mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-13 00:11:22 +08:00
commit
0c8daafff3
@ -0,0 +1,78 @@
|
||||
Linux 让我对电脑有了更深刻的理解
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
我花了大量时间和耐心在 Linux 上,我的朋友们都能为我证明这点。说起来你可能不信,两年前我还根本不知道 Linux 是什么,放弃 Windows 转投 Linux 更是不可能。
|
||||
|
||||
虽然转投 Linux 这事有点跳跃,但事后证明这是很明智的选择。口说无凭,分析一下我的路线可能会更有说服力一点。通过这个路线来说说我是怎么从小白到精通 Linux 桌面系统的。
|
||||
|
||||
### 安全意识的觉醒
|
||||
|
||||
两年前我也是像一般的 Windows 用户一样,在 Windows 操作系统下工作。虽然我也有跟进了解主流的科技新闻的习惯,但是对计算机我也说不上深刻了解。
|
||||
|
||||
2013 年夏天,美国国家安全局的一份情报项目报告让我对个人隐私安全的态度迅速发生了变化。爱德华斯诺登揭露的网络监控的广度令人不安,而且也凸显出,我们大多数人——甚至不知道如何做——来保护自己的隐私。
|
||||
|
||||
在之前我没有对电脑或它们在我的个人事务中所扮演的角色作出任何特别的考虑,我开始意识到控制一个人的数字生活,以及控制它的设备的重要性。
|
||||
|
||||
按理来说下一步应该是确定该怎么去做。虽然我制订的目标似乎是合乎逻辑的,但要实现它并不简单。在接下来的几个月里,我把自己的空闲时间花在了互联网上,寻找关于隐私保护、加密以及其它任何可以保护我的技术的指南。
|
||||
|
||||
专家们说想逃避情报机构的监控几乎是不可能的。然而,这些专家们也会告诉你,能帮你避开那怕只是避开那么一丢丢的监视 -- 在较小的机构中有相当比例的监控更有可能针对普通民众 -- 唯一可行的办法就是使用开源软件。
|
||||
|
||||
Linux,我很快意识到需要去了解它,因为它是这些开源软件的头头。
|
||||
|
||||
### 闭源与开源
|
||||
|
||||
在进一步的研究中,我开始熟悉开源软件的一些特点。我们每天使用的软件的绝大多数 -- 从聊天软件到操作系统,包括Windows -- 它们都是开源软件的对立面:它们是闭源的。
|
||||
|
||||
例如,当微软的开发人员在 Windows 上进行开发工作时,他们会用一些编程语言编写源代码,并且只在他们的团队内部流传这些代码。当他们准备发布软件时,他们会编译它,将它从人类可读的代码转换成计算机运行的 1 和 0,面对这些机器码,即使是最聪明的人也很难逆向工程到原始源代码。
|
||||
|
||||
在这种模式下,只有软件的开发者才知道这些软件实际在做些什么,有没有私底下监控用户行为。
|
||||
|
||||
开源软件会提供软件的源代码和编译好的二进制代码给公众下载使用。不论是不是每个用户都有能力去阅读这些源代码,评估它们的安全性和隐私性,这都不重要。因为源代码是公开的,总有那么一部分人有这个能力做这些事,一但他们发现这些代码有问题他们就能及时通知其它用户,让公众一起来监督这些开源软件的行为,让那些故意隐藏的恶意代码片段或者非故意的代码漏洞能及时被发现并处理掉。
|
||||
|
||||
经过彻底的研究之后,很明显,唯一能保证我的隐私和用户的自主权的操作系统就是那些具备透明开放的源代码哲学的操作系统。一位知识渊博的朋友和隐私倡导者推荐的最多的是 Linux。如果这是必须的话,我已经准备好接受一个艰难的过渡,但是我对隐私的重要性的信念给了我信心去尝试。
|
||||
|
||||
### 婴儿学步
|
||||
|
||||
虽然我决心转向 Linux 的是急切的,但饭得一口吃,路也得一步一步走。我是最开始是从安装 Ubuntu 开始的 —— 一个容易配置对初学者很友好的 Linux 发行版 —— 在我的老笔记本电脑上它与原有的 Windows 相处融洽井水不犯河水。
|
||||
|
||||
每次启动我的电脑时,我都能选择 Ubuntu 或 Windows ,这样我就能在 Linux 上找到自己的下脚点,同时保留熟悉的 Windows 以防前者可能缺失的一些辅助性功能。
|
||||
|
||||
不久后,一个硬盘驱动器损坏严重让我无法再继续享受这个设置,不过我认为这是一个机会,让我考虑一下买一台 Linux 的新笔记本电脑。由于 Linux 对标准的英特尔处理器、图形卡和无线适配器的驱动程序支持得很好,所以我买了一台联想的 ThinkPad。
|
||||
|
||||
我做了一个全新的开始,完全擦除我的新机器上的 Windows ,安装了 Debian ,这是一个广泛兼容和稳定的发行版,Ubuntu 就是基于它衍生出来的。我不仅在没有熟悉的 Windows 安全网络的情况下挺过来了,我还在不断的进步提高。我很快就沉浸在以前神秘的命令行世界里。
|
||||
|
||||
在我用了一年的 Linux 操作系统之后,我又进行了一次冒险,安装了 Arch Linux ,它需要一个更加复杂的手动用户安装过程,并带有完全的磁盘加密。那天晚上,我和一位 Linux 资深管理人士一起安装了 Arch ,这标志着我生命中最值得骄傲的成就之一。
|
||||
|
||||
在这个过程中,我面临着挑战 -- 有时,在Windows上无缝工作的应用程序需要额外的步骤或需要安装必要的驱动 -- 但是我克服了它们,或者说绕过它们,继续按照我自己的节奏摸索 Linux。
|
||||
|
||||
### 全速前进
|
||||
|
||||
就我而言,那时我才真正开始进行我的学习。我用 Linux 来驾驭计算机,并确保它可以为我工作,不过最让我着迷的是它提供对系统进行修改的自由和个性化处理。
|
||||
|
||||
作为一个开源操作系统,Linux 是无限开放的。尽管我最初期望花时间阅读安全实践(我现在仍然这么做),但我也发现自己深入到配置面板中,并把所有的颜色、图标和菜单都列出来,只是这样而已。
|
||||
|
||||
我花了一些时间去适应,但我越是投入到新事物中,我就变得越自信,越好奇。
|
||||
|
||||
自从在这条路上走了两年多以后,我在电脑上从来没有像今天这么多的感受。我不能像我想要的那样去个性化 Windows,另外依据我从开源社区学到的东西来看,我也不能完全信任它。
|
||||
|
||||
有一个叫电脑的东西,它曾经只是我的的一件不起眼的硬件设备,现在它和我之间的关系变得非常美妙 —— 超越记者和他的笔记本、也超越小提琴家和他的小提琴的关系。
|
||||
|
||||
我甚至为自己的手机不像我的笔记本电脑那样是真正的 Linux 而感到悲哀,我都不知道我能对它做些什么。不管怎么样,我将继续对我的 Arch 系统进行优化,只要有机会我将会再去发现新的领域并探索新的可能性。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84286.html
|
||||
|
||||
作者:[Jonathan Terrasi][a]
|
||||
译者:[zschong](https://github.com/zschong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linkedin.com/company/ect-news-network
|
||||
[1]:http://www.linuxinsider.com/story/84286.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84286
|
||||
@ -0,0 +1,97 @@
|
||||
4 个用于托管开源库的顶级 CDN 服务
|
||||
============================================================
|
||||
|
||||
> 内容分发网络可以加速你的网站图片、CSS、JS、以及其他静态内容。
|
||||
|
||||
|
||||

|
||||
|
||||
>图片版权:[Open Clip Art Library][3],它明确将其公开于**[公共领域][1]**([见此处][4])。由 Jen Wike Huger 修改。
|
||||
|
||||
CDN 或称内容分发网络是位于世界各地的策略性放置的服务器网络,用于更快地向用户传输文件。传统 CDN 能够加速你的网站的图像、CSS、JS 和任何其他静态内容的访问。它允许网站所有者加速自己的所有内容,并为他们提供额外的功能和配置选项,而这些高级服务通常需要根据项目使用的带宽量进行支付。
|
||||
|
||||
但是,如果你的项目无法证明值得实施传统 CDN ,那么使用开源 CDN 可能更合适。通常这些类型的 CDN 能让你链接到流行的 Web 库(例如 CSS/JS 框架),可以让你从免费的 CDN 服务器上传输给你的访问者。虽然开源库的 CDN 服务不允许你将自己的内容上传到服务器,但它们可以帮助你加速全局库并提高网站的冗余性。
|
||||
|
||||
CDN 在庞大的服务器网络上托管项目,因此网站维护者需要修改网站 HTML 代码中的资源链接来反映开源 CDN 的URL,后面跟上资源路径。根据你是否链接到 JavaScript 或 CSS 库,链接将包含在 `<script>` 或 `<link>` 标签中。
|
||||
|
||||
我们来探讨开源库的四大流行 CDN 服务。
|
||||
|
||||
### JsDelivr
|
||||
|
||||
[JsDelivr][5] 是一个使用高级 CDN 提供商(KeyCDN、Stackpath、Cloudflare)的开源 CDN 提供者来分发开源项目资源。jsDelivr 的一些亮点包括:
|
||||
|
||||
* 支持 2100 多个库
|
||||
* 110 个接入点
|
||||
* CDN 可在亚洲和中国使用
|
||||
* 支持 API
|
||||
* 没有流量限制
|
||||
* 完整的 HTTPS 支持
|
||||
|
||||
所有片段都以自定义 jsDelivr URL [https://cdn.jsdelivr.net/][6] 开始,然后是项目名称、版本号等。你还可以配置 jsDelivr 生成带脚本标签的 URL 并启用 SRI(子资源完整性)以增加安全性。
|
||||
|
||||
### Cdnjs
|
||||
|
||||
[Cdnjs][7] 是另一个流行的开源 CDN 提供者,类似于 jsDelivr。此服务还提供了一系列流行的 JavaScript 和 CSS 库,你可以在 Web 项目中进行链接。 该服务由 CDN 提供商 Cloudflare 和 [KeyCDN][8] 赞助。cdnjs 的一些亮点包括:
|
||||
|
||||
* 支持 2900 多个库
|
||||
* 超过一百万个网站使用
|
||||
* 支持 HTTP/2
|
||||
* 支持 HTTPS
|
||||
|
||||
与 jsDelivr 类似,使用 cdnjs,你也可以选择使用或者不使用脚本标签和 SRI 来复制资源 URL。
|
||||
|
||||
### Google 托管库
|
||||
|
||||
[Google 托管库][9]网站允许你链接到托管在 Google 强大的开源 CDN 网络上的流行 JavaScript 库。这个开源的 CDN 解决方案不提供像 jsDelivr 或 cdnjs 一样多的库或者功能。然而,当连接到 Google 托管库时,你可以期待高度的可靠性和信任。Google 开源 CDN 的几个亮点包括:
|
||||
|
||||
* HTTPS 支持
|
||||
* 文件提供 CORS 和 Timing-Allow 头
|
||||
* 提供每个库的最新版本
|
||||
|
||||
所有 Google 的托管库文件都以URL [https://ajax.googleapis.com/][10] 开头,后跟项目的名称、版本号和文件名。
|
||||
|
||||
### Microsoft Ajax CDN
|
||||
|
||||
[Microsoft Ajax CDN][11]与 Google 托管库非常类似,因为它只托管流行的库。但是,将 Microsoft Ajax CDN 与 Google 托管库区分开的两个主要区别是 Microsoft 提供了 CSS 和 JS 库,并且还提供了各种库的各种版本。Microsoft Ajax CDN 的几个亮点包括:
|
||||
|
||||
* HTTPS 支持
|
||||
* 每个库的以前版本通常都可用
|
||||
|
||||
所有的 Microsoft Ajax 文件都以 URL [http://ajax.aspnetcdn.com/ajax/][12] 开头,并且和其它文件一样,后面是库的名字,版本号等。
|
||||
|
||||
如果你的项目或网站尚未准备好利用优质的 CDN 服务,但你仍然希望加速网站的重要方面,那么使用开源 CDN 是一个很好的解决方案。它能够加速第三方库的传输,否则它们将从原始服务器发送,从而导致远方用户不必要的加载以及更慢的速度。
|
||||
|
||||
_你喜欢使用哪个开源 CDN 提供商?为什么?_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Cody Arsenault - Cody 热衷于网络性能,SEO 以及创业活动。他是 KeyCDN 的网络性能倡导者,致力于使网络更快。
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/4/top-cdn-services
|
||||
|
||||
作者:[Cody Arsenault][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/codya
|
||||
[1]:https://en.wikipedia.org/wiki/public_domain
|
||||
[2]:https://opensource.com/article/17/4/top-cdn-services?rate=lgZwEmWt7QXtuMhB-lnHWQ-jxknQ0Kh4YOfqdFGer5w
|
||||
[3]:https://en.wikipedia.org/wiki/Open_Clip_Art_Library
|
||||
[4]:https://openclipart.org/share
|
||||
[5]:http://www.jsdelivr.com/
|
||||
[6]:https://cdn.jsdelivr.net/
|
||||
[7]:https://cdnjs.com/
|
||||
[8]:https://www.keycdn.com/
|
||||
[9]:https://developers.google.com/speed/libraries/
|
||||
[10]:https://ajax.googleapis.com/
|
||||
[11]:https://www.asp.net/ajax/cdn
|
||||
[12]:http://ajax.aspnetcdn.com/ajax/
|
||||
[13]:https://opensource.com/user/128076/feed
|
||||
[14]:https://opensource.com/users/codya
|
||||
@ -1,35 +1,25 @@
|
||||
4 个用于构建优秀的命令行用户界面的 Python 库
|
||||
============================================================
|
||||
|
||||
### 在一个分为两部分的关于具有优秀命令行用户界面的应用的系列文章的第二篇安装教程中,我们将讨论 Prompt、Toolkit、Click、Pygments 和 Fuzzy Finder 。
|
||||
|
||||
> 在这个分为两篇的关于[具有绝佳命令行界面的终端程序][18]的系列文章的第二篇教程中,我们将讨论 Prompt、Toolkit、Click、Pygments 和 Fuzzy Finder 。
|
||||
|
||||

|
||||
>图片来自 : [美国 Mennonite 教堂档案][16] 。 Opensource.com. [CC BY-SA 4.0][17]
|
||||
|
||||
这是我的一个分为两部分的关于具有优秀命令行用户界面的应用的系列文章的第二篇安装教程。在[第一篇文章][18]中,我们讨论了一些能够使命令行应用用起来令人感到高兴的特性。在第二篇文章中,我们来看看如何用 Python 的一些库来实现这些特性。
|
||||
> 图片来自 : [美国 Mennonite 教堂档案][16] 。 Opensource.com. [CC BY-SA 4.0][17]
|
||||
|
||||
这是我的一个分为两篇的关于[具有绝佳命令行界面的终端程序][1]的系列文章的第二篇教程。在[第一篇文章][18]中,我们讨论了一些能够使命令行应用用起来令人感到愉悦的特性。在第二篇文章中,我们来看看如何用 Python 的一些库来实现这些特性。
|
||||
|
||||
我打算用少于 20 行 Python 代码来实现。让我们开始吧。
|
||||
|
||||
编程和开发的一些资源
|
||||
|
||||
* [最新的 Python 内容][1]
|
||||
|
||||
* [我们最新的 JavaScript 文章][2]
|
||||
|
||||
* [近期 Perl 文章][3]
|
||||
|
||||
* [Red Hat 开发者博客][4]
|
||||
|
||||
### Python Prompt Toolkit
|
||||
|
||||
我习惯于把这个库称为命令行应用的瑞士军刀,它可以作为 **[readline][5]** 、**[cursed][6]** 等的替代品。让我们首先安装这个库,然后开始该教程:
|
||||
我习惯于把这个库称为命令行应用的瑞士军刀,它可以作为 [readline][5] 、[curses][6] 等的替代品。让我们首先安装这个库,然后开始该教程:
|
||||
|
||||
```
|
||||
pip install prompt_toolkit
|
||||
```
|
||||
|
||||
我们以一个简单的 REPL 开始。一个典型的 REPL 会接收用户的输入,进行一个操作,然后输出结果。比如在我们的例子中,我们将要实现一个和 “echo” 功能一样的 REPL 。它仅仅是打印出用户的输入:
|
||||
我们以一个简单的 REPL (LCTT 译注:REPL —— Read-Eval-Print Loop,交互式开发环境)开始。一个典型的 REPL 会接收用户的输入,进行一个操作,然后输出结果。比如在我们的例子中,我们将要实现一个具有 “回显” 功能的 REPL 。它仅仅是原样打印出用户的输入:
|
||||
|
||||
#### REPL
|
||||
|
||||
@ -43,9 +33,9 @@ while 1:
|
||||
|
||||
这就是实现 REPL 的全部代码。它可以读取用户的输入,然后打印出用户的输入内容。在这段代码中使用的 `prompt` 函数来自 `prompt_toolkit` 库,它是 `readline` 库的一个替代品。
|
||||
|
||||
#### 历史命令
|
||||
#### 命令历史
|
||||
|
||||
为了提高我们的 REPL,我们可以添加历史命令:
|
||||
为了增强我们的 REPL 的功能,我们可以添加命令历史:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -58,11 +48,11 @@ while 1:
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
我们刚刚给 REPL 添加了持续的**历史命令**。现在,我们可以使用上/下箭头来浏览**历史命令**,并使用 **Ctrl+R** 来搜索**历史命令**。它满足命令行的基本准则。
|
||||
我们刚刚给 REPL 添加了持久的**命令历史**。现在,我们可以使用上/下箭头来浏览**命令历史**,并使用 `Ctrl-R` 来搜索**命令历史**。它满足了命令行的基本准则。
|
||||
|
||||
#### 自动推荐
|
||||
|
||||
在第一篇教程中,我讲到的一个已发现技巧是自动推荐**历史命令**。(我首先在 **fish** shell 中看到这一特性。)让我们把这一特性加入到我们的 REPL 中:
|
||||
在第一篇教程中,我讲到的一个可发现性技巧是自动推荐**历史命令**。(我是首先在 **fish shell** 中看到的这一特性)让我们把这一特性加入到我们的 REPL 中:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -81,11 +71,11 @@ while 1:
|
||||
|
||||
#### 自动补全
|
||||
|
||||
现在,让我们通过**自动补全**来加强 Tab-补全。它能够在用户开始输入的时候弹出可能的命令推荐。
|
||||
现在,让我们通过**自动补全**来加强 Tab 补全。它能够在用户开始输入的时候弹出可能的命令推荐。
|
||||
|
||||
REPL 如何来进行推荐呢?我们使用一个字典来进行可能项的推荐。
|
||||
|
||||
我们实现一个针对 SQL 的 REPL 。我们可以把自动补全字典和 SQL 存到一起。让我们看一看这是如何实现的:
|
||||
比如说我们实现一个针对 SQL 的 REPL 。我们可以把 SQL 关键字存到自动补全字典里面。让我们看一看这是如何实现的:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -107,11 +97,11 @@ while 1:
|
||||
|
||||
再次说明,我们只是简单的使用了 `prompt-toolkit` 内建的一个叫做 `WordCompleter` 的补全特性,它能够把用户输入和可能推荐的字典进行匹配,然后提供一个列表。
|
||||
|
||||
现在,我们有了一个能够自动补全、`fish shell` 风格的历史命令推荐以及上/下浏览历史的 REPL 。实现这些特性只用了不到 10 行的实际代码。
|
||||
现在,我们有了一个能够自动补全、fish shell 风格的历史命令推荐以及上/下浏览历史的 REPL 。实现这些特性只用了不到 10 行的实际代码。
|
||||
|
||||
### Click
|
||||
|
||||
`Click` 是一个命令行创建工具包,使用它能够更容易的为程序解析命令行选项的参数和常量。在这儿我们不讨论如何使用 `Click` 来作为参数解析器。相反,我们将会看到 `Click` 的一些实际功能。
|
||||
`Click` 是一个命令行创建工具包,使用它能够更容易的为程序解析命令行选项的参数和常量。在这儿我们不讨论如何使用 `Click` 来作为参数解析器。相反,我们将会看看 `Click` 带有的一些功能。
|
||||
|
||||
安装 `Click`:
|
||||
|
||||
@ -119,11 +109,11 @@ while 1:
|
||||
pip install click
|
||||
```
|
||||
|
||||
#### Pager
|
||||
#### 分页器
|
||||
|
||||
`Paper` 是 Unix 系统上的实用工具,它们能够一次性在一页上显示很长的输出。`Pager` 的一些例子包括 `less`、`more`、`most` 等。通过 `pager` 来显示一个命令的输出不仅仅是一个友好的设计,同时也是需要正确做的事。
|
||||
分页器是 Unix 系统上的实用工具,它们能够一次一页地显示很长的输出。分页器的一些例子包括 `less`、`more`、`most` 等。通过分页器来显示一个命令的输出不仅仅是一个友好的设计,同时也是必要的。
|
||||
|
||||
让我们进一步改进前面的例子。我们不再使用默认的 `print()` 语句,取而代之的是 `click.echo_via_pager()` 。它将会把输出通过 `pager` 发送到标准输出。这是平台无关的,因此在 Unix 系统或 Windows 系统上均能工作。如果必要的话,`click_via_pager` 会尝试使用一个合适的默认 `pager` 来输出,从而能够显示代码高亮。
|
||||
让我们进一步改进前面的例子。我们不再使用默认的 `print()` 语句,取而代之的是 `click.echo_via_pager()` 。它将会把输出通过分页器发送到标准输出。这是平台无关的,因此在 Unix 系统或 Windows 系统上均能工作。如果必要的话,`click_via_pager` 会尝试使用一个合适的默认分页器来输出,从而能够显示代码高亮。
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -146,7 +136,7 @@ while 1:
|
||||
|
||||
#### 编辑器
|
||||
|
||||
在我以前的文章中,一个值得一提的细节是,当命令过于复杂的时候进入编辑器来编辑。`Click` 有一个[简单的 API][24] 能够打开编辑器,然后把在编辑器中输入的文本返回给应用。
|
||||
在我前面的文章中一个值得一提的细节是,当命令过于复杂的时候进入编辑器来编辑。`Click` 有一个[简单的 API][24] 能够打开编辑器,然后把在编辑器中输入的文本返回给应用。
|
||||
|
