mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
0f64de9aae
@ -1,13 +1,13 @@
|
||||
translating by StdioA
|
||||
|
||||
搭个 Web 服务器(三)
|
||||
=====================================
|
||||
|
||||
>“当我们必须创造时,才能够学到更多。” ——伯爵
|
||||
>“当我们必须创造时,才能够学到更多。” ——皮亚杰
|
||||
|
||||
在本系列的第二部分中,你创造了一个可以处理基本 HTTP GET 请求的、朴素的 WSGI 服务器。当时我问了一个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”在这篇文章中,你会找到答案。系好安全带,我们要认真起来,全速前进了!你将会体验到一段非常快速的旅程。准备好你的 Linux,Mac OS X(或者其他 *nix 系统),还有你的 Python. 本文中所有源代码均可在 [GitHub][1] 上找到。
|
||||
在本系列的[第二部分](https://linux.cn/article-7685-1.html)中,你创造了一个可以处理基本 HTTP GET 请求的、朴素的 WSGI 服务器。当时我问了一个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”在这篇文章中,你会找到答案。系好安全带,我们要认真起来,全速前进了!你将会体验到一段非常快速的旅程。准备好你的 Linux、Mac OS X(或者其他 *nix 系统),还有你的 Python。本文中所有源代码均可在 [GitHub][1] 上找到。
|
||||
|
||||
首先,我们来回顾一下 Web 服务器的基本结构,以及服务器处理来自客户端的请求时,所需的必要步骤。你在第一及第二部分中创建的轮询服务器只能够在同一时间内处理一个请求。在处理完当前请求之前,它不能够打开一个新的客户端连接。所有请求为了等待服务都需要排队,在服务繁忙时,这个队伍可能会排的很长,一些客户端可能会感到不开心。
|
||||
### 服务器的基本结构及如何处理请求
|
||||
|
||||
首先,我们来回顾一下 Web 服务器的基本结构,以及服务器处理来自客户端的请求时,所需的必要步骤。你在[第一部分](https://linux.cn/article-7662-1.html)及[第二部分](https://linux.cn/article-7685-1.html)中创建的轮询服务器只能够一次处理一个请求。在处理完当前请求之前,它不能够接受新的客户端连接。所有请求为了等待服务都需要排队,在服务繁忙时,这个队伍可能会排的很长,一些客户端可能会感到不开心。
|
||||
|
||||
|
||||
|
||||
@ -53,7 +53,7 @@ if __name__ == '__main__':
|
||||
serve_forever()
|
||||
```
|
||||
|
||||
为了观察到你的服务器在同一时间只能处理一个请求,我们对服务器的代码做一点点修改:在将响应发送至客户端之后,将程序阻塞 60 秒。这个修改只需要一行代码,来告诉服务器进程暂停 60 秒钟。
|
||||
为了观察到你的服务器在同一时间只能处理一个请求的行为,我们对服务器的代码做一点点修改:在将响应发送至客户端之后,将程序阻塞 60 秒。这个修改只需要一行代码,来告诉服务器进程暂停 60 秒钟。
|
||||
|
||||
|
||||
|
||||
@ -84,7 +84,7 @@ HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
time.sleep(60) # 睡眠语句,阻塞该进程 60 秒
|
||||
time.sleep(60) ### 睡眠语句,阻塞该进程 60 秒
|
||||
|
||||
|
||||
def serve_forever():
|
||||
@ -126,88 +126,85 @@ $ curl http://localhost:8888/hello
|
||||
|
||||
|
||||
|
||||
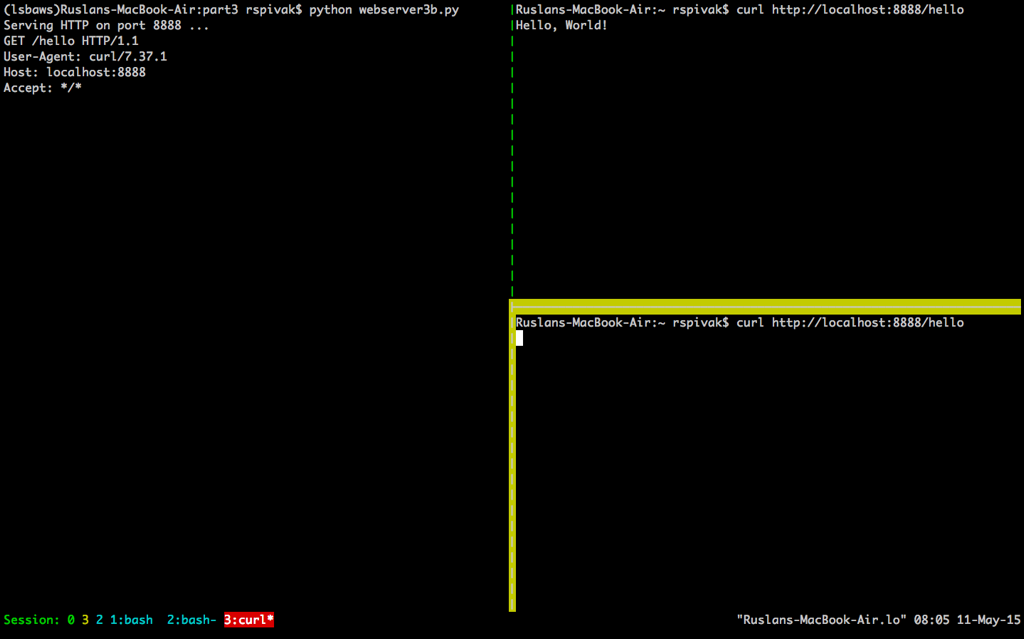
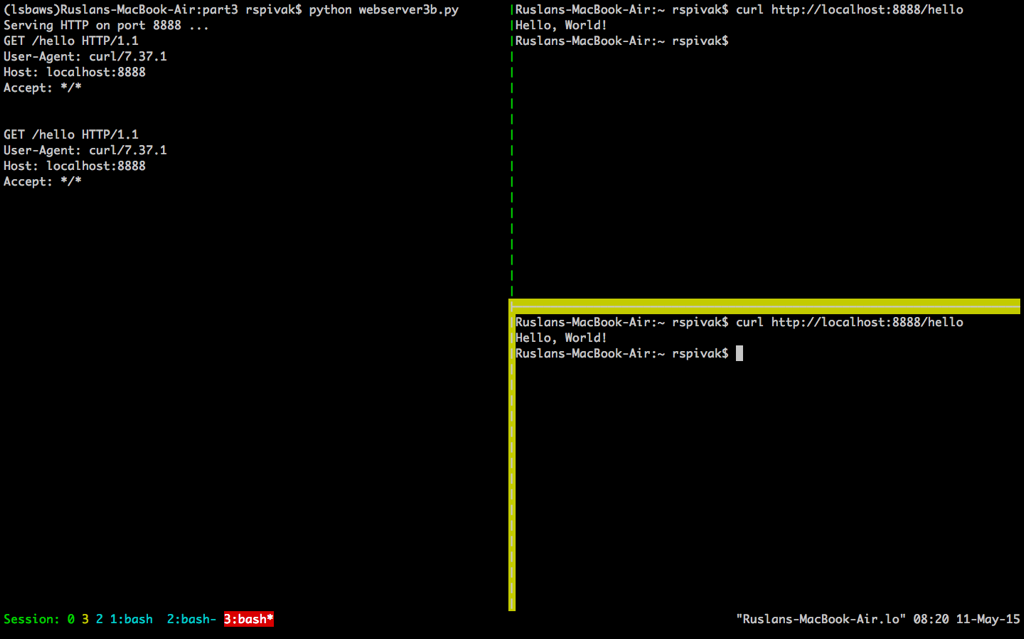
当你等待足够长的时间(60 秒以上)后,你会看到第一个 `curl` 程序完成,而第二个 `curl` 在屏幕上输出了“Hello, World!”,然后休眠 60 秒,进而停止运行。
|
||||
当你等待足够长的时间(60 秒以上)后,你会看到第一个 `curl` 程序完成,而第二个 `curl` 在屏幕上输出了“Hello, World!”,然后休眠 60 秒,进而终止。
|
||||
|
||||
|
||||
|
||||
这两个程序这样运行,是因为在服务器在处理完第一个来自 `curl` 的请求之后,只有等待 60 秒才能开始处理第二个请求。这个处理请求的过程按顺序进行(也可以说,迭代进行),一步一步进行,在我们刚刚给出的例子中,在同一时间内只能处理一个请求。
|
||||
这样运行的原因是因为在服务器在处理完第一个来自 `curl` 的请求之后,只有等待 60 秒才能开始处理第二个请求。这个处理请求的过程按顺序进行(也可以说,迭代进行),一步一步进行,在我们刚刚给出的例子中,在同一时间内只能处理一个请求。
|
||||
|
||||
现在,我们来简单讨论一下客户端与服务器的交流过程。为了让两个程序在网络中互相交流,它们必须使用套接字。你应当在本系列的前两部分中见过它几次了。但是,套接字是什么?
|
||||
|
||||
|
||||
|
||||
套接字是一个交互通道的端点的抽象形式,它可以让你的程序通过文件描述符来与其它程序进行交流。在这篇文章中,我只会单独讨论 Linux 或 Mac OS X 中的 TCP/IP 套接字。这里有一个重点概念需要你去理解:TCP 套接字对。
|
||||
套接字(socket)是一个通讯通道端点(endpoint)的抽象描述,它可以让你的程序通过文件描述符来与其它程序进行交流。在这篇文章中,我只会单独讨论 Linux 或 Mac OS X 中的 TCP/IP 套接字。这里有一个重点概念需要你去理解:TCP 套接字对(socket pair)。
|
||||
|
||||
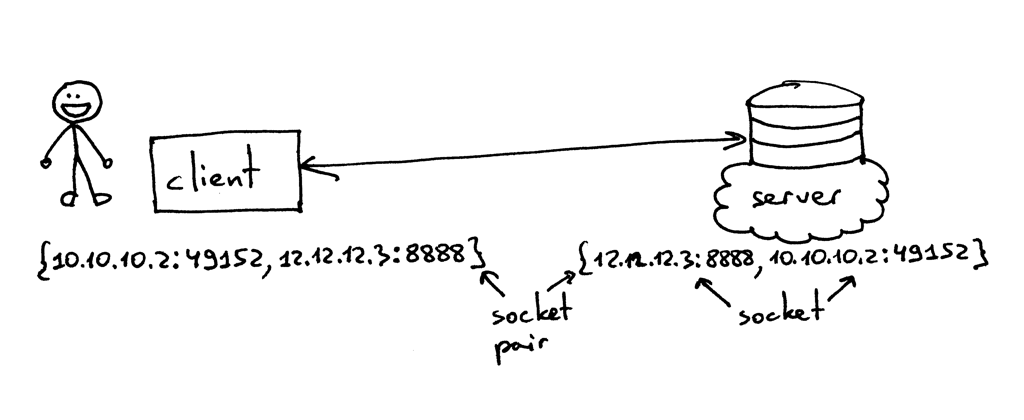
> TCP 连接使用的套接字对是一个由 4 个元素组成的元组,它确定了 TCP 连接的两端:本地 IP 地址、本地端口、远端 IP 地址及远端端口。一个套接字对独一无二地确定了网络中的每一个 TCP 连接。在连接一端的两个值:一个 IP 地址和一个端口,通常被称作一个套接字。[1][4]
|
||||
> TCP 连接使用的套接字对是一个由 4 个元素组成的元组,它确定了 TCP 连接的两端:本地 IP 地址、本地端口、远端 IP 地址及远端端口。一个套接字对唯一地确定了网络中的每一个 TCP 连接。在连接一端的两个值:一个 IP 地址和一个端口,通常被称作一个套接字。(引自[《UNIX 网络编程 卷1:套接字联网 API (第3版)》][4])
|
||||
|
||||
|
||||
|
||||
所以,元组 {10.10.10.2:49152, 12.12.12.3:8888} 就是一个能够在客户端确定 TCP 连接两端的套接字对,而元组 {12.12.12.3:8888, 10.10.10.2:49152} 则是在服务端确定 TCP 连接两端的套接字对。在这个例子中,确定 TCP 服务端的两个值(IP 地址 `12.12.12.3` 及端口 `8888`),代表一个套接字;另外两个值则代表客户端的套接字。
|
||||
所以,元组 `{10.10.10.2:49152, 12.12.12.3:8888}` 就是一个能够在客户端确定 TCP 连接两端的套接字对,而元组 `{12.12.12.3:8888, 10.10.10.2:49152}` 则是在服务端确定 TCP 连接两端的套接字对。在这个例子中,确定 TCP 服务端的两个值(IP 地址 `12.12.12.3` 及端口 `8888`),代表一个套接字;另外两个值则代表客户端的套接字。
|
||||
|
||||
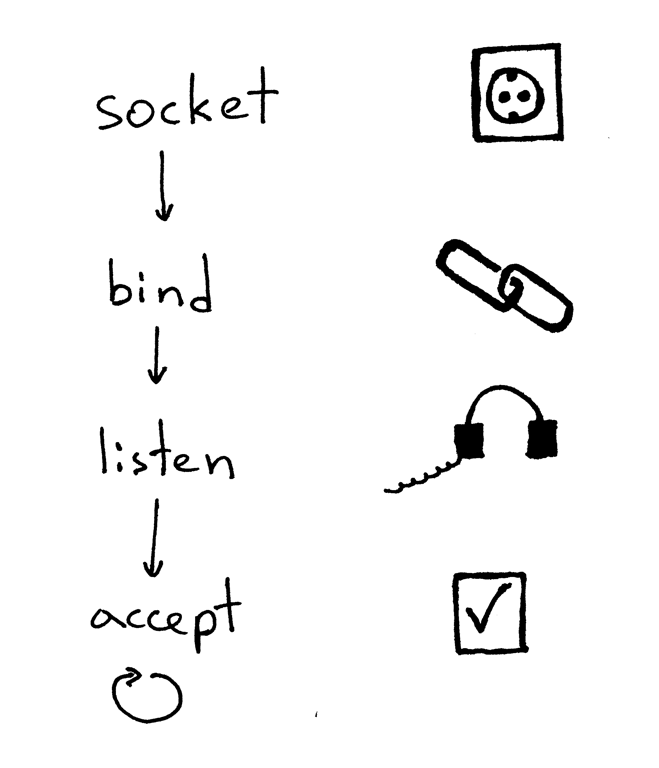
一个服务器创建一个套接字并开始建立连接的基本工作流程如下:
|
||||
|
||||
|
||||
|
||||
1. 服务器创建一个 TCP/IP 套接字。我们可以用下面那条 Python 语句来创建:
|
||||
1. 服务器创建一个 TCP/IP 套接字。我们可以用这条 Python 语句来创建:
|
||||
|
||||
```
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
```
|
||||
```
|
||||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
```
|
||||
2. 服务器可能会设定一些套接字选项(这个步骤是可选的,但是你可以看到上面的服务器代码做了设定,这样才能够在重启服务器时多次复用同一地址):
|
||||
|
||||
2. 服务器可能会设定一些套接字选项(这个步骤是可选的,但是你可以看到上面的服务器代码做了设定,这样才能够在重启服务器时多次复用同一地址)。
|
||||
|
||||
```
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
```
|
||||
|
||||
3. 然后,服务器绑定一个地址。绑定函数可以将一个本地协议地址赋给套接字。若使用 TCP 协议,调用绑定函数时,需要指定一个端口号,一个 IP 地址,或两者兼有,或两者兼无。[1][4]
|
||||
|
||||
```
|
||||
listen_socket.bind(SERVER_ADDRESS)
|
||||
```
|
||||
```
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
```
|
||||
3. 然后,服务器绑定一个地址。绑定函数 `bind` 可以将一个本地协议地址赋给套接字。若使用 TCP 协议,调用绑定函数 `bind` 时,需要指定一个端口号,一个 IP 地址,或两者兼有,或两者全无。(引自[《UNIX网络编程 卷1:套接字联网 API (第3版)》][4])
|
||||
|
||||
```
|
||||
listen_socket.bind(SERVER_ADDRESS)
|
||||
```
|
||||
4. 然后,服务器开启套接字的监听模式。
|
||||
|
||||
```
|
||||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||||
```
|
||||
```
|
||||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||||
```
|
||||
|
||||
监听函数只应在服务端调用。它会通知操作系统内核,标明它会接受所有向该套接字发送请求的链接。
|
||||
监听函数 `listen` 只应在服务端调用。它会通知操作系统内核,表明它会接受所有向该套接字发送的入站连接请求。
|
||||
|
||||
以上四步完成后,服务器将循环接收来自客户端的连接,一次循环处理一条。当有连接可用时,`accept` 函数将会返回一个已连接的客户端套接字。然后,服务器从客户端套接字中读取请求数据,将它在标准输出流中打印出来,并向客户端回送一条消息。然后,服务器会关闭这个客户端连接,并准备接收一个新的客户端连接。
|
||||
以上四步完成后,服务器将循环接收来自客户端的连接,一次循环处理一条。当有连接可用时,接受请求函数 `accept` 将会返回一个已连接的客户端套接字。然后,服务器从这个已连接的客户端套接字中读取请求数据,将数据在其标准输出流中输出出来,并向客户端回送一条消息。然后,服务器会关闭这个客户端连接,并准备接收一个新的客户端连接。
|
||||
|
||||
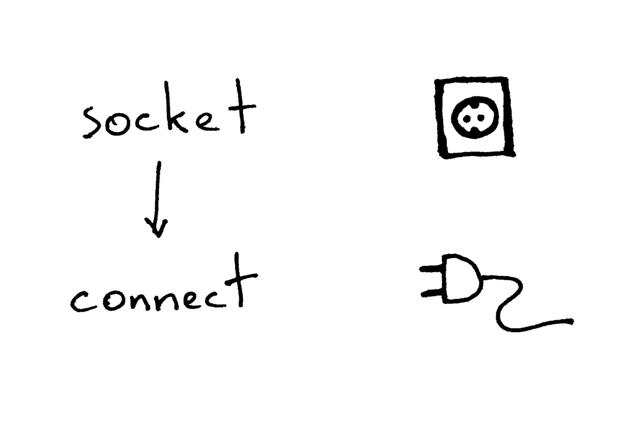
这是客户端使用 TCP/IP 协议与服务器通信的必要步骤:
|
||||
|
||||
|
||||
|
||||
下面是一段示例代码,使用这段代码,客户端可以连接你的服务器,发送一个请求,并打印响应内容:
|
||||
下面是一段示例代码,使用这段代码,客户端可以连接你的服务器,发送一个请求,并输出响应内容:
|
||||
|
||||
```
|
||||
import socket
|
||||
|
||||
# 创建一个套接字,并连接值服务器
|
||||
### 创建一个套接字,并连接值服务器
|
||||
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
sock.connect(('localhost', 8888))
|
||||
|
||||
# 发送一段数据,并接收响应数据
|
||||
### 发送一段数据,并接收响应数据
|
||||
sock.sendall(b'test')
|
||||
data = sock.recv(1024)
|
||||
print(data.decode())
|
||||
```
|
||||
|
||||
在创建套接字后,客户端需要连接至服务器。我们可以调用 `connect` 函数来完成这个操作:
|
||||
在创建套接字后,客户端需要连接至服务器。我们可以调用连接函数 `connect` 来完成这个操作:
|
||||
|
||||
```
|
||||
sock.connect(('localhost', 8888))
|
||||
```
|
||||
|
||||
客户端只需提供待连接服务器的 IP 地址(或主机名),及端口号,即可连接至远端服务器。
|
||||
客户端只需提供待连接的远程服务器的 IP 地址(或主机名),及端口号,即可连接至远端服务器。
|
||||
|
||||
你可能已经注意到了,客户端不需要调用 `bind` 及 `accept` 函数,就可以与服务器建立连接。客户端不需要调用 `bind` 函数是因为客户端不需要关注本地 IP 地址及端口号。操作系统内核中的 TCP/IP 协议栈会在客户端调用 `connect` 函数时,自动为套接字分配本地 IP 地址及本地端口号。这个本地端口被称为临时端口,也就是一个短暂开放的端口。
|
||||
你可能已经注意到了,客户端不需要调用 `bind` 及 `accept` 函数,就可以与服务器建立连接。客户端不需要调用 `bind` 函数是因为客户端不需要关注本地 IP 地址及端口号。操作系统内核中的 TCP/IP 协议栈会在客户端调用 `connect` 函数时,自动为套接字分配本地 IP 地址及本地端口号。这个本地端口被称为临时端口(ephemeral port),即一个短暂开放的端口。
|
||||
|
||||

|
||||
|
||||
服务器中有一些端口被用于承载一些众所周知的服务,它们被称作通用端口:如 80 端口用于 HTTP 服务,22 端口用于 SSH 服务。打开你的 Python shell,与你在本地运行的服务器建立一个连接,来看看内核给你的客户端套接字分配了哪个临时端口(在尝试这个例子之前,你需要运行服务器程序 `webserver3a.py` 或 `webserver3b.py`):
|
||||
服务器中有一些端口被用于承载一些众所周知的服务,它们被称作通用(well-known)端口:如 80 端口用于 HTTP 服务,22 端口用于 SSH 服务。打开你的 Python shell,与你在本地运行的服务器建立一个连接,来看看内核给你的客户端套接字分配了哪个临时端口(在尝试这个例子之前,你需要运行服务器程序 `webserver3a.py` 或 `webserver3b.py`):
|
||||
|
||||
```
|
||||
>>> import socket
|
||||
@ -222,12 +219,11 @@ sock.connect(('localhost', 8888))
|
||||
|
||||
在我开始回答我在第二部分中提出的问题之前,我还需要快速讲解一些概念。你很快就会明白这些概念为什么非常重要。这两个概念,一个是进程,另外一个是文件描述符。
|
||||
|
||||
什么是进程?进程就是一个程序执行的实体。举个例子:当你的服务器代码被执行时,它会被载入内存,而内存中表现此次程序运行的实体就叫做进程。内核记录了进程的一系列有关信息——比如进程 ID——来追踪它的运行情况。当你在执行轮询服务器 `webserver3a.py` 或 `webserver3b.py` 时,你只启动了一个进程。
|
||||
什么是进程?进程就是一个程序执行的实体。举个例子:当你的服务器代码被执行时,它会被载入内存,而内存中表现此次程序运行的实体就叫做进程。内核记录了进程的一系列有关信息——比如进程 ID——来追踪它的运行情况。当你在执行轮询服务器 `webserver3a.py` 或 `webserver3b.py` 时,你其实只是启动了一个进程。
|
||||
|
||||
|
||||
|
||||
我们在终端窗口中运行 `webserver3b.py`:
|
||||
Start the server webserver3b.py in a terminal window:
|
||||
|
||||
```
|
||||
$ python webserver3b.py
|
||||
@ -240,7 +236,7 @@ $ ps | grep webserver3b | grep -v grep
|
||||
7182 ttys003 0:00.04 python webserver3b.py
|
||||
```
|
||||
|
||||
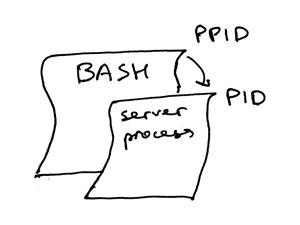
`ps` 命令显示,我们刚刚只运行了一个 Python 进程 `webserver3b`。当一个进程被创建时,内核会为其分配一个进程 ID,也就是 PID。在 UNIX 中,所有用户进程都有一个父进程;当然,这个父进程也有进程 ID,叫做父进程 ID,缩写为 PPID。假设你默认使用 BASH shell,那当你启动服务器时,一个新的进程会被启动,同时被赋予一个 PID,而它的父进程 PID 会被设为 BASH shell 的 PID。
|
||||
`ps` 命令显示,我们刚刚只运行了一个 Python 进程 `webserver3b.py`。当一个进程被创建时,内核会为其分配一个进程 ID,也就是 PID。在 UNIX 中,所有用户进程都有一个父进程;当然,这个父进程也有进程 ID,叫做父进程 ID,缩写为 PPID。假设你默认使用 BASH shell,那当你启动服务器时,就会启动一个新的进程,同时被赋予一个 PID,而它的父进程 PID 会被设为 BASH shell 的 PID。
|
||||
|
||||
|
||||
|
||||
@ -248,11 +244,11 @@ $ ps | grep webserver3b | grep -v grep
|
||||
|
||||
|
||||
|
||||
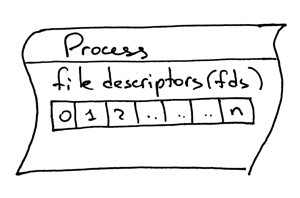
另外一个需要了解的概念,就是文件描述符。什么是文件描述符?文件描述符是一个非负整数,当进程打开一个现有文件、创建新文件或创建一个新的套接字时,内核会将这个数返回给进程。你以前可能听说过,在 UNIX 中,一切皆是文件。内核会根据一个文件描述符来为一个进程打开一个文件。当你需要读取文件或向文件写入时,我们同样通过文件描述符来定位这个文件。Python 提供了高层次的文件(或套接字)对象,所以你不需要直接通过文件描述符来定位文件。但是,在高层对象之下,我们就是用它来在 UNIX 中定位文件及套接字:整形的文件描述符。
|
||||
另外一个需要了解的概念,就是文件描述符。什么是文件描述符?文件描述符是一个非负整数,当进程打开一个现有文件、创建新文件或创建一个新的套接字时,内核会将这个数返回给进程。你以前可能听说过,在 UNIX 中,一切皆是文件。内核会按文件描述符来找到一个进程所打开的文件。当你需要读取文件或向文件写入时,我们同样通过文件描述符来定位这个文件。Python 提供了高层次的操作文件(或套接字)的对象,所以你不需要直接通过文件描述符来定位文件。但是,在高层对象之下,我们就是用它来在 UNIX 中定位文件及套接字,通过这个整数的文件描述符。
|
||||
|
||||
|
||||
|
||||
一般情况下,UNIX shell 会将一个进程的标准输入流的文件描述符设为 0,标准输出流设为 1,而标准错误打印的文件描述符会被设为 2。
|
||||
一般情况下,UNIX shell 会将一个进程的标准输入流(STDIN)的文件描述符设为 0,标准输出流(STDOUT)设为 1,而标准错误打印(STDERR)的文件描述符会被设为 2。
|
||||
|
||||
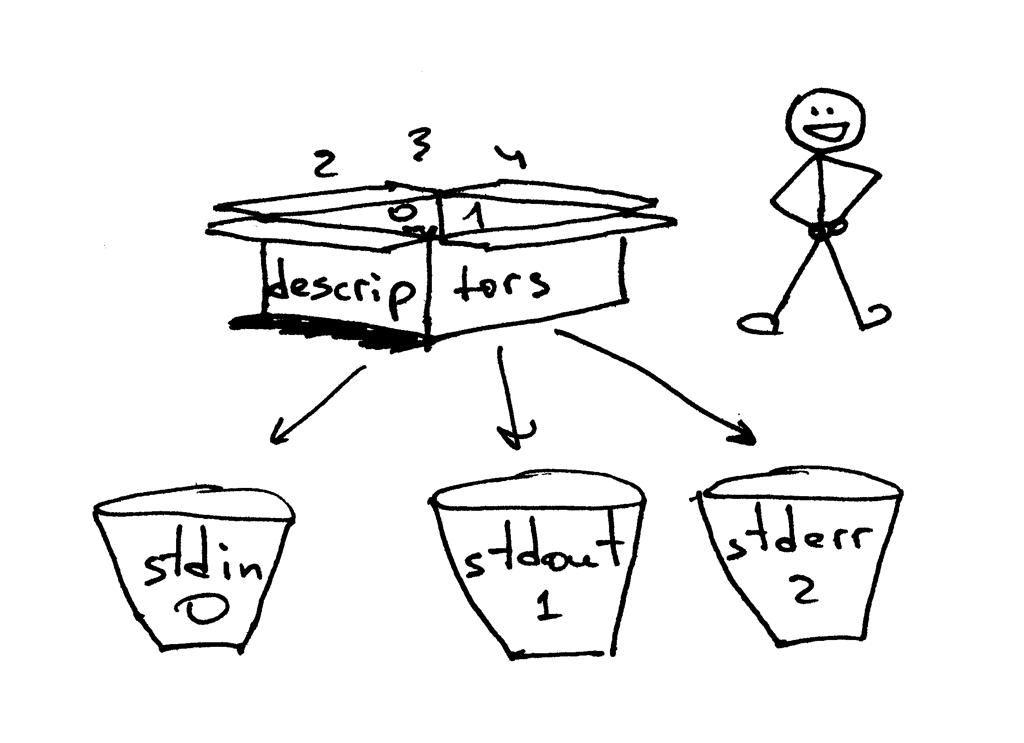
|
||||
|
||||
@ -289,7 +285,7 @@ hello
|
||||
3
|
||||
```
|
||||
|
||||
我还想再提一件事:不知道你有没有注意到,在我们的第二个轮询服务器 `webserver3b.py` 中,当你的服务器休眠 60 秒的过程中,你仍然可以通过第二个 `curl` 命令连接至服务器。当然 `curl` 命令并没有立刻输出任何内容而是挂在哪里,但是既然服务器没有接受连接,那它为什么不立即拒绝掉连接,而让它还能够继续与服务器建立连接呢?这个问题的答案是:当我在调用套接字对象的 `listen` 方法时,我为该方法提供了一个 `BACKLOG` 参数,在代码中用 `REQUEST_QUEUE_SIZE` 变量来表示。`BACKLOG` 参数决定了在内核中为存放即将到来的连接请求所创建的队列的大小。当服务器 `webserver3b.py` 被挂起的时候,你运行的第二个 `curl` 命令依然能够连接至服务器,因为内核中用来存放即将接收的连接请求的队列依然拥有足够大的可用空间。
|
||||
我还想再提一件事:不知道你有没有注意到,在我们的第二个轮询服务器 `webserver3b.py` 中,当你的服务器休眠 60 秒的过程中,你仍然可以通过第二个 `curl` 命令连接至服务器。当然 `curl` 命令并没有立刻输出任何内容而是挂在哪里,但是既然服务器没有接受连接,那它为什么不立即拒绝掉连接,而让它还能够继续与服务器建立连接呢?这个问题的答案是:当我在调用套接字对象的 `listen` 方法时,我为该方法提供了一个 `BACKLOG` 参数,在代码中用 `REQUEST_QUEUE_SIZE` 常量来表示。`BACKLOG` 参数决定了在内核中为存放即将到来的连接请求所创建的队列的大小。当服务器 `webserver3b.py` 在睡眠的时候,你运行的第二个 `curl` 命令依然能够连接至服务器,因为内核中用来存放即将接收的连接请求的队列依然拥有足够大的可用空间。
|
||||
|
||||
尽管增大 `BACKLOG` 参数并不能神奇地使你的服务器同时处理多个请求,但当你的服务器很繁忙时,将它设置为一个较大的值还是相当重要的。这样,在你的服务器调用 `accept` 方法时,不需要再等待一个新的连接建立,而可以立刻直接抓取队列中的第一个客户端连接,并不加停顿地立刻处理它。
|
||||
|
||||
@ -297,7 +293,7 @@ hello
|
||||
|
||||

|
||||
|
||||
- 迭代服务器
|
||||
- 轮询服务器
|
||||
- 服务端套接字创建流程(创建套接字,绑定,监听及接受)
|
||||
- 客户端连接创建流程(创建套接字,连接)
|
||||
- 套接字对
|
||||
@ -308,6 +304,8 @@ hello
|
||||
- 文件描述符
|
||||
- 套接字的 `listen` 方法中,`BACKLOG` 参数的含义
|
||||
|
||||
### 如何并发处理多个请求
|
||||
|
||||
现在,我可以开始回答第二部分中的那个问题了:“你该如何让你的服务器在同一时间处理多个请求呢?”或者换一种说法:“如何编写一个并发服务器?”
|
||||
|
||||
|
||||
@ -368,13 +366,13 @@ def serve_forever():
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中复制的套接字对象
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中复制的套接字对象
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0) # 子进程在这里退出
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中的客户端连接对象,并循环执行
|
||||
os._exit(0) ### 子进程在这里退出
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中的客户端连接对象,并循环执行
|
||||
|
||||
if __name__ == '__main__':
|
||||
serve_forever()
|
||||
@ -386,13 +384,13 @@ if __name__ == '__main__':
|
||||
$ python webserver3c.py
|
||||
```
|
||||
|
||||
然后,像我们之前测试轮询服务器那样,运行两个 `curl` 命令,来看看这次的效果。现在你可以看到,即使子进程在处理客户端请求后会休眠 60 秒,但它并不会影响其它客户端连接,因为他们都是由完全独立的进程来处理的。你应该看到你的 `curl` 命令立即输出了“Hello, World!”然后挂起 60 秒。你可以按照你的想法运行尽可能多的 `curl` 命令(好吧,并不能运行特别特别多 ^_^),所有的命令都会立刻输出来自服务器的响应“Hello, World!”,并不会出现任何可被察觉到的延迟行为。试试看吧。
|
||||
然后,像我们之前测试轮询服务器那样,运行两个 `curl` 命令,来看看这次的效果。现在你可以看到,即使子进程在处理客户端请求后会休眠 60 秒,但它并不会影响其它客户端连接,因为他们都是由完全独立的进程来处理的。你应该看到你的 `curl` 命令立即输出了“Hello, World!”然后挂起 60 秒。你可以按照你的想法运行尽可能多的 `curl` 命令(好吧,并不能运行特别特别多 `^_^`),所有的命令都会立刻输出来自服务器的响应 “Hello, World!”,并不会出现任何可被察觉到的延迟行为。试试看吧。
|
||||
|
||||
如果你要理解 `fork()`,那最重要的一点是:你调用了它一次,但是它会返回两次:一次在父进程中,另一次是在子进程中。当你创建了一个新进程,那么 `fork()` 在子进程中的返回值是 0。如果是在父进程中,那 `fork()` 函数会返回子进程的 PID。
|
||||
如果你要理解 `fork()`,那最重要的一点是:**你调用了它一次,但是它会返回两次** —— 一次在父进程中,另一次是在子进程中。当你创建了一个新进程,那么 `fork()` 在子进程中的返回值是 0。如果是在父进程中,那 `fork()` 函数会返回子进程的 PID。
|
||||
|
||||
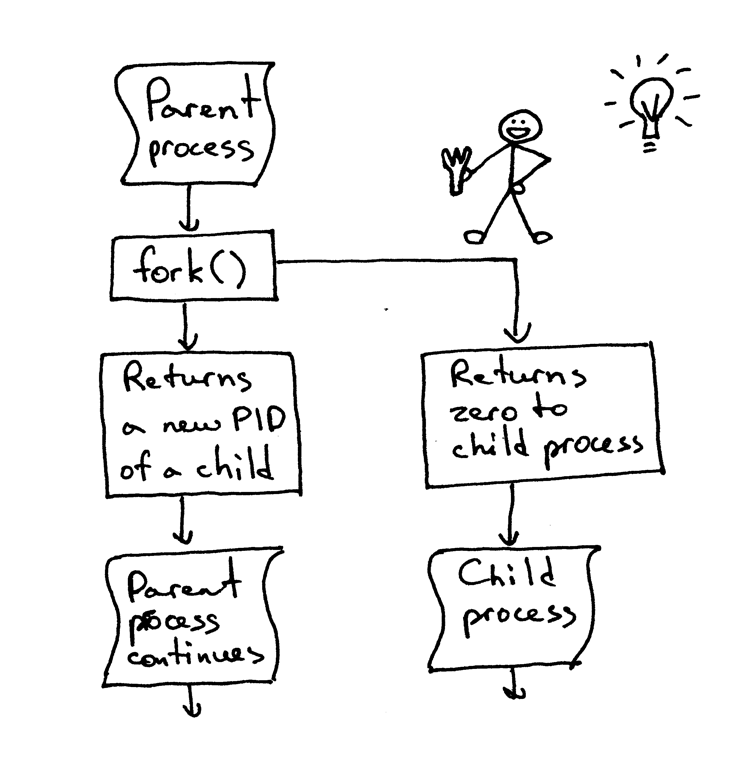
|
||||
|
||||
我依然记得在第一次看到它并尝试使用 `fork()` 的时候,我是多么的入迷。它在我眼里就像是魔法一样。这就好像我在读一段顺序执行的代码,然后“砰”地一声,代码变成了两份,然后出现了两个实体,同时并行地运行相同的代码。讲真,那个时候我觉得它真的跟魔法一样神奇。
|
||||
我依然记得在第一次看到它并尝试使用 `fork()` 的时候,我是多么的入迷。它在我眼里就像是魔法一样。这就好像我在读一段顺序执行的代码,然后“砰!”地一声,代码变成了两份,然后出现了两个实体,同时并行地运行相同的代码。讲真,那个时候我觉得它真的跟魔法一样神奇。
|
||||
|
||||
当父进程创建出一个新的子进程时,子进程会复制从父进程中复制一份文件描述符:
|
||||
|
||||
@ -401,38 +399,39 @@ $ python webserver3c.py
|
||||
你可能注意到,在上面的代码中,父进程关闭了客户端连接:
|
||||
|
||||
```
|
||||
else: # parent
|
||||
else: ### parent
|
||||
client_connection.close() # close parent copy and loop over
|
||||
```
|
||||
|
||||
不过,既然父进程关闭了这个套接字,那为什么子进程仍然能够从来自客户端的套接字中读取数据呢?答案就在上面的图片中。内核会使用描述符引用计数器来决定是否要关闭一个套接字。当你的服务器创建一个子进程时,子进程会复制父进程的所有文件描述符,内核中改描述符的引用计数也会增加。如果只有一个父进程及一个子进程,那客户端套接字的文件描述符引用数应为 2;当父进程关闭客户端连接的套接字时,内核只会减少它的引用计数,将其变为 1,但这仍然不会使内核关闭该套接字。子进程也关闭了父进程中 `listen_socket` 的复制实体,因为子进程不需要关注新的客户端连接,而只需要处理已建立的客户端连接中的请求。
|
||||
不过,既然父进程关闭了这个套接字,那为什么子进程仍然能够从来自客户端的套接字中读取数据呢?答案就在上面的图片中。内核会使用描述符引用计数器来决定是否要关闭一个套接字。当你的服务器创建一个子进程时,子进程会复制父进程的所有文件描述符,内核中该描述符的引用计数也会增加。如果只有一个父进程及一个子进程,那客户端套接字的文件描述符引用数应为 2;当父进程关闭客户端连接的套接字时,内核只会减少它的引用计数,将其变为 1,但这仍然不会使内核关闭该套接字。子进程也关闭了父进程中 `listen_socket` 的复制实体,因为子进程不需要关注新的客户端连接,而只需要处理已建立的客户端连接中的请求。
|
||||
|
||||
```
|
||||
listen_socket.close() # 关闭子进程中的复制实体
|
||||
listen_socket.close() ### 关闭子进程中的复制实体
|
||||
```
|
||||
|
||||
我们将会在后文中讨论,如果你不关闭那些重复的描述符,会发生什么。
|
||||
|
||||
你可以从你的并发服务器源码看到,父进程的主要职责为:接受一个新的客户端连接,复制出一个子进程来处理这个连接,然后继续循环来接受另外的客户端连接,仅此而已。服务器父进程并不会处理客户端连接——子进程才会做这件事。
|
||||
你可以从你的并发服务器源码中看到,父进程的主要职责为:接受一个新的客户端连接,复制出一个子进程来处理这个连接,然后继续循环来接受另外的客户端连接,仅此而已。服务器父进程并不会处理客户端连接——子进程才会做这件事。
|
||||
|
||||
打个岔:当我们说两个事件并发执行时,我们在说什么?
|
||||
A little aside. What does it mean when we say that two events are concurrent?
|
||||
打个岔:当我们说两个事件并发执行时,我们所要表达的意思是什么?
|
||||
|
||||
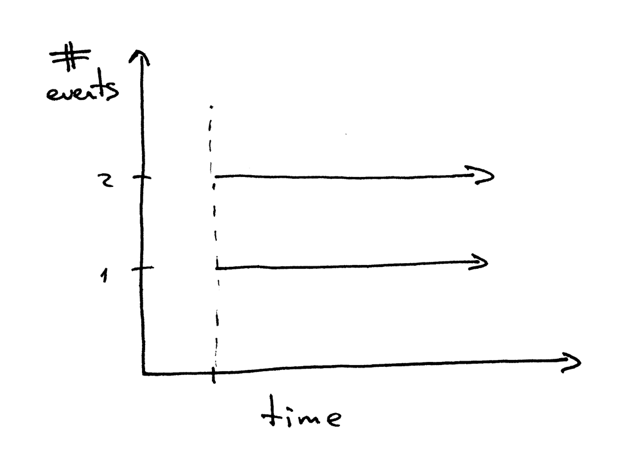
|
||||
|
||||
当我们说“两个事件并发执行”时,它通常意味着这两个事件同时发生。简单来讲,这个定义没问题,但你应该记住它的严格定义:
|
||||
|
||||
> 如果你阅读代码时,无法判断两个事件的发生顺序,那这两个事件就是并发执行的。[2][5]
|
||||
> 如果你不能在代码中判断两个事件的发生顺序,那这两个事件就是并发执行的。(引自[《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][5])
|
||||
|
||||
好的,现在你又该回顾一下你刚刚学过的知识点了。
|
||||
|
||||

