mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
0a4eac81dc
@ -1,67 +1,71 @@
|
||||
在 Linux 上使用 Lutries 管理你的游戏
|
||||
======
|
||||
|
||||
|
||||
|
||||
让我们用游戏开始 2018 的第一天吧!今天我们要讨论的是 **Lutris**,一个 Linux 上的开源游戏平台。你可以使用 Lutries 安装、移除、配置、启动和管理你的游戏。它可以以一个界面帮你管理你的 Linux 游戏、Windows 游戏、仿真控制台游戏和浏览器游戏。它还包含社区编写的安装脚本,使得游戏的安装过程更加简单。
|
||||
今天我们要讨论的是 **Lutris**,一个 Linux 上的开源游戏平台。你可以使用 Lutries 安装、移除、配置、启动和管理你的游戏。它可以在一个单一界面中帮你管理你的 Linux 游戏、Windows 游戏、仿真控制台游戏和浏览器游戏。它还包含社区编写的安装脚本,使得游戏的安装过程更加简单。
|
||||
|
||||
Lutries 自动安装(或者你可以单击点击安装)了超过 20 个模拟器,它提供了从七十年代到现在的大多数游戏系统。目前支持的游戏系统如下:
|
||||
|
||||
* Native Linux
|
||||
* Linux 原生
|
||||
* Windows
|
||||
* Steam (Linux and Windows)
|
||||
* Steam (Linux 和 Windows)
|
||||
* MS-DOS
|
||||
* 街机
|
||||
* Amiga 电脑
|
||||
* Atari 8 和 16 位计算机和控制器
|
||||
* 浏览器 (Flash 或者 HTML5 游戏)
|
||||
* Commmodore 8 位计算机
|
||||
* 基于 SCUMM 的游戏和其他点击冒险游戏
|
||||
* Magnavox Odyssey², Videopac+
|
||||
* 基于 SCUMM 的游戏和其他点击式冒险游戏
|
||||
* Magnavox Odyssey²、Videopac+
|
||||
* Mattel Intellivision
|
||||
* NEC PC-Engine Turbographx 16, Supergraphx, PC-FX
|
||||
* Nintendo NES, SNES, Game Boy, Game Boy Advance, DS
|
||||
* Game Cube and Wii
|
||||
* Sega Master Sytem, Game Gear, Genesis, Dreamcast
|
||||
* SNK Neo Geo, Neo Geo Pocket
|
||||
* NEC PC-Engine Turbographx 16、Supergraphx、PC-FX
|
||||
* Nintendo NES、SNES、Game Boy、Game Boy Advance、DS
|
||||
* Game Cube 和 Wii
|
||||
* Sega Master Sytem、Game Gear、Genesis、Dreamcast
|
||||
* SNK Neo Geo、Neo Geo Pocket
|
||||
* Sony PlayStation
|
||||
* Sony PlayStation 2
|
||||
* Sony PSP
|
||||
* 像 Zork 这样的 Z-Machine 游戏
|
||||
* 还有更多
|
||||
|
||||
|
||||
|
||||
### 安装 Lutris
|
||||
|
||||
就像 Steam 一样,Lutries 包含两部分:网站和客户端程序。从网站你可以浏览可用的游戏,添加最喜欢的游戏到个人库,以及使用安装链接安装他们。
|
||||
|
||||
首先,我们还是来安装客户端。它目前支持 Arch Linux、Debian、Fedroa、Gentoo、openSUSE 和 Ubuntu。
|
||||
|
||||
对于 Arch Linux 和它的衍生版本,像是 Antergos, Manjaro Linux,都可以在 [**AUR**][1] 中找到。因此,你可以使用 AUR 帮助程序安装它。
|
||||
对于 **Arch Linux** 和它的衍生版本,像是 Antergos, Manjaro Linux,都可以在 [AUR][1] 中找到。因此,你可以使用 AUR 帮助程序安装它。
|
||||
|
||||
使用 [Pacaur][2]:
|
||||
|
||||
使用 [**Pacaur**][2]:
|
||||
```
|
||||
pacaur -S lutris
|
||||
```
|
||||
|
||||
使用 **[Packer][3]** :
|
||||
使用 [Packer][3]:
|
||||
|
||||
```
|
||||
packer -S lutris
|
||||
```
|
||||
|
||||
使用 [**Yaourt**][4]:
|
||||
使用 [Yaourt][4]:
|
||||
|
||||
```
|
||||
yaourt -S lutris
|
||||
```
|
||||
|
||||
使用 [**Yay**][5]:
|
||||
使用 [Yay][5]:
|
||||
|
||||
```
|
||||
yay -S lutris
|
||||
```
|
||||
|
||||
**Debian:**
|
||||
|
||||
在 **Debian 9.0** 上以 **root** 身份运行以下命令:
|
||||
在 **Debian 9.0** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/home:/strycore/Debian_9.0/ /' > /etc/apt/sources.list.d/lutris.list
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/Debian_9.0/Release.key -O Release.key
|
||||
@ -71,6 +75,7 @@ apt-get install lutris
|
||||
```
|
||||
|
||||
在 **Debian 8.0** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/home:/strycore/Debian_8.0/ /' > /etc/apt/sources.list.d/lutris.list
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/Debian_8.0/Release.key -O Release.key
|
||||
@ -79,19 +84,22 @@ apt-get update
|
||||
apt-get install lutris
|
||||
```
|
||||
|
||||
在 **Fedora 27** 上以 **root** 身份运行以下命令: r
|
||||
在 **Fedora 27** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:strycore/Fedora_27/home:strycore.repo
|
||||
dnf install lutris
|
||||
```
|
||||
|
||||
在 **Fedora 26** 上以 **root** 身份运行以下命令:
|
||||
在 **Fedora 26** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:strycore/Fedora_26/home:strycore.repo
|
||||
dnf install lutris
|
||||
```
|
||||
|
||||
在 **openSUSE Tumbleweed** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
zypper addrepo https://download.opensuse.org/repositories/home:strycore/openSUSE_Tumbleweed/home:strycore.repo
|
||||
zypper refresh
|
||||
@ -99,13 +107,15 @@ zypper install lutris
|
||||
```
|
||||
|
||||
在 **openSUSE Leap 42.3** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
zypper addrepo https://download.opensuse.org/repositories/home:strycore/openSUSE_Leap_42.3/home:strycore.repo
|
||||
zypper refresh
|
||||
zypper install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 17.10**:
|
||||
**Ubuntu 17.10**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_17.10/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_17.10/Release.key -O Release.key
|
||||
@ -114,7 +124,8 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 17.04**:
|
||||
**Ubuntu 17.04**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_17.04/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_17.04/Release.key -O Release.key
|
||||
@ -123,7 +134,8 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 16.10**:
|
||||
**Ubuntu 16.10**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_16.10/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_16.10/Release.key -O Release.key
|
||||
@ -132,7 +144,8 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 16.04**:
|
||||
**Ubuntu 16.04**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_16.04/Release.key -O Release.key
|
||||
@ -141,71 +154,75 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
对于其他平台,参考 [**Lutris 下载链接**][6].
|
||||
对于其他平台,参考 [Lutris 下载链接][6]。
|
||||
|
||||
### 使用 Lutris 管理你的游戏
|
||||
|
||||
安装完成后,从菜单或者应用启动器里打开 Lutries。首次启动时,Lutries 的默认界面像下面这样:
|
||||
|
||||
[![][7]][8]
|
||||
![][8]
|
||||
|
||||
**登录你的 Lutris.net 账号**
|
||||
#### 登录你的 Lutris.net 账号
|
||||
|
||||
为了能同步你个人库中的游戏,下一步你需要在客户端中登录你的 Lutris.net 账号。如果你没有,先 [**注册一个新的账号**][9]。然后点击 **"连接到你的 Lutirs.net 账号同步你的库 "** 连接到 Lutries 客户端。
|
||||
为了能同步你个人库中的游戏,下一步你需要在客户端中登录你的 Lutris.net 账号。如果你没有,先 [注册一个新的账号][9]。然后点击 “Connecting to your Lutirs.net account to sync your library” 连接到 Lutries 客户端。
|
||||
|
||||
输入你的账号信息然后点击 **继续**。
|
||||
输入你的账号信息然后点击 “Connect”。
|
||||
|
||||
[![][7]][10]
|
||||
![][10]
|
||||
|
||||
现在你已经连接到你的 Lutries.net 账号了。
|
||||
|
||||
[![][7]][11]**Browse Games**
|
||||
![][11]
|
||||
|
||||
#### 浏览游戏
|
||||
|
||||
点击工具栏里的浏览图标(游戏控制器图标)可以搜索任何游戏。它会自动定向到 Lutries 网站的游戏页。你可以以字母顺序查看所有可用的游戏。Lutries 现在已经有了很多游戏,而且还有更多的不断添加进来。
|
||||
|
||||
[![][7]][12]
|
||||
![][12]
|
||||
|
||||
任选一个游戏,添加到你的库中。
|
||||
|
||||
[![][7]][13]
|
||||
![][13]
|
||||
|
||||
然后返回到你的 Lutries 客户端,点击 **菜单 - > Lutris -> 同步库**。现在你可以在本地的 Lutries 客户端中看到所有在库中的游戏了。
|
||||
然后返回到你的 Lutries 客户端,点击 “Menu -> Lutris -> Synchronize library”。现在你可以在本地的 Lutries 客户端中看到所有在库中的游戏了。
|
||||
|
||||
[![][7]][14]
|
||||
![][14]
|
||||
|
||||
如果你没有看到游戏,只需要重启一次。
|
||||
|
||||
**安装游戏**
|
||||
#### 安装游戏
|
||||
|
||||
安装游戏,只需要点击游戏,然后点击 **安装** 按钮。例如,我想在我的系统安装 [**2048**][15],就像你在底下的截图中看到的,它要求我选择一个版本去安装。因为它只有一个版本(例如,在线),它就会自动选择这个版本。点击 **继续**。
|
||||
安装游戏,只需要点击游戏,然后点击 “Install” 按钮。例如,我想在我的系统安装 [2048][15],就像你在底下的截图中看到的,它要求我选择一个版本去安装。因为它只有一个版本(例如,在线),它就会自动选择这个版本。点击 “Continue”。
|
||||
|
||||
[![][7]][16]Click Install:
|
||||
![][16]
|
||||
|
||||
[![][7]][17]
|
||||
点击“Install”:
|
||||
|
||||
![][17]
|
||||
|
||||
安装完成之后,你可以启动新安装的游戏或是关闭这个窗口,继续从你的库中安装其他游戏。
|
||||
|
||||
**导入 Steam 库**
|
||||
#### 导入 Steam 库
|
||||
|
||||
你也可以导入你的 Steam 库。在你的头像处点击 **"通过 Steam 登录"** 按钮。接下来你将被重定向到 Steam,输入你的账号信息。填写正确后,你的 Steam 账号将被连接到 Lutries 账号。请注意,为了同步库中的游戏,这里你的 Steam 账号将被公开。你可以在同步完成之后将其重新设为私密状态。
|
||||
你也可以导入你的 Steam 库。在你的头像处点击 “Sign in through Steam” 按钮。接下来你将被重定向到 Steam,输入你的账号信息。填写正确后,你的 Steam 账号将被连接到 Lutries 账号。请注意,为了同步库中的游戏,这里你的 Steam 账号将被公开。你可以在同步完成之后将其重新设为私密状态。
|
||||
|
||||
**手动添加游戏**
|
||||
#### 手动添加游戏
|
||||
|
||||
Lutries 有手动添加游戏的选项。在工具栏中点击 + 号登录。
|
||||
Lutries 有手动添加游戏的选项。在工具栏中点击 “+” 号登录。
|
||||
|
||||