||||
```
|
||||
import click
|
||||
@ -155,7 +145,7 @@ message = click.edit()
|
||||
|
||||
### Fuzzy Finder
|
||||
|
||||
`Fuzzy Finder` 是一种通过极小输入来为用户减少推荐的方法。幸运的是,有一个库可以实现 `Fuzzy Finder` 。让我们首先安装这个库:
|
||||
`Fuzzy Finder` 是一种通过少量输入来为用户减少推荐的方法。幸运的是,有一个库可以实现 `Fuzzy Finder` 。让我们首先安装这个库:
|
||||
|
||||
```
|
||||
pip install fuzzyfinder
|
||||
@ -202,9 +192,9 @@ while 1:
|
||||
|
||||
### Pygments
|
||||
|
||||
现在,让我们给用户输入添加语法高亮。我们搭建一个 SQL REPL,并且具有丰富多彩的 SQL 语句,这会很棒。
|
||||
现在,让我们给用户输入添加语法高亮。我们正在搭建一个 SQL REPL,如果具有彩色高亮的 SQL 语句,这会很棒。
|
||||
|
||||
`Pygments` 是一个提供语法高亮的库,内建支持超过 300 种语言。添加语法高亮能够使应用变得丰富多彩,从而能够帮助用户在执行程序前发现 SQL 中存在的错误,比如拼写错误、引号不匹配或括号不匹配。
|
||||
`Pygments` 是一个提供语法高亮的库,内建支持超过 300 种语言。添加语法高亮能够使应用变得彩色化,从而能够帮助用户在执行程序前发现 SQL 中存在的错误,比如拼写错误、引号不匹配或括号不匹配。
|
||||
|
||||
首先,安装 `Pygments` :
|
||||
|
||||
@ -246,7 +236,7 @@ while 1:
|
||||
|
||||
### 结论
|
||||
|
||||
我们的“旅途”通过创建一个强大的 REPL 结束,这个 REPL 具有常见的 shell 的全部特性,比如历史命令,键位绑定,用户友好性比如自动补全、模糊查找、`pager` 支持、编辑器支持和语法高亮。我们仅用少于 20 行 Python 代码实现了这个 REPL 。
|
||||
我们的“旅途”通过创建一个强大的 REPL 结束,这个 REPL 具有常见的 shell 的全部特性,比如历史命令,键位绑定,用户友好性比如自动补全、模糊查找、分页器支持、编辑器支持和语法高亮。我们仅用少于 20 行 Python 代码就实现了这个 REPL 。
|
||||
|
||||
不是很简单吗?现在,你没有理由不会写一个自己的命令行应用了。下面这些资源可能有帮助:
|
||||
|
||||
@ -262,15 +252,15 @@ while 1:
|
||||
|
||||
作者简介:
|
||||
|
||||
Amjith Ramanujam - Amjith Ramanujam 是 `pgcli` 和 `mycli` 的作者。人们认为它们很酷,但是他不同意。他喜欢用 Python、JavaScript 和 C 编程。他喜欢写一些简单、易于理解的代码,有时候这样做是成功的。
|
||||
Amjith Ramanujam - Amjith Ramanujam 是 `pgcli` 和 `mycli` 的创始人。人们认为它们很酷,他表示笑纳赞誉。他喜欢用 Python、JavaScript 和 C 编程。他喜欢写一些简单、易于理解的代码,有时候这样做是成功的。
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/4-practical-python-libraries
|
||||
|
||||
作者:[ Amjith Ramanujam][a]
|
||||
作者:[Amjith Ramanujam][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -292,7 +282,7 @@ via: https://opensource.com/article/17/5/4-practical-python-libraries
|
||||
[15]:https://opensource.com/article/17/5/4-practical-python-libraries?rate=SEw4SQN1U2QSXM7aUHJZb2ZsPwyFylPIbgcVLgC_RBg
|
||||
[16]:https://www.flickr.com/photos/mennonitechurchusa-archives/6987770030/in/photolist-bDu9zC-ovJ8gx-aecxqE-oeZerP-orVJHj-oubnD1-odmmg1-ouBNHR-otUoui-occFe4-ot7LTD-oundj9-odj4iX-9QSskz-ouaoMo-ous5V6-odJKBW-otnxbj-osXERb-iqdyJ8-ovgmPu-bDukCS-sdk9QB-5JQauY-fteJ53-ownm41-ov9Ynr-odxW52-rgqPBV-osyhxE-6QLRz9-i7ki3F-odbLQd-ownZP1-osDU6d-owrTXy-osLLXS-out7Dp-hNHsya-wPbFkS-od7yfD-ouA53c-otnzf9-ormX8L-ouTj6h-e8kAze-oya2zR-hn3B2i-aDNNqk-aDNNmR
|
||||
[17]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[18]:https://opensource.com/article/17/4/4-terminal-apps
|
||||
[18]:https://linux.cn/article-8526-1.html
|
||||
[19]:https://python-prompt-toolkit.readthedocs.io/en/latest/
|
||||
[20]:http://click.pocoo.org/5/
|
||||
[21]:http://pygments.org/
|
||||
200
published/20170518 Maintaining a Git Repository.md
Normal file
200
published/20170518 Maintaining a Git Repository.md
Normal file
@ -0,0 +1,200 @@
|
||||
如何瘦身 Git 仓库
|
||||
============================================================
|
||||
|
||||
对 Git 仓库的维护通常是为了减少仓库的大小。如果你从另外一个版本控制系统导入了一个仓库,你可能需要在导入后清除掉不必要的文件。本文着重于从一个 Git 仓库中删除大文件,并且包含下列主题:
|
||||
|
||||
* 理解从 Git 的历史记录中删除文件
|
||||
* 使用 BFG 重写历史记录
|
||||
* 可选,使用 `git filter-branch` 重写历史记录
|
||||
* 垃圾回收
|
||||
|
||||
> **请格外小心.....**
|
||||
|
||||
> 本文中的步骤和工具使用的高级技术涉及破坏性操作。确保您在开始之前仔细读过并**备份了你的仓库**,创建一个备份最容易的方式是使用 [--mirror][5] 标志对你的仓库克隆,然后对整个克隆的文件进行打包压缩。有了这个备份,如果在维护期间意外损坏了您的仓库的关键元素,那么你可以通过备份的仓库来恢复。
|
||||
|
||||
> 请记住,仓库维护对仓库的用户可能会是毁灭性的。与你的团队或者仓库的关注者进行沟通会是一个不错的主意。确保每个人都已经检查了他们的代码,并且同意在仓库维护期间停止开发。
|
||||
|
||||
### 理解从 Git 的历史记录中删除文件
|
||||
|
||||
回想一下,克隆仓库会克隆整个历史记录——包括每个源代码文件的所有版本。如果一个用户提交了一个较大的文件,比如一个 JAR,则随后的每次克隆都会包含这个文件。即使用户最终在后面的某次提交中删除了这个文件,但是这个文件仍然存在于这个仓库的历史记录中。要想完全的从你的仓库中删除这个文件,你必须:
|
||||
|
||||
* 从你的项目的*当前的*文件树中删除该文件;
|
||||
* 从仓库的历史记录中删除文件——*重写* Git 历史记录,从包含该文件的*所有的*提交中删除这个文件;
|
||||
* 删除指向*旧的*提交历史记录的所有 [reflog][6] 历史记录;
|
||||
* 重新整理仓库,使用 [git gc][7] 对现在没有使用的数据进行垃圾回收。
|
||||
|
||||
Git 的 “gc”(垃圾回收)将通过你的任何一个分支或者标签来删除仓库中所有的实际没用的或者以某种方式引用的数据。为了使其发挥作用,我们需要重写包含不需要的文件的所有 Git 仓库历史记录,仓库将不再引用它—— git gc 将会丢弃所有没用的数据。
|
||||
|
||||
重写存储库历史是一个棘手的事情,因为每个提交都依赖它的父提交,所以任何一个很小的改变都会改变它的每一个随后的提交的提交 ID。有两个自动化的工具可以做到这:
|
||||
|
||||
1. [BFG Repo Cleaner][8] 快速、简单且易于使用,需要 Java 6 或者更高版本的运行环境。
|
||||
2. [git filter-branch][9] 功能强大、配置麻烦,用于大于仓库时速度较慢,是核心 Git 套件的一部分。
|
||||
|
||||
切记,当你重写历史记录后,无论你是使用 BFG 还是使用 filter-branch,你都需要删除指向旧的历史记录的 `reflog` 条目,最后运行垃圾回收器来删除旧的数据。
|
||||
|
||||
### 使用 BFG 重写历史记录
|
||||
|
||||
[BFG][11] 是为将像大文件或者密码这些不想要的数据从 Git 仓库中删除而专门设计的,所以它有一一个简单的标志用来删除那些大的历史文件(不在当前的提交里面):`--strip-blobs-bigger-than`
|
||||
|
||||
```
|
||||
$ java -jar bfg.jar --strip-blobs-than 100M
|
||||
|
||||
```
|
||||
大小超过 100MB 的任何文件(不包含在你*最近的*提交中的文件——因为 BFG [默认会保护你的最新提交的内容][12])将会从你的 Git 仓库的历史记录中删除。如果你想用名字来指明具体的文件,你也可以这样做:
|
||||
|
||||
```
|
||||
$ java -jar bfg.jar --delete-files *.mp4
|
||||
|
||||
```
|
||||
|
||||
BFG 的速度要比 `git filter-branch` 快 [10-1000 倍][13],而且通常更容易使用——查看完整的[使用说明][14]和[示例][15]获取更多细节。
|
||||
|
||||
### 或者,使用 git filter-branch 来重写历史记录
|
||||
|
||||
`filter-branch` 命令可以对 Git 仓库的历史记录重写,就像 BFG 一样,但是过程更慢和更手动化。如果你不知道这些大文件在_哪里_,那么你第一步就需要找到它们:
|
||||
|
||||
#### 手动查看你 Git 仓库中的大文件
|
||||
|
||||
[Antony Stubbs][16] 写了一个可以很好地完成这个功能的 BASH 脚本。该脚本可以检查你的包文件的内容并列出大文件。在你开始删除文件之前,请执行以下操作获取并安装此脚本:
|
||||
|
||||
1、 [下载脚本][10]到你的本地的系统。
|
||||
|
||||
2、 将它放在一个可以访问你的 Git 仓库的易于找到的位置。
|
||||
|
||||
3、 让脚本成为可执行文件:
|
||||
|
||||
```
|
||||
$ chmod 777 git_find_big.sh
|
||||
```
|
||||
|
||||
4、 克隆仓库到你本地系统。
|
||||
|
||||
5、 改变当前目录到你的仓库根目录。
|
||||
|
||||
6、 手动运行 Git 垃圾回收器:
|
||||
|
||||
```
|
||||
git gc --auto
|
||||
```
|
||||
|
||||
7、 找出 .git 文件夹的大小
|
||||
|
||||
```
|
||||
$ du -hs .git/objects
|
||||
45M .git/objects
|
||||
```
|
||||
|
||||
注意文件大小,以便随后参考。
|
||||
|
||||
8、 运行 `git_find_big.sh` 脚本来列出你的仓库中的大文件。
|
||||
|
||||
```
|
||||
$ git_find_big.sh
|
||||
All sizes are in kB's. The pack column is the size of the object, compressed, inside the pack file.
|
||||
size pack SHA location
|
||||
592 580 e3117f48bc305dd1f5ae0df3419a0ce2d9617336 media/img/emojis.jar
|
||||
550 169 b594a7f59ba7ba9daebb20447a87ea4357874f43 media/js/aui/aui-dependencies.jar
|
||||
518 514 22f7f9a84905aaec019dae9ea1279a9450277130 media/images/screenshots/issue-tracker-wiki.jar
|
||||
337 92 1fd8ac97c9fecf74ba6246eacef8288e89b4bff5 media/js/lib/bundle.js
|
||||
240 239 e0c26d9959bd583e5ef32b6206fc8abe5fea8624 media/img/featuretour/heroshot.png
|
||||
```
|
||||
|
||||
大文件都是 JAR 文件,包的大小列是最相关的。`aui-dependencies.jar` 被压缩到 169kb,但是 `emojis.jar` 只压缩到 500kb。`emojis.jar` 就是一个待删除的对象。
|
||||
|
||||
#### 运行 filter-branch
|
||||
|
||||
你可以给这个命令传递一个用于重写 Git 索引的过滤器。例如,一个过滤器可以可以将每个检索的提交删除。这个用法如下:
|
||||
|
||||
```
|
||||
git filter-branch --index-filter 'git rm --cached --ignore-unmatch _pathname_ ' commitHASH
|
||||
```
|
||||
|
||||
`--index-filter` 选项可以修改仓库的索引,`--cached ` 选项从索引中而不是磁盘来删除文件。这样会更快,因为你不需要在运行这个过滤器前检查每个修订版本。`git rm` 中的 `ignore-unmatch` 选项可以防止在尝试移走不存在的文件 `pathname` 的时候命令失败。通过指定一个提交 HASH 值,你可以从每个以这个 HASH 值开始的提交中删除`pathname`。要从开始处删除,你可以省略这个参数或者指定为 `HEAD`。
|
||||
|
||||
如果你的大文件在不同的分支,你将需要通过名字来删除每个文件。如果大文件都在一个单独的分支,你可以直接删除这个分支本身。
|
||||
|
||||
#### 选项 1:通过文件名删除文件
|
||||
|
||||
使用下面的步骤来删除大文件:
|
||||
|
||||
1、 使用下面的命令来删除你找到的第一个大文件:
|
||||
|
||||
```
|
||||
git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
|
||||
|
||||
```
|
||||
|
||||
2、 重复步骤 1 找到剩下的每个大文件。
|
||||
|
||||
3、 在你的仓库里更新引用。 `filter-branch` 会为你原先的引用创建一个 `refs/original/` 下的备份。一旦你确信已经删除了正确的文件,你可以运行下面的命令来删除备份文件,同时可以让垃圾回收器回收大的对象:
|
||||
|
||||
```
|
||||
git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
|
||||
|
||||
```
|
||||
|
||||
#### 选项 2:直接删除分支
|
||||
|
||||
如果你所有的大文件都在一个单独的分支上,你可以直接删除这个分支。删除这个分支会自动删除所有的引用。
|
||||
|
||||
1、 删除分支。
|
||||
|
||||
```
|
||||
$ git branch -D PROJ567bugfix
|
||||
```
|
||||
|
||||
2、 从后面的分支中删除所有的 reflog 引用。
|
||||
|
||||
|
||||
### 对不用的数据垃圾回收
|
||||
|
||||
1、 删除从现在到后面的所有 reflog 引用(除非你明确地只在一个分支上操作)。
|
||||
|
||||
```
|
||||
$ git reflog expire --expire=now --all
|
||||
```
|
||||
|
||||
2、 通过运行垃圾回收器和删除旧的对象重新打包仓库。
|
||||
|
||||
```
|
||||
$ git gc --prune=now
|
||||
```
|
||||
|
||||
3、 把你所有的修改推送回仓库。
|
||||
|
||||
```
|
||||
$ git push --all --force
|
||||
```
|
||||
|
||||
4、 确保你所有的标签也是当前最新的:
|
||||
|
||||
```
|
||||
$ git push --tags --force
|
||||
```
|
||||
|
||||
----------
|
||||
via: https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
|
||||
|
||||
作者:[atlassian.com][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
|
||||
[1]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UnderstandingfileremovalfromGithistory
|
||||
[2]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UsingtheBFGtorewritehistory
|
||||
[3]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Alternatively,usinggitfilter-branchtorewritehistory
|
||||
[4]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Garbagecollectingdeaddata
|
||||
[5]:http://stackoverflow.com/questions/3959924/whats-the-difference-between-git-clone-mirror-and-git-clone-bare
|
||||
[6]:http://git-scm.com/docs/git-reflog
|
||||
[7]:http://git-scm.com/docs/git-gc
|
||||
[8]:http://rtyley.github.io/bfg-repo-cleaner/
|
||||
[9]:http://git-scm.com/docs/git-filter-branch
|
||||
[10]:https://confluence.atlassian.com/bitbucket/files/321848291/321979854/1/1360604134990/git_find_big.sh
|
||||
[11]:http://rtyley.github.io/bfg-repo-cleaner/
|
||||
[12]:http://rtyley.github.io/bfg-repo-cleaner/#protected-commits
|
||||
[13]:https://www.youtube.com/watch?v=Ir4IHzPhJuI
|
||||
[14]:http://rtyley.github.io/bfg-repo-cleaner/#usage
|
||||
[15]:http://rtyley.github.io/bfg-repo-cleaner/#examples
|
||||
[16]:https://stubbisms.wordpress.com/2009/07/10/git-script-to-show-largest-pack-objects-and-trim-your-waist-line/
|
||||
@ -1,7 +1,7 @@
|
||||
在 Linux 中使用 ‘pushd’ 和 ‘popd’ 命令来进行高效的文件浏览
|
||||
在 Linux 中使用 pushd 和 popd 命令来进行高效的目录导航
|
||||
======
|
||||
|
||||
有时候,通过命令来浏览 Linux 文件系统是一件非常痛苦的事情,特别是对于一些新手。通常情况下,我们主要使用 [cd(改变目录)命令][1]在 Linux 文件系统之间移动。
|
||||
有时候,通过命令来在 Linux 文件系统导航是一件非常痛苦的事情,特别是对于一些新手。通常情况下,我们主要使用 [cd(改变目录)命令][1]在 Linux 文件系统之间移动。
|
||||
|
||||
在之前的文章中,我们回顾了一个非常简单但很有用的 Linux 上的 CLI 工具,文章叫做 [bd:快速返回某级父目录而不用冗余地输入 “cd ../../..”][2]
|
||||
|
||||
@ -19,7 +19,7 @@
|
||||
|
||||
```
|
||||
$ dirs
|
||||
OR
|
||||
或
|
||||
$ dirs -v
|
||||
```
|
||||
|
||||
@ -102,15 +102,15 @@ via: https://www.tecmint.com/pushd-and-popd-linux-filesystem-navigation/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:hhttps://linux.cn/article-8491-1.html
|
||||
[3]:https://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
[4]:https://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
[2]:https://linux.cn/article-8491-1.html
|
||||
[3]:https://linux.cn/article-5983-1.html
|
||||
[4]:https://linux.cn/article-5983-1.html
|
||||
[5]:https://www.tecmint.com/author/aaronkili/
|
||||
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,54 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
Faster machine learning is coming to the Linux kernel
|
||||
============================================================
|
||||
|
||||
### The addition of heterogenous memory management to the Linux kernel will unlock new ways to speed up GPUs, and potentially other kinds of machine learning hardware
|
||||
|
||||
|
||||

|
||||
>Credit: Thinkstock
|
||||
|
||||
It's been a long time in the works, but a memory management feature intended to give machine learning or other GPU-powered applications a major performance boost is close to making it into one of the next revisions of the kernel.