|
||||
|
||||
- 在 Unix 中,编写一个并发服务器的最简单的方式——使用 `fork()` 系统调用;
|
||||
- 当一个进程复制出另一个进程时,它会变成刚刚复制出的进程的父进程;
|
||||
- 当一个进程分叉(`fork`)出另一个进程时,它会变成刚刚分叉出的进程的父进程;
|
||||
- 在进行 `fork` 调用后,父进程和子进程共享相同的文件描述符;
|
||||
- 系统内核通过描述符引用计数来决定是否要关闭该描述符对应的文件或套接字;
|
||||
- 服务器父进程的主要职责:现在它做的只是从客户端接受一个新的连接,复制出子进程来处理这个客户端连接,然后开始下一轮循环,去接收新的客户端连接。
|
||||
- 系统内核通过描述符的引用计数来决定是否要关闭该描述符对应的文件或套接字;
|
||||
- 服务器父进程的主要职责:现在它做的只是从客户端接受一个新的连接,分叉出子进程来处理这个客户端连接,然后开始下一轮循环,去接收新的客户端连接。
|
||||
|
||||
### 进程分叉后不关闭重复的套接字会发生什么?
|
||||
|
||||
我们来看看,如果我们不在父进程与子进程中关闭重复的套接字描述符会发生什么。下面是刚才的并发服务器代码的修改版本,这段代码(`webserver3d.py` 中,服务器不会关闭重复的描述符):
|
||||
|
||||
@ -470,15 +469,15 @@ def serve_forever():
|
||||
clients = []
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
# 将引用存储起来,否则在下一轮循环时,他们会被垃圾回收机制销毁
|
||||
### 将引用存储起来,否则在下一轮循环时,他们会被垃圾回收机制销毁
|
||||
clients.append(client_connection)
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的套接字
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0) # 子进程在这里结束
|
||||
else: # 父进程
|
||||
os._exit(0) ### 子进程在这里结束
|
||||
else: ### 父进程
|
||||
# client_connection.close()
|
||||
print(len(clients))
|
||||
|
||||
@ -503,7 +502,7 @@ Hello, World!
|
||||
|
||||
|
||||
|
||||
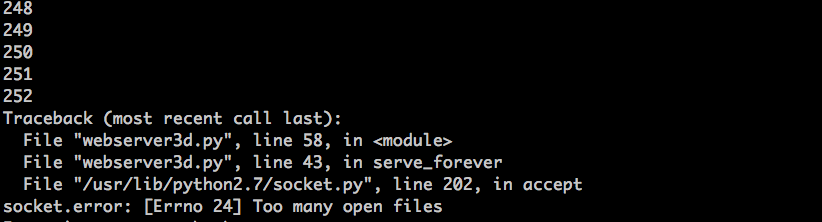
所以,为什么 `curl` 不终止呢?原因就在于多余的文件描述符。当子进程关闭客户端连接时,系统内核会减少客户端套接字的引用计数,将其变为 1。服务器子进程退出了,但客户端套接字并没有被内核关闭,因为该套接字的描述符引用计数并没有变为 0,所以,这就导致了连接终止包(在 TCP/IP 协议中称作 `FIN`)不会被发送到客户端,所以客户端会一直保持连接。这里就会出现另一个问题:如果你的服务器在长时间运行,并且不关闭重复的文件描述符,那么可用的文件描述符会被消耗殆尽:
|
||||
所以,为什么 `curl` 不终止呢?原因就在于文件描述符的副本。当子进程关闭客户端连接时,系统内核会减少客户端套接字的引用计数,将其变为 1。服务器子进程退出了,但客户端套接字并没有被内核关闭,因为该套接字的描述符引用计数并没有变为 0,所以,这就导致了连接终止包(在 TCP/IP 协议中称作 `FIN`)不会被发送到客户端,所以客户端会一直保持连接。这里也会出现另一个问题:如果你的服务器长时间运行,并且不关闭文件描述符的副本,那么可用的文件描述符会被消耗殆尽:
|
||||
|
||||
|
||||
|
||||
@ -529,7 +528,7 @@ virtual memory (kbytes, -v) unlimited
|
||||
file locks (-x) unlimited
|
||||
```
|
||||
|
||||
你可以从上面的结果看到,在我的 Ubuntu box 中,系统为我的服务器进程分配的最大可用文件描述符(文件打开)数为 1024。
|
||||
你可以从上面的结果看到,在我的 Ubuntu 机器中,系统为我的服务器进程分配的最大可用文件描述符(文件打开)数为 1024。
|
||||
|
||||
现在我们来看一看,如果你的服务器不关闭重复的描述符,它会如何消耗可用的文件描述符。在一个已有的或新建的终端窗口中,将你的服务器进程的最大可用文件描述符设为 256:
|
||||
|
||||
@ -607,15 +606,18 @@ if __name__ == '__main__':
|
||||
$ python client3.py --max-clients=300
|
||||
```
|
||||
|
||||
过一会,你的服务器就该爆炸了。这是我的环境中出现的异常截图:
|
||||
过一会,你的服务器进程就该爆了。这是我的环境中出现的异常截图:
|
||||
|
||||
|
||||
|
||||
这个例子很明显——你的服务器应该关闭重复的描述符。但是,即使你关闭了多余的描述符,你依然没有摆脱险境,因为你的服务器还有一个问题,这个问题在于“僵尸”!
|
||||
这个例子很明显——你的服务器应该关闭描述符副本。
|
||||
|
||||
#### 僵尸进程
|
||||
|
||||
但是,即使你关闭了描述符副本,你依然没有摆脱险境,因为你的服务器还有一个问题,这个问题在于“僵尸(zombies)”!
|
||||
|
||||
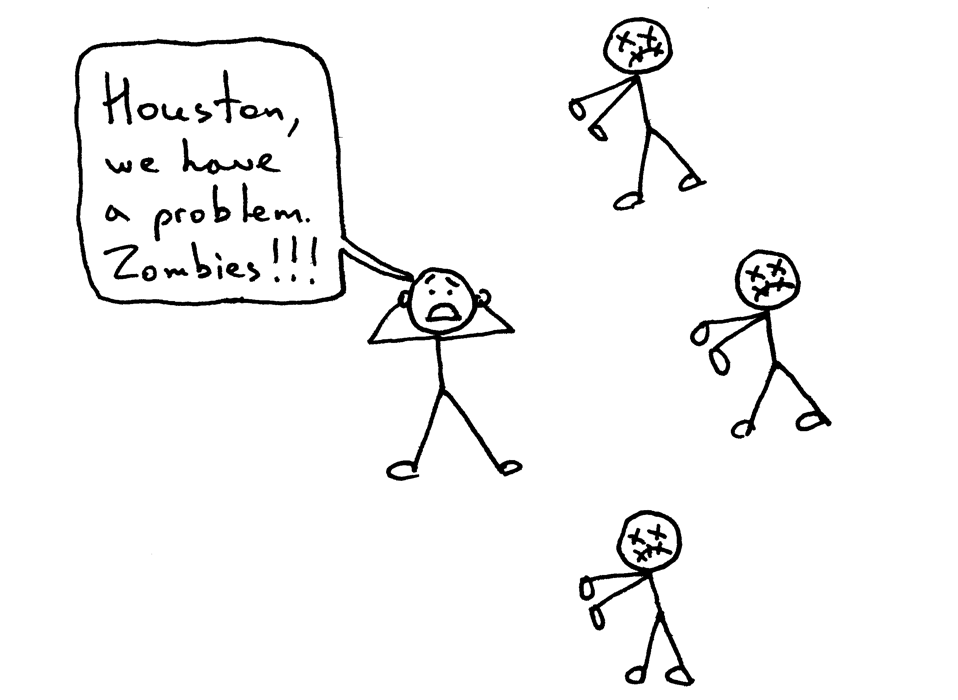
|
||||
|
||||
|
||||
没错,这个服务器代码确实在制造僵尸进程。我们来看看怎么回事。重新运行你的服务器:
|
||||
|
||||
```
|
||||
@ -636,13 +638,13 @@ vagrant 9099 0.0 1.2 31804 6256 pts/0 S+ 16:33 0:00 python webserve
|
||||
vagrant 9102 0.0 0.0 0 0 pts/0 Z+ 16:33 0:00 [python] <defunct>
|
||||
```
|
||||
|
||||
你看到第二行中,pid 为 9102,状态为 Z+,名字里面有个 `<defunct>` 的进程了吗?那就是我们的僵尸进程。这个僵尸进程的问题在于:你无法将它杀掉。
|
||||
你看到第二行中,pid 为 9102,状态为 `Z+`,名字里面有个 `<defunct>` 的进程了吗?那就是我们的僵尸进程。这个僵尸进程的问题在于:你无法将它杀掉!
|
||||
|
||||
|
||||
|
||||
就算你尝试使用 `kill -9` 来杀死僵尸进程,它们仍旧会存活。自己试试看,看看结果。
|
||||
|
||||
这个僵尸到底是什么,为什么我们的服务器会造出它们呢?一个僵尸进程是一个已经结束的进程,但它的父进程并没有等待它结束,并且也没有收到它的终结状态。如果一个进程在父进程退出之前退出,系统内核会把它变为一个僵尸进程,存储它的部分信息,以便父进程读取。内核保存的进程信息通常包括进程 ID,进程终止状态,以及进程的资源占用情况。OK,所以僵尸进程确实有存在的意义,但如果服务器不管这些僵尸进程,你的系统调用将会被阻塞。我们来看看这个要如何发生。首先,关闭你的服务器;然后,在一个新的终端窗口中,使用 `ulimit` 命令将最大用户进程数设为 400(同时,要确保你的最大可用描述符数大于这个数字,我们在这里设为 500):
|
||||
这个僵尸到底是什么,为什么我们的服务器会造出它们呢?一个僵尸进程(zombie)是一个已经结束的进程,但它的父进程并没有等待(`waited`)它结束,并且也没有收到它的终结状态。如果一个进程在父进程退出之前退出,系统内核会把它变为一个僵尸进程,存储它的部分信息,以便父进程读取。内核保存的进程信息通常包括进程 ID、进程终止状态,以及进程的资源占用情况。OK,所以僵尸进程确实有存在的意义,但如果服务器不管这些僵尸进程,你的系统将会被壅塞。我们来看看这个会如何发生。首先,关闭你运行的服务器;然后,在一个新的终端窗口中,使用 `ulimit` 命令将最大用户进程数设为 400(同时,要确保你的最大可用描述符数大于这个数字,我们在这里设为 500):
|
||||
|
||||
```
|
||||
$ ulimit -u 400
|
||||
@ -661,33 +663,35 @@ $ python webserver3d.py
|
||||
$ python client3.py --max-clients=500
|
||||
```
|
||||
|
||||
然后,过一会,你的服务器应该会再次爆炸,它会在创建新进程时抛出一个 `OSError: 资源暂时不可用` 异常。但它并没有达到系统允许的最大进程数。这是我的环境中输出的异常信息截图:
|
||||
然后,过一会,你的服务器进程应该会再次爆了,它会在创建新进程时抛出一个 `OSError: 资源暂时不可用` 的异常。但它并没有达到系统允许的最大进程数。这是我的环境中输出的异常信息截图:
|
||||
|
||||
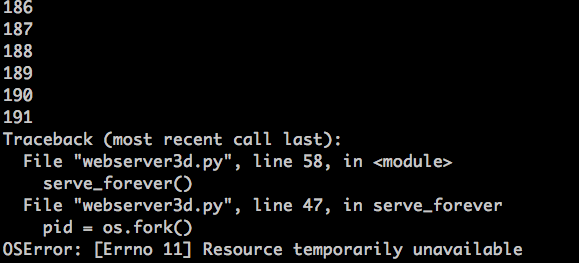
|
||||
|
||||
你可以看到,如果服务器不管僵尸进程,它们会引发问题。我会简单探讨一下僵尸进程问题的解决方案。
|
||||
你可以看到,如果服务器不管僵尸进程,它们会引发问题。接下来我会简单探讨一下僵尸进程问题的解决方案。
|
||||
|
||||
我们来回顾一下你刚刚掌握的知识点:
|
||||
|
||||

