mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
0a051d6067
166
published/20181220 7 CI-CD tools for sysadmins.md
Normal file
166
published/20181220 7 CI-CD tools for sysadmins.md
Normal file
@ -0,0 +1,166 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (jdh8383)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10578-1.html)
|
||||
[#]: subject: (7 CI/CD tools for sysadmins)
|
||||
[#]: via: (https://opensource.com/article/18/12/cicd-tools-sysadmins)
|
||||
[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
|
||||
|
||||
系统管理员的 7 个 CI/CD 工具
|
||||
======
|
||||
|
||||
> 本文是一篇简单指南:介绍一些顶级的开源的持续集成、持续交付和持续部署(CI/CD)工具。
|
||||
|
||||

|
||||
|
||||
虽然持续集成、持续交付和持续部署(CI/CD)在开发者社区里已经存在很多年,一些机构在其运维部门也有实施经验,但大多数公司并没有做这样的尝试。对于很多机构来说,让运维团队能够像他们的开发同行一样熟练操作 CI/CD 工具,已经变得十分必要了。
|
||||
|
||||
无论是基础设施、第三方应用还是内部开发的应用,都可以开展 CI/CD 实践。尽管你会发现有很多不同的工具,但它们都有着相似的设计模型。而且可能最重要的一点是:通过带领你的公司进行这些实践,会让你在公司内部变得举足轻重,成为他人学习的榜样。
|
||||
|
||||
一些机构在自己的基础设施上已有多年的 CI/CD 实践经验,常用的工具包括 [Ansible][1]、[Chef][2] 或者 [Puppet][3]。另一些工具,比如 [Test Kitchen][4],允许在最终要部署应用的基础设施上运行测试。事实上,如果使用更高级的配置方法,你甚至可以将应用部署到有真实负载的仿真“生产环境”上,来运行应用级别的测试。然而,单单是能够测试基础设施就是一项了不起的成就了。配置管理工具 Terraform 可以通过 Test Kitchen 来快速创建更[短暂][5]和[冥等的][6]的基础设施配置,这比它的前辈要强不少。再加上 Linux 容器和 Kubernetes,在数小时内,你就可以创建一套类似于生产环境的配置参数和系统资源,来测试整个基础设施和其上部署的应用,这在以前可能需要花费几个月的时间。而且,删除和再次创建整个测试环境也非常容易。
|
||||
|
||||
当然,作为初学者,你也可以把网络配置和 DDL(<ruby>数据定义语言<rt>data definition language</rt></ruby>)文件加入版本控制,然后开始尝试一些简单的 CI/CD 流程。虽然只能帮你检查一下语义语法或某些最佳实践,但实际上大多数开发的管道都是这样起步的。只要你把脚手架搭起来,建造就容易得多了。而一旦起步,你就会发现各种管道的使用场景。
|
||||
|
||||
举个例子,我经常会在公司内部写新闻简报,我使用 [MJML][7] 制作邮件模板,然后把它加入版本控制。我一般会维护一个 web 版本,但是一些同事喜欢 PDF 版,于是我创建了一个[管道][8]。每当我写好一篇新闻稿,就在 Gitlab 上提交一个合并请求。这样做会自动创建一个 index.html 文件,生成这篇新闻稿的 HTML 和 PDF 版链接。HTML 和 PDF 文件也会在该管道里同时生成。除非有人来检查确认,这些文件不会被直接发布出去。使用 GitLab Pages 发布这个网站后,我就可以下载一份 HTML 版,用来发送新闻简报。未来,我会修改这个流程,当合并请求成功或者在某个审核步骤后,自动发出对应的新闻稿。这些处理逻辑并不复杂,但的确为我节省了不少时间。实际上这些工具最核心的用途就是替你节省时间。
|
||||
|
||||
关键是要在抽象层创建出工具,这样稍加修改就可以处理不同的问题。值得留意的是,我创建的这套流程几乎不需要任何代码,除了一些[轻量级的 HTML 模板][9],一些[把 HTML 文件转换成 PDF 的 nodejs 代码][10],还有一些[生成索引页面的 nodejs 代码][11]。
|
||||
|
||||
这其中一些东西可能看起来有点复杂,但其中大部分都源自我使用的不同工具的教学文档。而且很多开发人员也会乐意跟你合作,因为他们在完工时会发现这些东西也挺有用。上面我提供的那些代码链接是给 [DevOps KC][12](LCTT 译注:一个地方性 DevOps 组织) 发送新闻简报用的,其中大部分用来创建网站的代码来自我在内部新闻简报项目上所作的工作。
|
||||
|
||||
下面列出的大多数工具都可以提供这种类型的交互,但是有些工具提供的模型略有不同。这一领域新兴的模型是用声明式的方法例如 YAML 来描述一个管道,其中的每个阶段都是短暂而幂等的。许多系统还会创建[有向无环图(DAG)][13],来确保管道上不同的阶段排序的正确性。
|
||||
|
||||
这些阶段一般运行在 Linux 容器里,和普通的容器并没有区别。有一些工具,比如 [Spinnaker][14],只关注部署组件,而且提供一些其他工具没有的操作特性。[Jenkins][15] 则通常把管道配置存成 XML 格式,大部分交互都可以在图形界面里完成,但最新的方案是使用[领域专用语言(DSL)][16](如 [Groovy][17])。并且,Jenkins 的任务(job)通常运行在各个节点里,这些节点上会装一个专门的 Java 代理,还有一堆混杂的插件和预装组件。
|
||||
|
||||
Jenkins 在自己的工具里引入了管道的概念,但使用起来却并不轻松,甚至包含一些禁区。最近,Jenkins 的创始人决定带领社区向新的方向前进,希望能为这个项目注入新的活力,把 CI/CD 真正推广开(LCTT 译注:详见后面的 Jenkins 章节)。我认为其中最有意思的想法是构建一个云原生 Jenkins,能把 Kubernetes 集群转变成 Jenkins CI/CD 平台。
|
||||
|
||||
当你更多地了解这些工具并把实践带入你的公司和运维部门,你很快就会有追随者,因为你有办法提升自己和别人的工作效率。我们都有多年积累下来的技术债要解决,如果你能给同事们提供足够的时间来处理这些积压的工作,他们该会有多感激呢?不止如此,你的客户也会开始看到应用变得越来越稳定,管理层会把你看作得力干将,你也会在下次谈薪资待遇或参加面试时更有底气。
|
||||
|
||||
让我们开始深入了解这些工具吧,我们将对每个工具做简短的介绍,并分享一些有用的链接。
|
||||
|
||||
### GitLab CI
|
||||
|
||||
- [项目主页](https://about.gitlab.com/product/continuous-integration/)
|
||||
- [源代码](https://gitlab.com/gitlab-org/gitlab-ce/)
|
||||
- 许可证:MIT
|
||||
|
||||
GitLab 可以说是 CI/CD 领域里新登场的玩家,但它却在权威调研机构 [Forrester 的 CI 集成工具的调查报告][20]中位列第一。在一个高水平、竞争充分的领域里,这是个了不起的成就。是什么让 GitLab CI 这么成功呢?它使用 YAML 文件来描述整个管道。另有一个功能叫做 Auto DevOps,可以为较简单的项目用多种内置的测试单元自动生成管道。这套系统使用 [Herokuish buildpacks][21] 来判断语言的种类以及如何构建应用。有些语言也可以管理数据库,它真正改变了构建新应用程序和从开发的开始将它们部署到生产环境的过程。它原生集成于 Kubernetes,可以根据不同的方案将你的应用自动部署到 Kubernetes 集群,比如灰度发布、蓝绿部署等。
|
||||
|
||||
除了它的持续集成功能,GitLab 还提供了许多补充特性,比如:将 Prometheus 和你的应用一同部署,以提供操作监控功能;通过 GitLab 提供的 Issues、Epics 和 Milestones 功能来实现项目评估和管理;管道中集成了安全检测功能,多个项目的检测结果会聚合显示;你可以通过 GitLab 提供的网页版 IDE 在线编辑代码,还可以快速查看管道的预览或执行状态。
|
||||
|
||||
### GoCD
|
||||
|
||||
- [项目主页](https://www.gocd.org/)
|
||||
- [源代码](https://github.com/gocd/gocd)
|
||||
- 许可证:Apache 2.0
|
||||
|
||||
GoCD 是由老牌软件公司 Thoughtworks 出品,这已经足够证明它的能力和效率。对我而言,GoCD 最具亮点的特性是它的[价值流视图(VSM)][22]。实际上,一个管道的输出可以变成下一个管道的输入,从而把管道串联起来。这样做有助于提高不同开发团队在整个开发流程中的独立性。比如在引入 CI/CD 系统时,有些成立较久的机构希望保持他们各个团队相互隔离,这时候 VSM 就很有用了:让每个人都使用相同的工具就很容易在 VSM 中发现工作流程上的瓶颈,然后可以按图索骥调整团队或者想办法提高工作效率。
|
||||
|
||||
为公司的每个产品配置 VSM 是非常有价值的;GoCD 可以使用 [JSON 或 YAML 格式存储配置][23],还能以可视化的方式展示数据等待时间,这让一个机构能有效减少学习它的成本。刚开始使用 GoCD 创建你自己的流程时,建议使用人工审核的方式。让每个团队也采用人工审核,这样你就可以开始收集数据并且找到可能的瓶颈点。
|
||||
|
||||
### Travis CI
|
||||
|
||||
- [项目主页](https://docs.travis-ci.com/)
|
||||
- [源代码](https://github.com/travis-ci/travis-ci)
|
||||
- 许可证:MIT
|
||||
|
||||
我使用的第一个软件既服务(SaaS)类型的 CI 系统就是 Travis CI,体验很不错。管道配置以源码形式用 YAML 保存,它与 GitHub 等工具无缝整合。我印象中管道从来没有失效过,因为 Travis CI 的在线率很高。除了 SaaS 版之外,你也可以使用自行部署的版本。我还没有自行部署过,它的组件非常多,要全部安装的话,工作量就有点吓人了。我猜更简单的办法是把它部署到 Kubernetes 上,[Travis CI 提供了 Helm charts][26],这些 charts 目前不包含所有要部署的组件,但我相信以后会越来越丰富的。如果你不想处理这些细枝末节的问题,还有一个企业版可以试试。
|
||||
|
||||
假如你在开发一个开源项目,你就能免费使用 SaaS 版的 Travis CI,享受顶尖团队提供的优质服务!这样能省去很多麻烦,你可以在一个相对通用的平台上(如 GitHub)研发开源项目,而不用找服务器来运行任何东西。
|
||||
|
||||
### Jenkins
|
||||
|
||||
- [项目主页](https://jenkins.io/)
|
||||
- [源代码](https://github.com/jenkinsci/jenkins)
|
||||
- 许可证:MIT
|
||||
|
||||
Jenkins 在 CI/CD 界绝对是元老级的存在,也是事实上的标准。我强烈建议你读一读这篇文章:“[Jenkins: Shifting Gears][27]”,作者 Kohsuke 是 Jenkins 的创始人兼 CloudBees 公司 CTO。这篇文章契合了我在过去十年里对 Jenkins 及其社区的感受。他在文中阐述了一些这几年呼声很高的需求,我很乐意看到 CloudBees 引领这场变革。长期以来,Jenkins 对于非开发人员来说有点难以接受,并且一直是其管理员的重担。还好,这些问题正是他们想要着手解决的。
|
||||
|
||||
[Jenkins 配置既代码][28](JCasC)应该可以帮助管理员解决困扰了他们多年的配置复杂性问题。与其他 CI/CD 系统类似,只需要修改一个简单的 YAML 文件就可以完成 Jenkins 主节点的配置工作。[Jenkins Evergreen][29] 的出现让配置工作变得更加轻松,它提供了很多预设的使用场景,你只管套用就可以了。这些发行版会比官方的标准版本 Jenkins 更容易维护和升级。
|
||||
|
||||
Jenkins 2 引入了两种原生的管道功能,我在 LISA(LCTT 译注:一个系统架构和运维大会) 2017 年的研讨会上已经[讨论过了][30]。这两种功能都没有 YAML 简便,但在处理复杂任务时它们很好用。
|
||||
|
||||
[Jenkins X][31] 是 Jenkins 的一个全新变种,用来实现云端原生 Jenkins(至少在用户看来是这样)。它会使用 JCasC 及 Evergreen,并且和 Kubernetes 整合的更加紧密。对于 Jenkins 来说这是个令人激动的时刻,我很乐意看到它在这一领域的创新,并且继续发挥领袖作用。