|
||||
|
||||
Heterogenous memory management (HMM) allows a device’s driver to mirror the address space for a process under its own memory management. As Red Hat developer Jérôme Glisse [explains][10], this makes it easier for hardware devices like GPUs to directly access the memory of a process without the extra overhead of copying anything. It also doesn't violate the memory protection features afforded by modern OSes.
|
||||
|
||||
|
||||
One class of application that stands to benefit most from HMM is GPU-based machine learning. Libraries like OpenCL and CUDA would be able to get a speed boost from HMM. HMM does this in much the same way as [speedups being done to GPU-based machine learning][11], namely by leaving data in place near the GPU, operating directly on it there, and moving it around as little as possible.
|
||||
|
||||
These kinds of speed-ups for CUDA, Nvidia’s library for GPU-based processing, would only benefit operations on Nvidia GPUs, but those GPUs currently constitute the vast majority of the hardware used to accelerate number crunching. However, OpenCL was devised to write code that could target multiple kinds of hardware—CPUs, GPUs, FPGAs, and so on—so HMM could provide much broader benefits as that hardware matures.
|
||||
|
||||
|
||||
There are a few obstacles to getting HMM into a usable state in Linux. First is kernel support, which has been under wraps for quite some time. HMM was first proposed as a Linux kernel patchset [back in 2014][12], with Red Hat and Nvidia both involved as key developers. The amount of work involved wasn’t trivial, but the developers believe code could be submitted for potential inclusion within the next couple of kernel releases.
|
||||
|
||||
The second obstacle is video driver support, which Nvidia has been working on separately. According to Glisse’s notes, AMD GPUs are likely to support HMM as well, so this particular optimization won’t be limited to Nvidia GPUs. AMD has been trying to ramp up its presence in the GPU market, potentially by [merging GPU and CPU processing][13] on the same die. However, the software ecosystem still plainly favors Nvidia; there would need to be a few more vendor-neutral projects like HMM, and OpenCL performance on a par with what CUDA can provide, to make real choice possible.
|
||||
|
||||
The third obstacle is hardware support, since HMM requires the presence of a replayable page faults hardware feature to work. Only Nvidia’s Pascal line of high-end GPUs supports this feature. In a way that’s good news, since it means Nvidia will only need to provide driver support for one piece of hardware—requiring less work on its part—to get HMM up and running.
|
||||
|
||||
Once HMM is in place, there will be pressure on public cloud providers with GPU instances to [support the latest-and-greatest generation of GPU][14]. Not just by swapping old-school Nvidia Kepler cards for bleeding-edge Pascal GPUs; as each succeeding generation of GPU pulls further away from the pack, support optimizations like HMM will provide strategic advantages.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3196884/linux/faster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&via=infoworld&text=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[3]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&title=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[4]:https://plus.google.com/share?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[5]:http://reddit.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&title=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[6]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[7]:http://www.infoworld.com/article/3196884/linux/faster-machine-learning-is-coming-to-the-linux-kernel.html#email
|
||||
[8]:http://www.infoworld.com/article/3152565/linux/5-rock-solid-linux-distros-for-developers.html#tk.ifw-infsb
|
||||
[9]:http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[10]:https://lkml.org/lkml/2017/4/21/872
|
||||
[11]:http://www.infoworld.com/article/3195437/machine-learning-analytics-get-a-boost-from-gpu-data-frame-project.html
|
||||
[12]:https://lwn.net/Articles/597289/
|
||||
[13]:http://www.infoworld.com/article/3099204/hardware/amd-mulls-a-cpugpu-super-chip-in-a-server-reboot.html
|
||||
[14]:http://www.infoworld.com/article/3126076/artificial-intelligence/aws-machine-learning-vms-go-faster-but-not-forward.html
|
||||
@ -1,329 +0,0 @@
|
||||
ictlyh Translating
|
||||
Writing a Linux Debugger Part 4: Elves and dwarves
|
||||
============================================================
|
||||
|
||||
Up until now you’ve heard whispers of dwarves, of debug information, of a way to understand the source code without just parsing the thing. Today we’ll be going into the details of source-level debug information in preparation for using it in following parts of this tutorial.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][1]
|
||||
|
||||
2. [Breakpoints][2]
|
||||
|
||||
3. [Registers and memory][3]
|
||||
|
||||
4. [Elves and dwarves][4]
|
||||
|
||||
5. [Source and signals][5]
|
||||
|
||||
6. [Source-level stepping][6]
|
||||
|
||||
7. Source-level breakpoints
|
||||
|
||||
8. Stack unwinding
|
||||
|
||||
9. Reading variables
|
||||
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### Introduction to ELF and DWARF
|
||||
|
||||
ELF and DWARF are two components which you may not have heard of, but probably use most days. ELF (Executable and Linkable Format) is the most widely used object file format in the Linux world; it specifies a way to store all of the different parts of a binary, like the code, static data, debug information, and strings. It also tells the loader how to take the binary and ready it for execution, which involves noting where different parts of the binary should be placed in memory, which bits need to be fixed up depending on the position of other components ( _relocations_ ) and more. I won’t cover much more of ELF in these posts, but if you’re interested, you can have a look at [this wonderful infographic][7] or [the standard][8].
|
||||
|
||||
DWARF is the debug information format most commonly used with ELF. It’s not necessarily tied to ELF, but the two were developed in tandem and work very well together. This format allows a compiler to tell a debugger how the original source code relates to the binary which is to be executed. This information is split across different ELF sections, each with its own piece of information to relay. Here are the different sections which are defined, taken from this highly informative if slightly out of date [Introduction to the DWARF Debugging Format][9]:
|
||||
|
||||
* `.debug_abbrev` Abbreviations used in the `.debug_info` section
|
||||
|
||||
* `.debug_aranges` A mapping between memory address and compilation
|
||||
|
||||
* `.debug_frame` Call Frame Information
|
||||
|
||||
* `.debug_info` The core DWARF data containing DWARF Information Entries (DIEs)
|
||||
|
||||
* `.debug_line` Line Number Program
|
||||
|
||||
* `.debug_loc` Location descriptions
|
||||
|
||||
* `.debug_macinfo` Macro descriptions
|
||||
|
||||
* `.debug_pubnames` A lookup table for global objects and functions
|
||||
|
||||
* `.debug_pubtypes` A lookup table for global types
|
||||
|
||||
* `.debug_ranges` Address ranges referenced by DIEs
|
||||
|
||||
* `.debug_str` String table used by `.debug_info`
|
||||
|
||||
* `.debug_types` Type descriptions
|
||||
|
||||
We are most interested in the `.debug_line` and `.debug_info` sections, so lets have a look at some DWARF for a simple program.
|
||||
|
||||
```
|
||||
int main() {
|
||||
long a = 3;
|
||||
long b = 2;
|
||||
long c = a + b;
|
||||
a = 4;
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### DWARF line table
|
||||
|
||||
If you compile this program with the `-g` option and run the result through `dwarfdump`, you should see something like this for the line number section:
|
||||
|
||||
```
|
||||
.debug_line: line number info for a single cu
|
||||
Source lines (from CU-DIE at .debug_info offset 0x0000000b):
|
||||
|
||||
NS new statement, BB new basic block, ET end of text sequence
|
||||
PE prologue end, EB epilogue begin
|
||||
IS=val ISA number, DI=val discriminator value
|
||||
<pc> [lno,col] NS BB ET PE EB IS= DI= uri: "filepath"
|
||||
0x00400670 [ 1, 0] NS uri: "/home/simon/play/MiniDbg/examples/variable.cpp"
|
||||
0x00400676 [ 2,10] NS PE
|
||||
0x0040067e [ 3,10] NS
|
||||
0x00400686 [ 4,14] NS
|
||||
0x0040068a [ 4,16]
|
||||
0x0040068e [ 4,10]
|
||||
0x00400692 [ 5, 7] NS
|
||||
0x0040069a [ 6, 1] NS
|
||||
0x0040069c [ 6, 1] NS ET
|
||||
|
||||
```
|
||||
|
||||
The first bunch of lines is some information on how to understand the dump – the main line number data starts at the line starting with `0x00400670`. Essentially this maps a code memory address with a line and column number in some file. `NS` means that the address marks the beginning of a new statement, which is often used for setting breakpoints or stepping. `PE`marks the end of the function prologue, which is helpful for setting function entry breakpoints. `ET` marks the end of the translation unit. The information isn’t actually encoded like this; the real encoding is a very space-efficient program of sorts which can be executed to build up this line information.
|
||||
|
||||
So, say we want to set a breakpoint on line 4 of variable.cpp, what do we do? We look for entries corresponding to that file, then we look for a relevant line entry, look up the address which corresponds to it, and set a breakpoint there. In our example, that’s this entry:
|
||||
|
||||
```
|
||||
0x00400686 [ 4,14] NS
|
||||
|
||||
```
|
||||
|
||||
So we want to set a breakpoint at address `0x00400686`. You could do so by hand with the debugger you’ve already written if you want to give it a try.
|
||||
|
||||
The reverse works just as well. If we have a memory location – say, a program counter value – and want to find out where that is in the source, we just find the closest mapped address in the line table information and grab the line from there.
|
||||
|
||||
* * *
|
||||
|
||||
### DWARF debug info
|
||||
|
||||
The `.debug_info` section is the heart of DWARF. It gives us information about the types, functions, variables, hopes, and dreams present in our program. The fundamental unit in this section is the DWARF Information Entry, affectionately known as DIEs. A DIE consists of a tag telling you what kind of source-level entity is being represented, followed by a series of attributes which apply to that entity. Here’s the `.debug_info` section for the simple example program I posted above:
|
||||
|
||||
```
|
||||
|
||||
.debug_info
|
||||
|
||||
COMPILE_UNIT<header overall offset = 0x00000000>:
|
||||
< 0><0x0000000b> DW_TAG_compile_unit
|
||||
DW_AT_producer clang version 3.9.1 (tags/RELEASE_391/final)
|
||||
DW_AT_language DW_LANG_C_plus_plus
|
||||
DW_AT_name /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_stmt_list 0x00000000
|
||||
DW_AT_comp_dir /super/secret/path/MiniDbg/build
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
|
||||
LOCAL_SYMBOLS:
|
||||
< 1><0x0000002e> DW_TAG_subprogram
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
DW_AT_name main
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000001
|
||||
DW_AT_type <0x00000077>
|
||||
DW_AT_external yes(1)
|
||||
< 2><0x0000004c> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -8
|
||||
DW_AT_name a
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000002
|
||||
DW_AT_type <0x0000007e>
|
||||
< 2><0x0000005a> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -16
|
||||
DW_AT_name b
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000003
|
||||
DW_AT_type <0x0000007e>
|
||||
< 2><0x00000068> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -24
|
||||
DW_AT_name c
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000004
|
||||
DW_AT_type <0x0000007e>
|
||||
< 1><0x00000077> DW_TAG_base_type
|
||||
DW_AT_name int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000004
|
||||
< 1><0x0000007e> DW_TAG_base_type
|
||||
DW_AT_name long int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000008
|
||||
|
||||
```
|
||||
|
||||
The first DIE represents a compilation unit (CU), which is essentially a source file with all of the `#includes` and such resolved. Here are the attributes annotated with their meaning:
|
||||
|
||||
```
|
||||
DW_AT_producer clang version 3.9.1 (tags/RELEASE_391/final) <-- The compiler which produced
|
||||
this binary
|
||||
DW_AT_language DW_LANG_C_plus_plus <-- The source language
|
||||
DW_AT_name /super/secret/path/MiniDbg/examples/variable.cpp <-- The name of the file which
|
||||
this CU represents
|
||||
DW_AT_stmt_list 0x00000000 <-- An offset into the line table
|
||||
which tracks this CU
|
||||
DW_AT_comp_dir /super/secret/path/MiniDbg/build <-- The compilation directory
|
||||
DW_AT_low_pc 0x00400670 <-- The start of the code for
|
||||
this CU
|
||||
DW_AT_high_pc 0x0040069c <-- The end of the code for
|
||||
this CU
|
||||
|
||||
```
|
||||
|
||||
The other DIEs follow a similar scheme, and you can probably intuit what the different attributes mean.
|
||||
|
||||
Now we can try and solve a few practical problems with our new-found knowledge of DWARF.
|
||||
|
||||
### Which function am I in?
|
||||
|
||||
Say we have a program counter value and want to figure out what function we’re in. A simple algorithm for this is:
|
||||
|
||||
```
|
||||
for each compile unit:
|
||||
if the pc is between DW_AT_low_pc and DW_AT_high_pc:
|
||||
for each function in the compile unit:
|
||||
if the pc is between DW_AT_low_pc and DW_AT_high_pc:
|
||||
return function information
|
||||
|
||||
```
|
||||
|
||||
This will work for many purposes, but things get a bit more difficult in the presence of member functions and inlining. With inlining, for example, once we’ve found the function whose range contains our PC, we’ll need to recurse over the children of that DIE to see if there are any inlined functions which are a better match. I won’t deal with inlining in my code for this debugger, but you can add support for this if you like.
|
||||
|
||||
### How do I set a breakpoint on a function?
|
||||
|
||||
Again, this depends on if you want to support member functions, namespaces and suchlike. For free functions you can just iterate over the functions in different compile units until you find one with the right name. If your compiler is kind enough to fill in the `.debug_pubnames` section, you can do this a lot more efficiently.
|
||||
|
||||
Once the function has been found, you can set a breakpoint on the memory address given by `DW_AT_low_pc`. However, that’ll break at the start of the function prologue, but it’s preferable to break at the start of the user code. Since the line table information can specify the memory address which specifies the prologue end, you could just lookup the value of `DW_AT_low_pc` in the line table, then keep reading until you get to the entry marked as the prologue end. Some compilers won’t output this information though, so another option is to just set a breakpoint on the address given by the second line entry for that function.
|
||||
|
||||
Say we want to set a breakpoint on `main` in our example program. We search for the function called `main`, and get this DIE:
|
||||
|
||||
```
|
||||
< 1><0x0000002e> DW_TAG_subprogram
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
DW_AT_name main
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000001
|
||||
DW_AT_type <0x00000077>
|
||||
DW_AT_external yes(1)
|
||||
|
||||
```
|
||||
|
||||
This tells us that the function begins at `0x00400670`. If we look this up in our line table, we get this entry:
|
||||
|
||||
```
|
||||
0x00400670 [ 1, 0] NS uri: "/super/secret/path/MiniDbg/examples/variable.cpp"
|
||||
|
||||
```
|
||||
|
||||
We want to skip the prologue, so we read ahead an entry:
|
||||
|
||||
```
|
||||
0x00400676 [ 2,10] NS PE
|
||||
|
||||
```
|
||||
|
||||
Clang has included the prologue end flag on this entry, so we know to stop here and set a breakpoint on address `0x00400676`.
|
||||
|
||||
### How do I read the contents of a variable?
|
||||
|
||||
Reading variables can be very complex. They are elusive things which can move around throughout a function, sit in registers, be placed in memory, be optimised out, hide in the corner, whatever. Fortunately our simple example is, well, simple. If we want to read the contents of variable `a`, we have a look at its `DW_AT_location` attribute:
|
||||
|
||||
```
|
||||
DW_AT_location DW_OP_fbreg -8
|
||||
|
||||
```
|
||||
|
||||
This says that the contents are stored at an offset of `-8` from the base of the stack frame. To work out where this base is, we look at the `DW_AT_frame_base` attribute on the containing function.
