mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
0fc468ee4f
@ -0,0 +1,140 @@
|
||||
为 Linux 初学者讲解 wc 命令
|
||||
======
|
||||
|
||||
在命令行工作时,有时您可能想要知道一个文件中的单词数量、字节数、甚至换行数量。如果您正在寻找这样做的工具,您会很高兴地知道,在 Linux 中,存在一个命令行实用程序,它被称为 `wc` ,它为您完成所有这些工作。在本文中,我们将通过简单易懂的例子来讨论这个工具。
|
||||
|
||||
但是在我们开始之前,值得一提的是,本教程中提供的所有示例都在 Ubuntu 16.04 上进行了测试。
|
||||
|
||||
### Linux wc 命令
|
||||
|
||||
`wc` 命令打印每个输入文件的新行、单词和字节数。以下是该命令行工具的语法:
|
||||
|
||||
```
|
||||
wc [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
以下是 `wc` 的 man 文档的解释:
|
||||
|
||||
```
|
||||
为每个文件打印新行、单词和字节数,如果指定多于一个文件,也列出总的行数。单词是由空格分隔的非零长度的字符序列。如果没有指定文件,或当文件为 `-`,则读取标准输入。
|
||||
```
|
||||
|
||||
下面的 Q&A 样式的示例将会让您更好地了解 `wc` 命令的基本用法。
|
||||
|
||||
注意:在所有示例中我们将使用一个名为 `file.txt` 的文件作为输入文件。以下是该文件包含的内容:
|
||||
|
||||
```
|
||||
hi
|
||||
hello
|
||||
how are you
|
||||
thanks.
|
||||
```
|
||||
|
||||
### Q1. 如何打印字节数
|
||||
|
||||
使用 `-c` 命令选项打印字节数.
|
||||
|
||||
```
|
||||
wc -c file.txt
|
||||
```
|
||||
|
||||
下面是这个命令在我们的系统上产生的输出:
|
||||
|
||||
[![如何打印字节数][1]][2]
|
||||
|
||||
文件包含 29 个字节。
|
||||
|
||||
### Q2. 如何打印字符数
|
||||
|
||||
要打印字符数,请使用 `-m` 命令行选项。
|
||||
|
||||
```
|
||||
wc -m file.txt
|
||||
```
|
||||
|
||||
下面是这个命令在我们的系统上产生的输出:
|
||||
|
||||
[![如何打印字符数][3]][4]
|
||||
|
||||
文件包含 29 个字符。
|
||||
|
||||
### Q3. 如何打印换行数
|
||||
|
||||
使用 `-l` 命令选项来打印文件中的新行数:
|
||||
|
||||
```
|
||||
wc -l file.txt
|
||||
```
|
||||
|
||||
这里是我们的例子的输出:
|
||||
|
||||
[![如何打印换行数][5]][6]
|
||||
|
||||
### Q4. 如何打印单词数
|
||||
|
||||
要打印文件中的单词数量,请使用 `-w` 命令选项。
|
||||
|
||||
```
|
||||
wc -w file.txt
|
||||
```
|
||||
|
||||
在我们的例子中命令的输出如下:
|
||||
|
||||
[![如何打印字数][7]][8]
|
||||
|
||||
这显示文件中有 6 个单词。
|
||||
|
||||
### Q5. 如何打印最长行的显示宽度或长度
|
||||
|
||||
如果您想要打印输入文件中最长行的长度,请使用 `-l` 命令行选项。
|
||||
|
||||
```
|
||||
wc -L file.txt
|
||||
```
|
||||
|
||||
下面是在我们的案例中命令产生的结果:
|
||||
|
||||
[![如何打印最长行的显示宽度或长度][9]][10]
|
||||
|
||||
所以文件中最长的行长度是 11。
|
||||
|
||||
### Q6. 如何从文件读取输入文件名
|
||||
|
||||
如果您有多个文件名,并且您希望 `wc` 从一个文件中读取它们,那么使用`-files0-from` 选项。
|
||||
|
||||
```
|
||||
wc --files0-from=names.txt
|
||||
```
|
||||
|
||||
[![如何从文件读取输入文件名][11]][12]
|
||||
|
||||
如你所见 `wc` 命令,在这个例子中,输出了文件 `file.txt` 的行、单词和字符计数。文件名为 `file.txt` 的文件在 `name.txt` 文件中提及。值得一提的是,要成功地使用这个选项,文件中的文件名应该用 NUL 终止——您可以通过键入`Ctrl + v` 然后按 `Ctrl + Shift + @` 来生成这个字符。
|
||||
|
||||
### 结论
|
||||
|
||||
正如您所认同的一样,从理解和使用目的来看, `wc` 是一个简单的命令。我们已经介绍了几乎所有的命令行选项,所以一旦你练习了我们这里介绍的内容,您就可以随时在日常工作中使用该工具了。想了解更多关于 `wc` 的信息,请参考它的 [man 文档][13]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-wc-command-explained-for-beginners-6-examples/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-c-option.png
|
||||
[2]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-c-option.png
|
||||
[3]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-m-option.png
|
||||
[4]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-m-option.png
|
||||
[5]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-l-option.png
|
||||
[6]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-l-option.png
|
||||
[7]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-w-option.png
|
||||
[8]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-w-option.png
|
||||
[9]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-L-option.png
|
||||
[10]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-L-option.png
|
||||
[11]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-file0-from-option.png
|
||||
[12]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-file0-from-option.png
|
||||
[13]:https://linux.die.net/man/1/wc
|
||||
100
published/20180106 Meltdown and Spectre Linux Kernel Status.md
Normal file
100
published/20180106 Meltdown and Spectre Linux Kernel Status.md
Normal file
@ -0,0 +1,100 @@
|
||||
Gerg:meltdown 和 spectre 影响下的 Linux 内核状况
|
||||
============================================================
|
||||
|
||||
现在(LCTT 译注:本文发表于 1 月初),每个人都知道一件关乎电脑安全的“大事”发生了,真见鬼,等[每日邮报报道][1]的时候,你就知道什么是糟糕了...
|
||||
|
||||
不管怎样,除了告诉你这篇写的及其出色的[披露该问题的 Zero 项目的论文][2]之外,我不打算去跟进这个问题已经被报道出来的细节。他们应该现在就直接颁布 2018 年的 [Pwnie][3] 奖,干的太棒了。
|
||||
|
||||
如果你想了解我们如何在内核中解决这些问题的技术细节,你可以保持关注了不起的 [lwn.net][4],他们会把这些细节写成文章。
|
||||
|
||||
此外,这有一条很好的关于[这些公告][5]的摘要,包括了各个厂商的公告。
|
||||
|
||||
至于这些涉及的公司是如何处理这些问题的,这可以说是如何**不**与 Linux 内核社区保持沟通的教科书般的例子。这件事涉及到的人和公司都知道发生了什么,我确定这件事最终会出现,但是目前我需要去关注的是如何修复这些涉及到的问题,然后不去点名指责,不管我有多么的想去这么做。
|
||||
|
||||
### 你现在能做什么
|
||||
|
||||
如果你的 Linux 系统正在运行一个正常的 Linux 发行版,那么升级你的内核。它们都应该已经更新了,然后在接下来的几个星期里保持更新。我们会统计大量在极端情况下出现的 bug ,这里涉及的测试很复杂,包括庞大的受影响的各种各样的系统和工作任务。如果你的 Linux 发行版没有升级内核,我强烈的建议你马上更换一个 Linux 发行版。
|
||||
|
||||
然而有很多的系统因为各种各样的原因(听说它们比起“传统”的企业发行版更多)不是在运行“正常的” Linux 发行版上。它们依靠长期支持版本(LTS)的内核升级,或者是正常的稳定内核升级,或者是内部的某人打造版本的内核。对于这部分人,这篇介绍了你能使用的上游内核中发生的混乱是怎么回事。
|
||||
|
||||
### Meltdown – x86
|
||||
|
||||
现在,Linus 的内核树包含了我们当前所知的为 x86 架构解决 meltdown 漏洞的所有修复。开启 `CONFIG_PAGE_TABLE_ISOLATION` 这个内核构建选项,然后进行重构和重启,所有的设备应该就安全了。
|
||||
|
||||
然而,Linus 的内核树当前处于 4.15-rc6 这个版本加上一些未完成的补丁。4.15-rc7 版本要明天才会推出,里面的一些补丁会解决一些问题。但是大部分的人不会在一个“正常”的环境里运行 -rc 内核。
|
||||
|
||||
因为这个原因,x86 内核开发者在<ruby>页表隔离<rt>page table isolation</rt></ruby>代码的开发过程中做了一个非常好的工作,好到要反向移植到最新推出的稳定内核 4.14 的话,我们只需要做一些微不足道的工作。这意味着最新的 4.14 版本(本文发表时是 4.14.12 版本),就是你应该运行的版本。4.14.13 会在接下来的几天里推出,这个更新里有一些额外的修复补丁,这些补丁是一些运行 4.14.12 内核且有启动时间问题的系统所需要的(这是一个显而易见的问题,如果它不启动,就把这些补丁加入更新排队中)。
|
||||
|
||||
我个人要感谢 Andy Lutomirski、Thomas Gleixner、Ingo Molnar、 Borislav Petkov、 Dave Hansen、 Peter Zijlstra、 Josh Poimboeuf、 Juergen Gross 和 Linus Torvalds。他们开发出了这些修复补丁,并且为了让我能轻松地使稳定版本能够正常工作,还把这些补丁以一种形式融合到了上游分支里。没有这些工作,我甚至不敢想会发生什么。
|
||||
|
||||
对于老的长期支持内核(LTS),我主要依靠 Hugh Dickins、 Dave Hansen、 Jiri Kosina 和 Borislav Petkov 优秀的工作,来为 4.4 到 4.9 的稳定内核代码树分支带去相同的功能。我同样在追踪讨厌的 bug 和缺失的补丁方面从 Guenter Roeck、 Kees Cook、 Jamie Iles 以及其他很多人那里得到了极大的帮助。我要感谢 David Woodhouse、 Eduardo Valentin、 Laura Abbott 和 Rik van Riel 在反向移植和集成方面的帮助,他们的帮助在许多棘手的地方是必不可少的。
|
||||
|
||||
这些长期支持版本的内核同样有 `CONFIG_PAGE_TABLE_ISOLATION` 这个内核构建选项,你应该开启它来获得全方面的保护。
|
||||
|
||||
从主线版本 4.14 和 4.15 的反向移植是非常不一样的,它们会出现不同的 bug,我们现在知道了一些在工作中遇见的 VDSO 问题。一些特殊的虚拟机安装的时候会报一些奇怪的错,但这是只是现在出现的少数情况,这种情况不应该阻止你进行升级。如果你在这些版本中遇到了问题,请让我们在稳定内核邮件列表中知道这件事。
|
||||
|
||||
如果你依赖于 4.4 和 4.9 或是现在的 4.14 以外的内核代码树分支,并且没有发行版支持你的话,你就太不幸了。比起你当前版本内核包含的上百个已知的漏洞和 bug,缺少补丁去解决 meltdown 问题算是一个小问题了。你现在最需要考虑的就是马上把你的系统升级到最新。
|
||||
|
||||
与此同时,臭骂那些强迫你运行一个已被废弃且不安全的内核版本的人,他们是那些需要知道这是完全不顾后果的行为的人中的一份子。
|
||||
|
||||
### Meltdown – ARM64
|
||||
|
||||
现在 ARM64 为解决 Meltdown 问题而开发的补丁还没有并入 Linus 的代码树,一旦 4.15 在接下来的几周里成功发布,他们就准备[阶段式地并入][6] 4.16-rc1,因为这些补丁还没有在一个 Linus 发布的内核中,我不能把它们反向移植进一个稳定的内核版本里(额……我们有这个[规矩][7]是有原因的)
|
||||
|
||||
由于它们还没有在一个已发布的内核版本中,如果你的系统是用的 ARM64 的芯片(例如 Android ),我建议你选择 [Android 公共内核代码树][8],现在,所有的 ARM64 补丁都并入 [3.18][9]、[4.4][10] 和 [4.9][11] 分支 中。
|
||||
|
||||
我强烈建议你关注这些分支,看随着时间的过去,由于测试了已并入补丁的已发布的上游内核版本,会不会有更多的修复补丁被补充进来,特别是我不知道这些补丁会在什么时候加进稳定的长期支持内核版本里。
|
||||
|
||||
对于 4.4 到 4.9 的长期支持内核版本,这些补丁有很大概率永远不会并入它们,因为需要大量的先决补丁。而所有的这些先决补丁长期以来都一直在 Android 公共内核版本中测试和合并,所以我认为现在对于 ARM 系统来说,仅仅依赖这些内核分支而不是长期支持版本是一个更好的主意。
|
||||
|
||||
同样需要注意的是,我合并所有的长期支持内核版本的更新到这些分支后通常会在一天之内或者这个时间点左右进行发布,所以你无论如何都要关注这些分支,来确保你的 ARM 系统是最新且安全的。
|
||||
|
||||
### Spectre
|
||||
|
||||
现在,事情变得“有趣”了……
|
||||
|
||||
再一次,如果你正在运行一个发行版的内核,一些内核融入了各种各样的声称能缓解目前大部分问题的补丁,你的内核*可能*就被包含在其中。如果你担心这一类的攻击的话,我建议你更新并测试看看。
|
||||
|
||||
对于上游来说,很好,现状就是仍然没有任何的上游代码树分支合并了这些类型的问题相关的修复补丁。有很多的邮件列表在讨论如何去解决这些问题的解决方案,大量的补丁在这些邮件列表中广为流传,但是它们尚处于开发前期,一些补丁系列甚至没有被构建或者应用到任何已知的代码树,这些补丁系列彼此之间相互冲突,这是常见的混乱。
|
||||
|
||||
这是由于 Spectre 问题是最近被内核开发者解决的。我们所有人都在 Meltdown 问题上工作,我们没有精确的 Spectre 问题全部的真实信息,而四处散乱的补丁甚至比公开发布的补丁还要糟糕。
|
||||
|
||||
因为所有的这些原因,我们打算在内核社区里花上几个星期去解决这些问题并把它们合并到上游去。修复补丁会进入到所有内核的各种各样的子系统中,而且在它们被合并后,会集成并在稳定内核的更新中发布,所以再次提醒,无论你使用的是发行版的内核还是长期支持的稳定内核版本,你最好并保持更新到最新版。
|
||||
|
||||
这不是好消息,我知道,但是这就是现实。如果有所安慰的话,似乎没有任何其它的操作系统完全地解决了这些问题,现在整个产业都在同一条船上,我们只需要等待,并让开发者尽快地解决这些问题。
|
||||
|
||||
提出的解决方案并非毫不重要,但是它们中的一些还是非常好的。一些新概念会被创造出来来帮助解决这些问题,Paul Turner 提出的 Retpoline 方法就是其中的一个例子。这将是未来大量研究的一个领域,想出方法去减轻硬件中涉及的潜在问题,希望在它发生前就去预见它。
|
||||
|
||||
### 其他架构的芯片
|
||||
|
||||
现在,我没有看见任何 x86 和 arm64 架构以外的芯片架构的补丁,听说在一些企业发行版中有一些用于其他类型的处理器的补丁,希望他们在这几周里能浮出水面,合并到合适的上游那里。我不知道什么时候会发生,如果你使用着一个特殊的架构,我建议在 arch-specific 邮件列表上问这件事来得到一个直接的回答。
|
||||
|
||||
### 结论
|
||||
|
||||
再次说一遍,更新你的内核,不要耽搁,不要止步。更新会在很长的一段时间里持续地解决这些问题。同样的,稳定和长期支持内核发行版里仍然有很多其它的 bug 和安全问题,它们和问题的类型无关,所以一直保持更新始终是一个好主意。
|
||||
|
||||
现在,有很多非常劳累、坏脾气、缺少睡眠的人,他们通常会生气地让内核开发人员竭尽全力地解决这些问题,即使这些问题完全不是开发人员自己造成的。请关爱这些可怜的程序猿。他们需要爱、支持,我们可以为他们免费提供的他们最爱的饮料,以此来确保我们都可以尽可能快地结束修补系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kroah.com/log/blog/2018/01/06/meltdown-status/
|
||||
|
||||
作者:[Greg Kroah-Hartman][a]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kroah.com
|
||||
[1]:http://www.dailymail.co.uk/sciencetech/article-5238789/Intel-says-security-updates-fix-Meltdown-Spectre.html
|
||||
[2]:https://googleprojectzero.blogspot.fr/2018/01/reading-privileged-memory-with-side.html
|
||||
[3]:https://pwnies.com/
|
||||
[4]:https://lwn.net/Articles/743265/
|
||||
[5]:https://lwn.net/Articles/742999/
|
||||
[6]:https://git.kernel.org/pub/scm/linux/kernel/git/arm64/linux.git/log/?h=kpti
|
||||
[7]:https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
|
||||
[8]:https://android.googlesource.com/kernel/common/
|
||||
[9]:https://android.googlesource.com/kernel/common/+/android-3.18
|
||||
[10]:https://android.googlesource.com/kernel/common/+/android-4.4
|
||||
[11]:https://android.googlesource.com/kernel/common/+/android-4.9
|
||||
[12]:https://support.google.com/faqs/answer/7625886
|
||||
@ -3,43 +3,42 @@ Linux 内核 4.15:“一个不同寻常的发布周期”
|
||||
|
||||
|
||||

|
||||
Linus Torvalds 在周日发布了 Linux 的 4.15 版内核,这个版本比原计划发布时间晚了一周。了解这次发行版的关键更新。[Creative Commons Zero][1]Pixabay
|
||||
|
||||
Linus Torvalds 在周日 [发布了 Linux 内核的 4.15 版][7],再一次比原计划晚了一周。延迟发布的罪魁祸首是 "Meltdown" 和 "Spectre" bug,由于这两个漏洞,使开发者不得不在这最后的周期中提交主要的补丁。Torvalds 不愿意“赶工”,因此,他又给了一周时间去制作这个发行版。
|
||||
> Linus Torvalds 在周日发布了 Linux 的 4.15 版内核,比原计划发布时间晚了一周。了解这次发行版的关键更新。
|
||||
|
||||
不出意外的话,这第一批补丁将是去修补前面提及的 [Meltdown 和 Spectre][8] 漏洞。为防范 Meltdown —— 这个影响 Intel 芯片的问题,在 x86 架构上[开发者实现了 _页表隔离_ (PTI)][9]。不论什么理由你如果想去关闭它,你可以使用内核引导选项 `pti=off` 去关闭这个特性。
|
||||
Linus Torvalds 在周日(1 月 28 日)[发布了 Linux 内核的 4.15 版][7],再一次比原计划晚了一周。延迟发布的罪魁祸首是 “Meltdown” 和 “Spectre” bug,由于这两个漏洞,使开发者不得不在这最后的周期中提交重大补丁。Torvalds 不愿意“赶工”,因此,他又给了一周时间去制作这个发行版本。
|
||||
|
||||
Spectre v2 漏洞对 Intel 和 AMD 芯片都有影响,为防范它,[内核现在带来了 _retpoline_ 机制][10]。Retpoline 要求 GCC 的版本支持 `-mindirect-branch=thunk-extern` 功能。由于使用了 PTI,Spectre 抑制机制可以被关闭,如果需要去关闭它,在引导时使用 `spectre_v2=off` 选项。尽管开发者努力去解决 Spectre v1,但是,到目前为止还没有一个解决方案,因此,在 4.15 的内核版本中并没有这个 bug 的修补程序。
|
||||
不出意外的话,这第一批补丁将是去修补前面提及的 [Meltdown 和 Spectre][8] 漏洞。为防范 Meltdown —— 这个影响 Intel 芯片的问题,在 x86 架构上[开发者实现了页表隔离(PTI)][9]。不论什么理由你如果想去关闭它,你可以使用内核引导选项 `pti=off` 去关闭这个特性。
|
||||
|
||||
对于在 ARM 上的 Meltdown 也将在下一个开发周期中推送。但是,[对于 PowerPC 上的 bug,在这个发行版中包含了一个补救措施,那就是使用 _L1-D 缓存的 RFI 冲刷_ 特性][11]。
|
||||
Spectre v2 漏洞对 Intel 和 AMD 芯片都有影响,为防范它,[内核现在带来了 retpoline 机制][10]。Retpoline 要求 GCC 的版本支持 `-mindirect-branch=thunk-extern` 功能。由于使用了 PTI,Spectre 抑制机制可以被关闭,如果需要去关闭它,在引导时使用 `spectre_v2=off` 选项。尽管开发者努力去解决 Spectre v1,但是,到目前为止还没有一个解决方案,因此,在 4.15 的内核版本中并没有这个 bug 的修补程序。
|
||||
|
||||
一个有趣的事情是,上面提及的所有受影响的新内核中,都带有一个 _/sys/devices/system/cpu/vulnerabilities/_ 虚拟目录。这个目录显示了影响你的 CPU 的漏洞以及当前应用的补救措施。
|
||||
对于在 ARM 上的 Meltdown 解决方案也将在下一个开发周期中推送。但是,[对于 PowerPC 上的 bug,在这个发行版中包含了一个补救措施,那就是使用 L1-D 缓存的 RFI 冲刷特性][11]。
|
||||
|
||||
一个有趣的事情是,上面提及的所有受影响的新内核中,都带有一个 `/sys/devices/system/cpu/vulnerabilities/` 虚拟目录。这个目录显示了影响你的 CPU 的漏洞以及当前应用的补救措施。
|
||||
|
||||
芯片带 bug (以及保守秘密的制造商)的问题重新唤起了开发可行的开源替代品的呼声。这使得已经合并到主线版本的内核提供了对 [RISC-V][12] 芯片的部分支持。RISC-V 是一个开源的指令集架构,它允许制造商去设计他们自己的基于 RISC-V 芯片的实现。并且因此也有了几个开源的芯片。虽然 RISC-V 芯片目前主要用于嵌入式设备,它能够去做像智能硬盘或者像 Arduino 这样的开发板,RISC-V 的支持者认为这个架构也可以用于个人电脑甚至是多节点的超级计算机上。
|
||||
|
||||
正如在上面提到的,[对 RISC-V 的支持][13],仍然没有全部完成,它虽然包含了架构代码,但是没有设备驱动。这意味着,虽然Linux 内核可以在 RISC-V 芯片上运行,但是没有可行的方式与底层的硬件进行实质的交互。也就是说,RISC-V 不会受到其它闭源架构上的任何 bug 的影响,并且对它的支持的开发工作也在加速进行,因为,[RISC-V 基金会已经得到了一些行业巨头的支持][14]。
|
||||
正如在上面提到的,[对 RISC-V 的支持][13],仍然没有全部完成,它虽然包含了架构代码,但是没有设备驱动。这意味着,虽然 Linux 内核可以在 RISC-V 芯片上运行,但是没有可行的方式与底层的硬件进行实质的交互。也就是说,RISC-V 不会受到其它闭源架构上的任何 bug 的影响,并且对它的支持的开发工作也在加速进行,因为,[RISC-V 基金会已经得到了一些行业巨头的支持][14]。
|
||||
|
||||
### 4.15 版新内核中的其它新特性
|
||||
|
||||
Torvalds 经常说他喜欢的事情是很无聊的。对他来说,幸运的是,除了 Spectre 和 Meltdown 引发的混乱之外,在 4.15 内核中的大部分其它东西都很普通,比如,对驱动的进一步改进、对新设备的支持等等。但是,还有几点需要重点指出,它们是:
|
||||
|
||||
* [AMD 对虚拟化安全加密的支持][3]。它允许内核通过加密来实现对虚拟机内存的保护。加密的内存仅能够被使用它的虚拟机所解密。就算是 hypervisor 也不能看到它内部的数据。这意味着在云中虚拟机正在处理的数据,在虚拟机外的任何进程都看不到。
|
||||
* 由于 [包含了_显示代码_][4], AMD GPU 得到了极大的提升,这使得 Radeon RX Vega 和 Raven Ridge 显卡得到了内核主线版本的支持,并且也在 AMD 显卡中实现了 HDMI/DP 音频。
|
||||
* 树莓派的爱好者应该很高兴,因为在新内核中, [7" 触摸屏现在已经得到原生支持][5],这将产生成百上千的有趣的项目。
|
||||
|
||||
* 由于 [包含了 _显示代码_][4], AMD GPU 得到了极大的提升,这使得 Radeon RX Vega 和 Raven Ridge 显卡得到了内核主线版本的支持,并且也在 AMD 显卡中实现了 HDMI/DP 音频。
|
||||
要发现更多的特性,你可以去查看在 [Kernel Newbies][15] 和 [Phoronix][16] 上的内容。
|
||||
|
||||
* 树莓派的爱好者应该很高兴,因为在新内核中, [7'' 触摸屏现在已经得到原生支持][5],这将产生成百上千的有趣的项目。
|
||||
|
||||
去发现更多的特性,你可以去查看在 [Kernel Newbies][15] 和 [Phoronix][16] 上写的代码。
|
||||
|
||||
_想学习更多的 Linux 的知识,可以去学习来自 Linux 基金会和 edX 的免费课程 —— ["了解 Linux" ][6]。_