|
||||
|
||||
### Concourse CI
|
||||
|
||||
- [项目主页](https://concourse-ci.org/)
|
||||
- [源代码](https://github.com/concourse/concourse)
|
||||
- 许可证:Apache 2.0
|
||||
|
||||
我第一次知道 Concourse 是通过 Pivotal Labs 的伙计们介绍的,当时它处于早期 beta 版本,而且那时候也很少有类似的工具。这套系统是基于微服务构建的,每个任务运行在一个容器里。它独有的一个优良特性是能够在你本地系统上运行任务,体现你本地的改动。这意味着你完全可以在本地开发(假设你已经连接到了 Concourse 的服务器),像在真实的管道构建流程一样从你本地构建项目。而且,你可以在修改过代码后从本地直接重新运行构建,来检验你的改动结果。
|
||||
|
||||
Concourse 还有一个简单的扩展系统,它依赖于“资源”这一基础概念。基本上,你想给管道添加的每个新功能都可以用一个 Docker 镜像实现,并作为一个新的资源类型包含在你的配置中。这样可以保证每个功能都被封装在一个不可变的独立工件中,方便对其单独修改和升级,改变其中一个时不会影响其他构建。
|
||||
|
||||
### Spinnaker
|
||||
|
||||
- [项目主页](https://www.spinnaker.io/)
|
||||
- [源代码](https://github.com/spinnaker/spinnaker)
|
||||
- 许可证:Apache 2.0
|
||||
|
||||
Spinnaker 出自 Netflix,它更关注持续部署而非持续集成。它可以与其他工具整合,比如 Travis 和 Jenkins,来启动测试和部署流程。它也能与 Prometheus、Datadog 这样的监控工具集成,参考它们提供的指标来决定如何部署。例如,在<ruby>金丝雀发布<rt>canary deployment</rt></ruby>里,我们可以根据收集到的相关监控指标来做出判断:最近的这次发布是否导致了服务降级,应该立刻回滚;还是说看起来一切 OK,应该继续执行部署。
|
||||
|
||||
谈到持续部署,一些另类但却至关重要的问题往往被忽略掉了,说出来可能有点让人困惑:Spinnaker 可以帮助持续部署不那么“持续”。在整个应用部署流程期间,如果发生了重大问题,它可以让流程停止执行,以阻止可能发生的部署错误。但它也可以在最关键的时刻让人工审核强制通过,发布新版本上线,使整体收益最大化。实际上,CI/CD 的主要目的就是在商业模式需要调整时,能够让待更新的代码立即得到部署。
|
||||
|
||||
### Screwdriver
|
||||
|
||||
- [项目主页](http://screwdriver.cd/)
|
||||
- [源代码](https://github.com/screwdriver-cd/screwdriver)
|
||||
- 许可证:BSD
|
||||
|
||||
Screwdriver 是个简单而又强大的软件。它采用微服务架构,依赖像 Nomad、Kubernetes 和 Docker 这样的工具作为执行引擎。官方有一篇很不错的[部署教学文档][34],介绍了如何将它部署到 AWS 和 Kubernetes 上,但如果正在开发中的 [Helm chart][35] 也完成的话,就更完美了。
|
||||
|
||||
Screwdriver 也使用 YAML 来描述它的管道,并且有很多合理的默认值,这样可以有效减少各个管道重复的配置项。用配置文件可以组织起高级的工作流,来描述各个任务间复杂的依赖关系。例如,一项任务可以在另一个任务开始前或结束后运行;各个任务可以并行也可以串行执行;更赞的是你可以预先定义一项任务,只在特定的拉取请求时被触发,而且与之有依赖关系的任务并不会被执行,这能让你的管道具有一定的隔离性:什么时候被构造的工件应该被部署到生产环境,什么时候应该被审核。
|
||||
|
||||
---
|
||||
|
||||
以上只是我对这些 CI/CD 工具的简单介绍,它们还有许多很酷的特性等待你深入探索。而且它们都是开源软件,可以自由使用,去部署一下看看吧,究竟哪个才是最适合你的那个。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/cicd-tools-sysadmins
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[jdh8383](https://github.com/jdh8383)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ansible.com/
|
||||
[2]: https://www.chef.io/
|
||||
[3]: https://puppet.com/
|
||||
[4]: https://github.com/test-kitchen/test-kitchen
|
||||
[5]: https://www.merriam-webster.com/dictionary/ephemeral
|
||||
[6]: https://en.wikipedia.org/wiki/Idempotence
|
||||
[7]: https://mjml.io/
|
||||
[8]: https://gitlab.com/devopskc/newsletter/blob/master/.gitlab-ci.yml
|
||||
[9]: https://gitlab.com/devopskc/newsletter/blob/master/index/index.html
|
||||
[10]: https://gitlab.com/devopskc/newsletter/blob/master/html-to-pdf.js
|
||||
[11]: https://gitlab.com/devopskc/newsletter/blob/master/populate-index.js
|
||||
[12]: https://devopskc.com/
|
||||
[13]: https://en.wikipedia.org/wiki/Directed_acyclic_graph
|
||||
[14]: https://www.spinnaker.io/
|
||||
[15]: https://jenkins.io/
|
||||
[16]: https://martinfowler.com/books/dsl.html
|
||||
[17]: http://groovy-lang.org/
|
||||
[18]: https://about.gitlab.com/product/continuous-integration/
|
||||
[19]: https://gitlab.com/gitlab-org/gitlab-ce/
|
||||
[20]: https://about.gitlab.com/2017/09/27/gitlab-leader-continuous-integration-forrester-wave/
|
||||
[21]: https://github.com/gliderlabs/herokuish
|
||||
[22]: https://www.gocd.org/getting-started/part-3/#value_stream_map
|
||||
[23]: https://docs.gocd.org/current/advanced_usage/pipelines_as_code.html
|
||||
[24]: https://docs.travis-ci.com/
|
||||
[25]: https://github.com/travis-ci/travis-ci
|
||||
[26]: https://github.com/travis-ci/kubernetes-config
|
||||
[27]: https://jenkins.io/blog/2018/08/31/shifting-gears/
|
||||
[28]: https://jenkins.io/projects/jcasc/
|
||||
[29]: https://github.com/jenkinsci/jep/blob/master/jep/300/README.adoc
|
||||
[30]: https://danbarker.codes/talk/lisa17-becoming-plumber-building-deployment-pipelines/
|
||||
[31]: https://jenkins-x.io/
|
||||
[32]: https://concourse-ci.org/
|
||||
[33]: https://github.com/concourse/concourse
|
||||
[34]: https://docs.screwdriver.cd/cluster-management/kubernetes
|
||||
[35]: https://github.com/screwdriver-cd/screwdriver-chart
|
||||
@ -0,0 +1,156 @@
|
||||
每个 Linux 游戏玩家都绝不想要的恼人体验
|
||||
===================
|
||||
|
||||
[][10]
|
||||
|
||||
(LCTT 译注:本文原文发表于 2016 年,可能有些信息已经过时。)
|
||||
|
||||
[在 Linux 平台上玩游戏][12] 并不是什么新鲜事,现在甚至有专门的 [Linux 游戏发行版][13],但是这不意味着在 Linux 上打游戏的体验和在 Windows 上一样顺畅。
|
||||
|
||||
为了确保我们和 Windows 用户同样地享受游戏乐趣,哪些问题是我们应该考虑的呢?
|
||||
|
||||
[Wine][14]、[PlayOnLinux][15] 和其它类似软件不总是能够让我们玩所有流行的 Windows 游戏。在这篇文章里,我想讨论一下为了拥有最好的 Linux 游戏体验所必须处理好的若干因素。
|
||||
|
||||
### #1 SteamOS 是开源平台,但 Steam for Linux 并不是
|
||||
|
||||
正如 [StemOS 主页][16]所说, 即便 SteamOS 是一个开源平台,但 Steam for Linux 仍然是专有的软件。如果 Steam for Linux 也开源,那么它从开源社区得到的支持将会是巨大的。既然它不是,那么 [Ascension 计划的诞生自然是不可避免的][17]:
|
||||
|
||||
- [Destination: Project Ascension • UI Design Mockups Reveal](https://youtu.be/07UiS5iAknA)
|
||||
|
||||
Ascension 是一个开源的游戏启动器,旨在能够启动从任何平台购买、下载的游戏。这些游戏可以是 Steam 平台的、[Origin 游戏][18]平台的、Uplay 平台的,以及直接从游戏开发者主页下载的,或者来自 DVD、CD-ROM 的。
|
||||
|
||||
Ascension 计划的开端是这样:[某个观点的分享][19]激发了一场与游戏社区读者之间有趣的讨论,在这场讨论中读者们纷纷发表了自己的观点并给出建议。
|
||||
|
||||
### #2 与 Windows 平台的性能比较
|
||||
|
||||
在 Linux 平台上运行 Windows 游戏并不总是一件轻松的任务。但是得益于一个叫做 [CSMT][20](多线程命令流)的特性,尽管离 Windows 级别的性能还有相当长的路要走,PlayOnLinux 现在依旧可以更好地解决这些性能方面的问题。
|
||||
|
||||
Linux 对游戏的原生支持在过去发行的游戏中从未尽如人意。
|
||||
|
||||
去年,有报道说 SteamOS 比 Windows 在游戏方面的表现要[差得多][21]。古墓丽影去年在 SteamOS 及 Steam for Linux 上发行,然而其基准测试的结果与 Windows 上的性能无法抗衡。
|
||||
|
||||
- [Destination: Tomb Raider benchmark video comparison, Linux vs Windows 10](https://youtu.be/nkWUBRacBNE)
|
||||
|
||||
这明显是因为游戏是基于 [DirectX][23] 而不是 [OpenGL][24] 开发的缘故。
|
||||
|
||||
古墓丽影是[第一个使用 TressFX 的游戏][25]。下面这个视频包涵了 TressFX 的比较:
|
||||
|
||||
- [Destination: Tomb Raider Benchmark - Ubuntu 15.10 vs Windows 8.1 + Ubuntu 16.04 vs Windows 10](https://youtu.be/-IeY5ZS-LlA)
|
||||
|
||||
下面是另一个有趣的比较,它显示出使用 Wine + CSMT 带来的游戏性能比 Steam 上原生的 Linux 版游戏带来的游戏性能要好得多!这就是开源的力量!
