保存对这些特殊提交的参考。 这也是为什么 `git stash list` 的输出看起来很像 `git reflog` 的输出。当你运行 `git stash apply stash@{1}` 时,你实际上在说,"从stash reflog 的位置 1 上应用这条提交 "
|
||||
在后台,`git stash` 命令实际创建了一系列特定的提交目标,这些目标对你搁置的改动做了编码并且维护一个 [reglog][70] 来保存对这些特殊提交的引用。 这也是为什么 `git stash list` 的输出看起来很像 `git reflog` 的输出。当你运行 `git stash apply stash@{1}` 时,你实际上在说,“从 stash reflog 的位置 1 上应用这条提交。”
|
||||
|
||||
直到 Git v2.11,你不再需要使用完整的 `stash@{n}` 语句。相反,你可以通过一个简单的整数指出搁置在 stash reflog 中的位置来引用它们。
|
||||
到了 Git v2.11,你不再需要使用完整的 `stash@{n}` 语句。相反,你可以通过一个简单的整数指出该搁置在 stash reflog 中的位置来引用它们。
|
||||
|
||||
```
|
||||
$ git stash show 1
|
||||
@ -577,25 +572,26 @@ $ git stash pop 1
|
||||
```
|
||||
|
||||
讲了很多了。如果你还想要多学一些搁置是怎么保存的,我在 [这篇教程][71] 中写了一点这方面的内容。
|
||||
### <2016> <2017>
|
||||
好了,结束了。感谢您的阅读!我希望您享受阅读这份长篇大论,正如我享受在 Git 的源码,发布文档,和 `man` 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 [Twitter][72] 上让我知道,我会努力写一份后续篇章。
|
||||
|
||||
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着日益增长的采用,我猜测简化,改进后的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得又大又旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
|
||||
### </2016> <2017>
|
||||
|
||||
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 [Git Merge][74] 。我会在[那里发言][75]!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
|
||||
好了,结束了。感谢您的阅读!我希望您喜欢阅读这份长篇大论,正如我乐于在 Git 的源码、发布文档和 `man` 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 [Twitter][72] 上让我知道,我会努力写一份后续篇章。
|
||||
|
||||
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着 Git 的采用日益增长,我猜测简化、改进的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得越来越大、越来越旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
|
||||
|
||||
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 [Git Merge][74] 。我会在[那里发言][75]!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
|
||||
|
||||
或者如果你实在等不及,想要获得更多的技巧和指南来改进你的工作流,请参看这份 Atlassian 的优秀作品: [Git 教程][76] 。
|
||||
|
||||
|
||||
*如果你翻到最下方来找第一节的脚注,请跳转到 [ [引用是需要的] ][77]一节去找生成统计信息的命令。免费的封面图片是由 [ instaco.de ][78] 生成的 ❤️。*
|
||||
封面图片是由 [instaco.de][78] 生成的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/git-in-2016-fad96ae22a15#.t5c5cm48f
|
||||
via: https://medium.com/hacker-daily/git-in-2016-fad96ae22a15
|
||||
|
||||
作者:[Tim Pettersen][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
用 NTP 把控时间(一):使用概览
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
这系列共三部分,首先,Chirs Binnie 探讨了在一个合理的架构中 NTP 服务的重要性。
|
||||
|
||||
鲜有互联网上的服务能如时间服务一样重要。影响你系统计时的小问题可能需要一两天才能被发现,而这些不期而遇的问题所带来的连锁反应几乎总是让人伤脑筋的。
|
||||
|
||||
设想你的备份服务器与网络时间协议(NTP)服务器断开连接,过了几天,引起了几小时的时间偏差。你的同事照常九点上班,发现需要大量带宽的备份服务器消耗了所有网络资源,这也就意味着他们在备份完成之前几乎不能登录工作台开始他们的日常工作。
|
||||
|
||||
这系列共三部分,首先,我将提供简要介绍 NTP 来防止这种困境的发生。从邮件的时间戳到记录你工作的进展,NTP 服务对于一个合理的架构是如此的重要。
|
||||
|
||||
可以把如此重要的 NTP 服务器(其他的服务器从此获取时钟数据)看做是倒置金字塔的底部,它被称之为<ruby>一层<rt>Stratum 1</rt></ruby>服务器(也被称为“<ruby>主<rt>primary</rt></ruby>”服务器)。这些服务器与国家级时间服务(称为<ruby>零层<rt>Stratum 0</rt></ruby>,通常这些设备是是原子钟和 GPS 钟之类的装置)直接交互。与之安全通讯的方法很多,例如通过卫星或者无线电。
|
||||
|
||||
令人惊讶的是,几乎所有的大型企业都会连接<ruby>二层<rt>Stratum 2</rt></ruby>服务器(或“<ruby>次级<rt>secondary</rt></ruby>”服务器)而是不是主服务器。如你所料,二层服务器和一层直接同步。如果你觉得大公司可能有自己的本地 NTP 服务器(至少两个,通常三个,为了灾难恢复之用),这些就是三层服务器。这样,三层服务器将连接上层预定义的次级服务器,负责任地传递时间给客户端和服务器,精确地反馈当前时间。
|
||||
|
||||
由简单设计而构成的 NTP 可以工作的前提是——多亏了通过互联网跨越了大范围的地理距离——在确认时间完全准确之前,来回时间(包什么时候发出和多少秒后被收到)都会被清楚记录。设置电脑的时间的背后要比你想象的复杂得多,如果你不相信,那[这神奇的网页][3]值得一看。
|
||||
|
||||
再次重提一遍,为了确保你的架构如预期般工作,NTP 是如此的关键,你的 NTP 与层次服务器之间的连接必须是完全可信赖并且能提供额外的冗余,才能保持你的内部时钟同步。在 [NTP 主站][4]有一个有用的一层服务器列表。
|
||||
|
||||
正如你在列表所见,一些 NTP 一层服务器以 “ClosedAccount” 状态运行;这些服务器需要事先接受才可以使用。但是只要你完全按照他们的使用引导做,“OpenAccess” 服务器是可以用于轮询使用的。而 “RestrictedAccess” 服务器有时候会因为大量客户端访问或者轮询间隙太小而受限。另外有时候也有一些专供某种类型的组织使用,例如学术界。
|
||||
|
||||
### 尊重我的权威
|
||||
|
||||
在公共 NTP 服务器上,你可能发现遵从某些规则的使用规范。现在让我们看看其中一些。
|
||||
|
||||
“iburst” 选项作用是如果在一个标准的轮询间隔内没有应答,客户端会发送一定数量的包(八个包而不是通常的一个)给 NTP 服务器。如果在短时间内呼叫 NTP 服务器几次,没有出现可辨识的应答,那么本地时间将不会变化。
|
||||
|
||||
不像 “iburst” ,按照 NTP 服务器的通用规则, “burst” 选项一般不允许使用(所以不要用它!)。这个选项不仅在轮询间隔发送大量包(明显又是八个),而且也会在服务器能正常使用时这样做。如果你在高层服务器持续发送包,甚至是它们在正常应答时,你可能会因为使用 “burst” 选项而被拉黑。
|
||||
|
||||
显然,你连接服务器的频率造成了它的负载差异(和少量的带宽占用)。使用 “minpoll” 和 “maxpoll” 选项可以本地设置频率。然而,根据连接 NTP 服务器的规则,你不应该分别修改其默认的 64 秒和 1024 秒。
|
||||
|
||||
此外,需要提出的是客户应该重视那些请求时间的服务器发出的“<ruby>亲一下就死(死亡之吻)<rt>Kiss-Of-Death</rt></ruby>” (KOD)消息。如果 NTP 服务器不想响应某个特定的请求,就像路由和防火墙技术那样,那么它最有可能的就是简单地遗弃或吞没任何相关的包。
|
||||
|
||||
换句话说,接受到这些数据的服务器并不需要特别处理这些包,简单地丢弃这些它认为这不值得回应的包即可。你可以想象,这并不是特别好的做法,有时候礼貌地问客户是否中止或停止比忽略请求更为有效。因此,这种特别的包类型叫做 KOD 包。如果一个客户端被发送了这种不受欢迎的 KOD 包,它应该记住这个发回了拒绝访问标志的服务器。
|
||||
|
||||
如果从该服务器收到不止一个 KOD 包,客户端会猜想服务器上发生了流量限速的情况(或类似的)。这种情况下,客户端一般会写入本地日志,提示与该服务器的交流不太顺利,以备将来排错之用。
|
||||
|
||||
牢记,出于显而易见的原因,关键在于 NTP 服务器的架构应该是动态的。因此,不要给你的 NTP 配置硬编码 IP 地址是非常重要的。通过使用 DNS 域名,个别服务器断开网络时服务仍能继续进行,而 IP 地址空间也能重新分配,并且可引入简单的负载均衡(具有一定程度的弹性)。
|
||||
|
||||
请别忘了我们也需要考虑呈指数增长的物联网(IoT),这最终将包括数以亿万计的新装置,意味着这些设备都需要保持正确时间。硬件卖家无意(或有意)设置他们的设备只能与一个提供者的(甚至一个) NTP 服务器连接终将成为过去,这是一个非常麻烦的问题。
|
||||
|
||||
你可能会想象,随着买入和上线更多的硬件单元,NTP 基础设施的拥有者大概不会为相关的费用而感到高兴,因为他们正被没有实际收入所困扰。这种情形并非杞人忧天。头疼的问题多呢 -- 由于 NTP 流量导致基础架构不堪重负 -- 这在过去几年里已发生过多次。
|
||||
|
||||
在下面两篇文章里,我将着重于一些重要的 NTP 安全配置选项和描述服务器的搭建。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/arrive-time-ntp-part-1-usage-overview
|
||||
|
||||
作者:[CHRIS BINNIE][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/files/images/ntp-timejpg
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm
|
||||
[4]:http://support.ntp.org/bin/view/Servers/StratumOneTimeServers
|
||||
@ -0,0 +1,632 @@
|
||||
如何在 CentOS 7 上安装 Elastic Stack
|
||||
============================================================
|
||||
|
||||
**Elasticsearch** 是基于 Lucene 由 Java 开发的开源搜索引擎。它提供了一个分布式、多租户的全文搜索引擎(LCTT 译注:多租户是指多租户技术,是一种软件架构技术,用来探讨与实现如何在多用户的环境下共用相同的系统或程序组件,并且仍可确保各用户间数据的隔离性。),并带有 HTTP 仪表盘的 Web 界面(Kibana)。数据会被 Elasticsearch 查询、检索,并且使用 JSON 文档方案存储。Elasticsearch 是一个可扩展的搜索引擎,可用于搜索所有类型的文本文档,包括日志文件。Elasticsearch 是 Elastic Stack 的核心,Elastic Stack 也被称为 ELK Stack。
|
||||
|
||||
**Logstash** 是用于管理事件和日志的开源工具。它为数据收集提供实时传递途径。 Logstash 将收集您的日志数据,将数据转换为 JSON 文档,并将其存储在 Elasticsearch 中。
|
||||
|
||||
**Kibana** 是 Elasticsearch 的开源数据可视化工具。Kibana 提供了一个漂亮的仪表盘 Web 界面。 你可以用它来管理和可视化来自 Elasticsearch 的数据。 它不仅美丽,而且强大。
|
||||
|
||||
在本教程中,我将向您展示如何在 CentOS 7 服务器上安装和配置 Elastic Stack 以监视服务器日志。 然后,我将向您展示如何在操作系统为 CentOS 7 和 Ubuntu 16 的客户端上安装 “Elastic beats”。
|
||||
|
||||
**前提条件**
|
||||
|
||||
* 64 位的 CentOS 7,4 GB 内存 - elk 主控机
|
||||
* 64 位的 CentOS 7 ,1 GB 内存 - 客户端 1
|
||||
* 64 位的 Ubuntu 16 ,1 GB 内存 - 客户端 2
|
||||
|
||||
### 步骤 1 - 准备操作系统
|
||||
|
||||
在本教程中,我们将禁用 CentOS 7 服务器上的 SELinux。 编辑 SELinux 配置文件。
|
||||
|
||||
```
|
||||
vim /etc/sysconfig/selinux
|
||||
```
|
||||
|
||||
将 `SELINUX` 的值从 `enforcing` 改成 `disabled` 。
|
||||
|
||||
```
|
||||
SELINUX=disabled
|
||||
```
|
||||
|
||||
然后重启服务器:
|
||||
|
||||
```
|
||||
reboot
|
||||
```
|
||||
|
||||
再次登录服务器并检查 SELinux 状态。
|
||||
|
||||
```
|
||||
getenforce
|
||||
```
|
||||
|
||||
确保结果是 `disabled`。
|
||||
|
||||
### 步骤 2 - 安装 Java
|
||||
|
||||
部署 Elastic stack 依赖于Java,Elasticsearch 需要 Java 8 版本,推荐使用 Oracle JDK 1.8 。我将从官方的 Oracle rpm 包安装 Java 8。
|
||||
|
||||
使用 `wget` 命令下载 Java 8 的 JDK。
|
||||
|
||||
```
|
||||
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http:%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u77-b02/jdk-8u77-linux-x64.rpm"
|
||||
```
|
||||
|
||||
然后使用 `rpm` 命令安装:
|
||||
|
||||
```
|
||||
rpm -ivh jdk-8u77-linux-x64.rpm
|
||||
```
|
||||
|
||||
最后,检查 java JDK 版本,确保它正常工作。
|
||||
|
||||
```
|
||||
java -version
|
||||
```
|
||||
|
||||
您将看到服务器的 Java 版本。
|
||||
|
||||
### 步骤 3 - 安装和配置 Elasticsearch
|
||||
|
||||
在此步骤中,我们将安装和配置 Elasticsearch。 从 elastic.co 网站提供的 rpm 包安装 Elasticsearch,并将其配置运行在 localhost 上(以确保该程序安全,而且不能从外部访问)。
|
||||
|
||||
在安装 Elasticsearch 之前,将 elastic.co 的密钥添加到服务器。
|
||||
|
||||
```
|
||||
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
```
|
||||
|
||||
接下来,使用 `wget` 下载 Elasticsearch 5.1,然后安装它。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.1.1.rpm
|
||||
rpm -ivh elasticsearch-5.1.1.rpm
|
||||
```
|
||||
|
||||
Elasticsearch 已经安装好了。 现在进入配置目录编辑 `elasticsaerch.yml` 配置文件。
|
||||
|
||||
```
|
||||
cd /etc/elasticsearch/
|
||||
vim elasticsearch.yml
|
||||
```
|
||||
|
||||
去掉第 40 行的注释,启用 Elasticsearch 的内存锁。这将禁用 Elasticsearch 的内存交换。
|
||||
|
||||
```
|
||||
bootstrap.memory_lock: true
|
||||
```
|
||||
|
||||
在 `Network` 块中,取消注释 `network.host` 和 `http.port` 行。
|
||||
|
||||
```
|
||||
network.host: localhost
|
||||
http.port: 9200
|
||||
```
|
||||
|
||||
保存文件并退出编辑器。
|
||||
|
||||
现在编辑 `elasticsearch.service` 文件的内存锁配置。
|
||||
|
||||
```
|
||||
vim /usr/lib/systemd/system/elasticsearch.service
|
||||
```
|
||||
|
||||
去掉第 60 行的注释,确保该值为 `unlimited`。
|
||||
|
||||
```
|
||||
MAX_LOCKED_MEMORY=unlimited
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
Elasticsearch 配置到此结束。Elasticsearch 将在本机的 9200 端口运行,我们通过在 CentOS 服务器上启用 `mlockall` 来禁用内存交换。重新加载 systemd,将 Elasticsearch 置为开机启动,然后启动服务。
|
||||
|
||||
```
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable elasticsearch
|
||||
sudo systemctl start elasticsearch
|
||||
```
|
||||
|
||||
等待 Eelasticsearch 启动成功,然后检查服务器上打开的端口,确保 9200 端口的状态是 `LISTEN`。
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
![Check elasticsearch running on port 9200] [10]
|
||||
|
||||
然后检查内存锁以确保启用 `mlockall`,并使用以下命令检查 Elasticsearch 是否正在运行。
|
||||
|
||||
```
|
||||
curl -XGET 'localhost:9200/_nodes?filter_path=**.mlockall&pretty'
|
||||
curl -XGET 'localhost:9200/?pretty'
|
||||
```
|
||||
|
||||
会看到如下结果。
|
||||
|
||||
![Check memory lock elasticsearch and check status] [11]
|
||||
|
||||
### 步骤 4 - 安装和配置 Kibana 和 Nginx
|
||||
|
||||
在这一步,我们将在 Nginx Web 服务器上安装并配置 Kibana。 Kibana 监听在 localhost 上,而 Nginx 作为 Kibana 的反向代理。
|
||||
|
||||
用 `wget` 下载 Kibana 5.1,然后使用 `rpm` 命令安装:
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.1.1-x86_64.rpm
|
||||
rpm -ivh kibana-5.1.1-x86_64.rpm
|
||||
```
|
||||
|
||||
编辑 Kibana 配置文件。
|
||||
|
||||
```
|
||||
vim /etc/kibana/kibana.yml
|
||||
```
|
||||
|
||||
去掉配置文件中 `server.port`、`server.host` 和 `elasticsearch.url` 这三行的注释。
|
||||
|
||||
```
|
||||
server.port: 5601
|
||||
server.host: "localhost"
|
||||
elasticsearch.url: "http://localhost:9200"
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
将 Kibana 设为开机启动,并且启动 Kibana 。
|
||||
|
||||
```
|
||||
sudo systemctl enable kibana
|
||||
sudo systemctl start kibana
|
||||
```
|
||||
|
||||
Kibana 将作为 node 应用程序运行在端口 5601 上。
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
![Kibana running as node application on port 5601] [12]
|
||||
|
||||
Kibana 安装到此结束。 现在我们需要安装 Nginx 并将其配置为反向代理,以便能够从公共 IP 地址访问 Kibana。
|
||||
|
||||
Nginx 在 Epel 资源库中可以找到,用 `yum` 安装 epel-release。
|
||||
|
||||
```
|
||||
yum -y install epel-release
|
||||
```
|
||||
|
||||
然后安装 Nginx 和 httpd-tools 这两个包。
|
||||
|
||||
```
|
||||
yum -y install nginx httpd-tools
|
||||
```
|
||||
|
||||
httpd-tools 软件包包含 Web 服务器的工具,可以为 Kibana 添加 htpasswd 基础认证。
|
||||
|
||||
编辑 Nginx 配置文件并删除 `server {}` 块,这样我们可以添加一个新的虚拟主机配置。
|
||||
|
||||
```
|
||||
cd /etc/nginx/
|
||||
vim nginx.conf
|
||||
```
|
||||
|
||||
删除 `server { }` 块。
|
||||
|
||||
![Remove Server Block on Nginx configuration] [13]
|
||||
|
||||
保存并退出。
|
||||
|
||||
现在我们需要在 `conf.d` 目录中创建一个新的虚拟主机配置文件。 用 `vim` 创建新文件 `kibana.conf`。
|
||||
|
||||
```
|
||||
vim /etc/nginx/conf.d/kibana.conf
|
||||
```
|
||||
|
||||
复制下面的配置。
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
server_name elk-stack.co;
|
||||
|
||||
auth_basic "Restricted Access";
|
||||
auth_basic_user_file /etc/nginx/.kibana-user;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:5601;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection 'upgrade';
|
||||
proxy_set_header Host $host;
|
||||
proxy_cache_bypass $http_upgrade;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
然后使用 `htpasswd` 命令创建一个新的基本认证文件。
|
||||
|
||||
```
|
||||
sudo htpasswd -c /etc/nginx/.kibana-user admin
|
||||
“输入你的密码”
|
||||
```
|
||||
|
||||
测试 Nginx 配置,确保没有错误。 然后设定 Nginx 开机启动并启动 Nginx。
|
||||
|
||||
```
|
||||
nginx -t
|
||||
systemctl enable nginx
|
||||
systemctl start nginx
|
||||
```
|
||||
|
||||
![Add nginx virtual host configuration for Kibana Application] [14]
|
||||
|
||||
### 步骤 5 - 安装和配置 Logstash
|
||||
|
||||
在此步骤中,我们将安装 Logstash,并将其配置为:从配置了 filebeat 的 logstash 客户端里集中化服务器的日志,然后过滤和转换 Syslog 数据,并将其移动到存储中心(Elasticsearch)中。
|
||||
|
||||
下载 Logstash 并使用 rpm 进行安装。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.1.1.rpm
|
||||
rpm -ivh logstash-5.1.1.rpm
|
||||
```
|
||||
|
||||
生成新的 SSL 证书文件,以便客户端可以识别 elastic 服务端。
|
||||
|
||||
进入 `tls` 目录并编辑 `openssl.cnf` 文件。
|
||||
|
||||
```
|
||||
cd /etc/pki/tls
|
||||
vim openssl.cnf
|
||||
```
|
||||
|
||||
在 `[v3_ca]` 部分添加服务器标识。
|
||||
|
||||
```
|
||||
[ v3_ca ]
|
||||
|
||||
# Server IP Address
|
||||
subjectAltName = IP: 10.0.15.10
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
使用 `openssl` 命令生成证书文件。
|
||||
|
||||
```
|
||||
openssl req -config /etc/pki/tls/openssl.cnf -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout /etc/pki/tls/private/logstash-forwarder.key -out /etc/pki/tls/certs/logstash-forwarder.crt
|
||||
```
|
||||
|
||||
证书文件可以在 `/etc/pki/tls/certs/` 和 `/etc/pki/tls/private/` 目录中找到。
|
||||
|
||||
接下来,我们会为 Logstash 创建新的配置文件。创建一个新的 `filebeat-input.conf` 文件来为 filebeat 配置日志源,然后创建一个 `syslog-filter.conf` 配置文件来处理 syslog,再创建一个 `output-elasticsearch.conf` 文件来定义输出日志数据到 Elasticsearch。
|
||||
|
||||
转到 logstash 配置目录,并在 `conf.d` 子目录中创建新的配置文件。
|
||||
|
||||
```
|
||||
cd /etc/logstash/
|
||||
vim conf.d/filebeat-input.conf
|
||||
```
|
||||
|
||||
输入配置,粘贴以下配置:
|
||||
|
||||
```
|
||||
input {
|
||||
beats {
|
||||
port => 5443
|
||||
ssl => true
|
||||
ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
|
||||
ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
创建 `syslog-filter.conf` 文件。
|
||||
|
||||
```
|
||||
vim conf.d/syslog-filter.conf
|
||||
```
|
||||
|
||||
粘贴以下配置:
|
||||
|
||||
```
|
||||
filter {
|
||||
if [type] == "syslog" {
|
||||
grok {
|
||||
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
|
||||
add_field => [ "received_at", "%{@timestamp}" ]
|
||||
add_field => [ "received_from", "%{host}" ]
|
||||
}
|
||||
date {
|
||||
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们使用名为 `grok` 的过滤器插件来解析 syslog 文件。
|
||||
|
||||
保存并退出。
|
||||
|
||||
创建输出配置文件 `output-elasticsearch.conf`。
|
||||
|
||||
```
|
||||
vim conf.d/output-elasticsearch.conf
|
||||
```
|
||||
|
||||
粘贴以下配置:
|
||||
|
||||
```
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"]
|
||||
hosts => "localhost:9200"
|
||||
manage_template => false
|
||||
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
|
||||
document_type => "%{[@metadata][type]}"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
最后,将 logstash 设定为开机启动并且启动服务。
|
||||
|
||||
```
|
||||
sudo systemctl enable logstash
|
||||
sudo systemctl start logstash
|
||||
```
|
||||
|
||||
![Logstash started on port 5443 with SSL Connection] [15]
|
||||
|
||||
### 步骤 6 - 在 CentOS 客户端上安装并配置 Filebeat
|
||||
|
||||
Beat 作为数据发送人的角色,是一种可以安装在客户端节点上的轻量级代理,将大量数据从客户机发送到 Logstash 或 Elasticsearch 服务器。有 4 种 beat,`Filebeat` 用于发送“日志文件”,`Metricbeat` 用于发送“指标”,`Packetbeat` 用于发送“网络数据”,`Winlogbeat` 用于发送 Windows 客户端的“事件日志”。
|
||||
|
||||
在本教程中,我将向您展示如何安装和配置 `Filebeat`,通过 SSL 连接将数据日志文件传输到 Logstash 服务器。
|
||||
|
||||
登录到客户端1的服务器上。 然后将证书文件从 elastic 服务器复制到客户端1的服务器上。
|
||||
|
||||
```
|
||||
ssh root@client1IP
|
||||
```
|
||||
|
||||
使用 `scp` 命令拷贝证书文件。
|
||||
|
||||
```
|
||||
scp root@elk-serverIP:~/logstash-forwarder.crt .
|
||||
输入 elk-server 的密码
|
||||
```
|
||||
|
||||
创建一个新的目录,将证书移动到这个目录中。
|
||||
|
||||
```
|
||||
sudo mkdir -p /etc/pki/tls/certs/
|
||||
mv ~/logstash-forwarder.crt /etc/pki/tls/certs/
|
||||
```
|
||||
|
||||
接下来,在客户端 1 服务器上导入 elastic 密钥。
|
||||
|
||||
```
|
||||
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
```
|
||||
|
||||
下载 Filebeat 并且用 `rpm` 命令安装。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.1.1-x86_64.rpm
|
||||
rpm -ivh filebeat-5.1.1-x86_64.rpm
|
||||
```
|
||||
|
||||
Filebeat 已经安装好了,请转到配置目录并编辑 `filebeat.yml` 文件。
|
||||
|
||||
```
|
||||
cd /etc/filebeat/
|
||||
vim filebeat.yml
|
||||
```
|
||||
|
||||
在第 21 行的路径部分,添加新的日志文件。 我们将创建两个文件,记录 ssh 活动的 `/var/log/secure` 文件 ,以及服务器日志 `/var/log/messages` 。
|
||||
|
||||
```
|
||||
paths:
|
||||
- /var/log/secure
|
||||
- /var/log/messages
|
||||
```
|
||||
|
||||
在第 26 行添加一个新配置来定义 syslog 类型的文件。
|
||||
|
||||
```
|
||||
document-type: syslog
|
||||
```
|
||||
|
||||
Filebeat 默认使用 Elasticsearch 作为输出目标。 在本教程中,我们将其更改为 Logshtash。 在 83 行和 85 行添加注释来禁用 Elasticsearch 输出。
|
||||
|
||||
禁用 Elasticsearch 输出:
|
||||
|
||||
```
|
||||
#-------------------------- Elasticsearch output ------------------------------
|
||||
#output.elasticsearch:
|
||||
# Array of hosts to connect to.
|
||||
# hosts: ["localhost:9200"]
|
||||
```
|
||||
|
||||
现在添加新的 logstash 输出配置。 去掉 logstash 输出配置的注释,并将所有值更改为下面配置中的值。
|
||||
|
||||
```
|
||||
output.logstash:
|
||||
# The Logstash hosts
|
||||
hosts: ["10.0.15.10:5443"]
|
||||
bulk_max_size: 1024
|
||||
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
|
||||
template.name: "filebeat"
|
||||
template.path: "filebeat.template.json"
|
||||
template.overwrite: false
|
||||
```
|
||||
|
||||
保存文件并退出 vim。
|
||||
|
||||
将 Filebeat 设定为开机启动并启动。
|
||||
|
||||
```
|
||||
sudo systemctl enable filebeat
|
||||
sudo systemctl start filebeat
|
||||
```
|
||||
|
||||
### 步骤 7 - 在 Ubuntu 客户端上安装并配置 Filebeat
|
||||
|
||||
使用 `ssh` 连接到服务器。
|
||||
|
||||
```
|
||||
ssh root@ubuntu-clientIP
|
||||
```
|
||||
|
||||
使用 `scp` 命令拷贝证书文件。
|
||||
|
||||
```
|
||||
scp root@elk-serverIP:~/logstash-forwarder.crt .
|
||||
```
|
||||
|
||||
创建一个新的目录,将证书移动到这个目录中。
|
||||
|
||||
```
|
||||
sudo mkdir -p /etc/pki/tls/certs/
|
||||
mv ~/logstash-forwarder.crt /etc/pki/tls/certs/
|
||||
```
|
||||
|
||||
在服务器上导入 elastic 密钥。
|
||||
|
||||
```
|
||||
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
|
||||
```
|
||||
|
||||
下载 Filebeat .deb 包并且使用 `dpkg` 命令进行安装。
|
||||
|
||||
```
|
||||
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.1.1-amd64.deb
|
||||
dpkg -i filebeat-5.1.1-amd64.deb
|
||||
```
|
||||
|
||||
转到配置目录并编辑 `filebeat.yml` 文件。
|
||||
|
||||
```
|
||||
cd /etc/filebeat/
|
||||
vim filebeat.yml
|
||||
```
|
||||
|
||||
在路径配置部分添加新的日志文件路径。
|
||||
|
||||
```
|
||||
paths:
|
||||
- /var/log/auth.log
|
||||
- /var/log/syslog
|
||||
```
|
||||
|
||||
设定文档类型为 `syslog` 。
|
||||
|
||||
```
|
||||
document-type: syslog
|
||||
```
|
||||
|
||||
将下列几行注释掉,禁用输出到 Elasticsearch。
|
||||
|
||||
```
|
||||
#-------------------------- Elasticsearch output ------------------------------
|
||||
#output.elasticsearch:
|
||||
# Array of hosts to connect to.
|
||||
# hosts: ["localhost:9200"]
|
||||
```
|
||||
|
||||
启用 logstash 输出,去掉以下配置的注释并且按照如下所示更改值。
|
||||
|
||||
```
|
||||
output.logstash:
|
||||
# The Logstash hosts
|
||||
hosts: ["10.0.15.10:5443"]
|
||||
bulk_max_size: 1024
|
||||
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
|
||||
template.name: "filebeat"
|
||||
template.path: "filebeat.template.json"
|
||||
template.overwrite: false
|
||||
```
|
||||
|
||||
保存并退出 vim。
|
||||
|
||||
将 Filebeat 设定为开机启动并启动。
|
||||
|
||||
```
|
||||
sudo systemctl enable filebeat
|
||||
sudo systemctl start filebeat
|
||||
```
|
||||
|
||||
检查服务状态:
|
||||
|
||||
```
|
||||
systemctl status filebeat
|
||||
```
|
||||
|
||||
![Filebeat is running on the client Ubuntu] [16]
|
||||
|
||||
### 步骤 8 - 测试
|
||||
|
||||
打开您的网络浏览器,并访问您在 Nginx 中配置的 elastic stack 域名,我的是“elk-stack.co”。 使用管理员密码登录,然后按 Enter 键登录 Kibana 仪表盘。
|
||||
|
||||
![Login to the Kibana Dashboard with Basic Auth] [17]
|
||||
|
||||
创建一个新的默认索引 `filebeat-*`,然后点击“创建”按钮。
|
||||
|
||||
![Create First index filebeat for Kibana] [18]
|
||||
|
||||
默认索引已创建。 如果 elastic stack 上有多个 beat,您可以在“星形”按钮上点击一下即可配置默认 beat。
|
||||
|
||||
![Filebeat index as default index on Kibana Dashboard] [19]
|
||||
|
||||
转到 “发现” 菜单,您就可以看到 elk-client1 和 elk-client2 服务器上的所有日志文件。
|
||||
|
||||
![Discover all Log Files from the Servers] [20]
|
||||
|
||||
来自 elk-client1 服务器日志中的无效 ssh 登录的 JSON 输出示例。
|
||||
|
||||
![JSON output for Failed SSH Login] [21]
|
||||
|
||||
使用其他的选项,你可以使用 Kibana 仪表盘做更多的事情。
|
||||
|
||||
Elastic Stack 已安装在 CentOS 7 服务器上。 Filebeat 已安装在 CentOS 7 和 Ubuntu 客户端上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/
|
||||
[1]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-nbspprepare-the-operating-system
|
||||
[2]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-java
|
||||
[3]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-elasticsearch
|
||||
[4]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-kibana-with-nginx
|
||||
[5]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-logstash
|
||||
[6]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-filebeat-on-the-centos-client
|
||||
[7]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-filebeat-on-the-ubuntu-client
|
||||
[8]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-testing
|
||||
[9]: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#reference
|
||||
[10]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/1.png
|
||||
[11]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/2.png
|
||||
[12]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/3.png
|
||||
[13]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/4.png
|
||||
[14]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/5.png
|
||||
[15]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/6.png
|
||||
[16]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/12.png
|
||||
[17]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/7.png
|
||||
[18]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/8.png
|
||||
[19]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/9.png
|
||||
[20]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/10.png
|
||||
[21]: https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/11.png
|
||||
@ -0,0 +1,82 @@
|
||||
让你的 Linux 远离黑客(三):问题回答
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Mike Guthrie 最近在 Linux 基金会的网络研讨会上回答了一些安全相关的问题。随时观看免费的研讨会。[Creative Commons Zero][1]
|
||||
|
||||
这个系列的[第一篇][6]和[第二篇][7]文章覆盖了 5 个让你的 Linux 远离黑客的最简单方法,并且知道他们是否已经进入。这一次,我将回答一些我最近在 Linux 基金会网络研讨会上收到的很好的安全性问题。[随时观看免费网络研讨会][8]。
|
||||
|
||||
### 如果系统自动使用私钥认证,如何存储密钥密码?
|
||||
|
||||
这个很难。这是我们一直在斗争的事情,特别是我们在做 “Red Team” 的时候,因为我们有些需要自动调用的东西。我使用 Expect,但我倾向于在这上面使用老方法。你需要编写脚本,是的,将密码存储在系统上不是那么简单的一件事,当你这么做时你需要加密它。
|
||||
|
||||
我的 Expect 脚本加密了存储的密码,然后解密,发送密码,并在完成后重新加密。我知道到这有一些缺陷,但它比使用无密码的密钥更好。
|
||||
|
||||
如果你有一个无密码的密钥,并且你确实需要使用它。我建议你尽量限制需要用它的用户。例如,如果你正在进行一些自动日志传输或自动化软件安装,则只给那些需要执行这些功能的程序权限。
|
||||
|
||||
你可以通过 SSH 运行命令,所以不要给它们一个 shell,使它只能运行那个命令就行,这样就能防止某人窃取了这个密钥并做其他事情。
|
||||
|
||||
### 你对密码管理器如 KeePass2 怎么看?
|
||||
|
||||
对我而言,密码管理器是一个非常好的目标。随着 GPU 破解的出现和 EC2 的一些破解能力,这些东西很容易就变成过去时。我一直在窃取这些密码库。
|
||||
|
||||
现在,我们在破解这些库的成功率是另外一件事。我们差不多有 10% 左右的破解成功率。如果人们不能为他们的密码库用一个安全的密码,那么我们就会进入并会获得丰硕成果。比不用要强,但是你仍需要保护好这些资产。如你保护其他密码一样保护好密码库。
|
||||
|
||||
### 你认为从安全的角度来看,除了创建具有更高密钥长度的主机密钥之外,创建一个新的 “Diffie-Hellman” 模数并限制 2048 位或更高值得么?
|
||||
|
||||
值得的。以前在 SSH 产品中存在弱点,你可以做到解密数据包流。有了它,你可以传递各种数据。作为一种加密机制,人们不假思索使用这种方式来传输文件和密码。使用健壮的加密并且改变你的密钥是很重要的。 我会轮换我的 SSH 密钥 - 这不像我的密码那么频繁,但是我每年会轮换一次。是的,这是一个麻烦,但它让我安心。我建议尽可能地使你的加密技术健壮。
|
||||
|
||||
### 使用完全随机的英语单词(大概 10 万个)作为密码合适么?
|
||||
|
||||
当然。我的密码实际上是一个完整的短语。它是带标点符号和大小写一句话。除此以外,我不再使用其他任何东西。
|
||||
|
||||
我是一个“你可以记住而不用写下来或者放在密码库的密码”的大大的支持者。一个你可以记住不必写下来的密码比你需要写下来的密码更安全。
|
||||
|
||||
使用短语或使用你可以记住的四个随机单词比那些需要经过几次转换的一串数字和字符的字符串更安全。我目前的密码长度大约是 200 个字符。这是我可以快速打出来并且记住的。
|
||||
|
||||
### 在物联网情景下对保护基于 Linux 的嵌入式系统有什么建议么?
|
||||
|
||||
物联网是一个新的领域,它是系统和安全的前沿,日新月异。现在,我尽量都保持离线。我不喜欢人们把我的灯光和冰箱搞乱。我故意不去购买支持联网的冰箱,因为我有朋友是黑客,我可不想我每天早上醒来都会看到那些不雅图片。封住它,锁住它,隔离它。
|
||||
|
||||
目前物联网设备的恶意软件取决于默认密码和后门,所以只需要对你所使用的设备进行一些研究,并确保没有其他人可以默认访问。然后确保这些设备的管理接口受到防火墙或其他此类设备的良好保护。
|
||||
|
||||
### 你可以提一个可以在 SMB 和大型环境中使用的防火墙/UTM(OS 或应用程序)么?
|
||||
|
||||
我使用 pfSense,它是 BSD 的衍生产品。我很喜欢它。它有很多模块,实际上现在它有商业支持,这对于小企业来说这是非常棒的。对于更大的设备、更大的环境,这取决于你有哪些管理员。
|
||||
|
||||
我一直都是 CheckPoint 管理员,但是 Palo Alto 也越来越受欢迎了。这些设备与小型企业或家庭使用很不同。我在各种小型网络中都使用 pfSense。
|
||||
|
||||
### 云服务有什么内在问题么?
|
||||
|
||||
并没有云,那只不过是其他人的电脑而已。云服务存在内在的问题。只知道谁访问了你的数据,你在上面放了什么。要知道当你向 Amazon 或 Google 或 Microsoft 上传某些东西时,你将不再完全控制它,并且该数据的隐私是有问题的。
|
||||
|
||||
### 要获得 OSCP 你建议需要准备些什么?
|
||||
|
||||
我现在准备通过这个认证。我的整个团队是这样。阅读他们的材料。记住, OSCP 将成为令人反感的安全基准。你一切都要使用 Kali。如果不这样做 - 如果你决定不使用 Kali,请确保仿照 Kali 实例安装所有的工具。
|
||||
|
||||
这将是一个基于工具的重要认证。这是一个很好的方式。看看一些名为“渗透测试框架”的内容,因为这将为你提供一个很好的测试流程,他们的实验室似乎是很棒的。这与我家里的实验室非常相似。
|
||||
|
||||
_[随时免费观看完整的网络研讨会][3]。查看这个系列的[第一篇][4]和[第二篇][5]文章获得 5 个简单的贴士来让你的 Linux 机器安全。_
|
||||
|
||||
_Mike Guthrie 为能源部工作,负责 “Red Team” 的工作和渗透测试。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/keep-hackers-outjpg
|
||||
[3]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[4]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
[6]:https://linux.cn/article-8189-1.html
|
||||
[7]:https://linux.cn/article-8338-1.html
|
||||
[8]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
@ -0,0 +1,140 @@
|
||||
在 Linux 上使用 Meld 比较文件夹
|
||||
============================================================
|
||||
|
||||
我们已经从一个新手的角度[了解][15]了 Meld (包括 Meld 的安装),我们也提及了一些 Meld 中级用户常用的小技巧。如果你有印象,在新手教程中,我们说过 Meld 可以比较文件和文件夹。已经讨论过怎么比较文件,今天,我们来看看 Meld 怎么比较文件夹。
|
||||
|
||||
**需要指出的是,本教程中的所有命令和例子都是在 Ubuntu 14.04 上测试的,使用的 Meld 版本为 3.14.2。**
|
||||
|
||||
### 用 Meld 比较文件夹
|
||||
|
||||
打开 Meld 工具,然后选择 <ruby>比较文件夹<rt>Directory comparison</rt></ruby> 选项来比较两个文件夹。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
选择你要比较的文件夹:
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
然后单击<ruby>比较<rt>Compare </rt></ruby>按钮,你会看到 Meld 像图中这样分成两栏比较目录,就像文件比较一样。
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
分栏会树形显示这些文件夹。你可以在上图中看到 —— 区别之处,不论是新建的还是被修改过的文件 —— 都会以不同的颜色高亮显示。
|
||||
|
||||
根据 Meld 的官方文档可以知道,在窗口中看到的每个不同的文件或文件夹都会被突出显示。这样就很容易看出这个文件/文件夹与另一个分栏中对应位置的文件/文件夹的区别。
|
||||
|
||||
下表是 Meld 网站上列出的在比较文件夹时突出显示的不同字体大小/颜色/背景等代表的含义。
|
||||
|
||||
|**状态** | **表现** | **含义** |
|
||||
| --- | --- | --- |
|
||||
| 相同 | 正常字体 | 比较的文件夹中所有文件/文件夹相同。|
|
||||
| 过滤后相同 | 斜体 | 文件夹中文件不同,但使用文本过滤器的话,文件是相同的。|
|
||||
| 修改过 | 蓝色粗体 | 比较的文件夹中这些文件不同。 |
|
||||
| 新建 | 绿色粗体 | 该文件/文件夹在这个目录中存在,但其它目录中没有。|
|
||||
| 缺失 | 置灰文本,删除线 | 该文件/文件夹在这个目录中不存在,在在其它某个目录中存在。 |
|
||||
| 错误 | 黄色背景的红色粗体 | 比较文件时发生错误,最常见错误原因是文件权限(例如,Meld 无法打开该文件)和文件名编码错误。 |
|
||||
|
||||
Meld 默认会列出比较文件夹中的所有内容,即使这些内容没有任何不同。当然,你也可以在工具栏中单击<ruby>相同<rt>Same</rt></ruby>按钮设置 Meld 不显示这些相同的文件/文件夹 —— 单击这个按钮使其不可用。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
下面是单击 <ruby>相同<rt>Same</rt></ruby> 按钮使其不可用的截图:
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
这样你会看到只显示了两个文件夹中不同的文件(新建的和修改过的)。同样,如果你单击 <ruby>新建<rt>New</rt></ruby> 按钮使其不可用,那么 Meld 就只会列出修改过的文件。所以,在比较文件夹时可以通过这些按钮自定义要显示的内容。
|
||||
|
||||
你可以使用工具窗口显示区的上下箭头来切换选择是显示新建的文件还是修改过的文件。要打开两个文件进行分栏比较,可以双击文件,或者单击箭头旁边的 <ruby>比较<rt>Compare</rt></ruby>按钮。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
**提示 1**:如果你仔细观察,就会看到 Meld 窗口的左边和右边有一些小条。这些条的目的是提供“简单的用颜色区分的比较结果”。对每个不同的文件/文件夹,条上就有一个小的颜色块。你可以单击每一个这样的小块跳到它对应的文件/文件夹。
|
||||
|
||||
**提示 2**:你总可以分栏比较文件,然后以你的方式合并不同的文件,假如你想要合并所有不同的文件/文件夹(就是说你想要一个特定的文件/文件夹与另一个完全相同),那么你可以用 <ruby>复制到左边<rt>Copy Left</rt></ruby>和 <ruby>复制到右边<rt>Copy Right</rt></ruby> 按钮:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
比如,你可以在左边的分栏中选择一个文件或文件夹,然后单击 <ruby>复制到右边<rt>Copy Right</rt></ruby> 按钮,使右边对应条目完全一样。
|
||||
|
||||
现在,在窗口的下拉菜单中找到 <ruby>过滤<rt>Filters </rt></ruby> 按钮,它就在 <ruby>相同<rt>Same</rt></ruby>、<ruby>新建<rt>New</rt></ruby> 和 <ruby>修改的<rt>Modified</rt></ruby> 这三个按钮下面。这里你可以选择或取消文件的类型,告知 Meld 在比较文件夹时是否显示这种类型的文件/文件夹。官方文档解释说菜单中的这个条目表示“执行文件夹比较时该类文件名不会被查看。”
|
||||
|
||||
该列表中条目包括备份文件,操作系统元数据,版本控制文件、二进制文件和多媒体文件。
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
前面提到的条目也可以通过这样的方式找到:_浏览->文件过滤_。你可以通过 _编辑->首选项->文件过滤_ 为这个条目增加新元素(也可以删除已经存在的元素)。
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
要新建一个过滤条件,你需要使用一组 shell 符号,下表列出了 Meld 支持的 shell 符号:
|
||||
|
||||
| **通配符** | **匹配** |
|
||||
| --- | --- |
|
||||
| * | 任何字符 (例如,零个或多个字符) |
|
||||
| ? | 一个字符 |
|
||||
| [abc] | 所列字符中的任何一个 |
|
||||
| [!abc] | 不在所列字符中的任何一个 |
|
||||
| {cat,dog} | “cat” 或 “dog” 中的一个 |
|
||||
|
||||
最重要的一点是 Meld 的文件名默认大小写敏感。也就是说,Meld 认为 readme 和 ReadMe 与 README 是不一样的文件。
|
||||
|
||||
幸运的是,你可以关掉 Meld 的大小写敏感。只需要打开 _浏览_ 菜单然后选择 <ruby>忽略文件名大小写<rt> Ignore Filename Case </rt></ruby> 选项。
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
### 结论
|
||||
|
||||
你是否觉得使用 Meld 比较文件夹很容易呢 —— 事实上,我认为它相当容易。只有新建一个文件过滤器会花点时间,但是这不意味着你没必要学习创建过滤器。显然,这取决于你的需求。
|
||||
|
||||
另外,你甚至可以用 Meld 比较三个文件夹。想要比较三个文件夹时,你可以通过单击 <ruby>三向比较<rt>3-way comparison</rt></ruby> 复选框。今天,我们不介绍怎么比较三个文件夹,但它肯定会出现在后续的教程中。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#compare-directories-using-meld
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-perform-directory-comparison-using-meld/#conclusion
|
||||
[3]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-button.png
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux/
|
||||
[5]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dir-comp-1.png
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-sel-dir-2.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-dircomp-begins-3.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-same-disabled.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-only-diff.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-compare-arrows.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-copy-right-left.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-filters.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-edit-filters-menu.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-3/big/meld-ignore-case.png
|
||||
[15]:https://linux.cn/article-8402-1.html
|
||||
@ -2,17 +2,18 @@
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
>Image by : [Pixabay][2]. Modified by Opensource.com. [CC BY-SA 4.0][3]
|
||||
|
||||
我认识的大部分人为了他们的日历、电子邮件、文件存储等,都会使用一些基于 Web 的应用。但是,如果像我这样,对隐私感到担忧、或者只是希望将你自己的数字生活简单化为一个你所控制的地方呢? [Cozy][4] 就是一个朝着健壮的自主云平台方向发展的项目。你可以从 [GitHub][5] 上获取 Cozy 的源代码,它采用 AGPL 3.0 协议。
|
||||
|
||||
### 安装
|
||||
|
||||
安装 Cozy 非常快捷简单,这里有多种平台的 [简单易懂安装指令][6]。在我的测试中,我使用 64 位的 Debian 8 系统。安装需要几分钟时间,然后你只需要到服务器的 IP 地址注册一个账号,就会加载并准备好默认的应用程序集。
|
||||
安装 Cozy 非常快捷简单,这里有多种平台的 [简单易懂的安装指令][6]。在我的测试中,我使用 64 位的 Debian 8 系统。安装需要几分钟时间,然后你只需要到服务器的 IP 地址注册一个账号,就会加载并准备好默认的应用程序集。
|
||||
|
||||
要注意的一点 - 安装假设没有正在运行任何其它 Web 服务,而且它会尝试安装 [Nginx web 服务器][7]。如果你的服务器已经有网站正在运行,配置可能就比较麻烦。我是在一个全新的 VPS(Virtual Private Server,虚拟个人服务器)上安装,因此比较简单。运行安装程序、启动 Nginx,然后你就可以访问云了。
|
||||
|
||||
Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序。有一些看起来非常有趣,例如 [Ghost 博客平台][9] 以及开源维基 [TiddlyWiki][10]。其中的目标,显然是允许把其它很多好的应用程序集成到这个平台。我认为你要看到很多其它流行的开源应用程序提供集成功能只是时间问题。此刻,已经支持 [Node.js][11],但是如何也支持其它应用层,你就可以看到很多其它很好的应用程序。
|
||||
Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序。有一些看起来非常有趣,例如 [Ghost 博客平台][9] 以及开源维基 [TiddlyWiki][10]。其目的,显然是允许把其它很多好的应用程序集成到这个平台。我认为你要看到很多其它流行的开源应用程序提供集成功能只是时间问题。此刻,已经支持 [Node.js][11],但是如果也支持其它应用层,你就可以看到很多其它很好的应用程序。
|
||||
|
||||
其中可能的一个功能是从安卓设备中使用免费的安卓应用程序访问你的信息。当前还没有 iOS 应用,但有计划要解决这个问题。
|
||||
|
||||
@ -20,27 +21,27 @@ Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序
|
||||
|
||||

|
||||
|
||||
主要 Cozy 界面
|
||||
*主要 Cozy 界面*
|
||||
|
||||
### 文件
|
||||
|
||||
和很多分支一样,我使用 [Dropbox][12] 进行文件存储。事实上,由于我有很多东西需要存储,我需要花钱买 DropBox Pro。对我来说,如果它有我想要的功能,那么把我的文件移动到 Cozy 能为我节省很多开销。
|
||||
|
||||
我希望我能说这是真的,我确实做到了。我被 Cozy 应用程序内建的基于 web 的文件上传和文件管理工具所惊讶。拖拽功能正如你期望的那样,界面也很干净整洁。我在上传事例文件和目录、随处跳转、移动、删除以及重命名文件时都没有遇到问题。
|
||||
我希望如此,而它真的可以。我被 Cozy 应用程序内建的基于 web 的文件上传和文件管理工具所惊讶。拖拽功能正如你期望的那样,界面也很干净整洁。我在上传事例文件和目录、随处跳转、移动、删除以及重命名文件时都没有遇到问题。
|
||||
|
||||
如果你想要的就是基于 web 的云文件存储,那么你做到了。对我来说,它缺失的是 DropBox 具有的选择性文件目录同步功能。在 DropBox 中,如果你拖拽一个文件到目录中,它就会被拷贝到云,几分钟后该文件在你所有同步设备中都可以看到。实际上,[Cozy 正在研发该功能][13],但此时它还处于 beta 版,而且只支持 Linux 客户端。另外,我有一个称为 [Download to Dropbox][15] 的 [Chrome][14] 扩展,我时不时用它抓取图片和其它内容,但当前 Cozy 中还没有类似的工具。
|
||||
如果你想要的就是基于 web 的云文件存储,那么你已经有了。对我来说,它缺失的是 DropBox 具有的选择性的文件目录同步功能。在 DropBox 中,如果你拖拽一个文件到目录中,它就会被拷贝到云,几分钟后该文件在你所有同步设备中都可以看到。实际上,[Cozy 正在研发该功能][13],但此时它还处于 beta 版,而且只支持 Linux 客户端。另外,我有一个称为 [Download to Dropbox][15] 的 [Chrome][14] 扩展,我时不时用它抓取图片和其它内容,但当前 Cozy 中还没有类似的工具。
|
||||
|
||||

|
||||
|
||||
文件管理界面
|
||||
*文件管理界面*
|
||||
|
||||
### 从 Google 导入数据
|
||||
|
||||
如果你正在使用 Google 日历和联系人,使用 Cozy 安装的应用程序很轻易的就可以导入它们。当你授权访问 Google 时,会给你一个 API 密钥,把它粘贴到 Cozy,它就会迅速高效地进行复制。两种情况下,内容都会被打上“从 Google 导入”的标签。对于我混乱的联系人,这可能是件好事情,因为它使得我有机会重新整理,把它们重新标记为更有意义的类别。“Google Calendar” 中所有的事件都导入了,但是我注意到其中一些事件的时间不对,可能是由于两端时区设置的影响。
|
||||
如果你正在使用 Google 日历和联系人,使用 Cozy 安装的应用程序很轻易的就可以导入它们。当你授权对 Google 的访问时,会给你一个 API 密钥,把它粘贴到 Cozy,它就会迅速高效地进行复制。两种情况下,内容都会被打上“从 Google 导入”的标签。对于我混乱的联系人,这可能是件好事情,因为它使得我有机会重新整理,把它们重新标记为更有意义的类别。“Google Calendar” 中所有的事件都导入了,但是我注意到其中一些事件的时间不对,可能是由于两端时区设置的影响。
|
||||
|
||||
### 联系人
|
||||
|
||||
联系人正如你期望的那样,界面也很像 Google 联系人。尽管如此,还是有一些不好的地方。和你(例如)智能手机的同步通过 [CardDAV][16] 完成,这是用于共享联系人数据的标准协议,但安卓手机并不原生支持该技术。为了把你的联系人同步到安卓设备,你需要在你的手机上安装一个应用。这对我来说是个很大的打击,因为我已经有很多类似这样的旧应用程序了(例如 work mail、Gmail以及其它 mail,我的天),我并不想安装一个不能和我智能手机原生联系人应用程序同步的软件。如果你正在使用 iPhone,你直接就能使用 CradDAV。
|
||||
联系人功能正如你期望的那样,界面也很像 Google 联系人。尽管如此,还是有一些不好的地方。例如,和你的智能手机的同步是通过 [CardDAV][16] 完成的,这是用于共享联系人数据的标准协议,但安卓手机并不原生支持该技术。为了把你的联系人同步到安卓设备,你需要在你的手机上安装一个应用。这对我来说是个很大的打击,因为我已经有很多类似这样的古怪应用程序了(例如 工作的邮件、Gmail 以及其它邮件,我的天),我并不想安装一个不能和我智能手机原生联系人应用程序同步的软件。如果你正在使用 iPhone,你直接就能使用 CradDAV。
|
||||
|
||||
### 日历
|
||||
|
||||
@ -48,15 +49,15 @@ Cozy 还有一个 [应用商店][8],你可以从中下载额外的应用程序
|
||||
|
||||
### 照片
|
||||
|
||||
照片应用让我印象深刻,它从文件应用程序借鉴了很多东西。你甚至可以把一个其它应用程序的照片文件添加到相册,或者直接通过拖拽上传。不幸的是,一旦上传后,我没有找到任何重拍和编辑照片的方法。你只能把它们从相册中删除。应用有一个通过令牌链接进行分享的工具,而且你可以指定一个或多个联系人。系统会给这些联系人发送邀请他们查看相册的电子邮件。当然还有很多比这个有更丰富功能的相册应用,但在 Cozy 平台中这算是一个好的起点。
|
||||
照片应用让我印象深刻,它从文件应用程序借鉴了很多东西。你甚至可以把一个其它应用程序的照片文件添加到相册,或者直接通过拖拽上传。不幸的是,一旦上传后,我没有找到任何重新排序和编辑照片的方法。你只能把它们从相册中删除。应用有一个通过令牌链接进行分享的工具,而且你可以指定一个或多个联系人。系统会给这些联系人发送邀请他们查看相册的电子邮件。当然还有很多比这个有更丰富功能的相册应用,但在 Cozy 平台中这算是一个好的起点。
|
||||
|
||||