|
||||
_想学习更多的 Linux 的知识,可以去学习来自 Linux 基金会和 edX 的免费课程 —— ["了解 Linux" ][6]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/1/linux-kernel-415-unusual-release-cycle
|
||||
|
||||
作者:[PAUL BROWN ][a]
|
||||
作者:[PAUL BROWN][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
How DevOps helps deliver cool apps to users
|
||||
======
|
||||
|
||||

|
||||
|
||||
A long time ago, in a galaxy far, far away, before DevOps became a mainstream practice, the software development process was excruciatingly slow, tedious, and methodical. By the time an application was ready to be deployed, a ginormous laundry list of changes and fixes to the next major release had already amassed. It took months to go back and work through the entire development cycle to prepare for each new release. Keep in mind that this process would be repeated again and again to deliver updates to users.
|
||||
|
||||
Today everything is done instantaneously and in real time, and this concept seems primitive. The mobile revolution has dramatically changed the way we interact with software, and companies that were early adopters of DevOps have totally changed the expectations for software development and deployment.
|
||||
|
||||
Consider Facebook: The Facebook mobile app is updated and refreshed every two weeks, like clockwork. This is the new standard, because users now expect software to be constantly fixed and updated. Any company that takes a month or more to deploy new features or simple bug fixes would surely fade into obscurity. If you cannot deliver what users expect, they will find someone who can.
|
||||
|
||||
Facebook, along with industry giants such as Amazon, Netflix, Google, and others, have forced enterprises to become faster and more efficient to meet today's customer expectations.
|
||||
|
||||
### Why DevOps?
|
||||
|
||||
Agile and DevOps are critically important to mobile app development since deployment cycles are lightning-quick. It’s a dense, fast-paced environment in which companies must outpace, out-think, and outmaneuver the competition to survive. In the App Store, the average top ten app remains in that position for only about a month.
|
||||
|
||||
To illustrate the old-school waterfall methodology, think back to when you first learned how to drive. Initially, you focused on every individual aspect, using a methodological process: You got in the car; fastened the seat belt; adjusted the seat, mirrors, and steering wheel; started the car, placed your hands at 10 and 2 o’clock, etc. Performing a simple task such as a lane change involved a painstaking, multi-step process executed in a particular order.
|
||||
|
||||
DevOps, in contrast, is how you would drive after several years of experience. Everything occurs intuitively and simultaneously, and you can move smoothly from A to B without putting much thought into the process.
|
||||
|
||||
The world of mobile apps is too fast-paced for old methods of app development. DevOps is designed to deliver effective, stable apps quickly and without the need for extensive resources. However, you cannot buy DevOps like an ordinary product or service. DevOps is about changing the culture and dynamics of how teams work together.
|
||||
|
||||
Large organizations like Amazon and Facebook are not the only ones embracing the DevOps culture; smaller mobile app companies are signing on as well. “Shortening the release cycle while keeping number of production incidents at a low level along with the overall cost of failure is what our customers looking for,” says Oleg Reshetnyak, head of engineering at mobile product agency [Reinvently.][1]
|
||||
|
||||
### DevOps: Not _if_ , but _when_
|
||||
|
||||
In today’s fast-paced business environment, choosing DevOps is like choosing to breathe: You either [do it or die][2].
|
||||
|
||||
According to the [U.S. Small Business Administration][3], only 16% of companies starting out today will last an entire generation. Mobile app companies that do not adopt DevOps risk going the way of the dinosaurs. Furthermore, the same study found that organizations that adopt DevOps are twice as likely to exceed profitability, product goals, and market share.
|
||||
|
||||
Innovating more quickly and securely requires three things: cloud, automation, and DevOps. Depending on how you define DevOps, the lines that separate these three factors can be unclear. However, one thing is certain: DevOps unifies everyone within the organization around the common goal of delivering higher-quality software more quickly and with less risk.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/devops-delivers-cool-apps-users
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://reinvently.com/
|
||||
[2]:https://squadex.com/insights/devops-or-die/
|
||||
[3]:https://www.sba.gov/
|
||||
@ -0,0 +1,73 @@
|
||||
Why Mainframes Aren't Going Away Any Time Soon
|
||||
======
|
||||
|
||||

|
||||
|
||||
IBM's last earnings report showed the [first uptick in revenue in more than five years.][1] Some of that growth was from an expected source, cloud revenue, which was up 24 percent year over year and now accounts for 21 percent of Big Blue's take. Another major boost, however, came from a spike in mainframe revenue. Z series mainframe sales were up 70 percent, the company said.
|
||||
|
||||
This may sound somewhat akin to a return to vacuum tube technology in a world where transistors are yesterday's news. In actuality, this is only a sign of the changing face of IT.
|
||||
|
||||
**Related:** [One Click and Voilà, Your Entire Data Center is Encrypted][2]
|
||||
|
||||
Modern mainframes definitely aren't your father's punch card-driven machines that filled entire rooms. These days, they most often run Linux and have found a renewed place in the data center, where they're being called upon to do a lot of heavy lifting. Want to know where the largest instance of Oracle's database runs? It's on a Linux mainframe. How about the largest implementation of SAP on the planet? Again, Linux on a mainframe.
|
||||
|
||||
"Before the advent of Linux on the mainframe, the people who bought mainframes primarily were people who already had them," Leonard Santalucia explained to Data Center Knowledge several months back at the All Things Open conference. "They would just wait for the new version to come out and upgrade to it, because it would run cheaper and faster.
|
||||
|
||||
**Related:** [IBM Designs a “Performance Beast” for AI][3]
|
||||
|
||||
"When Linux came out, it opened up the door to other customers that never would have paid attention to the mainframe. In fact, probably a good three to four hundred new clients that never had mainframes before got them. They don't have any old mainframes hanging around or ones that were upgraded. These are net new mainframes."
|
||||
|
||||
Although Santalucia is CTO at Vicom Infinity, primarily an IBM reseller, at the conference he was wearing his hat as chairperson of the Linux Foundation's Open Mainframe Project. He was joined in the conversation by John Mertic, the project's director of program management.
|
||||
|
||||
Santalucia knows IBM's mainframes from top to bottom, having spent 27 years at Big Blue, the last eight as CTO for the company's systems and technology group.
|
||||
|
||||
"Because of Linux getting started with it back in 1999, it opened up a lot of doors that were closed to the mainframe," he said. "Beforehand it was just z/OS, z/VM, z/VSE, z/TPF, the traditional operating systems. When Linux came along, it got the mainframe into other areas that it never was, or even thought to be in, because of how open it is, and because Linux on the mainframe is no different than Linux on any other platform."
|
||||
|
||||
The focus on Linux isn't the only motivator behind the upsurge in mainframe use in data centers. Increasingly, enterprises with heavy IT needs are finding many advantages to incorporating modern mainframes into their plans. For example, mainframes can greatly reduce power, cooling, and floor space costs. In markets like New York City, where real estate is at a premium, electricity rates are high, and electricity use is highly taxed to reduce demand, these are significant advantages.
|
||||
|
||||
"There was one customer where we were able to do a consolidation of 25 x86 cores to one core on a mainframe," Santalucia said. "They have several thousand machines that are ten and twenty cores each. So, as far as the eye could see in this data center, [x86 server workloads] could be picked up and moved onto this box that is about the size of a sub-zero refrigerator in your kitchen."
|
||||
|
||||
In addition to saving on physical data center resources, this customer by design would likely see better performance.
|
||||
|
||||
"When you look at the workload as it's running on an x86 system, the math, the application code, the I/O to manage the disk, and whatever else is attached to that system, is all run through the same chip," he explained. "On a Z, there are multiple chip architectures built into the system. There's one specifically just for the application code. If it senses the application needs an I/O or some mathematics, it sends it off to a separate processor to do math or I/O, all dynamically handled by the underlying firmware. Your Linux environment doesn't have to understand that. When it's running on a mainframe, it knows it's running on a mainframe and it will exploit that architecture."
|
||||
|
||||
The operating system knows it's running on a mainframe because when IBM was readying its mainframe for Linux it open sourced something like 75,000 lines of code for Linux distributions to use to make sure their OS's were ready for IBM Z.
|
||||
|
||||
"A lot of times people will hear there's 170 processors on the Z14," Santalucia said. "Well, there's actually another 400 other processors that nobody counts in that count of application chips, because it is taken for granted."
|
||||
|
||||
Mainframes are also resilient when it comes to disaster recovery. Santalucia told the story of an insurance company located in lower Manhattan, within sight of the East River. The company operated a large data center in a basement that among other things housed a mainframe backed up to another mainframe located in Upstate New York. When Hurricane Sandy hit in 2012, the data center flooded, electrocuting two employees and destroying all of the servers, including the mainframe. But the mainframe's workload was restored within 24 hours from the remote backup.
|
||||
|
||||
The x86 machines were all destroyed, and the data was never recovered. But why weren't they also backed up?
|
||||
|
||||
"The reason they didn't do this disaster recovery the same way they did with the mainframe was because it was too expensive to have a mirror of all those distributed servers someplace else," he explained. "With the mainframe, you can have another mainframe as an insurance policy that's lower in price, called Capacity BackUp, and it just sits there idling until something like this happens."
|
||||
|
||||
Mainframes are also evidently tough as nails. Santalucia told another story in which a data center in Japan was struck by an earthquake strong enough to destroy all of its x86 machines. The center's one mainframe fell on its side but continued to work.
|
||||
|
||||
The mainframe also comes with built-in redundancy to guard against situations that would be disastrous with x86 machines.
|
||||
|
||||
"What if a hard disk fails on a node in x86?" the Open Mainframe Project's Mertic asked. "You're taking down a chunk of that cluster potentially. With a mainframe you're not. A mainframe just keeps on kicking like nothing's ever happened."
|
||||
|
||||
Mertic added that a motherboard can be pulled from a running mainframe, and again, "the thing keeps on running like nothing's ever happened."
|
||||
|
||||
So how do you figure out if a mainframe is right for your organization? Simple, says Santalucia. Do the math.
|
||||
|
||||
"The approach should be to look at it from a business, technical, and financial perspective -- not just a financial, total-cost-of-acquisition perspective," he said, pointing out that often, costs associated with software, migration, networking, and people are not considered. The break-even point, he said, comes when at least 20 to 30 servers are being migrated to a mainframe. After that point the mainframe has a financial advantage.
|
||||
|
||||
"You can get a few people running the mainframe and managing hundreds or thousands of virtual servers," he added. "If you tried to do the same thing on other platforms, you'd find that you need significantly more resources to maintain an environment like that. Seven people at ADP handle the 8,000 virtual servers they have, and they need seven only in case somebody gets sick.
|
||||
|
||||
"If you had eight thousand servers on x86, even if they're virtualized, do you think you could get away with seven?"