|
||||
|
||||
- 如果你不关闭重复的描述符,客户端就不会在请求处理完成后终止,因为客户端连接没有被关闭;
|
||||
- 如果你不关闭重复的描述符,长久运行的服务器最终会把可用的文件描述符(最大文件打开数)消耗殆尽;
|
||||
- 当你创建一个新进程,而父进程不等待子进程,也不在子进程结束后收集它的终止状态,它会变为一个僵尸进程;
|
||||
- 僵尸通常都会吃东西,在我们的例子中,僵尸进程会占用资源。如果你的服务器不管僵尸进程,它最终会消耗掉所有的可用进程(最大用户进程数);
|
||||
- 你不能杀死僵尸进程,你需要等待它。
|
||||
- 如果你不关闭文件描述符副本,客户端就不会在请求处理完成后终止,因为客户端连接没有被关闭;
|
||||
- 如果你不关闭文件描述符副本,长久运行的服务器最终会把可用的文件描述符(最大文件打开数)消耗殆尽;
|
||||
- 当你创建一个新进程,而父进程不等待(`wait`)子进程,也不在子进程结束后收集它的终止状态,它会变为一个僵尸进程;
|
||||
- 僵尸通常都会吃东西,在我们的例子中,僵尸进程会吃掉资源。如果你的服务器不管僵尸进程,它最终会消耗掉所有的可用进程(最大用户进程数);
|
||||
- 你不能杀死(`kill`)僵尸进程,你需要等待(`wait`)它。
|
||||
|
||||
所以,你需要做什么来处理僵尸进程呢?你需要修改你的服务器代码,来等待僵尸进程,并收集它们的终止信息。你可以在代码中使用系统调用 `wait` 来完成这个任务。不幸的是,这个方法里理想目标还很远,因为在没有终止的子进程存在的情况下调用 `wait` 会导致程序阻塞,这会阻碍你的服务器处理新的客户端连接请求。那么,我们有其他选择吗?嗯,有的,其中一个解决方案需要结合信号处理以及 `wait` 系统调用。
|
||||
### 如何处理僵尸进程?
|
||||
|
||||
所以,你需要做什么来处理僵尸进程呢?你需要修改你的服务器代码,来等待(`wait`)僵尸进程,并收集它们的终止信息。你可以在代码中使用系统调用 `wait` 来完成这个任务。不幸的是,这个方法离理想目标还很远,因为在没有终止的子进程存在的情况下调用 `wait` 会导致服务器进程阻塞,这会阻碍你的服务器处理新的客户端连接请求。那么,我们有其他选择吗?嗯,有的,其中一个解决方案需要结合信号处理以及 `wait` 系统调用。
|
||||
|
||||

|
||||
|
||||
这是它的工作流程。当一个子进程退出时,内核会发送 `SIGCHLD` 信号。父进程可以设置一个信号处理器,它可以异步响应 `SIGCHLD` 信号,并在信号响应函数中等待子进程收集终止信息,从而阻止了僵尸进程的存在。
|
||||
这是它的工作流程。当一个子进程退出时,内核会发送 `SIGCHLD` 信号。父进程可以设置一个信号处理器,它可以异步响应 `SIGCHLD` 信号,并在信号响应函数中等待(`wait`)子进程收集终止信息,从而阻止了僵尸进程的存在。
|
||||
|
||||
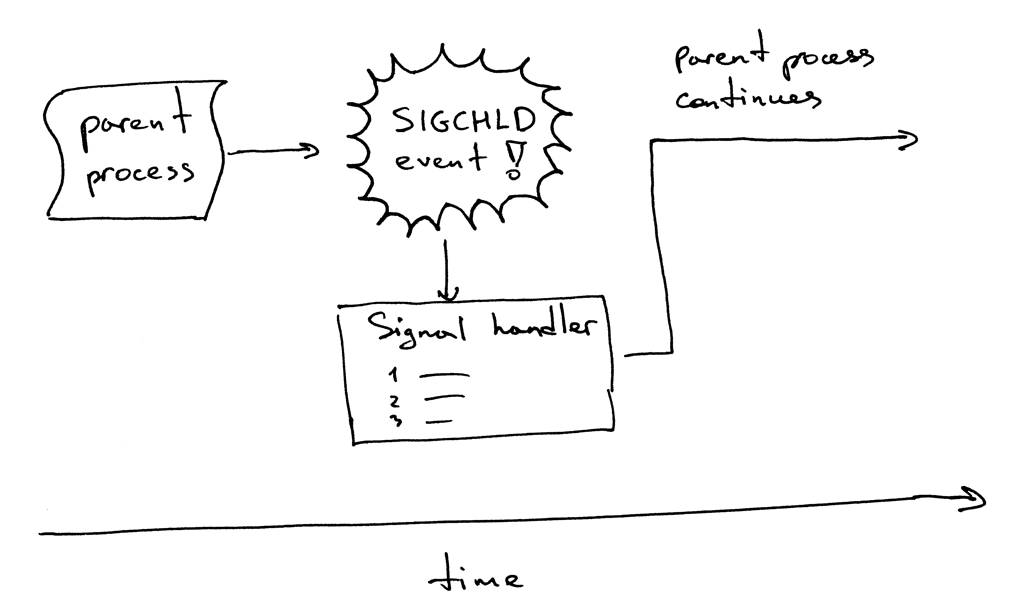
|
||||
|
||||
顺便,异步事件意味着父进程无法提前知道事件的发生时间。
|
||||
顺便说一下,异步事件意味着父进程无法提前知道事件的发生时间。
|
||||
|
||||
修改你的服务器代码,设置一个 `SIGCHLD` 信号处理器,在信号处理器中等待终止的子进程。修改后的代码如下(webserver3e.py):
|
||||
修改你的服务器代码,设置一个 `SIGCHLD` 信号处理器,在信号处理器中等待(`wait`)终止的子进程。修改后的代码如下(webserver3e.py):
|
||||
|
||||
```
|
||||
#######################################################
|
||||
@ -722,7 +726,7 @@ HTTP/1.1 200 OK
|
||||
Hello, World!
|
||||
"""
|
||||
client_connection.sendall(http_response)
|
||||
# 挂起进程,来允许父进程完成循环,并在 "accept" 处阻塞
|
||||
### 挂起进程,来允许父进程完成循环,并在 "accept" 处阻塞
|
||||
time.sleep(3)
|
||||
|
||||
|
||||
@ -738,12 +742,12 @@ def serve_forever():
|
||||
while True:
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的套接字
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
else: ### 父进程
|
||||
client_connection.close()
|
||||
|
||||
if __name__ == '__main__':
|
||||
@ -766,7 +770,7 @@ $ curl http://localhost:8888/hello
|
||||
|
||||
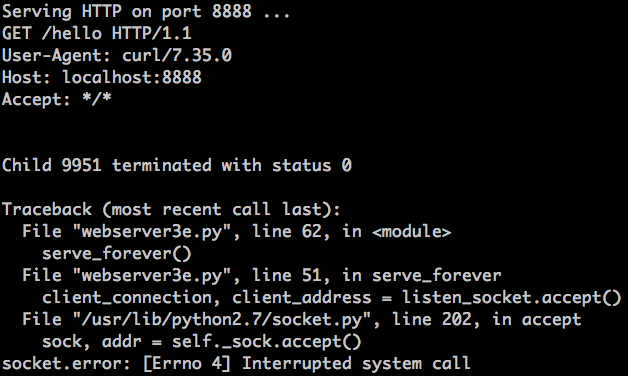
|
||||
|
||||
刚刚发生了什么?`accept` 调用失败了,错误信息为 `EINTR`
|
||||
刚刚发生了什么?`accept` 调用失败了,错误信息为 `EINTR`。
|
||||
|
||||

|
||||
|
||||
@ -822,20 +826,20 @@ def serve_forever():
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
except IOError as e:
|
||||
code, msg = e.args
|
||||
# 若 'accept' 被打断,那么重启它
|
||||
### 若 'accept' 被打断,那么重启它
|
||||
if code == errno.EINTR:
|
||||
continue
|
||||
else:
|
||||
raise
|
||||
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的描述符
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中多余的描述符,继续下一轮循环
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
@ -854,7 +858,7 @@ $ python webserver3f.py
|
||||
$ curl http://localhost:8888/hello
|
||||
```
|
||||
|
||||
看到了吗?没有 EINTR 异常出现了。现在检查一下,确保没有僵尸进程存活,调用 `wait` 函数的 `SIGCHLD` 信号处理器能够正常处理被终止的子进程。我们只需使用 `ps` 命令,然后看看现在没有处于 Z+ 状态(或名字包含 `<defunct>` )的 Python 进程就好了。很棒!僵尸进程没有了,我们很安心。
|
||||
看到了吗?没有 EINTR 异常出现了。现在检查一下,确保没有僵尸进程存活,调用 `wait` 函数的 `SIGCHLD` 信号处理器能够正常处理被终止的子进程。我们只需使用 `ps` 命令,然后看看现在没有处于 `Z+` 状态(或名字包含 `<defunct>` )的 Python 进程就好了。很棒!僵尸进程没有了,我们很安心。
|
||||
|
||||