[![][7]][18]
|
||||
![][18]
|
||||
|
||||
在下一个窗口,输入游戏名,在游戏信息栏选择一个运行器。运行器是指 Linux 上类似 wine,Steam 之类的程序,它们可以帮助你启动这个游戏。你可以从 菜单 -> 管理运行器 中安装运行器。
|
||||
在下一个窗口,输入游戏名,在游戏信息栏选择一个运行器。运行器是指 Linux 上类似 wine、Steam 之类的程序,它们可以帮助你启动这个游戏。你可以从 “Menu -> Manage” 中安装运行器。
|
||||
|
||||
[![][7]][19]
|
||||
![][19]
|
||||
|
||||
然后在下一栏中选择可执行文件或者 ISO。最后点击保存。有一个好消息是,你可以添加一个游戏的多个版本。
|
||||
|
||||
**移除游戏**
|
||||
#### 移除游戏
|
||||
|
||||
移除任何已安装的游戏,只需在 Lutries 客户端的本地库中点击对应的游戏。选择 **移除** 然后 **应用**。
|
||||
移除任何已安装的游戏,只需在 Lutries 客户端的本地库中点击对应的游戏。选择 “Remove” 然后 “Apply”。
|
||||
|
||||
[![][7]][20]
|
||||
![][20]
|
||||
|
||||
Lutries 就像 Steam。只是从网站向你的库中添加游戏,并在客户端中为你安装它们。
|
||||
|
||||
@ -215,15 +232,13 @@ Lutries 就像 Steam。只是从网站向你的库中添加游戏,并在客户
|
||||
|
||||
:)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/manage-games-using-lutris-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -234,17 +249,16 @@ via: https://www.ostechnix.com/manage-games-using-lutris-linux/
|
||||
[4]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]:https://lutris.net/downloads/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-1-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-1-1.png
|
||||
[9]:https://lutris.net/user/register/
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-2.png ()
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-3.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-15-1.png ()
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-16.png ()
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-6.png ()
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-2.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-3.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-15-1.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-16.png
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-6.png
|
||||
[15]:https://www.ostechnix.com/let-us-play-2048-game-terminal/
|
||||
[16]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-12.png ()
|
||||
[17]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-13.png ()
|
||||
[18]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-18-1.png ()
|
||||
[19]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-19.png ()
|
||||
[20]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-14-1.png ()
|
||||
[16]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-12.png
|
||||
[17]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-13.png
|
||||
[18]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-18-1.png
|
||||
[19]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-19.png
|
||||
[20]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-14-1.png
|
||||
@ -1,34 +1,32 @@
|
||||
如何在 Ubuntu 服务器中禁用终端欢迎消息中的广告
|
||||
如何禁用 Ubuntu 服务器中终端欢迎消息中的广告
|
||||
======
|
||||
|
||||
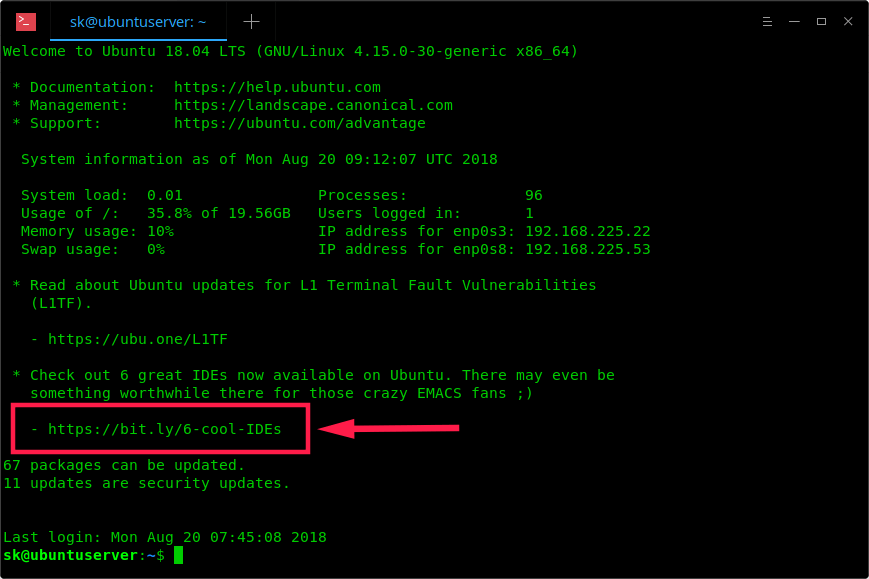
如果你正在使用最新的 Ubuntu 服务器版本,你可能已经注意到欢迎消息中有一些与 Ubuntu 服务器平台无关的促销链接。你可能已经知道 **MOTD**,即 **M**essage **O**f **T**he **D**ay 的开头首字母,在 Linux 系统每次登录时都会显示欢迎信息。通常,欢迎消息包含操作系统版本,基本系统信息,官方文档链接以及有关最新安全更新等的链接。这些是我们每次通过 SSH 或本地登录时通常会看到的内容。但是,最近在终端欢迎消息中出现了一些其他链接。我已经几次注意到这些链接,但我并在意,也从未点击过。以下是我的 Ubuntu 18.04 LTS 服务器上显示的终端欢迎消息。
|
||||
|
||||
|
||||
|
||||
正如你在上面截图中所看到的,欢迎消息中有一个 bit.ly 链接和 Ubuntu wiki 链接。有些人可能会惊讶并想知道这是什么。其实欢迎信息中的链接无需担心。它可能看起来像广告,但并不是商业广告。链接实际上指的是 [**Ubuntu 官方博客**][1] 和 [**Ubuntu wiki**][2]。正如我之前所说,其中的一个链接是不相关的,没有任何与 Ubuntu 服务器相关的细节,这就是为什么我开头称它们为广告。
|
||||
(to 校正:这里是其中一个链接不相关还是两个链接都不相关)
|
||||
正如你在上面截图中所看到的,欢迎消息中有一个 bit.ly 链接和 Ubuntu wiki 链接。有些人可能会惊讶并想知道这是什么。其实欢迎信息中的链接无需担心。它可能看起来像广告,但并不是商业广告。链接实际上指向到了 [Ubuntu 官方博客][1] 和 [Ubuntu wiki][2]。正如我之前所说,其中的一个链接是不相关的,没有任何与 Ubuntu 服务器相关的细节,这就是为什么我开头称它们为广告。
|
||||
|
||||
虽然我们大多数人都不会访问 bit.ly 链接,但是有些人可能出于好奇去访问这些链接,结果失望地发现它只是指向一个外部链接。你可以使用任何 URL 短网址服务,例如 unshorten.it,在访问真正链接之前,查看它会指向哪里。或者,你只需在 bit.ly 链接的末尾输入加号(**+**)即可查看它们的实际位置以及有关链接的一些统计信息。
|
||||
虽然我们大多数人都不会访问 bit.ly 链接,但是有些人可能出于好奇去访问这些链接,结果失望地发现它只是指向一个外部链接。你可以使用任何 URL 去短网址服务,例如 unshorten.it,在访问真正链接之前,查看它会指向哪里。或者,你只需在 bit.ly 链接的末尾输入加号(`+`)即可查看它们的实际位置以及有关链接的一些统计信息。
|
||||
|
||||

|
||||
|
||||
### 什么是 MOTD 以及它是如何工作的?
|
||||
|
||||
2009 年,来自 Canonical 的 **Dustin Kirkland** 在 Ubuntu 中引入了 MOTD 的概念。它是一个灵活的框架,使管理员或发行包能够在 /etc/update-motd.d/* 位置添加可执行脚本,目的是生成在登录时显示有益的,有趣的消息。它最初是为 Landscape(Canonical 的商业服务)实现的,但是其它发行版维护者发现它很有用,并且在他们自己的发行版中也采用了这个特性。
|
||||
2009 年,来自 Canonical 的 Dustin Kirkland 在 Ubuntu 中引入了 MOTD 的概念。它是一个灵活的框架,使管理员或发行包能够在 `/etc/update-motd.d/` 位置添加可执行脚本,目的是生成在登录时显示有益的、有趣的消息。它最初是为 Landscape(Canonical 的商业服务)实现的,但是其它发行版维护者发现它很有用,并且在他们自己的发行版中也采用了这个特性。
|
||||
|
||||
如果你在 Ubuntu 系统中查看 **/etc/update-motd.d/**,你会看到一组脚本。一个是打印通用的 “ Welcome” 横幅。下一个打印 3 个链接,显示在哪里可以找到操作系统的帮助。另一个计算并显示本地系统包可以更新的数量。另一个脚本告诉你是否需要重新启动等等。
|
||||
如果你在 Ubuntu 系统中查看 `/etc/update-motd.d/`,你会看到一组脚本。一个是打印通用的 “欢迎” 横幅。下一个打印 3 个链接,显示在哪里可以找到操作系统的帮助。另一个计算并显示本地系统包可以更新的数量。另一个脚本告诉你是否需要重新启动等等。
|
||||
|
||||
从 Ubuntu 17.04 起,开发人员添加了 **/etc/update-motd.d/50-motd-news**,这是一个脚本用来在欢迎消息中包含一些附加信息。这些附加信息是:
|
||||
|
||||
1. 重要的关键信息,例如 ShellShock, Heartbleed 等
|
||||
从 Ubuntu 17.04 起,开发人员添加了 `/etc/update-motd.d/50-motd-news`,这是一个脚本用来在欢迎消息中包含一些附加信息。这些附加信息是:
|
||||
|
||||
1. 重要的关键信息,例如 ShellShock、Heartbleed 等
|
||||
2. 生命周期(EOL)消息,新功能可用性等
|
||||
|
||||
3. 在 Ubuntu 官方博客和其他有关 Ubuntu 的新闻中发布的一些有趣且有益的帖子
|
||||
|
||||
另一个特点是异步,启动后约 60 秒,systemd 计时器运行 “/etc/update-motd.d/50-motd-news –force” 脚本。它提供了 /etc/default/motd-news 脚本中定义的 3 个配置变量。默认值为:ENABLED=1, URLS=”<https://motd.ubuntu.com”>, WAIT=”5″。
|
||||
另一个特点是异步,启动后约 60 秒,systemd 计时器运行 `/etc/update-motd.d/50-motd-news –force` 脚本。它提供了 `/etc/default/motd-news` 脚本中定义的 3 个配置变量。默认值为:`ENABLED=1, URLS="https://motd.ubuntu.com", WAIT="5"`。
|
||||
|
||||
以下是 `/etc/default/motd-news` 文件的内容:
|
||||
|
||||
以下是 /etc/default/motd-news 文件的内容:
|
||||
```
|
||||
$ cat /etc/default/motd-news
|
||||
# Enable/disable the dynamic MOTD news service
|
||||
@ -50,20 +48,20 @@ URLS="https://motd.ubuntu.com"
|
||||
# Note that news messages are fetched in the background by
|
||||
# a systemd timer, so this should never block boot or login
|
||||
WAIT=5
|
||||
|
||||
```
|
||||
|
||||
好事情是 MOTD 是完全可定制的,所以你可以彻底禁用它(ENABLED=0),根据你的意愿更改或添加脚本,并以秒为单位更改等待时间。
|
||||
好事情是 MOTD 是完全可定制的,所以你可以彻底禁用它(`ENABLED=0`)、根据你的意愿更改或添加脚本、以秒为单位更改等待时间等等。
|
||||
|
||||
如果启用了 MOTD,那么 systemd 计时器作业将循环遍历每个 URL,将它们缩减到每行 80 个字符,最多 10 行,并将它们连接(to 校正:也可能是链接?)到 /var/cache/motd-news 中的缓存文件。此 systemd 计时器作业将每隔 12 小时运行并更新 /var/cache/motd-news。用户登录后,/var/cache/motd-news 的内容会打印到屏幕上。这就是 MOTD 的工作原理。
|
||||
如果启用了 MOTD,那么 systemd 计时器作业将循环遍历每个 URL,将它们的内容缩减到每行 80 个字符、最多 10 行,并将它们连接到 `/var/cache/motd-news` 中的缓存文件。此 systemd 计时器作业将每隔 12 小时运行并更新 `/var/cache/motd-news`。用户登录后,`/var/cache/motd-news` 的内容会打印到屏幕上。这就是 MOTD 的工作原理。
|
||||
|
||||
此外,`/etc/update-motd.d/50-motd-news` 文件中包含自定义的用户代理字符串,以报告有关计算机的信息。如果你查看 `/etc/update-motd.d/50-motd-news` 文件,你会看到:
|
||||
|
||||
此外,**/etc/update-motd.d/50-motd-news** 文件中包含自定义用户代理字符串,以报告有关计算机的信息。如果你查看 **/etc/update-motd.d/50-motd-news** 文件,你会看到
|
||||
```
|
||||
# Piece together the user agent
|
||||
USER_AGENT="curl/$curl_ver $lsb $platform $cpu $uptime"
|
||||
```
|
||||
|
||||
这意味着,MOTD 检索器将向 Canonical 报告你的**操作系统版本**,**硬件平台**,**CPU 类型**和**正常运行时间**。
|
||||
这意味着,MOTD 检索器将向 Canonical 报告你的操作系统版本、硬件平台、CPU 类型和正常运行时间。
|
||||
|
||||
到这里,希望你对 MOTD 有了一个基本的了解。
|
||||
|
||||
@ -72,11 +70,13 @@ USER_AGENT="curl/$curl_ver $lsb $platform $cpu $uptime"
|
||||
### 在 Ubuntu 服务器中禁用终端欢迎消息中的广告
|
||||
|
||||
要禁用这些广告,编辑文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/default/motd-news
|
||||
```
|
||||
|
||||
找到以下行并将其值设置为 0(零)。
|
||||
找到以下行并将其值设置为 `0`(零)。
|
||||
|
||||
```
|
||||
[...]