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datacenterknowledge.com/hardware/why-mainframes-arent-going-away-any-time-soon
|
||||
|
||||
作者:[Christine Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datacenterknowledge.com/archives/author/christine-hall
|
||||
[1]:http://www.datacenterknowledge.com/ibm/mainframe-sales-fuel-growth-ibm
|
||||
[2]:http://www.datacenterknowledge.com/design/one-click-and-voil-your-entire-data-center-encrypted
|
||||
[3]:http://www.datacenterknowledge.com/design/ibm-designs-performance-beast-ai
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by erialin
|
||||
|
||||
|
||||
Linux Gunzip Command Explained with Examples
|
||||
======
|
||||
|
||||
|
||||
@ -1,85 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to reload .vimrc file without restarting vim on Linux/Unix
|
||||
======
|
||||
|
||||
I am a new vim text editor user. I usually load ~/.vimrc usingfor configuration. Once edited my .vimrc file I need to reload it without having to quit Vim session. How do I edit my .vimrc file and reload it without having to restart Vim on Linux or Unix-like system?
|
||||
|
||||
Vim is free and open source text editor that is upwards compatible to Vi. It can be used to edit all kinds of good old text. It is especially useful for editing programs written in C/Perl/Python. One can use it for editing Linux/Unix configuration files. ~/.vimrc is your personal Vim initializations and customization file.
|
||||
|
||||
### How to reload .vimrc file without restarting vim session
|
||||
|
||||
The procedure to reload .vimrc in Vim without restart:
|
||||
|
||||
1. Start vim text editor by typing: `vim filename`
|
||||
2. Load vim config file by typing vim command: `Esc` followed by `:vs ~/.vimrc`
|
||||
3. Add customization like:
|
||||
```
|
||||
filetype indent plugin on
|
||||
set number
|
||||
syntax on
|
||||
```
|
||||
4. Use `:wq` to save a file and exit from ~/.vimrc window.
|
||||
5. Reload ~/.vimrc by typing any one of the following command:
|
||||
```
|
||||
:so $MYVIMRC
|
||||
```
|
||||
OR
|
||||
```
|
||||
:source ~/.vimrc
|
||||
```
|
||||
|
||||
[![How to reload .vimrc file without restarting vim][1]][1]
|
||||
Fig.01: Editing ~/.vimrc and reloading it when needed without quiting vim so that you can continuing editing program
|
||||
|
||||
The `:so[urce]! {file}` vim command read vim configfileor ommands from given file such as ~/.vimrc. These are commands that are executed from Normal mode, like you type them. When used after :global, :argdo, :windo, :bufdo, in a loop or when another command follows the display won't be updated while executing the commands.
|
||||
|
||||
### How to may keys for edit and reload ~/.vimrc
|
||||
|
||||
Append the following in your ~/.vimrc file
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap confe :e $MYVIMRC<CR>
|
||||
"
|
||||
|
||||
Reload vims configuration file
|
||||
nnoremap confr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
" Edit vimr configuration file nnoremap confe :e $MYVIMRC<CR> " Reload vims configuration file nnoremap confr :source $MYVIMRC<CR>
|
||||
|
||||
Now just press `Esc` followed by `confe` to edit ~/.vimrc file. To reload type `Esc` followed by `confr`. Some people like to use the <Leader> key in a .vimrc file. So above mapping becomes:
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap <Leader>ve :e $MYVIMRC<CR>
|
||||
"
|
||||
" Reload vimr configuration file
|
||||
nnoremap <Leader>vr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
" Edit vimr configuration file nnoremap <Leader>ve :e $MYVIMRC<CR> " " Reload vimr configuration file nnoremap <Leader>vr :source $MYVIMRC<CR>
|
||||
|
||||
The <Leader> key is mapped to \ by default. So you just press \ followed by ve to edit the file. To reload the ~/vimrc file you press \ followed by vr
|
||||
And there you have it, you just reload .vimrc file without restarting vim ever.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][2], [Facebook][3], [Google+][4]. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[my RSS/XML feed][5]**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-reload-vimrc-file-without-restarting-vim-on-linux-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/02/How-to-reload-.vimrc-file-without-restarting-vim.jpg
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
[5]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,261 @@
|
||||
23 open source audio-visual production tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
Open source is well established in cloud infrastructure, web hosting, embedded devices, and many other areas. Fewer people know that open source is a great option for producing professional-level audio-visual materials.
|
||||
|
||||
As a product owner and sometimes marketing support person, I produce a lot of content for end users: documentation, web articles, video tutorials, event booth materials, white papers, interviews, and more. I have found plenty of great open source software that helps me do my job producing audio, video, print, and screen graphics. There are a lot of [reasons][1] that people choose open source over proprietary options, and I've compiled this list of open source audio and video tools for people who:
|
||||
|
||||
* want to switch to GNU/Linux, but need to start slowly with cross-platform software on their regular operating system;
|
||||
* are already open source enthusiasts, but are new to open source A/V software and want to know which options to trust;
|
||||
* want to discover new tools to fuel their creativity and don't want to use the same approaches or software everyone else uses; or
|
||||
* have some other reason to use open source A/V solutions (if this is you, share your reason in the comments).
|
||||
|
||||
|
||||
|
||||
Fortunately, there is a lot of open source software available for A/V creators, as well as hardware that supports those applications. All of the software on this list meets the following criteria:
|
||||
|
||||
* cross-platform
|
||||
* open source (for software and drivers)
|
||||
* stable
|
||||
* actively maintained
|
||||
* well documented and supported
|
||||
|
||||
|
||||
|
||||
I've divided this list into graphics, audio, video, and animation solutions. Note that the software applications in this article are not exact equivalents of well-known proprietary software, they'll require you to learn new applications, and you may need to modify your workflow, but learning new tools enables you to create differently.
|
||||
|
||||
### Graphics
|
||||
|
||||
I create a lot of graphics for print and web, including logos, banners, video titles, and mockups. Here are some of the open source applications I use, as well as the hardware I use with them.
|
||||
|
||||
#### Software
|
||||
|
||||
**1.[Inkscape][2]** (vector graphics)
|
||||
Inkscape is a good vector graphics editor for creating SVG and PDF files in the RGB color space. (It can create CMYK images, but that's not the main aim.) It's a lifesaver for manipulating SVG maps and charts for web applications; not only can you open files with the integrated XML editor, you can also see all of an object's parameters. One drawback: it is not well optimized on Mac. For examples, see [Inkscape's gallery][3].
|
||||
|
||||
**2.[GIMP][4]** (picture editor)
|
||||
GIMP is my favorite application to edit images, including manipulating color, cropping and resizing, and (especially) optimizing file size for the web (many of my Photoshop-using colleagues ask me to do that last step for them). You can also create and draw images from scratch, but GIMP is not my favorite tool for that. See [GIMP Artists on DeviantArt][5] for examples.
|
||||
|
||||
**3.[Krita][6]** (digital painting)
|
||||
So you have this beautiful Wacom drawing tablet on your desk, and you want to try a true digital painting application? Krita is what you need to create beautiful drawings and paintings. See [Krita's Gallery][7] to see what I mean.
|
||||
|
||||
**4.[Scribus][8]** (desktop publishing)
|
||||
You can use Scribus to create a complete document, or just to convert a PDF from Inkscape or Libre Office from RGB to CMYK. One feature I really like: You can simulate and check what people with visual disabilities will experience with a Scribus document. I count on Scribus when I send PDF files to a commercial printer. While printing companies may be used to files created with proprietary solutions like InDesign, if your Scribus file is done correctly, your printer won't have any issues. Free trick: The first time you send a file, don't tell the printer the name of the software you used to create it. See [Made with Scribus][9] for examples of documents created with this software.
|
||||
|
||||
**5.[RawTherapee][10]** (RAW image photo development)
|
||||
RawTherapee is the only completely cross-platform alternative to Lightroom I know of. You can use your camera in RAW mode, and then use RawTherapee to "develop" your picture. It provides a very powerful engine and a non-destructive editor. For examples, see [RawTherapee screenshots][11].
|
||||
|
||||
**6.[LibreOffice Draw][12]** (desktop publishing)
|
||||
Although you may not think of LibreOffice Draw as a professional desktop publishing solution, it can save you in many situations; for example, if you are creating whitepapers, diagrams, or posters that other people (even those who don't know graphics software) can update later. Not only is it easy to use, it's also a great alternative to Impress or PowerPoint for creating interesting documents.
|
||||
|
||||
#### Graphics hardware
|
||||
|
||||
**Graphics tablets**
|
||||
[Wacom][13] tablets (and compatibles) are usually well supported on all operating systems.
|
||||
|
||||
**Color calibration**
|
||||
Color calibration products are available on all operating systems, including GNU/Linux. The [Spyder][14] products by Datacolor are well supported with applications for all platforms.
|
||||
|
||||
**Scanners and printers**
|
||||
Graphic artists need the colors they output (whether print or electronic) to be accurate. But devices that are truly cross-platform, with easy-to-install drivers for all platform, are not as common as you'd think. Your best choices are scanners that are compatible with TWAIN and printers that are compatible with Postscript. In my experience, professional-range printers and scanners from Epson and Xerox are less likely to have driver issues, and they always work out of the box, with beautiful and accurate colors.
|
||||
|
||||
### Audio
|
||||
|
||||
There are plenty of open source audio software options for musicians, video makers, game makers, music publishers, and others. Here are the ones that I've used for content creation and audio recording.
|
||||
|
||||
#### Software
|
||||
|
||||
**7. [Ardour][15] **(digital audio recording)
|
||||
For recording and editing audio, the best alternative to the professional Pro Tools music-creation software is, hands down, Ardour. It sounds great, the mixer section is complete and flexible, it supports your favorite plugins, and it makes it very easy to edit, listen, and compare your modifications. I use it a lot for audio recording or mixing sound on videos. It's not easy to find music recorded with Ardour, because musicians rarely credit the software they use. However, you can get an idea of its capabilities by looking at its [features and screenshots][16].
|
||||
|
||||
(If you are looking for an "analog feeling" in term of sound and workflow, you can try [Harrison Mixbus][17], which is not an open source project, but is heavily based on Ardour, with Harrison's analog console emulator. I really like to work with it and my customers like the sound. Mixbus is cross platform.)
|
||||
|
||||
**8.[Audacity][18]** (audio editing)
|
||||
Audacity is the "Swiss Army knife" of audio software. It's not perfect, but you can do almost everything with it. Plus it's very easy to use, and anyone can learn it in a few minutes. Like Ardour, it's hard to find work credited to Audacity, but you can find ways to use it on these [screenshots][19].
|
||||
|
||||
**9.[LMMS][20]** (music production)
|
||||
LMMS, designed as an alternative to FL Studio, might not be as popular, but it is very complete and easy to use. You can use your favorite plugins, edit instruments using "piano roll" sequencing, play drum samples with a step sequencer, mix your tracks ... almost anything is possible. I use it to create audio loops for videos when I don't have the time to record musicians. See [The Best of LMMS][21] playlists for examples.
|
||||
|
||||
**10.[Mixxx][22]** (DJ, music mixing)
|
||||
If you need powerful software to mix music and play DJ, Mixx is the one to use. It's compatible with most MIDI controllers, timecoded discs, and dedicated sound cards. You can manage your music library, add effects, and have fun. Take a look at the [features][23] to see how it works.
|
||||
|
||||
#### Audio interface hardware
|
||||
|
||||
While you can record audio with any computer's sound card, to record well, you need an audio interface—a specialized type of external sound card that records high-quality audio input. For cross-platform compatibility, most "USB Class Compliant" or "compatible with iOS" audio interface devices should work for MIDI or other audio. Below is a list of cross-platform devices I use and know well.
|
||||
|
||||
**[Behringer U-PHORIA UMC22][24]**
|
||||
The UMC22 is the cheapest option you should consider. With less expensive options, the preamps are too noisy and the quality of the box is very low.
|
||||
|
||||
**[Presonus AudioBox USB][25]**
|
||||
The AudioBox USB is one of the first USB Class Compliant (and thereby cross-platform) recording systems out there. It is very robust and available on the second-hand market.
|
||||
|
||||
**[Focusrite Scarlett][26]**
|
||||
The Scarlett range is, in my opinion, the highest quality cross-platform sound card available. The various options range from devices with two to 18 input/outputs. You can find first-version models on the second-hand market, and the new second version offers better preamps and specs. I've worked a lot with the [2i2][27] model.
|
||||
|
||||
**[Arturia AudioFuse][28]**
|
||||
The AudioFuse allows you to plug in nearly anything, from a microphone to a vinyl disc player to various digital inputs. It provides both great sound and great design, and it's what I'm using the most now. It is cross-platform, but the configuration software is not yet available for GNU/Linux. It remembers my configuration even after I unplug it from my Windows PC, but really, Arturia, please be serious and make the software available for GNU/Linux.
|
||||
|
||||
#### MIDI controllers
|
||||
|
||||
A MIDI controller is a musical instrument—e.g., keyboards, drum pads, etc.—that allow you to control music software and hardware. Most of the recent USB MIDI controllers are cross-platform and compatible with the main software used to record and edit audio. Web-based tutorials will help you configure them for different software; although it may be harder to find info on GNU/Linux configurations, they will work. I've used many Akai and M-Audio devices without any issues. It's best to try a musical instrument before you buy, at least to listen to the sound quality or to touch the buttons.
|
||||
|
||||
#### Audio codecs
|
||||
|
||||
Audio codecs compress and decompress digital audio to deliver the best-quality audio at the smallest possible file size. Fortunately, the best codec for listening and streaming happens to be open source: [FLAC][29]. [Ogg Vorbis][30] is another open source audio codec worth checking out; it's far better than MP3 at the same bitrate. If you need to export audio in different file formats, I recommend always exporting and archiving audio at the best possible quality, then compressing a specific version if it's needed.
|
||||
|
||||
### Video
|
||||
|
||||
The impact of video in brand communications is significant. Even if you are not a video specialist, it's smart to learn the basics.
|
||||
|
||||
#### Software
|
||||
|
||||
**11.[VLC][31]** (video player and converter)
|
||||
Originally developed for media streaming, VLC is now known for its ability to read all video formats on all devices. It's very useful; for example, you can also use it to convert a video into another codec or container or to recover a broken video.
|
||||
|
||||
**12.[OpenShot][32]** (video editor)
|
||||
OpenShot is simple software that produces great results, especially for short videos. (It is a bit limited in terms of editing or improving the sound of a video, but it will do the job.) I especially like the tool to move, resize, or crop a clip; it's perfect to create intros and outros that you can export, then use in a more complex editor. You can see [examples][33] (and get more information) on OpenShot's website.
|
||||
|
||||
**13.[Shotcut][34]** (video editor)
|
||||
I think Shotcut is a bit more complete than OpenShot—it's a very good competitor to the basic editors in your operating system, and it supports 4K and professional codecs. Give it a try, I think you will love it. You can see examples in these [video tutorials][35].