|
||||
|
||||
```
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
|
||||
```
|
||||
|
||||
`reg6` on x86 is the frame pointer register, as specified by the [System V x86_64 ABI][10]. Now we read the contents of the frame pointer, subtract 8 from it, and we’ve found our variable. If we actually want to make sense of the thing, we’ll need to look at its type:
|
||||
|
||||
```
|
||||
< 2><0x0000004c> DW_TAG_variable
|
||||
DW_AT_name a
|
||||
DW_AT_type <0x0000007e>
|
||||
|
||||
```
|
||||
|
||||
If we look up this type in the debug information, we get this DIE:
|
||||
|
||||
```
|
||||
< 1><0x0000007e> DW_TAG_base_type
|
||||
DW_AT_name long int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000008
|
||||
|
||||
```
|
||||
|
||||
This tells us that the type is a 8 byte (64 bit) signed integer type, so we can go ahead and interpret those bytes as an `int64_t` and display it to the user.
|
||||
|
||||
Of course, types can get waaaaaaay more complex than that, as they have to be able to express things like C++ types, but this gives you a basic idea of how they work.
|
||||
|
||||
Coming back to that frame base for a second, Clang was nice enough to track the frame base with the frame pointer register. Recent versions of GCC tend to prefer `DW_OP_call_frame_cfa`, which involves parsing the `.eh_frame` ELF section, and that’s an entirely different article which I won’t be writing. If you tell GCC to use DWARF 2 instead of more recent versions, it’ll tend to output location lists, which are somewhat easier to read:
|
||||
|
||||
```
|
||||
DW_AT_frame_base <loclist at offset 0x00000000 with 4 entries follows>
|
||||
low-off : 0x00000000 addr 0x00400696 high-off 0x00000001 addr 0x00400697>DW_OP_breg7+8
|
||||
low-off : 0x00000001 addr 0x00400697 high-off 0x00000004 addr 0x0040069a>DW_OP_breg7+16
|
||||
low-off : 0x00000004 addr 0x0040069a high-off 0x00000031 addr 0x004006c7>DW_OP_breg6+16
|
||||
low-off : 0x00000031 addr 0x004006c7 high-off 0x00000032 addr 0x004006c8>DW_OP_breg7+8
|
||||
|
||||
```
|
||||
|
||||
A location list gives different locations depending on where the program counter is. This example says that if the PC is at an offset of `0x0` from `DW_AT_low_pc` then the frame base is an offset of 8 away from the value stored in register 7, if it’s between `0x1` and `0x4` away, then it’s at an offset of 16 away from the same, and so on.
|
||||
|
||||
* * *
|
||||
|
||||
### Take a breath
|
||||
|
||||
That’s a lot of information to get your head round, but the good news is that in the next few posts we’re going to have a library do the hard work for us. It’s still useful to understand the concepts at play, particularly when something goes wrong or when you want to support some DWARF concept which isn’t implemented in whatever DWARF library you use.
|
||||
|
||||
If you want to learn more about DWARF, then you can grab the standard [here][11]. At the time of writing, DWARF 5 has just been released, but DWARF 4 is more commonly supported.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
|
||||
作者:[ TartanLlama ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/corkami/pics/raw/master/binary/elf101/elf101-64.pdf
|
||||
[8]:http://www.skyfree.org/linux/references/ELF_Format.pdf
|
||||
[9]:http://www.dwarfstd.org/doc/Debugging%20using%20DWARF-2012.pdf
|
||||
[10]:https://www.uclibc.org/docs/psABI-x86_64.pdf
|
||||
[11]:http://dwarfstd.org/Download.php
|
||||
@ -1,108 +0,0 @@
|
||||
Top 4 CDN services for hosting open source libraries
|
||||
============================================================
|
||||
|
||||
### Content delivery networks accelerate your website's images, CSS files, JS files, and other static content.
|
||||
|
||||
|
||||

|
||||
>Image credits : [Open Clip Art Library][3], which released it explicitly into the **[public domain][1]** ([see here][4]). Modified by Jen Wike Huger.
|
||||
|
||||
A CDN, or content delivery network, is a network of strategically placed servers located around the world used for the purpose of delivering files faster to users. A traditional CDN will allow you to accelerate your website's images, CSS files, JS files, and any other piece of static content. This allows website owners to accelerate all of their own content as well as provide them with additional features and configuration options. These premium services typically require payment based on the amount of bandwidth a project uses.
|
||||
|
||||
However, if your project doesn't justify the cost of implementing a traditional CDN, the use of an open source CDN may be more suitable. Typically, these types of CDNs allow you to link to popular web-based libraries (CSS/JS frameworks, for example), which are then delivered to your web visitors from the free CDN's servers. Although CDN services for open source libraries do not allow you to upload your own content to their servers, they can help you accelerate libraries globally and improve your website's redundancy.
|
||||
|
||||
CDNs host projects on a vast network of servers, so website maintainers need to modify their asset links in the website's HTML code to reflect the open source CDN's URL followed by the path to the resource. Depending upon whether you're linking to a JavaScript or CSS library, the links you'll include will live in either a <script> or <link> tag.
|
||||
|
||||
Let's explore four popular CDN services for open source libraries.
|
||||
|
||||
### JsDelivr
|
||||
|
||||
[JsDelivr][5] is an open source CDN provider that uses the networks of premium CDN providers (KeyCDN, Stackpath, and Cloudflare) to deliver open source project assets. A few highlights of jsDelivr include:
|
||||
|
||||
* Search from over 2,100 libraries
|
||||
|
||||
* 110 POP locations
|
||||
|
||||
* CDN is accessible in Asia and China
|
||||
|
||||
* API support
|
||||
|
||||
* No traffic limits
|
||||
|
||||
* Full HTTPS support
|
||||
|
||||
All snippets start off with the custom jsDelivr URL [https://cdn.jsdelivr.net/][6], and are then followed by the name of the project, version number, etc. You can also configure jsDelivr to generate the URL with the script tags and enable SRI (subresource Integrity) for added security.
|
||||
|
||||
### **Cdnjs**
|
||||
|
||||
[Cdnjs][7] is another popular open source CDN provider that's similar to jsDelivr. This service also offers an array of popular JavaScript and CSS libraries that you can choose from to link within your web project. This service is sponsored by CDN providers Cloudflare and [KeyCDN][8]. A few highlights of cdnjs include:
|
||||
|
||||
* Search from over 2,900 libraries
|
||||
|
||||
* Used by over 1 million websites
|
||||
|
||||
* Supports HTTP/2
|
||||
|
||||
* Supports HTTPS
|
||||
|
||||
Similar to jsDelivr, with cdnjs you also have the option to simply copy the asset URL with or without the script tag and SRI.
|
||||
|
||||
### Google Hosted Libraries
|
||||
|
||||
The [Google's Hosted Libraries][9] site allows you to link to popular JavaScript libraries that are hosted on Google's powerful open source CDN network. This open source CDN solution doesn't offer as many libraries or features as jsDelivr or cdnjs; however, a high level of reliability and trust can be expected when linking to Google's Hosted Libraries. A few highlights of Google's open source CDN include:
|
||||
|
||||
* HTTPS support
|
||||
|
||||
* Files are served with CORS and Timing-Allow headers
|
||||
|
||||
* Offers the latest version of each library
|
||||
|
||||
All of Google's Hosted libraries files start with the URL [https://ajax.googleapis.com/][10], and are followed by the project's name, version number, and file name.
|
||||
|
||||
### Microsoft Ajax CDN
|
||||
|
||||
The [Microsoft Ajax Content Delivery Network][11] is quite similar to Google's Hosted Libraries in that it only hosts popular libraries. However, two major differences that separate Microsoft Ajax CDN from Google's Hosted Libraries are that Microsoft provides both CSS as well as JS libraries and also offers various versions of each library. A few highlights of the Microsoft Ajax CDN include:
|
||||
|
||||
* HTTPS support
|
||||
|
||||
* Previous versions of each library are often available
|
||||
|
||||
All Microsoft Ajax files begin with the URL [http://ajax.aspnetcdn.com/ajax/][12], and like the others, are followed by the library's name, version number, etc.
|
||||
|
||||
If your project or website isn't ready to take advantage of a premium CDN service, but you would still like to accelerate vital aspects of your site, then using an open source CDN can be a great solution. They allow you to accelerate the delivery of third-party libraries that would otherwise be delivered from your origin server causing unnecessary load and slower speeds for distant users.
|
||||
|
||||
_Which open source CDN provider do you prefer to use and why?_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Cody Arsenault - Cody is passionate about all things web performance, SEO and entrepreneurship. He is a web performance advocate at KeyCDN and works towards making the web faster.
|
||||
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/4/top-cdn-services
|
||||
|
||||
作者:[Cody Arsenault ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/codya
|
||||
[1]:https://en.wikipedia.org/wiki/public_domain
|
||||
[2]:https://opensource.com/article/17/4/top-cdn-services?rate=lgZwEmWt7QXtuMhB-lnHWQ-jxknQ0Kh4YOfqdFGer5w
|
||||
[3]:https://en.wikipedia.org/wiki/Open_Clip_Art_Library
|
||||
[4]:https://openclipart.org/share
|
||||
[5]:http://www.jsdelivr.com/
|
||||
[6]:https://cdn.jsdelivr.net/
|
||||
[7]:https://cdnjs.com/
|
||||
[8]:https://www.keycdn.com/
|
||||
[9]:https://developers.google.com/speed/libraries/
|
||||
[10]:https://ajax.googleapis.com/
|
||||
[11]:https://www.asp.net/ajax/cdn
|
||||
[12]:http://ajax.aspnetcdn.com/ajax/
|
||||
[13]:https://opensource.com/user/128076/feed
|
||||
[14]:https://opensource.com/users/codya
|
||||
@ -1,72 +0,0 @@
|
||||
What Fuchsia could mean for Android
|
||||
============================================================
|
||||
|
||||
Fuchsia could be next replacement for Android, or Android and Chrome OS. Speculation abounds, and Jack Wallen adds to this speculation some kudos and caveats for Google to consider.
|
||||
|
||||
In this white paper, you’ll learn why legacy IT systems create drag on businesses, and how companies can transform their operations and reap the benefits of hybrid IT by partnering with the right managed services provider. [Download Now][9]
|
||||
|
||||
 Image: Jack Wallen
|
||||
|
||||
Google has never been one to settle or to do things in a way that is not decidedly "Google". So it should have come as no surprise to anyone that they began working on a project that had many scratching their heads. The project is called [Fuschia][6] and most people that follow Google and Android closely, know of this new platform.
|
||||
|
||||
For those that haven't been following the latest and greatest from Google, Fuschia is a new, real-time, open source operating system that first popped up on the radar in August, 2016\. Back then, Fuchsia was nothing more than a command line. Less than a year has zipped by and the platform already has a rather interesting GUI.
|
||||
|
||||
Much to the chagrin of the Linux faithful, Fuchsia does not use the Linux kernel. This project is all Google and uses a Google-developed microkernel, named "Magenta." Why would they do this? Consider the fact that Google's newest device, the Pixel, runs kernel 3.18 and you have your answer. The 3.18 Linux kernel was released in 2014 (which, in tech terms is ancient). With that in mind, why wouldn't Google want to break out completely on their own to keep their mobile platform as up to date as possible?
|
||||
|
||||
Although it pains me to think that Linux might not be (in some unknown future date) powering the most widely-used ecosystem on the planet, I believe this is the right move for Google, with one major caveat.
|
||||
|
||||
### First, a couple of kudos
|
||||
|
||||
I have to first say, bravo to Google for open sourcing Fuchsia. This was the right move. Android has benefitted from the open source Linux kernel for years, so it only makes sense that Google would open up their latest project. To be perfectly honest, had it not been for open source and the Linux kernel, Android would not have risen nearly as quickly as it did. In fact, I would venture a guess to say that, had it not been for Android being propped up by Linux and open source, the mobile market share would show a very different, apple-shaped, picture at the moment.
|
||||
|
||||
The next bit of bravo comes by way of necessity. Operating systems need to be completely rethought now and then. Android is an amazing platform that serves the mobile world quite well. However, there's only so much evolution one can squeeze out of it; and considering the consuming world is always looking for next big thing, Android (and iOS) can only deliver so many times before they have been wrung dry. Couple that with a sorely out of date kernel and you have a perfect storm ready for the likes of Fuchsia.
|
||||
|
||||
Google has never been one to remain stagnant and this new platform is proof.
|
||||
|
||||
### That darned caveat
|
||||
|
||||
I will preface this by reminding everyone of my open source background. I have been a user of Linux since the late 90s and have covered nearly every aspect of open source to be found. Over the last few years, I've been watching and commenting on the goings on with Ubuntu and their (now) failed attempt at convergence. With that said, here's my concern with Fuchsia.
|
||||
|
||||
My suspicion is that Google's big plan for Fucshia is to create a single operating system for all devices: Smartphones, IoT, Chromebooks. On the surface, that sounds like an idea that would bear significant fruit; but if you examine the struggles Canonical endured with Unity 8/Mir/Convergence, you cringe at the idea of "one platform to rule them all". Of course, this isn't quite the same. I doubt Google is creating a single platform that will allow you to "converge" all of your devices. After all, what benefit would there be to converging IoT with your smartphone? It's not like we need to start exchanging data between a phone and a thermostat. Right? Right???
|
||||
|
||||
Even so, should that be the plan for Google, I would caution them to look closely at what befell Canonical and Unity 8\. It was an outstanding idea that simply couldn't come to fruition.
|
||||
|
||||
I could be wrong about this. Google might be thinking of Fuchsia as nothing more than a replacement for Android. It is quite possible this was Google needing to replace the outdated Linux kernel and deciding they may as well go "all in". But considering Armadillo (the Fuchsia UI) has been written in the cross-platform [Flutter SDK][7], the idea of crossing the platform boundary starts to fall into the realm of the possible.
|
||||
|
||||
Or, maybe Fuchsia is simply just Google saying "Let's rebuild our smartphone platform with the knowledge we have today and see where it goes." If that's the case, I would imagine the Google mobile OS will be primed for major success. However, there's one elephant in the room that many have yet to address that hearkens back to "one platform to rule them all". Google has been teasing Android apps on Chromebooks for quite some time. Unfortunately, the success with this idea has been moderate (at best). With Microsoft going out of their way to compete with Chromebooks, Google knows they have to expand that ecosystem, or else lose precious ground (such as within the education arena). One way to combat this is with a single OS to drive both smartphones and Chromebooks. It would mean all apps would work on both platforms (which would be a serious boon) and a universality to the ecosystem (again, massive boon).
|
||||
|
||||
### Speculation
|
||||
|
||||
Google is very good at keeping this sort of thing close to the vest; which translates to a lot of speculation on the part of pundits. Generally speaking, at least with Android, Google has always seemed to make the right moves. If they believe Fuchsia is the way to go, then I'm inclined to believe them. However, there are so many uncertainties surrounding this platform that one is left constantly scratching one's head in wonder.
|
||||
|
||||
What do you think? What will Fuchsia become? Speculate with me.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack Wallen is an award-winning writer for TechRepublic and Linux.com. He’s an avid promoter of open source and the voice of The Android Expert. For more news about Jack Wallen, visit his website jackwallen.com.