|
||||
|
||||
Photos 界面
|
||||
*Photos 界面*
|
||||
|
||||
### 总结
|
||||
|
||||
Cozy 目标远大。他们尝试搭建你能部署任意你想要的基于云的服务的平台。它已经到了黄金时段吗?我并不认为。对于一些重度用户来说我之前提到的一些问题很严重,而且还没有 iOS 应用,这可能阻碍用户使用它。不管怎样,继续关注吧 - 随着研发的继续,Cozy 有一家代替很多应用程序的潜能。
|
||||
Cozy 目标远大。他们尝试搭建一个你能部署任意你想要的基于云服务的平台。它已经到了成熟期吗?我并不认为。对于一些重度用户来说我之前提到的一些问题很严重,而且还没有 iOS 应用,这可能阻碍用户使用它。不管怎样,继续关注吧 - 随着研发的继续,Cozy 有一家代替很多应用程序的潜能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -70,7 +71,7 @@ via: https://opensource.com/article/17/2/cozy-personal-cloud
|
||||
|
||||
作者:[D Ruth Bavousett][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
OpenContrail:一个 OpenStack 生态中的重要工具
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
*OpenContrail 是用于 OpenStack 云计算平台的 SDN 平台,它正在成为管理员需要具备的技能的重要工具。*
|
||||
|
||||
[Creative Commons Zero] [1] Pixabay
|
||||
|
||||
整个 2016 年,软件定义网络(SDN)迅速发展,开源和云计算领域的众多参与者正帮助其获得增长。结合这一趋势,用在 OpenStack 云计算平台上的流行的 SDN 平台 [OpenContrail][3] 正成为许多管理员需要具备的技能的重要工具。
|
||||
|
||||
正如管理员和开发人员在 OpenStack 生态系统中围绕着诸如 Ceph 等重要工具提升技能一样,他们将需要拥抱 OpenContrail,它是由 Apache 软件基金会全面开源并管理的软件。
|
||||
|
||||
考虑到这些,OpenStack 领域中最活跃的公司之一 Mirantis 已经[宣布][4]对 OpenContrail 的提供商业支持和贡献。该公司提到:“添加了 OpenContrail 后,Mirantis 将会为与 OpenStack 一起使用的开源技术,包括用于存储的 Ceph、用于计算的 OpenStack/KVM、用于 SDN 的 OpenContrail 或 Neutron 提供一站式的支持。”
|
||||
|
||||
根据 Mirantis 公告,“OpenContrail 是一个使用基于标准协议构建的 Apache 2.0 许可项目,为网络虚拟化提供了所有必要的组件 - SDN 控制器、虚拟路由器、分析引擎和已发布的上层 API,它有一个可扩展 REST API 用于配置以及从系统收集操作和分析数据。作为规模化构建,OpenContrail 可以作为云基础设施的基础网络平台。”
|
||||
|
||||
有消息称 Mirantis [收购了 TCP Cloud][5],这是一家专门从事 OpenStack、OpenContrail 和 Kubernetes 管理服务的公司。Mirantis 将使用 TCP Cloud 的云架构持续交付技术来管理将在 Docker 容器中运行的 OpenContrail 控制面板。作为这项工作的一部分,Mirantis 也会一直致力于 OpenContrail。
|
||||
|
||||
OpenContrail 的许多贡献者正在与 Mirantis 紧密合作,他们特别注意了 Mirantis 将提供的支持计划。
|
||||
|
||||
“OpenContrail 是 OpenStack 社区中一个重要的项目,而 Mirantis 很好地容器化并提供商业支持。我们团队正在做的工作使 OpenContrail 能轻松地扩展并更新,并与 Mirantis OpenStack 的其余部分进行无缝滚动升级。 ” Mirantis 的工程师总监和 OpenContrail 咨询委员会主任 Jakub Pavlik 说:“商业支持也将使 Mirantis 能够使该项目与各种交换机兼容,从而为客户提供更多的硬件和软件选择。”
|
||||
|
||||
除了 OpenContrail 的商业支持外,我们很可能还会看到 Mirantis 为那些想要学习如何利用它的云管理员和开发人员提供的教育服务。Mirantis 已经以其 [OpenStack 培训][6]课程而闻名,并将 Ceph 纳入了培训课程中。
|
||||
|
||||
在 2016 年,SDN 种类快速演变,并且对许多部署 OpenStack 的组织也有意义。IDC 最近发布了 SDN 市场的[一项研究][7],预计从 2014 年到 2020 年 SDN 市场的年均复合增长率为 53.9%,届时市场价值将达到 125 亿美元。此外,“Technology Trends 2016” 报告将 SDN 列为组织最佳的技术投资之一。
|
||||
|
||||
IDC 网络基础设施总裁 [Rohit Mehra][8] 说:“云计算和第三方平台推动了 SDN 的需求,它将在 2020 年代表一个价值超过 125 亿美元的市场。丝毫不用奇怪的是 SDN 的价值将越来越多地渗透到网络虚拟化软件和 SDN 应用中,包括虚拟化网络和安全服务。大型企业在数据中心中实现 SDN 的价值,但它们最终将会认识到其在横跨分支机构和校园网络的广域网中的广泛应用。”
|
||||
|
||||
同时,Linux 基金会最近[宣布][9]发布了其 2016 年度报告[“开放云指导:当前趋势和开源项目”][10]。第三份年度报告全面介绍了开放云计算,并包含一个关于 SDN 的部分。
|
||||
|
||||
Linux 基金会还提供了[软件定义网络基础知识][11](LFS265),这是一个自定进度的 SDN 在线课程,另外作为 [Open Daylight][12] 项目的领导者,另一个重要的开源 SDN 平台正在迅速成长。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/open-networking-summit/2017/2/opencontrail-essential-tool-openstack-ecosystem
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/contrails-cloudjpg
|
||||
[3]:https://www.globenewswire.com/Tracker?data=brZ3aJVRyVHeFOyzJ1Dl4DMY3CsSV7XcYkwRyOcrw4rDHplSItUqHxXtWfs18mLsa8_bPzeN2EgZXWcQU8vchg==
|
||||
[4]:http://www.econotimes.com/Mirantis-Becomes-First-Vendor-to-Offer-Support-and-Managed-Services-for-OpenContrail-SDN-486228
|
||||
[5]:https://www.globenewswire.com/Tracker?data=Lv6LkvREFzGWgujrf1n6r_qmjSdu67-zdRAYt2itKQ6Fytomhfphuk5EbDNjNYtfgAsbnqI8H1dn_5kB5uOSmmSYY9XP2ibkrPw_wKi5JtnAyV43AjuR_epMmOUkZZ8QtFdkR33lTGDmN6O5B4xkwv7fENcDpm30nI2Og_YrYf0b4th8Yy4S47lKgITa7dz2bJpwpbCIzd7muk0BZ17vsEp0S3j4kQJnmYYYk5udOMA=
|
||||
[6]:https://training.mirantis.com/
|
||||
[7]:https://www.idc.com/getdoc.jsp?containerId=prUS41005016
|
||||
[8]:http://www.idc.com/getdoc.jsp?containerId=PRF003513
|
||||
[9]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[10]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/software-defined-networking-fundamentals
|
||||
[12]:https://www.opendaylight.org/
|
||||
@ -0,0 +1,198 @@
|
||||
lnav:Linux 下一个基于控制台的高级日志文件查看器
|
||||
============================================================
|
||||
|
||||
[LNAV][3](Log file Navigator)是 Linux 下一个基于控制台的高级日志文件查看器。它和其它文件查看器,例如 cat、more、tail 等,完成相同的任务,但有很多普通文件查看器没有的增强功能(尤其是它自带多种颜色和易于阅读的格式)。
|
||||
|
||||
它能在解压多个压缩日志文件(zip、gzip、bzip)的同时把它们合并到一起进行导航。基于消息的时间戳,`lnav` 能把多个日志文件合并到一个视图(Single Log Review),从而避免打开多个窗口。左边的颜色栏帮助显示消息所属的文件。
|
||||
|
||||
警告和错误的数量以(黄色和红色)高亮显示,因此我们能够很轻易地看到问题出现在哪里。它会自动加载新的日志行。
|
||||
|
||||
它按照消息时间戳排序显示所有文件的日志消息。顶部和底部的状态栏会告诉你位于哪个日志文件。如果你想按特定的模式查找,只需要在搜索弹窗中输入就会即时显示。
|
||||
|
||||
内建的日志消息解析器会自动从每一行中发现和提取详细信息。
|
||||
|
||||
服务器日志是一个由服务器创建并经常更新、用于抓取特定服务和应用的所有活动信息的日志文件。当你的应用或者服务出现问题时这个文件就会非常有用。从日志文件中你可以获取所有关于该问题的信息,例如基于警告或者错误信息它什么时候开始表现不正常。
|
||||
|
||||
当你用一个普通文件查看器打开一个日志文件时,它会用纯文本格式显示所有信息(如果用更直白的话说的话:纯白——黑底白字),这样很难去发现和理解哪里有警告或错误信息。为了克服这种情况,快速找到警告和错误信息来解决问题, lnav 是一个入手可用的更好的解决方案。
|
||||
|
||||
大部分常见的 Linux 日志文件都放在 `/var/log/`。
|
||||
|
||||
**lnav 自动检测以下日志格式**
|
||||
|
||||
* Common Web Access Log format(普通 web 访问日志格式)
|
||||
* CUPS page_log
|
||||
* Syslog
|
||||
* Glog
|
||||
* VMware ESXi/vCenter 日志
|
||||
* dpkg.log
|
||||
* uwsgi
|
||||
* “Generic” – 以时间戳开始的任何消息
|
||||
* Strace
|
||||
* sudo
|
||||
* gzib & bizp
|
||||
|
||||
**lnav 高级功能**
|
||||
|
||||
* 单一日志视图 - 基于消息时间戳,所有日志文件内容都会被合并到一个单一视图
|
||||
* 自动日志格式检测 - `lnav` 支持大部分日志格式
|
||||
* 过滤器 - 能进行基于正则表达式的过滤
|
||||
* 时间线视图
|
||||
* 适宜打印视图(Pretty-Print)
|
||||
* 使用 SQL 查询日志
|
||||
* 自动数据抽取
|
||||
* 实时操作
|
||||
* 语法高亮
|
||||
* Tab 补全
|
||||
* 当你查看相同文件集时可以自动保存和恢复会话信息。
|
||||
* Headless 模式
|
||||
|
||||
### 如何在 Linux 中安装 lnav
|
||||
|
||||
大部分发行版(Debian、Ubuntu、Mint、Fedora、suse、openSUSE、Arch Linux、Manjaro、Mageia 等等)默认都有 `lnav` 软件包,在软件包管理器的帮助下,我们可以很轻易地从发行版官方仓库中安装它。对于 CentOS/RHEL 我们需要启用 **[EPEL 仓库][1]**。
|
||||
|
||||
```
|
||||
[在 Debian/Ubuntu/LinuxMint 上安装 lnav]
|
||||
$ sudo apt-get install lnav
|
||||
|
||||
[在 RHEL/CentOS 上安装 lnav]
|
||||
$ sudo yum install lnav
|
||||
|
||||
[在 Fedora 上安装 lnav]
|
||||
$ sudo dnf install lnav
|
||||
|
||||
[在 openSUSE 上安装 lnav]
|
||||
$ sudo zypper install lnav
|
||||
|
||||
[在 Mageia 上安装 lnav]
|
||||
$ sudo urpmi lnav
|
||||
|
||||
[在基于 Arch Linux 的系统上安装 lnav]
|
||||
$ yaourt -S lnav
|
||||
```
|
||||
|
||||
如果你的发行版没有 `lnav` 软件包,别担心,开发者提供了 `.rpm` 和 `.deb` 安装包,因此我们可以轻易安装。确保你从 [开发者 github 页面][4] 下载最新版本的安装包。
|
||||
|
||||
```
|
||||
[在 Debian/Ubuntu/LinuxMint 上安装 lnav]
|
||||
$ sudo wget https://github.com/tstack/lnav/releases/download/v0.8.1/lnav_0.8.1_amd64.deb
|
||||
$ sudo dpkg -i lnav_0.8.1_amd64.deb
|
||||
|
||||
[在 RHEL/CentOS 上安装 lnav]
|
||||
$ sudo yum install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[在 Fedora 上安装 lnav]
|
||||
$ sudo dnf install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[在 openSUSE 上安装 lnav]
|
||||
$ sudo zypper install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[在 Mageia 上安装 lnav]
|
||||
$ sudo rpm -ivh https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
```
|
||||
|
||||
### 不带参数运行 lnav
|
||||
|
||||
默认情况下你不带参数运行 `lnav` 时它会打开 `syslog` 文件。
|
||||
|
||||
```
|
||||
# lnav
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
### 使用 lnav 查看特定日志文件
|
||||
|
||||
要用 `lnav` 查看特定的日志文件,在 `lnav` 命令后面添加日志文件路径。例如我们想看 `/var/log/dpkg.log` 日志文件。
|
||||
|
||||
```
|
||||
# lnav /var/log/dpkg.log
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
### 用 lnav 查看多个日志文件
|
||||
|
||||
要用 `lnav` 查看多个日志文件,在 lnav 命令后面逐个添加日志文件路径,用一个空格隔开。例如我们想查看 `/var/log/dpkg.log` 和 `/var/log/kern.log` 日志文件。
|
||||
|
||||
左边的颜色栏帮助显示消息所属的文件。另外顶部状态栏还会显示当前日志文件的名称。为了显示多个日志文件,大部分应用经常会打开多个窗口、或者在窗口中水平或竖直切分,但 `lnav` 使用不同的方式(它基于日期组合在同一个窗口显示多个日志文件)。
|
||||
|
||||
```
|
||||
# lnav /var/log/dpkg.log /var/log/kern.log
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
### 使用 lnav 查看压缩的日志文件
|
||||
|
||||
要查看并同时解压被压缩的日志文件(zip、gzip、bzip),在 `lnav` 命令后面添加 `-r` 选项。
|
||||
|
||||
```
|
||||
# lnav -r /var/log/Xorg.0.log.old.gz
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
### 直方图视图
|
||||
|
||||
首先运行 `lnav` 然后按 `i` 键切换到/出直方图视图。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
### 查看日志解析器结果
|
||||
|
||||
首先运行 `lnav` 然后按 `p` 键打开显示日志解析器结果。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 语法高亮
|
||||
|
||||
你可以搜索任何给定的字符串,它会在屏幕上高亮显示。首先运行 `lnav` 然后按 `/` 键并输入你想查找的字符串。为了测试,我搜索字符串 `Default`,看下面的截图。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
### Tab 补全
|
||||
|
||||
命令窗口支持大部分操作的 tab 补全。例如,在进行搜索时,你可以使用 tab 补全屏幕上显示的单词,而不需要复制粘贴。为了测试,我搜索字符串 `/var/log/Xorg`,看下面的截图。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/install-and-use-advanced-log-file-viewer-navigator-lnav-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[2]:http://www.2daygeek.com/author/magesh/
|
||||
[3]:http://lnav.org/
|
||||
[4]:https://github.com/tstack/lnav/releases
|
||||
[5]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-1.png
|
||||
[6]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-2.png
|
||||
[7]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-3.png
|
||||
[8]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-6.png
|
||||
[9]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-4.png
|
||||
[10]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-5.png
|
||||
[11]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-7.png
|
||||
[12]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-8.png
|
||||
@ -0,0 +1,292 @@
|
||||
史上最全的使用 gnome-screenshot 获取屏幕快照指南
|
||||
============================================================
|
||||
|
||||
在应用市场中有好几种屏幕截图工具,但其中大多数都是基于 GUI 的。如果你花时间在 linux 命令行上工作,而且正在寻找一款优秀的功能丰富的基于命令行的屏幕截图工具,你可能会想尝试 [gnome-screenshot][17]。在本教程中,我将使用易于理解的例子来解释这个实用程序。
|
||||
|
||||
请注意,本教程中提到的所有例子已经在 Ubuntu 16.04 LTS 上测试过,测试所使用的 gonme-screenshot 版本是 3.18.0。
|
||||
|
||||
### 关于 Gnome-screenshot
|
||||
|
||||
Gnome-screenshot 是一款 GNOME 工具,顾名思义,它是一款用来对整个屏幕、一个特定的窗口或者用户所定义一些其他区域进行捕获的工具。该工具提供了几个其他的功能,包括对所捕获的截图的边界进行美化的功能。
|
||||
|
||||
### Gnome-screenshot 安装
|
||||
|
||||
Ubuntu 系统上已经预安装了 gnome-screeshot 工具,但是如果你出于某些原因需要重新安装这款软件程序,你可以使用下面的命令来进行安装:
|
||||
|
||||
```
|
||||
sudo apt-get install gnome-screeshot
|
||||
```
|
||||
|
||||
一旦软件安装完成后,你可以使用下面的命令来启动它:
|
||||
|
||||
```
|
||||
gnome-screenshot
|
||||
```
|
||||
|
||||
### Gnome-screenshot 用法/特点
|
||||
|
||||
在这部分,我们将讨论如何使用 gnome-screenshot ,以及它提供的所有功能。
|
||||
|
||||
默认情况下,使用该工具且不带任何命令行选项时,就会抓取整个屏幕。
|
||||
|
||||
[
|
||||
|
||||
][18]
|
||||
|
||||
#### 捕获当前活动窗口
|
||||
|
||||
如何你需要的话,你可以使用 `-w` 选项限制到只对当前活动窗口截图。
|
||||
|
||||
```
|
||||
gnome-screenshot -w
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][19]
|
||||
|
||||
#### 窗口边框
|
||||
|
||||
默认情况下,这个程序会将它捕获的窗口的边框包含在内,尽管还有一个明确的命令行选项 `-b` 可以启用此功能(以防你在某处想使用它)。以下是如何使用这个程序的:
|
||||
|
||||
```
|
||||
gnome-screenshot -wb
|
||||
```
|
||||
|
||||
当然,你需要同时使用 `-w` 选项和 `-b` 选项,以便捕获的是当前活动的窗口(否则,`-b` 将没有作用)。
|
||||
|
||||
更重要的是,如果你需要的话,你也可以移除窗口的边框。可以使用 `-B` 选项来完成。下面是你可以如何使用这个选项的一个例子:
|
||||
|
||||
```
|
||||
gnome-screenshot -wB
|
||||
```
|
||||
|
||||
下面是例子的截图:
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
#### 添加效果到窗口边框
|
||||
|
||||
在 gnome-screenshot 工具的帮助下,您还可以向窗口边框添加各种效果。这可以使用 `--border-effect` 选项来做到。
|
||||
|
||||
你可以添加这款程序所提供的任何效果,比如 `shadow` 效果(在窗口添加阴影)、`bordor` 效果(在屏幕截图周围添加矩形区域)和 `vintage` 效果(使截图略微淡化,着色并在其周围添加矩形区域)。
|
||||
|
||||
```
|
||||
gnome-screenshot --border-effect=[EFFECT]
|
||||
```
|
||||
|
||||
例如,运行下面的命令添加 shadow 效果:
|
||||
|
||||
```
|
||||
gnome-screenshot –border-effect=shadow
|
||||
```
|
||||
|
||||
以下是 shadow 效果的示例快照:
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
请注意,上述屏幕截图主要集中在终端的一个角落,以便您清楚地看到阴影效果。
|
||||
|
||||
#### 对特定区域的截图
|
||||
|
||||
如何你需要,你还可以使用 gnome-screenshot 程序对你电脑屏幕的某一特定区域进行截图。这可以通过使用 `-a` 选项来完成。
|
||||
|
||||
```
|
||||
gnome-screenshot -a
|
||||
```
|
||||
|
||||
当上面的命令被运行后,你的鼠标指针将会变成 '+' 这个符号。在这种模式下,你可以按住鼠标左键移动鼠标来对某个特定区域截图。
|
||||
|
||||
这是一个示例截图,裁剪了我的终端窗口的一小部分。
|
||||
|
||||
[
|
||||
|
||||
][22]
|
||||
|
||||
#### 在截图中包含鼠标指针
|
||||
|
||||
默认情况下,每当你使用这个工具截图的时候,截的图中并不会包含鼠标指针。然而,这个程序是可以让你把指针包括进去的,你可以使用 `-p` 命令行选项做到。
|
||||
|
||||
```
|
||||
gnome-screenshot -p
|
||||
```
|
||||
|
||||
这是一个示例截图:
|
||||
|
||||
[
|
||||
|
||||
][23]
|
||||
|
||||
#### 延时截图
|
||||
|
||||
截图时你还可以引入时间延迟。要做到这,你不需要给 `--delay` 选项赋予一个以秒为单位的值。
|
||||
|
||||
```
|
||||
gnome-screenshot –delay=[SECONDS]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
gnome-screenshot --delay=5
|
||||
```
|
||||
|
||||
示例截图如下:
|
||||
|
||||
[
|
||||
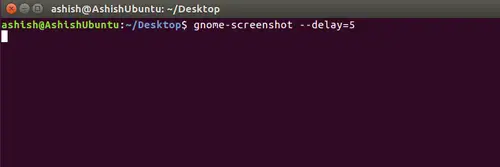
|
||||
][24]
|
||||
|
||||
#### 以交互模式运行这个工具
|
||||
|
||||
这个工具还允许你使用一个单独的 `-i` 选项来访问其所有功能。使用这个命令行选项,用户可以在运行这个命令时使用这个工具的一个或多个功能。
|
||||
|
||||
```
|
||||
gnome-screenshot -i
|
||||
```
|
||||
|
||||
示例截图如下:
|
||||
|
||||
[
|
||||
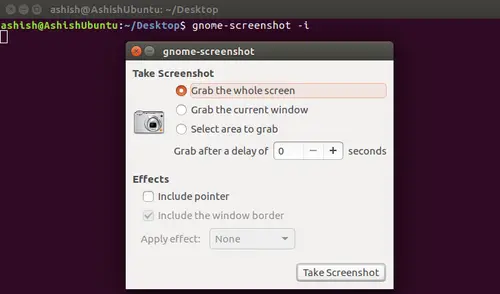
|
||||
][25]
|
||||
|
||||
你可以从上面的截图中看到,`-i` 选项提供了对很多功能的访问,比如截取整个屏幕、截取当前窗口、选择一个区域进行截图、延时选项和特效选项等都在交互模式里。
|
||||
|
||||
#### 直接保存你的截图
|
||||
|
||||
如果你需要的话,你可以直接将你截的图片从终端中保存到你当前的工作目录,这意味着,在这个程序运行后,它并不要求你为截取的图片输入一个文件名。这个功能可以使用 `--file` 命令行选项来获取,很明显,需要给它传递一个文件名。
|
||||
|
||||
```
|
||||
gnome-screenshot –file=[FILENAME]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
gnome-screenshot --file=ashish
|
||||
```
|
||||
|
||||
示例截图如下:
|
||||
|
||||
[
|
||||
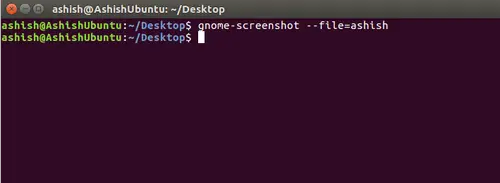
|
||||
][26]
|
||||
|
||||
#### 复制到剪切板
|
||||
|
||||
gnome-screenshot 也允许你把你截的图复制到剪切板。这可以通过使用 `-c` 命令行选项做到。
|
||||
|
||||
```
|
||||
gnome-screenshot -c
|
||||
```
|
||||
|
||||
[
|
||||
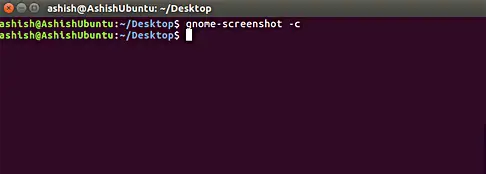
|
||||
][27]
|
||||
|
||||
在这个模式下,例如,你可以把复制的图直接粘贴到你的任何一个图片编辑器中(比如 GIMP)。
|
||||
|
||||
#### 多显示器情形下的截图
|
||||
|
||||
如果有多个显示器连接到你的系统,你想对某一个进行截图,那么你可以使用 `--then` 命令行选项。需要给这个选项一个显示器设备 ID 的值(需要被截图的显示器的 ID)。
|
||||
|
||||
```
|
||||
gnome-screenshot --display=[DISPLAY]
|
||||
```
|
||||
例如:
|
||||
|
||||
```
|
||||
gnome-screenshot --display=VGA-0
|
||||
```
|
||||
|
||||
在上面的例子中,VAG-0 是我正试图对其进行截图的显示器的 ID。为了找到你想对其进行截图的显示器的 ID,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
xrandr --query
|
||||
```
|
||||
|
||||
为了让你明白一些,在我的例子中这个命令产生了下面的输出:
|
||||
|
||||
```
|
||||
$ xrandr --query
|
||||
Screen 0: minimum 320 x 200, current 1366 x 768, maximum 8192 x 8192
|
||||
VGA-0 connected primary 1366x768+0+0 (normal left inverted right x axis y axis) 344mm x 194mm
|
||||
1366x768 59.8*+
|
||||
1024x768 75.1 75.0 60.0
|
||||
832x624 74.6
|
||||
800x600 75.0 60.3 56.2
|
||||
640x480 75.0 60.0
|
||||
720x400 70.1
|
||||
HDMI-0 disconnected (normal left inverted right x axis y axis)
|
||||
```
|
||||
|
||||
#### 自动化屏幕截图过程
|
||||
|
||||
正如我们之前讨论的,`-a` 命令行选项可以帮助我们对屏幕的某一个特定区域进行截图。然而,我们需要用鼠标手动选取这个区域。如果你想的话,你可以使用 gnome-screenshot 来自动化完成这个过程,但是在那种情形下,你将需要使用一个名为 `xdotol` 的工具,它可以模仿敲打键盘甚至是点击鼠标这些事件。
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
(gnome-screenshot -a &); sleep 0.1 && xdotool mousemove 100 100 mousedown 1 mousemove 400 400 mouseup 1
|
||||
```
|
||||
|
||||
`mousemove` 子命令自动把鼠标指针定位到明确的 `X` 坐标和 `Y` 坐标的位置(上面例子中是 100 和 100)。`mousedown` 子命令触发一个与点击执行相同操作的事件(因为我们想左击,所以我们使用了参数 1),然而 `mouseup` 子命令触发一个执行用户释放鼠标按钮的任务的事件。
|
||||
|
||||
所以总而言之,上面所示的 `xdotool` 命令做了一项本来需要使用鼠标手动执行对同一区域进行截图的工作。特别说明,该命令把鼠标指针定位到屏幕上坐标为 `100,100` 的位置并选择封闭区域,直到指针到达屏幕上坐标为 `400,400` 的位置。所选择的区域随之被 gnome-screenshot 捕获。
|
||||
|
||||
这是上述命令的截图:
|
||||
|
||||
[
|
||||
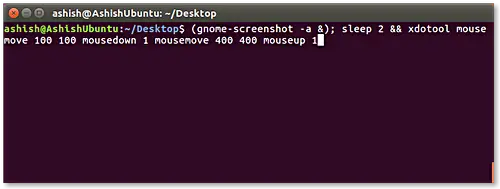
|
||||
][28]
|
||||
|
||||
这是输出的结果:
|
||||
|
||||
[
|
||||
|
||||
][29]
|
||||
|
||||
想获取更多关于 `xdotool` 的信息,[请到这来][30]。
|
||||
|
||||
#### 获取帮助
|
||||
|
||||
如果你有疑问或者你正面临一个与该命令行的其中某个选项有关的问题,那么你可以使用 --help、-? 或者 -h 选项来获取相关信息。
|
||||
|
||||
```
|
||||
gnome-screenshot -h
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
我推荐你至少使用一次这个程序,因为它不仅对初学者来说比较简单,而且还提供功能丰富的高级用法体验。动起手来,尝试一下吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
[17]:https://linux.die.net/man/1/gnome-screenshot
|
||||
[18]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/gnome-default.png
|
||||
[19]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/activewindow.png
|
||||
[20]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/removeborder.png
|
||||
[21]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/shadoweffect-new.png
|
||||
[22]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/area.png
|
||||
[23]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/includecursor.png
|
||||
[24]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/delay.png
|
||||
[25]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/interactive.png
|
||||
[26]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/ashish.png
|
||||
[27]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/copy.png
|
||||
[28]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/automatedcommand.png
|
||||
[29]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/outputxdo.png
|
||||
[30]:http://manpages.ubuntu.com/manpages/trusty/man1/xdotool.1.html
|
||||
@ -1,118 +1,119 @@
|
||||
OpenVAS - Vulnerability Assessment install on Kali Linux
|
||||
OpenVAS:Kali Linux 中的漏洞评估工具
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
本教程将介绍在 Kali Linux 中安装 OpenVAS 8.0 的过程。 OpenVAS 是一个可以自动执行网络安全审核和漏洞评估的开源[漏洞评估][6]程序。请注意,漏洞评估(Vulnerability Assessment)也称为 VA 并不是渗透测试(penetration test),渗透测试会进一步验证是否存在发现的漏洞,请参阅[什么是渗透测试][7]来对渗透测试的构成以及不同类型的安全测试有一个了解。
|
||||
|
||||
1. [What is Kali Linux?][1]
|
||||
2. [Updating Kali Linux][2]
|
||||
3. [Installing OpenVAS 8][3]
|
||||
4. [Start OpenVAS on Kali][4]
|
||||
### 什么是 Kali Linux?
|
||||
|
||||
This tutorial documents the process of installing OpenVAS 8.0 on Kali Linux rolling. OpenVAS is open source [vulnerability assessment][6] application that automates the process of performing network security audits and vulnerability assessments. Note, a vulnerability assessment also known as VA is not a penetration test, a penetration test goes a step further and validates the existence of a discovered vulnerability, see [what is penetration testing][7] for an overview of what pen testing consists of and the different types of security testing.
|
||||
Kali Linux 是 Linux 渗透测试分发版。它基于 Debian,并且预安装了许多常用的渗透测试工具,例如 Metasploit Framework (MSF)和其他通常在安全评估期间由渗透测试人员使用的命令行工具。
|
||||
|
||||
### What is Kali Linux?
|
||||
在大多数使用情况下,Kali 运行在虚拟机中,你可以在这里获取最新的 VMWare 或 Vbox 镜像:[https://www.offensive-security.com/kali-linux-vmware-virtualbox-image-download/][8] 。
|
||||
|
||||
Kali Linux is a Linux penetration testing distribution. It's Debian based and comes pre-installed with many commonly used penetration testing tools such as Metasploit Framework and other command line tools typically used by penetration testers during a security assessment.
|
||||
除非你有特殊的原因想要一个更小的虚拟机占用空间,否则请下载完整版本而不是 Kali light。 下载完成后,你需要解压文件并打开 vbox 或者 VMWare .vmx 文件,虚拟机启动后,默认帐号是 `root`/`toor`。请将 root 密码更改为安全的密码。
|
||||
|
||||
For most use cases Kali runs in a VM, you can grab the latest VMWare or Vbox image of Kali from here: [https://www.offensive-security.com/kali-linux-vmware-virtualbox-image-download/][8]
|
||||
或者,你可以下载 ISO 版本,并在裸机上执行 Kali 的安装。
|
||||
|
||||
Download the full version not Kali light, unless you have a specific reason for wanting a smaller virtual machine footprint. After the download finishes you will need to extract the contents and open the vbox or VMWare .vmx file, when the machine boots the default credentials are root / toor. Change the root password to a secure password.
|
||||
### 升级 Kali Linux
|
||||
|
||||
Alternatively, you can download the ISO version and perform an installation of Kali on the bare metal.
|
||||
完成安装后,为 Kail Linux 执行一次完整的升级。
|
||||
|
||||
### Updating Kali Linux
|
||||
|
||||
After installation, perform a full update of Kali Linux.
|
||||
|
||||
Updating Kali:
|
||||
升级 Kali:
|
||||
|
||||
```
|
||||
apt-get update && apt-get dist-upgrade -y
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
The update process might take some time to complete. Kali is now a rolling release meaning you can update to the current version from any version of Kali rolling. However, there are release numbers but these are point in time versions of Kali rolling for VMWare snapshots. You can update to the current stable release from any of the VMWare images.
|
||||
更新过程可能需要一些时间才能完成。Kali 目前是滚动更新,这意味着你可以从任何版本的 Kali 滚动更新到当前版本。然而它仍有发布号,但这些是针对特定 Kali 时间点版本的 VMWare 快照。你可以从任何 VMWare 镜像更新到当前的稳定版本。
|
||||
|
||||
After updating perform a reboot.
|
||||
更新完成后重新启动。
|
||||
|
||||
### Installing OpenVAS 8
|
||||
### 安装 OpenVAS 8
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
```
|
||||
apt-get install openvas
|
||||
|
||||
openvas-setup
|
||||
```
|
||||
|
||||
During installation you'll be prompted about redis, select the default option to run as a UNIX socket.
|
||||
在安装中,你会被询问关于 redis 的问题,选择默认选项来以 UNIX 套接字运行。
|
||||
|
||||
[
|
||||
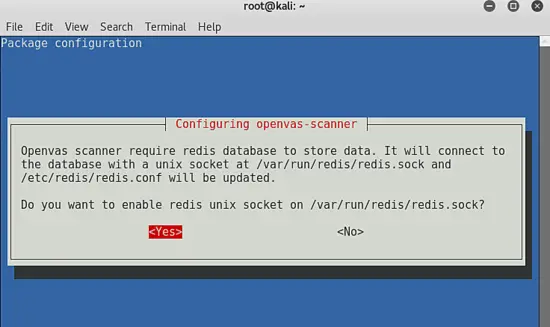
|
||||
][11]
|
||||
|
||||
Even on a fast connection openvas-setup takes a long time to download and update all the required CVE, SCAP definitions.
|
||||
即使是有快速的网络连接,openvas-setup 仍需要很长时间来下载和更新所有所需的 CVE、SCAP 定义。
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
Pay attention to the command output during openvas-setup, the password is generated during installation and printed to console near the end of the setup.
|
||||
请注意 openvas-setup 的命令输出,密码会在安装过程中生成,并在安装的最后在控制台中打印出来。
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
Verify openvas is running:
|
||||
验证 openvas 正在运行:
|
||||
|
||||
```
|
||||
netstat -tulpn
|
||||
```
|
||||
|
||||
[
|
||||
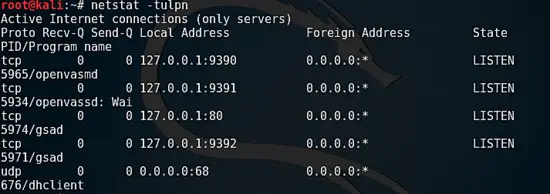
|
||||
][14]
|
||||
|
||||
### Start OpenVAS on Kali
|
||||
### 在 Kali 中运行 OpenVAS
|
||||
|
||||
To start the OpenVAS service on Kali run:
|
||||
要在 Kali 中启动 OpenVAS:
|
||||
|
||||
```
|
||||
openvas-start
|
||||
```
|
||||
|
||||
After installation, you should be able to access the OpenVAS web application at **https://127.0.0.1:9392**
|
||||
安装后,你应该可以通过 `https://127.0.0.1:9392` 访问 OpenVAS 的 web 程序了。
|
||||
|
||||
**[
|
||||
[
|
||||
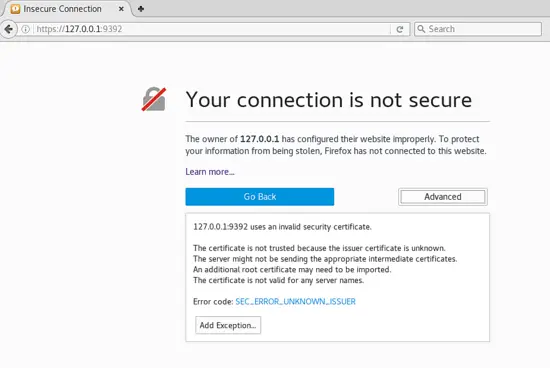
|
||||
][5]**
|
||||
][5]
|
||||
|
||||
Accept the self-signed certificate and login to the application using the credentials admin and the password displayed during openvas-setup.
|
||||
接受自签名证书,并使用 openvas-setup 输出的 admin 凭证和密码登录程序。
|
||||
|
||||
[
|
||||
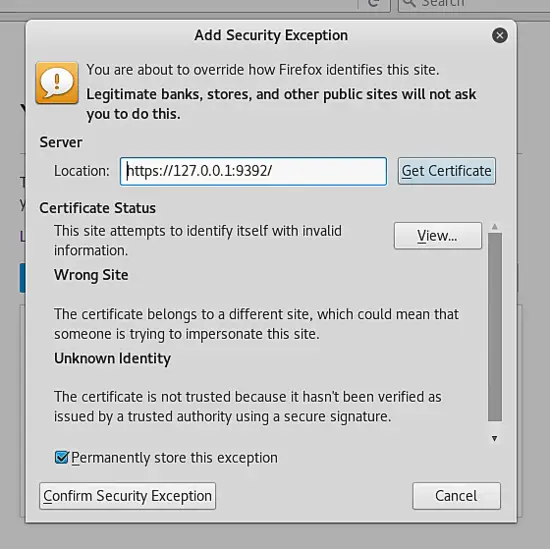
|
||||
][15]
|
||||
|
||||
After accepting the self-signed certificate, you should be presented with the login screen:
|
||||
接受自签名证书后,你应该可以看到登录界面了。
|
||||
|
||||
[
|
||||
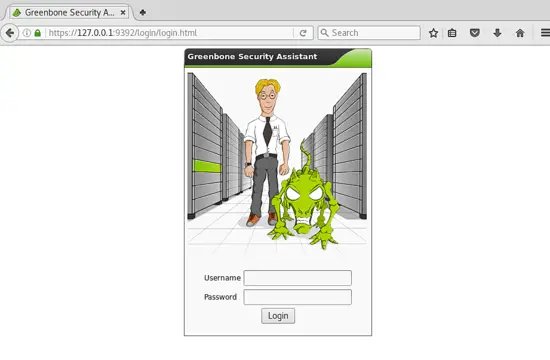
|
||||
][16]
|
||||
|
||||
After logging in you should be presented with the following screen:
|
||||
登录后,你应该可以看到下面的页面:
|
||||
|
||||
[
|
||||
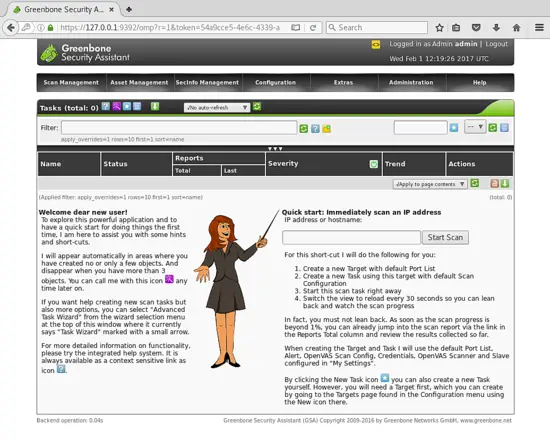
|
||||
][17]
|
||||
|
||||
From this point you should be able to configure your own vulnerability scans using the wizard.
|
||||
从此,你应该可以使用向导配置自己的漏洞扫描了。
|
||||
|
||||
It's recommended to read the documentation. Be aware of what a vulnerability assessment conductions (depending on configuration OpenVAS could attempt exploitation) and the traffic it will generate on a network as well as the DOS effect it can have on services / servers and hosts / devices on a network.
|
||||
我建议阅读文档。请注意漏洞评估导向(取决于 OpenVAS 可能尝试利用的配置)及其在网络上生成的流量以及网络上可能对服务/服务器和主机/设备产生的 DOS 影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/openvas-vulnerability-assessment-install-on-kali-linux/
|
||||
|
||||
作者:[KJS ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[KJS][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
在 PC 上尝试树莓派的 PIXEL OS
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片版权:树莓派基金会, CC BY-SA
|
||||
|
||||
在过去四年中,树莓派基金会非常努力地针对树莓派的硬件优化了 Debian 的移植版 Raspbian,包括创建新的教育软件、编程工具和更美观的桌面。
|
||||
|
||||
在(去年) 9 月份,我们发布了一个更新,介绍了树莓派新的桌面环境 PIXEL(Pi Improved Xwindows Environment,轻量级)。在圣诞节之前,我们[发布](https://linux.cn/article-8064-1.html)了一个在 x86 PC 上运行的操作系统版本,所以现在可以将它安装在 PC、Mac 或笔记本电脑上。
|
||||
|
||||

|
||||
|
||||
当然,像许多支持良好的 Linux 发行版一样,操作系统在旧的硬件上也能正常运行。 Raspbian 是让你几年前就丢弃的旧式 Windows 机器焕发新生的好方法。
|
||||
|
||||
[PIXEL ISO][13] 可从树莓派网站上下载,在 “[MagPi][14]” 杂志封面上也有赠送可启动的 Live DVD 。
|
||||
|
||||

|
||||
|
||||
为了消除想要学习计算机的人们的入门障碍,我们发布了树莓派的个人电脑操作系统。它比购买一块树莓派更便宜,因为它是免费的,你可以在现有的计算机上使用它。PIXEL 是我们一直想要的 Linux 桌面,我们希望它可供所有人使用。
|
||||
|
||||
### 由 Debian 提供支持
|
||||
|
||||
不构建在 Debian 之上的话,Raspbian 或 x86 PIXEL 发行版就都不会存在。 Debian 拥有庞大的可以从一个 apt 仓库中获得的免费开源软件、程序、游戏和其他工具。在树莓派中,你仅限运行为 [ARM][15] 芯片编译的软件包。然而,在 PC 镜像中,你可以在机器上运行的软件包的范围更广,因为 PC 中的 Intel 芯片有更多的支持。
|
||||
|
||||
 repository")
|
||||
|
||||
### PIXEL 包含什么
|
||||
|
||||
带有 PIXEL 的 Raspbian 和带有 PIXEL 的 Debian 都捆绑了大量的软件。Raspbian 自带:
|
||||
|
||||
* Python、Java、Scratch、Sonic Pi、Mathematica*、Node-RED 和 Sense HAT 仿真器的编程环境
|
||||
* LibreOffice 办公套件
|
||||
* Chromium(包含 Flash)和 Epiphany 网络浏览器
|
||||
* Minecraft:树莓派版(包括 Python API)*
|
||||
* 各种工具和实用程序
|
||||
|
||||
*由于许可证限制,本列表中唯一没有包含在 x86 版本中的程序是 Mathematica 和 Minecraft。
|
||||
|
||||

|
||||
|
||||
### 创建一个 PIXEL Live 盘
|
||||
|
||||
你可以下载 PIXEL ISO 并将其写入空白 DVD 或 USB 记忆棒中。 然后,你就可以从盘中启动你的电脑,这样你可以立刻看到 PIXEL 桌面。你可以浏览网页、打开编程环境或使用办公套件,而无需在计算机上安装任何内容。完成后,只需拿出 DVD 或 USB 驱动器,关闭计算机,再次重新启动计算机时,将会像以前一样重新启动到你平常的操作系统。
|
||||
|
||||
### 在虚拟机中运行 PIXEL
|
||||
|
||||
另外一种尝试 PIXEL 的方法是在像 VirtualBox 这样的虚拟机中安装它。
|
||||
|
||||

|
||||
|
||||
这允许你体验镜像而不用安装它,也可以在主操作系统里面的窗口中运行它,并访问 PIXEL 中的软件和工具。这也意味着你的会话会一直存在,而不是每次重新启动时从头开始,就像使用 Live 盘一样。
|
||||
|
||||
### 在 PC 中安装 PIXEL
|
||||
|
||||
如果你真的准备开始,你可以擦除旧的操作系统并将 PIXEL 安装在硬盘上。如果你想使用旧的闲置的笔记本电脑,这可能是个好主意。
|
||||
|
||||
### 用于教育的 PIXEL
|
||||
|
||||
许多学校在所有电脑上使用 Windows,并且对它们可以安装的软件进行严格的控制。这使得教师难以使用必要的软件工具和 IDE(集成开发环境)来教授编程技能。即使在线编程计划(如 Scratch 2)也可能被过于谨慎的网络过滤器阻止。在某些情况下,安装像 Python 这样的东西根本是不可能的。树莓派硬件通过提供包含教育软件的 SD 卡引导的小型廉价计算机来解决这个问题,学生可以连接到现有 PC 的显示器、鼠标和键盘上。
|
||||
|
||||
然而,PIXEL Live 光盘允许教师引导到装有能立即使用的编程语言和工具的系统中,所有这些都不需要安装权限。在课程结束时,他们可以安全关闭,使计算机恢复原状。这也是 Code Clubs、CoderDojos、青年俱乐部、Raspberry Jams 等等的一个方便的解决方案。
|
||||
|
||||
### 远程 GPIO
|
||||
|
||||
树莓派与传统台式 PC 区别的功能之一是 GPIO 引脚(通用输入/输出)引脚的存在,它允许你将现实世界中的电子元件和附加板连接设备上,这将开放一个新的世界,如业余项目、家庭自动化、连接的设备和物联网。
|
||||
|
||||
[GPIO Zero][16] Python 库的一个很棒的功能是通过在 PC 上写入一些简单的代码,然后在网络上控制树莓派的 GPIO 引脚。
|
||||
|
||||
远程 GPIO 可以从一台树莓派连接到另一台树莓派,或者从运行任何系统的 OS 的 PC 连接到树莓派上,但是,使用 PIXEL x86 的话所有需要的软件都是开箱即用的。参见 Josh 的[博文][17],并参考我的 [gist][18] 了解更多信息。
|
||||
|
||||
### 更多指南
|
||||
|
||||
[MagPi 的第 53 期][19]提供了一些试用和安装 PIXEL 的指南,包括使用带持久驱动的 Live 光盘来维护你的文件和应用程序。你可以购买一份,或免费下载 PDF 来了解更多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Nuttall - Ben Nuttall 是一名树莓派社区管理员。他除了为树莓派基金会工作外,他还对自由软件、数学、皮划艇、GitHub、Adventure Time 和 Futurama 等感兴趣。在 Twitter @ben_nuttall 上关注 Ben。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://twitter.com/ben_nuttall
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=811511740907261952
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=811511740907261952
|
||||
[4]:https://twitter.com/intent/like?tweet_id=811511740907261952
|
||||
[5]:https://twitter.com/ben_nuttall
|
||||
[6]:https://twitter.com/ben_nuttall/status/811511740907261952
|
||||
[7]:https://twitter.com/search?q=place%3A3bc1b6cfd27ef7f6
|
||||
[8]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[9]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[10]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[11]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[12]:https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc?rate=iqVrGV3EhwRuqh68sf6Zye6Y7VSpXRCUQoZV3sg-QJM
|
||||
[13]:http://downloads.raspberrypi.org/pixel_x86/images/pixel_x86-2016-12-13/
|
||||
[14]:https://www.raspberrypi.org/magpi/issues/53/
|
||||
[15]:https://en.wikipedia.org/wiki/ARM_Holdings
|
||||
[16]:http://gpiozero.readthedocs.io/
|
||||
[17]:http://www.allaboutcode.co.uk/single-post/2016/12/21/GPIOZero-Remote-GPIO-with-PIXEL-x86
|
||||
[18]:https://gist.github.com/bennuttall/572789b0aa5fc2e7c05c7ada1bdc813e
|
||||
[19]:https://www.raspberrypi.org/magpi/issues/53/
|
||||
[20]:https://opensource.com/user/26767/feed
|
||||
[21]:https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc#comments
|
||||
[22]:https://opensource.com/users/bennuttall
|
||||
@ -0,0 +1,233 @@
|
||||
使用 badIPs.com 保护你的服务器,并通过 Fail2ban 报告恶意 IP
|
||||
============================================================
|
||||
|
||||
这篇指南向你介绍使用 badips 滥用追踪器(abuse tracker) 和 Fail2ban 保护你的服务器或计算机的步骤。我已经在 Debian 8 Jessie 和 Debian 7 Wheezy 系统上进行了测试。
|
||||
|
||||
**什么是 badIPs?**
|
||||
|
||||
BadIps 是通过 [fail2ban][8] 报告为不良 IP 的列表。
|
||||
|
||||
这个指南包括两个部分,第一部分介绍列表的使用,第二部分介绍数据注入。
|
||||
|
||||
### 使用 badIPs 列表
|
||||
|
||||
#### 定义安全等级和类别
|
||||
|
||||
你可以通过使用 REST API 获取 IP 地址列表。
|
||||
|
||||
* 当你使用 GET 请求获取 URL:[https://www.badips.com/get/categories][9] 后,你就可以看到服务中现有的所有不同类别。
|
||||
* 第二步,决定适合你的等级。 参考 badips 应该有所帮助(我个人使用 `scope = 3`):
|
||||
* 如果你想要编译一个统计信息模块或者将数据用于实验目的,那么你应该用等级 0 开始。
|
||||
* 如果你想用防火墙保护你的服务器或者网站,使用等级 2。可能也要和你的结果相结合,尽管它们可能没有超过 0 或 1 的情况。
|
||||
* 如果你想保护一个网络商店、或高流量、赚钱的电子商务服务器,我推荐你使用值 3 或 4。当然还是要和你的结果相结合。
|
||||
* 如果你是偏执狂,那就使用 5。
|
||||
|
||||
现在你已经有了两个变量,通过把它们两者连接起来获取你的链接。
|
||||
|
||||
```
|
||||
http://www.badips.com/get/list/{{SERVICE}}/{{LEVEL}}
|
||||
```
|
||||
|
||||
注意:像我一样,你可以获取所有服务。在这种情况下把服务的名称改为 `any`。
|
||||
|
||||
最终的 URL 就是:
|
||||
|
||||
```
|
||||
https://www.badips.com/get/list/any/3
|
||||
```
|
||||
|
||||
### 创建脚本
|
||||
|
||||
所有都完成了之后,我们就会创建一个简单的脚本。
|
||||
|
||||
1、 把你的列表放到一个临时文件。
|
||||
|
||||
2、 在 iptables 中创建一个链(chain)(只需要创建一次)。(LCTT 译注:iptables 可能包括多个表(tables),表可能包括多个链(chains),链可能包括多个规则(rules))
|
||||
|
||||
3、 把所有链接到该链的数据(旧条目)刷掉。
|
||||
|
||||
4、 把每个 IP 链接到这个新的链。
|
||||
|
||||
5、 完成后,阻塞所有链接到该链的 INPUT / OUTPUT /FORWARD 请求。
|
||||
|
||||
6、 删除我们的临时文件。
|
||||
|
||||
为此,我们创建脚本:
|
||||
|
||||
```
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
```
|
||||
|
||||
把以下内容输入到文件。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
### based on this version http://www.timokorthals.de/?p=334
|
||||
### adapted by Stéphane T.
|
||||
|
||||
_ipt=/sbin/iptables ### iptables 路径(应该是这个)
|
||||
_input=badips.db ### 数据库的名称(会用这个名称下载)
|
||||
_pub_if=eth0 ### 连接到互联网的设备(执行 $ifconfig 获取)
|
||||
_droplist=droplist ### iptables 中链的名称(如果你已经有这么一个名称的链,你就换另外一个)
|
||||
_level=3 ### Blog(LCTT 译注:Bad log)等级:不怎么坏(0)、确认坏(3)、相当坏(5)(从 www.badips.com 获取详情)
|
||||
_service=any ### 记录日志的服务(从 www.badips.com 获取详情)
|
||||
|
||||
# 获取不良 IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### 设置我们的黑名单 ###
|
||||
### 首先清除该链
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
### 创建新的链
|
||||
### 首次运行时取消下面一行的注释
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
### 过滤掉注释和空行
|
||||
### 保存每个 ip 到 $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
### 添加到 $_droplist
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j LOG --log-prefix "Drop Bad IP List "
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j DROP
|
||||
done
|
||||
|
||||
### 最后,插入或者追加到我们的黑名单列表
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
### 删除你的临时文件
|
||||
rm $_input
|
||||
exit 0
|
||||
```
|
||||
|
||||
完成这些后,你应该创建一个定时任务定期更新我们的黑名单。
|
||||
|
||||
为此,我使用 crontab 在每天晚上 11:30(在我的延迟备份之前) 运行脚本。
|
||||
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
```
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
```
|
||||
|
||||
别忘了更改脚本的权限:
|
||||
|
||||
````
|
||||
chmod + x myBlacklist.sh
|
||||
```
|
||||
|
||||
现在终于完成了,你的服务器/计算机应该更安全了。
|
||||
|
||||
你也可以像下面这样手动运行脚本:
|
||||
|
||||
```
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
```
|
||||
|
||||
它可能要花费一些时间,因此期间别中断脚本。事实上,耗时取决于该脚本的最后一行。
|
||||
|
||||
### 使用 Fail2ban 向 badIPs 报告 IP 地址
|
||||
|
||||
在本篇指南的第二部分,我会向你展示如何通过使用 Fail2ban 向 badips.com 网站报告不良 IP 地址。
|
||||
|
||||
#### Fail2ban >= 0.8.12
|
||||
|
||||
通过 Fail2ban 完成报告。取决于你 Fail2ban 的版本,你要使用本章的第一或第二节。
|
||||
|
||||
如果你 fail2ban 的版本是 0.8.12 或更新版本。
|
||||
|
||||
```
|
||||
fail2ban-server --version
|
||||
```
|
||||
|
||||
在每个你要报告的类别中,添加一个 action。
|
||||
|
||||
```
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
```
|
||||
|
||||
正如你看到的,类别是 SSH,从 ([https://www.badips.com/get/categories][11]) 查找正确类别。
|
||||
|
||||
#### Fail2ban < 0.8.12
|
||||
|
||||
如果版本是 0.8.12 之前,你需要新建一个 action。你可以从 [https://www.badips.com/asset/fail2ban/badips.conf][12] 下载。
|
||||
|
||||
```
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
```
|
||||
|
||||
在上面的 badips.conf 中,你可以像前面那样激活每个类别,也可以全局启用它:
|
||||
|
||||
```
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
```
|
||||
|
||||
```
|
||||
[DEFAULT]
|
||||
...
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
```
|
||||
|
||||
现在重启 fail2ban - 从现在开始它就应该开始报告了。
|
||||
|
||||
service fail2ban restart
|
||||
|
||||
### 你的 IP 报告统计信息
|
||||
|
||||
最后一步 - 没那么有用。你可以创建一个密钥。 但如果你想看你的数据,这一步就很有帮助。
|
||||
|
||||
复制/粘贴下面的命令,你的控制台中就会出现一个 JSON 响应。
|
||||
|
||||
```
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
```
|
||||
|
||||
到 [badips][13] 网站,输入你的 “key” 并点击 “statistics”。
|
||||
|
||||
现在你就可以看到不同类别的统计信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
|
||||
作者:[Stephane T][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
[1]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#define-your-security-level-and-category
|
||||
[2]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-gt-
|
||||
[3]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-ltnbsp
|
||||
[4]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#use-the-badips-list
|
||||
[5]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#lets-create-the-script
|
||||
[6]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#report-ip-addresses-to-badips-with-failban
|
||||
[7]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#statistics-of-your-ip-reporting
|
||||
[8]:http://www.fail2ban.org/
|
||||
[9]:https://www.badips.com/get/categories
|
||||
[10]:http://www.timokorthals.de/?p=334
|
||||
[11]:https://www.badips.com/get/categories
|
||||
[12]:https://www.badips.com/asset/fail2ban/badips.conf
|
||||
[13]:https://www.badips.com/
|
||||
@ -1,42 +1,39 @@
|
||||
Windows Trojan hacks into embedded devices to install Mirai
|
||||
Windows 木马攻破嵌入式设备来安装 Mirai 恶意软件
|
||||
============================================================
|
||||
|
||||
> The Trojan tries to authenticate over different protocols with factory default credentials and, if successful, deploys the Mirai bot
|
||||
|
||||
> 木马尝试使用出厂默认凭证对不同协议进行身份验证,如果成功则会部署 Mirai 僵尸程序。
|
||||
|
||||

|
||||
|
||||
*图片来源: Gerd Altmann / Pixabay*
|
||||
|
||||
Attackers have started to use Windows and Android malware to hack into embedded devices, dispelling the widely held belief that if such devices are not directly exposed to the Internet they're less vulnerable.
|
||||
攻击者已经开始使用 Windows 和 Android 恶意软件入侵嵌入式设备,这消除了人们广泛持有的想法,认为如果设备不直接暴露在互联网上,那么它们就不那么脆弱。
|
||||
|
||||
Researchers from Russian antivirus vendor Doctor Web have recently [come across a Windows Trojan program][21] that was designed to gain access to embedded devices using brute-force methods and to install the Mirai malware on them.
|
||||
来自俄罗斯防病毒供应商 Doctor Web 的研究人员最近[遇到了一个 Windows 木马程序][21],它使用暴力方法访问嵌入式设备,并在其上安装 Mirai 恶意软件。
|
||||
|
||||
Mirai is a malware program for Linux-based internet-of-things devices, such as routers, IP cameras, digital video recorders and others. It's used primarily to launch distributed denial-of-service (DDoS) attacks and spreads over Telnet by using factory device credentials.
|
||||
Mirai 是一种用在基于 Linux 的物联网设备的恶意程序,例如路由器、IP 摄像机、数字录像机等。它主要通过使用出厂设备凭据来发动分布式拒绝服务 (DDoS) 攻击并通过 Telnet 传播。
|
||||
|
||||
The Mirai botnet has been used to launch some of the largest DDoS attacks over the past six months. After [its source code was leaked][22], the malware was used to infect more than 500,000 devices.
|
||||
Mirai 的僵尸网络在过去六个月里一直被用来发起最大型的 DDoS 攻击。[它的源代码泄漏][22]之后,恶意软件被用来感染超过 50 万台设备。
|
||||
|
||||
Once installed on a Windows computer, the new Trojan discovered by Doctor Web downloads a configuration file from a command-and-control server. That file contains a range of IP addresses to attempt authentication over several ports including 22 (SSH) and 23 (Telnet).
|
||||
Doctor Web 发现,一旦在一台 Windows 上安装之后,该新木马会从命令控制服务器下载配置文件。该文件包含一系列 IP 地址,通过多个端口,包括 22(SSH)和 23(Telnet),尝试进行身份验证。
|
||||
|
||||
#### [■ GET YOUR DAILY SECURITY NEWS: Sign up for CSO's security newsletters][11]
|
||||
如果身份验证成功,恶意软件将会根据受害系统的类型。执行配置文件中指定的某些命令。在通过 Telnet 访问的 Linux 系统中,木马会下载并执行一个二进制包,然后安装 Mirai 僵尸程序。
|
||||
|
||||
如果按照设计或配置,受影响的设备不会从 Internet 直接访问,那么许多物联网供应商会降低漏洞的严重性。这种思维方式假定局域网是信任和安全的环境。
|
||||
|
||||
If authentication is successful, the malware executes certain commands specified in the configuration file, depending on the type of compromised system. In the case of Linux systems accessed via Telnet, the Trojan downloads and executes a binary package that then installs the Mirai bot.
|
||||
然而事实并非如此,其他威胁如跨站点请求伪造已经出现了多年。但 Doctor Web 发现的新木马似乎是第一个专门设计用于劫持嵌入式或物联网设备的 Windows 恶意软件。
|
||||
|
||||
Many IoT vendors downplay the severity of vulnerabilities if the affected devices are not intended or configured for direct access from the Internet. This way of thinking assumes that LANs are trusted and secure environments.
|
||||
Doctor Web 发现的新木马被称为 [Trojan.Mirai.1][23],从它可以看到,攻击者还可以使用受害的计算机来攻击不能从互联网直接访问的物联网设备。
|
||||
|
||||
This was never really the case, with other threats like cross-site request forgery attacks going around for years. But the new Trojan that Doctor Web discovered appears to be the first Windows malware specifically designed to hijack embedded or IoT devices.
|
||||
|
||||
This new Trojan found by Doctor Web, dubbed [Trojan.Mirai.1][23], shows that attackers can also use compromised computers to target IoT devices that are not directly accessible from the internet.
|
||||
|
||||
Infected smartphones can be used in a similar way. Researchers from Kaspersky Lab have already [found an Android app][24] designed to perform brute-force password guessing attacks against routers over the local network.
|
||||
受感染的智能手机可以以类似的方式使用。卡巴斯基实验室的研究人员已经[发现了一个 Android 程序][24],通过本地网络对路由器执行暴力密码猜测攻击。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
|
||||
作者:[ Lucian Constantin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -51,7 +48,6 @@ via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into
|
||||
[8]:http://www.csoonline.com/article/3144197/security/upgraded-mirai-botnet-disrupts-deutsche-telekom-by-infecting-routers.html
|
||||
[9]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[10]:http://www.csoonline.com/video/73795/security-sessions-the-csos-role-in-active-shooter-planning
|
||||
[11]:http://csoonline.com/newsletters/signup.html#tk.cso-infsb
|
||||
[12]:http://www.csoonline.com/author/Lucian-Constantin/
|
||||
[13]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html&via=csoonline&text=Windows+Trojan+hacks+into+embedded+devices+to+install+Mirai
|
||||
[14]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.csoonline.com%2Farticle%2F3168357%2Fsecurity%2Fwindows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
@ -0,0 +1,129 @@
|
||||
使用 tmux 打造更强大的终端
|
||||
============================
|
||||
|
||||

|
||||
|
||||
一些 Fedora 用户把大部分甚至是所有时间花费在了[命令行][4]终端上。 终端可让您访问整个系统,以及数以千计的强大的实用程序。 但是,它默认情况下一次只显示一个命令行会话。 即使有一个大的终端窗口,整个窗口也只会显示一个会话。 这浪费了空间,特别是在大型显示器和高分辨率的笔记本电脑屏幕上。 但是,如果你可以将终端分成多个会话呢? 这正是 tmux 最方便的地方,或者说不可或缺的。
|
||||
|
||||
### 安装并启动 tmux
|
||||
|
||||
tmux 应用程序的名称来源于终端(terminal)复用器(muxer)或多路复用器(multiplexer)。 换句话说,它可以将您的单终端会话分成多个会话。 它管理窗口和窗格:
|
||||
|
||||
- 窗口(window)是一个单一的视图 - 也就是终端中显示的各种东西。
|
||||
- 窗格(pane) 是该视图的一部分,通常是一个终端会话。
|
||||
|
||||
开始前,请在系统上安装 `tmux` 应用程序。 你需要为您的用户帐户设置 `sudo` 权限(如果需要,请[查看本文][5]获取相关说明)。
|
||||
|
||||
```
|
||||
sudo dnf -y install tmux
|
||||
```
|
||||
|
||||
运行 `tmux`程序:
|
||||
|
||||
```
|
||||
tmux
|
||||
```
|
||||
|
||||
### 状态栏
|
||||
|
||||
首先,似乎什么也没有发生,除了出现在终端的底部的状态栏:
|
||||
|
||||
|
||||
|
||||
底部栏显示:
|
||||
|
||||
* `[0]` – 这是 `tmux` 服务器创建的第一个会话。编号从 0 开始。`tmux` 服务器会跟踪所有的会话确认其是否存活。
|
||||
* `0:testuser@scarlett:~` – 有关该会话的第一个窗口的信息。编号从 0 开始。这表示窗口的活动窗格中的终端归主机名 `scarlett` 中 `testuser` 用户所有。当前目录是 `~` (家目录)。
|
||||
* `*` – 显示你目前在此窗口中。
|
||||
* `“scarlett.internal.fri”` – 你正在使用的 `tmux` 服务器的主机名。
|
||||
* 此外,还会显示该特定主机上的日期和时间。
|
||||
|
||||
当你向会话中添加更多窗口和窗格时,信息栏将随之改变。
|
||||
|
||||
### tmux 基础知识
|
||||
|
||||
把你的终端窗口拉伸到最大。现在让我们尝试一些简单的命令来创建更多的窗格。默认情况下,所有的命令都以 `Ctrl+b` 开头。
|
||||
|
||||
* 敲 `Ctrl+b, "` 水平分割当前单个窗格。 现在窗口中有两个命令行窗格,一个在顶部,一个在底部。请注意,底部的新窗格是活动窗格。
|
||||
* 敲 `Ctrl+b, %` 垂直分割当前单个窗格。 现在你的窗口中有三个命令行窗格,右下角的窗格是活动窗格。
|
||||
|
||||
|
||||
|
||||
注意当前窗格周围高亮显示的边框。要浏览所有的窗格,请做以下操作:
|
||||
|
||||
* 敲 `Ctrl+b`,然后点箭头键
|
||||
* 敲 `Ctrl+b, q`,数字会短暂的出现在窗格上。在这期间,你可以你想要浏览的窗格上对应的数字。
|
||||
|
||||
现在,尝试使用不同的窗格运行不同的命令。例如以下这样的:
|
||||
|
||||
* 在顶部窗格中使用 `ls` 命令显示目录内容。
|
||||
* 在左下角的窗格中使用 `vi` 命令,编辑一个文本文件。
|
||||
* 在右下角的窗格中运行 `top` 命令监控系统进程。
|
||||
|
||||
屏幕将会如下显示:
|
||||
|
||||
|
||||
|
||||
到目前为止,这个示例中只是用了一个带多个窗格的窗口。你也可以在会话中运行多个窗口。
|
||||
|
||||
* 为了创建一个新的窗口,请敲`Ctrl+b, c` 。请注意,状态栏显示当前有两个窗口正在运行。(敏锐的读者会看到上面的截图。)
|
||||
* 要移动到上一个窗口,请敲 `Ctrl+b, p` 。
|
||||
* 要移动到下一个窗口,请敲 `Ctrl+b, n` 。
|
||||
* 要立即移动到特定的窗口,请敲 `Ctrl+b` 然后跟上窗口编号。
|
||||
|
||||
如果你想知道如何关闭窗格,只需要使用 `exit` 、`logout`,或者 `Ctrl+d` 来退出特定的命令行 shell。一旦你关闭了窗口中的所有窗格,那么该窗口也会消失。
|
||||
|
||||
### 脱离和附加
|
||||
|
||||
`tmux` 最强大的功能之一是能够脱离和重新附加到会话。 当你脱离的时候,你可以离开你的窗口和窗格独立运行。 此外,您甚至可以完全注销系统。 然后,您可以登录到同一个系统,重新附加到 `tmux` 会话,查看您离开时的所有窗口和窗格。 脱离的时候你运行的命令一直保持运行状态。
|
||||
|
||||
为了脱离一个会话,请敲 `Ctrl+b, d`。然后会话消失,你重新返回到一个标准的单一 shell。如果要重新附加到会话中,使用一下命令:
|
||||
|
||||
```
|
||||
tmux attach-session
|
||||
```
|
||||
|
||||
当你连接到主机的网络不稳定时,这个功能就像救生员一样有用。如果连接失败,会话中的所有的进程都会继续运行。只要连接恢复了,你就可以恢复正常,就好像什么事情也没有发生一样。
|
||||
|
||||
如果这些功能还不够,在每个会话的顶层窗口和窗格中,你可以运行多个会话。你可以列举出这些窗口和窗格,然后通过编号或者名称把他们附加到正确的会话中:
|
||||
|
||||
```
|
||||
tmux list-sessions
|
||||
```
|
||||
|
||||
### 延伸阅读
|
||||
|
||||
本文只触及的 `tmux` 的表面功能。你可以通过其他方式操作会话:
|
||||
|
||||
* 将一个窗格和另一个窗格交换
|
||||
* 将窗格移动到另一个窗口中(可以在同一个会话中也可以在不同的会话中)
|
||||
* 设定快捷键自动执行你喜欢的命令
|
||||
* 在 `~/.tmux.conf` 文件中配置你最喜欢的配置项,这样每一个会话都会按照你喜欢的方式呈现
|
||||
|
||||
有关所有命令的完整说明,请查看以下参考:
|
||||
|
||||
* 官方[手册页][1]
|
||||
* `tmux` [电子书][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields 自 1997 年以来一直是 Linux 用户和爱好者,并于 2003 年加入 Fedora 项目,这个项目刚推出不久。他是 Fedora 项目委员会的创始成员,在文档,网站发布,宣传,工具链开发和维护软件方面都有贡献。他于2008 年 2 月至 2010 年 7 月加入 Red Hat,担任 Fedora 项目负责人,并担任 Red Hat 的工程经理。目前他和妻子以及两个孩子居住在弗吉尼亚。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: http://man.openbsd.org/OpenBSD-current/man1/tmux.1
|
||||
[2]: https://pragprog.com/book/bhtmux2/tmux-2
|
||||
[3]: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[4]: http://www.cryptonomicon.com/beginning.html
|
||||
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -0,0 +1,110 @@
|
||||
Linux 下网络协议分析器 Wireshark 使用基础
|
||||
=================
|
||||
|
||||
Wireshark 是 Kali 中预置的众多有价值工具中的一种。与其它工具一样,它可以被用于正面用途,同样也可以被用于不良目的。当然,本文将会介绍如何追踪你自己的网络流量来发现潜在的非正常活动。
|
||||
|
||||
Wireshark 相当的强大,当你第一次见到它的时候可能会被它吓到,但是它的目的始终就只有一个,那就是追踪网络流量,并且它所实现的所有选项都只为了加强它追踪流量的能力。
|
||||
|
||||
### 安装
|
||||
|
||||
Kali 中预置了 Wireshark 。不过,`wireshark-gtk` 包提供了一个更好的界面使你在使用 Wireshark 的时候会有更友好的体验。因此,在使用 Wireshark 前的第一步是安装 `wireshark-gtk` 这个包。
|
||||
|
||||
```
|
||||
# apt install wireshark-gtk
|
||||
```
|
||||
|
||||
如果你的 Kali 是从 live 介质上运行的也不需要担心,依然有效。
|
||||
|
||||
|
||||
### 基础配置
|
||||
|
||||
在你使用 Wireshark 之前,将它设置成你使用起来最舒适的状态可能是最好的。Wireshark 提供了许多不同的布局方案和选项来配置程序的行为。尽管数量很多,但是使用起来是相当直接明确的。
|
||||
|
||||
从启动 Wireshark-gtk 开始。需要确定启动的是 GTK 版本的。在 Kali 中它们是被分别列出的。
|
||||
|
||||

|
||||
|
||||
### 布局
|
||||
|
||||
默认情况下,Wireshark 的信息展示分为三块内容,每一块都叠在另一块上方。(LCTT 译注:这里的三部分指的是展示抓包信息的时候的那三块内容,本段配图没有展示,配图 4、5、6 的设置不是默认设置,与这里的描述不符)最上方的一块是所抓包的列表。中间的一块是包的详细信息。最下面那块中包含的是包的原始字节信息。通常来说,上面的两块中的信息比最下面的那块有用的多,但是对于资深用户来说这块内容仍然是重要信息。
|
||||
|
||||
每一块都是可以缩放的,可并不是每一个人都必须使用这样叠起来的布局方式。你可以在 Wireshark 的“选项(Preferences)”菜单中进行更改。点击“编辑(Edit)”菜单,最下方就是的“选项”菜单。这个选项会打开一个有更多选项的新窗口。单击侧边菜单中“用户界面(User Interface)”下的“布局(Layout)”选项。
|
||||
|
||||

|
||||
|
||||
你将会看到一些不同的布局方案。上方的图示可以让你选择不同的面板位置布局方案,下面的单选框可以让你选择不同面板中的数据内容。
|
||||
|
||||
下面那个标记为“列(Columns)”的标签可以让你选择展示所抓取包的哪些信息。选择那些你需要的数据信息,或者全部展示。
|
||||
|
||||
### 工具条
|
||||
|
||||
对于 Wireshark 的工具条能做的设置不是太多,但是如果你想设置的话,你依然在前文中提到的“布局”菜单中的窗口管理工具下方找到一些有用的设置选项。那些能让你配置工具条和工具条中条目的选项就在窗口选项下方。
|
||||
|
||||
你还可以在“视图(View)”菜单下勾选来配置工具条的显示内容。
|
||||
|
||||
### 功能
|
||||
|
||||
主要的用来控制 Wireshark 抓包的控制选项基本都集中在“捕捉(Capture)”菜单下的“选项(Options)”选项中。
|
||||
|
||||
在开启的窗口中最上方的“捕捉(Capture)”部分可以让你选择 Wireshark 要监控的某个具体的网络接口。这部分可能会由于你系统的配置不同而会有相当大的不同。要记得勾选正确的选择框才能获得正确的数据。虚拟机和伴随它们一起的网络接口也同样会在这个列表里显示。同样也会有多种不同的选项对应这多种不同的网络接口。
|
||||
|
||||

|
||||
|
||||
在网络接口列表的下方是两个选项。其中一个选项是全选所有的接口。另一个选项用来选择是否开启混杂模式。这个选项可以使你的计算机监控到所选网络上的所有的计算机。(LCTT 译注:混杂模式可以在 HUB 中或监听模式的交换机接口上捕获那些由于 MAC 地址非本机而会被自动丢弃的数据包)如果你想监控你所在的整个网络,这个选项是你所需要的。
|
||||
|
||||
**注意:** 在一个不属于你或者不拥有权限的网络上使用混杂模式来监控是非法的!
|
||||
|
||||
在窗口下方的右侧是“显示选项(Display Options)”和“名称解析(Name Resolution)”选项块。对于“显示选项(Display Options)”来说,三个选项全选可能就是一个很好的选择了。当然你也可以取消选择,但是最好还是保留选择“实时更新抓包列表”。
|
||||
|
||||
在“名称解析(Name Resolution)”中你也可以设置你的偏好。这里的选项会产生附加的请求因此选得越多就会有越多的请求产生使你的抓取的包列表显得杂乱。把 MAC 解析选项选上是个好主意,那样就可以知道所使用的网络硬件的品牌了。这可以帮助你来确定你是在与哪台设备上的哪个接口进行交互。
|
||||
|
||||
### 抓包
|
||||
|
||||
抓包是 Wireshark 的核心功能。监控和记录特定网络上的流量就是它最初产生的目的。使用它最基本的方式来作这个抓包的工作是相当简单方便的。当然,越多的配置和选项就越可以充分利用 Wireshark 的力量。这里的介绍的关注点依然还是它最基本的记录方式。
|
||||
|
||||
按下那个看起来像蓝色鲨鱼鳍的新建实时抓包按钮就可以开始抓包了。(LCTT 译注:在我的 Debian 上它是绿色的)
|
||||
|
||||
|
||||

|
||||
|
||||
在抓包的过程中,Wireshark 会收集所有它能收集到的包的数据并且记录下来。如果没有更改过相关设置的话,在抓包的过程中你会看见不断的有新的包进入到“包列表”面板中。你可以实时的查看你认为有趣的包,或者就让 Wireshark 运行着,同时你可以做一些其它的事情。
|
||||
|
||||
当你完成了,按下红色的正方形“停止”按钮就可以了。现在,你可以选择是否要保存这些所抓取的数据了。要保存的话,你可以使用“文件”菜单下的“保存”或者是“另存为”选项。
|
||||
|
||||
### 读取数据
|
||||
|
||||
Wireshark 的目标是向你提供你所需要的所有数据。这样做时,它会在它监控的网络上收集大量的与网络包相关的数据。它使用可折叠的标签来展示这些数据使得这些数据看起来没有那么吓人。每一个标签都对应于网络包中一部分的请求数据。
|
||||
|
||||
这些标签是按照从最底层到最高层一层层堆起来的。顶部标签总是包含数据包中包含的字节数据。最下方的标签可能会是多种多样的。在下图的例子中是一个 HTTP 请求,它会包含 HTTP 的信息。您遇到的大多数数据包将是 TCP 数据,它将展示在底层的标签中。
|
||||
|
||||

|
||||
|
||||
每一个标签页都包含了抓取包中对应部分的相关数据。一个 HTTP 包可能会包含与请求类型相关的信息,如所使用的网络浏览器,服务器的 IP 地址,语言,编码方式等的数据。一个 TCP 包会包含服务器与客户端使用的端口信息和 TCP 三次握手过程中的标志位信息。
|
||||
|
||||

|
||||
|
||||
在上方的其它标签中包含了一些大多数用户都感兴趣的少量信息。其中一个标签中包含了数据包是否是通过 IPv4 或者 IPv6 传输的,以及客户端和服务器端的 IP 地址。另一个标签中包含了客户端和接入因特网的路由器或网关的设备的 MAC 地址信息。
|
||||
|
||||
### 结语
|
||||
|
||||
即使只使用这些基础选项与配置,你依然可以发现 Wireshark 会是一个多么强大的工具。监控你的网络流量可以帮助你识别、终止网络攻击或者提升连接速度。它也可以帮你找到问题应用。下一篇 Wireshark 指南我们将会一起探索 Wireshark 的包过滤选项。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
[1]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-1-layout
|
||||
[2]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-2-toolbars
|
||||
[3]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-3-functionality
|
||||
[4]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h1-installation
|
||||
[5]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-basic-configuration
|
||||
[6]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h3-capture
|
||||
[7]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h4-reading-data
|
||||
[8]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h5-closing-thoughts
|
||||
@ -1,30 +1,31 @@
|
||||
在 RHEL,CentOS 及 Fedora 上安装 Drupal 8
|
||||
在 RHEL、CentOS 及 Fedora 上安装 Drupal 8
|
||||
============================================================
|
||||
|
||||
**Drupal** 是一个开源,灵活,高度可拓展和安全的<ruby>内容管理系统<rt>Content Management System</rt></ruby>(CMS),使用户轻松的创建网站。
|
||||
|
||||
它可以使用模块拓展,使用户将内容管理转换为强大的数字解决方案。
|
||||
|
||||
**Drupal** 运行在诸如 **Apache,IIS,Lighttpd,Cherokee,Nginx** 的 Web 服务器上,后端数据库可以使用 **Mysql,MongoDB,MariaDB,PostgreSQL,MSSQL Server**。
|
||||
**Drupal** 运行在诸如 Apache、IIS、Lighttpd、Cherokee、Nginx 的 Web 服务器上,后端数据库可以使用 MySQL、MongoDB、MariaDB、PostgreSQL、MSSQL Server。
|
||||
|
||||
在这篇文章中, 我们会展示在 RHEL 7/6,CentOS 7/6 和 Fedora 20-25 发行版本使用 LAMP,如何手动安装和配置 Drupal 8。
|
||||
在这篇文章中, 我们会展示在 RHEL 7/6、CentOS 7/6 和 Fedora 20-25 发行版上使用 LAMP 架构,如何手动安装和配置 Drupal 8。
|
||||
|
||||
#### Drupal 需求:
|
||||
#### Drupal 需求:
|
||||
|
||||
1. **Apache 2.x** (推荐)
|
||||
2. **PHP 5.5.9** 或 更高 (推荐 PHP 5.5)
|
||||
3. **MYSQL 5.5.3** 或 **MariaDB 5.5.20** 与 PHP 数据对象(PDO)
|
||||
1. **Apache 2.x** (推荐)
|
||||
2. **PHP 5.5.9** 或 更高 (推荐 PHP 5.5)
|
||||
3. **MySQL 5.5.3** 或 **MariaDB 5.5.20** 与 PHP 数据对象(PDO) 支持
|
||||
|
||||
安装过程中,我使用 `drupal.tecmint.com` 作为网站主机名,IP 地址为 `192.168.0.104`。你的环境也许与这些设置不同,因此请适当做出更改。
|
||||
|
||||
### 步骤 1: 安装 Apache Web 服务器
|
||||
### 步骤 1:安装 Apache Web 服务器
|
||||
|
||||
1. 首先我们从官方仓库开始安装 Apache Web 服务器。
|
||||
1、 首先我们从官方仓库开始安装 Apache Web 服务器。
|
||||
|
||||
```
|
||||
# yum install httpd
|
||||
```
|
||||
|
||||
2. 安装完成后,服务将会被被禁用,因此我们需要手动启动它,同时让它下次系统启动时自动启动,如下:
|
||||
2、 安装完成后,服务开始是被禁用的,因此我们需要手动启动它,同时让它下次系统启动时自动启动,如下:
|
||||
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 和 Fedora 22+ -------------------
|
||||
@ -36,7 +37,7 @@
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
3. 接下来,为了允许通过 **HTTP** 和 **HTTPS** 访问 Apache 服务,我们必须打开 **HTTPD** 守护进程正在监听的 **80** 和 **443** 端口,如下所示:
|
||||
3、 接下来,为了允许通过 **HTTP** 和 **HTTPS** 访问 Apache 服务,我们必须打开 **HTTPD** 守护进程正在监听的 **80** 和 **443** 端口,如下所示:
|
||||
|
||||
```
|
||||
------------ 通过 Firewalld - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
@ -51,7 +52,7 @@
|
||||
# service iptables restart
|
||||
```
|
||||
|
||||
4. 现在验证 Apache 是否正常工作, 打开浏览器在地址栏中输入 http://server_IP, 输入你的服务器 IP 地址, 默认 Apache2 页面应出现,如下面截图所示:
|
||||
4、 现在验证 Apache 是否正常工作, 打开浏览器在地址栏中输入 `http://server_IP`, 输入你的服务器 IP 地址, 默认 Apache2 页面应出现,如下面截图所示:
|
||||
|
||||
[
|
||||

