mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
0e82c76cc7
@ -1,26 +1,28 @@
|
||||
自动共享和上传文件到兼容的托管站点
|
||||
======
|
||||

|
||||
前阵子我们写了一个关于[**Transfer.sh**][1]的指南,它允许你使用命令行通过互联网来分享文件。今天,我们来看看另一种文件分享实用工具**Anypaste**。这是一个基于文件类型自动共享和上传文件到兼容托管站点的简单脚本。你不需要去手动登录到托管站点来上传或分享你的文件。Anypaste将会根据你想上传的文件的类型来**自动挑选合适的托管站点**。简单地说,照片将被上传到图像托管站点,视频被传到视频站点,代码被传到pastebins。难道不是很酷的吗?Anypaste是一个完全开源、免费、轻量的脚本,你可以通过命令行完成所有操作。因此,你不需要依靠那些臃肿的,需要消耗大量内存的GUI应用来上传和共享文件。
|
||||
|
||||
### Anypaste-自动共享和上传文件到兼容的托管站点
|
||||
#### 安装
|
||||
正如我所说,这仅仅是一个脚本。所以不存在任何复杂的安装步骤。只需要将脚本下载后放置在你想要运行的位置(例如/usr/bin/anypaste),并将其设置为可执行文件后就可以直接使用了。此外,你也可以通过下面的这两条命令来快速安装Anypaste。
|
||||

|
||||
|
||||
前阵子我们写了一个关于 [Transfer.sh][1]的指南,它允许你使用命令行通过互联网来分享文件。今天,我们来看看另一种文件分享实用工具 Anypaste。这是一个基于文件类型自动共享和上传文件到兼容托管站点的简单脚本。你不需要去手动登录到托管站点来上传或分享你的文件。Anypaste 将会根据你想上传的文件的类型来**自动挑选合适的托管站点**。简单地说,照片将被上传到图像托管站点,视频被传到视频站点,代码被传到 pastebin。难道不是很酷的吗?Anypaste 是一个完全开源、免费、轻量的脚本,你可以通过命令行完成所有操作。因此,你不需要依靠那些臃肿的、需要消耗大量内存的 GUI 应用来上传和共享文件。
|
||||
|
||||
### 安装
|
||||
|
||||
正如我所说,这仅仅是一个脚本。所以不存在任何复杂的安装步骤。只需要将脚本下载后放置在你想要运行的位置(例如 `/usr/bin/`),并将其设置为可执行文件后就可以直接使用了。此外,你也可以通过下面的这两条命令来快速安装 Anypaste。
|
||||
|
||||
```
|
||||
sudo curl -o /usr/bin/anypaste https://anypaste.xyz/sh
|
||||
```
|
||||
```
|
||||
sudo chmod +x /usr/bin/anypaste
|
||||
```
|
||||
|
||||
就是这样简单。如果需要更新老的Anypaste版本,只需要用新的可执行文件覆写旧的即可。
|
||||
就是这样简单。如果需要更新老的 Anypaste 版本,只需要用新的可执行文件覆写旧的即可。
|
||||
|
||||
现在,让我们看看一些实例。
|
||||
|
||||
#### 配置
|
||||
Anypaste开箱即用,并不需要特别的配置。默认的配置文件是 **~/.config/anypaste.conf** ,这个文件在你第一次运行Anypaste时会自动创建。
|
||||
### 配置
|
||||
|
||||
需要配置的选项只有**ap_plugins**。Anypaste使用插件系统去上传文件。每个站点(上传)都由一个特定的插件表示。你可以在anypaste.conf文件中的**ap-plugins directive**位置浏览可用的插件列表。
|
||||
Anypaste 开箱即用,并不需要特别的配置。默认的配置文件是 `~/.config/anypaste.conf`,这个文件在你第一次运行 Anypaste 时会自动创建。
|
||||
|
||||
需要配置的选项只有 `ap_plugins`。Anypaste 使用插件系统上传文件。每个站点(的上传)都由一个特定的插件表示。你可以在 `anypaste.conf` 文件中的 `ap-plugins directive` 位置浏览可用的插件列表。
|
||||
|
||||
```
|
||||
# List of plugins
|
||||
@ -42,13 +44,19 @@ ap_plugins=(
|
||||
)
|
||||
[...]
|
||||
```
|
||||
如果你要安装一个新的插件,将它添加进这个列表中就可以了。如果你想禁用一个默认插件,只需要将它从列表中移除即可。如果多个插件是相互依存的关系,排列中的第一个会被选择,因此**顺序很重要**。
|
||||
#### 用法
|
||||
上传一个简单的文件,例如test.png,可以运行以下命令:
|
||||
|
||||
如果你要安装一个新的插件,将它添加进这个列表中就可以了。如果你想禁用一个默认插件,只需要将它从列表中移除即可。如果有多个兼容的插件,排列中的第一个会被选择,因此**顺序很重要**。
|
||||
|
||||
### 用法
|
||||
|
||||
上传一个简单的文件,例如 `test.png`,可以运行以下命令:
|
||||
|
||||
```
|
||||
anypaste test.png
|
||||
```
|
||||
**输出示例:**
|
||||
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Current file: test.png
|
||||
Attempting to upload with plugin 'tinyimg'
|
||||
@ -59,9 +67,10 @@ Direct Link: https://tinyimg.io/i/Sa1zsjj.png
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
正如输出结果中所看到的,Anypaste通过自动匹配图像文件**test.png**发现了兼容的托管站点(https://tinyimg.io),并将文件上传到了该站点。此外,Anypaste也为我们提供了用于直接浏览/下载该文件的链接。
|
||||
|
||||
不仅png格式文件,你还可以上传任何其他图片格式的文件。例如,下面的命令将会上传gif格式文件:
|
||||
正如输出结果中所看到的,Anypaste 通过自动匹配图像文件 `test.png` 发现了兼容的托管站点(https://tinyimg.io),并将文件上传到了该站点。此外,Anypaste 也为我们提供了用于直接浏览/下载该文件的链接。
|
||||
|
||||
不仅是 png 格式文件,你还可以上传任何其他图片格式的文件。例如,下面的命令将会上传 gif 格式文件:
|
||||
|
||||
```
|
||||
$ anypaste file.gif
|
||||
@ -78,17 +87,21 @@ Direct(ish) Link: https://thumbs.gfycat.com/MisguidedQuaintBergerpicard-size_res
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
你可以将链接分享给你的家庭,朋友和同事们。下图是我刚刚将图片上传到**gfycat**网站的截图。
|
||||
|
||||
[![][2]][3]
|
||||
你可以将链接分享给你的家庭、朋友和同事们。下图是我刚刚将图片上传到 gfycat 网站的截图。
|
||||
|
||||
![][3]
|
||||
|
||||
也可以一次同时上传多个(相同格式或不同格式)文件。
|
||||
|
||||
下面的例子提供参考,这里我会上传两个不同的文件,包含一个图片文件和一个视频文件:
|
||||
|
||||
```
|
||||
anypaste image.png video.mp4
|
||||
```
|
||||
**输出示例:**
|
||||
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Current file: image.png
|
||||
Attempting to upload with plugin 'tinyimg'
|
||||
@ -109,13 +122,16 @@ Delete/Edit: http://sendvid.com/wwy7w96h?secret=39c0af2d-d8bf-4d3d-bad3-ad37432a
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
Anypaste针对两个文件自动发现了与之相兼容的托管站点并成功上传。
|
||||
|
||||
正如你在上述用法介绍部分的例子中注意到的,Anypaste会自动挑选最佳的插件。此外,你可以指定插件进行文件上传,这里提供一个上传**gfycat**类型文件的案例,运行以下命令:
|
||||
Anypaste 针对两个文件自动发现了与之相兼容的托管站点并成功上传。
|
||||
|
||||
正如你在上述用法介绍部分的例子中注意到的,Anypaste 会自动挑选最佳的插件。此外,你可以指定插件进行文件上传,这里提供一个上传到 gfycat 的案例,运行以下命令:
|
||||
|
||||
```
|
||||
anypaste -p gfycat file.gif
|
||||
```
|
||||
**输出示例:**
|
||||
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Current file: file.gif
|
||||
@ -131,15 +147,21 @@ Direct(ish) Link: https://thumbs.gfycat.com/GrayDifferentCollie-size_restricted.
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
|
||||
如果要使用特定插件进行文件上传,可以通过以下命令绕过兼容性检查:
|
||||
|
||||
```
|
||||
anypaste -fp gfycat file.gif
|
||||
```
|
||||
如果你发现在配置文件中忽略了特定的插件,你仍然可以强制Anypaste去使用特定的插件,只不过需要加上'-xp'参数。
|
||||
|
||||
如果你发现在配置文件中忽略了特定的插件,你仍然可以强制 Anypaste 去使用特定的插件,只不过需要加上 `-xp` 参数。
|
||||
|
||||
```
|
||||
anypaste -xp gfycat file.gif
|
||||
```
|
||||
如果想要以交互模式上传文件,可以在命令后加上'-i'标签:
|
||||
|
||||
如果想要以交互模式上传文件,可以在命令后加上 `-i` 标签:
|
||||
|
||||
```
|
||||
$ anypaste -i file.gif
|
||||
Current file: file.gif
|
||||
@ -159,15 +181,16 @@ Direct(ish) Link: https://thumbs.gfycat.com/WaryAshamedBlackbear-size_restricted
|
||||
Upload complete.
|
||||
All files processed. Have a nice day!
|
||||
```
|
||||
正如你所见,Anypaste首先询问了我是否需要自动确定插件。因为我不想自动寻找插件,所以我回复了'No'。之后,Anypaste列出了所有可选择的插件,并要求我从列表中选择一个。同样的,你可以上传和共享不同类型的文件,相关文件会被上传到相兼容的站点。
|
||||
|
||||
无论你何时上传一个视频文件,Anypaste都会将其上传到以下站点中的一个:
|
||||
正如你所见,Anypaste 首先询问了我是否需要自动确定插件。因为我不想自动寻找插件,所以我回复了 “No”。之后,Anypaste 列出了所有可选择的插件,并要求我从列表中选择一个。同样的,你可以上传和共享不同类型的文件,相关文件会被上传到相兼容的站点。
|
||||
|
||||
无论你何时上传一个视频文件,Anypaste 都会将其上传到以下站点中的一个:
|
||||
|
||||
1. sendvid
|
||||
2. streamable
|
||||
3. gfycat
|
||||
|
||||
这里注意列表顺序,Anypaste将首先将文件上传到sendvid站点,如果没有sendvid的插件可供使用,Anypaste将会尝试顺序中的另外两个站点。当然你也可以通过更改配置文件来修改顺序。
|
||||
这里注意列表顺序,Anypaste 将首先将文件上传到 sendvid 站点,如果没有 sendvid 的插件可供使用,Anypaste 将会尝试顺序中的另外两个站点。当然你也可以通过更改配置文件来修改顺序。
|
||||
|
||||
图像文件上传站点:
|
||||
|
||||
@ -195,8 +218,9 @@ All files processed. Have a nice day!
|
||||
|
||||
上面列出来的部分站点一段特定的时间后会删除上传的内容,所以在上传和分享内容时应先明确这些站点的条款和条件。
|
||||
|
||||
#### 结论
|
||||
在我看来,识别文件并决定将其上传到何处的想法非常棒,而且开发者也以恰当的方式完美地实现了它。毫无疑问,Anypaste对那些在互联网上需要频繁分享文件的人们非常有用,我希望你也能这么觉得。
|
||||
### 结论
|
||||
|
||||
在我看来,识别文件并决定将其上传到何处的想法非常棒,而且开发者也以恰当的方式完美地实现了它。毫无疑问,Anypaste 对那些在互联网上需要频繁分享文件的人们非常有用,我希望你也能这么觉得。
|
||||
|
||||
这就是今天的全部内容,后面会有越来越多的好东西分享给大家。再见啦!
|
||||
|
||||
@ -206,7 +230,7 @@ via: https://www.ostechnix.com/anypaste-share-upload-files-compatible-hosting-si
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lixin555](https://github.com/lixin555)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
全球化思考:怎样克服交流中的文化差异
|
||||
======
|
||||
|
||||
> 这有一些建议帮助你的全球化开发团队能够更好地理解你们的讨论并能参与其中。
|
||||
|
||||
|
||||
|
||||
几周前,我见证了两位同事之间一次有趣的互动,他们分别是 Jason,我们的一位美国员工,和 Raj,一位来自印度的访问工作人员。
|
||||
|
||||
Raj 在印度时,他一般会通过电话参加美国中部时间上午 9 点的每日立会,现在他到美国工作了,就可以和组员们坐在同一间会议室里开会了。Jason 拦下了 Raj,说:“Raj 你要去哪?你不是一直和我们开电话会议吗?你突然出现在会议室里我还不太适应。” Raj 听了说,“是这样吗?没问题。”就回到自己工位前准备和以前一样参加电话会议了。
|
||||
|
||||
我去找 Raj,问他为什么不去参加每日立会,Raj 说 Jason 让自己给组员们打电话参会,而与此同时,Jason 也在会议室等着 Raj 来参加立会。
|
||||
|
||||
到底是哪里出的问题?Jason 明显只是调侃 Raj 终于能来一起开会了,为什么 Raj 没能听懂呢?
|
||||
|
||||
Jason 明显是在开玩笑,但 Raj 把它当真了。这就是在两人互相不了解对方文化语境时发生的一个典型误会。
|
||||
|
||||
我经常会遇到有人在电子邮件的末尾写“请复原”,最开始我很迷惑,“这有什么需要我复原的内容?”后来我才搞懂,“请复原”其实是“请回复”的意思。
|
||||
|
||||
在 Ricardo Fernandez 的TED 演讲“[如何管理跨文化团队][1]” 中,他提到了自己与一位南非同事发生的小故事。那位同事用一句“我一会给你打电话。”结束了两人的 IM 会话,Ricardo 回到办公室后就开始等这位同事的电话,十五分钟后他忍不住主动给这位同事打了电话,问他:“你不是说要给我打电话吗?”,这位同事答到:“是啊,我是说以后有机会给你打电话。”这时 Ricardo 才理解那位同事说的“一会”是“以后”的意思。
|
||||
|
||||
现在是全球化时代,我们的同事很可能不跟我们面对面接触,甚至不在同一座城市,来自不同的国家。越来越多的技术公司拥有全球化的工作场所,和来自世界各地的员工,他们有着不同的背景和经历。这种多样性使得技术公司能够在这个快速发展的科技大环境下拥有更强的竞争力。
|
||||
|
||||
但是这种地域的多样性也会给团队带来挑战。管理和维持高性能的团队发展对于同地协作的团队来说就有着很大难度,对于有着多样背景成员的全球化团队来说,无疑更加困难。成员之间的交流会发生延迟,误解时有发生,成员之间甚至会互相怀疑,这些都会影响着公司的成功。
|
||||
|
||||
到底是什么因素让全球化交流间发生误解呢?我们可以参照 Erin Meyer 的书《[文化地图][2]》,她在书中将全球文化分为八个类型,其中美国文化被分为低语境文化,与之相对的,日本为高语境文化。
|
||||
|
||||
看到这里你可能会问,高、低语境文化到底是什么意思?美国人从小就教育孩子们简洁表达,“直言不讳”是他们的表达准则;另一边,日本人从小学习在高效处理社交线索的同时进行交流,“察言观色”是他们的交流习惯。
|
||||
|
||||
大部分亚洲国家的文化都属于高语境文化。作为一个年轻的移民国家,美国毫不意外地拥有着低语境文化。移民来自于世界各地,拥有着不同的文化背景,他们不得不选择简洁而直接的交流方式,这或许就是其拥有低语境文化的原因。
|
||||
|
||||
### 从文化语境的角度与异国同事交流的三个步骤:
|
||||
|
||||
怎样面临跨文化交流中遇到的挑战?比如说一位美国人与他的日本同事交流,他更应该注重日本同事的非语言线索,同样的日本同事应当更关注美国人直接表达出的信息。如果你也面临类似的挑战,按照下面这三个步骤做,可以帮助你更有效地和异国同事交流,增进与他们的感情。
|
||||
|
||||
#### 认识到文化语境的差异
|
||||
|
||||
跨文化交流的第一步是认识到文化差异,跨文化交流从认识其他文化开始。
|
||||
|
||||
#### 尊重文化语境的差异
|
||||
|
||||
一旦你意识到了文化语境的差异会影响跨文化交流,你要做的就是尊重这些差异。在你遇到一种不同的交流方式时,学会接受差异,学会积极听取他人意见。
|
||||
|
||||
#### 调和文化语境的差异
|
||||
|
||||
只是认识和尊重差异还远远不够,你还需要学会如何调和这些差异。互相理解和换位思考可以增进差异的调和,你还要学着用它们去提高同事间的交流效率,推动生产力。
|
||||
|
||||
### 五种促进不同文化语境间交流的方法
|
||||
|
||||
为了加强组员们之间关系,这么多年来我一直在收集各种各样的方法和建议。这些方法帮助我解决了与外国组员间产生的很多交流问题,下面有其中一些例子:
|
||||
|
||||
#### 与外国组员交流时尽量使用视频会议的形式
|
||||
|
||||
研究表明,交流中约 55% 的内容不是靠语言传递的。肢体语言传达着一种十分微妙的信息,你可以根据它们理解对方的意思,而视频会议中处于异地的组员们能够看到对方的肢体语言。因此,组织远程会议时我一般都会采用视频会议的形式。
|
||||
|
||||
#### 确保每位成员都有机会分享他们的想法
|
||||
|
||||
我虽然喜欢开视频会议,但不是每次都能开的成。如果视频会议对你的团队来说并不常用,大家可能要一些时间去适应,你需要积极鼓励大家参与到其中,先从进行语音会议开始。
|
||||
|
||||
我们有一个外地的组员,每次都和我们进行语音会议,和我们提到她经常会有些想法想要分享,或者想做些贡献,但是我们互相看不到,她不知道该怎样开口。如果你一直在进行语音会议,注意要给组员们足够的时间和机会分享他们的想法。
|
||||
|
||||
#### 互相学习
|
||||
|
||||
通过你身边一两名外国朋友来学习他们的文化,你可以把从一位同事身上学到的应用于所有来自这个国家的同事。我有几位南亚和南美的同事,他们帮助我理解他们的文化,而这些也使得我更加专业。
|
||||
|
||||
对编程人员来说,我建议请你全世界的同行们检查你的代码,这个过程能让你观察到其他文化中人们怎样进行反馈、劝说他人,和最终进行技术决策。
|
||||
|
||||
#### 学会感同身受
|
||||
|
||||
同理心是一段牢固关系的核心。你越能换位思考,就越容易获得信任,来建立长久的关系。你可以在每次会议开始之前和大家闲聊几句,这样大家更容易处于一个放松的状态,如果团队中有很多外国人,要确保大家都能参与进来。
|
||||
|
||||
#### 和你的外国同事们单独见面
|
||||
|
||||
保持长久关系最好的方法是和你的组员们单独见面。如果你的公司可以报销这些费用,那么努力去和组员们见面吧。和一起工作了很长时间的组员们见面能够使你们的关系更加坚固。我所在的公司就有着周期性交换员工的传统,每隔一段时间,世界各地的员工就会来到美国工作,美国员工再到其他分部工作。
|
||||
|
||||
另一种聚齐组员们的机会是研讨会。研讨会创造的不仅是学习和培训的机会,你还可以挤出一些时间和组员们培养感情。
|
||||
|
||||
在如今,全球化经济不断发展,拥有来自不同国家和地区的员工对维持一个公司的竞争力来说越来越重要。即使组员们来自世界各地,团队中会出现一些交流问题,但拥有一支国际化的高绩效团队不是问题。如果你在工作中有什么促进团队交流的小窍门,请在评论中告诉我们吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/think-global-communication-challenges
|
||||
|
||||
作者:[Avindra Fernando][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/avindrafernando
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/watch?v=QIoAkFpN8wQ
|
||||
[2]: https://www.amazon.com/The-Culture-Map-Invisible-Boundaries/dp/1610392507
|
||||
@ -0,0 +1,247 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11691-1.html)
|
||||
[#]: subject: (Easily Upload Text Snippets To Pastebin-like Services From Commandline)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-like-services-from-commandline/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
从命令行轻松将文本片段上传到类似 Pastebin 的服务中
|
||||
======
|
||||
|
||||

|
||||
|
||||
每当需要在线共享代码片段时,我们想到的第一个便是 Pastebin.com,这是 Paul Dixon 于 2002 年推出的在线文本共享网站。现在,有几种可供选择的文本共享服务可以上传和共享文本片段、错误日志、配置文件、命令输出或任何类型的文本文件。如果你碰巧经常使用各种类似于 Pastebin 的服务来共享代码,那么这对你来说确实是个好消息。向 Wgetpaste 打个招呼吧,它是一个命令行 BASH 实用程序,可轻松地将文本摘要上传到类似 Pastebin 的服务中。使用 Wgetpaste 脚本,任何人都可以与自己的朋友、同事或想在类似 Unix 的系统中的命令行中查看/使用/审查代码的人快速共享文本片段。
|
||||
|
||||
### 安装 Wgetpaste
|
||||
|
||||
Wgetpaste 在 Arch Linux [Community] 存储库中可用。要将其安装在 Arch Linux 及其变体(如 Antergos 和 Manjaro Linux)上,只需运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo pacman -S wgetpaste
|
||||
```
|
||||
|
||||
对于其他发行版,请从 [Wgetpaste 网站][1] 获取源代码,并按如下所述手动安装。
|
||||
|
||||
首先下载最新的 Wgetpaste tar 文件:
|
||||
|
||||
```
|
||||
$ wget http://wgetpaste.zlin.dk/wgetpaste-2.28.tar.bz2
|
||||
```
|
||||
|
||||
提取它:
|
||||
|
||||
```
|
||||
$ tar -xvjf wgetpaste-2.28.tar.bz2
|
||||
```
|
||||
|
||||
它将 tar 文件的内容提取到名为 `wgetpaste-2.28` 的文件夹中。
|
||||
|
||||
转到该目录:
|
||||
|
||||
```
|
||||
$ cd wgetpaste-2.28/
|
||||
```
|
||||
|
||||
将 `wgetpaste` 二进制文件复制到 `$PATH` 中,例如 `/usr/local/bin/`。
|
||||
|
||||
```
|
||||
$ sudo cp wgetpaste /usr/local/bin/
|
||||
```
|
||||
|
||||
最后,使用命令使其可执行:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/wgetpaste
|
||||
```
|
||||
|
||||
### 将文本片段上传到类似 Pastebin 的服务中
|
||||
|
||||
使用 Wgetpaste 上传文本片段很简单。让我向你展示一些示例。
|
||||
|
||||
#### 1、上传文本文件
|
||||
|
||||
要使用 Wgetpaste 上传任何文本文件,只需运行:
|
||||
|
||||
```
|
||||
$ wgetpaste mytext.txt
|
||||
```
|
||||
|
||||
此命令将上传 `mytext.txt` 文件的内容。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Your paste can be seen here: https://paste.pound-python.org/show/eO0aQjTgExP0wT5uWyX7/
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以通过邮件、短信、whatsapp 或 IRC 等任何媒体共享 pastebin 的 URL。拥有此 URL 的人都可以访问它,并在他们选择的 Web 浏览器中查看文本文件的内容。
|
||||
|
||||
这是 Web 浏览器中 `mytext.txt` 文件的内容:
|
||||
|
||||
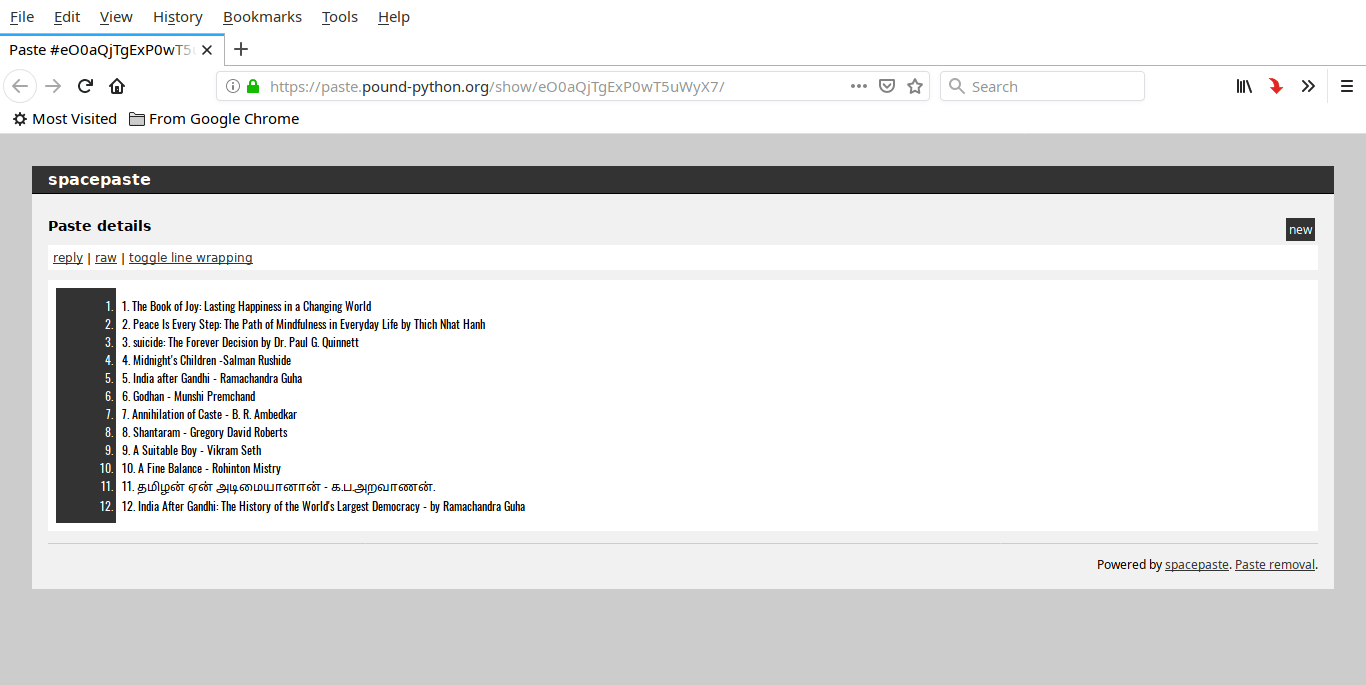
|
||||
|
||||
你也可以使用 `tee` 命令显示粘贴的内容,而不是盲目地上传它们。
|
||||
|
||||
为此,请使用如下的 `-t` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -t mytext.txt
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
#### 2、将文字片段上传到其他服务
|
||||
|
||||
默认情况下,Wgetpaste 会将文本片段上传到 poundpython(<https://paste.pound-python.org/>)服务。
|
||||
|
||||
要查看支持的服务列表,请运行:
|
||||
|
||||
```
|
||||
$ wgetpaste -S
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Services supported: (case sensitive):
|
||||
Name: | Url:
|
||||
=============|=================
|
||||
bpaste | https://bpaste.net/
|
||||
codepad | http://codepad.org/
|
||||
dpaste | http://dpaste.com/
|
||||
gists | https://api.github.com/gists
|
||||
*poundpython | https://paste.pound-python.org/
|
||||
```
|
||||
|
||||
在这里,`*` 表示默认服务。
|
||||
|
||||
如你所见,Wgetpaste 当前支持五种文本共享服务。我并没有全部尝试,但是我相信所有服务都可以使用。
|
||||
|
||||
要将内容上传到其他服务,例如 bpaste.net,请使用如下所示的 `-s` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -s bpaste mytext.txt
|
||||
Your paste can be seen here: https://bpaste.net/show/5199e127e733
|
||||
```
|
||||
|
||||
#### 3、从标准输入读取输入
|
||||
|
||||
Wgetpaste 也可以从标准输入读取。
|
||||
|
||||
```
|
||||
$ uname -a | wgetpaste
|
||||
```
|
||||
|
||||
此命令将上传 `uname -a` 命令的输出。
|
||||
|
||||
#### 4、上传命令及命令的输出
|
||||
|
||||
有时,你可能需要粘贴命令及其输出。为此,请在如下所示的引号内指定命令的内容。
|
||||
|
||||
```
|
||||
$ wgetpaste -c 'ls -l'
|
||||
```
|
||||
|
||||
这会将命令 `ls -l` 及其输出上传到 pastebin 服务。
|
||||
|
||||
当你想让其他人清楚地知道你刚运行的确切命令及其输出时,此功能很有用。
|
||||
|
||||
![][4]
|
||||
|
||||
如你在输出中看到的,我运行了 `ls -l` 命令。
|
||||
|
||||
#### 5、上载系统日志文件、配置文件
|
||||
|
||||
就像我已经说过的,我们可以上载你的系统中任何类型的文本文件,而不仅仅是普通的文本文件,例如日志文件、特定命令的输出等。例如,你刚刚更新了 Arch Linux 机器,最后系统损坏了。你问你的同事该如何解决此问题,他(她)想阅读 `pacman.log` 文件。 这是上传 `pacman.log` 文件内容的命令:
|
||||
|
||||
```
|
||||
$ wgetpaste /var/log/pacman.log
|
||||
```
|
||||
|
||||
与你的同事共享 pastebin URL,以便他/她可以查看 `pacman.log`,并通过查看日志文件来帮助你解决问题。
|
||||
|
||||
通常,日志文件的内容可能太长,你不希望全部共享它们。在这种情况下,只需使用 `cat` 命令读取输出,然后使用 `tail -n` 命令定义要共享的行数,最后将输出通过管道传递到 Wgetpaste,如下所示。
|
||||
|
||||
```
|
||||
$ cat /var/log/pacman.log | tail -n 50 | wgetpaste
|
||||
```
|
||||
|
||||
上面的命令将仅上传 `pacman.log` 文件的“最后 50 行”。
|
||||
|
||||
#### 6、将输入网址转换为短链接
|
||||
|
||||
默认情况下,Wgetpaste 将在输出中显示完整的 pastebin URL。如果要将输入 URL 转换为短链接,只需使用 `-u` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -u mytext.txt
|
||||
Your paste can be seen here: http://tinyurl.com/y85d8gtz
|
||||
```
|
||||
|
||||
#### 7、设定语言
|
||||
|
||||
默认情况下,Wgetpaste 将上传“纯文本”中的文本片段。
|
||||
|
||||
要列出指定服务支持的语言,请使用 `-L` 选项。
|
||||
|
||||
```
|
||||
$ wgetpaste -L
|
||||
```
|
||||
|
||||
该命令将列出默认服务(poundpython <https://paste.pound-python.org/>)支持的所有语言。
|
||||
|
||||
我们可以使用 `-l` 选项来改变它。
|
||||
|
||||
```
|
||||
$ wgetpaste -l Bash mytext.txt
|
||||
```
|
||||
|
||||
#### 8、在输出中禁用语法突出显示或 html
|
||||
|
||||
如上所述,文本片段将以特定的语言格式(纯文本、Bash 等)显示。
|
||||
|
||||
但是,你可以更改此行为,以使用 `-r` 选项显示原始文本摘要。
|
||||
|
||||
```
|
||||
$ wgetpaste -r mytext.txt
|
||||
Your raw paste can be seen here: https://paste.pound-python.org/raw/CUJhQ3jEmr2UvfmD2xCL/
|
||||
```
|
||||
|
||||

|
||||
|
||||
如你在上面的输出中看到的,没有语法突出显示,没有 html 格式。只是原始输出。
|
||||
|
||||
#### 9、更改 Wgetpaste 默认值
|
||||
|
||||
所有默认值(`DEFAULT_{NICK,LANGUAGE,EXPIRATION}[_${SERVICE}]` 和 `DEFAULT_SERVICE`)都可以在 `/etc/wgetpaste.conf` 中全局更改,也可以在 `~/.wgetpaste.conf` 文件中针对每个用户更改。但是,这些文件在我的系统中默认情况下并不存在。我想我们需要手动创建它们。开发人员已经在[这里][5]和[这里][6]为这两个文件提供了示例内容。只需使用给定的样本内容手动创建这些文件,并相应地修改参数即可更改 Wgetpaste 的默认设置。
|
||||
|
||||
#### 10、获得帮助
|
||||
|
||||
要显示帮助部分,请运行:
|
||||
|
||||
```
|
||||
$ wgetpaste -h
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-like-services-from-commandline/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://wgetpaste.zlin.dk/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/12/wgetpaste-3.png
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2018/12/wgetpaste-4.png
|
||||
[5]: http://wgetpaste.zlin.dk/zlin.conf
|
||||
[6]: http://wgetpaste.zlin.dk/wgetpaste.example
|
||||
@ -0,0 +1,207 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11711-1.html)
|
||||
[#]: subject: (Install Android 8.1 Oreo on Linux To Run Apps & Games)
|
||||
[#]: via: (https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux)
|
||||
[#]: author: (Python Programmer;Open Source Software Enthusiast. Worked On Developing A Lot Of Free Software. The Founder Of Foss Post;Foss Project. Computer Science Major. )
|
||||
|
||||
在 Linux 上安装安卓 8.1 Oreo 来运行应用程序和游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
[android x86][1] 是一个自由而开源的项目,将谷歌制作的安卓系统从 ARM 架构移植到了 x86 架构,可以让用户在他们的桌面电脑上运行安卓系统来享受所有的安卓功能和应用程序及游戏。
|
||||
|
||||
在前一段时间,android x86 项目完成了安卓 8.1 Oreo 系统的 x86 架构移植。在这篇文章中,我们将解释如何在你的 Linux 系统上安装它,以便你能够随时使用你的安卓 用程序和游戏。
|
||||
|
||||
### 在 Linux 上安装安卓 x86 8.1 Oreo
|
||||
|
||||
#### 准备环境
|
||||
|
||||
首先,让我们下载 android x86 8.1 Oreo 系统镜像。你可以从[这个页面][2]下载它,只需单击 “android-x86_64-8.1-r1.iso” 文件下的 “View” 按钮。
|
||||
|
||||
我们将在我们的 Linux 系统上使用 QEMU 来运行 android x86。QEMU 是一个非常好的模拟器软件,它也是自由而开源的,并且在所有主要的 Linux 发行版存储库中都是可用的。
|
||||
|
||||
在 Ubuntu/Linux Mint/Debian 上安装 QEMU:
|
||||
|
||||
```
|
||||
sudo apt-get install qemu qemu-kvm libvirt-bin
|
||||
```
|
||||
|
||||
在 Fedora 上安装 QEMU:
|
||||
|
||||
```
|
||||
sudo dnf install qemu qemu-kvm
|
||||
```
|
||||
|
||||
对于其它发行版,只需要搜索 “qemu” 和 “qemu-kvm” 软件包,并安装它们。
|
||||
|
||||
在你安装 QEMU 后,我们将需要运行下面的命令来创建 `android.img` 文件,它就像某种分配给安卓系统的磁盘空间。所有安卓文件和系统都将位于该镜像文件中:
|
||||
|
||||
```
|
||||
qemu-img create -f qcow2 android.img 15G
|
||||
```
|
||||
|
||||
我们在这里的意思是,我们想为该安卓系统分配一个最大 15GB 的磁盘空间,但是,你可以更改它到你想要的任意大小(确保它至少大于 5GB)。
|
||||
|
||||
现在,首次启动运行该安卓系统,运行:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img -cdrom /home/mhsabbagh/android-x86_64-8.1-r1.iso
|
||||
```
|
||||
|
||||
将 `/home/mhsabbagh/android-x86_64-8.1-r1.iso` 替换为你从 android x86 网站下载的文件的路径。关于我们在这里正在使用的其它选项的解释,你可以参考[这篇文章][3]。
|
||||
|
||||
在你运行上面的命令后,该安卓系统将启动:
|
||||
|
||||
![][4]
|
||||
|
||||
#### 安装系统
|
||||
|
||||
从这个窗口中,选择 “Advanced options”, 它将引导到下面的菜单,你应如下在其中选择 “Auto_installation” :
|
||||
|
||||
![][5]
|
||||
|
||||
在这以后,安装器将告知你是否想要继续,选择 “Yes”:
|
||||
|
||||
![][6]
|
||||
|
||||
接下来,安装器将无需你的指示而继续进行:
|
||||
|
||||
![][7]
|
||||
|
||||
最后,你将收到这个信息,它表示你已经成功安装安卓 8.1 :
|
||||
|
||||
![][8]
|
||||
|
||||
现在,关闭 QEMU 窗口即可。
|
||||
|
||||
#### 启动和使用 安卓 8.1 Oreo
|
||||
|
||||
现在,安卓系统已经完全安装在你的 `android.img` 文件中,你应该使用下面的 QEMU 命令来启动它,而不是前面的命令:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img
|
||||
```
|
||||
|
||||
注意,我们所做的只是移除 `-cdrom` 选项及其参数。这是告诉 QEMU,我们不再想从我们下载的 ISO 文件启动,相反,从这个安装的安卓系统启动。
|
||||
|
||||
你现在能够看到安卓的启动菜单:
|
||||
|
||||
![][9]
|
||||
|
||||
然后,你将进入第一个准备向导,选择你的语言并继续:
|
||||
|
||||
![][10]
|
||||
|
||||
从这里,选择 “Set up as new” 选项:
|
||||
|
||||
![][11]
|
||||
|
||||
然后,安卓将询问你是否想登录到你当前的谷歌账号。这步骤是可选的,但是这很重要,以便你随后可以使用谷歌 Play 商店:
|
||||
|
||||
![][12]
|
||||
|
||||
然后,你将需要接受条款:
|
||||
|
||||
![][13]
|
||||
|
||||
现在,你可以选择你当前的时区:
|
||||
|
||||
![][14]
|
||||
|
||||
系统将询问你是否想启动一些数据收集功能。如果我是你的话,我将简单地全部关闭它们,像这样:
|
||||
|
||||
![][15]
|
||||
|
||||
最后,你将有两种启动类型可供选择,我建议你选择 Launcher3 选项,并使其成为默认项:
|
||||
|
||||
![][16]
|
||||
|
||||
然后,你将看到完整工作的安卓系统主屏幕:
|
||||
|
||||
![][17]
|
||||
|
||||
从现在起,你可以做你想做的任何事情;你可以使用内置的安卓应用程序,或者你可以浏览你的系统设置来根据你的喜好进行调整。你可以更改你的系统的外观和体验,或者你可以像示例一样运行 Chrome :
|
||||
|
||||
![][18]
|
||||
|
||||
你可以开始从谷歌 Play 商店安装一些应用程序程序,像 WhatsApp 和其它的应用程序,以供你自己使用:
|
||||
|
||||
![][19]
|
||||
|
||||
你现在可以用你的系统做任何你想做的事。恭喜!
|
||||
|
||||
### 以后如何轻松地运行安卓 8.1 Oreo
|
||||
|
||||
我们不想总是不得不打开终端窗口,并写那些长长的 QEMU 命令来运行安卓系统,相反,我们想在我们需要时一次单击就运行它。
|
||||
|
||||
为此,我们将使用下面的命令在 `/usr/share/applications` 下创建一个名为 `android.desktop` 的新文件:
|
||||
|
||||
```
|
||||
sudo nano /usr/share/applications/android.desktop
|
||||
```
|
||||
|
||||
并在其中粘贴下面的内容(右键单击然后粘贴):
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=Android 8.1
|
||||
Comment=Run Android 8.1 Oreo on Linux using QEMU
|
||||
Icon=phone
|
||||
Exec=bash -c 'pkexec env DISPLAY=$DISPLAY XAUTHORITY=$XAUTHORITY qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda /home/mhsabbagh/android.img'
|
||||
Terminal=false
|
||||
Type=Application
|
||||
StartupNotify=true
|
||||
Categories=GTK;
|
||||
```
|
||||
|
||||
再强调一次,你必需使用你系统上的本地镜像路径来替换 `/home/mhsabbagh/android.img` 。然后保存文件(`Ctrl+X`,然后按 `Y`,然后按回车)。
|
||||
|
||||
注意,我们需要使用 `pkexec` 来使用 root 权限运行 QEMU ,因为从较新的版本开始,普通用户不允许通过 libvirt 访问 KVM 技术;这就是为什么它将每次要求你输入 root 密码的原因。
|
||||
|
||||
现在,你将在应用程序菜单中看到安卓图标,你可以在你想使用安卓的任何时间来简单地单击该图标,QEMU 程序将启动:
|
||||
|
||||
![][20]
|
||||
|
||||
### 总结
|
||||
|
||||
我们向你展示如何在你的 Linux 系统上安装和运行安卓 8.1 Oreo 。从现在起,在没有其它一些软件的(像 Blutsticks 和类似的方法)的情况下,你可以更容易地完成基于安卓的任务。在这里,你有一个完整工作和功能的安卓系统,你可以随心所欲地操作它,如果一些东西出错,你可以简单地干掉该镜像文件,然后随时再一次重新运行安装程序。
|
||||
|
||||
你之前尝试过 android x86 吗?你的体验如何?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux
|
||||
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/mhsabbagh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.android-x86.org/
|
||||
[2]: http://www.android-x86.org/download
|
||||
[3]: https://fosspost.org/tutorials/use-qemu-test-operating-systems-distributions
|
||||
[4]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-16.png?resize=694%2C548&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 40 android 8.1 oreo on linux)
|
||||
[5]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-15.png?resize=673%2C537&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 42 android 8.1 oreo on linux)
|
||||
[6]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-14.png?resize=769%2C469&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 44 android 8.1 oreo on linux)
|
||||
[7]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-13.png?resize=767%2C466&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 46 android 8.1 oreo on linux)
|
||||
[8]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-12.png?resize=750%2C460&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 48 android 8.1 oreo on linux)
|
||||
[9]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-11.png?resize=754%2C456&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 50 android 8.1 oreo on linux)
|
||||
[10]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-10.png?resize=850%2C559&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 52 android 8.1 oreo on linux)
|
||||
[11]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-09.png?resize=850%2C569&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 54 android 8.1 oreo on linux)
|
||||
[12]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-08.png?resize=850%2C562&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 56 android 8.1 oreo on linux)
|
||||
[13]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-07-1.png?resize=850%2C561&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 58 android 8.1 oreo on linux)
|
||||
[14]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-06.png?resize=850%2C569&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 60 android 8.1 oreo on linux)
|
||||
[15]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-05.png?resize=850%2C559&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 62 android 8.1 oreo on linux)
|
||||
[16]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-04.png?resize=850%2C553&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 64 android 8.1 oreo on linux)
|
||||
[17]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-03.png?resize=850%2C571&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 66 android 8.1 oreo on linux)
|
||||
[18]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-02.png?resize=850%2C555&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 68 android 8.1 oreo on linux)
|
||||
[19]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-01.png?resize=850%2C557&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 70 android 8.1 oreo on linux)
|
||||
[20]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-17-1539.png?resize=850%2C557&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 72 android 8.1 oreo on linux)
|
||||
183
published/20190225 Netboot a Fedora Live CD.md
Normal file
183
published/20190225 Netboot a Fedora Live CD.md
Normal file
@ -0,0 +1,183 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11708-1.html)
|
||||
[#]: subject: (Netboot a Fedora Live CD)
|
||||
[#]: via: (https://fedoramagazine.org/netboot-a-fedora-live-cd/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
网络启动一个 Fedora Live CD
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Live CD][1] 对于很多任务是很有用的,例如:
|
||||
|
||||
* 将操作系统安装到一个硬盘驱动器
|
||||
* 修复一个启动加载程序或执行其它救援模式操作
|
||||
* 为 Web 浏览提供一个相适应的最小环境
|
||||
* …以及[更多的东西][2]。
|
||||
|
||||
作为使用 DVD 和 USB 驱动器来存储你的 Live CD 镜像是一个替代方案,你可以上传它们到一个不太可能丢失或损坏的 [iSCSI][3] 服务器中。这个指南向你展示如何加载你的 Live CD 镜像到一个 ISCSI 服务器上,并使用 [iPXE][4] 启动加载程序来访问它们。
|
||||
|
||||
### 下载一个 Live CD 镜像
|
||||
|
||||
```
|
||||
$ MY_RLSE=27
|
||||
$ MY_LIVE=$(wget -q -O - https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/$MY_RLSE/Workstation/x86_64/iso | perl -ne '/(Fedora[^ ]*?-Live-[^ ]*?\.iso)(?{print $^N})/;')
|
||||
$ MY_NAME=fc$MY_RLSE
|
||||
$ wget -O $MY_NAME.iso https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/$MY_RLSE/Workstation/x86_64/iso/$MY_LIVE
|
||||
```
|
||||
|
||||
上面的命令下载 `Fedora-Workstation-Live-x86_64-27-1.6.iso` Fedora Live 镜像,并保存为 `fc27.iso`。更改 `MY_RLSE` 的值来下载其它档案版本。或者,你可以浏览 <https://getfedora.org/> 来下载最新的 Fedora live 镜像。在 21 之前的版本使用不同的命名约定,必需[在这里手动下载][5]。如果你手动下载一个 Live CD 镜像,设置 `MY_NAME` 变量为不带有扩展名的文件的基本名称。用此方法,下面部分中命令将引用正确的文件。
|
||||
|
||||
### 转换 Live CD 镜像
|
||||
|
||||
使用 `livecd-iso-to-disk` 工具来转换 ISO 文件为一个磁盘镜像,并添加 `netroot` 参数到嵌入的内核命令行:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y livecd-tools
|
||||
$ MY_SIZE=$(du -ms $MY_NAME.iso | cut -f 1)
|
||||
$ dd if=/dev/zero of=$MY_NAME.img bs=1MiB count=0 seek=$(($MY_SIZE+512))
|
||||
$ MY_SRVR=server-01.example.edu
|
||||
$ MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
$ MY_LOOP=$(sudo losetup --show --nooverlap --find $MY_NAME.img)
|
||||
$ sudo livecd-iso-to-disk --format --extra-kernel-args netroot=iscsi:$MY_SRVR:::1:iqn.$MY_RVRS:$MY_NAME $MY_NAME.iso $MY_LOOP
|
||||
$ sudo losetup -d $MY_LOOP
|
||||
```
|
||||
|
||||
### 上传 Live 镜像到你的服务器
|
||||
|
||||
在你的 ISCSI 服务器上创建一个目录来存储你的 live 镜像,随后上传你修改的镜像到其中。
|
||||
|
||||
对于 21 及更高发布版本:
|
||||
|
||||
```
|
||||
$ MY_FLDR=/images
|
||||
$ scp $MY_NAME.img $MY_SRVR:$MY_FLDR/
|
||||
```
|
||||
|
||||
对于 21 以前发布版本:
|
||||
|
||||
```
|
||||
$ MY_FLDR=/images
|
||||
$ MY_LOOP=$(sudo losetup --show --nooverlap --find --partscan $MY_NAME.img)
|
||||
$ sudo tune2fs -O ^has_journal ${MY_LOOP}p1
|
||||
$ sudo e2fsck ${MY_LOOP}p1
|
||||
$ sudo dd status=none if=${MY_LOOP}p1 | ssh $MY_SRVR "dd of=$MY_FLDR/$MY_NAME.img"
|
||||
$ sudo losetup -d $MY_LOOP
|
||||
```
|
||||
|
||||
### 定义 iSCSI 目标
|
||||
|
||||
在你的 iSCSI 服务器上运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# MY_NAME=fc27
|
||||
# MY_FLDR=/images
|
||||
# MY_SRVR=`hostname`
|
||||
# MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
# cat << END > /etc/tgt/conf.d/$MY_NAME.conf
|
||||
<target iqn.$MY_RVRS:$MY_NAME>
|
||||
backing-store $MY_FLDR/$MY_NAME.img
|
||||
readonly 1
|
||||
allow-in-use yes
|
||||
</target>
|
||||
END
|
||||
# tgt-admin --update ALL
|
||||
```
|
||||
|
||||
### 创建一个可启动 USB 驱动器
|
||||
|
||||
[iPXE][4] 启动加载程序有一个 [sanboot][6] 命令,你可以使用它来连接并启动托管于你 ISCSI 服务器上运行的 live 镜像。它可以以很多不同的[格式][7]编译。最好的工作格式依赖于你正在运行的硬件。例如,下面的说明向你展示如何在一个 USB 驱动器上从 [syslinux][9] 中 [链式加载][8] iPXE。
|
||||
|
||||
首先,下载 iPXE,并以它的 lkrn 格式构建。这应该作为一个工作站上的普通用户完成:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y git
|
||||
$ git clone http://git.ipxe.org/ipxe.git $HOME/ipxe
|
||||
$ sudo dnf groupinstall -y "C Development Tools and Libraries"
|
||||
$ cd $HOME/ipxe/src
|
||||
$ make clean
|
||||
$ make bin/ipxe.lkrn
|
||||
$ cp bin/ipxe.lkrn /tmp
|
||||
```
|
||||
|
||||
接下来,准备一个带有一个 MSDOS 分区表和一个 FAT32 文件系统的 USB 驱动器。下面的命令假设你已经连接将要格式化的 USB 驱动器。**注意:你要格式正确的驱动器!**
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# dnf install -y parted util-linux dosfstools
|
||||
# echo; find /dev/disk/by-id ! -regex '.*-part.*' -name 'usb-*' -exec readlink -f {} \; | xargs -i bash -c "parted -s {} unit MiB print | perl -0 -ne '/^Model: ([^(]*).*\n.*?([0-9]*MiB)/i && print \"Found: {} = \$2 \$1\n\"'"; echo; read -e -i "$(find /dev/disk/by-id ! -regex '.*-part.*' -name 'usb-*' -exec readlink -f {} \; -quit)" -p "Drive to format: " MY_USB
|
||||
# umount $MY_USB?
|
||||
# wipefs -a $MY_USB
|
||||
# parted -s $MY_USB mklabel msdos mkpart primary fat32 1MiB 100% set 1 boot on
|
||||
# mkfs -t vfat -F 32 ${MY_USB}1
|
||||
```
|
||||
|
||||
最后,在 USB 驱动器上安装并配置 syslinux ,来链式加载 iPXE:
|
||||
|
||||
```
|
||||
# dnf install -y syslinux-nonlinux
|
||||
# syslinux -i ${MY_USB}1
|
||||
# dd if=/usr/share/syslinux/mbr.bin of=${MY_USB}
|
||||
# MY_MNT=$(mktemp -d)
|
||||
# mount ${MY_USB}1 $MY_MNT
|
||||
# MY_NAME=fc27
|
||||
# MY_SRVR=server-01.example.edu
|
||||
# MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
# cat << END > $MY_MNT/syslinux.cfg
|
||||
ui menu.c32
|
||||
default $MY_NAME
|
||||
timeout 100
|
||||
menu title SYSLINUX
|
||||
label $MY_NAME
|
||||
menu label ${MY_NAME^^}
|
||||
kernel ipxe.lkrn
|
||||
append dhcp && sanboot iscsi:$MY_SRVR:::1:iqn.$MY_RVRS:$MY_NAME
|
||||
END
|
||||
# cp /usr/share/syslinux/menu.c32 $MY_MNT
|
||||
# cp /usr/share/syslinux/libutil.c32 $MY_MNT
|
||||
# cp /tmp/ipxe.lkrn $MY_MNT
|
||||
# umount ${MY_USB}1
|
||||
```
|
||||
|
||||
通过简单地编辑 `syslinux.cfg` 文件,并添加附加的菜单项,你应该能够使用这同一个 USB 驱动器来网络启动附加的 ISCSI 目标。
|
||||
|
||||
这仅是加载 IPXE 的一种方法。你可以直接在你的工作站上安装 syslinux 。再一种选项是编译 iPXE 为一个 EFI 可执行文件,并直接放置它到你的 [ESP][10] 中。又一种选项是编译 iPXE 为一个 PXE 加载器,并放置它到你的能够被 DHCP 引用的 TFTP 服务器。最佳的选项依赖于的环境
|
||||
|
||||
### 最后说明
|
||||
|
||||
* 如果你以 IPXE 的 EFI 格式编译 IPXE ,你可能想添加 `–filename \EFI\BOOT\grubx64.efi` 参数到 `sanboot` 命令。
|
||||
* 能够创建自定义 live 镜像。更多信息参考[创建和使用 live CD][11]。
|
||||
* 可以添加 `–overlay-size-mb` 和 `–home-size-mb` 参数到 `livecd-iso-to-disk` 命令来创建永久存储的 live 镜像。然而,如果你有多个并发用户,你将需要设置你的 ISCSI 服务器来管理独立的每个用户的可写覆盖。这与 “[如何构建一个网络启动服务器,部分 4][12]” 一文所示类似。
|
||||
* Live 镜像在它们的内核命令行中支持一个 `persistenthome` 选项(例如, `persistenthome=LABEL=HOME`)。与经过 CHAP 身份验证的 iSCSI 目标一起使用,对于中心控制主目录,`persistenthome` 选项为 NFS 提供一个有趣的替代方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/netboot-a-fedora-live-cd/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Live_CD
|
||||
[2]: https://en.wikipedia.org/wiki/Live_CD#Uses
|
||||
[3]: https://en.wikipedia.org/wiki/ISCSI
|
||||
[4]: https://ipxe.org/
|
||||
[5]: https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/
|
||||
[6]: http://ipxe.org/cmd/sanboot/
|
||||
[7]: https://ipxe.org/appnote/buildtargets#boot_type
|
||||
[8]: https://en.wikipedia.org/wiki/Chain_loading
|
||||
[9]: https://www.syslinux.org/wiki/index.php?title=SYSLINUX
|
||||
[10]: https://en.wikipedia.org/wiki/EFI_system_partition
|
||||
[11]: https://docs.fedoraproject.org/en-US/quick-docs/creating-and-using-a-live-installation-image/#proc_creating-and-using-live-cd
|
||||
[12]: https://fedoramagazine.org/how-to-build-a-netboot-server-part-4/
|
||||
|
||||
79
published/20190322 Easy means easy to debug.md
Normal file
79
published/20190322 Easy means easy to debug.md
Normal file
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11693-1.html)
|
||||
[#]: subject: (Easy means easy to debug)
|
||||
[#]: via: (https://arp242.net/weblog/easy.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
简单就是易于调试
|
||||
======
|
||||
|
||||
对于框架、库或者工具来说,怎样做才算是“简单”?也许有很多的定义,但我的理解通常是**易于调试**。我经常见到人们宣传某个特定的程序、框架、库、文件格式或者其它什么东西是简单的,因为他们会说“看,我只需要这么一点工作量就能够完成某项工作,这太简单了”。非常好,但并不完善。
|
||||
|
||||
你可能只编写一次软件,但几乎总要经历好几个调试周期。注意我说的调试周期并不意味着“代码里面有 bug 你需要修复”,而是说“我需要再看一下这份代码来修复 bug”。为了调试代码,你需要理解它,因此“易于调试”延伸来讲就是“易于理解”。
|
||||
|
||||
抽象使得程序易于编写,但往往是以难以理解为代价。有时候这是一个很好的折中,但通常不是。大体上,如果能使程序在日后易于理解和调试,我很乐意花更多的时间来写一些东西,因为这样实际上更省时间。
|
||||
|
||||
简洁并不是让程序易于调试的**唯一**方法,但它也许是最重要的。良好的文档也是,但不幸的是好的文档太少了。(注意,质量并**不**取决于字数!)
|
||||
|
||||
这种影响是真是存在的。难以调试的程序会有更多的 bug,即使最初的 bug 数量与易于调试的程序完全相同,而是因为修复 bug 更加困难、更花时间。
|
||||
|
||||
在公司的环境中,把时间花在难以修复的 bug 上通常被认为是不划算的投资。而在开源的环境下,人们花的时间会更少。(大多数项目都有一个或多个定期的维护者,但成百上千的贡献者提交的仅只是几个补丁)
|
||||
|
||||
---
|
||||
|
||||
这并不全是 1974 年由 Brian W. Kernighan 和 P. J. Plauger 合著的《<ruby>编程风格的元素<rt>The Elements of Programming Style</rt></ruby>》中的观点:
|
||||
|
||||
> 每个人都知道调试比起编写程序困难两倍。当你写程序的时候耍小聪明,那么将来应该怎么去调试?
|
||||
|
||||
我见过许多看起来写起来“极尽精妙”,但却导致难以调试的代码。我会在下面列出几种样例。争论这些东西本身有多坏并不是我的本意,我仅想强调对于“易于使用”和“易于调试”之间的折中。
|
||||
|
||||
* <ruby>ORM<rt>对象关系映射</rt></ruby> 库可以让数据库查询变得简单,代价是一旦你想解决某个问题,事情就变得难以理解。
|
||||
* 许多测试框架让调试变得困难。Ruby 的 rspec 就是一个很好的例子。有一次我不小心使用错了,结果花了很长时间搞清楚**究竟**哪里出了问题(因为它给出错误提示非常含糊)。
|
||||
|
||||
我在《[测试并非万能][1]》这篇文章中写了更多关于以上的例子。
|
||||
* 我用过的许多 JavaScript 框架都很难完全理解。Clever(LCTT 译注:一种 JS 框架)的语句一向很有逻辑,直到某条语句不能如你预期的工作,这时你就只能指望 Stack Overflow 上的某篇文章或 GitHub 上的某个回帖来帮助你了。
|
||||
|
||||
这些函数库**确实**让任务变得非常简单,使用它们也没有什么错。但通常人们都过于关注“易于使用”而忽视了“易于调试”这一点。
|
||||
* Docker 非常棒,并且让许多事情变得非常简单,直到你看到了这条提示:
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch:
|
||||
oci runtime error: container_linux.go:247: starting container process caused "process_linux.go:258:
|
||||
applying cgroup configuration for process caused \"failed to write 898 to cgroup.procs: write
|
||||
/sys/fs/cgroup/cpu,cpuacct/docker/b13312efc203e518e3864fc3f9d00b4561168ebd4d9aad590cc56da610b8dd0e/cgroup.procs:
|
||||
invalid argument\""
|
||||
```
|
||||
|
||||
或者这条:
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch: EOF
|
||||
```
|
||||
|
||||
那么...你怎么看?
|
||||
* `Systemd` 比起 `SysV`、`init.d` 脚本更加简单,因为编写 `systemd` 单元文件比起编写 `shell` 脚本更加方便。这也是 Lennart Poetterin 在他的 [systemd 神话][2] 中解释 `systemd` 为何简单时使用的论点。
|
||||
|
||||
我非常赞同 Poettering 的观点——也可以看 [shell 脚本陷阱][3] 这篇文章。但是这种角度并不全面。单元文件简单的背后意味着 `systemd` 作为一个整体要复杂的多,并且用户确实会受到它的影响。看看我遇到的这个[问题][4]和为它所做的[修复][5]。看起来很简单吗?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/easy.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.arp242.net/testing.html
|
||||
[2]: http://0pointer.de/blog/projects/the-biggest-myths.html
|
||||
[3]:https://www.arp242.net/shell-scripting-trap.html
|
||||
[4]:https://unix.stackexchange.com/q/185495/33645
|
||||
[5]:https://cgit.freedesktop.org/systemd/systemd/commit/?id=6e392c9c45643d106673c6643ac8bf4e65da13c1
|
||||
186
published/20190513 How To Set Password Complexity On Linux.md
Normal file
186
published/20190513 How To Set Password Complexity On Linux.md
Normal file
@ -0,0 +1,186 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11709-1.html)
|
||||
[#]: subject: (How To Set Password Complexity On Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux 如何设置密码复杂度?
|
||||
======
|
||||
|
||||
对于 Linux 系统管理员来说,用户管理是最重要的事之一。这涉及到很多因素,实现强密码策略是用户管理的其中一个方面。移步后面的 URL 查看如何 [在 Linux 上生成一个强密码][1]。它会限制系统未授权的用户的访问。
|
||||
|
||||
所有人都知道 Linux 的默认策略很安全,然而我们还是要做一些微调,这样才更安全。弱密码有安全隐患,因此,请特别注意。移步后面的 URL 查看生成的强密码的[密码长度和分值][2]。本文将教你在 Linux 中如何实现最安全的策略。
|
||||
|
||||
在大多数 Linux 系统中,我们可以用 PAM(<ruby>可插拔认证模块<rt>pluggable authentication module</rt></ruby>)来加强密码策略。在下面的路径可以找到这个文件。
|
||||
|
||||
- 在红帽系列的系统中,路径:`/etc/pam.d/system-auth`。
|
||||
- Debian 系列的系统中,路径:`/etc/pam.d/common-password`。
|
||||
|
||||
关于默认的密码过期时间,可以在 `/etc/login.defs` 文件中查看详细信息。
|
||||
|
||||
为了更好理解,我摘取了文件的部分内容:
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 99999
|
||||
PASS_MIN_DAYS 0
|
||||
PASS_MIN_LEN 5
|
||||
PASS_WARN_AGE 7
|
||||
```
|
||||
|
||||
详细解释:
|
||||
|
||||
* `PASS_MAX_DAYS`:一个密码可使用的最大天数。
|
||||
* `PASS_MIN_DAYS`:两次密码修改之间最小的间隔天数。
|
||||
* `PASS_MIN_LEN`:密码最小长度。
|
||||
* `PASS_WARN_AGE`:密码过期前给出警告的天数。
|
||||
|
||||
我们将会展示在 Linux 中如何实现下面的 11 个密码策略。
|
||||
|
||||
* 一个密码可使用的最大天数
|
||||
* 两次密码修改之间最小的间隔天数
|
||||
* 密码过期前给出警告的天数
|
||||
* 密码历史记录/拒绝重复使用密码
|
||||
* 密码最小长度
|
||||
* 最少的大写字母个数
|
||||
* 最少的小写字母个数
|
||||
* 最少的数字个数
|
||||
* 最少的其他字符(符号)个数
|
||||
* 账号锁定 — 重试
|
||||
* 账号解锁时间
|
||||
|
||||
### 密码可使用的最大天数是什么?
|
||||
|
||||
这一参数限制一个密码可使用的最大天数。它强制用户在过期前修改他/她的密码。如果他们忘记修改,那么他们会登录不了系统。他们需要联系管理员才能正常登录。这个参数可以在 `/etc/login.defs` 文件中设置。我把这个参数设置为 90 天。
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 90
|
||||
```
|
||||
|
||||
### 密码最小天数是什么?
|
||||
|
||||
这个参数限制两次修改之间的最少天数。举例来说,如果这个参数被设置为 15 天,用户今天修改了密码,那么在 15 天之内他都不能修改密码。这个参数可以在 `/etc/login.defs` 文件中设置。我设置为 15 天。
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MIN_DAYS 15
|
||||
```
|
||||
|
||||
### 密码警告天数是什么?
|
||||
|
||||
这个参数控制密码警告的前置天数,在密码即将过期时会给用户警告提示。在警告天数结束前,用户会收到日常警告提示。这可以提醒用户在密码过期前修改他们的密码,否则我们就需要联系管理员来解锁密码。这个参数可以在 `/etc/login.defs` 文件中设置。我设置为 10 天。
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_WARN_AGE 10
|
||||
```
|
||||
|
||||
**注意:** 上面的所有参数仅对新账号有效,对已存在的账号无效。
|
||||
|
||||
### 密码历史或拒绝重复使用密码是什么?
|
||||
|
||||
这个参数控制密码历史。它记录曾经使用过的密码(禁止使用的曾用密码的个数)。当用户设置新的密码时,它会检查密码历史,如果他们要设置的密码是一个曾经使用过的旧密码,将会发出警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置密码历史为 5。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password sufficient pam_unix.so md5 shadow nullok try_first_pass use_authtok remember=5
|
||||
```
|
||||
|
||||
### 密码最小长度是什么?
|
||||
|
||||
这个参数表示密码的最小长度。当用户设置新密码时,系统会检查这个参数,如果新设的密码长度小于这个参数设置的值,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置最小密码长度为 12。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12
|
||||
```
|
||||
|
||||
`try_first_pass retry=3`:在密码设置交互界面,用户有 3 次机会重设密码。
|
||||
|
||||
### 设置最少的大写字母个数?
|
||||
|
||||
这个参数表示密码中至少需要的大写字母的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有大写字母,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置密码(中的大写字母)的最小长度为 1 个字母。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ucredit=-1
|
||||
```
|
||||
|
||||
### 设置最少的小写字母个数?
|
||||
|
||||
这个参数表示密码中至少需要的小写字母的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有小写字母,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置为 1 个字母。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 lcredit=-1
|
||||
```
|
||||
|
||||
### 设置密码中最少的数字个数?
|
||||
|
||||
这个参数表示密码中至少需要的数字的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有数字,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置为 1 个数字。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 dcredit=-1
|
||||
```
|
||||
|
||||
### 设置密码中最少的其他字符(符号)个数?
|
||||
|
||||
这个参数表示密码中至少需要的特殊符号的个数。这些是密码强度参数,可以让密码更健壮。当用户设置新密码时,系统会检查这个参数,如果密码中没有特殊符号,会收到警告提示。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。我设置为 1 个字符。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ocredit=-1
|
||||
```
|
||||
|
||||
### 设置账号锁定?
|
||||
|
||||
这个参数控制用户连续登录失败的最大次数。当达到设定的连续失败登录次数阈值时,锁定账号。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
### 设定账号解锁时间?
|
||||
|
||||
这个参数表示用户解锁时间。如果一个用户账号在连续认证失败后被锁定了,当过了设定的解锁时间后,才会解锁。设置被锁定中的账号的解锁时间(900 秒 = 15分钟)。这个参数可以在 `/etc/pam.d/system-auth` 文件中设置。
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5 unlock_time=900
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/
|
||||
73
published/20190711 DevOps for introverted people.md
Normal file
73
published/20190711 DevOps for introverted people.md
Normal file
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (XLCYun)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11725-1.html)
|
||||
[#]: subject: (DevOps for introverted people)
|
||||
[#]: via: (https://opensource.com/article/19/7/devops-introverted-people)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||
|
||||
内向者的 DevOps
|
||||
======
|
||||
|
||||
> 我们邀请 Opensource.com 的 DevOps 团队,希望他们能够谈一谈作为 DevOps 内向者的休验,同时给 DevOps 外向者一些建议。下面是他们的回答。
|
||||
|
||||

|
||||
|
||||
我们邀请我们的 [DevOps 团队][2] 谈一谈他们作为一个内向者的体验,并给外向者们一些建议。但是在我们开始了解他们的回答之前,让我们先来定义一下这些词汇。
|
||||
|
||||
### “内向者”是什么意思?
|
||||
|
||||
内向者通常指的是一部分人群,当他们和别人相处的时候,会使他们的能量耗尽,而不是激发他们更多的能量。当我们思考我们是如何恢复能量时,这是一个非常有用的词汇:内向者通常需要更多的独处时间来恢复能量,特别是和一群人在一起很长时间后。关于内向者的一个非常大的误解就是他们一定是“害羞的”,但是科学表明,那不过是另一种不同的性格特征。
|
||||
|
||||
内向性与外向性是通过 [Myers Briggs 类型指标][4] 而为人所知的,现在也常常被称作一个 [光谱][5] 的两端。虽然这个世界看起来好像外向者比内向者要多,但是心理学者则倾向于认为大部分人在光谱上的位置是落在 [中间性格或偏内向性格的][6]。
|
||||
|
||||
现在,我们来看看问答。
|
||||
|
||||
### DevOps 技术主管可以通过哪些方式来让内向者感觉他们是团队的一部分并且愿意分享他们的想法?
|
||||
|
||||
“每个人都会不大一样,所以观察敏锐就很重要了。从 GitLab 过来的一个人告诉我,他们的哲学就是如果他们没有提供任何意见,那么他们就是被排除在外的。如果有人在一个会议上没有提供任何的意见,那就想办法让他们加入进来。**当我知道一个内向者对我们将要讨论的会议论题感兴趣的时候,我会提前请他写一些书面文本。有非常多的会议其实是可以避免的,只要通过把讨论放到 Slack 或者 GitLab 上就行了,内向者会更愿意参与进来**。在站立会议中,每个人都会交代最新的进展,在这个环境下,内向者表现得很好。有时候我们在其实会议上会重复做一些事情,仅仅是为了保证每个人都有时间发言。我同时也会鼓励内向者在工作小组或者社区小组面前发言,以此来锻炼他们的这些技能。”—— 丹·巴克
|
||||
|
||||
“**我觉得别人对我做的最好的事情,就是他们保证了当重大问题来临的时候,我拥有必要的技能去回答它**。彼时,我作为一名非常年轻的入伍空军的一员,我需要给我们部队的高级领导做状态简报的汇报。我必须在任何时候都有一些可用的数据点,以及在实现我们确立的目标的过程中,产生延误以及偏差的背后的原因。那样的经历推动着我从一个‘幕后人员’逐渐变得更加愿意和别人分享自己的观点和想法。”—— 克里斯·肖特
|
||||
|
||||
“**通过文化去领导。为你的同僚一起设计和尝试仪式。**你可以为给你的小组或团队设计一个小的每周仪式,甚至给你的部门或组织设计一个年度的大仪式。它的意义在于去尝试一些事物,并观察你在其中的领导角色。去找到你们文化当中的代沟以及对立。回顾团队的信仰和行为。你能从哪里观察到对立?你们的文化中缺失了什么?从一个小陈述开始‘我从 X 和 Y 之间看到了对立’,或者‘我的团队缺少了 Z’。接着,将代沟与对立转换为问题:写下三个‘我们如何能……(How might we's, HMWs)’。”—— 凯瑟琳·路易斯
|
||||
|
||||
“内向者不是一个不同的群体,他们要么是在分享他们的想法之前想得太多或等得太久的一些人,要么就是一些根本不知道发生了什么的人。我就是第一种,我想太多了,有时候还担心我的意见会被其他人嘲笑,或者没有什么意思,或者想偏了。形成那样的思维方式很难,但它同时也在吞噬着我学习更好事物的机会。有一次,我们团队在讨论一个实现问题。我当时的老大一次又一次地问我,为什么我没有作为团队中更具经验的人参与进来,然后我就(集齐了全宇宙的力量之后)开口说我想说的大家都已经说过了。他说,有时候我可以重复说一次,事情纷繁,如果你能够重复一遍你的想法,即使它已经被讨论过了,也会大有裨益。好吧,虽然它不是一种特别信服的方式,但是我知道了至少有人想听听我怎么说,它给了我一点信心。
|
||||
|
||||
“现在,我所使用的让团队中的人发言的方法是**我经常向内向的人求助,即使我知道解决方法,并且在团队会议和讨论中感谢他们来建立他们的自信心,通过给他们时间让他们一点一点的从他们寡言的本性中走出来,从而跟团队分享很多的知识**。他们在外面的世界中可能仍然会有一点点孤立,但是在团队里面,有些会成为我们可以信赖的人。”—— 阿布希什克·塔姆拉卡尔
|
||||
|
||||
“我给参加会议的内向者的建议是,找一个同样要参加会议的朋友或者同事,这样到时你就会有人可以跟你一起舒服地交谈,在会议开始之前,提前跟其他的与会者(朋友、行业联系人、前同事等等)约着见个面或者吃顿饭,**要注意你的疲劳程度,并且照顾好自己**:如果你需要重新恢复能量,就跳过那些社交或者夜晚的活动,在事后回顾中记录一下自己的感受。”—— 伊丽莎白·约瑟夫
|
||||
|
||||
### 和一个内向者倾向的同事一起工作时,有什么提高生产效率的小建议?
|
||||
|
||||
“在保证质量时,生产效率会越来越具备挑战性。在大多数时候,工作中的一个小憩或者轻松随意的交谈,可能正是我们的创造性活动中需要的一个火花。再说一次,我发现当你的团队中有内向者时, Slack 和 Github 会是一个非常有用的用于交换想法以及和其他人互动的媒介。**我同时也发现,结对编程对于大部分的内向者也非常有用,虽然一对一的交流对于他们来说,并不像交税那么频繁,但是生产质量和效率的提升却是重大的**。但是,当一个内向者在独自工作的时间,团队中的所有人都不应该去打断他们。最好是发个邮件,或者使用没有那么强的侵入性的媒介。”—— 丹·巴克
|
||||
|
||||
“给他们趁手的工具,让他们工作并归档他们的工作。**让他们能够在他们的工作上做到最好**。要足够经常地去检查一下,保证他们没有走偏路,但是要记住,相比外向者而言,这样做是更大的一种让人分心的困扰。”—— 克里斯·肖特
|
||||
|
||||
“**当我低着头的时候,不要打断我。真的,别打断我!**当我沉浸在某件事物中时,这样做会造成我至少需要花费两个小时,才能让我的大脑重新回到之前的状态。感觉很痛苦。真的。你可以发个邮件让我去有白板的地方。然后从客户的角度而不是你的角度——通过画图的方式——分享下有什么问题。要知道,可能同时会有十几个客户问题缠绕在我的脑海中,如果你的问题听起来就是‘这样子做会让我在我的领导面前显得很好’的那一类问题,那么相比我脑袋中已经有的真正的客户问题而言,它不会得到更多的关注的。画个图,给我点时间思考。当我准备分享我的看法的时候,保证有多支马克笔可以使用。准备好接受你对问题的假设有可能完全是错误的。”—— 凯瑟琳·路易斯
|
||||
|
||||
“感谢和鼓励就是解决的方法,感谢可能不是一份工作评估,但是感谢能让人舒服地感受到自己并不仅仅是一个活着的独立实体,**因而每个人都能够感觉到自己是被倾听的,而不是被嘲笑或者低估的**。”—— 阿布希什克·塔姆拉卡尔
|
||||
|
||||
### 结语
|
||||
|
||||
在与内向的 DevOps 爱好者的这次交谈中,我们最大的启迪就是平等:其他人需要被怎样对待,就怎样对待他们,同时你想被怎样对待,就去要求别人怎样对待你。无论你是内向还是外向,我们都需要承认我们并非全以相同的一种方式体验这个世界。我们的同事应当被给予足够的空间以完成他们的工作,通过讨论他们的需求作为了解如何支持他们的开始。我们的差异正是我们的社区如此特别的原因,它让我们的工作对更多的人更加的有用。与别人沟通最有效的方式,就是对于你们两者而言都可行的方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/devops-introverted-people
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_QandAorange_520x292_0311LL.png?itok=qa3hHSou (Q and A letters)
|
||||
[2]: https://opensource.com/devops-team
|
||||
[3]: https://www.inc.com/melanie-curtin/are-you-shy-or-introverted-science-says-this-is-1-primary-difference.html
|
||||
[4]: https://www.myersbriggs.org/my-mbti-personality-type/mbti-basics/extraversion-or-introversion.htm?bhcp=1
|
||||
[5]: https://lifehacker.com/lets-quit-it-with-the-introvert-extrovert-nonsense-1713772952
|
||||
[6]: https://www.psychologytoday.com/us/blog/the-gen-y-guide/201710/the-majority-people-are-not-introverts-or-extroverts
|
||||
@ -0,0 +1,235 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11673-1.html)
|
||||
[#]: subject: (24 sysadmin job interview questions you should know)
|
||||
[#]: via: (https://opensource.com/article/19/7/sysadmin-job-interview-questions)
|
||||
[#]: author: (DirectedSoul https://opensource.com/users/directedsoul)
|
||||
|
||||
24 个必知必会的系统管理员面试问题
|
||||
======
|
||||
|
||||
> 即将进行系统管理员工作面试吗?阅读本文,了解你可能会遇到的一些问题以及可能的答案。
|
||||
|
||||

|
||||
|
||||
作为一个经常与计算机打交道的极客,在硕士毕业后在 IT 行业选择我的职业是很自然的选择。因此,我认为走上系统管理员之路是正确的路径。在我的职业生涯中,我对求职面试过程非常熟悉。现在来看一下对该职位的预期、职业发展道路,以及一系列常见面试问题及我的回答。
|
||||
|
||||
### 系统管理员的典型任务和职责
|
||||
|
||||
组织需要了解系统工作原理的人员,以确保数据安全并保持服务平稳运行。你可能会问:“等等,是不是系统管理员还能做更多的事情?”
|
||||
|
||||
你是对的。现在,一般来说,让我们看一下典型的系统管理员的日常任务。根据公司的需求和人员的技能水平,系统管理员的任务从管理台式机、笔记本电脑、网络和服务器到设计组织的 IT 策略不等。有时,系统管理员甚至负责购买和订购新的 IT 设备。
|
||||
|
||||
那些寻求系统管理工作以作为其职业发展道路的人可能会发现,由于 IT 领域的快速变化是不可避免的,因此难以保持其技能和知识的最新状态。所有人都会想到的下一个自然而然的问题是 IT 专业人员如何掌握最新的更新和技能。
|
||||
|
||||
### 简单的问题
|
||||
|
||||
这是你将遇到的一些最基本的问题,以及我的答案:
|
||||
|
||||
**1、你在 \*nix 服务器上登录后键入的前五个命令是什么?**
|
||||
|
||||
> * `lsblk` 以查看所有的块设备信息
|
||||
> * `who` 查看谁登录到服务器
|
||||
> * `top`,以了解服务器上正在运行的进程
|
||||
> * `df -khT` 以查看服务器上可用的磁盘容量
|
||||
> * `netstat` 以查看哪些 TCP 网络连接处于活动状态
|
||||
|
||||
**2、如何使进程在后台运行,这样做的好处是什么?**
|
||||
|
||||
> 你可以通过在命令末尾添加特殊字符 `&` 来使进程在后台运行。通常,执行时间太长并且不需要用户交互的应用程序可以放到后台,以便我们可以在终端中继续工作。([引文][2])
|
||||
|
||||
**3、以 root 用户身份运行这些命令是好事还是坏事?**
|
||||
|
||||
> 由于两个主要问题,以 root 身份运行(任何命令)是不好的。第一个是*风险*。当你以 **root** 身份登录时,无法避免你由于粗心大意而犯错。如果你尝试以带有潜在危害的方式更改系统,则需要使用 `sudo`,它会引入一个暂停(在你输入密码时),以确保你不会犯错。
|
||||
>
|
||||
> 第二个原因是*安全*。如果你不知道管理员用户的登录信息,则系统更难被攻击。拥有 root 的访问权限意味着你已经能够进行管理员身份下的一半工作任务。
|
||||
|
||||
**4、`rm` 和 `rm -rf` 有什么区别?**
|
||||
|
||||
> `rm` 命令本身仅删除指明的文件(而不删除目录)。使用 `-rf` 标志,你添加了两个附加功能:`-r`(或等价的 `-R`、`--recursive`)标志可以递归删除目录的内容,包括隐藏的文件和子目录;而 `-f`(或 `--force`)标志使 `rm` 忽略不存在的文件,并且从不提示你进行确认。
|
||||
|
||||
**5、有一个大小约为 15GB 的 `Compress.tgz` 文件。你如何列出其内容,以及如何仅提取出特定文件?**
|
||||
|
||||
> 要列出文件的内容:
|
||||
>
|
||||
> `tar tf archive.tgz`
|
||||
>
|
||||
> 要提取特定文件:
|
||||
>
|
||||
> `tar xf archive.tgz filename`
|
||||
|
||||
### 有点难度的问题
|
||||
|
||||
这是你可能会遇到的一些较难的问题,以及我的答案:
|
||||
|
||||
**6、什么是 RAID?什么是 RAID 0、RAID 1、RAID 5、RAID 6 和 RAID 10?**
|
||||
|
||||
> RAID(<ruby>廉价磁盘冗余阵列<rt>Redundant Array of Inexpensive Disks</rt></ruby>)是一种用于提高数据存储性能和/或可靠性的技术。RAID 级别为:
|
||||
>
|
||||
> * RAID 0:也称为磁盘条带化,这是一种分解文件并将数据分布在 RAID 组中所有磁盘驱动器上的技术。它没有防止磁盘失败的保障。([引文][3])
|
||||
> * RAID 1:一种流行的磁盘子系统,通过在两个驱动器上写入相同的数据来提高安全性。RAID 1 被称为*镜像*,它不会提高写入性能,但读取性能可能会提高到每个磁盘性能的总和。另外,如果一个驱动器发生故障,则会使用第二个驱动器,发生故障的驱动器需要手动更换。更换后,RAID 控制器会将可工作的驱动器的内容复制到新驱动器上。
|
||||
> * RAID 5:一种磁盘子系统,可通过计算奇偶校验数据来提高安全性和提高速度。RAID 5 通过跨三个或更多驱动器交错数据(条带化)来实现此目的。在单个驱动器发生故障时,后续读取可以从分布式奇偶校验计算出,从而不会丢失任何数据。
|
||||
> * RAID 6:通过添加另一个奇偶校验块来扩展 RAID 5。此级别至少需要四个磁盘,并且可以在任何两个并发磁盘故障的情况下继续执行读/写操作。RAID 6 不会对读取操作造成性能损失,但由于与奇偶校验计算相关的开销,因此确实会对写入操作造成性能损失。
|
||||
> * RAID 10:RAID 10 也称为 RAID 1 + 0,它结合了磁盘镜像和磁盘条带化功能来保护数据。它至少需要四个磁盘,并且跨镜像对对数据进行条带化。只要每个镜像对中的一个磁盘起作用,就可以检索数据。如果同一镜像对中的两个磁盘发生故障,则所有数据将丢失,因为带区集中没有奇偶校验。([引文][4])
|
||||
|
||||
**7、`ping` 命令使用哪个端口?**
|
||||
|
||||
> `ping` 命令使用 ICMP。具体来说,它使用 ICMP 回显请求和应答包。
|
||||
>
|
||||
> ICMP 不使用 UDP 或 TCP 通信服务:相反,它使用原始的 IP 通信服务。这意味着,ICMP 消息直接承载在 IP 数据报数据字段中。
|
||||
|
||||
**8、路由器和网关之间有什么区别?什么是默认网关?**
|
||||
|
||||
> *路由器*描述的是一种通用技术功能(第 3 层转发)或用于该目的的硬件设备,而*网关*描述的是本地网段的功能(提供到其他地方的连接性)。你还可以说“将路由器设置为网关”。另一个术语是“跳”,它描述了子网之间的转发。
|
||||
>
|
||||
> 术语*默认网关*表示局域网上的路由器,它的责任是作为对局域网外部的计算机通信的第一个联系点。
|
||||
|
||||
**9、解释一下 Linux 的引导过程。**
|
||||
|
||||
> BIOS -> 主引导记录(MBR) -> GRUB -> 内核 -> 初始化 -> 运行级
|
||||
|
||||
**10、服务器启动时如何检查错误消息?**
|
||||
|
||||
> 内核消息始终存储在 kmsg 缓冲区中,可通过 `dmesg` 命令查看。
|
||||
>
|
||||
> 引导出现的问题和错误要求系统管理员结合某些特定命令来查看某些重要文件,这些文件不同版本的 Linux 处理方式不同:
|
||||
>
|
||||
> * `/var/log/boot.log` 是系统引导日志,其中包含系统引导过程中展开的所有内容。
|
||||
> * `/var/log/messages` 存储全局系统消息,包括系统引导期间记录的消息。
|
||||
> * `/var/log/dmesg` 包含内核环形缓冲区信息。
|
||||
|
||||
**11、符号链接和硬链接有什么区别?**
|
||||
|
||||
> *符号链接*(*软链接*)实际是到原始文件的链接,而*硬链接*是原始文件的镜像副本。如果删除原始文件,则该软链接就没有用了,因为它指向的文件不存在了。如果是硬链接,则完全相反。如果删除原始文件,则硬链接仍然包含原始文件中的数据。([引文][5])
|
||||
|
||||
**12、如何更改内核参数?你可能需要调整哪些内核选项?**
|
||||
|
||||
> 要在类 Unix 系统中设置内核参数,请首先编辑文件 `/etc/sysctl.conf`。进行更改后,保存文件并运行 `sysctl -p` 命令。此命令使更改永久生效,而无需重新启动计算机
|
||||
|
||||
**13、解释一下 `/proc` 文件系统。**
|
||||
|
||||
> `/proc` 文件系统是虚拟的,并提供有关内核、硬件和正在运行的进程的详细信息。由于 `/proc` 包含虚拟文件,因此称为“虚拟文件系统”。这些虚拟文件具有独特性。其中大多数显示为零字节。
|
||||
>
|
||||
> 虚拟文件,例如 `/proc/interrupts`、`/proc/meminfo`、`/proc/mounts` 和 `/proc/partitions`,提供了系统硬件的最新信息。其他诸如 `/proc/filesystems` 和 `/proc/sys` 目录提供系统配置信息和接口。
|
||||
|
||||
**14、如何在没有密码的情况下以其他用户身份运行脚本?**
|
||||
|
||||
> 例如,如果你可以编辑 sudoers 文件(例如 `/private/etc/sudoers`),则可以使用 `visudo` 添加以下[内容][2]:
|
||||
>
|
||||
> `user1 ALL =(user2)NOPASSWD:/opt/scripts/bin/generate.sh`
|
||||
|
||||
**15、什么是 UID 0 toor 帐户?是被入侵了么?**
|
||||
|
||||
> `toor` 用户是备用的超级用户帐户,其中 `toor` 是 `root` 反向拼写。它预期与非标准 shell 一起使用,因此 `root` 的默认 shell 不需要更改。
|
||||
>
|
||||
> 此用途很重要。这些 shell 不是基本发行版的一部分,而是从 ports 或软件包安装的,它们安装在 `/usr/local/bin` 中,默认情况下,位于其他文件系统上。如果 root 的 shell 位于 `/usr/local/bin` 中,并且未挂载包含 `/usr/local/bin` 的文件系统,则 root 无法登录以解决问题,并且系统管理员必须重新启动进入单用户模式来输入 shell 程序的路径。
|
||||
|
||||
### 更难的问题
|
||||
|
||||
这是你可能会遇到的甚至更困难的问题:
|
||||
|
||||
**16、`tracert` 如何工作,使用什么协议?**
|
||||
|
||||
> 命令 `tracert`(或 `traceroute`,具体取决于操作系统)使你可以准确地看到在连接到最终目的地的连接链条中所触及的路由器。如果你遇到无法连接或无法 `ping` 通最终目的地的问题,则可以使用 `tracert` 来帮助你确定连接链在何处停止。([引文][6])
|
||||
>
|
||||
> 通过此信息,你可以联系正确的人;无论是你自己的防火墙、ISP、目的地的 ISP 还是中间的某个位置。 `tracert` 命令像 `ping` 一样使用 ICMP 协议,但也可以使用 TCP 三步握手的第一步来发送 SYN 请求以进行响应。
|
||||
|
||||
**17、使用 `chroot` 的主要优点是什么?我们何时以及为什么使用它?在 chroot 环境中,`mount /dev`、`mount /proc` 和 `mount /sys` 命令的作用是什么?**
|
||||
|
||||
> chroot 环境的优点是文件系统与物理主机是隔离的,因为 chroot 在文件系统内部有一个单独的文件系统。区别在于 `chroot` 使用新创建的根目录(`/`)作为其根目录。
|
||||
>
|
||||
> chroot 监狱可让你将进程及其子进程与系统其余部分隔离。它仅应用于不以 root 身份运行的进程,因为 root 用户可以轻松地脱离监狱。
|
||||
>
|
||||
> 该思路是创建一个目录树,在其中复制或链接运行该进程所需的所有系统文件。然后,你可以使用 `chroot()` 系统调用来告诉它根目录现在位于此新树的基点上,然后启动在该 chroot 环境中运行的进程。由于该命令因此而无法引用修改后的根目录之外的路径,因此它无法在这些位置上执行恶意操作(读取、写入等)。([引文][7])
|
||||
|
||||
**18、如何保护你的系统免遭黑客攻击?**
|
||||
|
||||
> 遵循最低特权原则和这些做法:
|
||||
>
|
||||
> * 使用公钥加密,它可提供出色的安全性。
|
||||
> * 增强密码复杂性。
|
||||
> * 了解为什么要对上述规则设置例外。
|
||||
> * 定期检查你的例外情况。
|
||||
> * 让具体的人对失败负责。(它使你保持警惕。)([引文][8])
|
||||
|
||||
**19、什么是 LVM,使用 LVM 有什么好处?**
|
||||
|
||||
> LVM(逻辑卷管理)是一种存储设备管理技术,该技术使用户能够合并和抽象化组件存储设备的物理布局,从而可以更轻松、灵活地进行管理。使用设备映射器的 Linux 内核框架,当前迭代(LVM2)可用于将现有存储设备收集到组中,并根据需要从组合的空间分配逻辑单元。
|
||||
|
||||
**20、什么是粘性端口?**
|
||||
|
||||
> 粘性端口是网络管理员最好的朋友,也是最头痛的事情之一。它们允许你设置网络,以便通过将交换机上的每个端口锁定到特定的 MAC 地址,仅允许一台(或你指定的数字)计算机在该端口上进行连接。
|
||||
|
||||
**21、解释一下端口转发?**
|
||||
|
||||
> 尝试与安全的网络内部的系统进行通信时,从外部进行通信可能非常困难,这是很显然的。因此,在路由器本身或其他连接管理设备中使用端口转发表可以使特定流量自动转发到特定目的地。例如,如果你的网络上运行着一台 Web 服务器,并且想从外部授予对该服务器的访问权限,则可以将端口转发设置为该服务器上的端口 80。这意味着在 Web 浏览器中输入你的(外网)IP 地址的任何人都将立即连接到该服务器的网站。
|
||||
>
|
||||
> 请注意,通常不建议允许从你的网络外部直接访问服务器。
|
||||
|
||||
**22、对于 IDS,误报和漏报是什么?**
|
||||
|
||||
> 当入侵检测系统(IDS)设备为实际上没有发生的入侵生成警报时,这是<ruby>误报(假阳性)<rt>false positive</rt></ruby>。如果设备未生成任何警报,而入侵实际上已发生,则为<ruby>漏报(假阴性)</rt></ruby>。
|
||||
|
||||
**23、解释一下 `:(){ :|:& };:`,如果已经登录系统,如何停止此代码?**
|
||||
|
||||
> 这是一枚复刻炸弹。它分解如下:
|
||||
>
|
||||
> * `:()` 定义了函数,以 `:` 作为函数名,并且空括号表示它不接受任何参数。
|
||||
> * `{}` 是函数定义的开始和结束。
|
||||
> * `:|:` 将函数 `:` 的副本加载到内存中,并将其输出通过管道传递给函数 `:` 的另一个副本,该副本也必须加载到内存中。
|
||||
> * `&` 使前一个命令行成为后台进程,因此即使父进程被自动杀死,子进程也不会被杀死。
|
||||
> * `:` 执行该函数,因此连锁反应开始。
|
||||
>
|
||||
> 保护多用户系统的最佳方法是使用特权访问管理(PAM)来限制用户可以使用的进程数。
|
||||
>
|
||||
> 复刻炸弹的最大问题是它发起了太多进程。因此,如果你已经登录系统,我们有两种尝试解决此问题的方法。一种选择是执行一个 `SIGSTOP` 命令来停止进程,例如:
|
||||
>
|
||||
> `killall -STOP -u user1`
|
||||
>
|
||||
> 如果由于占用了所有进程而无法使用命令行,则必须使用 `exec` 强制其运行:
|
||||
>
|
||||
> `exec killall -STOP -u user1`
|
||||
>
|
||||
> 对于复刻炸弹,最好的选择是防患于未然。
|
||||
|
||||
**24、什么是 OOM 杀手,它如何决定首先杀死哪个进程?**
|
||||
|
||||
> 如果内存被进程彻底耗尽,可能会威胁到系统的稳定性,那么<ruby>内存不足<rt>out of memory</rt></ruby>(OOM)杀手就登场了。
|
||||
>
|
||||
> OOM 杀手首先必须选择要杀死的最佳进程。*最佳*在这里指的是在被杀死时将释放最大内存的进程,并且对系统来说最不重要。主要目标是杀死最少数量的进程,以最大程度地减少造成的损害,同时最大化释放的内存量。
|
||||
>
|
||||
> 为了实现此目标,内核为每个进程维护一个 `oom_score`。你可以在 `/proc` 文件系统中的 `pid` 目录下的看到每个进程的 `oom_score`:
|
||||
>
|
||||
> `$ cat /proc/10292/oom_score`
|
||||
>
|
||||
> 任何进程的 `oom_score` 值越高,在内存不足的情况下被 OOM 杀手杀死的可能性就越高。([引文][9])
|
||||
|
||||
### 总结
|
||||
|
||||
系统管理人员的薪水[差别很大][10],有些网站上说年薪在 70,000 到 100,000 美元之间,具体取决于地点、组织的规模以及你的教育水平以及多年的工作经验。系统管理的职业道路最终归结为你对使用服务器和解决那些酷问题的兴趣。现在,我要说,继续前进,实现你的梦想之路吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/sysadmin-job-interview-questions
|
||||
|
||||
作者:[DirectedSoul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/directedsoul
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_HowToFish_520x292.png?itok=DHbdxv6H (Question and answer.)
|
||||
[2]: https://github.com/trimstray/test-your-sysadmin-skills
|
||||
[3]: https://www.waytoeasylearn.com/2016/05/netapp-filer-tutorial.html
|
||||
[4]: https://searchstorage.techtarget.com/definition/RAID-10-redundant-array-of-independent-disks
|
||||
[5]: https://www.answers.com/Q/What_is_hard_link_and_soft_link_in_Linux
|
||||
[6]: https://www.wisdomjobs.com/e-university/network-administrator-interview-questions.html
|
||||
[7]: https://unix.stackexchange.com/questions/105/chroot-jail-what-is-it-and-how-do-i-use-it
|
||||
[8]: https://serverfault.com/questions/391370/how-to-prevent-zero-day-attacks
|
||||
[9]: https://unix.stackexchange.com/a/153586/8369
|
||||
[10]: https://blog.netwrix.com/2018/07/23/systems-administrator-salary-in-2018-how-much-can-you-earn/
|
||||
200
published/20191004 What-s in an open source name.md
Normal file
200
published/20191004 What-s in an open source name.md
Normal file
@ -0,0 +1,200 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (laingke)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11688-1.html)
|
||||
[#]: subject: (What's in an open source name?)
|
||||
[#]: via: (https://opensource.com/article/19/10/open-source-name-origins)
|
||||
[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
|
||||
|
||||
开源软件名称中的故事
|
||||
======
|
||||
|
||||
> 有没有想过你喜欢的开源项目或编程语言的名称来自何处?让我们按字母顺序了解一下流行的技术术语背后的起源故事。
|
||||
|
||||

|
||||
|
||||
GNOME、Java、Jupyter、Python……如果你的朋友或家人曾留意过你的工作对话,他们可能会认为你从事文艺复兴时期的民间文学艺术、咖啡烘焙、天文学或动物学工作。这些开源技术的名称从何而来?我们请我们的作者社区提供意见,并汇总了一些我们最喜欢的技术名称的起源故事。
|
||||
|
||||
### Ansible
|
||||
|
||||
“Ansible”这个名称直接来自科幻小说。Ursula Le Guin 的《Rocannon's World》一书中能进行即时(比光速更快)通信的设备被称为 ansibles(显然来自 “answerable” 一词)。Ansibles 开始流行于科幻小说之中,Orson Scott Card 的《Ender's Game》(后来成为受欢迎的电影)中,该设备控制了许多远程太空飞船。对于控制分布式机器的软件来说,这似乎是一个很好的模型,因此 Michael DeHaan(Ansible 的创建者和创始人)借用了这个名称。
|
||||
|
||||
### Apache
|
||||
|
||||
[Apache][2] 是最初于 1995 年发布的开源 Web 服务器。它的名称与著名的美国原住民部落无关;相反,它是指对原始软件代码的重复补丁。因此称之为,“<ruby>一个修补的<rt>A-patchy</rt></ruby>服务器”。
|
||||
|
||||
### awk
|
||||
|
||||
“awk(1) 代表着 Aho、Weinberger、Kernighan(作者)”—— Michael Greenberg
|
||||
|
||||
### Bash
|
||||
|
||||
“最初的 Unix shell,即 Bourne shell,是以其创造者的名字命名的。在开发出来 Bash 时,csh(发音为 ‘seashell’)实际上更受交互登录用户的欢迎。Bash 项目旨在赋予 Bourne shell 新的生命,使其更适合于交互式使用,因此它被命名为 ‘Bourne again shell’,是‘<ruby>重生<rt>born again</rt></ruby>’的双关语。”——Ken Gaillot
|
||||
|
||||
### C
|
||||
|
||||
在早期,AT&T 的 Ken Thompson 和 Dennis Ritchie 发现可以使用更高级的编程语言(而不是低级的、可移植性更低的汇编编程)来编写操作系统和工具。早期有一个叫做 BCPL(<ruby>基本组合编程语言<rt>Basic Combined programming Language</rt></ruby>)的编程系统,Thompson 创建了一个名为 B 的简化版 BCPL,但 B 的灵活性和速度都不高。然后,Ritchie 把 B 的思想扩展成一种叫做 C 的编译语言。”——Jim Hall
|
||||
|
||||
### dd
|
||||
|
||||
“我想你发表这样一篇文章不能不提到 dd。我的外号叫 Didi。发音正确的话听起来像 ‘dd’。我开始学的是 Unix,然后是 Linux,那是在 1993 年,当时我还是个学生。然后我去了军队,来到了我的部队中少数几个使用 Unix(Ultrix)的部门之一(其它部门主要是 VMS),那里的一个人说:‘这么说,你是一个黑客,对吗?你以为你了解 Unix 吗?好的,那么 dd 这个名字的是怎么来的呢?’我不知道,试着猜道:‘<ruby>数据复印机<rt>Data duplicator</rt></ruby>?’所以他说,‘我要告诉你 dd 的故事。dd 是<ruby>转换<rt>convert</rt></ruby>和<ruby>复制<rt>copy</rt></ruby>的缩写(如今人们仍然可以在手册页中看到),但由于 cc 这个缩写已经被 C 编译器占用,所以它被命名为 dd。’就在几年后,我听闻了关于 JCL 的数据定义和 Unix dd 命令不统一的、半开玩笑的语法的真实故事,某种程度是基于此的。”——Yedidyah Bar David
|
||||
|
||||
### Emacs
|
||||
|
||||
经典的<ruby>反 vi<rt>anti-vi</rt></ruby>编辑器,其名称的真正词源并不明显,因为它源自“<ruby>编辑宏<rt>Editing MACroS</rt></ruby>”。但是,它作为一个伟大的宗教亵渎和崇拜的对象,吸引了许多恶作剧般的缩写,例如“Escape Meta Alt Control Shift”(以调侃其对键盘的大量依赖),“<ruby>8MB 并经常发生内存交换<rt>Eight Megabytes And Constantly Swapping</rt></ruby>”(从那时起就很吃内存了),“<ruby>最终分配了所有的计算机存储空间<rt>Eventually malloc()s All Computer Storage</rt></ruby>”和 “<ruby>EMACS 使一台计算机慢<rt>EMACS Makes A Computer Slow</rt></ruby>”——改编自 Jargon File/Hacker's Dictionary
|
||||
|
||||
### Enarx
|
||||
|
||||
[Enarx][3] 是机密计算领域的一个新项目。该项目的设计原则之一是它应该是“可替代的”。因此最初的名字是“psilocybin”(著名的魔术蘑菇)。一般情况下,经理级别的人可能会对这个名称有所抵触,因此考虑使用新名称。该项目的两位创始人 Mike Bursell 和 Nathaniel McCallum 都是古老语言极客,因此他们考虑了许多不同的想法,包括 тайна(Tayna——俄语中代表秘密或神秘——虽然俄语并不是一门古老的语言,但你就不要在乎这些细节了),crypticon(希腊语的意思是完全私生的),cryptidion(希腊中表示小密室),arconus(拉丁语中表示秘密的褒义形容词),arcanum(拉丁语中表示秘密的中性形容词)和 ærn(盎格鲁撒克逊人表示地方、秘密的地方、壁橱、住所、房子,或小屋的词汇)。最后,由于各种原因,包括域名和 GitHub 项目名称的可用性,他们选择了 enarx,这是两个拉丁词根的组合:en-(表示内部)和 -arx(表示城堡、要塞或堡垒)。
|
||||
|
||||
### GIMP
|
||||
|
||||
没有 [GIMP][4] 我们会怎么样?<ruby>GNU 图像处理项目<rt>GNU Image Manipulation Project</rt></ruby>多年来一直是开源的重要基础。[维基百科][5]指出,“1995 年,[Spencer Kimball][6] 和 [Peter Mattis][7] 在加州大学伯克利分校开始为<ruby>实验计算设施<rt>eXperimental Computing Facility</rt></ruby>开发 GIMP,这是一个为期一个学期的项目。”
|
||||
|
||||
### GNOME
|
||||
|
||||
你有没有想过为什么 GNOME 被称为 GNOME?根据[维基百科][8],GNOME 最初是一个表示“<ruby>GNU 网络对象模型环境<rt>GNU Network Object Model Environment</rt></ruby>”的缩写词。现在,该名称不再表示该项目,并且该项目已被放弃,但这个名称仍然保留了下来。[GNOME 3][9] 是 Fedora、红帽企业版、Ubuntu、Debian、SUSE Linux 企业版等发行版的默认桌面环境。
|
||||
|
||||
### Java
|
||||
|
||||
你能想象这种编程语言还有其它名称吗?Java 最初被称为 Oak,但是遗憾的是,Sun Microsystems 的法律团队由于已有该商标而否决了它。所以开发团队又重新给它命名。[据说][10]该语言的工作组在 1995 年 1 月举行了一次大规模的头脑风暴。许多其它名称也被扔掉了,包括 Silk、DNA、WebDancer 等。该团队不希望新名称与过度使用的术语“web”或“net”有任何关系。取而代之的是,他们在寻找更有活力、更有趣、更容易记住的东西。Java 满足了这些要求,并且奇迹般地,团队同意通过了!
|
||||
|
||||
### Jupyter
|
||||
|
||||
现在许多数据科学家和学生在工作中使用 [Jupyter][11] 笔记本。“Jupyter”这个名字是三种开源计算机语言的融合,这三种语言在这个笔记本中都有使用,在数据科学中也很突出:[Julia][12]、[Python][13] 和 [R][14]。
|
||||
|
||||
### Kubernetes
|
||||
|
||||
Kubernetes 源自希腊语中的舵手。Kubernetes 项目创始人 Craig McLuckie 在 [2015 Hacker News][15] 回应中证实了这种词源。他坚持航海主题,解释说,这项技术可以驱动集装箱,就像舵手或驾驶员驾驶集装箱船一样,因此,他选择了 Kubernetes 这个名字。我们中的许多人仍然在尝试正确的发音(koo-bur-NET-eez),因此 替代使用 K8s 也是可以接受的。有趣的是,它与英语单词“<ruby>行政长官<rt>governor</rt></ruby>”具有相同的词源,也与蒸汽机上的机械负反馈装置相同。
|
||||
|
||||
### KDE
|
||||
|
||||
那 K 桌面呢?KDE 最初代表“<ruby>酷桌面环境<rt>Kool Desktop Environment</rt></ruby>”。 它由 [Matthias Ettrich][16] 于 1996 年创立。根据[维基百科][17]上的说法,该名称是对 Unix 上 <ruby>[通用桌面环境][18]<rt>Common Desktop Environment</rt></ruby>(CDE)一词的调侃。
|
||||
|
||||
### Linux
|
||||
|
||||
[Linux][19] 因其发明者 Linus Torvalds 的名字命名的。Linus 最初想将他的作品命名为“Freax”,因为他认为以他自己的名字命名太自负了。根据[维基百科][19]的说法,“赫尔辛基科技大学 Torvalds 的同事 Ari Lemmke 当时是 FTP 服务器的志愿管理员之一,他并不认为‘Freax’是个好名字。因此,他没有征询 Torvalds 就将服务器上的这个项目命名为‘Linux’。”
|
||||
|
||||
以下是一些最受欢迎的 Linux 发行版。
|
||||
|
||||
#### CentOS
|
||||
|
||||
[CentOS][20] 是<ruby>社区企业操作系统<rt>Community Enterprise Operating System</rt></ruby>的缩写。它包含来自 Red Hat Enterprise Linux 的上游软件包。
|
||||
|
||||
#### Debian
|
||||
|
||||
[Debian][21] Linux 创建于 1993 年 9 月,是其创始人 Ian Murdock 和他当时的女友 Debra Lynn 的名字的混成词。
|
||||
|
||||
#### RHEL
|
||||
|
||||
[Red Hat Linux][22] 得名于它的创始人 Marc Ewing,他戴着一顶祖父送给他的康奈尔大学红色<ruby>软呢帽<rt>fedora</rt></ruby>。红帽公司成立于 1993 年 3 月 26 日。[Fedora Linux][23] 最初是一个志愿者项目,旨在为红帽发行版提供额外的软件,它的名字来自红帽的“Shadowman”徽标。
|
||||
|
||||
#### Ubuntu
|
||||
|
||||
[Ubuntu][24] 旨在广泛分享开源软件,它以非洲哲学“<ruby>人的本质<rt>ubuntu</rt></ruby>”命名,可以翻译为“对他人的人道主义”或“我之所以是我,是因为我们都是这样的人”。
|
||||
|
||||
### Moodle
|
||||
|
||||
开源学习平台 [Moodle][25] 是“<ruby>模块化面向对象动态学习环境<rt>modular object-oriented dynamic learning environment</rt></ruby>”的首字母缩写。Moodle 仍然是领先的线上学习平台。全球有近 10.4 万个注册的 Moodle 网站。
|
||||
|
||||
另外两个流行的开源内容管理系统是 Drupal 和 Joomla。Drupal 的名字来自荷兰语 “druppel”,意思是“掉落”。根据维基百科,Joomla 是斯瓦希里语单词“jumla”的[英式拼写][26],在阿拉伯语、乌尔都语和其他语言中是“在一起”的意思。
|
||||
|
||||
### Mozilla
|
||||
|
||||
[Mozilla][27] 是一个成立于 1998 年的开源软件社区。根据其网站,“Mozilla 项目创建于 1998 年,发布了 Netscape 浏览器套件源代码。其旨在利用互联网上成千上万的程序员的创造力,并推动浏览器市场上前所未有的创新水平。” 这个名字是 [Mosaic] [28] 和 Godzilla 的混成词。
|
||||
|
||||
### Nginx
|
||||
|
||||
“许多技术人员都试图装酷,并将它念成‘n’‘g’‘n’‘x’。实际上,很少的一些人做点基本的调查工作,就可以很快发现该名称实际上应该被念成是“EngineX”,指的是功能强大的 web 服务器,像个引擎。”——Jean Sebastien Tougne
|
||||
|
||||
### Perl
|
||||
|
||||
Perl 的创始人 Larry Wall 最初将他的项目命名为“Pearl”。根据维基百科,Wall 想给这种语言起一个有积极含义的简短名字。在 Perl 正式发布之前,Wall 发现了已有 [PEARL][29] 编程语言,于是更改了名称的拼写。
|
||||
|
||||
### Piet 和 Mondrian
|
||||
|
||||
“有两种编程语言以艺术家 Piet Mondrian 命名。一种叫做‘Piet’,另一种叫做‘Mondrian’。(David Morgan-Mar [写道][30]):‘Piet 是一种编程语言,其中的程序看起来像抽象绘画。该语言以几何抽象艺术的开创者 Piet Mondrian 的名字命名。我曾想将这种语言命名为 Mondrian,但是有人告诉我这会让它看起来像一种很普通的脚本语言。哦,好吧,我想我们不能都是深奥的语言作家。’”——Yuval Lifshitz
|
||||
|
||||
### Python
|
||||
|
||||
Python 编程语言的独特名称来自其创建者 Guido Van Rossum,他是英国六人喜剧团体 Monty Python 的粉丝。
|
||||
|
||||
### Raspberry Pi
|
||||
|
||||
Raspberry Pi 以其微小但强大的功能和对低廉的价格而闻名,在开源社区中是最受欢迎的。但是它可爱(和好吃)的名字是从哪里来的呢?在 70 年代和 80 年代,以水果命名的计算机是一种流行的趋势。苹果、橘子、杏……有人饿了吗?根据创始人 Eben Upton 的 [2012 采访] [31],“<ruby>树莓派<rt>Raspberry Pi</rt></ruby>”这个名称是对这种趋势的致敬。树莓也很小,但却很有味道。名称中的“Pi”暗示着这样的事实:最初,该计算机只能运行 Python。
|
||||
|
||||
### Samba
|
||||
|
||||
[Server Message Block][32] 用于在 Linux 上共享 Windows 文件。
|
||||
|
||||
### ScummVM
|
||||
|
||||
[ScummVM][33](《疯狂大楼》虚拟机的脚本创建实用程序)是一个程序,可以在现代计算机上运行一些经典的计算机冒险游戏。最初,它旨在玩用 SCUMM 构建的 LucasArts 的冒险游戏,该游戏最初用于开发《疯狂大楼》,后来又被用来开发 LucasArts 的其它大多数冒险游戏。目前,ScummVM 支持大量游戏引擎,包括 Sierra Online 的 AGI 和 SCI,但仍保留着名称 ScummVM。
|
||||
|
||||
有一个相关的项目 [ResidualVM][34] 之所以得名,是因为它涵盖了 ScummVM 未涵盖的“<ruby>剩余的<rt>residual</rt></ruby>” LucasArts 冒险游戏。 ResidualVM 涵盖的 LucasArts 游戏是使用 GrimE(Grim Engine)开发的,该引擎最初用于开发 Grim Fandango,因此 ResidualVM 的名称是双关语。
|
||||
|
||||
### SQL
|
||||
|
||||
“你可能知道 SQL 代表<ruby>结构化查询语言<rt>Structured Query Language</rt></ruby>,但你知道为什么它经常被读作‘sequel’吗?它是作为原本的‘QUEL’(<ruby>查询语言<rt>QUEry Language</rt></ruby>)的后续(如<ruby>结局<rt>sequel</rt></ruby>)而创建的。”——Ken Gaillot
|
||||
|
||||
### XFCE
|
||||
|
||||
[XFCE][35] 是由 [Olivier Fourdan][36] 创建的一个流行的桌面。它在 1996 年作为 CDE 的替代品出现,最初是 <ruby>XForms 公共环境<rt>XForms Common Environment</rt></ruby>的缩写。
|
||||
|
||||
### Zsh
|
||||
|
||||
Zsh 是一个交互式登录 shell。1990 年,普林斯顿大学的学生 Paul Falstad 写了该 shell 的第一个版本。他在看到当时在普林斯顿大学担任助教的 Zhong Sha 的登录 ID(zsh)后,觉得这个名字听起来像 [shell 的好名字][37],给它起了这个名字。
|
||||
|
||||
还有更多的项目和名称还没有包括在这个列表中。请一定要在评论中分享你的收藏。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/open-source-name-origins
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[laingke](https://github.com/laingke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/holmja
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003784_02_os.comcareers_resume_rh1x.png?itok=S3HGxi6E (A person writing.)
|
||||
[2]: https://httpd.apache.org/
|
||||
[3]: https://enarx.io
|
||||
[4]: https://www.gimp.org/
|
||||
[5]: https://en.wikipedia.org/wiki/GIMP
|
||||
[6]: https://en.wikipedia.org/wiki/Spencer_Kimball_(computer_programmer)
|
||||
[7]: https://en.wikipedia.org/wiki/Peter_Mattis
|
||||
[8]: https://en.wikipedia.org/wiki/GNOME
|
||||
[9]: https://www.gnome.org/gnome-3/
|
||||
[10]: https://www.javaworld.com/article/2077265/so-why-did-they-decide-to-call-it-java-.html
|
||||
[11]: https://jupyter.org/
|
||||
[12]: https://julialang.org/
|
||||
[13]: https://www.python.org/
|
||||
[14]: https://www.r-project.org/
|
||||
[15]: https://news.ycombinator.com/item?id=9653797
|
||||
[16]: https://en.wikipedia.org/wiki/Matthias_Ettrich
|
||||
[17]: https://en.wikipedia.org/wiki/KDE
|
||||
[18]: https://sourceforge.net/projects/cdesktopenv/
|
||||
[19]: https://en.wikipedia.org/wiki/Linux
|
||||
[20]: https://www.centos.org/
|
||||
[21]: https://www.debian.org/
|
||||
[22]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[23]: https://getfedora.org/
|
||||
[24]: https://ubuntu.com/about
|
||||
[25]: https://moodle.org/
|
||||
[26]: https://en.wikipedia.org/wiki/Joomla#Historical_background
|
||||
[27]: https://www.mozilla.org/en-US/
|
||||
[28]: https://en.wikipedia.org/wiki/Mosaic_(web_browser)
|
||||
[29]: https://en.wikipedia.org/wiki/PEARL_(programming_language)
|
||||
[30]: http://www.dangermouse.net/esoteric/piet.html
|
||||
[31]: https://www.techspot.com/article/531-eben-upton-interview/
|
||||
[32]: https://www.samba.org/
|
||||
[33]: https://www.scummvm.org/
|
||||
[34]: https://www.residualvm.org/
|
||||
[35]: https://www.xfce.org/
|
||||
[36]: https://en.wikipedia.org/wiki/Olivier_Fourdan
|
||||
[37]: http://www.zsh.org/mla/users/2005/msg00951.html
|
||||
265
published/20191007 Using the Java Persistence API.md
Normal file
265
published/20191007 Using the Java Persistence API.md
Normal file
@ -0,0 +1,265 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11717-1.html)
|
||||
[#]: subject: (Using the Java Persistence API)
|
||||
[#]: via: (https://opensource.com/article/19/10/using-java-persistence-api)
|
||||
[#]: author: (Stephon Brown https://opensource.com/users/stephb)
|
||||
|
||||
使用 Java 持久化 API
|
||||
======
|
||||
|
||||
> 我们通过为自行车商店构建示例应用程序来学习如何使用 JPA。
|
||||
|
||||

|
||||
|
||||
对应用开发者来说,<ruby>Java 持久化 API<rt>Java Persistence API</rt></ruby>(JPA)是一项重要的 java 功能,需要透彻理解。它为 Java 开发人员定义了如何将对象的方法调用转换为访问、持久化及管理存储在 NoSQL 和关系型数据库中的数据的方案。
|
||||
|
||||
本文通过构建自行车借贷服务的教程示例来详细研究 JPA。此示例会使用 Spring Boot 框架、MongoDB 数据库([已经不开源][2])和 Maven 包管理来构建一个大型应用程序,并且构建一个创建、读取、更新和删除(CRUD)层。这儿我选择 NetBeans 11 作为我的 IDE。
|
||||
|
||||
此教程仅从开源的角度来介绍 Java 持久化 API 的工作原理,不涉及其作为工具的使用说明。这全是关于编写应用程序模式的学习,但对于理解具体的软件实现也很益处。可以从我的 [GitHub 仓库][3]来获取相关代码。
|
||||
|
||||
### Java: 不仅仅是“豆子”
|
||||
|
||||
Java 是一门面向对象的编程语言,自 1996 年发布第一版 Java 开发工具(JDK)起,已经变化了很多很多。要了解其各种发展及其虚拟机本身就是一堂历史课。简而言之,和 Linux 内核很相似,自发布以来,该语言已经向多个方向分支发展。有对社区免费的标准版本、有针对企业的企业版本及由多家供应商提供的开源替代品。主要版本每六个月发布一次,其功能往往差异很大,所以确认选用版本前得先做些研究。
|
||||
|
||||
总而言之,Java 的历史很悠久。本教程重点介绍 Java 11 的开源实现 [JDK 11][4]。因其是仍然有效的长期支持版本之一。
|
||||
|
||||
* **Spring Boot** 是由 Pivotal 公司开发的大型 Spring 框架的一个模块。Spring 是 Java 开发中一个非常流行的框架。它支持各种框架和配置,也为 WEB 应用程序及安全提供了保障。Spring Boot 为快速构建各种类型的 Java 项目提供了基本的配置。本教程使用 Spring Boot 来快速编写控制台应用程序并针对数据库编写测试用例。
|
||||
* **Maven** 是由 Apache 开发的项目/包管理工具。Maven 通过 `POM.xml` 文件来管理包及其依赖项。如果你使用过 NPM 的话,可能会非常熟悉包管理器的功能。此外 Maven 也用来进行项目构建及生成功能报告。
|
||||
* **Lombok** 是一个库,它通过在对象文件里面添加注解来自动创建 getters/setters 方法。像 C# 这些语言已经实现了此功能,Lombok 只是把此功能引入 Java 语言而已。
|
||||
* **NetBeans** 是一款很流行的开源 IDE,专门用于 Java 开发。它的许多工具都随着 Java SE 和 EE 的版本更新而更新。
|
||||
|
||||
我们会用这组工具为一个虚构自行车商店创建一个简单的应用程序。会实现对 `Customer` 和 `Bike` 对象集合的的插入操作。
|
||||
|
||||
### 酿造完美
|
||||
|
||||
导航到 [Spring Initializr][5] 页面。该网站可以生成基于 Spring Boot 和其依赖项的基本项目。选择以下选项:
|
||||
|
||||
1. **项目:** Maven 工程
|
||||
2. **语言:** Java
|
||||
3. **Spring Boot:** 2.1.8(或最稳定版本)
|
||||
4. **项目元数据:** 无论你使用什么名字,其命名约定都是像 `com.stephb` 这样的。
|
||||
* 你可以保留 Artifact 名字为 “Demo”。
|
||||
5. **依赖项:** 添加:
|
||||
* Spring Data MongoDB
|
||||
* Lombok
|
||||
|
||||
点击 **下载**,然后用你的 IDE(例如 NetBeans) 打开此新项目。
|
||||
|
||||
#### 模型层概要
|
||||
|
||||
在项目里面,<ruby>模型<rt>model</rt></ruby>代表从数据库里取出的信息的具体对象。我们关注两个对象:`Customer` 和 `Bike`。首先,在 `src` 目录创建 `dto` 目录;然后,创建两个名为 `Customer.java` 和 `Bike.java` 的 Java 类对象文件。其结构如下示:
|
||||
|
||||
```Java
|
||||
package com.stephb.JavaMongo.dto;
|
||||
|
||||
import lombok.Getter;
|
||||
import lombok.Setter;
|
||||
import org.springframework.data.annotation.Id;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
@Getter @Setter
|
||||
public class Customer {
|
||||
|
||||
private @Id String id;
|
||||
private String emailAddress;
|
||||
private String firstName;
|
||||
private String lastName;
|
||||
private String address;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
*Customer.Java*
|
||||
|
||||
```Java
|
||||
package com.stephb.JavaMongo.dto;
|
||||
|
||||
import lombok.Getter;
|
||||
import lombok.Setter;
|
||||
import org.springframework.data.annotation.Id;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
@Getter @Setter
|
||||
public class Bike {
|
||||
private @Id String id;
|
||||
private String modelNumber;
|
||||
private String color;
|
||||
private String description;
|
||||
|
||||
@Override
|
||||
public String toString() {
|
||||
return "This bike model is " + this.modelNumber + " is the color " + this.color + " and is " + description;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
*Bike.java*
|
||||
|
||||
如你所见,对象中使用 Lombok 注解来为定义的<ruby>属性<rt>properties</rt></ruby>/<ruby>特性<rt>attributes</rt></ruby>生成 getters/setters 方法。如果你不想对该类的所有特性都生成 getters/setters 方法,可以在属性上专门定义这些注解。这两个类会变成容器,里面携带有数据,无论在何处想显示信息都可以使用。
|
||||
|
||||
#### 配置数据库
|
||||
|
||||
我使用 [Mongo Docker][7] 容器来进行此次测试。如果你的系统上已经安装了 MongoDB,则不必运行 Docker 实例。你也可以登录其官网,选择系统信息,然后按照安装说明来安装 MongoDB。
|
||||
|
||||
安装后,就可以使用命令行、GUI(例如 MongoDB Compass)或用于连接数据源的 IDE 驱动程序来与新的 MongoDB 服务器进行交互。到目前为止,可以开始定义数据层了,用来拉取、转换和持久化数据。需要设置数据库访问属性,请导航到程序中的 `applications.properties` 文件,然后添加如下内容:
|
||||
|
||||
```
|
||||
spring.data.mongodb.host=localhost
|
||||
spring.data.mongodb.port=27017
|
||||
spring.data.mongodb.database=BikeStore
|
||||
```
|
||||
|
||||
#### 定义数据访问对象/数据访问层
|
||||
|
||||
<ruby>数据访问层<rt>data access layer</rt></ruby>(DAL)中的<ruby>数据访问对象<rt>data access objects</rt></ruby>(DAO)定义了与数据库中的数据的交互过程。令人惊叹的就是在使用 `spring-boot-starter` 后,查询数据库的大部分工作已经完成。
|
||||
|
||||
让我们从 `Customer` DAO 开始。在 `src` 下的新目录 `dao` 中创建一个接口文件,然后再创建一个名为 `CustomerRepository.java` 的 Java 类文件,其内容如下示:
|
||||
|
||||
```
|
||||
package com.stephb.JavaMongo.dao;
|
||||
|
||||
import com.stephb.JavaMongo.dto.Customer;
|
||||
import java.util.List;
|
||||
import org.springframework.data.mongodb.repository.MongoRepository;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
public interface CustomerRepository extends MongoRepository<Customer, String>{
|
||||
@Override
|
||||
public List<Customer> findAll();
|
||||
public List<Customer> findByFirstName(String firstName);
|
||||
public List<Customer> findByLastName(String lastName);
|
||||
}
|
||||
```
|
||||
|
||||
这个类是一个接口,扩展或继承于 `MongoRepository` 类,而 `MongoRepository` 类依赖于 DTO (`Customer.java`)和一个字符串,它们用来实现自定义函数查询功能。因为你已继承自此类,所以你可以访问许多方法函数,这些函数允许持久化和查询对象,而无需实现或引用自己定义的方法函数。例如,在实例化 `CustomerRepository` 对象后,你就可以直接使用 `Save` 函数。如果你需要扩展更多的功能,也可以重写这些函数。我创建了一些自定义查询来搜索我的集合,这些集合对象是我自定义的元素。
|
||||
|
||||
`Bike` 对象也有一个存储源负责与数据库交互。与 `CustomerRepository` 的实现非常类似。其实现如下所示:
|
||||
|
||||
```
|
||||
package com.stephb.JavaMongo.dao;
|
||||
|
||||
import com.stephb.JavaMongo.dto.Bike;
|
||||
import java.util.List;
|
||||
import org.springframework.data.mongodb.repository.MongoRepository;
|
||||
|
||||
/**
|
||||
*
|
||||
* @author stephon
|
||||
*/
|
||||
public interface BikeRepository extends MongoRepository<Bike,String>{
|
||||
public Bike findByModelNumber(String modelNumber);
|
||||
@Override
|
||||
public List<Bike> findAll();
|
||||
public List<Bike> findByColor(String color);
|
||||
}
|
||||
```
|
||||
|
||||
#### 运行程序
|
||||
|
||||
现在,你已经有了一种结构化数据的方式,可以对数据进行提取、转换和持久化,然后运行这个程序。
|
||||
|
||||
找到 `Application.java` 文件(有可能不是此名称,具体取决于你的应用程序名称,但都会包含有 “application” )。在定义此类的地方,在后面加上 `implements CommandLineRunner`。这将允许你实现 `run` 方法来创建命令行应用程序。重写 `CommandLineRunner` 接口提供的 `run` 方法,并包含如下内容用来测试 `BikeRepository` :
|
||||
|
||||
```
|
||||
package com.stephb.JavaMongo;
|
||||
|
||||
import com.stephb.JavaMongo.dao.BikeRepository;
|
||||
import com.stephb.JavaMongo.dao.CustomerRepository;
|
||||
import com.stephb.JavaMongo.dto.Bike;
|
||||
import java.util.Scanner;
|
||||
import org.springframework.beans.factory.annotation.Autowired;
|
||||
import org.springframework.boot.CommandLineRunner;
|
||||
import org.springframework.boot.SpringApplication;
|
||||
import org.springframework.boot.autoconfigure.SpringBootApplication;
|
||||
|
||||
|
||||
@SpringBootApplication
|
||||
public class JavaMongoApplication implements CommandLineRunner {
|
||||
@Autowired
|
||||
private BikeRepository bikeRepo;
|
||||
private CustomerRepository custRepo;
|
||||
|
||||
public static void main(String[] args) {
|
||||
SpringApplication.run(JavaMongoApplication.class, args);
|
||||
}
|
||||
@Override
|
||||
public void run(String... args) throws Exception {
|
||||
Scanner scan = new Scanner(System.in);
|
||||
String response = "";
|
||||
boolean running = true;
|
||||
while(running){
|
||||
System.out.println("What would you like to create? \n C: The Customer \n B: Bike? \n X:Close");
|
||||
response = scan.nextLine();
|
||||
if ("B".equals(response.toUpperCase())) {
|
||||
String[] bikeInformation = new String[3];
|
||||
System.out.println("Enter the information for the Bike");
|
||||
System.out.println("Model Number");
|
||||
bikeInformation[0] = scan.nextLine();
|
||||
System.out.println("Color");
|
||||
bikeInformation[1] = scan.nextLine();
|
||||
System.out.println("Description");
|
||||
bikeInformation[2] = scan.nextLine();
|
||||
|
||||
Bike bike = new Bike();
|
||||
bike.setModelNumber(bikeInformation[0]);
|
||||
bike.setColor(bikeInformation[1]);
|
||||
bike.setDescription(bikeInformation[2]);
|
||||
|
||||
bike = bikeRepo.save(bike);
|
||||
System.out.println(bike.toString());
|
||||
|
||||
|
||||
} else if ("X".equals(response.toUpperCase())) {
|
||||
System.out.println("Bye");
|
||||
running = false;
|
||||
} else {
|
||||
System.out.println("Sorry nothing else works right now!");
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
其中的 `@Autowired` 注解会自动依赖注入 `BikeRepository` 和 `CustomerRepository` Bean。我们将使用这些类来从数据库持久化和采集数据。
|
||||
|
||||
已经好了。你已经创建了一个命令行应用程序。该应用程序连接到数据库,并且能够以最少的代码执行 CRUD 操作
|
||||
|
||||
### 结论
|
||||
|
||||
从诸如对象和类之类的编程语言概念转换为用于在数据库中存储、检索或更改数据的调用对于构建应用程序至关重要。Java 持久化 API(JPA)正是为 Java 开发人员解决这一难题的重要工具。你正在使用 Java 操纵哪些数据库呢?请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/using-java-persistence-api
|
||||
|
||||
作者:[Stephon Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stephb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-beans.jpg?itok=3hkjX5We (Coffee beans)
|
||||
[2]: https://www.techrepublic.com/article/mongodb-ceo-tells-hard-truths-about-commercial-open-source/
|
||||
[3]: https://github.com/StephonBrown/SpringMongoJava
|
||||
[4]: https://openjdk.java.net/projects/jdk/11/
|
||||
[5]: https://start.spring.io/
|
||||
[6]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[7]: https://hub.docker.com/_/mongo
|
||||
[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+exception
|
||||
[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
140
published/20191017 How to type emoji on Linux.md
Normal file
140
published/20191017 How to type emoji on Linux.md
Normal file
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11702-1.html)
|
||||
[#]: subject: (How to type emoji on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/10/how-type-emoji-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在 Linux 系统中输入 emoji
|
||||
======
|
||||
|
||||
> 使用 GNOME 桌面可以让你在文字中轻松加入 emoji。
|
||||
|
||||

