mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
0a18bd07be
@ -1,15 +1,15 @@
|
||||
如何使用Tmux提高终端环境下的生产率
|
||||
如何使用Tmux提高终端环境下的效率
|
||||
===
|
||||
|
||||
鼠标的采用是次精彩的创新,它让电脑更加接近普通人。但从程序员和系统管理员的角度,使用电脑办公时,手一旦离开键盘,就会有些分心
|
||||
鼠标的发明是了不起的创新,它让电脑更加接近普通人。但从程序员和系统管理员的角度,使用电脑工作时,手一旦离开键盘,就会有些分心。
|
||||
|
||||
作为一名系统管理员,我大量的工作都需要在终端环境下。打开很多标签,然后在多个终端之间切换窗口会让我慢下来。而且当我的服务器出问题的时候,我不能浪费任何时间
|
||||
作为一名系统管理员,我大量的工作都需要在终端环境下。打开很多标签,然后在多个终端之间切换窗口会让我慢下来。尤其是当我的服务器出问题的时候,我不能浪费任何时间!
|
||||
|
||||
|
||||
|
||||
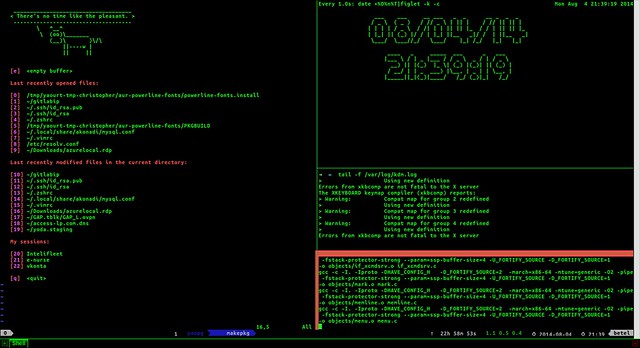
[Tmux][1]是我日常工作必要的工具之一。我可以借助Tmux创造出复杂的开发环境,同时还可以在一旁进行SSH远程连接。我可以开出很多窗口,拆分成很多面板,附加和分离会话等等。掌握了Tmux之后,你就可以扔掉鼠标了(只是个玩笑:D)
|
||||
[Tmux][1]是我日常工作必要的工具之一。我可以借助Tmux构建出复杂的开发环境,同时还可以在一旁进行SSH远程连接。我可以开出很多窗口,将其拆分成很多面板,接管和分离会话等等。掌握了Tmux之后,你就可以扔掉鼠标了(只是个玩笑:D)。
|
||||
|
||||
Tmux("Terminal Multiplexer"的简称)可以让我们在单个屏幕的灵活布局下开出很多终端,我们就可以协作地使用它们。举个例子,在一个面板中,我们用Vim修改一些配置文件,在另一个面板,我们使用irssi聊天,而在其余的面板,跟踪一些日志。然后,我们还可以打开新的窗口来升级系统,再开一个新窗口来进行服务器的ssh连接。在这些窗口面板间浏览切换和创建它们一样简单。它的高度可配置和可定制的,让其成为你心中的延伸
|
||||
Tmux("Terminal Multiplexer"的简称)可以让我们在单个屏幕的灵活布局下开出很多终端,我们就可以协作地使用它们。举个例子,在一个面板中,我们用Vim修改一些配置文件,在另一个面板,我们使用`irssi`聊天,而在其余的面板,可以跟踪一些日志。然后,我们还可以打开新的窗口来升级系统,再开一个新窗口来进行服务器的ssh连接。在这些窗口面板间浏览切换和创建它们一样简单。它的高度可配置和可定制的,让其成为你心中的延伸
|
||||
|
||||
### 在Linux/OSX下安装Tmux ###
|
||||
|
||||
@ -20,22 +20,21 @@ Tmux("Terminal Multiplexer"的简称)可以让我们在单个屏幕的灵活布
|
||||
# sudo brew install tmux
|
||||
# sudo port install tmux
|
||||
|
||||
### Debian/Ubuntu ###
|
||||
#### Debian/Ubuntu: ####
|
||||
|
||||
# sudo apt-get install tmux
|
||||
|
||||
RHEL/CentOS/Fedora(RHEL/CentOS 要求 [EPEL repo][2]):
|
||||
####RHEL/CentOS/Fedora(RHEL/CentOS 要求 [EPEL repo][2]):####
|
||||
|
||||
$ sudo yum install tmux
|
||||
|
||||
Archlinux:
|
||||
####Archlinux:####
|
||||
|
||||
$ sudo pacman -S tmux
|
||||
|
||||
### 使用不同会话工作 ###
|
||||
|
||||
使用Tmux的最好方式是使用不同的会话,这样你就可以以你想要的方式,将任务和应用组织到不同的会话中。如果你想改变一个会话,会话里面的任何工作都无须停止或者杀掉,让我们来看看这是怎么工作的
|
||||
|
||||
使用Tmux的最好方式是使用会话的方式,这样你就可以以你想要的方式,将任务和应用组织到不同的会话中。如果你想改变一个会话,会话里面的任何工作都无须停止或者杀掉。让我们来看看这是怎么工作的。
|
||||
|
||||
让我们开始一个叫做"session"的会话,并且运行top命令
|
||||
|
||||
@ -46,20 +45,20 @@ Archlinux:
|
||||
|
||||
$ tmux attach-session -t session
|
||||
|
||||
之后你会看到top操作仍然运行在重新连接的会话上
|
||||
之后你会看到top操作仍然运行在重新连接的会话上。
|
||||
|
||||
一些管理sessions的命令:
|
||||
|
||||
$ tmux list-session
|
||||
$ tmux new-session <session-name>
|
||||
$ tmux attach-session -t <session-name>
|
||||
$ tmux rename-session -t <session-name>
|
||||
$ tmux choose-session -t <session-name>
|
||||
$ tmux kill-session -t <session-name>
|
||||
$ tmux new-session <会话名>
|
||||
$ tmux attach-session -t <会话名>
|
||||
$ tmux rename-session -t <会话名>
|
||||
$ tmux choose-session -t <会话名>
|
||||
$ tmux kill-session -t <会话名>
|
||||
|
||||
### 使用不同的窗口工作
|
||||
|
||||
很多情况下,你需要在一个会话中运行多个命令,并且执行多个任务。我们可以在一个会话的多个窗口里组织他们。在现代化的GUI终端(比如 iTerm或者Konsole),一个窗口被视为一个标签。在会话中配置了我们默认的环境,我们就能够在一个会话中创建许多我们需要的窗口。窗口就像运行在会话中的应用程序,当我们脱离当前会话的时候,它仍在持续,让我们来看一个例子:
|
||||
很多情况下,你需要在一个会话中运行多个命令,执行多个任务。我们可以在一个会话的多个窗口里组织他们。在现代的GUI终端(比如 iTerm或者Konsole),一个窗口被视为一个标签。在会话中配置了我们默认的环境之后,我们就能够在一个会话中创建许多我们需要的窗口。窗口就像运行在会话中的应用程序,当我们脱离当前会话的时候,它仍在持续,让我们来看一个例子:
|
||||
|
||||
$ tmux new -s my_session
|
||||
|
||||
@ -67,7 +66,7 @@ Archlinux:
|
||||
|
||||
按下**CTRL-b c**
|
||||
|
||||
这将会创建一个新的窗口,然后屏幕的光标移向它。现在你就可以在新窗口下运行你的新应用。你可以写下你当前窗口的名字。在目前的案例下,我运行的top程序,所以top就是该窗口的名字
|
||||
这将会创建一个新的窗口,然后屏幕的光标移向它。现在你就可以在新窗口下运行你的新应用。你可以修改你当前窗口的名字。在目前的例子里,我运行的top程序,所以top就是该窗口的名字
|
||||
|
||||
如果你想要重命名,只需要按下:
|
||||
|
||||
@ -77,15 +76,15 @@ Archlinux:
|
||||
|
||||
|
||||
|
||||
一旦在一个会话中创建多个窗口,我们需要在这些窗口间移动的办法。窗口以数组的形式被组织在一起,每个窗口都有一个从0开始计数的号码,想要快速跳转到其余窗口:
|
||||
一旦在一个会话中创建多个窗口,我们需要在这些窗口间移动的办法。窗口像数组一样组织在一起,从0开始用数字标记每个窗口,想要快速跳转到其余窗口:
|
||||
|
||||
**CTRL-b <window number>**
|
||||
**CTRL-b <窗口号>**
|
||||
|
||||
如果我们给窗口起了名字,我们可以使用下面的命令切换:
|
||||
如果我们给窗口起了名字,我们可以使用下面的命令找到它们:
|
||||
|
||||
**CTRL-b f**
|
||||
|
||||
列出所有窗口:
|
||||
也可以列出所有窗口:
|
||||
|
||||
**CTRL-b w**
|
||||
|
||||
@ -94,21 +93,21 @@ Archlinux:
|
||||
**CTRL-b n**(到达下一个窗口)
|
||||
**CTRL-b p**(到达上一个窗口)
|
||||
|
||||
想要离开一个窗口:
|
||||
想要离开一个窗口,可以输入 exit 或者:
|
||||
|
||||
**CTRL-b &**
|
||||
|
||||
关闭窗口之前,你需要确认一下
|
||||
关闭窗口之前,你需要确认一下。
|
||||
|
||||
### 把窗口分成许多面板
|
||||
|
||||
有时候你在编辑器工作的同时,需要查看日志文件。编辑的同时追踪日志真的很有帮助。Tmux可以让我们把窗口分成许多面板。举了例子,我们可以创建一个控制台监测我们的服务器,同时拥有一个复杂的编辑器环境,这样就能同时进行编译和debug
|
||||
有时候你在编辑器工作的同时,需要查看日志文件。在编辑的同时追踪日志真的很有帮助。Tmux可以让我们把窗口分成许多面板。举个例子,我们可以创建一个控制台监测我们的服务器,同时用编辑器构造复杂的开发环境,这样就能同时进行编译和调试了。
|
||||
|
||||
让我们创建另一个Tmux会话,让其以面板的方式工作。首先,如果我们在某个会话中,那就从Tmux会话中脱离出来
|
||||
让我们创建另一个Tmux会话,让其以面板的方式工作。首先,如果我们在某个会话中,那就从Tmux会话中脱离出来:
|
||||
|
||||
**CTRL-b d**
|
||||
|
||||
开始一个叫做"panes"的新会话
|
||||
开始一个叫做"panes"的新会话:
|
||||
|
||||
$ tmux new -s panes
|
||||
|
||||
@ -120,17 +119,17 @@ Archlinux:
|
||||
|
||||
**CRTL-b %**
|
||||
|
||||
又增加了两个
|
||||
又增加了两个:
|
||||
|
||||
|
||||
|
||||
在他们之间移动:
|
||||
|
||||
**CTRL-b <Arrow keys>**
|
||||
**CTRL-b <光标键>**
|
||||
|
||||
### 结论
|
||||
|
||||
我希望这篇教程能对你有作用。作为奖励,像[Tmuxinator][3] 或者 [Tmuxifier][4]这样的工具,可以简化Tmux会话,窗口和面板的创建及加载,你可以很容易就配置Tmux。如果你没有使用过这些,尝试一下吧
|
||||
我希望这篇教程能对你有作用。此外,像[Tmuxinator][3] 或者 [Tmuxifier][4]这样的工具,可以简化Tmux会话,窗口和面板的创建及加载,你可以很容易就配置Tmux。如果你没有使用过这些,尝试一下吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -138,7 +137,7 @@ via: http://xmodulo.com/2014/08/improve-productivity-terminal-environment-tmux.h
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
Linux有问必答——如何在CentOS上安装Shutter
|
||||
Linux有问必答:如何在CentOS上安装Shutter
|
||||
================================================================================
|
||||
> **问题**:我想要在我的CentOS桌面上试试Shutter屏幕截图程序,但是,当我试着用yum来安装Shutter时,它总是告诉我“没有shutter包可用”。我怎样才能在CentOS上安装Shutter啊?
|
||||
|
||||
[Shutter][1]是一个用于Linux桌面的开源(GPLv3)屏幕截图工具。它打包有大量用户友好的功能,这让它成为Linux中功能最强大的屏幕截图程序之一。你可以用Shutter来捕捉一个规则区域、一个窗口、整个桌面屏幕、或者甚至是来自任意专用地址的一个网页的截图。除此之外,你也可以用它内建的图像编辑器来对捕获的截图进行编辑,应用不同的效果,将图像导出为不同的图像格式(svg,pdf,ps),或者上传图片到公共图像主机或者FTP站点。
|
||||
Shutter is not available as a pre-built package on CentOS (as of version 7). Fortunately, there exists a third-party RPM repository called Nux Dextop, which offers Shutter package. So [enable Nux Dextop repository][2] on CentOS. Then use the following command to install Shutter.
|
||||
|
||||
Shutter 在 CentOS (截止至版本 7)上没有预先构建好的软件包。幸运的是,有一个第三方提供的叫做 Nux Dextop 的 RPM 中提供了 Shutter 软件包。 所以在 CentOS 上[启用 Nux Dextop 软件库][2],然后使用下列命令来安装它:
|
||||
|
||||
$ sudo yum --enablerepo=nux-dextop install shutter
|
||||
|
||||
@ -14,9 +15,9 @@ Shutter is not available as a pre-built package on CentOS (as of version 7). For
|
||||
via: http://ask.xmodulo.com/install-shutter-centos.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://shutter-project.org/
|
||||
[2]:http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
|
||||
[2]:http://linux.cn/article-3889-1.html
|
||||
@ -1,3 +1,5 @@
|
||||
barney-ro translating
|
||||
|
||||
What is a good subtitle editor on Linux
|
||||
================================================================================
|
||||
If you watch foreign movies regularly, chances are you prefer having subtitles rather than the dub. Grown up in France, I know that most Disney movies during my childhood sounded weird because of the French dub. If now I have the chance to be able to watch them in their original version, I know that for a lot of people subtitles are still required. And I surprise myself sometimes making subtitles for my family. Hopefully for me, Linux is not devoid of fancy and open source subtitle editors. In short, this is the non-exhaustive list of open source subtitle editors for Linux. Share your opinion on what you think of the best subtitle editor.
|
||||
@ -47,7 +49,7 @@ Which subtitle editor do you use and why? Or is there another one that you prefe
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -61,4 +63,4 @@ via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by haimingfg
|
||||
|
||||
What are useful CLI tools for Linux system admins
|
||||
================================================================================
|
||||
System administrators (sysadmins) are responsible for day-to-day operations of production systems and services. One of the critical roles of sysadmins is to ensure that operational services are available round the clock. For that, they have to carefully plan backup policies, disaster management strategies, scheduled maintenance, security audits, etc. Like every other discipline, sysadmins have their tools of trade. Utilizing proper tools in the right case at the right time can help maintain the health of operating systems with minimal service interruptions and maximum uptime.
|
||||
@ -184,4 +186,4 @@ via: http://xmodulo.com/2014/08/useful-cli-tools-linux-system-admins.html
|
||||
[17]:http://rsync.samba.org/
|
||||
[18]:http://www.nongnu.org/rdiff-backup/
|
||||
[19]:http://nethogs.sourceforge.net/
|
||||
[20]:http://code.google.com/p/inxi/
|
||||
[20]:http://code.google.com/p/inxi/
|
||||
|
||||
@ -1,209 +0,0 @@
|
||||
How to install and configure ownCloud on Debian
|
||||
================================================================================
|
||||
According to its official website, ownCloud gives you universal access to your files through a web interface or WebDAV. It also provides a platform to easily view, edit and sync your contacts, calendars and bookmarks across all your devices. Even though ownCloud is very similar to the widely-used Dropbox cloud storage, the primary difference is that ownCloud is free and open-source, making it possible to set up a Dropbox-like cloud storage service on your own server. With ownCloud, only you have complete access and control over your private data, with no limits on storage space (except for hard disk capacity) or the number of connected clients.
|
||||
|
||||
ownCloud is available in Community Edition (free of charge) and Enterprise Edition (business-oriented with paid support). The pre-built package of ownCloud Community Edition is available for CentOS, Debian, Fedora openSUSE, SLE and Ubuntu. This tutorial will demonstrate how to install and configure ownCloud Community Edition on Debian Wheezy.
|
||||
|
||||
### Installing ownCloud on Debian ###
|
||||
|
||||
Go to the official website: [http://owncloud.org][1], and click on the 'Install' button (upper right corner).
|
||||
|
||||