|
||||
@ -59,15 +60,15 @@
|
||||
|
||||
*Apache 默认页面*
|
||||
|
||||
### 步骤 2: 安装 Apache PHP 支持
|
||||
### 步骤 2: 安装 Apache PHP 支持
|
||||
|
||||
5. 接下来,安装 PHP 和 PHP 所需模块.
|
||||
5、 接下来,安装 PHP 和 PHP 所需模块。
|
||||
|
||||
```
|
||||
# yum install php php-mbstring php-gd php-xml php-pear php-fpm php-mysql php-pdo php-opcache
|
||||
```
|
||||
|
||||
**重要**: 假如你想要安装 **PHP7**, 你需要增加以下仓库:**EPEL** 和 **Webtactic** 才可以使用 yum 安装 PHP7.0:
|
||||
**重要**: 假如你想要安装 **PHP7**, 你需要增加以下仓库:**EPEL** 和 **Webtactic** 才可以使用 yum 安装 PHP7.0:
|
||||
|
||||
```
|
||||
------------- Install PHP 7 in CentOS/RHEL and Fedora -------------
|
||||
@ -76,7 +77,7 @@
|
||||
# yum install php70w php70w-opcache php70w-mbstring php70w-gd php70w-xml php70w-pear php70w-fpm php70w-mysql php70w-pdo
|
||||
```
|
||||
|
||||
6. 接下来,要从浏览器得到关于 PHP 安装和配置完整信息,使用下面命令在 Apache 文档根目录 (/var/www/html) 创建一个 `info.php` 文件。
|
||||
6、 接下来,要从浏览器得到关于 PHP 安装和配置完整信息,使用下面命令在 Apache 文档根目录 (`/var/www/html`) 创建一个 `info.php` 文件。
|
||||
|
||||
```
|
||||
# echo "<?php phpinfo(); ?>" > /var/www/html/info.php
|
||||
@ -98,7 +99,7 @@
|
||||
|
||||
### 步骤 3: 安装和配置 MariaDB 数据库
|
||||
|
||||
7. 请了解, **Red Hat Enterprise Linux/CentOS 7.0** 从支持 **MYSQL** 转为了 **MariaDB** 作为默认数据库管理系统。
|
||||
7、 请知晓, **Red Hat Enterprise Linux/CentOS 7.0** 从支持 **MySQL** 转为了 **MariaDB** 作为默认数据库管理系统。
|
||||
|
||||
要安装 **MariaDB** 数据库, 你需要添加 [官方 MariaDB 库][3] 到 `/etc/yum.repos.d/MariaDB.repo` 中,如下所示。
|
||||
|
||||
@ -110,13 +111,13 @@ gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
当仓库文件准备好后,你可以像这样安装 MariaDB :
|
||||
当仓库文件准备好后,你可以像这样安装 MariaDB:
|
||||
|
||||
```
|
||||
# yum install mariadb-server mariadb
|
||||
```
|
||||
|
||||
8. 当 MariaDB 数据库安装完成,启动数据库的守护进程,同时使它能够在下次启动后自动启动。
|
||||
8、 当 MariaDB 数据库安装完成,启动数据库的守护进程,同时使它能够在下次启动后自动启动。
|
||||
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
@ -127,7 +128,7 @@ gpgcheck=1
|
||||
# chkconfig --level 35 mysqld on
|
||||
```
|
||||
|
||||
9. 然后运行 `mysql_secure_installation` 脚本去保护数据库(设置 root 密码, 禁用远程登录,移除测试数据库并移除匿名用户),如下所示:
|
||||
9、 然后运行 `mysql_secure_installation` 脚本去保护数据库(设置 root 密码, 禁用远程登录,移除测试数据库并移除匿名用户),如下所示:
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
@ -136,25 +137,25 @@ gpgcheck=1
|
||||

|
||||
][4]
|
||||
|
||||
*Mysql 安全安装*
|
||||
*MySQL 安全安装*
|
||||
|
||||
### 步骤 4: 在 CentOS 中安装和配置 Drupal 8
|
||||
### 步骤 4: 在 CentOS 中安装和配置 Drupal 8
|
||||
|
||||
10. 这里我们使用 [wget 命令][6] [下载最新版本 Drupal][5](例如 8.2.6),如果你没有安装 wget 和 gzip 包 ,请使用下面命令安装它们:
|
||||
10、 这里我们使用 [wget 命令][6] [下载最新版本 Drupal][5](例如 8.2.6),如果你没有安装 wget 和 gzip 包 ,请使用下面命令安装它们:
|
||||
|
||||
```
|
||||
# yum install wget gzip
|
||||
# wget -c https://ftp.drupal.org/files/projects/drupal-8.2.6.tar.gz
|
||||
```
|
||||
|
||||
11. 之后,[解压 tar 文件][7] 并移动 Drupal 目录到 Apache 文档根目录(`/var/www/html`).
|
||||
11、 之后,[解压 tar 文件][7] 并移动 Drupal 目录到 Apache 文档根目录(`/var/www/html`)。
|
||||
|
||||
```
|
||||
# tar -zxvf drupal-8.2.6.tar.gz
|
||||
# mv drupal-8.2.6 /var/www/html/drupal
|
||||
```
|
||||
|
||||
12. 然后,依据 `/var/www/html/drupal/sites/default` 目录下的示例设置文件 default.settings.php,创建设置文件 `settings.php`,然后给 Drupal 站点目录设置适当权限,包括子目录和文件,如下所示:
|
||||
12、 然后,依据 `/var/www/html/drupal/sites/default` 目录下的示例设置文件 `default.settings.php`,创建设置文件 `settings.php`,然后给 Drupal 站点目录设置适当权限,包括子目录和文件,如下所示:
|
||||
|
||||
```
|
||||
# cd /var/www/html/drupal/sites/default/
|
||||
@ -162,13 +163,13 @@ gpgcheck=1
|
||||
# chown -R apache:apache /var/www/html/drupal/
|
||||
```
|
||||
|
||||
13. 更重要的是在 `/var/www/html/drupal/sites/` 目录设置 **SElinux** 规则,如下:
|
||||
13、 更重要的是在 `/var/www/html/drupal/sites/` 目录设置 **SElinux** 规则,如下:
|
||||
|
||||
```
|
||||
# chcon -R -t httpd_sys_content_rw_t /var/www/html/drupal/sites/
|
||||
```
|
||||
|
||||
14. 现在我们必须为 Drupal 站点去创建一个数据库和用户来管理。
|
||||
14、 现在我们必须为 Drupal 站点去创建一个用于管理的数据库和用户。
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
@ -191,7 +192,7 @@ Query OK, 0 rows affected (0.00 sec)
|
||||
Bye
|
||||
```
|
||||
|
||||
15. 最后,打开地址: `http://server_IP/drupal/` 开始网站的安装,选择你首选的安装语言然后点击保存以继续。
|
||||
15、 最后,打开地址: `http://server_IP/drupal/` 开始网站的安装,选择你首选的安装语言然后点击保存以继续。
|
||||
|
||||
[
|
||||
|
||||
@ -199,7 +200,7 @@ Bye
|
||||
|
||||
*Drupal 安装语言*
|
||||
|
||||
16. 下一步,选择安装配置文件,选择 Standard(标准),点击保存继续。
|
||||
16、 下一步,选择安装配置文件,选择 Standard(标准),点击保存继续。
|
||||
|
||||
[
|
||||

|
||||
@ -207,7 +208,7 @@ Bye
|
||||
|
||||
*Drupal 安装配置文件*
|
||||
|
||||
17. 在进行下一步之前查看并通过需求审查并启用 `Clean URL`。
|
||||
17、 在进行下一步之前查看并通过需求审查并启用 `Clean URL`。
|
||||
|
||||
[
|
||||
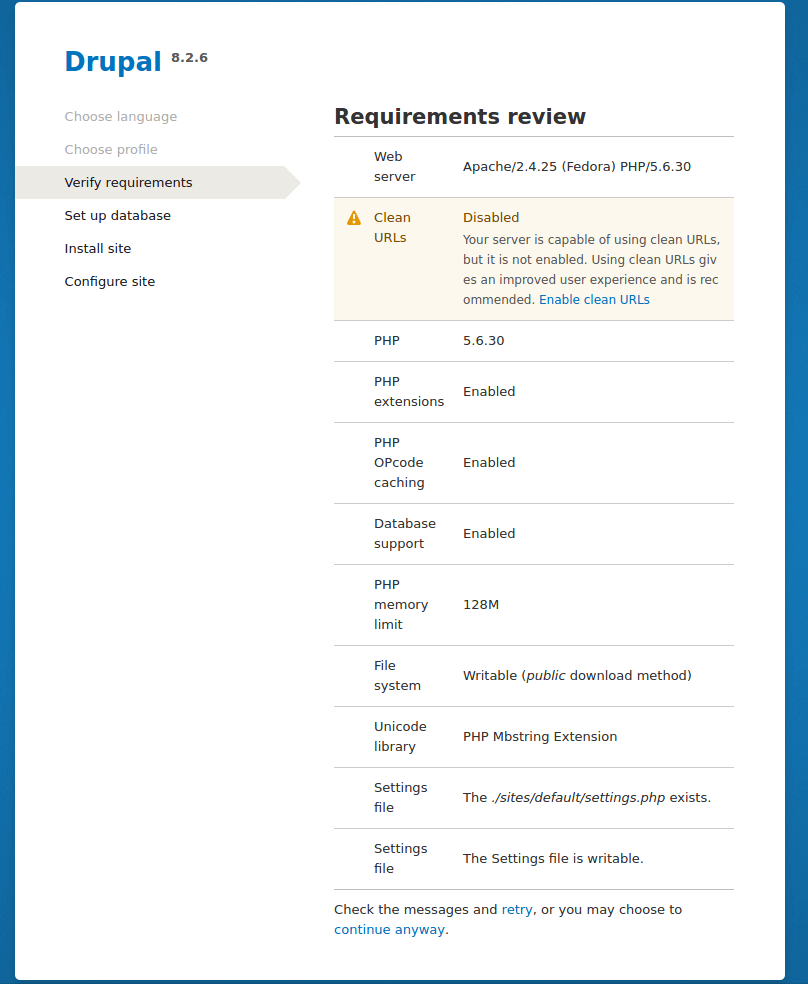
|
||||
@ -215,13 +216,13 @@ Bye
|
||||
|
||||
*验证 Drupal 需求*
|
||||
|
||||
现在在你的 Apache 配置下启用 Clean URL Drupal。
|
||||
现在在你的 Apache 配置下启用 Clean URL 的 Drupal。
|
||||
|
||||
```
|
||||
# vi /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
确保为默认根文档目录 **/var/www/html** 设置 **AllowOverride All**,如下图所示:
|
||||
确保为默认根文档目录 `/var/www/html` 设置 `AllowOverride All`,如下图所示:
|
||||
|
||||
[
|
||||
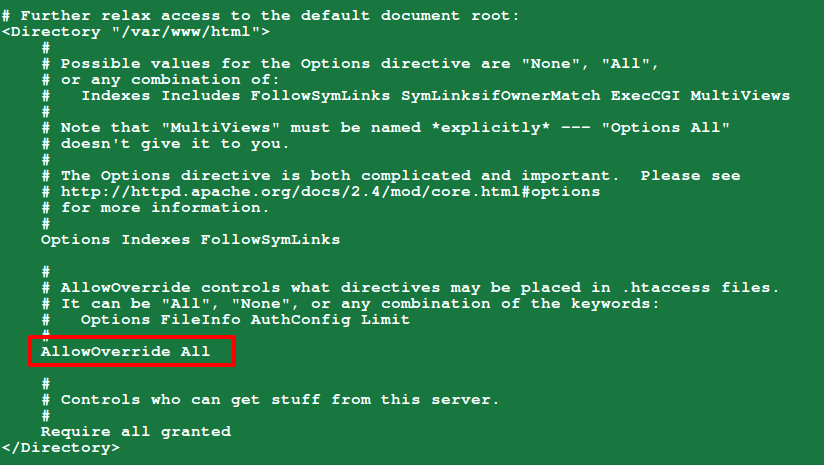
|
||||
@ -229,7 +230,7 @@ Bye
|
||||
|
||||
*在 Drupal 中启用 Clean URL*
|
||||
|
||||
18. 当你为 Drupal 启用 `Clean URL`,刷新页面从下面界面执行数据库配置,输入 Drupal 站点数据库名,数据库用户和数据库密码。
|
||||
18、 当你为 Drupal 启用 Clean URL,刷新页面从下面界面执行数据库配置,输入 Drupal 站点数据库名,数据库用户和数据库密码。
|
||||
|
||||
当填写完所有信息点击**保存并继续**。
|
||||
|
||||
@ -247,15 +248,15 @@ Bye
|
||||
|
||||
*Drupal 安装*
|
||||
|
||||
19. 接下来配置站点为下面的设置(使用适用你的情况的值):
|
||||
19、 接下来配置站点为下面的设置(使用适用你的情况的值):
|
||||
|
||||
- **站点名称** – TecMint Drupal Site
|
||||
- **站点邮箱地址** – admin@tecmint.com
|
||||
- **用户名** – admin
|
||||
- **密码** – ##########
|
||||
- **用户的邮箱地址** – admin@tecmint.com
|
||||
- **默认国家** – India
|
||||
- **默认时区** – UTC
|
||||
- **站点名称** – TecMint Drupal Site
|
||||
- **站点邮箱地址** – admin@tecmint.com
|
||||
- **用户名** – admin
|
||||
- **密码** – ##########
|
||||
- **用户的邮箱地址** – admin@tecmint.com
|
||||
- **默认国家** – India
|
||||
- **默认时区** – UTC
|
||||
|
||||
设置适当的值后,点击**保存并继续**完成站点安装过程。
|
||||
|
||||
@ -275,7 +276,7 @@ Bye
|
||||
|
||||
现在你可以点击**增加内容**,创建示例网页内容。
|
||||
|
||||
选项: 有些人[使用 MYSQL 命令行管理数据库][16]不舒服,可以从浏览器界面 [安装 PHPMYAdmin 管理数据库][17]
|
||||
选项: 有些人[使用 MySQL 命令行管理数据库][16]不舒服,可以从浏览器界面 [安装 PHPMYAdmin 管理数据库][17]
|
||||
|
||||
浏览 Drupal 文档 : [https://www.drupal.org/docs/8][18]
|
||||
|
||||
@ -1,33 +1,31 @@
|
||||
|
||||
Inxi —— 一个功能强大的获取 Linux 系统信息的命令行工具
|
||||
inxi:一个功能强大的获取 Linux 系统信息的命令行工具
|
||||
============================================================
|
||||
|
||||
Inxi 最初是为控制台和 IRC(网络中继聊天)开发的一个强大且优秀的系统命令行工具。现在可以使用它获取用户的硬件和系统信息,它也能作为一个调试器使用或者一个社区技术支持工具。
|
||||
Inxi 最初是为控制台和 IRC(网络中继聊天)开发的一个强大且优秀的命令行系统信息脚本。可以使用它获取用户的硬件和系统信息,它也用于调试或者社区技术支持工具。
|
||||
|
||||
使用 Inxi 可以很容易的获取所有的硬件信息:硬盘、声卡、显卡、网卡、CPU 和 RAM 等。同时也能够获取大量的操作系统信息,比如硬件驱动、Xorg 、桌面环境、内核、GCC 版本,进程,开机时间和内存等信息。
|
||||
|
||||
|
||||
命令行和 IRC 上的 Inxi 输出略有不同,IRC 上会有一些可供用户使用的过滤器和颜色选项。支持 IRC 的客户端有:BitchX、Gaim/Pidgin、ircII、Irssi、 Konversation、 Kopete、 KSirc、 KVIrc、 Weechat 和 Xchat ;其他的一些客户端都会有一些过滤器和颜色选项,或者用 Inxi 的输出体现出这种区别。
|
||||
|
||||
|
||||
运行在命令行和 IRC 上的 Inxi 输出略有不同,IRC 上会有一些可供用户使用的默认过滤器和颜色选项。支持的 IRC 客户端有:BitchX、Gaim/Pidgin、ircII、Irssi、 Konversation、 Kopete、 KSirc、 KVIrc、 Weechat 和 Xchat 以及其它的一些客户端,它们具有展示内置或外部 Inxi 输出的能力。
|
||||
|
||||
### 在 Linux 系统上安装 Inxi
|
||||
|
||||
大多数主流 Linux 发行版的仓库中都有 Inxi ,包括大多数 BSD 系统。
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt-get install inxi [On Debian/Ubuntu/Linux Mint]
|
||||
$ sudo yum install inxi [On CentOs/RHEL/Fedora]
|
||||
$ sudo dnf install inxi [On Fedora 22+]
|
||||
```
|
||||
在使用 Inxi 之前,用下面的命令查看 Inxi 的介绍信息,包括各种各样的文件夹和需要安装的包。
|
||||
|
||||
在使用 Inxi 之前,用下面的命令查看 Inxi 所有依赖和推荐的应用,以及各种目录,并显示需要安装哪些包来支持给定的功能。
|
||||
|
||||
|
||||
```
|
||||
$ inxi --recommends
|
||||
```
|
||||
|
||||
Inxi 的输出:
|
||||
|
||||
```
|
||||
inxi will now begin checking for the programs it needs to operate. First a check of the main languages and tools
|
||||
inxi uses. Python is only for debugging data collection.
|
||||
@ -122,12 +120,13 @@ File: /var/run/dmesg.boot
|
||||
All tests completed.
|
||||
```
|
||||
|
||||
### Inxi 工具的基本用法
|
||||
|
||||
用下面的操作获取系统和硬件的详细信息。
|
||||
用下面的基本用法获取系统和硬件的详细信息。
|
||||
|
||||
#### 获取系统信息
|
||||
Inix 不加任何选项就能输出下面的信息:CPU 、内核、开机时长、内存大小、硬盘大小、进程数、登陆终端以及 Inxi 版本。
|
||||
#### 获取 Linux 系统信息
|
||||
|
||||
Inix 不加任何选项就能输出下面的信息:CPU 、内核、开机时长、内存大小、硬盘大小、进程数、登录终端以及 Inxi 版本。
|
||||
|
||||
```
|
||||
$ inxi
|
||||
@ -136,8 +135,7 @@ CPU~Dual core Intel Core i5-4210U (-HT-MCP-) speed/max~2164/2700 MHz Kernel~4.4.
|
||||
|
||||
#### 获取内核和发行版本信息
|
||||
|
||||
使用 Inxi 的 `-S` 选项查看本机系统信息:
|
||||
|
||||
使用 Inxi 的 `-S` 选项查看本机系统信息(主机名、内核信息、桌面环境和发行版):
|
||||
|
||||
```
|
||||
$ inxi -S
|
||||
@ -145,8 +143,8 @@ System: Host: TecMint Kernel: 4.4.0-21-generic x86_64 (64 bit) Desktop: Cinnamon
|
||||
Distro: Linux Mint 18 Sarah
|
||||
```
|
||||
|
||||
|
||||
### 获取电脑机型
|
||||
|
||||
使用 `-M` 选项查看机型(笔记本/台式机)、产品 ID 、机器版本、主板、制造商和 BIOS 等信息:
|
||||
|
||||
|
||||
@ -157,8 +155,8 @@ Mobo: LENOVO model: Lancer 5A5 v: 31900059WIN Bios: LENOVO v: 9BCN26WW date: 07/
|
||||
```
|
||||
|
||||
### 获取 CPU 及主频信息
|
||||
使用 `-C` 选项查看完整的 CPU 信息,包括每核 CPU 的频率及可用的最大主频。
|
||||
|
||||
使用 `-C` 选项查看完整的 CPU 信息,包括每核 CPU 的频率及可用的最大主频。
|
||||
|
||||
```
|
||||
$ inxi -C
|
||||
@ -166,10 +164,9 @@ CPU: Dual core Intel Core i5-4210U (-HT-MCP-) cache: 3072 KB
|
||||
clock speeds: max: 2700 MHz 1: 1942 MHz 2: 1968 MHz 3: 1734 MHz 4: 1710 MHz
|
||||
```
|
||||
|
||||
|
||||
#### 获取显卡信息
|
||||
使用 `-G` 选项查看显卡信息,包括显卡类型、图形服务器、系统分辨率、GLX 渲染器(译者注: GLX 是一个 X 窗口系统的 OpenGL 扩展)和 GLX 版本。
|
||||
|
||||
使用 `-G` 选项查看显卡信息,包括显卡类型、显示服务器、系统分辨率、GLX 渲染器和 GLX 版本等等(LCTT 译注: GLX 是一个 X 窗口系统的 OpenGL 扩展)。
|
||||
|
||||
```
|
||||
$ inxi -G
|
||||
@ -179,10 +176,9 @@ Display Server: X.Org 1.18.4 drivers: intel (unloaded: fbdev,vesa) Resolution: 1
|
||||
GLX Renderer: Mesa DRI Intel Haswell Mobile GLX Version: 3.0 Mesa 11.2.0
|
||||
```
|
||||
|
||||
|
||||
#### 获取声卡信息
|
||||
使用 `-A` 选项查看声卡信息:
|
||||
|
||||
使用 `-A` 选项查看声卡信息:
|
||||
|
||||
```
|
||||
$ inxi -A
|
||||
@ -190,8 +186,8 @@ Audio: Card-1 Intel 8 Series HD Audio Controller driver: snd_hda_intel Sound
|
||||
Card-2 Intel Haswell-ULT HD Audio Controller driver: snd_hda_intel
|
||||
```
|
||||
|
||||
|
||||
#### 获取网卡信息
|
||||
|
||||
使用 `-N` 选项查看网卡信息:
|
||||
|
||||
```
|
||||
@ -201,18 +197,17 @@ Card-2: Realtek RTL8723BE PCIe Wireless Network Adapter driver: rtl8723be
|
||||
```
|
||||
|
||||
#### 获取硬盘信息
|
||||
使用 `-D` 选项查看硬盘信息(大小、ID、型号):
|
||||
|
||||
使用 `-D` 选项查看硬盘信息(大小、ID、型号):
|
||||
|
||||
```
|
||||
$ inxi -D
|
||||
Drives: HDD Total Size: 1000.2GB (20.0% used) ID-1: /dev/sda model: ST1000LM024_HN size: 1000.2GB
|
||||
```
|
||||
|
||||
|
||||
#### 获取简要的系统信息
|
||||
|
||||
使用 `-b` 选项显示简要系统信息:
|
||||
使用 `-b` 选项显示上述信息的简要系统信息:
|
||||
|
||||
```
|
||||
$ inxi -b
|
||||
System: Host: TecMint Kernel: 4.4.0-21-generic x86_64 (64 bit) Desktop: Cinnamon 3.0.7
|
||||
@ -231,18 +226,17 @@ Info: Processes: 233 Uptime: 3:23 Memory: 3137.5/7879.9MB Client: Shell (ba
|
||||
```
|
||||
|
||||
#### 获取硬盘分区信息
|
||||
使用 `-p` 选项输出完整的硬盘分区信息,包括每个分区的分区大小、已用空间、可用空间、文件系统以及文件系统类型。
|
||||
|
||||
使用 `-p` 选项输出完整的硬盘分区信息,包括每个分区的分区大小、已用空间、可用空间、文件系统以及文件系统类型。
|
||||
|
||||
```
|
||||
$ inxi -p
|
||||
Partition: ID-1: / size: 324G used: 183G (60%) fs: ext4 dev: /dev/sda10
|
||||
ID-2: swap-1 size: 4.00GB used: 0.00GB (0%) fs: swap dev: /dev/sda9
|
||||
```
|
||||
|
||||
|
||||
#### 获取完整的 Linux 系统信息
|
||||
使用 `-F` 选项查看可以完整的 Inxi 输出(安全起见比如网络 IP 地址信息不会显示,下面的示例只显示部分输出信息):
|
||||
|
||||
使用 `-F` 选项查看可以完整的 Inxi 输出(安全起见比如网络 IP 地址信息没有显示,下面的示例只显示部分输出信息):
|
||||
|
||||
```
|
||||
$ inxi -F
|
||||
@ -275,16 +269,17 @@ Info: Processes: 234 Uptime: 3:26 Memory: 3188.9/7879.9MB Client: Shell (ba
|
||||
|
||||
下面是监控 Linux 系统进程、开机时间和内存的几个选项的使用方法。
|
||||
|
||||
|
||||
#### 监控 Linux 进程的内存使用
|
||||
|
||||
使用下面的命令查看进程数、开机时间和内存使用情况:
|
||||
|
||||
```
|
||||
$ inxi -I
|
||||
Info: Processes: 232 Uptime: 3:35 Memory: 3256.3/7879.9MB Client: Shell (bash) inxi: 2.2.35
|
||||
```
|
||||
|
||||
#### 监控进程占用的 CPU 和内存资源
|
||||
|
||||
Inxi 默认显示 [前 5 个最消耗 CPU 和内存的进程][1]。 `-t` 选项和 `c` 选项一起使用查看前 5 个最消耗 CPU 资源的进程,查看最消耗内存的进程使用 `-t` 选项和 `m` 选项; `-t`选项 和 `cm` 选项一起使用显示前 5 个最消耗 CPU 和内存资源的进程。
|
||||
|
||||
```
|
||||
@ -325,8 +320,8 @@ Memory: MB / % used - Used/Total: 3223.6/7879.9MB - top 5 active
|
||||
4: mem: 244.45MB (3.1%) command: chrome pid: 7405
|
||||
5: mem: 211.68MB (2.6%) command: chrome pid: 6146
|
||||
```
|
||||
|
||||
可以在选项 `cm` 后跟一个整数(在 1-20 之间)设置显示多少个进程,下面的命令显示了前 10 个最消耗 CPU 和内存的进程:
|
||||
We can use `cm` number (number can be 1-20) to specify a number other than 5, the command below will show us the [top 10 most active processes][2] eating up CPU and memory.
|
||||
|
||||
```
|
||||
$ inxi -t cm10
|
||||
@ -355,8 +350,8 @@ Memory: MB / % used - Used/Total: 3163.1/7879.9MB - top 10 active
|
||||
```
|
||||
|
||||
#### 监控网络设备
|
||||
下面的命令会列出网卡信息,包括接口信息、网络频率、mac 地址、网卡状态和网络 IP 等信息。
|
||||
|
||||
下面的命令会列出网卡信息,包括接口信息、网络频率、mac 地址、网卡状态和网络 IP 等信息。
|
||||
|
||||
```
|
||||
$ inxi -Nni
|
||||
@ -369,8 +364,8 @@ IF: enp1s0 ip-v4: 192.168.0.103
|
||||
```
|
||||
|
||||
#### 监控 CPU 温度和电脑风扇转速
|
||||
可以使用 `-s` 选项监控 [配置了传感器的机器][2] 获取温度和风扇转速:
|
||||
|
||||
可以使用 `-s` 选项监控 [配置了传感器的机器][2] 获取温度和风扇转速:
|
||||
|
||||
```
|
||||
$ inxi -s
|
||||
@ -379,8 +374,8 @@ Fan Speeds (in rpm): cpu: N/A
|
||||
```
|
||||
|
||||
#### 用 Linux 查看天气预报
|
||||
使用 `-w` 选项查看本地区的天气情况(虽然使用的 API 可能不是很可靠),使用 `-w` `<different_location>` 设置所在的地区。
|
||||
|
||||
使用 `-w` 选项查看本地区的天气情况(虽然使用的 API 可能不是很可靠),使用 `-W <different_location>` 设置另外的地区。
|
||||
|
||||
```
|
||||
$ inxi -w
|
||||
@ -391,9 +386,9 @@ $ inxi -W Nairobi,Kenya
|
||||
Weather: Conditions: 70 F (21 C) - Mostly Cloudy Time: February 20, 11:08 AM EAT
|
||||
```
|
||||
|
||||
#### 查看所有的 Linux 仓库信息。
|
||||
另外,可以使用 `-r` 选项查看一个 Linux 发行版的仓库信息:
|
||||
#### 查看所有的 Linux 仓库信息
|
||||
|
||||
另外,可以使用 `-r` 选项查看一个 Linux 发行版的仓库信息:
|
||||
|
||||
```
|
||||
$ inxi -r
|
||||
@ -426,16 +421,16 @@ Active apt sources in file: /etc/apt/sources.list.d/ubuntu-mozilla-security-ppa-
|
||||
deb http://ppa.launchpad.net/ubuntu-mozilla-security/ppa/ubuntu xenial main
|
||||
deb-src http://ppa.launchpad.net/ubuntu-mozilla-security/ppa/ubuntu xenial main
|
||||
```
|
||||
下面是查看 Inxi 的安装版本、快速帮助和打开 man 主页的方法,以及更多的 Inxi 使用细节。
|
||||
|
||||
下面是查看 Inxi 的安装版本、快速帮助和打开 man 主页的方法,以及更多的 Inxi 使用细节。
|
||||
|
||||
```
|
||||
$ inxi -v #显示版本信息
|
||||
$ inxi -h #快速帮助
|
||||
$ man inxi #打开 man 主页
|
||||
```
|
||||
|
||||
浏览 Inxi 的官方 GitHub 主页 [https://github.com/smxi/inxi][4] 查看更多的信息。
|
||||
For more information, visit official GitHub Repository: [https://github.com/smxi/inxi][4]
|
||||
|
||||
Inxi 是一个功能强大的获取硬件和系统信息的命令行工具。这也是我使用过的最好的 [获取硬件和系统信息的命令行工具][5] 之一。
|
||||
|
||||
@ -446,7 +441,8 @@ Inxi 是一个功能强大的获取硬件和系统信息的命令行工具。这
|
||||
|
||||
|
||||
作者简介:
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(译者注:一个 Linux 开源门户网站)的狂热爱好者,即任的 Linux 系统管理员,web 开发者,TecMint 网站的专栏作者,他喜欢使用计算机工作,并且乐于分享计算机技术。
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 的狂热爱好者,即任的 Linux 系统管理员,web 开发者,TecMint 网站的专栏作者,他喜欢使用计算机工作,并且乐于分享计算机技术。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -455,7 +451,7 @@ via: http://www.tecmint.com/inxi-command-to-find-linux-system-information/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
99
published/201704/20170309 8 reasons to use LXDE.md
Normal file
99
published/201704/20170309 8 reasons to use LXDE.md
Normal file
@ -0,0 +1,99 @@
|
||||
使用 LXDE 的 8 个理由
|
||||
============================================================
|
||||
|
||||
> 考虑使用轻量级桌面环境 LXDE 作为你 Linux 桌面的理由
|
||||
|
||||

|
||||
|
||||
>Image by : opensource.com
|
||||
|
||||
去年年底,升级到 Fedora 25 所装的新版本 [KDE][7] Plasma 给我带来了严重问题,让我难以完成任何工作。出于两个原因我决定尝试其它 Linux 桌面环境。第一,我需要完成我的工作。第二,一心使用 KDE 已经有很多年,我认为是时候尝试一些不同的桌面了。
|
||||
|
||||
我第一个尝试了几周的替代桌面是 [Cinnamon][8],我在 1 月份介绍过它。这次我已经使用了 LXDE(轻量级 X11 桌面环境(Lightweight X11 Desktop Environment))大概 6 周,我发现它有很多我喜欢的东西。这是我使用 LXDE 的 8 个理由。
|
||||
|
||||
更多 Linux 相关资源
|
||||
|
||||
* [Linux 是什么?][1]
|
||||
* [Linux 容器是什么?][2]
|
||||
* [在 Linux 中管理设备][3]
|
||||
* [马上下载:Linux 命令速查表][4]
|
||||
* [我们最新的 Linux 文章][5]
|
||||
|
||||
### 1、 LXDE 支持多个面板
|
||||
|
||||
和 KDE 以及 Cinnamon 一样,LXDE 支持包括系统菜单、应用启动器的面板,以及显示正在运行应用图标的任务栏。我第一次登录到 LXDE 时,面板的配置看起来异常熟悉。LDXE 看起来已经根据我的 KDE 配置情况为我准备好了喜欢的顶部和底部面板,并包括了系统托盘设置。顶部面板上的应用程序启动器看似来自 Cinnamon 。面板上的东西使得启动和管理程序变得容易。默认情况下,只在桌面底部有一个面板。
|
||||
|
||||

|
||||
|
||||
*打开了 Openbox 配置管理器的 LXDE 桌面。这个桌面还没有更改过,因此它使用了默认的颜色和图标主题。*
|
||||
|
||||
### 2、 Openbox 配置管理器提供了一个用于管理和体验桌面外观的简单工具。
|
||||
|
||||
它为主题、窗口修饰、多个显示器的窗口行为、移动和调整窗口大小、鼠标控制、多桌面等提供了选项。虽然这看起来似乎很多,但它远不如配置 KDE 桌面那么复杂,尽管如此 Openbox 仍然提供了绝佳的效果。
|
||||
|
||||
### 3、 LXDE 有一个强大的菜单工具
|
||||
|
||||
在桌面偏好(Desktop Preference)菜单的高级(Advanced)标签页有个有趣的选项。这个选项的名称是 “点击桌面时显示窗口管理器提供的菜单(Show menus provided by window managers when desktop is clicked)”。选中这个复选框,当你右击桌面时,会显示 Openbox 桌面菜单,而不是标准的 LXDE 桌面菜单。
|
||||
|
||||
Openbox 桌面菜单包括了几乎每个你可能想要的菜单选项,所有都可从桌面便捷访问。它包括了所有的应用程序菜单、系统管理、以及首选项。它甚至有一个菜单包括了所有已安装的终端模拟器应用程序的列表,因此系统管理员可以轻易地启动他们喜欢的终端。
|
||||
|
||||
### 4、 LXDE 桌面的设计干净简单
|
||||
|
||||
它没有任何会妨碍你完成工作的东西。尽管你可以添加一些文件、目录、应用程序的链接到桌面,但是没有可以添加到桌面的小部件。在我的 KDE 和 Cinnamon 桌面上我确实喜欢一些小部件,但它们很容易被覆盖住,然后我就需要移动或者最小化窗口,或者使用 “显示桌面(Show Desktop)” 按钮清空整个桌面才能看到它们。 LXDE 确实有一个 “图标化所有窗口(Iconify all windows)” 按钮,但我很少需要使用它,除非我想看我的壁纸。
|
||||
|
||||
### 5、 LXDE 有一个强大的文件管理器
|
||||
|
||||
LXDE 默认的文件管理器是 PCManFM,因此在我使用 LXDE 的时候它成为了我的文件管理器。PCManFM 非常灵活、可以配置为适用于大部分人和场景。它看起来没有我常用的文件管理器 Krusader 那么可配置,但我确实喜欢 Krusader 所没有的 PCManFM 侧边栏。
|
||||
|
||||
PCManFM 允许打开多个标签页,可以通过右击侧边栏的任何条目或者单击图标栏的新标签图标打开。PCManFM 窗口左边的位置(Places)面板显示了应用程序菜单,你可以从 PCManFM 启动应用程序。位置(Places)面板上面也显示了一个设备图标,可以用于查看你的物理存储设备,一系列带按钮的可移除设备允许你挂载和卸载它们,还有可以便捷访问的主目录、桌面、回收站。位置(Places)面板的底部包括一些默认目录的快捷方式,例如 Documents、Music、Pictures、Videos 以及 Downloads。你也可以拖拽其它目录到位置(Places)面板的快捷方式部分。位置(Places) 面板可以换为正常的目录树。
|
||||
|
||||
### 6、 如果在现有窗口后面打开,新窗口的标题栏会闪烁
|
||||
|
||||
这是一个在大量现有窗口中定位新窗口的好方法。
|
||||
|
||||
### 7、 大部分现代桌面环境允许多个桌面,LXDE 也不例外
|
||||
|
||||
我喜欢使用一个桌面用于我的开发、测试以及编辑工作,另一个桌面用于普通任务,例如电子邮件和网页浏览。LXDE 默认提供两个桌面,但你可以配置为只有一个或者多个。右击桌面切换器(Desktop Pager)配置它。
|
||||
|
||||
通过一些有害但不是破坏性的测试,我发现最大允许桌面数目是 100。我还发现当我把桌面数目减少到低于我实际已经在使用的 3 个时,不活动桌面上的窗口会被移动到桌面 1。多么有趣的发现!
|
||||
|
||||
### 8、 Xfce 电源管理器是一个小巧但强大的应用程序,它允许你配置电源管理如何工作
|
||||
|
||||
它提供了一个标签页用于通用配置,以及用于系统、显示和设备的标签页。设备标签页显示了我系统上已有设备的表格,例如电池供电的鼠标、键盘,甚至我的 UPS(不间断电源)。它显示了每个设备的详细信息,包括厂商和系列号,如果可用的话,还有电池充电状态。当我写这篇博客的时候,我 UPS 的电量是 100%,而我罗技鼠标的电量是 75%。 Xfce 电源管理器还在系统托盘显示了一个图标,因此你可以从那里快速了解你设备的电池状态。
|
||||
|
||||
关于 LXDE 桌面还有很多喜欢的东西,但这些就是抓住了我的注意力,它们也是对我使用现代图形用户界面工作非常重要、不可或缺的东西。
|
||||
|
||||
我注意到奇怪的一点是,我一直没有弄明白桌面(Openbox)菜单的 “重新配置(Reconfigure)” 选项是干什么的。我点击了几次,从没有注意到有任何类型的任何活动表明该选项实际起了作用。
|
||||
|
||||
我发现 LXDE 是一个简单但强大的桌面。我享受使用它写这篇文章的几周时间。通过允许我访问我想要的应用程序和文件,同时在其余时间保持不会让我分神,LXDE 使我得以高效地工作。我也没有遇到任何妨碍我完成工作的问题——当然,除了我用于探索这个好桌面所花的时间。我非常推荐 LXDE 桌面。
|
||||
|
||||
我现在正在试用 GNOME 3 和 GNOME Shell,并将在下一期中报告。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both 是一个 Linux 和开源倡导者,他居住在北卡罗莱纳州的 Raleigh。他在 IT 行业已经超过 40 年,在他工作的 IBM 公司教授 OS/2 超过 20 年,他在 1981 年为最早的 IBM PC 写了第一个培训课程。他教过 Red Hat 的 RHCE 课程,在 MCI Worldcom、 Cisco 和北卡罗莱纳州 工作过。他一直在使用 Linux 和开源软件近 20 年。
|
||||
|
||||
--------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/8-reasons-use-lxde
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/article/17/3/8-reasons-use-lxde?rate=QigvkBy_9zLvktdsL-QaIWedjIqjtlwwJIVFQDQzsSY
|
||||
[7]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[8]:https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||
[9]:https://opensource.com/user/14106/feed
|
||||
[10]:https://opensource.com/article/17/3/8-reasons-use-lxde#comments
|
||||
[11]:https://opensource.com/users/dboth
|
||||
@ -1,4 +1,4 @@
|
||||
如何在 AWS EC2 的 Linux 服务器上打开端口
|
||||
如何在 AWS EC2 的 Linux 服务器上开放一个端口
|
||||
============================================================
|
||||
|
||||
_这是一篇用屏幕截图解释如何在 AWS EC2 Linux 服务器上打开端口的教程。它能帮助你管理 EC2 服务器上特定端口的服务。_
|
||||
@ -9,13 +9,13 @@ AWS(即 Amazon Web Services)不是 IT 世界中的新术语了。它是亚
|
||||
|
||||
AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹性计算)。使用它可以构建我们的 Linux 服务器。我们已经看到了[如何在 AWS 上设置免费的 Linux 服务器][11]了。
|
||||
|
||||
默认情况下,所有基于 EC2 的 Linux 服务器都只打开 22 端口,即 SSH 服务端口(所有 IP 的入站)。因此,如果你托管了任何特定端口的服务,则要为你的服务器在 AWS 防火墙上打开相应端口。
|
||||
默认情况下,所有基于 EC2 的 Linux 服务器都只打开 22 端口,即 SSH 服务端口(允许所有 IP 的入站连接)。因此,如果你托管了任何特定端口的服务,则要为你的服务器在 AWS 防火墙上打开相应端口。
|
||||
|
||||
同样它的 1 到 65535 的端口是打开的(所有出站流量)。如果你想改变这个,你可以使用下面的方法编辑出站规则。
|
||||
同样它的 1 到 65535 的端口是打开的(对于所有出站流量)。如果你想改变这个,你可以使用下面的方法编辑出站规则。
|
||||
|
||||
在 AWS 上为你的服务器设置防火墙规则很容易。你能够在几秒钟内为你的服务器打开端口。我将用截图指导你如何打开 EC2 服务器的端口。
|
||||
|
||||
_步骤 1 :_
|
||||
### 步骤 1 :
|
||||
|
||||
登录 AWS 帐户并进入 **EC2 管理控制台**。进入<ruby>“网络及安全”<rt>Network & Security </rt></ruby>菜单下的<ruby>**安全组**<rt>Security Groups</rt></ruby>,如下高亮显示:
|
||||
|
||||
@ -23,9 +23,7 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
|
||||
*AWS EC2 管理控制台*
|
||||
|
||||
* * *
|
||||
|
||||
_步骤 2 :_
|
||||
### 步骤 2 :
|
||||
|
||||
在<ruby>安全组<rt>Security Groups</rt></ruby>中选择你的 EC2 服务器,并在 <ruby>**行动**<rt>Actions</rt></ruby> 菜单下选择 <ruby>**编辑入站规则**<rt>Edit inbound rules</rt></ruby>。
|
||||
|
||||
@ -33,7 +31,7 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
|
||||
*AWS 入站规则菜单*
|
||||
|
||||
_步骤 3:_
|
||||
### 步骤 3:
|
||||
|
||||
现在你会看到入站规则窗口。你可以在此处添加/编辑/删除入站规则。这有几个如 http、nfs 等列在下拉菜单中,它们可以为你自动填充端口。如果你有自定义服务和端口,你也可以定义它。
|
||||
|
||||
@ -46,15 +44,13 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
* 类型:http
|
||||
* 协议:TCP
|
||||
* 端口范围:80
|
||||
* 源:任何来源(打开 80 端口接受来自任何IP(0.0.0.0/0)的请求),我的 IP:那么它会自动填充你当前的公共互联网 IP
|
||||
* 源:任何来源:打开 80 端口接受来自“任何IP(0.0.0.0/0)”的请求;我的 IP:那么它会自动填充你当前的公共互联网 IP
|
||||
|
||||
* * *
|
||||
|
||||
_步骤 4:_
|
||||
### 步骤 4:
|
||||
|
||||
就是这样了。保存完毕后,你的服务器入站 80 端口将会打开!你可以通过 telnet 到 EC2 服务器公共域名的 80 端口来检验(可以在 EC2 服务器详细信息中找到)。
|
||||
|
||||
|
||||
你也可以在 [ping.eu][12] 等网站上检验。
|
||||
|
||||
* * *
|
||||
@ -65,7 +61,7 @@ AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹
|
||||
|
||||
via: http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||
|
||||
作者:[Shrikant Lavhate ][a]
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -0,0 +1,128 @@
|
||||
如何在树莓派上安装 Fedora 25
|
||||
============================================================
|
||||
|
||||
> 了解 Fedora 第一个官方支持树莓派的版本
|
||||
|
||||

|
||||
|
||||
>图片提供 opensource.com
|
||||
|
||||
2016 年 10 月,Fedora 25 Beta 发布了,随之而来的还有对 [树莓派 2 和 3 的初步支持][6]。Fedora 25 的最终“通用”版在一个月后发布,从那时起,我一直在树莓派上尝试不同的 Fedora spins。
|
||||
|
||||
这篇文章不仅是一篇<ruby>树莓派<rt>Raspberry Pi</rt></ruby> 3 上的 Fedora 25 的点评,还集合了技巧、截图以及我对 Fedora 第一个官方支持 Pi 的这个版本的一些个人看法。
|
||||
|
||||
在我开始之前,需要说一下的是,为写这篇文章所做的所有工作都是在我的运行 Fedora 25 的个人笔记本电脑上完成的。我使用一张 microSD 插到 SD 适配器中,复制和编辑所有的 Fedora 镜像到 32GB 的 microSD 卡中,然后用它在一台三星电视上启动了树莓派 3。 因为 Fedora 25 尚不支持内置 Wi-Fi,所以树莓派 3 使用了以太网线缆进行网络连接。最后,我使用了 Logitech K410 无线键盘和触摸板进行输入。
|
||||
|
||||
如果你没有条件使用以太网线连接在你的树莓派上玩 Fedora 25,我曾经用过一个 Edimax Wi-Fi USB 适配器,它也可以在 Fedora 25 上工作,但在本文中,我只使用了以太网连接。
|
||||
|
||||
### 在树莓派上安装 Fedora 25 之前
|
||||
|
||||
阅读 Fedora 项目 wiki 上的[树莓派支持文档][7]。你可以从 wiki 下载 Fedora 25 安装所需的镜像,那里还列出了所有支持和不支持的内容。
|
||||
|
||||
此外,请注意,这是初始支持版本,还有许多新的工作和支持将随着 Fedora 26 的发布而出现,所以请随时报告 bug,并通过 [Bugzilla][8]、Fedora 的 [ARM 邮件列表][9]、或者 Freenode IRC 频道#fedora-arm,分享你在树莓派上使用 Fedora 25 的体验反馈。
|
||||
|
||||
### 安装
|
||||
|
||||
我下载并安装了五个不同的 Fedora 25 spin:GNOME(默认工作站)、KDE、Minimal、LXDE 和 Xfce。在多数情况下,它们都有一致和易于遵循的步骤,以确保我的树莓派 3 上启动正常。有的 spin 有已知 bug 的正在解决之中,而有的按照 Fedora wik 遵循标准操作程序即可。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、 GNOME 版本*
|
||||
|
||||
### 安装步骤
|
||||
|
||||
1、 在你的笔记本上,从支持文档页面的链接下载一个树莓派的 Fedora 25 镜像。
|
||||
|
||||
2、 在笔记本上,使用 `fedora-arm-installer` 或下述命令行将镜像复制到 microSD:
|
||||
|
||||
```
|
||||
xzcat Fedora-Workstation-armhfp-25-1.3-sda.raw.xz | dd bs=4M status=progress of=/dev/mmcblk0
|
||||
```
|
||||
|
||||
注意:`/dev/mmclk0` 是我的 microSD 插到 SD 适配器后,在我的笔记本电脑上挂载的设备名。虽然我在笔记本上使用 Fedora,可以使用 `fedora-arm-installer`,但我还是喜欢命令行。
|
||||
|
||||
3、 复制完镜像后,_先不要启动你的系统_。我知道你很想这么做,但你仍然需要进行几个调整。
|
||||
|
||||
4、 为了使镜像文件尽可能小以便下载,镜像上的根文件系统是很小的,因此你必须增加根文件系统的大小。如果你不这么做,你仍然可以启动你的派,但如果你一旦运行 `dnf update` 来升级你的系统,它就会填满文件系统,导致糟糕的事情发生,所以趁着 microSD 还在你的笔记本上进行分区:
|
||||
|
||||
```
|
||||
growpart /dev/mmcblk0 4
|
||||
resize2fs /dev/mmcblk0p4
|
||||
```
|
||||
|
||||
注意:在 Fedora 中,`growpart` 命令由 `cloud-utils-growpart.noarch` 这个 RPM 提供的。
|
||||
|
||||
5、文件系统更新后,您需要将 `vc4` 模块列入黑名单。[更多有关此 bug 的信息在此。][10]
|
||||
|
||||
我建议在启动树莓派之前这样做,因为不同的 spin 有不同表现方式。例如,(至少对我来说)在没有黑名单 `vc4` 的情况下,GNOME 在我启动后首先出现,但在系统更新后,它不再出现。 KDE spin 则在第一次启动时根本不会出现 KDE。因此我们可能需要在我们的第一次启动之前将 `vc4` 加入黑名单,直到这个错误以后解决了。
|
||||
|
||||
黑名单应该出现在两个不同的地方。首先,在你的 microSD 根分区上,在 `etc/modprode.d/` 下创建一个 `vc4.conf`,内容是:`blacklist vc4`。第二,在你的 microSD 启动分区,添加 `rd.driver.blacklist=vc4` 到 `extlinux/extlinux.conf` 文件的末尾。
|
||||
|
||||
6、 现在,你可以启动你的树莓派了。
|
||||
|
||||
### 启动
|
||||
|
||||
你要有耐心,特别是对于 GNOME 和 KDE 发行版来说。在 SSD(固态驱动器)几乎即时启动的时代,你很容易就对派的启动速度感到不耐烦,特别是第一次启动时。在第一次启动 Window Manager 之前,会先弹出一个初始配置页面,可以配置 root 密码、常规用户、时区和网络。配置完毕后,你就应该能够 SSH 到你的树莓派上,方便地调试显示问题了。
|
||||
|
||||
### 系统更新
|
||||
|
||||
在树莓派上运行 Fedora 25 后,你最终(或立即)会想要更新系统。
|
||||
|
||||
首先,进行内核升级时,先熟悉你的 `/boot/extlinux/extlinux.conf` 文件。如果升级内核,下次启动时,除非手动选择正确的内核,否则很可能会启动进入救援( Rescue )模式。避免这种情况发生最好的方法是,在你的 `extlinux.conf` 中将定义 Rescue 镜像的那五行移动到文件的底部,这样最新的内核将在下次自动启动。你可以直接在派上或通过在笔记本挂载来编辑 `/boot/extlinux/extlinux.conf`:
|
||||
```
|
||||
label Fedora 25 Rescue fdcb76d0032447209f782a184f35eebc (4.9.9-200.fc25.armv7hl)
|
||||
kernel /vmlinuz-0-rescue-fdcb76d0032447209f782a184f35eebc
|
||||
append ro root=UUID=c19816a7-cbb8-4cbb-8608-7fec6d4994d0 rd.driver.blacklist=vc4
|
||||
fdtdir /dtb-4.9.9-200.fc25.armv7hl/
|
||||
initrd /initramfs-0-rescue-fdcb76d0032447209f782a184f35eebc.img
|
||||
```
|
||||
|
||||
第二点,如果无论什么原因,如果你的显示器在升级后再次变暗,并且你确定已经将 `vc4` 加入黑名单,请运行 `lsmod | grep vc4`。你可以先启动到多用户模式而不是图形模式,并从命令行中运行 `startx`。 请阅读 `/etc/inittab` 中的内容,了解如何切换 target 的说明。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、 KDE 版本*
|
||||
|
||||
### Fedora Spin
|
||||
|
||||
在我尝试过的所有 Fedora Spin 中,唯一有问题的是 XFCE spin,我相信这是由于这个[已知的 bug][11] 导致的。
|
||||
|
||||
按照我在这里分享的步骤操作,GNOME、KDE、LXDE 和 minimal 都运行得很好。考虑到 KDE 和 GNOME 会占用更多资源,我会推荐想要在树莓派上使用 Fedora 25 的人使用 LXDE 和 Minimal。如果你是一位系统管理员,想要一台廉价的 SELinux 支持的服务器来满足你的安全考虑,而且只是想要使用树莓派作为你的服务器,开放 22 端口以及 vi 可用,那就用 Minimal 版本。对于开发人员或刚开始学习 Linux 的人来说,LXDE 可能是更好的方式,因为它可以快速方便地访问所有基于 GUI 的工具,如浏览器、IDE 和你可能需要的客户端。
|
||||
|
||||

|
||||
|
||||
*树莓派 3 上的 Fedora 25 workstation、LXDE。*
|
||||
|
||||
看到越来越多的 Linux 发行版在基于 ARM 的树莓派上可用,那真是太棒了。对于其第一个支持的版本,Fedora 团队为日常 Linux 用户提供了更好的体验。我很期待 Fedora 26 的改进和 bug 修复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Anderson Silva - Anderson 于 1996 年开始使用 Linux。更精确地说是 Red Hat Linux。 2007 年,他作为 IT 部门的发布工程师时加入红帽,他的职业梦想成为了现实。此后,他在红帽担任过多个不同角色,从发布工程师到系统管理员、高级经理和信息系统工程师。他是一名 RHCE 和 RHCA 以及一名活跃的 Fedora 包维护者。
|
||||
|
||||
----------------
|
||||
|
||||
via: https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ansilva
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi?rate=gIIRltTrnOlwo4h81uDvdAjAE3V2rnwoqH0s_Dx44mE
|
||||
[6]:https://fedoramagazine.org/raspberry-pi-support-fedora-25-beta/
|
||||
[7]:https://fedoraproject.org/wiki/Raspberry_Pi
|
||||
[8]:https://bugzilla.redhat.com/show_bug.cgi?id=245418
|
||||
[9]:https://lists.fedoraproject.org/admin/lists/arm%40lists.fedoraproject.org/
|
||||
[10]:https://bugzilla.redhat.com/show_bug.cgi?id=1387733
|
||||
[11]:https://bugzilla.redhat.com/show_bug.cgi?id=1389163
|
||||
[12]:https://opensource.com/user/26502/feed
|
||||
[13]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi#comments
|
||||
[14]:https://opensource.com/users/ansilva
|
||||
@ -1,20 +1,19 @@
|
||||
如何在现有的 Linux 系统上添加新的磁盘
|
||||
============================================================
|
||||
|
||||
作为一个系统管理员,我们会有这样的一些需求:作为升级服务器容量的一部分,或者有时出现磁盘故障时更换磁盘,我们需要将新的硬盘配置到现有服务器。
|
||||
|
||||
作为一个系统管理员,我们会有这样的一些需求:作为升级服务器容量的一部分、或者有时出现磁盘故障时更换磁盘,我们需要将新的硬盘配置到现有服务器。
|
||||
在这篇文章中,我会向你逐步介绍添加新硬盘到现有 **RHEL/CentOS** 或者 **Debian/Ubuntu Linux** 系统的步骤。
|
||||
|
||||
在这篇文章中,我会向你逐步介绍添加新硬盘到现有 RHEL/CentOS 或者 Debian/Ubuntu Linux 系统的步骤。
|
||||
|
||||
**推荐阅读:** [如何将超过 2TB 的新硬盘添加到现有 Linux][1]
|
||||
**推荐阅读:** [如何将超过 2TB 的新硬盘添加到现有 Linux][1]。
|
||||
|
||||
重要:请注意这篇文章的目的只是告诉你如何创建新的分区,而不包括分区扩展或者其它选项。
|
||||
|
||||
我使用 [fdisk 工具][2] 完成这些配置。
|
||||
|
||||
我已经添加了一块 20GB 容量的硬盘,挂载到了 `/data` 分区。
|
||||
我已经添加了一块 **20GB** 容量的硬盘,挂载到了 `/data` 分区。
|
||||
|
||||
fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行工具。
|
||||
`fdisk` 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行工具。
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
@ -26,7 +25,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||

|
||||
][3]
|
||||
|
||||
查看 Linux 分区详情
|
||||
*查看 Linux 分区详情*
|
||||
|
||||
添加了 20GB 容量的硬盘后,`fdisk -l` 的输出像下面这样。
|
||||
|
||||
@ -37,9 +36,9 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
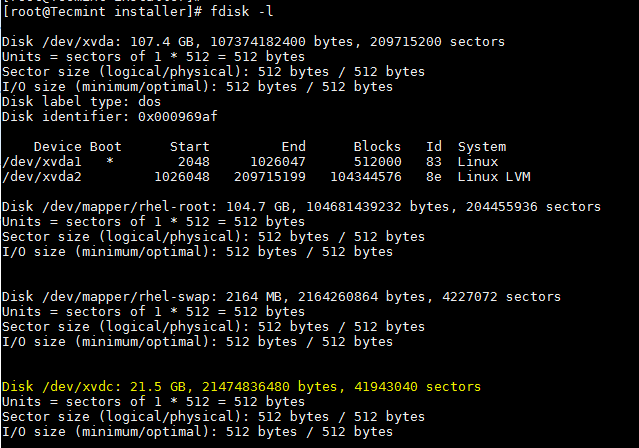
|
||||
][4]
|
||||
|
||||
查看新分区详情
|
||||
*查看新分区详情*
|
||||
|
||||
新添加的磁盘显示为 `/dev/xvdc`。如果我们添加的是物理磁盘,基于磁盘类型它会显示类似 `/dev/sda`。这里我使用的是虚拟磁盘。
|
||||
新添加的磁盘显示为 `/dev/xvdc`。如果我们添加的是物理磁盘,基于磁盘类型它会显示为类似 `/dev/sda`。这里我使用的是虚拟磁盘。
|
||||
|
||||
要在特定硬盘上分区,例如 `/dev/xvdc`。
|
||||
|
||||
@ -47,7 +46,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
# fdisk /dev/xvdc
|
||||
```
|
||||
|
||||
常用 fdisk 命令。
|
||||
常用的 fdisk 命令。
|
||||
|
||||
* `n` - 创建分区
|
||||
* `p` - 打印分区表
|
||||
@ -61,7 +60,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
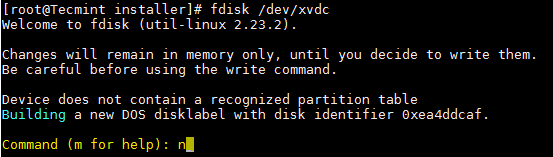
|
||||
][5]
|
||||
|
||||
在 Linux上创建新分区
|
||||
*在 Linux 上创建新分区*
|
||||
|
||||
创建主分区或者扩展分区。默认情况下我们最多可以有 4 个主分区。
|
||||
|
||||
@ -69,7 +68,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
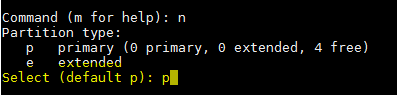
|
||||
][6]
|
||||
|
||||
创建主分区
|
||||
*创建主分区*
|
||||
|
||||
按需求输入分区编号。推荐使用默认的值 `1`。
|
||||
|
||||
@ -77,7 +76,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
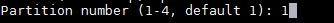
|
||||
][7]
|
||||
|
||||
分配分区编号
|
||||
*分配分区编号*
|
||||
|
||||
输入第一个扇区的大小。如果是一个新的磁盘,通常选择默认值。如果你是在同一个磁盘上创建第二个分区,我们需要在前一个分区的最后一个扇区的基础上加 `1`。
|
||||
|
||||
@ -85,7 +84,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
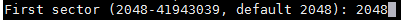
|
||||
][8]
|
||||
|
||||
为分区分配扇区
|
||||
*为分区分配扇区*
|
||||
|
||||
输入最后一个扇区或者分区大小的值。通常推荐输入分区的大小。总是添加前缀 `+` 以防止值超出范围错误。
|
||||
|
||||
@ -93,7 +92,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
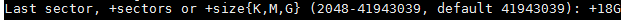
|
||||
][9]
|
||||
|
||||
分配分区大小
|
||||
*分配分区大小*
|
||||
|
||||
保存更改并退出。
|
||||
|
||||
@ -101,9 +100,9 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
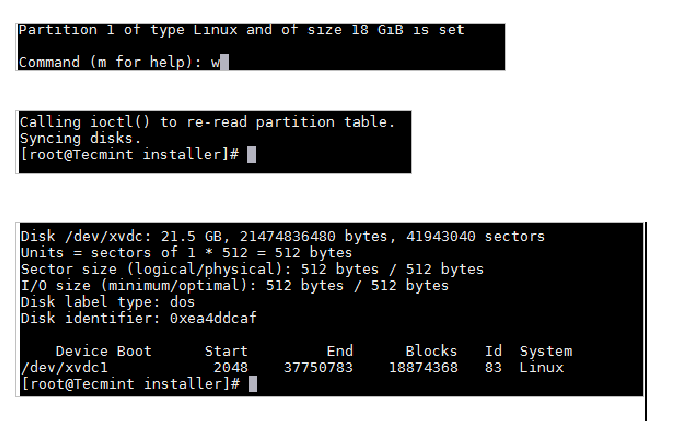
|
||||
][10]
|
||||
|
||||
保存分区更改
|
||||
*保存分区更改*
|
||||
|
||||
现在使用 mkfs 命令格式化磁盘。
|
||||
现在使用 **mkfs** 命令格式化磁盘。
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/xvdc1
|
||||
@ -112,7 +111,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
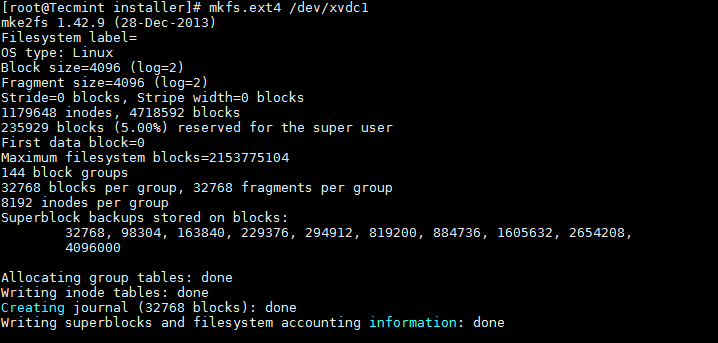
|
||||
][11]
|
||||
|
||||
格式化新分区
|
||||
*格式化新分区*
|
||||
|
||||
格式化完成后,按照下面的命令挂载分区。
|
||||
|
||||
@ -130,7 +129,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
现在你知道如何使用 [fdisk 命令][12] 在新磁盘上创建分区并挂载了。
|
||||
|
||||
当处理分区、尤其是编辑已配置磁盘的时候我们需要格外的小心。请分享你的反馈和建议吧。
|
||||
当处理分区、尤其是编辑已配置磁盘的时候,我们需要格外的小心。请分享你的反馈和建议吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -144,12 +143,12 @@ via: http://www.tecmint.com/add-new-disk-to-an-existing-linux/
|
||||
|
||||
作者:[Lakshmi Dhandapani][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/lakshmi/
|
||||
[1]:http://www.tecmint.com/add-disk-larger-than-2tb-to-an-existing-linux/
|
||||
[1]:https://linux.cn/article-8398-1.html
|
||||
[2]:http://www.tecmint.com/fdisk-commands-to-manage-linux-disk-partitions/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Partition-Details.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-New-Partition-Details.png
|
||||
@ -0,0 +1,366 @@
|
||||
关于 Linux 进程你所需要知道的一切
|
||||
============================================================
|
||||
|
||||
在这篇指南中,我们会逐步对进程做基本的了解,然后简要看看如何用特定命令[管理 Linux 进程][9]。
|
||||
|
||||
进程(process)是指正在执行的程序;是程序正在运行的一个实例。它由程序指令,和从文件、其它程序中读取的数据或系统用户的输入组成。
|
||||
|
||||
### 进程的类型
|
||||
|
||||
在 Linux 中主要有两种类型的进程:
|
||||
|
||||
* 前台进程(也称为交互式进程) - 这些进程由终端会话初始化和控制。换句话说,需要有一个连接到系统中的用户来启动这样的进程;它们不是作为系统功能/服务的一部分自动启动。
|
||||
* 后台进程(也称为非交互式/自动进程) - 这些进程没有连接到终端;它们不需要任何用户输入。
|
||||
|
||||
#### 什么是守护进程(daemon)
|
||||
|
||||
这是后台进程的特殊类型,它们在系统启动时启动,并作为服务一直运行;它们不会死亡。它们自发地作为系统任务启动(作为服务运行)。但是,它们能被用户通过 init 进程控制。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
*Linux 进程状态*
|
||||
|
||||
### 在 Linux 中创建进程
|
||||
|
||||
(LCTT 译注:此节原文不确,根据译者理解重新提供)
|
||||
|
||||
在 Linux 中创建进程有三种方式:
|
||||
|
||||
#### fork() 方式
|
||||
|
||||
使用 fork() 函数以父进程为蓝本复制一个进程,其 PID号与父进程 PID 号不同。在 Linux 环境下,fork() 是以写复制实现的,新的子进程的环境和父进程一样,只有内存与父进程不同,其他与父进程共享,只有在父进程或者子进程进行了修改后,才重新生成一份。
|
||||
|
||||
#### system() 方式
|
||||
|
||||
system() 函数会调用 `/bin/sh –c command` 来执行特定的命令,并且阻塞当前进程的执行,直到 command 命令执行完毕。新的子进程会有新的 PID。
|
||||
|
||||
#### exec() 方式
|
||||
|
||||
exec() 方式有若干种不同的函数,与之前的 fork() 和 system() 函数不同,exec() 方式会用新进程代替原有的进程,系统会从新的进程运行,新的进程的 PID 值会与原来的进程的 PID 值相同。
|
||||
|
||||
### Linux 如何识别进程?
|
||||
|
||||
由于 Linux 是一个多用户系统,意味着不同的用户可以在系统上运行各种各样的程序,内核必须唯一标识程序运行的每个实例。
|
||||
|
||||
程序由它的进程 ID(PID)和它父进程的进程 ID(PPID)识别,因此进程可以被分类为:
|
||||
|
||||
* 父进程 - 这些是在运行时创建其它进程的进程。
|
||||
* 子进程 - 这些是在运行时由其它进程创建的进程。
|
||||
|
||||
#### init 进程
|
||||
|
||||
init 进程是系统中所有进程的父进程,它是[启动 Linux 系统][11]后第一个运行的程序;它管理着系统上的所有其它进程。它由内核自身启动,因此理论上说它没有父进程。
|
||||
|
||||
init 进程的进程 ID 总是为 1。它是所有孤儿进程的收养父母。(它会收养所有孤儿进程)。
|
||||
|
||||
#### 查找进程 ID
|
||||
|
||||
你可以用 pidof 命令查找某个进程的进程 ID:
|
||||
|
||||
```
|
||||
# pidof systemd
|
||||
# pidof top
|
||||
# pidof httpd
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
*查找 Linux 进程 ID*
|
||||
|
||||
要查找当前 shell 的进程 ID 以及它父进程的进程 ID,可以运行:
|
||||
|
||||
```
|
||||
$ echo $$
|
||||
$ echo $PPID
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
*查找 Linux 父进程 ID*
|
||||
|
||||
### 在 Linux 中启动进程
|
||||
|
||||
每次你运行一个命令或程序(例如 cloudcmd - CloudCommander),它就会在系统中启动一个进程。你可以按照下面的方式启动一个前台(交互式)进程,它会被连接到终端,用户可以发送输入给它:
|
||||
|
||||
```
|
||||
# cloudcmd
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
*启动 Linux 交互进程*
|
||||
|
||||
#### Linux 后台任务
|
||||
|
||||
要在后台(非交互式)启动一个进程,使用 `&` 符号,此时,该进程不会从用户中读取输入,直到它被移到前台。
|
||||
|
||||
```
|
||||
# cloudcmd &
|
||||
# jobs
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
*在后台启动 Linux 进程*
|
||||
|
||||
你也可以使用 `[Ctrl + Z]` 暂停执行一个程序并把它发送到后台,它会给进程发送 SIGSTOP 信号,从而暂停它的执行;它就会变为空闲:
|
||||
|
||||
```
|
||||
# tar -cf backup.tar /backups/* #press Ctrl+Z
|
||||
# jobs
|
||||
```
|
||||
|
||||
要在后台继续运行上面被暂停的命令,使用 `bg` 命令:
|
||||
|
||||
```
|
||||
# bg
|
||||
```
|
||||
|
||||
要把后台进程发送到前台,使用 `fg` 命令以及任务的 ID,类似:
|
||||
|
||||
```
|
||||
# jobs
|
||||
# fg %1
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
*Linux 后台进程任务*
|
||||
|
||||
你也可能想要阅读:[如何在后台启动 Linux 命令以及在终端分离(Detach)进程][17]
|
||||
|
||||
### Linux 中进程的状态
|
||||
|
||||
在执行过程中,取决于它的环境一个进程会从一个状态转变到另一个状态。在 Linux 中,一个进程有下面的可能状态:
|
||||
|
||||
* Running - 此时它正在运行(它是系统中的当前进程)或准备运行(它正在等待分配 CPU 单元)。
|
||||
* Waiting - 在这个状态,进程正在等待某个事件的发生或者系统资源。另外,内核也会区分两种不同类型的等待进程;可中断等待进程(interruptible waiting processes) - 可以被信号中断,以及不可中断等待进程(uninterruptible waiting processes)- 正在等待硬件条件,不能被任何事件/信号中断。
|
||||
* Stopped - 在这个状态,进程已经被停止了,通常是由于收到了一个信号。例如,正在被调试的进程。
|
||||
* Zombie - 该进程已经死亡,它已经停止了但是进程表(process table)中仍然有它的条目。
|
||||
|
||||
### 如何在 Linux 中查看活跃进程
|
||||
|
||||
有很多 Linux 工具可以用于查看/列出系统中正在运行的进程,两个传统众所周知的是 [ps][18] 和 [top][19] 命令:
|
||||
|
||||
#### 1. ps 命令
|
||||
|
||||
它显示被选中的系统中活跃进程的信息,如下图所示:
|
||||
|
||||
```
|
||||
# ps
|
||||
# ps -e | head
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
*列出 Linux 活跃进程*
|
||||
|
||||
#### 2. top - 系统监控工具
|
||||
|
||||
[top 是一个强大的工具][21],它能给你提供 [运行系统的动态实时视图][22],如下面截图所示:
|
||||
|
||||
```
|
||||
# top
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][23]
|
||||
|
||||
*列出 Linux 正在运行的程序*
|
||||
|
||||
阅读这篇文章获取更多 top 使用事例:[Linux 中 12 个 top 命令事例][24]
|
||||
|
||||
#### 3. glances - 系统监控工具
|
||||
|
||||
glances 是一个相对比较新的系统监控工具,它有一些比较高级的功能:
|
||||
|
||||
```
|
||||
# glances
|
||||
```
|
||||
|
||||
[
|
||||
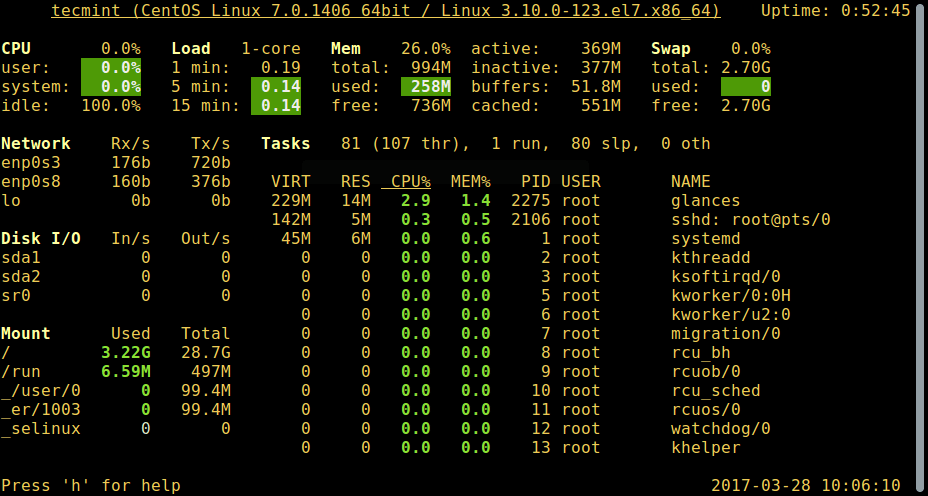
|
||||
][25]
|
||||
|
||||
*Glances – Linux 进程监控*
|
||||
|
||||
要获取完整使用指南,请阅读:[Glances - Linux 的一个高级实时系统监控工具][26]
|
||||
|
||||
还有很多你可以用来列出活跃进程的其它有用的 Linux 系统监视工具,打开下面的链接了解更多关于它们的信息:
|
||||
|
||||
1. [监控 Linux 性能的 20 个命令行工具][1]
|
||||
2. [13 个有用的 Linux 监控工具][2]
|
||||
|
||||
### 如何在 Linux 中控制进程
|
||||
|
||||
Linux 也有一些命令用于控制进程,例如 `kill`、`pkill`、`pgrep` 和 `killall`,下面是一些如何使用它们的基本事例:
|
||||
|
||||
````
|
||||
$ pgrep -u tecmint top
|
||||
$ kill 2308
|
||||
$ pgrep -u tecmint top
|
||||
$ pgrep -u tecmint glances
|
||||
$ pkill glances
|
||||
$ pgrep -u tecmint glances
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][27]
|
||||
|
||||
*控制 Linux 进程*
|
||||
|
||||
想要深入了解如何使用这些命令,在 Linux 中杀死/终止活跃进程,可以点击下面的链接:
|
||||
|
||||
1. [终止 Linux 进程的 Kill、Pkill 和 Killall 命令指南][3]
|
||||
2. [如何在 Linux 中查找并杀死进程][4]
|
||||
|
||||
注意当你系统僵死(freeze)时你可以使用它们杀死 [Linux 中的不响应程序][28]。
|
||||
|
||||
#### 给进程发送信号
|
||||
|
||||
Linux 中控制进程的基本方法是给它们发送信号。你可以发送很多信号给一个进程,运行下面的命令可以查看所有信号:
|
||||
|
||||
```
|
||||
$ kill -l
|
||||
```
|
||||
[
|
||||

|
||||
][29]
|
||||
|
||||
*列出所有 Linux 信号*
|
||||
|
||||
要给一个进程发送信号,可以使用我们之前提到的 `kill`、`pkill` 或 `pgrep` 命令。但只有被编程为能识别这些信号时程序才能响应这些信号。
|
||||
|
||||
大部分信号都是系统内部使用,或者给程序员编写代码时使用。下面是一些对系统用户非常有用的信号:
|
||||
|
||||
* SIGHUP 1 - 当控制它的终端被被关闭时给进程发送该信号。
|
||||
* SIGINT 2 - 当用户使用 `[Ctrl+C]` 中断进程时控制它的终端给进程发送这个信号。
|
||||
* SIGQUIT 3 - 当用户发送退出信号 `[Ctrl+D]` 时给进程发送该信号。
|
||||
* SIGKILL 9 - 这个信号会马上中断(杀死)进程,进程不会进行清理操作。
|
||||
* SIGTERM 15 - 这是一个程序终止信号(kill 默认发送这个信号)。
|
||||
* SIGTSTP 20 - 它的控制终端发送这个信号给进程要求它停止(终端停止);通过用户按 `[Ctrl+Z]` 触发。
|
||||
|
||||
下面是当 Firefox 应用程序僵死时通过它的 PID 杀死它的 kill 命令事例:
|
||||
|
||||
```
|
||||
$ pidof firefox
|
||||
$ kill 9 2687
|
||||
或
|
||||
$ kill -KILL 2687
|
||||
或
|
||||
$ kill -SIGKILL 2687
|
||||
```
|
||||
|
||||
使用它的名称杀死应用,可以像下面这样使用 pkill 或 killall:
|
||||
|
||||
```
|
||||
$ pkill firefox
|
||||
$ killall firefox
|
||||
```
|
||||
|
||||
#### 更改 Linux 进程优先级
|
||||
|
||||
在 Linux 系统中,所有活跃进程都有一个优先级以及 nice 值。有比点优先级进程有更高优先级的进程一般会获得更多的 CPU 时间。
|
||||
|
||||
但是,有 root 权限的系统用户可以使用 `nice` 和 `renice` 命令影响(更改)优先级。
|
||||
|
||||
在 top 命令的输出中, NI 显示了进程的 nice 值:
|
||||
|
||||
```
|
||||
$ top
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][30]
|
||||
|
||||
*列出 Linux 正在运行的进程*
|
||||
|
||||
使用 `nice` 命令为一个进程设置 nice 值。记住一个普通用户可以给他拥有的进程设置 0 到 20 的 nice 值。
|
||||
|
||||
只有 root 用户可以使用负的 nice 值。
|
||||
|
||||
要重新设置一个进程的优先级,像下面这样使用 `renice` 命令:
|
||||
|
||||
```
|
||||
$ renice +8 2687
|
||||
$ renice +8 2103
|
||||
```
|
||||
|
||||
阅读我们其它如何管理和控制 Linux 进程的有用文章。
|
||||
|
||||
1. [Linux 进程管理:启动、停止以及中间过程][5]
|
||||
2. [使用 ‘top’ 命令 Batch 模式查找内存使用最高的 15 个进程][6]
|
||||
3. [在 Linux 中查找内存和 CPU 使用率最高的进程][7]
|
||||
4. [在 Linux 中如何使用进程 ID 查找进程名称][8]
|
||||
|
||||
就是这些!如果你有任何问题或者想法,通过下面的反馈框和我们分享吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software) 爱好者,一个 Linux 系统管理员、web 开发员,现在也是 TecMint 的内容创建者,他喜欢和电脑一起工作,他相信知识共享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-process-management/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[2]:http://www.tecmint.com/linux-performance-monitoring-tools/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
[4]:http://www.tecmint.com/find-and-kill-running-processes-pid-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
[6]:http://www.tecmint.com/find-processes-by-memory-usage-top-batch-mode/
|
||||
[7]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[8]:http://www.tecmint.com/find-process-name-pid-number-linux/
|
||||
[9]:http://www.tecmint.com/dstat-monitor-linux-server-performance-process-memory-network/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/ProcessState.png
|
||||
[11]:http://www.tecmint.com/linux-boot-process/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Process-ID.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-Linux-Parent-Process-ID.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Start-Linux-Interactive-Process.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Start-Linux-Process-in-Background.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Linux-Background-Process-Jobs.png
|
||||
[17]:http://www.tecmint.com/run-linux-command-process-in-background-detach-process/
|
||||
[18]:http://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||
[19]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/ps-command.png
|
||||
[21]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[22]:http://www.tecmint.com/bcc-best-linux-performance-monitoring-tools/
|
||||
[23]:http://www.tecmint.com/wp-content/uploads/2017/03/top-command.png
|
||||
[24]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
[25]:http://www.tecmint.com/wp-content/uploads/2017/03/glances.png
|
||||
[26]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[27]:http://www.tecmint.com/wp-content/uploads/2017/03/Control-Linux-Processes.png
|
||||
[28]:http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
[29]:http://www.tecmint.com/wp-content/uploads/2017/03/list-all-signals.png
|
||||
[30]:http://www.tecmint.com/wp-content/uploads/2017/03/top-command.png
|
||||
[31]:http://www.tecmint.com/author/aaronkili/
|
||||
[32]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[33]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
172
published/201704/20170403 Yes Python is Slow and I Dont Care.md
Normal file
172
published/201704/20170403 Yes Python is Slow and I Dont Care.md
Normal file
@ -0,0 +1,172 @@
|
||||
Python 是慢,但我无所谓
|
||||
=====================================
|
||||
|
||||
> 为牺牲性能追求生产率而呐喊
|
||||
|
||||