|
||||
|
||||
emoji 是潜藏在 Unicode 字符空间里的有趣表情图,它们已经风靡于整个互联网。emoji 可以用来在社交媒体上表示自己的心情状态,也可以作为重要文件名的视觉标签,总之它们的各种用法层出不穷。在 Linux 系统中有很多种方式可以输入 Unicode 字符,但 GNOME 桌面能让你更轻松地查找和输入 emoji。
|
||||
|
||||
![Emoji in Emacs][2]
|
||||
|
||||
### 准备工作
|
||||
|
||||
首先,你需要一个运行 [GNOME][3] 桌面的 Linux 系统。
|
||||
|
||||
同时还需要安装一款支持 emoji 的字体。符合这个要求的字体有很多,使用你喜欢的软件包管理器直接搜索 `emoji` 并选择一款安装就可以了。
|
||||
|
||||
例如在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf search emoji
|
||||
emoji-picker.noarch : An emoji selection tool
|
||||
unicode-emoji.noarch : Unicode Emoji Data Files
|
||||
eosrei-emojione-fonts.noarch : A color emoji font
|
||||
twitter-twemoji-fonts.noarch : Twitter Emoji for everyone
|
||||
google-android-emoji-fonts.noarch : Android Emoji font released by Google
|
||||
google-noto-emoji-fonts.noarch : Google “Noto Emoji” Black-and-White emoji font
|
||||
google-noto-emoji-color-fonts.noarch : Google “Noto Color Emoji” colored emoji font
|
||||
[...]
|
||||
```
|
||||
|
||||
对于 Ubuntu 或者 Debian,需要使用 `apt search`。
|
||||
|
||||
在这篇文章中,我会使用 [Google Noto Color Emoji][4] 这款字体为例。
|
||||
|
||||
### 设置
|
||||
|
||||
要开始设置,首先打开 GNOME 的设置面板。
|
||||
|
||||
1、在左边侧栏中,选择“<ruby>地区与语言<rt>Region & Language</rt></ruby>”类别。
|
||||
|
||||
2、点击“<ruby>输入源<rt>Input Sources</rt></ruby>”选项下方的加号(+)打开“<ruby>添加输入源<rt>Add an Input Source</rt></ruby>”面板。
|
||||
|
||||
![Add a new input source][5]
|
||||
|
||||
3、在“<ruby>添加输入源<rt>Add an Input Source</rt></ruby>”面板中,点击底部的菜单按钮。
|
||||
|
||||
![Add an Input Source panel][6]
|
||||
|
||||
4、滑动到列表底部并选择“<ruby>其它<rt>Other</rt></ruby>”。
|
||||
|
||||
5、在“<ruby>其它<rt>Other</rt></ruby>”列表中,找到“<ruby>其它<rt>Other</rt></ruby>(<ruby>快速输入<rt>Typing Booster</rt></ruby>)”。
|
||||
|
||||
![Find Other \(Typing Booster\) in inputs][7]
|
||||
|
||||
6、点击右上角的“<ruby>添加<rt>Add</rt></ruby>”按钮,将输入源添加到 GNOME 桌面。
|
||||
|
||||
以上操作完成之后,就可以关闭设置面板了。
|
||||
|
||||
#### 切换到快速输入
|
||||
|
||||
现在 GNOME 桌面的右上角会出现一个新的图标,一般情况下是当前语言的双字母缩写(例如英语是 en,世界语是 eo,西班牙语是 es,等等)。如果你按下了<ruby>超级键<rt>Super key</rt></ruby>(也就是键盘上带有 Linux 企鹅/Windows 徽标/Mac Command 标志的键)+ 空格键的组合键,就会切换到输入列表中的下一个输入源。在这里,我们只有两个输入源,也就是默认语言和快速输入。
|
||||
|
||||
你可以尝试使用一下这个组合键,观察图标的变化。
|
||||
|
||||
#### 配置快速输入
|
||||
|
||||
在快速输入模式下,点击右上角的输入源图标,选择“<ruby>Unicode 符号和 emoji 联想<rt>Unicode symbols and emoji predictions</rt></ruby>”选项,设置为“<ruby>开<rt>On</rt></ruby>”。
|
||||
|
||||
![Set Unicode symbols and emoji predictions to On][8]
|
||||
|
||||
现在快速输入模式已经可以输入 emoji 了。这正是我们现在所需要的,当然快速输入模式的功能也并不止于此。
|
||||
|
||||
### 输入 emoji
|
||||
|
||||
在快速输入模式下,打开一个文本编辑器,或者网页浏览器,又或者是任意一种支持输入 Unicode 字符的软件,输入“thumbs up”,快速输入模式就会帮你迅速匹配的 emoji 了。
|
||||
|
||||
![Typing Booster searching for emojis][9]
|
||||
|
||||
要退出 emoji 模式,只需要再次使用超级键+空格键的组合键,输入源就会切换回你的默认输入语言。
|
||||
|
||||
### 使用其它切换方式
|
||||
|
||||
如果你觉得“超级键+空格键”这个组合用起来不顺手,你也可以换成其它键的组合。在 GNOME 设置面板中选择“<ruby>设备<rt>Device</rt></ruby>”→“<ruby>键盘<rt>Keyboard</rt></ruby>”。
|
||||
|
||||
在“<ruby>键盘<rt>Keyboard</rt></ruby>”页面中,将“<ruby>切换到下一个输入源<rt>Switch to next input source</rt></ruby>”更改为你喜欢的组合键。
|
||||
|
||||
![Changing keystroke combination in GNOME settings][10]
|
||||
|
||||
### 输入 Unicode
|
||||
|
||||
实际上,现代键盘的设计只是为了输入 26 个字母以及尽可能多的数字和符号。但 ASCII 字符的数量已经比键盘上能看到的字符多得多了,遑论上百万个 Unicode 字符。因此,如果你想要在 Linux 应用程序中输入 Unicode,但又不想使用快速输入,你可以尝试一下 Unicode 输入。
|
||||
|
||||
1. 打开任意一种支持输入 Unicode 字符的软件,但仍然使用你的默认输入语言
|
||||
2. 使用 `Ctrl+Shift+U` 组合键进入 Unicode 输入模式
|
||||
3. 在 Unicode 输入模式下,只需要输入某个 Unicode 字符的对应序号,就实现了对这个 Unicode 字符的输入。例如 `1F44D` 对应的是 👍,而 `2620` 则对应了 ☠。想要查看所有 Unicode 字符的对应序号,可以参考 [Unicode 规范][11]。
|
||||
|
||||
### emoji 的实用性
|
||||
|
||||
emoji 可以让你的文本变得与众不同,这就是它们有趣和富有表现力的体现。同时 emoji 也有很强的实用性,因为它们本质上是 Unicode 字符,在很多支持自定义字体的地方都可以用到它们,而且跟使用其它常规字符没有什么太大的差别。因此,你可以使用 emoji 来对不同的文件做标记,在搜索的时候就可以使用 emoji 把这些文件快速筛选出来。
|
||||
|
||||
![Labeling a file with emoji][12]
|
||||
|
||||
你可以在 Linux 中尽情地使用 emoji,因为 Linux 是一个对 Unicode 友好的环境,未来也会对 Unicode 有着越来越好的支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/how-type-emoji-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead_cat-keyboard.png?itok=fuNmiGV- "A cat under a keyboard."
|
||||
[2]: https://opensource.com/sites/default/files/uploads/emacs-emoji.jpg "Emoji in Emacs"
|
||||
[3]: https://www.gnome.org/
|
||||
[4]: https://www.google.com/get/noto/help/emoji/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/gnome-setting-region-add.png "Add a new input source"
|
||||
[6]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-list.png "Add an Input Source panel"
|
||||
[7]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-other-typing-booster.png "Find Other (Typing Booster) in inputs"
|
||||
[8]: https://opensource.com/sites/default/files/uploads/emoji-input-on.jpg "Set Unicode symbols and emoji predictions to On"
|
||||
[9]: https://opensource.com/sites/default/files/uploads/emoji-input.jpg "Typing Booster searching for emojis"
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gnome-setting-keyboard-switch-input.jpg "Changing keystroke combination in GNOME settings"
|
||||
[11]: http://unicode.org/emoji/charts/full-emoji-list.html
|
||||
[12]: https://opensource.com/sites/default/files/uploads/file-label.png "Labeling a file with emoji"
|
||||
|
||||
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11669-1.html)
|
||||
[#]: subject: (14 SCP Command Examples to Securely Transfer Files in Linux)
|
||||
[#]: via: (https://www.linuxtechi.com/scp-command-examples-in-linux/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
在 Linux 上安全传输文件的 14 SCP 命令示例
|
||||
======
|
||||
|
||||

|
||||
|
||||
SCP(<ruby>安全复制<rt>Secure Copy</rt></ruby>)是 Linux 和 Unix 之类的系统中的命令行工具,用于通过网络安全地跨系统传输文件和目录。当我们使用 `scp` 命令将文件和目录从本地系统复制到远程系统时,则在后端与远程系统建立了 ssh 连接。换句话说,我们可以说 `scp` 在后端使用了相同的 SSH 安全机制,它需要密码或密钥进行身份验证。
|
||||
|
||||
![scp-command-examples-linux][2]
|
||||
|
||||
在本教程中,我们将讨论 14 个有用的 Linux `scp` 命令示例。
|
||||
|
||||
`scp` 命令语法:
|
||||
|
||||
```
|
||||
# scp <选项> <文件或目录> 用户名@目标主机:/<文件夹>
|
||||
|
||||
# scp <选项> 用户名@目标主机:/文件 <本地文件夹>
|
||||
```
|
||||
|
||||
`scp` 命令的第一个语法演示了如何将文件或目录从本地系统复制到特定文件夹下的目标主机。
|
||||
|
||||
`scp` 命令的第二种语法演示了如何将目标主机中的文件复制到本地系统中。
|
||||
|
||||
下面列出了 `scp` 命令中使用最广泛的一些选项,
|
||||
|
||||
* `-C` 启用压缩
|
||||
* `-i` 指定识别文件或私钥
|
||||
* `-l` 复制时限制带宽
|
||||
* `-P` 指定目标主机的 ssh 端口号
|
||||
* `-p` 复制时保留文件的权限、模式和访问时间
|
||||
* `-q` 禁止 SSH 警告消息
|
||||
* `-r` 递归复制文件和目录
|
||||
* `-v` 详细输出
|
||||
|
||||
现在让我们跳入示例!
|
||||
|
||||
### 示例:1)使用 scp 将文件从本地系统复制到远程系统
|
||||
|
||||
假设我们要使用 `scp` 命令将 jdk 的 rpm 软件包从本地 Linux 系统复制到远程系统(172.20.10.8),请使用以下命令,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 27.1MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
上面的命令会将 jdk 的 rpm 软件包文件复制到 `/opt` 文件夹下的远程系统。
|
||||
|
||||
### 示例:2)使用 scp 将文件从远程系统复制到本地系统
|
||||
|
||||
假设我们想将文件从远程系统复制到本地系统下的 `/tmp` 文件夹,执行以下 `scp` 命令,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp root@linuxtechi:/root/Technical-Doc-RHS.odt /tmp
|
||||
root@linuxtechi's password:
|
||||
Technical-Doc-RHS.odt 100% 1109KB 31.8MB/s 00:00
|
||||
[root@linuxtechi ~]$ ls -l /tmp/Technical-Doc-RHS.odt
|
||||
-rwx------. 1 pkumar pkumar 1135521 Oct 19 11:12 /tmp/Technical-Doc-RHS.odt
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:3)使用 scp 传输文件时的详细输出(-v)
|
||||
|
||||
在 `scp` 命令中,我们可以使用 `-v` 选项启用详细输出。使用详细输出,我们可以轻松地发现后台确切发生了什么。这对于调试连接、认证和配置等问题非常有用。
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -v jdk-linux-x64_bin.rpm root@linuxtechi:/opt
|
||||
Executing: program /usr/bin/ssh host 172.20.10.8, user root, command scp -v -t /opt
|
||||
OpenSSH_7.8p1, OpenSSL 1.1.1 FIPS 11 Sep 2018
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config
|
||||
debug1: Reading configuration data /etc/ssh/ssh_config.d/05-redhat.conf
|
||||
debug1: Reading configuration data /etc/crypto-policies/back-ends/openssh.config
|
||||
debug1: /etc/ssh/ssh_config.d/05-redhat.conf line 8: Applying options for *
|
||||
debug1: Connecting to 172.20.10.8 [172.20.10.8] port 22.
|
||||
debug1: Connection established.
|
||||
…………
|
||||
debug1: Next authentication method: password
|
||||
root@linuxtechi's password:
|
||||
```
|
||||
|
||||
### 示例:4)将多个文件传输到远程系统
|
||||
|
||||
可以使用 `scp` 命令一次性将多个文件复制/传输到远程系统,在 `scp` 命令中指定多个文件,并用空格隔开,示例如下所示
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp install.txt index.html jdk-linux-x64_bin.rpm root@linuxtechi:/mnt
|
||||
root@linuxtechi's password:
|
||||
install.txt 100% 0 0.0KB/s 00:00
|
||||
index.html 100% 85KB 7.2MB/s 00:00
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 25.3MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:5)在两个远程主机之间传输文件
|
||||
|
||||
使用 `scp` 命令,我们可以在两个远程主机之间复制文件和目录,假设我们有一个可以连接到两个远程 Linux 系统的本地 Linux 系统,因此从我的本地 Linux 系统中,我可以使用 `scp` 命令在这两个系统之间复制文件,
|
||||
|
||||
命令语法:
|
||||
|
||||
```
|
||||
# scp 用户名@远程主机1:/<要传输的文件> 用户名@远程主机2:/<文件夹>
|
||||
```
|
||||
|
||||
示例如下:
|
||||
|
||||
```
|
||||
# scp root@linuxtechi:~/backup-Oct.zip root@linuxtechi:/tmp
|
||||
# ssh root@linuxtechi "ls -l /tmp/backup-Oct.zip"
|
||||
-rwx------. 1 root root 747438080 Oct 19 12:02 /tmp/backup-Oct.zip
|
||||
```
|
||||
|
||||
### 示例:6)递归复制文件和目录(-r)
|
||||
|
||||
在 `scp` 命令中使用 `-r` 选项将整个目录从一个系统递归地复制到另一个系统,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -r Downloads root@linuxtechi:/opt
|
||||
```
|
||||
|
||||
使用以下命令验证 `Downloads` 文件夹是否已复制到远程系统,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ ssh root@linuxtechi "ls -ld /opt/Downloads"
|
||||
drwxr-xr-x. 2 root root 75 Oct 19 12:10 /opt/Downloads
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:7)通过启用压缩来提高传输速度(-C)
|
||||
|
||||
在 `scp` 命令中,我们可以通过使用 `-C` 选项启用压缩来提高传输速度,它将自动在源主机上启用压缩并在目标主机上解压缩。
|
||||
|
||||
```
|
||||
root@linuxtechi ~]$ scp -r -C Downloads root@linuxtechi:/mnt
|
||||
```
|
||||
|
||||
在以上示例中,我们正在启用压缩的情况下传输下载目录。
|
||||
|
||||
### 示例:8)复制时限制带宽(-l)
|
||||
|
||||
在 `scp` 命令中使用 `-l` 选项设置复制时对带宽使用的限制。带宽以 Kbit/s 为单位指定,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -l 500 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
### 示例:9)在 scp 时指定其他 ssh 端口(-P)
|
||||
|
||||
在某些情况下,目标主机上的 ssh 端口会更改,因此在使用 `scp` 命令时,我们可以使用 `-P` 选项指定 ssh 端口号。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -P 2022 jdk-linux-x64_bin.rpm root@linuxtechi:/var
|
||||
```
|
||||
|
||||
在上面的示例中,远程主机的 ssh 端口为 “2022”。
|
||||
|
||||
### 示例:10)复制时保留文件的权限、模式和访问时间(-p)
|
||||
|
||||
从源复制到目标时,在 `scp` 命令中使用 `-p` 选项保留权限、访问时间和模式。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -p jdk-linux-x64_bin.rpm root@linuxtechi:/var/tmp
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 13.5MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:11)在 scp 中以安静模式传输文件(-q)
|
||||
|
||||
在 `scp` 命令中使用 `-q` 选项可禁止显示 ssh 的传输进度、警告和诊断消息。示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -q -r Downloads root@linuxtechi:/var/tmp
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:12)在传输时使用 scp 中的识别文件(-i)
|
||||
|
||||
在大多数 Linux 环境中,首选基于密钥的身份验证。在 `scp` 命令中,我们使用 `-i` 选项指定识别文件(私钥文件),示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -i my_key.pem -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
在上面的示例中,`my_key.pem` 是识别文件或私钥文件。
|
||||
|
||||
### 示例:13)在 scp 中使用其他 ssh_config 文件(-F)
|
||||
|
||||
在某些情况下,你使用不同的网络连接到 Linux 系统,可能某些网络位于代理服务器后面,因此在这种情况下,我们必须具有不同的 `ssh_config` 文件。
|
||||
|
||||
通过 `-F` 选项在 `scp` 命令中指定了不同的 `ssh_config` 文件,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]$ scp -F /home/pkumar/new_ssh_config -r Downloads root@linuxtechi:/root
|
||||
root@linuxtechi's password:
|
||||
jdk-linux-x64_bin.rpm 100% 10MB 16.6MB/s 00:00
|
||||
backup-Oct.zip 100% 713MB 41.9MB/s 00:17
|
||||
index.html 100% 85KB 6.6MB/s 00:00
|
||||
[root@linuxtechi ~]$
|
||||
```
|
||||
|
||||
### 示例:14)在 scp 命令中使用其他加密方式(-c)
|
||||
|
||||
默认情况下,`scp` 使用 AES-128 加密方式来加密文件。如果你想在 `scp` 命令中使用其他加密方式,请使用 `-c` 选项,后接加密方式名称。
|
||||
|
||||
假设我们要在用 `scp` 命令传输文件时使用 3des-cbc 加密方式,请运行以下 `scp` 命令:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# scp -c 3des-cbc -r Downloads root@linuxtechi:/root
|
||||
```
|
||||
|
||||
使用以下命令列出 `ssh` 和 `scp` 支持的加密方式:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ssh -Q cipher localhost | paste -d , -s -
|
||||
3des-cbc,aes128-cbc,aes192-cbc,aes256-cbc,root@linuxtechi,aes128-ctr,aes192-ctr,aes256-ctr,root@linuxtechi,root@linuxtechi,root@linuxtechi
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
以上就是本教程的全部内容,要获取有关 `scp` 命令的更多详细信息,请参考其手册页。请在下面的评论部分中分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/scp-command-examples-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/scp-command-examples-linux.jpg
|
||||
[3]: https://www.linuxtechi.com/cdn-cgi/l/email-protection
|
||||
@ -0,0 +1,467 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11687-1.html)
|
||||
[#]: subject: (How to program with Bash: Logical operators and shell expansions)
|
||||
[#]: via: (https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
怎样用 Bash 编程:逻辑操作符和 shell 扩展
|
||||
======
|
||||
|
||||
> 学习逻辑操作符和 shell 扩展,本文是三篇 Bash 编程系列的第二篇。
|
||||
|
||||

|
||||
|
||||
Bash 是一种强大的编程语言,完美契合命令行和 shell 脚本。本系列(三篇文章,基于我的 [三集 Linux 自学课程][2])讲解如何在 CLI 使用 Bash 编程。
|
||||
|
||||
[第一篇文章][3] 讲解了 Bash 的一些简单命令行操作,包括如何使用变量和控制操作符。第二篇文章探讨文件、字符串、数字等类型和各种各样在执行流中提供控制逻辑的的逻辑运算符,还有 Bash 中的各类 shell 扩展。本系列第三篇也是最后一篇文章,将会探索能重复执行操作的 `for` 、`while` 和 `until` 循环。
|
||||
|
||||
逻辑操作符是程序中进行判断的根本要素,也是执行不同的语句组合的依据。有时这也被称为流控制。
|
||||
|
||||
### 逻辑操作符
|
||||
|
||||
Bash 中有大量的用于不同条件表达式的逻辑操作符。最基本的是 `if` 控制结构,它判断一个条件,如果条件为真,就执行一些程序语句。操作符共有三类:文件、数字和非数字操作符。如果条件为真,所有的操作符返回真值(`0`),如果条件为假,返回假值(`1`)。
|
||||
|
||||
这些比较操作符的函数语法是,一个操作符加一个或两个参数放在中括号内,后面跟一系列程序语句,如果条件为真,程序语句执行,可能会有另一个程序语句列表,该列表在条件为假时执行:
|
||||
|
||||
|
||||
```
|
||||
if [ arg1 operator arg2 ] ; then list
|
||||
或
|
||||
if [ arg1 operator arg2 ] ; then list ; else list ; fi
|
||||
```
|
||||
|
||||
像例子中那样,在比较表达式中,空格不能省略。中括号的每部分,`[` 和 `]`,是跟 `test` 命令一样的传统的 Bash 符号:
|
||||
|
||||
```
|
||||
if test arg1 operator arg2 ; then list
|
||||
```
|
||||
|
||||
还有一个更新的语法能提供一点点便利,一些系统管理员比较喜欢用。这种格式对于不同版本的 Bash 和一些 shell 如 ksh(Korn shell)兼容性稍差。格式如下:
|
||||
|
||||
```
|
||||
if [[ arg1 operator arg2 ]] ; then list
|
||||
```
|
||||
|
||||
#### 文件操作符
|
||||
|
||||
文件操作符是 Bash 中一系列强大的逻辑操作符。图表 1 列出了 20 多种不同的 Bash 处理文件的操作符。在我的脚本中使用频率很高。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`-a filename` | 如果文件存在,返回真值;文件可以为空也可以有内容,但是只要它存在,就返回真值
|
||||
`-b filename` | 如果文件存在且是一个块设备,如 `/dev/sda` 或 `/dev/sda1`,则返回真值
|
||||
`-c filename` | 如果文件存在且是一个字符设备,如 `/dev/TTY1`,则返回真值
|
||||
`-d filename` | 如果文件存在且是一个目录,返回真值
|
||||
`-e filename` | 如果文件存在,返回真值;与上面的 `-a` 相同
|
||||
`-f filename` | 如果文件存在且是一个一般文件,不是目录、设备文件或链接等的其他的文件,则返回 真值
|
||||
`-g filename` | 如果文件存在且 `SETGID` 标记被设置在其上,返回真值
|
||||
`-h filename` | 如果文件存在且是一个符号链接,则返回真值
|
||||
`-k filename` | 如果文件存在且粘滞位已设置,则返回真值
|
||||
`-p filename` | 如果文件存在且是一个命名的管道(FIFO),返回真值
|
||||
`-r filename` | 如果文件存在且有可读权限(它的可读位被设置),返回真值
|
||||
`-s filename` | 如果文件存在且大小大于 0,返回真值;如果一个文件存在但大小为 0,则返回假值
|
||||
`-t fd` | 如果文件描述符 `fd` 被打开且被关联到一个终端设备上,返回真值
|
||||
`-u filename` | 如果文件存在且它的 `SETUID` 位被设置,返回真值
|
||||
`-w filename` | 如果文件存在且有可写权限,返回真值
|
||||
`-x filename` | 如果文件存在且有可执行权限,返回真值
|
||||
`-G filename` | 如果文件存在且文件的组 ID 与当前用户相同,返回真值
|
||||
`-L filename` | 如果文件存在且是一个符号链接,返回真值(同 `-h`)
|
||||
`-N filename` | 如果文件存在且从文件上一次被读取后文件被修改过,返回真值
|
||||
`-O filename` | 如果文件存在且你是文件的拥有者,返回真值
|
||||
`-S filename` | 如果文件存在且文件是套接字,返回真值
|
||||
`file1 -ef file2` | 如果文件 `file1` 和文件 `file2` 指向同一设备的同一 INODE 号,返回真值(即硬链接)
|
||||
`file1 -nt file2` | 如果文件 `file1` 比 `file2` 新(根据修改日期),或 `file1` 存在而 `file2` 不存在,返回真值
|
||||
`file1 -ot file2` | 如果文件 `file1` 比 `file2` 旧(根据修改日期),或 `file1` 不存在而 `file2` 存在
|
||||
|
||||
*图表 1:Bash 文件操作符*
|
||||
|
||||
以测试一个文件存在与否来举例:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; if [ -e $File ] ; then echo "The file $File exists." ; else echo "The file $File does not exist." ; fi
|
||||
The file TestFile1 does not exist.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
创建一个用来测试的文件,命名为 `TestFile1`。目前它不需要包含任何数据:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ touch TestFile1
|
||||
```
|
||||
|
||||
在这个简短的 CLI 程序中,修改 `$File` 变量的值相比于在多个地方修改表示文件名的字符串的值要容易:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; if [ -e $File ] ; then echo "The file $File exists." ; else echo "The file $File does not exist." ; fi
|
||||
The file TestFile1 exists.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在,运行一个测试来判断一个文件是否存在且长度不为 0(表示它包含数据)。假设你想判断三种情况:
|
||||
|
||||
1. 文件不存在;
|
||||
2. 文件存在且为空;
|
||||
3. 文件存在且包含数据。
|
||||
|
||||
因此,你需要一组更复杂的测试代码 — 为了测试所有的情况,使用 `if-elif-else` 结构中的 `elif` 语句:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; if [ -s $File ] ; then echo "$File exists and contains data." ; fi
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
在这个情况中,文件存在但不包含任何数据。向文件添加一些数据再运行一次:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is file $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; fi
|
||||
TestFile1 exists and contains data.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
这组语句能返回正常的结果,但是仅仅是在我们已知三种可能的情况下测试某种确切的条件。添加一段 `else` 语句,这样你就可以更精确地测试。把文件删掉,你就可以完整地测试这段新代码:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; rm $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
|
||||
TestFile1 does not exist or is empty.
|
||||
```
|
||||
|
||||
现在创建一个空文件用来测试:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; touch $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
|
||||
TestFile1 does not exist or is empty.
|
||||
```
|
||||
|
||||
向文件添加一些内容,然后再测试一次:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is file $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
|
||||
TestFile1 exists and contains data.
|
||||
```
|
||||
|
||||
现在加入 `elif` 语句来辨别是文件不存在还是文件为空:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; touch $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; elif [ -e $File ] ; then echo "$File exists and is empty." ; else echo "$File does not exist." ; fi
|
||||
TestFile1 exists and is empty.
|
||||
[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; elif [ -e $File ] ; then echo "$File exists and is empty." ; else echo "$File does not exist." ; fi
|
||||
TestFile1 exists and contains data.
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在你有一个可以测试这三种情况的 Bash CLI 程序,但是可能的情况是无限的。
|
||||
|
||||
如果你能像保存在文件中的脚本那样组织程序语句,那么即使对于更复杂的命令组合也会很容易看出它们的逻辑结构。图表 2 就是一个示例。 `if-elif-else` 结构中每一部分的程序语句的缩进让逻辑更变得清晰。
|
||||
|
||||
|
||||
```
|
||||
File="TestFile1"
|
||||
echo "This is $File" > $File
|
||||
if [ -s $File ]
|
||||
then
|
||||
echo "$File exists and contains data."
|
||||
elif [ -e $File ]
|
||||
then
|
||||
echo "$File exists and is empty."
|
||||
else
|
||||
echo "$File does not exist."
|
||||
fi
|
||||
```
|
||||
|
||||
*图表 2: 像在脚本里一样重写书写命令行程序*
|
||||
|
||||
对于大多数 CLI 程序来说,让这些复杂的命令变得有逻辑需要写很长的代码。虽然 CLI 可能是用 Linux 或 Bash 内置的命令,但是当 CLI 程序很长或很复杂时,创建一个保存在文件中的脚本将更有效,保存到文件中后,可以随时运行。
|
||||
|
||||
#### 字符串比较操作符
|
||||
|
||||
字符串比较操作符使我们可以对字符串中的字符按字母顺序进行比较。图表 3 列出了仅有的几个字符串比较操作符。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`-z string` | 如果字符串的长度为 0 ,返回真值
|
||||
`-n string` |如果字符串的长度不为 0 ,返回真值
|
||||
`string1 == string2` 或 `string1 = string2` | 如果两个字符串相等,返回真值。处于遵从 POSIX 一致性,在测试命令中应使用一个等号 `=`。与命令 `[[` 一起使用时,会进行如上描述的模式匹配(混合命令)。
|
||||
`string1 != string2` | 两个字符串不相等,返回真值
|
||||
`string1 < string2` | 如果对 `string1` 和 `string2` 按字母顺序进行排序,`string1` 排在 `string2` 前面(即基于地区设定的对所有字母和特殊字符的排列顺序)
|
||||
`string1 > string2` | 如果对 `string1` 和 `string2` 按字母顺序进行排序,`string1` 排在 `string2` 后面
|
||||
|
||||
*图表 3: Bash 字符串逻辑操作符*
|
||||
|
||||
首先,检查字符串长度。比较表达式中 `$MyVar` 两边的双引号不能省略(你仍应该在目录 `~/testdir` 下 )。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ MyVar="" ; if [ -z "" ] ; then echo "MyVar is zero length." ; else echo "MyVar contains data" ; fi
|
||||
MyVar is zero length.
|
||||
[student@studentvm1 testdir]$ MyVar="Random text" ; if [ -z "" ] ; then echo "MyVar is zero length." ; else echo "MyVar contains data" ; fi
|
||||
MyVar is zero length.
|
||||
```
|
||||
|
||||
你也可以这样做:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ MyVar="Random text" ; if [ -n "$MyVar" ] ; then echo "MyVar contains data." ; else echo "MyVar is zero length" ; fi
|
||||
MyVar contains data.
|
||||
[student@studentvm1 testdir]$ MyVar="" ; if [ -n "$MyVar" ] ; then echo "MyVar contains data." ; else echo "MyVar is zero length" ; fi
|
||||
MyVar is zero length
|
||||
```
|
||||
|
||||
有时候你需要知道一个字符串确切的长度。这虽然不是比较,但是也与比较相关。不幸的是,计算字符串的长度没有简单的方法。有很多种方法可以计算,但是我认为使用 `expr`(求值表达式)命令是相对最简单的一种。阅读 `expr` 的手册页可以了解更多相关知识。注意表达式中你检测的字符串或变量两边的引号不要省略。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ MyVar="" ; expr length "$MyVar"
|
||||
0
|
||||
[student@studentvm1 testdir]$ MyVar="How long is this?" ; expr length "$MyVar"
|
||||
17
|
||||
[student@studentvm1 testdir]$ expr length "We can also find the length of a literal string as well as a variable."
|
||||
70
|
||||
```
|
||||
|
||||
关于比较操作符,在我们的脚本中使用了大量的检测两个字符串是否相等(例如,两个字符串是否实际上是同一个字符串)的操作。我使用的是非 POSIX 版本的比较表达式:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ Var1="Hello World" ; Var2="Hello World" ; if [ "$Var1" == "$Var2" ] ; then echo "Var1 matches Var2" ; else echo "Var1 and Var2 do not match." ; fi
|
||||
Var1 matches Var2
|
||||
[student@studentvm1 testdir]$ Var1="Hello World" ; Var2="Hello world" ; if [ "$Var1" == "$Var2" ] ; then echo "Var1 matches Var2" ; else echo "Var1 and Var2 do not match." ; fi
|
||||
Var1 and Var2 do not match.
|
||||
```
|
||||
|
||||
在你自己的脚本中去试一下这些操作符。
|
||||
|
||||
#### 数字比较操作符
|
||||
|
||||
数字操作符用于两个数字参数之间的比较。像其他类操作符一样,大部分都很容易理解。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`arg1 -eq arg2` | 如果 `arg1` 等于 `arg2`,返回真值
|
||||
`arg1 -ne arg2` | 如果 `arg1` 不等于 `arg2`,返回真值
|
||||
`arg1 -lt arg2` | 如果 `arg1` 小于 `arg2`,返回真值
|
||||
`arg1 -le arg2` | 如果 `arg1` 小于或等于 `arg2`,返回真值
|
||||
`arg1 -gt arg2` | 如果 `arg1` 大于 `arg2`,返回真值
|
||||
`arg1 -ge arg2` | 如果 `arg1` 大于或等于 `arg2`,返回真值
|
||||
|
||||
*图表 4: Bash 数字比较逻辑操作符*
|
||||
|
||||
来看几个简单的例子。第一个示例设置变量 `$X` 的值为 1,然后检测 `$X` 是否等于 1。第二个示例中,`$X` 被设置为 0,所以比较表达式返回结果不为真值。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ X=1 ; if [ $X -eq 1 ] ; then echo "X equals 1" ; else echo "X does not equal 1" ; fi
|
||||
X equals 1
|
||||
[student@studentvm1 testdir]$ X=0 ; if [ $X -eq 1 ] ; then echo "X equals 1" ; else echo "X does not equal 1" ; fi
|
||||
X does not equal 1
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
自己来多尝试一下其他的。
|
||||
|
||||
#### 杂项操作符
|
||||
|
||||
这些杂项操作符展示一个 shell 选项是否被设置,或一个 shell 变量是否有值,但是它不显示变量的值,只显示它是否有值。
|
||||
|
||||
操作符 | 描述
|
||||
---|---
|
||||
`-o optname` | 如果一个 shell 选项 `optname` 是启用的(查看内建在 Bash 手册页中的 set `-o` 选项描述下面的选项列表),则返回真值
|
||||
`-v varname` | 如果 shell 变量 `varname` 被设置了值(被赋予了值),则返回真值
|
||||
`-R varname` | 如果一个 shell 变量 `varname` 被设置了值且是一个名字引用,则返回真值
|
||||
|
||||
*图表 5: 杂项 Bash 逻辑操作符*
|
||||
|
||||
自己来使用这些操作符实践下。
|
||||
|
||||
### 扩展
|
||||
|
||||
Bash 支持非常有用的几种类型的扩展和命令替换。根据 Bash 手册页,Bash 有七种扩展格式。本文只介绍其中五种:`~` 扩展、算术扩展、路径名称扩展、大括号扩展和命令替换。
|
||||
|
||||
#### 大括号扩展
|
||||
|
||||
大括号扩展是生成任意字符串的一种方法。(下面的例子是用特定模式的字符创建大量的文件。)大括号扩展可以用于产生任意字符串的列表,并把它们插入一个用静态字符串包围的特定位置或静态字符串的两端。这可能不太好想象,所以还是来实践一下。
|
||||
|
||||
首先,看一下大括号扩展的作用:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo {string1,string2,string3}
|
||||
string1 string2 string3
|
||||
```
|
||||
|
||||
看起来不是很有用,对吧?但是用其他方式使用它,再来看看:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo "Hello "{David,Jen,Rikki,Jason}.
|
||||
Hello David. Hello Jen. Hello Rikki. Hello Jason.
|
||||
```
|
||||
|
||||
这看起来貌似有点用了 — 我们可以少打很多字。现在试一下这个:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo b{ed,olt,ar}s
|
||||
beds bolts bars
|
||||
```
|
||||
|
||||
我可以继续举例,但是你应该已经理解了它的用处。
|
||||
|
||||
#### ~ 扩展
|
||||
|
||||
资料显示,使用最多的扩展是波浪字符(`~`)扩展。当你在命令中使用它(如 `cd ~/Documents`)时,Bash shell 把这个快捷方式展开成用户的完整的家目录。
|
||||
|
||||
使用这个 Bash 程序观察 `~` 扩展的作用:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo ~
|
||||
/home/student
|
||||
[student@studentvm1 testdir]$ echo ~/Documents
|
||||
/home/student/Documents
|
||||
[student@studentvm1 testdir]$ Var1=~/Documents ; echo $Var1 ; cd $Var1
|
||||
/home/student/Documents
|
||||
[student@studentvm1 Documents]$
|
||||
```
|
||||
|
||||
#### 路径名称扩展
|
||||
|
||||
路径名称扩展是展开文件通配模式为匹配该模式的完整路径名称的另一种说法,匹配字符使用 `?` 和 `*`。文件通配指的是在大量操作中匹配文件名、路径和其他字符串时用特定的模式字符产生极大的灵活性。这些特定的模式字符允许匹配字符串中的一个、多个或特定字符。
|
||||
|
||||
* `?` — 匹配字符串中特定位置的一个任意字符
|
||||
* `*` — 匹配字符串中特定位置的 0 个或多个任意字符
|
||||
|
||||
这个扩展用于匹配路径名称。为了弄清它的用法,请确保 `testdir` 是当前工作目录(`PWD`),先执行基本的列出清单命令 `ls`(我家目录下的内容跟你的不一样)。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ ls
|
||||
chapter6 cpuHog.dos dmesg1.txt Documents Music softlink1 testdir6 Videos
|
||||
chapter7 cpuHog.Linux dmesg2.txt Downloads Pictures Templates testdir
|
||||
testdir cpuHog.mac dmesg3.txt file005 Public testdir tmp
|
||||
cpuHog Desktop dmesg.txt link3 random.txt testdir1 umask.test
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在列出以 `Do`、`testdir/Documents` 和 `testdir/Downloads` 开头的目录:
|
||||
|
||||
```
|
||||
Documents:
|
||||
Directory01 file07 file15 test02 test10 test20 testfile13 TextFiles
|
||||
Directory02 file08 file16 test03 test11 testfile01 testfile14
|
||||
file01 file09 file17 test04 test12 testfile04 testfile15
|
||||
file02 file10 file18 test05 test13 testfile05 testfile16
|
||||
file03 file11 file19 test06 test14 testfile09 testfile17
|
||||
file04 file12 file20 test07 test15 testfile10 testfile18
|
||||
file05 file13 Student1.txt test08 test16 testfile11 testfile19
|
||||
file06 file14 test01 test09 test18 testfile12 testfile20
|
||||
|
||||
Downloads:
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
然而,并没有得到你期望的结果。它列出了以 `Do` 开头的目录下的内容。使用 `-d` 选项,仅列出目录而不列出它们的内容。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ ls -d Do*
|
||||
Documents Downloads
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
在两个例子中,Bash shell 都把 `Do*` 模式展开成了匹配该模式的目录名称。但是如果有文件也匹配这个模式,会发生什么?
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ touch Downtown ; ls -d Do*
|
||||
Documents Downloads Downtown
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
因此所有匹配这个模式的文件也被展开成了完整名字。
|
||||
|
||||
#### 命令替换
|
||||
|
||||
命令替换是让一个命令的标准输出数据流被当做参数传给另一个命令的扩展形式,例如,在一个循环中作为一系列被处理的项目。Bash 手册页显示:“命令替换可以让你用一个命令的输出替换为命令的名字。”这可能不太好理解。
|
||||
|
||||
命令替换有两种格式:\`command\` 和 `$(command)`。在更早的格式中使用反引号(\`),在命令中使用反斜杠(`\`)来保持它转义之前的文本含义。然而,当用在新版本的括号格式中时,反斜杠被当做一个特殊字符处理。也请注意带括号的格式打开个关闭命令语句都是用一个括号。
|
||||
|
||||
我经常在命令行程序和脚本中使用这种能力,一个命令的结果能被用作另一个命令的参数。
|
||||
|
||||
来看一个非常简单的示例,这个示例使用了这个扩展的两种格式(再一次提醒,确保 `testdir` 是当前工作目录):
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo "Todays date is `date`"
|
||||
Todays date is Sun Apr 7 14:42:46 EDT 2019
|
||||
[student@studentvm1 testdir]$ echo "Todays date is $(date)"
|
||||
Todays date is Sun Apr 7 14:42:59 EDT 2019
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
`-seq` 工具用于一个数字序列:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ seq 5
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
[student@studentvm1 testdir]$ echo `seq 5`
|
||||
1 2 3 4 5
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
现在你可以做一些更有用处的操作,比如创建大量用于测试的空文件。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for I in $(seq -w 5000) ; do touch file-$I ; done
|
||||
```
|
||||
|
||||
`seq` 工具加上 `-w` 选项后,在生成的数字前面会用 0 补全,这样所有的结果都等宽,例如,忽略数字的值,它们的位数一样。这样在对它们按数字顺序进行排列时很容易。
|
||||
|
||||
`seq -w 5000` 语句生成了 1 到 5000 的数字序列。通过把命令替换用于 `for` 语句,`for` 语句就可以使用该数字序列来生成文件名的数字部分。
|
||||
|
||||
#### 算术扩展
|
||||
|
||||
Bash 可以进行整型的数学计算,但是比较繁琐(你一会儿将看到)。数字扩展的语法是 `$((arithmetic-expression))` ,分别用两个括号来打开和关闭表达式。算术扩展在 shell 程序或脚本中类似命令替换;表达式结算后的结果替换了表达式,用于 shell 后续的计算。
|
||||
|
||||
我们再用一个简单的用法来开始:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ echo $((1+1))
|
||||
2
|
||||
[student@studentvm1 testdir]$ Var1=5 ; Var2=7 ; Var3=$((Var1*Var2)) ; echo "Var 3 = $Var3"
|
||||
Var 3 = 35
|
||||
```
|
||||
|
||||
下面的除法结果是 0,因为表达式的结果是一个小于 1 的整型数字:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ Var1=5 ; Var2=7 ; Var3=$((Var1/Var2)) ; echo "Var 3 = $Var3"
|
||||
Var 3 = 0
|
||||
```
|
||||
|
||||
这是一个我经常在脚本或 CLI 程序中使用的一个简单的计算,用来查看在 Linux 主机中使用了多少虚拟内存。 `free` 不提供我需要的数据:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ RAM=`free | grep ^Mem | awk '{print $2}'` ; Swap=`free | grep ^Swap | awk '{print $2}'` ; echo "RAM = $RAM and Swap = $Swap" ; echo "Total Virtual memory is $((RAM+Swap))" ;
|
||||
RAM = 4037080 and Swap = 6291452
|
||||
Total Virtual memory is 10328532
|
||||
```
|
||||
|
||||
我使用 \` 字符来划定用作命令替换的界限。
|
||||
|
||||
我用 Bash 算术扩展的场景主要是用脚本检查系统资源用量后基于返回的结果选择一个程序运行的路径。
|
||||
|
||||
### 总结
|
||||
|
||||
本文是 Bash 编程语言系列的第二篇,探讨了 Bash 中文件、字符串、数字和各种提供流程控制逻辑的逻辑操作符还有不同种类的 shell 扩展。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_5.png?itok=YHpNs_ss (Women in computing and open source v5)
|
||||
[2]: http://www.both.org/?page_id=1183
|
||||
[3]: https://linux.cn/article-11552-1.html
|
||||
336
published/20191023 How to program with Bash- Loops.md
Normal file
336
published/20191023 How to program with Bash- Loops.md
Normal file
@ -0,0 +1,336 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11714-1.html)
|
||||
[#]: subject: (How to program with Bash: Loops)
|
||||
[#]: via: (https://opensource.com/article/19/10/programming-bash-loops)
|
||||
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||
|
||||
怎样用 Bash 编程:循环
|
||||
======
|
||||
|
||||
> 本文是 Bash 编程系列三篇中的最后一篇,来学习使用循环执行迭代的操作。
|
||||
|
||||

|
||||
|
||||
Bash 是一种强大的用于命令行和 shell 脚本的编程语言。本系列的三部分都是基于我的三集 [Linux 自学课程][2] 写的,探索怎么用 CLI 进行 bash 编程。
|
||||
|
||||
本系列的 [第一篇文章][3] 讨论了 bash 编程的一些简单命令行操作,如使用变量和控制操作符。[第二篇文章][4] 探讨了文件、字符串、数字等类型和各种各样在执行流中提供控制逻辑的的逻辑运算符,还有 bash 中不同种类的扩展。本文是第三篇(也是最后一篇),意在考察在各种迭代的操作中使用循环以及怎么合理控制循环。
|
||||
|
||||
### 循环
|
||||
|
||||
我使用过的所有编程语言都至少有两种循环结构来用来执行重复的操作。我经常使用 `for` 循环,然而我发现 `while` 和 `until` 循环也很有用处。
|
||||
|
||||
#### for 循环
|
||||
|
||||
我的理解是,在 bash 中实现的 `for` 命令比大部分语言灵活,因为它可以处理非数字的值;与之形成对比的是,诸如标准 C 语言的 `for` 循环只能处理数字类型的值。
|
||||
|
||||
Bash 版的 `for` 命令基本的结构很简单:
|
||||
|
||||
```
|
||||
for Var in list1 ; do list2 ; done
|
||||
```
|
||||
|
||||
解释一下:“对于 `list1` 中的每一个值,把 `$Var` 设置为那个值,使用该值执行 `list2` 中的程序语句;`list1` 中的值都执行完后,整个循环结束,退出循环。” `list1` 中的值可以是一个简单的显式字符串值,也可以是一个命令执行后的结果(`` 包含其内的命令执行的结果,本系列第二篇文章中有描述)。我经常使用这种结构。
|
||||
|
||||
要测试它,确认 `~/testdir` 仍然是当前的工作目录(PWD)。删除目录下所有东西,来看下这个显式写出值列表的 `for` 循环的简单的示例。这个列表混合了字母和数字 — 但是不要忘了,在 bash 中所有的变量都是字符串或者可以被当成字符串来处理。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rm *
|
||||
[student@studentvm1 testdir]$ for I in a b c d 1 2 3 4 ; do echo $I ; done
|
||||
a
|
||||
b
|
||||
c
|
||||
d
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
```
|
||||
|
||||
给变量赋予更有意义的名字,变成前面版本的进阶版:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for Dept in "Human Resources" Sales Finance "Information Technology" Engineering Administration Research ; do echo "Department $Dept" ; done
|
||||
Department Human Resources
|
||||
Department Sales
|
||||
Department Finance
|
||||
Department Information Technology
|
||||
Department Engineering
|
||||
Department Administration
|
||||
Department Research
|
||||
```
|
||||
|
||||
创建几个目录(创建时显示一些处理信息):
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for Dept in "Human Resources" Sales Finance "Information Technology" Engineering Administration Research ; do echo "Working on Department $Dept" ; mkdir "$Dept" ; done
|
||||
Working on Department Human Resources
|
||||
Working on Department Sales
|
||||
Working on Department Finance
|
||||
Working on Department Information Technology
|
||||
Working on Department Engineering
|
||||
Working on Department Administration
|
||||
Working on Department Research
|
||||
[student@studentvm1 testdir]$ ll
|
||||
total 28
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Administration
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Engineering
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Finance
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 'Human Resources'
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 'Information Technology'
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Research
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:45 Sales
|
||||
```
|
||||
|
||||
在 `mkdir` 语句中 `$Dept` 变量必须用引号包裹起来;否则名字中间有空格(如 `Information Technology`)会被当做两个独立的目录处理。我一直信奉的一条实践规则:所有的文件和目录都应该为一个单词(中间没有空格)。虽然大部分现代的操作系统可以处理名字中间有空格的情况,但是系统管理员需要花费额外的精力去确保脚本和 CLI 程序能正确处理这些特例。(即使它们很烦人,也务必考虑它们,因为你永远不知道将拥有哪些文件。)
|
||||
|
||||
再次删除 `~/testdir` 下的所有东西 — 再运行一次下面的命令:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rm -rf * ; ll
|
||||
total 0
|
||||
[student@studentvm1 testdir]$ for Dept in Human-Resources Sales Finance Information-Technology Engineering Administration Research ; do echo "Working on Department $Dept" ; mkdir "$Dept" ; done
|
||||
Working on Department Human-Resources
|
||||
Working on Department Sales
|
||||
Working on Department Finance
|
||||
Working on Department Information-Technology
|
||||
Working on Department Engineering
|
||||
Working on Department Administration
|
||||
Working on Department Research
|
||||
[student@studentvm1 testdir]$ ll
|
||||
total 28
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Administration
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Engineering
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Finance
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Human-Resources
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Information-Technology
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Research
|
||||
drwxrwxr-x 2 student student 4096 Apr 8 15:52 Sales
|
||||
```
|
||||
|
||||
假设现在有个需求,需要列出一台 Linux 机器上所有的 RPM 包并对每个包附上简短的描述。我为北卡罗来纳州工作的时候,曾经遇到过这种需求。由于当时开源尚未得到州政府的“批准”,而且我只在台式机上使用 Linux,对技术一窍不通的老板(PHB)需要我列出我计算机上安装的所有软件,以便他们可以“批准”一个特例。
|
||||
|
||||
你怎么实现它?有一种方法是,已知 `rpm –qa` 命令提供了 RPM 包的完整描述,包括了白痴老板想要的东西:软件名称和概要描述。
|
||||
|
||||
让我们一步步执行出最后的结果。首先,列出所有的 RPM 包:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rpm -qa
|
||||
perl-HTTP-Message-6.18-3.fc29.noarch
|
||||
perl-IO-1.39-427.fc29.x86_64
|
||||
perl-Math-Complex-1.59-429.fc29.noarch
|
||||
lua-5.3.5-2.fc29.x86_64
|
||||
java-11-openjdk-headless-11.0.ea.28-2.fc29.x86_64
|
||||
util-linux-2.32.1-1.fc29.x86_64
|
||||
libreport-fedora-2.9.7-1.fc29.x86_64
|
||||
rpcbind-1.2.5-0.fc29.x86_64
|
||||
libsss_sudo-2.0.0-5.fc29.x86_64
|
||||
libfontenc-1.1.3-9.fc29.x86_64
|
||||
<snip>
|
||||
```
|
||||
|
||||
用 `sort` 和 `uniq` 命令对列表进行排序和打印去重后的结果(有些已安装的 RPM 包具有相同的名字):
|
||||
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ rpm -qa | sort | uniq
|
||||
a2ps-4.14-39.fc29.x86_64
|
||||
aajohan-comfortaa-fonts-3.001-3.fc29.noarch
|
||||
abattis-cantarell-fonts-0.111-1.fc29.noarch
|
||||
abiword-3.0.2-13.fc29.x86_64
|
||||
abrt-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-ccpp-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-coredump-helper-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-kerneloops-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-pstoreoops-2.11.0-1.fc29.x86_64
|
||||
abrt-addon-vmcore-2.11.0-1.fc29.x86_64
|
||||
<snip>
|
||||
```
|
||||
|
||||
以上命令得到了想要的 RPM 列表,因此你可以把这个列表作为一个循环的输入信息,循环最终会打印每个 RPM 包的详细信息:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done
|
||||
```
|
||||
|
||||
这段代码产出了多余的信息。当循环结束后,下一步就是提取出白痴老板需要的信息。因此,添加一个 `egrep` 命令用来搜索匹配 `^Name` 或 `^Summary` 的行。脱字符(`^`)表示行首,整个命令表示显示所有以 Name 或 Summary 开头的行。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done | egrep -i "^Name|^Summary"
|
||||
Name : a2ps
|
||||
Summary : Converts text and other types of files to PostScript
|
||||
Name : aajohan-comfortaa-fonts
|
||||
Summary : Modern style true type font
|
||||
Name : abattis-cantarell-fonts
|
||||
Summary : Humanist sans serif font
|
||||
Name : abiword
|
||||
Summary : Word processing program
|
||||
Name : abrt
|
||||
Summary : Automatic bug detection and reporting tool
|
||||
<snip>
|
||||
```
|
||||
|
||||
在上面的命令中你可以试试用 `grep` 代替 `egrep` ,你会发现用 `grep` 不能得到正确的结果。你也可以通过管道把命令结果用 `less` 过滤器来查看。最终命令像这样:
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done | egrep -i "^Name|^Summary" > RPM-summary.txt
|
||||
```
|
||||
|
||||
这个命令行程序用到了管道、重定向和 `for` 循环,这些全都在一行中。它把你的 CLI 程序的结果重定向到了一个文件,这个文件可以在邮件中使用或在其他地方作为输入使用。
|
||||
|
||||
这个一次一步构建程序的过程让你能看到每步的结果,以此来确保整个程序以你期望的流程进行且输出你想要的结果。
|
||||
|
||||
白痴老板最终收到了超过 1900 个不同的 RPM 包的清单,我严重怀疑根本就没人读过这个列表。我给了他们想要的东西,没有从他们嘴里听到过任何关于 RPM 包的信息。
|
||||
|
||||
### 其他循环
|
||||
|
||||
Bash 中还有两种其他类型的循环结构:`while` 和 `until` 结构,两者在语法和功能上都类似。这些循环结构的基础语法很简单:
|
||||
|
||||
```
|
||||
while [ expression ] ; do list ; done
|
||||
```
|
||||
|
||||
逻辑解释:表达式(`expression`)结果为 true 时,执行程序语句 `list`。表达式结果为 false 时,退出循环。
|
||||
|
||||
```
|
||||
until [ expression ] ; do list ; done
|
||||
```
|
||||
|
||||
逻辑解释:执行程序语句 `list`,直到表达式的结果为 true。当表达式结果为 true 时,退出循环。
|
||||
|
||||
#### While 循环
|
||||
|
||||
`while` 循环用于当逻辑表达式结果为 true 时执行一系列程序语句。假设你的 PWD 仍是 `~/testdir`。
|
||||
|
||||
最简单的 `while` 循环形式是这个会一直运行下去的循环。下面格式的条件语句永远以 `true` 作为返回。你也可以用简单的 `1` 代替 `true`,结果一样,但是这解释了 true 表达式的用法。
|
||||
|
||||
```
|
||||
[student@studentvm1 testdir]$ X=0 ; while [ true ] ; do echo $X ; X=$((X+1)) ; done | head
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
[student@studentvm1 testdir]$
|
||||
```
|
||||
|
||||
既然你已经学了 CLI 的各部分知识,那就让它变得更有用处。首先,为了防止变量 `$X` 在前面的程序或 CLI 命令执行后有遗留的值,设置 `$X` 的值为 0。然后,因为逻辑表达式 `[ true ]` 的结果永远是 1,即 true,在 `do` 和 `done` 中间的程序指令列表会一直执行 — 或者直到你按下 `Ctrl+C` 抑或发送一个 2 号信号给程序。那些程序指令是算数扩展,用来打印变量 `$X` 当前的值并加 1.
|
||||
|
||||
《[系统管理员的 Linux 哲学][5]》的信条之一是追求优雅,实现优雅的一种方式就是简化。你可以用操作符 `++` 来简化这个程序。在第一个例子中,变量当前的值被打印出来,然后变量的值增加了。可以在变量后加一个 `++` 来表示这个逻辑:
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; while [ true ] ; do echo $((X++)) ; done | head
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
```
|
||||
|
||||
现在删掉程序最后的 `| head` 再运行一次。
|
||||
|
||||
在下面这个版本中,变量在值被打印之前就自增了。这是通过在变量之前添加 `++` 操作符实现的。你能看出区别吗?
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; while [ true ] ; do echo $((++X)) ; done | head
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
```
|
||||
|
||||
你已经把打印变量的值和自增简化到了一条语句。类似 `++` 操作符,也有 `--` 操作符。
|
||||
|
||||
你需要一个在循环到某个特定数字时终止循环的方法。把 true 表达式换成一个数字比较表达式来实现它。这里有一个循环到 5 终止的程序。在下面的示例代码中,你可以看到 `-le` 是 “小于或等于” 的数字逻辑操作符。整个语句的意思:只要 `$X` 的值小于或等于 5,循环就一直运行。当 `$X` 增加到 6 时,循环终止。
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; while [ $X -le 5 ] ; do echo $((X++)) ; done
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
[student@studentvm1 ~]$
|
||||
```
|
||||
|
||||
#### Until 循环
|
||||
|
||||
`until` 命令非常像 `while` 命令。不同之处是,它直到逻辑表达式的值是 `true` 之前,会一直循环。看一下这种结构最简单的格式:
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; until false ; do echo $((X++)) ; done | head
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
[student@studentvm1 ~]$
|
||||
```
|
||||
|
||||
它用一个逻辑比较表达式来计数到一个特定的值:
|
||||
|
||||
```
|
||||
[student@studentvm1 ~]$ X=0 ; until [ $X -eq 5 ] ; do echo $((X++)) ; done
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
[student@studentvm1 ~]$ X=0 ; until [ $X -eq 5 ] ; do echo $((++X)) ; done
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
[student@studentvm1 ~]$
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
本系列探讨了构建 Bash 命令行程序和 shell 脚本的很多强大的工具。但是这仅仅是你能用 Bash 做的很多有意思的事中的冰山一角,接下来就看你的了。
|
||||
|
||||
我发现学习 Bash 编程最好的方法就是实践。找一个需要多个 Bash 命令的简单项目然后写一个 CLI 程序。系统管理员们要做很多适合 CLI 编程的工作,因此我确信你很容易能找到自动化的任务。
|
||||
|
||||
很多年前,尽管我对其他的 Shell 语言和 Perl 很熟悉,但还是决定用 Bash 做所有系统管理员的自动化任务。我发现,有时稍微搜索一下,我可以用 Bash 实现我需要的所有事情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/programming-bash-loops
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
|
||||
[2]: http://www.both.org/?page_id=1183
|
||||
[3]: https://linux.cn/article-11552-1.html
|
||||
[4]: https://linux.cn/article-11687-1.html
|
||||
[5]: https://www.apress.com/us/book/9781484237298
|
||||
240
published/20191024 Get sorted with sort at the command line.md
Normal file
240
published/20191024 Get sorted with sort at the command line.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11657-1.html)
|
||||
[#]: subject: (Get sorted with sort at the command line)
|
||||
[#]: via: (https://opensource.com/article/19/10/get-sorted-sort)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在命令行用 sort 进行排序
|
||||
======
|
||||
|
||||
> 在 Linux、BSD 或 Mac 的终端中使用 sort 命令,按自己的需求重新整理数据。
|
||||
|
||||

|
||||
|
||||
如果你曾经用过数据表应用程序,你就会知道可以按列的内容对行进行排序。例如,如果你有一个费用列表,你可能希望对它们进行按日期或价格升序抑或按类别进行排序。如果你熟悉终端的使用,你不会仅为了排序文本数据就去使用庞大的办公软件。这正是 [sort][2] 命令的用处。
|
||||
|
||||
### 安装
|
||||
|
||||
你不必安装 `sort` ,因为它向来都包含在 [POSIX][3] 系统里。在大多数 Linux 系统中,`sort` 命令来自 GNU 组织打包的实用工具集合中。在其他的 POSIX 系统中,像 BSD 和 Mac,默认的 `sort` 命令不是 GNU 提供的,所以有一些选项可能不一样。本文中我尽量对 GNU 和 BSD 两者的实现都进行说明。
|
||||
|
||||
### 按字母顺序排列行
|
||||
|
||||
`sort` 命令默认会读取文件每行的第一个字符并对每行按字母升序排序后输出。两行中的第一个字符相同的情况下,对下一个字符进行对比。例如:
|
||||
|
||||
```
|
||||
$ cat distro.list
|
||||
Slackware
|
||||
Fedora
|
||||
Red Hat Enterprise Linux
|
||||
Ubuntu
|
||||
Arch
|
||||
1337
|
||||
Mint
|
||||
Mageia
|
||||
Debian
|
||||
$ sort distro.list
|
||||
1337
|
||||
Arch
|
||||
Debian
|
||||
Fedora
|
||||
Mageia
|
||||
Mint
|
||||
Red Hat Enterprise Linux
|
||||
Slackware
|
||||
Ubuntu
|
||||
```
|
||||
|
||||
使用 `sort` 不会改变原文件。`sort` 仅起到过滤的作用,所以如果你希望按排序后的格式保存数据,你需要用 `>` 或 `tee` 进行重定向。
|
||||
|
||||
|
||||
```
|
||||
$ sort distro.list | tee distro.sorted
|
||||
1337
|
||||
Arch
|
||||
Debian
|
||||
[...]
|
||||
$ cat distro.sorted
|
||||
1337
|
||||
Arch
|
||||
Debian
|
||||
[...]
|
||||
```
|
||||
|
||||
### 按列排序
|
||||
|
||||
复杂数据集有时候不止需要对每行的第一个字符进行排序。例如,假设有一个动物列表,每个都有其种和属,用可预见的分隔符分隔每一个“字段”(即数据表中的“单元格”)。这类由数据表导出的格式很常见,CSV(<ryby>以逗号分隔的数据<rt>comma-separated values</rt></ruby>)后缀可以标识这些文件(虽然 CSV 文件不一定用逗号分隔,有分隔符的文件也不一定用 CSV 后缀)。以下数据作为示例:
|
||||
|
||||
```
|
||||
Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Spheniscus;demersus;Brisson;1760;African
|
||||
Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Eudyptes;chrysocome;Viellot;1816;Southern Rockhopper
|
||||
Torvaldis;linux;Ewing,L;1996;Tux
|
||||
```
|
||||
|
||||
对于这组示例数据,你可以用 `--field-separator` (在 BSD 和 Mac 用 `-t`,在 GNU 上也可以用简写 `-t` )设置分隔符为分号(因为该示例数据中是用分号而不是逗号,理论上分隔符可以是任意字符),用 `--key`(在 BSD 和 Mac 上用 `-k`,在 GNU 上也可以用简写 `-k`)选项指定哪个字段被排序。例如,对每行第二个字段进行排序(计数以 1 开头而不是 0):
|
||||
|
||||
```
|
||||
sort --field-separator=";" --key=2
|
||||
Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
Spheniscus;demersus;Brisson;1760;African
|
||||
Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Torvaldis;linux;Ewing,L;1996;Tux
|
||||
Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
```
|
||||
|
||||
结果有点不容易读,但是 Unix 以构造命令的管道方式而闻名,所以你可以使用 `column` 命令美化输出结果。使用 GNU `column`:
|
||||
|
||||
```
|
||||
$ sort --field-separator=";" \
|
||||
\--key=2 penguins.list | column --table --separator ";"
|
||||
Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
|
||||
Eudyptes chrysocome Viellot 1816 Southern Rockhopper
|
||||
Spheniscus demersus Brisson 1760 African
|
||||
Aptenodytes forsteri Miller,JF 1778 Emperor
|
||||
Torvaldis linux Ewing,L 1996 Tux
|
||||
Eudyptula minor Bonaparte 1867 Little Blue
|
||||
Pygoscelis papua Wagler 1832 Gentoo
|
||||
```
|
||||
|
||||
对于初学者可能有点不好理解(但是写起来简单),BSD 和 Mac 上的命令选项:
|
||||
|
||||
```
|
||||
$ sort -t ";" \
|
||||
-k2 penguins.list | column -t -s ";"
|
||||
Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
|
||||
Eudyptes chrysocome Viellot 1816 Southern Rockhopper
|
||||
Spheniscus demersus Brisson 1760 African
|
||||
Aptenodytes forsteri Miller,JF 1778 Emperor
|
||||
Torvaldis linux Ewing,L 1996 Tux
|
||||
Eudyptula minor Bonaparte 1867 Little Blue
|
||||
Pygoscelis papua Wagler 1832 Gentoo
|
||||
```
|
||||
|
||||
当然 `-k` 不一定非要设为 `2`。任意存在的字段都可以被设为排序的键。
|
||||
|
||||
### 逆序排列
|
||||
|
||||
你可以用 `--reverse`(BSD/Mac 上用 `-r`,GNU 上也可以用简写 `-r`)选项来颠倒已经排好序的列表。
|
||||
|
||||
```
|
||||
$ sort --reverse alphabet.list
|
||||
z
|
||||
y
|
||||
x
|
||||
w
|
||||
[...]
|
||||
```
|
||||
|
||||
你也可以把输出结果通过管道传给命令 [tac][4] 来实现相同的效果。
|
||||
|
||||
### 按月排序(仅 GNU 支持)
|
||||
|
||||
理想情况下,所有人都按照 ISO 8601 标准来写日期:年、月、日。这是一种合乎逻辑的指定精确日期的方法,也可以很容易地被计算机理解。也有很多情况下,人类用其他的方式标注日期,包括用很名字随意的月份。
|
||||
|
||||
幸运的是,GNU `sort` 命令能识别这种写法,并可以按月份的名称正确排序。使用 `--month-sort`(`-M`)选项:
|
||||
|
||||
```
|
||||
$ cat month.list
|
||||
November
|
||||
October
|
||||
September
|
||||
April
|
||||
[...]
|
||||
$ sort --month-sort month.list
|
||||
January
|
||||
February
|
||||
March
|
||||
April
|
||||
May
|
||||
[...]
|
||||
November
|
||||
December
|
||||
```
|
||||
|
||||
月份的全称和简写都可以被识别。
|
||||
|
||||
### 人类可读的数字排序(仅 GNU 支持)
|
||||
|
||||
另一个人类和计算机的常见混淆点是数字的组合。例如,人类通常把 “1024 kilobytes” 写成 “1KB”,因为人类解析 “1 KB” 比 “1024” 要容易且更快(数字越大,这种差异越明显)。对于计算机来说,一个 9 KB 的字符串要比诸如 1 MB 的字符串大(尽管 9 KB 是 1 MB 很小一部分)。GNU `sort` 命令提供了`--human-numeric-sort`(`-h`)选项来帮助正确解析这些值。
|
||||
|
||||
```
|
||||
$ cat sizes.list
|
||||
2M
|
||||
12MB
|
||||
1k
|
||||
9k
|
||||
900
|
||||
7000
|
||||
$ sort --human-numeric-sort
|
||||
900
|
||||
7000
|
||||
1k
|
||||
9k
|
||||
2M
|
||||
12MB
|
||||
```
|
||||
|
||||
有一些情况例外。例如,“16000 bytes” 比 “1 KB” 大,但是 `sort` 识别不了。
|
||||
|
||||
```
|
||||
$ cat sizes0.list
|
||||
2M
|
||||
12MB
|
||||
16000
|
||||
1k
|
||||
$ sort -h sizes0.list
|
||||
16000
|
||||
1k
|
||||
2M
|
||||
12MB
|
||||
```
|
||||
|
||||
逻辑上来说,这个示例中 16000 应该写成 16 KB,所以也不应该全部归咎于GNU `sort`。只要你确保数字的一致性,`--human-numeric-sort` 可以用一种计算机友好的方式解析成人类可读的数字。
|
||||
|
||||
### 随机排序(仅 GNU 支持)
|
||||
|
||||
有时候工具也提供了一些与设计初衷相悖的选项。某种程度上说,`sort` 命令提供对一个文件进行随机排序的能力没有任何意义。这个命令的工作流让这个特性变得很方便。你*可以*用其他的命令,像 [shuf][5] ,或者你可以用现在的命令添加一个选项。不管你认为它是一个臃肿的还是极具创造力的用户体验设计,GNU `sort` 命令提供了对文件进行随机排序的功能。
|
||||
|
||||
最纯粹的随机排序格式选项是 `--random-sort` 或 `-R`(不要跟 `-r` 混淆,`-r` 是 `--reverse` 的简写)。
|
||||
|
||||
```
|
||||
$ sort --random-sort alphabet.list
|
||||
d
|
||||
m
|
||||
p
|
||||
a
|
||||
[...]
|
||||
```
|
||||
|
||||
每次对文件运行随机排序都会有不同的结果。
|
||||
|
||||
### 结语
|
||||
|
||||
GNU 和 BSD 的 `sort` 命令还有很多功能,所以花点时间去了解这些选项。你会惊异于 `sort` 的灵活性,尤其是当它和其他的 Unix 工具一起使用时。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/get-sorted-sort
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl "Coding on a computer"
|
||||
[2]: https://en.wikipedia.org/wiki/Sort_(Unix)
|
||||
[3]: https://en.wikipedia.org/wiki/POSIX
|
||||
[4]: https://opensource.com/article/19/9/tac-command
|
||||
[5]: https://www.gnu.org/software/coreutils/manual/html_node/shuf-invocation.html
|
||||
@ -0,0 +1,222 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11666-1.html)
|
||||
[#]: subject: (How to remove duplicate lines from files with awk)
|
||||
[#]: via: (https://opensource.com/article/19/10/remove-duplicate-lines-files-awk)
|
||||
[#]: author: (Lazarus Lazaridis https://opensource.com/users/iridakos)
|
||||
|
||||
怎样使用 awk 删掉文件中重复的行
|
||||
======
|
||||
|
||||
> 学习怎样使用 awk 的 `!visited[$0]++` 在不重新排序或改变原排列顺序的前提下删掉重复的行。
|
||||
|
||||

|
||||
|
||||
假设你有一个文本文件,你需要删掉所有重复的行。
|
||||
|
||||
### TL;DR
|
||||
|
||||
*要保持原来的排列顺序*删掉重复行,使用:
|
||||
|
||||
```
|
||||
awk '!visited[$0]++' your_file > deduplicated_file
|
||||
```
|
||||
|
||||
### 工作原理
|
||||
|
||||
这个脚本维护一个关联数组,索引(键)为文件中去重后的行,每个索引对应的值为该行出现的次数。对于文件的每一行,如果这行(之前)出现的次数为 0,则值加 1,并打印这行,否则值加 1,不打印这行。
|
||||
|
||||
我之前不熟悉 `awk`,我想弄清楚这么短小的一个脚本是怎么实现的。我调研了下,下面是调研心得:
|
||||
|
||||
* 这个 awk “脚本” `!visited[$0]++` 对输入文件的*每一行*都执行。
|
||||
* `visited[]` 是一个[关联数组][2](又名[映射][3])类型的变量。`awk` 会在第一次执行时初始化它,因此我们不需要初始化。
|
||||
* `$0` 变量的值是当前正在被处理的行的内容。
|
||||
* `visited[$0]` 通过与 `$0`(正在被处理的行)相等的键来访问该映射中的值,即出现次数(我们在下面设置的)。
|
||||
* `!` 对表示出现次数的值取反:
|
||||
* 在 `awk` 中,[任意非零的数或任意非空的字符串的值是 `true`][4]。
|
||||
* [变量默认的初始值为空字符串][5],如果被转换为数字,则为 0。
|
||||
* 也就是说:
|
||||
* 如果 `visited[$0]` 的值是一个比 0 大的数,取反后被解析成 `false`。
|
||||
* 如果 `visited[$0]` 的值为等于 0 的数字或空字符串,取反后被解析成 `true` 。
|
||||
* `++` 表示变量 `visited[$0]` 的值加 1。
|
||||
* 如果该值为空,`awk` 自动把它转换为 `0`(数字) 后加 1。
|
||||
* 注意:加 1 操作是在我们取到了变量的值之后执行的。
|
||||
|
||||
总的来说,整个表达式的意思是:
|
||||
|
||||
* `true`:如果表示出现次数为 0 或空字符串
|
||||
* `false`:如果出现的次数大于 0
|
||||
|
||||
`awk` 由 [模式或表达式和一个与之关联的动作][6] 组成:
|
||||
|
||||
```
|
||||
<模式/表达式> { <动作> }
|
||||
```
|
||||
|
||||
如果匹配到了模式,就会执行后面的动作。如果省略动作,`awk` 默认会打印(`print`)输入。
|
||||
|
||||
> 省略动作等价于 `{print $0}`。
|
||||
|
||||
我们的脚本由一个 `awk` 表达式语句组成,省略了动作。因此这样写:
|
||||
|
||||
```
|
||||
awk '!visited[$0]++' your_file > deduplicated_file
|
||||
```
|
||||
|
||||
等于这样写:
|
||||
|
||||
```
|
||||
awk '!visited[$0]++ { print $0 }' your_file > deduplicated_file
|
||||
```
|
||||
|
||||
对于文件的每一行,如果表达式匹配到了,这行内容被打印到输出。否则,不执行动作,不打印任何东西。
|
||||
|
||||
### 为什么不用 uniq 命令?
|
||||
|
||||
`uniq` 命令仅能对相邻的行去重。这是一个示例:
|
||||
|
||||
```
|
||||
$ cat test.txt
|
||||
A
|
||||
A
|
||||
A
|
||||
B
|
||||
B
|
||||
B
|
||||
A
|
||||
A
|
||||
C
|
||||
C
|
||||
C
|
||||
B
|
||||
B
|
||||
A
|
||||
$ uniq < test.txt
|
||||
A
|
||||
B
|
||||
A
|
||||
C
|
||||
B
|
||||
A
|
||||
```
|
||||
|
||||
### 其他方法
|
||||
|
||||
#### 使用 sort 命令
|
||||
|
||||
我们也可以用下面的 [sort][7] 命令来去除重复的行,但是*原来的行顺序没有被保留*。
|
||||
|
||||
|
||||
```
|
||||
sort -u your_file > sorted_deduplicated_file
|
||||
```
|
||||
|
||||
#### 使用 cat + sort + cut
|
||||
|
||||
上面的方法会产出一个去重的文件,各行是基于内容进行排序的。[通过管道连接命令][8]可以解决这个问题。
|
||||
|
||||
|
||||
```
|
||||
cat -n your_file | sort -uk2 | sort -nk1 | cut -f2-
|
||||
```
|
||||
|
||||
**工作原理**
|
||||
|
||||
假设我们有下面一个文件:
|
||||
|
||||
```
|
||||
abc
|
||||
ghi
|
||||
abc
|
||||
def
|
||||
xyz
|
||||
def
|
||||
ghi
|
||||
klm
|
||||
```
|
||||
|
||||
`cat -n test.txt` 在每行前面显示序号:
|
||||
|
||||
```
|
||||
1 abc
|
||||
2 ghi
|
||||
3 abc
|
||||
4 def
|
||||
5 xyz
|
||||
6 def
|
||||
7 ghi
|
||||
8 klm
|
||||
```
|
||||
|
||||
`sort -uk2` 基于第二列(`k2` 选项)进行排序,对于第二列相同的值只保留一次(`u` 选项):
|
||||
|
||||
```
|
||||
1 abc
|
||||
4 def
|
||||
2 ghi
|
||||
8 klm
|
||||
5 xyz
|
||||
```
|
||||
|
||||
`sort -nk1` 基于第一列排序(`k1` 选项),把列的值作为数字来处理(`-n` 选项):
|
||||
|
||||
```
|
||||
1 abc
|
||||
2 ghi
|
||||
4 def
|
||||
5 xyz
|
||||
8 klm
|
||||
```
|
||||
|
||||
最后,`cut -f2-` 从第二列开始打印每一行,直到最后的内容(`-f2-` 选项:留意 `-` 后缀,它表示这行后面的内容都包含在内)。
|
||||
|
||||
```
|
||||
abc
|
||||
ghi
|
||||
def
|
||||
xyz
|
||||
klm
|
||||
```
|
||||
|
||||
### 参考
|
||||
|
||||
* [GNU awk 用户手册][9]
|
||||
* [awk 中的数组][2]
|
||||
* [Awk — 真值][4]
|
||||
* [Awk 表达式][5]
|
||||
* [Unix 怎么删除文件中重复的行?][10]
|
||||
* [不用排序去掉重复的行(去重)][11]
|
||||
* ['!a[$0]++' 工作原理][12]
|
||||
|
||||
以上为全文。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/remove-duplicate-lines-files-awk
|
||||
|
||||
作者:[Lazarus Lazaridis][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/iridakos
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: http://kirste.userpage.fu-berlin.de/chemnet/use/info/gawk/gawk_12.html
|
||||
[3]: https://en.wikipedia.org/wiki/Associative_array
|
||||
[4]: https://www.gnu.org/software/gawk/manual/html_node/Truth-Values.html
|
||||
[5]: https://ftp.gnu.org/old-gnu/Manuals/gawk-3.0.3/html_chapter/gawk_8.html
|
||||
[6]: http://kirste.userpage.fu-berlin.de/chemnet/use/info/gawk/gawk_9.html
|
||||
[7]: http://man7.org/linux/man-pages/man1/sort.1.html
|
||||
[8]: https://stackoverflow.com/a/20639730/2292448
|
||||
[9]: https://www.gnu.org/software/gawk/manual/html_node/
|
||||
[10]: https://stackoverflow.com/questions/1444406/how-can-i-delete-duplicate-lines-in-a-file-in-unix
|
||||
[11]: https://stackoverflow.com/questions/11532157/remove-duplicate-lines-without-sorting
|
||||
[12]: https://unix.stackexchange.com/questions/159695/how-does-awk-a0-work/159734#159734
|
||||
[13]: https://opensource.com/sites/default/files/uploads/duplicate-cat.jpg (Duplicate cat)
|
||||
[14]: https://iridakos.com/about/
|
||||
[15]: http://creativecommons.org/licenses/by-nc/4.0/
|
||||
@ -0,0 +1,242 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11684-1.html)
|
||||
[#]: subject: (Awk one-liners and scripts to help you sort text files)
|
||||
[#]: via: (https://opensource.com/article/19/11/how-sort-awk)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
帮助你排序文本文件的 Awk 命令行或脚本
|
||||
======
|
||||
|
||||
> Awk 是一个强大的工具,可以执行某些可能由其它常见实用程序(包括 `sort`)来完成的任务。
|
||||
|
||||

|
||||
|
||||
Awk 是个普遍存在的 Unix 命令,用于扫描和处理包含可预测模式的文本。但是,由于它具有函数功能,因此也可以合理地称之为编程语言。
|
||||
|
||||
令人困惑的是,有不止一个 awk。(或者,如果你认为只有一个,那么其它几个就是克隆。)有 `awk`(由Aho、Weinberger 和 Kernighan 编写的原始程序),然后有 `nawk` 、`mawk` 和 GNU 版本的 `gawk`。GNU 版本的 awk 是该实用程序的一个高度可移植的自由软件版本,具有几个独特的功能,因此本文是关于 GNU awk 的。
|
||||
|
||||
虽然它的正式名称是 `gawk`,但在 GNU+Linux 系统上,它的别名是 `awk`,并用作该命令的默认版本。 在其他没有带有 GNU awk 的系统上,你必须先安装它并将其称为 `gawk`,而不是 `awk`。本文互换使用术语 `awk` 和 `gawk`。
|
||||
|
||||
`awk` 既是命令语言又是编程语言,这使其成为一个强大的工具,可以处理原本留给 `sort`、`cut`、`uniq` 和其他常见实用程序的任务。幸运的是,开源中有很多冗余空间,因此,如果你面临是否使用 `awk` 的问题,答案可能是肯定的“随便”。
|
||||
|
||||
`awk` 的灵活之美在于,如果你已经确定使用 `awk` 来完成一项任务,那么无论接下来发生什么,你都可以继续使用 `awk`。这包括对数据排序而不是按交付给你的顺序的永恒需求。
|
||||
|
||||
### 样本数据集
|
||||
|
||||
在探索 `awk` 的排序方法之前,请生成要使用的样本数据集。保持简单,这样你就不会为极端情况和意想不到的复杂性所困扰。这是本文使用的样本集:
|
||||
|
||||
```
|
||||
Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Spheniscus;demersus;Brisson;1760;African
|
||||
Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
Torvaldis;linux;Ewing,L;1996;Tux
|
||||
```
|
||||
|
||||
这是一个很小的数据集,但它提供了多种数据类型:
|
||||
|
||||
* 属名和种名,彼此相关但又是分开的
|
||||
* 姓,有时是以逗号开头的首字母缩写
|
||||
* 代表日期的整数
|
||||
* 任意术语
|
||||
* 所有字段均以分号分隔
|
||||
|
||||
根据你的教育背景,你可能会认为这是二维数组或表格,或者只是行分隔的数据集合。你如何看待它只是你的问题,而 `awk` 只认识文本。由你决定告诉 `awk` 你想如何解析它。
|
||||
|
||||
### 只想排序
|
||||
|
||||
如果你只想按特定的可定义字段(例如电子表格中的“单元格”)对文本数据集进行排序,则可以使用 [sort 命令][2]。
|
||||
|
||||
### 字段和记录
|
||||
|
||||
无论输入的格式如何,都必须在其中找到模式才可以专注于对你重要的数据部分。在此示例中,数据由两个因素定界:行和字段。每行都代表一个新的*记录*,就如你在电子表格或数据库转储中看到的一样。在每一行中,都有用分号(`;`)分隔的不同的*字段*(将其视为电子表格中的单元格)。
|
||||
|
||||
`awk` 一次只处理一条记录,因此,当你在构造发给 `awk` 的这指令时,你可以只关注一行记录。写下你想对一行数据执行的操作,然后在下一行进行测试(无论是心理上还是用 `awk` 进行测试),然后再进行其它的一些测试。最后,你要对你的 `awk` 脚本要处理的数据做好假设,以便可以按你要的数据结构提供给你数据。
|
||||
|
||||
在这个例子中,很容易看到每个字段都用分号隔开。为简单起见,假设你要按每行的第一字段对列表进行排序。
|
||||
|
||||
在进行排序之前,你必须能够让 `awk` 只关注在每行的第一个字段上,因此这是第一步。终端中 awk 命令的语法为 `awk`,后跟相关选项,最后是要处理的数据文件。
|
||||
|
||||
```
|
||||
$ awk --field-separator=";" '{print $1;}' penguins.list
|
||||
Aptenodytes
|
||||
Pygoscelis
|
||||
Eudyptula
|
||||
Spheniscus
|
||||
Megadyptes
|
||||
Eudyptes
|
||||
Torvaldis
|
||||
```
|
||||
|
||||
因为字段分隔符是对 Bash shell 具有特殊含义的字符,所以必须将分号括在引号中或在其前面加上反斜杠。此命令仅用于证明你可以专注于特定字段。你可以使用另一个字段的编号尝试相同的命令,以查看数据的另一个“列”的内容:
|
||||
|
||||
```
|
||||
$ awk --field-separator=";" '{print $3;}' penguins.list
|
||||
Miller,JF
|
||||
Wagler
|
||||
Bonaparte
|
||||
Brisson
|
||||
Milne-Edwards
|
||||
Viellot
|
||||
Ewing,L
|
||||
```
|
||||
|
||||
我们尚未进行任何排序,但这是良好的基础。
|
||||
|
||||
### 脚本编程
|
||||
|
||||
`awk` 不仅仅是命令,它是一种具有索引、数组和函数的编程语言。这很重要,因为这意味着你可以获取要排序的字段列表,将列表存储在内存中,进行处理,然后打印结果数据。对于诸如此类的一系列复杂操作,在文本文件中进行操作会更容易,因此请创建一个名为 `sort.awk` 的新文件并输入以下文本:
|
||||
|
||||
```
|
||||
#!/bin/gawk -f
|
||||
|
||||
BEGIN {
|
||||
FS=";";
|
||||
}
|
||||
```
|
||||
|
||||
这会将该文件建立为 `awk` 脚本,该脚本中包含执行的行。
|
||||
|
||||
`BEGIN` 语句是 `awk` 提供的特殊设置功能,用于只需要执行一次的任务。定义内置变量 `FS`,它代表<ruby>字段分隔符<rt>field separator</rt></ruby>,并且与你在 `awk` 命令中使用 `--field-separator` 设置的值相同,它只需执行一次,因此它包含在 `BEGIN` 语句中。
|
||||
|
||||
#### awk 中的数组
|
||||
|
||||
你已经知道如何通过使用 `$` 符号和字段编号来收集特定字段的值,但是在这种情况下,你需要将其存储在数组中而不是将其打印到终端。这是通过 `awk` 数组完成的。`awk` 数组的重要之处在于它包含键和值。 想象一下有关本文的内容;它看起来像这样:`author:"seth",title:"How to sort with awk",length:1200`。诸如作者、标题和长度之类的元素是键,跟着的内容为值。
|
||||
|
||||
在排序的上下文中这样做的好处是,你可以将任何字段分配为键,将任何记录分配为值,然后使用内置的 `awk` 函数 `asorti()`(按索引排序)按键进行排序。现在,随便假设你*只*想按第二个字段排序。
|
||||
|
||||
*没有*被特殊关键字 `BEGIN` 或 `END` 引起来的 `awk` 语句是在每个记录都要执行的循环。这是脚本的一部分,该脚本扫描数据中的模式并进行相应的处理。每次 `awk` 将注意力转移到一条记录上时,都会执行 `{}` 中的语句(除非以 `BEGIN` 或 `END` 开头)。
|
||||
|
||||
要将键和值添加到数组,请创建一个包含数组的变量(在本示例脚本中,我将其称为 `ARRAY`,虽然不是很原汁原味,但很清楚),然后在方括号中分配给它键,用等号(`=`)连接值。
|
||||
|
||||
```
|
||||
{ # dump each field into an array
|
||||
ARRAY[$2] = $R;
|
||||
}
|
||||
```
|
||||
|
||||
在此语句中,第二个字段的内容(`$2`)用作关键字,而当前记录(`$R`)用作值。
|
||||
|
||||
### asorti() 函数
|
||||
|
||||
除了数组之外,`awk` 还具有一些基本函数,你可以将它们用作常见任务的快速简便的解决方案。GNU awk中引入的函数之一 `asorti()` 提供了按键(*索引*)或值对数组进行排序的功能。
|
||||
|
||||
你只能在对数组进行填充后对其进行排序,这意味着此操作不能对每个新记录都触发,而只能在脚本的最后阶段进行。为此,`awk` 提供了特殊的 `END` 关键字。与 `BEGIN` 相反,`END` 语句仅在扫描了所有记录之后才触发一次。
|
||||
|
||||
将这些添加到你的脚本:
|
||||
|
||||
```
|
||||
END {
|
||||
asorti(ARRAY,SARRAY);
|
||||
# get length
|
||||
j = length(SARRAY);
|
||||
|
||||
for (i = 1; i <= j; i++) {
|
||||
printf("%s %s\n", SARRAY[i],ARRAY[SARRAY[i]])
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`asorti()` 函数获取 `ARRAY` 的内容,按索引对其进行排序,然后将结果放入名为 `SARRAY` 的新数组(我在本文中发明的任意名称,表示“排序的 ARRAY”)。
|
||||
|
||||
接下来,将变量 `j`(另一个任意名称)分配给 `length()` 函数的结果,该函数计算 `SARRAY` 中的项数。
|
||||
|
||||
最后,使用 `for` 循环使用 `printf()` 函数遍历 `SARRAY` 中的每一项,以打印每个键,然后在 `ARRAY` 中打印该键的相应值。
|
||||
|
||||
### 运行该脚本
|
||||
|
||||
要运行你的 `awk` 脚本,先使其可执行:
|
||||
|
||||
```
|
||||
$ chmod +x sorter.awk
|
||||
```
|
||||
|
||||
然后针对 `penguin.list` 示例数据运行它:
|
||||
|
||||
```
|
||||
$ ./sorter.awk penguins.list
|
||||
antipodes Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
chrysocome Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
demersus Spheniscus;demersus;Brisson;1760;African
|
||||
forsteri Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
linux Torvaldis;linux;Ewing,L;1996;Tux
|
||||
minor Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
papua Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
```
|
||||
|
||||
如你所见,数据按第二个字段排序。
|
||||
|
||||
这有点限制。最好可以在运行时灵活选择要用作排序键的字段,以便可以在任何数据集上使用此脚本并获得有意义的结果。
|
||||
|
||||
### 添加命令选项
|
||||
|
||||
你可以通过在脚本中使用字面值 `var` 将命令变量添加到 `awk` 脚本中。更改脚本,以使迭代子句在创建数组时使用 `var`:
|
||||
|
||||
```
|
||||
{ # dump each field into an array
|
||||
ARRAY[$var] = $R;
|
||||
}
|
||||
```
|
||||
|
||||
尝试运行该脚本,以便在执行脚本时使用 `-v var` 选项将其按第三字段排序:
|
||||
|
||||
```
|
||||
$ ./sorter.awk -v var=3 penguins.list
|
||||
Bonaparte Eudyptula;minor;Bonaparte;1867;Little Blue
|
||||
Brisson Spheniscus;demersus;Brisson;1760;African
|
||||
Ewing,L Torvaldis;linux;Ewing,L;1996;Tux
|
||||
Miller,JF Aptenodytes;forsteri;Miller,JF;1778;Emperor
|
||||
Milne-Edwards Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
|
||||
Viellot Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
|
||||
Wagler Pygoscelis;papua;Wagler;1832;Gentoo
|
||||
```
|
||||
|
||||
### 修正
|
||||
|
||||
本文演示了如何在纯 GNU awk 中对数据进行排序。你可以对脚本进行改进,以便对你有用,花一些时间在`gawk` 的手册页上研究 [awk 函数][3]并自定义脚本以获得更好的输出。
|
||||
|
||||
这是到目前为止的完整脚本:
|
||||
|
||||
```
|
||||
#!/usr/bin/awk -f
|
||||
# GPLv3 appears here
|
||||
# usage: ./sorter.awk -v var=NUM FILE
|
||||
|
||||
BEGIN { FS=";"; }
|
||||
|
||||
{ # dump each field into an array
|
||||
ARRAY[$var] = $R;
|
||||
}
|
||||
|
||||
END {
|
||||
asorti(ARRAY,SARRAY);
|
||||
# get length
|
||||
j = length(SARRAY);
|
||||
|
||||
for (i = 1; i <= j; i++) {
|
||||
printf("%s %s\n", SARRAY[i],ARRAY[SARRAY[i]])
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/how-sort-awk
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
|
||||
[2]: https://opensource.com/article/19/10/get-sorted-sort
|
||||
[3]: https://www.gnu.org/software/gawk/manual/html_node/Built_002din.html#Built_002din
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hanwckf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11667-1.html)
|
||||
[#]: subject: (Debugging Software Deployments with strace)
|
||||
[#]: via: (https://theartofmachinery.com/2019/11/14/deployment_debugging_strace.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
@ -10,20 +10,20 @@
|
||||
在软件部署中使用 strace 进行调试
|
||||
======
|
||||
|
||||
我的大部分工作都包括部署软件系统,这意味着我需要花费很多时间来解决以下问题:
|
||||

|
||||
|
||||
* 这个软件可以在原始开发者的机器上工作,但是为什么不能在我这里运行?
|
||||
* 这个软件昨天可以在我的机器上工作,但是为什么今天就不行?
|
||||
我的大部分工作都涉及到部署软件系统,这意味着我需要花费很多时间来解决以下问题:
|
||||
|
||||
* 这个软件可以在原开发者的机器上工作,但是为什么不能在我这里运行?
|
||||
* 这个软件昨天可以在我的机器上工作,但是为什么今天就不行?
|
||||
|
||||
|
||||
这是调试的一种类型,但是与传统的软件调试有所不同。传统的调试通常只关心代码的逻辑,但是在软件部署中的调试关注的是程序的代码和它所在的运行环境之间的相互影响。即便问题的根源是代码的逻辑错误,但软件显然可以在别的机器上运行的事实意味着这类问题与运行环境密切相关。
|
||||
这是一种调试的类型,但是与一般的软件调试有所不同。一般的调试通常只关心代码的逻辑,但是在软件部署中的调试关注的是程序的代码和它所在的运行环境之间的相互影响。即便问题的根源是代码的逻辑错误,但软件显然可以在别的机器上运行的事实意味着这类问题与运行环境密切相关。
|
||||
|
||||
所以,在软件部署过程中,我没有使用传统的调试工具(例如 `gdb`),而是选择了其它工具进行调试。我最喜欢的用来解决“为什么这个软件无法在这台机器上运行?”这类问题的工具就是 `strace`。
|
||||
|
||||
### 什么是 `strace`?
|
||||
### 什么是 strace?
|
||||
|
||||
[`strace`][1] 是一个用来“追踪系统调用”的工具。它主要是一个 Linux 工具,但是你也可以在其它系统上使用类似的工具(例如 [DTrace][2] 和 [ktrace][3])。
|
||||
[strace][1] 是一个用来“追踪系统调用”的工具。它主要是一个 Linux 工具,但是你也可以在其它系统上使用类似的工具(例如 [DTrace][2] 和 [ktrace][3])。
|
||||
|
||||
它的基本用法非常简单。只需要在 `strace` 后面跟上你需要运行的命令,它就会显示出该命令触发的所有系统调用(你可能需要先安装好 `strace`):
|
||||
|
||||
@ -37,41 +37,39 @@ exit_group(0) = ?
|
||||
+++ exited with 0 +++
|
||||
```
|
||||
|
||||
这些系统调用都是什么?他们就像是操作系统提供的 API。很久以前,软件拥有直接访问硬件的权限。如果软件需要在屏幕上显示一些东西,它将会与视频硬件的端口和内存映射寄存器纠缠不清。当多任务操作系统变得流行以后,这就导致了混乱的局面,因为不同的应用程序将“争夺”硬件,并且一个应用程序的错误可能致使其它应用程序崩溃,甚至导致整个系统崩溃。所以 CPUs 开始支持多种不同的特权模式 (或者称为“保护环”)。它们让操作系统内核在具有完全硬件访问权限的最高特权模式下运行,于此同时,其它在低特权模式下运行的应用程序必须通过向内核发起系统调用才能够与硬件进行交互。
|
||||
这些系统调用都是什么?它们就像是操作系统内核提供的 API。很久以前,软件拥有直接访问硬件的权限。如果软件需要在屏幕上显示一些东西,它将会与视频硬件的端口和内存映射寄存器纠缠不清。当多任务操作系统变得流行以后,这就导致了混乱的局面,因为不同的应用程序将“争夺”硬件,并且一个应用程序的错误可能致使其它应用程序崩溃,甚至导致整个系统崩溃。所以 CPU 开始支持多种不同的特权模式(或者称为“保护环”)。它们让操作系统内核在具有完全硬件访问权限的最高特权模式下运行,于此同时,其它在低特权模式下运行的应用程序必须通过向内核发起系统调用才能够与硬件进行交互。
|
||||
|
||||
在二进制级别上,发起系统调用相比简单的函数调用有一些区别,但是大部分程序都使用标准库提供的封装函数。例如,POSIX C 标准库包含一个 `write()` 函数,该函数包含用于进行 `write` 系统调用的所有与硬件体系结构相关的代码。
|
||||
|
||||
![][4]
|
||||
|
||||
简单来说,一个应用程序与其环境(计算机系统)的相互影响都是通过系统调用来作用的。所以当软件在一台机器上可以工作但是在另一台机器无法工作的时候,追踪系统调用是一个很好的查错方法。具体地说,你可以通过追踪系统调用分析以下典型操作:
|
||||
简单来说,一个应用程序与其环境(计算机系统)的交互都是通过系统调用来完成的。所以当软件在一台机器上可以工作但是在另一台机器无法工作的时候,追踪系统调用是一个很好的查错方法。具体地说,你可以通过追踪系统调用分析以下典型操作:
|
||||
|
||||
* 控制台输入与输出 (IO)
|
||||
* 网络 IO
|
||||
* 文件系统访问以及文件 IO
|
||||
* 进程/线程 生命周期管理
|
||||
* 进程/线程生命周期管理
|
||||
* 原始内存管理
|
||||
* 访问特定的设备驱动
|
||||
|
||||
|
||||
|
||||
### 什么时候可以使用 `strace`?
|
||||
### 什么时候可以使用 strace?
|
||||
|
||||
理论上,`strace` 适用于任何用户空间程序,因为所有的用户空间程序都需要进行系统调用。`strace` 对于已编译的低级程序最有效果,但如果你可以避免运行时环境和解释器带来的大量额外输出,则仍然可以与 Python 等高级语言程序一起使用。
|
||||
|
||||
当软件在一台机器上正常工作,但在另一台机器上却不能正常工作,同时抛出有关文件、权限或者不能运行某某命令等模糊的错误信息时,`strace` 往往能大显身手。不幸的是,它不能诊断高等级的问题,例如数字证书验证错误等。这些问题通常需要结合 `strace`(有时候是 [`ltrace`][5]),以及其它高级工具(例如使用 `openssl` 命令行工具调试数字证书错误)。
|
||||
当软件在一台机器上正常工作,但在另一台机器上却不能正常工作,同时抛出了有关文件、权限或者不能运行某某命令等模糊的错误信息时,`strace` 往往能大显身手。不幸的是,它不能诊断高等级的问题,例如数字证书验证错误等。这些问题通常需要组合使用 `strace`(有时候是 [`ltrace`][5])和其它高级工具(例如使用 `openssl` 命令行工具调试数字证书错误)。
|
||||
|
||||
本文中的示例基于独立的服务器,但是对系统调用的追踪通常也可以在更复杂的部署平台上完成,仅需要找到合适的工具。
|
||||
|
||||
### 一个简单的例子
|
||||
|
||||
假设你正在尝试运行一个叫做 foo 的服务器应用程序,但是发生了以下情况:
|
||||
假设你正在尝试运行一个叫做 `foo` 的服务器应用程序,但是发生了以下情况:
|
||||
|
||||
```
|
||||
$ foo
|
||||
Error opening configuration file: No such file or directory
|
||||
```
|
||||
|
||||
显然,它没有找到你已经写好的配置文件。之所以会发生这种情况,是因为包管理工具有时候在编译应用程序时指定了自定义的路径,所以你应当遵循特定发行版提供的安装指南。如果错误信息告诉你正确的配置文件应该在什么地方,你就可以在几秒钟内解决这个问题,但事实并非如此。你该如何找到正确的路径?
|
||||
显然,它没有找到你已经写好的配置文件。之所以会发生这种情况,是因为包管理工具有时候在编译应用程序时指定了自定义的路径,所以你应当遵循特定发行版提供的安装指南。如果错误信息告诉你正确的配置文件应该在什么地方,你就可以在几秒钟内解决这个问题,但如果没有告诉你呢?你该如何找到正确的路径?
|
||||
|
||||
如果你有权访问源代码,则可以通过阅读源代码来解决问题。这是一个好的备用计划,但不是最快的解决方案。你还可以使用类似 `gdb` 的单步调试器来观察程序的行为,但使用专门用于展示程序与系统环境交互作用的工具 `strace` 更加有效。
|
||||
|
||||
@ -116,16 +114,14 @@ exit_group(1) = ?
|
||||
+++ exited with 1 +++
|
||||
```
|
||||
|
||||
`strace` 输出的第一页通常是低级的进程启动过程。(你可以看到很多 `mmap`,`mprotect`,`brk` 调用,这是用来分配原始内存和映射动态链接库的。)实际上,在查找错误时,最好从下往上阅读 `strace` 的输出。你可以看到 `write` 调用在最后返回了错误信息。如果你努力了,你将会看到第一个失败的系统调用是 `openat`,它在尝试打开 `/etc/foo/config.json` 时抛出了 `ENOENT` (“No such file or directory”)的错误。现在我们已经知道了配置文件应该放在哪里。
|
||||
`strace` 输出的第一页通常是低级的进程启动过程。(你可以看到很多 `mmap`、`mprotect`、`brk` 调用,这是用来分配原始内存和映射动态链接库的。)实际上,在查找错误时,最好从下往上阅读 `strace` 的输出。你可以看到 `write` 调用在最后返回了错误信息。如果你向上找,你将会看到第一个失败的系统调用是 `openat`,它在尝试打开 `/etc/foo/config.json` 时抛出了 `ENOENT` (“No such file or directory”)的错误。现在我们已经知道了配置文件应该放在哪里。
|
||||
|
||||
这是一个简单的例子,但我敢说在 90% 的情况下,使用 `strace` 进行调试不需要更多复杂的工作。以下是完整的调试步骤:
|
||||
|
||||
1. 从程序中获得含糊不清的错误信息
|
||||
2. 使用 `strace` 运行程序
|
||||
3. 在输出中找到错误信息
|
||||
4. 往前追溯并找到第一个失败的系统调用
|
||||
|
||||
|
||||
1. 从程序中获得含糊不清的错误信息
|
||||
2. 使用 `strace` 运行程序
|
||||
3. 在输出中找到错误信息
|
||||
4. 往前追溯并找到第一个失败的系统调用
|
||||
|
||||
第四步中的系统调用很可能向你显示出问题所在。
|
||||
|
||||
@ -133,27 +129,27 @@ exit_group(1) = ?
|
||||
|
||||
在开始更加复杂的调试之前,这里有一些有用的调试技巧帮助你高效使用 `strace`:
|
||||
|
||||
#### `man` 是你的朋友
|
||||
#### man 是你的朋友
|
||||
|
||||
在很多 *nix 操作系统中,你可以通过 `man syscalls` 查看系统调用的列表。你将会看到类似于 `brk(2)` 之类的东西,这意味着你可以通过运行 `man 2 brk` 得到与此相关的更多信息。
|
||||
|
||||
一个小问题:`man 2 fork` 会显示出在 GNU `libc` 里封装的 `fork()` 手册页,而 `fork()` 现在实际上是由 `clone` 系统调用实现的。`fork` 的语义与 `clone` 相同,但是如果我写了一个含有 `fork()` 的程序并使用 `strace` 去调试它,我将找不到任何关于 `fork` 调用的信息,只能看到 `clone` 调用。只有在将源代码与 `strace` 的输出进行比较的时候,这种问题才会让人感到困惑。
|
||||
一个小问题:`man 2 fork` 会显示出在 GNU `libc` 里封装的 `fork()` 手册页,而 `fork()` 现在实际上是由 `clone` 系统调用实现的。`fork` 的语义与 `clone` 相同,但是如果我写了一个含有 `fork()` 的程序并使用 `strace` 去调试它,我将找不到任何关于 `fork` 调用的信息,只能看到 `clone` 调用。如果将源代码与 `strace` 的输出进行比较的时候,像这种问题会让人感到困惑。
|
||||
|
||||
#### 使用 `-o` 将输出保存到文件
|
||||
#### 使用 -o 将输出保存到文件
|
||||
|
||||
`strace` 可以生成很多输出,所以将输出保存到单独的文件是很有帮助的 (就像上面的例子一样)。它还能够在控制台中避免程序自身的输出与 `strace` 的输出发生混淆。
|
||||
`strace` 可以生成很多输出,所以将输出保存到单独的文件是很有帮助的(就像上面的例子一样)。它还能够在控制台中避免程序自身的输出与 `strace` 的输出发生混淆。
|
||||
|
||||
#### 使用 `-s` 查看更多的参数
|
||||
#### 使用 -s 查看更多的参数
|
||||
|
||||
你可能已经注意到,错误信息的第二部分没有出现在上面的例子中。这是因为 `strace` 默认仅显示字符串参数的前 32 个字节。如果你需要捕获更多参数,请向 `strace` 追加类似于 `-s 128` 之类的参数。
|
||||
|
||||
#### `-y` 使得追踪文件或套接字更加容易
|
||||
#### -y 使得追踪文件或套接字更加容易
|
||||
|
||||
“一切皆文件”意味着 *nix 系统通过文件描述符进行所有 IO 操作,不管是真实的文件还是通过网络或者进程间管道。这对于编程而言是很方便的,但是在追踪系统调用时,你将很难分辨出 `read` 和 `write` 的真实行为。
|
||||
|
||||
`-y` 参数使 `strace` 在注释中注明每个文件描述符的具体指向。
|
||||
|
||||
#### 使用 `-p` 附加到正在运行的进程中
|
||||
#### 使用 -p 附加到正在运行的进程中
|
||||
|
||||
正如我们将在后面的例子中看到的,有时候你想追踪一个正在运行的程序。如果你知道这个程序的进程号为 1337 (可以通过 `ps` 查询),则可以这样操作:
|
||||
|
||||
@ -164,15 +160,15 @@ $ strace -p 1337
|
||||
|
||||
你可能需要 root 权限才能运行。
|
||||
|
||||
#### 使用 `-f` 追踪子进程
|
||||
#### 使用 -f 追踪子进程
|
||||
|
||||
`strace` 默认只追踪一个进程。如果这个进程产生了一个子进程,你将会看到创建子进程的系统调用(一般是 `clone`),但是你看不到子进程内触发的任何调用。
|
||||
|
||||
如果你认为在子进程中存在 bug,则需要使用 `-f` 参数启用子进程追踪功能。这样做的缺点是输出的内容会让人更加困惑。当追踪一个进程时,`strace` 显示的是单个调用事件流。当追踪多个进程的时候,你将会看到以 `<unfinished ...>` 开始的初始调用,接着是一系列针对其它线程的调用,最后才出现以 `<... foocall resumed>` 结束的初始调用。此外,你可以使用 `-ff` 参数将所有的调用分离到不同的文件中(查看 [the `strace` manual][6] 获取更多信息)。
|
||||
如果你认为在子进程中存在错误,则需要使用 `-f` 参数启用子进程追踪功能。这样做的缺点是输出的内容会让人更加困惑。当追踪一个进程时,`strace` 显示的是单个调用事件流。当追踪多个进程的时候,你将会看到以 `<unfinished ...>` 开始的初始调用,接着是一系列针对其它线程的调用,最后才出现以 `<... foocall resumed>` 结束的初始调用。此外,你可以使用 `-ff` 参数将所有的调用分离到不同的文件中(查看 [strace 手册][6] 获取更多信息)。
|
||||
|
||||
#### 使用 `-e` 进行过滤
|
||||
#### 使用 -e 进行过滤
|
||||
|
||||
正如你所看到的,默认的追踪输出是所有的系统调用。你可以使用 `-e` 参数过滤你需要追踪的调用(查看 [the `strace` manual][6])。这样做的好处是运行过滤后的 `strace` 比起使用 `grep` 进行二次过滤要更快。老实说,我大部分时间都不会被打扰。
|
||||
正如你所看到的,默认的追踪输出是所有的系统调用。你可以使用 `-e` 参数过滤你需要追踪的调用(查看 [strace 手册][6])。这样做的好处是运行过滤后的 `strace` 比起使用 `grep` 进行二次过滤要更快。老实说,我大部分时间都不会被打扰。
|
||||
|
||||
#### 并非所有的错误都是不好的
|
||||
|
||||
@ -187,17 +183,17 @@ stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0
|
||||
...
|
||||
```
|
||||
|
||||
“错误信息之前的最后一次失败调用”这种启发式方法非常适合于查找错误。无论如何,自下而上地工作是有道理的。
|
||||
“错误信息之前的最后一次失败调用”这种启发式方法非常适合于查找错误。无论如何,自下而上地查找是有道理的。
|
||||
|
||||
#### C编程指南非常有助于理解系统调用
|
||||
#### C 编程指南非常有助于理解系统调用
|
||||
|
||||
标准 C 库函数调用不属于系统调用,但它们仅是系统调用之上的唯一一个薄层。所以如果你了解(甚至只是略知一二)如何使用 C 语言,那么阅读系统调用追踪信息就非常容易。例如,如果你在调试网络系统调用,你可以尝试略读 [Beej’s classic Guide to Network Programming][7]。
|
||||
标准 C 库函数调用不属于系统调用,但它们仅是系统调用之上的唯一一个薄层。所以如果你了解(甚至只是略知一二)如何使用 C 语言,那么阅读系统调用追踪信息就非常容易。例如,如果你在调试网络系统调用,你可以尝试略读 [Beej 经典的《网络编程指南》][7]。
|
||||
|
||||
### 一个更复杂的调试例子
|
||||
|
||||
就像我说的那样,简单的调试例子代表我在大部分情况下如何使用 `strace` 。然而,有时候需要一些更加细致的工作,所以这里有一个稍微复杂(且真实)的例子。
|
||||
就像我说的那样,简单的调试例子表现了我在大部分情况下如何使用 `strace`。然而,有时候需要一些更加细致的工作,所以这里有一个稍微复杂(且真实)的例子。
|
||||
|
||||
[`bcron`][8] 是一个任务调度器,它是经典 *nix `cron` 守护程序的一种实现。它已经被安装到一台服务器上,但是当有人尝试编辑作业时间表时,发生了以下情况:
|
||||
[bcron][8] 是一个任务调度器,它是经典 *nix `cron` 守护程序的另一种实现。它已经被安装到一台服务器上,但是当有人尝试编辑作业时间表时,发生了以下情况:
|
||||
|
||||
```
|
||||
# crontab -e -u logs
|
||||
@ -232,9 +228,9 @@ exit_group(111) = ?
|
||||
|
||||
在程序结束之前有一个 `write` 的错误信息,但是这次有些不同。首先,在此之前没有任何相关的失败系统调用。其次,我们看到这个错误信息是由 `read` 从别的地方读取而来的。这看起来像是真正的错误发生在别的地方,而 `bcrontab` 只是在转播这些信息。
|
||||
|
||||
如果你查阅了 `man 2 read`,你将会看到 `read` 的第三个参数 (3) 代表文件描述符,这是 *nix 操作系统用于所有 IO 操作的句柄。你该如何知道文件描述符 3 代表什么?在这种情况下,你可以使用 `-y` 参数运行 `strace`(如上文所述),它将会在注释里告诉你文件描述符的具体指向,但是了解如何从上面这种输出中分析追踪结果是很有用的。
|
||||
如果你查阅了 `man 2 read`,你将会看到 `read` 的第一个参数 (`3`) 是一个文件描述符,这是 *nix 操作系统用于所有 IO 操作的句柄。你该如何知道文件描述符 3 代表什么?在这种情况下,你可以使用 `-y` 参数运行 `strace`(如上文所述),它将会在注释里告诉你文件描述符的具体指向,但是了解如何从上面这种输出中分析追踪结果是很有用的。
|
||||
|
||||
一个文件描述符可以来自于许多系统调用之一(这取决于它是用于控制台、网络套接字还是真实文件等的描述符),但不论如何,我们都可以搜索返回值为 3 的系统调用(例如,在 `strace` 的输出中查找 “=3”)。在这次 `strace` 中可以看到有两个这样的调用:最上面的 `openat` 以及中间的 `socket`。`openat` 打开一个文件,但是紧接着的 `close(3)` 表明其已经被关闭。(注意:文件描述符可以在打开并关闭后重复使用。)所以 `socket` 调用才是与此相关的(它是在 `read` 之前的最后一次),这告诉我们 `brcontab` 正在与一个网络套接字通信。在下一行,`connect` 表明文件描述符 3 是一个连接到 `/var/run/bcron-spool` 的 Unix 域套接字。
|
||||
一个文件描述符可以来自于许多系统调用之一(这取决于它是用于控制台、网络套接字还是真实文件等的描述符),但不论如何,我们都可以搜索返回值为 `3` 的系统调用(例如,在 `strace` 的输出中查找 `=3`)。在这次 `strace` 中可以看到有两个这样的调用:最上面的 `openat` 以及中间的 `socket`。`openat` 打开一个文件,但是紧接着的 `close(3)` 表明其已经被关闭。(注意:文件描述符可以在打开并关闭后重复使用。)所以 `socket` 调用才是与此相关的(它是在 `read` 之前的最后一个),这告诉我们 `brcontab` 正在与一个网络套接字通信。在下一行,`connect` 表明文件描述符 3 是一个连接到 `/var/run/bcron-spool` 的 Unix 域套接字。
|
||||
|
||||
因此,我们需要弄清楚 Unix 套接字的另一侧是哪个进程在监听。有两个巧妙的技巧适用于在服务器部署中调试。一个是使用 `netstat` 或者较新的 `ss`。这两个命令都描述了当前系统中活跃的网络套接字,使用 `-l` 参数可以显示出处于监听状态的套接字,而使用 `-p` 参数可以得到正在使用该套接字的程序信息。(它们还有更多有用的选项,但是这两个已经足够完成工作了。)
|
||||
|
||||
@ -243,7 +239,7 @@ exit_group(111) = ?
|
||||
u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))
|
||||
```
|
||||
|
||||
这告诉我们 `/var/run/bcron-spool` 套接字的监听程序是 `unixserver` 这个命令,它的进程 ID 为 20629。(巧合的是,这个程序也使用文件描述符 3 去连接这个套接字。)
|
||||
这告诉我们 `/var/run/bcron-spool` 套接字的监听程序是 `unixserver` 这个命令,它的进程 ID 为 20629。(巧合的是,这个程序也使用文件描述符 `3` 去连接这个套接字。)
|
||||
|
||||
第二个常用的工具就是使用 `lsof` 查找相同的信息。它可以列出当前系统中打开的所有文件(或文件描述符)。或者,我们可以得到一个具体文件的信息:
|
||||
|
||||
@ -277,7 +273,7 @@ rt_sigreturn({mask=[]}) = 43
|
||||
accept(3, NULL, NULL
|
||||
```
|
||||
|
||||
(最后一个 `accept` 调用没有在追踪周期里完成。)不幸的是,这次追踪没有包含我们想要的错误信息。我们没有观察到 `bcrontan` 往套接字发送或接受的任何信息。然而,我们看到了很多进程管理操作(`clone`,`wait4`,`SIGCHLD`,等等)。这个进程产生了子进程,我们猜测真实的工作是由子进程完成的。如果我们想捕获子进程的追踪信息,就必须往 `strace` 追加 `-f` 参数。以下是我们最终使用 `strace -f -o /tmp/trace -p 20629` 找到的错误信息:
|
||||
(最后一个 `accept` 调用没有在追踪期间完成。)不幸的是,这次追踪没有包含我们想要的错误信息。我们没有观察到 `bcrontan` 往套接字发送或接受的任何信息。然而,我们看到了很多进程管理操作(`clone`、`wait4`、`SIGCHLD`,等等)。这个进程产生了子进程,我们猜测真实的工作是由子进程完成的。如果我们想捕获子进程的追踪信息,就必须往 `strace` 追加 `-f` 参数。以下是我们最终使用 `strace -f -o /tmp/trace -p 20629` 找到的错误信息:
|
||||
|
||||
```
|
||||
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
|
||||
@ -305,7 +301,9 @@ accept(3, NULL, NULL
|
||||
21470 +++ exited with 111 +++
|
||||
```
|
||||
|
||||
(如果你在这里失败了,你可能需要阅读 [我之前有关 *nix 进程管理和 shell 的文章][9])好的,现在 PID 为 20629 的服务器进程没有权限在 `/var/spool/cron/tmp/spool.21470.1573692319.854640` 创建文件。最可能的原因就是典型的 *nix 文件系统权限设置。让我们检查一下:
|
||||
(如果你在这里迷糊了,你可能需要阅读 [我之前有关 \*nix 进程管理和 shell 的文章][9])
|
||||
|
||||
现在 PID 为 20629 的服务器进程没有权限在 `/var/spool/cron/tmp/spool.21470.1573692319.854640` 创建文件。最可能的原因就是典型的 *nix 文件系统权限设置。让我们检查一下:
|
||||
|
||||
```
|
||||
# ls -ld /var/spool/cron/tmp/
|
||||
@ -330,7 +328,7 @@ via: https://theartofmachinery.com/2019/11/14/deployment_debugging_strace.html
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hanwckf](https://github.com/hanwckf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
201
published/20191115 How to port an awk script to Python.md
Normal file
201
published/20191115 How to port an awk script to Python.md
Normal file
@ -0,0 +1,201 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11654-1.html)
|
||||
[#]: subject: (How to port an awk script to Python)
|
||||
[#]: via: (https://opensource.com/article/19/11/awk-to-python)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
如何把 awk 脚本移植到 Python
|
||||
======
|
||||
|
||||
> 将一个 awk 脚本移植到 Python 主要在于代码风格而不是转译。
|
||||
|
||||