|
||||
|
||||
- [Destination: [LinuxBenchmark] Tomb Raider Linux vs Wine comparison](https://youtu.be/sCJkC6oJ08A)
|
||||
|
||||
以防 FPS 损失,TressFX 已经被关闭。
|
||||
|
||||
以下是另一个有关在 Linux 上最新发布的 “[Life is Strange][27]” 在 Linux 与 Windows 上的比较:
|
||||
|
||||
- [Destination: Life is Strange on radeonsi (Linux nine_csmt vs Windows 10)](https://youtu.be/Vlflu-pIgIY)
|
||||
|
||||
[Steam for Linux][28] 开始在这个新游戏上展示出比 Windows 更好的游戏性能,这是一件好事。
|
||||
|
||||
在发布任何 Linux 版的游戏前,开发者都应该考虑优化游戏,特别是基于 DirectX 并需要进行 OpenGL 转制的游戏。我们十分希望 Linux 上的<ruby>[杀出重围:人类分裂][29]<rt>Deus Ex: Mankind Divided</rt></ruby> 在正式发行时能有一个好的基准测试结果。由于它是基于 DirectX 的游戏,我们希望它能良好地移植到 Linux 上。[该游戏执行总监说过这样的话][30]。
|
||||
|
||||
### #3 专有的 NVIDIA 驱动
|
||||
|
||||
相比于 [NVIDIA][32],[AMD 对于开源的支持][31]绝对是值得称赞的。尽管 [AMD][33] 因其更好的开源驱动在 Linux 上的驱动支持挺不错,而 NVIDIA 显卡用户由于开源版本的 NVIDIA 显卡驱动 “Nouveau” 有限的能力,仍不得不用专有的 NVIDIA 驱动。
|
||||
|
||||
曾经,Linus Torvalds 大神也分享过他关于“来自 NVIDIA 的 Linux 支持完全不可接受”的想法。
|
||||
|
||||
- [Destination: Linus Torvalds Publicly Attacks NVidia for lack of Linux & Android Support](https://youtu.be/O0r6Pr_mdio)
|
||||
|
||||
你可以在这里观看完整的[谈话][35],尽管 NVIDIA 回应 [承诺更好的 Linux 平台支持][36],但其开源显卡驱动仍如之前一样毫无起色。
|
||||
|
||||
### #4 需要 Linux 平台上的 Uplay 和 Origin 的 DRM 支持
|
||||
|
||||
- [Destination: Uplay #1 Rayman Origins em Linux - como instalar - ago 2016](https://youtu.be/rc96NFwyxWU)
|
||||
|
||||
以上的视频描述了如何在 Linux 上安装 [Uplay][37] DRM。视频上传者还建议说并不推荐使用 Wine 作为 Linux 上的主要的应用和游戏支持软件。相反,更鼓励使用原生的应用。
|
||||
|
||||
以下视频是一个关于如何在 Linux 上安装 [Origin][38] DRM 的教程。
|
||||
|
||||
- [Destination: Install EA Origin in Ubuntu with PlayOnLinux (Updated)](https://youtu.be/ga2lNM72-Kw)
|
||||
|
||||
数字版权管理(DRM)软件给游戏运行又加了一层阻碍,使得在 Linux 上良好运行 Windows 游戏这一本就充满挑战性的任务更有难度。因此除了使游戏能够运行之外,W.I.N.E 不得不同时负责运行像 Uplay 或 Origin 之类的 DRM 软件。如果能像 Steam 一样,Linux 也能够有自己原生版本的 Uplay 和 Origin 那就好了。
|
||||
|
||||
### #5 DirectX 11 对于 Linux 的支持
|
||||
|
||||
尽管我们在 Linux 平台上有可以运行 Windows 应用的工具,每个游戏为了能在 Linux 上运行都带有自己的配套调整需求。尽管去年在 Code Weavers 有一篇关于 [DirectX 11 对于 Linux 的支持][40] 的公告,在 Linux 上畅玩新发大作仍是长路漫漫。
|
||||
|
||||
现在你可以[从 Codweavers 购买 Crossover][41] 以获得可得到的最佳 DirectX 11 支持。这个在 Arch Linux 论坛上的[频道][42]清楚展现了将这个梦想成真需要多少的努力。以下是一个 [Reddit 频道][44] 上的有趣 [发现][43]。这个发现提到了[来自 Codeweavers 的 DirectX 11 补丁][45],现在看来这无疑是好消息。
|
||||
|
||||
### #6 不是全部的 Steam 游戏都可跑在 Linux 上
|
||||
|
||||
随着 Linux 游戏玩家一次次错过主要游戏的发行,这是需要考虑的一个重点,因为大部分主要游戏都在 Windows 上发行。这是[如何在 Linux 上安装 Windows 版的 Steam 的教程][46]。
|
||||
|
||||
### #7 游戏发行商对 OpenGL 更好的支持
|
||||
|
||||
目前开发者和发行商主要着眼于用 DirectX 而不是 OpenGL 来开发游戏。现在随着 Steam 正式登录 Linux,开发者应该同样考虑在 OpenGL 下开发。
|
||||
|
||||
[Direct3D][47] 仅仅是为 Windows 平台而打造。而 OpenGL API 拥有开放性标准,并且它不仅能在 Windows 上同样也能在其它各种各样的平台上实现。
|
||||
|
||||
尽管是一篇很老的文章,但[这个很有价值的资源][48]分享了许多有关 OpenGL 和 DirectX 现状的很有想法的信息。其所提出的观点确实十分明智,基于按时间排序的事件也能给予读者启迪。
|
||||
|
||||
在 Linux 平台上发布大作的发行商绝不应该忽视一个事实:在 OpenGL 下直接开发游戏要比从 DirectX 移植到 OpenGL 合算得多。如果必须进行平台转制,移植必须被仔细优化并谨慎研究。发布游戏可能会有延迟,但这绝对值得。
|
||||
|
||||
有更多的烦恼要分享?务必在评论区让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-gaming-problems/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[1]:https://itsfoss.com/author/avimanyu/
|
||||
[2]:https://itsfoss.com/linux-gaming-problems/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21&url=https://itsfoss.com/linux-gaming-problems/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg&url=https://itsfoss.com/linux-gaming-problems/&is_video=false&description=Linux%20gamer%27s%20problem
|
||||
[12]:https://itsfoss.com/linux-gaming-guide/
|
||||
[13]:https://itsfoss.com/linux-gaming-distributions/
|
||||
[14]:https://itsfoss.com/use-windows-applications-linux/
|
||||
[15]:https://www.playonlinux.com/en/
|
||||
[16]:http://store.steampowered.com/steamos/
|
||||
[17]:http://www.ibtimes.co.uk/reddit-users-want-replace-steam-open-source-game-launcher-project-ascension-1498999
|
||||
[18]:https://www.origin.com/
|
||||
[19]:https://www.reddit.com/r/pcmasterrace/comments/33xcvm/we_hate_valves_monopoly_over_pc_gaming_why/
|
||||
[20]:https://github.com/wine-compholio/wine-staging/wiki/CSMT
|
||||
[21]:http://arstechnica.com/gaming/2015/11/ars-benchmarks-show-significant-performance-hit-for-steamos-gaming/
|
||||
[22]:https://www.gamingonlinux.com/articles/tomb-raider-benchmark-video-comparison-linux-vs-windows-10.7138
|
||||
[23]:https://en.wikipedia.org/wiki/DirectX
|
||||
[24]:https://en.wikipedia.org/wiki/OpenGL
|
||||
[25]:https://www.gamingonlinux.com/articles/tomb-raider-released-for-linux-video-thoughts-port-report-included-the-first-linux-game-to-use-tresfx.7124
|
||||
[26]:https://itsfoss.com/osu-new-linux/
|
||||
[27]:http://lifeisstrange.com/
|
||||
[28]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[29]:https://itsfoss.com/deus-ex-mankind-divided-linux/
|
||||
[30]:http://wccftech.com/deus-ex-mankind-divided-director-console-ports-on-pc-is-disrespectful/
|
||||
[31]:http://developer.amd.com/tools-and-sdks/open-source/
|
||||
[32]:http://nvidia.com/
|
||||
[33]:http://amd.com/
|
||||
[34]:http://www.makeuseof.com/tag/open-source-amd-graphics-now-awesome-heres-get/
|
||||
[35]:https://youtu.be/MShbP3OpASA
|
||||
[36]:https://itsfoss.com/nvidia-optimus-support-linux/
|
||||
[37]:http://uplay.com/
|
||||
[38]:http://origin.com/
|
||||
[39]:https://itsfoss.com/linux-foundation-head-uses-macos/
|
||||
[40]:http://www.pcworld.com/article/2940470/hey-gamers-directx-11-is-coming-to-linux-thanks-to-codeweavers-and-wine.html
|
||||
[41]:https://itsfoss.com/deal-run-windows-software-and-games-on-linux-with-crossover-15-66-off/
|
||||
[42]:https://bbs.archlinux.org/viewtopic.php?id=214771
|
||||
[43]:https://ghostbin.com/paste/sy3e2
|
||||
[44]:https://www.reddit.com/r/linux_gaming/comments/3ap3uu/directx_11_support_coming_to_codeweavers/
|
||||
[45]:https://www.codeweavers.com/about/blogs/caron/2015/12/10/directx-11-really-james-didnt-lie
|
||||
[46]:https://itsfoss.com/linux-gaming-guide/
|
||||
[47]:https://en.wikipedia.org/wiki/Direct3D
|
||||
[48]:http://blog.wolfire.com/2010/01/Why-you-should-use-OpenGL-and-not-DirectX
|
||||
@ -0,0 +1,96 @@
|
||||
8 个在 KDE Plasma 桌面环境下提高生产力的技巧和提示
|
||||
======
|
||||
|
||||

