mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
finish translating and pull the newest lctt master
This commit is contained in:
commit
0c1199ac37
published
20170111 The difference between development and deployment.md20170308 Our guide to a Golang logs world.md20170426 Python-mode – A Vim Plugin to Develop Python Applications in Vim Editor.md20170509 How to Password Protect a Vim File in Linux.md20170511 How to Delete HUGE 100-200GB Files in Linux.md20170515 Show a Custom Message to Users Before Linux Server Shutdown.md20170518 How to make Vim user-friendly with Cream.md20170518 Linfo – Shows Linux Server Health Status in Real-Time.md20170519 How to Kill a Process from the Command Line.md
sources
talk
tech
20170303 A Programmes Introduction to Unicode.md20170403 Discovering my inner curmudgeon A Linux laptop review.md20170426 Python-mode – A Vim Plugin to Develop Python Applications in Vim Editor.md20170426 Top 4 CDN services for hosting open source libraries.md20170505 WPSeku – A Vulnerability Scanner to Find Security Issues in WordPress.md20170523 An introduction to Libral a systems management library for Linux.md20170524 How to Configure Thunderbird with iRedMail for Samba4 AD – Part 13.md20170525 An introduction to Linux s EXT4 filesystem.md20170526 Use pushd and popd for Efficient Filesystem Navigation in Linux.md
translated
talk
tech
20170403 Discovering my inner curmudgeon A Linux laptop review.md20170504 A beginner s guide to Linux syscalls.md20170505 WPSeku – A Vulnerability Scanner to Find Security Issues in WordPress.md20170509 4 Python libraries for building great command-line user interfaces.md20170519 How to Kill a Process from the Command Line.md
@ -0,0 +1,59 @@
|
||||
一位老极客的眼中的开发和部署
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
图片提供 : opensource.com
|
||||
|
||||
多年前,我曾是一名 Smalltalk 程序员,这种经验让我以一种不同的视角来观察编程的世界,例如,需要花时间来适应源代码应该存储在文本文件中的这种做法。
|
||||
|
||||
我们作为程序员通常会区分“开发”和“部署”,特别是我们在开发的地方所使用的工具不同于我们在之后部署软件时的地点和工具时。而在 Smalltalk 世界里,没有这样的区别。
|
||||
|
||||
Smalltalk 构建于虚拟机包含了你的开发环境(IDE、调试器、文本编辑器、版本控制等)的思路之上,如果你需要修改任何一处代码,你得修改内存中运行副本。如果需要的话,你可以为运行中的机器做个快照;如果你想分发你的代码,你可以发送一个运行中的机器的镜像副本(包括 IDE、调试器、文本编辑器、版本控制等)给用户。这就是上世纪 90 年代软件开发的方式(对我们中的一些人来说)。
|
||||
|
||||
如今,部署环境与开发环境有了很大的不同。起初,你不要期望那里(指部署环境)有任何开发工具。一旦部署,就没有版本控制、没有调试、没有开发环境。有的是记录和监视,这些在我们的开发环境中都没有,而有一个“构建管道”,它将我们的软件从开发形式转换为部署形式。作为一个例证,Docker 容器则试图重新找回上世纪 90 年代 Smalltalk 程序员部署体验的那种简单性,而避免同样的开发体验。
|
||||
|
||||
我想如果 Smalltalk 世界是我唯一的编程方面的体验,让我无法区分开发和部署环境,我可能会偶尔回顾一下它。但是在我成为一名 Smalltalk 程序员之前,我还是一位 APL 程序员,这也是一个可修改的虚拟机镜像的世界,其中开发和部署是无法区分的。因此,我相信,在当前的时代,人们编辑单独的源代码文件,然后运行构建管道以创建在编辑代码时尚不存在的部署作品,然后将这些作品部署给用户。我们已经以某种方式将这种反模式的软件开发制度化,而不断发展的软件环境的需求正在迫使我们找回到上世纪 90 年代的更有效的技术方法。因此才会有 Docker 的成功,所以,我需要提出我的建议。
|
||||
|
||||
我有两个建议:我们在运行时系统中实现(并使用)版本控制,以及,我们通过更改运行中的系统来开发软件,而不是用新的运行系统替换它们。这两个想法是相关的。为了安全地更改正在运行的系统,我们需要一些版本控制功能来支持“撤消”功能。也许公平地说,我只提出了一个建议。让我举例来说明。
|
||||
|
||||
让我们开始假设一个静态网站。你要修改一些 HTML 文件。你应该如何工作?如果你像大多数开发者一样,你会有两个,也许三个网站 - 一个用于开发,一个用于 QA(或者预发布),一个用于生产。你将直接编辑开发实例中的文件。准备就绪后,你将把你的修改“部署”到预发布实例。在用户验收测试之后,你将再次部署,这次是生产环境。
|
||||
|
||||
使用 Occam 的 Razor,让我们可以避免不必要地创建实例。我们需要多少台机器?我们可以使用一台电脑。我们需要多少台 web 服务器?我们可以使用具有多个虚拟主机的单台 web 服务器。如果不使用多个虚拟主机的话,我们可以只使用单个虚拟主机吗?那么我们就需要多个目录,并需要使用 URL 的顶级路径来区分不同的版本,而不是虚拟主机名。但是为什么我们需要多个目录?因为 web 服务器将从文件系统中提供静态文件。我们的问题是,目录有三个不同的版本,我们的解决方案是创建目录的三个不同的副本。这不是正是 Subversion 和 Git 这样的版本控制系统解决的问题吗?制作目录的多个副本以存储多个版本的策略回到了版本控制 CVS 之前的日子。为什么不使用比如说一个空的的 Git 仓库来存储文件呢?要这样做,web 服务器将需要能够从 git 仓库读取文件(参见 [mod_git] [3])。
|
||||
|
||||
这将是一个支持版本控制的运行时系统。
|
||||
|
||||
使用这样的 web 服务器,使用的版本可以由 cookie 来标识。这样,任何人都可以推送到仓库,用户将继续看到他们发起会话时所分配的版本。版本控制系统有不可改变的提交; 一旦会话开始,开发人员可以在不影响正在运行的用户的情况下快速推送更改。开发人员可以重置其会话以跟踪他们的新提交,因此开发人员或测试人员就可能如普通用户一样查看在同台服务器上同一个 URL 上正在开发或正在测试的版本。作为偶然的副作用,A/B 测试仅仅是将不同的用户分配给不同的提交的情况。所有用于管理多个版本的 git 设施都可以在运行环境中发挥作用。当然,git reset 为我们提供了前面提到的“撤销”功能。
|
||||
|
||||
为什么不是每个人都这样做?
|
||||
|
||||
一种可能性是,诸如版本控制系统的工具没有被设计为在生产环境中使用。例如,给某人推送到测试分支而不是生产分支的许可是不可能的。对这个方案最常见的反对是,如果发现了一个漏洞,你会想要将某些提交标记为不可访问。这将是另一种更细粒度的权限的情况;开发人员将具有对所有提交的读取权限,但外部用户不会。我们可能需要对现有工具进行一些额外的改造以支持这种模式,但是这些功能很容易理解,并已被设计到其他软件中。例如,Linux (或 PostgreSQL)实现了对不同用户的细粒度权限的想法。
|
||||
|
||||
随着云环境变得越来越普及,这些想法变得更加相关:云总是在运行。例如,我们可以看到,AWS 中等价的 “文件系统”(S3)实现了版本控制,所以你可能有一个不同的想法,使用一台 web 服务器提供来自 S3 的资源文件,并根据会话信息选择不同版本的资源文件。重要的并不是哪个实现是最好的,而是支持这种运行时版本控制的愿景。
|
||||
|
||||
部署的软件环境应该是“版本感知”的原则,应该扩展到除了服务静态文件的 web 服务器之外的其他工具。在将来的文章中,我将介绍版本库,数据库和应用程序服务器的方法。
|
||||
|
||||
_在 linux.conf.au 中了解更多 Robert Lefkowitz 2017 年 ([#lca2017][1])在 Hobart:[保持 Linux 伟大][2]的主题。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Robert M. Lefkowitz - Robert(即 r0ml)是一个喜欢复杂编程语言的编程语言爱好者。 他是一个提高清晰度、提高可靠性和最大限度地简化的编程技术收藏家。他通过让计算机更加容易获得来使它普及化。他经常演讲中世纪晚期和早期文艺复兴对编程艺术的影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/difference-between-development-deployment
|
||||
|
||||
作者:[Robert M. Lefkowitz][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Bestony](https://github.com/Bestony)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/r0ml
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://www.linux.conf.au/schedule/presentation/107/
|
||||
[3]:https://github.com/r0ml/mod_git
|
||||
@ -1,17 +1,17 @@
|
||||
Go 日志指南
|
||||
Go 语言日志指南
|
||||
============================================================
|
||||
|
||||

|
||||

|
||||
|
||||
你是否厌烦了那些使用复杂语言编写、难以部署、总是在构建的解决方案?Golang 是解决这些问题的好方法,它和 C 语言一样快,又和 Python 一样简单。
|
||||
你是否厌烦了那些使用复杂语言编写的、难以部署的、总是在不停构建的解决方案?Golang 是解决这些问题的好方法,它和 C 语言一样快,又和 Python 一样简单。
|
||||
|
||||
但是你如何使用 Golang 日志监控你的应用程序呢?Golang 没有异常,只有错误。因此你的第一印象可能就是开发 Golang 日志策略并不是一件简单的事情。不支持异常事实上并不是什么问题,异常在很多编程语言中已经失去了特殊用处:它们过于被滥用以至于它们的作用都被忽视了。
|
||||
但是你是如何使用 Golang 日志监控你的应用程序的呢?Golang 没有异常,只有错误。因此你的第一印象可能就是开发 Golang 日志策略并不是一件简单的事情。不支持异常事实上并不是什么问题,异常在很多编程语言中已经失去了其异常性:它们过于被滥用以至于它们的作用都被忽视了。
|
||||
|
||||
在进一步深入之前,我们首先会介绍 Golang 日志基础并讨论 Golang 日志标准、元数据意义、以及最小化 Golang 日志对性能的影响。通过日志,你可以追踪用户在你应用中的活动,快速识别你项目中失效的组件,并监控总的性能以及用户体验。
|
||||
在进一步深入之前,我们首先会介绍 Golang 日志的基础,并讨论 Golang 日志标准、元数据意义、以及最小化 Golang 日志对性能的影响。通过日志,你可以追踪用户在你应用中的活动,快速识别你项目中失效的组件,并监控总体性能以及用户体验。
|
||||
|
||||
### I. Golang 日志基础
|
||||
|
||||
### 1) 使用 Golang "log" 库
|
||||
#### 1) 使用 Golang “log” 库
|
||||
|
||||
Golang 给你提供了一个称为 “log” 的原生[日志库][3] 。它的日志器完美适用于追踪简单的活动,例如通过使用可用的[选项][4]在错误信息之前添加一个时间戳。
|
||||
|
||||
@ -39,9 +39,9 @@ if err != nil {
|
||||
}
|
||||
```
|
||||
|
||||
如果你尝试除以0,你就会得到类似下面的结果:
|
||||
如果你尝试除以 0,你就会得到类似下面的结果:
|
||||
|
||||

|
||||

|
||||
|
||||
为了快速测试一个 Golang 函数,你可以使用 [go playground][5]。
|
||||
|
||||
@ -59,11 +59,11 @@ func main() {
|
||||
if err != nil {
|
||||
log.Fatal(err)
|
||||
}
|
||||
// 完成后延迟关闭,而不是你认为这是惯用的!
|
||||
// 完成后延迟关闭,而不是习惯!
|
||||
defer f.Close()
|
||||
//设置日志输出到 f
|
||||
log.SetOutput(f)
|
||||
//测试例
|
||||
//测试用例
|
||||
log.Println("check to make sure it works")
|
||||
}
|
||||
```
|
||||
@ -73,13 +73,14 @@ func main() {
|
||||
现在你就可以记录它们的错误以及根本原因啦。
|
||||
|
||||
另外,日志也可以帮你将活动流拼接在一起,查找需要修复的错误上下文,或者调查在你的系统中单个请求如何影响其它应用层和 API。
|
||||
|
||||
为了获得更好的日志效果,你首先需要在你的项目中使用尽可能多的上下文丰富你的 Golang 日志,并标准化你使用的格式。这就是 Golang 原生库能达到的极限。使用最广泛的库是 [glog][8] 和 [logrus][9]。必须承认还有很多好的库可以使用。如果你已经在使用支持 JSON 格式的库,你就不需要再换其它库了,后面我们会解释。
|
||||
|
||||
### II. 你 Golang 日志的统一格式
|
||||
### II. 为你 Golang 日志统一格式
|
||||
|
||||
### 1) JSON 格式的结构优势
|
||||
#### 1) JSON 格式的结构优势
|
||||
|
||||
在一个项目或者多个微服务中结构化你的 Golang 日志可能是最困难的事情,但一旦完成,它看起来就微不足道了。结构化你的日志能使机器可读(参考我们 [收集日志的最佳实践博文][10])。灵活性和层级是 JSON 格式的核心,因此信息能够轻易被人类和机器解析以及处理。
|
||||
在一个项目或者多个微服务中结构化你的 Golang 日志可能是最困难的事情,但一旦完成就很轻松了。结构化你的日志能使机器可读(参考我们 [收集日志的最佳实践博文][10])。灵活性和层级是 JSON 格式的核心,因此信息能够轻易被人类和机器解析以及处理。
|
||||
|
||||
下面是一个使用 [Logrus/Logmatic.io][11] 如何用 JSON 格式记录日志的例子:
|
||||
|
||||
@ -110,9 +111,9 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
### 2) 标准化 Golang 日志
|
||||
#### 2) 标准化 Golang 日志
|
||||
|
||||
出现在你代码不同部分的同一个错误以不同形式被记录下来是一件可耻的事情。下面是一个由于一个变量错误导致无法确定 web 页面加载状态的例子。一个开发者日志格式是:
|
||||
同一个错误出现在你代码的不同部分,却以不同形式被记录下来是一件可耻的事情。下面是一个由于一个变量错误导致无法确定 web 页面加载状态的例子。一个开发者日志格式是:
|
||||
|
||||
```
|
||||
message: 'unknown error: cannot determine loading status from unknown error: missing or invalid arg value client'</span>
|
||||
@ -124,13 +125,13 @@ message: 'unknown error: cannot determine loading status from unknown error: mis
|
||||
unknown error: cannot determine loading status - invalid client</span>
|
||||
```
|
||||
|
||||
强制日志标准化的一个好的解决办法是在你的代码和日志库之间创建一个接口。这个标准化接口会包括所有你想添加到你日志中的可能行为的预定义日志消息。这么做可以防止不符合你想要的标准格式的自定义日志信息。这么做也便于日志调查。
|
||||
强制日志标准化的一个好的解决办法是在你的代码和日志库之间创建一个接口。这个标准化接口会包括所有你想添加到你日志中的可能行为的预定义日志消息。这么做可以防止出现不符合你想要的标准格式的自定义日志信息。这么做也便于日志调查。
|
||||
|
||||

|
||||

|
||||
|
||||
由于日志格式都被统一处理,使它们保持更新也变得更加简单。如果出现了一种新的错误类型,它只需要被添加到一个接口,这样每个组员都会使用完全相同的信息。
|
||||
|
||||
最长使用的简单例子就是在 Golang 日志信息前面添加日志器名称和 id。你的代码然后就会发送 “事件” 到你的标准化接口,它会继续讲它们转化为 Golang 日志消息。
|
||||
最常使用的简单例子就是在 Golang 日志信息前面添加日志器名称和 id。你的代码然后就会发送 “事件” 到你的标准化接口,它会继续讲它们转化为 Golang 日志消息。
|
||||
|
||||
```
|
||||
// 主要部分,我们会在这里定义所有消息。
|
||||
@ -170,10 +171,10 @@ JSON 格式如下:
|
||||
|
||||
现在 Golang 日志已经按照特定结构和标准格式记录,时间会决定需要添加哪些上下文以及相关信息。为了能从你的日志中抽取信息,例如追踪一个用户活动或者工作流,上下文和元数据的顺序非常重要。
|
||||
|
||||
例如在 logrus 库中可以按照下面这样使用 JSON 格式添加 Hostname、appname 和 session 参数:
|
||||
例如在 logrus 库中可以按照下面这样使用 JSON 格式添加 `hostname`、`appname` 和 `session` 参数:
|
||||
|
||||
```
|
||||
// 对于元数据,通常做法是通过复用重用日志语句中的字段。
|
||||
// 对于元数据,通常做法是通过复用来重用日志语句中的字段。
|
||||
contextualizedLog := log.WithFields(log.Fields{
|
||||
"hostname": "staging-1",
|
||||
"appname": "foo-app",
|
||||
@ -182,7 +183,7 @@ JSON 格式如下:
|
||||
contextualizedLog.Info("Simple event with global metadata")
|
||||
```
|
||||
|
||||
元数据可以视为 javascript 片段。为了更好地说明它们有多么重要,让我们看看几个 Golang 微服务中元数据的使用。你会清楚地看到在你的应用程序中跟踪用户的决定性。这是因为你不仅需要知道一个错误发生了,还要知道是哪个实例以及什么模式导致了错误。假设我们有两个按顺序调用的微服务。上下文信息被传输并保存在头部(header):
|
||||
元数据可以视为 javascript 片段。为了更好地说明它们有多么重要,让我们看看几个 Golang 微服务中元数据的使用。你会清楚地看到是怎么在你的应用程序中跟踪用户的。这是因为你不仅需要知道一个错误发生了,还要知道是哪个实例以及什么模式导致了错误。假设我们有两个按顺序调用的微服务。上下文信息保存在头部(header)中传输:
|
||||
|
||||
```
|
||||
func helloMicroService1(w http.ResponseWriter, r *http.Request) {
|
||||
@ -229,7 +230,7 @@ io.WriteString(w, fmt.Sprintf(aResponseMessage, 2, session, track, parent))
|
||||
}
|
||||
```
|
||||
|
||||
现在第二个微服务中已经有和初始查询相关的上下文和信息,一个 JSON 格式的日志消息看起来类似:
|
||||
现在第二个微服务中已经有和初始查询相关的上下文和信息,一个 JSON 格式的日志消息看起来类似如下。
|
||||
|
||||
在第一个微服务:
|
||||
|
||||
@ -245,26 +246,27 @@ io.WriteString(w, fmt.Sprintf(aResponseMessage, 2, session, track, parent))
|
||||
|
||||
如果在第二个微服务中出现了错误,多亏了 Golang 日志中保存的上下文信息,现在我们就可以确定它是怎样被调用的以及什么模式导致了这个错误。
|
||||
|
||||
如果你想进一步深挖 Golang 的追踪能力,这里还有一些库提供了追踪功能,例如 [Opentracing][12]。这个库提供了一种简单的方式在复杂(或简单)的架构中添加追踪实现。它通过不同步骤允许你追踪用户的查询,就像下面这样:
|
||||
如果你想进一步深挖 Golang 的追踪能力,这里还有一些库提供了追踪功能,例如 [Opentracing][12]。这个库提供了一种简单的方式在或复杂或简单的架构中添加追踪的实现。它通过不同步骤允许你追踪用户的查询,就像下面这样:
|
||||
|
||||

|
||||

|
||||
|
||||
### IV. Golang 日志对性能的影响
|
||||
|
||||
### 1) 不要在 Goroutine 中使用日志
|
||||
#### 1) 不要在 Goroutine 中使用日志
|
||||
|
||||
在每个 goroutine 中创建一个新的日志器看起来很诱人。但最好别这么做。Goroutine 是一个轻量级线程管理器,它用于完成一个 “简单的” 任务。因此它不应该负责日志。它可能导致并发问题,因为在每个 goroutine 中使用 `log.New()` 会重复接口,所有日志器会并发尝试访问同一个 io.Writer。
|
||||
|
||||
在每个 goroutine 中创建一个新的日志器看起来很诱人。但最好别这么做。Goroutine 是一个轻量级线程管理器,它用于完成一个 “简单的” 任务。因此它不应该负责日志。它可能导致并发问题,因为在每个 goroutine 中使用 log.New() 会复用接口,所有日志器会并发尝试访问同一个 io.Writer。
|
||||
为了限制对性能的影响以及避免并发调用 io.Writer,库通常使用一个特定的 goroutine 用于日志输出。
|
||||
|
||||
### 2) 使用异步库
|
||||
#### 2) 使用异步库
|
||||
|
||||
尽管有很多可用的 Golang 日志库,要注意它们中的大部分都是同步的(事实上是伪异步)。原因很可能是到现在为止它们中没有一个由于日志对性能有严重影响。
|
||||
尽管有很多可用的 Golang 日志库,要注意它们中的大部分都是同步的(事实上是伪异步)。原因很可能是到现在为止它们中没有一个会由于日志严重影响性能。
|
||||
|
||||
但正如 Kjell Hedström 在[他的实验][13]中展示的,使用多个线程创建成千上万日志,在最坏情况下异步 Golang 日志也会有 40% 的性能提升。因此日志是有开销的,也会对你的应用程序性能产生影响。如果你并不需要处理大量的日志,使用伪异步 Golang 日志库可能就足够了。但如果你是处理大量的日志,或者很关注性能,Kjell Hedström 的异步解决方案就很有趣(尽管事实上你可能需要进一步开发,因为它只包括了最小的功能需求)。
|
||||
但正如 Kjell Hedström 在[他的实验][13]中展示的,使用多个线程创建成千上万日志,即便是在最坏情况下,异步 Golang 日志也会有 40% 的性能提升。因此日志是有开销的,也会对你的应用程序性能产生影响。如果你并不需要处理大量的日志,使用伪异步 Golang 日志库可能就足够了。但如果你需要处理大量的日志,或者很关注性能,Kjell Hedström 的异步解决方案就很有趣(尽管事实上你可能需要进一步开发,因为它只包括了最小的功能需求)。
|
||||
|
||||
### 3)使用严重等级管理 Golang 日志
|
||||
#### 3)使用严重等级管理 Golang 日志
|
||||
|
||||
一些日志库允许你启用或停用特定日志器,这可能会派上用场。例如在生产环境中你可能不需要一些特定等级的日志。下面是一个如何在 glog 库中停用日志器的例子,其中日志器被定义为布尔值:
|
||||
一些日志库允许你启用或停用特定的日志器,这可能会派上用场。例如在生产环境中你可能不需要一些特定等级的日志。下面是一个如何在 glog 库中停用日志器的例子,其中日志器被定义为布尔值:
|
||||
|
||||
```
|
||||
type Log bool
|
||||
@ -279,14 +281,15 @@ if debug {
|
||||
|
||||
然后你就可以在配置文件中定义这些布尔参数来启用或者停用日志器。
|
||||
|
||||
没有一个好的 Golang 日志策略,Golang 日志可能开销很大。开发人员应该抵制记录几乎所有事情的诱惑 - 尽管它非常有趣!如果日志的目的是为了获取尽可能多的信息,为了避免包含没用元素的日志的白噪音,必须正确使用日志。
|
||||
没有一个好的 Golang 日志策略,Golang 日志可能开销很大。开发人员应该抵制记录几乎所有事情的诱惑 - 尽管它非常有趣!如果日志的目的是为了获取尽可能多的信息,为了避免包含无用元素的日志的白噪音,必须正确使用日志。
|
||||
|
||||
### V. 集中 Golang 日志
|
||||
### V. 集中化 Golang 日志
|
||||
|
||||

|
||||
如果你的应用程序是部署在多台服务器上的,可以避免为了调查一个现象需要连接到每一台服务器的麻烦。日志集中确实有用。
|
||||

|
||||
|
||||
使用日志装箱工具,例如 windows 中的 Nxlog,linux 中的 Rsyslog(默认安装了的)、Logstash 和 FluentD,是最好的实现方式。日志装箱工具的唯一目的就是发送日志,因此它们管理连接失效以及其它你很可能会遇到的问题。
|
||||
如果你的应用程序是部署在多台服务器上的,这样可以避免为了调查一个现象需要连接到每一台服务器的麻烦。日志集中确实有用。
|
||||
|
||||
使用日志装箱工具,例如 windows 中的 Nxlog,linux 中的 Rsyslog(默认安装了的)、Logstash 和 FluentD 是最好的实现方式。日志装箱工具的唯一目的就是发送日志,因此它们能够处理连接失效以及其它你很可能会遇到的问题。
|
||||
|
||||
这里甚至有一个 [Golang syslog 软件包][14] 帮你将 Golang 日志发送到 syslog 守护进程。
|
||||
|
||||
@ -294,11 +297,11 @@ if debug {
|
||||
|
||||
在你项目一开始就考虑你的 Golang 日志策略非常重要。如果在你代码的任意地方都可以获得所有的上下文,追踪用户就会变得很简单。从不同服务中阅读没有标准化的日志是已经很痛苦的事情。一开始就计划在多个微服务中扩展相同用户或请求 id,后面就会允许你比较容易地过滤信息并在你的系统中跟踪活动。
|
||||
|
||||
你是构架一个很大的 Golang 项目还是几个微服务也会影响你的日志策略。一个大项目的主要组件应该有按照它们功能命名的特定 Golang 日志器。这使你可以立即判断出日志来自你的哪一部分代码。然而对于微服务或者小的 Golang 项目,较少的核心组件需要它们自己的日志器。但在每种情形中,日志器的数目都应该保持低于核心功能的数目。
|
||||
你是在构架一个很大的 Golang 项目还是几个微服务也会影响你的日志策略。一个大项目的主要组件应该有按照它们功能命名的特定 Golang 日志器。这使你可以立即判断出日志来自你的哪一部分代码。然而对于微服务或者小的 Golang 项目,只有较少的核心组件需要它们自己的日志器。但在每种情形中,日志器的数目都应该保持低于核心功能的数目。
|
||||
|
||||
你现在已经可以使用 Golang 日志量化决定你的性能或者用户满意度啦!