|
||||
|
||||
**14.[Blender Velvets][36]** (vdeo editing, compositing, effects)
|
||||
While the learning curve is not the lightest on this list, Blender Velvets is one of the most powerful solutions you will find. It is a collection of extensions and scripts, created by movie makers, that transform the Blender 3D creation software into a 2D video editor. While it's complexity means it's not my top choice for video editing, you can find plenty of tutorials on YouTube and other sites, and once you learn it, you can do everything with this software. Watch this [tutorial video][37] to see its functions and how it works.
|
||||
|
||||
**15.[Natron][38]** (compositing)
|
||||
I don't use Natron, but I've gotten great feedback from people who do. It's an alternative to Adobe's After Effects, but works differently. To learn more, watch a few video tutorials, like these on [Natron's YouTube][39] channel.
|
||||
|
||||
**16.[OBS][40]** (live editing, recording, and streaming)
|
||||
Open Broadcaster Software (OBS) is the leading solution for recording or [livestreaming][41] e-sports and video games on YouTube or Twitch. I use it a lot to record users' screens, conferences, meetups, etc. For more information, see the tutorial I wrote for Opensource.com about recording live presentations, [Part 1: Choosing your equipment][42] and [Part 2: Software setup][43].
|
||||
|
||||
#### Video hardware
|
||||
|
||||
First things first: You will need a powerful workstation with a fast hard drive and updated software and drivers.
|
||||
|
||||
**Graphics processing unit (GPU)**
|
||||
Some software on this list, including Blender and Shotcut, use OpenGL and hardware acceleration, which have high GPU demands. I recommend the most powerful GPU you can afford. I've had good experience with AMD and Nvidia, depending on the platform. Don't forget to install the latest drivers.
|
||||
|
||||
**Hard drives**
|
||||
In general, the faster and bigger the hard drive, the better it is for video. Don't forget to configure your software to use the right path.
|
||||
|
||||
**Video capture hardware**
|
||||
|
||||
* [Blackmagic Design][44]: Blackmagic provides very good, professional-grade video capture and playback hardware. Drivers are available for Mac, Windows, and GNU/Linux (but not all distributions).
|
||||
* [Epiphan][45]: Among Epiphan's professional USB video capture devices is a new USB Class Compliant model for HDMI and high screen resolutions. However, you can find the older VGA devices on the secondhand market, for which they continue to provide dedicated drivers for GNU/Linux and Windows.
|
||||
|
||||
|
||||
|
||||
#### Video codecs
|
||||
|
||||
Unfortunately, it is still difficult to work with open source codecs. For example, many cameras use proprietary codecs to record videos in H.264 and sound in AC3, in a format called AVCHD. Therefore, we have to be pragmatic and use what is available.
|
||||
|
||||
The good news is that the content industry is moving to open source codecs to avoid fees and to use open standards. For distribution and streaming, [Google'][46][s WebM][46] is a good open source codec, and most video editors can export in that format. Also, [GoPro's][47][Cineform][47] codec for very high resolution and 360° video is now open source. Hopefully more devices and vendors will use it soon.
|
||||
|
||||
### 2D and 3D animation
|
||||
|
||||
Animation is not my field of expertise, so I've asked my friends who are working on animated content, including movies and series for kids, for their recommendations to compile this list.
|
||||
|
||||
#### Software
|
||||
|
||||
**17. [Blender][48] **(3D modeling and rendering)
|
||||
Blender is the top open source and cross-platform software for 3D modeling and rendering. You can do your entire project directly in Blender, or use it to create 3D effects for a movie or video. You will find a lot of video tutorials on the web, so even though it isn't simple software, it's very easy to get started. Blender is a very active project and regularly produces short movies to showcase the technology. You can see some of them on [Blender Open Movies][49].
|
||||
|
||||
**18.[Synfig Studio][50]** (2D animation)
|
||||
The first time I used Synfig, it reminded me of the good, old Macromedia Flash editor. Since then, it has grown into a full-featured 2D animation studio. You can use it to produce promotional stories, commercials, presentations, or original intros, outros, and transitions for your videos, or even to work on full animated movies. See [Synfig's portfolio][51] for some examples.
|
||||
|
||||
**19.[TupiTube][52]** (stop-motion, 2D animation)
|
||||
TupiTube is an excellent way to learn the basics of 2D animation. You can transform a set of drawings or other pictures into a video or create an animated GIF or small loops. It's quite simple software, but very complete. Check out [TupiTube's YouTube][53] channel for some tutorials and examples.
|
||||
|
||||
#### Hardware
|
||||
|
||||
Animation uses the same hardware as graphic design, so look at the hardware list in the first section of this article for recommendations.
|
||||
|
||||
One additional note: You will need a powerful GPU for 3D modeling and rendering. The choices can be limited, depending on your platform or PC maker, but don't forget to install the latest drivers. Carefully choose your graphics card: they are expensive and critical for big 3D projects, particularly in the rendering step.
|
||||
|
||||
### Linux options
|
||||
|
||||
If you are a GNU/Linux user, I have some more good options for you. They aren't fully cross-platform, but some of them have a Windows installer, and some can be installed on Mac with Macports.
|
||||
|
||||
**20.[Kdenlive][54]** (video editor)
|
||||
With its last release (a few months ago), Kdenlive became my favorite video editor, especially when I work on a long video on my Linux machine. If you are a regular user of popular non-linear video editors, Kdenlive (which stands for KDE Non-Linear Video Editor) will be easy for you to use. It has good video and audio effects, is great when you need to work on details, and works on BSD and MacOS (although it's aimed at GNU/Linux) and is being ported to Windows.
|
||||
|
||||
**21.[Darktable][55]** (RAW development)
|
||||
Darktable is a very complete alternative to DxO that is made by photographers for photographers. Some research projects are using it as a platform for development and testing of new image processing algorithms. It is a very active project, and I can't wait until it becomes truly cross-platform.
|
||||
|
||||
**22.[MyPaint][56]** (digital painting)
|
||||
MyPaint is like a light table for digital painting. It works well with Wacom devices, and its brush engine is particularly appreciated, so GIMP developers are looking closely at it.
|
||||
|
||||
**23.[Shutter][57]** (desktop screenshots)
|
||||
When I create tutorials, I use a lot of screenshots to illustrate them. My favorite screenshot tool for GNU/Linux is Shutter; actually, I can't find an equivalent in terms of features for Windows or Mac. One missing piece: I would like to see Shutter add a feature to create animated GIF screenshots over a few seconds.
|
||||
|
||||
I hope this has convinced you that open source software is an excellent, viable solution for A/V content producers. If you are using other open source software—or have advice about using cross-platform software and hardware—for audio and video projects, please share your ideas in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/open-source-audio-visual-production-tools
|
||||
|
||||
作者:[Antoine Thomas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ttoine
|
||||
[1]:https://opensource.com/resources/what-open-source
|
||||
[2]:https://inkscape.org/
|
||||
[3]:https://inkscape.org/en/gallery/
|
||||
[4]:https://www.gimp.org/
|
||||
[5]:https://gimp-artists.deviantart.com/gallery/
|
||||
[6]:https://krita.org/
|
||||
[7]:https://krita.org/en/features/gallery/
|
||||
[8]:https://www.scribus.net/
|
||||
[9]:https://www.scribus.net/category/made-with-scribus/
|
||||
[10]:http://rawtherapee.com/
|
||||
[11]:http://rawtherapee.com/blog/screenshots
|
||||
[12]:https://www.libreoffice.org/discover/draw/
|
||||
[13]:http://www.wacom.com/en-us
|
||||
[14]:http://www.datacolor.com/photography-design/product-overview/#workflow_2
|
||||
[15]:https://www.ardour.org/
|
||||
[16]:http://ardour.org/features.html
|
||||
[17]:http://harrisonconsoles.com/site/mixbus.html
|
||||
[18]:http://www.audacityteam.org/
|
||||
[19]:http://www.audacityteam.org/about/screenshots/
|
||||
[20]:https://lmms.io/
|
||||
[21]:https://lmms.io/showcase/
|
||||
[22]:https://www.mixxx.org/
|
||||
[23]:https://www.mixxx.org/features/
|
||||
[24]:http://www.musictri.be/Categories/Behringer/Computer-Audio/Interfaces/UMC22/p/P0AUX
|
||||
[25]:https://www.presonus.com/products/audiobox-usb
|
||||
[26]:https://us.focusrite.com/scarlett-range
|
||||
[27]:https://us.focusrite.com/usb-audio-interfaces/scarlett-2i2
|
||||
[28]:https://www.arturia.com/products/audio/audiofuse/overview
|
||||
[29]:https://en.wikipedia.org/wiki/FLAC
|
||||
[30]:https://xiph.org/vorbis/
|
||||
[31]:https://www.videolan.org/
|
||||
[32]:https://www.openshot.org/
|
||||
[33]:https://www.openshot.org/videos/
|
||||
[34]:https://shotcut.com/
|
||||
[35]:https://shotcut.org/tutorials/
|
||||
[36]:http://blendervelvets.org/
|
||||
[37]:http://blendervelvets.org/video-tutorial-new-functions-for-the-blender-velvets/
|
||||
[38]:https://natron.fr/
|
||||
[39]:https://www.youtube.com/playlist?list=PL2n8LbT_b5IeMwi3AIzqG4Rbg8y7d6Amk
|
||||
[40]:https://obsproject.com/
|
||||
[41]:https://opensource.com/article/17/7/obs-studio-pro-level-streaming
|
||||
[42]:https://opensource.com/article/17/9/equipment-recording-presentations
|
||||
[43]:https://opensource.com/article/17/9/equipment-setup-live-presentations
|
||||
[44]:https://www.blackmagicdesign.com/
|
||||
[45]:https://www.epiphan.com/
|
||||
[46]:https://www.webmproject.org/
|
||||
[47]:https://fr.gopro.com/news/gopro-open-sources-the-cineform-codec
|
||||
[48]:https://www.blender.org/
|
||||
[49]:https://www.blender.org/about/projects/
|
||||
[50]:https://www.synfig.org/
|
||||
[51]:https://www.synfig.org/#portfolio
|
||||
[52]:https://maefloresta.com/
|
||||
[53]:https://www.youtube.com/channel/UCBavSfmoZDnqZalr52QZRDw
|
||||
[54]:https://kdenlive.org/
|
||||
[55]:https://www.darktable.org/
|
||||
[56]:http://mypaint.org/
|
||||
[57]:http://shutter-project.org/
|
||||
@ -0,0 +1,96 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Easily Correct Misspelled Bash Commands In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
I know, I know! You could just hit the UP arrow to bring up the command you just ran, and navigate to the misspelled word using the LEFT/RIGHT keys, and correct the misspelled word(s), finally hit ENTER key to run it again, right? But, wait. There is another easier way to correct misspelled Bash commands in GNU/Linux. This brief tutorial explains how to do it. Read on.
|
||||
|
||||
### Correct Misspelled Bash Commands In Linux
|
||||
|
||||
Have you run a mistyped command something like below?
|
||||
```
|
||||
$ unme -r
|
||||
bash: unme: command not found
|
||||
|
||||
```
|
||||
|
||||
Did you notice? There is a typo in the above command. I missed the letter “a” in the “uname” command.
|
||||
|
||||
I have done this kind of silly mistakes in many occasions. Before I know this trick, I used to hit UP arrow to bring up the command and go to the misspelled word in the command, correct the spelling and typos and hit the ENTER key to run that command again. But believe me. The below trick is super easy to correct any typos and spelling mistakes in a command you just ran.
|
||||
|
||||
To easily correct the above misspelled command, just run:
|
||||
```
|
||||
$ ^nm^nam^
|
||||
|
||||
```
|
||||
|
||||
This will replace the characters “nm” with “nam” in the “uname” command. Cool, yeah? It’s not only corrects the typos, but also runs the command. Check the following screenshot.
|
||||
|
||||
![][2]
|
||||
|
||||
Use this trick when you made a typo in a command. Please note that it works only in Bash shell.
|
||||
|
||||
**Bonus tip:**
|
||||
|
||||
Have you ever wondered how to automatically correct spelling mistakes and typos when using “cd” command? No? It’s alright! The following trick will explain how to do it.
|
||||
|
||||
This trick will only help to correct the spelling mistakes and typos when using “cd” command.
|
||||
|
||||
Let us say, you want to switch to “Downloads” directory using command:
|
||||
```
|
||||
$ cd Donloads
|
||||
bash: cd: Donloads: No such file or directory
|
||||
|
||||
```
|
||||
|
||||
Oops! There is no such file or directory with name “Donloads”. Well, the correct name was “Downloads”. The “w” is missing in the above command.
|
||||
|
||||
To fix this issue and automatically correct the typos while using cd command, edit your **.bashrc** file:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Add the following line at end.
|
||||
```
|
||||
[...]
|
||||
shopt -s cdspell
|
||||
|
||||
```
|
||||
|
||||
Type **:wq** to save and exit the file.
|
||||
|
||||
Finally, run the following command to update the changes.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Now, if there are any typos or spelling mistakes in the path while using cd command, it will automatically corrects and land you in the correct directory.
|
||||
|
||||
![][3]
|
||||
|
||||
As you see in the above command, I intentionally made a typo (“Donloads” instead of “Downloads”), but Bash automatically detected the correct directory name and cd into it.
|
||||
|
||||
[**Fish**][4] and **Zsh** shells have this feature built-in. So, you don’t need this trick if you use them.
|
||||
|
||||
This trick, however, has some limitations. It works only if you use the correct case. In the above example, if you type “cd donloads” instead of “cd Donloads”, it won’t recognize the correct path. Also, if there were more than one letters missing in the path, it won’t work either.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/misspelled-command.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/cd-command.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
243
sources/tech/20180208 Apache Beam- a Python example.md
Normal file
243
sources/tech/20180208 Apache Beam- a Python example.md
Normal file
@ -0,0 +1,243 @@
|
||||
Apache Beam: a Python example
|
||||
======
|
||||
|
||||

|
||||
|
||||
Nowadays, being able to handle huge amounts of data can be an interesting skill: analytics, user profiling, statistics — virtually any business that needs to extrapolate information from whatever data is, in one way or another, using some big data tools or platforms.
|
||||
|
||||
One of the most interesting tool is Apache Beam, a framework that gives us the instruments to generate procedures to transform, process, aggregate, and manipulate data for our needs.
|
||||
|
||||
Let’s try and see how we can use it in a very simple scenario.
|
||||
|
||||
### The context
|
||||
|
||||
Imagine that we have a database with information about users visiting a website, with each record containing:
|
||||
|
||||
* country of the visiting user
|
||||
* duration of the visit
|
||||
* user name
|
||||
|
||||
|
||||
|
||||
We want to create some reports containing:
|
||||
|
||||
1. for each country, the **number of users** visiting the website
|
||||
2. for each country, the **average visit time**
|
||||
|
||||
|
||||
|
||||
We will use **Apache Beam** , a Google SDK (previously called Dataflow) representing a **programming model** aimed at simplifying the mechanism of large-scale data processing.
|
||||
|
||||
It’s been donated to the Apache Foundation, and called Beam because it’s able to process data in whatever form you need: **batches** and **streams** (b-eam). It gives you the chance to define **pipelines** to process real-time data ( **streams** ) and historical data ( **batches** ).
|
||||
|
||||
The pipeline definition is totally disjointed by the context that you will use to run it, so Beam gives you the chance to choose one of the supported runners you can use:
|
||||
|
||||
* Beam model: local execution of your pipeline
|
||||
* Google Cloud Dataflow: dataflow as a service
|
||||
* Apache Flink
|
||||
* Apache Spark
|
||||
* Apache Gearpump
|
||||
* Apache Hadoop MapReduce
|
||||
* JStorm
|
||||
* IBM Streams
|
||||
|
||||
|
||||
|
||||
We will be running the beam model one, which basically executes everything on your local machine.
|
||||
|
||||
### The programming model
|
||||
|
||||
Though this is not going to be a deep explanation of the DataFlow programming model, it’s necessary to understand what a pipeline is: a set of manipulations being made on an input data set that provides a new set of data. More precisely, a pipeline is made of **transforms** applied to **collections.**
|
||||
|
||||
Straight from the [Apache Beam website][1]:
|
||||
|
||||
> A pipeline encapsulates your entire data processing task, from start to finish. This includes reading input data, transforming that data, and writing output data.
|
||||
|
||||
The pipeline gets data injected from the outside and represents it as **collections** (formally named `PCollection` s ), each of them being
|
||||
|
||||
> a potentially distributed, multi-element, data set
|
||||
|
||||
When one or more `Transform` s are applied to a `PCollection`, a brand new `PCollection` is generated (and for this reason the resulting `PCollection` s are **immutable** objects).
|
||||
|
||||
The first and last step of a pipeline are, of course, the ones that can read and write data to and from several kind of storages — you can find a list [here][2].
|
||||
|
||||
### The application
|
||||
|
||||
We will have the data in a `csv` file, so the first thing we need to do is to read the contents of the file and provide a structured representation of all of the rows.