|
||||
|
||||
众所周知,KDE 的 Plasma 是 Linux 下最强大的桌面环境之一。它是高度可定制的,并且看起来也很棒。当你完成所有的配置工作后,你才能体会到它的所有特性。
|
||||
|
||||
你能够轻松地配置 Plasma 桌面并且使用它大量方便且节省时间的特性来加速你的工作,拥有一个能够帮助你而非阻碍你的桌面环境。
|
||||
|
||||
以下这些提示并没有特定顺序,因此你无需按次序阅读。你只需要挑出最适合你的工作流的那几个即可。
|
||||
|
||||
**相关阅读**:[10 个你应该尝试的最佳 KDE Plasma 应用][1]
|
||||
|
||||
### 1、多媒体控制
|
||||
|
||||
这点不太算得上是一条提示,因为它是很容易被记在脑海里的。Plasma 可在各处进行多媒体控制。当你需要暂停、继续或跳过一首歌时,你不需要每次都打开你的媒体播放器。你能够通过将鼠标移至那个最小化窗口之上,甚至通过锁屏进行控制。当你需要切换歌曲或忘了暂停时,你也不必麻烦地登录再进行操作。
|
||||
|
||||
### 2、KRunner
|
||||
|
||||
![KDE Plasma KRunner][2]
|
||||
|
||||
KRunner 是 Plasma 桌面中一个经常受到赞誉的特性。大部分人习惯于穿过层层的应用启动菜单来找到想要启动的程序。当你使用 KRunner 时就不需要这么做。
|
||||
|
||||
为了使用 KRunner,确保你当前的活动焦点在桌面本身(点击桌面而不是窗口)。然后开始输入你想要启动的应用名称,KRunner 将会带着建议项从你的屏幕顶部自动下拉。在你寻找的匹配项上点击或敲击回车键。这比记住你每个应用所属的类别要更快。
|
||||
|
||||
### 3、跳转列表
|
||||
|
||||
![KDE Plasma 的跳转列表][3]
|
||||
|
||||
跳转列表功能是最近才被添加进 Plasma 桌面的。它允许你在启动应用时直接跳转至特定的区域或特性部分。
|
||||
|
||||
因此如果你在菜单栏上有一个应用启动图标,你可以通过右键得到可跳转位置的列表。选择你想要跳转的位置,然后就可以“起飞”了。
|
||||
|
||||
### 4、KDE Connect
|
||||
|
||||
![KDE Connect Android 客户端菜单][4]
|
||||
|
||||
如果你有一个安卓手机,那么 [KDE Connect][5] 会为你提供大量帮助。它可以将你的手机连接至你的桌面,由此你可以在两台设备间无缝地共享。
|
||||
|
||||
通过 KDE Connect,你能够在你的桌面上实时地查看 [Android 设备通知][6]。它同时也让你能够从 Plasma 中收发文字信息,甚至不需要拿起你的手机。
|
||||
|
||||
KDE Connect 也允许你在手机和电脑间发送文件或共享网页。你可以轻松地从一个设备转移至另一设备,而无需烦恼或打乱思绪。
|
||||
|
||||
### 5、Plasma Vaults
|
||||
|
||||
![KDE Plasma Vault][7]
|
||||
|
||||
Plasma Vaults 是 Plasma 桌面的另一个新功能。它的 KDE 为加密文件和文件夹提供的简单解决方案。如果你不使用加密文件,此项功能不会为你节省时间。如果你使用,Vaults 是一个更简单的途径。
|
||||
|
||||
Plasma Vaults 允许你以无 root 权限的普通用户创建加密目录,并通过你的任务栏来管理它们。你能够快速地挂载或卸载目录,而无需外部程序或附加权限。
|
||||
|
||||
### 6、Pager 控件
|
||||
|
||||
![KDE Plasma Pager][8]
|
||||
|
||||
配置你的桌面的 pager 控件。它允许你轻松地切换至另三个附加工作区,带来更大的屏幕空间。
|
||||
|
||||
将控件添加到你的菜单栏上,然后你就可以在多个工作区间滑动切换。每个工作区都与你原桌面的尺寸相同,因此你能够得到数倍于完整屏幕的空间。这就使你能够排布更多的窗口,而不必受到一堆混乱的最小化窗口的困扰。
|
||||
|
||||
### 7、创建一个 Dock
|
||||
|
||||
![KDE Plasma Dock][9]
|
||||
|
||||
Plasma 以其灵活性和可配置性出名,同时也是它的优势。如果你有常用的程序,你可以考虑将常用程序设置为 OS X 风格的 dock。你能够通过单击启动,而不必深入菜单或输入它们的名字。
|
||||
|
||||
### 8、为 Dolphin 添加文件树
|
||||
|
||||
![Plasma Dolphin 目录][10]
|
||||
|
||||
通过目录树来浏览文件夹会更加简单。Dolphin 作为 Plasma 的默认文件管理器,具有在文件夹窗口一侧,以树的形式展示目录列表的内置功能。
|
||||
|
||||
为了启用目录树,点击“控制”标签,然后“配置 Dolphin”、“显示模式”、“详细”,最后选择“可展开文件夹”。
|
||||
|
||||
记住这些仅仅是提示,不要强迫自己做阻碍自己的事情。你可能讨厌在 Dolphin 中使用文件树,你也可能从不使用 Pager,这都没关系。当然也可能会有你喜欢但是此处没列举出来的功能。选择对你有用处的,也就是说,这些技巧中总有一些能帮助你度过日常工作中的艰难时刻。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/kde-plasma-tips-tricks-improve-productivity/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/10-best-kde-plasma-applications/ (10 of the Best KDE Plasma Applications You Should Try)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-krunner.jpg (KDE Plasma KRunner)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-jumplist.jpg (KDE Plasma Jump Lists)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/05/kde-connect-menu-e1494899929112.jpg (KDE Connect Menu Android)
|
||||
[5]:https://www.maketecheasier.com/send-receive-sms-linux-kde-connect/
|
||||
[6]:https://www.maketecheasier.com/android-notifications-ubuntu-kde-connect/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-vault.jpg (KDE Plasma Vault)
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-pager.jpg (KDE Plasma Pager)
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dock.jpg (KDE Plasma Dock)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dolphin.jpg (Plasma Dolphin Directory)
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10574-1.html)
|
||||
[#]: subject: (Get started with Org mode without Emacs)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-org-mode)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Org 模式吧,在没有 Emacs 的情况下
|
||||
======
|
||||
|
||||
> 不,你不需要 Emacs 也能用 Org,这是我开源工具系列的第 16 集,将会让你在 2019 年变得更加有生产率。
|
||||
|
||||

|
||||
|
||||
每到年初似乎总有这么一个疯狂的冲动来寻找提高生产率的方法。新年决心,正确地开始一年的冲动,以及“向前看”的态度都是这种冲动的表现。软件推荐通常都会选择闭源和专利软件。但这不是必须的。
|
||||
|
||||
这是我 2019 年改进生产率的 19 个新工具中的第 16 个。
|
||||
|
||||
### Org (非 Emacs)
|
||||
|
||||
[Org 模式][1] (或者就称为 Org) 并不是新鲜货,但依然有许多人没有用过。他们很乐意试用一下以体验 Org 是如何改善生产率的。但最大的障碍来自于 Org 是与 Emacs 相关联的,而且很多人都认为两者缺一不可。并不是这样的!一旦你理解了其基础,Org 就可以与各种其他工具和编辑器一起使用。
|
||||
|
||||
|
||||
|
||||
Org,本质上,是一个结构化的文本文件。它有标题、子标题,以及各种关键字,其他工具可以根据这些关键字将文件解析成日程表和代办列表。Org 文件可以被任何纯文本编辑器编辑(例如,[Vim][2]、[Atom][3] 或 [Visual Studio Code][4]),而且很多编辑器都有插件可以帮你创建和管理 Org 文件。
|
||||
|
||||
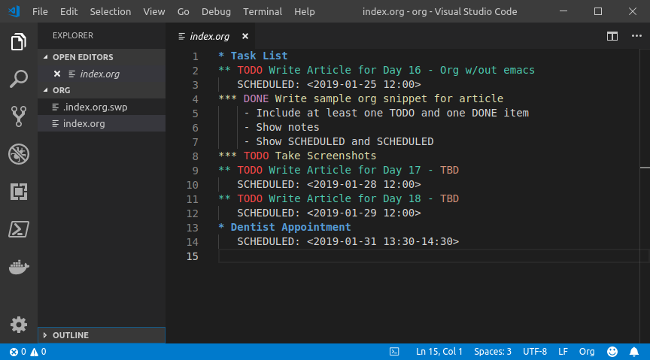
一个基础的 Org 文件看起来是这样的:
|
||||
|
||||
```
|
||||
* Task List
|
||||
** TODO Write Article for Day 16 - Org w/out emacs
|
||||
DEADLINE: <2019-01-25 12:00>
|
||||
*** DONE Write sample org snippet for article
|
||||
- Include at least one TODO and one DONE item
|
||||
- Show notes
|
||||
- Show SCHEDULED and DEADLINE
|
||||
*** TODO Take Screenshots
|
||||
** Dentist Appointment
|
||||
SCHEDULED: <2019-01-31 13:30-14:30>
|
||||
```
|
||||
|
||||
Org 是一种大纲格式,它使用 `*` 作为标识指明事项的级别。任何以 `TODO`(是的,全大些)开头的事项都是代办事项。标注为 `DONE` 的工作表示该工作已经完成。`SCHEDULED` 和 `DEADLINE` 标识与该事务相关的日期和时间。如何任何地方都没有时间,则该事务被视为全天活动。
|
||||
|
||||
使用正确的插件,你喜欢的文本编辑器可以成为一个充满生产率和组织能力的强大工具。例如,[vim-orgmode][5] 插件包括创建 Org 文件、语法高亮的功能,以及各种用来生成跨文件的日程和综合代办事项列表的关键命令。
|
||||
|
||||
|
||||
|
||||
Atom 的 [Organized][6] 插件可以在屏幕右边添加一个侧边栏,用来显示 Org 文件中的日程和代办事项。默认情况下它从配置项中设置的路径中读取多个 Org 文件。Todo 侧边栏允许你通过点击未完事项来将其标记为已完成,它会自动更新源 Org 文件。
|
||||
|
||||
|
||||
|
||||
还有一大堆 Org 工具可以帮助你保持生产率。使用 Python、Perl、PHP、NodeJS 等库,你可以开发自己的脚本和工具。当然,少不了 [Emacs][7],它的核心功能就包括支持 Org。
|
||||
|
||||
|
||||
|
||||
Org 模式是跟踪需要完成的工作和时间的最好工具之一。而且,与传闻相反,它无需 Emacs,任何一个文本编辑器都行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://orgmode.org/
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://atom.io/
|
||||
[4]: https://code.visualstudio.com/
|
||||
[5]: https://github.com/jceb/vim-orgmode
|
||||
[6]: https://atom.io/packages/organized
|
||||
[7]: https://www.gnu.org/software/emacs/
|
||||
@ -0,0 +1,124 @@
|
||||
Qalculate! :全宇宙最好的计算器软件
|
||||
======
|
||||
|
||||
十多年来,我一直都是 GNU-Linux 以及 [Debian][1] 的用户。随着我越来越频繁的使用桌面环境,我发现对我来说除了少数基于 web 的服务以外我的大多数需求都可以通过 Debian 软件库里自带的[桌面应用][2]解决。
|
||||
|
||||