|
||||
ENABLED=0
|
||||
@ -101,7 +101,7 @@ via: https://www.ostechnix.com/how-to-disable-ads-in-terminal-welcome-message-in
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
推动 DevOps 变革的三个方面
|
||||
======
|
||||
|
||||
推动大规模的组织变革是一个痛苦的过程。对于 DevOps 来说,尽管也有阵痛,但变革带来的价值则相当可观。
|
||||
> 推动大规模的组织变革是一个痛苦的过程。对于 DevOps 来说,尽管也有阵痛,但变革带来的价值则相当可观。
|
||||
|
||||

|
||||
|
||||
@ -1,71 +1,74 @@
|
||||
Kali Linux:在开始使用之前你必须知道的 – FOSS Post
|
||||
在你开始使用 Kali Linux 之前必须知道的事情
|
||||
======
|
||||
|
||||

|
||||
|
||||
Kali Linux 在渗透测试和白帽子方面,是业界领先的 Linux 发行版。默认情况下,该发行版附带了大量黑客和渗透工具和软件,并且在全世界都得到了广泛认可。即使在那些甚至可能不知道 Linux 是什么的 Windows 用户中也是如此。
|
||||
Kali Linux 在渗透测试和白帽子方面是业界领先的 Linux 发行版。默认情况下,该发行版附带了大量入侵和渗透的工具和软件,并且在全世界都得到了广泛认可。即使在那些甚至可能不知道 Linux 是什么的 Windows 用户中也是如此。
|
||||
|
||||
由于后者的原因,许多人都试图单独使用 Kali Linux,尽管他们甚至不了解 Linux 系统的基础知识。原因可能各不相同,有的为了玩乐,有的是为了取悦女友而伪装成黑客,有的仅仅是试图破解邻居的 WiFi 网络以免费上网。如果你打算使用 Kali Linux,所有的这些都是不好的事情。
|
||||
由于后者的原因(LCTT 译注:Windows 用户),许多人都试图单独使用 Kali Linux,尽管他们甚至不了解 Linux 系统的基础知识。原因可能各不相同,有的为了玩乐,有的是为了取悦女友而伪装成黑客,有的仅仅是试图破解邻居的 WiFi 网络以免费上网。如果你打算使用 Kali Linux,记住,所有的这些都是不好的事情。
|
||||
|
||||
在计划使用 Kali Linux 之前,你应该了解一些提示。
|
||||
|
||||
### Kali Linux 不适合初学者
|
||||
|
||||

|
||||
Kali Linux 默认 GNOME 桌面
|
||||
|
||||
如果你是几个月前刚开始使用 Linux 的人,或者你认为自己的知识水平低于平均水平,那么 Kali Linux 就不适合你。如果你打算问“如何在 Kali 上安装 Stream?如何让我的打印机在 Kali 上工作?如何解决 Kali 上的 APT 源错误?”这些东西,那么 Kali Linux 并不适合你。
|
||||
*Kali Linux 默认 GNOME 桌面*
|
||||
|
||||
Kali Linux 主要面向想要运行渗透测试的专家或想要学习成为白帽子和数字取证的人。但即使你来自后者,普通的 Kali Linux 用户在日常使用时也会遇到很多麻烦。他还被要求以非常谨慎的方式使用工具和软件,而不仅仅是“让我们安装并运行一切”。每一个工具必须小心使用,你安装的每一个软件都必须仔细检查。
|
||||
如果你是几个月前刚开始使用 Linux 的人,或者你认为自己的知识水平低于平均水平,那么 Kali Linux 就不适合你。如果你打算问“如何在 Kali 上安装 Steam?如何让我的打印机在 Kali 上工作?如何解决 Kali 上的 APT 源错误?”这些东西,那么 Kali Linux 并不适合你。
|
||||
|
||||
**建议阅读:** [Linux 系统的组件是什么?][1]
|
||||
Kali Linux 主要面向想要运行渗透测试套件的专家或想要学习成为白帽子和数字取证的人。但即使你属于后者,普通的 Kali Linux 用户在日常使用时也会遇到很多麻烦。他还被要求以非常谨慎的方式使用工具和软件,而不仅仅是“让我们安装并运行一切”。每一个工具必须小心使用,你安装的每一个软件都必须仔细检查。
|
||||
|
||||
普通 Linux 用户无法做正常的事情。(to 校正:这里什么意思呢?)一个更好的方法是花几周时间学习 Linux 及其守护进程,服务,软件,发行版及其工作方式,然后观看几十个关于白帽子攻击的视频和课程,然后再尝试使用 Kali 来应用你学习到的东西。
|
||||
**建议阅读:** [Linux 系统的组件有什么?][1]
|
||||
|
||||
普通 Linux 用户都无法自如地使用它。一个更好的方法是花几周时间学习 Linux 及其守护进程、服务、软件、发行版及其工作方式,然后观看几十个关于白帽子攻击的视频和课程,然后再尝试使用 Kali 来应用你学习到的东西。
|
||||
|
||||
### 它会让你被黑客攻击
|
||||
|
||||

|
||||
Kali Linux 入侵和测试工具
|
||||
|
||||
*Kali Linux 入侵和测试工具*
|
||||
|
||||
在普通的 Linux 系统中,普通用户有一个账户,而 root 用户也有一个单独的账号。但在 Kali Linux 中并非如此。Kali Linux 默认使用 root 账户,不提供普通用户账户。这是因为 Kali 中几乎所有可用的安全工具都需要 root 权限,并且为了避免每分钟要求你输入 root 密码,所以这样设计。
|
||||
|
||||
当然,你可以简单地创建一个普通用户账户并开始使用它。但是,这种方式仍然不推荐,因为这不是 Kali Linux 系统设计的工作方式。然后,在使用程序,打开端口,调试软件时,你会遇到很多问题,你会发现为什么这个东西不起作用,最终却发现它是一个奇怪的权限错误。另外每次在系统上做任何事情时,你会被每次运行工具都要求输入密码而烦恼。
|
||||
当然,你可以简单地创建一个普通用户账户并开始使用它。但是,这种方式仍然不推荐,因为这不是 Kali Linux 系统设计的工作方式。使用普通用户在使用程序,打开端口,调试软件时,你会遇到很多问题,你会发现为什么这个东西不起作用,最终却发现它是一个奇怪的权限错误。另外每次在系统上做任何事情时,你会被每次运行工具都要求输入密码而烦恼。
|
||||
|
||||
现在,由于你被迫以 root 用户身份使用它,因此你在系统上运行的所有软件也将以 root 权限运行。如果你不知道自己在做什么,那么这很糟糕,因为如果 Firefox 中存在漏洞,并且你访问了一个受感染的网站,那么黑客能够在你的 PC 上获得全部 root 权限并入侵你。如果你使用的是普通用户账户,则会收到限制。此外,你安装和使用的某些工具可能会在你不知情的情况下打开端口并泄露信息,因此如果你不是非常小心,人们可能会以你尝试入侵他们的方式入侵你。
|
||||
现在,由于你被迫以 root 用户身份使用它,因此你在系统上运行的所有软件也将以 root 权限运行。如果你不知道自己在做什么,那么这很糟糕,因为如果 Firefox 中存在漏洞,并且你访问了一个受感染的网站,那么黑客能够在你的 PC 上获得全部 root 权限并入侵你。如果你使用的是普通用户账户,则会受到限制。此外,你安装和使用的某些工具可能会在你不知情的情况下打开端口并泄露信息,因此如果你不是非常小心,人们可能会以你尝试入侵他们的方式入侵你。
|
||||
|
||||
如果你在一些情况下访问于与 Kali Linux 相关的 Facebook 群组,你会发现这些群组中几乎有四分之一的帖子是人们在寻求帮助,因为有人入侵了他们。
|
||||
如果你曾经访问过与 Kali Linux 相关的 Facebook 群组,你会发现这些群组中几乎有四分之一的帖子是人们在寻求帮助,因为有人入侵了他们。
|
||||
|
||||
### 它可以让你入狱
|
||||
|
||||
Kali Linux 仅提供软件。那么,如何使用它们完全是你自己的责任。
|
||||
Kali Linux 只是提供了软件。那么,如何使用它们完全是你自己的责任。
|
||||
|
||||
在世界上大多数发达国家,使用针对公共 WiFi 网络或其他设备的渗透测试工具很容易让你入狱。现在不要以为你使用了 Kali 就无法被跟踪,许多系统都配置了复杂的日志记录设备来简单地跟踪试图监听或入侵其网络的人,你可能无意间成为其中的一个,那么它会毁掉你的生活。
|
||||
|
||||
永远不要对不属于你的设备或网络使用 Kali Linux 系统,也不要明确允许对它们进行入侵。如果你说你不知道你在做什么,在法庭上它不会被当作借口来接受。
|
||||
|
||||
### 修改了内核和软件
|
||||
### 修改了的内核和软件
|
||||
|
||||
Kali [基于][2] Debian(测试分支,这意味着 Kali Linux 使用滚动发布模型),因此它使用了 Debian 的大部分软件体系结构,你会发现 Kali Linux 中的大部分软件跟 Debian 中的没什么区别。
|
||||
Kali [基于][2] Debian(“测试”分支,这意味着 Kali Linux 使用滚动发布模型),因此它使用了 Debian 的大部分软件体系结构,你会发现 Kali Linux 中的大部分软件跟 Debian 中的没什么区别。
|
||||
|
||||
但是,Kali 修改了一些包来加强安全性并修复了一些可能的漏洞。例如,Kali 使用的 Linux 内核被打了补丁,允许在各种设备上进行无线注入。这些补丁通常在普通内核中不可用。此外,Kali Linux 不依赖于 Debian 服务器和镜像,而是通过自己的服务器构建软件包。以下是最新版本中的默认软件源:
|
||||
|
||||
```
|
||||
deb http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
deb-src http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
deb http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
deb-src http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
```
|
||||
|
||||
这就是为什么,对于某些特定的软件,当你在 Kali Linux 和 Fedora 中使用相同的程序时,你会发现不同的行为。你可以从 [git.kali.org][3] 中查看 Kali Linux 软件的完整列表。你还可以在 Kali Linux(GNOME)上找到我们[自己生成的已安装包列表][4]。
|
||||
|
||||
更重要的是,Kali Linux 官方文档极力建议不要添加任何其他第三方软件仓库,因为 Kali Linux 是一个滚动发行版,并且依赖于 Debian 测试,由于依赖关系冲突和包钩子,所以你很可能只是添加一个新的仓库源就会破坏系统。
|
||||
更重要的是,Kali Linux 官方文档极力建议不要添加任何其他第三方软件仓库,因为 Kali Linux 是一个滚动发行版,并且依赖于 Debian 测试分支,由于依赖关系冲突和包钩子,所以你很可能只是添加一个新的仓库源就会破坏系统。
|
||||
|
||||
### 不要安装 Kali Linux
|
||||
|
||||

|
||||
|
||||
使用 Kali Linux 在 fosspost.org 上运行 wpscan
|
||||
*使用 Kali Linux 在 fosspost.org 上运行 wpscan*
|
||||
|
||||
我在极少数情况下使用 Kali Linux 来测试我部署的软件和服务器。但是,我永远不敢安装它并将其用作主系统。
|
||||
|
||||
如果你要将其用作主系统,那么你必须保留自己的个人文件,密码,数据以及系统上的所有内容。你还需要安装大量日常使用的软件,以解放你的生活。但正如我们上面提到的,使用 Kali Linux 是非常危险的,应该非常小心地进行,如果你被入侵了,你将丢失所有数据,并且可能会暴露给更多的人。如果你在做一些不合法的事情,你的个人信息也可用于跟踪你。如果你不小心使用这些工具,那么你甚至可能会毁掉自己的数据。
|
||||
如果你要将其用作主系统,那么你必须保留自己的个人文件、密码、数据以及系统上的所有内容。你还需要安装大量日常使用的软件,以解放你的生活。但正如我们上面提到的,使用 Kali Linux 是非常危险的,应该非常小心地进行,如果你被入侵了,你将丢失所有数据,并且可能会暴露给更多的人。如果你在做一些不合法的事情,你的个人信息也可用于跟踪你。如果你不小心使用这些工具,那么你甚至可能会毁掉自己的数据。
|
||||
|
||||
即使是专业的白帽子也不建议将其作为主系统安装,而是通过 USB 使用它来进行渗透测试工作,然后再回到普通的 Linux 发行版。
|
||||
|
||||
@ -83,7 +86,7 @@ via: https://fosspost.org/articles/must-know-before-using-kali-linux
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
HankChow translating
|
||||
|
||||
Ultimate Plumber – Writing Linux Pipes With Instant Live Preview
|
||||
======
|
||||
|
||||
|
||||
@ -1,114 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Machine learning with Python: Essential hacks and tricks
|
||||
======
|
||||
Master machine learning, AI, and deep learning with Python.