|
||||
|
||||
让我从关于 Python 中的 asyncio 这个标准库的讨论中休息一会,谈谈我最近正在思考的一些东西:Python 的速度。对不了解我的人说明一下,我是一个 Python 的粉丝,而且我在我能想到的所有地方都积极地使用 Python。人们对 Python 最大的抱怨之一就是它的速度比较慢,有些人甚至拒绝尝试使用 Python,因为它比其他语言速度慢。这里说说为什么我认为应该尝试使用 Python,尽管它是有点慢。
|
||||
|
||||
### 速度不再重要
|
||||
|
||||
过去的情形是,程序需要花费很长的时间来运行,CPU 比较贵,内存也很贵。程序的运行时间是一个很重要的指标。计算机非常的昂贵,计算机运行所需要的电也是相当贵的。对这些资源进行优化是因为一个永恒的商业法则:
|
||||
|
||||
> 优化你最贵的资源。
|
||||
|
||||
在过去,最贵的资源是计算机的运行时间。这就是导致计算机科学致力于研究不同算法的效率的原因。然而,这已经不再是正确的,因为现在硅芯片很便宜,确实很便宜。运行时间不再是你最贵的资源。公司最贵的资源现在是它的员工时间。或者换句话说,就是你。把事情做完比把它变快更加重要。实际上,这是相当的重要,我将把它再次放在这里,仿佛它是一个引文一样(给那些只是粗略浏览的人):
|
||||
|
||||
> 把事情做完比快速地做事更加重要。
|
||||
|
||||
你可能会说:“我的公司在意速度,我开发一个 web 应用程序,那么所有的响应时间必须少于 x 毫秒。”或者,“我们失去了客户,因为他们认为我们的 app 运行太慢了。”我并不是想说速度一点也不重要,我只是想说速度不再是最重要的东西;它不再是你最贵的资源。
|
||||
|
||||

|
||||
|
||||
### 速度是唯一重要的东西
|
||||
|
||||
当你在编程的背景下说 _速度_ 时,你通常是说性能,也就是 CPU 周期。当你的 CEO 在编程的背景下说 _速度_ 时,他指的是业务速度,最重要的指标是产品上市的时间。基本上,你的产品/web 程序是多么的快并不重要。它是用什么语言写的也不重要。甚至它需要花费多少钱也不重要。在一天结束时,让你的公司存活下来或者死去的唯一事物就是产品上市时间。我不只是说创业公司的想法 -- 你开始赚钱需要花费多久,更多的是“从想法到客户手中”的时间期限。企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。如果在你的产品上市之前,你的竞争对手已经提前上市了,那么你想出了多少好的主意也将不再重要。你必须第一个上市,或者至少能跟上。一但你放慢了脚步,你就输了。
|
||||
|
||||
> 企业能够存活下来的唯一方法就是比你的竞争对手更快地创新。
|
||||
|
||||
#### 一个微服务的案例
|
||||
|
||||
像 Amazon、Google 和 Netflix 这样的公司明白快速前进的重要性。他们创建了一个业务系统,可以使用这个系统迅速地前进和快速的创新。微服务是针对他们的问题的解决方案。这篇文章不谈你是否应该使用微服务,但是至少要理解为什么 Amazon 和 Google 认为他们应该使用微服务。
|
||||
|
||||

|
||||
|
||||
微服务本来就很慢。微服务的主要概念是用网络调用来打破边界。这意味着你正在把使用的函数调用(几个 cpu 周期)转变为一个网络调用。没有什么比这更影响性能了。和 CPU 相比较,网络调用真的很慢。但是这些大公司仍然选择使用微服务。我所知道的架构里面没有比微服务还要慢的了。微服务最大的弊端就是它的性能,但是最大的长处就是上市的时间。通过在较小的项目和代码库上建立团队,一个公司能够以更快的速度进行迭代和创新。这恰恰表明了,非常大的公司也很在意上市时间,而不仅仅只是只有创业公司。
|
||||
|
||||
#### CPU 不是你的瓶颈
|
||||
|
||||

|
||||
|
||||
如果你在写一个网络应用程序,如 web 服务器,很有可能的情况会是,CPU 时间并不是你的程序的瓶颈。当你的 web 服务器处理一个请求时,可能会进行几次网络调用,例如到数据库,或者像 Redis 这样的缓存服务器。虽然这些服务本身可能比较快速,但是对它们的网络调用却很慢。[这里有一篇很好的关于特定操作的速度差异的博客文章][1]。在这篇文章里,作者把 CPU 周期时间缩放到更容易理解的人类时间。如果一个单独的 CPU 周期等同于 **1 秒**,那么一个从 California 到 New York 的网络调用将相当于 **4 年**。那就说明了网络调用是多少的慢。按一些粗略估计,我们可以假设在同一数据中心内的普通网络调用大约需要 3 毫秒。这相当于我们“人类比例” **3 个月**。现在假设你的程序是高 CPU 密集型,这需要 100000 个 CPU 周期来对单一调用进行响应。这相当于刚刚超过 **1 天**。现在让我们假设你使用的是一种要慢 5 倍的语言,这将需要大约 **5 天**。很好,将那与我们 3 个月的网络调用时间相比,4 天的差异就显得并不是很重要了。如果有人为了一个包裹不得不至少等待 3 个月,我不认为额外的 4 天对他们来说真的很重要。
|
||||
|
||||
上面所说的终极意思是,尽管 Python 速度慢,但是这并不重要。语言的速度(或者 CPU 时间)几乎从来不是问题。实际上谷歌曾经就这一概念做过一个研究,[并且他们就此发表过一篇论文][2]。那篇论文论述了设计高吞吐量的系统。在结论里,他们说到:
|
||||
|
||||
> 在高吞吐量的环境中使用解释性语言似乎是矛盾的,但是我们已经发现 CPU 时间几乎不是限制因素;语言的表达性是指,大多数程序是源程序,同时它们的大多数时间花费在 I/O 读写和本机的运行时代码上。而且,解释性语言无论是在语言层面的轻松实验还是在允许我们在很多机器上探索分布计算的方法都是很有帮助的,
|
||||
|
||||
再次强调:
|
||||
|
||||
> CPU 时间几乎不是限制因素。
|
||||
|
||||
### 如果 CPU 时间是一个问题怎么办?
|
||||
|
||||
你可能会说,“前面说的情况真是太好了,但是我们确实有过一些问题,这些问题中 CPU 成为了我们的瓶颈,并造成了我们的 web 应用的速度十分缓慢”,或者“在服务器上 X 语言比 Y 语言需要更少的硬件资源来运行。”这些都可能是对的。关于 web 服务器有这样的美妙的事情:你可以几乎无限地负载均衡它们。换句话说,可以在 web 服务器上投入更多的硬件。当然,Python 可能会比其他语言要求更好的硬件资源,比如 c 语言。只是把硬件投入在 CPU 问题上。相比于你的时间,硬件就显得非常的便宜了。如果你在一年内节省了两周的生产力时间,那将远远多于所增加的硬件开销的回报。
|
||||
|
||||

|
||||
|
||||
### 那么,Python 更快一些吗?
|
||||
|
||||
这一篇文章里面,我一直在谈论最重要的是开发时间。所以问题依然存在:当就开发时间而言,Python 要比其他语言更快吗?按常规惯例来看,我、[google][3] [还有][4][其他][5][几个人][6]可以告诉你 Python 是多么的[高效][7]。它为你抽象出很多东西,帮助你关注那些你真正应该编写代码的地方,而不会被困在琐碎事情的杂草里,比如你是否应该使用一个向量或者一个数组。但你可能不喜欢只是听别人说的这些话,所以让我们来看一些更多的经验数据。
|
||||
|
||||
在大多数情况下,关于 python 是否是更高效语言的争论可以归结为脚本语言(或动态语言)与静态类型语言两者的争论。我认为人们普遍接受的是静态类型语言的生产力较低,但是,[这有一篇优秀的论文][8]解释了为什么不是这样。就 Python 而言,这里有一项[研究][9],它调查了不同语言编写字符串处理的代码所需要花费的时间,供参考。
|
||||
|
||||
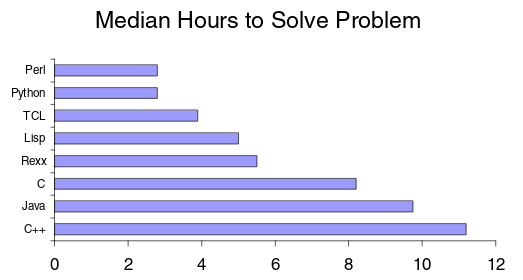
|
||||
|
||||
在上述研究中,Python 的效率比 Java 高出 2 倍。有一些其他研究也显示相似的东西。 Rosetta Code 对编程语言的差异进行了[深入的研究][10]。在论文中,他们把 python 与其他脚本语言/解释性语言相比较,得出结论:
|
||||
|
||||
> Python 更简洁,即使与函数式语言相比较(平均要短 1.2 到 1.6 倍)
|
||||
|
||||
普遍的趋势似乎是 Python 中的代码行总是更少。代码行听起来可能像一个可怕的指标,但是包括上面已经提到的两项研究在内的[多项研究][11]表明,每种语言中每行代码所需要花费的时间大约是一样的。因此,限制代码行数就可以提高生产效率。甚至 codinghorror(一名 C# 程序员)本人[写了一篇关于 Python 是如何更有效率的文章][12]。
|
||||
|
||||
我认为说 Python 比其他的很多语言更加的有效率是公正的。这主要是由于 Python 有大量的自带以及第三方库。[这里是一篇讨论 Python 和其他语言间的差异的简单的文章][13]。如果你不知道为何 Python 是如此的小巧和高效,我邀请你借此机会学习一点 python,自己多实践。这儿是你的第一个程序:
|
||||
|
||||
```
|
||||
import __hello__
|
||||
```
|
||||
|
||||
### 但是如果速度真的重要呢?
|
||||
|
||||

|
||||
|
||||
上述论点的语气可能会让人觉得优化与速度一点也不重要。但事实是,很多时候运行时性能真的很重要。一个例子是,你有一个 web 应用程序,其中有一个特定的端点需要用很长的时间来响应。你知道这个程序需要多快,并且知道程序需要改进多少。
|
||||
|
||||
在我们的例子中,发生了两件事:
|
||||
|
||||
1. 我们注意到有一个端点执行缓慢。
|
||||
2. 我们承认它是缓慢,因为我们有一个可以衡量是否足够快的标准,而它没达到那个标准。
|
||||
|
||||
我们不必在应用程序中微调优化所有内容,只需要让其中每一个都“足够快”。如果一个端点花费了几秒钟来响应,你的用户可能会注意到,但是,他们并不会注意到你将响应时间由 35 毫秒降低到 25 毫秒。“足够好”就是你需要做到的所有事情。_免责声明: 我应该说有**一些**应用程序,如实时投标程序,**确实**需要细微优化,每一毫秒都相当重要。但那只是例外,而不是规则。_
|
||||
|
||||
为了明白如何对端点进行优化,你的第一步将是配置代码,并尝试找出瓶颈在哪。毕竟:
|
||||
|
||||
> <ruby>任何除了瓶颈之外的改进都是错觉。<rt>Any improvements made anywhere besides the bottleneck are an illusion.</rt></ruby> -- Gene Kim
|
||||
|
||||
如果你的优化没有触及到瓶颈,你只是浪费你的时间,并没有解决实际问题。在你优化瓶颈之前,你不会得到任何重要的改进。如果你在不知道瓶颈是什么前就尝试优化,那么你最终只会在部分代码中玩耍。在测量和确定瓶颈之前优化代码被称为“过早优化”。人们常提及 Donald Knuth 说的话,但他声称这句话实际上是他从别人那里听来的:
|
||||
|
||||
> <ruby>过早优化是万恶之源<rt>Premature optimization is the root of all evil</rt></ruby>。
|
||||
|
||||
在谈到维护代码库时,来自 Donald Knuth 的更完整的引文是:
|
||||
|
||||
> 在 97% 的时间里,我们应该忘记微不足道的效率:**过早的优化是万恶之源**。然而在关
|
||||
> 键的 3%,我们不应该错过优化的机会。 —— Donald Knuth
|
||||
|
||||
换句话说,他所说的是,在大多数时间你应该忘记对你的代码进行优化。它几乎总是足够好。在不是足够好的情况下,我们通常只需要触及 3% 的代码路径。比如因为你使用了 if 语句而不是函数,你的端点快了几纳秒,但这并不会使你赢得任何奖项。
|
||||
|
||||
过早的优化包括调用某些更快的函数,或者甚至使用特定的数据结构,因为它通常更快。计算机科学认为,如果一个方法或者算法与另一个具有相同的渐近增长(或称为 Big-O),那么它们是等价的,即使在实践中要慢两倍。计算机是如此之快,算法随着数据/使用增加而造成的计算增长远远超过实际速度本身。换句话说,如果你有两个 O(log n) 的函数,但是一个要慢两倍,这实际上并不重要。随着数据规模的增大,它们都以同样的速度“慢下来”。这就是过早优化是万恶之源的原因;它浪费了我们的时间,几乎从来没有真正有助于我们的性能改进。
|
||||
|
||||
就 Big-O 而言,你可以认为对你的程序而言,所有的语言都是 O(n),其中 n 是代码或者指令的行数。对于同样的指令,它们以同样的速率增长。对于渐进增长,一种语言的速度快慢并不重要,所有语言都是相同的。在这个逻辑下,你可以说,为你的应用程序选择一种语言仅仅是因为它的“快速”是过早优化的最终形式。你选择某些预期快速的东西,却没有测量,也不理解瓶颈将在哪里。
|
||||
|
||||
> 为您的应用选择语言只是因为它的“快速”,是过早优化的最终形式。
|
||||
|
||||
|
||||

|
||||
|
||||
### 优化 Python
|
||||
|
||||
我最喜欢 Python 的一点是,它可以让你一次优化一点点代码。假设你有一个 Python 的方法,你发现它是你的瓶颈。你对它优化过几次,可能遵循[这里][14]和[那里][15]的一些指导,现在,你很肯定 Python 本身就是你的瓶颈。Python 有调用 C 代码的能力,这意味着,你可以用 C 重写这个方法来减少性能问题。你可以一次重写一个这样的方法。这个过程允许你用任何可以编译为 C 兼容汇编程序的语言,编写良好优化后的瓶颈方法。这让你能够在大多数时间使用 Python 编写,只在必要的时候都才用较低级的语言来写代码。
|
||||
|
||||
有一种叫做 Cython 的编程语言,它是 Python 的超集。它几乎是 Python 和 C 的合并,是一种渐进类型的语言。任何 Python 代码都是有效的 Cython 代码,Cython 代码可以编译成 C 代码。使用 Cython,你可以编写一个模块或者一个方法,并逐渐进步到越来越多的 C 类型和性能。你可以将 C 类型和 Python 的鸭子类型混在一起。使用 Cython,你可以获得混合后的完美组合,只在瓶颈处进行优化,同时在其他所有地方不失去 Python 的美丽。
|
||||
|
||||

|
||||
|
||||
*星战前夜的一幅截图:这是用 Python 编写的 space MMO 游戏。*
|
||||
|
||||
当您最终遇到 Python 的性能问题阻碍时,你不需要把你的整个代码库用另一种不同的语言来编写。你只需要用 Cython 重写几个函数,几乎就能得到你所需要的性能。这就是[星战前夜][16]采取的策略。这是一个大型多玩家的电脑游戏,在整个架构中使用 Python 和 Cython。它们通过优化 C/Cython 中的瓶颈来实现游戏级别的性能。如果这个策略对他们有用,那么它应该对任何人都有帮助。或者,还有其他方法来优化你的 Python。例如,[PyPy][17] 是一个 Python 的 JIT 实现,它通过使用 PyPy 替掉 CPython(这是 Python 的默认实现),为长时间运行的应用程序提供重要的运行时改进(如 web 服务器)。
|
||||
|
||||

|
||||
|
||||
让我们回顾一下要点:
|
||||
|
||||
* 优化你最贵的资源。那就是你,而不是计算机。
|
||||
* 选择一种语言/框架/架构来帮助你快速开发(比如 Python)。不要仅仅因为某些技术的快而选择它们。
|
||||
* 当你遇到性能问题时,请找到瓶颈所在。
|
||||
* 你的瓶颈很可能不是 CPU 或者 Python 本身。
|
||||
* 如果 Python 成为你的瓶颈(你已经优化过你的算法),那么可以转向热门的 Cython 或者 C。
|
||||
* 尽情享受可以快速做完事情的乐趣。
|
||||
|
||||
我希望你喜欢阅读这篇文章,就像我喜欢写这篇文章一样。如果你想说谢谢,请为我点下赞。另外,如果某个时候你想和我讨论 Python,你可以在 twitter 上艾特我(@nhumrich),或者你可以在 [Python slack channel][18] 找到我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nick Humrich -- 坚持采用持续交付的方法,并为之写了很多工具。同是还是一名 Python 黑客与技术狂热者,目前是一名 DevOps 工程师。
|
||||
|
||||
via: https://medium.com/hacker-daily/yes-python-is-slow-and-i-dont-care-13763980b5a1
|
||||
|
||||
作者:[Nick Humrich][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@nhumrich
|
||||
[1]:https://blog.codinghorror.com/the-infinite-space-between-words/
|
||||
[2]:https://static.googleusercontent.com/media/research.google.com/en//archive/sawzall-sciprog.pdf
|
||||
[3]:https://www.codefellows.org/blog/5-reasons-why-python-is-powerful-enough-for-google/
|
||||
[4]:https://www.lynda.com/Python-tutorials/Python-Programming-Efficiently/534425-2.html
|
||||
[5]:https://www.linuxjournal.com/article/3882
|
||||
[6]:https://www.codeschool.com/blog/2016/01/27/why-python/
|
||||
[7]:http://pythoncard.sourceforge.net/what_is_python.html
|
||||
[8]:http://www.tcl.tk/doc/scripting.html
|
||||
[9]:http://www.connellybarnes.com/documents/language_productivity.pdf
|
||||
[10]:https://arxiv.org/pdf/1409.0252.pdf
|
||||
[11]:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.113.1831&rep=rep1&type=pdf
|
||||
[12]:https://blog.codinghorror.com/are-all-programming-languages-the-same/
|
||||
[13]:https://www.python.org/doc/essays/comparisons/
|
||||
[14]:https://wiki.python.org/moin/PythonSpeed
|
||||
[15]:https://wiki.python.org/moin/PythonSpeed/PerformanceTips
|
||||
[16]:https://www.eveonline.com/
|
||||
[17]:http://pypy.org/
|
||||
[18]:http://pythondevelopers.herokuapp.com/
|
||||
@ -1,16 +1,15 @@
|
||||
pyDash — 一个基于 web 的 Linux 性能监测工具
|
||||
pyDash:一个基于 web 的 Linux 性能监测工具
|
||||
============================================================
|
||||
|
||||
pyDash 是一个轻量且[基于 web 的 Linux 性能监测工具][1],它是用 Python 和 [Django][2] 加上 Chart.js 来写的。经测试,在下面这些主流 Linux 发行版上可运行:CentOS、Fedora、Ubuntu、Debian、Raspbian 以及 Pidora 。
|
||||
`pyDash` 是一个轻量且[基于 web 的 Linux 性能监测工具][1],它是用 Python 和 [Django][2] 加上 Chart.js 来写的。经测试,在下面这些主流 Linux 发行版上可运行:CentOS、Fedora、Ubuntu、Debian、Raspbian 以及 Pidora 。
|
||||
|
||||
你可以使用这个工具来监视你的 Linux 个人电脑/服务器资源,比如 CPU、内存
|
||||
、网络统计,包括在线用户以及更多的进程。仪表盘是完全使用主要的 Python 版本提供的 Python 库开发的,因此它的依赖关系很少,你不需要安装许多包或库来运行它。
|
||||
你可以使用这个工具来监视你的 Linux 个人电脑/服务器资源,比如 CPU、内存、网络统计,包括在线用户的进程以及更多。仪表盘完全由主要的 Python 发行版本所提供的 Python 库开发,因此它的依赖关系很少,你不需要安装许多包或库来运行它。
|
||||
|
||||
在这篇文章中,我将展示如果安装 pyDash 来监测 Linux 服务器性能。
|
||||
在这篇文章中,我将展示如何安装 `pyDash` 来监测 Linux 服务器性能。
|
||||
|
||||
#### 如何在 Linux 系统下安装 pyDash
|
||||
### 如何在 Linux 系统下安装 pyDash
|
||||
|
||||
1、首先,像下面这样安装需要的软件包 git 和 Python pip:
|
||||
1、首先,像下面这样安装需要的软件包 `git` 和 `Python pip`:
|
||||
|
||||
```
|
||||
-------------- 在 Debian/Ubuntu 上 --------------
|
||||
@ -22,7 +21,7 @@ $ sudo apt-get install git python-pip
|
||||
# dnf install git python-pip
|
||||
```
|
||||
|
||||
2、如果安装好了 git 和 Python pip,那么接下来,像下面这样安装 virtualenv,它有助于处理针对 Python 项目的依赖关系:
|
||||
2、如果安装好了 git 和 Python pip,那么接下来,像下面这样安装 `virtualenv`,它有助于处理针对 Python 项目的依赖关系:
|
||||
|
||||
```
|
||||
# pip install virtualenv
|
||||
@ -30,14 +29,14 @@ $ sudo apt-get install git python-pip
|
||||
$ sudo pip install virtualenv
|
||||
```
|
||||
|
||||
3、现在,像下面这样使用 git 命令,把 pyDash 仓库克隆到 home 目录中:
|
||||
3、现在,像下面这样使用 `git` 命令,把 pyDash 仓库克隆到 home 目录中:
|
||||
|
||||
```
|
||||
# git clone https://github.com/k3oni/pydash.git
|
||||
# cd pydash
|
||||
```
|
||||
|
||||
4、下一步,使用下面的 virtualenv 命令为项目创建一个叫做 pydashtest 虚拟环境:
|
||||
4、下一步,使用下面的 `virtualenv` 命令为项目创建一个叫做 `pydashtest` 虚拟环境:
|
||||
|
||||
```
|
||||
$ virtualenv pydashtest #give a name for your virtual environment like pydashtest
|
||||
@ -48,9 +47,9 @@ $ virtualenv pydashtest #give a name for your virtual environment like pydashtes
|
||||
|
||||
*创建虚拟环境*
|
||||
|
||||
重点:请注意,上面的屏幕截图中,虚拟环境的 bin 目录被高亮显示,你的可能和这不一样,取决于你把 pyDash 目录克隆到什么位置。
|
||||
重要:请注意,上面的屏幕截图中,虚拟环境的 `bin` 目录被高亮显示,你的可能和这不一样,取决于你把 pyDash 目录克隆到什么位置。
|
||||
|
||||
5、创建好虚拟环境(pydashtest)以后,你需要在使用前像下面这样激活它:
|
||||
5、创建好虚拟环境(`pydashtest`)以后,你需要在使用前像下面这样激活它:
|
||||
|
||||
```
|
||||
$ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
@ -61,16 +60,16 @@ $ source /home/aaronkilik/pydash/pydashtest/bin/activate
|
||||
|
||||
*激活虚拟环境*
|
||||
|
||||
从上面的屏幕截图中,你可以注意到,提示字符串 1(PS1)已经发生改变,这表明虚拟环境已经被激活,而且可以开始使用。
|
||||
从上面的屏幕截图中,你可以注意到,提示字符串 1(`PS1`)已经发生改变,这表明虚拟环境已经被激活,而且可以开始使用。
|
||||
|
||||
6、现在,安装 pydash 项目 requirements;如何你是一个细心的人,那么可以使用 [cat 命令][5]查看 requirements.txt 的内容,然后像下面展示这样进行安装:
|
||||
6、现在,安装 pydash 项目 requirements;如何你好奇的话,可以使用 [cat 命令][5]查看 `requirements.txt` 的内容,然后像下面所示那样进行安装:
|
||||
|
||||
```
|
||||
$ cat requirements.txt
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
7、现在,进入 `pydash` 目录,里面包含一个名为 `settings.py` 的文件,也可直接运行下面的命令打开这个文件,然后把 `SECRET_KEY` 改为一个特定值:
|
||||
7、现在,进入 `pydash` 目录,里面包含一个名为 `settings.py` 的文件,也可直接运行下面的命令打开这个文件,然后把 `SECRET_KEY` 改为一个特定值:
|
||||
|
||||
```
|
||||
$ vi pydash/settings.py
|
||||
@ -83,7 +82,7 @@ $ vi pydash/settings.py
|
||||
|
||||
保存文件然后退出。
|
||||
|
||||
8、之后,运行下面的命令来创建一个项目数据库和安装 Django 的身份验证系统,并创建一个项目的超级用户:
|
||||
8、之后,运行下面的命令来创建一个项目数据库和安装 Django 的身份验证系统,并创建一个项目的超级用户:
|
||||
|
||||
```
|
||||
$ python manage.py syncdb
|
||||
@ -104,13 +103,13 @@ Password (again): ############
|
||||
|
||||
*创建项目数据库*
|
||||
|
||||
9、这个时候,一切都设置好了,然后,运行下面的命令来启用 Django 开发服务器:
|
||||
9、这个时候,一切都设置好了,然后,运行下面的命令来启用 Django 开发服务器:
|
||||
|
||||
```
|
||||
$ python manage.py runserver
|
||||
```
|
||||
|
||||
10、接下来,打开你的 web 浏览器,输入网址:http://127.0.0.1:8000/ 进入 web 控制台登录界面,输入你在第 8 步中创建数据库和安装 Django 身份验证系统时创建的超级用户名和密码,然后点击登录。
|
||||
10、接下来,打开你的 web 浏览器,输入网址:`http://127.0.0.1:8000/` 进入 web 控制台登录界面,输入你在第 8 步中创建数据库和安装 Django 身份验证系统时创建的超级用户名和密码,然后点击登录。
|
||||
|
||||
[
|
||||
|
||||
@ -118,7 +117,7 @@ $ python manage.py runserver
|
||||
|
||||
*pyDash 登录界面*
|
||||
|
||||
11、登录到 pydash 主页面以后,你将会得到一段监测系统的基本信息,包括 CPU、内存和硬盘使用量以及系统平均负载。
|
||||
11、登录到 pydash 主页面以后,你将会可以看到监测系统的基本信息,包括 CPU、内存和硬盘使用量以及系统平均负载。
|
||||
|
||||
向下滚动便可查看更多部分的信息。
|
||||
|
||||
@ -128,7 +127,7 @@ $ python manage.py runserver
|
||||
|
||||
*pydash 服务器性能概述*
|
||||
|
||||
12、下一个屏幕截图显示的是一段 pydash 的跟踪界面,包括 IP 地址、互联网流量、硬盘读/写、在线用户以及 netstats 。
|
||||
12、下一个屏幕截图显示的是一段 pydash 的跟踪界面,包括 IP 地址、互联网流量、硬盘读/写、在线用户以及 netstats 。
|
||||
|
||||
[
|
||||

|
||||
@ -136,7 +135,7 @@ $ python manage.py runserver
|
||||
|
||||
*pyDash 网络概述*
|
||||
|
||||
13、下一个 pydash 主页面的截图显示了一部分系统中被监视的活跃进程。
|
||||
13、下一个 pydash 主页面的截图显示了一部分系统中被监视的活跃进程。
|
||||
|
||||
|
||||
[
|
||||
@ -154,16 +153,16 @@ $ python manage.py runserver
|
||||
|
||||
作者简介:
|
||||
|
||||
我叫 Ravi Saive,是 TecMint 的创建者,是一个喜欢在网上分享技巧和知识的计算机极客和 Linux Guru 。我的大多数服务器都运行在叫做 Linux 的开源平台上。请关注我:[Twitter][10]、[Facebook][01] 以及 [Google+][02] 。
|
||||
我叫 Ravi Saive,是 TecMint 的原创作者,是一个喜欢在网上分享技巧和知识的计算机极客和 Linux Guru。我的大多数服务器都运行在 Linux 开源平台上。请关注我:[Twitter][10]、[Facebook][01] 以及 [Google+][02] 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/pydash-a-web-based-linux-performance-monitoring-tool/
|
||||
|
||||
作者:[Ravi Saive ][a]
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
# Anbox
|
||||
Anbox:容器中的 Android
|
||||
===============
|
||||
|
||||
Anbox 是一个基于容器的方式,在像 Ubuntu 这样的常规的 GNU Linux 系统上启动一个完整的 Android 系统。
|
||||
Anbox 以基于容器的方式,在像 Ubuntu 这样的常规的 GNU Linux 系统上启动一个完整的 Android 系统。
|
||||
|
||||
## 概述
|
||||
### 概述
|
||||
|
||||
Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在容器中运行完整的 Android 系统,并提供任何基于 GNU Linux 平台的 Android 程序。
|
||||
Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在容器中运行完整的 Android 系统,并在任何基于 GNU Linux 平台上提供 Android 应用。
|
||||
|
||||
容器内的 Android 无法直接访问任何硬件。所有硬件访问都通过主机上的 anbox 守护进程进行。我们重用基于 QEMU 的模拟器实现的 Android 中的 GL、ES 加速渲染。容器内的 Android 系统使用不同的管道与主机系统通信,并通过它发送所有硬件访问命令。
|
||||
|
||||
@ -15,19 +16,19 @@ Anbox 使用 Linux 命名空间(user、pid、uts、net、mount、ipc)来在
|
||||
* [Android 的 “qemud” 复用守护进程](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD.TXT)
|
||||
* [Android qemud 服务](https://android.googlesource.com/platform/external/qemu/+/emu-master-dev/android/docs/ANDROID-QEMUD-SERVICES.TXT)
|
||||
|
||||
Anbox 目前适合桌面使用,但也可使用移动操作系统,如 Ubuntu Touch、Sailfish OS 或 Lune OS。然而,由于 Android 程序映射目前只针对桌面环境,因此还需要额外的工作来支持其他的用户界面。
|
||||
Anbox 目前适合桌面使用,但也用在移动操作系统上,如 Ubuntu Touch、Sailfish OS 或 Lune OS。然而,由于 Android 程序的映射目前只针对桌面环境,因此还需要额外的工作来支持其他的用户界面。
|
||||
|
||||
Android 运行时环境带有一个基于[ Android 开源项目](https://source.android.com/)镜像的最小自定义 Android 系统。所使用的镜像目前基于 Android 7.1.1。
|
||||
Android 运行时环境带有一个基于 [Android 开源项目](https://source.android.com/)镜像的最小自定义 Android 系统。所使用的镜像目前基于 Android 7.1.1。
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
目前,安装过程包括一些添加额外组件到系统的步骤。包括:
|
||||
|
||||
* 没有分发版内核同时启用的 binder 和 ashmen 原始内核模块。
|
||||
* 使用 udev 规则为 /dev/binder 和 /dev/ashmem 设置正确权限。
|
||||
* 能够启动 Anbox 会话管理器作为用户会话的一个启动任务。
|
||||
* 启用用于 binder 和 ashmen 的非发行的树外内核模块。
|
||||
* 使用 udev 规则为 /dev/binder 和 /dev/ashmem 设置正确权限。
|
||||
* 能够启动 Anbox 会话管理器作为用户会话的一个启动任务。
|
||||
|
||||
为了使这个过程尽可能简单,我们将必要的步骤绑定在一个 snap(见 https://snapcraft.io) 中,称为“anbox-installer”。这个安装程序会执行所有必要的步骤。你可以在所有支持 snap 的系统运行下面的命令安装它。
|
||||
为了使这个过程尽可能简单,我们将必要的步骤绑定在一个 snap(见 https://snapcraft.io) 中,称之为 “anbox-installer”。这个安装程序会执行所有必要的步骤。你可以在所有支持 snap 的系统运行下面的命令安装它。
|
||||
|
||||
```
|
||||
$ snap install --classic anbox-installer
|
||||
@ -49,11 +50,11 @@ $ anbox-installer
|
||||
|
||||
它会引导你完成安装过程。
|
||||
|
||||
**注意:** Anbox 目前处于** pre-alpha 开发状态**。不要指望它具有生产环境你需要的所有功能。你肯定会遇到错误和崩溃。如果你遇到了,请不要犹豫并报告它们!
|
||||
**注意:** Anbox 目前处于 **pre-alpha 开发状态**。不要指望它具有生产环境你需要的所有功能。你肯定会遇到错误和崩溃。如果你遇到了,请不要犹豫并报告它们!
|
||||
|
||||
**注意:** Anbox snap 目前 **完全没有约束**,因此它只能从边缘渠道获取。正确的约束是我们想要在未来实现的,但由于 Anbox 的性质和复杂性,这不是一个简单的任务。
|
||||
|
||||
## 已支持的 Linux 发行版
|
||||
### 已支持的 Linux 发行版
|
||||
|
||||
目前我们官方支持下面的 Linux 发行版:
|
||||
|
||||
@ -65,9 +66,9 @@ $ anbox-installer
|
||||
* Ubuntu 16.10 (yakkety)
|
||||
* Ubuntu 17.04 (zesty)
|
||||
|
||||
## 安装并运行 Android 程序
|
||||
### 安装并运行 Android 程序
|
||||
|
||||
## 从源码构建
|
||||
#### 从源码构建
|
||||
|
||||
要构建 Anbox 运行时不需要特别了解什么,我们使用 cmake 作为构建系统。你的主机系统中应已有下面这些构建依赖:
|
||||
|
||||
@ -132,11 +133,11 @@ $ snapcraft
|
||||
$ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
```
|
||||
|
||||
## 运行 Anbox
|
||||
#### 运行 Anbox
|
||||
|
||||
要从本地构建运行 Anbox ,你需要了解更多一点。请参考[“运行时步骤”](docs/runtime-setup.md)文档。
|
||||
|
||||
## 文档
|
||||
### 文档
|
||||
|
||||
在项目源代码的子目录下,你可以找到额外的关于 Anbox 的文档。
|
||||
|
||||
@ -145,15 +146,15 @@ $ snap install --dangerous --devmode anbox_1_amd64.snap
|
||||
* [运行时步骤](docs/runtime-setup.md)
|
||||
* [构建 Android 镜像](docs/build-android.md)
|
||||
|
||||
## 报告 bug
|
||||
### 报告 bug
|
||||
|
||||
如果你发现了一个 Anbox 问题,请[提交一个 bug](https://github.com/anbox/anbox/issues/new)。
|
||||
如果你发现了一个 Anbox 问题,请[提交 bug](https://github.com/anbox/anbox/issues/new)。
|
||||
|
||||
## 取得联系
|
||||
### 取得联系
|
||||
|
||||
如果你想要与开发者联系,你可以在 [FreeNode](https://freenode.net/) 中加入 *#anbox* 的 IRC 频道。
|
||||
|
||||
## 版权与许可
|
||||
### 版权与许可
|
||||
|
||||
Anbox 重用了像 Android QEMU 模拟器这样的其他项目的代码。这些项目可在外部/带有许可声明的子目录中得到。
|
||||
|
||||
@ -163,7 +164,7 @@ anbox 源码本身,如果没有在相关源码中声明其他的许可,默
|
||||
|
||||
via: https://github.com/anbox/anbox/blob/master/README.md
|
||||
|
||||
作者:[ Anbox][a]
|
||||
作者:[Anbox][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -0,0 +1,238 @@
|
||||
GoTTY:把你的 Linux 终端放到浏览器里面
|
||||
============================================================
|
||||
|
||||
GoTTY 是一个简单的基于 Go 语言的命令行工具,它可以将你的终端(TTY)作为 web 程序共享。它会将命令行工具转换为 web 程序。
|
||||
|
||||
它使用 Chrome OS 的终端仿真器(hterm)来在 Web 浏览器上执行基于 JavaScript 的终端。重要的是,GoTTY 运行了一个 Web 套接字服务器,它基本上是将 TTY 的输出传输给客户端,并从客户端接收输入(即允许客户端的输入),并将其转发给 TTY。
|
||||
|
||||
它的架构(hterm + web socket 的想法)灵感来自 [Wetty 项目][1],它使终端能够通过 HTTP 和 HTTPS 使用。
|
||||
|
||||
### 先决条件
|
||||
|
||||
你需要在 Linux 中安装 [GoLang (Go 编程语言)][2] 环境来运行 GoTTY。
|
||||
|
||||
### 如何在 Linux 中安装 GoTTY
|
||||
|
||||
如果你已经有一个[可以工作的 Go 语言环境][3],运行下面的 `go get` 命令来安装它:
|
||||
|
||||
```
|
||||
# go get github.com/yudai/gotty
|
||||
```
|
||||
|
||||
上面的命令会在你的 `GOBIN` 环境变量中安装 GOTTY 的二进制,尝试检查下是否如此:
|
||||
|
||||
```
|
||||
# $GOPATH/bin/
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*检查 GOBIN 环境*
|
||||
|
||||
### 如何在 Linux 中使用 GoTTY
|
||||
|
||||
要运行它,你可以使用 GOBIN 环境变量并用命令补全:
|
||||
|
||||
```
|
||||
# $GOBIN/gotty
|
||||
```
|
||||
|
||||
另外,要不带完整命令路径运行 GoTTY 或其他 Go 程序,使用 `export` 命令将 `GOBIN` 变量添加到 `~/.profile` 文件中的 `PATH` 环境变量中。
|
||||
|
||||
```
|
||||
export PATH="$PATH:$GOBIN"
|
||||
```
|
||||
|
||||
保存文件并关闭。接着运行 `source` 来使更改生效:
|
||||
|
||||
```
|
||||
# source ~/.profile
|
||||
```
|
||||
|
||||
运行 GoTTY 命令的常规语法是:
|
||||
|
||||
```
|
||||
Usage: gotty [options] <Linux command here> [<arguments...>]
|
||||
```
|
||||
|
||||
现在用 GoTTY 运行任意命令,如 [df][5] 来从 Web 浏览器中查看系统分区空间及使用率。
|
||||
|
||||
```
|
||||
# gotty df -h
|
||||
```
|
||||
|
||||
GoTTY 默认会在 8080 启动一个 Web 服务器。在浏览器中打开 URL:`http://127.0.0.1:8080/`,你会看到运行的命令仿佛运行在终端中一样:
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
*Gotty 查看 Linux 磁盘使用率*
|
||||
|
||||
### 如何在 Linux 中自定义 GoTTY
|
||||
|
||||
你可以在 `~/.gotty` 配置文件中修改默认选项以及终端,如果该文件存在,它会在每次启动时加载这个文件。
|
||||
|
||||
这是由 getty 命令读取的主要自定义文件,因此,按如下方式创建:
|
||||
|
||||
```
|
||||
# touch ~/.gotty
|
||||
```
|
||||
|
||||
并为配置选项设置你自己的有效值(在此处查找所有配置选项)以自定义 GoTTY,例如:
|
||||
|
||||
```
|
||||
// Listen at port 9000 by default
|
||||
port = "9000"
|
||||
// Enable TSL/SSL by default
|
||||
enable_tls = true
|
||||
// hterm preferences
|
||||
// Smaller font and a little bit bluer background color
|
||||
preferences {
|
||||
font_size = 5,
|
||||
background_color = "rgb(16, 16, 32)"
|
||||
}
|
||||
```
|
||||
|
||||
你可以使用命令行中的 `--html` 选项设置你自己的 `index.html` 文件:
|
||||
|
||||
```
|
||||
# gotty --index /path/to/index.html uptime
|
||||
```
|
||||
|
||||
### 如何在 GoTTY 中使用安全功能
|
||||
|
||||
由于 GoTTY 默认不提供可靠的安全保障,你需要手动使用下面说明的某些安全功能。
|
||||
|
||||
#### 允许客户端在终端中运行命令
|
||||
|
||||
请注意,默认情况下,GoTTY 不允许客户端输入到TTY中,它只支持窗口缩放。
|
||||
|
||||
但是,你可以使用 `-w` 或 `--permit-write` 选项来允许客户端写入 TTY,但是并不推荐这么做因为会有安全威胁。
|
||||
|
||||
以下命令会使用 [vi 命令行编辑器][7]在 Web 浏览器中打开文件 `fossmint.txt` 进行编辑:
|
||||
|
||||
```
|
||||
# gotty -w vi fossmint.txt
|
||||
```
|
||||
|
||||
以下是从 Web 浏览器看到的 vi 界面(像平常一样使用 vi 命令):
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
*Gotty Web Vi 编辑器*
|
||||
|
||||
#### 使用基本(用户名和密码)验证运行 GoTTY
|
||||
|
||||
尝试激活基本身份验证机制,这样客户端将需要输入指定的用户名和密码才能连接到 GoTTY 服务器。
|
||||
|
||||
以下命令使用 `-c` 选项限制客户端访问,以向用户询问指定的凭据(用户名:`test` 密码:`@67890`):
|
||||
|
||||
```
|
||||
# gotty -w -p "9000" -c "test@67890" glances
|
||||
```
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
*使用基本验证运行 GoTTY*
|
||||
|
||||
#### Gotty 生成随机 URL
|
||||
|
||||
限制访问服务器的另一种方法是使用 `-r` 选项。GoTTY 会生成一个随机 URL,这样只有知道该 URL 的用户才可以访问该服务器。
|
||||
|
||||
还可以使用 `-title-format "GoTTY – {{ .Command }} ({{ .Hostname }})"` 选项来定义浏览器标题。[glances][10] 用于显示系统监控统计信息:
|
||||
|
||||
```
|
||||
# gotty -r --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
以下是从浏览器中看到的上面的命令的结果:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
*使用 Gotty 随机 URL 用于 Glances 系统监控*
|
||||
|
||||
#### 带有 SSL/TLS 使用 GoTTY
|
||||
|
||||
因为默认情况下服务器和客户端之间的所有连接都不加密,当你通过 GoTTY 发送秘密信息(如用户凭据或任何其他信息)时,你需要使用 `-t` 或 `--tls` 选项才能在会话中启用 TLS/SSL:
|
||||
|
||||
默认情况下,GoTTY 会读取证书文件 `~/.gotty.crt` 和密钥文件 `~/.gotty.key`,因此,首先使用下面的 `openssl` 命令创建一个自签名的证书以及密钥( 回答问题以生成证书和密钥文件):
|
||||
|
||||
```
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ~/.gotty.key -out ~/.gotty.crt
|
||||
```
|
||||
|
||||
按如下所示,通过启用 SSL/TLS,以安全方式使用 GoTTY:
|
||||
|
||||
```
|
||||
# gotty -tr --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
#### 与多个客户端分享你的终端
|
||||
|
||||
你可以使用[终端复用程序][12]来与多个客户端共享一个进程,以下命令会启动一个名为 gotty 的新 [tmux 会话][13]来运行 [glances][14](确保你安装了 tmux):
|
||||
|
||||
```
|
||||
# gotty tmux new -A -s gotty glances
|
||||
```
|
||||
|
||||
要读取不同的配置文件,像下面那样使用 `–config "/path/to/file"` 选项:
|
||||
|
||||
```
|
||||
# gotty -tr --config "~/gotty_new_config" --title-format "GoTTY - {{ .Command }} ({{ .Hostname }})" glances
|
||||
```
|
||||
|
||||
要显示 GoTTY 版本,运行命令:
|
||||
|
||||
```
|
||||
# gotty -v
|
||||
```
|
||||
|
||||
访问 GoTTY GitHub 仓库以查找更多使用示例:[https://github.com/yudai/gotty][15] 。
|
||||
|
||||
就这样了!你有尝试过了吗?如何知道 GoTTY 的?通过下面的反馈栏与我们分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,即将成为 Linux SysAdmin 和网络开发人员,目前是 TecMint 的内容创作者,他喜欢在电脑上工作,并坚信分享知识。
|
||||
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: http://www.tecmint.com/gotty-share-linux-terminal-in-web-browser/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/access-linux-server-terminal-in-web-browser-using-wetty/
|
||||
[2]:http://www.tecmint.com/install-go-in-linux/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Go-Environment.png
|
||||
[5]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Linux-Disk-Usage.png
|
||||
[7]:http://www.tecmint.com/vi-editor-usage/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Web-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-use-basic-authentication.png
|
||||
[10]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Gotty-Random-URL-for-Glances-Linux-Monitoring.png
|
||||
[12]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[13]:http://www.tecmint.com/tmux-to-access-multiple-linux-terminals-inside-a-single-console/
|
||||
[14]:http://www.tecmint.com/glances-an-advanced-real-time-system-monitoring-tool-for-linux/
|
||||
[15]:https://github.com/yudai/gotty
|
||||
[16]:http://www.tecmint.com/author/aaronkili/
|
||||
[17]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[18]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,169 @@
|
||||
cpustat:在 Linux 下根据运行的进程监控 CPU 使用率
|
||||
============================================================
|
||||
|
||||
cpustat 是 Linux 下一个强大的系统性能测量程序,它用 [Go 编程语言][3] 编写。它通过使用 “[用于分析任意系统的性能的方法(USE)](http://www.brendangregg.com/usemethod.html)”,以有效的方式显示 CPU 利用率和饱和度。
|
||||
|
||||
它高频率对系统中运行的每个进程进行取样,然后以较低的频率汇总这些样本。例如,它能够每 200ms 测量一次每个进程,然后每 5 秒汇总这些样本,包括某些度量的最小/平均/最大值(min/avg/max)。
|
||||
|
||||
**推荐阅读:** [监控 Linux 性能的 20 个命令行工具][4]
|
||||
|
||||
cpustat 能用两种方式输出数据:定时汇总的纯文本列表和每个取样的彩色滚动面板。
|
||||
|
||||
### 如何在 Linux 中安装 cpustat
|
||||
|
||||
为了使用 cpustat,你的 Linux 系统中必须安装有 Go 语言(GoLang),如果你还没有安装它,点击下面的链接逐步安装 GoLang:
|
||||
|
||||
- [在 Linux 下安装 GoLang(Go 编程语言)][1]
|
||||
|
||||
安装完 Go 以后,输入下面的 `go get` 命令安装 cpustat,这个命令会将 cpustat 二进制文件安装到你的 `GOBIN` 变量(所指的路径):
|
||||
|
||||
```
|
||||
# go get github.com/uber-common/cpustat
|
||||
```
|
||||
|
||||
### 如何在 Linux 中使用 cpustat
|
||||
|
||||
安装过程完成后,如果你不是以 root 用户控制系统,像下面这样使用 sudo 命令获取 root 权限运行 cpustat,否则会出现下面显示的错误信息:
|
||||
|
||||
```
|
||||
$ $GOBIN/cpustat
|
||||
This program uses the netlink taskstats interface, so it must be run as root.
|
||||
```
|
||||
|
||||
注意:想要像你系统中已经安装的其它 Go 程序那样运行 cpustat,你需要把 `GOBIN` 变量添加到 `PATH` 环境变量。打开下面的链接学习如何在 Linux 中设置 `PATH` 变量。
|
||||
|
||||
- [学习如何在 Linux 中永久设置你的 $PATH 变量][2]
|
||||
|
||||
cpustat 是这样工作的:在每个时间间隔查询 `/proc` 目录获取当前[进程 ID 列表][5],然后:
|
||||
|
||||
* 对于每个 PID,读取 `/proc/pid/stat`,然后计算和前一个样本的差别。
|
||||
* 如果是一个新的 PID,读取 `/proc/pid/cmdline`。
|
||||
* 对于每个 PID,发送 `netlink` 消息获取 `taskstat`,计算和前一个样本的差别。
|
||||
* 读取 `/proc/stat` 获取总的系统统计信息。
|
||||
|
||||
根据获取所有这些统计信息所花费的时间,会调整每个休息间隔。另外,通过每次取样之间实际经过的时间,每个样本也会记录它用于测量的时间。这可用于计算 cpustat 自身的延迟。
|
||||
|
||||
当不带任何参数运行时,cpustat 默认会显示以下信息:样本间隔:200ms;汇总间隔:2s(10 个样本);[显示前 10 个进程][6];用户过滤器:all;pid 过滤器:all。正如下面截图所示:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*cpustat – 监控 Linux CPU 使用*
|
||||
|
||||
在上面的输出中,之前显示的系统范围的度量字段意义如下:
|
||||
|
||||
* usr - 用户模式运行时间占 CPU 百分比的 min/avg/max 值。
|
||||
* sys - 系统模式运行时间占 CPU 百分比的 min/avg/max 值。
|
||||
* nice - 用户模式低优先级运行时间占 CPU 百分比的 min/avg/max 值。
|
||||
* idle - 用户模式空闲时间占 CPU 百分比的 min/avg/max 值。
|
||||
* iowait - 等待磁盘 IO 的 min/avg/max 延迟时间。
|
||||
* prun - 处于可运行状态的 min/avg/max 进程数量(同“平均负载”一样)。
|
||||
* pblock - 被磁盘 IO 阻塞的 min/avg/max 进程数量。
|
||||
* pstat - 在本次汇总间隔里启动的进程/线程数目。
|
||||
|
||||
同样还是上面的输出,对于一个进程,不同列的意思分别是:
|
||||
|
||||
* name - 从 `/proc/pid/stat` 或 `/proc/pid/cmdline` 获取的进程名称。
|
||||
* pid - 进程 ID,也被用作 “tgid” (线程组 ID)。
|
||||
* min - 该 pid 的用户模式+系统模式时间的最小样本,取自 `/proc/pid/stat`。比率是 CPU 的百分比。
|
||||
* max - 该 pid 的用户模式+系统模式时间的最大样本,取自 `/proc/pid/stat`。
|
||||
* usr - 在汇总期间该 pid 的平均用户模式运行时间,取自 `/proc/pid/stat`。
|
||||
* sys - 在汇总期间该 pid 的平均系统模式运行时间,取自 `/proc/pid/stat`。
|
||||
* nice - 表示该进程的当前 “nice” 值,取自 `/proc/pid/stat`。值越高表示越好(nicer)。
|
||||
* runq - 进程和它所有线程可运行但等待运行的时间,通过 netlink 取自 taskstats。比率是 CPU 的百分比。
|
||||
* iow - 进程和它所有线程被磁盘 IO 阻塞的时间,通过 netlink 取自 taskstats。比率是 CPU 的百分比,对整个汇总间隔平均。
|
||||
* swap - 进程和它所有线程等待被换入(swap in)的时间,通过 netlink 取自 taskstats。Scale 是 CPU 的百分比,对整个汇总间隔平均。
|
||||
* vcx 和 icx - 在汇总间隔期间进程和它的所有线程自动上下文切换总的次数,通过 netlink 取自 taskstats。
|
||||
* rss - 从 `/proc/pid/stat` 获取的当前 RSS 值。它是指该进程正在使用的内存数量。
|
||||
* ctime - 在汇总间隔期间等待子进程退出的用户模式+系统模式 CPU 时间总和,取自 `/proc/pid/stat`。
|
||||
注意长时间运行的子进程可能导致混淆这个值,因为只有在子进程退出后才会报告时间。但是,这对于计算高频 cron 任务以及 CPU 时间经常被多个子进程使用的健康检查非常有帮助。
|
||||
* thrd - 汇总间隔最后线程的数目,取自 `/proc/pid/stat`。
|
||||
* sam - 在这个汇总间隔期间该进程的样本数目。最近启动或退出的进程可能看起来比汇总间隔的样本数目少。
|
||||
|
||||
|
||||
下面的命令显示了系统中运行的前 10 个 root 用户进程:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -u root
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*查找 root 用户正在运行的进程*
|
||||
|
||||
要想用更好看的终端模式显示输出,像下面这样用 `-t` 选项:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -u root -t
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*root 用户正在运行的进程*
|
||||
|
||||
要查看前 [x 个进程][10](默认是 10),你可以使用 `-n` 选项,下面的命令显示了系统中 [正在运行的前 20 个进程][11]:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -n 20
|
||||
```
|
||||
|
||||
你也可以像下面这样使用 `-cpuprofile` 选项将 CPU 信息写到文件,然后用 [cat 命令][12]查看文件:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -cpuprofile cpuprof.txt
|
||||
$ cat cpuprof.txt
|
||||
```
|
||||
|
||||
要显示帮助信息,像下面这样使用 `-h` 选项:
|
||||
|
||||
```
|
||||
$ sudo $GOBIN/cpustat -h
|
||||
```
|
||||
|
||||
可以从 cpustat 的 Github 仓库:[https://github.com/uber-common/cpustat][13] 查阅其它资料。
|
||||
|
||||
就是这些!在这篇文章中,我们向你展示了如何安装和使用 cpustat,Linux 下的一个有用的系统性能测量工具。通过下面的评论框和我们分享你的想法吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software) 爱好者,一个 Linux 系统管理员、web 开发员,现在也是 TecMint 的内容创建者,他喜欢和电脑一起工作,他相信知识共享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/cpustat-monitors-cpu-utilization-by-processes-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/install-go-in-linux/
|
||||
[2]:http://www.tecmint.com/set-path-variable-linux-permanently/
|
||||
[3]:http://www.tecmint.com/install-go-in-linux/
|
||||
[4]:http://www.tecmint.com/command-line-tools-to-monitor-linux-performance/
|
||||
[5]:http://www.tecmint.com/find-process-name-pid-number-linux/
|
||||
[6]:http://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/cpustat-Monitor-Linux-CPU-Usage.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/show-root-user-processes.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Root-User-Runnng-Processes.png
|
||||
[10]:http://www.tecmint.com/find-processes-by-memory-usage-top-batch-mode/
|
||||
[11]:http://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||
[12]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[13]:https://github.com/uber-common/cpustat
|
||||
[14]:http://www.tecmint.com/author/aaronkili/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
69
published/20170422 The root of all eval.md
Normal file
69
published/20170422 The root of all eval.md
Normal file
@ -0,0 +1,69 @@
|
||||
eval 之源
|
||||
============================================================
|
||||
|
||||
(LCTT 译注:本文标题 “The root of all eval” 影射著名歌曲“The root of all evil”(万恶之源))
|
||||
|
||||
唉,`eval` 这个函数让我爱恨交织,而且多半是后者居多。
|
||||
|
||||
```
|
||||
$ perl -E'my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
当 `eval` 函数在 Perl 6 中被重命名为 `EVAL` 时,我感到有点震惊(这要追溯到 2013 年,[在这里][2]讨论规范之后)。我一直没有从内心接受这样这样的做法。虽然这是个很好的意见,但是在这个意见上我似乎或多或少是孤独的。
|
||||
|
||||
理由是“这个函数真的很奇怪,所以我们应该用大写标记”。就像我们用 `BEGIN` 和其他 phaser 一样。使用 `BEGIN` 和其他 phaser,鼓励使用大写,这点我是同意的。phaser 能将程序“脱离正常控制流”。 但是 `eval` 函数并不能。(LCTT 译注: 在 Perl 6 当中,[phaser](https://docs.perl6.org/language/phasers) 是在一个特定的执行阶段中调用的代码块。)
|
||||
|
||||
其他大写的地方像是 .WHAT 这样的东西,它看起来像属性,但是会在编译时将代码变成完全不同的东西。因为这发生在常规情况之外,因此大写甚至是被鼓励的。
|
||||
|
||||
`eval` 归根到底是另一个函数。是的,这是一个潜在存在大量副作用的函数。但是那么多的标准函数都有大量的副作用。(举几个例子:`shell`、 `die`、 `exit`)你没看到有人呼吁将它们大写。
|
||||
|
||||
我猜有人会争论说 `eval` 是非常特别的,因为它以正常函数所没有的方式钩到编译器和运行时里面。(这也是 TimToady 在将该函数重命名的提交中的[提交消息][3]中解释的。)这是一个来自实现细节的争论,然而这并不令人满意。这也同样适用与刚才提到的那些小写函数。
|
||||
|
||||
雪上加霜的是,更名后 `EVAL` 也更难于使用:
|
||||
|
||||
```
|
||||
$ perl6 -e'my $program = q[say "OH HAI"]; EVAL $program'
|
||||
===SORRY!=== Error while compiling -e
|
||||
EVAL is a very dangerous function!!! (use the MONKEY-SEE-NO-EVAL pragma to override this error,
|
||||
but only if you're VERY sure your data contains no injection attacks)
|
||||
at -e:1
|
||||
------> program = q[say "OH HAI"]; EVAL $program⏏<EOL>
|
||||
|
||||
$ perl6 -e'use MONKEY-SEE-NO-EVAL; my $program = q[say "OH HAI"]; EVAL $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
首先,注入攻击是一个真实的问题,并不是一个笑话。我们应该互相教育对方和新手。
|
||||
|
||||
其次,这个错误消息(`"EVAL is a very dangerous function!!!"`)完全是恐吓多于帮助。我觉得当我们向人们解释代码注入的危险时,我们需要冷静并且切合实际,而不是用三个感叹号。这个错误信息对[已经知道什么是注入攻击的人][4]来说是有意义的,对于那些不了解这种风险的人员,它没有提供任何提示或线索。
|
||||
|
||||
(Perl 6 社区并不是唯一对 `eval` 歇斯底里的,昨天我偶然发现了一个 StackOverflow 主题,关于如何将一个有类型名称的字符串转换为 JavaScript 中的相应构造函数,一些人不幸地提出了用 `eval`,而其他人立即集结起来指出这是多么不负责任,就像膝跳反射那样——“因为 eval 是坏的”)。
|
||||
|
||||
第三,“MOKNEY-SEE-NO-EVAL”。拜托,我们能不能不要这样……汗,启用一个核弹级的函数时,就像是猴子般的随机引用和轻率的尝试,我奇怪地发现_启用_ `EVAL` 函数的是一个称为 `NO-EVAL` 的东西。这并不符合“<ruby>最少惊喜<rt>Least Surprise</rt></ruby>”原则。
|
||||
|
||||
不管怎样,有一天,我意识到我可以同时解决全大写名字问题和该指令的必要问题:
|
||||
|
||||
```
|
||||
$ perl6 -e'my &eval = &EVAL; my $program = q[say "OH HAI"]; eval $program'
|
||||
OH HAI
|
||||
```
|
||||
|
||||
我很高兴我能想到这点子并记录下来。显然我们把它改回了旧名字,这个非常危险的功能(`!!!`)就又好了。 耶!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
|
||||
作者:[Carl Mäsak][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://strangelyconsistent.org/about
|
||||
[1]:http://strangelyconsistent.org/blog/the-root-of-all-eval
|
||||
[2]:https://github.com/perl6/specs/issues/50
|
||||
[3]:https://github.com/perl6/specs/commit/0b7df09ecc096eed5dc30f3dbdf568bbfd9de8f6
|
||||
[4]:http://bobby-tables.com/
|
||||
@ -1,54 +0,0 @@
|
||||
The Many, the Humble, the Ubuntu Users
|
||||
============================================================
|
||||
|
||||
#### The proverbial “better mousetrap” isn’t one that takes a certified biologist to use. Like Ubuntu, it just needs to do its job extremely well and with little fuss.
|
||||
|
||||
### Roblimo’s Hideaway
|
||||
|
||||