|
||||
|
||||
_如果你有想阅读的特定编程语言,在 Twitter [][1][@logmatic][2] 上告诉我们吧。_
|
||||
_如果你有想阅读的特定编程语言,在 Twitter [@logmatic][2] 上告诉我们吧。_
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -307,7 +310,7 @@ via: https://logmatic.io/blog/our-guide-to-a-golang-logs-world/
|
||||
|
||||
作者:[Nils][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,134 @@
|
||||
Python-mode:在 Vim 编辑器中开发 Python 应用的 Vim 插件
|
||||
============================================================
|
||||
|
||||
Python-mode 是一个 Vim 插件,它使你能够在 [Vim 编辑器][1]中更快的利用包括 pylint、rope、pydoc、pyflakes、pep8、autopep8、pep257 和 mccable 在内的各种库来写 Python 代码,这些库提供了一些编码功能,比如静态分析、特征重构、折叠、补全和文档等。
|
||||
|
||||
**推荐阅读:** [如何用 Bash-Support 插件将 Vim 编辑器打造成编写 Bash 脚本的 IDE][2]
|
||||
|
||||
这个插件包含了所有你在 Vim 编辑器中可以用来开发 Python 应用的特性。
|
||||
|
||||
### Python-mode 的特性
|
||||
|
||||
它包含下面这些值得一提的特性:
|
||||
|
||||
* 支持 Python 2.6+ 至 Python 3.2 版本
|
||||
* 语法高亮
|
||||
* 提供 virtualenv 支持
|
||||
* 支持 Python 式折叠
|
||||
* 提供增强的 Python 缩进
|
||||
* 能够在 Vim 中运行 Python 代码
|
||||
* 能够添加/删除断点
|
||||
* 支持 Python 的 motion 和运算符
|
||||
* 能够在运行的同时检查代码(pylint、pyflakes、pylama ……)
|
||||
* 支持自动修复 PEP8 错误
|
||||
* 允许在 Python 文档中进行搜索
|
||||
* 支持代码重构
|
||||
* 支持强代码补全
|
||||
* 支持定义跳转
|
||||
|
||||
在这篇教程中,我将阐述如何在 Linux 中为 Vim 安装设置 Python-mode,从而在 Vim 编辑器中开发 Python 应用。
|
||||
|
||||
### 如何在 Linux 系统中为 Vim 安装 Python-mode
|
||||
|
||||
首先安装 [Pathogen][3] (它使得安装插件超级简单,并且运行文件位于私有目录中),从而更加容易的安装 Python-mode
|
||||
|
||||
运行下面的命令来获取 `pathogen.vim` 文件和它需要的目录:
|
||||
|
||||
```
|
||||
# mkdir -p ~/.vim/autoload ~/.vim/bundle && \
|
||||
# curl -LSso ~/.vim/autoload/pathogen.vim https://tpo.pe/pathogen.vim
|
||||
```
|
||||
|
||||
然后把下面这些内容加入 `~/.vimrc` 文件中:
|
||||
|
||||
```
|
||||
execute pathogen#infect()
|
||||
syntax on
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
安装好 pathogen 以后,你可以像下面这样把 Python-mode 插件放入 `~/.vim/bunble` 目录中:
|
||||
|
||||
```
|
||||
# cd ~/.vim/bundle
|
||||
# git clone https://github.com/klen/python-mode.git
|
||||
```
|
||||
|
||||
然后像下面这样在 Vim 中重建 `helptags` :
|
||||
|
||||
```
|
||||
:helptags
|
||||
```
|
||||
|
||||
你需要启用 `filetype-plugin` (:help filetype-plugin-on)和 `filetype-indent` (:help filetype-indent-on)来使用 Python-mode 。
|
||||
|
||||
### 在 Debian 和 Ubuntu 中安装 Python-mode
|
||||
|
||||
另一种在 Debian 和 Ubuntu 中安装 Python-mode 的方法是使用 PPA,就像下面这样
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository https://klen.github.io/python-mode/deb main
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install vim-python-mode
|
||||
```
|
||||
|
||||
如果你遇到消息:“The following signatures couldn’t be verified because the public key is not available”,请运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys B5DF65307000E266
|
||||
```
|
||||
|
||||
现在,使用 `vim-addon-manager` 启用 Python-mode:
|
||||
|
||||
```
|
||||
$ sudo apt install vim-addon-manager
|
||||
$ vim-addons install python-mode
|
||||
```
|
||||
|
||||
### 在 Linux 中定制 Python-mode
|
||||
|
||||
如果想覆盖默认键位绑定,可以在 `.vimrc` 文件中重定义它们,比如:
|
||||
|
||||
```
|
||||
" Override go-to.definition key shortcut to Ctrl-]
|
||||
let g:pymode_rope_goto_definition_bind = "<C-]>"
|
||||
" Override run current python file key shortcut to Ctrl-Shift-e
|
||||
let g:pymode_run_bind = "<C-S-e>"
|
||||
" Override view python doc key shortcut to Ctrl-Shift-d
|
||||
let g:pymode_doc_bind = "<C-S-d>"
|
||||
```
|
||||
|
||||
注意,默认情况下, Python-mode 使用 Python 2 进行语法检查。你可以在 `.vimrc` 文件中加入下面这行内容从而启动 Python 3 语法检查。
|
||||
|
||||
```
|
||||
let g:pymode_python = 'python3'
|
||||
```
|
||||
|
||||
你可以在 Python-mode 的 GitHub 仓库找到更多的配置选项: [https://github.com/python-mode/python-mode][4]
|
||||
|
||||
这就是全部内容了。在本教程中,我向你们展示了如何在 Linux 中使用 Python-mode 来配置 Vim 。请记得通过下面的反馈表来和我们分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网络开发人员,现在也是 TecMint 的内容创作者,他喜欢和电脑一起工作,坚信共享知识。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/python-mode-a-vim-editor-plugin/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/vi-editor-usage/
|
||||
[2]:https://linux.cn/article-8467-1.html
|
||||
[3]:https://github.com/tpope/vim-pathogen
|
||||
[4]:https://github.com/python-mode/python-mode
|
||||
[5]:https://www.tecmint.com/author/aaronkili/
|
||||
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,13 +1,11 @@
|
||||
怎样在 Linux 中对 Vim 文件进行密码保护
|
||||
怎样在 Linux 中用 Vim 对文件进行密码保护
|
||||
============================================================
|
||||
|
||||
现在下载你的免费电子书籍 - [给管理员的 10 本免费的 Linux 电子书籍][16] | [4 本免费的 Shell 脚本电子书籍][17]
|
||||
[Vim][5] 是一种流行的、功能丰富的和高度可扩展的 [Linux 文本编辑器][6],它的一个特殊功能便是支持用带密码各种的加密方法来加密文本文件。
|
||||
|
||||
[Vim][5] 是一种流行的、功能丰富的和高度可扩展的 [Linux 文本编辑器][6],它的重要功能之一便是支持用各种带密码的加密方法来加密文本文件。
|
||||
本文中,我们将向你介绍一种简单的 Vim 使用技巧:在 Linux 中使用 Vim 对文件进行密码保护。我们将向你展示如何让一个文件在它创建的时侯以及为了修改目的而被打开了之后获得安全防护。
|
||||
|
||||
本文中,我们将向你介绍一种简单的 Vim 使用技巧;在 Linux 中使用 Vim 对文件进行密码保护。我们将向你展示如何让一个文件在它创建的时侯以及为了修改目的而被打开了之后获得安全防护。
|
||||
|
||||
**建议阅读:** [你应该在 Linux 中使用 Vim 编辑器的 10 个原因][7]
|
||||
**建议阅读:** [你应该在 Linux 中使用 Vim 编辑器的 7 个原因][7]
|
||||
|
||||
要安装 Vim 完整版,只需运行这些命令:
|
||||
|
||||
@ -16,9 +14,9 @@ $ sudo apt install vim #Debian/Ubuntu 系统
|
||||
$ sudo yum install vim #RHEL/CentOS 系统
|
||||
$ sudo dnf install vim #Fedora 22+
|
||||
```
|
||||
参阅: [十年后 Vim 8.0 发布了– 在 Linux 上安装][8]
|
||||
参阅: [十年后 Vim 8.0 发布了][8a] – [在 Linux 上安装][8]
|
||||
|
||||
### 怎样在 Linux 中对 Vim 文件进行密码保护
|
||||
### 怎样在 Linux 中用 Vim 对文件进行密码保护
|
||||
|
||||
Vim 有个 `-x` 选项,这个选项能让你在创建文件时用它来加密。一旦你运行下面的 [vim 命令][9],你会被提示输入一个密钥:
|
||||
|
||||
@ -29,13 +27,13 @@ $ vim -x file.txt
|
||||
再次输入相同密钥:*******
|
||||
```
|
||||
|
||||
如果第二次输入的密钥无误,你就能进去修改此文件了。
|
||||
如果第二次输入的密钥无误,你就能可以修改此文件了。
|
||||
|
||||
[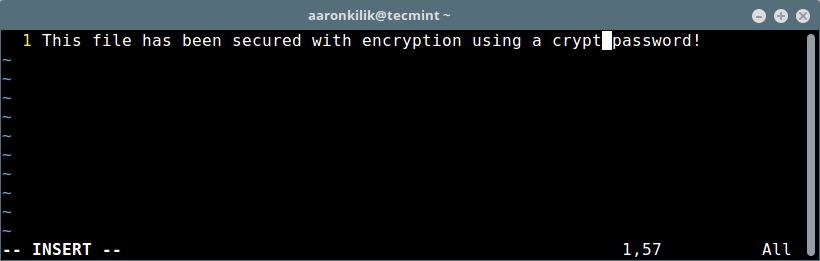][10]
|
||||
|
||||
被密码保护的 Vim 文件
|
||||
*被密码保护的 Vim 文件*
|
||||
|
||||
等你修改好之后,摁 `[Esc]` 和键入 `:wq` 来保存及关闭文件。下次你想打开它编辑一下,你就必须像这样去输入密钥:
|
||||
等你修改好之后,摁 `Esc` 和键入 `:wq` 来保存及关闭文件。下次你想打开它编辑一下,你就必须像这样去输入密钥:
|
||||
|
||||
```
|
||||
$ vim file.txt
|
||||
@ -48,54 +46,54 @@ $ vim file.txt
|
||||
|
||||
[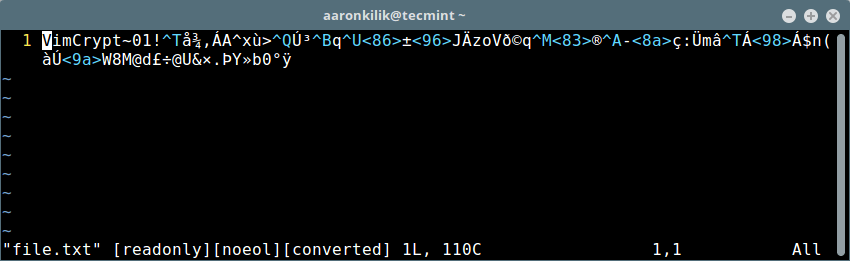][11]
|
||||
|
||||
Vim 中的加密内容
|
||||
*Vim 中的加密内容*
|
||||
|
||||
#### 在 Vim 中设置一种强加密方法
|
||||
|
||||
注意:有条告警信息暗示一种弱加密方法已被用于保护文件。那么接下来,我们来看看怎么在 Vim 中设置一种强加密方法。
|
||||
注意:警告信息暗示保护文件的是弱加密方法。那么接下来,我们来看看怎么在 Vim 中设置一种强加密方法。
|
||||
|
||||
[][12]
|
||||
|
||||
Vim 中文件弱加密
|
||||
*Vim 中文件弱加密*
|
||||
|
||||
为了查看 crytmethod(cm) 集,键入(向下滚动可查看所有可用的方法):
|
||||
为了查看加密方式(cm)集,键入如下:
|
||||
|
||||
```
|
||||
:help 'cm'
|
||||
```
|
||||
|
||||
##### 输出样例
|
||||
输出样例:
|
||||
|
||||
```
|
||||
*'cryptmethod'* *'cm'*
|
||||
'cryptmethod' 'cm' string (默认 "zip")
|
||||
global or local to buffer |global-local|
|
||||
{not in Vi}
|
||||
当缓冲区写进文件中所用的方法:
|
||||
*pkzip*
|
||||
zip PkZip 兼容法。 一种弱加密方法。
|
||||
与 Vim 7.2 及更老版本后向兼容。
|
||||
*blowfish*
|
||||
blowfish 河豚法。 中级强度加密方法但有实现上
|
||||
的瑕疵。需要 Vim 7.3 及以上版本,用它加密的文件不
|
||||
能被 Vim 7.2 及更老版本读取。它会添加一个 “种子”,
|
||||
每次你对这个文件写操作时……
|
||||
options.txt [帮助][只读]
|
||||
'cryptmethod' string (默认 "zip")
|
||||
全局或本地到缓冲区 |global-local|
|
||||
{not in Vi}
|
||||
当缓冲区写进文件中所用的加密方式:
|
||||
*pkzip*
|
||||
zip PkZip 兼容方式。 一种弱加密方法。
|
||||
与 Vim 7.2 及更老版本后向兼容。
|
||||
*blowfish*
|
||||
blowfish 河豚加密方式。 中级强度加密方法但有实现上
|
||||
的瑕疵。需要 Vim 7.3 及以上版本,用它加密的文件不
|
||||
能被 Vim 7.2 及更老版本读取。它会添加一个 “种子”,
|
||||
每次你当你写入文件时,这个加密字节都不同。
|
||||
|
||||
```
|
||||
|
||||
你可以像如下所示的那样给一个 Vim 文件设置个新的 cryptomethod(加密方法)(本例中我们用 blowfish2 加密方法)
|
||||
你可以像如下所示的那样给一个 Vim 文件设置个新的加密方法(本例中我们用 `blowfish2` 加密方法)
|
||||
|
||||
```
|
||||
:setlocal cm=blowfish2
|
||||
```
|
||||
|
||||
然后键入 `[Enter]` 和 `:wq` 保存下文件。
|
||||
然后键入回车和 `:wq` 保存文件。
|
||||
|
||||
[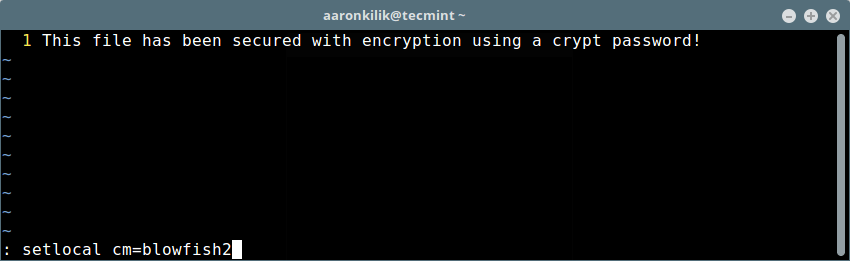][13]
|
||||
|
||||
对 Vim 文件设置强加密
|
||||
*对 Vim 文件设置强加密*
|
||||
|
||||
现在你再打开下示的文件时应该就看不到那条警告信息了。
|
||||
现在你再打开下面的文件时应该就看不到那条警告信息了。
|
||||
|
||||
```
|
||||
$ vim file.txt
|
||||
@ -103,35 +101,32 @@ $ vim file.txt
|
||||
输入加密密钥:*******
|
||||
```
|
||||
|
||||
你也可以在打开 Vim 文件之后来设置密码,用 `:X` 命令就能像上面所示的那样去设置一个密码关卡。
|
||||
你也可以在打开 Vim 文件之后来设置密码,用 `:X` 命令就能像上面所示的那样去设置一个加密密码。
|
||||
|
||||
可以看看我们其他的关于 Vim 编辑器的有用的文章。
|
||||
|
||||
1. [在 Linux 中学习有用的 Vim 编辑器的旅行与技巧][1]
|
||||
|
||||
1. [在 Linux 中学习有用的 Vim 编辑器的技巧][1]
|
||||
2. [给每个 Linux 用户的 8 种有用的 Vim 编辑器技巧][2]
|
||||
|
||||
3. [spf13-vim – Vim 编辑器的顶级发行版][3]
|
||||
|
||||
3. [spf13-vim – Vim 编辑器的顶级分发版][3]
|
||||
4. [怎样在 Linux 种把 Vim 编辑当作 Bash IDE 来用][4]
|
||||
|
||||
本文到这里就结束了!文章中我们介绍了怎么通过 Linux 下的 Vim 文本编辑器来给一个文件做加密防护。
|
||||
|
||||
永远记住要用强加密方式及密码来适当的保护那些可能包含了诸如用户名及密码、财务账户信息等等机密信息的文本文件。
|
||||
永远记住要用强加密方式及密码来适当的保护那些可能包含了诸如用户名及密码、财务账户信息等机密信息的文本文件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software,自由及开放源代码软件)爱好者,未来的 Linux 系统管理员、web 开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,且崇尚分享知识。
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software,自由及开放源代码软件)爱好者,未来的 Linux 系统管理员、Web 开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,且崇尚分享知识。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/password-protect-vim-file-in-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ch-cn](https://github.com/ch-cn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -139,11 +134,12 @@ via: https://www.tecmint.com/password-protect-vim-file-in-linux/
|
||||
[1]:https://www.tecmint.com/learn-vi-and-vim-editor-tips-and-tricks-in-linux/
|
||||
[2]:https://www.tecmint.com/how-to-use-vi-and-vim-editor-in-linux/
|
||||
[3]:https://www.tecmint.com/spf13-vim-offers-vim-plugins-vim-editor/
|
||||
[4]:https://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||
[4]:https://linux.cn/article-8467-1.html
|
||||
[5]:https://www.tecmint.com/vi-editor-usage/
|
||||
[6]:https://www.tecmint.com/best-open-source-linux-text-editors/
|
||||
[7]:https://www.tecmint.com/reasons-to-learn-vi-vim-editor-in-linux/
|
||||
[8]:https://www.tecmint.com/vim-8-0-install-in-ubuntu-linux-systems/
|
||||
[7]:https://linux.cn/article-7728-1.html
|
||||
[8a]:https://linux.cn/article-7766-1.html
|
||||
[8]:https://linux.cn/article-8094-1.html
|
||||
[9]:https://www.tecmint.com/linux-command-line-editors/
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/05/Vim-File-Password-Protected-File.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/05/Vim-Content-Encrypted.png
|
||||
@ -1,19 +1,18 @@
|
||||
在 Linux 服务器关机前向用户显示一条自定义消息
|
||||
============================================================
|
||||
|
||||
|
||||
在先前的文章中,我们解释了 Linux 中[ shutdown、poweroff、halt、reboot 命令的不同之处][3],并揭示了在用不同的选项执行这些命令时它们实际做了什么。
|
||||
在先前的文章中,我们解释了 Linux 中 [shutdown、poweroff、halt、reboot 命令的不同之处][3],并揭示了在用不同的选项执行这些命令时它们实际做了什么。
|
||||
|
||||
本篇将会向你展示如何在系统关机时向所有的系统用户发送一条自定义的消息。
|
||||
|
||||
**建议阅读:**[tuptime - 显示 Linux 系统的历史和统计运行时间][4]
|
||||
|
||||
作为一名系统管理员,在你关闭服务器之前,你也许想要发送一条消息来警告他们系统将要关闭。默认上,shutdown 命令会如下所示给其他系统用户广播这条信息:
|
||||
作为一名系统管理员,在你关闭服务器之前,你也许想要发送一条消息来警告他们系统将要关闭。默认上,`shutdown` 命令会如下所示给其他系统用户广播这条信息:
|
||||
|
||||
```
|
||||
# shutdown 13:25
|
||||
```
|
||||
Linux Shutdown Broadcast Message
|
||||
Linux 关机操作广播消息:
|
||||
```
|
||||
Shutdown scheduled for Fri 2017-05-12 13:25:00 EAT, use 'shutdown -c' to cancel.
|
||||
Broadcast message for root@tecmint (Fri 2017-05-12 13:23:34 EAT):
|
||||
@ -27,14 +26,14 @@ The system is going down for power-off at Fri 2017-05-12 13:25:00 EAT!
|
||||
```
|
||||
[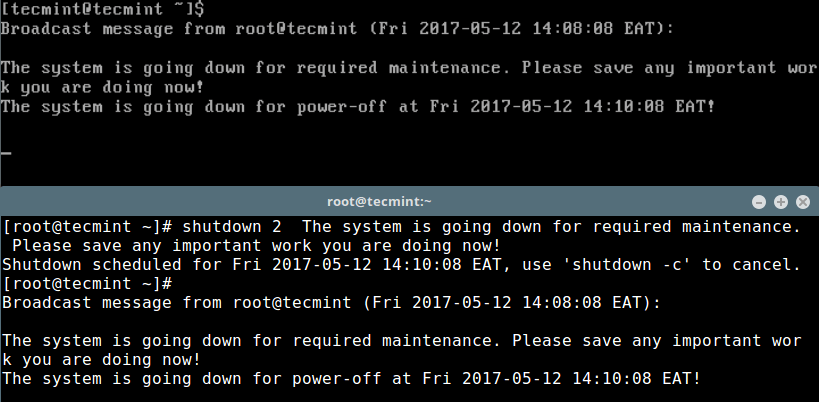][5]
|
||||
|
||||
Linux 系统关闭消息
|
||||
*Linux 系统关闭消息*
|
||||
|
||||
假设你有一些关键的系统操作,如计划系统备份或更新会在系统关闭的时候进行,如下所示,你可以使用 `-c` 选项取消关机,并在执行玩这些操作后继续执行:
|
||||
|
||||
```
|
||||
# shutdown -c
|
||||
```
|
||||
Linux Shutdown Cancel Message
|
||||
Linux 关机操作取消消息:
|
||||
```
|
||||
Shutdown scheduled for Fri 2017-05-12 14:10:22 EAT, use 'shutdown -c' to cancel.
|
||||
Broadcast message for root@tecmint (Fri 2017-05-14 :10:27 EAT):
|
||||
@ -45,8 +44,7 @@ The system shutdown has been cancelled at Fri 2017-05-12 14:11:27 EAT!
|
||||
|
||||
不要错过:
|
||||
|
||||
1. [关系系统启动进程和服务(SysVinit、Systemd 和 Upstart)][1]
|
||||
|
||||
1. [管理系统启动进程和服务(SysVinit、Systemd 和 Upstart)][1]
|
||||
2. [11 个 Linux 中 cron 计划任务示例][2]
|
||||
|
||||
现在你知道了如何在系统关闭前向其他系统用户发送自定义消息了。你有其他关于这个主题想要分享的想法么?何不使用下面的评论栏?
|
||||
@ -61,9 +59,9 @@ Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网
|
||||
|
||||
via: https://www.tecmint.com/show-linux-server-shutdown-message/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,35 @@
|
||||
如何使用 Cream 提高 Vim 的用户友好性
|
||||
============================================================
|
||||
|
||||
### Cream 附加包通过把一个更加熟悉的"面孔"置于 Vim 文本编辑器之上,同时保留 Vim 的功能,使其更加容易使用
|
||||
|
||||
|
||||
> Cream 附加包通过把一个更加熟悉的“面孔”置于 Vim 文本编辑器之上,同时保留 Vim 的功能,使其更加容易使用
|
||||
|
||||

|
||||
图片来自 :
|
||||
|
||||
opensource.com
|
||||
图片来自 : opensource.com
|
||||
|
||||
大约 10 年前,我既使用 Emacs 进行文本编辑,也使用 Vim 进行文本编辑。说到底,我的确是一个热衷于 Emacs 的家伙。尽管 Emacs 在我的心里占据了很重要的地位,但我知道, Vim 也不赖。
|
||||
|
||||
一些人,或者像我一样的人,在技术方面可能都会有些笨手笨脚的。多年来,我已经和很多下面这样的 Linux 新手交谈过,他们想使用 Vim,但是却失望的发现, Vim 编辑器和他们在其它操作系统上使用过的编辑器似乎不一样。
|
||||
一些人,或者像我一样的人,在技术方面有些笨手笨脚。多年来,我和一些 Linux 新手交流,了解到他们想使用 Vim,但是却失望的发现, Vim 编辑器和他们在其它操作系统上使用过的编辑器不一样。
|
||||
|
||||
但是,当我把 Cream 介绍给他们以后,他们的失望就变成了满意。Cream 是 Vim 的一个附加包,它使得 Vim 更加容易使用。Cream 让这些 Linux 新手变成了 Vim 的坚决拥护者和忠心用户。
|
||||
|
||||
让我们来看一看 Cream 是什么以及它是如何让 Vim 变得更加容易使用的。
|
||||
|
||||
### Cream 安装
|
||||
### Cream 的安装
|
||||
|
||||
在安装 Cream 之前,你需要先在你的电脑上安装好 Vim 和 GVim 的 GUI 组件。我发现最容易完成这件事的方法是使用 Linux 版本的包管理器。
|
||||
|
||||
安装好 Vim 以后,便可[下载 Cream 的安装程序][2],或者你也可以再次使用 Linux 发行版的包管理器进行安装。
|
||||
|
||||
安装好 Cream 以后,你可以通过从应用菜单选择输入(比如,**Applications**->**Cream**)或者在程序启动器中输入 **Cream**,从而启动 Cream 。
|
||||
安装好 Cream 以后,你可以从应用菜单选择它(比如,**Applications**->**Cream**)或者在程序启动器中输入 `Cream`,从而启动 Cream 。
|
||||
|
||||

|
||||

|
||||
|
||||
### Cream 使用
|
||||
### Cream 的使用
|
||||
|
||||
如果你之前已经使用过 Gvim,那么你会注意到, Cream 几乎没改变编辑器的外观和感觉。最大的不同是 Cream 的菜单栏和工具栏,它们取代了 Gvim 陈旧的菜单栏和工具栏,新的菜单栏和工具栏的外观和群组功能看起来和其它编辑器的一样。
|
||||
如果你之前已经使用过 Gvim,那么你会注意到, Cream 几乎没改变该编辑器的外观和感觉。最大的不同是 Cream 的菜单栏和工具栏,它们取代了 Gvim 陈旧的菜单栏和工具栏,新的菜单栏和工具栏的外观和功能分组看起来和其它编辑器的一样。
|
||||
|
||||
Cream 的菜单栏隐藏了更多的技术选项,比如指定一个编译器的能力,以及来自用户的 `make` 命令的能力。当你通过使用 Cream 更加熟悉 Vim 以后,你只需要从 `Setting->Preferences->Behavior` 选择选项,就可以更容易的访问这些特性。有了这些选项,你可以(如果你想)体验到一个包含了 Cream 和传统 Vim 二者优点的强大编辑器。
|
||||
Cream 的菜单栏对用户隐藏了更多的技术选项,比如指定一个编译器的能力,以及运行 `make` 命令的能力。当你通过使用 Cream 更加熟悉 Vim 以后,你只需要从 **Setting**->**Preferences**->**Behavior** 选择选项,就可以更容易地访问这些特性。有了这些选项,你可以(如果你想)体验到一个兼有 Cream 和传统 Vim 二者优点的强大编辑器。
|
||||
|
||||
Cream 并不是仅由菜单驱动。尽管编辑器的功能仅有单击或双击两种方式,但是你也可以使用常见的键盘快捷键来执行操作,比如 `CTRL-O`(打开一个文件),`CTRL-C`(复制文本)。你不需要在几种模式之间切换,也不需要记住一些很难记住的命令。
|
||||
|
||||
@ -40,7 +37,7 @@ Cream 开始运行以后,打开一个文件,或者新建一个文件,然
|
||||
|
||||

|
||||
|
||||
并不是说 Cream 是 Vim 的简化版,或者说 Cream “离” Vim 很远。事实上, Cream 保留了 Vim 的全部特性,同时,它还有一系列其他有用的特性。我发现的 Cream 的一些有用的特性包括:
|
||||
并不是说 Cream 是 Vim 的简化版,远远不是。事实上, Cream 保留了 Vim 的全部特性,同时,它还有[一系列其他有用的特性][7]。我发现的 Cream 的一些有用的特性包括:
|
||||
|
||||
* 一个标签式界面
|
||||
* 语法高亮(特别是针对 Markdown、LaTeX 和 HTML)
|
||||
@ -48,16 +45,15 @@ Cream 开始运行以后,打开一个文件,或者新建一个文件,然
|
||||
* 字数统计
|
||||
* 内建文件浏览器
|
||||
|
||||
Cream 本身也有许多附加包,可以给编辑器增加一些新的特性。这些特性包括文本加密、清理电子邮件内容,甚至还有一个使用教程。老实说,我还没有发现哪一个附加包是真正有用的,不过你的感受可能会有所不同。
|
||||
|
||||
Cream 也有许多附加包,可以给编辑器增加一些新的特性。这些特性包括文本加密、清理电子邮件内容,甚至还有一个使用教程。老实说,我还没有发现哪一个附加包是真正有用的,不过你的里程可能会有所不同。
|
||||
|
||||
我曾听过一些 Vi/Vim 的狂热分子谴责 Cream “简化”(它们的话)了 Vi/Vim 编辑器的功能。的确,Cream 并不是为他们设计的。它是为那些想快速使用 Vim ,同时保留他们曾经使用过的编辑器的外观和感觉的人准备的。在这种情况下, Cream 是值得赞赏的,它使得 Vim 更加容易使用,更加广泛的被人们使用。
|
||||
我曾听过一些 Vi/Vim 的狂热分子谴责 Cream “降低”(这是他们的原话)了 Vi/Vim 编辑器的水准。的确,Cream 并不是为他们设计的。它是为那些想快速使用 Vim ,同时保留他们曾经使用过的编辑器的外观和感觉的人准备的。在这种情况下, Cream 是值得赞赏的,它使得 Vim 更加容易使用,更加广泛的被人们使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/stir-bit-cream-make-vim-friendlier
|
||||
|
||||
作者:[ Scott Nesbitt][a]
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -70,3 +66,4 @@ via: https://opensource.com/article/17/5/stir-bit-cream-make-vim-friendlier
|
||||
[4]:https://opensource.com/user/14925/feed
|
||||
[5]:https://opensource.com/article/17/5/stir-bit-cream-make-vim-friendlier#comments
|
||||
[6]:https://opensource.com/users/scottnesbitt
|
||||
[7]:http://cream.sourceforge.net/featurelist.html
|
||||
@ -1,22 +1,20 @@
|
||||
Linfo — 实时显示你的 Linux 服务器运行状况
|
||||
Linfo:实时显示你的 Linux 服务器运行状况
|
||||
============================================================
|
||||
|
||||
|
||||
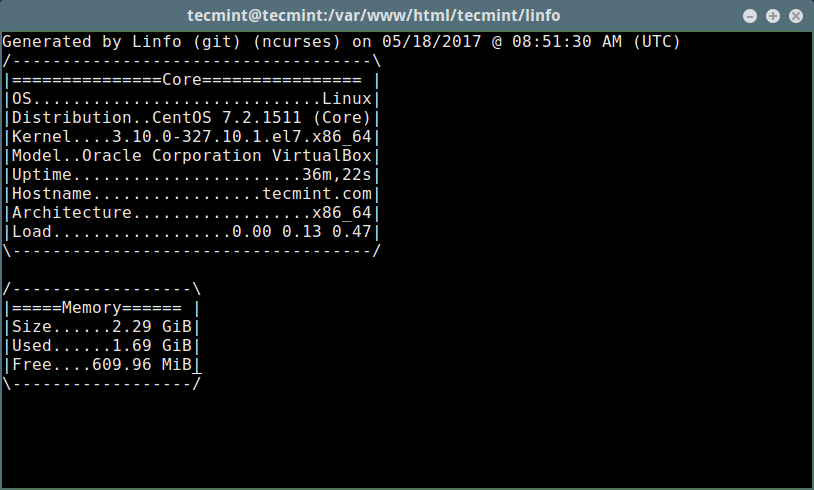
Linfo 是一个免费且开源的跨平台服务器统计 UI/库,它可以显示大量的系统信息。Linfo 是可扩展的,通过 `composer`,很容易使用 PHP5 库以程序化方式获取来自 PHP 应用的扩展系统统计。它是 `Web UI` 的一个 `Ncurses CLI view`,在 Linux、Windows、BSD、Darwin/Mac OSX、Solaris 和 Minix 系统上均可用。
|
||||
Linfo 是一个自由开源的跨平台的服务器统计 UI 或库,它可以显示大量的系统信息。Linfo 是可扩展的,通过 `composer`,很容易使用 PHP5 库以程序化方式获取来自 PHP 应用的丰富的系统统计数据。它有 Web UI 及其Ncurses CLI 视图,在 Linux、Windows、BSD、Darwin/Mac OSX、Solaris 和 Minix 系统上均可用。
|
||||
|
||||
Linfo 显示的系统信息包括 [CPU 类型/速度][2]、服务器的体系结构、挂载点使用量、硬盘/光纤/flash 驱动器、硬件设备、网络设备和统计信息、运行时间/启动日期、主机名、内存使用量(RAM 和 swap)、温度/电压/风扇速度和 RAID 阵列等。
|
||||
Linfo 显示的系统信息包括 [CPU 类型/速度][2]、服务器的体系结构、挂载点用量、硬盘/光纤/Flash 驱动器、硬件设备、网络设备和统计信息、运行时间/启动日期、主机名、内存使用量(RAM 和 swap)、温度/电压/风扇速度和 RAID 阵列等。
|
||||
|
||||
#### 环境要求:
|
||||
### 环境要求:
|
||||
|
||||
* PHP 5.3
|
||||
|
||||
* pcre 扩展
|
||||
* Linux – `/proc` 和 `/sys` 已挂载且可对 `PHP` 可读,已经在 2.6.x/3.x 内核中测试过
|
||||
|
||||
* Linux – /proc 和 /sys 已挂载且可对 `PHP` 可读,已经在 2.6.x/3.x 内核中测试过
|
||||
### 如何在 Linux 中安装 Linfo 服务器统计 UI及库
|
||||
|
||||
### 如何在 Linux 中安装服务器统计 UI/库 Info
|
||||
|
||||
首先,在 `Apache` 或 `Nginx` 的 Web 根目录下创建一个 `Linfo` 目录,然后,克隆仓库文件并使用下面展示的 [rsync 命令][3]将其移动到目录 `/var/www/html/linfo` 下:
|
||||
首先,在 Apache 或 Nginx 的 Web 根目录下创建 Linfo 的目录,然后,使用下面展示的 [rsync 命令][3] 克隆仓库文件并将其移动到目录 `/var/www/html/linfo` 下:
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /var/www/html/linfo
|
||||
@ -38,7 +36,7 @@ $ sudo mv sample.config.inc.php config.inc.php
|
||||
|
||||
*Linux 服务器运行信息*
|
||||
|
||||
你可以将下面一行内容加入配置文件 `config.inc.php` 中,从而可以产生错误信息,以便进行故障排查。
|
||||
你可以将下面一行内容加入配置文件 `config.inc.php` 中,以便进行故障排查时看到错误信息。
|
||||
|
||||
```
|
||||
$settings['show_errors'] = true;
|
||||
@ -54,7 +52,7 @@ Linfo 有一个基于 `ncurses` 的简单界面,它依赖于 `php` 的 `ncurse
|
||||
$ sudo apt-get install php5-dev libncurses5-dev [在 Debian/Ubuntu 上]
|
||||
```
|
||||
|
||||
现在,像下面这样编译这个 `php` 扩展:
|
||||
现在,像下面这样编译这个 php 扩展:
|
||||
|
||||
```
|
||||
$ wget http://pecl.php.net/get/ncurses-1.0.2.tgz
|
||||
@ -66,7 +64,7 @@ $ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
接下来,如果编译成功并安装好了该 `php` 扩展,运行下面的命令:
|
||||
接下来,如果编译成功并安装好了该 php 扩展,运行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo echo extension=ncurses.so > /etc/php5/cli/conf.d/ncurses.ini
|
||||
@ -78,30 +76,27 @@ $ sudo echo extension=ncurses.so > /etc/php5/cli/conf.d/ncurses.ini
|
||||
$ php -m | grep ncurses
|
||||
```
|
||||
|
||||
Now run the Linfo.