|
||||
|
||||
脚本是解决问题的有效方法,而 awk 是编写脚本的出色语言。它特别擅长于简单的文本处理,它可以带你完成配置文件的某些复杂重写或目录中文件名的重新格式化。
|
||||
|
||||
### 何时从 awk 转向 Python
|
||||
|
||||
但是在某些方面,awk 的限制开始显现出来。它没有将文件分解为模块的真正概念,它缺乏质量错误报告,并且缺少了现在被认为是编程语言工作原理的其他内容。当编程语言的这些丰富功能有助于维护关键脚本时,移植将是一个不错的选择。
|
||||
|
||||
我最喜欢的完美移植 awk 的现代编程语言是 Python。
|
||||
|
||||
在将 awk 脚本移植到 Python 之前,通常值得考虑一下其原始使用场景。例如,由于 awk 的局限性,通常从 Bash 脚本调用 awk 代码,其中包括一些对 `sed`、`sort` 之类的其它命令行常见工具的调用。 最好将所有内容转换为一个一致的 Python 程序。有时,脚本会做出过于宽泛的假设,例如,即使实际上只运行一个文件,该代码也可能允许任意数量的文件。
|
||||
|
||||
在仔细考虑了上下文并确定了要用 Python 替代的东西之后,该编写代码了。
|
||||
|
||||
### 标准 awk 到 Python 功能
|
||||
|
||||
以下 Python 功能是有用的,需要记住:
|
||||
|
||||
```
|
||||
with open(some_file_name) as fpin:
|
||||
for line in fpin:
|
||||
pass # do something with line
|
||||
```
|
||||
|
||||
此代码将逐行循环遍历文件并处理这些行。
|
||||
|
||||
如果要访问行号(相当于 awk 的 `NR`),则可以使用以下代码:
|
||||
|
||||
```
|
||||
with open(some_file_name) as fpin:
|
||||
for nr, line in enumerate(fpin):
|
||||
pass # do something with line
|
||||
```
|
||||
|
||||
### 在 Python 中实现多文件的 awk 式行为
|
||||
|
||||
如果你需要能够遍历任意数量的文件同时保持行数的持续计数(类似 awk 的 `FNR`),则此循环可以做到这一点:
|
||||
|
||||
```
|
||||
def awk_like_lines(list_of_file_names):
|
||||
def _all_lines():
|
||||
for filename in list_of_file_names:
|
||||
with open(filename) as fpin:
|
||||
yield from fpin
|
||||
yield from enumerate(_all_lines())
|
||||
```
|
||||
|
||||
此语法使用 Python 的*生成器*和 `yield from` 来构建*迭代器*,该迭代器将遍历所有行并保持一个持久计数。
|
||||
|
||||
如果你需要同时使用 `FNR` 和 `NR`,这是一个更复杂的循环:
|
||||
|
||||
```
|
||||
def awk_like_lines(list_of_file_names):
|
||||
def _all_lines():
|
||||
for filename in list_of_file_names:
|
||||
with open(filename) as fpin:
|
||||
yield from enumerate(fpin)
|
||||
for nr, (fnr, line) in _all_lines:
|
||||
yield nr, fnr, line
|
||||
```
|
||||
|
||||
### 更复杂的 FNR、NR 和行数的 awk 行为
|
||||
|
||||
如果 `FNR`、`NR` 和行数这三个你全都需要,仍然会有一些问题。如果确实如此,则使用三元组(其中两个项目是数字)会导致混淆。命名参数可使该代码更易于阅读,因此最好使用 `dataclass`:
|
||||
|
||||
```
|
||||
import dataclass
|
||||
|
||||
@dataclass.dataclass(frozen=True)
|
||||
class AwkLikeLine:
|
||||
content: str
|
||||
fnr: int
|
||||
nr: int
|
||||
|
||||
def awk_like_lines(list_of_file_names):
|
||||
def _all_lines():
|
||||
for filename in list_of_file_names:
|
||||
with open(filename) as fpin:
|
||||
yield from enumerate(fpin)
|
||||
for nr, (fnr, line) in _all_lines:
|
||||
yield AwkLikeLine(nr=nr, fnr=fnr, line=line)
|
||||
```
|
||||
|
||||
你可能想知道,为什么不一直用这种方法呢?使用其它方式的的原因是总用这种方法太复杂了。如果你的目标是把一个通用库更容易地从 awk 移植到 Python,请考虑这样做。但是编写一个可以使你确切地了解特定情况所需的循环的方法通常更容易实现,也更容易理解(因而易于维护)。
|
||||
|
||||
### 理解 awk 字段
|
||||
|
||||
一旦有了与一行相对应的字符串,如果要转换 awk 程序,则通常需要将其分解为*字段*。Python 有几种方法可以做到这一点。这将把行按任意数量的连续空格拆分,返回一个字符串列表:
|
||||
|
||||
```
|
||||
line.split()
|
||||
```
|
||||
|
||||
如果需要另一个字段分隔符,比如以 `:` 分隔行,则需要 `rstrip` 方法来删除最后一个换行符:
|
||||
|
||||
```
|
||||
line.rstrip("\n").split(":")
|
||||
```
|
||||
|
||||
完成以下操作后,列表 `parts` 将存有分解的字符串:
|
||||
|
||||
```
|
||||
parts = line.rstrip("\n").split(":")
|
||||
```
|
||||
|
||||
这种拆分非常适合用来处理参数,但是我们处于[偏差一个的错误][2]场景中。现在 `parts[0]` 将对应于 awk 的 `$1`,`parts[1]` 将对应于 awk 的 `$2`,依此类推。之所以偏差一个,是因为 awk 计数“字段”从 1 开始,而 Python 从 0 开始计数。在 awk 中,`$0` 是整个行 —— 等同于 `line.rstrip("\n")`,而 awk 的 `NF`(字段数)更容易以 `len(parts)` 的形式得到。
|
||||
|
||||
### 移植 awk 字段到 Python
|
||||
|
||||
例如,让我们将这个单行代码“[如何使用 awk 从文件中删除重复行][3]”转换为 Python。
|
||||
|
||||
`awk` 中的原始代码是:
|
||||
|
||||
```
|
||||
awk '!visited[$0]++' your_file > deduplicated_file
|
||||
```
|
||||
|
||||
“真实的” Python 转换将是:
|
||||
|
||||
```
|
||||
import collections
|
||||
import sys
|
||||
|
||||
visited = collections.defaultdict(int)
|
||||
for line in open("your_file"):
|
||||
did_visit = visited[line]
|
||||
visited[line] += 1
|
||||
if not did_visit:
|
||||
sys.stdout.write(line)
|
||||
```
|
||||
|
||||
但是,Python 比 awk 具有更多的数据结构。与其计数访问次数(除了知道是否看到一行,我们不使用它),为什么不记录访问的行呢?
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
visited = set()
|
||||
for line in open("your_file"):
|
||||
if line in visited:
|
||||
continue
|
||||
visited.add(line)
|
||||
sys.stdout.write(line)
|
||||
```
|
||||
|
||||
### 编写 Python 化的 awk 代码
|
||||
|
||||
Python 社区提倡编写 Python 化的代码,这意味着它要遵循公认的代码风格。更加 Python 化的方法将区分*唯一性*和输入/输出的关注点。此更改将使对代码进行单元测试更加容易:
|
||||
|
||||
```
|
||||
def unique_generator(things):
|
||||
visited = set()
|
||||
for thing in things:
|
||||
if thing in visited:
|
||||
continue
|
||||
visited.add(things)
|
||||
yield thing
|
||||
|
||||
import sys
|
||||
|
||||
for line in unique_generator(open("your_file")):
|
||||
sys.stdout.write(line)
|
||||
```
|
||||
|
||||
将所有逻辑置于输入/输出代码之外,可以更好地分离问题,并提高代码的可用性和可测试性。
|
||||
|
||||
### 结论:Python 可能是一个不错的选择
|
||||
|
||||
将 awk 脚本移植到 Python 时,通常是在考虑适当的 Python 代码风格时重新实现核心需求,而不是按条件/操作进行笨拙的音译。考虑原始上下文并产生高质量的 Python 解决方案。虽然有时候使用 awk 的 Bash 单行代码可以完成这项工作,但 Python 编码是通往更易于维护的代码的途径。
|
||||
|
||||
另外,如果你正在编写 awk 脚本,我相信您也可以学习 Python!如果你有任何疑问,请告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/awk-to-python
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_4.png?itok=VGZO8CxT (Woman sitting in front of her laptop)
|
||||
[2]: https://en.wikipedia.org/wiki/Off-by-one_error
|
||||
[3]: https://opensource.com/article/19/10/remove-duplicate-lines-files-awk
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11661-1.html)
|
||||
[#]: subject: (6 Methods to Quickly Check if a Website is up or down from the Linux Terminal)
|
||||
[#]: via: (https://www.2daygeek.com/linux-command-check-website-is-up-down-alive/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在 Linux Terminal 快速检测网站是否宕机的 6 个方法
|
||||
在 Linux 终端快速检测网站是否宕机的 6 个方法
|
||||
======
|
||||
|
||||
本教程教你怎样在 Linux terminal 快速检测一个网站是否宕机。
|
||||
> 本教程教你怎样在 Linux 终端快速检测一个网站是否宕机。
|
||||
|
||||
你可能已经了解了一些类似的命令,像 ping,curl 和 wget。我们在本教程中又加入了一些其他命令。同时,对于要检测单个和多个主机的信息我们也加入了不同的选项。
|
||||

|
||||
|
||||
本文将帮助你检测网站是否宕机。但是如果你在维护一个网站,希望网站宕掉时得到实时的报警,我推荐你去使用实时网站监控工具。这种工具有很多,有些是免费的,大部分收费。根据你的需求,选择合适的工具。在后续的文章中我们会涉及这个主题。
|
||||
你可能已经了解了一些类似的命令,像 `ping`、`curl` 和 `wget`。我们在本教程中又加入了一些其他命令。同时,我们也加入了不同的选项来检测单个和多个主机的信息。
|
||||
|
||||
本文将帮助你检测网站是否宕机。但是如果你在维护一些网站,希望网站宕掉时得到实时的报警,我推荐你去使用实时网站监控工具。这种工具有很多,有些是免费的,大部分收费。根据你的需求,选择合适的工具。在后续的文章中我们会涉及这个主题。
|
||||
|
||||
### 方法 1:使用 fping 命令检测一个网站是否宕机
|
||||
|
||||
**[fping 命令][1]** 是一个类似 ping 的程序,使用互联网控制消息协议回应请求报文(ICMP echo request)来判断目标主机是否能回应。fping 与 ping 的不同之处在于它可以并行地 ping 任意数量的主机,也可以从一个文本文件读入主机。fping 发送一个 ICMP echo request 后不等待目标主机响应,就以 round-robin 模式向下一个目标主机发请求。如果一个目标主机有响应,那么它就被标记为存活的(active)然后从检查目标列表里去掉。如果一个目标主机在限定的时间和(或)重试次数内没有响应,则被指定为网站无法到达(unreachable)。
|
||||
[fping 命令][1] 是一个类似 `ping` 的程序,使用互联网控制消息协议(ICMP)的<ruby>回应请求报文<rt>echo request</rt></ruby>来判断目标主机是否能回应。`fping` 与 `ping` 的不同之处在于它可以并行地 `ping` 任意数量的主机,也可以从一个文本文件读入主机名称。`fping` 发送一个 ICMP 回应请求后不等待目标主机响应,就以轮询模式向下一个目标主机发请求。如果一个目标主机有响应,那么它就被标记为存活的,然后从检查目标列表里去掉。如果一个目标主机在限定的时间和(或)重试次数内没有响应,则被指定为网站无法到达的。
|
||||
|
||||
```
|
||||
# fping 2daygeek.com linuxtechnews.com magesh.co.in
|
||||
@ -30,7 +32,7 @@ magesh.co.in is alive
|
||||
|
||||
### 方法 2:使用 http 命令检测一个网站是否宕机
|
||||
|
||||
HTTPie(读作 aitch-tee-tee-pie)是一个命令行 HTTP 客户端。**[httpie tool][2]** 是一个可以与 web 服务通过 CLI(command-line interface)进行交互的现代工具。httpie tool 提供了简单的 http 命令,可以通过发送简单的、自然语言语法的任意 HTTP 请求得到多彩的结果输出。HTTPie 可以用来对 HTTP 服务器进行测试、调试和基本的交互。
|
||||
HTTPie(读作 aitch-tee-tee-pie)是一个命令行 HTTP 客户端。[httpie][2] 是一个可以与 web 服务通过 CLI 进行交互的现代工具。httpie 工具提供了简单的 `http` 命令,可以通过发送简单的、自然语言语法的任意 HTTP 请求得到多彩的结果输出。HTTPie 可以用来对 HTTP 服务器进行测试、调试和基本的交互。
|
||||
|
||||
```
|
||||
# http 2daygeek.com
|
||||
@ -49,7 +51,7 @@ Vary: Accept-Encoding
|
||||
|
||||
### 方法 3:使用 curl 命令检测一个网站是否宕机
|
||||
|
||||
**[curl 命令](https://www.2daygeek.com/curl-linux-command-line-download-manager/)** 是一个用于在服务器间通过支持的协议(DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET 和 TFTP)传输数据的工具。这个工具不支持用户交互。curl 也支持使用代理、用户认证、FTP 上传、HTTP post、SSL 连接、cookies、断点续传、Metalink等等。curl 由 libcurl 库提供所有与传输有关的能力。
|
||||
[curl 命令][3] 是一个用于在服务器间通过支持的协议(DICT、FILE、FTP、FTPS、GOPHER、HTTP、HTTPS、IMAP、IMAPS、LDAP、LDAPS、POP3、POP3S、RTMP、RTSP、SCP、SFTP、SMTP、SMTPS、TELNET 和 TFTP)传输数据的工具。这个工具不支持用户交互。`curl` 也支持使用代理、用户认证、FTP 上传、HTTP POST 请求、SSL 连接、cookie、断点续传、Metalink 等等。`curl `由 libcurl 库提供所有与传输有关的能力。
|
||||
|
||||
```
|
||||
# curl -I https://www.magesh.co.in
|
||||
@ -67,7 +69,7 @@ server: cloudflare
|
||||
cf-ray: 535b74123ca4dbf3-LHR
|
||||
```
|
||||
|
||||
如果你只想看 HTTP 状态码而不是返回的全部信息,用下面的 curl 命令:
|
||||
如果你只想看 HTTP 状态码而不是返回的全部信息,用下面的 `curl` 命令:
|
||||
|
||||
```
|
||||
# curl -I "www.magesh.co.in" 2>&1 | awk '/HTTP\// {print $2}'
|
||||
@ -87,7 +89,7 @@ else
|
||||
fi
|
||||
```
|
||||
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# sh curl-url-check.sh
|
||||
@ -113,7 +115,7 @@ echo "----------------------------------"
|
||||
done
|
||||
```
|
||||
|
||||
当你把上面脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把上面脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# sh curl-url-check-1.sh
|
||||
@ -130,7 +132,7 @@ www.xyzzz.com is down
|
||||
|
||||
### 方法 4:使用 wget 命令检测一个网站是否宕机
|
||||
|
||||
**[wget 命令][4]** (前身是 Geturl)是一个免费的开源命令行下载工具,通过 HTTP、HTTPS、FTP和其他广泛使用的互联网协议检索文件。wget 是非交互式的命令行工具,由 World Wide Web 和 get 得名。wget 相对于其他工具来说更优秀,功能包括后台运行、递归下载、多文件下载、断点续传、非交互式下载和大文件下载。
|
||||
[wget 命令][4](前身是 Geturl)是一个自由开源的命令行下载工具,通过 HTTP、HTTPS、FTP 和其他广泛使用的互联网协议获取文件。`wget` 是非交互式的命令行工具,由 World Wide Web 和 get 得名。`wget` 相对于其他工具来说更优秀,功能包括后台运行、递归下载、多文件下载、断点续传、非交互式下载和大文件下载。
|
||||
|
||||
```
|
||||
# wget -S --spider https://www.magesh.co.in
|
||||
@ -158,7 +160,7 @@ Remote file exists and could contain further links,
|
||||
but recursion is disabled -- not retrieving.
|
||||
```
|
||||
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 wget 命令:
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 `wget` 命令:
|
||||
|
||||
```
|
||||
# wget --spider -S "www.magesh.co.in" 2>&1 | awk '/HTTP\// {print $2}'
|
||||
@ -178,7 +180,7 @@ else
|
||||
fi
|
||||
```
|
||||
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# wget-url-check.sh
|
||||
@ -221,7 +223,7 @@ www.xyzzz.com is down
|
||||
|
||||
### 方法 5:使用 lynx 命令检测一个网站是否宕机
|
||||
|
||||
**[lynx][5]** 是一个在可寻址光标字符单元终端上使用的基于文本的高度可配的 web 浏览器,它是最古老的 web 浏览器并且现在仍在开发。
|
||||
[lynx][5] 是一个在<ruby>可寻址光标字符单元终端<rt>cursor-addressable character cell terminals</rt></ruby>上使用的基于文本的高度可配的 web 浏览器,它是最古老的 web 浏览器并且现在仍在活跃开发。
|
||||
|
||||
```
|
||||
# lynx -head -dump http://www.magesh.co.in
|
||||
@ -240,7 +242,7 @@ Server: cloudflare
|
||||
CF-RAY: 535fc5704a43e694-LHR
|
||||
```
|
||||
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 lynx 命令:
|
||||
如果你只想看 HTTP 状态码而不是返回的全部结果,用下面的 `lynx` 命令:
|
||||
|
||||
```
|
||||
# lynx -head -dump https://www.magesh.co.in 2>&1 | awk '/HTTP\// {print $2}'
|
||||
@ -260,7 +262,7 @@ else
|
||||
fi
|
||||
```
|
||||
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果
|
||||
当你把脚本内容添加到一个文件后,执行文件,查看结果:
|
||||
|
||||
```
|
||||
# sh lynx-url-check.sh
|
||||
@ -303,7 +305,7 @@ www.xyzzz.com is down
|
||||
|
||||
### 方法 6:使用 ping 命令检测一个网站是否宕机
|
||||
|
||||
**[ping 命令][1]** (Packet Internet Groper)是网络工具的代表,用于在互联网协议(IP)的网络中测试一个目标主机是否可用/可连接。通过向目标主机发送 ICMP 回应请求报文包并等待 ICMP 回应响应报文来检测主机的可用性。它基于已发送的包、接收到的包和丢失了的包来统计结果数据,通常包含最小/平均/最大响应时间。
|
||||
[ping 命令][1](Packet Internet Groper)是网络工具的代表,用于在互联网协议(IP)的网络中测试一个目标主机是否可用/可连接。通过向目标主机发送 ICMP 回应请求报文包并等待 ICMP 回应响应报文来检测主机的可用性。它基于已发送的包、接收到的包和丢失了的包来统计结果数据,通常包含最小/平均/最大响应时间。
|
||||
|
||||
```
|
||||
# ping -c 5 2daygeek.com
|
||||
@ -320,9 +322,9 @@ PING 2daygeek.com (104.27.157.177) 56(84) bytes of data.
|
||||
rtt min/avg/max/mdev = 170.668/213.824/250.295/28.320 ms
|
||||
```
|
||||
|
||||
### 方法 7:使用 telnet 命令检测一个网站是否宕机
|
||||
### 附加 1:使用 telnet 命令检测一个网站是否宕机
|
||||
|
||||
telnet 命令是一个使用 TELNET 协议用于 TCP/IP 网络中多个主机相互通信的古老的网络协议。它通过 23 端口连接其他设备如计算机和网络设备。telnet 是不安全的协议,现在由于用这个协议发送的数据没有经过加密可能被黑客拦截,所以不推荐使用。大家都使用经过加密且非常安全的 SSH 协议来代替 telnet。
|
||||
`telnet` 命令是一个使用 TELNET 协议用于 TCP/IP 网络中多个主机相互通信的古老的网络协议。它通过 23 端口连接其他设备如计算机和网络设备。`telnet` 是不安全的协议,现在由于用这个协议发送的数据没有经过加密可能被黑客拦截,所以不推荐使用。大家都使用经过加密且非常安全的 SSH 协议来代替 `telnet`。
|
||||
|
||||
```
|
||||
# telnet google.com 80
|
||||
@ -335,11 +337,11 @@ telnet> quit
|
||||
Connection closed.
|
||||
```
|
||||
|
||||
### 方法 8:使用 bash 脚本检测一个网站是否宕机
|
||||
### 附加 2:使用 bash 脚本检测一个网站是否宕机
|
||||
|
||||
简而言之,一个 **[shell 脚本][6]** 就是一个包含一系列命令的文件。shell 从文件读取内容按输入顺序逐行在命令行执行。为了让它更有效,我们添加一些条件。这也减轻了 Linux 管理员的负担。
|
||||
简而言之,一个 [shell 脚本][6] 就是一个包含一系列命令的文件。shell 从文件读取内容按输入顺序逐行在命令行执行。为了让它更有效,我们添加一些条件。这也减轻了 Linux 管理员的负担。
|
||||
|
||||
如果你想想用 wget 命令看多个网站的状态,使用下面的 shell 脚本:
|
||||
如果你想想用 `wget` 命令看多个网站的状态,使用下面的 shell 脚本:
|
||||
|
||||
```
|
||||
# vi wget-url-check-2.sh
|
||||
@ -365,7 +367,7 @@ google.co.in is up
|
||||
www.xyzzz.com is down
|
||||
```
|
||||
|
||||
如果你想想用 wget 命令看多个网站的状态,使用下面的 **[shell 脚本][7]**:
|
||||
如果你想用 `wget` 命令看多个网站的状态,使用下面的 [shell 脚本][7]:
|
||||
|
||||
```
|
||||
# vi curl-url-check-2.sh
|
||||
@ -398,7 +400,7 @@ via: https://www.2daygeek.com/linux-command-check-website-is-up-down-alive/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11699-1.html)
|
||||
[#]: subject: (How internet security works: TLS, SSL, and CA)
|
||||
[#]: via: (https://opensource.com/article/19/11/internet-security-tls-ssl-certificate-authority)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson)
|
||||
|
||||
互联网的安全是如何保证的:TLS、SSL 和 CA
|
||||
======
|
||||
|
||||
> 你的浏览器里的锁的图标的后面是什么?
|
||||
|
||||
![Lock][1]
|
||||
|
||||
每天你都会重复这件事很多次,访问网站,网站需要你用你的用户名或者电子邮件地址和你的密码来进行登录。银行网站、社交网站、电子邮件服务、电子商务网站和新闻网站。这里只在使用了这种机制的网站中列举了其中一小部分。
|
||||
|
||||
每次你登录进一个这种类型的网站时,你实际上是在说:“是的,我信任这个网站,所以我愿意把我的个人信息共享给它。”这些数据可能包含你的姓名、性别、实际地址、电子邮箱地址,有时候甚至会包括你的信用卡信息。
|
||||
|
||||
但是你怎么知道你可以信任这个网站?换个方式问,为了让你可以信任它,网站应该如何保护你的交易?
|
||||
|
||||
本文旨在阐述使网站变得安全的机制。我会首先论述 web 协议 http 和 https,以及<ruby>传输层安全<rt>Transport Layer Security</rt></ruby>(TLS)的概念,后者是<ruby>互联网协议<rt>Internet Protocol</rt></ruby>(IP)层中的加密协议之一。然后,我会解释<ruby>证书颁发机构<rt>certificate authority</rt></ruby>和自签名证书,以及它们如何帮助保护一个网站。最后,我会介绍一些开源的工具,你可以使用它们来创建和管理你的证书。
|
||||
|
||||
### 通过 https 保护路由
|
||||
|
||||
了解一个受保护的网站的最简单的方式就是在交互中观察它,幸运的是,在今天的互联网上,发现一个安全的网站远远比找到一个不安全的网站要简单。但是,因为你已经在 Opensource.com 这个网站上了,我会使用它来作为案例,无论你使用的是哪个浏览器,你应该在你的地址栏旁边看到一个像锁一样的图标。点击这个锁图标,你应该会看见一些和下面这个类似的东西。
|
||||
|
||||
![Certificate information][2]
|
||||
|
||||
默认情况下,如果一个网站使用的是 http 协议,那么它是不安全的。为通过网站主机的路由添加一个配置过的证书,可以把这个网站从一个不安全的 http 网站变为一个安全的 https 网站。那个锁图标通常表示这个网站是受 https 保护的。
|
||||
|
||||
点击证书来查看网站的 CA,根据你的浏览器,你可能需要下载证书来查看它。
|
||||
|
||||
![Certificate information][3]
|
||||
|
||||
在这里,你可以了解有关 Opensource.com 证书的信息。例如,你可以看到 CA 是 DigiCert,并以 Opensource.com 的名称提供给 Red Hat。
|
||||
|
||||
这个证书信息可以让终端用户检查该网站是否可以安全访问。
|
||||
|
||||
> 警告:如果你没有在网站上看到证书标志,或者如果你看见的标志显示这个网站不安全——请不要登录或者做任何需要你个人数据的操作。这种情况非常危险!
|
||||
|
||||
如果你看到的是警告标志,对于大多数面向公众开放的网站来说,这很少见,它通常意味着该证书已经过期或者是该证书是自签名的,而非通过一个受信任的第三方来颁发。在我们进入这些主题之前,我想解释一下 TLS 和 SSL。
|
||||
|
||||
### 带有 TLS 和 SSL 的互联网协议
|
||||
|
||||
TLS 是旧版<ruby>安全套接字层协议<rt>Secure Socket Layer</rt></ruby>(SSL)的最新版本。理解这一点的最好方法就是仔细理解互联网协议的不同协议层。
|
||||
|
||||
![IP layers][4]
|
||||
|
||||
我们知道当今的互联网是由 6 个层面组成的:物理层、数据链路层、网络层、传输层、安全层、应用层。物理层是基础,这一层是最接近实际的硬件设备的。应用层是最抽象的一层,是最接近终端用户的一层。安全层可以被认为是应用层的一部分,TLS 和 SSL,是被设计用来在一个计算机网络中提供通信安全的加密协议,它们位于安全层中。
|
||||
|
||||
这个过程可以确保终端用户使用网络服务时,通信的安全性和保密性。
|
||||
|
||||
### 证书颁发机构和自签名证书
|
||||
|
||||
<ruby>证书颁发机构<rt>Certificate authority</rt></ruby>(CA)是受信任的组织,它可以颁发数字证书。
|
||||
|
||||
TLS 和 SSL 可以使连接更安全,但是这个加密机制需要一种方式来验证它;这就是 SSL/TLS 证书。TLS 使用了一种叫做非对称加密的加密机制,这个机制有一对称为私钥和公钥的安全密钥。(这是一个非常复杂的主题,超出了本文的讨论范围,但是如果你想去了解这方面的东西,你可以阅读“[密码学和公钥密码基础体系简介][5]”)你要知道的基础内容是,证书颁发机构们,比如 GlobalSign、DigiCert 和 GoDaddy,它们是受人们信任的可以颁发证书的供应商,它们颁发的证书可以用于验证网站使用的 TLS/SSL 证书。网站使用的证书是导入到主机服务器里的,用于保护网站。
|
||||
|
||||
然而,如果你只是要测试一下正在开发中的网站或服务,CA 证书可能对你而言太昂贵或者是太复杂了。你必须有一个用于生产目的的受信任的证书,但是开发者和网站管理员需要有一种更简单的方式来测试网站,然后他们才能将其部署到生产环境中;这就是自签名证书的来源。
|
||||
|
||||
自签名证书是一种 TLS/SSL 证书,是由创建它的人而非受信任的 CA 机构颁发的。用电脑生成一个自签名证书很简单,它可以让你在无需购买昂贵的 CA 颁发的证书的情况下测试一个安全网站。虽然自签名证书肯定不能拿到生产环境中去使用,但对于开发和测试阶段来说,这是一种简单灵活的方法。
|
||||
|
||||
### 生成证书的开源工具
|
||||
|
||||
有几种开源工具可以用来管理 TLS/SSL 证书。其中最著名的就是 openssl,这个工具包含在很多 Linux 发行版中和 MacOS 中。当然,你也可以使用其他开源工具。
|
||||
|
||||
| 工具名 | 描述 | 许可证 |
|
||||
| --------- | ------------------------------------------------------------------------------ | --------------------------------- |
|
||||
| [OpenSSL][7] | 实现 TLS 和加密库的最著名的开源工具 | Apache License 2.0 |
|
||||
| [EasyRSA][8] | 用于构建 PKI CA 的命令行实用工具 | GPL v2 |
|
||||
| [CFSSL][9] | 来自 cloudflare 的 PKI/TLS 瑞士军刀 | BSD 2-Clause "Simplified" License |
|
||||
| [Lemur][10] | 来自<ruby>网飞<rt>Netflix</rt></ruby>的 TLS 创建工具 | Apache License 2.0 |
|
||||
|
||||
如果你的目的是扩展和对用户友好,网飞的 Lemur 是一个很有趣的选择。你在[网飞的技术博客][6]上可以查看更多有关它的信息。
|
||||
|
||||
### 如何创建一个 Openssl 证书
|
||||
|
||||
你可以靠自己来创建证书,下面这个案例就是使用 Openssl 生成一个自签名证书。
|
||||
|
||||
1、使用 `openssl` 命令行生成一个私钥:
|
||||
|
||||
```
|
||||
openssl genrsa -out example.key 2048
|
||||
```
|
||||
|
||||
|
||||
|
||||
2、使用在第一步中生成的私钥来创建一个<ruby>证书签名请求<rt>certificate signing request</rt></ruby>(CSR):
|
||||
|
||||
```
|
||||
openssl req -new -key example.key -out example.csr -subj "/C=US/ST=TX/L=Dallas/O=Red Hat/OU=IT/CN=test.example.com"
|
||||
```
|
||||
|
||||
|
||||
|
||||
3、使用你的 CSR 和私钥创建一个证书:
|
||||
|
||||
```
|
||||
openssl x509 -req -days 366 -in example.csr -signkey example.key -out example.crt
|
||||
```
|
||||
|
||||
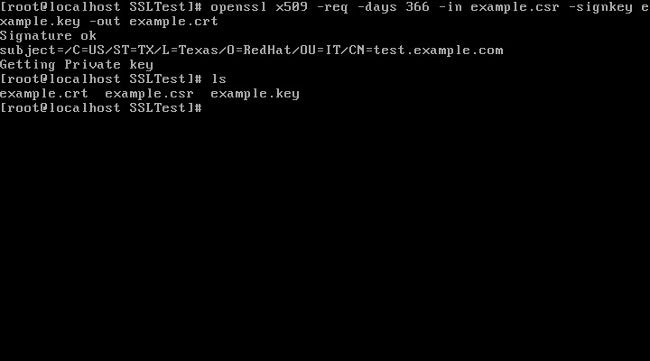
|
||||
|
||||
### 了解更多关于互联网安全的知识
|
||||
|
||||
如果你想要了解更多关于互联网安全和网站安全的知识,请看我为这篇文章一起制作的 Youtube 视频。
|
||||
|
||||
- <https://youtu.be/r0F1Hlcmjsk>
|
||||
|
||||
你有什么问题?发在评论里让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/internet-security-tls-ssl-certificate-authority
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security-lock-password.jpg?itok=KJMdkKum
|
||||
[2]: https://opensource.com/sites/default/files/uploads/1_certificatecheckwebsite.jpg
|
||||
[3]: https://opensource.com/sites/default/files/uploads/2_certificatedisplaywebsite.jpg
|
||||
[4]: https://opensource.com/sites/default/files/uploads/3_internetprotocol.jpg
|
||||
[5]: https://opensource.com/article/18/5/cryptography-pki
|
||||
[6]: https://medium.com/netflix-techblog/introducing-lemur-ceae8830f621
|
||||
[7]: https://www.openssl.org/
|
||||
[8]: https://github.com/OpenVPN/easy-rsa
|
||||
[9]: https://github.com/cloudflare/cfssl
|
||||
[10]: https://github.com/Netflix/lemur
|
||||
225
published/20191125 The many faces of awk.md
Normal file
225
published/20191125 The many faces of awk.md
Normal file
@ -0,0 +1,225 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (luuming)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11658-1.html)
|
||||
[#]: subject: (The many faces of awk)
|
||||
[#]: via: (https://www.networkworld.com/article/3454979/the-many-faces-of-awk.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
千面 awk
|
||||
======
|
||||
|
||||
> `awk` 命令不仅提供了简单的输入字符串筛选功能,还包含提取数据列、打印简单文本、筛选内容——甚至做一些数学计算。
|
||||
|
||||
![Thinkstock][6]
|
||||
|
||||
如果你仅使用 `awk` 选取一行中的特定文本,那么你可能错过了它的很多功能。在这篇文章中,我们会来看看使用 `awk` 可以帮你做一些其他的什么事情,并提供一些例子。
|
||||
|
||||
### 提取数据列
|
||||
|
||||
`awk` 所提供的最简单与最常用的功能便是从文件或管道传输的数据中选取特定的内容。默认使用空格当做分隔符,这非常简单。
|
||||
|
||||
```
|
||||
$ echo one two three four five | awk ‘{print $4}’
|
||||
four
|
||||
$ who | awk ‘{print $1}’
|
||||
jdoe
|
||||
fhenry
|
||||
```
|
||||
|
||||
空格指的是一系列的 `space` 或 `tab` 字符。在下面所展示的命令里,`awk` 从提供的数据中筛选第一和第四项。
|
||||
|
||||
`awk` 命令也可以通过在其后增加文件名参数的方式从文本文件中获取数据。
|
||||
|
||||
```
|
||||
$ awk '{print $1,$5,$NF}' HelenKellerQuote
|
||||
The beautiful heart.
|
||||
```
|
||||
|
||||
(LCTT 译注:“The best and most beautiful things in the world can not be seen or even touched , they must be felt with heart.” ——海伦凯勒)
|
||||
|
||||
在这个例子中,`awk` 挑选了一行中的第一个、第五个和最后一个字段。
|
||||
|
||||
命令中的 `$NF` 指定选取每行的最后一个字段。这是因为 `NF` 代表一行中的<ruby>字段数量<rt>Number of Field</rt></ruby>,也就是 23,而 `$NF` 就代表着那个字段的值,也就是`heart`。最后的句号也包含进去了,因为它是最后一个字符串的一部分。
|
||||
|
||||
字段能以任何有用的形式打印。在这个例子中,我们将字段以日期的格式进行打印输出。
|
||||
|
||||
```
|
||||
$ date | awk '{print $4,$3,$2}'
|
||||
2019 Nov 22
|
||||
```
|
||||
|
||||
如果你省略了 `awk` 命令中字段指示符之间的逗号,输出将会挤成一个字符串。
|
||||
|
||||
```
|
||||
$ date | awk '{print $4 $3 $2}'
|
||||
2019Nov21
|
||||
```
|
||||
|
||||
如果你将通常使用的逗号替换为连字符,`awk` 就会尝试将两个字段的值相减——或许这并不是你想要的。它不会将连字符插入到输出结果中。相反地,它对输出做了一些数学计算。
|
||||
|
||||
```
|
||||
$ date | awk '{print $4-$3-$2}'
|
||||
1997
|
||||
```
|
||||
|
||||
在这个例子中,它将年 “2019” 和日期 “22” 相减,并忽略了中间的 “Nov”。
|
||||
|
||||
如果你想要空格之外的字符作为输出分隔符,你可以通过 `OFS`(<ruby>输出分隔符<rt>output field separator</rt></ruby>)指定分隔符,就像这样:
|
||||
|
||||
```
|
||||
$ date | awk '{OFS="-"; print $4,$3,$2}'
|
||||
2019-Nov-22
|
||||
```
|
||||
|
||||
### 打印简单文本
|
||||
|
||||
你也可以使用 `awk` 简单地显示一些文本。当然了,比起 `awk` 你可能更想使用 `echo` 命令。但换句话说,作为 `awk` 脚本的一部分,打印某些相关性文本将会非常实用。这里有一个没什么用的例子:
|
||||
|
||||
```
|
||||
$ awk 'BEGIN {print "Hello, World" }'
|
||||
Hello, World
|
||||
```
|
||||
|
||||
下面的例子更加合理,添加一行文本标签来更好的辨识数据。
|
||||
|
||||
```
|
||||
$ who | awk 'BEGIN {print "Current logins:"} {print $1}'
|
||||
Current logins:
|
||||
shs
|
||||
nemo
|
||||
```
|
||||
|
||||
### 指定字段分隔符
|
||||
|
||||
不是所有的输入都以空格作为分隔符的。如果你的文本通过其它的字符作为分隔符(例如:逗号、冒号、分号),你可以通过 `-F` 选项(输入分隔符)告诉 `awk`:
|
||||
|
||||
```
|
||||
$ cat testfile
|
||||
a:b:c,d:e
|
||||
$ awk -F : '{print $2,$3}' testfile
|
||||
b c,d
|
||||
```
|
||||
|
||||
下面是一个更加有用的例子——从冒号分隔的 `/etc/passwd` 文件中获取数据:
|
||||
|
||||
```
|
||||
$ awk -F: '{print $1}' /etc/passwd | head -11
|
||||
root
|
||||
daemon
|
||||
bin
|
||||
sys
|
||||
sync
|
||||
games
|
||||
man
|
||||
lp
|
||||
mail
|
||||
news
|
||||
uucp
|
||||
```
|
||||
|
||||
### 筛选内容
|
||||
|
||||
你也可以使用 `awk` 命令评估字段。例如你仅仅想列出 `/etc/passwd` 中的用户账号,就可以对第三个字段做一些筛选。下面的例子中我们只关注大于等于 1000 的 UID:
|
||||
|
||||
```
|
||||
$ awk -F":" ' $3 >= 1000 ' /etc/passwd
|
||||
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
|
||||
shs:x:1000:1000:Sandra Henry-Stocker,,,:/home/shs:/bin/bash
|
||||
nemo:x:1001:1001:Nemo,,,:/home/nemo:/usr/bin/zsh
|
||||
dory:x:1002:1002:Dory,,,:/home/dory:/bin/bash
|
||||
...
|
||||
```
|
||||
|
||||
如果你想为输出增加标题,可以添加 `BEGIN` 从句:
|
||||
|
||||
```
|
||||
$ awk -F":" 'BEGIN {print "user accounts:"} $3 >= 1000 ' /etc/passwd
|
||||
user accounts:
|
||||
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
|
||||
shs:x:1000:1000:Sandra Henry-Stocker,,,:/home/shs:/bin/bash
|
||||
nemo:x:1001:1001:Nemo,,,:/home/nemo:/usr/bin/zsh
|
||||
dory:x:1002:1002:Dory,,,:/home/dory:/bin/bash
|
||||
```
|
||||
|
||||
如果你想要不止一行的标题,你可以通过 `"\n"` 分隔输出:
|
||||
|
||||
```
|
||||
$ awk -F":" 'BEGIN {print "user accounts\n============="} $3 >= 1000 ' /etc/passwd
|
||||
user accounts
|
||||
=============
|
||||
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
|
||||
shs:x:1000:1000:Sandra Henry-Stocker,,,:/home/shs:/bin/bash
|
||||
nemo:x:1001:1001:Nemo,,,:/home/nemo:/usr/bin/zsh
|
||||
dory:x:1002:1002:Dory,,,:/home/dory:/bin/bash
|
||||
```
|
||||
|
||||
### 在 awk 中进行数学计算
|
||||
|
||||
`awk` 提供了惊人的数学计算能力,并且可以开平方,算 `log`,算 `tan` 等等。
|
||||
|
||||
这里有一对例子:
|
||||
|
||||
```
|
||||
$ awk 'BEGIN {print sqrt(2019)}'
|
||||
44.9333
|
||||
$ awk 'BEGIN {print log(2019)}'
|
||||
7.61036
|
||||
```
|
||||
|
||||
想要详细了解 `awk` 的数学计算能力,可以看《[使用 awk 进行数学计算][3]》这篇文章。
|
||||
|
||||
### awk 脚本
|
||||
|
||||
你也可以使用 `awk` 写一套单独的脚本。下面的例子模仿了之前写过的一个,不过还计算了系统里账户的数量。
|
||||
|
||||
```
|
||||
#!/usr/bin/awk -f
|
||||
|
||||
# 这一行是注释
|
||||
|
||||
BEGIN {
|
||||
printf "%s\n","User accounts:"
|
||||
print "=============="
|
||||
FS=":"
|
||||
n=0
|
||||
}
|
||||
|
||||
# 现在开始遍历数据
|
||||
{
|
||||
if ($3 >= 1000) {
|
||||
print $1
|
||||
n ++
|
||||
}
|
||||
}
|
||||
|
||||
END {
|
||||
print "=============="
|
||||
print n " accounts"
|
||||
}
|
||||
```
|
||||
|
||||
注意 `BEGIN` 那一节是如何提供标题、指定字段分隔符和初始化计数器的,它仅在脚本初始化时期执行。这个脚本也包含 `END` 节,它仅在中间所有命令处理完成之后运行,显示了所有中间小节所筛选数据的最终行数(第三个字段大于等于 1000)。
|
||||
|
||||
作为一个长存于 Unix 之上的命令,`awk` 依旧提供着非常有用的服务,这也是我几十年前爱上 Unix 的原因之一。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3454979/the-many-faces-of-awk.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.networkworld.com/article/2974753/doing-math-with-awk.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
[6]:https://images.techhive.com/images/article/2015/09/thinkstockphotos-512100549-100611755-large.jpg
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11716-1.html)
|
||||
[#]: subject: (Create virtual machines with Cockpit in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/)
|
||||
[#]: author: (Karlis KavacisPaul W. Frields https://fedoramagazine.org/author/karlisk/https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
在 Fedora 中使用 Cockpit 创建虚拟机
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
本文向你展示如何在 Fedora 31 上使用安装 Cockpit 所需软件来创建和管理虚拟机。Cockpit 是一个[交互式管理界面][2],可让你在任何受支持的 Web 浏览器上访问和管理系统。随着 [virt-manager 逐渐被废弃][3],鼓励用户使用 Cockpit 来替换它。
|
||||
|
||||
Cockpit 是一个正在活跃开发的项目,它有许多扩展其工作的插件。例如,其中一个是 “Machines”,它与 libvirtd 交互并允许用户创建和管理虚拟机。
|
||||
|
||||
### 安装软件
|
||||
|
||||
先决所需软件是 `libvirt`、`cockpit` 和 `cockpit-machines`。要将它们安装在 Fedora 31 上,请在终端[使用 sudo][4] 运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install libvirt cockpit cockpit-machines
|
||||
```
|
||||
|
||||
Cockpit 也在 “Headless Management” 软件包组中。该软件组对于仅通过网络访问的基于 Fedora 的服务器很有用。在这里,请使用以下命令进行安装:
|
||||
|
||||
```
|
||||
$ sudo dnf groupinstall "Headless Management"
|
||||
```
|
||||
|
||||
### 设置 Cockpit 服务
|
||||
|
||||
安装了必要的软件包后,就该启用服务了。`libvirtd` 服务运行虚拟机,而 Cockpit 有一个激活的套接字服务,可让你访问 Web GUI:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable libvirtd --now
|
||||
$ sudo systemctl enable cockpit.socket --now
|
||||
```
|
||||
|
||||
这应该足以运行虚拟机并通过 Cockpit 对其进行管理。(可选)如果要从网络上的另一台设备访问并管理计算机,那么需要将该服务开放给网络。为此,请在防火墙配置中添加新规则:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --zone=public --add-service=cockpit --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
要确认服务正在运行并且没有发生任何问题,请检查服务的状态:
|
||||
|
||||
```
|
||||
$ sudo systemctl status libvirtd
|
||||
$ sudo systemctl status cockpit.socket
|
||||
```
|
||||
|
||||
此时一切都应该正常工作。Cockpit Web GUI 应该可通过 <https://localhost:9090> 或 <https://127.0.0.1:9090> 访问。或者,在连接到同一网络的任何其他设备上的 Web 浏览器中输入本地网络 IP。(如果未设置 SSL 证书,那么可能需要允许来自浏览器的连接。)
|
||||
|
||||
### 创建和安装机器
|
||||
|
||||
使用系统的用户名和密码登录界面。你还可以选择是否允许在此会话中将密码用于管理任务。
|
||||
|
||||
选择 “Virtual Machines”,然后选择 “Create VM” 来创建一台新的虚拟机。控制台为你提供几个选项:
|
||||
|
||||
* 使用 Cockpit 的内置库下载操作系统
|
||||
* 使用系统上已下载的安装媒体
|
||||
* 指向系统安装树的 URL
|
||||
* 通过 [PXE][5] 协议通过网络引导媒体
|
||||
|
||||
输入所有必要的参数。然后选择 “Create” 启动新虚拟机。
|
||||
|
||||
此时,将出现一个图形控制台。大多数现代 Web 浏览器都允许你使用键盘和鼠标与 VM 控制台进行交互。现在,你可以完成安装并使用新的 VM,就像[过去通过 virt-manager][6] 一样。
|
||||
|
||||
*照片由 [Miguel Teixeira][7] 发布于 [Flickr][8](CC BY-SA 2.0)*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/create-virtual-machines-with-cockpit-in-fedora/
|
||||
|
||||
作者:[Karlis Kavacis][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/karlisk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/11/create-vm-cockpit-816x345.jpg
|
||||
[2]: https://cockpit-project.org/
|
||||
[3]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/8.0_release_notes/rhel-8_0_0_release#virtualization_4
|
||||
[4]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[5]: https://en.wikipedia.org/wiki/Preboot_Execution_Environment
|
||||
[6]: https://fedoramagazine.org/full-virtualization-system-on-fedora-workstation-30/
|
||||
[7]: https://flickr.com/photos/miguelteixeira/
|
||||
[8]: https://flickr.com/photos/miguelteixeira/2964851828/
|
||||
140
published/20191127 How to write a Python web API with Flask.md
Normal file
140
published/20191127 How to write a Python web API with Flask.md
Normal file
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hj24)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11701-1.html)
|
||||
[#]: subject: (How to write a Python web API with Flask)
|
||||
[#]: via: (https://opensource.com/article/19/11/python-web-api-flask)
|
||||
[#]: author: (Rachel Waston https://opensource.com/users/rachelwaston)
|
||||
|
||||
如何使用 Flask 编写 Python Web API
|
||||
======
|
||||
|
||||
> 这是一个快速教程,用来展示如何通过 Flask(目前发展最迅速的 Python 框架之一)来从服务器获取数据。
|
||||
|
||||
![spiderweb diagram][1]
|
||||
|
||||
[Python][2] 是一个以语法简洁著称的高级的、面向对象的程序语言。它一直都是一个用来构建 RESTful API 的顶级编程语言。
|
||||
|
||||
[Flask][3] 是一个高度可定制化的 Python 框架,可以为开发人员提供用户访问数据方式的完全控制。Flask 是一个基于 Werkzeug 的 [WSGI][4] 工具包和 Jinja 2 模板引擎的”微框架“。它是一个被设计来开发 RESTful API 的 web 框架。
|
||||
|
||||
Flask 是 Python 发展最迅速的框架之一,很多知名网站如:Netflix、Pinterest 和 LinkedIn 都将 Flask 纳入了它们的开发技术栈。下面是一个简单的示例,展示了 Flask 是如何允许用户通过 HTTP GET 请求来从服务器获取数据的。
|
||||
|
||||
### 初始化一个 Flask 应用
|
||||
|
||||
首先,创建一个你的 Flask 项目的目录结构。你可以在你系统的任何地方来做这件事。
|
||||
|
||||
```
|
||||
$ mkdir tutorial
|
||||
$ cd tutorial
|
||||
$ touch main.py
|
||||
$ python3 -m venv env
|
||||
$ source env/bin/activate
|
||||
(env) $ pip3 install flask-restful
|
||||
Collecting flask-restful
|
||||
Downloading https://files.pythonhosted.org/packages/17/44/6e49...8da4/Flask_RESTful-0.3.7-py2.py3-none-any.whl
|
||||
Collecting Flask>=0.8 (from flask-restful)
|
||||
[...]
|
||||
```
|
||||
|
||||
### 导入 Flask 模块
|
||||
|
||||
然后,在你的 `main.py` 代码中导入 `flask` 模块和它的 `flask_restful` 库:
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask_restful import Resource, Api
|
||||
|
||||
app = Flask(__name__)
|
||||
api = Api(app)
|
||||
|
||||
class Quotes(Resource):
|
||||
def get(self):
|
||||
return {
|
||||
'William Shakespeare': {
|
||||
'quote': ['Love all,trust a few,do wrong to none',
|
||||
'Some are born great, some achieve greatness, and some greatness thrust upon them.']
|
||||
},
|
||||
'Linus': {
|
||||
'quote': ['Talk is cheap. Show me the code.']
|
||||
}
|
||||
}
|
||||
|
||||
api.add_resource(Quotes, '/')
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
### 运行 app
|
||||
|
||||
Flask 包含一个内建的用于测试的 HTTP 服务器。来测试一下这个你创建的简单的 API:
|
||||
|
||||
```
|
||||
(env) $ python main.py
|
||||
* Serving Flask app "main" (lazy loading)
|
||||
* Environment: production
|
||||
WARNING: This is a development server. Do not use it in a production deployment.
|
||||
Use a production WSGI server instead.
|
||||
* Debug mode: on
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
启动开发服务器时将启动 Flask 应用程序,该应用程序包含一个名为 `get` 的方法来响应简单的 HTTP GET 请求。你可以通过 `wget`、`curl` 命令或者任意的 web 浏览器来测试它。
|
||||
|
||||
```
|
||||
$ curl http://localhost:5000
|
||||
{
|
||||
"William Shakespeare": {
|
||||
"quote": [
|
||||
"Love all,trust a few,do wrong to none",
|
||||
"Some are born great, some achieve greatness, and some greatness thrust upon them."
|
||||
]
|
||||
},
|
||||
"Linus": {
|
||||
"quote": [
|
||||
"Talk is cheap. Show me the code."
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
要查看使用 Python 和 Flask 的类似 Web API 的更复杂版本,请导航至美国国会图书馆的 [Chronicling America][5] 网站,该网站可提供有关这些信息的历史报纸和数字化报纸。
|
||||
|
||||
### 为什么使用 Flask?
|
||||
|
||||
Flask 有以下几个主要的优点:
|
||||
|
||||
1. Python 很流行并且广泛被应用,所以任何熟悉 Python 的人都可以使用 Flask 来开发。
|
||||
2. 它轻巧而简约。
|
||||
3. 考虑安全性而构建。
|
||||
4. 出色的文档,其中包含大量清晰,有效的示例代码。
|
||||
|
||||
还有一些潜在的缺点:
|
||||
|
||||
1. 它轻巧而简约。但如果你正在寻找具有大量捆绑库和预制组件的框架,那么这可能不是最佳选择。
|
||||
2. 如果必须围绕 Flask 构建自己的框架,则你可能会发现维护自定义项的成本可能会抵消使用 Flask 的好处。
|
||||
|
||||
|
||||
如果你要构建 Web 程序或 API,可以考虑选择 Flask。它功能强大且健壮,并且其优秀的项目文档使入门变得容易。试用一下,评估一下,看看它是否适合你的项目。
|
||||
|
||||
在本课中了解更多信息关于 Python 异常处理以及如何以安全的方式进行操作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/11/python-web-api-flask
|
||||
|
||||
作者:[Rachel Waston][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hj24](https://github.com/hj24)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rachelwaston
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-cms-build-howto-tutorial.png?itok=bRbCJt1U (spiderweb diagram)
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://palletsprojects.com/p/flask/
|
||||
[4]: https://en.wikipedia.org/wiki/Web_Server_Gateway_Interface
|
||||
[5]: https://chroniclingamerica.loc.gov/about/api
|
||||
@ -1,26 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11651-1.html)
|
||||
[#]: subject: (A quick introduction to Toolbox on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/a-quick-introduction-to-toolbox-on-fedora/)
|
||||
[#]: author: (Ryan Walter https://fedoramagazine.org/author/rwaltr/)
|
||||
|
||||
快速介绍 Fedora 中的 Toolbox
|
||||
Fedora 中的 Toolbox 简介
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Toolbox 使你可以[在容器中分类和管理开发环境][2],而无需 root 权限或手动添加卷。它创建一个容器,你可以在其中安装自己的命令行工具,而无需在基础系统中安装它们。当你没有root 权限或无法直接安装程序时,也可以使用它。本文会介绍 Toolbox 及其功能。
|
||||
Toolbox 使你可以[在容器中分类和管理开发环境][2],而无需 root 权限或手动添加卷。它创建一个容器,你可以在其中安装自己的命令行工具,而无需在基础系统中安装它们。当你没有 root 权限或无法直接安装程序时,也可以使用它。本文会介绍 Toolbox 及其功能。
|
||||
|
||||
### 安装 Toolbox
|
||||
|
||||
[Silverblue][3] 默认包含 Toolbox。对于 Workstation 和 Server 版本,你可以使用 _dnf install toolbox_ 从默认仓库中获取它。
|
||||
[Silverblue][3] 默认包含 Toolbox。对于 Workstation 和 Server 版本,你可以使用 `dnf install toolbox` 从默认仓库中获取它。
|
||||
|
||||
### 创建 Toolbox
|
||||
|
||||
打开终端并运行 _toolbox enter_。程序将自动请求许可来下载最新的镜像,创建第一个容器并将你的 shell 放在该容器中。
|
||||
打开终端并运行 `toolbox enter`。程序将自动请求许可来下载最新的镜像,创建第一个容器并将你的 shell 放在该容器中。
|
||||
|
||||
```
|
||||
$ toolbox enter
|
||||
@ -29,7 +29,7 @@ Image required to create toolbox container.
|
||||
Download registry.fedoraproject.org/f30/fedora-toolbox:30 (500MB)? [y/N]: y
|
||||
```
|
||||
|
||||
当前,toolbox 和你的基本系统之间没有区别。你的文件系统和软件包未更改。这是一个使用仓库的示例,它包含 _~/src/resume_ 文件夹下的简历的文档源。简历是使用 _pandoc_ 工具构建的。
|
||||
当前,Toolbox 和你的基本系统之间没有区别。你的文件系统和软件包未曾改变。下面是一个使用仓库的示例,它包含 `~/src/resume` 文件夹下的简历的文档源文件。简历是使用 `pandoc` 工具构建的。
|
||||
|
||||
```
|
||||
$ pwd
|
||||
@ -47,7 +47,7 @@ $ pandoc -v
|
||||
bash: pandoc: command not found
|
||||
```
|
||||
|
||||
这个 toolbox 没有构建简历所需的程序。你可以通过使用 _dnf_ 安装工具来解决此问题。由于正在容器中运行,因此不会提示你输入 root 密码。
|
||||
这个 toolbox 没有构建简历所需的程序。你可以通过使用 `dnf` 安装工具来解决此问题。由于正在容器中运行,因此不会提示你输入 root 密码。
|
||||
|
||||
```
|
||||
$ sudo dnf groupinstall "Authoring and Publishing" -y && sudo dnf install pandoc make -y
|
||||
@ -63,7 +63,7 @@ $ ls BUILDS/
|
||||
resume.docx resume.html resume.pdf resume.rtf resume.txt
|
||||
```
|
||||
|
||||
运行 _exit_ 退出 toolbox。
|
||||
运行 `exit` 可以退出 toolbox。
|
||||
|
||||
```
|
||||
$ cd BUILDS/
|
||||
@ -80,21 +80,17 @@ bash: pandoc: command not found...
|
||||
resume.docx resume.html resume.pdf resume.rtf resume.txt
|
||||
```
|
||||
|
||||
你会在主目录中得到由 toolbox 创建的文件。toolbox 中安装的程序无法在外部访问。
|
||||
你会在主目录中得到由 toolbox 创建的文件。而在 toolbox 中安装的程序无法在外部访问。
|
||||
|
||||
### 提示和技巧
|
||||
|
||||
本介绍仅涉及 toolbox 的表明。还有一些其他提示,但是你也可以查看[官方文档][2]。
|
||||
本介绍仅涉及 toolbox 的表面。还有一些其他提示,但是你也可以查看[官方文档][2]。
|
||||
|
||||
* _Toolbox –help_ 会显示 Toolbox 的手册页
|
||||
* 你可以一次有多个 toolbox。使用 _toolbox create -c Toolboxname_ 和 _toolbox enter -c Toolboxname_。
|
||||
* Toolbox 使用 [Podman][4] 来完成繁重的工作。使用 _toolbox list_ 查找 Toolbox 创建的容器的 ID。Podman 可以使用这些 ID 来执行 _rm_ 和 _stop_ 之类的操作。 (你也可以在[此文章][5]中阅读有关 Podman 的更多信息。)
|
||||
* `toolbox –help` 会显示 Toolbox 的手册页。
|
||||
* 你可以一次有多个 toolbox。使用 `toolbox create -c Toolboxname` 和 `toolbox enter -c Toolboxname`。
|
||||
* Toolbox 使用 [Podman][4] 来完成繁重的工作。使用 `toolbox list` 可以查找 Toolbox 创建的容器的 ID。Podman 可以使用这些 ID 来执行 `rm` 和 `stop` 之类的操作。 (你也可以在[此文章][5]中阅读有关 Podman 的更多信息。)
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_照片出自 [Flickr][7] 的 [Florian Richter][6]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/a-quick-introduction-to-toolbox-on-fedora/
|
||||
@ -102,7 +98,7 @@ via: https://fedoramagazine.org/a-quick-introduction-to-toolbox-on-fedora/
|
||||
作者:[Ryan Walter][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,20 +1,21 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11650-1.html)
|
||||
[#]: subject: (Use the Window Maker desktop on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-window-maker-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 Linux 上使用 Window Maker 桌面
|
||||
======
|
||||
本文是 24 天 Linux 桌面特别系列的一部分。与 Window Maker 一起倒退,它为如今的用户实现了老式 Unix NeXTSTEP 环境。
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。让我们和 Window Maker 一起时光倒流,它为如今的用户实现了老式 Unix NeXTSTEP 环境。
|
||||
|
||||
![Penguin with green background][1]
|
||||
|
||||
在 Mac OS X 之前,有一个古怪的闭源 Unix 系统,称为 [NeXTSTEP][2]。Sun Microsystems 后来将 NeXTSTEP 的基础设为开放规范,这使其他项目可以创建许多免费开源的 NeXT 库和组件。GNUStep 实现了 NeXTSTEP 的大量库,[Window Maker][3] 实现了其桌面环境。
|
||||
在 Mac OS X 之前,有一个奇怪的闭源 Unix 系统,称为 [NeXTSTEP][2]。Sun Microsystems 后来将 NeXTSTEP 的底层设为开放规范,这使其它项目可以创建许多自由开源的 NeXT 库和组件。GNUStep 实现了许多 NeXTSTEP 库,而 [Window Maker][3] 实现了其桌面环境。
|
||||
|
||||
Window Maker 非常接近地模仿了 NeXTSTEP 桌面GUI,并提供了一些有趣东西来了解 80 年代末 90 年代初的 Unix 是什么样子。它还揭示了窗口管理器(例如 Fluxbox 和 Openbox)背后的一些基本概念。
|
||||
Window Maker 非常接近地模仿了 NeXTSTEP 桌面 GUI,并提供了一个有趣的视角,可以让人了解 80 年代末 90 年代初的 Unix 是什么样子的。它还揭示了窗口管理器(例如 Fluxbox 和 Openbox)背后的一些基本概念。
|
||||
|
||||
你可以从发行版的仓库中安装 Window Maker。要尝试它,请在安装完成后退出桌面会话。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,这取决于你的设置)将继续将登录到默认桌面,因此登录时必须覆盖默认设置。
|
||||
|
||||
@ -26,20 +27,19 @@ Window Maker 非常接近地模仿了 NeXTSTEP 桌面GUI,并提供了一些有
|
||||
|
||||
![Selecting the Window Maker desktop in KDM][5]
|
||||
|
||||
### Window Maker dock
|
||||
### Window Maker 程序坞
|
||||
|
||||
默认情况下,Window Maker 桌面是空的,但每个角落都有几个 _dock_。像在 NeXTSTEP 中一样,在 Window Maker 中,在 dock 区,应用可最小化成图标后停靠,可创建启动器来快速访问常见应用,并且可运行微型的 ”dockapp“。
|
||||
|
||||
你可以在软件仓库中搜索 “dockapp” 来试用 dockapp。它们常常是网络和系统监控器、音频设置面板、时钟等。这是在 Fedora 上运行 Window Maker:
|
||||
默认情况下,Window Maker 桌面是空的,但每个角落都有几个*程序坞*。像在 NeXTSTEP 中一样,在 Window Maker 中,在程序坞区域,应用可最小化成图标后停靠,可创建启动器来快速访问常见应用,并且可运行微型的 “dockapp”。
|
||||
|
||||
你可以在软件仓库中搜索 “dockapp” 来试用 dockapp。它们常常是网络和系统监控器、音频设置面板、时钟等。这是在 Fedora 上运行的 Window Maker:
|
||||
|
||||
![Window Maker running on Fedora][6]
|
||||
|
||||
### 应用菜单
|
||||
|
||||
要访问应用菜单,请右键单击桌面上的任意位置。要再次关闭它,请单击鼠标右键。Window Maker 不是桌面环境。而是一个窗口管理器。它可以帮助你安排和管理窗口。它唯一捆绑的程序是 [WPrefs][7](或更常见的说法 Window Maker Preferences),它可帮助你配置常用设置,而应用菜单则提供对其他选项(包括主题)的访问。
|
||||
要访问应用菜单,请右键单击桌面上的任意位置。要关闭它,请再次单击鼠标右键。Window Maker 不是桌面环境(DE),而是一个窗口管理器(DM)。它可以帮助你安排和管理窗口。它唯一捆绑的程序是 [WPrefs][7](或更常见的说法 Window Maker 偏好),它可帮助你配置常用设置,而应用菜单则提供对其他选项(包括主题)的访问。
|
||||
|
||||
运行什么应用完全由你决定。在 Window Maker 中,你可以选择运行 KDE 应用、GNOME 应用以及不被视为任何其他不被视为桌面程序的应用。你可以创建自己的工作环境,并且可以使用 Window Maker 对其进行管理。
|
||||
运行什么应用完全由你决定。在 Window Maker 中,你可以选择运行 KDE 应用、GNOME 应用以及不被视为任何其他主流桌面应用的程序。你可以创建自己的工作环境,并且可以使用 Window Maker 对其进行管理。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -48,7 +48,7 @@ via: https://opensource.com/article/19/12/linux-window-maker-desktop
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,46 +1,55 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (algzjh)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11681-1.html)
|
||||
[#]: subject: (An idiot's guide to Kubernetes, low-code developers, and other industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/12/technology-advice-and-other-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
面向 Kubernetes,低代码开发人员和其他行业趋势的傻瓜指南
|
||||
每周开源点评:Kubernetes 傻瓜指南、低代码开发人员和其他行业趋势
|
||||
======
|
||||
每周查看开源社区,市场和行业趋势。
|
||||
> 每周开源社区、市场和行业趋势。
|
||||
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
我在一家采用开源开发模型的企业软件公司担任高级产品营销经理,作为该职位的一部分,我定期为产品营销人员,经理和其他有影响力的人发布有关开源社区,市场和行业趋势的最新信息。这里有该更新中我和他们最喜欢的四篇文章。
|
||||
作为我在具有开源开发模型的企业软件公司担任高级产品营销经理的角色的一部分,我为产品营销人员、经理和其他影响者定期发布有关开源社区,市场和行业趋势的定期更新。这里有该更新中我和他们最喜欢的四篇文章。
|
||||
|
||||
## [Kubernetes 的傻瓜指南][2]
|
||||
### Kubernetes 傻瓜指南
|
||||
|
||||
- [文章链接][2]
|
||||
|
||||
> Kubernetes 已经发展出了新的特性,这使其成为企业软件的更好的容器平台。安全性和高级网络等元素已被纳入 Kubernetes 上游代码的主体,并且现在可供所有人使用。
|
||||
>
|
||||
> 然而,企业解决方案的其他方面总会有补充需求;比如日志记录和性能监控。这就是像 Istio 等辅助包发挥作用的地方,它带来了额外的功能,但是仍使 Kubernetes 的核心保持了合理的大小和特性集。
|
||||
|
||||
**影响**: 我总是发现,人们很容易把对技术发展的认识视为理所当然。当与你打交道的每个人都处于“最前沿”时,你的观点就会歪曲到这样的程度:你甚至可能会认为对最新的(此处插入首选技术)一无所知的人跟不上潮流,而实际上这并没有开始影响他们做自己需要做的事情的能力。那些人不是白痴;他们是我们的朋友、客户、合作伙伴、合作者和社区。
|
||||
**影响**: 我总是发现,人们很容易把对技术发展的认识视为理所当然。当与你打交道的每个人都处于“最前沿”时,你的观点就会歪曲到这样的程度:你甚至可能会认为对最新的(*此处插入首选技术*)一无所知的人跟不上潮流,而实际上这并没有开始影响他们做自己需要做的事情的能力。那些人不是白痴;他们是我们的朋友、客户、合作伙伴、合作者和社区。
|
||||
|
||||
## [Gartner: 采用低代码开发之前应该考虑什么][3]
|
||||
### Gartner: 采用低代码开发之前应该考虑什么
|
||||
|
||||
> 尽管专注于业务 IT 团队,但 Gartner(高德纳咨询公司) 发现,一个日益重要的开发人员社区是需要快速开发简单应用程序或构建最低可行产品或多体验功能的核心 IT 专业开发人员。当应用程序领导者在传统的应用程序项目中使用低代码时,他们可能希望使用标准的 IT DevOps 自动化方法和低代码工具。
|
||||
- [文章链接][3]
|
||||
|
||||
> 尽管专注于商业 IT 团队,但 Gartner 发现,一个日益重要的开发人员社区是需要快速开发简单应用程序或构建最低可行产品或多体验功能的核心 IT 专业开发人员。当应用程序领导者在传统的应用程序项目中使用低代码时,他们可能希望使用标准的 IT DevOps 自动化方法和低代码工具。
|
||||
|
||||
**影响**: 越来越多的用例和用户体验可以通过需要更少时间和技能来创建的应用程序来处理和交互。而低代码开发人员也可能会结合成一个具有他们自己的规范和亚文化的独特群体。
|
||||
|
||||
## [诺基亚认为云原生对 5G 核心至关重要][4]
|
||||
### 诺基亚认为云原生对 5G 核心至关重要
|
||||
|
||||
- [文章链接][4]
|
||||
|
||||
> 诺基亚概述了 5G 的五个关键业务目标,这些目标只能通过云原生环境来实现。其中包括:更好的带宽、延迟和密度;通过网络切片将服务扩展到新的企业、行业和[物联网][5]市场;根据敏捷性和效率定义的快速服务部署;超越传统带宽、语音和信息传递的新服务;以及利用端到端网络获取更多收入的数字服务的出现。
|
||||
|
||||
**影响**: 在越来越多的事物连接到网络的情况下,这是最有意义的。4G 主要与越来越多的手机有关;只有当你开始连接其他所有东西时,5G 才是真正必要的。4G 意味着我们的手机上有更丰富的应用程序,而 5G 几乎与手机无关。
|
||||
|
||||
## [APIs: 隐藏的业务加速器][6]
|
||||
### API:隐藏的业务加速器
|
||||
|
||||
> 要想让组织成功地进行数字化转型,API 策略至关重要。从解锁有价值的数据到加快开发时间,API 都是数字时代谦逊的英雄。那些已经尝试过 API 的人已经感受到了好处。例如,研究表明,使用 API 的企业中,有 53% 认为它们提高了生产力,而 29% 声称它们的收入增长是使用 API 的直接结果。当 API 被视为存在于一个项目之外的可发现和可重用的产品时,它有助于为持续的变更奠定灵活的基础。
|
||||
- [文章链接][6]
|
||||
|
||||
> 要想让组织成功地进行数字化转型,API 策略至关重要。从解锁有价值的数据到加快开发时间,API 都是数字时代的幕后英雄。那些已经尝试过 API 的人已经感受到了好处。例如,研究表明,使用 API 的企业中,有 53% 认为它们提高了生产力,而 29% 声称它们的收入增长是使用 API 的直接结果。当 API 被视为存在于一个项目之外的可发现和可重用的产品时,它有助于为持续的变更奠定灵活的基础。
|
||||
|
||||
**影响**: 隐藏的业务加速器实际上是这样一种思想,即功能应该以一种方式进行打包,使其能够在原始提供者没有预料到的环境中进行重新利用和组合。
|
||||
|
||||
_我希望你喜欢这份上周给我留下深刻印象的列表,并于下周一回来了解更多开源社区、市场和行业的趋势。_
|
||||
我希望你喜欢这份上周给我留下深刻印象的列表,并于下周一回来了解更多开源社区、市场和行业的趋势。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -49,7 +58,7 @@ via: https://opensource.com/article/19/12/technology-advice-and-other-industry-t
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[algzjh](https://github.com/algzjh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,34 +1,34 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hj24)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11653-1.html)
|
||||
[#]: subject: (Using Ansible to organize your SSH keys in AWS)
|
||||
[#]: via: (https://fedoramagazine.org/using-ansible-to-organize-your-ssh-keys-in-aws/)
|
||||
[#]: author: (Daniel Leite de Abreu https://fedoramagazine.org/author/dabreu/)
|
||||
|
||||
在 AWS 中使用 Ansible 来管理你的 SSH keys
|
||||
在 AWS 中使用 Ansible 来管理你的 SSH 密钥
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
如果你长期使用亚马逊Web服务(AWS)中的实例,你可能会遇到下面这个常见的问题,它不是因为技术性的原因导致的,更多的是因为人类追求方便舒适的天性:当你登录一台你最近没有使用的区域的实例,你最终就会创建一个新的SSH密钥对,久而久之这最终就会造成个人拥有太多密钥,导致管理起来复杂混乱。
|
||||
如果你长期使用亚马逊 Web 服务(AWS)中的实例,你可能会遇到下面这个常见的问题,它不是因为技术性的原因导致的,更多的是因为人类追求方便舒适的天性:当你登录一台你最近没有使用的区域的新实例,你最终会创建一个新的 SSH 密钥对,久而久之这最终就会造成个人拥有太多密钥,导致管理起来复杂混乱。
|
||||
|
||||
本文将会介绍一种在所有区域中使用你的公钥的方法。最近,一篇[Fedora Magazine article][2]介绍了另一种解决方案。但本文中的解决方案可以进一步的以更简洁和可扩展的方式实现自动化。
|
||||
本文将会介绍一种在所有区域中使用你的公钥的方法。最近,一篇 [Fedora Magazine 的文章][2]介绍了另一种解决方案。但本文中的解决方案可以进一步的以更简洁和可扩展的方式实现自动化。
|
||||
|
||||
假设你有一个Fedora 30或31系统,其中存储了你的密钥,并且还安装了Ansible。当这两件事同时满足时,就提供了解决这个问题的办法,甚至它还能做到更多。
|
||||
假设你有一个 Fedora 30 或 31 系统,其中存储了你的密钥,并且还安装了 Ansible。当这两件事同时满足时,就提供了解决这个问题的办法,甚至它还能做到更多。
|
||||
|
||||
使用Ansible的[ec2_key 模块][3],你可以创建一个简单的playbook来在所有区域中维护你的SSH密钥对。如果你需要增加或者删除密钥,在ansible中这就像从文件中添加和删除行一样简单。
|
||||
使用 Ansible 的 [ec2_key 模块][3],你可以创建一个简单的 Ansible 剧本来在所有区域中维护你的 SSH 密钥对。如果你需要增加或者删除密钥,在 Ansible 中这就像从文件中添加和删除行一样简单。
|
||||
|
||||
### 设置和运行 playbook
|
||||
### 设置和运行 Ansible 剧本
|
||||
|
||||
如果要使用playbook,首先需要安装 _ec2_key_ 模块的必要依赖项:
|
||||
如果要使用剧本,首先需要安装 `ec2_key` 模块的必要依赖项:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-boto python3-boto3
|
||||
```
|
||||
|
||||
playbook很简单:你只需要像下面的例子一样,修改其中的密钥及其对应的名称。然后,运行playbook,它会帮你遍历所有列出的公共AWS区域。该示例还包括一些受限区域,以防你有访问权限,只需根据需要来取消对应行的注释,然后,保存文件重新运行playbook即可。
|
||||
该剧本很简单:你只需要像下面的例子一样,修改其中的密钥及其对应的名称。然后,运行该剧本,它会帮你遍历所有列出的公共 AWS 区域。该示例还包括一些你可能要访问的受限区域,只需根据需要来取消对应行的注释,然后,保存文件重新运行剧本即可。
|
||||
|
||||
```
|
||||
---
|
||||
@ -71,34 +71,35 @@ playbook很简单:你只需要像下面的例子一样,修改其中的密钥
|
||||
# - cn-northwest-1 #China (Ningxia)
|
||||
```
|
||||
|
||||
这个playbook需要通过API访问AWS,为此,请使用环境变量,如下所示:
|
||||
这个剧本需要通过 API 访问 AWS,为此,请使用环境变量,如下所示:
|
||||
|
||||
```
|
||||
$ AWS_ACCESS_KEY="aws-access-key-id" AWS_SECRET_KEY="aws-secret-key-id" ansible-playbook ec2-playbook.yml
|
||||
```
|
||||
|
||||
另一个选项是安装aws cli工具并添加凭据,如以前的一篇[Fedora Magazine article][4]文章所述。如果你在线存储它们,这些参数将不建议插入到playbook中!你可以在[GitHub][5]中找到本文的playbook代码。
|
||||
另一个方式是安装 aws 命令行工具并添加凭据,如以前的一篇 [Fedora Magazine 文章][4]所述。如果你在线存储它们,这些参数将**不建议**插入到剧本中!你可以在 [GitHub][5] 中找到本文的剧本代码。
|
||||
|
||||
完成playbook之后,请确认你的密钥在AWS控制台上可用。为此,可以做如下操作:
|
||||
1. 登录你的AWS控制台
|
||||
2. 转到 **EC2 > Key Pairs**
|
||||
3. 您应该会看到列出的密钥。唯一的限制是你必须使用此方法逐个区域来检查。
|
||||
完成该剧本之后,请确认你的密钥在 AWS 控制台上可用。为此,可以做如下操作:
|
||||
|
||||
另一种方法是在shell中使用一个快速命令来为你做这些检查。
|
||||
1. 登录你的 AWS 控制台
|
||||
2. 转到 “EC2 > Key Pairs”
|
||||
3. 你应该会看到列出的密钥。唯一的限制是你必须使用此方法逐个区域来检查。
|
||||
|
||||
首先在playbook上创建一个包含所有区域的变量:
|
||||
另一种方法是在 shell 中使用一个快速命令来为你做这些检查。
|
||||
|
||||
首先在剧本上创建一个包含所有区域的变量:
|
||||
|
||||
```
|
||||
AWS_REGION="us-east-1 us-west-1 us-west-2 ap-east-1 ap-south-1 ap-northeast-2 ap-southeast-1 ap-southeast-2 ap-northeast-1 ca-central-1 eu-central-1 eu-west-1 eu-west-2 eu-west-3 eu-north-1 me-south-1 sa-east-1"
|
||||
```
|
||||
|
||||
然后,执行如下循环,你就可以从aws的API获得结果:
|
||||
然后,执行如下循环,你就可以从 aws 的 API 获得结果:
|
||||
|
||||
```
|
||||
for each in ${AWS_REGION} ; do aws ec2 describe-key-pairs --key-name <YOUR KEY GOES HERE> ; done
|
||||
```
|
||||
|
||||
请记住,要执行上述操作,您需要安装 aws cli。
|
||||
请记住,要执行上述操作,你需要安装 aws 命令行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -107,7 +108,7 @@ via: https://fedoramagazine.org/using-ansible-to-organize-your-ssh-keys-in-aws/
|
||||
作者:[Daniel Leite de Abreu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hj24](https://github.com/hj24)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11660-1.html)
|
||||
[#]: subject: (Why use the Pantheon desktop for Linux Elementary OS)
|
||||
[#]: via: (https://opensource.com/article/19/12/pantheon-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
为何 Elementary OS 中使用 Pantheon 桌面
|
||||
======
|
||||
|
||||
> 本文是 Linux 桌面特别系列的一部分。通过在 Elementary OS 上运行 Pantheon 桌面获得广受喜爱的 Mac OS 特性。
|
||||
|
||||
|
||||
|
||||
你愿意为 Linux 桌面支付 20 美元吗?事实上,我会在下载自由软件时选择支付更多的钱!我这样做的原因是开源是值得的。对于 [Elementary OS][2] 的拷贝,默认价格是 20 美元(你可以选择 1 美元,如果你无法负担,你甚至可以用 0 美元下载)。作为回报,你将获得一个出色且精心制作的发行版,同时拥有它自己的 Pantheon 桌面设计。
|
||||
|
||||
你可能会发现 Pantheon 已包含在软件仓库中,因为它是开源的,但你更可能需要下载并安装 [Elementary][3] Linux 才能体验它。如果你还不准备在计算机上将 Elementary 作为主操作系统,那么可以将其安装到虚拟机中,例如 [GNOME Boxes][4] 中。
|
||||
|
||||
Pantheon 桌面整洁、吸引人,并且有许多用户希望在桌面中获得的东西,但在普通的 Linux 桌面上却无法获得。
|
||||
|
||||
### Pantheon 桌面之旅
|
||||
|
||||
乍一看,Pantheon 桌面看起来有点像 Cinnamon、Budgie 或 GNOME 3 的经典模式。但是,Pantheon 最令人兴奋的功能是极小的接触。它在你很少注意到的地方都表现出色,直到有一天这里成为了你一天都会看的地方,并且会意识到它的工作方式确实改善了你的生活质量,更不用说让你过得愉快多了。
|
||||
|
||||
最明显的例子是“文件名高亮”。几十年来,Mac OS 一直有一个广受欢迎的功能,你可以高亮显示重要文件的名称。人们使用此功能作为快速视觉指示器,来告诉自己哪个文件是这几个的“最佳”版本,或者哪个文件应该发送给朋友,或者哪个文件仍然需要处理。它们可以是任意颜色,可以表示用户想要的任何含义。最重要的是,它是引人注目的视觉元数据。
|
||||
|
||||
从 Mac OS 切换过来用户往往会在 GNOME 和 KDE 以及 Linux 提供的其它桌面里怀念这个功能。Pantheon 悄悄地随手解决了这个问题。
|
||||
|
||||
![A highlighted file in the Pantheon desktop][5]
|
||||
|
||||
当然,那只是其中一个例子。Pantheon 有很多你直到用才会想到的小功能。
|
||||
|
||||
桌面精致而吸引人,有所有其他很多桌面缺少的直观组件。在许多方面,它充分吸取了其他桌面好的想法,并避免实现多余的东西。
|
||||
|
||||
![Pantheon desktop on Elementary OS][6]
|
||||
|
||||
### 自定义 Pantheon 桌面
|
||||
|
||||
Pantheon 桌面表达了如何操作计算机的清晰愿景。这种设计的“问题”(至少在开源之外)是,一个人的偏好可能无法满足另一个人的效率。
|
||||
|
||||
但它是开源的。它可以更改,任何不能改变的东西都可以被丢弃。Pantheon 绝对是针对特定用户群的桌面,但是即使对于那些对桌面应该如何工作抱有自己期望的人,Pantheon 也会比初看上去更加灵活。许多内置设计都具有替代选项,当你无法根据自己的喜好进行调整时,你可以轻松选择其他应用。主题引擎可确保你的替换应用看起来与桌面的其它部分和谐一致,而通常的 Linux 系统兼容性可确保你选择的所有应用都能按预期相互配合。
|
||||
|
||||
![Which one is the guest?][7]
|
||||
|
||||
这些替代品,可使你事半功倍。
|
||||
|
||||
### 受欢迎的补充
|
||||
|
||||
撇开这个桌面的词源不说,此桌面确实是许多 Linux 用户祈祷的答案(LCTT 译注:Pantheon 的意思是“万神庙”)。无论它是否是你的风格,Pantheon 桌面都是 Linux 用户体验中重要且受欢迎的补充。自己尝试一下,看看它是否是你一直期待的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/pantheon-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||
[2]: https://elementary.io/
|
||||
[3]: http://elementary.io
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-pantheon-highlight.jpg (A highlighted file in the Pantheon desktop)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-pantheon.jpg (Pantheon desktop on Elementary OS)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-pantheon-pcmanfm.jpg (Which one is the guest?)
|
||||
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11664-1.html)
|
||||
[#]: subject: (Dell XPS 13 7390 Review: The Best Laptop For Desktop Linux Users)
|
||||
[#]: via: (https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Dell XPS 13 7390:最好的 Linux 桌面笔记本
|
||||
======
|
||||
|
||||

|
||||
|
||||
曾经,我们必须进行大量研究、阅读大量评论,才能找到一种在所选的 Linux 桌面发行版上可以以最少的麻烦工作的机器。而如今,这种日子已经一去不复返了,几乎每台机器都可以运行 Linux。Linux 内核社区在设备驱动程序支持方面做得非常出色,可以使一切都开箱即用。
|
||||
|
||||
不过,有的是**可以**运行 Linux d 机器,有的是运行 Linux 的机器。戴尔计算机属于后一类。五年前,Barton George 在戴尔内部启动了一项计划,将桌面版 Linux 引入到消费级的高端戴尔系统。从一台机器开始,到现在整套从产品线的高端笔记本电脑和台式机都可以运行 Linux。
|
||||
|
||||
在这些机器中,XPS 13 是我的最爱。尽管我需要一个功能强大的台式机来处理 4K UHD、多机位视频制作,但我还需要一台超便携的笔记本电脑,可以随身携带,而不必担心笨重的背包和充电器。XPS 13 也是我的第一台笔记本电脑,陪了我 7 年多。因此,是的,这还有一个怀旧因素。
|
||||
|
||||
戴尔几乎每年都会更新其 XPS 产品线,并且最新的[产品展示宣布于 10 月][3]。[XPS 13(7390)] [4] 是该系列的增量更新,而且戴尔非常乐意向我寄来一台测评设备。
|
||||
|
||||

|
||||
|
||||
它由 6 核 Core i7-10710U CPU 所支持。它配备 16GB 内存和 1TB SSD。在 1.10 GHz 的基本频率(可以超频到 4.1 GHz)的情况下,这是一台用于常规工作负载的出色机器。它没有使用任何专用的 GPU,因此它并不适合进行游戏或从源代码进行编译的 Gentoo Linux 或 Arch Linux。但是,我确实设法在上面运行了一些 Steam 游戏。
|
||||
|
||||
如果你想运行 Kubernetes 集群、AI 框架或虚拟现实,那么 Precision 系列中还有更强大的机器,这些机器可以运行 Red Hat Enterprise Linux 和 Ubuntu。
|
||||
|
||||
该机器的底盘与上一代相同。边框保持与上一代一样的薄,依旧比 MacBook 和微软的 Surface Pro 薄。
|
||||
|
||||
它具有三个端口,其中两个是 USB-C Thunderbolt 3,可用于连接 4K 显示器、USB 附件以及用于对等网络的计算机之间的高速数据传输。
|
||||
|
||||
它还具有一个 microSD 插槽。作为视频记者,SD 卡插槽会更有用。大量使用树莓派的用户也会喜欢这种卡。
|
||||
|
||||
它具有 4 个麦克风和一个改进的摄像头,该摄像头现在位于顶部(再见,鼻孔摄像头!)。
|
||||
|
||||
XPS 13(7390)光滑纤薄。它的重量仅为 2.7 磅(1.2kg),可以与苹果的 MacBook Air 相提并论。 这台机器可以成为你的旅行伴侣,并且可以执行日常任务,例如检查电子邮件、浏览网络和写作。
|
||||
|
||||
其 4K UHD 屏幕支持 HDR,这意味着你将可以尽享《The Mandalorian》的全部美妙之处。另外,车载扬声器并没有那么好,听起来有些沉闷。它们适合进行视频聊天或休闲的 YouTube 观看,但是如果你想在今年晚些时候观看《The Witcher》剧集,或者想欣赏 Amazon、Apple Music 或 YouTube Music 的音乐,则需要耳机或外接扬声器。
|
||||
|
||||

|
||||
|
||||
但是,在插入充电线之前,你可以能使用这台机器多少时间?在正常工作量的情况下,它为我提供了大约 7-8 个小时的电池续航时间:我打开了几个选项卡浏览网络,只是看看电影或听音乐。多任务处理,尤其是各种 Web 活动,都会加速消耗电池电量。在 Linux 上进行一些微调可能会给你带来更多的续航时间,而在 Windows 10 上,我可以使用 10 多个小时呢!
|
||||
|
||||
作为仍在从事大量写作工作的视频记者,我非常喜欢键盘。但是,我们这么多年来在 Linux 台式机上听到的触控板故事一直没变:它与 MacBook 或 Windows 上的品质相差甚远。这或许有一天能改变。值得称道的是,他们确实发布了可增强体验的触控板驱动程序,但我没有运行此系统随附的提供的 Ubuntu 18.04 LTS。我全新安装了 Ubuntu 19.10,因为 Gnome 在 18.04 中的运行速度非常慢。我尝试过 openSUSE Tumbleweed、Zorin OS、elementary OS、Fedora、KDE neon 和 Arch Linux。一切正常,尽管有些需要额外的努力才能运行。
|
||||
|
||||
那么,该系统适用于谁?显然,这是给那些想要设计精良的、他们信赖的品牌的高端机器的专业人士打造的。适用于喜欢 MacBook Air,但更喜欢 Linux 台式机生态系统的用户。适用于那些希望使用 Linux 来工作,而不是使 Linux 可以工作的人。
|
||||
|
||||
我使用这台机器一周的时间,进一步说明了为什么我如此喜欢戴尔的 XPS 系列。它们是目前最好的 Linux 笔记本电脑。这款 XPS 13(7390),你值得拥有!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/dell-xps-13-7390-review-the-best-laptop-for-desktop-linux-user/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390-1068x665.jpg (dell-xps-13-7390)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/12/dell-xps-13-7390.jpg
|
||||
[3]: https://bartongeorge.io/2019/08/21/please-welcome-the-9th-generation-of-the-xps-13-developer-edition/
|
||||
[4]: https://blog.dell.com/en-us/dells-new-consumer-pc-portfolio-unveiled-ifa-2019/
|
||||
130
published/20191204 Java vs. Python- Which should you choose.md
Normal file
130
published/20191204 Java vs. Python- Which should you choose.md
Normal file
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11679-1.html)
|
||||
[#]: subject: (Java vs. Python: Which should you choose?)
|
||||
[#]: via: (https://opensource.com/article/19/12/java-vs-python)
|
||||
[#]: author: (Archit Modi https://opensource.com/users/architmodi)
|
||||
|
||||
Java 与 Python:你应该选择哪个?
|
||||
======
|
||||
|
||||
> 比较世界上最流行的两种编程语言,并在投票中让我们知道你喜欢哪一个。
|
||||
|
||||

|
||||
|
||||
让我们比较一下世界上两种最受欢迎、最强大的编程语言:Java 和 Python!这两种语言有巨大的社区支持和库来执行几乎任何编程任务,尽管选择编程语言通常取决于开发人员的场景。在比较和对比之后,请投票分享你的观点。
|
||||
|
||||
### 是什么?
|
||||
|
||||
* **Java** 是一门通用面向对象的编程语言,主要用于开发从移动端到 Web 到企业级应用的各种应用。
|
||||
* **Python** 是一门高级面向对象的编程语言,主要用于 Web 开发、人工智能、机器学习、自动化和其他数据科学应用。
|
||||
|
||||
### 创建者
|
||||
|
||||
* **Java** 是由 James Gosling(Sun Microsystems)创造的。
|
||||
* **Python** 是由 Guido van Rossum 创造的。
|
||||
|
||||
### 开源状态
|
||||
|
||||
* **Java** 是免费的,(大部分)开源,但商业用途除外。
|
||||
* **Python** 对于所有场景都是免费、开源的。
|
||||
|
||||
### 平台依赖
|
||||
|
||||
* **Java** 根据它的 WORA (“<ruby>一次编写,到处运行<rt>write once, run anywhere</rt></ruby>”)哲学,它是平台无关的。
|
||||
* **Python** 依赖于平台。
|
||||
|
||||
### 编译或解释
|
||||
|
||||
* **Java** 是一门编译语言。Java 程序在编译时转换为字节码,而不是运行时。
|
||||
* **Python** 是一门解释性语言。Python 程序在运行时进行解释。
|
||||
|
||||
### 文件创建
|
||||
|
||||
* **Java**:编译后生成 `<filename>.class` 文件。
|
||||
* **Python**:在运行期,创建 `<filename>.pyc` 文件。
|
||||
|
||||
### 错误类型
|
||||
|
||||
* **Java** 有 2 种错误类型:编译和运行时错误。
|
||||
* **Python** 有 1 种错误类型:回溯(或运行时)错误。
|
||||
|
||||
### 静态或动态类型
|
||||
|
||||
* **Java** 是静态类型。当初始化变量时,需要在程序中指定变量的类型,因为类型检查是在编译时完成的。
|
||||
* **Python** 是动态类型。变量不需要在初始化时指定类型,因为类型检查是在运行时完成的。
|
||||
|
||||
### 语法
|
||||
|
||||
* **Java**:每个语句都需要以分号(`;` )结尾,并且代码块由大括号( `{}` )分隔。
|
||||
* **Python**:代码块通过缩进分隔(用户可以选择要使用的空格数,但在整个块中应保持一致)。
|
||||
|
||||
### 类的数量
|
||||
|
||||
* **Java**:在 Java 中的单个文件中只能存在一个公有顶级类。
|
||||
* **Python**:Python 中的单个文件中可以存在任意数量的类。
|
||||
|
||||
### 代码多少?
|
||||
|
||||
* **Java** 通常比 Python 要写更多代码行。
|
||||
* **Python**通常比 Java 要写更少代码行。
|
||||
|
||||
### 多重继承
|
||||
|
||||
* **Java** 不支持多重继承(从两个或多个基类继承)。
|
||||
* **Python** 支持多重继承,但由于继承复杂性、层次结构、依赖等各种问题,它很少实现。
|
||||
|
||||
### 多线程
|
||||
|
||||
* **Java** 多线程可以支持同时运行的两个或多个并发线程。
|
||||
* **Python** 使用全局解释器锁 (GIL),一次只允许运行单个线程(一个 CPU 核)。
|
||||
|
||||
### 执行速度
|
||||
|
||||
* **Java** 的执行时间通常比 Python 快。
|
||||
* **Python** 的执行时间通常比 Java 慢。
|
||||
|
||||
### Hello world
|
||||
|
||||
Java 的:
|
||||
|
||||
```
|
||||
public class Hello {
|
||||
public static void main([String][3][] args) {
|
||||
[System][4].out.println("Hello Opensource.com from Java!");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python 的:
|
||||
|
||||
```
|
||||
print("Hello Opensource.com from Java!")
|
||||
```
|
||||
|
||||
### 运行程序
|
||||
|
||||
![Java vs. Python][5]
|
||||
|
||||
要运行 java 程序 `Hello.java`,你需要先编译它,这将创建一个 `Hello.class` 文件。只需运行类名 `java Hello`。对于 Python,只需运行文件 `python3 helloworld.py`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/java-vs-python
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/architmodi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: tmp.Bpi8QYfp8j#poll
|
||||
[3]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
[5]: https://opensource.com/sites/default/files/uploads/python-java-hello-world_0.png (Java vs. Python)
|
||||
103
published/20191206 5 cool terminal pagers in Fedora.md
Normal file
103
published/20191206 5 cool terminal pagers in Fedora.md
Normal file
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11676-1.html)
|
||||
[#]: subject: (5 cool terminal pagers in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/5-cool-terminal-pagers-in-fedora/)
|
||||
[#]: author: (Jacob Burns https://fedoramagazine.org/author/jaek/)
|
||||
|
||||
5 个最酷的终端分页器
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
像日志或源代码这样的大文件可能会多达成千上万行,这使得在文件内导航非常困难,尤其是在终端上。此外,大多数终端仿真器的回滚缓冲区只有几百行。这可能使得无法使用打印到标准输出的实用程序(例如 `cat`、`head` 和 `tail`)在终端中浏览大型文件。在计算时代的早期,程序员通过开发用于以虚拟“页面”形式显示文本的实用程序来解决这些问题,该实用程序被形象地描述为<ruby>分页器<rt>pager</rt></ruby>。
|
||||
|
||||
*分页器*提供了许多使文本文件导航更加简单的功能,包括滚动、搜索功能,以及作为命令[管道][2]的一部分而具有的功能。与大多数文本编辑器相比,某些终端分页器不需要加载整个文件即可查看,这使得它们更快,特别是对于非常大的文件。
|
||||
|
||||
在现代 Linux 计算时代,终端仿真器比以往更加复杂。它们提供了对缤纷的色彩、终端尺寸调整以及许多其它功能的支持,这些功能使得辨析屏幕上的文本变得更加轻松和高效。从诸如 `pg` 和 `more` 这样极其简单的 UNIX 实用程序,到涵盖各种使用场景的、功能广泛的复杂程序,终端分页器也经历了类似的演变。考虑到这一点,我们或“多”或“少”地汇总了一些最受欢迎的终端分页实用程序的列表。
|
||||
|
||||
### more
|
||||
|
||||
`more` 是最早的分页器之一,最初在 3.0 BSD 版本中出现。`more` 的第一个实现由 [Daniel Halbert][3] 编写于 1978 年。从那时起,`more` 已成为许多操作系统的普遍功能,包括 Windows、OS/2,MacOS 和大多数 Linux 发行版。
|
||||
|
||||
`more` 是一个非常轻量级的实用程序。util-linux 软件包中提供的版本只有不到 2100 行的 C 语言代码。但是,这种较小的代码大小是有代价的。大多数版本的 `more` 的功能相对有限,不支持向后滚动或搜索。命令也同样精简:按回车键可滚动一行,或按空格键滚动一页。其他一些有用的命令包括:
|
||||
|
||||
* 在阅读时按 `v` 键以在默认的终端编辑器中打开当前文件。
|
||||
* `/模式` 可以让你搜索下一个出现的“模式”。
|
||||
* 以多个文件作为参数调用 `more` 时,`:n` 和 `:p` 将分别打开下一个和上一个文件
|
||||
|
||||
### less
|
||||
|
||||
`less` 最初被认为是 `more` 的继承者,解决了它的一些局限性。`less` 以 `more` 的功能为基础,增加了许多有用的功能,包括向后滚动、向后搜索。它也更适合窗口大小调整。
|
||||
|
||||
`less` 中的导航方式与 `more` 类似,尽管 `less` 也从 `vi` 编辑器借用了一些有用的命令。用户可以使用熟悉的<ruby>主行导航键<rt>home row navigational keys</rt></ruby>(LCTT 译注:指 左手的 `A`、`S`、`D`、`F` 和右手的 `J`、`K`、`L`、`;`,及大拇指所在的空格键)浏览文档。看一眼 `less` 的手册页,就会发现相当多的可用命令。一些特别有用的示例包括:
|
||||
|
||||
* `?模式` 可让你在文件中向后搜索“模式”。
|
||||
* `&模式` 仅显示具有“模式”特征的行。这对于发现自己经常要使用 `$ grep 模式 | less` 的人特别有用。
|
||||
* 使用 `-s`(或 `–sqeueeze-blank-lines`)标志来调用 `less`,使你可以查看空白较大的文本文件。 多个换行符被简化为单个中断行。
|
||||
* 在该程序中调用的 `s 文件名` 将输入保存到 `文件名`中(如果输入来自管道)。
|
||||
* 或者,使用 `-o 文件名` 标志来调用 `less` 将把 `less` 的输入保存到 `文件名` 中。
|
||||
|
||||
随着这些增强的功能也带来了体积的略微增大。在写作本文时,Fedora 随附的 `less` 版本大约有 25000 行源代码。当然,除非是受存储限制最大的系统,在所有其它的系统上这都不是问题。`less` 比 `more` 功能更多。
|
||||
|
||||
### most
|
||||
|
||||
`less` 旨在扩展 `more` 的现有功能,而 `most` 采用另一种方法。`most` 不是在传统的单个文件视图上进行扩展,而是使用户能够将其视图拆分为“窗口”。每个窗口以不同的查看模式包含不同的文件。
|
||||
|
||||
重要的是,`most` 考虑了其输入文本的宽度。默认的查看模式是不换行的(`less` 中的 `-S` 参数),此功能在处理“宽”文件时特别有用。尽管对于某些用户来说,这些设计决策可能代表着与传统的重大偏离,但最终结果却非常强大。
|
||||
|
||||
除了 `more` 提供的导航命令外,`most` 使用直观的助记符进行文件导航。例如,`t` 移至文件的顶部(Top),而 `b` 移至底部(Bottom)。这样,不熟悉 `vi` 及其衍生品的用户会发现 `most` 非常简单好用。
|
||||
|
||||
`most` 的与众不同之处在于它能够快速轻松地拆分窗口和上下文。例如,可以使用以下命令打开两个不同的文本文件:
|
||||
|
||||
```
|
||||
$ most textFile1.txt textFile2.txt
|
||||
```
|
||||
|
||||
为了水平拆分屏幕,请使用组合键 `Ctrl+x, 2` 或 `Ctrl+w, 2`。 `:n` 命令将在给定窗口中打开下一个文件参数,提供两个文件的分屏视图:
|
||||
|
||||
![][4]
|
||||
|
||||
如果在一个窗口中关闭自动换行,它不会影响其他窗口的行为。(行末的)`\` 字符表示换行或折叠,而 `$` 字符表示文件超出了当前窗口的限制。
|
||||
|
||||
### pspg
|
||||
|
||||
使用 SQL 数据库的人员通常需要能够一目了然地检查数据库的内容。许多流行的开源 DBMS(例如 MySQL 和 PostGreSQL)的命令行界面都使用系统默认的分页器来查看无法显示在单个屏幕上的输出。诸如 `more` 和 `less` 之类的实用程序是围绕呈现文本文件的想法而设计的,但是对于更结构化的数据,还有一些不足之处。天真的文本分页程序没有宽的表格数据的概念,当处理大型查询时,这可能会令人感到沮丧。
|
||||
|
||||
[pspg][5] 试图通过为用户提供在查看时冻结列、*原位*排序数据并为输出着色的功能来解决此问题。尽管`pspg` 最初是专门用作 `psql` 的分页器的替代品,但该程序还支持查看 CSV 数据,并且是 `mysql` 和 `pgcli` 的合适的直接替代品。
|
||||
|
||||
### Vim
|
||||
|
||||
在现代的颜色鲜明的终端中,无休止的黑色页面上的灰色文字感觉太过时了。强大的文本编辑器(如 `vim`)提供的语法高亮显示选项对于浏览源代码很有用。此外,`vim` 提供的搜索功能远远超过了竞争对手。考虑到这一点,`vim` 附带了一个 shell 脚本 `less.sh`,该脚本可以使 `vim` 替代传统的分页器。
|
||||
|
||||
要将 `vim` 设置为手册页的[默认分页器][6],请将以下内容添加到 shell 的配置中(如果使用默认的bash shell 的话是 `~/.bashrc`):
|
||||
|
||||
```
|
||||
export MANPAGER="/bin/sh -c \"col -b | vim -c 'set ft=man ts=8 nomod nolist nonu noma' -\""
|
||||
```
|
||||
|
||||
或者,要将 `vim` 设置为系统范围内的默认分页器,请找到 `less.sh` 脚本。(你可以在当前 Fedora 系统上的 `/usr/share/vim/vim81/macros/` 找到它。)将此位置导出为变量 `PAGER` 以将其设置为默认值,或者将其设置为别名以显式调用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-terminal-pagers-in-fedora/
|
||||
|
||||
作者:[Jacob Burns][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/jaek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/11/5-pagers-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/command-line-quick-tips-using-pipes-to-connect-tools/
|
||||
[3]: https://danhalbert.org/more.html
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/11/image-2.png
|
||||
[5]: https://github.com/okbob/pspg
|
||||
[6]: https://zameermanji.com/blog/2012/12/30/using-vim-as-manpager/
|
||||
[7]: https://unsplash.com/@zyljosa?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/s/photos/pages?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,225 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11663-1.html)
|
||||
[#]: subject: (6 Ways to Send Email from the Linux Command Line)
|
||||
[#]: via: (https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux 命令行发送邮件的 5 种方法
|
||||
======
|
||||
|
||||
当你需要在 shell 脚本中创建邮件时,就需要用到命令行发送邮件的知识。Linux 中有很多命令可以实现发送邮件。本教程中包含了最流行的 5 个命令行邮件客户端,你可以选择其中一个。这 5 个命令分别是:
|
||||
|
||||
* `mail` / `mailx`
|
||||
* `mutt`
|
||||
* `mpack`
|
||||
* `sendmail`
|
||||
* `ssmtp`
|
||||
|
||||
### 工作原理
|
||||
|
||||
我先从整体上来解释下 Linux 中邮件命令怎么把邮件传递给收件人的。邮件命令撰写邮件并发送给一个本地邮件传输代理(MTA,如 sendmail、Postfix)。邮件服务器和远程邮件服务器之间通信以实际发送和接收邮件。下面的流程可以看得更详细。
|
||||
|
||||
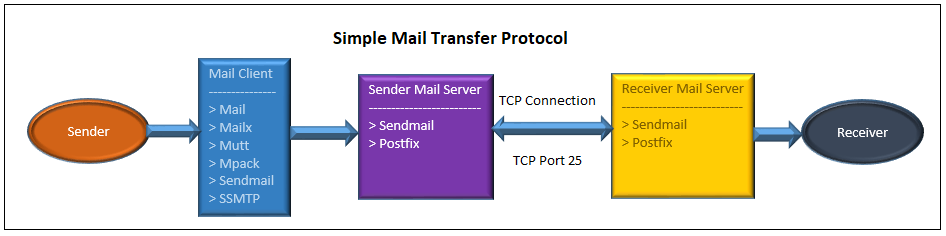
|
||||
|
||||
### 1) 如何在 Linux 上安装 mail/mailx 命令
|
||||
|
||||
`mail` 命令是 Linux 终端发送邮件用的最多的命令。`mailx` 是 `mail` 命令的更新版本,基于 Berkeley Mail 8.1,意在提供 POSIX `mailx` 命令的功能,并支持 MIME、IMAP、POP3、SMTP 和 S/MIME 扩展。mailx 在某些交互特性上更加强大,如缓冲邮件消息、垃圾邮件评分和过滤等。在 Linux 发行版上,`mail` 命令是 `mailx` 命令的软链接。可以运行下面的命令从官方发行版仓库安装 `mail` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mailutils。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mailutils
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo yum install mailx
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mailx。
|
||||
|
||||
```
|
||||
$ sudo dnf install mailx
|
||||
```
|
||||
|
||||
#### 1a) 如何在 Linux 上使用 mail 命令发送邮件
|
||||
|
||||
`mail` 命令简单易用。如果你不需要发送附件,使用下面的 `mail` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 `mail` 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mail -a test1.txt -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
- `-a`:用于在基于 Red Hat 的系统上添加附件。
|
||||
- `-A`:用于在基于 Debian 的系统上添加附件。
|
||||
- `-s`:指定消息标题。
|
||||
|
||||
### 2) 如何在 Linux 上安装 mutt 命令
|
||||
|
||||
`mutt` 是另一个很受欢迎的在 Linux 终端发送邮件的命令。`mutt` 是一个小而强大的基于文本的程序,用来在 unix 操作系统下阅读和发送电子邮件,并支持彩色终端、MIME、OpenPGP 和按邮件线索排序的模式。可以运行下面的命令从官方发行版仓库安装 `mutt` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mutt
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo yum install mutt
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mutt。
|
||||
|
||||
```
|
||||
$ sudo dnf install mutt
|
||||
```
|
||||
|
||||
#### 2b) 如何在 Linux 上使用 mutt 命令发送邮件
|
||||
|
||||
`mutt` 一样简单易用。如果你不需要发送附件,使用下面的 `mutt` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 `mutt` 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mutt -s "Subject" 2daygeek@gmail.com -a test1.txt
|
||||
```
|
||||
|
||||
### 3) 如何在 Linux 上安装 mpack 命令
|
||||
|
||||
`mpack` 是另一个很受欢迎的在 Linux 终端上发送邮件的命令。`mpack` 程序会在一个或多个 MIME 消息中对命名的文件进行编码。编码后的消息被发送到一个或多个收件人。可以运行下面的命令从官方发行版仓库安装 `mpack` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo apt-get install mpack
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo yum install mpack
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 mpack。
|
||||
|
||||
```
|
||||
$ sudo dnf install mpack
|
||||
```
|
||||
|
||||
#### 3a) 如何在 Linux 上使用 mpack 命令发送邮件
|
||||
|
||||
`mpack` 同样简单易用。如果你不需要发送附件,使用下面的 `mpack` 命令格式就可以发送邮件了:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
如果你要发送附件,使用下面的 mpack 命令格式:
|
||||
|
||||
```
|
||||
$ echo "This is the mail body" | mpack -s "Subject" 2daygeek@gmail.com -a test1.txt
|
||||
```
|
||||
|
||||
### 4) 如何在 Linux 上安装 sendmail 命令
|
||||
|
||||
sendmail 是一个上广泛使用的通用 SMTP 服务器,你也可以从命令行用 `sendmail` 发邮件。可以运行下面的命令从官方发行版仓库安装 `sendmail` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4]安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo apt-get install sendmail
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo yum install sendmail
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 sendmail。
|
||||
|
||||
```
|
||||
$ sudo dnf install sendmail
|
||||
```
|
||||
|
||||
#### 4a) 如何在 Linux 上使用 sendmail 命令发送邮件
|
||||
|
||||
`sendmail` 同样简单易用。使用下面的 `sendmail` 命令发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/send-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ sendmail 2daygeek@gmail.com < send-mail.txt
|
||||
```
|
||||
|
||||
### 5) 如何在 Linux 上安装 ssmtp 命令
|
||||
|
||||
`ssmtp` 是类似 `sendmail` 的一个只发送不接收的工具,可以把邮件从本地计算机传递到配置好的 邮件主机(mailhub)。用户可以在 Linux 命令行用 `ssmtp` 把邮件发送到 SMTP 服务器。可以运行下面的命令从官方发行版仓库安装 `ssmtp` 命令。
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4]安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo apt-get install ssmtp
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][5] 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo yum install ssmtp
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 ssmtp。
|
||||
|
||||
```
|
||||
$ sudo dnf install ssmtp
|
||||
```
|
||||
|
||||
### 5a) 如何在 Linux 上使用 ssmtp 命令发送邮件
|
||||
|
||||
`ssmtp` 同样简单易用。使用下面的 `ssmtp` 命令格式发送邮件。
|
||||
|
||||
```
|
||||
$ echo -e "Subject: Test Mail\nThis is the mail body" > /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
```
|
||||
$ ssmtp 2daygeek@gmail.com < /tmp/ssmtp-mail.txt
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-ways-to-send-email-from-the-linux-command-line/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.2daygeek.com/wp-content/uploads/2019/12/smtp-simple-mail-transfer-protocol.png
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[5]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
93
published/20191206 Pekwm- A lightweight Linux desktop.md
Normal file
93
published/20191206 Pekwm- A lightweight Linux desktop.md
Normal file
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11670-1.html)
|
||||
[#]: subject: (Pekwm: A lightweight Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/pekwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Pekwm:一个轻量级的 Linux 桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你是一个觉得传统桌面会妨碍你的极简主义者,那么试试 Pekwm Linux 桌面。
|
||||
|
||||
|
||||
|
||||
假设你想要一个轻量级桌面环境,它只需要能在屏幕上显示图形、四处移动窗口,而别无杂物。你会发现传统桌面的通知、任务栏和系统托盘会妨碍你的工作。你想主要通过终端工作,但也希望运行图形应用。如果听起来像是你的想法,那么 [Pekwm][2] 可能是你一直在寻找的东西。
|
||||
|
||||
Pekwm 的灵感大概来自于 Window Maker 和 Fluxbox 等。它提供了一个应用菜单、窗口装饰、而不是一大堆其他东西。它非常适合极简主义者,即那些希望节省资源的用户和喜欢在终端工作的用户。
|
||||
|
||||
从发行版仓库安装 Pekwm。安装后,请先退出当前桌面会话,以便可以登录到新桌面。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,具体取决于你的设置)将继续登录到以前的桌面,因此需要在登录之前修改它。
|
||||
|
||||
在 GDM 中覆盖之前的桌面:
|
||||
|
||||
![Selecting your desktop in GDM][3]
|
||||
|
||||
在 KDM 中:
|
||||
|
||||
![Selecting your desktop in KDM][4]
|
||||
|
||||
第一次登录 Pekwm 时,你可能会看到黑屏。可能难以置信,但这是正常的。你看到的是一个空白桌面,没有背景壁纸。你可以使用 `feh` 命令设置壁纸(你可能需要从仓库中安装它)。此命令有几个用于设置背景的选项,包括 `--bg-fill` 用壁纸填充屏幕,`--bg-scale` 缩放到合适大小,等等。
|
||||
|
||||
```
|
||||
$ feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg
|
||||
```
|
||||
|
||||
### 应用菜单
|
||||
|
||||
默认情况下,Pekwm 自动生成一个菜单,可在桌面上的任意位置右键单击,从而可让你运行应用。此菜单还提供一些首选项设置,例如选择主题和注销 Pekwm 会话。
|
||||
|
||||
![Pekwm running on Fedora][5]
|
||||
|
||||
### 配置
|
||||
|
||||
Pekwm 主要通过保存在 `$HOME/.pekwm` 下的文本配置文件来配置。`menu` 文件定义你的应用菜单,`keys` 文件定义键盘快捷键,等等。
|
||||
|
||||
`start` 文件是在 Pekwm 启动后执行的 shell 脚本。它类似于传统 Unix 系统上的 `rc.local`。它故意放在最后执行的,因此这里的东西将覆盖之前的一切。这是一个重要文件,它可能是你要设置背景的地方,以便*你的*选择会覆盖正在使用的主题的默认值。
|
||||
|
||||
`start` 文件也是可以启动 dockapp 的地方。dockapp 是一种小程序,它在 Window Maker 和 Fluxbox 引起了人们的关注。它们通常有网络监视器、时钟、音频设置,和其它你可能会在系统托盘或作为一个 KDE plasmoid 或者完整桌面环境中看到的小部件。你可能会在发行版仓库中找到一些 dockapp,或者可以在 [dockapps.net][6] 上在线查找它们。
|
||||
|
||||
你可以在启动时运行 dockapp,将它们列在 `start` 文件中,跟上 `&` 符号:
|
||||
|
||||
|
||||
```
|
||||
feh --bg-fill ~/Pictures/wallpapers/mybackground.jpg
|
||||
wmnd &
|
||||
bubblemon -d &
|
||||
```
|
||||
|
||||
`start` 文件必须[设置为可执行][7],才能在 Pekwm 启动时运行。
|
||||
|
||||
```
|
||||
$ chmod +x $HOME/.pekwm/start
|
||||
```
|
||||
|
||||
### 功能
|
||||
|
||||
Pekwm 的功能不多,但这就是它的美。如果你希望在桌面上运行额外的服务,那么由你来启动这些服务。如果你仍在学习 Linux,这是了解那些与完整的桌面环境捆绑在一起时通常不会注意到的微小 GUI 组件的好方法(像是[任务栏][8])。这也习惯一些 Linux 命令(例如 [nmcli][9])的好方法。
|
||||
|
||||
Pekwm 是一个有趣的窗口管理器。它分散、简洁、轻巧。请试试看!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/pekwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
|
||||
[2]: http://www.pekwm.org/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/advent-gdm_1.jpg (Selecting your desktop in GDM)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-enlightenment-kdm_0.jpg (Selecting your desktop in KDM)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-pekwm.jpg (Pekwm running on Fedora)
|
||||
[6]: http://dockapps.net
|
||||
[7]: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
[9]: https://opensource.com/article/19/5/set-static-network-connection-linux
|
||||
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11675-1.html)
|
||||
[#]: subject: (Getting started with the GNOME Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/gnome-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNOME Linux 桌面入门
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。GNOME 是大多数现代 Linux 发行版的默认桌面,它干净、简单、组织良好。
|
||||
|
||||
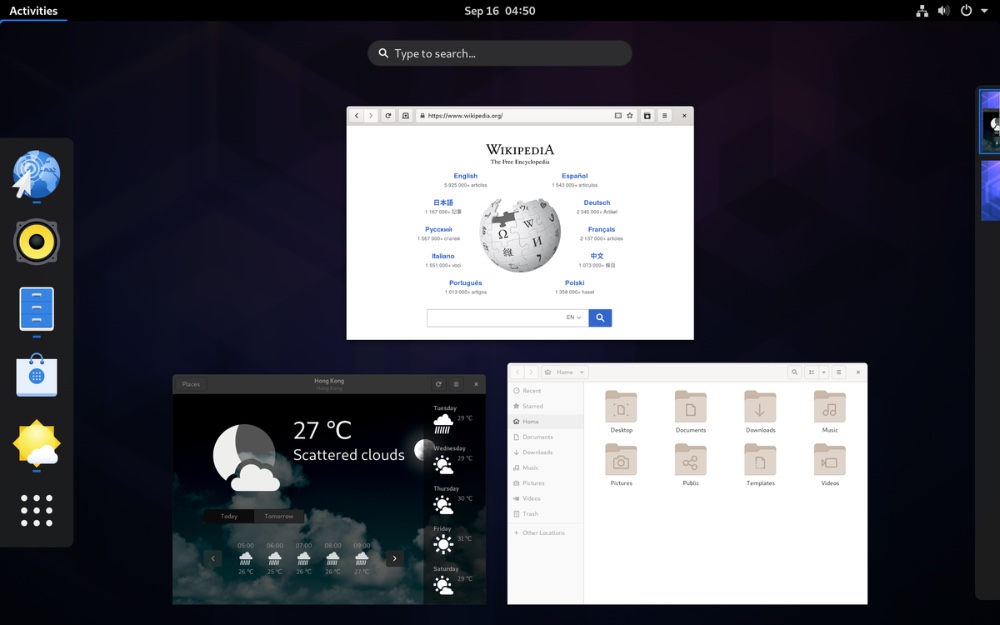
|
||||
|
||||
[GNOME][2] 项目理所应当是 Linux 桌面的宠儿。它起初是专有桌面(当时包括 KDE)的自由开源的桌面替代品,此后一直发展强劲。GNOME 采用了[由 GIMP 项目开发][3]的 GTK+,并将其开发为强大的通用 GTK 框架。该项目开创了用户界面的先声,挑战了桌面“应有”外观的先入之见,并为用户提供了新的范例和选项。
|
||||
|
||||
在大多数主流现代 Linux 发行版(包括 RHEL、Fedora、Debian 和 Ubuntu)中,GNOME 作为默认桌面而广泛使用。如果你的发行版不提供它的某个版本,那么你可以从软件仓库中安装 GNOME。但是,在执行此操作之前,请注意,为了提供完整的桌面体验,这会随桌面一起安装许多 GNOME 应用。如果你在用其他桌面,那么你可能会发现有冗余的应用(两个 PDF 阅读器、两个媒体播放器、两个文件管理器,等等)。如果你只想尝试 GNOME 桌面,请考虑在虚拟机,如 [GNOME Boxes][4],中安装 GNOME 发行版。
|
||||
|
||||
### GNOME 功能
|
||||
|
||||
GNOME 桌面很干净,顶部有一个简单的任务栏,右上角的系统托盘中只有很少的图标。GNOME 上没有桌面图标,这是设计使然。如果你是喜欢在桌面上保存*任何东西*的用户,那么你可能会意识到桌面会定期地变得混乱,而且,更糟糕的是,由于你的应用掩盖了桌面,因此桌面永远不会显示出来。
|
||||
|
||||
GNOME 解决了两个问题:(在功能上)没有桌面,并且动态生成新的虚拟工作区,因此你可以在全屏模式下运行应用。如果你常把屏幕弄乱,那么可能需要一些时间来习惯,但实际上,从各个方面来说,这都是一种改进的工作流程。你将学习如何使文件井井有条(或者将它们分散在家目录中),并且可以像在手机上一样快速地在屏幕之间切换。
|
||||
|
||||
当然,并非所有应用都设计为在全屏模式下运行,因此,如果你更喜欢单击切换窗口,也可以这样做。
|
||||
|
||||
![GNOME running on Debian][5]
|
||||
|
||||
GNOME 哲学褒扬了 Canonical 对常见任务的解决方案。在 GNOME 中,你通常不会发现“回字有四种写法”。你会找到一种或两种官方方法来完成一项任务,你了解了这些方法后,便只需记住这些即可。它非常简单,但由于它在 Linux 上运行,因此在技术上也很灵活(毕竟,你不必因为运行 GNOME 桌面而必须要使用 GNOME 应用)。
|
||||
|
||||
### 应用菜单
|
||||
|
||||
要访问名为“活动”的应用菜单,请在桌面的左上角单击。此菜单将占满整个屏幕,屏幕最左侧有一栏常见应用的 dock,或可以在网格中浏览应用的图标。你可以通过浏览已安装的应用,或输入软件的头几个字母来过滤列表,然后来启动应用。
|
||||
|
||||
![GNOME activities][6]
|
||||
|
||||
### GNOME 应用
|
||||
|
||||
GNOME 不仅是桌面。它是一个桌面以及一组丰富的集成应用,例如 Gedit 文本编辑器、Evince PDF 查看器、Web 浏览器、图像查看器、Nautilus 文件管理器等等。GNOME 应用(例如桌面本身)遵循 [GNOME 人机界面指南][7],因此用户体验既愉悦又一致。无论你是否使用 GNOME 桌面,都可能使用 GTK 应用,也可能会使用 GNOME 应用。
|
||||
|
||||
### GNOME 3 及更高版本
|
||||
|
||||
GNOME 项目进展顺利,还有几个令人兴奋的项目(例如 MATE 和 [Cinnamon][8])。它流行、令人舒适,被视为 Linux 桌面的代表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/gnome-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/custom_gnomes.png?itok=iG98iL8d (Gnomes in a window.)
|
||||
[2]: https://www.gnome.org/
|
||||
[3]: https://www.gtk.org/overview.php
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-gnome.jpg (GNOME running on Debian)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-gnome-activities.jpg (GNOME activities)
|
||||
[7]: https://developer.gnome.org/hig/stable/
|
||||
[8]: https://opensource.com/article/19/11/advent-2019-cinnamon
|
||||
125
published/20191209 Counting down the days using bash.md
Normal file
125
published/20191209 Counting down the days using bash.md
Normal file
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11672-1.html)
|
||||
[#]: subject: (Counting down the days using bash)
|
||||
[#]: via: (https://www.networkworld.com/article/3487712/counting-down-the-days-using-bash.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
用 bash 倒计时日期
|
||||
======
|
||||
|
||||
> 需要知道重要事件发生前有多少天吗?让 Linux bash 和 date 命令可以帮助你!
|
||||
|
||||