|
||||

|
||||
|
||||
It's never been easier to get started with machine learning. In addition to structured massive open online courses (MOOCs), there are a huge number of incredible, free resources available around the web. Here are a few that have helped me.
|
||||
|
||||
2. Learn to clearly differentiate between the buzzwords—for example, machine learning, artificial intelligence, deep learning, data science, computer vision, and robotics. Read or listen to talks by experts on each of them. Watch this [amazing video by Brandon Rohrer][1], an influential data scientist. Or this video about the [clear differences between various roles][2] associated with data science.
|
||||
|
||||
|
||||
3. Clearly set a goal for what you want to learn. Then go and take [that Coursera course][3]. Or take the one [from the University of Washington][4], which is pretty good too.
|
||||
|
||||
|
||||
5. If you are enthusiastic about taking online courses, check out this article for guidance on [choosing the right MOOC][5].
|
||||
|
||||
|
||||
6. Most of all, develop a feel for it. Join some good social forums, but resist the temptation to latch onto sensationalized headlines and news. Do your own reading to understand what it is and what it is not, where it might go, and what possibilities it can open up. Then sit back and think about how you can apply machine learning or imbue data science principles into your daily work. Build a simple regression model to predict the cost of your next lunch or download your electricity usage data from your energy provider and do a simple time-series plot in Excel to discover some pattern of usage. And after you are thoroughly enamored with machine learning, you can watch this video.
|
||||
|
||||
<https://www.youtube.com/embed/IpGxLWOIZy4>
|
||||
|
||||
### Is Python a good language for machine learning/AI?
|
||||
|
||||
Familiarity and moderate expertise in at least one high-level programming language is useful for beginners in machine learning. Unless you are a Ph.D. researcher working on a purely theoretical proof of some complex algorithm, you are expected to mostly use the existing machine learning algorithms and apply them in solving novel problems. This requires you to put on a programming hat.
|
||||
|
||||
There's a lot of talk about the best language for data science. While the debate rages, grab a coffee and read this insightful FreeCodeCamp article to learn about [data science languages][6] . Or, check out this post on KDnuggets to dive directly into the [Python vs. R debate][7]
|
||||
|
||||
For now, it's widely believed that Python helps developers be more productive from development to deployment and maintenance. Python's syntax is simpler and at a higher level when compared to Java, C, and C++. It has a vibrant community, open source culture, hundreds of high-quality libraries focused on machine learning, and a huge support base from big names in the industry (e.g., Google, Dropbox, Airbnb, etc.).
|
||||
|
||||
### Fundamental Python libraries
|
||||
|
||||
Assuming you go with the widespread opinion that Python is the best language for machine learning, there are a few core Python packages and libraries you need to master.
|
||||
|
||||
#### NumPy
|
||||
|
||||
Short for [Numerical Python][8], NumPy is the fundamental package required for high-performance scientific computing and data analysis in the Python ecosystem. It's the foundation on which nearly all of the higher-level tools, such as [Pandas][9] and [scikit-learn][10], are built. [TensorFlow][11] uses NumPy arrays as the fundamental building blocks underpinning Tensor objects and graphflow for deep learning tasks. Many NumPy operations are implemented in C, making them super fast. For data science and modern machine learning tasks, this is an invaluable advantage.
|
||||
|
||||

|
||||
|
||||
#### Pandas
|
||||
|
||||
Pandas is the most popular library in the scientific Python ecosystem for doing general-purpose data analysis. Pandas is built upon a NumPy array, thereby preserving fast execution speed and offering many data engineering features, including:
|
||||
|
||||
* Reading/writing many different data formats
|
||||
* Selecting subsets of data
|
||||
* Calculating across rows and down columns
|
||||
* Finding and filling missing data
|
||||
* Applying operations to independent groups within the data
|
||||
* Reshaping data into different forms
|
||||
* Combing multiple datasets together
|
||||
* Advanced time-series functionality
|
||||
* Visualization through Matplotlib and Seaborn
|
||||
|
||||

|
||||
|
||||
#### Matplotlib and Seaborn
|
||||
|
||||
Data visualization and storytelling with data are essential skills for every data scientist because it's crtitical to be able to communicate insights from analyses to any audience effectively. This is an equally critical part of your machine learning pipeline, as you often have to perform an exploratory analysis of a dataset before deciding to apply a particular machine learning algorithm.
|
||||
|
||||
[Matplotlib][12] is the most widely used 2D Python visualization library. It's equipped with a dazzling array of commands and interfaces for producing publication-quality graphics from your data. This amazingly detailed and rich article will help you [get started with Matplotlib][13].
|
||||
|
||||
|
||||
[Seaborn][14] is another great visualization library focused on statistical plotting. It provides an API (with flexible choices for plot style and color defaults) on top of Matplotlib, defines simple high-level functions for common statistical plot types, and integrates with functionality provided by Pandas. You can start with this great tutorial on [Seaborn for beginners][15].
|
||||
|
||||
|
||||
|
||||
#### Scikit-learn
|
||||
|
||||
Scikit-learn is the most important general machine learning Python package to master. It features various [classification][16], [regression][17], and [clustering][18] algorithms, including [support vector machines][19], [random forests][20], [gradient boosting][21], [k-means][22], and [DBSCAN][23], and is designed to interoperate with the Python numerical and scientific libraries NumPy and [SciPy][24]. It provides a range of supervised and unsupervised learning algorithms via a consistent interface. The library has a level of robustness and support required for use in production systems. This means it has a deep focus on concerns such as ease of use, code quality, collaboration, documentation, and performance. Look at this [gentle introduction to machine learning vocabulary][25] used in the Scikit-learn universe or this article demonstrating [a simple machine learning pipeline][26] method using Scikit-learn.
|
||||
|
||||
This article was originally published on [Heartbeat][27] under [CC BY-SA 4.0][28].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/machine-learning-python-essential-hacks-and-tricks
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/watch?v=tKa0zDDDaQk
|
||||
[2]: https://www.youtube.com/watch?v=Ura_ioOcpQI
|
||||
[3]: https://www.coursera.org/learn/machine-learning
|
||||
[4]: https://www.coursera.org/specializations/machine-learning
|
||||
[5]: https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f
|
||||
[6]: https://medium.freecodecamp.org/which-languages-should-you-learn-for-data-science-e806ba55a81f
|
||||
[7]: https://www.kdnuggets.com/2017/09/python-vs-r-data-science-machine-learning.html
|
||||
[8]: http://numpy.org/
|
||||
[9]: https://pandas.pydata.org/
|
||||
[10]: http://scikit-learn.org/
|
||||
[11]: https://www.tensorflow.org/
|
||||
[12]: https://matplotlib.org/
|
||||
[13]: https://realpython.com/python-matplotlib-guide/
|
||||
[14]: https://seaborn.pydata.org/
|
||||
[15]: https://www.datacamp.com/community/tutorials/seaborn-python-tutorial
|
||||
[16]: https://en.wikipedia.org/wiki/Statistical_classification
|
||||
[17]: https://en.wikipedia.org/wiki/Regression_analysis
|
||||
[18]: https://en.wikipedia.org/wiki/Cluster_analysis
|
||||
[19]: https://en.wikipedia.org/wiki/Support_vector_machine
|
||||
[20]: https://en.wikipedia.org/wiki/Random_forests
|
||||
[21]: https://en.wikipedia.org/wiki/Gradient_boosting
|
||||
[22]: https://en.wikipedia.org/wiki/K-means_clustering
|
||||
[23]: https://en.wikipedia.org/wiki/DBSCAN
|
||||
[24]: https://en.wikipedia.org/wiki/SciPy
|
||||
[25]: http://scikit-learn.org/stable/tutorial/basic/tutorial.html
|
||||
[26]: https://towardsdatascience.com/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-19e8a1ddbd49
|
||||
[27]: https://heartbeat.fritz.ai/some-essential-hacks-and-tricks-for-machine-learning-with-python-5478bc6593f2
|
||||
[28]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
@ -0,0 +1,181 @@
|
||||
Create a containerized machine learning model
|
||||
======
|
||||
|
||||

|
||||
|
||||
After data scientists have created a machine learning model, it has to be deployed into production. To run it on different infrastructures, using containers and exposing the model via a REST API is a common way to deploy a machine learning model. This article demonstrates how to roll out a [TensorFlow][1] machine learning model, with a REST API delivered by [Connexion][2] in a container with [Podman][3].
|
||||
|
||||
### Preparation
|
||||
|
||||
First, install Podman with the following command:
|
||||
|
||||
```
|
||||
sudo dnf -y install podman
|
||||
```
|
||||
|
||||
Next, create a new folder for the container and switch to that directory.
|
||||
|
||||
```
|
||||
mkdir deployment_container && cd deployment_container
|
||||
```
|
||||
|
||||
### REST API for the TensorFlow model
|
||||
|
||||
The next step is to create the REST-API for the machine learning model. This [github repository][4] contains a pretrained model, and well as the setup already configured for getting the REST API working.
|
||||
|
||||
Clone this in the deployment_container directory with the command:
|
||||
|
||||
```
|
||||
git clone https://github.com/svenboesiger/titanic_tf_ml_model.git
|
||||
```
|
||||
|
||||
#### prediction.py & ml_model/
|
||||
|
||||
The [prediction.py][5] file allows for a Tensorflow prediction, while the weights for the 20x20x20 neural network are located in folder [ml_model/][6].
|
||||
|
||||
#### swagger.yaml
|
||||
|
||||
The file swagger.yaml defines the API for the Connexion library using the [Swagger specification][7]. This file contains all of the information necessary to configure your server to provide input parameter validation, output response data validation, URL endpoint definition.
|
||||
|
||||
As a bonus Connexion will provide you also with a simple but useful single page web application that demonstrates using the API with JavaScript and updating the DOM with it.
|
||||
|
||||
```
|
||||
swagger: "2.0"
|
||||
info:
|
||||
description: This is the swagger file that goes with our server code
|
||||
version: "1.0.0"
|
||||
title: Tensorflow Podman Article
|
||||
consumes:
|
||||
- "application/json"
|
||||
produces:
|
||||
- "application/json"
|
||||
|
||||
|
||||
basePath: "/"
|
||||
|
||||
paths:
|
||||
/survival_probability:
|
||||
post:
|
||||
operationId: "prediction.post"
|
||||
tags:
|
||||
- "Prediction"
|
||||
summary: "The prediction data structure provided by the server application"
|
||||
description: "Retrieve the chance of surviving the titanic disaster"
|
||||
parameters:
|
||||
- in: body
|
||||
name: passenger
|
||||
required: true
|
||||
schema:
|
||||
$ref: '#/definitions/PredictionPost'
|
||||
responses:
|
||||
'201':
|
||||
description: 'Survival probability of an individual Titanic passenger'
|
||||
|
||||
definitions:
|
||||
PredictionPost:
|
||||
type: object
|
||||
```
|
||||
|
||||
#### server.py & requirements.txt
|
||||
|
||||
[server.py][8] defines an entry point to start the Connexion server.
|
||||
|
||||
```
|
||||
import connexion
|
||||
|
||||
app = connexion.App(__name__, specification_dir='./')
|
||||
|
||||
app.add_api('swagger.yaml')
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True)
|
||||
```
|
||||
|
||||
[requirements.txt][9] defines the python requirements we need to run the program.
|
||||
|
||||
```
|
||||
connexion
|
||||
tensorflow
|
||||
pandas
|
||||
```
|
||||
|
||||
### Containerize!
|
||||
|
||||
For Podman to be able to build an image, create a new file called “Dockerfile” in the **deployment_container** directory created in the preparation step above:
|
||||
|
||||
```
|
||||
FROM fedora:28
|
||||
|
||||
# File Author / Maintainer
|
||||
MAINTAINER Sven Boesiger <donotspam@ujelang.com>
|
||||
|
||||
# Update the sources
|
||||
RUN dnf -y update --refresh
|
||||
|
||||
# Install additional dependencies
|
||||
RUN dnf -y install libstdc++
|
||||
|
||||
RUN dnf -y autoremove
|
||||
|
||||
# Copy the application folder inside the container
|
||||
ADD /titanic_tf_ml_model /titanic_tf_ml_model
|
||||
|
||||
# Get pip to download and install requirements:
|
||||
RUN pip3 install -r /titanic_tf_ml_model/requirements.txt
|
||||
|
||||
# Expose ports
|
||||
EXPOSE 5000
|
||||
|
||||
# Set the default directory where CMD will execute
|
||||
WORKDIR /titanic_tf_ml_model
|
||||
|
||||
# Set the default command to execute
|
||||
# when creating a new container
|
||||
CMD python3 server.py
|
||||
```
|
||||
|
||||
Next, build the container image with the command:
|
||||
|
||||
```
|
||||
podman build -t ml_deployment .
