mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
commit
0ae98883d2
@ -14,7 +14,7 @@
|
||||
|
||||
### 1、操作系统
|
||||
|
||||
操作系统就是一个非常复杂的程序。它的任务就是组织安排计算机上的其它程序,包括共享计算机的时间、内存、硬件和其它资源。你可能听说过的一些比较大的桌面操作系统家族有 GNU/Linux、Mac OS X 和 Microsoft Windows。其它的设备比如电话,也需要操作系统,它可能使用的操作系统是 Android、iOS 和 [Windows Phone](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/introduction.html#note1)。
|
||||
操作系统就是一个非常复杂的程序。它的任务就是组织安排计算机上的其它程序,包括共享计算机的时间、内存、硬件和其它资源。你可能听说过的一些比较大的桌面操作系统家族有 GNU/Linux、Mac OS X 和 Microsoft Windows。其它的设备比如电话,也需要操作系统,它可能使用的操作系统是 Android、iOS 和 Windows Phone。 [^1]
|
||||
|
||||
由于操作系统是用来与计算机系统上的硬件进行交互的,所以它必须了解系统上硬件专有的信息。为了能让操作系统适用于各种类型的计算机,发明了 **驱动程序** 的概念。驱动程序是为了能够让操作系统与特定的硬件进行交互而添加(并可删除)到操作系统上的一小部分代码。在本课程中,我们并不涉及如何创建可删除的驱动程序,而是专注于特定的一个硬件:树莓派。
|
||||
|
||||
@ -26,7 +26,7 @@
|
||||
|
||||
本课程几乎要完全靠汇编代码来写。汇编代码非常接近计算机的底层。计算机其实是靠一个叫处理器的设备来工作的,处理器能够执行像加法这样的简单任务,还有一组叫做 RAM 的芯片,它能够用来保存数字。当计算机通电后,处理器执行程序员给定的一系列指令,这将导致内存中的数字发生变化,以及与连接的硬件进行交互。汇编代码只是将这些机器命令转换为人类可读的文本。
|
||||
|
||||
常规的编程就是,程序员使用编程语言,比如 C++、Java、C#、Basic 等等来写代码,然后一个叫编译器的程序将程序员写的代码转换成汇编代码,然后进一步转换为[二进制代码](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/introduction.html#note2)。二进制代码才是计算机真正能够理解的东西,但它是人类无法读取的东西。汇编代码比二进制代码好一点,至少它的命令是人类可读的,但它仍然让人很沮丧。请记住,你用汇编代码写的每个命令都是处理器可以直接认识的,因此这些命令设计的很简单,因为物理电路必须能够处理每个命令。
|
||||
常规的编程就是,程序员使用编程语言,比如 C++、Java、C#、Basic 等等来写代码,然后一个叫编译器的程序将程序员写的代码转换成汇编代码,然后进一步转换为二进制代码。[^2] 二进制代码才是计算机真正能够理解的东西,但它是人类无法读取的东西。汇编代码比二进制代码好一点,至少它的命令是人类可读的,但它仍然让人很沮丧。请记住,你用汇编代码写的每个命令都是处理器可以直接认识的,因此这些命令设计的很简单,因为物理电路必须能够处理每个命令。
|
||||
|
||||
![Compiler process][1]
|
||||
|
||||
@ -34,6 +34,9 @@
|
||||
|
||||
现在,你已经准备好进入第一节课了,它是 [课程 1 OK01][2]
|
||||
|
||||
[^1]: 要查看更完整的操作系统列表,请参照:[操作系统列表 - Wikipedia](http://en.wikipedia.org/wiki/List_of_operating_systems)
|
||||
[^2]: 当然,我简化了普通编程的这种解释,实际上它在很大程度上取决于语言和机器。感兴趣的话,参见 [编译器 - Wikipedia](http://en.wikipedia.org/wiki/Compiler)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/introduction.html
|
||||
|
||||
@ -0,0 +1,205 @@
|
||||
使用 Ansible 来管理你的工作站:配置自动化
|
||||
======
|
||||
> 学习如何使 Ansible 自动对一系列台式机和笔记本应用配置。
|
||||
|
||||

|
||||
|
||||
Ansible 是一个令人惊讶的自动化的配置管理工具。其主要应用在服务器和云部署上,但在工作站上的应用(无论是台式机还是笔记本)却鲜少得到关注,这就是本系列所要关注的。
|
||||
|
||||
在这个系列的[第一部分][1],我向你展示了 `ansible-pull` 命令的基本用法,我们创建了一个安装了少量包的剧本。它本身是没有多大的用处的,但是为后续的自动化做了准备。
|
||||
|
||||
在这篇文章中,将会达成闭环,而且在最后部分,我们将会有一个针对工作站自动配置的完整的工作解决方案。现在,我们将要设置 Ansible 的配置,这样未来将要做的改变将会自动的部署应用到我们的工作站上。现阶段,假设你已经完成了[第一部分][1]的工作。如果没有的话,当你完成的时候回到本文。你应该已经有一个包含第一篇文章中代码的 GitHub 库。我们将直接在之前创建的部分之上继续。
|
||||
|
||||
首先,因为我们要做的不仅仅是安装包文件,所以我们要做一些重新的组织工作。现在,我们已经有一个名为 `local.yml` 并包含以下内容的剧本:
|
||||
|
||||
```
|
||||
- hosts: localhost
|
||||
become: true
|
||||
tasks:
|
||||
- name: Install packages
|
||||
apt: name={{item}}
|
||||
with_items:
|
||||
- htop
|
||||
- mc
|
||||
- tmux
|
||||
```
|
||||
|
||||
如果我们仅仅想实现一个任务那么上面的配置就足够了。随着向我们的配置中不断的添加内容,这个文件将会变的相当的庞大和杂乱。最好能够根据不同类型的配置将我们的<ruby>动作<rt>play</rt></ruby>分为独立的文件。为了达到这个要求,创建一个名为<ruby>任务手册<rt>taskbook</rt></ruby>的东西,它和<ruby>剧本<rt>playbook</rt></ruby>很像但内容更加的流线型。让我们在 Git 库中为任务手册创建一个目录。
|
||||
|
||||
```
|
||||
mkdir tasks
|
||||
```
|
||||
|
||||
`local.yml ` 剧本中的代码可以很好地过渡为安装包文件的任务手册。让我们把这个文件移动到刚刚创建好的 `task` 目录中,并重新命名。
|
||||
|
||||
```
|
||||
mv local.yml tasks/packages.yml
|
||||
```
|
||||
|
||||
现在,我们编辑 `packages.yml` 文件将它进行大幅的瘦身,事实上,我们可以精简除了独立任务本身之外的所有内容。让我们把 `packages.yml` 编辑成如下的形式:
|
||||
|
||||
```
|
||||
- name: Install packages
|
||||
apt: name={{item}}
|
||||
with_items:
|
||||
- htop
|
||||
- mc
|
||||
- tmux
|
||||
```
|
||||
|
||||
正如你所看到的,它使用同样的语法,但我们去掉了对这个任务无用没有必要的所有内容。现在我们有了一个专门安装包文件的任务手册。然而我们仍然需要一个名为 `local.yml` 的文件,因为执行 `ansible-pull` 命令时仍然会去找这个文件。所以我们将在我们库的根目录下(不是在 `task` 目录下)创建一个包含这些内容的全新文件:
|
||||
|
||||
```
|
||||
- hosts: localhost
|
||||
become: true
|
||||
pre_tasks:
|
||||
- name: update repositories
|
||||
apt: update_cache=yes
|
||||
changed_when: False
|
||||
|
||||
tasks:
|
||||
- include: tasks/packages.yml
|
||||
```
|
||||
|
||||
这个新的 `local.yml` 扮演的是导入我们的任务手册的索引的角色。我已经在这个文件中添加了一些你在这个系列中还没见到的内容。首先,在这个文件的开头处,我添加了 `pre_tasks`,这个任务的作用是在其他所有任务运行之前先运行某个任务。在这种情况下,我们给 Ansible 的命令是让它去更新我们的发行版的软件库的索引,下面的配置将执行这个任务要求:
|
||||
|
||||
```
|
||||
apt: update_cache=yes
|
||||
```
|
||||
|
||||
通常 `apt` 模块是用来安装包文件的,但我们也能够让它来更新软件库索引。这样做的目的是让我们的每个动作在 Ansible 运行的时候能够以最新的索引工作。这将确保我们在使用一个老旧的索引安装一个包的时候不会出现问题。因为 `apt` 模块仅仅在 Debian、Ubuntu 及它们的衍生发行版下工作。如果你运行的一个不同的发行版,你要使用特定于你的发行版的模块而不是 `apt`。如果你需要使用一个不同的模块请查看 Ansible 的相关文档。
|
||||
|
||||
下面这行也需要进一步解释:
|
||||
|
||||
```
|
||||
changed_when: False
|
||||
```
|
||||
|
||||
在某个任务中的这行阻止了 Ansible 去报告动作改变的结果,即使是它本身在系统中导致的一个改变。在这里,我们不会去在意库索引是否包含新的数据;它几乎总是会的,因为库总是在改变的。我们不会去在意 `apt` 库的改变,因为索引的改变是正常的过程。如果我们删除这行,我们将在过程报告的后面看到所有的变动,即使仅仅库的更新而已。最好忽略这类的改变。
|
||||
|
||||
接下来是常规任务的阶段,我们将创建好的任务手册导入。我们每次添加另一个任务手册的时候,要添加下面这一行:
|
||||
|
||||
```
|
||||
tasks:
|
||||
- include: tasks/packages.yml
|
||||
```
|
||||
|
||||
如果你现在运行 `ansible-pull` 命令,它应该基本上像上一篇文章中做的一样。不同的是我们已经改进了我们的组织方式,并且能够更有效的扩展它。为了节省你到上一篇文章中去寻找,`ansible-pull` 命令的语法参考如下:
|
||||
|
||||
```
|
||||
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
|
||||
```
|
||||
|
||||
如果你还记得话,`ansible-pull` 的命令拉取一个 Git 仓库并且应用它所包含的配置。
|
||||
|
||||
既然我们的基础已经搭建好,我们现在可以扩展我们的 Ansible 并且添加功能。更特别的是,我们将添加配置来自动化的部署对工作站要做的改变。为了支撑这个要求,首先我们要创建一个特殊的账户来应用我们的 Ansible 配置。这个不是必要的,我们仍然能够在我们自己的用户下运行 Ansible 配置。但是使用一个隔离的用户能够将其隔离到不需要我们参与的在后台运行的一个系统进程中,
|
||||
|
||||
我们可以使用常规的方式来创建这个用户,但是既然我们正在使用 Ansible,我们应该尽量避开使用手动的改变。替代的是,我们将会创建一个任务手册来处理用户创建任务。这个任务手册目前将会仅仅创建一个用户,但你可以在这个任务手册中添加额外的动作来创建更多的用户。我将这个用户命名为 `ansible`,你可以按照自己的想法来命名(如果你做了这个改变要确保更新所有出现地方)。让我们来创建一个名为 `user.yml` 的任务手册并且将以下代码写进去:
|
||||
|
||||
```
|
||||
- name: create ansible user
|
||||
user: name=ansible uid=900
|
||||
```
|
||||
|
||||
下一步,我们需要编辑 `local.yml` 文件,将这个新的任务手册添加进去,像如下这样写:
|
||||
|
||||
```
|
||||
- hosts: localhost
|
||||
become: true
|
||||
pre_tasks:
|
||||
- name: update repositories
|
||||
apt: update_cache=yes
|
||||
changed_when: False
|
||||
|
||||
tasks:
|
||||
- include: tasks/users.yml
|
||||
- include: tasks/packages.yml
|
||||
```
|
||||
|
||||
现在当我们运行 `ansible-pull` 命令的时候,一个名为 `ansible` 的用户将会在系统中被创建。注意我特地通过参数 `uid` 为这个用户声明了用户 ID 为 900。这个不是必须的,但建议直接创建好 UID。因为在 1000 以下的 UID 在登录界面是不会显示的,这样是很棒的,因为我们根本没有需要去使用 `ansibe` 账户来登录我们的桌面。UID 900 是随便定的;它应该是在 1000 以下没有被使用的任何一个数值。你可以使用以下命令在系统中去验证 UID 900 是否已经被使用了:
|
||||
|
||||
```
|
||||
cat /etc/passwd |grep 900
|
||||
```
|
||||
|
||||
不过,你使用这个 UID 应该不会遇到什么问题,因为迄今为止在我使用的任何发行版中我还没遇到过它是被默认使用的。
|
||||
|
||||
现在,我们已经拥有了一个名为 `ansible` 的账户,它将会在之后的自动化配置中使用。接下来,我们可以创建实际的定时作业来自动操作。我们应该将其分开放到它自己的文件中,而不是将其放置到我们刚刚创建的 `users.yml` 文件中。在任务目录中创建一个名为 `cron.yml` 的任务手册并且将以下的代码写进去:
|
||||
|
||||
```
|
||||
- name: install cron job (ansible-pull)
|
||||
cron: user="ansible" name="ansible provision" minute="*/10" job="/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null"
|
||||
```
|
||||
|
||||
`cron` 模块的语法几乎不需加以说明。通过这个动作,我们创建了一个通过用户 `ansible` 运行的定时作业。这个作业将每隔 10 分钟执行一次,下面是它将要执行的命令:
|
||||
|
||||
```
|
||||
/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null
|
||||
```
|
||||
|
||||
同样,我们也可以添加想要我们的所有工作站部署的额外的定时作业到这个文件中。我们只需要在新的定时作业中添加额外的动作即可。然而,仅仅是添加一个定时的任务手册是不够的,我们还需要将它添加到 `local.yml` 文件中以便它能够被调用。将下面的一行添加到末尾:
|
||||
|
||||
```
|
||||
- include: tasks/cron.yml
|
||||
```
|
||||
|
||||
现在当 `ansible-pull` 命令执行的时候,它将会以用户 `ansible` 每隔十分钟设置一个新的定时作业。但是,每个十分钟运行一个 Ansible 作业并不是一个好的方式,因为这个将消耗很多的 CPU 资源。每隔十分钟来运行对于 Ansible 来说是毫无意义的,除非我们已经在 Git 仓库中改变一些东西。
|
||||
|
||||
然而,我们已经解决了这个问题。注意我在定时作业中的命令 `ansible-pill` 添加的我们之前从未用到过的参数 `-o`。这个参数告诉 Ansible 只有在从上次 `ansible-pull` 被调用以后库有了变化后才会运行。如果库没有任何变化,它将不会做任何事情。通过这个方法,你将不会无端的浪费 CPU 资源。当然在拉取存储库的时候会使用一些 CPU 资源,但不会像再一次应用整个配置的时候使用的那么多。当 `ansible-pull` 执行的时候,它将会遍历剧本和任务手册中的所有任务,但至少它不会毫无目的的运行。
|
||||
|
||||
尽管我们已经添加了所有必须的配置要素来自动化 `ansible-pull`,它仍然还不能正常的工作。`ansible-pull` 命令需要 `sudo` 的权限来运行,这将允许它执行系统级的命令。然而我们创建的用户 `ansible` 并没有被设置为以 `sudo` 的权限来执行命令,因此当定时作业触发的时候,执行将会失败。通常我们可以使用命令 `visudo` 来手动的去设置用户 `ansible` 去拥有这个权限。然而我们现在应该以 Ansible 的方式来操作,而且这将会是一个向你展示 `copy` 模块是如何工作的机会。`copy` 模块允许你从库复制一个文件到文件系统的任何位置。在这个案列中,我们将会复制 `sudo` 的一个配置文件到 `/etc/sudoers.d/` 以便用户 `ansible` 能够以管理员的权限执行任务。
|
||||
|
||||
打开 `users.yml`,将下面的的动作添加到文件末尾。
|
||||
|
||||
```
|
||||
- name: copy sudoers_ansible
|
||||
copy: src=files/sudoers_ansible dest=/etc/sudoers.d/ansible owner=root group=root mode=0440
|
||||
```
|
||||
|
||||
正如我们看到的,`copy`模块从我们的仓库中复制一个文件到其他任何位置。在这个过程中,我们正在抓取一个名为 `sudoers_ansible`(我们将在后续创建)的文件并将它复制为 `/etc/sudoers/ansible`,并且拥有者为 `root`。
|
||||
|
||||
接下来,我们需要创建我们将要复制的文件。在你的仓库的根目录下,创建一个名为 `files` 的目录:
|
||||
|
||||
```
|
||||
mkdir files
|
||||
```
|
||||
|
||||
然后,在我们刚刚创建的 `files` 目录里,创建名为 `sudoers_ansible` 的文件,包含以下内容:
|
||||
|
||||
```
|
||||
ansible ALL=(ALL) NOPASSWD: ALL
|
||||
```
|
||||
|
||||
就像我们正在这样做的,在 `/etc/sudoer.d` 目录里创建一个文件允许我们为一个特殊的用户配置 `sudo` 权限。现在我们正在通过 `sudo` 允许用户 `ansible` 不需要密码提示就拥有完全控制权限。这将允许 `ansible-pull` 以后台任务的形式运行而不需要手动去运行。
|
||||
|
||||
现在,你可以通过再次运行 `ansible-pull` 来拉取最新的变动:
|
||||
|
||||
```
|
||||
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
|
||||
```
|
||||
|
||||
从这里开始,`ansible-pull` 的定时作业将会在后台每隔十分钟运行一次来检查你的仓库是否有变化,如果它发现有变化,将会运行你的剧本并且应用你的任务手册。
|
||||
|
||||
所以现在我们有了一个完整的可工作方案。当你第一次设置一台新的笔记本或者台式机的时候,你要去手动的运行 `ansible-pull` 命令,但仅仅是在第一次的时候。从第一次之后,用户 `ansible` 将会在后台接手后续的运行任务。当你想对你的机器做变动的时候,你只需要简单的去拉取你的 Git 仓库来做变动,然后将这些变化回传到库中。接着,当定时作业下次在每台机器上运行的时候,它将会拉取变动的部分并应用它们。你现在只需要做一次变动,你的所有工作站将会跟着一起变动。这方法尽管有一点不同寻常,通常,你会有一个包含你的机器列表和不同机器所属规则的清单文件。然而,`ansible-pull` 的方法,就像在文章中描述的,是管理工作站配置的非常有效的方法。
|
||||
|
||||
我已经在我的 [Github 仓库][2]中更新了这篇文章中的代码,所以你可以随时去浏览来对比检查你的语法。同时我将前一篇文章中的代码移到了它自己的目录中。
|
||||
|
||||
在[第三部分][3],我们将通过介绍使用 Ansible 来配置 GNOME 桌面设置来结束这个系列。我将会告诉你如何设置你的墙纸和锁屏壁纸、应用一个桌面主题以及更多的东西。
|
||||
|
||||
同时,到了布置一些作业的时候了,大多数人都有我们所使用的各种应用的配置文件。可能是 Bash、Vim 或者其他你使用的工具的配置文件。现在你可以尝试通过我们在使用的 Ansible 库来自动复制这些配置到你的机器中。在这篇文章中,我已将向你展示了如何去复制文件,所以去尝试以下看看你是都已经能应用这些知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2
|
||||
|
||||
作者:[Jay LaCroix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jlacroix
|
||||
[1]:https://linux.cn/article-10434-1.html
|
||||
[2]:https://github.com/jlacroix82/ansible_article.git
|
||||
[3]:https://opensource.com/article/18/5/manage-your-workstation-ansible-part-3
|
||||
@ -1,20 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (Turn an old Linux desktop into a home media center)
|
||||
[#]: via: (https://opensource.com/article/18/11/old-linux-desktop-new-home-media-center)
|
||||
[#]: author: ([Alan Formy-Duval](https://opensource.com/users/alanfdoss))
|
||||
[#]: url: ( )
|
||||
[#]: url: (https://linux.cn/article-10446-1.html)
|
||||
|
||||
将旧的 Linux 桌面变成家庭媒体中心
|
||||
将旧的 Linux 台式机变成家庭媒体中心
|
||||
======
|
||||
重新利用过时的计算机来浏览互联网并在大屏电视上观看视频。
|
||||
|
||||
> 重新利用过时的计算机来浏览互联网并在大屏电视上观看视频。
|
||||
|
||||

|
||||
|
||||
我第一次尝试搭建一台“娱乐电脑”是在 20 世纪 90 年代后期,使用一台带 Trident ProVidia 9685 PCI 显卡的普通旧台式电脑。我使用了所谓的“电视输出”卡,它有一个额外的输出连接到标准电视端子上。屏幕显示看起来不太好,而且没有音频输出。并且外观很丑:有一条 S-Video 线穿过了客厅地板连接到我的 19 英寸 Sony Trinitron CRT 电视机上。
|
||||
我第一次尝试搭建一台“娱乐电脑”是在 20 世纪 90 年代后期,使用了一台带 Trident ProVidia 9685 PCI 显卡的普通旧台式电脑。我使用了所谓的“电视输出”卡,它有一个额外的输出可以连接到标准电视端子上。屏幕显示看起来不太好,而且没有音频输出。并且外观很丑:有一条 S-Video 线穿过了客厅地板连接到我的 19 英寸 Sony Trinitron CRT 电视机上。
|
||||
|
||||
我在 Linux 和 Windows 98 上也得到了同样令人遗憾的结果。在和那些看起来不对劲的系统挣扎之后,我放弃了几年。值得庆幸的是,如今的 HDMI 拥有更好的性能和标准化的分辨率,这使得廉价的家庭媒体中心成为现实。
|
||||
我在 Linux 和 Windows 98 上得到了同样令人遗憾的结果。在和那些看起来不对劲的系统挣扎之后,我放弃了几年。值得庆幸的是,如今的 HDMI 拥有更好的性能和标准化的分辨率,这使得廉价的家庭媒体中心成为现实。
|
||||
|
||||
我的新媒体中心娱乐电脑实际上是我的旧 Ubuntu Linux 桌面,最近我用更快的电脑替换了它。这台电脑在工作中太慢,但是它的 3.4GHz 的 AMD Phenom II X4 965 处理器和 8GB 的 RAM 足以满足一般浏览和视频流的要求。
|
||||
|
||||
@ -30,37 +32,37 @@
|
||||
|
||||
### 音频
|
||||
|
||||
Nvidia GeForce GTX 音频设备在 GNOME 控制中心的声音设置中被列为 GK107 HDMI Audio Controller,因此单条 HDMI 线缆可同时处理音频和视频。无需将音频线连接到板载声卡的输出插孔。
|
||||
Nvidia GeForce GTX 音频设备在 GNOME 控制中心的声音设置中被显示为 GK107 HDMI Audio Controller,因此单条 HDMI 线缆可同时处理音频和视频。无需将音频线连接到板载声卡的输出插孔。
|
||||
|
||||
![Sound settings screenshot][2]
|
||||
|
||||
GNOME 音频设置中的 HDMI 音频控制器。
|
||||
*GNOME 音频设置中的 HDMI 音频控制器。*
|
||||
|
||||
### 键盘和鼠标
|
||||
|
||||
我有罗技的无线键盘和鼠标。当我安装它们时,我插入了两个外置 USB 接收器,它们可以使用,但我经常遇到信号反应问题。接着我发现其中一个被标记为联合接收器,这意味着它可以自己处理多个罗技输入设备。罗技不提供在 Linux 中配置统一接收器的软件。但幸运的是,有个开源程序 [Solaar][3] 能够做到。使用单个接收器解决了我的输入性能问题。
|
||||
我有罗技的无线键盘和鼠标。当我安装它们时,我插入了两个外置 USB 接收器,它们可以使用,但我经常遇到信号反应问题。接着我发现其中一个被标记为联合接收器,这意味着它可以自己处理多个罗技输入设备。罗技不提供在 Linux 中配置联合接收器的软件。但幸运的是,有个开源程序 [Solaar][3] 能够做到。使用单个接收器解决了我的输入性能问题。
|
||||
|
||||
![Solaar][5]
|
||||
|
||||
Solaar 联合接收器界面。
|
||||
*Solaar 联合接收器界面。*
|
||||
|
||||
### 视频
|
||||
|
||||
最初很难在我的 47 英寸平板电视上阅读,所以我在 Universal Access 下启用了“大文字”。我下载了一些与电视 1920x1080 分辨率相匹配的壁纸,这看起来很棒!
|
||||
最初很难在我的 47 英寸平板电视上阅读文字,所以我在 Universal Access 下启用了“大文字”。我下载了一些与电视 1920x1080 分辨率相匹配的壁纸,这看起来很棒!
|
||||
|
||||
### 最后处理
|
||||
|
||||
我需要在电脑的冷却需求和我对不受阻碍的娱乐的渴望之间取得平衡。由于这是一台标准的 ATX 微型塔式计算机,我确保我有足够的风扇,以及在 BIOS 中精心配置过的温度以减少噪音。我还把电脑放在我的娱乐控制台后面,以进一步减少风扇噪音,但同时我可以按到电源按钮。
|
||||
我需要在电脑的冷却需求和我对不受阻碍的娱乐的渴望之间取得平衡。由于这是一台标准的 ATX 微型塔式计算机,我确保我有足够的风扇转速,以及在 BIOS 中精心配置过的温度以减少噪音。我还把电脑放在我的娱乐控制台后面,以进一步减少风扇噪音,但同时我可以按到电源按钮。
|
||||
|
||||
最后得到一台简单的没有巨大噪音的机器,而且只使用了两根线缆—交流电源线和 HDMI。它应该能够运行任何主流或专门的媒体中心 Linux 发行版。我不期望去玩高端的游戏,因为这可能需要更多的处理能力。
|
||||
最后得到一台简单的、没有巨大噪音的机器,而且只使用了两根线缆:交流电源线和 HDMI。它应该能够运行任何主流或专门的媒体中心 Linux 发行版。我不期望去玩高端的游戏,因为这可能需要更多的处理能力。
|
||||
|
||||
![Showing Ubuntu Linux About page onscreen][7]
|
||||
|
||||
Ubuntu Linux 的关于页面。
|
||||
*Ubuntu Linux 的关于页面。*
|
||||
|
||||
![YouTube on the big screen][9]
|
||||
|
||||
在大屏幕上测试 YouTube 视频。
|
||||
*在大屏幕上测试 YouTube 视频。*
|
||||
|
||||
我还没安装像 [Kodi][10] 这样专门的媒体中心发行版。截至目前,它运行的是 Ubuntu Linux 18.04.1 LTS,而且很稳定。
|
||||
|
||||
@ -73,7 +75,7 @@ via: https://opensource.com/article/18/11/old-linux-desktop-new-home-media-cente
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -84,4 +86,4 @@ via: https://opensource.com/article/18/11/old-linux-desktop-new-home-media-cente
|
||||
[5]: https://opensource.com/sites/default/files/uploads/solaar_interface.png (Solaar)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/finalresult1.png (Showing Ubuntu Linux About page onscreen)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/finalresult2.png (YouTube on the big screen)
|
||||
[10]: https://kodi.tv/
|
||||
[10]: https://kodi.tv/
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10447-1.html)
|
||||
[#]: subject: (Powers of two, powers of Linux: 2048 at the command line)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-2048)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
2 的力量,Linux 的力量:终端中的 2048
|
||||
2 的威力,Linux 的威力:终端中的 2048
|
||||
======
|
||||
正在寻找基于终端的游戏来打发时间么?来看看 2048-cli 吧。
|
||||
|
||||
> 正在寻找基于终端的游戏来打发时间么?来看看 2048-cli 吧。
|
||||
|
||||
|
||||
|
||||
你好,欢迎来到今天的 Linux 命令行玩具日历。每天,我们会为你的终端带来一个不同的玩具:它可能是一个游戏或任何简单的消遣,可以帮助你获得乐趣。
|
||||
|
||||
很可能你们中的一些人之前已经看过我们日历中的各种玩具,但我们希望每个人至少见到一件新事物。
|
||||
|
||||
今天的玩具是我最喜欢的休闲游戏之一 [2048][2] (它本身就是另外一个克隆的克隆)的[命令行版本][1]。
|
||||
今天的玩具是我最喜欢的休闲游戏之一 [2048][2] (它本身就是另外一个克隆品的克隆)的[命令行版本][1]。
|
||||
|
||||
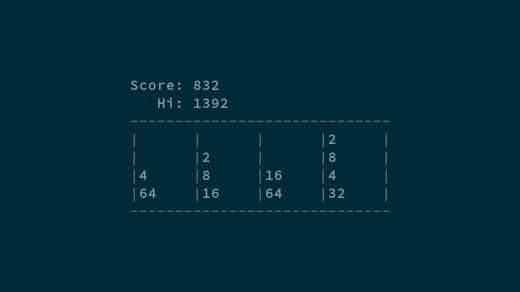
要进行游戏,你只需将滑块向上、向下、向左、向右移动,组合成对的数字,并增加数字,直到你得到数字 2048 的块。吸引人的地方(以及挑战)是你不能只移动一个滑块,而是需要移动屏幕上的每一块。
|
||||
要进行游戏,你只需将滑块向上、向下、向左、向右移动,组合成对的数字,并增加数值,直到你得到数字为 2048 的块。最吸引人的地方(以及挑战)是你不能只移动一个滑块,而是需要移动屏幕上的每一块。(LCTT 译注:不知道有没有人在我们 Linux 中国的网站上遇到过 404 页面?那就是一个 2048 游戏,经常我错误地打开一个不存在的页面时,本应该去修复这个问题,却不小心沉迷于其中……)
|
||||
|
||||
它简单、有趣,很容易在里面沉迷几个小时。这个 2048 的克隆 [2048-cli][1] 是 Marc Tiehuis 用 C 编写的,并在 MIT 许可下开源。你可以在 [GitHub][1] 上找到源代码,你也可在这找到适用于你的平台的安装说明。由于它已为 Fedora 打包,因此我来说,安装就像下面那样简单:
|
||||
|
||||
@ -41,7 +43,7 @@ via: https://opensource.com/article/18/12/linux-toy-2048
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -49,4 +51,4 @@ via: https://opensource.com/article/18/12/linux-toy-2048
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tiehuis/2048-cli
|
||||
[2]: https://github.com/gabrielecirulli/2048
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-tetris
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-tetris
|
||||
86
published/20181211 Winterize your Bash prompt in Linux.md
Normal file
86
published/20181211 Winterize your Bash prompt in Linux.md
Normal file
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10450-1.html)
|
||||
[#]: subject: (Winterize your Bash prompt in Linux)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-bash-prompt)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
在 Linux 中打扮你的冬季 Bash 提示符
|
||||
======
|
||||
|
||||
> 你的 Linux 终端可能支持 Unicode,那么为何不利用它在提示符中添加季节性的图标呢?
|
||||
|
||||
|
||||
|
||||
欢迎再次来到 Linux 命令行玩具日历的另一篇。如果这是你第一次访问该系列,你甚至可能会问自己什么是命令行玩具?我们对此比较随意:它会是终端上有任何有趣的消遣,对于任何节日主题相关的还有额外的加分。
|
||||
|
||||
也许你以前见过其中的一些,也许你没有。不管怎样,我们希望你玩得开心。
|
||||
|
||||
今天的玩具非常简单:它是你的 Bash 提示符。你的 Bash 提示符?是的!我们还有几个星期的假期可以盯着它看,在北半球冬天还会再多几周,所以为什么不玩玩它。
|
||||
|
||||
目前你的 Bash 提示符号可能是一个简单的美元符号( `$`),或者更有可能是一个更长的东西。如果你不确定你的 Bash 提示符是什么,你可以在环境变量 `$PS1` 中找到它。要查看它,请输入:
|
||||
|
||||
```
|
||||
echo $PS1
|
||||
```
|
||||
|
||||
对于我而言,它返回:
|
||||
|
||||
```
|
||||
[\u@\h \W]\$
|
||||
```
|
||||
|
||||
`\u`、`\h` 和 `\W` 分别是用户名、主机名和工作目录的特殊字符。你还可以使用其他一些符号。为了帮助构建你的 Bash 提示符,你可以使用 [EzPrompt][1],这是一个 `PS1` 配置的在线生成器,它包含了许多选项,包括日期和时间、Git 状态等。
|
||||
|
||||
你可能还有其他变量来组成 Bash 提示符。对我来说,`$PS2` 包含了我命令提示符的结束括号。有关详细信息,请参阅 [这篇文章][2]。
|
||||
|
||||
要更改提示符,只需在终端中设置环境变量,如下所示:
|
||||
|
||||
```
|
||||
$ PS1='\u is cold: '
|
||||
jehb is cold:
|
||||
```
|
||||
|
||||
要永久设置它,请使用你喜欢的文本编辑器将相同的代码添加到 `/etc/bashrc` 中。
|
||||
|
||||
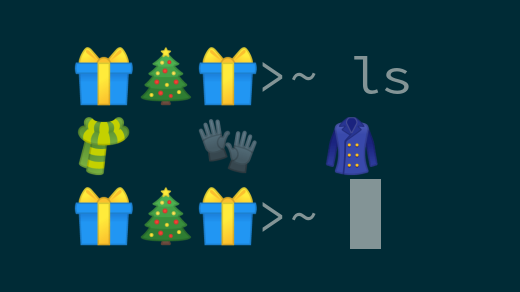
那么这些与冬季化有什么关系呢?好吧,你很有可能有现代一下的机器,你的终端支持 Unicode,所以你不仅限于标准的 ASCII 字符集。你可以使用任何符合 Unicode 规范的 emoji,包括雪花 ❄、雪人 ☃ 或一对滑雪板 🎿。你有很多冬季 emoji 可供选择。
|
||||
|
||||
```
|
||||
🎄 圣诞树
|
||||
🧥 外套
|
||||
🦌 鹿
|
||||
🧤 手套
|
||||
🤶 圣诞夫人
|
||||
🎅 圣诞老人
|
||||
🧣 围巾
|
||||
🎿 滑雪者
|
||||
🏂 滑雪板
|
||||
❄ 雪花
|
||||
☃ 雪人
|
||||
⛄ 没有雪的雪人
|
||||
🎁 包装好的礼物
|
||||
```
|
||||
|
||||
选择你最喜欢的,享受冬天的欢乐。有趣的事实:现代文件系统也支持文件名中的 Unicode 字符,这意味着技术上你可以将你下个程序命名为 `❄❄❄❄❄.py`。只是说说,不要这么做。
|
||||
|
||||
你有特别喜欢的命令行小玩具需要我介绍的吗?这个系列要介绍的小玩具大部分已经有了落实,但还预留了几个空位置。如果你有特别想了解的可以评论留言,我会查看的。如果还有空位置,我会考虑介绍它的。如果没有,但如果我得到了一些很好的意见,我会在最后做一些有价值的提及。
|
||||
|
||||
查看昨天的玩具,[在 Linux 终端玩贪吃蛇][3],记得明天再来!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://opensource.com/article/18/12/linux-toy-bash-prompt
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://ezprompt.net/
|
||||
[2]: https://access.redhat.com/solutions/505983
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-snake
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10448-1.html)
|
||||
[#]: subject: (5 resolutions for open source project maintainers)
|
||||
[#]: via: (https://opensource.com/article/18/12/resolutions-open-source-project-maintainers)
|
||||
[#]: author: (Ben Cotton https://opensource.com/users/bcotton)
|
||||
|
||||
一位开源项目维护者的 5 个决心
|
||||
======
|
||||
|
||||
> 不管怎么说,好的交流是一个活跃的开源社区的必备品。
|
||||
|
||||

|
||||
|
||||
我通常不会定下大的新年决心。当然,我在自我提升方面没有任何问题,这篇文章我希望锚定的是这个日历中的另外一部分。不过即使是这样,这里也有一些东西要从今年的免费日历上划掉,并将其替换为一些可以激发我的自省的新日历内容。
|
||||
|
||||
在 2017 年,我从不在社交媒体上分享我从未阅读过的文章。我一直保持这样的状态,我也认为它让我成为了一个更好的互联网公民。对于 2019 年,我正在考虑让我成为更好的开源软件维护者的决心。
|
||||
|
||||
下面是一些我在一些项目中担任维护者或共同维护者时坚持的决心:
|
||||
|
||||
### 1、包含行为准则
|
||||
|
||||
Jono Bacon 在他的文章“[7 个你可能犯的错误][1]”中包含了一条“不强制执行行为准则”。当然,要强制执行行为准则,你首先需要有一个行为准则。我打算默认用[贡献者契约][2],但是你可以使用其他你喜欢的。关于这个许可协议,最好的方法是使用别人已经写好的,而不是你自己写的。但是重要的是,要找到一些能够定义你希望你的社区执行的,无论它们是什么样子。一旦这些被记录下来并强制执行,人们就能自行决定是否成为他们想象中社区的一份子。
|
||||
|
||||
### 2、使许可证清晰且明确
|
||||
|
||||
你知道什么真的很烦么?不清晰的许可证。"这个软件基于 GPL 授权",如果没有进一步提供更多信息的文字,我无法知道更多信息。基于哪个版本的[GPL][3]?我可以用它吗?对于项目的非代码部分,“根据知识共享许可证(CC)授权”更糟糕。我喜欢[知识共享许可证][4],但它有几个不同的许可证包含着不同的权利和义务。因此,我将非常清楚的说明哪个许可证的变种和版本适用于我的项目。我将会在仓库中包含许可的全文,并在其他文件中包含简明的注释。
|
||||
|
||||
与此相关的一类问题是使用 [OSI][5] 批准的许可证。想出一个新的准确的说明了你想要表达什么的许可证是有可能的,但是如果你需要强制推行它,祝你好运。会坚持使用它么?使用您项目的人会理解么?
|
||||
|
||||
### 3、快速分类错误报告和问题
|
||||
|
||||
在技术领域, 很少有比开源维护者更贫乏的东西了。即使在小型项目中,也很难找到时间去回答每个问题并修复每个错误。但这并不意味着我不能哪怕回应一下,它没必要是多段的回复。即使只是给 GitHub 问题贴了个标签也表明了我看见它了。也许我马上就会处理它,也许一年后我会处理它。但是让社区看到它很重要,是的,这里还有人管。
|
||||
|
||||
### 4、如果没有伴随的文档,请不要推送新特性或错误修复
|
||||
|
||||
尽管多年来我的开源贡献都围绕着文档,但我的项目并没有反映出我对它的重视。我能推送的提交不多,并不不需要某种形式的文档。新的特性显然应该在他们被提交时甚至是在之前就编写文档。但即使是错误修复,也应该在发行说明中有一个条目提及。如果没有什么意外,推送提交也是很好的改善文档的机会。
|
||||
|
||||
### 5、放弃一个项目时,要说清楚
|
||||
|
||||
我很不擅长对事情说“不”,我告诉编辑我会为 [Opensource.com][6] 写一到两篇文章,而现在我有了将近 60 篇文章。哎呀。但在某些时候,曾经我有兴趣的事情也会不再有兴趣。也许该项目是不必要的,因为它的功能被吸收到更大的项目中;也许只是我厌倦了它。但这对社区是不公平的(并且存在潜在的危险,正如最近的 [event-stream 恶意软件注入][7]所示),会让该项目陷入困境。维护者有权随时离开,但他们离开时应该说清楚。
|
||||
|
||||
无论你是开源维护者还是贡献者,如果你知道项目维护者应该作出的其他决心,请在评论中分享!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/resolutions-open-source-project-maintainers
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/8/mistakes-open-source-avoid
|
||||
[2]: https://www.contributor-covenant.org/
|
||||
[3]: https://opensource.org/licenses/gpl-license
|
||||
[4]: https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[5]: https://opensource.org/
|
||||
[6]: http://Opensource.com
|
||||
[7]: https://arstechnica.com/information-technology/2018/11/hacker-backdoors-widely-used-open-source-software-to-steal-bitcoin/
|
||||
@ -1,111 +0,0 @@
|
||||
怎样如软件工程师一样组织知识
|
||||
==========
|
||||
|
||||
总体上说,软件开发和技术是以非常快的速度发展的领域,所以持续学习是必不可少的。在互联网上花几分钟找一下,在 Twitter、媒体、RSS 订阅、Hacker News 和其它专业网站和社区等地方,就可以从文章、案例研究、教程、代码片段、新应用程序和信息中找到大量有用的信息。
|
||||
|
||||
保存和组织所有这些信息可能是一项艰巨的任务。在这篇文章中,我将介绍一些我用来组织信息的工具。
|
||||
|
||||
我认为在知识管理方面非常重要的一点就是避免锁定在特定平台。我使用的所有工具都允许以标准格式(如 Markdown 和 HTML)导出数据。
|
||||
|
||||
请注意,我的流程并不完美,我一直在寻找新工具和方法来优化它。每个人都不同,所以对我有用的东西可能不适合你。
|
||||
|
||||
|
||||
### 用 NotionHQ 做知识库
|
||||
|
||||
对我来说,知识管理的基本部分是拥有某种个人知识库或维基。这是一个你可以以有组织的方式保存链接、书签、备注等的地方。
|
||||
|
||||
我使用 [NotionHQ][7] 做这件事。我使用它来记录各种主题,包括资源列表,如通过编程语言分组的优秀的库或教程,为有趣的博客文章和教程添加书签等等,不仅与软件开发有关,而且与我的个人生活有关。
|
||||
|
||||
我真正喜欢 NotionHQ 的是,创建新内容是如此简单。你可以使用 Markdown 编写它并将其组织为树状。
|
||||
|
||||
这是我的“开发”工作区的顶级页面:
|
||||
|
||||
[][8]
|
||||
|
||||
NotionHQ 有一些很棒的其他功能,如集成了电子表格/数据库和任务板。
|
||||
|
||||
如果您想认真使用 NotionHQ,您将需要订阅付费个人计划,因为免费计划有所限制。我觉得它物有所值。NotionHQ 允许将整个工作区导出为 Markdown 文件。导出功能存在一些重要问题,例如丢失页面层次结构,希望 Notion 团队可以改进这一点。
|
||||
|
||||
作为一个免费的替代方案,我可能会使用 [VuePress][9] 或 [GitBook][10] 来托管我自己的知识库。
|
||||
|
||||
### 用 Pocket 保存感兴趣的文章
|
||||
|
||||
[Pocket][11] 是我最喜欢的应用之一!使用 Pocket,您可以创建一个来自互联网上的文章的阅读列表。每当我看到一篇看起来很有趣的文章时,我都会使用 Chrome 扩展程序将其保存到 Pocket。稍后,我会阅读它,如果我发现它足够有用,我将使用 Pocket 的“存档”功能永久保存该文章并清理我的 Pocket 收件箱。
|
||||
|
||||
我尽量保持这个阅读清单足够小,并存档我已经处理过的信息。Pocket 允许您标记文章,以便以后更轻松地搜索特定主题的文章。
|
||||
|
||||
如果原始网站消失,您还可以在 Pocket 服务器中保存文章的副本,但是您需要 Pocket Premium 订阅计划。
|
||||
|
||||
Pocket 还具有“发现”功能,根据您保存的文章推荐类似的文章。这是找到可以阅读的新内容的好方法。
|
||||
|
||||
### 用 SnippetStore 做代码片段管理
|
||||
|
||||
从 GitHub 到 Stack Overflow 的答案,到博客文章,经常能找到一些你想要保存备用的好代码片段。它可能是一些不错的算法实现、一个有用的脚本或如何在某种语言中执行某种操作的示例。
|
||||
|
||||
我尝试了很多应用程序,从简单的 GitHub Gists 到 [Boostnote][12],直到我发现 [SnippetStore][13]。
|
||||
|
||||
SnippetStore 是一个开源的代码片段管理应用。SnippetStore 与其他产品的区别在于其简单性。您可以按语言或标签整理片段,并且可以拥有多个文件片段。它不完美,但是可以用。例如,Boostnote 具有更多功能,但我更喜欢 SnippetStore 组织内容的简单方法。
|
||||
|
||||
对于我每天使用的缩写和片段,我更喜欢使用我的编辑器 / IDE 的代码片段功能,因为它更便于使用。我使用 SnippetStore 更像是作为编码示例的参考。
|
||||
|
||||
[Cacher][14] 也是一个有趣的选择,因为它与许多编辑器进行了集成,他有一个命令行工具,并使用 GitHub Gists 作为后端,但其专业计划为 6 美元/月,我觉这有点太贵。
|
||||
|
||||
### 用 DevHints 管理速查表
|
||||
|
||||
[Devhints][15] 是由 Rico Sta. Cruz 创建的一个速查表集合。它是开源的,是用 Jekyll 生成的,Jekyll 是最受欢迎的静态站点生成器之一。
|
||||
|
||||
这些速查表是用 Markdown 编写的,带有一些额外的格式化支持,例如支持列。
|
||||
|
||||
我非常喜欢其界面的外观,并且不像可以在 [Cheatography][16] 等网站上找到 PDF 或图像格式的速查表, Markdown 非常容易添加新内容并保持更新和进行版本控制。
|
||||
|
||||
因为它是开源,我创建了自己的分叉版本,删除了一些我不需要的速查表,并添加了更多。
|
||||
|
||||
我使用速查表作为如何使用某些库或编程语言或记住一些命令的参考。速查表的单个页面非常方便,例如,可以列出特定编程语言的所有基本语法。
|
||||
|
||||
我仍在尝试这个工具,但到目前为止它的工作很好。
|
||||
|
||||
### Diigo
|
||||
|
||||
[Diigo][17] 允许您注释和突出显示部分网站。我在研究新东西时使用它来注释重要信息,或者从文章、Stack Overflow 答案或来自 Twitter 的鼓舞人心的引语中保存特定段落!;)
|
||||
|
||||
* * *
|
||||
|
||||
就这些了。某些工具的功能方面可能存在一些重叠,但正如我在开始时所说的那样,这是一个不断演进的工作流程,因为我一直在尝试和寻找改进和提高工作效率的方法。
|
||||
|
||||
你呢?是如何组织你的知识的?请随时在下面发表评论。
|
||||
|
||||
谢谢你的阅读。
|
||||
|
||||
------------------------------------------------------------------------
|
||||
|
||||
作者简介:Bruno Paz,Web 工程师,专精 #PHP 和 @Symfony 框架。热心于新技术。喜欢运动,@FCPorto 的粉丝!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dev.to/brpaz/how-do-i-organize-my-knowledge-as-a-software-engineer-4387
|
||||
|
||||
作者:[Bruno Paz][a]
|
||||
选题:[oska874](https://github.com/oska874)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://brunopaz.net/
|
||||
[1]:https://dev.to/brpaz
|
||||
[2]:http://twitter.com/brunopaz88
|
||||
[3]:http://github.com/brpaz
|
||||
[4]:https://dev.to/t/knowledge
|
||||
[5]:https://dev.to/t/learning
|
||||
[6]:https://dev.to/t/development
|
||||
[7]:https://www.notion.so/
|
||||
[8]:https://res.cloudinary.com/practicaldev/image/fetch/s--uMbaRUtu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/http://i.imgur.com/kRnuvMV.png
|
||||
[9]:https://vuepress.vuejs.org/
|
||||
[10]:https://www.gitbook.com/?t=1
|
||||
[11]:https://getpocket.com/
|
||||
[12]:https://boostnote.io/
|
||||
[13]:https://github.com/ZeroX-DG/SnippetStore
|
||||
[14]:https://www.cacher.io/
|
||||
[15]:https://devhints.io/
|
||||
[16]:https://cheatography.com/
|
||||
[17]:https://www.diigo.com/index
|
||||
84
sources/talk/20190108 Hacking math education with Python.md
Normal file
84
sources/talk/20190108 Hacking math education with Python.md
Normal file
@ -0,0 +1,84 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Hacking math education with Python)
|
||||
[#]: via: (https://opensource.com/article/19/1/hacking-math)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Hacking math education with Python
|
||||
======
|
||||
Teacher, programmer, and author Peter Farrell explains why teaching math with Python works better than the traditional approach.
|
||||