|
||||
|
||||
-------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/
|
||||
|
||||
作者:[About Jack Wallen ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/#modal-bio
|
||||
[1]:http://www.techrepublic.com/article/biometric-mobile-payments-will-hit-2b-this-year/
|
||||
[2]:http://www.techrepublic.com/article/apple-invests-200m-in-us-manufacturing-to-help-corning-produce-new-state-of-the-art-glass/
|
||||
[3]:http://www.techrepublic.com/article/google-will-soon-require-android-for-work-profiles-for-enterprise-users/
|
||||
[4]:http://www.techrepublic.com/newsletters/
|
||||
[5]:http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/#postComments
|
||||
[6]:https://github.com/fuchsia-mirror
|
||||
[7]:https://flutter.io/
|
||||
[8]:http://intent.cbsi.com/redir?tag=medc-content-top-leaderboard&siteId=11&rsid=cbsitechrepublicsite&pagetype=article&sl=en&sc=us&topicguid=09288d3a-8606-11e2-a661-024c619f5c3d&assetguid=714cb8ff-ebf0-4584-a421-e8464aae66cf&assettype=content_article&ftag_cd=LGN3588bd2&devicetype=desktop&viewguid=4c47ca57-283d-4861-a131-09e058b652ac&q=&ctype=docids;promo&cval=33109435;7205&ttag=&ursuid=&bhid=&destUrl=http%3A%2F%2Fwww.techrepublic.com%2Fresource-library%2Fwhitepapers%2Ftaming-it-complexity-with-managed-services-japanese%2F%3Fpromo%3D7205%26ftag%3DLGN3588bd2%26cval%3Dcontent-top-leaderboard
|
||||
[9]:http://intent.cbsi.com/redir?tag=medc-content-top-leaderboard&siteId=11&rsid=cbsitechrepublicsite&pagetype=article&sl=en&sc=us&topicguid=09288d3a-8606-11e2-a661-024c619f5c3d&assetguid=714cb8ff-ebf0-4584-a421-e8464aae66cf&assettype=content_article&ftag_cd=LGN3588bd2&devicetype=desktop&viewguid=4c47ca57-283d-4861-a131-09e058b652ac&q=&ctype=docids;promo&cval=33109435;7205&ttag=&ursuid=&bhid=&destUrl=http%3A%2F%2Fwww.techrepublic.com%2Fresource-library%2Fwhitepapers%2Ftaming-it-complexity-with-managed-services-japanese%2F%3Fpromo%3D7205%26ftag%3DLGN3588bd2%26cval%3Dcontent-top-leaderboard
|
||||
[10]:http://www.techrepublic.com/rssfeeds/topic/android/
|
||||
[11]:http://www.techrepublic.com/meet-the-team/us/jack-wallen/
|
||||
[12]:https://twitter.com/intent/user?screen_name=jlwallen
|
||||
@ -1,3 +1,4 @@
|
||||
翻译中 zhousiyu325
|
||||
What's the point of DevOps?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
10 Useful Tips for Writing Effective Bash Scripts in Linux
|
||||
============================================================
|
||||
ch-cn translating
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
ucasFL translating
|
||||
5 reasons the D programming language is a great choice for development
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,52 @@
|
||||
更快的机器学习即将来到 Linux 内核
|
||||
============================================================
|
||||
|
||||
### Linux 内核新增的异构内存管理将解锁加速 GPU 的新途径,并挖掘其它机器学习硬件的潜能
|
||||
|
||||
|
||||

|
||||
>Credit: Thinkstock
|
||||
|
||||
一项开发了很久的内存管理技术将会给机器学习和其它 GPU 驱动的程序很大幅度的提升,而它也将在接下来的几个版本中进入 Linux 内核。
|
||||
|
||||
异构内存管理(HMM)可以允许设备驱动为在其自身内存管理下的进程镜像地址空间。正如红帽的开发者 Jérôme Glisse [所解释的][10],这让像 GPU 这样的硬件设备可以直接访问进程内存,而不用花费复制带来的额外开销。它还不违反现代才做系统提供的内存保护功能。
|
||||
|
||||
|
||||
一类会从 HMM 中获益最多的应用是基于 GPU 的机器学习。像 OpenCL 和 CUDA 这样的库能够从 HMM 中获得速度的提升。HMM 实现这个的方式和[加速基于 GPU 的机器学习][11]相似,就是让数据留在原地,靠近 GPU,在那里直接操作数据,尽可能少地移动数据。
|
||||
|
||||
像这样的加速对于 CUDA(英伟达基于 GPU 的处理库)来说,只会有益于在英伟达 GPU 上的操作,这些 GPU 也是目前加速数据处理的主要硬件。但是,OpenCL 设计用来编写可以针对多种硬件的代码——CPU,GPU,FPGA等等——随着这些硬件的成熟,HMM 能够提供更加广泛的益处。
|
||||
|
||||
|
||||
要让 Linux 中的 HMM 处于可用状态还有一些阻碍。第一个是内核支持,在很长一段时间里都很不明了。[早在 2014][12]年,HMM 最初作为 Linux 内核补丁集提出,红帽和英伟达都是关键开发者。需要做的工作不少,但是开发者相信可以提交代码,也许接下来的几个内核版本就能把它包含进去。
|
||||
|
||||
第二个阻碍是显卡驱动支持,英伟达一直在自己单独做一些工作。据 Glisse 的说法,AMD 的 GPU 可能也会支持 HMM,所以这种特殊优化不会仅限于英伟达的 GPU。AMD 一直都在尝试提升它的 GPU 市场占有率,有可能会[将 GPU 和 CPU 整合][13]到同一模具。但是,软件生态系统依然更偏向英伟达;要让可以选择成为现实,还需要更多的像 HMM 这样的中立项目,以及让 OpenCL 提供和 CUDA 相当的性能。
|
||||
|
||||
第三个阻碍是硬件支持,因为 HMM 的工作需要一项称作可重现页面故障(replayable page faults)的硬件特性。只有英伟达的帕斯卡系列高端 GPU 才支持这项特性。从某些意义上来说这是个好消息,因为这意味着英伟达只需要提供单一硬件的驱动支持就能让 HMM 正常使用,工作量就少了。
|
||||
|
||||
一旦 HMM 到位,对于提供 GPU 实例的公有云提供商就会面临压力,他们需要[支持最新最好一代的 GPU][14]。这并不是仅仅将老款的开普勒架构显卡换成最新的帕斯卡架构显卡就行了,因为后续的每一代显卡都会更加优秀,像 HMM 这样的支持优化将提供战略优势。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3196884/linux/faster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&via=infoworld&text=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[3]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&title=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[4]:https://plus.google.com/share?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[5]:http://reddit.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html&title=Faster+machine+learning+is+coming+to+the+Linux+kernel
|
||||
[6]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3196884%2Flinux%2Ffaster-machine-learning-is-coming-to-the-linux-kernel.html
|
||||
[7]:http://www.infoworld.com/article/3196884/linux/faster-machine-learning-is-coming-to-the-linux-kernel.html#email
|
||||
[8]:http://www.infoworld.com/article/3152565/linux/5-rock-solid-linux-distros-for-developers.html#tk.ifw-infsb
|
||||
[9]:http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[10]:https://lkml.org/lkml/2017/4/21/872
|
||||
[11]:http://www.infoworld.com/article/3195437/machine-learning-analytics-get-a-boost-from-gpu-data-frame-project.html
|
||||
[12]:https://lwn.net/Articles/597289/
|
||||
[13]:http://www.infoworld.com/article/3099204/hardware/amd-mulls-a-cpugpu-super-chip-in-a-server-reboot.html
|
||||
[14]:http://www.infoworld.com/article/3126076/artificial-intelligence/aws-machine-learning-vms-go-faster-but-not-forward.html
|
||||
@ -1,79 +0,0 @@
|
||||
Linux 让我对电脑有了更深刻的理解
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
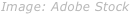
|
||||
|
||||
我花了大量时间和耐心在 Linux 上,我的朋友们都能为我证明这点。说起来你可能不信,两年前我还跟本不知道 Linux 是什么,放弃 Windows 转投 Linux 更是不可能。
|
||||
|
||||
虽然转投 Linux 这事有点跳跃,但事后证明这是很明知的选择。口说无任,分析一下我的路线可能会更有说服力一点。通过这个路线来说说我是怎么从小白到精通 Linux 桌面系统。
|
||||
|
||||
### 安全的意识觉醒
|
||||
|
||||
两年前我也是像一般 Window 用户一样,在 Windows 操作系统下工作。虽然我也有跟进了解主流的科技新闻的习惯,但是对 Linux 我也说不上了解。
|
||||
|
||||
2013年夏天,美国国家安全局的一份情报项目报告让我的个人隐私安全的态度迅速发生了变化。爱德华斯诺登揭露的网络监控的广度令人不安,而且也突显出,我们大多数人——甚至不知道如何做——来保护自己的隐私。
|
||||
|
||||
在我之前没有对电脑或他们在我的个人事务中所扮演的角色作出任何特别的考虑,我开始意识到控制一个人的数字生活,以及控制它的设备的重要性。
|
||||
|
||||
按理来说下一步应该是确定该怎么去做。虽然我制订的目标似乎是合乎逻辑的,但要实现它并不简单。在接下来的几个月里,我把自己的空闲时间花在了互联网上,寻找关于隐私保护、加密以及其他任何可以保护我的技术的指南。
|
||||
|
||||
专家们说想逃避情报机构的监控几乎是不可能的。然而,这些专家们也会告诉你,能帮你避开那怕只是那怕是避开那么一丢丢的监视 -- 在较小的机构中有相当比例的监控更有可能针对普通民众 -- 唯一可行的办法就是使用开源软件。
|
||||
|
||||
Linux 我很很快意识到要去了解它,因为它是这些开源软件的头头。
|
||||
|
||||
### 闭源与开源
|
||||
|
||||
在进一步的研究中,我开始熟悉开源软件的一些特点。我们每天使用的软件的绝大多数 -- 从聊天软件到操作系统,包括Windows -- 它们都是开源软件的对立面:它们是闭源的。
|
||||
|
||||
例如,当微软的开发人员在 Windows 上进行开发工作时,他们会用一些编程语言编写源代码,并且只在他们的团队内部流传这些代码。当他们准备发布软件时,他们会编译它,将它从人类可读的代码转换成计算机运行的1和0,面对这些机器码,即使是最聪明的人也很难逆向工程到原始源代码。
|
||||
|
||||
在这种模式下,只有软件的开发者才知道这些软件实际在做些什么,有没有私底下监控用户行为。
|
||||
|
||||
开源软件提供软件的源代码和编译好的二进制代码给公众下载使用。不论是不是每个用户都有能力去阅读这些源代码,评估它们的安全性和隐私性,这都不重要。因为源代码是公开的,总有那么一部分人有这个能力做这些事,一但他们发现这些代码有问题他们就能及时通知其它用户,让公众一起来监督这些开源软件的行为,让那些故意隐藏的恶意代码片段或者非故意的代码漏洞能及时被发现并处理掉。
|
||||
|
||||
经过彻底的研究,很明显,唯一能保证我的隐私和用户的自主权的操作系统就是那些具备透明开放的源码哲学的操作系统。一个知识渊博的朋友和隐私倡导者推荐的最多的是 Linux。如果不得不的话,我已经准备好接受一个艰难的过渡,但是我对隐私的重要性的信念给了我信心去尝试。
|
||||
|
||||
### 婴儿学步
|
||||
|
||||
虽然我决心转向 Linux 的是急切的,但饭得一口吃,路也得一步一步走。我是最开始是从安装 Ubuntu 开始的 -- 一个容易配置对初学者很友好的 Linux 发行版 -- 在我的老笔记本电脑上它与原有的 Windows 相处融洽井水不犯河水。
|
||||
|
||||
每次启动我的电脑时,我都能选择 Ubuntu 或 Windows ,这样我就能在 Linux 上找到自己的下脚点,同时保留熟悉的 Windows 以防前者可能缺失的一些辅助性功能。
|
||||
|
||||
不久后,一个硬盘驱动器损坏严重让我无法再继续享受这个设置,不过我认为这是一个机会,让我考虑一下买一台 Linux 的新笔记本电脑。由于 Linux 对标准的英特尔处理器、图形卡和无线适配器的驱动程序支持得很好,所以我买了一台联想的 ThinkPad。
|
||||
|
||||
我做了一个全新的开始,完全擦除我的新机器上的 Windows ,安装了 Debian ,一个广泛兼容和稳定的发行版,Ubuntu 就是基于它开衍生出来的。我不仅在没有熟悉的 Windows 安全网络的情况下挺过来了,我还在不断的进步提高。我很快就沉浸在以前神秘的命令行世界里。
|
||||
|
||||
在我用了一年的 Linux 操作系统之后,我又进行了一次冒险,安装了 Arch Linux ,它需要一个更加复杂的手动用户安装过程,并带有完全的磁盘加密。那天晚上,我和一位 Linux 资深管理人士一起安装了 Arch ,这标志着我生命中最值得骄傲的成就之一。
|
||||
|
||||
在这个过程中,我面临着挑战 -- 有时,在Windows上无缝工作的应用程序需要额外的步骤或需要安装必要的驱动 -- 但是我克服了它们,或者绕过它们,继续按照我自己的节奏摸索 Linux。
|
||||
|
||||
### 全速前进
|
||||
|
||||
就我而言,那时我才真正开始进行我的学习。我用 Linux 来驾驭计算机,并确保它只给我对我工作,不过最让我着迷的是它提供对系统自由的进行修改和个性化处理。
|
||||
|
||||
作为一个开源操作系统,Linux是无限开放的。尽管我最初期望花时间阅读安全实践(我现在仍然这么做),但我也发现自己深入到配置面板中,并把所有的颜色、图标和菜单都列出来,只是这样而已。
|
||||
|
||||
我花了一些时间去适应,但我越是投入到新事物中,我就变得越自信,越好奇。
|
||||
|
||||
自从在这条路上走了两年多以后,我在电脑上的感觉从来没有像今天这么多。我不能像我想要的那样去个性化 Windows ,另外依据我从开源社区学到的东西来看,我也不能完全信任它。
|
||||
|
||||
有一个叫电脑的东西,它曾经只是我的的一件不起眼的硬件设备,现在它和我之间的关系变得非常美妙 —— 超越记者和他的笔记本也超越小提琴家和他的小提琴和关系。
|
||||
|
||||
我甚至为自己的手机不像我的笔记本电脑那样顺从 Linux 而感到悲哀,我都不知道我能对它做些什么。不管怎么样,我将继续对我的 Arch 系统进行优化,只要机会出现我将会再去发现新的角落并探索新的可能性。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84286.html?rss=1
|
||||
|
||||
作者:[Jonathan Terrasi ][a]
|
||||
译者:[zschong](https://github.com/zschong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linkedin.com/company/ect-news-network
|
||||
[1]:http://www.linuxinsider.com/story/84286.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84286
|
||||
@ -1,40 +1,40 @@
|
||||
ictlyh Translating
|
||||
Writing a Linux Debugger Part 3: Registers and memory
|
||||
开发 Linux 调试器第三部分:寄存器和内存
|
||||
============================================================
|
||||
|
||||
In the last post we added simple address breakpoints to our debugger. This time we’ll be adding the ability to read and write registers and memory, which will allow us to screw around with our program counter, observe state and change the behaviour of our program.
|
||||
上一篇博文中我们给调试器添加了一个简单的地址断点。这次,我们将添加读写寄存器和内存的功能,这将使我们能够使用我们的程序计数器、观察状态和改变程序的行为。
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
### 系列文章索引
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [Setup][3]
|
||||
1. [启动][3]
|
||||
|
||||
2. [Breakpoints][4]
|
||||
2. [断点][4]
|
||||
|
||||
3. [Registers and memory][5]
|
||||
3. [寄存器和内存][5]
|
||||
|
||||
4. [Elves and dwarves][6]
|
||||
4. [Elves 和 dwarves][6]
|
||||
|
||||
5. [Source and signals][7]
|
||||
5. [源码和信号][7]
|
||||
|
||||
6. [Source-level stepping][8]
|
||||
6. [源码级逐步执行][8]
|
||||
|
||||
7. Source-level breakpoints
|
||||
7. 源码级断点
|
||||
|
||||
8. Stack unwinding
|
||||
8. 调用栈展开
|
||||
|
||||
9. Reading variables
|
||||
9. 读取变量
|
||||
|
||||
10. Next steps
|
||||
10. 下一步
|
||||
|
||||
译者注:ELF([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format "Executable and Linkable Format") 可执行文件格式),DWARF(一种广泛使用的调试数据格式,参考 [WIKI](https://en.wikipedia.org/wiki/DWARF "DWARF WIKI"))
|
||||
* * *
|
||||
|
||||
### Registering our registers
|
||||
### 注册我们的寄存器
|
||||
|
||||
Before we actually read any registers, we need to teach our debugger a bit about our target, which is x86_64\. Alongside sets of general and special purpose registers, x86_64 has floating point and vector registers available. I’ll be omitting the latter two for simplicity, but you can choose to support them if you like. x86_64 also allows you to access some 64 bit registers as 32, 16, or 8 bit registers, but I’ll just be sticking to 64\. Due to these simplifications, for each register we just need its name, its DWARF register number, and where it is stored in the structure returned by `ptrace`. I chose to have a scoped enum for referring to the registers, then I laid out a global register descriptor array with the elements in the same order as in the `ptrace` register structure.
|
||||
在我们真正读取任何寄存器之前,我们需要告诉调试器更多关于我们平台,也就是 x86_64 的信息。除了多组通用和专用目的寄存器,x86_64 还提供浮点和向量寄存器。为了简化,我将跳过后两种寄存器,但是你如果喜欢的话也可以选择支持它们。x86_64 也允许你像访问 32、16 或者 8 位寄存器那样访问一些 64 位寄存器,但我只会介绍 64 位寄存器。由于这些简化,对于每个寄存器我们只需要它的名称,它的 DWARF 寄存器编号以及 `ptrace` 返回结构体中的存储地址。我使用范围枚举引用这些寄存器,然后我列出了一个全局寄存器描述符数组,其中元素顺序和 `ptrace` 中寄存器结构体相同。
|
||||
|
||||
```
|
||||
enum class reg {
|
||||
@ -87,9 +87,9 @@ const std::array<reg_descriptor, n_registers> g_register_descriptors {{
|
||||
}};
|
||||
```
|
||||
|
||||
You can typically find the register data structure in `/usr/include/sys/user.h` if you’d like to look at it yourself, and the DWARF register numbers are taken from the [System V x86_64 ABI][11].
|
||||
如果你想自己看看的话,你通常可以在 `/usr/include/sys/user.h` 找到寄存器数据结构,另外 DWARF 寄存器编号取自 [System V x86_64 ABI][11]。
|
||||
|
||||
Now we can write a bunch of functions to interact with registers. We’d like to be able to read registers, write to them, retrieve a value from a DWARF register number, and lookup registers by name and vice versa. Let’s start with implementing `get_register_value`:
|
||||
现在我们可以编写一堆函数来和寄存器交互。我们想要读取寄存器、写入数据、根据 DWARF 寄存器编号获取值,以及通过名称查找寄存器,反之类似。让我们先从实现 `get_register_value` 开始:
|
||||
|
||||
```
|
||||
uint64_t get_register_value(pid_t pid, reg r) {
|
||||
@ -99,9 +99,9 @@ uint64_t get_register_value(pid_t pid, reg r) {
|
||||
}
|
||||
```
|
||||
|
||||
Again, `ptrace` gives us easy access to the data we want. We just construct an instance of `user_regs_struct` and give that to `ptrace` alongside the `PTRACE_GETREGS` request.
|
||||
`ptrace` 使得我们可以轻易获得我们想要的数据。我们只需要构造一个 `user_regs_struct` 实例并把它和 `PTRACE_GETREGS` 请求传递给 `ptrace`。
|
||||
|
||||
Now we want to read `regs` depending on which register was requested. We could write a big switch statement, but since we’ve laid out our `g_register_descriptors` table in the same order as `user_regs_struct`, we can just search for the index of the register descriptor, and access `user_regs_struct` as an array of `uint64_t`s.[1][9]
|
||||
现在取决于被请求的寄存器,我们想要读取 `regs`。我们可以写一个很大的 switch 语句,但由于我们 `g_register_descriptors` 表的布局顺序和 `user_regs_struct` 相同,我们只需要搜索寄存器描述符的索引,然后作为 `uint64_t` 数组访问 `user_regs_struct`。[1][9]
|
||||
|
||||
```
|
||||
auto it = std::find_if(begin(g_register_descriptors), end(g_register_descriptors),
|
||||
@ -110,9 +110,9 @@ Now we want to read `regs` depending on which register was requested. We could
|
||||
return *(reinterpret_cast<uint64_t*>(®s) + (it - begin(g_register_descriptors)));
|
||||
```
|
||||
|
||||
The cast to `uint64_t` is safe because `user_regs_struct` is a standard layout type, but I think the pointer arithmetic is technically UB. No current compilers even warn about this and I’m lazy, but if you want to maintain utmost correctness, write a big switch statement.