|
||||
|
||||
随着即将来临的重要假期,你可能需要提醒你还要准备多久。
|
||||
|
||||
幸运的是,你可以从 `date` 命令获得很多帮助。在本篇中,我们将研究 `date` 和 bash 脚本如何告诉你从今天到你预期的事件之间有多少天。
|
||||
|
||||
首先,在进行之前有几个提示。`date` 命令的 `%j` 选项将以 1 至 366 之间的数字显示当前日期。如你所想的一样,1 月 1 日将显示为 1,12 月 31 日将显示为 365 或 366,这取决于是否是闰年。继续尝试。你应该会看到以下内容:
|
||||
|
||||
```
|
||||
$ date +%j
|
||||
339
|
||||
```
|
||||
|
||||
但是,你可以通过以下方式,在 `date` 命令中得到一年中*任何*一天的数字:
|
||||
|
||||
```
|
||||
$ date -d "Mar 18" +%j
|
||||
077
|
||||
```
|
||||
|
||||
要记住的是,即使该日期是过去的日期,上面命令也会向你显示*当年*的日期。但是,你可以在命令中添加年来修复该问题:
|
||||
|
||||
```
|
||||
$ date -d "Apr 29" +%j
|
||||
119
|
||||
$ date -d "Apr 29 2020" +%j
|
||||
120
|
||||
```
|
||||
|
||||
在闰年中,4 月 29 日将是一年的 120 天,而不是 119 天。
|
||||
|
||||
如果你想倒数圣诞节之前的日子并且不想在挂历上留下指纹,你可以使用以下脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
XMAS=`date -d "Dec 25" +%j`
|
||||
TODAY=`date +%j`
|
||||
DAYS=$(($XMAS - $TODAY))
|
||||
|
||||
case $DAYS in
|
||||
0) echo "It's today! Merry Christmas!";;
|
||||
[0-9]*) echo "$DAYS days remaining";;
|
||||
-[0-9]*) echo "Oops, you missed it";;
|
||||
esac
|
||||
```
|
||||
|
||||
在此脚本中,我们获取 12 月 25 日和今天的日期,然后相减。如果结果是正数,我们将显示剩余天数。如果为零,则发出 “Merry Christmas” 的消息,如果为负,那么仅告诉运行脚本的人他们错过了假期。也许他们沉迷在蛋酒中了。
|
||||
|
||||
`case` 语句由用来打印信息的语句组成,当剩余时间等于 0,或任意数字或以 `-` 符号开头的数字(也就是过去)分别打印不同的信息。
|
||||
|
||||
对于人们想要关注的任何日期,都可以使用相同方法。实际上,我们可以要求运行脚本的人员提供日期,然后让他们知道从现在到那天还有多少天。这个脚本是这样的。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
echo -n "Enter event date (e.g., June 6): "
|
||||
read dt
|
||||
EVENT=`date -d "$dt" +%j`
|
||||
TODAY=`date +%j`
|
||||
DAYS=`expr $EVENT - $TODAY`
|
||||
|
||||
case $DAYS in
|
||||
0) echo "It's today!";;
|
||||
[0-9]*) echo "$DAYS days remaining";;
|
||||
-[0-9]*) echo "Oops, you missed it";;
|
||||
esac
|
||||
```
|
||||
|
||||
使用此脚本会遇到的一个问题,如果运行该脚本的人希望知道到第二年这个特殊日子还有多少天,他们会感到失望。即使他们输入日期时提供了年,`date -d` 命令仍将仅提供今年中的天数,而不会提供从现在到那时的天数。
|
||||
|
||||
计算从今天到某年的日期之间的天数可能有些棘手。你需要包括所有中间年份,并注意那些闰年。
|
||||
|
||||
### 使用 Unix 纪元时间
|
||||
|
||||
计算从现在到某个特殊日期之间的天数的另一种方法是利用 Unix 系统存储日期的方法。如果将自 1970 年 1 月 1 日开始的秒数转换为天数,那么就可以很容易地执行此操作,如下脚本所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Enter target date (e.g., Mar 18 2021)> "
|
||||
read target_date
|
||||
today=`echo $(($(date --utc --date "$1" +%s)/86400))`
|
||||
target=`echo $(($(date --utc --date "$target_date" +%s)/86400))`
|
||||
days=`expr $target - $today`
|
||||
echo "$days days until $target_date"
|
||||
```
|
||||
|
||||
解释一下,86400 是一天中的秒数。将自 Unix 纪元开始以来的秒数除该数即为天数。
|
||||
|
||||
```
|
||||
$ ./countdown
|
||||
Enter target date (e.g., Mar 18 2021)> Mar 18 2020
|
||||
104 days until Mar 18 2020
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3487712/counting-down-the-days-using-bash.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,158 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11696-1.html)
|
||||
[#]: subject: (3 easy steps to update your apps to Python 3)
|
||||
[#]: via: (https://opensource.com/article/19/12/update-apps-python-3)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
将你的应用迁移到 Python 3 的三个步骤
|
||||
======
|
||||
|
||||
> Python 2 气数将尽,是时候将你的项目从 Python 2 迁移到 Python 3 了。
|
||||
|
||||

|
||||
|
||||
Python 2.x 很快就要[失去官方支持][2]了,尽管如此,从 Python 2 迁移到 Python 3 却并没有想象中那么难。我在上周用了一个晚上的时间将一个 3D 渲染器的前端代码及其对应的 [PySide][3] 迁移到 Python 3,回想起来,尽管在迁移过程中无可避免地会遇到一些牵一发而动全身的修改,但整个过程相比起痛苦的重构来说简直是出奇地简单。
|
||||
|
||||
每个人都别无选择地有各种必须迁移的原因:或许是觉得已经拖延太久了,或许是依赖了某个在 Python 2 下不再维护的模块。但如果你仅仅是想通过做一些事情来对开源做贡献,那么把一个 Python 2 应用迁移到 Python 3 就是一个简单而又有意义的做法。
|
||||
|
||||
无论你从 Python 2 迁移到 Python 3 的原因是什么,这都是一项重要的任务。按照以下三个步骤,可以让你把任务完成得更加清晰。
|
||||
|
||||
### 1、使用 2to3
|
||||
|
||||
从几年前开始,Python 在你或许还不知道的情况下就已经自带了一个名叫 [2to3][4] 的脚本,它可以帮助你实现大部分代码从 Python 2 到 Python 3 的自动转换。
|
||||
|
||||
下面是一段使用 Python 2.6 编写的代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
mystring = u'abcdé'
|
||||
print ord(mystring[-1])
|
||||
```
|
||||
|
||||
对其执行 2to3 脚本:
|
||||
|
||||
|
||||
```
|
||||
$ 2to3 example.py
|
||||
RefactoringTool: Refactored example.py
|
||||
--- example.py (original)
|
||||
+++ example.py (refactored)
|
||||
@@ -1,5 +1,5 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
-mystring = u'abcdé'
|
||||
-print ord(mystring[-1])
|
||||
+mystring = 'abcdé'
|
||||
+print(ord(mystring[-1]))
|
||||
RefactoringTool: Files that need to be modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
在默认情况下,`2to3` 只会对迁移到 Python 3 时必须作出修改的代码进行标示,在输出结果中显示的 Python 3 代码是直接可用的,但你可以在 2to3 加上 `-w` 或者 `--write` 参数,这样它就可以直接按照给出的方案修改你的 Python 2 代码文件了。
|
||||
|
||||
```
|
||||
$ 2to3 -w example.py
|
||||
[...]
|
||||
RefactoringTool: Files that were modified:
|
||||
RefactoringTool: example.py
|
||||
```
|
||||
|
||||
`2to3` 脚本不仅仅对单个文件有效,你还可以把它用于一个目录下的所有 Python 文件,同时它也会递归地对所有子目录下的 Python 文件都生效。
|
||||
|
||||
### 2、使用 Pylint 或 Pyflakes
|
||||
|
||||
有一些不良的代码在 Python 2 下运行是没有异常的,在 Python 3 下运行则会或多或少报出错误,这种情况并不鲜见。因为这些不良代码无法通过语法转换来修复,所以 `2to3` 对它们没有效果,但一旦使用 Python 3 来运行就会产生报错。
|
||||
|
||||
要找出这种问题,你需要使用 [Pylint][5]、[Pyflakes][6](或 [flake8][7] 封装器)这类工具。其中我更喜欢 Pyflakes,它会忽略代码风格上的差异,在这一点上它和 Pylint 不同。尽管代码优美是 Python 的一大特点,但在代码迁移的层面上,“让代码功能保持一致”无疑比“让代码风格保持一致”重要得多。
|
||||
|
||||
以下是 Pyflakes 的输出样例:
|
||||
|
||||
```
|
||||
$ pyflakes example/maths
|
||||
example/maths/enum.py:19: undefined name 'cmp'
|
||||
example/maths/enum.py:105: local variable 'e' is assigned to but never used
|
||||
example/maths/enum.py:109: undefined name 'basestring'
|
||||
example/maths/enum.py:208: undefined name 'EnumValueCompareError'
|
||||
example/maths/enum.py:208: local variable 'e' is assigned to but never used
|
||||
```
|
||||
|
||||
上面这些由 Pyflakes 输出的内容清晰地给出了代码中需要修改的问题。相比之下,Pylint 会输出多达 143 行的内容,而且多数是诸如代码缩进这样无关紧要的问题。
|
||||
|
||||
值得注意的是第 19 行这个容易产生误导的错误。从输出来看你可能会以为 `cmp` 是一个在使用前未定义的变量,实际上 `cmp` 是 Python 2 的一个内置函数,而它在 Python 3 中被移除了。而且这段代码被放在了 `try` 语句块中,除非认真检查这段代码的输出值,否则这个问题很容易被忽略掉。
|
||||
|
||||
```
|
||||
try:
|
||||
result = cmp(self.index, other.index)
|
||||
except:
|
||||
result = 42
|
||||
|
||||
return result
|
||||
```
|
||||
|
||||
在代码迁移过程中,你会发现很多原本在 Python 2 中能正常运行的函数都发生了变化,甚至直接在 Python 3 中被移除了。例如 PySide 的绑定方式发生了变化、`importlib` 取代了 `imp` 等等。这样的问题只能见到一个解决一个,而涉及到的功能需要重构还是直接放弃,则需要你自己权衡。但目前来说,大多数问题都是已知的,并且有[完善的文档记录][8]。所以难的不是修复问题,而是找到问题,从这个角度来说,使用 Pyflake 是很有必要的。
|
||||
|
||||
### 3、修复被破坏的 Python 2 代码
|
||||
|
||||
尽管 `2to3` 脚本能够帮助你把代码修改成兼容 Python 3 的形式,但对于一个完整的代码库,它就显得有点无能为力了,因为一些老旧的代码在 Python 3 中可能需要不同的结构来表示。在这样的情况下,只能人工进行修改。
|
||||
|
||||
例如以下代码在 Python 2.6 中可以正常运行:
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
TICKS_PER_SECOND = 16
|
||||
TICK_RATES = [int(i * TICKS_PER_SECOND)
|
||||
for i in (0.5, 1, 2, 3, 4, 6, 8, 11, 20)]
|
||||
|
||||
class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND
|
||||
```
|
||||
|
||||
类似 `2to3` 和 Pyflakes 这些自动化工具并不能发现其中的问题,但如果上述代码使用 Python 3 来运行,解释器会认为 `CLOCK_SPEED.TICKS_PER_SECOND` 是未被明确定义的。因此就需要把代码改成面向对象的结构:
|
||||
|
||||
```
|
||||
class CLOCK_SPEED:
|
||||
def TICKS_PER_SECOND():
|
||||
TICKS_PER_SECOND = 16
|
||||
TICK_RATES = [int(i * TICKS_PER_SECOND)
|
||||
for i in (0.5, 1, 2, 3, 4, 6, 8, 11, 20)]
|
||||
return TICKS_PER_SECOND
|
||||
|
||||
class FPS:
|
||||
STATS_UPDATE_FREQUENCY = CLOCK_SPEED.TICKS_PER_SECOND()
|
||||
```
|
||||
|
||||
你也许会认为如果把 `TICKS_PER_SECOND()` 改写为一个构造函数(用 `__init__` 函数设置默认值)能让代码看起来更加简洁,但这样就需要把这个方法的调用形式从 `CLOCK_SPEED.TICKS_PER_SECOND()` 改为 `CLOCK_SPEED()` 了,这样的改动或多或少会对整个库造成一些未知的影响。如果你对整个代码库的结构烂熟于心,那么你确实可以随心所欲地作出这样的修改。但我通常认为,只要我做出了修改,都可能会影响到其它代码中的至少三处地方,因此我更倾向于不使代码的结构发生改变。
|
||||
|
||||
### 坚持信念
|
||||
|
||||
如果你正在尝试将一个大项目从 Python 2 迁移到 Python 3,也许你会觉得这是一个漫长的过程。你可能会费尽心思也找不到一条有用的报错信息,这种情况下甚至会有将代码推倒重建的冲动。但从另一个角度想,代码原本在 Python 2 中就可以运行,要让它能在 Python 3 中继续运行,你需要做的只是对它稍加转换而已。
|
||||
|
||||
但只要你完成了迁移,你就得到了这个模块或者整个应用程序的 Python 3 版本,外加 Python 官方的长期支持。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/update-apps-python-3
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python-programming-code-keyboard.png?itok=fxiSpmnd "Hands on a keyboard with a Python book "
|
||||
[2]: https://linux.cn/article-11629-1.html
|
||||
[3]: https://pypi.org/project/PySide/
|
||||
[4]: https://docs.python.org/3.1/library/2to3.html
|
||||
[5]: https://opensource.com/article/19/10/python-pylint-introduction
|
||||
[6]: https://pypi.org/project/pyflakes/
|
||||
[7]: https://opensource.com/article/19/5/python-flake8
|
||||
[8]: https://docs.python.org/3.0/whatsnew/3.0.html
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11682-1.html)
|
||||
[#]: subject: (Breaking Linux files into pieces with the split command)
|
||||
[#]: via: (https://www.networkworld.com/article/3489256/breaking-linux-files-into-pieces-with-the-split-command.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
使用 split 命令分割 Linux 文件
|
||||
======
|
||||
|
||||
> 一些简单的 Linux 命令能让你根据需要分割以及重新组合文件,来适应存储或电子邮件附件大小的限制。
|
||||
|
||||
![Marco Verch][1]
|
||||
|
||||
Linux 系统提供了一个非常易于使用的命令来分割文件。在将文件上传到限制大小的存储网站或者作为邮件附件之前,你可能需要执行此操作。要将文件分割为多个文件块,只需使用 `split` 命令。
|
||||
|
||||
```
|
||||
$ split bigfile
|
||||
```
|
||||
|
||||
默认情况下,`split` 命令使用非常简单的命名方案。文件块将被命名为 `xaa`、`xab`、`xac` 等,并且,大概地,如果你将足够大的文件分割,你甚至可能会得到名为 `xza` 和 `xzz` 的块。
|
||||
|
||||
除非你要求,否则该命令将无任何反馈地运行。但是,如果你想在创建文件块时看到反馈,可以使用 `--verbose` 选项。
|
||||
|
||||
```
|
||||
$ split –-verbose bigfile
|
||||
creating file 'xaa'
|
||||
creating file 'xab'
|
||||
creating file 'xac'
|
||||
```
|
||||
|
||||
你还可以给文件命名前缀。例如,要将你原始文件分割并命名为 `bigfile.aa`、`bigfile.ab` 等,你可以将前缀添加到 `split` 命令的末尾,如下所示:
|
||||
|
||||
```
|
||||
$ split –-verbose bigfile bigfile.
|
||||
creating file 'bigfile.aa'
|
||||
creating file 'bigfile.ab'
|
||||
creating file 'bigfile.ac'
|
||||
```
|
||||
|
||||
请注意,上述命令中显示的前缀的末尾会添加一个点。否则,文件将是 `bigfileaa` 之类的名称,而不是 `bigfile.aa`。
|
||||
|
||||
请注意,`split` 命令*不会*删除你的原始文件,只是创建了文件块。如果要指定文件块的大小,可以使用 `-b` 选项将其添加到命令中。例如:
|
||||
|
||||
```
|
||||
$ split -b100M bigfile
|
||||
```
|
||||
|
||||
文件大小可以是 KB、MB,GB,最大可以是 YB!只需使 K、M、G、T、P、E、Z 和 Y 这些合适的字母。
|
||||
|
||||
如果要基于每个块中的行数而不是字节数来拆分文件,那么可以使用 `-l`(行)选项。在此示例中,每个文件将有 1000 行,当然,最后一个文件可能有较少的行。
|
||||
|
||||
```
|
||||
$ split --verbose -l1000 logfile log.
|
||||
creating file 'log.aa'
|
||||
creating file 'log.ab'
|
||||
creating file 'log.ac'
|
||||
creating file 'log.ad'
|
||||
creating file 'log.ae'
|
||||
creating file 'log.af'
|
||||
creating file 'log.ag'
|
||||
creating file 'log.ah'
|
||||
creating file 'log.ai'
|
||||
creating file 'log.aj'
|
||||
```
|
||||
|
||||
如果你需要在远程站点上重新组合文件,那么可以使用如下所示的 `cat` 命令轻松地完成此操作:
|
||||
|
||||
```
|
||||
$ cat x?? > original.file
|
||||
$ cat log.?? > original.file
|
||||
```
|
||||
|
||||
上面所示的分割和组合命令适合于二进制和文本文件。在此示例中,我们将 zip 二进制文件分割为 50KB 的块,之后使用 `cat` 重新组合了它们,然后比较了组合后的文件和原始文件。`diff` 命令验证文件是否相同。
|
||||
|
||||
```
|
||||
$ split --verbose -b50K zip zip.
|
||||
creating file 'zip.aa'
|
||||
creating file 'zip.ab'
|
||||
creating file 'zip.ac'
|
||||
creating file 'zip.ad'
|
||||
creating file 'zip.ae'
|
||||
$ cat zip.a? > zip.new
|
||||
$ diff zip zip.new
|
||||
$ <== 无输出 = 无差别
|
||||
```
|
||||
|
||||
我唯一要提醒的一点的是,如果你经常使用 `split` 并使用默认命名,那么某些文件块可能会覆盖其他的文件块,甚至会比你预期的更多,因为有些是更早之前分割的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489256/breaking-linux-files-into-pieces-with-the-split-command.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/08/chocolate-chunks-100767935-large.jpg
|
||||
[2]: https://creativecommons.org/licenses/by/2.0/legalcode
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
77
published/20191210 Customize your Linux desktop with FVWM.md
Normal file
77
published/20191210 Customize your Linux desktop with FVWM.md
Normal file
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11712-1.html)
|
||||
[#]: subject: (Customize your Linux desktop with FVWM)
|
||||
[#]: via: (https://opensource.com/article/19/12/fvwm-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 FVWM 自定义 Linux 桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你正在寻找轻巧、快速且简单的 Linux 窗口管理器,那么 FVWM 可以胜任。但是,如果你正在寻找可以深入、探索和魔改的窗口管理器,那么 FVWM 是必须的。
|
||||
|
||||
|
||||
|
||||
[FVWM][2] 窗口管理器最早脱胎于对 1993 年的 [TWM][3] 的修改。经过几年的迭代,诞生了一个可高度自定义的环境,它可以配置任何行为、动作或事件。它支持自定义键绑定、鼠标手势、主题、脚本等。
|
||||
|
||||
尽管 FVWM 在安装后即可投入使用,但默认分发版本仅提供了极其少的配置。这是开始自定义桌面环境的良好基础,但是,如果你只想将其用作桌面,那么可能要安装由其它用户发布的完整配置版本。FVWM 有几种不同的分发版,包括模仿 Windows 95 的 FVWM95(至少在外观和布局上)。我尝试了 [FVWM-Crystal][4],这是一个具有一些现代 Linux 桌面约定的现代主题。
|
||||
|
||||
可以从 Linux 发行版的软件仓库中安装要尝试的 FVWM 分发版。如果找不到特定的 FVWM 分发版,那么可以安装基础的 FVWM2 包,然后进入 [Box-Look.org][5] 手动下载主题包。这样就需要更多的工作,但比从头开始构建要少。
|
||||
|
||||
安装后,请注销当前的桌面会话,以便你可以登录 FVWM。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该桌面。
|
||||
|
||||
对于 GDM:
|
||||
|
||||
![Select your desktop session in GDM][6]
|
||||
|
||||
对于 KDM:
|
||||
|
||||
![Select your desktop session with KDM][7]
|
||||
|
||||
### FVWM 桌面
|
||||
|
||||
无论你使用什么主题和配置,当你在桌面上单击鼠标左键时,FVWM 至少会显示一个菜单。菜单的内容取决于你所安装的内容。FVWM-Crystal 分发版中的菜单包含对常用首选项的快速访问,例如屏幕分辨率、壁纸设置、窗口装饰等。
|
||||
|
||||
同 FVWM 中的几乎所有东西一样,你可以编辑菜单中你要想的内容,但 FVWM-Crystal 的特色在于其应用菜单栏。应用菜单位于屏幕的左上角,每个图标都包含了相关的应用启动器的菜单。例如,GIMP 图标表示图像编辑器,KDevelop 图标表示集成开发环境(IDE),GNU 图标表示文本编辑器,等等,具体取决于你在系统上安装的程序。
|
||||
|
||||
![FVWM-crystal running on Slackware 14.2][8]
|
||||
|
||||
FVWM-Crystal 还提供了虚拟桌面、任务栏、时钟和应用栏。
|
||||
|
||||
关于背景,你可以使用与 FVWM-Crystal 捆绑在一起的壁纸,也可以使用 `feh` 命令设置自己的壁纸(你可能需要从仓库中安装它)。此命令有一些设置背景的选项,包括 `--bg-scale` 使用你选择的图片缩放填充屏幕,`--bg-fill` 直接填充而不缩放图片,等等。
|
||||
|
||||
```
|
||||
$ feh --bg-scale ~/Pictures/wallpapers/mybackground.jpg
|
||||
```
|
||||
|
||||
大多数配置文件都包含在 `$HOME/.fvwm-crystal` 中,某些系统范围的默认文件位于 `/usr/share/fvwm-crystal`。
|
||||
|
||||
### 自己尝试一下
|
||||
|
||||
FVWM 是大多作为一个桌面构建平台,它也是窗口管理器。它不会为你做到面面俱到,它期望你来配置尽可能的一切。
|
||||
|
||||
如果你正在寻找轻巧、快速且简单的窗口管理器,那么 FVWM 可以胜任。但是,如果你正在寻找可以深入、探索和魔改的窗口管理器,那么 FVWM 是必须的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/fvwm-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
|
||||
[2]: http://www.fvwm.org/
|
||||
[3]: https://en.wikipedia.org/wiki/Twm
|
||||
[4]: https://www.box-look.org/p/1018270/
|
||||
[5]: http://box-look.org
|
||||
[6]: https://opensource.com/sites/default/files/advent-gdm_0.jpg (Select your desktop session in GDM)
|
||||
[7]: https://opensource.com/sites/default/files/advent-kdm.jpg (Select your desktop session with KDM)
|
||||
[8]: https://opensource.com/sites/default/files/advent-fvwm-crystal.jpg (FVWM-crystal running on Slackware 14.2)
|
||||
100
published/20191211 Annotate screenshots on Linux with Ksnip.md
Normal file
100
published/20191211 Annotate screenshots on Linux with Ksnip.md
Normal file
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11695-1.html)
|
||||
[#]: subject: (Annotate screenshots on Linux with Ksnip)
|
||||
[#]: via: (https://opensource.com/article/19/12/annotate-screenshots-linux-ksnip)
|
||||
[#]: author: (Clayton Dewey https://opensource.com/users/cedewey)
|
||||
|
||||
在 Linux 上使用 Ksnip 注释截图
|
||||
======
|
||||
|
||||
> Ksnip 让你能轻松地在 Linux 中创建和标记截图。
|
||||
|
||||
![a checklist for a team][1]
|
||||
|
||||
我最近从 MacOS 切换到了 [Elementary OS][2],这是一个专注于易用性和隐私性的 Linux 发行版。作为用户体验设计师和自由软件支持者,我会经常截图并进行注释。在尝试了几种不同的工具之后,到目前为止,我最喜欢的工具是 [Ksnip][3],它是 GPLv2 许可下的一种开源工具。
|
||||
|
||||
![Ksnip screenshot][4]
|
||||
|
||||
### 安装
|
||||
|
||||
使用你首选的包管理器安装 Ksnip。我通过 Apt 安装了它:
|
||||
|
||||
```
|
||||
sudo apt-get install ksnip
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
Ksnip 有许多配置选项,包括:
|
||||
|
||||
* 保存截图的地方
|
||||
* 默认截图的文件名
|
||||
* 图像采集器行为
|
||||
* 光标颜色和宽度
|
||||
* 文字字体
|
||||
|
||||
你也可以将其与你的 Imgur 帐户集成。
|
||||
|
||||
![Ksnip configuration options][5]
|
||||
|
||||
### 用法
|
||||
|
||||
Ksnip 提供了大量的[功能][6]。我最喜欢的 Ksnip 部分是它拥有我需要的所有注释工具(还有一个我没想到的工具!)。
|
||||
|
||||
你可以使用以下注释:
|
||||
|
||||
* 钢笔
|
||||
* 记号笔
|
||||
* 矩形
|
||||
* 椭圆
|
||||
* 文字
|
||||
|
||||
你还可以模糊区域来移除敏感信息。还有使用我最喜欢的新工具:用于在界面上表示步骤的带数字的点。
|
||||
|
||||
### 关于作者
|
||||
|
||||
我非常喜欢 Ksnip,因此我联系了作者 [Damir Porobic][7] 来了解有关该项目的更多信息。
|
||||
|
||||
当我问到是什么启发了他编写 Ksnip 时,他说:
|
||||
|
||||
> “几年前我从 Windows 切换到 Linux,却没有了在 Windows 中常用的 Windows Snipping Tool。当时的所有其他截图工具要么很大(很多按钮和复杂功能),要么缺少诸如注释等关键功能,所以我决定编写一个简单的 Windows Snipping Tool 克隆版,但是随着时间的流逝,它开始有越来越多的功能。“
|
||||
|
||||
这正是我在评估截图工具时发现的。他花时间构建解决方案并免费共享给他人使用,这真是太好了。
|
||||
|
||||
至于 Ksnip 的未来,Damir 希望添加全局快捷方式(至少对于 Windows 是这样)和用于新截图的选项卡,并允许该应用在后台运行。GitHub 上的功能请求列表也越来越多。
|
||||
|
||||
### 帮助的方式
|
||||
|
||||
Damir 最需要的是帮助开发 Ksnip。他和他的妻子很快就会有孩子了,所以他将没有太多的时间放在这个项目上。不过,他可以检查和接受拉取请求。
|
||||
|
||||
此外,此项目还可以通过 Snap 、Flatpak 以及 MacOS 安装包、Windows 安装包等其他安装方式安装。如果你想提供帮助,请查看 Ksnip 的 README 的 [Contribution][8] 部分。
|
||||
|
||||
* * *
|
||||
|
||||
> 此文章最初发表在 [Agaric Tech Cooperative 的博客][9]上,并经允许重新发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/annotate-screenshots-linux-ksnip
|
||||
|
||||
作者:[Clayton Dewey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cedewey
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_hands_team_collaboration.png?itok=u82QepPk (a checklist for a team)
|
||||
[2]: https://elementary.io/
|
||||
[3]: https://github.com/damirporobic/ksnip
|
||||
[4]: https://opensource.com/sites/default/files/uploads/ksnip.png (Ksnip screenshot)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/ksnip-configuration.png (Ksnip configuration options)
|
||||
[6]: https://github.com/DamirPorobic/ksnip#features
|
||||
[7]: https://github.com/damirporobic/
|
||||
[8]: https://github.com/DamirPorobic/ksnip/blob/master/README.md#contribution
|
||||
[9]: https://agaric.coop/blog/annotate-screenshots-linux-ksnip
|
||||
@ -0,0 +1,166 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lxbwolf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11678-1.html)
|
||||
[#]: subject: (How to Find High CPU Consumption Processes in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-find-high-cpu-consumption-processes-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 中找出 CPU 占用高的进程
|
||||
======
|
||||
|
||||