|
||||
```
|
||||
|
||||
### Run the container
|
||||
|
||||
With the Container image built and ready to go, you can run it locally with the command:
|
||||
|
||||
```
|
||||
podman run -p 5000:5000 ml_deployment
|
||||
```
|
||||
|
||||
Navigate to [http://0.0.0.0:5000/ui][10] in your web browser to access the Swagger/Connexion UI and to test-drive the model:
|
||||
|
||||
![][11]
|
||||
|
||||
Of course you can now also access the model with your application via the REST-API.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/create-containerized-machine-learning-model/
|
||||
|
||||
作者:[Sven Bösiger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/r00nz/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.tensorflow.org
|
||||
[2]: https://connexion.readthedocs.io/en/latest/
|
||||
[3]: https://fedoramagazine.org/running-containers-with-podman/
|
||||
[4]: https://github.com/svenboesiger/titanic_tf_ml_model
|
||||
[5]: https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/prediction.py
|
||||
[6]: https://github.com/svenboesiger/titanic_tf_ml_model/tree/master/ml_model/titanic
|
||||
[7]: https://github.com/OAI/OpenAPI-Specification/blob/master/versions/2.0.md
|
||||
[8]: https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/server.py
|
||||
[9]: https://github.com/svenboesiger/titanic_tf_ml_model/blob/master/requirements.txt
|
||||
[10]: http://0.0.0.0:5000/
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/10/Screenshot-from-2018-10-27-14-46-56-682x1024.png
|
||||
@ -0,0 +1,78 @@
|
||||
How To Create A Bootable Linux USB Drive From Windows OS 7,8 and 10?
|
||||
======
|
||||
If you would like to learn about Linux, the first thing you have to do is install the Linux OS on your system.
|
||||
|
||||
It can be achieved in two ways either go with virtualization applications like Virtualbox, VMWare, etc, or install Linux on your system.
|
||||
|
||||
If you are preferring to move from windows OS to Linux OS or planning to install Linux operating system on your spare machine then you have to create a bootable USB stick for that.
|
||||
|
||||
We had wrote many articles for creating [bootable USB drive on Linux][1] such as [BootISO][2], [Etcher][3] and [dd command][4] but we never get an opportunity to write an article about creating Linux bootable USB drive in windows. Somehow, we got a opportunity today to perform this task.
|
||||
|
||||
In this article we are going to show you, how to create a bootable Ubuntu USB flash drive from windows 10.
|
||||
|
||||
These step will work for other Linux as well but you have to choose the corresponding OS from the drop down instead of Ubuntu.
|
||||
|
||||
### Step-1: Download Ubuntu ISO
|
||||
|
||||
Visit [Ubuntu releases][5] page and download a latest version. I would like to advise you to download a latest LTS version and not for a normal release.
|
||||
|
||||
Make sure you have downloaded the proper ISO by performing checksum using MD5 or SHA256. The output value should be matched with the Ubuntu releases page value.
|
||||
|
||||
### Step-2: Download Universal USB Installer
|
||||
|
||||
There are many applications are available for this but my preferred application is [Universal USB Installer][6] which is very simple to perform this task. Just visit Universal USB Installer page and download the app.
|
||||
|
||||
### Step-3: How To Create a bootable Ubuntu ISO using Universal USB Installer
|
||||
|
||||
There is no complication on this application to perform this. First connect your USB drive then hit the downloaded Universal USB Installer. Once it’s launched you can see the interface similar to us.
|
||||
![][8]
|
||||
|
||||
* **`Step-1:`** Select Ubuntu OS.
|
||||
* **`Step-2:`** Navigate to Ubuntu ISO downloaded location.
|
||||
* **`Step-3:`** By default it’s select a USB drive however verify this then check the option to format it.
|
||||
|
||||
|
||||
|
||||
![][9]
|
||||
|
||||
When you hit `Create` button, it will pop-up a window with warnings. No need to worry, just hit `Yes` to proceed further on this.
|
||||
![][10]
|
||||
|
||||
USB drive partition is in progress.
|
||||
![][11]
|
||||
|
||||
Wait for sometime to complete this. If you would like to move this process to background, yes, you can by hitting `Background` button.
|
||||
![][12]
|
||||
|
||||
Yes, it’s completed.
|
||||
![][13]
|
||||
|
||||
Now you are ready to perform [Ubuntu OS installation][14]. However, it’s offering a live mode also so, you can play around it if you want to try before performing the installation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/create-a-bootable-live-usb-drive-from-windows-using-universal-usb-installer/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/bootable-usb/
|
||||
[2]: https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/
|
||||
[3]: https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/
|
||||
[4]: https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/
|
||||
[5]: http://releases.ubuntu.com/
|
||||
[6]: https://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
|
||||
[7]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-1.png
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-2.png
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-3.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-4.png
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-5.png
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-6.png
|
||||
[14]: https://www.2daygeek.com/how-to-install-ubuntu-16-04/
|
||||
@ -0,0 +1,104 @@
|
||||
CPod: An Open Source, Cross-platform Podcast App
|
||||
======
|
||||
Podcasts are a great way to be entertained and informed. In fact, I listen to about ten different podcasts covering technology, mysteries, history, and comedy. Of course, [Linux podcasts][1] are also on this list.
|
||||
|
||||
Today, we will take a look at a simple cross-platform application for handling your podcasts.
|
||||
|
||||
![][2]
|
||||
Recommended podcasts and podcast search
|
||||
|
||||
### The Application
|
||||
|
||||
[CPod][3] is the creation of [Zack Guard (z————-)][4]. **It is an[Election][5] app** , which gives it the ability to run on the largest operating systems (Linux, Windows, Mac OS).
|
||||
|
||||
Trivia: CPod was originally named Cumulonimbus.
|
||||
|
||||
The majority of the application is taken up by two large panels to display content and options. A small bar along the left side of the screen gives you access to the different parts of the application. The different sections of CPod include Home, Queue, Subscriptions, Explore and Settings.
|
||||
|
||||
![cpod settings][6]Settings
|
||||
|
||||
### Features of CPod
|
||||
|
||||
Here is a list of features that CPod has to offer:
|
||||
|
||||
* Simple, clean design
|
||||
* Available on the top computer platforms
|
||||
* Available as a Snap
|
||||
* Search iTunes’ podcast directory
|
||||
* Download and play episodes without downloading
|
||||
* View podcast information and episode
|
||||
* Search for an individual episode of a podcast
|
||||
* Dark mode
|
||||
* Change playback speed
|
||||
* Keyboard shortcuts
|
||||
* Sync your podcast subscriptions with gpodder.net
|
||||
* Import and export subscriptions
|
||||
* Sort subscriptions based on length, date, download status, and play progress
|
||||
* Auto-fetch new episodes on application startup
|
||||
* Multiple language support
|
||||
|
||||
|
||||
|
||||
![search option in cpod application][7]Searching for ZFS episode
|
||||
|
||||
### Experiencing CPod on Linux
|
||||
|
||||
I ended up installing CPod on two systems: ArchLabs and Windows. There are two versions of CPod in the [Arch User Repository][8]. However, they are both out of date, one is version 1.14.0 and the other was 1.22.6. The most recent version of CPod is 1.27.0. Because of the version difference between ArchLabs and Windows, I had to different experiences. For this article, I will focus on 1.27.0, since that is the most current and has the most features.
|
||||
|
||||
Right out of the gate, I was able to find most of my favorite podcasts. I was able to add the ones that were not on the iTunes’ list by pasting in the URL for the RSS feed.
|
||||
|
||||
It was also very easy to find a particular episode of a podcast. for example, I was recently looking for an episode of [Late Night Linux][9] where they were talking about [ZFS][10]. I clicked on the podcast, typed “ZFS” in the search box and found it.
|
||||
|
||||
I quickly discovered that the easiest way to play a bunch of podcast episodes was to add them to the queue. Once they are in the queue, you can either stream them or download them. You can also reorder them by dragging and dropping. As each episode played, it displayed a visualization of the sound wave, along with the episode summary.
|
||||
|
||||
### Installating CPod
|
||||
|
||||
On [GitHub][11], you can download an AppImage or Deb file for Linux, a .exe file for Windows or a .dmg file for Mac OS.
|
||||
|
||||
You can also install CPod as a [Snap][12]. All you need to do is use the following command:
|
||||
|
||||
```
|
||||
sudo snap install cpod
|
||||
```
|
||||
|
||||
Like I said earlier, the [Arch User Repository][8] version of CPod is old. I already messaged one of the packagers. If you use Arch (or an Arch-based distro), I would recommend doing the same.
|
||||
|
||||
![cpod for Linux pidcasts][13]Playing one of my favorite podcasts
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Overall, I liked CPod. It was nice looking and simple to use. In fact, I like the original name (Cumulonimbus) better, but it is a bit of a mouthful.
|
||||
|
||||
I just had two problems with the application. First, I wish that the ratings were available for each podcast. Second, the menus that allow you to sort episodes based on length, date, download status, and play progress don’t work when the dork mode is turned on.
|
||||
|
||||
Have you ever used CPod? If not, what is your favorite podcast app? What are some of your favorite podcasts? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Red][14][d][14][it][14].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cpod-podcast-app/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/linux-podcasts/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod1.1.jpg
|
||||
[3]: https://github.com/z-------------/CPod
|
||||
[4]: https://github.com/z-------------
|
||||
[5]: https://electronjs.org/
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod2.1.png
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod4.1.jpg
|
||||
[8]: https://aur.archlinux.org/packages/?O=0&K=cpod
|
||||
[9]: https://latenightlinux.com/
|
||||
[10]: https://itsfoss.com/what-is-zfs/
|
||||
[11]: https://github.com/z-------------/CPod/releases
|
||||
[12]: https://snapcraft.io/cumulonimbus
|
||||
[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/cpod3.1.jpg
|
||||
[14]: http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,229 @@
|
||||
Commandline quick tips: How to locate a file
|
||||
======
|
||||
|
||||

|
||||
|
||||
We all have files on our computers — documents, photos, source code, you name it. So many of them. Definitely more than I can remember. And if not challenging, it might be time consuming to find the right one you’re looking for. In this post, we’ll have a look at how to make sense of your files on the command line, and especially how to quickly find the ones you’re looking for.
|
||||
|
||||
Good news is there are few quite useful utilities in the Linux commandline designed specifically to look for files on your computer. We’ll have a look at three of those: ls, tree, and find.
|
||||
|
||||
### ls
|
||||
|
||||
If you know where your files are, and you just need to list them or see information about them, ls is here for you.
|
||||
|
||||
Just running ls lists all visible files and directories in the current directory:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
Adding the **-l** option shows basic information about the files. And together with the **-h** option you’ll see file sizes in a human-readable format:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 60K
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**Is** can also search a specific place:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
trees.png wallpaper.png
|
||||
```
|
||||
|
||||
Or a specific file — even with just a part of the name:
|
||||
|
||||
```
|
||||
$ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
Something missing? Looking for a hidden file? No problem, use the **-a** option:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
. .bash_logout .bashrc Documents Pictures notes.txt
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
There are many other useful options for **ls** , and you can combine them together to achieve what you need. Learn about them by running:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
```
|
||||
|
||||
### tree
|
||||
|
||||
If you want to see, well, a tree structure of your files, tree is a good choice. It’s probably not installed by default which you can do yourself using the package manager DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
Running tree without any options or parameters shows the whole tree starting at the current directory. Just a warning, this output might be huge, because it will include all files and directories:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| | `-- christmas-presents.txt
|
||||
| `-- work
|
||||
| |-- project-abc
|
||||
| | |-- README.md
|
||||
| | |-- do-things.sh
|
||||
| | `-- project-notes.txt
|
||||
| `-- status-reports.txt
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
If that’s too much, I can limit the number of levels it goes using the -L option followed by a number specifying the number of levels I want to see:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| `-- work
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
You can also display a tree of a specific path:
|
||||
|
||||
```
|
||||
$ tree Documents/work/
|
||||
Documents/work/
|
||||
|-- project-abc
|
||||
| |-- README.md
|
||||
| |-- do-things.sh
|
||||
| `-- project-notes.txt
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
To browse and search a huge tree, you can use it together with less:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
Again, there are other options you can use with three, and you can combine them together for even more power. The manual page has them all:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
```
|
||||
|
||||
### find
|
||||
|
||||
And what about files that live somewhere in the unknown? Let’s find them!