|
||||
|
||||
I have never been much of a leading-edge computing person. In fact, I first got mildly famous online writing a weekly column titled “This Old PC” for Time/Life about making do with used gear — often by installing Linux on it — and after that an essentially identical column for Andover.net titled “Cheap Computing,” which was also about saving money in a world where most online computing columns seemed to be about getting you to spend until you had no money left to spend on food.
|
||||
|
||||
Most of the early Linux adopters I knew were infatuated with their computers and the software that made them useful. They loved poring over source code and making minor changes. They were, for the most part, computer science students or worked as IT people. Their computers and computer networks fascinated them, as they should have.
|
||||
|
||||
I was (and still am) a writer, not a computer science guy. For me, computers have always been tools. I want them to sit quietly until I tell them to do something, then follow my orders with the minimum possible fuss and bother. I like a GUI, since I don’t administer my PC or network often enough to memorize long command strings. Sure, I can look them up and type them in, but I’d really rather be at the beach.
|
||||
|
||||
There was a time when, in Linux circles, mere _users_ were rare. “What do you mean, you just want to use your computer to type articles and maybe add a little HTML to them?” the developer and admin types seemed to ask, as if all fields of endeavor other than coding were inferior to what they did.
|
||||
|
||||
But despite the sneers, I kept hammering a theme in speech after speech and conversation after conversation that went sort of like this: “Instead of scratching only your own itches, why not scratch your girlfriend’s itch? How about your coworkers? And people who work at your favorite restaurant? And what about your doctor? Don’t you want him to spend his time doctoring, not worrying about apt get this and grep that?”
|
||||
|
||||
So yes, since I wanted easy-to-use Linux, I was an [early Mandrake user][1]. And today, I am a happy Ubuntu user.
|
||||
|
||||
Why Ubuntu? Hey! Why not?! It’s the Toyota Camry (or maybe Honda Civic) of Linux distros. Plain-jane. So popular that support is easy to find on IRC, Linux Questions, and Ubuntu’s own extensive forums, and many other places.
|
||||
|
||||
Sure, it’s cooler to use Debian or Fedora, and Mint looks jazzier out of the box, but I’m _still_ mostly interested in writing stories and adding a little HTML to them, along with reading this and that in my browser, editing work in Google Docs for a corporate client or two, keeping up with my email, doing this or that with a picture now and then…. all basic computer user stuff.
|
||||
|
||||
And with all this going on, the appearance of my desktop is meaningless. I can’t see it! It’s covered with application windows! And I’m talking two monitors, not just one. I have, let’s see…. 17 Chrome tabs open in two windows. And GIMP running. And [Bluefish][2], which I’m using right now, to type this essay.
|
||||
|
||||
So for me Ubuntu is the path of least resistance. Mint may be a little cuter, but when you come right down to it, and strip away the trim, isn’t it really Ubuntu? So if I use the same few programs over and over, which I do, and can’t see the desktop anyway, who cares if it’s brown?
|
||||
|
||||
Some studies say Mint is more popular. Others say Debian. But they all show Ubuntu in the top few, year after year.
|
||||
|
||||
So call me mass-average. Call me boring. Call me one of the many, the humble, the Ubuntu users — at least for now…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Robin "Roblimo" Miller is a freelance writer and former editor-in-chief at Open Source Technology Group, the company that owned SourceForge, freshmeat, Linux.com, NewsForge, ThinkGeek and Slashdot, and until recently served as a video editor at Slashdot. He also publishes the blog Robin ‘Roblimo’ Miller’s Personal Site. @robinAKAroblimo
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2017/01/many-humble-ubuntu-users/
|
||||
|
||||
作者:[Robin "Roblimo" Miller][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.roblimo.com/
|
||||
[1]:https://linux.slashdot.org/story/00/11/02/2324224/mandrake-72-in-wal-mart-a-good-idea
|
||||
[2]:http://bluefish.openoffice.nl/index.html
|
||||
@ -1,53 +0,0 @@
|
||||
Why do developers who could work anywhere flock to the world’s most expensive cities?
|
||||
============================================================
|
||||

|
||||
|
||||
Politicians and economists [lament][10] that certain alpha regions — SF, LA, NYC, Boston, Toronto, London, Paris — attract all the best jobs while becoming repellently expensive, reducing economic mobility and contributing to further bifurcation between haves and have-nots. But why don’t the best jobs move elsewhere?
|
||||
|
||||
Of course, many of them can’t. The average financier in NYC or London (until Brexit annihilates London’s banking industry, of course…) would be laughed out of the office, and not invited back, if they told their boss they wanted to henceforth work from Chiang Mai.
|
||||
|
||||
But this isn’t true of (much of) the software field. The average web/app developer might have such a request declined; but they would not be laughed at, or fired. The demand for good developers greatly outstrips supply, and in this era of Skype and Slack, there’s nothing about software development that requires meatspace interactions.
|
||||
|
||||
(This is even more true of writers, of course; I did in fact post this piece from Pohnpei. But writers don’t have anything like the leverage of software developers.)
|
||||
|
||||
Some people will tell you that remote teams are inherently less effective and productive than localized ones, or that “serendipitous collisions” are so important that every employee must be forced to the same physical location every day so that these collisions can be manufactured. These people are wrong, as long as the team in question is small — on the order of handfuls, dozens or scores, rather than hundreds or thousands — and flexible.
|
||||
|
||||
I should know: at [HappyFunCorp][11], we work extensively with remote teams, and actively recruit remote developers, and it works out fantastically well. A day in which I interact and collaborate with developers in Stockholm, São Paulo, Shanghai, Brooklyn and New Delhi, from my own home base in San Francisco, is not at all unusual.
|
||||
|
||||
At this point, whether it’s a good idea is almost irrelevant, though. Supply and demand is such that any sufficiently skilled developer could become a so-called digital nomad if they really wanted to. But many who could, do not. I recently spent some time in Reykjavik at a house Airbnb-ed for the month by an ever-shifting crew of temporary remote workers, keeping East Coast time to keep up with their jobs, while spending mornings and weekends exploring Iceland — but almost all of us then returned to live in the Bay Area.
|
||||
|
||||
Economically, of course, this is insane. Moving to and working from Southeast Asia would save us thousands of dollars a month in rent alone. So why do people who could live in Costa Rica on a San Francisco salary, or in Berlin while charging NYC rates, choose not to do so? Why are allegedly hardheaded engineers so financially irrational?
|
||||
|
||||
Of course there are social and cultural reasons. Chiang Mai is very nice, but doesn’t have the Met, or steampunk masquerade parties or 50 foodie restaurants within a 15-minute walk. Berlin is lovely, but doesn’t offer kite surfing, or Sierra hiking or California weather. Neither promises an effectively limitless population of people with whom you share values and a first language.
|
||||
|
||||
And yet I think there’s much more to it than this. I believe there’s a more fundamental economic divide opening than the one between haves and have-nots. I think we are witnessing a growing rift between the world’s Extremistan cities, in which truly extraordinary things can be achieved, and its Mediocristan towns, in which you can work and make money and be happy but never achieve greatness. (Labels stolen from the great Nassim Taleb.)
|
||||
|
||||
The arts have long had Extremistan cities. That’s why aspiring writers move to New York City, and even directors and actors who found international success are still drawn to L.A. like moths to a klieg light. Now it is true of tech, too. Even if you don’t even want to try to (help) build something extraordinary — and the startup myth is so powerful today that it’s a very rare engineer indeed who hasn’t at least dreamed about it — the prospect of being _where great things happen_ is intoxicatingly enticing.
|
||||
|
||||
But the interesting thing about this is that it could, in theory, change; because — as of quite recently — distributed, decentralized teams can, in fact, achieve extraordinary things. The cards are arguably stacked against them, because VCs tend to be quite myopic. But no law dictates that unicorns may only be born in California and a handful of other secondary territories; and it seems likely that, for better or worse, Extremistan is spreading. It would be pleasantly paradoxical if that expansion ultimately leads to _lower_ rents in the Mission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
|
||||
作者:[ Jon Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/jon-evans/
|
||||
[1]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#comments
|
||||
[2]:https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/#
|
||||
[3]:http://twitter.com/share?via=techcrunch&url=http://tcrn.ch/2owXJ0C&text=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&hashtags=
|
||||
[4]:https://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Ftechcrunch.com%2F2017%2F04%2F02%2Fwhy-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities%2F&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[5]:https://plus.google.com/share?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[6]:http://www.reddit.com/submit?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F
|
||||
[7]:http://www.stumbleupon.com/badge/?url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[8]:mailto:?subject=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities?&body=Article:%20https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[9]:https://share.flipboard.com/bookmarklet/popout?v=2&title=Why%20do%20developers%20who%20could%20work%20anywhere%20flock%20to%20the%20world%E2%80%99s%20most%20expensive%C2%A0cities%3F&url=https://techcrunch.com/2017/04/02/why-do-developers-who-could-work-anywhere-flock-to-the-worlds-most-expensive-cities/
|
||||
[10]:https://mobile.twitter.com/Noahpinion/status/846054187288866
|
||||
[11]:http://happyfuncorp.com/
|
||||
[12]:https://twitter.com/rezendi
|
||||
[13]:https://techcrunch.com/author/jon-evans/
|
||||
[14]:https://techcrunch.com/2017/04/01/discussing-the-limits-of-artificial-intelligence/
|
||||
152
sources/tech/ 20170422 FEWER MALLOCS IN CURL.md
Normal file
152
sources/tech/ 20170422 FEWER MALLOCS IN CURL.md
Normal file
@ -0,0 +1,152 @@
|
||||
FEWER MALLOCS IN CURL
|
||||
===========================================================
|
||||
|
||||

|
||||
|
||||
Today I landed yet [another small change][4] to libcurl internals that further reduces the number of small mallocs we do. This time the generic linked list functions got converted to become malloc-less (the way linked list functions should behave, really).
|
||||
|
||||
### Instrument mallocs
|
||||
|
||||
I started out my quest a few weeks ago by instrumenting our memory allocations. This is easy since we have our own memory debug and logging system in curl since many years. Using a debug build of curl I run this script in my build dir:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
export CURL_MEMDEBUG=$HOME/tmp/curlmem.log
|
||||
./src/curl http://localhost
|
||||
./tests/memanalyze.pl -v $HOME/tmp/curlmem.log
|
||||
```
|
||||
|
||||
For curl 7.53.1, this counted about 115 memory allocations. Is that many or a few?
|
||||
|
||||
The memory log is very basic. To give you an idea what it looks like, here’s an example snippet:
|
||||
|
||||
```
|
||||
MEM getinfo.c:70 free((nil))
|
||||
MEM getinfo.c:73 free((nil))
|
||||
MEM url.c:294 free((nil))
|
||||
MEM url.c:297 strdup(0x559e7150d616) (24) = 0x559e73760f98
|
||||
MEM url.c:294 free((nil))
|
||||
MEM url.c:297 strdup(0x559e7150d62e) (22) = 0x559e73760fc8
|
||||
MEM multi.c:302 calloc(1,480) = 0x559e73760ff8
|
||||
MEM hash.c:75 malloc(224) = 0x559e737611f8
|
||||
MEM hash.c:75 malloc(29152) = 0x559e737a2bc8
|
||||
MEM hash.c:75 malloc(3104) = 0x559e737a9dc8
|
||||
```
|
||||
|
||||
### Check the log
|
||||
|
||||
I then studied the log closer and I realized that there were many small memory allocations done from the same code lines. We clearly had some rather silly code patterns where we would allocate a struct and then add that struct to a linked list or a hash and that code would then subsequently add yet another small struct and similar – and then often do that in a loop. (I say _we_ here to avoid blaming anyone, but of course I myself am to blame for most of this…)
|
||||
|
||||
Those two allocations would always happen in pairs and they would be freed at the same time. I decided to address those. Doing very small (less than say 32 bytes) allocations is also wasteful just due to the very large amount of data in proportion that will be used just to keep track of that tiny little memory area (within the malloc system). Not to mention fragmentation of the heap.
|
||||
|
||||
So, fixing the hash code and the linked list code to not use mallocs were immediate and easy ways to remove over 20% of the mallocs for a plain and simple ‘curl http://localhost’ transfer.
|
||||
|
||||
At this point I sorted all allocations based on size and checked all the smallest ones. One that stood out was one we made in _curl_multi_wait(),_ a function that is called over and over in a typical curl transfer main loop. I converted it over to [use the stack][5] for most typical use cases. Avoiding mallocs in very repeatedly called functions is a good thing.
|
||||
|
||||
### Recount
|
||||
|
||||
Today, the script from above shows that the same “curl localhost” command is down to 80 allocations from the 115 curl 7.53.1 used. Without sacrificing anything really. An easy 26% improvement. Not bad at all!
|
||||
|
||||
But okay, since I modified curl_multi_wait() I wanted to also see how it actually improves things for a slightly more advanced transfer. I took the [multi-double.c][6] example code, added the call to initiate the memory logging, made it uses curl_multi_wait() and had it download these two URLs in parallel:
|
||||
|
||||
```
|
||||
http://www.example.com/
|
||||
http://localhost/512M
|
||||
```
|
||||
|
||||
The second one being just 512 megabytes of zeroes and the first being a 600 bytes something public html page. Here’s the [count-malloc.c code][7].
|
||||
|
||||
First, I brought out 7.53.1 and built the example against that and had the memanalyze script check it:
|
||||
|
||||
```
|
||||
Mallocs: 33901
|
||||
Reallocs: 5
|
||||
Callocs: 24
|
||||
Strdups: 31
|
||||
Wcsdups: 0
|
||||
Frees: 33956
|
||||
Allocations: 33961
|
||||
Maximum allocated: 160385
|
||||
```
|
||||
|
||||
Okay, so it used 160KB of memory totally and it did over 33,900 allocations. But ok, it downloaded over 512 megabytes of data so it makes one malloc per 15KB of data. Good or bad?
|
||||
|
||||
Back to git master, the version we call 7.54.1-DEV right now – since we’re not quite sure which version number it’ll become when we release the next release. It can become 7.54.1 or 7.55.0, it has not been determined yet. But I digress, I ran the same modified multi-double.c example again, ran memanalyze on the memory log again and it now reported…
|
||||
|
||||
```
|
||||
Mallocs: 69
|
||||
Reallocs: 5
|
||||
Callocs: 24
|
||||
Strdups: 31
|
||||
Wcsdups: 0
|
||||
Frees: 124
|
||||
Allocations: 129
|
||||
Maximum allocated: 153247
|
||||
```
|
||||
|
||||
I had to look twice. Did I do something wrong? I better run it again just to double-check. The results are the same no matter how many times I run it…
|
||||
|
||||
### 33,961 vs 129
|
||||
|
||||
curl_multi_wait() is called a lot of times in a typical transfer, and it had at least one of the memory allocations we normally did during a transfer so removing that single tiny allocation had a pretty dramatic impact on the counter. A normal transfer also moves things in and out of linked lists and hashes a bit, but they too are mostly malloc-less now. Simply put: the remaining allocations are not done in the transfer loop so they’re way less important.
|
||||
|
||||
The old curl did 263 times the number of allocations the current does for this example. Or the other way around: the new one does 0.37% the number of allocations the old one did…
|
||||
|
||||
As an added bonus, the new one also allocates less memory in total as it decreased that amount by 7KB (4.3%).
|
||||
|
||||
### Are mallocs important?
|
||||
|
||||
In the day and age with many gigabytes of RAM and all, does a few mallocs in a transfer really make a notable difference for mere mortals? What is the impact of 33,832 extra mallocs done for 512MB of data?
|
||||
|
||||
To measure what impact these changes have, I decided to compare HTTP transfers from localhost and see if we can see any speed difference. localhost is fine for this test since there’s no network speed limit, but the faster curl is the faster the download will be. The server side will be equally fast/slow since I’ll use the same set for both tests.
|
||||
|
||||
I built curl 7.53.1 and curl 7.54.1-DEV identically and ran this command line:
|
||||
|
||||
```
|
||||
curl http://localhost/80GB -o /dev/null
|
||||
```
|
||||
|
||||
80 gigabytes downloaded as fast as possible written into the void.
|
||||
|
||||
The exact numbers I got for this may not be totally interesting, as it will depend on CPU in the machine, which HTTP server that serves the file and optimization level when I build curl etc. But the relative numbers should still be highly relevant. The old code vs the new.
|
||||
|
||||
7.54.1-DEV repeatedly performed 30% faster! The 2200MB/sec in my build of the earlier release increased to over 2900 MB/sec with the current version.
|
||||
|
||||
The point here is of course not that it easily can transfer HTTP over 20GB/sec using a single core on my machine – since there are very few users who actually do that speedy transfers with curl. The point is rather that curl now uses less CPU per byte transferred, which leaves more CPU over to the rest of the system to perform whatever it needs to do. Or to save battery if the device is a portable one.
|
||||
|
||||
On the cost of malloc: The 512MB test I did resulted in 33832 more allocations using the old code. The old code transferred HTTP at a rate of about 2200MB/sec. That equals 145,827 mallocs/second – that are now removed! A 600 MB/sec improvement means that curl managed to transfer 4300 bytes extra for each malloc it didn’t do, each second.
|
||||
|
||||
### Was removing these mallocs hard?
|
||||
|
||||
Not at all, it was all straight forward. It is however interesting that there’s still room for changes like this in a project this old. I’ve had this idea for some years and I’m glad I finally took the time to make it happen. Thanks to our test suite I could do this level of “drastic” internal change with a fairly high degree of confidence that I don’t introduce too terrible regressions. Thanks to our APIs being good at hiding internals, this change could be done completely without changing anything for old or new applications.
|
||||
|
||||
(Yeah I haven’t shipped the entire change in a release yet so there’s of course a risk that I’ll have to regret my “this was easy” statement…)
|
||||
|
||||
### Caveats on the numbers
|
||||
|
||||
There have been 213 commits in the curl git repo from 7.53.1 till today. There’s a chance one or more other commits than just the pure alloc changes have made a performance impact, even if I can’t think of any.
|
||||
|
||||
### More?
|
||||
|
||||
Are there more “low hanging fruits” to pick here in the similar vein?
|
||||
|
||||
Perhaps. We don’t do a lot of performance measurements or comparisons so who knows, we might do more silly things that we could stop doing and do even better. One thing I’ve always wanted to do, but never got around to, was to add daily “monitoring” of memory/mallocs used and how fast curl performs in order to better track when we unknowingly regress in these areas.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://daniel.haxx.se/blog/2017/04/22/fewer-mallocs-in-curl/
|
||||
|
||||
作者:[DANIEL STENBERG ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://daniel.haxx.se/blog/author/daniel/
|
||||
[1]:https://daniel.haxx.se/blog/author/daniel/
|
||||
[2]:https://daniel.haxx.se/blog/2017/04/22/fewer-mallocs-in-curl/
|
||||
[3]:https://daniel.haxx.se/blog/2017/04/22/fewer-mallocs-in-curl/#comments
|
||||
[4]:https://github.com/curl/curl/commit/cbae73e1dd95946597ea74ccb580c30f78e3fa73
|
||||
[5]:https://github.com/curl/curl/commit/5f1163517e1597339d
|
||||
[6]:https://github.com/curl/curl/commit/5f1163517e1597339d
|
||||
[7]:https://gist.github.com/bagder/dc4a42cb561e791e470362da7ef731d3
|
||||
@ -1,5 +1,3 @@
|
||||
Firstadream translating
|
||||
|
||||
[How debuggers work: Part 2 - Breakpoints][26]
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,349 +0,0 @@
|
||||
[How debuggers work: Part 3 - Debugging information][25]
|
||||
============================================================
|
||||
|
||||
|
||||
This is the third part in a series of articles on how debuggers work. Make sure you read [the first][26] and [the second][27] parts before this one.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to explain how the debugger figures out where to find the C functions and variables in the machine code it wades through, and the data it uses to map between C source code lines and machine language words.
|
||||
|
||||
### Debugging information
|
||||
|
||||
Modern compilers do a pretty good job converting your high-level code, with its nicely indented and nested control structures and arbitrarily typed variables into a big pile of bits called machine code, the sole purpose of which is to run as fast as possible on the target CPU. Most lines of C get converted into several machine code instructions. Variables are shoved all over the place - into the stack, into registers, or completely optimized away. Structures and objects don't even _exist_ in the resulting code - they're merely an abstraction that gets translated to hard-coded offsets into memory buffers.
|
||||
|
||||
So how does a debugger know where to stop when you ask it to break at the entry to some function? How does it manage to find what to show you when you ask it for the value of a variable? The answer is - debugging information.
|
||||
|
||||
Debugging information is generated by the compiler together with the machine code. It is a representation of the relationship between the executable program and the original source code. This information is encoded into a pre-defined format and stored alongside the machine code. Many such formats were invented over the years for different platforms and executable files. Since the aim of this article isn't to survey the history of these formats, but rather to show how they work, we'll have to settle on something. This something is going to be DWARF, which is almost ubiquitously used today as the debugging information format for ELF executables on Linux and other Unix-y platforms.
|
||||
|
||||
### The DWARF in the ELF
|
||||
|
||||

|
||||
|
||||
According to [its Wikipedia page][17], DWARF was designed alongside ELF, although it can in theory be embedded in other object file formats as well [[1]][18].
|
||||
|
||||
DWARF is a complex format, building on many years of experience with previous formats for various architectures and operating systems. It has to be complex, since it solves a very tricky problem - presenting debugging information from any high-level language to debuggers, providing support for arbitrary platforms and ABIs. It would take much more than this humble article to explain it fully, and to be honest I don't understand all its dark corners well enough to engage in such an endeavor anyway [[2]][19]. In this article I will take a more hands-on approach, showing just enough of DWARF to explain how debugging information works in practical terms.
|
||||
|
||||
### Debug sections in ELF files
|
||||
|
||||
First let's take a glimpse of where the DWARF info is placed inside ELF files. ELF defines arbitrary sections that may exist in each object file. A _section header table_ defines which sections exist and their names. Different tools treat various sections in special ways - for example the linker is looking for some sections, the debugger for others.
|
||||
|
||||
We'll be using an executable built from this C source for our experiments in this article, compiled into tracedprog2:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff(int my_arg)
|
||||
{
|
||||
int my_local = my_arg + 2;
|
||||
int i;
|
||||
|
||||
for (i = 0; i < my_local; ++i)
|
||||
printf("i = %d\n", i);
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Dumping the section headers from the ELF executable using objdump -h we'll notice several sections with names beginning with .debug_ - these are the DWARF debugging sections:
|
||||
|
||||
```
|
||||
26 .debug_aranges 00000020 00000000 00000000 00001037
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
27 .debug_pubnames 00000028 00000000 00000000 00001057
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
28 .debug_info 000000cc 00000000 00000000 0000107f
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
29 .debug_abbrev 0000008a 00000000 00000000 0000114b
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
30 .debug_line 0000006b 00000000 00000000 000011d5
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
31 .debug_frame 00000044 00000000 00000000 00001240
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
32 .debug_str 000000ae 00000000 00000000 00001284
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
33 .debug_loc 00000058 00000000 00000000 00001332
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
```
|
||||
|
||||
The first number seen for each section here is its size, and the last is the offset where it begins in the ELF file. The debugger uses this information to read the section from the executable.
|
||||
|
||||
Now let's see a few practical examples of finding useful debug information in DWARF.
|
||||
|
||||
### Finding functions
|
||||
|
||||
One of the most basic things we want to do when debugging is placing breakpoints at some function, expecting the debugger to break right at its entrance. To be able to perform this feat, the debugger must have some mapping between a function name in the high-level code and the address in the machine code where the instructions for this function begin.
|
||||
|
||||
This information can be obtained from DWARF by looking at the .debug_info section. Before we go further, a bit of background. The basic descriptive entity in DWARF is called the Debugging Information Entry (DIE). Each DIE has a tag - its type, and a set of attributes. DIEs are interlinked via sibling and child links, and values of attributes can point at other DIEs.
|
||||
|
||||
Let's run:
|
||||
|
||||
```
|
||||
objdump --dwarf=info tracedprog2
|
||||
```
|
||||
|
||||
The output is quite long, and for this example we'll just focus on these lines [[3]][20]:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
|
||||
<1><b3>: Abbrev Number: 9 (DW_TAG_subprogram)
|
||||
<b4> DW_AT_external : 1
|
||||
<b5> DW_AT_name : (...): main
|
||||
<b9> DW_AT_decl_file : 1
|
||||
<ba> DW_AT_decl_line : 14
|
||||
<bb> DW_AT_type : <0x4b>
|
||||
<bf> DW_AT_low_pc : 0x804863e
|
||||
<c3> DW_AT_high_pc : 0x804865a
|
||||
<c7> DW_AT_frame_base : 0x2c (location list)
|
||||
```
|
||||
|
||||
There are two entries (DIEs) tagged DW_TAG_subprogram, which is a function in DWARF's jargon. Note that there's an entry for do_stuff and an entry for main. There are several interesting attributes, but the one that interests us here is DW_AT_low_pc. This is the program-counter (EIP in x86) value for the beginning of the function. Note that it's 0x8048604 for do_stuff. Now let's see what this address is in the disassembly of the executable by running objdump -d:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
8048613: c7 45 (...) mov DWORD PTR [ebp-0x10],0x0
|
||||
804861a: eb 18 jmp 8048634 <do_stuff+0x30>
|
||||
804861c: b8 20 (...) mov eax,0x8048720
|
||||
8048621: 8b 55 f0 mov edx,DWORD PTR [ebp-0x10]
|
||||
8048624: 89 54 24 04 mov DWORD PTR [esp+0x4],edx
|
||||
8048628: 89 04 24 mov DWORD PTR [esp],eax
|
||||
804862b: e8 04 (...) call 8048534 <printf@plt>
|
||||
8048630: 83 45 f0 01 add DWORD PTR [ebp-0x10],0x1
|
||||
8048634: 8b 45 f0 mov eax,DWORD PTR [ebp-0x10]
|
||||
8048637: 3b 45 f4 cmp eax,DWORD PTR [ebp-0xc]
|
||||
804863a: 7c e0 jl 804861c <do_stuff+0x18>
|
||||
804863c: c9 leave
|
||||
804863d: c3 ret
|
||||
```
|
||||
|
||||
Indeed, 0x8048604 is the beginning of do_stuff, so the debugger can have a mapping between functions and their locations in the executable.
|
||||
|
||||
### Finding variables
|
||||
|
||||
Suppose that we've indeed stopped at a breakpoint inside do_stuff. We want to ask the debugger to show us the value of the my_local variable. How does it know where to find it? Turns out this is much trickier than finding functions. Variables can be located in global storage, on the stack, and even in registers. Additionally, variables with the same name can have different values in different lexical scopes. The debugging information has to be able to reflect all these variations, and indeed DWARF does.
|
||||
|
||||
I won't cover all the possibilities, but as an example I'll demonstrate how the debugger can find my_local in do_stuff. Let's start at .debug_info and look at the entry for do_stuff again, this time also looking at a couple of its sub-entries:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
<2><8a>: Abbrev Number: 6 (DW_TAG_formal_parameter)
|
||||
<8b> DW_AT_name : (...): my_arg
|
||||
<8f> DW_AT_decl_file : 1
|
||||
<90> DW_AT_decl_line : 4
|
||||
<91> DW_AT_type : <0x4b>
|
||||
<95> DW_AT_location : (...) (DW_OP_fbreg: 0)
|
||||
<2><98>: Abbrev Number: 7 (DW_TAG_variable)
|
||||
<99> DW_AT_name : (...): my_local
|
||||
<9d> DW_AT_decl_file : 1
|
||||
<9e> DW_AT_decl_line : 6
|
||||
<9f> DW_AT_type : <0x4b>
|
||||
<a3> DW_AT_location : (...) (DW_OP_fbreg: -20)
|
||||
<2><a6>: Abbrev Number: 8 (DW_TAG_variable)
|
||||
<a7> DW_AT_name : i
|
||||
<a9> DW_AT_decl_file : 1
|
||||
<aa> DW_AT_decl_line : 7
|
||||
<ab> DW_AT_type : <0x4b>
|
||||
<af> DW_AT_location : (...) (DW_OP_fbreg: -24)
|
||||
```
|
||||
|
||||
Note the first number inside the angle brackets in each entry. This is the nesting level - in this example entries with <2> are children of the entry with <1>. So we know that the variable my_local (marked by the DW_TAG_variable tag) is a child of the do_stuff function. The debugger is also interested in a variable's type to be able to display it correctly. In the case of my_local the type points to another DIE - <0x4b>. If we look it up in the output of objdump we'll see it's a signed 4-byte integer.
|
||||
|
||||
To actually locate the variable in the memory image of the executing process, the debugger will look at the DW_AT_location attribute. For my_local it says DW_OP_fbreg: -20. This means that the variable is stored at offset -20 from the DW_AT_frame_base attribute of its containing function - which is the base of the frame for the function.
|
||||
|
||||
The DW_AT_frame_base attribute of do_stuff has the value 0x0 (location list), which means that this value actually has to be looked up in the location list section. Let's look at it:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=loc tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Contents of the .debug_loc section:
|
||||
|
||||
Offset Begin End Expression
|
||||
00000000 08048604 08048605 (DW_OP_breg4: 4 )
|
||||
00000000 08048605 08048607 (DW_OP_breg4: 8 )
|
||||
00000000 08048607 0804863e (DW_OP_breg5: 8 )
|
||||
00000000 <End of list>
|
||||
0000002c 0804863e 0804863f (DW_OP_breg4: 4 )
|
||||
0000002c 0804863f 08048641 (DW_OP_breg4: 8 )
|
||||
0000002c 08048641 0804865a (DW_OP_breg5: 8 )
|
||||
0000002c <End of list>
|
||||
```
|
||||
|
||||
The location information we're interested in is the first one [[4]][21]. For each address where the debugger may be, it specifies the current frame base from which offsets to variables are to be computed as an offset from a register. For x86, bpreg4 refers to esp and bpreg5 refers to ebp.
|
||||
|
||||
It's educational to look at the first several instructions of do_stuff again:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
```
|
||||
|
||||
Note that ebp becomes relevant only after the second instruction is executed, and indeed for the first two addresses the base is computed from esp in the location information listed above. Once ebp is valid, it's convenient to compute offsets relative to it because it stays constant while esp keeps moving with data being pushed and popped from the stack.
|
||||
|
||||
So where does it leave us with my_local? We're only really interested in its value after the instruction at 0x8048610 (where its value is placed in memory after being computed in eax), so the debugger will be using the DW_OP_breg5: 8 frame base to find it. Now it's time to rewind a little and recall that the DW_AT_location attribute for my_local says DW_OP_fbreg: -20. Let's do the math: -20 from the frame base, which is ebp + 8. We get ebp - 12. Now look at the disassembly again and note where the data is moved from eax - indeed, ebp - 12 is where my_local is stored.
|
||||
|
||||
### Looking up line numbers
|
||||
|
||||
When we talked about finding functions in the debugging information, I was cheating a little. When we debug C source code and put a breakpoint in a function, we're usually not interested in the first _machine code_ instruction [[5]][22]. What we're _really_ interested in is the first _C code_ line of the function.
|
||||
|
||||
This is why DWARF encodes a full mapping between lines in the C source code and machine code addresses in the executable. This information is contained in the .debug_line section and can be extracted in a readable form as follows:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=decodedline tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Decoded dump of debug contents of section .debug_line:
|
||||
|
||||
CU: /home/eliben/eli/eliben-code/debugger/tracedprog2.c:
|
||||
File name Line number Starting address
|
||||
tracedprog2.c 5 0x8048604
|
||||
tracedprog2.c 6 0x804860a
|
||||
tracedprog2.c 9 0x8048613
|
||||
tracedprog2.c 10 0x804861c
|
||||
tracedprog2.c 9 0x8048630
|
||||
tracedprog2.c 11 0x804863c
|
||||
tracedprog2.c 15 0x804863e
|
||||
tracedprog2.c 16 0x8048647
|
||||
tracedprog2.c 17 0x8048653
|
||||
tracedprog2.c 18 0x8048658
|
||||
```
|
||||
|
||||
It shouldn't be hard to see the correspondence between this information, the C source code and the disassembly dump. Line number 5 points at the entry point to do_stuff - 0x8040604. The next line, 6, is where the debugger should really stop when asked to break in do_stuff, and it points at 0x804860a which is just past the prologue of the function. This line information easily allows bi-directional mapping between lines and addresses:
|
||||
|
||||
* When asked to place a breakpoint at a certain line, the debugger will use it to find which address it should put its trap on (remember our friend int 3 from the previous article?)
|
||||
* When an instruction causes a segmentation fault, the debugger will use it to find the source code line on which it happened.
|
||||
|
||||
### <tt class="docutils literal" style="font-family: Consolas, monaco, monospace; color: rgb(0, 0, 0); background-color: rgb(247, 247, 247); white-space: nowrap; border-radius: 2px; font-size: 21.6px; padding: 2px;">libdwarf - Working with DWARF programmatically
|
||||
|
||||
Employing command-line tools to access DWARF information, while useful, isn't fully satisfying. As programmers, we'd like to know how to write actual code that can read the format and extract what we need from it.
|
||||
|
||||
Naturally, one approach is to grab the DWARF specification and start hacking away. Now, remember how everyone keeps saying that you should never, ever parse HTML manually but rather use a library? Well, with DWARF it's even worse. DWARF is _much_ more complex than HTML. What I've shown here is just the tip of the iceberg, and to make things even harder, most of this information is encoded in a very compact and compressed way in the actual object file [[6]][23].
|
||||
|
||||
So we'll take another road and use a library to work with DWARF. There are two major libraries I'm aware of (plus a few less complete ones):
|
||||
|
||||
1. BFD (libbfd) is used by the [GNU binutils][11], including objdump which played a star role in this article, ld (the GNU linker) and as (the GNU assembler).
|
||||
2. libdwarf - which together with its big brother libelf are used for the tools on Solaris and FreeBSD operating systems.
|
||||
|
||||
I'm picking libdwarf over BFD because it appears less arcane to me and its license is more liberal (LGPLvs. GPL).
|
||||
|
||||
Since libdwarf is itself quite complex it requires a lot of code to operate. I'm not going to show all this code here, but [you can download][24] and run it yourself. To compile this file you'll need to have libelfand libdwarf installed, and pass the -lelf and -ldwarf flags to the linker.
|
||||
|
||||
The demonstrated program takes an executable and prints the names of functions in it, along with their entry points. Here's what it produces for the C program we've been playing with in this article:
|
||||
|
||||
```
|
||||
$ dwarf_get_func_addr tracedprog2
|
||||
DW_TAG_subprogram: 'do_stuff'
|
||||
low pc : 0x08048604
|
||||
high pc : 0x0804863e
|
||||
DW_TAG_subprogram: 'main'
|
||||
low pc : 0x0804863e
|
||||
high pc : 0x0804865a
|
||||
```
|
||||
|
||||
The documentation of libdwarf (linked in the References section of this article) is quite good, and with some effort you should have no problem pulling any other information demonstrated in this article from the DWARF sections using it.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
Debugging information is a simple concept in principle. The implementation details may be intricate, but in the end of the day what matters is that we now know how the debugger finds the information it needs about the original source code from which the executable it's tracing was compiled. With this information in hand, the debugger bridges between the world of the user, who thinks in terms of lines of code and data structures, and the world of the executable, which is just a bunch of machine code instructions and data in registers and memory.
|
||||
|
||||
This article, with its two predecessors, concludes an introductory series that explains the inner workings of a debugger. Using the information presented here and some programming effort, it should be possible to create a basic but functional debugger for Linux.
|
||||
|
||||
As for the next steps, I'm not sure yet. Maybe I'll end the series here, maybe I'll present some advanced topics such as backtraces, and perhaps debugging on Windows. Readers can also suggest ideas for future articles in this series or related material. Feel free to use the comments or send me an email.
|
||||
|
||||
### References
|
||||
|
||||
* objdump man page
|
||||
* Wikipedia pages for [ELF][12] and [DWARF][13].
|
||||
* [Dwarf Debugging Standard home page][14] - from here you can obtain the excellent DWARF tutorial by Michael Eager, as well as the DWARF standard itself. You'll probably want version 2 since it's what gccproduces.
|
||||
* [libdwarf home page][15] - the download package includes a comprehensive reference document for the library
|
||||
* [BFD documentation][16]
|
||||
|
||||
|
||||
[1] DWARF is an open standard, published here by the DWARF standards committee. The DWARF logo displayed above is taken from that website.
|
||||
|
||||
[2] At the end of the article I've collected some useful resources that will help you get more familiar with DWARF, if you're interested. Particularly, start with the DWARF tutorial.
|
||||
|
||||
[3] Here and in subsequent examples, I'm placing (...) instead of some longer and un-interesting information for the sake of more convenient formatting.
|
||||
|
||||
[4] Because the DW_AT_frame_base attribute of do_stuff contains offset 0x0 into the location list. Note that the same attribute for main contains the offset 0x2c which is the offset for the second set of location expressions.
|
||||
|
||||
[5] Where the function prologue is usually executed and the local variables aren't even valid yet.
|
||||
|
||||
[6] Some parts of the information (such as location data and line number data) are encoded as instructions for a specialized virtual machine. Yes, really.
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id1
|
||||
[2]:http://dwarfstd.org/
|
||||
[3]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.gnu.org/software/binutils/
|
||||
[12]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[13]:http://en.wikipedia.org/wiki/DWARF
|
||||
[14]:http://dwarfstd.org/
|
||||
[15]:http://reality.sgiweb.org/davea/dwarf.html
|
||||
[16]:http://sourceware.org/binutils/docs-2.21/bfd/index.html
|
||||
[17]:http://en.wikipedia.org/wiki/DWARF
|
||||
[18]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id7
|
||||
[19]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id8
|
||||
[20]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id9
|
||||
[21]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id10
|
||||
[22]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id11
|
||||
[23]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id12
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2011/dwarf_get_func_addr.c
|
||||
[25]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
[26]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
[27]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints/
|
||||
@ -1,220 +0,0 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Linux on UEFI:A Quick Installation Guide
|
||||
============================================================
|
||||
|
||||
|
||||
This Web page is provided free of charge and with no annoying outside ads; however, I did take time to prepare it, and Web hosting does cost money. If you find this Web page useful, please consider making a small donation to help keep this site up and running. Thanks!
|
||||
|
||||
### Introduction
|
||||
|
||||
For several years, a new firmware technology has been lurking in the wings, unknown to most ordinary users. Known as the [Extensible Firmware Interface (EFI),][29] or more recently as the Unified EFI (UEFI, which is essentially EFI 2. _x_ ), this technology has begun replacing the older [Basic Input/Output System (BIOS)][30] firmware with which most experienced computer users are at least somewhat familiar.
|
||||
|
||||
This page is a quick introduction to EFI for Linux users, including advice on getting started installing Linux to such a computer. Unfortunately, EFI is a dense topic; the EFI software itself is complex, and many implementations have system-specific quirks and even bugs. Thus, I cannot describe everything you'll need to know to install and use Linux on an EFI computer on this one page. It's my hope that you'll find this page a useful starting point, though, and links within each section and in the [References][31] section at the end will point you toward additional documentation.
|
||||
|
||||
#### Contents
|
||||
|
||||
* [Introduction][18]
|
||||
* [Does Your Computer Use EFI?][19]
|
||||
* [Does Your Distribution Support EFI?][20]
|
||||
* [Preparing to Install Linux][21]
|
||||
* [Installing Linux][22]
|
||||
* [Fixing Post-Installation Problems][23]
|
||||
* [Oops: Converting a Legacy-Mode Install to Boot in EFI Mode][24]
|
||||
* [References][25]
|
||||
|
||||
### Does Your Computer Use EFI?
|
||||
|
||||
EFI is a type of _firmware,_ meaning that it's software built into the computer to handle low-level tasks. Most importantly, the firmware controls the computer's boot process, which in turn means that EFI-based computers boot differently than do BIOS-based computers. (A partial exception to this rule is described shortly.) This difference can greatly complicate the design of OS installation media, but it has little effect on the day-to-day operation of the computer, once everything is set up and running. Note that most manufacturers use the term "BIOS" to refer to their EFIs. I consider this usage confusing, so I avoid it; in my view, EFIs and BIOSes are two different types of firmware.
|
||||
|
||||
**Note:** The EFI that Apple uses on Macs is unusual in many respects. Although much of this page applies to Macs, some details differ, particularly when it comes to setting up EFI boot loaders. This task is best handled from OS X by using the Mac's [bless utility,][49]which I don't describe here.
|
||||
|
||||
EFI has been used on Intel-based Macs since they were first introduced in 2006\. Beginning in late 2012, most computers that ship with Windows 8 or later boot using UEFI by default, and in fact most PCs released since mid-2011 use UEFI, although they may not boot in EFI mode by default. A few PCs sold prior to 2011 also support EFI, although most such computers boot in BIOS mode by default.
|
||||
|
||||
If you're uncertain about your computer's EFI support status, you should check your firmware setup utility and your user manual for references to _EFI_ , _UEFI_ , or _legacy booting_ . (Searching a PDF of your user manual can be a quick way to do this.) If you find no such references, your computer probably uses an old-style ("legacy") BIOS; but if you find references to these terms, it almost certainly uses EFI. You can also try booting a medium that contains _only_ an EFI-mode boot loader. The USB flash drive or CD-R image of [rEFInd][50] is a good choice for this test.
|
||||
|
||||
Before proceeding further, you should understand that most EFIs on _x_ 86 and _x_ 86-64 computers include a component known as the _Compatibility Support Module (CSM),_ which enables the EFI to boot OSes using the older BIOS-style boot mechanisms. This can be a great convenience because it provides backwards compatibility; but it also creates complications because there's no standardization in the rules and user interfaces for controlling when a computer boots in EFI mode vs. when it boots in BIOS (aka CSM or legacy) mode. In particular, it's far too easy to accidentally boot your Linux installation medium in BIOS/CSM/legacy mode, which will result in a BIOS/CSM/legacy-mode installation of Linux. This can work fine if Linux is your only OS, but it complicates the boot process if you're dual-booting with Windows in EFI mode. (The opposite problem can also occur.) The following sections should help you boot your installer in the right mode. If you're reading this page after you've installed Linux in BIOS mode and want to switch boot modes, read the upcoming section, [Oops: Converting a Legacy-Mode Install to Boot in EFI Mode.][51]
|
||||
|
||||
One optional feature of UEFI deserves mention: _Secure Boot._ This feature is designed to minimize the risk of a computer becoming infected with a _boot kit,_ which is a type of malware that infects the computer's boot loader. Boot kits can be particularly difficult to detect and remove, which makes blocking them a priority. Microsoft requires that all desktop and laptop computers that bear a Windows 8 logo ship with Secure Boot enabled. This type of configuration complicates Linux installation, although some distributions handle this problem better than do others. Do not confuse Secure Boot with EFI or UEFI, though; it's possible for an EFI computer to not support Secure Boot, and it's possible to disable Secure Boot even on _x_ 86-64 EFI computers that support it. Microsoft requires that users can disable Secure Boot for Windows 8 certification on _x_ 86 and _x_ 86-64 computers; however, this requirement is reversed for ARM computers—such computers that ship with Windows 8 must _not_ permit the user to disable Secure Boot. Fortunately, ARM-based Windows 8 computers are currently rare. I recommend avoiding them.
|
||||
|
||||
### Does Your Distribution Support EFI?
|
||||
|
||||
Most Linux distributions have supported EFI for years. The quality of that support varies from one distribution to another, though. Most of the major distributions (Fedora, OpenSUSE, Ubuntu, and so on) provide good EFI support, including support for Secure Boot. Some more "do-it-yourself" distributions, such as Gentoo, have weaker EFI support, but their nature makes it easy to add EFI support to them. In fact, it's possible to add EFI support to _any_ Linux distribution: You need to install it (even in BIOS mode) and then install an EFI boot loader on the computer. See the [Oops: Converting a Legacy-Mode Install to Boot in EFI Mode][52] section for information on how to do this.
|
||||
|
||||
You should check your distribution's feature list to determine if it supports EFI. You should also pay attention to your distribution's support for Secure Boot, particularly if you intend to dual-boot with Windows 8\. Note that even distributions that officially support Secure Boot may require that this feature be disabled, since Linux Secure Boot support is often poor or creates complications.
|
||||
|
||||
### Preparing to Install Linux
|
||||
|
||||
A few preparatory steps will help make your Linux installation on an EFI-based computer go more smoothly:
|
||||
|
||||
1. **Upgrade your firmware**—Some EFIs are badly broken, but hardware manufacturers occasionally release updates to their firmware. Thus, I recommend upgrading your firmware to the latest version available. If you know from forum posts or the like that your EFI is problematic, you should do this before installing Linux, because some problems will require extra steps to correct if the firmware is upgraded after the installation. On the other hand, upgrading firmware is always a bit risky, so holding off on such an upgrade may be best if you've heard good things about your manufacturer's EFI support.
|
||||
3. **Learn how to use your firmware**—You</a> can usually enter a firmware setup utility by hitting the Del key or a function key early in the boot process. Check for prompts soon after you power on the computer or just try each function key. Similarly, the Esc key or a function key usually enters the firmware's built-in boot manager, which enables you to select which OS or external device to boot. Some manufacturers are making it hard to reach such settings. In some cases, you can do so from inside Windows 8, as described on [this page.][32]
|
||||
4. **Adjust the following firmware settings:**
|
||||
* **Fast boot**—This feature can speed up the boot process by taking shortcuts in hardware initialization. Sometimes this is fine, but sometimes it can leave USB hardware uninitialized, which can make it impossible to boot from a USB flash drive or similar device. Thus, disabling fast boot _may_ be helpful, or even required; but you can safely leave it active and deactivate it only if you have trouble getting the Linux installer to boot. Note that this feature sometimes goes by another name. In some cases, you must _enable_ USB support rather than _disable_ a fast boot feature.
|
||||
* **Secure Boot**—Fedora, OpenSUSE, Ubuntu, and some other distributions officially support Secure Boot; but if you have problems getting a boot loader or kernel to start, you might want to disable this feature. Unfortunately, fully describing how to do so is impossible because the settings vary from one computer to another. See [my Secure Boot page][1] for more on this topic.
|
||||
|
||||
**Note:** Some guides say to enable BIOS/CSM/legacy support to install Linux. As a general rule, they're wrong to do so. Enabling this support can overcome hurdles involved in booting the installer, but doing so creates new problems down the line. Guides to install in this way often overcome these later problems by running Boot Repair, but it's better to do it correctly from the start. This page provides tips to help you get your Linux installer to boot in EFI mode, thus bypassing the later problems.
|
||||
|
||||
* **CSM/legacy options**—If you want to install in EFI mode, set such options _off._ Some guides recommend enabling these options, and in some cases they may be required—for instance, they may be needed to enable the BIOS-mode firmware in some add-on video cards. In most cases, though, enabling CSM/legacy support simply increases the risk of inadvertently booting your Linux installer in BIOS mode, which you do _not_ want to do. Note that Secure Boot and CSM/legacy options are sometimes intertwined, so be sure to check each one after changing the other.
|
||||
5. **Disable the Windows Fast Startup feature**—[This page][33] describes how to disable this feature, which is almost certain to cause filesystem corruption if left enabled. Note that this feature is distinct from the firmware's fast boot feature.
|
||||
6. **Check your partition table**—Using [GPT fdisk,][34] parted, or any other partitioning tool, check your disk's partitions. Ideally, you should create a hardcopy that includes the exact start and end points (in sectors) of each partition. This will be a useful reference, particularly if you use a manual partitioning option in the installer. If Windows is already installed, be sure to identify your [EFI System Partition (ESP),][35] which is a FAT partition with its "boot flag" set (in parted or GParted) or that has a type code of EF00 in gdisk.
|
||||
|
||||
### Installing Linux
|
||||
|
||||
Most Linux distributions provide adequate installation instructions; however, I've observed a few common stumbling blocks on EFI-mode installations:
|
||||
|
||||
* **Ensure that you're using a distribution that's the right bit depth**—EFI runs boot loaders that are the same bit depth as the EFI itself. This is normally 64-bit for modern computers, although the first couple generations of Intel-based Macs, some modern tablets and convertibles, and a handful of obscure computers use 32-bit EFIs. I have yet to encounter a 32-bit Linux distribution that officially supports EFI, although it is possible to add a 32-bit EFI boot loader to 32-bit distributions. (My [Managing EFI Boot Loaders for Linux][36] covers boot loaders generally, and understanding those principles may enable you to modify a 32-bit distribution's installer, although that's not a task for a beginner.) Installing a 32-bit Linux distribution on a computer with a 64-bit EFI is difficult at best, and I don't describe the process here; you should use a 64-bit distribution on a computer with a 64-bit EFI.
|
||||
* **Properly prepare your boot medium**—Third-party tools for moving .iso images onto USB flash drives, such as unetbootin, often fail to create the proper EFI-mode boot entries. I recommend you follow whatever procedure your distribution maintainer suggests for creating USB flash drives. If no such recommendation is made, use the Linux dd utility, as in dd if=image.iso of=/dev/sdc to create an image on the USB flash drive on /dev/sdc. Ports of dd to Windows, such as [WinDD][37] and [dd for Windows,][38] exist, but I've never tested them. Note that using tools that don't understand EFI to create your installation medium is one of the mistakes that leads people into the bigger mistake of installing in BIOS mode and then having to correct the ensuing problems, so don't ignore this point!
|
||||
* **Back up the ESP**—If you're installing to a computer that already boots Windows or some other OS, I recommend backing up your ESP before installing Linux. Although Linux _shouldn't_ damage files that are already on the ESP, this does seem to happen from time to time. Having a backup will help in such cases. A simple file-level backup (using cp, tar, or zip, for example) should work fine.
|
||||
* **Booting in EFI mode**—It's too easy to accidentally boot your Linux installer in BIOS/CSM/legacy mode, particularly if you leave the CSM/legacy options enabled in your firmware. A few tips can help you to avoid this problem:
|
||||
|
||||
* You should verify an EFI-mode boot by dropping to a Linux shell and typing ls /sys/firmware/efi. If you see a list of files and directories, you've booted in EFI mode and you can ignore the following additional tips; if not, you've probably booted in BIOS mode and should review your settings.
|
||||
* Use your firmware's built-in boot manager (which you should have located earlier; see [Learn how to use your firmware][26]) to boot in EFI mode. Typically, you'll see two options for a CD-R or USB flash drive, one of which includes the string _EFI_ or _UEFI_ in its description, and one of which does not. Use the EFI/UEFI option to boot your medium.
|
||||
* Disable Secure Boot—Even if you're using a distribution that officially supports Secure Boot, sometimes this doesn't work. In this case, the computer will most likely silently move on to the next boot loader, which could be your medium's BIOS-mode boot loader, resulting in a BIOS-mode boot. See [my page on Secure Boot][27] for some tips on how to disable Secure Boot.
|
||||
* If you can't seem to get the Linux installer to boot in EFI mode, try using a USB flash drive or CD-R version of my [rEFInd boot manager.][28] If rEFInd boots, it's guaranteed to be running in EFI mode, and on a UEFI-based PC, it will show only EFI-mode boot options, so if you can then boot to the Linux installer, it should be in EFI mode. (On Macs, though, rEFInd shows BIOS-mode boot options in addition to EFI-mode options.)
|
||||
|
||||
* **Preparing your ESP**—Except on Macs, EFIs use the ESP to hold boot loaders. If your computer came with Windows pre-installed, an ESP should already exist, and you can use it in Linux. If not, I recommend creating an ESP that's 550MiB in size. (If your existing ESP is smaller than this, go ahead and use it.) Create a FAT32 filesystem on it. If you use GParted or parted to prepare your disk, give the ESP a "boot flag." If you use GPT fdisk (gdisk, cgdisk, or sgdisk) to prepare the disk, give it a type code of EF00\. Some installers create a smallish ESP and put a FAT16 filesystem on it. This usually works fine, although if you subsequently need to re-install Windows, its installer will become confused by the FAT16 ESP, so you may need to back it up and convert it to FAT32 form.
|
||||
* **Using the ESP**—Different distributions' installers have different ways of identifying the ESP. For instance, some versions of Debian and Ubuntu call the ESP the "EFI boot partition" and do not show you an explicit mount point (although it will mount it behind the scenes); but a distribution like Arch or Gentoo will require you to mount it. The closest thing to a standard ESP mount point in Linux is /boot/efi, although /boot works well with some configurations—particularly if you want to use gummiboot or ELILO. Some distributions won't let you use a FAT partition as /boot, though. Thus, if you're asked to set a mount point for the ESP, make it /boot/efi. Do _not_ create a fresh filesystem on the ESP unless it doesn't already have one—if Windows or some other OS is already installed, its boot loader lives on the ESP, and creating a new filesystem will destroy that boot loader!
|
||||
* **Setting the boot loader location**—Some distributions may ask about the boot loader's (GRUB's) location. If you've properly flagged the ESP as such, this question should be unnecessary, but some distributions' installers still ask. Try telling it to use the ESP.
|
||||
* **Other partitions**—Other than the ESP, no other special partitions are required; you can set up root (/), swap, /home, or whatever else you like in the same way you would for a BIOS-mode installation. Note that you do _not_ need a [BIOS Boot Partition][39] for an EFI-mode installation, so if your installer is telling you that you need one, this may be a sign that you've accidentally booted in BIOS mode. On the other hand, if you create a BIOS Boot Partition, that will give you some extra flexibility, since you'll be able to install a BIOS version of GRUB to boot in either mode (EFI or BIOS).
|
||||
* **Fixing blank displays**—A problem that many people had through much of 2013 (but with decreasing frequency since then) was blank displays when booted in EFI mode. Sometimes this problem can be fixed by adding nomodeset to the kernel's command line. You can do this by typing e to open a simple text editor in GRUB. In many cases, though, you'll need to research this problem in more detail, because it often has more hardware-specific causes.
|
||||
|
||||
In some cases, you may be forced to install Linux in BIOS mode. You can sometimes then manually install an EFI-mode boot loader for Linux to begin booting in EFI mode. See my [Managing EFI Boot Loaders for Linux][53] page for information on available boot loaders and how to install them.
|
||||
|
||||
### Fixing Post-Installation Problems
|
||||
|
||||
If you can't seem to get an EFI-mode boot of Linux working but a BIOS-mode boot works, you can abandon EFI mode entirely. This is easiest on a Linux-only computer; just install a BIOS-mode boot loader (which the installer should have done if you installed in BIOS mode). If you're dual-booting with an EFI-mode Windows, though, the easiest solution is to install my [rEFInd boot manager.][54] Install it from Windows and edit the refind.conf file: Uncomment the scanfor line and ensure that hdbios is among the options. This will enable rEFInd to redirect the boot process to a BIOS-mode boot loader. This solution works for many systems, but sometimes it fails for one reason or another.
|
||||
|
||||
If you reboot the computer and it boots straight into Windows, it's likely that your Linux boot loader or boot manager was not properly installed. (You should try disabling Secure Boot first, though; as I've said, it often causes problems.) There are several possible solutions to this problem:
|
||||
|
||||
* **Use efibootmgr**—You can boot a Linux emergency disc _in EFI mode_ and use the efibootmgr utility to re-register your Linux boot loader, as described [here.][40]
|
||||
* **Use bcdedit in Windows**—In a Windows Administrator Command Prompt window, typing bcdedit /set {bootmgr} path \EFI\fedora\grubx64.efi will set the EFI/fedora/grubx64.efi file on the ESP as the default boot loader. Change that path as necessary to point to your desired boot loader. If you're booting with Secure Boot enabled, you should set shim.efi, shimx64.efi, or PreLoader.efi (whichever is present) as the boot program, rather than grubx64.efi.
|
||||
* **Install rEFInd**—Sometimes rEFInd can overcome this problem. I recommend testing by using the [CD-R or USB flash drive image.][41] If it can boot Linux, install the Debian package, RPM, or .zip file package. (Note that you may need to edit your boot options by highlighting a Linux vmlinuz* option and hitting F2 or Insert twice. This is most likely to be required if you've got a separate /bootpartition, since in this situation rEFInd can't locate the root (/) partition to pass to the kernel.)
|
||||
* **Use Boot Repair**—Ubuntu's [Boot Repair utility][42] can auto-repair some boot problems; however, I recommend using it only on Ubuntu and closely-related distributions, such as Mint. In some cases, it may be necessary to click the Advanced option and check the box to back up and replace the Windows boot loader.
|
||||
* **Hijack the Windows boot loader**—Some buggy EFIs boot only the Windows boot loader, which is called EFI/Microsoft/Boot/bootmgfw.efi on the ESP. Thus, you may need to rename this boot loader to something else (I recommend moving it down one level, to EFI/Microsoft/bootmgfw.efi) and putting a copy of your preferred boot loader in its place. (Most distributions put a copy of GRUB in a subdirectory of EFI named after themselves, such as EFI/ubuntu for Ubuntu or EFI/fedora for Fedora.) Note that this solution is an ugly hack, and some users have reported that Windows will replace its boot loader, so it may not even work 100% of the time. It is, however, the only solution that works on some badly broken EFIs. Before attempting this solution, I recommend upgrading your firmware and re-registering your own boot loader with efibootmgr in Linux or bcdedit in Windows.
|
||||
|
||||
Another class of problems relates to boot loader troubles—If you see GRUB (or whatever boot loader or boot manager your distribution uses by default) but it doesn't boot an OS, you must fix that problem. Windows often fails to boot because GRUB 2 is very finicky about booting Windows. This problem can be exacerbated by Secure Boot in some cases. See [my page on GRUB 2][55] for a sample GRUB 2 entry for booting Windows. Linux boot problems, once GRUB appears, can have a number of causes, and are likely to be similar to BIOS-mode Linux boot problems, so I don't cover them here.
|
||||
|
||||
Despite the fact that it's very common, my opinion of GRUB 2 is rather low—it's an immensely complex program that's difficult to configure and use. Thus, if you run into problems with GRUB, my initial response is to replace it with something else. [My Web page on EFI boot loaders for Linux][56] describes the options that are available. These include my own [rEFInd boot manager,][57] which is much easier to install and maintain, aside from the fact that many distributions do manage to get GRUB 2 working—but if you're considering replacing GRUB 2 because of its problems, that's obviously not worked out for you!
|
||||
|
||||
Beyond these issues, EFI booting problems can be quite idiosyncratic, so you may need to post to a Web forum for help. Be sure to describe the problem as thoroughly as you can. The [Boot Info Script][58] can provide useful information—run it and it should produce a file called RESULTS.txt that you can paste into your forum post. Be sure to precede this pasted text with the string [code] and follow it with [/code], though; otherwise people will complain. Alternatively, upload RESULTS.txt to a pastebin site, such as [pastebin.com,][59] and post the URL that the site gives you.
|
||||
|
||||
### Oops: Converting a Legacy-Mode Install to Boot in EFI Mode
|
||||
|
||||
**Warning:** These instructions are written primarily for UEFI-based PCs. If you've installed Linux in BIOS mode on a Mac but want to boot Linux in EFI mode, you can install your boot program _in OS X._ rEFInd (or the older rEFIt) is the usual choice on Macs, but GRUB can be made to work with some extra effort.
|
||||
|
||||
As of early 2015, one very common problem I see in online forums is that people follow bad instructions and install Linux in BIOS mode to dual-boot with an existing EFI-mode Windows installation. This configuration works poorly because most EFIs make it difficult to switch between boot modes, and GRUB can't handle the task, either. You might also find yourself in this situation if you've got a very flaky EFI that simply won't boot an external medium in EFI mode, or if you have video or other problems with Linux when it's booted in EFI mode.
|
||||
|
||||
As noted earlier, in [Fixing Post-Installation Problems,][60] one possible solution to such problems is to install rEFInd _in Windows_ and configure it to support BIOS-mode boots. You can then boot rEFInd and chainload to your BIOS-mode GRUB. I recommend this fix mainly when you have EFI-specific problems in Linux, such as a failure to use your video card. If you don't have such EFI-specific problems, installing rEFInd and a suitable EFI filesystem driver in Windows will enable you to boot Linux directly in EFI mode. This can be a perfectly good solution, and it will be equivalent to what I describe next.
|
||||
|
||||
In most cases, it's best to configure Linux to boot in EFI mode. There are many ways to do this, but the best way requires using an EFI-mode boot of Linux (or conceivably Windows or an EFI shell) to register an EFI-mode version of your preferred boot manager. One way to accomplish this goal is as follows:
|
||||
|
||||
1. Download a USB flash drive or CD-R version of my [rEFInd boot manager.][43]
|
||||
2. Prepare a medium from the image file you've downloaded. You can do this from any computer, booted in either EFI or BIOS mode (or in other ways on other platforms).
|
||||
3. If you've not already done so, [disable Secure Boot.][44] This is necessary because the rEFInd CD-R and USB images don't support Secure Boot. If you want to keep Secure Boot, you can re-enable it later.
|
||||
4. Boot rEFInd on your target computer. As described earlier, you may need to adjust your firmware settings and use the built-in boot manager to select your boot medium. The option you select may need to include the string _UEFI_ in its description.
|
||||
5. In rEFInd, examine the boot options. You should see at least one option for booting a Linux kernel (with a name that includes the string vmlinuz). Boot it in one of two ways:
|
||||
* If you do _not_ have a separate /boot partition, simply highlight the kernel and press Enter. Linux should boot.
|
||||
* If you _do_ have a separate /boot partition, press Insert or F2 twice. This action will open a line editor in which you can edit your kernel options. Add a root= specification to those options to identify your root (/) filesystem, as in root=/dev/sda5 if root (/) is on /dev/sda5. If you don't know what your root filesystem is, you should reboot in any way possible to figure it out.In some rare cases, you may need to add other kernel options instead of or in addition to a root= option. Gentoo with an LVM configuration requires dolvm, for example.
|
||||
6. Once Linux is booted, install your desired boot program. rEFInd is usually pretty easy to install via the RPM, Debian package, PPA, or binary .zip file referenced on the [rEFInd downloads page.][45] On Ubuntu and similar distributions, Boot Repair can fix your GRUB setup relatively simply, but it will be a bit of a leap of faith that it will work correctly. (It usually works fine, but in some cases it will make a hash of things.) Other options are described on my [Managing EFI Boot Loaders for Linux][46] page.
|
||||
7. If you want to boot with Secure Boot active, reboot and enable it. Note, however, that you may need to take extra installation steps to set up your boot program to use Secure Boot. Consult [my page on the topic][47] or your boot program's Secure Boot documentation for details.
|
||||
|
||||
When you reboot, you should see the boot program you just installed. If the computer instead boots into a BIOS-mode version of GRUB, you should enter your firmware and disable the BIOS/CSM/legacy support, or perhaps adjust your boot order options. If the computer boots straight to Windows, then you should read the preceding section, [Fixing Post-Installation Problems.][61]
|
||||
|
||||
You may want or need to tweak your configuration at this point. It's common to see extra boot options, or for an option you want to not be visible. Consult your boot program's documentation to learn how to make such changes.
|
||||
|
||||
### References and Additional Information
|
||||
|
||||
|
||||
* **Informational Web pages**
|
||||
* My [Managing EFI Boot Loaders for Linux][2] page covers the available EFI boot loaders and boot managers.
|
||||
* The [man page for OS X's bless tool][3] may be helpful in setting up a boot loader or boot manager on that platform.
|
||||
* [The EFI Boot Process][4] describes, in broad strokes, how EFI systems boot.
|
||||
* The [Arch Linux UEFI wiki page][5] has a great deal of information on UEFI and Linux.
|
||||
* Adam Williamson has written a good [summary of what EFI is and how it works.][6]
|
||||
* [This page][7] describes how to adjust EFI firmware settings from within Windows 8.
|
||||
* Matthew J. Garrett, the developer of the Shim boot loader to manage Secure Boot, maintains [a blog][8] in which he often writes about EFI issues.
|
||||
* If you're interested in developing EFI software yourself, my [Programming for EFI][9] can help you get started.
|
||||
* **Additional programs**
|
||||
* [The official rEFInd Web page][10]
|
||||
* [The official gummiboot Web page][11]
|
||||
* [The official ELILO Web page][12]
|
||||
* [The official GRUB Web page][13]
|
||||
* [The official GPT fdisk partitioning software Web page][14]
|
||||
* Ubuntu's [Boot Repair utility][15] can help fix some boot problems
|
||||
* **Communications**
|
||||
* The [rEFInd discussion forum on Sourceforge][16] provides a way to discuss rEFInd with other users or with me.
|
||||
* Pastebin sites, such as [http://pastebin.com,][17] provide a convenient way to exchange largeish text files with users on Web forums.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.rodsbooks.com/linux-uefi/
|
||||
|
||||
作者:[Roderick W. Smith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:rodsmith@rodsbooks.com
|
||||
[1]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[2]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[3]:http://ss64.com/osx/bless.html
|
||||
[4]:http://homepage.ntlworld.com/jonathan.deboynepollard/FGA/efi-boot-process.html
|
||||
[5]:https://wiki.archlinux.org/index.php/Unified_Extensible_Firmware_Interface
|
||||
[6]:https://www.happyassassin.net/2014/01/25/uefi-boot-how-does-that-actually-work-then/
|
||||
[7]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[8]:http://mjg59.dreamwidth.org/
|
||||
[9]:http://www.rodsbooks.com/efi-programming/
|
||||
[10]:http://www.rodsbooks.com/refind/
|
||||
[11]:http://freedesktop.org/wiki/Software/gummiboot
|
||||
[12]:http://elilo.sourceforge.net/
|
||||
[13]:http://www.gnu.org/software/grub/
|
||||
[14]:http://www.rodsbooks.com/gdisk/
|
||||
[15]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[16]:https://sourceforge.net/p/refind/discussion/
|
||||
[17]:http://pastebin.com/
|
||||
[18]:http://www.rodsbooks.com/linux-uefi/#intro
|
||||
[19]:http://www.rodsbooks.com/linux-uefi/#isitefi
|
||||
[20]:http://www.rodsbooks.com/linux-uefi/#distributions
|
||||
[21]:http://www.rodsbooks.com/linux-uefi/#preparing
|
||||
[22]:http://www.rodsbooks.com/linux-uefi/#installing
|
||||
[23]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[24]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[25]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[26]:http://www.rodsbooks.com/linux-uefi/#using_firmware
|
||||
[27]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[28]:http://www.rodsbooks.com/refind/getting.html
|
||||
[29]:https://en.wikipedia.org/wiki/Uefi
|
||||
[30]:https://en.wikipedia.org/wiki/BIOS
|
||||
[31]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[32]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[33]:http://www.eightforums.com/tutorials/6320-fast-startup-turn-off-windows-8-a.html
|
||||
[34]:http://www.rodsbooks.com/gdisk/
|
||||
[35]:http://en.wikipedia.org/wiki/EFI_System_partition
|
||||
[36]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[37]:https://sourceforge.net/projects/windd/
|
||||
[38]:http://www.chrysocome.net/dd
|
||||
[39]:https://en.wikipedia.org/wiki/BIOS_Boot_partition
|
||||
[40]:http://www.rodsbooks.com/efi-bootloaders/installation.html
|
||||
[41]:http://www.rodsbooks.com/refind/getting.html
|
||||
[42]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[43]:http://www.rodsbooks.com/refind/getting.html
|
||||
[44]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[45]:http://www.rodsbooks.com/refind/getting.html
|
||||
[46]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[47]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html
|
||||
[48]:mailto:rodsmith@rodsbooks.com
|
||||
[49]:http://ss64.com/osx/bless.html
|
||||
[50]:http://www.rodsbooks.com/refind/getting.html
|
||||
[51]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[52]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[53]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[54]:http://www.rodsbooks.com/refind/
|
||||
[55]:http://www.rodsbooks.com/efi-bootloaders/grub2.html
|
||||
[56]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[57]:http://www.rodsbooks.com/refind/
|
||||
[58]:http://sourceforge.net/projects/bootinfoscript/
|
||||
[59]:http://pastebin.com/
|
||||
[60]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[61]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
@ -1,505 +0,0 @@
|
||||
svtter 翻译中
|
||||
|
||||
GitLab Workflow: An Overview
|
||||
======
|
||||
|
||||
GitLab is a Git-based repository manager and a powerful complete application for software development.
|
||||
|
||||
With an _"user-and-newbie-friendly" interface_, GitLab allows you to work effectively, both from the command line and from the UI itself. It's not only useful for developers, but can also be integrated across your entire team to bring everyone into a single and unique platform.
|
||||
|
||||
The GitLab Workflow logic is intuitive and predictable, making the entire platform easy to use and easier to adopt. Once you do, you won't want anything else!
|
||||
|
||||
* * *
|
||||
|
||||
### In this post
|
||||
|
||||
* [GitLab Workflow][53]
|
||||
* [Stages of Software Development][22]
|
||||
* [GitLab Issue Tracker][52]
|
||||
* [Confidential Issues][21]
|
||||
* [Due dates][20]
|
||||
* [Assignee][19]
|
||||
* [Labels][18]
|
||||
* [Issue Weight][17]
|
||||
* [GitLab Issue Board][16]
|
||||
* [Code Review with GitLab][51]
|
||||
* [First Commit][15]
|
||||
* [Merge Request][14]
|
||||
* [WIP MR][13]
|
||||
* [Review][12]
|
||||
* [Build, Test, and Deploy][50]
|
||||
* [Koding][11]
|
||||
* [Use-Cases][10]
|
||||
* [Feedback: Cycle Analytics][49]
|
||||
* [Enhance][48]
|
||||
* [Issue and MR Templates][9]
|
||||
* [Milestones][8]
|
||||
* [Pro Tips][47]
|
||||
* [For both Issues and MRs][7]
|
||||
* [Subscribe][3]
|
||||
* [Add TO-DO][2]
|
||||
* [Search for your Issues and MRs][1]
|
||||
* [Moving Issues][6]
|
||||
* [Code Snippets][5]
|
||||
* [GitLab WorkFlow Use-Case Scenario][46]
|
||||
* [Conclusions][45]
|
||||
|
||||
* * *
|
||||
|
||||
### GitLab Workflow
|
||||
|
||||
The **GitLab Workflow** is a logical sequence of possible actions to be taken during the entire lifecycle of the software development process, using GitLab as the platform that hosts your code.
|
||||
|
||||
The GitLab Workflow takes into account the [GitLab Flow][97], which consists of **Git-based** methods and tactics for version management, such as **branching strategy**, **Git best practices**, and so on.
|
||||
|
||||
With the GitLab Workflow, the [goal][96] is to help teams work cohesively and effectively from the first stage of implementing something new (ideation) to the last stage—deploying implementation to production. That's what we call "going faster from idea to production in 10 steps."
|
||||
|
||||

|
||||
|
||||
### Stages of Software Development
|
||||
|
||||
The natural course of the software development process passes through 10 major steps; GitLab has built solutions for all of them:
|
||||
|
||||
1. **IDEA:** Every new proposal starts with an idea, which usually come up in a chat. For this stage, GitLab integrates with [Mattermost][44].
|
||||
2. **ISSUE:** The most effective way to discuss an idea is creating an issue for it. Your team and your collaborators can help you to polish and improve it in the [issue tracker][43].
|
||||
3. **PLAN:** Once the discussion comes to an agreement, it's time to code. But wait! First, we need to prioritize and organize our workflow. For this, we can use the [Issue Board][42].
|
||||
4. **CODE:** Now we're ready to write our code, once we have everything organized.
|
||||
5. **COMMIT:** Once we're happy with our draft, we can commit our code to a feature-branch with version control.
|
||||
6. **TEST:** With [GitLab CI][41], we can run our scripts to build and test our application.
|
||||
7. **REVIEW:** Once our script works and our tests and builds succeeds, we are ready to get our [code reviewed][40] and approved.
|
||||
8. **STAGING:** Now it's time to [deploy our code to a staging environment][39] to check if everything worked as we were expecting or if we still need adjustments.
|
||||
9. **PRODUCTION:** When we have everything working as it should, it's time to [deploy to our production environment][38]!
|
||||
10. **FEEDBACK:** Now it's time to look back and check what stage of our work needs improvement. We use [Cycle Analytics][37] for feedback on the time we spent on key stages of our process.
|
||||
|
||||
To walk through these stages smoothly, it's important to have powerful tools to support this workflow. In the following sections, you'll find an overview of the toolset available from GitLab.
|
||||
|
||||
### GitLab Issue Tracker
|
||||
|
||||
GitLab has a powerful issue tracker that allows you, your team, and your collaborators to share and discuss ideas, before and while implementing them.
|
||||
|
||||
|
||||
|
||||
Issues are the first essential feature of the GitLab Workflow. [Always start a discussion with an issue][95]; it's the best way to track the evolution of a new idea.
|
||||
|
||||
It's most useful for:
|
||||
|
||||
* Discussing ideas
|
||||
* Submitting feature proposals
|
||||
* Asking questions
|
||||
* Reporting bugs and malfunction
|
||||
* Obtaining support
|
||||
* Elaborating new code implementations
|
||||
|
||||
Each project hosted by GitLab has an issue tracker. To create a new issue, navigate to your project's **Issues** > **New issue**, give it a title that summarizes the subject to be treated, and describe it using [Markdown][94]. Check the [pro tips][93] below to enhance your issue description.
|
||||
|
||||
The GitLab Issue Tracker presents extra functionalities to make it easier to organize and prioritize your actions, described in the following sections.
|
||||
|
||||
|
||||
|
||||
### Confidential Issues
|
||||
|
||||
Whenever you want to keep the discussion presented in a issue within your team only, you can make that [issue confidential][92]. Even if your project is public, that issue will be preserved. The browser will respond with a 404 error whenever someone who is not a project member with at least [Reporter level][91] tries to access that issue's URL.
|
||||
|
||||
### Due dates
|
||||
|
||||
Every issue enables you to attribute a [due date][90] to it. Some teams work on tight schedules, and it's important to have a way to setup a deadline for implementations and for solving problems. This can be facilitated by the due dates.
|
||||
|
||||
When you have due dates for multi-task projects—for example, a new release, product launch, or for tracking tasks by quarter—you can use [milestones][89].
|
||||
|
||||
### Assignee
|
||||
|
||||
Whenever someone starts to work on an issue, it can be assigned to that person. You can change the assignee as much as you need. The idea is that the assignee is responsible for that issue until he/she reassigns it to someone else to take it from there.
|
||||
|
||||
It also helps with filtering issues per assignee.
|
||||
|
||||
### Labels
|
||||
|
||||
GitLab labels are also an important part of the GitLab flow. You can use them to categorize your issues, to localize them in your workflow, and to organize them by priority with [Priority Labels][88].
|
||||
|
||||
Labels will enable you to work with the [GitLab Issue Board][87], facilitating your plan stage and organizing your workflow.
|
||||
|
||||
**New!** You can also create [Group Labels][86], which give you the ability to use the same labels per group of projects.
|
||||
|
||||
### Issue Weight
|
||||
|
||||
You can attribute an [Issue Weight][85] to make it clear how difficult the implementation of that idea is. Less difficult would receive weights of 01-03, more difficult, 07-09, and the ones in the middle, 04-06\. Still, you can get to an agreement with your team to standardize the weights according to your needs.
|
||||
|
||||
### GitLab Issue Board
|
||||
|
||||
The [GitLab Issue Board][84] is a tool ideal for planning and organizing your issues according to your project's workflow.
|
||||
|
||||
It consists of a board with lists corresponding to its respective labels. Each list contains their corresponding labeled issues, displayed as cards.
|
||||
|
||||
The cards can be moved between lists, which will cause the label to be updated according to the list you moved the card into.
|
||||
|
||||
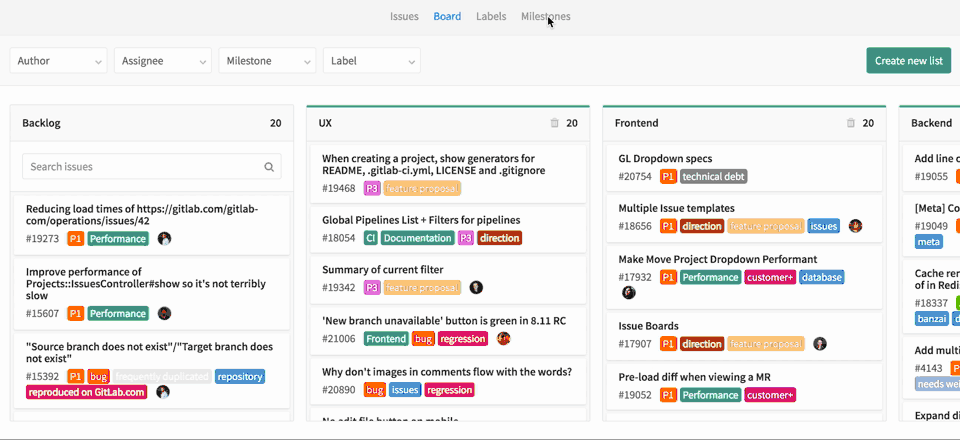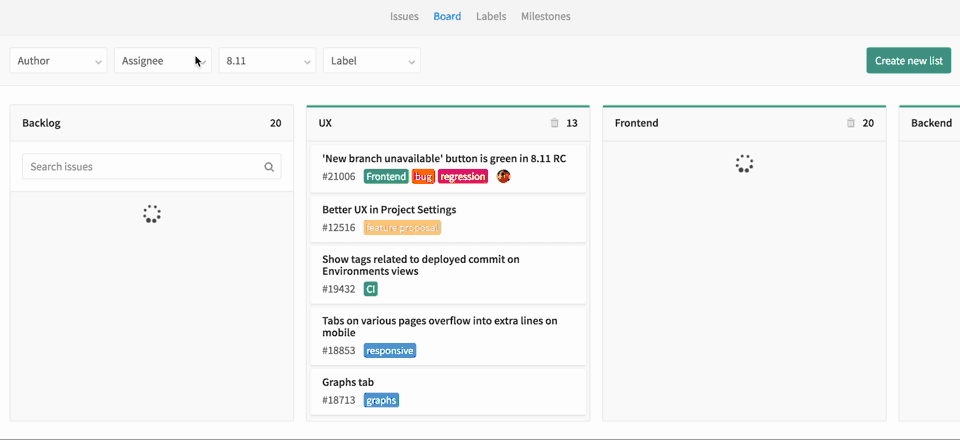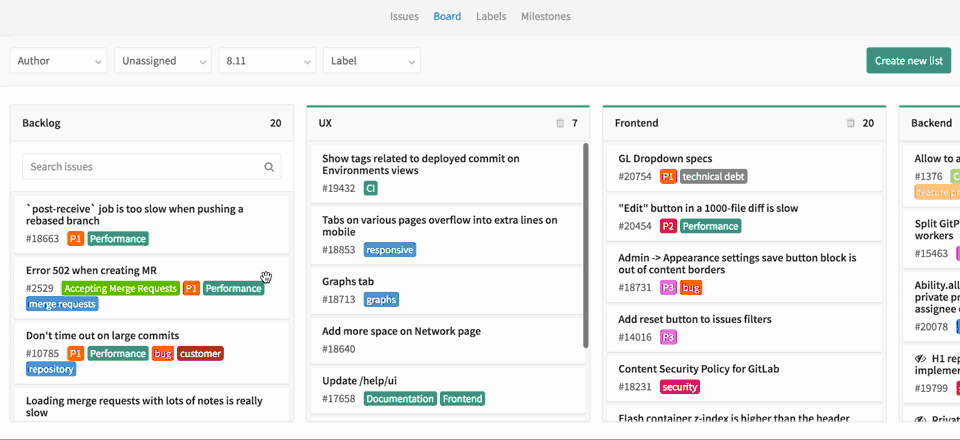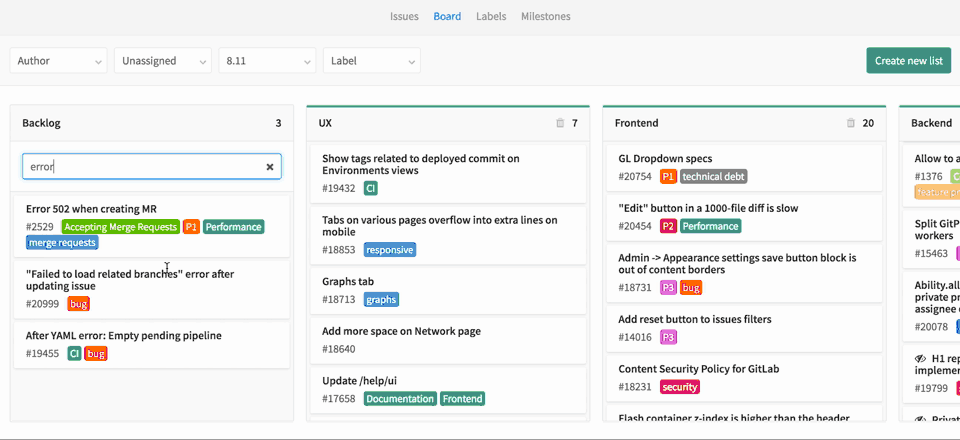
|
||||
|
||||
**New!** You can also create issues right from the Board, by clicking the button on the top of a list. When you do so, that issue will be automatically created with the label corresponding to that list.
|
||||
|
||||
**New!** We've [recently introduced][83] **Multiple Issue Boards** per project ([GitLab Enterprise Edition][82] only); it is the best way to organize your issues for different workflows.
|
||||
|
||||
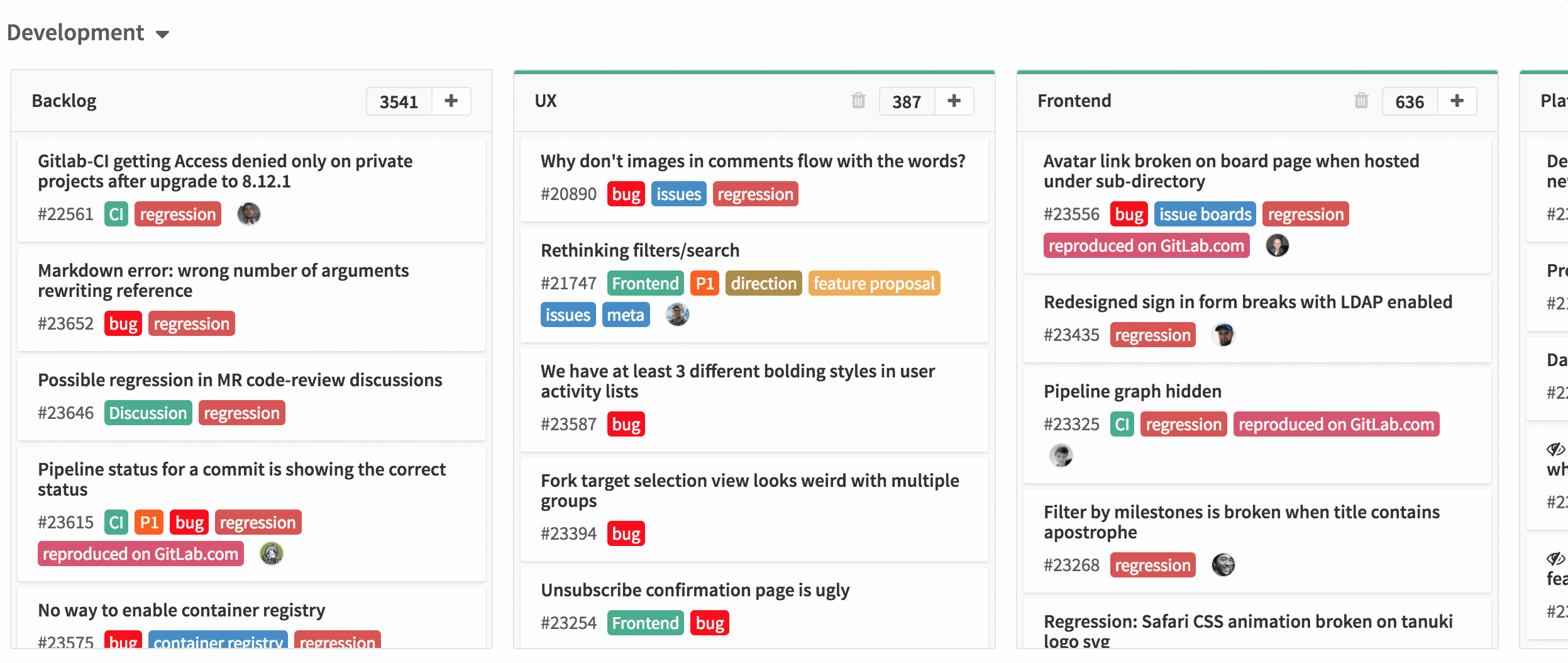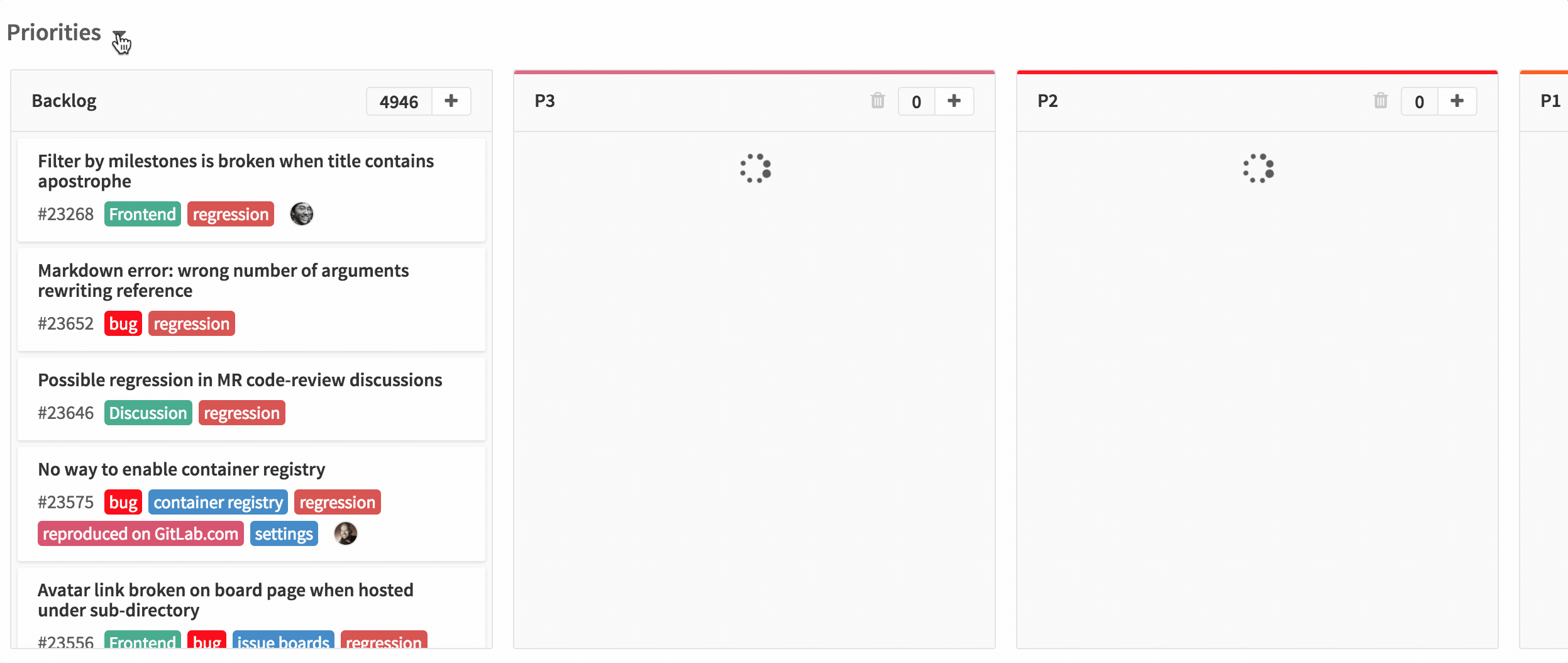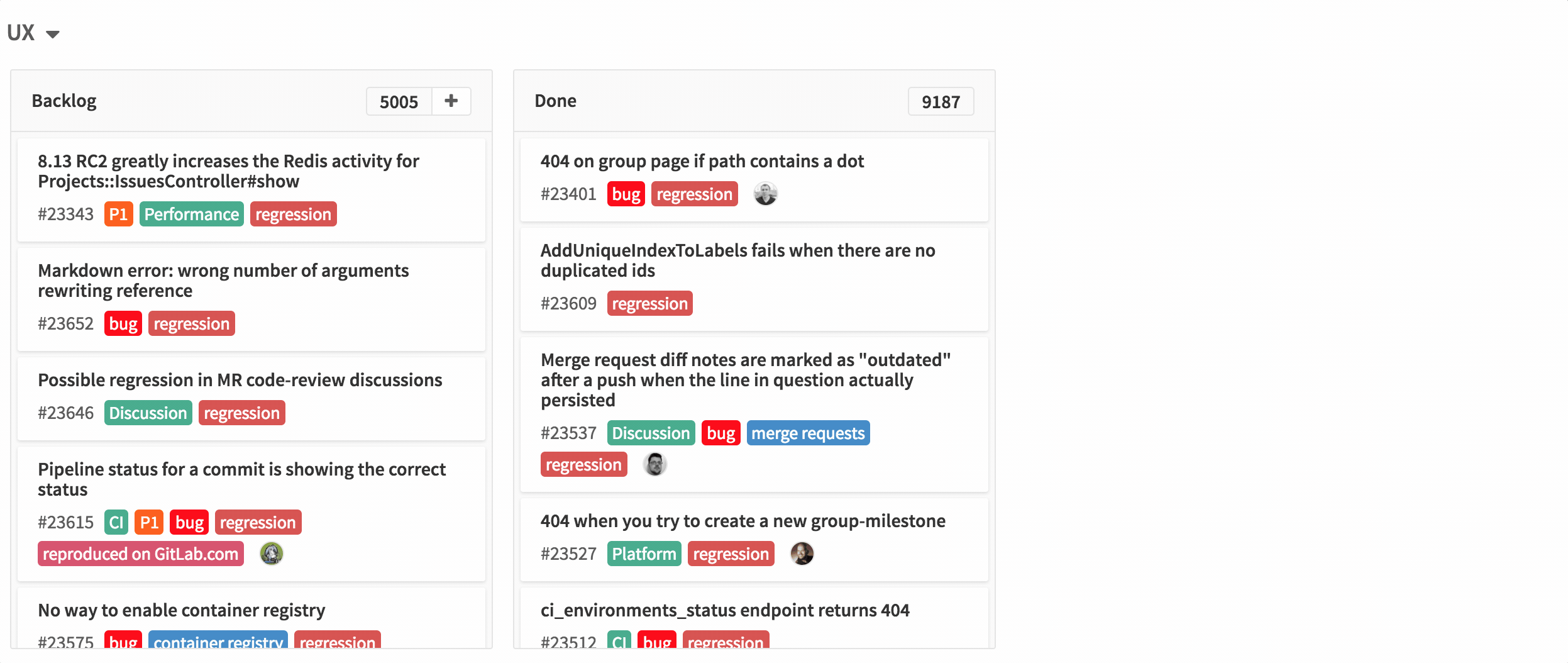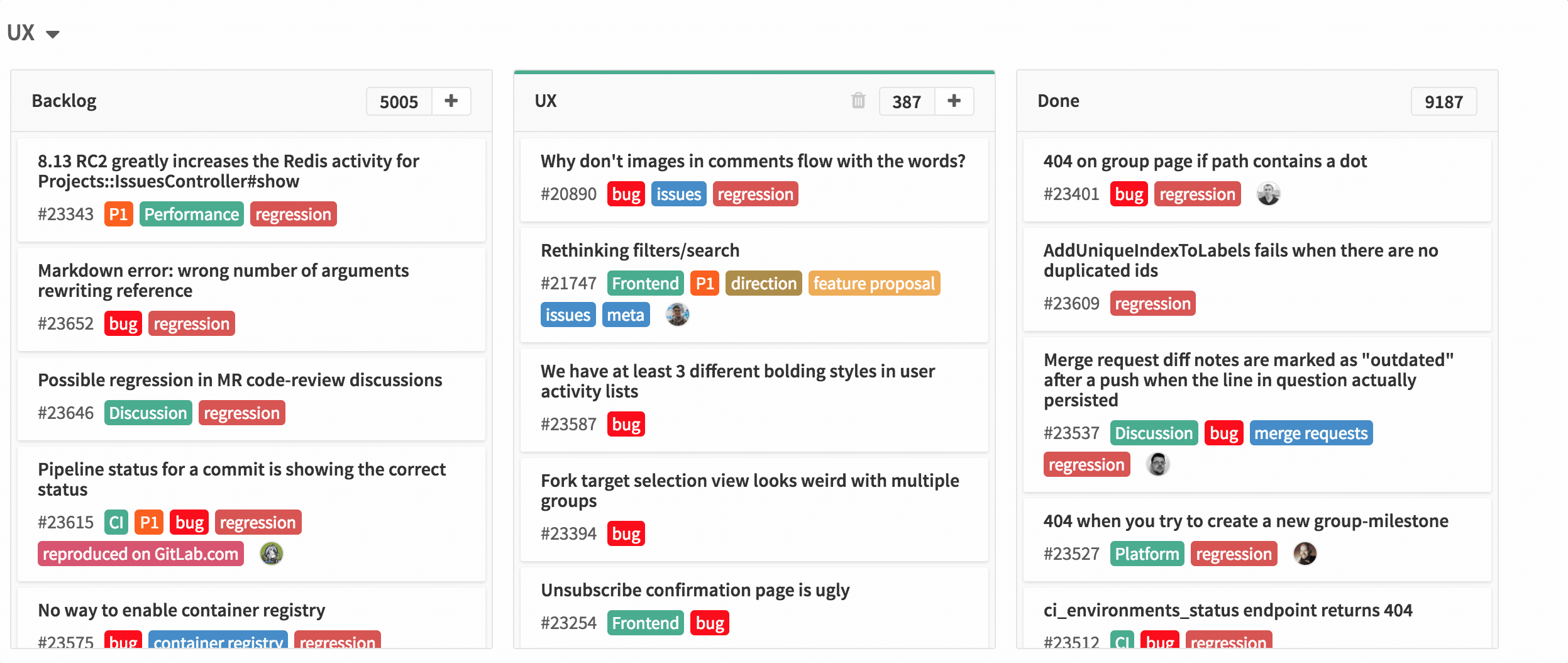
|
||||
|
||||
### Code Review with GitLab
|
||||
|
||||
After discussing a new proposal or implementation in the issue tracker, it's time to work on the code. You write your code locally and, once you're done with your first iteration, you commit your code and push to your GitLab repository. Your Git-based management strategy can be improved with the [GitLab Flow][81].
|
||||
|
||||
### First Commit
|
||||
|
||||
In your first commit message, you can add the number of the issue related to that commit message. By doing so, you create a link between the two stages of the development workflow: the issue itself and the first commit related to that issue.
|
||||
|
||||
To do so, if the issue and the code you're committing are both in the same project, you simply add `#xxx` to the commit message, where `xxx` is the issue number. If they are not in the same project, you can add the full URL to the issue (`https://gitlab.com/<username>/<projectname>/issues/<xxx>`).
|
||||
|
||||
```
|
||||
`git commit -m "this is my commit message. Ref #xxx"`
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```
|
||||
`git commit -m "this is my commit message. Related to https://gitlab.com/<username>/<projectname>/issues/<xxx>"`
|
||||
```
|
||||
|
||||
Of course, you can replace `gitlab.com` with the URL of your own GitLab instance.
|
||||
|
||||
**Note:** Linking your first commit to your issue is going to be relevant for tracking your process far ahead with [GitLab Cycle Analytics][80]. It will measure the time taken for planning the implementation of that issue, which is the time between creating an issue and making the first commit.
|
||||
|
||||
### Merge Request
|
||||
|
||||
Once you push your changes to a feature-branch, GitLab will identify this change and will prompt you to create a Merge Request (MR).
|
||||
|
||||
Every MR will have a title (something that summarizes that implementation) and a description supported by [Markdown][79]. In the description, you can shortly describe what that MR is doing, mention any related issues and MRs (creating a link between them), and you can also add the [issue closing pattern][78], which will close that issue(s) once the MR is **merged**.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
`## Add new page
|
||||
|
||||
This MR creates a `readme.md` to this project, with an overview of this app.
|
||||
|
||||
Closes #xxx and https://gitlab.com/<username>/<projectname>/issues/<xxx>
|
||||
|
||||
Preview:
|
||||
|
||||

|
||||
|
||||
cc/ @Mary @Jane @John`
|
||||
```
|
||||
|
||||
When you create an MR with a description like the one above, it will:
|
||||
|
||||
* Close both issues `#xxx` and `https://gitlab.com/<username>/<projectname>/issues/<xxx>` when merged
|
||||
* Display an image
|
||||
* Notify the users `@Mary`, `@Jane`, and `@John` by e-mail
|
||||
|
||||
You can assign the MR to yourself until you finish your work, then assign it to someone else to conduct a review. It can be reassigned as many times as necessary, to cover all the reviews you need.
|
||||
|
||||
It can also be labeled and added to a [milestone][77] to facilitate organization and prioritization.
|
||||
|
||||
When you add or edit a file and commit to a new branch from the UI instead of from the command line, it's also easy to create a new merge request. Just mark the checkbox "start a new merge request with these changes" and GitLab will automatically create a new MR once you commit your changes.
|
||||
|
||||
|
||||
|
||||
**Note:** It's important to add the [issue closing pattern][76] to your MR in order to be able to track the process with [GitLab Cycle Analytics][75]. It will track the "code" stage, which measures the time between pushing a first commit and creating a merge request related to that commit.
|
||||
|
||||
**New!** We're currently developing [Review Apps][74], a new feature that gives you the ability to deploy your app to a dynamic environment, from which you can preview the changes based on the branch name, per merge request. See a [working example][73] here.
|
||||
|
||||
### WIP MR
|
||||
|
||||
A WIP MR, which stands for **Work in Progress Merge Request**, is a technique we use at GitLab to prevent that MR from getting merged before it's ready. Just add `WIP:` to the beginning of the title of an MR, and it will not be merged unless you remove it from there.
|
||||
|
||||
When your changes are ready to get merged, remove the `WIP:` pattern either by editing the issue and deleting manually, or use the shortcut available for you just below the MR description.
|
||||
|
||||