|
||||
|
||||
在之前的文章中我们已经讨论过 [如何在 Linux 中找出内存消耗最大的进程][1]。你可能也会遇到在 Linux 系统中找出 CPU 占用高的进程的情形。如果是这样,那么你需要列出系统中 CPU 占用高的进程列表来确定。我认为只有两种方法能实现:使用 [top 命令][2] 和 [ps 命令][3]。出于一些理由,我更倾向于用 `top` 命令而不是 `ps` 命令。但是两个工具都能达到你要的目的,所以你可以根据需求决定使用哪个。这两个工具都被 Linux 系统管理员广泛使用。
|
||||
|
||||
### 1) 怎样使用 top 命令找出 Linux 中 CPU 占用高的进程
|
||||
|
||||
在所有监控 Linux 系统性能的工具中,Linux 的 `top` 命令是最好的也是最知名的一个。`top` 命令提供了 Linux 系统运行中的进程的动态实时视图。它能显示系统的概览信息和 Linux 内核当前管理的进程列表。它显示了大量的系统信息,如 CPU 使用、内存使用、交换内存、运行的进程数、目前系统开机时间、系统负载、缓冲区大小、缓存大小、进程 PID 等等。默认情况下,`top` 命令的输出结果按 CPU 占用进行排序,每 5 秒中更新一次结果。如果你想要一个更清晰的视图来更深入的分析结果,[以批处理模式运行 top 命令][4] 是最好的方法。同时,你需要 [理解 top 命令输出结果的含义][5] ,这样才能解决系统的性能问题。
|
||||
|
||||
```
|
||||
# top -b | head -50
|
||||
|
||||
top - 00:19:17 up 14:23, 1 user, load average: 2.46, 2.18, 1.97
|
||||
Tasks: 306 total, 1 running, 305 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu0 : 10.4 us, 3.0 sy, 0.0 ni, 83.9 id, 0.0 wa, 1.3 hi, 1.3 si, 0.0 st
|
||||
%Cpu1 : 17.0 us, 3.0 sy, 0.0 ni, 78.7 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu2 : 13.0 us, 4.0 sy, 0.0 ni, 81.3 id, 0.0 wa, 0.3 hi, 1.3 si, 0.0 st
|
||||
%Cpu3 : 12.3 us, 3.3 sy, 0.0 ni, 82.5 id, 0.3 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
%Cpu4 : 12.2 us, 3.0 sy, 0.0 ni, 82.8 id, 0.7 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu5 : 6.4 us, 2.7 sy, 0.0 ni, 89.2 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
%Cpu6 : 26.7 us, 3.4 sy, 0.0 ni, 68.6 id, 0.0 wa, 0.7 hi, 0.7 si, 0.0 st
|
||||
%Cpu7 : 15.6 us, 4.0 sy, 0.0 ni, 78.8 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
KiB Mem : 16248556 total, 1448920 free, 8571484 used, 6228152 buff/cache
|
||||
KiB Swap: 17873388 total, 17873388 free, 0 used. 4596044 avail Mem
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
2179 daygeek 20 3106324 613584 327564 S 79.5 3.8 14:19.76 Web Content
|
||||
1714 daygeek 20 4603372 974600 403504 S 20.2 6.0 65:18.91 firefox
|
||||
1227 daygeek 20 4192012 376332 180348 S 13.9 2.3 20:43.26 gnome-shell
|
||||
18324 daygeek 20 3296192 766040 127948 S 6.3 4.7 9:18.12 Web Content
|
||||
1170 daygeek 20 1008264 572036 546180 S 6.0 3.5 18:07.85 Xorg
|
||||
4684 daygeek 20 3363708 1.1g 1.0g S 3.6 7.2 13:49.92 VirtualBoxVM
|
||||
4607 daygeek 20 4591040 1.7g 1.6g S 3.0 11.0 14:09.65 VirtualBoxVM
|
||||
1211 daygeek 9 -11 2865268 21032 16588 S 2.0 0.1 10:46.37 pulseaudio
|
||||
4562 daygeek 20 1096888 28812 21044 S 1.7 0.2 4:42.93 VBoxSVC
|
||||
1783 daygeek 20 3123888 376896 134788 S 1.3 2.3 39:32.56 Web Content
|
||||
3286 daygeek 20 3089736 404088 184968 S 1.0 2.5 41:57.44 Web Content
|
||||
```
|
||||
|
||||
上面的命令的各部分解释:
|
||||
|
||||
* `top`:命令
|
||||
* `-b`:批次档模式
|
||||
* `head -50`:显示输出结果的前 50 个
|
||||
* `PID`:进程的 ID
|
||||
* `USER`:进程的归属者
|
||||
* `PR`:进程的等级
|
||||
* `NI`:进程的 NICE 值
|
||||
* `VIRT`:进程使用的虚拟内存
|
||||
* `RES`:进程使用的物理内存
|
||||
* `SHR`:进程使用的共享内存
|
||||
* `S`:这个值表示进程的状态: `S` = 睡眠,`R` = 运行,`Z` = 僵尸进程
|
||||
* `%CPU`:进程占用的 CPU 比例
|
||||
* `%MEM`:进程使用的 RAM 比例
|
||||
* `TIME+`:进程运行了多长时间
|
||||
* `COMMAND`:进程名字
|
||||
|
||||
如果你想看命令的完整路径而不是命令名字,以运行下面的格式 `top` 命令:
|
||||
|
||||
```
|
||||
# top -c -b | head -50
|
||||
|
||||
top - 00:28:49 up 14:33, 1 user, load average: 2.43, 2.49, 2.23
|
||||
Tasks: 305 total, 1 running, 304 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu0 : 11.7 us, 3.7 sy, 0.0 ni, 82.3 id, 0.0 wa, 1.0 hi, 1.3 si, 0.0 st
|
||||
%Cpu1 : 13.6 us, 3.3 sy, 0.0 ni, 81.1 id, 0.7 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu2 : 10.9 us, 2.6 sy, 0.0 ni, 85.1 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu3 : 16.0 us, 2.6 sy, 0.0 ni, 80.1 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu4 : 9.2 us, 3.6 sy, 0.0 ni, 85.9 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu5 : 15.6 us, 2.9 sy, 0.0 ni, 80.5 id, 0.0 wa, 0.3 hi, 0.7 si, 0.0 st
|
||||
%Cpu6 : 11.6 us, 4.3 sy, 0.0 ni, 82.7 id, 0.0 wa, 0.3 hi, 1.0 si, 0.0 st
|
||||
%Cpu7 : 8.0 us, 3.0 sy, 0.0 ni, 87.3 id, 0.0 wa, 0.7 hi, 1.0 si, 0.0 st
|
||||
KiB Mem : 16248556 total, 1022456 free, 8778508 used, 6447592 buff/cache
|
||||
KiB Swap: 17873388 total, 17873388 free, 0 used. 4201560 avail Mem
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
18527 daygeek 20 3151820 624808 325748 S 52.8 3.8 59:26.72 /usr/lib/firefox/firefox -contentproc -childID 18 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
1714 daygeek 20 4764668 910940 443228 S 21.5 5.6 68:59.33 /usr/lib/firefox/firefox --new-window
|
||||
1227 daygeek 20 4193108 377344 181404 S 11.6 2.3 21:47.36 /usr/bin/gnome-shell
|
||||
1170 daygeek 20 1008820 572700 546844 S 5.6 3.5 19:05.10 /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty -verbose 3
|
||||
18324 daygeek 20 3300288 789344 127948 S 5.0 4.9 9:46.89 /usr/lib/firefox/firefox -contentproc -childID 16 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
4684 daygeek 20 3363708 1.1g 1.0g S 3.6 7.2 14:10.18 /usr/lib/virtualbox/VirtualBoxVM --comment CentOS7 --startvm 002f47b8-2af2-48f5-be1d-67b67e03514c --no-startvm-errormsgbox
|
||||
4607 daygeek 20 4591040 1.7g 1.6g S 3.0 11.0 14:28.86 /usr/lib/virtualbox/VirtualBoxVM --comment Ubuntu-18.04 --startvm e8c32dbb-8b01-41b0-977a-bf28b9db1117 --no-startvm-errormsgbox
|
||||
1783 daygeek 20 3132640 451924 132168 S 2.6 2.8 39:49.66 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/l+
|
||||
1211 daygeek 9 -11 2865268 21272 16828 S 2.0 0.1 11:01.29 /usr/bin/pulseaudio --daemonize=no
|
||||
4562 daygeek 20 1096888 28812 21044 S 1.7 0.2 4:49.33 /usr/lib/virtualbox/VBoxSVC --auto-shutdown
|
||||
16865 daygeek 20 3073364 430596 124652 S 1.3 2.7 8:04.02 /usr/lib/firefox/firefox -contentproc -childID 15 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /+
|
||||
2179 daygeek 20 2945348 429644 172940 S 1.0 2.6 15:20.90 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 7821 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /us+
|
||||
```
|
||||
|
||||
### 2) 怎样使用 ps 命令找出 Linux 中 CPU 占用高的进程
|
||||
|
||||
`ps` 是<ruby>进程状态<rt>process status</rt></ruby>的缩写,它能显示系统中活跃的/运行中的进程的信息。它提供了当前进程及其详细信息,诸如用户名、用户 ID、CPU 使用率、内存使用、进程启动日期时间、命令名等等的快照。
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%cpu | head
|
||||
|
||||
PID PPID %MEM %CPU CMD
|
||||
18527 1714 4.2 40.3 /usr/lib/firefox/firefox -contentproc -childID 18 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1714 1152 5.6 8.0 /usr/lib/firefox/firefox --new-window
|
||||
18324 1714 4.9 6.3 /usr/lib/firefox/firefox -contentproc -childID 16 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
3286 1714 2.0 5.1 /usr/lib/firefox/firefox -contentproc -childID 14 -isForBrowser -prefsLen 8078 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1783 1714 3.0 4.5 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -prefsLen 1 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
1227 1152 2.3 2.5 /usr/bin/gnome-shell
|
||||
1170 1168 3.5 2.2 /usr/lib/Xorg vt2 -displayfd 3 -auth /run/user/1000/gdm/Xauthority -nolisten tcp -background none -noreset -keeptty -verbose 3
|
||||
16865 1714 2.5 2.1 /usr/lib/firefox/firefox -contentproc -childID 15 -isForBrowser -prefsLen 10002 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
2179 1714 2.7 1.8 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -prefsLen 7821 -prefMapSize 213431 -parentBuildID 20191031132559 -greomni /usr/lib/firefox/omni.ja -appomni /usr/lib/firefox/browser/omni.ja -appdir /usr/lib/firefox/browser 1714 true tab
|
||||
```
|
||||
|
||||
上面的命令的各部分解释:
|
||||
|
||||
* `ps`:命令名字
|
||||
* `-e`:选择所有进程
|
||||
* `-o`:自定义输出格式
|
||||
* `–sort=-%cpu`:基于 CPU 使用率对输出结果排序
|
||||
* `head`:显示结果的前 10 行
|
||||
* `PID`:进程的 ID
|
||||
* `PPID`:父进程的 ID
|
||||
* `%MEM`:进程使用的 RAM 比例
|
||||
* `%CPU`:进程占用的 CPU 比例
|
||||
* `Command`:进程名字
|
||||
|
||||
如果你只想看命令名字而不是命令的绝对路径,以运行下面的格式 `ps` 命令:
|
||||
|
||||
```
|
||||
# ps -eo pid,ppid,%mem,%cpu,comm --sort=-%cpu | head
|
||||
|
||||
PID PPID %MEM %CPU COMMAND
|
||||
18527 1714 4.1 40.4 Web Content
|
||||
1714 1152 5.7 8.0 firefox
|
||||
18324 1714 4.9 6.3 Web Content
|
||||
3286 1714 2.0 5.1 Web Content
|
||||
1783 1714 3.0 4.5 Web Content
|
||||
1227 1152 2.3 2.5 gnome-shell
|
||||
1170 1168 3.5 2.2 Xorg
|
||||
16865 1714 2.4 2.1 Web Content
|
||||
2179 1714 2.7 1.8 Web Content
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-high-cpu-consumption-processes-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11542-1.html
|
||||
[2]: https://www.2daygeek.com/linux-top-command-linux-system-performance-monitoring-tool/
|
||||
[3]: https://www.2daygeek.com/linux-ps-command-find-running-process-monitoring/
|
||||
[4]: https://www.2daygeek.com/linux-run-execute-top-command-in-batch-mode/
|
||||
[5]: https://www.2daygeek.com/understanding-linux-top-command-output-usage/
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11698-1.html)
|
||||
[#]: subject: (How to configure Openbox for your Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/openbox-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何为 Linux 桌面配置 Openbox
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。Openbox 窗口管理器占用很小的系统资源、易于配置、使用愉快。
|
||||
|
||||

|
||||
|
||||
你可能不知道你使用过 [Openbox][2] 桌面:尽管 Openbox 本身是一个出色的窗口管理器,但它还是 LXDE 和 LXQT 等桌面环境的窗口管理器“引擎”,它甚至可以管理 KDE 和 GNOME。除了作为多个桌面的基础之外,Openbox 可以说是最简单的窗口管理器之一,可以为那些不想学习那么多配置选项的人配置。通过使用基于菜单的 obconf 的配置应用,可以像在 GNOME 或 KDE 这样的完整桌面中一样轻松地设置所有常用首选项。
|
||||
|
||||
### 安装 Openbox
|
||||
|
||||
你可能会在 Linux 发行版的软件仓库中找到 Openbox,也可以在 [Openbox.org][3] 中找到它。如果你已经在运行其他桌面,那么可以安全地在同一系统上安装 Openbox,因为 Openbox 除了几个配置面板之外,不包括任何捆绑的应用。
|
||||
|
||||
安装后,退出当前桌面会话,以便你可以登录 Openbox 桌面。默认情况下,会话管理器(KDM、GDM、LightDM 或 XDM,这取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该选择。
|
||||
|
||||
要使用 GDM 覆盖它:
|
||||
|
||||
![Select your desktop session in GDM][4]
|
||||
|
||||
要使用 SDDM 覆盖它:
|
||||
|
||||
![Select your desktop session with KDM][5]
|
||||
|
||||
### 配置 Openbox 桌面
|
||||
|
||||
默认情况下,Openbox 包含 obconf 应用,你可以使用它来选择和安装主题、修改鼠标行为、设置桌面首选项等。你可能会在仓库中发现其他配置应用,如 obmenu,用于配置窗口管理器的其他部分。
|
||||
|
||||
![Openbox Obconf configuration application][6]
|
||||
|
||||
构建你自己的桌面环境相对容易。它有一些所有常见的桌面组件,例如系统托盘 [stalonetray][7]、任务栏 [Tint2][8] 或 [Xfce4-panel][9] 等几乎你能想到的。任意组合应用,直到拥有梦想的开源桌面为止。
|
||||
|
||||
![Openbox][10]
|
||||
|
||||
### 为何使用 Openbox
|
||||
|
||||
Openbox 占用的系统资源很小、易于配置、使用起来很愉悦。它基本不会让你感觉到阻碍,会是一个容易熟悉的系统。你永远不会知道你面前的桌面环境秘密使用了 Openbox 作为窗口管理器(知道如何自定义它会不会很高兴?)。如果开源吸引你,那么试试看 Openbox。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/openbox-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_general_openfield.png?itok=MeVN97oy (open with sky and grass)
|
||||
[2]: http://openbox.org
|
||||
[3]: http://openbox.org/wiki/Openbox:Download
|
||||
[4]: https://opensource.com/sites/default/files/advent-gdm_0.jpg (Select your desktop session in GDM)
|
||||
[5]: https://opensource.com/sites/default/files/advent-kdm.jpg (Select your desktop session with KDM)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-openbox-obconf_675px.jpg (Openbox Obconf configuration application)
|
||||
[7]: https://sourceforge.net/projects/stalonetray/
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
[9]: http://xfce.org
|
||||
[10]: https://opensource.com/sites/default/files/uploads/advent-openbox_675px.jpg (Openbox)
|
||||
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mayunmeiyouming)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11703-1.html)
|
||||
[#]: subject: (What GNOME 2 fans love about the Mate Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/mate-linux-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNOME 2 粉丝喜欢 Mate Linux 桌面的什么?
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你还在怀念 GNOME 2,那么 Mate Linux 桌面将满足你的怀旧情怀。
|
||||
|
||||

|
||||
|
||||
如果你以前听过这个传闻:当 GNOME3 第一次发布时,很多 GNOME 用户还没有准备好放弃 GNOME 2。[Mate][2](以<ruby>马黛茶<rt>yerba mate</rt></ruby>植物命名)项目的开始是为了延续 GNOME 2 桌面,刚开始时它使用 GTK 2(GNOME 2 所基于的工具包),然后又合并了 GTK 3。由于 Linux Mint 的简单易用,使得该桌面变得非常流行,并且从那时起,它已经普遍用于 Fedora、Ubuntu、Slackware、Arch 和许多其他 Linux 发行版上。今天,Mate 继续提供一个传统的桌面环境,它的外观和感觉与 GNOME 2 完全一样,使用 GTK 3 工具包。
|
||||
|
||||
你可以在你的 Linux 发行版的软件仓库中找到 Mate,也可以下载并[安装][3]一个把 Mate 作为默认桌面的发行版。不过,在你这样做之前,请注意为了提供完整的桌面体验,所以许多 Mate 应用程序都是随该桌面一起安装的。如果你运行的是不同的桌面,你可能会发现自己有多余的应用程序(两个 PDF 阅读器、两个媒体播放器、两个文件管理器,等等)。所以如果你只想尝试 Mate 桌面,可以在虚拟机(例如 [GNOME box][4])中安装基于 Mate 的发行版。
|
||||
|
||||
### Mate 桌面之旅
|
||||
|
||||
Mate 项目不仅仅可以让你想起来 GNOME 2;它就是 GNOME 2。如果你是 00 年代中期 Linux 桌面的粉丝,至少,你会从中感受到 Mate 的怀旧情怀。我不是 GNOME 2 的粉丝,我更倾向于使用 KDE,但是有一个地方我无法想象没有 GNOME 2:[OpenSolaris][5]。OpenSolaris 项目并没有持续太久,在 Sun Microsystems 被并入 Oracle 之前,Ian Murdock 加入 Sun 时它就显得非常突出,我当时是一个初级的 Solaris 管理员,使用 OpenSolaris 来让自己更多学会那种 Unix 风格。这是我使用过 GNOME 2 的唯一平台(因为我一开始不知道如何更改桌面,后来习惯了它),而今天的 [OpenIndiana project][6] 是 OpenSolaris 的社区延续,它通过 Mate 桌面使用 GNOME 2。
|
||||
|
||||
![Mate on OpenIndiana][7]
|
||||
|
||||
Mate 的布局由左上角的三个菜单组成:应用程序、位置和系统。应用程序菜单提供对系统上安装的所有的应用程序启动器的快速访问。位置菜单提供对常用位置(如家目录、网络文件夹等)的快速访问。系统菜单包含全局选项,如关机和睡眠。右上角是一个系统托盘,屏幕底部有一个任务栏和一个虚拟桌面切换栏。
|
||||
|
||||
就桌面设计而言,这是一种稍微有点奇怪的配置。它从早期的 Linux 桌面、MacFinder 和 Windows 中借用了一些相同的部分,但是又创建了一个独特的配置,这种配置很直观而有些熟悉。Mate 执意保持这个模型,而这正是它的用户喜欢的地方。
|
||||
|
||||
### Mate 和开源
|
||||
|
||||
Mate 是一个最直接的例子,展示了开源如何使开发人员能够对抗项目生命的终结。从理论上讲,GNOME 2 会被 GNOME 3 所取代,但它依然存在,因为一个开发人员建立了该代码的一个分支并继续发展了下去。它的发展势头越来越庞大,更多的开发人员加入进来,并且这个让用户喜爱的桌面比以往任何时候都要更好。并不是所有的软件都有第二次机会,但是开源永远是一个机会,否则就永远没有机会。
|
||||
|
||||
使用和支持开源意味着支持用户和开发人员的自由。而且 Mate 桌面是他们的努力的有力证明。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/mate-linux-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[mayunmeiyouming](https://github.com/mayunmeiyouming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
|
||||
[2]: https://mate-desktop.org/
|
||||
[3]: https://mate-desktop.org/install/
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://en.wikipedia.org/wiki/OpenSolaris
|
||||
[6]: https://www.openindiana.org/documentation/faq/#what-is-openindiana
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-mate-openindiana_675px.jpg (Mate on OpenIndiana)
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11706-1.html)
|
||||
[#]: subject: (Get started with Lumina for your Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-lumina-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 Linux 桌面中开始使用 Lumina
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。Lumina 桌面是让你使用快速、合理的基于 Fluxbox 桌面的捷径,它具有你无法缺少的所有功能。
|
||||
|
||||
|
||||
|
||||
多年来,有一个名为 PC-BSD 的基于 FreeBSD 的桌面操作系统(OS)。它旨在作为一个常规使用的系统,因此值得注意,因为 BSD 主要用于服务器。大多数时候,PC-BSD 默认带 KDE 桌面,但是 KDE 越来越依赖于 Linux 特定的技术,因此 PC-BSD 越来越从 KDE 迁离。PC-BSD 变成了 [Trident][2],它的默认桌面是 [Lumina][3],它是一组小部件,它们使用与 KDE 相同的基于 Qt 的工具包,运行在 Fluxbox 窗口管理器上。
|
||||
|
||||
你可以在 Linux 发行版的软件仓库或 BSD 的 ports 树中找到 Lumina 桌面。如果你安装了 Lumina 并且已经在运行另一个桌面,那么你可能会发现有冗余的应用(两个 PDF 阅读器、两个文件管理器,等等),因为 Lumina 包含一些集成的应用。如果你只想尝试 Lumina 桌面,那么可以在虚拟机如 [GNOME Boxes][4] 中安装基于 Lumina 的 BSD 发行版。
|
||||
|
||||
如果在当前的操作系统上安装 Lumina,那么必须注销当前的桌面会话,才能登录到新的会话。默认情况下,会话管理器(SDDM、GDM、LightDM 或 XDM,取决于你的设置)将继续登录到以前的桌面,因此你必须在登录之前覆盖该桌面。
|
||||
|
||||
在 GDM 中:
|
||||
|
||||
![Selecting your desktop in GDM][5]
|
||||
|
||||
在 SDDM 中:
|
||||
|
||||
![Selecting your desktop in KDM][6]
|
||||
|
||||
### Lumina 桌面
|
||||
|
||||
Lumina 提供了一个简单而轻巧的桌面环境。屏幕底部有一个面板,它的左侧是应用菜单,中间是任务栏,右边是系统托盘。桌面上有图标,可以快速访问常见的应用和路径。
|
||||
|
||||
除了这个基本的桌面结构外,Lumina 还有自定义文件管理器、PDF 查看器,截图工具、媒体播放器、文本编辑器和存档工具。还有一个配置程序可以帮助你自定义 Lumina 桌面,并且右键单击桌面可以找到更多配置选项。
|
||||
|
||||
![Lumina desktop running on Project Trident][7]
|
||||
|
||||
Lumina 与几个 Linux 轻量级桌面非常相似,尤其是 LXQT,不同之处在于 Lumina 完全不依赖于基于 Linux 的桌面框架(例如 ConsoleKit、PolicyKit、D-Bus 或 systemd)。对于你而言,这是否具有优势取决于所运行的操作系统。毕竟,如果你运行的是可以访问这些功能的 Linux,那么使用不使用这些特性的桌面可能就没有多大意义,还会减少功能。如果你运行的是 BSD,那么在 Fluxbox 中运行 Lumina 部件意味着你不必从 ports 安装 Linux 兼容库。
|
||||
|
||||
### 为什么要使用 Lumina
|
||||
|
||||
Lumina 设计简单,它没有很多功能,但是你可以安装 Fluxbox 你喜欢的组件(用于文件管理的 [PCManFM][8]、各种 [LXQt 应用][9]、[Tint2][10] 面板等)。在开源中,开源用户喜欢寻找不要重复发明轮子的方法(几乎与我们喜欢重新发明轮子一样多)。
|
||||
|
||||
Lumina 桌面是让你使用快速、合理的基于 Fluxbox 桌面的捷径,它具有你无法缺少的所有功能,并且你很少需要调整细节。试一试 Lumina 桌面,看看它是否适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-lumina-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lightbulb-idea-think-yearbook-lead.png?itok=5ZpCm0Jh (Lightbulb)
|
||||
[2]: https://project-trident.org/
|
||||
[3]: https://lumina-desktop.org/
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/sites/default/files/uploads/advent-gdm_400x400_1.jpg (Selecting your desktop in GDM)
|
||||
[6]: https://opensource.com/sites/default/files/uploads/advent-kdm_400x400_1.jpg (Selecting your desktop in KDM)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-lumina.jpg (Lumina desktop running on Project Trident)
|
||||
[8]: https://wiki.lxde.org/en/PCManFM
|
||||
[9]: http://lxqt.org
|
||||
[10]: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
@ -0,0 +1,207 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11720-1.html)
|
||||
[#]: subject: (Build a retro Apple desktop with the Linux MLVWM)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-mlvwm-desktop)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Linux MLVWM 打造复古苹果桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果老式的苹果电脑是用开源 POSIX 构建的呢?你可以通过构建 Macintosh 式的虚拟窗口管理器来实现。
|
||||
|
||||
![Person typing on a 1980's computer][1]
|
||||
|
||||
想象一下穿越到另一段平行历史,Apple II GS 和 MacOS 7 是基于开源 [POSIX][2] 构建的,它使用了与现代 Linux 相同的所有惯例,例如纯文本配置文件和模块化系统设计。这样的操作系统将为其用户带来什么?你可以使用 [Macintosh 式的虚拟窗口管理器(MLVWM)][3]来回答这些问题(甚至更多!)。
|
||||
|
||||
![MLVWM running on Slackware 14.2][4]
|
||||
|
||||
### 安装 MLVWM
|
||||
|
||||
MLVWM 安装并不容易,并且可能不在你的发行版软件仓库中。如果你有时间理解翻译不佳的 README 文件,编辑一些配置文件,收集并调整一些旧的 .xpm 图片,编辑一两个 Xorg 选项,那么你就可以体验 MLVWM。不管怎么说,这是一个新奇的窗口管理器,其最新版本可以追溯到 2000 年。
|
||||
|
||||
要编译 MLVWM,你必须安装 imake,它提供了 `xmkmf` 命令。你可以从发行版的软件仓库中安装 imake,也可以直接从 [Freedesktop.org][5] 获得。假设你已经有 `xmkmf` 命令,请进入包含 MLVWM 源码的目录,然后运行以下命令进行构建:
|
||||
|
||||
```
|
||||
$ xmkmf -a
|
||||
$ make
|
||||
```
|
||||
|
||||
构建后,编译后的 `mlvwm` 二进制文件位于 `mlvwm` 目录中。将其移动到[你的 PATH][6] 的任何位置:
|
||||
|
||||
```
|
||||
$ mv mlvwm/mlvwm /usr/local/bin/
|
||||
```
|
||||
|
||||
#### 编辑配置文件
|
||||
|
||||
现在已经安装好 MLVWM,但是如果不调整几个配置文件并仔细放好所需的图像文件,它将无法正确启动。示例配置文件位于你下载的源代码的 `sample_rc` 目录中。将文件 `Mlvwm-Netscape` 和 `Mlvwm-Xterm` 复制到你的主目录:
|
||||
|
||||
```
|
||||
$ cp sample_rc/Mlvwm-{Netscape,Xterm} $HOME
|
||||
```
|
||||
|
||||
将 `Mlvwmrc` 改名为 `$HOME/.mlvwmrc`(是的,即使示例文件的名称看似是大写字母,但你也必须使用小写的 “m”):
|
||||
|
||||
```
|
||||
$ cp sample_rc/Mlvwmrc $HOME/.mlvwmrc
|
||||
```
|
||||
|
||||
打开 `.mlwmrc` 并找到第 54-55 行,它们定义了 MLVWM 在菜单和 UI 中使用的像素图的路径(`IconPath`):
|
||||
|
||||
```
|
||||
# Set icon search path. It needs before "Style".
|
||||
IconPath /usr/local/include/X11/pixmaps:/home2/tak/bin/pixmap
|
||||
```
|
||||
|
||||
调整路径以匹配你填充图像的路径(我建议使用 `$HOME/.local/share/pixmaps`)。MLVWM 不提供像素图,因此需要你提供构建桌面所需图标。
|
||||
|
||||
即使你有位于系统其他位置的像素图(例如 `/usr/share/pixmaps`),也要这样做,因为你需要调整像素图的大小,你可能也不想在系统范围内执行此操作。
|
||||
|
||||
```
|
||||
# Set icon search path. It needs before "Style".
|
||||
IconPath /home/seth/.local/share/pixmaps
|
||||
```
|
||||
|
||||
#### 选择像素图
|
||||
|
||||
你已将 `.local/share/pixmaps` 目录定义为像素图源路径,但是该目录和图像均不存在。创建目录:
|
||||
|
||||
```
|
||||
$ mkdir -p $HOME/.local/share/pixmaps
|
||||
```
|
||||
|
||||
现在,配置文件将图像分配给菜单项和 UI 元素,但是系统中不存在这些图像。要解决此问题,请通读配置文件并找到每个 .xpm 图像。对于配置中列出的每个图像,将具有相同文件名的图像(或更改配置文件中的文件名)添加到你的 IconPath 目录。
|
||||
|
||||
`.mlvwmrc` 文件的注释很好,因此你可以大致了解要编辑的内容。无论如何,这只是第一步。你可以随时回来更改桌面外观。
|
||||
|
||||
这有些例子。
|
||||
|
||||
此代码块设置屏幕左上角的图标:
|
||||
|
||||
```
|
||||
# Register the menu
|
||||
Menu Apple, Icon label1.xpm, Stick
|
||||
```
|
||||
|
||||
`label1.xpm` 图像实际上在源代码的 `pixmap` 目录中,但我更喜欢使用来自 `/usr/share/pixmaps` 的 `Penguin.xpm`(在 Slackware 上)。无论使用什么,都必须将自定义像素图放在 `~/.local/share/pixmaps` 中,并在配置中更改像素图的名称,或者重命名像素图以匹配配置文件中当前的名称。
|
||||
|
||||
此代码块定义了左侧菜单中列出的应用:
|
||||
|
||||
```
|
||||
"About this Workstation..." NonSelect, Gray, Action About
|
||||
"" NonSelect
|
||||
"Terminal" Icon mini-display.xpm, Action Exec "kterm" exec kterm -ls
|
||||
"Editor" Action Exec "mule" exec mule, Icon mini-edit.xpm
|
||||
"calculator" Action Exec "xcal" exec xcalc, Icon mini-calc.xpm
|
||||
END
|
||||
```
|
||||
|
||||
通过遵循与配置文件中相同的语法,你可以自定义像素图并将自己的应用添加到菜单中(例如,我将 `mule` 更改为 `emacs`)。这是你在 MLVWM GUI 中打开应用的入口,因此请列出你要快速访问的所有内容。你可能还希望包括指向 `/usr/share/applications` 文件夹的快捷方式。
|
||||
|
||||
```
|
||||
"Applications" Icon Penguin.xpm, Action Exec "thunar /usr/share/applications" exec thunar /usr/share/applications
|
||||
```
|
||||
|
||||
完成编辑配置文件并将自己的图像添加到 IconPath 目录后,必须将所有像素图的大小都调整为大约 16x16 像素。(MLVWM 的默认设置不一致,因此存在变化空间。)你可以使用 ImageMagick 进行批量操作:
|
||||
|
||||
```
|
||||
$ for i in ~/.local/share/mlvwm-pixmaps/*xpm ; do convert -resize '16x16^' $i; done
|
||||
```
|
||||
|
||||
### 启动 MLVWM
|
||||
|
||||
最简单的运行 MLVWM 的方式是让 Xorg 完成大部分工作。首先,你必须创建一个 `$HOME/.xinitrc` 文件。我从 Slackware 复制了这个,它也是从 Xorg 拿来的:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
# $XConsortium: xinitrc.cpp,v 1.4 91/08/22 11:41:34 rws Exp $
|
||||
|
||||
userresources=$HOME/.Xresources
|
||||
usermodmap=$HOME/.Xmodmap
|
||||
sysresources=/etc/X11/xinit/.Xresources
|
||||
sysmodmap=/etc/X11/xinit/.Xmodmap
|
||||
|
||||
# merge in defaults and keymaps
|
||||
|
||||
if [ -f $sysresources ]; then
|
||||
xrdb -merge $sysresources
|
||||
fi
|
||||
|
||||
if [ -f $sysmodmap ]; then
|
||||
xmodmap $sysmodmap
|
||||
fi
|
||||
|
||||
if [ -f $userresources ]; then
|
||||
xrdb -merge $userresources
|
||||
fi
|
||||
|
||||
if [ -f $usermodmap ]; then
|
||||
xmodmap $usermodmap
|
||||
fi
|
||||
|
||||
# Start the window manager:
|
||||
if [ -z "$DESKTOP_SESSION" -a -x /usr/bin/ck-launch-session ]; then
|
||||
exec ck-launch-session /usr/local/bin/mlvwm
|
||||
else
|
||||
exec /usr/local/bin/mlvwm
|
||||
fi
|
||||
```
|
||||
|
||||
根据此文件,`startx` 命令的默认操作是启动 MLVWM。但是,你的发行版可能对于图形服务器启动(或被终止以重新启动)时会发生的情况有其他做法,因此此文件可能对你没有什么帮助。在许多发行版上,你可以添加 .desktop 文件到 `/usr/share/xsessions` 中,以将其列在 GDM 或 KDM 菜单中,因此创建名为 `mlvwm.desktop` 的文件并输入:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=Mlvwm
|
||||
Comment=Macintosh-like virtual window manager
|
||||
Exec=/usr/local/bin/mlvwm
|
||||
TryExec=ck-launch-session /usr/local/bin/mlvwm
|
||||
Type=Application
|
||||
```
|
||||
|
||||
从桌面会话注销并重新登录到 MLVWM。默认情况下,会话管理器(KDM、GDM 或 LightDM,具体取决于你的设置)将继续登录到以前的桌面,因此在登录之前必须覆盖它。
|
||||
|
||||
对于 GDM:
|
||||
|
||||
![][7]
|
||||
|
||||
对于 SDDM:
|
||||
|
||||
![][8]
|
||||
|
||||
#### 强制启动
|
||||
|
||||
如果 MLVWM 无法启动,请尝试安装 XDM,这是一个轻量级会话管理器,它不会查询 `/usr/share/xsessions` 的内容,而是执行经过身份验证用户的所有 `.xinitrc` 操作。
|
||||
|
||||
![MLVWM][9]
|
||||
|
||||
### 打造自己的复古苹果
|
||||
|
||||
MLVWM 桌面未经打磨、不完美、模仿到位且充满乐趣。你看到的许多菜单项都是未实现的,但你可以使它们变得活跃且有意义。
|
||||
|
||||
这是一次让你时光倒流、改变历史,让老式苹果系列电脑成为开源堡垒的机会。成为一名修正主义者,设计你自己的复古苹果桌面,最重要的是,它有乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-mlvwm-desktop
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
|
||||
[2]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
|
||||
[3]: http://www2u.biglobe.ne.jp/~y-miyata/mlvwm.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/advent-mlvwm-file.jpg (MLVWM running on Slackware 14.2)
|
||||
[5]: http://cgit.freedesktop.org/xorg/util/imake
|
||||
[6]: https://opensource.com/article/17/6/set-path-linux
|
||||
[7]: https://opensource.com/sites/default/files/advent-gdm_2.jpg
|
||||
[8]: https://opensource.com/sites/default/files/advent-kdm_1.jpg
|
||||
[9]: https://opensource.com/sites/default/files/uploads/advent-mlvwm-chess.jpg (MLVWM)
|
||||
131
published/20191218 How tracking pixels work.md
Normal file
131
published/20191218 How tracking pixels work.md
Normal file
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11721-1.html)
|
||||
[#]: subject: (How tracking pixels work)
|
||||
[#]: via: (https://jvns.ca/blog/how-tracking-pixels-work/)
|
||||
[#]: author: (Julia Evans https://jvns.ca/)
|
||||
|
||||
网络广告商的像素追踪是如何工作的?
|
||||
======
|
||||
|
||||

|
||||
|
||||
昨天,我和一名记者谈到了一个问题:广告商是如何在互联网上对人们进行追踪的?我们津津有味地查看了 Firefox 的开发者工具(虽然我不是一个互联网隐私专家,但至少还会使用开发者工具中的“network”标签页),从中我终于弄明白<ruby>像素追踪<rt>tracking pixels</rt></ruby>在实际中是如何工作的了。
|
||||
|
||||
### 问题:Facebook 怎么知道你逛了 Old Navy?
|
||||
|
||||
我时常听人们说起这种有些诡异的上网经历:你在线上浏览了一个商品,一天之后,竟然看到了同一款靴子(或者是别的什么你当时浏览的商品)的广告。这就是所谓的“再营销”,但它到底是如何实现的呢?
|
||||
|
||||
在本文中,我们来进行一个小实验,看看 Facebook 究竟是怎么知道你在线上浏览了什么商品的。这里使用 Facebook 作为示例,只是因为很容易找到使用了 Facebook 像素追踪技术的网站;其实,几乎所有互联网广告公司都会使用类似的追踪技术。
|
||||
|
||||
### 准备:允许第三方追踪器,同时关闭广告拦截器
|
||||
|
||||
我使用的浏览器是 Firefox,但是 Firefox 默认拦截了很多这种类型的追踪,所以需要修改 Firefox 的隐私设置,才能让这种追踪生效。
|
||||
|
||||
首先,我将隐私设置从默认设置([截图][1])修改为允许第三方追踪器的个性化设置([截图][2]),然后禁用了一些平时运行的隐私保护扩展。
|
||||
|
||||
![截图][1]
|
||||
|
||||
![截图][2]
|
||||
|
||||
### 像素追踪:关键不在于 gif,而在于请求参数
|
||||
|
||||
像素追踪是网站用来追踪你的一个 1x1 大小的 gif。就其本身而言,一个小小的 1x1 gif 显然起不到什么作用。那么,像素追踪到底是如何进行追踪的?其中涉及两个方面:
|
||||
|
||||
1. 通过使用像素追踪上的**请求参数**,网站可以添加额外的信息,比如你正在访问的页面。这样一来,请求的就不是 `https://www.facebook.com/tr/`(这个链接是一个 44 字节大小的 1x1 gif),而是 `https://www.facebook.com/tr/?the_website_you're_on`。(邮件营销人员会使用类似的技巧,通过为像素追踪指定一个独特的 URL,弄清楚你是否打开了某一封邮件。)
|
||||
2. 在发送该请求的同时,还发送了相应的 cookie。这样一来广告商就可以知道,访问 oldnavy.com 的这个人和在同一台电脑上使用 Facebook 的是同一个人。
|
||||
|
||||
### Old Navy 网站上的 Facebook 像素追踪
|
||||
|
||||
为了对此进行验证,我在 Old Navy(GAP 旗下的一个服装品牌)网站上浏览了一个商品,相应的 URL 是 `https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1`(这是一件“男款短绒格子花呢大衣”)。
|
||||
|
||||
在我浏览这个商品的同时,页面上运行的 Javascript(用的应该是[这段代码][4])向 facebook.com 发送了一个请求。在开发者工具中,该请求看上去是这样的:(我屏蔽了大部分 cookie 值,因为其中有一些是我的登录 cookie)
|
||||
|
||||
![][5]
|
||||
|
||||
下面对其进行拆解分析:
|
||||
|
||||
1. 我的浏览器向如下 URL 发送了一个请求;
|
||||
|
||||
```
|
||||
https://www.facebook.com/tr/?id=937725046402747&ev=PageView&dl=https%3A%2F%2Foldnavy.gap.com%2Fbrowse%2Fproduct.do%3Fpid%3D504753002%26cid%3D1125694%26pcid%3Dxxxxxx0%26vid%3D1%26grid%3Dpds_0_109_1%23pdp-page-content&rl=https%3A%2F%2Foldnavy.gap.com%2Fbrowse%2Fcategory.do%3Fcid%3D1135640%26mlink%3D5155%2Cm_mts_a&if=false&ts=1576684838096&sw=1920&sh=1080&v=2.9.15&r=stable&a=tmtealium&ec=0&o=30&fbp=fb.1.1576684798512.1946041422&it=15xxxxxxxxxx4&coo=false&rqm=GET
|
||||
```
|
||||
2. 与该请求同时发送的,还有一个名为 `fr` 的 cookie,取值为
|
||||
|
||||
```
|
||||
10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.
|
||||
```
|
||||
(估计是我的 Facebook 广告追踪 ID)
|
||||
|
||||
在所发送的像素追踪查询字符串里,有三个值得注意的地方:
|
||||
|
||||
* 我当前访问的页面:`https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1#pdp-page-content`
|
||||
* 引导我来到当前页面的上一级页面:`https://oldnavy.gap.com/browse/category.do?cid=1135640&mlink=5155,m_mts_a`;
|
||||
* 作为我的身份标识的 cookie:`10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.`
|
||||
|
||||
### 下面来逛逛 Facebook!
|
||||
|
||||
下面来逛逛 Facebook 吧。我之前已经登入了 Facebook,猜猜看,我的浏览器发送给 Facebook 的 cookie 是什么?
|
||||
|
||||
不出所料,正是之前见过的 `fr` cookie:`10oGXEcKfGekg67iy.AWVdJq5MG3VLYaNjz4MTNRaU1zg.Bd-kxt.KU.F36.0.0.Bd-kx6.`。Facebook 现在一定知道我(Julia Evans,这个 Facebook 账号所关联的人)在几分钟之前访问了 Old Navy 网站,并且浏览了“男款短绒格子花呢大衣”,因为他们可以使用这个 cookie 将数据串联起来。
|
||||
|
||||
### 这里涉及到的是第三方 cookie
|
||||
|
||||
Facebook 用来追踪我访问了哪些网站的 cookie,属于所谓的“第三方 cookie”,因为 Old Navy 的网站使用它为一个第三方(即 facebook.com)确认我的身份。这和用来维持登录状态的“第一方 cookie”有所不同。
|
||||
|
||||
Safari 和 Firefox 默认都会拦截许多第三方 cookie(所以需要更改 Firefox 的隐私设置,才能够进行这个实验),而 Chrome 目前并不进行拦截(很可能是因为 Chrome 的所有者正是一个广告公司)。(LCTT 译注:Chrome 可以设置阻拦)
|
||||
|
||||
### 网站上的像素追踪有很多
|
||||
|
||||
如我所料,网站上的像素追踪有 **很多**。比如,wrangler.com 在我的浏览器里加载了来自不同域的 19 个不同的像素追踪。wrangler.com 上的像素追踪分别来自:`ct.pinterest.com`、`af.monetate.net`、`csm.va.us.criteo.net`、`google-analytics.com`、`dpm.demdex.net`、`google.ca`、`a.tribalfusion.com`、`data.photorank.me`、`stats.g.doubleclick.net`、`vfcorp.dl.sc.omtrdc.net`、`ib.adnxs.com`、`idsync.rlcdn.com`、`p.brsrvr.com`,以及 `adservice.google.com`。
|
||||
|
||||
Firefox 贴心地指出,如果使用 Firefox 的标准隐私设置,其中的大部分追踪器都会被拦截:
|
||||
|
||||
![][8]
|
||||
|
||||
### 浏览器的重要性
|
||||
|
||||
浏览器之所以如此重要,是因为你的浏览器最终决定了发送你的什么信息、发送到哪些网站。Old Navy 网站上的 Javascript 可以请求你的浏览器向 Facebook 发送关于你的追踪信息,但浏览器可以拒绝执行。浏览器的决定可以是:“哈,我知道 facebook.com/tr/ 是一个像素追踪,我不想让我的用户被追踪,所以我不会发送这个请求”。
|
||||
|
||||
浏览器还可以允许用户对上述行为进行配置,方法包括更改浏览器设置,以及安装浏览器扩展(所以才会有如此多的隐私保护扩展)。
|
||||
|
||||
### 摸清其中原理,实为一件趣事
|
||||
|
||||
在我看来,弄清楚 cookie/像素追踪是怎么用于对你进行追踪的,实在是一件趣事(尽管有点吓人)。我之前大概明白其中的道理,但是并没有亲自查看过像素追踪上的 cookie,也没有看过发送的查询参数上究竟包含什么样的信息。
|
||||
|
||||
当然,明白了其中的原理,也就更容易降低被追踪的概率了。
|
||||
|
||||
### 可以采取的措施
|
||||
|
||||
为了尽量避免在互联网上被追踪,我采取了几种简单的措施:
|
||||
|
||||
* 安装一个广告拦截器(比如 ublock origin 之类)。广告拦截器可以针对许多追踪器的域进行拦截。
|
||||
* 使用目前默认隐私保护强度更高的 Firefox/Safari,而不是 Chrome。
|
||||
* 使用 [Facebook Container][9] 这个 Firefox 扩展。该扩展针对 Facebook 进一步采取了防止追踪的措施。
|
||||
|
||||
虽然在互联网上被追踪的方式还有很多(尤其是在使用手机应用的时候,因为在这种情况下,你没有和像对浏览器一样的控制程度),但是能够理解这种追踪方法的工作原理,稍微减少一些被追踪的可能性,也总归是一件好事。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/how-tracking-pixels-work/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://jvns.ca/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://jvns.ca/images/trackers.png
|
||||
[2]: https://jvns.ca/images/firefox-insecure-settings.png
|
||||
[3]: https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1
|
||||
[4]: https://developers.facebook.com/docs/facebook-pixel/implementation/
|
||||
[5]: https://jvns.ca/images/fb-old-navy.png
|
||||
[6]: https://oldnavy.gap.com/browse/product.do?pid=504753002&cid=1125694&pcid=1135640&vid=1&grid=pds_0_109_1#pdp-page-content
|
||||
[7]: https://oldnavy.gap.com/browse/category.do?cid=1135640&mlink=5155,m_mts_a
|
||||
[8]: https://jvns.ca/images/firefox-helpful.png
|
||||
[9]: https://addons.mozilla.org/en-CA/firefox/addon/facebook-container/
|
||||
@ -0,0 +1,179 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11722-1.html)
|
||||
[#]: subject: (How to Start, Stop & Restart Services in Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/start-stop-restart-services-linux/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
如何在 Ubuntu 和其他 Linux 发行版中启动、停止和重启服务
|
||||
======
|
||||
|
||||

|
||||
|
||||
服务是必不可少的后台进程,它通常随系统启动,并在关机时关闭。如果你是系统管理员,那么你会定期处理服务。如果你是普通桌面用户,你可能会遇到需要重启服务的情况,例如[安装 Barrier 来用于在计算机之间共享鼠标和键盘][1]。或[在使用 ufw 设置防火墙][2]时。
|
||||
|
||||
今天,我将向你展示两种管理服务的方式。你将学习在 Ubuntu 或任何其他 Linux 发行版中启动、停止和重启服务。
|
||||
|
||||
> systemd 与 init
|
||||
>
|
||||
> 如今,Ubuntu 和许多其他发行版都使用 systemd 而不是旧的 init。
|
||||
>
|
||||
> 在 systemd 中,可以使用 `systemctl` 命令管理服务。
|
||||
>
|
||||
> 在 init 中,你可以使用 `service` 命令管理服务。
|
||||
>
|
||||
> 你会注意到,即使你的 Linux 系统使用 systemd,它仍然可以使用 `service` 命令(与 init 系统一起使用的)。这是因为 `service` 命令实际上已重定向到 `systemctl`。systemd 引入了向后兼容性,因为系统管理员们习惯使用 `service` 命令。
|
||||
>
|
||||
> 在本教程中,我将同时展示 `systemctl` 和 `service` 命令。
|
||||
|
||||
我用的是 Ubuntu 18.04,但其他版本的过程也一样。
|
||||
|
||||
### 方法 1:使用 systemd 在 Linux 中管理服务
|
||||
|
||||
我从 systemd 开始,因为它被广泛接受。
|
||||
|
||||
#### 1、列出所有服务
|
||||
|
||||
为了管理服务,你首先需要知道系统上有哪些服务可用。你可以使用 systemd 的命令列出 Linux 系统上的所有服务:
|
||||
|
||||
```
|
||||
systemctl list-unit-files --type service -all
|
||||
```
|
||||
|
||||
![systemctl list-unit-files][3]
|
||||
|
||||
此命令将输出所有服务的状态。服务状态有<ruby>启用<rt>enabled</rt></ruby>、<ruby>禁用<rt>disabled</rt></ruby>、<ruby>屏蔽<rt>masked</rt></ruby>(在取消屏蔽之前处于非活动状态)、<ruby>静态<rt>static</rt></ruby>和<ruby>已生成<rt>generated</rt></ruby>。
|
||||
|
||||
与 [grep 命令][4] 结合,你可以仅显示正在运行的服务:
|
||||
|
||||
```
|
||||
sudo systemctl | grep running
|
||||
```
|
||||
|
||||
![Display running services systemctl][5]
|
||||
|
||||
现在,你知道了如何引用所有不同的服务,你可以开始主动管理它们。
|
||||
|
||||
**注意:** 下列命令中的 `<service-name>` 应该用你想管理的服务名代替。(比如:network-manager、ufw 等)
|
||||
|
||||
#### 2、启动服务
|
||||
|
||||
要在 Linux 中启动服务,你只需使用它的名字:
|
||||
|
||||
```
|
||||
systemctl start <service-name>
|
||||
```
|
||||
|
||||
#### 3、停止服务
|
||||
|
||||
要停止 systemd 服务,可以使用 `systemctl` 命令的 `stop` 选项:
|
||||
|
||||
```
|
||||
systemctl stop <service-name>
|
||||
```
|
||||
|
||||
#### 4、重启服务
|
||||
|
||||
要重启 systemd 服务,可以使用:
|
||||
|
||||
```
|
||||
systemctl restart <service-name>
|
||||
```
|
||||
|
||||
#### 5、检查服务状态
|
||||
|
||||
你可以通过打印服务状态来确认你已经成功执行特定操作:
|
||||
|
||||
```
|
||||
systemctl status <service-name>
|
||||
```
|
||||
|
||||
这将以以下方式输出:
|
||||
|
||||
![systemctl status][6]
|
||||
|
||||
这是 systemd 的内容。现在切换到 init。
|
||||
|
||||
### 方法 2:使用 init 在 Linux 中管理服务
|
||||
|
||||
init 的命令和 systemd 的一样简单。
|
||||
|
||||
#### 1、列出所有服务
|
||||
|
||||
要列出所有 Linux 服务,使用:
|
||||
|
||||
```
|
||||
service --status-all
|
||||
```
|
||||
|
||||
![service –status-all][7]
|
||||
|
||||
前面的 `[ – ]` 代表**禁用**,`[ + ]` 代表**启用**。
|
||||
|
||||
#### 2、启动服务
|
||||
|
||||
要在 Ubuntu 和其他发行版中启动服务,使用命令:
|
||||
|
||||
```
|
||||
service <service-name> start
|
||||
```
|
||||
|
||||
#### 3、停止服务
|
||||
|
||||
停止服务同样简单。
|
||||
|
||||
```
|
||||
service <service-name> stop
|
||||
```
|
||||
|
||||
#### 4、重启服务
|
||||
|
||||
如果你想重启服务,命令是:
|
||||
|
||||
```
|
||||
service <service-name> restart
|
||||
```
|
||||
|
||||
#### 5、检查服务状态
|
||||
|
||||
此外,要检查是否达到了预期的结果,你可以输出服务状态:
|
||||
|
||||
```
|
||||
service <service-name> status
|
||||
```
|
||||
|
||||
这将以以下方式输出:
|
||||
|
||||
![service status][8]
|
||||
|
||||
最重要的是,这将告诉你某项服务是否处于活跃状态(正在运行)。
|
||||
|
||||
### 总结
|
||||
|
||||
今天,我详细介绍了两种在 Ubuntu 或任何其他 Linux 系统上管理服务的非常简单的方法。 希望本文对你有所帮助。
|
||||
|
||||
你更喜欢哪种方法? 让我在下面的评论中知道!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/start-stop-restart-services-linux/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/keyboard-mouse-sharing-between-computers/
|
||||
[2]: https://itsfoss.com/set-up-firewall-gufw/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_list_services.png?ssl=1
|
||||
[4]: https://linuxhandbook.com/grep-command-examples/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_grep_running.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/systemctl_status.jpg?ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/service_status_all.png?ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/service_status.jpg?ssl=1
|
||||
@ -0,0 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11728-1.html)
|
||||
[#]: subject: (Customize your Linux desktop with KDE Plasma)
|
||||
[#]: via: (https://opensource.com/article/19/12/linux-kde-plasma)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 KDE Plasma 定制 Linux 桌面
|
||||
======
|
||||
|
||||
> 本文是 24 天 Linux 桌面特别系列的一部分。如果你认为没有太多自定义桌面的需要,KDE Plasma 可能适合你。
|
||||
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
KDE 社区的 Plasma 桌面是开源桌面环境中的巅峰之作。KDE 很早就进入了 Linux 桌面环境市场,但是由于它的基础 Qt 工具包当时没有完全开放的许可证,因此才有 [GNOME][2] 桌面。在此之后,Qt 开源了,并且 KDE(及其衍生产品,例如 [Trinity 桌面][3])开始蓬勃发展。
|
||||
|
||||
你可能会在发行版的软件仓库中找到 KDE 桌面,或者可以下载并安装将 KDE 作为默认桌面的发行版。在安装之前,请注意,KDE 提供了完整、集成且强大的桌面体验,因此会同时安装几个 KDE 应用。如果你已经在运行其他桌面,那么将发现有几个冗余的应用(两个 PDF 阅读器、多个媒体播放器、两个或多个文件管理器,等等)。如果你只想尝试而不是一直使用 KDE 桌面,那么可以在虚拟机,如 [GNOME Boxes][4] 中安装基于 KDE 的发行版,也可以尝试使用可引导的操作系统,例如 [Porteus][5]。
|
||||
|
||||
### KDE 桌面之旅
|
||||
|
||||
乍一看,[KDE Plasma][6] 桌面相对无聊,但让人感到舒适。它有行业标准的布局:左下角弹出应用菜单,中间是任务栏,右边是系统托盘。这正是你对标准家用或商用计算机的期望。
|
||||
|
||||
![KDE Plasma desktop][7]
|
||||
|
||||
但是,使 KDE 与众不同的是,你几乎可以更改任何想要的东西。Qt 工具包可以以令人惊讶的方式分割和重新排列,这意味着你实质上可以使用 KDE 的部件作为基础来设计自己的桌面。桌面行为的可用设置也很多。KDE 可以充当标准桌面、平铺窗口管理器以及两者之间的任意形式。你可以通过窗口类、角色、类型、标题或它们的任意组合来创建自己的窗口规则,因此,如果希望特定应用的行为不同于其他行为,那么可以创建全局设置的例外。
|
||||
|
||||
此外,它还有丰富的小部件集合,使你可以自定义与桌面交互的方式。它有一个类似 GNOME 的全屏应用启动器,一个类似 Unity 的 dock 启动器和仅有图标的任务栏,以及一个传统的任务栏。你可以在屏幕的任何边缘上创建和放置面板。
|
||||
|
||||
![A slightly customized KDE desktop][8]
|
||||
|
||||
实际上,它有太多的自定义项了,因此 KDE 最常见的批评之一是它的*太过可定制化*,所以请记住,自定义项是可选的。你可以在默认配置下使用 Plasma 桌面,并仅在你认为必要时逐步进行更改。Plasma 桌面配置选项最重要的不是它们的数目,而是它们容易发现和直观,它们都在系统设置应用或者右键单击中。
|
||||
|
||||
事实是,在 KDE 上,几乎绝不会只有一种方法可以完成任何给定的任务,并且它的用户将这个视为其最大的优势。KDE 中没有隐含的工作流,只有默认的。并且可以更改所有默认设置,直到你需要桌面做的成为你的习惯。
|
||||
|
||||
### 一致性和集成
|
||||
|
||||
KDE 社区以一致性和集成为荣,出色的开发人员、社区管理以及 KDE 库使其成为可能。KDE 的开发人员不只是桌面开发人员。它们提供了[惊人的应用集合][9],每个应用都使用 KDE 库创建,这些库扩展并标准化了常见的 Qt 小部件。使用 KDE 几个月后,无论是打开 [DigiKam][10] 进行照片管理,还是打开 Kmail 来检查电子邮件,还是打开 KTorrent 来获取最新的 ISO 或者使用 Dolphin 管理文件,你的肌肉记忆会在你思考之前直接带你进入对应 UI。
|
||||
|
||||
![KDE on Porteus][11]
|
||||
|
||||
### 尝试 KDE
|
||||
|
||||
KDE 适合所有人。使用其默认设置可获得流畅、原始的桌面体验,或对其进行自定义以使其成为自己专属。它是一个稳定、有吸引力且强大的桌面环境,可能有你想要在 Linux 完成要做的事的一切。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/linux-kde-plasma
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
[2]: https://opensource.com/article/19/12/gnome-linux-desktop
|
||||
[3]: https://opensource.com/article/19/12/linux-trinity-desktop-environment-tde
|
||||
[4]: https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization
|
||||
[5]: https://opensource.com/article/19/6/linux-distros-to-try
|
||||
[6]: https://kde.org/plasma-desktop
|
||||
[7]: https://opensource.com/sites/default/files/uploads/advent-kde-presskit.jpg (KDE Plasma desktop)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/advent-kde-dock.jpg (A slightly customized KDE desktop)
|
||||
[9]: https://kde.org/applications/
|
||||
[10]: https://opensource.com/life/16/5/how-use-digikam-photo-management
|
||||
[11]: https://opensource.com/sites/default/files/uploads/advent-kde.jpg (KDE on Porteus)
|
||||
@ -0,0 +1,129 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11726-1.html)
|
||||
[#]: subject: (How to Update Grub on Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/update-grub/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 和其它 Linux 发行版上更新 grub
|
||||
======
|
||||
|
||||

