mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
0be5ea4176
@ -1,47 +1,48 @@
|
||||
PKI 和 密码学中的私钥的角色
|
||||
公钥基础设施和密码学中的私钥的角色
|
||||
======
|
||||
> 了解如何验证某人所声称的身份。
|
||||
|
||||

|
||||
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密),<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
在[上一篇文章][1]中,我们概述了密码学并讨论了密码学的核心概念:<ruby>保密性<rt>confidentiality</rt></ruby> (让数据保密)、<ruby>完整性<rt>integrity</rt></ruby> (防止数据被篡改)和<ruby>身份认证<rt>authentication</rt></ruby> (确认数据源的<ruby>身份<rt>identity</rt></ruby>)。由于要在存在各种身份混乱的现实世界中完成身份认证,人们逐渐建立起一个复杂的<ruby>技术生态体系<rt>technological ecosystem</rt></ruby>,用于证明某人就是其声称的那个人。在本文中,我们将大致介绍这些体系是如何工作的。
|
||||
|
||||
### 公钥密码学及数字签名快速回顾
|
||||
### 快速回顾公钥密码学及数字签名
|
||||
|
||||
互联网世界中的身份认证依赖于公钥密码学,其中密钥分为两部分:拥有者需要保密的私钥和可以对外公开的公钥。经过公钥加密过的数据,只能用对应的私钥解密。举个例子,对于希望与[记者][2]建立联系的举报人来说,这个特性非常有用。但就本文介绍的内容而言,私钥更重要的用途是与一个消息一起创建一个<ruby>数字签名<rt>digital signature</rt></ruby>,用于提供完整性和身份认证。
|
||||
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,由于不断发现微妙的触发条件,签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
在实际应用中,我们签名的并不是真实消息,而是经过<ruby>密码学哈希函数<rt>cryptographic hash function</rt></ruby>处理过的消息<ruby>摘要<rt>digest</rt></ruby>。要发送一个包含源代码的压缩文件,发送者会对该压缩文件的 256 比特长度的 [SHA-256][3] 摘要进行签名,而不是文件本身进行签名,然后用明文发送该压缩包(和签名)。接收者会独立计算收到文件的 SHA-256 摘要,然后结合该摘要、收到的签名及发送者的公钥,使用签名验证算法进行验证。验证过程取决于加密算法,加密算法不同,验证过程也相应不同;而且,很微妙的是签名验证[漏洞][4]依然[层出不穷][5]。如果签名验证通过,说明文件在传输过程中没有被篡改而且来自于发送者,这是因为只有发送者拥有创建签名所需的私钥。
|
||||
|
||||
### 方案中缺失的环节
|
||||
|
||||
上述方案中缺失了一个重要的环节:我们从哪里获得发送者的公钥?发送者可以将公钥与消息一起发送,但除了发送者的自我宣称,我们无法核验其身份。假设你是一名银行柜员,一名顾客走过来向你说,“你好,我是 Jane Doe,我要取一笔钱”。当你要求其证明身份时,她指着衬衫上贴着的姓名标签说道,“看,Jane Doe!”。如果我是这个柜员,我会礼貌的拒绝她的请求。
|
||||
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办聚会并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe (尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个[<ruby>信任网络<rt>Web of Trust</rt></ruby>][8]。
|
||||
如果你认识发送者,你们可以私下见面并彼此交换公钥。如果你并不认识发送者,你们可以私下见面,检查对方的证件,确认真实性后接受对方的公钥。为提高流程效率,你可以举办[聚会][6]并邀请一堆人,检查他们的证件,然后接受他们的公钥。此外,如果你认识并信任 Jane Doe(尽管她在银行的表现比较反常),Jane 可以参加聚会,收集大家的公钥然后交给你。事实上,Jane 可以使用她自己的私钥对这些公钥(及对应的身份信息)进行签名,进而你可以从一个[线上密钥库][7]获取公钥(及对应的身份信息)并信任已被 Jane 签名的那部分。如果一个人的公钥被很多你信任的人(即使你并不认识他们)签名,你也可能选择信任这个人。按照这种方式,你可以建立一个<ruby>[信任网络][8]<rt>Web of Trust</rt></ruby>。
|
||||
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificates</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure, PKI</rt></ruby>。
|
||||
但事情也变得更加复杂:我们需要建立一种标准的编码机制,可以将公钥和其对应的身份信息编码成一个<ruby>数字捆绑<rt>digital bundle</rt></ruby>,以便我们进一步进行签名。更准确的说,这类数字捆绑被称为<ruby>证书<rt>cerificate</rt></ruby>。我们还需要可以创建、使用和管理这些证书的工具链。满足诸如此类的各种需求的方案构成了<ruby>公钥基础设施<rt>public key infrastructure</rt></ruby>(PKI)。
|
||||
|
||||
### 比信任网络更进一步
|
||||
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:不妨以社交圈为例。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
你可以用人际关系网类比信任网络。如果人们之间广泛互信,可以很容易找到(两个人之间的)一条<ruby>短信任链<rt>short path of trust</rt></ruby>:就像一个社交圈。基于 [GPG][9] 加密的邮件依赖于信任网络,([理论上][10])只适用于与少量朋友、家庭或同事进行联系的情形。
|
||||
|
||||
(LCTT 译注:作者提到的“短信任链”应该是暗示“六度空间理论”,即任意两个陌生人之间所间隔的人一般不会超过 6 个。对 GPG 的唱衰,一方面是因为密钥管理的复杂性没有改善,另一方面 Yahoo 和 Google 都提出了更便利的端到端加密方案。)
|
||||
|
||||
在实际应用中,信任网络有一些[<ruby>"硬伤"<rt>significant problems</rt></ruby>][11],主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接逐渐降低时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链;具体而言,你与其它组织建立联系,验证它们的密钥符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
在实际应用中,信任网络有一些“<ruby>[硬伤][11]<rt>significant problems</rt></ruby>”,主要是在可扩展性方面。当网络规模逐渐增大或者人们之间的连接较少时,信任网络就会慢慢失效。如果信任链逐渐变长,信任链中某人有意或无意误签证书的几率也会逐渐增大。如果信任链不存在,你不得不自己创建一条信任链,与其它组织建立联系,验证它们的密钥以符合你的要求。考虑下面的场景,你和你的朋友要访问一个从未使用过的在线商店。你首先需要核验网站所用的公钥属于其对应的公司而不是伪造者,进而建立安全通信信道,最后完成下订单操作。核验公钥的方法包括去实体店、打电话等,都比较麻烦。这样会导致在线购物变得不那么便利(或者说不那么安全,毕竟很多人会图省事,不去核验密钥)。
|
||||
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authorities, CAs</rt></ruby>的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>。
|
||||
如果世界上有那么几个格外值得信任的人,他们专门负责核验和签发网站证书,情况会怎样呢?你可以只信任他们,那么浏览互联网也会变得更加容易。整体来看,这就是当今互联网的工作方式。那些“格外值得信任的人”就是被称为<ruby>证书颁发机构<rt>cerificate authoritie</rt></ruby>(CA)的公司。当网站希望获得公钥签名时,只需向 CA 提交<ruby>证书签名请求<rt>certificate signing request</rt></ruby>(CSR)。
|
||||
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>DV<rt>Domain Validated</rt></ruby> 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>EV<rt>Extended Validated</rt></ruby> 类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
CSR 类似于包括公钥和身份信息(在本例中,即服务器的主机名)的<ruby>存根<rt>stub</rt></ruby>证书,但 CA 并不会直接对 CSR 本身进行签名。CA 在签名之前会进行一些验证。对于一些证书类型(LCTT 译注:<ruby>域名证实<rt>Domain Validated</rt></ruby>(DV) 类型),CA 只验证申请者的确是 CSR 中列出主机名对应域名的控制者(例如通过邮件验证,让申请者完成指定的域名解析)。[对于另一些证书类型][12] (LCTT 译注:链接中提到<ruby>扩展证实<rt>Extended Validated</rt></ruby>(EV)类型,其实还有 <ruby>OV<rt>Organization Validated</rt></ruby> 类型),CA 还会检查相关法律文书,例如公司营业执照等。一旦验证完成,CA(一般在申请者付费后)会从 CSR 中取出数据(即公钥和身份信息),使用 CA 自己的私钥进行签名,创建一个(签名)证书并发送给申请者。申请者将该证书部署在网站服务器上,当用户使用 HTTPS (或其它基于 [TLS][13] 加密的协议)与服务器通信时,该证书被分发给用户。
|
||||
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥核验服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>Key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
当用户访问该网站时,浏览器获取该证书,接着检查证书中的主机名是否与当前正在连接的网站一致(下文会详细说明),核验 CA 签名有效性。如果其中一步验证不通过,浏览器会给出安全警告并切断与网站的连接。反之,如果验证通过,浏览器会使用证书中的公钥来核验该服务器发送的签名信息,确认该服务器持有该证书的私钥。有几种算法用于协商后续通信用到的<ruby>共享密钥<rt>shared secret key</rt></ruby>,其中一种也用到了服务器发送的签名信息。<ruby>密钥交换<rt>key exchange</rt></ruby>算法不在本文的讨论范围,可以参考这个[视频][14],其中仔细说明了一种密钥交换算法。
|
||||
|
||||
### 建立信任
|
||||
|
||||
你可能会问,“如果 CA 使用其私钥对证书进行签名,也就意味着我们需要使用 CA 的公钥验证证书。那么 CA 的公钥从何而来,谁对其进行签名呢?” 答案是 CA 对自己签名!可以使用证书公钥对应的私钥,对证书本身进行签名!这类签名证书被称为是<ruby>自签名的<rt>self-signed</rt></ruby>;在 PKI 体系下,这意味着对你说“相信我”。(为了表达方便,人们通常说用证书进行了签名,虽然真正用于签名的私钥并不在证书中。)
|
||||
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchors</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificates</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
通过遵守[浏览器][15]和[操作系统][16]供应商建立的规则,CA 表明自己足够可靠并寻求加入到浏览器或操作系统预装的一组自签名证书中。这些证书被称为“<ruby>信任锚<rt>trust anchor</rt></ruby>”或 <ruby>CA 根证书<rt>root CA certificate</rt></ruby>,被存储在根证书区,我们<ruby>约定<rt>implicitly</rt></ruby>信任该区域内的证书。
|
||||
|
||||
CA 也可以签发一种特殊的证书,该证书自身可以作为 CA。在这种情况下,它们可以生成一个证书链。要核验证书链,需要从“信任锚”(也就是 CA 根证书)开始,使用当前证书的公钥核验下一层证书的签名(或其它一些信息)。按照这个方式依次核验下一层证书,直到证书链底部。如果整个核验过程没有问题,信任链也建立完成。当向 CA 付费为网站签发证书时,实际购买的是将证书放置在证书链下的权利。CA 将卖出的证书标记为“不可签发子证书”,这样它们可以在适当的长度终止信任链(防止其继续向下扩展)。
|
||||
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module, HSM</rt></ruby>,该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
为何要使用长度超过 2 的信任链呢?毕竟网站的证书可以直接被 CA 根证书签名。在实际应用中,很多因素促使 CA 创建<ruby>中间 CA 证书<rt>intermediate CA certificate</rt></ruby>,最主要是为了方便。由于价值连城,CA 根证书对应的私钥通常被存放在特定的设备中,一种需要多人解锁的<ruby>硬件安全模块<rt>hardware security module</rt></ruby>(HSM),该模块完全离线并被保管在配备监控和报警设备的[地下室][18]中。
|
||||
|
||||
<ruby>CA/浏览器论坛<rt>CAB Forum, CA/Browser Forum</rt></ruby>负责管理 CA,[要求][19]任何与 CA 根证书(LCTT 译注:就像前文提到的那样,这里是指对应的私钥)相关的操作必须由人工完成。设想一下,如果每个证书请求都需要员工将请求内容拷贝到保密介质中、进入地下室、与同事一起解锁 HSM、(使用 CA 根证书对应的私钥)签名证书,最后将签名证书从保密介质中拷贝出来;那么每天为大量网站签发证书是相当繁重乏味的工作。因此,CA 创建内部使用的中间 CA,用于证书签发自动化。
|
||||
|
||||
@ -72,12 +73,12 @@ via: https://opensource.com/article/18/7/private-keys
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/awood
|
||||
[1]:https://opensource.com/article/18/5/cryptography-pki
|
||||
[1]:https://linux.cn/article-9792-1.html
|
||||
[2]:https://theintercept.com/2014/10/28/smuggling-snowden-secrets/
|
||||
[3]:https://en.wikipedia.org/wiki/SHA-2
|
||||
[4]:https://www.ietf.org/mail-archive/web/openpgp/current/msg00999.html
|
||||
@ -1,26 +1,27 @@
|
||||
如何在 Linux 上使用 tcpdump 命令捕获和分析数据包
|
||||
======
|
||||
tcpdump 是一个有名的命令行**数据包分析**工具。我们可以使用 tcpdump 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 tcpdump 命令进行分析。tcpdump 命令在网络级故障排除时变得非常方便。
|
||||
|
||||
`tcpdump` 是一个有名的命令行**数据包分析**工具。我们可以使用 `tcpdump` 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 `tcpdump` 命令进行分析。`tcpdump` 命令在网络层面进行故障排除时变得非常方便。
|
||||
|
||||

|
||||
|
||||
tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 apt 命令安装它
|
||||
`tcpdump` 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 `apt` 命令安装它。
|
||||
|
||||
```
|
||||
# apt install tcpdump -y
|
||||
```
|
||||
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 yum 命令安装 tcpdump
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 `yum` 命令安装 `tcpdump`。
|
||||
|
||||
```
|
||||
# yum install tcpdump -y
|
||||
```
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口的数据包。因此,要停止或取消 tcpdump 命令,请输入 '**ctrl+c**'。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包,
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口的数据包。因此,要停止或取消 `tcpdump` 命令,请键入 `ctrl+c`。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包。
|
||||
|
||||
### 示例: 1) 从特定接口捕获数据包
|
||||
### 示例:1)从特定接口捕获数据包
|
||||
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 '**-i**',后跟接口名称。
|
||||
当我们在没用任何选项的情况下运行 `tcpdump` 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 `-i`,后跟接口名称。
|
||||
|
||||
语法:
|
||||
|
||||
@ -28,7 +29,7 @@ tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux
|
||||
# tcpdump -i {接口名}
|
||||
```
|
||||
|
||||
假设我想从接口“enp0s3”捕获数据包
|
||||
假设我想从接口 `enp0s3` 捕获数据包。
|
||||
|
||||
输出将如下所示,
|
||||
|
||||
@ -49,21 +50,21 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
### 示例: 2) 从特定接口捕获特定数量数据包
|
||||
### 示例:2)从特定接口捕获特定数量数据包
|
||||
|
||||
假设我们想从特定接口(如“enp0s3”)捕获12个数据包,这可以使用选项 '**-c {数量} -I {接口名称}**' 轻松实现
|
||||
假设我们想从特定接口(如 `enp0s3`)捕获 12 个数据包,这可以使用选项 `-c {数量} -I {接口名称}` 轻松实现。
|
||||
|
||||
```
|
||||
root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
```
|
||||
|
||||
上面的命令将生成如下所示的输出
|
||||
上面的命令将生成如下所示的输出,
|
||||
|
||||
[![N-Number-Packsets-tcpdump-interface][1]][2]
|
||||
|
||||
### 示例: 3) 显示 tcpdump 的所有可用接口
|
||||
### 示例:3)显示 tcpdump 的所有可用接口
|
||||
|
||||
使用 '**-D**' 选项显示 tcpdump 命令的所有可用接口,
|
||||
使用 `-D` 选项显示 `tcpdump` 命令的所有可用接口,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -D
|
||||
@ -86,11 +87,11 @@ root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
[[email protected] ~]#
|
||||
```
|
||||
|
||||
我正在我的一个openstack计算节点上运行tcpdump命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和vxlan接口
|
||||
我正在我的一个 openstack 计算节点上运行 `tcpdump` 命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和 vxlan 接口
|
||||
|
||||
### 示例: 4) 捕获带有可读时间戳(-tttt 选项)的数据包
|
||||
### 示例:4)捕获带有可读时间戳的数据包(`-tttt` 选项)
|
||||
|
||||
默认情况下,在tcpdump命令输出中,没有显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 '**-tttt**'选项,示例如下所示,
|
||||
默认情况下,在 `tcpdump` 命令输出中,不显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 `-tttt` 选项,示例如下所示,
|
||||
|
||||
```
|
||||
[[email protected] ~]# tcpdump -c 8 -tttt -i enp0s3
|
||||
@ -108,12 +109,11 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
134 packets received by filter
|
||||
69 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 5) 捕获数据包并将其保存到文件( -w 选项)
|
||||
### 示例:5)捕获数据包并将其保存到文件(`-w` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 '**-w**' 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
使用 `tcpdump` 命令中的 `-w` 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
|
||||
语法:
|
||||
|
||||
@ -121,9 +121,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
# tcpdump -w 文件名.pcap -i {接口名}
|
||||
```
|
||||
|
||||
注意:文件扩展名必须为 **.pcap**
|
||||
注意:文件扩展名必须为 `.pcap`。
|
||||
|
||||
假设我要把 '**enp0s3**' 接口捕获到的包保存到文件名为 **enp0s3-26082018.pcap**
|
||||
假设我要把 `enp0s3` 接口捕获到的包保存到文件名为 `enp0s3-26082018.pcap`。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
@ -140,24 +140,23 @@ tcpdump: listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 b
|
||||
[root@compute-0-1 ~]# ls
|
||||
anaconda-ks.cfg enp0s3-26082018.pcap
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
捕获并保存大小**大于 N 字节**的数据包
|
||||
捕获并保存大小**大于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-2.pcap greater 1024
|
||||
```
|
||||
|
||||
捕获并保存大小**小于 N 字节**的数据包
|
||||
捕获并保存大小**小于 N 字节**的数据包。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-3.pcap less 1024
|
||||
```
|
||||
|
||||
### 示例: 6) 从保存的文件中读取数据包( -r 选项)
|
||||
### 示例:6)从保存的文件中读取数据包(`-r` 选项)
|
||||
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 '**-r**' 从文件中读取这些数据包,例子如下所示,
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 `-r` 从文件中读取这些数据包,例子如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -r enp0s3-26082018.pcap
|
||||
@ -183,12 +182,11 @@ p,TS val 81359114 ecr 81350901], length 508
|
||||
2018-08-25 22:03:17.647502 IP controller0.example.com.amqp > compute-0-1.example.com.57788: Flags [.], ack 1956, win 1432, options [nop,nop,TS val 813
|
||||
52753 ecr 81359114], length 0
|
||||
.........................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 7) 仅捕获特定接口上的 IP 地址数据包( -n 选项)
|
||||
### 示例:7)仅捕获特定接口上的 IP 地址数据包(`-n` 选项)
|
||||
|
||||
使用 tcpdump 命令中的 -n 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
使用 `tcpdump` 命令中的 `-n` 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3
|
||||
@ -211,19 +209,18 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:22:28.539595 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1572, win 9086, options [nop,nop,TS val 20666614 ecr 82510006], length 0
|
||||
22:22:28.539760 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1572:1912, ack 1, win 291, options [nop,nop,TS val 82510007 ecr 20666614], length 340
|
||||
.........................................................................
|
||||
|
||||
```
|
||||
|
||||
您还可以使用 tcpdump 命令中的 -c 和 -N 选项捕获 N 个 IP 地址包,
|
||||
您还可以使用 `tcpdump` 命令中的 `-c` 和 `-N` 选项捕获 N 个 IP 地址包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 25 -n -i enp0s3
|
||||
```
|
||||
|
||||
|
||||
### 示例: 8) 仅捕获特定接口上的TCP数据包
|
||||
### 示例:8)仅捕获特定接口上的 TCP 数据包
|
||||
|
||||
在 tcpdump 命令中,我们能使用 '**tcp**' 选项来只捕获TCP数据包,
|
||||
在 `tcpdump` 命令中,我们能使用 `tcp` 选项来只捕获 TCP 数据包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -i enp0s3 tcp
|
||||
@ -241,9 +238,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
...................................................................................................................................................
|
||||
```
|
||||
|
||||
### 示例: 9) 从特定接口上的特定端口捕获数据包
|
||||
### 示例:9)从特定接口上的特定端口捕获数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以从特定接口 enp0s3 上的特定端口(例如 22 )捕获数据包
|
||||
使用 `tcpdump` 命令,我们可以从特定接口 `enp0s3` 上的特定端口(例如 22)捕获数据包。
|
||||
|
||||
语法:
|
||||
|
||||
@ -262,13 +259,12 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:54:55.038564 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 940, win 9177, options [nop,nop,TS val 21153238 ecr 84456505], length 0
|
||||
22:54:55.038708 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 940:1304, ack 1, win 291, options [nop,nop,TS val 84456506 ecr 21153238], length 364
|
||||
............................................................................................................................
|
||||
[root@compute-0-1 ~]#
|
||||
```
|
||||
|
||||
|
||||
### 示例: 10) 在特定接口上捕获来自特定来源 IP 的数据包
|
||||
### 示例:10)在特定接口上捕获来自特定来源 IP 的数据包
|
||||
|
||||
在tcpdump命令中,使用 '**src**' 关键字后跟 '**IP 地址**',我们可以捕获来自特定来源 IP 的数据包,
|
||||
在 `tcpdump` 命令中,使用 `src` 关键字后跟 IP 地址,我们可以捕获来自特定来源 IP 的数据包,
|
||||
|
||||
语法:
|
||||
|
||||
@ -296,17 +292,16 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
10 packets captured
|
||||
12 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例: 11) 在特定接口上捕获来自特定目的IP的数据包
|
||||
### 示例:11)在特定接口上捕获来自特定目的 IP 的数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -n -i {接口名} dst {IP 地址}
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 dst 169.144.0.1
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -318,42 +313,39 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
23:10:43.522157 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 800:996, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
23:10:43.522346 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 996:1192, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
.........................................................................................
|
||||
|
||||
```
|
||||
|
||||
### 示例: 12) 捕获两台主机之间的 TCP 数据包通信
|
||||
### 示例:12)捕获两台主机之间的 TCP 数据包通信
|
||||
|
||||
假设我想捕获两台主机 169.144.0.1 和 169.144.0.20 之间的 TCP 数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-tcp-comm.pcap -i enp0s3 tcp and \(host 169.144.0.1 or host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
使用 tcpdump 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
使用 `tcpdump` 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w ssh-comm-two-hosts.pcap -i enp0s3 src 169.144.0.1 and port 22 and dst 169.144.0.20 and port 22
|
||||
|
||||
```
|
||||
|
||||
示例: 13) 捕获两台主机之间的 UDP 网络数据包(来回)
|
||||
### 示例:13)捕获两台主机之间(来回)的 UDP 网络数据包
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -w -s -i udp and \(host and host \)
|
||||
```
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-comm.pcap -s 1000 -i enp0s3 udp and \(host 169.144.0.10 and host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
### 示例: 14) 捕获十六进制和ASCII格式的数据包
|
||||
### 示例:14)捕获十六进制和 ASCII 格式的数据包
|
||||
|
||||
使用 tcpdump 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
使用 `tcpdump` 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
|
||||
要使用** -A **选项捕获ASCII格式的数据包,示例如下所示:
|
||||
要使用 `-A` 选项捕获 ASCII 格式的数据包,示例如下所示:
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -A -i enp0s3
|
||||
@ -376,7 +368,7 @@ root@compute-0-1 @..........
|
||||
..................................................................................................................................................
|
||||
```
|
||||
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用** -XX **选项
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用 `-XX` 选项。
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -XX -i enp0s3
|
||||
@ -406,10 +398,9 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
0x0030: 3693 7c0e 0000 0101 080a 015a a734 0568 6.|........Z.4.h
|
||||
0x0040: 39af
|
||||
.......................................................................
|
||||
|
||||
```
|
||||
|
||||
这就是本文的全部内容,我希望您能了解如何使用 tcpdump 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
这就是本文的全部内容,我希望您能了解如何使用 `tcpdump` 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -418,7 +409,7 @@ via: https://www.linuxtechi.com/capture-analyze-packets-tcpdump-command-linux/
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,48 +3,46 @@
|
||||
|
||||

|
||||
|
||||
有什么好的方法,既可以宣传开源的精神又不用写代码呢?这里有个点子:“开源食堂”。在过去的8年间,这就是我们在慕尼黑做的事情。
|
||||
有什么好的方法,既可以宣传开源的精神又不用写代码呢?这里有个点子:“<ruby>开源食堂<rt>open source cooking</rt></ruby>”。在过去的 8 年间,这就是我们在慕尼黑做的事情。
|
||||
|
||||
开源食堂已经是我们常规的开源宣传活动了,因为我们发现开源与烹饪有很多共同点。
|
||||
|
||||
### 协作烹饪
|
||||
|
||||
[慕尼黑开源聚会][1]自2009年7月在[Café Netzwerk][2]创办以来,已经组织了若干次活动,活动一般在星期五的晚上组织。该聚会为开源项目工作者或者开源爱好者们提供了相互认识的方式。我们的信条是:“每四周的星期五属于免费软件(Every fourth Friday for free software)”。当然在一些周末,我们还会举办一些研讨会。那之后,我们很快加入了很多其他的活动,包括白香肠早餐、桑拿与烹饪活动。
|
||||
[慕尼黑开源聚会][1]自 2009 年 7 月在 [Café Netzwerk][2] 创办以来,已经组织了若干次活动,活动一般在星期五的晚上组织。该聚会为开源项目工作者或者开源爱好者们提供了相互认识的方式。我们的信条是:“<ruby>每四周的星期五属于自由软件<rt>Every fourth Friday for free software</rt></ruby>”。当然在一些周末,我们还会举办一些研讨会。那之后,我们很快加入了很多其他的活动,包括白香肠早餐、桑拿与烹饪活动。
|
||||
|
||||
事实上,第一次开源烹饪聚会举办的有些混乱,但是我们经过这8年来以及15次的组织,已经可以为25-30个与会者提供丰盛的美食了。
|
||||
事实上,第一次开源烹饪聚会举办的有些混乱,但是我们经过这 8 年来以及 15 次的活动,已经可以为 25-30 个与会者提供丰盛的美食了。
|
||||
|
||||
回头看看这些夜晚,我们愈发发现共同烹饪与开源社区协作之间,有很多相似之处。
|
||||
|
||||
### 烹饪步骤中的开源精神
|
||||
### 烹饪步骤中的自由开源精神
|
||||
|
||||
这里是几个烹饪与开源精神相同的地方:
|
||||
|
||||
* 我们乐于合作且朝着一个共同的目标前进
|
||||
* 我们成立社区组织
|
||||
* 我们成了一个社区
|
||||
* 由于我们有相同的兴趣与爱好,我们可以更多的了解我们自身与他人,并且可以一同协作
|
||||
* 我们也会犯错,但我们会从错误中学习,并为了共同的李医生去分享关于错误的经验,从而让彼此避免再犯相同的错误
|
||||
* 我们也会犯错,但我们会从错误中学习,并为了共同的利益去分享关于错误的经验,从而让彼此避免再犯相同的错误
|
||||
* 每个人都会贡献自己擅长的事情,因为每个人都有自己的一技之长
|
||||
* 我们会动员其他人去做出贡献并加入到我们之中
|
||||
* 虽说协作是关键,但难免会有点混乱
|
||||
* 每个人都会从中收益
|
||||
|
||||
|
||||
|
||||
### 烹饪中的开源气息
|
||||
|
||||
同很多成功的开源聚会一样,开源烹饪也需要一些协作和组织结构。在每次活动之前,我们会组织所有的成员对菜单进行投票,而不单单是直接给每个人分一角披萨,我们希望真正的作出一道美味,迄今为止我们做过日本、墨西哥、匈牙利、印度等地区风味的美食,限于篇幅就不一一列举了。
|
||||
|
||||
就像在生活中,共同烹饪一样需要各个成员之间相互的尊重和理解,所以我们也会试着为素食主义者、食物过敏者、或者对某些事物有偏好的人提供针对性的事物。正式开始烹饪之前,在家预先进行些小规模的测试会非常有帮助(乐趣!)