|
||||
|
||||
In case you don’t have find on your system, you can install it using DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
Running find without any options or parameters recursively lists all files and directories in the current directory.
|
||||
|
||||
```
|
||||
$ find
|
||||
.
|
||||
./Documents
|
||||
./Documents/secret
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc
|
||||
./Documents/work/project-abc/README.md
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./.bash_logout
|
||||
./.bashrc
|
||||
./Videos
|
||||
./.bash_profile
|
||||
./.vimrc
|
||||
./Pictures
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
./notes.txt
|
||||
./Music
|
||||
```
|
||||
|
||||
But the true power of find is that you can search by name:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
```
|
||||
|
||||
Or just a part of a name — like the file extension. Let’s find all .txt files:
|
||||
|
||||
```
|
||||
$ find -name "*.txt"
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
|
||||
You can also look for files by size. That might be especially useful if you’re running out of space. Let’s list all files larger than 1 MB:
|
||||
|
||||
```
|
||||
$ find -size +1M
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
```
|
||||
|
||||
Searching a specific directory is also possible. Let’s say I want to find a file in my Documents directory, and I know it has the word “project” in its name:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*"
|
||||
Documents/work/project-abc
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
Ah! That also showed the directory. One thing I can do is to limit the search query to files only:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
And again, find have many more options you can use, the man page might definitely help you:
|
||||
|
||||
```
|
||||
$ man find
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,169 @@
|
||||
Introducing pydbgen: A random dataframe/database table generator
|
||||
======
|
||||
Simple tool generates large database files with multiple tables to practice SQL commands for data science.
|
||||
|
||||

|
||||
|
||||
When you start learning data science, often your biggest worry is not the algorithms or techniques but getting access to raw data. While there are many high-quality, real-life datasets available on the web for trying out cool machine learning techniques, I've found that the same is not true when it comes to learning SQL.
|
||||
|
||||
For data science, having a basic familiarity with SQL is almost as important as knowing how to write code in Python or R. But it's far easier to find toy datasets on Kaggle than it is to access a large enough database with real data (such as name, age, credit card, social security number, address, birthday, etc.) specifically designed or curated for machine learning tasks.
|
||||
|
||||
Wouldn't it be great to have a simple tool or library to generate a large database with multiple tables filled with data of your own choice?
|
||||
|
||||
Aside from beginners in data science, even seasoned software testers may find it useful to have a simple tool where, with a few lines of code, they can generate arbitrarily large data sets with random (fake), yet meaningful entries.
|
||||
|
||||
For this reason, I am glad to introduce a lightweight Python library called **[pydbgen][1]**. In this article, I'll briefly share some information about the package, and you can learn much more [by reading the docs][2].
|
||||
|
||||
### What is pydbgen?
|
||||
|
||||
Pydbgen is a lightweight, pure-Python library to generate random useful entries (e.g., name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in a Pandas dataframe object, as an SQLite table in a database file, or in a Microsoft Excel file.
|
||||
|
||||
### How to install pydbgen
|
||||
|
||||
The current version (1.0.5) is hosted on PyPI (the Python Package Index repository). You need to have [Faker][3] installed to make this work. To install Pydbgen, enter:
|
||||
|
||||
```
|
||||
pip install pydbgen
|
||||
```
|
||||
|
||||
It has been tested on Python 3.6 and won't work on Python 2 installations.
|
||||
|
||||
### How to use it
|
||||
|
||||
To start using Pydbgen, initiate a **pydb** object.
|
||||
|
||||
```
|
||||
import pydbgen
|
||||
from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
|
||||
```
|
||||
myDB.city_real()
|
||||
>> 'Otterville'
|
||||
for _ in range(10):
|
||||
print(myDB.license_plate())
|
||||
>> 8NVX937
|
||||
6YZH485
|
||||
XBY-564
|
||||
SCG-2185
|
||||
XMR-158
|
||||
6OZZ231
|
||||
CJN-850
|
||||
SBL-4272
|
||||
TPY-658
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
By the way, if you enter **city** instead of **city_real** , it will return fictitious city names.
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
>>
|
||||
New Michelle
|
||||
Robinborough
|
||||
Leebury
|
||||
Kaylatown
|
||||
Hamiltonfort
|
||||
Lake Christopher
|
||||
Hannahstad
|
||||
West Adamborough
|
||||
```
|
||||
|
||||
### Generate a Pandas dataframe with random entries
|
||||
|
||||
You can choose how many and what data types will be generated. Note that everything returns as string/texts.
|
||||
|
||||
```
|
||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||
testdf
|
||||
```
|
||||
|
||||
The resulting dataframe looks like the following image.
|
||||
|
||||
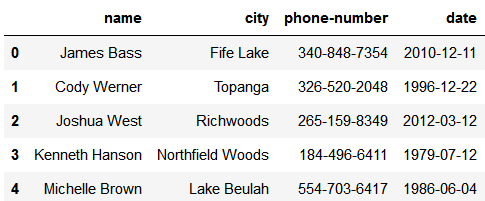
|
||||
|
||||
### Generate a database table
|
||||
|
||||
You can choose how many and what data types will be generated. Everything is returned in the text/VARCHAR data type for the database. You can specify the database filename and the table name.
|
||||
|
||||
```
|
||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||
|
||||
fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
This generates a .db file which can be used with MySQL or the SQLite database server. The following image shows a database table opened in DB Browser for SQLite.
|
||||
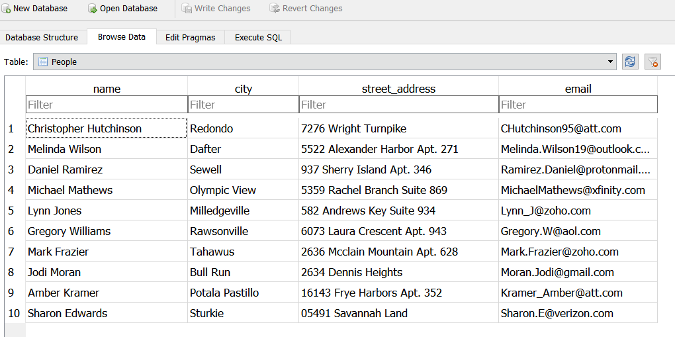
|
||||
|
||||
### Generate an Excel file
|
||||
|
||||
Similar to the examples above, the following code will generate an Excel file with random data. Note that **phone_simple** is set to **False** so it can generate complex, long-form phone numbers. This can come in handy when you want to experiment with more involved data extraction codes.
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
The resulting file looks like this image:
|
||||
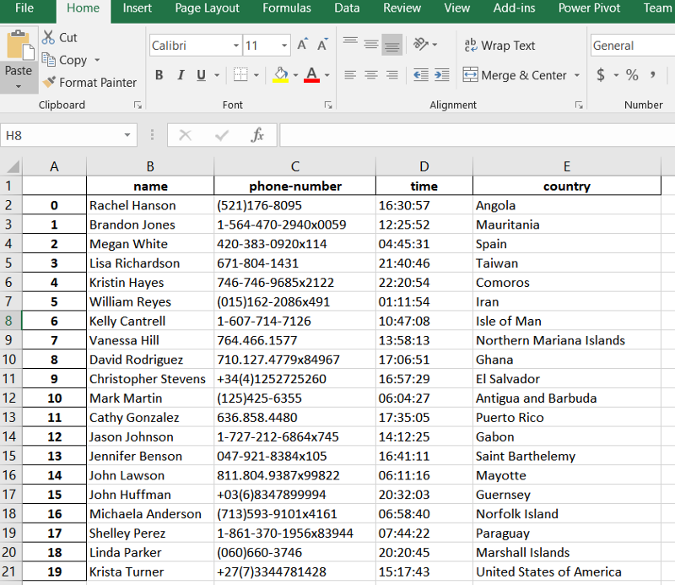
|
||||
|
||||
### Generate random email IDs for scrap use
|
||||
|
||||
A built-in method in pydbgen is **realistic_email** , which generates random email IDs from a seed name. This is helpful when you don't want to use your real email address on the web—but something close.
|
||||
|
||||
```
|
||||
for _ in range(10):
|
||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||
>>
|
||||
Tirtha_Sarkar@gmail.com
|
||||
Sarkar.Tirtha@outlook.com
|
||||
Tirtha_S48@verizon.com
|
||||
Tirtha_Sarkar62@yahoo.com
|
||||
Tirtha.S46@yandex.com
|
||||
Tirtha.S@att.com
|
||||
Sarkar.Tirtha60@gmail.com
|
||||
TirthaSarkar@zoho.com
|
||||
Sarkar.Tirtha@protonmail.com
|
||||
Tirtha.S@comcast.net
|
||||
```
|
||||
|
||||
### Future improvements and user contributions
|
||||
|
||||
There may be many bugs in the current version—if you notice any and your program crashes during execution (except for a crash due to your incorrect entry), please let me know. Also, if you have a cool idea to contribute to the source code, the [GitHub repo][1] is open. Some questions readily come to mind:
|
||||
|
||||
* Can we integrate some machine learning/statistical modeling with this random data generator?
|
||||
* Should a visualization function be added to the generator?
|
||||
|
||||
|
||||
|
||||
The possibilities are endless and exciting!
|
||||
|
||||
If you have any questions or ideas to share, please contact me at [tirthajyoti[AT]gmail.com][4]. If you are, like me, passionate about machine learning and data science, please [add me on LinkedIn][5] or [follow me on Twitter][6]. Also, check my [GitHub repo][7] for other fun code snippets in Python, R, or MATLAB and some machine learning resources.
|
||||
|
||||
Originally published on [Towards Data Science][8]. Licensed under [CC BY-SA 4.0][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tirthajyoti/pydbgen
|
||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||
[4]: mailto:tirthajyoti@gmail.com
|
||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[6]: https://twitter.com/tirthajyotiS
|
||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
104
sources/tech/20181105 Revisiting the Unix philosophy in 2018.md
Normal file
104
sources/tech/20181105 Revisiting the Unix philosophy in 2018.md
Normal file
@ -0,0 +1,104 @@
|
||||
Revisiting the Unix philosophy in 2018
|
||||
======
|
||||
The old strategy of building small, focused applications is new again in the modern microservices environment.
|
||||

|
||||
|
||||
In 1984, Rob Pike and Brian W. Kernighan published an article called "[Program Design in the Unix Environment][1]" in the AT&T Bell Laboratories Technical Journal, in which they argued the Unix philosophy, using the example of BSD's **cat -v** implementation. In a nutshell that philosophy is: Build small, focused programs—in whatever language—that do only one thing but do this thing well, communicate via **stdin** / **stdout** , and are connected through pipes.
|
||||
|
||||
Sound familiar?
|
||||
|
||||
Yeah, I thought so. That's pretty much the [definition of microservices][2] offered by James Lewis and Martin Fowler:
|
||||
|
||||
> In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
|
||||
|
||||
While one *nix program or one microservice may be very limited or not even very interesting on its own, it's the combination of such independently working units that reveals their true benefit and, therefore, their power.
|
||||
|
||||
### *nix vs. microservices
|
||||
|
||||
The following table compares programs (such as **cat** or **lsof** ) in a *nix environment against programs in a microservices environment.
|
||||
|
||||
| | *nix | Microservices |
|
||||
| ----------------------------------- | -------------------------- | ----------------------------------- |
|
||||
| Unit of execution | program using stdin/stdout | service with HTTP or gRPC API |
|
||||
| Data flow | Pipes | ? |
|
||||
| Configuration & parameterization | Command-line arguments, | |
|
||||
| environment variables, config files | JSON/YAML docs | |
|
||||
| Discovery | Package manager, man, make | DNS, environment variables, OpenAPI |
|
||||
|
||||
Let's explore each line in slightly greater detail.
|
||||
|
||||
#### Unit of execution
|
||||
|
||||
**stdin** and writes output to **stdout**. A microservices setup deals with a service that exposes one or more communication interfaces, such as HTTP or gRPC APIs. In both cases, you'll find stateless examples (essentially a purely functional behavior) and stateful examples, where, in addition to the input, some internal (persisted) state decides what happens.
|
||||
|
||||
#### Data flow
|
||||
|
||||
The unit of execution in *nix (such as Linux) is an executable file (binary or interpreted script) that, ideally, reads input fromand writes output to. A microservices setup deals with a service that exposes one or more communication interfaces, such as HTTP or gRPC APIs. In both cases, you'll find stateless examples (essentially a purely functional behavior) and stateful examples, where, in addition to the input, some internal (persisted) state decides what happens.
|
||||
|
||||
Traditionally, *nix programs could communicate via pipes. In other words, thanks to [Doug McIlroy][3], you don't need to create temporary files to pass around and each can process virtually endless streams of data between processes. To my knowledge, there is nothing comparable to a pipe standardized in microservices, besides my little [Apache Kafka-based experiment from 2017][4].