|
||||
|
||||
在这篇文章中,你将学习在 Ubuntu 或任何其它 Linux 发行版上更新 grub 。你也将学习一个或两个关于更新这个 grub 过程如何工作的事情。
|
||||
|
||||
### 如何更新 grub
|
||||
|
||||
Ubuntu 和很多其它的 Linux 发行版提供一个易使用的称为 `update-grub` 命令行实用程序。
|
||||
|
||||
为更新 grub ,你所要的全部工作就是使用 `sudo` 在终端中运行这个命令。
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
你应该看到一个像这样的输出:
|
||||
|
||||
```
|
||||
[email protected]:~$ sudo update-grub
|
||||
[sudo] password for abhishek:
|
||||
Sourcing file `/etc/default/grub'
|
||||
Generating grub configuration file ...
|
||||
Found linux image: /boot/vmlinuz-5.0.0-37-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-37-generic
|
||||
Found linux image: /boot/vmlinuz-5.0.0-36-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-36-generic
|
||||
Found linux image: /boot/vmlinuz-5.0.0-31-generic
|
||||
Found initrd image: /boot/initrd.img-5.0.0-31-generic
|
||||
Found Ubuntu 19.10 (19.10) on /dev/sda4
|
||||
Found MX 19 patito feo (19) on /dev/sdb1
|
||||
Adding boot menu entry for EFI firmware configuration
|
||||
done
|
||||
```
|
||||
|
||||
你可能看到一个类似的称为 `update-grub2` 的命令。不需要在 `update-grub` 和 `update-grub2` 之间感到害怕或不知所措。这两个命令执行相同的动作。
|
||||
|
||||
大约在 10 年前,当 grub2 刚刚被引进时,`update-grub2` 命令也被引进。现在,`update-grub2` 只是一个链接到 `update-grub` 的符号,它们都更新 grub2 配置(因为 grub2 是默认的)。
|
||||
|
||||
#### 不能找到 update-grub 命令?这里是在这种情况下该做什么
|
||||
|
||||
它可能是,你的 Linux 发行版可能没有可用的 `update-grub` 命令。
|
||||
|
||||
在这种情况下你该做什么?你如何在这样一个 Linux 发行版上更新 grub ?
|
||||
|
||||
在这里不需要惊慌。`update-grub` 命令只是一个入口,用于运行 `grub-mkconfig -o /boot/grub/grub.cfg` 来生成 grub2 配置文件。
|
||||
|
||||
这意味着你可以在任意 Linux 发行版上使用下面的命令更新 grub :
|
||||
|
||||
```
|
||||
sudo grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
当然,记住 `update-grub` 命令比上面的命令容易很多,这是为什么它在一开始被创建的原因。
|
||||
|
||||
### update-grub 是如何工作的?
|
||||
|
||||
当你安装一个 Linux 发行版时,它(通常)要求你安装 [grub 启动引导程序][1]。
|
||||
|
||||
grub 的一部分安装在 MBR/ESP 分区上。grub 的剩余部分保留在 Linux 发行版的 `/boot/grub` 目录中。
|
||||
|
||||
依据它的 [man 页面][2],`update-grub` 通过查找 `/boot` 目录来工作。所有以 [vmlinuz-][3] 开头的文件将被作为内核来对待,并且它们将得到一个 grub 菜单项。它也将为与所找到内核版本相同的 [ramdisk][4] 镜像添加 initrd 行。
|
||||
|
||||
它也使用 [os-prober][5] 为其它操作系统查找所有磁盘分区。如果找到其它操作系统,它添加它们到 grub 菜单。
|
||||
|
||||
![Representational image of Grub Menu][6]
|
||||
|
||||
### 为什么你需要更新 grub ?
|
||||
|
||||
在有很多场景下你需要更新 grub。
|
||||
|
||||
假设你修改 grub 配置文件(`/etc/default/grub`)以 [更改默认启动顺序][7] 或减少默认启动时间。除非你更新 grub ,否则你的修改将不会生效。
|
||||
|
||||
另一种情况是,你在同一个电脑系统上安装多个 Linux 发行版。
|
||||
|
||||
例如,在我的 Intel NUC 上,我有两个磁盘。第一个磁盘有 Ubuntu 19.10 ,并且我在其上面安装了 Ubuntu 18.04 。第二个操作系统(Ubuntu 18.04)安装了其自己的 grub ,现在 grub 启动屏幕由 Ubuntu 18.04 grub 控制。
|
||||
|
||||
在第二个磁盘上,我安装了 MX Linux ,但是这次我没有安装 grub。我希望现有的 grub(由 Ubuntu 18.04 控制)来处理所有的操作系统项目。
|
||||
|
||||
现在,在这种情况中,在 Ubuntu 18.04 上的 grub 需要更新,以便它能够看到 [MX Linux][8] 。
|
||||
|
||||
![][9]
|
||||
|
||||
如上图所示,当我更新 grub 时,它在 18.04 上找到很多安装的 Linux 内核, 以及在不同的分区上 Ubntu 19.10 和 MX Linux 。
|
||||
|
||||
如果你想让 MX Linux 控制 grub ,我可以使用 [grub-install][10] 命令来在 MX Linux 上安装 grub,然后在 MX Linux 上的 grub 将开始控制 grub 启动屏幕。你已经明白这点,对吧?
|
||||
|
||||
使用一个像 [Grub Customizer][11] 的 GUI 工具是在 grub 中进行更改的一种简单的方法。
|
||||
|
||||
### 最后…
|
||||
|
||||
最初,我打算保持它为一篇短文作为一种快速提示。但是后来我想解释一些与之相关的东西,以便(相对)新的 Linux 用户能够学到更多,而不仅仅是一个简单命令。
|
||||
|
||||
你喜欢它吗?你有一些问题或建议吗?请随意发表评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/update-grub/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[2]: https://manpages.debian.org/testing/grub-legacy/update-grub.8.en.html
|
||||
[3]: https://www.ibm.com/developerworks/community/blogs/mhhaque/entry/anatomy_of_the_initrd_and_vmlinuz?lang=en
|
||||
[4]: https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[5]: https://packages.debian.org/sid/utils/os-prober
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/grub_screen.png?ssl=1
|
||||
[7]: https://itsfoss.com/grub-customizer-ubuntu/
|
||||
[8]: https://mxlinux.org/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/update_grub.png?ssl=1
|
||||
[10]: https://www.gnu.org/software/grub/manual/grub/html_node/Installing-GRUB-using-grub_002dinstall.html
|
||||
[11]: https://itsfoss.com/customize-grub-linux/
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11718-1.html)
|
||||
[#]: subject: (Why your Python code needs to be beautiful and explicit)
|
||||
[#]: via: (https://opensource.com/article/19/12/zen-python-beauty-clarity)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
为什么 Python 代码要写得美观而明确
|
||||
======
|
||||
|
||||
> 欢迎阅读“Python 光明节(Pythonukkah)”系列文章,这个系列文章将会讨论《Python 之禅》。我们首先来看《Python 之禅》里的前两个原则:美观与明确。
|
||||
|
||||

|
||||
|
||||
早在 1999 年,Python 的贡献者之一,Tim Peters 就提出了《[Python 之禅][2]》,直到二十年后的今天,《Python 之禅》中的 19 条原则仍然对整个社区都产生着深远的影响。为此,就像庆典光明的<ruby>光明节<rt>Hanukkah</rt></ruby>一样,我们举行了这一次的“<ruby>Python 光明节<rt>Pythonukkah</rt></ruby>”。首先,我们会讨论《Python 之禅》中的前两个原则:美观和明确。
|
||||
|
||||
> “Hanukkah is the Festival of Lights,
|
||||
>
|
||||
> Instead of one day of presents, we get eight crazy nights.”
|
||||
>
|
||||
> —亚当·桑德勒,[光明节之歌][3]
|
||||
|
||||
### 美观胜于丑陋
|
||||
|
||||
著名的《[<ruby>计算机程序的构造和解释<rt>Structure and Interpretation of Computer Programs</rt></ruby>][4]》中有这么一句话:<ruby>代码是写给人看的,只是恰好能让机器运行。<rt>Programs must be written for people to read and only incidentally for machines to execute.</rt></ruby>机器并不在乎代码的美观性,但人类在乎。
|
||||
|
||||
阅读美观的代码对人们来说是一种享受,这就要求在整套代码中保持一致的风格。使用诸如 [Black][5]、[flake8][6]、[Pylint][7] 这一类工具能够有效地接近这一个目标。
|
||||
|
||||
但实际上,只有人类自己才知道什么才是真正的美观。因此,代码审查和协同开发是其中的不二法门,同时,在开发过程中倾听别人的意见也是必不可少的。
|
||||
|
||||
最后,个人的主观能动性也很重要,否则一切工具和流程都会变得毫无意义。只有意识到美观的重要性,才能主动编写出美观的代码。
|
||||
|
||||
这就是为什么美观在众多原则当中排到了首位,它让“美”成为了 Python 社区的一种价值。如果有人要问,”我们*真的*在乎美吗?“社区会以代码给出肯定的答案。
|
||||
|
||||
### 明确胜于隐晦
|
||||
|
||||
人类会欢庆光明、惧怕黑暗,那是因为光能够让我们看到难以看清的事物。同样地,尽管有些时候我们会不自觉地把代码写得含糊不清,但明确地编写代码确实能够让我们理解很多抽象的概念。
|
||||
|
||||
“为什么类方法中要将 `self` 显式指定为第一个参数?”
|
||||
|
||||
这个问题已经是老生常谈了,但网络上很多流传已久的回答都是不准确的。在编写<ruby>元类<rt>metaclass</rt></ruby>时,显式指定 `self` 参数就显得毫无意义。如果你没有编写过元类,希望你可以尝试一下,这是很多 Python 程序员的必经之路。
|
||||
|
||||
显式指定 `self` 参数的原因并不是 Python 的设计者不想将这样的元类视为“默认”元类,而是因为第一个参数必须是*显式*的。
|
||||
|
||||
即使 Python 中确实允许非显式的情况存在(例如上下文变量),但我们还是应该提出疑问:某个东西是不是有存在的必要呢?如果非显式地传递参数会不会出现问题呢?有些时候,由于种种原因,这是会有问题的。总之,在写代码时一旦能够优先考虑到明确性,至少意味着能对不明确的地方提出疑问并对结果作出有效的估计。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/zen-python-beauty-clarity
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_python_programming.png?itok=ynSL8XRV "Searching for code"
|
||||
[2]: https://www.python.org/dev/peps/pep-0020/
|
||||
[3]: https://en.wikipedia.org/wiki/The_Chanukah_Song
|
||||
[4]: https://en.wikipedia.org/wiki/Structure_and_Interpretation_of_Computer_Programs
|
||||
[5]: https://opensource.com/article/19/5/python-black
|
||||
[6]: https://opensource.com/article/19/5/python-flake8
|
||||
[7]: https://opensource.com/article/19/10/python-pylint-introduction
|
||||
|
||||
116
published/20191224 Unix is turning 50. What does that mean.md
Normal file
116
published/20191224 Unix is turning 50. What does that mean.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11724-1.html)
|
||||
[#]: subject: (Unix is turning 50. What does that mean?)
|
||||
[#]: via: (https://www.networkworld.com/article/3511428/unix-is-turning-50-what-does-that-mean.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Unix 即将迎来 50 岁
|
||||
======
|
||||
|
||||
Unix 时间(又称为“<ruby>纪元时间<rt>epoch time</rt></ruby>”)是自 1970 年 1 月 1 日以来经过的秒数。当 Unix 即将 50 岁时,让我们看一下让内核开发人员担心的地方。
|
||||
|
||||

|
||||
|
||||
对于 Unix 而言,2020 年是重要的一年。在这一年年初,Unix 进入 50 岁。
|
||||
|
||||
尽管 Unix 的某些早期开发早于其“纪元”的正式开始,但 1970 年 1 月 1 日仍然是 POSIX 时间的零点,也是公认的 Unix 的万物之始。自那一刻算起,2020 年 1 月 1 日将是其 50 周年。(LCTT 译注:实际上,在 1971/11/3 出版的第一版《Unix 程序员手册》中,将 1971/1/1 作为 Unix 纪元的开始,并且一秒钟记录 60 个数,但是后来发现这样 32 位整型数字只能记录两年多,后来这个纪元被一再重新定义,改为从 1970/1/1 开始,每秒 1 个数。)
|
||||
|
||||
### Unix 时间与人类时间
|
||||
|
||||
就人类时间而言,50 年是很重要的。就 Unix 时间而言,50 年没有什么特别的。48.7 年同样重要。
|
||||
|
||||
Unix(包括 Linux)系统将日期/时间值存储为自 1970-01-01 00:00:00 UTC 以来经过的秒数(32 位整型)。要确定自该时间以来经过了多少秒钟,看看 Unix 时间值是什么样子,你可以发出如下命令:
|
||||
|
||||
```
|
||||
$ date +%s
|
||||
1576883876
|
||||
```
|
||||
|
||||
`%s` 参数告诉 `date` 命令将当前日期/时间显示为自 1970-01-01 开始以来的秒数。
|
||||
|
||||
### Unix 系统可以管理多少时间?
|
||||
|
||||
要了解 Unix 系统可以容纳多少时间,我们需要查看 32 位字段的容量。可以这样计算:
|
||||
|
||||
```
|
||||
$ echo '2^32' | bc
|
||||
4294967296
|
||||
```
|
||||
|
||||
但是,由于 Unix 需要容纳负数,因此它会为数字的符号保留一位,从而将其减少为:
|
||||
|
||||
```
|
||||
$ echo '2^31' | bc
|
||||
2147483648
|
||||
```
|
||||
|
||||
并且,由于 Unix 计数以 0 开头,这意味着我们有 2,147,483,648 个值,但最大的可能值为 2,147,483,647 个。Unix 日期/时间值不能超过该数字——就像汽车上的里程表可能不能超过 999,999 英里一样。加 1 该值就变为了 -2147483648。(LCTT 译注:此处原文描述有误,已修改。在达到最大值之后,即 2038/1/19 03:14:07,下 1 秒导致符号位变为 1,其余 31 位为 0,即 -2147483648,时间变为 1901/12/13 20:45:52,这就是 Y2K38 问题。)
|
||||
|
||||
### 一年有多少秒?
|
||||
|
||||
大多数年份的秒数可以这样计算:每天的小时数乘以每小时的分钟数乘以每分钟的秒数乘以一年中的天数:
|
||||
|
||||
```
|
||||
$ expr 24 \* 60 \* 60 \* 365
|
||||
31536000
|
||||
```
|
||||
|
||||
在闰年,我们再增加一天:
|
||||
|
||||
```
|
||||
$ expr 24 \* 60 \* 60 \* 366
|
||||
31622400
|
||||
```
|
||||
|
||||
(LCTT 译注:Unix 时间将一天精确定义为 24 * 60 * 60 = 86400 秒,忽略闰秒。)
|
||||
|
||||
### Unix 将如何庆祝其 50 岁生日?
|
||||
|
||||
2020 年 1 月 1 日中午 12:00 是纪元时间的 1577836800。这个计算有些棘手,但主要是因为我们必须适应闰年。自该纪元开始以来,我们经历了 12 个闰年,从 1972 年开始,到上一个闰年是 2016 年。而且,当我们达到 2020 年时,我们将有 38 个常规年份。
|
||||
|
||||
这是使用 `expr` 命令进行的计算,以计算这 50 年的秒数:
|
||||
|
||||
```
|
||||
$ expr 24 \* 60 \* 60 \* 365 \* 38 + 24 \* 60 \* 60 \* 366 \* 12
|
||||
1577836800
|
||||
```
|
||||
|
||||
前半部分是计算 38 个非闰年的秒数。然后,我们加上闰年的 366 天的类似计算。或者,你可以使用前面介绍的每年秒数,然后执行以下操作:
|
||||
|
||||
```
|
||||
$ expr 31536000 \* 38 + 31622400 \* 12
|
||||
1577836800
|
||||
```
|
||||
|
||||
这种跟踪日期和时间的方式使 Unix 系统完全不受 Y2K 恐慌的影响,1999 年末人们开始担心进入 2000 年会对计算机系统造成严重破坏,但是实际遇到的问题比人们担心的少得多。实际上,只有以两位数格式存储年份的应用程序才会将年份变为 00,以表示时间倒退。尽管如此,许多应用程序开发人员还是做了很多额外的繁琐工作,以确保 2000 年到来时,他们的系统不会出现严重问题。
|
||||
|
||||
### Unix 时间何时会遇到问题?
|
||||
|
||||
在 2038 年之前,Unix 系统不会遇到 Y2K 类型的问题,直到如上所述存储的日期将超过其 32 位空间分配。但这距离现在已经只有 18 年了,内核开发人员已经在研究如何避免灾难。但现在开始恐慌还为时过早。
|
||||
|
||||
2038 年的问题有时称为 Y2K38 问题。我们必须在 2038 年 1 月 19 日星期二之前解决这个问题。如果问题到时候仍未解决,则该日期之后的系统可能会认为是 1901 年。解决该问题的一种方法是切换为日期/时间信息的 64 位表示形式。有些人认为,即使那样,也会有比听起来更复杂的问题。无论如何,恐慌还为时过早。并且,与此同时,也许在新年前夜演唱了《Auld Lang Syne》之后,你可以向 Unix 唱《生日快乐》歌了。Unix 50 岁了,这仍然是大事。
|
||||
|
||||
(LCTT 译注:建议阅读一下 Unix 时间的[维基百科][6]页面,有更多有趣和不为人知的信息。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3511428/unix-is-turning-50-what-does-that-mean.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2017/10/birthday-cake-candles-100739452-large.jpg
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
[6]: https://en.wikipedia.org/wiki/Unix_time
|
||||
@ -1,105 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Zorin OS Responds to the Privacy Concerns)
|
||||
[#]: via: (https://itsfoss.com/zorin-os-privacy-concerns/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Zorin OS Responds to the Privacy Concerns
|
||||
======
|
||||
|
||||
_**There were some privacy concerns around ‘data collection’ in Zorin OS. It’s FOSS spoke to Zorin OS CEO and here is his response to the controversy.**_
|
||||
|
||||
After a few days of [Zorin OS 15 Lite][1] release, a Reddit thread surfaced which flagged a privacy concern regarding the Linux distribution.
|
||||
|
||||
The [Reddit thread][2] focuses on the [privacy policy][3] of Zorin OS and warns users that Zorin OS is sending anonymous pings every 60 minutes without users’ consent, which is potentially a privacy issue.
|
||||
|
||||
![][4]
|
||||
|
||||
The policy in question can be quoted here as:
|
||||
|
||||
> _**Anonymous pings**: When using Zorin OS, your computer may occasionally send us a ping which includes an anonymous unique identifier for your computer. We use this information to count the number of active users of Zorin OS. The unique identifier does not identify you unless you (or someone acting on your behalf) discloses it separately. You may choose to disable these pings by uninstalling the “Zorin-os-census” package from your computer_
|
||||
|
||||
Now, there’s a lot of [discussions][5] surrounding the concern. There’s also a [YouTube video][6] talking about it.
|
||||
|
||||
In a nutshell, it’s a mess. Some insist that they collect our IP addresses and some users complain that they should ask about it while installing Zorin OS.
|
||||
|
||||
While I agree that they could add an opt-out option in the installation process – so I reached out to **Artyom Zorin** (_CEO, Zorin Group_) to clarify the situation.
|
||||
|
||||
### Zorin’s Clarification On What They Collect With Every Anonymous Ping
|
||||
|
||||
When I asked for an elaborate explanation of what the “**anonymous unique identifier**” includes, Artyom mentioned – “_It appears that there are some inaccuracies and misconceptions about the census in the comments sections_“.
|
||||
|
||||
To continue the explanation about the unique identifier, he assured that **their servers do not log IP addresses** when a ping arrives.
|
||||
|
||||
The zorin-os-census script **simply counts the number of unique computers using Zorin OS** and no personal data is being collected along with it.
|
||||
|
||||
Artyom explained in detail:
|
||||
|
||||
> The anonymous identifier is a series of letters and numbers which is randomly generated (not based on any external data) and only used for the Zorin OS Census. Its single purpose is to make sure that the computer isn’t double-counted when a ping is sent from a computer to the server. On a fully-installed Zorin OS system, the anonymous identifier can be found in /var/lib/zorin-os-census/uuid and should look like this:_68f2d95b-f51f-4a5d-9b48-a99c28691b89_
|
||||
> *
|
||||
> *We would like to clarify that no personal or personally-identifiable data is being collected by us and the server does not log IP addresses when pings arrive. The zorin-os-census script is only used to count the number of computers and users running Zorin OS after installation. Even I wouldn’t be able to tell which computer is my own from looking at the server-side database. I have attached a screenshot of a snippet of the database table displaying the information we store.
|
||||
|
||||
He also stressed his ‘commitment on privacy’:
|
||||
|
||||
> Privacy is an essential human right. It’s a core tenet of our mission to give you back control of your technology, and not the other way around. We make privacy a priority with every decision we make, and we’re committed to protecting it in every level of the software we build.
|
||||
|
||||
As you can observe in the response above, he shared a screenshot of how their database of unique identifiers looks like:
|
||||
|
||||
![][7]
|
||||
|
||||
If you’re still curious, you can also check out the [source code][8] for the zorin-os-census script.
|
||||
|
||||
### Can We Opt-Out Of It?
|
||||
|
||||
While the data collected may be ‘harmless’, it is important to give the option to the user whether or not they want Zorin OS to collect the data, right?
|
||||
|
||||
So, when I inquired about the same, he mentioned that i**t was already something planned for Zorin OS 15 Lite release**.
|
||||
|
||||
However, they did not want to rush to add it before properly testing it. Hence, they decided to keep it for the upcoming release (**Zorin OS 15.1**) which is planned to arrive in **early-to-mid December this year.**
|
||||
|
||||
> We have in fact been working on implementing an opt-out option for this into the Zorin OS installer (Ubiquity). To ensure the stability and accessibility of this new functionality we’re adding to Ubiquity, we have scheduled a period of time to translate the text strings and rigorously test the software (in order to avoid regressions), as the installer is a critical component of the operating system. Unfortunately, the testing period for the opt-out option didn’t complete before our planned release of Zorin OS 15 Lite, and we, therefore, decided not to risk adding it before we could guarantee its stability. However, we are on track to include the opt-out option in the upcoming Zorin OS 15.1 release, which we plan to release in early-to-mid December.
|
||||
|
||||
### Will It Be Something Similar To What Ubuntu Does?
|
||||
|
||||
Ubuntu does let you opt-out from collecting information about your computer.
|
||||
|
||||
So, when I asked if Zorin OS will add something similar to that, he responded with some details about how Ubuntu collects data and how Zorin OS is different from that.
|
||||
|
||||
He mentioned the fact that Ubuntu comes pre-installed with a **popularity-contest** package that **occasionally sends data of what packages the user has installed** to the Ubuntu Developers.
|
||||
|
||||
And, further clarified that **Zorin OS does not include that**.
|
||||
|
||||
> While Ubuntu’s telemetry tool gives users the option to not send extensive information about the computers to the Ubuntu developers, selecting the “No” option still sends a ping to Ubuntu’s servers .
|
||||
>
|
||||
> From our research, it is not clear whether Ubuntu’s servers store logs of users’ IP addresses when they receive telemetry data. In addition, Zorin OS does not include the “popularity-contest” package that is pre-installed in Ubuntu. This package is designed to occasionally send a list of all packages a user has installed on their computer to the Ubuntu developers.
|
||||
|
||||
**In the end…**
|
||||
|
||||
While the concern regarding the anonymous pings may not seem to a privacy threat, an opt-out option should be presented to the user while installing Zorin OS. Let’s wait and watch if it should arrive in the upcoming Zorin OS 15.1 release.
|
||||
|
||||
What do you think about the privacy concern mentioned above? Let us know your thoughts in the comments down below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/zorin-os-privacy-concerns/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/zorin-os-lite/
|
||||
[2]: https://www.reddit.com/r/FreeAsInFreedom/comments/e0yhw4/beware_zorin_os_sends_anonymous_pings_every_60/
|
||||
[3]: https://zorinos.com/legal/privacy/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/11/zorin-os-privacy-reddit.jpg?ssl=1
|
||||
[5]: https://www.reddit.com/r/linux/comments/e0zd5n/beware_zorin_os_sends_anonymous_pings_every_60/
|
||||
[6]: https://www.youtube.com/watch?v=bcgk9LvC36Y&feature=youtu.be&t=860
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/11/zorin-census-database.png?ssl=1
|
||||
[8]: https://launchpad.net/~zorinos/+archive/ubuntu/stable/+sourcepub/10183568/+listing-archive-extra
|
||||
@ -1,89 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Open Source Music Notations Software MuseScore 3.3 Released!)
|
||||
[#]: via: (https://itsfoss.com/musescore/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Open Source Music Notations Software MuseScore 3.3 Released!
|
||||
======
|
||||
|
||||
_**Brief: MuseScore is an open-source software to help you create, play, and print sheet music. They released a major update recently. So, we take a look at what MuseScore has to offer**_ _**overall.**_
|
||||
|
||||
### MuseScore: A Music Composition and Notation Software
|
||||
|
||||
![][1]
|
||||
|
||||
[MuseScore][2] is open-source software that lets you create, play, and print [sheet music][3].
|
||||
|
||||
You can even use a MIDI keyboard as input and simply play the tune you want to create the notation of.
|
||||
|
||||
In order to make use of it, you need to know how sheet music notations work. In either case, you can just play something using your MIDI keyboard or any other instrument and learn how the music notations work while using it.
|
||||
|
||||
So, it should come in handy for beginners and experts as well.
|
||||
|
||||
You can download and use MuseScore for free. However, if you want to share your music/composition and reach out to a wider community on the MuseScore platform, you can opt to create a free or premium account on [MuseScore.com][4].
|
||||
|
||||
### Features of MuseScore
|
||||
|
||||
![Musescore 3 Screenshot][5]
|
||||
|
||||
MuseScore includes a lot of things that can be highlighted. If you are someone who is not involved in making music notations for your compositions – you might have to dig deeper just like me.
|
||||
|
||||
Usually, I just head over to any [DAW available on Linux][6] and start playing something to record/loop it without needing to create the music notations. So, for me, MuseScore definitely presents a learning curve with all the features offered.
|
||||
|
||||
I’ll just list out the features with some brief descriptions – so you can explore them if it sounds interesting to you.
|
||||
|
||||
* Supports Input via MIDI keyboard
|
||||
* You can transfer to/from other programs via [MusicXML][7], MIDI, and other options.
|
||||
* A Huge collection of palettes (music symbols) to choose from.
|
||||
* You also get the ability to re-arrange the palettes and create your own list of most-used palettes or edit them.
|
||||
* Some plugins supported to extend the functionality
|
||||
* Import PDFs to read and play notations
|
||||
* Several instruments supported
|
||||
* Basic or Advanced layout of palettes to get started
|
||||
|
||||
|
||||
|
||||
Some of the recent key changes include the palettes redesign, accessibility, and the not input workflow. For reference, you can check out how the new palettes work:
|
||||
|
||||
### Installing MuseScore 3.3.3 on Ubuntu/Linux
|
||||
|
||||
The latest version of MuseScore is 3.3.3 with all the bug fixes and improvements to its recent [MuseScore 3.3 release][8].
|
||||
|
||||
You may find an older release in your Software Center (or your official repo). So, you can either opt for a Flatpak package, Snap, or maybe an AppImage from its [download page][9] with links for different Linux distributions.
|
||||
|
||||
[Download MuseScore][9]
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
I was quite fascinated to learn about MuseScore being an open-source and free solution to create, play, and print sheet music.
|
||||
|
||||
It may not be the most easy-to-use software there is – but when considering the work with music notations, it will help you learn more about it and help you with your work as well.
|
||||
|
||||
What do you think about MuseScore? Do share your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/musescore/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/11/musescore-3.jpg?ssl=1
|
||||
[2]: https://musescore.org/en
|
||||
[3]: https://en.wikipedia.org/wiki/Sheet_music
|
||||
[4]: https://musescore.com/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/11/musescore-3-screenshot.jpg?ssl=1
|
||||
[6]: https://itsfoss.com/best-audio-editors-linux/
|
||||
[7]: https://en.wikipedia.org/wiki/MusicXML
|
||||
[8]: https://musescore.org/en/3.3
|
||||
[9]: https://musescore.org/en/download
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (New machine learning from Alibaba and Netflix, mimicking animal vision, and more open source news)
|
||||
[#]: via: (https://opensource.com/article/19/12/news-december-7)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
New machine learning from Alibaba and Netflix, mimicking animal vision, and more open source news
|
||||
======
|
||||
Catch up on the biggest open source headlines from the past two weeks.
|
||||
![Weekly news roundup with TV][1]
|
||||
|
||||
In this edition of our open source news roundup, we take a look an open source election auditing tool, new open source from Alibaba and Netflix, mimicking animal vision, and more!
|
||||
|
||||
### Alibaba and Netflix share machine learning and data science software
|
||||
|
||||
Two companies at the forefront of machine learning and data science have just released some of their tools under open source licenses.
|
||||
|
||||
Chinese ecommerce giant Alibaba just [open sourced the algorithm libraries][2] for its Alink platform. The algorithms "are essential to support machine learning tasks such as online product recommendations and smart customer services." According to Jia Yangqing, president of Alibaba Cloud, Alink is a good fit for "developers seeking big data and machine-learning tools." You can find the source code for Alink (which is under an Apache 2.0 license) [on GitHub][3], with documentation in both Chinese and English.
|
||||
|
||||
Not to be outdone, streaming service Netflix just released its [Metaflow Python library][4] under an Apache 2.0 license. Metaflow enables data scientists to "see early on whether a prototyped model would fail in production, allowing them to fix whatever the issue was". It also works with a number of Python data science libraries, like SciKit Learn, Pytorch, and Tensorflow. You can grab Metaflow's code from [its GitHub repository][5] or learn more about it at the [Metaflow website][6].
|
||||
|
||||
### Open source software to mimic animal vision
|
||||
|
||||
Have you ever wondered how your dog or cat sees the world? Thanks to work by researchers at the University of Exeter in the UK and Australia's University of Queensland, you can find out. The team just released [software that allows humans to see the world as animals do][7].
|
||||
|
||||
Called micaToolbox, the software can interpret digital photos and process images of various environments by mimicking the limitations of animal vision. Anyone with a camera, a computer, or smartphone can use the software without knowing how to code. But micaToolbox isn't just a novelty. It's a serious scientific tool that can help "help biologists better understand a variety of animal behaviors, including mating systems, distance-dependent signalling and mimicry." And, according to researcher Jolyon Troscianko, the software can help identify "how an animal's camouflage works so that we can manage our land to protect certain species."
|
||||
|
||||
You can [download micaBox][8] or [browse its source code][9] on GitHub.
|
||||
|
||||
### New tool for post-election auditing
|
||||
|
||||
More and more aspects of our lives and institutions are being automated. With that comes an increased danger of systems breaking down or malicious someones tampering with those systems. Open source gives us an opportunity to look at exactly how the automation works.
|
||||
|
||||
Elections, in particular, are increasingly vulnerable. To combat election tampering, the US Cybersecurity and Infrastructure Security Agency (CISA) has joined forces with the non-profit organization VotingWorks to create a [web-based application for auditing ballots][10].
|
||||
|
||||
Called Arlo, the application is designed to ensure that "elections are secure, resilient, and transparent," said CISA's director Chris Krebs. Arlo works with a range of automated voting systems to help "officials compare audited votes to tabulated votes, and providing monitoring & reporting capabilities." Arlo was used to verify the results of recent state and local elections and is being further field-tested in the states of Georgia, Michigan, Missouri, Ohio, Pennsylvania, and Virginia.
|
||||
|
||||
Arlo's source code, released under an AGPL-3.0 license, is [available on GitHub][11].
|
||||
|
||||
### Royal Navy debuts open source application development kit
|
||||
|
||||
Consistency across user interfaces is key to a successful set of applications and services. The UK's Royal Navy understands the importance of this and has released the [open source NELSON standards toolkit][12] to help its developers and suppliers "save time and give users a consistent experience."
|
||||
|
||||
Named after the legendary British admiral, NELSON is intended to "maintain high visual consistency and user-experience quality across the different applications developed or subcontracted by the Royal Navy." The toolkit consists of a set of components including visual styles, typographic elements, forms, elements like buttons and checkboxes, and notifications.
|
||||
|
||||
NELSON has its own [GitHub repository][13], from which the Royal Navy encourages developers to make pull requests.
|
||||
|
||||
#### In other news
|
||||
|
||||
* [Council group plans for open source revenues and benefits platform][14]
|
||||
* [Introducing Nebula, the open source global overlay network from Slack][15]
|
||||
* [webOS Open Source Edition 2.0 keeps Palm's spirit alive in cars and IoT][16]
|
||||
* [Duke University Introduces an Open Source Tool as an Alternative to a Monolithic LMS][17]
|
||||
* [Open Source Technology Could Be a Boon to Farmers][18]
|
||||
|
||||
|
||||
|
||||
_Thanks, as always, to Opensource.com staff members and moderators for their help this week._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/news-december-7
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
|
||||
[2]: https://www.zdnet.com/article/alibaba-cloud-publishes-machine-learning-algorithm-on-github/
|
||||
[3]: https://github.com/alibaba/alink
|
||||
[4]: https://www.zdnet.com/article/netflix-our-metaflow-python-library-for-faster-data-science-is-now-open-source/
|
||||
[5]: https://github.com/Netflix/metaflow
|
||||
[6]: https://metaflow.org/
|
||||
[7]: https://www.upi.com/Science_News/2019/12/03/Novel-software-helps-scientists-see-what-animals-see/5961575389734/
|
||||
[8]: http://www.empiricalimaging.com/download/micatoolbox/
|
||||
[9]: https://github.com/troscianko/micaToolbox
|
||||
[10]: https://www.zdnet.com/article/cisa-and-votingworks-release-open-source-post-election-auditing-tool/
|
||||
[11]: https://github.com/votingworks/arlo
|
||||
[12]: https://joinup.ec.europa.eu/collection/open-source-observatory-osor/news/open-source-royal-navy
|
||||
[13]: https://github.com/Royal-Navy/standards-toolkit
|
||||
[14]: https://www.ukauthority.com/articles/council-group-plans-for-open-source-revenues-and-benefits/
|
||||
[15]: https://slack.engineering/introducing-nebula-the-open-source-global-overlay-network-from-slack-884110a5579
|
||||
[16]: https://www.slashgear.com/webos-open-source-edition-2-0-keeps-palms-spirit-alive-in-cars-and-iot-25601309/
|
||||
[17]: https://iblnews.org/duke-university-introduces-an-open-source-tool-as-an-alternative-to-a-monolithic-lms/
|
||||
[18]: https://civileats.com/2019/12/02/open-source-technology-could-be-a-boon-to-farmers/
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (First Ever Release of Ubuntu Cinnamon Distribution is Finally Here!)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-cinnamon/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
First Ever Release of Ubuntu Cinnamon Distribution is Finally Here!
|
||||
======
|
||||
|
||||
_**Brief: Ubuntu Cinnamon is a new distribution that utilizes Linux Mint’s Cinnamon desktop environment on top of Ubuntu code base. It’s first stable release is based on Ubuntu 19.10 Eoan Ermine.**_
|
||||
|
||||
[Cinnamon][1] is Linux Mint’s flagship desktop environment. Like [MATE desktop][2], Cinnamon is also a product of dissatisfaction with GNOME 3. With the GNOME Classic like user interface and relatively lower hardware requirements, Cinnamon soon gathered a dedicated userbase.
|
||||
|
||||
Like any other desktop environment out there, you can [install Cinnamon on Ubuntu][3] and other distributions.
|
||||
|
||||
Installing multiple [desktop environments][4] (DE) is not a difficult task but it often leads to conflicts (with other DE’s elements) and may not always provide the best experience. This is why major Linux distributions separate spins/flavors with various popular desktop environments.
|
||||
|
||||
[Ubuntu also has various official flavors][5] featuring [KDE][6] (Kubuntu), [LXQt][7] (Lubuntu), Xfce (Xubuntu), Budgie ([Ubuntu Budgie][8]) etc. Cinnamon was not in this list but Ubuntu Cinnamon Remix project is trying to change that.
|
||||
|
||||
### Ubuntu Cinnamon distribution
|
||||
|
||||
![Ubuntu Cinnamon Desktop Screenshot][9]
|
||||
|
||||
[Ubuntu Cinnamon][10] (website under construction) is a new Linux distribution that brings Cinnamon desktop to Ubuntu distribution. Joshua Peisach is the lead developer for the project and he is being helped by other volunteer contributors. The ex-developer of the now discontinued Ubuntu GNOME project and some members from Ubuntu team are also advising the team to help with the development.
|
||||
|
||||
![Ubuntu Cinnamon Remix Screeenshot 1][11]
|
||||
|
||||
Do note that Ubuntu Cinnamon is not an official flavor of Ubuntu. They are trying to get the flavorship but I think that will take a few more releases.
|
||||
|
||||
The first stable release of Ubuntu Cinnamon is based on [Ubuntu 19.10 Eoan Ermine][12]. It uses Calamares installer from Lubuntu and features Cinnamon desktop version 4.0.10. Naturally, it uses Nemo file manager and LightDM.
|
||||
|
||||
It supports EFI and UEFI and only comes with 64-bit support.
|
||||
|
||||
You’ll get your regular goodies like LibreOffice, Firefox and some GNOME software and games. You can of course install more applications as per your need.
|
||||
|
||||
### Download and install Ubuntu Cinnamon
|
||||
|
||||
Do note that this is the first ever release of Ubuntu Cinnamon and the developers are not that experienced at this moment.
|
||||
|
||||
If you don’t like troubleshooting, don’t use it on your main system. I expect this release to have a few bugs and issues which will be fixed eventually as more users test it out.
|
||||
|
||||
You can download Ubuntu Cinnamon ISO from Sourceforge website:
|
||||
|
||||
[Download Ubuntu Cinnamon][13]
|
||||
|
||||
### What next from here?
|
||||
|
||||
The dev team has a few improvements planned for the 20.04 release. The changes are mostly on the cosmetics though. There will be new GRUB and Plymouth theme, layout application and welcome screen.
|
||||
|
||||
I downloaded it and tried it in a live session. Here’s what this distribution looks like:
|
||||
|
||||
[Subscribe to our YouTube channel for more Linux videos][14]
|
||||
|
||||
Meanwhile, if you manage to try it on your own, why not share your experience in the comments? If you use Linux Mint, will you switch to Ubuntu Cinnamon in near future? What are your overall opinion about this new project? Do share it in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-cinnamon/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Cinnamon_(desktop_environment)
|
||||
[2]: https://mate-desktop.org/
|
||||
[3]: https://itsfoss.com/install-cinnamon-on-ubuntu/
|
||||
[4]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[5]: https://itsfoss.com/which-ubuntu-install/
|
||||
[6]: https://kde.org/
|
||||
[7]: https://lxqt.org/
|
||||
[8]: https://itsfoss.com/ubuntu-budgie-18-review/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/ubuntu_cinnamon_distribution_screenshot.jpg?ssl=1
|
||||
[10]: https://ubuntucinnamon.org/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/ubuntu_cinnamon_remix_screeenshot_1.jpg?ssl=1
|
||||
[12]: https://itsfoss.com/ubuntu-19-10-released/
|
||||
[13]: https://sourceforge.net/projects/ubuntu-cinnamon-remix/
|
||||
[14]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (KubeCon gets bigger, the kernel gets better, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/12/kubecon-bigger-kernel-better-more-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
KubeCon gets bigger, the kernel gets better, and more industry trends
|
||||
======
|
||||
A weekly look at open source community, market, and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [KubeCon showed Kubernetes is big, but is it a Unicorn?][2]
|
||||
|
||||
> It’s hard to remember now but there was a time when Kubernetes was a distant No. 3 in terms of container orchestrators being used in the market. It’s also eye opening to now realize that [the firms][3] that hatched the two platforms that [towered over][4] Kubernetes have had to completely re-jigger their business models under the Kubernetes onslaught.
|
||||
>
|
||||
> And full credit to the CNCF for attempting to diffuse some of that attention from Kubernetes by spending the vast majority of the KubeCon opening keynote address touting some of the nearly two dozen graduated, incubating, and sandbox projects it also hosts. But, it was really the Big K that stole the show.
|
||||
|
||||
**The impact:** Open source is way more than the source code; governance is a big deal and can be the difference between longevity and irrelevance. Gathering, organizing, and maintaining humans is an entirely different skill set than doing the same for bits, but can have just as big an influence on the success of a project.
|
||||
|
||||
## [Report: Kubernetes use on the rise][5]
|
||||
|
||||
> At the same time, the Datadog report notes that container churn rates are approximately 10 times higher in orchestrated environments. Churn rates in container environments that lack an orchestration platform such as Kubernetes have increased in the last year as well. The average container lifespan at a typical company running infrastructure without orchestration is about two days, down from about six days in mid-2018. In 19% of those environments not running orchestration, the average container lifetime exceeded 30 days. That compares to only 3% of organizations running containers longer than 30 days in Kubernetes environments, according to the report’s findings.
|
||||
|
||||
**The impact**: If your containers aren't churning, you're probably not getting the full benefit of the technology you've adopted.
|
||||
|
||||
## [Upcoming Linux 5.5 kernel improves live patching, scheduling][6]
|
||||
|
||||
> A new WFX Wi-Fi driver for the Silicon Labs WF200 ASIC transceiver is coming to Linux kernel 5.5. This particular wireless transceiver is geared toward low-power IoT devices and uses a 2.4 GHz 802.11b/g/n radio optimized for low power RF performance in crowded RF environments. This new driver can interface via both Serial Peripheral Interface (SPI) and Secure Digital Input Output (SDIO).
|
||||
|
||||
**The impact**: The kernel's continued relevance is a direct result of the never-ending grind to keep being where people need it to be (i.e. basically everywhere).
|
||||
|
||||
## [DigitalOcean Currents: December 2019][7]
|
||||
|
||||
> In that spirit, this fall’s installment of our seasonal Currents report is dedicated to open source for the second year running. We surveyed more than 5800 developers around the world on the overall health and direction of the open source community. When we last checked in with the community in [2018][8], more than half of developers reported contributing to open source projects, and most felt the community was healthy and growing.
|
||||
|
||||
**The impact**: While the good news outweighs the bad, there are a couple of things to keep an eye on: namely, making open source more inclusive and mitigating potential negative impact of big money.
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/kubecon-bigger-kernel-better-more-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.sdxcentral.com/articles/opinion-editorial/kubecon-showed-kubernetes-is-big-but-is-it-a-unicorn/2019/11/
|
||||
[3]: https://www.sdxcentral.com/articles/news/docker-unloads-enterprise-biz-to-mirantis/2019/11/
|
||||
[4]: https://www.sdxcentral.com/articles/news/mesosphere-is-now-d2iq-and-kubernetes-is-its-game/2019/08/
|
||||
[5]: https://containerjournal.com/topics/container-ecosystems/report-kubernetes-use-on-the-rise/
|
||||
[6]: https://thenewstack.io/upcoming-linux-5-5-kernel-improves-live-patching-scheduling/
|
||||
[7]: https://blog.digitalocean.com/digitalocean-currents-december-2019/
|
||||
[8]: https://www.digitalocean.com/currents/october-2018/
|
||||
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Annual release cycle for Python, new Python Software Foundation fellows from Africa, and more updates)
|
||||
[#]: via: (https://opensource.com/article/19/12/python-news-december)
|
||||
[#]: author: (Christian Heimes https://opensource.com/users/christian-heimes)
|
||||
|
||||
Annual release cycle for Python, new Python Software Foundation fellows from Africa, and more updates
|
||||
======
|
||||
Find out what's going on in the Python community in December.
|
||||
![Python in a coffee cup.][1]
|
||||
|
||||
The Python Software Foundation (PSF) is a nonprofit organization behind the Python programming language. I am fortunate to be a PSF Fellow (honorable member for life,) a Python core developer, and the liaison between my company, Red Hat, and the PSF. Part of that liaison work is providing updates on what’s happening in the Python community. Here’s a look at what we have going on in December.
|
||||
|
||||
### Upcoming events
|
||||
|
||||
A significant part of the Python community is its in-person events. These events are where users and contributors intermingle and learn together. Here are the big announcements of upcoming opportunities to connect.
|
||||
|
||||
#### PyCon US 2020
|
||||
|
||||
[PyCon US][2] is by far the largest annual Python event. The next PyCon is April 15-23, 2020, in Pittsburgh. The call for proposals is open to all until December 20, 2019. I’m planning to attend PyCon for the conference and its [famous post-con sprints][3].
|
||||
|
||||
#### EuroPython
|
||||
|
||||
EuroPython is the largest Python conference in Europe with about 1,000 attendees in the last years. [EP20][4] will be held in Dublin, Ireland, July 20-26, 2020. As a liaison for Red Hat, I’m proud to say that Red Hat sponsored EP18 in Edinburgh and donated the sponsoring tickets to Women Who Code Scotland.
|
||||
|
||||
#### PyData
|
||||
|
||||
[PyData][5] is a separate nonprofit related to the Python community through a focus on data science. They host many international events throughout the year, with upcoming events in [Austin, Texas][6], and [Warsaw, Poland][7] before the end of the year.
|
||||
|
||||
### New PSF fellows from Africa
|
||||
|
||||
The PSF promotes a few members to fellow every quarter. Yesterday, twelve new PSF fellows were [announced][8].
|
||||
|
||||
I’d like to highlight the four new fellows from Ghana, who are also the organizers of the first pan-African [PyCon Africa][9], which took place in August 2019 in Accra, Ghana. The Python community in Africa is growing at an amazing speed. PyCon Africa 2020 will be in Accra again, and I’m planning to spend my summer vacation there.
|
||||
|
||||
### Annual release cycle for Python
|
||||
|
||||
Python used to release a new major version about every 18 months. This timeline will change with the Python 3.9 release. With [PEP 602,][10] a new major version of Python will be released annually in October. The new cadence means fewer changes between releases and more predictable release dates. October was chosen to align with Linux distribution releases such as Fedora. Miro Hrončok from the Python maintenance team joined the discussion and has helped to find a convenient release date for us; for more details, please see <https://discuss.python.org/t/pep-602-annual-release-cycle-for-python/2296/79?u=ambv>.
|
||||
|
||||
### Steering council election
|
||||
|
||||
The Python Steering Council governs the development of Python. It was established after [Guido van Rossum stepped down][11] as benevolent dictator for life. Python core developers elect a new steering council for every major Python release. For the upcoming term, nine candidates were nominated for five seats on the council (with Guido being nominated, but [withdrawing][12]). See <https://www.python.org/dev/peps/pep-8101/> for all the details. Election results are expected to be announced mid-December.
|
||||
|
||||
That covers what’s new in the Python community for December. Stay tuned for more updates in the future and mark your calendars for the conferences mentioned above.
|
||||
|
||||
So you have a great business idea for a wonderful IT product or service, and you want to build your...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/python-news-december
|
||||
|
||||
作者:[Christian Heimes][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/christian-heimes
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_python.jpg?itok=G04cSvp_ (Python in a coffee cup.)
|
||||
[2]: https://us.pycon.org/2020/
|
||||
[3]: https://opensource.com/article/19/5/pycon-developer-sprints
|
||||
[4]: https://www.europython-society.org/post/188741002380/europython-2020-venue-and-location-selected
|
||||
[5]: https://pydata.org/
|
||||
[6]: https://pydata.org/austin2019/
|
||||
[7]: https://pydata.org/warsaw2019/
|
||||
[8]: https://pyfound.blogspot.com/2019/11/python-software-foundation-fellow.html
|
||||
[9]: https://africa.pycon.org/
|
||||
[10]: https://www.python.org/dev/peps/pep-0602/
|
||||
[11]: https://opensource.com/article/19/6/command-line-heroes-python
|
||||
[12]: https://discuss.python.org/t/steering-council-nomination-guido-van-rossum-2020-term/2657/11
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (2020 technology must haves, a guide to Kubernetes etcd, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/12/gartner-ectd-and-more-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
2020 technology must haves, a guide to Kubernetes etcd, and more industry trends
|
||||
======
|
||||
A weekly look at open source community, market, and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [Gartner's top 10 infrastructure and operations trends for 2020][2]
|
||||
|
||||
> “The vast majority of organisations that do not adopt a shared self-service platform approach will find that their DevOps initiatives simply do not scale,” said Winser. "Adopting a shared platform approach enables product teams to draw from an I&O digital toolbox of possibilities, while benefiting from high standards of governance and efficiency needed for scale."
|
||||
|
||||
**The impact**: The breakneck change of technology development and adoption will not slow down next year, as the things you've been reading about for the last two years become things you have to figure out to deal with every day.
|
||||
|
||||
## [A guide to Kubernetes etcd: All you need to know to set up etcd clusters][3]
|
||||
|
||||
> Etcd is a distributed reliable key-value store which is simple, fast and secure. It acts like a backend service discovery and database, runs on different servers in Kubernetes clusters at the same time to monitor changes in clusters and to store state/configuration data that should to be accessed by a Kubernetes master or clusters. Additionally, etcd allows Kubernetes master to support discovery service so that deployed application can declare their availability for inclusion in service.
|
||||
|
||||
**The impact**: This is actually way more than I needed to know about setting up etcd clusters, but now I have a mental model of what that could look like, and you can too.
|
||||
|
||||
## [How the open source model could fuel the future of digital marketing][4]
|
||||
|
||||
> In other words, the broad adoption of open source culture has the power to completely invert the traditional marketing funnel. In the future, prospective customers could be first introduced to “late funnel” materials and then buy into the broader narrative — a complete reversal of how traditional marketing approaches decision-makers today.
|
||||
|
||||
**The impact**: The SEO on this cuts two ways: It can introduce uninitiated marketing people to open source and uninitiated technical people to the ways that technology actually gets adopted. Neat!
|
||||
|
||||
## [Kubernetes integrates interoperability, storage, waits on sidecars][5]
|
||||
|
||||
> In a [recent interview][6], Lachlan Evenson, and was also a lead on the Kubernetes 1.16 release, said sidecar containers was one of the features that team was a “little disappointed” it could not include in their release.
|
||||
>
|
||||
> Guinevere Saenger, software engineer at GitHub and lead for the 1.17 release team, explained that sidecar containers gained increased focus “about a month ago,” and that its implementation “changes the pod spec, so this is a change that affects a lot of areas and needs to be handled with care.” She noted that it did move closer to completion and “will again be prioritized for 1.18.”
|
||||
|
||||
**The impact**: You can read between the lines to understand a lot more about the Kubernetes sausage-making process. It's got governance, tradeoffs, themes, and timeframes; all the stuff that is often invisible to consumers of a project.
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/gartner-ectd-and-more-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.information-age.com/gartner-top-10-infrastructure-and-operations-trends-2020-123486509/
|
||||
[3]: https://superuser.openstack.org/articles/a-guide-to-kubernetes-etcd-all-you-need-to-know-to-set-up-etcd-clusters/
|
||||
[4]: https://www.forbes.com/sites/forbescommunicationscouncil/2019/11/19/how-the-open-source-model-could-fuel-the-future-of-digital-marketing/#71b602fb20a5
|
||||
[5]: https://www.sdxcentral.com/articles/news/kubernetes-integrates-interoperability-storage-waits-on-sidecars/2019/12/
|
||||
[6]: https://kubernetes.io/blog/2019/12/06/when-youre-in-the-release-team-youre-family-the-kubernetes-1.16-release-interview/
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Mint 19.3 “Tricia” Released: Here’s What’s New and How to Get it)
|
||||
[#]: via: (https://itsfoss.com/linux-mint-19-3/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Linux Mint 19.3 “Tricia” Released: Here’s What’s New and How to Get it
|
||||
======
|
||||
|
||||
_**Linux Mint 19.3 “Tricia” has been released. See what’s new in it and learn how to upgrade to Linux Mint 19.3.**_
|
||||
|
||||
The Linux Mint team finally announced the release of Linux Mint 19.3 codenamed ‘Tricia’ with useful feature additions along with a ton of improvements under-the-hood.
|
||||
|
||||
This is a point release based on the latest **Ubuntu 18.04.3** and it comes packed with the **Linux kernel 5.0**.
|
||||
|
||||
I downloaded and quickly tested the edition featuring the [Cinnamon 4.4][1] desktop environment. You may also try the Xfce or MATE edition of Linux Mint 19.3.
|
||||
|
||||
### Linux Mint 19.3: What’s New?
|
||||
|
||||
![Linux Mint 19 3 Desktop][2]
|
||||
|
||||
While being an LTS release that will be supported until 2023 – it brings in a couple of useful features and improvements. Let me highlight some of them for you.
|
||||
|
||||
#### System Reports
|
||||
|
||||
![][3]
|
||||
|
||||
Right after installing Linux Mint 19.3 (or upgrading it), you will notice a warning icon on the right side of the panel (taskbar).
|
||||
|
||||
When you click on it, you should be displayed a list of potential issues that you can take care of to ensure the best out of Linux Mint experience.
|
||||
|
||||
For starters, it will suggest that you should create a root password, install a language pack, or update software packages – in the form of a warning. This is particularly useful to make sure that you perform important actions even after following the first set of steps on the welcome screen.
|
||||
|
||||
#### Improved Language Settings
|
||||
|
||||
Along with the ability to install/set a language, you will also get the ability to change the time format.
|
||||
|
||||
So, the language settings are now more useful than ever before.
|
||||
|
||||
#### HiDPI Support
|
||||
|
||||
As a result of [HiDPI][4] support, the system tray icons will look crisp and overall, you should get a pleasant user experience on a high-res display.
|
||||
|
||||
#### New Applications
|
||||
|
||||
![Linux Mint Drawing App][5]
|
||||
|
||||
With the new release, you will n longer find “**GIMP**” pre-installed.
|
||||
|
||||
Even though GIMP is a powerful utility, they decided to add a simpler “**Drawing**” app to let users to easily crop/resize images while being able to tweak it a little.
|
||||
|
||||
Also, **Gnote** replaces **Tomboy** as the default note-taking application on Linux Mint 19.3
|
||||
|
||||
In addition to both these replacements, Celluloid video player has also been added instead of Xplayer. In case you did not know, Celluloid happens to be one of the [best open source video players][6] for Linux.
|
||||
|
||||
#### Cinnamon 4.4 Desktop
|
||||
|
||||
![Cinnamon 4 4 Desktop][7]
|
||||
|
||||
In my case, the new Cinnamon 4.4 desktop experience introduces a couple of new abilities like adjusting/tweaking the panel zones individually as you can see in the screenshot above.
|
||||
|
||||
#### Other Improvements
|
||||
|
||||
There are several other improvements including more customizability options in the file manager and so on.
|
||||
|
||||
You can read more about the detailed changes in the [official release notes][8].
|
||||
|
||||
[Subscribe to our YouTube channel for more Linux videos][9]
|
||||
|
||||
### Linux Mint 19 vs 19.1 vs 19.2 vs 19.3: What’s the difference?
|
||||
|
||||
You probably already know that Linux Mint releases are based on Ubuntu long term support releases. Linux Mint 19 series is based on Ubuntu 18.04 LTS.
|
||||
|
||||
Ubuntu LTS releases get ‘point releases’ on the interval of a few months. Point release basically consists of bug fixes and security updates that have been pushed since the last release of the LTS version. This is similar to the Service Pack concept in Windows XP if you remember it.
|
||||
|
||||
If you are going to download Ubuntu 18.04 which was released in April 2018 in 2019, you’ll get Ubuntu 18.04.2. The ISO image of 18.04.2 will consist of 18.04 and the bug fixes and security updates applied till 18.04.2. Imagine if there were no point releases, then right after [installing Ubuntu 18.04][10], you’ll have to install a few gigabytes of system updates. Not very convenient, right?
|
||||
|
||||
But Linux Mint has it slightly different. Linux Mint has a major release based on Ubuntu LTS release and then it has three minor releases based on Ubuntu LTS point releases.
|
||||
|
||||
Mint 19 was based on Ubuntu 18.04, 19.1 was based on 18.04.1 and Mint 19.2 is based on Ubuntu 18.04.2. Similarly, Mint 19.3 is based on Ubuntu 18.04.3. It is worth noting that all Mint 19.x releases are long term support releases and will get security updates till 2023.
|
||||
|
||||
Now, if you are using Ubuntu 18.04 and keep your system updated, you’ll automatically get updated to 18.04.1, 18.04.2 etc. That’s not the case in Linux Mint.
|
||||
|
||||
Linux Mint minor releases also consist of _feature changes_ along with bug fixes and security updates and this is the reason why updating Linux Mint 19 won’t automatically put you on 19.1.
|
||||
|
||||
Linux Mint gives you the option if you want the new features or not. For example, Mint 19.3 has Cinnamon 4.4 and several other visual changes. If you are happy with the existing features, you can stay on Mint 19.2. You’ll still get the necessary security and maintenance updates on Mint 19.2 till 2023.
|
||||
|
||||
Now that you understand the concept of minor releases and want the latest minor release, let’s see how to upgrade to Mint 19.3.
|
||||
|
||||
### Linux Mint 19.3: How to Upgrade?
|
||||
|
||||
No matter whether you have Linux Mint 19.1 or 19, you can follow these steps to [upgrade Linux Mint version][11].
|
||||
|
||||
**Note**: _You should consider making a system snapshot (just in case) for backup. In addition, the Linux Mint team advises you to disable the screensaver and upgrade Cinnamon spices (if installed) from the System settings._
|
||||
|
||||
![][12]
|
||||
|
||||
1. Launch the Update Manager.
|
||||
2. Now, refresh it to load up the latest available updates (or you can change the mirror if you want).
|
||||
3. Once done, simply click on the Edit button to find “**Upgrade to Linux Mint 19.3 Tricia**” button similar to the image above.
|
||||
4. Finally, just follow the on-screen instructions to easily update it.
|
||||
|
||||
|
||||
|
||||
Based on your internet connection, it should take anything between a couple of minutes to 30 minutes.
|
||||
|
||||
### Don’t see Mint 19.3 update yet? Here’s what you can do
|
||||
|
||||
If you don’t see the option to upgrade to Linux Mint 19.3 Tricia, don’t lose hope. Here are a couple of things you can do.
|
||||
|
||||
#### **Step 1: Make sure to use mint-upgrade-info version 1.1.3**
|
||||
|
||||
Make sure that mint-upgrade-info is updated to version 1.1.3. You can try the install command that will update it to a newer version (if there is any).
|
||||
|
||||
```
|
||||
sudo apt install mint-upgrade-info
|
||||
```
|
||||
|
||||
#### **Step 2: Switch to default software sources**
|
||||
|
||||
Chances are that you are using a mirror closer to you to get faster software downloads. But this could cause a problem as the mirrors might not have the new upgrade info yet.
|
||||
|
||||
Go to Software Source and change the sources to default. Now run the update manager again and see if Mint 19.3 upgrade is available.
|
||||
|
||||
### Download Linux Mint 19.3 ‘Tricia’
|
||||
|
||||
If you want to perform a fresh install, you can easily download the latest available version from the official download page (depending on what edition you want).
|
||||
|
||||
You will also find multiple mirrors available to download the ISOs – feel free to try the nearest mirror for potentially faster download.
|
||||
|
||||
[Linux Mint 19.3][13]
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
Have you tried Linux Mint 19.3 yet? Let me know your thoughts in the comments down below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-mint-19-3/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/linuxmint/cinnamon/releases/tag/4.4.0
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/linux-mint-19-3-desktop.jpg?ssl=1
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/linux-mint-system-report.jpg?ssl=1
|
||||
[4]: https://wiki.archlinux.org/index.php/HiDPI
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/12/linux-mint-drawing-app.jpg?ssl=1
|
||||
[6]: https://itsfoss.com/video-players-linux/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/cinnamon-4-4-desktop.jpg?ssl=1
|
||||
[8]: https://linuxmint.com/rel_tricia_cinnamon.php
|
||||
[9]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[10]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[11]: https://itsfoss.com/upgrade-linux-mint-version/
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/mintupgrade.png?ssl=1
|
||||
[13]: https://linuxmint.com/download.php
|
||||
@ -0,0 +1,76 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Eliminating gender bias in open source software development, a database of microbes, and more open source news)
|
||||
[#]: via: (https://opensource.com/article/19/12/news-december-21)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Eliminating gender bias in open source software development, a database of microbes, and more open source news
|
||||
======
|
||||
Catch up on the biggest open source headlines from the past two weeks.
|
||||
![Weekly news roundup with TV][1]
|
||||
|
||||
In this edition of our open source news roundup, we take a look at eliminating gender bias in open source software development, an open source database of microbes, an open source index for cooperatives, and more!
|
||||
|
||||
### Eliminating gender bias from open source development
|
||||
|
||||
It's a sad fact that certain groups, among them women, are woefully underrepresented in open source projects. It's like a bug in the open source development process. Fortunately, there are initiatives to make that under representation a thing of the past. A study out of Oregon State University (OSU) intends to resolve the issue of the lack of women in open source development by "[finding these bugs and proposing redesigns around them][2], leading to more gender-inclusive tools used by software developers."
|
||||
|
||||
The study will look at tools commonly used in open source development — including Eclipse, GitHub, and Hudson — to determine if they "significantly discourage newcomers, especially women, from joining OSS projects." According to Igor Steinmacher, one of the principal investigators of the study, the study will examine "how people use tools because the 'bugs' may be embedded in how the tool was designed, which may place people with different cognitive styles at a disadvantage."
|
||||
|
||||
The developers of the tools being studied will walk through their software and answer questions based on specific personas. The researchers at OSU will suggest ways to redesign the software to eliminate gender bias and will "create a list of best practices for fixing gender-bias bugs in both products and processes."
|
||||
|
||||
### Canadian university compiles open source microbial database
|
||||
|
||||
What do you do when you have a vast amount of data but no way to effectively search and build upon it? You turn it into a database, of course. That's what researchers at Simon Fraser University in British Columbia, along with collaborators from around the globe, did with [information about chemical compounds created by bacteria and fungi][3]. Called the Natural Products Atlas, the database "holds information on nearly 25,000 natural compounds and serves as a knowledge base and repository for the global scientific community."
|
||||
|
||||
Licensed under a Creative Commons Attribution 4.0 International License, the Natural Products Atlas "holds information on nearly 25,000 natural compounds and serves as a knowledge base and repository for the global scientific community." The [website for the Natural Products Atlas][4] hosts the database also includes a number of visualization tools and is fully searchable.
|
||||
|
||||
Roger Linington, an associate professor at SFU who spearheaded the creation of the database, said that having "all the available data in one place and in a standardized format means we can now index natural compounds for anyone to freely access and learn more about."
|
||||
|
||||
### Open source index for cooperatives
|
||||
|
||||
Europe has long been a hotbed of both open source development and open source adoption. While European governments strongly advocate open source, non profits have been following suit. One of those is Cooperatives Europe, which is developing "[open source software to allow users to index co-op information and resources in a standardised way][5]."
|
||||
|
||||
The idea behind the software, called Coop Starter, reinforces the [essential freedoms of free software][6]: it's intended to provide "education, training and information. The software may be used and repurposed by the public for their own needs and on their own infrastructure." Anyone can use it "to reference existing material on co-operative entrepreneurship" and can contribute "by sharing resources and information."
|
||||
|
||||
The [code for Coop Starter][7], along with a related WordPress plugin, is available from Cooperative Europe's GitLab repository.
|
||||
|
||||
#### In other news
|
||||
|
||||
* [Nancy recognised as France’s top digital free and collaborative public service][8]
|
||||
* [Open Source and AI: Ready for primetime in government?][9]
|
||||
* [Open Software Means Kinder Science][10]
|
||||
* [New Open-Source CoE to be launched by Wipro and Oman’s Ministry of Tech & Communication][11]
|
||||
|
||||
|
||||
|
||||
_Thanks, as always, to Opensource.com staff members and [Correspondents][12] for their help this week._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/news-december-21
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
|
||||
[2]: https://techxplore.com/news/2019-12-professors-gender-biased-bugs-open-source-software.html
|
||||
[3]: https://www.sfu.ca/sfunews/stories/2019/12/sfu-global-collaboration-creates-world-s-first-open-source-datab.html
|
||||
[4]: https://www.npatlas.org/joomla/
|
||||
[5]: https://www.thenews.coop/144412/sector/regional-organisations/cooperatives-europe-builds-open-source-index-for-the-co-op-movement/
|
||||
[6]: https://www.gnu.org/philosophy/free-sw.en.html
|
||||
[7]: https://git.happy-dev.fr/startinblox/applications/coop-starter
|
||||
[8]: https://joinup.ec.europa.eu/collection/open-source-observatory-osor/news/territoire-numerique-libre
|
||||
[9]: https://federalnewsnetwork.com/commentary/2019/12/open-source-and-ai-ready-for-primetime-in-government/
|
||||
[10]: https://blogs.scientificamerican.com/observations/open-software-means-kinder-science/
|
||||
[11]: https://www.indianweb2.com/2019/12/11/new-open-source-coe-to-be-launched-by-wipro-and-omans-ministry-of-tech-communication/
|
||||
[12]: https://opensource.com/correspondent-program
|
||||
@ -0,0 +1,112 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Darktable 3 Released With GUI Rework and New Features)
|
||||
[#]: via: (https://itsfoss.com/darktable-3-release/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Darktable 3 Released With GUI Rework and New Features
|
||||
======
|
||||
|
||||
Here’s the Christmas gift for the photography enthusiasts. Darktable 3.0 has just released.
|
||||
|
||||
[Darktable][1] is one of the [best applications for editing RAW images on Linux][2]. You can consider it as a [free and open source alternative to Adobe Lightroom][3].
|
||||
|
||||
Darktable 3 is a major new release with tons of feature improvements and a complete rework of the user interface. The GUI is now completely controlled by GTK+ CSS rules, which makes the whole GUI themable. There are eight themes available by default.
|
||||
|
||||
With the help of over 3000 commits and 553 pull requests, the new release has fixed 66 bugs and added many new features.
|
||||
|
||||
Let’s see what features this new release brings.
|
||||
|
||||
### New features in Darktable 3.0
|
||||
|
||||
![Darktable 3.0 Screenshot][4]
|
||||
|
||||
Here are the highlighted new features:
|
||||
|
||||
* Reworked UI
|
||||
* A new module for handling 3D RGB Lut transformations
|
||||
* Many improvements to the ‘denoise (profiled)’ module
|
||||
* A new ‘culling’ mode and timeline view added
|
||||
* Many improvements to the ‘denoise (profiled)’ module
|
||||
* New tone equalizer’ basic and filmic RGB modules
|
||||
* Better 4K/5K display support
|
||||
* Undo/redo support for more operations
|
||||
* Many code optimizations for CPU and SSE paths
|
||||
* Support for exporting to Google Photos
|
||||
* More camera support, white balance presets, and noise profiles
|
||||
* Plenty of bug fixes and feature improvements
|
||||
|
||||
|
||||
|
||||
You can read about all the changes in the [release notes on GitHub][5].
|
||||
|
||||
### Installing Darktable 3.0 on Linux
|
||||
|
||||
Let’s see how to get the latest Darktable release.
|
||||
|
||||
#### Installing Darktable 3.0 on Ubuntu-based distributions
|
||||
|
||||
Darktable is available in Ubuntu but you won’t get the latest release immediately. For the LTS version, it may take months before you have this version update.
|
||||
|
||||
Worry not! Darktable provides its [own PPA][6] to install the latest release on Ubuntu-based distributions.
|
||||
|
||||
Unfortuntaley, That Darktable PPA has not been updated with the new release.
|
||||
|
||||
Worry not (again)! Thanks to our friend [Ji M of Ubuntu Handbook][7], we have an unofficial PPA for easily installing Darktable 3.0 on Ubuntu and other Ubuntu based distributions.
|
||||
|
||||
Open a terminal and use these commands one by one:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:ubuntuhandbook1/darktable
|
||||
sudo apt update
|
||||
sudo apt install darktable
|
||||
```
|
||||
|
||||
#### Uninstall Darktable 3
|
||||
|
||||
To remove Darktable installed via this PPA, you can first uninstall the application:
|
||||
|
||||
```
|
||||
sudo apt remove darktable
|
||||
```
|
||||
|
||||
And then [remove the PPA][8] as well:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -r ppa:ubuntuhandbook1/darktable
|
||||
```
|
||||
|
||||
#### Installing Darktable on other Linux distributions
|
||||
|
||||
You may wait for your distribution to provide this new release through the software manager.
|
||||
|
||||
You may also download the tarball or the entire source code from the GitHub release page (it’s at the bottom of the page).
|
||||
|
||||
[Download Darktable 3.0][5]
|
||||
|
||||
With Darktable 3, you can edit your holiday pictures better :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/darktable-3-release/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.darktable.org/
|
||||
[2]: https://itsfoss.com/raw-image-tools-linux/
|
||||
[3]: https://itsfoss.com/open-source-photoshop-alternatives/
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/12/darktable_3_screenshot.jpg?ssl=1
|
||||
[5]: https://github.com/darktable-org/darktable/releases/tag/release-3.0.0
|
||||
[6]: https://launchpad.net/~pmjdebruijn/+archive/ubuntu/darktable-release
|
||||
[7]: http://ubuntuhandbook.org/index.php/2019/12/install-darktable-3-0-0-ubuntu-18-04-19-10/
|
||||
[8]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
@ -1,95 +0,0 @@
|
||||
translating
|
||||
|
||||
Think global: How to overcome cultural communication challenges
|
||||
======
|
||||
Use these tips to ensure that every member of your global development team feels involved and understood.
|
||||

|
||||
|
||||
A few weeks ago, I witnessed an interesting interaction between two work colleagues—Jason, who is from the United States; and Raj, who was visiting from India.
|
||||
|
||||
Raj typically calls into a daily standup meeting at 9:00am US Central Time from India, but since he was in the US, he and his teammates headed toward the scrum area for the meeting. Jason stopped Raj and said, “Raj, where are you going? Don’t you always call into the stand-up? It would feel strange if you don’t call in.” Raj responded, “Oh, is that so? No worries,” and headed back to his desk to call into the meeting.
|
||||
|
||||
I went to Raj’s desk. “Hey, Raj, why aren’t you going to the daily standup?” Raj replied, “Jason asked me to call in.” Meanwhile, Jason was waiting for Raj to come to the standup.
|
||||
|
||||
What happened here? Jason was obviously joking when he made the remark about Raj calling into the meeting. But how did Raj miss this?
|
||||
|
||||
Jason’s statement was meant as a joke, but Raj took it literally. This was a clear example of a misunderstanding that occurred due to unfamiliarity with each other’s cultural context.
|
||||
|
||||
I often encounter emails that end with “Please revert back to me.” At first, this phrase left me puzzled. I thought, "What changes do they want me to revert?" Finally, I figured out that “please revert” means “Please reply.”
|
||||
|
||||
In his TED talk, “[Managing Cross Cultural Remote Teams,][1]” Ricardo Fernandez describes an interaction with a South African colleague who ended an IM conversation with “I’ll call you just now.” Ricardo went back to his office and waited for the call. After fifteen minutes, he called his colleague: “Weren’t you going to call me just now?” The colleague responded, “Yes, I was going to call you just now.” That's when Ricardo realized that to his South African colleague, the phrase “just now” meant “sometime in the future.”
|
||||
|
||||
In today's workplace, our colleagues may not be located in the same office, city, or even country. A growing number of tech companies have a global workforce comprised of employees with varied experiences and perspectives. This diversity allows companies to compete in the rapidly evolving technological environment.
|
||||
|
||||
But geographically dispersed teams can face challenges. Managing and maintaining high-performing development teams is difficult even when the members are co-located; when team members come from different backgrounds and locations, that makes it even harder. Communication can deteriorate, misunderstandings can happen, and teams may stop trusting each other—all of which can affect the success of the company.
|
||||
|
||||
What factors can cause confusion in global communication? In her book, “[The Culture Map][2],” Erin Meyer presents eight scales into which all global cultures fit. We can use these scales to improve our relationships with international colleagues. She identifies the United States as a very low-context culture in the communication scale. In contrast, Japan is identified as a high-context culture.
|
||||
|
||||
What does it mean to be a high- or low-context culture? In the United States, children learn to communicate explicitly: “Say what you mean; mean what you say” is a common principle of communication. On the other hand, Japanese children learn to communicate effectively by mastering the ability to “read the air.” That means they are able to read between the lines and pick up on social cues when communicating.
|
||||
|
||||
Most Asian cultures follow the high-context style of communication. Not surprisingly, the United States, a young country composed of immigrants, follows a low-context culture: Since the people who immigrated to the United States came from different cultural backgrounds, they had no choice but to communicate explicitly and directly.
|
||||
|
||||
### The three R’s
|
||||
|
||||
How can we overcome challenges in cross-cultural communication? Americans communicating with Japanese colleagues, for example, should pay attention to the non-verbal cues, while Japanese communicating with Americans should prepare for more direct language. If you are facing a similar challenge, follow these three steps to communicate more effectively and improve relationships with your international colleagues.
|
||||
|
||||
#### Recognize the differences in cultural context
|
||||
|
||||
The first step toward effective cross-cultural communication is to recognize that there are differences. Start by increasing your awareness of other cultures.
|
||||
|
||||
#### Respect the differences in cultural context
|
||||
|
||||
Once you become aware that differences in cultural context can affect cross-cultural communication, the next step is to respect these differences. When you notice a different style of communication, learn to embrace the difference and actively listen to the other person’s point of view.
|
||||
|
||||
#### Reconcile the differences in cultural context
|
||||
|
||||
Merely recognizing and respecting cultural differences is not enough; you must also learn how to reconcile the cultural differences. Understanding and being empathetic towards the other culture will help you reconcile the differences and learn how to use them to better advance productivity.
|
||||
|
||||
### 5 ways to improve communications for cultural context
|
||||
|
||||
Over the years, I have incorporated various approaches, tips, and tricks to strengthen relationships among team members across the globe. These approaches have helped me overcome communication challenges with global colleagues. Here are a few examples:
|
||||
|
||||
#### Always use video conferencing when communicating with global teammates
|
||||
|
||||
Studies show that about 55% of communication is non-verbal. Body language offers many subtle cues that can help you decipher messages, and video conferencing enables geographically dispersed team members to see each other. Videoconferencing is my default choice when conducting remote meetings.
|
||||
|
||||
#### Ensure that every team member gets an opportunity to share their thoughts and ideas
|
||||
|
||||
Although I prefer to conduct meetings using video conferencing, this is not always possible. If video conferencing is not a common practice at your workplace, it might take some effort to get everyone comfortable with the concept. Start by encouraging everyone to participate in audio meetings.
|
||||
|
||||
One of our remote team members, who frequently met with us in audio conferences, mentioned that she often wanted to share ideas and contribute to the meeting but since we couldn’t see her and she couldn’t see us, she had no idea when to start speaking. If you are using audio conferencing, one way to mitigate this is to ensure that every team member gets an opportunity to share their ideas.
|
||||
|
||||
#### Learn from one another
|
||||
|
||||
Leverage your international friends to learn about their cultural context. This will help you interact more effectively with colleagues from these countries. I have friends from South Asia and South America who have helped me better understand their cultures, and this knowledge has helped me professionally.
|
||||
|
||||
For programmers, I recommend conducting code reviews with your global peers. This will help you understand how those from different cultures give and receive feedback, persuade others, and make technical decisions.
|
||||
|
||||
#### Be empathetic
|
||||
|
||||
Empathy is the key to strong relationships. The more you are able to put yourself in someone else's shoes, the better able you will be to gain trust and build long-lasting connections. Encourage “water-cooler” conversations among your global colleagues by allocating the first few minutes of each meeting for small talk. This offers the additional benefit of putting everyone in a more relaxed mindset. If you manage a global team, make sure every member feels included in the discussion.
|
||||
|
||||
#### Meet your global colleagues in person
|
||||
|
||||
The best way to build long-lasting relationships is to meet your team members in person. If your company can afford it, arrange for this to happen. Meeting colleagues with whom you have been working will likely strengthen your relationship with them. The companies I have worked for have a strong record of periodically sending US team members to other countries and global colleagues to the US office.
|
||||
|
||||
Another way to bring teams together is to attend conferences. This not only creates educational and training opportunities, but you can also carve out some in-person team time.
|
||||
|
||||
In today's increasingly global economy, it is becoming more important for companies to maintain a geographically diverse workforce to remain competitive. Although global teams can face communication challenges, it is possible to maintain a high-performing development team despite geographical and cultural differences. Share some of the techniques you use in the comments.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/think-global-communication-challenges
|
||||
|
||||
作者:[Avindra Fernando][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/avindrafernando
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/watch?v=QIoAkFpN8wQ
|
||||
[2]: https://www.amazon.com/The-Culture-Map-Invisible-Boundaries/dp/1610392507
|
||||
@ -1,198 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (laingke)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What's in an open source name?)
|
||||
[#]: via: (https://opensource.com/article/19/10/open-source-name-origins)
|
||||
[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
|
||||
|
||||
What's in an open source name?
|
||||
======
|
||||
Ever wonder where the names of your favorite open source projects or
|
||||
programming languages came from? Get the origin stories behind popular
|
||||
tech nomenclature from A to Z.
|
||||
![A person writing.][1]
|
||||
|
||||
GNOME, Java, Jupyter, Python. If your friends or family members have ever eavesdropped on your work conversations, they might think you've made a career in Renaissance folklore, coffee roasting, astronomy, or zoology. Where did the names of these open source technologies come from? We asked our writer community for input and rounded up some of our favorite tech name origin stories.
|
||||
|
||||
### Ansible
|
||||
|
||||
The name "Ansible" is lifted directly from science fiction. Ursula Le Guin's book _Rocannon's World_ had devices allowing instantaneous (faster than light) communication called ansibles (derived, apparently, from the word "answerable"). Ansibles became a staple of science fiction, including in Orson Scott Card's _Ender's Game_ (which later became a popular film), where the device controlled many remote space ships. This seemed to be a good model for software that controls distributed machines, so Michael DeHaan (creator and founder of Ansible) borrowed the name.
|
||||
|
||||
### Apache
|
||||
|
||||
[Apache][2] is an open source web server that was originally released in 1995. Its name is not related to the famous Native American tribe; it instead refers to the repeated patches to its original software code. Hence, "A-patchy server."
|
||||
|
||||
### awk
|
||||
|
||||
"awk(1) Stands for Aho, Weinberger, Kernighan (authors)" —Michael Greenberg
|
||||
|
||||
### Bash
|
||||
|
||||
"The original Unix shell, the Bourne shell, was named after its creator. At the time Bash was being developed, csh (pronounced 'seashell') was actually more popular for interactive user logins. The Bash project aimed to give new life to the Bourne shell by making it more suitable for interactive use, thus it was named the 'Bourne again shell,' a pun on 'born again.'" —Ken Gaillot
|
||||
|
||||
### C
|
||||
|
||||
"In early days, Ken Thompson and Dennis Ritchie at AT&T found it interesting that you could use a higher-level programming language (instead of low-level and less-portable assembly programming) to write operating systems and tools. There was an early programming system called BCPL (Basic Combined Programming Language), and Thompson created a stripped-down version of BCPL called B. But B wasn't very flexible or fast. Ritchie then took the ideas of B and expanded it into a compiled language called C." —Jim Hall
|
||||
|
||||
### dd
|
||||
|
||||
"I don't think you can publish such an article without mentioning dd. My nickname is Didi. Correctly pronounced, it sounds like 'dd.' I first learned Unix, and then Linux, in 1993 as a student. Then I went to the army, arrived to one of the very few sections in my unit that used Unix (Ultrix) (the rest were mainly VMS), and one of the people there said: 'So, you are a hacker, right? You think you know Unix? OK, so what's the reason for the name dd?' I had no idea and tried to guess: "Data duplicator?" So he said, 'I'll tell you the story of dd. dd is short for _convert and copy_ (as anyone can still see today on the manpage), but since cc was already taken by the c compiler, it was named dd.' Only years later, I heard the true story about JCL's data definition and the non-uniform, semi-joking syntax for the Unix dd command somewhat being based on it." —Yedidyah Bar David
|
||||
|
||||
### Emacs
|
||||
|
||||
The classic anti-vi editor, the true etymology of the name is unremarkable, in that it derives from "Editing MACroS." Being an object of great religious opprobrium and worship it has, however, attracted many spoof bacronyms such as "Escape Meta Alt Control Shift" (to spoof its heavy reliance on keystrokes), "Eight Megabytes And Constantly Swapping" (from when that was a lot of memory), "Eventually malloc()s All Computer Storage," and "EMACS Makes A Computer Slow." —Adapted from the Jargon File/Hacker's Dictionary
|
||||
|
||||
### Enarx
|
||||
|
||||
[Enarx][3] is a new project in the confidential computing space. One of the project's design principles was that it should be "fungible." so an initial name was "psilocybin" (the famed magic mushroom). The general feeling was that manager types would probably be resistant, so new names were considered. The project's two founders, Mike Bursell and Nathaniel McCallum, are both ancient language geeks, so they considered lots of different ideas, including тайна (Tayna—Russian for secret or mystery—although Russian, admittedly, is not ancient, but hey), crypticon (total bastardization of Greek), cryptidion (Greek for small secret place), arcanus (Latin masculine adjective for secret), arcanum (Latin neuter adjective for secret), and ærn (Anglo-Saxon for place, secret place, closet, habitation, house, or cottage). In the end, for various reasons, including the availability of domains and GitHub project names, they settled on enarx, a combination of two Latin roots: en- (meaning within) and -arx (meaning citadel, stronghold, or fortress).
|
||||
|
||||
### GIMP
|
||||
|
||||
Where would we be without [GIMP][4]? The GNU Image Manipulation Project has been an open source staple for many years. [Wikipedia][5] states, "In 1995, [Spencer Kimball][6] and [Peter Mattis][7] began developing GIMP as a semester-long project at the University of California, Berkeley, for the eXperimental Computing Facility."
|
||||
|
||||
### GNOME
|
||||
|
||||
Have you ever wondered why GNOME is called GNOME? According to [Wikipedia][8], GNOME was originally an acronym that represented the "GNU Network Object Model Environment." Now that name no longer represents the project and has been dropped, but the name has stayed. [GNOME 3][9] is the default desktop environment for Fedora, Red Hat Enterprise, Ubuntu, Debian, SUSE Linux Enterprise, and more.
|
||||
|
||||
### Java
|
||||
|
||||
Can you imagine this programming language being named anything else? Java was originally called Oak, but alas, the legal team at Sun Microsystems vetoed that name due to its existing trademark. So it was back to the drawing board for the development team. [Legend has it][10] that a massive brainstorm was held by the language's working group in January 1995. Lots of other names were tossed around including Silk, DNA, WebDancer, and so on. The team did not want the new name to have anything to do with the overused terms, "web" or "net." Instead, they were searching for something more dynamic, fun, and easy to remember. Java met the requirements and miraculously, the team agreed!
|
||||
|
||||
### Jupyter
|
||||
|
||||
Many of today's data scientists and students use [Jupyter][11] notebooks in their work. The name Jupyter is an amalgamation of three open source computer languages that are used in the notebooks and prominent in data science: [Julia][12], [Python][13], and [R][14].
|
||||
|
||||
### Kubernetes
|
||||
|
||||
Kubernetes is derived from the Greek word for helmsman. This etymology was corroborated in a [2015 Hacker News][15] response by a Kubernetes project founder, Craig McLuckie. Wanting to stick with the nautical theme, he explained that the technology drives containers, much like a helmsman or pilot drives a container ship. Thus, Kubernetes was the chosen name. Many of us are still trying to get the pronunciation right (koo-bur-NET-eez), so K8s is an acceptable substitute. Interestingly, it shares its etymology with the English word "governor," so has that in common with the mechanical negative-feedback device on steam engines.
|
||||
|
||||
### KDE
|
||||
|
||||
What about the K desktop? KDE originally represented the "Kool Desktop Environment." It was founded in 1996 by [Matthias Ettrich][16]. According to [Wikipedia][17], the name was a play on the words [Common Desktop Environment][18] (CDE) on Unix.
|
||||
|
||||
### Linux
|
||||
|
||||
[Linux][19] was named for its inventor, Linus Torvalds. Linus originally wanted to name his creation "Freax" as he thought that naming the creation after himself was too egotistical. According to [Wikipedia][19], "Ari Lemmke, Torvalds' coworker at the Helsinki University of Technology, who was one of the volunteer administrators for the FTP server at the time, did not think that 'Freax' was a good name. So, he named the project 'Linux' on the server without consulting Torvalds."
|
||||
|
||||
Following are some of the most popular Linux distributions.
|
||||
|
||||
#### CentOS
|
||||
|
||||
[CentOS][20] is an acronym for Community Enterprise Operating System. It contains the upstream packages from Red Hat Enterprise Linux.
|
||||
|
||||
#### Debian
|
||||
|
||||
[Debian][21] Linux, founded in September 1993, is a portmanteau of its founder, Ian Murdock, and his then-girlfriend Debra Lynn.
|
||||
|
||||
#### RHEL
|
||||
|
||||
[Red Hat Linux][22] got its name from its founder Marc Ewing, who wore a red Cornell University fedora given to him by his grandfather. Red Hat was founded on March 26, 1993. [Fedora Linux][23] began as a volunteer project to provide extra software for the Red Hat distribution and got its name from Red Hat's "Shadowman" logo.
|
||||
|
||||
#### Ubuntu
|
||||
|
||||
[Ubuntu][24] aims to share open source widely and is named after the African philosophy of ubuntu, which can be translated as "humanity to others" or "I am what I am because of who we all are."
|
||||
|
||||
### Moodle
|
||||
|
||||
The open source learning platform [Moodle][25] is an acronym for "modular object-oriented dynamic learning environment." Moodle continues to be a leading platform for e-learning. There are nearly 104,000 registered Moodle sites worldwide.
|
||||
|
||||
Two other popular open source content management systems are Drupal and Joomla. Drupal's name comes from the Dutch word for "druppel" which means "drop." Joomla is an [anglicized spelling][26] of the Swahili word "jumla," which means "all together" in Arabic, Urdu, and other languages, according to Wikipedia.
|
||||
|
||||
### Mozilla
|
||||
|
||||
[Mozilla][27] is an open source software community founded in 1998. According to its website, "The Mozilla project was created in 1998 with the release of the Netscape browser suite source code. It was intended to harness the creative power of thousands of programmers on the internet and fuel unprecedented levels of innovation in the browser market." The name was a portmanteau of [Mosaic][28] and Godzilla.
|
||||
|
||||
### Nginx
|
||||
|
||||
"Many tech people try to be cool and say it 'n' 'g' 'n' 'x'. Few actually did the basic actions of researching a bit more to find out very quickly that the name is actually supposed to be said as 'EngineX,' in reference to the powerful web server, like an engine." —Jean Sebastien Tougne
|
||||
|
||||
### Perl
|
||||
|
||||
Perl's founder Larry Wall originally named his project "Pearl." According to Wikipedia, Wall wanted to give the language a short name with positive connotations. Wall discovered the existing [PEARL][29] programming language before Perl's official release and changed the spelling of the name.
|
||||
|
||||
### Piet and Mondrian
|
||||
|
||||
"There are two programming language named after the artist Piet Mondrian. One is called 'Piet' and the other 'Mondrian.' [David Morgan-Mar [writes][30]]: 'Piet is a programming language in which programs look like abstract paintings. The language is named after Piet Mondrian, who pioneered the field of geometric abstract art. I would have liked to call the language Mondrian, but someone beat me to it with a rather mundane-looking scripting language. Oh well, we can't all be esoteric language writers, I suppose.'" —Yuval Lifshitz
|
||||
|
||||
### Python
|
||||
|
||||
The Python programming language received its unique name from its creator, Guido Van Rossum, who was a fan of the comedy group Monty Python.
|
||||
|
||||
### Raspberry Pi
|
||||
|
||||
Known for its tiny-but-mighty capabilities and wallet-friendly price tag, the Raspberry Pi is a favorite in the open source community. But where did its endearing (and yummy) name come from? In the '70s and '80s, it was a popular trend to name computers after fruit. Apple, Tangerine, Apricot... anyone getting hungry? According to a [2012 interview][31] with founder Eben Upton, the name "Raspberry Pi" is a nod to that trend. Raspberries are also tiny in size, yet mighty in flavor. The "Pi" in the name alludes to the fact that, originally, the computer could only run Python.
|
||||
|
||||
### Samba
|
||||
|
||||
[Server Message Block][32] for sharing Windows files on Linux.
|
||||
|
||||
### ScummVM
|
||||
|
||||
[ScummVM][33] (Script Creation Utility for Maniac Mansion Virtual Machine) is a program that makes it possible to run some classic computer adventure games on a modern computer. Originally, it was designed to play LucasArts adventure games that were built using SCUMM, which was originally used to develop Maniac Mansion before being used to develop most of LucasArts's other adventure games. Currently, ScummVM supports a large number of game engines, including Sierra Online's AGI and SCI, but still retains the name ScummVM. A related project, [ResidualVM][34], got its name because it covers the "residual" LucasArts adventure games not covered by ScummVM. The LucasArts games covered by ResidualVM were developed using GrimE (Grim Engine), which was first used to develop Grim Fandango, so the ResidualVM name is a double pun.
|
||||
|
||||
### SQL
|
||||
|
||||
"You may know [SQL] stands for Structured Query Language, but do you know why it's often pronounced 'sequel'? It was created as a follow-up (i.e. sequel) to the original 'QUEL' (QUEry Language)." —Ken Gaillot
|
||||
|
||||
### XFCE
|
||||
|
||||
[XFCE][35] is a popular desktop founded by [Olivier Fourdan][36]. It began as an alternative to CDE in 1996 and its name was originally an acronym for XForms Common Environment.
|
||||
|
||||
### Zsh
|
||||
|
||||
Zsh is an interactive login shell. In 1990, the first version of the shell was written by Princeton student Paul Falstad. He named it after seeing the login ID of Zhong Sha (zsh), then a teaching assistant at Princeton, and thought that it sounded like a [good name for a shell][37].
|
||||
|
||||
There are many more projects and names that we have not included in this list. Be sure to share your favorites in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/10/open-source-name-origins
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[laingke](https://github.com/laingke)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/holmja
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003784_02_os.comcareers_resume_rh1x.png?itok=S3HGxi6E (A person writing.)
|
||||
[2]: https://httpd.apache.org/
|
||||
[3]: https://enarx.io
|
||||
[4]: https://www.gimp.org/
|
||||
[5]: https://en.wikipedia.org/wiki/GIMP
|
||||
[6]: https://en.wikipedia.org/wiki/Spencer_Kimball_(computer_programmer)
|
||||
[7]: https://en.wikipedia.org/wiki/Peter_Mattis
|
||||
[8]: https://en.wikipedia.org/wiki/GNOME
|
||||
[9]: https://www.gnome.org/gnome-3/
|
||||
[10]: https://www.javaworld.com/article/2077265/so-why-did-they-decide-to-call-it-java-.html
|
||||
[11]: https://jupyter.org/
|
||||
[12]: https://julialang.org/
|
||||
[13]: https://www.python.org/
|
||||
[14]: https://www.r-project.org/
|
||||
[15]: https://news.ycombinator.com/item?id=9653797
|
||||
[16]: https://en.wikipedia.org/wiki/Matthias_Ettrich
|
||||
[17]: https://en.wikipedia.org/wiki/KDE
|
||||
[18]: https://sourceforge.net/projects/cdesktopenv/
|
||||
[19]: https://en.wikipedia.org/wiki/Linux
|
||||
[20]: https://www.centos.org/
|
||||
[21]: https://www.debian.org/
|
||||
[22]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[23]: https://getfedora.org/
|
||||
[24]: https://ubuntu.com/about
|
||||
[25]: https://moodle.org/
|
||||
[26]: https://en.wikipedia.org/wiki/Joomla#Historical_background
|
||||
[27]: https://www.mozilla.org/en-US/
|
||||
[28]: https://en.wikipedia.org/wiki/Mosaic_(web_browser)
|
||||
[29]: https://en.wikipedia.org/wiki/PEARL_(programming_language)
|
||||
[30]: http://www.dangermouse.net/esoteric/piet.html
|
||||
[31]: https://www.techspot.com/article/531-eben-upton-interview/
|
||||
[32]: https://www.samba.org/
|
||||
[33]: https://www.scummvm.org/
|
||||
[34]: https://www.residualvm.org/
|
||||
[35]: https://www.xfce.org/
|
||||
[36]: https://en.wikipedia.org/wiki/Olivier_Fourdan
|
||||
[37]: http://www.zsh.org/mla/users/2005/msg00951.html
|
||||
@ -1,157 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Java vs. Python: Which should you choose?)
|
||||
[#]: via: (https://opensource.com/article/19/12/java-vs-python)
|
||||
[#]: author: (Archit Modi https://opensource.com/users/architmodi)
|
||||
|
||||
Java vs. Python: Which should you choose?
|
||||
======
|
||||
Compare the two most popular programming languages in the world, and let
|
||||
us know which one you prefer in our poll.
|
||||
![Developing code.][1]
|
||||
|
||||
Let's compare the two most popular and powerful programming languages in the world: Java and Python! Both languages have huge community support and libraries to perform almost any programming task, although selecting a programming language usually depends on the developer's use case. After you compare and contrast, please make sure to answer our poll to [share your opinion][2] on which is best.
|
||||
|
||||
### What is it?
|
||||
|
||||
* **Java** is a general-purpose object-oriented programming language used mostly for developing a wide range of applications from mobile to web to enterprise apps.
|
||||
* **Python** is a high-level object-oriented programming language used mostly for web development, artificial intelligence, machine learning, automation, and other data science applications.
|
||||
|
||||
|
||||
|
||||
### Creator
|
||||
|
||||
* **Java** was created by James Gosling (Sun Microsystems).
|
||||
* **Python** was created by Guido van Rossum.
|
||||
|
||||
|
||||
|
||||
### Open source status
|
||||
|
||||
* **Java** is free and (mostly) open source except for corporate use.
|
||||
* **Python** is free and open source for all use cases.
|
||||
|
||||
|
||||
|
||||
### Platform dependencies
|
||||
|
||||
* **Java** is platform-independent (although JVM isn't) per its WORA ("write once, run anywhere") philosophy.
|
||||
* **Python** is platform-dependent.
|
||||
|
||||
|
||||
|
||||
### Compiled or interpreted
|
||||
|
||||
* **Java** is a compiled language. Java programs are translated to byte code at compile time and not runtime.
|
||||
* **Python** is an interpreted language. Python programs are translated at runtime.
|
||||
|
||||
|
||||
|
||||
### File creation
|
||||
|
||||
* **Java**: After compilation, **<filename>.class** is generated.
|
||||
* **Python**: During runtime, **<filename>.pyc** is created.
|
||||
|
||||
|
||||
|
||||
### Errors types
|
||||
|
||||
* **Java** has ****2 ****types of errors: compile and runtime errors.
|
||||
* **Python** has 1 error type: traceback (or runtime) error.
|
||||
|
||||
|
||||
|
||||
### Statically or dynamically typed
|
||||
|
||||
* **Java** is statically typed. When initiating variables, their types need to be specified in the program because type checking is done at compile time.
|
||||
* **Python** is dynamically typed. Variables don't need to have a type specified when initiated because type checking is done at runtime.
|
||||
|
||||
|
||||
|
||||
### Syntax
|
||||
|
||||
* **Java**: Every statement needs to end with a semicolon ( **;** ), and blocks of code are separated by curly braces ( **{}** ).
|
||||
* **Python**: Blocks of code are separated by indentation (the user can choose how many white spaces to use, but it should be consistent throughout the block).
|
||||
|
||||
|
||||
|
||||
### Number of classes
|
||||
|
||||
* **Java**: Only one public top-level class can exist in a single file in Java.
|
||||
* **Python**: Any number of classes can exist in a single file in Python.
|
||||
|
||||
|
||||
|
||||
### More or less code?
|
||||
|
||||
* **Java** generally involves writing more lines of code compared to Python.
|
||||
* **Python** involves writing fewer lines of code compared to Java.
|
||||
|
||||
|
||||
|
||||
### Multiple inheritance
|
||||
|
||||
* **Java** does not support multiple inheritance (inheriting from two or more base classes)
|
||||
* **Python** supports multiple inheritance although it is rarely implemented due to various issues like inheritance complexity, hierarchy, dependency issues, etc.
|
||||
|
||||
|
||||
|
||||
### Multi-threading
|
||||
|
||||
* **Java** multi-threading can support two or more concurrent threads running at the same time.
|
||||
* **Python** uses a global interpreter lock (GIL), allowing only a single thread (CPU core) to run at a time.
|
||||
|
||||
|
||||
|
||||
### Execution speed
|
||||
|
||||
* **Java** is usually faster in execution time than Python.
|
||||
* **Python** is usually slower in execution time than Java.
|
||||
|
||||
|
||||
|
||||
### Hello world in Java
|
||||
|
||||
|
||||
```
|
||||
public class Hello {
|
||||
public static void main([String][3][] args) {
|
||||
[System][4].out.println("Hello Opensource.com from Java!");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Hello world in Python
|
||||
|
||||
|
||||
```
|
||||
`print("Hello Opensource.com from Java!")`
|
||||
```
|
||||
|
||||
### Run the programs
|
||||
|
||||
![Java vs. Python][5]
|
||||
|
||||
To run the java program "Hello.java" you need to compile it first which creates a "Hello.class" file. To run just the class name, use "java Hello." For Python, you would just run the file "python3 helloworld.py."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/java-vs-python
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/architmodi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: tmp.Bpi8QYfp8j#poll
|
||||
[3]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
[5]: https://opensource.com/sites/default/files/uploads/python-java-hello-world_0.png (Java vs. Python)
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Researchers experiment with glass-based storage that doesn't require electronics cooling)
|
||||
[#]: via: (https://www.networkworld.com/article/3488556/researchers-experiment-with-glass-based-storage-that-doesnt-require-electronics-cooling.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Researchers experiment with glass-based storage that doesn't require electronics cooling
|
||||
======
|
||||
A Microsoft Research project uses laser optics and artificial intelligence to store data in quartz glass.
|
||||
Thinkstock
|
||||
|
||||
Hard drives aren’t going to be capacious enough for future data archiving and retrieval requirements, scientists believe, as applications such as artificial intelligence, wide-scale Internet of Things connectivity, and virtual and augmented reality take hold. Glass could be the answer.
|
||||
|
||||
Encoding in glass would have advantages over hard drives and other mediums, experts suggest. Holding capacity is greater, and the slivers of quartz being experimented with don’t need cooling or dehumidifying environments.
|
||||
|
||||
Microsoft Research, working in the UK along with the University of Southampton, [announced][1] that it has been able to store an entire movie on a quartz, glass-based storage medium. The team stored and retrieved a full-length Superman film on a small slab of the special material that measures about 3 inches square and less than a tenth of an inch thick. .
|
||||
|
||||
[][2]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][2]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
“It looks like we’re now in a phase where we’re working on refinement and experimentation, rather asking the question ‘can we do it?’” said Mark Russinovich, Microsoft Azure’s chief technology officer, in a statement.
|
||||
|
||||
### Laser improvements fuel glass-based storage technology
|
||||
|
||||
Improvements in laser technology are behind the proof of concept Microsoft Research dubbed Project Silica. The femtosecond infrared lasers that are used in the process function similarly to eye surgery lasers. Those kinds of laser beams are much better and more precise than traditional ones. They don’t crack the glass, for one thing.
|
||||
|
||||
The glass is, in fact, structurally changed by the laser, which means that the data could last as long as the material does—possibly centuries, unlike existing mediums like tape. It’s robust, too. Interestingly, even if one were to break the glass, the data remains encoded in the shards, the researchers say.
|
||||
|
||||
“It’s somewhat like creating upside down icebergs at a nanoscale level, with different depths and sizes and grooves that make them unique,” Microsoft said. Voxels, which are a three-dimensional version of a pixel, are embedded in the glass, one-time, rather than just written to the top, as occurs with other mediums. That three-dimensional aspect, along with the inherent opaqueness, helps with low-latency retrieval—the reading can occur rapidly along all of the axis (x, y and z).
|
||||
|
||||
* [Backup vs. archive: Why it’s important to know the difference][3]
|
||||
* [How to pick an off-site data-backup method][4]
|
||||
* [Tape vs. disk storage: Why isn’t tape dead yet?][5]
|
||||
* [The correct levels of backup save time, bandwidth, space][6]
|
||||
|
||||
|
||||
|
||||
### Cloud storage alternatives
|
||||
|
||||
Glass isn’t the only potential replacement for old-school magnetic, solid-state and tape storage as the world increasingly collects data. Chemical, molecule and DNA options are all being suggested as potential alternatives to existing cloud storage.
|
||||
|
||||
Fitting transistors onto individual molecules is one answer, [say researchers at Arizona State University][7].
|
||||
|
||||
Synthetic DNA is another proposed option. Large amounts of information last a long time in DNA; a 45,000-year-old human bone was DNA-decoded a few years ago, for example. [Synthetic DNA could end up having similar advantages to that organic version][8], scientists think.
|
||||
|
||||
A third option, at a chemical level, is storing data on molecules and then dissolving that mix into liquids. [Massive amounts of data could be held in small containers][9], Brown University has said of its experiments in that area.
|
||||
|
||||
Perhaps most interestingly, with all of the these potential storage replacements (should any of them take off), the traditional environmental controls that we require for heat-generating electronics in data center environments would become moot.
|
||||
|
||||
“Quartz glass doesn’t need energy-intensive air conditioning to keep material at a constant temperature or systems that remove moisture from the air,” Microsoft said of Project Silica. “Both of which could lower the environmental footprint of large-scale data storage.”
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3488556/researchers-experiment-with-glass-based-storage-that-doesnt-require-electronics-cooling.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://news.microsoft.com/innovation-stories/ignite-project-silica-superman/
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.networkworld.com/article/3285652/storage/backup-vs-archive-why-its-important-to-know-the-difference.html
|
||||
[4]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[5]: https://www.networkworld.com/article/3315156/storage/tape-vs-disk-storage-why-isnt-tape-dead-yet.html
|
||||
[6]: https://www.networkworld.com/article/3302804/storage/the-correct-levels-of-backup-save-time-bandwidth-space.html
|
||||
[7]: https://www.networkworld.com/article/3344599/new-chemistry-based-data-storage-would-blow-moores-law-out-of-the-water.html
|
||||
[8]: https://www.networkworld.com/article/3268646/dna-data-storage-closer-to-becoming-reality.html
|
||||
[9]: https://www.networkworld.com/article/3251071/data-could-one-day-be-stored-on-molecules.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The current state of blockchain and where it's going)
|
||||
[#]: via: (https://opensource.com/article/19/12/blockchain-evolution)
|
||||
[#]: author: (axel simon https://opensource.com/users/axel)
|
||||
|
||||
The current state of blockchain and where it's going
|
||||
======
|
||||
Take a look at the ecosystem and the projects trying to solve some of
|
||||
the limitations of blockchain technology.
|
||||
![Arrows moving a process forward][1]
|
||||
|
||||
In an earlier post, [_Blockchain evolution: A quick guide and why open source is at the heart of it_][2], I discussed the first generations of blockchains: the public Bitcoin and cryptocurrency blockchains, followed by the Ethereum blockchain capable of executing programs ("smart contracts"), leading to permissioned versions of code-executing blockchains (e.g., Hyperledger Fabric, Quorum).
|
||||
|
||||
Let's step back into the blockchain jungle and take a look at the current state of the ecosystem and the projects trying to solve some of the limitations of blockchain technology: speed and throughput, cross-blockchain information and value exchange, governance, and identity and account management.
|
||||
|
||||
### Speeding things up
|
||||
|
||||
One of the oft-heard gripes about current blockchain technologies is their limited speed, often measured by the number of transactions per second (TPS) that they can manage. This issue strongly limits their use in systems that need to process massive amounts of events. For instance, it has often been said (correctly) that Bitcoin can't handle more than seven transactions per second, and Ethereum can't do much more. Possibly the simplest way of defining the next generation of blockchains is with novel ways to try to solve the scalability problems that current generations of blockchains constantly battle. (Permissionless ones especially. I will return to what separates permissionless and permissioned chains below.)
|
||||
|
||||
The most obvious option—and one of the most fiercely debated one in the Bitcoin community—is "simply" to make the blocks of transactions bigger so that they can handle more transactions per block, and thus per second. Opposing interests in Bitcoin have made this solution very hard to implement (a clear problem with the "governance by code" model I mentioned in my previous article, which I will return to in a future article), but it nonetheless remains a relatively straightforward option for blockchain projects in general. Increasing the frequency at which blocks are created is another one.
|
||||
|
||||
I also mentioned another way to handle more transactions per second in the first article: changing the constraints of the problem. Going from a permissionless network—one that anyone can join and participate in—to a permissioned one—where joining requires permission—changes the constraints and offers the option of reconsidering the security requirements. When you know everyone in a consortium—and have legal ties to them—you can choose to use consensus mechanisms, which don't assume everything should be verified at all times and thus speed things up. Furthermore, permissioned blockchain frameworks, such as Hyperledger Fabric, will typically offer the option to choose the number of transactions contained in a block and their frequency. Whether it's the number of transactions per block or the number of blocks generated that increases, the end result will be an increase in TPS.
|
||||
|
||||
This is how permissioned systems can reach tens of thousands of TPS, numbers far beyond the major permissionless networks. It is also unsurprising, then, that Facebook's recently announced Libra cryptocurrency plans to use a permissioned model (although its "blockchainness" is debated) to handle a high number of transactions, in line with its stated goals.
|
||||
|
||||
### Holding out for consensus
|
||||
|
||||
However, private, permissioned ledgers will not be suited to all use cases. There need to be improvements in general to permissionless networks' capacity to manage more events at a time. This leads us to where the most ambitious work might be happening: consensus mechanisms.
|
||||
|
||||
Getting all participants to come to a consensus on the "truth" of all the transactions (i.e., the changes) that happen on the network and on their order is one of the great difficulties of distributed systems. As a type of distributed system, blockchains inevitably contend with it, too.
|
||||
|
||||
Bitcoin's solution is to organize a race every 10 minutes to solve a computational puzzle and let the winner settle what transactions happened in the last time period and in which order, which everyone else can then easily verify and agree on. By virtue of the kind of puzzle used, the winner is essentially random, but the problem with this "Nakamoto-style proof of work" is that the puzzles used in this race also require horrendously high computational resources to solve (by design), and the work of everyone but the winner is thrown away after each round.
|
||||
|
||||
While it is secure, proof of work is also energy-consuming and slow.
|
||||
|
||||
What we need are better consensus mechanisms that will allow participants of blockchain networks to come to agreement more efficiently, making it possible for the whole system to process more events per second.
|
||||
|
||||
Ethereum, notably, is working on numerous innovations to solve these limitations. First of all, it plans to let go of proof of work to move to a proof of stake consensus mechanism, often referred to as the [Casper protocol][3]. It uses economic incentives and disincentives to get the nodes to secure the network and make cheating (very) costly.
|
||||
|
||||
Another problem a blockchain that can execute smart contracts must contend with is how the execution of code is guaranteed to be correct and what impact this has on the processing capacity of the overall network. Currently, Ethereum requires each validating node to execute the code to verify that the results offered by other nodes are correct. This poses scalability issues, as the greater the success of the Ethereum "world computer," the more code validators need to check: all the nodes need to agree on the order _and_ the validity of each line of code executed and will inevitably be held back by the slowest node.
|
||||
|
||||
One of the options to alleviate this issue is [_sharding_][4], a solution where only part of the network executes the code and returns results the rest of the network can verify.
|
||||
|
||||
Pushing this idea further, [ZEXE][5], a project by the team behind Zcash, deals with this situation by making it possible to submit the result of the execution of code along with a cryptographic proof that the result is correct. Other nodes can then take this proof and check it very quickly without redoing the computation. This, combined with bounties for proving results wrong, creates a system where code can be executed by a single node and checked by many, and it makes for a clever way of speeding up the execution of distributed applications (dapps).
|
||||
|
||||
Consensus in distributed systems is not exactly a new research field, but as blockchains have become popular, there has been renewed interest in consensus research. I could mention many more (Tendermint, Ouroboros, and Algorand come to mind), but I'll offer one other interesting approach regarding consensus: consensus agility. For instance, Hyperledger Sawtooth can [change consensus][6] on the fly, "putting all blockchain configuration on the chain itself." This makes it possible to start a network using a given consensus mechanism and switch to a different, more adapted one when the network and its users have changed, say going from a small-scale deployment to a large consortium.
|
||||
|
||||
This is starting to shed light on an important aspect of the evolution of blockchains: modularity. While the first projects were very tightly integrated, over time, efforts have been made to separate the different layers: networking, consensus, application, and even information storage.
|
||||
|
||||
### Layer 2 solutions: Generation 2.5?
|
||||
|
||||
Solutions baked directly into the blockchain—such as the ones above—are considered to be layer 1. Solutions built on top of a blockchain are called layer 2 solutions.
|
||||
|
||||
These layer 2 solutions, such as the [Lightning Network][7] for Bitcoin or [Raiden][8] for Ethereum, are designed to speed up the overall system by offloading transactions to a secondary network. It's designed to achieve much higher throughput while still connecting to the main blockchain and maintaining its important characteristics: distributed, permissionless, and trust-minimizing. While similar to some degree to sidechains (connecting another system to the main chain, an idea I will return to in the next article), they don't use the idea of a secondary chain. Instead, they build overlay networks that rely on the underlying chain for security and accountability but can exchange information much, much faster and in a peer-to-peer manner.
|
||||
|
||||
Layer 2 solutions are essentially built for cryptocurrencies and create payment tunnels anchored to the underlying cryptocurrency's blockchain, where the amounts exchanged between two parties are eventually settled. By taking most transactions off-chain and alleviating how much needs to happen on the main chain and offloading most transactions to the second layer, they help speed up the entire system.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Speed is the great limiter on the potential of permissionless blockchains. There is a great deal of work going on to explore solutions to this challenge while maintaining the integrity of the chain. Recent research on consensus is leading to new approaches which offer less environmentally unfriendly guarantees on accuracy.
|
||||
|
||||
Open source software is constantly evolving, and as an open source ecosystem, blockchains are a prime example of this reality: Many projects are experimenting with various solutions to shared problems, and these solutions are being studied, refined, and improved by the rest of the community.
|
||||
|
||||
The next installment of this series will examine how current generations of blockchain technologies are trying not just to make individual blockchains more efficient but also capable of working together.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/blockchain-evolution
|
||||
|
||||
作者:[axel simon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/axel
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_twoforward.png?itok=exkV49ts (Arrows moving a process forward)
|
||||
[2]: https://opensource.com/article/18/6/blockchain-guide-next-generation
|
||||
[3]: https://github.com/ethereum/eth2.0-specs/tree/dev/specs/core
|
||||
[4]: https://github.com/ethereum/wiki/wiki/Sharding-FAQ
|
||||
[5]: https://eprint.iacr.org/2018/962.pdf
|
||||
[6]: https://www.hyperledger.org/blog/2017/11/22/un-pluggable-consensus-with-hyperledger-sawtooth
|
||||
[7]: https://lightning.network/
|
||||
[8]: https://raiden.network/
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5G in 2020: Still just a private party)
|
||||
[#]: via: (https://www.networkworld.com/article/3488563/5g-in-2020-still-just-a-private-party.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
5G in 2020: Still just a private party
|
||||
======
|
||||
|
||||
Vertigo3D / Getty Images
|
||||
|
||||
To hear the major mobile carriers talk about it, [5G][1] is here. They’ve deployed it, it works, and it’s ready to start changing the world just about right away, with ultra-fast connectivity, low latency and a dramatically improved ability to handle huge numbers of different connections at once.
|
||||
|
||||
Eventually, that will all be true – but, according to experts in the field, it isn’t yet, and most of it won’t take place within the coming calendar year. The 3GPP standards that will underpin all new-radio 5G technology are still not yet finalized, although that is expected to happen in early 2020, which means the much-touted 5G deployments in the U.S. are based partially on pre-standard technology.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][2]
|
||||
|
||||
Those deployments are also, at this point, quite limited in size, confined to a few major cities, and only covering centrally located intersections and occasional landmarks. It’s worth noting, though, that the parts of the 5G standard that work over some of the same frequencies as existing LTE have been finalized.
|
||||
|
||||
[][3]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][3]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
Babak Beheshti, a member of the IEEE’s board of directors, said that the main way 5G will make a mark in 2020 will be in private deployments. A company can use pre-standard versions of 5G to create very fast, low-latency networks within its own facilities. Vendors like Ericsson and Nokia are already getting ready to sell the requisite equipment, and a private 5G network has a number of potential upsides, thanks in part to it being based on existing carrier technology.
|
||||
|
||||
“Because of its inherent privacy and security, in that sense, it’ll provide wireless access to employees at a much more secure level,” he said.
|
||||
|
||||
Beheshti also noted that there are potential downsides to the use of private 5G – including cost and the fact that it will require a fairly dense deployment of access points, given its use of comparatively high-frequency radio waves.
|
||||
|
||||
According to Forrester Research vice president Glenn O’Donnell, another potential issue is power consumption – compared to a [Wi-Fi 6][4] network of similar capacity, at least – but that’s an arguable point, and both technologies will be competitive for this type of deployment.
|
||||
|
||||
“This is one of the many holy wars we’ve seen in technology,” he said. “You’ll get people who fall into one camp or the other – a lot of it, unfortunately, is going to come down to who’s marketing better.”
|
||||
|
||||
Still, it seems clear that there’s a potential market there in the enterprise sector for a fast, low-latency network that’s also highly secure. O’Donnell said that the manufacturing, warehousing and logistics verticals might be particularly interested in private 5G, given the networking needs created by IoT and related developments and a lesser incidence of highly sophisticated Wi-Fi implementations.
|
||||
|
||||
Beheshti concurred, saying that a relatively green field makes the most sense for private 5G deployment.
|
||||
|
||||
“Given the expenditure involved, where it would really provide most ROI is for companies that have no private wireless or very little private wireless setup or infrastructure,” he said.
|
||||
|
||||
Widespread carrier-based implementation of 5G technology, however, is unlikely to happen over the course of 2020, and a big part of the reason why is that the devices on the market that are compatible with 5G networks are slim to non-existent.
|
||||
|
||||
According to O’Donnell, software-defined 5G radios are present on some of the latest Samsung phones and a few handsets made in China, and they’re likely capable of being reconfigured with OTA updates to mesh with any final standard for the millimeter-wave technology that provides 5G’s most impressive connection speeds. Yet that’s not a guarantee.
|
||||
|
||||
“If a new band opened up that nobody foresaw as a possibility, that could cause hiccups,” he said.
|
||||
|
||||
It’s easy to understand the reason behind all the hype. The mobile carriers are eager to tout their cutting-edge technology, and full-fledged 5G will be an undeniably impressive achievement. It will enable a huge range of new wireless applications, and improve overall connectivity for just about every user. But the fact remains that it’s not going to do all that in 2020, and, beyond the limited use case for private implementations of the technology, 5G isn’t something that enterprise users will need to concern themselves with too heavily in the coming year.
|
||||
|
||||
“I fully believe 5G is going to be transformative, but it needs to be built out,” said O’Donnell. “This is going to take time and a lot of money.”
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3488563/5g-in-2020-still-just-a-private-party.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[2]: https://www.networkworld.com/newsletters/signup.html
|
||||
[3]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[4]: https://www.networkworld.com/article/3356838/how-to-determine-if-wi-fi-6-is-right-for-you.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,132 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Data centers in 2020: Automation, cheaper memory)
|
||||
[#]: via: (https://www.networkworld.com/article/3487684/data-centers-in-2020-automation-cheaper-memory.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Data centers in 2020: Automation, cheaper memory
|
||||
======
|
||||
As data centers grow in 2020, enterprises will refine the balance between on-premises and cloud resources, adopt AI on servers and try to manage data sprawl effectively.
|
||||
[Arthur Ogleznev / Unsplash][1] [(CC0)][2]
|
||||
|
||||
It’s that time of year again when those of us in the press make our annual prognostications for the coming year. Some things we saw coming; the rise of the cloud and the advance of SSD. Others, like the return of many cloud migrations to on-premises or the roaring comeback of AMD, went right by us. We do our best but occasionally there are surprises.
|
||||
|
||||
So with that, let’s take a peek into the always cloudy (no pun intended) crystal ball and make 10 data-center-oriented predictions.
|
||||
|
||||
### IoT spawns data-center growth in urban areas
|
||||
|
||||
This isn’t a hard prediction to make since it’s already happening. For the longest time, [data centers][3] were placed in the middle of nowhere near renewable energy (usually hydro), but need is going to force more expansion in major metro areas. [IoT][3] will be one driver but so will the increasing use of data center providers like Equinix and DRT as interconnection providers.
|
||||
|
||||
[][4]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][4]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
### Rise of network accelerators
|
||||
|
||||
Big Data and artificial intelligence of all flavors mean enormous amounts of data, and not all of it can be found in one place. Add to it that for now, CPUs are required to power network traffic controllers, thus taking them away from their main job of crunching data.
|
||||
|
||||
So you will see more and more network accelerators coming to market like Mellanox’s [ConnectX line][5] to let CPUs do the job of processing data and accelerators do the job of moving around massive amounts of data faster than is done now.
|
||||
|
||||
### NVMe over fabrics grows
|
||||
|
||||
Non-volatile memory express ([NVMe][6]) is a storage interface, like serial advanced technology attachment (SATA). The downside of SATA is that its legacy is in hard disks so it fails to take full advantage of the speed and parallelism of [SSD][7]s. But early enterprise SSDs had a problem: They could only talk to the physical server in which they were installed. Either that or a server needed storage arrays, which meant network hops, which meant latency.
|
||||
|
||||
NVMe over fabrics ([NVMeoF][8]) is an important advance. It lets an SSD in one server communicate over the network to another drive somewhere else on the network. This direct communication will be vital for improved data movement in enterprise computing and digital transformation.
|
||||
|
||||
* [Backup vs. archive: Why it’s important to know the difference][9]
|
||||
* [How to pick an off-site data-backup method][10]
|
||||
* [Tape vs. disk storage: Why isn’t tape dead yet?][11]
|
||||
* [The correct levels of backup save time, bandwidth, space][12]
|
||||
|
||||
|
||||
|
||||
### Cheaper storage-class memory
|
||||
|
||||
Storage-class memory is memory that goes in a DRAM slot and can function like DRAM but can also function like an SSD. It has near-DRAM-like speed but has storage capabilities, too, effectively turning it into a cache for SSD.
|
||||
|
||||
Intel and Micron were working on SCM together but parted company. Intel released its SCM product, [Optane][13], in May, and Micron came to market in October with QuantX. South Korean memory giant SK Hynix is also working on a SCM product that’s different from the 3D XPoint technology Micron and Intel use as well.
|
||||
|
||||
All of this should do wonders to advance the technology and hopefully bring the price down. Right now a 512GB stick of Optane runs an insane $8,000. Granted, Xeons sell for even more than that, but after a while it becomes prohibitively expensive to assemble a fully decked-out server. Advancement of the technology and competition should lower prices, which will make this class of memory more attractive to enterprises.
|
||||
|
||||
### AI automation on brand-name servers
|
||||
|
||||
All of the server vendors are adding AI to their systems but Oracle is really taking the lead with its autonomous everything, from the hardware through OS and application and middleware stack. HPE, Dell, and Lenovo will continue to make their own advances as well but the hyperscale-server vendors like Inspur and Supermicro will lag because they have only the hardware stack and have done next to nothing in the OS space. They also are lagging in storage, something the big-three server vendors excel at.
|
||||
|
||||
Oracle may not be a top-five server vendor, but no one can ignore what they are doing in the automation space. Expect the other brand name-vendors to provide their own increasing levels of automation.
|
||||
|
||||
### Cloud migrations slow
|
||||
|
||||
Remember when everyone was looking forward to shutting down their data centers entirely and moving to the cloud? So much for that idea. IDC’s latest CloudPulse survey suggests that 85% of enterprises plan to move workload from public to private environments over the next year. And a recent survey by Nutanix found 73% of respondents reported that they are moving some applications off the public cloud and back on-prem. Security was cited as the primary reason.
|
||||
|
||||
And since it’s doubtful security will ever be good enough for some companies and some data, it seems the mad rush to the cloud will likely slow a little as people become more picky about what they put in the cloud and what they keep behind their firewall.
|
||||
|
||||
### Data sprawl, Part 1
|
||||
|
||||
Most data is not where it should be, according to IDC. Only 10% of corporate data is “hot” – data that is repeatedly accessed and used – while 30% is “warm ” – used semi-regularly – and the other 60% belongs in cold storage where it is rarely if ever accessed.
|
||||
|
||||
But the problem is that data is scattered all over the place and often in the wrong tier. Many storage firms have focused on deduplication but not on storage tiers. A startup called Spectra Logic is targeting that very problem, and I suspect it won’t be the last firm to make such an effort. If it really takes off, I expect HPE and Dell to lock horns over the company, too.
|
||||
|
||||
### Data sprawl, Part 2
|
||||
|
||||
IDC [predicts][14] the total global data haul to weigh in at 175 zettabytes by 2025, and we are already at 32ZB of data, much of it useless. There was a time when data warehousing ruled that data was sorted and processed and stored as something useful. Now people fill data lakes with an endless supply of data from a growing number of sources, like social media and IoT.
|
||||
|
||||
Sooner or later, something will have to give. People will take a look at petabytes of data-lake junk and say enough is enough and start to become considerably more picky about what they store. They will question the rationale behind spending a fortune on hard disks and storage arrays to store vast quantities of unused and valueless data. The pendulum will swing back to the data-warehouse model of keeping usable data. It has to or people will be overwhelmed.
|
||||
|
||||
### More servers with a mix of processors
|
||||
|
||||
Ten years ago, it didn’t matter if your definition of a server was a single-socket Xeon tower sitting under a desk or four-socket rack-mount in a seven-foot cabinet, they were defined by an x86 processor. But now we are seeing more server designs with on-board GPUs, Arm processors, AI accelerators, and network accelerators.
|
||||
|
||||
This will require some changes in server designs. First, liquid cooling will become more necessary with this multitude of chips running faster and hotter and in an enclosed space. Second, the software stack will need to be more robust to handle all these chips, requiring some work on the part of Microsoft and the Linux distros.
|
||||
|
||||
### IT workload will change
|
||||
|
||||
Don’t think that automation means you can sit around playing games on your iPhone. Thanks to their ever-evolving systems, IT pros will have a bunch of new headaches including:
|
||||
|
||||
* Combating shadow IT
|
||||
* Addressing digital transformation
|
||||
* Developing AI strategies to keep up with competitors
|
||||
* Reacting appropriately to the fallout from new AI strategies
|
||||
* Maintaining security governance across the company
|
||||
* Handling an increasing inflow of data and figuring out what to do with it
|
||||
* Responding faster than ever to customers and to company reputation on social media
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][15] and [LinkedIn][16] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3487684/data-centers-in-2020-automation-cheaper-memory.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://unsplash.com/photos/rWDumHFt8E8
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[5]: https://www.networkworld.com/article/3433924/mellanox-introduces-smartnics-to-eliminate-network-load-on-cpus.html
|
||||
[6]: https://www.networkworld.com/article/3280991/what-is-nvme-and-how-is-it-changing-enterprise-storage.html
|
||||
[7]: https://www.networkworld.com/article/3326058/what-is-an-ssd.html
|
||||
[8]: https://www.networkworld.com/article/3394296/nvme-over-fabrics-creates-data-center-storage-disruption.html
|
||||
[9]: https://www.networkworld.com/article/3285652/storage/backup-vs-archive-why-its-important-to-know-the-difference.html
|
||||
[10]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[11]: https://www.networkworld.com/article/3315156/storage/tape-vs-disk-storage-why-isnt-tape-dead-yet.html
|
||||
[12]: https://www.networkworld.com/article/3302804/storage/the-correct-levels-of-backup-save-time-bandwidth-space.html
|
||||
[13]: https://www.networkworld.com/article/3279271/intel-launches-optane-the-go-between-for-memory-and-storage.html
|
||||
[14]: https://www.networkworld.com/article/3325397/idc-expect-175-zettabytes-of-data-worldwide-by-2025.html
|
||||
[15]: https://www.facebook.com/NetworkWorld/
|
||||
[16]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Google Cloud bare-metal initiative targets migrating legacy apps from on-prem)
|
||||
[#]: via: (https://www.networkworld.com/article/3487626/google-cloud-bare-metal-initiative-targets-migrating-legacy-apps-from-on-prem.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Google Cloud bare-metal initiative targets migrating legacy apps from on-prem
|
||||
======
|
||||
Google Cloud now offers Google Bare Metal Solution, a service that supplies hardware in the cloud for enterprises that want full control of the entire stack from operating system on up to their most important legacy apps.
|
||||
Google
|
||||
|
||||
In the cloud-services market, [bare metal offerings][1] have lagged behind virtualized ones, mostly because the use of the cloud for things like elastic apps and developer environments are better suited to instances with a native operating system.
|
||||
|
||||
The term “bare metal” simply means no software of any kind, not even a [hypervisor][2]. Customers provide their own operating environments, and the provider offers nothing more than CPUs, memory, and storage. Up to now, IBM has led the charge with bare-metal services because SoftLayer, the major data-center provider it acquired in 2014, was heavily involved in that business.
|
||||
|
||||
Now Google Cloud is going after that market, especially targeting “lift and shift” of an entire operating environment – OS, hypervisor, apps, and data -- from on-premises data centers to the cloud.
|
||||
|
||||
[][3]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[HPE Synergy For Dummies][3]
|
||||
|
||||
Here’s how IT can provide an anytime, anywhere, any workload infrastructure.
|
||||
|
||||
Google [recently announced][4] the Google Bare Metal Solution for legacy applications that must run on dedicated hardware and have strict hardware certification requirements, as well as dedicated, low-latency and highly resilient interconnects, and connections to all native Google Cloud services.
|
||||
|
||||
Bare Metal Solution uses OEM hardware that is certified for many ISV software applications as well as custom-built applications, with Oracle Database the one commercial software product specifically named. The hardware is a bit of a mystery, since Google, like most hyperscale data-center operators, uses off-brand hardware from Gigabyte, Inspur, and Supermicro, but it’s usually hardware from HPE, Dell, and Lenovo that gets those kinds of certifications. Not that the white-box brands don’t have it, but it’s usually not as much of a priority for them.
|
||||
|
||||
These hardware configurations are offered as a subscription, billed monthly with a preferred term length of 36 months, which means they want you to stick around a while. There are no data ingress and egress charges between Bare Metal Solution and Google Cloud in the same region, however for now, Bare Metal Solutions are only available in East Coast data centers.
|
||||
|
||||
Moving an Oracle database to the cloud isn’t trivial. If the database stretches into the petabytes, that could get very expensive. Not to mention Oracle is doing its darnedest to keep that business by making it easier for customers to migrate their databases into Oracle’s cloud infrastructure.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][5]
|
||||
|
||||
Storage comes in 1TB increments, either a mix of HDD and SSD or all-flash. As for the rest of the configurations:
|
||||
|
||||
Dual-socket x86 systems
|
||||
|
||||
* 16 core with 384 GB DRAM
|
||||
* 24 core with 768 GB DRAM
|
||||
* 56 core with 1536 GB DRAM
|
||||
|
||||
|
||||
|
||||
Quad-socket x86 systems
|
||||
|
||||
* 56 core with 1536 GB DRAM
|
||||
* 112 core with 3072 GB DRAM
|
||||
|
||||
|
||||
|
||||
Other benefits of the service are:
|
||||
|
||||
* End-to-end infrastructure management such as compute, storage and networking, as well as fully managed and monitored environments such as power, cooling and facilities.
|
||||
* Support for infrastructure, including defined SLAs for initial response; 24X7 coverage for all Priority 1 and 2 issues; unified billing across Google Cloud and Bare Metal Solution.
|
||||
* Enterprise-grade SLAs for hardware uptime and interconnect availability.
|
||||
|
||||
|
||||
|
||||
Bare metal has its appeal but caveats, too. The allure of the cloud is its bursty elasticity. Many on-prem apps are used to running all out for much if not all of the day. In a cloud setting that can get expensive in a hurry, so it’s up to IT staff to decide if it’s a good idea to migrate an Oracle database to the cloud. If it's serving up reads and writes constantly, any savings from moving it off premises will be immediately offset by paying to run it at high utilization in the cloud.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3487626/google-cloud-bare-metal-initiative-targets-migrating-legacy-apps-from-on-prem.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3261113/why-a-bare-metal-cloud-provider-might-be-just-what-you-need.html
|
||||
[2]: https://www.networkworld.com/article/3243262/what-is-a-hypervisor.html
|
||||
[3]: https://www.networkworld.com/article/3399618/hpe-synergy-for-dummies.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE19718&utm_content=sidebar (HPE Synergy For Dummies)
|
||||
[4]: https://cloud.google.com/blog/products/gcp/bare-metal-solution-enabling-specialized-workloads-in-google-cloud
|
||||
[5]: https://www.networkworld.com/newsletters/signup.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (LibreCorps mentors humanitarian startups on how to run the open source way)
|
||||
[#]: via: (https://opensource.com/article/19/12/humanitarian-startups-open-source)
|
||||
[#]: author: (Justin W. Flory https://opensource.com/users/jflory)
|
||||
|
||||
LibreCorps mentors humanitarian startups on how to run the open source way
|
||||
======
|
||||
NGOs and nonprofits can increase their reach by building open source
|
||||
communities.
|
||||
![Two diverse hands holding a globe][1]
|
||||
|
||||
Free and open source software are no longer workplace taboos, at least not in the same way they were fifteen years ago. Today, distributed collaboration platforms and tools empower people around the world to contribute code, documentation, design, leadership, and other skills to open source projects. But do newcomers actually have a deep understanding of free and open source software?
|
||||
|
||||
If you hang around in open source communities for long enough, you realize there is more to open source than slapping a free software license on a project and throwing it over an imaginary fence to wait for contributors who never come. To address this problem in the humanitarian sector, the LibreCorps program, led by Rochester Institute of Technology's FOSS initiative at the [Center for Media, Arts, Interaction & Creativity][2] (MAGIC,) partnered with UNICEF to develop a set of resources to help new open source maintainers chart an "open source roadmap" to build a community.
|
||||
|
||||
![Grassroots presentation in UNICEF office ][3]
|
||||
|
||||
### What is LibreCorps?
|
||||
|
||||
[LibreCorps][4] connects RIT students interested in open source to humanitarian and civic coding opportunities; specifically, opportunities for co-operative education placements (co-ops,) which are full-time paid internships included in the university's graduation requirements.
|
||||
|
||||
LibreCorps students work in two major areas on co-ops. The first, not surprisingly, is technology. The second is FOSS community and processes. Many NGOs and civic organizations put openly licensed work in repositories but need a plan to build and maintain a community of contributors around their technology.
|
||||
|
||||
LibreCorps has worked with numerous humanitarian projects over the years. Recently, LibreCorps was contracted by [UNICEF Innovation][5] to support the [Innovation Fund][6] by mentoring several cohorts of international start-ups in adopting best practices to meet the open source requirement of their funding.
|
||||
|
||||
Periodically, the UNICEF Innovation Fund invites the companies together for cohort workshops, with hands-on mentorship a primary component of the workshop. [Stephen Jacobs][7] and [Justin W. Flory][8] represented LibreCorps at [two UNICEF Innovation Fund workshops][9] to help these teams better understand free and open source, as well as how to successfully build communities and teams that operate as [open organizatio][10][ns][10]. Most of these teams have either never worked in open source projects or only have a basic understanding of licenses and GitHub. Often, for these teams, working on your code in a way where anyone can see what you are doing is a radical shift in process.
|
||||
|
||||
UNICEF Innovation has engaged with open source for years and currently provides funded teams with a course on [open source business models][11].
|
||||
|
||||
> "We'd approached open-source pretty tentatively and definitely naively. We were keen to move to open source for transparency and perception but, beyond that, had no plans around deriving or creating value, and we were nervous about the perceived risks. The mentorship from Mike Nolan has given us clear direction and a deeper understanding that open source isn't a compromise but a communication channel and a way to build a community, and he's giving us the tools that enable that." — Michael Nunan, Director at Tupaia.
|
||||
|
||||
### How do we create workable community strategy guides?
|
||||
|
||||
This past summer, LibreCorps began developing and evolving resources to help these teams take the complex and difficult challenge of building an open source community and break it down into smaller, more manageable steps. [Mike Nolan][12] and [Kent Reese][13] developed a roadmap template for teams to evaluate their current status in maintainership best practices and chart out milestones for where to go next. For a cohort working in open source for the first time, the LibreCorps team offers advice and suggestions on crafting a mission statement, choosing the right license for your project, and more. The rubrics provide an interactive, color-coded reference to unlock a deeper understanding of their progress towards each milestone.
|
||||
|
||||
Let's explore each resource in more detail to understand how they work:
|
||||
|
||||
### Roadmap template
|
||||
|
||||
The [roadmap template][14] is a resource that gets hands-on and personal to a specific open source project. There are five tracks within the roadmaps with different tasks to gradually ramp up the areas of focus for community management.
|
||||
|
||||
The first track includes milestones like writing a mission statement, choosing a free software license, and establishing a code of conduct, and provides a set of open source tools or frameworks for users to learn more about. The second track includes gradually more advanced milestones like documenting how to set up a development environment, learning the pull request workflow, choosing a project hosting platform, and more. Further tracks include milestones like implementing continuous integration (CI,) organizing community events, and gathering user testimonials.
|
||||
|
||||
The LibreCorps team works with each Innovation Fund team within the cohort to create a rubric specific to their projects. The cohort identifies their current position based on which milestone they are currently working toward. Then, we work together to determine next steps for growing their open source community, then create a strategy to reach and accomplish those goals.
|
||||
|
||||
### Self-evaluation rubric
|
||||
|
||||
The milestone template provides high-level guidance on which direction to go, but the [self-evaluation rubric][15] is a feedback mechanism to give cohorts a picture of exceptional, acceptable, and poor implementations for each assigned task. The self-evaluation rubrics enable LibreCorps cohorts to independently self-evaluate progress towards building a sustainable and open community.