|
||||
现在,运行 Info:
|
||||
|
||||
```
|
||||
$ cd /var/www/html/linfo/
|
||||
$ ./linfo-curses
|
||||
```
|
||||
[][5]
|
||||
|
||||
[][5]
|
||||
|
||||
*Linux 服务器信息*
|
||||
|
||||
Info 中尚未加入下面这些功能:
|
||||
Info 中尚欠缺下面这些功能:
|
||||
|
||||
1. 支持更多 Unix 操作系统(比如 Hurd、IRIX、AIX 和 HP UX 等)
|
||||
|
||||
2. 支持不太出名的操作系统 Haiku/BeOS
|
||||
|
||||
3. 额外功能/扩展
|
||||
5. 在 ncurses 模式中支持 [htop 类][1] 特性
|
||||
|
||||
5. 在 ncurses 模式中支持 [htop-like][1] 特性
|
||||
如果想了解更多信息,请访问 Linfo 的 GitHub 仓库: [https://github.com/jrgp/linfo][6]
|
||||
|
||||
如果想了解更多信息,请访问 Info 的 GitHub 仓库: [https://github.com/jrgp/linfo][6]
|
||||
|
||||
这就是本文的全部内容了。从现在起,你可以使用 Info 在 Web 浏览器中查看 Linux 系统的信息。尝试一下,并在评论中和我们分享你的想法。另外,你是否还知道与之类似的有用工具/库?如果有,请给我们提供一些相关信息。
|
||||
这就是本文的全部内容了。从现在起,你可以使用 Linfo 在 Web 浏览器中查看 Linux 系统的信息。尝试一下,并在评论中和我们分享你的想法。另外,你是否还知道与之类似的有用工具/库?如果有,请给我们提供一些相关信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -113,9 +108,9 @@ Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux 系统管理员和
|
||||
|
||||
via: https://www.tecmint.com/linfo-shows-linux-server-health-status-in-real-time/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,123 @@
|
||||
怎样在 Linux 命令行下杀死一个进程
|
||||
============================================================
|
||||
|
||||
> Linux 的命令行里面有用来停止正在运行的进程的所有所需工具。Jack Wallen 将为您讲述细节。
|
||||
|
||||

|
||||
|
||||
想像一下:你打开了一个程序(可能来自于你的桌面菜单或者命令行),然后开始使用这个程序,没想到程序会锁死、停止运行、或者意外死机。你尝试再次运行该程序,但是它反馈说原来的进程没有完全关闭。
|
||||
|
||||
你该怎么办?你要结束进程。但该如何做?不管你信与不信,最好的解决方法大都在命令行里。值得庆幸的是, Linux 有供用户杀死错误的进程的每个必要的工具,然而,你在执行杀死进程的命令之前,你首先需要知道进程是什么。该如何处理这一类的任务。一旦你能够掌握这种工具,它实际是十分简单的……
|
||||
|
||||
让我来介绍给你这些工具。
|
||||
|
||||
我来概述的步骤是每个 Linux 发行版都能用的,不论是桌面版还是服务器版。我将限定只使用命令行,请打开你的终端开始输入命令吧。
|
||||
|
||||
### 定位进程
|
||||
|
||||
杀死一个没有响应的进程的第一个步骤是定位这个进程。我用来定位进程的命令有两个:`top` 和 `ps` 命令。`top` 是每个系统管理员都知道的工具,用 `top` 命令,你能够知道到所有当前正在运行的进程有哪些。在命令行里,输入 `top` 命令能够就看到你正在运行的程序进程(图1)
|
||||
|
||||

|
||||
|
||||
*图 1: top 命令给出你许多的信息。*
|
||||
|
||||
从显示的列表中你能够看到相当重要的信息,举个例子,Chrome 浏览器反映迟钝,依据我们的 `top` 命令显示,我们能够辨别的有四个 Chrome 浏览器的进程在运行,进程的 pid 号分别是 3827、3919、10764 和 11679。这个信息是重要的,可以用一个特殊的方法来结束进程。
|
||||
|
||||
尽管 `top` 命令很是方便,但也不是得到你所要信息最有效的方法。 你知道你要杀死的 Chrome 进程是那个,并且你也不想看 `top` 命令所显示的实时信息。 鉴于此,你能够使用 `ps` 命令然后用 `grep` 命令来过滤出输出结果。这个 `ps` 命令能够显示出当前进程列表的快照,然后用 `grep` 命令输出匹配的样式。我们通过 `grep` 命令过滤 `ps` 命令的输出的理由很简单:如果你只输入 `ps` 命令,你将会得到当前所有进程的列表快照,而我们需要的是列出 Chrome 浏览器进程相关的。所以这个命令是这个样子:
|
||||
|
||||
```
|
||||
ps aux | grep chrome
|
||||
```
|
||||
|
||||
这里 `aux` 选项如下所示:
|
||||
|
||||
* a = 显示所有用户的进程
|
||||
* u = 显示进程的用户和拥有者
|
||||
* x = 也显示不依附于终端的进程
|
||||
|
||||
当你搜索图形化程序的信息时,这个 `x` 参数是很重要的。
|
||||
|
||||
当你输入以上命令的时候,你将会得到比图 2 更多的信息,而且它有时用起来比 `top` 命令更有效。
|
||||
|
||||

|
||||
|
||||
*图 2:用 ps 命令来定位所需的内容信息。*
|
||||
|
||||
### 结束进程
|
||||
|
||||
现在我们开始结束进程的任务。我们有两种可以帮我们杀死错误的进程的信息。
|
||||
|
||||
* 进程的名字
|
||||
* 进程的 ID (PID)
|
||||
|
||||
你用哪一个将会决定终端命令如何使用,通常有两个命令来结束进程:
|
||||
|
||||
* `kill` - 通过进程 ID 来结束进程
|
||||
* `killall` - 通过进程名字来结束进程
|
||||
|
||||
有两个不同的信号能够发送给这两个结束进程的命令。你发送的信号决定着你想要从结束进程命令中得到的结果。举个例子,你可以发送 `HUP`(挂起)信号给结束进程的命令,命令实际上将会重启这个进程。当你需要立即重启一个进程(比如就守护进程来说),这是一个明智的选择。你通过输入 `kill -l` 可以得到所有信号的列表,你将会发现大量的信号。
|
||||
|
||||

|
||||
|
||||
*图 3: 可用的结束进程信号。*
|
||||
|
||||
最经常使用的结束进程的信号是:
|
||||
|
||||
| Signal Name | Single Value | Effect |
|
||||
|-----------|-----------|----------|
|
||||
| SIGHUP | 1 | 挂起 |
|
||||
| SIGINT | 2 | 键盘的中断信号 |
|
||||
| SIGKILL | 9 | 发出杀死信号 |
|
||||
| SIGTERM | 15 | 发出终止信号 |
|
||||
| SIGSTOP | 17, 19, 23 | 停止进程 |
|
||||
|
||||
好的是,你能用信号值来代替信号名字。所以你没有必要来记住所有各种各样的信号名字。
|
||||
|
||||
所以,让我们现在用 `kill` 命令来杀死 Chrome 浏览器的进程。这个命令的结构是:
|
||||
|
||||
```
|
||||
kill SIGNAL PID
|
||||
```
|
||||
|
||||
这里 SIGNAL 是要发送的信号,PID 是被杀死的进程的 ID。我们已经知道,来自我们的 `ps` 命令显示我们想要结束的进程 ID 号是 3827、3919、10764 和 11679。所以要发送结束进程信号,我们输入以下命令:
|
||||
|
||||
```
|
||||
kill -9 3827
|
||||
kill -9 3919
|
||||
kill -9 10764
|
||||
kill -9 11679
|
||||
```
|
||||
|
||||
一旦我们输入了以上命令,Chrome 浏览器的所有进程将会成功被杀死。
|
||||
|
||||
我们有更简单的方法!如果我们已经知道我们想要杀死的那个进程的名字,我们能够利用 `killall` 命令发送同样的信号,像这样:
|
||||
|
||||
```
|
||||
killall -9 chrome
|
||||
```
|
||||
|
||||
附带说明的是,上边这个命令可能不能捕捉到所有正在运行的 Chrome 进程。如果,运行了上边这个命令之后,你输入 `ps aux | grep chrome` 命令过滤一下,看到剩下正在运行的 Chrome 进程有那些,最好的办法还是回到 `kIll` 命令通过进程 ID 来发送信号值 `9` 来结束这个进程。
|
||||
|
||||
### 结束进程很容易
|
||||
|
||||
正如你看到的,杀死错误的进程并没有你原本想的那样有挑战性。当我让一个顽固的进程结束的时候,我趋向于用 `killall`命令来作为有效的方法来终止,然而,当我让一个真正的活跃的进程结束的时候,`kill`命令是一个好的方法。
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/5/how-kill-process-command-line
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[hwlog](https://github.com/hwlog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[5]:https://www.linux.com/files/images/killajpg
|
||||
[6]:https://www.linux.com/files/images/killbjpg
|
||||
[7]:https://www.linux.com/files/images/killcjpg
|
||||
[8]:https://www.linux.com/files/images/stop-processesjpg
|
||||
128
sources/talk/20170426 How to get started learning to program.md
Normal file
128
sources/talk/20170426 How to get started learning to program.md
Normal file
@ -0,0 +1,128 @@
|
||||
How to get started learning to program
|
||||
============================================================
|
||||
|
||||
### Ever wondered, "How can I learn to program?" We provide guidance to help you find the approach that best suits your needs and situation.
|
||||
|
||||
|
||||

|
||||
>Image by : Artist unknown. Public domain, [via Wikimedia Commons][20]. Modified by Opensource.com.
|
||||
|
||||
There's a lot of buzz lately about learning to program. Not only is there a [shortage of people][21] compared with the open and pending positions in software development, programming is also a career with one of the [highest salaries][22] and [highest job satisfaction rates][23]. No wonder so many people are looking to break into the industry!
|
||||
|
||||
But how, exactly, do you do that? "**How can I learn to program?**" is a common question. Although I don't have all the answers, hopefully this article will provide guidance to help you find the approach that best suits your needs and situation.
|
||||
|
||||
|
||||
|
||||
### What's your learning style?
|
||||
|
||||
Before you start your learning process, consider not only your options, but also yourself. The ancient Greeks had a saying, [γνῶθι σεαυτόν][24] (gnothi seauton), meaning "know thyself". Undertaking a large learning program is difficult. Self awareness is necessary to make sure you are making the choices that will lead to the highest chance of success. Be honest with yourself when you answer the following questions:
|
||||
|
||||
* **What is your preferred learning style?** How do you learn best? Is it by reading? Hearing a lecture? Mostly hands-on experimentation? Choose the style that is most effective for you. Don't choose a style because it's popular or because someone else said it worked for them.
|
||||
|
||||
* **What are your needs and requirements?** Why are you looking into learning how to program? Is it because you wish to change jobs? If so, how quickly do you need to do that? Keep in mind, these are _needs_ , not _wants_ . You may _want_ a new job next week, but _need_ one within a year to help support your growing family. This sort of timing will matter when selecting a path.
|
||||
|
||||
* **What are your available resources?** Sure, going back to college and earning a computer science degree might be nice, but you must be realistic with yourself. Your life must accommodate your learning. Can you afford—both in time and money—to set aside several months to participate in a bootcamp? Do you even live in an area that provides learning opportunities, such as meetups or college courses? The resources available to you will have a large impact on how you proceed in your learning. Research these before diving in.
|
||||
|
||||
### Picking a language
|
||||
|
||||
As you start your path and consider your options, remember that despite what many will say, the choice of which programming language you use to start learning simply does _not_ matter. Yes, some languages are more popular than others. For instance, right now JavaScript, Java, PHP, and Python are among the [most popular languages][25] according to one study. But what is popular today may be passé next year, so don't get too hung up on choice of language. The underlying principles of methods, classes, functions, conditionals, control flow, and other programming concepts will remain more or less the same regardless of the language you use. Only the grammar and community best practices will change. Therefore you can learn to program just as well in [Perl][26] as you can in [Swift][27] or [Rust][28]. As a programmer, you will work with and in many different languages over the course of your career. Don't feel you're "stuck" with the first one you learn.
|
||||
|
||||
### Test the waters
|
||||
|
||||
Unless you already have dabbled a bit and know for sure that programming is something you'd like to spend the rest of your life doing, I advise you to dip a toe into the waters before diving in headfirst. This work is not for everyone. Before going all-in on a learning program, take a little time to try out one of the smaller, cheaper options to get a sense of whether you'll enjoy the work enough to spend 40 hours a week doing it. If you don't enjoy this work, it's unlikely you'll even finish the program. If you do finish your learning program despite that, you may be miserable in your subsequent job. Life is too short to spend a third of it doing something you don't enjoy.
|
||||
|
||||
Thankfully, there is a lot more to software development than simply programming. It's incredibly helpful to be familiar with programming concepts and to understand how software comes together, but you don't need to be a programmer to get a well-paying job in software development. Additional vital roles in the process are technical writer, project manager, product manager, quality assurance, designer, user experience, ops/sysadmin, and data scientist, among others. Many different roles and people are required to launch software successfully. Don't feel that learning to program requires you to become a programmer. Explore your options and choose what's best for you.
|
||||
|
||||
### Learning resources
|
||||
|
||||
What are your options for learning resources? As you've probably already discovered, those options are many and varied, although not all of them may be available in your area.
|
||||
|
||||
* **Bootcamps**: Bootcamps such as [App Academy][5] and [Bloc][6] have become popular in recent years. Often charging a fee of $10K USD or more, bootcamps advertise that they can train a student to become an employable programmer in a matter of weeks. Before enrolling in a coding bootcamp, research the program to make sure it delivers on its promises and is able to place its students in well-paying, long-term positions after graduation. The money is one cost, whereas the time is another—these typically are full-time programs that require the student to set aside any other obligations for several weeks in a row. These two costs often put bootcamps outside the budget of many prospective programmers.
|
||||
|
||||
* **Community college/vocational training center**: Community colleges often are overlooked by people investigating their options for learning to program, and that's a shame. The education you can receive at a community college or vocational training center can be as effective as other options, at a fraction of the cost.
|
||||
|
||||
* **State/local training programs**: Many regions recognize the economic benefits of boosting technology investments in their area and have developed training programs to create well-educated and -prepared workforces. Training program examples include [Code Oregon][7] and [Minneapolis TechHire][8]. Check to see whether your state, province, or municipality offers such a program.
|
||||
|
||||
* **Online training**: Many companies and organizations offer online technology training programs. Some, such as [Linux Foundation][9], are dedicated to training people to be successful with open source technologies. Others, like [O'Reilly Media][10], [Lynda.com][11], and [Coursera][12] provide training in many aspects of software development. [Codecademy][13] provides an online introduction to programming concepts. The costs of each program will vary, but most of them will allow you to learn on your schedule.
|
||||
|
||||
* **MOOCs**: MOOCs—Massive Open Online Courses—have really picked up steam in the past few years. World-class universities, such as [Harvard][14], [Stanford][15], [MIT][16], and others have been recording their courses and making them available online for free. The self-directed nature of the courses may not be a good fit for everyone, but the material available makes this a valuable learning option.
|
||||
|
||||
* **Books**: Many people love self-directed learning using books. It's quite economical and provides ready reference material after the initial learning phase. Although you can order and access books through online services like [Safari][17] and [Amazon][18], don't forget to check your local public library as well.
|
||||
|
||||
### Support network
|
||||
|
||||
Whichever learning resources you choose, the process will be more successful with a support network. Sharing your experiences and challenges with others can help keep you motivated, while providing a safe place to ask questions that you might not feel confident enough to ask elsewhere yet. Many towns have local user groups that gather to discuss and learn about software technologies. Often you can find these listed at [Meetup.com][29]. Special interest groups, such as [Women Who Code][30] and [Code2040][31], frequently hold meetings and hackathons in most urban areas and are a great way to meet and build a support network while you're learning. Some software conferences host "hack days" where you can meet experienced software developers and get help with concepts on which you're stuck. For instance, every year [PyCon][32] features several days of the conference for people to gather and work together. Some projects, such as [BeeWare][33], use these sprint days to assist new programmers to learn and contribute to the project.
|
||||
|
||||
Your support network doesn't have to come from a formal meetup. A small study group can be as effective at keeping you motivated to stay with your learning program and can be as easy to form as posting an invitation on your favorite social network. This is particularly useful if you live in an area that doesn't currently have a large community of software developers to support several meetups and user groups.
|
||||
|
||||
### Steps for getting started
|
||||
|
||||
In summary, to give yourself the best chance of success should you decide to learn to program, follow these steps:
|
||||
|
||||
1. Gather your list of requirements/needs and resources
|
||||
|
||||
2. Research the options available to you in your area
|
||||
|
||||
3. Discard the options that do not meet your requirements and resources
|
||||
|
||||
4. Select the option(s) that best suit your requirements, resources, and learning style
|
||||
|
||||
5. Find a support network
|
||||
|
||||
Remember, though: Your learning process will never be complete. The software industry moves quickly, with new technologies and advances popping up nearly every day. Once you learn to program, you must commit to spending time to learn about these new advances. You cannot rely on your job to provide you this training. Only you are responsible for your own career development, so if you wish to stay up-to-date and employable, you must stay abreast of the latest technologies in the industry.
|
||||
|
||||
Good luck!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
VM (Vicky) Brasseur - VM (aka Vicky) is a manager of technical people, projects, processes, products and p^Hbusinesses. In her more than 18 years in the tech industry she has been an analyst, programmer, product manager, software engineering manager, and director of software engineering. Currently she is a Senior Engineering Manager in service of an upstream open source development team at Hewlett Packard Enterprise. VM blogs at anonymoushash.vmbrasseur.com and tweets at @vmbrasseur.
|
||||
|
||||
--------
|
||||
|
||||
via: https://opensource.com/article/17/4/how-get-started-learning-program
|
||||
|
||||
作者:[VM (Vicky) Brasseur ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/vmbrasseur
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://www.appacademy.io/
|
||||
[6]:https://www.bloc.io/
|
||||
[7]:http://codeoregon.org/
|
||||
[8]:http://www.minneapolismn.gov/cped/metp/TechHire#start
|
||||
[9]:https://training.linuxfoundation.org/
|
||||
[10]:http://shop.oreilly.com/category/learning-path.do
|
||||
[11]:https://www.lynda.com/
|
||||
[12]:https://www.coursera.org/
|
||||
[13]:https://www.codecademy.com/
|
||||
[14]:https://www.edx.org/school/harvardx
|
||||
[15]:http://online.stanford.edu/courses
|
||||
[16]:https://ocw.mit.edu/index.htm
|
||||
[17]:https://www.safaribooksonline.com/
|
||||
[18]:https://amazon.com/
|
||||
[19]:https://opensource.com/article/17/4/how-get-started-learning-program?rate=txl_aE6F2oOUSgQDveWFtrPWIbA1ULFwfOp017zV35M
|
||||
[20]:https://commons.wikimedia.org/wiki/File:Roman-mosaic-know-thyself.jpg
|
||||
[21]:http://www.techrepublic.com/article/report-40-of-employers-worldwide-face-talent-shortages-driven-by-it/
|
||||
[22]:http://web.archive.org/web/20170328065655/http://www.businessinsider.com/highest-paying-jobs-in-america-2017-3/#-25
|
||||
[23]:https://stackoverflow.com/insights/survey/2017/#career-satisfaction
|
||||
[24]:https://en.wikipedia.org/wiki/Know_thyself
|
||||
[25]:https://stackoverflow.com/insights/survey/2017/#most-popular-technologies
|
||||
[26]:https://learn.perl.org/tutorials/
|
||||
[27]:http://shop.oreilly.com/product/0636920045946.do
|
||||
[28]:https://doc.rust-lang.org/book/
|
||||
[29]:https://www.meetup.com/
|
||||
[30]:https://www.womenwhocode.com/
|
||||
[31]:http://www.code2040.org/
|
||||
[32]:https://us.pycon.org/
|
||||
[33]:http://pybee.org/
|
||||
[34]:https://opensource.com/user/10683/feed
|
||||
[35]:https://opensource.com/article/17/4/how-get-started-learning-program#comments
|
||||
[36]:https://opensource.com/users/vmbrasseur
|
||||
@ -1,291 +0,0 @@
|
||||
translating by chenxinlong
|
||||
[A Programmer’s Introduction to Unicode][18]
|
||||
============================================================
|
||||
|
||||
|
||||
Unicode! 🅤🅝🅘🅒🅞🅓🅔‽ 🇺🇳🇮🇨🇴🇩🇪! 😄 The very name strikes fear and awe into the hearts of programmers worldwide. We all know we ought to “support Unicode” in our software (whatever that means—like using `wchar_t` for all the strings, right?). But Unicode can be abstruse, and diving into the thousand-page [Unicode Standard][27] plus its dozens of supplementary [annexes, reports][28], and [notes][29]can be more than a little intimidating. I don’t blame programmers for still finding the whole thing mysterious, even 30 years after Unicode’s inception.
|
||||
|
||||
A few months ago, I got interested in Unicode and decided to spend some time learning more about it in detail. In this article, I’ll give an introduction to it from a programmer’s point of view.
|
||||
|
||||
I’m going to focus on the character set and what’s involved in working with strings and files of Unicode text. However, in this article I’m not going to talk about fonts, text layout/shaping/rendering, or localization in detail—those are separate issues, beyond my scope (and knowledge) here.
|
||||
|
||||
* [Diversity and Inherent Complexity][10]
|
||||
* [The Unicode Codespace][11]
|
||||
* [Codespace Allocation][2]
|
||||
* [Scripts][3]
|
||||
* [Usage Frequency][4]
|
||||
* [Encodings][12]
|
||||
* [UTF-8][5]
|
||||
* [UTF-16][6]
|
||||
* [Combining Marks][13]
|
||||
* [Canonical Equivalence][7]
|
||||
* [Normalization Forms][8]
|
||||
* [Grapheme Clusters][9]
|
||||
* [And More…][14]
|
||||
|
||||
### [][30]Diversity and Inherent Complexity
|
||||
|
||||
As soon as you start to study Unicode, it becomes clear that it represents a large jump in complexity over character sets like ASCII that you may be more familiar with. It’s not just that Unicode contains a much larger number of characters, although that’s part of it. Unicode also has a great deal of internal structure, features, and special cases, making it much more than what one might expect a mere “character set” to be. We’ll see some of that later in this article.
|
||||
|
||||
When confronting all this complexity, especially as an engineer, it’s hard not to find oneself asking, “Why do we need all this? Is this really necessary? Couldn’t it be simplified?”
|
||||
|
||||
However, Unicode aims to faithfully represent the _entire world’s_ writing systems. The Unicode Consortium’s stated goal is “enabling people around the world to use computers in any language”. And as you might imagine, the diversity of written languages is immense! To date, Unicode supports 135 different scripts, covering some 1100 languages, and there’s still a long tail of [over 100 unsupported scripts][31], both modern and historical, which people are still working to add.
|
||||
|
||||
Given this enormous diversity, it’s inevitable that representing it is a complicated project. Unicode embraces that diversity, and accepts the complexity inherent in its mission to include all human writing systems. It doesn’t make a lot of trade-offs in the name of simplification, and it makes exceptions to its own rules where necessary to further its mission.
|
||||
|
||||
Moreover, Unicode is committed not just to supporting texts in any _single_ language, but also to letting multiple languages coexist within one text—which introduces even more complexity.
|
||||
|
||||
Most programming languages have libaries available to handle the gory low-level details of text manipulation, but as a programmer, you’ll still need to know about certain Unicode features in order to know when and how to apply them. It may take some time to wrap your head around it all, but don’t be discouraged—think about the billions of people for whom your software will be more accessible through supporting text in their language. Embrace the complexity!
|
||||
|
||||
### [][32]The Unicode Codespace
|
||||
|
||||
Let’s start with some general orientation. The basic elements of Unicode—its “characters”, although that term isn’t quite right—are called _code points_ . Code points are identified by number, customarily written in hexadecimal with the prefix “U+”, such as [U+0041 “A” latin capital letter a][33] or [U+03B8 “θ” greek small letter theta][34]. Each code point also has a short name, and quite a few other properties, specified in the [Unicode Character Database][35].
|
||||
|
||||
The set of all possible code points is called the _codespace_ . The Unicode codespace consists of 1,114,112 code points. However, only 128,237 of them—about 12% of the codespace—are actually assigned, to date. There’s plenty of room for growth! Unicode also reserves an additional 137,468 code points as “private use” areas, which have no standardized meaning and are available for individual applications to define for their own purposes.
|
||||
|
||||
### [][36]Codespace Allocation
|
||||
|
||||
To get a feel for how the codespace is laid out, it’s helpful to visualize it. Below is a map of the entire codespace, with one pixel per code point. It’s arranged in tiles for visual coherence; each small square is 16×16 = 256 code points, and each large square is a “plane” of 65,536 code points. There are 17 planes altogether.
|
||||
|
||||
[
|
||||
")
|
||||
][37]
|
||||
|
||||
White represents unassigned space. Blue is assigned code points, green is private-use areas, and the small red area is surrogates (more about those later). As you can see, the assigned code points are distributed somewhat sparsely, but concentrated in the first three planes.
|
||||
|
||||
Plane 0 is also known as the “Basic Multilingual Plane”, or BMP. The BMP contains essentially all the characters needed for modern text in any script, including Latin, Cyrillic, Greek, Han (Chinese), Japanese, Korean, Arabic, Hebrew, Devanagari (Indian), and many more.
|
||||
|
||||
(In the past, the codespace was just the BMP and no more—Unicode was originally conceived as a straightforward 16-bit encoding, with only 65,536 code points. It was expanded to its current size in 1996\. However, the vast majority of code points in modern text belong to the BMP.)
|
||||
|
||||
Plane 1 contains historical scripts, such as Sumerian cuneiform and Egyptian hieroglyphs, as well as emoji and various other symbols. Plane 2 contains a large block of less-common and historical Han characters. The remaining planes are empty, except for a small number of rarely-used formatting characters in Plane 14; planes 15–16 are reserved entirely for private use.
|
||||
|
||||
### [][38]Scripts
|
||||
|
||||
Let’s zoom in on the first three planes, since that’s where the action is:
|
||||
|
||||
[
|
||||
")
|
||||
][39]
|
||||
|
||||
This map color-codes the 135 different scripts in Unicode. You can see how Han <nobr>()</nobr> and Korean <nobr>()</nobr>take up most of the range of the BMP (the left large square). By contrast, all of the European, Middle Eastern, and South Asian scripts fit into the first row of the BMP in this diagram.
|
||||
|
||||
Many areas of the codespace are adapted or copied from earlier encodings. For example, the first 128 code points of Unicode are just a copy of ASCII. This has clear benefits for compatibility—it’s easy to losslessly convert texts from smaller encodings into Unicode (and the other direction too, as long as no characters outside the smaller encoding are used).
|
||||
|
||||
### [][40]Usage Frequency
|
||||
|
||||
One more interesting way to visualize the codespace is to look at the distribution of usage—in other words, how often each code point is actually used in real-world texts. Below is a heat map of planes 0–2 based on a large sample of text from Wikipedia and Twitter (all languages). Frequency increases from black (never seen) through red and yellow to white.
|
||||
|
||||
[
|
||||
")
|
||||
][41]
|
||||
|
||||
You can see that the vast majority of this text sample lies in the BMP, with only scattered usage of code points from planes 1–2\. The biggest exception is emoji, which show up here as the several bright squares in the bottom row of plane 1.
|
||||
|
||||
### [][42]Encodings
|
||||
|
||||
We’ve seen that Unicode code points are abstractly identified by their index in the codespace, ranging from U+0000 to U+10FFFF. But how do code points get represented as bytes, in memory or in a file?
|
||||
|
||||
The most convenient, computer-friendliest (and programmer-friendliest) thing to do would be to just store the code point index as a 32-bit integer. This works, but it consumes 4 bytes per code point, which is sort of a lot. Using 32-bit ints for Unicode will cost you a bunch of extra storage, memory, and performance in bandwidth-bound scenarios, if you work with a lot of text.
|
||||
|
||||
Consequently, there are several more-compact encodings for Unicode. The 32-bit integer encoding is officially called UTF-32 (UTF = “Unicode Transformation Format”), but it’s rarely used for storage. At most, it comes up sometimes as a temporary internal representation, for examining or operating on the code points in a string.
|
||||
|
||||
Much more commonly, you’ll see Unicode text encoded as either UTF-8 or UTF-16\. These are both _variable-length_ encodings, made up of 8-bit or 16-bit units, respectively. In these schemes, code points with smaller index values take up fewer bytes, which saves a lot of memory for typical texts. The trade-off is that processing UTF-8/16 texts is more programmatically involved, and likely slower.
|
||||
|
||||
### [][43]UTF-8
|
||||
|
||||
In UTF-8, each code point is stored using 1 to 4 bytes, based on its index value.
|
||||
|
||||
UTF-8 uses a system of binary prefixes, in which the high bits of each byte mark whether it’s a single byte, the beginning of a multi-byte sequence, or a continuation byte; the remaining bits, concatenated, give the code point index. This table shows how it works:
|
||||
|
||||
| UTF-8 (binary) | Code point (binary) | Range |
|
||||
| --- | --- | --- |
|
||||
| 0xxxxxxx | xxxxxxx | U+0000–U+007F |
|
||||
| 110xxxxx 10yyyyyy | xxxxxyyyyyy | U+0080–U+07FF |
|
||||
| 1110xxxx 10yyyyyy 10zzzzzz | xxxxyyyyyyzzzzzz | U+0800–U+FFFF |
|
||||
| 11110xxx 10yyyyyy 10zzzzzz 10wwwwww | xxxyyyyyyzzzzzzwwwwww | U+10000–U+10FFFF |
|
||||
|
||||
A handy property of UTF-8 is that code points below 128 (ASCII characters) are encoded as single bytes, and all non-ASCII code points are encoded using sequences of bytes 128–255\. This has a couple of nice consequences. First, any strings or files out there that are already in ASCII can also be interpreted as UTF-8 without any conversion. Second, lots of widely-used string programming idioms—such as null termination, or delimiters (newlines, tabs, commas, slashes, etc.)—will just work on UTF-8 strings. ASCII bytes never occur inside the encoding of non-ASCII code points, so searching byte-wise for a null terminator or a delimiter will do the right thing.
|
||||
|
||||
Thanks to this convenience, it’s relatively simple to extend legacy ASCII programs and APIs to handle UTF-8 strings. UTF-8 is very widely used in the Unix/Linux and Web worlds, and many programmers argue [UTF-8 should be the default encoding everywhere][44].
|
||||
|
||||
However, UTF-8 isn’t a drop-in replacement for ASCII strings in all respects. For instance, code that iterates over the “characters” in a string will need to decode UTF-8 and iterate over code points (or maybe grapheme clusters—more about those later), not bytes. When you measure the “length” of a string, you’ll need to think about whether you want the length in bytes, the length in code points, the width of the text when rendered, or something else.
|
||||
|
||||
### [][45]UTF-16
|
||||
|
||||
The other encoding that you’re likely to encounter is UTF-16\. It uses 16-bit words, with each code point stored as either 1 or 2 words.
|
||||
|
||||
Like UTF-8, we can express the UTF-16 encoding rules in the form of binary prefixes:
|
||||
|
||||
| UTF-16 (binary) | Code point (binary) | Range |
|
||||
| --- | --- | --- |
|
||||
| xxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxx | U+0000–U+FFFF |
|
||||
| 110110xxxxxxxxxx 110111yyyyyyyyyy | xxxxxxxxxxyyyyyyyyyy + 0x10000 | U+10000–U+10FFFF |
|
||||
|
||||
A more common way that people talk about UTF-16 encoding, though, is in terms of code points called “surrogates”. All the code points in the range U+D800–U+DFFF—or in other words, the code points that match the binary prefixes `110110` and `110111` in the table above—are reserved specifically for UTF-16 encoding, and don’t represent any valid characters on their own. They’re only meant to occur in the 2-word encoding pattern above, which is called a “surrogate pair”. Surrogate code points are illegal in any other context! They’re not allowed in UTF-8 or UTF-32 at all.
|
||||
|
||||
Historically, UTF-16 is a descendant of the original, pre-1996 versions of Unicode, in which there were only 65,536 code points. The original intention was that there would be no different “encodings”; Unicode was supposed to be a straightforward 16-bit character set. Later, the codespace was expanded to make room for a long tail of less-common (but still important) Han characters, which the Unicode designers didn’t originally plan for. Surrogates were then introduced, as—to put it bluntly—a kludge, allowing 16-bit encodings to access the new code points.
|
||||
|
||||
Today, Javascript uses UTF-16 as its standard string representation: if you ask for the length of a string, or iterate over it, etc., the result will be in UTF-16 words, with any code points outside the BMP expressed as surrogate pairs. UTF-16 is also used by the Microsoft Win32 APIs; though Win32 supports either 8-bit or 16-bit strings, the 8-bit version unaccountably still doesn’t support UTF-8—only legacy code-page encodings, like ANSI. This leaves UTF-16 as the only way to get proper Unicode support in Windows.
|
||||
|
||||
By the way, UTF-16’s words can be stored either little-endian or big-endian. Unicode has no opinion on that issue, though it does encourage the convention of putting [U+FEFF zero width no-break space][46] at the top of a UTF-16 file as a [byte-order mark][47], to disambiguate the endianness. (If the file doesn’t match the system’s endianness, the BOM will be decoded as U+FFFE, which isn’t a valid code point.)
|
||||
|
||||
### [][48]Combining Marks
|
||||
|
||||
In the story so far, we’ve been focusing on code points. But in Unicode, a “character” can be more complicated than just an individual code point!
|
||||
|
||||
Unicode includes a system for _dynamically composing_ characters, by combining multiple code points together. This is used in various ways to gain flexibility without causing a huge combinatorial explosion in the number of code points.
|
||||
|
||||
In European languages, for example, this shows up in the application of diacritics to letters. Unicode supports a wide range of diacritics, including acute and grave accents, umlauts, cedillas, and many more. All these diacritics can be applied to any letter of any alphabet—and in fact, _multiple_ diacritics can be used on a single letter.
|
||||
|
||||
If Unicode tried to assign a distinct code point to every possible combination of letter and diacritics, things would rapidly get out of hand. Instead, the dynamic composition system enables you to construct the character you want, by starting with a base code point (the letter) and appending additional code points, called “combining marks”, to specify the diacritics. When a text renderer sees a sequence like this in a string, it automatically stacks the diacritics over or under the base letter to create a composed character.