|
||||
到 `uint64_t` 的转换是安全的,因为 `user_regs_struct` 是一个标准布局类型,但我认为指针算术技术上是未定义的行为(undefined behavior)。当前没有编译器会对此产生警告,我也懒得修改,但是如果你想保持最严格的正确性,那就写一个大的 switch 语句。
|
||||
|
||||
`set_register_value` is much the same, we just write to the location and write the registers back at the end:
|
||||
`set_register_value` 非常类似,我们只是写入到地址并在最后写回寄存器:
|
||||
|
||||
```
|
||||
void set_register_value(pid_t pid, reg r, uint64_t value) {
|
||||
@ -126,7 +126,7 @@ void set_register_value(pid_t pid, reg r, uint64_t value) {
|
||||
}
|
||||
```
|
||||
|
||||
Next is lookup by DWARF register number. This time I’ll actually check for an error condition just in case we get some weird DWARF information:
|
||||
下一步是通过 DWARF 寄存器编号查找。这次我会真正检查一个错误条件以防我们得到一些奇怪的 DWARF 信息。
|
||||
|
||||
```
|
||||
uint64_t get_register_value_from_dwarf_register (pid_t pid, unsigned regnum) {
|
||||
@ -140,7 +140,7 @@ uint64_t get_register_value_from_dwarf_register (pid_t pid, unsigned regnum) {
|
||||
}
|
||||
```
|
||||
|
||||
Nearly finished, now he have register name lookups:
|
||||
就快完成啦,现在我们已经有了寄存器名称查找:
|
||||
|
||||
```
|
||||
std::string get_register_name(reg r) {
|
||||
@ -156,7 +156,7 @@ reg get_register_from_name(const std::string& name) {
|
||||
}
|
||||
```
|
||||
|
||||
And finally we’ll add a simple helper to dump the contents of all registers:
|
||||
最后我们会添加一个简单的帮助函数用于导出所有寄存器的内容:
|
||||
|
||||
```
|
||||
void debugger::dump_registers() {
|
||||
@ -167,15 +167,15 @@ void debugger::dump_registers() {
|
||||
}
|
||||
```
|
||||
|
||||
As you can see, iostreams has a very concise interface for outputting hex data nicely[2][10]. Feel free to make an I/O manipulator to get rid of this mess if you like.
|
||||
正如你看到的,iostreams 有非常精确的接口用于美观地输出十六进制数据[2][10]。如果你喜欢你也可以通过 I/O 操纵器来摆脱这种混乱。
|
||||
|
||||
This gives us enough support to handle registers easily in the rest of the debugger, so we can now add this to our UI.
|
||||
这些已经足够支持我们在调试器接下来的部分轻松地处理寄存器,因为我们现在可以把这些添加到我们的用户界面。
|
||||
|
||||
* * *
|
||||
|
||||
### Exposing our registers
|
||||
### 显示我们的寄存器
|
||||
|
||||
All we need to do here is add a new command to the `handle_command` function. With the following code, users will be able to type `register read rax`, `register write rax 0x42` and so on.
|
||||
这里我们要做的就是给 `handle_command` 函数添加一个命令。通过下面的代码,用户可以输入 `register read rax`、 `register write rax 0x42` 以及类似的语句。
|
||||
|
||||
```
|
||||
else if (is_prefix(command, "register")) {
|
||||
@ -194,9 +194,9 @@ All we need to do here is add a new command to the `handle_command` function.
|
||||
|
||||
* * *
|
||||
|
||||
### Where is my mind?
|
||||
### 接下来做什么?
|
||||
|
||||
We’ve already read from and written to memory when setting our breakpoints, so we just need to add a couple of functions to hide the `ptrace` call a bit.
|
||||
设置断点的时候我们已经读取和写入内存,因此我们只需要添加一些函数用于隐藏 `ptrace`调用。
|
||||
|
||||
```
|
||||
uint64_t debugger::read_memory(uint64_t address) {
|
||||
@ -208,9 +208,9 @@ void debugger::write_memory(uint64_t address, uint64_t value) {
|
||||
}
|
||||
```
|
||||
|
||||
You might want to add support for reading and writing more than a word at a time, which you can do by just incrementing the address each time you want to read another word. You could also use [`process_vm_readv` and `process_vm_writev`][12] or `/proc/<pid>/mem` instead of `ptrace` if you like.
|
||||
你可能想要添加支持一次读取或者写入多个字节,你可以在每次希望读取另一个字节时通过递增地址来实现。如果你需要的话,你也可以使用 [`process_vm_readv` 和 `process_vm_writev`][12] 或 `/proc/<pid>/mem` 代替 `ptrace`。
|
||||
|
||||
Now we’ll add commands for our UI:
|
||||
现在我们会给我们的用户界面添加命令:
|
||||
|
||||
```
|
||||
else if(is_prefix(command, "memory")) {
|
||||
@ -228,11 +228,11 @@ Now we’ll add commands for our UI:
|
||||
|
||||
* * *
|
||||
|
||||
### Patching `continue_execution`
|
||||
### 给 `continue_execution` 打补丁
|
||||
|
||||
Before we test out our changes, we’re now in a position to implement a more sane version of `continue_execution`. Since we can get the program counter, we can check our breakpoint map to see if we’re at a breakpoint. If so, we can disable the breakpoint and step over it before continuing.
|
||||
在我们测试我们的更改之前,我们现在可以实现一个更健全的 `continue_execution` 版本。由于我们可以获取程序计数器,我们可以检查我们的断点映射来判断我们是否处于一个断点。如果是的话,我们可以停用断点并在继续之前跳过它。
|
||||
|
||||
First we’ll add for couple of helper functions for clarity and brevity:
|
||||
为了清晰和简洁,首先我们要添加一些帮助函数:
|
||||
|
||||
```
|
||||
uint64_t debugger::get_pc() {
|
||||
@ -244,7 +244,7 @@ void debugger::set_pc(uint64_t pc) {
|
||||
}
|
||||
```
|
||||
|
||||
Then we can write a function to step over a breakpoint:
|
||||
然后我们可以编写函数来跳过断点:
|
||||
|
||||
```
|
||||
void debugger::step_over_breakpoint() {
|
||||
@ -267,9 +267,9 @@ void debugger::step_over_breakpoint() {
|
||||
}
|
||||
```
|
||||
|
||||
First we check to see if there’s a breakpoint set for the value of the current PC. If there is, we first put execution back to before the breakpoint, disable it, step over the original instruction, and re-enable the breakpoint.
|
||||
首先我们检查当前程序计算器的值是否设置了一个断点。如果有,首先我们把执行返回到断点之前,停用它,跳过原来的指令,再重新启用断点。
|
||||
|
||||
`wait_for_signal` will encapsulate our usual `waitpid` pattern:
|
||||
`wait_for_signal` 封装了我们常用的 `waitpid` 模式:
|
||||
|
||||
```
|
||||
void debugger::wait_for_signal() {
|
||||
@ -279,7 +279,7 @@ void debugger::wait_for_signal() {
|
||||
}
|
||||
```
|
||||
|
||||
Finally we rewrite `continue_execution` like this:
|
||||
最后我们像下面这样重写 `continue_execution`:
|
||||
|
||||
```
|
||||
void debugger::continue_execution() {
|
||||
@ -291,9 +291,10 @@ void debugger::continue_execution() {
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
### 测试效果
|
||||
|
||||
现在我们可以读取和修改寄存器了,我们可以对我们的 hello world 程序做一些有意思的更改。类似第一次测试,再次尝试在 call 指令处设置断点然后从那里继续执行。你可以看到输出了 `Hello world`。现在是有趣的部分,在输出调用后设一个断点、继续、将 call 参数设置代码的地址写入程序计数器(`rip`) 并继续。由于程序计数器操纵,你应该再次看到输出了 `Hello world`。为了以防你不确定在哪里设置断点,下面是我上一篇博文中的 `objdump` 输出:
|
||||
|
||||
Now that we can read and modify registers, we can have a bit of fun with our hello world program. As a first test, try setting a breakpoint on the call instruction again and continue from it. You should see `Hello world` being printed out. For the fun part, set a breakpoint just after the output call, continue, then write the address of the call argument setup code to the program counter (`rip`) and continue. You should see `Hello world` being printed a second time due to this program counter manipulation. Just in case you aren’t sure where to set the breakpoint, here’s my `objdump` output from the last post again:
|
||||
|
||||
```
|
||||
0000000000400936 <main>:
|
||||
@ -308,24 +309,24 @@ Now that we can read and modify registers, we can have a bit of fun with our hel
|
||||
|
||||
```
|
||||
|
||||
You’ll want to move the program counter back to `0x40093a` so that the `esi` and `edi` registers are set up properly.
|
||||
你要将程序计数器移回 `0x40093a` 使得正确设置 `esi` and `edi` 寄存器。
|
||||
|
||||
In the next post, we’ll take our first look at DWARF information and add various kinds of single stepping to our debugger. After that, we’ll have a mostly functioning tool which can step through code, set breakpoints wherever we like, modify data and so forth. As always, drop a comment below if you have any questions!
|
||||
在下一篇博客中,我们会第一次接触到 DWARF 信息并给我们的调试器添加一系列逐步调试的功能。之后,我们会有一个功能工具,它能逐步执行代码、在想要的地方设置断点、修改数据以及其它。一如以往,如果你有任何问题请留下你的评论!
|
||||
|
||||
You can find the code for this post [here][13].
|
||||
你可以在[这里][13]找到这篇博文的代码。
|
||||
|
||||
* * *
|
||||
|
||||
1. You could also reorder the `reg` enum and cast them to the underlying type to use as indexes, but I wrote it this way in the first place, it works, and I’m too lazy to change it. [↩][1]
|
||||
1. 你也可以重新排序 `reg` 枚举变量,然后使用索引把它们转换为底层类型,但第一次我就使用这种方式编写,它能正常工作,我也就懒得改它了。 [↩][1]
|
||||
|
||||
2. Ahahahahahahahahahahahahahahahaha [↩][2]
|
||||
2. Ahahahahahahahahahahahahahahahaha [↩][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
|
||||
作者:[ TartanLlama ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,324 @@
|
||||
开发 Linux 调试器第四部分:Elves 和 dwarves
|
||||
============================================================
|
||||
|
||||
到目前为止,你已经听到了关于 dwarves、调试信息、一种无需解析就可以理解源码方式的窃窃私语。今天我们会详细介绍源码级的调试信息,作为本指南后面部分使用它的准备。
|
||||
|
||||
* * *
|
||||
|
||||
### 系列文章索引
|
||||
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [启动][1]
|
||||
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [Elves 和 dwarves][4]
|
||||
|
||||
5. [源码和信号][5]
|
||||
|
||||
6. [源码级逐步执行][6]
|
||||
|
||||
7. 源码级断点
|
||||
|
||||
8. 调用栈展开
|
||||
|
||||
9. 读取变量
|
||||
|
||||
10. 下一步
|
||||
|
||||
译者注:ELF([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format "Executable and Linkable Format") 可执行文件格式),DWARF(一种广泛使用的调试数据格式,参考 [WIKI](https://en.wikipedia.org/wiki/DWARF "DWARF WIKI"))
|
||||
* * *
|
||||
|
||||
### ELF 和 DWARF 简介
|
||||
|
||||
ELF 和 DWARF 可能是两个你没有听说过,但可能大部分时间都在使用的组件。ELF(Executable and Linkable Format,可执行和可链接格式)是 Linux 系统中使用最广泛的目标文件格式;它指定了一种方式存储二进制文件的所有不同部分,例如代码、静态数据、调试信息以及字符串。它还告诉加载器如何加载二进制文件并准备执行,其中包括说明二进制文件不同部分在内存中应该放置的地点,哪些位需要根据其它组件的位置固定(_重分配_)以及其它。在这些博文中我不会用太多篇幅介绍 ELF,但是如果你感兴趣的话,你可以查看[这个很好的信息图][7]或[标准][8]。
|
||||
|
||||
DWARF 是通常和 ELF 一起使用的调试信息格式。它不一定要绑定到 ELF,但它们两者是一起发展的,一起工作得很好。这种格式允许编译器告诉调试器最初的源代码如何和被执行的二进制文件相关联。这些信息分散到不同的 ELF 部分,每个部分都有一份它自己中继的信息。这是从这种高度信息集成中定义、提取的不同部分,可能有些过时[DWARF 调试格式简介][9]:
|
||||
|
||||
* `.debug_abbrev` `.debug_info` 部分使用的缩略语
|
||||
|
||||
* `.debug_aranges` 内存地址和编译的映射
|
||||
|
||||
* `.debug_frame` 调用帧信息
|
||||
|
||||
* `.debug_info` 包括 DWARF 信息条目(DIEs:DWARF Information Entries)的核心 DWARF 数据
|
||||
|
||||
* `.debug_line` 行号程序
|
||||
|
||||
* `.debug_loc` 位置描述
|
||||
|
||||
* `.debug_macinfo` 宏描述
|
||||
|
||||
* `.debug_pubnames` 全局对象和函数查找表
|
||||
|
||||
* `.debug_pubtypes` 全局类型查找表
|
||||
|
||||
* `.debug_ranges` DIEs 的引用地址范围
|
||||
|
||||
* `.debug_str` `.debug_info` 使用的字符串列表
|
||||
|
||||
* `.debug_types` 类型描述
|
||||
|
||||
我们最关心 `.debug_line` 和 `.debug_info` 部分,让我们来看一个简单程序的 DWARF 信息。
|
||||
|
||||
```
|
||||
int main() {
|
||||
long a = 3;
|
||||
long b = 2;
|
||||
long c = a + b;
|
||||
a = 4;
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### DWARF 行表
|
||||
|
||||
如果你用 `-g` 选项编译这个程序,然后将结果传递给 `dwarfdump` 执行,在行号部分你应该可以看到类似这样的东西:
|
||||
|
||||
```
|
||||
.debug_line: line number info for a single cu
|
||||
Source lines (from CU-DIE at .debug_info offset 0x0000000b):
|
||||
|
||||
NS new statement, BB new basic block, ET end of text sequence
|
||||
PE prologue end, EB epilogue begin
|
||||
IS=val ISA number, DI=val discriminator value
|
||||
<pc> [lno,col] NS BB ET PE EB IS= DI= uri: "filepath"
|
||||
0x00400670 [ 1, 0] NS uri: "/home/simon/play/MiniDbg/examples/variable.cpp"
|
||||
0x00400676 [ 2,10] NS PE
|
||||
0x0040067e [ 3,10] NS
|
||||
0x00400686 [ 4,14] NS
|
||||
0x0040068a [ 4,16]
|
||||
0x0040068e [ 4,10]
|
||||
0x00400692 [ 5, 7] NS
|
||||
0x0040069a [ 6, 1] NS
|
||||
0x0040069c [ 6, 1] NS ET
|
||||
|
||||
```
|
||||
|
||||
前面几行是一些如何理解 dump 的信息 - 主要的行号数据从以 `0x00400670` 开头的行开始。实际上这是一个代码内存地址到文件中行列号的映射。`NS` 表示地址标记一个新语句的开始,这通常用于设置断点或逐步执行。`PE` 表示函数序言(LCTT 译注:在汇编语言中,[function prologue](https://en.wikipedia.org/wiki/Function_prologue "function prologue") 是程序开始的几行代码,用于准备函数中用到的栈和寄存器)的结束,这对于设置函数断点非常有帮助。`ET` 表示转换单元的结束。信息实际上并不像这样编码;真正的编码是一种非常节省空间的排序程序,可以通过执行它来建立这些行信息。
|
||||
|
||||
那么,假设我们想在 variable.cpp 的第 4 行设置断点,我们该怎么做呢?我们查找和该文件对应的条目,然后查找对应的行条目,查找对应的地址,在那里设置一个断点。在我们的例子中,条目是:
|
||||
|
||||
```
|
||||
0x00400686 [ 4,14] NS
|
||||
|
||||
```
|
||||
|
||||
假设我们想在地址 `0x00400686` 处设置断点。如果你想尝试的话你可以在已经编写好的调试器上手动实现。
|
||||
|
||||
反过来也是如此。如果我们已经有了一个内存地址 - 例如说,一个程序计数器值 - 想找到它在源码中的位置,我们只需要从行表信息中查找最接近的映射地址并从中抓取行号。
|
||||
|
||||
* * *
|
||||
|
||||
### DWARF 调试信息
|
||||
|
||||
`.debug_info` 部分是 DWARF 的核心。它给我们关于我们程序中存在的类型、函数、变量、希望和梦想的信息。这部分的基本单元是 DWARF 信息条目(DWARF Information Entry),我们亲切地称之为 DIEs。一个 DIE 包括能告诉你正在展现什么样的源码级实体的标签,后面跟着一系列该实体的属性。这是我上面展示的简单事例程序的 `.debug_info` 部分:
|
||||
|
||||
```
|
||||
|
||||
.debug_info
|
||||
|
||||
COMPILE_UNIT<header overall offset = 0x00000000>:
|
||||
< 0><0x0000000b> DW_TAG_compile_unit
|
||||
DW_AT_producer clang version 3.9.1 (tags/RELEASE_391/final)
|
||||
DW_AT_language DW_LANG_C_plus_plus
|
||||
DW_AT_name /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_stmt_list 0x00000000
|
||||
DW_AT_comp_dir /super/secret/path/MiniDbg/build
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
|
||||
LOCAL_SYMBOLS:
|
||||
< 1><0x0000002e> DW_TAG_subprogram
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
DW_AT_name main
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000001
|
||||
DW_AT_type <0x00000077>
|
||||
DW_AT_external yes(1)
|
||||
< 2><0x0000004c> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -8
|
||||
DW_AT_name a
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000002
|
||||
DW_AT_type <0x0000007e>
|
||||
< 2><0x0000005a> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -16
|
||||
DW_AT_name b
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000003
|
||||
DW_AT_type <0x0000007e>
|
||||
< 2><0x00000068> DW_TAG_variable
|
||||
DW_AT_location DW_OP_fbreg -24
|
||||
DW_AT_name c
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000004
|
||||
DW_AT_type <0x0000007e>
|
||||
< 1><0x00000077> DW_TAG_base_type
|
||||
DW_AT_name int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000004
|
||||
< 1><0x0000007e> DW_TAG_base_type
|
||||
DW_AT_name long int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000008
|
||||
|
||||
```
|
||||
|
||||
第一个 DIE 表示一个编译单元(CU),实际上是一个包括了所有 `#includes` 和类似语句的源文件。下面是带含义注释的属性:
|
||||
|
||||
```
|
||||
DW_AT_producer clang version 3.9.1 (tags/RELEASE_391/final) <-- 产生该二进制文件的编译器
|
||||
DW_AT_language DW_LANG_C_plus_plus <-- 原编程语言
|
||||
DW_AT_name /super/secret/path/MiniDbg/examples/variable.cpp <-- 该 CU 表示的文件名称
|
||||
DW_AT_stmt_list 0x00000000 <-- 跟踪该 CU 的行表偏移
|
||||
DW_AT_comp_dir /super/secret/path/MiniDbg/build <-- 编译目录
|
||||
DW_AT_low_pc 0x00400670 <-- 该 CU 的代码起始
|
||||
DW_AT_high_pc 0x0040069c <-- 该 CU 的代码结尾
|
||||
|
||||
```
|
||||
|
||||
其它的 DIEs 遵循类似的模式,你也很可能推测出不同属性的含义。
|
||||
|
||||
现在我们可以根据新学到的 DWARF 知识尝试和解决一些实际问题。
|
||||
|
||||
### 当前我在哪个函数?
|
||||
|
||||
假设我们有一个程序计数器值然后想找到当前我们在哪一个函数。一个解决该问题的简单算法:
|
||||
|
||||
```
|
||||
for each compile unit:
|
||||
if the pc is between DW_AT_low_pc and DW_AT_high_pc:
|
||||
for each function in the compile unit:
|
||||
if the pc is between DW_AT_low_pc and DW_AT_high_pc:
|
||||
return function information
|
||||
|
||||
```
|
||||
|
||||
这对于很多目的都有效,但如果有成员函数或者内联,就会变得更加复杂。假如有内联,一旦我们找到范围包括我们程序计数器的函数,我们需要递归遍历该 DIE 的所有孩子检查是否有内联函数能更好地匹配。在我的代码中,我不会为该调试器处理内联,但如果你想要的话你可以添加该功能。
|
||||
|
||||
### 如何在一个函数上设置断点?
|
||||
|
||||
再次说明,这取决于你是否想要支持成员函数,命名空间以及类似的东西。对于简单的函数你只需要迭代遍历不同编译单元中的函数直到你找到一个合适的名字。如果你的编译器能够填充 `.debug_pubnames` 部分,你可以更高效地做到这点。
|
||||
|
||||
一旦找到了函数,你可以在 `DW_AT_low_pc` 给定的内存地址设置一个断点。尽管如此,那会在函数序言处中断,但更合适的是在用户代码出中断。由于行表信息可以指定内存地址、后者指定序言的结束,你只需要在行表中查找 `DW_AT_low_pc` 的值,然后一直读取直到被标记为序言结束的条目。一些编译器不会输出这些信息,因此另一种方式是在该函数第二行条目指定的地址处设置断点。
|
||||
|
||||
假如我们想在我们事例程序中的 `main` 函数设置断点。我们查找名为 `main` 的函数,获取到它的 DIE:
|
||||
|
||||
```
|
||||
< 1><0x0000002e> DW_TAG_subprogram
|
||||
DW_AT_low_pc 0x00400670
|
||||
DW_AT_high_pc 0x0040069c
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
DW_AT_name main
|
||||
DW_AT_decl_file 0x00000001 /super/secret/path/MiniDbg/examples/variable.cpp
|
||||
DW_AT_decl_line 0x00000001
|
||||
DW_AT_type <0x00000077>
|
||||
DW_AT_external yes(1)
|
||||
|
||||
```
|
||||
|
||||
这告诉我们函数从 `0x00400670` 开始。如果我们在行表中查找这个,我们可以获得条目:
|
||||
|
||||
```
|
||||
0x00400670 [ 1, 0] NS uri: "/super/secret/path/MiniDbg/examples/variable.cpp"
|
||||
|
||||
```
|
||||
|
||||
我们希望跳过序言,因此我们再读取一个条目:
|
||||
|
||||
```
|
||||
0x00400676 [ 2,10] NS PE
|
||||
|
||||
```
|
||||
|
||||
Clang 在这个条目中包括了序言结束标记,因此我们知道在这里停止,然后在地址 `0x00400676` 处设一个断点。
|
||||
|
||||
### 我如何读取一个变量的内容?
|
||||
|
||||
读取变量可能非常复杂。它们是难以捉摸的东西,可能在整个函数中移动、保存在寄存器中、被放置于内存、被优化掉、隐藏在角落里,等等。幸运的是我们的简单事例是真的简单。如果我们想读取变量 `a` 的内容,我们需要看它的 `DW_AT_location` 属性:
|
||||
|
||||
```
|
||||
DW_AT_location DW_OP_fbreg -8
|
||||
|
||||
```
|
||||
|
||||
这告诉我们内容被保存在以栈帧基偏移为 `-8` 的地方。为了找到栈帧基,我们查找所在函数的 `DW_AT_frame_base` 属性。
|
||||
|
||||
```
|
||||
DW_AT_frame_base DW_OP_reg6
|
||||
|
||||
```
|
||||
|
||||
从 [System V x86_64 ABI][10] 我们可以知道 `reg6` 在 x86 中是帧指针寄存器。现在我们读取帧指针的内容,从中减去 8,就找到了我们的变量。如果我们真的想它变得有意义,我们还需要看它的类型:
|
||||
|
||||
```
|
||||
< 2><0x0000004c> DW_TAG_variable
|
||||
DW_AT_name a
|
||||
DW_AT_type <0x0000007e>
|
||||
|
||||
```
|
||||
|
||||
如果我们在调试信息中查找该类型,我们得到下面的 DIE:
|
||||
|
||||
```
|
||||
< 1><0x0000007e> DW_TAG_base_type
|
||||
DW_AT_name long int
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000008
|
||||
|
||||
```
|
||||
|
||||
这告诉我们该类型是 8 字节(64 位)有符号整型,因此我们可以继续并把这些字节解析为 `int64_t` 并向用户显示。
|
||||
|
||||
当然,类型可能比那要复杂得多,因为它们要能够表示类似 C++ 的类型,但是这能给你它们如何工作的基本认识。
|
||||
|
||||
再次回到帧基,Clang 可以通过帧指针寄存器跟踪帧基。最近版本的 GCC 倾向于 `DW_OP_call_frame_cfa`,它包括解析 `.eh_frame` ELF 部分,那是一个我不会去写的完全不同的内容。如果你告诉 GCC 使用 DWARF 2 而不是最近的版本,它会倾向于输出位置列表,这更便于阅读:
|
||||
|
||||
```
|
||||
DW_AT_frame_base <loclist at offset 0x00000000 with 4 entries follows>
|
||||
low-off : 0x00000000 addr 0x00400696 high-off 0x00000001 addr 0x00400697>DW_OP_breg7+8
|
||||
low-off : 0x00000001 addr 0x00400697 high-off 0x00000004 addr 0x0040069a>DW_OP_breg7+16
|
||||
low-off : 0x00000004 addr 0x0040069a high-off 0x00000031 addr 0x004006c7>DW_OP_breg6+16
|
||||
low-off : 0x00000031 addr 0x004006c7 high-off 0x00000032 addr 0x004006c8>DW_OP_breg7+8
|
||||
|
||||
```
|
||||
|
||||
位置列表取决于程序计数器所处的位置给出不同的位置。这个例子告诉我们如果程序计数器是在 `DW_AT_low_pc` 偏移量为 `0x0` 的位置,那么帧基就在和寄存器 7 中保存的值偏移量为 8 的位置,如果它是在 `0x1` 和 `0x4` 之间,那么帧基就在和相同位置偏移量为 16 的位置,以此类推。
|
||||
|
||||
* * *
|
||||
|
||||
### 休息一会
|
||||
|
||||
这里有很多的信息需要你的大脑消化,但好消息是在后面的几篇文章中我们会用一个库替我们完成这些艰难的工作。理解概念仍然很有帮助,尤其是当出现错误或者你想支持一些你使用的 DWARF 库所没有实现的 DWARF 概念时。
|
||||
|
||||
如果你想了解更多关于 DWARF 的内容,那么你可以从[这里][11]获取标准。在写这篇博客时,刚刚发布了 DWARF 5,但更普遍支持 DWARF 4。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
|
||||
作者:[ TartanLlama ][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/corkami/pics/raw/master/binary/elf101/elf101-64.pdf
|
||||
[8]:http://www.skyfree.org/linux/references/ELF_Format.pdf
|
||||
[9]:http://www.dwarfstd.org/doc/Debugging%20using%20DWARF-2012.pdf
|
||||
[10]:https://www.uclibc.org/docs/psABI-x86_64.pdf
|
||||
[11]:http://dwarfstd.org/Download.php
|
||||
@ -0,0 +1,70 @@
|
||||
Fuchsia 对 Android 意味着什么
|
||||
============================================================
|
||||
|
||||
Fuchsia 可能是下个会替代 Android 或 Chrome OS 的系统。猜测有很多,Jack Wallen 对此补充了一些让 Google 考虑的赞誉和告诫。
|
||||
|
||||
 Image: Jack Wallen
|
||||
|
||||
Google 总是以 “Google” 的方式解决或者做某件事。因此, 他们开始做一个让很多人挠头的项目,大家是不觉得奇怪的。该项目被称为 [Fuschia][6],大多数紧跟 Google 和 Android 的人都知道这个新平台。
|
||||
|
||||
对于那些还没紧跟 Google 最新消息的用户而言,Fuschia 是一个新的实时开源操作系统,它首先出现于 2016 年 8 月。那时,Fuchsia 只不过是一个命令行。一年不到的时间过去了,这个平台已经有了一个相当有趣的 GUI。
|
||||
|
||||
最让 Linux 拥趸失望的是,Fuchsia 并没有使用 Linux 内核。这个项目完全是 Google 的,并使用 Google 开发的微内核,名为 “Magenta”。他们为什么这么做?考虑到 Google 的最新设备 Pixel 运行的内核是 3.18,你就会有你自己的答案了。Linux 3.18 发布于 2014 年(技术上是古老的)。考虑到这一点,为什么 Google 不会自己完全发挥出来,尽可能地保持移动平台的最新状态?
|
||||
|
||||
尽管我觉得 Linux 可能不会(在未来的某个时期)是驱动全球最广泛使用的生态系统,但我相信这是 Google 的正确举措,有一个重要的告诫。
|
||||
|
||||
### 首先,一些赞誉
|
||||
|
||||
首先我必须说,Google 开源 Fuchsia 是很好的。Android 已经从开源的 Linux 内核中受益多年,所以 Google 才会开放他们最新的项目。说实话,如果不是开源和 Linux 内核,Android 就不会发展得那么快了。事实上,我大胆猜测,如果 Android 没有 Linux 和开源的支持,现在移动市场份额会显示出非常不同的苹果状的形式。
|
||||
|
||||
一些喝彩是有必要的。操作系统不时需要完全重新思考。Android 是一个为移动平台服务得很好的令人惊奇的平台。然而,从中也就能前进这么多了。考虑到消费世界一直在寻找下一个大事件,Android(和 iOS)已近乎枯竭。与一个严重过时的内核相比,准备迎接对 Fuchsia 的喜爱吧。
|
||||
|
||||
谷歌从来不会停滞不前,这个新平台是证明。
|
||||
|
||||
### 一个十足的告诫
|
||||
|
||||
开始这部分之前,我先提醒大家我的开源背景。自从 90 年代末以来,我一直是 Linux 的用户,并几乎涵盖了开源的各个方面。在过去几年中,我一直在观看并评论和 Ubuntu 的进展和他们(现在)失败的融合尝试。也就是说,这也是我对 Fuchsia 的担心。
|
||||
|
||||
我怀疑 Google 对 Fucshia 的大计划是为所有设备创建一个操作系统:智能手机、IoT、Chromebook。从表面看来,这听起来像是一个会有重大成果的想法。但是,如果你看过 Canonical 对 Unity 8/Mir 融合的斗争,你就会对“一个平台统治所有”的想法感到畏惧。当然这并不完全相同。我怀疑 Google 正在创建一个单一的平台,让你 “融合” 所有的设备。毕竟,智能手机与物联网融合有什么好处?我们不需要在手机和恒温器之间交换数据。对么?对么???
|
||||
|
||||
即使如此,这应该是谷歌的计划,我会提醒他们仔细观察 Canonical和 Unity 8 发生的事。这是一个很好的想法,但根本无法实现。
|
||||
|
||||
我也有可能错了。Google 可能只是将 Fuchsia 看作是 Android 的替代品。这很可能是 Google 需要替换过时的 Linux 内核,并决定“把一切都包含进来”。但是考虑到 Armadillo(Fuchsia UI)由跨平台的 [Flutter SDK][7] 编写,跨越平台边界的想法开始变为可能。
|
||||
|
||||
或者,也许 Fuchsia 只是谷歌说的 “让我们用我们今天所知道的知识重建我们的智能手机平台,看看它会走向何方”。如果是这样,我可以想象,Google 移动操作系统将会取得重大成功。然而,房间里有一只大象,人们不由想起“一个平台统治所有”还有许多要解决的事情。Google 已经在 Chromebook 上测试 Android app 很长时间了。不幸的是,这个想法一直反响平平(最多如此)。随着微软以自己的方式走出来与 Chromebook 竞争,Google 知道他们必须扩大生态系统,否则将会失去宝贵的领地(如在教育领域)。要解决这个问题的一种方法是使用单个操作系统来驱动智能手机和 Chromebook。这意味着所有的程序都可以在两个平台(这是一个重要的福音)运行以及生态系统的普遍性(再一次是巨大的福音)。
|
||||
|
||||
### 猜测
|
||||
|
||||
Google 对这类事情一直小心谨慎,这就会引发很多行家的猜测。一般来说,至少对于 Android,谷歌似乎一直都在做出正确的选择。如果他们相信 Fuchsia 是要走的路,那么我就倾向于相信他们。然而,围绕这个平台有如此多的不确定性以至于让人们一直挠破头想要知道。
|
||||
|
||||
那你怎么看?Fuchsia 会成为什么?和我一起猜猜看。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack Wallen 是 TechRepublic 和 Linux.com 的获奖作家。他是开源的狂热倡导者, 也是 The Android Expert 的代言人。有关 Jack Wallen 的更多消息, 请访问他的网站 jackwallen.com。
|
||||
|
||||
|
||||
-------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/
|
||||
|
||||
作者:[About Jack Wallen ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/#modal-bio
|
||||
[1]:http://www.techrepublic.com/article/biometric-mobile-payments-will-hit-2b-this-year/
|
||||
[2]:http://www.techrepublic.com/article/apple-invests-200m-in-us-manufacturing-to-help-corning-produce-new-state-of-the-art-glass/
|
||||
[3]:http://www.techrepublic.com/article/google-will-soon-require-android-for-work-profiles-for-enterprise-users/
|
||||
[4]:http://www.techrepublic.com/newsletters/
|
||||
[5]:http://www.techrepublic.com/article/what-fuchsia-could-mean-for-android/#postComments
|
||||
[6]:https://github.com/fuchsia-mirror
|
||||
[7]:https://flutter.io/
|
||||
[8]:http://intent.cbsi.com/redir?tag=medc-content-top-leaderboard&siteId=11&rsid=cbsitechrepublicsite&pagetype=article&sl=en&sc=us&topicguid=09288d3a-8606-11e2-a661-024c619f5c3d&assetguid=714cb8ff-ebf0-4584-a421-e8464aae66cf&assettype=content_article&ftag_cd=LGN3588bd2&devicetype=desktop&viewguid=4c47ca57-283d-4861-a131-09e058b652ac&q=&ctype=docids;promo&cval=33109435;7205&ttag=&ursuid=&bhid=&destUrl=http%3A%2F%2Fwww.techrepublic.com%2Fresource-library%2Fwhitepapers%2Ftaming-it-complexity-with-managed-services-japanese%2F%3Fpromo%3D7205%26ftag%3DLGN3588bd2%26cval%3Dcontent-top-leaderboard
|
||||
[10]:http://www.techrepublic.com/rssfeeds/topic/android/
|
||||
[11]:http://www.techrepublic.com/meet-the-team/us/jack-wallen/
|
||||
[12]:https://twitter.com/intent/user?screen_name=jlwallen
|
||||
@ -1,227 +0,0 @@
|
||||
维护一个Git仓库
|
||||
============================================================
|
||||
|
||||
维护Git仓库通常包括减少仓库的大小。如果你从另外一个版本控制系统导入了一个仓库,你可能需要在导入后清除掉不必要的文件。本文着重于从一个Git仓库中删除大文件,并且包含下列主题:
|
||||
|
||||
* [理解从Git的历史记录中删除文件][1]
|
||||
|
||||
* [使用BFG重写历史记录][2]
|
||||
|
||||
* [可选,使用git filter-branch重写历史记录][3]
|
||||
|
||||
* [垃圾回收][4]
|
||||
|
||||
请格外小心.....