|
||||
就像在生活中,共同烹饪同样需要各个成员之间相互的尊重和理解,所以我们也会试着为素食主义者、食物过敏者、或者对某些事物有偏好的人提供针对性的事物。正式开始烹饪之前,在家预先进行些小规模的测试会非常有帮助(和乐趣!)
|
||||
|
||||
可扩展性也很重要,在杂货店采购必要的食材很容易就消耗掉3个小时。所以我们使用一些表格工具(自然是 LibreOffice Calc)来做一些所需要的食材以及相应的成本。
|
||||
可扩展性也很重要,在杂货店采购必要的食材很容易就消耗掉 3 个小时。所以我们使用一些表格工具(自然是 LibreOffice Calc)来做一些所需要的食材以及相应的成本。
|
||||
|
||||
我们会同志愿者一起,为每次晚餐准备一个“包管理器”,从而及时的制作出菜单并在问题产生的时候寻找一些独到的解决方法。
|
||||
我们会同志愿者一起,对于每次晚餐我们都有一个“包维护者”,从而及时的制作出菜单并在问题产生的时候寻找一些独到的解决方法。
|
||||
|
||||
虽然不是所有人都是大厨,但是只要给与一些帮助,并比较合理的分配任务和责任,就很容易让每个人都参与其中。某种程度上来说,处理 18kg 的西红柿和 100 个鸡蛋都不会让你觉得是件难事,相信我!唯一的限制是一个烤炉只有四个灶,所以可能是时候对基础设施加大投入了。
|
||||
|
||||
发布有时间要求,当然要求也不那么严格,我们通常会在21:30和01:30之间的相当“灵活”时间内供应主菜,即便如此,这个时间也是硬性的发布规定。
|
||||
发布有时间要求,当然要求也不那么严格,我们通常会在 21:30 和 01:30 之间的相当“灵活”时间内供应主菜,即便如此,这个时间也是硬性的发布规定。
|
||||
|
||||
最后,想很多开源项目一样,烹饪文档同样有提升的空间。类似洗碟子这样的扫尾工作同样也有可优化的地方。
|
||||
最后,像很多开源项目一样,烹饪文档同样有提升的空间。类似洗碟子这样的扫尾工作同样也有可优化的地方。
|
||||
|
||||
### 未来的一些新功能点
|
||||
|
||||
@ -54,21 +52,18 @@
|
||||
* 购买和烹饪一个价值 700 欧元的大南瓜,并且
|
||||
* 找家可以为我们采购提供折扣的商店
|
||||
|
||||
|
||||
最后一点,也是开源软件的动机:永远记住,还有一些人们生活在阴影中,他们为没有同等的权限去访问资源而苦恼着。我们如何通过开源的精神去帮助他们呢?
|
||||
|
||||
一想到这点,我便期待这下一次的开源烹饪聚会。如果读了上面的东西让你觉得不够完美,并且想自己运作这样的活动,我们非常乐意你能够借鉴我们的想法,甚至抄袭一个。我们也乐意你能够参与到我们其中,甚至做一些演讲和问答。
|
||||
|
||||
Article originally appeared on [blog.effenberger.org][3]. Reprinted with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-cooking
|
||||
|
||||
作者:[Florian Effenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/sd886393)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[sd886393](https://github.com/sd886393)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
110
published/20180910 3 open source log aggregation tools.md
Normal file
110
published/20180910 3 open source log aggregation tools.md
Normal file
@ -0,0 +1,110 @@
|
||||
3 个开源日志聚合工具
|
||||
======
|
||||
|
||||
> 日志聚合系统可以帮助我们进行故障排除和其它任务。以下是三个主要工具介绍。
|
||||
|
||||

|
||||
|
||||
<ruby>指标聚合<rt>metrics aggregation</rt></ruby>与<ruby>日志聚合<rt>log aggregation</rt></ruby>有何不同?日志不能包括指标吗?日志聚合系统不能做与指标聚合系统相同的事情吗?
|
||||
|
||||
这些是我经常听到的问题。我还看到供应商推销他们的日志聚合系统作为所有可观察问题的解决方案。日志聚合是一个有价值的工具,但它通常对时间序列数据的支持不够好。
|
||||
|
||||
时间序列的指标聚合系统中几个有价值的功能是专门为时间序列数据定制的<ruby>固定间隔<rt>regular interval</rt></ruby>和存储系统。固定间隔允许用户不断地收集实时的数据结果。如果要求日志聚合系统以固定间隔收集指标数据,它也可以。但是,它的存储系统没有针对指标聚合系统中典型的查询类型进行优化。使用日志聚合工具中的存储系统处理这些查询将花费更多的资源和时间。
|
||||
|
||||
所以,我们知道日志聚合系统可能不适合时间序列数据,但是它有什么好处呢?日志聚合系统是收集事件数据的好地方。这些无规律的活动是非常重要的。最好的例子为 web 服务的访问日志,这些很重要,因为我们想知道什么正在访问我们的系统,什么时候访问的。另一个例子是应用程序错误记录 —— 因为它不是正常的操作记录,所以在故障排除过程中可能很有价值的。
|
||||
|
||||
日志记录的一些规则:
|
||||
|
||||
* **须**包含时间戳
|
||||
* **须**格式化为 JSON
|
||||
* **不**记录无关紧要的事件
|
||||
* **须**记录所有应用程序的错误
|
||||
* **可**记录警告错误
|
||||
* **可**开关的日志记录
|
||||
* **须**以可读的形式记录信息
|
||||
* **不**在生产环境中记录信息
|
||||
* **不**记录任何无法阅读或反馈的内容
|
||||
|
||||
### 云的成本
|
||||
|
||||
当研究日志聚合工具时,云服务可能看起来是一个有吸引力的选择。然而,这可能会带来巨大的成本。当跨数百或数千台主机和应用程序聚合时,日志数据是大量的。在基于云的系统中,数据的接收、存储和检索是昂贵的。
|
||||
|
||||
以一个真实的系统来参考,大约 500 个节点和几百个应用程序的集合每天产生 200GB 的日志数据。这个系统可能还有改进的空间,但是在许多 SaaS 产品中,即使将它减少一半,每月也要花费将近 10000 美元。而这通常仅保留 30 天,如果你想查看一年一年的趋势数据,就不可能了。
|
||||
|
||||
并不是要不使用这些基于云的系统,尤其是对于较小的组织它们可能非常有价值的。这里的目的是指出可能会有很大的成本,当这些成本很高时,就可能令人非常的沮丧。本文的其余部分将集中讨论自托管的开源和商业解决方案。
|
||||
|
||||
### 工具选择
|
||||
|
||||
#### ELK
|
||||
|
||||
[ELK][1],即 Elasticsearch、Logstash 和 Kibana 简称,是最流行的开源日志聚合工具。它被 Netflix、Facebook、微软、LinkedIn 和思科使用。这三个组件都是由 [Elastic][2] 开发和维护的。[Elasticsearch][3] 本质上是一个 NoSQL 数据库,以 Lucene 搜索引擎实现的。[Logstash][4] 是一个日志管道系统,可以接收数据,转换数据,并将其加载到像 Elasticsearch 这样的应用中。[Kibana][5] 是 Elasticsearch 之上的可视化层。
|
||||
|
||||
几年前,引入了 Beats 。Beats 是数据采集器。它们简化了将数据运送到 Logstash 的过程。用户不需要了解每种日志的正确语法,而是可以安装一个 Beats 来正确导出 NGINX 日志或 Envoy 代理日志,以便在 Elasticsearch 中有效地使用它们。
|
||||
|
||||
安装生产环境级 ELK 套件时,可能会包括其他几个部分,如 [Kafka][6]、[Redis][7] 和 [NGINX][8]。此外,用 Fluentd 替换 Logstash 也很常见,我们将在后面讨论。这个系统操作起来很复杂,这在早期导致了很多问题和抱怨。目前,这些问题基本上已经被修复,不过它仍然是一个复杂的系统,如果你使用少部分的功能,建议不要使用它了。
|
||||
|
||||
也就是说,有其它可用的服务,所以你不必苦恼于此。可以使用 [Logz.io][9],但是如果你有很多数据,它的标价有点高。当然,你可能规模比较小,没有很多数据。如果你买不起 Logz.io,你可以看看 [AWS Elasticsearch Service][10] (ES) 。ES 是 Amazon Web Services (AWS) 提供的一项服务,它很容易就可以让 Elasticsearch 马上工作起来。它还拥有使用 Lambda 和 S3 将所有AWS 日志记录到 ES 的工具。这是一个更便宜的选择,但是需要一些管理操作,并有一些功能限制。
|
||||
|
||||
ELK 套件的母公司 Elastic [提供][11] 一款更强大的产品,它使用<ruby>开源核心<rt>open core</rt></ruby>模式,为分析工具和报告提供了额外的选项。它也可以在谷歌云平台或 AWS 上托管。由于这种工具和托管平台的组合提供了比大多数 SaaS 选项更加便宜,这也许是最好的选择,并且很有用。该系统可以有效地取代或提供 [安全信息和事件管理][12](SIEM)系统的功能。
|
||||
|
||||
ELK 套件通过 Kibana 提供了很好的可视化工具,但是它缺少警报功能。Elastic 在付费的 X-Pack 插件中提供了警报功能,但是在开源系统没有内置任何功能。Yelp 已经开发了一种解决这个问题的方法,[ElastAlert][13],不过还有其他方式。这个额外的软件相当健壮,但是它增加了已经复杂的系统的复杂性。
|
||||
|
||||
#### Graylog
|
||||
|
||||
[Graylog][14] 最近越来越受欢迎,但它是在 2010 年由 Lennart Koopmann 创建并开发的。两年后,一家公司以同样的名字诞生了。尽管它的使用者越来越多,但仍然远远落后于 ELK 套件。这也意味着它具有较少的社区开发特征,但是它可以使用与 ELK 套件相同的 Beats 。由于 Graylog Collector Sidecar 使用 [Go][15] 编写,所以 Graylog 在 Go 社区赢得了赞誉。
|
||||
|
||||
Graylog 使用 Elasticsearch、[MongoDB][16] 和底层的 Graylog Server 。这使得它像 ELK 套件一样复杂,也许还要复杂一些。然而,Graylog 附带了内置于开源版本中的报警功能,以及其他一些值得注意的功能,如流、消息重写和地理定位。
|
||||
|
||||
流功能可以允许数据在被处理时被实时路由到特定的 Stream。使用此功能,用户可以在单个 Stream 中看到所有数据库错误,在另外的 Stream 中看到 web 服务器错误。当添加新项目或超过阈值时,甚至可以基于这些 Stream 提供警报。延迟可能是日志聚合系统中最大的问题之一,Stream 消除了 Graylog 中的这一问题。一旦日志进入,它就可以通过 Stream 路由到其他系统,而无需完全处理好。
|
||||
|
||||
消息重写功能使用开源规则引擎 [Drools][17] 。允许根据用户定义的规则文件评估所有传入的消息,从而可以删除消息(称为黑名单)、添加或删除字段或修改消息。
|
||||
|
||||
Graylog 最酷的功能或许是它的地理定位功能,它支持在地图上绘制 IP 地址。这是一个相当常见的功能,在 Kibana 也可以这样使用,但是它增加了很多价值 —— 特别是如果你想将它用作 SIEM 系统。地理定位功能在系统的开源版本中提供。
|
||||
|
||||
如果你需要的话,Graylog 公司会提供对开源版本的收费支持。它还为其企业版提供了一个开源核心模式,提供存档、审计日志记录和其他支持。其它提供支持或托管服务的不太多,如果你不需要 Graylog 公司的,你可以托管。
|
||||
|
||||
#### Fluentd
|
||||
|
||||
[Fluentd][18] 是 [Treasure Data][19] 开发的,[CNCF][20] 已经将它作为一个孵化项目。它是用 C 和 Ruby 编写的,并被 [AWS][21] 和 [Google Cloud][22] 所推荐。Fluentd 已经成为许多系统中 logstach 的常用替代品。它可以作为一个本地聚合器,收集所有节点日志并将其发送到中央存储系统。它不是日志聚合系统。
|
||||
|
||||
它使用一个强大的插件系统,提供不同数据源和数据输出的快速和简单的集成功能。因为有超过 500 个插件可用,所以你的大多数用例都应该包括在内。如果没有,这听起来是一个为开源社区做出贡献的机会。
|
||||
|
||||
Fluentd 由于占用内存少(只有几十兆字节)和高吞吐量特性,是 Kubernetes 环境中的常见选择。在像 [Kubernetes][23] 这样的环境中,每个 pod 都有一个 Fluentd 附属件 ,内存消耗会随着每个新 pod 的创建而线性增加。在这种情况下,使用 Fluentd 将大大降低你的系统利用率。这对于 Java 开发的工具来说是一个常见的问题,这些工具旨在为每个节点运行一个工具,而内存开销并不是主要问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.elastic.co/webinars/introduction-elk-stack
|
||||
[2]: https://www.elastic.co/
|
||||
[3]: https://www.elastic.co/products/elasticsearch
|
||||
[4]: https://www.elastic.co/products/logstash
|
||||
[5]: https://www.elastic.co/products/kibana
|
||||
[6]: http://kafka.apache.org/
|
||||
[7]: https://redis.io/
|
||||
[8]: https://www.nginx.com/
|
||||
[9]: https://logz.io/
|
||||
[10]: https://aws.amazon.com/elasticsearch-service/
|
||||
[11]: https://www.elastic.co/cloud
|
||||
[12]: https://en.wikipedia.org/wiki/Security_information_and_event_management
|
||||
[13]: https://github.com/Yelp/elastalert
|
||||
[14]: https://www.graylog.org/
|
||||
[15]: https://opensource.com/tags/go
|
||||
[16]: https://www.mongodb.com/
|
||||
[17]: https://www.drools.org/
|
||||
[18]: https://www.fluentd.org/
|
||||
[19]: https://www.treasuredata.com/
|
||||
[20]: https://www.cncf.io/
|
||||
[21]: https://aws.amazon.com/blogs/aws/all-your-data-fluentd/
|
||||
[22]: https://cloud.google.com/logging/docs/agent/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
|
||||
@ -1,17 +1,17 @@
|
||||
使用 `top` 命令了解 Fedora 的内存使用情况
|
||||
使用 top 命令了解 Fedora 的内存使用情况
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你使用过 `top` 命令来查看 Fedora 系统中的内存使用情况,你可能会惊讶,显示的数值看起来比系统可用的内存消耗更多。下面会详细介绍内存使用情况以及如何理解这些数据。
|
||||
如果你使用过 `top` 命令来查看 Fedora 系统中的内存使用情况,你可能会惊讶,看起来消耗的数量比系统可用的内存更多。下面会详细介绍内存使用情况以及如何理解这些数据。
|
||||
|
||||
### 内存实际使用情况
|
||||
|
||||
操作系统对内存的使用方式并不是太通俗易懂,而是有很多不为人知的巧妙方式。通过这些方式,可以在无需用户干预的情况下,让操作系统更有效地使用内存。
|
||||
操作系统对内存的使用方式并不是太通俗易懂。事实上,其背后有很多不为人知的巧妙技术在发挥着作用。通过这些方式,可以在无需用户干预的情况下,让操作系统更有效地使用内存。
|
||||
|
||||
大多数应用程序都不是系统自带的,但每个应用程序都依赖于安装在系统中的库中的一些函数集。在 Fedora 中,RPM 包管理系统能够确保在安装应用程序时也会安装所依赖的库。
|
||||
|
||||
当应用程序运行时,操作系统并不需要将它要用到的所有信息都加载到物理内存中。而是会为存放代码的存储构建一个映射,称为虚拟内存。操作系统只把需要的部分加载到内存中,当某一个部分不再需要后,这一部分内存就会被释放掉。
|
||||
当应用程序运行时,操作系统并不需要将它要用到的所有信息都加载到物理内存中。而是会为存放代码的存储空间构建一个映射,称为虚拟内存。操作系统只把需要的部分加载到内存中,当某一个部分不再需要后,这一部分内存就会被释放掉。
|
||||
|
||||
这意味着应用程序可以映射大量的虚拟内存,而使用较少的系统物理内存。特殊情况下,映射的虚拟内存甚至可以比系统实际可用的物理内存更多!而且在操作系统中这种情况也并不少见。
|
||||
|
||||
@ -21,25 +21,25 @@
|
||||
|
||||
### 使用 `top` 命令查看内存使用量
|
||||
|
||||
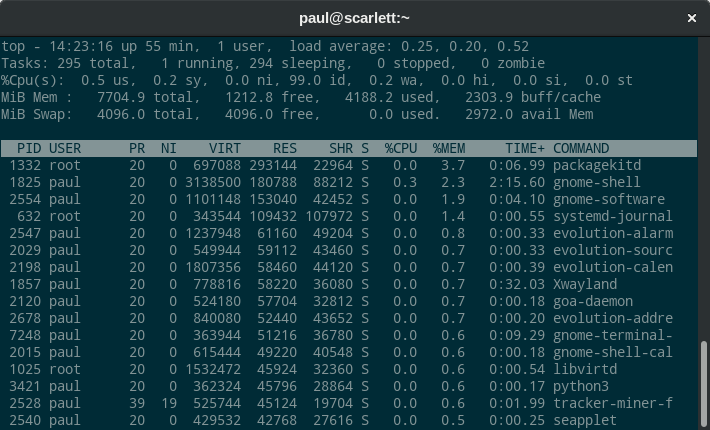
如果你还没有使用过 `top` 命令,可以打开终端直接执行查看。使用 **Shift + M** 可以按照内存使用量来进行排序。下图是在 Fedora Workstation 中执行的结果,在你的机器上显示的结果可能会略有不同:
|
||||
如果你还没有使用过 `top` 命令,可以打开终端直接执行查看。使用 `Shift + M` 可以按照内存使用量来进行排序。下图是在 Fedora Workstation 中执行的结果,在你的机器上显示的结果可能会略有不同:
|
||||
|
||||
|
||||
|
||||
主要通过一下三列来查看内存使用情况:VIRT,RES 和 SHR。目前以 KB 为单位显示相关数值。
|
||||
主要通过以下三列来查看内存使用情况:`VIRT`、`RES` 和 `SHR`。目前以 KB 为单位显示相关数值。
|
||||
|
||||
VIRT 列代表该进程映射的虚拟内存。如上所述,虚拟内存不是实际消耗的物理内存。例如, GNOME Shell 进程 gnome-shell 实际上没有消耗超过 3.1 GB 的物理内存,但它对很多更低或更高级的库都有依赖,系统必须对每个库都进行映射,以确保在有需要时可以加载这些库。
|
||||
`VIRT` 列代表该进程映射的<ruby>虚拟<rt>virtual</rt></ruby>内存。如上所述,虚拟内存不是实际消耗的物理内存。例如, GNOME Shell 进程 `gnome-shell` 实际上没有消耗超过 3.1 GB 的物理内存,但它对很多更低或更高级的库都有依赖,系统必须对每个库都进行映射,以确保在有需要时可以加载这些库。
|
||||
|
||||
RES 列代表应用程序消耗了多少实际(驻留)内存。对于 GNOME Shell 大约是 180788 KB。例子中的系统拥有大约 7704 MB 的物理内存,因此内存使用率显示为 2.3%。
|
||||
`RES` 列代表应用程序消耗了多少实际(<ruby>驻留<rt>resident</rt></ruby>)内存。对于 GNOME Shell 大约是 180788 KB。例子中的系统拥有大约 7704 MB 的物理内存,因此内存使用率显示为 2.3%。
|
||||
|
||||
但根据 SHR 列显示,其中至少有 88212 KB 是共享内存,这部分内存可能是其它应用程序也在使用的库函数。这意味着 GNOME Shell 本身大约有 92 MB 内存不与其他进程共享。需要注意的是,上述例子中的其它程序也共享了很多内存。在某些应用程序中,共享内存在内存使用量中会占很大的比例。
|
||||
但根据 `SHR` 列显示,其中至少有 88212 KB 是<ruby>共享<rt>shared</rt></ruby>内存,这部分内存可能是其它应用程序也在使用的库函数。这意味着 GNOME Shell 本身大约有 92 MB 内存不与其他进程共享。需要注意的是,上述例子中的其它程序也共享了很多内存。在某些应用程序中,共享内存在内存使用量中会占很大的比例。
|
||||
|
||||
值得一提的是,有时进程之间通过内存通信,这些内存也是共享的,但 `top` 工具却不一定能检测到,所以以上的说明也不一定准确。(这一句不太会翻译出来,烦请校对大佬帮忙看看,谢谢)
|
||||
值得一提的是,有时进程之间通过内存通信,这些内存也是共享的,但 `top` 这样的工具却不一定能检测到,所以以上的说明也不一定准确。
|
||||
|
||||
### 关于交换分区
|
||||
|
||||
系统还可以通过交换分区来存储数据(例如硬盘),但读写的速度相对较慢。当物理内存渐渐用满,操作系统就会查找内存中暂时不会使用的部分,将其写出到交换区域等待需要的时候使用。
|
||||
|
||||
因此,如果交换内存的使用量一直偏高,表明系统的物理内存已经供不应求了。尽管错误的内存申请也有可能导致出现这种情况,但如果这种现象经常出现,就需要考虑提升物理内存或者限制某些程序的运行了。
|
||||
因此,如果交换内存的使用量一直偏高,表明系统的物理内存已经供不应求了。有时候一个不正常的应用也有可能导致出现这种情况,但如果这种现象经常出现,就需要考虑提升物理内存或者限制某些程序的运行了。
|
||||
|
||||
感谢 [Stig Nygaard][1] 在 [Flickr][2] 上提供的图片(CC BY 2.0)。
|
||||
|
||||
@ -50,7 +50,7 @@ via: https://fedoramagazine.org/understand-fedora-memory-usage-top/
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,234 +0,0 @@
|
||||
Translating by qhwdw
|
||||
|
||||
# Caffeinated 6.828:Lab 2: Memory Management
|
||||
|
||||
### Introduction
|
||||
|
||||
In this lab, you will write the memory management code for your operating system. Memory management has two components.
|
||||
|
||||
The first component is a physical memory allocator for the kernel, so that the kernel can allocate memory and later free it. Your allocator will operate in units of 4096 bytes, called pages. Your task will be to maintain data structures that record which physical pages are free and which are allocated, and how many processes are sharing each allocated page. You will also write the routines to allocate and free pages of memory.
|
||||
|
||||
The second component of memory management is virtual memory, which maps the virtual addresses used by kernel and user software to addresses in physical memory. The x86 hardware’s memory management unit (MMU) performs the mapping when instructions use memory, consulting a set of page tables. You will modify JOS to set up the MMU’s page tables according to a specification we provide.
|
||||
|
||||
### Getting started
|
||||
|
||||
In this and future labs you will progressively build up your kernel. We will also provide you with some additional source. To fetch that source, use Git to commit changes you’ve made since handing in lab 1 (if any), fetch the latest version of the course repository, and then create a local branch called lab2 based on our lab2 branch, origin/lab2:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab2 origin/lab2
|
||||
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
|
||||
Switched to a new branch "lab2"
|
||||
athena%
|
||||
```
|
||||
|
||||
You will now need to merge the changes you made in your lab1 branch into the lab2 branch, as follows:
|
||||
|
||||
```
|
||||
athena% git merge lab1
|
||||
Merge made by recursive.
|
||||
kern/kdebug.c | 11 +++++++++--
|
||||
kern/monitor.c | 19 +++++++++++++++++++
|
||||
lib/printfmt.c | 7 +++----
|
||||
3 files changed, 31 insertions(+), 6 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
Lab 2 contains the following new source files, which you should browse through:
|
||||
|
||||
- inc/memlayout.h
|
||||
- kern/pmap.c
|
||||
- kern/pmap.h
|
||||
- kern/kclock.h
|
||||
- kern/kclock.c
|
||||
|
||||
memlayout.h describes the layout of the virtual address space that you must implement by modifying pmap.c. memlayout.h and pmap.h define the PageInfo structure that you’ll use to keep track of which pages of physical memory are free. kclock.c and kclock.h manipulate the PC’s battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things. The code in pmap.c needs to read this device hardware in order to figure out how much physical memory there is, but that part of the code is done for you: you do not need to know the details of how the CMOS hardware works.
|
||||
|
||||
Pay particular attention to memlayout.h and pmap.h, since this lab requires you to use and understand many of the definitions they contain. You may want to review inc/mmu.h, too, as it also contains a number of definitions that will be useful for this lab.
|
||||
|
||||
Before beginning the lab, don’t forget to add exokernel to get the 6.828 version of QEMU.
|
||||
|
||||
### Hand-In Procedure
|
||||
|
||||
When you are ready to hand in your lab code and write-up, add your answers-lab2.txt to the Git repository, commit your changes, and then run make handin.
|
||||
|
||||
```
|
||||
athena% git add answers-lab2.txt
|
||||
athena% git commit -am "my answer to lab2"
|
||||
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
|
||||
athena% make handin
|
||||
```
|
||||
|
||||
### Part 1: Physical Page Management
|
||||
|
||||
The operating system must keep track of which parts of physical RAM are free and which are currently in use. JOS manages the PC’s physical memory with page granularity so that it can use the MMU to map and protect each piece of allocated memory.
|
||||
|
||||
You’ll now write the physical page allocator. It keeps track of which pages are free with a linked list of struct PageInfo objects, each corresponding to a physical page. You need to write the physical page allocator before you can write the rest of the virtual memory implementation, because your page table management code will need to allocate physical memory in which to store page tables.
|
||||
|
||||
> Exercise 1
|
||||
>
|
||||
> In the file kern/pmap.c, you must implement code for the following functions (probably in the order given).
|
||||
>
|
||||
> boot_alloc()
|
||||
>
|
||||
> mem_init() (only up to the call to check_page_free_list())
|
||||
>
|
||||
> page_init()
|
||||
>
|
||||
> page_alloc()
|
||||
>
|
||||
> page_free()
|
||||
>
|
||||
> check_page_free_list() and check_page_alloc() test your physical page allocator. You should boot JOS and see whether check_page_alloc() reports success. Fix your code so that it passes. You may find it helpful to add your own assert()s to verify that your assumptions are correct.
|
||||
|
||||
This lab, and all the 6.828 labs, will require you to do a bit of detective work to figure out exactly what you need to do. This assignment does not describe all the details of the code you’ll have to add to JOS. Look for comments in the parts of the JOS source that you have to modify; those comments often contain specifications and hints. You will also need to look at related parts of JOS, at the Intel manuals, and perhaps at your 6.004 or 6.033 notes.
|
||||
|
||||
### Part 2: Virtual Memory
|
||||
|
||||
Before doing anything else, familiarize yourself with the x86’s protected-mode memory management architecture: namely segmentationand page translation.
|
||||
|
||||
> Exercise 2
|
||||
>
|
||||
> Look at chapters 5 and 6 of the Intel 80386 Reference Manual, if you haven’t done so already. Read the sections about page translation and page-based protection closely (5.2 and 6.4). We recommend that you also skim the sections about segmentation; while JOS uses paging for virtual memory and protection, segment translation and segment-based protection cannot be disabled on the x86, so you will need a basic understanding of it.
|
||||
|
||||
### Virtual, Linear, and Physical Addresses
|
||||
|
||||
In x86 terminology, a virtual address consists of a segment selector and an offset within the segment. A linear address is what you get after segment translation but before page translation. A physical address is what you finally get after both segment and page translation and what ultimately goes out on the hardware bus to your RAM.
|
||||
|
||||

|
||||
|
||||
Recall that in part 3 of lab 1, we installed a simple page table so that the kernel could run at its link address of 0xf0100000, even though it is actually loaded in physical memory just above the ROM BIOS at 0x00100000. This page table mapped only 4MB of memory. In the virtual memory layout you are going to set up for JOS in this lab, we’ll expand this to map the first 256MB of physical memory starting at virtual address 0xf0000000 and to map a number of other regions of virtual memory.