我的需求之一就是进行单位换算。尽管有很多很多在线服务可以做这件事,但是我还是需要一个可以在桌面环境使用的应用。这主要是因为隐私问题以及我不想一而再再而三的寻找在线服务做事。为此我搜寻良久,直到找到 Qalculate!。
|
||||
|
||||
### Qalculate! 最强多功能计算器应用
|
||||
|
||||
![最佳计算器应用 Qalculator][3]
|
||||
|
||||
这是 aptitude 上关于 [Qalculate!][4] 的介绍,我没法总结的比他们更好了:
|
||||
|
||||
> 强大易用的桌面计算器 - GTK+ 版
|
||||
>
|
||||
> Qalculate! 是一款外表简单易用,内核强大且功能丰富的应用。其功能包含自定义函数、单位、高计算精度、作图以及可以输入一行表达式(有容错措施)的图形界面(也可以选择使用传统按钮)。
|
||||
|
||||
这款应用也发行过 KDE 的界面,但是至少在 Debian Testing 软件库里,只出现了 GTK+ 版的界面,你也可以在 GitHub 上的这个[仓库][5]里面看到。
|
||||
|
||||
不必多说,Qalculate! 在 Debian 的软件源内处于可用状态,因此可以使用 [apt][6] 命令或者是基于 Debian 的发行版比如 Ubuntu 提供的软件中心轻松安装。在 Windows 或者 macOS 上也可以使用这款软件。
|
||||
|
||||
#### Qalculate! 特性一览
|
||||
|
||||
列出全部的功能清单会有点长,请允许我只列出一部分功能并使用截图来展示极少数 Qalculate! 提供的功能。这么做是为了让你熟悉 Qalculate! 的基本功能,并在之后可以自由探索 Qalculate! 到底还能干什么。
|
||||
|
||||
* 代数
|
||||
* 微积分
|
||||
* 组合数学
|
||||
* 复数
|
||||
* 数据集
|
||||
* 日期与时间
|
||||
* 经济学
|
||||
* 对数和指数
|
||||
* 几何
|
||||
* 逻辑学
|
||||
* 向量和矩阵
|
||||
* 杂项
|
||||
* 数论
|
||||
* 统计学
|
||||
* 三角学
|
||||
|
||||
#### 使用 Qalculate!
|
||||
|
||||
Qalculate! 的使用不是很难。你甚至可以在里面写简单的英文。但是我还是推荐先[阅读手册][7]以便充分发挥 Qalculate! 的潜能。
|
||||
|
||||
![使用 Qalculate 进行字节到 GB 的换算][8]
|
||||
|
||||
![摄氏度到华氏度的换算][9]
|
||||
|
||||
#### qalc 是 Qalculate! 的命令行版
|
||||
|
||||
你也可以使用 Qalculate! 的命令行版 `qalc`:
|
||||
|
||||
```
|
||||
$ qalc 62499836 byte to gibibyte
|
||||
62499836 * byte = approx. 0.058207508 gibibyte
|
||||
|
||||
$ qalc 40 degree celsius to fahrenheit
|
||||
(40 * degree) * celsius = 104 deg*oF
|
||||
```
|
||||
|
||||
Qalculate! 的命令行界面可以让不喜欢 GUI 而是喜欢命令行界面(CLI)或者是使用无头结点(没有 GUI)的人可以使用 Qalculate!。这些人大多是在服务器环境下工作。
|
||||
|
||||
如果你想要在脚本里使用这一软件的话,我想 libqalculate 是最好的解决方案。看一看 `qalc` 以及 qalculate-gtk 是如何依赖于它工作的就足以知晓如何使用了。
|
||||
|
||||
再提一嘴,你还可以了解下如何根据一系列数据绘图,其他应用方式就留给你自己发掘了。不要忘记查看 `/usr/share/doc/qalculate/index.html` 以获取 Qalculate! 的全部功能。
|
||||
|
||||
注释:注意 Debian 更喜欢 [gnuplot][10],因为其输出的图片很精美。
|
||||
|
||||
#### 附加技巧:你可以通过在 Debian 下通过命令行感谢开发者
|
||||
|
||||
如果你使用 Debian 而且喜欢哪个包的话,你可以使用如下命令感谢 Debian 下这个软件包的开发者或者是维护者:
|
||||
|
||||
```
|
||||
reportbug --kudos $PACKAGENAME
|
||||
```
|
||||
|
||||
因为我喜欢 Qalculate!,我想要对 Debian 的开发者以及维护者 Vincent Legout 的卓越工作表示感谢:
|
||||
|
||||
```
|
||||
reportbug --kudos qalculate
|
||||
```
|
||||
|
||||
建议各位阅读我写的关于如何使用报错工具[在 Debian 中上报 BUG][11]的详细指南。
|
||||
|
||||
#### 一位高分子化学家对 Qalculate! 的评价
|
||||
|
||||
经由作者 [Philip Prado][12],我们联系上了 Timothy Meyers 先生,他目前是在高分子实验室工作的高分子化学家。
|
||||
|
||||
他对 Qaclulate! 的专业评价是:
|
||||
|
||||
> 看起来几乎任何科学家都可以使用这个软件,因为如果你知道指令以及如何使其生效的话,几乎任何数据计算都可以使用这个软件计算。
|
||||
|
||||
> 我觉得这个软件少了些物理常数,但我想不起来缺了哪些。我觉得它没有太多有关[流体动力学][13]的东西,再就是少了点部分化合物的[光吸收][14]系数,但这些东西只对我这个化学家来说比较重要,我不知道这些是不是对别人来说也是特别必要的。[自由能][15]可能也是。
|
||||
|
||||
最后,我分享的关于 Qalculate! 的介绍十分简陋,其实际功能与你的需要以及你的想象力有关系。希望你能喜欢 Qalculate!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/qalculate/
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/shirish/
|
||||
[1]:https://www.debian.org/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[3]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/05/qalculate-app-featured-1.jpeg?w=800&ssl=1
|
||||
[4]:https://qalculate.github.io/
|
||||
[5]:https://github.com/Qalculate
|
||||
[6]:https://itsfoss.com/apt-command-guide/
|
||||
[7]:https://qalculate.github.io/manual/index.html
|
||||
[8]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/04/qalculate-byte-conversion.png?zoom=2&ssl=1
|
||||
[9]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/04/qalculate-gtk-weather-conversion.png?zoom=2&ssl=1
|
||||
[10]:http://www.gnuplot.info/
|
||||
[11]:https://itsfoss.com/bug-report-debian/
|
||||
[12]:https://itsfoss.com/author/phillip/
|
||||
[13]:https://en.wikipedia.org/wiki/Fluid_dynamics
|
||||
[14]:https://en.wikipedia.org/wiki/Absorption_(electromagnetic_radiation)
|
||||
[15]:https://en.wikipedia.org/wiki/Gibbs_free_energy
|
||||
144
published/201902/20181123 Three SSH GUI Tools for Linux.md
Normal file
144
published/201902/20181123 Three SSH GUI Tools for Linux.md
Normal file
@ -0,0 +1,144 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (Three SSH GUI Tools for Linux)
|
||||
[#]: via: (https://www.linux.com/blog/learn/intro-to-linux/2018/11/three-ssh-guis-linux)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
[#]: url: (https://linux.cn/article-10559-1.html)
|
||||
|
||||
3 个 Linux 上的 SSH 图形界面工具
|
||||
======
|
||||
|
||||
> 了解一下这三个用于 Linux 上的 SSH 图形界面工具。
|
||||
|
||||

|
||||
|
||||
在你担任 Linux 管理员的职业生涯中,你会使用 Secure Shell(SSH)远程连接到 Linux 服务器或桌面。可能你曾经在某些情况下,会同时 SSH 连接到多个 Linux 服务器。实际上,SSH 可能是 Linux 工具箱中最常用的工具之一。因此,你应该尽可能提高体验效率。对于许多管理员来说,没有什么比命令行更有效了。但是,有些用户更喜欢使用 GUI 工具,尤其是在从台式机连接到远程并在服务器上工作时。
|
||||
|
||||
如果你碰巧喜欢好的图形界面工具,你肯定很乐于了解一些 Linux 上优秀的 SSH 图形界面工具。让我们来看看这三个工具,看看它们中的一个(或多个)是否完全符合你的需求。
|
||||
|
||||
我将在 [Elementary OS][1] 上演示这些工具,但它们都可用于大多数主要发行版。
|
||||
|
||||
### PuTTY
|
||||
|
||||
已经有一些经验的人都知道 [PuTTY][2]。实际上,从 Windows 环境通过 SSH 连接到 Linux 服务器时,PuTTY 是事实上的标准工具。但 PuTTY 不仅适用于 Windows。事实上,通过标准软件库,PuTTY 也可以安装在 Linux 上。 PuTTY 的功能列表包括:
|
||||
|
||||
* 保存会话。
|
||||
* 通过 IP 或主机名连接。
|
||||
* 使用替代的 SSH 端口。
|
||||
* 定义连接类型。
|
||||
* 日志。
|
||||
* 设置键盘、响铃、外观、连接等等。
|
||||
* 配置本地和远程隧道。
|
||||
* 支持代理。
|
||||
* 支持 X11 隧道。
|
||||
|
||||
PuTTY 图形工具主要是一种保存 SSH 会话的方法,因此可以更轻松地管理所有需要不断远程进出的各种 Linux 服务器和桌面。一旦连接成功,PuTTY 就会建立一个到 Linux 服务器的连接窗口,你将可以在其中工作。此时,你可能会有疑问,为什么不在终端窗口工作呢?对于一些人来说,保存会话的便利确实使 PuTTY 值得使用。
|
||||
|
||||
在 Linux 上安装 PuTTY 很简单。例如,你可以在基于 Debian 的发行版上运行命令:
|
||||
|
||||
```
|
||||
sudo apt-get install -y putty
|
||||
```
|
||||
|
||||
安装后,你可以从桌面菜单运行 PuTTY 图形工具或运行命令 `putty`。在 PuTTY “Configuration” 窗口(图 1)中,在 “HostName (or IP address) ” 部分键入主机名或 IP 地址,配置 “Port”(如果不是默认值 22),从 “Connection type”中选择 SSH,然后单击“Open”。
|
||||
|
||||
![PuTTY Connection][4]
|
||||
|
||||
*图 1:PuTTY 连接配置窗口*
|
||||
|
||||
建立连接后,系统将提示你输入远程服务器上的用户凭据(图2)。
|
||||
|
||||
![log in][7]
|
||||
|
||||
*图 2:使用 PuTTY 登录到远程服务器*
|
||||
|
||||
要保存会话(以便你不必始终键入远程服务器信息),请填写主机名(或 IP 地址)、配置端口和连接类型,然后(在单击 “Open” 之前),在 “Saved Sessions” 部分的顶部文本区域中键入名称,然后单击 “Save”。这将保存会话的配置。若要连接到已保存的会话,请从 “Saved Sessions” 窗口中选择它,单击 “Load”,然后单击 “Open”。系统会提示你输入远程服务器上的远程凭据。
|
||||
|
||||
### EasySSH
|
||||
|
||||