|
||||
|
||||
For example, the accented character “Á” can be expressed as a string of two code points: [U+0041 “A” latin capital letter a][49] plus [U+0301 “◌́” combining acute accent][50]. This string automatically gets rendered as a single character: “Á”.
|
||||
|
||||
Now, Unicode does also include many “precomposed” code points, each representing a letter with some combination of diacritics already applied, such as [U+00C1 “Á” latin capital letter a with acute][51] or [U+1EC7 “ệ” latin small letter e with circumflex and dot below][52]. I suspect these are mostly inherited from older encodings that were assimilated into Unicode, and kept around for compatibility. In practice, there are precomposed code points for most of the common letter-with-diacritic combinations in European-script languages, so they don’t use dynamic composition that much in typical text.
|
||||
|
||||
Still, the system of combining marks does allow for an _arbitrary number_ of diacritics to be stacked on any base character. The reductio-ad-absurdum of this is [Zalgo text][53], which works by ͖͟ͅr͞aṋ̫̠̖͈̗d͖̻̹óm̪͙͕̗̝ļ͇̰͓̳̫ý͓̥̟͍ ̕s̫t̫̱͕̗̰̼̘͜a̼̩͖͇̠͈̣͝c̙͍k̖̱̹͍͘i̢n̨̺̝͇͇̟͙ģ̫̮͎̻̟ͅ ̕n̼̺͈͞u̮͙m̺̭̟̗͞e̞͓̰̤͓̫r̵o̖ṷs҉̪͍̭̬̝̤ ̮͉̝̞̗̟͠d̴̟̜̱͕͚i͇̫̼̯̭̜͡ḁ͙̻̼c̲̲̹r̨̠̹̣̰̦i̱t̤̻̤͍͙̘̕i̵̜̭̤̱͎c̵s ͘o̱̲͈̙͖͇̲͢n͘ ̜͈e̬̲̠̩ac͕̺̠͉h̷̪ ̺̣͖̱ḻ̫̬̝̹ḙ̙̺͙̭͓̲t̞̞͇̲͉͍t̷͔̪͉̲̻̠͙e̦̻͈͉͇r͇̭̭̬͖,̖́ ̜͙͓̣̭s̘̘͈o̱̰̤̲ͅ ̛̬̜̙t̼̦͕̱̹͕̥h̳̲͈͝ͅa̦t̻̲ ̻̟̭̦̖t̛̰̩h̠͕̳̝̫͕e͈̤̘͖̞͘y҉̝͙ ̷͉͔̰̠o̞̰v͈͈̳̘͜er̶f̰͈͔ḻ͕̘̫̺̲o̲̭͙͠ͅw̱̳̺ ͜t̸h͇̭͕̳͍e̖̯̟̠ ͍̞̜͔̩̪͜ļ͎̪̲͚i̝̲̹̙̩̹n̨̦̩̖ḙ̼̲̼͢ͅ ̬͝s̼͚̘̞͝p͙̘̻a̙c҉͉̜̤͈̯̖i̥͡n̦̠̱͟g̸̗̻̦̭̮̟ͅ ̳̪̠͖̳̯̕a̫͜n͝d͡ ̣̦̙ͅc̪̗r̴͙̮̦̹̳e͇͚̞͔̹̫͟a̙̺̙ț͔͎̘̹ͅe̥̩͍ a͖̪̜̮͙̹n̢͉̝ ͇͉͓̦̼́a̳͖̪̤̱p̖͔͔̟͇͎͠p̱͍̺ę̲͎͈̰̲̤̫a̯͜r̨̮̫̣̘a̩̯͖n̹̦̰͎̣̞̞c̨̦̱͔͎͍͖e̬͓͘ ̤̰̩͙̤̬͙o̵̼̻̬̻͇̮̪f̴ ̡̙̭͓͖̪̤“̸͙̠̼c̳̗͜o͏̼͙͔̮r̞̫̺̞̥̬ru̺̻̯͉̭̻̯p̰̥͓̣̫̙̤͢t̳͍̳̖ͅi̶͈̝͙̼̙̹o̡͔n̙̺̹̖̩͝ͅ”̨̗͖͚̩.̯͓
|
||||
|
||||
A few other places where dynamic character composition shows up in Unicode:
|
||||
|
||||
* [Vowel-pointing notation][15] in Arabic and Hebrew. In these languages, words are normally spelled with some of their vowels left out. They then have diacritic notation to indicate the vowels (used in dictionaries, language-teaching materials, children’s books, and such). These diacritics are expressed with combining marks.
|
||||
|
||||
| A Hebrew example, with [niqqud][1]: | אֶת דַלְתִּי הֵזִיז הֵנִיעַ, קֶטֶב לִשְׁכַּתִּי יָשׁוֹד |
|
||||
| Normal writing (no niqqud): | את דלתי הזיז הניע, קטב לשכתי ישוד |
|
||||
|
||||
* [Devanagari][16], the script used to write Hindi, Sanskrit, and many other South Asian languages, expresses certain vowels as combining marks attached to consonant letters. For example, “ह” + “ि” = “हि” (“h” + “i” = “hi”).
|
||||
|
||||
* Korean characters stand for syllables, but they are composed of letters called [jamo][17] that stand for the vowels and consonants in the syllable. While there are code points for precomposed Korean syllables, it’s also possible to dynamically compose them by concatenating their jamo. For example, “ᄒ” + “ᅡ” + “ᆫ” = “한” (“h” + “a” + “n” = “han”).
|
||||
|
||||
### [][54]Canonical Equivalence
|
||||
|
||||
In Unicode, precomposed characters exist alongside the dynamic composition system. A consequence of this is that there are multiple ways to express “the same” string—different sequences of code points that result in the same user-perceived characters. For example, as we saw earlier, we can express the character “Á” either as the single code point U+00C1, _or_ as the string of two code points U+0041 U+0301.
|
||||
|
||||
Another source of ambiguity is the ordering of multiple diacritics in a single character. Diacritic order matters visually when two diacritics apply to the same side of the base character, e.g. both above: “ǡ” (dot, then macron) is different from “ā̇” (macron, then dot). However, when diacritics apply to different sides of the character, e.g. one above and one below, then the order doesn’t affect rendering. Moreover, a character with multiple diacritics might have one of the diacritics precomposed and others expressed as combining marks.
|
||||
|
||||
For example, the Vietnamese letter “ệ” can be expressed in _five_ different ways:
|
||||
|
||||
* Fully precomposed: U+1EC7 “ệ”
|
||||
* Partially precomposed: U+1EB9 “ẹ” + U+0302 “◌̂”
|
||||
* Partially precomposed: U+00EA “ê” + U+0323 “◌̣”
|
||||
* Fully decomposed: U+0065 “e” + U+0323 “◌̣” + U+0302 “◌̂”
|
||||
* Fully decomposed: U+0065 “e” + U+0302 “◌̂” + U+0323 “◌̣”
|
||||
|
||||
Unicode refers to set of strings like this as “canonically equivalent”. Canonically equivalent strings are supposed to be treated as identical for purposes of searching, sorting, rendering, text selection, and so on. This has implications for how you implement operations on text. For example, if an app has a “find in file” operation and the user searches for “ệ”, it should, by default, find occurrences of _any_ of the five versions of “ệ” above!
|
||||
|
||||
### [][55]Normalization Forms
|
||||
|
||||
To address the problem of “how to handle canonically equivalent strings”, Unicode defines several _normalization forms_ : ways of converting strings into a canonical form so that they can be compared code-point-by-code-point (or byte-by-byte).
|
||||
|
||||
The “NFD” normalization form fully _decomposes_ every character down to its component base and combining marks, taking apart any precomposed code points in the string. It also sorts the combining marks in each character according to their rendered position, so e.g. diacritics that go below the character come before the ones that go above the character. (It doesn’t reorder diacritics in the same rendered position, since their order matters visually, as previously mentioned.)
|
||||
|
||||
The “NFC” form, conversely, puts things back together into precomposed code points as much as possible. If an unusual combination of diacritics is called for, there may not be any precomposed code point for it, in which case NFC still precomposes what it can and leaves any remaining combining marks in place (again ordered by rendered position, as in NFD).
|
||||
|
||||
There are also forms called NFKD and NFKC. The “K” here refers to _compatibility_ decompositions, which cover characters that are “similar” in some sense but not visually identical. However, I’m not going to cover that here.
|
||||
|
||||
### [][56]Grapheme Clusters
|
||||
|
||||
As we’ve seen, Unicode contains various cases where a thing that a user thinks of as a single “character” might actually be made up of multiple code points under the hood. Unicode formalizes this using the notion of a _grapheme cluster_ : a string of one or more code points that constitute a single “user-perceived character”.
|
||||
|
||||
[UAX #29][57] defines the rules for what, precisely, qualifies as a grapheme cluster. It’s approximately “a base code point followed by any number of combining marks”, but the actual definition is a bit more complicated; it accounts for things like Korean jamo, and [emoji ZWJ sequences][58].
|
||||
|
||||
The main thing grapheme clusters are used for is text _editing_ : they’re often the most sensible unit for cursor placement and text selection boundaries. Using grapheme clusters for these purposes ensures that you can’t accidentally chop off some diacritics when you copy-and-paste text, that left/right arrow keys always move the cursor by one visible character, and so on.
|
||||
|
||||
Another place where grapheme clusters are useful is in enforcing a string length limit—say, on a database field. While the true, underlying limit might be something like the byte length of the string in UTF-8, you wouldn’t want to enforce that by just truncating bytes. At a minimum, you’d want to “round down” to the nearest code point boundary; but even better, round down to the nearest _grapheme cluster boundary_ . Otherwise, you might be corrupting the last character by cutting off a diacritic, or interrupting a jamo sequence or ZWJ sequence.
|
||||
|
||||
### [][59]And More…
|
||||
|
||||
There’s much more that could be said about Unicode from a programmer’s perspective! I haven’t gotten into such fun topics as case mapping, collation, compatibility decompositions and confusables, Unicode-aware regexes, or bidirectional text. Nor have I said anything yet about implementation issues—how to efficiently store and look-up data about the sparsely-assigned code points, or how to optimize UTF-8 decoding, string comparison, or NFC normalization. Perhaps I’ll return to some of those things in future posts.
|
||||
|
||||
Unicode is a fascinating and complex system. It has a many-to-one mapping between bytes and code points, and on top of that a many-to-one (or, under some circumstances, many-to-many) mapping between code points and “characters”. It has oddball special cases in every corner. But no one ever claimed that representing _all written languages_ was going to be _easy_ , and it’s clear that we’re never going back to the bad old days of a patchwork of incompatible encodings.
|
||||
|
||||
Further reading:
|
||||
|
||||
* [The Unicode Standard][21]
|
||||
* [UTF-8 Everywhere Manifesto][22]
|
||||
* [Dark corners of Unicode][23] by Eevee
|
||||
* [ICU (International Components for Unicode)][24]—C/C++/Java libraries implementing many Unicode algorithms and related things
|
||||
* [Python 3 Unicode Howto][25]
|
||||
* [Google Noto Fonts][26]—set of fonts intended to cover all assigned code points
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I’m a graphics programmer, currently freelancing in Seattle. Previously I worked at NVIDIA on the DevTech software team, and at Sucker Punch Productions developing rendering technology for the Infamous series of games for PS3 and PS4.
|
||||
|
||||
I’ve been interested in graphics since about 2002 and have worked on a variety of assignments, including fog, atmospheric haze, volumetric lighting, water, visual effects, particle systems, skin and hair shading, postprocessing, specular models, linear-space rendering, and GPU performance measurement and optimization.
|
||||
|
||||
You can read about what I’m up to on my blog. In addition to graphics, I’m interested in theoretical physics, and in programming language design.
|
||||
|
||||
You can contact me at nathaniel dot reed at gmail dot com, or follow me on Twitter (@Reedbeta) or Google+. I can also often be found answering questions at Computer Graphics StackExchange.
|
||||
|
||||
-------------------
|
||||
|
||||
via: http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311
|
||||
|
||||
作者:[ Nathan][a]
|
||||
译者:[译者ID](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:https://en.wikipedia.org/wiki/Niqqud
|
||||
[2]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#codespace-allocation
|
||||
[3]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#scripts
|
||||
[4]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#usage-frequency
|
||||
[5]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-8
|
||||
[6]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-16
|
||||
[7]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#canonical-equivalence
|
||||
[8]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#normalization-forms
|
||||
[9]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#grapheme-clusters
|
||||
[10]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#diversity-and-inherent-complexity
|
||||
[11]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#the-unicode-codespace
|
||||
[12]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#encodings
|
||||
[13]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#combining-marks
|
||||
[14]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#and-more
|
||||
[15]:https://en.wikipedia.org/wiki/Vowel_pointing
|
||||
[16]:https://en.wikipedia.org/wiki/Devanagari
|
||||
[17]:https://en.wikipedia.org/wiki/Hangul#Letters
|
||||
[18]:http://reedbeta.com/blog/programmers-intro-to-unicode/
|
||||
[19]:http://reedbeta.com/blog/category/coding/
|
||||
[20]:http://reedbeta.com/blog/programmers-intro-to-unicode/#comments
|
||||
[21]:http://www.unicode.org/versions/latest/
|
||||
[22]:http://utf8everywhere.org/
|
||||
[23]:https://eev.ee/blog/2015/09/12/dark-corners-of-unicode/
|
||||
[24]:http://site.icu-project.org/
|
||||
[25]:https://docs.python.org/3/howto/unicode.html
|
||||
[26]:https://www.google.com/get/noto/
|
||||
[27]:http://www.unicode.org/versions/latest/
|
||||
[28]:http://www.unicode.org/reports/
|
||||
[29]:http://www.unicode.org/notes/
|
||||
[30]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#diversity-and-inherent-complexity
|
||||
[31]:http://linguistics.berkeley.edu/sei/
|
||||
[32]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#the-unicode-codespace
|
||||
[33]:http://unicode.org/cldr/utility/character.jsp?a=A
|
||||
[34]:http://unicode.org/cldr/utility/character.jsp?a=%CE%B8
|
||||
[35]:http://www.unicode.org/reports/tr44/
|
||||
[36]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#codespace-allocation
|
||||
[37]:http://reedbeta.com/blog/programmers-intro-to-unicode/codespace-map.png
|
||||
[38]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#scripts
|
||||
[39]:http://reedbeta.com/blog/programmers-intro-to-unicode/script-map.png
|
||||
[40]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#usage-frequency
|
||||
[41]:http://reedbeta.com/blog/programmers-intro-to-unicode/heatmap-wiki+tweets.png
|
||||
[42]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#encodings
|
||||
[43]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-8
|
||||
[44]:http://utf8everywhere.org/
|
||||
[45]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-16
|
||||
[46]:http://unicode.org/cldr/utility/character.jsp?a=FEFF
|
||||
[47]:https://en.wikipedia.org/wiki/Byte_order_mark
|
||||
[48]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#combining-marks
|
||||
[49]:http://unicode.org/cldr/utility/character.jsp?a=A
|
||||
[50]:http://unicode.org/cldr/utility/character.jsp?a=0301
|
||||
[51]:http://unicode.org/cldr/utility/character.jsp?a=%C3%81
|
||||
[52]:http://unicode.org/cldr/utility/character.jsp?a=%E1%BB%87
|
||||
[53]:https://eeemo.net/
|
||||
[54]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#canonical-equivalence
|
||||
[55]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#normalization-forms
|
||||
[56]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#grapheme-clusters
|
||||
[57]:http://www.unicode.org/reports/tr29/
|
||||
[58]:http://blog.emojipedia.org/emoji-zwj-sequences-three-letters-many-possibilities/
|
||||
[59]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#and-more
|
||||
@ -1,103 +0,0 @@
|
||||
translating by [kenxx](https://github.com/kenxx)
|
||||
|
||||
# [Discovering my inner curmudgeon: A Linux laptop review][1]
|
||||
|
||||
|
||||
Quick refresher: I'm a life-long Mac user, but I was [disappointed by Apple's latest MacBook Pro release][2]. I researched [a set of alternative computers][3] to consider. And, as a surprise even to myself, I decided to leave the Mac platform.
|
||||
|
||||
I chose the HP Spectre x360 13" laptop that was released after CES 2017, the new version with a 4K display. I bought the machine [from BestBuy][4] (not an affiliate link) because that was the only retailer selling this configuration. My goal was to run Ubuntu Linux instead of Windows.
|
||||
|
||||
Here are my impressions from using this computer over the past month, followed by some realizations about myself.
|
||||
|
||||
Ubuntu
|
||||
|
||||
Installing Ubuntu was easy. The machine came with Windows 10 preinstalled. I used Windows' built-in Disk Management app to [shrink the main partition][5] and free up space for Linux. I [loaded the Ubuntu image on a USB drive][6], which conveniently fit in the machine's USB-A port (missing on new Macs). Then I followed [Ubuntu's simple install instructions][7], which required some BIOS changes to [enable booting from USB][8].
|
||||
|
||||
Screen
|
||||
|
||||
The 4K screen on the Spectre x360 is gorgeous. The latest Ubuntu handles High DPI screens well, which surprised me. With a combination of the built-in settings app and additional packages like [gnome-tweak-tool][9], you can get UI controls rendering on the 4K display at 2x native size, so they look right. You can also boost the default font size to make it proportional. There are even settings to adjust icon sizes in the window titlebar and task manager. It's fiddly, but I got everything set up relatively quickly.
|
||||
|
||||
Trackpad
|
||||
|
||||
The trackpad hardware rattles a little, but it follows your fingers well and supports multi-touch input in Ubuntu by default. However, you immediately realize that something is wrong when you try to type and the mouse starts jumping around. The default Synaptics driver for Linux doesn't properly ignore palm presses on this machine. The solution is to switch to the [new libinput system][10]. By adjusting the [xinput settings][11] you can get it to work decently well.
|
||||
|
||||
But the gestures I'm used to, like two finger swipe to go back in Chrome, or four-finger swipe to switch workspaces, don't work by default in Ubuntu. You have to use a tool like [libinput-gestures][12] to enable them. Even then, the gestures are only recognized about 50% of the time, which is frustrating. The "clickpad" functionality is also problematic: When you press your thumb on the dual-purpose trackpad/button surface in order to click, the system will often think you meant to move the mouse or you're trying to multi-touch resize. Again: It's frustrating.
|
||||
|
||||
Keyboard
|
||||
|
||||
Physically the keyboard is good. The keys have a lot of travel and I can type fast. The left control key is in the far bottom left so it's usable (unlike Macs that put the function key there). The arrow keys work well. One peculiarity is the keyboard has an extra column of keys on the right side, which includes Delete, Home, Page Up, Page Down, and End. This caused my muscle memory for switching from arrow keys to home row keys to be off by one column. This also puts your hands off center while typing, which can make you feel like you're slightly reaching on your right side.
|
||||
|
||||
At first I thought that the extra column of keys (Home, Page Up, etc) was superfluous. But after struggling to use Sublime Text while writing some code, I realized that the text input controls on Linux and Windows rely on these keys. It makes sense that HP decided to include them. As a Mac user I'm used to Command-Right going to the end of line, where a Windows or Linux user would reach for the End key. Remapping every key to match the Mac setup is possible, but hard to make consistent across all programs. The right thing to do is to relearn how to do text input with these new keys. I spent some time trying to retrain my muscle memory, but it was frustrating, like that summer when I tried [Dvorak][13].
|
||||
|
||||
Sound
|
||||
|
||||
The machine comes with four speakers: two fancy Bang & Olufsen speakers on top, and two normal ones on the bottom. The top speakers don't work on Linux and there's a [kernel bug open][14] to figure it out. The bottom speakers do work, but they're too quiet. The headphone jack worked correctly, and it would even mute the speakers automatically when you plugged in headphones. I believe this only happened because I had upgraded my kernel to the bleeding edge [4.10 version][15] in my attempts to make other hardware functional. I figure the community will eventually resolve the kernel bug, so the top speaker issue is likely temporary. But this situation emphasizes why HP needs to ship their own custom distribution of Windows with a bunch of extra magical drivers.
|
||||
|
||||
Battery & power
|
||||
|
||||
Initially the battery life was terrible. The 4K screen burns a lot of power. I also noticed that the CPU fan would turn on frequently and blow warm air out the left side of the machine. It's hot enough that it's very uncomfortable if it's on your lap. I figured out that this was mostly the result of a lack of power management in Ubuntu's default configuration. You can enable a variety of powersaving tools, including [powertop][16] and [pm-powersave][17]. Intel also provides [Linux firmware support][18] to make the GPU idle properly. With all of these changes applied, my battery life got up to nearly 5 hours: a disappointment compared to the 9+ hours advertised. On a positive note, the USB-C charger works great and fills the battery quickly. It was also nice to be able to charge my Nexus X phone with the same plug.
|
||||
|
||||
Two-in-one
|
||||
|
||||
The Spectre x360 gets its name from the fact that its special hinges let the laptop's screen rotate completely around, turning it into a tablet. Without any special configuration, touching the screen in Ubuntu works properly for clicking, scrolling, and zooming. Touch even works for forward/back gestures that don't work on the trackpad. The keyboard and trackpad also automatically disable themselves when you rotate into tablet mode. You can set up [Onboard][19], Gnome's on-screen keyboard, and it's decent. Screen auto-rotation doesn't work, but I was able to cobble something together using [iio-sensor-proxy][20] and [this one-off script][21]. Once I did this, though, I realized that the 16:9 aspect ratio of the screen is too much: It hurts my eyeballs to scan down so far vertically in tablet mode.
|
||||
|
||||
Window manager and programs
|
||||
|
||||
I haven't used Linux regularly on a desktop machine since RedHat 5.0 in 1998\. It's come a long way. Ubuntu boots very quickly. The default UI uses their Unity window manager, a Gnome variant, and it's decent. I tried plain Gnome and it felt clunky in comparison. I ended up liking KDE the most, and would choose the KDE [Kubuntu variant][22] if I were to start again. Overall the KDE window manager felt nice and did everything I needed.
|
||||
|
||||
On this journey back into Linux I realized that most of the time I only use eight programs: a web browser (Chrome), a terminal (no preference), a text editor (Sublime Text 3), a settings configurator, a GUI file manager, an automatic backup process (Arq), a Flux-like screen dimmer, and an image editor (the Gimp). My requirements beyond that are also simple. I rely on four widgets: clock, wifi status, battery level, and volume level. I need a task manager (like the Dock) and virtual work spaces (like Mission Control / Expose). I don't use desktop icons, notifications, recent apps, search, or an applications menu. I was able to accommodate all of these preferences on Linux.
|
||||
|
||||
Conclusion
|
||||
|
||||
If you're in the market for a new laptop, by all means check this one out. However, I'll be selling my Spectre x360 and going back to my mid-2012 MacBook Air. It's not HP's fault or because of the Linux desktop. The problem is how I value my time.
|
||||
|
||||
I'm so accustomed to the UX of a Mac that it's extremely difficult for me to use anything else as efficiently. My brain is tuned to a Mac's trackpad, its keyboard layout, its behaviors of text editing, etc. Using the HP machine and Linux slows me down so much that it feels like I'm starting over. When I'm using my computer I want to spend my time improving my (programming, writing, etc) skills. I want to invest all of my "retraining" energy into understanding unfamiliar topics, like [new functional languages][23] and [homomorphic encryption][24]. I don't want to waste my time relearning the fundamentals.
|
||||
|
||||
In contrast, I've spent the past two years learning how to play the piano. It's required rote memorization and repeated physical exercises. By spending time practicing piano, I've opened myself up to ideas that I couldn't appreciate before. I've learned things about music that I couldn't comprehend in the past. My retraining efforts have expanded my horizons. I'm skeptical that adopting HP hardware and the Linux desktop could have a similar effect on me.
|
||||
|
||||
I'm stubborn. There will come a time when I need to master a new way of working to stay relevant, much like how telegraph operators had to switch from Morse code to [teletypes][25]. I hope that I will have the patience and foresight to make such a transition smoothly in the future. Choosing to retrain only when it would create new possibilities seems like a good litmus test for achieving that goal. In the meantime, I'll keep using a Mac.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'm the author of the book Effective Python. I'm a software engineer and I've worked at Google for the past 11 years. My current focus is survey statistics. I formerly worked on Cloud infrastructure and open protocols.
|
||||
|
||||
Follow @haxor if you'd like to read posts from me in the future. You can also email me here if you have questions, or leave a comment below. If you enjoyed this post, look here for some of my other favorites.
|
||||
|
||||
-----------------
|
||||
|
||||
via: http://www.onebigfluke.com/2017/04/discovering-my-inner-curmudgeon-linux.html
|
||||
|
||||
作者:[Brett Slatkin ][a]
|
||||
译者:[kenxx](https://github.com/kenxx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.onebigfluke.com/
|
||||
[1]:http://www.onebigfluke.com/2017/04/discovering-my-inner-curmudgeon-linux.html
|
||||
[2]:http://www.onebigfluke.com/2016/10/lamenting-progress.html
|
||||
[3]:http://www.onebigfluke.com/2016/10/alternatives-to-apple-computers.html
|
||||
[4]:http://www.bestbuy.com/site/hp-spectre-x360-2-in-1-13-3-4k-ultra-hd-touch-screen-laptop-intel-core-i7-16gb-memory-512gb-solid-state-drive-dark-ash-silver/5713178.p?skuId=5713178
|
||||
[5]:https://www.howtogeek.com/101862/how-to-manage-partitions-on-windows-without-downloading-any-other-software/
|
||||
[6]:https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-windows
|
||||
[7]:https://www.ubuntu.com/download/desktop/install-ubuntu-desktop
|
||||
[8]:http://support.hp.com/us-en/document/c00364979
|
||||
[9]:https://launchpad.net/gnome-tweak-tool
|
||||
[10]:https://launchpad.net/xserver-xorg-input-libinput
|
||||
[11]:https://wiki.archlinux.org/index.php/Libinput#Configuration
|
||||
[12]:https://github.com/bulletmark/libinput-gestures
|
||||
[13]:https://en.wikipedia.org/wiki/Dvorak_Simplified_Keyboard
|
||||
[14]:https://bugzilla.kernel.org/show_bug.cgi?id=189331
|
||||
[15]:http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.10/
|
||||
[16]:https://blog.sleeplessbeastie.eu/2015/08/10/how-to-set-all-tunable-powertop-options-at-system-boot/
|
||||
[17]:http://askubuntu.com/questions/765840/does-pm-powersave-start-automatically-when-running-on-battery
|
||||
[18]:https://01.org/linuxgraphics/downloads/firmware
|
||||
[19]:https://launchpad.net/onboard
|
||||
[20]:https://github.com/hadess/iio-sensor-proxy
|
||||
[21]:http://askubuntu.com/questions/634151/auto-rotate-screen-on-dell-13-7000-with-15-04-gnome/889591#889591
|
||||
[22]:https://www.kubuntu.org/
|
||||
[23]:http://docs.idris-lang.org/en/latest/tutorial/index.html#tutorial-index
|
||||
[24]:https://arxiv.org/abs/1702.07588
|
||||
[25]:https://en.wikipedia.org/wiki/Teleprinter
|
||||
@ -1,150 +0,0 @@
|
||||
ucasFL translating
|
||||
|
||||
Python-mode – A Vim Plugin to Develop Python Applications in Vim Editor
|
||||
============================================================
|
||||
|
||||
|
||||
Python-mode is a vim plugin that enables you to write Python code in [Vim editor][1] in a fast manner by utilizing libraries including pylint, rope, pydoc, pyflakes, pep8, autopep8, pep257 and mccabe for coding features such as static analysis, refactoring, folding, completion, documentation, and more.
|
||||
|
||||
**Suggested Read:** [Bash-Support – A Vim Plugin That Converts Vim Editor to Bash-IDE][2]
|
||||
|
||||
This plugin contains all the features that you can use to develop python applications in Vim editor.
|
||||
|
||||
#### Python-mode Features
|
||||
|
||||
It has the following notable features:
|
||||
|
||||
* Support Python version 2.6+ and 3.2+.
|
||||
|
||||
* Supports syntax highlighting.
|
||||
|
||||
* Offers virtualenv support.
|
||||
|
||||
* Supports python folding.
|
||||
|
||||
* Offers enhanced python indentation.
|
||||
|
||||
* Enables running of python code from within Vim.
|
||||
|
||||
* Enables addition/removal of breakpoints.
|
||||
|
||||
* Supports python motions and operators.
|
||||
|
||||
* Enables code checking (pylint, pyflakes, pylama, …) that can be run simultaneouslyi>
|
||||
|
||||
* Supports autofixing of PEP8 errors.
|
||||
|
||||
* Allows searching in python documentation.
|
||||
|
||||
* Supports code refactoring.
|
||||
|
||||
* Supports strong code completion.
|
||||
|
||||
* Supports going to definition.
|
||||
|
||||
In this tutorial, we will show you how to setup Vim to use Python-mode in Linux to develop Python applications in Vim editor.
|
||||
|
||||
### How to Install Python-mode for Vim in Linux
|
||||
|
||||
Start by installing [Pathogen][3] (makes it super easy to install plugins and runtime files in their own private directories) for easy installation of Python-mode.
|
||||
|
||||
Run the commands below to get the pathogen.vim file and the directories it needs:
|
||||
|
||||
```
|
||||
# mkdir -p ~/.vim/autoload ~/.vim/bundle && \
|
||||
# curl -LSso ~/.vim/autoload/pathogen.vim https://tpo.pe/pathogen.vim
|
||||
```
|
||||
|
||||
Then add the following lines below to your ~/.vimrc file:
|
||||
|
||||
```
|
||||
execute pathogen#infect()
|
||||
syntax on
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
Once you have installed pathogen, and you can now put Python-mode into ~/.vim/bundle as follows.
|
||||
|
||||
```
|
||||
# cd ~/.vim/bundle
|
||||
# git clone https://github.com/klen/python-mode.git
|
||||
```
|
||||
|
||||
Then rebuild helptags in vim like this.
|
||||
|
||||
```
|
||||
:helptags
|
||||
```
|
||||
|
||||
You need to enable filetype-plugin (:help filetype-plugin-on) and filetype-indent (:help filetype-indent-on) to use python-mode.
|
||||
|
||||
### Install Python-mode in Debian and Ubuntu
|
||||
|
||||
Another way you can install python-mode in Debian and Ubuntu systems using PPA as shown.