|
||||
|
||||
> Exercise 3
|
||||
>
|
||||
> While GDB can only access QEMU’s memory by virtual address, it’s often useful to be able to inspect physical memory while setting up virtual memory. Review the QEMU monitor commands from the lab tools guide, especially the xp command, which lets you inspect physical memory. To access the QEMU monitor, press Ctrl-a c in the terminal (the same binding returns to the serial console).
|
||||
>
|
||||
> Use the xp command in the QEMU monitor and the x command in GDB to inspect memory at corresponding physical and virtual addresses and make sure you see the same data.
|
||||
>
|
||||
> Our patched version of QEMU provides an info pg command that may also prove useful: it shows a compact but detailed representation of the current page tables, including all mapped memory ranges, permissions, and flags. Stock QEMU also provides an info mem command that shows an overview of which ranges of virtual memory are mapped and with what permissions.
|
||||
|
||||
From code executing on the CPU, once we’re in protected mode (which we entered first thing in boot/boot.S), there’s no way to directly use a linear or physical address. All memory references are interpreted as virtual addresses and translated by the MMU, which means all pointers in C are virtual addresses.
|
||||
|
||||
The JOS kernel often needs to manipulate addresses as opaque values or as integers, without dereferencing them, for example in the physical memory allocator. Sometimes these are virtual addresses, and sometimes they are physical addresses. To help document the code, the JOS source distinguishes the two cases: the type uintptr_t represents opaque virtual addresses, and physaddr_trepresents physical addresses. Both these types are really just synonyms for 32-bit integers (uint32_t), so the compiler won’t stop you from assigning one type to another! Since they are integer types (not pointers), the compiler will complain if you try to dereference them.
|
||||
|
||||
The JOS kernel can dereference a uintptr_t by first casting it to a pointer type. In contrast, the kernel can’t sensibly dereference a physical address, since the MMU translates all memory references. If you cast a physaddr_t to a pointer and dereference it, you may be able to load and store to the resulting address (the hardware will interpret it as a virtual address), but you probably won’t get the memory location you intended.
|
||||
|
||||
To summarize:
|
||||
|
||||
| C type | Address type |
|
||||
| ------------ | ------------ |
|
||||
| `T*` | Virtual |
|
||||
| `uintptr_t` | Virtual |
|
||||
| `physaddr_t` | Physical |
|
||||
|
||||
>Question
|
||||
>
|
||||
>Assuming that the following JOS kernel code is correct, what type should variable x have, >uintptr_t or physaddr_t?
|
||||
>
|
||||
>
|
||||
>
|
||||
|
||||
The JOS kernel sometimes needs to read or modify memory for which it knows only the physical address. For example, adding a mapping to a page table may require allocating physical memory to store a page directory and then initializing that memory. However, the kernel, like any other software, cannot bypass virtual memory translation and thus cannot directly load and store to physical addresses. One reason JOS remaps of all of physical memory starting from physical address 0 at virtual address 0xf0000000 is to help the kernel read and write memory for which it knows just the physical address. In order to translate a physical address into a virtual address that the kernel can actually read and write, the kernel must add 0xf0000000 to the physical address to find its corresponding virtual address in the remapped region. You should use KADDR(pa) to do that addition.
|
||||
|
||||
The JOS kernel also sometimes needs to be able to find a physical address given the virtual address of the memory in which a kernel data structure is stored. Kernel global variables and memory allocated by boot_alloc() are in the region where the kernel was loaded, starting at 0xf0000000, the very region where we mapped all of physical memory. Thus, to turn a virtual address in this region into a physical address, the kernel can simply subtract 0xf0000000. You should use PADDR(va) to do that subtraction.
|
||||
|
||||
### Reference counting
|
||||
|
||||
In future labs you will often have the same physical page mapped at multiple virtual addresses simultaneously (or in the address spaces of multiple environments). You will keep a count of the number of references to each physical page in the pp_ref field of thestruct PageInfo corresponding to the physical page. When this count goes to zero for a physical page, that page can be freed because it is no longer used. In general, this count should equal to the number of times the physical page appears below UTOP in all page tables (the mappings above UTOP are mostly set up at boot time by the kernel and should never be freed, so there’s no need to reference count them). We’ll also use it to keep track of the number of pointers we keep to the page directory pages and, in turn, of the number of references the page directories have to page table pages.
|
||||
|
||||
Be careful when using page_alloc. The page it returns will always have a reference count of 0, so pp_ref should be incremented as soon as you’ve done something with the returned page (like inserting it into a page table). Sometimes this is handled by other functions (for example, page_insert) and sometimes the function calling page_alloc must do it directly.
|
||||
|
||||
### Page Table Management
|
||||
|
||||
Now you’ll write a set of routines to manage page tables: to insert and remove linear-to-physical mappings, and to create page table pages when needed.
|
||||
|
||||
> Exercise 4
|
||||
>
|
||||
> In the file kern/pmap.c, you must implement code for the following functions.
|
||||
>
|
||||
> pgdir_walk()
|
||||
>
|
||||
> boot_map_region()
|
||||
>
|
||||
> page_lookup()
|
||||
>
|
||||
> page_remove()
|
||||
>
|
||||
> page_insert()
|
||||
>
|
||||
> check_page(), called from mem_init(), tests your page table management routines. You should make sure it reports success before proceeding.
|
||||
|
||||
### Part 3: Kernel Address Space
|
||||
|
||||
JOS divides the processor’s 32-bit linear address space into two parts. User environments (processes), which we will begin loading and running in lab 3, will have control over the layout and contents of the lower part, while the kernel always maintains complete control over the upper part. The dividing line is defined somewhat arbitrarily by the symbol ULIM in inc/memlayout.h, reserving approximately 256MB of virtual address space for the kernel. This explains why we needed to give the kernel such a high link address in lab 1: otherwise there would not be enough room in the kernel’s virtual address space to map in a user environment below it at the same time.
|
||||
|
||||
You’ll find it helpful to refer to the JOS memory layout diagram in inc/memlayout.h both for this part and for later labs.
|
||||
|
||||
### Permissions and Fault Isolation
|
||||
|
||||
Since kernel and user memory are both present in each environment’s address space, we will have to use permission bits in our x86 page tables to allow user code access only to the user part of the address space. Otherwise bugs in user code might overwrite kernel data, causing a crash or more subtle malfunction; user code might also be able to steal other environments’ private data.
|
||||
|
||||
The user environment will have no permission to any of the memory above ULIM, while the kernel will be able to read and write this memory. For the address range [UTOP,ULIM), both the kernel and the user environment have the same permission: they can read but not write this address range. This range of address is used to expose certain kernel data structures read-only to the user environment. Lastly, the address space below UTOP is for the user environment to use; the user environment will set permissions for accessing this memory.
|
||||
|
||||
### Initializing the Kernel Address Space
|
||||
|
||||
Now you’ll set up the address space above UTOP: the kernel part of the address space. inc/memlayout.h shows the layout you should use. You’ll use the functions you just wrote to set up the appropriate linear to physical mappings.
|
||||
|
||||
> Exercise 5
|
||||
>
|
||||
> Fill in the missing code in mem_init() after the call to check_page().
|
||||
|
||||
Your code should now pass the check_kern_pgdir() and check_page_installed_pgdir() checks.
|
||||
|
||||
> Question
|
||||
>
|
||||
> 1、What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
|
||||
>
|
||||
> EntryBase Virtual AddressPoints to (logically):
|
||||
>
|
||||
> 1023 ? Page table for top 4MB of phys memory
|
||||
>
|
||||
> 1022 ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> 2 0x00800000 ?
|
||||
>
|
||||
> 1 0x00400000 ?
|
||||
>
|
||||
> 0 0x00000000 [see next question]
|
||||
>
|
||||
> 2、(From 20 Lecture3) We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
|
||||
>
|
||||
> 3、What is the maximum amount of physical memory that this operating system can support? Why?
|
||||
>
|
||||
> 4、How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
|
||||
>
|
||||
> 5、Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
|
||||
|
||||
### Address Space Layout Alternatives
|
||||
|
||||
The address space layout we use in JOS is not the only one possible. An operating system might map the kernel at low linear addresses while leaving the upper part of the linear address space for user processes. x86 kernels generally do not take this approach, however, because one of the x86’s backward-compatibility modes, known as virtual 8086 mode, is “hard-wired” in the processor to use the bottom part of the linear address space, and thus cannot be used at all if the kernel is mapped there.
|
||||
|
||||
It is even possible, though much more difficult, to design the kernel so as not to have to reserve any fixed portion of the processor’s linear or virtual address space for itself, but instead effectively to allow allow user-level processes unrestricted use of the entire 4GB of virtual address space - while still fully protecting the kernel from these processes and protecting different processes from each other!
|
||||
|
||||
Generalize the kernel’s memory allocation system to support pages of a variety of power-of-two allocation unit sizes from 4KB up to some reasonable maximum of your choice. Be sure you have some way to divide larger allocation units into smaller ones on demand, and to coalesce multiple small allocation units back into larger units when possible. Think about the issues that might arise in such a system.
|
||||
|
||||
This completes the lab. Make sure you pass all of the make grade tests and don’t forget to write up your answers to the questions inanswers-lab2.txt. Commit your changes (including adding answers-lab2.txt) and type make handin in the lab directory to hand in your lab.
|
||||
|
||||
------
|
||||
|
||||
via: <https://sipb.mit.edu/iap/6.828/lab/lab2/>
|
||||
|
||||
作者:[Mit][<https://sipb.mit.edu/iap/6.828/lab/lab2/>]
|
||||
译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID)
|
||||
校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,81 +0,0 @@
|
||||
5 of the Best Linux Educational Software and Games for Kids
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux is a very powerful operating system, and that explains why it powers most of the servers on the Internet. Though it may not be the best OS in terms of user friendliness, its diversity is commendable. Everyone has their own need for Linux. Be it for coding, educational purposes or the internet of things (IoT), you’ll always find a suitable Linux distro for every use. To that end, many have dubbed Linux as the OS for future computing.
|
||||
|
||||
Because the future belongs to the kids of today, introducing them to Linux is the best way to prepare them for what the future holds. This OS may not have a reputation for popular games such as FIFA or PES; however, it offers the best educational software and games for kids. These are five of the best Linux educational software to keep your kids ahead of the game.
|
||||
|
||||
**Related** : [The Beginner’s Guide to Using a Linux Distro][1]
|
||||
|
||||
### 1. GCompris
|
||||
|
||||
If you’re looking for the best educational software for kids, [GCompris][2] should be your starting point. This software is specifically designed for kids education and is ideal for kids between two and ten years old. As the pinnacle of all Linux educational software suites for children, GCompris offers about 100 activities for kids. It packs everything you want for your kids from reading practice to science, geography, drawing, algebra, quizzes, and more.
|
||||
|
||||
![Linux educational software and games][3]
|
||||
|
||||
GCompris even has activities for helping your kids learn computer peripherals. If your kids are young and you want them to learn alphabets, colors, and shapes, GCompris has programmes for those, too. What’s more, it also comes with helpful games for kids such as chess, tic-tac-toe, memory, and hangman. GCompris is not a Linux-only app. It’s also available for Windows and Android.
|
||||
|
||||
### 2. TuxMath
|
||||
|
||||
Most students consider math a tough subject. You can change that perception by acquainting your kids with mathematical skills through Linux software applications such as [TuxMath][4]. TuxMath is a top-rated educational Math tutorial game for kids. In this game your role is to help Tux the penguin of Linux protect his planet from a rain of mathematical problems.
|
||||
|
||||
![linux-educational-software-tuxmath-1][5]
|
||||
|
||||
By finding the answer, you help Tux save the planet by destroying the asteroids with your laser before they make an impact. The difficulty of the math problems increases with each level you pass. This game is ideal for kids, as it can help them rack their brains for solutions. Besides making them good at math, it also helps them improve their mental agility.
|
||||
|
||||
### 3. Sugar on a Stick
|
||||
|
||||
[Sugar on a Stick][6] is a dedicated learning program for kids – a brand new pedagogy that has gained a lot of traction. This program provides your kids with a fully-fledged learning platform where they can gain skills in creating, exploring, discovering and also reflecting on ideas. Just like GCompris, Sugar on a Stick comes with a host of learning resources for kids, including games and puzzles.
|
||||
|
||||
![linux-educational-software-sugar-on-a-stick][7]
|
||||
|
||||
The best thing about Sugar on a Stick is that you can set it up on a USB Drive. All you need is an X86-based PC, then plug in the USB, and boot the distro from it. Sugar on a Stick is a project by Sugar Labs – a non-profit organization that is run by volunteers.
|
||||
|
||||
### 4. KDE Edu Suite
|
||||
|
||||
[KDE Edu Suite][8] is a package of software for different user purposes. With a host of applications from different fields, the KDE community has proven that it isn’t just serious about empowering adults; it also cares about bringing the young generation to speed with everything surrounding them. It comes packed with various applications for kids ranging from science to math, geography, and more.
|
||||
|
||||
![linux-educational-software-kde-1][9]
|
||||
|
||||
The KDE Suite can be used for adult needs based on necessities, as a school teaching software, or as a kid’s leaning app. It offers a huge software package and is free to download. The KDE Edu suite can be installed on most GNU/Linux Distros.
|
||||
|
||||
### 5. Tux Paint
|
||||
|
||||
![linux-educational-software-tux-paint-2][10]
|
||||
|
||||
[Tux Paint][11] is another great Linux educational software for kids. This award-winning drawing program is used in schools around the world to help children nurture the art of drawing. It comes with a clean, easy-to-use interface and fun sound effects that help children use the program. There is also an encouraging cartoon mascot that guides kids as they use the program. Tux Paint comes with a variety of drawing tools that help kids unleash their creativity.
|
||||
|
||||
### Summing Up
|
||||
|
||||
Due to the popularity of these educational software for kids, many institutions have embraced these programs as teaching aids in schools and kindergartens. A typical example is [Edubuntu][12], an Ubuntu-derived distro that is widely used by teachers and parents for educating kids.
|
||||
|
||||
Tux Paint is another great example that has grown in popularity over the years and is being used in schools to teach children how to draw. This list is by no means exhaustive. There are hundreds of other Linux educational software and games that can be very useful for your kids.
|
||||
|
||||
If you know of any other great Linux educational software and games for kids, share with us in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
|
||||
|
||||
作者:[Kenneth Kimari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/kennkimari/
|
||||
[1]:https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/ (The Beginner’s Guide to Using a Linux Distro)
|
||||
[2]:http://www.gcompris.net/downloads-en.html
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg (Linux educational software and games)
|
||||
[4]:https://tuxmath.en.uptodown.com/ubuntu
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg (linux-educational-software-tuxmath-1)
|
||||
[6]:http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png (linux-educational-software-sugar-on-a-stick)
|
||||
[8]:https://edu.kde.org/
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg (linux-educational-software-kde-1)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg (linux-educational-software-tux-paint-2)
|
||||
[11]:http://www.tuxpaint.org/
|
||||
[12]:http://edubuntu.org/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension)
|
||||
======
|
||||
A Unity feature that I miss (it only actually worked for a short while though) is automatically getting player controls in the Ubuntu Sound Indicator when visiting a website like YouTube in a web browser, so you could pause or stop the video directly from the top bar, as well as see the video / song information and a preview.
|
||||
|
||||
@ -1,74 +0,0 @@
|
||||
translated by hopefully2333
|
||||
|
||||
Steam Makes it Easier to Play Windows Games on Linux
|
||||
======
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
It’s no secret that the [Linux gaming][2] library offers only a fraction of what the Windows library offers. In fact, many people wouldn’t even consider [switching to Linux][3] simply because most of the games they want to play aren’t available on the platform.
|
||||
|
||||
At the time of writing this article, Linux has just over 5,000 games available on Steam compared to the library’s almost 27,000 total games. Now, 5,000 games may be a lot, but it isn’t 27,000 games, that’s for sure.
|
||||
|
||||
And though almost every new indie game seems to launch with a Linux release, we are still left without a way to play many [Triple-A][4] titles. For me, though there are many titles I would love the opportunity to play, this has never been a make-or-break problem since almost all of my favorite titles are available on Linux since I primarily play indie and [retro games][5] anyway.
|
||||
|
||||
### Meet Proton: a WINE Fork by Steam
|
||||
|
||||
Now, that problem is a thing of the past since this week Valve [announced][6] a new update to Steam Play that adds a forked version of Wine to the Linux and Mac Steam clients called Proton. Yes, the tool is open-source, and Valve has made the source code available on [Github][7]. The feature is still in beta though, so you must opt into the beta Steam client in order to take advantage of this functionality.
|
||||
|
||||
#### With proton, more Windows games are available for Linux on Steam
|
||||
|
||||
What does that actually mean for us Linux users? In short, it means that both Linux and Mac computers can now play all 27,000 of those games without needing to configure something like [PlayOnLinux][8] or [Lutris][9] to do so! Which, let me tell you, can be quite the headache at times.
|
||||
|
||||
The more complicated answer to this is that it sounds too good to be true for a reason. Though, in theory, you can play literally every Windows game on Linux this way, there is only a short list of games that are officially supported at launch, including DOOM, Final Fantasy VI, Tekken 7, Star Wars: Battlefront 2, and several more.
|
||||
|
||||
#### You can play all Windows games on Linux (in theory)
|
||||
|
||||
Though the list only has about 30 games thus far, you can force enable Steam to install and play any game through Proton by marking the “Enable Steam Play for all titles” checkbox. But don’t get your hopes too high. They do not guarantee the stability and performance you may be hoping for, so keep your expectations reasonable.
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
#### Experiencing Proton: Not as bad as I expected
|
||||
|
||||
For example, I installed a few moderately taxing games to put Proton through its paces. One of which was The Elder Scrolls IV: Oblivion, and in the two hours I played the game, it only crashed once, and it was almost immediately after an autosave point during the tutorial.
|
||||
|
||||
I have an Nvidia Gtx 1050 Ti, so I was able to play the game at 1080p with high settings, and I didn’t see a single problem outside of that one crash. The only negative feedback I really have is that the framerate was not nearly as high as it would have been if it was a native game. I got above 60 frames 90% of the time, but I admit it could have been better.
|
||||
|
||||
Every other game that I have installed and launched has also worked flawlessly, granted I haven’t played any of them for an extended amount of time yet. Some games I installed include The Forest, Dead Rising 4, H1Z1, and Assassin’s Creed II (can you tell I like horror games?).
|
||||
|
||||
#### Why is Steam (still) betting on Linux?
|
||||
|
||||
Now, this is all fine and dandy, but why did this happen? Why would Valve spend the time, money, and resources needed to implement something like this? I like to think they did so because they value the Linux community, but if I am honest, I don’t believe we had anything to do with it.
|
||||
|
||||
If I had to put money on it, I would say Valve has developed Proton because they haven’t given up on [Steam machines][11] yet. And since [Steam OS][12] is running on Linux, it is in their best interest financially to invest in something like this. The more games available on Steam OS, the more people might be willing to buy a Steam Machine.
|
||||
|
||||
Maybe I am wrong, but I bet this means we will see a new wave of Steam machines coming in the not-so-distant future. Maybe we will see them in one year, or perhaps we won’t see them for another five, who knows!
|
||||
|
||||
Either way, all I know is that I am beyond excited to finally play the games from my Steam library that I have slowly accumulated over the years from all of the Humble Bundles, promo codes, and random times I bought a game on sale just in case I wanted to try to get it running in Lutris.
|
||||
|
||||
#### Excited for more gaming on Linux?
|
||||
|
||||
What do you think? Are you excited about this, or are you afraid fewer developers will create native Linux games because there is almost no need to now? Does Valve love the Linux community, or do they love money? Let us know what you think in the comment section below, and check back in for more FOSS content like this.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
@ -1,3 +1,4 @@
|
||||
LuuMing translating
|
||||
How to Use the Netplan Network Configuration Tool on Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,107 @@
|
||||
Backup Installed Packages And Restore Them On Freshly Installed Ubuntu
|
||||
======
|
||||
|
||||

|
||||
|
||||
Installing the same set of packages on multiple Ubuntu systems is time consuming and boring task. You don’t want to spend your time to install the same packages over and over on multiple systems. When it comes to install packages on similar architecture Ubuntu systems, there are many methods available to make this task easier. You could simply migrate your old Ubuntu system’s applications, settings and data to a newly installed system with a couple mouse clicks using [**Aptik**][1]. Or, you can take the [**backup entire list of installed packages**][2] using your package manager (Eg. APT), and install them later on a freshly installed system. Today, I learned that there is also yet another dedicated utility available to do this job. Say hello to **apt-clone** , a simple tool that lets you to create a list of installed packages for Debian/Ubuntu systems that can be restored on freshly installed systems or containers or into a directory.
|
||||
|
||||
Apt-clone will help you on situations where you want to,
|
||||
|
||||
* Install consistent applications across multiple systems running with similar Ubuntu (and derivatives) OS.
|
||||
* Install same set of packages on multiple systems often.
|
||||
* Backup the entire list of installed applications and restore them on demand wherever and whenever necessary.
|
||||
|
||||
|
||||
|
||||
In this brief guide, we will be discussing how to install and use Apt-clone on Debian-based systems. I tested this utility on Ubuntu 18.04 LTS system, however it should work on all Debian and Ubuntu-based systems.
|
||||
|
||||
### Backup Installed Packages And Restore Them Later On Freshly Installed Ubuntu System
|
||||
|
||||
Apt-clone is available in the default repositories. To install it, just enter the following command from the Terminal:
|
||||
|
||||
```
|
||||
$ sudo apt install apt-clone
|
||||
```
|
||||
|
||||
Once installed, simply create the list of installed packages and save them in any location of your choice.
|
||||
|
||||
```
|
||||
$ mkdir ~/mypackages
|
||||
|
||||
$ sudo apt-clone clone ~/mypackages
|
||||
```
|
||||
|
||||
The above command saved all installed packages in my Ubuntu system in a file named **apt-clone-state-ubuntuserver.tar.gz** under **~/mypackages** directory.
|
||||
|
||||
To view the details of the backup file, run:
|
||||
|
||||
```
|
||||
$ apt-clone info mypackages/apt-clone-state-ubuntuserver.tar.gz
|
||||
Hostname: ubuntuserver
|
||||
Arch: amd64
|
||||
Distro: bionic
|
||||
Meta:
|
||||
Installed: 516 pkgs (33 automatic)
|
||||
Date: Sat Sep 15 10:23:05 2018
|
||||
```
|
||||
|
||||
As you can see, I have 516 packages in total in my Ubuntu server.
|
||||
|
||||
Now, copy this file on your USB or external drive and go to any other system that want to install the same set of packages. Or you can also transfer the backup file to the system on the network and install the packages by using the following command:
|
||||
|
||||
```
|
||||
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
|
||||
```
|
||||
|
||||
Please be mindful that this command will overwrite your existing **/etc/apt/sources.list** and will install/remove packages. You have been warned! Also, just make sure the destination system is on same arch and same OS. For example, if the source system is running with 18.04 LTS 64bit, the destination system must also has the same.
|
||||
|
||||
If you don’t want to restore packages on the system, you can simply use `--destination /some/location` option to debootstrap the clone into this directory.
|
||||
|
||||
```
|
||||
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz --destination ~/oldubuntu
|
||||
```
|
||||
|
||||
In this case, the above command will restore the packages in a folder named **~/oldubuntu**.
|
||||
|
||||
For more details, refer help section:
|
||||
|
||||
```
|
||||
$ apt-clone -h
|
||||
```
|
||||
|
||||
Or, man pages:
|
||||
|
||||
```
|
||||
$ man apt-clone
|
||||
```
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
+ [Systemback – Restore Ubuntu Desktop and Server to previous state][3]
|
||||
+ [Cronopete – An Apple’s Time Machine Clone For Linux][4]
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/backup-installed-packages-and-restore-them-on-freshly-installed-ubuntu-system/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/how-to-migrate-system-settings-and-data-from-an-old-system-to-a-newly-installed-ubuntu-system/
|
||||
[2]: https://www.ostechnix.com/create-list-installed-packages-install-later-list-centos-ubuntu/#comment-12598
|
||||
|
||||
[3]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
|
||||
|
||||
[4]: https://www.ostechnix.com/cronopete-apples-time-machine-clone-linux/
|
||||
@ -1,171 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Linux tricks that can save you time and trouble
|
||||
======
|
||||
Some command line tricks can make you even more productive on the Linux command line.
|
||||
|
||||

|
||||
|
||||
Good Linux command line tricks don’t only save you time and trouble. They also help you remember and reuse complex commands, making it easier for you to focus on what you need to do, not how you should go about doing it. In this post, we’ll look at some handy command line tricks that you might come to appreciate.
|
||||
|
||||
### Editing your commands
|
||||
|
||||
When making changes to a command that you're about to run on the command line, you can move your cursor to the beginning or the end of the command line to facilitate your changes using the ^a (control key plus “a”) and ^e (control key plus “e”) sequences.
|
||||
|
||||
You can also fix and rerun a previously entered command with an easy text substitution by putting your before and after strings between **^** characters -- as in ^before^after^.
|
||||
|
||||
```
|
||||
$ eho hello world <== oops!
|
||||
|
||||
Command 'eho' not found, did you mean:
|
||||
|
||||
command 'echo' from deb coreutils
|
||||
command 'who' from deb coreutils
|
||||
|
||||
Try: sudo apt install <deb name>
|
||||
|
||||
$ ^e^ec^ <== replace text
|
||||
echo hello world
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
### Logging into a remote system with just its name
|
||||
|
||||
If you log into other systems from the command line (I do this all the time), you might consider adding some aliases to your system to supply the details. Your alias can provide the username you want to use (which may or may not be the same as your username on your local system) and the identity of the remote server. Use an alias server_name=’ssh -v -l username IP-address' type of command like this:
|
||||
|
||||
```
|
||||
$ alias butterfly=”ssh -v -l jdoe 192.168.0.11”
|
||||
```
|
||||
|
||||
You can use the system name in place of the IP address if it’s listed in your /etc/hosts file or available through your DNS server.
|
||||
|
||||
And remember you can list your aliases with the **alias** command.
|
||||
|
||||
```
|
||||
$ alias
|
||||
alias butterfly='ssh -v -l jdoe 192.168.0.11'
|
||||
alias c='clear'
|
||||
alias egrep='egrep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias grep='grep --color=auto'
|
||||
alias l='ls -CF'
|
||||
alias la='ls -A'
|
||||
alias list_repos='grep ^[^#] /etc/apt/sources.list /etc/apt/sources.list.d/*'
|
||||
alias ll='ls -alF'
|
||||
alias ls='ls --color=auto'
|
||||
alias show_dimensions='xdpyinfo | grep '\''dimensions:'\'''
|
||||
```
|
||||
|
||||
It's good practice to test new aliases and then add them to your ~/.bashrc or similar file to be sure they will be available any time you log in.
|
||||
|
||||
### Freezing and thawing out your terminal window
|
||||
|
||||
The ^s (control key plus “s”) sequence will stop a terminal from providing output by running an XOFF (transmit off) flow control. This affects PuTTY sessions, as well as terminal windows on your desktop. Sometimes typed by mistake, however, the way to make the terminal window responsive again is to enter ^q (control key plus “q”). The only real trick here is remembering ^q since you aren't very likely run into this situation very often.
|
||||
|
||||
### Repeating commands
|
||||
|
||||
Linux provides many ways to reuse commands. The key to command reuse is your history buffer and the commands it collects for you. The easiest way to repeat a command is to type an ! followed by the beginning letters of a recently used command. Another is to press the up-arrow on your keyboard until you see the command you want to reuse and then press enter. You can also display previously entered commands and then type ! followed by the number shown next to the command you want to reuse in the displayed command history entries.
|
||||
|
||||
```
|
||||
!! <== repeat previous command
|
||||
!ec <== repeat last command that started with "ec"
|
||||
!76 <== repeat command #76 from command history
|
||||
```
|
||||
|
||||
### Watching a log file for updates
|
||||
|
||||
Commands such as tail -f /var/log/syslog will show you lines as they are being added to the specified log file — very useful if you are waiting for some particular activity or want to track what’s happening right now. The command will show the end of the file and then additional lines as they are added.
|
||||
|
||||
```
|
||||
$ tail -f /var/log/auth.log
|
||||
Sep 17 09:41:01 fly CRON[8071]: pam_unix(cron:session): session closed for user smmsp
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session closed for user root
|
||||
Sep 17 09:47:00 fly sshd[8124]: Accepted password for shs from 192.168.0.22 port 47792
|
||||
Sep 17 09:47:00 fly sshd[8124]: pam_unix(sshd:session): session opened for user shs by
|
||||
Sep 17 09:47:00 fly systemd-logind[776]: New session 215 of user shs.