|
||||
|
||||
#### Configuration and parameterization
|
||||
|
||||
How do you configure a program or service—either on a permanent or a by-call basis? Well, with *nix programs you essentially have three options: command-line arguments, environment variables, or full-blown config files. In microservices, you typically deal with YAML (or even worse, JSON) documents, defining the layout and configuration of a single microservice as well as dependencies and communication, storage, and runtime settings. Examples include [Kubernetes resource definitions][5], [Nomad job specifications][6], or [Docker Compose][7] files. These may or may not be parameterized; that is, either you have some templating language, such as [Helm][8] in Kubernetes, or you find yourself doing an awful lot of **sed -i** commands.
|
||||
|
||||
#### Discovery
|
||||
|
||||
How do you know what programs or services are available and how they are supposed to be used? Well, in *nix, you typically have a package manager as well as good old man; between them, they should be able to answer all the questions you might have. In a microservices setup, there's a bit more automation in finding a service. In addition to bespoke approaches like [Airbnb's SmartStack][9] or [Netflix's Eureka][10], there usually are environment variable-based or DNS-based [approaches][11] that allow you to discover services dynamically. Equally important, [OpenAPI][12] provides a de-facto standard for HTTP API documentation and design, and [gRPC][13] does the same for more tightly coupled high-performance cases. Last but not least, take developer experience (DX) into account, starting with writing good [Makefiles][14] and ending with writing your docs with (or in?) [**style**][15].
|
||||
|
||||
### Pros and cons
|
||||
|
||||
Both *nix and microservices offer a number of challenges and opportunities
|
||||
|
||||
#### Composability
|
||||
|
||||
It's hard to design something that has a clear, sharp focus and can also play well with others. It's even harder to get it right across different versions and to introduce respective error case handling capabilities. In microservices, this could mean retry logic and timeouts—maybe it's a better option to outsource these features into a service mesh? It's hard, but if you get it right, its reusability can be enormous.
|
||||
|
||||
#### Observability
|
||||
|
||||
In a monolith (in 2018) or a big program that tries to do it all (in 1984), it's rather straightforward to find the culprit when things go south. But, in a
|
||||
|
||||
```
|
||||
yes | tr \\n x | head -c 450m | grep n
|
||||
```
|
||||
|
||||
or a request path in a microservices setup that involves, say, 20 services, how do you even start to figure out which one is behaving badly? Luckily we have standards, notably [OpenCensus][16] and [OpenTracing][17]. Observability still might be the biggest single blocker if you are looking to move to microservices.
|
||||
|
||||
#### Global state
|
||||
|
||||
While it may not be such a big issue for *nix programs, in microservices, global state remains something of a discussion. Namely, how to make sure the local (persistent) state is managed effectively and how to make the global state consistent with as little effort as possible.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
In the end, the question remains: Are you using the right tool for a given task? That is, in the same way a specialized *nix program implementing a range of functions might be the better choice for certain use cases or phases, it might be that a monolith [is the best option][18] for your organization or workload. Regardless, I hope this article helps you see the many, strong parallels between the Unix philosophy and microservices—maybe we can learn something from the former to benefit the latter.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/revisiting-unix-philosophy-2018
|
||||
|
||||
作者:[Michael Hausenblas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhausenblas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://harmful.cat-v.org/cat-v/
|
||||
[2]: https://martinfowler.com/articles/microservices.html
|
||||
[3]: https://en.wikipedia.org/wiki/Douglas_McIlroy
|
||||
[4]: https://speakerdeck.com/mhausenblas/distributed-named-pipes-and-other-inter-services-communication
|
||||
[5]: http://kubernetesbyexample.com/
|
||||
[6]: https://www.nomadproject.io/docs/job-specification/index.html
|
||||
[7]: https://docs.docker.com/compose/overview/
|
||||
[8]: https://helm.sh/
|
||||
[9]: https://github.com/airbnb/smartstack-cookbook
|
||||
[10]: https://github.com/Netflix/eureka
|
||||
[11]: https://kubernetes.io/docs/concepts/services-networking/service/#discovering-services
|
||||
[12]: https://www.openapis.org/
|
||||
[13]: https://grpc.io/
|
||||
[14]: https://suva.sh/posts/well-documented-makefiles/
|
||||
[15]: https://www.linux.com/news/improve-your-writing-gnu-style-checkers
|
||||
[16]: https://opencensus.io/
|
||||
[17]: https://opentracing.io/
|
||||
[18]: https://robertnorthard.com/devops-days-well-architected-monoliths-are-okay/
|
||||
308
sources/tech/20181105 Some Good Alternatives To ‘du- Command.md
Normal file
308
sources/tech/20181105 Some Good Alternatives To ‘du- Command.md
Normal file
@ -0,0 +1,308 @@
|
||||
Some Good Alternatives To ‘du’ Command
|
||||
======
|
||||
|
||||

|
||||
|
||||
As you may already know, the **“du”** command is used to compute and summarize the file and directory space usage in Unix-like systems. If you are a heavy user of du command, you will find this guide interesting! Today, I came across five good **alternatives to du** command. There could be many, but these are the ones that I am aware of at the moment. If I came across anything in future, I will add it in this list. Also, if you know any other alternatives, please let me know in the comment section below. I will review and add them in the list as well.
|
||||
|
||||
### 1\. Ncdu
|
||||
|
||||
The **Ncdu** is the popular alternative to du command in the Linux community. The developer of Ncdu is not satisfied with the performance of the du command, so he ended up creating his own. Ncdu is simple, yet fast disk usage analyzer written using **C** programming language with an **ncurses** interface to find which directories or files are taking up more space either on a local or remote systems. We already have published a detailed guide about Ncdu. Check the following link if you are interested to know more about it.
|
||||
|
||||
### 2\. Tin Summer
|
||||
|
||||
The **Tin Summer** is used to find the build artifacts that are taking up disk space. It is also an yet another good alternative for du command. Thanks to multi-threading, Tin-summer is significantly faster than du command when calculating the size of the big directories. Unlike Du command, it reads file sizes, not disk usage. Tin SUmmer is free, open source tool written using **Rust** programming language.
|
||||
|
||||
The developer claims Tin Summer is good alternative to du command, because,
|
||||
|
||||
* It is faster on larger directories compared to du command,
|
||||
* It displays the disk usage results in human-readable format by default,
|
||||
* It uses **regex** to exclude files/directories,
|
||||
* Provides sorted and colorized output,
|
||||
* Extensible,
|
||||
* And more.
|
||||
|
||||
|
||||
|
||||
**Installing Tin Summer**
|
||||
|
||||
To install Tin Summer, open your Terminal and run the following command:
|
||||
|
||||
```
|
||||
$ curl -LSfs https://japaric.github.io/trust/install.sh | sh -s -- --git vmchale/tin-summer
|
||||
```
|
||||
|
||||
Alternatively, you can install Tin Summer using **Cargo** package manager. Make sure you have installed **Rust** on your system as described in the following link.
|
||||
|
||||
After installing Rust, run the following command to install Tin Summer:
|
||||
|
||||
```
|
||||
$ cargo install tin-summer
|
||||
```
|
||||
|
||||
If either of the above mentioned methods doesn’t not work, download the latest binary from the [**releases page**][1] and compile and install it manually.
|
||||
|
||||
**Usage**
|
||||
|
||||
To find the file sizes in a current working directory, use this command:
|
||||
|
||||
```
|
||||
$ sn f
|
||||
749 MB ./.rustup/toolchains
|
||||
749 MB ./.rustup
|
||||
147 MB ./.cargo/bin
|
||||
147 MB ./.cargo
|
||||
900 MB .
|
||||
```
|
||||
|
||||
See? It displays a nicer input in human-readable format by default. You need not to use any extra flags (like **-h** in du command) to get this result.
|
||||
|
||||
To find the file sizes in a specific directory, mention the actual path like below:
|
||||
|
||||
```
|
||||
$ sn f <path-to-the-directory>
|
||||
```
|
||||
|
||||
We can also sort the list in the output as well. To display the sorted list of the top 5 biggest directories, run:
|
||||
|
||||
```
|
||||
$ sn sort /home/sk/ -n5
|
||||
749 MB /home/sk/.rustup
|
||||
749 MB /home/sk/.rustup/toolchains
|
||||
147 MB /home/sk/.cargo
|
||||
147 MB /home/sk/.cargo/bin
|
||||
2.6 MB /home/sk/mcelog
|
||||
900 MB /home/sk/
|
||||
```
|
||||
|
||||
For your information, the last result in the above output is the total size of the biggest directories in the given directory i.e **/home/sk/**. So, don’t wonder why you get six results instead of 5.
|
||||
|
||||
To search current directory for directories with build artifacts:
|
||||
|
||||
```
|
||||
$ sn ar
|
||||
```
|
||||
|
||||
Tin Summer can also search for directories containing artifacts that occupy a certain size of the disk space. Say for example, to search for directories containing artifacts that occupy more than **100MB** of disk space, run:
|
||||
|
||||
```
|
||||
$ sn ar -t100M
|
||||
```
|
||||
|
||||
Like already mentioned, Tin Summer is faster on larger directories, but it is also slower on small ones. However, the developer assures he will find a way to fix this in the future releases!
|
||||
|
||||
To get help, run:
|
||||
|
||||
```
|
||||
$ sn --help
|
||||
```
|
||||
|
||||
For more details, check the project’s GitHub repository given at the end of this guide.
|
||||
|
||||
### 3\. Dust
|
||||
|
||||
**Dust** (du+rust=dust) is more intuitive version of du utility. It will give us an instant overview of which directories are occupying the disk space without having to use **head** or **sort** commands. Like Tin Summer, it also displays the size of each directory in human-readable format by default. It is free, open source and written using **Rust** programming language.
|
||||
|
||||
**Installing Dust**
|
||||
|
||||
Since the dust utility is written in Rust, It can be installed using “cargo” package manager like below.
|
||||
|
||||
```
|
||||
$ cargo install du-dust
|
||||
```
|
||||
|
||||
Alternatively, you can download the latest binary from the [**releases page**][2] and install it as shown below. As of writing this guide, the latest version was **0.3.1**.
|
||||
|
||||
```
|
||||
$ wget https://github.com/bootandy/dust/releases/download/v0.3.1/dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
```
|
||||
|
||||
Extract the download file:
|
||||
|
||||
```
|
||||
$ tar -xvf dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
```
|
||||
|
||||
Finally, copy the executable file to your $PATH, for example **/usr/local/bin**.
|
||||
|
||||
```
|
||||
$ sudo mv dust /usr/local/bin/
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
To find the total file sizes in the current directory and its sub-directories, run:
|
||||
|
||||
```
|
||||
$ dust
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||

|
||||
|
||||
We can also get the full path of all directories using **-p** flag.
|
||||
|
||||
```
|
||||
$ dust -p
|
||||
```
|
||||
|
||||
![dust 2][4]
|
||||
|
||||
To get the total size of multiple directories, just mention them with space-separated:
|
||||
|
||||
```
|
||||
$ dust <dir1> <dir2>
|
||||
```
|
||||
|
||||
Here are some more examples.
|
||||
|
||||
Show the apparent size of the files:
|
||||
|
||||
```
|
||||
$ dust -s
|
||||
```
|
||||
|
||||
Show particular number of directories only:
|
||||
|
||||
```
|
||||
$ dust -n 10
|
||||
```
|
||||
|
||||
Show 3 levels of sub-directories in the current directory:
|
||||
|
||||
```
|
||||
$ dust -d 3
|
||||
```
|
||||
|
||||
For help, run:
|
||||
|
||||
```
|
||||
$ dust -h
|
||||
```
|
||||
|
||||
For more details, refer the project’s GitHub page given at the end.
|
||||
|
||||
### 4\. Diskus
|
||||
|
||||
**Diskus** It is a simple and fast alternative command line utility to `du -sh`command. The diskus utility computes the total file size of the current directory. It is a parallelized version of `du -sh` or rather `du -sh --bytes` command. The developer of diskus utility claims that it is about **nine times faster** compared to ‘du -sh’. Diskus is minimal, fast and open source program written in **Rust** programming language.
|
||||
|
||||
**Installing diskus**
|
||||
|
||||
The diskus utility is available in [**AUR**][5], so you can install it on Arch-based systems using any AUR helper programs, for example [**Yay**][6] , as shown below.
|
||||
|
||||
```
|
||||
$ yay -S diskus
|
||||
```
|
||||
|
||||
On Ubuntu and its derivatives, download the latest diskus utility from the [**releases page**][7] and install it as shown below.
|
||||
|
||||
```
|
||||
$ wget "https://github.com/sharkdp/diskus/releases/download/v0.3.1/diskus_0.3.1_amd64.deb"
|
||||
|
||||
$ sudo dpkg -i diskus_0.3.1_amd64.deb
|
||||
```
|
||||
|
||||
Alternatively, you can install diskus using **Cargo** package manager. Make sure you have installed **Rust 1.29** or higher on your system as described in the link given above in “Installing Tin Summer” section.
|
||||
|
||||
Once you have Rust on your system, run the following command to install diskus:
|
||||
|
||||
```
|
||||
$ cargo install diskus
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
Usually, when I want to check the total disk space used by a particular directory, I use the **-sh** flags with **du** command as shown below.
|
||||
|
||||
```
|
||||
$ du -sh dir
|
||||
```
|
||||
|
||||
Here, **-s** flag indicates summary.
|
||||
|
||||
Using Diskus tool, I find the total size of current working directory with command:
|
||||
|
||||
```
|
||||
$ diskus
|
||||
```
|
||||
|
||||

|
||||
|
||||
I tested diskus to compute the total size of different directories in my Arch Linux system. The speed of computing the total size of the directory is pretty impressive! I must admit that this utility is quite faster than ‘du -sh’. Please be mindful that it can find the size of the current directory only at the moment.
|
||||
|
||||
For getting help, run:
|
||||
|
||||
```
|
||||
$ diskus -h
|
||||
```
|
||||
|
||||
For more details about Diskus, refer the official GitHub page (link at the end).