虽然 [EasySSH][8] 没有提供 PuTTY 中的那么多的配置选项,但它(顾名思义)非常容易使用。 EasySSH 的最佳功能之一是它提供了一个标签式界面,因此你可以打开多个 SSH 连接并在它们之间快速切换。EasySSH 的其他功能包括:
|
||||
|
||||
* 分组(出于更好的体验效率,可以对标签进行分组)。
|
||||
* 保存用户名、密码。
|
||||
* 外观选项。
|
||||
* 支持本地和远程隧道。
|
||||
|
||||
在 Linux 桌面上安装 EasySSH 很简单,因为可以通过 Flatpak 安装应用程序(这意味着你必须在系统上安装 Flatpak)。安装 Flatpak 后,使用以下命令添加 EasySSH:
|
||||
|
||||
```
|
||||
sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
|
||||
sudo flatpak install flathub com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
用如下命令运行 EasySSH:
|
||||
|
||||
```
|
||||
flatpak run com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
将会打开 EasySSH 应用程序,你可以单击左上角的 “+” 按钮。 在结果窗口(图 3)中,根据需要配置 SSH 连接。
|
||||
|
||||
![Adding a connection][10]
|
||||
|
||||
*图 3:在 EasySSH 中添加连接很简单*
|
||||
|
||||
添加连接后,它将显示在主窗口的左侧导航中(图 4)。
|
||||
|
||||
![EasySSH][12]
|
||||
|
||||
*图 4:EasySSH 主窗口*
|
||||
|
||||
要在 EasySSH 连接到远程服务器,请从左侧导航栏中选择它,然后单击 “Connect” 按钮(图 5)。
|
||||
|
||||
![Connecting][14]
|
||||
|
||||
*图 5:用 EasySSH 连接到远程服务器*
|
||||
|
||||
对于 EasySSH 的一个警告是你必须将用户名和密码保存在连接配置中(否则连接将失败)。这意味着任何有权访问运行 EasySSH 的桌面的人都可以在不知道密码的情况下远程访问你的服务器。因此,你必须始终记住在你离开时锁定桌面屏幕(并确保使用强密码)。否则服务器容易受到意外登录的影响。
|
||||
|
||||
### Terminator
|
||||
|
||||
(LCTT 译注:这个选择不符合本文主题,本节删节)
|
||||
|
||||
### termius
|
||||
|
||||
(LCTT 译注:本节是根据网友推荐补充的)
|
||||
|
||||
termius 是一个商业版的 SSH、Telnet 和 Mosh 客户端,不是开源软件。支持包括 [Linux](https://www.termius.com/linux)、Windows、Mac、iOS 和安卓在内的各种操作系统。对于单一设备是免费的,支持多设备的白金账号需要按月付费。
|
||||
|
||||
### 很少(但值得)的选择
|
||||
|
||||
Linux 上没有很多可用的 SSH 图形界面工具。为什么?因为大多数管理员更喜欢简单地打开终端窗口并使用标准命令行工具来远程访问其服务器。但是,如果你需要图形界面工具,则有两个可靠选项,可以更轻松地登录多台计算机。虽然对于那些寻找 SSH 图形界面工具的人来说只有不多的几个选择,但那些可用的工具当然值得你花时间。尝试其中一个,亲眼看看。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/11/three-ssh-guis-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://elementary.io/
|
||||
[2]: https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
|
||||
[3]: https://www.linux.com/files/images/sshguis1jpg
|
||||
[4]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_1.jpg?itok=DiNTz_wO (PuTTY Connection)
|
||||
[5]: https://www.linux.com/licenses/category/used-permission
|
||||
[6]: https://www.linux.com/files/images/sshguis2jpg
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_2.jpg?itok=4ORsJlz3 (log in)
|
||||
[8]: https://github.com/muriloventuroso/easyssh
|
||||
[9]: https://www.linux.com/files/images/sshguis3jpg
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_3.jpg?itok=bHC2zlda (Adding a connection)
|
||||
[11]: https://www.linux.com/files/images/sshguis4jpg
|
||||
[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_4.jpg?itok=hhJzhRIg (EasySSH)
|
||||
[13]: https://www.linux.com/files/images/sshguis5jpg
|
||||
[14]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_5.jpg?itok=piFEFYTQ (Connecting)
|
||||
[15]: https://www.linux.com/files/images/sshguis6jpg
|
||||
[16]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_6.jpg?itok=-kYl6iSE (Terminator)
|
||||
@ -1,76 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10560-1.html)
|
||||
[#]: subject: (PowerTOP – Monitors Power Usage and Improve Laptop Battery Life in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
PowerTOP – Monitors Power Usage and Improve Laptop Battery Life in Linux
|
||||
PowerTOP:在 Linux 上监视电量使用和改善笔记本电池寿命
|
||||
======
|
||||
|
||||
We all know, we almost 80-90% migrated from PC (Desktop) to laptop.
|
||||
我们都知道,现在几乎都从 PC 机换到了笔记本电脑了。但是使用笔记本有个问题,我们希望电池耐用,我们可以使用到每一点电量。所以,我们需要知道电量都去哪里了,是不是浪费了。
|
||||
|
||||
But one thing we want from a laptop, it’s long battery life and we want to use every drop of power.
|
||||
你可以使用 PowerTOP 工具来查看没有接入电源线时电量都用在了何处。你需要在终端中使用超级用户权限来运行 PowerTOP 工具。它可以访问该电池硬件并测量电量使用情况。
|
||||
|
||||
So it’s good to know where our power is going and getting waste.
|
||||
### 什么是 PowerTOP
|
||||
|
||||
You can use the powertop utility to see what’s drawing power when your system’s not plugged in.
|
||||
PowerTOP 是一个 Linux 工具,用于诊断电量消耗和电源管理的问题。
|
||||
|
||||
You need to run the powertop utility in terminal with super user privilege.
|
||||
它是由 Intel 开发的,可以在内核、用户空间和硬件中启用各种节电模式。
|
||||
|
||||
It will access the hardware and measure power usage.
|
||||
除了作为一个一个诊断工具之外,PowweTop 还有一个交互模式,可以让你实验 Linux 发行版没有启用的各种电源管理设置。
|
||||
|
||||
### What is PowerTOP
|
||||
它也能监控进程,并展示其中哪个正在使用 CPU,以及从休眠状态页将其唤醒,也可以找出电量消耗特别高的应用程序。
|
||||
|
||||
PowerTOP is a Linux tool to diagnose issues with power consumption and power management.
|
||||
### 如何安装 PowerTOP
|
||||
|
||||
It was developed by Intel to enable various power-saving modes in kernel, userspace, and hardware.
|
||||
PowerTOP 软件包在大多数发行版的软件库中可用,使用发行版的 [包管理器][1] 安装即可。
|
||||
|
||||
In addition to being a diagnostic tool, PowerTOP also has an interactive mode where the user can experiment various power management settings for cases where the Linux distribution has not enabled these settings.
|
||||
|
||||
It is possible to monitor processes and show which of them are utilizing the CPU and wake it from its Idle-States, allowing to identify applications with particular high power demands.
|
||||
|
||||
### How to Install PowerTOP
|
||||
|
||||
PowerTOP package is available in most of the distributions official repository so, use the distributions **[Package Manager][1]** to install it.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][2]** to install PowerTOP.
|
||||
对于 Fedora 系统,使用 [DNF 命令][2] 来安装 PowerTOP。
|
||||
|
||||
```
|
||||
$ sudo dnf install powertop
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][3]** or **[APT Command][4]** to install PowerTOP.
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][3] 或 [APT 命令][4] 来安装 PowerTOP。
|
||||
|
||||
```
|
||||
$ sudo apt install powertop
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][5]** to install PowerTOP.
|
||||
对于基于 Arch Linux 的系统,使用 [Pacman 命令][5] 来安装 PowerTOP。
|
||||
|
||||
```
|
||||
$ sudo pacman -S powertop
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][6]** to install PowerTOP.
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][6] 来安装 PowerTOP。
|
||||
|
||||
```
|
||||
$ sudo yum install powertop
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][7]** to install PowerTOP.