|
||||
|
||||
Now choose "Packages for auto updates" for the current version (v7 in the image below). This will allow you to easily keep ownCloud up to date using Debian's package management system, with packages maintained by the ownCloud community.
|
||||
|
||||

|
||||
|
||||
Then click on Continue on the next screen:
|
||||
|
||||

|
||||
|
||||
Select Debian 7 [Wheezy] from the list of available operating systems:
|
||||
|
||||

|
||||
|
||||
Add the ownCloud's official Debian repository:
|
||||
|
||||
# echo 'deb http://download.opensuse.org/repositories/isv:/ownCloud:/community/Debian_7.0/ /' >> /etc/apt/sources.list.d/owncloud.list
|
||||
|
||||
Add the repository key to apt:
|
||||
|
||||
# wget http://download.opensuse.org/repositories/isv:ownCloud:community/Debian_7.0/Release.key
|
||||
# apt-key add - < Release.key
|
||||
|
||||
Go ahead and install ownCloud:
|
||||
|
||||
# aptitude update
|
||||
# aptitude install owncloud
|
||||
|
||||
Open your web browser and navigate to your ownCloud instance, which can be found at http://<server-ip>/owncloud:
|
||||
|
||||

|
||||
|
||||
Note that ownCloud may be alerting about an Apache misconfiguration. Follow the steps below to solve this issue, and get rid of that error message.
|
||||
|
||||
a) Edit the /etc/apache2/apache2.conf file (set the AllowOverride directive to All):
|
||||
|
||||
<Directory /var/www/>
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
b) Edit the /etc/apache2/conf.d/owncloud.conf file
|
||||
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
c) Restart the web server:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
d) Refresh the web browser. Verify that the security warning has disappeared.
|
||||
|
||||

|
||||
|
||||
### Setting up a Database ###
|
||||
|
||||
Now it's time to set up a database for ownCloud.
|
||||
|
||||
First, log in to the local MySQL/MariaDB server:
|
||||
|
||||
$ mysql -u root -h localhost -p
|
||||
|
||||
Create a database and user account for ownCloud as follows.
|
||||
|
||||
mysql> CREATE DATABASE owncloud_DB;
|
||||
mysql> CREATE USER ‘owncloud-web’@'localhost' IDENTIFIED BY ‘whateverpasswordyouchoose’;
|
||||
mysql> GRANT ALL PRIVILEGES ON owncloud_DB.* TO ‘owncloud-web’@'localhost';
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
|
||||
Go to ownCloud page at http://<server-ip>/owncloud, and choose the 'Storage & database' section. Enter the rest of the requested information (MySQL/MariaDB user, password, database and hostname), and click on Finish setup.
|
||||
|
||||

|
||||
|
||||
### Configuring ownCloud for SSL Connections ###
|
||||
|
||||
Before you start using ownCloud, it is strongly recommended to enable SSL support in ownCloud. Using SSL provides important security benefits such as encrypting ownCloud traffic and providing proper authentication. In this tutorial, a self-signed certificate will be used for SSL.
|
||||
|
||||
Create a new directory where we will store the server key and certificate:
|
||||
|
||||
# mkdir /etc/apache2/ssl
|
||||
|
||||
Create a certificate (and the key that will protect it) which will remain valid for one year.
|
||||
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/apache2/ssl/apache.key -out /etc/apache2/ssl/apache.crt
|
||||
|
||||

|
||||
|
||||
Edit the /etc/apache2/conf.d/owncloud.conf file to enable HTTPS. For details on the meaning of the rewrite rules NC, R, and L, you can refer to the [Apache docs][2]:
|
||||
|
||||
Alias /owncloud /var/www/owncloud
|
||||
|
||||
<VirtualHost 192.168.0.15:80>
|
||||
RewriteEngine on
|
||||
ReWriteCond %{SERVER_PORT} !^443$
|
||||
RewriteRule ^/(.*) https://%{HTTP_HOST}/$1 [NC,R,L]
|
||||
</VirtualHost>
|
||||
|
||||
<VirtualHost 192.168.0.15:443>
|
||||
SSLEngine on
|
||||
SSLCertificateFile /etc/apache2/ssl/apache.crt
|
||||
SSLCertificateKeyFile /etc/apache2/ssl/apache.key
|
||||
DocumentRoot /var/www/owncloud/
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Enable the rewrite module and restart Apache:
|
||||
|
||||
# a2enmod rewrite
|
||||
# service apache2 restart
|
||||
|
||||
Open your ownCloud instance. Notice that even if you try to use plain HTTP, you will be automatically redirected to HTTPS.
|
||||
|
||||
Be advised that even having followed the above steps, the first time that you launch your ownCloud instance, an error message will be displayed stating that the certificate has not been issued by a trusted authority (that is because we created a self-signed certificate). You can safely ignore this message, but if you are considering deploying ownCloud in a production server, you may want to purchase a certificate from a trusted company.
|
||||
|
||||
### Create an Account ###
|
||||
|
||||
Now we are ready to create an ownCloud admin account.
|
||||
|
||||

|
||||
|
||||
Welcome to your new personal cloud! Note that you can install a desktop or mobile client app to sync your files, calendars, contacts and more.
|
||||
|
||||

|
||||
|
||||
In the upper right corner, click on your user name, and a drop-down menu is displayed:
|
||||
|
||||
|
||||
|
||||
Click on Personal to change your settings, such as password, display name, email address, profile picture, and more.
|
||||
|
||||
### ownCloud Use Case: Access Calendar ###
|
||||
|
||||
Let's start by adding an event to your calendar and later downloading it.
|
||||
|
||||
Click on the upper left corner drop-down menu and choose Calendar.
|
||||
|
||||