|
||||
|
||||
Mathematics instruction has a bad reputation, especially with people (like me) who've had trouble with the traditional approach, which emphasizes rote memorization and theory that seems far removed from students' real world.
|
||||
|
||||
While teaching a student who was baffled by his math lessons, [Peter Farrell][1], a Python developer and mathematics teacher, decided to try using Python to teach the boy the math concepts he was having trouble learning.
|
||||
|
||||
Peter was inspired by the work of [Seymour Papert][2], the father of the Logo programming language, which lives on in Python's [Turtle module][3]. The Turtle metaphor hooked Peter on Python and using it to teach math, much like [I was drawn to Python][4].
|
||||
|
||||
Peter shares his approach in his new book, [Math Adventures with Python][5]: An Illustrated Guide to Exploring Math with Code. And, I recently interviewed him to learn more about it.
|
||||
|
||||
**Don Watkins:** What is your background?
|
||||
|
||||
**Peter Farrell:** I was a math teacher for eight years, and I tutored math for 10 years after that. When I was a teacher, I read Papert's [Mindstorms][6] and was inspired to introduce all my math classes to Logo and Turtles.
|
||||
|
||||
**DW:** Why did you start using Python?
|
||||
|
||||
**PF:** I was working with a homeschooled boy on a very dry, textbook-driven math curriculum, which at the time seemed like a curse to me. But I found ways to sneak in the Logo Turtles, and he was a programming fan, so he liked that. Once we got into functions and real programming, he asked if we could continue in Python. I didn't know any Python but it didn't seem that different from Logo, so I agreed. And I never looked back!
|
||||
|
||||
I was also looking for a 3D graphics package I could use to model a solar system and lead students through making planets move and get pulled by the force of attraction between the bodies, according to Newton's formula. Many graphics packages required programming in C or something hard, but I found an excellent package called Visual Python that was very easy to use. I used [VPython][7] for years after that.
|
||||
|
||||
So, I was introduced to Python in the context of working with a student on math. For some time after that, he was my programming tutor while I was his math tutor!
|
||||
|
||||
**DW:** What got you interested in math?
|
||||
|
||||
**PF:** I learned it the old-fashioned way: by hand, on paper and blackboards. I was good at manipulating symbols, so algebra was never a problem, and I liked drawing and graphing, so geometry and trig could be fun, too. I did some programming in BASIC and Fortran in college, but it never inspired me. Later on, programming inspired me greatly! I'm still tickled by the way programming makes easy work of the laborious stuff you have to do in math class, freeing you up to do the more fun of exploring, graphing, tweaking, and discovering.
|
||||
|
||||
**DW:** What inspired you to consider your Python approach to math?
|
||||
|
||||
**PF:** When I was teaching the homeschooled student, I was amazed at what we could do by writing a simple function and then calling it a bunch of times with different values using a loop. That would take a half an hour by hand, but the computer spit it out instantly! Then we could look for patterns (which is what a math student should be doing), express the pattern as a function, and extend it further.
|
||||
|
||||
**DW:** How does your approach to teaching help students—especially those who struggle with math? How does it make math more relevant?
|
||||
|
||||
**PF:** Students, especially high-schoolers, question the need to be doing all this calculating, graphing, and solving by hand in the 21st century, and I don't disagree with them. Learning to use Excel, for example, to crunch numbers should be seen as a basic necessity to work in an office. Learning to code, in any language, is becoming a very valuable skill to companies. So, there's a real-world appeal to me.
|
||||
|
||||
But the idea of making art with code can revolutionize math class. Just putting a shape on a screen requires math—the position (x-y coordinates), the dimensions, and even the color are all numbers. If you want something to move or change, you'll need to use variables, and not the "guess what x equals" kind of variable. You'll vary the position using a variable or, more efficiently, using a vector. [This makes] math topics like vectors and matrices seen as helpful tools you can use, rather than required information you'll never use.
|
||||
|
||||
Students who struggle with math might just be turned off to "school math," which is heavy on memorization and following rules and light on creativity and real applications. They might find they're actually good at math, just not the way it was taught in school. I've had parents see the cool graphics their kids have created with code and say, "I never knew that's what sines and cosines were used for!"
|
||||
|
||||
**DW:** How do you see your approach to math and programming encouraging STEM in schools?
|
||||
|
||||
**PF:** I love the idea of combining previously separated topics into an idea like STEM or STEAM! Unfortunately for us math folks, the "M" is very often neglected. I see lots of fun projects being done in STEM labs, even by very young children, and they're obviously getting an education in technology, engineering, and science. But I see precious little math material in the projects. STEM/[mechatronics][8] teacher extraordinaire Ken Hawthorn and I are creating projects to try to remedy that.
|
||||
|
||||
Hopefully, my book helps encourage students, girls and boys, to get creative with technology, real and virtual. There are a lot of beautiful graphics in the book, which I hope will inspire people to go through the coding adventure and make them. All the software I use ([Python Processing][9]) is available for free and can be easily installed, or is already installed, on the Raspberry Pi. Entry into the STEM world should not be cost-prohibitive to schools or individuals.
|
||||
|
||||
**DW:** What would you like to share with other math teachers?
|
||||
|
||||
**PF:** If the math establishment is really serious about teaching students the standards they have agreed upon, like numerical reasoning, logic, analysis, modeling, geometry, interpreting data, and so on, they're going to have to admit that coding can help with every single one of those goals. My approach was born, as I said before, from just trying to enrich a dry, traditional approach, and I think any teacher can do that. They just need somebody who can show them how to do everything they're already doing, just using code to automate the laborious stuff.
|
||||
|
||||
My graphics-heavy approach is made possible by the availability of free graphics software. Folks might need to be shown where to find these packages and how to get started. But a math teacher can soon be leading students through solving problems using 21st-century technology and visualizing progress or results and finding more patterns to pursue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/hacking-math
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twitter.com/hackingmath
|
||||
[2]: https://en.wikipedia.org/wiki/Seymour_Papert
|
||||
[3]: https://en.wikipedia.org/wiki/Turtle_graphics
|
||||
[4]: https://opensource.com/life/15/8/python-turtle-graphics
|
||||
[5]: https://nostarch.com/mathadventures
|
||||
[6]: https://en.wikipedia.org/wiki/Mindstorms_(book)
|
||||
[7]: http://vpython.org/
|
||||
[8]: https://en.wikipedia.org/wiki/Mechatronics
|
||||
[9]: https://processing.org/
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (NSA to Open Source its Reverse Engineering Tool GHIDRA)
|
||||
[#]: via: (https://itsfoss.com/nsa-ghidra-open-source)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
NSA to Open Source its Reverse Engineering Tool GHIDRA
|
||||
======
|
||||
|
||||
GHIDRA – NSA’s reverse engineering tool is getting ready for a free public release this March at the [RSA Conference 2019][1] to be held in San Francisco.
|
||||
|
||||
The National Security Agency (NSA) did not officially announce this – however – a senior NSA advisor, Robert Joyce’s [session description][2] on the official RSA conference website revealed about it before any official statement or announcement.
|
||||
|
||||
Here’s what it mentioned:
|
||||
|
||||
![][3]
|
||||
Image Credits: [Twitter][4]
|
||||
|
||||
In case the text in the image isn’t properly visible, let me quote the description here:
|
||||
|
||||
> NSA has developed a software reverse engineering framework known as GHIDRA, which will be demonstrated for the first time at RSAC 2019. An interactive GUI capability enables reverse engineers to leverage an integrated set of features that run on a variety of platforms including Windows, Mac OS, and Linux and supports a variety of processor instruction sets. The GHISDRA platform includes all the features expected in high-end commercial tools, with new and expanded functionality NSA uniquely developed. and will be released for free public use at RSA.
|
||||
|
||||
### What is GHIDRA?
|
||||
|
||||
GHIDRA is a software reverse engineering framework developed by [NSA][5] that is in use by the agency for more than a decade.
|
||||
|
||||
Basically, a software reverse engineering tool helps to dig up the source code of a proprietary program which further gives you the ability to detect virus threats or potential bugs. You should read how [reverse engineering][6] works to know more.
|
||||
|
||||
The tool is is written in Java and quite a few people compared it to high-end commercial reverse engineering tools available like [IDA][7].
|
||||
|
||||
A [Reddit thread][8] involves more detailed discussion where you will find some ex-employees giving good amount of details before the availability of the tool.
|
||||
|
||||
![NSA open source][9]
|
||||
|
||||
### GHIDRA was a secret tool, how do we know about it?
|
||||
|
||||
The existence of the tool was uncovered in a series of leaks by [WikiLeaks][10] as part of [Vault 7 documents of CIA][11].
|
||||
|
||||
### Is it going to be open source?
|
||||
|
||||
We do think that the reverse engineering tool to be released could be made open source. Even though there is no official confirmation mentioning “open source” – but a lot of people do believe that NSA is definitely targeting the open source community to help improve their tool while also reducing their effort to maintain this tool.
|
||||
|
||||
This way the tool can remain free and the open source community can help improve GHIDRA as well.
|
||||
|
||||
You can also check out the existing [Vault 7 document at WikiLeaks][12] to come up with your prediction.
|
||||
|
||||
### Is NSA doing a good job here?
|
||||
|
||||
The reverse engineering tool is going to be available for Windows, Linux, and Mac OS for free.
|
||||
|
||||
Of course, we care about the Linux platform here – which could be a very good option for people who do not want to or cannot afford a thousand dollar license for a reverse engineering tool with the best-in-class features.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
If GHIDRA becomes open source and is available for free, it would definitely help a lot of researchers and students and on the other side – the competitors will be forced to adjust their pricing.
|
||||
|
||||
What are your thoughts about it? Is it a good thing? What do you think about the tool going open sources Let us know what you think in the comments below.
|
||||
|
||||
![][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/nsa-ghidra-open-source
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.rsaconference.com/events/us19
|
||||
[2]: https://www.rsaconference.com/events/us19/agenda/sessions/16608-come-get-your-free-nsa-reverse-engineering-tool
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/come-get-your-free-nsa.jpg?fit=800%2C337&ssl=1
|
||||
[4]: https://twitter.com/0xffff0800/status/1080909700701405184
|
||||
[5]: http://nsa.gov
|
||||
[6]: https://en.wikipedia.org/wiki/Reverse_engineering
|
||||
[7]: https://en.wikipedia.org/wiki/Interactive_Disassembler
|
||||
[8]: https://www.reddit.com/r/ReverseEngineering/comments/ace2m3/come_get_your_free_nsa_reverse_engineering_tool/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/nsa-open-source.jpeg?resize=800%2C450&ssl=1
|
||||
[10]: https://www.wikileaks.org/
|
||||
[11]: https://en.wikipedia.org/wiki/Vault_7
|
||||
[12]: https://wikileaks.org/ciav7p1/cms/page_9536070.html
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/nsa-open-source.jpeg?fit=800%2C450&ssl=1
|
||||
64
sources/talk/20190110 Toyota Motors and its Linux Journey.md
Normal file
64
sources/talk/20190110 Toyota Motors and its Linux Journey.md
Normal file
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Toyota Motors and its Linux Journey)
|
||||
[#]: via: (https://itsfoss.com/toyota-motors-linux-journey)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Toyota Motors and its Linux Journey
|
||||
======
|
||||
|
||||
**This is a community submission from It’s FOSS reader Malcolm Dean.**
|
||||
|
||||
I spoke with Brian R Lyons of TMNA Toyota Motor Corp North America about the implementation of Linux in Toyota and Lexus infotainment systems. I came to find out there is an Automotive Grade Linux (AGL) being used by several autmobile manufacturers.
|
||||
|
||||
I put together a short article comprising of my discussion with Brian about Toyota and its tryst with Linux. I hope that Linux enthusiasts will like this quick little chat.
|
||||
|
||||
All [Toyota vehicles and Lexus vehicles are going to use Automotive Grade Linux][1] (AGL) majorly for the infotainment system. This is instrumental in Toyota Motor Corp because as per Mr. Lyons “As a technology leader, Toyota realized that adopting open source development methodology is the best way to keep up with the rapid pace of new technologies”.
|
||||
|
||||
Toyota among other automotive companies thought, going with a Linux based operating system might be cheaper and quicker when it comes to updates, and upgrades compared to using proprietary software.
|
||||
|
||||
Wow! Finally Linux in a vehicle. I use Linux every day on my desktop; what a great way to expand the use of this awesome software to a completely different industry.
|
||||
|
||||
I was curious when Toyota decided to use the [Automotive Grade Linux][2] (AGL). According to Mr. Lyons, it goes back to 2011.
|
||||
|
||||
> “Toyota has been an active member and contributor to AGL since its launch more than five years ago, collaborating with other OEMs, Tier 1s and suppliers to develop a robust, Linux-based platform with increased security and capabilities”
|
||||
|
||||
![Toyota Infotainment][3]
|
||||
|
||||
In 2011, [Toyota joined the Linux Foundation][4] and started discussions about IVI (In-Vehicle Infotainment) software with other car OEMs and software companies. As a result, in 2012, Automotive Grade Linux working group was formed in the Linux Foundation.
|
||||
|
||||
What Toyota did at first in AGL group was to take “code first” approach as normal as in the open source domains, and then start the conversation about the initial direction by specifying requirement specifications which had been discussed among car OEMs, IVI Tier-1 companies, software companies, and so on.
|
||||
|
||||
Toyota had already realized that sharing the software code among Tier1 companies was going to essential at the time when it joined the Linux Foundation. This was because the cost of maintaining such a huge software was very costly and was no longer differentiation by Tier1 companies. Toyota and its Tier1 supplier companies wanted to spend more resources n new functions and new user experiences rather than maintaining conventional code all by themselves.
|
||||
|
||||
This is a huge thing as automotive companies have gone in together to further their cooperation. Many companies have adopted this after finding proprietary software to be expensive.
|
||||
|
||||
Today, AGL is used for all Toyota and Lexus vehicles and is used in all markets where vehicles are sold.
|
||||
|
||||
As someone who has sold cars for Lexus, I think this is a huge step forward. I and other sales associates had many customers who would come back to speak with a technology specialist to learn about the full capabilities of their infotainment system.
|
||||
|
||||
I see this as a huge step forward for the Linux community, and users. The operating system we use on a daily basis is being put to use right in front of us albeit in a modified form but is there none-the-less.
|
||||
|
||||
Where does this lead? Hopefully a better user-friendly and less glitchy experience for consumers.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/toyota-motors-linux-journey
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxfoundation.org/press-release/2018/01/automotive-grade-linux-hits-road-globally-toyota-amazon-alexa-joins-agl-support-voice-recognition/
|
||||
[2]: https://www.automotivelinux.org/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/toyota-interiors.jpg?resize=800%2C450&ssl=1
|
||||
[4]: https://www.linuxfoundation.org/press-release/2011/07/toyota-joins-linux-foundation/
|
||||
130
sources/talk/20190114 Remote Working Survival Guide.md
Normal file
130
sources/talk/20190114 Remote Working Survival Guide.md
Normal file
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Remote Working Survival Guide)
|
||||
[#]: via: (https://www.jonobacon.com/2019/01/14/remote-working-survival/)
|
||||
[#]: author: (Jono Bacon https://www.jonobacon.com/author/admin/)
|
||||
|
||||
Remote Working Survival Guide
|
||||
======
|
||||

|
||||
|
||||
Remote working seems to be all the buzz. Apparently, [70% of professionals work from home at least once a week][1]. Similarly, [77% of people work more productively][2] and [68% of millennials would consider a company more if they offered remote working][3]. It seems to make sense: technology, connectivity, and culture seem to be setting the world up more and more for remote working. Oh, and home-brewed coffee is better than ever too.
|
||||
|
||||
Now, I am going to write another piece for how companies should optimize for remote working (so make sure you [Join As a Member][4] to stay tuned — it is free).
|
||||
|
||||
Today though I want to **share recommendations for how individuals can do remote working well themselves**. Whether you are a full-time remote worker or have the option of working from home a few days a week, this article should hopefully be helpful.
|
||||
|
||||
Now, you need to know that **remote working is not a panacea**. Sure, it seems like hanging around at home in your jimjams, listening to your antisocial music, and sipping on buckets of coffee is perfect, but it isn’t for everyone.
|
||||
|
||||
Some people need the structure of an office. Some people need the social element of an office. Some people need to get out the house. Some people lack the discipline to stay focused at home. Some people are avoiding the government coming and knocking on the door due to years of unpaid back taxes.
|
||||
|
||||
**Remote working is like a muscle: it can bring enormous strength and capabilities IF you train and maintain it**. If you don’t, your results are going to vary.
|
||||
|
||||
I have worked from home for the vast majority of my career. I love it. I am more productive, happier, and empowered when I work from home. I don’t dislike working in an office, and I enjoy the social element, but I am more in my “zone” when I work from home. I also love blisteringly heavy metal, which can pose a problem when the office don’t want to listen to [After The Burial][5].
|
||||
|
||||
![][6]
|
||||
“Squirrel.”
|
||||
[Credit][7]
|
||||
|
||||
I have learned how I need to manage remote work, using the right balance of work routine, travel, and other elements, and here are some of my recommendations. Be sure to **share yours in the comments**.
|
||||
|
||||
### 1\. You need discipline and routine (and to understand your “waves”)
|
||||
|
||||
Remote work really is a muscle that needs to be trained. Just like building actual muscle, there needs to be a clear routine and a healthy dollop of discipline mixed in.
|
||||
|
||||
Always get dressed (no jimjams). Set your start and end time for your day (I work 9am – 6pm most days). Choose your lunch break (mine is 12pm). Choose your morning ritual (mine is email followed by a full review of my client needs). Decide where your main workplace will be (mine is my home office). Decide when you will exercise each day (I do it at 5pm most days).
|
||||
|
||||
**Design a realistic routine and do it for 66 days**. It takes this long to build a habit. Try not to deviate from the routine. The more you stick the routine, the less work it will seem further down the line. By the end of the 66 days it will feel natural and you won’t have to think about it.
|
||||
|
||||
Here’s the deal though, we don’t live in a vacuum ([cleaner, or otherwise][8]). We all have waves.
|
||||
|
||||
A wave is when you need a change of routine to mix things up. For example, in summertime I generally want more sunlight. I will often work outside in the garden. Near the holidays I get more distracted, so I need more structure in my day. Sometimes I just need more human contact, so I will work from coffee shops for a few weeks. Sometimes I just fancy working in the kitchen or on the couch. You need to learn your waves and listen to your body. **Build your habit first, and then modify it as you learn your waves**.
|
||||
|
||||
### 2\. Set expectations with your management and colleagues
|
||||
|
||||
Not everyone knows how to do remote working, and if your company is less familiar with remote working, you especially need to set expectations with colleagues.
|
||||
|
||||
This can be pretty simple: **when you have designed your routine, communicate it clearly to your management and team**. Let them know how they can get hold of you, how to contact you in an emergency, and how you will be collaborating while at home.
|
||||
|
||||
The communication component here is critical. There are some remote workers who are scared to leave their computer for fear that someone will send them a message while they are away (and they are worried people may think they are just eating Cheetos and watching Netflix).
|
||||
|
||||
You need time away. You need to eat lunch without one eye on your computer. You are not a 911 emergency responder. **Set expectations that sometimes you may not be immediately responsive, but you will get back to them as soon as possible**.
|
||||
|
||||
Similarly, set expectations on your general availability. For example, I set expectations with clients that I generally work from 9am – 6pm every day. Sure, if a client needs something urgently, I am more than happy to respond outside of those hours, but as a general rule I am usually working between those hours. This is necessary for a balanced life.
|
||||
|
||||
### 3\. Distractions are your enemy and they need managing
|
||||
|
||||
We all get distracted. It is human nature. It could be your young kid getting home and wanting to play Rescue Bots. It could be checking Facebook, Instagram, or Twitter to ensure you don’t miss any unwanted political opinions or photos of people’s lunches. It could be that there is something else going on your life that is taking your attention (such as an upcoming wedding, event, or big trip.)
|
||||
|
||||
**You need to learn what distracts you and how to manage it**. For example, I know I get distracted by my email and Twitter. I check it religiously and every check gets me out of the zone of what I am working on. I also get distracted by grabbing coffee and water, which then may turn into a snack and a YouTube video.
|
||||
|
||||
![][9]
|
||||
My nemesis for distractions.
|
||||
|
||||
The digital distractions have a simple solution: **lock them out**. Close down the tabs until you complete what you are doing. I do this all the time with big chunks of work: I lock out the distractions until I am done. It requires discipline, but all of this does.
|
||||
|
||||
The human elements are tougher. If you have a family you need to make it clear that when you are work, you need to be generally left alone. This is why a home office is so important: you need to set boundaries that mum or dad is working. Come in if there is emergency, but otherwise they need to be left alone.
|
||||
|
||||
There are all kinds of opportunities for locking these distractions out. Put your phone on silent. Set yourself as away. Move to a different room (or building) where the distraction isn’t there. Again, be honest in what distracts you and manage it. If you don’t, you will always be at their mercy.
|
||||
|
||||
### 4\. Relationships need in-person attention
|
||||
|
||||
Some roles are more attuned to remote working than others. For example, I have seen great work from engineering, quality assurance, support, security, and other teams (typically more focused on digital collaboration). Other teams such as design or marketing often struggle more in remote environments (as they are often more tactile.)
|
||||
|
||||
With any team though, having strong relationship is critical, and in-person discussion, collaboration, and socializing is essential to this. So many of our senses (such as body language) are removed in a digital environment, and these play a key role in how we build trust and relationships.
|
||||
|
||||
![][10]
|
||||
Rockets also help.
|
||||
|
||||
This is especially important if (a) you are new a company and need to build these relationships, (b) are new to a role and need to build relationships with your team, or (c) are in a leadership position where building buy-in and engagement is a key part of your job.
|
||||
|
||||
**The solution? A sensible mix of remote and in-person time.** If your company is nearby, work from home part of the week and at the office part of the week. If your company is further a away, schedule regular trips to the office (and set expectations with your management that you need this). For example, when I worked at XPRIZE I flew to LA every few weeks for a few days. When I worked at Canonical (who were based in London), we had sprints every three months.
|
||||
|
||||
### 5\. Stay focused, but cut yourself some slack
|
||||
|
||||
The crux of everything in this article is about building a capability, and developing a remote working muscle. This is as simple as building a routine, sticking to it, and having an honest view of your “waves” and distractions and how to manage them.
|
||||
|
||||
I see the world in a fairly specific way: **everything we do has the opportunity to be refined and improved**. For example, I have been public speaking now for over 15 years, but I am always discovering new ways to improve, and new mistakes to fix (speaking of which, see my [10 Ways To Up Your Public Speaking Game][11].)
|
||||
|
||||
There is a thrill in the discovery of new ways to get better, and to see every stumbling block and mistake as an “aha!” moment to kick ass in new and different ways. It is no different with remote working: look for patterns that help to unlock ways in which you can make your remote working time more efficient, more comfortable, and more fun.
|
||||
|
||||
![][12]
|
||||
Get these books. They are fantastic for personal development.
|
||||
See my [$150 Personal Development Kit][13] article
|
||||
|
||||
…but don’t go crazy over it. There are some people who obsesses every minute of their day about how to get better. They beat themselves up constantly for “not doing well enough”, “not getting more done”, and not meeting their internal unrealistic view of perfection.
|
||||
|
||||
We are humans. We are animals, and we are not robots. Always strive to improve, but be realistic that not everything will be perfect. You are going to have some off-days or off-weeks. You are going to struggle at times with stress and burnout. You are going to handle a situation poorly remotely that would have been easier in the office. Learn from these moments but don’t obsess over them. Life is too damn short.
|
||||
|
||||
**What are your tips, tricks, and recommendations? How do you manage remote working? What is missing from my recommendations? Share them in the comments box!**
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.jonobacon.com/2019/01/14/remote-working-survival/
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.jonobacon.com/author/admin/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cnbc.com/2018/05/30/70-percent-of-people-globally-work-remotely-at-least-once-a-week-iwg-study.html
|
||||
[2]: http://www.cosocloud.com/press-release/connectsolutions-survey-shows-working-remotely-benefits-employers-and-employees
|
||||
[3]: https://www.aftercollege.com/cf/2015-annual-survey
|
||||
[4]: https://www.jonobacon.com/join/
|
||||
[5]: https://www.facebook.com/aftertheburial/
|
||||
[6]: https://www.jonobacon.com/wp-content/uploads/2019/01/aftertheburial2.jpg
|
||||
[7]: https://skullsnbones.com/burial-live-photos-vans-warped-tour-denver-co/
|
||||
[8]: https://www.youtube.com/watch?v=wK1PNNEKZBY
|
||||
[9]: https://www.jonobacon.com/wp-content/uploads/2019/01/IMG_20190114_102429-1024x768.jpg
|
||||
[10]: https://www.jonobacon.com/wp-content/uploads/2019/01/15381733956_3325670fda_k-1024x576.jpg
|
||||
[11]: https://www.jonobacon.com/2018/12/11/10-ways-to-up-your-public-speaking-game/
|
||||
[12]: https://www.jonobacon.com/wp-content/uploads/2019/01/DwVBxhjX4AgtJgV-1024x532.jpg
|
||||
[13]: https://www.jonobacon.com/2017/11/13/150-dollar-personal-development-kit/
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Art of Unix Programming, reformatted)
|
||||
[#]: via: (https://arp242.net/weblog/the-art-of-unix-programming.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
The Art of Unix Programming, reformatted
|
||||
======
|
||||
|
||||
tl;dr: I reformatted Eric S. Raymond’s The Art of Unix Programming for readability; [read it here][1].
|
||||
|
||||
I recently wanted to look up a quote for an article I was writing, and I was fairly sure I had read it in The Art of Unix Programming. Eric S. Raymond (esr) has [kindly published it online][2], but it’s difficult to search as it’s distributed over many different pages, and the formatting is not exactly conducive for readability.
|
||||
|
||||
I `wget --mirror`’d it to my drive, and started out with a simple [script][3] to join everything to a single page, but eventually ended up rewriting a lot of the HTML from crappy 2003 docbook-generated tagsoup to more modern standards, and I slapped on some CSS to make it more readable.
|
||||
|
||||
The results are fairly nice, and it should work well in any version of any browser (I haven’t tested Internet Explorer and Edge, lacking access to a Windows computer, but I’m reasonably confident it should work without issues; if not, see the bottom of this page on how to get in touch).
|
||||
|
||||
The HTML could be simplified further (so rms can read it too), but dealing with 360k lines of ill-formatted HTML is not exactly my idea of fun, so this will have to do for now.
|
||||
|
||||
The entire page is self-contained. You can save it to your laptop or mobile phone and read it on a plane or whatnot.
|
||||
|
||||
Why spend so much work on an IT book from 2003? I think a substantial part of the book still applies very much today, for all programmers (not just Unix programmers). For example the [Basics of the Unix Philosophy][4] was good advice in 1972, is still good advice in 2019, and will continue to be good advice well in to the future.
|
||||
|
||||
Other parts have aged less gracefully; for example “since 2000, practice has been moving toward use of XML-DocBook as a documentation interchange format” doesn’t really represent the current state of things, and the [Data File Metaformats][5] section mentions XML and INI, but not JSON or YAML (as they weren’t invented until after the book was written)
|
||||
|
||||
I find this adds, rather than detracts. It makes for an interesting window in to past. The downside is that the uninitiated will have a bit of a hard time distinguishing between the good and outdated parts; as a rule of thumb: if it talks about abstract concepts, it probably still applies today. If it talks about specific software, it may be outdated.
|
||||
|
||||
I toyed with the idea of updating or annotating the text, but the license doesn’t allow derivative works, so that’s not going to happen. Perhaps I’ll email esr and ask nicely. Another project, for another weekend :-)
|
||||
|
||||
You can mail me at [martin@arp242.net][6] or [create a GitHub issue][7] for feedback, questions, etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/the-art-of-unix-programming.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://arp242.net/the-art-of-unix-programming/
|
||||
[2]: http://catb.org/~esr/writings/taoup/html/
|
||||
[3]: https://arp242.net/the-art-of-unix-programming/fix-taoup.py
|
||||
[4]: https://arp242.net/the-art-of-unix-programming#ch01s06
|
||||
[5]: https://arp242.net/the-art-of-unix-programming/#ch05s02
|
||||
[6]: mailto:martin@arp242.net
|
||||
[7]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
85
sources/talk/20191110 What is DevSecOps.md
Normal file
85
sources/talk/20191110 What is DevSecOps.md
Normal file
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is DevSecOps?)
|
||||
[#]: via: (https://opensource.com/article/19/1/what-devsecops)
|
||||
[#]: author: (Brett Hunoldt https://opensource.com/users/bretthunoldtcom)
|
||||
|
||||
What is DevSecOps?
|
||||
======
|
||||
The journey to DevSecOps begins with empowerment, enablement, and education. Here's how to get started.
|
||||

|
||||
|
||||
> “DevSecOps enables organizations to deliver inherently secure software at DevOps speed.” -Stefan Streichsbier
|
||||
|
||||
DevSecOps as a practice or an art form is an evolution on the concept of DevOps. To better understand DevSecOps, you should first have an understanding of what DevOps means.
|
||||
|
||||
DevOps was born from merging the practices of development and operations, removing the silos, aligning the focus, and improving efficiency and performance of both the teams and the product. A new synergy was formed, with DevOps focused on building products and services that are easy to maintain and that automate typical operations functions.
|
||||
|
||||
Security is a common silo in many organizations. Security’s core focus is protecting the organization, and sometimes this means creating barriers or policies that slow down the execution of new services or products to ensure that everything is well understood and done safely and that nothing introduces unnecessary risk to the organization.
|
||||
|
||||
**[[Download the Getting started with DevSecOps guide]][1]**
|
||||
|
||||
Because of the distinct nature of the security silo and the friction it can introduce, development and operations sometimes bypass or work around security to meet their objectives. At some firms, the silo creates an expectation that security is entirely the responsibility of the security team and it is up to them to figure out what security defects or issues may be introduced as a result of a product.
|
||||
|
||||
DevSecOps looks at merging the security discipline within DevOps. By enhancing or building security into the developer and/or operational role, or including a security role within the product engineering team, security naturally finds itself in the product by design.
|
||||
|
||||
This allows companies to release new products and updates more quickly and with full confidence that security is embedded into the product.
|
||||
|
||||
### Where does rugged software fit into DevSecOps?
|
||||
|
||||
Building rugged software is more an aspect of the DevOps culture than a distinct practice, and it complements and enhances a DevSecOps practice. Think of a rugged product as something that has been battle-hardened through experimentation or experience.
|
||||
|
||||
It’s important to note that rugged software is not necessarily 100% secure (although it may have been at some point in time). However, it has been designed to handle most of what is thrown at it.
|
||||
|
||||
The key tenets of a rugged software practice are fostering competition, experimentation, controlled failure, and cooperation.
|
||||
|
||||
### How do you get started in DevSecOps?
|
||||
|
||||
Gettings started with DevSecOps involves shifting security requirements and execution to the earliest possible stage in the development process. It ultimately creates a shift in culture where security becomes everyone’s responsibility, not only the security team’s.
|
||||
|
||||
You may have heard teams talking about a "shift left." If you flatten the development pipeline into a horizontal line to include the key stages of the product evolution—from initiation to design, building, testing, and finally to operating—the goal of a security is to be involved as early as possible. This allows the risks to be better evaluated, socialized, and mitigated by design. The "shift-left" mentality is about moving this engagement far left in this pipeline.
|
||||
|
||||
This journey begins with three key elements:
|
||||
|
||||
* empowerment
|
||||
* enablement
|
||||
* education
|
||||
|
||||
|
||||
|
||||
Empowerment, in my view, is about releasing control and allowing teams to make independent decisions without fear of failure or repercussion (within reason). The only caveat in this process is that information is critical to making informed decisions (more on that below).
|
||||
|
||||
To achieve empowerment, business and executive support (which can be created through internal sales, presentations, and establishing metrics to show the return on this investment) is critical to break down the historic barriers and siloed teams. Integrating security into the development and operations teams and increasing both communication and transparency can help you begin the journey to DevSecOps.
|
||||
|
||||
This integration and mobilization allows teams to focus on a single outcome: Building a product for which they share responsibility and collaborate on development and security in a reliable way. This will take you most of the way towards empowerment. It places the shared responsibility for the product with the teams building it and ensures that any part of the product can be taken apart and maintain its security.
|
||||
|
||||
Enablement involves placing the right tools and resources in the hands of the teams. It’s about creating a culture of knowledge-sharing through forums, wikis, and informal gatherings.
|
||||
|
||||
Creating a culture that focuses on automation and the concept that repetitive tasks should be coded will likely reduce operational overhead and strengthen security. This scenario is about more than providing knowledge; it is about making this knowledge highly accessible through multiple channels and mediums (which are enabled through tools) so that it can be consumed and shared in whatever way teams or individuals prefer. One medium might work best when team members are coding and another when they are on the road. Make the tools accessible and simple and let the team play with them.
|
||||
|
||||
Different DevSecOp teams will have different preferences, so allow them to be independent whenever possible. This is a delicate balancing exercise because you do want economies of scale and the ability to share among products. Collaboration and involvement in the selection and renewal of these tools will help lower the barriers of adoption.
|
||||
|
||||
Finally, and perhaps most importantly, DevSecOps is about training and awareness building. Meetups, social gatherings, or formal presentations within the organization are great ways for peers to teach and share their learnings. Sometimes these highlight shared challenges, concerns, or risks others may not have considered. Sharing and teaching are also effective ways to learn and to mentor teams.
|
||||
|
||||
In my experience, each organization's culture is unique, so you can’t take a “one-size-fits-all” approach. Reach out to your teams and find out what tools they want to use. Test different forums and gatherings and see what works best for your culture. Seek feedback and ask the teams what is working, what they like, and why. Adapt and learn, be positive, and never stop trying, and you’ll almost always succeed.
|
||||
|
||||
[Download the Getting started with DevSecOps guide][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/what-devsecops
|
||||
|
||||
作者:[Brett Hunoldt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bretthunoldtcom
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/downloads/devsecops
|
||||
212
sources/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
Normal file
212
sources/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
Normal file
@ -0,0 +1,212 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (JSON vs XML vs TOML vs CSON vs YAML)
|
||||
[#]: via: (https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/)
|
||||
[#]: author: (Tim Anderson https://www.zionandzion.com)
|
||||
|
||||
JSON vs XML vs TOML vs CSON vs YAML
|
||||
======
|
||||
|
||||
|
||||
### A Super Serious Segment About Sets, Subsets, and Supersets of Sample Serialization
|
||||
|
||||
I’m a developer. I read code. I write code. I write code that writes code. I write code that writes code for other code to read. It’s all very mumbo-jumbo, but beautiful in its own way. However, that last bit, writing code that writes code for other code to read, can get more convoluted than this paragraph—quickly. There are a lot of ways to do it. One not-so-convoluted way and a favorite among the developer community is through data serialization. For those who aren’t savvy on the super buzzword I just threw at you, data serialization is the process of taking some information from one system, churning it into a format that other systems can read, and then passing it along to those other systems.
|
||||
|
||||
While there are enough [data serialization formats][1] out there to bury the Burj Khalifa, they all mostly fall into two categories:
|
||||
|
||||
* simplicity for humans to read and write,
|
||||
* and simplicity for machines to read and write.
|
||||
|
||||
|
||||
|
||||
It’s difficult to have both as we humans enjoy loosely typed, flexible formatting standards that allow us to be more expressive, whereas machines tend to enjoy being told exactly what everything is without doubt or lack of detail, and consider “strict specifications” to be their favorite flavor of Ben & Jerry’s.
|
||||
|
||||
Since I’m a web developer and we’re an agency who creates websites, we’ll stick to those special formats that web systems can understand, or be made to understand without much effort, and that are particularly useful for human readability: XML, JSON, TOML, CSON, and YAML. Each has benefits, cons, and appropriate use cases.
|
||||
|
||||
### Facts First
|
||||
|
||||
Back in the early days of the interwebs, [some really smart fellows][2] decided to put together a standard language which every system could read and creatively named it Standard Generalized Markup Language, or SGML for short. SGML was incredibly flexible and well defined by its publishers. It became the father of languages such as XML, SVG, and HTML. All three fall under the SGML specification, but are subsets with stricter rules and shorter flexibility.
|
||||
|
||||
Eventually, people started seeing a great deal of benefit in having very small, concise, easy to read, and easy to generate data that could be shared programmatically between systems with very little overhead. Around that time, JSON was born and was able to fulfil all requirements. In turn, other languages began popping up to deal with more specialized cases such as CSON, TOML, and YAML.
|
||||
|
||||
### XML: Ixnayed
|
||||
|
||||
Originally, the XML language was amazingly flexible and easy to write, but its drawback was that it was verbose, difficult for humans to read, really difficult for computers to read, and had a lot of syntax that wasn’t entirely necessary to communicate information.
|
||||
|
||||
Today, it’s all but dead for data serialization purposes on the web. Unless you’re writing HTML or SVG, both siblings to XML, you probably aren’t going to see XML in too many other places. Some outdated systems still use it today, but using it to pass data around tends to be overkill for the web.
|
||||
|
||||
I can already hear the XML greybeards beginning to scribble upon their stone tablets as to why XML is ah-may-zing, so I’ll provide a small addendum: XML can be easy to read and write by systems and people. However, it is really, and I mean ridiculously, hard to create a system that can read it to specification. Here’s a simple, beautiful example of XML:
|
||||
|
||||
```
|
||||
<book id="bk101">
|
||||
<author>Gambardella, Matthew</author>
|
||||
<title>XML Developer's Guide</title>
|
||||
<genre>Computer</genre>
|
||||
<price>44.95</price>
|
||||
<publish_date>2000-10-01</publish_date>
|
||||
<description>An in-depth look at creating applications
|
||||
with XML.</description>
|
||||
</book>
|
||||
```
|
||||
|
||||
Wonderful. Easy to read, reason about, write, and code a system that can read and write. But consider this example:
|
||||
|
||||
```
|
||||
<!DOCTYPE r [ <!ENTITY y "a]>b"> ]>
|
||||
<r>
|
||||
<a b="&y;>" />
|
||||
<![CDATA[[a>b <a>b <a]]>
|
||||
<?x <a> <!-- <b> ?> c --> d
|
||||
</r>
|
||||
```
|
||||
|
||||
The above is 100% valid XML. Impossible to read, understand, or reason about. Writing code that can consume and understand this would cost at least 36 heads of hair and 248 pounds of coffee grounds. We don’t have that kind of time nor coffee, and most of us greybeards are balding nowadays. So let’s let it live only in our memory alongside [css hacks][3], [internet explorer 6][4], and [vacuum tubes][5].
|
||||
|
||||
### JSON: Juxtaposition Jamboree
|
||||
|
||||
Okay, we’re all in agreement. XML = bad. So, what’s a good alternative? JavaScript Object Notation, or JSON for short. JSON (read like the name Jason) was invented by Brendan Eich, and made popular by the great and powerful Douglas Crockford, the [Dutch Uncle of JavaScript][6]. It’s used just about everywhere nowadays. The format is easy to write by both human and machine, fairly easy to [parse][7] with strict rules in the specification, and flexible—allowing deep nesting of data, all of the primitive data types, and interpretation of collections as either arrays or objects. JSON became the de facto standard for transferring data from one system to another. Nearly every language out there has built-in functionality for reading and writing it.
|
||||
|
||||
JSON syntax is straightforward. Square brackets denote arrays, curly braces denote records, and two values separated by semicolons denote properties (or ‘keys’) on the left, and values on the right. All keys must be wrapped in double quotes:
|
||||
|
||||
```
|
||||
{
|
||||
"books": [
|
||||
{
|
||||
"id": "bk102",
|
||||
"author": "Crockford, Douglas",
|
||||
"title": "JavaScript: The Good Parts",
|
||||
"genre": "Computer",
|
||||
"price": 29.99,
|
||||
"publish_date": "2008-05-01",
|
||||
"description": "Unearthing the Excellence in JavaScript"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
This should make complete sense to you. It’s nice and concise, and has stripped much of the extra nonsense from XML to convey the same amount of information. JSON is king right now, and the rest of this article will go into other language formats that are nothing more than JSON boiled down in an attempt to be either more concise or more readable by humans, but follow very similar structure.
|
||||
|
||||
### TOML: Truncated to Total Altruism
|
||||
|
||||
TOML (Tom’s Obvious, Minimal Language) allows for defining deeply-nested data structures rather quickly and succinctly. The name-in-the-name refers to the inventor, [Tom Preston-Werner][8], an inventor and software developer who’s active in our industry. The syntax is a bit awkward when compared to JSON, and is more akin to an [ini file][9]. It’s not a bad syntax, but could take some getting used to:
|
||||
|
||||
```
|
||||
[[books]]
|
||||
id = 'bk101'
|
||||
author = 'Crockford, Douglas'
|
||||
title = 'JavaScript: The Good Parts'
|
||||
genre = 'Computer'
|
||||
price = 29.99
|
||||
publish_date = 2008-05-01T00:00:00+00:00
|
||||
description = 'Unearthing the Excellence in JavaScript'
|
||||
```
|
||||
|
||||
A couple great features have been integrated into TOML, such as multiline strings, auto-escaping of reserved characters, datatypes such as dates, time, integers, floats, scientific notation, and “table expansion”. That last bit is special, and is what makes TOML so concise:
|
||||
|
||||
```
|
||||
[a.b.c]
|
||||
d = 'Hello'
|
||||
e = 'World'
|
||||
```
|
||||
|
||||
The above expands to the following:
|
||||
|
||||
```
|
||||
{
|
||||
"a": {
|
||||
"b": {
|
||||
"c": {
|
||||
"d": "Hello"
|
||||
"e": "World"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can definitely see how much you can save in both time and file length using TOML. There are few systems which use it or something very similar for configuration, and that is its biggest con. There simply aren’t very many languages or libraries out there written to interpret TOML.
|
||||
|
||||
### CSON: Simple Samples Enslaved by Specific Systems
|
||||
|
||||
First off, there are two CSON specifications. One stands for CoffeeScript Object Notation, the other stands for Cursive Script Object Notation. The latter isn’t used too often, so we won’t be getting into it. Let’s just focus on the CoffeeScript one.
|
||||
|
||||
[CSON][10] will take a bit of intro. First, let’s talk about CoffeeScript. [CoffeeScript][11] is a language that runs through a compiler to generate JavaScript. It allows you to write JavaScript in a more syntactically concise way, and have it [transcompiled][12] into actual JavaScript, which you would then use in your web application. CoffeeScript makes writing JavaScript easier by removing a lot of the extra syntax necessary in JavaScript. A big one that CoffeeScript gets rid of is curly braces—no need for them. In that same token, CSON is JSON without the curly braces. It instead relies on indentation to determine hierarchy of your data. CSON is very easy to read and write and usually requires fewer lines of code than JSON because there are no brackets.
|
||||
|
||||
CSON also offers up some extra niceties that JSON doesn’t have to offer. Multiline strings are incredibly easy to write, you can enter [comments][13] by starting a line with a hash, and there’s no need for separating key-value pairs with commas.
|
||||
|
||||
```
|
||||
books: [
|
||||
id: 'bk102'
|
||||
author: 'Crockford, Douglas'
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: 'Computer'
|
||||
price: 29.99
|
||||
publish_date: '2008-05-01'
|
||||
description: 'Unearthing the Excellence in JavaScript'
|
||||
]
|
||||
```
|
||||
|
||||
Here’s the big issue with CSON. It’s **CoffeeScript** Object Notation. Meaning CoffeeScript is what you use to parse/tokenize/lex/transcompile or otherwise use CSON. CoffeeScript is the system that reads the data. If the intent of data serialization is to allow data to be passed from one system to another, and here we have a data serialization format that’s only read by a single system, well that makes it about as useful as a fireproof match, or a waterproof sponge, or that annoyingly flimsy fork part of a spork.
|
||||
|
||||
If this format is adopted by other systems, it could be pretty useful in the developer world. Thus far that hasn’t happened in a comprehensive manner, so using it in alternative languages such as PHP or JAVA are a no-go.
|
||||
|
||||
### YAML: Yielding Yips from Youngsters
|
||||
|
||||
Developers rejoice, as YAML comes into the scene from [one of the contributors to Python][14]. YAML has the same feature set and similar syntax as CSON, a boatload of new features, and parsers available in just about every web programming language there is. It also has some extra features, like circular referencing, soft-wraps, multi-line keys, typecasting tags, binary data, object merging, and [set maps][15]. It has incredibly good human readability and writability, and is a superset of JSON, so you can use fully qualified JSON syntax inside YAML and all will work well. You almost never need quotes, and it can interpret most of your base data types (strings, integers, floats, booleans, etc.).
|
||||
|
||||
```
|
||||
books:
|
||||
- id: bk102
|
||||
author: Crockford, Douglas
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: Computer
|
||||
price: 29.99
|
||||
publish_date: !!str 2008-05-01
|
||||
description: Unearthing the Excellence in JavaScript
|
||||
```
|
||||
|
||||
The younglings of the industry are rapidly adopting YAML as their preferred data serialization and system configuration format. They are smart to do so. YAML has all the benefits of being as terse as CSON, and all the features of datatype interpretation as JSON. YAML is as easy to read as Canadians are to hang out with.
|
||||
|
||||
There are two issues with YAML that stick out to me, and the first is a big one. At the time of this writing, YAML parsers haven’t yet been built into very many languages, so you’ll need to use a third-party library or extension for your chosen language to parse .yaml files. This wouldn’t be a big deal, however it seems most developers who’ve created parsers for YAML have chosen to throw “additional features” into their parsers at random. Some allow [tokenization][16], some allow [chain referencing][17], some even allow inline calculations. This is all well and good (sort of), except that none of these features are part of the specification, and so are difficult to find amongst other parsers in other languages. This results in system-locking; you end up with the same issue that CSON is subject to. If you use a feature found in only one parser, other parsers won’t be able to interpret the input. Most of these features are nonsense that don’t belong in a dataset, but rather in your application logic, so it’s best to simply ignore them and write your YAML to specification.
|
||||
|
||||
The second issue is there are few parsers that yet completely implement the specification. All the basics are there, but it can be difficult to find some of the more complex and newer things like soft-wraps, document markers, and circular references in your preferred language. I have yet to see an absolute need for these things, so hopefully they shouldn’t slow you down too much. With the above considered, I tend to keep to the more matured feature set presented in the [1.1 specification][18], and avoid the newer stuff found in the [1.2 specification][19]. However, programming is an ever-evolving monster, so by the time you finish reading this article, you’re likely to be able to use the 1.2 spec.
|
||||
|
||||
### Final Philosophy
|
||||
|
||||
The final word here is that each serialization language should be treated with a case-by-case reverence. Some are the bee’s knees when it comes to machine readability, some are the cat’s meow for human readability, and some are simply gilded turds. Here’s the ultimate breakdown: If you are writing code for other code to read, use YAML. If you are writing code that writes code for other code to read, use JSON. Finally, if you are writing code that transcompiles code into code that other code will read, rethink your life choices.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/
|
||||
|
||||
作者:[Tim Anderson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.zionandzion.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Comparison_of_data_serialization_formats
|
||||
[2]: https://en.wikipedia.org/wiki/Standard_Generalized_Markup_Language#History
|
||||
[3]: https://www.quirksmode.org/css/csshacks.html
|
||||
[4]: http://www.ie6death.com/
|
||||
[5]: https://en.wikipedia.org/wiki/Vacuum_tube
|
||||
[6]: https://twitter.com/BrendanEich/status/773403975865470976
|
||||
[7]: https://en.wikipedia.org/wiki/Parsing#Parser
|
||||
[8]: https://en.wikipedia.org/wiki/Tom_Preston-Werner
|
||||
[9]: https://en.wikipedia.org/wiki/INI_file
|
||||
[10]: https://github.com/bevry/cson#what-is-cson
|
||||
[11]: http://coffeescript.org/
|
||||
[12]: https://en.wikipedia.org/wiki/Source-to-source_compiler
|
||||
[13]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[14]: http://clarkevans.com/
|
||||
[15]: http://exploringjs.com/es6/ch_maps-sets.html
|
||||
[16]: https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm
|
||||
[17]: https://en.wikipedia.org/wiki/Fluent_interface
|
||||
[18]: http://yaml.org/spec/1.1/current.html
|
||||
[19]: http://www.yaml.org/spec/1.2/spec.html
|
||||
@ -1,141 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Working with modules in Fedora 28
|
||||
======
|
||||