|
||||
|
||||
**New!** The `WIP` pattern can be also [quickly added to the merge request][72] with the [slash command][71] `/wip`. Simply type it and submit the comment or the MR description.
|
||||
|
||||
### Review
|
||||
|
||||
Once you've created a merge request, it's time to get feedback from your team or collaborators. Using the diffs available on the UI, you can add inline comments, reply to them and resolve them.
|
||||
|
||||
You can also grab the link for each line of code by clicking on the line number.
|
||||
|
||||
The commit history is available from the UI, from which you can track the changes between the different versions of that file. You can view them inline or side-by-side.
|
||||
|
||||

|
||||
|
||||
**New!** If you run into merge conflicts, you can quickly [solve them right for the UI][70], or even edit the file to fix them as you need:
|
||||
|
||||
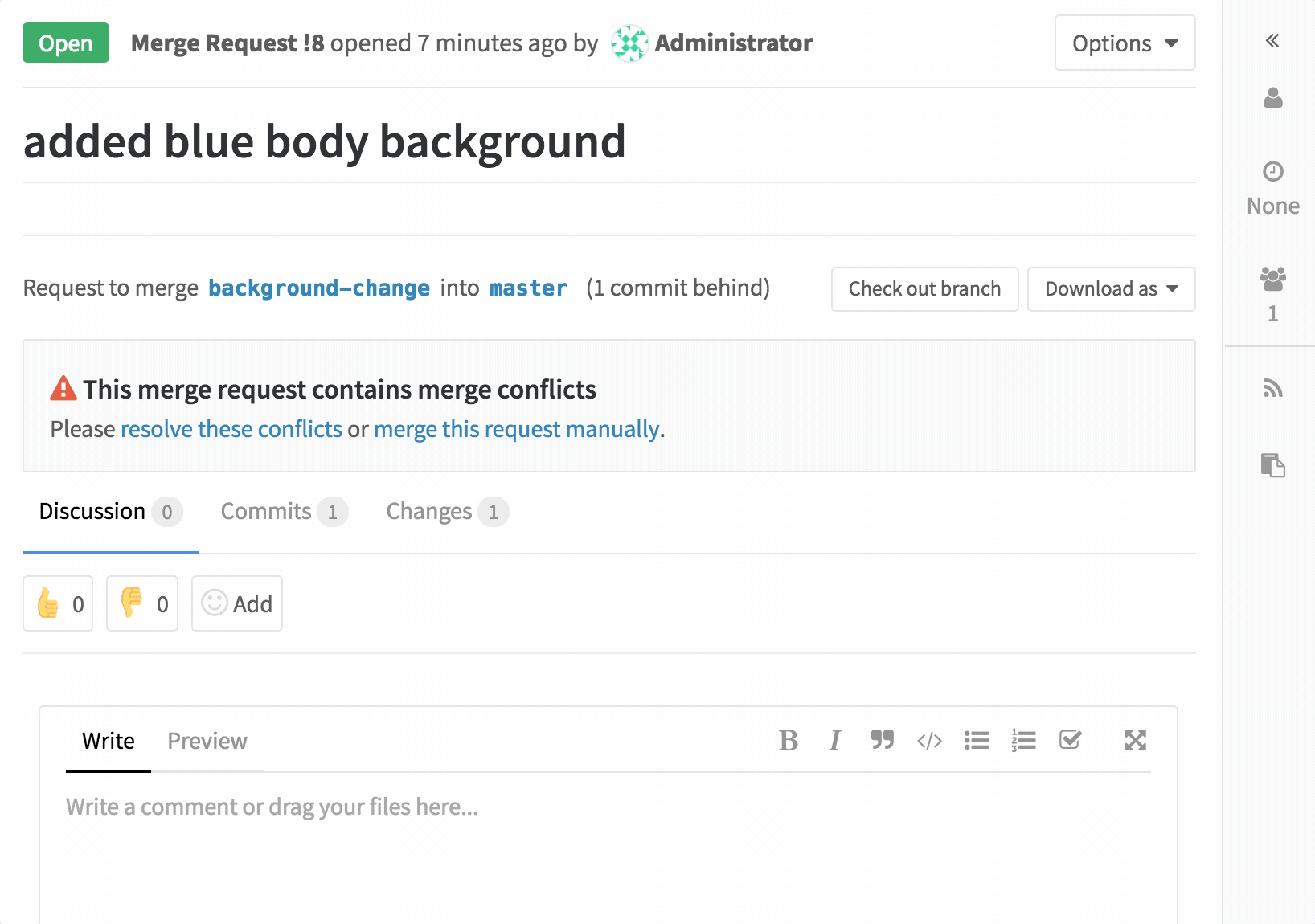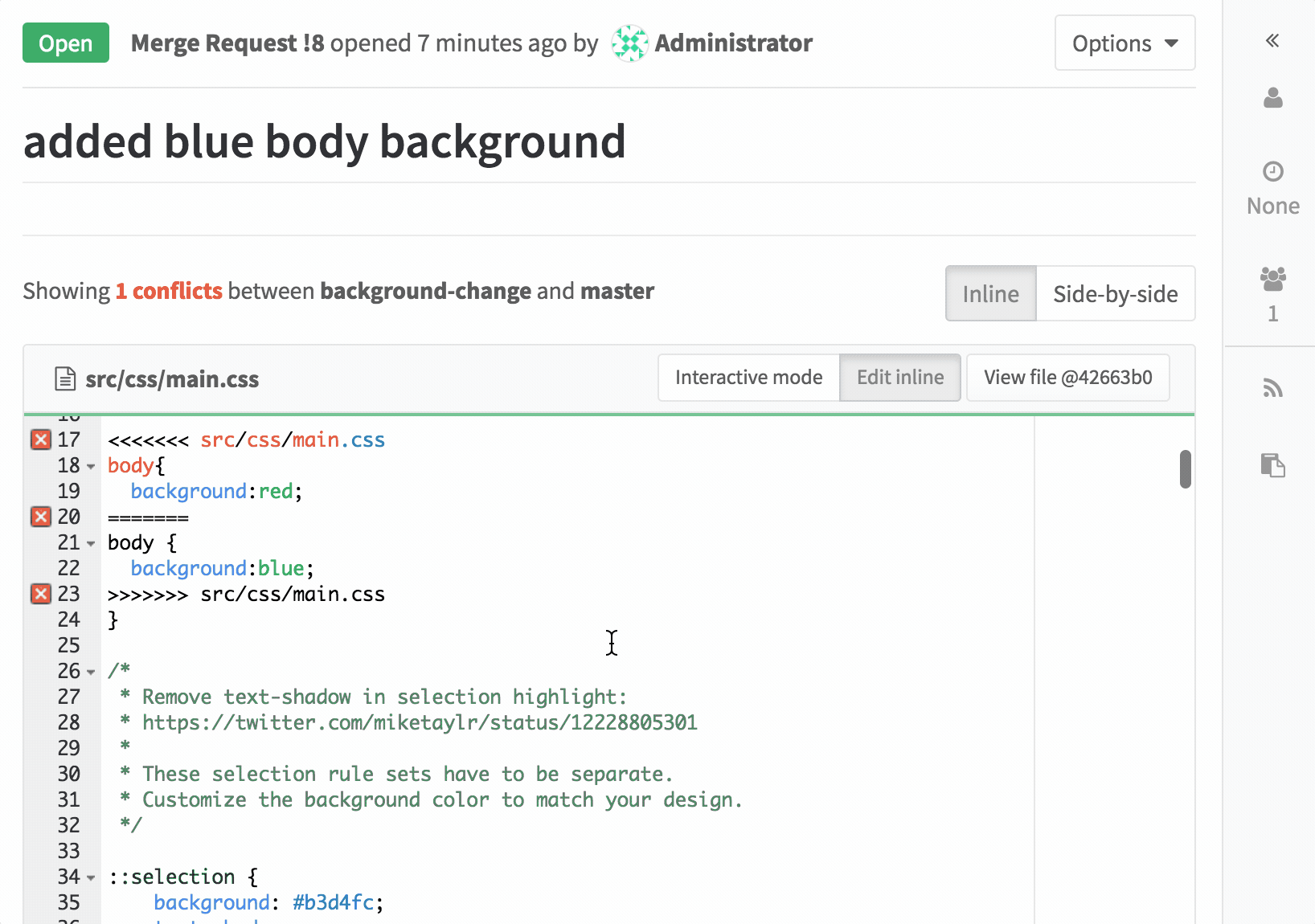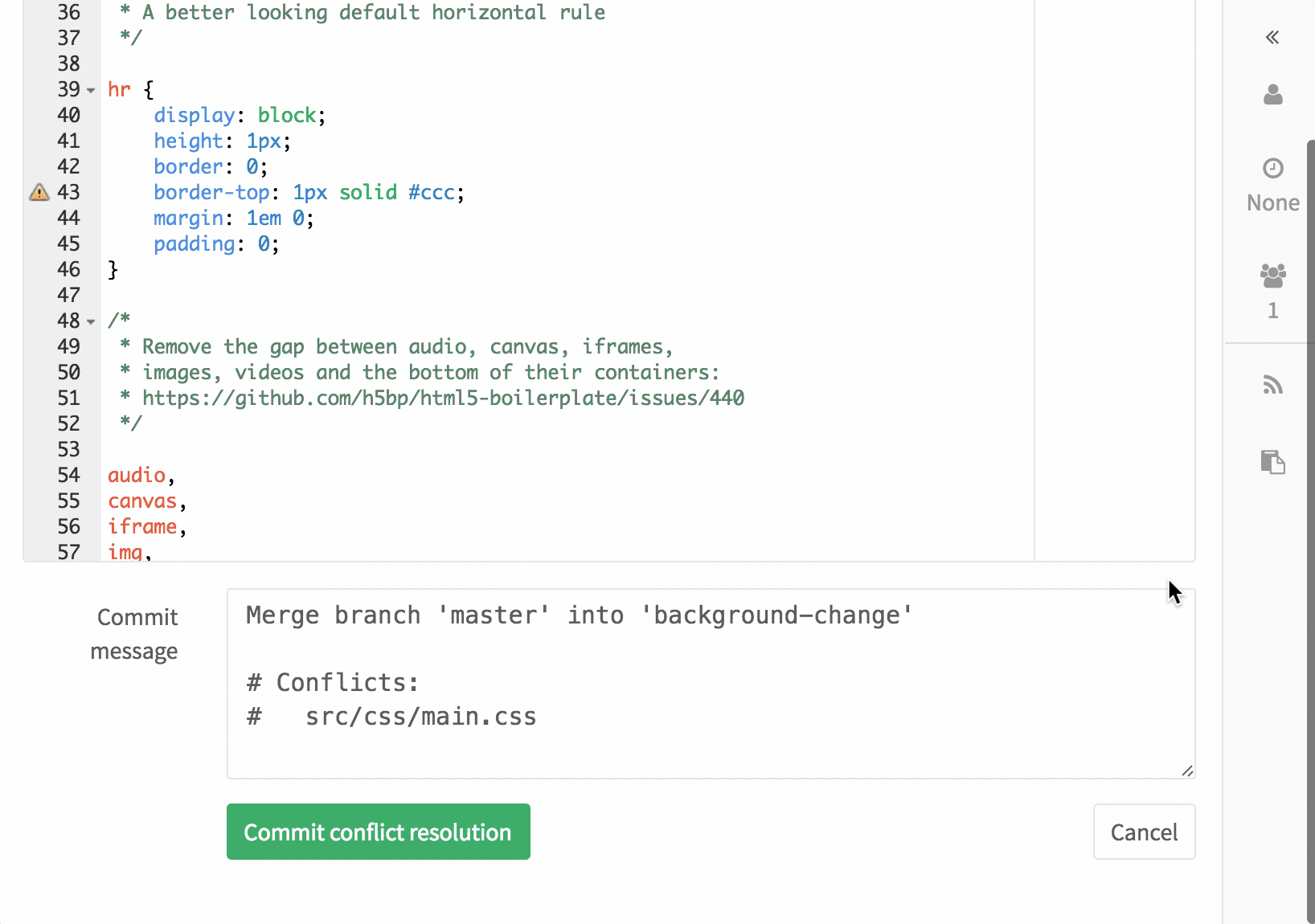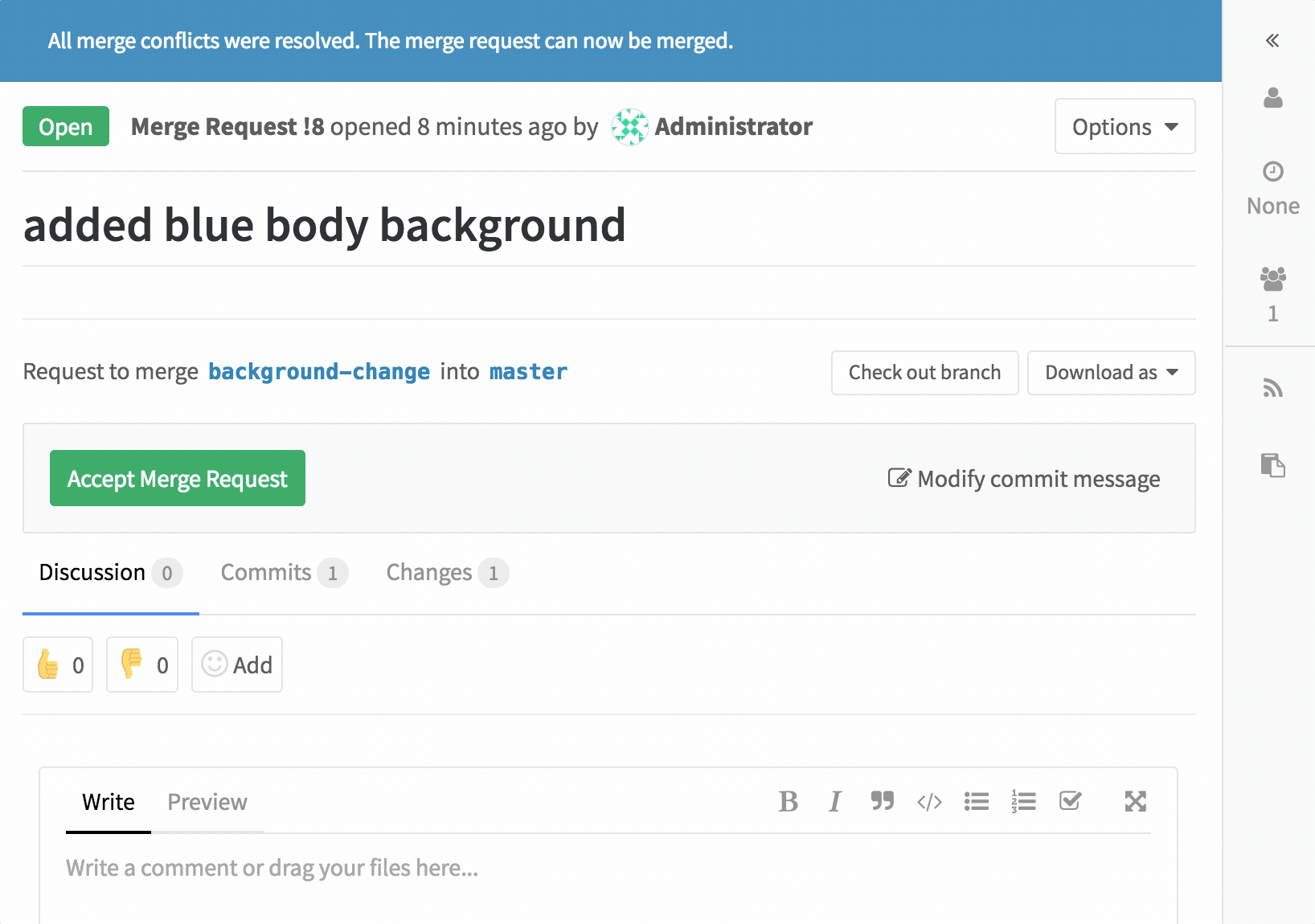
|
||||
|
||||
### Build, Test, and Deploy
|
||||
|
||||
[GitLab CI][69] is an powerful built-in tool for [Continuous Integration, Continuos Deployment, and Continuous Delivery][68], which can be used to run scripts as you wish. The possibilities are endless: think of it as if it was your own command line running the jobs for you.
|
||||
|
||||
It's all set by an Yaml file called, `.gitlab-ci.yml`, placed at your project's repository. Enjoy the CI templates by simply adding a new file through the web interface, and type the file name as `.gitlab-ci.yml` to trigger a dropdown menu with dozens of possible templates for different applications.
|
||||
|
||||
|
||||
|
||||
### Koding
|
||||
|
||||
Use GitLab's [Koding integration][67] to run your entire development environment in the cloud. This means that you can check out a project or just a merge request in a full-fledged IDE with the press of a button.
|
||||
|
||||
### Use-Cases
|
||||
|
||||
Examples of GitLab CI use-cases:
|
||||
|
||||
* Use it to [build][36] any [Static Site Generator][35], and deploy your website with [GitLab Pages][34]
|
||||
* Use it to [deploy your website][33] to `staging` and `production` [environments][32]
|
||||
* Use it to [build an iOS application][31]
|
||||
* Use it to [build and deploy your Docker Image][30] with [GitLab Container Registry][29]
|
||||
|
||||
We have prepared a dozen of [GitLab CI Example Projects][66] to offer you guidance. Check them out!
|
||||
|
||||
### Feedback: Cycle Analytics
|
||||
|
||||
When you follow the GitLab Workflow, you'll be able to gather feedback with [GitLab Cycle Analytics][65] on the time your team took to go from idea to production, for [each key stage of the process][64]:
|
||||
|
||||
* **Issue:** the time from creating an issue to assigning the issue to a milestone or adding the issue to a list on your Issue Board
|
||||
* **Plan:** the time from giving an issue a milestone or adding it to an Issue Board list, to pushing the first commit
|
||||
* **Code:** the time from the first commit to creating the merge request
|
||||
* **Test:** the time CI takes to run the entire pipeline for the related merge request
|
||||
* **Review:** the time from creating the merge request to merging it
|
||||
* **Staging:** the time from merging until deploy to production
|
||||
* **Production** (Total): The time it takes between creating an issue and deploying the code to [production][28]
|
||||
|
||||
### Enhance
|
||||
|
||||
### Issue and MR Templates
|
||||
|
||||
[Issue and MR templates][63] allow you to define context-specific templates for issue and merge request description fields for your project.
|
||||
|
||||
You write them in [Markdown][62] and add them to the default branch of your repository. They can be accessed by the dropdown menu whenever an issue or MR is created.
|
||||
|
||||
They save time when describing issues and MRs and standardize the information necessary to follow along. It makes sure everything you need to proceed is there.
|
||||
|
||||
As you can create multiple templates, they serve for different purposes. For example, you can have one for feature proposals, and a different one for bug reports. Check the ones in [GitLab CE project][61] for real examples.
|
||||
|
||||
|
||||
|
||||
### Milestones
|
||||
|
||||
[Milestones][60] are the best tool you have at GitLab to track the work of your team based on a common target, in a specific date.
|
||||
|
||||
The goal can be different for each situation, but the panorama is the same: you have a collection of issues and merge requests being worked on to achieve that particular objective.
|
||||
|
||||
This goal can be basically anything that groups the team work and effort to do something by a deadline. For example, publish a new release, launch a new product, get things done by that date, or assemble projects to get done by year quarters.
|
||||
|
||||
For instance, you can create a milestone for Q1 2017 and assign every issue and MR that should be finished by the end of March, 2017\. You can also create a milestone for an event that your company is organizing. Then you access that milestone and view an entire panorama on the progress of your team to get things done.
|
||||
|
||||
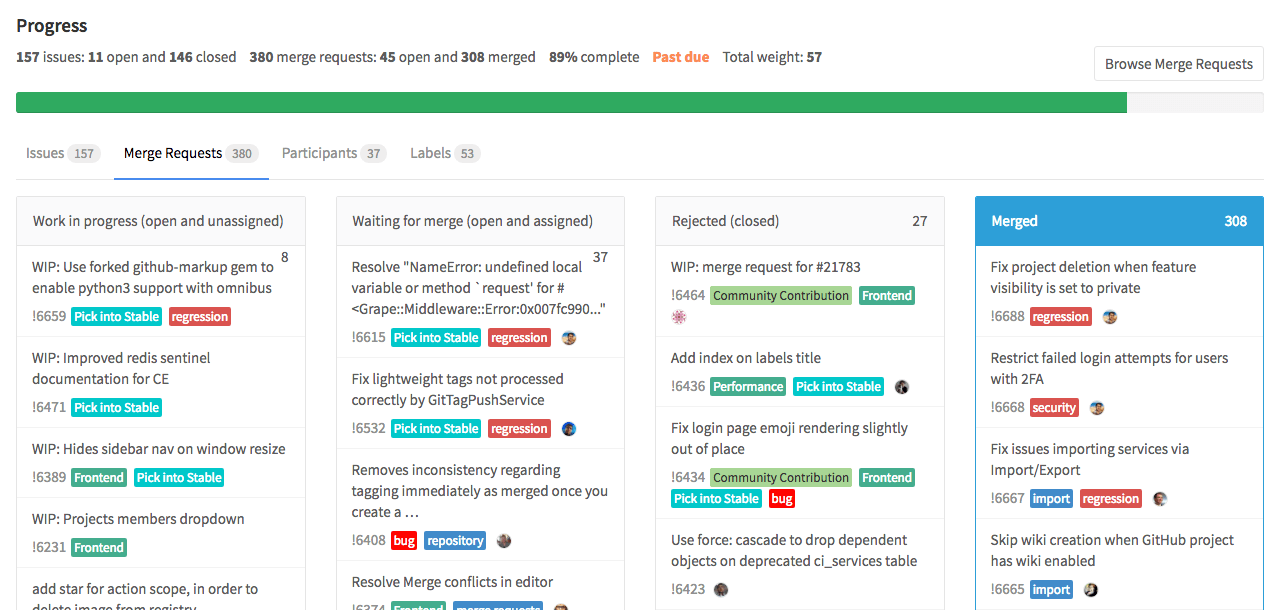
|
||||
|
||||
### Pro Tips
|
||||
|
||||
### For both Issues and MRs
|
||||
|
||||
* In issues and MRs descriptions:
|
||||
* Type `#` to trigger a dropdown list of existing issues
|
||||
* Type `!` to trigger a dropdown list of existing MRs
|
||||
* Type `/` to trigger [slash commands][4]
|
||||
* Type `:` to trigger emojis (also supported for inline comments)
|
||||
* Add images (jpg, png, gif) and videos to inline comments with the button **Attach a file**
|
||||
* [Apply labels automatically][27] with [GitLab Webhooks][26]
|
||||
* [Fenced blockquote][24]: use the syntax `>>>` to start and finish a blockquote
|
||||
|
||||
```
|
||||
`>>>
|
||||
Quoted text
|
||||
|
||||
Another paragraph
|
||||
>>>`
|
||||
```
|
||||
* Create [task lists][23]:
|
||||
|
||||
```
|
||||
`- [ ] Task 1
|
||||
- [ ] Task 2
|
||||
- [ ] Task 3`
|
||||
```
|
||||
|
||||
#### Subscribe
|
||||
|
||||
Have you found an issue or an MR that you want to follow up? Expand the navigation on your right and click [Subscribe][59] and you'll be updated whenever a new comment comes up. What if you want to subscribe to multiple issues and MRs at once? Use [bulk subscriptions][58]. 😃
|
||||
|
||||
#### Add TO-DO
|
||||
|
||||
Besides keeping an eye on an issue or MR, if you want to take a future action on it, or whenever you want it in your GitLab TO-DO list, expand the navigation tab at your right and [click on **Add todo**][57].
|
||||
|
||||
#### Search for your Issues and MRs
|
||||
|
||||
When you're looking for an issue or MR you opened long ago in a project with dozens, hundreds or even thousands of them, it turns out to be hard to find. Expand the navigation on your left and click on **Issues** or **Merge Requests**, and you'll see the ones assigned to you. From there or from any issue tracker, you can filter issues or MRs by author, assignee, milestone, label and weight, also search for opened, merged, closed, and all of them (both merged, closed, and opened).
|
||||
|
||||
### Moving Issues
|
||||
|
||||
An issue end up in a wrong project? Don't worry. Click on **Edit**, and [move the issue][56] to the correct project.
|
||||
|
||||
### Code Snippets
|
||||
|
||||
Sometimes do you use exactly the same code snippet or template in different projects or files? Create a code snippet and leave it available for you whenever you want. Expand the navigation on your left and click **[Snippets][25]**. All of your snippets will be there. You can set them to public, internal (only for GitLab logged users), or private.
|
||||
|
||||
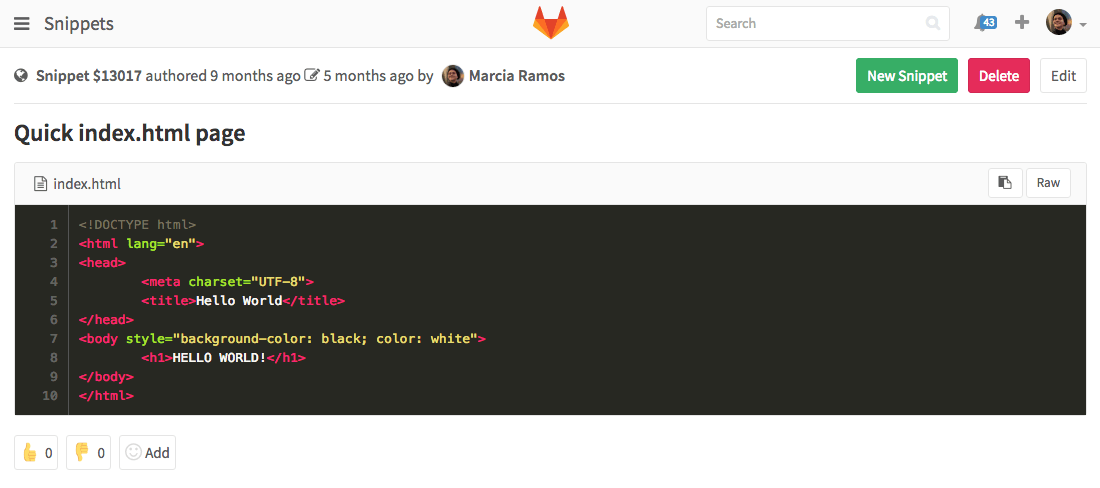
|
||||
|
||||
### GitLab WorkFlow Use-Case Scenario
|
||||
|
||||
To wrap-up, let's put everything together. It's easy!
|
||||
|
||||
Let's suppose you work at a company focused in software development. You created a new issue for developing a new feature to be implemented in one of your applications.
|
||||
|
||||
### Labels Strategy
|
||||
|
||||
For this application, you already have created labels for "discussion", "backend", "frontend", "working on", "staging", "ready", "docs", "marketing", and "production." All of them already have their own lists in the Issue Board. Your issue currently have the label "discussion."
|
||||
|
||||
After the discussion in the issue tracker came to an agreement, your backend team started to work on that issue, so their lead moved the issue from the list "discussion" to the list "backend." The first developer to start writing the code assigned the issue to himself, and added the label "working on."
|
||||
|
||||
### Code & Commit
|
||||
|
||||
In his first commit message, he referenced the issue number. After some work, he pushed his commits to a feature-branch and created a new merge request, including the issue closing pattern in the MR description. His team reviewed his code and made sure all the tests and builds were passing.
|
||||
|
||||
### Using the Issue Board
|
||||
|
||||
Once the backend team finished their work, they removed the label "working on" and moved the issue from the list "backend" to "frontend" in the Issue Board. So, the frontend team knew that issue was ready for them.
|
||||
|
||||
### Deploying to Staging
|
||||
|
||||
When a frontend developer started working on that issue, he or she added back the label "working on" and reassigned the issue to him/herself. When ready, the implementation was deployed to a **staging** environment. The label "working on" was removed and the issue card was moved to the "staging" list in the Issue Board.
|
||||
|
||||
### Teamwork
|
||||
|
||||
Finally, when the implementation succeeded, your team moved it to the list "ready."
|
||||
|
||||
Then, the time came for your technical writing team to create the documentation for the new feature, and once someone got started, he/she added the label "docs." At the same time, your marketing team started to work on the campaign to launch and promote that feature, so someone added the label "marketing." When the tech writer finished the documentation, he/she removed the label "docs." Once the marketing team finished their work, they moved the issue from the list "marketing" to "production."
|
||||
|
||||
### Deploying to Production
|
||||
|
||||
At last, you, being the person responsible for new releases, merged the MR and deployed the new feature into the **production**environment and the issue was **closed**.
|
||||
|
||||
### Feedback
|
||||
|
||||
With [Cycle Analytics][55], you studied the time taken to go from idea to production with your team, and opened another issue to discuss the improvement of the process.
|
||||
|
||||
### Conclusions
|
||||
|
||||
GitLab Workflow helps your team to get faster from idea to production using a single platform:
|
||||
|
||||
* It's **effective**, because you get your desired results.
|
||||
* It's **efficient**, because you achieve maximum productivity with minimum effort and expense.
|
||||
* It's **productive**, because you are able to plan effectively and act efficiently.
|
||||
* It's **easy**, because you don't need to setup different tools to accomplish what you need with just one, GitLab.
|
||||
* It's **fast**, because you don't need to jump across multiple platforms to get your job done.
|
||||
|
||||
A new GitLab version is released every single month (on the 22nd), for making it a better integrated solution for software development, and for bringing teams to work together in one single and unique interface.
|
||||
|
||||
At GitLab, everyone can contribute! Thanks to our amazing community we've got where we are. And thanks to them, we keep moving forward to provide you with a better product.
|
||||
|
||||
Questions? Feedback? Please leave a comment or tweet at us [@GitLab][54]! 🙌
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/
|
||||
|
||||
作者:[Marcia Ramos][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twitter.com/XMDRamos
|
||||
[1]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#search-for-your-issues-and-mrs
|
||||
[2]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#add-to-do
|
||||
[3]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#subscribe
|
||||
[4]:https://docs.gitlab.com/ce/user/project/slash_commands.html
|
||||
[5]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#code-snippets
|
||||
[6]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#moving-issues
|
||||
[7]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#for-both-issues-and-mrs
|
||||
[8]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#milestones
|
||||
[9]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#issue-and-mr-templates
|
||||
[10]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#use-cases
|
||||
[11]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#koding
|
||||
[12]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#review
|
||||
[13]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#wip-mr
|
||||
[14]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#merge-request
|
||||
[15]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#first-commit
|
||||
[16]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-board
|
||||
[17]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#issue-weight
|
||||
[18]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#labels
|
||||
[19]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#assignee
|
||||
[20]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#due-dates
|
||||
[21]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#confidential-issues
|
||||
[22]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#stages-of-software-development
|
||||
[23]:https://docs.gitlab.com/ee/user/markdown.html#task-lists
|
||||
[24]:https://about.gitlab.com/2016/07/22/gitlab-8-10-released/#blockquote-fence-syntax
|
||||
[25]:https://gitlab.com/dashboard/snippets
|
||||
[26]:https://docs.gitlab.com/ce/web_hooks/web_hooks.html
|
||||
[27]:https://about.gitlab.com/2016/08/19/applying-gitlab-labels-automatically/
|
||||
[28]:https://docs.gitlab.com/ce/ci/yaml/README.html#environment
|
||||
[29]:https://about.gitlab.com/2016/05/23/gitlab-container-registry/
|
||||
[30]:https://about.gitlab.com/2016/08/11/building-an-elixir-release-into-docker-image-using-gitlab-ci-part-1/
|
||||
[31]:https://about.gitlab.com/2016/03/10/setting-up-gitlab-ci-for-ios-projects/
|
||||
[32]:https://docs.gitlab.com/ce/ci/yaml/README.html#environment
|
||||
[33]:https://about.gitlab.com/2016/08/26/ci-deployment-and-environments/
|
||||
[34]:https://pages.gitlab.io/
|
||||
[35]:https://about.gitlab.com/2016/06/17/ssg-overview-gitlab-pages-part-3-examples-ci/
|
||||
[36]:https://about.gitlab.com/2016/04/07/gitlab-pages-setup/
|
||||
[37]:https://about.gitlab.com/solutions/cycle-analytics/
|
||||
[38]:https://about.gitlab.com/2016/08/05/continuous-integration-delivery-and-deployment-with-gitlab/
|
||||
[39]:https://about.gitlab.com/2016/08/05/continuous-integration-delivery-and-deployment-with-gitlab/
|
||||
[40]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-code-review
|
||||
[41]:https://about.gitlab.com/gitlab-ci/
|
||||
[42]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-board
|
||||
[43]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-tracker
|
||||
[44]:https://about.gitlab.com/2015/08/18/gitlab-loves-mattermost/
|
||||
[45]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#conclusions
|
||||
[46]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-workflow-use-case-scenario
|
||||
[47]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#pro-tips
|
||||
[48]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#enhance
|
||||
[49]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#feedback
|
||||
[50]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#build-test-and-deploy
|
||||
[51]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#code-review-with-gitlab
|
||||
[52]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-tracker
|
||||
[53]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-workflow
|
||||
[54]:https://twitter.com/gitlab
|
||||
[55]:https://about.gitlab.com/solutions/cycle-analytics/
|
||||
[56]:https://about.gitlab.com/2016/03/22/gitlab-8-6-released/#move-issues-to-other-projects
|
||||
[57]:https://about.gitlab.com/2016/06/22/gitlab-8-9-released/#manually-add-todos
|
||||
[58]:https://about.gitlab.com/2016/07/22/gitlab-8-10-released/#bulk-subscribe-to-issues
|
||||
[59]:https://about.gitlab.com/2016/03/22/gitlab-8-6-released/#subscribe-to-a-label
|
||||
[60]:https://about.gitlab.com/2016/08/05/feature-highlight-set-dates-for-issues/#milestones
|
||||
[61]:https://gitlab.com/gitlab-org/gitlab-ce/issues/new
|
||||
[62]:https://docs.gitlab.com/ee/user/markdown.html
|
||||
[63]:https://docs.gitlab.com/ce/user/project/description_templates.html
|
||||
[64]:https://about.gitlab.com/2016/09/21/cycle-analytics-feature-highlight/
|
||||
[65]:https://about.gitlab.com/solutions/cycle-analytics/
|
||||
[66]:https://docs.gitlab.com/ee/ci/examples/README.html
|
||||
[67]:https://about.gitlab.com/2016/08/22/gitlab-8-11-released/#koding-integration
|
||||
[68]:https://about.gitlab.com/2016/08/05/continuous-integration-delivery-and-deployment-with-gitlab/
|
||||
[69]:https://about.gitlab.com/gitlab-ci/
|
||||
[70]:https://about.gitlab.com/2016/08/22/gitlab-8-11-released/#merge-conflict-resolution
|
||||
[71]:https://docs.gitlab.com/ce/user/project/slash_commands.html
|
||||
[72]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#wip-slash-command
|
||||
[73]:https://gitlab.com/gitlab-examples/review-apps-nginx/
|
||||
[74]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#ability-to-stop-review-apps
|
||||
[75]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#feedback
|
||||
[76]:https://docs.gitlab.com/ce/administration/issue_closing_pattern.html
|
||||
[77]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#milestones
|
||||
[78]:https://docs.gitlab.com/ce/administration/issue_closing_pattern.html
|
||||
[79]:https://docs.gitlab.com/ee/user/markdown.html
|
||||
[80]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#feedback
|
||||
[81]:https://about.gitlab.com/2014/09/29/gitlab-flow/
|
||||
[82]:https://about.gitlab.com/free-trial/
|
||||
[83]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#multiple-issue-boards-ee
|
||||
[84]:https://about.gitlab.com/solutions/issueboard
|
||||
[85]:https://docs.gitlab.com/ee/workflow/issue_weight.html
|
||||
[86]:https://about.gitlab.com/2016/10/22/gitlab-8-13-released/#group-labels
|
||||
[87]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#gitlab-issue-board
|
||||
[88]:https://docs.gitlab.com/ee/user/project/labels.html#prioritize-labels
|
||||
[89]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#milestones
|
||||
[90]:https://about.gitlab.com/2016/08/05/feature-highlight-set-dates-for-issues/#due-dates-for-issues
|
||||
[91]:https://docs.gitlab.com/ce/user/permissions.html
|
||||
[92]:https://about.gitlab.com/2016/03/31/feature-highlihght-confidential-issues/
|
||||
[93]:https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/#pro-tips
|
||||
[94]:https://docs.gitlab.com/ee/user/markdown.html
|
||||
[95]:https://about.gitlab.com/2016/03/03/start-with-an-issue/
|
||||
[96]:https://about.gitlab.com/2016/09/13/gitlab-master-plan/
|
||||
[97]:https://about.gitlab.com/2014/09/29/gitlab-flow/
|
||||
@ -1,322 +0,0 @@
|
||||
GitFuture is translating.
|
||||
|
||||
Top open source creative tools in 2016
|
||||
============================================================
|
||||
|
||||
### Whether you want to manipulate images, edit audio, or animate stories, there's a free and open source tool to do the trick.
|
||||
|
||||

|
||||
|
||||
>Image by : opensource.com
|
||||
|
||||
A few years ago, I gave a lightning talk at Red Hat Summit that took attendees on a tour of the [2012 open source creative tools][12] landscape. Open source tools have evolved a lot in the past few years, so let's take a tour of 2016 landscape.
|
||||
|
||||
### Core applications
|
||||
|
||||
These six applications are the juggernauts of open source design tools. They are well-established, mature projects with full feature sets, stable releases, and active development communities. All six applications are cross-platform; each is available on Linux, OS X, and Windows, although in some cases the Linux versions are the most quickly updated. These applications are so widely known, I've also included highlights of the latest features available that you may have missed if you don't closely follow their development.
|
||||
|
||||
If you'd like to follow new developments more closely, and perhaps even help out by testing the latest development versions of the first four of these applications—GIMP, Inkscape, Scribus, and MyPaint—you can install them easily on Linux using [Flatpak][13]. Nightly builds of each of these applications are available via Flatpak by [following the instructions][14] for _Nightly Graphics Apps_. One thing to note: If you'd like to install brushes or other extensions to each Flatpak version of the app, the directory to drop the extensions in will be under the directory corresponding to the application inside the **~/.var/app** directory.
|
||||
|
||||
### GIMP
|
||||
|
||||
[GIMP][15] [celebrated its 20th anniversary in 2015][16], making it one of the oldest open source creative applications out there. GIMP is a solid program for photo manipulation, basic graphic creation, and illustration. You can start using GIMP by trying simple tasks, such as cropping and resizing images, and over time work into a deep set of functionality. Available for Linux, Mac OS X, and Windows, GIMP is cross-platform and can open and export to a wide breadth of file formats, including those popularized by its proprietary analogue, Photoshop.
|
||||
|
||||
The GIMP team is currently working toward the 2.10 release; [2.8.18][17] is the latest stable version. More exciting is the unstable version, [2.9.4][18], with a revamped user interface featuring space-saving symbolic icons and dark themes, improved color management, more GEGL-based filters with split-preview, MyPaint brush support (shown in screenshot below), symmetrical drawing, and command-line batch processing. For more details, check out [the full release notes][19].
|
||||
|
||||