|
||||
|
||||
Add a new event and save it to your calendar.
|
||||
|
||||

|
||||
|
||||
Download your calendar and add it to your Thunderbird calendar by going to 'Event and Tasks' -> 'Import...' -> 'Select file':
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
TIP: You also need to set your time zone in order to successfully import your calendar in another application (by default, the Calendar application uses the UTC +00:00 time zone). To change the time zone, go to the bottom left corner and click on the small gear icon. The Calendar settings menu will appear and you will be able to select your time zone:
|
||||
|
||||

|
||||
|
||||
### ownCloud Use Case: Upload a File ###
|
||||
|
||||
Next, we will upload a file from the client computer.
|
||||
|
||||
Go to the Files menu (upper left corner) and click on the up arrow to open a select-file dialog.
|
||||
|
||||

|
||||
|
||||
Select a file and click on Open.
|
||||
|
||||

|
||||
|
||||
You can then open/edit the selected file, move it into another folder, or delete it.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
ownCloud is a versatile and powerful cloud storage that makes the transition from another provider quick, easy, and painless. In addition, it is FOSS, and with little time and effort you can configure it to meet all your needs. For further information, you can always refer to the [User][3], [Admin][4], or [Developer][5] manuals.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/install-configure-owncloud-debian.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.gabrielcanepa.com.ar/
|
||||
[1]:http://owncloud.org/
|
||||
[2]:http://httpd.apache.org/docs/2.2/rewrite/flags.html
|
||||
[3]:http://doc.owncloud.org/server/7.0/ownCloudUserManual.pdf
|
||||
[4]:http://doc.owncloud.org/server/7.0/ownCloudAdminManual.pdf
|
||||
[5]:http://doc.owncloud.org/server/7.0/ownCloudDeveloperManual.pdf
|
||||
@ -1,125 +0,0 @@
|
||||
translating by cvsher
|
||||
Sysstat – All-in-One System Performance and Usage Activity Monitoring Tool For Linux
|
||||
================================================================================
|
||||
**Sysstat** is really a handy tool which comes with number of utilities to monitor system resources, their performance and usage activities. Number of utilities that we all use in our daily bases comes with sysstat package. It also provide the tool which can be scheduled using cron to collect all performance and activity data.
|
||||
|
||||

|
||||
|
||||
Install Sysstat in Linux
|
||||
|
||||
Following are the list of tools included in sysstat packages.
|
||||
|
||||
### Sysstat Features ###
|
||||
|
||||
- [**iostat**][1]: Reports all statistics about your CPU and I/O statistics for I/O devices.
|
||||
- **mpstat**: Details about CPUs (individual or combined).
|
||||
- **pidstat**: Statistics about running processes/task, CPU, memory etc.
|
||||
- **sar**: Save and report details about different resources (CPU, Memory, IO, Network, kernel etc..).
|
||||
- **sadc**: System activity data collector, used for collecting data in backend for sar.
|
||||
- **sa1**: Fetch and store binary data in sadc data file. This is used with sadc.
|
||||
- **sa2**: Summaries daily report to be used with sar.
|
||||
- **Sadf**: Used for displaying data generated by sar in different formats (CSV or XML).
|
||||
- **Sysstat**: Man page for sysstat utility.
|
||||
- **nfsiostat**-sysstat: I/O statistics for NFS.
|
||||
- **cifsiostat**: Statistics for CIFS.
|
||||
|
||||
Recenlty, on 17th of June 2014, **Sysstat 11.0.0** (stable version) has been released with some new interesting features as follows.
|
||||
|
||||
pidstat command has been enhanced with some new options: first is “-R” which will provide information about the policy and task scheduling priority. And second one is “**-G**” which we can search processes with name and to get the list of all matching threads.
|
||||
|
||||
Some new enhancement have been brought to sar, sadc and sadf with regards to the data files: Now data files can be renamed using “**saYYYYMMDD**” instead of “**saDD**” using option **–D** and can be located in directory different from “**/var/log/sa**”. We can define new directory by setting variable “SA_DIR”, which is being used by sa1 and sa2.
|
||||
|
||||
### Installation of Sysstat in Linux ###
|
||||
|
||||
The ‘**Sysstat**‘ package also available to install from default repository as a package in all major Linux distributions. However, the package which is available from the repo is little old and outdated version. So, that’s the reason, we here going to download and install the latest version of sysstat (i.e. version **11.0.0**) from source package.
|
||||
|
||||
First download the latest version of sysstat package using the following link or you may also use **wget** command to download directly on the terminal.
|
||||
|
||||
- [http://sebastien.godard.pagesperso-orange.fr/download.html][2]
|
||||
|
||||
# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.0.0.tar.gz
|
||||
|
||||

|
||||
|
||||
Download Sysstat Package
|
||||
|
||||
Next, extract the downloaded package and go inside that directory to begin compile process.
|
||||
|
||||
# tar -xvf sysstat-11.0.0.tar.gz
|
||||
# cd sysstat-11.0.0/
|
||||
|
||||
Here you will have two options for compilation:
|
||||
|
||||
a). Firstly, you can use **iconfig** (which will give you flexibility for choosing/entering the customized values for each parameters).
|
||||
|
||||
# ./iconfig
|
||||
|
||||

|
||||
|
||||
Sysstat iconfig Command
|
||||
|
||||
b). Secondly, you can use standard **configure** command to define options in single line. You can run **./configure –help command** to get list of different supported options.
|
||||
|
||||
# ./configure --help
|
||||
|
||||

|
||||
|
||||
Sysstat Configure Help
|
||||
|
||||
Here, we are moving ahead with standard option i.e. **./configure** command to compile sysstat package.
|
||||
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
|
||||