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository https://klen.github.io/python-mode/deb main
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install vim-python-mode
|
||||
```
|
||||
|
||||
If you you encounter the message: “The following signatures couldn’t be verified because the public key is not available”, run the command below:
|
||||
|
||||
```
|
||||
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys B5DF65307000E266
|
||||
```
|
||||
|
||||
Now enable python-mode using vim-addon-manager like so.
|
||||
|
||||
```
|
||||
$ sudo apt install vim-addon-manager
|
||||
$ vim-addons install python-mode
|
||||
```
|
||||
|
||||
### Customizing Python-mode in Linux
|
||||
|
||||
To override the default key bindings, redefine them in the .vimrc files, for instance:
|
||||
|
||||
```
|
||||
" Override go-to.definition key shortcut to Ctrl-]
|
||||
let g:pymode_rope_goto_definition_bind = "<C-]>"
|
||||
" Override run current python file key shortcut to Ctrl-Shift-e
|
||||
let g:pymode_run_bind = "<C-S-e>"
|
||||
" Override view python doc key shortcut to Ctrl-Shift-d
|
||||
let g:pymode_doc_bind = "<C-S-d>"
|
||||
```
|
||||
|
||||
Note that python-mode uses python 2 syntax checking by default. You can enable python 3 syntax checking by adding this in your .vimrc.
|
||||
|
||||
```
|
||||
let g:pymode_python = 'python3'
|
||||
```
|
||||
|
||||
You can find additional configuration options on the Python-mode Github Repository: [https://github.com/python-mode/python-mode][4]
|
||||
|
||||
That’s all for now! In this tutorial, we will show you how to integrate Vim to with Python-mode in Linux. Share your thoughts with us via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/python-mode-a-vim-editor-plugin/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/vi-editor-usage/
|
||||
[2]:https://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||
[3]:https://github.com/tpope/vim-pathogen
|
||||
[4]:https://github.com/python-mode/python-mode
|
||||
[5]:https://www.tecmint.com/author/aaronkili/
|
||||
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,108 @@
|
||||
Top 4 CDN services for hosting open source libraries
|
||||
============================================================
|
||||
|
||||
### Content delivery networks accelerate your website's images, CSS files, JS files, and other static content.
|
||||
|
||||
|
||||

|
||||
>Image credits : [Open Clip Art Library][3], which released it explicitly into the **[public domain][1]** ([see here][4]). Modified by Jen Wike Huger.
|
||||
|
||||
A CDN, or content delivery network, is a network of strategically placed servers located around the world used for the purpose of delivering files faster to users. A traditional CDN will allow you to accelerate your website's images, CSS files, JS files, and any other piece of static content. This allows website owners to accelerate all of their own content as well as provide them with additional features and configuration options. These premium services typically require payment based on the amount of bandwidth a project uses.
|
||||
|
||||
However, if your project doesn't justify the cost of implementing a traditional CDN, the use of an open source CDN may be more suitable. Typically, these types of CDNs allow you to link to popular web-based libraries (CSS/JS frameworks, for example), which are then delivered to your web visitors from the free CDN's servers. Although CDN services for open source libraries do not allow you to upload your own content to their servers, they can help you accelerate libraries globally and improve your website's redundancy.
|
||||
|
||||
CDNs host projects on a vast network of servers, so website maintainers need to modify their asset links in the website's HTML code to reflect the open source CDN's URL followed by the path to the resource. Depending upon whether you're linking to a JavaScript or CSS library, the links you'll include will live in either a <script> or <link> tag.
|
||||
|
||||
Let's explore four popular CDN services for open source libraries.
|
||||
|
||||
### JsDelivr
|
||||
|
||||
[JsDelivr][5] is an open source CDN provider that uses the networks of premium CDN providers (KeyCDN, Stackpath, and Cloudflare) to deliver open source project assets. A few highlights of jsDelivr include:
|
||||
|
||||
* Search from over 2,100 libraries
|
||||
|
||||
* 110 POP locations
|
||||
|
||||
* CDN is accessible in Asia and China
|
||||
|
||||
* API support
|
||||
|
||||
* No traffic limits
|
||||
|
||||
* Full HTTPS support
|
||||
|
||||
All snippets start off with the custom jsDelivr URL [https://cdn.jsdelivr.net/][6], and are then followed by the name of the project, version number, etc. You can also configure jsDelivr to generate the URL with the script tags and enable SRI (subresource Integrity) for added security.
|
||||
|
||||
### **Cdnjs**
|
||||
|
||||
[Cdnjs][7] is another popular open source CDN provider that's similar to jsDelivr. This service also offers an array of popular JavaScript and CSS libraries that you can choose from to link within your web project. This service is sponsored by CDN providers Cloudflare and [KeyCDN][8]. A few highlights of cdnjs include:
|
||||
|
||||
* Search from over 2,900 libraries
|
||||
|
||||
* Used by over 1 million websites
|
||||
|
||||
* Supports HTTP/2
|
||||
|
||||
* Supports HTTPS
|
||||
|
||||
Similar to jsDelivr, with cdnjs you also have the option to simply copy the asset URL with or without the script tag and SRI.
|
||||
|
||||
### Google Hosted Libraries
|
||||
|
||||
The [Google's Hosted Libraries][9] site allows you to link to popular JavaScript libraries that are hosted on Google's powerful open source CDN network. This open source CDN solution doesn't offer as many libraries or features as jsDelivr or cdnjs; however, a high level of reliability and trust can be expected when linking to Google's Hosted Libraries. A few highlights of Google's open source CDN include:
|
||||
|
||||
* HTTPS support
|
||||
|
||||
* Files are served with CORS and Timing-Allow headers
|
||||
|
||||
* Offers the latest version of each library
|
||||
|
||||
All of Google's Hosted libraries files start with the URL [https://ajax.googleapis.com/][10], and are followed by the project's name, version number, and file name.
|
||||
|
||||
### Microsoft Ajax CDN
|
||||
|
||||
The [Microsoft Ajax Content Delivery Network][11] is quite similar to Google's Hosted Libraries in that it only hosts popular libraries. However, two major differences that separate Microsoft Ajax CDN from Google's Hosted Libraries are that Microsoft provides both CSS as well as JS libraries and also offers various versions of each library. A few highlights of the Microsoft Ajax CDN include:
|
||||
|
||||
* HTTPS support
|
||||
|
||||
* Previous versions of each library are often available
|
||||
|
||||
All Microsoft Ajax files begin with the URL [http://ajax.aspnetcdn.com/ajax/][12], and like the others, are followed by the library's name, version number, etc.
|
||||
|
||||
If your project or website isn't ready to take advantage of a premium CDN service, but you would still like to accelerate vital aspects of your site, then using an open source CDN can be a great solution. They allow you to accelerate the delivery of third-party libraries that would otherwise be delivered from your origin server causing unnecessary load and slower speeds for distant users.
|
||||
|
||||
_Which open source CDN provider do you prefer to use and why?_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Cody Arsenault - Cody is passionate about all things web performance, SEO and entrepreneurship. He is a web performance advocate at KeyCDN and works towards making the web faster.
|
||||
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/4/top-cdn-services
|
||||
|
||||
作者:[Cody Arsenault ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/codya
|
||||
[1]:https://en.wikipedia.org/wiki/public_domain
|
||||
[2]:https://opensource.com/article/17/4/top-cdn-services?rate=lgZwEmWt7QXtuMhB-lnHWQ-jxknQ0Kh4YOfqdFGer5w
|
||||
[3]:https://en.wikipedia.org/wiki/Open_Clip_Art_Library
|
||||
[4]:https://openclipart.org/share
|
||||
[5]:http://www.jsdelivr.com/
|
||||
[6]:https://cdn.jsdelivr.net/
|
||||
[7]:https://cdnjs.com/
|
||||
[8]:https://www.keycdn.com/
|
||||
[9]:https://developers.google.com/speed/libraries/
|
||||
[10]:https://ajax.googleapis.com/
|
||||
[11]:https://www.asp.net/ajax/cdn
|
||||
[12]:http://ajax.aspnetcdn.com/ajax/
|
||||
[13]:https://opensource.com/user/128076/feed
|
||||
[14]:https://opensource.com/users/codya
|
||||
@ -1,91 +0,0 @@
|
||||
WPSeku – A Vulnerability Scanner to Find Security Issues in WordPress
|
||||
============================================================
|
||||
|
||||
by [Aaron Kili][9] | Published: May 5, 2017 | Last Updated: May 5, 2017
|
||||
|
||||
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][10] | [4 Free Shell Scripting eBooks][11]
|
||||
|
||||
WordPress is a free and open-source, highly customizable content management system (CMS) that is being used by millions around the world to run blogs and fully functional websites. Because it is the most used CMS out there, there are so many potential WordPress security issues/vulnerabilities to be concerned about.
|
||||
|
||||
However, these security issues can be dealt with, if we follow common WordPress security best practices. In this article, we will show you how to use WPSeku, a WordPress vulnerability scanner in Linux, that can be used to find security holes in your WordPress installation and block potential threats.
|
||||
|
||||
WPSeku is a simple WordPress vulnerability scanner written using Python, it can be used to scan local and remote WordPress installations to find security issues.
|
||||
|
||||
### How to Install WPSeku – WordPress Vulnerability Scanner in Linux
|
||||
|
||||
To install WPSeku in Linux, you need to clone the most recent version of WPSeku from its Github repository as shown.
|
||||
|
||||
```
|
||||
$ cd ~
|
||||
$ git clone https://github.com/m4ll0k/WPSeku
|
||||
```
|
||||
|
||||
Once you have obtained it, move into the WPSeku directory and run it as follows.
|
||||
|
||||
```
|
||||
$ cd WPSeku
|
||||
```
|
||||
|
||||
Now run the WPSeku using the `-u` option to specify your WordPress installation URL like this.
|
||||
|
||||
```
|
||||
$ ./wpseku.py -u http://yourdomain.com
|
||||
```
|
||||
[][1]
|
||||
|
||||
WordPress Vulnerability Scanner
|
||||
|
||||
The command below will search for cross site scripting, local file inclusion, and SQL injection vulnerabilities in your WordPress plugins using the `-p` option, you need to specify the location of plugins in the URL:
|
||||
|
||||
```
|
||||
$ ./wpseku.py -u http://yourdomain.com/wp-content/plugins/wp/wp.php?id= -p [x,l,s]
|
||||
```
|
||||
|
||||
The following command will execute a brute force password login and password login via XML-RPC using the option `-b`. Also, you can set a username and wordlist using the `--user` and `--wordlist` options respectively as shown below.
|
||||
|
||||
```
|
||||
$ ./wpseku.py -u http://yourdomian.com --user username --wordlist wordlist.txt -b [l,x]
|
||||
```
|
||||
|
||||
To view all WPSeku usage options, type.
|
||||
|
||||
```
|
||||
$ ./wpseku.py --help
|
||||
```
|
||||
[][2]
|
||||
|
||||
WPSeku WordPress Vulnerability Scanner Help
|
||||
|
||||
WPSeku Github repository: [https://github.com/m4ll0k/WPSeku][3]
|
||||
|
||||
That’s it! In this article, we showed you how to get and use WPSeku for WordPress vulnerability scanning in Linux. WordPress is secure but only if we follow WordPress security best practices. Do you have any thoughts to share? If yes, then use the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/wp-content/uploads/2017/05/WordPress-Vulnerability-Scanner.png
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/05/WPSeku-WordPress-Vulnerability-Scanner-Help.png
|
||||
[3]:https://github.com/m4ll0k/WPSeku
|
||||
[4]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[5]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[6]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[7]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[8]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#comments
|
||||
[9]:https://www.tecmint.com/author/aaronkili/
|
||||
[10]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[11]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,196 @@
|
||||
An introduction to Libral, a systems management library for Linux
|
||||
============================================================
|
||||
|
||||
### Libral provides a uniform management API across system resources and serves as a solid foundation for scripting management tasks and building configuration-management systems.
|
||||
|
||||
|
||||

|
||||
>Image by : [Internet Archive Book Images][10]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
Linux, in keeping with Unix traditions, doesn't have a comprehensive systems management API. Instead, management is done through a variety of special-purpose tools and APIs, all with their own conventions and idiosyncrasies. That makes scripting even simple systems-management tasks difficult and brittle.
|
||||
|
||||
For example, changing the login shell of the "app" user is done by running **usermod -s /sbin/nologin app**. This works great until it is attempted on a system that does not have an app user. To fix the ensuing failure, the enterprising script writer might now resort to:
|
||||
|
||||
```
|
||||
grep -q app /etc/passwd \
|
||||
&& usermod -s /sbin/nologin app \
|
||||
|| useradd ... -s /sbin/nologin app
|
||||
```
|
||||
|
||||
So that the change in the login shell is performed when the app user is present on the system, and the user is created if it is not present yet. Unfortunately, this approach to scripting systems-management tasks is not sustainable: For each kind of resource, a different set of tools and their idiosyncrasies must be taken into account; inconsistent and often incomplete error reporting makes error handling difficult; and it is easy to trip over small bugs caused by the ad hoc nature of the tools involved.
|
||||
|
||||
In fact, the above example is not correct: **grep** doesn't look for the **app** user, it simply looks for any line in **/etc/passwd** that contains the string **app**, something that might work most of the time, but can fail—usually at the worst possible moment.
|
||||
|
||||
|
||||
|
||||
Clearly, management tools that make it hard to perform simple tasks from scripts are, at best, a difficult basis for larger management systems. Recognizing this, existing configuration-management systems, such as Puppet, Chef, or Ansible, have gone to great lengths to build their own internal APIs around the management of basic operating system resources. These resource abstractions are internal APIs, and closely tied to the needs of their respective tools. This causes not only a colossal duplication of effort, but also creates a strong barrier to entry for new and innovative management tools.
|
||||
|
||||
One area where this barrier to entry becomes evident is in building VM or container images: In the course of building such images, it is often necessary to either answer simple questions about them or make simple changes to them. But since the tools for this all require special treatment, these questions and changes face exactly the problems that somebody trying to script them faces. As a consequence, image building must rely on either ad hoc scripts or using (and installing) a quite substantial configuration-management system.
|
||||
|
||||
[Libral][11] establishes a solid foundation for management tools and tasks by providing a common management API across system resources and by making it available through a command line tool, **ralsh**, that enables users to query and to modify system resources in a uniform way, with predictable error reporting. In the above example, checking whether the app user exists is done with **ralsh -aq user app**; checking whether the package **foo** is installed is done with **ralsh -aq package foo**; and, in general, checking whether a resource of type **TYPE** with name **NAME** is present is done with **ralsh -aq TYPE NAME**. Similarly, to create or change an existing user, one runs:
|
||||
|
||||
```
|
||||
ralsh user app home=/srv/app shell=/sbin/nologin
|
||||
```
|
||||
|
||||
and to create or change an entry in **/etc/hosts**, one runs:
|
||||
|
||||
```
|
||||
ralsh hostmyhost.example.com ip=10.0.0.1 \
|
||||
host_aliases=myhost,apphost
|
||||
```
|
||||
|
||||
In this manner, the user of ralsh is isolated from the fact that these two commands work quite differently internally: The first one needs to use the proper invocation of **useradd** or **usermod**, whereas the second needs to edit the file **/etc/hosts**. For the user, though, they both appear to take the same shape: "Make sure that this resource is in the state that I need."
|
||||
|
||||
### Where to get Libral and how to use it
|
||||
|
||||
Libral is available from [this git repo][12]. Its core is written in C++, and instructions for building it can be found [in the repo][13]. That is only necessary if you actually want to contribute to Libral's C++ core. The Libral site also contains a [prebuilt tarball][14] that can be used on any Linux machine that uses **glibc 2.12** or later. The contents of that tarball can be used both to explore ralsh further and to develop new providers, which give Libral the capability to manage new kinds of resources.
|
||||
|
||||
After downloading and unpacking the tarball, the **ralsh** command can be found in **ral/bin**. Running it without arguments will list all resource types that Libral knows about. Passing the **--help **option prints output that contains more example of how to use **ralsh**.
|
||||
|
||||
### Relationship to configuration-management systems
|
||||
|
||||
Well-known configuration-management systems, such as Puppet, Chef, or Ansible, address some of the same problems that Libral addresses. What sets Libral apart from them is mostly in the things that these systems do and Libral doesn't. Configuration-management systems are built to deal with the variety and complexity of managing many different things across large numbers of nodes. Libral, on the other hand, aims at providing a low-level systems management API that is well-defined, independent of any particular tool, and usable with a wide variety of programming languages.
|
||||
|
||||
By removing the application logic that the large configuration-management systems contain, Libral is much more versatile in how it can be used, from the simple scripting tasks mentioned in the introduction, to serving as the building blocks for complex management applications. Focusing on these basics also allows it to be very small, currently less than 2.5 MB, an important consideration for resource-constrained environments, including containers and small devices.
|
||||
|
||||
### The Libral API
|
||||
|
||||
The design of the Libral API is guided by the experience of implementing large configuration-management systems over the last decade; while it is not directly tied to any of them, it takes them into account and makes choices to overcome their shortcomings.
|
||||
|
||||
There are four important principles that the API design rests on:
|
||||
|
||||
* Desired state
|
||||
|
||||
* Bidirectionality
|
||||
|
||||
* Lightweight abstractions
|
||||
|
||||
* Ease of extension
|
||||
|
||||
Basing a management API on desired state, i.e., the idea that the user expresses what the system should look like after an operation rather than how to get into that state, is hardly controversial at this point. Bidirectionality makes it possible to use the same API and, more importantly, the same resource abstractions to read existing state and to enforce changes to it. Lightweight abstractions ensure that it is easy to learn the API and make use of it quickly; past attempts at such management APIs have unduly burdened the user with learning a modeling framework, an important factor in their lack of adoption.
|
||||
|
||||
Finally, it has to be easy to extend Libral's management capabilities so that users can teach Libral how to manage new kinds of resources. This is important both because of the sheer amount of resources that one might want to manage (and that Libral will manage in due time), as well as because even a fully built-out Libral will always fall short of a user's custom management needs.
|
||||
|
||||
Currently, the main way to interact with the Libral API is through the **ralsh **command line tool. It exposes the underlying C++ API, which is still in flux, and is mainly geared at simple scripting tasks. The project also provides language bindings for CRuby, with others to follow.
|
||||
|
||||
In the future, Libral will also provide a daemon with a remote API, so that it can serve as the basis for management systems that do not need to install additional agents on managed nodes. This, coupled with the ability to tailor the management capabilities of Libral, makes it possible to tightly control which aspects of a system can be managed and which ones are protected from any interference.
|
||||
|
||||
For example, a Libral installation that is restricted to managing users and services will be guaranteed to not interfere with the packages installed on a node. Controlling what gets managed in this manner is currently not possible with any of the existing configuration-management systems; in particular, systems that require arbitrary SSH access to a managed node also expose that system to unwanted accidental or malicious interference.
|
||||
|
||||
The basis of the Libral API is formed by two very simple operations: **get** to retrieve the current state of resources, and **set** to enforce the state of current resources. Idealizing a little from the actual implementation, they can be thought of as:
|
||||
|
||||
```
|
||||
provider.get(names) -> List[resource]
|
||||
provider.set(List[update]) -> List[change]
|
||||
```
|
||||
|
||||
The **provider** is the object that knows how to manage a certain kind of resource, like a user, a service, or a package, and the Libral API provides ways to look up the provider for a certain kind of resource.
|
||||
|
||||
The **get** operation receives a list of resource names, e.g., usernames, and needs to produce a list of resources, which are essentially hashes listing the attributes of each resource. This list must contain resources with the provided names, but might contain more, so that a naive **get** implementation can simply ignore the names and list all the resources it knows about.
|
||||
|
||||
The **set** operation is used to enforce desired state and receives a list of updates. Each update contains **update.is**, a resource representing the current state, and **update.should**, a resource representing the desired state. Calling the **set** method will make sure that the resources mentioned in the update list will be in the state indicated in **update.should** and produces a list of the changes made to each resource.
|
||||
|
||||
With **ralsh**, the current state of the **root** user can be retrieved with the command **ralsh user root**; by default, the command produces human-readable output, reminiscent of Puppet, but **ralsh** also supports a **--json** flag to make it produce JSON output for consumption by
|
||||
scripts. The human-readable output is:
|
||||
|
||||
```
|
||||
# ralsh user root
|
||||
user::useradd { 'root':
|
||||
ensure => 'present',
|
||||
comment => 'root',
|
||||
gid => '0',
|
||||
groups => ['root'],
|
||||
home => '/root',
|
||||
shell => '/bin/bash',
|
||||
uid => '0',
|
||||
}
|
||||
```
|
||||
|
||||
Similarly, the user can be changed with:
|
||||
|
||||
```
|
||||
# ralsh user root comment='The superuser'
|
||||
user::useradd { 'root':
|
||||
ensure => 'present',
|
||||
comment => 'The superuser',
|
||||
gid => '0',
|
||||
groups => ['root'],
|
||||
home => '/root',
|
||||
shell => '/bin/bash',
|
||||
uid => '0',
|
||||
}
|
||||
comment(root->The superuser)
|
||||
```
|
||||
|
||||
The output of ralsh lists both the new state of the root user, with the changed comment attribute, and what changes were made (solely to the **comment** attribute in this case). Running the same command a second time will produce much the same output, but without any change indication, as none will be needed.
|
||||
|
||||
### Writing providers
|
||||
|
||||
It is crucially important that writing new providers for ralsh is easy and requires a minimum amount of effort. For this reason, ralsh offers a number of calling conventions that make it possible to trade the complexity of implementing a provider against the power of what the provider can do. Providers can either be external scripts that adhere to a specific calling convention or be implemented in C++ and built into Libral. Currently, there are three calling conventions:
|
||||
|
||||
* The [simple][6] calling convention is geared towards writing shell scripts that serve as providers
|
||||
|
||||
* The [JSON][7] calling convention is meant for writing providers in scripting languages like Ruby or Python
|
||||
|
||||
* The [internal C++ API][8] can be used to implement providers natively
|
||||
|
||||
It is highly recommended to start provider development using the **simple** or the **JSON** calling convention. The file [simple.prov][15] on GitHub contains a skeleton for a simple shell provider, and it should be easy to adapt it for one's own provider. The file [python.prov][16] contains the skeleton of a JSON provider written in Python.
|
||||
|
||||
One problem with using higher-level scripting languages for providers is that the runtimes, including all supporting libraries, for these languages need to be present on the system on which Libral will run. In some cases, that is not an obstacle; for example, a provider that does package management based on **yum** can expect that Python is present on the system, as **yum** is written in it.
|
||||
|
||||
In many other cases though, there's no logical choice for a language beyond Bourne shell (or Bash) that can be expected to be installed on all managed systems. Often, provider writers need a more powerful scripting environment than just that. Unfortunately, bundling a full Ruby or Python interpreter with its runtime would increase Libral's size beyond what can reasonably be
|
||||
used in resource-constrained environments. On the other hand, the canonical choices of Lua or Javascript as small embeddable scripting languages are not suitable for this context as they are both not familiar to most provider writers, and require quite a bit of work to expose commonly needed facilities for systems management.
|
||||
|
||||
Libral bundles a version of [mruby][17], a small, embeddable version of Ruby, to give provider writers a stable foundation, and a powerful programming language for their implementation. mruby is a full implementation of the Ruby language, albeit with a much reduced standard library. The mruby bundled with Libral contains the parts of Ruby's standard library most important for scripting management tasks, which will be enhanced further over time based on the needs of provider writers. Libral's mruby also bundles an API adpater that makes writing providers to the json convention more comfortable, as it contains simple utilities (like [Augeas][18] for modifying structured files) and conveniences around parsing and outputting JSON. The file [mruby.prov][19] contains a skeleton example of a json provider written in mruby.
|
||||
|
||||
### Future work
|
||||
|
||||
The most important next steps for Libral are to make it more widely usable—the [precompiled tarball][20] is a great way to get started and sufficient to develop providers, but Libral also needs to be packaged and made available in mainstream distributions. In a similar vein, the utility of Libral strongly depends on the set of providers it ships with and those need to be expanded to cover a core set of management functionality. The Libral site contains [a todo list][21] showing the providers that are most urgently needed.
|
||||
|
||||
There are also several ways in which the availability of Libral for different uses can be improved: from writing bindings for additional languages, for example, Python or Go, to making the use of **ralsh** in shell scripts even easier by offering, besides the existing human-readable output and JSON output, an output format that is easy to process in shell scripts. Use of Libral for larger-scale management can also be improved by adding the remote API discussed above, and by better supporting bulk installation of Libral via transports like SSH—that mostly requires providing prebuilt tarballs for more architectures and scripts that can select the right one based on the discovered architecture of the target system.
|
||||
|
||||
There are many more ways in which Libral, its API, and its capabilities could evolve; one intriguing possibility is adding notification capabilities to the API so that Libral can report changes to system resources as they happen outside of its purview. The challenge for Libral will be to continue to be a small, lightweight and well-defined tool while covering an ever increasing set of uses and management capabilities—a challenge and a journey that I encourage every reader to become a part of.
|
||||
|
||||
If any of this has made you curious, I would love to hear from you, be it in the form of a pull request, an enhancement request, or just a report of your experience trying out **ralsh**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Lutterkort - David is a software engineer at Puppet, where he’s worked on projects such as Direct Puppet and Razor, the best provisioning tool, ever. He was one of the earliest contributors to Puppet and is the main author of Augeas, a configuration editing tool.
|
||||
|
||||
------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/intro-libral-systems-management-library-linux
|
||||
|
||||
作者:[David Lutterkort][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/david-lutterkort
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://github.com/puppetlabs/libral/blob/master/doc/invoke-simple.md
|
||||
[7]:https://github.com/puppetlabs/libral/blob/master/doc/invoke-json.md
|
||||
[8]:https://github.com/puppetlabs/libral/blob/master/doc/invoke-native.md
|
||||
[9]:https://opensource.com/article/17/5/intro-libral-systems-management-library-linux?rate=PqOZGb7A0LUlHQRwkzl23iaJZ2ZUy6gKcc6HOzaRL58
|
||||
[10]:https://www.flickr.com/photos/internetarchivebookimages/14803082483/in/photolist-oy6EG4-pZR3NZ-i6r3NW-e1tJSX-boBtf7-oeYc7U-o6jFKK-9jNtc3-idt2G9-i7NG1m-ouKjXe-owqviF-92xFBg-ow9e4s-gVVXJN-i1K8Pw-4jybMo-i1rsBr-ouo58Y-ouPRzz-8cGJHK-85Evdk-cru4Ly-rcDWiP-gnaC5B-pAFsuf-hRFPcZ-odvBMz-hRCE7b-mZN3Kt-odHU5a-73dpPp-hUaaAi-owvUMK-otbp7Q-ouySkB-hYAgmJ-owo4UZ-giHgqu-giHpNc-idd9uQ-osAhcf-7vxk63-7vwN65-fQejmk-pTcLgA-otZcmj-fj1aSX-hRzHQk-oyeZfR
|
||||
[11]:https://github.com/puppetlabs/libral
|
||||
[12]:https://github.com/puppetlabs/libral
|
||||
[13]:https://github.com/puppetlabs/libral#building-and-installation
|
||||
[14]:http://download.augeas.net/libral/ralsh-latest.tgz
|
||||
[15]:https://github.com/puppetlabs/libral/blob/master/examples/providers/simple.prov
|
||||
[16]:https://github.com/puppetlabs/libral/blob/master/examples/providers/python.prov
|
||||
[17]:http://mruby.org/
|
||||
[18]:http://augeas.net/
|
||||
[19]:https://github.com/puppetlabs/libral/blob/master/examples/providers/mruby.prov
|
||||
[20]:http://download.augeas.net/libral/ralsh-latest.tgz
|
||||
[21]:https://github.com/puppetlabs/libral#todo-list
|
||||
[22]:https://opensource.com/user/140051/feed
|
||||
[23]:https://opensource.com/users/david-lutterkort
|
||||
@ -0,0 +1,177 @@
|
||||
How to Configure Thunderbird with iRedMail for Samba4 AD – Part 13
|
||||
============================================================
|
||||
|
||||
|
||||
This tutorial will guide you on how to configure Mozilla Thunderbird client with an iRedMail server in order to send and receive mail via IMAPS and SMTP submission protocols, how to setup contacts database with Samba AD LDAP server and how to configure other related mail features, such as enabling Thunderbird contacts via LDAP database offline replica.
|
||||
|
||||
The process of installing and configuring Mozilla Thunderbird client described here is valid for Thunderbird clients installed on Windows or Linux operating systems.
|
||||
|
||||
#### Requirements
|
||||
|
||||
1. [How to Configure and Integrate iRedMail Services to Samba4 AD DC][1]
|
||||
|
||||
2. [Integrate iRedMail Roundcube with Samba4 AD DC][2]
|
||||
|
||||
### Step 1: Configure Thunderbird for iRedMail Server
|
||||
|
||||
1. After installing Thunderbird mail client, hit on the launcher or shortcut to open the program and on the first screen check E-mail System Integration and click on Skip Integration button to continue.
|
||||
|
||||
[][3]
|
||||
|
||||
Thunderbird System Integration
|
||||
|
||||
2. On the welcome screen hit on Skip this and use my existing mail button and add your name, your Samba account e-mail address and password, check Remember password field and hit on Continue button to start your mail account setup.
|
||||
|
||||
After Thunderbird client tries to identify the correct IMAP settings provided by iRedMail server hit on Manual config button to manually setup Thunderbird.
|
||||
|
||||
[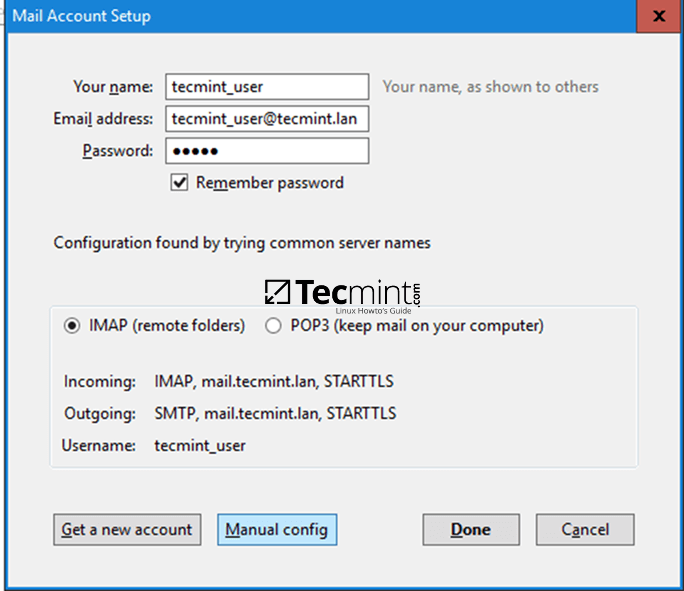][4]
|
||||
|
||||
Thunderbird Mail Account Setup
|
||||
|
||||
3. After the Mail Account Setup window expands, manually edit IMAP and SMTP settings by adding your proper iRedMail server FQDN, add secured ports for both mail services (993 for IMAPS and 587 for submission), select the proper SSL communication channel for each port and authentication and hit Done to complete the setup. Use the below image as a guide.
|
||||
|
||||
[][5]
|
||||
|
||||
Thunderbird iRedMail Settings
|
||||
|
||||
4. A new Security Exception window should appear on your screen due to the Self-Signed Certificates your iRedMail server enforces. Check on Permanently store this exception and hit on Confirm Security Exception button to add this security exception and the Thunderbird client should be successfully configured.
|
||||
|
||||
[][6]
|
||||
|
||||
Thunderbird Security Exception
|
||||
|
||||
You will see all received mail for your domain account and you should be able to send or receive mail to and from your domain or other domain accounts.
|
||||
|
||||
[][7]
|
||||
|
||||
Domain Mails Inbox
|
||||
|
||||
### Step 2: Setup Thunderbird Contacts Database with Samba AD LDAP
|
||||
|
||||
5. In order for Thunderbird clients to query Samba AD LDAP database for contacts, hit on Settings menu by right clicking on your account from the left plane and navigate to Composition & Addressing → Addressing → Use a different LDAP server → Edit Directories button as illustrated on the below images.