|
||||
|
||||
### Inkscape
|
||||
|
||||
[Inkscape][20] is a richly featured vector-based graphic design workhorse. Use it to create simple graphics, diagrams, layouts, or icon art.
|
||||
|
||||
The latest stable version is [0.91][21]; similarly to GIMP, more excitement can be found in a pre-release version, 0.92pre3, which was released November 2016\. The premiere feature of the latest pre-release is the [gradient mesh feature][22](demonstrated in screenshot below); new features introduce in the 0.91 release include [power stroke][23] for fully configurable calligraphic strokes (the "open" in "opensource.com" in the screenshot below uses powerstroke), the on-canvas measure tool, and [the new symbols dialog][24] (shown in the right side of the screenshot below). (Many symbol libraries for Inkscape are available on GitHub; [Xaviju's inkscape-open-symbols set][25] is fantastic.) A new feature available in development/nightly builds is the _Objects_ dialog that catalogs all objects in a document and provides tools to manage them.
|
||||
|
||||

|
||||
|
||||
### Scribus
|
||||
|
||||
[Scribus][26] is a powerful desktop publishing and page layout tool. Scribus enables you to create sophisticated and beautiful items, including newsletters, books, and magazines, as well as other print pieces. Scribus has color management tools that can handle and output CMYK and spot colors for files that are ready for reliable reproduction at print shops.
|
||||
|
||||
[1.4.6][27] is the latest stable release of Scribus; the [1.5.x][28] series of releases is the most exciting as they serve as a preview to the upcoming 1.6.0 release. Version 1.5.3 features a Krita file (*.KRA) file import tool; other developments in the 1.5.x series include the _Table_ tool, text frame welding, footnotes, additional PDF formats for export, improved dictionary support, dockable palettes, a symbols tool, and expanded file format support.
|
||||
|
||||

|
||||
|
||||
### MyPaint
|
||||
|
||||
[MyPaint][29] is a drawing tablet-centric expressive drawing and illustration tool. It's lightweight and has a minimal interface with a rich set of keyboard shortcuts so that you can focus on your drawing without having to drop your pen.
|
||||
|
||||
[MyPaint 1.2.0][30] is the latest stable release and includes new features, such as the [intuitive inking tool][31] for tracing over pencil drawings, new flood fill tool, layer groups, brush and color history panel, user interface revamp including a dark theme and small symbolic icons, and editable vector layers. To try out the latest developments in MyPaint, I recommend installing the nightly Flatpak build, although there have not been significant feature additions since the 1.2.0 release.
|
||||
|
||||

|
||||
|
||||
### Blender
|
||||
|
||||
Initially released in January 1995, [Blender][32], like GIMP, has been around for more than 20 years. Blender is a powerful open source 3D creation suite that includes tools for modeling, sculpting, rendering, realistic materials, rigging, animation, compositing, video editing, game creation, and simulation.
|
||||
|
||||
The latest stable Blender release is [2.78a][33]. The 2.78 release was a large one and includes features such as the revamped _Grease Pencil_ 2D animation tool; VR rendering support for spherical stereo images; and a new drawing tool for freehand curves.
|
||||
|
||||

|
||||
|
||||
To try out the latest exciting Blender developments, you have many options, including:
|
||||
|
||||
* The Blender Foundation makes [unstable daily builds][2] available on the official Blender website.
|
||||
* If you're looking for builds that include particular in-development features, [graphicall.org][3] is a community-moderated site that provides special versions of Blender (and occasionally other open source creative apps) to enable artists to try out the latest available code and experiments.
|
||||
* Mathieu Bridon has made development versions of Blender available via Flatpak. See his blog post for details: [Blender nightly in Flatpak][4].
|
||||
|
||||
### Krita
|
||||
|
||||
[Krita][34] is a digital drawing application with a deep set of capabilities. The application is geared toward illustrators, concept artists, and comic artists and is fully loaded with extras, such as brushes, palettes, patterns, and templates.
|
||||
|
||||
The latest stable version is [Krita 3.0.1][35], released in September 2016\. Features new to the 3.0.x series include 2D frame-by-frame animation; improved layer management and functionality; expanded and more usable shortcuts; improvements to grids, guides, and snapping; and soft-proofing.
|
||||
|
||||

|
||||
|
||||
### Video tools
|
||||
|
||||
There are many, many options for open source video editing tools. Of the members of the pack, [Flowblade][36] is a newcomer and Kdenlive is the established, newbie-friendly, and most fully featured contender. The main criteria that may help you eliminate some of this array of options is supported platforms—some of these only support Linux. These all have active upstreams and the latest stable versions of each have been released recently, within weeks of each other.
|
||||
|
||||
### Kdenlive
|
||||
|
||||
[Kdenlive][37], which was initially released back in 2002, is a powerful non-linear video editor available for Linux and OS X (although the OS X version is out-of-date). Kdenlive has a user-friendly drag-and-drop-based user interface that accommodates beginners, and with the depth experts need.
|
||||
|
||||
Learn how to use Kdenlive with an [multi-part Kdenlive tutorial series][38] by Seth Kenlon.
|
||||
|
||||
* Latest Stable: 16.08.2 (October 2016)
|
||||
|
||||

|
||||
|
||||
### Flowblade
|
||||
|
||||
Released in 2012, [Flowblade][39], a Linux-only video editor, is a relative newcomer.
|
||||
|
||||
* Latest Stable: 1.8 (September 2016)
|
||||
|
||||
### Pitivi
|
||||
|
||||
[Pitivi][40] is a user-friendly free and open source video editor. Pitivi is written in [Python][41] (the "Pi" in Pitivi), uses the [GStreamer][42] multimedia framework, and has an active community.
|
||||
|
||||
* Latest stable: 0.97 (August 2016)
|
||||
* Get the [latest version with Flatpak][5]
|
||||
|
||||
### Shotcut
|
||||
|
||||
[Shotcut][43] is a free, open source, cross-platform video editor that started [back in 2004][44] and was later rewritten by current lead developer [Dan Dennedy][45].
|
||||
|
||||
* Latest stable: 16.11 (November 2016)
|
||||
* 4K resolution support
|
||||
* Ships as a tarballed binary
|
||||
|
||||
|
||||
|
||||
### OpenShot Video Editor
|
||||
|
||||
Started in 2008, [OpenShot Video Editor][46] is a free, open source, easy-to-use, cross-platform video editor.
|
||||
|
||||
* Latest stable: [2.1][6] (August 2016)
|
||||
|
||||
|
||||
### Utilities
|
||||
|
||||
### SwatchBooker
|
||||
|
||||
[SwatchBooker][47] is a handy utility, and although it hasn't been updated in a few years, it's still useful. SwatchBooker helps users legally obtain color swatches from various manufacturers in a format that you can use with other free and open source tools, including Scribus.
|
||||
|
||||
### GNOME Color Manager
|
||||
|
||||
[GNOME Color Manager][48] is the built-in color management system for the GNOME desktop environment, the default desktop for a bunch of Linux distros. The tool allows you to create profiles for your display devices using a colorimeter, and also allows you to load/managed ICC color profiles for those devices.
|
||||
|
||||
### GNOME Wacom Control
|
||||
|
||||
[The GNOME Wacom controls][49] allow you to configure your Wacom tablet in the GNOME desktop environment; you can modify various options for interacting with the tablet, including customizing the sensitivity of the tablet and which monitors the tablet maps to.
|
||||
|
||||
### Xournal
|
||||
|
||||
[Xournal][50] is a humble but solid app that allows you to hand write/doodle notes using a tablet. Xournal is a useful tool for signing or otherwise annotating PDF documents.
|
||||
|
||||
### PDF Mod
|
||||
|
||||
[PDF Mod][51] is a handy utility for editing PDFs. PDF Mod lets users remove pages, add pages, bind multiple single PDFs together into a single PDF, reorder the pages, and rotate the pages.
|
||||
|
||||
### SparkleShare
|
||||
|
||||
[SparkleShare][52] is a git-backed file-sharing tool artists use to collaborate and share assets. Hook it up to a GitLab repo and you've got a nice open source infrastructure for asset management. The SparkleShare front end nullifies the inscrutability of git by providing a dropbox-like interface on top of it.
|
||||
|
||||
### Photography
|
||||
|
||||
### Darktable
|
||||
|
||||
[Darktable][53] is an application that allows you to develop digital RAW files and has a rich set of tools for the workflow management and non-destructive editing of photographic images. Darktable includes support for an extensive range of popular cameras and lenses.
|
||||
|
||||

|
||||
|
||||
### Entangle
|
||||
|
||||
[Entangle][54] allows you to tether your digital camera to your computer and enables you to control your camera completely from the computer.
|
||||
|
||||
### Hugin
|
||||
|
||||
[Hugin][55] is a tool that allows you to stitch together photos in order to create panoramic photos.
|
||||
|
||||
### 2D animation
|
||||
|
||||
### Synfig Studio
|
||||
|
||||
[Synfig Studio][56] is a vector-based 2D animation suite that also supports bitmap artwork and is tablet-friendly.
|
||||
|
||||
### Blender Grease Pencil
|
||||
|
||||
I covered Blender above, but particularly notable from a recent release is [a refactored grease pencil feature][57], which adds the ability to create 2D animations.
|
||||
|
||||
|
||||
### Krita
|
||||
|
||||
[Krita][58] also now provides 2D animation functionality.
|
||||
|
||||
|
||||
### Music and audio editing
|
||||
|
||||
### Audacity
|
||||
|
||||
[Audacity][59] is popular, user-friendly tool for editing audio files and recording sound.
|
||||
|
||||
### Ardour
|
||||
|
||||
[Ardour][60] is a digital audio workstation with an interface centered around a record, edit, and mix workflow. It's a little more complicated than Audacity to use but allows for automation and is generally more sophisticated. (Available for Linux, Mac OS X, and Windows.)
|
||||
|
||||
### Hydrogen
|
||||
|
||||
[Hydrogen][61] is an open source drum machine with an intuitive interface. It provides the ability to create and arrange various patterns using synthesized instruments.
|
||||
|
||||
### Mixxx
|
||||
|
||||
[Mixxx][62] is a four-deck DJ suite that allows you to DJ and mix songs together with powerful controls, including beat looping, time stretching, and pitch bending, as well as live broadcast your mixes and interface with DJ hardware controllers.
|
||||
|
||||
### Rosegarden
|
||||
|
||||
[Rosegarden][63] is a music composition suite that includes tools for score writing and music composition/editing and provides an audio and MIDI sequencer.
|
||||
|
||||
### MuseScore
|
||||
|
||||
[MuseScore][64] is a music score creation, notation, and editing tool with a community of musical score contributors.
|
||||
|
||||
### Additional creative tools
|
||||
|
||||
### MakeHuman
|
||||
|
||||
[MakeHuman][65] is a 3D graphical tool for creating photorealistic models of humanoid forms.
|
||||
|
||||
<iframe allowfullscreen="" frameborder="0" height="293" src="https://www.youtube.com/embed/WiEDGbRnXdE?rel=0" width="520"></iframe>
|
||||
|
||||
### Natron
|
||||
|
||||
[Natron][66] is a node-based compositor tool used for video post-production and motion graphic and special effect design.
|
||||
|
||||
### FontForge
|
||||
|
||||
[FontForge][67] is a typeface creation and editing tool. It allows you to edit letter forms in a typeface as well as generate fonts for using those typeface designs.
|
||||
|
||||
### Valentina
|
||||
|
||||
[Valentina][68] is an application for drafting sewing patterns.
|
||||
|
||||
### Calligra Flow
|
||||
|
||||
[Calligra Flow][69] is a Visio-like diagramming tool. (Available for Linux, Mac OS X, and Windows.)
|
||||
|
||||
### Resources
|
||||
|
||||
There are a lot of toys and goodies to try out there. Need some inspiration to start your exploration? These websites and conference are chock-full of tutorials and beautiful creative works to inspire you get you going:
|
||||
|
||||
1. [pixls.us][7]: Blog hosted by photographer Pat David that focuses on free and open source tools and workflow for professional photographers.
|
||||
2. [David Revoy's Blog][8] The blog of David Revoy, an immensely talented free and open source illustrator, concept artist, and advocate, with credits on several of the Blender Foundation films.
|
||||
3. [The Open Source Creative Podcast][9]: Hosted by Opensource.com community moderator and columnist [Jason van Gumster][10], who is a Blender and GIMP expert, and author of _[Blender for Dummies][1]_, this podcast is directed squarely at those of us who enjoy open source creative tools and the culture around them.
|
||||
4. [Libre Graphics Meeting][11]: Annual conference for free and open source creative software developers and the creatives who use the software. This is the place to find out about what cool features are coming down the pipeline in your favorite open source creative tools, and to enjoy what their users are creating with them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Máirín Duffy - Máirín is a principal interaction designer at Red Hat. She is passionate about software freedom and free & open source tools, particularly in the creative domain: her favorite application is Inkscape (http://inkscape.org).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/16/12/yearbook-top-open-source-creative-tools-2016
|
||||
|
||||
作者:[Máirín Duffy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mairin
|
||||
[1]:http://www.blenderbasics.com/
|
||||
[2]:https://builder.blender.org/download/
|
||||
[3]:http://graphicall.org/
|
||||
[4]:https://mathieu.daitauha.fr/blog/2016/09/23/blender-nightly-in-flatpak/
|
||||
[5]:https://pitivi.wordpress.com/2016/07/18/get-pitivi-directly-from-us-with-flatpak/
|
||||
[6]:http://www.openshotvideo.com/2016/08/openshot-21-released.html
|
||||
[7]:http://pixls.us/
|
||||
[8]:http://davidrevoy.com/
|
||||
[9]:http://monsterjavaguns.com/podcast/
|
||||
[10]:https://opensource.com/users/jason-van-gumster
|
||||
[11]:http://libregraphicsmeeting.org/2016/
|
||||
[12]:https://opensource.com/life/12/9/tour-through-open-source-creative-tools
|
||||
[13]:https://opensource.com/business/16/8/flatpak
|
||||
[14]:http://flatpak.org/apps.html
|
||||
[15]:https://opensource.com/tags/gimp
|
||||
[16]:https://www.gimp.org/news/2015/11/22/20-years-of-gimp-release-of-gimp-2816/
|
||||
[17]:https://www.gimp.org/news/2016/07/14/gimp-2-8-18-released/
|
||||
[18]:https://www.gimp.org/news/2016/07/13/gimp-2-9-4-released/
|
||||
[19]:https://www.gimp.org/news/2016/07/13/gimp-2-9-4-released/
|
||||
[20]:https://opensource.com/tags/inkscape
|
||||
[21]:http://wiki.inkscape.org/wiki/index.php/Release_notes/0.91
|
||||
[22]:http://wiki.inkscape.org/wiki/index.php/Mesh_Gradients
|
||||
[23]:https://www.youtube.com/watch?v=IztyV-Dy4CE
|
||||
[24]:https://inkscape.org/cs/~doctormo/%E2%98%85symbols-dialog
|
||||
[25]:https://github.com/Xaviju/inkscape-open-symbols
|
||||
[26]:https://opensource.com/tags/scribus
|
||||
[27]:https://www.scribus.net/scribus-1-4-6-released/
|
||||
[28]:https://www.scribus.net/scribus-1-5-2-released/
|
||||
[29]:http://mypaint.org/
|
||||
[30]:http://mypaint.org/blog/2016/01/15/mypaint-1.2.0-released/
|
||||
[31]:https://github.com/mypaint/mypaint/wiki/v1.2-Inking-Tool
|
||||
[32]:https://opensource.com/tags/blender
|
||||
[33]:http://www.blender.org/features/2-78/
|
||||
[34]:https://opensource.com/tags/krita
|
||||
[35]:https://krita.org/en/item/krita-3-0-1-update-brings-numerous-fixes/
|
||||
[36]:https://opensource.com/life/16/9/10-reasons-flowblade-linux-video-editor
|
||||
[37]:https://opensource.com/tags/kdenlive
|
||||
[38]:https://opensource.com/life/11/11/introduction-kdenlive
|
||||
[39]:http://jliljebl.github.io/flowblade/
|
||||
[40]:http://pitivi.org/
|
||||
[41]:http://wiki.pitivi.org/wiki/Why_Python%3F
|
||||
[42]:https://gstreamer.freedesktop.org/
|
||||
[43]:http://shotcut.org/
|
||||
[44]:http://permalink.gmane.org/gmane.comp.lib.fltk.general/2397
|
||||
[45]:http://www.dennedy.org/
|
||||
[46]:http://openshot.org/
|
||||
[47]:http://www.selapa.net/swatchbooker/
|
||||
[48]:https://help.gnome.org/users/gnome-help/stable/color.html.en
|
||||
[49]:https://help.gnome.org/users/gnome-help/stable/wacom.html.en
|
||||
[50]:http://xournal.sourceforge.net/
|
||||
[51]:https://wiki.gnome.org/Apps/PdfMod
|
||||
[52]:https://www.sparkleshare.org/
|
||||
[53]:https://opensource.com/life/16/4/how-use-darktable-digital-darkroom
|
||||
[54]:https://entangle-photo.org/
|
||||
[55]:http://hugin.sourceforge.net/
|
||||
[56]:https://opensource.com/article/16/12/synfig-studio-animation-software-tutorial
|
||||
[57]:https://wiki.blender.org/index.php/Dev:Ref/Release_Notes/2.78/GPencil
|
||||
[58]:https://opensource.com/tags/krita
|
||||
[59]:https://opensource.com/tags/audacity
|
||||
[60]:https://ardour.org/
|
||||
[61]:http://www.hydrogen-music.org/
|
||||
[62]:http://mixxx.org/
|
||||
[63]:http://www.rosegardenmusic.com/
|
||||
[64]:https://opensource.com/life/16/03/musescore-tutorial
|
||||
[65]:http://makehuman.org/
|
||||
[66]:https://natron.fr/
|
||||
[67]:http://fontforge.github.io/en-US/
|
||||
[68]:http://valentina-project.org/
|
||||
[69]:https://www.calligra.org/flow/
|
||||
@ -1,3 +1,4 @@
|
||||
++++翻译中++++++
|
||||
How to set up a Continuous Integration server for Android development (Ubuntu + Jenkins + SonarQube)
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
GraphQL In Use: Building a Blogging Engine API with Golang and PostgreSQL
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,69 +0,0 @@
|
||||
+++
|
||||
++翻译中
|
||||
+++++
|
||||
The 6 unwritten rules of open source development
|
||||
============================================================
|
||||
|
||||
> Do you want to be a successful and valued member of an open source project? Follow these unwritten rules
|
||||
|
||||
|
||||

|
||||
|
||||
>_Matt Hicks is vice president of software engineering at Red Hat and one of the founding members of the Red Hat OpenShift team. He has spent 15 years in software engineering with a variety of roles in development, operations, architecture, and management._
|
||||
|
||||
The sports world is rife with unwritten rules. These are the behaviors and rituals that are observed but rarely documented in an official capacity. For example, in baseball, unwritten rules range from not stealing bases when well ahead to never giving up an intentional walk when there’s a runner on first. To outsiders, these are esoteric, perhaps even nonsensical guidelines, but they are followed by every player who wants to be a valued teammate and respected opponent.
|
||||
|
||||
Software development, particularly _open source_ software development, also has an invisible rulebook. As in other team sports, these rules can have a significant impact on how an open source community treats a developer, especially newcomers.
|
||||
|
||||
|
||||
### Walk before you run
|
||||
|
||||
Before interacting with any community, open source or otherwise, you need to do your homework. For prospective open source contributors, this means understanding the community’s mission and learning where you can help from the onset. Everyone wants to contribute code, but far fewer developers are ready, willing, and able to do the grunt work: testing patches, reviewing code, sifting through documentation and correcting errors, and all of those other generally undesirable tasks that are required for a healthy community.
|
||||
|
||||
Why do this when you can start cranking out beautiful lines of code? It’s about trust and, more important, showing that you care about the community as a whole and not developing only the features that you care about.
|
||||
|
||||
|
||||
### Make an impact, not a crater
|
||||
|
||||
As you build up your reputation with a given open source community, it’s important to develop a broad understanding of the project and the code base. Don’t stop at the mission statement; dive into the project itself and understand what makes it tick outside of your own area of expertise. Beyond broadening your own understanding as a developer, this helps you gain insight into how your code contributions could impact the larger project, not only your little piece of the pie.
|
||||
|
||||
For example, maybe you want to create a revision to a networking module. You build it and test it, and it looks good, so you send it off to the community for more testing. As it turns out, this module breaks a security setting or causes a major storage incident when deployed in a certain manner -- issues that could have been remedied had you looked at the code base as a whole rather than your piece alone. Showing that you have a broad understanding of how various parts of the project interact with others -- and developing your patches to make an impact, not a crater -- will go a long way toward making your contributions appreciated.
|
||||
|
||||
### Patch bombing is not OK
|
||||
|
||||
Your work is not over when your code is submitted. There will be discussion about the change and a lot of QA and testing yet to be done if accepted. You want to make sure you are putting in the time and effort to understand how you can move your code and patches forward without them becoming a burden on other members.
|
||||
|
||||
### Help others before helping yourself
|
||||
|
||||
Open source communities aren’t a dog-eat-dog world; they’re about putting the value of the project before individual contributions and individual success. If you want to increase your odds of being seen as a valued member of the community (and get your code accepted), help others with their efforts. If you know about networking, review networking modules -- apply your expertise to make the whole code base better. It’s no surprise that top reviewers often correlate to top contributors. The more you help, the more valued you are.
|
||||
|
||||
### Address the edge
|
||||
|
||||
As a developer, you’re likely looking to contribute to an open source project to address a particular pain point. Maybe your preferred operating system isn’t supported or you desperately want to modernize the security technology used by the community. The best way to introduce changes, especially more aggressive ones, is to make them impossible to refuse. Know enough about the code base to think through every edge case. Add capabilities without breaking existing functionality. Pour your energy into the completeness of your feature, not only the submission.
|
||||
|
||||
### Don’t give up
|
||||
|
||||
Open source communities have plenty of fly-by-night members, but with commitment comes credibility. Don’t merely walk away when a patch is rejected. Find out why it was rejected, make those fixes, and try again. As you work on your patch, keep up with changes to the code base and make sure your patch remains mergeable as the project evolves. Don’t leave it to others to patch up your patch. As the author, take the burden on yourself and keep other community members free to do the same with their work.
|
||||
|
||||
These unwritten rules might seem simple, but too many open source contributors don’t follow them. Developers who do so will not only succeed in advancing a project for themselves; they will help to advance open source in general.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html
|
||||
|
||||
作者:[Matt Hicks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/blog/new-tech-forum/
|
||||
[1]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&via=infoworld&text=The+6+unwritten+rules+of+open+source+development
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[3]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[4]:https://plus.google.com/share?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[5]:http://reddit.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[6]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[7]:http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html#email
|
||||
[8]:http://www.infoworld.com/article/3152565/linux/5-rock-solid-linux-distros-for-developers.html#tk.ifw-infsb
|
||||
[9]:http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
@ -1,61 +0,0 @@
|
||||
Arrive On Time With NTP -- Part 1: Usage Overview
|
||||
============================================================
|
||||
|
||||