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][7] 来安装 PowerTOP。
|
||||
|
||||
```
|
||||
$ sudo zypper install powertop
|
||||
```
|
||||
|
||||
### How To Access PowerTOP
|
||||
### 如何使用 PowerTOP
|
||||
|
||||
PowerTOP requires super user privilege so, run as root to use PowerTOP utility on your Linux system.
|
||||
PowerTOP 需要超级用户权限,所以在 Linux 系统中以 root 身份运行 PowerTOP 工具。
|
||||
|
||||
By default it shows `Overview` tab where we can see the power usage consumption for all the devices. Also shows your system wakeups seconds.
|
||||
默认情况下其显示 “概览” 页,在这里我们可以看到所有设备的电量消耗情况,也可以看到系统的唤醒秒数。
|
||||
|
||||
```
|
||||
$ sudo powertop
|
||||
@ -132,11 +124,11 @@ Summary: 1692.9 wakeups/second, 0.0 GPU ops/seconds, 0.0 VFS ops/sec and 54.9%
|
||||
Exit | / Navigate |
|
||||
```
|
||||
|
||||
The powertop output looks similar to the above screenshot, it will be slightly different based on your hardware. This have many screen you can switch between screen the using `Tab` and `Shift+Tab` button.
|
||||
PowerTOP 的输出类似如上截屏,在你的机器上由于硬件不同会稍有不同。它的显示有很多页,你可以使用 `Tab` 和 `Shift+Tab` 在它们之间切换。
|
||||
|
||||
### Idle Stats Tab
|
||||
### 空闲状态页
|
||||
|
||||
It displays various information about the processor.
|
||||
它会显示处理器的各种信息。
|
||||
|
||||
```
|
||||
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
|
||||
@ -194,9 +186,9 @@ C10 (pc10) 0.0% | | C10 39.5% 4.7 ms 41.4%
|
||||
Exit | / Navigate |
|
||||
```
|
||||
|
||||
### Frequency Stats Tab
|
||||
### 频率状态页
|
||||
|
||||
It displays the frequency of CPU.
|
||||
它会显示 CPU 的主频。
|
||||
|
||||
```
|
||||
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
|
||||
@ -220,9 +212,9 @@ Idle | Idle | Idle
|
||||
|
||||
```
|
||||
|
||||
### Device Stats Tab
|
||||
### 设备状态页
|
||||
|
||||
It displays power usage information against only devices.
|
||||
它仅针对设备显示其电量使用信息。
|
||||
|
||||
```
|
||||
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
|
||||
@ -277,12 +269,12 @@ The power consumed was 280 J
|
||||
0.0% runtime-coretemp.0
|
||||
0.0% runtime-alarmtimer
|
||||
|
||||
Exit | / Navigate |
|
||||
Exit | / Navigate |
|
||||
```
|
||||
|
||||
### Tunables Stats Tab
|
||||
### 可调整状态页
|
||||
|
||||
This tab is important area that provides suggestions to optimize your laptop battery.
|
||||
这个页面是个重要区域,可以为你的笔记本电池优化提供建议。
|
||||
|
||||
```
|
||||
PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunables
|
||||
@ -340,9 +332,9 @@ PowerTOP v2.9 Overview Idle stats Frequency stats Device stats Tunab
|
||||
Exit | Toggle tunable | Window refresh
|
||||
```
|
||||
|
||||
### How To Generate PowerTop HTML Report
|
||||
### 如何生成 PowerTop 的 HTML 报告
|
||||
|
||||
Run the following command to generate the PowerTop HTML report.
|
||||
运行如下命令生成 PowerTop 的 HTML 报告。
|
||||
|
||||
```
|
||||
$ sudo powertop --html=powertop.html
|
||||
@ -363,12 +355,13 @@ Taking 1 measurement(s) for a duration of 20 second(s) each.
|
||||
PowerTOP outputing using base filename powertop.html
|
||||
```
|
||||
|
||||
Navigate to `file:///home/daygeek/powertop.html` file to access the generated PowerTOP HTML report.
|
||||
打开 `file:///home/daygeek/powertop.html` 文件以访问生成的 PowerTOP 的 HTML 报告。
|
||||
|
||||
![][9]
|
||||
|
||||
### Auto-Tune mode
|
||||
### 自动调整模式
|
||||
|
||||
This feature sets all tunable options from `BAD` to `GOOD` which increase the laptop battery life in Linux.
|
||||
这个功能可以将所有可调整选项从 BAD 设置为 GOOD,这可以提升 Linux 中的笔记本电池寿命。
|
||||
|
||||
```
|
||||
$ sudo powertop --auto-tune
|
||||
@ -393,8 +386,8 @@ via: https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10564-1.html)
|
||||
[#]: subject: (How to use Magit to manage Git projects)
|
||||
[#]: via: (https://opensource.com/article/19/1/how-use-magit)
|
||||
[#]: author: (Sachin Patil https://opensource.com/users/psachin)
|
||||
|
||||
如何在 Emacs 中使用 Magit 管理 Git 项目
|
||||
======
|
||||
|
||||
> Emacs 的 Magit 扩展插件使得使用 Git 进行版本控制变得简单起来。
|
||||
|
||||

|
||||
|
||||
[Git][1] 是一个很棒的用于项目管理的 [版本控制][2] 工具,就是新人学习起来太难。Git 的命令行工具很难用,你不仅需要熟悉它的标志和选项,还需要知道什么环境下使用它们。这使人望而生畏,因此不少人只会非常有限的几个用法。
|
||||
|
||||
好在,现今大多数的集成开发环境 (IDE) 都包含了 Git 扩展,大大地简化了使用使用的难度。Emacs 中就有这么一款 Git 扩展名叫 [Magit][3]。
|
||||
|
||||
Magit 项目成立有差不多 10 年了,它将自己定义为 “一件 Emacs 内的 Git 瓷器”。也就是说,它是一个操作界面,每个操作都能一键完成。本文会带你领略一下 Magit 的操作界面并告诉你如何使用它来管理 Git 项目。
|
||||
|
||||