|
||||
|
||||
Configure Sysstat in Linux
|
||||
|
||||
After compilation process completes, you will see the output similar to above. Now, verify the sysstat version by running following command.
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
### Updating Sysstat in Linux ###
|
||||
|
||||
By default sysstat use “**/usr/local**” as its prefix directory. So, all binary/utilities will get installed in “**/usr/local/bin**” directory. If you have existing sysstat package installed, then those will be there in “**/usr/bin**”.
|
||||
|
||||
Due to existing sysstat package, you will not get your updated version reflected, because your “**$PATH**” variable don’t have “**/usr/local/bin set**”. So, make sure that “**/usr/local/bin**” exist there in your “$PATH” or set **–prefix** option to “**/usr**” during compilation and remove existing version before starting updating.
|
||||
|
||||
# yum remove sysstat [On RedHat based System]
|
||||
# apt-get remove sysstat [On Debian based System]
|
||||
|
||||
----------
|
||||
|
||||
# ./configure --prefix=/usr
|
||||
# make
|
||||
# make install
|
||||
|
||||
Now again, verify the updated version of systat using same ‘mpstat’ command with option ‘**-V**’.
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
**Reference**: For more information please go through [Sysstat Documentation][3]
|
||||
|
||||
That’s it for now, in my upcoming article, I will show some practical examples and usages of sysstat command, till then stay tuned to updates and don’t forget to add your valuable thoughts about the article at below comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-sysstat-in-linux/
|
||||
|
||||
作者:[Kuldeep Sharma][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/kuldeepsharma47/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[2]:http://sebastien.godard.pagesperso-orange.fr/download.html
|
||||
[3]:http://sebastien.godard.pagesperso-orange.fr/documentation.html
|
||||
@ -1,151 +0,0 @@
|
||||
How to manage configurations in Linux with Puppet and Augeas
|
||||
================================================================================
|
||||
Although [Puppet][1](注:此文原文原文中曾今做过,文件名:“20140808 How to install Puppet server and client on CentOS and RHEL.md”,如果翻译发布过,可修改此链接为发布地址) is a really unique and useful tool, there are situations where you could use a bit of a different approach. Situations like modification of configuration files which are already present on several of your servers and are unique on each one of them at the same time. Folks from Puppet labs realized this as well, and integrated a great tool called [Augeas][2] that is designed exactly for this usage.
|
||||
|
||||
Augeas can be best thought of as filling for the gaps in Puppet's capabilities where an objectspecific resource type (such as the host resource to manipulate /etc/hosts entries) is not yet available. In this howto, you will learn how to use Augeas to ease your configuration file management.
|
||||
|
||||
### What is Augeas? ###
|
||||
|
||||
Augeas is basically a configuration editing tool. It parses configuration files in their native formats and transforms them into a tree. Configuration changes are made by manipulating this tree and saving it back into native config files.
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
We will install and configure the Augeas tool for use with our previously built Puppet server. We will create and test several different configurations with this tool, and learn how to properly use it to manage our system configurations.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
We will need a working Puppet server and client setup. If you don't have it, please follow my previous tutorial.
|
||||
|
||||
Augeas package can be found in our standard CentOS/RHEL repositories. Unfortunately, Puppet uses Augeas ruby wrapper which is only available in the puppetlabs repository (or [EPEL][4]). If you don't have this repository in your system already, add it using following command:
|
||||
|
||||
On CentOS/RHEL 6.5:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabsrelease610.noarch.rpm
|
||||
|
||||
On CentOS/RHEL 7:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabsrelease710.noarch.rpm
|
||||
|
||||
After you have successfully added this repository, install RubyAugeas in your system:
|
||||
|
||||
# yum install rubyaugeas
|
||||
|
||||
Or if you are continuing from my last tutorial, install this package using the Puppet way. Modify your custom_utils class inside of your /etc/puppet/manifests/site.pp to contain "rubyaugeas" inside of the packages array:
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vimenhanced","traceroute","rubyaugeas"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
### Augeas without Puppet ###
|
||||
|
||||
As it was said in the beginning, Augeas is not originally from Puppet Labs, which means we can still use it even without Puppet itself. This approach can be useful for verifying your modifications and ideas before applying them in your Puppet environment. To make this possible, you need to install one additional package in your system. To do so, please execute following command:
|
||||
|
||||
# yum install augeas
|
||||
|
||||
### Puppet Augeas Examples ###
|
||||
|
||||
For demonstration, here are a few example Augeas use cases.
|
||||
|
||||
#### Management of /etc/sudoers file ####
|
||||
|
||||
1. Add sudo rights to wheel group
|
||||
|
||||
This example will show you how to add simple sudo rights for group %wheel in your GNU/Linux system.
|
||||
|
||||
# Install sudo package
|
||||
package { 'sudo':
|
||||
ensure => installed, # ensure sudo package installed
|
||||
}
|
||||
|
||||
# Allow users belonging to wheel group to use sudo
|
||||
augeas { 'sudo_wheel':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
# allow wheel users to use sudo
|
||||
'set spec[user = "%wheel"]/user %wheel',
|
||||
'set spec[user = "%wheel"]/host_group/host ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command/runas_user ALL',
|
||||
]
|
||||
}
|
||||
|
||||
Now let's explain what the code does: **spec** defines the user section in /etc/sudoers, **[user]** defines given user from the array, and all definitions behind slash ( / ) are subparts of this user. So in typical configuration this would be represented as:
|
||||
|
||||
user host_group/host host_group/command host_group/command/runas_user
|
||||
|
||||
Which is translated into this line of /etc/sudoers:
|
||||
|
||||
%wheel ALL = (ALL) ALL
|
||||
|
||||
2. Add command alias
|
||||
|
||||
The following part will show you how to define command alias which you can use inside your sudoers file.
|
||||
|
||||
# Create new alias SERVICES which contains some basic privileged commands
|
||||
augeas { 'sudo_cmdalias':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/name SERVICES",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[1] /sbin/service",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[2] /sbin/chkconfig",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[3] /bin/hostname",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[4] /sbin/shutdown",
|
||||
]
|
||||
}
|
||||
|
||||
Syntax of sudo command aliases is pretty simple: **Cmnd_Alias** defines the section of command aliases, **[alias/name]** binds all to given alias name, /alias/name **SERVICES** defines the actual alias name and alias/command is the array of all the commands that should be part of this alias. The output of this command will be following:
|
||||
|
||||
Cmnd_Alias SERVICES = /sbin/service , /sbin/chkconfig , /bin/hostname , /sbin/shutdown
|
||||
|
||||
For more information about /etc/sudoers, visit the [official documentation][5].
|
||||
|
||||
#### Adding users to a group ####
|
||||
|
||||
To add users to groups using Augeas, you might want to add the new user either after the gid field or after the last user. We'll use group SVN for the sake of this example. This can be achieved by using the following command:
|
||||
|
||||
In Puppet:
|
||||
|
||||
augeas { 'augeas_mod_group:
|
||||
context => '/files/etc/group', # The target file is /etc/group
|
||||
changes => [
|
||||
"ins user after svn/*[self::gid or self::user][last()]",
|
||||
"set svn/user[last()] john",
|
||||
]
|
||||
}
|
||||
|
||||
Using augtool:
|
||||
|
||||
augtool> ins user after /files/etc/group/svn/*[self::gid or self::user][last()] augtool> set /files/etc/group/svn/user[last()] john
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now, you should have a good idea on how to use Augeas in your Puppet projects. Feel free to experiment with it and definitely go through the official Augeas documentation. It will help you get the idea how to use Augeas properly in your own projects, and it will show you how much time you can actually save by using it.
|
||||
|
||||
If you have any questions feel free to post them in the comments and I will do my best to answer them and advise you.
|
||||
|
||||
### Useful Links ###
|
||||
|
||||
- [http://www.watzmann.net/categories/augeas.html][6]: contains a lot of tutorials focused on Augeas usage.
|
||||
- [http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas][7]: Puppet wiki with a lot of practical examples.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/manage-configurations-linux-puppet-augeas.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
[2]:http://augeas.net/
|
||||
[3]:http://xmodulo.com/manage-configurations-linux-puppet-augeas.html
|
||||
[4]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://augeas.net/docs/references/lenses/files/sudoers-aug.html
|
||||
[6]:http://www.watzmann.net/categories/augeas.html
|
||||
[7]:http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas
|
||||
@ -1,91 +0,0 @@
|
||||
Translating by haimingfg
|
||||
|
||||
Learning Vim in 2014: Working with Files
|
||||
================================================================================
|
||||
As a software developer, you shouldn't have to spend time thinking about how to get to the code you want to edit. One of the messiest parts of my transition to using Vim full time was its way of dealing with files. Coming to Vim after primarily using Eclipse and Sublime Text, it frustrated me that Vim doesn't bundle a persistent file system viewer, and the built-in ways of opening and switching files always felt extremely painful.
|
||||
|
||||
At this point I appreciate the depth of Vim's file management features. I've put together a system that works for me even better than more visual editors once did. Because it's purely keyboard based, it allows me to move through my code much faster. That took some time though, and involves several plugins. But the first step was me understanding Vim's built in options for dealing with files. This post will be looking at the most important structures Vim provides you for file management, with a quick peek at some of the more advanced features you can get through plugins.
|
||||
|
||||
### The Basics: Opening a new file ###
|
||||
|
||||
One of the biggest obstacles to learning Vim is its lack of visual affordances. Unlike modern GUI based editors, there is no obvious way to do anything when you open a new instance of Vim in the terminal. Everything is done through keyboard commands, and while that ends up being more efficient for experienced users, new Vim users will find themselves looking up even basic commands routinely. So lets start with the basics.
|
||||
|
||||
The command to open a new file in Vim is **:e <filename>. :e** opens up a new buffer with the contents of the file inside. If the file doesn't exist yet it opens up an empty buffer and will write to the file location you specify once you make changes and save. Buffers are Vim's term for a "block of text stored in memory". That text can be associated with an existing file or not, but there will be one buffer for each file you have open.
|
||||
|
||||
After you open a file and make changes, you can save the contents of the buffer back to the file with the write command **:w**. If the buffer is not yet associated with a file or you want to save to a different location, you can save to a specific file with **:w <filename>**. You may need to add a ! and use **:w! <filename>** if you're overwriting an existing file.
|
||||
|
||||
This is the survival level knowledge for dealing with Vim files. Plenty of developers get by with just these commands, and its technically all you need. But Vim offers a lot more for those who dig a bit deeper.
|
||||
|
||||
### Buffer Management ###
|
||||
|
||||
Moving beyond the basics, let's talk some more about buffers. Vim handles open files a bit differently than other editors. Rather than leaving all open files visible as tabs, or only allowing you to have one file open at a time, Vim allows you to have multiple buffers open. Some of these may be visible while others are not. You can view a list of all open buffers at any time with **:ls**. This shows each open buffer, along with their buffer number. You can then switch to a specific buffer with the **:b <buffer-number>** command, or move in order along the list with the **:bnext** and **:bprevious** commands. (these can be shortened to **:bn** and **:bp** respectively).
|
||||
|
||||
While these commands are the fundamental Vim solutions for managing buffers, I've found that they don't map well to my own way of thinking about files. I don't want to care about the order of buffers, I just want to go to the file I'm thinking about, or maybe to the file I was just in before the current one. So while its important to understand Vim's underlying buffer model, I wouldn't necessarily recommend its builtin commands as your main file management strategy. There are more powerful options available.
|
||||
|
||||