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session closed for user root
|
||||
<== waits for additional lines to be added
|
||||
```
|
||||
|
||||
### Asking for help
|
||||
|
||||
For most Linux commands, you can enter the name of the command followed by the option **\--help** to get some fairly succinct information on what the command does and how to use it. Less extensive than the man command, the --help option often tells you just what you need to know without expanding on all of the options available.
|
||||
|
||||
```
|
||||
$ mkdir --help
|
||||
Usage: mkdir [OPTION]... DIRECTORY...
|
||||
Create the DIRECTORY(ies), if they do not already exist.
|
||||
|
||||
Mandatory arguments to long options are mandatory for short options too.
|
||||
-m, --mode=MODE set file mode (as in chmod), not a=rwx - umask
|
||||
-p, --parents no error if existing, make parent directories as needed
|
||||
-v, --verbose print a message for each created directory
|
||||
-Z set SELinux security context of each created directory
|
||||
to the default type
|
||||
--context[=CTX] like -Z, or if CTX is specified then set the SELinux
|
||||
or SMACK security context to CTX
|
||||
--help display this help and exit
|
||||
--version output version information and exit
|
||||
|
||||
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
|
||||
Full documentation at: <http://www.gnu.org/software/coreutils/mkdir>
|
||||
or available locally via: info '(coreutils) mkdir invocation'
|
||||
```
|
||||
|
||||
### Removing files with care
|
||||
|
||||
To add a little caution to your use of the rm command, you can set it up with an alias that asks you to confirm your request to delete files before it goes ahead and deletes them. Some sysadmins make this the default. In that case, you might like the next option even more.
|
||||
|
||||
```
|
||||
$ rm -i <== prompt for confirmation
|
||||
```
|
||||
|
||||
### Turning off aliases
|
||||
|
||||
You can always disable an alias interactively by using the unalias command. It doesn’t change the configuration of the alias in question; it just disables it until the next time you log in or source the file in which the alias is set up.
|
||||
|
||||
```
|
||||
$ unalias rm
|
||||
```
|
||||
|
||||
If the **rm -i** alias is set up as the default and you prefer to never have to provide confirmation before deleting files, you can put your **unalias** command in one of your startup files (e.g., ~/.bashrc).
|
||||
|
||||
### Remembering to use sudo
|
||||
|
||||
If you often forget to precede commands that only root can run with “sudo”, there are two things you can do. You can take advantage of your command history by using the “sudo !!” (use sudo to run your most recent command with sudo prepended to it), or you can turn some of these commands into aliases with the required "sudo" attached.
|
||||
|
||||
```
|
||||
$ alias update=’sudo apt update’
|
||||
```
|
||||
|
||||
### More complex tricks
|
||||
|
||||
Some useful command line tricks require a little more than a clever alias. An alias, after all, replaces a command, often inserting options so you don't have to enter them and allowing you to tack on additional information. If you want something more complex than an alias can manage, you can write a simple script or add a function to your .bashrc or other start-up file. The function below, for example, creates a directory and moves you into it. Once it's been set up, source your .bashrc or other file and you can use commands such as "md temp" to set up a directory and cd into it.
|
||||
|
||||
```
|
||||
md () { mkdir -p "$@" && cd "$1"; }
|
||||
```
|
||||
|
||||
### Wrap-up
|
||||
|
||||
Working on the Linux command line remains one of the most productive and enjoyable ways to get work done on my Linux systems, but a group of command line tricks and clever aliases can make that experience even better.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3305811/linux/linux-tricks-that-even-you-can-love.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
@ -1,124 +0,0 @@
|
||||
belitex 翻译中
|
||||
8 Python packages that will simplify your life with Django
|
||||
======
|
||||
|
||||
This month's Python column looks at Django packages that will benefit your work, personal, or side projects.
|
||||
|
||||

|
||||
|
||||
Django developers, we're devoting this month's Python column to packages that will help you. These are our favorite [Django][1] libraries for saving time, cutting down on boilerplate code, and generally simplifying our lives. We've got six packages for Django apps and two for Django's REST Framework, and we're not kidding when we say these packages show up in almost every project we work on.
|
||||
|
||||
But first, see our tips for making the [Django Admin more secure][2] and an article on 5 favorite [open source Django packages][3].
|
||||
|
||||
### A kitchen sink of useful time-savers: django-extensions
|
||||
|
||||
[Django-extensions][4] is a favorite Django package chock full of helpful tools like these management commands:
|
||||
|
||||
* **shell_plus** starts the Django shell with all your database models already loaded. No more importing from several different apps to test one complex relationship!
|
||||
* **clean_pyc** removes all .pyc projects from everywhere inside your project directory.
|
||||
* **create_template_tags** creates a template tag directory structure inside the app you specify.
|
||||
* **describe_form** displays a form definition for a model, which you can then copy/paste into forms.py. (Note that this produces a regular Django form, not a ModelForm.)
|
||||
* **notes** displays all comments with stuff like TODO, FIXME, etc. throughout your project.
|
||||
|
||||
|
||||
* **TimeStampedModel** : This base class includes the fields **created** and **modified** and a **save()** method that automatically updates these fields appropriately.
|
||||
* **ActivatorModel** : If your model will need fields like **status** , **activate_date** , and **deactivate_date** , use this base class. It comes with a manager that enables **.active()** and **.inactive()** querysets.
|
||||
* **TitleDescriptionModel** and **TitleSlugDescriptionModel** : These include the **title** and **description** fields, and the latter also includes a **slug** field. The **slug** field will automatically populate based on the **title** field.
|
||||
|
||||
|
||||
|
||||
Django-extensions also includes useful abstract base classes to use for common patterns in your own models. Inherit from these base classes when you create your models to get their:
|
||||
|
||||
Django-extensions has more features you may find useful in your projects, so take a tour through its [docs][5]!
|
||||
|
||||
### 12-factor-app settings: django-environ
|
||||
|
||||
[Django-environ][6] allows you to use [12-factor app][7] methodology to manage your settings in your Django project. It collects other libraries, including [envparse][8] and [honcho][9]. Once you install django-environ, create an .env file at your project's root. Define in that module any settings variables that may change between environments or should remain secret (like API keys, debug status, and database URLs).
|
||||
|
||||
Then, in your project's settings.py file, import **environ** and set up variables for **environ.PATH()** and **environ.Env()** according to the [example][10]. Access settings variables defined in your .env file with **env('VARIABLE_NAME')**.
|
||||
|
||||
### Creating great management commands: django-click
|
||||
|
||||
[Django-click][11], based on [Click][12] (which we have recommended [before][13]… [twice][14]), helps you write Django management commands. This library doesn't have extensive documentation, but it does have a directory of [test commands][15] in its repository that are pretty useful. A basic Hello World command would look like this:
|
||||
|
||||
```
|
||||
# app_name.management.commands.hello.py
|
||||
import djclick as click
|
||||
|
||||
@click.command()
|
||||
@click.argument('name')
|
||||
def command(name):
|
||||
click.secho(f'Hello, {name}')
|
||||
```
|
||||
|
||||
Then in the command line, run:
|
||||
|
||||
```
|
||||
>> ./manage.py hello Lacey
|
||||
Hello, Lacey
|
||||
```
|
||||
|
||||
### Handling finite state machines: django-fsm
|
||||
|
||||
[Django-fsm][16] adds support for finite state machines to your Django models. If you run a news website and need articles to process through states like Writing, Editing, and Published, django-fsm can help you define those states and manage the rules and restrictions around moving from one state to another.
|
||||
|
||||
Django-fsm provides an FSMField to use for the model attribute that defines the model instance's state. Then you can use django-fsm's **@transition** decorator to define methods that move the model instance from one state to another and handle any side effects from that transition.
|
||||
|
||||
Although django-fsm is light on documentation, [Workflows (States) in Django][17] is a gist that serves as an excellent introduction to both finite state machines and django-fsm.
|
||||
|
||||
### Contact forms: #django-contact-form
|
||||
|
||||
A contact form is such a standard thing on a website. But don't write all that boilerplate code yourself—set yours up in minutes with [django-contact-form][18]. It comes with an optional spam-filtering contact form class (and a regular, non-filtering class) and a **ContactFormView** base class with methods you can override or customize, and it walks you through the templates you will need to create to make your form work.
|
||||
|
||||
### Registering and authenticating users: django-allauth
|
||||
|
||||
[Django-allauth][19] is an app that provides views, forms, and URLs for registering users, logging them in and out, resetting their passwords, and authenticating users with outside sites like GitHub or Twitter. It supports email-as-username authentication and is extensively documented. It can be a little confusing to set up the first time you use it; follow the [installation instructions][20] carefully and read closely when you [customize your settings][21] to make sure you're using all the settings you need to enable a specific feature.
|
||||
|
||||
### Handling user authentication with Django REST Framework: django-rest-auth
|
||||
|
||||
If your Django development includes writing APIs, you're probably using [Django REST Framework][22] (DRF). If you're using DRF, you should check out [django-rest-auth][23], a package that enables endpoints for user registration, login/logout, password reset, and social media authentication (by adding django-allauth, which works well with django-rest-auth).
|
||||
|
||||
### Visualizing a Django REST Framework API: django-rest-swagger
|
||||
|
||||
[Django REST Swagger][24] provides a feature-rich user interface for interacting with your Django REST Framework API. Once you've installed Django REST Swagger and added it to installed apps, add the Swagger view and URL pattern to your urls.py file; the rest is taken care of in the docstrings of your APIs.
|
||||
|
||||
|
||||
|
||||
The UI for your API will include all your endpoints and available methods broken out by app. It will also list available operations for those endpoints and enable you to interact with the API (adding/deleting/fetching records, for example). It uses the docstrings in your API views to generate documentation for each endpoint, creating a set of API documentation for your project that's useful to you, your frontend developers, and your users.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/django-packages
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/laceynwilliams
|
||||
[1]: https://www.djangoproject.com/
|
||||
[2]: https://opensource.com/article/18/1/10-tips-making-django-admin-more-secure
|
||||
[3]: https://opensource.com/business/15/12/5-favorite-open-source-django-packages
|
||||
[4]: https://django-extensions.readthedocs.io/en/latest/
|
||||
[5]: https://django-extensions.readthedocs.io/
|
||||
[6]: https://django-environ.readthedocs.io/en/latest/
|
||||
[7]: https://www.12factor.net/
|
||||
[8]: https://github.com/rconradharris/envparse
|
||||
[9]: https://github.com/nickstenning/honcho
|
||||
[10]: https://django-environ.readthedocs.io/
|
||||
[11]: https://github.com/GaretJax/django-click
|
||||
[12]: http://click.pocoo.org/5/
|
||||
[13]: https://opensource.com/article/18/9/python-libraries-side-projects
|
||||
[14]: https://opensource.com/article/18/5/3-python-command-line-tools
|
||||
[15]: https://github.com/GaretJax/django-click/tree/master/djclick/test/testprj/testapp/management/commands
|
||||
[16]: https://github.com/viewflow/django-fsm
|
||||
[17]: https://gist.github.com/Nagyman/9502133
|
||||
[18]: https://django-contact-form.readthedocs.io/en/1.5/
|
||||
[19]: https://django-allauth.readthedocs.io/en/latest/
|
||||
[20]: https://django-allauth.readthedocs.io/en/latest/installation.html
|
||||
[21]: https://django-allauth.readthedocs.io/en/latest/configuration.html
|
||||
[22]: http://www.django-rest-framework.org/
|
||||
[23]: https://django-rest-auth.readthedocs.io/
|
||||
[24]: https://django-rest-swagger.readthedocs.io/en/latest/
|
||||
@ -0,0 +1,136 @@
|
||||
Clinews – Read News And Latest Headlines From Commandline
|
||||
======
|
||||
|
||||

|
||||
|
||||
A while ago, we have written about a CLI news client named [**InstantNews**][1] that helps you to read news and latest headlines from commandline instantly. Today, I stumbled upon a similar utility named **Clinews** which serves the same purpose – reading news and latest headlines from popular websites, blogs from Terminal. You don’t need to install GUI applications or mobile apps. You can read what’s happening in the world right from your Terminal. It is free, open source utility written using **NodeJS**.
|
||||
|
||||
### Installing Clinews
|
||||
|
||||
Since Clinews is written using NodeJS, you can install it using NPM package manager. If you haven’t install NodeJS, install it as described in the following link.
|
||||
|
||||
Once node installed, run the following command to install Clinews:
|
||||
|
||||
```
|
||||
$ npm i -g clinews
|
||||
```
|
||||
|
||||
You can also install Clinews using **Yarn** :
|
||||
|
||||
```
|
||||
$ yarn global add clinews
|
||||
```
|
||||
|
||||
Yarn itself can installed using npm
|
||||
|
||||
```
|
||||
$ npm -i yarn
|
||||
```
|
||||
|
||||
### Configure News API
|
||||
|
||||
Clinews retrieves all news headlines from [**News API**][2]. News API is a simple and easy-to-use API that returns JSON metadata for the headlines currently published on a range of news sources and blogs. It currently provides live headlines from 70 popular sources, including Ars Technica, BBC, Blooberg, CNN, Daily Mail, Engadget, ESPN, Financial Times, Google News, hacker News, IGN, Mashable, National Geographic, Reddit r/all, Reuters, Speigel Online, Techcrunch, The Guardian, The Hindu, The Huffington Post, The Newyork Times, The Next Web, The Wall street Journal, USA today and [**more**][3].
|
||||
|
||||
First, you need an API key from News API. Go to [**https://newsapi.org/register**][4] URL and register a free account to get the API key.
|
||||
|
||||
Once you got the API key from News API site, edit your **.bashrc** file:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Add newsapi API key at the end like below:
|
||||
|
||||
```
|
||||
export IN_API_KEY="Paste-API-key-here"
|
||||
|
||||
```
|
||||
|
||||
Please note that you need to paste the key inside the double quotes. Save and close the file.
|
||||
|
||||
Run the following command to update the changes.
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Done. Now let us go ahead and fetch the latest headlines from new sources.
|
||||
|
||||
### Read News And Latest Headlines From Commandline
|
||||
|
||||
To read news and latest headlines from specific new source, for example **The Hindu** , run:
|
||||
|
||||
```
|
||||
$ news fetch the-hindu
|
||||
|
||||
```
|
||||
|
||||
Here, **“the-hindu”** is the new source id (fetch id).
|
||||
|
||||
The above command will fetch latest 10 headlines from The Hindu news portel and display them in the Terminal. Also, it displays a brief description of the news, the published date and time, and the actual link to the source.
|
||||
|
||||
**Sample output:**
|
||||
|
||||
|
||||
|
||||
To read a news in your browser, hold Ctrl key and click on the URL. It will open in your default web browser.
|
||||
|
||||
To view all the sources you can get news from, run:
|
||||
|
||||
```
|
||||
$ news sources
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
|
||||
|
||||
As you see in the above screenshot, Clinews lists all news sources including the name of the news source, fetch id, description of the site, website URL and the country where it is located. As of writing this guide, Clinews currently supports 70+ news sources.
|
||||
|
||||
Clinews can also able to search for news stories across all sources matching search criteria/term. Say for example, to list all news stories with titles containing the words **“Tamilnadu”** , use the following command:
|
||||
|
||||
```
|
||||
$ news search "Tamilnadu"
|
||||
```
|
||||
|
||||
This command will scrap all news sources for stories that match term **Tamilnadu**.
|
||||
|
||||
Clinews has some extra flags that helps you to
|
||||
|
||||
* limit the amount of news stories you want to see,
|
||||
* sort news stories (top, latest, popular),
|
||||
* display news stories category wise (E.g. business, entertainment, gaming, general, music, politics, science-and-nature, sport, technology)
|
||||
|
||||
|
||||
|
||||
For more details, see the help section:
|
||||
|
||||
```
|
||||
$ clinews -h
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/clinews-read-news-and-latest-headlines-from-commandline/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/get-news-instantly-commandline-linux/
|
||||
[2]: https://newsapi.org/
|
||||
[3]: https://newsapi.org/sources
|
||||
[4]: https://newsapi.org/register
|
||||
@ -0,0 +1,104 @@
|
||||
Gunpoint is a Delight for Stealth Game Fans
|
||||
======
|
||||
Gunpoint is a 2D stealth game in which you play as a spy stealing secrets and hacking networks like Ethan Hunt of Mission Impossible movie series.
|
||||
|
||||
<https://youtu.be/QMS3s3xZFlY>
|
||||
|
||||
Hi, Fellow Linux gamers. Let’s take a look at a fun stealth game. Let’s take a look at [Gunpoint][1].
|
||||
|
||||
Gunpoint is neither free nor open source. It is an independent game you can purchase directly from the creator or from Steam.
|
||||
|
||||
![][2]
|
||||
|
||||
### The Interesting History of Gunpoint
|
||||
|
||||
> The instant success of Gunpoint enabled its creator to become a full time game developer.
|
||||
|
||||
Gunpoint is a stealth game created by [Tom Francis][3]. Francis was inspired to create the game after he heard about Spelunky, which was created by one person. Francis played games as part of his day job, as an editor for PC Gamer UK magazine. He had no previous programming experience but used the easy-to-use Game Maker. He planned to create a demo with the hopes of getting a job as a developer.
|
||||
|
||||
He released his first prototype in May 2010 under the name Private Dick. Based on the response, Francis continued to work on the game. The final version was released in June of 2013 to high praise.
|
||||
|
||||
In a [blog post][4] weeks after Gunpoint’s launch, Francis revealed that he made back all the money he spent on development ($30 for Game Maker 8) in 64 seconds. Francis didn’t reveal Gunpoint’s sales figures, but he did quit his job and today creates [games][5] full time.
|
||||
|
||||
### Experiencing the Gunpoint Gameplay
|
||||
|
||||
![Gunpoint Gameplay][6]
|
||||
|
||||
Like I said earlier, Gunpoint is a stealth game. You play a freelance spy named Richard Conway. As Conway, you will use a pair of Bullfrog hypertrousers to infiltrate buildings for clients. The hypertrousers allow you to jump very high, even through windows. You can also cling to walls or ceilings like a ninja.
|
||||
|
||||
Another tool you have is the Crosslink, which allows you to rewire circuits. Often you will need to use the Crosslink to reroute motion detections to unlock doors instead of setting off an alarm or rewire a light switch to turn off the light on another floor to distract a guard.
|
||||
|
||||
When you sneak into a building, your biggest concern is the on-site security guards. If they see Conway, they will shoot and in this game, it’s one shot one kill. You can jump off a three-story building no problem, but bullets will take you down. Thankfully, if Conway is killed you can just jump back a few seconds and try again.
|
||||
|
||||
Along the way, you will earn money to upgrade your tools and unlock new features. For example, I just unlocked the ability to rewire a guard’s gun. Don’t ask me how that works.
|
||||
|
||||
### Minimum System Requirements
|
||||
|
||||
Here are the minimum system requirements for Gunpoint:
|
||||
|
||||
##### Linux
|
||||
|
||||
* Processor: 2GHz
|
||||
* Memory: 1GB RAM
|
||||
* Video card: 512MB
|
||||
* Hard Drive: 700MB HD space
|
||||
|
||||
|
||||
|
||||
##### Windows
|
||||
|
||||
* OS: Windows XP, Visa, 7 or 8
|
||||
* Processor: 2GHz
|
||||
* Memory: 1GB RAM
|
||||
* Video card: 512MB
|
||||
* DirectX®: 9.0
|
||||
* Hard Drive: 700MB HD space
|
||||
|
||||
|
||||
|
||||
##### macOS
|
||||
|
||||
* OS: OS X 10.7 or later
|
||||
* Processor: 2GHz
|
||||
* Memory: 1GB RAM
|
||||
* Video card: 512MB
|
||||
* Hard Drive: 700MB HD space
|
||||
|
||||
|
||||
|
||||
### Thoughts on Gunpoint
|
||||
|
||||
![Gunpoint game on Linux][7]
|
||||
Image Courtesy: Steam Community
|
||||
|
||||
Gunpoint is a very fun game. The early levels are easy to get through, but the later levels make you put your thinking cap on. The hypertrousers and Crosslink are fun to play with. There is nothing like turning the lights off on a guard and bouncing over his head to hack a terminal.
|
||||
|
||||
Besides the fun mechanics, it also has an interesting [noir][8] murder mystery story. Several different (and conflicting) clients hire you to look into different aspects of the case. Some of them seem to have ulterior motives that are not in your best interest.
|
||||
|
||||
I always enjoy good mysteries and this one is no different. If you like noir or platforming games, be sure to check out [Gunpoint][1].
|
||||
|
||||
Have you every played Gunpoint? What other games should we review for your entertainment? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gunpoint-game-review/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]: http://www.gunpointgame.com/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint.jpg
|
||||
[3]: https://www.pentadact.com/
|
||||
[4]: https://www.pentadact.com/2013-06-18-gunpoint-recoups-development-costs-in-64-seconds/
|
||||
[5]: https://www.pentadact.com/2014-08-09-what-im-working-on-and-what-ive-done/
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint-gameplay-1.jpeg
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gunpoint-game-1.jpeg
|
||||
[8]: https://en.wikipedia.org/wiki/Noir_fiction
|
||||
[9]: http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,169 @@
|
||||
5 ways to play old-school games on a Raspberry Pi
|
||||
======
|
||||
|
||||
Relive the golden age of gaming with these open source platforms for Raspberry Pi.
|
||||
|
||||

|
||||
|
||||
They don't make 'em like they used to, do they? Video games, I mean.
|
||||
|
||||
Sure, there's a bit more grunt in the gear now. Princess Zelda used to be 16 pixels in each direction; there's now enough graphics power for every hair on her head. Today's processors could beat up 1988's processors in a cage-fight deathmatch without breaking a sweat.
|
||||
|
||||
But you know what's missing? The fun.
|
||||
|
||||
You've got a squillion and one buttons to learn just to get past the tutorial mission. There's probably a storyline, too. You shouldn't need a backstory to kill bad guys. All you need is jump and shoot. So, it's little wonder that one of the most enduring popular uses for a Raspberry Pi is to relive the 8- and 16-bit golden age of gaming in the '80s and early '90s. But where to start?
|
||||
|
||||
There are a few ways to play old-school games on the Pi. Each has its strengths and weaknesses, which I'll discuss here.
|
||||
|
||||
### Retropie
|
||||
|
||||
[Retropie][1] is probably the most popular retro-gaming platform for the Raspberry Pi. It's a solid all-rounder and a great default option for emulating classic desktop and console gaming systems.
|
||||
|
||||
#### What is it?
|
||||
|
||||
Retropie is built to run on [Raspbian][2]. It can also be installed over an existing Raspbian image if you'd prefer. It uses [EmulationStation][3] as a graphical front-end for a library of open source emulators, including the [Libretro][4] emulators.
|
||||
|
||||
You don't need to understand a word of that to play your games, though.
|
||||
|
||||
#### What's great about it
|
||||
|
||||
It's very easy to get started. All you need to do is burn the image to an SD card, configure your controllers, copy your games over, and start killing bad guys.
|
||||
|
||||
The huge user base means that there is a wealth of support and information out there, and active online communities to turn to for questions.
|
||||
|
||||
In addition to the emulators that come installed with the Retropie image, there's a huge library of emulators you can install from the package manager, and it's growing all the time. Retropie also offers a user-friendly menu system to manage this, saving you time.
|
||||
|
||||
From the Retropie menu, it's easy to add Kodi and the Raspbian desktop, which comes with the Chromium web browser. This means your retro-gaming rig is also good for home theatre, [YouTube][5], [SoundCloud][6], and all those other “lounge room computer” goodies.
|
||||
|
||||
Retropie also has a number of other customization options: You can change the graphics in the menus, set up different control pad configurations for different emulators, make your Raspberry Pi file system visible to your local Windows network—all sorts of stuff.
|
||||
|
||||
Retropie is built on Raspbian, which means you have the Raspberry Pi's most popular operating system to explore. Most Raspberry Pi projects and tutorials you find floating around are written for Raspbian, making it easy to customize and install new things on it. I've used my Retropie rig as a wireless bridge, installed MIDI synthesizers on it, taught myself a bit of Python, and more—all without compromising its use as a gaming machine.
|
||||
|
||||
#### What's not so great about it
|
||||
|
||||
Retropie's simple installation and ease of use is, in a way, a double-edged sword. You can go for a long time with Retropie without ever learning simple stuff like `sudo apt-get`, which means you're missing out on a lot of the Raspberry Pi experience.
|
||||
|
||||
It doesn't have to be this way; the command line is still there under the hood when you want it, but perhaps users are a bit too insulated from a Bash shell that's ultimately a lot less scary than it looks. Retropie's main menu is operable only with a control pad, which can be annoying when you don't have one plugged in because you've been using the system for things other than gaming.
|
||||
|
||||
#### Who's it for?
|
||||
|
||||
Anyone who wants to get straight into some gaming, anyone who wants the biggest and best library of emulators, and anyone who wants a great way to start exploring Linux when they're not playing games.
|
||||
|
||||
### Recalbox
|
||||
|
||||
[Recalbox][7] is a newer open source suite of emulators for the Raspberry Pi. It also supports other ARM-based small-board computers.
|
||||
|
||||
#### What is it?
|
||||
|
||||
Like Retropie, Recalbox is built on EmulationStation and Libretro. Where it differs is that it's not built on Raspbian, but on its own flavor of Linux: RecalboxOS.
|
||||
|
||||
#### What's great about it
|
||||
|
||||
The setup for Recalbox is even easier than for Retropie. You don't even need to image an SD card; simply copy some files over and go. It also has out-of-the-box support for some game controllers, getting you to Level 1 that little bit faster. Kodi comes preinstalled. This is a ready-to-go gaming and media rig.
|
||||
|
||||
#### What's not so great about it
|
||||
|
||||
Recalbox has fewer emulators than Retropie, fewer customization options, and a smaller user community.
|
||||
|
||||
Your Recalbox rig is probably always just going to be for emulators and Kodi, the same as when you installed it. If you feel like getting deeper into Linux, you'll probably want a new SD card for Raspbian.
|
||||
|
||||
#### Who's it for?
|
||||
|
||||
Recalbox is great if you want the absolute easiest retro gaming experience and can happily go without some of the more obscure gaming platforms, or if you are intimidated by the idea of doing anything a bit technical (and have no interest in growing out of that).
|
||||
|
||||
For most opensource.com readers, Recalbox will probably come in most handy to recommend to your not-so-technical friend or relative. Its super-simple setup and overall lack of options might even help you avoid having to help them with it.
|
||||
|
||||
### Roll your own
|
||||
|
||||
Ok, if you've been paying attention, you might have noticed that both Retropie and Recalbox are built from many of the same open source components. So what's to stop you from putting them together yourself?
|
||||
|
||||
#### What is it?
|
||||
|
||||
Whatever you want it to be, baby. The nature of open source software means you could use an existing emulator suite as a starting point, or pilfer from them at will.
|
||||
|
||||
#### What's great about it
|
||||
|
||||
If you have your own custom interface in mind, I guess there's nothing to do but roll your sleeves up and get to it. This is also a way to install emulators that haven't quite found their way into Retropie yet, such as [BeebEm][8] or [ArcEm][9].
|
||||
|
||||
#### What's not so great about it
|
||||
|
||||
Well, it's a bit of work, isn't it?
|
||||
|
||||
#### Who's it for?
|
||||
|
||||
Hackers, tinkerers, builders, seasoned hobbyists, and such.
|
||||
|
||||
### Native RISC OS gaming
|
||||
|
||||
Now here's a dark horse: [RISC OS][10], the original operating system for ARM devices.