|
||||
The recent Fedora Magazine article entitled [Modularity in Fedora 28 Server Edition][1] did a great job of explaining Modularity in Fedora 28. It also pointed out a few example modules and explained the problems they solve. This article puts one of those modules to practical use, covering installation and setup of Review Board 3.0 using modules.
|
||||
|
||||
### Getting started
|
||||
|
||||
To follow along with this article and use modules, you need a system running [Fedora 28 Server Edition][2] along with [sudo administrative privileges][3]. Also, run this command to make sure all the packages on the system are current:
|
||||
```
|
||||
sudo dnf -y update
|
||||
|
||||
```
|
||||
|
||||
While you can use modules on Fedora 28 non-server editions, be aware of the [caveats described in the comments of the previous article][4].
|
||||
|
||||
### Examining modules
|
||||
|
||||
First, take a look at what modules are available for Fedora 28. Run the following command:
|
||||
```
|
||||
dnf module list
|
||||
|
||||
```
|
||||
|
||||
The output lists a collection of modules that shows the associated stream, version, and available installation profiles for each. A [d] next to a particular module stream indicates the default stream used if the named module is installed.
|
||||
|
||||
The output also shows most modules have a profile named default. That’s not a coincidence, since default is the name used for the default profile.
|
||||
|
||||
To see where all those modules are coming from, run:
|
||||
```
|
||||
dnf repolist
|
||||
|
||||
```
|
||||
|
||||
Along with the usual [fedora and updates package repositories][5], the output shows the fedora-modular and updates-modular repositories.
|
||||
|
||||
The introduction stated you’d be setting up Review Board 3.0. Perhaps a module named reviewboard caught your attention in the earlier output. Next, to get some details about that module, run this command:
|
||||
```
|
||||
dnf module info reviewboard
|
||||
|
||||
```
|
||||
|
||||
The description confirms it is the Review Board module, but also says it’s the 2.5 stream. However, you want 3.0. Look at the available reviewboard modules:
|
||||
```
|
||||
dnf module list reviewboard
|
||||
|
||||
```
|
||||
|
||||
The [d] next to the 2.5 stream means it is configured as the default stream for reviewboard. Therefore, be explicit about the stream you want:
|
||||
```
|
||||
dnf module info reviewboard:3.0
|
||||
|
||||
```
|
||||
|
||||
Now for even more details about the reviewboard:3.0 module, add the verbose option:
|
||||
```
|
||||
dnf module info reviewboard:3.0 -v
|
||||
|
||||
```
|
||||
|
||||
### Installing the Review Board 3.0 module
|
||||
|
||||
Now that you’ve tracked down the module you want, install it with this command:
|
||||
```
|
||||
sudo dnf -y module install reviewboard:3.0
|
||||
|
||||
```
|
||||
|
||||
The output shows the ReviewBoard package was installed, along with several other dependent packages, including several from the django:1.6 module. The installation also enabled the reviewboard:3.0 module and the dependent django:1.6 module.
|
||||
|
||||
Next, to see enabled modules, use this command:
|
||||
```
|
||||
dnf module list --enabled
|
||||
|
||||
```
|
||||
|
||||
The output shows [e] for enabled streams, and [i] for installed profiles. In the case of the reviewboard:3.0 module, the default profile was installed. You could have specified a different profile when installing the module. In fact, you still can — and this time you don’t need to specify the 3.0 stream since it was already enabled:
|
||||
```
|
||||
sudo dnf -y module install reviewboard/server
|
||||
|
||||
```
|
||||
|
||||
However, installation of the reviewboard:3.0/server profile is rather uneventful. The reviewboard:3.0 module’s server profile is the same as the default profile — so there’s nothing more to install.
|
||||
|
||||
### Spin up a Review Board site
|
||||
|
||||
Now that the Review Board 3.0 module and its dependent packages are installed, [create a Review Board site][6] running on the local system. Without further ado or explanation, copy and paste the following commands to do that:
|
||||
```
|
||||
sudo rb-site install --noinput \
|
||||
--domain-name=localhost --db-type=sqlite3 \
|
||||
--db-name=/var/www/rev.local/data/reviewboard.db \
|
||||
--admin-user=rbadmin --admin-password=secret \
|
||||
/var/www/rev.local
|
||||
sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \
|
||||
/var/www/rev.local/data
|
||||
sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \
|
||||
/etc/httpd/conf.d/reviewboard-localhost.conf
|
||||
sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \
|
||||
httpd_can_network_memcache=1 httpd_unified=1
|
||||
sudo systemctl enable --now httpd
|
||||
|
||||
```
|
||||
|
||||
Now fire up a web browser on the system, point it at <http://localhost>, and enjoy the shiny new Review Board site! To login as the Review Board admin, use the userid and password seen in the rb-site command above.
|
||||
|
||||
### Module cleanup
|
||||
|
||||
It’s good practice to clean up after yourself. To do that, remove the Review Board module and the site directory:
|
||||
```
|
||||
sudo dnf -y module remove reviewboard:3.0
|
||||
sudo rm -rf /var/www/rev.local
|
||||
|
||||
```
|
||||
|
||||
### Closing remarks
|
||||
|
||||
Now that you’ve explored how to examine and administer the Review Board module, go experiment with the other modules available in Fedora 28.
|
||||
|
||||
Learn more about using modules in Fedora 28 on the [Fedora Modularity][7] web site. The dnf manual page’s Module Command section also contains useful information.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/working-modules-fedora-28/
|
||||
|
||||
作者:[Merlin Mathesius][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/merlinm/
|
||||
[1]:https://fedoramagazine.org/modularity-fedora-28-server-edition/
|
||||
[2]:https://getfedora.org/server/
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]:https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696
|
||||
[5]:https://fedoraproject.org/wiki/Repositories
|
||||
[6]:https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/
|
||||
[7]:https://docs.pagure.org/modularity/
|
||||
@ -1,3 +1,4 @@
|
||||
Scoutydren is translating.
|
||||
5 open source strategy and simulation games for Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,85 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Winterize your Bash prompt in Linux)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-bash-prompt)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Winterize your Bash prompt in Linux
|
||||
======
|
||||
Your Linux terminal probably supports Unicode, so why not take advantage of that and add a seasonal touch to your prompt?
|
||||

|
||||
|
||||
Hello once again for another installment of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is? Really, we're keeping it pretty open-ended: It's anything that's a fun diversion at the terminal, and we're giving bonus points for anything holiday-themed.
|
||||
|
||||
Maybe you've seen some of these before, maybe you haven't. Either way, we hope you have fun.
|
||||
|
||||
Today's toy is super-simple: It's your Bash prompt. Your Bash prompt? Yep! We've got a few more weeks of the holiday season left to stare at it, and even more weeks of winter here in the northern hemisphere, so why not have some fun with it.
|
||||
|
||||
Your Bash prompt currently might be a simple dollar sign ( **$** ), or more likely, it's something a little longer. If you're not sure what makes up your Bash prompt right now, you can find it in an environment variable called $PS1. To see it, type:
|
||||
|
||||
```
|
||||
echo $PS1
|
||||
```
|
||||
|
||||
For me, this returns:
|
||||
|
||||
```
|
||||
[\u@\h \W]\$
|
||||
```
|
||||
|
||||
The **\u** , **\h** , and **\W** are special characters for username, hostname, and working directory. There are others you can use as well; for help building out your Bash prompt, you can use [EzPrompt][1], an online generator of PS1 configurations that includes lots of options including date and time, Git status, and more.
|
||||
|
||||
You may have other variables that make up your Bash prompt set as well; **$PS2** for me contains the closing brace of my command prompt. See [this article][2] for more information.
|
||||
|
||||
To change your prompt, simply set the environment variable in your terminal like this:
|
||||
|
||||
```
|
||||
$ PS1='\u is cold: '
|
||||
jehb is cold:
|
||||
```
|
||||
|
||||
To set it permanently, add the same code to your **/etc/bashrc **using your favorite text editor.
|
||||
|
||||
So what does this have to do with winterization? Well, chances are on a modern machine, your terminal support Unicode, so you're not limited to the standard ASCII character set. You can use any emoji that's a part of the Unicode specification, including a snowflake ❄, a snowman ☃, or a pair of skis 🎿. You've got plenty of wintery options to choose from.
|
||||
|
||||
```
|
||||
🎄 Christmas Tree
|
||||
🧥 Coat
|
||||
🦌 Deer
|
||||
🧤 Gloves
|
||||
🤶 Mrs. Claus
|
||||
🎅 Santa Claus
|
||||
🧣 Scarf
|
||||
🎿 Skis
|
||||
🏂 Snowboarder
|
||||
❄ Snowflake
|
||||
☃ Snowman
|
||||
⛄ Snowman Without Snow
|
||||
🎁 Wrapped Gift
|
||||
```
|
||||
|
||||
Pick your favorite, and enjoy some winter cheer. Fun fact: modern filesystems also support Unicode characters in their filenames, meaning you can technically name your next program **"❄❄❄❄❄.py"**. That said, please don't.
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to include? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [Snake your way across your Linux terminal][3], and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-bash-prompt
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://ezprompt.net/
|
||||
[2]: https://access.redhat.com/solutions/505983
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-snake
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -96,7 +96,7 @@ via: https://anarc.at/blog/2018-12-21-large-files-with-git/
|
||||
|
||||
作者:[Anarc.at][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (s-tui: A Terminal Tool To Monitor CPU Temperature, Frequency, Power And Utilization In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
|
||||
s-tui: A Terminal Tool To Monitor CPU Temperature, Frequency, Power And Utilization In Linux
|
||||
======
|
||||
|
||||
By default every Linux administrator would go with **[lm_sensors to monitor CPU temperature][1]**.
|
||||
|
||||
lm_sensors (Linux monitoring sensors) is a free and open-source application that provides tools and drivers for monitoring temperatures, voltage, and fans.
|
||||
|
||||
It’s a CLI utility and if you are looking for alternative tools.
|
||||
|
||||
I would suggest you to go for s-tui.
|
||||
|
||||
It’s a Stress Terminal UI which helps administrator to view CPU temperature with colors.
|
||||
|
||||
### What is s-tui
|
||||
|
||||
s-tui is a terminal UI for monitoring your computer. s-tui allows to monitor CPU temperature, frequency, power and utilization in a graphical way from the terminal.
|
||||
|
||||
Also, shows performance dips caused by thermal throttling, it requires minimal resources and doesn’t requires X-server. It was written in Python and requires root privilege to use this.
|
||||
|
||||
s-tui is a self-contained application which can run out-of-the-box and doesn’t need config files to drive its core features.
|
||||
|
||||
s-tui uses psutil to probe some of your hardware information. If your hardware is not supported, you might not see all the information.
|
||||
|
||||
Running s-tui as root gives access to the maximum Turbo Boost frequency available to your CPU when stressing all cores.
|
||||
|
||||
It uses Stress utility in the background to check the temperature of its components do not exceed their acceptable range by imposes certain types of compute stress on your system.
|
||||
|
||||
Running an overclocked PC is fine as long as it is stable and that the temperature of its components do not exceed their acceptable range.
|
||||
|
||||
There are several programs available to assess system stability through stress testing the system and thereby the overclock level.
|
||||
|
||||
### How to Install s-tui In Linux
|
||||
|
||||
It was written in Python and pip installation is a recommended method to install s-tui on Linux. Make sure you should have installed python-pip package on your system. If no, use the following command to install it.
|
||||
|
||||
For Debian/Ubuntu users, use **[Apt Command][2]** or **[Apt-Get Command][3]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo apt install python-pip stress
|
||||
```
|
||||
|
||||
For Archlinux users, use **[Pacman Command][4]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo pacman -S python-pip stress
|
||||
```
|
||||
|
||||
For Fedora users, use **[DNF Command][5]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo dnf install python-pip stress
|
||||
```
|
||||
|
||||
For CentOS/RHEL users, use **[YUM Command][6]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo yum install python-pip stress
|
||||
```
|
||||
|
||||
For openSUSE users, use **[Zypper Command][7]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo zypper install python-pip stress
|
||||
```
|
||||
|
||||
Finally run the following **[pip command][8]** to install s-tui tool in Linux.
|
||||
|
||||
For Python 2.x:
|
||||
|
||||
```
|
||||
$ sudo pip install s-tui
|
||||
```
|
||||
|
||||
For Python 3.x:
|
||||
|
||||
```
|
||||
$ sudo pip3 install s-tui
|
||||
```
|
||||
|
||||
### How to Access s-tui
|
||||
|
||||
As i told in the beginning of the article. It requires root privilege to get all the information from your system. Just run the following command to launch s-tui.
|
||||
|
||||
```
|
||||
$ sudo s-tui
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
By default it enable hardware monitoring and select the “Stress” option to do the stress test on your system.
|
||||
![][11]
|
||||
|
||||
To check other options, navigate to help page.
|
||||
|
||||
```
|
||||
$ s-tui --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/view-check-cpu-hard-disk-temperature-linux/
|
||||
[2]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[6]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[7]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[8]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
|
||||
[9]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/12/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency-1.jpg
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/12/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency-2.jpg
|
||||
116
sources/tech/20190104 Managing dotfiles with rcm.md
Normal file
116
sources/tech/20190104 Managing dotfiles with rcm.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managing dotfiles with rcm)
|
||||
[#]: via: (https://fedoramagazine.org/managing-dotfiles-rcm/)
|
||||
[#]: author: (Link Dupont https://fedoramagazine.org/author/linkdupont/)
|
||||
|
||||
Managing dotfiles with rcm
|
||||
======
|
||||
|
||||

|
||||
|
||||
A hallmark feature of many GNU/Linux programs is the easy-to-edit configuration file. Nearly all common free software programs store configuration settings inside a plain text file, often in a structured format like JSON, YAML or [“INI-like”][1]. These configuration files are frequently found hidden inside a user’s home directory. However, a basic ls won’t reveal them. UNIX standards require that any file or directory name that begins with a period (or “dot”) is considered “hidden” and will not be listed in directory listings unless requested by the user. For example, to list all files using the ls program, pass the -a command-line option.
|
||||
|
||||
Over time, these configuration files become highly customized, and managing them becomes increasingly more challenging as time goes on. Not only that, but keeping them synchronized between multiple computers is a common challenge in large organizations. Finally, many users find a sense of pride in their unique configuration settings and want an easy way to share them with friends. That’s where **rcm** steps in.
|
||||
|
||||
**rcm** is a “rc” file management suite (“rc” is another convention for naming configuration files that has been adopted by some GNU/Linux programs like screen or bash). **rcm** provides a suite of commands to manage and list files it tracks. Install **rcm** using **dnf**.
|
||||
|
||||
### Getting started
|
||||
|
||||
By default, **rcm** uses ~/.dotfiles for storing all the dotfiles it manages. A managed dotfile is actually stored inside ~/.dotfiles, and a symlink is placed in the expected file’s location. For example, if ~/.bashrc is tracked by **rcm** , a long listing would look like this.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ ls -l ~/.bashrc
|
||||
lrwxrwxrwx. 1 link link 27 Dec 16 05:19 .bashrc -> /home/link/.dotfiles/bashrc
|
||||
[link@localhost ~]$
|
||||
```
|
||||
|
||||
**rcm** consists of 4 commands:
|
||||
|
||||
* mkrc – convert a file into a dotfile managed by rcm
|
||||
* lsrc – list files managed by rcm
|
||||
* rcup – synchronize dotfiles managed by rcm
|
||||
* rcdn – remove all the symlinks managed by rcm
|
||||
|
||||
|
||||
|
||||
### Share bashrc across two computers
|
||||
|
||||
It is not uncommon today for a user to have shell accounts on more than one computer. Keeping dotfiles synchronized between those computers can be a challenge. This scenario will present one possible solution, using only **rcm** and **git**.
|
||||
|
||||
First, convert (or “bless”) a file into a dotfile managed by **rcm** with mkrc.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ mkrc -v ~/.bashrc
|
||||
Moving...
|
||||
'/home/link/.bashrc' -> '/home/link/.dotfiles/bashrc'
|
||||
Linking...
|
||||
'/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc'
|
||||
[link@localhost ~]$
|
||||
```
|
||||
|
||||
Next, verify the listings are correct with lsrc.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ lsrc
|
||||
/home/link/.bashrc:/home/link/.dotfiles/bashrc
|
||||
[link@localhost ~]$
|
||||
```
|
||||
|
||||
Now create a git repository inside ~/.dotfiles and set up an accessible remote repository using your choice of hosted git repositories. Commit the bashrc file and push a new branch.
|
||||
|
||||
```
|
||||
[link@localhost ~]$ cd ~/.dotfiles
|
||||
[link@localhost .dotfiles]$ git init
|
||||
Initialized empty Git repository in /home/link/.dotfiles/.git/
|
||||
[link@localhost .dotfiles]$ git remote add origin git@github.com:linkdupont/dotfiles.git
|
||||
[link@localhost .dotfiles]$ git add bashrc
|
||||
[link@localhost .dotfiles]$ git commit -m "initial commit"
|
||||
[master (root-commit) b54406b] initial commit
|
||||
1 file changed, 15 insertions(+)
|
||||
create mode 100644 bashrc
|
||||
[link@localhost .dotfiles]$ git push -u origin master
|
||||
...
|
||||
[link@localhost .dotfiles]$
|
||||
```
|
||||
|
||||
On the second machine, clone this repository into ~/.dotfiles.
|
||||
|
||||
```
|
||||
[link@remotehost ~]$ git clone git@github.com:linkdupont/dotfiles.git ~/.dotfiles
|
||||
...
|
||||
[link@remotehost ~]$
|
||||
```
|
||||
|
||||
Now update the symlinks managed by **rcm** with rcup.
|
||||
|
||||
```
|
||||
[link@remotehost ~]$ rcup -v
|
||||
replacing identical but unlinked /home/link/.bashrc
|
||||
removed '/home/link/.bashrc'
|
||||
'/home/link/.dotfiles/bashrc' -> '/home/link/.bashrc'
|
||||
[link@remotehost ~]$
|
||||
```
|
||||
|
||||
Overwrite the existing ~/.bashrc (if it exists) and restart the shell.
|
||||
|
||||
That’s it! The host-specific option (-o) is a useful addition to the scenario above. And as always, be sure to read the manpages; they contain a wealth of example commands.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-dotfiles-rcm/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/linkdupont/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/INI_file
|
||||
@ -0,0 +1,223 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Search, Study And Practice Linux Commands On The Fly!)
|
||||
[#]: via: (https://www.ostechnix.com/search-study-and-practice-linux-commands-on-the-fly/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Search, Study And Practice Linux Commands On The Fly!
|
||||
======
|
||||
|
||||

|
||||
|
||||
The title may look like sketchy and click bait. Allow me to explain what I am about to explain in this tutorial. Let us say you want to download an archive file, extract it and move the file from one location to another from command line. As per the above scenario, we may need at least three Linux commands, one for downloading the file, one for extracting the downloaded file and one for moving the file. If you’re intermediate or advanced Linux user, you could do this easily with an one-liner command or a script in few seconds/minutes. But, if you are a noob who don’t know much about Linux commands, you might need little help.
|
||||
|
||||
Of course, a quick google search may yield many results. Or, you could use [**man pages**][1]. But some man pages are really long, comprehensive and lack in useful example. You might need to scroll down for quite a long time when you’re looking for a particular information on the specific flags/options. Thankfully, there are some [**good alternatives to man pages**][2], which are focused on mostly practical commands. One such good alternative is **TLDR pages**. Using TLDR pages, we can quickly and easily learn a Linux command with practical examples. To access the TLDR pages, we require a TLDR client. There are many clients available. Today, we are going to learn about one such client named **“Tldr++”**.
|
||||
|
||||
Tldr++ is a fast and interactive tldr client written with **Go** programming language. Unlike the other Tldr clients, it is fully interactive. That means, you can pick a command, read all examples , and immediately run any command without having to retype or copy/paste each command in the Terminal. Still don’t get it? No problem. Read on to learn and practice Linux commands on the fly.
|
||||
|
||||
### Install Tldr++
|
||||
|
||||
Installing Tldr++ is very simple. Download tldr++ latest version from the [**releases page**][3]. Extract it and move the tldr++ binary to your $PATH.
|
||||
|
||||
```
|
||||
$ wget https://github.com/isacikgoz/tldr/releases/download/v0.5.0/tldr_0.5.0_linux_amd64.tar.gz
|
||||
|
||||
$ tar xzf tldr_0.5.0_linux_amd64.tar.gz
|
||||
|
||||
$ sudo mv tldr /usr/local/bin
|
||||
|
||||
$ sudo chmod +x /usr/local/bin/tldr
|
||||
```
|
||||
|
||||
Now, run ‘tldr’ binary to populate the tldr pages in your local system.
|
||||
|
||||
```
|
||||
$ tldr
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
Enumerating objects: 6, done.
|
||||
Counting objects: 100% (6/6), done.
|
||||
Compressing objects: 100% (6/6), done.
|
||||
Total 18157 (delta 0), reused 3 (delta 0), pack-reused 18151
|
||||
Successfully cloned into: /home/sk/.local/share/tldr
|
||||
```
|
||||
|
||||
|
||||
|
||||
Tldr++ is available in AUR. If you’re on Arch Linux, you can install it using any AUR helper, for example [**YaY**][4]. Make sure you have removed any existing tldr client from your system and run the following command to install tldr++.
|
||||
|
||||
```
|
||||
$ yay -S tldr++
|
||||
```
|
||||
|
||||
Alternatively, you can build from source as described below. Since Tldr++ is written using Go language, make sure you have installed it on your Linux box. If it isn’t installed yet, refer the following guide.
|
||||
|
||||
+ [How To Install Go Language In Linux](https://www.ostechnix.com/install-go-language-linux/)
|
||||
|
||||
After installing Go, run the following command to install Tldr++.
|
||||
|
||||
```
|
||||
$ go get -u github.com/isacikgoz/tldr
|
||||
```
|
||||
|
||||
This command will download the contents of tldr repository in a folder named **‘go’** in the current working directory.
|
||||
|
||||
Now run the ‘tldr’ binary to populate all tldr pages in your local system using command:
|
||||
|
||||
```
|
||||
$ go/bin/tldr
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][6]
|
||||
|
||||
Finally, copy the tldr binary to your PATH.
|
||||
|
||||
```
|
||||
$ sudo mv tldr /usr/local/bin
|
||||
```
|
||||
|
||||
It is time to see some examples.
|
||||
|
||||
### Tldr++ Usage
|
||||
|
||||
Type ‘tldr’ command without any options to display all command examples in alphabetical order.
|
||||
|
||||
![][7]
|
||||
|
||||
Use the **UP/DOWN arrows** to navigate through the commands, type any letters to search or type a command name to view the examples of that respective command. Press **?** for more and **Ctrl+c** to return/exit.
|
||||
|
||||
To display the example commands of a specific command, for example **apt** , simply do:
|
||||
|
||||
```
|
||||
$ tldr apt
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
Choose any example command from the list and hit ENTER. You will see a *** symbol** before the selected command. For example, I choose the first command i.e ‘sudo apt update’. Now, it will ask you whether to continue or not. If the command is correct, just type ‘y’ to continue and type your sudo password to run the selected command.
|
||||
|
||||
![][9]
|
||||
|
||||
See? You don’t need to copy/paste or type the actual command in the Terminal. Just choose it from the list and run on the fly!
|
||||
|
||||
There are hundreds of Linux command examples are available in Tldr pages. You can choose one or two commands per day and learn them thoroughly. And keep this practice everyday to learn as much as you can.
|
||||
|
||||
### Learn And Practice Linux Commands On The Fly Using Tldr++
|
||||
|
||||
Now think of the scenario that I mentioned in the first paragraph. You want to download a file, extract it and move it to different location and make it executable. Let us see how to do it interactively using Tldr++ client.
|
||||
|
||||
**Step 1 – Download a file from Internet**
|
||||
|
||||
To download a file from command line, we mostly use **‘curl’** or **‘wget’** commands. Let me use ‘wget’ to download the file. To open tldr page of wget command, just run:
|
||||
|
||||
```
|
||||
$ tldr wget
|
||||
```
|
||||
|
||||
Here is the examples of wget command.
|
||||
|
||||

|
||||
|
||||
You can use **UP/DOWN** arrows to go through the list of commands. Once you choose the command of your choice, press ENTER. Here I chose the first command.
|
||||
|
||||
Now, enter the path of the file to download.
|
||||
|
||||

|
||||
|
||||
You will then be asked to confirm if it is the correct command or not. If the command is correct, simply type ‘yes’ or ‘y’ to start downloading the file.
|
||||
|
||||
![][10]
|
||||
|
||||
We have downloaded the file. Let us go ahead and extract this file.
|
||||
|
||||
**Step 2 – Extract downloaded archive**
|
||||
|
||||
We downloaded the **tar.gz** file. So I am going to open the ‘tar’ tldr page.
|
||||
|
||||
```
|
||||
$ tldr tar
|
||||
```
|
||||
|
||||
You will see the list of example commands. Go through the examples and find which command is suitable to extract tar.gz(gzipped archive) file and hit ENTER key. In our case, it is the third command.
|
||||
|
||||
![][11]
|
||||
|
||||
Now, you will be prompted to enter the path of the tar.gz file. Just type the path and hit ENTER key. Tldr++ supports smart file suggestions. That means it will suggest the file name automatically as you type. Just press TAB key for auto-completion.
|
||||
|
||||
![][12]
|
||||
|
||||
If you downloaded the file to some other location, just type the full path, for example **/home/sk/Downloads/tldr_0.5.0_linux_amd64.tar.gz.**
|
||||
|
||||
Once you enter the path of the file to extract, press ENTER and then, type ‘y’ to confirm.
|
||||
|
||||
![][13]
|
||||
|
||||
**Step 3 – Move file from one location to another**
|
||||
|
||||
We extracted the archive. Now we need to move the file to another location. To move the files from one location to another, we use ‘mv’ command. So, let me open the tldr page for mv command.
|
||||
|
||||
```
|
||||
$ tldr mv
|
||||
```
|
||||
|
||||
Choose the correct command to move the files from one location to another. In our case, the first command will work, so let me choose it.
|
||||
|
||||
![][14]
|
||||
|
||||
Type the path of the file that you want to move and enter the destination path and hit ENTER key.
|
||||
|
||||
![][15]
|
||||
|
||||
**Note:** Type **y!** or **yes!** to run command with **sudo** privileges.
|
||||
|
||||
As you see in the above screenshot, I moved the file named **‘tldr’** to **‘/usr/local/bin/’** location.
|
||||
|
||||
For more details, refer the project’s GitHub page given at the end.
|
||||
|
||||
|
||||
### Conclusion
|
||||
|
||||
Don’t get me wrong. **Man pages are great!** There is no doubt about it. But, as I already said, many man pages are comprehensive and doesn’t have useful examples. There is no way I could memorize all lengthy commands with tricky flags. Some times I spent much time on man pages and remained clueless. The Tldr pages helped me to find what I need within few minutes. Also, we use some commands once in a while and then we forget them completely. Tldr pages on the other hand actually helps when it comes to using commands we rarely use. Tldr++ client makes this task much easier with smart user interaction. Give it a go and let us know what you think about this tool in the comment section below.
|
||||
|
||||
And, that’s all. More good stuffs to come. Stay tuned!
|
||||
|
||||
Good luck!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/search-study-and-practice-linux-commands-on-the-fly/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/learn-use-man-pages-efficiently/
|
||||
[2]: https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
[3]: https://github.com/isacikgoz/tldr/releases
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-1.png
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-11.png
|
||||
[8]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-12.png
|
||||
[9]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-13.png
|
||||
[10]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-4.png
|
||||
[11]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-6.png
|
||||
[12]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-7.png
|
||||
[13]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-8.png
|
||||
[14]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-9.png
|
||||
[15]: http://www.ostechnix.com/wp-content/uploads/2019/01/tldr-10.png
|
||||
@ -0,0 +1,224 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Setting up an email server, part 1: The Forwarder)
|
||||
[#]: via: (https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/)
|
||||
[#]: author: (Julian Andres Klode https://blog.jak-linux.org/)
|
||||
|
||||
Setting up an email server, part 1: The Forwarder
|
||||
======
|
||||
|
||||
This week, I’ve been working on rolling out mail services on my server. I started working on a mail server setup at the end of November, while the server was not yet in use, but only for about two days, and then let it rest.
|
||||
|
||||
As my old shared hosting account expired on January 1, I had to move mail forwarding duties over to the new server. Yes forwarding - I do plan to move hosting the actual email too, but at the moment it’s “just” forwarding to gmail.
|
||||
|
||||
### The Software
|
||||
|
||||
As you might know from the web server story, my server runs on Ubuntu 18.04. I set up a mail server on this system using
|
||||
|
||||
* [Postfix][1] for SMTP duties (warning, they oddly do not have an https page)
|
||||
* [rspamd][2] for spam filtering, and signing DKIM / ARC
|
||||
* [bind9][3] for DNS resolving
|
||||
* [postsrsd][4] for SRS
|
||||
|
||||
|
||||
|
||||
You might wonder why bind9 is in there. It turns out that DNS blacklists used by spam filters block the caching DNS servers you usually use, so you have to use your own recursive DNS server. Ubuntu offers you the choice between bind9 and dnsmasq in main, and it seems like bind9 is more appropriate here than dnsmasq.
|
||||
|
||||
### Setting up postfix
|
||||
|
||||
Most of the postfix configuration is fairly standard. So, let’s skip TLS configuration and outbound SMTP setups (this is email, and while they support TLS, it’s all optional, so let’s not bother that much here).
|
||||
|
||||
The most important part is restrictions in `main.cf`.
|
||||
|
||||
First of all, relay restrictions prevent us from relaying emails to weird domains:
|
||||
|
||||
```
|
||||
# Relay Restrictions
|
||||
smtpd_relay_restrictions = reject_non_fqdn_recipient reject_unknown_recipient_domain permit_mynetworks permit_sasl_authenticated defer_unauth_destination
|
||||
```
|
||||
|
||||
We also only accept mails from hosts that know their own full qualified name:
|
||||
|
||||
```
|
||||
# Helo restrictions (hosts not having a proper fqdn)
|
||||
smtpd_helo_required = yes
|
||||
smtpd_helo_restrictions = permit_mynetworks reject_invalid_helo_hostname reject_non_fqdn_helo_hostname reject_unknown_helo_hostname
|
||||
```
|
||||
|
||||
We also don’t like clients (other servers) that send data too early, or have an unknown hostname:
|
||||
|
||||
```
|
||||
smtpd_data_restrictions = reject_unauth_pipelining
|
||||
smtpd_client_restrictions = permit_mynetworks reject_unknown_client_hostname
|
||||
```
|
||||
|
||||
I also set up a custom apparmor profile that’s pretty lose, I plan to migrate to the one in the apparmor git eventually but it needs more testing and some cleanup.
|
||||
|
||||
### Sender rewriting scheme
|
||||
|
||||
For SRS using postsrsd, we define the `SRS_DOMAIN` in `/etc/default/postsrsd` and then configure postfix to talk to it:
|
||||
|
||||
```
|
||||
# Handle SRS for forwarding
|
||||
recipient_canonical_maps = tcp:localhost:10002
|
||||
recipient_canonical_classes= envelope_recipient,header_recipient
|
||||
|
||||
sender_canonical_maps = tcp:localhost:10001
|
||||
sender_canonical_classes = envelope_sender
|
||||
```
|
||||
|
||||
This has a minor issue that it also rewrites the `Return-Path` when it delivers emails locally, but as I am only forwarding, I’m worrying about that later.
|
||||
|
||||
### rspamd basics
|
||||
|
||||
rspamd is a great spam filtering system. It uses a small core written in C and a bunch of Lua plugins, such as:
|
||||
|
||||
* IP score, which keeps track of how good a specific server was in the past
|
||||
* Replies, which can check whether an email is a reply to another one
|
||||
* DNS blacklisting
|
||||
* DKIM and ARC validation and signing
|
||||
* DMARC validation
|
||||
* SPF validation
|
||||
|
||||
|
||||
|
||||
It also has a nice web UI:
|
||||
|
||||
![rspamd web ui status][5]
|
||||
|
||||
rspamd web ui status
|
||||
|
||||
![rspamd web ui investigating a spam message][6]
|
||||
|
||||
rspamd web ui investigating a spam message
|
||||
|
||||
Setting up rspamd is quite easy. You basically just drop a bunch of configuration overrides into `/etc/rspamd/local.d` and you’re done. Heck, it mostly works out of the box. There’s a fancy `rspamadm configwizard` too.
|
||||
|
||||
What you do want for rspamd is a redis server. redis is needed in [many places][7], such as rate limiting, greylisting, dmarc, reply tracking, ip scoring, neural networks.
|
||||
|
||||
I made a few changes to the defaults:
|
||||
|
||||
* I enabled subject rewriting instead of adding headers, so spam mail subjects get `[SPAM]` prepended, in `local.d/actions.conf`:
|
||||
|
||||
```
|
||||
reject = 15;
|
||||
rewrite_subject = 6;
|
||||
add_header = 6;
|
||||
greylist = 4;
|
||||
subject = "[SPAM] %s";
|
||||
```
|
||||
|
||||
* I set `autolearn = true;` in `local.d/classifier-bayes.conf` to make it learn that an email that has a score of at least 15 (those that are rejected) is spam, and emails with negative scores are ham.
|
||||
|
||||
* I set `extended_spam_headers = true;` in `local.d/milter_headers.conf` to get a report from rspamd in the header seeing the score and how the score came to be.
|
||||
|
||||
|
||||
|
||||
|
||||
### ARC setup
|
||||
|
||||
[ARC][8] is the ‘Authenticated Received Chain’ and is currently a DMARC working group work item. It allows forwarders / mailing lists to authenticate their forwarding of the emails and the checks they have performed.
|
||||
|
||||
rspamd is capable of validating and signing emails with ARC, but I’m not sure how much influence ARC has on gmail at the moment, for example.
|
||||
|
||||
There are three parts to setting up ARC:
|
||||
|
||||
1. Generate a DKIM key pair (use `rspamadm dkim_keygen`)
|
||||
2. Setup rspamd to sign incoming emails using the private key
|
||||
3. Add a DKIM `TXT` record for the public key. `rspamadm` helpfully tells you how it looks like.
|
||||
|
||||
|
||||
|
||||
For step two, what we need to do is configure `local.d/arc.conf`. You can basically use the example configuration from the [rspamd page][9], the key point for signing incoming email is to specifiy `sign_incoming = true;` and `use_domain_sign_inbound = "recipient";` (FWIW, none of these options are documented, they are fairly new, and nobody updated the documentation for them).
|
||||
|
||||
My configuration looks like this at the moment:
|
||||
|
||||
```
|
||||
# If false, messages with empty envelope from are not signed
|
||||
allow_envfrom_empty = true;
|
||||
# If true, envelope/header domain mismatch is ignored
|
||||
allow_hdrfrom_mismatch = true;
|
||||
# If true, multiple from headers are allowed (but only first is used)
|
||||
allow_hdrfrom_multiple = false;
|
||||
# If true, username does not need to contain matching domain
|
||||
allow_username_mismatch = false;
|
||||
# If false, messages from authenticated users are not selected for signing
|
||||
auth_only = true;
|
||||
# Default path to key, can include '$domain' and '$selector' variables
|
||||
path = "${DBDIR}/arc/$domain.$selector.key";
|
||||
# Default selector to use
|
||||
selector = "arc";
|
||||
# If false, messages from local networks are not selected for signing
|
||||
sign_local = true;
|
||||
#
|
||||
sign_inbound = true;
|
||||
# Symbol to add when message is signed
|
||||
symbol_signed = "ARC_SIGNED";
|
||||
# Whether to fallback to global config
|
||||
try_fallback = true;
|
||||
# Domain to use for ARC signing: can be "header" or "envelope"
|
||||
use_domain = "header";
|
||||
use_domain_sign_inbound = "recipient";
|
||||
# Whether to normalise domains to eSLD
|
||||
use_esld = true;
|
||||
# Whether to get keys from Redis
|
||||
use_redis = false;
|
||||
# Hash for ARC keys in Redis
|
||||
key_prefix = "ARC_KEYS";
|
||||
```
|
||||
|
||||
This would also sign any outgoing email, but I’m not sure that’s necessary - my understanding is that we only care about ARC when forwarding/receiving incoming emails, not when sending them (at least that’s what gmail does).
|
||||
|
||||
### Other Issues
|
||||
|
||||
There are few other things to keep in mind when running your own mail server. I probably don’t know them all yet, but here we go:
|
||||
|
||||
* You must have a fully qualified hostname resolving to a public IP address
|
||||
|
||||
* Your public IP address must resolve back to the fully qualified host name
|
||||
|
||||
* Again, you should run a recursive DNS resolver so your DNS blacklists work (thanks waldi for pointing that out)
|
||||
|
||||
* Setup an SPF record. Mine looks like this:
|
||||
|
||||
`jak-linux.org. 3600 IN TXT "v=spf1 +mx ~all"`
|
||||
|
||||
this states that all my mail servers may send email, but others probably should not (a softfail). Not having an SPF record can punish you; for example, rspamd gives missing SPF and DKIM a score of 1.
|
||||
|
||||
* All of that software is sandboxed using AppArmor. Makes you question its security a bit less!
|
||||
|
||||
|
||||
|
||||
|
||||
### Source code, outlook
|
||||
|
||||
As always, you can find the Ansible roles on [GitHub][10]. Feel free to point out bugs! 😉
|
||||
|
||||
In the next installment of this series, we will be looking at setting up Dovecot, and configuring DKIM. We probably also want to figure out how to run notmuch on the server, keep messages in matching maildirs, and have my laptop synchronize the maildir and notmuch state with the server. Ugh, sounds like a lot of work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/
|
||||
|
||||
作者:[Julian Andres Klode][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.jak-linux.org/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.postfix.org/
|
||||
[2]: https://rspamd.com/
|
||||
[3]: https://www.isc.org/downloads/bind/
|
||||
[4]: https://github.com/roehling/postsrsd
|
||||
[5]: https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/rspamd-status.png
|
||||
[6]: https://blog.jak-linux.org/2019/01/05/setting-up-an-email-server-part1/rspamd-spam.png
|
||||
[7]: https://rspamd.com/doc/configuration/redis.html
|
||||
[8]: http://arc-spec.org/
|
||||
[9]: https://rspamd.com/doc/modules/arc.html
|
||||
[10]: https://github.com/julian-klode/ansible.jak-linux.org
|
||||
176
sources/tech/20190107 Aliases- To Protect and Serve.md
Normal file
176
sources/tech/20190107 Aliases- To Protect and Serve.md
Normal file
@ -0,0 +1,176 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Aliases: To Protect and Serve)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Aliases: To Protect and Serve
|
||||
======
|
||||
|
||||