|
||||
|
||||
### Splits ###
|
||||
|
||||
One of the best parts of managing files in Vim is its splits. With Vim, you can split your current window into 2 windows at any time, and then resize and arrange them into any configuration you like. Its not unusual for me to have 6 files open at a given time, each with its own small split of the window.
|
||||
|
||||
You can open a new split with **:sp <filename>** or **:vs <filename>**, for horizontal and vertical splits respectively. There are keyword commands you can use to then resize the windows the way you want them, but to be honest this is the one Vim task I prefer to do with my mouse. A mouse gives me more precision without having to guess the number of columns I want or fiddle back and forth between 2 widths.
|
||||
|
||||
After you create some splits, you can switch back and forth between them with **ctrl-w [h|j|k|l]**. This is a bit clunky though, and it's important for common operations to be efficient and easy. If you use splits heavily, I would personally recommend aliasing these commands to **ctrl-h** **ctrl-j** etc in your .vimrc using this snippet.
|
||||
|
||||
nnoremap <C-J> <C-W><C-J> "Ctrl-j to move down a split
|
||||
nnoremap <C-K> <C-W><C-K> "Ctrl-k to move up a split
|
||||
nnoremap <C-L> <C-W><C-L> "Ctrl-l to move right a split
|
||||
nnoremap <C-H> <C-W><C-H> "Ctrl-h to move left a split
|
||||
|
||||
### The jumplist ###
|
||||
|
||||
Splits solve the problem of viewing multiple related files at a time, but we still haven't seen a satisfactory solution for moving quickly between open and hidden files. The jumplist is one tool you can use for that.
|
||||
|
||||
The jumplist is one of those Vim features that can appear weird or even useless at first. Vim keeps track of every motion command and file switch you make as you're editing files. Every time you "jump" from one place to another in a split, Vim adds an entry to the jumplist. While this may initially seem like a small thing, it becomes powerful when you're switching files a lot, or moving around in a large file. Instead of having to remember your place, or worry about what file you were in, you can instead retrace your footsteps quickly using some quick key commands. **Ctrl-o** allows you to jump back to your last jump location. Repeating it multiple times allows you to quickly jump back to the last file or code chunk you were working on, without having to keep the details of where that code is in your head. You can then move back up the chain with **ctrl-i**. This turns out to be immensely powerful when you're moving around in code quickly, debugging a problem in multiple files or flipping back and forth between 2 files. Instead of typing file names or remembering buffer numbers, you can just move up and down the existing path. It's not the answer to everything, but like other Vim concepts, it's a small focused tool that adds to the overall power of the editor without trying to do everything.
|
||||
|
||||
### Plugins ###
|
||||
|
||||
So let's be real, if you're coming to Vim from something like Sublime Text or Atom, there's a good chance all of this looks a bit arcane, scary, and inefficient. "Why would I want to type the full path to open a file when Sublime has fuzzy finding?" "How can I get a view of a project's structure without a sidebar to show the directory tree?" Legitimate questions. The good news is that Vim has solutions. They're just not baked into the Vim core. I'll touch more on Vim configuration and plugins in later posts, but for now here's a pointer to 3 helpful plugins that you can use to get Sublime-like file management.
|
||||
|
||||
- [CtrlP][1] is a fuzzy finding file search similar to Sublime's "Go to Anything" bar. It's lightning fast and pretty configurable. I use it as my main way of opening new files. With it I only need to know part of the file name and don't need to memorize my project's directory structure.
|
||||
- [The NERDTree][2] is a "file navigation drawer" plugin that replicates the side file navigation that many editors have. I actually rarely use it, as fuzzy search always seems faster to me. But it can be useful coming into a project, when you're trying to learn the project structure and see what's available. NERDTree is immensely configurable, and also replaces Vim's built in directory tools when installed.
|
||||
- [Ack.vim][3] is a code search plugin for Vim that allows you to search across your project for text expressions. It acts as a light wrapper around Ack or Ag, [2 great code search tools][4], and allows you to quickly jump to any occurrence of a search term in your project.
|
||||
|
||||
Between it's core and its plugin ecosystem, Vim offers enough tools to allow you to craft your workflow anyway you want. File management is a key part of a good software development system, and it's worth experimenting to get it right.
|
||||
|
||||
Start with the basics for long enough to understand them, and then start adding tools on top until you find a comfortable workflow. It will all be worth it when you're able to seamlessly move to the code you want to work on without the mental overhead of figuring out how to get there.
|
||||
|
||||
### More Resources ###
|
||||
|
||||
- [Seamlessly Navigate Vim & Tmux Splits][5] This is a must read for anyone who wants to use vim with [tmux][6]. It presents an easy system for treating Vim and Tmux splits as equals, and moving between them easily.
|
||||
- [Using Tab Pages][7] One file management feature I didn't cover, since it's poorly named and a bit confusing to use, is Vim's "tab" feature. This post on the Vim wiki gives a good overview of how you can use "tab pages" to have multiple views of your current workspace
|
||||
- [Vimcasts: The edit command][8] Vimcasts in general is a great resource for anyone learning Vim, but this screenshot does a good job of covering the file opening basics mentioned above, with some suggestions on improving the builtin workflow
|
||||
|
||||
### Subscribe ###
|
||||
|
||||
This was the third in a series of posts on learning Vim in a modern way. If you enjoyed the post consider subscribing to the [feed][8] or joining my [mailing list][10]. I'll be continuing with [a post on Vim configuration next week][11] after a brief JavaScript interlude later this week. You should also checkout the first 2 posts in this series, on [the basics of using Vim][12], and [the language of Vim and Vi][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
|
||||
作者:[Ben McCormick][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
[1]:https://github.com/kien/ctrlp.vim
|
||||
[2]:https://github.com/scrooloose/nerdtree
|
||||
[3]:https://github.com/mileszs/ack.vim
|
||||
[4]:http://benmccormick.org/2013/11/25/a-look-at-ack/
|
||||
[5]:http://robots.thoughtbot.com/seamlessly-navigate-vim-and-tmux-splits
|
||||
[6]:http://tmux.sourceforge.net/
|
||||
[7]:http://vim.wikia.com/wiki/Using_tab_pages
|
||||
[8]:http://vimcasts.org/episodes/the-edit-command/
|
||||
[9]:http://feedpress.me/benmccormick
|
||||
[10]:http://eepurl.com/WFYon
|
||||
[11]:http://benmccormick.org/2014/07/14/learning-vim-in-2014-configuring-vim/
|
||||
[12]:http://benmccormick.org/2014/06/30/learning-vim-in-2014-the-basics/
|
||||
[13]:http://benmccormick.org/2014/07/02/learning-vim-in-2014-vim-as-language/
|
||||
138
sources/tech/20141004 Practical Lessons in Peer Code Review.md
Normal file
138
sources/tech/20141004 Practical Lessons in Peer Code Review.md
Normal file
@ -0,0 +1,138 @@
|
||||
johnhoow translating...
|
||||
# Practical Lessons in Peer Code Review #
|
||||
|
||||
Millions of years ago, apes descended from the trees, evolved opposable thumbs and—eventually—turned into human beings.
|
||||
|
||||
We see mandatory code reviews in a similar light: something that separates human from beast on the rolling grasslands of the software
|
||||
development savanna.
|
||||
|
||||
Nonetheless, I sometimes hear comments like these from our team members:
|
||||
|
||||
"Code reviews on this project are a waste of time."
|
||||
"I don't have time to do code reviews."
|
||||
"My release is delayed because my dastardly colleague hasn't done my review yet."
|
||||
"Can you believe my colleague wants me to change something in my code? Please explain to them that the delicate balance of the universe will
|
||||
be disrupted if my pristine, elegant code is altered in any way."
|
||||
|
||||
### Why do we do code reviews? ###
|
||||
|
||||
Let us remember, first of all, why we do code reviews. One of the most important goals of any professional software developer is to
|
||||
continually improve the quality of their work. Even if your team is packed with talented programmers, you aren't going to distinguish
|
||||
yourselves from a capable freelancer unless you work as a team. Code reviews are one of the most important ways to achieve this. In
|
||||
particular, they:
|
||||
|
||||
provide a second pair of eyes to find defects and better ways of doing something.
|
||||
ensure that at least one other person is familiar with your code.
|
||||
help train new staff by exposing them to the code of more experienced developers.
|
||||
promote knowledge sharing by exposing both the reviewer and reviewee to the good ideas and practices of the other.
|
||||
encourage developers to be more thorough in their work since they know it will be reviewed by one of their colleagues.
|
||||
|
||||
### Doing thorough reviews ###
|
||||
|
||||
However, these goals cannot be achieved unless appropriate time and care are devoted to reviews. Just scrolling through a patch, making sure
|
||||
that the indentation is correct and that all the variables use lower camel case, does not constitute a thorough code review. It is
|
||||
instructive to consider pair programming, which is a fairly popular practice and adds an overhead of 100% to all development time, as the
|
||||
baseline for code review effort. You can spend a lot of time on code reviews and still use much less overall engineer time than pair
|
||||
programming.
|
||||
|
||||
My feeling is that something around 25% of the original development time should be spent on code reviews. For example, if a developer takes
|
||||
two days to implement a story, the reviewer should spend roughly four hours reviewing it.
|
||||
|
||||
Of course, it isn't primarily important how much time you spend on a review as long as the review is done correctly. Specifically, you must
|
||||
understand the code you are reviewing. This doesn't just mean that you know the syntax of the language it is written in. It means that you
|
||||
must understand how the code fits into the larger context of the application, component or library it is part of. If you don't grasp all the
|
||||
implications of every line of code, then your reviews are not going to be very valuable. This is why good reviews cannot be done quickly: it
|
||||
takes time to investigate the various code paths that can trigger a given function, to ensure that third-party APIs are used correctly
|
||||
(including any edge cases) and so forth.
|
||||
|
||||
In addition to looking for defects or other problems in the code you are reviewing, you should ensure that:
|
||||
|
||||
All necessary tests are included.
|
||||
Appropriate design documentation has been written.
|
||||
Even developers who are good about writing tests and documentation don't always remember to update them when they change their code. A
|
||||
gentle nudge from the code reviewer when appropriate is vital to ensure that they don't go stale over time.
|
||||
|
||||
### Preventing code review overload ###
|
||||
|
||||
If your team does mandatory code reviews, there is the danger that your code review backlog will build up to the point where it is
|
||||
unmanageable. If you don't do any reviews for two weeks, you can easily have several days of reviews to catch up on. This means that your
|
||||
own development work will take a large and unexpected hit when you finally decide to deal with them. It also makes it a lot harder to do
|
||||
good reviews since proper code reviews require intense and sustained mental effort. It is difficult to keep this up for days on end.
|
||||
|
||||
For this reason, developers should strive to empty their review backlog every day. One approach is to tackle reviews first thing in the
|
||||
morning. By doing all outstanding reviews before you start your own development work, you can keep the review situation from getting out of
|
||||
hand. Some might prefer to do reviews before or after the midday break or at the end of the day. Whenever you do them, by considering code
|
||||
reviews as part of your regular daily work and not a distraction, you avoid:
|
||||
|
||||
Not having time to deal with your review backlog.
|
||||
Delaying a release because your reviews aren't done yet.
|
||||
Posting reviews that are no longer relevant since the code has changed so much in the meantime.
|
||||
Doing poor reviews since you have to rush through them at the last minute.
|
||||
|
||||
### Writing reviewable code ###
|
||||
|
||||
The reviewer is not always the one responsible for out-of-control review backlogs. If my colleague spends a week adding code willy-nilly
|
||||
across a large project then the patch they post is going to be really hard to review. There will be too much to get through in one session.
|
||||
It will be difficult to understand the purpose and underlying architecture of the code.
|
||||
|
||||
This is one of many reasons why it is important to split your work into manageable units. We use scrum methodology so the appropriate unit
|
||||
for us is the story. By making an effort to organize our work by story and submit reviews that pertain only to the specific story we are
|
||||
working on, we write code that is much easier to review. Your team may use another methodology but the principle is the same.
|
||||
|
||||
There are other prerequisites to writing reviewable code. If there are tricky architectural decisions to be made, it makes sense to meet
|
||||
with the reviewer beforehand to discuss them. This will make it much easier for the reviewer to understand your code, since they will know
|
||||
what you are trying to achieve and how you plan to achieve it. This also helps avoid the situation where you have to rewrite large swathes
|
||||
of code after the reviewer suggests a different and better approach.
|
||||
|
||||
Project architecture should be described in detail in your design documentation. This is important anyway since it enables a new project
|
||||
member to get up to speed and understand the existing code base. It has the further advantage of helping a reviewer to do their job
|
||||
properly. Unit tests are also helpful in illustrating to the reviewer how components should be used.
|
||||
|
||||
If you are including third-party code in your patch, commit it separately. It is much harder to review code properly when 9000 lines of
|
||||
jQuery are dropped into the middle.
|
||||
|
||||
One of the most important steps for creating reviewable code is to annotate your code reviews. This means that you go through the review
|
||||
yourself and add comments anywhere you feel that this will help the reviewer to understand what is going on. I have found that annotating
|
||||
code takes relatively little time (often just a few minutes) and makes a massive difference in how quickly and well the code can be
|
||||
reviewed. Of course, code comments have many of the same advantages and should be used where appropriate, but often a review annotation
|
||||
makes more sense. As a bonus, studies have shown that developers find many defects in their own code while rereading and annotating it.
|
||||
|
||||
### Large code refactorings ###
|
||||
|
||||
Sometimes it is necessary to refactor a code base in a way that affects many components. In the case of a large application, this can take
|
||||
several days (or more) and result in a huge patch. In these cases a standard code review may be impractical.
|
||||
|
||||
The best solution is to refactor code incrementally. Figure out a partial change of reasonable scope that results in a working code base and
|
||||
brings you in the direction you want to go. Once that change has been completed and a review posted, proceed to a second incremental change
|
||||
and so forth until the full refactoring has been completed. This might not always be possible, but with thought and planning it is usually
|
||||
realistic to avoid massive monolithic patches when refactoring. It might take more time for the developer to refactor in this way, but it
|
||||
also leads to better quality code as well as making reviews much easier.
|
||||
|
||||
If it really isn't possible to refactor code incrementally (which probably says something about how well the original code was written and
|
||||
organized), one solution might be to do pair programming instead of code reviews while working on the refactoring.
|
||||
|
||||
### Resolving disputes ###
|
||||
|
||||
Your team is doubtless made up of intelligent professionals, and in almost all cases it should be possible to come an agreement when
|
||||
opinions about a specific coding question differ. As a developer, keep an open mind and be prepared to compromise if your reviewer prefers a
|
||||
different approach. Don't take a proprietary attitude to your code and don't take review comments personally. Just because someone feels
|
||||
that you should refactor some duplicated code into a reusable function, it doesn't mean that you are any less of an attractive, brilliant
|
||||
and charming individual.
|
||||
|
||||
As a reviewer, be tactful. Before suggesting changes, consider whether your proposal is really better or just a matter of taste. You will
|
||||
have more success if you choose your battles and concentrate on areas where the original code clearly requires improvement. Say things like
|
||||
"it might be worth considering..." or "some people recommend..." instead of "my pet hamster could write a more efficient sorting algorithm
|
||||
than this."
|
||||
|
||||
If you really can't find middle ground, ask a third developer who both of you respect to take a look and give their opinion.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.salsitasoft.com/practical-lessons-in-peer-code-review/
|
||||
作者:[Matt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,209 @@
|
||||
如何在Debian上安装配置ownCloud
|
||||
================================================================================
|
||||
据其官方网站,ownCloud可以让你通过一个网络接口或者WebDAV访问你的文件。它还提供了一个平台,可以轻松地查看、编辑和同步您所有设备的通讯录、日历和书签。尽管ownCloud与广泛使用Dropbox非常相似,但主要区别在于ownCloud是免费的,开源的,从而可以自己的服务器上建立与Dropbox类似的云存储服务。使用ownCloud你可以完整地访问和控制您的私人数据而对存储空间没有限制(除了硬盘容量)或者连客户端的连接数量。
|
||||
|
||||
ownCloud提供了社区版(免费)和企业版(面向企业的有偿支持)。预编译的ownCloud社区版可以提供了CentOS、Debian、Fedora、openSUSE、,SLE和Ubuntu版本。本教程将演示如何在Debian Wheezy上安装和在配置ownCloud社区版。
|
||||
|
||||
### 在Debian上安装 ownCloud ###
|
||||
|
||||
进入官方网站:[http://owncloud.org][1],并点击‘Install’按钮(右上角)。
|
||||
|
||||