|
||||
|
||||
#### What is it?
|
||||
|
||||
Before ARM went on to become the world's most popular CPU architecture, it was originally built to be the heart of the Acorn Archimedes. That's kind of a forgotten beast nowadays, but for a few years it was light years ahead as the most powerful desktop computer in the world, and it attracted a lot of games development.
|
||||
|
||||
Because the ARM processor in the Pi is the great-grandchild of the one in the Archimedes, we can still install RISC OS on it, and with a little bit of work, get these games running. This is different to the emulator options we've covered so far because we're playing our games on the operating system and CPU architecture for which they were written.
|
||||
|
||||
#### What's great about it
|
||||
|
||||
It's the perfect introduction to RISC OS. This is an absolute gem of an operating system and well worth checking out in its own right.
|
||||
|
||||
The fact that you're using much the same operating system as back in the day to load and play your games makes your retro gaming rig just that little bit more of a time machine. This definitely adds some charm and retro value to the project.
|
||||
|
||||
There are a few superb games that were released only on the Archimedes. The massive hardware advantage of the Archimedes also means that it often had the best graphics and smoothest gameplay of a lot of multi-platform titles. The rights holders to many of these games have been generous enough to make them legally available for free download.
|
||||
|
||||
#### What's not so great about it
|
||||
|
||||
Once you have installed RISC OS, it still takes a bit of elbow grease to get the games working. Here's a [guide to getting started][11].
|
||||
|
||||
This is definitely not a great all-rounder for the lounge room. There's nothing like [Kodi][12]. There's a web browser, [NetSurf][13], but it's struggling to catch up to the modern web. You won't get the range of titles to play as you would with an emulator suite. RISC OS Open is free for hobbyists to download and use and much of the source code has been made open. But despite the name, it's not a 100% open source operating system.
|
||||
|
||||
#### Who's it for?
|
||||
|
||||
This one's for novelty seekers, absolute retro heads, people who want to explore an interesting operating system from the '80s, people who are nostalgic for Acorn machines from back in the day, and people who want a totally different retro gaming project.
|
||||
|
||||
### Command line gaming
|
||||
|
||||
Do you really need to install an emulator or an exotic operating system just to relive the glory days? Why not just install some native linux games from the command line?
|
||||
|
||||
#### What is it?
|
||||
|
||||
There's a whole range of native Linux games tested to work on the [Raspberry Pi][14].
|
||||
|
||||
#### What's great about it
|
||||
|
||||
You can install most of these from packages using the command line and start playing. Easy. If you've already got Raspbian up and running, it's probably your fastest path to getting a game running.
|
||||
|
||||
#### What's not so great about it
|
||||
|
||||
This isn't, strictly speaking, actual retro gaming. Linux was born in 1991 and took a while longer to come together as a gaming platform. This isn't quite gaming from the classic 8- and 16-bit era; these are ports and retro-influenced games that were built later.
|
||||
|
||||
#### Who's it for?
|
||||
|
||||
If you're just after a bucket of fun, no problem. But if you're trying to relive the actual era, this isn't quite it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/retro-gaming-raspberry-pi
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dxmjames
|
||||
[1]: https://retropie.org.uk/
|
||||
[2]: https://www.raspbian.org/
|
||||
[3]: https://emulationstation.org/
|
||||
[4]: https://www.libretro.com/
|
||||
[5]: https://www.youtube.com/
|
||||
[6]: https://soundcloud.com/
|
||||
[7]: https://www.recalbox.com/
|
||||
[8]: http://www.mkw.me.uk/beebem/
|
||||
[9]: http://arcem.sourceforge.net/
|
||||
[10]: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||
[11]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
|
||||
[12]: https://kodi.tv/
|
||||
[13]: https://www.netsurf-browser.org/
|
||||
[14]: https://www.raspberrypi.org/forums/viewtopic.php?f=78&t=51794
|
||||
@ -0,0 +1,112 @@
|
||||
A Simple, Beautiful And Cross-platform Podcast App
|
||||
======
|
||||
|
||||

|
||||
|
||||
Podcasts have become very popular in the last few years. Podcasts are what’s called “infotainment”, they are generally light-hearted, but they generally give you valuable information. Podcasts have blown up in the last few years, and if you like something, chances are there is a podcast about it. There are a lot of podcast players out there for the Linux desktop, but if you want something that is visually beautiful, has slick animations, and works on every platform, there aren’t a lot of alternatives to **CPod**. CPod (formerly known as **Cumulonimbus** ) is an open source and slickest podcast app that works on Linux, MacOS and Windows.
|
||||
|
||||
CPod runs on something called **Electron** – a tool that allows developers to build cross-platform (E.g Windows, MacOs and Linux) desktop GUI applications. In this brief guide, we will be discussing – how to install and use CPod podcast app in Linux.
|
||||
|
||||
### Installing CPod
|
||||
|
||||
Go to the [**releases page**][1] of CPod. Download and Install the binary for your platform of choice. If you use Ubuntu/Debian, you can just download and install the .deb file from the releases page as shown below.
|
||||
|
||||
```
|
||||
$ wget https://github.com/z-------------/CPod/releases/download/v1.25.7/CPod_1.25.7_amd64.deb
|
||||
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt install gdebi
|
||||
|
||||
$ sudo gdebi CPod_1.25.7_amd64.deb
|
||||
```
|
||||
|
||||
If you use any other distribution, you probably should use the **AppImage** in the releases page.
|
||||
|
||||
Download the AppImage file from the releases page.
|
||||
|
||||
Open your terminal, and go to the directory where the AppImage file has been stored. Change the permissions to allow execution:
|
||||
|
||||
```
|
||||
$ chmod +x CPod-1.25.7-x86_64.AppImage
|
||||
```
|
||||
|
||||
Execute the AppImage File:
|
||||
|
||||
```
|
||||
$ ./CPod-1.25.7-x86_64.AppImage
|
||||
```
|
||||
|
||||
You’ll be presented a dialog asking whether to integrate the app with the system. Click **Yes** if you want to do so.
|
||||
|
||||
### Features
|
||||
|
||||
**Explore Tab**
|
||||
|
||||

|
||||
|
||||
CPod uses the Apple iTunes database to find podcasts. This is good, because the iTunes database is the biggest one out there. If there is a podcast out there, chances are it’s on iTunes. To find podcasts, just use the top search bar in the Explore section. The Explore Section also shows a few popular podcasts.
|
||||
|
||||
**Home Tab**
|
||||
|
||||

|
||||
|
||||
The Home Tab is the tab that opens by default when you open the app. The Home Tab shows a chronological list of all the episodes of all the podcasts that you have subscribed to.
|
||||
|
||||
From the home tab, you can:
|
||||
|
||||
1. Mark episodes read.
|
||||
2. Download them for offline playing
|
||||
3. Add them to the queue.
|
||||
|
||||

|
||||
|
||||
**Subscriptions Tab**
|
||||
|
||||

|
||||
|
||||
You can of course, subscribe to podcasts that you like. A few other things you can do in the Subscriptions Tab is:
|
||||
|
||||
1. Refresh Podcast Artwork
|
||||
2. Export and Import Subscriptions to/from an .OPML file.
|
||||
|
||||
|
||||
|
||||
**The Player**
|
||||
|
||||

|
||||
|
||||
The player is perhaps the most beautiful part of CPod. The app changes the overall look and feel according to the banner of the podcast. There’s a sound visualiser at the bottom. To the right, you can see and search for other episodes of this podcast.
|
||||
|
||||
**Cons/Missing Features**
|
||||
|
||||
While I love this app, there are a few features and disadvantages that CPod does have:
|
||||
|
||||
1. Poor MPRIS Integration – You can play/pause the podcast from the media player dialog of your desktop environment, but not much more. The name of the podcast is not shown, and you can go to the next/previous episode.
|
||||
2. No support for chapters.
|
||||
3. No auto-downloading – you have to manually download episodes.
|
||||
4. CPU usage during use is pretty high (even for an Electron app).
|
||||
|
||||
|
||||
|
||||
### Verdict
|
||||
|
||||
While it does have its cons, CPod is clearly the most aesthetically pleasing podcast player app out there, and it has most basic features down. If you love using visually beautiful apps, and don’t need the advanced features, this is the perfect app for you. I know for a fact that I’m going to use it.
|
||||
|
||||
Do you like CPod? Please put your opinions on the comments below!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cpod-a-simple-beautiful-and-cross-platform-podcast-app/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://github.com/z-------------/CPod/releases
|
||||
@ -0,0 +1,278 @@
|
||||
How To Find Out Which Port Number A Process Is Using In Linux
|
||||
======
|
||||
As a Linux administrator, you should know whether the corresponding service is binding/listening with correct port or not.
|
||||
|
||||
This will help you to easily troubleshoot further when you are facing port related issues.
|
||||
|
||||
A port is a logical connection that identifies a specific process on Linux. There are two kind of port are available like, physical and software.
|
||||
|
||||
Since Linux operating system is a software hence, we are going to discuss about software port.
|
||||
|
||||
Software port is always associated with an IP address of a host and the relevant protocol type for communication. The port is used to distinguish the application.
|
||||
|
||||
Most of the network related services have to open up a socket to listen incoming network requests. Socket is unique for every service.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [4 Easiest Ways To Find Out Process ID (PID) In Linux][1]
|
||||
**(#)** [3 Easy Ways To Kill Or Terminate A Process In Linux][2]
|
||||
|
||||
Socket is combination of IP address, software Port and protocol. The port numbers area available for both TCP and UDP protocol.
|
||||
|
||||
The Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) use port numbers for communication. It is a value from 0 to 65535.
|
||||
|
||||
Below are port assignments categories.
|
||||
|
||||
* `0-1023:` Well Known Ports or System Ports
|
||||
* `1024-49151:` Registered Ports for applications
|
||||
* `49152-65535:` Dynamic Ports or Private Ports
|
||||
|
||||
|
||||
|
||||
You can check the details of the reserved ports in the /etc/services file on Linux.
|
||||
|
||||
```
|
||||
# less /etc/services
|
||||
# /etc/services:
|
||||
# $Id: services,v 1.55 2013/04/14 ovasik Exp $
|
||||
#
|
||||
# Network services, Internet style
|
||||
# IANA services version: last updated 2013-04-10
|
||||
#
|
||||
# Note that it is presently the policy of IANA to assign a single well-known
|
||||
# port number for both TCP and UDP; hence, most entries here have two entries
|
||||
# even if the protocol doesn't support UDP operations.
|
||||
# Updated from RFC 1700, ``Assigned Numbers'' (October 1994). Not all ports
|
||||
# are included, only the more common ones.
|
||||
#
|
||||
# The latest IANA port assignments can be gotten from
|
||||
# http://www.iana.org/assignments/port-numbers
|
||||
# The Well Known Ports are those from 0 through 1023.
|
||||
# The Registered Ports are those from 1024 through 49151
|
||||
# The Dynamic and/or Private Ports are those from 49152 through 65535
|
||||
#
|
||||
# Each line describes one service, and is of the form:
|
||||
#
|
||||
# service-name port/protocol [aliases ...] [# comment]
|
||||
|
||||
tcpmux 1/tcp # TCP port service multiplexer
|
||||
tcpmux 1/udp # TCP port service multiplexer
|
||||
rje 5/tcp # Remote Job Entry
|
||||
rje 5/udp # Remote Job Entry
|
||||
echo 7/tcp
|
||||
echo 7/udp
|
||||
discard 9/tcp sink null
|
||||
discard 9/udp sink null
|
||||
systat 11/tcp users
|
||||
systat 11/udp users
|
||||
daytime 13/tcp
|
||||
daytime 13/udp
|
||||
qotd 17/tcp quote
|
||||
qotd 17/udp quote
|
||||
msp 18/tcp # message send protocol (historic)
|
||||
msp 18/udp # message send protocol (historic)
|
||||
chargen 19/tcp ttytst source
|
||||
chargen 19/udp ttytst source
|
||||
ftp-data 20/tcp
|
||||
ftp-data 20/udp
|
||||
# 21 is registered to ftp, but also used by fsp
|
||||
ftp 21/tcp
|
||||
ftp 21/udp fsp fspd
|
||||
ssh 22/tcp # The Secure Shell (SSH) Protocol
|
||||
ssh 22/udp # The Secure Shell (SSH) Protocol
|
||||
telnet 23/tcp
|
||||
telnet 23/udp
|
||||
# 24 - private mail system
|
||||
lmtp 24/tcp # LMTP Mail Delivery
|
||||
lmtp 24/udp # LMTP Mail Delivery
|
||||
|
||||
```
|
||||
|
||||
This can be achieved using the below six methods.
|
||||
|
||||
* `ss:` ss is used to dump socket statistics.
|
||||
* `netstat:` netstat is displays a list of open sockets.
|
||||
* `lsof:` lsof – list open files.
|
||||
* `fuser:` fuser – list process IDs of all processes that have one or more files open
|
||||
* `nmap:` nmap – Network exploration tool and security / port scanner
|
||||
* `systemctl:` systemctl – Control the systemd system and service manager
|
||||
|
||||
|
||||
|
||||
In this tutorial we are going to find out which port number the SSHD daemon is using.
|
||||
|
||||
### Method-1: Using ss Command
|
||||
|
||||
ss is used to dump socket statistics. It allows showing information similar to netstat. It can display more TCP and state informations than other tools.
|
||||
|
||||
It can display stats for all kind of sockets such as PACKET, TCP, UDP, DCCP, RAW, Unix domain, etc.
|
||||
|
||||
```
|
||||
# ss -tnlp | grep ssh
|
||||
LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
|
||||
LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
|
||||
```
|
||||
# ss -tnlp | grep ":22"
|
||||
LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
|
||||
LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
|
||||
```
|
||||
|
||||
### Method-2: Using netstat Command
|
||||
|
||||
netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
|
||||
|
||||
By default, netstat displays a list of open sockets. If you don’t specify any address families, then the active sockets of all configured address families will be printed. This program is obsolete. Replacement for netstat is ss.
|
||||
|
||||
```
|
||||
# netstat -tnlp | grep ssh
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 997/sshd
|
||||
tcp6 0 0 :::22 :::* LISTEN 997/sshd
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
|
||||
```
|
||||
# netstat -tnlp | grep ":22"
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1208/sshd
|
||||
tcp6 0 0 :::22 :::* LISTEN 1208/sshd
|
||||
```
|
||||
|
||||
### Method-3: Using lsof Command
|
||||
|
||||
lsof – list open files. The Linux lsof command lists information about files that are open by processes running on the system.
|
||||
|
||||
```
|
||||
# lsof -i -P | grep ssh
|
||||
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
|
||||
sshd 11584 root 3u IPv4 27625 0t0 TCP *:22 (LISTEN)
|
||||
sshd 11584 root 4u IPv6 27627 0t0 TCP *:22 (LISTEN)
|
||||
sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
|
||||
```
|
||||
# lsof -i tcp:22
|
||||
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
|
||||
sshd 1208 root 3u IPv4 20919 0t0 TCP *:ssh (LISTEN)
|
||||
sshd 1208 root 4u IPv6 20921 0t0 TCP *:ssh (LISTEN)
|
||||
sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
|
||||
```
|
||||
|
||||
### Method-4: Using fuser Command
|
||||
|
||||
The fuser utility shall write to standard output the process IDs of processes running on the local system that have one or more named files open.
|
||||
|
||||
```
|
||||
# fuser -v 22/tcp
|
||||
USER PID ACCESS COMMAND
|
||||
22/tcp: root 1208 F.... sshd
|
||||
root 12388 F.... sshd
|
||||
root 49339 F.... sshd
|
||||
```
|
||||
|
||||
### Method-5: Using nmap Command
|
||||
|
||||
Nmap (“Network Mapper”) is an open source tool for network exploration and security auditing. It was designed to rapidly scan large networks, although it works fine against single hosts.
|
||||
|
||||
Nmap uses raw IP packets in novel ways to determine what hosts are available on the network, what services (application name and version) those hosts are offering, what operating systems (and OS versions) they are running, what type of packet filters/firewalls are in use, and dozens of other characteristics.
|
||||
|
||||
```
|
||||
# nmap -sV -p 22 localhost
|
||||
|
||||
Starting Nmap 6.40 ( http://nmap.org ) at 2018-09-23 12:36 IST
|
||||
Nmap scan report for localhost (127.0.0.1)
|
||||
Host is up (0.000089s latency).
|
||||
Other addresses for localhost (not scanned): 127.0.0.1
|
||||
PORT STATE SERVICE VERSION
|
||||
22/tcp open ssh OpenSSH 7.4 (protocol 2.0)
|
||||
|
||||
Service detection performed. Please report any incorrect results at http://nmap.org/submit/ .
|
||||
Nmap done: 1 IP address (1 host up) scanned in 0.44 seconds
|
||||
```
|
||||
|
||||
### Method-6: Using systemctl Command
|
||||
|
||||
systemctl – Control the systemd system and service manager. This is the replacement of old SysV init system management and most of the modern Linux operating systems were adapted systemd.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][3]
|
||||
**(#)** [How To Check All Running Services In Linux][4]
|
||||
|
||||
```
|
||||
# systemctl status sshd
|
||||
● sshd.service - OpenSSH server daemon
|
||||
Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Sun 2018-09-23 02:08:56 EDT; 6h 11min ago
|
||||
Docs: man:sshd(8)
|
||||
man:sshd_config(5)
|
||||
Main PID: 11584 (sshd)
|
||||
CGroup: /system.slice/sshd.service
|
||||
└─11584 /usr/sbin/sshd -D
|
||||
|
||||
Sep 23 02:08:56 vps.2daygeek.com systemd[1]: Starting OpenSSH server daemon...
|
||||
Sep 23 02:08:56 vps.2daygeek.com sshd[11584]: Server listening on 0.0.0.0 port 22.
|
||||
Sep 23 02:08:56 vps.2daygeek.com sshd[11584]: Server listening on :: port 22.
|
||||
Sep 23 02:08:56 vps.2daygeek.com systemd[1]: Started OpenSSH server daemon.
|
||||
Sep 23 02:09:15 vps.2daygeek.com sshd[11589]: Connection closed by 103.5.134.167 port 49899 [preauth]
|
||||
Sep 23 02:09:41 vps.2daygeek.com sshd[11592]: Accepted password for root from 103.5.134.167 port 49902 ssh2
|
||||
```
|
||||
|
||||
The above out will be showing the actual listening port of SSH service when you start the SSHD service recently. Otherwise it won’t because it updates recent logs in the output frequently.
|
||||
|
||||
```
|
||||
# systemctl status sshd
|
||||
● sshd.service - OpenSSH server daemon
|
||||
Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Thu 2018-09-06 07:40:59 IST; 2 weeks 3 days ago
|
||||
Docs: man:sshd(8)
|
||||
man:sshd_config(5)
|
||||
Main PID: 1208 (sshd)
|
||||
CGroup: /system.slice/sshd.service
|
||||
├─ 1208 /usr/sbin/sshd -D
|
||||
├─23951 sshd: [accepted]
|
||||
└─23952 sshd: [net]
|
||||
|
||||
Sep 23 12:50:36 vps.2daygeek.com sshd[23909]: Invalid user pi from 95.210.113.142 port 51666
|
||||
Sep 23 12:50:36 vps.2daygeek.com sshd[23909]: input_userauth_request: invalid user pi [preauth]
|
||||
Sep 23 12:50:37 vps.2daygeek.com sshd[23911]: pam_unix(sshd:auth): check pass; user unknown
|
||||
Sep 23 12:50:37 vps.2daygeek.com sshd[23911]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=95.210.113.142
|
||||
Sep 23 12:50:37 vps.2daygeek.com sshd[23909]: pam_unix(sshd:auth): check pass; user unknown
|
||||
Sep 23 12:50:37 vps.2daygeek.com sshd[23909]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=95.210.113.142
|
||||
Sep 23 12:50:39 vps.2daygeek.com sshd[23911]: Failed password for invalid user pi from 95.210.113.142 port 51670 ssh2
|
||||
Sep 23 12:50:39 vps.2daygeek.com sshd[23909]: Failed password for invalid user pi from 95.210.113.142 port 51666 ssh2
|
||||
Sep 23 12:50:40 vps.2daygeek.com sshd[23911]: Connection closed by 95.210.113.142 port 51670 [preauth]
|
||||
Sep 23 12:50:40 vps.2daygeek.com sshd[23909]: Connection closed by 95.210.113.142 port 51666 [preauth]
|
||||
```
|
||||
|
||||
Most of the time the above output won’t shows the process actual port number. in this case i would suggest you to check the details using the below command from the journalctl log file.
|
||||
|
||||
```
|
||||
# journalctl | grep -i "openssh\|sshd"
|
||||
Sep 23 02:08:56 vps138235.vps.ovh.ca sshd[997]: Received signal 15; terminating.
|
||||
Sep 23 02:08:56 vps138235.vps.ovh.ca systemd[1]: Stopping OpenSSH server daemon...
|
||||
Sep 23 02:08:56 vps138235.vps.ovh.ca systemd[1]: Starting OpenSSH server daemon...
|
||||
Sep 23 02:08:56 vps138235.vps.ovh.ca sshd[11584]: Server listening on 0.0.0.0 port 22.
|
||||
Sep 23 02:08:56 vps138235.vps.ovh.ca sshd[11584]: Server listening on :: port 22.
|
||||
Sep 23 02:08:56 vps138235.vps.ovh.ca systemd[1]: Started OpenSSH server daemon.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-using-in-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[1]: https://www.2daygeek.com/how-to-check-find-the-process-id-pid-ppid-of-a-running-program-in-linux/
|
||||
[2]: https://www.2daygeek.com/kill-terminate-a-process-in-linux-using-kill-pkill-killall-command/
|
||||
[3]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
[4]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
@ -0,0 +1,131 @@
|
||||
HankChow translating
|
||||
|
||||
Make The Output Of Ping Command Prettier And Easier To Read
|
||||
======
|
||||
|
||||

|
||||
|
||||
As we all know, the **ping** command is used to check if a target host is reachable or not. Using Ping command, we can send ICMP Echo request to our target host, and verify whether the destination host is up or down. If you use ping command often, I’d like to recommend you to try **“Prettyping”**. Prettyping is just a wrapper for the standard ping tool and makes the output of the ping command prettier, easier to read, colorful and compact. The prettyping runs the standard ping command in the background and parses the output with colors and unicode characters. It is free and open source tool written in **Bash** and **awk** and supports most Unix-like operating systems such as GNU/Linux, FreeBSD and Mac OS X. Prettyping is not only used to make the output of ping command prettier, but also ships with other notable features as listed below.
|
||||
|
||||
* Detects the lost or missing packets and marks them in the output.
|
||||
* Shows live statistics. The statistics are constantly updated after each response is received, while ping only shows after it ends.
|
||||
* Smart enough to handle “unknown messages” (like error messages) without messing up the output.
|
||||
* Avoids printing the repeated messages.
|
||||
* You can use most common ping parameters with Prettyping.
|
||||
* Can run as normal user.
|
||||
* Can be able to redirect the output to a file.
|
||||
* Requires no installation. Just download the binary, make it executable and run.
|
||||
* Fast and lightweight.
|
||||
* And, finally makes the output pretty, colorful and very intuitive.
|
||||
|
||||
|
||||
|
||||
### Installing Prettyping
|
||||
|
||||
Like I said already, Prettyping does not requires any installation. It is portable application! Just download the Prettyping binary file using command:
|
||||
|
||||
```
|
||||
$ curl -O https://raw.githubusercontent.com/denilsonsa/prettyping/master/prettyping
|
||||
```
|
||||
|
||||
Move the binary file to your $PATH, for example **/usr/local/bin**.
|
||||
|
||||
```
|
||||
$ sudo mv prettyping /usr/local/bin
|
||||
```
|
||||
|
||||
And, make it executable as like below:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/prettyping
|
||||
```
|
||||
|
||||
It’s that simple.
|
||||
|
||||
### Let us Make The Output Of Ping Command Prettier And Easier To Read
|
||||
|
||||
Once installed, ping any host or IP address and see the ping command output in graphical way.
|
||||
|
||||
```
|
||||
$ prettyping ostechnix.com
|
||||
```
|
||||
|
||||
Here is the visually displayed ping output:
|
||||
|
||||

|
||||
|
||||
If you run Prettyping without any arguments, it will keep running until you manually stop it by pressing **Ctrl+c**.
|
||||
|
||||
Since Prettyping is just a wrapper to the ping command, you can use most common ping parameters. For instance, you can use **-c** flag to ping a host only a specific number of times, for example **5** :
|
||||
|
||||
```
|
||||
$ prettyping -c 5 ostechnix.com
|
||||
```
|
||||
|
||||
By default, prettynping displays the output in colored format. Don’t like the colored output? No problem! Use `--nocolor` option.
|
||||
|
||||
```
|
||||
$ prettyping --nocolor ostechnix.com
|
||||
```
|
||||
|
||||
Similarly, you can disable mult-color support using `--nomulticolor` option:
|
||||
|
||||
```
|
||||
$ prettyping --nomulticolor ostechnix.com
|
||||
```
|
||||
|
||||
To disable unicode characters, use `--nounicode` option:
|
||||
|
||||
|
||||
|
||||
This can be useful if your terminal does not support **UTF-8**. If you can’t fix the unicode (fonts) in your system, simply pass `--nounicode` option.
|
||||
|
||||
Prettyping can redirect the output to a file as well. The following command will write the output of `prettyping ostechnix.com` command in `ostechnix.txt` file.
|
||||
|
||||
```
|
||||
$ prettyping ostechnix.com | tee ostechnix.txt
|
||||
```
|
||||
|
||||
Prettyping has few more options which helps you to do various tasks, such as,
|
||||
|
||||
* Enable/disable the latency legend. (default value is: enabled)
|
||||
* Force the output designed to a terminal. (default: auto)
|
||||
* Use the last “n” pings at the statistics line. (default: 60)
|
||||
* Override auto-detection of terminal dimensions.
|
||||
* Override the awk interpreter. (default: awk)
|
||||
* Override the ping tool. (default: ping)
|
||||
|
||||
|
||||
|
||||
For more details, view the help section:
|
||||
|
||||
```
|
||||
$ prettyping --help
|
||||
```
|
||||
|
||||
Even though Prettyping doesn’t add any extra functionality, I personally like the following feature implementations in it:
|
||||
|
||||
* Live statistics – You can see all the live statistics all the time. The standard ping command will only shows the statistics after it ends.
|
||||
* Compact – You can see a longer timespan at your terminal.
|
||||
* Prettyping detects missing responses.
|
||||
|
||||
|
||||
|
||||
If you’re ever looking for a way to visually display the output of the ping command, Prettyping will definitely help. Give it a try, you won’t be disappointed.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/prettyping-make-the-output-of-ping-command-prettier-and-easier-to-read/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
171
sources/tech/20180924 Why Linux users should try Rust.md
Normal file
171
sources/tech/20180924 Why Linux users should try Rust.md
Normal file
@ -0,0 +1,171 @@
|
||||
Why Linux users should try Rust
|
||||
======
|
||||
|
||||

|
||||
|
||||
Rust is a fairly young and modern programming language with a lot of features that make it incredibly flexible and very secure. It's also becoming quite popular, having won first place for the "most loved programming language" in the Stack Overflow Developer Survey three years in a row — [2016][1], [2017][2], and [2018][3].
|
||||
|
||||
Rust is also an _open-source_ language with a suite of special features that allow it to be adapted to many different programming projects. It grew out of what was a personal project of a Mozilla employee back in 2006, was picked up as a special project by Mozilla a few years later (2009), and then announced for public use in 2010.
|
||||
|
||||
Rust programs run incredibly fast, prevent segfaults, and guarantee thread safety. These attributes make the language tremendously appealing to developers focused on application security. Rust is also a very readable language and one that can be used for anything from simple programs to very large and complex projects.
|
||||
|
||||
Rust is:
|
||||
|
||||
* Memory safe — Rust will not suffer from dangling pointers, buffer overflows, or other memory-related errors. And it provides memory safety without garbage collection.
|
||||
* General purpose — Rust is an appropriate language for any type of programming
|
||||
* Fast — Rust is comparable in performance to C/C++ but with far better security features.