|
||||
|
||||
Happy 2019! Here in the new year, we’re continuing our series on aliases. By now, you’ve probably read our [first article on aliases][1], and it should be quite clear how they are the easiest way to save yourself a lot of trouble. You already saw, for example, that they helped with muscle-memory, but let's see several other cases in which aliases come in handy.
|
||||
|
||||
### Aliases as Shortcuts
|
||||
|
||||
One of the most beautiful things about Linux's shells is how you can use zillions of options and chain commands together to carry out really sophisticated operations in one fell swoop. All right, maybe beauty is in the eye of the beholder, but let's agree that this feature published practical.
|
||||
|
||||
The downside is that you often come up with recipes that are often hard to remember or cumbersome to type. Say space on your hard disk is at a premium and you want to do some New Year's cleaning. Your first step may be to look for stuff to get rid off in you home directory. One criteria you could apply is to look for stuff you don't use anymore. `ls` can help with that:
|
||||
|
||||
```
|
||||
ls -lct
|
||||
```
|
||||
|
||||
The instruction above shows the details of each file and directory (`-l`) and also shows when each item was last accessed (`-c`). It then orders the list from most recently accessed to least recently accessed (`-t`).
|
||||
|
||||
Is this hard to remember? You probably don’t use the `-c` and `-t` options every day, so perhaps. In any case, defining an alias like
|
||||
|
||||
```
|
||||
alias lt='ls -lct'
|
||||
```
|
||||
|
||||
will make it easier.
|
||||
|
||||
Then again, you may want to have the list show the oldest files first:
|
||||
|
||||
```
|
||||
alias lo='lt -F | tac'
|
||||
```
|
||||
|
||||
![aliases][3]
|
||||
|
||||
Figure 1: The lt and lo aliases in action.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
There are a few interesting things going here. First, we are using an alias (`lt`) to create another alias -- which is perfectly okay. Second, we are passing a new parameter to `lt` (which, in turn gets passed to `ls` through the definition of the `lt` alias).
|
||||
|
||||
The `-F` option appends special symbols to the names of items to better differentiate regular files (that get no symbol) from executable files (that get an `*`), files from directories (end in `/`), and all of the above from links, symbolic and otherwise (that end in an `@` symbol). The `-F` option is throwback to the days when terminals where monochrome and there was no other way to easily see the difference between items. You use it here because, when you pipe the output from `lt` through to `tac` you lose the colors from `ls`.
|
||||
|
||||
The third thing to pay attention to is the use of piping. Piping happens when you pass the output from an instruction to another instruction. The second instruction can then use that output as its own input. In many shells (including Bash), you pipe something using the pipe symbol (`|`).
|
||||
|
||||
In this case, you are piping the output from `lt -F` into `tac`. `tac`'s name is a bit of a joke. You may have heard of `cat`, the instruction that was nominally created to con _cat_ enate files together, but that in practice is used to print out the contents of a file to the terminal. `tac` does the same, but prints out the contents it receives in reverse order. Get it? `cat` and `tac`. Developers, you so funny!
|
||||
|
||||
The thing is both `cat` and `tac` can also print out stuff piped over from another instruction, in this case, a list of files ordered chronologically.
|
||||
|
||||
So... after that digression, what comes out of the other end is the list of files and directories of the current directory in inverse order of freshness.
|
||||
|
||||
The final thing you have to bear in mind is that, while `lt` will work the current directory and any other directory...
|
||||
|
||||
```
|
||||
# This will work:
|
||||
lt
|
||||
# And so will this:
|
||||
lt /some/other/directory
|
||||
```
|
||||
|
||||
... `lo` will only work with the current directory:
|
||||
|
||||
```
|
||||
# This will work:
|
||||
lo
|
||||
# But this won't:
|
||||
lo /some/other/directory
|
||||
```
|
||||
|
||||
This is because Bash expands aliases into their components. When you type this:
|
||||
|
||||
```
|
||||
lt /some/other/directory
|
||||
```
|
||||
|
||||
Bash REALLY runs this:
|
||||
|
||||
```
|
||||
ls -lct /some/other/directory
|
||||
```
|
||||
|
||||
which is a valid Bash command.
|
||||
|
||||
However, if you type this:
|
||||
|
||||
```
|
||||
lo /some/other/directory
|
||||
```
|
||||
|
||||
Bash tries to run this:
|
||||
|
||||
```
|
||||
ls -lct -F | tac /some/other/directory
|
||||
```
|
||||
|
||||
which is not a valid instruction, because `tac` mainly because _/some/other/directory_ is a directory, and `cat` and `tac` don't do directories.
|
||||
|
||||
### More Alias Shortcuts
|
||||
|
||||
* `alias lll='ls -R'` prints out the contents of a directory and then drills down and prints out the contents of its subdirectories and the subdirectories of the subdirectories, and so on and so forth. It is a way of seeing everything you have under a directory.
|
||||
|
||||
* `mkdir='mkdir -pv'` let's you make directories within directories all in one go. With the base form of `mkdir`, to make a new directory containing a subdirectory you have to do this:
|
||||
|
||||
```
|
||||
mkdir newdir
|
||||
mkdir newdir/subdir
|
||||
```
|
||||
|
||||
Or this:
|
||||
|
||||
```
|
||||
mkdir -p newdir/subdir
|
||||
```
|
||||
|
||||
while with the alias you would only have to do this:
|
||||
|
||||
```
|
||||
mkdir newdir/subdir
|
||||
```
|
||||
|
||||
Your new `mkdir` will also tell you what it is doing while is creating new directories.
|
||||
|
||||
|
||||
|
||||
|
||||
### Aliases as Safeguards
|
||||
|
||||
The other thing aliases are good for is as safeguards against erasing or overwriting your files accidentally. At this stage you have probably heard the legendary story about the new Linux user who ran:
|
||||
|
||||
```
|
||||
rm -rf /
|
||||
```
|
||||
|
||||
as root, and nuked the whole system. Then there's the user who decided that:
|
||||
|
||||
```
|
||||
rm -rf /some/directory/ *
|
||||
```
|
||||
|
||||
was a good idea and erased the complete contents of their home directory. Notice how easy it is to overlook that space separating the directory path and the `*`.
|
||||
|
||||
Both things can be avoided with the `alias rm='rm -i'` alias. The `-i` option makes `rm` ask the user whether that is what they really want to do and gives you a second chance before wreaking havoc in your file system.
|
||||
|
||||
The same goes for `cp`, which can overwrite a file without telling you anything. Create an alias like `alias cp='cp -i'` and stay safe!
|
||||
|
||||
### Next Time
|
||||
|
||||
We are moving more and more into scripting territory. Next time, we'll take the next logical step and see how combining instructions on the command line gives you really interesting and sophisticated solutions to everyday admin problems.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/learn/2019/1/aliases-protect-and-serve
|
||||
[2]: https://www.linux.com/files/images/fig01png-0
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fig01_0.png?itok=crqTm_va (aliases)
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
@ -0,0 +1,232 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Different Ways To Update Linux Kernel For Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/different-ways-to-update-linux-kernel-for-ubuntu/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Different Ways To Update Linux Kernel For Ubuntu
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this guide, we have given 7 different ways to update Linux kernel for Ubuntu. Among the 7 methods, five methods requires system reboot to apply the new Kernel and two methods don’t. Before updating Linux Kernel, it is **highly recommended to backup your important data!** All methods mentioned here are tested on Ubuntu OS only. We are not sure if they will work on other Ubuntu flavors (Eg. Xubuntu) and Ubuntu derivatives (Eg. Linux Mint).
|
||||
|
||||
### Part A – Kernel Updates with reboot
|
||||
|
||||
The following methods requires you to reboot your system to apply the new Linux Kernel. All of the following methods are recommended for personal or testing systems. Again, please backup your important data, configuration files and any other important stuff from your Ubuntu system.
|
||||
|
||||
#### Method 1 – Update the Linux Kernel with dpkg (The manual way)
|
||||
|
||||
This method helps you to manually download and install the latest available Linux kernel from **[kernel.ubuntu.com][1]** website. If you want to install most recent version (either stable or release candidate), this method will help. Download the Linux kernel version from the above link. As of writing this guide, the latest available version was **5.0-rc1** and latest stable version was **v4.20**.
|
||||
|
||||
![][3]
|
||||
|
||||
Click on the Linux Kernel version link of your choice and find the section for your architecture (‘Build for XXX’). In that section, download the two files with these patterns (where X.Y.Z is the highest version):
|
||||
|
||||
1. linux-image-*X.Y.Z*-generic-*.deb
|
||||
2. linux-modules-X.Y.Z*-generic-*.deb
|
||||
|
||||
|
||||
|
||||
In a terminal, change directory to where the files are and run this command to manually install the kernel:
|
||||
|
||||
```
|
||||
$ sudo dpkg --install *.deb
|
||||
```
|
||||
|
||||
Reboot to use the new kernel:
|
||||
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
Check the kernel is as expected:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
```
|
||||
|
||||
For step by step instructions, please check the section titled under “Install Linux Kernel 4.15 LTS On DEB based systems” in the following guide.
|
||||
|
||||
+ [Install Linux Kernel 4.15 In RPM And DEB Based Systems](https://www.ostechnix.com/install-linux-kernel-4-15-rpm-deb-based-systems/)
|
||||
|
||||
The above guide is specifically written for 4.15 version. However, all the steps are same for installing latest versions too.
|
||||
|
||||
**Pros:** No internet needed (You can download the Linux Kernel from any system).
|
||||
|
||||
**Cons:** Manual update. Reboot necessary.
|
||||
|
||||
#### Method 2 – Update the Linux Kernel with apt-get (The recommended method)
|
||||
|
||||
This is the recommended way to install latest Linux kernel on Ubuntu-like systems. Unlike the previous method, this method will download and install latest Kernel version from Ubuntu official repositories instead of **kernel.ubuntu.com** website..
|
||||
|
||||
To update the whole system including the Kernel, just do:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get upgrade
|
||||
```
|
||||
|
||||
If you want to update the Kernel only, run:
|
||||
|
||||
```
|
||||
$ sudo apt-get upgrade linux-image-generic
|
||||
```
|
||||
|
||||
**Pros:** Simple. Recommended method.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
Updating Kernel from official repositories will mostly work out of the box without any problems. If it is the production system, this is the recommended way to update the Kernel.
|
||||
|
||||
Method 1 and 2 requires user intervention to update Linux Kernels. The following methods (3, 4 & 5) are mostly automated.
|
||||
|
||||
#### Method 3 – Update the Linux Kernel with Ukuu
|
||||
|
||||
**Ukuu** is a Gtk GUI and command line tool that downloads the latest main line Linux kernel from **kernel.ubuntu.com** , and install it automatically in your Ubuntu desktop and server editions. Ukku is not only simplifies the process of manually downloading and installing new Kernels, but also helps you to safely remove the old and unnecessary Kernels. For more details, refer the following guide.
|
||||
|
||||
+ [Ukuu – An Easy Way To Install And Upgrade Linux Kernel In Ubuntu-based Systems](https://www.ostechnix.com/ukuu-an-easy-way-to-install-and-upgrade-linux-kernel-in-ubuntu-based-systems/)
|
||||
|
||||
**Pros:** Easy to install and use. Automatically installs main line Kernel.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
#### Method 4 – Update the Linux Kernel with UKTools
|
||||
|
||||
Just like Ukuu, the **UKTools** also fetches the latest stable Kernel from from **kernel.ubuntu.com** site and installs it automatically on Ubuntu and its derivatives like Linux Mint. More details about UKTools can be found in the link given below.
|
||||
|
||||
+ [UKTools – Upgrade Latest Linux Kernel In Ubuntu And Derivatives](https://www.ostechnix.com/uktools-upgrade-latest-linux-kernel-in-ubuntu-and-derivatives/)
|
||||
|
||||
**Pros:** Simple. Automated.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
#### Method 5 – Update the Linux Kernel with Linux Kernel Utilities
|
||||
|
||||
**Linux Kernel Utilities** is yet another program that makes the process of updating Linux kernel easy in Ubuntu-like systems. It is actually a set of BASH shell scripts used to compile and/or update latest Linux kernels for Debian and derivatives. It consists of three utilities, one for manually compiling and installing Kernel from source from [**http://www.kernel.org**][4] website, another for downloading and installing pre-compiled Kernels from from **<https://kernel.ubuntu.com>** website. and third script is for removing the old kernels. For more details, please have a look at the following link.
|
||||
|
||||
+ [Linux Kernel Utilities – Scripts To Compile And Update Latest Linux Kernel For Debian And Derivatives](https://www.ostechnix.com/linux-kernel-utilities-scripts-compile-update-latest-linux-kernel-debian-derivatives/)
|
||||
|
||||
**Pros:** Simple. Automated.
|
||||
|
||||
**Cons:** Internet necessary. Reboot necessary.
|
||||
|
||||
|
||||
### Part B – Kernel Updates without reboot
|
||||
|
||||
As I already said, all of above methods need you to reboot the server before the new kernel is active. If they are personal systems or testing machines, you could simply reboot and start using the new Kernel. But, what if they are production systems that requires zero downtime? No problem. This is where **Livepatching** comes in handy!
|
||||
|
||||
The **livepatching** (or hot patching) allows you to install Linux updates or patches without rebooting, keeping your server at the latest security level, without any downtime. This is attractive for ‘always-on’ servers, such as web hosts, gaming servers, in fact, any situation where the server needs to stay on all the time. Linux vendors maintain patches only for security fixes, so this approach is best when security is your main concern.
|
||||
|
||||
The following two methods doesn’t require system reboot and useful for updating Linux Kernel on production and mission-critical Ubuntu servers.
|
||||
|
||||
#### Method 6 – Update the Linux Kernel Canonical Livepatch Service
|
||||
|
||||
![][5]
|
||||
|
||||
[**Canonical Livepatch Service**][6] applies Kernel updates, patches and security hotfixes automatically without rebooting the Ubuntu systems. It reduces the Ubuntu systems downtime and keep them secure. Canonical Livepatch Service can be set up either during or after installation. If you are using desktop Ubuntu, the Software Updater will automatically check for kernel patches and notify you. In a console-based system, it is up to you to run apt-get update regularly. It will install kernel security patches only when you run the command “apt-get upgrade”, hence is semi-automatic.
|
||||
|
||||
Livepatch is free for three systems. If you have more than three, you need to upgrade to enterprise support solution named **Ubuntu Advantage** suite. This suite includes **Kernel Livepatching** and other services such as,
|
||||
|
||||
* Extended Security Maintenance – critical security updates after Ubuntu end-of-life.
|
||||
* Landscape – the systems management tool for using Ubuntu at scale.
|
||||
* Knowledge Base – A private collection of articles and tutorials written by Ubuntu experts.
|
||||
* Phone and web-based support.
|
||||
|
||||
|
||||
|
||||
**Cost**
|
||||
|
||||
Ubuntu Advantage includes three paid plans namely, Essential, Standard and Advanced. The basic plan (Essential plan) starts from **225 USD per year for one physical node** and **75 USD per year for one VPS**. It seems there is no monthly subscription for Ubuntu servers and desktops. You can view detailed information on all plans [**here**][7].
|
||||
|
||||
**Pros:** Simple. Semi-automatic. No reboot necessary. Free for 3 systems.
|
||||
|
||||
**Cons:** Expensive for 4 or more hosts. No patch rollback.
|
||||
|
||||
**Enable Canonical Livepatch Service**
|
||||
|
||||
If you want to setup Livepatch service after installation, just do the following steps.
|
||||
|
||||
Get a key at [**https://auth.livepatch.canonical.com/**][8].
|
||||
|
||||
```
|
||||
$ sudo snap install canonical-livepatch
|
||||
|
||||
$ sudo canonical-livepatch enable your-key
|
||||
```
|
||||
|
||||
#### Method 7 – Update the Linux Kernel with KernelCare
|
||||
|
||||
![][9]
|
||||
|
||||
[**KernelCare**][10] is the newest of all the live patching solutions. It is the product of [CloudLinux][11]. KernelCare runs on Ubuntu and other flavors of Linux. It checks for patch releases every 4 hours and will install them without confirmation. Patches can be rolled back if there are problems.
|
||||
|
||||
**Cost**
|
||||
|
||||
Fees, per server: **4 USD per month** , **45 USD per year**.
|
||||
|
||||
Compared to Ubuntu Livepatch, kernelCare seems very cheap and affordable. Good thing is **monthly subscriptions are also available**. Another notable feature is it supports other Linux distributions, such as Red Hat, CentOS, Debian, Oracle Linux, Amazon Linux and virtualization platforms like OpenVZ, Proxmox etc.
|
||||
|
||||
You can read all the features and benefits of KernelCare [**here**][12] and check all available plan details [**here**][13].
|
||||
|
||||
**Pros:** Simple. Fully automated. Wide OS coverage. Patch rollback. No reboot necessary. Free license for non-profit organizations. Low cost.
|
||||
|
||||
**Cons:** Not free (except for 30 day trial).
|
||||
|
||||
**Enable KernelCare Service**
|
||||
|
||||
Get a 30-day trial key at [**https://cloudlinux.com/kernelcare-free-trial5**][14].
|
||||
|
||||
Run the following commands to enable KernelCare and register the key.
|
||||
|
||||
```
|
||||
$ sudo wget -qq -O - https://repo.cloudlinux.com/kernelcare/kernelcare_install.sh | bash
|
||||
|
||||
$ sudo /usr/bin/kcarectl --register KEY
|
||||
```
|
||||
|
||||
If you’re looking for an affordable and reliable commercial service to keep the Linux Kernel updated on your Linux servers, KernelCare is good to go.
|
||||
|
||||
*with inputs from **Paul A. Jacobs** , a Technical Evangelist and Content Writer from Cloud Linux.*
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
And, that’s all for now. Hope this was useful. If you believe any other tools/methods should include in this list, feel free to let us know in the comment section below. I will check and update this guide accordingly.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/different-ways-to-update-linux-kernel-for-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/01/Ubuntu-mainline-kernel.png
|
||||
[4]: http://www.kernel.org
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2019/01/Livepatch.png
|
||||
[6]: https://www.ubuntu.com/livepatch
|
||||
[7]: https://www.ubuntu.com/support/plans-and-pricing
|
||||
[8]: https://auth.livepatch.canonical.com/
|
||||
[9]: http://www.ostechnix.com/wp-content/uploads/2019/01/KernelCare.png
|
||||
[10]: https://www.kernelcare.com/
|
||||
[11]: https://www.cloudlinux.com/
|
||||
[12]: https://www.kernelcare.com/update-kernel-linux/
|
||||
[13]: https://www.kernelcare.com/pricing/
|
||||
[14]: https://cloudlinux.com/kernelcare-free-trial5
|
||||
@ -0,0 +1,239 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (DriveSync – Easy Way to Sync Files Between Local And Google Drive from Linux CLI)
|
||||
[#]: via: (https://www.2daygeek.com/drivesync-google-drive-sync-client-for-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
DriveSync – Easy Way to Sync Files Between Local And Google Drive from Linux CLI
|
||||
======
|
||||
|
||||
Google Drive is an one of the best cloud storage compared with other cloud storage.
|
||||
|
||||
It’s one of the application which is used by millions of users in daily basics.
|
||||
|
||||
It allow users to access the application anywhere irrespective of devices.
|
||||
|
||||
We can upload, download & share documents, photo, files, docs, spreadsheet, etc to anyone with securely.
|
||||
|
||||
We had already written few articles in 2daygeek website about google drive mapping with Linux.
|
||||
|
||||
If you would like to check those, navigate to the following link.
|
||||
|
||||
GNOME desktop offers easy way to **[Integrate Google Drive Using Gnome Nautilus File Manager in Linux][1]** without headache.
|
||||
|
||||
Also, you can give a try with **[Google Drive Ocamlfuse Client][2]**.
|
||||
|
||||
### What’s DriveSync?
|
||||
|
||||
[DriveSync][3] is a command line utility that synchronizes your files between local system and Google Drive via command line.
|
||||
|
||||
Downloads new remote files, uploads new local files to your Drive and deletes or updates files both locally and on Drive if they have changed in one place.
|
||||
|
||||
Allows blacklisting or whitelisting of files and folders that should not / should be synced.
|
||||
|
||||
It was written in Ruby scripting language so, make sure your system should have ruby installed. If it’s not installed then install it as a prerequisites for DriveSync.
|
||||
|
||||
### DriveSync Features
|
||||
|
||||
* Downloads new remote files
|
||||
* Uploads new local files
|
||||
* Delete or Update files in both locally and Drive
|
||||
* Allow blacklist to disable sync for files and folders
|
||||
* Automate the sync using cronjob
|
||||
* Allow us to set file upload/download size (Defautl 512MB)
|
||||
* Allow us to modify Timeout threshold
|
||||
|
||||
|
||||
|
||||
### How to Install Ruby Scripting Language in Linux?
|
||||
|
||||
Ruby is an interpreted scripting language for quick and easy object-oriented programming. It has many features to process text files and to do system management tasks (like in Perl). It is simple, straight-forward, and extensible.
|
||||
|
||||
It’s available in all the Linux distribution official repository. Hence we can easily install it with help of distribution official **[Package Manager][4]**.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][5]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo dnf install ruby rubygem-bundler
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][6]** or **[APT Command][7]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo apt install ruby ruby-bundler
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][8]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo pacman -S ruby ruby-bundler
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][9]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo yum install ruby ruby-bundler
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][10]** to install Ruby.
|
||||
|
||||
```
|
||||
$ sudo zypper install ruby ruby-bundler
|
||||
```
|
||||
|
||||
### How to Install DriveSync in Linux?
|
||||
|
||||
DriveSync installation also easy to do it. Follow the below procedure to get it done.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/MStadlmeier/drivesync.git
|
||||
$ cd drivesync/
|
||||
$ bundle install
|
||||
```
|
||||
|
||||
### How to Set Up DriveSync in Linux?
|
||||
|
||||
As of now, we had successfully installed DriveSync and still we need to perform few steps to use this.
|
||||
|
||||
Run the following command to set up this and Sync the files.
|
||||
|
||||
```
|
||||
$ ruby drivesync.rb
|
||||
```
|
||||
|
||||
When you ran the above command you will be getting the below url.
|
||||
![][12]
|
||||
|
||||
Navigate to the given URL in your preferred Web Browser and follow the instruction. It will open a google sign-in page in default web browser. Enter your credentials then hit Sign in button.
|
||||
![][13]
|
||||
|
||||
Input your password.
|
||||
![][14]
|
||||
|
||||
Hit **`Allow`** button to allow DriveSync to access your Google Drive.
|
||||
![][15]
|
||||
|
||||
Finally, it will give you an authorization code.
|
||||
![][16]
|
||||
|
||||
Just copy and past it on the terminal and hit **`Enter`** button to start the sync.
|
||||
![][17]
|
||||
|
||||
Yes, it’s syncing the files from Google Drive to my local folder.
|
||||
|
||||
```
|
||||
$ ruby drivesync.rb
|
||||
Warning: Could not find config file at /home/daygeek/.drivesync/config.yml . Creating default config...
|
||||
Open the following URL in the browser and enter the resulting code after authorization
|
||||
https://accounts.google.com/o/oauth2/auth?access_type=offline&approval_prompt=force&client_id=xxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com&include_granted_scopes=true&redirect_uri=urn:ietf:wg:oauth:2.0:oob&response_type=code&scope=https://www.googleapis.com/auth/drive
|
||||
4/ygAxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
Local folder is 1437 files behind and 0 files ahead of remote
|
||||
Starting sync at 2019-01-06 19:48:49 +0530
|
||||
Downloading file 2018-07-31-17-48-54-635_1533039534635_XXXPM0534X_ITRV.zip ...
|
||||
Downloading file 5459XXXXXXXXXX25_11-03-2018.PDF ...
|
||||
Downloading file 2g-image-design/new-design-28-Mar-2018/new-base-format-icon-theme.svg ...
|
||||
Downloading file 2g-image-design/new-design-28-Mar-2018/2g-banner-format.svg ...
|
||||
Downloading file 2g-image-design/new-design-28-Mar-2018/new-base-format.svg ...
|
||||
Downloading file documents/Magesh_Resume_Updated_26_Mar_2018.doc ...
|
||||
Downloading file documents/Magesh_Resume_updated-new.doc ...
|
||||
Downloading file documents/Aadhaar-Thanu.PNG ...
|
||||
Downloading file documents/Aadhaar-Magesh.PNG ...
|
||||
Downloading file documents/Copy of PP-docs.pdf ...
|
||||
Downloading file EAadhaar_2189821080299520170807121602_25082017123052_172991.pdf ...
|
||||
Downloading file Tanisha/VID_20170223_113925.mp4 ...
|
||||
Downloading file Tanisha/VID_20170224_073234.mp4 ...
|
||||
Downloading file Tanisha/VID_20170304_170457.mp4 ...
|
||||
Downloading file Tanisha/IMG_20170225_203243.jpg ...
|
||||
Downloading file Tanisha/IMG_20170226_123949.jpg ...
|
||||
Downloading file Tanisha/IMG_20170226_123953.jpg ...
|
||||
Downloading file Tanisha/IMG_20170304_184227.jpg ...
|
||||
.
|
||||
.
|
||||
.
|
||||
Sync complete.
|
||||
```
|
||||
|
||||
It will create the **`drive`** folder under **`/home/user/Documents/`** and sync all the files in it.
|
||||
![][18]
|
||||
|
||||
DriveSync configuration files are located in the following location **`/home/user/.drivesync/`** if you had installed it on your **home** directory.
|
||||
|
||||
```
|
||||
$ ls -lh ~/.drivesync/
|
||||
total 176K
|
||||
-rw-r--r-- 1 daygeek daygeek 1.9K Jan 6 19:42 config.yml
|
||||
-rw-r--r-- 1 daygeek daygeek 170K Jan 6 21:31 manifest
|
||||
```
|
||||
|
||||
You can make your changes by modifying the **`config.yml`** file.
|
||||
|
||||
### How to Verify Whether Sync is Working Fine or Not?
|
||||
|
||||
To test this, we are going to create a new folder called **`2g-docs-2019`**. Also, adding an image file in it. Once it’s done, run the **`drivesync.rb`** command again.
|
||||
|
||||
```
|
||||
$ ruby drivesync.rb
|
||||
Local folder is 0 files behind and 1 files ahead of remote
|
||||
Starting sync at 2019-01-06 21:59:32 +0530
|
||||
Uploading file 2g-docs-2019/Asciinema - Record And Share Your Terminal Activity On The Web.png ...
|
||||
```
|
||||
|
||||
Yes, it has been synced to Google Drive. The same has been verified through Web Browser.
|
||||
![][19]
|
||||
|
||||
Create the below **CronJob** to enable an auto sync. The following “CronJob” will be running an every mins.
|
||||
|
||||
```
|
||||
$ vi crontab
|
||||
*/1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated ruby ~/drivesync/drivesync.rb
|
||||
```
|
||||
|
||||
I have added one more file to test this. Yes, it got success.
|
||||
|
||||
```
|
||||
Jan 07 09:36:01 daygeek-Y700 crond[590]: (daygeek) RELOAD (/var/spool/cron/daygeek)
|
||||
Jan 07 09:36:01 daygeek-Y700 crond[20942]: pam_unix(crond:session): session opened for user daygeek by (uid=0)
|
||||
Jan 07 09:36:01 daygeek-Y700 CROND[20943]: (daygeek) CMD (ruby ~/drivesync/drivesync.rb)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Local folder is 0 files behind and 1 files ahead of remote)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Starting sync at 2019-01-07 09:36:26 +0530)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Uploading file 2g-docs-2019/Check CPU And HDD Temperature In Linux.png ...)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT ()
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: (daygeek) CMDOUT (Sync complete.)
|
||||
Jan 07 09:36:29 daygeek-Y700 CROND[20942]: pam_unix(crond:session): session closed for user daygeek
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/drivesync-google-drive-sync-client-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/mount-access-setup-google-drive-in-linux/
|
||||
[2]: https://www.2daygeek.com/mount-access-google-drive-on-linux-with-google-drive-ocamlfuse-client/
|
||||
[3]: https://github.com/MStadlmeier/drivesync
|
||||
[4]: https://www.2daygeek.com/category/package-management/
|
||||
[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[6]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[7]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[9]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-1.jpg
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-2.png
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-3.png
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-4.png
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-5.png
|
||||
[17]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-6.jpg
|
||||
[18]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-7.jpg
|
||||
[19]: https://www.2daygeek.com/wp-content/uploads/2019/01/drivesync-easy-way-to-sync-files-between-local-and-google-drive-from-linux-cli-8.png
|
||||
@ -0,0 +1,223 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Pelican: A Python-based static site generator)
|
||||
[#]: via: (https://opensource.com/article/19/1/getting-started-pelican)
|
||||
[#]: author: (Craig Sebenik https://opensource.com/users/craig5)
|
||||
|
||||
Getting started with Pelican: A Python-based static site generator
|
||||
======
|
||||
Pelican is a great choice for Python users who want to self-host a simple website or blog.
|
||||
|
||||