|
||||
|
||||
@ -862,6 +866,8 @@ $ curl http://localhost:8888/hello
|
||||
- 使用 `SIGCHLD` 信号处理器可以异步地等待子进程终止,并收集其终止状态;
|
||||
- 当使用事件处理器时,你需要牢记,系统调用可能会被打断,所以你需要处理这种情况发生时带来的异常。
|
||||
|
||||
#### 正确处理 SIGCHLD 信号
|
||||
|
||||
好的,一切顺利。是不是没问题了?额,几乎是。重新尝试运行 `webserver3f.py` 但我们这次不会只发送一个请求,而是同步创建 128 个连接:
|
||||
|
||||
```
|
||||
@ -882,7 +888,7 @@ $ ps auxw | grep -i python | grep -v grep
|
||||
|
||||
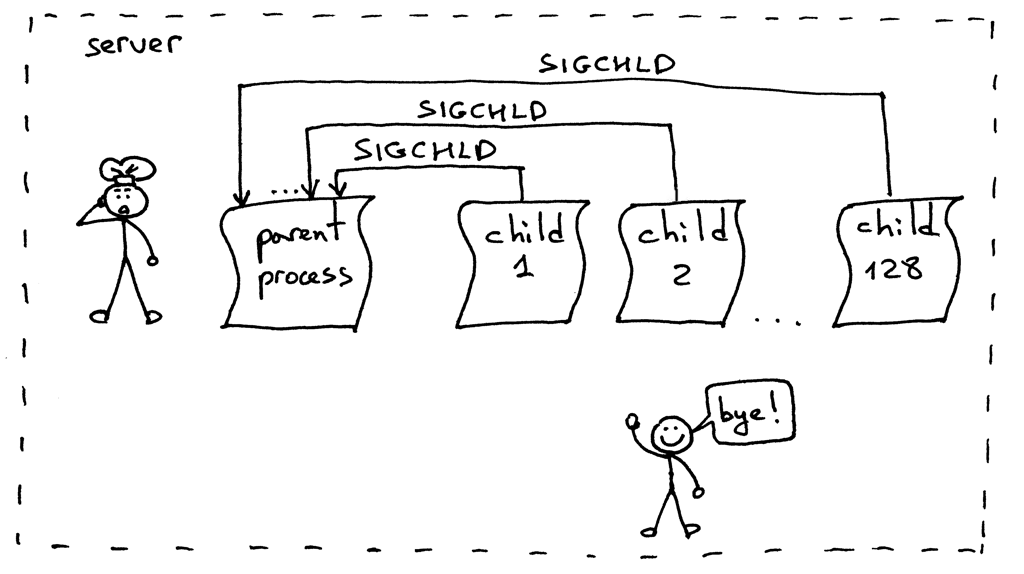
|
||||
|
||||
这个问题的解决方案依然是设置 `SIGCHLD` 事件处理器。但我们这次将会用 `WNOHANG` 参数循环调用 `waitpid`,来保证所有处于终止状态的子进程都会被处理。下面是修改后的代码,`webserver3g.py`:
|
||||
这个问题的解决方案依然是设置 `SIGCHLD` 事件处理器。但我们这次将会用 `WNOHANG` 参数循环调用 `waitpid` 来替代 `wait`,以保证所有处于终止状态的子进程都会被处理。下面是修改后的代码,`webserver3g.py`:
|
||||
|
||||
```
|
||||
#######################################################
|
||||
@ -904,13 +910,13 @@ def grim_reaper(signum, frame):
|
||||
while True:
|
||||
try:
|
||||
pid, status = os.waitpid(
|
||||
-1, # 等待所有子进程
|
||||
os.WNOHANG # 无终止进程时,不阻塞进程,并抛出 EWOULDBLOCK 错误
|
||||
-1, ### 等待所有子进程
|
||||
os.WNOHANG ### 无终止进程时,不阻塞进程,并抛出 EWOULDBLOCK 错误
|
||||
)
|
||||
except OSError:
|
||||
return
|
||||
|
||||
if pid == 0: # 没有僵尸进程存在了
|
||||
if pid == 0: ### 没有僵尸进程存在了
|
||||
return
|
||||
|
||||
|
||||
@ -939,20 +945,20 @@ def serve_forever():
|
||||
client_connection, client_address = listen_socket.accept()
|
||||
except IOError as e:
|
||||
code, msg = e.args
|
||||
# 若 'accept' 被打断,那么重启它
|
||||
### 若 'accept' 被打断,那么重启它
|
||||
if code == errno.EINTR:
|
||||
continue
|
||||
else:
|
||||
raise
|
||||
|
||||
pid = os.fork()
|
||||
if pid == 0: # 子进程
|
||||
listen_socket.close() # 关闭子进程中多余的描述符
|
||||
if pid == 0: ### 子进程
|
||||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||||
handle_request(client_connection)
|
||||
client_connection.close()
|
||||
os._exit(0)
|
||||
else: # 父进程
|
||||
client_connection.close() # 关闭父进程中多余的描述符,继续下一轮循环
|
||||
else: ### 父进程
|
||||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||||
|
||||
if __name__ == '__main__':
|
||||
serve_forever()
|
||||
@ -970,17 +976,19 @@ $ python webserver3g.py
|
||||
$ python client3.py --max-clients 128
|
||||
```
|
||||
|
||||
现在来查看一下,确保没有僵尸进程存在。耶!没有僵尸的生活真美好 ^_^
|
||||
现在来查看一下,确保没有僵尸进程存在。耶!没有僵尸的生活真美好 `^_^`。
|
||||
|
||||

|
||||
|
||||
恭喜!你刚刚经历了一段很长的旅程,我希望你能够喜欢它。现在你拥有了自己的建议并发服务器,并且这段代码能够为你在继续研究生产级 Web 服务器的路上奠定基础。
|
||||
### 大功告成
|
||||
|
||||
我将会留一个作业:你需要将第二部分中的 WSGI 服务器升级,将它改造为一个并发服务器。你可以在[这里][12]找到更改后的代码。但是,当你实现了自己的版本之后,你才应该来看我的代码。你已经拥有了实现这个服务器所需的所有信息。所以,快去实现它吧 ^_^
|
||||
恭喜!你刚刚经历了一段很长的旅程,我希望你能够喜欢它。现在你拥有了自己的简易并发服务器,并且这段代码能够为你在继续研究生产级 Web 服务器的路上奠定基础。
|
||||
|
||||
我将会留一个作业:你需要将第二部分中的 WSGI 服务器升级,将它改造为一个并发服务器。你可以在[这里][12]找到更改后的代码。但是,当你实现了自己的版本之后,你才应该来看我的代码。你已经拥有了实现这个服务器所需的所有信息。所以,快去实现它吧 `^_^`。
|
||||
|
||||
然后要做什么呢?乔希·比林斯说过:
|
||||
|
||||
> “我们应该做一枚邮票——专注于一件事,不达目的不罢休。”
|
||||
> “就像一枚邮票一样——专注于一件事,不达目的不罢休。”
|
||||
|
||||
开始学习基本知识。回顾你已经学过的知识。然后一步一步深入。
|
||||
|
||||
@ -990,13 +998,13 @@ $ python client3.py --max-clients 128
|
||||
|
||||
下面是一份书单,我从这些书中提炼出了这篇文章所需的素材。他们能助你在我刚刚所述的几个方面中发掘出兼具深度和广度的知识。我极力推荐你们去搞到这几本书看看:从你的朋友那里借,在当地的图书馆中阅读,或者直接在亚马逊上把它买回来。下面是我的典藏秘籍:
|
||||
|
||||
1. [UNIX网络编程 (卷1):套接字联网API (第3版)][6]
|
||||
2. [UNIX环境高级编程 (第3版)][7]
|
||||
3. [Linux/UNIX系统编程手册][8]
|
||||
4. [TCP/IP详解 (卷1):协议 (第2版) (爱迪生-韦斯莱专业编程系列)][9]
|
||||
5. [信号系统简明手册 (第二版): 并发控制深入浅出及常见错误][10]. 这本书也可以从[作者的个人网站][11]中买到。
|
||||
1. [《UNIX 网络编程 卷1:套接字联网 API (第3版)》][6]
|
||||
2. [《UNIX 环境高级编程(第3版)》][7]
|
||||
3. [《Linux/UNIX 系统编程手册》][8]
|
||||
4. [《TCP/IP 详解 卷1:协议(第2版)][9]
|
||||
5. [《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][10],这本书也可以从[作者的个人网站][11]中免费下载到。
|
||||
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅邮件列表,你就可以获取到这本书的最新进展,以及发布日期。
|
||||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅[原文下方的邮件列表][13],你就可以获取到这本书的最新进展,以及发布日期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1004,7 +1012,7 @@ via: https://ruslanspivak.com/lsbaws-part3/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1013,12 +1021,13 @@ via: https://ruslanspivak.com/lsbaws-part3/
|
||||
[1]: https://github.com/rspivak/lsbaws/blob/master/part3/
|
||||
[2]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3a.py
|
||||
[3]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3b.py
|
||||
[4]: https://ruslanspivak.com/lsbaws-part3/#fn:1
|
||||
[5]: https://ruslanspivak.com/lsbaws-part3/#fn:2
|
||||
[6]: http://www.amazon.com/gp/product/0131411551/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0131411551&linkCode=as2&tag=russblo0b-20&linkId=2F4NYRBND566JJQL
|
||||
[7]: http://www.amazon.com/gp/product/0321637739/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0321637739&linkCode=as2&tag=russblo0b-20&linkId=3ZYAKB537G6TM22J
|
||||
[8]: http://www.amazon.com/gp/product/1593272200/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1593272200&linkCode=as2&tag=russblo0b-20&linkId=CHFOMNYXN35I2MON
|
||||
[9]: http://www.amazon.com/gp/product/0321336313/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0321336313&linkCode=as2&tag=russblo0b-20&linkId=K467DRFYMXJ5RWAY
|
||||
[4]: http://www.epubit.com.cn/book/details/1692
|
||||
[5]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||||
[6]: http://www.epubit.com.cn/book/details/1692
|
||||
[7]: http://www.epubit.com.cn/book/details/1625
|
||||
[8]: http://www.epubit.com.cn/book/details/1432
|
||||
[9]: http://www.epubit.com.cn/book/details/4232
|
||||
[10]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||||
[11]: http://greenteapress.com/semaphores/
|
||||
[12]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3h.py
|
||||
[13]: https://ruslanspivak.com/lsbaws-part1/
|
||||
@ -0,0 +1,231 @@
|
||||
内容安全策略(CSP),防御 XSS 攻击的好助手
|
||||
=====
|
||||
|
||||
很久之前,我的个人网站被攻击了。我不知道它是如何发生的,但它确实发生了。幸运的是,攻击带来的破坏是很小的:一小段 JavaScript 被注入到了某些页面的底部。我更新了 FTP 和其它的口令,清理了一些文件,事情就这样结束了。
|
||||
|
||||
有一点使我很恼火:在当时,还没有一种简便的方案能够使我知道那里有问题,更重要的是能够保护网站的访客不被这段恼人的代码所扰。
|
||||
|
||||
现在有一种方案出现了,这种技术在上述两方面都十分的成功。它就是内容安全策略(content security policy,CSP)。
|
||||
|
||||
### 什么是 CSP?
|
||||
|
||||
其核心思想十分简单:网站通过发送一个 CSP 头部,来告诉浏览器什么是被授权执行的与什么是需要被禁止的。
|
||||
|
||||
这里有一个 PHP 的例子:
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy: <your directives>");
|
||||
?>
|
||||
```
|
||||
|
||||
#### 一些指令
|
||||
|
||||
你可以定义一些全局规则或者定义一些涉及某一类资源的规则:
|
||||
|
||||
```
|
||||
default-src 'self' ;
|
||||
# self = 同端口,同域名,同协议 => 允许
|
||||
```
|
||||
|
||||
基础参数是 `default-src`:如果没有为某一类资源设置指令规则,那么浏览器就会使用这个默认参数值。
|
||||
|
||||
```
|
||||
script-src 'self' www.google-analytics.com ;
|
||||
# 来自这些域名的 JS 文件 => 允许
|
||||
```
|
||||
|
||||
在这个例子中,我们已经授权了 www.google-analytics.com 这个域名来源的 JavaScript 文件使用到我们的网站上。我们也添加了 `'self'` 这个关键词;如果我们通过 `script-src` 来重新设置其它的规则指令,它将会覆盖 `default-src` 规则。
|
||||
|
||||
如果没有指明协议(scheme)或端口,它就会强制选择与当前页面相同的协议或端口。这样做防止了混合内容(LCTT 译注:混合内容指 HTTPS 页面中也有非 HTTPS 资源,可参见: https://developer.mozilla.org/zh-CN/docs/Security/MixedContent )。如果页面是 https://example.com,那么你将无法加载 http://www.google-analytics.com/file.js 因为它已经被禁止了(协议不匹配)。然而,有一个例外就是协议的提升是被允许的。如果 http://example.com 尝试加载 https://www.google-analytics.com/file.js,接着协议或端口允许被更改以便协议的提升。
|
||||
|
||||
```
|
||||
style-src 'self' data: ;
|
||||
# Data-Uri 嵌入 CSS => 允许
|
||||
```
|
||||
|
||||
在这个例子中,关键词 `data:` 授权了在 CSS 文件中 data 内嵌内容。
|
||||
|
||||
在 CSP 1 规范下,你也可以设置如下规则:
|
||||
|
||||
- `img-src` 有效的图片来源
|
||||
- `connect-src` 应用于 XMLHttpRequest(AJAX),WebSocket 或 EventSource
|
||||
- `font-src` 有效的字体来源
|
||||
- `object-src` 有效的插件来源(例如,`<object>`,`<embed>`,`<applet>`)
|
||||
- `media-src` 有效的 `<audio>` 和 `<video>` 来源
|
||||
|
||||
CSP 2 规范包含了如下规则:
|
||||
|
||||
- `child-src` 有效的 web workers 和 元素来源,如 `<frame>` 和 `<iframe>` (这个指令用来替代 CSP 1 中废弃了的 `frame-src` 指令)
|
||||
- `form-action` 可以作为 HTML `<form>` 的 action 的有效来源
|
||||
- `frame-ancestors` 使用 `<frame>`,`<iframe>`,`<object>`,`<embed>` 或 `<applet>` 内嵌资源的有效来源
|
||||
- `upgrade-insecure-requests` 命令用户代理来重写 URL 协议,将 HTTP 改到 HTTPS (为一些需要重写大量陈旧 URL 的网站提供了方便)。
|
||||
|
||||
为了更好的向后兼容一些废弃的属性,你可以简单的复制当前指令的内容同时为那个废弃的指令创建一个相同的副本。例如,你可以复制 `child-src` 的内容同时在 `frame-src` 中添加一份相同的副本。
|
||||
|
||||
CSP 2 允许你添加路径到白名单中(CSP 1 只允许域名被添加到白名单中)。因此,相较于将整个 www.foo.com 域添加到白名单,你可以通过添加 www.foo.com/some/folder 这样的路径到白名单中来作更多的限制。这个需要浏览器中 CSP 2 的支持,但它很明显更安全。
|
||||
|
||||
#### 一个例子
|
||||
|
||||
我为 Web 2015 巴黎大会上我的演讲 “[CSP in Action][1]”制作了一个简单的例子。
|
||||
|
||||
在没有 CSP 的情况下,页面展示如下图所示:
|
||||
|
||||