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
### 5\. Duu
|
||||
|
||||
**Duu** , short for **D** irectory **U** sage **U** tility, is another tool to find the disk usage of given directory. It is a cross-platform, so you can use it on Windows, Mac OS and Linux operating systems. It is written in **Python** programming language.
|
||||
|
||||
**Installing Duu**
|
||||
|
||||
Make sure you have installed Python3. Python3 is available in the default repositories of most Linux distributions, so the installation wouldn’t be a problem.
|
||||
|
||||
Once Python3 is installed, download the latest Duu version from the official [**releases page**][8].
|
||||
|
||||
```
|
||||
$ wget https://github.com/jftuga/duu/releases/download/2.20/duu.py
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
To find the disk space occupied by the current working directory, simply run:
|
||||
|
||||
```
|
||||
$ python3 duu.py
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||

|
||||
|
||||
As you can see in the above output, Duu utility will display a nice summary of total number of files and directories and their total size in bytes, KB and MB. It will also display the total size of each item.
|
||||
|
||||
To display the total disk usage of a specific directory, just mention the full path like below:
|
||||
|
||||
```
|
||||
$ python3 duu.py /home/sk/Downloads/
|
||||
```
|
||||
|
||||
For more details, refer Duu github page included at the end.
|
||||
|
||||
And, that’s all for now. Hope this was useful. You know now five alternatives to du command. Personally, I prefer Ncdu over all of them given in this guide. Now is your turn. Give them a try and let us know your thoughts on these tools in the comment section below.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/some-good-alternatives-to-du-command/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/vmchale/tin-summer/releases
|
||||
[2]: https://github.com/bootandy/dust/releases
|
||||
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2018/11/dust-2.png
|
||||
[5]: https://aur.archlinux.org/packages/diskus-bin/
|
||||
[6]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[7]: https://github.com/sharkdp/diskus/releases
|
||||
[8]: https://github.com/jftuga/duu/releases
|
||||
@ -0,0 +1,123 @@
|
||||
Python 机器学习的必备技巧
|
||||
======
|
||||
> 尝试使用 Python 掌握机器学习、人工智能和深度学习。
|
||||
|
||||

|
||||
|
||||
想要入门机器学习并不难。除了<ruby>大规模网络公开课<rt>Massive Open Online Courses</rt></ruby>(MOOCs)之外,还有很多其它优秀的免费资源。下面我分享一些我觉得比较有用的方法。
|
||||
|
||||
1. 阅览一些关于这方面的视频、文章或者书籍,例如 [The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World][29],你肯定会喜欢这些[关于机器学习的互动页面][30]。
|
||||
|
||||
2. 对于“机器学习”、“人工智能”、“深度学习”、“数据科学”、“计算机视觉”和“机器人技术”这一堆新名词,你需要知道它们之前的区别。你可以阅览这些领域的专家们的演讲,例如[数据科学家 Brandon Rohrer 的这个视频][1]。
|
||||
|
||||
3. 明确你自己的学习目标,并选择合适的 [Coursera 课程][3],或者参加高校的网络公开课。例如[华盛顿大学的课程][4]就很不错。
|
||||
|
||||
4. 关注优秀的博客:例如 [KDnuggets][32] 的博客、[Mark Meloon][33] 的博客、[Brandon Rohrer][34] 的博客、[Open AI][35] 的博客,这些都值得推荐。
|
||||
|
||||
5. 如果你对在线课程有很大兴趣,后文中会有如何[正确选择 MOOC 课程][31]的指导。
|
||||
|
||||
6. 最重要的是,培养自己对这些技术的兴趣。加入一些优秀的社交论坛,专注于阅读和了解,将这些技术的背景知识和发展方向理解透彻,并积极思考在日常生活和工作中如何应用机器学习或数据科学的原理。例如建立一个简单的回归模型来预测下一次午餐的成本,又或者是从电力公司的网站上下载历史电费数据,在 Excel 中进行简单的时序分析以发现某种规律。在你对这些技术产生了浓厚兴趣之后,可以观看以下这个视频。
|
||||
|
||||
<https://www.youtube.com/embed/IpGxLWOIZy4>
|
||||
|
||||
### Python 是机器学习和人工智能方面的最佳语言吗?
|
||||
|
||||
除非你是一名专业的研究一些复杂算法纯理论证明的研究人员,否则,对于一个机器学习的入门者来说,需要熟悉至少一种高级编程语言一家相关的专业知识。因为大多数情况下都是需要考虑如何将机器学习算法应用于解决实际问题,而这需要有一定的编程能力作为基础。
|
||||
|
||||
哪一种语言是数据科学的最佳语言?这个讨论一直没有停息过。对于这方面,你可以提起精神来看一下 FreeCodeCamp 上这一篇关于[数据科学语言][6]的文章,又或者是 KDnuggets 关于 [Python 和 R][7] 之间的深入探讨。
|
||||
|
||||
目前人们普遍认为 Python 在开发、部署、维护各方面的效率都是比较高的。与 Java、C 和 C++ 这些较为传统的语言相比,Python 的语法更为简单和高级。而且 Python 拥有活跃的社区群体、广泛的开源文化、数百个专用于机器学习的优质代码库,以及来自业界巨头(包括Google、Dropbox、Airbnb 等)的强大技术支持。
|
||||
|
||||
### 基础 Python 库
|
||||
|
||||
如果你打算使用 Python 实施机器学习,你必须掌握一些 Python 包和库的使用方法。
|
||||
|
||||
#### NumPy
|
||||
|
||||
NumPy 的完整名称是 [Numerical Python][8],它是 Python 生态里高性能科学计算和数据分析都需要用到的基础包,几乎所有高级工具(例如 [Pandas][9] 和 [scikit-learn][10])都依赖于它。[TensorFlow][11] 使用了 NumPy 数组作为基础构建块以支持 Tensor 对象和深度学习的图形流。很多 NumPy 操作的速度都非常快,因为它们都是通过 C 实现的。高性能对于数据科学和现代机器学习来说是一个非常宝贵的优势。
|
||||
|
||||

|
||||
|
||||
#### Pandas
|
||||
|
||||
Pandas 是 Python 生态中用于进行通用数据分析的最受欢迎的库。Pandas 基于 NumPy 数组构建,在保证了可观的执行速度的同时,还提供了许多数据工程方面的功能,包括:
|
||||
|
||||
* 对多种不同数据格式的读写操作
|
||||
* 选择数据子集
|
||||
* 跨行列计算
|
||||
* 查找并补充缺失的数据
|
||||
* 将操作应用于数据中的独立组
|
||||
* 按照多种格式转换数据
|
||||
* 组合多个数据集
|
||||
* 高级时间序列功能
|
||||
* 通过 Matplotlib 和 Seaborn 进行可视化
|
||||
|
||||

|
||||
|
||||
#### Matplotlib 和 Seaborn
|
||||
|
||||
数据可视化和数据分析是数据科学家的必备技能,毕竟仅凭一堆枯燥的数据是无法有效地将背后蕴含的信息向受众传达的。这两项技能对于机器学习来说同样重要,因为首先要对数据集进行一个探索性分析,才能更准确地选择合适的机器学习算法。
|
||||
|
||||
[Matplotlib][12] 是应用最广泛的 2D Python 可视化库。它包含海量的命令和接口,可以让你根据数据生成高质量的图表。要学习使用 Matplotlib,可以参考这篇详尽的[文章][13]。
|
||||
|
||||

|
||||
|
||||
[Seaborn][14] 也是一个强大的用于统计和绘图的可视化库。它在 Matplotlib 的基础上提供样式灵活的 API、用于统计和绘图的常见高级函数,还可以和 Pandas 提供的功能相结合。要学习使用 Seaborn,可以参考这篇优秀的[教程][15]。
|
||||
|
||||

|
||||
|
||||
#### Scikit-learn
|
||||
|
||||
Scikit-learn 是机器学习方面通用的重要 Python 包。它实现了多种[分类][16]、[回归][17]和[聚类][18]算法,包括[支持向量机][19]、[随机森林][20]、[梯度增强][21]、[k-means 算法][22]和 [DBSCAN 算法][23],可以与 Python 的数值库 NumPy 和科学计算库 [SciPy][24] 结合使用。它通过兼容的接口提供了有监督和无监督的学习算法。Scikit-learn 的强壮性让它可以稳定运行在生产环境中,同时它在易用性、代码质量、团队协作、文档和性能等各个方面都有良好的表现。可以参考这篇基于 Scikit-learn 的[机器学习入门][25],或者这篇基于 Scikit-learn 的[简单机器学习用例演示][26]。
|
||||
|
||||
本文使用 [CC BY-SA 4.0][28] 许可,在 [Heartbeat][27] 上首发。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/machine-learning-python-essential-hacks-and-tricks
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/watch?v=tKa0zDDDaQk
|
||||
[2]: https://www.youtube.com/watch?v=Ura_ioOcpQI
|
||||
[3]: https://www.coursera.org/learn/machine-learning
|
||||
[4]: https://www.coursera.org/specializations/machine-learning
|
||||
[5]: https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f
|
||||
[6]: https://medium.freecodecamp.org/which-languages-should-you-learn-for-data-science-e806ba55a81f
|
||||
[7]: https://www.kdnuggets.com/2017/09/python-vs-r-data-science-machine-learning.html
|
||||
[8]: http://numpy.org/
|
||||
[9]: https://pandas.pydata.org/
|
||||
[10]: http://scikit-learn.org/
|
||||
[11]: https://www.tensorflow.org/
|
||||
[12]: https://matplotlib.org/
|
||||
[13]: https://realpython.com/python-matplotlib-guide/
|
||||
[14]: https://seaborn.pydata.org/
|
||||
[15]: https://www.datacamp.com/community/tutorials/seaborn-python-tutorial
|
||||
[16]: https://en.wikipedia.org/wiki/Statistical_classification
|
||||
[17]: https://en.wikipedia.org/wiki/Regression_analysis
|
||||
[18]: https://en.wikipedia.org/wiki/Cluster_analysis
|
||||
[19]: https://en.wikipedia.org/wiki/Support_vector_machine
|
||||
[20]: https://en.wikipedia.org/wiki/Random_forests
|
||||
[21]: https://en.wikipedia.org/wiki/Gradient_boosting
|
||||
[22]: https://en.wikipedia.org/wiki/K-means_clustering
|
||||
[23]: https://en.wikipedia.org/wiki/DBSCAN
|
||||
[24]: https://en.wikipedia.org/wiki/SciPy
|
||||
[25]: http://scikit-learn.org/stable/tutorial/basic/tutorial.html
|
||||
[26]: https://towardsdatascience.com/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-19e8a1ddbd49
|
||||
[27]: https://heartbeat.fritz.ai/some-essential-hacks-and-tricks-for-machine-learning-with-python-5478bc6593f2
|
||||
[28]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[29]: https://www.goodreads.com/book/show/24612233-the-master-algorithm
|
||||
[30]: http://www.r2d3.us/visual-intro-to-machine-learning-part-1/
|
||||
[31]: https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f
|
||||
[32]: https://www.kdnuggets.com/
|
||||
[33]: http://www.markmeloon.com/
|
||||
[34]: https://brohrer.github.io/blog.html
|
||||
[35]: https://blog.openai.com/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user