|
||||
|
||||
If you want to create a custom website or blog, you have a lot of options. Many providers will host your website and do much of the work for you. (WordPress is an extremely popular option.) But you lose some flexibility by using a hosted solution. As a software developer, I prefer to manage my own server and keep more freedom in how my website operates.
|
||||
|
||||
However, it is a fair amount of work to manage a web server. Installing it and getting a simple application up to serve content is easy enough. But keeping on top of security patches and updates is very time-consuming. If you just want to serve static web pages, having a web server and a host of applications may be more effort than it's worth. Creating HTML pages by hand is also not a good option.
|
||||
|
||||
This is where a static site generator can come in. These applications use templates to create all the static pages you want and cross-link them with associated metadata. (e.g., showing all the pages with a common tag or keyword.) Static site generators help you create a site with a common look and feel using elements like navigation areas and a header and footer.
|
||||
|
||||
I have been using [Python][1] for years now. So, when I first started looking for something to generate static HTML pages, I wanted something written in Python. The main reason is that I often want to peek into the internals of how an application works, and using a language that I already know makes that easier. (If that isn't important to you or you don't use Python, there are some other great [static site generators][2] that use Ruby, JavaScript, and other languages.)
|
||||
|
||||
I decided to give [Pelican][3] a try. It is a commonly used static site generator written in Python. It directly supports [reStructuredText][4] and can support [Markdown][5] when the required package is installed. All the tasks are performed via command-line interface (CLI) tools, which makes it simple for anyone familiar with the command line. And its simple quickstart CLI tool makes creating a website extremely easy.
|
||||
|
||||
In this article, I'll explain how to install Pelican 4, add an article, and change the default theme. (Note: This was all developed on MacOS; it should work the same using any flavor of Unix/Linux, but I don't have a Windows host to test on.)
|
||||
|
||||
### Installation and configuration
|
||||
|
||||
The first step is to create a [virtualenv][6] and install Pelican.
|
||||
|
||||
```
|
||||
$ mkdir test-site
|
||||
$ cd test-site
|
||||
$ python3 -m venv venv
|
||||
$ ./venv/bin/pip install --upgrade pip
|
||||
...
|
||||
Successfully installed pip-18.1
|
||||
$ ./venv/bin/pip install pelican
|
||||
Collecting pelican
|
||||
...
|
||||
Successfully installed MarkupSafe-1.1.0 blinker-1.4 docutils-0.14 feedgenerator-1.9 jinja2-2.10 pelican-4.0.1 pygments-2.3.1 python-dateutil-2.7.5 pytz-2018.7 six-1.12.0 unidecode-1.0.23
|
||||
```
|
||||
|
||||
To keep things simple, I entered values for the title and author and replied N to URL prefix and article pagination. (For the rest of the questions, I used the default given.)
|
||||
|
||||
Pelican's quickstart CLI tool will create the basic layout and a few files to get you started. Run the **pelican-quickstart** command. To keep things simple, I entered values for the **title** and **author** and replied **N** to URL prefix and article pagination. It is very easy to change these settings in the configuration file later.
|
||||
|
||||
```
|
||||
$ ./venv/bin/pelicanquickstart
|
||||
Welcome to pelicanquickstart v4.0.1.
|
||||
|
||||
This script will help you create a new Pelican-based website.
|
||||
|
||||
Please answer the following questions so this script can generate the files needed by Pelican.
|
||||
|
||||
> Where do you want to create your new web site? [.]
|
||||
> What will be the title of this web site? My Test Blog
|
||||
> Who will be the author of this web site? Craig
|
||||
> What will be the default language of this web site? [en]
|
||||
> Do you want to specify a URL prefix? e.g., https://example.com (Y/n) n
|
||||
> Do you want to enable article pagination? (Y/n) n
|
||||
> What is your time zone? [Europe/Paris]
|
||||
> Do you want to generate a tasks.py/Makefile to automate generation and publishing? (Y/n)
|
||||
> Do you want to upload your website using FTP? (y/N)
|
||||
> Do you want to upload your website using SSH? (y/N)
|
||||
> Do you want to upload your website using Dropbox? (y/N)
|
||||
> Do you want to upload your website using S3? (y/N)
|
||||
> Do you want to upload your website using Rackspace Cloud Files? (y/N)
|
||||
> Do you want to upload your website using GitHub Pages? (y/N)
|
||||
Done. Your new project is available at /Users/craig/tmp/pelican/test-site
|
||||
```
|
||||
|
||||
All the files you need to get started are ready to go.
|
||||
|
||||
The quickstart defaults to the Europe/Paris time zone, so change that before proceeding. Open the **pelicanconf.py** file in your favorite text editor. Look for the **TIMEZONE** variable.
|
||||
|
||||
```
|
||||
TIMEZONE = 'Europe/Paris'
|
||||
```
|
||||
|
||||
Change it to **UTC**.
|
||||
|
||||
```
|
||||
TIMEZONE = 'UTC'
|
||||
```
|
||||
|
||||
To update the social settings, look for the **SOCIAL** variable in **pelicanconf.py**.
|
||||
|
||||
```
|
||||
SOCIAL = (('You can add links in your config file', '#'),
|
||||
('Another social link', '#'),)
|
||||
```
|
||||
|
||||
I'll add a link to my Twitter account.
|
||||
|
||||
```
|
||||
SOCIAL = (('Twitter (#craigs55)', 'https://twitter.com/craigs55'),)
|
||||
```
|
||||
|
||||
Notice that trailing comma—it's important. That comma helps Python recognize the variable is actually a set. Make sure you don't delete that comma.
|
||||
|
||||
Now you have the basics of a site. The quickstart created a Makefile with a number of targets. Giving the **devserver** target to **make** will start a development server on your machine so you can preview everything. The CLI commands used in the Makefile are assumed to be part of your **PATH** , so you need to **activate** the **virtualenv** first.
|
||||
|
||||
```
|
||||
$ source ./venv/bin/activate
|
||||
$ make devserver
|
||||
pelican -lr /Users/craig/tmp/pelican/test-site/content o
|
||||
/Users/craig/tmp/pelican/test-site/output -s /Users/craig/tmp/pelican/test-site/pelicanconf.py
|
||||
|
||||
-> Modified: theme, settings. regenerating...
|
||||
WARNING: No valid files found in content for the active readers:
|
||||
| BaseReader (static)
|
||||
| HTMLReader (htm, html)
|
||||
| RstReader (rst)
|
||||
Done: Processed 0 articles, 0 drafts, 0 pages, 0 hidden pages and 0 draft pages in 0.18 seconds.
|
||||
```
|
||||
|
||||
Point your favorite browser to <http://localhost:8000> to see your simple test blog.
|
||||
|
||||
|
||||
|
||||
You can see the Twitter link on the right side and some links to Pelican, Python, and Jinja to the left of it. (Jinja is a great templating language that Pelican can use. You can learn more about it in [Jinja's documentation][7].)
|
||||
|
||||
### Adding content
|
||||
|
||||
Now that you have a basic site, add some content. First, add a file called **welcome.rst** to the site's **content** directory. In your favorite text editor, create a file with the following text:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/Users/craig/tmp/pelican/test-site
|
||||
$ cat content/welcome.rst
|
||||
|
||||
Welcome to my blog!
|
||||
###################
|
||||
|
||||
:date: 20181216 08:30
|
||||
:tags: welcome
|
||||
:category: Intro
|
||||
:slug: welcome
|
||||
:author: Craig
|
||||
:summary: Welcome document
|
||||
|
||||
Welcome to my blog.
|
||||
This is a short page just to show how to put up a static page.
|
||||
```
|
||||
|
||||
The metadata lines—date, tags, etc.—are automatically parsed by Pelican.
|
||||
|
||||
After you write the file, the **devserver** should output something like this:
|
||||
|
||||
```
|
||||
-> Modified: content. regenerating...
|
||||
Done: Processed 1 article, 0 drafts, 0 pages, 0 hidden pages and 0 draft pages in 0.10 seconds.
|
||||
```
|
||||
|
||||
Reload your test site in your browser to view the changes.
|
||||
|
||||
|
||||
|
||||
The metadata (e.g., date and tags) were automatically added to the page. Also, Pelican automatically detected the **intro** category and added the section to the top navigation.
|
||||
|
||||
### Change the theme
|
||||
|
||||
One of the nicest parts of working with popular, open source software like Pelican is that many users will make changes and contribute them back to the project. Many of the contributions are in the form of themes.
|
||||
|
||||
A site's theme sets colors, layout options, etc. It's really easy to try out new themes. You can preview many of them at [Pelican Themes][8].
|
||||
|
||||
First, clone the GitHub repo:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ git clone --recursive https://github.com/getpelican/pelicanthemes
|
||||
Cloning into 'pelicanthemes'...
|
||||
```
|
||||
|
||||
Since I like the color blue, I'll try [blueidea][9].
|
||||
|
||||
Edit **pelicanconf.py** and add the following line:
|
||||
|
||||
```
|
||||
THEME = '/Users/craig/tmp/pelican/pelican-themes/blueidea/'
|
||||
```
|
||||
|
||||
The **devserver** will regenerate your output. Reload the webpage in your browser to see the new theme.
|
||||
|
||||
|
||||
|
||||
The theme controls many aspects of the layout. For example, in the default theme, you can see the category (Intro) with the meta tags next to the article. But that category is not displayed in the blueidea theme.
|
||||
|
||||
### Other considerations
|
||||
|
||||
This was a pretty quick introduction to Pelican. There are a couple of important topics that I did not cover.
|
||||
|
||||
First, one reason I was hesitant to move to a static site was that it wouldn't allow discussions on the articles. Fortunately, there are some third-party providers that will host discussions for you. The one I am currently looking at is [Disqus][10].
|
||||
|
||||
Next, everything above was done on my local machine. If I want others to view my site, I'll have to upload the pre-generated HTML files somewhere. If you look at the **pelican-quickstart** output, you will see options for using FTP, SSH, S3, and even GitHub Pages. Each option has its pros and cons. But, if I had to choose one, I would likely publish to GitHub Pages.
|
||||
|
||||
Pelican has many other features—I am still learning more about it every day. If you want to self-host a website or a blog with simple, static content and you want to use Python, Pelican is a great choice. It has an active user community that is fixing bugs, adding features, and creating new and interesting themes. Give it a try!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/getting-started-pelican
|
||||
|
||||
作者:[Craig Sebenik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/craig5
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/resources/python
|
||||
[2]: https://opensource.com/sitewide-search?search_api_views_fulltext=static%20site%20generator
|
||||
[3]: http://docs.getpelican.com/en/stable/
|
||||
[4]: http://docutils.sourceforge.net/rst.html
|
||||
[5]: https://daringfireball.net/projects/markdown/
|
||||
[6]: https://virtualenv.pypa.io/en/latest/
|
||||
[7]: http://jinja.pocoo.org/docs/2.10/
|
||||
[8]: http://www.pelicanthemes.com/
|
||||
[9]: https://github.com/nasskach/pelican-blueidea/tree/58fb13112a2707baa7d65075517c40439ab95c0a
|
||||
[10]: https://disqus.com/
|
||||
303
sources/tech/20190107 How to manage your media with Kodi.md
Normal file
303
sources/tech/20190107 How to manage your media with Kodi.md
Normal file
@ -0,0 +1,303 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to manage your media with Kodi)
|
||||
[#]: via: (https://opensource.com/article/19/1/manage-your-media-kodi)
|
||||
[#]: author: (Steve Ovens https://opensource.com/users/stratusss)
|
||||
|
||||
How to manage your media with Kodi
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you, like me, like to own your own data, chances are you also like to purchase movies and TV shows on Blu-Ray or DVD discs. And you may also like to make [ISOs][1] of the videos to keep exact digital copies, as I do.
|
||||
|
||||
For a little while, it might be manageable to have a bunch of files stored in some sort of directory structure. However, as your collection grows, you may want features like resuming from a specific spot; keeping track of where you left off watching a video (i.e., its watched status); storing episode or movie summaries and movie trailers; buying media in multiple languages; or just having a sane way to play all those ISOs you ripped.
|
||||
|
||||
This is where Kodi comes in.
|
||||
|
||||
### What is Kodi?
|
||||
|
||||
Modern [Kodi][2] is the successor to Xbox Media Player, which was discontinued way back in 2003. In June 2004, Xbox Media Center (XBMC) was born. For over three years, XBMC remained on the Xbox. Then in 2007, work began in earnest to port the media player over to Linux.
|
||||
|
||||
|
||||
|
||||
Aside from some uninteresting technical history, things remained fairly stable, and XBMC grew in prominence. By 2014, XBMC had a thriving community, and its core functionality grew to include playing games, streaming content from the web, and connecting to mobile devices. This, combined with legal issues involving Xbox in the name, lead the team behind XBMC to rename it Kodi. Kodi is now branded as an "entertainment hub that brings all your digital media together into a beautiful and user-friendly package."
|
||||
|
||||
Today, Kodi has an extensible interface that has allowed the open source community to build new functionality using plugins. Note that, as with all open source software, Kodi's developers are not responsible for the ecosystem's plugins.
|
||||
|
||||
### How do I start?
|
||||
|
||||
For Ubuntu-based distributions, Kodi is just a few short commands away:
|
||||
|
||||
```
|
||||
sudo apt install software-properties-common
|
||||
sudo add-apt-repository ppa:team-xbmc/ppa
|
||||
sudo apt update
|
||||
sudo apt install kodi
|
||||
```
|
||||
|
||||
In Arch Linux, you can install the latest version from the community repo:
|
||||
|
||||
```
|
||||
sudo pacman -S kodi
|
||||
```
|
||||
|
||||
Packages were maintained for Fedora 26 by RPM Fusion (referenced in the [Kodi documentation][3]). I tried it on Fedora 29, and it was quite unstable. I'm sure that this will improve over time, but my experience is that Fedora 29 is not the ideal platform for Kodi.
|
||||
|
||||
### OK, it's installed… now what?
|
||||
|
||||
Before we proceed, note that I am making two assumptions about your media content:
|
||||
|
||||
1. You have your own local, legally attained content.
|
||||
2. You have already transferred this content from your DVDs, Blu-Rays, or another digital distribution source to your local directory or network.
|
||||
|
||||
|
||||
|
||||
Kodi uses a scraping service to pull down TV and movie metadata. For Kodi to match things appropriately, I recommend adopting a directory and file-naming structure similar to this:
|
||||
|
||||
```
|
||||
Utopia
|
||||
├── Utopia.S01.dvd_rip.x264
|
||||
│ ├── Utopia.S01E01.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E02.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E03.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E04.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E05.dvd_rip.x264.mkv
|
||||
│ ├── Utopia.S01E06.dvd_rip.x264.mkv
|
||||
└── Utopia.S02.dvd_rip.x264
|
||||
├── Utopia.S02E01.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E02.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E03.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E04.dvd_rip.x264.mkv
|
||||
├── Utopia.S02E05.dvd_rip.x264.mkv
|
||||
└── Utopia.S02E06.dvd_rip.x264.mkv
|
||||
```
|
||||
|
||||
I put the source (my DVD) and the codec (x264) in the title, but these are optional. For a TV series, you can include the episode title in the filename if you like. The important part is **SxxExx** , which stands for Season and Episode. This is how Kodi (and by extension the scrapers) can identify your media.
|
||||
|
||||
Assuming you have organized your media like this, let's do some basic Kodi configuration.
|
||||
|
||||
### Add video sources
|
||||
|
||||
Adding video sources is a simple, six-step process:
|
||||
|
||||
1. Enter the files section
|
||||
2. Select **Files**
|
||||
3. Click **Add source**
|
||||
4. Browse to your source
|
||||
5. Define the video content type
|
||||
6. Refresh the metadata
|
||||
|
||||
|
||||
|
||||
If you're impatient, feel free to navigate these steps on your own. But if you want details, keep reading.
|
||||
|
||||
When you first launch Kodi, you'll see the home screen below. Click **Enter files section**. It doesn't matter whether you do this under Movies (as shown here) or TV shows.
|
||||
|
||||
|
||||
|
||||
Next, select the **Videos** folder, click **Files** , and choose **Add videos**.
|
||||
|
||||
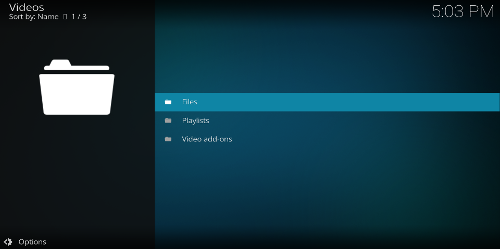
|
||||
|
||||
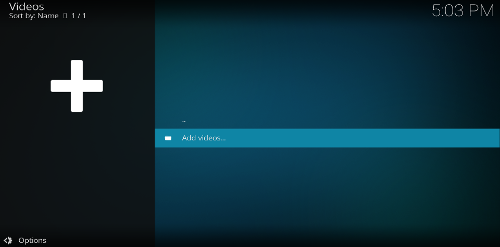
|
||||
|
||||
Either click on **None** and start typing the path to your files or click **Browse** and use the file navigation.
|
||||
|
||||
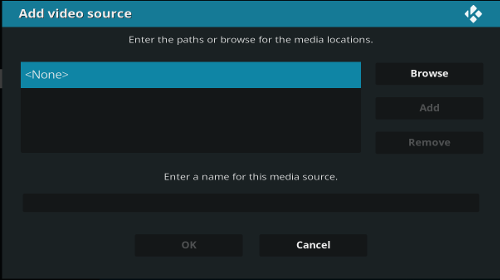
|
||||
|
||||
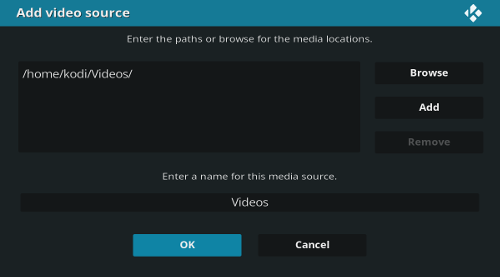
|
||||
|
||||
As you can see in this screenshot, I added my local **Videos** directory. You can set some default options through **Browse** , such as specifying your home folder and any drives you have mounted—maybe on a network file system (NFS), universal plug and play (UPnP) device, Windows Network ([SMB/CIFS][4]), or [zeroconf][5]. I won't cover most of these, as they are outside the scope of this article, but we will use NFS later for one of Kodi's advanced features.
|
||||
|
||||
After you select your path and click OK, identify the type of content you're working with.
|
||||
|
||||
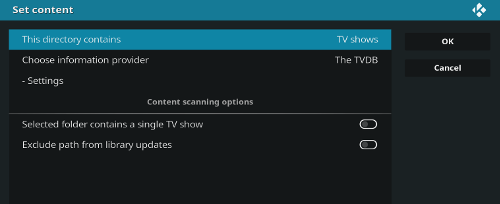
|
||||
|
||||
Next, Kodi prompts you to refresh the metadata for the content in the selected directory. This is how Kodi knows what videos you have and their synopsis, cast information, thumbnails, fan art, etc. Select **Yes** , and you can watch the video-scanning progress in the top right-hand corner.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
When the scan completes, you'll see lots of useful information, such as video overviews and season and episode descriptions for TV shows.
|
||||
|
||||
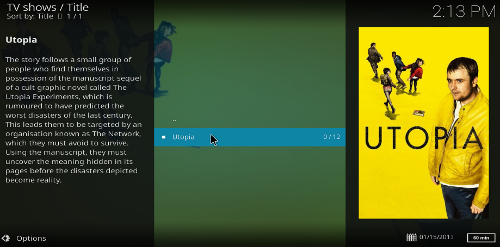
|
||||
|
||||
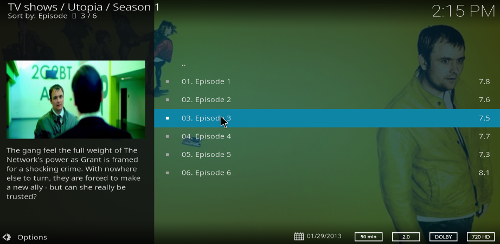
|
||||
|
||||
You can use the same process for other types of content, such as music or music videos.
|
||||
|
||||
### Increase functionality with add-ons
|
||||
|
||||
One of the most interesting things about open source projects is that the community often extends them well beyond their initial scope. Kodi has a very robust add-on infrastructure. Most of them are produced by Kodi fans who want to extend its default functionality, and sometimes companies (such as the [Plex][6] content streaming service) release official plugins. Be very careful about adding plugins from untrusted sources. Just because you find an add-on on the internet does not mean it is safe!
|
||||
|
||||
**Be warned:** Add-ons are not supported by Kodi's core team!
|
||||
|
||||
Having said that, there are many useful add-ons that are worth your consideration. In my house, we use Kodi for local playback and Plex when we want to access our content outside the house—with one exception. One of our rooms has a poor WiFi signal. I rip my Blu-Rays to very large MKV files (usually 20–40GB each), and the WiFi (and therefore Kodi) can't handle the files without stuttering. Although you can (and we have) dug into some of the advanced buffering options, even those tweaks have proved insufficient with very large files. Since we already have a Plex server that can transcode content, we solved our problem with a Kodi add-on.
|
||||
|
||||
To show how to install an add-on, I'll use Plex as an example. First, click on **Add-ons** in the side panel and select **Enter add-on browser**. Either use the search function or scroll down until you find Plex.
|
||||
|
||||
|
||||
|
||||
Select the Plex add-on and click the **Install** button in the lower right-hand corner.
|
||||
|
||||
|
||||
|
||||
Once the download completes, you can access Plex on the main Kodi screen under **Add-ons**.
|
||||
|
||||
|
||||
|
||||
There are several ways to configure an add-on. Some add-ons, such as NHL TV, are configured via a menu accessed by right-clicking the add-on and selecting Configure. Others, such as Plex, display a configuration walk-through when they launch. If an add-on doesn't seem to be configured when you first launch it, try right-clicking its menu and see if a settings option is available there.
|
||||
|
||||
### Coordinating metadata across Kodi devices
|
||||
|
||||
In our house, we have multiple machines that run Kodi. By default, Kodi tracks metadata, such as a video's watched status and show information, locally. Therefore, content updates on one machine won't appear on any other machine—unless you configure all your Kodi devices to store metadata inside an SQL database (which is a feature Kodi supports). This technique is not particularly difficult, but it is more advanced. If you're willing to put in the effort, here's how to do it.
|
||||
|
||||
#### Before you begin
|
||||
|
||||
There are a few things you need to know before configuring shared status for Kodi.
|
||||
|
||||
1. All content must be on a network share ([Samba][7], NFS, etc.).
|
||||
2. All content must be mounted via the network protocol, even if the disks are local to the machine. That means that no matter where the content is physically located, each client must be configured to use a network fileshare source.
|
||||
3. You need to be running an SQL-style database. Kodi's official guide walks through MySQL, but I chose MariaDB.
|
||||
4. All clients need to have the database port open (port 3306 in the case of MySQL/MariaDB) or the firewalls disabled.
|
||||
5. All clients must be running the same version of Kodi
|
||||
|
||||
|
||||
|
||||
#### Install and configure the database
|
||||
|
||||
If you're running Ubuntu, you can install MariaDB with the following commands:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install mariadb-server -y
|
||||
```
|
||||
|
||||
I am running MariaDB on an Arch Linux machine. The [Arch Wiki][8] documents the initial setup process well, but I'll summarize it here.
|
||||
|
||||
To install, issue the following command:
|
||||
|
||||
```
|
||||
sudo pacman -S mariadb
|
||||
```
|
||||
|
||||
Most distributions of MariaDB will have the same setup commands. I recommend that you understand what the commands do, but you can safely take the defaults if you're in a home environment.
|
||||
|
||||
```
|
||||
sudo systemctl start mariadb
|
||||
sudo mysql_install_db --user=mysql --basedir=/usr --datadir=/var/lib/mysql
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
Next, edit the MariaDB config file. This file is different depending on your distribution. On Ubuntu, you want to edit **/etc/mysql/mariadb.conf.d/50-server.cnf**. On Arch, the file is either **/etc/my.cnf** or **/etc/mysql/my.cnf**. Locate the line that says **bind-address = 127.0.0.1** and change it to your desired Ethernet port's IP address or to **bind-address = 0.0.0.0** if you want it to listen on all interfaces.
|
||||
|
||||
Restart the service so the change will take effect:
|
||||
|
||||
```
|
||||
sudo systemctl restart mariadb
|
||||
```
|
||||
|
||||
#### Configure Kodi and MariaDB/MySQL
|
||||
|
||||
To enable Kodi to write to the database, one of two things needs to happen: You can create the database yourself, or you can let Kodi do it for you. In this case, since the only database on this system is for Kodi, I'll create a user with the rights to create any databases that Kodi requires. Do NOT do this if the machine runs more than one database.
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
CREATE USER 'kodi' IDENTIFIED BY 'kodi';
|
||||
GRANT ALL ON core.md Dict.md lctt2014.md lctt2016.md lctt2018.md README.md TO 'kodi';
|
||||
flush privileges;
|
||||
\q
|
||||
```
|
||||
|
||||
This grants the user all rights—essentially enabling it to act as a root user. For my purposes, this is fine.
|
||||
|
||||
Next, on each Kodi device where you want to share metadata, create the following file: **/home/ <USER>/.kodi/userdata/advancedsettings.xml**. This file can contain a lot of very advanced, tweakable settings. My devices have these settings:
|
||||
|
||||
```
|
||||
<advancedsettings>
|
||||
<videodatabase>
|
||||
<type>mysql</type>
|
||||
<host>mysql-arch.example.com</host>
|
||||
<port>3306</port>
|
||||
<user>kodi</user>
|
||||
<pass>kodi</pass>
|
||||
</videodatabase>
|
||||
<videolibrary>
|
||||
<importwatchedstate>true</importwatchedstate>
|
||||
<importresumepoint>true</importresumepoint>
|
||||
</videolibrary>
|
||||
<cache>
|
||||
<!--- The three settings will go in this space, between the two network tags. --->
|
||||
<buffermode>1</buffermode>
|
||||
<memorysize>322122547</memorysize>
|
||||
<readfactor>20</readfactor>
|
||||
</cache>
|
||||
</advancedsettings>
|
||||
```
|
||||
|
||||
The **< cache>** section—which sets how much of a file Kodi will buffer over the network— is optional in this scenario. See the [Kodi wiki][9] for a full breakdown of this file and its options.
|
||||
|
||||
Once the configuration is complete, it's a good idea to close and reopen Kodi to make sure the settings are applied.
|
||||
|
||||
The final step is configuring all the Kodi clients to use the same network share for all their content. Only one client needs to scrap/refresh the metadata if everything is created successfully. When data is collected, you should see that Kodi creates a new database on your SQL server:
|
||||
|
||||
```
|
||||
[kodi@kodi-mysql ~]$ mysql -u root -p
|
||||
Enter password:
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MariaDB connection id is 180
|
||||
Server version: 10.1.37-MariaDB MariaDB Server
|
||||
|
||||
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
|
||||
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
|
||||
MariaDB [(none)]> show databases;
|
||||
+--------------------+
|
||||
| Database |
|
||||
+--------------------+
|
||||
| MyVideos107 |
|
||||
| information_schema |
|
||||
| mysql |
|
||||
| performance_schema |
|
||||
+--------------------+
|
||||
4 rows in set (0.00 sec)
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
This article walked through how to get up and running with the basic functionality of Kodi. You should be able to add content and pull down metadata to make browsing your media more convenient.
|
||||
|
||||
You also know how to search for, install, and potentially configure add-ons for additional features. Be extra careful when downloading add-ons, as they are provided by the community at large and not the core developers. It's best to use add-ons only from organizations or companies you trust.
|
||||
|
||||
And you know a bit about sharing metadata across multiple devices. You've been introduced to **advancedsettings.xml** ; hopefully it has piqued your interest. Kodi has a lot of dials and knobs to turn, and you can squeeze a lot of performance and functionality out of the platform with enough experimentation.
|
||||
|
||||
Are you interested in doing more tweaking? What are some of your favorite add-ons or settings? Do you want to know how to change the user interface? What are some of your favorite skins? Let me know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/manage-your-media-kodi
|
||||
|
||||
作者:[Steve Ovens][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stratusss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/ISO_image
|
||||
[2]: https://kodi.tv/
|
||||
[3]: https://kodi.wiki/view/HOW-TO:Install_Kodi_for_Linux#Fedora
|
||||
[4]: https://en.wikipedia.org/wiki/Server_Message_Block
|
||||
[5]: https://en.wikipedia.org/wiki/Zero-configuration_networking
|
||||
[6]: https://www.plex.tv
|
||||
[7]: https://www.samba.org/
|
||||
[8]: https://wiki.archlinux.org/index.php/MySQL
|
||||
[9]: https://kodi.wiki/view/Advancedsettings.xml
|
||||
135
sources/tech/20190107 Testing isn-t everything.md
Normal file
135
sources/tech/20190107 Testing isn-t everything.md
Normal file
@ -0,0 +1,135 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Testing isn't everything)
|
||||
[#]: via: (https://arp242.net/weblog/testing.html)
|
||||
[#]: author: (Martin Tournoij https://arp242.net/)
|
||||
|
||||
Testing isn't everything
|
||||
======
|
||||
|
||||
This is adopted from a discussion about [Want to write good unit tests in go? Don’t panic… or should you?][1] While this mainly talks about Go a lot of the points also apply to other languages.
|
||||
|
||||
Some of the most difficult code I’ve worked with is code that is “easily testable”. Code that abstracts everything to the point where you have no idea what’s going on, just so that it can add a “unit test” to what would otherwise be a very straightforward function. DHH called this [Test-induced design damage][2].
|
||||
|
||||
Testing is just one tool to make sure that your program works, out of several. Another very important tool is writing code in such a way that it is easy to understand and reason about (“simplicity”).
|
||||
|
||||
Books that advocate extensive testing – such as Robert C. Martin’s Clean Code – were written, in part, as a response to ever more complex programs, where you read 1,000 lines of code but still had no idea what’s going on. I recently had to port a simple Java “emoji replacer” (😂 ➙ 😂) to Go. To ensure compatibility I looked up the implementation. It was a whole bunch of classes, factories, and whatnot which all just resulted in calling a regexp on a string. 🤷
|
||||
|
||||
In dynamic languages like Ruby and Python tests are important for a different reason, as something like this will “work” just fine:
|
||||
|
||||
```
|
||||
if condition:
|
||||
print('w00t')
|
||||
else:
|
||||
nonexistent_function()
|
||||
```
|
||||
|
||||
Except of course if that `else` branch is entered. It’s easy to typo stuff, or mix stuff up.
|
||||
|
||||
In Go, both of these problems are less of a concern. It has a good static type system, and the focus is on simple straightforward code that is easy to comprehend. Even for a number of dynamic languages there are optional typing systems (function annotations in Python, TypeScript for JavaScript).
|
||||
|
||||
Sometimes you can do a straightforward implementation that doesn’t sacrifice anything for testability; great! But sometimes you have to strike a balance. For some code, not adding a unit test is fine.
|
||||
|
||||
Intensive focus on “unit tests” can be incredibly damaging to a code base. Some codebases have a gazillion unit tests, which makes any change excessively time-consuming as you’re fixing up a whole bunch of tests for even trivial changes. Often times a lot of these tests are just duplicates; adding tests to every layer of a simple CRUD HTTP endpoint is a common example. In many apps it’s fine to just rely on a single integration test.
|
||||
|
||||
Stuff like SQL mocks is another great example. It makes code more complex, harder to change, all so we can say we added a “unit test” to `select * from foo where x=?`. The worst part is, it doesn’t even test anything other than verifying you didn’t typo an SQL query. As soon as the test starts doing anything useful, such as verifying that it actually returns the correct rows from the database, the Unit Test purists will start complaining that it’s not a True Unit Test™ and that You’re Doing It Wrong™.
|
||||
For most queries, the integration tests and/or manual tests are fine, and extensive SQL mocks are entirely superfluous at best, and harmful at worst.
|
||||
|
||||
There are exceptions, of course; if you’ve got a lot of `if cond { q += "more sql" }` then adding SQL mocks to verify the correctness of that logic might be a good idea. Even in those cases a “non-unit unit test” (e.g. one that just accesses the database) is still a viable option. Integration tests are also still an option. A lot of applications don’t have those kind of complex queries anyway.
|
||||
|
||||
One important reason for the focus on unit tests is to ensure test code runs fast. This was a response to massive test harnesses that take a day to run. This, again, is not really a problem in Go. All integration tests I’ve written run in a reasonable amount of time (several seconds at most, usually faster). The test cache introduced in Go 1.10 makes it even less of a concern.
|
||||
|
||||
Last year a coworker refactored our ETag-based caching library. The old code was very straightforward and easy to understand, and while I’m not claiming it was guaranteed bug-free, it did work very well for a long time.
|
||||
|
||||
It should have been written with some tests in place, but it wasn’t (I didn’t write the original version). Note that the code was not completely untested, as we did have integration tests.
|
||||
|
||||
The refactored version is much more complex. Aside from the two weeks lost on refactoring a working piece of code to … another working piece of code (topic for another post), I’m not so convinced it’s actually that much better. I consider myself a reasonably accomplished and experienced programmer, with a reasonable knowledge and experience in Go. I think that in general, based on feedback from peers and performance reviews, I am at least a programmer of “average” skill level, if not more.
|
||||
|
||||
If an average programmer has trouble comprehending what is in essence a handful of simple functions because there are so many layers of abstractions, then something has gone wrong. The refactor traded one tool to verify correctness (simplicity) with another (testing). Simplicity is hardly a guarantee to ensure correctness, but neither are unit tests. Ideally, we should do both.
|
||||
|
||||
Postscript: the refactor introduced a bug and removed a feature that was useful, but is now harder to add, not in the least because the code is much more complex.
|
||||
|
||||
All units working correctly gives exactly zero guarantees that the program is working correctly. A lot of logic errors won’t be caught because the logic consists of several units working together. So you need integration tests, and if the integration tests duplicate half of your unit tests, then why bother with those unit tests?
|
||||
|
||||
Test Driven Development (TDD) is also just one tool. It works well for some problems; not so much for others. In particular, I think that “forced to write code in tiny units” can be terribly harmful in some cases. Some code is just a serial script which says “do this, and then that, and then this”. Splitting that up in a whole bunch of “tiny units” can greatly reduce how easy the code is to understand, and thus harder to verify that it is correct.
|
||||
|
||||
I’ve had to fix some Ruby code where everything was in tiny units – there is a strong culture of TDD in the Ruby community – and even though the units were easy to understand I found it incredibly hard to understand the application logic. If everything is split in “tiny units” then understanding how everything fits together to create an actual program that does something useful will be much harder.
|
||||
|
||||
You see the same friction in the old microkernel vs. monolithic kernel debate, or the more recent microservices vs. monolithic app one. In principle splitting everything up in small parts sounds like a great idea, but in practice it turns out that making all the small parts work together is a very hard problem. A hybrid approach seems to work best for kernels and app design, balancing the advantages and downsides of both approaches. I think the same applies to code.
|
||||
|
||||
To be clear, I am not against unit tests or TDD and claiming we should all gung-go cowboy code our way through life 🤠. I write unit tests and practice TDD, when it makes sense. My point is that unit tests and TDD are not the solution to every single last problem and should applied indiscriminately. This is why I use words such as “some” and “often” so frequently.
|
||||
|
||||
This brings me to the topic of testing frameworks. I have never understood what problem libraries such as [goblin][3] are solving. How is this:
|
||||
|
||||
```
|
||||
Expect(err).To(nil)
|
||||
Expect(out).To(test.wantOut)
|
||||
```
|
||||
|
||||
An improvement over this?
|
||||
|
||||
```
|
||||
if err != nil {
|
||||
t.Fatal(err)
|
||||
}
|
||||
|
||||
if out != tt.want {
|
||||
t.Errorf("out: %q\nwant: %q", out, tt.want)
|
||||
}
|
||||
```
|
||||
|
||||
What’s wrong with `if` and `==`? Why do we need to abstract it? Note that with table-driven tests you’re only typing these checks once, so you’re saving just a few lines here.
|
||||
|
||||
[Ginkgo][4] is even worse. It turns a very simple, straightforward, and understandable piece of code and doesn’t just abstract `if`, it also chops up the execution in several different functions (`BeforeEach()` and `DescribeTable()`).
|
||||
|
||||
This is known as Behaviour-driven development (BDD). I am not entirely sure what to think of BDD. I am skeptical, but I’ve never properly used it in a large project so I’m hesitant to just dismiss it. Note that I said “properly”: most projects don’t really use BDD, they just use a library with a BDD syntax and shoehorn their testing code in to that. That’s ad-hoc BDD, or faux-BDD.
|
||||
|
||||
Whatever merits BDD may have, they are not present simply because your testing code vaguely resembles BDD-style syntax. This on its own demonstrates that BDD is perhaps not a great idea for many projects.
|
||||
|
||||
I think there are real problems with these BDD(-ish) test tools, as they obfuscate what you’re actually doing. No matter what, testing remains a matter of getting the output of a function and checking if that matches what you expected. No testing methodology is going to change that fundamental. The more layers you add on top of that, the harder it will be to debug.
|
||||
|
||||
When determining if something is “easy” then my prime concern is not how easy something is to write, but how easy something is to debug when things fail. I will gladly spend a bit more effort writing things if that makes things a lot easier to debug.
|
||||
|
||||
All code – including testing code – can fail in confusing, surprising, and unexpected ways (a “bug”), and then you’re expected to debug that code. The more complex the code, the harder it is to debug.
|
||||
|
||||
You should expect all code – including testing code – to go through several debugging cycles. Note that with debugging cycle I don’t mean “there is a bug in the code you need to fix”, but rather “I need to look at this code to fix the bug”.
|
||||
|
||||
In general, I already find testing code harder to debug than regular code, as the “code surface” tends to be larger. You have the testing code and the actual implementation code to think of. That’s a lot more than just thinking of the implementation code.
|
||||
|
||||
Adding these abstractions means you will now also have to think about that, too! This might be okay if the abstractions would reduce the scope of what you have to think about, which is a common reason to add abstractions in regular code, but it doesn’t. It just adds more things to think about.
|
||||
|
||||
So these are exactly the wrong kind of abstractions: they wrap and obfuscate, rather than separate concerns and reduce the scope.
|
||||
|
||||
If you’re interested in soliciting contributions from other people in open source projects then making your tests understandable is a very important concern (it’s also important in business context, but a bit less so, as you’ve got actual time to train people).
|
||||
|
||||
Seeing PRs with “here’s the code, it works, but I couldn’t figure out the tests, plz halp!” is not uncommon; and I’m fairly sure that at least a few people never even bothered to submit PRs just because they got stuck on the tests. I know I have.
|
||||
|
||||
There is one open source project that I contributed to, and would like to contribute more to, but don’t because it’s just too hard to write and run tests. Every change is “write working code in 15 minutes, spend 45 minutes dealing with tests”. It’s … no fun at all.
|
||||
|
||||
Writing good software is hard. I’ve got some ideas on how to do it, but don’t have a comprehensive view. I’m not sure if anyone really does. I do know that “always add unit tests” and “always practice TDD” isn’t the answer, in spite of them being useful concepts. To give an analogy: most people would agree that a free market is a good idea, but at the same time even most libertarians would agree it’s not the complete solution to every single problem (well, [some do][5], but those ideas are … rather misguided).
|
||||
|
||||
You can mail me at [martin@arp242.net][6] or [create a GitHub issue][7] for feedback, questions, etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arp242.net/weblog/testing.html
|
||||
|
||||
作者:[Martin Tournoij][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://arp242.net/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://medium.com/@jens.neuse/want-to-write-good-unit-tests-in-go-dont-panic-or-should-you-ba3eb5bf4f51
|
||||
[2]: http://david.heinemeierhansson.com/2014/test-induced-design-damage.html
|
||||
[3]: https://github.com/franela/goblin
|
||||
[4]: https://github.com/onsi/ginkgo
|
||||
[5]: https://en.wikipedia.org/wiki/Murray_Rothbard#Children's_rights_and_parental_obligations
|
||||
[6]: mailto:martin@arp242.net
|
||||
[7]: https://github.com/Carpetsmoker/arp242.net/issues/new
|
||||
@ -0,0 +1,301 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create your own video streaming server with Linux)
|
||||
[#]: via: (https://opensource.com/article/19/1/basic-live-video-streaming-server)
|
||||
[#]: author: (Aaron J.Prisk https://opensource.com/users/ricepriskytreat)
|
||||
|
||||
Create your own video streaming server with Linux
|
||||
======
|
||||
Set up a basic live streaming server on a Linux or BSD operating system.
|
||||

|
||||
|
||||
Live video streaming is incredibly popular—and it's still growing. Platforms like Amazon's Twitch and Google's YouTube boast millions of users that stream and consume countless hours of live and recorded media. These services are often free to use but require you to have an account and generally hold your content behind advertisements. Some people don't need their videos to be available to the masses or just want more control over their content. Thankfully, with the power of open source software, anyone can set up a live streaming server.
|
||||
|
||||
### Getting started
|
||||
|
||||
In this tutorial, I'll explain how to set up a basic live streaming server with a Linux or BSD operating system.
|
||||
|
||||
This leads to the inevitable question of system requirements. These can vary, as there are a lot of variables involved with live streaming, such as:
|
||||
|
||||
* **Stream quality:** Do you want to stream in high definition or will standard definition fit your needs?
|
||||
* **Viewership:** How many viewers are you expecting for your videos?
|
||||
* **Storage:** Do you plan on keeping saved copies of your video stream?
|
||||
* **Access:** Will your stream be private or open to the world?
|
||||
|
||||
|
||||
|
||||
There are no set rules when it comes to system requirements, so I recommend you experiment and find what works best for your needs. I installed my server on a virtual machine with 4GB RAM, a 20GB hard drive, and a single Intel i7 processor core.
|
||||
|
||||
This project uses the Real-Time Messaging Protocol (RTMP) to handle audio and video streaming. There are other protocols available, but I chose RTMP because it has broad support. As open standards like WebRTC become more compatible, I would recommend that route.
|
||||
|
||||
It's also very important to know that "live" doesn't always mean instant. A video stream must be encoded, transferred, buffered, and displayed, which often adds delays. The delay can be shortened or lengthened depending on the type of stream you're creating and its attributes.
|
||||
|
||||
### Setting up a Linux server
|
||||
|
||||
You can use many different distributions of Linux, but I prefer Ubuntu, so I downloaded the [Ubuntu Server][1] edition for my operating system. If you prefer your server to have a graphical user interface (GUI), feel free to use [Ubuntu Desktop][2] or one of its many flavors. Then, I fired up the Ubuntu installer on my computer or virtual machine and chose the settings that best matched my environment. Below are the steps I took.
|
||||
|
||||
Note: Because this is a server, you'll probably want to set some static network settings.
|
||||
|
||||
|
||||
|
||||
After the installer finishes and your system reboots, you'll be greeted with a lovely new Ubuntu system. As with any newly installed operating system, install any updates that are available:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
This streaming server will use the very powerful and versatile Nginx web server, so you'll need to install it:
|
||||
|
||||
```
|
||||
sudo apt install nginx
|
||||
```
|
||||
|
||||
Then you'll need to get the RTMP module so Nginx can handle your media stream:
|
||||
|
||||
```
|
||||
sudo add-apt-repository universe
|
||||
sudo apt install libnginx-mod-rtmp
|
||||
```
|
||||
|
||||
Adjust your web server's configuration so it can accept and deliver your media stream.
|
||||
|
||||
```
|
||||
sudo nano /etc/nginx/nginx.conf
|
||||
```
|
||||
|
||||
Scroll to the bottom of the configuration file and add the following code:
|
||||
|
||||
```
|
||||
rtmp {
|
||||
server {
|
||||
listen 1935;
|
||||
chunk_size 4096;
|
||||
|
||||
application live {
|
||||
live on;
|
||||
record off;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
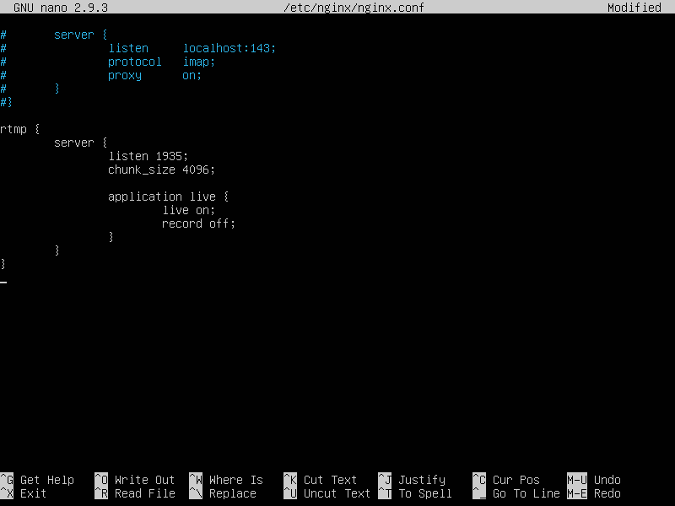
|
||||
|
||||
Save the config. Because I'm a heretic, I use [Nano][3] for editing configuration files. In Nano, you can save your config by pressing **Ctrl+X** , **Y** , and then **Enter.**
|
||||
|
||||
This is a very minimal config that will create a working streaming server. You'll add to this config later, but this is a great starting point.
|
||||
|
||||
However, before you can begin your first stream, you'll need to restart Nginx with its new configuration:
|
||||
|
||||
```
|
||||
sudo systemctl restart nginx
|
||||
```
|
||||
|
||||
### Setting up a BSD server
|
||||
|
||||
If you're of the "beastie" persuasion, getting a streaming server up and running is also devilishly easy.
|
||||
|
||||
Head on over to the [FreeBSD][4] website and download the latest release. Fire up the FreeBSD installer on your computer or virtual machine and go through the initial steps and choose settings that best match your environment. Since this is a server, you'll likely want to set some static network settings.
|
||||
|
||||
After the installer finishes and your system reboots, you should have a shiny new FreeBSD system. Like any other freshly installed system, you'll likely want to get everything updated (from this step forward, make sure you're logged in as root):
|
||||
|
||||
```
|
||||
pkg update
|
||||
pkg upgrade
|
||||
```
|
||||
|
||||
I install [Nano][3] for editing configuration files:
|
||||
|
||||
```
|
||||
pkg install nano
|
||||
```
|
||||
|
||||
This streaming server will use the very powerful and versatile Nginx web server. You can build Nginx using the excellent ports system that FreeBSD boasts.
|
||||
|
||||
First, update your ports tree:
|
||||
|
||||
```
|
||||
portsnap fetch
|
||||
portsnap extract
|
||||
```
|
||||
|
||||
Browse to the Nginx ports directory:
|
||||
|
||||
```
|
||||
cd /usr/ports/www/nginx
|
||||
```
|
||||
|
||||
And begin building Nginx by running:
|
||||
|
||||
```
|
||||
make install
|
||||
```
|
||||
|
||||
You'll see a screen asking what modules to include in your Nginx build. For this project, you'll need to add the RTMP module. Scroll down until the RTMP module is selected and press **Space**. Then Press **Enter** to proceed with the rest of the build and installation.
|
||||
|
||||
Once Nginx has finished installing, it's time to configure it for streaming purposes.
|
||||
|
||||
First, add an entry into **/etc/rc.conf** to ensure the Nginx server starts when your system boots:
|
||||
|
||||
```
|
||||
nano /etc/rc.conf
|
||||
```
|
||||
|
||||
Add this text to the file:
|
||||
|
||||
```
|
||||
nginx_enable="YES"
|
||||
```
|
||||
|
||||
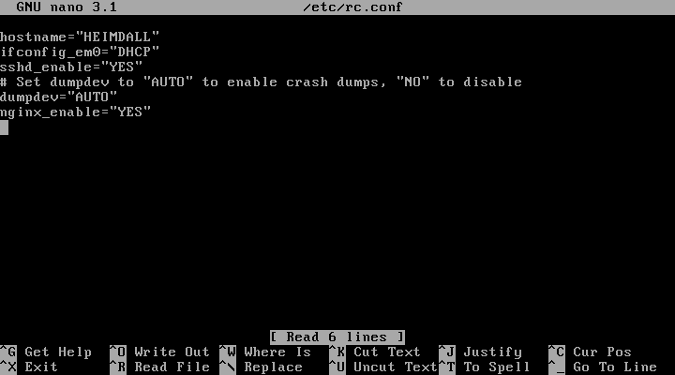
|
||||
|
||||
Next, create a webroot directory from where Nginx will serve its content. I call mine **stream** :
|
||||
|
||||
```
|
||||
cd /usr/local/www/
|
||||
mkdir stream
|
||||
chmod -R 755 stream/
|
||||
```
|
||||
|
||||
Now that you have created your stream directory, configure Nginx by editing its configuration file:
|
||||
|
||||
```
|
||||
nano /usr/local/etc/nginx/nginx.conf
|
||||
```
|
||||
|
||||
Load your streaming modules at the top of the file:
|
||||
|
||||
```
|
||||
load_module /usr/local/libexec/nginx/ngx_stream_module.so;
|
||||
load_module /usr/local/libexec/nginx/ngx_rtmp_module.so;
|
||||
```
|
||||
|
||||
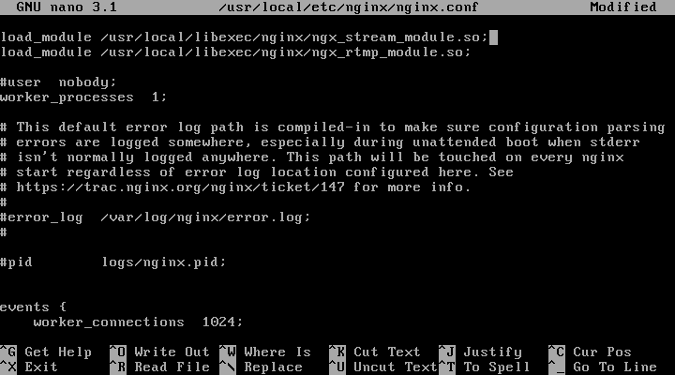
|
||||
|
||||
Under the **Server** section, change the webroot location to match the one you created earlier:
|
||||
|
||||
```
|
||||
Location / {
|
||||
root /usr/local/www/stream
|
||||
}
|
||||
```
|
||||
|
||||
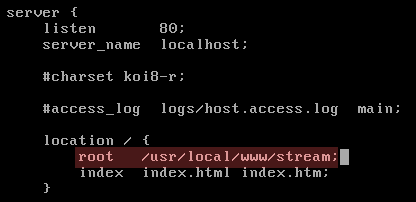
|
||||
|
||||
And finally, add your RTMP settings so Nginx will know how to handle your media streams:
|
||||
|
||||
```
|
||||
rtmp {
|
||||
server {
|
||||
listen 1935;
|
||||
chunk_size 4096;
|
||||
|
||||
application live {
|
||||
live on;
|
||||
record off;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save the config. In Nano, you can do this by pressing **Ctrl+X** , **Y** , and then **Enter.**
|
||||
|
||||
As you can see, this is a very minimal config that will create a working streaming server. Later, you'll add to this config, but this will provide you with a great starting point.
|
||||
|
||||
However, before you can begin your first stream, you'll need to restart Nginx with its new config:
|
||||
|
||||
```
|
||||
service nginx restart
|
||||
```
|
||||
|
||||
### Set up your streaming software
|
||||
|
||||
#### Broadcasting with OBS
|
||||
|
||||
Now that your server is ready to accept your video streams, it's time to set up your streaming software. This tutorial uses the powerful and open source Open Broadcast Studio (OBS).
|
||||
|
||||
Head over to the [OBS website][5] and find the build for your operating system and install it. Once OBS launches, you should see a first-time-run wizard that will help you configure OBS with the settings that best fit your hardware.
|
||||
|
||||
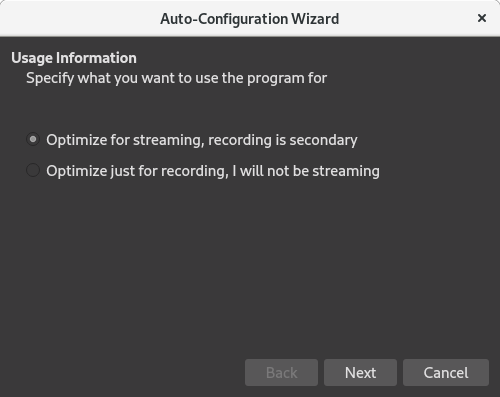
|
||||
|
||||
OBS isn't capturing anything because you haven't supplied it with a source. For this tutorial, you'll just capture your desktop for the stream. Simply click the **+** button under **Source** , choose **Screen Capture** , and select which desktop you want to capture.
|
||||
|
||||
Click OK, and you should see OBS mirroring your desktop.
|
||||
|
||||
Now it's time to send your newly configured video stream to your server. In OBS, click **File** > **Settings**. Click on the **Stream** section, and set **Stream Type** to **Custom Streaming Server**.
|
||||
|
||||
In the URL box, enter the prefix **rtmp://** followed the IP address of your streaming server followed by **/live**. For example, **rtmp://IP-ADDRESS/live**.
|
||||
|
||||
Next, you'll probably want to enter a Stream key—a special identifier required to view your stream. Enter whatever key you want (and can remember) in the **Stream key** box.
|
||||
|
||||
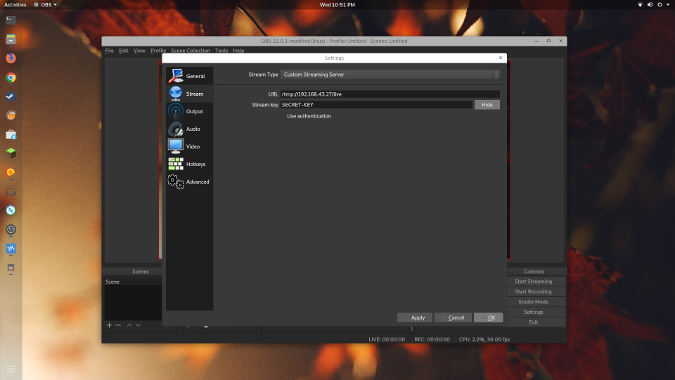
|
||||
|
||||
Click **Apply** and then **OK**.
|
||||
|
||||
Now that OBS is configured to send your stream to your server, you can start your first stream. Click **Start Streaming**.
|
||||
|
||||
If everything worked, you should see the button change to **Stop Streaming** and some bandwidth metrics will appear at the bottom of OBS.
|
||||
|
||||