|
||||
|
||||
不是十分优美。要是我们启用了如下的 CSP 指令又会怎样呢?
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy:
|
||||
default-src 'self' ;
|
||||
script-src 'self' www.google-analytics.com stats.g.doubleclick.net ;
|
||||
style-src 'self' data: ;
|
||||
img-src 'self' www.google-analytics.com stats.g.doubleclick.net data: ;
|
||||
frame-src 'self' ;");
|
||||
?>
|
||||
```
|
||||
|
||||
浏览器将会作什么呢?它会(非常严格的)在 CSP 基础规则之下应用这些指令,这意味着**任何没有在 CSP 指令中被授权允许的都将会被禁止**(“blocked” 指的是不被执行、不被显示并且不被使用在网站中)。
|
||||
|
||||
在 CSP 的默认设置中,内联脚本和样式是不被授权的,意味着每一个 `<script>`,`onclick` 事件属性或 `style` 属性都将会被禁止。你可以使用 `style-src 'unsafe-inline' ;` 指令来授权使用内联 CSS。
|
||||
|
||||
在一个支持 CSP 的现代浏览器中,上述示例看起来如下图:
|
||||
|
||||

|
||||
|
||||
发生了什么?浏览器应用了指令并且拒绝了所有没有被授权的内容。它在浏览器调试终端中发送了这些通知:
|
||||
|
||||

|
||||
|
||||
如果你依然不确定 CSP 的价值,请看一下 Aaron Gustafson 文章 “[More Proof We Don't Control Our Web Pages][2]”。
|
||||
|
||||
当然,你可以使用比我们在示例中提供的更严格的指令:
|
||||
|
||||
- 设置 `default-src` 为 'none'
|
||||
- 为每条规则指定你的设置
|
||||
- 为请求的文件指定它的绝对路径
|
||||
- 等
|
||||
|
||||
### 更多关于 CSP 的信息
|
||||
|
||||
#### 支持
|
||||
|
||||
CSP 不是一个需要复杂的配置才能正常工作的每日构建特性。CSP 1 和 2 是候选推荐标准![浏览器可以非常完美的支持 CSP 1][3]。
|
||||
|
||||

|
||||
|
||||
[CSP 2 是较新的规范][4],因此对它的支持会少那么一点。
|
||||
|
||||

|
||||
|
||||
现在 CSP 3 还是一个早期草案,因此还没有被支持,但是你依然可以使用 CSP 1 和 2 来做一些重大的事。
|
||||
|
||||
#### 其他需要考虑的因素
|
||||
|
||||
CSP 被设计用来降低跨站脚本攻击(XSS)的风险,这就是不建议开启内联脚本和 `script-src` 指令的原因。Firefox 对这个问题做了很好的说明:在浏览器中,敲击 `Shift + F2` 并且键入 `security csp`,它就会向你展示指令和对应的建议。这里有一个在 Twitter 网站中应用的例子:
|
||||
|
||||

|
||||
|
||||
如果你确实需要使用内联脚本和样式的话,另一种可能就是生成一份散列值。例如,我们假定你需要使用如下的内联脚本:
|
||||
|
||||
```
|
||||
<script>alert('Hello, world.');</script>
|
||||
```
|
||||
|
||||
你应该在 `script-src` 指令中添加 `sha256-qznLcsROx4GACP2dm0UCKCzCG-HiZ1guq6ZZDob_Tng=` 作为有效来源。这个散列值用下面的 PHP 脚本执行获得的结果:
|
||||
|
||||
```
|
||||
<?php
|
||||
echo base64_encode(hash('sha256', "alert('Hello, world.');", true));
|
||||
?>
|
||||
```
|
||||
|
||||
我在前文中说过 CSP 被设计用来降低 XSS 风险,我还得加上“……与降低未经请求内容的风险。”伴随着 CSP 的使用,你必须**知道你内容的来源是哪里**与**它们在你的前端都作了些什么**(内联样式,等)。CSP 同时可以帮助你让贡献者、开发人员和其他人员来遵循你内容来源的规则!
|
||||
|
||||
现在你的问题就只是,“不错,这很好,但是我们如何在生产环境中使用它呢?”
|
||||
|
||||
### 如何在现实世界中使用它
|
||||
|
||||
想要在第一次使用 CSP 之后就失望透顶的方法就是在生产环境中测试。不要想当然的认为,“这会很简单。我的代码是完美并且相当清晰的。”不要这样作。我这样干过。相信我,这相当的蠢。
|
||||
|
||||
正如我之前说明的,CSP 指令由 CSP 头部来激活,这中间没有过渡阶段。你恰恰就是其中的薄弱环节。你可能会忘记授权某些东西或者遗忘了你网站中的一小段代码。CSP 不会饶恕你的疏忽。然而,CSP 的两个特性将这个问题变得相当的简单。
|
||||
|
||||
#### report-uri
|
||||
|
||||
还记得 CSP 发送到终端中的那些通知么?`report-uri` 指令可以被用来告诉浏览器发送那些通知到指定的地址。报告以 JSON 格式送出。
|
||||
|
||||
```
|
||||
report-uri /csp-parser.php ;
|
||||
```
|
||||
|
||||
因此,我们可以在 csp-parser.php 文件中处理有浏览器送出的数据。这里有一个由 PHP 实现的最基础的例子:
|
||||
|
||||
```
|
||||
$data = file_get_contents('php://input');
|
||||
|
||||
if ($data = json_decode($data, true)) {
|
||||
$data = json_encode(
|
||||
$data,
|
||||
JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES
|
||||
);
|
||||
mail(EMAIL, SUBJECT, $data);
|
||||
}
|
||||
```
|
||||
|
||||
这个通知将会被转换成为一封邮件。在开发过程中,你可能不会需要比这更复杂的其它东西。
|
||||
|
||||
对于一个生产环境(或者是一个有较多访问的开发环境),你应该使用一种比邮件更好的收集信息的方式,因为这种方式在节点上没有验证和速率限制,并且 CSP 可能变得乱哄哄的。只需想像一个会产生 100 个 CSP 通知(例如,一个从未授权来源展示图片的脚本)并且每天会被浏览 100 次的页面,那你就会每天收到 10000 个通知啊!
|
||||
|
||||
例如 [report-uri.io](https://report-uri.io/) 这样的服务可以用来简化你的通知管理。你也可以在 GitHub上看一些另外的使用 `report-uri` (与数据库搭配,添加一些优化,等)的简单例子。
|
||||
|
||||
### report-only
|
||||
|
||||
正如我们所见的,最大的问题就是在使用和不使用 CSP 之间没有中间地带。然而,一个名为 `report-only` 的特性会发送一个稍有不同的头部:
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy-Report-Only: <your directives>");
|
||||
?>
|
||||
```
|
||||
|
||||
总的来说,这个头部就是告诉浏览器,“表现得似乎所有的 CSP 指令都被应用了,但是不禁止任何东西。只是发送通知给自己。”这是一种相当棒的测试指令的方式,避免了任何有价值的东西被禁止的风险。
|
||||
|
||||
在 `report-only` 和 `report-uri` 的帮助下你可以毫无风险的测试 CSP 指令,并且可以实时的监控网站上一切与 CSP 相关的内容。这两个特性对部署和维护 CSP 来说真是相当的有用!
|
||||
|
||||
### 结论
|
||||
|
||||
#### 为什么 CSP 很酷
|
||||
|
||||
CSP 对你的用户来说是尤其重要的:他们在你的网站上不再需要遭受任何的未经请求的脚本,内容或 XSS 的威胁了。
|
||||
|
||||
对于网站维护者来说 CSP 最重要的优势就是可感知。如果你对图片来源设置了严格的规则,这时一个脚本小子尝试在你的网站上插入一张未授权来源的图片,那么这张图片就会被禁止,并且你会在第一时间收到提醒。
|
||||
|
||||
开发者也需要确切的知道他们的前端代码都在做些什么,CSP 可以帮助他们掌控一切。会促使他们去重构他们代码中的某些部分(避免内联函数和样式,等)并且促使他们遵循最佳实践。
|
||||
|
||||
#### 如何让 CSP 变得更酷
|
||||
|
||||
讽刺的是,CSP 在一些浏览器中过分的高效了,在和书签栏小程序一起使用时会产生一些 bug。因此,不要更新你的 CSP 指令来允许书签栏小程序。我们无法单独的责备任何一个浏览器;它们都有些问题:
|
||||
|
||||
- Firefox
|
||||
- Chrome (Blink)
|
||||
- WebKit
|
||||
|
||||
大多数情况下,这些 bug 都是禁止通知中的误报。所有的浏览器提供者都在努力解决这些问题,因此我们可以期待很快就会被解决。无论怎样,这都不会成为你使用 CSP 的绊脚石。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.smashingmagazine.com/2016/09/content-security-policy-your-future-best-friend/
|
||||
|
||||
作者:[Nicolas Hoffmann][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.smashingmagazine.com/author/nicolashoffmann/
|
||||
[1]: https://rocssti.net/en/example-csp-paris-web2015
|
||||
[2]: https://www.aaron-gustafson.com/notebook/more-proof-we-dont-control-our-web-pages/
|
||||
[3]: http://caniuse.com/#feat=contentsecuritypolicy
|
||||
[4]: http://caniuse.com/#feat=contentsecuritypolicy2
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
Ryver:你应该使用它替代 Slack
|
||||
===============
|
||||
|
||||

|
||||
|
||||
貌似每个人都听说过 [Slack][1],它是一款跨平台的,可以使你时刻保持与他人同步的团队沟通应用。它革新了用户讨论和规划项目的方式,显而易见,它升级了 email 的沟通功能。
|
||||
|
||||
我在一个非常小的写作团队工作,不管是通过手机还是电脑,我从未在使用 Slack 过程中遇到过沟通问题。若想与任何规模的团队保持同步,继续使用 Slack 仍然不失为不错的方式。
|
||||
|
||||
既然如此,为什么我们还要讨论今天的话题?Ryver 被人们认为是下一个热点,相比 Slack,Ryver 提供了升级版的服务。Ryver 完全免费,它的团队正在奋力争取更大的市场份额。
|
||||
|
||||
是否 Ryver 已经强大到可以扮演 Slack 杀手的角色?这两种旗鼓相当的消息应用究竟有何不同?
|
||||
|
||||
欲知详情,请阅读下文。
|
||||
|
||||
### 为什么用 Ryver ?
|
||||
|
||||

|
||||
|
||||
既然 Slack 能用为什么还要折腾呢?Ryver 的开发者对 Slack 的功能滚瓜烂熟,他们希望 Ryver 改进的服务足以让你移情别恋。他们承诺 Ryver 提供完全免费的团队沟通服务,并且不会在任何一个环节隐形收费。
|
||||
|
||||
谢天谢地,他们用高质量产品兑现了自己的承诺。
|
||||
|
||||
额外的内容是关键所在,他们承诺去掉一些你在 Slack 免费账号上面遇到的限制。无限的存储空间是一个加分点,除此之外,在许多其他方面 Ryver 也更加开放。如果存储空间限制对你来说是个痛点,不防试试 Ryver。
|
||||
|
||||
这是一个简单易用的系统,所有的功能都可以一键搞定。这种设计哲学使 Apple 大获成功。当你开始使用它之后,也不会遭遇成长的烦恼。
|
||||
|
||||

|
||||
|
||||
会话分为私聊和公示,这意味着团队平台和私人用途有明确的界限。它应该有助于避免将任何尴尬的广而告之给你的同事,这些问题我在使用 Slack 期间都遇到过。
|
||||
|
||||
Ryver 支持与大量现成的 App 的集成,并在大多数平台上有原生应用程序。
|
||||
|
||||
在需要时,你可以添加访客而无需增加费用,如果你经常和外部客户打交道,这将是一个非常有用的功能。访客可以增加更多的访客,这种流动性的元素是无法从其他更流行的消息应用中看到的。
|
||||
|
||||
考虑到 Ryver 是一个为迎合不同需求而产生的完全不同的服务。如果你需要一个账户来处理几个客户,Ryver 值得一试。
|
||||
|
||||
问题是它是如何做到免费的呢? 简单的答案是高级用户将为你的使用付了费。 就像 Spotify 和其他应用一样,有一小部分人为我们其他人支付了费用。 这里有一个[直接链接][2]到他们的下载页面的地址,如果有兴趣就去试一试吧。
|
||||
|
||||
### 你应该切换到 Ryver 吗?
|
||||
|
||||

|
||||
|
||||
像我一样在小团队使用 Slack 的体验还是非常棒,但是 Ryver 可以给予的更多。一个完全免费的团队沟通应用的想法不可谓不宏伟,更何况它工作的十分完美。
|
||||
|
||||
同时使用这两种消息应用也无可厚非,但是如果你不愿意为一个白金 Slack 账户付费,一定要尝试一下竞争对手的服务。你可能会发现,两者各擅胜场,这取决于你需要什么。
|
||||
|
||||
最重要的是,Ryver 是一个极棒的免费替代品,它不仅仅是一个 Slack 克隆。他们清楚地知道他们想要实现什么,他们有一个可以在拥挤不堪的市场提供不同的东西的不错的产品。
|
||||
|
||||
但是,如果将来持续缺乏资金,Ryver 有可能消失。 它可能会让你的团队和讨论陷入混乱。 目前一切还好,但是如果你计划把更大的业务委托给这个新贵还是需要三思而行。
|
||||
|
||||
如果你厌倦了 Slack 对免费帐户的限制,你会对 Ryver 印象深刻。 要了解更多,请访问其网站以获取有关服务的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/why-use-ryver-instead-of-slack/
|
||||
|
||||
作者:[James Milin-Ashmore][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/james-ashmore/
|
||||
[1]: https://www.maketecheasier.com/new-slack-features/
|
||||
[2]: http://www.ryver.com/downloads/
|
||||
@ -1,5 +1,3 @@
|
||||
lujianbo
|
||||
|
||||
How to Setup Pfsense Firewall and Basic Configuration
|
||||
================================================================================
|
||||
In this article our focus is Pfsense setup, basic configuration and overview of features available in the security distribution of FreeBSD. In this tutorial we will run network wizard for basic setting of firewall and detailed overview of services. After the [installation process][1] following snapshot shows the IP addresses of WAN/LAN and different options for the management of Pfsense firewall.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Translating by cposture
|
||||
Translated by chunyang-wen
|
||||
Python unittest: assertTrue is truthy, assertFalse is falsy
|
||||
===========================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by ivo-wang
|
||||
Microfluidic cooling may prevent the demise of Moore's Law
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
translated by pspkforever
|
||||
translated by pspkforever,now Firstadream
|
||||
DOCKER DATACENTER IN AWS AND AZURE IN A FEW CLICKS
|
||||
===================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
(翻译中 by runningwater)
|
||||
CANONICAL CONSIDERING TO DROP 32 BIT SUPPORT IN UBUNTU
|
||||
========================================================
|
||||
|
||||
@ -30,7 +29,7 @@ I understand why they need to make this move from a security standpoint, but it
|
||||
via: https://itsfoss.com/ubuntu-32-bit-support-drop/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,86 +0,0 @@
|
||||
sevenot translating
|
||||
Terminator A Linux Terminal Emulator With Multiple Terminals In One Window
|
||||
=============================================================================
|
||||
|
||||

|
||||
|
||||
Each Linux distribution has a default terminal emulator for interacting with system through commands. But the default terminal app might not be perfect for you. There are so many terminal apps that will provide you more functionalities to perform more tasks simultaneously to sky-rocket speed of your work. Such useful terminal emulators include Terminator, a multi-windows supported free terminal emulator for your Linux system.
|
||||
|
||||
### What Is Linux Terminal Emulator?
|
||||
|
||||
A Linux terminal emulator is a program that lets you interact with the shell. All Linux distributions come with a default Linux terminal app that let you pass commands to the shell.
|
||||
|
||||
### Terminator, A Free Linux Terminal App
|
||||
|
||||
Terminator is a Linux terminal emulator that provides several features that your default terminal app does not support. It provides the ability to create multiple terminals in one window and faster your work progress. Other than multiple windows, it allows you to change other properties such as, terminal fonts, fonts colour, background colour and so on. Let's see how we can install and use Terminator in different Linux distributions.
|
||||
|
||||
### How To Install Terminator In Linux?
|
||||
|
||||
#### Install Terminator In Ubuntu Based Distributions
|
||||
|
||||
Terminator is available in the default Ubuntu repository. So you don't require to add any additional PPA. Just use APT or Software App to install it in Ubuntu.
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
In case Terminator is not available in your default repository, just compile Terminator from source code.
|
||||
|
||||
[DOWNLOAD SOURCE CODE][1]
|
||||
|
||||
Download Terminator source code and extract it on your desktop. Now open your default terminal & cd into the extracted folder.
|
||||
|
||||
Now use the following command to install Terminator -
|
||||
|
||||
```
|
||||
sudo ./setup.py install
|
||||
```
|
||||
|
||||
#### Install Terminator In Fedora & Other Derivatives
|
||||
|
||||
```
|
||||
dnf install terminator
|
||||
```
|
||||
|
||||
#### Install Terminator In OpenSuse
|
||||
|
||||
[INSTALL IN OPENSUSE][2]
|
||||
|
||||
### How To Use Multiple Terminals In One Window?
|
||||
|
||||
After you have installed Terminator, simply open multiple terminals in one window. Simply right click and divide.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
You can create as many terminals as you want, if you can manage them.
|
||||
|
||||

|
||||
|
||||
### Customise Terminals
|
||||
|
||||
Right click the terminal and click Properties. Now you can customise fonts, fonts colour, title colour & background and terminal fonts colour & background.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Conclusion & What Is Your Favorite Terminal Emulator?
|
||||
|
||||
Terminator is an advanced terminal emulator and it also let you customize the interface. If you have not yet switched from your default terminal emulator then just try this one. I know you'll like it. If you're using any other free terminal emulator, then let us know your favorite terminal emulator. Also don't forget to share this article with your friends. Perhaps your friends are searching for something like this.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[author][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[1]: https://launchpad.net/terminator/+download
|
||||
[2]: http://software.opensuse.org/download.html?project=home%3AKorbi123&package=terminator
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by Flowsnow!
|
||||
Best Password Manager — For Windows, Linux, Mac, Android, iOS and Enterprise
|
||||
==============================
|
||||
|
||||
|
||||
@ -1,40 +0,0 @@
|
||||
ch_cn translating
|
||||
Introducing React Native Ubuntu
|
||||
=====================
|
||||
|
||||
In the Webapps team at Canonical, we are always looking to make sure that web and near-web technologies are available to developers. We want to make everyone's life easier, enable the use of tools that are familiar to web developers and provide an easy path to using them on the Ubuntu platform.
|
||||
|
||||
We have support for web applications and creating and packaging Cordova applications, both of these enable any web framework to be used in creating great application experiences on the Ubuntu platform.
|
||||
|
||||
One popular web framework that can be used in these environments is React.js; React.js is a UI framework with a declarative programming model and strong component system, which focuses primarily on the composition of the UI, so you can use what you like elsewhere.
|
||||
|
||||
While these environments are great, sometimes you need just that bit more performance, or to be able to work with native UI components directly, but working in a less familiar environment might not be a good use of time. If you are familiar with React.js, it's easy to move into full native development with all your existing knowledge and tools by developing with React Native. React Native is the sister to React.js, you can use the same style and code to create an application that works directly with native components with native levels of performance, but with the ease of and rapid development you would expect.
|
||||
|
||||
|
||||