|
||||
|
||||
[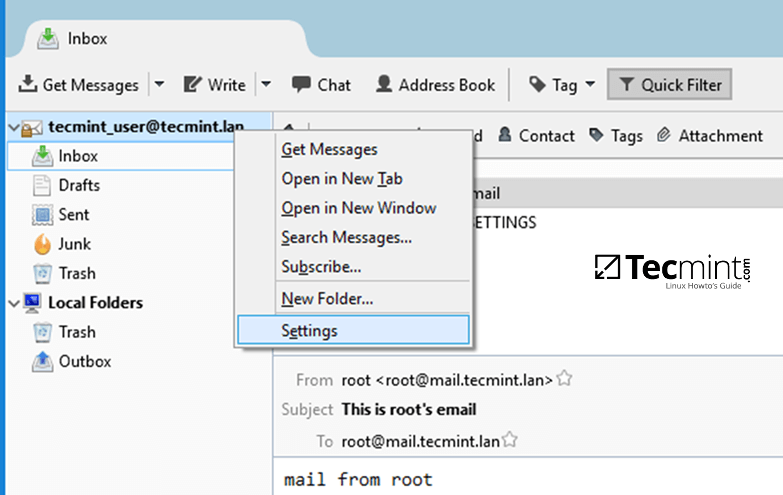][8]
|
||||
|
||||
Thunderbird Samba AD LDAP Settings
|
||||
|
||||
[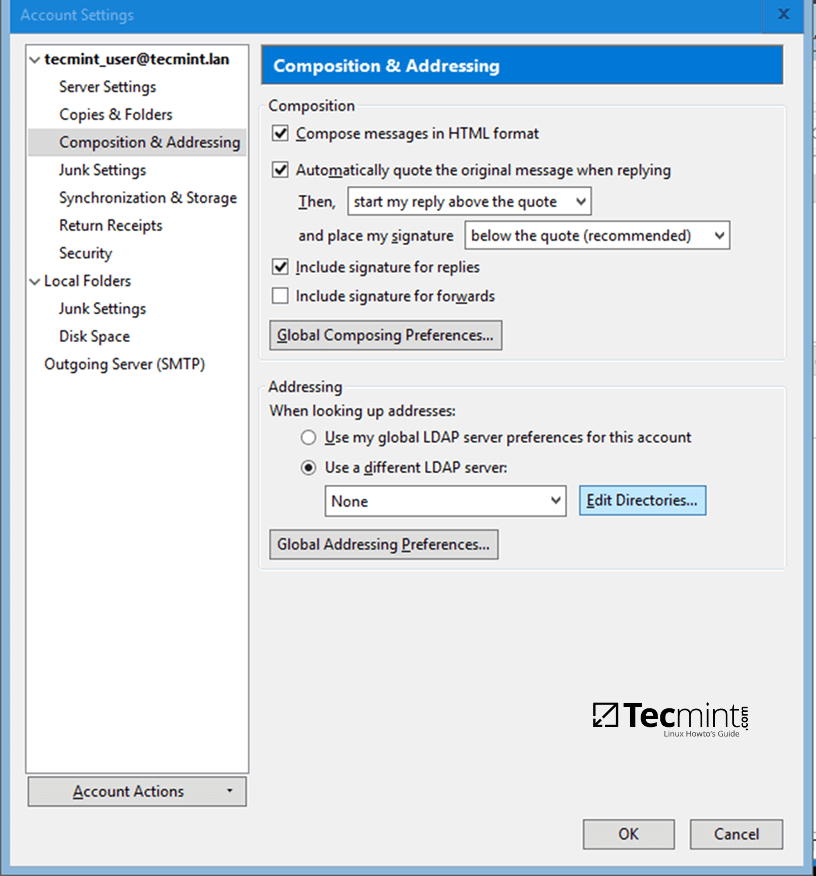][9]
|
||||
|
||||
Thunderbird Composition & Addressing Settings
|
||||
|
||||
6. The LDAP Directory Servers windows should open by now. Hit on Add button and fill Directory Server Properties windows with the following content:
|
||||
|
||||
On General tab add descriptive name for this object, add the name of your domain or the FQDN of a Samba domain controller, the base DN of your domain in the form dc=your_domain,dc=tld, LDAP port number 389 and the vmail Bind DN account used to query the Samba AD LDAP database in the form vmail@your_domain.tld.
|
||||
|
||||
Use the below screenshot as a guide.
|
||||
|
||||
[][10]
|
||||
|
||||
Directory Server Properties
|
||||
|
||||
7. On the next step, move to Advanced tab from Directory Server Properties, and add the following content in Search filter filed:
|
||||
|
||||
```
|
||||
(&(mail=*)(|(&(objectClass=user)(!(objectClass=computer)))(objectClass=group)))
|
||||
```
|
||||
[][11]
|
||||
|
||||
Add Search Filter
|
||||
|
||||
Leave the rest of the settings as default and hit on OK button to apply changes and again on OK button to close LDAP Directory Servers window and OK button again on Account Settings to close the window.
|
||||
|
||||
[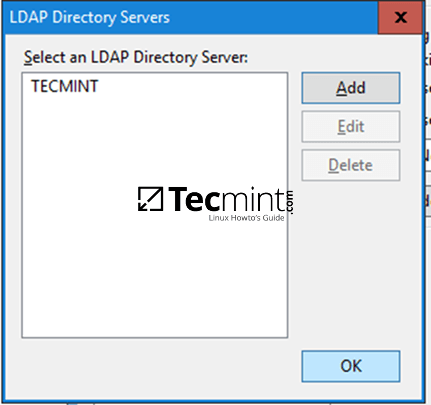][12]
|
||||
|
||||
Select LDAP Directory Server
|
||||
|
||||
8. To test if Thunderbird client can query Samba AD LDAP database for contacts, hit on the upper Address Book icon, select the name of the LDAP database created earlier.
|
||||
|
||||
Add the password for the Bind DN account configured to interrogate the AD LDAP server (vmail@your_domain.tld), check Use Password Manager to remember the password and hit OK button to reflect changes and close the window.
|
||||
|
||||
[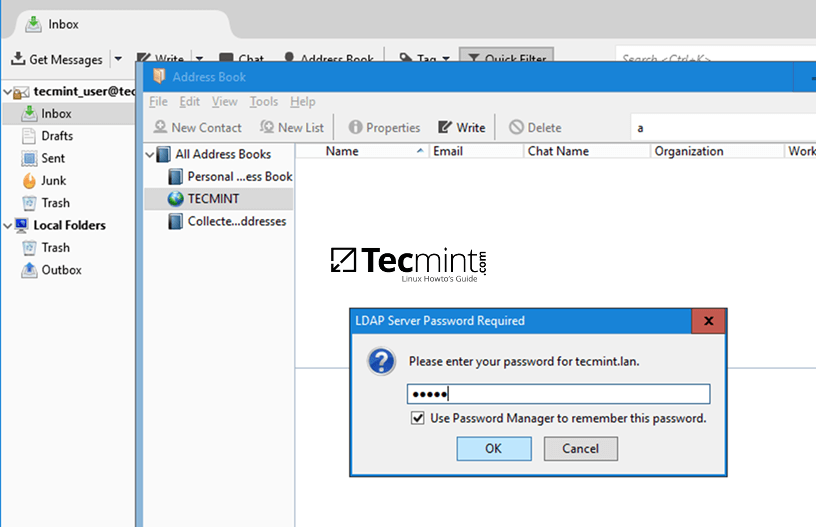][13]
|
||||
|
||||
Thunderbird Samba AD LDAP Testing
|
||||
|
||||
9. Search for a Samba AD contact by using the upper search filed and suppling a domain account name. Be aware that Samba AD accounts with no e-mail address declared in their AD E-mail field will not be listed in Thunderbird Address Book searches.
|
||||
|
||||
[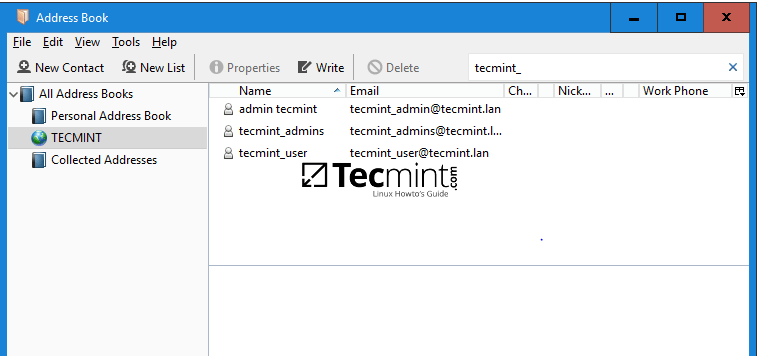][14]
|
||||
|
||||
Search Samba AD Mail Contacts
|
||||
|
||||
10. To search for a contact while composing an e-mail, click on View → Contacts Sidebar or press F9 key to open Contacts panel.
|
||||
|
||||
[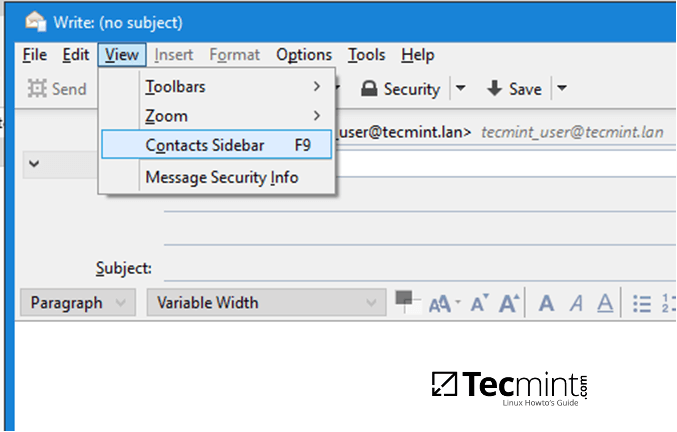][15]
|
||||
|
||||
Search Mail Contacts in Thunderbird
|
||||
|
||||
11. Select the proper Address Book and you should be able to search and add an e-mail address for your recipient. When sending the first mail, a new security alert window should appear. Hit on Confirm Security Exception and the mail should be sent to your recipient e-mail address.
|
||||
|
||||
[][16]
|
||||
|
||||
Send Mail in Thunderbird
|
||||
|
||||
12. In case you want to search contacts through Samba LDAP database only for a specific AD Organizational Unit, edit the Address Book for your Directory Server name from the left plane, hit on Properties and add the custom Samba AD OU as illustrated on the below example.
|
||||
|
||||
```
|
||||
ou=your_specific_ou,dc=your_domain,dc=tld
|
||||
```
|
||||
[][17]
|
||||
|
||||
Search Contacts in Samba LDAP Database
|
||||
|
||||
### Step 3: Setup LDAP Offline Replica
|
||||
|
||||
13. To configure Samba AD LDAP offline replica for Thunderbird hit on Address Book button, select your LDAP Address Book, open Directory Server Properties -> General tab and change the port number to 3268.
|
||||
|
||||
Then switch to Offline tab and hit on Download Now button to start replicate Samba AD LDAP database locally.
|
||||
|
||||
[][18]
|
||||
|
||||
Setup LDAP Offline Replica in Thunderbird
|
||||
|
||||
[][19]
|
||||
|
||||
Download LDAP Database for Offline
|
||||
|
||||
When the process of synchronizing contacts finishes you will be informed with the message Replication succeeded. Hit OK and close all windows. In case Samba domain controller cannot be reached you can still search for LDAP contacts by working in offline mode.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
|
||||
|
||||
--------------
|
||||
|
||||
via: https://www.tecmint.com/configure-thunderbird-with-iredmail-for-samba4-ad-ldap/
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/integrate-iredmail-to-samba4-ad-dc-on-centos-7/
|
||||
[2]:https://www.tecmint.com/integrate-iredmail-roundcube-with-samba4-ad-dc/
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/05/Thunderbird-System-Integration.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/Thunderbird-Mail-Account-Setup.png
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Thunderbird-iRedMail-Settings.png
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/05/Thunderbird-Security-Exception.png
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/05/Domain-Mails-Inbox.png
|
||||
[8]:https://www.tecmint.com/wp-content/uploads/2017/05/Thunderbird-Samba-AD-LDAP-Settings.png
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/05/Thunderbird-Composition-Addressing-Settings.png
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/05/Directory-Server-Properties.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/05/Add-Search-Filter.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/05/Select-LDAP-Directory-Server.png
|
||||
[13]:https://www.tecmint.com/wp-content/uploads/2017/05/Thunderbird-Samba-AD-LDAP-Testing.png
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/05/Search-Samba-AD-Mail-Contacts.png
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/05/Search-Mail-Contact-in-Thunderbird.png
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/05/Send-Mail-in-Thunderbird.jpg
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/05/Search-Contacts-in-Samba-LDAP-Database.png
|
||||
[18]:https://www.tecmint.com/wp-content/uploads/2017/05/Setup-LDAP-Offline-Replica-in-Thunderbird.png
|
||||
[19]:https://www.tecmint.com/wp-content/uploads/2017/05/Download-Samba-LDAP-Database-Offline.png
|
||||
[20]:https://www.tecmint.com/author/cezarmatei/
|
||||
[21]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[22]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,301 @@
|
||||
An introduction to Linux's EXT4 filesystem
|
||||
============================================================
|
||||
|
||||
### Take a walk through EXT4's history, features, and optimal use, and learn how it differs from previous iterations of the EXT filesystem.
|
||||
|
||||
|
||||

|
||||
>Image credits : [WIlliam][8][ Warby][9]. Modified by [Jason Baker][10]. Creative Commons [BY-SA 2.0][11].
|
||||
|
||||
In previous articles about Linux filesystems, I wrote [an introduction to Linux filesystems][12] and about some higher-level concepts such as [everything is a file][13]. I want to go into more detail about the specifics of the EXT filesystems, but first, let's answer the question, "What is a filesystem?" A filesystem is all of the following:
|
||||
|
||||
1. **Data storage: **The primary function of any filesystem is to be a structured place to store and retrieve data.
|
||||
|
||||
2. **Namespace: **A naming and organizational methodology that provides rules for naming and structuring data.
|
||||
|
||||
3. **Security model: **A scheme for defining access rights.
|
||||
|
||||
4. **API: **System function calls to manipulate filesystem objects like directories and files.
|
||||
|
||||
5. **Implementation: **The software to implement the above.
|
||||
|
||||
This article concentrates on the first item in the list and explores the metadata structures that provide the logical framework for data storage in an EXT filesystem.
|
||||
|
||||
### EXT filesystem history
|
||||
|
||||
Although written for Linux, the EXT filesystem has its roots in the Minix operating system and the Minix filesystem, which predate Linux by about five years, being first released in 1987\. Understanding the EXT4 filesystem is much easier if we look at the history and technical evolution of the EXT filesystem family from its Minix roots.
|
||||
|
||||
### Minix
|
||||
|
||||
When writing the original Linux kernel, Linus Torvalds needed a filesystem but didn't want to write one then. So he simply included the [Minix filesystem][14], which had been written by [Andrew S. Tanenbaum][15] and was a part of Tanenbaum's Minix operating system. [Minix][16] was a Unix-like operating system written for educational purposes. Its code was freely available and appropriately licensed to allow Torvalds to include it in his first version of Linux.
|
||||
|
||||
Minix has the following structures, most of which are located in the partition where the filesystem is generated:
|
||||
|
||||
* A [**boot sector**][6] in the first sector of the hard drive on which it is installed. The boot block includes a very small boot record and a partition table.
|
||||
|
||||
* The first block in each partition is a **superblock **that contains the metadata that defines the other filesystem structures and locates them on the physical disk assigned to the partition.
|
||||
|
||||
* An **inode bitmap block**, which determines which inodes are used and which are free.
|
||||
|
||||
* The **inodes**, which have their own space on the disk. Each inode contains information about one file, including the locations of the data blocks, i.e., zones belonging to the file.
|
||||
|
||||
* A **zone bitmap** to keep track of the used and free data zones.
|
||||
|
||||
* A **data zone**, in which the data is actually stored.
|
||||
|
||||
For both types of bitmaps, one bit represents one specific data zone or one specific inode. If the bit is zero, the zone or inode is free and available for use, but if the bit is one, the data zone or inode is in use.
|
||||
|
||||
What is an [inode][17]? Short for index-node, an inode is a 256-byte block on the disk and stores data about the file. This includes the file's size; the user IDs of the file's user and group owners; the file mode (i.e., the access permissions); and three timestamps specifying the time and date that: the file was last accessed, last modified, and the data in the inode was last modified.
|
||||
|
||||
The inode also contains data that points to the location of the file's data on the hard drive. In Minix and the EXT1-3 filesystems, this is a list of data zones or blocks. The Minix filesystem inodes supported nine data blocks, seven direct and two indirect. If you'd like to learn more, there is an excellent PDF with a detailed description of the [Minix filesystem structure][18] and a quick overview of the [inode pointer structure][19] on Wikipedia.
|
||||
|
||||
### EXT
|
||||
|
||||
The original [EXT filesystem][20] (Extended) was written by [Rémy Card][21] and released with Linux in 1992 to overcome some size limitations of the Minix filesystem. The primary structural changes were to the metadata of the filesystem, which was based on the Unix filesystem (UFS), which is also known as the Berkeley Fast File System (FFS). I found very little published information about the EXT filesystem that can be verified, apparently because it had significant problems and was quickly superseded by the EXT2 filesystem.
|
||||
|
||||
### EXT2
|
||||
|
||||
The [EXT2 filesystem][22] was quite successful. It was used in Linux distributions for many years, and it was the first filesystem I encountered when I started using Red Hat Linux 5.0 back in about 1997\. The EXT2 filesystem has essentially the same metadata structures as the EXT filesystem, however EXT2 is more forward-looking, in that a lot of disk space is left between the metadata structures for future use.
|
||||
|
||||
Like Minix, EXT2 has a [boot sector][23] in the first sector of the hard drive on which it is installed, which includes a very small boot record and a partition table. Then there is some reserved space after the boot sector, which spans the space between the boot record and the first partition on the hard drive that is usually on the next cylinder boundary. [GRUB2][24]—and possibly GRUB1—uses this space for part of its boot code.
|
||||
|
||||
The space in each EXT2 partition is divided into cylinder groups that allow for more granular management of the data space. In my experience, the group size usually amounts to about 8MB. Figure 1, below, shows the basic structure of a cylinder group. The data allocation unit in a cylinder is the block, which is usually 4K in size.
|
||||
|
||||

|
||||
|
||||
Figure 1: The structure of a cylinder group in the EXT filesystems
|
||||
|
||||
The first block in the cylinder group is a superblock, which contains the metadata that defines the other filesystem structures and locates them on the physical disk. Some of the additional groups in the partition will have backup superblocks, but not all. A damaged superblock can be replaced by using a disk utility such as **dd** to copy the contents of a backup superblock to the primary superblock. It does not happen often, but once, many years ago, I had a damaged superblock, and I was able to restore its contents using one of the backup superblocks. Fortunately, I had been foresighted and used the **dumpe2fs** command to dump the descriptor information of the partitions on my system.
|
||||
|
||||
Following is the partial output from the **dumpe2fs** command. It shows the metadata contained in the superblock, as well as data about each of the first two cylinder groups in the filesystem.
|
||||
|
||||
```
|
||||
# dumpe2fs /dev/sda1
|
||||
Filesystem volume name: boot
|
||||
Last mounted on: /boot
|
||||
Filesystem UUID: 79fc5ed8-5bbc-4dfe-8359-b7b36be6eed3
|
||||
Filesystem magic number: 0xEF53
|
||||
Filesystem revision #: 1 (dynamic)
|
||||
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir nlink extra_isize
|
||||
Filesystem flags: signed_directory_hash
|
||||
Default mount options: user_xattr acl
|
||||
Filesystem state: clean
|
||||
Errors behavior: Continue
|
||||
Filesystem OS type: Linux
|
||||
Inode count: 122160
|
||||
Block count: 488192
|
||||
Reserved block count: 24409
|
||||
Free blocks: 376512
|
||||
Free inodes: 121690
|
||||
First block: 0
|
||||
Block size: 4096
|
||||
Fragment size: 4096
|
||||
Group descriptor size: 64
|
||||
Reserved GDT blocks: 238
|
||||
Blocks per group: 32768
|
||||
Fragments per group: 32768
|
||||
Inodes per group: 8144
|
||||
Inode blocks per group: 509
|
||||
Flex block group size: 16
|
||||
Filesystem created: Tue Feb 7 09:33:34 2017
|
||||
Last mount time: Sat Apr 29 21:42:01 2017
|
||||
Last write time: Sat Apr 29 21:42:01 2017
|
||||
Mount count: 25
|
||||
Maximum mount count: -1
|
||||
Last checked: Tue Feb 7 09:33:34 2017
|
||||
Check interval: 0 (<none>)
|
||||
Lifetime writes: 594 MB
|
||||
Reserved blocks uid: 0 (user root)
|
||||
Reserved blocks gid: 0 (group root)
|
||||
First inode: 11
|
||||
Inode size: 256
|
||||
Required extra isize: 32
|
||||
Desired extra isize: 32
|
||||
Journal inode: 8
|
||||
Default directory hash: half_md4
|
||||
Directory Hash Seed: c780bac9-d4bf-4f35-b695-0fe35e8d2d60
|
||||
Journal backup: inode blocks
|
||||
Journal features: journal_64bit
|
||||
Journal size: 32M
|
||||
Journal length: 8192
|
||||
Journal sequence: 0x00000213
|
||||
Journal start: 0
|
||||
|
||||
Group 0: (Blocks 0-32767)
|
||||
Primary superblock at 0, Group descriptors at 1-1
|
||||
Reserved GDT blocks at 2-239
|
||||
Block bitmap at 240 (+240)
|
||||
Inode bitmap at 255 (+255)
|
||||
Inode table at 270-778 (+270)
|
||||
24839 free blocks, 7676 free inodes, 16 directories
|
||||
Free blocks: 7929-32767
|
||||
Free inodes: 440, 470-8144
|
||||
Group 1: (Blocks 32768-65535)
|
||||
Backup superblock at 32768, Group descriptors at 32769-32769
|
||||
Reserved GDT blocks at 32770-33007
|
||||
Block bitmap at 241 (bg #0 + 241)
|
||||
Inode bitmap at 256 (bg #0 + 256)
|
||||
Inode table at 779-1287 (bg #0 + 779)
|
||||
8668 free blocks, 8142 free inodes, 2 directories
|
||||
Free blocks: 33008-33283, 33332-33791, 33974-33975, 34023-34092, 34094-34104, 34526-34687, 34706-34723, 34817-35374, 35421-35844, 35935-36355, 36357-36863, 38912-39935, 39940-40570, 42620-42623, 42655, 42674-42687, 42721-42751, 42798-42815, 42847, 42875-42879, 42918-42943, 42975, 43000-43007, 43519, 43559-44031, 44042-44543, 44545-45055, 45116-45567, 45601-45631, 45658-45663, 45689-45695, 45736-45759, 45802-45823, 45857-45887, 45919, 45950-45951, 45972-45983, 46014-46015, 46057-46079, 46112-46591, 46921-47103, 49152-49395, 50027-50355, 52237-52255, 52285-52287, 52323-52351, 52383, 52450-52479, 52518-52543, 52584-52607, 52652-52671, 52734-52735, 52743-53247
|
||||
Free inodes: 8147-16288
|
||||
Group 2: (Blocks 65536-98303)
|
||||
Block bitmap at 242 (bg #0 + 242)
|
||||
Inode bitmap at 257 (bg #0 + 257)
|
||||
Inode table at 1288-1796 (bg #0 + 1288)
|
||||
6326 free blocks, 8144 free inodes, 0 directories
|
||||
Free blocks: 67042-67583, 72201-72994, 80185-80349, 81191-81919, 90112-94207
|
||||
Free inodes: 16289-24432
|
||||
Group 3: (Blocks 98304-131071)
|
||||
|
||||
<snip>
|
||||
```
|
||||
|
||||
Each cylinder group has its own inode bitmap that is used to determine which inodes are used and which are free within that group. The inodes have their own space in each group. Each inode contains information about one file, including the locations of the data blocks belonging to the file. The block bitmap keeps track of the used and free data blocks within the filesystem. Notice that there is a great deal of data about the filesystem in the output shown above. On very large filesystems the group data can run to hundreds of pages in length. The group metadata includes a listing of all of the free data blocks in the group.
|
||||
|
||||
The EXT filesystem implemented data-allocation strategies that ensured minimal file fragmentation. Reducing fragmentation improved filesystem performance. Those strategies are described below, in the section on EXT4.
|
||||
|
||||
The biggest problem with the EXT2 filesystem, which I encountered on some occasions, was that it could take many hours to recover after a crash because the **fsck** (file system check) program took a very long time to locate and correct any inconsistencies in the filesystem. It once took over 28 hours on one of my computers to fully recover a disk upon reboot after a crash—and that was when disks were measured in the low hundreds of megabytes in size.
|
||||
|
||||
### EXT3
|
||||
|
||||
The [EXT3 filesystem][25] had the singular objective of overcoming the massive amounts of time that the **fsck** program required to fully recover a disk structure damaged by an improper shutdown that occurred during a file-update operation. The only addition to the EXT filesystem was the [journal][26], which records in advance the changes that will be performed to the filesystem. The rest of the disk structure is the same as it was in EXT2.
|
||||
|
||||
Instead of writing data to the disk's data areas directly, as in previous versions, the journal in EXT3 writes file data, along with its metadata, to a specified area on the disk. Once the data is safely on the hard drive, it can be merged in or appended to the target file with almost zero chance of losing data. As this data is committed to the data area of the disk, the journal is updated so that the filesystem will remain in a consistent state in the event of a system failure before all the data in the journal is committed. On the next boot, the filesystem will be checked for inconsistencies, and data remaining in the journal will then be committed to the data areas of the disk to complete the updates to the target file.
|
||||
|
||||
Journaling does reduce data-write performance, however there are three options available for the journal that allow the user to choose between performance and data integrity and safety. My personal preference is on the side of safety because my environments do not require heavy disk-write activity.
|
||||
|
||||
The journaling function reduces the time required to check the hard drive for inconsistencies after a failure from hours (or even days) to mere minutes, at the most. I have had many issues over the years that have crashed my systems. The details could fill another article, but suffice it to say that most were self-inflicted, like kicking out a power plug. Fortunately, the EXT journaling filesystems have reduced that bootup recovery time to two or three minutes. In addition, I have never had a problem with lost data since I started using EXT3 with journaling.
|
||||
|
||||
The journaling feature of EXT3 can be turned off and it then functions as an EXT2 filesystem. The journal itself still exists, empty and unused. Simply remount the partition with the mount command using the type parameter to specify EXT2\. You may be able to do this from the command line, depending upon which filesystem you are working with, but you can change the type specifier in the **/etc/fstab** file and then reboot. I strongly recommend against mounting an EXT3 filesystem as EXT2 because of the additional potential for lost data and extended recovery times.
|
||||
|
||||
An existing EXT2 filesystem can be upgraded to EXT3 with the addition of a journal using the following command.
|
||||
|
||||
```
|
||||
tune2fs -j /dev/sda1
|
||||
```
|
||||
|
||||
Where **/dev/sda1** is the drive and partition identifier. Be sure to change the file type specifier in **/etc/fstab** and remount the partition or reboot the system to have the change take effect.
|
||||
|
||||
### EXT4
|
||||
|
||||
The [EXT4 filesystem][27] primarily improves performance, reliability, and capacity. To improve reliability, metadata and journal checksums were added. To meet various mission-critical requirements, the filesystem timestamps were improved with the addition of intervals down to nanoseconds. The addition of two high-order bits in the timestamp field defers the [Year 2038 problem][28] until 2446—for EXT4 filesystems, at least.
|
||||
|
||||
In EXT4, data allocation was changed from fixed blocks to extents. An extent is described by its starting and ending place on the hard drive. This makes it possible to describe very long, physically contiguous files in a single inode pointer entry, which can significantly reduce the number of pointers required to describe the location of all the data in larger files. Other allocation strategies have been implemented in EXT4 to further reduce fragmentation.
|
||||
|
||||
EXT4 reduces fragmentation by scattering newly created files across the disk so that they are not bunched up in one location at the beginning of the disk, as many early PC filesystems did. The file-allocation algorithms attempt to spread the files as evenly as possible among the cylinder groups and, when fragmentation is necessary, to keep the discontinuous file extents as close as possible to others in the same file to minimize head seek and rotational latency as much as possible. Additional strategies are used to pre-allocate extra disk space when a new file is created or when an existing file is extended. This helps to ensure that extending the file will not automatically result in its becoming fragmented. New files are never allocated immediately after existing files, which also prevents fragmentation of the existing files.
|
||||
|
||||
Aside from the actual location of the data on the disk, EXT4 uses functional strategies, such as delayed allocation, to allow the filesystem to collect all the data being written to the disk before allocating space to it. This can improve the likelihood that the data space will be contiguous.
|
||||
|
||||
Older EXT filesystems, such as EXT2 and EXT3, can be mounted as EXT4 to make some minor performance gains. Unfortunately, this requires turning off some of the important new features of EXT4, so I recommend against this.
|
||||
|
||||
EXT4 has been the default filesystem for Fedora since Fedora 14\. An EXT3 filesystem can be upgraded to EXT4 using the [procedure ][29]described in the Fedora documentation, however its performance will still suffer due to residual EXT3 metadata structures. The best method for upgrading to EXT4 from EXT3 is to back up all the data on the target filesystem partition, use the **mkfs** command to write an empty EXT4 filesystem to the partition, and then restore all the data from the backup.
|
||||
|
||||
### Inode
|
||||
|
||||
The inode, described previously, is a key component of the metadata in EXT filesystems. Figure 2 shows the relationship between the inode and the data stored on the hard drive. This diagram is the directory and inode for a single file which, in this case, may be highly fragmented. The EXT filesystems work actively to reduce fragmentation, so it is very unlikely you will ever see a file with this many indirect data blocks or extents. In fact, as you will see below, fragmentation is extremely low in EXT filesystems, so most inodes will use only one or two direct data pointers and none of the indirect pointers.
|
||||
|
||||
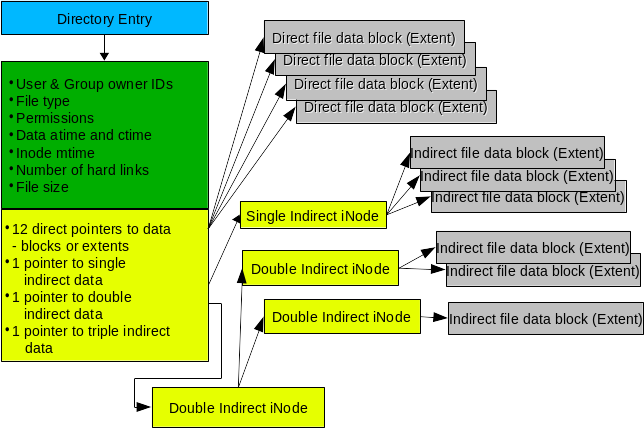
|
||||
|
||||
Figure 2: The inode stores information about each file and enables the EXT filesystem to locate all data belonging to it.
|
||||
|
||||
The inode does not contain the name of the file. Access to a file is via the directory entry, which itself is the name of the file and contains a pointer to the inode. The value of that pointer is the inode number. Each inode in a filesystem has a unique ID number, but inodes in other filesystems on the same computer (and even the same hard drive) can have the same inode number. This has implications for [links][30], and this discussion is beyond the scope of this article.
|
||||
|
||||
The inode contains the metadata about the file, including its type and permissions as well as its size. The inode also contains space for 15 pointers that describe the location and length of data blocks or extents in the data portion of the cylinder group. Twelve of the pointers provide direct access to the data extents and should be sufficient to handle most files. However, for files that have significant fragmentation, it becomes necessary to have some additional capabilities in the form of indirect nodes. Technically these are not really inodes, so I use the term "node" here for convenience.
|
||||
|
||||
An indirect node is a normal data block in the filesystem that is used only for describing data and not for storage of metadata, thus more than 15 entries can be supported. For example, a block size of 4K can support 512 4-byte indirect nodes, allowing **12 (direct) + 512 (indirect) = 524** extents for a single file. Double and triple indirect node support is also supported, but most of us are unlikely to encounter files requiring that many extents.
|
||||
|
||||
### Data fragmentation
|
||||
|
||||
For many older PC filesystems, such as FAT (and all its variants) and NTFS, fragmentation has been a significant problem resulting in degraded disk performance. Defragmentation became an industry in itself with different brands of defragmentation software that ranged from very effective to only marginally so.
|
||||
|
||||
Linux's extended filesystems use data-allocation strategies that help to minimize fragmentation of files on the hard drive and reduce the effects of fragmentation when it does occur. You can use the **fsck** command on EXT filesystems to check the total filesystem fragmentation. The following example checks the home directory of my main workstation, which was only 1.5% fragmented. Be sure to use the **-n** parameter, because it prevents **fsck** from taking any action on the scanned filesystem.
|
||||
|
||||
```
|
||||
fsck -fn /dev/mapper/vg_01-home
|
||||
```
|
||||
|
||||
I once performed some theoretical calculations to determine whether disk defragmentation might result in any noticeable performance improvement. While I did make some assumptions, the disk performance data I used were from a new 300GB, Western Digital hard drive with a 2.0ms track-to-track seek time. The number of files in this example was the actual number that existed in the filesystem on the day I did the calculation. I did assume that a fairly large amount of the fragmented files (20%) would be touched each day.