|
||||
|
||||
If you receive an error, double-check Stream Settings in OBS for misspellings. If everything looks good, there could be another issue preventing it from working.
|
||||
|
||||
### Viewing your stream
|
||||
|
||||
A live video isn't much good if no one is watching it, so be your first viewer!
|
||||
|
||||
There are a multitude of open source media players that support RTMP, but the most well-known is probably [VLC media player][6].
|
||||
|
||||
After you install and launch VLC, open your stream by clicking on **Media** > **Open Network Stream**. Enter the path to your stream, adding the Stream Key you set up in OBS, then click **Play**. For example, **rtmp://IP-ADDRESS/live/SECRET-KEY**.
|
||||
|
||||
You should now be viewing your very own live video stream!
|
||||
|
||||
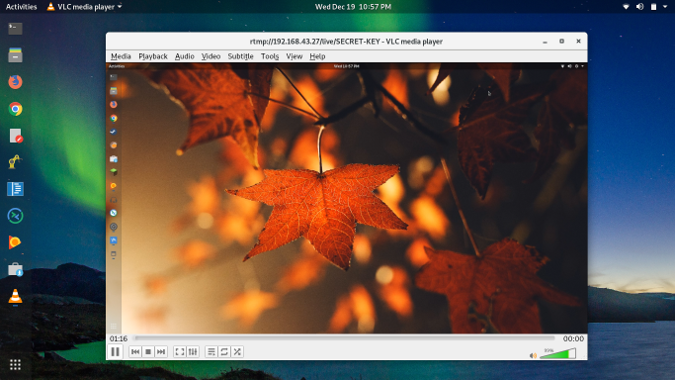
|
||||
|
||||
### Where to go next?
|
||||
|
||||
This is a very simple setup that will get you off the ground. Here are two other features you likely will want to use.
|
||||
|
||||
* **Limit access:** The next step you might want to take is to limit access to your server, as the default setup allows anyone to stream to and from the server. There are a variety of ways to set this up, such as an operating system firewall, [.htaccess file][7], or even using the [built-in access controls in the STMP module][8].
|
||||
|
||||
* **Record streams:** This simple Nginx configuration will only stream and won't save your videos, but this is easy to add. In the Nginx config, under the RTMP section, set up the recording options and the location where you want to save your videos. Make sure the path you set exists and Nginx is able to write to it.
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
application live {
|
||||
live on;
|
||||
record all;
|
||||
record_path /var/www/html/recordings;
|
||||
record_unique on;
|
||||
}
|
||||
```
|
||||
|
||||
The world of live streaming is constantly evolving, and if you're interested in more advanced uses, there are lots of other great resources you can find floating around the internet. Good luck and happy streaming!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/basic-live-video-streaming-server
|
||||
|
||||
作者:[Aaron J.Prisk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ricepriskytreat
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ubuntu.com/download/server
|
||||
[2]: https://www.ubuntu.com/download/desktop
|
||||
[3]: https://www.nano-editor.org/
|
||||
[4]: https://www.freebsd.org/
|
||||
[5]: https://obsproject.com/
|
||||
[6]: https://www.videolan.org/vlc/index.html
|
||||
[7]: https://httpd.apache.org/docs/current/howto/htaccess.html
|
||||
[8]: https://github.com/arut/nginx-rtmp-module/wiki/Directives#access
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How ASLR protects Linux systems from buffer overflow attacks)
|
||||
[#]: via: (https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How ASLR protects Linux systems from buffer overflow attacks
|
||||
======
|
||||
|
||||

|
||||
|
||||
Address Space Layout Randomization (ASLR) is a memory-protection process for operating systems that guards against buffer-overflow attacks. It helps to ensure that the memory addresses associated with running processes on systems are not predictable, thus flaws or vulnerabilities associated with these processes will be more difficult to exploit.
|
||||
|
||||
ASLR is used today on Linux, Windows, and MacOS systems. It was first implemented on Linux in 2005. In 2007, the technique was deployed on Microsoft Windows and MacOS. While ASLR provides the same function on each of these operating systems, it is implemented differently on each one.
|
||||
|
||||
The effectiveness of ASLR is dependent on the entirety of the address space layout remaining unknown to the attacker. In addition, only executables that are compiled as Position Independent Executable (PIE) programs will be able to claim the maximum protection from ASLR technique because all sections of the code will be loaded at random locations. PIE machine code will execute properly regardless of its absolute address.
|
||||
|
||||
**[ Also see:[Invaluable tips and tricks for troubleshooting Linux][1] ]**
|
||||
|
||||
### ASLR limitations
|
||||
|
||||
In spite of ASLR making exploitation of system vulnerabilities more difficult, its role in protecting systems is limited. It's important to understand that ASLR:
|
||||
|
||||
* Doesn't _resolve_ vulnerabilities, but makes exploiting them more of a challenge
|
||||
* Doesn't track or report vulnerabilities
|
||||
* Doesn't offer any protection for binaries that are not built with ASLR support
|
||||
* Isn't immune to circumvention
|
||||
|
||||
|
||||
|
||||
### How ASLR works
|
||||
|
||||
ASLR increases the control-flow integrity of a system by making it more difficult for an attacker to execute a successful buffer-overflow attack by randomizing the offsets it uses in memory layouts.
|
||||
|
||||
ASLR works considerably better on 64-bit systems, as these systems provide much greater entropy (randomization potential).
|
||||
|
||||
### Is ASLR working on your Linux system?
|
||||
|
||||
Either of the two commands shown below will tell you whether ASLR is enabled on your system.
|
||||
|
||||
```
|
||||
$ cat /proc/sys/kernel/randomize_va_space
|
||||
2
|
||||
$ sysctl -a --pattern randomize
|
||||
kernel.randomize_va_space = 2
|
||||
```
|
||||
|
||||
The value (2) shown in the commands above indicates that ASLR is working in full randomization mode. The value shown will be one of the following:
|
||||
|
||||
```
|
||||
0 = Disabled
|
||||
1 = Conservative Randomization
|
||||
2 = Full Randomization
|
||||
```
|
||||
|
||||
If you disable ASLR and run the commands below, you should notice that the addresses shown in the **ldd** output below are all the same in the successive **ldd** commands. The **ldd** command works by loading the shared objects and showing where they end up in memory.
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=0 <== disable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 0
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
```
|
||||
|
||||
If the value is set back to **2** to enable ASLR, you will see that the addresses will change each time you run the command.
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=2 <== enable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 2
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007fff47d0e000) <== first set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007f1cb7ce0000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f1cb7cda000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1cb7af0000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007f1cb8045000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffe1cbd7000) <== second set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007fed59742000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fed5973c000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fed59552000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007fed59aa7000)
|
||||
```
|
||||
|
||||
### Attempting to bypass ASLR
|
||||
|
||||
In spite of its advantages, attempts to bypass ASLR are not uncommon and seem to fall into several categories:
|
||||
|
||||
* Using address leaks
|
||||
* Gaining access to data relative to particular addresses
|
||||
* Exploiting implementation weaknesses that allow attackers to guess addresses when entropy is low or when the ASLR implementation is faulty
|
||||
* Using side channels of hardware operation
|
||||
|
||||
|
||||
|
||||
### Wrap-up
|
||||
|
||||
ASLR is of great value, especially when run on 64 bit systems and implemented properly. While not immune from circumvention attempts, it does make exploitation of system vulnerabilities considerably more difficult. Here is a reference that can provide a lot more detail [on the Effectiveness of Full-ASLR on 64-bit Linux][2], and here is a paper on one circumvention effort to [bypass ASLR][3] using branch predictors.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[2]: https://cybersecurity.upv.es/attacks/offset2lib/offset2lib-paper.pdf
|
||||
[3]: http://www.cs.ucr.edu/~nael/pubs/micro16.pdf
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,359 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Understand And Identify File types in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Understand And Identify File types in Linux
|
||||
======
|
||||
|
||||
We all are knows, that everything is a file in Linux which includes Hard Disk, Graphics Card, etc.
|
||||
|
||||
When you are navigating the Linux filesystem most of the files are fall under regular files and directories.
|
||||
|
||||
But it has other file types as well for different purpose which fall in five categories.
|
||||
|
||||
So, it’s very important to understand the file types in Linux that helps you in many ways.
|
||||
|
||||
If you can’t believe this, you just gone through the complete article then you come to know how important is.
|
||||
|
||||
If you don’t understand the file types you can’t make any changes on that without fear.
|
||||
|
||||
If you made the changes wrongly that damage your system very badly so be careful when you are doing that.
|
||||
|
||||
Files are very important in Linux because all the devices and daemon’s were stored as a file in Linux system.
|
||||
|
||||
### How Many Types of File is Available in Linux?
|
||||
|
||||
As per my knowledge, totally 7 types of files are available in Linux with 3 Major categories. The details are below.
|
||||
|
||||
* Regular File
|
||||
* Directory File
|
||||
* Special Files (This category having five type of files)
|
||||
* Link File
|
||||
* Character Device File
|
||||
* Socket File
|
||||
* Named Pipe File
|
||||
* Block File
|
||||
|
||||
|
||||
|
||||
Refer the below table for better understanding of file types in Linux.
|
||||
| Symbol | Meaning |
|
||||
| – | Regular File. It starts with underscore “_”. |
|
||||
| d | Directory File. It starts with English alphabet letter “d”. |
|
||||
| l | Link File. It starts with English alphabet letter “l”. |
|
||||
| c | Character Device File. It starts with English alphabet letter “c”. |
|
||||
| s | Socket File. It starts with English alphabet letter “s”. |
|
||||
| p | Named Pipe File. It starts with English alphabet letter “p”. |
|
||||
| b | Block File. It starts with English alphabet letter “b”. |
|
||||
|
||||
### Method-1: Manual Way to Identify File types in Linux
|
||||
|
||||
If you are having good knowledge in Linux then you can easily identify the files type with help of above table.
|
||||
|
||||
#### How to view the Regular files in Linux?
|
||||
|
||||
Use the below command to view the Regular files in Linux. Regular files are available everywhere in Linux filesystem.
|
||||
The Regular files color is `WHITE`
|
||||
|
||||
```
|
||||
# ls -la | grep ^-
|
||||
-rw-------. 1 mageshm mageshm 1394 Jan 18 15:59 .bash_history
|
||||
-rw-r--r--. 1 mageshm mageshm 18 May 11 2012 .bash_logout
|
||||
-rw-r--r--. 1 mageshm mageshm 176 May 11 2012 .bash_profile
|
||||
-rw-r--r--. 1 mageshm mageshm 124 May 11 2012 .bashrc
|
||||
-rw-r--r--. 1 root root 26 Dec 27 17:55 liks
|
||||
-rw-r--r--. 1 root root 104857600 Jan 31 2006 test100.dat
|
||||
-rw-r--r--. 1 root root 104874307 Dec 30 2012 test100.zip
|
||||
-rw-r--r--. 1 root root 11536384 Dec 30 2012 test10.zip
|
||||
-rw-r--r--. 1 root root 61 Dec 27 19:05 test2-bzip2.txt
|
||||
-rw-r--r--. 1 root root 61 Dec 31 14:24 test3-bzip2.txt
|
||||
-rw-r--r--. 1 root root 60 Dec 27 19:01 test-bzip2.txt
|
||||
```
|
||||
|
||||
#### How to view the Directory files in Linux?
|
||||
|
||||
Use the below command to view the Directory files in Linux. Directory files are available everywhere in Linux filesystem. The Directory files colour is `BLUE`
|
||||
|
||||
```
|
||||
# ls -la | grep ^d
|
||||
drwxr-xr-x. 3 mageshm mageshm 4096 Dec 31 14:24 links/
|
||||
drwxrwxr-x. 2 mageshm mageshm 4096 Nov 16 15:44 perl5/
|
||||
drwxr-xr-x. 2 mageshm mageshm 4096 Nov 16 15:37 public_ftp/
|
||||
drwxr-xr-x. 3 mageshm mageshm 4096 Nov 16 15:37 public_html/
|
||||
```
|
||||
|
||||
#### How to view the Link files in Linux?
|
||||
|
||||
Use the below command to view the Link files in Linux. Link files are available everywhere in Linux filesystem.
|
||||
Two type of link files are available, it’s Soft link and Hard link. The Link files color is `LIGHT TURQUOISE`
|
||||
|
||||
```
|
||||
# ls -la | grep ^l
|
||||
lrwxrwxrwx. 1 root root 31 Dec 7 15:11 s-link-file -> /links/soft-link/test-soft-link
|
||||
lrwxrwxrwx. 1 root root 38 Dec 7 15:12 s-link-folder -> /links/soft-link/test-soft-link-folder
|
||||
```
|
||||
|
||||
#### How to view the Character Device files in Linux?
|
||||
|
||||
Use the below command to view the Character Device files in Linux. Character Device files are available only in specific location.
|
||||
|
||||
It’s available under `/dev` directory. The Character Device files color is `YELLOW`
|
||||
|
||||
```
|
||||
# ls -la | grep ^c
|
||||
crw-------. 1 root root 5, 1 Jan 28 14:05 console
|
||||
crw-rw----. 1 root root 10, 61 Jan 28 14:05 cpu_dma_latency
|
||||
crw-rw----. 1 root root 10, 62 Jan 28 14:05 crash
|
||||
crw-rw----. 1 root root 29, 0 Jan 28 14:05 fb0
|
||||
crw-rw-rw-. 1 root root 1, 7 Jan 28 14:05 full
|
||||
crw-rw-rw-. 1 root root 10, 229 Jan 28 14:05 fuse
|
||||
```
|
||||
|
||||
#### How to view the Block files in Linux?
|
||||
|
||||
Use the below command to view the Block files in Linux. The Block files are available only in specific location.
|
||||
It’s available under `/dev` directory. The Block files color is `YELLOW`
|
||||
|
||||
```
|
||||
# ls -la | grep ^b
|
||||
brw-rw----. 1 root disk 7, 0 Jan 28 14:05 loop0
|
||||
brw-rw----. 1 root disk 7, 1 Jan 28 14:05 loop1
|
||||
brw-rw----. 1 root disk 7, 2 Jan 28 14:05 loop2
|
||||
brw-rw----. 1 root disk 7, 3 Jan 28 14:05 loop3
|
||||
brw-rw----. 1 root disk 7, 4 Jan 28 14:05 loop4
|
||||
```
|
||||
|
||||
#### How to view the Socket files in Linux?
|
||||
|
||||
Use the below command to view the Socket files in Linux. The Socket files are available only in specific location.
|
||||
The Socket files color is `PINK`
|
||||
|
||||
```
|
||||
# ls -la | grep ^s
|
||||
srw-rw-rw- 1 root root 0 Jan 5 16:36 system_bus_socket
|
||||
```
|
||||
|
||||
#### How to view the Named Pipe files in Linux?
|
||||
|
||||
Use the below command to view the Named Pipe files in Linux. The Named Pipe files are available only in specific location. The Named Pipe files color is `YELLOW`
|
||||
|
||||
```
|
||||
# ls -la | grep ^p
|
||||
prw-------. 1 root root 0 Jan 28 14:06 replication-notify-fifo|
|
||||
prw-------. 1 root root 0 Jan 28 14:06 stats-mail|
|
||||
```
|
||||
|
||||
### Method-2: How to Identify File types in Linux Using file Command?
|
||||
|
||||
The file command allow us to determine various file types in Linux. There are three sets of tests, performed in this order: filesystem tests, magic tests, and language tests to identify file types.
|
||||
|
||||
#### How to view the Regular files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Regular file. The file command will read the given file contents and display exactly what kind of file it is.
|
||||
|
||||
That’s why we are seeing different results for each Regular files. See the below various results for Regular files.
|
||||
|
||||
```
|
||||
# file 2daygeek_access.log
|
||||
2daygeek_access.log: ASCII text, with very long lines
|
||||
|
||||
# file powertop.html
|
||||
powertop.html: HTML document, ASCII text, with very long lines
|
||||
|
||||
# file 2g-test
|
||||
2g-test: JSON data
|
||||
|
||||
# file powertop.txt
|
||||
powertop.txt: HTML document, UTF-8 Unicode text, with very long lines
|
||||
|
||||
# file 2g-test-05-01-2019.tar.gz
|
||||
2g-test-05-01-2019.tar.gz: gzip compressed data, last modified: Sat Jan 5 18:22:20 2019, from Unix, original size 450560
|
||||
```
|
||||
|
||||
#### How to view the Directory files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Directory file. See the results below.
|
||||
|
||||
```
|
||||
# file Pictures/
|
||||
Pictures/: directory
|
||||
```
|
||||
|
||||
#### How to view the Link files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Link file. See the results below.
|
||||
|
||||
```
|
||||
# file log
|
||||
log: symbolic link to /run/systemd/journal/dev-log
|
||||
```
|
||||
|
||||
#### How to view the Character Device files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Character Device file. See the results below.
|
||||
|
||||
```
|
||||
# file vcsu
|
||||
vcsu: character special (7/64)
|
||||
```
|
||||
|
||||
#### How to view the Block files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Block file. See the results below.
|
||||
|
||||
```
|
||||
# file sda1
|
||||
sda1: block special (8/1)
|
||||
```
|
||||
|
||||
#### How to view the Socket files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Socket file. See the results below.
|
||||
|
||||
```
|
||||
# file system_bus_socket
|
||||
system_bus_socket: socket
|
||||
```
|
||||
|
||||
#### How to view the Named Pipe files in Linux Using file Command?
|
||||
|
||||
Simple enter the file command on your terminal and followed by Named Pipe file. See the results below.
|
||||
|
||||
```
|
||||
# file pipe-test
|
||||
pipe-test: fifo (named pipe)
|
||||
```
|
||||
|
||||
### Method-3: How to Identify File types in Linux Using stat Command?
|
||||
|
||||
The stat command allow us to check file types or file system status. This utility giving more information than file command. It shows lot of information about the given file such as Size, Block Size, IO Block Size, Inode Value, Links, File permission, UID, GID, File Access, Modify and Change time details.
|
||||
|
||||
#### How to view the Regular files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Regular file.
|
||||
|
||||
```
|
||||
# stat 2daygeek_access.log
|
||||
File: 2daygeek_access.log
|
||||
Size: 14406929 Blocks: 28144 IO Block: 4096 regular file
|
||||
Device: 10301h/66305d Inode: 1727555 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2019-01-03 14:05:26.430328867 +0530
|
||||
Modify: 2019-01-03 14:05:26.460328868 +0530
|
||||
Change: 2019-01-03 14:05:26.460328868 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Directory files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Directory file. See the results below.
|
||||
|
||||
```
|
||||
# stat Pictures/
|
||||
File: Pictures/
|
||||
Size: 4096 Blocks: 8 IO Block: 4096 directory
|
||||
Device: 10301h/66305d Inode: 1703982 Links: 3
|
||||
Access: (0755/drwxr-xr-x) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2018-11-24 03:22:11.090000828 +0530
|
||||
Modify: 2019-01-05 18:27:01.546958817 +0530
|
||||
Change: 2019-01-05 18:27:01.546958817 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Link files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Link file. See the results below.
|
||||
|
||||
```
|
||||
# stat /dev/log
|
||||
File: /dev/log -> /run/systemd/journal/dev-log
|
||||
Size: 28 Blocks: 0 IO Block: 4096 symbolic link
|
||||
Device: 6h/6d Inode: 278 Links: 1
|
||||
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2019-01-05 16:36:31.033333447 +0530
|
||||
Modify: 2019-01-05 16:36:30.766666768 +0530
|
||||
Change: 2019-01-05 16:36:30.766666768 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Character Device files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Character Device file. See the results below.
|
||||
|
||||
```
|
||||
# stat /dev/vcsu
|
||||
File: /dev/vcsu
|
||||
Size: 0 Blocks: 0 IO Block: 4096 character special file
|
||||
Device: 6h/6d Inode: 16 Links: 1 Device type: 7,40
|
||||
Access: (0660/crw-rw----) Uid: ( 0/ root) Gid: ( 5/ tty)
|
||||
Access: 2019-01-05 16:36:31.056666781 +0530
|
||||
Modify: 2019-01-05 16:36:31.056666781 +0530
|
||||
Change: 2019-01-05 16:36:31.056666781 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Block files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Block file. See the results below.
|
||||
|
||||
```
|
||||
# stat /dev/sda1
|
||||
File: /dev/sda1
|
||||
Size: 0 Blocks: 0 IO Block: 4096 block special file
|
||||
Device: 6h/6d Inode: 250 Links: 1 Device type: 8,1
|
||||
Access: (0660/brw-rw----) Uid: ( 0/ root) Gid: ( 994/ disk)
|
||||
Access: 2019-01-05 16:36:31.596666806 +0530
|
||||
Modify: 2019-01-05 16:36:31.596666806 +0530
|
||||
Change: 2019-01-05 16:36:31.596666806 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Socket files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Socket file. See the results below.
|
||||
|
||||
```
|
||||
# stat /var/run/dbus/system_bus_socket
|
||||
File: /var/run/dbus/system_bus_socket
|
||||
Size: 0 Blocks: 0 IO Block: 4096 socket
|
||||
Device: 15h/21d Inode: 576 Links: 1
|
||||
Access: (0666/srw-rw-rw-) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Access: 2019-01-05 16:36:31.823333482 +0530
|
||||
Modify: 2019-01-05 16:36:31.810000149 +0530
|
||||
Change: 2019-01-05 16:36:31.810000149 +0530
|
||||
Birth: -
|
||||
```
|
||||
|
||||
#### How to view the Named Pipe files in Linux Using stat Command?
|
||||
|
||||
Simple enter the stat command on your terminal and followed by Named Pipe file. See the results below.
|
||||
|
||||
```
|
||||
# stat pipe-test
|
||||
File: pipe-test
|
||||
Size: 0 Blocks: 0 IO Block: 4096 fifo
|
||||
Device: 10301h/66305d Inode: 1705583 Links: 1
|
||||
Access: (0644/prw-r--r--) Uid: ( 1000/ daygeek) Gid: ( 1000/ daygeek)
|
||||
Access: 2019-01-06 02:00:03.040394731 +0530
|
||||
Modify: 2019-01-06 02:00:03.040394731 +0530
|
||||
Change: 2019-01-06 02:00:03.040394731 +0530
|
||||
Birth: -
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-understand-and-identify-file-types-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,152 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automating deployment strategies with Ansible)
|
||||
[#]: via: (https://opensource.com/article/19/1/automating-deployment-strategies-ansible)
|
||||
[#]: author: (Jario da Silva Junior https://opensource.com/users/jairojunior)
|
||||
|
||||
Automating deployment strategies with Ansible
|
||||
======
|
||||
Use automation to eliminate time sinkholes due to repetitive tasks and unplanned work.
|
||||

|
||||
|
||||
When you examine your technology stack from the bottom layer to the top—hardware, operating system (OS), middleware, and application—with their respective configurations, it's clear that changes are far more frequent as you go up in the stack. Your hardware will hardly change, your OS has a long lifecycle, and your middleware will keep up with the application's needs, but even if your release cycle is long (weeks or months), your applications will be the most volatile.
|
||||
|
||||
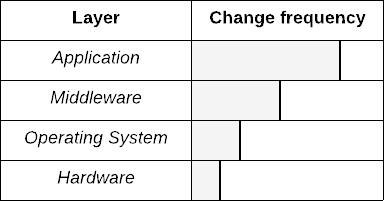
|
||||
|
||||
In [The Practice of System and Network Administration][1], the authors categorize the biggest "time sinkholes" in IT as manual/non-standard provisioning of OSes and application deployments. These time sinkholes will consume you with repetitive tasks or unplanned work.
|
||||
|
||||
How so? Let's say you provision a new server without Network Time Protocol (NTP) properly configured, and a small percentage of your requests—in a cluster of dozens of servers—start to behave strangely because an application uses some sort of scheduler that relies on correct time. When you look at it like this, it is an easy problem to fix, but how long it would it take your team figure it out? Incidents or unplanned work consume a lot of your time and, even worse, your greatest talents. Should you really be wasting time investigating production systems like this? Wouldn't it be better to set this server aside and automatically provision a new one from scratch?
|
||||
|
||||
What about manual deployment? Imagine 20 binaries deployed across a farm or nodes with their respective configuration files? How error-prone is this? Inevitably, it will eventually end up in unplanned work.
|
||||
|
||||
The [State of DevOps Report 2018][2] introduces the stages of DevOps adoption, and it's no surprise that Stage 0 includes deployment automation and reuse of deployment patterns, while Stage 1 and 2 focus on standardization of your infrastructure stack to reduce inconsistencies across your environment.
|
||||
|
||||
Note that, more than once, I have seen an ops team using this "standardization" as an excuse to limit a development team's ability to deliver, forcing them to use a hammer on something that is definitely not a nail. Don't do it; the price is extremely high.
|
||||
|
||||
The lesson to be learned here is that lack of automation not only increases your lead time but also the rate of problems in your process and the amount of unplanned work you face. If you've read [The Phoenix Project][3], you know this is the root of all evil in any value stream, and if you don't get rid of it, it will eventually kill your business.
|
||||
|
||||
When trying to fill the biggest time sinkholes, why not start with automating operating system installation? We could, but the results would take longer to appear since new virtual machines are not created as frequently as applications are deployed. In other words, this may not free up the time we need to power our initiative, so it could die prematurely.
|
||||
|
||||
Still not convinced? Smaller and more frequent releases are also extremely positive from the development side. Let's explain a little further…
|
||||
|
||||
### Deploy ≠ Release
|
||||
|
||||
The first thing to understand is that, although they're used interchangeably, deployment and release do **NOT** mean the same thing. Release refers to providing the user a new version, while deployment is the technical process of deploying the new version. Let's focus on the technical process of deployment.
|
||||
|
||||
### Tasks, groups, and Ansible
|
||||
|
||||
We need to understand the deployment process from the beginning to the end, including everything in the middle—the tasks, which servers are involved in the process, and which steps are executed—to avoid falling into the pitfalls described by Mattias Geniar in [Automating the unknown][4].
|
||||
|
||||
#### Tasks
|
||||
|
||||
The steps commonly executed in a regular deployment process include:
|
||||
|
||||
* Deploy application(s)/database(s) or database(s) change(s)
|
||||
* Stop/start services and monitoring
|
||||
* Add/remove the server from our load balancers
|
||||
* Verify application state—is it ready to serve requests?
|
||||
* Manual approval—is it necessary?
|
||||
|
||||
|
||||
|
||||
For some people, automating the deployment process but leaving a manual approval step is like riding a bike with training wheels. As someone once told me: "It's better to ride with training wheels than not ride at all."
|
||||
|
||||
What if a tool doesn't include an API or a command-line interface (CLI) to enable task automation? Well, maybe it's time to think about changing tools. There are many open source application servers, databases, monitoring systems, and load balancers that are easily automated—thanks in large part to the [Unix way][5]. When adopting a new technology, eliminate options that are not automated and use your creativity to support your legacy technologies. For example, I've seen people versioning network appliance configuration files and updating them using FTP.
|
||||
|
||||
And guess what? It's a wonderful time to adopt open source tools. The recent [Accelerate: State of DevOps][6] report found that open source technologies are in predominant use in high-performance organizations. The logic is pretty simple: open source projects function in a "Darwinist" model, where those that do not adapt and evolve will die for lack of a user base or contributions. Feedback is paramount to software evolution.
|
||||
|
||||
#### Groups
|
||||
|
||||
To identify groups of servers to target for automation, think about the most tasks you want to automate, such as those that:
|
||||
|
||||
* Deploy application(s)/database(s) or database change(s)
|
||||
* Stop/start services and monitoring
|
||||
* Add/remove server(s) from load balancer(s)
|
||||
* Verify application state—is it ready to serve requests?
|
||||
|
||||
|
||||
|
||||
#### The playbook
|
||||
|
||||
A high-level deployment process could be:
|
||||
|
||||
1. Stop monitoring (to avoid false-positives)
|
||||
2. Remove server from the load balancer (to prevent the user from receiving an error code)
|
||||
3. Stop the service (to enable a graceful shutdown)
|
||||
4. Deploy the new version of the application
|
||||
5. Wait for the application to be ready to receive new requests
|
||||
6. Execute steps 3, 2, and 1.
|
||||
7. Do the same for the next N servers.
|
||||
|
||||
|
||||
|
||||
Having documentation of your process is nice, but having an executable documenting your deployment is better! Here's what steps 1–5 would look like in Ansible for a fully open source stack:
|
||||
|
||||
```
|
||||
- name: Disable alerts
|
||||
nagios:
|
||||
action: disable_alerts
|
||||
host: "{{ inventory_hostname }}"
|
||||
services: webserver
|
||||
delegate_to: "{{ item }}"
|
||||
loop: "{{ groups.monitoring }}"
|
||||
|
||||
- name: Disable servers in the LB
|
||||
haproxy:
|
||||
host: "{{ inventory_hostname }}"
|
||||
state: disabled
|
||||
backend: app
|
||||
delegate_to: "{{ item }}"
|
||||
loop: " {{ groups.lbserver }}"
|
||||
|
||||
- name: Stop the service
|
||||
service: name=httpd state=stopped
|
||||
|
||||
- name: Deploy a new version
|
||||
unarchive: src=app.tar.gz dest=/var/www/app
|
||||
|
||||
- name: Verify application state
|
||||
uri:
|
||||
url: "http://{{ inventory_hostname }}/app/healthz"
|
||||
status_code: 200
|
||||
retries: 5
|
||||
```
|
||||
|
||||
### Why Ansible?
|
||||
|
||||
There are other alternatives for application deployment, but the things that make Ansible an excellent choice include:
|
||||
|
||||
* Multi-tier orchestration (i.e., **delegate_to** ) allowing you to orderly target different groups of servers: monitoring, load balancer, application server, database, etc.
|
||||
* Rolling upgrade (i.e., serial) to control how changes are made (e.g., 1 by 1, N by N, X% at a time, etc.)
|
||||
* Error control, **max_fail_percentage** and **any_errors_fatal** , is my process all-in or will it tolerate fails?
|
||||
* A vast library of modules for:
|
||||
* Monitoring (e.g., Nagios, Zabbix, etc.)
|
||||
* Load balancers (e.g., HAProxy, F5, Netscaler, Cisco, etc.)
|
||||
* Services (e.g., service, command, file)
|
||||
* Deployment (e.g., copy, unarchive)
|
||||
* Programmatic verifications (e.g., command, Uniform Resource Identifier)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
|
||||
|
||||
作者:[Jario da Silva Junior][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jairojunior
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.amazon.com/Practice-System-Network-Administration-Enterprise/dp/0321919165/ref=dp_ob_title_bk
|
||||
[2]: https://puppet.com/resources/whitepaper/state-of-devops-report
|
||||
[3]: https://www.amazon.com/Phoenix-Project-DevOps-Helping-Business/dp/0988262592
|
||||
[4]: https://ma.ttias.be/automating-unknown/
|
||||
[5]: https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
[6]: https://cloudplatformonline.com/2018-state-of-devops.html
|
||||
80
sources/tech/20190109 Bash 5.0 Released with New Features.md
Normal file
80
sources/tech/20190109 Bash 5.0 Released with New Features.md
Normal file
@ -0,0 +1,80 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bash 5.0 Released with New Features)
|
||||
[#]: via: (https://itsfoss.com/bash-5-release)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Bash 5.0 Released with New Features
|
||||
======
|
||||
|
||||
The [mailing list][1] confirmed the release of Bash-5.0 recently. And, it is exciting to know that it comes baked with new features and variable.
|
||||
|
||||
Well, if you’ve been using Bash 4.4.XX, you will definitely love the fifth major release of [Bash][2].
|
||||
|
||||
The fifth release focuses on new shell variables and a lot of major bug fixes with an overhaul. It also introduces a couple of new features along with some incompatible changes between bash-4.4 and bash-5.0.
|
||||
|
||||
![Bash logo][3]
|
||||
|
||||
### What about the new features?
|
||||
|
||||
The mailing list explains the bug fixed in this new release:
|
||||
|
||||
> This release fixes several outstanding bugs in bash-4.4 and introduces several new features. The most significant bug fixes are an overhaul of how nameref variables resolve and a number of potential out-of-bounds memory errors discovered via fuzzing. There are a number of changes to the expansion of $@ and $* in various contexts where word splitting is not performed to conform to a Posix standard interpretation, and additional changes to resolve corner cases for Posix conformance.
|
||||
|
||||
It also introduces some new features. As per the release note, these are the most notable new features are several new shell variables:
|
||||
|
||||
> The BASH_ARGV0, EPOCHSECONDS, and EPOCHREALTIME. The ‘history’ builtin can remove ranges of history entries and understands negative arguments as offsets from the end of the history list. There is an option to allow local variables to inherit the value of a variable with the same name at a preceding scope. There is a new shell option that, when enabled, causes the shell to attempt to expand associative array subscripts only once (this is an issue when they are used in arithmetic expressions). The ‘globasciiranges‘ shell option is now enabled by default; it can be set to off by default at configuration time.
|
||||
|
||||
### What about the changes between Bash-4.4 and Bash-5.0?
|
||||
|
||||
The update log mentioned about the incompatible changes and the supported readline version history. Here’s what it said:
|
||||
|
||||
> There are a few incompatible changes between bash-4.4 and bash-5.0. The changes to how nameref variables are resolved means that some uses of namerefs will behave differently, though I have tried to minimize the compatibility issues. By default, the shell only sets BASH_ARGC and BASH_ARGV at startup if extended debugging mode is enabled; it was an oversight that it was set unconditionally and caused performance issues when scripts were passed large numbers of arguments.
|
||||
>
|
||||
> Bash can be linked against an already-installed Readline library rather than the private version in lib/readline if desired. Only readline-8.0 and later versions are able to provide all of the symbols that bash-5.0 requires; earlier versions of the Readline library will not work correctly.
|
||||
|
||||
I believe some of the features/variables added are very useful. Some of my favorites are:
|
||||
|
||||
* There is a new (disabled by default, undocumented) shell option to enable and disable sending history to syslog at runtime.
|
||||
* The shell doesn’t automatically set BASH_ARGC and BASH_ARGV at startup unless it’s in debugging mode, as the documentation has always said, but will dynamically create them if a script references them at the top level without having enabled debugging mode.
|
||||
* The ‘history’ can now delete ranges of history entries using ‘-d start-end’.
|
||||
* If a non-interactive shell with job control enabled detects that a foreground job died due to SIGINT, it acts as if it received the SIGINT.
|
||||
* BASH_ARGV0: a new variable that expands to $0 and sets $0 on assignment.
|
||||
|
||||
|
||||
|
||||
To check the complete list of changes and features you should refer to the [Mailing list post][1].
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
You can check your current Bash version, using this command:
|
||||
|
||||
```
|
||||
bash --version
|
||||
```
|
||||
|
||||
It’s more likely that you’ll have Bash 4.4 installed. If you want to get the new version, I would advise waiting for your distribution to provide it.
|
||||
|
||||
With Bash-5.0 available, what do you think about it? Are you using any alternative to bash? If so, would this update change your mind?
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/bash-5-release
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://lists.gnu.org/archive/html/bug-bash/2019-01/msg00063.html
|
||||
[2]: https://www.gnu.org/software/bash/
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/bash-logo.jpg?resize=800%2C450&ssl=1
|
||||
@ -0,0 +1,76 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding /etc/services file in Linux)
|
||||
[#]: via: (https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/)
|
||||
[#]: author: (kerneltalks https://kerneltalks.com)
|
||||
|
||||
Understanding /etc/services file in Linux
|
||||
======
|
||||
|
||||
Article which helps you to understand /etc/services file in Linux. Learn about content, format & importance of this file.
|
||||
|
||||
![/etc/services file in Linux][1]
|
||||
/etc/services file in Linux
|
||||
|
||||
Internet daemon is important service in Linux world. It takes care of all network services with the help of `/etc/services` file. In this article we will walk you through content, format of this file and what it means to a Linux system.
|
||||
|
||||
`/etc/services` file contains list of network services and ports mapped to them. `inetd` or `xinetd` looks at these details so that it can call particular program when packet hits respective port and demand for service.
|
||||
|
||||
As a normal user you can view this file since file is world readable. To edit this file you need to have root privileges.
|
||||
|
||||
```
|
||||
$ ll /etc/services
|
||||
-rw-r--r--. 1 root root 670293 Jun 7 2013 /etc/services
|
||||
```
|
||||
|
||||
### `/etc/services` file format
|
||||
|
||||
```
|
||||
service-name port/protocol [aliases..] [#comment]
|
||||
```
|
||||
|
||||
Last two fields are optional hence denoted in `[` `]`
|
||||
|
||||
where –
|
||||
|
||||
* service-name is name of the network service. e.g. [telnet][2], [ftp][3] etc.
|
||||
* port/protocol is port being used by that network service (numerical value) and protocol (TCP/UDP) used for communication by service.
|
||||
* alias is alternate name for service.
|
||||
* comment is note or description you can add to service. Starts with `#` mark
|
||||
|
||||
|
||||
|
||||
### Sample` /etc/services` file
|
||||
|
||||
```
|
||||
# Each line describes one service, and is of the form:
|
||||
#
|
||||
# service-name port/protocol [aliases ...] [# comment]
|
||||
|
||||
tcpmux 1/tcp # TCP port service multiplexer
|
||||
rje 5/tcp # Remote Job Entry
|
||||
echo 7/udp
|
||||
discard 9/udp sink null
|
||||
```
|
||||
|
||||
Here, you can see use of optional last two fields as well. `discard` service has alternate name as `sink` or `null`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/linux/understanding-etc-services-file-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kerneltalks.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/kerneltalks.com/wp-content/uploads/2019/01/undestanding-etc-service-file-in-linux.png?ssl=1
|
||||
[2]: https://kerneltalks.com/config/configure-telnet-server-linux/
|
||||
[3]: https://kerneltalks.com/config/ftp-server-configuration-steps-rhel-6/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (pityonline)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -350,7 +350,7 @@ via: https://opensource.com/article/19/1/vim-plugins-developers
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[pityonline](https://github.com/pityonline)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,170 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top 5 Linux Distributions for Productivity)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/top-5-linux-distributions-productivity)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
Top 5 Linux Distributions for Productivity
|
||||
======
|
||||
|
||||

|
||||
|
||||
I have to confess, this particular topic is a tough one to address. Why? First off, Linux is a productive operating system by design. Thanks to an incredibly reliable and stable platform, getting work done is easy. Second, to gauge effectiveness, you have to consider what type of work you need a productivity boost for. General office work? Development? School? Data mining? Human resources? You see how this question can get somewhat complicated.
|
||||
|
||||
That doesn’t mean, however, that some distributions aren’t able to do a better job of configuring and presenting that underlying operating system into an efficient platform for getting work done. Quite the contrary. Some distributions do a much better job of “getting out of the way,” so you don’t find yourself in a work-related hole, having to dig yourself out and catch up before the end of day. These distributions help strip away the complexity that can be found in Linux, thereby making your workflow painless.
|
||||
|
||||
Let’s take a look at the distros I consider to be your best bet for productivity. To help make sense of this, I’ve divided them into categories of productivity. That task itself was challenging, because everyone’s productivity varies. For the purposes of this list, however, I’ll look at:
|
||||
|
||||
* General Productivity: For those who just need to work efficiently on multiple tasks.
|
||||
|
||||
* Graphic Design: For those that work with the creation and manipulation of graphic images.
|
||||
|
||||
* Development: For those who use their Linux desktops for programming.
|
||||
|
||||
* Administration: For those who need a distribution to facilitate their system administration tasks.
|
||||
|
||||
* Education: For those who need a desktop distribution to make them more productive in an educational environment.
|
||||
|
||||
|
||||
|
||||
|
||||
Yes, there are more categories to be had, many of which can get very niche-y, but these five should fill most of your needs.
|
||||
|
||||
### General Productivity
|
||||
|
||||
For general productivity, you won’t get much more efficient than [Ubuntu][1]. The primary reason for choosing Ubuntu for this category is the seamless integration of apps, services, and desktop. You might be wondering why I didn’t choose Linux Mint for this category? Because Ubuntu now defaults to the GNOME desktop, it gains the added advantage of GNOME Extensions (Figure 1).
|
||||
|
||||
![GNOME Clipboard][3]
|
||||
|
||||
Figure 1: The GNOME Clipboard Indicator extension in action.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
These extensions go a very long way to aid in boosting productivity (so Ubuntu gets the nod over Mint). But Ubuntu didn’t just accept a vanilla GNOME desktop. Instead, they tweaked it to make it slightly more efficient and user-friendly, out of the box. And because Ubuntu contains just the right mixture of default, out-of-the-box, apps (that just work), it makes for a nearly perfect platform for productivity.
|
||||
|
||||
Whether you need to write a paper, work on a spreadsheet, code a new app, work on your company website, create marketing images, administer a server or network, or manage human resources from within your company HR tool, Ubuntu has you covered. The Ubuntu desktop distribution also doesn’t require the user to jump through many hoops to get things working … it simply works (and quite well). Finally, thanks to it’s Debian base, Ubuntu makes installing third-party apps incredibly easy.
|
||||
|
||||
Although Ubuntu tends to be the go-to for nearly every list of “top distributions for X,” it’s very hard to argue against this particular distribution topping the list of general productivity distributions.
|
||||
|
||||
### Graphic Design
|
||||
|
||||
If you’re looking to up your graphic design productivity, you can’t go wrong with [Fedora Design Suite][5]. This Fedora respin was created by the team responsible for all Fedora-related art work. Although the default selection of apps isn’t a massive collection of tools, those it does include are geared specifically for the creation and manipulation of images.
|
||||
|
||||
With apps like GIMP, Inkscape, Darktable, Krita, Entangle, Blender, Pitivi, Scribus, and more (Figure 2), you’ll find everything you need to get your image editing jobs done and done well. But Fedora Design Suite doesn’t end there. This desktop platform also includes a bevy of tutorials that cover countless subjects for many of the installed applications. For anyone trying to be as productive as possible, this is some seriously handy information to have at the ready. I will say, however, the tutorial entry in the GNOME Favorites is nothing more than a link to [this page][6].
|
||||
|
||||
![Fedora Design Suite Favorites][8]
|
||||
|
||||
Figure 2: The Fedora Design Suite Favorites menu includes plenty of tools for getting your graphic design on.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Those that work with a digital camera will certainly appreciate the inclusion of the Entangle app, which allows you to control your DSLR from the desktop.
|
||||
|
||||
### Development
|
||||
|
||||
Nearly all Linux distributions are great platforms for programmers. However, one particular distributions stands out, above the rest, as one of the most productive tools you’ll find for the task. That OS comes from [System76][9] and it’s called [Pop!_OS][10]. Pop!_OS is tailored specifically for creators, but not of the artistic type. Instead, Pop!_OS is geared toward creators who specialize in developing, programming, and making. If you need an environment that is not only perfected suited for your development work, but includes a desktop that’s sure to get out of your way, you won’t find a better option than Pop!_OS (Figure 3).
|
||||
|
||||
What might surprise you (given how “young” this operating system is), is that Pop!_OS is also one of the single most stable GNOME-based platforms you’ll ever use. This means Pop!_OS isn’t just for creators and makers, but anyone looking for a solid operating system. One thing that many users will greatly appreciate with Pop!_OS, is that you can download an ISO specifically for your video hardware. If you have Intel hardware, [download][10] the version for Intel/AMD. If your graphics card is NVIDIA, download that specific release. Either way, you are sure go get a solid platform for which to create your masterpiece.
|
||||
|
||||
![Pop!_OS][12]
|
||||
|
||||
Figure 3: The Pop!_OS take on GNOME Overview.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Interestingly enough, with Pop!_OS, you won’t find much in the way of pre-installed development tools. You won’t find an included IDE, or many other dev tools. You can, however, find all the development tools you need in the Pop Shop.
|
||||
|
||||
### Administration
|
||||
|
||||
If you’re looking to find one of the most productive distributions for admin tasks, look no further than [Debian][13]. Why? Because Debian is not only incredibly reliable, it’s one of those distributions that gets out of your way better than most others. Debian is the perfect combination of ease of use and unlimited possibility. On top of which, because this is the distribution for which so many others are based, you can bet if there’s an admin tool you need for a task, it’s available for Debian. Of course, we’re talking about general admin tasks, which means most of the time you’ll be using a terminal window to SSH into your servers (Figure 4) or a browser to work with web-based GUI tools on your network. Why bother making use of a desktop that’s going to add layers of complexity (such as SELinux in Fedora, or YaST in openSUSE)? Instead, chose simplicity.
|
||||
|
||||
![Debian][15]
|
||||
|
||||
Figure 4: SSH’ing into a remote server on Debian.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
And because you can select which desktop you want (from GNOME, Xfce, KDE, Cinnamon, MATE, LXDE), you can be sure to have the interface that best matches your work habits.
|
||||
|
||||
### Education
|
||||
|
||||
If you are a teacher or student, or otherwise involved in education, you need the right tools to be productive. Once upon a time, there existed the likes of Edubuntu. That distribution never failed to be listed in the top of education-related lists. However, that distro hasn’t been updated since it was based on Ubuntu 14.04. Fortunately, there’s a new education-based distribution ready to take that title, based on openSUSE. This spin is called [openSUSE:Education-Li-f-e][16] (Linux For Education - Figure 5), and is based on openSUSE Leap 42.1 (so it is slightly out of date).
|
||||
|
||||
openSUSE:Education-Li-f-e includes tools like:
|
||||
|
||||
* Brain Workshop - A dual n-back brain exercise
|
||||
|
||||
* GCompris - An educational software suite for young children
|
||||
|
||||
* gElemental - A periodic table viewer
|
||||
|
||||
* iGNUit - A general purpose flash card program
|
||||
|
||||
* Little Wizard - Development environment for children based on Pascal
|
||||
|
||||
* Stellarium - An astronomical sky simulator
|
||||
|
||||
* TuxMath - An math tutor game
|
||||
|
||||
* TuxPaint - A drawing program for young children
|
||||
|
||||
* TuxType - An educational typing tutor for children
|
||||
|
||||
* wxMaxima - A cross platform GUI for the computer algebra system
|
||||
|
||||
* Inkscape - Vector graphics program
|
||||
|
||||
* GIMP - Graphic image manipulation program
|
||||
|
||||
* Pencil - GUI prototyping tool
|
||||
|
||||
* Hugin - Panorama photo stitching and HDR merging program
|
||||
|
||||
|
||||
![Education][18]
|
||||
|
||||
Figure 5: The openSUSE:Education-Li-f-e distro has plenty of tools to help you be productive in or for school.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Also included with openSUSE:Education-Li-f-e is the [KIWI-LTSP Server][19]. The KIWI-LTSP Server is a flexible, cost effective solution aimed at empowering schools, businesses, and organizations all over the world to easily install and deploy desktop workstations. Although this might not directly aid the student to be more productive, it certainly enables educational institutions be more productive in deploying desktops for students to use. For more information on setting up KIWI-LTSP, check out the openSUSE [KIWI-LTSP quick start guide][20].
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][21]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/top-5-linux-distributions-productivity
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ubuntu.com/
|
||||
[2]: /files/images/productivity1jpg
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_1.jpg?itok=yxez3X1w (GNOME Clipboard)
|
||||
[4]: /licenses/category/used-permission
|
||||
[5]: https://labs.fedoraproject.org/en/design-suite/
|
||||
[6]: https://fedoraproject.org/wiki/Design_Suite/Tutorials
|
||||
[7]: /files/images/productivity2jpg
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_2.jpg?itok=ke0b8qyH (Fedora Design Suite Favorites)
|
||||
[9]: https://system76.com/
|
||||
[10]: https://system76.com/pop
|
||||
[11]: /files/images/productivity3jpg-0
|
||||
[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_3_0.jpg?itok=8UkCUfsD (Pop!_OS)
|
||||
[13]: https://www.debian.org/
|
||||
[14]: /files/images/productivity4jpg
|
||||
[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_4.jpg?itok=c9yD3Xw2 (Debian)
|
||||
[16]: https://en.opensuse.org/openSUSE:Education-Li-f-e
|
||||
[17]: /files/images/productivity5jpg
|
||||
[18]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_5.jpg?itok=oAFtV8nT (Education)
|
||||
[19]: https://en.opensuse.org/Portal:KIWI-LTSP
|
||||
[20]: https://en.opensuse.org/SDB:KIWI-LTSP_quick_start
|
||||
[21]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
168
sources/tech/20190113 Editing Subtitles in Linux.md
Normal file
168
sources/tech/20190113 Editing Subtitles in Linux.md
Normal file
@ -0,0 +1,168 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Editing Subtitles in Linux)
|
||||
[#]: via: (https://itsfoss.com/editing-subtitles)
|
||||
[#]: author: (Shirish https://itsfoss.com/author/shirish/)
|
||||
|
||||
Editing Subtitles in Linux
|
||||
======
|
||||
|
||||
I have been a world movie and regional movies lover for decades. Subtitles are the essential tool that have enabled me to enjoy the best movies in various languages and from various countries.
|
||||
|
||||
If you enjoy watching movies with subtitles, you might have noticed that sometimes the subtitles are not synced or not correct.
|
||||
|
||||
Did you know that you can edit subtitles and make them better? Let me show you some basic subtitle editing in Linux.
|
||||
|
||||
![Editing subtitles in Linux][1]
|
||||
|
||||
### Extracting subtitles from closed captions data
|
||||
|
||||
Around 2012, 2013 I came to know of a tool called [CCEextractor.][2] As time passed, it has become one of the vital tools for me, especially if I come across a media file which has the subtitle embedded in it.
|
||||
|
||||
CCExtractor analyzes video files and produces independent subtitle files from the closed captions data.
|
||||
|
||||
CCExtractor is a cross-platform, free and open source tool. The tool has matured quite a bit from its formative years and has been part of [GSOC][3] and Google Code-in now and [then.][4]
|
||||
|
||||
The tool, to put it simply, is more or less a set of scripts which work one after another in a serialized order to give you an extracted subtitle.
|
||||
|
||||
You can follow the installation instructions for CCExtractor on [this page][5].
|
||||
|
||||
After installing when you want to extract subtitles from a media file, do the following:
|
||||
|
||||
```
|
||||
ccextractor <path_to_video_file>
|
||||
```
|
||||
|
||||
The output of the command will be something like this:
|
||||
|
||||
It basically scans the media file. In this case, it found that the media file is in malyalam and that the media container is an [.mkv][6] container. It extracted the subtitle file with the same name as the video file adding _eng to it.
|
||||
|
||||
CCExtractor is a wonderful tool which can be used to enhance subtitles along with Subtitle Edit which I will share in the next section.
|
||||
|
||||
```
|
||||
Interesting Read: There is an interesting synopsis of subtitles at [vicaps][7] which tells and shares why subtitles are important to us. It goes into quite a bit of detail of movie-making as well for those interested in such topics.
|
||||
```
|
||||
|
||||
### Editing subtitles with SubtitleEditor Tool
|
||||
|
||||
You probably are aware that most subtitles are in [.srt format][8] . The beautiful thing about this format is and was you could load it in your text editor and do little fixes in it.
|
||||
|
||||
A srt file looks something like this when launched into a simple text-editor:
|
||||
|
||||
The excerpt subtitle I have shared is from a pretty Old German Movie called [The Cabinet of Dr. Caligari (1920)][9]
|
||||
|
||||
Subtitleeditor is a wonderful tool when it comes to editing subtitles. Subtitle Editor is and can be used to manipulate time duration, frame-rate of the subtitle file to be in sync with the media file, duration of breaks in-between and much more. I’ll share some of the basic subtitle editing here.
|
||||
|
||||
![][10]
|
||||
|
||||
First install subtitleeditor the same way you installed ccextractor, using your favorite installation method. In Debian, you can use this command:
|
||||
|
||||
```
|
||||
sudo apt install subtitleeditor
|
||||
```
|
||||
|
||||
When you have it installed, let’s see some of the common scenarios where you need to edit a subtitle.
|
||||
|
||||
#### Manipulating Frame-rates to sync with Media file
|
||||
|
||||
If you find that the subtitles are not synced with the video, one of the reasons could be the difference between the frame rates of the video file and the subtitle file.
|
||||
|
||||
How do you know the frame rates of these files, then?
|
||||
|
||||
To get the frame rate of a video file, you can use the mediainfo tool. You may need to install it first using your distribution’s package manager.
|
||||
|
||||
Using mediainfo is simple:
|
||||
|
||||
```
|
||||
$ mediainfo somefile.mkv | grep Frame
|
||||
Format settings : CABAC / 4 Ref Frames
|
||||
Format settings, ReFrames : 4 frames
|
||||
Frame rate mode : Constant
|
||||
Frame rate : 25.000 FPS
|
||||
Bits/(Pixel*Frame) : 0.082
|
||||
Frame rate : 46.875 FPS (1024 SPF)
|
||||
```
|
||||
|
||||
Now you can see that framerate of the video file is 25.000 FPS. The other Frame-rate we see is for the audio. While I can share why particular fps are used in Video-encoding, Audio-encoding etc. it would be a different subject matter. There is a lot of history associated with it.
|
||||
|
||||
Next is to find out the frame rate of the subtitle file and this is a slightly complicated.
|
||||
|
||||
Usually, most subtitles are in a zipped format. Unzipping the .zip archive along with the subtitle file which ends in something.srt. Along with it, there is usually also a .info file with the same name which sometime may have the frame rate of the subtitle.
|
||||
|
||||
If not, then it usually is a good idea to go some site and download the subtitle from a site which has that frame rate information. For this specific German file, I will be using [Opensubtitle.org][11]
|
||||
|
||||
As you can see in the link, the frame rate of the subtitle is 23.976 FPS. Quite obviously, it won’t play well with my video file with frame rate 25.000 FPS.
|
||||
|
||||
In such cases, you can change the frame rate of the subtitle file using the Subtitle Editor tool:
|
||||
|
||||
Select all the contents from the subtitle file by doing CTRL+A. Go to Timings -> Change Framerate and change frame rates from 23.976 fps to 25.000 fps or whatever it is that is desired. Save the changed file.
|
||||
|
||||
![synchronize frame rates of subtitles in Linux][12]
|
||||
|
||||
#### Changing the Starting position of a subtitle file
|
||||
|
||||
Sometimes the above method may be enough, sometimes though it will not be enough.
|
||||
|
||||
You might find some cases when the start of the subtitle file is different from that in the movie or a media file while the frame rate is the same.
|
||||
|
||||
In such cases, do the following:
|
||||
|
||||
Select all the contents from the subtitle file by doing CTRL+A. Go to Timings -> Select Move Subtitle.
|
||||
|
||||
![Move subtitles using Subtitle Editor on Linux][13]
|
||||
|
||||
Change the new Starting position of the subtitle file. Save the changed file.
|
||||
|
||||
![Move subtitles using Subtitle Editor in Linux][14]
|
||||
|
||||
If you wanna be more accurate, then use [mpv][15] to see the movie or media file and click on the timing, if you click on the timing bar which shows how much the movie or the media file has elapsed, clicking on it will also reveal the microsecond.
|
||||
|
||||
I usually like to be accurate so I try to be as precise as possible. It is very difficult in MPV as human reaction time is imprecise. If I wanna be super accurate then I use something like [Audacity][16] but then that is another ball-game altogether as you can do so much more with it. That may be something to explore in a future blog post as well.
|
||||
|
||||
#### Manipulating Duration
|
||||
|
||||
Sometimes even doing both is not enough and you even have to shrink or add the duration to make it sync with the media file. This is one of the more tedious works as you have to individually fix the duration of each sentence. This can happen especially if you have variable frame rates in the media file (nowadays rare but you still get such files).
|
||||
|
||||
In such a scenario, you may have to edit the duration manually and automation is not possible. The best way is either to fix the video file (not possible without degrading the video quality) or getting video from another source at a higher quality and then [transcode][17] it with the settings you prefer. This again, while a major undertaking I could shed some light on in some future blog post.
|
||||
|
||||
### Conclusion
|
||||
|
||||
What I have shared in above is more or less on improving on existing subtitle files. If you were to start a scratch you need loads of time. I haven’t shared that at all because a movie or any video material of say an hour can easily take anywhere from 4-6 hours or even more depending upon skills of the subtitler, patience, context, jargon, accents, native English speaker, translator etc. all of which makes a difference to the quality of the subtitle.
|
||||
|
||||
I hope you find this interesting and from now onward, you’ll handle your subtitles slightly better. If you have any suggestions to add, please leave a comment below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/editing-subtitles
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/shirish/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/editing-subtitles-in-linux.jpeg?resize=800%2C450&ssl=1
|
||||
[2]: https://www.ccextractor.org/
|
||||
[3]: https://itsfoss.com/best-open-source-internships/
|
||||
[4]: https://www.ccextractor.org/public:codein:google_code-in_2018
|
||||
[5]: https://github.com/CCExtractor/ccextractor/wiki/Installation
|
||||
[6]: https://en.wikipedia.org/wiki/Matroska
|
||||
[7]: https://www.vicaps.com/blog/history-of-silent-movies-and-subtitles/
|
||||
[8]: https://en.wikipedia.org/wiki/SubRip#SubRip_text_file_format
|
||||
[9]: https://www.imdb.com/title/tt0010323/
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/subtitleeditor.jpg?ssl=1
|
||||
[11]: https://www.opensubtitles.org/en/search/sublanguageid-eng/idmovie-4105
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/subtitleeditor-frame-rate-sync.jpg?resize=800%2C450&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Move-subtitles-Caligiri.jpg?resize=800%2C450&ssl=1
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/move-subtitles.jpg?ssl=1
|
||||
[15]: https://itsfoss.com/mpv-video-player/
|
||||
[16]: https://www.audacityteam.org/
|
||||
[17]: https://en.wikipedia.org/wiki/Transcoding
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/editing-subtitles-in-linux.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,139 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Hegemon – A Modular System And Hardware Monitoring Tool For Linux)
|
||||
[#]: via: (https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Hegemon – A Modular System And Hardware Monitoring Tool For Linux
|
||||
======
|
||||
|
||||
I know that everybody is preferring for **[TOP Command][1]** to monitor system utilization.
|
||||
|
||||
It’s one of the best and native command which used by vast of Linux administrators.
|
||||
|
||||
In Linux there is an alternative for everything respective of packages.
|
||||
|
||||
There are many utilities are available for this purpose in Linux and i prefer **[HTOP Command][2]**.
|
||||
|
||||
If you want to know about other alternatives, i would suggest you to navigate to the each link to know more about it.
|
||||
|
||||
Those are htop, CorFreq, glances, atop, Dstat, Gtop, Linux Dash, Netdata, Monit, etc.
|
||||
|
||||
All these tools only allow us to monitor system utilization and not for the system hardware’s.
|
||||
|
||||
But Hegemon is allow us to monitor both in the single dashboard.
|
||||
|
||||
If you are looking for system hardware monitoring then i would suggest you to check **[lm_sensors][3]** and **[s-tui Stress Terminal UI][4]** utilities.
|
||||
|
||||
### What’s Hegemon?
|
||||
|
||||
Hegemon is a work-in-progress modular system monitor written in safe Rust.
|
||||
|
||||
It allow users to monitor both utilization in a single dashboard. It’s system utilization and hardware temperatures.
|
||||
|
||||
### Currently Available Features in Hegemon
|
||||
|
||||
* Monitor CPU and memory usage, temperatures, and fan speeds
|
||||
* Expand any data stream to reveal a more detailed graph and additional information
|
||||
* Adjustable update interval
|
||||
* Clean MVC architecture with good code quality
|
||||
* Unit tests
|
||||
|
||||
|
||||
|
||||
### Planned Features include
|
||||
|
||||
* macOS and BSD support (only Linux is supported at the moment)
|
||||
* Monitor disk and network I/O, GPU usage (maybe), and more
|
||||
* Select and reorder data streams
|
||||
* Mouse control
|
||||
|
||||
|
||||
|
||||
### How to Install Hegemon in Linux?
|
||||
|
||||
Hegemon is requires Rust 1.26 or later and the development files for libsensors. So, make sure these packages were installed before your perform Hegemon installation.
|
||||
|
||||
libsensors library package is available in most of the distribution official repository so, use the following command to install it.
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][5]** or **[APT Command][6]** to install libsensors on your systems.
|
||||
|
||||
```
|
||||
# apt install lm_sensors-devel
|
||||
```
|
||||
|
||||
For **`Fedora`** system, use **[DNF Package Manager][7]** to install libsensors on your system.
|
||||
|
||||
```
|
||||
# dnf install libsensors4-dev
|
||||
```
|
||||
|
||||
Run the following command to install Rust programming language and follow the instruction. Navigate to the following URL if you want handy tutorials for **[Rust installation][8]**.
|
||||
|
||||
```
|
||||
$ curl https://sh.rustup.rs -sSf | sh
|
||||
```
|
||||
|
||||
If you have successfully installed Rust. Run the following command to install Hegemon.
|
||||
|
||||
```
|
||||
$ cargo install hegemon
|
||||
```
|
||||
|
||||
### How to Lunch Hegemon in Linux?
|
||||
|
||||
Once you successfully install Hegemon package. Run run the below command to launch it.
|
||||
|
||||
```
|
||||
$ hegemon
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
I was facing an issue when i was launching the “Hegemon” application due to libsensors.so.4 libraries issue.
|
||||
|
||||
```
|
||||
$ hegemon
|
||||
error while loading shared libraries: libsensors.so.4: cannot open shared object file: No such file or directory manjaro
|
||||
```
|
||||
|
||||
I’m using Manjaro 18.04. It has the libsensors.so & libsensors.so.5 shared libraries and not for libsensors.so.4. So, i just created the following symlink to fix the issue.
|
||||
|
||||
```
|
||||
$ sudo ln -s /usr/lib/libsensors.so /usr/lib/libsensors.so.4
|
||||
```
|
||||
|
||||
Here is the sample gif file which was taken from my Lenovo-Y700 laptop.
|
||||
![][11]
|
||||
|
||||
By default it shows only overall summary and if you would like to see the detailed output then you need to expand the each section. See the expanded output with Hegemon.
|
||||
![][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
|
||||
[2]: https://www.2daygeek.com/linux-htop-command-linux-system-performance-resource-monitoring-tool/
|
||||
[3]: https://www.2daygeek.com/view-check-cpu-hard-disk-temperature-linux/
|
||||
[4]: https://www.2daygeek.com/s-tui-stress-terminal-ui-monitor-linux-cpu-temperature-frequency/
|
||||
[5]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[6]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[7]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[8]: https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/
|
||||
[9]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2019/01/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux-1.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2019/01/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux-2a.gif
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux-3.png
|
||||
183
sources/tech/20190115 Linux Tools- The Meaning of Dot.md
Normal file
183
sources/tech/20190115 Linux Tools- The Meaning of Dot.md
Normal file
@ -0,0 +1,183 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Tools: The Meaning of Dot)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Linux Tools: The Meaning of Dot
|
||||
======
|
||||
|
||||