|
||||
|
||||
We are happy to announce that along with our HTML5 application support, it is now possible to develop React Native applications on the Ubuntu platform. You can port existing iOS or Android React Native applications, or you can start a new application leveraging your web-dev skills.
|
||||
|
||||
You can find the source code for React Native Ubuntu [here][1],
|
||||
|
||||
To get started, follow the instructions in [README-ubuntu.md][2] and create your first application.
|
||||
|
||||
The Ubuntu support includes the ability to generate packages. Managed by the React Native CLI, building a snap is as easy as 'react-native package-ubuntu --snap'. It's also possible to build a click package for Ubuntu devices; meaning React Native Ubuntu apps are store ready from the start.
|
||||
|
||||
Over the next little while there will be blogs posts on everything you need to know about developing a React Native Application for the Ubuntu platform; creating the app, the development process, packaging and releasing to the store. There will also be some information on how to develop new reusable modules, that can add extra functionality to the runtime and be distributed as Node Package Manager (npm) modules.
|
||||
|
||||
Go and experiment, and see what you can create.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://developer.ubuntu.com/en/blog/2016/08/05/introducing-react-native-ubuntu/?utm_source=javascriptweekly&utm_medium=email
|
||||
|
||||
作者:[Justin McPherson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://developer.ubuntu.com/en/blog/authors/justinmcp/
|
||||
[1]: https://github.com/CanonicalLtd/react-native
|
||||
[2]: https://github.com/CanonicalLtd/react-native/blob/ubuntu/README-ubuntu.md
|
||||
@ -1,3 +1,6 @@
|
||||
|
||||
###################Translating by messon007###################
|
||||
|
||||
Going Serverless with AWS Lambda and API Gateway
|
||||
============================
|
||||
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
hkurj translating
|
||||
I Best Modern Linux ‘init’ Systems (1992-2015)
|
||||
5 Best Modern Linux ‘init’ Systems (1992-2015)
|
||||
============================================
|
||||
|
||||
In Linux and other Unix-like operating systems, the init (initialization) process is the first process executed by the kernel at boot time. It has a process ID (PID) of 1, it is executed in the background until the system is shut down.
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by cposture
|
||||
How to Mount Remote Linux Filesystem or Directory Using SSHFS Over SSH
|
||||
============================
|
||||
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
JianhuanZhuo
|
||||
|
||||
translating by ucasFL
|
||||
Building a Real-Time Recommendation Engine with Data Science
|
||||
======================
|
||||
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
Tranlating by lengmi.
|
||||
OneNewLife translating
|
||||
|
||||
Building your first Atom plugin
|
||||
=====
|
||||
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
chisper is translating.
|
||||
|
||||
Translated by chunyang-wen
|
||||
A Raspberry Pi Hadoop Cluster with Apache Spark on YARN: Big Data 101
|
||||
======
|
||||
|
||||
|
||||
@ -1,258 +0,0 @@
|
||||
wcnnbdk1 Translating
|
||||
Content Security Policy, Your Future Best Friend
|
||||
=====
|
||||
|
||||
A long time ago, my personal website was attacked. I do not know how it happened, but it happened. Fortunately, the damage from the attack was quite minor: A piece of JavaScript was inserted at the bottom of some pages. I updated the FTP and other credentials, cleaned up some files, and that was that.
|
||||
|
||||
One point made me mad: At the time, there was no simple solution that could have informed me there was a problem and — more importantly — that could have protected the website’s visitors from this annoying piece of code.
|
||||
|
||||
A solution exists now, and it is a technology that succeeds in both roles. Its name is content security policy (CSP).
|
||||
|
||||
### What Is A CSP? Link
|
||||
|
||||
The idea is quite simple: By sending a CSP header from a website, you are telling the browser what it is authorized to execute and what it is authorized to block.
|
||||
|
||||
Here is an example with PHP:
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy: <your directives>");
|
||||
?>
|
||||
```
|
||||
|
||||
#### SOME DIRECTIVES LINK
|
||||
|
||||
You may define global rules or define rules related to a type of asset:
|
||||
|
||||
```
|
||||
default-src 'self' ;
|
||||
# self = same port, same domain name, same protocol => OK
|
||||
```
|
||||
|
||||
The base argument is default-src: If no directive is defined for a type of asset, then the browser will use this value.
|
||||
|
||||
```
|
||||
script-src 'self' www.google-analytics.com ;
|
||||
# JS files on these domains => OK
|
||||
```
|
||||
|
||||
In this example, we’ve authorized the domain name www.google-analytics.com as a source of JavaScript files to use on our website. We’ve added the keyword 'self'; if we redefined the directive script-src with another rule, it would override default-src rules.
|
||||
|
||||
If no scheme or port is specified, then it enforces the same scheme or port from the current page. This prevents mixed content. If the page is https://example.com, then you wouldn’t be able to load http://www.google-analytics.com/file.js because it would be blocked (the scheme wouldn’t match). However, there is an exception to allow a scheme upgrade. If http://example.com tries to load https://www.google-analytics.com/file.js, then the scheme or port would be allowed to change to facilitate the scheme upgrade.
|
||||
|
||||
```
|
||||
style-src 'self' data: ;
|
||||
# Data-Uri in a CSS => OK
|
||||
```
|
||||
|
||||
In this example, the keyword data: authorizes embedded content in CSS files.
|
||||
|
||||
Under the CSP level 1 specification, you may also define rules for the following:
|
||||
|
||||
- `img-src`
|
||||
|
||||
valid sources of images
|
||||
|
||||
- `connect-src`
|
||||
|
||||
applies to XMLHttpRequest (AJAX), WebSocket or EventSource
|
||||
|
||||
- `font-src`
|
||||
|
||||
valid sources of fonts
|
||||
|
||||
- `object-src`
|
||||
|
||||
valid sources of plugins (for example, `<object>, <embed>, <applet>`)
|
||||
|
||||
- `media-src`
|
||||
|
||||
valid sources of `<audio> and <video>`
|
||||
|
||||
|
||||
CSP level 2 rules include the following:
|
||||
|
||||
- `child-src`
|
||||
|
||||
valid sources of web workers and elements such as `<frame>` and `<iframe>` (this replaces the deprecated frame-src from CSP level 1)
|
||||
|
||||
- `form-action`
|
||||
|
||||
valid sources that can be used as an HTML `<form>` action
|
||||
|
||||
- `frame-ancestors`
|
||||
|
||||
valid sources for embedding the resource using `<frame>, <iframe>, <object>, <embed> or <applet>`.
|
||||
|
||||
- `upgrade-insecure-requests`
|
||||
|
||||
instructs user agents to rewrite URL schemes, changing HTTP to HTTPS (for websites with a lot of old URLs that need to be rewritten).
|
||||
|
||||
For better backwards-compatibility with deprecated properties, you may simply copy the contents of the actual directive and duplicate them in the deprecated one. For example, you may copy the contents of child-src and duplicate them in frame-src.
|
||||
|
||||
CSP 2 allows you to whitelist paths (CSP 1 allows only domains to be whitelisted). So, rather than whitelisting all of www.foo.com, you could whitelist www.foo.com/some/folder to restrict it further. This does require CSP 2 support in the browser, but it is obviously more secure.
|
||||
|
||||
#### AN EXAMPLE
|
||||
|
||||
I made a simple example for the Paris Web 2015 conference, where I presented a talk entitled “[CSP in Action][1].”
|
||||
Without CSP, the page would look like this:
|
||||
|
||||

|
||||
|
||||
Not very nice. What if we enabled the following CSP directives?
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy:
|
||||
default-src 'self' ;
|
||||
script-src 'self' www.google-analytics.com stats.g.doubleclick.net ;
|
||||
style-src 'self' data: ;
|
||||
img-src 'self' www.google-analytics.com stats.g.doubleclick.net data: ;
|
||||
frame-src 'self' ;");
|
||||
?>
|
||||
```
|
||||
|
||||
What would the browser do? It would (very strictly) apply these directives under the primary rule of CSP, which is that anything not authorized in a CSP directive will be blocked (“blocked” meaning not executed, not displayed and not used by the website).
|
||||
|
||||
By default in CSP, inline scripts and styles are not authorized, which means that every `<script>`, onclick or style attribute will be blocked. You could authorize inline CSS with style-src 'unsafe-inline' ;.
|
||||
|
||||
In a modern browser with CSP support, the example would look like this:
|
||||
|
||||

|
||||
|
||||
What happened? The browser applied the directives and rejected anything that was not authorized. It sent these notifications to the console:
|
||||
|
||||

|
||||
|
||||
If you’re still not convinced of the value of CSP, have a look at Aaron Gustafson’s article “[More Proof We Don’t Control Our Web Pages][2].”
|
||||
|
||||
Of course, you may use stricter directives than the ones in the example provided above:
|
||||
|
||||
- set default-src to 'none',
|
||||
- specify what you need for each rule,
|
||||
- specify the exact paths of required files,
|
||||
- etc.
|
||||
|
||||
|
||||
### More Information On CSP
|
||||
|
||||
#### SUPPORT
|
||||
|
||||
CSP is not a nightly feature requiring three flags to be activated in order for it to work. CSP levels 1 and 2 are candidate recommendations! [Browser support for CSP level 1][3] is excellent.
|
||||
|
||||

|
||||
|
||||
The [level 2 specification][4] is more recent, so it is a bit less supported.
|
||||
|
||||

|
||||
|
||||
CSP level 3 is an early draft now, so it is not yet supported, but you can already do great things with levels 1 and 2.
|
||||
|
||||
#### OTHER CONSIDERATIONS
|
||||
|
||||
CSP has been designed to reduce cross-site scripting (XSS) risks, which is why enabling inline scripts in script-src directives is not recommended. Firefox illustrates this issue very nicely: In the browser, hit Shift + F2 and type security csp, and it will show you directives and advice. For example, here it is used on Twitter’s website:
|
||||
|
||||

|
||||
|
||||
Another possibility for inline scripts or inline styles, if you really have to use them, is to create a hash value. For example, suppose you need to have this inline script:
|
||||
|
||||
```
|
||||
<script>alert('Hello, world.');</script>
|
||||
```
|
||||
|
||||
You might add 'sha256-qznLcsROx4GACP2dm0UCKCzCG-HiZ1guq6ZZDob_Tng=' as a valid source in your script-src directives. The hash generated is the result of this in PHP:
|
||||
|
||||
```
|
||||
<?php
|
||||
echo base64_encode(hash('sha256', "alert('Hello, world.');", true));
|
||||
?>
|
||||
```
|
||||
|
||||
I said earlier that CSP is designed to reduce XSS risks — I could have added, “… and reduce the risks of unsolicited content.” With CSP, you have to know where your sources of content are and what they are doing on your front end (inline styles, etc.). CSP can also help you force contributors, developers and others to respect your rules about sources of content!
|
||||
|
||||
Now your question is, “OK, this is great, but how do we use it in a production environment?”
|
||||
|
||||
### How To Use It In The Real World
|
||||
|
||||
The easiest way to get discouraged with using CSP the first time is to test it in a live environment, thinking, “This will be easy. My code is bad ass and perfectly clean.” Don’t do this. I did it. It’s stupid, trust me.
|
||||
|
||||
As I explained, CSP directives are activated with a CSP header — there is no middle ground. You are the weak link here. You might forget to authorize something or forget a piece of code on your website. CSP will not forgive your oversight. However, two features of CSP greatly simplify this problem.
|
||||
|
||||
#### REPORT-URI
|
||||
|
||||
Remember the notifications that CSP sends to the console? The directive report-uri can be used to tell the browser to send them to the specified address. Reports are sent in JSON format.
|
||||
|
||||
```
|
||||
report-uri /csp-parser.php ;
|
||||
```
|
||||
|
||||
So, in the csp-parser.php file, we can process the data sent by the browser. Here is the most basic example in PHP:
|
||||
|
||||
```
|
||||
$data = file_get_contents('php://input');
|
||||
|
||||
if ($data = json_decode($data, true)) {
|
||||
$data = json_encode(
|
||||
$data,
|
||||
JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES
|
||||
);
|
||||
mail(EMAIL, SUBJECT, $data);
|
||||
}
|
||||
```
|
||||
|
||||
This notification will be transformed into an email. During development, you might not need anything more complex than this.
|
||||
|
||||
For a production environment (or a more visited development environment), you’d better use a way other than email to collect information, because there is no auth or rate limiting on the endpoint, and CSP can be very noisy. Just imagine a page that generates 100 CSP notifications (for example, a script that display images from an unauthorized source) and that is viewed 100 times a day — you could get 10,000 notifications a day!
|
||||
|
||||
A service such as report-uri.io can be used to simplify the management of reporting. You can see other simple examples for report-uri (with a database, with some optimizations, etc.) on GitHub.
|
||||
|
||||
### REPORT-ONLY
|
||||
|
||||
As we have seen, the biggest issue is that there is no middle ground between CSP being enabled and disabled. However, a feature named report-only sends a slightly different header:
|
||||
|
||||
```
|
||||
<?php
|
||||
header("Content-Security-Policy-Report-Only: <your directives>");
|
||||
?>
|
||||
```
|
||||
|
||||
Basically, this tells the browser, “Act as if these CSP directives were being applied, but do not block anything. Just send me the notifications.” It is a great way to test directives without the risk of blocking any required assets.
|
||||
|
||||
With report-only and report-uri, you can test CSP directives with no risk, and you can monitor in real time everything CSP-related on a website. These two features are really powerful for deploying and maintaining CSP!
|
||||
|
||||
### Conclusion
|
||||
|
||||
#### WHY CSP IS COOL
|
||||
|
||||
CSP is most important for your users: They don’t have to suffer any unsolicited scripts or content or XSS vulnerabilities on your website.
|
||||
|
||||
The most important advantage of CSP for website maintainers is awareness. If you’ve set strict rules for image sources, and a script kiddie attempts to insert an image on your website from an unauthorized source, that image will be blocked, and you will be notified instantly.
|
||||
|
||||
Developers, meanwhile, need to know exactly what their front-end code does, and CSP helps them master that. They will be prompted to refactor parts of their code (avoiding inline functions and styles, etc.) and to follow best practices.
|
||||
|
||||
#### HOW CSP COULD BE EVEN COOLER LINK
|
||||
|
||||
Ironically, CSP is too efficient in some browsers — it creates bugs with bookmarklets. So, do not update your CSP directives to allow bookmarklets. We can’t blame any one browser in particular; all of them have issues:
|
||||
|
||||
- Firefox
|
||||
- Chrome (Blink)
|
||||
- WebKit
|
||||
|
||||
Most of the time, the bugs are false positives in blocked notifications. All browser vendors are working on these issues, so we can expect fixes soon. Anyway, this should not stop you from using CSP.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.smashingmagazine.com/2016/09/content-security-policy-your-future-best-friend/?utm_source=webopsweekly&utm_medium=email
|
||||
|
||||
作者:[Nicolas Hoffmann][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.smashingmagazine.com/author/nicolashoffmann/
|
||||
[1]: https://rocssti.net/en/example-csp-paris-web2015
|
||||
[2]: https://www.aaron-gustafson.com/notebook/more-proof-we-dont-control-our-web-pages/
|
||||
[3]: http://caniuse.com/#feat=contentsecuritypolicy
|
||||
[4]: http://caniuse.com/#feat=contentsecuritypolicy2
|
||||
|
||||
@ -1,96 +0,0 @@
|
||||
jiajia9linuxer
|
||||
The Five Principles of Monitoring Microservices
|
||||
====
|
||||
|
||||

|
||||
|
||||
The need for microservices can be summed up in just one word: speed. The need to deliver more functionality and reliability faster has revolutionized the way developers create software. Not surprisingly, this change has caused ripple effects within software management, including monitoring systems. In this post, we’ll focus on the radical changes required to monitor your microservices in production efficiently. We’ll lay out five guiding principles for adapting your monitoring approach for this new software architecture.
|
||||
|
||||
Monitoring is a critical piece of the control systems of microservices, as the more complex your software gets, the harder it is to understand its performance and troubleshoot problems. Given the dramatic changes to software delivery, however, monitoring needs an overhaul to perform well in a microservice environment. The rest of this article presents the five principles of monitoring microservices, as follows:
|
||||
|
||||
1. Monitor containers and what’s inside them.
|
||||
2. Alert on service performance, not container performance.
|
||||
3. Monitor services that are elastic and multi-location.
|
||||
4. Monitor APIs.
|
||||
5. Map your monitoring to your organizational structure.
|
||||
|
||||
Leveraging these five principles will allow you to establish more effective monitoring as you make your way towards microservices. These principles will allow you to address both the technological changes associated with microservices, in addition to the organizational changes related to them.
|
||||
|
||||
### The Principles of Microservice Monitoring
|
||||
|
||||
#### 1. Monitor Containers and What’s Running Inside Them
|
||||
|
||||
Containers gained prominence as the building blocks of microservices. The speed, portability, and isolation of containers made it easy for developers to embrace a microservice model. There’s been a lot written on the benefits of containers so we won’t recount it all here.
|
||||
|
||||
Containers are black boxes to most systems that live around them. That’s incredibly useful for development, enabling a high level of portability from development through production, from developer laptop to cloud. But when it comes to operating, monitoring and troubleshooting a service, black boxes make common activities harder, leading us to wonder: what’s running in the container? How is the application/code performing? Is it spitting out important custom metrics? From the DevOps perspective, you need deep visibility inside containers rather than just knowing that some containers exist.
|
||||
|
||||

|
||||
|
||||
The typical process for instrumentation in a non-containerized environment — an agent that lives in the user space of a host or VM — doesn’t work particularly well for containers. That’s because containers benefit from being small, isolated processes with as few dependencies as possible.
|
||||
|
||||
And, at scale, running thousands of monitoring agents for even a modestly-sized deployment is an expensive use of resources and an orchestration nightmare. Two potential solutions arise for containers: 1) ask your developers to instrument their code directly, or 2) leverage a universal kernel-level instrumentation approach to see all application and container activity on your hosts. We won’t go into depth here, but each method has pros and cons.
|
||||
|
||||
#### 2. Leverage Orchestration Systems to Alert on Service Performance
|
||||
|
||||
Making sense of operational data in a containerized environment is a new challenge. The metrics of a single container have a much lower marginal value than the aggregate information from all the containers that make up a function or a service.
|
||||
|
||||
This particularly applies to application-level information, like which queries have the slowest response times or which URLs are seeing the most errors, but also applies to infrastructure-level monitoring, like which services’ containers are using the most resources beyond their allocated CPU shares.
|
||||
|
||||
Increasingly, software deployment requires an orchestration system to “translate” a logical application blueprint into physical containers. Common orchestration systems include Kubernetes, Mesosphere DC/OS and Docker Swarm. Teams use an orchestration system to (1) define your microservices and (2) understand the current state of each service in deployment. You could argue that the orchestration system is even more important than the containers. The actual containers are ephemeral — they matter only for the short time that they exist — while your services matter for the life of their usefulness.
|
||||
|
||||
DevOps teams should redefine alerts to focus on characteristics that get as close to monitoring the experience of the service as possible. These alerts are the first line of defense in assessing if something is impacting the application. But getting to these alerts is challenging, if not impossible unless your monitoring system is container-native.
|
||||
|
||||
Container-native solutions leverage orchestration metadata to dynamically aggregate container and application data and calculate monitoring metrics on a per-service basis. Depending on your orchestration tool, you might have different layers of a hierarchy that you’d like to drill into. For example, in Kubernetes, you typically have a Namespace, ReplicaSets, Pods and some containers. Aggregating at these various layers is essential for logical troubleshooting, regardless of the physical deployment of the containers that make up the service.
|
||||
|
||||

|
||||
|
||||
#### 3. Be Prepared for Services that are Elastic and Multi-Location
|
||||
|
||||
Elastic services are certainly not a new concept, but the velocity of change is much faster in container-native environments than virtualized environments. Rapidly changing environments can wreak havoc on brittle monitoring systems.
|
||||
|
||||
Frequently monitoring legacy systems required manual tuning of metrics and checks based on individual deployments of software. This tuning can be as specific as defining the individual metrics to be captured, or configuring collection based on what application is operating in a particular container. While that may be acceptable on a small scale (think tens of containers), it would be unbearable in anything larger. Microservice focused monitoring must be able to comfortably grow and shrink in step with elastic services, without human intervention.
|
||||
|
||||
For example, if the DevOps team must manually define what service a container is included in for monitoring purposes, they no doubt drop the ball as Kubernetes or Mesos spins up new containers regularly throughout the day. Similarly, if Ops were required to install a custom stats endpoint when new code is built and pushed into production, challenges may arise as developers pull base images from a Docker registry.
|
||||
|
||||
In production, build monitoring toward a sophisticated deployment that spans multiple data centers or multiple clouds. Leveraging, for example, AWS CloudWatch will only get you so far if your services span your private data center as well as AWS. That leads back to implementing a monitoring system that can span these different locations as well as operate in dynamic, container-native environments.
|
||||
|
||||
#### 4. Monitor APIs
|
||||
|
||||
In microservice environments, APIs are the lingua franca. They are essentially the only elements of a service that are exposed to other teams. In fact, response and consistency of the API may be the “internal SLA” even if there isn’t a formal SLA defined.
|
||||
|
||||
As a result, API monitoring is essential. API monitoring can take many forms but clearly, must go beyond binary up/down checks. For instance, it’s valuable to understand the most frequently used endpoints as a function of time. This allows teams to see if anything noticeable has changed in the usage of services, whether it be due to a design change or a user change.
|
||||
|
||||
You can also consider the slowest endpoints of your service, as these can reveal significant problems, or, at the very least, point to areas that need the most optimization in your system.
|
||||
|
||||
Finally, the ability to trace service calls through your system represents another critical capability. While typically used by developers, this type of profiling will help you understand the overall user experience while breaking information down into infrastructure and application-based views of your environment.
|
||||
|
||||
#### 5. Map Monitoring to Your Organizational Structure
|
||||
|
||||
While most of this post has been focused on the technological shift in microservices and monitoring, like any technology story, this is as much about people as it is about software bits.
|
||||
|
||||
For those of you familiar with Conway’s law, he reminds us that the design of systems is defined by the organizational structure of the teams building them. The allure of creating faster, more agile software has pushed teams to think about restructuring their development organization and the rules that govern it.
|
||||
|
||||