|
||||
* Efficient — Rust is built to facilitate concurrent programming.
|
||||
* Project-oriented — Rust has a built-in dependency and build management system called Cargo.
|
||||
* Well supported — Rust has an impressive [support community][4].
|
||||
|
||||
|
||||
|
||||
Rust also enforces RAII (Resource Acquisition Is Initialization). That means when an object goes out of scope, its destructor will be called and its resources will be freed, providing a shield against resource leaks. It provides functional abstractions and a great [type system][5] together with speed and mathematical soundness.
|
||||
|
||||
In short, Rust is an impressive systems programming language with features that other most languages lack, making it a serious contender for languages like C, C++ and Objective-C that have been used for years.
|
||||
|
||||
### Installing Rust
|
||||
|
||||
Installing Rust is a fairly simple process.
|
||||
|
||||
```
|
||||
$ curl https://sh.rustup.rs -sSf | sh
|
||||
```
|
||||
|
||||
Once Rust in installed, calling rustc with the **\--version** argument or using the **which** command displays version information.
|
||||
|
||||
```
|
||||
$ which rustc
|
||||
rustc 1.27.2 (58cc626de 2018-07-18)
|
||||
$ rustc --version
|
||||
rustc 1.27.2 (58cc626de 2018-07-18)
|
||||
```
|
||||
|
||||
### Getting started with Rust
|
||||
|
||||
The simplest code example is not all that different from what you'd enter if you were using one of many scripting languages.
|
||||
|
||||
```
|
||||
$ cat hello.rs
|
||||
fn main() {
|
||||
// Print a greeting
|
||||
println!("Hello, world!");
|
||||
}
|
||||
```
|
||||
|
||||
In these lines, we are setting up a function (main), adding a comment describing the function, and using a println statement to create output. You could compile and then run a program like this using the command shown below.
|
||||
|
||||
```
|
||||
$ rustc hello.rs
|
||||
$ ./hello
|
||||
Hello, world!
|
||||
```
|
||||
|
||||
Alternately, you might create a "project" (generally used only for more complex programs than this one!) to keep your code organized.
|
||||
|
||||
```
|
||||
$ mkdir ~/projects
|
||||
$ cd ~/projects
|
||||
$ mkdir hello_world
|
||||
$ cd hello_world
|
||||
```
|
||||
|
||||
Notice that even a simple program, once compiled, becomes a fairly large executable.
|
||||
|
||||
```
|
||||
$ ./hello
|
||||
Hello, world!
|
||||
$ ls -l hello*
|
||||
-rwxrwxr-x 1 shs shs 5486784 Sep 23 19:02 hello <== executable
|
||||
-rw-rw-r-- 1 shs shs 68 Sep 23 15:25 hello.rs
|
||||
```
|
||||
|
||||
And, of course, that's just a start — the traditional "Hello, world!" program. The Rust language has a suite of features to get you moving quickly to advanced levels of programming skill.
|
||||
|
||||
### Learning Rust
|
||||
|
||||
![rust programming language book cover][6]
|
||||
No Starch Press
|
||||
|
||||
The Rust Programming Language book by Steve Klabnik and Carol Nichols (2018) provides one of the best ways to learn Rust. Written by two members of the core development team, this book is available in print from [No Starch Press][7] or in ebook format at [rust-lang.org][8]. It has earned its reference as "the book" among the Rust developer community.
|
||||
|
||||
Among the many topics covered, you will learn about these advanced topics:
|
||||
|
||||
* Ownership and borrowing
|
||||
* Safety guarantees
|
||||
* Testing and error handling
|
||||
* Smart pointers and multi-threading
|
||||
* Advanced pattern matching
|
||||
* Using Cargo (the built-in package manager)
|
||||
* Using Rust's advanced compiler
|
||||
|
||||
|
||||
|
||||
#### Table of Contents
|
||||
|
||||
The table of contents is shown below.
|
||||
|
||||
```
|
||||
Foreword by Nicholas Matsakis and Aaron Turon
|
||||
Acknowledgements
|
||||
Introduction
|
||||
Chapter 1: Getting Started
|
||||
Chapter 2: Guessing Game
|
||||
Chapter 3: Common Programming Concepts
|
||||
Chapter 4: Understanding Ownership
|
||||
Chapter 5: Structs
|
||||
Chapter 6: Enums and Pattern Matching
|
||||
Chapter 7: Modules
|
||||
Chapter 8: Common Collections
|
||||
Chapter 9: Error Handling
|
||||
Chapter 10: Generic Types, Traits, and Lifetimes
|
||||
Chapter 11: Testing
|
||||
Chapter 12: An Input/Output Project
|
||||
Chapter 13: Iterators and Closures
|
||||
Chapter 14: More About Cargo and Crates.io
|
||||
Chapter 15: Smart Pointers
|
||||
Chapter 16: Concurrency
|
||||
Chapter 17: Is Rust Object Oriented?
|
||||
Chapter 18: Patterns
|
||||
Chapter 19: More About Lifetimes
|
||||
Chapter 20: Advanced Type System Features
|
||||
Appendix A: Keywords
|
||||
Appendix B: Operators and Symbols
|
||||
Appendix C: Derivable Traits
|
||||
Appendix D: Macros
|
||||
Index
|
||||
|
||||
```
|
||||
|
||||
[The Rust Programming Language][7] takes you from basic installation and language syntax to complex topics, such as modules, error handling, crates (synonymous with a ‘library’ or ‘package’ in other languages), modules (allowing you to partition your code within the crate itself), lifetimes, etc.
|
||||
|
||||
Probably the most important thing to say is that the book can move you from basic programming skills to building and compiling complex, secure and very useful programs.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
If you're ready to get into some serious programming with a language that's well worth the time and effort to study and becoming increasingly popular, Rust is a good bet!
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3308162/linux/why-you-should-try-rust.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://insights.stackoverflow.com/survey/2016#technology-most-loved-dreaded-and-wanted
|
||||
[2]: https://insights.stackoverflow.com/survey/2017#technology-most-loved-dreaded-and-wanted-languages
|
||||
[3]: https://insights.stackoverflow.com/survey/2018#technology-most-loved-dreaded-and-wanted-languages
|
||||
[4]: https://www.rust-lang.org/en-US/community.html
|
||||
[5]: https://doc.rust-lang.org/reference/type-system.html
|
||||
[6]: https://images.idgesg.net/images/article/2018/09/rust-programming-language_book-cover-100773679-small.jpg
|
||||
[7]: https://nostarch.com/Rust
|
||||
[8]: https://doc.rust-lang.org/book/2018-edition/index.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,160 @@
|
||||
How to Replace one Linux Distro With Another in Dual Boot [Guide]
|
||||
======
|
||||
**If you have a Linux distribution installed, you can replace it with another distribution in the dual boot. You can also keep your personal documents while switching the distribution.**
|
||||
|
||||
![How to Replace One Linux Distribution With Another From Dual Boot][1]
|
||||
|
||||
Suppose you managed to [successfully dual boot Ubuntu and Windows][2]. But after reading the [Linux Mint versus Ubuntu discussion][3], you realized that [Linux Mint][4] is more suited for your needs. What would you do now? How would you [remove Ubuntu][5] and [install Mint in dual boot][6]?
|
||||
|
||||
You might think that you need to uninstall [Ubuntu][7] from dual boot first and then repeat the dual booting steps with Linux Mint. Let me tell you something. You don’t need to do all of that.
|
||||
|
||||
If you already have a Linux distribution installed in dual boot, you can easily replace it with another. You don’t have to uninstall the existing Linux distribution. You simply delete its partition and install the new distribution on the disk space vacated by the previous distribution.
|
||||
|
||||
Another good news is that you may be able to keep your Home directory with all your documents and pictures while switching the Linux distributions.
|
||||
|
||||
Let me show you how to switch Linux distributions.
|
||||
|
||||
### Replace one Linux with another from dual boot
|
||||
|
||||
<https://youtu.be/ptF2RUehbKs>
|
||||
|
||||
Let me describe the scenario I am going to use here. I have Linux Mint 19 installed on my system in dual boot mode with Windows 10. I am going to replace it with elementary OS 5. I’ll also keep my personal files (music, pictures, videos, documents from my home directory) while switching distributions.
|
||||
|
||||
Let’s first take a look at the requirements:
|
||||
|
||||
* A system with Linux and Windows dual boot
|
||||
* Live USB of Linux you want to install
|
||||
* Backup of your important files in Windows and in Linux on an external disk (optional yet recommended)
|
||||
|
||||
|
||||
|
||||
#### Things to keep in mind for keeping your home directory while changing Linux distribution
|
||||
|
||||
If you want to keep your files from existing Linux install as it is, you must have a separate root and home directory. You might have noticed that in my [dual boot tutorials][8], I always go for ‘Something Else’ option and then manually create root and home partitions instead of choosing ‘Install alongside Windows’ option. This is where all the troubles in manually creating separate home partition pay off.
|
||||
|
||||
Keeping Home on a separate partition is helpful in situations when you want to replace your existing Linux install with another without losing your files.
|
||||
|
||||
Note: You must remember the exact username and password of your existing Linux install in order to use the same home directory as it is in the new distribution.
|
||||
|
||||
If you don’t have a separate Home partition, you may create it later as well BUT I won’t recommend that. That process is slightly complicated and I don’t want you to mess up your system.
|
||||
|
||||
With that much background information, it’s time to see how to replace a Linux distribution with another.
|
||||
|
||||
#### Step 1: Create a live USB of the new Linux distribution
|
||||
|
||||
Alright! I already mentioned it in the requirements but I still included it in the main steps to avoid confusion.
|
||||
|
||||
You can create a live USB using a start up disk creator like [Etcher][9] in Windows or Linux. The process is simple so I am not going to list the steps here.
|
||||
|
||||
#### Step 2: Boot into live USB and proceed to installing Linux
|
||||
|
||||
Since you have already dual booted before, you probably know the drill. Plugin the live USB, restart your system and at the boot time, press F10 or F12 repeatedly to enter BIOS settings.
|
||||
|
||||
In here, choose to boot from the USB. And then you’ll see the option to try the live environment or installing it immediately.
|
||||
|
||||
You should start the installation procedure. When you reach the ‘Installation type’ screen, choose the ‘Something else’ option.
|
||||
|
||||
![Replacing one Linux with another from dual boot][10]
|
||||
Select ‘Something else’ here
|
||||
|
||||
#### Step 3: Prepare the partition
|
||||
|
||||
You’ll see the partitioning screen now. Look closely and you’ll see your Linux installation with Ext4 file system type.
|
||||
|
||||
![Identifying Linux partition in dual boot][11]
|
||||
Identify where your Linux is installed
|
||||
|
||||
In the above picture, the Ext4 partition labeled as Linux Mint 19 is the root partition. The second Ext4 partition of 82691 MB is the Home partition. I [haven’t used any swap space][12] here.
|
||||
|
||||
Now, if you have just one Ext4 partition, that means that your home directory is on the same partition as root. In this case, you won’t be able to keep your Home directory. I suggest that you copy the important files to an external disk else you’ll lose them forever.
|
||||
|
||||
It’s time to delete the root partition. Select the root partition and click the – sign. This will create some free space.
|
||||
|
||||
![Delete root partition of your existing Linux install][13]
|
||||
Delete root partition
|
||||
|
||||
When you have the free space, click on + sign.
|
||||
|
||||
![Create root partition for the new Linux][14]
|
||||
Create a new root partition
|
||||
|
||||
Now you should create a new partition out of this free space. If you had just one root partition in your previous Linux install, you should create root and home partitions here. You can also create the swap partition if you want to.
|
||||
|
||||
If you had root and home partition separately, just create a root partition from the deleted root partition.
|
||||
|
||||
![Create root partition for the new Linux][15]
|
||||
Creating root partition
|
||||
|
||||
You may ask why did I use delete and add instead of using the ‘change’ option. It’s because a few years ago, using change didn’t work for me. So I prefer to do a – and +. Is it superstition? Maybe.
|
||||
|
||||
One important thing to do here is to mark the newly created partition for format. f you don’t change the size of the partition, it won’t be formatted unless you explicitly ask it to format. And if the partition is not formatted, you’ll have issues.
|
||||
|
||||
![][16]
|
||||
It’s important to format the root partition
|
||||
|
||||
Now if you already had a separate Home partition on your existing Linux install, you should select it and click on change.
|
||||
|
||||
![Recreate home partition][17]
|
||||
Retouch the already existing home partition (if any)
|
||||
|
||||
You just have to specify that you are mounting it as home partition.
|
||||
|
||||
![Specify the home mount point][18]
|
||||
Specify the home mount point
|
||||
|
||||
If you had a swap partition, you can repeat the same steps as the home partition. This time specify that you want to use the space as swap.
|
||||
|
||||
At this stage, you should have a root partition (with format option selected) and a home partition (and a swap if you want to). Hit the install now button to start the installation.
|
||||
|
||||
![Verify partitions while replacing one Linux with another][19]
|
||||
Verify the partitions
|
||||
|
||||
The next few screens would be familiar to you. What matters is the screen where you are asked to create user and password.
|
||||
|
||||
If you had a separate home partition previously and you want to use the same home directory, you MUST use the same username and password that you had before. Computer name doesn’t matter.
|
||||
|
||||
![To keep the home partition intact, use the previous user and password][20]
|
||||
To keep the home partition intact, use the previous user and password
|
||||
|
||||
Your struggle is almost over. You don’t have to do anything else other than waiting for the installation to finish.
|
||||
|
||||
![Wait for installation to finish][21]
|
||||
Wait for installation to finish
|
||||
|
||||
Once the installation is over, restart your system. You’ll have a new Linux distribution or version.
|
||||
|
||||
In my case, I had the entire home directory of Linux Mint 19 as it is in the elementary OS. All the videos, pictures I had remained as it is. Isn’t that nice?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/replace-linux-from-dual-boot/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Replace-Linux-Distro-from-dual-boot.png
|
||||
[2]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[3]: https://itsfoss.com/linux-mint-vs-ubuntu/
|
||||
[4]: https://www.linuxmint.com/
|
||||
[5]: https://itsfoss.com/uninstall-ubuntu-linux-windows-dual-boot/
|
||||
[6]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[7]: https://www.ubuntu.com/
|
||||
[8]: https://itsfoss.com/guide-install-elementary-os-luna/
|
||||
[9]: https://etcher.io/
|
||||
[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-1.jpg
|
||||
[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-2.jpg
|
||||
[12]: https://itsfoss.com/swap-size/
|
||||
[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-3.jpg
|
||||
[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-4.jpg
|
||||
[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-5.jpg
|
||||
[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-6.jpg
|
||||
[17]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-7.jpg
|
||||
[18]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-8.jpg
|
||||
[19]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-9.jpg
|
||||
[20]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-10.jpg
|
||||
[21]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/replace-linux-with-another-11.jpg
|
||||
@ -0,0 +1,161 @@
|
||||
Taking the Audiophile Linux distro for a spin
|
||||
======
|
||||
|
||||
This lightweight open source audio OS offers a rich feature set and high-quality digital sound.
|
||||
|
||||

|
||||
|
||||
I recently stumbled on the [Audiophile Linux project][1], one of a number of special-purpose music-oriented Linux distributions. Audiophile Linux:
|
||||
|
||||
1. is based on [ArchLinux][2]
|
||||
|
||||
2. provides a real-time Linux kernel customized for playing music
|
||||
|
||||
3. uses the lightweight [Fluxbox][3] window manager
|
||||
|
||||
4. avoids unnecessary daemons and services
|
||||
|
||||
5. allows playback of DSF and supports the usual PCM formats
|
||||
|
||||
6. supports various music players, including one of my favorite combos: MPD + Cantata
|
||||
|
||||
|
||||
|
||||
|
||||
The Audiophile Linux site hasn’t shown a lot of activity since April 2017, but it does contain some updates and commentary from this year. Given its orientation and feature set, I decided to take it for a spin on my old Toshiba laptop.
|
||||
|
||||
### Installing Audiophile Linux
|
||||
|
||||
The site provides [a clear set of install instructions][4] that require the use of the terminal. The first step after downloading the .iso is burning it to a USB stick. I used the GNOME Disks utility’s Restore Disk Image for this purpose. Once I had the USB set up and ready to go, I plugged it into the Toshiba and booted it. When the splash screen came up, I set the boot device to the USB stick and a minute or so later, the Arch Grub menu was displayed. I booted Linux from that menu, which put me in a root shell session, where I could carry out the install to the hard drive:
|
||||
|
||||
|
||||
|
||||
I was willing to sacrifice the 320-GB hard drive in the Toshiba for this test, so I was able to use the previous Linux partitioning (from the last experiment). I then proceeded as follows:
|
||||
|
||||
```
|
||||
fdisk -l # find the disk / partition, in my case /dev/sda and /dev/sda1
|
||||
mkfs.ext4 /dev/sda1 # build the ext4 filesystem in the root partition
|
||||
mount /dev/sda1 /mnt # mount the new file system
|
||||
time cp -ax / /mnt # copy over the OS
|
||||
# reported back cp -ax / /mnt 1.36s user 136.54s system 88% cpu 2:36.37 total
|
||||
arch-chroot /mnt /bin/bash # run in the new system root
|
||||
cd /etc/apl-files
|
||||
./runme.sh # do the rest of the install
|
||||
grub-install --target=i386-pc /dev/sda # make the new OS bootable part 1
|
||||
grub-mkconfig -o /boot/grub/grub.cfg # part 2
|
||||
passwd root # set root’s password
|
||||
ln -s /usr/share/zoneinfo/America/Vancouver /etc/localtime # set my time zone
|
||||
hwclock --systohc --utc # update the hardware clock
|
||||
./autologin.sh # set the system up so that it automatically logs in
|
||||
exit # done with the chroot session
|
||||
genfstab -U /mnt >> /mnt/etc/fstab # create the fstab for the new system
|
||||
```
|
||||
|
||||
At that point, I was ready to boot the new operating system, so I did—and voilà, up came the system!
|
||||
|
||||
|
||||
|
||||
### Finishing the configuration
|
||||
|
||||
Once Audiophile Linux was up and running, I needed to [finish the configuration][4] and load some music. Grabbing the application menu by right-clicking on the screen background, I started **X-terminal** and entered the remaining configuration commands:
|
||||
|
||||
```
|
||||
ping 8.8.8.8 # check connectivity (works fine)
|
||||
su # become root
|
||||
pacman-key –init # create pacman’s encryption data part 1
|
||||
pacman-key --populate archlinux # part 2
|
||||
pacman -Sy # part 3
|
||||
pacman -S archlinux-keyring # part 4
|
||||
```
|
||||
|
||||
At this point, the install instructions note that there is a problem with updating software with the `pacman -Suy` command, and that first the **libxfont** package must be removed using `pacman -Rc libxfont`. I followed this instruction, but the second run of `pacman -Suy` led to another dependency error, this time with the **x265** package. I looked further down the page in the install instructions and saw this recommendation:
|
||||
|
||||
_Again there is an error in upstream repo of Arch packages. Try to remove conflicting packages with “pacman -R ffmpeg2.8” and then do pacman -Suy later._
|
||||
|
||||
I chose to use `pacman -Rc ffmpeg2.8`, and then reran `pacman -Suy`. (As an aside, typing all these **pacman** commands made me realize how familiar I am with **apt** , and how much this whole process made me feel like I was trying to write an email in some language I don’t know using an online translator.)
|
||||
|
||||
To be clear, here was my sequence of operations:
|
||||
|
||||
```
|
||||
pacman -Suy # failed
|
||||
pacman -Rc libxfont
|
||||
pacman -Suy # failed, again
|
||||
pacman -Rc ffmpeg2.8 # uninstalled Cantata, have to fix that later!
|
||||
pacman -Suy # worked!
|
||||
```
|
||||
|
||||
Now back to the rest of the instructions:
|
||||
|
||||
```
|
||||
pacman -S terminus-font
|
||||
pacman -S xorg-server
|
||||
pacman -S firefox # the docs suggested installing chromium but I prefer FF
|
||||
reboot
|
||||
```
|
||||
|
||||
And the last little bit, fiddling `/etc/fstab` to avoid access time modifications. I also thought I’d try installing [Cantata][5] once more using `pacman -S cantata`, and it worked just fine (no `ffmpeg2.8` problems).
|
||||
|
||||
I found the `DAC Setup > List cards` on the application menu, which showed the built-in Intel sound hardware plus my USB DAC that I had plugged in earlier. Then I selected `DAC Setup > Edit mpd.conf` and adjusted the output stanza of `mpd.conf`. I used `scp` to copy an album over from my main music server into **~/Music**. And finally, I used the application menu `DAC Setup > Restart mpd`. And… nothing… the **conky** info on the screen indicated “MPD not responding”. So I scanned again through the comments at the bottom of the installation instructions and spotted this:
|
||||
|
||||
_After every update of mpd, you have to do:
|
||||
1. Become root
|
||||
```
|
||||
$su
|
||||
```
|
||||
2. run this commands
|
||||
```
|
||||
# cat /etc/apl-files/mpd.service > /usr/lib/systemd/system/mpd.service
|
||||
# systemctl daemon-reload
|
||||
# systemctl restart mpd.service_
|
||||
```
|
||||
_And this will be fixed._
|
||||
|
||||
|
||||
|
||||
And it works! Right now I’m enjoying [Nils Frahm’s "All Melody"][6] from the album of the same name, playing over my [Schiit Fulla 2][7] in glorious high-resolution sound. Time to copy in some more music so I can give it a better listen.
|
||||
|
||||
So… does it sound better than the same DAC connected to my regular work laptop and playing back through [Guayadeque][8] or [GogglesMM][9]? I’m going to see if I can detect a difference at some point, but right now all I can say is it sounds just wonderful; plus [I like the Cantata / mpd combo a lot][10], and I really enjoy having the heads-up display in the upper right of the screen.
|
||||
|
||||
### As for the music...
|
||||
|
||||
The other day I was reorganizing my work hard drive a bit and I decided to check to make sure that 1) all the music on it was also on the house music servers and 2) _vice versa_ (gotta set up `rsync` for that purpose one day soon). In doing so, I found some music I hadn’t enjoyed for a while, which is kind of like buying a brand-new album, except it costs much less.
|
||||
|
||||
[Six Degrees Records][11] has long been one of my favorite purveyors of unusual music. A great example is the group [Zuco 103][12]'s album [Whaa!][13], whose CD version I purchased from Six Degrees’ online store some years ago. Check out [this fun documentary about the group][14].
|
||||
|
||||
<https://youtu.be/ncaqD92cjQ8>
|
||||
|
||||
For a completely different experience, take a look at the [Ragazze Quartet’s performance of Terry Riley’s "Four Four Three."][15] I picked up ahigh-resolutionn version of this fascinating music from [Channel Classics][16], which operates a Linux-friendly download store (no bloatware to install on your computer).
|
||||
|
||||
And finally, I was saddened to hear of the recent passing of [Rachid Taha][17], whose wonderful blend of North African and French musical traditions, along with his frank confrontation of the challenges of being North African and living in Europe, has made some powerful—and fun—music. Check out [Taha’s version of "Rock the Casbah."][18] I have a few of his songs scattered around various compilation albums, and some time ago bought the CD version of [Rachid Taha: The Definitive Collection][19], which I’ve been enjoying again recently.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/audiophile-linux-distro
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://www.ap-linux.com/
|
||||
[2]: https://www.archlinux.org/
|
||||
[3]: http://fluxbox.org/
|
||||
[4]: https://www.ap-linux.com/documentation/ap-linux-v4-install-instructions/
|
||||
[5]: https://github.com/CDrummond/cantata
|
||||
[6]: https://www.youtube.com/watch?v=1PTj1qIqcWM
|
||||
[7]: https://www.audiostream.com/content/listening-session-history-lesson-bw-schiit-and-shinola-together-last
|
||||
[8]: http://www.guayadeque.org/
|
||||
[9]: https://gogglesmm.github.io/
|
||||
[10]: https://opensource.com/article/17/8/cantata-music-linux
|
||||
[11]: https://www.sixdegreesrecords.com/
|
||||
[12]: https://www.sixdegreesrecords.com/?s=zuco+103
|
||||
[13]: https://www.musicomh.com/reviews/albums/zuco-103-whaa
|
||||
[14]: https://www.youtube.com/watch?v=ncaqD92cjQ8
|
||||
[15]: https://www.youtube.com/watch?v=DwMaO7bMVD4
|
||||
[16]: https://www.channelclassics.com/catalogue/37816-Riley-Four-Four-Three/
|
||||
[17]: https://en.wikipedia.org/wiki/Rachid_Taha
|
||||
[18]: https://www.youtube.com/watch?v=n1p_dkJo6Y8
|
||||
[19]: http://www.bbc.co.uk/music/reviews/26rg/
|
||||
@ -0,0 +1,232 @@
|
||||
# Caffeinated 6.828:实验 2:内存管理
|
||||
|
||||
### 简介
|
||||
|
||||
在本实验中,你将为你的操作系统写内存管理方面的代码。内存管理有两部分组成。
|
||||
|
||||
第一部分是内核的物理内存分配器,内核通过它来分配内存,以及在不需要时释放所分配的内存。分配器以页为单位分配内存,每个页的大小为 4096 字节。你的任务是去维护那个数据结构,它负责记录物理页的分配和释放,以及每个分配的页有多少进程共享它。本实验中你将要写出分配和释放内存页的全套代码。
|
||||
|
||||
第二个部分是虚拟内存的管理,它负责由内核和用户软件使用的虚拟内存地址到物理内存地址之间的映射。当使用内存时,x86 架构的硬件是由内存管理单元(MMU)负责执行映射操作来查阅一组页表。接下来你将要修改 JOS,以根据我们提供的特定指令去设置 MMU 的页表。
|
||||
|
||||
### 预备知识
|
||||
|
||||
在本实验及后面的实验中,你将逐步构建你的内核。我们将会为你提供一些附加的资源。使用 Git 去获取这些资源、提交自实验 1 以来的改变(如有需要的话)、获取课程仓库的最新版本、以及在我们的实验 2 (origin/lab2)的基础上创建一个称为 lab2 的本地分支:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab2 origin/lab2
|
||||
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
|
||||
Switched to a new branch "lab2"
|
||||
athena%
|
||||
```
|
||||
|
||||
现在,你需要将你在 lab1 分支中的改变合并到 lab2 分支中,命令如下:
|
||||
|
||||
```
|
||||
athena% git merge lab1
|
||||
Merge made by recursive.