|
||||
|
||||
Let's face it: writing one-liners and scripts using shell commands can be confusing. Many of the names of the tools at your disposal are far from obvious in terms of what they do ( _grep_ , _tee_ and _awk_ , anyone?) and, when you combine two or more, the resulting "sentence" looks like some kind of alien gobbledygook.
|
||||
|
||||
None of the above is helped by the fact that many of the symbols you use to build a chain of instructions can mean different things depending on their context.
|
||||
|
||||
### Location, location, location
|
||||
|
||||
Take the humble dot (`.`) for example. Used with instructions that are expecting the name of a directory, it means "this directory" so this:
|
||||
|
||||
```
|
||||
find . -name "*.jpg"
|
||||
```
|
||||
|
||||
translates to " _find in this directory (and all its subdirectories) files that have names that end in`.jpg`_ ".
|
||||
|
||||
Both `ls .` and `cd .` act as expected, so they list and "change" to the current directory, respectively, although including the dot in these two cases is not necessary.
|
||||
|
||||
Two dots, one after the other, in the same context (i.e., when your instruction is expecting a directory path) means " _the directory immediately above the current one_ ". If you are in _/home/your_directory_ and run
|
||||
|
||||
```
|
||||
cd ..
|
||||
```
|
||||
|
||||
you will be taken to _/home_. So, you may think this still kind of fits into the “dots represent nearby directories” narrative and is not complicated at all, right?
|
||||
|
||||
How about this, then? If you use a dot at the beginning of a directory or file, it means the directory or file will be hidden:
|
||||
|
||||
```
|
||||
$ touch somedir/file01.txt somedir/file02.txt somedir/.secretfile.txt
|
||||
$ ls -l somedir/
|
||||
total 0
|
||||
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file01.txt
|
||||
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file02.txt
|
||||
$ # Note how there is no .secretfile.txt in the listing above
|
||||
$ ls -la somedir/
|
||||
total 8
|
||||
drwxr-xr-x 2 paul paul 4096 Jan 13 19:57 .
|
||||
drwx------ 48 paul paul 4096 Jan 13 19:57 ..
|
||||
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file01.txt
|
||||
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 file02.txt
|
||||
-rw-r--r-- 1 paul paul 0 Jan 13 19:57 .secretfile.txt
|
||||
$ # The -a option tells ls to show "all" files, including the hidden ones
|
||||
```
|
||||
|
||||
And then there's when you use `.` as a command. Yep! You heard me: `.` is a full-fledged command. It is a synonym of `source` and you use that to execute a file in the current shell, as opposed to running a script some other way (which usually mean Bash will spawn a new shell in which to run it).
|
||||
|
||||
Confused? Don't worry -- try this: Create a script called _myscript_ that contains the line
|
||||
|
||||
```
|
||||
myvar="Hello"
|
||||
```
|
||||
|
||||
and execute it the regular way, that is, with `sh myscript` (or by making the script executable with `chmod a+x myscript` and then running `./myscript`). Now try and see the contents of `myvar` with `echo $myvar` (spoiler: You will get nothing). This is because, when your script plunks " _Hello_ " into `myvar`, it does so in a separate bash shell instance. When the script ends, the spawned instance disappears and control returns to the original shell, where `myvar` never even existed.
|
||||
|
||||
However, if you run _myscript_ like this:
|
||||
|
||||
```
|
||||
. myscript
|
||||
```
|
||||
|
||||
`echo $myvar` will print _Hello_ to the command line.
|
||||
|
||||
You will often use the `.` (or `source`) command after making changes to your _.bashrc_ file, [like when you need to expand your `PATH` variable][1]. You use `.` to make the changes available immediately in your current shell instance.
|
||||
|
||||
### Double Trouble
|
||||
|
||||
Just like the seemingly insignificant single dot has more than one meaning, so has the double dot. Apart from pointing to the parent of the current directory, the double dot (`..`) is also used to build sequences.
|
||||
|
||||
Try this:
|
||||
|
||||
```
|
||||
echo {1..10}
|
||||
```
|
||||
|
||||
It will print out the list of numbers from 1 to 10. In this context, `..` means " _starting with the value on my left, count up to the value on my right_ ".
|
||||
|
||||
Now try this:
|
||||
|
||||
```
|
||||
echo {1..10..2}
|
||||
```
|
||||
|
||||
You'll get _1 3 5 7 9_. The `..2` part of the command tells Bash to print the sequence, but not one by one, but two by two. In other words, you'll get all the odd numbers from 1 to 10.
|
||||
|
||||
It works backwards, too:
|
||||
|
||||
```
|
||||
echo {10..1..2}
|
||||
```
|
||||
|
||||
You can also pad your numbers with 0s. Doing:
|
||||
|
||||
```
|
||||
echo {000..121..2}
|
||||
```
|
||||
|
||||
will print out every even number from 0 to 121 like this:
|
||||
|
||||
```
|
||||
000 002 004 006 ... 050 052 054 ... 116 118 120
|
||||
```
|
||||
|
||||
But how is this sequence-generating construct useful? Well, suppose one of your New Year's resolutions is to be more careful with your accounts. As part of that, you want to create directories in which to classify your digital invoices of the last 10 years:
|
||||
|
||||
```
|
||||
mkdir {2009..2019}_Invoices
|
||||
```
|
||||
|
||||
Job done.
|
||||
|
||||
Or maybe you have a hundreds of numbered files, say, frames extracted from a video clip, and, for whatever reason, you want to remove only every third frame between the frames 43 and 61:
|
||||
|
||||
```
|
||||
rm frame_{043..61..3}
|
||||
```
|
||||
|
||||
It is likely that, if you have more than 100 frames, they will be named with padded 0s and look like this:
|
||||
|
||||
```
|
||||
frame_000 frame_001 frame_002 ...
|
||||
```
|
||||
|
||||
That’s why you will use `043` in your command instead of just `43`.
|
||||
|
||||
### Curly~Wurly
|
||||
|
||||
Truth be told, the magic of sequences lies not so much in the double dot as in the sorcery of the curly braces (`{}`). Look how it works for letters, too. Doing:
|
||||
|
||||
```
|
||||
touch file_{a..z}.txt
|
||||
```
|
||||
|
||||
creates the files _file_a.txt_ through _file_z.txt_.
|
||||
|
||||
You must be careful, however. Using a sequence like `{Z..a}` will run through a bunch of non-alphanumeric characters (glyphs that are neither numbers or letters) that live between the uppercase alphabet and the lowercase one. Some of these glyphs are unprintable or have a special meaning of their own. Using them to generate names of files could lead to a whole bevy of unexpected and potentially unpleasant effects.
|
||||
|
||||
One final thing worth pointing out about sequences encased between `{...}` is that they can also contain lists of strings:
|
||||
|
||||
```
|
||||
touch {blahg, splurg, mmmf}_file.txt
|
||||
```
|
||||
|
||||
Creates _blahg_file.txt_ , _splurg_file.txt_ and _mmmf_file.txt_.
|
||||
|
||||
Of course, in other contexts, the curly braces have different meanings (surprise!). But that is the stuff of another article.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Bash and the utilities you can run within it have been shaped over decades by system administrators looking for ways to solve very particular problems. To say that sysadmins and their ways are their own breed of special would be an understatement. Consequently, as opposed to other languages, Bash was not designed to be user-friendly, easy or even logical.
|
||||
|
||||
That doesn't mean it is not powerful -- quite the contrary. Bash's grammar and shell tools may be inconsistent and sprawling, but they also provide a dizzying range of ways to do everything you can possibly imagine. It is like having a toolbox where you can find everything from a power drill to a spoon, as well as a rubber duck, a roll of duct tape, and some nail clippers.
|
||||
|
||||
Apart from fascinating, it is also fun to discover all you can achieve directly from within the shell, so next time we will delve ever deeper into how you can build bigger and better Bash command lines.
|
||||
|
||||
Until then, have fun!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-otherwise
|
||||
@ -1,70 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 resolutions for open source project maintainers)
|
||||
[#]: via: (https://opensource.com/article/18/12/resolutions-open-source-project-maintainers)
|
||||
[#]: author: (Ben Cotton https://opensource.com/users/bcotton)
|
||||
|
||||
5个为开源项目维护者而生的解决方案
|
||||
======
|
||||
|
||||
不管你怎么说,好的交流是一个活跃的开源社区的必备品。
|
||||
|
||||

|
||||
|
||||
我不会给你一个大而全的新年的解决方案。关于自我提升,我没有任何问题,这篇文章我希望锚定这个日历中的另外一部分。不过即使是这样,这里也有一些关于取消今年的免费日历并将其替换为新的日历的内容,以激发自省。
|
||||
|
||||
在 2017 年,我从不在社交媒体上分享我从未阅读过的文章。我一直保持这样的状态,我也认为它让我成为了一个更好的互联网公民。对于 2019 年,我正在考虑让我成为更好的开源软件维护者的解决方案。
|
||||
|
||||
|
||||
下面是一些我在一些项目中担任维护者或共同维护者时坚持的决议:
|
||||
|
||||
### 1\. 包含行为准则
|
||||
|
||||
Jono Bacon 在他的文章“[7个你可能犯的错误][1]”中包含了“不强制执行行为准则”。当然,去强制执行行为准则,你首先需要有一个行为准则。我设计了一个默认的[贡献者契约][2],但是你可以使用其他你喜欢的。关于这个 License ,最好的方法是使用别人已经写好的,而不是你自己写的。但是重要的是,要找到一些能够定义你希望你的社区执行的,无论他们是什么样子。一旦这些被记录下来并强制执行,人们就能自行决定是否成为他们想象中社区的一份子。
|
||||
|
||||
|
||||
### 2\. 使许可证清晰且明确
|
||||
|
||||
你知道什么真的很烦么?不清晰的许可证。"这个软件基于 GPL 授权",如果没有进一步提供更多信息的文字,我无法知道更多信息。基于哪个版本的[GPL][3]?对于项目的非代码部分,“根据知识共享许可证授权”更糟糕。我喜欢[知识共享许可证][4],但其中有几个不同的许可证包含着不同的权利和义务。因此,我将清楚的说明许可证的版本适用于我的项目。我将会在 repo 中包含许可的全文,并在其他文件中包含简明的注释。
|
||||
|
||||
与此相关的一类是使用 [OSI][5]批准的许可证。想出一个新的准确的说明了你想要表达什么的许可证是有可能的,但是如果你需要强制执行它,祝你好运。会坚持使用它么?使用您项目的人会理解么?
|
||||
|
||||
|
||||
|
||||
### 3\. 快速分类错误报告和问题
|
||||
|
||||
技术的规模很难会和开源维护者一样差。即使在小型项目中,也很难找到时间去回答每个问题并修复每个错误。但这并不意味着我至少不能去回应这个人,它没必要是多段的回复。即使只是标记了 Github Issue 也表明了我看见它了。也许我马上就会处理它,也许一年后我会处理它。但是让社区看到它很重要。是的,这里还有其他人。
|
||||
|
||||
### 4\. 如果没有伴随的文档,请不要推送新特性或 Bugfix
|
||||
|
||||
尽管多年来我的开源贡献都围绕着文档,但我的项目并没有反映出我对他们的重视。我很少有不需要某种形式文档的推送。新的特性显然应该在他们被提交甚至是之前编写文档。但即使是错误修复,也应该在发行说明中有一个条目。如果没有什么其他的,一个 push 也是很好的改善文档的机会。
|
||||
|
||||
### 5\. 放弃一个项目时,要说清楚
|
||||
|
||||
我很擅长对事情说“不”,我告诉编辑我会为 [Opensource.com][6] 写一到两篇文章,现在我有了将近 60 篇文章。Oops。但在某些时候,曾经符合我利益的事情不再有用。也许该项目是不必要的,因为它的功能被吸收到更大的项目中,也许只是我厌倦了它。但这对社区是不公平的(并且存在潜在的危险,正如最近的[event-stream 恶意软件注入][7]所示),会让项目陷入困境。维护者有权随时离开,但他们离开时应该清清楚楚。
|
||||
|
||||
无论你是开源维护者还是贡献者,如果你知道项目维护者应该作出的其他决议,请在评论中分享!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/resolutions-open-source-project-maintainers
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/8/mistakes-open-source-avoid
|
||||
[2]: https://www.contributor-covenant.org/
|
||||
[3]: https://opensource.org/licenses/gpl-license
|
||||
[4]: https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[5]: https://opensource.org/
|
||||
[6]: http://Opensource.com
|
||||
[7]: https://arstechnica.com/information-technology/2018/11/hacker-backdoors-widely-used-open-source-software-to-steal-bitcoin/
|
||||
@ -1,16 +1,16 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ()
|
||||
[#]: publisher: ()
|
||||
[#]: url: ()
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 1 OK01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室 - 树莓派:课程 1:OK01
|
||||
计算机实验室之树莓派:课程 1 OK01
|
||||
======
|
||||
|
||||
OK01 课程讲解了树莓派如何开始,以及在树莓派上如何启用靠近 RCA 和 USB 端口的 `OK` 或 `ACT` 的 **LED** 指示灯。这个指示灯最初是为了指示 `OK` 的,但它在第二版的树莓派上被重命名为 `ACT`。
|
||||
OK01 课程讲解了树莓派如何入门,以及在树莓派上如何启用靠近 RCA 和 USB 端口的 OK 或 ACT 的 LED 指示灯。这个指示灯最初是为了指示 OK 状态的,但它在第二版的树莓派上被改名为 ACT。
|
||||
|
||||
### 1、入门
|
||||
|
||||
@ -18,17 +18,13 @@ OK01 课程讲解了树莓派如何开始,以及在树莓派上如何启用靠
|
||||
|
||||
### 2、开始
|
||||
|
||||
```
|
||||
扩展名为 '.s' 的文件一般是汇编代码,需要记住的是,在这里它是 ARMv6 的汇编代码。
|
||||
```
|
||||
|
||||
现在,你已经展开了这个模板,在 `source` 目录中创建一个名为 `main.s` 的文件。这个文件包含了这个操作系统的代码。具体来看,这个文件夹的结构应该像下面这样:
|
||||
现在,你已经展开了这个模板文件,在 `source` 目录中创建一个名为 `main.s` 的文件。这个文件包含了这个操作系统的代码。具体来看,这个文件夹的结构应该像下面这样:
|
||||
|
||||
```
|
||||
build/
|
||||
(empty)
|
||||
(empty)
|
||||
source/
|
||||
main.s
|
||||
main.s
|
||||
kernel.ld
|
||||
LICENSE
|
||||
Makefile
|
||||
@ -36,6 +32,8 @@ Makefile
|
||||
|
||||
用文本编辑器打开 `main.s` 文件,这样我们就可以输入汇编代码了。树莓派使用了称为 ARMv6 的汇编代码变体,这就是我们即将要写的汇编代码类型。
|
||||
|
||||
> 扩展名为 `.s` 的文件一般是汇编代码,需要记住的是,在这里它是 ARMv6 的汇编代码。
|
||||
|
||||
首先,我们复制下面的这些命令。
|
||||
|
||||
```
|
||||
@ -44,13 +42,13 @@ Makefile
|
||||
_start:
|
||||
```
|
||||
|
||||
实际上,上面这些指令并没有在树莓派上做任何事情,它们是提供给汇编器的指令。汇编器是一个转换程序,它将树莓派能够理解的机器代码转换成我们能够理解的汇编代码,在汇编代码中,每个行都是一个新的命令。上面的第一行告诉汇编器在哪里放我们的代码。我们提供的模板中将它放到一个名为 `.init` 的节中的原因是,它是输出的起始点。这很重要,因为我们希望确保我们能够控制哪个代码首先运行。如果不这样做,首先运行的代码将是按字母顺序排在前面的代码!`.section` 命令简单地告诉汇编器,哪个节中放置代码,从这个点开始,直到下一个 `.section` 或文件结束为止。
|
||||
实际上,上面这些指令并没有在树莓派上做任何事情,它们是提供给汇编器的指令。汇编器是一个转换程序,它将我们能够理解的汇编代码转换成树莓派能够理解的机器代码。在汇编代码中,每个行都是一个新的命令。上面的第一行告诉汇编器 [^1] 在哪里放我们的代码。我们提供的模板中将它放到一个名为 `.init` 的节中的原因是,它是输出的起始点。这很重要,因为我们希望确保我们能够控制哪个代码首先运行。如果不这样做,首先运行的代码将是按字母顺序排在前面的代码!`.section` 命令简单地告诉汇编器,哪个节中放置代码,从这个点开始,直到下一个 `.section` 或文件结束为止。
|
||||
|
||||
```
|
||||
在汇编代码中,你可以跳行、在命令前或后放置空格去提升可读性。
|
||||
```
|
||||
|
||||
接下来两行是停止一个警告消息,它们并不重要。
|
||||
接下来两行是停止一个警告消息,它们并不重要。[^2]
|
||||
|
||||
### 3、第一行代码
|
||||
|
||||
@ -62,59 +60,55 @@ _start:
|
||||
ldr r0,=0x20200000
|
||||
```
|
||||
|
||||
```
|
||||
ldr reg,=val 将数字 val 加载到名为 reg 的寄存器中。
|
||||
```
|
||||
> `ldr reg,=val` 将数字 `val` 加载到名为 `reg` 的寄存器中。
|
||||
|
||||
那是我们的第一个命令。它告诉处理器将数字 0x20200000 保存到寄存器 r0 中。在这里我需要去回答两个问题,寄存器是什么?0x20200000 是一个什么样的数字?
|
||||
那是我们的第一个命令。它告诉处理器将数字 `0x20200000` 保存到寄存器 `r0` 中。在这里我需要去回答两个问题,<ruby>寄存器<rt>register</rt></ruby>是什么?`0x20200000` 是一个什么样的数字?
|
||||
|
||||
```
|
||||
树莓派上的一个单独的寄存器能够保存任何介于 0 到 4,294,967,295(含) 之间的任意整数,它可能看起来像一个很大的内存,实际上它仅有 32 个二进制比特。
|
||||
```
|
||||
寄存器在处理器中就是一个极小的内存块,它是处理器保存正在处理的数字的地方。处理器中有很多寄存器,很多都有专门的用途,我们在后面会一一接触到它们。最重要的有十三个(命名为 `r0`、`r1`、`r2`、…、`r9`、`r10`、`r11`、`r12`),它们被称为通用寄存器,你可以使用它们做任何计算。由于是写我们的第一行代码,我们在示例中使用了 `r0`,当然你可以使用它们中的任何一个。只要后面始终如一就没有问题。
|
||||
|
||||
一个寄存器在处理器中就是一个极小的内存块,它是处理器保存正在处理的数字的地方。处理器中有很多寄存器,很多都有专门的用途,我们在后面会一一接触到它们。重要的是,它们有十三个(命名为 r0、r1、r2、…、r9、r10、r11、r12),它们被称为通用寄存器,你可以使用它们做任何计算。由于是写我们的第一行代码,我们在示例中使用了 r0,当然你可以使用它们中的任何一个。只要后面始终如一就没有问题。
|
||||
> 树莓派上的一个单独的寄存器能够保存任何介于 `0` 到 `4,294,967,295`(含)之间的任意整数,它可能看起来像一个很大的内存,实际上它仅有 32 个二进制比特。
|
||||
|
||||
0x20200000 是一个准确的数字。只不过它是以十六进制表示的。下面的内容详细解释了十六进制的相关信息:
|
||||
`0x20200000` 确实是一个数字。只不过它是以十六进制表示的。下面的内容详细解释了十六进制的相关信息:
|
||||
|
||||
十六进制是另一种表示数字的方式。你或许只知道十进制的数字表示方法,十进制共有十个数字:0、1、2、3、4、5、6、7、8 和 9。十六进制共有十六个数字:0、1、2、3、4、5、6、7、8、9、a、b、c、d、e 和 f。
|
||||
> 延伸阅读:十六进制解释
|
||||
|
||||
![567 is 5 hundreds, 6 tens and 7 units.][2]
|
||||
> 十六进制是另一种表示数字的方式。你或许只知道十进制的数字表示方法,十进制共有十个数字:`0`、`1`、`2`、`3`、`4`、`5`、`6`、`7`、`8` 和 `9`。十六进制共有十六个数字:`0`、`1`、`2`、`3`、`4`、`5`、`6`、`7`、`8`、`9`、`a`、`b`、`c`、`d`、`e` 和 `f`。
|
||||
|
||||
你可能还记得十进制是如何用位制来表示的。即最右侧的数字是个位,紧接着的左边一位是十位,再接着的左边一位是百位,依此类推。也就是说,它的值是 100 × 百位的数字,再加上 10 × 十位的数字,再加上 1 × 个位的数字。
|
||||
> 你可能还记得十进制是如何用位制来表示的。即最右侧的数字是个位,紧接着的左边一位是十位,再接着的左边一位是百位,依此类推。也就是说,它的值是 100 × 百位的数字,再加上 10 × 十位的数字,再加上 1 × 个位的数字。
|
||||
|
||||
![567 is 5x10^2+6x10^1+7x10^0][3]
|
||||
> ![567 is 5 hundreds, 6 tens and 7 units.][2]
|
||||
|
||||
从数学的角度来看,我们可以发现规律,最右侧的数字是 10<sup>0</sup>=1s,紧接着的左边一位是 10<sup>1</sup>=10s,再接着是 10<sup>2</sup>=100s,依此类推。我们设定在系统中,0 是最低位,紧接着是 1,依此类推。但如果我们使用一个不同于 10 的数字为幂底会是什么样呢?我们在系统中使用的十六进制就是这样的一个数字。
|
||||
> 从数学的角度来看,我们可以发现规律,最右侧的数字是 10<sup>0</sup> = 1s,紧接着的左边一位是 10<sup>1</sup> = 10s,再接着是 10<sup>2</sup> = 100s,依此类推。我们设定在系统中,0 是最低位,紧接着是 1,依此类推。但如果我们使用一个不同于 10 的数字为幂底会是什么样呢?我们在系统中使用的十六进制就是这样的一个数字。
|
||||
|
||||
![567 = 5x10^2+6x10^1+7x10^0 = 2x16^2+3x16^1+7x16^0][4]
|
||||
> ![567 is 5x10^2+6x10^1+7x10^0][3]
|
||||
|
||||
上面的数学等式表明,十进制的数字 567 等于十六进制的数字 237。通常我们需要在系统中明确它们,我们使用下标 <sub>10</sub> 表示它是十进制数字,用下标 <sub>16</sub> 表示它是十六进制数字。由于在汇编代码中写上下标的小数字很困难,因此我们使用 0x 来表示它是一个十六进制的数字,因此 0x237 的意思就是 237<sub>16</sub> 。
|
||||
> ![567 = 5x10^2+6x10^1+7x10^0 = 2x16^2+3x16^1+7x16^0][4]
|
||||
|
||||
那么,后面的 a、b、c、d、e 和 f 又是什么呢?好问题!在十六进制中为了能够写每个数字,我们就需要额外的东西。例如 9<sub>16</sub> = 9×16<sup>0</sup> = 9<sub>10</sub> ,但是 10<sub>16</sub> = 1×16<sup>1</sup> + 1×16<sup>0</sup> = 16<sub>10</sub> 。因此,如果我们只使用 0、1、2、3、4、5、6、7、8 和 9,我们就无法写出 10<sub>10</sub> 、11<sub>10</sub> 、12<sub>10</sub> 、13<sub>10</sub> 、14<sub>10</sub> 、15<sub>10</sub> 。因此我们引入了 6 个新的数字,这样 a<sub>16</sub> = 10<sub>10</sub> 、b<sub>16</sub> = 11<sub>10</sub> 、c<sub>16</sub> = 12<sub>10</sub> 、d<sub>16</sub> = 13<sub>10</sub> 、e<sub>16</sub> = 14<sub>10</sub> 、f<sub>16</sub> = 15<sub>10</sub> 。
|
||||
> 上面的数学等式表明,十进制的数字 567 等于十六进制的数字 237。通常我们需要在系统中明确它们,我们使用下标 <sub>10</sub> 表示它是十进制数字,用下标 <sub>16</sub> 表示它是十六进制数字。由于在汇编代码中写上下标的小数字很困难,因此我们使用 0x 来表示它是一个十六进制的数字,因此 0x237 的意思就是 237<sub>16</sub> 。
|
||||
|
||||
所以,我们就有了另一种写数字的方式。但是我们为什么要这么麻烦呢?好问题!由于计算机总是工作在二进制中,事实证明,十六进制是非常有用的,因为每个十六进制数字正好是四个二进制数字的长度。这种方法还有另外一个好处,那就是许多计算机的数字都是十六进制的整数倍,而不是十进制的整数倍。比如,我在上面的汇编代码中使用的一个数字 20200000<sub>16</sub> 。如果我们用十进制来写,它就是一个不太好记住的数字 538968064<sub>10</sub> 。
|
||||
> 那么,后面的 `a`、`b`、`c`、`d`、`e` 和 `f` 又是什么呢?好问题!在十六进制中为了能够写每个数字,我们就需要额外的东西。例如 9<sub>16</sub> = 9×16<sup>0</sup> = 9<sub>10</sub> ,但是 10<sub>16</sub> = 1×16<sup>1</sup> + 1×16<sup>0</sup> = 16<sub>10</sub> 。因此,如果我们只使用 0、1、2、3、4、5、6、7、8 和 9,我们就无法写出 10<sub>10</sub> 、11<sub>10</sub> 、12<sub>10</sub> 、13<sub>10</sub> 、14<sub>10</sub> 、15<sub>10</sub> 。因此我们引入了 6 个新的数字,这样 a<sub>16</sub> = 10<sub>10</sub> 、b<sub>16</sub> = 11<sub>10</sub> 、c<sub>16</sub> = 12<sub>10</sub> 、d<sub>16</sub> = 13<sub>10</sub> 、e<sub>16</sub> = 14<sub>10</sub> 、f<sub>16</sub> = 15<sub>10</sub> 。
|
||||
|
||||
我们可以用下面的简单方法将十进制转换成十六进制:
|
||||
> 所以,我们就有了另一种写数字的方式。但是我们为什么要这么麻烦呢?好问题!由于计算机总是工作在二进制中,事实证明,十六进制是非常有用的,因为每个十六进制数字正好是四个二进制数字的长度。这种方法还有另外一个好处,那就是许多计算机的数字都是十六进制的整数倍,而不是十进制的整数倍。比如,我在上面的汇编代码中使用的一个数字 20200000<sub>16</sub> 。如果我们用十进制来写,它就是一个不太好记住的数字 538968064<sub>10</sub> 。
|
||||
|
||||
![Conversion example][5]
|
||||
> 我们可以用下面的简单方法将十进制转换成十六进制:
|
||||
|
||||
1. 我们以十进制数字 567 为例来说明。
|
||||
2. 将十进制数字 567 除以 16 并计算其余数。例如 567 ÷ 16 = 35 余数为 7。
|
||||
3. 在十六进制中余数就是答案中的最后一位数字,在我们的例子中它是 7。
|
||||
4. 重复第 2 步和第 3 步,直到除法结果的整数部分为 0。例如 35 ÷ 16 = 2 余数为 3,因此 3 就是答案中的下一位。2 ÷ 16 = 0 余数为 2,因此 2 就是答案的接下来一位。
|
||||
5. 一旦除法结果的整数部分为 0 就结束了。答案就是反序的余数,因此 567<sub>10</sub> = 237<sub>16</sub>。
|
||||
> ![Conversion example][5]
|
||||
|
||||
> 1. 我们以十进制数字 567 为例来说明。
|
||||
> 2. 将十进制数字 567 除以 16 并计算其余数。例如 567 ÷ 16 = 35 余数为 7。
|
||||
> 3. 在十六进制中余数就是答案中的最后一位数字,在我们的例子中它是 7。
|
||||
> 4. 重复第 2 步和第 3 步,直到除法结果的整数部分为 0。例如 35 ÷ 16 = 2 余数为 3,因此 3 就是答案中的下一位。2 ÷ 16 = 0 余数为 2,因此 2 就是答案的接下来一位。
|
||||
> 5. 一旦除法结果的整数部分为 0 就结束了。答案就是反序的余数,因此 567<sub>10</sub> = 237<sub>16</sub>。
|
||||
|
||||
> 转换十六进制数字为十进制,也很容易,将数字展开即可,因此 237<sub>16</sub> = 2×16<sup>2</sup> + 3×16<sup>1</sup> +7 ×16<sup>0</sup> = 2×256 + 3×16 + 7×1 = 512 + 48 + 7 = 567。
|
||||
|
||||
转换十六进制数字为十进制,也很容易,将数字展开即可,因此 237<sub>16</sub> = 2×16<sup>2</sup> + 3×16<sup>1</sup> +7 ×16<sup>0</sup> = 2×256 + 3×16 + 7×1 = 512 + 48 + 7 = 567。
|
||||
|
||||
因此,我们所写的第一个汇编命令是将数字 20200000<sub>16</sub> 加载到寄存器 r0 中。那个命令看起来似乎没有什么用,但事实并非如此。在计算机中,有大量的内存块和设备。为了能够访问它们,我们给每个内存块和设备指定了一个地址。就像邮政地址或网站地址一样,它用于标识我们想去访问的内存块或设备的位置。计算机中的地址就是一串数字,因此上面的数字 20200000<sub>16</sub> 就是 GPIO 控制器的地址。这个地址是由制造商的设计所决定的,他们也可以使用其它地址(只要不与其它的冲突即可)。我之所以知道这个地址是 GPIO 控制器的地址是因为我看了它的[手册][https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/SoC-Peripherals.pdf],地址的使用没有专门的规范(除了它们都是以十六进制表示的大数以外)。
|
||||
因此,我们所写的第一个汇编命令是将数字 20200000<sub>16</sub> 加载到寄存器 `r0` 中。那个命令看起来似乎没有什么用,但事实并非如此。在计算机中,有大量的内存块和设备。为了能够访问它们,我们给每个内存块和设备指定了一个地址。就像邮政地址或网站地址一样,它用于标识我们想去访问的内存块或设备的位置。计算机中的地址就是一串数字,因此上面的数字 20200000<sub>16</sub> 就是 GPIO 控制器的地址。这个地址是由制造商的设计所决定的,他们也可以使用其它地址(只要不与其它的冲突即可)。我之所以知道这个地址是 GPIO 控制器的地址是因为我看了它的手册,[^3] 地址的使用没有专门的规范(除了它们都是以十六进制表示的大数以外)。
|
||||
|
||||
### 4、启用输出
|
||||
|
||||
![A diagram showing key parts of the GPIO controller.][6]
|
||||
|
||||
阅读了手册可以得知,我们需要给 GPIO 控制器发送两个消息。我们必须用它的语言告诉它,如果我们这样做了,它将非常乐意实现我们的意图,去打开 `OK` 的 LED 指示灯。幸运的是,它是一个非常简单的芯片,为了让它能够理解我们要做什么,只需要给它设定几个数字即可。
|
||||
阅读了手册可以得知,我们需要给 GPIO 控制器发送两个消息。我们必须用它的语言告诉它,如果我们这样做了,它将非常乐意实现我们的意图,去打开 OK 的 LED 指示灯。幸运的是,它是一个非常简单的芯片,为了让它能够理解我们要做什么,只需要给它设定几个数字即可。
|
||||
|
||||
```
|
||||
mov r1,#1
|
||||
@ -122,51 +116,51 @@ lsl r1,#18
|
||||
str r1,[r0,#4]
|
||||
```
|
||||
|
||||
```
|
||||
mov reg,#val 将数字 val 放到名为 reg 的寄存器中。
|
||||
> `mov reg,#val` 将数字 `val` 放到名为 `reg` 的寄存器中。
|
||||
|
||||
lsl reg,#val 将寄存器 reg 中的二进制操作数左移 val 位。
|
||||
> `lsl reg,#val` 将寄存器 `reg` 中的二进制操作数左移 `val` 位。
|
||||
|
||||
str reg,[dest,#val] 将寄存器 reg 中的数字保存到地址 dest + val 上。
|
||||
```
|
||||
> `str reg,[dest,#val]` 将寄存器 `reg` 中的数字保存到地址 `dest + val` 上。
|
||||
|
||||
这些命令的作用是在 GPIO 的第 16 号插针上启用输出。首先我们在寄存器 r1 中获取一个必需的值,接着将这个值发送到 GPIO 控制器。因此,前两个命令是尝试取值到寄存器 r1 中,我们可以像前面一样使用另一个命令 `ldr` 来实现,但 `lsl` 命令对我们后面能够设置任何给定的 GPIO 针比较有用,因此从一个公式中推导出值要比直接写入来好一些。表示 `OK` 的 LED 灯是直接连线到 GPIO 的第 16 号针脚上的,因此我们需要发送一个命令去启用第 16 号针脚。
|
||||
这些命令的作用是在 GPIO 的第 16 号插针上启用输出。首先我们在寄存器 `r1` 中获取一个必需的值,接着将这个值发送到 GPIO 控制器。因此,前两个命令是尝试取值到寄存器 `r1` 中,我们可以像前面一样使用另一个命令 `ldr` 来实现,但 `lsl` 命令对我们后面能够设置任何给定的 GPIO 针比较有用,因此从一个公式中推导出值要比直接写入来好一些。表示 OK 的 LED 灯是直接连线到 GPIO 的第 16 号针脚上的,因此我们需要发送一个命令去启用第 16 号针脚。
|
||||
|
||||
寄存器 r1 中的值是启用 LED 针所需要的。第一行命令将数字 1<sub>10</sub> 放到 r1 中。在这个操作中 `mov` 命令要比 `ldr` 命令快很多,因为它不需要与内存交互,而 `ldr` 命令是将需要的值从内存中加载到寄存器中。尽管如此,`mov` 命令仅能用于加载某些值。在 ARM 汇编代码中,基本上每个指令都使用一个三字母代码表示。它们被称为助记词,用于表示操作的用途。`mov` 是 “move" 的简写,而 `ldr` 是 “load register” 的简写。`mov` 是将第二个参数 #1 移动到前面的 r1 寄存器中。一般情况下,`#` 肯定是表示一个数字,但我们已经看到了不符合这种情况的一个反例。
|
||||
寄存器 `r1` 中的值是启用 LED 针所需要的。第一行命令将数字 1<sub>10</sub> 放到 `r1` 中。在这个操作中 `mov` 命令要比 `ldr` 命令快很多,因为它不需要与内存交互,而 `ldr` 命令是将需要的值从内存中加载到寄存器中。尽管如此,`mov` 命令仅能用于加载某些值。[^4] 在 ARM 汇编代码中,基本上每个指令都使用一个三字母代码表示。它们被称为助记词,用于表示操作的用途。`mov` 是 “move” 的简写,而 `ldr` 是 “load register” 的简写。`mov` 是将第二个参数 `#1` 移动到前面的 `r1` 寄存器中。一般情况下,`#` 肯定是表示一个数字,但我们已经看到了不符合这种情况的一个反例。
|
||||
|
||||
第二个指令是 `lsl`(逻辑左移)。它的意思是将第一个参数的二进制操作数向左移第二个参数所表示的位数。在这个案例中,将 1<sub>10</sub> (即 1<sub>2</sub> )向左移 18 位(将它变成 1000000000000000000<sub>2</sub>=262144<sub>10</sub> )。
|
||||
|
||||
如果你不熟悉二进制表示法,可以看下面的内容:
|
||||
|
||||
与十六进制一样,二进制是写数字的另一种方法。在二进制中只有两个数字,即 0 和 1。它在计算机中非常有用,因为我们可以用电路来实现它,即电流能够通过电路表示为 1,而电流不能通过电路表示为 0。这就是计算机能够完成真实工作和做数学运算的原理。尽管二进制只有两个数字,但它却能够表示任何一个数字,只是写起来有点长而已。
|
||||
> 延伸阅读: 二进制解释
|
||||
|
||||
![567 in decimal = 1000110111 in binary][7]
|
||||
> 与十六进制一样,二进制是写数字的另一种方法。在二进制中只有两个数字,即 `0` 和 `1`。它在计算机中非常有用,因为我们可以用电路来实现它,即电流能够通过电路表示为 `1`,而电流不能通过电路表示为 `0`。这就是计算机能够完成真实工作和做数学运算的原理。尽管二进制只有两个数字,但它却能够表示任何一个数字,只是写起来有点长而已。
|
||||
|
||||
这个图片展示了 567<sub>10</sub> 的二进制表示是 1000110111<sub>2</sub> 。我们使用下标 2 来表示这个数字是用二进制写的。
|
||||
> ![567 in decimal = 1000110111 in binary][7]
|
||||
|
||||
我们在汇编代码中大量使用二进制的其中一个巧合之处是,数字可以很容易地被 2 的幂(即 1、2、4、8、16)乘或除。通常乘法和除法都是非常难的,而在某些特殊情况下却变得非常容易,所以二进制非常重要。
|
||||
> 这个图片展示了 567<sub>10</sub> 的二进制表示是 1000110111<sub>2</sub> 。我们使用下标 2 来表示这个数字是用二进制写的。
|
||||
|
||||
![13*4 = 52, 1101*100=110100][8]
|
||||
> 我们在汇编代码中大量使用二进制的其中一个巧合之处是,数字可以很容易地被 `2` 的幂(即 `1`、`2`、`4`、`8`、`16`)乘或除。通常乘法和除法都是非常难的,而在某些特殊情况下却变得非常容易,所以二进制非常重要。
|
||||
|
||||
将一个二进制数字左移 **n** 位就相当于将这个数字乘以 2<sup> **n**</sup>。因此,如果我们想将一个数乘以 4,我们只需要将这个数字左移 2 位。如果我们想将它乘以 256,我们只需要将它左移 8 位。如果我们想将一个数乘以 12 这样的数字,我们可以有一个替代做法,就是先将这个数乘以 8,然后再将那个数乘以 4,最后将两次相乘的结果相加即可得到最终结果(N × 12 = N × (8 + 4) = N × 8 + N × 4)。
|
||||
> ![13*4 = 52, 1101*100=110100][8]
|
||||
|
||||
![53/16 = 3, 110100/10000=11][9]
|
||||
> 将一个二进制数字左移 `n` 位就相当于将这个数字乘以 2<sup>n</sup>。因此,如果我们想将一个数乘以 4,我们只需要将这个数字左移 2 位。如果我们想将它乘以 256,我们只需要将它左移 8 位。如果我们想将一个数乘以 12 这样的数字,我们可以有一个替代做法,就是先将这个数乘以 8,然后再将那个数乘以 4,最后将两次相乘的结果相加即可得到最终结果(N × 12 = N × (8 + 4) = N × 8 + N × 4)。
|
||||
|
||||
右移一个二进制数 **n** 位就相当于这个数除以 2 <sup>**n**</sup> 。在右移操作中,除法的余数位将被丢弃。不幸的是,如果对一个不能被 2 的幂次方除尽的二进制数字做除法是非常难的,这将在 [课程 9:Screen04][10] 中讲到。
|
||||
> ![53/16 = 3, 110100/10000=11][9]
|
||||
|
||||
![Binary Terminology][11]
|
||||
> 右移一个二进制数 `n` 位就相当于这个数除以 2<sup>n</sup> 。在右移操作中,除法的余数位将被丢弃。不幸的是,如果对一个不能被 2 的幂次方除尽的二进制数字做除法是非常难的,这将在 [课程 9 Screen04][10] 中讲到。
|
||||
|
||||
这个图展示了二进制常用的术语。一个<ruby>比特<rt>bit</rt></ruby>就是一个单独的二进制位。一个“<ruby>半字节<rt>nibble</rt></ruby>“ 是 4 个二进制位。一个<ruby>字节<rt>byte</rt></ruby>是 2 个半字节,也就是 8 个比特。在一个<ruby>字<rt>word</rt></ruby>用两个字节来表示的情况下,一半是指一个字长度的一半。一个字是指处理器上寄存器的大小,因此,树莓派的字长是 4 字节。按惯例,将一个数字最高有效位标识为 31,而将最低有效位标识为 0。顶部或最高位表示最高有效位,而底部或最低位表示最低有效位。一个 kilobyte(KB)就是 1000 字节,一个 megabyte 就是 1000 KB。这样表示会导致一些困惑,到底应该是 1000 还是 1024(二进制中的整数)。鉴于这种情况,新的国际标准规定,一个 KB 等于 1000 字节,而一个 Kibibyte(KiB)是 1024 字节。一个 Kb 是 1000 比特,而一个 Kib 是 1024 比特。
|
||||
> ![Binary Terminology][11]
|
||||
|
||||
树莓派默认采用小端法,也就是说,你刚才写的从地址上加载一个字节时,是从一个字的低位字节开始加载的。
|
||||
> 这个图展示了二进制常用的术语。一个<ruby>比特<rt>bit</rt></ruby>就是一个单独的二进制位。一个“<ruby>半字节<rt>nibble</rt></ruby>“ 是 4 个二进制位。一个<ruby>字节<rt>byte</rt></ruby>是 2 个半字节,也就是 8 个比特。<ruby>半字<rt>half</rt></ruby>是指一个字长度的一半,这里是 2 个字节。<ruby>字<rt>word</rt></ruby>是指处理器上寄存器的大小,因此,树莓派的字长是 4 字节。按惯例,将一个字最高有效位标识为 31,而将最低有效位标识为 0。顶部或最高位表示最高有效位,而底部或最低位表示最低有效位。一个 kilobyte(KB)就是 1000 字节,一个 megabyte 就是 1000 KB。这样表示会导致一些困惑,到底应该是 1000 还是 1024(二进制中的整数)。鉴于这种情况,新的国际标准规定,一个 KB 等于 1000 字节,而一个 Kibibyte(KiB)是 1024 字节。一个 Kb 是 1000 比特,而一个 Kib 是 1024 比特。
|
||||
|
||||
再强调一次,我们只有去阅读手册才能知道我们所需要的值。手册上说,GPIO 控制器中有一个 24 字节的集合,由它来决定 GPIO 针脚的设置。第一个 4 字节与前 10 个 GPIO 针脚有关,第二个 4 字节与接下来的 10 个针脚有关,依此类推。总共有 54 个 GPIO 针脚,因此,我们需要 6 个 4 字节的一个集合,总共是 24 个字节。在每个 4 字节中,每 3 个比特与一个特定的 GPIO 针脚有关。我们想去启用的是第 16 号 GPIO 针脚,因此我们需要去设置第二组 4 字节,因为第二组的 4 字节用于处理 GPIO 针脚的第 10-19 号,而我们需要 3 比特集合的第 6 位,它在上面的代码中的编号是 18(6×3)。
|
||||
> 树莓派默认采用小端法,也就是说,从你刚才写的地址上加载一个字节时,是从一个字的低位字节开始加载的。
|
||||
|
||||
最后的 `str`(store register)命令去保存第一个参数中的值,将寄存器 r1 中的值保存到后面的表达式计算出来的地址上。这个表达式可以是一个寄存器,在上面的例子中是 r0,我们知道 r0 中保存了GPIO 控制器的地址,而另一个值是加到它上面的,在这个例子中是 #4。它的意思是将 GPIO 控制器地址加上 4 得到一个新的地址,并将寄存器 r1 中的值写到那个地址上。那个地址就是我们前面提到的第二个 4 字节集合的位置,因此,我们发送我们的第一个消息到 GPIO 控制器上,告诉它准备启用 GPIO 第 16 号针脚的输出。
|
||||
再强调一次,我们只有去阅读手册才能知道我们所需要的值。手册上说,GPIO 控制器中有一个 24 字节的集合,由它来决定 GPIO 针脚的设置。第一个 4 字节与前 10 个 GPIO 针脚有关,第二个 4 字节与接下来的 10 个针脚有关,依此类推。总共有 54 个 GPIO 针脚,因此,我们需要 6 个 4 字节的一个集合,总共是 24 个字节。在每个 4 字节中,每 3 个比特与一个特定的 GPIO 针脚有关。我们想去启用的是第 16 号 GPIO 针脚,因此我们需要去设置第二组 4 字节,因为第二组的 4 字节用于处理 GPIO 针脚的第 10-19 号,而我们需要第 6 组 3 比特,它在上面的代码中的编号是 18(6×3)。
|
||||
|
||||
### 5、一个活跃信号
|
||||
最后的 `str`(“store register”)命令去保存第一个参数中的值,将寄存器 `r1` 中的值保存到后面的表达式计算出来的地址上。这个表达式可以是一个寄存器,在上面的例子中是 `r0`,我们知道 `r0` 中保存了 GPIO 控制器的地址,而另一个值是加到它上面的,在这个例子中是 `#4`。它的意思是将 GPIO 控制器地址加上 `4` 得到一个新的地址,并将寄存器 `r1` 中的值写到那个地址上。那个地址就是我们前面提到的第二组 4 字节的位置,因此,我们发送我们的第一个消息到 GPIO 控制器上,告诉它准备启用 GPIO 第 16 号针脚的输出。
|
||||
|
||||
现在,LED 已经做好了打开准备,我们还需要实际去打开它。意味着需要给 GPIO 控制器发送一个消息去关闭 16 号针脚。是的,你没有看错,就是要发送一个关闭的消息。芯片制造商认为,在 GPIO 针脚关闭时打开 LED 更有意义。硬件工程师经常做这种反常理的决策,似乎是为了让操作系统开发者保持警觉。可以认为是给自己的一个警告。
|
||||
### 5、生命的信号
|
||||
|
||||
现在,LED 已经做好了打开准备,我们还需要实际去打开它。意味着需要给 GPIO 控制器发送一个消息去关闭 16 号针脚。是的,你没有看错,就是要发送一个关闭的消息。芯片制造商认为,在 GPIO 针脚关闭时打开 LED 更有意义。[^5] 硬件工程师经常做这种反常理的决策,似乎是为了让操作系统开发者保持警觉。可以认为是给自己的一个警告。
|
||||
|
||||
```
|
||||
mov r1,#1
|
||||
@ -174,26 +168,25 @@ lsl r1,#16
|
||||
str r1,[r0,#40]
|
||||
```
|
||||
|
||||
希望你能够认识上面全部的命令,先不要管它的值。第一个命令和前面一样,是将值 1 推入到寄存器 r1 中。第二个命令是将二进制的 1 左移 16 位。由于我们是希望关闭 GPIO 的 16 号针脚,我们需要在下一个消息中将第 16 比特设置为 1(想设置其它针脚只需要改变相应的比特位即可)。最后,我们写这个值到 GPIO 控制器地址加上 40<sub>10</sub> 的地址上,这将使那个针脚关闭(加上 28 将打开针脚)。
|
||||
希望你能够认识上面全部的命令,先不要管它的值。第一个命令和前面一样,是将值 `1` 推入到寄存器 `r1` 中。第二个命令是将二进制的 `1` 左移 16 位。由于我们是希望关闭 GPIO 的 16 号针脚,我们需要在下一个消息中将第 16 比特设置为 1(想设置其它针脚只需要改变相应的比特位即可)。最后,我们写这个值到 GPIO 控制器地址加上 40<sub>10</sub> 的地址上,这将使那个针脚关闭(加上 28 将打开针脚)。
|
||||
|
||||
### 6、永远幸福快乐
|
||||
|
||||
现在结束,可能有点意犹未尽,但不幸的是,处理器并不知道我们做了什么。事实上,处理器只要通电,它就永不停止地运转。因此,我们需要给它一个任务,让它一直运转下去,否则,树莓派将进入休眠(本示例中不会,因为 LED 灯一直亮着)。
|
||||
似乎我们现在就可以结束了,但不幸的是,处理器并不知道我们做了什么。事实上,处理器只要通电,它就永不停止地运转。因此,我们需要给它一个任务,让它一直运转下去,否则,树莓派将进入休眠(本示例中不会,LED 灯会一直亮着)。
|
||||
|
||||
```
|
||||
loop$:
|
||||
b loop$
|
||||
```
|
||||
|
||||
```
|
||||
name: labels 下一行的名字。
|
||||
|
||||
b label 下一行将去运行标签。
|
||||
```
|
||||
> `name:` 下一行的名字。
|
||||
|
||||
第一行不是一个命令,而是一个标签。它是下一行循环 `loop$` 的名字,这意味着我们能够通过名字来指向到行。这就称为一个标签。当代码被转换成二进制后,标签将被丢弃,但这对我们通过名字而不是数字(地址)找到行比较有用。按惯例,我们使用一个 $ 表示标签,这个标签只对这个代码块中的代码起作用,让其它人知道,它不对整个程序起作用。`b`(branch)命令将去运行指定的标签中的命令,而不是去运行它后面的下一个命令。因此,下一行将再次去运行这个 `b` 命令,这将导致永远循环下去。因此处理器将进入一个无限循环中,直到它安全关闭为止。
|
||||
> `b label` 下一行将去标签 `label` 处运行。
|
||||
|
||||
代码块结尾的新行是有意这样写的。GNU 工具链要求所有的汇编代码文件都是以空行结束的,因此,这就需要你确保确实是要结束了,并且文件不能被截断。如果你不这样处理,在汇编器运行时,你将收到烦人的警告。
|
||||
第一行不是一个命令,而是一个标签。它给下一行命名为 `loop$`,这意味着我们能够通过名字来指向到该行。这就称为一个标签。当代码被转换成二进制后,标签将被丢弃,但这对我们通过名字而不是数字(地址)找到行比较有用。按惯例,我们使用一个 `$` 表示这个标签只对这个代码块中的代码起作用,让其它人知道,它不对整个程序起作用。`b`(“branch”)命令将去运行指定的标签中的命令,而不是去运行它后面的下一个命令。因此,下一行将再次去运行这个 `b` 命令,这将导致永远循环下去。因此处理器将进入一个无限循环中,直到它安全关闭为止。
|
||||
|
||||
代码块结尾的一个空行是有意这样写的。GNU 工具链要求所有的汇编代码文件都是以空行结束的,因此,这就可以你确实是要结束了,并且文件没有被截断。如果你不这样处理,在汇编器运行时,你将收到烦人的警告。
|
||||
|
||||
### 7、树莓派上场
|
||||
|
||||
@ -201,7 +194,17 @@ b label 下一行将去运行标签。
|
||||
|
||||
为安装你的操作系统,需要先有一个已经安装了树莓派操作系统的 SD 卡。如果你浏览 SD 卡中的文件,你应该能看到一个名为 `kernel.img` 的文件。将这个文件重命名为其它名字,比如 `kernel_linux.img`。然后,复制你编译的 `kernel.img` 文件到 SD 卡中原来的位置,这将用你的操作系统镜像文件替换现在的树莓派操作系统镜像。想切换回来时,只需要简单地删除你自己的 `kernel.img` 文件,然后将前面重命名的文件改回 `kernel.img` 即可。我发现,保留一个原始的树莓派操作系统的备份是非常有用的,万一你要用到它呢。
|
||||
|
||||
将这个 SD 卡插入到树莓派,并打开它的电源。这个 `OK` 的 LED 灯将亮起来。如果不是这样,请查看故障排除页面。如果一切如愿,恭喜你,你已经写出了你的第一个操作系统。[课程 2:OK02][12] 将指导你让 LED 灯闪烁和关闭闪烁。
|
||||
将这个 SD 卡插入到树莓派,并打开它的电源。这个 OK 的 LED 灯将亮起来。如果不是这样,请查看故障排除页面。如果一切如愿,恭喜你,你已经写出了你的第一个操作系统。[课程 2 OK02][12] 将指导你让 LED 灯闪烁和关闭闪烁。
|
||||
|
||||
[^1]: OK, I'm lying it tells the linker, which is another program used to link several assembled files together. It doesn't really matter.
|
||||
[^2]: Clearly they're important to you. Since the GNU toolchain is mainly used for creating programs, it expects there to be an entry point labelled `_start`. As we're making an operating system, the `_start` is always whatever comes first, which we set up with the `.section .init` command. However, if we don't say where the entry point is, the toolchain gets upset. Thus, the first line says that we are going to define a symbol called `_start` for all to see (globally), and the second line says to make the symbol `_start` the address of the next line. We will come onto addresses shortly.
|
||||
[^3]: This tutorial is designed to spare you the pain of reading it, but, if you must, it can be found here [SoC-Peripherals.pdf](https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/downloads/SoC-Peripherals.pdf). For added confusion, the manual uses a different addressing system. An address listed as 0x7E200000 would be 0x20200000 in our OS.
|
||||
[^4]: Only values which have a binary representation which only has 1s in the first 8 bits of the representation. In other words, 8 1s or 0s followed by only 0s.
|
||||
[^5]: A hardware engineer was kind enough to explain this to me as follows:
|
||||
|
||||
The reason is that modern chips are made of a technology called CMOS, which stands for Complementary Metal Oxide Semiconductor. The Complementary part means each signal is connected to two transistors, one made of material called N-type semiconductor which is used to pull it to a low voltage and another made of P-type material to pull it to a high voltage. Only one transistor of the pair turns on at any time, otherwise we'd get a short circuit. P-type isn't as conductive as N-type, which means the P-type transistor has to be about 3 times as big to provide the same current. This is why LEDs are often wired to turn on by pulling them low, because the N-type is stronger at pulling low than the P-type is in pulling high.
|
||||
|
||||
There's another reason. Back in the 1970s chips were made out of entirely out of N-type material ('NMOS'), with the P-type replaced by a resistor. That means that when a signal is pulled low the chip is consuming power (and getting hot) even while it isn't doing anything. Your phone getting hot and flattening the battery when it's in your pocket doing nothing wouldn't be good. So signals were designed to be 'active low' so that they're high when inactive and so don't take any power. Even though we don't use NMOS any more, it's still often quicker to pull a signal low with the N-type than to pull it high with the P-type. Often a signal that's 'active low' is marked with a bar over the top of the name, or written as SIGNAL_n or /SIGNAL. But it can still be confusing, even for hardware engineers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -210,7 +213,7 @@ via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,231 +0,0 @@
|
||||
使用Ansible来管理你的工作站:配置自动化
|
||||
======
|
||||
|
||||