|
||||
|
||||
本文中的步骤和工具使用的高级技术涉及破坏性操作。确保您在开始之前仔细读过**备份你的仓库**,创建一个备份的方式是使用[--mirror][5]标志对你的仓库克隆,然后对整个克隆的文件进行打包压缩。如果在维护期间意外损坏了您的仓库的关键元素,那么你可以通过备份的仓库来恢复。
|
||||
|
||||
请记住,仓库维护对仓库的用户可能会是毁灭性的。与你的团队或者仓库的关注者进行沟通会是一个不错的主意。确保每个人都已经检查了他们的代码,并且同意在仓库维护期间停止开发。
|
||||
|
||||
### 理解从Git的历史记录中删除文件
|
||||
|
||||
回想一下,克隆存储库会克隆整个历史记录——包括每个源代码文件的所有版本。如果一个用户提交了一个较大的文件,比如一个JAR,则随后的每次克隆都会包含这个文件。即使用户最终在后面的某次提交中删除了这个文件,但是这个文件仍然存在于这个仓库的历史记录中。要想完全的从你的仓库中删除这个文件,你必须:
|
||||
|
||||
* 从你的项目的*当前的*文件树中删除该文件;
|
||||
|
||||
* 从仓库的历史记录中删除文件——*重写*Git历史记录,从包含该文件的*所有的*提交中删除这个文件;
|
||||
|
||||
* 删除指向*旧的*提交历史记录的所有[reflog][6]历史记录;
|
||||
|
||||
* 重新整理仓库,使用[git gc][7]对现在没有使用的数据进行垃圾回收。
|
||||
|
||||
Git的'gc'(垃圾回收)通过任何一个你的分支或者标签来删除仓库中所有的实际没用的或者用某种方式引用的数据。为了使其有用,我们需要重写包含不需要的文件的所有Git仓库历史记录,仓库将不再引用它——git gc将会丢弃所有没用的数据。
|
||||
|
||||
重写存储库历史是一个棘手的事情,因为每次提交都依赖它的父提交,所以任何一个很小的改变都会改变它的每一个子拼音的提交ID。有两个自动化的工具可以做到这:
|
||||
|
||||
1. [BFG Repo Cleaner][8] 快速、简单且易于使用,需要Java 6或者更高版本的运行环境。
|
||||
|
||||
2. [git filter-branch][9] 功能强大、配置麻烦,用于大于仓库时速度较慢,是核心Git套件的一部分。
|
||||
|
||||
切记,当你重写历史记录后,无论你是使用BFG还是使用filter-branch,你都需要删除撒向指向旧的历史记录的`reflog`条目,最后运行垃圾回收器来删除旧的数据。
|
||||
|
||||
### 使用BFG重写历史记录
|
||||
|
||||
[BFG][11]是为将像大文件或者密码这些不想要的数据从Git仓库中删除而专门设计的,所以它有一一个简单的标志用来删除那些大的历史文件(不是当前提交的文件):`'--strip-blobs-bigger-than'`
|
||||
|
||||
```
|
||||
$ java -jar bfg.jar --strip-blobs-than 100M
|
||||
|
||||
```
|
||||
大小超过100MB的任何文件(不在你*最近的*提交中——因为BFG[默认会保护你的最新提交的内容][12])将会从你的Git仓库的历史记录中删除。如果你想用名字来指明具体的文件,你也可以这样做:
|
||||
|
||||
```
|
||||
$ java -jar bfg.jar --delete-files *.mp4
|
||||
|
||||
```
|
||||
|
||||
BFG的速度要比git filter-branch快[10-1000x][13],而且通常更容易使用——查看完整的[使用说明][14]和[示例][15]获取更多细节。
|
||||
|
||||
### 或者,使用git filter-branch来重写历史记录
|
||||
|
||||
`filter-branch`命令可以对Git仓库的历史记录重写,就像BFG一样,但是过程更慢和更手动化。如果你不知道这些大文件在_哪里_,那么你第一步就需要找到它们:
|
||||
|
||||
### 手动查看你Git仓库中的大文件
|
||||
|
||||
[Antony Stubbs][16]写了一个可以很好地完成这个功能的BASH脚本。该脚本可以检查你的包文件的内容并列出大文件。在你开始删除文件之前,请执行以下操作获取并安装此脚本:
|
||||
|
||||
1\. [下载脚本][10]到你的本地的系统。
|
||||
|
||||
2\. 将它放在一个可以访问你的Git仓库的易于找到的位置。
|
||||
|
||||
3\. 让脚本成为可执行文件:
|
||||
|
||||
```
|
||||
$ chmod 777 git_find_big.sh
|
||||
|
||||
```
|
||||
4\. 克隆仓库到你本地系统。
|
||||
|
||||
5\. 改变当前目录到你的仓库根目录。
|
||||
|
||||
6\. 手动运行Git垃圾回收器:
|
||||
|
||||
```
|
||||
git gc --auto
|
||||
```
|
||||
|
||||
7\. 找出.git文件夹的大小
|
||||
|
||||
```
|
||||
$ du -hs .git/objects
|
||||
```
|
||||
```
|
||||
45M .git/objects
|
||||
```
|
||||
注意文件大小,以便随后参考。
|
||||
|
||||
8\. 运行`git_find_big.sh`脚本来列出你的仓库中的大文件。
|
||||
|
||||
```
|
||||
$ git_find_big.sh
|
||||
|
||||
```
|
||||
所有文件大小都用kb表示,pack列是在pack文件内压缩后的大小。
|
||||
|
||||
```
|
||||
size pack SHA location
|
||||
```
|
||||
```
|
||||
592 580 e3117f48bc305dd1f5ae0df3419a0ce2d9617336 media/img/emojis.jar
|
||||
```
|
||||
```
|
||||
550 169 b594a7f59ba7ba9daebb20447a87ea4357874f43 media/js/aui/aui-dependencies.jar
|
||||
```
|
||||
|
||||
```
|
||||
518 514 22f7f9a84905aaec019dae9ea1279a9450277130 media/images/screenshots/issue-tracker-wiki.jar
|
||||
```
|
||||
```
|
||||
337 92 1fd8ac97c9fecf74ba6246eacef8288e89b4bff5 media/js/lib/bundle.js
|
||||
```
|
||||
```
|
||||
240 239 e0c26d9959bd583e5ef32b6206fc8abe5fea8624 media/img/featuretour/heroshot.png
|
||||
```
|
||||
大文件都是JAR文件,包的大小列是最相关的。`aui-dependencies.jar` 被压缩到169kb,但是`emojis.jar`只压缩到500kb。`emojis.jar`就是一个待删除的对象。
|
||||
|
||||
|
||||
### 运行filter-branch
|
||||
|
||||
|
||||
你可以给这个命令传递一个用于重写Git索引的过滤器。例如,一个过滤器可以可以将每个检索的提交删除。这个用法如下:
|
||||
|
||||
```
|
||||
git filter-branch --index-filter 'git rm --cached --ignore-unmatch _pathname_ ' commitHASH
|
||||
|
||||
```
|
||||
`--index-filter`选项可以修改仓库的索引,`--cached ` 选项从不是磁盘的索引中删除文件。这样会更快,因为你不需要在运行这个过滤器前检查每个修订版。`git rm`中的`ignore-unmatch`选项可以防止当 _pathname_ 正在尝试不在那的文件的时候这个命令失败。通过明确一个提交HASH值,你可以从每个以这个HASH值开始的提交中删除`pathname`。为了从开始处删除,你可以省略这个或者明确HEAD。
|
||||
|
||||
如果所有你的大文件在不同的分支,你将需要通过名字来删除每个文件。如果所有大文件在一个单独的分支,你可以直接删除这个分支本身。
|
||||
|
||||
### 选项1:通过文件名删除文件
|
||||
|
||||
使用下面的步骤来删除大文件:
|
||||
|
||||
1\. 使用下面的命令来删除你找到的第一个大文件:
|
||||
|
||||
```
|
||||
git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
|
||||
|
||||
```
|
||||
|
||||
2\. 对于剩下的每个大文件,重复步骤1。
|
||||
|
||||
3\. 在你的仓库里更新引用。 `filter-branch`会为你原先的引用创建一个以`refs/original/`命名的备份。一旦你确信已经删除了正确的文件,你可以运行下面的命令来删除备份文件,同时可以让垃圾回收器回收大的对象:
|
||||
|
||||
```
|
||||
git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
|
||||
|
||||
```
|
||||
|
||||
### 选项2:直接删除分支
|
||||
|
||||
如果你所有的大文件都在一个单独的分支上,你可以直接删除这个分支。删除这个分支会自动删除所有的引用。
|
||||
|
||||
1\. 删除分支。
|
||||
|
||||
```
|
||||
$ git branch -D PROJ567bugfix
|
||||
|
||||
```
|
||||
|
||||
2\. 从后面的分支中删除所有的reflog引用。
|
||||
|
||||
|
||||
### 对不用的数据垃圾回收
|
||||
|
||||
1\. 删除从现在到后面的所有reflog引用(除非你明确地只在一个分支上操作)。
|
||||
|
||||
```
|
||||
$ git reflog expire --expire=now --all
|
||||
|
||||
```
|
||||
|
||||
2\. 通过运行垃圾回收器和删除旧的对象重新打包仓库。
|
||||
|
||||
```
|
||||
$ git gc --prune=now
|
||||
|
||||
```
|
||||
|
||||
3\. 把你所有的修改推送回Bitbucket仓库。
|
||||
|
||||
```
|
||||
$ git push --all --force
|
||||
```
|
||||
|
||||
4\. 确保你所有的tags也是当前最新的:
|
||||
|
||||
```
|
||||
$ git push --tags --force
|
||||
|
||||
```
|
||||
|
||||
via: https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
|
||||
|
||||
作者:[atlassian.com][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html
|
||||
[1]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UnderstandingfileremovalfromGithistory
|
||||
[2]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-UsingtheBFGtorewritehistory
|
||||
[3]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Alternatively,usinggitfilter-branchtorewritehistory
|
||||
[4]:https://confluence.atlassian.com/bitbucket/maintaining-a-git-repository-321848291.html#MaintainingaGitRepository-Garbagecollectingdeaddata
|
||||
[5]:http://stackoverflow.com/questions/3959924/whats-the-difference-between-git-clone-mirror-and-git-clone-bare
|
||||
[6]:http://git-scm.com/docs/git-reflog
|
||||
[7]:http://git-scm.com/docs/git-gc
|
||||
[8]:http://rtyley.github.io/bfg-repo-cleaner/
|
||||
[9]:http://git-scm.com/docs/git-filter-branch
|
||||
[10]:https://confluence.atlassian.com/bitbucket/files/321848291/321979854/1/1360604134990/git_find_big.sh
|
||||
[11]:http://rtyley.github.io/bfg-repo-cleaner/
|
||||
[12]:http://rtyley.github.io/bfg-repo-cleaner/#protected-commits
|
||||
[13]:https://www.youtube.com/watch?v=Ir4IHzPhJuI
|
||||
[14]:http://rtyley.github.io/bfg-repo-cleaner/#usage
|
||||
[15]:http://rtyley.github.io/bfg-repo-cleaner/#examples
|
||||
[16]:https://stubbisms.wordpress.com/2009/07/10/git-script-to-show-largest-pack-objects-and-trim-your-waist-line/
|
||||
@ -1,121 +0,0 @@
|
||||
### 新基于SMB漏洞的蠕虫病毒用了7个NSA的黑客工具,WannaCry只用了两个。
|
||||
|
||||
20170519 New SMB Worm Uses Seven NSA Hacking Tools. WannaCry Used Just Two.md
|
||||

|
||||
|
||||
研究人员们发现有一个新的蠕虫病毒正在通过SMB文件共享漏洞传播,, 但是不同于WannaCry勒索病毒的构成,这个病毒用了7个NSA黑客工具,而不是两个。
|
||||
|
||||
这个蠕虫病毒的存在首次发现是在周三,他感染了克罗地亚政府计算机应急响应小组成员,用来探测和利用SQL注入漏洞的SQLMAP工具的制造者叫做[Miroslav Stampar][15]的SMB文件共享的蜜罐。
|
||||
|
||||
### 永恒之石用了七个NSA的工具
|
||||
|
||||
Stampar命名这个在样本中被发现的病毒为永恒之石,是基于蠕虫病毒可执行的特性,它通过6个以SMB文件共享漏洞为中心的NSA工具来感染暴露在外网的一台开启SMB端口的计算机。这些被叫做 **永恒之蓝**, **永恒战士**, **永恒浪漫**, and **永恒协同**的SMB漏洞被利用危害易受攻击的计算机,而 **SMBTOUCH** 和 **ARCHITOUCH** 这两个NSA工具是起检测SMB文件共享漏洞的作用。
|
||||
一旦这个蠕虫病毒获得了最初的立足点,那么它会用另一个叫做**DOUBLEPULSAR**的NSA工具扩散到新的易受攻击的机器上。
|
||||
|
||||
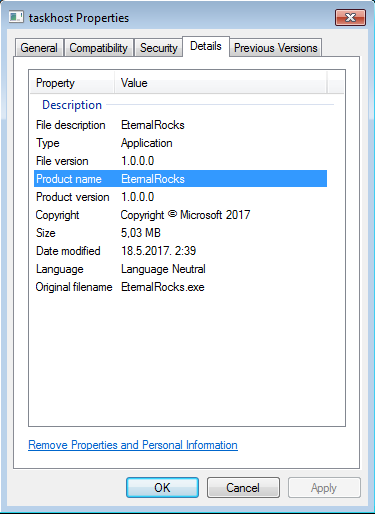
|
||||
**永恒之石名字的起源**
|
||||
|
||||
[WannaCry勒索病毒爆发][16], 用了一个SMB蠕虫病毒感染计算机并扩散给新的受害人,这影响了超过24万受害者。
|
||||
|
||||
|
||||
不同于永恒之石,WannaCry的SMB蠕虫病毒只用了永恒之蓝这一个初始伤害,然后通过 DOUBLEPULSAR 来扩散到其他的计算机上。
|
||||
|
||||
### 永恒之石更加复杂且危险
|
||||
|
||||
作为蠕虫病毒,永恒之石比WannaCry更加危险,由于它当前不传递任何恶意的内容,然而,并不意味着永恒之石不复杂,据Stampar说,实际恰恰相反。
|
||||
|
||||
首先, 永恒之石要比WannaCry的SMB蠕虫病毒构成更加狡猾,一旦病毒感染了一台计算机,它会发起有两个阶段的安装过程,其中另一个是延迟执行的。
|
||||
|
||||
在病毒的第一个安装过程阶段,永恒之石获取一个感染计算机主机的立足点,下载tor客户端,然后连接到它的命令控制服务器,定位在暗网的一个.onion的域名上。
|
||||
|
||||
在一个预定的时间内,一般24个小时,命令控制器会响应,这个延迟执行进程的角色最有可能绕过沙盒安全测试环境和安全研究人员们分析这个病毒,因为没多少人愿意一整天来等命令控制器响应。
|
||||
<twitterwidget class="twitter-tweet twitter-tweet-rendered" id="twitter-widget-0" data-tweet-id="865494946974900224" style="position: static; visibility: visible; display: block; transform: rotate(0deg); width: 500px; margin: 10px auto; max-width: 100%; min-width: 220px;">[View image on Twitter][10] [][5]
|
||||
|
||||
> [ Follow][1] [ Miroslav Stampar @stamparm][6]
|
||||
>
|
||||
> Update on [#EternalRocks][7]. Original name is actually "MicroBotMassiveNet" while author's nick is "tmc" [https://github.com/stamparm/EternalRocks/#debug-strings …][8]
|
||||
>
|
||||
> [<time class="dt-updated" datetime="2017-05-19T09:10:50+0000" pubdate="" title="Time posted: 19 May 2017, 09:10:50 (UTC)">5:10 PM - 19 May 2017</time>][9]
|
||||
>
|
||||
> * [][2]
|
||||
>
|
||||
> * [ 2525 Retweets][3]
|
||||
>
|
||||
> * [ 1717 likes][4]
|
||||
|
||||
[Twitter Ads info & Privacy][11]</twitterwidget>
|
||||
|
||||
### 没有停止开关的域名
|
||||
|
||||
此外,永恒之石病毒也会用和他相同的名字的另一个WannaCry的SMB的蠕虫病毒文件,企图愚弄安全研究人员来误判它。
|
||||
|
||||
但是不同于WannaCry病毒,永恒之石不包括停止开关的域名,但这是安全研究人员唯一用来停止Wannacry爆发的方法。
|
||||
在病毒隐匿期满且命令控制器有了响应,永恒之石开始进入安装过程的第二阶段,它会下载一个名为shadowbrokers.zip形式的第二阶段恶意组件。
|
||||
|
||||
这个文件能够自解压,它包含着shadow Brokers黑客组织在2017年4月泄漏的七个NSA的SMB漏洞工具。
|
||||
这个蠕虫病毒会开始一个快速的ip扫描过程并且尝试连接随机的ip地址。
|
||||
|
||||
|
||||
**在shadowbrokers.zip压缩包里发现了NSA工具的配置文件。**
|
||||
|
||||
### 永恒之石可以马上成为武器
|
||||
|
||||
由于该病毒集成的漏洞较多且广泛,缺少停止开关的域名,而且有它的隐匿期,如何病毒的作者决定用它来作为勒索,银行木马,远程控制或者其他功能的武器,永恒之石可能会对SMB端口暴露在外网的易受攻击的计算机造成严重的威胁。
|
||||
|
||||
就目前来看,蠕虫病毒看起来像是一个试验,或者是恶意软件作者在进行测试或者微调一个未来的威胁。
|
||||
|
||||
然而,这并不意味着永恒之石是无害的,感染了这个病毒的计算机是通过命令控制服务器来控制,并且蠕虫病毒的制造者能够隐藏这个通讯连接,然后发送新的恶意软件到这台感染了病毒的电脑上。
|
||||
|
||||
此外, DOUBLEPULSAR,一个带有后门的植入仍然运行在感染了永恒之石的PC上,不幸的是,该病毒的作者没有采取任何措施来保护这个DOUBLEPULSAR的植入,这意味这在缺省为被保护的状态下,其他的具有威胁的用户能把感染了永恒之石的计算机作为后门,发送他们自己的恶意软件到这些感染病毒的PC上。
|
||||
关于这个病毒的感染过程的输入输出体系和更多信息能够在Stampar在几天前设置的[GitHub repo]库上获得。
|
||||
|
||||
### SMB漏洞的混战
|
||||
|
||||
当前, 有多个用户在扫描旧的和未打补丁的SMB服务,系统管理员已经注意到并且开始给易受攻击的计算机打补丁,关闭旧版的SMBv1协议,慢慢的来减少被永恒之石感染的计算机数量。
|
||||
|
||||
此外, 像Adylkuzz这类恶意软件,也会关闭SMB端口,来阻止来自其他威胁的漏洞,同时也导致了永恒之石和其他利用SMB漏洞的恶意软件潜在目标数量的减少,报告来自 [Forcepoint][21], [Cyphort][22], and [Secdo][23] 细节是当前其他软件会威胁有SMB端口的计算机。
|
||||
|
||||
虽然如此, 系统管理员补丁打的越快,系统越安全,“蠕虫病毒感染速度正在和系统管理员给机器打补丁速度比赛”,Stampar在一次私人谈话告诉BleepingComputer记者 . "一旦计算机被感染, 他能在任何时间将其作为武器,不论你打多时间多近的补丁."
|
||||
|
||||
_Image credits: Miroslav Stampar, BleepingComputer & [Ana María Lora Macias][13]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Catalin涉及了各方面,像数据泄漏, 软件漏洞, 漏洞利用, 黑客新闻, 暗网, 编程话题, 社交媒体, web技术, 产品研发等领域.
|
||||
|
||||
---------------
|
||||
|
||||
via: https://www.bleepingcomputer.com/news/security/new-smb-worm-uses-seven-nsa-hacking-tools-wannacry-used-just-two/
|
||||
|
||||
作者:[CATALIN CIMPANU ][a]
|
||||
译者:[hwlog](https://github.com/hwlog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||
[1]:https://twitter.com/stamparm
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=865494946974900224
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=865494946974900224
|
||||
[4]:https://twitter.com/intent/like?tweet_id=865494946974900224
|
||||
[5]:https://twitter.com/stamparm/status/865494946974900224/photo/1
|
||||
[6]:https://twitter.com/stamparm
|
||||
[7]:https://twitter.com/hashtag/EternalRocks?src=hash
|
||||
[8]:https://t.co/xqoxkNYfM7
|
||||
[9]:https://twitter.com/stamparm/status/865494946974900224
|
||||
[10]:https://twitter.com/stamparm/status/865494946974900224/photo/1
|
||||
[11]:https://support.twitter.com/articles/20175256
|
||||
[12]:https://www.bleepingcomputer.com/news/security/new-smb-worm-uses-seven-nsa-hacking-tools-wannacry-used-just-two/#comment_form
|
||||
[13]:https://thenounproject.com/search/?q=worm&i=24323
|
||||
[14]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||
[15]:https://about.me/stamparm
|
||||
[16]:https://www.bleepingcomputer.com/news/security/wana-decrypt0r-ransomware-using-nsa-exploit-leaked-by-shadow-brokers-is-on-a-rampage/
|
||||
[17]:https://www.bleepingcomputer.com/news/security/shadow-brokers-release-new-files-revealing-windows-exploits-swift-attacks/
|
||||
[18]:https://www.bleepingcomputer.com/news/security/over-36-000-computers-infected-with-nsas-doublepulsar-malware/
|
||||
[19]:https://github.com/stamparm/EternalRocks/
|
||||
[20]:https://www.bleepingcomputer.com/news/security/adylkuzz-cryptocurrency-miner-may-have-saved-you-from-the-wannacry-ransomware/
|
||||
[21]:https://blogs.forcepoint.com/security-labs/wannacry-multiple-malware-families-using-eternalblue-exploit
|
||||
[22]:https://www.cyphort.com/eternalblue-exploit-actively-used-deliver-remote-access-trojans/
|
||||
[23]:http://blog.secdo.com/multiple-groups-exploiting-eternalblue-weeks-before-wannacry
|
||||
Loading…
Reference in New Issue
Block a user