|
||||
|
||||
The rubric is organized into five tracks:
|
||||
|
||||
* Community outreach
|
||||
* Continuous integration and health checks
|
||||
* Documentation
|
||||
* Project management
|
||||
* Workflow
|
||||
|
||||
|
||||
|
||||
Each track includes detailed sets of sub-tasks or specific components of building an open source community. For example, documentation includes writing guidelines for how to contribute, and community outreach includes maintaining a project website and engaging with an upstream project community, if one exists.
|
||||
|
||||
The LibreCorps team mostly works with the rubric to evaluate whether Innovation Fund cohort teams sufficiently meet the open source requirement for their project. Some teams make use of the rubric to get a more detailed understanding of whether they are heading in the right direction with their community work.
|
||||
|
||||
### Contribute to these resources
|
||||
|
||||
Do these resources sound useful or interesting? Fortunately, the LibreCorps content is licensed under Creative Commons licenses. Learn more about LibreCorps on the [FOSS@MAGIC website][4] and keep up with what we are doing on [our GitHub][16]. To get in touch with us, visit our community Discourse forums on [fossrit.community][17].
|
||||
|
||||
A few months ago, we profiled open source projects working to make the world a better place. In...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/humanitarian-startups-open-source
|
||||
|
||||
作者:[Justin W. Flory][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jflory
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/world_hands_diversity.png?itok=zm4EDxgE (Two diverse hands holding a globe)
|
||||
[2]: https://www.rit.edu/magic/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/unicef-flory_0.jpg (Grassroots presentation in UNICEF office )
|
||||
[4]: https://fossrit.github.io/librecorps/
|
||||
[5]: https://www.wired.com/story/wired25-stories-people-racing-to-save-us/
|
||||
[6]: https://unicefinnovationfund.org/
|
||||
[7]: https://www.rit.edu/magic/affiliate-spotlight-stephen-jacobs
|
||||
[8]: https://justinwflory.com/
|
||||
[9]: https://fossrit.github.io/announcements/2019/04/01/unicef-foss-community-building/
|
||||
[10]: https://opensource.com/open-organization/resources/open-org-maturity-model
|
||||
[11]: https://www.google.com/url?q=https://agora.unicef.org/course/info.php?id%3D18096&sa=D&ust=1573658770972000&usg=AFQjCNGemgWoJ3kCoKImLCDok7opIo2RCA
|
||||
[12]: https://nolski.rocks/
|
||||
[13]: https://kentr.itch.io/
|
||||
[14]: https://docs.google.com/document/d/1M2nVwh7ArjAU31M7QZWP4AQz1cOyMhw90iP8Wg9lZNo/edit?usp=sharing
|
||||
[15]: https://docs.google.com/spreadsheets/d/11DaQxbiOv9_EiZEozEkUapf2AsVQ4vBFelhnZ0a8R4w/edit?usp=sharing
|
||||
[16]: https://github.com/librecorps/
|
||||
[17]: https://fossrit.community/
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Italian job: Translating our mission statement in the open)
|
||||
[#]: via: (https://opensource.com/open-organization/19/12/translating-mission-statement)
|
||||
[#]: author: (Antonella Iecle https://opensource.com/users/aiecle)
|
||||
|
||||
Italian job: Translating our mission statement in the open
|
||||
======
|
||||
A seemingly straightforward translation exercise turned into a lesson
|
||||
about the power of open decision making.
|
||||
![Yellow arrows going both ways with texture][1]
|
||||
|
||||
At Red Hat, part of my job is to ensure that company messages maintain their meaning and effectiveness in my native language—Italian—so that customers in my region can learn not only about our products and services but also about [our organizational values][2].
|
||||
|
||||
The work tends to be simple and straightforward. But in an open organization, even the tasks that seem small can present big opportunities for learning about the power of working the open way.
|
||||
|
||||
That was the case for me recently, when what I thought would be a quick translation exercise turned into a lesson in the [benefits of open decision making][3].
|
||||
|
||||
### A crowdsourced decision
|
||||
|
||||
A few months ago, I noticed a post on our company's internal collaboration platform that seemed to be calling my name. Colleagues from around the world were leaving comments on translated versions of one particular (and very important) corporate message: the [company's mission statement][4]. And they had questions about the Italian translation.
|
||||
|
||||
So I joined the conversation with no hesitation, assuming I'd engage in a quick exchange of opinions and reach a conclusion about the best way to translate Red Hat's mission statement:
|
||||
|
||||
_To be the catalyst in communities of customers, contributors, and partners creating better technology the open source way._
|
||||
|
||||
That's a single sentence consisting of less than 20 words. Translating it into another language should be a no-brainer, right? If anything, the work should take no longer than a few minutes: Read it out loud, spot room for improvement, swap a word for a more effective synonym, maybe rephrase a bit, and you're done!
|
||||
|
||||
As a matter of fact, that's not always the case.
|
||||
|
||||
Translations of the mission statement in a few languages were already available, but comments from colleagues reflected a need for some review. And as more Red Hatters from different parts of the globe joined the discussion and shared their perspectives, I began to see many possibilities for solving this translation problem—and the challenges that come with this abundance of ideas.
|
||||
|
||||
Seeing so many inspiring comments can make reaching a decision much more complicated. One might put concepts into words in a _number_ of ways, but how do we all agree on the _best_ way? How do we deliver a message that reflects our common goal? How do we make sure that all employees can identify with it? And how do we ensure that our customers understand how we can help them grow?
|
||||
|
||||
It's true: When you're about to make a decision that has an impact on other people, you have to ask yourself—and each other—a lot of questions.
|
||||
|
||||
It's true: When you're about to make a decision that has an impact on other people, you have to ask yourself—and each other—a lot of questions.
|
||||
|
||||
### Found in translation
|
||||
|
||||
Localising a message for our readers around the world means more than just translating it word by word. A literal translation may not be fully understandable, especially when the original message was written with English native speakers in mind. On the other hand, a creative translation may be just one of many possible interpretations of the original text. And then there are personal preferences: Which translation sounds better to me? Is there a particular reason? If so, how do I get my point across?
|
||||
|
||||
Linguistic debates can highlight complex aspects of communication, from the subtle nuances in the meaning of a particular word to the cultural traits, mindsets, and levels of familiarity with a topic that define how the same message can be perceived by readers from different countries. Our own conversations delved into known linguistic dilemmas like the use of anglicisms and the disambiguation of expressions that can have more than one interpretation.
|
||||
|
||||
Localisation teams must ensure that messages are delivered accurately and consistently. Working collaboratively is essential to achieving this goal.
|
||||
|
||||
To get started, we only had to look at how our original mission statement had come together in the first place. Since we were trying to do something that someone else had done before, we needed to ask: "[How did Red Hat find its mission][5]?"
|
||||
|
||||
The answer? By asking the whole company what it should be.
|
||||
|
||||
Opening up the conversation doesn't always accelerate the decision making process.
|
||||
|
||||
It may be counterintuitive, but engaging the broader community can be a very efficient way to overcome uncertainties and address problems you weren't even aware of. Opening up the conversation doesn't always accelerate the decision making process, but by bringing people together you allow them to draw a clearer picture of the problem and provide you with the elements you need to make better decisions.
|
||||
|
||||
With that in mind, all you have to do is ask other teams to contribute, then give them a reasonable amount of time to make room in their busy schedule and think about how they can help. Suggestions will come, and how you will channel the incoming information is up to you.
|
||||
|
||||
Surveys are often a great way to gather feedback and keep track of incoming responses, and this is the approach we chose. We submitted a new translation, and asked our teams in Italy to tell us if they were happy with it. The majority of the respondents were. However, a few participants had their own versions to share (and valid comments to add).
|
||||
|
||||
After considering everyone's input, we submitted a second survey. We asked the participants to choose between the solution we offered in the first survey and a _newer_ version, one we obtained by incorporating the feedback we'd received from our recent collaborative discussion.
|
||||
|
||||
The second option was the winner.
|
||||
|
||||
The initial translation did not represent Red Hat's mission as clearly and faithfully as the improved statement did. For example, in the original version, Red Hat was a “point of reference” rather than a "catalyst," and worked with "a community" rather than a larger and more diverse number of "communities." We were using the word "collaborators" instead of "contributors," and our actions were following a set of "principles" rather than the open source "way."
|
||||
|
||||
The changes we made reaffirmed Red Hat's role in the communities and its commitment to open source technology, but also to open source as a way of working.
|
||||
|
||||
Don't be afraid to jump into a conversation—or even to take the lead—if you think you can help to make better decisions.
|
||||
|
||||
So here is some advice this experience taught me: Don't be afraid to jump into a conversation—or even to take the lead—if you think you can help to make better decisions. Because as Jim Whitehurst likes to say, in the open source world, we believe [the best ideas should win][6], no matter where they come from.
|
||||
|
||||
In short, here is my five-point checklist for open decision-making, regardless of the task you face:
|
||||
|
||||
1. Encourage wide participation.
|
||||
2. Welcome all responses as they arrive.
|
||||
3. Identify the best ideas and get the most out of everyone's suggestions.
|
||||
4. Answer questions and address concerns.
|
||||
5. Communicate the outcome, and summarize the steps of the decision process. In doing so, reassert the value of broad collaboration.
|
||||
|
||||
|
||||
|
||||
One more thing (I know I said I only had five more points, but don't switch off yet): Keep listening to what people might have to say about the decision you just made together.
|
||||
|
||||
The best ideas may take longer to brew.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/12/translating-mission-statement
|
||||
|
||||
作者:[Antonella Iecle][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/aiecle
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/arrows_translation_lead.jpg?itok=S4vAh9CP (Yellow arrows going both ways with texture)
|
||||
[2]: https://www.redhat.com/en/book-of-red-hat#our-values
|
||||
[3]: https://opensource.com/open-organization/resources/open-decision-framework
|
||||
[4]: https://www.redhat.com/en/book-of-red-hat#our-vision-intro
|
||||
[5]: https://www.managementexchange.com/blog/how-red-hat-used-open-source-way-develop-company-mission
|
||||
[6]: https://opensource.com/open-organization/16/8/how-make-meritocracy-work
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Passive optical LAN: Its day is dawning)
|
||||
[#]: via: (https://www.networkworld.com/article/3489477/passive-optical-lan-its-day-is-dawning.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
Passive optical LAN: Its day is dawning
|
||||
======
|
||||
|
||||
Getty Images
|
||||
|
||||
The concept of using passive optical LANs in enterprise campuses has been around for years, but hasn’t taken off because most businesses consider all-fiber networks to be overkill for their needs. I’ve followed this market for the better part of two decades, and now I believe we’re on the cusp of seeing POL go mainstream, starting in certain verticals.
|
||||
|
||||
The primary driver of change from copper to optical is that the demands on the network have evolved. Every company now considers its network to be business critical where just a few years ago, it was considered best effort in nature. Downtime or a congested network meant inconvenienced users, but today they mean the business is likely losing big money.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][1]
|
||||
|
||||
There are also a number of new trends driving the evolution of the campus network. These include:
|
||||
|
||||
[][2]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][2]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
* Cloud services. The cloud is certainly the way of the future but it’s playing havoc with enterprise networks. As data centers evolved to modernized systems, East-West traffic was superseded by North-South. Today, businesses are connecting direct to cloud for [hybrid-cloud][3] deployments driving more North-South traffic. Traditional networks can be a bottleneck.
|
||||
* [Internet of Things][4] (IoT). [Wi-Fi 6 and 5G][5] will enable more devices to be connected in more places leading to more bandwidth on the network. For the first time in history, wireless speeds will match wired speeds straining the campus network.
|
||||
* Video of all kinds is on the rise. Surveillance, collaboration, room systems, streaming and other kinds of video usage are on the rise. Video requires high-quality, low-latency connectivity.
|
||||
|
||||
|
||||
|
||||
### Copper is running out of life
|
||||
|
||||
The increased speeds pose quite a predicament for companies. If the organization has Cat5 cabling, the speed is capped at 1Gbps. If Cat6 is deployed, speeds of 10Gbps can be reached but only 55 meter’s distance. If the company wants to reach the full 100M length of copper, Cat6A or higher must be used. Optical cable has no distance limitations because POL is completely passive and requires no electronics to boost the signal. Optical cabling can carry petabytes of bandwidth over long distances. Also, with optical, there’s no concern over what type of cable is being used and having the quality degrade over time. Lastly, upgrading speeds is easier. The cabling can stay in place and just the optics get changed out at the ends of the cable making the process simple.
|
||||
|
||||
### POL is a cheaper, longer lasting than copper upgrades
|
||||
|
||||
If businesses are faced with having to upgrade their networks from Cat5 to another type of cabling, it might make sense to look at POL as it can be the foundation for the campus network for years.
|
||||
|
||||
The early adopters of POL are companies that are highly distributed with large campuses and need to get more network services in more places. This includes manufacturing organizations, universities, hospitality, cities and airports. Although I’ve highlighted a few verticals, the fact is that any business can take advantage of POL.
|
||||
|
||||
### POL in a mixed-use development
|
||||
|
||||
At a Huawei conference earlier this year the company showcased the Dubai Creek Harbor project being built by Emaar Properties – a six-square-mile development including residences, offices, retail and cultural facilities. The complex is designed to be fully digital and the network has to support IoT, cloud computing, AI-based analytics and more.
|
||||
|
||||
The project features an optical network built on Huawei’s Campus OptiX solution that simplifies the network as the architecture moves from a three-tier hierarchical design to a two-tier one. That design uses less equipment and reduces power and cooling requirements. Also, the flat, 10Gbps network obviates the need for parallel overlay networks, making it easier to manage and giving it a degree of future-proofing as the network can easily be upgraded. The all-optical network resulted in a 60% improvement in operational efficiency and a deployment time that was cut in half compared a similar network using Ethernet.
|
||||
|
||||
### Cost effective **
|
||||
|
||||
**
|
||||
|
||||
Although there are many benefits to POL, adoption has been light. The biggest impediment to its adoption is a general lack of awareness and a misunderstanding of cost. The actual cost of fiber cabling is higher than copper, but I’ve talked to many companies that have looked at fully loaded costs and often optical is cheaper. Optical isn’t subject to electromagnetic interference like copper is so there’s no need to lay a pipeline down first. Also, copper cabling requires distribution cabinets to boost the signal and that adds the cost of UPSes, cooling and power that fiber does not.
|
||||
|
||||
North American buyers may not have the same awareness of POL as those in China, where:
|
||||
|
||||
* The engineering standard of POL was released in June, outlining the system, design, cabling, testing and acceptance rules.
|
||||
* An alliance was established Oct. 22 bringing together a number of companies including Nokia, Huawei, and Yangtze Optical Fiber and Cable.
|
||||
|
||||
|
||||
|
||||
Both of these will help drive innovation and standardization.
|
||||
|
||||
Copper has been the preferred campus backbone, but businesses are changing and so is the network. It’s not enough to just change the infrastructure but the cabling that connects everything should be looked at and POL used as a next-generation backbone.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489477/passive-optical-lan-its-day-is-dawning.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.networkworld.com/article/3268448/what-is-hybrid-cloud-really-and-whats-the-best-strategy.html
|
||||
[4]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
|
||||
[5]: https://www.networkworld.com/article/3402316/when-to-use-5g-when-to-use-wi-fi-6.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Passive optical networking: Its day is dawning)
|
||||
[#]: via: (https://www.networkworld.com/article/3489477/passive-optical-networking-its-day-is-dawning.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
Passive optical networking: Its day is dawning
|
||||
======
|
||||
|
||||
Getty Images
|
||||
|
||||
The concept of using passive optical LANs in enterprise campuses has been around for years, but hasn’t taken off because most businesses consider all-fiber networks to be overkill for their needs. I’ve followed this market for the better part of two decades, and now I believe we’re on the cusp of seeing POL go mainstream, starting in certain verticals.
|
||||
|
||||
The primary driver of change from copper to optical is that the demands on the network have evolved. Every company now considers its network to be business critical where just a few years ago, it was considered best effort in nature. Downtime or a congested network meant inconvenienced users, but today they mean the business is likely losing big money.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][1]
|
||||
|
||||
There are also a number of new trends driving the evolution of the campus network. These include:
|
||||
|
||||
[][2]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][2]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
* Cloud services. The cloud is certainly the way of the future but it’s playing havoc with enterprise networks. As data centers evolved to modernized systems, East-West traffic was superseded by North-South. Today, businesses are connecting direct to cloud for [hybrid-cloud][3] deployments driving more North-South traffic. Traditional networks can be a bottleneck.
|
||||
* [Internet of Things][4] (IoT). [Wi-Fi 6 and 5G][5] will enable more devices to be connected in more places leading to more bandwidth on the network. For the first time in history, wireless speeds will match wired speeds straining the campus network.
|
||||
* Video of all kinds is on the rise. Surveillance, collaboration, room systems, streaming and other kinds of video usage are on the rise. Video requires high-quality, low-latency connectivity.
|
||||
|
||||
|
||||
|
||||
### Copper is running out of life
|
||||
|
||||
The increased speeds pose quite a predicament for companies. If the organization has Cat5 cabling, the speed is capped at 1Gbps. If Cat6 is deployed, speeds of 10Gbps can be reached but only 55 meter’s distance. If the company wants to reach the full 100M length of copper, Cat6A or higher must be used. Optical cable has no distance limitations because POL is completely passive and requires no electronics to boost the signal. Optical cabling can carry petabytes of bandwidth over long distances. Also, with optical, there’s no concern over what type of cable is being used and having the quality degrade over time. Lastly, upgrading speeds is easier. The cabling can stay in place and just the optics get changed out at the ends of the cable making the process simple.
|
||||
|
||||
### POL is a cheaper, longer lasting than copper upgrades
|
||||
|
||||
If businesses are faced with having to upgrade their networks from Cat5 to another type of cabling, it might make sense to look at POL as it can be the foundation for the campus network for years.
|
||||
|
||||
The early adopters of POL are companies that are highly distributed with large campuses and need to get more network services in more places. This includes manufacturing organizations, universities, hospitality, cities and airports. Although I’ve highlighted a few verticals, the fact is that any business can take advantage of POL.
|
||||
|
||||
### POL in a mixed-use development
|
||||
|
||||
At a Huawei conference earlier this year the company showcased the Dubai Creek Harbor project being built by Emaar Properties – a six-square-mile development including residences, offices, retail and cultural facilities. The complex is designed to be fully digital and the network has to support IoT, cloud computing, AI-based analytics and more.
|
||||
|
||||
The project features an optical network built on Huawei’s Campus OptiX solution that simplifies the network as the architecture moves from a three-tier hierarchical design to a two-tier one. That design uses less equipment and reduces power and cooling requirements. Also, the flat, 10Gbps network obviates the need for parallel overlay networks, making it easier to manage and giving it a degree of future-proofing as the network can easily be upgraded. The all-optical network resulted in a 60% improvement in operational efficiency and a deployment time that was cut in half compared a similar network using Ethernet.
|
||||
|
||||
### Cost effective **
|
||||
|
||||
**
|
||||
|
||||
Although there are many benefits to POL, adoption has been light. The biggest impediment to its adoption is a general lack of awareness and a misunderstanding of cost. The actual cost of fiber cabling is higher than copper, but I’ve talked to many companies that have looked at fully loaded costs and often optical is cheaper. Optical isn’t subject to electromagnetic interference like copper is so there’s no need to lay a pipeline down first. Also, copper cabling requires distribution cabinets to boost the signal and that adds the cost of UPSes, cooling and power that fiber does not.
|
||||
|
||||
North American buyers may not have the same awareness of POL as those in China, where:
|
||||
|
||||
* The engineering standard of POL was released in June, outlining the system, design, cabling, testing and acceptance rules.
|
||||
* An alliance was established Oct. 22 bringing together a number of companies including Nokia, Huawei, and Yangtze Optical Fiber and Cable.
|
||||
|
||||
|
||||
|
||||
Both of these will help drive innovation and standardization.
|
||||
|
||||
Copper has been the preferred campus backbone, but businesses are changing and so is the network. It’s not enough to just change the infrastructure but the cabling that connects everything should be looked at and POL used as a next-generation backbone.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489477/passive-optical-networking-its-day-is-dawning.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.networkworld.com/article/3268448/what-is-hybrid-cloud-really-and-whats-the-best-strategy.html
|
||||
[4]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
|
||||
[5]: https://www.networkworld.com/article/3402316/when-to-use-5g-when-to-use-wi-fi-6.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Companies Prefer Hybrid Cloud to Escape Public Cloud Data Grabbity)
|
||||
[#]: via: (https://www.linux.com/articles/companies-prefer-hybrid-cloud-to-escape-public-cloud-data-grabbity/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Companies Prefer Hybrid Cloud to Escape Public Cloud Data Grabbity
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
As the cloud native space is maturing, customers have started to discern the pros and cons of public cloud. They can see not just the facade of convenience and promised cost savings, but also the bills piling up and having to hand over critical business data to public cloud companies.
|
||||
|
||||
[Red Hat recently conducted a global customer survey][3] about this and results indicate that customers prefer hybrid cloud over public cloud. More than 31% respondents actually used the term hybrid cloud as their cloud strategy.
|
||||
|
||||
Rob Hirschfeld, founder and CEO of RackN and attendee of the recent [Gartner IT Infrastructure, Operations & Cloud Strategies Conference][4], noticed a similar tone. “Discussions and data from the Gartner IO Summit support that hybrid is preferred. There’s just so much existing infrastructure that it’s not practical to be ‘pure’ anything! It’s not so much that they want hybrid but that it’s the reality they are facing.”
|
||||
|
||||
There are many reasons why customers prefer hybrid over public cloud or pure private cloud. Red Hat says it boils down to three factors: data security, cost benefits, and data integration.
|
||||
|
||||
“Everyone accepts that cloud is secure; however, operators are starting to question how well they can control their data in cloud. Also, some of them don’t trust the cloud vendors, especially with some of the new analytics services,” said Hirschfeld.
|
||||
|
||||
Hybrid cloud enables customers to balance all three factors highlighted in the Red Hat survey. They can move pieces of their infrastructure between public and private cloud depending on the need. It lets them reap the benefits of public cloud without having to compromise their data.
|
||||
|
||||
Although 31% might seem like a small number, it doesn’t mean that the remaining 69% is running their workloads on public cloud. In fact, only 12% described themselves as having either a public cloud first strategy or a strategy to standardize on a single public cloud. Red Hat says 6% described their strategy as multi-cloud based on multiple public clouds, while 21% have a private cloud first strategy.
|
||||
|
||||
In particular, EMEA respondents described themselves as having a private cloud strategy, not hybrid. This region is concerned about handing over their data to US-based cloud companies, given its current political landscape. A simple embargo on your country will cut your entire business out of the public cloud run by Google, AWS, and Azure. Some of the biggest use cases in this region involve companies building their own private and public cloud using OpenStack.
|
||||
|
||||
Perhaps the most worrisome finding is that there are still companies without any concrete cloud strategy. Around 17% of the respondents were still working on a plan, while 12% respondents didn’t have any plan at all. Unfortunately, these companies are so far behind the curve that their future hangs in the balance. Hirschfeld warns that there is an urgency to cut their technical debt and embrace cloud now or they will find it hard to survive in the modern world.
|
||||
|
||||
In fact, Hirschfeld states that you need to have a cloud strategy even if you don’t use cloud. “The reality is that cloud is the default deployment choice for everything — from demos and proof-of-concept to training — because it’s predictable and accessible.” Teams must adapt to the patterns, even if they are not adopting.
|
||||
|
||||
The Red Hat survey found that companies do recognize the importance of building up technical skills. When asked to choose their top non-IT funding priorities, respondents chose both technical skills training (16%) and a digital transformation strategy (16%).
|
||||
|
||||
However, new technologies and jargon are emerging at such a fast pace that it’s virtually impossible to find experts (or even skilled professionals) in technologies that were open-sourced at CNCF just a month ago. The hype/adoption curve is so accelerated that it has gotten silly. Therefore, porting to the latest shiny requires evaluation.
|
||||
|
||||
“The reality is that new projects, even Kubernetes, still need baking time for scale operations. If there are not enough people with knowledge, then it’s OK (really, it’s required) to pick your battles or slow your adoption,” said Hirschfeld.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/companies-prefer-hybrid-cloud-to-escape-public-cloud-data-grabbity/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/12/computer-2930704_1280-1068x634.jpg (computer-2930704_1280)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/12/computer-2930704_1280.jpg
|
||||
[3]: https://www.redhat.com/en/blog/red-hat-global-customer-tech-outlook-2020-hybrid-cloud-leads-strategy-aiml-leaps-forefront
|
||||
[4]: https://www.gartner.com/en/conferences/na/infrastructure-operations-cloud-us
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Liquid cooling and edge computing are featured at Gartner show)
|
||||
[#]: via: (https://www.networkworld.com/article/3489467/liquid-cooling-and-edge-computing-are-featured-at-gartner-show.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Liquid cooling and edge computing are featured at Gartner show
|
||||
======
|
||||
Non-traditional hardware makes the news at Gartner’s show focused on data-center operations.
|
||||
ExaScaler
|
||||
|
||||
Research firm Gartner is holding its IT Infrastructure, Operations, and Cloud Strategies Conference (IOCS) in Las Vegas this week, and a few news announcements from the show give an indication as to where [data-center][1] technology is headed.
|
||||
|
||||
First up, Schneider Electric and Iceotope formally introduced their integrated rack with chassis-based immersive liquid-cooling designs. The deal was [announced][2] in October but now the details are out. In addition to Schneider and Iceotope, the alliance also includes Avnet, an electronic-component distributor.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
|
||||
|
||||
The server is optimized for compute-intensive applications such as analytics and artificial intelligence. It combines a high-powered GPU server with Iceotope’s liquid-cooling technology, while Avnet integrates the server with Schneider’s NetShelter liquid-cooled enclosure system for simple deployment into data centers or edge-computing environments.
|
||||
|
||||
[][4]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][4]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
This is a big advance because most immersion solutions have been using a bathtub design where the motherboard sat vertically in the immersion fluid and the ports stuck out at the top. It was something of a clumsy design that just begged for spillage. Here, the chassis looks like any other rack-mounted server, but it is enclosed and sealed.
|
||||
|
||||
The system is certified EcoStruxure Ready, meaning it works with Schneider’s enclosures, and comes with next-generation data center management software EcoStruxure IT Expert and digital service EcoStruxure Asset Advisor.
|
||||
|
||||
“This latest development marks a significant step toward industrializing chassis-based immersion solutions which offer the efficiency and effectiveness of tank-based solutions while providing the compatibility and serviceability of more traditional, ‘direct-to-chip’ liquid-cooling designs. Given the growth of compute-intensive applications, we believe this approach is very promising,” said Kevin Brown, CTO and senior vice president of innovation, secure power at Schneider Electric in a statement.
|
||||
|
||||
### Scale Computing: Tiny edge device
|
||||
|
||||
Scale Computing introduced the HE150 at the show, the latest addition to its HC3 Edge product line intended for space-constrained and edge customers.
|
||||
|
||||
The HE150 is a very small device based on the [Intel NUC][5] design, and Scale notes it is about the size of three smartphones, with a width and depth of just over 11 centimeters and a height of just over three centimeters.
|
||||
|
||||
The HE150 appliance is a small, all-flash, [NVMe][6] storage-based compute appliance that supports disaster recovery, high availability clustering, rolling upgrades and integrated data protection. As it is, Scale sells them in three-node clusters.
|
||||
|
||||
Scale also announced it plans to make its HC3 Edge software for Intel NUC-based systems from other hardware suppliers. HC3 Edge software will be available soon for Lenovo’s new Smart Edge portfolio of fan-less, small-form-factor PCs.
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489467/liquid-cooling-and-edge-computing-are-featured-at-gartner-show.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[2]: https://www.networkworld.com/article/3444624/schneider-electric-launches-wall-mounted-server-rack.html
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[5]: https://www.intel.com/content/www/us/en/products/boards-kits/nuc.html
|
||||
[6]: https://www.networkworld.com/article/3280991/what-is-nvme-and-how-is-it-changing-enterprise-storage.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Secure SD-WAN: The security vendors and their SD-WAN offerings)
|
||||
[#]: via: (https://www.networkworld.com/article/3489480/secure-sd-wan-the-security-vendors-and-their-sd-wan-offerings.html)
|
||||
[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
Secure SD-WAN: The security vendors and their SD-WAN offerings
|
||||
======
|
||||
A networking vendor simply can’t jump into this space. Some SD-WANs add stateful packet filters and call this security.
|
||||
[Gerd Altmann][1] [(CC0)][2]
|
||||
|
||||
During its inception, we had the early adopters and pure SD-WAN players. Soon it became obvious that something was missing, and that missing component was “security.” However, security vendors have highlighted the importance of security from the very beginning.
|
||||
|
||||
Today, the market seems to be moving in the direction where the security vendors are focusing on delivering SD-WAN features around pervasive security. The Magic Quadrant for WAN Edge Infrastructure has made a substantial prediction. It states, “By 2024, 50% of new firewall purchases in distributed enterprises will utilize SD-WAN features with the growing adoption of cloud-based services, up from less than 20% today.”
|
||||
|
||||
Nowadays we have security vendors like Forcepoint, SonicWall and Barracuda that follow the pattern of Fortinet. The vendors offer a built-in security stack to the WAN edge architecture for distributed enterprise use cases.
|
||||
|
||||
[][3]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][3]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
### Introducing secure SD-WAN
|
||||
|
||||
Pronouncedly, secure SD-WAN includes the best-of-breed next-generation firewall security, SD-WAN, advanced routing, and WAN optimization to deliver a security-driven WAN edge. It combines the SD-WAN feature and security features together.
|
||||
|
||||
The secure SD-WAN solution can be placed fully in the branch and the cloud or a hybrid approach can be adopted. For those who don’t want to put everything in the cloud, a hybrid approach could be more viable.
|
||||
|
||||
To me, it is quite interesting seeing how the queries are coming into the analysts and how customers are giving attention to this field. Markedly, Gartner estimates that Fortinet has more than 21,000 WAN edge customers. That’s a considerable user base and makes a compelling case, especially when strong and built-in security capabilities are the key requirements.
|
||||
|
||||
### Adding security to networking
|
||||
|
||||
It is definitely easier for a security company to add new networking features than for an SD-WAN company to add 20 years of advanced security features. We can safely assume that no SD-WAN vendor is going to become a security vendor.
|
||||
|
||||
**[ Now read [20 hot jobs ambitious IT pros should shoot for][4]. ]**
|
||||
|
||||
As the market developed, in due course, some features had to be renamed: when we talk about application identification, encryption, path monitoring, routing protocols and WAN link load balancing. Fundamentally, all of these advanced routing features are not new and specific to SD-WAN. These are not overnight successes and have been in the market even before the market existed.
|
||||
|
||||
However, in some scenarios, maybe you have to implement a proprietary routing protocol across the WAN. In this case, yes, of course, you require a new device. But for most of the part, a comprehensive firewall at the edge will suffice.
|
||||
|
||||
### The firewall at the WAN edge
|
||||
|
||||
Firewalls are evolving into network security platforms, thereby offering SD-WAN capabilities. The Magic Quadrant for Network Firewalls states “The SMB multifunction firewall market grew 10.1% in 2018, with SD-WAN adoption being a strong driver.”
|
||||
|
||||
When you think about it, you will realize that the firewall has been acting as a router for a long time. Essentially, the firewall can provide all the routing protocols to facilitate private WAN, internet and internal routing. This functionality is usually provided by a basic device that just does the routing. However, now we are witnessing the replacement of these by an edge appliance with firewalls.
|
||||
|
||||
Firewalls have resided in the networks for decades. Their role has not just been confined to doing the firewalling but also participating in the routed networks. Time and again, they have been providing a routed WAN edge device.
|
||||
|
||||
### Issues with legacy security design
|
||||
|
||||
How do you integrate security with SD-WAN? Primarily, the common design involves the integration of multiple security point solutions. Now, let’s learn about the aftermath of these point solutions.
|
||||
|
||||
### Complexity
|
||||
|
||||
The point solution only addresses one issue and requires a considerable amount of integration with others. Because of this, they are often service-chained together. Each part must be carefully integrated with the other.
|
||||
|
||||
You must continuously add solutions to the stack, which is likely to result in management overhead and increased complexity. Not to mention the challenges with NOC and SOC team integration. Contrarily, the original selling point for SD-WAN was to reduce complexity and not intensify it.
|
||||
|
||||
If we examine security in the world of SD-WAN; the way it has been geared up at the moment is provided in parts that actually increase complexity. It’s like building a house with individual pieces when you actually just want to buy a house.
|
||||
|
||||
If you analyze, you will find that many SD-WANs are merely bringing in security technologies from other vendors, joined together to sell them to the customers.
|
||||
|
||||
### Associated costs
|
||||
|
||||
Having multiple point solutions often from different vendors dispersed around the network is expensive. There’s never a fixed price. Some security vendors may charge on usage models which you may not have the quantity for yet. So, how do you effectively plan for this when you have multiples?
|
||||
|
||||
As the costs keep adding up, the security professionals may decide to trade-off certain point solutions due to the associated costs. We know now this is not an effective risk management strategy. Ideally, in terms of security, you don't do something when it is needed; you do it before it is needed. This means threat intelligence is the key, which is often overlooked by many SD-WAN vendors.
|
||||
|
||||
It’s far more critical from both technical and cost perspective to bring each of the security point solution functionalities together under one hood. And to do this, someone that specializes in security from day one would fit the bill. This is why there has been a move to provide SD-WAN features along with advanced security into one comprehensive integrated platform.
|
||||
|
||||
Secure SD-WAN is what combines both network and security into one integrated platform. This leads to no more complex management, licensing issues, high costs or unnecessary service chaining.
|
||||
|
||||
### SD-WAN is not about features
|
||||
|
||||
There is a lot of noise in the SD-WAN market about the features. Let’s face it ‘features really don’t draw much value to create market separation’. Practically, the value proposition for SD-WAN is not about the feature. Everyone is doing a good job in classifying applications and sending them across the best path. Let’s understand the true value proposition for SD-WAN.
|
||||
|
||||
### Performance and scalability
|
||||
|
||||
When it comes to SD-WAN, the bell to ring is often application steering, but if you don’t have, for example, the deep TLS1.3 inspection with solid performance, how can you get accurate identification and make sure your branch is secure? Not enough people are talking about this.
|
||||
|
||||
For this, we need custom SD-WAN-specific application-specific integrated circuits (ASICs). This offers an incredible advantage for the high resource intensive encryption/decryption and overlay scalability.
|
||||
|
||||
With IPSec, there are intensive encrypting operations that consume a lot of CPU and RAM. Therefore, a purpose-built SD-WAN ASIC is built just to do that so it consumes less CPU and RAM per tunnel.
|
||||
|
||||
In general, the scalability stops at 1,000 or 1,500. With the proper ASIC, this number can be scaled to over 100,000, which may be useful for some hub site designs. By using the ASIC, you can run the networking stack and security stack in the same appliance, making a very efficient and cost-effective solution.
|
||||
|
||||
### The importance of threat intelligence
|
||||
|
||||
The next-generation firewall is in the datasheets for many SD-WAN vendors. However, what about the threat detection and threat prevention? A big piece missing from the many SD-WAN vendors is threat intelligence in alliance with threat research. The threat landscape is evolving, so too should the security solution to keep in line with today’s and tomorrow's threats.
|
||||
|
||||
Threat prevention has core features from layer 4 to layer 7 such as IPS, content filtering, deep SSL inspection, and anti-malware. Furthermore, we also have a threat detection piece. Nowadays, you can no longer rely on detecting known threats, you have to detect unknown threats too. So having a stack of both prevention and detection features is very important. With the two features glued together, we can have experienced security research and analyst teams. It is significant to observe whether the SD-WAN vendor has its own threat intelligence.
|
||||
|
||||
For this, we really do need the security company pedigree. The core value for any security vendor comes with their level of intelligence research. This is what creates market separation, not SD-WAN features.
|
||||
|
||||
However, there is another step, which is to confirm if the proposed features have been validated by 3rd parties such as NSS labs. NSS Labs has evaluated some of these security vendors for their SD-WAN leading products on areas such as the quality of experience (QoE) of VoIP and video, performance (WAN impairments and HA), the total cost of ownership (TCO) along with security effectiveness.
|
||||
|
||||
Also, we must question how often does the ‘SD-WAN device providing firewalling’ gets updated with the latest threat information. Is this process carried a few times per day or per week? Some SD-WAN solutions market them as a secure SD-WAN vendor, but if we go back to the point of building effective security, we need a solid threat intelligence team. Do startups have enough manpower to do that? A networking vendor simply can’t jump into this space. Some SD-WANs add stateful packet filters and call this security.
|
||||
|
||||
Let’s be honest, a next-generation firewall can be used by anyone. However, the importance of the breadth of the features, the intelligence they provide and the recognition in the market play a huge role. This is what builds trust in the next-generation firewall in the branch and ensures that the best security posture remains the best.
|
||||
|
||||
When you’re looking for secure SD-WAN vendors, highlight these questions and examine how old their security stack is. Also, assess if they have an experienced threat intelligence team.
|
||||
|
||||
The market is moving towards a secure SD-WAN solution. The industry analysis and the rise of the customer base have a great impact in today’s time. It is not the case that people are recognizing security vendors as strong SD-WAN players.
|
||||
|
||||
However, recognizing the market demands secure SD-WAN in one integrated comprehensive platform.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network. [Want to Join?][5]**
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489480/secure-sd-wan-the-security-vendors-and-their-sd-wan-offerings.html
|
||||
|
||||
作者:[Matt Conran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pixabay.com/illustrations/network-control-block-chain-hexagon-4478145/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[4]: https://www.networkworld.com/article/3276025/careers/20-hot-jobs-ambitious-it-pros-should-shoot-for.html
|
||||
[5]: https://www.networkworld.com/contributor-network/signup.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
83
sources/talk/20191213 Space-data-as-a-service gets going.md
Normal file
83
sources/talk/20191213 Space-data-as-a-service gets going.md
Normal file
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Space-data-as-a-service gets going)
|
||||
[#]: via: (https://www.networkworld.com/article/3489484/space-data-as-a-service-gets-going.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Space-data-as-a-service gets going
|
||||
======
|
||||
Development of IoT services in space will require ruggedized edge computing. OrbitsEdge, a vendor has announced a deal with HPE for development.
|
||||
[REUTERS/Joe Skipper/File Photo][1]
|
||||
|
||||
Upcoming space commercialization will require hardened edge-computing environments in a small footprint with robust links back to Earth, says vendor [OrbitsEdge][2], which recently announced that it had started collaborating with Hewlett Packard Enterprise on computing-in-orbit solutions.
|
||||
|
||||
OrbitsEdge says it’s the first to provide a commercial [data-center][3] environment for installing in orbit, and will be using HPE’s Edgeline Converged Edge System in a hardened, satellite [micro-data-center][4] platform that it’s selling called SatFrame.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][5]
|
||||
|
||||
The idea is “to run analytics such as artificial intelligence (AI) on the vast amounts of data that will be created as space is commercialized,” says Barbara Stinnett, CEO of OrbitsEdge, in a [press release][6].
|
||||
|
||||
[][7]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][7]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
### Why data in space?
|
||||
|
||||
[IoT][8] data collection along with analysis and experimental testing are two examples of space industrialization that the company gives as use cases for its micro-data center product. However, commercial use of space also includes imagery, communications, weather forecasting and navigation. Space tourism and commercial recovery of space resources, such as mined raw materials from asteroids are likely to be future space-uses, too.
|
||||
|
||||
Also, manufacturing – taking advantage of vacuums and zero-gravity environments – is among the economic activities that could take advantage of number crunching in orbit.
|
||||
|
||||
Additionally, [Cloud Constellation Corp., a company I wrote about in 2017, unrelated to OrbitsEdge or HPE, reckons highly sensitive data should be stored isolated][9] [in][9] [space][9]. That would be the “ultimate air-gap security,” it describes its [SpaceBelt][10] product.
|
||||
|
||||
### Why edge in space?
|
||||
|
||||
OrbitsEdge believes that data must be processed where it is collected, in space, in order to reduce transmission bottlenecks as streams are piped back to Earth stations. “Due to the new wave of low-cost commercial space activity, the bottleneck will get worse,” the company explains on its website.
|
||||
|
||||
What it means is that getting satellites into space is now cheap and is getting cheaper (due primarily to reusable rocket technology), but that there’s a problem getting the information back to traditional cloud environments on the surface of the Earth; there’s not enough backhaul data capacity, and that increases processing costs. Therefore, the cloud needs to move to the data-collection point: It’s “IoT above the cloud,” ObitsEdge cleverly taglines.
|
||||
|
||||
### How it works
|
||||
|
||||
Satellite-mounted solar arrays collect power from the sun. They fill batteries to be used when the satellite is in the shadow of Earth.
|
||||
|
||||
Cooling- and radiation-shielding protect a standard 5U, 19-inch server rack. There’s a separate rack for the avionics. Then integrated, traditional space-to-space, and space-to-ground radio communications handle the comms. Future-proofing is also considered: laser data pipes, too, could be supported, the company says.
|
||||
|
||||
#### On Earth option
|
||||
|
||||
Interestingly, the company is also pitching its no-maintenance, low Earth orbit (LEO)-geared product as being suitable for terrestrial extreme environments, too. OrbitsEdge claims that SatFrame is robust enough for extreme chemical and temperature environments on Earth. Upselling, it also says that one could combine two micro-data centers: a LEO SatFrame running HPE’s Edgeline, communicating with another one in an extreme on-Earth location—one at the Poles, maybe.
|
||||
|
||||
“To keep up with the rate of change and the number of satellites being launched into low Earth orbit, new services have to be made available,” OrbitsEdge says. “Shipping data back to terrestrial clouds is impractical, however today it is the only choice,” it says.
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489484/space-data-as-a-service-gets-going.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3489484/Reuters
|
||||
[2]: https://orbitsedge.com/
|
||||
[3]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[4]: https://www.networkworld.com/article/3445382/10-hot-micro-data-center-startups-to-watch.html
|
||||
[5]: https://www.networkworld.com/newsletters/signup.html
|
||||
[6]: https://orbitsedge.com/press-releases/f/orbitsedge-oem-agreement-with-hewlett-packard-enterprise
|
||||
[7]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[8]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[9]: https://www.networkworld.com/article/3200242/data-should-be-stored-data-in-space-firm-says.html
|
||||
[10]: http://spacebelt.com/
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Space-data-as-a-service prepares to take off)
|
||||
[#]: via: (https://www.networkworld.com/article/3489484/space-data-as-a-service-prepares-to-take-off.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Space-data-as-a-service prepares to take off
|
||||
======
|
||||
Development of IoT services in space will require ruggedized edge computing. OrbitsEdge, a vendor has announced a deal with HPE for development.
|
||||
REUTERS/Joe Skipper/File Photo
|
||||
|
||||
Upcoming space commercialization will require hardened edge-computing environments in a small footprint with robust links back to Earth, says vendor [OrbitsEdge][1], which recently announced that it had started collaborating with Hewlett Packard Enterprise on computing-in-orbit solutions.
|
||||
|
||||
OrbitsEdge says it’s the first to provide a commercial [data-center][2] environment for installing in orbit, and will be using HPE’s Edgeline Converged Edge System in a hardened, satellite [micro-data-center][3] platform that it’s selling called SatFrame.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][4]
|
||||
|
||||
The idea is “to run analytics such as artificial intelligence (AI) on the vast amounts of data that will be created as space is commercialized,” says Barbara Stinnett, CEO of OrbitsEdge, in a [press release][5].
|
||||
|
||||
[][6]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][6]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
### Why data in space?
|
||||
|
||||
[IoT][7] data collection along with analysis and experimental testing are two examples of space industrialization that the company gives as use cases for its micro-data center product. However, commercial use of space also includes imagery, communications, weather forecasting and navigation. Space tourism and commercial recovery of space resources, such as mined raw materials from asteroids are likely to be future space-uses, too.
|
||||
|
||||
Also, manufacturing – taking advantage of vacuums and zero-gravity environments – is among the economic activities that could take advantage of number crunching in orbit.
|
||||
|
||||
Additionally, [Cloud Constellation Corp., a company I wrote about in 2017, unrelated to OrbitsEdge or HPE, reckons highly sensitive data should be stored isolated][8] [in][8] [space][8]. That would be the “ultimate air-gap security,” it describes its [SpaceBelt][9] product.
|
||||
|
||||
### Why edge in space?
|
||||
|
||||
OrbitsEdge believes that data must be processed where it is collected, in space, in order to reduce transmission bottlenecks as streams are piped back to Earth stations. “Due to the new wave of low-cost commercial space activity, the bottleneck will get worse,” the company explains on its website.
|
||||
|
||||
What it means is that getting satellites into space is now cheap and is getting cheaper (due primarily to reusable rocket technology), but that there’s a problem getting the information back to traditional cloud environments on the surface of the Earth; there’s not enough backhaul data capacity, and that increases processing costs. Therefore, the cloud needs to move to the data-collection point: It’s “IoT above the cloud,” ObitsEdge cleverly taglines.
|
||||
|
||||
### How it works
|
||||
|
||||
Satellite-mounted solar arrays collect power from the sun. They fill batteries to be used when the satellite is in the shadow of Earth.
|
||||
|
||||
Cooling- and radiation-shielding protect a standard 5U, 19-inch server rack. There’s a separate rack for the avionics. Then integrated, traditional space-to-space, and space-to-ground radio communications handle the comms. Future-proofing is also considered: laser data pipes, too, could be supported, the company says.
|
||||
|
||||
#### On Earth option
|
||||
|
||||
Interestingly, the company is also pitching its no-maintenance, low Earth orbit (LEO)-geared product as being suitable for terrestrial extreme environments, too. OrbitsEdge claims that SatFrame is robust enough for extreme chemical and temperature environments on Earth. Upselling, it also says that one could combine two micro-data centers: a LEO SatFrame running HPE’s Edgeline, communicating with another one in an extreme on-Earth location—one at the Poles, maybe.
|
||||
|
||||
“To keep up with the rate of change and the number of satellites being launched into low Earth orbit, new services have to be made available,” OrbitsEdge says. “Shipping data back to terrestrial clouds is impractical, however today it is the only choice,” it says.
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489484/space-data-as-a-service-prepares-to-take-off.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://orbitsedge.com/
|
||||
[2]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[3]: https://www.networkworld.com/article/3445382/10-hot-micro-data-center-startups-to-watch.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://orbitsedge.com/press-releases/f/orbitsedge-oem-agreement-with-hewlett-packard-enterprise
|
||||
[6]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[7]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[8]: https://www.networkworld.com/article/3200242/data-should-be-stored-data-in-space-firm-says.html
|
||||
[9]: http://spacebelt.com/
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,119 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What’s hot at the edge for 2020? Everything)
|
||||
[#]: via: (https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
What’s hot at the edge for 2020? Everything
|
||||
======
|
||||
From SD-WAN and cloud interconnection to security, the edge will be one active place in 2020
|
||||
Thinkstock
|
||||
|
||||
Few areas of the enterprise face as much churn as the edge of the network. Experts say a variety of challenges drive this change – from increased [SD-WAN][1] access demand to cloud interconnected resources and [IoT][2], the traditional perimeter of the enterprise is shifting radically and will continue to do so throughout 2020.
|
||||
|
||||
One indicator: Gartner research that says by 2023, more than 50% of enterprise-generated data will be created and processed outside the [data center][3] or cloud, up from less than 10% in 2019.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][4]
|
||||
|
||||
Hand-in-hand with that change is a shift in what technologies are supported at the edge of the network – and that means information processing, content collection and delivery are placed closer to the sources, repositories and consumers of this information. Edge networking tries to keep the traffic and processing local to reduce latency, exploit the capabilities of the edge and enable greater autonomy at the edge, [Gartner says][5].
|
||||
|
||||
[][6]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][6]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
The scope of enterprise WAN networks is broadening. No longer is it only from a branch edge to a data-center edge. Now the boundaries have shifted across the LAN from individual clients and devices on the one end and across the WAN to individual containers in data centers or clouds on the other, said Sanjay Uppal, vice president and general manager of VMware’s VeloCloud Business Unit. “This broadening of the WAN scope is a direct consequence of the democratization of data generation and the need to secure that data. So, we end up with edges at clients, servers, devices, branches, private data centers, public data centers, telco POP, RAN and the list goes on. Additionally, with IoT and mobility taking hold at the enterprise, the edge is moving out from the traditional ‘branch’ to the individual clients and devices.”
|
||||
|
||||
“The evolution of business applications from monolithic constructs to flexible containerized workloads necessitates the evolution of the edge itself to move closer to the application data,” Uppal said. “This, in turn, requires the enterprise network to adjust and meet and exceed the requirements of the modern enterprise.”
|
||||
|
||||
Such changes will ultimately make defining what constitutes the edge of the network more difficult.
|
||||
|
||||
“With increased adoption of cloud-delivered services, unmanaged mobile and IoT devices, and integration of networks outside the enterprise (particularly partners), the edge is more difficult to define. Each of these paradigms extend the boundaries of today's organizations,” said Martin Kuppinger, principal analyst with [KuppingerCole Analysts A][7]G. “On the other hand, there is a common perception that there is no such perimeter anymore with statements such as “the device is the perimeter” or “identity is the new perimeter”. To some extent, all of this is true – and wrong. There still might be perimeters in defined micro-segments. But there is not that one, large perimeter anymore.”
|
||||
|
||||
The enterprise is not the only arena that will see continued change in 2020, there are big changes afoot on the WAN was well.
|
||||
|
||||
Analysts from [IDC wrote][8] earlier this year that traditional enterprise WANs are increasingly not meeting the needs of digital businesses, especially as it relates to supporting SaaS apps and multi- and [hybrid-cloud][9] usage. Enterprises are interested in easier management of multiple connection types across their WAN to improve application performance and end-user experience – hence the growth of SD-WAN technologies.
|
||||
|
||||
“The market for branch-office WAN-edge functionality continues to shift from dedicated routing, security and WAN optimization appliances to feature-rich software-defined WAN and, to a lesser extent, [universal customer-premises equipment] platforms,” [Gartner wrote][10]. “SD-WAN is replacing routing and adding application-aware path selection among multiple links, centralized orchestration and native security, as well as other functions. Consequently, it includes incumbent and emerging vendors from multiple markets (namely routing, security, WAN optimization and SD-WAN), each bringing its own differentiators and limitations.”
|
||||
|
||||
One of the biggest changes for 2020 could come around the SD-WAN. One of the drivers stems from the relationships that networking vendors such as Cisco, VMware, Juniper, Arista and others have with the likes of Amazon Web Services, Microsoft Azure, Google Anthos and IBM RedHat.
|
||||
|
||||
An indicator of those changes came this month when AWS announced a slew of services for its cloud offering that included new integration technologies such as [AWS Transit Gateway][11], which lets customers connect their Amazon Virtual Private Clouds (VPCs) and their on-premises networks to a single gateway. Aruba, Aviatrix Cisco, Citrix Systems, Silver Peak and Versa already announced support for the technology which promises to simplify and enhance the performance of SD-WAN integration with AWS cloud resources.
|
||||
|
||||
The ecosystem around this type of cloud interconnection is likely one of the hottest areas of growth for 2020, experts say.
|
||||
|
||||
SD-WAN is critical for businesses adopting cloud services, acting as a connective tissue between the campus, branch, IoT, data center and cloud, said Sachin Gupta, senior vice president, product management, with Cisco Enterprise Networking in a recent [Network World][12] article. “It brings all the network domains together and delivers the outcomes business requires."
|
||||
|
||||
"It must align user and device policies, and provide assurance to meet application service-level agreements. It must deliver robust security to every device and every cloud that the enterprise’s data touches.” The AWS Transit Gateway will let IT teams implement consistent network and data security rules, he said.
|
||||
|
||||
All of these edge transformations will most certainly bring with it security challenges. Kuppinger noted a few including:
|
||||
|
||||
* Has "shadow IT" subscribed to SaaS, which now contains important business data? How is it managed?
|
||||
* Does the IT department use IaaS for dev/test or pre-production? Is it loaded with copies of production data? How is that controlled?
|
||||
* Does IT use IaaS and PaaS for line-of-business applications? Is it managed centrally like legacy applications?
|
||||
* Does the enterprise allow BYOD? Are unified endpoint-management or mobile anti-malware solutions mandated for such devices?
|
||||
* Are IoT devices on the networks? Are they outside of your networks, but delivering critical services for customers?
|
||||
* Are third-party risks enumerated and controlled?
|
||||
|
||||
|
||||
|
||||
“Each of these situations is beyond the traditional edge and can increase your enterprise attack surface and risk,” Kuppinger said. “Once identified, enterprises must figure out how to secure the edges and get more complete visibility to all risks and mitigations. New tools may be needed. Some organizations may choose to engage more managed security services,” he said.
|
||||
|
||||
The perimeter needs to be everywhere and hence the advent of the zero-trust architecture, VMware’s Uppal said. “This requires an end-to-end view where posture is checked at the edge, and based on that assessment network traffic is segmented both to reduce the attack surface and also the blast radius. i.e., first reduce the likelihood that something is going to go wrong, but if it does then minimize the impact,” Uppal said.
|
||||
|
||||
“As traffic traverses the network, security services, both letting through the good while blocking the bad are inserted based on policy. Here again the network of cloud services that dynamically sequences security based on business policy is critical,” Uppal said.
|
||||
|
||||
Going forward enterprise organizations might need to focus less on the network itself. “Protect the services, protect the communication between devices and services, protect the devices and the identities of the users accessing these devices. This is very much what the “[zero trust][13]” paradigm has in mind – notably, this is not primarily “zero-trust networks”, but zero trust at all levels,” Kuppinger said.
|
||||
|
||||
“The most important learning is: Protecting just the network at its edge is not sufficient anymore. If there is a defined network – either physical such as in OT or virtual such as in many data centers – this adds to protection,” Kuppinger said.
|
||||
|
||||
The mixture of cloud and security services at the edge will lead to another trend in 2020, one that Gartner calls secure access service edge (SASE) which is basically the melding of network and security-as-a-service capabilities into a cloud-delivered package. By 2024, at least 40% of enterprises will have explicit strategies to adopt [SASE][14], up from less than 1% at year-end 2018, Gartner says.
|
||||
|
||||
“SASE is in the early stages of development,” Gartner says. “Its evolution and demand are being driven by the needs of digital business transformation due to the adoption of SaaS and other cloud-based services accessed by increasingly distributed and mobile workforces, and to the adoption of edge computing.”
|
||||
|
||||
Early manifestations of SASE are in the form of SD-WAN vendors adding network security capabilities and cloud-based security vendors offering secure web gateways, zero-trust network access and cloud-access security broker services, Gartner says.
|
||||
|
||||
Regardless of what it’s called, it is clear the melding of cloud applications, security and new edge WAN services will be increasing in 2020.
|
||||
|
||||
“We are seeing the rise of microservices in application development, allowing applications to be built based upon a collection of discrete technology elements. Beyond new application architectures, there are demands for new applications to support IoT initiatives and to push compute closer to the user for lower latency and better application performance,” VMware’s Uppal said. “With the maturation of Kubernetes, what is needed is the next set of application-development and -deployment tools that work cooperatively with the underlying infrastructure, compute, network and storage to serve the needs of that distributed application.”
|
||||
|
||||
[See more predictions about what's big in IT tech for the coming year.][15]
|
||||
|
||||
Join the Network World communities on [Facebook][16] and [LinkedIn][17] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[2]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[3]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.networkworld.com/article/3447397/gartner-10-infrastructure-trends-you-need-to-know.html
|
||||
[6]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[7]: https://twitter.com/kuppingercole
|
||||
[8]: https://www.idc.com/getdoc.jsp?containerId=prUS45380319
|
||||
[9]: https://www.networkworld.com/article/3268448/what-is-hybrid-cloud-really-and-whats-the-best-strategy.html
|
||||
[10]: https://www.networkworld.com/article/3489480/secure-sd-wan-the-security-vendors-and-their-sd-wan-offerings.html
|
||||
[11]: https://aws.amazon.com/transit-gateway/
|
||||
[12]: https://www.networkworld.com/article/3487831/what-s-hot-for-cisco-in-2020.html
|
||||
[13]: https://www.networkworld.com/article/3487720/the-vpn-is-dying-long-live-zero-trust.html
|
||||
[14]: https://www.networkworld.com/article/3481519/sase-redefining-the-network-and-security-architecture.html
|
||||
[15]: https://www.networkworld.com/article/3488562/whats-big-in-it-tech-for-the-coming-year.html
|
||||
[16]: https://www.facebook.com/NetworkWorld/
|
||||
[17]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,192 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (10 tips for onboarding open source contributors)
|
||||
[#]: via: (https://opensource.com/article/19/12/open-source-contributors)
|
||||
[#]: author: (rowasc https://opensource.com/users/rowasc)
|
||||
|
||||
10 tips for onboarding open source contributors
|
||||
======
|
||||
Making new contributors feel welcome in your community is essential to
|
||||
your project's future, so it's important to put time and attention into
|
||||
onboarding them.
|
||||
![Women programming][1]
|
||||
|
||||
Contributors are the lifeblood of many open source projects because they enable smaller projects to grow and improve without a lot of financial support and they bring fresh perspectives to the project. That is the case at [Ushahidi][2], a non-profit organization that is building and using software to help raise the voices of underserved, marginalized communities. Our products enable local observers to submit reports about local humanitarian crises (such as political unrest and natural disasters) using their mobile phones or the internet, while simultaneously creating a temporal and geospatial archive of events.
|
||||
|
||||
Ushahidi always strives for openness, but **it's very hard to evaluate how open your organization works from the inside**. Staff and longtime contributors know too much: they are cursed by knowledge and access to the people who know how things work. While a crisis brings out the good in people who want to help, getting involved with an open source project during a crisis is complex. The maintainers are usually going through a stressful time. New requests for features are coming every day. New bugs are being reported all the time.
|
||||
|
||||
There are never enough people to fix everything, which is why it's so important for projects to have a good process for onboarding new contributors.
|
||||
|
||||
### Why Ushahidi needed to re-engage with its community
|
||||
|
||||
In the beginning, Ushahidi had a really big community and did a lot of community engagement. We had community dev calls, where core developers and community developers talked about what they were working on. We had t-shirts and swag; we had community badges and blog posts celebrating the top contributor of the month. We sponsored tech events and made sure to have a booth or a presentation showcasing the platform.
|
||||
|
||||
Our documentation was good and extensive with toolkits and examples for different use cases, our forum was active, we were active!
|
||||
|
||||
But then a few things happened. The software got outdated, and the core team started working on a new version. At the same time, we adopted a new strategy around sustainability and started a Software-as-a-Service model, spanning from free grassroots deployments to more complex enterprise plans, to try to bring much-needed financial stability and sustainability and serve new use cases and needs.
|
||||
|
||||
All of this took longer than expected, and we did not want to bring in new contributors "just yet." Not getting our contributors engaged from the beginning resulted in our docs being unclear, unfinished, and unstructured. We did not adjust the software to be easy for our open source users to install or use. **Nothing was intentional, but we were not serving our open source community as well as we would like.** Now, our main focus is to re-engage with our community.
|
||||
|
||||
The following are 10 things we've learned and done that may help you improve your contributor onboarding processes if you're in a similar situation.
|
||||
|
||||
### 1\. Evaluate your processes
|
||||
|
||||
To evaluate how open your organization's processes are and how they are working for new contributors, source new folks who can try to answer questions like: "How do you get new code into production?" and "Who can trigger a production release?" or "How does testing happen?"
|
||||
|
||||
Some things to look for:
|
||||
|
||||
* Is it clear to new contributors about how to get started? Are getting-started guides hard to find, too complex, or disorganized?
|
||||
* Are communication and coordination happening in the open? Or are they hidden in Slack rooms, making it hard to know what is going on?
|
||||
* Is the process for code reviews and merges clear? What about the safety nets for code contributions and the QA process?
|
||||
|
||||
|
||||
|
||||
When you're deep into a project with your community, it's difficult to know how it looks to new contributors. We learned that **what feels like an open process from the inside can feel very closed from the perspective of a new contributor**.
|
||||
|
||||
### 2\. Set the foundation
|
||||
|
||||
Diversity and inclusion are core to Ushahidi; about 80% of people working on the project are women and non-binary genders, a majority of our team are people of color, and we live on four continents. This reflects the reality that many of our users live in. They are not all in the United States, they are from diverse backgrounds, and they have different goals. What unites them is that they are all working to improve their communities in their own way.
|
||||
|
||||
For us, **having a good foundation starts with having a diverse team that represents our users and stakeholders**. But that's not all; we have also improved our contributor resources with:
|
||||
|
||||
* A new developers hub
|
||||
* New and updated documentation
|
||||
* New pathways to contributing
|
||||
* Videos
|
||||
* FAQs
|
||||
|
||||
|
||||
|
||||
We're also restarting our community engagement by:
|
||||
|
||||
* Doing webinars
|
||||
* Hosting hackathons
|
||||
* Proactively organizing and triaging issues
|
||||
* Announcing releases and contributors to each release
|
||||
|
||||
|
||||
|
||||
### 3\. Make "getting started" clear
|
||||
|
||||
When someone wants to start contributing, there needs to be clarity on how to start. We label good starter contributions as first-timer issues; these describe in detail what needs to be done, how to find the code, and what you need to do. It takes us longer to write these issues than it would to fix the actual thing ourselves, but that is not the goal. The goal is to **give people who may be new to open source a chance to contribute and learn about the work we do**.
|
||||
|
||||
#### Find the blockers
|
||||
|
||||
It is also important to understand where the blockers for getting started are. One of Ushahidi's biggest blockers was installing the software in development environments. We assumed that because our engineers could get things set up, others would be able to do so. But other people may not have the same environment, and they absolutely did not have the amount of support that our core engineering team gets.
|
||||
|
||||
To resolve this, we created videos on installation procedures, and we also created an **installation-helper** feature that checks common things that people forget during configuration and installation and also gives hints on how to solve problems.
|
||||
|
||||
![Ushahidi's installation-helper][3]
|
||||
|
||||
### 4\. Learn from diverse perspectives
|
||||
|
||||
It's important to ask others to evaluate and double-check the documentation we provide to our contributors. We are really lucky that our team has people in programs, community, and design roles that really care about open source, and their input often helps us figure out how to **reach people who are less experienced with coding or who may want to contribute in different ways than writing code or doing QA**.
|
||||
|
||||
When we were creating videos for our new developers hub, our community engagement officer was a big help. She is not a developer, and she is an excellent writer, so she helped by watching us go through the documentation, taking notes, then writing the initial scripts for our videos. She ensured that the things that we encounter daily—and know how to deal with by heart—are addressed in the documentation.
|
||||
|
||||
Input like this is very valuable, since it reminds us what we know and take for granted that could confuse and turn away new contributors.
|
||||
|
||||
### 5\. When possible, make short calls
|
||||
|
||||
Try to invest in calls when needed and when your schedule allows. **Sometimes a five-minute call with a new contributor will give a better return than a 30-minute text chat.** If you reach a point in a chat that it's clear your instructions aren't working for the person, ask them to jump on a call to show you what they are doing. It's important to set a time limit (e.g., "I have 10 minutes now, so let's see if we can solve it right away"); otherwise, you may end up spending the whole day fixing unrelated things, which is not a great way to scale yourself.
|
||||
|
||||
Make sure to use what you learn from these interactions to improve your documentation. Otherwise, you will find yourself doing so many 10-minute calls that you will never get anything done.
|
||||
|
||||
### 6\. Always say thank you
|
||||
|
||||
**Thank people even when it feels all you are getting are requests to do more work.** We say thank you for everything. We say thank you for bug reports, feature requests, for code contributions. We say thank you for reaching out and asking for help.
|
||||
|
||||
It is hard for some people to reach out, and thanking them validates that it was OK to do so. This validation may also help people not only for the current situation but also for other projects and situations in the future.
|
||||
|
||||
### 7\. Be kind in code reviews
|
||||
|
||||
Someone has found you, gotten set up, fixed a bug, and finally sent a pull request. It's time to review the code. Step away from your personal opinions on how things should be. It's not time to be nit-picky and rude.
|
||||
|
||||
When performing code reviews, **ensure you are helping the person make the code better** and not just following your personal preferences. Find at least one good thing to say about the pull request, and _always thank the contributor_.
|
||||
|
||||
If you get a pull request that you don't plan to merge, maybe because it's the wrong scope or direction or simply something you don't want to add, it is important to deal with it straightaway instead of ignoring it. It does not help anyone to ignore pull requests, and it only serves to clutter your repository. Thank the contributor, explain why you don't plan to merge the changes, and close the pull request.
|
||||
|
||||
If you merge the changes, make sure to tag the contributor when it goes out so that they know it had an impact.
|
||||
|
||||
### 8\. Be responsive
|
||||
|
||||
Throughout this process, **it is important to be responsive and not let people wait**. Giving someone some kind of response—even if you can't help them right now—and setting the expectation for when you'll be able to follow up is super-important.
|
||||
|
||||
Sometimes a comment goes undiscovered—you miss a notification and find it three months later. It's tricky to respond in those situations, but it's still better to acknowledge the message, apologize for the delay, and ask if they still want help (with this or something else) rather than just ignoring them forever. It sets the tone that you care about your work and community, even when you make mistakes.
|
||||
|
||||
### 9\. Help contributors thrive
|
||||
|
||||
Sometimes a contributor comes in, sends their contributions, and leaves without much interaction. But, on some occasions, you get the opportunity to work with people over a longer time. Working with new contributors over a period of weeks or months is extremely valuable because you will gain insights into how people—especially those new to your project or tech—see your work and what challenges they face. It's also a chance to help people grow and learn. It's a win-win for everyone.
|
||||
|
||||
In 2019, we participated in the [Google Summer of Code][4] and [Outreachy][5], and these experiences helped both the interns and our team learn new things. By working with interns, we get to understand what it's like to join our project, what onboarding looks like for a very junior engineer, and what blockers there might be to them contributing to our project.
|
||||
|
||||
#### Prevent imposter syndrome
|
||||
|
||||
On a related note, it's important to help prevent [impostor syndrome][6]. The feeling of not belonging or of "how did I even get here" is so common, especially among underrepresented groups in tech. It is written and talked about a lot, especially in the past tense, but rarely by people who are actively going through it.
|
||||
|
||||
How do you spot it? How do you know someone is feeling like they aren't accomplishing enough or are feeling like a fraud?
|
||||
|
||||
**Showing senior folks failing and learning from their mistakes helps to create an inclusive environment.** Things like pair programming, sharing your past experiences, discussing your career path, and telling people about when you made mistakes are ways to help to bridge gaps between senior engineers and new people. It helps new folks feel like they belong in tech because the smart, senior people in front of them also had concerns and made mistakes, but they picked themselves up and kept going.
|
||||
|
||||
### 10\. Avoid communication barriers
|
||||
|
||||
This may be obvious, but not all your contributors speak English as their first language. For many, it'll be their second, or maybe even third or fourth, language. A lot of your contributors may not speak English at a level that allows them to collaborate seamlessly, and it's important to remember that broken English is fine, even expected, in a global project. Be empathetic, be nice, and support these folks. Don't assume that someone is "dumb" just because they have bad grammar in English. Just because someone does not speak perfect English, it does not mean they aren't talented. It literally only means they don't speak perfect English.
|
||||
|
||||
Another potential communication barrier is using mannerisms that others may perceive in different ways than we intended. For example, signing an email "Thanks, Romina" or saying "OK, bye!" sound perfectly appropriate to me, but they could signal to someone else that you don't respect them. To assign the label "rude" to someone because of this would be… quite rude?
|
||||
|
||||
**When you are dealing with a multicultural, global network of contributors, try not to worry about language barriers or mannerisms that aren't meant to be offensive.**
|
||||
|
||||
This doesn't mean that you should excuse bad behavior. There are no excuses for calling another person names, putting someone down, or misgendering someone on purpose, and maintainers are obligated to act on the code of conduct and resolve the situation.
|
||||
|
||||
### In summary
|
||||
|
||||
Making new contributors feel welcome in your community is essential to your project's future, so it's important to put time and attention into onboarding them.
|
||||
|
||||
* Make sure to see your community from the contributors' side.
|
||||
* Enabling underrepresented minorities to thrive creates a more welcoming community for everyone.
|
||||
* Be aware of the community you are serving and ask yourself what their specific needs are.
|
||||
* Allow questions both in private and public.
|
||||
* Be nice, set the tone.
|
||||
* Say thank you.
|
||||
* Be responsive.
|
||||
* Be consistent.
|
||||
|
||||
|
||||
|
||||
### Other resources
|
||||
|
||||
* [Ushahidi's documentation][7]
|
||||
* [First Timers Only][8] offers good tips for first-time contributors
|
||||
* [GitHub's all-contributors repository][9] provides specs for recognizing all types of open source contributors
|
||||
* [Up For Grabs][10] to find open issues for OSS and how to label issues
|
||||
|
||||
|
||||
|
||||
The four-day-long siege of a Nairobi mall ended Tuesday with a death toll of more than 60 people –...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/open-source-contributors
|
||||
|
||||
作者:[rowasc][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rowasc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/collab-team-pair-programming-code-keyboard2.png?itok=WnKfsl-G (Women programming)
|
||||
[2]: https://www.ushahidi.com/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/ushahidi_installation-helper.png (Ushahidi's installation-helper)
|
||||
[4]: https://summerofcode.withgoogle.com/archive/
|
||||
[5]: https://www.outreachy.org/
|
||||
[6]: https://opensource.com/open-organization/17/5/team-impostor-syndrome
|
||||
[7]: https://docs.ushahidi.com/index/
|
||||
[8]: https://www.firsttimersonly.com/
|
||||
[9]: https://github.com/all-contributors/all-contributors
|
||||
[10]: https://up-for-grabs.net/
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 considerations when buying network-automation tools)
|
||||
[#]: via: (https://www.networkworld.com/article/3490459/7-considerations-when-buying-network-automation-tools.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
7 considerations when buying network-automation tools
|
||||
======
|
||||
Here’s the factors you need to weigh so you can make a smart decision about the network automation tool that’s best for your organization.
|
||||
bananajazz / Getty Images
|
||||
|
||||
The concept of network automation has been around for as long as there have been networks, and until now the uptake has been slow for a number of reasons including resistance from network engineers. But now forces are coming together to create a perfect storm of sorts, driving a need for network automation tools.
|
||||
|
||||
One factor is that more and more network teams are starting to feel the pain of working in the fast-paced digital world where doing things the old way simply does not work. The manual, box-by-box, method of configuring and updating routers and switches through a command-line interface (CLI) is too slow and error prone.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][1]
|
||||
|
||||
Also, the rise of software-defined networks ([SDN][2]), including software-defined WANs ([SD-WAN][3]), has enabled network-automation tools to evolve from operationally focused point products that address things like change management and configuration into policy and orchestration tools.
|
||||
|
||||
[][4]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][4]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
Today, network-automation tools are strategic, enable business alignment, and provide a roadmap to the utopian state of a fully intent-based system where the network runs and secures itself. Their time is now, but there is a wide range of them. Below are seven key criteria that enterprises should consider when deciding which is best for them.
|
||||
|
||||
### Single vendor or multi-vendor?
|
||||
|
||||
There are several third-party and vendor-specific network automation tools. Red Hat, NetBrain and Forward Networks are three of the leading multi-vendor tools. All of the major network vendors including Cisco, Juniper, Arista and Extreme have their own automation platforms.
|
||||
|
||||
Customers need to determine if they want to go all in with a single vendor or strive for multiple vendors. Neither is better per se; it’s a choice the enterprise needs to make. If a single vendor platform is chosen, ensure it works with the vendor's entire product line and not just a subset. If a third-party tool is chosen, seek out one that that supports the current and likely future vendors whose gear will be in the organization’s network.
|
||||
|
||||
### Breadth of APIs
|
||||
|
||||
It’s important that network-automation tools interface with other tools such as ServiceNow and Splunk. This means every feature should be available as an API, which isn’t always the case. Even if a tool is being used standalone today, it will likely need to interface with another application in the near future for broader automation capabilities, so this should not be overlooked.
|
||||
|
||||
### Orchestration
|
||||
|
||||
When network devices change, it’s often the case that another element of the infrastructure must also change. For example, when a network device is added, it may require changing a [firewall][5] setting or connecting to a load balancer. This drives up the need for orchestration capabilities so the network-automation tool can trigger other automation frameworks to change devices that are upstream or downstream from it.
|
||||
|
||||
### AI/intent-based networking capabilities
|
||||
|
||||
The concept of an [intent-based network][6] is that it runs, heals and secures itself. This can’t be done with a bevy of rules because the environment changes too fast. Instead, AI capabilities should be included in the system to fully automate all operations so the network itself can adapt to changes.
|
||||
|
||||
ZK Research recommends that the system have two modes of operation – one that recommends changes for the engineer to execute on and then one that fully executes changes without requiring human intervention. This will let the customer get comfortable with AI first. (One question ZK Research gets a lot is how one knows it’s really AI based. The answer is that the tool gets smarter over time. All changes should feed back into the system as part of the learning data set and make the system smarter. Rules-based systems will not.)
|
||||
|
||||
### SaaS or on-prem?
|
||||
|
||||
Traditional network-automation tools have been offered only as on-premises software or appliances. There is a growing number of companies that prefer to buy the tools in a software as a service (SaaS) model to ensure rapid deployment and continuous updates.
|
||||
|
||||
Again, there’s no wrong choice. The company needs to determine which option best fits its operating model and compliance requirements.
|
||||
|
||||
One important note: It’s the belief of ZK Research that all solutions will eventually be hybrid where customers may keep the data on the local premises, but advanced, artificial intelligence capabilities and cross-company comparisons will be done in the cloud. On-prem solutions do not have the necessary horsepower to deliver real-time AI capabilities
|
||||
|
||||
### Compliance and security reporting
|
||||
|
||||
There’s a growing push from leading organizations to bring IT and security operations together. This means network-automation tools need to provide information that shows security policies are continually being adhered to and compliance mandates are being met. The reporting capabilities need to provide visibility into every phase of the network lifecycle including planning, deploying and optimization.
|
||||
|
||||
### Ease of use
|
||||
|
||||
This is an often-overlooked component of management platforms. Feature-rich tools with long learning curves can require years before IT teams realize their full value. Also, when a product is too technical, the company is put at risk if people with the best knowledge of it exit the organization.
|
||||
|
||||
Network automation tools should be fully GUI based, which means every feature available via the CLI should also be accessible through the graphical interface. The tools should be easy to use as well so lower level engineers can work with it. This will obviate the need to always include a senior, more expensive engineer.
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3490459/7-considerations-when-buying-network-automation-tools.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
|
||||
[3]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[5]: https://www.networkworld.com/article/3230457/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
|
||||
[6]: https://www.networkworld.com/article/3202699/what-is-intent-based-networking.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How open source eases the shift to a hybrid cloud strategy)
|
||||
[#]: via: (https://opensource.com/article/19/12/open-source-hybrid-cloud)
|
||||
[#]: author: (Bart Copeland https://opensource.com/users/bartcopeland)
|
||||
|
||||
How open source eases the shift to a hybrid cloud strategy
|
||||
======
|
||||
Open source software is key to adopting a multicloud or hybrid cloud
|
||||
strategy.
|
||||
![Person on top of a mountain, arm raise][1]
|
||||
|
||||
Cloud adoption continues to grow as organizations seek to move away from legacy and monolithic strategies. Cloud-specific spending is expected to grow at more than six times the rate of general IT spending through 2020, according to [McKinsey Research][2]. But cloud adoption raises fear of [vendor lock-in][3], which is preventing many companies from going all-in on public cloud. This has led to a rise in multi-cloud and hybrid cloud deployments, which also have their challenges.
|
||||
|
||||
Open source technology is the key to unlocking the value in a hybrid and multi-cloud strategy.
|
||||
|
||||
### What's the appeal of a hybrid cloud strategy?
|
||||
|
||||
The hybrid cloud market is growing rapidly because it offers the benefits of the cloud without some of the drawbacks. It typically costs less to move storage to the cloud than it does to maintain a private data center. At the same time, there are certain mission-critical applications and/or sensitive data that an organization may still want to keep on-premise, which is why hybrid cloud–a mix of private and public, on-prem and off-prem–is appealing.
|
||||
|
||||
This is why [58 percent of enterprises][4] have a hybrid cloud strategy, according to the Rightscale State of the Cloud 2019 report. It is also why IBM acquired Red Hat for the kingly sum of $34 billion. IBM CEO Ginni Rometty noted at the time that hybrid cloud is a $1 trillion market and that IBM’s goal is to be number one in that market.
|
||||
|
||||
### Common challenges of moving to a hybrid cloud strategy
|
||||
|
||||
One challenge is the lack of a strategic plan. According to [McKinsey Research][2], many companies fall into the trap of thinking that simply moving IT systems to the cloud is equivalent to a transformational digital strategy. The "lift and shift" approach is not enough to enjoy all the benefits of the cloud, though.
|
||||
|
||||
Cybersecurity applications provide a good case in point. The traditional perimeter approach to security won’t translate well to the cloud, whose approach must be quite different since a cloud perimeter is nearly impossible to define. If organizations are relying on legacy perimeter security to keep their holdings in the cloud safe, they are in for a nasty surprise.
|
||||
|
||||
Another challenge to effective cloud migration is the status quo. For many companies, it comes down to the mindset of "If it’s not broken, why fix it? If it works fine as it is, why move it?" While many organizations understand the need for and benefits of having newer applications in the cloud, it’s not always obvious whether it also makes sense to move legacy applications over, too. In the case of cybersecurity, it very well may not be, but other applications may be best served with a move to the cloud.
|
||||
|
||||
To further complicate matters, public cloud providers like Microsoft Azure, Google Cloud, and AWS [are not immune to outages][5]. Whatever the reason for downtime–a database glitch, bad weather, overzealous security features–being able to share workloads across clouds can be key in the event of an outage.
|
||||
|
||||
### Bringing it all together with open source
|
||||
|
||||
Hybrid cloud and open source go hand-in-hand. In fact, many of the public cloud providers rely heavily on different open source technologies and technology stacks to run them, so open source can be used easily across both private and public clouds in most situations. Companies like [Red Hat][6], in fact, were built on the concept of facilitating hybrid cloud. Many of its customers are moving toward an open hybrid cloud strategy.
|
||||
|
||||
This is, in part, because open source provides flexibility and helps avoid the issues of cloud vendor lock-in. In addition, open source technologies bring breadth and depth for managers and developers alike; they give developers the tools they enjoy using.
|
||||
|
||||
Though the cloud market is growing quickly, it is not without its limitations and drawbacks. The majority of enterprises have what they call a hybrid cloud strategy, but it may be less strategic than they think since the "lift and shift" approach falls short. Mindsets need to shift as well to overcome the status quo, and organizations need to guard against cloud outages.
|
||||
|
||||
Vital to a multi-cloud approach is managing distributed workloads. Modern software architecture methodologies break monolithic applications into microservices that can be run wherever it makes sense–on-premise, in the cloud, or across both. By leveraging open source technologies from Linux to containers to Kubernetes, organizations can deploy, run and manage workloads in a secure and optimized manner. This kind of open source approach allows organizations to derive benefits far beyond just "lift and shift" in order to become more efficient, run their processes more cost-effectively, and adopt a more flexible operating model.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/open-source-hybrid-cloud
|
||||
|
||||
作者:[Bart Copeland][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bartcopeland
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/developer_mountain_cloud_top_strong_win.jpg?itok=axK3EX-q (Person on top of a mountain, arm raise)
|
||||
[2]: https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/cloud-adoption-to-accelerate-it-modernization
|
||||
[3]: https://searchconvergedinfrastructure.techtarget.com/definition/vendor-lock-in
|
||||
[4]: https://www.flexera.com/about-us/press-center/rightscale-2019-state-of-the-cloud-report-from-flexera-identifies-cloud-adoption-trends.html
|
||||
[5]: https://www.crn.com/slide-shows/cloud/the-10-biggest-cloud-outages-of-2018
|
||||
[6]: https://siliconangle.com/2019/04/12/red-hat-strategy-validated-as-open-hybrid-cloud-goes-mainstream-googlenext19/
|
||||
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (SD-WAN management means more than reviewing logs and parsing events)
|
||||
[#]: via: (https://www.networkworld.com/article/3490333/sd-wan-management-means-more-than-reviewing-logs-and-parsing-events.html)
|
||||
[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
SD-WAN management means more than reviewing logs and parsing events
|
||||
======
|
||||
Creating a single view of the different types of data requires specialized skills, custom integration and a significant budget. Just look at the SIEM.
|
||||
Getty Images
|
||||
|
||||
By creating a single view of all network data, you can do things better like correlating threat information to identify real attacks or keep a log of packet statistics to better diagnose intermittent networking problems.
|
||||
|
||||
However, to turn data into value with the limitations of traditional systems, we must be creative with the solution. We must find ways to integrate the different repositories in various appliances. It’s not an easy task but an architectural shift that I’ve written about in the past, SASE (Secure Access Service Edge), should help significantly.
|
||||
|
||||
SASE is a new enterprise networking technology category introduced by Gartner in 2019. It represents a change in how we connect our sites, users, and cloud resources.
|
||||
|
||||
[][1]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][1]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
This can be of considerable support, especially when it comes to the challenges faced with SIEM (Security Information and Event Management).
|
||||
|
||||
### Creating a single view is challenging
|
||||
|
||||
Creating a single view of the different types of data requires specialized skills, custom integration, and a significant budget. The SIEM is used to bring data from multiple products, apply rules and orchestrate a variety of platforms to act together. In reality, there is a lot of custom integration involved.
|
||||
|
||||
The questions that surface is; how do logs get into the SIEM when off the network? How do you normalize the data, write the rules to detect for suspicious activity and then investigate if there are legitimate alerts? Unfortunately, the results are terrible for the investment that people make. The SIEM can’t be performed in a small organization. You will need the resources to pull it off.
|
||||
|
||||
### Challenges with the SIEM
|
||||
|
||||
In a previous consultancy role, I experienced first-hand the challenges of running a SIEM. Ultimately, the company had to improve its security monitoring. Like most, they came across the same problem and recognized there was a big gap when it came to detection.
|
||||
|
||||
[The time of 5G is almost here][2]
|
||||
|
||||
When I first came across the potentials of the SIEM, like most, I was thoroughly excited by its hype. Now, there was a tool that allowed me to take my ideas and run them against numerous rich data sets. From these sets, I could get immediately gain insight into threats on the network and act. However, this is far from reality - the SIEM is complex.
|
||||
|
||||
### Different data from different devices
|
||||
|
||||
Both security and networking store and expose data differently. Each of them carries out an individual role and have access to different data. Data can be abstracted from the management, control and data planes to build analytics that can be queried. This results in multiple levels of data available for analysis. Essentially, for this, you need to be an expert in each of these planes.
|
||||
|
||||
Preparing all the data gathered from your entire infrastructure is complicated. Developing a timeline of events requires mastering a range of protocols and APIs just to retrieve the necessary data from networking and security appliances. Therefore, it can be a challenge to find the right data for your problem.
|
||||
|
||||
### First, you need to collect the right data
|
||||
|
||||
Firstly, you need to collect the right data - the SIEM is only as good as the data you feed it with. This emerges the urge for the right data that needs to get loaded to the SIEM. Since the data available with SIEM rules is provided from logs and event data from other software products, the quality of the data comes down to what was first chosen to be logged. This is compounded by the accuracy/availability of the SIEM vendor's connector.
|
||||
|
||||
The data may be fed into the SIEM with Syslog, which requires parsing, loss of data and context from the original source. Evidently, a lot of the times, the SIEM is loaded with useless data. Many often stumble with this first step.
|
||||
|
||||
### Aggregate the data
|
||||
|
||||
When new threats materialize, it’s challenging to gather more data to support the new detection rules. There is also a long lead time associated with collecting new data and putting the brakes on agility. In short, the SIEM requires extensive data collection infrastructure and inter-team collaboration.
|
||||
|
||||
### Normalize the data
|
||||
|
||||
There will also be some kind of normalizing event where the data is cleaned up. Here, data interpretation and normalization technologies are needed to store the event data in a common format for analysis.
|
||||
|
||||
A big claim-to-fame for the SIEM products is that they normalize data input. If you examine a windows security event, there is a big distinction between each of these events. Therefore, it’s recommended not to count on the SIEM products to interpret the inputs they receive.
|
||||
|
||||
### No investigation support
|
||||
|
||||
The SIEM has no investigation support. Hence, once the data is in your SIEM, you must be the one to tell the SIEM what to do with it. It’s like buying an alarm clock without the batteries. Consider an intrusion detection system, we all know that a skilled analyst is required to translate the output into actionable intelligence; a SIEM is no different.
|
||||
|
||||
Typically, the SIEM rules are targeted for detecting the activities of interest rather than investigating them. For example, an event can only tell you that a file was uploaded. However, it tells nothing about what type of site it was uploaded to, where it came from and what the file was.
|
||||
|
||||
This, predominantly, involves investigation between the security analyst and the operations team. Performing the querying and utilizing this information requires specialized skills and knowledge.
|
||||
|
||||
### Deployment/resource-heavy
|
||||
|
||||
A lot of resources are spent to manage SIEM. Time is needed for deploying agents, parsing logs, or performing the upgrade. Concisely, SIEM technology requires 24x7 monitoring and maintenance. By and large, the SIEM takes too long to deploy and some of these stages can even take years to complete. You really need a handful of full-time security analysts to do this. As it stands, there is a worldwide shortage of experienced security analysts.
|
||||
|
||||
### Point solutions address one issue
|
||||
|
||||
The way networking and security have been geared up is that we are sold everything in pieces. We have point solutions that only address one issue. Then there are servers, routers, switches and a variety of security devices. When a device operates within its own domain, it will only see that domain. Therefore, these point solutions need to be integrated so the user can form a picture of what is happening on the network.
|
||||
|
||||
Consider an IDS, it looks at individual packets and tries to ascertain whether there is a threat or not. Practically, it does not have a holistic overall view of what is truly happening in networking. So, when you actually identity there was a problem, you simply don’t have the right information at hand to identify who the user is, what it does and what happened.
|
||||
|
||||
For threat investigation, the user will need to log on to other systems and glue the information. This will result in a high number of false positives in a world that already has alert-fatigue.
|
||||
|
||||
### How SASE can help – a common datastore
|
||||
|
||||
Significantly, SASE converges the functions of both networking and security into a unified and global cloud-native service. Therefore, it pulls data from both the domains into a common data store. There are of course many benefits to this but one of the substantial benefits is troubleshooting.
|
||||
|
||||
SASE vendors could make it very easy to drill deep into the networking and security events that should already be stored and normalized in a common data warehouse. SASE unlocks the potential for super-efficient troubleshooting without the pain of deploying a SIEM.
|
||||
|
||||
A case in point is Cato network’s recent announcement of [Cato Instant*Insight][3]. The new feature to its SASE platform provides a single tool for mining the security and networking event data generated across a customer’s Cato instance. That’s how SASE helps. Profoundly, everything becomes easier when your networking and security data is being gathered by one platform.
|
||||
|
||||
With data pulled together, investigation and analysis become easier. Cato Instant*Insight, for example, organizes the millions of networking and security events tracked by Cato into a single and queryable timeline. Here we have an automated aggregation, faceted search, and a built-in network analysis workbench.
|
||||
|
||||
[Netsurion][4], another SD-WAN vendor, provides a managed SIEM service. This is offered as SOC-as-a-Service. However, with this and other managed SIEMs, there may still be a strong separation between the network domain and a security domain. In the sense that they’re only gathering security data and not network data. Therefore, both NOC and SOC teams have a fragmented view. And the common challenge for the enterprise will still remain.
|
||||
|
||||
With the SIEM, there is no such thing as delivering visibility out-of-the-box. Realistically, it requires extensive custom integration and development. For many companies, SIEMs wasn’t feasible. The integration costs were just too high and too much time was needed to gather baseline data.
|
||||
|
||||
But that’s all premised on a misconception that you continue to build your network from the appliances from different vendors. If you were to replace appliances with a converged cloud infrastructure, then you eliminate much of the challenge of the SIEM.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network. [Want to Join?][5]**
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3490333/sd-wan-management-means-more-than-reviewing-logs-and-parsing-events.html
|
||||
|
||||
作者:[Matt Conran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[2]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[3]: https://www.catonetworks.com/news/it-managers-analyze-1-million-events-in-1-second-at-no-charge-with-cato-instant-insight/
|
||||
[4]: https://www.netsurion.com/solutions/threat-protection
|
||||
[5]: https://www.networkworld.com/contributor-network/signup.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (X factor: Populating the globe with open leaders)
|
||||
[#]: via: (https://opensource.com/open-organization/19/12/open-leaders-x-mozilla)
|
||||
[#]: author: (chadsansing https://opensource.com/users/csansing)
|
||||
|
||||
X factor: Populating the globe with open leaders
|
||||
======
|
||||
Open Leaders X, a growing program supported by Mozilla, aims to
|
||||
cultivate leaders who think and act openly—all over the world.
|
||||
![Leaders are catalysts][1]
|
||||
|
||||
At Mozilla, we think of open leadership as a set of principles, practices, and skills people can use to mobilize their communities to solve shared problems and achieve shared goals. Open leaders design and build projects that empower others to collaborate within inclusive communities.
|
||||
|
||||
[Mozilla's Open Leaders program][2] connects and trains leaders from around the world whose communities can help one another address the challenges and opportunities they face in creating a healthier internet, more trustworthy AI, and better online lives for all.
|
||||
|
||||
### Starting small
|
||||
|
||||
Open Leaders began in 2016 with a face-to-face meeting between dozens of scientists interested in creating more open labs, datasets, methods, and communications. Their passion, questions, and insights helped shape "working open workshops," which quickly developed into an open leadership curriculum reaching hundreds of people online—from all across the open ecosystem.
|
||||
|
||||
What began as a small, collaborative inquiry into the nature and possibilities of open science has become a thriving community of open leaders helping one another infuse their projects and cultures with the principles and practices of openness.
|
||||
|
||||
While [Mozilla staffers][3] have historically organized the program, returning graduates have served as the experts, mentors, and community call co-hosts of each subsequent round of programming, contributing their time and expertise back to the program and its participants. They have also helped us at Mozilla better participate in discussions of engagement, value exchange, sustainability, power-sharing, care, and labor (among many, many other interwoven open topics).
|
||||
|
||||
We are humbled by the notion that a meeting of 25 like-minded people dedicated to opening their practice in science has become a network of hundreds of leaders working to connect their home communities and parts of the open ecosystem—like open art, campaigning, data, education, hardware, government, and software—with the [internet health movement][4] and the push for more [trustworthy AI][5].
|
||||
|
||||
### Growing up
|
||||
|
||||
At Mozilla, we think of open leadership as a set of principles, practices, and skills people can use to mobilize their communities to solve shared problems and achieve shared goals.
|
||||
|
||||
As we tried to think of how best to bring core lessons from the Open Leaders program to the global MozFest community while also sustaining the program, we organized the most recent round of Open Leaders—the last we'll organize for now—as a train-the-trainer program. Working with program graduates, Mozilla staff and fellows, and [leads from 10 different community projects][6], we co-designed Open Leaders X (OLx) to help community members run, connect, and sustain their own open leadership programs. We hoped that by distributing the development and ownership of Open Leaders across the open ecosystem and internet health movement, we could ensure its survival and strengthen its development through community co-ownership. This would allow each program to tailor itself to the needs, challenges, and opportunities each group faces.
|
||||
|
||||
We are so proud of the entire Open Leaders community and especially grateful to our OLx leads and contributors, who took the plunge with us and dove into this new train-the-trainer model. Rather than close the loop on Open Leaders, the decision to make it a community-driven program continues its upward spiral.
|
||||
|
||||
In October, we brought together nearly all 30 of our OLx leads at [MozFest 2019][7], the momentous 10th anniversary of the festival. They launched their programs and issued their calls for applications, as well as their invitations to community members (like you!) to serve as mentors, experts, and guest speakers for each program. In 2020, these 30 leads and their 10 projects will welcome the next 200 open leaders into the community and the internet health movement.
|
||||
|
||||
We look forward to all the new connections we'll make together between these new Open Leaders cohorts and the burgeoning MozFest community. Our goal is to help people across these communities stay connected and engaged with both one another and the open, federated principles and practices of MozFest all year long.
|
||||
|
||||
We can't wait to collaborate, learn together and to discover what's next for Open Leaders, internet health, and more trustworthy AI.
|
||||
|
||||
You are invited to join this work and all of its challenges, learning, and fun! Watch the OLx launch party videos and find links to each program [online][8]!
|
||||
|
||||
You can also check out the [OLx syllabus][9]. You can even look further back at the most recent Open Leaders syllabi from round 7, both the [project track][10] and the [culture track][11]. You can visit [Mozilla Pulse][12], as well, to keep track of each project and [sign up for our newsletter][13] to keep up with our latest programming.
|
||||
|
||||
We hope you'll join the Open Leaders community and visit us at the next MozFest! We can't wait to collaborate, learn together and to discover what's next for Open Leaders, internet health, and more trustworthy AI.
|
||||
|
||||
My theme this week is organizational openness and transparency and today I'd like to highlight a...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/12/open-leaders-x-mozilla
|
||||
|
||||
作者:[chadsansing][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/csansing
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/leaderscatalysts.jpg?itok=f8CwHiKm (Leaders are catalysts)
|
||||
[2]: https://foundation.mozilla.org/en/opportunity/mozilla-open-leaders/
|
||||
[3]: https://foundation.mozilla.org/en/initiatives/open-leadership-events/who-we-are/
|
||||
[4]: https://internethealthreport.org/
|
||||
[5]: https://medium.com/read-write-participate/update-digging-deeper-on-trustworthy-ai-588fcd01a321
|
||||
[6]: https://medium.com/read-write-participate/meet-the-open-leaders-x-cohort-1dc230a4c56a
|
||||
[7]: https://mozillafestival.org
|
||||
[8]: https://foundation.mozilla.org/en/blog/streaming-week-open-leaders-x/
|
||||
[9]: https://docs.google.com/document/d/1rKvMn0uXSoLvOj7t1jEW9JkQePqhGRu37V1YEMeV8Nw/edit
|
||||
[10]: https://docs.google.com/document/d/1G_opVoiO1VXlfjs-xvbbHVaF97jZBE3DH-DWxAEqtT4/edit?usp=sharing
|
||||
[11]: https://docs.google.com/document/d/1dpH_LPZQ2FTUbK1y1tIDrJfYvesFp3Ivwqp1_jju-5E/edit#heading=h.5qlxraoq91j2
|
||||
[12]: https://www.mozillapulse.org/projects?keyword=olx
|
||||
[13]: https://foundation.mozilla.org/en/initiatives/open-leadership-events/
|
||||
135
sources/talk/20191218 Cisco- 5 hot networking trends for 2020.md
Normal file
135
sources/talk/20191218 Cisco- 5 hot networking trends for 2020.md
Normal file
@ -0,0 +1,135 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco: 5 hot networking trends for 2020)
|
||||
[#]: via: (https://www.networkworld.com/article/3505883/cisco-5-hot-networking-trends-for-2020.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco: 5 hot networking trends for 2020
|
||||
======
|
||||
Cisco exec says SD-WAN, Wi-Fi 6, multi-domain control, virtual networking and the evolving role of network engineers will be big in 2020
|
||||
Thinkstock
|
||||
|
||||
[Hot trends][1] in networking for the coming year include [SD-WAN][2], [Wi-Fi 6][3], multi-domain control, virtual networking and the evolving role of the network engineer into that of a network progrmmer, at least according to [Cisco][4].
|
||||
|
||||
They revolve around the changing shape of networking in general, that is the broadening of [data-center][5] operations into the cloud and the implications of that change, said Anand Oswal, senior vice president of engineering in Cisco’s Enterprise Networking Business.
|
||||
|
||||
“These fundamental shifts in where business processes run and how they’re accessed, is changing how we connect our locations together, how we think about security, the economics of networking, and what we ask of the people who take care of them,” Oswal said.
|
||||
|
||||
[][6]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][6]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
[See more predictions about what's big in IT tech for the coming year.][7]
|
||||
|
||||
In [blog][8] outlining the key trends for 2020, Oswal detailed his thoughts about the five areas.
|
||||
|
||||
### Wi-Fi 6 and 5G
|
||||
|
||||
First up, wireless technology – especially Wi-Fi 6 – will get into the enterprise through the employee door and through enterprise access-point refreshes. The latest smartphones from Apple, Samsung, and other manufacturers are Wi-Fi 6 enabled, and Wi-Fi 6 access points are currently shipping to businesses and consumers.
|
||||
|
||||
5G phones are not yet in wide circulation, although that will begin to change in 2020, athough mostly for consumers and towards the end of the year. Oswal wrote that Cisco projects more people will be using Wi-Fi 6 than 5G through 2020.
|
||||
|
||||
2020 will also see the beginning of a big improvement in how people use Wi-Fi networks. The potential growth of the Cisco-lead OpenRoaming project will make joining participating Wi-Fi networks much easier, Oswal said. [OpenRoaming][9], which uses the underlying technology behind HotSpot 2.0/ IEEE 802.11u promises to let users move seamlessly between wireless networks and LTE without interruption -- emulating mobile network connectivity. Current project partners include Samsung, Boingo, and GlobalReach Technologies.
|
||||
|
||||
2020 will also see the adoption of new frequency bands, including the beginning of the rollout of “millimeter wave” (24Ghz to 100Ghz) spectrum for ultra-fast, but short-range 5G as well as Citizens Broadband Radio Service (CBRS), at about 3.5Ghz. This may lead to new _private_ networks that use LTE and 5G technology, especially for IoT applications.
|
||||
|
||||
“We will also see continued progress in opening up the 6GHz range for unlicensed Wi-Fi usage in the United States and the rest of world,” Oswal wrote.
|
||||
|
||||
As for [5G][10] services, some will roll out in 2020 but “almost none of it will be the ultra-high speed connectivity that we have been promised or that we will see in future years,” Oswal said. “With 5G unable to deliver on that promise initially, we will see a lot of high-speed wireless traffic offloaded to Wi-Fi networks.”
|
||||
|
||||
In the long run, “In combination with the improved performance of both Wi-Fi 6 and (eventually) 5G, we are in for a large – and long-lived – period of innovation in access networking,” Oswal wrote.
|
||||
|
||||
### It’s a SD-WAN world
|
||||
|
||||
“We are seeing a ton of momentum in the SD-WAN area as large numbers of companies need secure access to cloud applications,” Oswal said. The dispersal of connectivity – the growth of multicloud networking – will force many businesses to re-tool their networks in favor of SD-WAN technology, he said.
|
||||
|
||||
“Meanwhile the large cloud service providers, like [Amazon, Google, and Microsoft][1], are connecting to networking companies – like Cisco – to forge deep partnership links between networking stacks and services,” Oswal wrote.
|
||||
|
||||
Oswal said he expects such partnerships will only deepen next year, and that concurs with recent analysis by Gartner.
|
||||
|
||||
“SD-WAN is replacing routing and adding application-aware path selection among multiple links, centralized orchestration and native security, as well as other functions. Consequently, it includes incumbent and emerging vendors from multiple markets (namely routing, security, WAN optimization and SD-WAN), each bringing its own differentiators and limitations,” [Gartner wrote][11] in a recent report.
|
||||
|
||||
In addition Oswal said SD-WAN technology is going to lead to a growth in business for managed service providers (MSPs), many more of which will begin to offer SD-WAN as a service.
|
||||
|
||||
“We expect MSPs to grow at about double the rate of the SD-WAN market itself, and expect that MSPs will begin to hyper-specialize, by industry and network size,” Oswal wrote.
|
||||
|
||||
### All-inclusive multi-domain networks
|
||||
|
||||
In the Cisco world, blending typically siloed domains across the enterprise and cloud to the wide-area network is getting easier, and Oswal says that will continue in 2020. The idea is that its key software components – [Application Centric Infrastructure (ACI) and DNA Center][12] – now enable what Cisco calls multidomain integration, which lets customers set policies to apply uniform access controls to users, devices and applications regardless of where they connect to the network.
|
||||
|
||||
ACI is [Cisco’s software-defined networking][13] ([SDN][13]) data-center package, but it also delivers the company’s intent-based networking technology, which brings customers the ability to automatically implement network and policy changes on the fly and ensure data delivery.
|
||||
|
||||
DNA Center is a key package as it features automation capabilities, assurance setting, fabric provisioning and policy-based segmentation for enterprise networks. Cisco DNA Center gives IT teams the ability to control access through policies using software-defined access (SD-Access), automatically provision through Cisco DNA Automation, virtualize devices through Cisco Network Functions Virtualization (NFV), and lower security risks through segmentation and encrypted traffic analysis.
|
||||
|
||||
“For better management, agility, and especially for security, these multiple domains need to work together,” Oswal wrote. “Each domain’s controller needs to work in a coordinated manner to enable automation, analytics and security across the various domains.”
|
||||
|
||||
The next generation of controller-first architectures for network fabrics allows the unified management of loosely coupled systems using APIs and defined data structures for inter-device and inter-domain communication, Oswal wrote. “The intent-based networking model that enterprises began adopting in 2019 is making network management more straightforward by absorbing the complexities of the network,” he wrote.
|
||||
|
||||
### The network as sensor
|
||||
|
||||
The notion of the [network being used for something more important][14] than speeds and feeds has been talked about for a while, but the idea may be coming home to roost next year.
|
||||
|
||||
“With software that is able to profile and classify the devices, end points, and applications – even when they are sending fully encrypted data – the network will be able to place the devices into virtual networks automatically, enable the correct rule set to protect those devices, and eventually identify security issues extremely quickly,” Oswal wrote.
|
||||
|
||||
“Ultimately, systems will be able to remediate issues on their own, or at least file their own help-desk tickets. This becomes increasingly important as networks grow increasingly complex.”
|
||||
|
||||
Oswal said this intelligence could prove useful in wireless networks where the network can collect data on how people and things move through and use physical spaces, such as IoT devices in a business or medical devices in a hospital.
|
||||
|
||||
“That data can directly help facility owners optimize their physical spaces, for productivity, ease of navigation, or even to improve retail sales,” Oswal wrote. “These are capabilities that have been rolling out in 2019, but as business execs become aware of the power of this location data, the use of this technology will begin to snowball.”
|
||||
|
||||
### The network engineer career change
|
||||
|
||||
The growing software-oriented network environment is changing the resume requirements of network professional. “The standard way that network operators work – provisioning network equipment using command-line interfaces like CLI – is nearing the end of the line,” Oswal wrote. “Today, _intent-based networking_ lets us tell the network what we want it to do, and leave the individual device configuration to the larger system itself.”
|
||||
|
||||
Oswal said customers can now program updates, rollouts, and changes using centralized networking controllers*,* rather than working directly with devices or their own unique interfaces.
|
||||
|
||||
“New networks run by APIs require programming skills to manage,” Oswal wrote. “Code is the resource behind the creation of new business solutions. It remains critical for individuals to validate their proficiency with new infrastructure and network engineering concepts.”
|
||||
|
||||
Oswal noted that it will not be an easy change because retraining individuals or whole teams can be expensive, and not everyone will adapt to the new order.
|
||||
|
||||
“For those that do, the benefits are big,” Oswal said. “Network operators will be closer to the businesses they work for, able to better help businesses achieve their digital transformations. The speed and agility they gain thanks to having a programmable network, plus telemetry and analytics, opens up vast new opportunities.”
|
||||
|
||||
This year [Cisco revamped some of its most critical certification][15] and career-development tools in an effort to address the emerging software-oriented network environment. Perhaps one of the biggest additions is the [new set of professional certifications][16] for developers utilizing Cisco’s growing DevNet developer community.
|
||||
|
||||
The Cisco Certified DevNet Associate, Specialist and Professional certifications will cover software development for applications, automation, DevOps, cloud and IoT. They will also target software developers and network engineers who develop software proficiency to develop applications and automated workflows for operational networks and infrastructure.
|
||||
|
||||
Join the Network World communities on [Facebook][17] and [LinkedIn][18] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3505883/cisco-5-hot-networking-trends-for-2020.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html
|
||||
[2]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[3]: https://www.networkworld.com/article/3258807/what-is-802-11ax-wi-fi-and-what-will-it-mean-for-802-11ac.html
|
||||
[4]: https://www.networkworld.com/article/3487831/what-s-hot-for-cisco-in-2020.html
|
||||
[5]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[6]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[7]: https://www.networkworld.com/article/3488562/whats-big-in-it-tech-for-the-coming-year.html
|
||||
[8]: https://blogs.cisco.com/enterprise/enterprise-networking-in-2020-5-trends-to-watch
|
||||
[9]: https://blogs.cisco.com/wireless/openroaming-seamless-across-wi-fi-6-and-5g?oid=psten016624
|
||||
[10]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[11]: https://www.networkworld.com/article/3489480/secure-sd-wan-the-security-vendors-and-their-sd-wan-offerings.html
|
||||
[12]: https://www.networkworld.com/article/3401523/cisco-software-to-make-networks-smarter-safer-more-manageable.html
|
||||
[13]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
|
||||
[14]: https://www.networkworld.com/article/3400382/cisco-will-use-aiml-to-boost-intent-based-networking.html
|
||||
[15]: https://www.networkworld.com/article/3401524/cisco-launches-a-developer-community-cert-program.html
|
||||
[16]: https://www.networkworld.com/article/3446044/are-new-cisco-certs-too-much-network-pros-react.html
|
||||
[17]: https://www.facebook.com/NetworkWorld/
|
||||
[18]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bamboo Systems redesigns server motherboards for greater performance)
|
||||
[#]: via: (https://www.networkworld.com/article/3490385/bamboo-systems-redesigns-server-motherboards-for-greater-performance.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Bamboo Systems redesigns server motherboards for greater performance
|
||||
======
|
||||
Bamboo Systems, formerly Kaleao, claims its motherboard architecture is more power efficient than traditional designs that cater to x86 processors.
|
||||
Thinkstock
|
||||
|
||||
UK chip designer Kaleao has re-launched as Bamboo Systems with some pre-Series A funding and claims its [Arm][1]-based server chips will be considerably more power efficient than the competition.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][2]
|
||||
|
||||
Bamboo is targeting x86 servers, which have a 95% market share, unlike Marvell with its [ThunderX2][3] and Ampere Systems with its [eMAG Arm processors][4]. The company argues that the two Arm processors are no different than x86.
|
||||
|
||||
“Marvell and Ampere are chip manufacturers that have built a chip to pretty much slot into the motherboard and chassis configuration that an Intel/AMD chip would fit into. They are therefore going head on against Intel/AMD as chip manufacturers – and history is showing, not creating a sustainable solution for the OEMs,” says John Goodacre, co-founder and chief scientific officer of Bamboo.
|
||||
|
||||
[][5]
|
||||
|
||||
BrandPost Sponsored by HPE
|
||||
|
||||
[Take the Intelligent Route with Consumption-Based Storage][5]
|
||||
|
||||
Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
|
||||
|
||||
The motherboard is changed, but the CPU and software layer are not. Currently the company is in the prototype stage. Its server is based on Samsung Arm Cortex-A57 design, so the CPU itself is not changed. Even though they have essentially thrown out traditional motherboard design, Goodacre said the software is fully compatible and will run unchanged. So Linux and Arm-based apps will all run.
|
||||
|
||||
Goodacre, a 17-year veteran of Arm and researcher at the University of Manchester working on exascale research projects, said just putting more cores in a die in a workstation designed system isn’t the most power efficient way to build scale out power efficient servers.
|
||||
|
||||
“We realized that the system architecture was where your power was consumed more than instruction set. There have been several Arm chips [in servers] and they show the difference in power efficiency in an Arm gives you a few tens of percent. There is very little power efficiency in Arm over x86,” he said.
|
||||
|
||||
What he noticed was that because of the motherboard and all of its ports, like USB and I/O, a lot of power was wasted on the motherboard resources. Kaleo, now Bamboo, redesigned the whole motherboard where things like I/O and memory are pooled, so doubling the processor count doesn’t require doubling of motherboards.
|
||||
|
||||
This means a shared infrastructure with pooling of non-CPU resources and NVMe to scale up storage. A 3U box can hold up to 192 eight-core servers, 42 U.2 SSDs and 192 directly attached SATA 6 drives.
|
||||
|
||||
“The concept of a motherboard is gone. Instead, you put the infrastructure to support processors. We build clusters of machines on boards where the infrastructure is shared across processor elements,” he said.
|
||||
|
||||
The result, he claims, is the Bamboo system can deliver the same amount of web traffic in 10x less server space for 5x less energy. “One rack of our stuff equals 10 racks of the competition,” said Goodacre.
|
||||
|
||||
Bamboo says it will announce more details in early January.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3490385/bamboo-systems-redesigns-server-motherboards-for-greater-performance.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3306447/a-new-arm-based-server-processor-challenges-for-the-data-center.html
|
||||
[2]: https://www.networkworld.com/newsletters/signup.html
|
||||
[3]: https://www.networkworld.com/article/3271073/cavium-launches-thunderx2-arm-based-server-processors.html
|
||||
[4]: https://www.networkworld.com/article/3482248/ampere-preps-an-80-core-arm-processor-for-the-cloud.html
|
||||
[5]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why We Need Interoperable Service Identity?)
|
||||
[#]: via: (https://www.linux.com/articles/why-we-need-interoperable-identity/)
|
||||
[#]: author: (TC CURRIE https://www.linux.com/author/tc_currie/)
|
||||
|
||||
Why We Need Interoperable Service Identity?
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
Interoperable service identity is necessary to secure communication between different cloud providers and different platforms. This presents a challenge with multi-cloud and hybrid deployments. How do you secure service to service communication across those boundaries?
|
||||
|
||||
Evan Gilman, Staff Engineer at [Scytale.io][3] and co-author of _Zero Trust Networks_, illustrates this issue: when you’re in AWS, you’ll use an AWS IAM role in order to identify which instance a certain role should or should not have access to. But in today’s multi-platform world, you can be communicating from AWS to GCP to your on-prem infrastructure. Those systems do not understand what IAM role is because it is AWS-specific.
|
||||
|
||||
This is what Scytale is trying to address. *“*We are bringing a platform-agnostic identity, meaning, an identity that is not specific to a cloud provider or a platform, or any specific kind of technology,” he said.
|
||||
|
||||
**What’s SPIFFE?**
|
||||
|
||||
[Secure Production Identity Framework for Everyone (SPIFFE)][4] is a set of specifications that define interoperability across all tech platforms, such as how to format the name, the shape of the document, how you validate documents, etc. “This SPIFFE level is like a secure dial tone,” Gilman explains. “You pick up the phone, it rings the other side, doesn’t really matter what platform it is or where it’s running or anything like that. The SPIFFE authentication occurs and you get a nice little layer of encryption and some authenticity insurances as well.”
|
||||
|
||||
But at the end of the day, SPIFFE is just a set of documents. SPIRE is the software implementation of the SPIFFE specifications.
|
||||
|
||||
“Think about the way the passports work,” he said. “If you look at passports from different countries, they may be slightly different, but they have similar characteristics like SPIFFE specifications. They’re all the same size. They all have a picture in the same spot. They have the same funny-looking barcode at the bottom, and so on. So, when you show your passport at a country border, they know how to read your passport, no matter what country that passport is from. SPIRE is the passport agency in this analogy. Where does this passport come from? Who gives it to you? How do you get it and how do you do that in an automated fashion?”
|
||||
|
||||
SPIRE implements these SPIFFE specifications and enables workloads and services to get these passports as soon as they boot in a way that is very reliable, scalable, and very highly automated.
|
||||
|
||||
**Zero Trust**
|
||||
|
||||
Gilman is taking the philosophy of Zero Trust — don’t trust anybody whatsoever — and applying it to network infrastructure and service-to-service communication. “We do this by removing all the security functions from the network and making no assumptions about what should or should not be allowed based on IP address,” he said.
|
||||
|
||||
“Instead, we build systems in such a way that they don’t rely on that network to deliver trustworthy information. We use protocols for strong authentication and authorization to try to mitigate any kind of funny business that might happen on the wire.”
|
||||
|
||||
**Into the New Decade**
|
||||
|
||||
For Scytale, Gilman’s biggest push for 2020 is to provide documentation with detailed examples of how to solve different use cases, and how to configure the software to solve those use cases. “Very clear-cut guidance,” he states. “We have a lot of flexibility and features built into the software, but we don’t have conceptual guidelines that can teach people how the internals are working and stuff like that. We button everything up and make the experience really easy to pick up for folks who might not necessarily want to get in the weeds with it. They just want it to work.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/why-we-need-interoperable-identity/
|
||||
|
||||
作者:[TC CURRIE][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/tc_currie/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/12/computer-2930704_1280-696x413.jpg (computer-2930704_1280)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/12/computer-2930704_1280.jpg
|
||||
[3]: http://scytale.io/
|
||||
[4]: https://spiffe.io/
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to run a business with open source: Top reads)
|
||||
[#]: via: (https://opensource.com/article/19/12/business-open-source)
|
||||
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||
|
||||
How to run a business with open source: Top reads
|
||||
======
|
||||
Open source software is open for business, as evidenced in the these top
|
||||
5 articles from 2019.
|
||||
![Open for business][1]
|
||||
|
||||
Open source is ready to get to work, and in 2019, Opensource.com had many great articles about how organizations have adopted open source software or open methods to drive their business. As open source matures, we've seen open source not just replace proprietary software, but create entirely new business models.
|
||||
|
||||
Check out this list of five outstanding articles from Opensource.com in 2019 about running a business with open source.
|
||||
|
||||
### Get your business up and running with these open source tools
|
||||
|
||||
In [_Get your business up and running with these open source tools_][2], I explain: "Yes, you really can operate a business using open source software." In this article, I review the key open source software tools that I use to run my company, including Inkscape, GIMP, LibreOffice, and Scribus.
|
||||
|
||||
### What's your favorite open source BI software?
|
||||
|
||||
As Lauren Maffeo explains in _[What's your favorite open source BI software?][3]_ "Open source business intelligence (BI) software helps users upload, visualize, and make decisions based on data that is pulled from several sources... BI involves turning data into insights that help your business make better decisions... Before choosing which open source BI tool to adopt, it's worth weighing the pros and cons of each tool against your business needs." The article's accompanying poll asks readers whether they prefer Pentaho, Logz.io, Cluvio, Qlikview, Sisense, or another BI application. Answer the poll to let us know which is your favorite and to see what other readers say.
|
||||
|
||||
### Scrum vs. kanban: Which agile framework is better?
|
||||
|
||||
Because scrum and kanban both fall under the agile framework umbrella, many people confuse them or think they're the same thing. There are differences, however. In [_Scrum vs. kanban: Which agile framework is better?_][4] Taz Brown explains the differences between scrum and kanban and helps you decide which one may be best for your team.
|
||||
|
||||
### What is Small Scale Scrum?
|
||||
|
||||
"Agile is fast becoming a mainstream way industries act, behave, and work as they look to improve efficiency, minimize costs, and empower staff. Most software developers naturally think, act, and work this way, and alignment towards agile software methodologies has gathered pace in recent years," write Agnieszka Gancarczyk and Leigh Griffin in [_What is Small Scale Scrum?_][5] In this article, they explain how the scrum agile methodology can help small teams work more efficiently.
|
||||
|
||||
### What does DevOps mean to you?
|
||||
|
||||
In *[What does DevOps mean to you?][6] *Girish Managoli offers one answer to this article's headline: "DevOps is a process of software development focusing on communication and collaboration to facilitate rapid application and product deployment." But there are a range of opinions and expectations around DevOps. To help explain DevOps and how to leverage it in organizations, Girish interviewed six experts to break down DevOps and the key practices and philosophies in making DevOps work for you.
|
||||
|
||||
### Open source is open for business
|
||||
|
||||
As open source plays an increasingly important role in business, there's more to learn about the topic. What do you want to know about it in 2020? Please share your ideas for articles in the comments—or even share your own experiences with running a business on open source software by [writing an article for Opensource.com][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/12/business-open-source
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_openseries.png?itok=rCtTDz5G (Open for business)
|
||||
[2]: https://opensource.com/article/19/9/business-creators-open-source-tools
|
||||
[3]: https://opensource.com/article/19/8/favorite-open-source-bi-software
|
||||
[4]: https://opensource.com/article/19/8/scrum-vs-kanban
|
||||
[5]: https://opensource.com/article/19/1/what-small-scale-scrum
|
||||
[6]: https://opensource.com/article/19/1/what-does-devops-mean-you
|
||||
[7]: https://opensource.com/how-submit-article
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by robsean
|
||||
How to create an e-book chapter template in LibreOffice Writer
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,12 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create and manage MacOS LaunchAgents using Go)
|
||||
[#]: via: (https://ieftimov.com/post/create-manage-macos-launchd-agents-golang/)
|
||||
[#]: author: (https://ieftimov.com/about)
|
||||
|
||||
Create and manage MacOS LaunchAgents using Go
|
||||
============================================================
|
||||
|
||||
@ -287,7 +296,7 @@ This is where I write about software development, programming languages and ever
|
||||
via: https://ieftimov.com/create-manage-macos-launchd-agents-golang
|
||||
|
||||
作者:[Ilija Eftimov ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -302,4 +311,4 @@ via: https://ieftimov.com/create-manage-macos-launchd-agents-golang
|
||||
[7]:https://golang.org/x/sys
|
||||
[8]:https://docs.google.com/document/d/1QXzI9I1pOfZPujQzxhyRy6EeHYTQitKKjHfpq0zpxZs/edit
|
||||
[9]:https://golang.org/x/sys
|
||||
[10]:https://github.com/jteeuwen/go-bindata
|
||||
[10]:https://github.com/jteeuwen/go-bindata
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
chenmu-kk is translating.
|
||||
How the four components of a distributed tracing system work together
|
||||
======
|
||||