|
||||
|
||||
Ansible是一个令人惊讶的自动化的配置管理工具。主要应用在服务器和云部署上,但在工作站上的应用(无论是台式机还是笔记本)却得到了很少的关注,这就是本系列所要关注的。
|
||||
|
||||
在这个系列的第一部分,我会向你展示'ansible-pull'命令的基本用法,我们创建了一个安装了少量包的palybook.它本身是没有多大的用处的,但是它为后续的自动化做了准备。
|
||||
|
||||
在这篇文章中,所有的事件操作都是闭环的,而且在最后部分,我们将会有一个针对工作站自动配置的完整的工作解决方案。现在,我们将要设置Ansible的配置,这样未来将要做的改变将会自动的部署应用到我们的工作站上。现阶段,假设你已经完成了第一部分的工作。如果没有的话,当你完成的时候回到本文。你应该已经有一个包含第一篇文章中代码的Github库。我们将直接按照之前的方式创建。
|
||||
|
||||
首先,因为我们要做的不仅仅是安装包文件,所以我们要做一些重新的组织工作。现在,我们已经有一个名为'local.yml'并包含以下内容的playbook:
|
||||
```
|
||||
- hosts: localhost
|
||||
|
||||
become: true
|
||||
|
||||
tasks:
|
||||
|
||||
- name: Install packages
|
||||
|
||||
apt: name={{item}}
|
||||
|
||||
with_items:
|
||||
|
||||
- htop
|
||||
|
||||
- mc
|
||||
|
||||
- tmux
|
||||
|
||||
```
|
||||
|
||||
如果我们仅仅想实现一个任务那么上面的配置就足够了。随着向我们的配置中不断的添加内容,这个文件将会变的相当的庞大和杂乱。最好能够根据不同类型的配置将play文件分为独立的文件。为了达到这个要求,创建一个名为taskbook的文件,它和playbook很像但内容更加的流线型。让我们在Git库中为taskbook创建一个目录。
|
||||
```
|
||||
mkdir tasks
|
||||
|
||||
```
|
||||
|
||||
在'local.yml'playbook中的代码使它很好过过渡到成为安装包文件的taskbook.让我们把这个文件移动到刚刚创建好并新命名的目录中。
|
||||
|
||||
```
|
||||
mv local.yml tasks/packages.yml
|
||||
|
||||
```
|
||||
现在,我们编辑'packages.yml'文件将它进行大幅的瘦身,事实上,我们可以精简除了独立任务本身之外的所有内容。让我们把'packages.yml'编辑成如下的形式:
|
||||
```
|
||||
- name: Install packages
|
||||
|
||||
apt: name={{item}}
|
||||
|
||||
with_items:
|
||||
|
||||
- htop
|
||||
|
||||
- mc
|
||||
|
||||
- tmux
|
||||
|
||||
```
|
||||
|
||||
正如你所看到的,它使用同样的语法,但我们去掉了对这个任务无用没有必要的所有内容。现在我们有了一个专门安装包文件的taskbook.然而我们仍然需要一个名为'local.yml'的文件,因为执行'ansible-pull'命令时仍然会去发现这个文件。所以我们将在我们库的根目录下(不是在'task'目录下)创建一个包含这些内容的全新文件:
|
||||
```
|
||||
- hosts: localhost
|
||||
|
||||
become: true
|
||||
|
||||
pre_tasks:
|
||||
|
||||
- name: update repositories
|
||||
|
||||
apt: update_cache=yes
|
||||
|
||||
changed_when: False
|
||||
|
||||
|
||||
|
||||
tasks:
|
||||
|
||||
- include: tasks/packages.yml
|
||||
|
||||
```
|
||||
|
||||
这个新的'local.yml'扮演的是将要导入我们的taksbooks的主页的角色。我已经在这个文件中添加了一些你在这个系列中看不到的内容。首先,在这个文件的开头处,我添加了'pre——tasks',这个任务的作用是在其他所有任务运行之前先运行某个任务。在这种情况下,我们给Ansible的命令是让它去更新我们的分布存储库主页,下面的配置将执行这个任务要求:
|
||||
|
||||
```
|
||||
apt: update_cache=yes
|
||||
|
||||
```
|
||||
通常'apt'模块是用来安装包文件的,但我们也能够让它来更新库索引。这样做的目的是让我们的每个play在Ansible运行的时候能够以最新的索引工作。这将确保我们在使用一个老旧的索引安装一个包的时候不会出现问题。因为'apt'模块仅仅在Debian,Ubuntu和他们的衍生环境下工作。如果你运行的一个不同的环境,你期望在你的环境中使用一个特殊的模块而不是'apt'。如果你需要使用一个不同的模块请查看Ansible的相关文档。
|
||||
|
||||
下面这行值得以后解释:
|
||||
```
|
||||
changed_when: False
|
||||
|
||||
```
|
||||
在独立任务中的这行阻止了Ansible去报告play改变的结果即使是它本身在系统中导致的一个改变。在这中情况下,我们不会去在意库索引是否包含新的数据;它几乎总是会的,因为库总是在改变的。我们不会去在意'apt'库的改变,因为索引的改变是正常的过程。如果我们删除这行,我们将在过程保告的后面看到所有的变动,即使仅仅库的更新而已。最好能够去忽略这类的改变。
|
||||
|
||||
接下来是常规任务的阶段,我们将创建好的taskbook导入。我们每次添加另一个taskbook的时候,要添加下面这一行:
|
||||
```
|
||||
tasks:
|
||||
|
||||
- include: tasks/packages.yml
|
||||
|
||||
```
|
||||
|
||||
如果你将要运行'ansible-pull'命令,他应该向上一篇文章中的那样做同样重要的事情。 不同的是我们已经提高了我们的组织并且能够更有效的扩展它。'ansible-pull'命令的语法,为了节省你到上一篇文章中去寻找,参考如下:
|
||||
```
|
||||
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
|
||||
|
||||
```
|
||||
如果你还记得话,'ansible-pull'的命令拉取一个Git库并且应用了它所包含的配置。
|
||||
|
||||
既然我们的基础已经搭建好,我们现在可以扩展我们的Ansible并且添加功能。更特别的是,我们将添加配置来自动化的部署对工作站要做的改变。为了支撑这个要求,首先我们要创建一个特殊的账户来应用我们的Ansible配置。这个不是必要的,我们仍然能够在我们自己的用户下运行Ansible配置。但是使用一个隔离的用户能够将其隔离到不需要我们参与的在后台运行的一个系统进程中,
|
||||
|
||||
我们可以使用常规的方式来创建这个用户,但是既然我们正在使用Ansible,我们应该尽量避开使用手动的改变。替代的是,我们将会创建一个taskbook来处理用户的创建任务。这个taskbook目前将会仅仅创建一个用户,但你可以在这个taskbook中添加额外的plays来创建更多的用户。我将这个用户命名为'ansible',你可以按照自己的想法来命名(如果你做了这个改变要确保更新所有的变动)。让我们来创建一个名为'user.yml'的taskbook并且将以下代码写进去:
|
||||
|
||||
```
|
||||
- name: create ansible user
|
||||
|
||||
user: name=ansible uid=900
|
||||
|
||||
```
|
||||
下一步,我们需要编辑'local.yml'文件,将这个新的taskbook添加进去,像如下这样写:
|
||||
|
||||
```
|
||||
- hosts: localhost
|
||||
|
||||
become: true
|
||||
|
||||
pre_tasks:
|
||||
|
||||
- name: update repositories
|
||||
|
||||
apt: update_cache=yes
|
||||
|
||||
changed_when: False
|
||||
|
||||
|
||||
|
||||
tasks:
|
||||
|
||||
- include: tasks/users.yml
|
||||
|
||||
- include: tasks/packages.yml
|
||||
|
||||
```
|
||||
现在当我们运行'ansible-pull'命令的时候,一个名为'ansible'的用户将会在系统中被创建。注意我特地通过参数'UID'为这个用户声明了用户ID为900。这个不是必须的,但建议直接创建好UID。因为在1000以下的UID在登陆界面是不会显示的,这样是很棒的因为我们根本没有需要去使用'ansibe'账户来登陆我们的桌面。UID 900是固定的;它应该是在1000以下没有被使用的任何一个数值。你可以使用以下命令在系统中去验证UID 900是否已经被使用了:
|
||||
|
||||
```
|
||||
cat /etc/passwd |grep 900
|
||||
|
||||
```
|
||||
然而,你使用这个UID应该不会遇到什么问题,因为迄今为止在我使用的任何发行版中我还没遇到过它是被默认使用的。
|
||||
|
||||
现在,我们已经拥有了一个名为'ansible'的账户,它将会在之后的自动化配置中使用。接下来,我们可以创建实际的定时作业来自动操作它。而不是将其放置到我们刚刚创建的'users.yml'文件中,我们应该将其分开放到它自己的文件中。在任务目录中创建一个名为'cron.yml'的taskbook并且将以下的代买写进去:
|
||||
```
|
||||
- name: install cron job (ansible-pull)
|
||||
|
||||
cron: user="ansible" name="ansible provision" minute="*/10" job="/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null"
|
||||
|
||||
```
|
||||
定时模块的语法几乎是不需加以说明的。通过这个play,我们创建了一个通过用户'ansible'运行的定时作业。这个作业将每隔10分钟执行一次,下面是它将要执行的命令:
|
||||
|
||||
```
|
||||
/usr/bin/ansible-pull -o -U https://github.com/<github_user>/ansible.git > /dev/null
|
||||
|
||||
```
|
||||
同样,我们也可以添加想要我们的所有工作站部署的额外定时作业到这个文件中。我们只需要在新的定时作业中添加额外的palys即可。然而,仅仅是添加一个定时的taskbook是不够的,我们还需要将它添加到'local.yml'文件中以便它能够被调用。将下面的一行添加到末尾:
|
||||
```
|
||||
- include: tasks/cron.yml
|
||||
|
||||
```
|
||||
现在当'ansible-pull'命令执行的时候,它将会以通过用户'ansible'每个十分钟设置一个新的定时作业。但是,每个十分钟运行一个Ansible作业并不是一个好的方式因为这个将消耗很多的CPU资源。每隔十分钟来运行对于Ansible来说是毫无意义的除非欧文已经在Git库中改变一些东西。
|
||||
|
||||
然而,我们已经解决了这个问题。注意到我在定时作业中的命令'ansible-pill'添加的我们之前从未用到过的参数'-o'.这个参数告诉Ansible只有在从上次'ansible-pull'被调用以后库有了变化后才会运行。如果库没有任何变化,他将不会做任何事情。通过这个方法,你将不会无端的浪费CPU资源。当然,一些CPU资源将会在下来存储库的时候被使用,但不会像再一次应用整个配置的时候使用的那么多。当'ansible-pull'执行的时候,它将会遍历在playbooks和taskbooks中的所有任务,但至少它不会毫无目的的运行。
|
||||
|
||||
尽管我们已经添加了所有必须的配置要素来自动化'ansible-pull',它任然还不能正常的工作。'ansible-pull'命令需要sudo的权限来运行,这将允许它执行系统级的命令。然而我们创建的用户'ansible'并没有被设置为以'sudo'的权限来执行命令,因此当定时作业触发的时候,执行将会失败。通常沃恩可以使用命令'visudo'来手动的去设置用户'ansible'的拥有这个权限。然而我们现在应该以Ansible的方式来操作,而且这将会是一个向你展示'copy'模块是如何工作的机会。'copy'模块允许你从库复制一个文件到文件系统的任何位置。在这个案列中,我们将会复制'sudo'的一个配置文件到'/etc/sudoers.d/'以便用户'ansible'能够以管理员的权限执行任务。
|
||||
|
||||
打开'users.yml',将下面的play添加到文件末尾。
|
||||
|
||||
```
|
||||
- name: copy sudoers_ansible
|
||||
|
||||
copy: src=files/sudoers_ansible dest=/etc/sudoers.d/ansible owner=root group=root mode=0440
|
||||
|
||||
```
|
||||
'copy'模块,正如我们看到的,从库复制一个文件到其他任何位置。在这个过程中,我们正在抓取一个名为'sudoers_ansible'(我们将在后续创建)的文件并将它复制到拥有者为'root'的'/etc/sudoers/ansible'中。
|
||||
|
||||
接下来,我们需要创建我们将要复制的文件。在你的库的根目录下,创建一个名为'files'的目录:
|
||||
|
||||
```
|
||||
mkdir files
|
||||
|
||||
```
|
||||
然后,在我们刚刚创建的'files'目录里,创建包含以下内容的名为'sudoers_ansible'的文件:
|
||||
```
|
||||
ansible ALL=(ALL) NOPASSWD: ALL
|
||||
|
||||
```
|
||||
在'/etc/sudoer.d'目录里创建一个文件,就像我们正在这样做的,允许我们为一个特殊的用户配置'sudo'权限。现在我们正在通过'sudo'允许用户'ansible'不需要密码拥有完全控制权限。这将允许'ansible-pull'以后台任务的形式运行而不需要手动去运行。
|
||||
|
||||
现在,你可以通过再次运行'ansible-pull'来拉取最新的变动:
|
||||
```
|
||||
sudo ansible-pull -U https://github.com/<github_user>/ansible.git
|
||||
|
||||
```
|
||||
从这个节点开始,'ansible-pull'的定时作业将会在后台每隔十分钟运行一次来检查你的库是否有变化,如果它发现有变化,将会运行你的palybook并且应用你的taskbooks.
|
||||
|
||||
所以现在我们有了一个完整的工作方案。当你第一次设置一台新的笔记本或者台式机的时候,你要去手动的运行'ansible-pull'命令,但仅仅是在第一次的时候。从第一次之后,用户'ansible'将会在后台接手后续的运行任务。当你想对你的机器做变动的时候,你只需要简单的去拉取你的Git库来做变动,然后将这些变化回传到库中。接着,当定时作业下次在每台机器上运行的时候,它将会拉取变动的部分并应用它们。你现在只需要做一次变动,你的所有工作站将会跟着一起变动。这方法尽管有一点不方便,通常,你会有一个你的机器列表的文件和包含不同机器的规则。不管怎样,'ansible-pull'的方法,就像在文章中描述的,是管理工作站配置的非常有效的方法。
|
||||
|
||||
我已经在我的[Github repository]中更新了这篇文章中的代码,所以你可以随时去浏览来再一次检查你的语法。同时我将前一篇文章中的代码移到了它自己的目录中。
|
||||
|
||||
在第三部分,我们将通过介绍使用Ansible来配置GNOME桌面设置来结束这个系列。我将会告诉你如何设置你的墙纸和锁屏壁纸,应用一个桌面主题以及更多的东西。
|
||||
|
||||
同时,到了布置一些作业的时候了,大多数人有我们使用的各种应用的配置文件。可能是Bash,Vim或者其他你使用的工具的配置文件。现在你可以尝试通过我们在使用的Ansible库来自动复制这些配置到你的机器中。在这篇文章中,我已将想你展示了如何去复制文件,所以去尝试以下看看你是都已经能应用这些知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2
|
||||
|
||||
作者:[Jay LaCroix][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jlacroix
|
||||
[1]:https://opensource.com/article/18/3/manage-workstation-ansible
|
||||
[2]:https://github.com/jlacroix82/ansible_article.git
|
||||
134
translated/tech/20180606 Working with modules in Fedora 28.md
Normal file
134
translated/tech/20180606 Working with modules in Fedora 28.md
Normal file
@ -0,0 +1,134 @@
|
||||
使用 Fedora 28 中的模块
|
||||
======
|
||||

|
||||
最近 Fedora Magazine 中题为 [Fedora 28 服务器版的模块化][1]在解释 Fedora 28 中的模块化方面做得很好。它还给出了一些示例模块并解释了它们解决的问题。本文将其中一个模块用于实际应用,包括使用模块安装设置 Review Board 3.0。
|
||||
|
||||
### 入门
|
||||
|
||||
想要继续并使用模块,你需要一个 [Fedora 28 服务器版][2]并拥有 [sudo 管理权限][3]。另外,运行此命令以确保系统上的所有软件包都是最新的:
|
||||
|
||||
```
|
||||
sudo dnf -y update
|
||||
```
|
||||
|
||||
虽然你可以在 Fedora 28 非服务器版本上使用模块,但请注意[上一篇文章评论中提到的警告][4]。
|
||||
|
||||
### 检查模块
|
||||
|
||||
首先,看看 Fedora 28 可用的模块。运行以下命令:
|
||||
|
||||
```
|
||||
dnf module list
|
||||
```
|
||||
|
||||
输出列出了一组模块,这些模块显示了每个模块的关联流,版本和可用安装配置文件。模块流旁边的 [d] 表示安装命名模块时使用的默认流。
|
||||
|
||||
输出还显示大多数模块都有名为 default 的配置文件。这不是巧合,因为 default 是默认配置文件使用的名称。
|
||||
|
||||
要查看所有这些模块的来源,请运行:
|
||||
|
||||
```
|
||||
dnf repolist
|
||||
```
|
||||
|
||||
与通常的 [fedora 和更新包仓库][5]一起,输出还显示了fedora-modular 和 updates-modular 仓库。
|
||||
|
||||
介绍声明你将设置 Review Board 3.0。也许名为 reviewboard 的模块在之前的输出中引起了你的注意。接下来,要获取有关该模块的一些详细信息,请运行以下命令:
|
||||
|
||||
```
|
||||
dnf module info reviewboard
|
||||
```
|
||||
|
||||
根据描述确认它是 Review Board 模块,但也说明是 2.5 的流。然而你想要 3.0 的。查看可用的 reviewboard 模块:
|
||||
|
||||
```
|
||||
dnf module list reviewboard
|
||||
```
|
||||
|
||||
2.5 旁边的 [d] 表示它被配置为 reviewboard 的默认流。因此,请明确你想要的流:
|
||||
|
||||
```
|
||||
dnf module info reviewboard:3.0
|
||||
```
|
||||
|
||||
有关 reviewboard:3.0 模块的更多详细信息,请添加详细选项:
|
||||
|
||||
```
|
||||
dnf module info reviewboard:3.0 -v
|
||||
```
|
||||
|
||||
### 安装 Review Board 3.0 模块
|
||||
|
||||
现在你已经跟踪了所需的模块,请使用以下命令安装它:
|
||||
|
||||
```
|
||||
sudo dnf -y module install reviewboard:3.0
|
||||
```
|
||||
|
||||
输出显示已安装 ReviewBoard 以及其他几个依赖软件包,其中包括 django:1.6 模块中的几个软件包。安装还启用了reviewboard:3.0 模块和相关的 django:1.6 模块。
|
||||
|
||||
接下来,要查看已启用的模块,请使用以下命令:
|
||||
|
||||
```
|
||||
dnf module list --enabled
|
||||
```
|
||||
|
||||
输出中,[e] 表示已启用的流,[i] 表示已安装的配置。对于 reviewboard:3.0 模块,已安装默认配置。你可以在安装模块时指定其他配置。实际上,你仍然可以安装它,而且这次你不需要指定 3.0,因为它已经启用:
|
||||
|
||||
```
|
||||
sudo dnf -y module install reviewboard/server
|
||||
```
|
||||
|
||||
但是,安装 reviewboard:3.0/服务配置非常平常。reviewboard:3.0 模块的服务器配置与默认配置文件相同 - 因此无需安装。
|
||||
|
||||
### 启动 Review Board 网站
|
||||
|
||||
现在已经安装了 Review Board 3.0 模块及其相关软件包,[创建一个本地运行的 Review Board 网站][6]。无需解释,请复制并粘贴以下命令:
|
||||
|
||||
```
|
||||
sudo rb-site install --noinput \
|
||||
--domain-name=localhost --db-type=sqlite3 \
|
||||
--db-name=/var/www/rev.local/data/reviewboard.db \
|
||||
--admin-user=rbadmin --admin-password=secret \
|
||||
/var/www/rev.local
|
||||
sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \
|
||||
/var/www/rev.local/data
|
||||
sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \
|
||||
/etc/httpd/conf.d/reviewboard-localhost.conf
|
||||
sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \
|
||||
httpd_can_network_memcache=1 httpd_unified=1
|
||||
sudo systemctl enable --now httpd
|
||||
```
|
||||
|
||||
现在启动系统中的 Web 浏览器,打开 <http://localhost>,然后享受全新的 Review Board 网站!要以 Review Board 管理员身份登录,请使用上面 rb-site 命令中的用户 ID 和密码。
|
||||
|
||||
### 模块清理
|
||||
|
||||
完成后清理是个好习惯。为此,删除 Review Board 模块和站点目录:
|
||||
|
||||
```
|
||||
sudo dnf -y module remove reviewboard:3.0
|
||||
sudo rm -rf /var/www/rev.local
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
现在你已经探索了如何检测和管理 Review Board 模块,那么去体验 Fedora 28 中提供的其他模块吧。
|
||||
|
||||
在 [Fedora 模块化][7]网站上了解有关在 Fedora 28 中使用模块的更多信息。dnf 手册页中的 module 命令部分也包含了有用的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://fedoramagazine.org/working-modules-fedora-28/
|
||||
作者:[Merlin Mathesius][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
[a]:https://fedoramagazine.org/author/merlinm/
|
||||
[1]:https://fedoramagazine.org/modularity-fedora-28-server-edition/
|
||||
[2]:https://getfedora.org/server/
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]:https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696
|
||||
[5]:https://fedoraproject.org/wiki/Repositories
|
||||
[6]:https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/
|
||||
[7]:https://docs.pagure.org/modularity/
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wwhio)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Wekan, an open source kanban board)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-wekan)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Wekan 吧,一款开源看板软件
|
||||
======
|
||||
这是开源工具类软件推荐的第二期,本文将让你在 2019 年更具生产力。来,让我们一起看看 Wekan 吧。
|
||||

|
||||
|
||||
每年年初,人们似乎都在想方设法地让自己更具生产力。对新年目标、期待,当然还有“新年新气象”这样的口号等等都促人上进。可大部分生产力软件的推荐都严重偏向闭源的专有软件,但事实上并不用这样。
|
||||
|
||||
这是我挑选的 19 款帮助你在 2019 年提升生产力的开源工具中的第 2 个。
|
||||
|
||||
### Wekan
|
||||
|
||||
[看板][1]是当今敏捷开发流程中的重要组成部分。我们中的很多人使用它同时管理自己的工作和生活。有些人在用 [Trello][2] 这样的 APP 来跟踪他们的项目,例如哪些事务正在处理,哪些事务已经完成。
|
||||
|
||||
|
||||
|
||||
但这些 APP 通常需要连接到一个工作账户或者商业服务中。而 [Wekan][3] 作为一款开源看板工具,你可以让他完全在本地运行,或者使用你自己选择的服务运行它。其他的看板 APP 提供的功能在 Wekan 里几乎都有,例如创建看板、列表、泳道、卡片,在列表间拖放,给指定的用户安排任务,给卡片添加标签等等,基本上你对一款现代看板软件的功能需求它都能提供。
|
||||
|
||||
|
||||
|
||||
Wekan 的独到之处在于它的内置规则。虽然其他的看板软件支持<ruby>邮件更新<rt>emailing updates</rt></ruby>,但 Wekan 允许用户自行设定触发器,其触发条件可以是卡片变动、清单变动或标签变动等等。
|
||||
|
||||
|
||||
|
||||
当触发条件满足时, Wekan 可以自动执行如移动卡片、更新标签、添加清单或者发送邮件等操作。
|
||||
|
||||
|
||||
|
||||
Wekan 的本地搭建可以直接使用 snap 。如果你的桌面环境支持 [Snapcraft][4] 构建的应用,那么只需要一条命令就能安装 Wekan :
|
||||
|
||||
```
|
||||
sudo snap install wekan
|
||||
```
|
||||
|
||||
此外 Wekan 还支持 Docker 安装,这使它在大部分服务器环境和桌面环境下的搭建变得相当容易。
|
||||
|
||||
最后,如果你想寻找一款能自建又好用的看板软件,你已经遇上了 Wekan 。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-wekan
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wwhio](https://github.com/wwhio)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Kanban
|
||||
[2]: https://www.trello.com
|
||||
[3]: https://wekan.github.io/
|
||||
[4]: https://snapcraft.io/
|
||||
Loading…
Reference in New Issue
Block a user