|
||||
kern/kdebug.c | 11 +++++++++--
|
||||
kern/monitor.c | 19 +++++++++++++++++++
|
||||
lib/printfmt.c | 7 +++----
|
||||
3 files changed, 31 insertions(+), 6 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
实验 2 包含如下的新源代码,后面你将遍历它们:
|
||||
|
||||
- inc/memlayout.h
|
||||
- kern/pmap.c
|
||||
- kern/pmap.h
|
||||
- kern/kclock.h
|
||||
- kern/kclock.c
|
||||
|
||||
`memlayout.h` 描述虚拟地址空间的布局,这个虚拟地址空间是通过修改 `pmap.c`、`memlayout.h` 和 `pmap.h` 所定义的 *PageInfo* 数据结构来实现的,这个数据结构用于跟踪物理内存页面是否被释放。`kclock.c` 和 `kclock.h` 维护 PC 基于电池的时钟和 CMOS RAM 硬件,在 BIOS 中记录了 PC 上安装的物理内存数量,以及其它的一些信息。在 `pmap.c` 中的代码需要去读取这个设备硬件信息,以算出在这个设备上安装了多少物理内存,这些只是由你来完成的一部分代码:你不需要知道 CMOS 硬件工作原理的细节。
|
||||
|
||||
特别需要注意的是 `memlayout.h` 和 `pmap.h`,因为本实验需要你去使用和理解的大部分内容都包含在这两个文件中。你或许还需要去复习 `inc/mmu.h` 这个文件,因为它也包含了本实验中用到的许多定义。
|
||||
|
||||
开始本实验之前,记得去添加 `exokernel` 以获取 QEMU 的 6.828 版本。
|
||||
|
||||
### 实验过程
|
||||
|
||||
在你准备进行实验和写代码之前,先添加你的 `answers-lab2.txt` 文件到 Git 仓库,提交你的改变然后去运行 `make handin`。
|
||||
|
||||
```
|
||||
athena% git add answers-lab2.txt
|
||||
athena% git commit -am "my answer to lab2"
|
||||
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
|
||||
athena% make handin
|
||||
```
|
||||
|
||||
### 第 1 部分:物理页面管理
|
||||
|
||||
操作系统必须跟踪物理内存页是否使用的状态。JOS 以页为最小粒度来管理 PC 的物理内存,以便于它使用 MMU 去映射和保护每个已分配的内存片段。
|
||||
|
||||
现在,你将要写内存的物理页分配器的代码。它使用链接到 `PageInfo` 数据结构的一组列表来保持对物理页的状态跟踪,每个列表都对应到一个物理内存页。在你能够写出剩下的虚拟内存实现之前,你需要先写出物理内存页面分配器,因为你的页表管理代码将需要去分配物理内存来存储页表。
|
||||
|
||||
> 练习 1
|
||||
>
|
||||
> 在文件 `kern/pmap.c` 中,你需要去实现以下函数的代码(或许要按给定的顺序来实现)。
|
||||
>
|
||||
> boot_alloc()
|
||||
>
|
||||
> mem_init()(只要能够调用 check_page_free_list() 即可)
|
||||
>
|
||||
> page_init()
|
||||
>
|
||||
> page_alloc()
|
||||
>
|
||||
> page_free()
|
||||
>
|
||||
> `check_page_free_list()` 和 `check_page_alloc()` 可以测试你的物理内存页分配器。你将需要引导 JOS 然后去看一下 `check_page_alloc()` 是否报告成功即可。如果没有报告成功,修复你的代码直到成功为止。你可以添加你自己的 `assert()` 以帮助你去验证是否符合你的预期。
|
||||
|
||||
本实验以及所有的 6.828 实验中,将要求你做一些检测工作,以便于你搞清楚它们是否按你的预期来工作。这个任务不需要详细描述你添加到 JOS 中的代码的细节。查找 JOS 源代码中你需要去修改的那部分的注释;这些注释中经常包含有技术规范和提示信息。你也可能需要去查阅 JOS、和 Intel 的技术手册、以及你的 6.004 或 6.033 课程笔记的相关部分。
|
||||
|
||||
### 第 2 部分:虚拟内存
|
||||
|
||||
在你开始动手之前,需要先熟悉 x86 内存管理架构的保护模式:即分段和页面转换。
|
||||
|
||||
> 练习 2
|
||||
>
|
||||
> 如果你对 x86 的保护模式还不熟悉,可以查看 Intel 80386 参考手册的第 5 章和第 6 章。阅读这些章节(5.2 和 6.4)中关于页面转换和基于页面的保护。我们建议你也去了解关于段的章节;在虚拟内存和保护模式中,JOS 使用了分页、段转换、以及在 x86 上不能禁用的基于段的保护,因此你需要去理解这些基础知识。
|
||||
|
||||
### 虚拟地址、线性地址和物理地址
|
||||
|
||||
在 x86 的专用术语中,一个虚拟地址是由一个段选择器和在段中的偏移量组成。一个线性地址是在页面转换之前、段转换之后得到的一个地址。一个物理地址是段和页面转换之后得到的最终地址,它最终将进入你的物理内存中的硬件总线。
|
||||
|
||||

|
||||
|
||||
回顾实验 1 中的第 3 部分,我们安装了一个简单的页表,这样内核就可以在 0xf0100000 链接的地址上运行,尽管它实际上是加载在 0x00100000 处的 ROM BIOS 的物理内存上。这个页表仅映射了 4MB 的内存。在实验中,你将要为 JOS 去设置虚拟内存布局,我们将从虚拟地址 0xf0000000 处开始扩展它,首先将物理内存扩展到 256MB,并映射许多其它区域的虚拟内存。
|
||||
|
||||
> 练习 3
|
||||
>
|
||||
> 虽然 GDB 能够通过虚拟地址访问 QEMU 的内存,它经常用于在配置虚拟内存期间检查物理内存。在实验工具指南中复习 QEMU 的监视器命令,尤其是 `xp` 命令,它可以让你去检查物理内存。访问 QEMU 监视器,可以在终端中按 `Ctrl-a c`(相同的绑定返回到串行控制台)。
|
||||
>
|
||||
> 使用 QEMU 监视器的 `xp` 命令和 GDB 的 `x` 命令去检查相应的物理内存和虚拟内存,以确保你看到的是相同的数据。
|
||||
>
|
||||
> 我们的打过补丁的 QEMU 版本提供一个非常有用的 `info pg` 命令:它可以展示当前页表的一个简单描述,包括所有已映射的内存范围、权限、以及标志。Stock QEMU 也提供一个 `info mem` 命令用于去展示一个概要信息,这个信息包含了已映射的虚拟内存范围和使用了什么权限。
|
||||
|
||||
在 CPU 上运行的代码,一旦处于保护模式(这是在 boot/boot.S 中所做的第一件事情)中,是没有办法去直接使用一个线性地址或物理地址的。所有的内存引用都被解释为虚拟地址,然后由 MMU 来转换,这意味着在 C 语言中的指针都是虚拟地址。
|
||||
|
||||
例如在物理内存分配器中,JOS 内存经常需要在不反向引用的情况下,去维护作为地址的一个很难懂的值或一个整数。有时它们是虚拟地址,而有时是物理地址。为便于在代码中证明,JOS 源文件中将它们区分为两种:类型 `uintptr_t` 表示一个难懂的虚拟地址,而类型 `physaddr_trepresents` 表示物理地址。这些类型其实不过是 32 位整数(uint32_t)的同义词,因此编译器不会阻止你将一个类型的数据指派为另一个类型!因为它们都是整数(而不是指针)类型,如果你想去反向引用它们,编译器将报错。
|
||||
|
||||
JOS 内核能够通过将它转换为指针类型的方式来反向引用一个 `uintptr_t` 类型。相反,内核不能反向引用一个物理地址,因为这是由 MMU 来转换所有的内存引用。如果你转换一个 `physaddr_t` 为一个指针类型,并反向引用它,你或许能够加载和存储最终结果地址(硬件将它解释为一个虚拟地址),但你并不会取得你想要的内存位置。
|
||||
|
||||
总结如下:
|
||||
|
||||
| C type | Address type |
|
||||
| ------------ | ------------ |
|
||||
| `T*` | Virtual |
|
||||
| `uintptr_t` | Virtual |
|
||||
| `physaddr_t` | Physical |
|
||||
|
||||
>问题:
|
||||
>
|
||||
>假设下面的 JOS 内核代码是正确的,那么变量 `x` 应该是什么类型?uintptr_t 还是 physaddr_t ?
|
||||
>
|
||||
>
|
||||
>
|
||||
|
||||
JOS 内核有时需要去读取或修改它知道物理地址的内存。例如,添加一个映射到页表,可以要求分配物理内存去存储一个页目录,然后去初始化它们。然而,内核也和其它的软件一样,并不能跳过虚拟地址转换,内核并不能直接加载和存储物理地址。一个原因是 JOS 将重映射从虚拟地址 0xf0000000 处物理地址 0 开始的所有的物理地址,以帮助内核去读取和写入它知道物理地址的内存。为转换一个物理地址为一个内核能够真正进行读写操作的虚拟地址,内核必须添加 0xf0000000 到物理地址以找到在重映射区域中相应的虚拟地址。你应该使用 KADDR(pa) 去做那个添加操作。
|
||||
|
||||
JOS 内核有时也需要能够通过给定的内核数据结构中存储的虚拟地址找到内存中的物理地址。内核全局变量和通过 `boot_alloc()` 分配的内存是加载到内核的这些区域中,从 0xf0000000 处开始,到全部物理内存映射的区域。因此,在这些区域中转变一个虚拟地址为物理地址时,内核能够只是简单地减去 0xf0000000 即可得到物理地址。你应该使用 PADDR(va) 去做那个减法操作。
|
||||
|
||||
### 引用计数
|
||||
|
||||
在以后的实验中,你将会经常遇到多个虚拟地址(或多个环境下的地址空间中)同时映射到相同的物理页面上。你将在 PageInfo 数据结构中用 pp_ref 字段来提供一个引用到每个物理页面的计数器。如果一个物理页面的这个计数器为 0,表示这个页面已经被释放,因为它不再被使用了。一般情况下,这个计数器应该等于相应的物理页面出现在所有页表下面的 UTOP 的次数(UTOP 上面的映射大都是在引导时由内核设置的,并且它从不会被释放,因此不需要引用计数器)。我们也使用它去跟踪到页目录的指针数量,反过来就是,页目录到页表的数量。
|
||||
|
||||
使用 `page_alloc` 时要注意。它返回的页面引用计数总是为 0,因此,一旦对返回页做了一些操作(比如将它插入到页表),`pp_ref` 就应该增加。有时这需要通过其它函数(比如,`page_instert`)来处理,而有时这个函数是直接调用 `page_alloc` 来做的。
|
||||
|
||||
### 页表管理
|
||||
|
||||
现在,你将写一套管理页表的代码:去插入和删除线性地址到物理地址的映射表,并且在需要的时候去创建页表。
|
||||
|
||||
> 练习 4
|
||||
>
|
||||
> 在文件 `kern/pmap.c` 中,你必须去实现下列函数的代码。
|
||||
>
|
||||
> pgdir_walk()
|
||||
>
|
||||
> boot_map_region()
|
||||
>
|
||||
> page_lookup()
|
||||
>
|
||||
> page_remove()
|
||||
>
|
||||
> page_insert()
|
||||
>
|
||||
> `check_page()`,调用 `mem_init()`,测试你的页表管理动作。在进行下一步流程之前你应该确保它成功运行。
|
||||
|
||||
### 第 3 部分:内核地址空间
|
||||
|
||||
JOS 分割处理器的 32 位线性地址空间为两部分:用户环境(进程),我们将在实验 3 中开始加载和运行,它将控制其上的布局和低位部分的内容,而内核总是维护对高位部分的完全控制。线性地址的定义是在 `inc/memlayout.h` 中通过符号 ULIM 来划分的,它为内核保留了大约 256MB 的虚拟地址空间。这就解释了为什么我们要在实验 1 中给内核这样的一个高位链接地址的原因:如是不这样做的话,内核的虚拟地址空间将没有足够的空间去同时映射到下面的用户空间中。
|
||||
|
||||
你可以在 `inc/memlayout.h` 中找到一个图表,它有助于你去理解 JOS 内存布局,这在本实验和后面的实验中都会用到。
|
||||
|
||||
### 权限和缺页隔离
|
||||
|
||||
由于内核和用户的内存都存在于它们各自环境的地址空间中,因此我们需要在 x86 的页表中使用权限位去允许用户代码只能访问用户所属地址空间的部分。否则的话,用户代码中的 bug 可能会覆写内核数据,导致系统崩溃或者发生各种莫名其妙的的故障;用户代码也可能会偷窥其它环境的私有数据。
|
||||
|
||||
对于 ULIM 以上部分的内存,用户环境没有任何权限,只有内核才可以读取和写入这部分内存。对于 [UTOP,ULIM] 地址范围,内核和用户都有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围是用于向用户环境暴露某些只读的内核数据结构。最后,低于 UTOP 的地址空间是为用户环境所使用的;用户环境将为访问这些内核设置权限。
|
||||
|
||||
### 初始化内核地址空间
|
||||
|
||||
现在,你将去配置 UTOP 以上的地址空间:内核部分的地址空间。`inc/memlayout.h` 中展示了你将要使用的布局。我将使用函数去写相关的线性地址到物理地址的映射配置。
|
||||
|
||||
> 练习 5
|
||||
>
|
||||
> 完成调用 `check_page()` 之后在 `mem_init()` 中缺失的代码。
|
||||
|
||||
现在,你的代码应该通过了 `check_kern_pgdir()` 和 `check_page_installed_pgdir()` 的检查。
|
||||
|
||||
> 问题:
|
||||
>
|
||||
> 1、在这个时刻,页目录中的条目(行)是什么?它们映射的址址是什么?以及它们映射到哪里了?换句话说就是,尽可能多地填写这个表:
|
||||
>
|
||||
> EntryBase Virtual AddressPoints to (logically):
|
||||
>
|
||||
> 1023 ? Page table for top 4MB of phys memory
|
||||
>
|
||||
> 1022 ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> . ? ?
|
||||
>
|
||||
> 2 0x00800000 ?
|
||||
>
|
||||
> 1 0x00400000 ?
|
||||
>
|
||||
> 0 0x00000000 [see next question]
|
||||
>
|
||||
> 2、(来自课程 3) 我们将内核和用户环境放在相同的地址空间中。为什么用户程序不能去读取和写入内核的内存?有什么特殊机制保护内核内存?
|
||||
>
|
||||
> 3、这个操作系统能够支持的最大的物理内存数量是多少?为什么?
|
||||
>
|
||||
> 4、我们真实地拥有最大数量的物理内存吗?管理内存的开销有多少?这个开销可以减少吗?
|
||||
>
|
||||
> 5、复习在 `kern/entry.S` 和 `kern/entrypgdir.c` 中的页表设置。一旦我们打开分页,EIP 中是一个很小的数字(稍大于 1MB)。在什么情况下,我们转而去运行在 KERNBASE 之上的一个 EIP?当我们启用分页并开始在 KERNBASE 之上运行一个 EIP 时,是什么让我们能够持续运行一个很低的 EIP?为什么这种转变是必需的?
|
||||
|
||||
### 地址空间布局的其它选择
|
||||
|
||||
在 JOS 中我们使用的地址空间布局并不是我们唯一的选择。一个操作系统可以在低位的线性地址上映射内核,而为用户进程保留线性地址的高位部分。然而,x86 内核一般并不采用这种方法,而 x86 向后兼容模式是不这样做的其中一个原因,这种模式被称为“虚拟 8086 模式”,处理器使用线性地址空间的最下面部分是“不可改变的”,所以,如果内核被映射到这里是根本无法使用的。
|
||||
|
||||
虽然很困难,但是设计这样的内核是有这种可能的,即:不为处理器自身保留任何固定的线性地址或虚拟地址空间,而有效地允许用户级进程不受限制地使用整个 4GB 的虚拟地址空间 —— 同时还要在这些进程之间充分保护内核以及不同的进程之间相互受保护!
|
||||
|
||||
将内核的内存分配系统进行概括类推,以支持二次幂为单位的各种页大小,从 4KB 到一些你选择的合理的最大值。你务必要有一些方法,将较大的分配单位按需分割为一些较小的单位,以及在需要时,将多个较小的分配单位合并为一个较大的分配单位。想一想在这样的一个系统中可能会出现些什么样的问题。
|
||||
|
||||
这个实验做完了。确保你通过了所有的等级测试,并记得在 `answers-lab2.txt` 中写下你对上述问题的答案。提交你的改变(包括添加 `answers-lab2.txt` 文件),并在 `lab` 目录下输入 `make handin` 去提交你的实验。
|
||||
|
||||
------
|
||||
|
||||
via: <https://sipb.mit.edu/iap/6.828/lab/lab2/>
|
||||
|
||||
作者:[Mit][<https://sipb.mit.edu/iap/6.828/lab/lab2/>]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,80 @@
|
||||
# 5 个给孩子的非常好的 Linux 教育软件和游戏
|
||||
|
||||

|
||||
|
||||
Linux 是一个非常强大的操作系统,因此因特网上的大多数服务器都使用它。尽管它算不上是对用户友好的最佳操作系统,但它的多元化还是值的称赞的。对于 Linux 来说,每个人都能在它上面找到他们自己的所需。不论你是用它来写代码、还是用于教学或物联网(IoT),你总能找到一个适合你用的 Linux 发行版。为此,许多人认为 Linux 是未来计算的最佳操作系统。
|
||||
|
||||
未来是属于孩子们的,让孩子们了解 Linux 是他们掌控未来的最佳方式。这个操作系统上或许并没有一些像 FIFA 或 PES 那样的声名赫赫的游戏;但是,它为孩子们提供了一些非常好的教育软件和游戏。这里有五款最好的 Linux 教育软件,可以让你的孩子远离游戏。
|
||||
|
||||
**相关阅读**:[使用一个 Linux 发行版的新手指南][1]
|
||||
|
||||
### 1. GCompris
|
||||
|
||||
如果你正在为你的孩子寻找一款最佳的教育软件,[GCompris][2] 将是你的最好的开端。这款软件专门为 2 到 10 岁的孩子所设计。作为所有的 Linux 教育软件套装的巅峰之作,GCompris 为孩子们提供了大约 100 项活动。它囊括了你期望你的孩子学习的所有内容,从阅读材料到科学、地理、绘画、代数、测验、等等。
|
||||
|
||||
![Linux educational software and games][3]
|
||||
|
||||
GCompris 甚至有一项活动可以帮你的孩子学习计算机的相关知识。如果你的孩子还很小,你希望他去学习字母、颜色、和形状,GCompris 也有这方面的相关内容。更重要的是,它也为孩子们准备了一些益智类游戏,比如国际象棋、井字棋、好记性、以及猜词游戏。GCompris 并不是一个仅在 Linux 上可运行的游戏。它也可以运行在 Windows 和 Android 上。
|
||||
|
||||
### 2. TuxMath
|
||||
|
||||
很多学生认为数学是们非常难的课程。你可以通过 Linux 教育软件如 [TuxMath][4] 来让你的孩子了解数学技能,从而来改变这种看法。TuxMath 是为孩子开发的顶级的数学教育辅助游戏。在这个游戏中,你的角色是在如雨点般下降的数学问题中帮助 Linux 企鹅 Tux 来保护它的星球。
|
||||
|
||||
![linux-educational-software-tuxmath-1][5]
|
||||
|
||||
在它们落下来毁坏 Tux 的星球之前,找到问题的答案,就可以使用你的激光去帮助 Tux 拯救它的星球。数字问题的难度每过一关就会提升一点。这个游戏非常适合孩子,因为它可以让孩子们去开动脑筋解决问题。而且还有助他们学好数学,以及帮助他们开发智力。
|
||||
|
||||
### 3. Sugar on a Stick
|
||||
|
||||
[Sugar on a Stick][6] 是献给孩子们的学习程序 —— 一个广受好评的全新教学法。这个程序为你的孩子提供一个成熟的教学平台,在那里,他们可以收获创造、探索、发现和思考方面的技能。和 GCompris 一样,Sugar on a Stick 为孩子们带来了包括游戏和谜题在内的大量学习资源。
|
||||
|
||||
![linux-educational-software-sugar-on-a-stick][7]
|
||||
|
||||
关于 Sugar on a Stick 最大的一个好处是你可以将它配置在一个 U 盘上。你只要有一台 X86 的 PC,插入那个 U 盘,然后就可以从 U 盘引导这个发行版。Sugar on a Stick 是由 Sugar 实验室提供的一个项目 —— 这个实验室是一个由志愿者运作的非盈利组织。
|
||||
|
||||
### 4. KDE Edu Suite
|
||||
|
||||
[KDE Edu Suite][8] 是一个用途与众不同的软件包。带来了大量不同领域的应用程序,KDE 社区已经证实,它不仅是一系列成年人授权的问题;它还关心年青一代如何适应他们周围的一切。它囊括了一系列孩子们使用的应用程序,从科学到数学、地理等等。
|
||||
|
||||
![linux-educational-software-kde-1][9]
|
||||
|
||||
KDE Edu 套件根据长大后所必需的知识为基础,既能够用作学校的教学软件,也能够作为孩子们的学习 APP。它提供了大量的可免费下载的软件包。KDE Edu 套件在主流的 GNU/Linux 发行版都能安装。
|
||||
|
||||
### 5. Tux Paint
|
||||
|
||||
![linux-educational-software-tux-paint-2][10]
|
||||
|
||||
[Tux Paint][11] 是给孩子们的另一个非常好的 Linux 教育软件。这个屡获殊荣的绘画软件在世界各地被用于帮助培养孩子们的绘画技能,它有一个简洁的、易于使用的界面和有趣的音效,可以高效地帮助孩子去使用这个程序。它也有一个卡通吉祥物去鼓励孩子们使用这个程序。Tux Paint 中有许多绘画工具,它们可以帮助孩子们放飞他们的创意。
|
||||
|
||||
### 总结
|
||||
|
||||
由于这些教育软件深受孩子们的欢迎,许多学校和幼儿园都使用这些程序进行辅助教学。典型的一个例子就是 [Edubuntu][12],它是儿童教育领域中广受老师和家长们欢迎的一个基于 Ubuntu 的发行版。
|
||||
|
||||
Tux Paint 是另一个非常好的例子,它在这些年越来越流行,它大量地用于学校中教孩子们如何绘画。以上的这个清单并不很详细。还有成百上千的对孩子有益的其它 Linux 教育软件和游戏。
|
||||
|
||||
如果你还知道给孩子们的其它非常好的 Linux 教育软件和游戏,在下面的评论区分享给我们吧。
|
||||
|
||||
------
|
||||
|
||||
via: https://www.maketecheasier.com/5-best-linux-software-packages-for-kids/
|
||||
|
||||
作者:[Kenneth Kimari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/kennkimari/
|
||||
[1]: https://www.maketecheasier.com/beginner-guide-to-using-linux-distro/ "The Beginner’s Guide to Using a Linux Distro"
|
||||
[2]: http://www.gcompris.net/downloads-en.html
|
||||
[3]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-gcompris.jpg "Linux educational software and games"
|
||||
[4]: https://tuxmath.en.uptodown.com/ubuntu
|
||||
[5]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tuxmath-1.jpg "linux-educational-software-tuxmath-1"
|
||||
[6]: http://wiki.sugarlabs.org/go/Sugar_on_a_Stick/Downloads
|
||||
[7]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-sugar-on-a-stick.png "linux-educational-software-sugar-on-a-stick"
|
||||
[8]: https://edu.kde.org/
|
||||
[9]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-kde-1.jpg "linux-educational-software-kde-1"
|
||||
[10]: https://www.maketecheasier.com/assets/uploads/2018/07/Linux-educational-software-tux-paint-2.jpg "linux-educational-software-tux-paint-2"
|
||||
[11]: http://www.tuxpaint.org/
|
||||
[12]: http://edubuntu.org/
|
||||
@ -0,0 +1,73 @@
|
||||
|
||||
steam 让我们在 Linux 上玩 Windows 的游戏更加容易
|
||||
======
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
总所周知,Linux 游戏库中的游戏只有 Windows 游戏库中的一部分,实际上,许多人甚至都不会考虑将操作系统转换为 Linux,原因很简单,因为他们喜欢的游戏,大多数都不能在这个平台上运行。
|
||||
|
||||
在撰写本文时,steam 上已有超过 5000 种游戏可以在 Linux 上运行,而 steam 上的游戏总数已经接近 27000 种了。现在 5000 种游戏可能看起来很多,但还没有达到 27000 种,确实没有。
|
||||
|
||||
虽然几乎所有的新的独立游戏都是在 Linux 中推出的,但我们仍然无法在这上面玩很多的 3A 大作。对我而言,虽然这其中有很多游戏我都很希望能有机会玩,但这从来都不是一个非黑即白的问题。因为我主要是玩独立游戏和复古游戏,所以几乎所有我喜欢的游戏都可以在 Linux 系统上运行。
|
||||
|
||||
### 认识 Proton,Steam 的一次 WINE 分叉。
|
||||
|
||||
现在,这个问题已经成为过去式了,因为本周 Valve 宣布要对 Steam Play 进行一次更新,此次更新会将一个名为 Proton 的分叉版本的 Wine 添加到 Linux 和 Mac 的客户端中。是的,这个工具是开源的,Valve 已经在 GitHub 上开源了源代码,但该功能仍然处于测试阶段,所以你必须使用测试版的 Steam 客户端才能使用这项功能。
|
||||
|
||||
#### 使用 proton ,可以在 Linux 系统上使用 Steam 运行更多的 Windows 上的游戏。
|
||||
|
||||
这对我们这些 Linux 用户来说,实际上意味着什么?简单来说,这意味着我们可以在 Linux 和 Mac 这两种操作系统的电脑上运行全部 27000 种游戏,而无需配置像 PlayOnLinux 或 Lutris 这样的服务。我要告诉你的是,配置这些东西有时候会非常让人头疼。
|
||||
|
||||
对此更为复杂的答案是,某种原因听起来非常美好。虽然在理论上,你可以用这种方式在 Linux 上玩所有的 Windows 平台上的游戏。但只有一少部分游戏在推出时会正式支持 Linux。这少部分游戏包括 DOOM,最终幻想 VI,铁拳 7,星球大战:前线 2,和其他几个。
|
||||
|
||||
#### 你可以在 Linux 上玩所有的 Windows 平台的游戏(理论上)
|
||||
|
||||
虽然目前该列表只有大约 30 个游戏,你可以点击“为所有游戏使用 Steam play 进行运行”复选框来强制使用 Steam 的 Proton 来安装和运行任意游戏。但你最好不要有太高的期待,它们的稳定性和性能表现不一定有你希望的那么好,所以请把期望值压低一点。
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
#### 体验 Proton,没有我想的那么烂。
|
||||
|
||||
例如,我安装了一些中等价格的游戏,使用 Proton 来进行安装。其中一个是上古卷轴 4:湮没,在我玩这个游戏的两个小时里,它只崩溃了一次,而且几乎是紧跟在游戏教程的自动保存点之后。
|
||||
|
||||
我有一块英伟达 Gtx 1050 Ti 的显卡。所以我可以使用 1080P 的高配置来玩这个游戏。而且我没有遇到除了这次崩溃之外的任何问题。我唯一真正感到不爽的只有它的帧数没有原本的高。在 90% 的时间里,游戏的帧数都在 60 帧以上,但我知道它的帧数应该能更高。
|
||||
|
||||
我安装和发布的其他所有游戏都运行得很完美,虽然我还没有较长时间地玩过它们中的任何一个。我安装的游戏中包括森林,丧尸围城 4,H1Z1,和刺客信条 2.(你能说我这是喜欢恐怖游戏吗?)。
|
||||
|
||||
#### 为什么 Steam(仍然)要下注在 Linux 上?
|
||||
|
||||
现在,一切都很好,这件事为什么会发生呢?为什么 Valve 要花费时间,金钱和资源来做这样的事?我倾向于认为,他们这样做是因为他们懂得 Linux 社区的价值,但是如果要我老实地说,我不相信我们和它有任何的关系。
|
||||
|
||||
如果我一定要在这上面花钱,我想说 Valve 开发了 Proton,因为他们还没有放弃 Steam 机器。因为 Steam OS 是基于 Linux 的发行版,在这类东西上面投资可以获取最大的利润,Steam OS 上可用的游戏越多,就会有更多的人愿意购买 Steam 的机器。
|
||||
|
||||
可能我是错的,但是我敢打赌啊,我们会在不远的未来看到新一批的 Steam 机器。可能我们会在一年内看到它们,也有可能我们再等五年都见不到,谁知道呢!
|
||||
|
||||
无论哪种方式,我所知道的是,我终于能兴奋地从我的 Steam 游戏库里玩游戏了。多年来我通过所有的收藏包,游戏促销,和不定时地买一个贱卖的游戏来以防万一,我想去尝试让它在 Lutris 中运行。
|
||||
|
||||
#### 为 Linux 上越来越多的游戏而激动?
|
||||
|
||||
你怎么看?你对此感到激动吗?或者说你会害怕只有很少的开发者会开发 Linux 平台上的游戏,因为现在几乎没有需求?Valve 喜欢 Linux 社区,还是说他们喜欢钱?请在下面的评论区告诉我们您的想法,然后重新搜索来查看更多类似这样的开源软件方面的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
@ -1,118 +0,0 @@
|
||||
|
||||
|
||||
|
||||
3个开源日志聚合工具
|
||||
======
|
||||
|
||||
日志聚合系统可以帮助我们故障排除并进行其他的任务。以下是三个主要工具介绍。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
指标聚合与日志聚合有何不同?日志不能包括指标吗?日志聚合系统不能做与指标聚合系统相同的事情吗?