|
||||
|
||||
为当前的版本选择“Packages for auto updates”(下面的图是v7)。这可以让你轻松的让你使用的ownCloud与Debian的包管理系统保持一致,包是由ownCloud社区维护的。
|
||||
|
||||

|
||||
|
||||
在下一屏职工点击继续:
|
||||
|
||||

|
||||
|
||||
在可用的操作系统列表中选择Debian 7 [Wheezy]:
|
||||
|
||||

|
||||
|
||||
加入ownCloud的官方Debian仓库:
|
||||
|
||||
# echo 'deb http://download.opensuse.org/repositories/isv:/ownCloud:/community/Debian_7.0/ /' >> /etc/apt/sources.list.d/owncloud.list
|
||||
|
||||
加入仓库密钥到apt中:
|
||||
|
||||
# wget http://download.opensuse.org/repositories/isv:ownCloud:community/Debian_7.0/Release.key
|
||||
# apt-key add - < Release.key
|
||||
|
||||
继续安装ownCLoud:
|
||||
|
||||
# aptitude update
|
||||
# aptitude install owncloud
|
||||
|
||||
打开你的浏览器并定位到你的ownCloud实例中,地址是http://<server-ip>/owncloud:
|
||||
|
||||

|
||||
|
||||
注意ownCloud可能会包一个Apache配置错误的警告。使用下面的步骤来解决这个错误来摆脱这些错误信息。
|
||||
|
||||
a) 编辑 the /etc/apache2/apache2.conf (设置 AllowOverride 为 All):
|
||||
|
||||
<Directory /var/www/>
|
||||
Options Indexes FollowSymLinks
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
b) 编辑 the /etc/apache2/conf.d/owncloud.conf
|
||||
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
|
||||
c) 重启web服务器:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
d) 刷新浏览器,确认安全警告已经消失
|
||||
|
||||

|
||||
|
||||
### 设置数据库 ###
|
||||
|
||||
是时候为ownCloud设置数据库了。
|
||||
|
||||
首先登录本地的MySQL/MariaDB数据库:
|
||||
|
||||
$ mysql -u root -h localhost -p
|
||||
|
||||
为ownCloud创建数据库和用户账户。
|
||||
|
||||
mysql> CREATE DATABASE owncloud_DB;
|
||||
mysql> CREATE USER ‘owncloud-web’@'localhost' IDENTIFIED BY ‘whateverpasswordyouchoose’;
|
||||
mysql> GRANT ALL PRIVILEGES ON owncloud_DB.* TO ‘owncloud-web’@'localhost';
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
|
||||
通过http://<server-ip>/owncloud 进入ownCloud页面,并选择‘Storage & database’ 选项。输入所需的信息(MySQL/MariaDB用户名,密码,数据库和主机名),并点击完成按钮。
|
||||
|
||||

|
||||
|
||||
### 为ownCloud配置SSL连接 ###
|
||||
|
||||
在你开始使用ownCloud之前,强烈建议你在ownCloud中启用SSL支持。使用SSL可以提供重要的安全好处,比如加密ownCloud流量并提供适当的验证。在本教程中,将会为SSL使用一个自签名的证书。
|
||||
|
||||
创建一个储存服务器密钥和证书的目录:
|
||||
|
||||
# mkdir /etc/apache2/ssl
|
||||
|
||||
创建一个证书(并有一个密钥来保护它),它有一年的有效期。
|
||||
|
||||
# openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/apache2/ssl/apache.key -out /etc/apache2/ssl/apache.crt
|
||||
|
||||

|
||||
|
||||
编辑/etc/apache2/conf.d/owncloud.conf 启用HTTPS。对于余下的NC、R和L重写规则的意义,你可以参考[Apache 文档][2]:
|
||||
|
||||
Alias /owncloud /var/www/owncloud
|
||||
|
||||
<VirtualHost 192.168.0.15:80>
|
||||
RewriteEngine on
|
||||
ReWriteCond %{SERVER_PORT} !^443$
|
||||
RewriteRule ^/(.*) https://%{HTTP_HOST}/$1 [NC,R,L]
|
||||
</VirtualHost>
|
||||
|
||||
<VirtualHost 192.168.0.15:443>
|
||||
SSLEngine on
|
||||
SSLCertificateFile /etc/apache2/ssl/apache.crt
|
||||
SSLCertificateKeyFile /etc/apache2/ssl/apache.key
|
||||
DocumentRoot /var/www/owncloud/
|
||||
<Directory /var/www/owncloud>
|
||||
Options Indexes FollowSymLinks MultiViews
|
||||
AllowOverride All
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
启用重写模块并重启Apache:
|
||||
|
||||
# a2enmod rewrite
|
||||
# service apache2 restart
|
||||
|
||||
打开你的ownCloud实例。注意一下,即使你尝试使用HTTP,你也会自动被重定向到HTTPS。
|
||||
|
||||
注意,即使你已经按照上述步骤做了,在你启动ownCloud你仍将看到一条错误消息,指出该证书尚未被受信的机构颁发(那是因为我们创建了一个自签名证书)。您可以放心地忽略此消息,但如果你考虑在生产服务器上部署ownCloud,你可以从一个值得信赖的公司购买证书。
|
||||
|
||||
### 创建一个账号 ###
|
||||
|
||||
现在我们准备创建一个ownCloud管理员帐号了。
|
||||
|
||||

|
||||
|
||||
欢迎来自你的个人云!注意你可以安装一个桌面或者移动端app来同步你的文件、日历、通讯录或者更多了。
|
||||
|
||||

|
||||
|
||||
在右上叫,点击你的用户名,会显示一个下拉菜单:
|
||||
|
||||

|
||||
|
||||
点击Personal来改变你的设置,比如密码,显示名,email地址、头像还有更多。
|
||||
|
||||
### ownCloud 使用案例:访问日历 ###
|
||||
|
||||
让我开始添加一个事件到日历中并稍后下载。
|
||||
|
||||
点击左上角的下拉菜单并选择日历。
|
||||
|
||||

|
||||
|
||||
添加一个时间并保存到你的日历中。
|
||||
|
||||

|
||||
|
||||
通过 'Event and Tasks' -> 'Import...' -> 'Select file' 下载你的日历并添加到你的Thunderbird日历中:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
提示:你还需要设置你的时区以便在其他程序中成功地导入你的日历(默认情况下,日历程序将使用UTC+00:00时区)。要更改时区在左下角点击小齿轮图标,接着日历设置菜单就会出现,你就可以选择时区了:
|
||||
|
||||

|
||||
|
||||
### ownCloud 使用案例:上传一个文件 ###
|
||||
|
||||
接下来,我们会从本机上传一个文件
|
||||
|
||||
进入文件菜单(左上角)并点击向上箭头来打开一个选择文件对话框。
|
||||
|
||||