|
||||
|
||||
A generic row of the `csv` file will be like the following:
|
||||
```
|
||||
United States Of America, 0.5, John Doe
|
||||
|
||||
```
|
||||
|
||||
with the columns being the country, the visit time in seconds, and the user name, respectively.
|
||||
|
||||
Given the data we want to provide, let’s see what our pipeline will be doing and how.
|
||||
|
||||
### Read the input data set
|
||||
|
||||
The first step will be to read the input file.
|
||||
```
|
||||
with apache_beam.Pipeline(options=options) as p:
|
||||
|
||||
rows = (
|
||||
p |
|
||||
ReadFromText(input_filename) |
|
||||
apache_beam.ParDo(Split())
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
In the above context, `p` is an instance of `apache_beam.Pipeline` and the first thing that we do is to apply a built-in transform, `apache_beam.io.textio.ReadFromText` that will load the contents of the file into a `PCollection`. After this, we apply a specific logic, `Split`, to process every row in the input file and provide a more convenient representation (a dictionary, specifically).
|
||||
|
||||
Here’s the `Split` function:
|
||||
```
|
||||
class Split(apache_beam.DoFn):
|
||||
|
||||
def process(self, element):
|
||||
country, duration, user = element.split(",")
|
||||
|
||||
return [{
|
||||
'country': country,
|
||||
'duration': float(duration),
|
||||
'user': user
|
||||
}]
|
||||
|
||||
```
|
||||
|
||||
The `ParDo` transform is a core one, and, as per official Apache Beam documentation:
|
||||
|
||||
`ParDo` is useful for a variety of common data processing operations, including:
|
||||
|
||||
* **Filtering a data set.** You can use `ParDo` to consider each element in a `PCollection` and either output that element to a new collection or discard it.
|
||||
* **Formatting or type-converting each element in a data set.** If your input `PCollection` contains elements that are of a different type or format than you want, you can use `ParDo` to perform a conversion on each element and output the result to a new `PCollection`.
|
||||
* **Extracting parts of each element in a data set.** If you have a`PCollection` of records with multiple fields, for example, you can use a `ParDo` to parse out just the fields you want to consider into a new `PCollection`.
|
||||
* **Performing computations on each element in a data set.** You can use `ParDo` to perform simple or complex computations on every element, or certain elements, of a `PCollection` and output the results as a new `PCollection`.
|
||||
|
||||
|
||||
|
||||
Please read more of this [here][3].
|
||||
|
||||
### Grouping relevant information under proper keys
|
||||
|
||||
At this point, we have a list of valid rows, but we need to reorganize the information under keys that are the countries referenced by such rows. For example, if we have three rows like the following:
|
||||
|
||||
> Spain (ES), 2.2, John Doe> Spain (ES), 2.9, John Wayne> United Kingdom (UK), 4.2, Frank Sinatra
|
||||
|
||||
we need to rearrange the information like this:
|
||||
```
|
||||
{
|
||||
"Spain (ES)": [2.2, 2.9],
|
||||
"United kingdom (UK)": [4.2]
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
If we do this, we have all the information in good shape to make all the calculations we need.
|
||||
|
||||
Here we go:
|
||||
```
|
||||
timings = (
|
||||
rows |
|
||||
apache_beam.ParDo(CollectTimings()) |
|
||||
"Grouping timings" >> apache_beam.GroupByKey() |
|
||||
"Calculating average" >> apache_beam.CombineValues(
|
||||
apache_beam.combiners.MeanCombineFn()
|
||||
)
|
||||
)
|
||||
|
||||
users = (
|
||||
rows |
|
||||
apache_beam.ParDo(CollectUsers()) |
|
||||
"Grouping users" >> apache_beam.GroupByKey() |
|
||||
"Counting users" >> apache_beam.CombineValues(
|
||||
apache_beam.combiners.CountCombineFn()
|
||||
)
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
The classes `CollectTimings` and `CollectUsers` basically filter the rows that are of interest for our goal. They also rearrange each of them in the right form, that is something like:
|
||||
|
||||
> (“Spain (ES)”, 2.2)
|
||||
|
||||
At this point, we are able to use the `GroupByKey` transform, that will create a single record that, incredibly, groups all of the info that shares the same keys:
|
||||
|
||||
> (“Spain (ES)”, (2.2, 2.9))
|
||||
|
||||
Note: the key is always the first element of the tuple.
|
||||
|
||||
The very last missing bit of the logic to apply is the one that has to process the values associated to each key. The built-in transform is `apache_beam.CombineValues`, which is pretty much self explanatory.
|
||||
|
||||
The logics that are applied are `apache_beam.combiners.MeanCombineFn` and `apache_beam.combiners.CountCombineFn` respectively: the former calculates the arithmetic mean, the latter counts the element of a set.
|
||||
|
||||
For the sake of completeness, here is the definition of the two classes `CollectTimings` and `CollectUsers`:
|
||||
```
|
||||
class CollectTimings(apache_beam.DoFn):
|
||||
|
||||
def process(self, element):
|
||||
"""
|
||||
Returns a list of tuples containing country and duration
|
||||
"""
|
||||
|
||||
result = [
|
||||
(element['country'], element['duration'])
|
||||
]
|
||||
return result
|
||||
|
||||
|
||||
class CollectUsers(apache_beam.DoFn):
|
||||
|
||||
def process(self, element):
|
||||
"""
|
||||
Returns a list of tuples containing country and user name
|
||||
"""
|
||||
result = [
|
||||
(element['country'], element['user'])
|
||||
]
|
||||
return result
|
||||
|
||||
```
|
||||
|
||||
Note: the operation of applying multiple times some transforms to a given `PCollection` generates multiple brand new collections. This is called **collection branching**. It’s very well represented here:
|
||||
|
||||
Source: <https://beam.apache.org/images/design-your-pipeline-multiple-pcollections.png>
|
||||
|
||||
Basically, now we have two sets of information — the average visit time for each country and the number of users for each country. What we're missing is a single structure containing all of the information we want.
|
||||
|
||||
Also, having made a pipeline branching, we need to recompose the data. We can do this by using `CoGroupByKey`, which is nothing less than a **join** made on two or more collections that have the same keys.
|
||||
|
||||
The last two transforms are ones that format the info into `csv` entries while the other writes them to a file.
|
||||
|
||||
After this, the resulting `output.txt` file will contain rows like this one:
|
||||
|
||||
`Italy (IT),36,2.23611111111`
|
||||
|
||||
meaning that 36 people visited the website from Italy, spending, on average, 2.23 seconds on the website.
|
||||
|
||||
### The input data
|
||||
|
||||
The data used for this simulation has been procedurally generated: 10,000 rows, with a maximum of 200 different users, spending between 1 and 5 seconds on the website. This was needed to have a rough estimate on the resulting values we obtained. A new article about **pipeline testing** will probably follow.
|
||||
|
||||
### GitHub repository
|
||||
|
||||
The GitHub repository for this article is [here][4].
|
||||
|
||||
The README.md file contains everything needed to try it locally.!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/brunoripa/apache-beam-a-python-example-gapr8smod
|
||||
|
||||
作者:[Bruno Ripa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/brunoripa
|
||||
[1]:https://href.li/?https://beam.apache.org
|
||||
[2]:https://href.li/?https://beam.apache.org/documentation/programming-guide/#pipeline-io
|
||||
[3]:https://beam.apache.org/documentation/programming-guide/#pardo
|
||||
[4]:https://github.com/brunoripa/beam-example
|
||||
@ -0,0 +1,76 @@
|
||||
Become a Hollywood movie hacker with these three command line tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you ever spent time growing up watching spy thrillers, action flicks, or crime movies, you developed a clear picture in your mind of what a hacker's computer screen looked like. Rows upon rows of rapidly moving code, streams of grouped hexadecimal numbers flying past like [raining code][1] in The Matrix.
|
||||
|
||||
Perhaps there's a world map with flashing points of light and a few rapidly updating charts thrown in there for good measure. And probably a 3D rotating geometric shape, because why not? If possible, this is all shown on a ridiculous number of monitors in an ergonomically uncomfortable configuration. I think Swordfish sported seven.
|
||||
|
||||
Of course, those of us who pursued technical careers quickly realized that this was all utter nonsense. While many of us have dual monitors (or more), a dashboard of blinky, flashing data is usually pretty antithetical to focusing on work. Writing code, managing projects, and administering systems is not the same thing as day trading. Most of the situations we encounter require a great deal of thinking about the problem we're trying to solve, a good bit of communicating with stakeholders, some researching and organizing information, and very, very little [rapid-fire typing][7].
|
||||
|
||||
That doesn't mean that we sometimes don't feel like we want to be inside of one of those movies. Or maybe, we're just trying to look like we're "being productive."
|
||||
|
||||
**Side note: Of course I mean this article in jest.** If you're actually being evaluated on how busy you look, whether that's at your desk or in meetings, you've got a huge cultural problem at your workplace that needs to be addressed. A culture of manufactured busyness is a toxic culture and one that's almost certainly helping neither the company nor its employees.
|
||||
|
||||
That said, let's have some fun and fill our screens with some panels of good old-fashioned meaningless data and code snippets. (Well, the data might have some meaning, but not without context.) While there are plenty of fancy GUIs for this (consider checking out [Hacker Typer][8] or [GEEKtyper.com][9] for a web-based version), why not just use your standard Linux terminal? For a more old-school look, consider using [Cool Retro Term][10], which is indeed what it sounds like: A cool retro terminal. I'll use Cool Retro Term for the screenshots below because it does indeed look 100% cooler.
|
||||
|
||||
### Genact
|
||||
|
||||
The first tool we'll look at is Genact. Genact simply plays back a sequence of your choosing, slowly and indefinitely, letting your code “compile” while you go out for a coffee break. The sequence it plays is up to you, but included by default are a cryptocurrency mining simulator, Composer PHP dependency manager, kernel compiler, downloader, memory dump, and more. My favorite, though, is the setting which displays SimCity loading messages. So as long as no one checks too closely, you can spend all afternoon waiting on your computer to finish reticulating splines.
|
||||
|
||||
Genact has [releases][11] available for Linux, OS X, and Windows, and the Rust [source code][12] is available on GitHub under an [MIT license][13].
|
||||
|
||||
|
||||
|
||||
### Hollywood
|
||||
|
||||
Hollywood takes a more straightforward approach. It essentially creates a random number and configuration of split screens in your terminal and launches busy looking applications like htop, directory trees, source code files, and others, and switch them out every few seconds. It's put together as a shell script, so it's fairly straightforward to modify as you wish.
|
||||
|
||||
The [source code][14] for Hollywood can be found on GitHub under an [Apache 2.0][15] license.
|
||||
|
||||
|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
My personal favorite isn't actually an application designed for this purpose. Instead, it's the demo file for a Node.js-based terminal dashboard building library called Blessed-contrib. Unlike the other two, I actually have used Blessed-contrib's library for doing something that resembles actual work, as opposed to pretend-work, as it is a quite helpful library and set of widgets for displaying information at the command line. But it's also easy to fill with dummy data to fulfill your dream of simulating the computer from WarGames.
|
||||
|
||||
The [source code][16] for Blessed-contrib can be found on GitHub under an [MIT license][17].
|
||||
|
||||
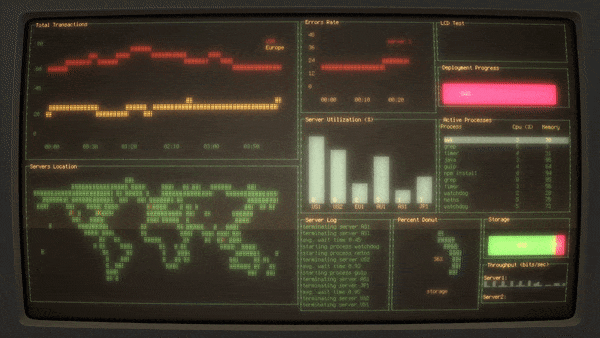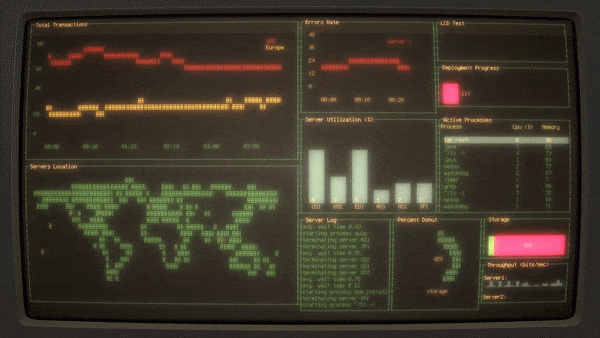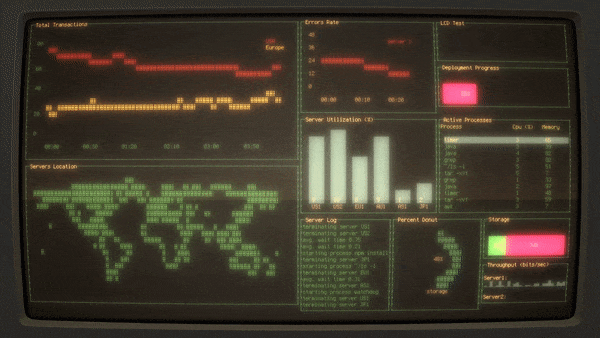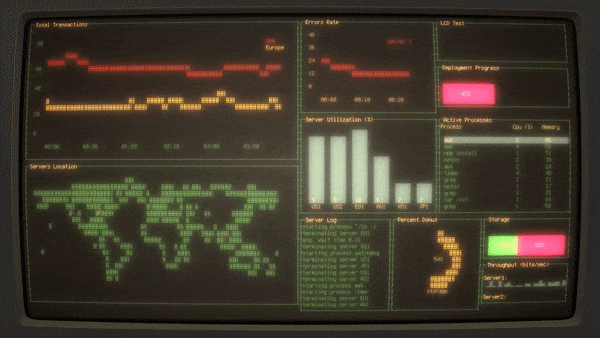
|
||||
|
||||
Of course, while these tools make it easy, there are plenty of ways to fill up your screen with nonsense. One of the most common tools you'll see in movies is Nmap, an open source security scanner. In fact, it is so overused as the tool to demonstrate on-screen hacking in Hollywood that the makers have created a page listing some of the movies it has [appeared in][18], from The Matrix Reloaded to The Bourne Ultimatum, The Girl with the Dragon Tattoo, and even Die Hard 4.
|
||||
|
||||
You can create your own combination, of course, using a terminal multiplexer like screen or tmux to fire up whatever selection of data-spitting applications you wish.
|
||||
|
||||
What's your go-to screen for looking busy?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
@ -0,0 +1,332 @@
|
||||
How to start writing macros in LibreOffice Basic
|
||||
======
|
||||
|
||||

|
||||
|
||||
I have long promised to write about the scripting language [Basic][1] and creating macros in LibreOffice. This article is devoted to the types of data used in LibreOffice Basic, and to a greater extent, descriptions of variables and the rules for using them. I will try to provide enough information for advanced as well as novice users.
|
||||
|
||||
(And, I would like to thank everyone who commented on and offered recommendations on the Russian article, especially those who helped answer difficult questions.)
|
||||
|
||||
### Variable naming conventions
|
||||
|
||||
Variable names cannot contain more than 255 characters. They should start with either upper- or lower-case letters of the Latin alphabet, and they can include underscores ("_") and numerals. Other punctuation or characters from non-Latin alphabets can cause a syntax error or a BASIC runtime error if names are not put within square brackets.
|
||||
|
||||
Here are some examples of correct variable names:
|
||||
```
|
||||
MyNumber=5
|
||||
|
||||
MyNumber5=15
|
||||
|
||||
MyNumber_5=20
|
||||
|
||||
_MyNumber=96
|
||||
|
||||
[My Number]=20.5
|
||||
|
||||
[5MyNumber]=12
|
||||
|
||||
[Number,Mine]=12
|
||||
|
||||
[DéjàVu]="It seems that I have seen it!"
|
||||
|
||||
[Моя переменная]="The first has went!"
|
||||
|
||||
[Мой % от зделки]=0.0001
|
||||
|
||||
```
|
||||
|
||||
Note: In examples that contain square brackets, if you remove the brackets, macros will show a window with an error. As you can see, you can use localized variable names. Whether it makes sense to do so is up to you.
|
||||
|
||||
### Declaring variables
|
||||
|
||||
Strictly speaking, it is not necessary to declare variables in LibreOffice Basic (except for arrays). If you write a macro from a pair of lines to work with small documents, you don't need to declare variables, as the variable will automatically be declared as the variant type. For longer macros or those that will work in large documents, it is strongly recommended that you declare variables. First, it increases the readability of the text. Second, it allows you to control variables that can greatly facilitate the search for errors. Third, the variant type is very resource-intensive, and considerable time is needed for the hidden conversion. In addition, the variant type does not choose the optimal variable type for data, which increases the workload of computer resources.