|
||||
|
||||
So if an organization wants to benefit from this new software architecture approach, their teams must, therefore, mirror microservices themselves. That means smaller teams, loosely coupled; that can choose their direction as long as it still meets the needs of the whole. Within each team, there is more control than ever over languages used, how bugs are handled, or even operational responsibilities.
|
||||
|
||||
DevOps teams can enable a monitoring platform that does exactly this: allows each microservice team to isolate their alerts, metrics, and dashboards, while still giving operations a view into the global system.
|
||||
|
||||
### Conclusion
|
||||
|
||||
There’s one, clear trigger event that precipitated the move to microservices: speed. Organizations wanted to deliver more capabilities to their customers in less time. Once this happened, technology stepped in, the architectural move to micro-services and the underlying shift to containers make speed happen. Anything that gets in the way of this progress train is going to get run over on the tracks.
|
||||
|
||||
As a result, the fundamental principles of monitoring need to adapt to the underlying technology and organizational changes that accompany microservices. Operations teams that recognize this shift can adapt to microservices earlier and easier.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
|
||||
作者:[Apurva Dave][a] [Loris Degioanni][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://thenewstack.io/author/apurvadave/
|
||||
[b]: http://thenewstack.io/author/lorisdegioanni/
|
||||
@ -1,160 +0,0 @@
|
||||
jiajia9linuxer
|
||||
Using Ansible to Provision Vagrant Boxes
|
||||
====
|
||||
|
||||

|
||||
|
||||
Ansible is a great tool for system administrators who want to automate system administration tasks. From configuration management to provisioning and managing containers for application deployments, Ansible [makes it easy][1]. The lightweight module based architecture is ideal for system administration. One advantage is that when the node is not being managed by Ansible, no resources are used.
|
||||
|
||||
This article covers how to use Ansible to provision Vagrant boxes. A [Vagrant box][2] in simple terms is a virtual machine prepackaged with tools required to run the development environment. You can use these boxes to distribute the development environment used by other team members for project work. Using Ansible, you can automate provisioning the Vagrant boxes with your development packages.
|
||||
|
||||
This tutorial uses Fedora 24 as the host system and [CentOS][3] 7 as the Vagrant box.
|
||||
|
||||
### Setting up prerequisites
|
||||
|
||||
To configure Vagrant boxes using Ansible, you’ll need a few things setup. This tutorial requires you to install Ansible and Vagrant on the host machine. On your host machine, execute the following command to install the tools:
|
||||
|
||||
```
|
||||
sudo dnf install ansible vagrant vagrant-libvirt
|
||||
```
|
||||
|
||||
The above command installs both Ansible and Vagrant on your host system, along with Vagrant’s libvirt provider. Vagrant doesn’t provide functionality to host your virtual machine guests (VMs). Rather, it depends on third party providers such as libvirt, VirtualBox, VMWare, etc. to host the VMs. This provider works directly with libvirt and KVM on your Fedora system.
|
||||
|
||||
Next, make sure your user is in the wheel group. This special group allows you to run system administration commands. If you created your user as an administrator, such as during installation, you’ll have this group membership. Run the following command:
|
||||
|
||||
```
|
||||
id | grep wheel
|
||||
```
|
||||
|
||||
If you see output, your user is in the group, and you can move on to the next section. If not, run the following command. You’ll need to provide the password for the root account. Substitute your user name for the text <username>:
|
||||
|
||||
```
|
||||
su -c 'usermod -a -G wheel <username>'
|
||||
```
|
||||
|
||||
Then you will need to logout, and log back in, to inherit the group membership properly.
|
||||
|
||||
Now it’s time to create your first Vagrant box, which you’ll then configure using Ansible.
|
||||
|
||||
### Setting up the Vagrant box
|
||||
|
||||
Before you use Ansible to provision a box, you must create the box. To start, create a new directory which will store files related to the Vagrant box. To create this directory and make it the current working directory, issue the following command:
|
||||
|
||||
```
|
||||
mkdir -p ~/lampbox && cd ~/lampbox
|
||||
```
|
||||
|
||||
Before you create the box, you should understand the goal. This box is a simple example that runs CentOS 7 as its base system, along with the Apache web server, MariaDB (the popular open source database server from the original developers of MySQL) and PHP.
|
||||
|
||||
To initialize the Vagrant box, use the vagrant init command:
|
||||
|
||||
```
|
||||
vagrant init centos/7
|
||||
```
|
||||
|
||||
This command initializes the Vagrant box and creates a file named Vagrantfile, with some pre-configured variables. Open this file so you can modify it. The following line lists the base box used by this configuration.
|
||||
|
||||
```
|
||||
config.vm.box = "centos/7"
|
||||
```
|
||||
|
||||
Now setup port forwarding, so after you finish setup and the Vagrant box is running, you can test the server. To setup port forwarding, add the following line just before the end statement in Vagrantfile:
|
||||
|
||||
```
|
||||
config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
```
|
||||
|
||||
This option maps port 80 of the Vagrant Box to port 8080 of the host machine.
|
||||
|
||||
The next step is to set Ansible as our provisioning provider for the Vagrant Box. Add the following lines before the end statement in your Vagrantfile to set Ansible as the provisioning provider:
|
||||
|
||||
```
|
||||
config.vm.provision :ansible do |ansible|
|
||||
ansible.playbook = "lamp.yml"
|
||||
end
|
||||
```
|
||||
|
||||
(You must add all three lines before the final end statement.) Notice the statement ansible.playbook = “lamp.yml”. This statement defines the name of the playbook used to provision the box.
|
||||
|
||||
### Creating the Ansible playbook
|
||||
|
||||
In Ansible, playbooks describe a policy to be enforced on your remote nodes. Put another way, playbooks manage configurations and deployments on remote nodes. Technically speaking, a playbook is a YAML file in which you write tasks to perform on remote nodes. In this tutorial, you’ll create a playbook named lamp.yml to provision the box.
|
||||
|
||||
To make the playbook, create a file named lamp.yml in the same directory where your Vagrantfile is located and add the following lines to it:
|
||||
|
||||
```
|
||||
---
|
||||
- hosts: all
|
||||
become: yes
|
||||
become_user: root
|
||||
tasks:
|
||||
- name: Install Apache
|
||||
yum: name=httpd state=latest
|
||||
- name: Install MariaDB
|
||||
yum: name=mariadb-server state=latest
|
||||
- name: Install PHP5
|
||||
yum: name=php state=latest
|
||||
- name: Start the Apache server
|
||||
service: name=httpd state=started
|
||||
- name: Install firewalld
|
||||
yum: name=firewalld state=latest
|
||||
- name: Start firewalld
|
||||
service: name=firewalld state=started
|
||||
- name: Open firewall
|
||||
command: firewall-cmd --add-service=http --permanent
|
||||
```
|
||||
|
||||
An explanation of each line of lamp.yml follows.
|
||||
|
||||
- hosts: all specifies the playbook should run over every host defined in the Ansible configuration. Since no hosts are configured hosts yet, the playbook will run on localhost.
|
||||
- sudo: true states the tasks should be performed with root privileges.
|
||||
- tasks: specifies the tasks to perform when the playbook runs. Under the tasks section:
|
||||
- - name: … provides a descriptive name to the task
|
||||
- - yum: … specifies the task should be executed by the yum module. The options name and state are key=value pairs for use by the yum module.
|
||||
|
||||
When this playbook executes, it installs the latest versions of the Apache (httpd) web server, MariaDB, and PHP. Then it installs and starts firewalld, and opens a port for the Apache server. You’re now done writing the playbook for the box. Now it’s time to provision it.
|
||||
|
||||
### Provisioning the box
|
||||
|
||||
A few final steps remain before using the Vagrant Box provisioned using Ansible. To run this provisioning, execute the following command:
|
||||
|
||||
```
|
||||
vagrant up --provider libvirt
|
||||
```
|
||||
|
||||
The above command starts the Vagrant box, downloads the base box image to the host system if not already present, and then runs the playbook lamp.yml to provision.
|
||||
|
||||
If everything works fine, the output looks somewhat similar to this example:
|
||||
|
||||

|
||||
|
||||
This output shows that the box has been provisioned. Now check whether the server is accessible. To confirm, open your web browser on the host machine and point it to the address http://localhost:8080. Remember, port 8080 of the local host is forwarded to port 80 of the Vagrant box. You should be greeted with the Apache welcome page like the one shown below:
|
||||
|
||||