|
||||
|
||||
| **Total files** | **271,794** |
|
||||
| % fragmentation | 5.00% |
|
||||
| Discontinuities | 13,590 |
|
||||
| | |
|
||||
| % fragmented files touched per day | 20% (assume) |
|
||||
| Number of additional seeks | 2,718 |
|
||||
| Average seek time | 10.90 ms |
|
||||
| Total additional seek time per day | 29.63 sec |
|
||||
| | 0.49 min |
|
||||
| | |
|
||||
| Track-to-track seek time | 2.00 ms |
|
||||
| Total additional seek time per day | 5.44 sec |
|
||||
| | 0.091 min |
|
||||
|
||||
Table 1: The theoretical effects of fragmentation on disk performance
|
||||
|
||||
I have done two calculations for the total additional seek time per day, one based on the track-to-track seek time, which is the more likely scenario for most files due to the EXT file allocation strategies, and one for the average seek time, which I assumed would make a fair worst-case scenario.
|
||||
|
||||
As you can see from Table 1, the impact of fragmentation on a modern EXT filesystem with a hard drive of even modest performance would be minimal and negligible for the vast majority of applications. You can plug the numbers from your environment into your own similar spreadsheet to see what you might expect in the way of performance impact. This type of calculation most likely will not represent actual performance, but it can provide a bit of insight into fragmentation and its theoretical impact on a system.
|
||||
|
||||
Most of my partitions are around 1.5% or 1.6% fragmented; I do have one that is 3.3% fragmented but that is a large, 128GB filesystem with fewer than 100 very large ISO image files; I've had to expand the partition several times over the years as it got too full.
|
||||
|
||||
That is not to say that some application environments don't require greater assurance of even less fragmentation. The EXT filesystem can be tuned with care by a knowledgeable admin who can adjust the parameters to compensate for specific workload types. This can be done when the filesystem is created or later using the **tune2fs** command. The results of each tuning change should be tested, meticulously recorded, and analyzed to ensure optimum performance for the target environment. In the worst case, where performance cannot be improved to desired levels, other filesystem types are available that may be more suitable for a particular workload. And remember that it is common to mix filesystem types on a single host system to match the load placed on each filesystem.
|
||||
|
||||
Due to the low amount of fragmentation on most EXT filesystems, it is not necessary to defragment. In any event, there is no safe defragmentation tool for EXT filesystems. There are a few tools that allow you to check the fragmentation of an individual file or the fragmentation of the remaining free space in a filesystem. There is one tool, **e4defrag**, which will defragment a file, directory, or filesystem as much as the remaining free space will allow. As its name implies, it only works on files in an EXT4 filesystem, and it does have some limitations.
|
||||
|
||||
If it becomes necessary to perform a complete defragmentation on an EXT filesystem, there is only one method that will work reliably. You must move all the files from the filesystem to be defragmented, ensuring that they are deleted after being safely copied to another location. If possible, you could then increase the size of the filesystem to help reduce future fragmentation. Then copy the files back onto the target filesystem. Even this does not guarantee that all the files will be completely defragmented.
|
||||
|
||||
### Conclusions
|
||||
|
||||
The EXT filesystems have been the default for many Linux distributions for more than 20 years. They offer stability, high capacity, reliability, and performance while requiring minimal maintenance. I have tried other filesystems but always return to EXT. Every place I have worked with Linux has used the EXT filesystems and found them suitable for all the mainstream loads used on them. Without a doubt, the EXT4 filesystem should be used for most Linux systems unless there is a compelling reason to use another filesystem.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
-------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/introduction-ext4-filesystem
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://en.wikipedia.org/wiki/Boot_sector
|
||||
[7]:https://opensource.com/article/17/5/introduction-ext4-filesystem?rate=B4QU3W_JYmEKsIKZf5yqMpztt7CRF6uzC0wfNBidEbs
|
||||
[8]:https://www.flickr.com/photos/wwarby/11644168395
|
||||
[9]:https://www.flickr.com/photos/wwarby/11644168395
|
||||
[10]:https://opensource.com/users/jason-baker
|
||||
[11]:https://creativecommons.org/licenses/by/2.0/
|
||||
[12]:https://opensource.com/life/16/10/introduction-linux-filesystems
|
||||
[13]:https://opensource.com/life/15/9/everything-is-a-file
|
||||
[14]:https://en.wikipedia.org/wiki/MINIX_file_system
|
||||
[15]:https://en.wikipedia.org/wiki/Andrew_S._Tanenbaum
|
||||
[16]:https://en.wikipedia.org/wiki/MINIX
|
||||
[17]:https://en.wikipedia.org/wiki/Inode
|
||||
[18]:http://ohm.hgesser.de/sp-ss2012/Intro-MinixFS.pdf
|
||||
[19]:https://en.wikipedia.org/wiki/Inode_pointer_structure
|
||||
[20]:https://en.wikipedia.org/wiki/Extended_file_system
|
||||
[21]:https://en.wikipedia.org/wiki/R%C3%A9my_Card
|
||||
[22]:https://en.wikipedia.org/wiki/Ext2
|
||||
[23]:https://en.wikipedia.org/wiki/Boot_sector
|
||||
[24]:https://opensource.com/article/17/2/linux-boot-and-startup
|
||||
[25]:https://en.wikipedia.org/wiki/Ext3
|
||||
[26]:https://en.wikipedia.org/wiki/Journaling_file_system
|
||||
[27]:https://en.wikipedia.org/wiki/Ext4
|
||||
[28]:https://en.wikipedia.org/wiki/Year_2038_problem
|
||||
[29]:https://docs.fedoraproject.org/en-US/Fedora/14/html/Storage_Administration_Guide/ext4converting.html
|
||||
[30]:https://en.wikipedia.org/wiki/Hard_link
|
||||
[31]:https://opensource.com/user/14106/feed
|
||||
[32]:https://opensource.com/article/17/5/introduction-ext4-filesystem#comments
|
||||
[33]:https://opensource.com/users/dboth
|
||||
@ -0,0 +1,122 @@
|
||||
ucasFL translating
|
||||
|
||||
Use ‘pushd’ and ‘popd’ for Efficient Filesystem Navigation in Linux
|
||||
============================================================
|
||||
|
||||
Sometimes it can be painful to navigate the Linux file system with commands, especially for the newbies. Normally, we primarily use the [cd (Change Directory) command][1] for moving around the Linux file system.
|
||||
|
||||
In a previous article, we reviewed a simple yet helpful CLI utility for Linux called [bd – for quickly moving back into a parent directory][2] without typing cd ../../.. repeatedly.
|
||||
|
||||
This tutorial will explain a related set of commands: “pushd” and “popd” which are used for efficient navigation of the Linux directory structure. They exist in most shells such as bash, tcsh etc.
|
||||
|
||||
**Suggested Read:** [Autojump – An Advanced ‘cd’ Command to Quickly Navigate Linux Filesystem][3]
|
||||
|
||||
### How pushd and popd Commands Work in Linux
|
||||
|
||||
pushd and popd work according to the “LIFO” (last in, first out) principle. In this principle, only two operations are allowed: push an item into the stack, and pop an item out of the stack.
|
||||
|
||||
pushd adds a directory to the top of the stack and popd removes a directory from the top of the stack.
|
||||
|
||||
To display directories in the directory stack (or history), we can use the dirs command as shown.
|
||||
|
||||
```
|
||||
$ dirs
|
||||
OR
|
||||
$ dirs -v
|
||||
```
|
||||
|
||||
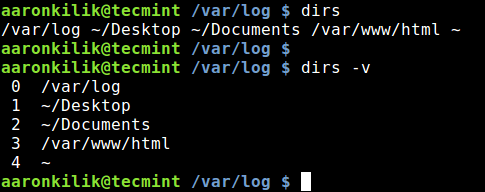
|
||||
|
||||
Dirs – Display Directories in Directory
|
||||
|
||||
pushd command – puts/adds directory paths onto a directory stack (history) and later allowing you to navigate back to any directory in history. While you add directories to the stack, it also echoes what’s existing in history (or “stack”).
|
||||
|
||||
The commands show how pushd works:
|
||||
|
||||
```
|
||||
$ pushd /var/www/html/
|
||||
$ pushd ~/Documents/
|
||||
$ pushd ~/Desktop/
|
||||
$ pushd /var/log/
|
||||
```
|
||||
|
||||
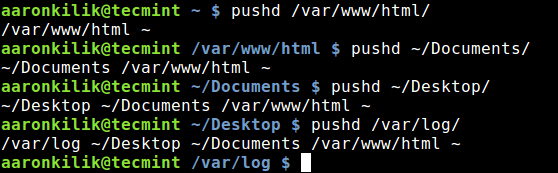
|
||||
|
||||
pushd – Add Directories to Stack
|
||||
|
||||
From directory stack in the output above (directory index is in reverse order):
|
||||
|
||||
* /var/log is the fifth [index 0] in the directory stack.
|
||||
|
||||
* ~/Desktop/ is fourth [index 1].
|
||||
|
||||
* ~/Documents/ is third [index 2].
|
||||
|
||||
* /var/www/html/ is second [index 3] and
|
||||
|
||||
* ~ is first [index 4].
|
||||
|
||||
Optionally, we can use the directory index in the form `pushd +#` or `pushd -#` to add directories to the stack. To move into ~/Documents, we would type:
|
||||
|
||||
```
|
||||
$ pushd +2
|
||||
```
|
||||
|
||||
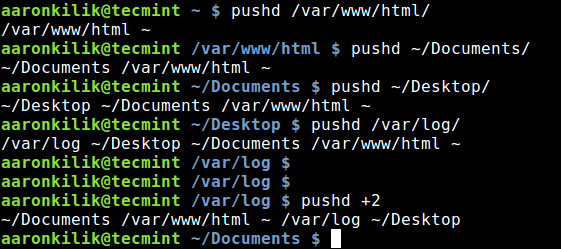
|
||||
|
||||
pushd – Directory Navigation with Number
|
||||
|
||||
Note after this, the stack content will change. So from the previous example, to move into /var/www/html, we would use:
|
||||
|
||||
```
|
||||
$ pushd +1
|
||||
```
|
||||
|
||||
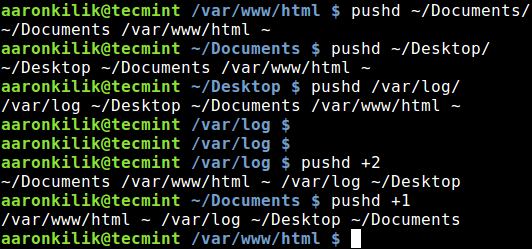
|
||||
|
||||
pushd – Navigate Directory with Number
|
||||
|
||||
popd command – removes a directory from the top of the stack or history. To list the directory stack, type:
|
||||
|
||||
```
|
||||
$ popd
|
||||
```
|
||||
|
||||
To remove a directory from the directory stack inded use `popd +#` or `popd -#`, in this case, we would type the command below to remove ~/Documents:
|
||||
|
||||
```
|
||||
$ popd +1
|
||||
```
|
||||
|
||||
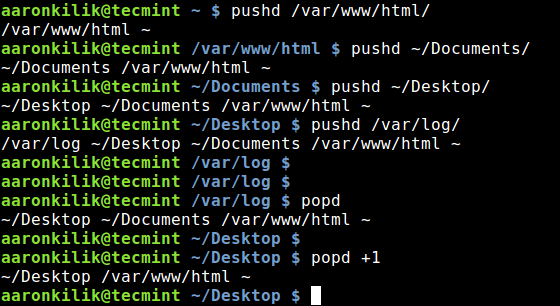
|
||||
|
||||
popd – Remove Directory from Stack
|
||||
|
||||
Also check out: [Fasd – A Commandline Tool That Offers Quick Access to Files and Directories][4]
|
||||
|
||||
In this tutorial we explained “pushd” and “popd” commands which are used for efficient navigation of the directory structure. Share your thoughts concerning this article via the feedback form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
-----
|
||||
|
||||
via: https://www.tecmint.com/pushd-and-popd-linux-filesystem-navigation/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:https://www.tecmint.com/bd-quickly-go-back-to-a-linux-parent-directory/
|
||||
[3]:https://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
[4]:https://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
[5]:https://www.tecmint.com/author/aaronkili/
|
||||
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,58 +0,0 @@
|
||||
开发和部署的不同
|
||||
============================================================
|
||||

|
||||
|
||||
图片提供 : opensource.com
|
||||
|
||||
多年前,我是一名 Smalltalk 程序员,这种经验给让我在观察编程世界时有不同的想法。例如,花时间来适应源代码应该存储在文本文件中的想法。
|
||||
|
||||
我们作为程序员通常区分“开发”和“部署”,特别是我们在一个地方开发使用的工具不同于我们之后部署软件时的地点和工具。在 Smalltalk 世界里,没有这样的区别。
|
||||
|
||||
Smalltalk 构建在包含了你的开发环境(IDE、调试器、文本编辑器、版本控制等)的虚拟机的想法之上,如果你不得不修改任何一处代码,你要修改内存中运行副本。如果你可以为运行中的机器打个快照,如果你想做的话,如果你想分发你的代码,你可以发送一个运行中的机器的镜像(包括IDE、调试器、文本编辑器、版本控制等)的副本到用户。这就是 90 年代软件开发的工作原理(对我们中的一些人来说)。
|
||||
|
||||
如今部署环境与开发环境有了很大的不同。对于初学者,你不要期望那里有任何开发工具。一旦部署,就没有版本控制、没有调试、没有开发环境。有的是记录和监视,这些在我们的开发环境中没有,并且有一个“构建管道”,它将我们的软件从我们开发形式转换为部署形式。例如,Docker 容器试图重新抓住 1990 年代 Smalltalk 程序员部署经验的一些简单性,而不希望对开发体验做同样的事情。
|
||||
|
||||
我想如果 Smalltalk 世界是我唯一的编程隐喻体验,无法区分开发和部署环境,我可能偶尔回顾一下它。但在我是一名 Smalltalk 程序员之前,我是一位 APL 程序员,这也是一个可以修改虚拟机镜像的世界,其中开发和部署是无法区分的。因此,我相信,在当前的世界,人们编辑单独的源代码文件,然后运行构建管道以创建在编辑代码时不存在的部署工作,然后将这些作品部署到用户。我们已经以某种方式将这种反模式软件开发制度化,并且不断发展的软件环境的需求正在迫使我们找到回到 20 世纪 90 年代更有效的技术的方法。因此会有 Docker 的成功。因此,我需要提出建议。
|
||||
|
||||
我有两个建议:我们在运行时系统中实现(和使用)版本控制,我们通过更改运行系统来开发软件,而不是用新的运行系统替换它们。这两个想法是相关的。为了安全地更改正在运行的系统,我们需要一些版本控制功能来支持“撤消”功能。也许公平地说,我只提出一个建议。让我举例来说明。
|
||||
|
||||
让我们开始想象一个静态网站。你要修改一些 HTML 文件。你应该如何工作?如果你像大多数开发者一样,你会有两个,也许三个网站 - 一个用于开发,一个用于QA(或者预发布),一个用于生产。你将直接编辑开发实例中的文件。准备就绪后,你将“部署”你的修改到预发布实例。在用户验收测试之后,你将再次部署,这次是生产环境。
|
||||
|
||||
使用 Occam 的 Razor,让我们避免不必要地创建实例。我们需要多少台机器?我们可以使用一台电脑。我们需要多少台网络服务器?我们可以使用具有多个虚拟主机的单台 web 服务器,而不是多个虚拟主机,我们可以使用单台虚拟主机吗?然后,我们需要多个目录,并需要使用 URL 的顶级路径来区分不同的版本,而不是虚拟主机名。但是为什么我们需要多个目录?因为 web 服务器将从文件系统中提供静态文件。我们的问题是,目录有三个不同的版本,我们的解决方案是创建目录的三个不同的副本。这不是像 Subversion 和 Git 这样的版本控制系统解决的问题?制作目录的多个副本以存储多个版本的策略回到了 CVS 之前的日子。为什么不使用,也就是一个空的的 Git 仓库来存储文件?因为要这样做,web 服务器将需要能够从 git 仓库读取文件(参见[mod_git] [3])。
|
||||
|
||||
这将是一个支持版本控制的运行时系统。
|
||||
|
||||
使用这样的 web 服务器,使用的版本可以由 cookie 来标识。这样,任何人都可以推送到仓库,用户将继续看到他们发起会话时分配的版本。版本控制系统有不可改变的提交; 一旦会话开始,开发人员可以在不影响正在运行的用户的情况下快速推送更改。开发人员可以重置其会话以跟踪他们的新提交,因此开发人员或测试人员就可能如普通用户一样查看在同台服务器上同一个URL上正在开发或正在测试的版本。作为偶然的副作用,A/B 测试仅仅是将不同的用户分配给不同的提交的情况。所有用于管理多个版本的 git 设施都在运行环境中发挥作用。当然,git reset 为我们提供了前面提到的“撤销”功能。
|
||||
|
||||
为什么不是每个人都这样做?
|
||||
|
||||
一种可能性是,诸如版本控制系统的工具不被设计为在生产环境中使用。例如,给某人许可推送到测试分支而不是生产分支是不可能的。对这个方案最常见的反对是,如果发现了一个漏洞,你会想要将某些提交标记为不可访问。这将是另一种更细粒度的权限的情况;开发人员将具有对所有提交的读取权限,但外部用户不会。我们可能需要对现有工具进行一些额外的工作以支持这种模式,但是这些功能很容易理解,并已被设计到其他软件中。例如,Linux (或 PostgreSQL)实现了对不同用户的细粒度权限的想法。
|
||||
|
||||
随着云环境变得越来越普及,这些想法变得更加相关:云总是在运行。例如,我们可以看到,AWS 中等价的 “文件系统”(S3)实现了版本控制,所以你可能有一个不同的想法,使用一台 web 服务器提供来自 S3 的资产,并使用会话信息选择不同版本的资产。重要的想法并不是实现是最好的,而是支持运行时版本控制的愿景。
|
||||
|
||||
部署的软件环境应该是“版本感知”的原则,扩展到除了服务静态资产的web服务器之外的其他工具。在将来的文章中,我将介绍版本库,数据库和应用程序服务器的方法。
|
||||
|
||||
_在 linux.conf.au 中了解更多 Robert Lefkowitz 2017 年 ([#lca2017][1])在 Hobart:[保持 Linux 伟大][2]的主题。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Robert M. Lefkowitz - Robert(a / k / a r0ml)是一个喜欢复杂编程语言的编程语言爱好者。 他是一个提高清晰度、提高可靠性和最大限度地简化编程技术的收藏家。他通过让计算机更加容易获得来使它普及化。他经常演讲中世纪晚期和早期文艺复兴对编程艺术的影响。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/1/difference-between-development-deployment
|
||||
|
||||
作者:[Robert M. Lefkowitz][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Bestony](https://github.com/Bestony)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/r0ml
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://www.linux.conf.au/schedule/presentation/107/
|
||||
[3]:https://github.com/r0ml/mod_git
|
||||
@ -0,0 +1,100 @@
|
||||
# 顽固如我:回顾 Liunx 笔记本电脑
|
||||
|
||||
简述:我是个 Mac 电脑重度用户,但我其实 [对目前最新的 MacBook Pro 是失望的][2]。由此我就开始去研究了下看是否有 [一些可以替代前者(New MacBook Pro)][3] 的选择。然而让我也意想不到的是,这居然使我产生了离开 Mac 平台的决定。
|
||||
|
||||
首先我们来看看 2017 年 CES(International Consumer Electronics Show,国际消费类电子产品展览会)大会后发布的 HP Spectre x360 13 寸笔记本电脑,拥有 4K 显示屏的新款笔记本电脑。我是从 [BestBuy][4](这不是一个合作链接)借来的这款电脑,因为这是唯一还在售卖这个配置的零售商。我得目标是使用 Ubuntu 这个系统替代 Windows 跑在这款笔记本上。
|
||||
|
||||
以下是我过去几个月使用这款笔记本的感受,还有一些在使用中对自己的使用习惯的重新认识。
|
||||
|
||||
## Ubuntu 系统
|
||||
|
||||
安装 Ubuntu 还是很简单的。当时电脑到手的时候预装的是 Windos 10 的系统。当时我使用 Windows 内建的硬盘管理工具来 [压缩主分区][5] 并将剩余的空间分配给 Linux 系统。我 [通过 USB 设备加载 Ubuntu 系统镜像][6],这款笔记本能够很方便的适配 USB-A 接口(这在新版的 Mac 系列电脑是没有的)。然后我就跟着 [Ubuntu 的简便安装说明][7],将 BIOS 设置到 [从USB启动][8]。
|
||||
|
||||
## 屏幕
|
||||
|
||||
Spectre x360 的 4k 显示屏简直惊艳。令我觉得吃惊的是,最新的 Ubuntu 系统在高 DPI 的屏幕上体验也是非常不错的。系统内建的设置工具配合 [gnome-tweak-tool][9] 这样的附加工具,你可以更好的控制用户界面在 4K 屏上的渲染,2 倍于原生大小的控件使得他们看起非常不错,还可以将默认字体大小调整到一个合适的比例,还可以调整窗口标题栏和任务管理器上的图标大小。虽然要比较精确的调整,但我自己设置时也没花多久时间。
|
||||
|
||||
## 触控板
|
||||
|
||||
实话说触控板有点细微的声音,但还是能够很不错的配合手指移动,Ubuntu 系统也默认支持多点触控。然而你会很快的发现你在打字的时候会误触触控板导致光标到处乱晃。在 Linux 上的默认 Synaptics 触控驱动并不能够很好的识别这款机型的手掌误触,解决方法是切换到 [新型输入系统驱动][10],通过调整 [xinput 设置][11] 就可以让触控板工作的不错。
|
||||
|
||||
但我所习惯的手势操作,比如两指滑动回到 Chrome 浏览器,又或者说四指滑动切换工作区,这些操作在 Ubuntu 系统上就没法用了,或者实在想用可以 [libinput-gestures][12] 这样的工具来启用他们。令人失望的是,就算使用上面的工具体验其实也一般,因为其实只有 50% 的几率能识别那些手势。“点击触控板”的功能也有些问题:当你使用大拇指双击触控板或触控板按钮表面想要点击,系统会认为你要移动光标或者使用多点触控来调整大小,又一次的失望。
|
||||
|
||||
## 键盘
|
||||
|
||||
键盘手感就还不错。键盘的键程挺长,这样打起字来就会比较快。左侧 Ctrl 键在左下角所以对我来说就几乎用不上了(不像 Macs 系列电脑就会将 function 键放在那)。比较奇特的是,键盘右侧有一列额外的键,分别是 Delete 键、Home 键、Page Up 键、Page Down 键和 End 键。由于肌肉记忆导致我在将手从箭头控制键换到 Home 键的时候没法额外考虑还有一列键。而且由于这样的设计我在打字时手没法维持在键盘中央,这让我觉得好像离键盘右侧的键远了许多。
|
||||
|
||||
起初我觉得那一列键(Home 键、Page Up 键之类)是多余的,但自从我使用 Sublime Text(一款代码编辑器)来写代码之后,我发现在 Linux 系统和 Windows 系统下输入文本时其实挺依赖那些键的,这就很好理解为什么惠普公司在设计时决定要加入这些键了。作为一个 Mac 用户,我经常会使用 Command 键和向右键来使光标到行结束的位置,而在 Linux 系统和 Windows 系统用户就直接使用 End 键。其实要将键盘映射成和 Mac 一样也不是不行的,但是却很难保证所有的程序都会一样的映射。我花了挺多时间在重组我的肌肉记忆上,这个过程蛮痛苦的,就好像我尝试去使用 [Dvorak 键盘布局][13] 的那个夏天。
|
||||
|
||||
## 音响
|
||||
|
||||
此款机型有四个扬声器:两个 B&O(Bang & Olufsen,音响制造商)扬声器在上部,两个在下部。上部的两个扬声器在 Ubuntu 系统中没法工作,这是一个 [内核问题][14],尚未解决。下部的两个扬声器正常工作但声音有点小。耳机插孔使用正常,当插上耳机时扬声器也会自动静音。但我相信这可能是由于我为了让其他的硬件工作而将内核升级到了 [4.10 测试版本][15] 所以才能够正常切换静音。我觉得社区最终会解决内核问题,所以上部扬声器无法工作的问题只是暂时性的。这些情况其实也就证明了为什么惠普公司推荐使用自带一堆额外的神奇的驱动的 Windows 系统。
|
||||
|
||||
## 电池续航
|
||||
|
||||
电池续航的问题真的就很糟糕了,我想主要是因为 4k 显示屏太耗电了。此外我还发现了 CPU 散热风扇在高速运转使会从笔记本左侧的出风口吹出热风。这风热的程度足以让你觉得使用这笔记本是多么的糟糕。我觉得这应该是 Ubuntu 的默认电源管理配置的缺陷。为了解决这个问题,你可以使用诸如 [powertop][16] 或者 [pm-powersave][17] 这样的工具。Intel 公司也提供 [Linux 系统固件支持][18] 来使 GPU 更好的工作。通过各种优化,我可以使电池续航能力接近 5 小时:和广告中宣传的 9 小时以上相去甚远。其实也有好的一点,使用 USB-C 接口充电速度快很多。这个接口也能很好的配合我得 Nexus X 手机充电,因为他们都是一样的接口。
|
||||
|
||||
## 二合一
|
||||
|
||||
惠普 Spectre x360 这款机型名字来源于它独特的设计,通过屏幕旋转可以变成一台平板电脑。变型后在 Ubuntu 系统上无需设置就可以完成点击、滚动和缩放操作。他甚至支持直接使用前进/后退手势操作,这些操作连它的触摸板也不支持。当你将它旋转为平板模式,键盘和触摸板会自动屏蔽。你可以将系统设置为 [便携模式][19],Gnome 桌面键盘就会启用,体验还不错哦。比较糟糕的是不支持屏幕自动旋转,但我还是东平西凑使用 [iio-sensor-proxy][20] 和 [this one-off script][21] 找到的方法来实现这个功能。最后我虽然实现了这个功能,但是我发现使用 16 比 9 的屏幕好伤我的眼睛,当电脑处于竖屏状态的时候我需要使我的眼睛移动很长一段距离。
|
||||
|
||||
## 窗口管理器和各种软件
|
||||
|
||||
从 1998 年 RedHat 5.0 版开始我就不怎么常用 Linux 桌面版本了。时光飞逝,Ubuntu 发展迅猛,默认用户界面是他们自主研发的 Unity(Gnome 的变体),感觉还不错。我其实用过原生的 Gnome 但它与别的桌面比较起来让我觉得非常的笨拙。我最后还是最喜欢 KDE,而且如果让我再次选择,我也会选择 KDE [Kubuntu][22]。总体来说 KDE 的窗口管理器让我觉得非常棒而且我想要的他都有!
|
||||
|
||||
在这次的回归 Linux 探索中,我意识到其实我基本上就在使用以下 8 个软件:浏览器(Chrome)、终端(没什么特别喜欢的)、文本编辑器(Sublime Text 3)、配置工具、可视化文件管理器、自动化备份工具(Arq)、流畅的屏幕亮度调节器和图片编辑器(GIMP)。这几乎就是我所需要的软件了,其他别的其实非常容易满足。此外,我还比较依赖几个控件:时钟、WIFI状态、电池状态和音量调节。我一般也会使用任务管理器(比如 Dock)和虚拟工作空间(比如 Mission Control 或 Expose)。我几乎不会用桌面图标、桌面提醒、最近使用的软件、搜索功能和应用软件菜单,所以我就可以适应 Linux 系统的种种设置了。
|
||||
|
||||
## 结论
|
||||
|
||||
如果你正在考虑购入一款笔记本电脑,或许可以试试这款。尽管我是这样说,我还是准备要卖掉这台 Spectre x360 然后回到我的 2012 年中产的 MacBook Air 怀抱中去。也不能说惠普公司或是 Linux 桌面平台的错吧,主要还是因为时间更宝贵。
|
||||
|
||||
我是如此的被 Mac 系统的高端用户体验所宠爱着,以至于我对别的东西都特别难以高效起来。我的脑袋几乎已经被 Mac 的触摸板、键盘布局和打字输入习惯等等体验所征服。所以我用起来惠普的电脑和 Linux 系统就觉得被拖慢了很多,感觉好像我就要完蛋了。当我使用计算机的时候,我只希望花更多的时间在提高我的技术(编程、写作等等)上。我只希望我将我仅有的“再学习”能力使用在一些尚未明白和不熟悉的课题上,比如 [新型函数式编程语言][23] 和 [同态加密][24] 等等。我再也不像花更多的时间去学习什么基础性的使用(注:指如何使用不熟悉的计算机或操作系统)。
|
||||
|
||||
反过来说,我也曾花了超过 2 年时间去学习弹钢琴,弹钢琴需要我死记硬背和不断的机械性重复训练。当我在学习钢琴的时候我发现这个过程其实打开了我的思维,让我对曾经有了更深的理解。我对音乐的学习,也让我懂得了许多曾经没有理解的事。可以说,我对音乐的“再学习”打开了我的视野。所以,我开始怀疑我去适应惠普的硬件和 Linux 桌面系统会不会也对我有这样的影响。
|
||||
|
||||
最终说明,我还是固执的。可能以后吧,我也会需要去适应新的工作方式来让我保持最新的状态,就好像电报员兄弟终有一天一定会从摩斯电码转向去使用 [电传打字机][25] 一样。我希望到了未来的那天,我仍然会有耐心和远见让我平滑的过渡。可能,只有当这样东西会创造出更多的可能性,我才会选择那些需要“再学习”的东西,就好像一个为达到目的才去做的石蕊试验(测试液体酸碱度?)一样。至少目前来说,我还是会选择留在 Mac 下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是《Effective Python》一书的作者,我是一名软件工程师,我曾在谷歌工作了 11 年,我目前专注于调查统计,此外,我还曾在云计算基础设施建设和开放协议上有过工作经验。
|
||||
|
||||
以后,如果你还想阅读我写的文章,可以关注我的推 @haxor。如果你遇到什么问题,也可以写邮件给我,或者直接在下面写评论。如果你觉得这篇文章还不错,点击这里也可以看看我别的兴趣爱好。
|
||||
|
||||
-----------------
|
||||
|
||||
via: http://www.onebigfluke.com/2017/04/discovering-my-inner-curmudgeon-linux.html
|
||||
|
||||
作者:[Brett Slatkin ][a]
|
||||
译者:[kenxx](https://github.com/kenxx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.onebigfluke.com/
|
||||
[1]:http://www.onebigfluke.com/2017/04/discovering-my-inner-curmudgeon-linux.html
|
||||
[2]:http://www.onebigfluke.com/2016/10/lamenting-progress.html
|
||||
[3]:http://www.onebigfluke.com/2016/10/alternatives-to-apple-computers.html
|
||||
[4]:http://www.bestbuy.com/site/hp-spectre-x360-2-in-1-13-3-4k-ultra-hd-touch-screen-laptop-intel-core-i7-16gb-memory-512gb-solid-state-drive-dark-ash-silver/5713178.p?skuId=5713178
|
||||
[5]:https://www.howtogeek.com/101862/how-to-manage-partitions-on-windows-without-downloading-any-other-software/
|
||||
[6]:https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-windows
|
||||
[7]:https://www.ubuntu.com/download/desktop/install-ubuntu-desktop
|
||||
[8]:http://support.hp.com/us-en/document/c00364979
|
||||
[9]:https://launchpad.net/gnome-tweak-tool
|
||||
[10]:https://launchpad.net/xserver-xorg-input-libinput
|
||||
[11]:https://wiki.archlinux.org/index.php/Libinput#Configuration
|
||||
[12]:https://github.com/bulletmark/libinput-gestures
|
||||
[13]:https://en.wikipedia.org/wiki/Dvorak_Simplified_Keyboard
|
||||
[14]:https://bugzilla.kernel.org/show_bug.cgi?id=189331
|
||||
[15]:http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.10/
|
||||
[16]:https://blog.sleeplessbeastie.eu/2015/08/10/how-to-set-all-tunable-powertop-options-at-system-boot/
|
||||
[17]:http://askubuntu.com/questions/765840/does-pm-powersave-start-automatically-when-running-on-battery
|
||||
[18]:https://01.org/linuxgraphics/downloads/firmware
|
||||
[19]:https://launchpad.net/onboard
|
||||
[20]:https://github.com/hadess/iio-sensor-proxy
|
||||
[21]:http://askubuntu.com/questions/634151/auto-rotate-screen-on-dell-13-7000-with-15-04-gnome/889591#889591
|
||||
[22]:https://www.kubuntu.org/
|
||||
[23]:http://docs.idris-lang.org/en/latest/tutorial/index.html#tutorial-index
|
||||
[24]:https://arxiv.org/abs/1702.07588
|
||||
[25]:https://en.wikipedia.org/wiki/Teleprinter
|
||||
@ -0,0 +1,59 @@
|
||||
Linux 系统调用的初学者指南
|
||||
============================================================
|
||||
|
||||

|
||||
>图片提供: opensource.com
|
||||
|
||||
在过去的几年中,我一直在做大量容器相关的工作。先前,我看到 [Julien Friedman][7] 的一个很棒的演讲,它用几行 Go 语言写了一个容器框架。这让我突然了解到容器只是一个受限的 Linux 进程中的机器。
|
||||
|
||||
构建这个受限视图涉及到[ Golang 系统调用包][8]中的很多调用。最初,我只是用到了表面的那些,但过了一段时间,我想剥下洋葱的下一层,看看这些系统调用是什么,以及它们的工作原理。我将在 OSCON 的演讲中分享我所学到的东西。
|
||||
|
||||
|
||||
顾名思义,[syscalls][9]是系统调用,它们是你从用户空间请求进入 Linux 内核的方式。内核为你做一些工作,例如创建一个进程,然后再回到用户空间。
|
||||
|
||||
有一个常见的机制使所有的系统调用转换到内核,它由 **libc** 库处理。 用户空间代码设置一些寄存器,包括其想要的系统调用的 ID 以及需要传递给系统调用的所有参数。它触发一个 “陷阱” 将控制转换到内核。
|
||||
|
||||
这是用户空间代码如何向内核请求的,但是 Linux 也有伪文件系统,它允许内核将信息传递给用户空间。内容看起来像普通的目录和文件。
|
||||
|
||||
**/proc** 目录是一个很好的例子。看看里面,你会发现有关机器上运行的进程的各种有趣的信息。在某些情况,像 **cgroups**(控制组)那样,用户空间可以通过写入这些伪文件系统下的文件来配置参数。
|
||||
|
||||
当你在使用容器时,特别有趣的是,主机的 **/proc** 包含了所有有关容器化进程的信息。这包括环境变量,它们也保存在 **/proc** 伪文件系统中,这意味着你的主机可以访问所有正在运行的容器的环境。如果你通过环境变量将诸如证书或数据库密码这类秘密传递到容器中,则可能会产生安全性后果。
|
||||
|
||||
许多编写常规程序的程序员可能不觉得他们经常使用系统调用。但实际上他们会经常调用,因为每天的活动比如制作文件或者更改目录都涉及 Linux 的系统调用。
|
||||
|
||||
你不必是一位系统程序元来享受系统调用的乐趣!