|
||||
|
||||
Basic can automatically assign a variable type by its prefix (the first letter in the name) to simplify the work if you prefer to use the Hungarian notation. For this, the statement **DefXXX** is used; **XXX** is the letter type designation. A statement with a letter will work in the module, and it must be specified before subprograms and functions appear. There are 11 types:
|
||||
```
|
||||
DefBool - for boolean variables;
|
||||
DefInt - for integer variables of type Integer;
|
||||
DefLng - for integer variables of type Long Integer;
|
||||
DefSng - for variables with a single-precision floating point;
|
||||
DefDbl - for variables with double-precision floating-point type Double;
|
||||
DefCur - for variables with a fixed point of type Currency;
|
||||
DefStr - for string variables;
|
||||
DefDate - for date and time variables;
|
||||
DefVar - for variables of Variant type;
|
||||
DefObj - for object variables;
|
||||
DefErr - for object variables containing error information.
|
||||
|
||||
```
|
||||
|
||||
If you already have an idea of the types of variables in LibreOffice Basic, you probably noticed that there is no **Byte** type in this list, but there is a strange beast with the **Error** type. Unfortunately, you just need to remember this; I have not yet discovered why this is true. This method is convenient because the type is assigned to the variables automatically. But it does not allow you to find errors related to typos in variable names. In addition, it will not be possible to specify non-Latin letters; that is, all names of variables in square brackets that need to be declared must be declared explicitly.
|
||||
|
||||
To avoid typos when using declared variables explicitly, you can use the statement **OPTION EXPLICIT**. This statement should be the first line of code in the module. All other commands, except comments, should be placed after it. This statement tells the interpreter that all variables must be declared explicitly; otherwise, it produces an error. Naturally, this statement makes it meaningless to use the **Def** statement in the code.
|
||||
|
||||
A variable is declared using the statement **Dim**. You can declare several variables simultaneously, even different types, if you separate their names with commas. To determine the type of a variable with an explicit declaration, you can use either a corresponding keyword or a type-declaration sign after the name. If a type-declaration sign or a keyword is not used after the variable, then the **Variant** type is automatically assigned to it. For example:
|
||||
```
|
||||
Dim iMyVar 'variable of Variant type
|
||||
Dim iMyVar1 As Integer, iMyVar2 As Integer 'in both cases Integer type
|
||||
Dim iMyVar3, iMyVar4 As Integer 'in this case the first variable
|
||||
'is Variant, and the second is Integer
|
||||
```
|
||||
|
||||
### Variable types
|
||||
|
||||
LibreOffice Basic supports seven classes of variables:
|
||||
|
||||
* Logical variables containing one of the values: **TRUE** or **FALSE**
|
||||
* Numeric variables containing numeric values. They can be integer, integer-positive, floating-point, and fixed-point
|
||||
* String variables containing character strings
|
||||
* Date variables can contain a date and/or time in the internal format
|
||||
* Object variables can contain objects of different types and structures
|
||||
* Arrays
|
||||
* Abstract type **Variant**
|
||||
|
||||
|
||||
|
||||
#### Logical variables – Boolean
|
||||
|
||||
Variables of the **Boolean** type can contain only one of two values: **TRUE** or **FALSE**. In the numerical equivalent, the value FALSE corresponds to the number 0, and the value TRUE corresponds to **-1** (minus one). Any value other than zero passed to a variable of the Boolean type will be converted to **TRUE** ; that is, converted to a minus one. You can explicitly declare a variable in the following way:
|
||||
```
|
||||
Dim MyBoolVar As Boolean
|
||||
```
|
||||
|
||||
I did not find a special symbol for it. For an implicit declaration, you can use the **DefBool** statement. For example:
|
||||
```
|
||||
DefBool b 'variables beginning with b by default are the type Boolean
|
||||
```
|
||||
|
||||
The initial value of the variable is set to **FALSE**. A Boolean variable requires one byte of memory.
|
||||
|
||||
#### Integer variables
|
||||
|
||||
There are three types of integer variables: **Byte** , **Integer** , and **Long Integer**. These variables can only contain integers. When you transfer numbers with a fraction into such variables, they are rounded according to the rules of classical arithmetic (not to the larger side, as it stated in the help section). The initial value for these variables is 0 (zero).
|
||||
|
||||
#### Byte
|
||||
|
||||
Variables of the **Byte** type can contain only integer-positive values in the range from 0 to 255. Do not confuse this type with the physical size of information in bytes. Although we can write down a hexadecimal number to a variable, the word "Byte" indicates only the dimensionality of the number. You can declare a variable of this type as follows:
|
||||
```
|
||||
Dim MyByteVar As Byte
|
||||
```
|
||||
|
||||
There is no a type-declaration sign for this type. There is no the statement Def of this type. Because of its small dimension, this type will be most convenient for a loop index, the values of which do not go beyond the range. A **Byte** variable requires one byte of memory.
|
||||
|
||||
#### Integer
|
||||
|
||||
Variables of the Integer type can contain integer values from -32768 to 32767. They are convenient for fast calculations in integers and are suitable for a loop index. **%** is a type-declaration sign. You can declare a variable of this type in the following ways:
|
||||
```
|
||||
Dim MyIntegerVar%
|
||||
Dim MyIntegerVar As Integer
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefInt** statement. For example:
|
||||
```
|
||||
DefInt i 'variables starting with i by default have type Integer
|
||||
```
|
||||
|
||||
An Integer variable requires two bytes of memory.
|
||||
|
||||
#### Long integer
|
||||
|
||||
Variables of the Long Integer type can contain integer values from -2147483648 to 2147483647. Long Integer variables are convenient in integer calculations when the range of type Integer is insufficient for the implementation of the algorithm. **&** is a type-declaration sign. You can declare a variable of this type in the following ways:
|
||||
```
|
||||
Dim MyLongVar&
|
||||
Dim MyLongVar As Long
|
||||
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefLng** statement. For example:
|
||||
```
|
||||
DefLng l 'variables starting with l have Long by default
|
||||
```
|
||||
|
||||
A Long Integer variable requires four bytes of memory.
|
||||
|
||||
#### Numbers with a fraction
|
||||
|
||||
All variables of these types can take positive or negative values of numbers with a fraction. The initial value for them is 0 (zero). As mentioned above, if a number with a fraction is assigned to a variable capable of containing only integers, LibreOffice Basic rounds the number according to the rules of classical arithmetic.
|
||||
|
||||
#### Single
|
||||
|
||||
Single variables can take positive or negative values in the range from 3.402823x10E+38 to 1.401293x10E-38. Values of variables of this type are in single-precision floating-point format. In this format, only eight numeric characters are stored, and the rest is stored as a power of ten (the number order). In the Basic IDE debugger, you can see only 6 decimal places, but this is a blatant lie. Computations with variables of the Single type take longer than Integer variables, but they are faster than computations with variables of the Double type. A type-declaration sign is **!**. You can declare a variable of this type in the following ways:
|
||||
```
|
||||
Dim MySingleVar!
|
||||
Dim MySingleVar As Single
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefSng** statement. For example:
|
||||
```
|
||||
DefSng f 'variables starting with f have the Single type by default
|
||||
```
|
||||
|
||||
A single variable requires four bytes of memory.
|
||||
|
||||
#### Double
|
||||
|
||||
Variables of the Double type can take positive or negative values in the range from 1.79769313486231598x10E308 to 1.0x10E-307. Why such a strange range? Most likely in the interpreter, there are additional checks that lead to this situation. Values of variables of the Double type are in double-precision floating-point format and can have 15 decimal places. In the Basic IDE debugger, you can see only 14 decimal places, but this is also a blatant lie. Variables of the Double type are suitable for precise calculations. Calculations require more time than the Single type. A type-declaration sign is **#**. You can declare a variable of this type in the following ways:
|
||||
```
|
||||
Dim MyDoubleVar#
|
||||
Dim MyDoubleVar As Double
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefDbl** statement. For example:
|
||||
```
|
||||
DefDbl d 'variables beginning with d have the type Double by default
|
||||
```
|
||||
|
||||
A variable of the Double type requires 8 bytes of memory.
|
||||
|
||||
#### Currency
|
||||
|
||||
Variables of the Currency type are displayed as numbers with a fixed point and have 15 signs in the integral part of a number and 4 signs in fractional. The range of values includes numbers from -922337203685477.6874 to +92337203685477.6874. Variables of the Currency type are intended for exact calculations of monetary values. A type-declaration sign is **@**. You can declare a variable of this type in the following ways:
|
||||
```
|
||||
Dim MyCurrencyVar@
|
||||
Dim MyCurrencyVar As Currency
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefCur** statement. For example:
|
||||
```
|
||||
DefCur c 'variables beginning with c have the type Currency by default
|
||||
```
|
||||
|
||||
A Currency variable requires 8 bytes of memory.
|
||||
|
||||
#### String
|
||||
|
||||
Variables of the String type can contain strings in which each character is stored as the corresponding Unicode value. They are used to work with textual information, and in addition to printed characters (symbols), they can also contain non-printable characters. I do not know the maximum size of the line. Mike Kaganski experimentally set the value to 2147483638 characters, after which LibreOffice falls. This corresponds to almost 4 gigabytes of characters. A type-declaration sign is **$**. You can declare a variable of this type in the following ways:
|
||||
```
|
||||
Dim MyStringVar$
|
||||
Dim MyStringVar As String
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefStr** statement. For example:
|
||||
```
|
||||
DefStr s 'variables starting with s have the String type by default
|
||||
```
|
||||
|
||||
The initial value of these variables is an empty string (""). The memory required to store string variables depends on the number of characters in the variable.
|
||||
|
||||
#### Date
|
||||
|
||||
Variables of the Date type can contain only date and time values stored in the internal format. In fact, this internal format is the double-precision floating-point format (Double), where the integer part is the number of days, and the fractional is part of the day (that is, 0.00001157407 is one second). The value 0 is equal to 30.12.1899. The Basic interpreter automatically converts it to a readable version when outputting, but not when loading. You can use the Dateserial, Datevalue, Timeserial, or Timevalue functions to quickly convert to the internal format of the Date type. To extract a certain part from a variable in the Date format, you can use the Day, Month, Year, Hour, Minute, or Second functions. The internal format allows us to compare the date and time values by calculating the difference between two numbers. There is no a type-declaration sing for the Date type, so if you explicitly define it, you need to use the Date keyword.
|
||||
```
|
||||
Dim MyDateVar As Date
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefDate** statement. For example:
|
||||
```
|
||||
DefDate y 'variables starting with y have the Date type by default
|
||||
```
|
||||
|
||||
A Date variable requires 8 bytes of memory.
|
||||
|
||||
**Types of object variables**
|
||||
|
||||
We can take two variables types of LibreOffice Basic to Objects.
|
||||
|
||||
#### Objects
|
||||
|
||||
Variables of the Object type are variables that store objects. In general, the object is any isolated part of the program that has the structure, properties, and methods of access and data processing. For example, a document, a cell, a paragraph, and dialog boxes are objects. They have a name, size, properties, and methods. In turn, these objects also consist of objects, which in turn can also consist of objects. Such a "pyramid" of objects is often called an object model, and it allows us, when developing small objects, to combine them into larger ones. Through a larger object, we have access to smaller ones. This allows us to operate with our documents, to create and process them while abstracting from a specific document. There is no a type-declaration sing for the Object type, so for an explicit definition, you need to use the Object keyword.
|
||||
```
|
||||
Dim MyObjectVar As Object
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefObj** statement. For example:
|
||||
```
|
||||
DefObj o 'variables beginning with o have the type Object by default
|
||||
```
|
||||
|
||||
The variable of type Object does not store in itself an object but is only a reference to it. The initial value for this type of variables is Null.
|
||||
|
||||
#### Structures
|
||||
|
||||
The structure is essentially an object. If you look in the Basic IDE debugger, most (but not all) are the Object type. Some are not; for example, the structure of the Error has the type Error. But roughly speaking, the structures in LibreOffice Basic are simply grouped into one object variable, without special access methods. Another significant difference is that when declaring a variable of the Structure type, we must specify its name, rather than the Object. For example, if MyNewStructure is the name of a structure, the declaration of its variable will look like this:
|
||||
```
|
||||
Dim MyStructureVar As MyNewStructure
|
||||
```
|
||||
|
||||
There are a lot of built-in structures, but the user can create personal ones. Structures can be convenient when we need to operate with sets of heterogeneous information that should be treated as a single whole. For example, to create a tPerson structure:
|
||||
```
|
||||
Type tPerson
|
||||
Name As String
|
||||
Age As Integer
|
||||
Weight As Double
|
||||
End Type
|
||||
|
||||
```
|
||||
|
||||
The definition of the structure should go before subroutines and functions that use it.
|
||||
|
||||
To fill a structure, you can use, for example, the built-in structure com.sun.star.beans.PropertyValue:
|
||||
```
|
||||
Dim oProp As New com.sun.star.beans.PropertyValue
|
||||
OProp.Name = "Age" 'Set the Name
|
||||
OProp.Value = "Amy Boyer" 'Set the Property
|
||||
```
|
||||
|
||||
For a simpler filling of the structure, you can use the **With** operator.
|
||||
```
|
||||
Dim oProp As New com.sun.star.beans.PropertyValue
|
||||
With oProp
|
||||
.Name = "Age" 'Set the Name
|
||||
.Value = "Amy Boyer" 'Set the Property
|
||||
End With
|
||||
```
|
||||
|
||||
The initial value is only for each variable in the structure and corresponds to the type of the variable.
|
||||
|
||||
#### Variant
|
||||
|
||||
This is a virtual type of variables. The Variant type is automatically selected for the data to be operated on. The only problem is that the interpreter does not need to save our resources, and it does not offer the most optimal variants of variable types. For example, it does not know that 1 can be written in Byte, and 100000 in Long Integer, although it reproduces a type if the value is passed from another variable with the declared type. Also, the transformation itself is quite resource-intensive. Therefore, this type of variable is the slowest of all. If you need to declare this kind of variable, you can use the **Variant** keyword. But you can omit the type description altogether; the Variant type will be assigned automatically. There is no a type-declaration sign for this type.
|
||||
```
|
||||
Dim MyVariantVar
|
||||
Dim MyVariantVar As Variant
|
||||
```
|
||||
|
||||
For an implicit declaration, you can use the **DefVar** statement. For example:
|
||||
```
|
||||
DefVar v 'variables starting with v have the Variant type by default
|
||||
```
|
||||
|
||||
This variables type is assigned by default to all undeclared variables.
|
||||
|
||||
#### Arrays
|
||||
|
||||
Arrays are a special type of variable in the form of a data set, reminiscent of a mathematical matrix, except that the data can be of different types and allow one to access its elements by index (element number). Of course, a one-dimensional array will be similar to a column or row, and a two-dimensional array will be like a table. There is one feature of arrays in LibreOffice Basic that distinguishes it from other programming languages. Since we have an abstract type of variant, then the elements of the array do not need to be homogeneous. That is, if there is an array MyArray and it has three elements numbered from 0 to 2, and we write the name in the first element of MyArray(0), the age in the second MyArray(1), and the weight in the third MyArray(2), we can have, respectively, the following type values: String for MyArray(0), Integer for MyArray(1), and Double for MyArray(2). In this case, the array will resemble a structure with the ability to access the element by its index. Array elements can also be homogeneous: Other arrays, objects, structures, strings, or any other data type can be used in LibreOffice Basic.
|
||||
|
||||
Arrays must be declared before they are used. Although the index space can be in the range of type Integer—from -32768 to 32767—by default, the initial index is selected as 0. You can declare an array in several ways:
|
||||
|
||||
| Dim MyArrayVar(5) as string | String array with 6 elements from 0 to 5 |
|
||||
| Dim MyArrayVar$(5) | Same as the previous |
|
||||
| Dim MyArrayVar(1 To 5) as string | String array with 5 elements from 1 to 5 |
|
||||
| Dim MyArrayVar(5,5) as string | Two-dimensional array of rows with 36 elements with indexes in each level from 0 to 5 |
|
||||
| Dim MyArrayVar$(-4 To 5, -4 To 5) | Two-dimensional strings array with 100 elements with indexes in each level from -4 to 5 |
|
||||
| Dim MyArrayVar() | Empty array of the Variant type |
|
||||
|
||||
You can change the lower bound of an array (the index of the first element of the array) by default using the **Option Base** statement; that must be specified before using subprograms, functions, and defining user structures. Option Base can take only two values, 0 or 1, which must follow immediately after the keywords. The action applies only to the current module.
|
||||
|
||||
### Learn more
|
||||
|
||||
If you are just starting out in programming, Wikipedia provides general information about the [array][2], structure, and many other topics.
|
||||
|
||||
For a more in-depth study of LibreOffice Basic, [Andrew Pitonyak's][3] website is a top resource, as is the [Basic Programmer's guide][4]. You can also use the LibreOffice [online help][1]. Completed popular macros can be found in the [Macros][5] section of The Document Foundation's wiki, where you can also find additional links on the topic.