|
||||
In this first of a three-part series, Chris Binnie looks at why NTP services are essential to a happy infrastructure.[Used with permission][1]
|
||||
|
||||
Few services on the Internet can claim to be so critical in nature as time. Subtle issues which affect the timekeeping of your systems can sometimes take a day or two to be realized, and they are almost always unwelcome because of the knock-on effects they cause.
|
||||
|
||||
Consider as an example that your backup server loses connectivity to your Network Time Protocol (NTP) server and, over a period of a few days, introduces several hours of clock skew. Your colleagues arrive at work at 9am as usual only to find the bandwidth-intensive backups consuming all the network resources meaning that they can barely even log into their workstations to start their day’s work until the backup has finished.
|
||||
|
||||
In this first of a three-part series, I’ll provide brief overview of NTP to help prevent such disasters. From the timestamps on your emails to remembering when you started your shift at work, NTP services are essential to a happy infrastructure.
|
||||
|
||||
You might consider that the really important NTP servers (from which other servers pick up their clock data) are at the bottom of an inverted pyramid and referred to as Stratum 1 servers (also known as “primary” servers). These servers speak directly to national time services (known as Stratum 0, which might be devices such as atomic clocks or GPS clocks, for example). There are a number of ways of communicating with them securely, via satellite or radio, for example.
|
||||
|
||||
Somewhat surprisingly, it’s reasonably common for even large enterprises to connect to Stratum 2 servers (or “secondary” servers) as opposed to primary servers. Stratum 2 servers, as you’d expect, synchronize directly with Stratum 1 servers. If you consider that a corporation might have their own onsite NTP servers (at least two, usually three, for resilience) then these would be Stratum 3 servers. As a result, such a corporation’s Stratum 3 servers would then connect upstream to predefined secondary servers and dutifully pass the time onto its many client and server machines as an accurate reflection of the current time.
|
||||
|
||||
A simple design component of NTP is that it works on the premise -- thanks to the large geographical distances travelled by Internet traffic -- that round-trip times (of when a packet was sent and how many seconds later it was received) are sensibly taken into account before trusting to a time as being entirely accurate. There’s a lot more to setting a computer’s clock than you might at first think, if you don’t believe me, then [this fascinating web page][3] is well worth looking at.
|
||||
|
||||
At the risk of revisiting the point, NTP is so key to making sure your infrastructure functions as expected that the Stratum servers to which your NTP servers connect to fuel your internal timekeeping must be absolutely trusted and additionally offer redundancy. There’s an informative list of the Stratum 1 servers available at the [main NTP site][4].
|
||||
|
||||
As you can see from that list, some NTP Stratum 1 servers run in a “ClosedAccount” state; these servers can’t be used without prior consent. However, as long as you adhere to their usage guidelines, “OpenAccess” servers are indeed open for polling. Any “RestrictedAccess” servers can sometimes be limited due to a maximum number of clients or a minimum poll interval. Additionally, these are sometimes only available to certain types of organizations, such as academia.
|
||||
|
||||
### Respect My Authority
|
||||
|
||||
On a public NTP server, you are likely to find that the usage guidelines follow several rules. Let’s have a look at some of them now.
|
||||
|
||||
The “iburst” option involves a client sending a number of packets (eight packets rather than the usual single packet) to an NTP server should it not respond during at a standard polling interval. If, after shouting loudly at the NTP server a few times within a short period of time, a recognized response isn’t forthcoming, then the local time is not changed.
|
||||
|
||||
Unlike “iburst” the “burst” option is not commonly allowed (so don’t use it!) as per the general rules for NTP servers. That option instead sends numerous packets (eight again apparently) at each polling interval and also when the server is available. If you are continually throwing packets at higher-up Stratum servers even when they are responding normally, you may get blacklisted for using the “burst” option.
|
||||
|
||||
Clearly, how often you connect to a server makes a difference to its load (and the negligible amount of bandwidth used). These settings can be configured locally using the “minpoll” and “maxpoll” options. However, to follow the connecting rules on to an NTP server, you shouldn’t generally alter the the defaults of 64 seconds and 1024 seconds, respectively.
|
||||
|
||||
Another, far from tacit, rule is that clients should always respect Kiss-Of-Death (KOD) messages generated by those servers from which they request time. If an NTP server doesn’t want to respond to a particular request, similar to certain routing and firewalling techniques, then it’s perfectly possible for it to simply discard or blackhole any associated packets.
|
||||
|
||||
In other words, the recipient server of these unwanted packets takes on no extra load to speak of and simply drops the traffic that it doesn’t think it should serve a response to. As you can imagine, however, this isn’t always entirely helpful, and sometimes it’s better to politely ask the client to cease and desist, rather than ignoring the requests. For this reason, there’s a specific packet type called the KOD packet. Should a client be sent an unwelcome KOD packet then it should then remember that particular server as having responded with an access-denied style marker.
|
||||
|
||||
If it’s not the first KOD packet received from back the server, then the client assumes that there is a rate-limiting condition (or something similar) present on the server. It’s common at this stage for the client to write to its local logs, noting the less-than-satisfactory outcome of the transaction with that particular server, if you ever need to troubleshoot such a scenario.
|
||||
|
||||
Bear in mind that, for obvious reasons, it’s key that your NTP’s infrastructure be dynamic. Thus, it’s important not to hard-code IP addresses into your NTP config. By using DNS names, individual servers can fall off the network and the service can still be maintained, IP address space can be reallocated and simple load balancing (with a degree of resilience) can be introduced.
|
||||
|
||||
Let’s not forget that we also need to consider that the exponential growth of the Internet of Things (IoT), eventually involving billions of new devices, will mean a whole host of equipment will need to keep its wristwatches set to the correct time. Should a hardware vendor inadvertently (or purposely) configure their devices to only communicate with one provider’s NTP servers (or even a single server) then there can be -- and have been in the past -- very unwelcome issues.
|
||||
|
||||
As you might imagine, as more units of hardware are purchased and brought online, the owner of the NTP infrastructure is likely to be less than grateful for the associated fees that they are incurring without any clear gain. This scenario is far from being unique to the realms of fantasy. Ongoing headaches -- thanks to NTP traffic forcing a provider’s infrastructure to creak -- have been seen several times over the last few years.
|
||||
|
||||
In the next two articles, I’ll look at some important NTP configuration options and examine server setup.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/arrive-time-ntp-part-1-usage-overview
|
||||
|
||||
作者:[CHRIS BINNIE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/files/images/ntp-timejpg
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm
|
||||
[4]:http://support.ntp.org/bin/view/Servers/StratumOneTimeServers
|
||||
@ -1,562 +0,0 @@
|
||||
How to Install Elastic Stack on CentOS 7
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Step 1 - Prepare the Operating System][1]
|
||||
2. [Step 2 - Install Java][2]
|
||||
3. [Step 3 - Install and Configure Elasticsearch][3]
|
||||
4. [Step 4 - Install and Configure Kibana with Nginx][4]
|
||||
5. [Step 5 - Install and Configure Logstash][5]
|
||||
6. [Step 6 - Install and Configure Filebeat on the CentOS Client][6]
|
||||
7. [Step 7 - Install and Configure Filebeat on the Ubuntu Client][7]
|
||||
8. [Step 8 - Testing][8]
|
||||
9. [Reference][9]
|
||||
|
||||
**Elasticsearch** is an open source search engine based on Lucene, developed in Java. It provides a distributed and multitenant full-text search engine with an HTTP Dashboard web-interface (Kibana). The data is queried, retrieved and stored with a JSON document scheme. Elasticsearch is a scalable search engine that can be used to search for all kind of text documents, including log files. Elasticsearch is the heart of the 'Elastic Stack' or ELK Stack.
|
||||
|
||||
**Logstash** is an open source tool for managing events and logs. It provides real-time pipelining for data collections. Logstash will collect your log data, convert the data into JSON documents, and store them in Elasticsearch.
|
||||
|
||||
**Kibana** is an open source data visualization tool for Elasticsearch. Kibana provides a pretty dashboard web interface. It allows you to manage and visualize data from Elasticsearch. It's not just beautiful, but also powerful.
|
||||
|
||||
In this tutorial, I will show you how to install and configure Elastic Stack on a CentOS 7 server for monitoring server logs. Then I'll show you how to install 'Elastic beats' on a CentOS 7 and a Ubuntu 16 client operating system.
|
||||
|
||||
**Prerequisite**
|
||||
|
||||
* CentOS 7 64 bit with 4GB of RAM - elk-master
|
||||
* CentOS 7 64 bit with 1 GB of RAM - client1
|
||||
* Ubuntu 16 64 bit with 1GB of RAM - client2
|
||||
|
||||
### Step 1 - Prepare the Operating System
|
||||
|
||||
In this tutorial, we will disable SELinux on the CentOS 7 server. Edit the SELinux configuration file.
|
||||
|
||||
vim /etc/sysconfig/selinux
|
||||
|
||||
Change SELINUX value from enforcing to disabled.
|
||||
|
||||
SELINUX=disabled
|
||||
|
||||
Then reboot the server.
|
||||
|
||||
reboot
|
||||
|
||||
Login to the server again and check the SELinux state.
|
||||
|
||||
getenforce
|
||||
|
||||
Make sure the result is disabled.
|
||||
|
||||
### Step 2 - Install Java
|
||||
|
||||
Java is required for the Elastic stack deployment. Elasticsearch requires Java 8, it is recommended to use the Oracle JDK 1.8\. I will install Java 8 from the official Oracle rpm package.
|
||||
|
||||
Download Java 8 JDK with the wget command.
|
||||
|
||||
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http:%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u77-b02/jdk-8u77-linux-x64.rpm"
|
||||
|
||||
Then install it with this rpm command;
|
||||
|
||||
rpm -ivh jdk-8u77-linux-x64.rpm
|
||||
|
||||
Finally, check java JDK version to ensure that it is working properly.
|
||||
|
||||
java -version
|
||||
|
||||
You will see Java version of the server.
|
||||
|
||||
### Step 3 - Install and Configure Elasticsearch
|
||||
|
||||
In this step, we will install and configure Elasticsearch. I will install Elasticsearch from an rpm package provided by elastic.co and configure it to run on localhost (to make the setup secure and ensure that it is not reachable from the outside).
|
||||
|
||||
Before installing Elasticsearch, add the elastic.co key to the server.
|
||||
|
||||
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
|
||||
Next, download Elasticsearch 5.1 with wget and then install it.
|
||||
|
||||
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.1.1.rpm
|
||||
rpm -ivh elasticsearch-5.1.1.rpm
|
||||
|
||||
Elasticsearch is installed. Now go to the configuration directory and edit the elasticsaerch.yml configuration file.
|
||||
|
||||
cd /etc/elasticsearch/
|
||||
vim elasticsearch.yml
|
||||
|
||||
Enable memory lock for Elasticsearch by removing a comment on line 40\. This disables memory swapping for Elasticsearch.
|
||||
|
||||
bootstrap.memory_lock: true
|
||||
|
||||
In the 'Network' block, uncomment the network.host and http.port lines.
|
||||
|
||||
network.host: localhost
|
||||
http.port: 9200
|
||||
|
||||
Save the file and exit the editor.
|
||||
|
||||
Now edit the elasticsearch.service file for the memory lock configuration.
|
||||
|
||||
vim /usr/lib/systemd/system/elasticsearch.service
|
||||
|
||||
Uncomment LimitMEMLOCK line.
|
||||
|
||||
LimitMEMLOCK=infinity
|
||||
|
||||
Save and exit.
|
||||
|
||||
Edit the sysconfig configuration file for Elasticsearch.
|
||||
|
||||
vim /etc/sysconfig/elasticsearch
|
||||
|
||||
Uncomment line 60 and make sure the value is 'unlimited'.
|
||||
|
||||
MAX_LOCKED_MEMORY=unlimited
|
||||
|
||||
Save and exit.
|
||||
|
||||
The Elasticsearch configuration is finished. Elasticsearch will run on the localhost IP address on port 9200, we disabled memory swapping for it by enabling mlockall on the CentOS server.
|
||||
|
||||
Reload systemd, enable Elasticsearch to start at boot time, then start the service.
|
||||
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable elasticsearch
|
||||
sudo systemctl start elasticsearch
|
||||
|
||||
Wait a second for Eelasticsearch to start, then check the open ports on the server, make sure 'state' for port 9200 is 'LISTEN'.
|
||||
|
||||
netstat -plntu
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
Then check the memory lock to ensure that mlockall is enabled, and check that Elasticsearch is running with the commands below.
|
||||
|
||||
curl -XGET 'localhost:9200/_nodes?filter_path=**.mlockall&pretty'
|
||||
curl -XGET 'localhost:9200/?pretty'
|
||||
|
||||
You will see the results below.
|
||||
|
||||
[
|
||||
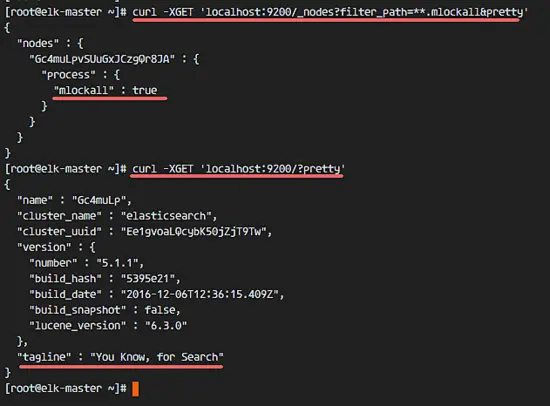
|
||||
][11]
|
||||
|
||||
### Step 4 - Install and Configure Kibana with Nginx
|
||||
|
||||
In this step, we will install and configure Kibana with a Nginx web server. Kibana will listen on the localhost IP address and Nginx acts as a reverse proxy for the Kibana application.
|
||||
|
||||
Download Kibana 5.1 with wget, then install it with the rpm command:
|
||||
|
||||
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.1.1-x86_64.rpm
|
||||
rpm -ivh kibana-5.1.1-x86_64.rpm
|
||||
|
||||
Now edit the Kibana configuration file.
|
||||
|
||||
vim /etc/kibana/kibana.yml
|
||||
|
||||
Uncomment the configuration lines for server.port, server.host and elasticsearch.url.
|
||||
|
||||
server.port: 5601
|
||||
server.host: "localhost"
|
||||
elasticsearch.url: "http://localhost:9200"
|
||||
|
||||
Save and exit.
|
||||
|
||||
Add Kibana to run at boot and start it.
|
||||
|
||||
sudo systemctl enable kibana
|
||||
sudo systemctl start kibana
|
||||
|
||||
Kibana will run on port 5601 as node application.
|
||||
|
||||
netstat -plntu
|
||||
|
||||
[
|
||||
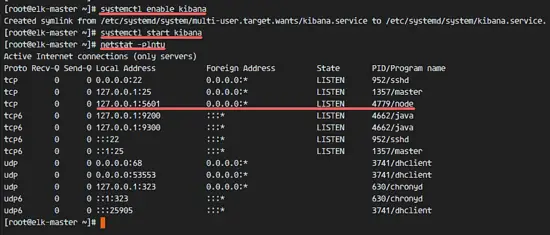
|
||||
][12]
|
||||
|
||||
The Kibana installation is finished. Now we need to install Nginx and configure it as reverse proxy to be able to access Kibana from the public IP address.
|
||||
|
||||
Nginx is available in the Epel repository, install epel-release with yum.
|
||||
|
||||
yum -y install epel-release
|
||||
|
||||
Next, install the Nginx and httpd-tools package.
|
||||
|
||||
yum -y install nginx httpd-tools
|
||||
|
||||
The httpd-tools package contains tools for the web server, we will use htpasswd basic authentication for Kibana.
|
||||
|
||||
Edit the Nginx configuration file and remove the **'server { }**' block, so we can add a new virtual host configuration.
|
||||
|
||||
cd /etc/nginx/
|
||||
vim nginx.conf
|
||||
|
||||
Remove the server { } block.
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now we need to create a new virtual host configuration file in the conf.d directory. Create the new file 'kibana.conf' with vim.
|
||||
|
||||
vim /etc/nginx/conf.d/kibana.conf
|
||||
|
||||
Paste the configuration below.
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
server_name elk-stack.co;
|
||||
|
||||
auth_basic "Restricted Access";
|
||||
auth_basic_user_file /etc/nginx/.kibana-user;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:5601;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection 'upgrade';
|
||||
proxy_set_header Host $host;
|
||||
proxy_cache_bypass $http_upgrade;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Then create a new basic authentication file with the htpasswd command.
|
||||
|
||||
sudo htpasswd -c /etc/nginx/.kibana-user admin
|
||||
TYPE YOUR PASSWORD
|
||||
|
||||
Test the Nginx configuration and make sure there is no error. Then add Nginx to run at the boot time and start Nginx.
|
||||
|
||||
nginx -t
|
||||
systemctl enable nginx
|
||||
systemctl start nginx
|
||||
|
||||
[
|
||||
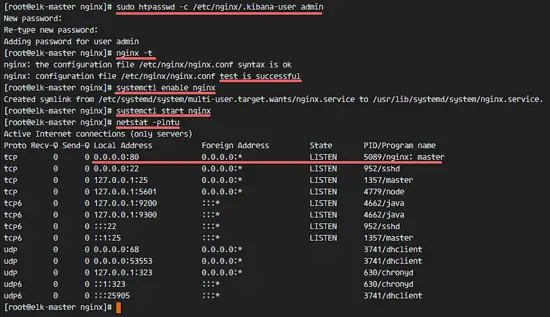
|
||||
][14]
|
||||
|
||||
### Step 5 - Install and Configure Logstash
|
||||
|
||||
In this step, we will install Logsatash and configure it to centralize server logs from clients with filebeat, then filter and transform the Syslog data and move it into the stash (Elasticsearch).
|
||||
|
||||
Download Logstash and install it with rpm.
|
||||
|
||||
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.1.1.rpm
|
||||
rpm -ivh logstash-5.1.1.rpm
|
||||
|
||||
Generate a new SSL certificate file so that the client can identify the elastic server.
|
||||
|
||||
Go to the tls directory and edit the openssl.cnf file.
|
||||
|
||||
cd /etc/pki/tls
|
||||
vim openssl.cnf
|
||||
|
||||
Add a new line in the '[ v3_ca ]' section for the server identification.
|
||||
|
||||
[ v3_ca ]
|
||||
|
||||
# Server IP Address
|
||||
subjectAltName = IP: 10.0.15.10
|
||||
|
||||
Save and exit.
|
||||
|
||||
Generate the certificate file with the openssl command.
|
||||
|
||||
openssl req -config /etc/pki/tls/openssl.cnf -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout /etc/pki/tls/private/logstash-forwarder.key -out /etc/pki/tls/certs/logstash-forwarder.crt
|
||||
|
||||
The certificate files can be found in the '/etc/pki/tls/certs/' and '/etc/pki/tls/private/' directories.
|
||||
|
||||
Next, we will create new configuration files for Logstash. We will create a new 'filebeat-input.conf' file to configure the log sources for filebeat, then a 'syslog-filter.conf' file for syslog processing and the 'output-elasticsearch.conf' file to define the Elasticsearch output.
|
||||
|
||||
Go to the logstash configuration directory and create the new configuration files in the 'conf.d' subdirectory.
|
||||
|
||||
cd /etc/logstash/
|
||||
vim conf.d/filebeat-input.conf
|
||||
|
||||
Input configuration: paste the configuration below.
|
||||
|
||||
```
|
||||
input {
|
||||
beats {
|
||||
port => 5443
|
||||
ssl => true
|
||||
ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
|
||||
ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Create the syslog-filter.conf file.
|
||||
|
||||
vim conf.d/syslog-filter.conf
|
||||
|
||||
Paste the configuration below.
|
||||
|
||||
```
|
||||
filter {
|
||||
if [type] == "syslog" {
|
||||
grok {
|
||||
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
|
||||
add_field => [ "received_at", "%{@timestamp}" ]
|
||||
add_field => [ "received_from", "%{host}" ]
|
||||
}
|
||||
date {
|
||||
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We use a filter plugin named '**grok**' to parse the syslog files.
|
||||
|
||||
Save and exit.
|
||||
|
||||
Create the output configuration file 'output-elasticsearch.conf'.
|
||||
|
||||
vim conf.d/output-elasticsearch.conf
|
||||
|
||||
Paste the configuration below.
|
||||
|
||||
```
|
||||
output {
|
||||
elasticsearch { hosts => ["localhost:9200"]
|
||||
hosts => "localhost:9200"
|
||||
manage_template => false
|
||||
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
|
||||
document_type => "%{[@metadata][type]}"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Finally add logstash to start at boot time and start the service.
|
||||
|
||||
sudo systemctl enable logstash
|
||||
sudo systemctl start logstash
|
||||
|
||||
[
|
||||
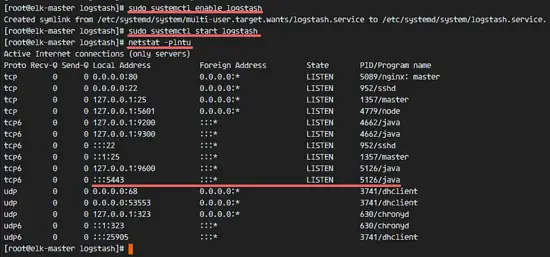
|
||||
][15]
|
||||
|
||||
### Step 6 - Install and Configure Filebeat on the CentOS Client
|
||||
|
||||
Beats are data shippers, lightweight agents that can be installed on the client nodes to send huge amounts of data from the client machine to the Logstash or Elasticsearch server. There are 4 beats available, 'Filebeat' for 'Log Files', 'Metricbeat' for 'Metrics', 'Packetbeat' for 'Network Data' and 'Winlogbeat' for the Windows client 'Event Log'.
|
||||
|
||||
In this tutorial, I will show you how to install and configure 'Filebeat' to transfer data log files to the Logstash server over an SSL connection.
|
||||
|
||||
Login to the client1 server. Then copy the certificate file from the elastic server to the client1 server.
|
||||
|
||||
ssh root@client1IP
|
||||
|
||||
Copy the certificate file with the scp command.
|
||||
|
||||
scp root@elk-serverIP:~/logstash-forwarder.crt .
|
||||
TYPE elk-server password
|
||||
|
||||
Create a new directory and move certificate file to that directory.
|
||||
|
||||
sudo mkdir -p /etc/pki/tls/certs/
|
||||
mv ~/logstash-forwarder.crt /etc/pki/tls/certs/
|
||||
|
||||
Next, import the elastic key on the client1 server.
|
||||
|
||||
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
|
||||
|
||||
Download Filebeat and install it with rpm.
|
||||
|
||||
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.1.1-x86_64.rpm
|
||||
rpm -ivh filebeat-5.1.1-x86_64.rpm
|
||||
|
||||
Filebeat has been installed, go to the configuration directory and edit the file 'filebeat.yml'.
|
||||
|
||||
cd /etc/filebeat/
|
||||
vim filebeat.yml
|
||||
|
||||
In the paths section on line 21, add the new log files. We will add two files '/var/log/secure' for ssh activity and '/var/log/messages' for the server log.
|
||||
|
||||
paths:
|
||||
- /var/log/secure
|
||||
- /var/log/messages
|
||||
|
||||
Add a new configuration on line 26 to define the syslog type files.
|
||||
|
||||
document-type: syslog
|
||||
|
||||
Filebeat is using Elasticsearch as the output target by default. In this tutorial, we will change it to Logshtash. Disable Elasticsearch output by adding comments on the lines 83 and 85.
|
||||
|
||||
Disable elasticsearch output.
|
||||
|
||||
#-------------------------- Elasticsearch output ------------------------------
|
||||
#output.elasticsearch:
|
||||
# Array of hosts to connect to.
|
||||
# hosts: ["localhost:9200"]
|
||||
|
||||
Now add the new logstash output configuration. Uncomment the logstash output configuration and change all value to the configuration that is shown below.
|
||||
|
||||
output.logstash:
|
||||
# The Logstash hosts
|
||||
hosts: ["10.0.15.10:5443"]
|
||||
bulk_max_size: 1024
|
||||
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
|
||||
template.name: "filebeat"
|
||||
template.path: "filebeat.template.json"
|
||||
template.overwrite: false
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
Add Filebeat to start at boot time and start it.
|
||||
|
||||
sudo systemctl enable filebeat
|
||||
sudo systemctl start filebeat
|
||||
|
||||
### Step 7 - Install and Configure Filebeat on the Ubuntu Client
|
||||
|
||||
Connect to the server by ssh.
|
||||
|
||||
ssh root@ubuntu-clientIP
|
||||
|
||||
Copy the certificate file to the client with the scp command.
|
||||
|
||||
scp root@elk-serverIP:~/logstash-forwarder.crt .
|
||||
|
||||
Create a new directory for the certificate file and move the file to that directory.
|
||||
|
||||
sudo mkdir -p /etc/pki/tls/certs/
|
||||
mv ~/logstash-forwarder.crt /etc/pki/tls/certs/
|
||||
|
||||
Add the elastic key to the server.
|
||||
|
||||
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
|
||||
|
||||
Download the Filebeat .deb package and install it with the dpkg command.
|
||||
|
||||
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.1.1-amd64.deb
|
||||
dpkg -i filebeat-5.1.1-amd64.deb
|
||||
|
||||
Go to the filebeat configuration directory and edit the file 'filebeat.yml' with vim.
|
||||
|
||||
cd /etc/filebeat/
|
||||
vim filebeat.yml
|
||||
|
||||
Add the new log file paths in the paths configuration section.
|
||||
|
||||
paths:
|
||||
- /var/log/auth.log
|
||||
- /var/log/syslog
|
||||
|
||||
Set the document type to syslog.
|
||||
|
||||
document-type: syslog
|
||||
|
||||
Disable elasticsearch output by adding comments to the lines shown below.
|
||||
|
||||
#-------------------------- Elasticsearch output ------------------------------
|
||||
#output.elasticsearch:
|
||||
# Array of hosts to connect to.
|
||||
# hosts: ["localhost:9200"]
|
||||
|
||||
Enable logstash output, uncomment the configuration and change the values as shown below.
|
||||
|
||||
output.logstash:
|
||||
# The Logstash hosts
|
||||
hosts: ["10.0.15.10:5443"]
|
||||
bulk_max_size: 1024
|
||||
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
|
||||
template.name: "filebeat"
|
||||
template.path: "filebeat.template.json"
|
||||
template.overwrite: false
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
Add Filebeat to start at boot time and start it.
|
||||
|
||||
sudo systemctl enable filebeat
|
||||
sudo systemctl start filebeat
|
||||
|
||||
Check the service status.
|
||||
|
||||
systemctl status filebeat
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
### Step 8 - Testing
|
||||
|
||||
Open your web browser and visit the elastic stack domain that you used in the Nginx configuration, mine is 'elk-stack.co'. Login as admin user with your password and press Enter to log in to the Kibana dashboard.
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
Create a new default index 'filebeat-*' and click on the 'Create' button.
|
||||
|
||||
[
|
||||
|
||||
][18]
|
||||
|
||||
Th default index has been created. If you have multiple beats on the elastic stack, you can configure the default beat with just one click on the 'star' button.
|
||||
|
||||
[
|
||||
|
||||
][19]
|
||||
|
||||
Go to the '**Discover**' menu and you will see all the log file from the elk-client1 and elk-client2 servers.
|
||||
|
||||
[
|
||||
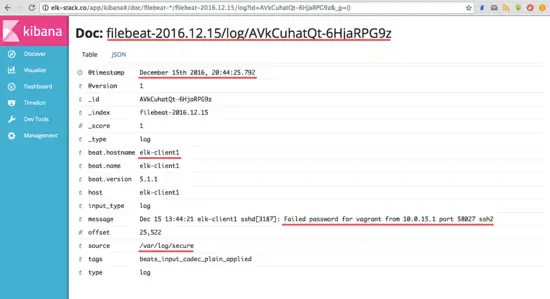
|
||||
][20]
|
||||
|
||||
An example of JSON output from the elk-client1 server log for an invalid ssh login.
|
||||
|
||||
[
|
||||
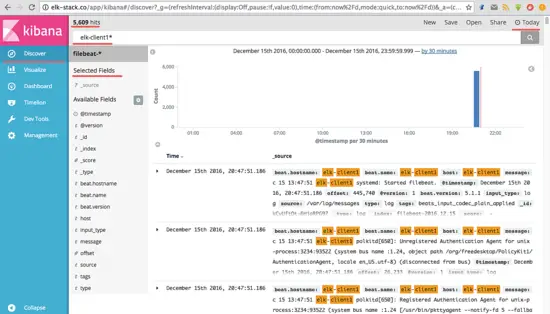
|
||||
][21]
|
||||
|
||||
And there is much more that you can do with Kibana dashboard, just play around with the available options.
|
||||
|
||||
Elastic Stack has been installed on a CentOS 7 server. Filebeat has been installed on a CentOS 7 and a Ubuntu client.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-nbspprepare-the-operating-system
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-java
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-elasticsearch
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-kibana-with-nginx
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-logstash
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-filebeat-on-the-centos-client
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-install-and-configure-filebeat-on-the-ubuntu-client
|
||||
[8]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#step-testing
|
||||
[9]:https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-on-centos-7/#reference
|
||||
[10]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/1.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/2.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/3.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/4.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/5.png
|
||||
[15]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/6.png
|
||||
[16]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/12.png
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/7.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/8.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/9.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/10.png
|
||||
[21]:https://www.howtoforge.com/images/how-to-install-elastic-stack-on-centos-7/big/11.png
|
||||
@ -1,81 +0,0 @@
|
||||
How to Keep Hackers out of Your Linux Machine Part 3: Your Questions Answered
|
||||
============================================================
|
||||
|
||||

|
||||
Mike Guthrie answers some of the security-related questions received during his recent Linux Foundation webinar. Watch the free webinar on-demand.[Creative Commons Zero][1]
|
||||
|
||||
Articles [one][6] and [two][7] in this series covered the five easiest ways to keep hackers out of your Linux machine, and know if they have made it in. This time, I’ll answer some of the excellent security questions I received during my recent Linux Foundation webinar. [Watch the free webinar on-demand.][8]
|
||||
|
||||
**How can I store a passphrase for a private key if private key authentication is used by automated systems?**
|
||||
|
||||
This is tough. This is something that we struggle with on our end, especially when we are doing Red Teams because we have stuff that calls back automatically. I use Expect but I tend to be old-school on that. You are going to have to script it and, yes, storing that passphrase on the system is going to be tough; you are going to have to encrypt it when you store it.
|
||||
|
||||
My Expect script encrypts the passphrase stored and then decrypts, sends the passphrase, and re-encrypts it when it's done. I do realize there are some flaws in that, but it's better than having a no-passphrase key.
|
||||
|
||||
If you do have a no-passphrase key, and you do need to use it. Then I would suggest limiting the user that requires that to almost nothing. For instance, if you are doing some automated log transfers or automated software installs, limit the access to only what it requires to perform those functions.
|
||||
|
||||
You can run commands by SSH, so don't give them a shell, make it so they just run that command and it will actually prevent somebody from stealing that key and doing something other than just that one command.
|
||||
|
||||
**What do you think of password managers such as KeePass2?**
|
||||
|
||||
Password managers, for me, are a very juicy target. With the advent of GPU cracking and some of the cracking capabilities in EC2, they become pretty easy to get past. I steal password vaults all the time.
|
||||
|
||||
Now, our success rate at cracking those, that's a different story. We are still in about the 10 percent range of crack versus no crack. If a person doesn't do a good job at keeping a secure passphrase on their password vault, then we tend to get into it and we have a large amount of success. It's better than nothing but still you need to protect those assets. Protect the password vault as you would protect any other passwords.
|
||||
|
||||
**Do you think it is worthwhile from a security perspective to create a new Diffie-Hellman moduli and limit them to 2048 bit or higher in addition to creating host keys with higher key lengths?**
|
||||
|
||||
Yeah. There have been weaknesses in SSH products in the past where you could actually decrypt the packet stream. With that, you can pull all kinds of data across. People use this safes to transfer files and passwords and they do it thoughtlessly as an encryption mechanism. Doing what you can to use strong encryption and changing your keys and whatnot is important. I rotate my SSH keys -- not as often as I do my passwords -- but I rotate them about once a year. And, yeah, it's a pain, but it gives me peace of mind. I would recommend doing everything you can to make your encryption technology as strong as you possibly can.
|
||||
|
||||
**Is using four completely random English words (around 100k words) for a passphrase okay?**
|
||||
|
||||
Sure. My passphrase is actually a full phrase. It's a sentence. With punctuation and capitalization. I don't use anything longer than that.
|
||||
|
||||
I am a big proponent of having passwords that you can remember that you don’t have to write down or store in a password vault. A password that you can remember that you don't have to write down is more secure than one that you have to write down because it's funky.
|
||||
|
||||
Using a phrase or using four random words that you will remember is much more secure than having a string of numbers and characters and having to hit shift a bunch of times. My current passphrase is roughly 200 characters long. It's something that I can type quickly and that I remember.
|
||||
|
||||
**Any advice for protecting Linux-based embedded systems in an IoT scenario?**
|
||||
|
||||
IoT is a new space, this is the frontier of systems and security. It is starting to be different every single day. Right now, I try to keep as much offline as I possibly can. I don't like people messing with my lights and my refrigerator. I purposely did not buy a connected refrigerator because I have friends that are hackers, and I know that I would wake up to inappropriate pictures every morning. Keep them locked down. Keep them locked up. Keep them isolated.
|
||||
|
||||
The current malware for IoT devices is dependent on default passwords and backdoors, so just do some research into what devices you have and make sure that there's nothing there that somebody could particularly access by default. Then make sure that the management interfaces for those devices are well protected by a firewall or another such device.
|
||||
|
||||
**Can you name a firewall/UTM (OS or application) to use in SMB and large environments?**
|
||||
|
||||
I use pfSense; it’s a BSD derivative. I like it a lot. There's a lot of modules, and there's actually commercial support for it now, which is pretty fantastic for small business. For larger devices, larger environments, it depends on what admins you can get a hold of.
|
||||
|
||||
I have been a CheckPoint admin for most of my life, but Palo Alto is getting really popular, too. Those types of installations are going to be much different from a small business or home use. I use pfSense for any small networks.
|
||||
|
||||
**Is there an inherent problem with cloud services?**
|
||||
|
||||
There is no cloud; there are only other people's computers. There are inherent issues with cloud services. Just know who has access to your data and know what you are putting out there. Realize that when you give something to Amazon or Google or Microsoft, then you no longer have full control over it and the privacy of that data is in question.
|
||||
|
||||
**What preparation would you suggest to get an OSCP?**
|
||||
|
||||
I am actually going through that certification right now. My whole team is. Read their materials. Keep in mind that OSCP is going to be the offensive security baseline. You are going to use Kali for everything. If you don't -- if you decide not to use Kali -- make sure that you have all the tools installed to emulate a Kali instance.
|
||||
|
||||
It's going to be a heavily tools-based certification. It's a good look into methodologies. Take a look at something called the Penetration Testing Framework because that would give you a good flow of how to do your test and their lab seems to be great. It's very similar to the lab that I have here at the house.
|
||||
|
||||
_[Watch the full webinar on demand][3], for free. And see [parts one][4] and [two][5] of this series for five easy tips to keep your Linux machine secure._
|
||||
|
||||
_Mike Guthrie works for the Department of Energy doing Red Team engagements and penetration testing._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/keep-hackers-outjpg
|
||||
[3]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[4]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
[6]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
[7]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
[8]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
@ -1,54 +0,0 @@
|
||||
OpenContrail: An Essential Tool in the OpenStack Ecosystem
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
OpenContrail, an SDN platform used with the OpenStack cloud computing platform, is emerging as an essential tool around which administrators will need to develop skillsets.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
Throughout 2016, software-defined networking (SDN) rapidly evolved, and numerous players in the open source and cloud computing arenas are now helping it gain momentum. In conjunction with that trend,[ OpenContrail][3], a popular SDN platform used with the OpenStack cloud computing platform, is emerging as an essential tool around which many administrators will have to develop skillsets.
|
||||
|
||||
Just as administrators and developers have ramped up their skillsets surrounding essential tools like Ceph in the OpenStack ecosystem, they will need to embrace OpenContrail, which is fully open source and stewarded by the Apache Software Foundation.
|
||||
|
||||
With all of this in mind, Mirantis, one of the most active companies on the OpenStack scene, has[ announced][4] commercial support for and contributions to OpenContrail. "With the addition of OpenContrail, Mirantis becomes a one-stop support shop for the entire stack of popular open source technologies used in conjunction with OpenStack, including Ceph for storage, OpenStack/KVM for compute and OpenContrail or Neutron for SDN," the company noted.
|
||||
|
||||
According to a Mirantis announcement, "OpenContrail is an Apache 2.0-licensed project that is built using standards-based protocols and provides all the necessary components for network virtualization–SDN controller, virtual router, analytics engine, and published northbound APIs. It has an extensive REST API to configure and gather operational and analytics data from the system. Built for scale, OpenContrail can act as a fundamental network platform for cloud infrastructure."
|
||||
|
||||
The news follows Mirantis’[ acquisition of TCP Cloud][5], a company specializing in managed services for OpenStack, OpenContrail, and Kubernetes. Mirantis will use TCP Cloud’s technology for continuous delivery of cloud infrastructure to manage the OpenContrail control plane, which will run in Docker containers. As a part of the effort, Mirantis has also been contributing to OpenContrail.
|
||||
|
||||
Many contributors behind OpenContrail are working closely with Mirantis, and they have especially taken note of the support programs that Mirantis will offer.
|
||||
|
||||
“OpenContrail is an essential project within the OpenStack community, and Mirantis is smart to containerize and commercially support it. The work our team is doing will make it easy to scale and update OpenContrail and perform seamless rolling upgrades alongside the rest of Mirantis OpenStack,” said Jakub Pavlik, Mirantis’ director of engineering and OpenContrail Advisory Board member. “Commercial support will also enable Mirantis to make the project compatible with a variety of switches, giving customers more choice in their hardware and software,” he said.
|
||||
|
||||
In addition to commercial support for OpenContrail, we are very likely to see Mirantis serve up educational offerings for cloud administrators and developers who want to learn how to leverage it. Mirantis is already well-known for its[ OpenStack training][6] curriculum and has wrapped Ceph into its training.
|
||||
|
||||
In 2016, the SDN category rapidly evolved, and it also became meaningful to many organizations with OpenStack deployments. IDC published [a study][7] of the SDN market recently and predicted a 53.9 percent CAGR from 2014 through 2020, at which point the market will be valued at $12.5 billion. In addition, the Technology Trends 2016 report ranked SDN as one of the best technology investments that organizations can make.
|
||||
|
||||
"Cloud computing and the 3rd Platform have driven the need for SDN, which will represent a market worth more than $12.5 billion in 2020\. Not surprisingly, the value of SDN will accrue increasingly to network-virtualization software and to SDN applications, including virtualized network and security services. Large enterprises are now realizing the value of SDN in the datacenter, but ultimately, they will also recognize its applicability across the WAN to branch offices and to the campus network," said[ Rohit Mehra][8], Vice President of Network Infrastructure at IDC.
|
||||
|
||||
Meanwhile, The Linux Foundation recently[ announced][9] the release of its 2016 report ["Guide to the Open Cloud: Current Trends and Open Source Projects."][10] This third annual report provides a comprehensive look at the state of open cloud computing, and includes a section on SDN.
|
||||
|
||||
The Linux Foundation also offers [Software Defined Networking Fundamentals][11] (LFS265), a self-paced, online course on SDN, and functions as the steward of the[ Open Daylight][12] project, another important open source SDN platform that is quickly gaining momentum.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/open-networking-summit/2017/2/opencontrail-essential-tool-openstack-ecosystem
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/contrails-cloudjpg
|
||||
[3]:https://www.globenewswire.com/Tracker?data=brZ3aJVRyVHeFOyzJ1Dl4DMY3CsSV7XcYkwRyOcrw4rDHplSItUqHxXtWfs18mLsa8_bPzeN2EgZXWcQU8vchg==
|
||||
[4]:http://www.econotimes.com/Mirantis-Becomes-First-Vendor-to-Offer-Support-and-Managed-Services-for-OpenContrail-SDN-486228
|
||||
[5]:https://www.globenewswire.com/Tracker?data=Lv6LkvREFzGWgujrf1n6r_qmjSdu67-zdRAYt2itKQ6Fytomhfphuk5EbDNjNYtfgAsbnqI8H1dn_5kB5uOSmmSYY9XP2ibkrPw_wKi5JtnAyV43AjuR_epMmOUkZZ8QtFdkR33lTGDmN6O5B4xkwv7fENcDpm30nI2Og_YrYf0b4th8Yy4S47lKgITa7dz2bJpwpbCIzd7muk0BZ17vsEp0S3j4kQJnmYYYk5udOMA=
|
||||
[6]:https://training.mirantis.com/
|
||||
[7]:https://www.idc.com/getdoc.jsp?containerId=prUS41005016
|
||||
[8]:http://www.idc.com/getdoc.jsp?containerId=PRF003513
|
||||
[9]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[10]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/software-defined-networking-fundamentals
|
||||
[12]:https://www.opendaylight.org/
|
||||
@ -1,195 +0,0 @@
|
||||
ictlyh Translating
|
||||
lnav – An Advanced Console Based Log File Viewer for Linux
|
||||
============================================================
|
||||
|
||||
[LNAV][3] stands for Log file Navigator is an advanced console based log file viewer for Linux. It does the same job how other file viewers doing like cat, more, tail, etc but have more enhanced features which is not available in normal file viewers (especially, it will comes with set of color and easy to read format).
|
||||
|
||||
This can decompresses all the compressed log files (zip, gzip, bzip) on the fly and merge them together for easy navigation. lnav Merge more than one log files (Single Log View) into a single view based on message timestamps which will reduce multiple windows open. The color bars on the left-hand side help to show which file a message belongs to.
|
||||
|
||||
The number of warnings and errors are highlighted in the display (Yellow & Red), so that we can easily see where the problems have occurred. New log lines are automatically loaded.
|
||||
|
||||
It display the log messages from all files sorted by the message timestamps. Top & Bottom status bars will tell you, where you are in the logs. If you want to grep any particular pattern, just type your inputs on search prompt which will be highlighted instantly.
|
||||
|
||||
The built-in log message parser can automatically discover and extract the each lines with detailed information.
|
||||
|
||||
A server log is a log file which is created and frequently updated by a server to capture all the activity for the particular service or application. This can be very useful when you have an issue with application or service. In log files you can get all the information about the issue like when it start behaving abnormal based on warning or error message.
|
||||
|
||||
When you open a log file with normal file viewer, it will display all the details in plain format (If i want to tell you in straight forward, plain white) it’s very difficult to identify/understand where is warning & errors messages are there. To overcome this kind of situation and quickly find the warning & error message to troubleshoot the issue, lnav comes in handy for a better solution.
|
||||
|
||||
Most of the common Linux log files are located at `/var/log/`.
|
||||
|
||||
**lnav automatically detect below log formats**
|
||||
|
||||
* Common Web Access Log format
|
||||
* CUPS page_log
|
||||
* Syslog
|
||||
* Glog
|
||||
* VMware ESXi/vCenter Logs
|
||||
* dpkg.log
|
||||
* uwsgi
|
||||
* “Generic” – Any message that starts with a timestamp
|
||||
* Strace
|
||||
* sudo
|
||||
* gzib & bizp
|
||||
|
||||
**Awesome lnav features**
|
||||
|
||||
* Single Log View – All log file contents are merged into a single view based on message timestamps.
|
||||
* Automatic Log Format Detection – Most of the log format is supported by lnav
|
||||
* Filters – regular expressions based filters can be performed.
|
||||
* Timeline View
|
||||
* Pretty-Print View
|
||||
* Query Logs Using SQL
|
||||
* Automatic Data Extraction
|
||||
* “Live” Operation
|
||||
* Syntax Highlighting
|
||||
* Tab-completion
|
||||
* Session information is saved automatically and restored when you are viewing the same set of files.
|
||||
* Headless Mode
|
||||
|
||||
#### How to install lnav on Linux
|
||||
|
||||
Most of the distribution (Debian, Ubuntu, Mint, Fedora, suse, openSUSE, Arch Linux, Manjaro, Mageia, etc.) has the lnav package by default, so we can easily install it from distribution official repository with help of package manager. For CentOS/RHEL we need to enable **[EPEL Repository][1]**.
|
||||
|
||||
```
|
||||
[Install lnav on Debian/Ubuntu/LinuxMint]
|
||||
$ sudo apt-get install lnav
|
||||
|
||||
[Install lnav on RHEL/CentOS]
|
||||
$ sudo yum install lnav
|
||||
|
||||
[Install lnav on Fedora]
|
||||
$ sudo dnf install lnav
|
||||
|
||||
[Install lnav on openSUSE]
|
||||
$ sudo zypper install lnav
|
||||
|
||||
[Install lnav on Mageia]
|
||||
$ sudo urpmi lnav
|
||||
|
||||
[Install lnav on Arch Linux based system]
|
||||
$ yaourt -S lnav
|
||||
```
|
||||
|
||||
If the distribution doesn’t have the lnav package don’t worry, Developer offering the `.rpm & .deb`packages, so we can easily install without any issues. Make sure you have to download the latest one from [developer github page][4].
|
||||
|
||||
```
|
||||
[Install lnav on Debian/Ubuntu/LinuxMint]
|
||||
$ sudo wget https://github.com/tstack/lnav/releases/download/v0.8.1/lnav_0.8.1_amd64.deb
|
||||
$ sudo dpkg -i lnav_0.8.1_amd64.deb
|
||||
|
||||
[Install lnav on RHEL/CentOS]
|
||||
$ sudo yum install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[Install lnav on Fedora]
|
||||
$ sudo dnf install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[Install lnav on openSUSE]
|
||||
$ sudo zypper install https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
|
||||
[Install lnav on Mageia]
|
||||
$ sudo rpm -ivh https://github.com/tstack/lnav/releases/download/v0.8.1/lnav-0.8.1-1.x86_64.rpm
|
||||
```
|
||||
|
||||
#### Run lnav without any argument
|
||||
|
||||
By default lnav brings `syslog` file when you are running without any arguments.
|
||||
|
||||
```
|
||||
# lnav
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
#### To view specific logs with lnav
|
||||
|
||||
To view specific logs with lnav, add the log file `path` followed by lnav command. For example we are going to view `/var/log/dpkg.log` logs.
|
||||
|
||||
```
|
||||
# lnav /var/log/dpkg.log
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
#### To view multiple log files with lnav
|
||||
|
||||
To view multiple log files with lnav, add the log files `path` one by one with single space followed by lnav command. For example we are going to view `/var/log/dpkg.log` & `/var/log/kern.log` logs.
|
||||
|
||||
The color bars on the left-hand side help to show which file a message belongs to. Alternatively top bar also showing the current log file name. Most of the application used to open multiple windows or horizontal or vertical windows within the window to display more than one log but lnav doing in different way (It display multiple logs in the same window based on date combination).
|
||||
|
||||
```
|
||||
# lnav /var/log/dpkg.log /var/log/kern.log
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
#### To view older/compressed logs with lnav
|
||||
|
||||
To view older/compressed logs which will decompresses all the compressed log files (zip, gzip, bzip) on the fly, add `-r` option followed by lnav command.
|
||||
|
||||
```
|
||||
# lnav -r /var/log/Xorg.0.log.old.gz
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
#### Histogram view
|
||||
|
||||
First run `lnav` then hit `i` to Switch to/from the histogram view.
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
#### View log parser results
|
||||
|
||||
First run `lnav` then hit `p` to Toggle the display of the log parser results.
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
#### Syntax Highlighting
|
||||
|
||||
You can search any given string which will be highlighting on screen. First run `lnav` then hit `/` and type the string which you want to grep. For testing purpose, i’m searching `Default` string, See the below screenshot.
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
#### Tab-completion
|
||||
|
||||
The command prompt supports tab-completion for almost all operations. For example, when doing a search, you can tab-complete words that are displayed on screen rather than having to do a copy & paste. For testing purpose, i’m searching `/var/log/Xorg` string, See the below screenshot.
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/install-and-use-advanced-log-file-viewer-navigator-lnav-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/install-enable-epel-repository-on-rhel-centos-scientific-linux-oracle-linux/
|
||||
[2]:http://www.2daygeek.com/author/magesh/
|
||||
[3]:http://lnav.org/
|
||||
[4]:https://github.com/tstack/lnav/releases
|
||||
[5]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-1.png
|
||||
[6]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-2.png
|
||||
[7]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-3.png
|
||||
[8]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-6.png
|
||||
[9]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-4.png
|
||||
[10]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-5.png
|
||||
[11]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-7.png
|
||||
[12]:http://www.2daygeek.com/wp-content/uploads/2017/01/lnav-advanced-log-file-viewer-8.png
|
||||
@ -1,3 +1,4 @@
|
||||
geekrainy translating
|
||||
A look at 6 iconic open source brands
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,292 +0,0 @@
|
||||
A comprehensive guide to taking screenshots in Linux using gnome-screenshot
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [About Gnome-screenshot][13]
|
||||
2. [Gnome-screenshot Installation][14]
|
||||
3. [Gnome-screenshot Usage/Features][15]
|
||||
1. [Capturing current active window][1]
|
||||
2. [Window border][2]
|
||||
3. [Adding effects to window borders][3]
|
||||
4. [Screenshot of a particular area][4]
|
||||
5. [Include mouse pointer in snapshot][5]
|
||||
6. [Delay in taking screenshots][6]
|
||||
7. [Run the tool in interactive mode][7]
|
||||
8. [Directly save your screenshot][8]
|
||||
9. [Copy to clipboard][9]
|
||||
10. [Screenshot in case of multiple displays][10]
|
||||
11. [Automate the screen grabbing process][11]
|
||||
12. [Getting help][12]
|
||||
4. [Conclusion][16]
|
||||
|
||||
There are several screenshot taking tools available in the market but most of them are GUI based. If you spend time working on the Linux command line, and are looking for a good, feature-rich command line-based screen grabbing tool, you may want to try out [gnome-screenshot][17]. In this tutorial, I will explain this utility using easy to understand examples.
|
||||
|
||||
Please note that all the examples mentioned in this tutorial have been tested on Ubuntu 16.04 LTS, and the gnome-screenshot version we have used is 3.18.0.
|
||||
|
||||
### About Gnome-screenshot
|
||||
|
||||
Gnome-screenshot is a GNOME tool which - as the name suggests - is used for capturing the entire screen, a particular application window, or any other user defined area. The tool provides several other features, including the ability to apply beautifying effects to borders of captured screenshots.
|
||||
|
||||
### Gnome-screenshot Installation
|
||||
|
||||
The gnome-screenshot tool is pre-installed on Ubuntu systems, but if for some reason you need to install the utility, you can do that using the following command:
|
||||
|
||||
sudo apt-get install gnome-screenshot
|
||||
|
||||
Once the tool is installed, you can launch it by using following command:
|
||||
|
||||
gnome-screenshot
|
||||
|
||||
### Gnome-screenshot Usage/Features
|
||||
|
||||
In this section, we will discuss how the gnome-screenshot tool can be used and what all features it provides.
|
||||
|
||||
By default, when the tool is run without any command line options, it captures the complete screen.
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
### Capturing current active window
|
||||
|
||||
If you want, you can limit the screenshot to the current active window by using the -w option.
|
||||
|
||||
gnome-screenshot -w
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
###
|
||||
Window border
|
||||
|
||||
By default, the utility includes the border of the window it captures, although there's also a specific command line option -b that enables this feature (in case you want to use it somewhere). Here's how it can be used:
|
||||
|
||||
gnome-screenshot -wb
|
||||
|
||||
Of course, you need to use the -w option with -b so that the captured area is the current active window (otherwise, -b will have no effect).
|
||||
|
||||
Moving on and more importantly, you can also remove the border of the window if you want. This can be done using the -B command line option. Following is an example of how you can use this option:
|
||||
|
||||
gnome-screenshot -wB
|
||||
|
||||
Here is an example snapshot:
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
### Adding effects to window borders
|
||||
|
||||
With the help of the gnome-screenshot tool, you can also add various effects to window borders. This can be done using the --border-effect option.
|
||||
|
||||
You can add any of the effects provided by the utility such as 'shadow' effect (which adds drop shadow to the window), 'border' effect (adds rectangular space around the screenshot), and 'vintage' effect (desaturating the screenshot slightly, tinting it and adding rectangular space around it).
|
||||
|
||||
gnome-screenshot --border-effect=[EFFECT]
|
||||
|
||||
For example, to add the shadow effect, run the following command
|
||||
|
||||
gnome-screenshot –border-effect=shadow
|
||||
|
||||
Here is an example snapshot of the shadow effect:
|
||||
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
Please note that the above screenshot focuses on a corner of the terminal to give you a clear view of the shadow effect.
|
||||
|
||||
### Screenshot of a particular area
|
||||
|
||||
If you want, you can also capture a particular area of your computer screen using the gnome-screenshot utility. This can be done by using the -a command line option.
|
||||
|
||||
gnome-screenshot -a
|
||||
|
||||
When the above command is run, your mouse pointer will change into a ‘+’ sign. In this mode, you can grab a particular area of your screen by moving the mouse with left-click pressed.
|
||||
|
||||
Here is an example screenshot wherein I cropped a small area of my terminal window.
|
||||
|
||||
[
|
||||

|
||||
][22]
|
||||
|
||||
###
|
||||
Include mouse pointer in snapshot
|
||||
|
||||
By default, whenever you take screenshot using this tool, it doesn’t include mouse pointer. However, the utility allows you to include the pointer, something which you can do using the -p command line option.
|
||||
|
||||
gnome-screenshot -p
|
||||
|
||||
Here is an example snapshot
|
||||
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
### Delay in taking screenshots
|
||||
|
||||
You can also introduce time delay while taking screenshots. For this, you have to assign a value to the --delay option in seconds.
|
||||
|
||||
gnome-screenshot –delay=[SECONDS]
|
||||
|
||||
For example:
|
||||
|
||||
gnome-screenshot --delay=5
|
||||
|
||||
Here is an example screenshot
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
### Run the tool in interactive mode
|
||||
|
||||
The tool also allows you to access all its features using a single option, which is -i. Using this command line option, user can select one or more of the tool’s features at run time.
|
||||
|
||||
$ gnome-screenshot -i
|
||||
|
||||
Here is an example screenshot
|
||||
|
||||
[
|
||||

|
||||
][25]
|
||||
|
||||
As you can see in the snapshot above, the -i option provides access to many features - such as grabbing the whole screen, grabbing the current window, selecting an area to grab, delay option, effects options - all in an interactive mode.
|
||||
|
||||
### Directly save your screenshot
|
||||
|
||||
If you want, you can directly save your screenshot from the terminal to your present working directory, meaning you won't be asked to enter a file name for the captured screenshot after the tool is run. This feature can be accessed using the --file command line option which, obviously, requires a filename to be passed to it.
|
||||
|
||||
gnome-screenshot –file=[FILENAME]
|
||||
|
||||
For example:
|
||||
|
||||
gnome-screenshot --file=ashish
|
||||
|
||||
Here is an example snapshot:
|
||||
|
||||
[
|
||||

|
||||
][26]
|
||||
|
||||
### Copy to clipboard
|
||||
|
||||
The gnome-screenshot tool also allows you to copy your screenshot to clipboard. This can be done using the -c command line option.
|
||||
|
||||
gnome-screenshot -c
|
||||
|
||||
[
|
||||

|
||||
][27]
|
||||
|
||||
In this mode, you can, for example, directly paste the copied screenshot in any of your image editors (such as GIMP).
|
||||
|
||||
### Screenshot in case of multiple displays
|
||||
|
||||
If there are multiple displays attached to your system and you want to take snapshot of a particular one, then you can use the --display command line option. This option requires a value which should be the display device ID (ID of the screen being grabbed).
|
||||
|
||||
gnome-screenshot --display=[DISPLAY]
|
||||
|
||||
For example:
|
||||
|
||||
gnome-screenshot --display=VGA-0
|
||||
|
||||
In the above example, VGA-0 is the id of the display that I am trying to capture. To find the ID of the display that you want to screenshot, you can use the following command:
|
||||
|
||||
xrandr --query
|
||||
|
||||
To give you an idea, this command produced the following output in my case:
|
||||
|
||||
**$ xrandr --query**
|
||||
Screen 0: minimum 320 x 200, current 1366 x 768, maximum 8192 x 8192
|
||||
**VGA-0** connected primary 1366x768+0+0 (normal left inverted right x axis y axis) 344mm x 194mm
|
||||
1366x768 59.8*+
|
||||
1024x768 75.1 75.0 60.0
|
||||
832x624 74.6
|
||||
800x600 75.0 60.3 56.2
|
||||
640x480 75.0 60.0
|
||||
720x400 70.1
|
||||
**HDMI-0** disconnected (normal left inverted right x axis y axis)
|
||||
|
||||
### Automate the screen grabbing process
|
||||
|
||||
As we have discussed earlier, the -a command line option helps us to grab a particular area of the screen. However, we have to select the area manually using the mouse. If you want, you can automate this process using gnome-screenshot, but in that case, you will have to use an external tool known as xdotool, which is capable of simulating key presses and even mouse events.
|
||||
|
||||
For example:
|
||||
|
||||
(gnome-screenshot -a &); sleep 0.1 && xdotool mousemove 100 100 mousedown 1 mousemove 400 400 mouseup 1
|
||||
|
||||
The mousemove sub-command automatically positions the mouse pointer at specified coordinates X and Y on screen (100 and 100 in the example above). The mousedown subcommand fires an event which performs the same operation as a click (since we wanted left-click, so we used the argument 1) , whereas the mouseup subcommand fires an event which performs the task of a user releasing the mouse-button.
|
||||
|
||||
So all in all, the xdotool command shown above does the same area-grabbing work that you otherwise have to manually do with mouse - specifically, it positions the mouse pointer to 100, 100 coordinates on the screen, selects the area enclosed until the pointer reaches 400,400 coordinates on then screen. The selected area is then captured by gnome-screenshot.
|
||||
|
||||
Here, is the screenshot of the above command:
|
||||
|
||||
[
|
||||

|
||||
][28]
|
||||
|
||||
And this is the output:
|
||||
|
||||
[
|
||||

|
||||
][29]
|
||||
|
||||
For more information on xdotool, head [here][30].
|
||||
|
||||
### Getting help
|
||||
|
||||
If you have a query or in case you are facing a problem related to any of the command line options, then you can use the --help, -? or -h options to get related information.
|
||||
|
||||
gnome-screenshot -h
|
||||
|
||||
For more information on gnome-screenshot, you can go through the command’s manual page or man page.
|
||||
|
||||
man gnome-screenshot
|
||||
|
||||
### Conclusion
|
||||
|
||||
I will recommend that you to use this utlity atleast once as it's not only easy to use for beginners, but also offers a feature-rich experience for advanced usage. Go ahead and give it a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/
|
||||
[1]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#capturing-current-active-window
|
||||
[2]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#window-border
|
||||
[3]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#adding-effects-to-window-borders
|
||||
[4]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#screenshot-of-a-particular-area
|
||||
[5]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#include-mouse-pointer-in-snapshot
|
||||
[6]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#delay-in-taking-screenshots
|
||||
[7]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#run-the-tool-in-interactive-mode
|
||||
[8]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#directly-save-your-screenshot
|
||||
[9]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#copy-to-clipboard
|
||||
[10]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#screenshot-in-case-of-multiple-displays
|
||||
[11]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#automate-the-screen-grabbing-process
|
||||
[12]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#getting-help
|
||||
[13]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#about-gnomescreenshot
|
||||
[14]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#gnomescreenshot-installation
|
||||
[15]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#gnomescreenshot-usagefeatures
|
||||
[16]:https://www.howtoforge.com/tutorial/taking-screenshots-in-linux-using-gnome-screenshot/#conclusion
|
||||
[17]:https://linux.die.net/man/1/gnome-screenshot
|
||||
[18]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/gnome-default.png
|
||||
[19]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/activewindow.png
|
||||
[20]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/removeborder.png
|
||||
[21]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/shadoweffect-new.png
|
||||
[22]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/area.png
|
||||
[23]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/includecursor.png
|
||||
[24]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/delay.png
|
||||
[25]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/interactive.png
|
||||
[26]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/ashish.png
|
||||
[27]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/copy.png
|
||||
[28]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/automatedcommand.png
|
||||
[29]:https://www.howtoforge.com/images/taking-screenshots-in-linux-using-gnome-screenshot/big/outputxdo.png
|
||||
[30]:http://manpages.ubuntu.com/manpages/trusty/man1/xdotool.1.html
|
||||
@ -1,281 +0,0 @@
|
||||
### Record and Replay Terminal Session with Asciinema on Linux
|
||||
|
||||

|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][11]
|
||||
* [2. Difficulty][12]
|
||||
* [3. Conventions][13]
|
||||
* [4. Standard Repository Installation][14]
|
||||
* [4.1. Arch Linux][1]
|
||||
* [4.2. Debian][2]
|
||||
* [4.3. Ubuntu][3]
|
||||
* [4.4. Fedora][4]
|
||||
* [5. Installation From Source][15]
|
||||
* [6. Prerequisites][16]
|
||||
* [6.1. Arch Linux][5]
|
||||
* [6.2. Debian][6]
|
||||
* [6.3. Ubuntu][7]
|
||||
* [6.4. Fedora][8]
|
||||
* [6.5. CentOS][9]
|
||||
* [7. Linuxbrew Installation][17]
|
||||
* [8. Asciinema Installation][18]
|
||||
* [9. Recording Terminal Session][19]
|
||||
* [10. Replay Recorded Terminal Session][20]
|
||||
* [11. Embedding Video as HTML][21]
|
||||
* [12. Conclusion][22]
|
||||
* [13. Troubleshooting][23]
|
||||
* [13.1. asciinema needs a UTF-8][10]
|
||||
|
||||
### Introduction
|
||||
|
||||
Asciinema is a lightweight and very efficient alternative to a `Script`terminal session recorder. It allows you to record, replay and share your JSON formatted terminal session recordings. The main advantage in comparison to desktop recorders such as Recordmydesktop, Simplescreenrecorder, Vokoscreen or Kazam is that Asciinema records all standard terminal input, output and error as a plain ASCII text with ANSI escape code .
|
||||
|
||||
As a result, JSON format file is minuscule in size even for a longer terminal session. Furthermore, JSON format gives the user the ability to share the Asciinema JSON output file via simple file transfer, on the public website as part of embedded HTML code or share it on Asciinema.org using asciinema account. Lastly, in case that you have made some mistake during your terminal session, your recorded terminal session can be retrospectively edited using any text editor, that is if you know your way around ANSI escape code syntax.
|
||||
|
||||
### Difficulty
|
||||
|
||||
EASY
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** - requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
* **$** - given command to be executed as a regular non-privileged user
|
||||
|
||||
### Standard Repository Installation
|
||||
|
||||
It is very likely that asciinema is installable as part fo your distribution repository. However, if Asciinema is not available on your system or you wish to install the latest version, you can use Linuxbrew package manager to perform Asciinema installation as described below in the "Installation From Source" section.
|
||||
|
||||
### Arch Linux
|
||||
|
||||
```
|
||||
# pacman -S asciinema
|
||||
```
|
||||
|
||||
### Debian
|
||||
|
||||
```
|
||||
# apt install asciinema
|
||||
```
|
||||
|
||||
### Ubuntu
|
||||
|
||||
```
|
||||
$ sudo apt install asciinema
|
||||
```
|
||||
|
||||
### Fedora
|
||||
|
||||
```
|
||||
$ sudo dnf install asciinema
|
||||
```
|
||||
|
||||
### Installation From Source
|
||||
|
||||
The easiest and recommended way to install the latest Asciinema version from source is by use of Linuxbrew package manager.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
The following list of prerequisites fulfils dependency requirements for both, Linuxbrew and Asciinema.
|
||||
|
||||
* git
|
||||
* gcc
|
||||
* make
|
||||
* ruby
|
||||
|
||||
Before you proceed with Linuxbrew installation make sure that the above packages are istalled on your Linux system.
|
||||
|
||||
### Arch Linux
|
||||
|
||||
```
|
||||
# pacman -S git gcc make ruby
|
||||
```
|
||||
|
||||
### Debian
|
||||
|
||||
```
|
||||
# apt install git gcc make ruby
|
||||
```
|
||||
|
||||
### Ubuntu
|
||||
|
||||
```
|
||||
$ sudo apt install git gcc make ruby
|
||||
```
|
||||
|
||||
### Fedora
|
||||
|
||||
```
|
||||
$ sudo dnf install git gcc make ruby
|
||||
```
|
||||
|
||||
### CentOS
|
||||
|
||||
```
|
||||
# yum install git gcc make ruby
|
||||
```
|
||||
|
||||
### Linuxbrew Installation
|
||||
|
||||
The Linuxbrew package manager is a fork of the popular Homebrew package manager used on Apple's MacOS operating system. Homebrew is known for its ease of use, which is to be seen shortly, when we use Linuxbrew to install Asciinema. Run the bellow command to install Linuxbrew on your Linux distribution:
|
||||
```
|
||||
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install)"
|
||||
```
|
||||
Linuxbrew is now installed under your `$HOME/.linuxbrew/`. What remains is to make it part of your executable `PATH` environment variable.
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.linuxbrew/bin:$PATH"' >>~/.bash_profile
|
||||
$ . ~/.bash_profile
|
||||
```
|
||||
To confirm the Linuxbrew installation you can use `brew` command to query its version:
|
||||
```
|
||||
$ brew --version
|
||||
Homebrew 1.1.7
|
||||
Homebrew/homebrew-core (git revision 5229; last commit 2017-02-02)
|
||||
```
|
||||
|
||||
### Asciinema Installation
|
||||
|
||||
With the Linuxbrew now installed, the installation of Asciinema should be easy as single one-liner:
|
||||
```
|
||||
$ brew install asciinema
|
||||
```
|
||||
Check the correctnes of asciinema installation:
|
||||
```
|
||||
$ asciinema --version
|
||||
asciinema 1.3.0
|
||||
```
|
||||
|
||||
### Recording Terminal Session
|
||||
|
||||
After all that hard work with the installation, it is finally time to have some fun. Asciinema is an extremely easy to use software. In fact, the current version 1.3 has only few command line options available and one of them is `--help`.
|
||||
|
||||
Let's start by recording a terminal session using the `rec` option. The following command will start recording your terminal session after which you will have an option to either discard your recording or upload it on asciinema.org website for a future reference.
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
Once you run the above command, you will be notified that your asciinema recording session has started, and that the recording can be stopped by entering `CTRL+D` key sequence or execution of `exit` command. If you are on Debian/Ubuntu/Mint Linux you can try this as your first asciinema recording:
|
||||
```
|
||||
$ su
|
||||
Password:
|
||||
# apt install sl
|
||||
# exit
|
||||
$ sl
|
||||
```
|
||||
Once you enter the last exit command you will be asked:
|
||||
```
|
||||
$ exit
|
||||
~ Asciicast recording finished.
|
||||
~ Press <Enter> to upload, <Ctrl-C> to cancel.
|
||||
|
||||
https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
If you do not feel like to upload your super secret kung-fu command line skills to asciinema.org, you have an option to store Asciinema recording as a local file in JSON format. For example, the following asciinema recording will be stored as `/tmp/my_rec.json`:
|
||||
```
|
||||
$ asciinema rec /tmp/my_rec.json
|
||||
```
|
||||
Another extremely useful asciinema feature is time trimming. If you happen to be a slow writer or perhaps you are doing multitasking, the time between entering and execution of your commands can stretch greatly. Asciinema records your keystrokes real-time, meaning every pause you make will reflect on the lenght of your resulting video. Use `-w` option to shorten the time between your keystrokes. For example, the following command trims the time between your keystrokes to 0.2 seconds:
|
||||
```
|
||||
$ asciinema rec -w 0.2
|
||||
```
|
||||
|
||||
### Replay Recorded Terminal Session
|
||||
|
||||
There are two options to replay your recorded terminal sessions. First, play you terminal session directly from asciinema.org. That is, provided that you have previously uploaded your recording to asciinema.org and you have valid URL:
|
||||
```
|
||||
$ asciinema play https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4
|
||||
```
|
||||
Alternatively, use your locally stored JSON file:
|
||||
```
|
||||
$ asciinema play /tmp/my_rec.json
|
||||
```
|
||||
Use `wget` command to download your previously uploaded recording. Simply add `.json` to your existing URL:
|
||||
```
|
||||
$ wget -q -O steam_locomotive.json https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4.json
|
||||
$ asciinema play steam_locomotive.json
|
||||
```
|
||||
|
||||
### Embedding Video as HTML
|
||||
|
||||
Lastly, Asciinema also comes with a stand-alone JavaScript player. Which means that it is easy to share your terminal session recordings on your website. The below lines illustrate this idea with a simple `index.html`code. First, download all necessary parts:
|
||||
```
|
||||
$ cd /tmp/
|
||||
$ mkdir steam_locomotive
|
||||
$ cd steam_locomotive/
|
||||
$ wget -q -O steam_locomotive.json https://asciinema.org/a/7lw94ys68gsgr1yzdtzwijxm4.json
|
||||
$ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0/asciinema-player.css
|
||||
$ wget -q https://github.com/asciinema/asciinema-player/releases/download/v2.4.0/asciinema-player.js
|
||||
```
|
||||
Next, create a new `/tmp/steam_locomotive/index.html` file with a following content:
|
||||
```
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" type="text/css" href="./asciinema-player.css" />
|
||||
</head>
|
||||
<body>
|
||||
<asciinema-player src="./steam_locomotive.json" cols="80" rows="24"></asciinema-player>
|
||||
<script src="./asciinema-player.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
Once ready, open up your web browser, hit CTRL+O and open your newly created `/tmp/steam_locomotive/index.html` file.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As mentioned before, the main advantage for recording your terminal sessions with the Asciinema recorder is the minuscule output file which makes your videos extremely easy to share. The example above produced a file containing 58 472 characters, that is 58KB for 22 seconds video session. When reviewing the output JSON file, even this number is greatly inflated, mostly due to the fact that we have seen a Steam Locomotive rushing across our terminal. Normal terminal session of this length should produce a much smaller output file.
|
||||
|
||||
Next, time when you are about to ask a question on forums about your Linux configuration issue and having a hard time to explain how to reproduce your problem, simply run:
|
||||
```
|
||||
$ asciinema rec
|
||||
```
|
||||
and paste the resulting URL into your forum post.
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
### asciinema needs a UTF-8
|
||||
|
||||
Error message:
|
||||
```
|
||||
asciinema needs a UTF-8 native locale to run. Check the output of `locale` command.
|
||||
```
|
||||
Solution:
|
||||
Generate and export UTF-8 locale. For example:
|
||||
```
|
||||
$ localedef -c -f UTF-8 -i en_US en_US.UTF-8
|
||||
$ export LC_ALL=en_US.UTF-8
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux
|
||||
|
||||
作者:[Lubos Rendek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux
|
||||
[1]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-1-arch-linux
|
||||
[2]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-2-debian
|
||||
[3]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-3-ubuntu
|
||||
[4]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-4-fedora
|
||||
[5]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-1-arch-linux
|
||||
[6]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-2-debian
|
||||
[7]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-3-ubuntu
|
||||
[8]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-4-fedora
|
||||
[9]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-5-centos
|
||||
[10]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h13-1-asciinema-needs-a-utf-8
|
||||
[11]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h1-introduction
|
||||
[12]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h2-difficulty
|
||||
[13]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h3-conventions
|
||||
[14]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h4-standard-repository-installation
|
||||
[15]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h5-installation-from-source
|
||||
[16]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h6-prerequisites
|
||||
[17]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h7-linuxbrew-installation
|
||||
[18]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h8-asciinema-installation
|
||||
[19]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h9-recording-terminal-session
|
||||
[20]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h10-replay-recorded-terminal-session
|
||||
[21]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h11-embedding-video-as-html
|
||||
[22]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h12-conclusion
|
||||
[23]:https://linuxconfig.org/record-and-replay-terminal-session-with-asciinema-on-linux#h13-troubleshooting
|
||||
@ -1,145 +0,0 @@
|
||||
Try Raspberry Pi's PIXEL OS on your PC
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Image credits :
|
||||
|
||||
Raspberry Pi Foundation, CC BY-SA
|
||||
|
||||
Over the last four years, the Raspberry Pi Foundation has put a great deal of effort into optimizing Raspbian, its port of Debian, for Pi hardware, including creating new educational software, programming tools, and a nicer looking desktop.
|
||||
|
||||
In September, we released an update that introduced PIXEL (Pi Improved Xwindows Environment, Lightweight), the Pi's new desktop environment. Just before Christmas, we released a version of the OS that runs on x86 PCs, so now you can install it on your PC, Mac, or laptop.
|
||||
|
||||

|
||||
|
||||
Of course, like many well-supported Linux distros, the OS runs really well on old hardware. Raspbian is a great way to breathe new life into that old Windows machine that you gave up on years ago.
|
||||
|
||||
The [PIXEL ISO][13] is available for download from the Raspberry Pi website, and a bootable live DVD was given away on the front of "[The MagPi][14]" magazine.
|
||||
|
||||

|
||||
|
||||
We released Raspberry Pi's OS for PCs to remove the barrier to entry for people looking to learn computing.This release is even cheaper than buying a Raspberry Pi because it is free and you can use it on your existing computer. PIXEL is the Linux desktop we've always wanted, and we want it to be available to everyone.
|
||||
|
||||
### Powered by Debian
|
||||
|
||||
Raspbian, or the x86 PIXEL distro, wouldn't be possible without its construction on top of Debian. Debian has a huge bank of amazing free and open source software, programs, games, and other tools from an apt repository. On the Raspberry Pi, you're limited to packages that are compiled to run on [ARM][15] chips. However, on the PC image, you have a much wider scope for which packages will run on your machine, because Intel chips found in PCs have much greater support.
|
||||
|
||||
 repository")
|
||||
|
||||
### What PIXEL contains
|
||||
|
||||
Both Raspbian with PIXEL and Debian with PIXEL come bundled with a whole host of software. Raspbian comes with:
|
||||
|
||||
* Programming environments for Python, Java, Scratch, Sonic Pi, Mathematica*, Node-RED, and the Sense HAT emulator
|
||||
* The LibreOffice office suite
|
||||
* Chromium (including Flash) and Epiphany web browsers
|
||||
* Minecraft: Pi edition (including a Python API)*
|
||||
* Various tools and utilities
|
||||
|
||||
*The only programs from this list not included in the x86 version are Mathematica and Minecraft, due to licensing limitations.
|
||||
|
||||

|
||||
|
||||
### Create a PIXEL live disk
|
||||
|
||||
You can download the PIXEL ISO and write it to a blank DVD or a USB stick. Then you can boot your PC from the disk, and you'll see the PIXEL desktop in no time. You can browse the web, open a programming environment, or use the office suite, all without installing anything on your computer. When you're done, just take out the DVD or USB drive, shut down your computer, and when you power up your computer again, it'll boot back up into your usual OS as before.
|
||||
|
||||
### Run PIXEL in a virtual machine
|
||||
|
||||
One way of trying out PIXEL is to install it in a virtual machine using a tool like VirtualBox.
|
||||
|
||||

|
||||
|
||||
This allows you to try out the image without installing it, or you can just run it in a window alongside your main OS, and get access to the software and tools in PIXEL. It also means your session will persist, rather than starting from scratch every time you reboot, as you would with a live disk.
|
||||
|
||||
### Install PIXEL on your PC
|
||||
|
||||
If you're really ready to commit, you can wipe your old operating system and install PIXEL on your hard drive. This might be a good idea if you're wanting to make use of an old unused laptop.
|
||||
|
||||
### PIXEL in education
|
||||
|
||||
Many schools use Windows on all their PCs, and have strict controls over what software can be installed on them. This makes it difficult for teachers to use the software tools and IDE (integrated development environment) necessary to teach programming skills. Even online-based programming initiatives like Scratch 2 can be blocked by overcautious network filters. In some cases, installing something like Python is simply not possible. The Raspberry Pi hardware addresses this by providing a small, cheap computer that boots from an SD card packed with educational software, which students can connect up to the monitor, mouse, and keyboard of an existing PC.
|
||||
|
||||
However, a PIXEL live disc allows teachers to boot into a system loaded with ready-to-use programming languages and tools, all of which do not require installation permissions. At the end of the lesson, they can shut down safely, bringing the computers back to their original state. This is also a handy solution for Code Clubs, CoderDojos, youth clubs, Raspberry Jams, and more.
|
||||
|
||||
### Remote GPIO
|
||||
|
||||
One of the features that sets the Raspberry Pi apart from traditional desktop PCs is the presence of GPIO pins (General Purpose Input/Output) pins, which allow you to connect electronic components and add-on boards to devices in the real world, opening up new worlds, such as hobby projects, home automation, connected devices, and the Internet of Things.
|
||||
|
||||
One wonderful feature of the [GPIO Zero][16] Python library is the ability to control the GPIO pins of a Raspberry Pi over the network with some simple code written on your PC.
|
||||
|
||||
<twitterwidget class="twitter-tweet twitter-tweet-rendered" id="twitter-widget-0" data-tweet-id="811511740907261952" style="position: static; visibility: visible; display: block; transform: rotate(0deg); max-width: 100%; width: 500px; min-width: 220px; margin-top: 10px; margin-bottom: 10px;">
|
||||
|
||||
<article class="MediaCard
|
||||
MediaCard--mediaForward
|
||||
|
||||
customisable-border" data-scribe="component:card" dir="ltr">[][11][
|
||||

|
||||
][8][
|
||||

|
||||
][9][
|
||||

|
||||
][10]</article>
|
||||
|
||||
> [ Follow][1][
|
||||
> 
|
||||
> Ben Nuttall @ben_nuttall][5]
|
||||
>
|
||||
> PC running x86 PIXEL controlling Pi's GPIO over the network using gpiozero
|
||||
>
|
||||
> [<time class="dt-updated" datetime="2016-12-21T10:00:50+0000" pubdate="" title="Time posted: 21 Dec 2016, 10:00:50 (UTC)">6:00 PM - 21 Dec 2016</time>][6] · [East, England][7]
|
||||
>
|
||||
> * [][2]
|
||||
>
|
||||
> * [ 3636 Retweets][3]
|
||||
>
|
||||
> * [ 109109 likes][4]
|
||||
|
||||
</twitterwidget>
|
||||
|
||||
Remote GPIO is possible from one Raspberry Pi to another or from any PC running any OS, but, of course, with PIXEL x86 you have everything you need pre-installed and it works out of the box. See Josh's [blog post][17] and refer to my [gist][18] for more information.
|
||||
|
||||
### Further guidance
|
||||
|
||||
[Issue #53 of The MagPi][19] features some great guides for trying out and installing PIXEL, including using the live disc with a persistence drive to maintain your files and applications. You can buy a copy, or download the PDF for free. Check it out to read more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
Ben Nuttall - Ben Nuttall is the Raspberry Pi Community Manager. In addition to his work for the Raspberry Pi Foundation, he's into free software, maths, kayaking, GitHub, Adventure Time, and Futurama. Follow Ben on Twitter @ben_nuttall.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://twitter.com/ben_nuttall
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=811511740907261952
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=811511740907261952
|
||||
[4]:https://twitter.com/intent/like?tweet_id=811511740907261952
|
||||
[5]:https://twitter.com/ben_nuttall
|
||||
[6]:https://twitter.com/ben_nuttall/status/811511740907261952
|
||||
[7]:https://twitter.com/search?q=place%3A3bc1b6cfd27ef7f6
|
||||
[8]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[9]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[10]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[11]:https://twitter.com/ben_nuttall/status/811511740907261952/photo/1
|
||||
[12]:https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc?rate=iqVrGV3EhwRuqh68sf6Zye6Y7VSpXRCUQoZV3sg-QJM
|
||||
[13]:http://downloads.raspberrypi.org/pixel_x86/images/pixel_x86-2016-12-13/
|
||||
[14]:https://www.raspberrypi.org/magpi/issues/53/
|
||||
[15]:https://en.wikipedia.org/wiki/ARM_Holdings
|
||||
[16]:http://gpiozero.readthedocs.io/
|
||||
[17]:http://www.allaboutcode.co.uk/single-post/2016/12/21/GPIOZero-Remote-GPIO-with-PIXEL-x86
|
||||
[18]:https://gist.github.com/bennuttall/572789b0aa5fc2e7c05c7ada1bdc813e
|
||||
[19]:https://www.raspberrypi.org/magpi/issues/53/
|
||||
[20]:https://opensource.com/user/26767/feed
|
||||
[21]:https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc#comments
|
||||
[22]:https://opensource.com/users/bennuttall
|
||||
@ -1,67 +0,0 @@
|
||||
5 Open Source Software Defined Networking Projects to Know
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
SDN is beginning to redefine corporate networking; here are five open source projects you should know.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
Throughout 2016, Software Defined Networking (SDN) continued to rapidly evolve and gain maturity. We are now beyond the conceptual phase of open source networking, and the companies that were assessing the potential of these projects two years ago have begun enterprise deployments. As has been predicted for several years, SDN is beginning to redefine corporate networking.
|
||||
|
||||
Market researchers are essentially unanimous on the topic. IDC published[ a study][3] of the SDN market earlier this year and predicted a 53.9 percent CAGR from 2014 through 2020, at which point the market will be valued at $12.5 billion. In addition, the Technology Trends 2016 report ranked SDN as the best technology investment for 2016.
|
||||
|
||||
"Cloud computing and the 3rd Platform have driven the need for SDN, which will represent a market worth more than $12.5 billion in 2020\. Not surprisingly, the value of SDN will accrue increasingly to network-virtualization software and to SDN applications, including virtualized network and security services. Large enterprises are now realizing the value of SDN in the datacenter, but ultimately, they will also recognize its applicability across the WAN to branch offices and to the campus network," said[ Rohit Mehra][4], Vice President of Network Infrastructure at IDC.
|
||||
|
||||
The Linux Foundation recently[ ][5]announced the release of its 2016 report[ "Guide to the Open Cloud: Current Trends and Open Source Projects."][6] This third annual report provides a comprehensive look at the state of open cloud computing, and includes a section on unikernels. You can[ download the report][7] now, and one of the first things to notice is that it aggregates and analyzes research, illustrating how trends in containers, unikernels, and more are reshaping cloud computing. The report provides descriptions and links to categorized projects central to today’s open cloud environment.
|
||||
|
||||
In this series, we are looking at various categories and providing extra insight on how the areas are evolving. Below, you’ll find several important SDN projects and the impact that they are having, along with links to their GitHub repositories, all gathered from the Guide to the Open Cloud:
|
||||
|
||||
### Software-Defined Networking
|
||||
|
||||
[ONOS][8]
|
||||
|
||||
Open Network Operating System (ONOS), a Linux Foundation project, is a software-defined networking OS for service providers that has scalability, high availability, high performance and abstractions to create apps and services. [ONOS on GitHub][9]
|
||||
|
||||
[OpenContrail][10]
|
||||
|
||||
OpenContrail is Juniper Networks’ open source network virtualization platform for the cloud. It provides all the necessary components for network virtualization: SDN controller, virtual router, analytics engine, and published northbound APIs. Its REST API configures and gathers operational and analytics data from the system. [OpenContrail on GitHub][11]
|
||||
|
||||
[OpenDaylight][12]
|
||||
|
||||
OpenDaylight, an OpenDaylight Foundation project at The Linux Foundation, is a programmable, software-defined networking platform for service providers and enterprises. Based on a microservices architecture, it enables network services across a spectrum of hardware in multivendor environments. [OpenDaylight on GitHub][13]
|
||||
|
||||
[Open vSwitch][14]
|
||||
|
||||
Open vSwitch, a Linux Foundation project, is a production-quality, multilayer virtual switch. It’s designed for massive network automation through programmatic extension, while still supporting standard management interfaces and protocols including NetFlow, sFlow, IPFIX, RSPAN, CLI, LACP, and 802.1ag. It supports distribution across multiple physical servers similar to VMware’s vNetwork distributed vswitch or Cisco’s Nexus 1000V. [OVS on GitHub][15]
|
||||
|
||||
[OPNFV][16]
|
||||
|
||||
Open Platform for Network Functions Virtualization (OPNFV), a Linux Foundation project, is a reference NFV platform for enterprise and service provider networks. It brings together upstream components across compute, storage and network virtualization in order create an end-to-end platform for NFV applications. [OPNFV on Bitergia][17]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/5-open-source-software-defined-networking-projects-know
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/software-defined-networkingjpg-0
|
||||
[3]:https://www.idc.com/getdoc.jsp?containerId=prUS41005016
|
||||
[4]:http://www.idc.com/getdoc.jsp?containerId=PRF003513
|
||||
[5]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[6]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[7]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[8]:http://onosproject.org/
|
||||
[9]:https://github.com/opennetworkinglab/onos
|
||||
[10]:http://www.opencontrail.org/
|
||||
[11]:https://github.com/Juniper/contrail-controller
|
||||
[12]:https://www.opendaylight.org/
|
||||
[13]:https://github.com/opendaylight
|
||||
[14]:http://openvswitch.org/
|
||||
[15]:https://github.com/openvswitch/ovs
|
||||
[16]:https://www.opnfv.org/
|
||||
[17]:http://projects.bitergia.com/opnfv/browser/
|
||||
@ -1,226 +0,0 @@
|
||||
How to protect your server with badIPs.com and report IPs with Fail2ban on Debian
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Use the badIPs list][4]
|
||||
1. [Define your security level and category][1]
|
||||
2. [Let's create the script][5]
|
||||
3. [Report IP addresses to badIPs with Fail2ban][6]
|
||||
1. [Fail2ban >= 0.8.12][2]
|
||||
2. [Fail2ban < 0.8.12][3]
|
||||
4. [Statistics of your IP reporting][7]
|
||||
|
||||
This tutorial documents the process of using the badips abuse tracker in conjunction with Fail2ban to protect your server or computer. I've tested it on a Debian 8 Jessie and Debian 7 Wheezy system.
|
||||
|
||||
**What is badIPs?**
|
||||
|
||||
BadIps is a listing of IP that are reported as bad in combinaison with [fail2ban][8].
|
||||
|
||||
This tutorial contains two parts, the first one will deal with the use of the list and the second will deal with the injection of data.
|
||||
|
||||
###
|
||||
Use the badIPs list
|
||||
|
||||
### Define your security level and category
|
||||
|
||||
You can get the IP address list by simply using the REST API.
|
||||
|
||||
When you GET this URL : [https://www.badips.com/get/categories][9]
|
||||
You’ll see all the different categories that are present on the service.
|
||||
|
||||
* Second step, determine witch score is made for you.
|
||||
Here a quote from badips that should help (personnaly I took score = 3):
|
||||
* If you'd like to compile a statistic or use the data for some experiment etc. you may start with score 0.
|
||||
* If you'd like to firewall your private server or website, go with scores from 2\. Maybe combined with your own results, even if they do not have a score above 0 or 1.
|
||||
* If you're about to protect a webshop or high traffic, money-earning e-commerce server, we recommend to use values from 3 or 4\. Maybe as well combined with your own results (key / sync).
|
||||
* If you're paranoid, take 5.
|
||||
|
||||
So now that you get your two variables, let's make your link by concatening them and grab your link.
|
||||
|
||||
http://www.badips.com/get/list/{{SERVICE}}/{{LEVEL}}
|
||||
|
||||
Note: Like me, you can take all the services. Change the name of the service to "any" in this case.
|
||||
|
||||
The resulting URL is:
|
||||
|
||||
https://www.badips.com/get/list/any/3
|
||||
|
||||
### Let's create the script
|
||||
|
||||
Alright, when that’s done, we’ll create a simple script.
|
||||
|
||||
1. Put our list in a tempory file.
|
||||
2. (only once) create a chain in iptables.
|
||||
3. Flush all the data linked to our chain (old entries).
|
||||
4. We’ll link each IP to our new chain.
|
||||
5. When it’s done, block all INPUT / OUTPUT / FORWARD that’s linked to our chain.
|
||||
6. Remove our temp file.
|
||||
|
||||
Nowe we'll create the script for that:
|
||||
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
|
||||
Enter the following content into that file.
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# based on this version http://www.timokorthals.de/?p=334
|
||||
# adapted by Stéphane T.
|
||||
|
||||
_ipt=/sbin/iptables # Location of iptables (might be correct)
|
||||
_input=badips.db # Name of database (will be downloaded with this name)
|
||||
_pub_if=eth0 # Device which is connected to the internet (ex. $ifconfig for that)
|
||||
_droplist=droplist # Name of chain in iptables (Only change this if you have already a chain with this name)
|
||||
_level=3 # Blog level: not so bad/false report (0) over confirmed bad (3) to quite aggressive (5) (see www.badips.com for that)
|
||||
_service=any # Logged service (see www.badips.com for that)
|
||||
|
||||
# Get the bad IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### Setup our black list ###
|
||||
# First flush it
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
# Create a new chain
|
||||
# Decomment the next line on the first run
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
# Filter out comments and blank lines
|
||||
# store each ip in $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
# Append everything to $_droplist
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j LOG --log-prefix "Drop Bad IP List "
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j DROP
|
||||
done
|
||||
|
||||
# Finally, insert or append our black list
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
# Delete your temp file
|
||||
rm $_input
|
||||
exit 0
|
||||
```
|
||||
|
||||
When that’s done, you should create a cronjob that will update our blacklist.
|
||||
|
||||
For this, I used crontab and I run the script every day on 11:30PM (just before my delayed backup).
|
||||
|
||||
crontab -e
|
||||
|
||||
```
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
```
|
||||
|
||||
Don’t forget to chmod your script:
|
||||
|
||||
chmod + x myBlacklist.sh
|
||||
|
||||
Now that’s done, your server/computer should be a little bit safer.
|
||||
|
||||
You can also run the script manually like this:
|
||||
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
|
||||
It should take some time… so don’t break the script. In fact, the value of it lies in the last lines.
|
||||
|
||||
### Report IP addresses to badIPs with Fail2ban
|
||||
|
||||
In the second part of this tutorial, I will show you how to report bd IP addresses bach to the badips.com website by using Fail2ban.
|
||||
|
||||
### Fail2ban >= 0.8.12
|
||||
|
||||
The reporting is made with Fail2ban. Depending on your Fail2ban version you must use the first or second section of this chapter.If you have fail2ban in version 0.8.12.
|
||||
|
||||
If you have fail2ban version 0.8.12 or later.
|
||||
|
||||
fail2ban-server --version
|
||||
|
||||
In each category that you’ll report, simply add an action.
|
||||
|
||||
```
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
```
|
||||
|
||||
As you can see, the category is SSH, take a look here ([https://www.badips.com/get/categories][11]) to find the correct category.
|
||||
|
||||
### Fail2ban < 0.8.12
|
||||
|
||||
If the version is less recent than 0.8.12, you’ll have a to create an action. This can be downloaded here: [https://www.badips.com/asset/fail2ban/badips.conf][12].
|
||||
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
|
||||
With the badips.conf from above, you can either activate per category as above or you can enable it globally:
|
||||
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
|
||||
```
|
||||
[DEFAULT]
|
||||
|
||||
...
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
```
|
||||
|
||||
Now restart fail2ban - it should start reporting from now on.
|
||||
|
||||
service fail2ban restart
|
||||
|
||||
### Statistics of your IP reporting
|
||||
|
||||
Last step – not really useful… You can create a key.
|
||||
This one is usefull if you want to see your data.
|
||||
Just copy / paste this and a JSON response will appear on your console.
|
||||
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
|
||||
```
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
```
|
||||
|
||||
Then go on [badips][13] website, enter your “key” and click “statistics”.
|
||||
|
||||
Here we go… all your stats by category.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
|
||||
作者:[Stephane T][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/
|
||||
[1]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#define-your-security-level-and-category
|
||||
[2]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-gt-
|
||||
[3]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#failban-ltnbsp
|
||||
[4]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#use-the-badips-list
|
||||
[5]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#lets-create-the-script
|
||||
[6]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#report-ip-addresses-to-badips-with-failban
|
||||
[7]:https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badips-and-fail2ban/#statistics-of-your-ip-reporting
|
||||
[8]:http://www.fail2ban.org/
|
||||
[9]:https://www.badips.com/get/categories
|
||||
[10]:http://www.timokorthals.de/?p=334
|
||||
[11]:https://www.badips.com/get/categories
|
||||
[12]:https://www.badips.com/asset/fail2ban/badips.conf
|
||||
[13]:https://www.badips.com/
|
||||
@ -1,129 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
# [Use tmux for a more powerful terminal][3]
|
||||
|
||||
|
||||

|
||||
|
||||
Some Fedora users spend most or all their time at a [command line][4] terminal. The terminal gives you access to your whole system, as well as thousands of powerful utilities. However, it only shows you one command line session at a time by default. Even with a large terminal window, the entire window only shows one session. This wastes space, especially on large monitors and high resolution laptop screens. But what if you could break up that terminal into multiple sessions? This is precisely where _tmux_ is handy — some say indispensable.
|
||||
|
||||
### Install and start _tmux_
|
||||
|
||||
The _tmux_ utility gets its name from being a terminal muxer, or multiplexer. In other words, it can break your single terminal session into multiple sessions. It manages both _windows_ and _panes_ :
|
||||
|
||||
* A _window_ is a single view — that is, an assortment of things shown in your terminal.
|
||||
* A _pane_ is one part of that view, often a terminal session.
|
||||
|
||||
To get started, install the _tmux_ utility on your system. You’ll need to have _sudo_ setup for your user account ([check out this article][5] for instructions if needed).
|
||||
|
||||
```
|
||||
sudo dnf -y install tmux
|
||||
```
|
||||
|
||||
Run the utility to get started:
|
||||
|
||||
tmux
|
||||
|
||||
### The status bar
|
||||
|
||||
At first, it might seem like nothing happens, other than a status bar that appears at the bottom of the terminal:
|
||||
|
||||

|
||||
|
||||
The bottom bar shows you:
|
||||
|
||||
* _[0] _ – You’re in the first session that was created by the _tmux_ server. Numbering starts with 0\. The server tracks all sessions whether they’re still alive or not.
|
||||
* _0:username@host:~_ – Information about the first window of that session. Numbering starts with 0\. The terminal in the active pane of the window is owned by _username_ at hostname _host_ . The current directory is _~ _ (the home directory).
|
||||
* _*_ – Shows that you’re currently in this window.
|
||||
* _“hostname” _ – the hostname of the _tmux_ server you’re using.
|
||||
* Also, the date and time on that particular host is shown.
|
||||
|
||||
The information bar will change as you add more windows and panes to the session.
|
||||
|
||||
### Basics of tmux
|
||||
|
||||
Stretch your terminal window to make it much larger. Now let’s experiment with a few simple commands to create additional panes. All commands by default start with _Ctrl+b_ .
|
||||
|
||||
* Hit _Ctrl+b, “_ to split the current single pane horizontally. Now you have two command line panes in the window, one on top and one on bottom. Notice that the new bottom pane is your active pane.
|
||||
* Hit _Ctrl+b, %_ to split the current pane vertically. Now you have three command line panes in the window. The new bottom right pane is your active pane.
|
||||
|
||||

|
||||
|
||||
Notice the highlighted border around your current pane. To navigate around panes, do any of the following:
|
||||
|
||||
* Hit _Ctrl+b _ and then an arrow key.
|
||||
* Hit _Ctrl+b, q_ . Numbers appear on the panes briefly. During this time, you can hit the number for the pane you want.
|
||||
|
||||
Now, try using the panes to run different commands. For instance, try this:
|
||||
|
||||
* Use _ls_ to show directory contents in the top pane.
|
||||
* Start _vi_ in the bottom left pane to edit a text file.
|
||||
* Run _top_ in the bottom right pane to monitor processes on your system.
|
||||
|
||||
The display will look something like this:
|
||||
|
||||

|
||||
|
||||
So far, this example has only used one window with multiple panes. You can also run multiple windows in your session.
|
||||
|
||||
* To create a new window, hit _Ctrl+b, c._ Notice that the status bar now shows two windows running. (Keen readers will see this in the screenshot above.)
|
||||
* To move to the previous window, hit _Ctrl+b, p._
|
||||
* If you want to move to the next window, hit _Ctrl+b, n_ .
|
||||
* To immediately move to a specific window (0-9), hit _Ctrl+b_ followed by the window number.
|
||||
|
||||
If you’re wondering how to close a pane, simply quit that specific command line shell using _exit_ , _logout_ , or _Ctrl+d._ Once you close all panes in a window, that window disappears as well.
|
||||
|
||||
### Detaching and attaching
|
||||
|
||||
One of the most powerful features of _tmux_ is the ability to detach and reattach to a session. You can leave your windows and panes running when you detach. Moreover, you can even logout of the system entirely. Then later you can login to the same system, reattach to the _tmux_ session, and see all your windows and panes where you left them. The commands you were running stay running while you’re detached.
|
||||
|
||||
To detach from a session, hit _Ctrl+b, d._ The session disappears and you’ll be back at the standard single shell. To reattach to the session, use this command:
|
||||
|
||||
```
|
||||
tmux attach-session
|
||||
```
|
||||
|
||||
This function is also a lifesaver when your network connection to a host is shaky. If your connection fails, all the processes in the session will stay running. Once your connection is back up, you can resume your work as if nothing happened.
|
||||
|
||||
And if that weren’t enough, on top of multiple windows and panes per session, you can also run multiple sessions. You can list these and then attach to the correct one by number or name:
|
||||
|
||||
```
|
||||
tmux list-sessions
|
||||
```
|
||||
|
||||
### Further reading
|
||||
|
||||
This article only scratches the surface of _tmux’_ s capabilities. You can manipulate your sessions in many other ways:
|
||||
|
||||
* Swap one pane with another
|
||||
* Move a pane to another window (in the same or a different session!)
|
||||
* Set keybindings that perform your favorite commands automatically
|
||||
* Configure a _~/.tmux.conf_ file with your favorite settings by default so each new session looks the way you like
|
||||
|
||||
For a full explanation of all commands, check out these references:
|
||||
|
||||
* The official [manual page][1]
|
||||
* This [eBook][2] all about _tmux_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields has been a Linux user and enthusiast since 1997, and joined the Fedora Project in 2003, shortly after launch. He was a founding member of the Fedora Project Board, and has worked on documentation, website publishing, advocacy, toolchain development, and maintaining software. He joined Red Hat as Fedora Project Leader from February 2008 to July 2010, and remains with Red Hat as an engineering manager. He currently lives with his wife and two children in Virginia.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: http://man.openbsd.org/OpenBSD-current/man1/tmux.1
|
||||
[2]: https://pragprog.com/book/bhtmux2/tmux-2
|
||||
[3]: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[4]: http://www.cryptonomicon.com/beginning.html
|
||||
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -1,149 +0,0 @@
|
||||
# Docker swarm mode - Adding worker nodes tutorial
|
||||
|
||||
Let us expand on what we started with CentOS 7.2 several weeks ago. In this [guide][1], we learned how to initiate and start the native clustering and orchestration functionality built into Docker 1.12\. But we only had our manager node and no other workers. Today, we will expand this.
|
||||
|
||||
I will show you how to add non-symmetrical nodes into the swarm, i.e. a [Fedora 24][2] that will sit alongside our CentOS box, and they will both participate in the cluster, with all the associated fancy loadbalancing and whatnot. Of course, this will not be trivial, and we will encounter some snags, and so it ought to be quite interesting. After me.
|
||||
|
||||

|
||||
|
||||
### Prerequisites
|
||||
|
||||
There are several things we need to do before we can successfully join additional nodes into the swarm. One, ideally, all nodes should be running the same version of Docker, and it should be at least 1.12 in order to support native orchestration. Like CentOS, Fedora does not have the latest built in its repo, so you will need to manually [add and install][3] the right software version, either manually or using the Docker repository, and then fix a few dependency conflicts. I have shown you how to do this with CentOS, and the exercise is identical.
|
||||
|
||||
Moreover, all your nodes will need to be able to communicate with one another. There will have to be routing and firewall rules in places so that the managers and workers can talk among them. Otherwise, you will not be able to join nodes into the swarm. The easiest way to work around problems is to temporarily flush firewall rules (iptables -F), but this may impair your security. Make sure you fully understand what you're doing, and that you create the right rules for your nodes and ports.
|
||||
|
||||
Error response from daemon: Timeout was reached before node was joined. The attempt to join the swarm will continue in the background. Use the "docker info" command to see the current swarm status of your node.
|
||||
|
||||
You need to have the same Docker images available on your hosts. In our previous tutorial, we created an Apache image, and you will need to do the same on your worker nodes, or distribute the created images. If you do not do that, you will encounter errors. If you need help setting up Docker, please read my [intro guide][4] and the [networking tutorial][5].
|
||||
|
||||
```
|
||||
7vwdxioopmmfp3amlm0ulimcu \_ websky.11 my-apache2:latest
|
||||
localhost.localdomain Shutdown Rejected 7 minutes ago
|
||||
"No such image: my-apache2:lat&"
|
||||
```
|
||||
|
||||
### Let's get started
|
||||
|
||||
So we have our CentOS box up and running, and it's spawning containers successfully. You are able to connect to the services using host ports, and everything looks peachy. At the moment, your swarm only has the manager.
|
||||
|
||||

|
||||
|
||||
### Join workers
|
||||
|
||||
To add new nodes, you will need to use the join command. But you first need to discover what token, IP address and port you must provide on the worker nodes for them to authenticate correctly against the swarm manager. Then execute (on Fedora).
|
||||
|
||||
```
|
||||
[root@localhost ~]# docker swarm join-token worker
|
||||
To add a worker to this swarm, run the following command:
|
||||
|
||||
docker swarm join \
|
||||
--token SWMTKN-1-0xvojvlza90nrbihu6gfu3qm34ari7lwnza ... \
|
||||
192.168.2.100:2377
|
||||
```
|
||||
|
||||
If you do not fix the firewall and routing rules, you will get timeout errors. If you've already joined the swarm, repeating the join command will create its own noise:
|
||||
|
||||
```
|
||||
Error response from daemon: This node is already part of a swarm. Use "docker swarm leave" to leave this swarm and join another one.
|
||||
```
|
||||
|
||||
If ever in doubt, you can leave the swarm and then try again:
|
||||
|
||||
```
|
||||
[root@localhost ~]# docker swarm leave
|
||||
Node left the swarm.
|
||||
|
||||
docker swarm join --token
|
||||
SWMTKN-1-0xvojvlza90nrbihu6gfu3qnza4 ... 192.168.2.100:2377
|
||||
This node joined a swarm as a worker.
|
||||
```
|
||||
|
||||
On the worker node, you can use docker info to check the status:
|
||||
|
||||
```
|
||||
Swarm: active
|
||||
NodeID: 2i27v3ce9qs2aq33nofaon20k
|
||||
Is Manager: false
|
||||
Node Address: 192.168.2.103
|
||||
|
||||
Likewise, on the manager:
|
||||
|
||||
Swarm: active
|
||||
NodeID: cneayene32jsb0t2inwfg5t5q
|
||||
Is Manager: true
|
||||
ClusterID: 8degfhtsi7xxucvi6dxvlx1n4
|
||||
Managers: 1
|
||||
Nodes: 3
|
||||
Orchestration:
|
||||
Task History Retention Limit: 5
|
||||
Raft:
|
||||
Snapshot Interval: 10000
|
||||
Heartbeat Tick: 1
|
||||
Election Tick: 3
|
||||
Dispatcher:
|
||||
Heartbeat Period: 5 seconds
|
||||
CA Configuration:
|
||||
Expiry Duration: 3 months
|
||||
Node Address: 192.168.2.100
|
||||
```
|
||||
|
||||
### Create or scale services
|
||||
|
||||
Now, we need to see if and how Docker distributes the containers between the nodes. My testing shows a rather simplistic balancing algorithm under very light load. Once or twice, Docker did not try to re-distribute running services to new workers, even after I tried to scale and update them. Likewise, on one occasion, it created a new service entirely on the worker node. Maybe it was the best choice.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
New service created entirely on the worker node.
|
||||
|
||||
After a while, there was some re-distribution of containers for existing services between the two, but it took some time. New services worked fine. This is an early observation only, so I cannot say much more at this point. For now, this is a good starting point to begin exploring and tweaking.
|
||||
|
||||

|
||||
|
||||
Load balancing kicks in after a while.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Docker is a neat little beast, and it will only continue to grow bigger, more complex, more powerful, and of course, more elegant. It is only a matter of time before it gets eaten by a big, juicy enterprise. When it comes to its native orchestration, the swarm mode works quite well, but it takes more than just a few containers to fully tap into the power of its algorithms and scalability.
|
||||
|
||||
My tutorial shows how to add a Fedora node to a cluster run by a CentOS box, and the two worked fine side by side. There are some questions around the loadbalancing, but this is something I will explore in future articles. All in all, I hope this was a worthwhile lesson. We've tackled some prerequisites and common problems that you might encounter when trying to setup a swarm, we fired up a bunch of containers, and we even briefly touched on how to scale and distribute the services. And remember, 'tis is just a beginning.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
My name is Igor Ljubuncic. I'm more or less 38 of age, married with no known offspring. I am currently working as a Principal Engineer with a cloud technology company, a bold new frontier. Until roughly early 2015, I worked as the OS Architect with an engineering computing team in one of the largest IT companies in the world, developing new Linux-based solutions, optimizing the kernel and hacking the living daylights out of Linux. Before that, I was a tech lead of a team designing new, innovative solutions for high-performance computing environments. Some other fancy titles include Systems Expert and System Programmer and such. All of this used to be my hobby, but since 2008, it's a paying job. What can be more satisfying than that?
|
||||
|
||||
From 2004 until 2008, I used to earn my bread by working as a physicist in the medical imaging industry. My work expertise focused on problem solving and algorithm development. To this end, I used Matlab extensively, mainly for signal and image processing. Furthermore, I'm certified in several major engineering methodologies, including MEDIC Six Sigma Green Belt, Design of Experiment, and Statistical Engineering.
|
||||
|
||||
I also happen to write books, including high fantasy and technical work on Linux; mutually inclusive.
|
||||
|
||||
Please see my full list of open-source projects, publications and patents, just scroll down.
|
||||
|
||||
For a complete list of my awards, nominations and IT-related certifications, hop yonder and yonder please.
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/docker-swarm-adding-worker-nodes.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
[1]:http://www.dedoimedo.com/computers/docker-swarm-intro.html
|
||||
[2]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
||||
[3]:http://www.dedoimedo.com/computers/docker-centos-upgrade-latest.html
|
||||
[4]:http://www.dedoimedo.com/computers/docker-guide.html
|
||||
[5]:http://www.dedoimedo.com/computers/docker-networking.html
|
||||
@ -1,112 +0,0 @@
|
||||
ictlyh Translating
|
||||
# Recover from a badly corrupt Linux EFI installation
|
||||
|
||||
In the past decade or so, Linux distributions would occasionally fail before, during and after the installation, but I was always able to somehow recover the system and continue working normally. Well, [Solus][1]broke my laptop. Literally.
|
||||
|
||||
GRUB rescue. No luck. Reinstall. No luck still! Ubuntu refused to install, complaining about the target device not being this or that. Wow. Something like this has never happened to me before. Effectively my test machine had become a useless brick. Should we despair? No, absolutely not. Let me show you how you can fix it.
|
||||
|
||||
### Problem in more detail
|
||||
|
||||
It all started with Solus trying to install its own bootloader - goofiboot. No idea what, who or why, but it failed to complete successfully, and I was left with a system that would not boot. After BIOS, I would get a GRUB rescue shell.
|
||||
|
||||

|
||||
|
||||
I tried manually working in the rescue shell, using this and that command, very similar to what I have outlined in my extensive [GRUB2 tutorial][2]. This did not really work. My next attempt was to recover from a live CD, again following my own advice, as I have outlined in my [GRUB2 & EFI tutorial][3]. I set up a new entry, and made sure to mark it active with the efibootmgr utility. Just as we did in the guide, and this has served us well before. Alas, this recovery method did not work, either.
|
||||
|
||||
I tried to perform a complete Ubuntu installation, into the same partition used by Solus, expecting the installer to sort out some of the fine details. But Ubuntu was not able to finish the install. It complained about: failed to install into /target. This was a first. What now?
|
||||
|
||||
### Manually clean up EFI partition
|
||||
|
||||
Obviously, something is very wrong with our EFI partition. Just to briefly recap, if you are using UEFI, then you must have a separate FAT32-formatted partition. This partition is used to store EFI boot images. For instance, when you install Fedora, the Fedora boot image will be copied into the EFI subdirectory. Every operating system is stored into a folder of its own, e.g. /boot/efi/EFI/<os version>/.
|
||||
|
||||

|
||||
|
||||
On my [G50][4] machine, there were multiple entries, from a variety of my distro tests, including: centos, debian, fedora, mx-15, suse, ubuntu, zorin, and many others. There was also a goofiboot folder. However, the efibootmgr was not showing a goofiboot entry in its menu. There was obviously something wrong with the whole thing.
|
||||
|
||||
```
|
||||
sudo efibootmgr -d /dev/sda
|
||||
BootCurrent: 0001
|
||||
Timeout: 0 seconds
|
||||
BootOrder: 0001,0005,2003,0000,2001,2002
|
||||
Boot0000* Lenovo Recovery System
|
||||
Boot0001* ubuntu
|
||||
Boot0003* EFI Network 0 for IPv4 (68-F7-28-4D-D1-A1)
|
||||
Boot0004* EFI Network 0 for IPv6 (68-F7-28-4D-D1-A1)
|
||||
Boot0005* Windows Boot Manager
|
||||
Boot0006* fedora
|
||||
Boot0007* suse
|
||||
Boot0008* debian
|
||||
Boot0009* mx-15
|
||||
Boot2001* EFI USB Device
|
||||
Boot2002* EFI DVD/CDROM
|
||||
Boot2003* EFI Network
|
||||
...
|
||||
```
|
||||
|
||||
P.S. The output above was generated running the command in a LIVE session!
|
||||
|
||||
I decided to clean up all the non-default and non-Microsoft entries and start fresh. Obviously, something was corrupt, and preventing new distros from setting up their own bootloader. So I deleted all the folders in the /boot/efi/EFI partition except Boot and Windows. And then, I also updated the boot manager by removing all the extras.
|
||||
|
||||
```
|
||||
efibootmgr -b <hex> -B <hex>
|
||||
```
|
||||
|
||||
Lastly, I reinstalled Ubuntu and closely monitored the progress with the GRUB installation and setup. This time, things completed fine. There were some errors with several invalid entries, as can be expected, but the whole sequenced completed just fine.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### More reading
|
||||
|
||||
If you don't fancy this manual fix, you may want to read:
|
||||
|
||||
```
|
||||
[Boot-Info][5] page, with automated tools to help you recover your system
|
||||
|
||||
[Boot-repair-cd][6] automatic repair tool download page
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you ever encounter a situation where your system is badly botched due to an EFI partition clobbering, then you may want to follow the advice in this guide. Delete all non-default entries. Make sure you do not touch anything Microsoft, if you're multi-booting with Windows. Then update the boot menu accordingly so the baddies are removed. Rerun the installation setup for your desired distro, or try to fix with a less stringent method as explained before.
|
||||
|
||||
I hope this little article saves you some bacon. I was quite annoyed by what Solus did to my system. This is not something that should happen, and the recovery ought to be simpler. However, while things may seem dreadful, the fix is not difficult. You just need to delete the corrupt files and start again. Your data should not be affected, and you will be able to promptly boot into a running system and continue working. There you go.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
My name is Igor Ljubuncic. I'm more or less 38 of age, married with no known offspring. I am currently working as a Principal Engineer with a cloud technology company, a bold new frontier. Until roughly early 2015, I worked as the OS Architect with an engineering computing team in one of the largest IT companies in the world, developing new Linux-based solutions, optimizing the kernel and hacking the living daylights out of Linux. Before that, I was a tech lead of a team designing new, innovative solutions for high-performance computing environments. Some other fancy titles include Systems Expert and System Programmer and such. All of this used to be my hobby, but since 2008, it's a paying job. What can be more satisfying than that?
|
||||
|
||||
From 2004 until 2008, I used to earn my bread by working as a physicist in the medical imaging industry. My work expertise focused on problem solving and algorithm development. To this end, I used Matlab extensively, mainly for signal and image processing. Furthermore, I'm certified in several major engineering methodologies, including MEDIC Six Sigma Green Belt, Design of Experiment, and Statistical Engineering.
|
||||
|
||||
I also happen to write books, including high fantasy and technical work on Linux; mutually inclusive.
|
||||
|
||||
Please see my full list of open-source projects, publications and patents, just scroll down.
|
||||
|
||||
For a complete list of my awards, nominations and IT-related certifications, hop yonder and yonder please.
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/grub2-efi-corrupt-part-recovery.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.dedoimedo.com/computers/solus-1-2-review.html
|
||||
[2]:http://www.dedoimedo.com/computers/grub-2.html
|
||||
[3]:http://www.dedoimedo.com/computers/grub2-efi-recovery.html
|
||||
[4]:http://www.dedoimedo.com/computers/lenovo-g50-distros-second-round.html
|
||||
[5]:https://help.ubuntu.com/community/Boot-Info
|
||||
[6]:https://sourceforge.net/projects/boot-repair-cd/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user