|
||||
|
||||
选择一个文件并点击打开。
|
||||
|
||||

|
||||
|
||||
接下来你就可以打开/编辑选中的文件,把它移到另外一个文件夹或者删除它了。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
ownCloud是一个灵活和强大的云存储,可以从其他供应商快速、简便、无痛的过渡。此外,它是开源软件,你只需要很少有时间和精力对其进行配置以满足你的所有需求。欲了解更多信息,可以随时参考[用户][3]、[管理][4]或[开发][5]手册。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/install-configure-owncloud-debian.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.gabrielcanepa.com.ar/
|
||||
[1]:http://owncloud.org/
|
||||
[2]:http://httpd.apache.org/docs/2.2/rewrite/flags.html
|
||||
[3]:http://doc.owncloud.org/server/7.0/ownCloudUserManual.pdf
|
||||
[4]:http://doc.owncloud.org/server/7.0/ownCloudAdminManual.pdf
|
||||
[5]:http://doc.owncloud.org/server/7.0/ownCloudDeveloperManual.pdf
|
||||
@ -0,0 +1,152 @@
|
||||
如何用Puppet和Augeas管理Linux配置
|
||||
================================================================================
|
||||
虽然[Puppet][1](注:此文原文原文中曾今做过,文件名:“20140808 How to install Puppet server and client on CentOS and RHEL.md”,如果翻译发布过,可修改此链接为发布地址)是一个非常独特的和有用的工具,在有些情况下你可以使用一点不同的方法。要修改的配置文件已经在几个不同的服务器上且它们在这时是互补相同的。Puppet实验室的人也意识到了这一点并集成了一个伟大的工具,称之为[Augeas][2],它是专为这种使用情况而设计的。
|
||||
|
||||
|
||||
Augeas可被认为填补了Puppet能力的缺陷,其中一个特定对象的资源类型(如主机资源来处理/etc/hosts中的条目)还不可用。在这个文档中,您将学习如何使用Augeas来减轻你管理配置文件的负担。
|
||||
|
||||
### Augeas是什么? ###
|
||||
|
||||
Augeas基本上就是一个配置编辑工具。它以他们原生的格式解析配置文件并且将它们转换成树。配置的更改可以通过操作树来完成,并可以以原生配置文件格式保存配置。
|
||||
|
||||
### 这篇教程要达成什么目的? ###
|
||||
|
||||
我们会安装并配置Augeas用于我们之前构建的Puppet服务器。我们会使用这个工具创建并测试几个不同的配置文件,并学习如何适当地使用它来管理我们的系统配置。
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
我们需要一台工作的Puppet服务器和客户端。如果你还没有,请先按照我先前的教程来。
|
||||
|
||||
Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet用到的ruby封装的Augeas只在puppetlabs仓库中(或者[EPEL][4])中才有。如果你系统中还没有这个仓库,请使用下面的命令:
|
||||
|
||||
在CentOS/RHEL 6.5上:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/6.5/products/x86_64/puppetlabsrelease610.noarch.rpm
|
||||
|
||||
在CentOS/RHEL 7上:
|
||||
|
||||
# rpm -ivh https://yum.puppetlabs.com/el/7/products/x86_64/puppetlabsrelease710.noarch.rpm
|
||||
|
||||
在你成功地安装了这个仓库后,在你的系统中安装RubyAugeas:
|
||||
|
||||
# yum install rubyaugeas
|
||||
|
||||
或者如果你是从我的上一篇教程中继续的,使用puppet的方法安装这个包。在/etc/puppet/manifests/site.pp中修改你的custom_utils类,在packages这行中加入“rubyaugeas”。
|
||||
|
||||
class custom_utils {
|
||||
package { ["nmap","telnet","vimenhanced","traceroute","rubyaugeas"]:
|
||||
ensure => latest,
|
||||
allow_virtual => false,
|
||||
}
|
||||
}
|
||||
|
||||
### 不带Puppet的Augeas ###
|
||||
|
||||
如我先前所说,最初Augeas并不是来自Puppet实验室,这意味着即使没有Puppet本身我们仍然可以使用它。这种方法可在你将它们部署到Puppet环境之前,验证你的修改和想法是否是正确的。要做到这一点,你需要在你的系统中安装一个额外的软件包。请执行以下命令:
|
||||
|
||||
# yum install augeas
|
||||
|
||||
### Puppet Augeas 示例 ###
|
||||
|
||||
用于演示,这里有几个Augeas使用案例。
|
||||
|
||||
#### 管理 /etc/sudoers 文件 ####
|
||||
|
||||
1. 给wheel组加上sudo权限。
|
||||
|
||||
这个例子会向你战士如何在你的GNU/Linux系统中为%wheel组加上sudo权限。
|
||||
|
||||
# 安装sudo包
|
||||
package { 'sudo':
|
||||
ensure => installed, # 确保sudo包已安装
|
||||
}
|
||||
|
||||
# 允许用户属于wheel组来使用sudo
|
||||
augeas { 'sudo_wheel':
|
||||
context => '/files/etc/sudoers', # 目标文件是 /etc/sudoers
|
||||
changes => [
|
||||
# 允许wheel用户使用sudo
|
||||
'set spec[user = "%wheel"]/user %wheel',
|
||||
'set spec[user = "%wheel"]/host_group/host ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command ALL',
|
||||
'set spec[user = "%wheel"]/host_group/command/runas_user ALL',
|
||||
]
|
||||
}
|
||||
|
||||
现在来解释这些代码做了什么:**spec**定义了/etc/sudoers中的用户段,**[user]**定义了数组中给定的用户,所有的定义的斜杠( / ) 后用户的子部分。因此在典型的配置中这个可以这么表达:
|
||||
|
||||
user host_group/host host_group/command host_group/command/runas_user
|
||||
|
||||
这个将被转换成/etc/sudoers下的这一行:
|
||||
|
||||
%wheel ALL = (ALL) ALL
|
||||
|
||||
2. 添加命令别称
|
||||
|
||||
下面这部分会向你展示如何定义命令别名,他可以在你的sudoer文件中使用。
|
||||
|
||||
# 创建新的SERVICE别名,包含了一些基本的特权命令。
|
||||
augeas { 'sudo_cmdalias':
|
||||
context => '/files/etc/sudoers', # The target file is /etc/sudoers
|
||||
changes => [
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/name SERVICES",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[1] /sbin/service",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[2] /sbin/chkconfig",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[3] /bin/hostname",
|
||||
"set Cmnd_Alias[alias/name = 'SERVICES']/alias/command[4] /sbin/shutdown",
|
||||
]
|
||||
}
|
||||
|
||||
sudo命令别名的语法很简单:**Cmnd_Alias**定义了命令别名字段,**[alias/name]**绑定所有给定的别名,/alias/name **SERVICES** 定义真实的别名以及alias/command 是所有命令的数组,每条命令是这个别名的一部分。
|
||||
|
||||
Cmnd_Alias SERVICES = /sbin/service , /sbin/chkconfig , /bin/hostname , /sbin/shutdown
|
||||
|
||||
关于/etc/sudoers的更多信息,请访问[官方文档][5]。
|
||||
|
||||
#### 向一个组中加入用户 ####
|
||||
|
||||
要使用Augeas向组中添加用户,你有也许要添加一个新用户,无论是在gid字段后或者在最后一个用户后。我们在这个例子中使用组SVN。这可以通过下面的命令达成:
|
||||
|
||||
在Puppet中:
|
||||
|
||||
augeas { 'augeas_mod_group:
|
||||
context => '/files/etc/group', # The target file is /etc/group
|
||||
changes => [
|
||||
"ins user after svn/*[self::gid or self::user][last()]",
|
||||
"set svn/user[last()] john",
|
||||
]
|
||||
}
|
||||
|
||||
使用 augtool:
|
||||
|
||||
augtool> ins user after /files/etc/group/svn/*[self::gid or self::user][last()] augtool> set /files/etc/group/svn/user[last()] john
|
||||
|
||||
### 总结 ###
|
||||
|
||||
目前为止,你应该对如何在Puppet项目中使用Augeas有一个好想法了。随意地试一下,你肯定会经历官方的Augeas文档。这会帮助你了解如何在你的个人项目中正确地使用Augeas,并且它会想你展示你可以用它节省多少时间。
|
||||
|
||||
如有任何问题,欢迎在下面的评论中发布,我会尽力解答和向你建议。
|
||||
|
||||
### 有用的链接 ###
|
||||
|
||||
- [http://www.watzmann.net/categories/augeas.html][6]: contains a lot of tutorials focused on Augeas usage.
|
||||
- [http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas][7]: Puppet wiki with a lot of practical examples.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/manage-configurations-linux-puppet-augeas.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
||||
[2]:http://augeas.net/
|
||||
[3]:http://xmodulo.com/manage-configurations-linux-puppet-augeas.html
|
||||
[4]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://augeas.net/docs/references/lenses/files/sudoers-aug.html
|
||||
[6]:http://www.watzmann.net/categories/augeas.html
|
||||
[7]:http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas
|
||||
@ -0,0 +1,122 @@
|
||||
集所有功能与一身的Linux系统性能和使用活动监控工具-Sysstat
|
||||
===========================================================================
|
||||
**Sysstat**是一个非常方便的工具,它带有众多的系统资源监控工具,用于监控系统的性能和使用情况。我们在日常使用的工具中有相当一部分是来自sysstat工具包的。同时,它还提供了一种使用cron表达式来制定性能和活动数据的收集计划。
|
||||
|
||||

|
||||
|
||||
在Linux系统中安装Sysstat
|
||||
|
||||
下表是包含在sysstat包中的工具
|
||||
|
||||
- [**isstat**][1]: 输出CPU的统计信息和所有I/O设备的输入输出(I/O)统计信息。
|
||||
- **mpstat**: 关于多有CPU的详细信息(单独输出或者分组输出)。
|
||||
- **pidstat**: 关于运行中的进程/任务、CPU、内存等的统计信息。
|
||||
- **sar**: 保存并输出不同系统资源(CPU、内存、IO、网络、内核、等。。。)的详细信息。
|
||||
- **sadc**: 系统活动数据收集器,用于手机sar工具的后端数据。
|
||||
- **sa1**: 系统手机并存储sadc数据文件的二进制数据,与sadc工具配合使用
|
||||
- **sa2**: 配合sar工具使用,产生每日的摘要报告。
|
||||
- **sadf**: 用于以不同的数据格式(CVS或者XML)来格式化sar工具的输出。
|
||||
- **Sysstat**: sysstat工具的man帮助页面。
|
||||
- **nfsiostat**: NFS(Network File System)的I/O统计信息。
|
||||
- **cifsiostat**: CIFS(Common Internet File System)的统计信息。
|
||||
|
||||
最近(在2014年6月17日),**sysstat 11.0.0**(稳定版)已经发布了,同时还新增了一些有趣的特性,如下:
|
||||
|
||||
pidstat命令新增了一些新的选项:首先是“-R”选项,该选项将会输出有关策略和任务调度的优先级信息。然后是“**-G**”选项,通过这个选项我们可以使用名称搜索进程,然后列出所有匹配的线程。
|
||||
|
||||
sar、sadc和sadf命令在数据文件方面同样带来了一些功能上的增强。与以往只能使用“**saDD**”来命名数据文件。现在使用**-D**选项可以用“**saYYYYMMDD**”来重命名数据文件,同样的,现在的数据文件不必放在“**var/log/sa**”目录中,我们可以使用“SA_DIR”变量来定义新的目录,该变量将应用与sa1和sa2命令。
|
||||
|
||||
###在Linux系统中安装Sysstat####
|
||||
|
||||
在主要的linux发行版中,‘**Sysstat**’工具包可以在默认的程序库中安装。然而,在默认程序库中的版本通常有点旧,因此,我们将会下载源代码包,编译安装最新版本(**11.0.0**版本)。
|
||||
|
||||
首先,使用下面的连接下载最新版本的sysstat包,或者你可以使用**wget**命令直接在终端中下载。
|
||||
|
||||
- [http://sebastien.godard.pagesperso-orange.fr/download.html][2]
|
||||
|
||||
# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.0.0.tar.gz
|
||||
|
||||

|
||||
|
||||
下载Sysstat包
|
||||
|
||||
然后解压缩下载下来的包,进去该目录,开始编译安装
|
||||
|
||||
# tar -xvf sysstat-11.0.0.tar.gz
|
||||
# cd sysstat-11.0.0/
|
||||
|
||||
这里,你有两种编译安装的方法:
|
||||
|
||||
a).第一,你可以使用**iconfig**(这将会给予你很大的灵活性,你可以选择/输入每个参数的自定义值)
|
||||
|
||||
# ./iconfig
|
||||
|
||||

|
||||
|
||||
Sysstat的iconfig命令
|
||||
|
||||
b).第二,你可以使用标准的**configure**命令在当行中定义所有选项。你可以运行 **./configure –help 命令**来列出该命令所支持的所有限选项。
|
||||
|
||||
# ./configure --help
|
||||
|
||||

|
||||
|
||||
Stsstat的cofigure -help
|
||||
|
||||
在这里,我们使用标准的**./configure**命令来编译安装sysstat工具包。
|
||||
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
|
||||