|
||||
|
||||
For more tips, or to ask questions, visit [Ask LibreOffice][6] and [OpenOffice forum][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/variables-data-types-libreoffice-basic
|
||||
|
||||
作者:[Lera Goncharuk][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tagezi
|
||||
[1]:https://helponline.libreoffice.org/latest/en-US/text/sbasic/shared/main0601.html?DbPAR=BASIC
|
||||
[2]:https://en.wikipedia.org/wiki/Array_data_structure
|
||||
[3]:http://www.pitonyak.org/book/
|
||||
[4]:https://wiki.documentfoundation.org/images/d/dd/BasicGuide_OOo3.2.0.odt
|
||||
[5]:https://wiki.documentfoundation.org/Macros
|
||||
[6]:https://ask.libreoffice.org/en/questions/scope:all/sort:activity-desc/tags:basic/page:1/
|
||||
[7]:https://forum.openoffice.org/en/forum/viewforum.php?f=20&sid=74f5894a7d7942953cd99d978d54e75b
|
||||
48
sources/tech/20180209 Gnome without chrome-gnome-shell.md
Normal file
48
sources/tech/20180209 Gnome without chrome-gnome-shell.md
Normal file
@ -0,0 +1,48 @@
|
||||
Gnome without chrome-gnome-shell
|
||||
======
|
||||
|
||||
New laptop, has a touchscreen, can be folded into a tablet, I heard gnome-shell would be a good choice of desktop environment, and I managed to tweak it enough that I can reuse existing habits.
|
||||
|
||||
I have a big problem, however, with how it encourages one to download random extensions off the internet and run them as part of the whole desktop environment. I have an even bigger problem with [gnome-core][1] having a hard dependency on [chrome-gnome-shell][2], a plugin which cannot be disabled without root editing files in `/etc`, which exposes parts of my destktop environment to websites.
|
||||
|
||||
Visit [this site][3] and it will know which extensions you have installed, and it will be able to install more. I do not trust that, I do not need that, I do not want that. I am horrified by the idea of that.
|
||||
|
||||
[I made a workaround.][4]
|
||||
|
||||
How can one do the same for firefox?
|
||||
|
||||
### Description
|
||||
|
||||
chrome-gnome-shell is a hard dependency of gnome-core, and it installs a browser plugin that one may not want, and mandates its use by system-wide chrome policies.
|
||||
|
||||
I consider having chrome-gnome-shell an unneeded increase of the attack surface of my system, in exchange for the dubious privilege of being able to download and execute, as my main user, random unreviewed code.
|
||||
|
||||
This package satifies the chrome-gnome-shell dependency, but installs nothing.
|
||||
|
||||
Note that after installing this package you need to purge chrome-gnome-shell if it was previously installed, to have it remove its chromium policy files in /etc/chromium
|
||||
|
||||
### Instructions
|
||||
```
|
||||
apt install equivs
|
||||
equivs-build contain-gnome-shell
|
||||
sudo dpkg -i contain-gnome-shell_1.0_all.deb
|
||||
sudo dpkg --purge chrome-gnome-shell
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.enricozini.org/blog/2018/debian/gnome-without-chrome-gnome-shell/
|
||||
|
||||
作者:[Enrico Zini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.enricozini.org/
|
||||
[1]:https://packages.debian.org/gnome-core
|
||||
[2]:https://packages.debian.org/chrome-gnome-shell
|
||||
[3]:https://extensions.gnome.org/
|
||||
[4]:https://salsa.debian.org/enrico/contain-gnome-shell
|
||||
@ -1,31 +1,32 @@
|
||||
KarenMrzhang Tranlating
|
||||
Linux / Unix Bash Shell List All Builtin Commands
|
||||
|
||||
Linux / Unix Bash Shell 列出所有内置命令
|
||||
======
|
||||
|
||||
Builtin commands contained within the bash shell itself. How do I list all built-in bash commands on Linux / Apple OS X / *BSD / Unix like operating systems without reading large size bash man page?
|
||||
内置命令包含在 bash shell 本身。我该如何在 Linux / Apple OS X / *BSD / Unix 上像操作系统不用去读大篇的 bash 操作说明页就可以列出所有的内置 bash 命令呢?
|
||||
|
||||
A shell builtin is nothing but command or a function, called from a shell, that is executed directly in the shell itself. The bash shell executes the command directly, without invoking another program. You can view information for Bash built-ins with help command. There are different types of built-in commands.
|
||||
一个 shell 内置函数是一个命令或一个函数,从shell中调用,它直接在shell中执行。 bash shell 是直接执行命令没有调用其他程序的。你可以使用帮助命令查看 Bash 内置命令的信息。以下是几种不同类型的内置命令。
|
||||
|
||||
|
||||
### built-in command types
|
||||
### 内置命令的类型
|
||||
|
||||
1. Bourne Shell Builtins: Builtin commands inherited from the Bourne Shell.
|
||||
2. Bash Builtins: Table of builtins specific to Bash.
|
||||
3. Modifying Shell Behavior: Builtins to modify shell attributes and optional behavior.
|
||||
4. Special Builtins: Builtin commands classified specially by POSIX.
|
||||
1. Bourne Shell 内置命令:内置命令继承自 Bourne Shell。
|
||||
2. Bash 内置命令:特定于 Bash 的内置命令表。
|
||||
3. 修改 Shell 行为:修改 shell 属性和选择行为的内置命令。
|
||||
4. 特别的内置命令:由 POSIX 特别分类的内置命令。
|
||||
|
||||
|
||||
|
||||
### How to see all bash builtins
|
||||
### 如何查看所有 bash 内置命令
|
||||
|
||||
Type the following command:
|
||||
有以下的命令:
|
||||
```
|
||||
$ help
|
||||
$ help | less
|
||||
$ help | grep read
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
样例输出:
|
||||
```
|
||||
GNU bash, version 4.1.5(1)-release (x86_64-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
@ -75,20 +76,20 @@ A star (*) next to a name means that the command is disabled.
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
### Viewing information for Bash built-ins
|
||||
### 查看 Bash 的内置命令信息
|
||||
|
||||
To get detailed info run:
|
||||
运行以下得到详细信息:
|
||||
```
|
||||
help command
|
||||
help read
|
||||
```
|
||||
To just get a list of all built-ins with a short description, execute:
|
||||
仅得到所有带简短描述的内置命令的列表,执行如下:
|
||||
|
||||
`$ help -d`
|
||||
|
||||
### Find syntax and other options for builtins
|
||||
### 查找内置命令的语法和其他选项
|
||||
|
||||
Use the following syntax ' to find out more about the builtins commands:
|
||||
使用下列语法去找出更多的相关内置命令:
|
||||
```
|
||||
help name
|
||||
help cd
|
||||
@ -98,7 +99,7 @@ help read
|
||||
help :
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
样例输出:
|
||||
```
|
||||
:: :
|
||||
Null command.
|
||||
@ -109,9 +110,9 @@ Sample outputs:
|
||||
Always succeeds
|
||||
```
|
||||
|
||||
### Find out if a command is internal (builtin) or external
|
||||
### 找出一个命令是内部的(内置的)还是外部的。
|
||||
|
||||
Use the type command or command command:
|
||||
使用类型命令或命令命令:
|
||||
```
|
||||
type -a command-name-here
|
||||
type -a cd
|
||||
@ -121,12 +122,12 @@ type -a ls
|
||||
```
|
||||
|
||||
|
||||
OR
|
||||
或者
|
||||
```
|
||||
type -a cd uname : ls uname
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
样例输出:
|
||||
```
|
||||
cd is a shell builtin
|
||||
uname is /bin/uname
|
||||
@ -141,7 +142,7 @@ l ()
|
||||
|
||||
```
|
||||
|
||||
OR
|
||||
或者
|
||||
```
|
||||
command -V ls
|
||||
command -V cd
|
||||
@ -150,16 +151,16 @@ command -V foo
|
||||
|
||||
[![View list bash built-ins command info on Linux or Unix][1]][1]
|
||||
|
||||
### about the author
|
||||
### 关于作者
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][2], [Facebook][3], [Google+][4].
|
||||
作者是网站站长的发起人和季度系统管理员和 Linux 操作系统/Unix shell 脚本教练。他与全球客户以及包括IT、教育、国防和空间研究以及非营利部门在内的各个行业合作。可以在 [Twitter][2], [Facebook][3], [Google+][4] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/linux-unix-bash-shell-list-all-builtin-commands/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[KarenMrzhang](https://github.com/KarenMrzhang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,117 +0,0 @@
|
||||
为 Linux 初学者讲解 WC 命令(6个例子)
|
||||
======
|
||||
|
||||
在命令行工作时,有时您可能想要访问一个文件中的单词数量、字节数、甚至换行数。如果您正在寻找这样做的工具,您会很高兴地知道,在 Linux 中,存在一个命令行实用程序,它被称为 -dubbed **wc** \-,它为您完成所有这些工作。在本文中,我们将通过简单易懂的例子来讨论这个工具。
|
||||
但是在我们开始之前,值得一提的是,本教程中提供的所有示例都在 Ubuntu 16.04上进行了测试。
|
||||
### Linux WC 命令
|
||||
|
||||
WC 命令打印每个输入文件的新行、字和字节数。以下是该命令行工具的语法:
|
||||
```wc [OPTION]... [FILE]...```
|
||||
|
||||
以下是 WC 人工文档的解释:
|
||||
```
|
||||
Print newline, word, and byte counts for each FILE, and a total line if more than one FILE is
|
||||
specified. A word is a non-zero-length sequence of characters delimited by white space. With no
|
||||
FILE, or when FILE is -, read standard input.
|
||||
为每个文件打印新行、单词和字节数,如果多于一个文件,则为总行指定。单词是由空格分隔的非零长度的字符序列。没有文件,或当文件为-,读取标准输入。
|
||||
```
|
||||
|
||||
下面的 Q&A 样式的示例将会让您更好地了解 WC 命令的基本用法。
|
||||
注意:在所有示例中我们将使用一个名为 ```file.txt``` 的文件作为输入文件。以下是该文件包含的内容:
|
||||
```
|
||||
hi
|
||||
hello
|
||||
how are you
|
||||
thanks.
|
||||
```
|
||||
|
||||
### Q1. 如何打印字节数
|
||||
|
||||
使用 **-c** 命令选项打印字节数.
|
||||
|
||||
**wc -c file.txt**
|
||||
|
||||
下面是这个命令在我们的系统上产生的输出:
|
||||
|
||||
[![如何打印字节数][1]][2]
|
||||
|
||||
文件包含29个字节。
|
||||
|
||||
### Q2. 如何打印字符数
|
||||
|
||||
要打印字符数,请使用 **-m** 命令行选项。
|
||||
**wc -m file.txt**
|
||||
|
||||
下面是这个命令在我们的系统上产生的输出:
|
||||
|
||||
[![如何打印字符数][3]][4]
|
||||
|
||||
文件包含29个字符。
|
||||
|
||||
### Q3. 如何打印换行数
|
||||
|
||||
使用 **-l**命令选项来打印文件中的新行数。
|
||||
|
||||
**wc -l file.txt**
|
||||
|
||||
这里是我们的例子的输出:
|
||||
|
||||
[![如何打印换行数][5]][6]
|
||||
|
||||
### Q4. 如何打印字数
|
||||
|
||||
要打印文件中的单词数量,请使用 **-w**命令选项。
|
||||
|
||||
**wc -w file.txt**
|
||||
|
||||
在我们的例子中命令的输出如下:
|
||||
[![如何打印字数][7]][8]
|
||||
|
||||
这显示文件中有6个单词。
|
||||
|
||||
### Q5. 如何打印最长行的显示宽度或长度
|
||||
|
||||
如果您想要打印输入文件中最长行的长度,请使用**-l**命令行选项。
|
||||
|
||||
**wc -L file.txt**
|
||||
|
||||
下面是在我们的案例中命令产生的结果:
|
||||
[![如何打印最长行的显示宽度或长度][9]][10]
|
||||
|
||||
所以文件中最长的行长度是11。
|
||||
### Q6. 如何从文件读取输入文件名
|
||||
|
||||
如果您有多个文件名,并且您希望 WC 从一个文件中读取它们,那么使用**\-files0-from**选项。
|
||||
**wc --files0-from=names.txt**
|
||||
|
||||
[![如何从文件读取输入文件名][11]][12]
|
||||
|
||||
因此,您可以看到 WC 命令,在示例中,文件 **file.txt**输出了行、单词和字符数三种输出模式。文件名为 **file.txt**的文件在**name.txt**文件中提及。值得一提的是,为了成功地使用这个选项,写入文件的名称应该用 NUL 终止——您可以通过键入**Ctrl + v**然后按**Ctrl +Shift+ @**来生成这个字符。
|
||||
### 结论
|
||||
|
||||
正如您所认同的一样,从理解和使用目的来看, WC 是一个简单的命令。我们已经介绍了几乎所有的命令行选项,所以您应该随时准备使用工具,在实践过程中以我们在这里解释过的内容为基础。想了解更多关于 WC 的信息,请参考它的[人工文档][13]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-wc-command-explained-for-beginners-6-examples/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-c-option.png
|
||||
[2]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-c-option.png
|
||||
[3]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-m-option.png
|
||||
[4]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-m-option.png
|
||||
[5]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-l-option.png
|
||||
[6]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-l-option.png
|
||||
[7]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-w-option.png
|
||||
[8]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-w-option.png
|
||||
[9]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-L-option.png
|
||||
[10]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-L-option.png
|
||||
[11]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/wc-file0-from-option.png
|
||||
[12]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/wc-file0-from-option.png
|
||||
[13]:https://linux.die.net/man/1/wc
|
||||
@ -1,102 +0,0 @@
|
||||
|
||||
meltdown 和 spectre 影响下的 Linux 内核状况
|
||||
============================================================
|
||||
|
||||
|
||||
截止到目前为止,每个人都知道一件关乎电脑安全的“大事”发生了,真见鬼,等每日邮报报道的时候,你就知道什么是糟糕了...