|
||||
|
||||
|
||||
_如果你想要了解更多_,Liz 会在 Austin,Texas 举办的 OSCON 2017 上演讲 [_Linux 系统调用的初学者指南_][10]。如果你对参加会议感兴趣,_[当你在注册时][11]_,使用这个折扣码:_**PCOS**_。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Liz Rice - Liz Rice 是一位技术传播者,也是 Aqua Security 的容器安全专家。此前,她共同创立了 Microscaling Systems,并开发了其实时伸缩引擎,以及流行的图像元数据网站 MicroBadger.com。她拥有丰富的从网络协议和分布式系统,以及数字技术领域,如 VOD,音乐和 VoIP 软件的开发、团队和产品管理经验。
|
||||
|
||||
----------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/5/beginners-guide-syscalls
|
||||
|
||||
作者:[Liz Rice ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/lizrice
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/article/17/5/beginners-guide-syscalls?rate=BT-vq0qMILAvJVxPFqug17N1RfhoAb_vkwNqRZFAqLQ
|
||||
[7]:https://twitter.com/doctor_julz
|
||||
[8]:https://golang.org/pkg/syscall/
|
||||
[9]:http://man7.org/linux/man-pages/man2/syscalls.2.html
|
||||
[10]:https://conferences.oreilly.com/oscon/oscon-tx/public/schedule/detail/56840
|
||||
[11]:http://www.oreilly.com/pub/cpc/44407?sc_cid=701600000012BzSAAU%20target=%22_blank%22
|
||||
[12]:https://opensource.com/user/129431/feed
|
||||
[13]:https://opensource.com/users/lizrice
|
||||
@ -0,0 +1,91 @@
|
||||
WPSeku - 一个找出 WordPress 安全问题的漏洞扫描器
|
||||
============================================================
|
||||
|
||||
by [Aaron Kili][9] | Published: May 5, 2017 | Last Updated: May 5, 2017
|
||||
|
||||
立即下载你的免费电子书 - [10 本给管理员的免费 Linux 电子书][10] | [4 本免费的 Shell 脚本电子书][11]
|
||||
|
||||
WordPress 是一个免费开源、高度可自定义的内容管理系统(CMS),它被全世界数以百万计的人来运行博客和完整的网站。因为它是被用的最多的 CMS,因此有许多潜在的 WordPress 安全问题/漏洞需要考虑。
|
||||
|
||||
然而,如果我们遵循通常的 WordPress 最佳实践,这些安全问题可以被处理。在本篇中,我们会向你展示如何使用 WPSeku,一个 Linux 中的 WordPress 漏洞扫描器,它可以被用来找出你的 WordPress 安装的安全漏洞,并阻止潜在的威胁。
|
||||
|
||||
WPSeku 是一个用 Python 写的简单 WordPress 漏洞扫描器,它可以被用来扫描本地以及远程的 WordPress 安装来找出安全问题。
|
||||
|
||||
### 如何安装 WPSeku - Linux 中的 WordPress 漏洞扫描器
|
||||
|
||||
要在 Linux 中安装 WPSeku,你需要如下从 Github clone 最新版本的 WPSeku。
|
||||
|
||||
```
|
||||
$ cd ~
|
||||
$ git clone https://github.com/m4ll0k/WPSeku
|
||||
```
|
||||
|
||||
完成之后,进入 WPSeku 目录,并如下运行。
|
||||
|
||||
```
|
||||
$ cd WPSeku
|
||||
```
|
||||
|
||||
使用 `-u` 选项指定 WordPress 的安装 URL,如下运行 WPSeku:
|
||||
|
||||
```
|
||||
$ ./wpseku.py -u http://yourdomain.com
|
||||
```
|
||||
[][1]
|
||||
|
||||
WordPress 漏洞扫描器
|
||||
|
||||
以下命令使用 `-p` 选项搜索 WordPress 插件中的跨站脚本、本地文件夹入和 SQL 注入漏洞,你需要在 URL 中指定插件的位置:
|
||||
|
||||
```
|
||||
$ ./wpseku.py -u http://yourdomain.com/wp-content/plugins/wp/wp.php?id= -p [x,l,s]
|
||||
```
|
||||
|
||||
以下命令将使用 `-b` 选项通过 XML-RPC 执行暴力密码登录。另外,你可以使用 `--user` 和 `--wordlist` 选项分别设置用户名和单词列表,如下所示。
|
||||
|
||||
```
|
||||
$ ./wpseku.py -u http://yourdomian.com --user username --wordlist wordlist.txt -b [l,x]
|
||||
```
|
||||
|
||||
要浏览所有 WPSeku 使用选项,输入:
|
||||
|
||||
```
|
||||
$ ./wpseku.py --help
|
||||
```
|
||||
[][2]
|
||||
|
||||
WPSeku WordPress 漏洞扫描帮助
|
||||
|
||||
WPSeku Github 仓库:[https://github.com/m4ll0k/WPSeku][3]
|
||||
|
||||
就是这样了!在本篇中,我们向你展示了如何在 Linux 中获取并使用 WPSeku 用于 WordPress 漏洞扫描。WordPress 是安全的,但仅在如果我们遵循 WordPress 安全最佳实践的情况下。你有要分享的想法么?如果有,请在评论区留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 及 F.O.S.S 热衷者,即将成为 Linux 系统管理员、web 开发者,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/wp-content/uploads/2017/05/WordPress-Vulnerability-Scanner.png
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/05/WPSeku-WordPress-Vulnerability-Scanner-Help.png
|
||||
[3]:https://github.com/m4ll0k/WPSeku
|
||||
[4]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[5]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[6]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[7]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||
[8]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#comments
|
||||
[9]:https://www.tecmint.com/author/aaronkili/
|
||||
[10]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[11]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,38 +1,37 @@
|
||||
ucasFL translating
|
||||
4 Python libraries for building great command-line user interfaces
|
||||
4 个用于构建优秀的命令行用户界面的 Python 库
|
||||
============================================================
|
||||
|
||||
### In the second installment of a two-part series on terminal applications with great command-line UIs, we explore Prompt Toolkit, Click, Pygments, and Fuzzy Finder.
|
||||
### 在一个分为两部分的关于具有优秀命令行用户界面的应用的系列文章的第二篇安装教程中,我们将讨论 Prompt、Toolkit、Click、Pygments 和 Fuzzy Finder 。
|
||||
|
||||
|
||||

|
||||
>Image by : [Mennonite Church USA Archives][16]. Modified by Opensource.com. [CC BY-SA 4.0][17]
|
||||
>图片来自 : [美国 Mennonite 教堂档案][16] 。 Opensource.com. [CC BY-SA 4.0][17]
|
||||
|
||||
This is the second installment in my two-part series on terminal applications with great command-line UIs. In the [first article][18], I discussed features that make a command-line application a pure joy to use. In part two, I'll look at how to implement those features in Python with the help of a few libraries. By the end of this article, readers should have a good understanding of how to use [Prompt Toolkit][19], [Click][20] (Command Line Interface Creation Kit), [Pygments][21], and [Fuzzy Finder][22] to implement an easy-to-use [REPL][23].
|
||||
这是我的一个分为两部分的关于具有优秀命令行用户界面的应用的系列文章的第二篇安装教程。在[第一篇文章][18]中,我们讨论了一些能够使命令行应用用起来令人感到高兴的特性。在第二篇文章中,我们来看看如何用 Python 的一些库来实现这些特性。
|
||||
|
||||
I plan to achieve this in fewer than 20 lines of Python code. Let's begin.
|
||||
我打算用少于 20 行 Python 代码来实现。让我们开始吧。
|
||||
|
||||
Programming and development
|
||||
编程和开发的一些资源
|
||||
|
||||
* [New Python content][1]
|
||||
* [最新的 Python 内容][1]
|
||||
|
||||
* [Our latest JavaScript articles][2]
|
||||
* [我们最新的 JavaScript 文章][2]
|
||||
|
||||
* [Recent Perl posts][3]
|
||||
* [近期 Perl 文章][3]
|
||||
|
||||
* [Red Hat Developers Blog][4]
|
||||
* [Red Hat 开发者博客][4]
|
||||
|
||||
### Python Prompt Toolkit
|
||||
|
||||
I like to think of this library as the Swiss Army knife of command-line apps—it acts as a replacement for **[readline][5]**, **[curses][6]**, and much more. Let's install the library and get started:
|
||||
我习惯于把这个库称为命令行应用的瑞士军刀,它可以作为 **[readline][5]** 、**[cursed][6]** 等的替代品。让我们首先安装这个库,然后开始该教程:
|
||||
|
||||
```
|
||||
pip install prompt_toolkit
|
||||
```
|
||||
|
||||
We'll start with a simple REPL. Typically a REPL will accept user input, do an operation, and print the results. For our example, we're going to build an "echo" REPL. It merely prints back what the user typed in:
|
||||
我们以一个简单的 REPL 开始。一个典型的 REPL 会接收用户的输入,进行一个操作,然后输出结果。比如在我们的例子中,我们将要实现一个和 “echo” 功能一样的 REPL 。它仅仅是打印出用户的输入:
|
||||
|
||||
### REPL
|
||||
#### REPL
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -42,11 +41,11 @@ while 1:
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
That is all it takes to implement a REPL. It can read user input and print out what they have entered. The **prompt** function used in this code snippet is from the **prompt_toolkit** library; it is a replacement for the **readline** library.
|
||||
这就是实现 REPL 的全部代码。它可以读取用户的输入,然后打印出用户的输入内容。在这段代码中使用的 `prompt` 函数来自 `prompt_toolkit` 库,它是 `readline` 库的一个替代品。
|
||||
|
||||
### History
|
||||
#### 历史命令
|
||||
|
||||
To enhance our REPL, we can add command history:
|
||||
为了提高我们的 REPL,我们可以添加历史命令:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -59,11 +58,11 @@ while 1:
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
We've just added persistent history to our REPL. Now we can use the up/down arrow to navigate the history, and use the **Ctrl**+**R** to search the history. This satisfies the basic etiquette of a command line.
|
||||
我们刚刚给 REPL 添加了持续的**历史命令**。现在,我们可以使用上/下箭头来浏览**历史命令**,并使用 **Ctrl+R** 来搜索**历史命令**。它满足命令行的基本准则。
|
||||
|
||||
### Auto-suggestion
|
||||
#### 自动推荐
|
||||
|
||||
One of the discoverability tricks I covered in part one was the automatic suggestion of commands from the history. (We saw this feature pioneered in the **fish** shell.) Let's add that feature to our REPL:
|
||||
在第一篇教程中,我讲到的一个已发现技巧是自动推荐**历史命令**。(我首先在 **fish** shell 中看到这一特性。)让我们把这一特性加入到我们的 REPL 中:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -78,15 +77,15 @@ while 1:
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
All we had to do was add a new argument to the **prompt()** API call. Now we have a REPL that has **fish**-style auto-suggestion from the history.
|
||||
我们只需要给 `prompt()` API 调用添加一个新的参数。现在,我们有了一个具有 **fish shell** 风格的 REPL,它可以自动推荐**历史命令**。
|
||||
|
||||
### Auto-completion
|
||||
#### 自动补全
|
||||
|
||||
Now let's implement an enhancement of Tab-completion via auto-completion, which pops up possible suggestions as the user starts typing input.
|
||||
现在,让我们通过**自动补全**来加强 Tab-补全。它能够在用户开始输入的时候弹出可能的命令推荐。
|
||||
|
||||
How will our REPL know what to suggest? We supply a dictionary of possible items to suggest.
|
||||
REPL 如何来进行推荐呢?我们使用一个字典来进行可能项的推荐。
|
||||
|
||||
Let's say we're implementing a REPL for SQL. We can stock our auto-completion dictionary with SQL keywords. Let's see how to do that:
|
||||
我们实现一个针对 SQL 的 REPL 。我们可以把自动补全字典和 SQL 存到一起。让我们看一看这是如何实现的:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -106,25 +105,25 @@ while 1:
|
||||
print(user_input)
|
||||
```
|
||||
|
||||
Once again, we simply can use a built-in completion routine of prompt-toolkit called **WordCompleter**, which matches the user input with the dictionary of possible suggestions and offers up a list.
|
||||
再次说明,我们只是简单的使用了 `prompt-toolkit` 内建的一个叫做 `WordCompleter` 的补全特性,它能够把用户输入和可能推荐的字典进行匹配,然后提供一个列表。
|
||||
|
||||
We now have a REPL that can do auto-completion, fish-style suggestions from history, and up/down traversal of history. All of that in less than 10 lines of actual code.
|
||||
现在,我们有了一个能够自动补全、`fish shell` 风格的历史命令推荐以及上/下浏览历史的 REPL 。实现这些特性只用了不到 10 行的实际代码。
|
||||
|
||||
### Click
|
||||
|
||||
Click is a command-line creation toolkit that makes it easy to parse command-line options arguments and parameters for the program. This section does not talk about how to use Click as an arguments parser; instead, I'm going to look at some utilities that ship with Click.
|
||||
`Click` 是一个命令行创建工具包,使用它能够更容易的为程序解析命令行选项的参数和常量。在这儿我们不讨论如何使用 `Click` 来作为参数解析器。相反,我们将会看到 `Click` 的一些实际功能。
|
||||
|
||||
Installing click is simple:
|
||||
安装 `Click`:
|
||||
|
||||
```
|
||||
pip install click
|
||||
```
|
||||
|
||||
### Pager
|
||||
#### Pager
|
||||
|
||||
Pagers are Unix utilities that display long output one page at a time. Examples of pagers are **less**, **more**, **most**, etc. Displaying the output of a command via a pager is not just friendly design, but also the decent thing to do.
|
||||
`Paper` 是 Unix 系统上的实用工具,它们能够一次性在一页上显示很长的输出。`Pager` 的一些例子包括 `less`、`more`、`most` 等。通过 `pager` 来显示一个命令的输出不仅仅是一个友好的设计,同时也是需要正确做的事。
|
||||
|
||||
Let's take the previous example further. Instead of using the default **print()** statement, we can use **click.echo_via_pager()**. This will take care of sending the output to stdout via a pager. It is platform-agnostic, so it will work in Unix or Windows. **click.echo_via_pager()** will try to use decent defaults for the pager to be able to show color codes if necessary:
|
||||
让我们进一步改进前面的例子。我们不再使用默认的 `print()` 语句,取而代之的是 `click.echo_via_pager()` 。它将会把输出通过 `pager` 发送到标准输出。这是平台无关的,因此在 Unix 系统或 Windows 系统上均能工作。如果必要的话,`click_via_pager` 会尝试使用一个合适的默认 `pager` 来输出,从而能够显示代码高亮。
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -145,9 +144,9 @@ while 1:
|
||||
click.echo_via_pager(user_input)
|
||||
```
|
||||
|
||||
### Editor
|
||||
#### 编辑器
|
||||
|
||||
One of the niceties mentioned in my previous article was falling back to an editor when the command gets too complicated. Once again **click** has an [easy API][24] to launch an editor and return the text entered in the editor back to the application:
|
||||
在我以前的文章中,一个值得一提的细节是,当命令过于复杂的时候进入编辑器来编辑。`Click` 有一个[简单的 API][24] 能够打开编辑器,然后把在编辑器中输入的文本返回给应用。
|
||||
|
||||
```
|
||||
import click
|
||||
@ -156,13 +155,13 @@ message = click.edit()
|
||||
|
||||
### Fuzzy Finder
|
||||
|
||||
Fuzzy Finder is a way for users to narrow down the suggestions with minimal typing. Once again, there is a library that implements Fuzzy Finder. Let's install the library:
|
||||
`Fuzzy Finder` 是一种通过极小输入来为用户减少推荐的方法。幸运的是,有一个库可以实现 `Fuzzy Finder` 。让我们首先安装这个库:
|
||||
|
||||
```
|
||||
pip install fuzzyfinder
|
||||
```
|
||||
|
||||
The API for Fuzzy Finder is simple. You pass in the partial string and a list of possible choices, and Fuzzy Finder will return a new list that matches the partial string using the fuzzy algorithm ranked in order of relevance. For example:
|
||||
`Fuzzy Finder` 的 API 很简单。用户向它传递部分字符串和一系列可能的选择,然后,`Fuzzy Finder` 将会返回一个与部分字符串匹配的列表,这一列表是通过模糊算法根据相关性排序得出的。比如:
|
||||
|
||||
```
|
||||
>>> from fuzzyfinder import fuzzyfinder
|
||||
@ -173,7 +172,7 @@ The API for Fuzzy Finder is simple. You pass in the partial string and a list of
|
||||
['abcd', 'defabca', 'aagbec']
|
||||
```
|
||||
|
||||
Now that we have our **fuzzyfinder**, let's add it into our SQL REPL. The way we do this is to define a custom completer instead of the **WordCompleter** that comes with **prompt-toolkit**. For example:
|
||||
现在我们有了 `fuzzyfinder`,让我们把它加入到我们的 SQL REPL 中。方法是我们自定义一个 `completer` 而不是使用来自 `prompt-toolkit` 库的 `WordCompleter` 。比如:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -203,17 +202,17 @@ while 1:
|
||||
|
||||
### Pygments
|
||||
|
||||
Now let's add syntax highlighting to the user input. We are building a SQL REPL, and having colorful SQL statements will be nice.
|
||||
现在,让我们给用户输入添加语法高亮。我们搭建一个 SQL REPL,并且具有丰富多彩的 SQL 语句,这会很棒。
|
||||
|
||||
Pygments is a syntax highlighting library with built-in support for more than 300 languages. Adding syntax highlighting makes an application colorful, which helps users spot mistakes—such as typos, unmatched quotes, or brackets—in their SQL before executing it.
|
||||
`Pygments` 是一个提供语法高亮的库,内建支持超过 300 种语言。添加语法高亮能够使应用变得丰富多彩,从而能够帮助用户在执行程序前发现 SQL 中存在的错误,比如拼写错误、引号不匹配或括号不匹配。
|
||||
|
||||
First install Pygments:
|
||||
首先,安装 `Pygments` :
|
||||
|
||||
```
|
||||
pip install pygments
|
||||
```
|
||||
|
||||
Let's use Pygments to add color to our SQL REPL:
|
||||
让我们使用 `Pygments` 来为 SQL REPL 添加颜色:
|
||||
|
||||
```
|
||||
from prompt_toolkit import prompt
|
||||
@ -243,38 +242,34 @@ while 1:
|
||||
click.echo_via_pager(user_input)
|
||||
```
|
||||
|
||||
Prompt Toolkit works well with the Pygments library. We pick **SqlLexer** supplied by **Pygments** and pass it into the **prompt** API from **prompt-toolkit**. Now all user input is treated as SQL statements and colored appropriately.
|
||||
`Prompt Toolkit` 能够和 `Pygments` 一同很好的工作。我们把 `Pygments` 提供的 `SqlLexer` 加入到来自 `prompt-toolkit` 的 `prompt` 中。现在,所有的用户输入都会被当作 SQL 语句,并进行适当着色。
|
||||
|
||||
### Conclusion
|
||||
### 结论
|
||||
|
||||
That concludes our journey through the creation of a powerful REPL that has all the features of a common shell, such as history, key bindings, and user-friendly features such as auto-completion, fuzzy finding, pager support, editor support, and syntax highlighting. We achieved all of that in fewer than 20 statements of Python.
|
||||
我们的“旅途”通过创建一个强大的 REPL 结束,这个 REPL 具有常见的 shell 的全部特性,比如历史命令,键位绑定,用户友好性比如自动补全、模糊查找、`pager` 支持、编辑器支持和语法高亮。我们仅用少于 20 行 Python 代码实现了这个 REPL 。
|
||||
|
||||
Wasn't that easy? Now you have no excuses not to write a stellar command-line app. These resources might help:
|
||||
|
||||
* [Click][7] (Command Line Interface Creation Kit)
|
||||
不是很简单吗?现在,你没有理由不会写一个自己的命令行应用了。下面这些资源可能有帮助:
|
||||
|
||||
* [Click][7] (命令行界面创建工具)
|
||||
* [Fuzzy Finder][8]
|
||||
|
||||
* [Prompt Toolkit][9]
|
||||
|
||||
* See the [Prompt Toolkit tutorial tutorial][10] and [examples][11] in the prompt-toolkit repository.
|
||||
|
||||
* 在 `prompt-toolkit` 的仓库中查看 [Prompt Toolkit 教程][10] 和[例子][11]
|
||||
* [Pygments][12]
|
||||
|
||||
_Learn more in Amjith Ramanujam's [PyCon US 2017][13] talk, [Awesome Commandline Tools][14], May 20th in Portland, Oregon._
|
||||
你也可以在我在 [PyCon US 2017][13] 的演讲[优秀的命令行工具][14]中学到更多东西,该会议是 5 月 20 日在波特兰,俄勒冈举行的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Amjith Ramanujam - Amjith Ramanujam is the creator of pgcli and mycli. People think they're pretty cool and he doesn't disagree. He likes programming in Python, Javascript and C. He likes to write simple, understandable code, sometimes he even succeeds.
|
||||
Amjith Ramanujam - Amjith Ramanujam 是 `pgcli` 和 `mycli` 的作者。人们认为它们很酷,但是他不同意。他喜欢用 Python、JavaScript 和 C 编程。他喜欢写一些简单、易于理解的代码,有时候这样做是成功的。
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/4-practical-python-libraries
|
||||
|
||||
作者:[ Amjith Ramanujam][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -283,7 +278,7 @@ via: https://opensource.com/article/17/5/4-practical-python-libraries
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&amp;src=programming_resource_menu
|
||||
[5]:https://docs.python.org/2/library/readline.html
|
||||
[6]:https://docs.python.org/2/library/curses.html
|
||||
[7]:http://click.pocoo.org/5/
|
||||
@ -1,202 +0,0 @@
|
||||
怎样在命令行下杀死一个进程
|
||||
============================================================
|
||||
|
||||

|
||||
>linux的命令行有你需要的用来停止正在运行的进程的所有工具。Jack Wallen透露出细节。[Creative Commons Zero][4]
|
||||
|
||||
想像一下: 你打开了一个程序 (可能来自于你的桌面菜单或者命令行) ,然后开始使用这个app, 没想到程序会锁死, 停止运行, 或者以外死机. 你尝试再次运行app, 但是结果是不能够完全真正的关机。
|
||||
|
||||
你该怎么办? 你要结束进程. 但该如何做? 信或者不信,最好的解决方法大都在命令行里. 值得庆幸的是, Linux有每个必要的工具来供用户杀死错误的进程,然而, 你在执行杀死进程的命令之前, 你首先必须知道进程是什么. 该如何处理这层的任务? 一旦你能够掌握这个工具,它实际是十分简单的...
|
||||
|
||||
让我来介绍给你这些工具.
|
||||
我来概述的步骤是每个linux发行版都能用的,不论是桌面版还是服务器版。
|
||||
我讲严格使用命令行,打开你的终端开始输入命令吧。
|
||||
|
||||
### 定位进程
|
||||
|
||||
杀死一个没有响应的进程的第一个步骤是定位这个进程。我用来定位进程的命令有两个:top和ps命令。top是每个系统管理员都知道的工具,用top命令,你能够get到所有当前正在运行的进程有那些。在命令行里,输入top命令能够就看到你正在运行的程序进程(图1)
|
||||
|
||||
|
||||
### [killa.jpg][5]
|
||||
|
||||

|
||||
|
||||
图1: top命令给出你许多的信息.[通过权限使用][1]
|
||||
|
||||
从显示的列表中你能够看到相当重要的信息,举个例子,Chrome浏览器反映迟钝,依据我们的top命令显示,我们能够辨别的有四个Chrome浏览器的进程在运行,进程的pid号分别是3827,3919,10764,和11679.这个信息是重要的,可以用一个特殊的方法来结束进程。
|
||||
|
||||
尽管top命令很是方便, 但也不是得到你所要信息最有效的方法。 你知道你要杀死的Chrome进程是那个,并且你也不想看top命令所显示的实时信息。 鉴于此, 你能够使用ps命令然后用grep命令来过滤出输出结果。这个ps命令能够显示出当前进程的快照,然后用grep命令输出匹配的样式。我们通过grep命令过滤ps命令的输出的理由很简单:如果你只输入ps命令,你将会得到当前所有进程的快照列表,而我们需要的是列出Chrome浏览器进程相关的。所以这个命令是这个样子:
|
||||
|
||||
```
|
||||
ps aux | grep chrome
|
||||
```
|
||||
|
||||
The _aux_ options are as follows: #辅助选项如下所示
|
||||
|
||||
* a = show processes for all users #a = 显示所有用户的进程
|
||||
|
||||
* u = display the process's user/owner #u = 显示进程的用户和拥有者
|
||||
|
||||
* x = also show processes not attached to a terminal #x = 显示进程不依附于终端
|
||||
|
||||
当你在图形化程序上搜寻信息的时候,这个x参数是很重要的。
|
||||
|
||||
当你输入以上命令的时候,你将会得到比图2更多的结束一个进程的信息,而且它有事用起来比top命令更有效。
|
||||
### [killb.jpg][6]
|
||||
|
||||

|
||||
|
||||
图2: 用ps命令来定位所需的内容信息。[通过权限使用][2]
|
||||
|
||||
### 结束进程
|
||||
|
||||
现在我们开始结束进程的任务。我们有两种信息来帮我们杀死错误的进程。
|
||||
|
||||
* Process name #进程的名字
|
||||
|
||||
* Process ID #进程的ID
|
||||
|
||||
你用哪一个将会决定终端命令如何使用,通常有两个命令来结束进程:
|
||||
|
||||
* kill - Kill a process by ID #通过ID来结束进程
|
||||
|
||||
* killall - Kill a process by name #通过进程名字来结束进程
|
||||
|
||||
有两个不同的信号能够发送给两个结束进程的命令。你发送的信号决定着你想要从结束进程命令中得到的结果。举个例子,你可以发送HUP(挂起)信号给结束进程的命令,命令实际上将会重启这个进程。当你需要立即重启一个进程(比如就守护进程来说),这是一个明智的选择。你通过输入kill -l可以得到所有信号的列表。,你将会发现大量的信号。(图3)
|
||||
|
||||
### [killc.jpg][7]
|
||||
|
||||

|
||||
|
||||
图3: 可用的结束进程信号.[通过权限使用][3]
|
||||
|
||||
最经常使用的结束进程的信号是:T
|
||||
|
||||
|
|
||||
|
||||
Signal Name
|
||||
|
||||
|
|
||||
|
||||
Single Value
|
||||
|
|
||||
|
||||
Effect
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGHUP
|
||||
|
||||
|
|
||||
|
||||
1
|
||||
|
||||
|
|
||||
|
||||
Hangup
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGINT
|
||||
|
||||
|
|
||||
|
||||
2
|
||||
|
||||
|
|
||||
|
||||
Interrupt from keyboard
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGKILL
|
||||
|
||||
|
|
||||
|
||||
9
|
||||
|
||||
|
|
||||
|
||||
Kill signal
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGTERM
|
||||
|
||||
|
|
||||
|
||||
15
|
||||
|
||||
|
|
||||
|
||||
Termination signal
|
||||
|
||||
|
|
||||
|
|
||||
|
||||
SIGSTOP
|
||||
|
||||
|
|
||||
|
||||
17, 19, 23
|
||||
|
||||
|
|
||||
|
||||
Stop the process
|
||||
|
||||
|
|
||||
|
||||
好的是,你能用信号值来代替信号名字。所以你没有必要来记住所有各种各样的信号名字。
|
||||
所以,让我们现在用kill命令来杀死Chrome浏览器的进程。这个命令的结构是:
|
||||
|
||||
```
|
||||
kill SIGNAL PID
|
||||
```
|
||||
|
||||
信号被发送到那里,进程的ID就会被结束。我们已经知道,来自我们的ps命令显示我们想要结束的进程ID号是3827, 3919, 10764, and 11679\。所以要发送结束进程信号,我们输入以下命令:
|
||||
|
||||
```
|
||||
kill -9 3827
|
||||
|
||||
kill -9 3919
|
||||
|
||||
kill -9 10764
|
||||
|
||||
kill -9 11679
|
||||
```
|
||||
|
||||
一旦我们输入了以上命令,Chrome浏览器的所有进程将会成功被杀死。
|
||||
|
||||
我们有更简单的方法! 如果我们已经知道我们想要杀死的那个进程的名字,我们能够利用killall命令发送同样的信号,像这样:
|
||||
|
||||
_killall -9 chrome_
|
||||
|
||||
附带说明的是,上边这个命令可能不能捕捉到所有正在运行的Chrome进程。如果,运行了上边这个命令之后,你输入ps aux|grep chrome 命令过滤一下,看到剩下正在运行的Chrome进程有那些,最好的办法还是回到KIll命令通过进程的ID来发送信号值9来结束这个进程。
|
||||
|
||||
### 结束进程变得容易
|
||||
|
||||
正如你看到的,杀死错误的进程并没有你原本想的那样有挑战性。当我让一个顽固的进程结束的时候,我趋向于用killall命令来作为有效的方法来终止,然而,当我让一个真正的活跃的进程结束的时候,kill命令是一个好的方法。
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/5/how-kill-process-command-line
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[hwlog](https://github.com/hwlog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[5]:https://www.linux.com/files/images/killajpg
|
||||
[6]:https://www.linux.com/files/images/killbjpg
|
||||
[7]:https://www.linux.com/files/images/killcjpg
|
||||
[8]:https://www.linux.com/files/images/stop-processesjpg
|
||||
Loading…
Reference in New Issue
Block a user