|
||||
|
||||
@ -1,259 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Easily Upload Text Snippets To Pastebin-like Services From Commandline)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-like-services-from-commandline/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Easily Upload Text Snippets To Pastebin-like Services From Commandline
|
||||
======
|
||||
|
||||

|
||||
|
||||
Whenever there is need to share the code snippets online, the first one probably comes to our mind is Pastebin.com, the online text sharing site launched by **Paul Dixon** in 2002. Now, there are several alternative text sharing services available to upload and share text snippets, error logs, config files, a command’s output or any sort of text files. If you happen to share your code often using various Pastebin-like services, I do have a good news for you. Say hello to **Wgetpaste** , a command line BASH utility to easily upload text snippets to pastebin-like services. Using Wgetpaste script, anyone can quickly share text snippets to their friends, colleagues, or whoever wants to see/use/review the code from command line in Unix-like systems.
|
||||
|
||||
### Installing Wgetpaste
|
||||
|
||||
Wgetpaste is available in Arch Linux [Community] repository. To install it on Arch Linux and its variants like Antergos and Manjaro Linux, just run the following command:
|
||||
|
||||
```
|
||||
$ sudo pacman -S wgetpaste
|
||||
```
|
||||
|
||||
For other distributions, grab the source code from [**Wgetpaste website**][1] and install it manually as described below.
|
||||
|
||||
First download the latest Wgetpaste tar file:
|
||||
|
||||
```
|
||||
$ wget http://wgetpaste.zlin.dk/wgetpaste-2.28.tar.bz2
|
||||
```
|
||||
|
||||
Extract it:
|
||||
|
||||
```
|
||||
$ tar -xvjf wgetpaste-2.28.tar.bz2
|
||||
```
|
||||
|
||||
It will extract the contents of the tar file in a folder named “wgetpaste-2.28”.
|
||||
|
||||
Go to that directory:
|
||||
|
||||
```
|
||||
$ cd wgetpaste-2.28/
|
||||
```
|
||||
|
||||
Copy the wgetpaste binary to your $PATH, for example **/usr/local/bin/**.
|
||||
|
||||
```
|
||||
$ sudo cp wgetpaste /usr/local/bin/
|
||||
```
|
||||
|
||||
Finally, make it executable using command:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/wgetpaste
|
||||
```
|
||||
|
||||
### Upload Text Snippets To Pastebin-like Services
|
||||
|
||||
Uploading text snippets using Wgetpaste is trivial. Let me show you a few examples.
|
||||
|
||||
**1\. Upload text files**
|
||||
|
||||
To upload any text file using Wgetpaste, just run:
|
||||
|
||||
```
|
||||
$ wgetpaste mytext.txt
|
||||
```
|
||||
|
||||
This command will upload the contents of mytext.txt file.
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Your paste can be seen here: https://paste.pound-python.org/show/eO0aQjTgExP0wT5uWyX7/
|
||||
```
|
||||
|
||||

|
||||
|
||||
You can share the pastebin URL via any medium like mail, message, whatsapp or IRC etc. Whoever has this URL can visit it and view the contents of the text file in a web browser of their choice.
|
||||
|
||||
Here is the contents of mytext.txt file in web browser:
|
||||
|
||||

|
||||
|
||||
You can also use **‘tee’** command to display what is being pasted, instead of uploading them blindly.
|
||||
|
||||
To do so, use **-t** option like below.
|
||||
|
||||
```
|
||||
$ wgetpaste -t mytext.txt
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
**2. Upload text snippets to different services
|
||||
**
|
||||
|
||||
By default, Wgetpaste will upload the text snippets to **poundpython** (<https://paste.pound-python.org/>) service.
|
||||
|
||||
To view the list of supported services, run:
|
||||
|
||||
```
|
||||
$ wgetpaste -S
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Services supported: (case sensitive):
|
||||
Name: | Url:
|
||||
=============|=================
|
||||
bpaste | https://bpaste.net/
|
||||
codepad | http://codepad.org/
|
||||
dpaste | http://dpaste.com/
|
||||
gists | https://api.github.com/gists
|
||||
*poundpython | https://paste.pound-python.org/
|
||||
```
|
||||
|
||||
Here, ***** indicates the default service.
|
||||
|
||||
As you can see, Wgetpaste currently supports five text sharing services. I didn’t try all of them, but I believe all services will work.
|
||||
|
||||
To upload the contents to other services, for example **bpaste.net** , use **-s** option like below.
|
||||
|
||||
```
|
||||
$ wgetpaste -s bpaste mytext.txt
|
||||
Your paste can be seen here: https://bpaste.net/show/5199e127e733
|
||||
```
|
||||
|
||||
**3\. Read input from stdin**
|
||||
|
||||
Wgetpaste can also read the input from stdin.
|
||||
|
||||
```
|
||||
$ uname -a | wgetpaste
|
||||
```
|
||||
|
||||
This command will upload the output of ‘uname -a’ command.
|
||||
|
||||
**4. Upload the COMMAND and the output of COMMAND together
|
||||
**
|
||||
|
||||
Sometimes, you may need to paste a COMMAND and its output. To do so, specify the contents of the command within quotes like below.
|
||||
|
||||
```
|
||||
$ wgetpaste -c 'ls -l'
|
||||
```
|
||||
|
||||
This will upload the command ‘ls -l’ along with its output to the pastebin service.
|
||||
|
||||
This can be useful when you wanted to let others to clearly know what was the exact command you just ran and its output.
|
||||
|
||||
![][4]
|
||||
|
||||
As you can see in the output, I ran ‘ls -l’ command.
|
||||
|
||||
**5. Upload system log files, config files
|
||||
**
|
||||
|
||||
Like I already said, we can upload any sort of text files, not just an ordinary text file, in your system such as log files, a specific command’s output etc. Say for example, you just updated your Arch Linux box and ended up with a broken system. You ask your colleague how to fix it and s/he wants to read the pacman.log file. Here is the command to upload the contents of the pacman.log file:
|
||||
|
||||
```
|
||||
$ wgetpaste /var/log/pacman.log
|
||||
```
|
||||
|
||||
Share the pastebin URL with your Colleague, so s/he will review the pacman.log and may help you to fix the problem by reviewing the log file.
|
||||
|
||||
Usually, the contents of log files might be too long and you don’t want to share them all. In such cases, just use **cat** command to read the output and use **tail** command with the **-n** switch to define the number of lines to share and finally pipe the output to Wgetpaste as shown below.
|
||||
|
||||
```
|
||||
$ cat /var/log/pacman.log | tail -n 50 | wgetpaste
|
||||
```
|
||||
|
||||
The above command will upload only the **last 50 lines** of pacman.log file.
|
||||
|
||||
**6\. Convert input url to tinyurl**
|
||||
|
||||
By default, Wgetpaste will display the full pastebin URL in the output. If you want to convert the input URL to a tinyurl, just use **-u** option.
|
||||
|
||||
```
|
||||
$ wgetpaste -u mytext.txt
|
||||
Your paste can be seen here: http://tinyurl.com/y85d8gtz
|
||||
```
|
||||
|
||||
**7. Set language
|
||||
**
|
||||
|
||||
By default, Wgetpaste will upload text snippets in **plain text**.
|
||||
|
||||
To list languages supported by the specified service, use **-L** option.
|
||||
|
||||
```
|
||||
$ wgetpaste -L
|
||||
```
|
||||
|
||||
This command will list all languages supported by default service i.e **poundpython** (<https://paste.pound-python.org/>).
|
||||
|
||||
We can change this using **-l** option.
|
||||
|
||||
```
|
||||
$ wgetpaste -l Bash mytext.txt
|
||||
```
|
||||
|
||||
**8\. Disable syntax highlighting or html in the output**
|
||||
|
||||
As I mentioned above, the text snippets will be displayed in a specific language format (plaintext, Bash etc.).
|
||||
|
||||
You can, however, change this behaviour to display the raw text snippets using **-r** option.
|
||||
|
||||
```
|
||||
$ wgetpaste -r mytext.txt
|
||||
Your raw paste can be seen here: https://paste.pound-python.org/raw/CUJhQ3jEmr2UvfmD2xCL/
|
||||
```
|
||||
|
||||

|
||||
|
||||
As you can see in the above output, there is no syntax highlighting, no html formatting. Just a raw output.
|
||||
|
||||
**9\. Change Wgetpaste defaults**
|
||||
|
||||
All Defaults values (DEFAULT_{NICK,LANGUAGE,EXPIRATION}[_${SERVICE}] and DEFAULT_SERVICE) can be changed globally in **/etc/wgetpaste.conf** or per user in **~/.wgetpaste.conf** files. These files, however, are not available by default in my system. I guess we need to manually create them. The developer has given the sample contents for both files [**here**][5] and [**here**][6]. Just create these files manually with given sample contents and modify the parameters accordingly to change Wgetpaste defaults.
|
||||
|
||||
**10\. Getting help**
|
||||
|
||||
To display the help section, run:
|
||||
|
||||
```
|
||||
$ wgetpaste -h
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this was useful. We will publish more useful content in the days to come. Stay tuned!
|
||||
|
||||
On behalf of **OSTechNix** , I wish you all a very **Happy New Year 2019**. I am grateful to all our readers, contributors, and mentors for supporting us from the beginning of our journey. We couldn’t come this far without your support and guidance. Thank you everyone! Have a great year ahead!!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-easily-upload-text-snippets-to-pastebin-like-services-from-commandline/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://wgetpaste.zlin.dk/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/12/wgetpaste-3.png
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2018/12/wgetpaste-4.png
|
||||
[5]: http://wgetpaste.zlin.dk/zlin.conf
|
||||
[6]: http://wgetpaste.zlin.dk/wgetpaste.example
|
||||
@ -1,208 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Install Android 8.1 Oreo on Linux To Run Apps & Games)
|
||||
[#]: via: (https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux)
|
||||
[#]: author: (Python Programmer;Open Source Software Enthusiast. Worked On Developing A Lot Of Free Software. The Founder Of Foss Post;Foss Project. Computer Science Major. )
|
||||
|
||||
Install Android 8.1 Oreo on Linux To Run Apps & Games
|
||||
======
|
||||
|
||||

|
||||
|
||||
[android x86][1] is a free and an open source project to port the android system made by Google from the ARM architecture to the x86 architecture, which allow users to run the android system on their desktop machines to enjoy all android functionalities + Apps & games.
|
||||
|
||||
The android x86 project finished porting the android 8.1 Oreo system to the x86 architecture few weeks ago. In this post, we’ll explain how to install it on your Linux system so that you can use your android apps and games any time you want.
|
||||
|
||||
### Installing Android x86 8.1 Oreo on Linux
|
||||
|
||||
#### Preparing the Environment
|
||||
|
||||
First, let’s download the android x86 8.1 Oreo system image. You can download it from [this page][2], just click on the “View” button under the android-x86_64-8.1-r1.iso file.
|
||||
|
||||
We are going to use QEMU to run android x86 on our Linux system. QEMU is a very good emulator software, which is also free and open source, and is available in all the major Linux distributions repositories.
|
||||
|
||||
To install QEMU on Ubuntu/Linux Mint/Debian:
|
||||
|
||||
```
|
||||
sudo apt-get install qemu qemu-kvm libvirt-bin
|
||||
```
|
||||
|
||||
To install QEMU on Fedora:
|
||||
|
||||
```
|
||||
sudo dnf install qemu qemu-kvm
|
||||
```
|
||||
|
||||
For other distributions, just search for the qemu and qemu-kvm packages and install them.
|
||||
|
||||
After you have installed QEMU, we’ll need to run the following command to create the android.img file, which will be like some sort of an allocated disk space just for the android system. All android files and system will be inside that image file:
|
||||
|
||||
```
|
||||
qemu-img create -f qcow2 android.img 15G
|
||||
```
|
||||
|
||||
Here we are saying that we want to allocate a maximum of 15GB for android, but you can change it to any size you want (make sure it’s at least bigger than 5GB).
|
||||
|
||||
Now, to start running the android system for the first time, run:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img -cdrom /home/mhsabbagh/android-x86_64-8.1-r1.iso
|
||||
```
|
||||
|
||||
Replace /home/mhsabbagh/android-x86_64-8.1-r1.iso with the path of the file that you downloaded from the android x86 website. For explaination of other options we are using here, you may refer to [this article][3].
|
||||
|
||||
After you run the above command, the android system will start:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 39 android 8.1 oreo on linux][4]
|
||||
|
||||
#### Installing the System
|
||||
|
||||
From this window, choose “Advanced options”, which should lead to the following menu, from which you should choose “Auto_installation” as follows:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 41 android 8.1 oreo on linux][5]
|
||||
|
||||
After that, the installer will just tell you about whether you want to continue or not, choose Yes:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 43 android 8.1 oreo on linux][6]
|
||||
|
||||
And the installation will carry on without any further instructions from you:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 45 android 8.1 oreo on linux][7]
|
||||
|
||||
Finally you’ll receive this message, which indicates that you have successfully installed android 8.1:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 47 android 8.1 oreo on linux][8]
|
||||
|
||||
For now, just close the QEMU window completely.
|
||||
|
||||
#### Booting and Using Android 8.1 Oreo
|
||||
|
||||
Now that the android system is fully installed in your android.img file, you should use the following QEMU command to start it instead of the previous one:
|
||||
|
||||
```
|
||||
sudo qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda android.img
|
||||
```
|
||||
|
||||
Notice that all we did was that we just removed the -cdrom option and its argument. This is to tell QEMU that we no longer want to boot from the ISO file that we downloaded, but from the installed android system.
|
||||
|
||||
You should see the android booting menu now:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 49 android 8.1 oreo on linux][9]
|
||||
|
||||
Then you’ll be taken to the first preparation wizard, choose your language and continue:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 51 android 8.1 oreo on linux][10]
|
||||
|
||||
From here, choose the “Set up as new” option:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 53 android 8.1 oreo on linux][11]
|
||||
|
||||
Then android will ask you about if you want to login to your current Google account. This step is optional, but important so that you can use the Play Store later:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 55 android 8.1 oreo on linux][12]
|
||||
|
||||
Then you’ll need to accept the terms and conditions:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 57 android 8.1 oreo on linux][13]
|
||||
|
||||
Now you can choose your current timezone:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 59 android 8.1 oreo on linux][14]
|
||||
|
||||
The system will ask you now if you want to enable any data collection features. If I were you, I’d simply turn them all off like that:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 61 android 8.1 oreo on linux][15]
|
||||
|
||||
Finally, you’ll have 2 launcher types to choose from, I recommend that you choose the Launcher3 option and make it the default:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 63 android 8.1 oreo on linux][16]
|
||||
|
||||
Then you’ll see your fully-working android system home screen:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 65 android 8.1 oreo on linux][17]
|
||||
|
||||
From here now, you can do all the tasks you want; You can use the built-in android apps, or you may browse the settings of your system to adjust it however you like. You may change look and feeling of your system, or you can run Chrome for example:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 67 android 8.1 oreo on linux][18]
|
||||
|
||||
You may start installing some apps like WhatsApp and others from the Google Play store for your own use:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 69 android 8.1 oreo on linux][19]
|
||||
|
||||
You can now do whatever you want with your system. Congratulations!
|
||||
|
||||
### How to Easily Run Android 8.1 Oreo Later
|
||||
|
||||
We don’t want to always have to open the terminal window and write that long QEMU command to run the android system, but we want to run it in just 1 click whenever we need that.
|
||||
|
||||
To do this, we’ll create a new file under /usr/share/applications called android.desktop with the following command:
|
||||
|
||||
```
|
||||
sudo nano /usr/share/applications/android.desktop
|
||||
```
|
||||
|
||||
And paste the following contents inside it (Right click and then paste):
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=Android 8.1
|
||||
Comment=Run Android 8.1 Oreo on Linux using QEMU
|
||||
Icon=phone
|
||||
Exec=bash -c 'pkexec env DISPLAY=$DISPLAY XAUTHORITY=$XAUTHORITY qemu-system-x86_64 -m 2048 -boot d -enable-kvm -smp 3 -net nic -net user -hda /home/mhsabbagh/android.img'
|
||||
Terminal=false
|
||||
Type=Application
|
||||
StartupNotify=true
|
||||
Categories=GTK;
|
||||
```
|
||||
|
||||
Again, you have to replace /home/mhsabbagh/android.img with the path to the local image on your system. Then save the file (Ctrl + X, then press Y, then Enter).
|
||||
|
||||
Notice that we needed to use “pkexec” to run QEMU with root privileges because starting from newer versions, accessing to the KVM technology via libvirt is not allowed for normal users; That’s why it will ask you for the root password each time.
|
||||
|
||||
Now, you’ll see the android icon in the applications menu all the time, you can simply click it any time you want to use android and the QEMU program will start:
|
||||
|
||||
![Install Android 8.1 Oreo on Linux To Run Apps & Games 71 android 8.1 oreo on linux][20]
|
||||
|
||||
### Conclusion
|
||||
|
||||
We showed you how install and run android 8.1 Oreo on your Linux system. From now on, it should be much easier on you to do your android-based tasks without some other software like Blutsticks and similar methods. Here, you have a fully-working and functional android system that you can manipulate however you like, and if anything goes wrong, you can simply nuke the image file and run the installation all over again any time you want.
|
||||
|
||||
Have you tried android x86 before? How was your experience with it?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/tutorials/install-android-8-1-oreo-on-linux
|
||||
|
||||
作者:[Python Programmer;Open Source Software Enthusiast. Worked On Developing A Lot Of Free Software. The Founder Of Foss Post;Foss Project. Computer Science Major.][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.android-x86.org/
|
||||
[2]: http://www.android-x86.org/download
|
||||
[3]: https://fosspost.org/tutorials/use-qemu-test-operating-systems-distributions
|
||||
[4]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-16.png?resize=694%2C548&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 40 android 8.1 oreo on linux)
|
||||
[5]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-15.png?resize=673%2C537&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 42 android 8.1 oreo on linux)
|
||||
[6]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-14.png?resize=769%2C469&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 44 android 8.1 oreo on linux)
|
||||
[7]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-13.png?resize=767%2C466&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 46 android 8.1 oreo on linux)
|
||||
[8]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-12.png?resize=750%2C460&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 48 android 8.1 oreo on linux)
|
||||
[9]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-11.png?resize=754%2C456&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 50 android 8.1 oreo on linux)
|
||||
[10]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-10.png?resize=850%2C559&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 52 android 8.1 oreo on linux)
|
||||
[11]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-09.png?resize=850%2C569&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 54 android 8.1 oreo on linux)
|
||||
[12]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-08.png?resize=850%2C562&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 56 android 8.1 oreo on linux)
|
||||
[13]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-07-1.png?resize=850%2C561&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 58 android 8.1 oreo on linux)
|
||||
[14]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-06.png?resize=850%2C569&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 60 android 8.1 oreo on linux)
|
||||
[15]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-05.png?resize=850%2C559&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 62 android 8.1 oreo on linux)
|
||||
[16]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-04.png?resize=850%2C553&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 64 android 8.1 oreo on linux)
|
||||
[17]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-03.png?resize=850%2C571&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 66 android 8.1 oreo on linux)
|
||||
[18]: https://i1.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-02.png?resize=850%2C555&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 68 android 8.1 oreo on linux)
|
||||
[19]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Android-8.1-Oreo-on-Linux-01.png?resize=850%2C557&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 70 android 8.1 oreo on linux)
|
||||
[20]: https://i0.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-17-1539.png?resize=850%2C557&ssl=1 (Install Android 8.1 Oreo on Linux To Run Apps & Games 72 android 8.1 oreo on linux)
|
||||
@ -1,187 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Netboot a Fedora Live CD)
|
||||
[#]: via: (https://fedoramagazine.org/netboot-a-fedora-live-cd/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
Netboot a Fedora Live CD
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Live CDs][1] are useful for many tasks such as:
|
||||
|
||||
* installing the operating system to a hard drive
|
||||
* repairing a boot loader or performing other rescue-mode operations
|
||||
* providing a consistent and minimal environment for web browsing
|
||||
* …and [much more][2].
|
||||
|
||||
|
||||
|
||||
As an alternative to using DVDs and USB drives to store your Live CD images, you can upload them to an [iSCSI][3] server where they will be less likely to get lost or damaged. This guide shows you how to load your Live CD images onto an iSCSI server and access them with the [iPXE][4] boot loader.
|
||||
|
||||
### Download a Live CD Image
|
||||
|
||||
```
|
||||
$ MY_RLSE=27
|
||||
$ MY_LIVE=$(wget -q -O - https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/$MY_RLSE/Workstation/x86_64/iso | perl -ne '/(Fedora[^ ]*?-Live-[^ ]*?\.iso)(?{print $^N})/;')
|
||||
$ MY_NAME=fc$MY_RLSE
|
||||
$ wget -O $MY_NAME.iso https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/$MY_RLSE/Workstation/x86_64/iso/$MY_LIVE
|
||||
```
|
||||
|
||||
The above commands download the Fedora-Workstation-Live-x86_64-27-1.6.iso Fedora Live image and save it as fc27.iso. Change the value of MY_RLSE to download other archived versions. Or you can browse to <https://getfedora.org/> to download the latest Fedora live image. Versions prior to 21 used different naming conventions, and must be [downloaded manually here][5]. If you download a Live CD image manually, set the MY_NAME variable to the basename of the file without the extension. That way the commands in the following sections will reference the correct file.
|
||||
|
||||
### Convert the Live CD Image
|
||||
|
||||
Use the livecd-iso-to-disk tool to convert the ISO file to a disk image and add the netroot parameter to the embedded kernel command line:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y livecd-tools
|
||||
$ MY_SIZE=$(du -ms $MY_NAME.iso | cut -f 1)
|
||||
$ dd if=/dev/zero of=$MY_NAME.img bs=1MiB count=0 seek=$(($MY_SIZE+512))
|
||||
$ MY_SRVR=server-01.example.edu
|
||||
$ MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
$ MY_LOOP=$(sudo losetup --show --nooverlap --find $MY_NAME.img)
|
||||
$ sudo livecd-iso-to-disk --format --extra-kernel-args netroot=iscsi:$MY_SRVR:::1:iqn.$MY_RVRS:$MY_NAME $MY_NAME.iso $MY_LOOP
|
||||
$ sudo losetup -d $MY_LOOP
|
||||
```
|
||||
|
||||
### Upload the Live Image to your Server
|
||||
|
||||
Create a directory on your iSCSI server to store your live images and then upload your modified image to it.
|
||||
|
||||
**For releases 21 and greater:**
|
||||
|
||||
```
|
||||
$ MY_FLDR=/images
|
||||
$ scp $MY_NAME.img $MY_SRVR:$MY_FLDR/
|
||||
```
|
||||
|
||||
**For releases prior to 21:**
|
||||
|
||||
```
|
||||
$ MY_FLDR=/images
|
||||
$ MY_LOOP=$(sudo losetup --show --nooverlap --find --partscan $MY_NAME.img)
|
||||
$ sudo tune2fs -O ^has_journal ${MY_LOOP}p1
|
||||
$ sudo e2fsck ${MY_LOOP}p1
|
||||
$ sudo dd status=none if=${MY_LOOP}p1 | ssh $MY_SRVR "dd of=$MY_FLDR/$MY_NAME.img"
|
||||
$ sudo losetup -d $MY_LOOP
|
||||
```
|
||||
|
||||
### Define the iSCSI Target
|
||||
|
||||
Run the following commands on your iSCSI server:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# MY_NAME=fc27
|
||||
# MY_FLDR=/images
|
||||
# MY_SRVR=`hostname`
|
||||
# MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
# cat << END > /etc/tgt/conf.d/$MY_NAME.conf
|
||||
<target iqn.$MY_RVRS:$MY_NAME>
|
||||
backing-store $MY_FLDR/$MY_NAME.img
|
||||
readonly 1
|
||||
allow-in-use yes
|
||||
</target>
|
||||
END
|
||||
# tgt-admin --update ALL
|
||||
```
|
||||
|
||||
### Create a Bootable USB Drive
|
||||
|
||||
The [iPXE][4] boot loader has a [sanboot][6] command you can use to connect to and start the live images hosted on your iSCSI server. It can be compiled in many different [formats][7]. The format that works best depends on the type of hardware you’re running. As an example, the following instructions show how to [chain load][8] iPXE from [syslinux][9] on a USB drive.
|
||||
|
||||
First, download iPXE and build it in its lkrn format. This should be done as a normal user on a workstation:
|
||||
|
||||
```
|
||||
$ sudo dnf install -y git
|
||||
$ git clone http://git.ipxe.org/ipxe.git $HOME/ipxe
|
||||
$ sudo dnf groupinstall -y "C Development Tools and Libraries"
|
||||
$ cd $HOME/ipxe/src
|
||||
$ make clean
|
||||
$ make bin/ipxe.lkrn
|
||||
$ cp bin/ipxe.lkrn /tmp
|
||||
```
|
||||
|
||||
Next, prepare a USB drive with a MSDOS partition table and a FAT32 file system. The below commands assume that you have already connected the USB drive to be formatted. **Be careful that you do not format the wrong drive!**
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# dnf install -y parted util-linux dosfstools
|
||||
# echo; find /dev/disk/by-id ! -regex '.*-part.*' -name 'usb-*' -exec readlink -f {} \; | xargs -i bash -c "parted -s {} unit MiB print | perl -0 -ne '/^Model: ([^(]*).*\n.*?([0-9]*MiB)/i && print \"Found: {} = \$2 \$1\n\"'"; echo; read -e -i "$(find /dev/disk/by-id ! -regex '.*-part.*' -name 'usb-*' -exec readlink -f {} \; -quit)" -p "Drive to format: " MY_USB
|
||||
# umount $MY_USB?
|
||||
# wipefs -a $MY_USB
|
||||
# parted -s $MY_USB mklabel msdos mkpart primary fat32 1MiB 100% set 1 boot on
|
||||
# mkfs -t vfat -F 32 ${MY_USB}1
|
||||
```
|
||||
|
||||
Finally, install syslinux on the USB drive and configure it to chain load iPXE:
|
||||
|
||||
```
|
||||
# dnf install -y syslinux-nonlinux
|
||||
# syslinux -i ${MY_USB}1
|
||||
# dd if=/usr/share/syslinux/mbr.bin of=${MY_USB}
|
||||
# MY_MNT=$(mktemp -d)
|
||||
# mount ${MY_USB}1 $MY_MNT
|
||||
# MY_NAME=fc27
|
||||
# MY_SRVR=server-01.example.edu
|
||||
# MY_RVRS=$(echo $MY_SRVR | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_SRVR})
|
||||
# cat << END > $MY_MNT/syslinux.cfg
|
||||
ui menu.c32
|
||||
default $MY_NAME
|
||||
timeout 100
|
||||
menu title SYSLINUX
|
||||
label $MY_NAME
|
||||
menu label ${MY_NAME^^}
|
||||
kernel ipxe.lkrn
|
||||
append dhcp && sanboot iscsi:$MY_SRVR:::1:iqn.$MY_RVRS:$MY_NAME
|
||||
END
|
||||
# cp /usr/share/syslinux/menu.c32 $MY_MNT
|
||||
# cp /usr/share/syslinux/libutil.c32 $MY_MNT
|
||||
# cp /tmp/ipxe.lkrn $MY_MNT
|
||||
# umount ${MY_USB}1
|
||||
```
|
||||
|
||||
You should be able to use this same USB drive to netboot additional iSCSI targets simply by editing the syslinux.cfg file and adding additional menu entries.
|
||||
|
||||
This is just one method of loading iPXE. You could install syslinux directly on your workstation. Another option is to compile iPXE as an EFI executable and place it directly in your [ESP][10]. Yet another is to compile iPXE as a PXE loader and place it on your TFTP server to be referenced by DHCP. The best option depends on your environment.
|
||||
|
||||
### Final Notes
|
||||
|
||||
* You may want to add the –filename \EFI\BOOT\grubx64.efi parameter to the sanboot command if you compile iPXE in its EFI format.
|
||||
* It is possible to create custom live images. Refer to [Creating and using live CD][11] for more information.
|
||||
* It is possible to add the –overlay-size-mb and –home-size-mb parameters to the livecd-iso-to-disk command to create live images with persistent storage. However, if you have multiple concurrent users, you’ll need to set up your iSCSI server to manage separate per-user writeable overlays. This is similar to what was shown in the “[How to Build a Netboot Server, Part 4][12]” article.
|
||||
* The live images support a persistenthome option on their kernel command line (e.g. persistenthome=LABEL=HOME). Used together with CHAP-authenticated iSCSI targets, the persistenthome option provides an interesting alternative to NFS for centralized home directories.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/netboot-a-fedora-live-cd/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Live_CD
|
||||
[2]: https://en.wikipedia.org/wiki/Live_CD#Uses
|
||||
[3]: https://en.wikipedia.org/wiki/ISCSI
|
||||
[4]: https://ipxe.org/
|
||||
[5]: https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/https://dl.fedoraproject.org/pub/archive/fedora/linux/releases/
|
||||
[6]: http://ipxe.org/cmd/sanboot/
|
||||
[7]: https://ipxe.org/appnote/buildtargets#boot_type
|
||||
[8]: https://en.wikipedia.org/wiki/Chain_loading
|
||||
[9]: https://www.syslinux.org/wiki/index.php?title=SYSLINUX
|
||||
[10]: https://en.wikipedia.org/wiki/EFI_system_partition
|
||||
[11]: https://docs.fedoraproject.org/en-US/quick-docs/creating-and-using-a-live-installation-image/#proc_creating-and-using-live-cd
|
||||
[12]: https://fedoramagazine.org/how-to-build-a-netboot-server-part-4/
|
||||
@ -1,83 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Easy means easy to debug)
|
||||
[#]: via: (https://arp242.net/weblog/easy.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
|
||||
What does it mean for a framework, library, or tool to be “easy”? There are many possible definitions one could use, but my definition is usually that it’s easy to debug. I often see people advertise a particular program, framework, library, file format, or something else as easy because “look with how little effort I can do task X, this is so easy!” That’s great, but an incomplete picture.
|
||||
|
||||
You only write software once, but will almost always go through several debugging cycles. With debugging cycle I don’t mean “there is a bug in the code you need to fix”, but rather “I need to look at this code to fix the bug”. To debug code, you need to understand it, so “easy to debug” by extension means “easy to understand”.
|
||||
|
||||
Abstractions which make something easier to write often come at the cost of make things harder to understand. Sometimes this is a good trade-off, but often it’s not. In general I will happily spend a little but more effort writing something now if that makes things easier to understand and debug later on, as it’s often a net time-saver.
|
||||
|
||||
Simplicity isn’t the only thing that makes programs easier to debug, but it is probably the most important. Good documentation helps too, but unfortunately good documentation is uncommon (note that quality is not measured by word count!)
|
||||
|
||||
This is not exactly a novel insight; from the 1974 The Elements of Programming Style by Brian W. Kernighan and P. J. Plauger:
|
||||
|
||||
> Everyone knows that debugging is twice as hard as writing a program in the first place. So if you’re as clever as you can be when you write it, how will you ever debug it?
|
||||
|
||||
A lot of stuff I see seems to be written “as clever as can be” and is consequently hard to debug. I’ll list a few examples of this pattern below. It’s not my intention to argue that any of these things are bad per se, I just want to highlight the trade-offs in “easy to use” vs. “easy to debug”.
|
||||
|
||||
* When I tried running [Let’s Encrypt][1] a few years ago it required running a daemon as root(!) to automatically rewrite nginx files. I looked at the source a bit to understand how it worked and it was all pretty complex, so I was “let’s not” and opted to just pay €10 to the CA mafia, as not much can go wrong with putting a file in /etc/nginx/, whereas a lot can go wrong with complex Python daemons running as root.
|
||||
|
||||
(I don’t know the current state/options for Let’s Encrypt; at a quick glance there may be better/alternative ACME clients that suck less now.)
|
||||
|
||||
* Some people claim that systemd is easier than SysV init.d scripts because it’s easier to write systemd unit files than it is to write shell scripts. In particular, this is the argument Lennart Poettering used in his [systemd myths][2] post (point 5).
|
||||
|
||||
I think is completely missing the point. I agree with Poettering that shell scripts are hard – [I wrote an entire post about that][3] – but by making the interface easier doesn’t mean the entire system becomes easier. Look at [this issue][4] I encountered and [the fix][5] for it. Does that look easy to you?
|
||||
|
||||
* Many JavaScript frameworks I’ve used can be hard to fully understand. Clever state keeping logic is great and all, until that state won’t work as you expect, and then you better hope there’s a Stack Overflow post or GitHub issue to help you out.
|
||||
|
||||
* Docker is great, right up to the point you get:
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch:
|
||||
oci runtime error: container_linux.go:247: starting container process caused "process_linux.go:258:
|
||||
applying cgroup configuration for process caused \"failed to write 898 to cgroup.procs: write
|
||||
/sys/fs/cgroup/cpu,cpuacct/docker/b13312efc203e518e3864fc3f9d00b4561168ebd4d9aad590cc56da610b8dd0e/cgroup.procs:
|
||||
invalid argument\""
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```
|
||||
ERROR: for elasticsearch Cannot start service elasticsearch: EOF
|
||||
```
|
||||
|
||||
And … now what?
|
||||
|
||||
* Many testing libraries can make things harder to debug. Ruby’s rspec is a good example where I’ve occasionally used the library wrong by accident and had to spend quite a long time figuring out what exactly went wrong (as the errors it gave me were very confusing!)
|
||||
|
||||
I wrote a bit more about that in my [Testing isn’t everything][6] post.
|
||||
|
||||
* ORM libraries can make database queries a lot easier, at the cost of making things a lot harder to understand once you want to solve a problem.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/easy.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Let%27s_Encrypt
|
||||
[2]: http://0pointer.de/blog/projects/the-biggest-myths.html
|
||||
[3]: https://arp242.net/weblog/shell-scripting-trap.html
|
||||
[4]: https://unix.stackexchange.com/q/185495/33645
|
||||
[5]: https://cgit.freedesktop.org/systemd/systemd/commit/?id=6e392c9c45643d106673c6643ac8bf4e65da13c1
|
||||
[6]: /weblog/testing.html
|
||||
[7]: mailto:martin@arp242.net
|
||||
[8]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -1,243 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Set Password Complexity On Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Set Password Complexity On Linux?
|
||||
======
|
||||
|
||||
User management is one of the important task of Linux system administration.
|
||||
|
||||
There are many aspect is involved in this and implementing the strong password policy is one of them.
|
||||
|
||||
Navigate to the following URL, if you would like to **[generate a strong password on Linux][1]**.
|
||||
|
||||
It will Restrict unauthorized access to systems.
|
||||
|
||||
By default Linux is secure that everybody know. however, we need to make necessary tweak on this to make it more secure.
|
||||
|
||||
Insecure password will leads to breach security. So, take additional care on this.
|
||||
|
||||
Navigate to the following URL, if you would like to see the **[password strength and score][2]** of the generated strong password.
|
||||
|
||||
In this article, we will teach you, how to implement the best security policy on Linux.
|
||||
|
||||
We can use PAM (the “pluggable authentication module”) to enforce password policy On most Linux systems.
|
||||
|
||||
The file can be found in the following location.
|
||||
|
||||
For Redhat based systems @ `/etc/pam.d/system-auth` and Debian based systems @ `/etc/pam.d/common-password`.
|
||||
|
||||
The default password aging details can be found in the `/etc/login.defs` file.
|
||||
|
||||
I have trimmed this file for better understanding.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 99999
|
||||
PASS_MIN_DAYS 0
|
||||
PASS_MIN_LEN 5
|
||||
PASS_WARN_AGE 7
|
||||
```
|
||||
|
||||
**Details:**
|
||||
|
||||
* **`PASS_MAX_DAYS:`**` ` Maximum number of days a password may be used.
|
||||
* **`PASS_MIN_DAYS:`**` ` Minimum number of days allowed between password changes.
|
||||
* **`PASS_MIN_LEN:`**` ` Minimum acceptable password length.
|
||||
* **`PASS_WARN_AGE:`**` ` Number of days warning given before a password expires.
|
||||
|
||||
|
||||
|
||||
We will show you, how to implement the below eleven password policies in Linux.
|
||||
|
||||
* Password Max days
|
||||
* Password Min days
|
||||
* Password warning days
|
||||
* Password history or Deny Re-Used Passwords
|
||||
* Password minimum length
|
||||
* Minimum upper case characters
|
||||
* Minimum lower case characters
|
||||
* Minimum digits in password
|
||||
* Minimum other characters (Symbols)
|
||||
* Account lock – retries
|
||||
* Account unlock time
|
||||
|
||||
|
||||
|
||||
### What Is Password Max days?
|
||||
|
||||
This parameter limits the maximum number of days a password can be used. It’s mandatory for user to change his/her account password before expiry.
|
||||
|
||||
If they forget to change, they are not allowed to login into the system. They need to work with admin team to get rid of it.
|
||||
|
||||
It can be set in `/etc/login.defs` file. I’m going to set `90 days`.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 90
|
||||
```
|
||||
|
||||
### What Is Password Min days?
|
||||
|
||||
This parameter limits the minimum number of days after password can be changed.
|
||||
|
||||
Say for example, if this parameter is set to 15 and user changed password today. Then he won’t be able to change the password again before 15 days from now.
|
||||
|
||||
It can be set in `/etc/login.defs` file. I’m going to set `15 days`.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MIN_DAYS 15
|
||||
```
|
||||
|
||||
### What Is Password Warning Days?
|
||||
|
||||
This parameter controls the password warning days and it will warn the user when the password is going to expires.
|
||||
|
||||
A warning will be given to the user regularly until the warning days ends. This can helps user to change their password before expiry. Otherwise we need to work with admin team for unlock the password.
|
||||
|
||||
It can be set in `/etc/login.defs` file. I’m going to set `10 days`.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_WARN_AGE 10
|
||||
```
|
||||
|
||||
**Note:** All the above parameters only applicable for new accounts and not for existing accounts.
|
||||
|
||||
### What Is Password History Or Deny Re-Used Passwords?
|
||||
|
||||
This parameter keep controls of the password history. Keep history of passwords used (the number of previous passwords which cannot be reused).
|
||||
|
||||
When the users try to set a new password, it will check the password history and warn the user when they set the same old password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `5` for history of password.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password sufficient pam_unix.so md5 shadow nullok try_first_pass use_authtok remember=5
|
||||
```
|
||||
|
||||
### What Is Password Minimum Length?
|
||||
|
||||
This parameter keeps the minimum password length. When the users set a new password, it will check against this parameter and warn the user if they try to set the password length less than that.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `12` character for minimum password length.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12
|
||||
```
|
||||
|
||||
**try_first_pass retry=3** : Allow users to set a good password before the passwd command aborts.
|
||||
|
||||
### Set Minimum Upper Case Characters?
|
||||
|
||||
This parameter keeps, how many upper case characters should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any upper case characters in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character for minimum password length.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ucredit=-1
|
||||
```
|
||||
|
||||
### Set Minimum Lower Case Characters?
|
||||
|
||||
This parameter keeps, how many lower case characters should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any lower case characters in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 lcredit=-1
|
||||
```
|
||||
|
||||
### Set Minimum Digits In Password?
|
||||
|
||||
This parameter keeps, how many digits should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any digits in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 dcredit=-1
|
||||
```
|
||||
|
||||
### Set Minimum Other Characters (Symbols) In Password?
|
||||
|
||||
This parameter keeps, how many Symbols should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any Symbol in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ocredit=-1
|
||||
```
|
||||
|
||||
### Set Account Lock?
|
||||
|
||||
This parameter controls users failed attempts. It locks user account after reaches the given number of failed login attempts.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
### Set Account Unlock Time?
|
||||
|
||||
This parameter keeps users unlock time. If the user account is locked after consecutive failed authentications.
|
||||
|
||||
It’s unlock the locked user account after reaches the given time. Sets the time (900 seconds = 15 minutes) for which the account should remain locked.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5 unlock_time=900
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/
|
||||
@ -1,73 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (DevOps for introverted people)
|
||||
[#]: via: (https://opensource.com/article/19/7/devops-introverted-people)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg/users/don-watkins/users/shawnhcorey/users/mbbroberg/users/marcobravo)
|
||||
|
||||
DevOps for introverted people
|
||||
======
|
||||
We asked the Opensource.com DevOps team to talk about their experience
|
||||
as DevOps introverts and to give DevOps extroverts some advice. Here are
|
||||
their answers.
|
||||
![Q and A letters][1]
|
||||
|
||||
We asked members of our [DevOps team][2] to talk about their experience as introverts and to give extroverts some advice. Before we get into their responses, though, let’s first define the term.
|
||||
|
||||
### What does being introverted mean?
|
||||
|
||||
Being an introvert is commonly defined as someone who finds it more energy depleting, as opposed to energizing, to be around people. It can be a helpful term when we think about how we recharge: introverted people may require more alone time to recharge, especially after spending a lot of time around groups of people. A big myth about introverts is that they are necessarily shy, but [science suggests][3] that is a separate personality trait.
|
||||
|
||||
Introversion and extraversion were popularized by the [Myers Briggs Type Indicators][4] and are now more commonly referred to as two ends of the same [spectrum][5]. Even though it may seem that there are more extroverted people in the world than introverts, psychologists tend to believe that a majority of us fall along the spectrum closer to [ambiverts or introverts][6].
|
||||
|
||||
Now, on to the questions and answers.
|
||||
|
||||
### What are some techniques DevOps leaders can use to make sure introverts feel like part of the team and increase their willingness to share ideas?
|
||||
|
||||
"Everyone is a little different, so it’s important to be observant. Someone from GitLab once told me their philosophy is that if you aren’t offering your opinion, then they’re being exclusionary. If someone isn’t offering an opinion in a meeting, then find ways to include them. **When I know an introvert is interested in a topic we’re meeting about, I’ll ask in advance for written input. A lot of meetings can be avoided by moving the discussion to slack or GitLab where introverts are more willing to engage.** In stand-up, everyone gives an update, and introverts seem to do fine in this context. So we sometimes do the same thing in other meetings just to make sure everyone has time to speak. I also encourage introverts to speak in front of small groups either at work or in the community in order to build those skills." —Dan Barker
|
||||
|
||||
"**I think the best thing that anyone ever did for me was to make sure I had the skills necessary to answer the big questions when they came.** As a very young enlisted Air Force member I was giving status briefings to my units’ senior leadership. That required that I have a number of data points available at any given moment as well as the why behind any delays or deviations on the way towards established objectives. That propelled me from a behind the scenes person into being willing to share my opinion and thoughts with others." —Chris Short
|
||||
|
||||
"**Lead through culture. Design and try out a ritual for your co-workers.** You can design a smaller weekly ritual for groups or teams or a bigger yearly event for your department or organization. The point is to try something and observe your leadership role in it. Identify gaps or tensions in your culture. Look back at the beliefs and behaviors of teams. Where do you observe tension? What’s missing from your culture? Start with a simple statement 'I see a tension between X and Y'. Or 'My team is missing Z'. Next, flip the gap or tension into a question: write down 3 'How might we’s (HMWs)'." —Catherine Louis
|
||||
|
||||
"Introverts are not a different class of people, they are either people who think or wait too much before they share their mind or people who have no idea what's going on. I was one among the first category, I thought too much and sometimes worried about what if my opinion is laughed upon or not entertained or thought otherwise. It was hard coming up of that kind of mindset but it was also eating my chances of learning better things. Once, we were discussing in the team about an implementation issue. My then manager asked me one on one, why I am not participating as I am one of the more experienced people on the team, and I opened up (after I gathered all the power in the universe to say something) saying everything I wanted to say was already shared. He suggested 'I could use a repetition sometimes, as there are many things going on, it would be helpful if you just repeat your thought even if it is discussed'. Well, that was not a very persuasive way but that gave me a bit of confidence that someone at-least wants to hear me.
|
||||
|
||||
"Now, the way I used to make people speak in my team, is **I often ask the introvert person for help, even if I know the resolution, and appreciate them in team meetings and discussions to boost up their confidence encouraging them to share more knowledge with the team, by slowly giving them time to come out of their reserved nature**. They may still remain a bit isolated in the outer world but within a team, some emerge a player we can count on." —Abhishek Tamrakar
|
||||
|
||||
"My advice to introverts when participating in conferences is to find friends/colleagues who are also attending so you have people to talk to comfortably, reach out prior to the event to schedule some smaller meetings/meals with other attendees (friends, industry contacts, former colleagues, etc.), **be mindful of your exhaustion level and take care of yourself**: skip the social/evening events if you need to recharge, write about your experience in a post-event retrospective." —Elizabeth Joseph
|
||||
|
||||
### What are some tips for increasing productivity when working with a teammate who tends to be more of an introvert?
|
||||
|
||||
"Productivity is increasingly challenging to really qualify. In many cases, a break from work or a casual conversation can be the spark needed in our creative endeavors. Again, I find slack and GitLab to be very helpful mediums for exchanging ideas and interacting with others when you have introverts on your team. **I also find pair programming to be very useful for most introverts as one on one interactions aren’t usually as taxing but the product quality and efficiency gains are substantial.** However, when an introvert is working alone, everyone on the team should be discouraged from interrupting them. It’s best to send them an email or some non-intrusive medium." —Dan Barker
|
||||
|
||||
"Give them great tools for doing and documenting their work. **Enable them to be the best they can be at their job.** Check in with them frequently enough to make sure they’re on the right track but also be mindful it’s a bigger distraction to them than it is more extroverted people." —Chris Short
|
||||
|
||||
"**Don’t interrupt me when I am heads down.** Really, don’t. It could take me 2 hours minimally to get my brain back to where I was when I was knee deep in something. It feels painful. Really. Instead, email me and ask me to come to a place where there is a whiteboard. Share the problem from the customer's point of view—draw it—not from your point of view. I may have dozens of customer issues niggling in the back of my brain. If your issues sound like 'make me look good to my upper management', it will get less attention from me than the true customer's issues I already have. Draw a picture. Give me time to think. Make sure there is more than one marker in case I am ready to share. Be prepared that your hypothesis about the problem is completely wrong." —Catherine Louis
|
||||
|
||||
"Appreciation and encouragement is the way out, appreciation may not be an appraisal, but an appreciation that encourages people to feel comfortable in presence of more than one living entities, **so that everyone feels heard and not laughed or underrated**." —Abhishek Tamrakar
|
||||
|
||||
### Final thoughts
|
||||
|
||||
The biggest takeaway from our conversations on introverted DevOps enthusiasts is one of equity: Treat people as they need to be treated, and ask people to treat you as you want to be treated. Whether you are extroverted or introverted, we all need to respect the fact that we do not all experience the world in the same way. Our colleagues deserve the space they need to get the work done, and knowing how to support them starts with a discussion on their needs. Our differences are what make our communities so special and it makes our work more useful for more people. The most effective way to communicate with others is to communicate in a style that works well for both of you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/devops-introverted-people
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg/users/don-watkins/users/shawnhcorey/users/mbbroberg/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_QandAorange_520x292_0311LL.png?itok=qa3hHSou (Q and A letters)
|
||||
[2]: https://opensource.com/devops-team
|
||||
[3]: https://www.inc.com/melanie-curtin/are-you-shy-or-introverted-science-says-this-is-1-primary-difference.html
|
||||
[4]: https://www.myersbriggs.org/my-mbti-personality-type/mbti-basics/extraversion-or-introversion.htm?bhcp=1
|
||||
[5]: https://lifehacker.com/lets-quit-it-with-the-introvert-extrovert-nonsense-1713772952
|
||||
[6]: https://www.psychologytoday.com/us/blog/the-gen-y-guide/201710/the-majority-people-are-not-introverts-or-extroverts
|
||||
@ -1,192 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to make an old computer useful again)
|
||||
[#]: via: (https://opensource.com/article/19/7/how-make-old-computer-useful-again)
|
||||
[#]: author: (Howard Fosdick https://opensource.com/users/howtechhttps://opensource.com/users/don-watkinshttps://opensource.com/users/suehlehttps://opensource.com/users/aseem-sharmahttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/dragonbitehttps://opensource.com/users/don-watkinshttps://opensource.com/users/jamesfhttps://opensource.com/users/seth)
|
||||
|
||||
How to make an old computer useful again
|
||||
======
|
||||
Refurbish an old machine with these step-by-step instructions.
|
||||
![Person typing on a 1980's computer][1]
|
||||
|
||||
Have an old computer gathering dust in your basement? Why not put it to use? A backup machine could come in handy if your primary computer fails and you want to be online with a larger screen than your smartphone. Or it could act as a cheap secondary computer shared by the family. You could even make it into a retro gaming box.
|
||||
|
||||
You can take any computer up to a dozen years old and—with the right software—perform many of the same tasks you can with new machines. Open source software is the key.
|
||||
|
||||
I've refurbished computers for two decades, and in this article, I'll share how I do it. We're talking about dual-core laptops and desktops between five and 12 years old.
|
||||
|
||||
### Verify the hardware
|
||||
|
||||
Step one is to verify that your hardware all works. Overlooking a problem here could cause you big headaches later.
|
||||
|
||||
Dust kills electronics, so open up the box and clean out the dirt. [Compressed air][2] comes in handy. Be careful that you're [grounded][3] whenever you touch the machine. And _don't_ rub anything with a cleaning cloth. Even a static shock so small you won't feel it can destroy circuitry.
|
||||
|
||||
Then close the clean computer and verify that all the hardware works. Test:
|
||||
|
||||
* Memory
|
||||
* Disk
|
||||
* Motherboard
|
||||
* Peripherals (DVD drive, USB ports, sound, etc.)
|
||||
|
||||
|
||||
|
||||
Run any diagnostic tests in the computer's boot panels (the [UEFI][4] or [BIOS][5] panels). [This list][6] tells you which program function (PF) key to press to access those panels for your computer.
|
||||
|
||||
Free resource kits like [Hirens BootCD][7] or [Ultimate Boot CD][8] enable you to test what your boot panels don't. They contain hundreds of testing programs; all are free, but not all are open source. You don't have to install anything to run these kits because they'll boot from a USB thumb drive or DVD drive.
|
||||
|
||||
Be thorough! Run the extended tests for memory and disk—not just the short tests. Let them run overnight. That's the only way to catch transient (sporadic) errors.
|
||||
|
||||
If you find problems, my [Quick guide to fixing hardware][9] will help you solve the most common hardware issues.
|
||||
|
||||
### Select the software
|
||||
|
||||
The key to refurbishing is to install software appropriate for the hardware resources you have. The three essential hardware resources are:
|
||||
|
||||
1. Processor (number of cores and speed)
|
||||
2. Memory
|
||||
3. Video memory
|
||||
|
||||
|
||||
|
||||
You can identify your computer's resources in its boot-time UEFI/BIOS panels. Write down your findings so that you don't forget them. Then, look up your processor at [CPU Benchmark][10]. That website gives you background on your CPU plus a CPU Mark that indicates its performance.
|
||||
|
||||
Now that you know your hardware's power, you're ready to select software that it can efficiently run. Your software choices are divided into four critical areas:
|
||||
|
||||
1. Operating system (OS)
|
||||
2. Desktop environment (DE)
|
||||
3. Browser
|
||||
4. Applications
|
||||
|
||||
|
||||
|
||||
A good Linux distribution covers all four. Don't be tempted to run an unsupported version of Windows like 8, Vista, or XP just because it's already on the computer! The [risk][11] of malware is too great. You're much better off with a more virus-resistant, up-to-date operating system.
|
||||
|
||||
How about Windows 7? [Extended support][12] ends January 14, 2020, meaning you get security fixes only until that date. After that, zilch. Now is the perfect time to migrate off Windows 7.
|
||||
|
||||
Linux's big benefit is that it offers [many distros][13] specifically designed for older hardware. Plus, its design decouples [DEs][14] from the OS, so you can mix and match the two. This is important because DEs heavily impact low-end system performance. (With Windows and MacOS, the OS version you run dictates the DE.)
|
||||
|
||||
Other Linux advantages: Its thousands of apps are free and open source, so you don't have to worry about activation and licensing. And Linux is portable. You can copy, move, or clone the OS and applications across partitions, disks, devices, or computers. (Windows binds itself to the computer it's installed on via its Registry.)
|
||||
|
||||
### What can your refurbished computer do?
|
||||
|
||||
We're talking dual-core machines dating from about 2006 to 2013, especially [Intel Core 2][15] CPUs and [AMD Athlon 64 X2][16] family processors. Most have a [CPU Mark][10] of between 1,000 and 4,000. You can often pick up these machines for a song, yet they're still powerful enough to run lightweight Linux software.
|
||||
|
||||
One caution: be sure your computer has at least 2GB of memory. Upgrade the RAM if you have to. End users on my refurbished machines typically use between 0.5 and 2GB of RAM (exclusive of data buffering); rarely do they go over 2 gig. So if you can bump memory to 2GB, your system won't be forced to _swap_, or substitute disk for memory. That's critical for good performance.
|
||||
|
||||
For example, I removed 1GB RAM from the decade-old rebuild I'm writing this article on, which dropped memory down to 1GB. The machine slowed to a crawl. Web surfing and other tasks became frustrating, even painful. I popped the memory stick back in and, with 2GB RAM, the desktop instantly reverted to its usable self.
|
||||
|
||||
With a 2 gig dual-core computer, most people can do whatever they want, so long as they run a lightweight distro and browser. You can web surf, email, edit documents, do spreadsheets, watch YouTube videos, bid on eBay auctions, post on social media, listen to podcasts, view photo collections, manage home finance and personal scheduling, play games, and more.
|
||||
|
||||
### Limitations
|
||||
|
||||
What can't these older computers do? Their concurrency is less than state-of-the-art machines. So run a fast browser and block ads, because that's what slows down web surfing. If your virtual private network (VPN) can block ads for you and offload that work from your processor, that's ideal. Disable autoplay of videos, Flash, and animation. Surf with a couple of tabs open rather than 20. Install a browser extension so you can toggle JavaScript.
|
||||
|
||||
Direct the processors to what you're working on; don't keep a ton of apps open or run lots of stuff in the background. High-end graphics and video editing may be slow. Virtual machine hosting is out.
|
||||
|
||||
How about games? The open source software repositories offer literally thousands of games. That's why I listed video memory as one of the three essential hardware resources. If your box doesn't have a video card, it likely has only 32 or 64MB of VRAM. Bump that to 256 or 512MB by adding a video card, and you'll find that processor-intensive games run much better. [Here's how][17] to see how much VRAM your computer has. Be sure to get a card that fits your computer's [video slot][18] (AGP, PCI-Express, or PCI) and has the right [cable connector][19] (VGA, DVI, or HDMI).
|
||||
|
||||
#### What about Windows compatibility?
|
||||
|
||||
People often ask about Windows compatibility. First, there's a [Linux equivalent][20] for every Windows program.
|
||||
|
||||
Second, if you really must run a specific Windows program, you can usually do that on Linux using [Wine][21]. Look up your application in the [Wine database][22] to verify it runs under Wine and learn any special install tricks. Then the auxiliary tools [Winetricks][23] or [PlayOnLinux][24] will help you with installation and setup.
|
||||
|
||||
Wine's other benefit is that it runs programs from old Windows versions like Vista, XP, ME/98/95, and 3.1. I know a guy who set up a fantastic game box running his old XP games. You can even run thousands of [free DOS programs][25] using [DOSBox.][26] One caution: if Windows programs can run, so can Windows [viruses][27]. You must protect your Wine environment inside Linux just as you would any other Windows environment.
|
||||
|
||||
How about compatibility with Microsoft Office? I use LibreOffice and routinely edit and exchange Word and Excel files without problems. You must, however, avoid using obscure or specialized features.
|
||||
|
||||
### Which distro?
|
||||
|
||||
Assuming Linux is the OS, you need to select a DE, browser, and applications. The easy way to do this is to install a distribution that bundles everything you need.
|
||||
|
||||
Remember that you can try out different distros without installing anything by booting from a [live USB][28] thumb drive or DVD. [Here's how to create a bootable Linux][29] from within Linux or Windows.
|
||||
|
||||
I rebuild computers for charity, so I can't assume any knowledge on the part of my users. I need a distro with these traits:
|
||||
|
||||
* User-friendly
|
||||
* Lightweight interface
|
||||
* Bundles lightweight apps
|
||||
* Big repository
|
||||
* Solid track record
|
||||
* Large user community with an active forum
|
||||
* Stability through long-term support releases (not rolling releases)
|
||||
* Prioritizes reliability over cutting-edge features
|
||||
* Configurable by a GUI rather than by text files
|
||||
|
||||
|
||||
|
||||
Many distros fulfill these criteria. The three I've successfully deployed are [Mint/Xfce][30], [Xubuntu,][31] and [Lubuntu][32]. The first two use the Xfce desktop environment, while the latter runs LXQt. These DEs [use less][33] processor and memory resources than alternatives like GNOME, Unity, KDE, MATE, and Cinnamon.
|
||||
|
||||
Xfce and LXQt are very easy to use. My clients have never seen Linux before, yet they have no trouble using these simple, menu-driven interfaces.
|
||||
|
||||
It's vital to run the fastest, most efficient browser on older equipment. [Many feel][34] Chromium wins the browser race. I also install Firefox Quantum because people are familiar with it and [its performance][35] rivals [that of Chromium][36]. I toss in Opera because it's speedy and has some unique features, like integrated ad-blocking and a free [virtual private network][37]. Opera is free but not open source.
|
||||
|
||||
Whatever browser you use, block ads and trackers! Minimize browser overhead. And don't allow videos or Flash to run without your explicit say-so.
|
||||
|
||||
For applications, I rely on the lightweight apps bundled with Mint/Xfce, Xubuntu, and Lubuntu. They address every possible need.
|
||||
|
||||
### Go for it
|
||||
|
||||
Will you be happy with your rebuild? The computers I've been using lately are both over a decade old. One has an Intel dual-core processor ([eMachines T5274a][38]) while the other features an AMD Athlon 64 x2 processor ([HP dc5750][39]). Both have 2 gig memory. They're as effective for my office workload as my quad-core i5 with 16GB RAM. The only function I miss when using them is the ability to host virtual machines.
|
||||
|
||||
We live in an amazing era. You can take a five- to 12-year-old computer and, with a little effort, restore it to practical use. What could be more fun?
|
||||
|
||||
Having recently co-authored a book about building things with the Raspberry Pi ( Raspberry Pi Hacks...
|
||||
|
||||
I can see the brightness of curiosity in my six year old niece Shuchi's eyes when she explores a...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/how-make-old-computer-useful-again
|
||||
|
||||
作者:[Howard Fosdick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/howtechhttps://opensource.com/users/don-watkinshttps://opensource.com/users/suehlehttps://opensource.com/users/aseem-sharmahttps://opensource.com/users/sethhttps://opensource.com/users/marcobravohttps://opensource.com/users/dragonbitehttps://opensource.com/users/don-watkinshttps://opensource.com/users/jamesfhttps://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
|
||||
[2]: https://www.amazon.com/s/ref=nb_sb_noss_1?url=search-alias%3Daps&field-keywords=compressed+air+for+computers&rh=i%3Aaps%2Ck%3Acompressed+air+for+computers
|
||||
[3]: https://www.wikihow.com/Ground-Yourself-to-Avoid-Destroying-a-Computer-with-Electrostatic-Discharge
|
||||
[4]: https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface
|
||||
[5]: http://en.wikipedia.org/wiki/BIOS
|
||||
[6]: http://www.disk-image.com/faq-bootmenu.htm
|
||||
[7]: http://www.hirensbootcd.org/download/
|
||||
[8]: http://www.ultimatebootcd.com/
|
||||
[9]: http://www.rexxinfo.org/Quick_Guide/Quick_Guide_To_Fixing_Computer_Hardware
|
||||
[10]: http://www.cpubenchmark.net/
|
||||
[11]: https://askleo.com/unsupported-software-really-mean/
|
||||
[12]: http://home.bt.com/tech-gadgets/computing/windows-7/windows-7-support-end-11364081315419
|
||||
[13]: https://fossbytes.com/best-lightweight-linux-distros/
|
||||
[14]: http://en.wikipedia.org/wiki/Desktop_environment
|
||||
[15]: https://en.wikipedia.org/wiki/Intel_Core_2
|
||||
[16]: https://en.wikipedia.org/wiki/Athlon_64_X2
|
||||
[17]: http://www.cyberciti.biz/faq/howto-find-linux-vga-video-card-ram/
|
||||
[18]: https://www.onlinecomputertips.com/support-categories/hardware/493-pci-vs-agp-vs-pci-express-video-cards/
|
||||
[19]: https://silentpc.com/articles/video-connectors
|
||||
[20]: http://wiki.linuxquestions.org/wiki/Linux_software_equivalent_to_Windows_software
|
||||
[21]: https://en.wikipedia.org/wiki/Wine_%28software%29
|
||||
[22]: https://appdb.winehq.org/
|
||||
[23]: https://en.wikipedia.org/wiki/Winetricks
|
||||
[24]: https://en.wikipedia.org/wiki/PlayOnLinux
|
||||
[25]: https://archive.org/details/softwarelibrary_msdos
|
||||
[26]: https://en.wikipedia.org/wiki/DOSBox
|
||||
[27]: https://wiki.winehq.org/FAQ#Is_Wine_malware-compatible.3F
|
||||
[28]: https://www.howtogeek.com/howto/linux/create-a-bootable-ubuntu-usb-flash-drive-the-easy-way/
|
||||
[29]: https://unetbootin.github.io/
|
||||
[30]: https://linuxmint.com/
|
||||
[31]: https://xubuntu.org/
|
||||
[32]: https://lubuntu.me/
|
||||
[33]: https://www.makeuseof.com/tag/best-lean-linux-desktop-environment-lxde-vs-xfce-vs-mate/
|
||||
[34]: https://www.zdnet.com/article/chrome-is-the-most-popular-web-browser-of-all/
|
||||
[35]: https://www.laptopmag.com/articles/firefox-quantum-vs-chrome
|
||||
[36]: https://www.zdnet.com/article/just-how-fast-is-firefox-quantum/
|
||||
[37]: http://en.wikipedia.org/wiki/Virtual_private_network
|
||||
[38]: https://www.cnet.com/products/emachines-t5274/specs/
|
||||
[39]: https://community.spiceworks.com/products/7727-hewlett-packard-dc5750-microtower
|
||||
@ -1,292 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (24 sysadmin job interview questions you should know)
|
||||
[#]: via: (https://opensource.com/article/19/7/sysadmin-job-interview-questions)
|
||||
[#]: author: (DirectedSoul https://opensource.com/users/directedsoul)
|
||||
|
||||
24 sysadmin job interview questions you should know
|
||||
======
|
||||
Have a sysadmin job interview coming up? Read this article for some
|
||||
questions you might encounter and possible answers.
|
||||
![Question and answer.][1]
|
||||
|
||||
As a geek who always played with computers, a career after my masters in IT was a natural choice. So, I decided the sysadmin path was the right one. In the process of my career, I have grown quite familiar with the job interview process. Here is a look at what to expect, the general career path, and a set of common questions and my answers to them.
|
||||
|
||||
### Typical sysadmin tasks and duties
|
||||
|
||||
Organizations need someone who understands the basics of how a system works so that they can keep their data safe, and keep their services running smoothly. You might ask: "Wait, isn’t there more that a sysadmin can do?"
|
||||
|
||||
You are right. Now, in general, let’s look at what might be a typical sysadmin’s day-to-day tasks. Depending on their company’s needs and the person’s skill level, a sysadmin’s tasks vary from managing desktops, laptops, networks, and servers, to designing the organization’s IT policies. Sometimes sysadmins are even in charge of purchasing and placing orders for new IT equipment.
|
||||
|
||||
Those seeking system administration as their career paths might find it difficult to keep their skills and knowledge up to date, as rapid changes in the IT field are inevitable. The next natural question that arises out of anyone’s mind is how IT professionals keep up with the latest updates and skills.
|
||||
|
||||
### Low difficulty questions
|
||||
|
||||
Here are some of the more basic questions you will encounter, and my answers:
|
||||
|
||||
1. What are the first five commands you type on a *nix server after login?
|
||||
|
||||
|
||||
|
||||
> * **lsblk** to see information on all block devices
|
||||
> * **who** to see who is logged into the server
|
||||
> * **top** to get a sense of what is running on the server
|
||||
> * **df -khT** to view the amount of disk space available on the server
|
||||
> * **netstat** to see what TCP network connections are active
|
||||
>
|
||||
|
||||
|
||||
2. How do you make a process run in the background, and what are the advantages of doing so?
|
||||
|
||||
|
||||
|
||||
> You can make a process run in the background by adding the special character **&** at the end of the command. Generally, applications that take too long to execute, and don’t require user interaction are sent to the background so that we can continue our work in the terminal. ([Citation][2])
|
||||
|
||||
3. Is running these commands as root a good or bad idea?
|
||||
|
||||
|
||||
|
||||
> Running (everything) as root is bad due to two major issues. The first is _risk_. Nothing prevents you from making a careless mistake when you are logged in as **root**. If you try to change the system in a potentially harmful way, you need to use **sudo**, which introduces a pause (while you’re entering the password) to ensure that you aren’t about to make a mistake.
|
||||
>
|
||||
> The second reason is _security_. Systems are harder to hack if you don’t know the admin user’s login information. Having access to root means you already have one half of the working set of admin credentials.
|
||||
|
||||
4. What is the difference between **rm** and **rm -rf**?
|
||||
|
||||
|
||||
|
||||
> The **rm** command by itself only deletes the named files (and not directories). With **-rf** you add two additional features: The **-r**, **-R**, or --**recursive** flag recursively deletes the directory’s contents, including hidden files and subdirectories, and the **-f**, or --**force**, flag makes **rm** ignore nonexistent files, and never prompt for confirmation.
|
||||
|
||||
5. **Compress.tgz** has a file size of approximately 15GB. How can you list its contents, and how do you list them only for a specific file?
|
||||
|
||||
|
||||
|
||||
> To list the file’s contents:
|
||||
>
|
||||
> **tar tf archive.tgz**
|
||||
>
|
||||
> To extract a specific file:
|
||||
>
|
||||
> **tar xf archive.tgz filename**
|
||||
|
||||
### Medium difficulty questions
|
||||
|
||||
Here are some harder questions you might encounter, and my answers:
|
||||
|
||||
6. What is RAID? What is RAID 0, RAID 1, RAID 5, RAID 6, and RAID 10?
|
||||
|
||||
|
||||
|
||||
> A RAID (Redundant Array of Inexpensive Disks) is a technology used to increase the performance and/or reliability of data storage. The RAID levels are:
|
||||
>
|
||||
> * RAID 0: Also known as disk striping, which is a technique that breaks up a file, and spreads the data across all of the disk drives in a RAID group. There are no safeguards against failure. ([Citation][3])
|
||||
> * RAID 1: A popular disk subsystem that increases safety by writing the same data on two drives. Called _mirroring_, RAID1 does not increase write performance, but read performance may increase up to the sum of each disks’ performance. Also, if one drive fails, the second drive is used, and the failed drive is manually replaced. After replacement, the RAID controller duplicates the contents of the working drive onto the new one.
|
||||
> * RAID 5: A disk subsystem that increases safety by computing parity data and increasing speed. RAID 5 does this by interleaving data across three or more drives (striping). Upon failure of a single drive, subsequent reads can be calculated from the distributed parity such that no data is lost.
|
||||
> * RAID 6: Which extends RAID 5 by adding another parity block. This level requires a minimum of four disks, and can continue to execute read/write with any two concurrent disk failures. RAID 6 does not have a performance penalty for reading operations, but it does have a performance penalty on write operations because of the overhead associated with parity calculations.
|
||||
> * RAID 10: Also known as RAID 1+0, RAID 10 combines disk mirroring and disk striping to protect data. It requires a minimum of four disks, and stripes data across mirrored pairs. As long as one disk in each mirrored pair is functional, data can be retrieved. If two disks in the same mirrored pair fail, all data will be lost because there is no parity in the striped sets. ([Citation][4])
|
||||
>
|
||||
|
||||
|
||||
7. Which port is used for the **ping** command?
|
||||
|
||||
|
||||
|
||||
> The **ping** command uses ICMP. Specifically, it uses ICMP echo requests and ICMP echo reply packets.
|
||||
>
|
||||
> ICMP does not use either UDP or TCP communication services: Instead, it uses raw IP communication services. This means that the ICMP message is carried directly in an IP datagram data field.
|
||||
|
||||
8. What is the difference between a router and a gateway? What is the default gateway?
|
||||
|
||||
|
||||
|
||||
> _Router_ describes the general technical function (layer 3 forwarding), or a hardware device intended for that purpose, while _gateway_ describes the function for the local segment (providing connectivity to elsewhere). You could also state that you "set up a router as a gateway." Another term is _hop_, which describes forwarding between subnets.
|
||||
>
|
||||
> The term _default gateway_ is used to mean the router on your LAN, which has the responsibility of being the first point of contact for traffic to computers outside the LAN.
|
||||
|
||||
9. Explain the boot process for Linux.
|
||||
|
||||
|
||||
|
||||
> BIOS -> Master Boot Record (MBR) -> GRUB -> the kernel -> init -> runlevel
|
||||
|
||||
10. How do you check the error messages while the server is booting up?
|
||||
|
||||
|
||||
|
||||
> Kernel messages are always stored in the kmsg buffer, visible via the **dmesg** command.
|
||||
>
|
||||
> Boot issues and errors call for a system administrator to look into certain important files, in conjunction with particular commands, which are each handled differently by different versions of Linux:
|
||||
>
|
||||
> * **/var/log/boot.log** is the system boot log, which contains all that unfolded during the system boot.
|
||||
> * **/var/log/messages** stores global system messages, including the messages logged during system boot.
|
||||
> * **/var/log/dmesg** contains kernel ring buffer information.
|
||||
>
|
||||
|
||||
|
||||
11. What is the difference between a symbolic link and a hard link?
|
||||
|
||||
|
||||
|
||||
> A _symbolic_ or _soft link_ is an actual link to the original file, whereas a _hard link_ is a mirror copy of the original file. If you delete the original file, the soft link has no value, because it then points to a non-existent file. In the case of a hard link, it is entirely the opposite. If you delete the original file, the hard link still contains the data from the original file. ([Citation][5])
|
||||
|
||||
12. How do you change kernel parameters? What kernel options might you need to tune?
|
||||
|
||||
|
||||
|
||||
> To set the kernel parameters in Unix-like systems, first edit the file **/etc/sysctl.conf**. After making the changes, save the file and run the **sysctl -p** command. This command makes the changes permanent without rebooting the machine
|
||||
|
||||
13. Explain the **/proc** filesystem.
|
||||
|
||||
|
||||
|
||||
> The **/proc** filesystem is virtual, and provides detailed information about the kernel, hardware, and running processes. Since **/proc** contains virtual files, it is called the _virtual file system_. These virtual files have unique qualities. Most of them are listed as zero bytes in size.
|
||||
>
|
||||
> Virtual files such as **/proc/interrupts**, **/proc/meminfo**, **/proc/mounts** and **/proc/partitions** provide an up-to-the-moment glimpse of the system’s hardware. Others, such as **/proc/filesystems** and the **/proc/sys** directory provide system configuration information and interfaces.
|
||||
|
||||
14. How do you run a script as another user without their password?
|
||||
|
||||
|
||||
|
||||
> For example, if you were editing the sudoers file (such as **/private/etc/sudoers**), you might use **visudo** to add the following:
|
||||
>
|
||||
> [**user1 ALL=(user2) NOPASSWD: /opt/scripts/bin/generate.sh**][2]
|
||||
|
||||
15. What is the UID 0 toor account? Have you been compromised?
|
||||
|
||||
|
||||
|
||||
> The toor user is an alternative superuser account, where toor is root spelled backward. It is intended to be used with a non-standard shell, so the default shell for root does not need to change.
|
||||
>
|
||||
> This purpose is important. Shells which are not part of the base distribution, but are instead installed from ports or packages, are installed in **/usr/local/bin**; which, by default, resides on a different file system. If root’s shell is located in **/usr/local/bin** and the file system containing **/usr/local/bin** is not mounted, root could not log in to fix a problem, and the sysadmin would have to reboot into single-user mode to enter the shell’s path.
|
||||
|
||||
### Advanced questions
|
||||
|
||||
Here are the even more difficult questions you may encounter:
|
||||
|
||||
16. How does **tracert** work and what protocol does it use?
|
||||
|
||||
|
||||
|
||||
> The command **tracert**—or **traceroute** depending on the operating system—allows you to see exactly what routers you touch as you move through the chain of connections to your final destination. If you end up with a problem where you can’t connect to or **ping** your final destination, a **tracert** can help in that you can tell exactly where the chain of connections stops. ([Citation][6])
|
||||
>
|
||||
> With this information, you can contact the correct people; whether it be your own firewall, your ISP, your destination’s ISP, or somewhere in the middle. The **tracert** command—like **ping**—uses the ICMP protocol, but also can use the first step of the TCP three-way handshake to send SYN requests for a response.
|
||||
|
||||
17. What is the main advantage of using **chroot**? When and why do we use it? What is the purpose of the **mount /dev**, **mount /proc**, and **mount /sys** commands in a **chroot** environment?
|
||||
|
||||
|
||||
|
||||
> An advantage of having a **chroot** environment is that the filesystem is isolated from the physical host, since **chroot** has a separate filesystem inside your filesystem. The difference is that **chroot** uses a newly created root (**/**) as its root directory.
|
||||
>
|
||||
> A **chroot** jail lets you isolate a process and its children from the rest of the system. It should only be used for processes that don’t run as **root**, as **root** users can break out of the jail easily.
|
||||
>
|
||||
> The idea is that you create a directory tree where you copy or link in all of the system files needed for the process to run. You then use the **chroot()** system call to tell it the root directory now exists at the base of this new tree, and then start the process running in that **chroot**’d environment. Since the command then can’t reference paths outside the modified root directory, it can’t perform operations (read, write, etc.) maliciously on those locations. ([Citation][7])
|
||||
|
||||
18. How do you protect your system from getting hacked?
|
||||
|
||||
|
||||
|
||||
> By following the principle of least privileges and these practices:
|
||||
>
|
||||
> * Encrypt with public keys, which provides excellent security.
|
||||
> * Enforce password complexity.
|
||||
> * Understand why you are making exceptions to the rules above.
|
||||
> * Review your exceptions regularly.
|
||||
> * Hold someone to account for failure. (It keeps you on your toes.) ([Citation][8])
|
||||
>
|
||||
|
||||
|
||||
19. What is LVM, and what are the advantages of using it?
|
||||
|
||||
|
||||
|
||||
> LVM, or Logical Volume Management, uses a storage device management technology that gives users the power to pool and abstract the physical layout of component storage devices for easier and flexible administration. Using the device mapper Linux kernel framework, the current iteration (LVM2) can be used to gather existing storage devices into groups and allocate logical units from the combined space as needed.
|
||||
|
||||
20. What are sticky ports?
|
||||
|
||||
|
||||
|
||||
> Sticky ports are one of the network administrator’s best friends and worst headaches. They allow you to set up your network so that each port on a switch only permits one (or a number that you specify) computer to connect on that port, by locking it to a particular MAC address.
|
||||
|
||||
21. Explain port forwarding?
|
||||
|
||||
|
||||
|
||||
> When trying to communicate with systems on the inside of a secured network, it can be very difficult to do so from the outside—and with good reason. Therefore, the use of a port forwarding table within the router itself, or other connection management device, can allow specific traffic to automatically forward to a particular destination. For example, if you had a web server running on your network and you wanted to grant access to it from the outside, you would set up port forwarding to port 80 on the server in question. This would mean that anyone entering your IP address in a web browser would connect to the server’s website immediately.
|
||||
>
|
||||
> Please note, it is usually not recommended to allow access to a server from the outside directly into your network.
|
||||
|
||||
22. What is a false positive and false negative in the case of IDS?
|
||||
|
||||
|
||||
|
||||
> When the Intrusion Detection System (IDS) device generates an alert for an intrusion which has actually not happened, this is false positive. If the device has not generated any alert and the intrusion has actually happened, this is the case of a false negative.
|
||||
|
||||
23. Explain **:(){ :|:& };:** and how to stop this code if you are already logged into the system?
|
||||
|
||||
|
||||
|
||||
> This is a fork bomb. It breaks down as follows:
|
||||
>
|
||||
> * **:()** defines the function, with **:** as the function name, and the empty parenthesis shows that it will not accept any arguments.
|
||||
> * **{ }** shows the beginning and end of the function definition.
|
||||
> * **:|:** loads a copy of the function **:** into memory, and pipes its output to another copy of the **:** function, which also has to be loaded into memory.
|
||||
> * **&** makes the previous item a background process, so that the child processes will not get killed even though the parent gets auto-killed.
|
||||
> * **:** at the end executes the function again, and hence the chain reaction begins.
|
||||
>
|
||||
|
||||
>
|
||||
> The best way to protect a multi-user system is to use Privileged Access Management (PAM) to limit the number of processes a user can use.
|
||||
>
|
||||
> The biggest problem with a fork bomb is the fact it takes up so many processes. So, we have two ways of attempting to fix this if you are already logged into the system. One option is to execute a SIGSTOP command to stop the process, such as:
|
||||
>
|
||||
> **killall -STOP -u user1**
|
||||
>
|
||||
> If you can’t use the command line due to all processes being used, you will have to use **exec** to force it to run:
|
||||
>
|
||||
> **exec killall -STOP -u user1**
|
||||
>
|
||||
> With fork bombs, your best option is preventing them from becoming too big of an issue in the first place
|
||||
|
||||
24. What is OOM killer and how does it decide which process to kill first?
|
||||
|
||||
|
||||
|
||||
> If memory is exhaustively used up by processes to the extent that possibly threatens the system’s stability, then the out of memory (OOM) killer comes into the picture.
|
||||
>
|
||||
> An OOM killer first has to select the best process(es) to kill. _Best_ here refers to the process which will free up the maximum memory upon being killed, and is also the least important to the system. The primary goal is to kill the least number of processes to minimize the damage done, and at the same time maximize the amount of memory freed.
|
||||
>
|
||||
> To facilitate this goal, the kernel maintains an oom_score for each of the processes. You can see the oom_score of each of the processes in the **/proc** filesystem under the **pid** directory:
|
||||
>
|
||||
> **$ cat /proc/10292/oom_score**
|
||||
>
|
||||
> The higher the value of oom_score for any process, the higher its likelihood is of being killed by the OOM Killer in an out-of-memory situation. ([Citation][9])
|
||||
|
||||
### Conclusion
|
||||
|
||||
System administration salaries have a [wide range][10] with some sites mentioning $70,000 to $100,000 a year, depending on the location, the size of the organization, and your education level plus years of experience. In the end, the system administration career path boils down to your interest in working with servers and solving cool problems. Now, I would say go ahead and achieve your dream path.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/sysadmin-job-interview-questions
|
||||
|
||||
作者:[DirectedSoul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/directedsoul
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_HowToFish_520x292.png?itok=DHbdxv6H (Question and answer.)
|
||||
[2]: https://github.com/trimstray/test-your-sysadmin-skills
|
||||
[3]: https://www.waytoeasylearn.com/2016/05/netapp-filer-tutorial.html
|
||||
[4]: https://searchstorage.techtarget.com/definition/RAID-10-redundant-array-of-independent-disks
|
||||
[5]: https://www.answers.com/Q/What_is_hard_link_and_soft_link_in_Linux
|
||||
[6]: https://www.wisdomjobs.com/e-university/network-administrator-interview-questions.html
|
||||
[7]: https://unix.stackexchange.com/questions/105/chroot-jail-what-is-it-and-how-do-i-use-it
|
||||
[8]: https://serverfault.com/questions/391370/how-to-prevent-zero-day-attacks
|
||||
[9]: https://unix.stackexchange.com/a/153586/8369
|
||||
[10]: https://blog.netwrix.com/2018/07/23/systems-administrator-salary-in-2018-how-much-can-you-earn/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user