|
||||
|
||||
不管怎样,我不打算去跟进这个问题被报道出来的细节,除了告诉你问题涉及范围内的精彩的零日文章,他们应该直接发布 2018 的 Pwnie award 奖,这非常好。
|
||||
|
||||
如果你想了解我们如何在内核中解决这些问题的技术细节,你可以持续关注了不起的 lwn.net,他们会把这些细节写成文章。
|
||||
|
||||
以此同时,很多的厂商发出了相关的公告,这有一条很好的关于这些公告的摘要。
|
||||
|
||||
至于这些涉及的公司是如何处理这些问题的,这可以说是如何适当的与 Linux 内核社区保持距离的教科书般的例子。这件事涉及到的人和公司都知道发生了什么,我确定这件事最终会出现,但是目前我需要去关注的是如何修复这些涉及到的问题,然后不要去点名指责,不管我有多么的想去这么做。
|
||||
|
||||
### 你现在能做什么
|
||||
|
||||
如果你的 Linux 系统正在运行一个正常的 Linux 分布式系统,那么升级你的内核。它们都应该已经更新了,然后在接下来的几个星期里保持更新。我们会统计大量在极端情况下出现的 bug ,这个情况的测试范围是复杂的,包括庞大的受影响的各种各样的系统和工作量。如果你的 Linux 发行版没有内核升级,我坚决的建议你马上更换你使用的 Linux 发行版。
|
||||
|
||||
然而有很多的系统因为各种各样的原因(它们比起相对“传统”的公司的分布式系统更加特殊)不是在运行“正常的”Linux 分布式系统。它们依靠长期支持版本的内核升级,或者是正常稳定的内核升级,或者是内部的 franken-kernels。对于这部分人,这个状况是在你能使用的上游的内核中关于这个混乱正在发生的。
|
||||
|
||||
### Meltdown – x86
|
||||
|
||||
现在,Linux 内核树包含所有我们当前知道的为 x86 架构解决 meltdown 漏洞的修复。去开启 CONFIG_PAGE_TABLE_ISOLATION 这个内核构建选项,然后进行重构和重启,所有的设备应该就安全了。
|
||||
|
||||
然而,Linux 的代码树分支在 4.15-rc6 这个版本加上一些出色的补丁。4.15-rc7 版本要明天才会推出,里面的一些补丁会解决一些问题。但是大部分的人不会运行 -rc kernel 在一个“正常”的环境里。
|
||||
|
||||
因为这个原因,x86 内核开发者在页表隔离代码开发过程中做了一个非常好的工作,好到以至于移植到了最新推出的稳定内核,4.14,对我们要做的事而言几乎是微不足道的了。这意味着最新的 4.14版本(现在是 4.14.12 版本),是你应该正在运行的版本,4.14.13 会在接下来的几天里推出,这个更新里有一些额外的修复补丁,这些补丁是一些运行 4.14.12 内核且有启动时间问题(这是一个显而易见的问题,如果它不启动,手动把这些补丁加入更新排队中)的系统所需要的。
|
||||
|
||||
我个人要去感谢 Andy Lutomirski, Thomas Gleixner, Ingo Molnar, Borislav Petkov, Dave Hansen, Peter Zijlstra, Josh Poimboeuf, Juergen Gross, 和 Linus Torvalds。他们开发出了这些修复补丁,并且为了让我们能简单地更新到稳定版本来正常工作,还把这些补丁用一张表单融合到了上游分支里。没有这些工作,我甚至不会想要去思考到底发生了什么。
|
||||
|
||||
对于老的长期支持内核,我大量地依靠 Hugh Dickins, Dave Hansen, Jiri Kosina 和 Borislav Petkov 优秀的工作所带来的针对 4.4 到 4.9 稳定内核代码树分支的相同功能。我同样在追踪讨厌的bug和缺失的补丁方面从 Guenter Roeck, Kees Cook, Jamie Iles,以及其他很多人那里得到了极大的帮助。我要感谢 David Woodhouse, Eduardo Valentin, Laura Abbott, 和 Rik van Riel 在反向移植和集成方面的帮助,他们的帮助在许多棘手的地方是必不可少的。
|
||||
|
||||
这些长期支持版本的内核同样有 CONFIG_PAGE_TABLE_ISOLATION 这个内核构建选项,你应该开启它来获得全方面的保护。
|
||||
|
||||
主要版本 4.14 和 4.15 的移植是非常不一样的,他们会出现不同的 bug,我们现在知道了一些在工作中遇见的 VDSO 上的问题。一些特殊的虚拟机安装的时候会报一些奇怪的错,但这是只是现在出现的少部分情况,这中情况不会阻止你进行全部的升级,请让我们在稳定内核邮件列表中知道这件事。
|
||||
|
||||
如果你依赖 4.4 和 4.9 以外的内核代码树分支或是现在的 4.14,并且没有分布式支持你的话,你就太不幸了。比起你当前版本内核包含的上百个已知的漏洞和 bug,缺少补丁去解决 meltdown 问题算是一个小问题了。你现在最需要考虑的就是马上把你的系统升级到最新。
|
||||
|
||||
以此同时,臭骂那些强迫你运行一个已被废弃且不安全的内核版本的人,他们是那些需要知道这是完全不顾后果的行为的人中的一份子。
|
||||
|
||||
### Meltdown – ARM64
|
||||
|
||||
现在 ARM64 为解决 Meltdown 问题而开发的补丁还没有并入 Linux 的代码树分支,一旦 4.15 在接下来的几周里成功发布,他们就准备阶段式地并入 4.16-rc1,因为这些补丁还没有在一个已发布的 Linux 内核中,我不能把它们移植进一个稳定的内核版本里(额。。我们有这个规矩是有原因的)
|
||||
|
||||
由于它们还没有在一个已发布的内核版本中,如果你的系统是用的 ARM64 的芯片(例如 Android ),我建议你在现在所有并入 3.18,4.4 和 4.9 分支的 ARM64 补丁中选择 Android 公共内核代码树分支。
|
||||
|
||||
我强烈建议你关注这些分支,看随着时间的过去,由于测试了已并入补丁的已发布的上游内核版本,会不会有更多的修复补丁被补充进来,特别是我不知道这些补丁会在什么时候加进稳定的长期支持内核版本里。
|
||||
|
||||
对于 4.4 到 4.9 的长期支持内核版本,这些补丁有很大概率永远不会并入它们,因为需要大量的依赖性补丁。而所有的这些依赖性补丁长期以来都一直在 Android 公共内核版本中测试和合并,所以我认为现在对于 ARM 系统来说,仅仅依赖这些内核分支而不是长期支持的发行版是一个更好的主意。
|
||||
|
||||
同样需要注意的是,我合并所有的长期支持内核版本的更新到这些分支后通常会在一天之内或者这个时间点左右进行发布,所以你无论如何都要关注这些分支,来确保你的 ARM 系统是最新且安全的。
|
||||
|
||||
### Spectre
|
||||
|
||||
现在,事情变得“有趣”了...
|
||||
|
||||
再一次,如果你正在运行一个发行版的内核。一些内核融入了各种各样的声称能缓解目前大部分问题的补丁,你的内核可能就被包含在其中。如果你担心这一类的攻击的话,我建议你更新并测试看看。
|
||||
|
||||
对于上游来说,很好,现状就是仍然没有任何的上游代码树分支有合并这些类型的问题相关的修复补丁。有很多的邮件列表在讨论如何去解决这些问题的解决方案,大量的补丁在这些邮件列表中广为流传,但是它们被压在了沉重的开发下,一些补丁系列甚至没有被构建或者应用到任何已知的代码树,这些系列彼此之间相互冲突,这是常见的混乱。
|
||||
|
||||
这是由于 Spectre 问题是最近被内核开发者解决的。我们所有人都在 Meltdown 问题上工作,我们没有精确的 Spectre 问题全部的真实信息,也没有比公开发布更糟糕的情形下什么补丁会广为流传的的真实信息。
|
||||
|
||||
因为所有的这些原因,我们打算在内核社区里花上几个星期去解决这些问题并把它们合并到内核中去。修复补丁会进入到所有内核的各种各样的子系统中,而且在它们被合并后,会集成并在稳定内核的更新中发布,所以再次提醒,你最好是在你使用的内核发行版和长期支持稳定的内核发行版中选择一个并保持更新到最新版。
|
||||
|
||||
这不是最好的新闻,我知道,但是这就是现实。如果它是任意的安慰的话,它就不会显得其他的操作系统也为这些问题准备了完整的解决方案,现在整个产业都在同一条船上,我们只需要等待,并让开发者尽他们所能快地解决这些问题。
|
||||
|
||||
计划解决方案已经不重要了,但是它们中的一些还是非常好的。一些新概念会被创造出来来帮助解决这些问题,Paul Turner 提出的 Retpoline 方法就是其中的一个例子。这将是未来大量研究的一个领域,想出方法去减轻硬件中涉及的潜在问题,想在它发生前就去预言它。
|
||||
|
||||
### 其他的 arches 芯片
|
||||
|
||||
现在,我没有看见任何 x86 和 arm64 架构以外的芯片架构的补丁,有一些谣传的补丁在一些企业为其他类型的处理器准备的分配方案中广为流传。希望他们在这几周里能在表面上适当地合并到开发者那里,这件事发生的时候我不知道,如果你使用着一个特殊的架构,我建议在 arch-specific 邮件列表上问这件事来得到一个直接的回答。
|
||||
|
||||
### 结论
|
||||
|
||||
再次,更新你的内核,不要耽搁,不要停止。更新会在很长的一段时间里持续地解决这些问题。同样的,稳定和长期支持内核发行版里仍然有很多其他的bug和安全问题,他们和问题的类型无关,所以一直保持更新始终是一个好主意。
|
||||
|
||||
现在,这里有很多非常劳累、坏脾气、缺少睡眠的人,他们通常会生气地让内核开发人员竭尽全力地解决这些问题,即使这些问题完全不是他们自己造成的。请关爱这些可怜的程序猿。他们需要爱、支持和我们可以为他们免费提供的他们最爱的饮料,以此来确保我们都可以尽可能快地结束修补系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kroah.com/log/blog/2018/01/06/meltdown-status/
|
||||
|
||||
作者:[Greg Kroah-Hartman ][a]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kroah.com
|
||||
[1]:http://www.dailymail.co.uk/sciencetech/article-5238789/Intel-says-security-updates-fix-Meltdown-Spectre.html
|
||||
[2]:https://googleprojectzero.blogspot.fr/2018/01/reading-privileged-memory-with-side.html
|
||||
[3]:https://pwnies.com/
|
||||
[4]:https://lwn.net/Articles/743265/
|
||||
[5]:https://lwn.net/Articles/742999/
|
||||
[6]:https://git.kernel.org/pub/scm/linux/kernel/git/arm64/linux.git/log/?h=kpti
|
||||
[7]:https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
|
||||
[8]:https://android.googlesource.com/kernel/common/
|
||||
[9]:https://android.googlesource.com/kernel/common/+/android-3.18
|
||||
[10]:https://android.googlesource.com/kernel/common/+/android-4.4
|
||||
[11]:https://android.googlesource.com/kernel/common/+/android-4.9
|
||||
[12]:https://support.google.com/faqs/answer/7625886
|
||||
@ -0,0 +1,83 @@
|
||||
如何在 Linux/Unix 中不重启 vim 而重新加载 .vimrc 文件
|
||||
======
|
||||
|
||||
我是一位新的 vim 编辑器用户。我通常加载 ~/.vimrc 用于配置。在编辑 .vimrc 时,我需要不重启 vim 会话而重新加载它。在 Linux 或者类 Unix 系统中,如何在编辑 .vimrc 后,重新加载它而不用重启 vim?
|
||||
|
||||
vim 是免费开源并且向上兼容 vi 的编辑器。它可以用来编辑各种文本。它在编辑用 C/Perl/Python 编写的程序时特别有用。可以用它来编辑 Linux/Unix 配置文件。~/.vimrc 是你个人的 vim 初始化和自定义文件。
|
||||
|
||||
### 如何在不重启 vim 会话的情况下重新加载 .vimrc
|
||||
|
||||
在 vim 中重新加载 .vimrc 而不重新启动的流程:
|
||||
|
||||
1. 输入 `vim filename` 启动 vim
|
||||
2. 按下 `Esc` 接着输入 `:vs ~/.vimrc` 来加载 vim 配置
|
||||
3. 像这样添加自定义:
|
||||
|
||||
```
|
||||
filetype indent plugin on
|
||||
set number
|
||||
syntax on
|
||||
```
|
||||
|
||||
4. 使用 `:wq` 保存文件,并从 ~/.vimrc 窗口退出
|
||||
5. 输入下面任一命令重载 ~/.vimrc:
|
||||
|
||||
```
|
||||
:so $MYVIMRC
|
||||
```
|
||||
或者
|
||||
```
|
||||
:source ~/.vimrc
|
||||
```
|
||||
|
||||
[![How to reload .vimrc file without restarting vim][1]][1]
|
||||
图1:编辑 ~/.vimrc 并在需要的时候重载而不用退出 vim,这样你就可以继续编辑程序了
|
||||
|
||||
`:so[urce]! {file}` 这个 vim 命令会从给定的文件比如 ~/.vimrc 读取配置。这些命令是在正常模式下执行,就像你输入它们一样。当你在 :global、:argdo、 :windo、:bufdo 之后、循环中或者跟着另一个命令时,显示不会再在执行命令时更新。
|
||||
|
||||
### 如何编辑按键来编辑并重载 ~/.vimrc
|
||||
|
||||
在你的 ~/.vimrc 后面跟上这些
|
||||
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap confe :e $MYVIMRC<CR>
|
||||
"
|
||||
|
||||
Reload vims configuration file
|
||||
nnoremap confr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
现在只要按下 `Esc` 接着输入 `confe` 开编辑 ~/.vimrc。按下 `Esc` ,接着输入 `confr` 来重新加载。一些喜欢在 .vimrc 中使用 <Leader>。因此上面的映射变成:
|
||||
|
||||
```
|
||||
" Edit vimr configuration file
|
||||
nnoremap <Leader>ve :e $MYVIMRC<CR>
|
||||
"
|
||||
" Reload vimr configuration file
|
||||
nnoremap <Leader>vr :source $MYVIMRC<CR>
|
||||
```
|
||||
|
||||
<Leader> 键默认映射成 \\ 键。因此只要输入 \\ 接着 ve 就能编辑文件。按下 \\ 接着 vr 就能重载 ~/vimrc。
|
||||
这就完成了,你可以不用再重启 vim 就能重新加载 .vimrc 了。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。通过[我的 RSS/XML 订阅][5]获取**最新的系统管理、Linux/Unix 以及开源主题教程**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-reload-vimrc-file-without-restarting-vim-on-linux-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/02/How-to-reload-.vimrc-file-without-restarting-vim.jpg
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
[5]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,74 @@
|
||||
Kali Linux 是什么,你需要它吗?
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你听到一个 13 岁的黑客吹嘘它是多么的牛逼,是有可能的,因为有 Kali Linux 的存在。尽管有可能会被称为“脚本小子”,但是事实上,Kali 仍旧是安全专家手头的重要工具(或工具集)。
|
||||
|
||||
Kali 是一个基于 Debian 的 Linux 发行版。它的目标就是为了简单;在一个实用的工具包里尽可能多的包含渗透和审计工具。Kali 实现了这个目标。大多数做安全测试的开源工具都被囊括在内。
|
||||
|
||||
**相关** : [4 个极好的为隐私和案例设计的 Linux 发行版][1]
|
||||
|
||||
### 为什么是 Kali?
|
||||
|
||||
![Kali Linux Desktop][2]
|
||||
|
||||
[Kali][3] 是由 Offensive Security (https://www.offensive-security.com/)公司开发和维护的。它在安全领域是一家知名的、值得信赖的公司,它甚至还有一些受人尊敬的认证,来对安全从业人员做资格认证。
|
||||
|
||||
Kali 也是一个简便的安全解决方案。Kali 并不要求你自己去维护一个 Linux,或者收集你自己的软件和依赖。它是一个“交钥匙工程”。所有这些繁杂的工作都不需要你去考虑,因此,你只需要专注于要审计的真实工作上,而不需要去考虑准备测试系统。
|
||||
|
||||
### 如何使用它?
|
||||
|
||||
Kali 是一个 Linux 发行版。与任何一个其它的 Linux 发行版一样,你可以将它永久安装到一个硬盘上。那样它会工作的更好,但是你不能将它作为一个日常使用的操作系统。因为它是为渗透测试构建的,这就是你使用它的全部理由。
|
||||
|
||||
最好是将 Kali 制作为自启动发行版。你可以将 Kali 刻录到一张 DVD 或者是制作到一个自启动 U 盘上来运行它。你没有必要在一个 Kali 上安装任何软件或者保存任何文件。你可以在需要测试一个系统时随时来启动它。它也有非常好的灵活性,可以让运行 Kali 的机器随时运行在想要测试的网络上。
|
||||
|
||||
### Kali 可以做什么?
|
||||
|
||||
Kali 里面有很多的安全工具而不是别的。这就是它能做的事。不管怎么说,Kali 就是一个安全工具。
|
||||
|
||||
![Kali Zenmap][4]
|
||||
|
||||
它有像 NMap 和 Wireskark 这样的经典信息采集工具。
|
||||
|
||||
![Kali Linux Wireshark][5]
|
||||
|
||||
Kali 也有面向 WiFi 的工具,像 Aircrack-ng、Kismet、以及 Pixie。
|
||||
|
||||
对于破解密码,它也有像 Hydra、Crunch、Hashcat、以及 John the Ripper 这样的工具。
|
||||
|
||||
![Kali Metasploit][6]
|
||||
|
||||
还有更多的成套工具,包括 Metasploit 和 Burp Suite。
|
||||
|
||||
这些只是 Kali 缺省内置的一小部分安全工具。完整的了解这些工具需要很多的时间,但是,你可以清楚地看到许多非常流行的工具它都有。
|
||||
|
||||
### Kali 是为你准备的吗?
|
||||
|
||||
Kali 并不是为普通用户准备的。它并不是一个运行在你的笔记本电脑上的普通 Linux 发行版,而是一个很酷的“黑客操作系统“。如果你使用这个操作系统,那么你将会运行着一个缺乏安全保障的系统,因为 Kali 被设计为以 root 权限运行。它自身并不安全,并且它的配置也与普通的 Linux 发行版不一样。它是一个攻击型工具,而不是一个防御型工具。
|
||||
|
||||
Kali 并不是个玩具。你可以使用它内置的工具去做一些会产生真实伤害的危险的事(你懂的),那将给你带来很多真实的麻烦。对于一个未受到严格教育的用户来说,做一些严重违法的事情是很容易的,并且之后你就会发现自己被陷入很无助的境地。
|
||||
|
||||
说了这么多,但是,Kali 对于一个专业用户来说,它是一个极好的工具。如果你是一个网络管理员,想对你的网络做一个真实的测试,Kali 可以做到你所希望的一切事情。Kali 也有一些优秀的开发工具,用于去实时审计它们的应用程序。
|
||||
|
||||
当然,如果你正好有兴趣学习关于安全的知识,你可以在某些受控环境中去使用 Kali,它可以教你学习很多的非常优秀的知识。
|
||||
|
||||
Kali Linux 是许多优秀的安全工具的集合。对于专业用户来说,它有难以置信的好处,但是对于一些不怀好意的人来说,也可以产生很多大麻烦。小心地使用 Kali,充分利用它的巨大优势。如果不这样的话,你将在某个地方(你懂的)度过你的余生。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/what-is-kali-linux-and-do-you-need-it/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/linux-distros-designed-for-privacy-security/ "4 Great Linux Distros Designed for Privacy and Security"
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/01/kl-desktop.jpg "Kali Linux Desktop"
|
||||
[3]:https://www.offensive-security.com/kali-linux-vmware-virtualbox-image-download/
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2018/01/kl-zenmap.jpg "Kali Zenmap"
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/01/kl-wireshark.jpg "Kali Linux Wireshark"
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2018/01/kl-metasploit.jpg "Kali Metasploit"
|
||||
Loading…
Reference in New Issue
Block a user