|
||||
|
||||
To make changes to your Vagrant box, first edit the Ansible playbook lamp.yml. You can find plentiful documentation on Ansible at [its official website][4]. Then run the following command to re-provision the box:
|
||||
|
||||
```
|
||||
vagrant provision
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
You’ve now seen how to use Ansible to provision Vagrant boxes. This was a basic example, but you can use these tools for many other use cases. For example, you can deploy complete applications along with up-to-date version of required tools. Be creative as you use Ansible to provision your remote nodes or containers.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-ansible-provision-vagrant-boxes/
|
||||
|
||||
作者:[Saurabh Badhwar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://h4xr.id.fedoraproject.org/
|
||||
[1]: https://ansible.com/
|
||||
[2]: https://www.vagrantup.com/
|
||||
[3]: https://centos.org/
|
||||
[4]: http://docs.ansible.com/ansible/index.html
|
||||
@ -0,0 +1,58 @@
|
||||
ARCH LINUX MAY SOON BE AVAILABLE ON WINDOWS SUBSYSTEM FOR LINUX
|
||||
====
|
||||
|
||||
[](https://itsfoss.com/wp-content/uploads/2016/10/Arch-Linux-on-windows-subsystem.jpg)
|
||||
|
||||
Ubuntu’s makers [Canonical](http://www.canonical.com/) had worked with Microsoft to bring you the much debated [Bash on Windows](https://itsfoss.com/bash-on-windows/). Although the same has had mixed reviews, many hardcore Linux users questioned its usability and some even considered [Bash on Windows a security risk](https://itsfoss.com/linux-bash-windows-security/).
|
||||
|
||||
Unix’s Bash shell was ported to Windows using a new feature called the “Windows Subsystem for Linux” or the WSL. We already saw how you can [install Bash on Windows](https://itsfoss.com/install-bash-on-windows/) easily.
|
||||
|
||||
The Bash on Windows from Canonical and Microsoft is simply the command line version of Ubuntu, not the regular graphical user interface.
|
||||
|
||||
Well, the good thing about Linux enthusiasts is that give them some time and they’ll do things on Windows Subsystem for Linux for which even the original developers will react with, “Wait, we can do that?”.
|
||||
|
||||
That’s precisely what is happening out there.
|
||||
|
||||

|
||||
|
||||
Yes. IT IS Ubuntu’s Unity shell running on Windows! Pablo Gonzalez, a programmer who goes by the name [Guerra24](https://github.com/Guerra24?tab=overview&from=2016-08-01&to=2016-08-31&utf8=%E2%9C%93) on GitHub has put together this beauty. With this, he has shown that what we can do with the Windows Subsystem for Linux is much more than what it previously was conceived for.
|
||||
|
||||
Now if Ubuntu Unity can be put on Windows subsystem, why not some other Linux distribution?
|
||||
|
||||
### ARCH LINUX FOR BASH ON WINDOWS
|
||||
|
||||
Full fledged distros running natively on WSL. Well, sooner or later it was bound to happen. I’m happier it’s [Arch Linux](https://www.archlinux.org/) though ([Antergos](https://itsfoss.com/tag/antergos/) Lover here).
|
||||
|
||||

|
||||
|
||||
Hold on, hold on there. The project is still in beta. It is being developed by “mintxomat” on GitHub and is currently is on version 0.6\. The first stable version will be released in late December this year.
|
||||
|
||||
Well, what’s the distinguishing point this project brings to the table?
|
||||
|
||||
You might already know that the Windows Subsystem for Linux is available on Windows 10 exclusively. But Arch Linux on Windows Subsystem for Linux (AWSL) has been successfully tested on windows7, Windows 8, Windows 8.1, Windows Server 2012(R2) and Windows 10 of course.
|
||||
|
||||
Whoa, how did they do it?
|
||||
|
||||
The developer says that AWSL protocol achieves this kind of portability by abstracting different frameworks available on different versions of Windows. So it’s the next level when AWSL finally hits 1.0\. And as we discussed the portability stuff already, this project will be the first to bring Bash on all versions of Windows.
|
||||
|
||||
This project is ambitious and promising. If You can’t wait till December then go ahead and give it a try. Just remember it’s a developers preview which is unstable at the moment. But hey, when’s that stopped us?
|
||||
|
||||
You can check out the project on GitHub:
|
||||
|
||||
[Arch on Windows Subsystem](https://github.com/turbo/alwsl)
|
||||
|
||||
[](https://itsfoss.com/10-funny-jokes-pictures-windows-mac-linux/)
|
||||
|
||||
Do share the article and let people know Arch Linux is going to land on Windows soon. Also, let us know which dbistro you want to see on WSL next. Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/arch-linux-windows-subsystem/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+ItsFoss+%28Its+FOSS%21+An+Open+Source+Blog%29
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
40
translated/20160805 Introducing React Native Ubuntu.md
Normal file
40
translated/20160805 Introducing React Native Ubuntu.md
Normal file
@ -0,0 +1,40 @@
|
||||
OneNewLife Translating
|
||||
|
||||
React Native Ubuntu 简介
|
||||
=====================
|
||||
|
||||
|
||||
在 Canonical 的 Webapps 团队,我们总是想确保 web 和 web 边缘技术可以为开发者所用。我们想让所有人的生活更轻松,让 web 开发者更加熟悉工具的用法,并且在 Ubuntu 上提供一个简单的途径来使用这些工具。
|
||||
|
||||
我们提供对 web 应用以及创建和打包 Cordova 应用的支持,这使得在 Ubuntu 上使用任意 web 框架来创造美妙的应用体验成为可能。
|
||||
|
||||
其中一个可以在这些情景中使用的主流框架就是 React.js。React.js 是一个拥有声明式编程模型和强大的组件系统的 UI 框架,它主要侧重于 UI 的构建,所以你可以在你喜欢的任何地方用上它。
|
||||
|
||||
然而这些应用场景太广泛了,有时候你只需要更高的性能,或者能够直接用原生 UI 组件来开发,但是在一个不太熟悉的场景中使用它可能不合时宜。如果你熟悉 React.js,那么通过 React Native 来开发可以毫不费力地将你所有现有的知识和工具迁移到完全的 native 开发中。React Native 是 React.js 的好姐妹,你可以用同样的方式和代码来创建一个直接使用原生组件并且拥有原生级别性能的应用,而且这就和你期待的一样轻松快捷。
|
||||
|
||||
|
||||

|
||||
|
||||
我们很高兴地宣布随着我们对 HTML5 应用的支持,现在可以在 Ubuntu 上开发 React Native 应用了。你可以移植你现有的 iOS 或 Android 版本的 React Native 应用,或者利用你的 web 开发技能来创建一个新的应用。
|
||||
|
||||
你可以在 [这里][1] 找到 React Native Ubuntu 的源代码,要开始使用时,遵循 [README-ubuntu.md][2] 的说明并创建你的第一个应用吧。
|
||||
|
||||
Ubuntu 的支持包括生成包的功能。通过 React Native CLI 来管理,构建一个模块就像 “react-native package-ubuntu --snap” 这条命令一样简单。还可以为 Ubuntu 设备构建一个 click 包,这意味着 React Native Ubuntu 应用可以在启动那一瞬间就准备就绪了。
|
||||
|
||||
在不久的将来会有很多关于在 Ubuntu 上开发一个 React Native 应用你所需要了解的东西的博客,例如创建应用、开发流程以及打包并发布到商店等等。还会有一些关于怎样开发新型的可复用的模块的信息,这些模块可以给运行时增加额外的功能并且可以发布为 npm 模块。
|
||||
|
||||
赶快去实践一下吧,看看你能创造出些什么来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://developer.ubuntu.com/en/blog/2016/08/05/introducing-react-native-ubuntu/?utm_source=javascriptweekly&utm_medium=email
|
||||
|
||||
作者:[Justin McPherson][a]
|
||||
译者:[Mars Wong](https://github.com/OneNewLife)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://developer.ubuntu.com/en/blog/authors/justinmcp/
|
||||
[1]: https://github.com/CanonicalLtd/react-native
|
||||
[2]: https://github.com/CanonicalLtd/react-native/blob/ubuntu/README-ubuntu.md
|
||||
@ -0,0 +1,87 @@
|
||||
Terminator 一款一个窗口包含多个终端的 Linux 终端仿真器
|
||||
=============================================================================
|
||||
|
||||

|
||||
|
||||
为了通过命令行和系统互动,每一款 Linux 发行版都有一款默认的终端仿真器。但是,默认的终端应用可能不适合你。为了加快你工作的速度,有好多款终端应用提供给你更多的功能来同时执行更多的任务。这些有用的终端仿真器包括 Terminator,一款 Linux 系统下支持多窗口的免费的终端仿真器。
|
||||
|
||||
|
||||
### 什么是 Linux 终端仿真器
|
||||
|
||||
Linux 终端仿真器是一个让你和 shell 交互的程序。所有的 Linux 发行版都会自带一款 Linux 终端应用让你向 shell 传递命令。
|
||||
|
||||
### Terminator,一款免费的 Linux 终端应用
|
||||
|
||||
Terminator 是一款 Linux 终端模拟器,提供了你的默认的终端应用不支持的多个特性。它提供了在一个窗口创建多个终端的功能,加快你的工作速度。除了多窗口外,它也允许你修改其他特性,例如字体、字体颜色、背景色等等。让我们看看我们如何安装它,并且如何在不同的 Linux 发行版下使用 Terminator。
|
||||
|
||||
### 如何在 Linux 下安装Terminator?
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Terminator
|
||||
|
||||
Terminator 在默认的 Ubuntu 仓库就可以使用。所以你不需要添加额外的 PPA。只需要使用 APT 或者 软件应用在 Ubuntu 下直接安装。
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
假如你的默认的仓库中 Terminator 不可使用,只需要使用源码编译 Terminator 即可。
|
||||
|
||||
[下载源码][1]
|
||||
|
||||
下载 Terminator 源码并且解压到你的桌面。现在打开你的默认的终端然后 cd 到解压的目录。
|
||||
|
||||
现在就可以使用下面的命令来安装 Terminator 了 -
|
||||
|
||||
```
|
||||
sudo ./setup.py install
|
||||
```
|
||||
|
||||
#### 在 Fedora 及衍生的操作系统上安装 Terminator
|
||||
|
||||
```
|
||||
dnf install terminator
|
||||
```
|
||||
|
||||
#### 在 OpenSuse 上安装 Terminator
|
||||
|
||||
[在 OPENSUSE 上安装][2]
|
||||
|
||||
### 如何在一个窗口使用多个终端?
|
||||
|
||||
安装好 Terminator 之后,你可以简单的在一个窗口打开多个终端。只需要右键并选择。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
只要你愿意,你可以创建尽可能多的终端,如果你能管理它们的话。
|
||||
|
||||

|
||||
|
||||
### 定制终端
|
||||
|
||||
右键点击终端,并单击属性。现在你可以定制字体、字体颜色、标题颜色和背景,还有终端字体颜色和背景。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 结论:什么是你最喜欢的终端模拟器
|
||||
|
||||
Terminator 是一款高级的终端模拟器,它让你自定义界面。如果你还没有从你默认的终端模拟器中切换过来的话,你可以尝试一下它。我知道你将会喜欢上它。如果你在使用其他的免费的终端模拟器的话,请让我们知道你最喜欢的那一款。而且不要忘了和你的朋友分享这篇文章。或许你的朋友正在寻找类似的东西。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
|
||||
作者:[author][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[1]: https://launchpad.net/terminator/+download
|
||||
[2]: http://software.opensuse.org/download.html?project=home%3AKorbi123&package=terminator
|
||||
@ -1,64 +0,0 @@
|
||||
|
||||
为什么你应该使用Ryver弃用Slack?
|
||||
=====
|
||||
貌似每个人都听说过Slack,它是一款跨平台的,可以使你时刻保持与他人同步的团队沟通应用。它革新了用户讨论和计划项目的方式,显而易见,它升级了email的沟通功能。
|
||||
|
||||
我在一个非常小的写作团队工作,不管是通过手机还是电脑,我从未在使用Slack过程中遇到过沟通问题。若想与任何规模的团队保持同步,继续使用Slack仍然不失为不错的方式。
|
||||
|
||||
既然如此,为什么我们还要讨论今天的话题?相比Slack,Ryver提供升级版的服务,这被认为是下一个大事件。Ryver完全免费,它的团队正在奋力争取更大的市场份额。
|
||||
|
||||
是否Ryver已经强大到可以扮演Slack杀手的角色?这两种旗鼓相当的消息应用究竟有何不同?
|
||||
|
||||
想了解更多,请阅读下文。
|
||||
|
||||
|
||||
###为什么是Ryver ?
|
||||
|
||||

|
||||
|
||||
为什么运行正常的功能仍然会引起混乱?Ryver的开发者对Slack的功能滚瓜烂熟,他们希望Ryver改进的服务足以让你移情别恋。他们承诺Ryver提供完全免费的团队沟通服务,并且不会在任何一个环节隐形收费。
|
||||
|
||||
谢天谢地,他们用高质量产品兑现了自己的承诺。
|
||||
|
||||
额外的内容是关键所在,他们承诺删除一些你在Slack免费账号上面的限制。无限的存储空间是一个加分点,除此之外,在许多其他方面Ryver也更加开放。如果存储空间限制对你来说是个痛点,不防试试Ryver。
|
||||
|
||||
这是一个简单易用的系统,所有的功能都可以一键搞定。这种设计哲学使Apple大获成功,当你开始使用后,也不会遭遇成长的烦恼。
|
||||
|
||||

|
||||
|
||||
会话区分私聊和公示,这意味着团队平台和私人应用有明确的界限。它应该有助于避免广播任何尴尬的公告给你的同事,这些我在使用Slack期间都遇到过。
|
||||
|
||||
Ryver支持与大量已有App的集成,并有大多数平台的原生应用程序 。
|
||||
|
||||
在需要时你可以添加额外客户而无需增加费用,如果你经常和外部客户打交道,这将是一个非常有用的功能。客户可以增加更多客户,这种流动性的元素是无法从其他更流行的消息应用中看到的。
|
||||
|
||||
考虑到Ryver是一个为迎合不同需求而产生的完全不同的服务。如果你需要一个账户来处理多种客户,Ryver值得一试。
|
||||
|
||||
问题是它是如何做到免费的? 快速的答案是高级用户将为你付费。 像Spotify和其他应用一样,有一小部分人为我们其他人支付费用。 这里有一个直接链接到他们的下载页面的地址,如果有兴趣就去试一试吧。
|
||||
|
||||
###你应该切换到Ryver吗?
|
||||
|
||||

|
||||
|
||||
像我一样在小团队使用Slack的体验还是非常棒,但是Ryver可以给予更多。一个完全免费的消息应用程序的想法不可谓不宏伟,更何况它工作的十分完美。
|
||||
|
||||
同时使用两种消息应用也无可厚非,但是如果你不愿意支付一个溢价的Slack账户,一定要尝试一下竞争对手的服务。你可能会发现,在不同的情况下,两者都更好,这取决于你需要什么。
|
||||
|
||||
最重要的是,Ryver是一个伟大的免费替代品,它不仅仅是一个Slack克隆。 他们清楚地知道他们想要实现什么,他们有一个体面的产品,在一个拥挤不堪的市场提供不同的东西。
|
||||
|
||||
但是,如果将来持续缺乏资金,Ryver有可能消失。 它可能会让你的团队和讨论陷入混乱。 目前一切还好,但是如果你计划把更大的业务委托给这个新贵还是需要三思而行。
|
||||
|
||||
|
||||
如果你厌倦了Slack对一个免费帐户的限制,你会对Ryver印象深刻。 要了解更多,请访问其网站以获取有关服务的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/why-use-ryver-instead-of-slack/?utm_medium=feed&utm_source=feedpress.me&utm_campaign=Feed%3A+maketecheasier
|
||||
|
||||
作者:[James Milin-Ashmore][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/james-ashmore/
|
||||
@ -0,0 +1,96 @@
|
||||
监控微服务的5条原则
|
||||
====
|
||||
|
||||

|
||||
|
||||
我们对微服务的需求可以归纳为一个词:速度,提供更多更可靠更快捷的功能的需求,彻底改变了软件开发模式,毫无疑问,这同样改变了软件管理和系统监控的方式。这里,我们着重于有效的监控生产过程中的微服务,我们将为这一新的软件开发模式制定5条原则来调整你的监控方法。
|
||||
|
||||
监控是微服务控制系统的关键部分,你的软件越复杂,那么你就越难了解其性能并解决问题。鉴于微服务给软件部署带来的巨大改变,监控系统同样需要进行彻底的改造。文章接下来介绍监控微服务的5条原则,如下:
|
||||
|
||||
1. 监控容器和里面的东西
|
||||
2. 在服务性能上做监控,而不是容器
|
||||
3. 监控弹性和多变的服务
|
||||
4. 监控开发接口
|
||||
5. 将您的监控映射到您的组织结构
|
||||
|
||||
利用这5条原则,你可以建立更有效的对微服务的监控。这些原则,可以让你定位微服务的技术变化和组织变化。
|
||||
|
||||
### 微服务监控的原则
|
||||
|
||||
#### 1.监控容器和里面的东西
|
||||
|
||||
容器是微服务重要的积木,容器的速度、可移植性和隔离特性让开发者很方便的建立微服务的模型。容器的好处已经写的够多了,在这里我们不再重复。
|
||||
|
||||
容器对于其他的系统来说就像是黑盒子,它的高度的可移植性,对于开发来说简直大有裨益,从开发到生产,甚至从一台笔记本开发直到云端。但是运行起来后,监控和解决服务问题,这个黑盒子让常规的方法失效了,我们会想:容器里到底在运行着什么?这些程序和代码是怎么运行的?它有什么重要的输出指标吗?在开发者的视角,你需要对容器有更深的了解而不是知道一些容器的存在。
|
||||
|
||||

|
||||
|
||||
非容器环境的典型特征,一个代理程序运行在一台主机或者虚机的用户空间,但是容器里不一样。容器的有点是小,讲各种进程分离开来,尽可能的减少依赖关系。
|
||||
|
||||
在规模上看,成千上万的监测代理,对即使是一个中等大小的部署都是一个昂贵的资源浪费和业务流程的噩梦。对于容器有两个潜在的解决方案:1)要求你的开发人员直接提交他们的代码,或者2)利用一个通用的内核级的检测方法来查看主机上的所有应用程序和容器活动。我们不会在这里深入,但每一种方法都有优点和缺点。
|
||||
|
||||
#### 2. 利用业务流程系统提醒服务性能
|
||||
|
||||
理解容器中数据的运行方式并不容易,一个容器的度量值比组成函数或服务的所有容器的聚合信息都要低得多。
|
||||
|
||||
这特别适用于应用程序级别的信息,就像哪个请求拥有最短响应时间或者哪个URLs有最多的错误,同样也适用于基础设施水平监测,比如哪个服务的容器使用CPU资源超过了事先分配的资源数。
|
||||
|
||||
越来越多的软件部署需要一个业务流程系统,将逻辑化的应用程序转化到一个物理的容器中。
|
||||
常见的转化系统包括Kubernetes、Mesosphere DC/OS和Docker Swarm。团队用一个业务流程系统来定义微服务和理解部署每个服务的当前状态。容器是短暂的,只有满足你的服务需求才会存在。
|
||||
|
||||
DevOps团队应该尽可能将重点放到如何更好的监控服务的运行特点上,如果应用受到了影响,这些告警点要放在第一道评估线上。但是能观察到这些告警点也并不容易,除非你的监控系统是容器本地的。
|
||||
|
||||
容器原生解决方案利用业务流程元数据来动态聚合容器和应用程序数据,并计算每个服务基础上的监控度量。根据您的业务流程工具,您可能有不同层次的层次结构想检测。比如,在Kubernetes里,你通常有Namespace、ReplicaSets、Pods和一些其他容器。聚集在这些不同的层有助于故障排除,这与构成服务的容器的物理部署无关。
|
||||
|
||||

|
||||
|
||||
#### 3. 监控弹性和多变的服务
|
||||
|
||||
弹性服务不是一个新概念,但是它在本地容器中的变化速度比在虚拟环境中快的多。迅速的变化会严重影响检测系统的正常运行。
|
||||
|
||||
经常监测系统所需的手动调整指标和单独部署的软件,这种调整可以是具体的,如定义要捕获的单个指标,或收集应用程序在一个特定的容器中操作的配置数据。小规模上我们可以接受,但是数以万计规模的容器就不行了。微服务的集中监控必须能够自由的监控弹性服务的增长和缩减,而且无人工干预。
|
||||
|
||||
比如,开发团队必须手动定义容器包含那个服务做监控使用,他们毫无疑问会把球抛给Kubernetes或者Mesos定期的创建新的容器。同样,如果开发团队需要配置一个自定义的状态点从新代码的产生到付诸生产,那么基础镜像从容器中注册会给开发者带来更多的挑战。
|
||||
|
||||
在生产中,建立一个复杂的跨越多个数据中心或多个云部署的监控,会使你的服务跨越你的死人数据中心,具体的应用,比如亚马逊的AWS CloudWatch。通过动态的本地容器环境,这个实时监控系统,会监控不同区域的数据中心。
|
||||
|
||||
#### 4.监控开发接口
|
||||
|
||||
在微服务环境中,API接口是通用的。它们是一个服务的必备组件,实际上,API的响应和一致性是服务的内部语言,虽然暂时还没人定义它们。
|
||||
|
||||
因此,API接口的监控也是必需的。API监控可以有不同的形式,但是它绝对不是简单的上下检查。例如,了解最常使用的点作为时间函数是有价值的。这使得团队可以看到,服务使用的变化,无论是由于设计变更或用户的改变。
|
||||
|
||||
你也可以记录服务最缓慢的点,这些可以揭示重大的问题,至少,指向需要在系统中做优化的区域。
|
||||
|
||||
最终,跟踪系统服务响应会成为一个很重要的能力,它会帮助开发者了解最终用户体验,同时将信息分成基础设施和应用程序环境两大部分。
|
||||
|
||||
#### 5. 将您的监控映射到您的组织结构
|
||||
|
||||
这篇文章着重在微服务和监控上,像其他科技文章一样,这是因为很多人都关注软件层面。
|
||||
|
||||
对于那些熟悉康威定律的人来说,系统的设计是基于开发团队的组织结构。创造更快,更敏捷的软件的迫力,推动团队思考重新调整他们的组织结构和管理它的规则。
|
||||
|
||||

|
||||
|
||||
如果他们想从新的软件架构比如微服务上获益,那么他们需要更小的更松散更耦合的团队,可以选择自己的方向只要能够满足整个需求即可。在一个团队中,对于什么开发语言的使用,bug的提交甚至工作职责都会有更大的控制能力。
|
||||
|
||||
开发团队可以启用一个监控平台:让每一个微服务团队可以定位自己的警报,指标,和控制面板,同时也要给全局系统的操作一个图表。
|
||||
|
||||
### 总结
|
||||
|
||||
快捷让微服务流行起来。开发组织要想为客户提供更快的更多的功能,然后微服务技术就来了,架构转向微服务并且容器的流行让快捷开发成为可能,所有相关的进程理所当然的搭上了这辆火车。
|
||||
|
||||
最后,基本的监控原则需要适应加入到微服务的技术和结构。越早认识到这种转变的开发团队,能更早更容易的适应微服务这一新的架构。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
|
||||
作者:[Apurva Dave][a] [Loris Degioanni][b]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://thenewstack.io/author/apurvadave/
|
||||
[b]: http://thenewstack.io/author/lorisdegioanni/
|
||||
@ -0,0 +1,159 @@
|
||||
用Ansible来配置Vagrant Boxes
|
||||
====
|
||||
|
||||

|
||||
|
||||
Ansible 是一款系统管理员进行自动化运维的强大工具。Ansible 让配置、交付、管理各种容器,软件部署变得非常简单[1]。基于轻量级模块的架构非常适合系统管理,一个优点就是如果某个节点没有被 Ansible 管理的话,它的资源是没有被使用的。
|
||||
|
||||
这篇文章介绍用 Ansible 来配置 Vagrant boxes,它是一个配置好的基础虚拟机映像,包含在开发环境中需要用到的工具。你可以用它来部署开发环境,然后和其他成员协同工作。用 Ansible,你可以用你的开发包自动化配置 Vagrant boxes。
|
||||
|
||||
我们用 Fedora 24 做主机,用 CentOS 7 来作 Vagrant box
|
||||
|
||||
### 设置工作环境
|
||||
|
||||
在用 Ansible 配置 Vagrant boxes 时,你需要做几件准备的事情。首先在主机上安装 Ansible 和 Vagrant,在主机上运行下面的命令来安装:
|
||||
|
||||
```
|
||||
sudo dnf install ansible vagrant vagrant-libvirt
|
||||
```
|
||||
|
||||
上面的命令将 Ansible 和 Vagrant 在你的主机上,也包括 Vagrant 的自动部署工具。Vagrant 不能自己管理虚拟主机,需要第三方工具比如:libirt,VirtualBox,VMWare等等。工具直接在你的 Fedora 系统上运行。
|
||||
|
||||
接着确认你的账户在正确的用户组 wheel 当中,确保你可以运行系统管理员命令。如果你的账号在安装过程中就创建为管理员,那么你就肯定在这个用户组里。运行下面的命令:
|
||||
|
||||
```
|
||||
id | grep wheel
|
||||
```
|
||||
|
||||
如果你能看到输出,那么你的账户就在这个组里,可以进行下一步。如果没有的话,你需要运行下面的命令,这一步需要你提供 root 账户的密码,在<username>里加上你的用户名:
|
||||
|
||||
```
|
||||
su -c 'usermod -a -G wheel <username>'
|
||||
```
|
||||
|
||||
然后,你需要注销然后重新登录,确保在用户组里。
|
||||
|
||||
现在要建立你的第一个 Vagrant box 了,你需要用 Ansible 来配置它。
|
||||
|
||||
### 设置 Vagrant box
|
||||
|
||||
配置一个镜像 box 之前,你需要先创建它。创建一个目录,存放 Vagrant box 相关的文件,并且将它设置为工作目录,用下面这条命令:
|
||||
|
||||
```
|
||||
mkdir -p ~/lampbox && cd ~/lampbox
|
||||
```
|
||||
|
||||
在创建镜像 box 之前,你需要搞清楚目的,这个镜像 box 是一个运行 CentOS 7 基础系统的模板包括 Apache 的 web 服务,MariaDB(MySQL 原始开发者创建的一个流行的开源数据库)数据库和 PHP 服务。
|
||||
|
||||
初始化 Vagrant box,用 vagrant 开发工具初始化命令:
|
||||
|
||||
```
|
||||
vagrant init centos/7
|
||||
```
|
||||
|
||||
这个命令初始化 Vagrant box 创建一些 Vagrantfile 名字的文件,也包含一些预先配置的文件。你可以打开和编辑它们,下面的命令显示基本的镜像box和配置。
|
||||
|
||||
```
|
||||
config.vm.box = "centos/7"
|
||||
```
|
||||
|
||||
设置端口转发,这样在你设置玩 Vagrant box 之后可以测试它。用下面的命令实现:
|
||||
|
||||
```
|
||||
config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
```
|
||||
|
||||
这个命令将 Vagrant Box 的 80 端口映射为主机的 8080 端口。
|
||||
|
||||
下一步是设置 Ansible 作为配置 Vagrant Box 的工具,下面的命令将 Ansible 作为配置工具在 end 之前加入到 Vagrantfile 中:
|
||||
|
||||
```
|
||||
config.vm.provision :ansible do |ansible|
|
||||
ansible.playbook = "lamp.yml"
|
||||
end
|
||||
```
|
||||
|
||||
(必须将这三行在最后的语句之前加入)ansible.playbook = "lamp.yml"这一句定义了配置镜像box的手册的名字。
|
||||
|
||||
### 创建Ansible详细手册
|
||||
|
||||
Ansible 的手册描述的是执行在你的远端节点的策略,换句话说,它管理远端节点的配置和部署。详细的说,手册是一个 Yaml 文件,在里面你写入在远端节点上将要执行的任务。所以,你需要创建一个名为 lamp.yml 的手册来配置镜像 box。
|
||||
|
||||
在 Vagrantfile 的目录里创建一个 lamp.yml 文件,将下面的内容粘贴到文件当中:
|
||||
|
||||
```
|
||||
---
|
||||
- hosts: all
|
||||
become: yes
|
||||
become_user: root
|
||||
tasks:
|
||||
- name: Install Apache
|
||||
yum: name=httpd state=latest
|
||||
- name: Install MariaDB
|
||||
yum: name=mariadb-server state=latest
|
||||
- name: Install PHP5
|
||||
yum: name=php state=latest
|
||||
- name: Start the Apache server
|
||||
service: name=httpd state=started
|
||||
- name: Install firewalld
|
||||
yum: name=firewalld state=latest
|
||||
- name: Start firewalld
|
||||
service: name=firewalld state=started
|
||||
- name: Open firewall
|
||||
command: firewall-cmd --add-service=http --permanent
|
||||
```
|
||||
|
||||
每一行代表的意思:
|
||||
|
||||
- hosts: 定义 Ansible 配置文件需要在所有的主机上运行,因为还没定义主机,暂时只在本地运行。
|
||||
- sudo: 需要用 root 权限运行的任务
|
||||
- tasks: 确定的任务
|
||||
- - name: 描述任务的名字
|
||||
- - yum: 描述任务需要调用 yum 模块,需要 key=value 成对被 yum 模块调用。
|
||||
|
||||
当手册运行时,它会安装最新的 Apache 的 web 服务,MariaDB 和 PHP。当安装完毕开始工作,会给 Apache 打开一个端口。你可以给镜像 box 写手册,并且可以配置它了。
|
||||
|
||||
### 配置镜像 box
|
||||
|
||||
用 Ansible 配置 Vagrant Box 只需要以下几部了:
|
||||
|
||||
```
|
||||
vagrant up --provider libvirt
|
||||
```
|
||||
|
||||
上面的命令运行 Vagrant box,将基本的镜像 box 下载到主机当中,然后运行 lamp.yml 手册来进行配置。
|
||||
|
||||
如果一切正常,输出应该和下面的例子类似:
|
||||
|
||||

|
||||
|
||||
这个输出显示镜像 box 已经被配置好了,现在检查服务是否可用,打开浏览器,输入 http://localhost:8080,记住主机的 8080 端口是 Vagrant box 映射过来的 80 端口。你应该可以看到如下的 Apache 的欢迎界面。
|
||||
|
||||

|
||||
|
||||
改变 Vagrantbox,你可以修改 lamp.yml 手册,你能从 Ansible 的官网上找到很多文章。然后运行下面的命令:
|
||||
|
||||
```
|
||||
vagrant provision
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
现在我们知道怎么用 Ansible 来配置 Vagrant boxes 了。这只是一个基本的例子,但是你可以用这些工具来实现不同的例子。比如你可以部署最新的工具,现在你可以用 Ansible 来配置你自己的远端服务器和容器了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-ansible-provision-vagrant-boxes/
|
||||
|
||||
作者:[Saurabh Badhwar][a]
|
||||
译者:[jiajia9linuxer](https://github.com/jiajia9linuxer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://h4xr.id.fedoraproject.org/
|
||||
[1]: https://ansible.com/
|
||||
[2]: https://www.vagrantup.com/
|
||||
[3]: https://centos.org/
|
||||
[4]: http://docs.ansible.com/ansible/index.html
|
||||
Loading…
Reference in New Issue
Block a user