|
||||
|
||||
在Linux系统中配置sysstat
|
||||
|
||||
在编译完成后,我们将会看到一些类似于上图的输出。现在运行如下命令来查看sysstat的版本。
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
###在Linux 系统中更新sysstat###
|
||||
|
||||
默认的,sysstat使用“**/usr/local**”作为其目录前缀。因此,所有的二进制数据/工具都会安装在“**/usr/local/bin**”目录中。如果你的系统已经安装了sysstat 工具包,则上面提到的二进制数据/工具有可能在“**/usr/bin**”目录中。
|
||||
|
||||
因为“**$PATH**”变量不包含“**/usr/local/bin**”路径,你在更新时可能会失败。因此,确保“**/usr/local/bin**”路径包含在“$PATH”环境变量中,或者在更新前,在编译和卸载旧版本时将**-prefix**选项指定值为“**/usr**”。
|
||||
|
||||
# yum remove sysstat [On RedHat based System]
|
||||
# apt-get remove sysstat [On Debian based System]
|
||||
|
||||
----------
|
||||
|
||||
# ./configure --prefix=/usr
|
||||
# make
|
||||
# make install
|
||||
|
||||
现在,使用‘mpstat’命令的‘**-V**’选项查看更新后的版本。
|
||||
|
||||
# mpstat -V
|
||||
|
||||
sysstat version 11.0.0
|
||||
(C) Sebastien Godard (sysstat <at> orange.fr)
|
||||
|
||||
**参考**: 更多详细的信息请到 [Sysstat Documentation][3]
|
||||
|
||||
在我的下一篇文章中,我将会展示一些sysstat命令使用的实际例子,敬请关注更新。别忘了在下面评论框中留下您宝贵的意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-sysstat-in-linux/
|
||||
|
||||
作者:[Kuldeep Sharma][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/kuldeepsharma47/
|
||||
[1]:http://www.tecmint.com/linux-performance-monitoring-with-vmstat-and-iostat-commands/
|
||||
[2]:http://sebastien.godard.pagesperso-orange.fr/download.html
|
||||
[3]:http://sebastien.godard.pagesperso-orange.fr/documentation.html
|
||||
@ -0,0 +1,113 @@
|
||||
2014年学习如何使用vim处理文件工作
|
||||
================================================================================
|
||||
|
||||
作为一名开发者你不能够只化时间去写你想要的代码。其中最难以处理的部分是我的工作只使用vim来处理文本。我感觉到很无语与无比的蛋疼,vim没有自己额外文件查看系统与内部打开与切换文件功能。因此,继vim之后,我主要使用Eclipse 和 Sublime Text.
|
||||
|
||||
就此,我非常欣赏深度定制的vim文件管理功能。在工作环境上我已经装配了这些工具,甚至比起那些视觉编辑器好很多。因为这个是纯键盘操作,促使我可以更加快地移动我的代码。第一篇文章使我明白这个vim内建功能只是处理文件的另一选择。在这篇文章里我会带你去认识vim文件管理功能与使用更高级的插件。
|
||||
|
||||
### 基础篇:打开新文件 ###
|
||||
|
||||
学习vim其中最大的一个障碍是缺少可视提示,不像现在的GUI图形编辑器,当你在终端打开一个新的vim是没有明显的提示去提醒你去走什么,所有事情都是靠键盘输入,同时也没有更多更好的界面交互,vim新手需要习惯如何靠自己去查找一些基本的操作指令。好吧,让我开始学习基础吧。
|
||||
|
||||
创建新文件的命令是**:e <filename>或:e** 打开一个新缓冲区保存文件内容。如果文件不存在它会开辟一个缓冲区去保存与修改你指定文件。缓冲区是vim是术语,意为"保存文本块到内存"。文本是否能够与存在的文件关联,要看是否每个你打开的文件都对应一个缓冲区。
|
||||
|
||||
|
||||
打开文件与修改文件之后,你可以使用**:w**命令来保存在缓冲区的文件内容到文件里面,如果缓冲区不能关联你的文件或者你想保存到另外一个地方,你需要使用**:w <filename>**来保存指定地方。
|
||||
|
||||
这些是vim处理文件的基本知识,很多的开发者都掌握了这些命令,这些技巧你都需要掌握。vim提供了很多技巧让人去深挖。
|
||||
|
||||
|
||||
### 缓冲区管理 ###
|
||||
|
||||
基础掌握了,就让我来说更多关于缓冲区得东西,vim处理打开文件与其他编辑器有一点不同,打开的文件不会作为一个标签留在一个可视地方,而是只允许你同时只有一个文件在缓冲区打开,vim允许你多个缓存打开。一些会显示出来,另外一些就不会,你需要用**:ls**来查看已经打开的缓存,这个命令会显示每个打开的缓存区,同时会有它们的序码,你可以通过这些序码实用**:b <buffer-number>**来切换或者使用循序移动命令**:bnext** 和 **:bprevious** 也可以使用它们的缩写**:bn**和**:bp**。
|
||||
|
||||
这些命令是vim管理文件缓冲区的一个基础,我发现他们不会按照我的思维去映射出来。我不想关心缓冲区的顺序,我只想按照我的思维去到那个文件或者想在当前这个文件.因此必需了解vim更深的缓存模式,我不是推荐你必须内部命令来作为主要的文件管理方案。但这些的确是很强大可行的选择。
|
||||
|
||||

|
||||
|
||||
### 分屏 ###
|
||||
|
||||
分屏是vim其中一个最好用的管理文件功能,在vim
|
||||
你可以在当前窗同时分开2个窗口,可以按照你喜欢的配置去重设大小和分配,这个很特别可以在不同地方同时打开6文件每个文件都拥有自己的窗口大少
|
||||
|
||||
你可以通过命令**:sp <filename>**来新建水平分割窗口或者 **:vs <filename>**垂直分割窗口。你可以使用这些关键命令去重置你想要的窗口,
|
||||
老实说,我喜欢用鼠标处理vim任务,因为鼠标能够给我更加准确的两列的宽度而不需要猜大概的宽度。
|
||||
|
||||
创建新的分屏后,你需要使用**ctrl-w
|
||||
[h|j|k|l]**来向后向前切换。这个有少少笨拙,但这个确实很重要很普遍很容易很高效的操作.如果你经常使用分屏,我建议你去.vimrc使用以下代码q去设置别名为**ctrl-h** **ctrl-j** 等等。
|
||||
|
||||
nnoremap <C-J> <C-W><C-J> "Ctrl-j to move down a split
|
||||
nnoremap <C-K> <C-W><C-K> "Ctrl-k to move up a split
|
||||
nnoremap <C-L> <C-W><C-L> "Ctrl-l to move right a split
|
||||
nnoremap <C-H> <C-W><C-H> "Ctrl-h to move left a split
|
||||
|
||||
### 跳转表 ###
|
||||
|
||||
分屏是解决多个关联文件同时查看问题,但我们仍然不能满足打开文件与隐藏文件之间快速移动。这时跳转表是一个能够解决的工具。
|
||||
|
||||
跳转表是众多插件中看其来奇怪而且很少使用。vim能够追踪每一步命令还有切换你正在修改的文件。每次从一个分屏窗口跳到另外一个,vim都会添加记录到跳转表里面。这个记录你去过的地方,这样就不需要担心之前的文件在哪里,你可以使用快捷键去快速追溯你的踪迹。**Ctrl-o**允许你返回你上一次地方。重复操作几次就能够返回到你最先编写的代码段地方。你可以使用**ctrl-i**来向前返回。当你在调试多个文件或两个文件之间切换能够发挥极大的快速移动功能。
|
||||
|
||||
|
||||
### 插件 ###
|
||||
|
||||
如果你想vim像Sublime Text 或者Atom一样,我就让你认清一下,这里有很好的机会让你看到一些难懂,可怕和低效的事情。例如大家会发出"当Sublime有了模糊查找功能,为什么我一定要输入全路径才能够打开文件" "没有侧边栏显示目录树我怎样查看项目结构" 。但vim有了解决方案。这些方案不需要破坏vim的核心。我只需要经常修改vim配置与添加一些最新的插件,这里有3个有用的插件可以让你像Sublime管理文件
|
||||
|
||||
- [CtrlP][1] 是一个跟Sublime的"Go to Anything"栏一样模糊查找文件.它快如闪电并且非常可配置性。我使用它最主要打开文件。我只需知道部分的文件名字不需要记住整个项目结构就可以查找了
|
||||
|
||||
- [The NERDTree][2]
|
||||
这个一个文件管理夹插件,它重复了很多编辑器的有的侧边文件管理夹功能。我实际上很少用它,对于我模糊查找会更加快。对于你接手一个项目,尝试学习项目结构与了解什么可以用是非常方便的,NERDTree是可以自己定制配置,安装它能够代替vim内置的目录工具。
|
||||
|
||||
|
||||
- [Ack.vim][3] 是一个专为vim的代码搜索插件,它允许你跨项目搜索文本。通过Ack 或 Ag 去高亮查找
|
||||
[第二个极其好用的搜索工具][4],允许你在任何时候在你项目之间快速搜索跳转
|
||||
|
||||
|
||||
在vim核心与它的插件生态系统之间,vim 提供足够的工具允许你构建你想要得工作环境。文件管理是软件开发系统的最核心部分并且你值得拥有体验的权利
|
||||
|
||||
|
||||
开始是需要通过很长的时间去理解它们,然后才找到你感觉舒服的工作流程之后才开始添加工具在上面。但依然值得你去使用,当你不需要头爆去理解如何去使用就能够轻易编写你的代码。
|
||||
|
||||
|
||||
### 更多插件资源 ###
|
||||
|
||||
- [Seamlessly Navigate Vim & Tmux Splits][5] 这个插件需要每一个想使用它的人都要懂得实用[tmux][6],这个跟vim的splits 一样简单好用
|
||||
|
||||
|
||||
- [Using Tab Pages][7] 它是一个vim的标签功能插件,虽然它的名字用起来有一点疑惑,但我不能说它是文件管理器。
|
||||
对如何在有多个工作可视区使用"tab
|
||||
pages" 在vim wiki 网站上有更好的概述
|
||||
|
||||
- [Vimcasts: The edit command][8] 一般来说 Vimcasts
|
||||
是大家学习vim的一个好资源。这个屏幕截图与一些内置工作流程是很好描述之前说得文件操作方面的知识
|
||||
|
||||
|
||||
### 订阅 ###
|
||||
|
||||
这篇文章通过第三个方面介绍如何通过一些好的手法学习vim。如果你喜欢这篇文章你可以通过[feed][8]来订阅或email我[mailing
|
||||
list][10]。在这个星期javascript小插曲之后,下星期我会继续介绍vim的配置方面的东西,你可以先看基础篇:使用vim
|
||||
看我前2篇系列文章和vim与vi的语言
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
|
||||
作者:[Ben McCormick][a]
|
||||
译者:[译者ID](https://github.com/haimingfg)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
[1]:https://github.com/kien/ctrlp.vim
|
||||
[2]:https://github.com/scrooloose/nerdtree
|
||||
[3]:https://github.com/mileszs/ack.vim
|
||||
[4]:http://benmccormick.org/2013/11/25/a-look-at-ack/
|
||||
[5]:http://robots.thoughtbot.com/seamlessly-navigate-vim-and-tmux-splits
|
||||
[6]:http://tmux.sourceforge.net/
|
||||
[7]:http://vim.wikia.com/wiki/Using_tab_pages
|
||||
[8]:http://vimcasts.org/episodes/the-edit-command/
|
||||
[9]:http://feedpress.me/benmccormick
|
||||
[10]:http://eepurl.com/WFYon
|
||||
[11]:http://benmccormick.org/2014/07/14/learning-vim-in-2014-configuring-vim/
|
||||
[12]:http://benmccormick.org/2014/06/30/learning-vim-in-2014-the-basics/
|
||||
[13]:http://benmccormick.org/2014/07/02/learning-vim-in-2014-vim-as-language/
|
||||
Loading…
Reference in New Issue
Block a user