|
||||
|
||||
这些是我经常听到的问题。我还看到供应商推销他们的日志聚合系统作为所有可观察问题的解决方案。日志聚合是一个有价值的工具,但它通常对时间序列数据的支持不够好。
|
||||
|
||||
时间序列指标聚合系统中几个有价值的功能为规则间隔与专门为时间序列数据定制的存储系统。规则间隔允许用户一次性地导出真实的数据结果。如果要求日志聚合系统定期收集指标数据,它也可以。但是,它的存储系统没有针对指标聚合系统中典型的查询类型进行优化。使用日志聚合工具中的存储系统处理这些查询将花费更多的资源和时间。
|
||||
|
||||
所以,我们知道日志聚合系统可能不适合时间序列数据,但是它有什么好处呢?日志聚合系统是收集事件数据的好地方。这些是非常重要的不规则活动。最好的例子为 web 服务的访问日志。这些都很重要,因为我们想知道什么东西正在访问我们的系统,什么时候访问。另一个例子是应用程序错误记录——因为它不是正常的操作记录,所以在故障排除过程中可能很有价值的。
|
||||
|
||||
日志记录的一些规则:
|
||||
|
||||
* 包含时间戳
|
||||
* 包含 JSON 格式
|
||||
* 不记录无关紧要的事件
|
||||
* 记录所有应用程序的错误
|
||||
* 记录警告错误
|
||||
* 日志记录开关
|
||||
* 以可读的形式记录信息
|
||||
* 不在生产环境中记录信息
|
||||
* 不记录任何无法阅读或无反馈的内容
|
||||
|
||||
|
||||
### 云的成本
|
||||
|
||||
当研究日志聚合工具时,云可能看起来是一个有吸引力的选择。然而,这可能会带来巨大的成本。当跨数百或数千台主机和应用程序聚合时,日志数据是大量的。在基于云的系统中,数据的接收、存储和检索是昂贵的。
|
||||
|
||||
作为一个真实的系统,大约500个节点和几百个应用程序的集合每天产生 200GB 的日志数据。这个系统可能还有改进的空间,但是在许多 SaaS 产品中,即使将它减少一半,每月也要花费将近10,000美元。这通常包括仅保留30天,如果你想查看一年一年的趋势数据,就不可能了。
|
||||
|
||||
并不是要不使用这些系统,尤其是对于较小的组织它们可能非常有价值的。目的是指出可能会有很大的成本,当这些成本达到时,就可能令人非常的沮丧。本文的其余部分将集中讨论自托管的开源和商业解决方案。
|
||||
|
||||
|
||||
### 工具选择
|
||||
|
||||
#### ELK
|
||||
|
||||
[ELK][1] ,简称 Elasticsearch、Logstash 和 Kibana,是最流行的开源日志聚合工具。它被Netflix、Facebook、微软、LinkedIn 和思科使用。这三个组件都是由 [Elastic][2] 开发和维护的。[Elasticsearch][3] 本质上是一个NoSQL,Lucene 搜索引擎实现的。[Logstash][4] 是一个日志管道系统,可以接收数据,转换数据,并将其加载到像 Elasticsearch 这样的应用中。[Kibana][5] 是 Elasticsearch 之上的可视化层。
|
||||
|
||||
几年前,Beats 被引入。Beats 是数据采集器。它们简化了将数据运送到日志存储的过程。用户不需要了解每种日志的正确语法,而是可以安装一个 Beats 来正确导出 NGINX 日志或代理日志,以便在Elasticsearch 中有效地使用它们。
|
||||
|
||||
安装生产环境级 ELK stack 时,可能会包括其他几个部分,如 [Kafka][6], [Redis][7], and [NGINX][8]。此外,用 Fluentd 替换 Logstash 也很常见,我们将在后面讨论。这个系统操作起来很复杂,这在早期导致很多问题和投诉。目前,这些基本上已经被修复,不过它仍然是一个复杂的系统,如果你使用少部分的功能,建议不要使用它了。
|
||||
|
||||
也就是说,服务是可用的,所以你不必担心。[Logz.io][9] 也可以使用,但是如果你有很多数据,它的标价有点高。当然,你可能没有很多数据,来使用用它。如果你买不起 Logz.io,你可以看看 [AWS Elasticsearch Service][10] (ES) 。ES 是 Amazon Web Services (AWS) 提供的一项服务,它使得 Elasticsearch 很容易快速工作。它还拥有使用 Lambda 和 S3 将所有AWS日志记录到 ES 的工具。这是一个更便宜的选择,但是需要一些管理操作,并有一些功能限制。
|
||||
|
||||
|
||||
Elastic [offers][11] 的母公司提供一款更强大的产品,它使用开放核心模型,为分析工具和报告提供了额外的选项。它也可以在谷歌云平台或 AWS 上托管。由于这种工具和托管平台的组合提供了比大多数 SaaS 选项更加便宜,这将是最好的选择并且具有很大的价值。该系统可以有效地取代或提供[security information and event management][12] ( SIEM )系统的功能。
|
||||
|
||||
ELK 栈通过 Kibana 提供了很好的可视化工具,但是它缺少警报功能。Elastic 在付费的 X-Pack 插件中提供了提醒功能,但是在开源系统没有内置任何功能。Yelp 已经开发了一种解决这个问题的方法,[ElastAlert][13], 不过还有其他方式。这个额外的软件相当健壮,但是它增加了已经复杂的系统的复杂性。
|
||||
|
||||
#### Graylog
|
||||
|
||||
[Graylog][14] 最近越来越受欢迎,但它是在2010年 Lennart Koopmann 创建并开发的。两年后,一家公司以同样的名字诞生了。尽管它的使用者越来越多,但仍然远远落后于 ELK 栈。这也意味着它具有较少的社区开发特征,但是它可以使用与 ELK stack 相同的 Beats 。Graylog 由于 Graylog Collector Sidecar 使用 [Go][15] 编写所以在 Go 社区赢得了赞誉。
|
||||
|
||||
Graylog 使用 Elasticsearch、[MongoDB][16] 并且 提供 Graylog Server 。这使得它像ELK 栈一样复杂,也许还要复杂一些。然而,Graylog 附带了内置于开源版本中的报警功能,以及其他一些值得注意的功能,如 streaming 、消息重写 和 地理定位。
|
||||
|
||||
streaming 能允许数据在被处理时被实时路由到特定的 Streams。使用此功能,用户可以在单个Stream 中看到所有数据库错误,在不同的 Stream 中看到 web 服务器错误。当添加新项目或超过阈值时,甚至可以基于这些 Stream 提供警报。延迟可能是日志聚合系统中最大的问题之一,Stream消除了灰色日志中的这一问题。一旦日志进入,它就可以通过 Stream 路由到其他系统,而无需全部处理。
|
||||
|
||||
消息重写功能使用开源规则引擎 [Drools][17] 。允许根据用户定义的规则文件评估所有传入的消息,从而可以删除消息(称为黑名单)、添加或删除字段或修改消息。
|
||||
|
||||
Graylog 最酷的功能是它的地理定位功能,它支持在地图上绘制 IP 地址。这是一个相当常见的功能,在 Kibana 也可以这样使用,但是它增加了很多价值——特别是如果你想将它用作 SIEM 系统。地理定位功能在系统的开源版本中提供。
|
||||
|
||||
Graylog 如果你想要的话,它会对开源版本的支持收费。它还为其企业版提供了一个开放的核心模型,提供存档、审计日志记录和其他支持。如果你不需要 Graylog (the company) 支持或托管的,你可以独立使用。
|
||||
|
||||
#### Fluentd
|
||||
|
||||
[Fluentd][18] 是 [Treasure Data][19] 开发的,[CNCF][20] 已经将它作为一个孵化项目。它是用 C 和 Ruby 编写的,并由[AWS][21] 和 [Google Cloud][22]推荐。fluentd已经成为许多装置中logstach的常用替代品。它充当本地聚合器,收集所有节点日志并将其发送到中央存储系统。它不是日志聚合系统。
|
||||
|
||||
它使用一个强大的插件系统,提供不同数据源和数据输出的快速和简单的集成功能。因为有超过500个插件可用,所以你的大多数用例都应该包括在内。如果没有,这听起来是一个为开源社区做出贡献的机会。
|
||||
|
||||
Fluentd 由于占用内存少(只有几十兆字节)和高吞吐量特性,是 Kubernetes 环境中的常见选择。在像 [Kubernetes][23] 这样的环境中,每个pod 都有一个 Fluentd sidecar ,内存消耗会随着每个新 pod 的创建而线性增加。在这中情况下,使用 Fluentd 将大大降低你的系统利用率。这对于Java开发的工具来说,这是一个常见的问题,这些工具旨在为每个节点运行一个工具,而内存开销并不是主要问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/open-source-log-aggregation-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.elastic.co/webinars/introduction-elk-stack
|
||||
[2]: https://www.elastic.co/
|
||||
[3]: https://www.elastic.co/products/elasticsearch
|
||||
[4]: https://www.elastic.co/products/logstash
|
||||
[5]: https://www.elastic.co/products/kibana
|
||||
[6]: http://kafka.apache.org/
|
||||
[7]: https://redis.io/
|
||||
[8]: https://www.nginx.com/
|
||||
[9]: https://logz.io/
|
||||
[10]: https://aws.amazon.com/elasticsearch-service/
|
||||
[11]: https://www.elastic.co/cloud
|
||||
[12]: https://en.wikipedia.org/wiki/Security_information_and_event_management
|
||||
[13]: https://github.com/Yelp/elastalert
|
||||
[14]: https://www.graylog.org/
|
||||
[15]: https://opensource.com/tags/go
|
||||
[16]: https://www.mongodb.com/
|
||||
[17]: https://www.drools.org/
|
||||
[18]: https://www.fluentd.org/
|
||||
[19]: https://www.treasuredata.com/
|
||||
[20]: https://www.cncf.io/
|
||||
[21]: https://aws.amazon.com/blogs/aws/all-your-data-fluentd/
|
||||
[22]: https://cloud.google.com/logging/docs/agent/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
|
||||
@ -0,0 +1,170 @@
|
||||
让你提高效率的 Linux 技巧
|
||||
======
|
||||
想要在 Linux 命令行工作中提高效率,你需要使用一些技巧。
|
||||
|
||||

|
||||
|
||||
巧妙的 Linux 命令行技巧能让你节省时间、避免出错,还能让你记住和复用各种复杂的命令,专注在需要做的事情本身,而不是做事的方式。以下介绍一些好用的命令行技巧。
|
||||
|
||||
### 命令编辑
|
||||
|
||||
如果要对一个已输入的命令进行修改,可以使用 ^a(ctrl + a)或 ^e(ctrl + e)将光标快速移动到命令的开头或命令的末尾。
|
||||
|
||||
还可以使用 `^` 字符实现对上一个命令的文本替换并重新执行命令,例如 `^before^after^` 相当于把上一个命令中的 `before` 替换为 `after` 然后重新执行一次。
|
||||
|
||||
```
|
||||
$ eho hello world <== 错误的命令
|
||||
|
||||
Command 'eho' not found, did you mean:
|
||||
|
||||
command 'echo' from deb coreutils
|
||||
command 'who' from deb coreutils
|
||||
|
||||
Try: sudo apt install <deb name>
|
||||
|
||||
$ ^e^ec^ <== 替换
|
||||
echo hello world
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
### 使用远程机器的名称登录到机器上
|
||||
|
||||
如果使用命令行登录其它机器上,可以考虑添加别名。在别名中,可以填入需要登录的用户名(与本地系统上的用户名可能相同,也可能不同)以及远程机器的登录信息。例如使用 `server_name ='ssh -v -l username IP-address'` 这样的别名命令:
|
||||
|
||||
```
|
||||
$ alias butterfly=”ssh -v -l jdoe 192.168.0.11”
|
||||
```
|
||||
|
||||
也可以通过在 `/etc/hosts` 文件中添加记录或者在 DNS 服务器中加入解析记录来把 IP 地址替换成易记的机器名称。
|
||||
|
||||
执行 `alias` 命令可以列出机器上已有的别名。
|
||||
|
||||
```
|
||||
$ alias
|
||||
alias butterfly='ssh -v -l jdoe 192.168.0.11'
|
||||
alias c='clear'
|
||||
alias egrep='egrep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias grep='grep --color=auto'
|
||||
alias l='ls -CF'
|
||||
alias la='ls -A'
|
||||
alias list_repos='grep ^[^#] /etc/apt/sources.list /etc/apt/sources.list.d/*'
|
||||
alias ll='ls -alF'
|
||||
alias ls='ls --color=auto'
|
||||
alias show_dimensions='xdpyinfo | grep '\''dimensions:'\'''
|
||||
```
|
||||
|
||||
只要将新的别名添加到 `~/.bashrc` 或类似的文件中,就可以让别名在每次登录后都能立即生效。
|
||||
|
||||
### 冻结、解冻终端界面
|
||||
|
||||
^s(ctrl + s)将通过执行流量控制命令 XOFF 来停止终端输出内容,这会对 PuTTY 会话和桌面终端窗口产生影响。如果误输入了这个命令,可以使用 ^q(ctrl + q)让终端重新响应。所以只需要记住^q 这个组合键就可以了,毕竟这种情况并不多见。
|
||||
|
||||
### 复用命令
|
||||
|
||||
Linux 提供了很多让用户复用命令的方法,其核心是通过历史缓冲区收集执行过的命令。复用命令的最简单方法是输入 `!` 然后接最近使用过的命令的开头字母;当然也可以按键盘上的向上箭头,直到看到要复用的命令,然后按 Enter 键。还可以先使用 `history` 显示命令历史,然后输入 `!` 后面再接命令历史记录中需要复用的命令旁边的数字。
|
||||
|
||||
```
|
||||
!! <== 复用上一条命令
|
||||
!ec <== 复用上一条以 “ec” 开头的命令
|
||||
!76 <== 复用命令历史中的 76 号命令
|
||||
```
|
||||
|
||||
### 查看日志文件并动态显示更新内容
|
||||
|
||||
使用形如 `tail -f /var/log/syslog` 的命令可以查看指定的日志文件,并动态显示文件中增加的内容,需要监控向日志文件中追加内容的的事件时相当有用。这个命令会输出文件内容的末尾部分,并逐渐显示新增的内容。
|
||||
|
||||
```
|
||||
$ tail -f /var/log/auth.log
|
||||
Sep 17 09:41:01 fly CRON[8071]: pam_unix(cron:session): session closed for user smmsp
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:45:01 fly CRON[8115]: pam_unix(cron:session): session closed for user root
|
||||
Sep 17 09:47:00 fly sshd[8124]: Accepted password for shs from 192.168.0.22 port 47792
|
||||
Sep 17 09:47:00 fly sshd[8124]: pam_unix(sshd:session): session opened for user shs by
|
||||
Sep 17 09:47:00 fly systemd-logind[776]: New session 215 of user shs.
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session opened for user root
|
||||
Sep 17 09:55:01 fly CRON[8208]: pam_unix(cron:session): session closed for user root
|
||||
<== 等待显示追加的内容
|
||||
```
|
||||
|
||||
### 寻求帮助
|
||||
|
||||
对于大多数 Linux 命令,都可以通过在输入命令后加上选项 `--help` 来获得这个命令的作用、用法以及它的一些相关信息。除了 `man` 命令之外, `--help` 选项可以让你在不使用所有扩展选项的情况下获取到所需要的内容。
|
||||
|
||||
```
|
||||
$ mkdir --help
|
||||
Usage: mkdir [OPTION]... DIRECTORY...
|
||||
Create the DIRECTORY(ies), if they do not already exist.
|
||||
|
||||
Mandatory arguments to long options are mandatory for short options too.
|
||||
-m, --mode=MODE set file mode (as in chmod), not a=rwx - umask
|
||||
-p, --parents no error if existing, make parent directories as needed
|
||||
-v, --verbose print a message for each created directory
|
||||
-Z set SELinux security context of each created directory
|
||||
to the default type
|
||||
--context[=CTX] like -Z, or if CTX is specified then set the SELinux
|
||||
or SMACK security context to CTX
|
||||
--help display this help and exit
|
||||
--version output version information and exit
|
||||
|
||||
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
|
||||
Full documentation at: <http://www.gnu.org/software/coreutils/mkdir>
|
||||
or available locally via: info '(coreutils) mkdir invocation'
|
||||
```
|
||||
|
||||
### 谨慎删除文件
|
||||
|
||||
如果要谨慎使用 `rm` 命令,可以为它设置一个别名,在删除文件之前需要进行确认才能删除。有些系统管理员会默认使用这个别名,对于这种情况,你可能需要看看下一个技巧。
|
||||
|
||||
```
|
||||
$ rm -i <== 请求确认
|
||||
```
|
||||
|
||||
### 关闭别名
|
||||
|
||||
你可以使用 `unalias` 命令以交互方式禁用别名。它不会更改别名的配置,而仅仅是暂时禁用,直到下次登录或重新设置了这一个别名才会重新生效。
|
||||
|
||||
```
|
||||
$ unalias rm
|
||||
```
|
||||
|
||||
如果已经将 `rm -i` 默认设置为 `rm` 的别名,但你希望在删除文件之前不必进行确认,则可以将 `unalias` 命令放在一个启动文件(例如 ~/.bashrc)中。
|
||||
|
||||
### 使用 sudo
|
||||
|
||||
如果你经常在只有 root 用户才能执行的命令前忘记使用 `sudo`,这里有两个方法可以解决。一是利用命令历史记录,可以使用 `sudo !!`(使用 `!!` 来运行最近的命令,并在前面添加 `sudo`)来重复执行,二是设置一些附加了所需 `sudo` 的命令别名。
|
||||
|
||||
```
|
||||
$ alias update=’sudo apt update’
|
||||
```
|
||||
|
||||
### 更复杂的技巧
|
||||
|
||||
有时命令行技巧并不仅仅是一个别名。毕竟,别名能帮你做的只有替换命令以及增加一些命令参数,节省了输入的时间。但如果需要比别名更复杂功能,可以通过编写脚本、向 `.bashrc` 或其他启动文件添加函数来实现。例如,下面这个函数会在创建一个目录后进入到这个目录下。在设置完毕后,执行 `source .bashrc`,就可以使用 `md temp` 这样的命令来创建目录立即进入这个目录下。
|
||||
|
||||
```
|
||||
md () { mkdir -p "$@" && cd "$1"; }
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
使用 Linux 命令行是在 Linux 系统上工作最有效也最有趣的方法,但配合命令行技巧和巧妙的别名可以让你获得更好的体验。
|
||||
|
||||
加入 [Facebook][1] 和 [LinkedIn][2] 上的 Network World 社区可以和我们一起讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3305811/linux/linux-tricks-that-even-you-can-love.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
|
||||
@ -0,0 +1,121 @@
|
||||
简化 Django 开发的八个 Python 包
|
||||
======
|
||||
|
||||
这个月的 Python 专栏将介绍一些 Django 包,它们有益于你的工作,以及你的个人或业余项目。
|
||||
|
||||

|
||||
|
||||
Django 开发者们,在这个月的 Python 专栏中,我们会介绍一些能帮助你们的软件包。这些软件包是我们最喜欢的 [Django][1] 库,能够节省开发时间,减少样板代码,通常来说,这会让我们的生活更加轻松。我们为 Django 应用准备了六个包,为 Django 的 REST 框架准备了两个包。几乎所有我们的项目里,都用到了这些包,真的,不是说笑。
|
||||
|
||||
不过在继续阅读之前,请先看看我们关于[让 Django 管理后台更安全][2]的几个提示,以及这篇关于 [5 个最受欢迎的开源 Django 包][3] 的文章。
|
||||
|
||||
### 有用又省时的工具集合:django-extensions
|
||||
|
||||
[Django-extensions][4] 这个 Django 包非常受欢迎,全是有用的工具,比如下面这些管理命令:
|
||||
|
||||
* **shell_plus** 打开 Django 的管理 shell,这个 shell 已经自动导入了所有的数据库模型。在测试复杂的数据关系时,就不需要再从几个不同的应用里做 import 的操作了。
|
||||
* **clean_pyc** 删除项目目录下所有位置的 .pyc 文件
|
||||
* **create_template_tags** 在指定的应用下,创建模板标签的目录结构。
|
||||
* **describe_form** 输出模型的表单定义,可以粘贴到 forms.py 文件中。(需要注意的是,这种方法创建的是普通 Django 表单,而不是模型表单。)
|
||||
* **notes** 输出你项目里所有带 TODO,FIXME 等标记的注释。
|
||||
|
||||
Django-extensions 还包括几个有用的抽象基类,在定义模型时,它们能满足常见的模式。当你需要以下模型时,可以继承这些基类:
|
||||
|
||||
|
||||
* **TimeStampedModel** : 这个模型的基类包含了 **created** 字段和 **modified** 字段,还有一个 **save()** 方法,在适当的场景下,该方法自动更新 created 和 modified 字段的值。
|
||||
* **ActivatorModel** : 如果你的模型需要像 **status**,**activate_date** 和 **deactivate_date** 这样的字段,可以使用这个基类。它还自带了一个启用 **.active()** 和 **.inactive()** 查询集的 manager。
|
||||
* **TitleDescriptionModel** 和 **TitleSlugDescriptionModel** : 这两个模型包括了 **title** 和 **description** 字段,其中 description 字段还包括 **slug**,它根据 **title** 字段自动产生。
|
||||
|
||||
Django-extensions 还有其他更多的功能,也许对你的项目有帮助,所以,去浏览一下它的[文档][5]吧!
|
||||
|
||||
### 12 因子应用的配置:django-environ
|
||||
|
||||
在 Django 项目的配置方面,[Django-environ][6] 提供了符合 [12 因子应用][7] 方法论的管理方法。它是其他一些库的集合,包括 [envparse][8] 和 [honcho][9] 等。安装了 django-environ 之后,在项目的根目录创建一个 .env 文件,用这个文件去定义那些随环境不同而不同的变量,或者需要保密的变量。(比如 API keys,是否启用 debug,数据库的 URLs 等)
|
||||
|
||||
然后,在项目的 settings.py 中引入 **environ**,并参考[官方文档的例子][10]设置好 **environ.PATH()** 和 **environ.Env()**。就可以通过 **env('VARIABLE_NAME')** 来获取 .env 文件中定义的变量值了。
|
||||
|
||||
### 创建出色的管理命令:django-click
|
||||
|
||||
[Django-click][11] 是基于 [Click][12] 的, ( 我们[之前推荐过][13]… [两次][14] Click),它对编写 Django 管理命令很有帮助。这个库没有很多文档,但是代码仓库中有个存放[测试命令][15]的目录,非常有参考价值。 Django-click 基本的 Hello World 命令是这样写的:
|
||||
|
||||
```
|
||||
# app_name.management.commands.hello.py
|
||||
import djclick as click
|
||||
|
||||
@click.command()
|
||||
@click.argument('name')
|
||||
def command(name):
|
||||
click.secho(f'Hello, {name}')
|
||||
```
|
||||
|
||||
在命令行下调用它,这样执行即可:
|
||||
|
||||
```
|
||||
>> ./manage.py hello Lacey
|
||||
Hello, Lacey
|
||||
```
|
||||
|
||||
### 处理有限状态机:django-fsm
|
||||
|
||||
[Django-fsm][16] 给 Django 的模型添加了有限状态机的支持。如果你管理一个新闻网站,想用类似于“写作中”,“编辑中”,“已发布”来流转文章的状态,django-fsm 能帮你定义这些状态,还能管理状态变化的规则与限制。
|
||||
|
||||
Django-fsm 为模型提供了 FSMField 字段,用来定义模型实例的状态。用 django-fsm 的 **@transition** 修饰符,可以定义状态变化的方法,并处理状态变化的任何副作用。
|
||||
|
||||
虽然 django-fsm 文档很轻量,不过 [Django 中的工作流(状态)][17] 这篇 GitHubGist 对有限状态机和 django-fsm 做了非常好的介绍。
|
||||
|
||||
### 联系人表单:#django-contact-form
|
||||
|
||||
联系人表单可以说是网站的标配。但是不要自己去写全部的样板代码,用 [django-contact-form][18] 在几分钟内就可以搞定。它带有一个可选的能过滤垃圾邮件的表单类(也有不过滤的普通表单类)和一个 **ContactFormView** 基类,基类的方法可以覆盖或自定义修改。而且它还能引导你完成模板的创建,好让表单正常工作。
|
||||
|
||||
### 用户注册和认证:django-allauth
|
||||
|
||||
[Django-allauth][19] 是一个 Django 应用,它为用户注册,登录注销,密码重置,还有第三方用户认证(比如 GitHub 或 Twitter)提供了视图,表单和 URLs,支持邮件地址作为用户名的认证方式,而且有大量的文档记录。第一次用的时候,它的配置可能会让人有点晕头转向;请仔细阅读[安装说明][20],在[自定义你的配置][21]时要专注,确保启用某个功能的所有配置都用对了。
|
||||
|
||||
### 处理 Django REST 框架的用户认证:django-rest-auth
|
||||
|
||||
如果 Django 开发中涉及到对外提供 API,你很可能用到了 [Django REST Framework][22] (DRF)。如果你在用 DRF,那么你应该试试 django-rest-auth,它提供了用户注册,登录/注销,密码重置和社交媒体认证的 endpoints (是通过添加 django-allauth 的支持来实现的,这两个包协作得很好)。
|
||||
|
||||
### Django REST 框架的 API 可视化:django-rest-swagger
|
||||
|
||||
[Django REST Swagger][24] 提供了一个功能丰富的用户界面,用来和 Django REST 框架的 API 交互。你只需要安装 Django REST Swagger,把它添加到 Django 项目的 installed apps 中,然后在 urls.py 中添加 Swagger 的视图和 URL 模式就可以了,剩下的事情交给 API 的 docstring 处理。
|
||||
|
||||

|
||||
|
||||
API 的用户界面按照 app 的维度展示了所有 endpoints 和可用方法,并列出了这些 endpoints 的可用操作,而且它提供了和 API 交互的功能(比如添加/删除/获取记录)。django-rest-swagger 从 API 视图中的 docstrings 生成每个 endpoint 的文档,通过这种方法,为你的项目创建了一份 API 文档,这对你,对前端开发人员和用户都很有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/django-packages
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[belitex](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/laceynwilliams
|
||||
[1]: https://www.djangoproject.com/
|
||||
[2]: https://opensource.com/article/18/1/10-tips-making-django-admin-more-secure
|
||||
[3]: https://opensource.com/business/15/12/5-favorite-open-source-django-packages
|
||||
[4]: https://django-extensions.readthedocs.io/en/latest/
|
||||
[5]: https://django-extensions.readthedocs.io/
|
||||
[6]: https://django-environ.readthedocs.io/en/latest/
|
||||
[7]: https://www.12factor.net/
|
||||
[8]: https://github.com/rconradharris/envparse
|
||||
[9]: https://github.com/nickstenning/honcho
|
||||
[10]: https://django-environ.readthedocs.io/
|
||||
[11]: https://github.com/GaretJax/django-click
|
||||
[12]: http://click.pocoo.org/5/
|
||||
[13]: https://opensource.com/article/18/9/python-libraries-side-projects
|
||||
[14]: https://opensource.com/article/18/5/3-python-command-line-tools
|
||||
[15]: https://github.com/GaretJax/django-click/tree/master/djclick/test/testprj/testapp/management/commands
|
||||
[16]: https://github.com/viewflow/django-fsm
|
||||
[17]: https://gist.github.com/Nagyman/9502133
|
||||
[18]: https://django-contact-form.readthedocs.io/en/1.5/
|
||||
[19]: https://django-allauth.readthedocs.io/en/latest/
|
||||
[20]: https://django-allauth.readthedocs.io/en/latest/installation.html
|
||||
[21]: https://django-allauth.readthedocs.io/en/latest/configuration.html
|
||||
[22]: http://www.django-rest-framework.org/
|
||||
[23]: https://django-rest-auth.readthedocs.io/
|
||||
[24]: https://django-rest-swagger.readthedocs.io/en/latest/
|
||||
Loading…
Reference in New Issue
Block a user