若你还没有做,请在开始本教程之前先 [安装 Emacs][4],再 [安装 Magit][5]。
|
||||
|
||||
### Magit 的界面
|
||||
|
||||
首先用 Emacs 的 [Dired 模式][6] 访问一个项目的目录。比如我所有的 Emacs 配置存储在 `~/.emacs.d/` 目录中,就是用 Git 来进行管理的。
|
||||
|
||||
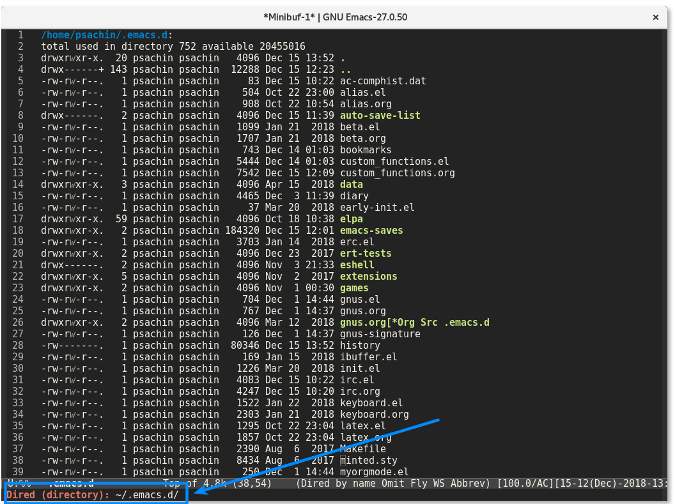
|
||||
|
||||
若你在命令行下工作,则你需要输入 `git status` 来查看项目的当前状态。Magit 也有类似的功能:`magit-status`。你可以通过 `M-x magit-status` (快捷方式是 `Alt+x magit-status` )来调用该功能。结果看起来像下面这样:
|
||||
|
||||
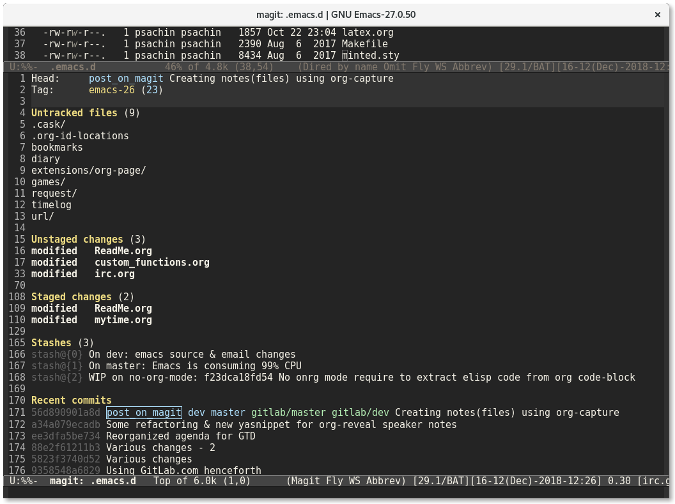
|
||||
|
||||
Magit 显示的信息比 `git status` 命令的要多得多。它分别列出了未追踪文件列表、未暂存文件列表以及已暂存文件列表。它还列出了<ruby>储藏<rt>stash</rt></ruby>列表以及最近几次的提交 —— 所有这些信息都在一个窗口中展示。
|
||||
|
||||
如果你想查看修改了哪些内容,按下 `Tab` 键。比如,我移动光标到未暂存的文件 `custom_functions.org` 上,然后按下 `Tab` 键,Magit 会显示修改了哪些内容:
|
||||
|
||||
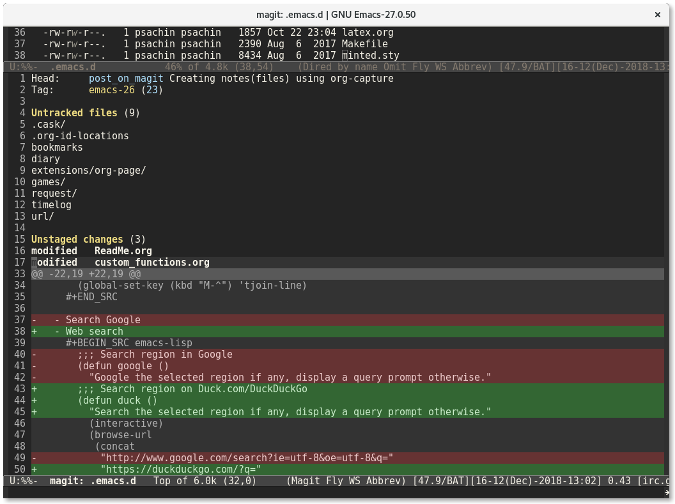
|
||||
|
||||
这跟运行命令 `git diff custom_functions.org` 类似。储藏文件更简单。只需要移动光标到文件上然后按下 `s` 键。该文件就会迅速移动到已储藏文件列表中:
|
||||
|
||||
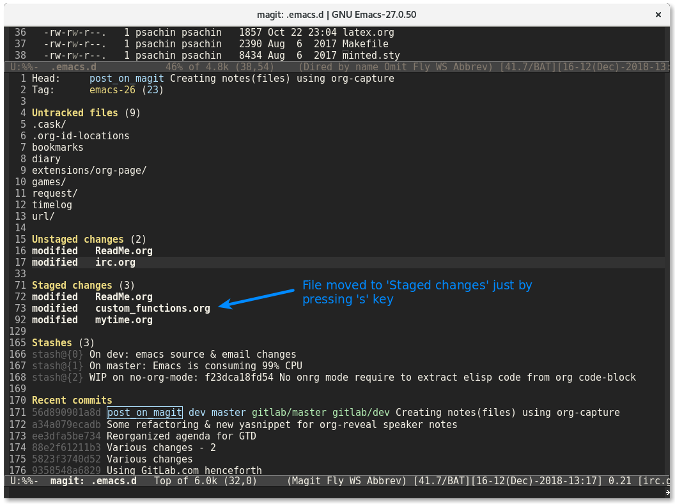
|
||||
|
||||
要<ruby>反储藏<rt>unstage</rt></ruby>某个文件,使用 `u` 键。按下 `s` 和 `u` 键要比在命令行输入 `git add -u <file>` 和 `git reset HEAD <file>` 快的多也更有趣的多。
|
||||
|
||||
### 提交更改
|
||||
|
||||
在同一个 Magit 窗口中,按下 `c` 键会显示一个提交窗口,其中提供了许多标志,比如 `--all` 用来暂存所有文件或者 `--signoff` 来往提交信息中添加签名行。
|
||||
|
||||
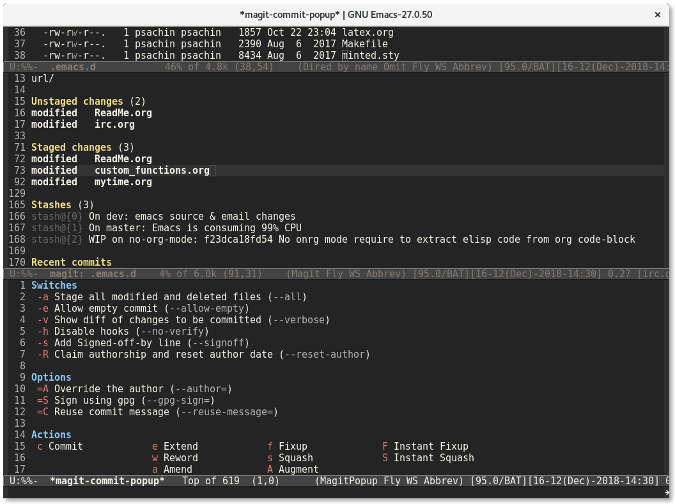
|
||||
|
||||
将光标移动到想要启用签名标志的行,然后按下回车。`--signoff` 文本会变成高亮,这说明该标志已经被启用。
|
||||
|
||||
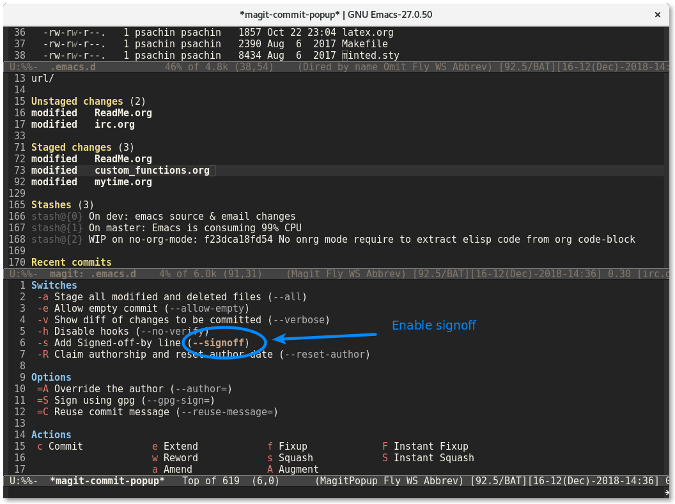
|
||||
|
||||
再次按下 `c` 键会显示一个窗口供你输入提交信息。
|
||||
|
||||
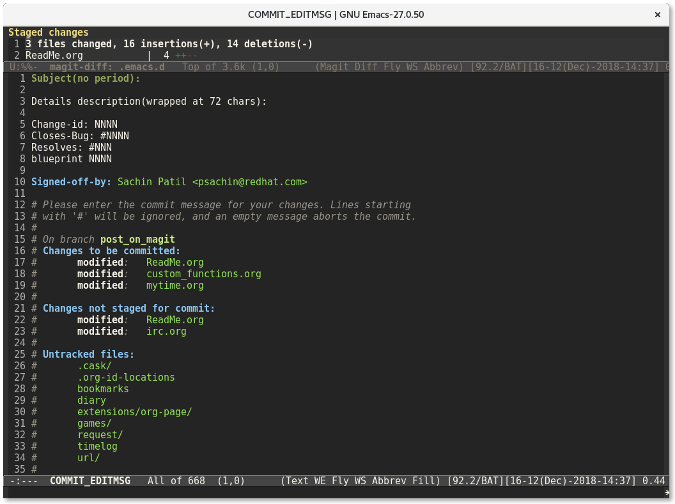
|
||||
|
||||
最后,使用 `C-c C-c `(按键 `Ctrl+cc` 的缩写形式) 来提交更改。
|
||||
|
||||
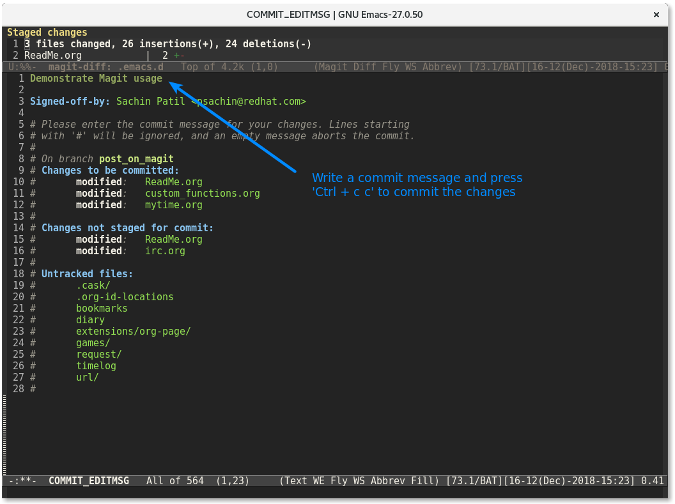
|
||||
|
||||
### 推送更改
|
||||
|
||||
更改提交后,提交行将会显示在 `Recent commits` 区域中显示。
|
||||
|
||||
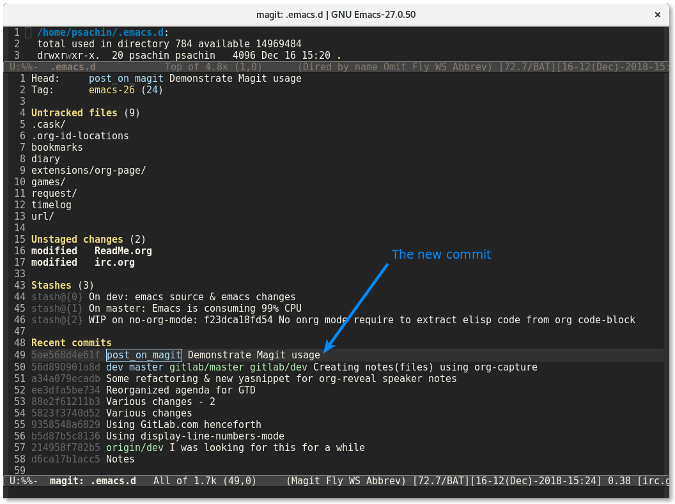
|
||||
|
||||
将光标放到该提交处然后按下 `p` 来推送该变更。
|
||||
|
||||
若你想感受一下使用 Magit 的感觉,我已经在 YouTube 上传了一段 [演示][7]。本文只涉及到 Magit 的一点皮毛。它有许多超酷的功能可以帮你使用 Git 分支、变基等功能。你可以在 Magit 的主页上找到 [文档、支持,以及更多][8] 的链接。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/how-use-magit
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/psachin
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://git-scm.com
|
||||
[2]: https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control
|
||||
[3]: https://magit.vc
|
||||
[4]: https://www.gnu.org/software/emacs/download.html
|
||||
[5]: https://magit.vc/manual/magit/Installing-from-Melpa.html#Installing-from-Melpa
|
||||
[6]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Dired-Enter.html#Dired-Enter
|
||||
[7]: https://youtu.be/Vvw75Pqp7Mc
|
||||
[8]: https://magit.vc/
|
||||
371
published/201902/20190110 5 useful Vim plugins for developers.md
Normal file
371
published/201902/20190110 5 useful Vim plugins for developers.md
Normal file
@ -0,0 +1,371 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (pityonline)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10563-1.html)
|
||||
[#]: subject: (5 useful Vim plugins for developers)
|
||||
[#]: via: (https://opensource.com/article/19/1/vim-plugins-developers)
|
||||
[#]: author: (Ricardo Gerardi https://opensource.com/users/rgerardi)
|
||||
|
||||
5 个好用的开发者 Vim 插件
|
||||
======
|
||||
|
||||
> 通过这 5 个插件扩展 Vim 功能来提升你的编码效率。
|
||||
|
||||

|
||||
|
||||
我用 Vim 已经超过 20 年了,两年前我决定把它作为我的首要文本编辑器。我用 Vim 来编写代码、配置文件、博客文章及其它任意可以用纯文本表达的东西。Vim 有很多超级棒的功能,一旦你适合了它,你的工作会变得非常高效。
|
||||
|
||||
在日常编辑工作中,我更倾向于使用 Vim 稳定的原生功能,但开源社区对 Vim 开发了大量的插件,可以扩展 Vim 的功能、改进你的工作流程和提升工作效率。
|
||||
|
||||
以下列举 5 个非常好用的可以用于编写任意编程语言的插件。
|
||||
|
||||
### 1、Auto Pairs
|
||||
|
||||
[Auto Pairs][2] 插件可以帮助你插入和删除成对的文字,如花括号、圆括号或引号。这在编写代码时非常有用,因为很多编程语言都有成对标记的语法,就像圆括号用于函数调用,或引号用于字符串定义。
|
||||
|
||||
Auto Pairs 最基本的功能是在你输入一个左括号时会自动补全对应的另一半括号。比如,你输入了一个 `[`,它会自动帮你补充另一半 `]`。相反,如果你用退格键删除开头的一半括号,Auto Pairs 会删除另一半。
|
||||
|
||||
如果你设置了自动缩进,当你按下回车键时 Auto Pairs 会在恰当的缩进位置补全另一半括号,这比你找到放置另一半的位置并选择一个正确的括号要省劲多了。
|
||||
|
||||
例如下面这段代码:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
在 `items` 后面输入一个左花括号按下回车会产生下面的结果:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items {
|
||||
| (cursor here)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Auto Pairs 提供了大量其它选项(你可以在 [GitHub][3] 上找到),但最基本的功能已经很让人省时间了。
|
||||
|
||||
### 2、NERD Commenter
|
||||
|
||||
[NERD Commenter][4] 插件给 Vim 增加了代码注释的功能,类似在 <ruby>IDE<rt>integrated development environment</rt></ruby> 中注释功能。有了这个插件,你可以一键注释单行或多行代码。
|
||||
|
||||
NERD Commenter 可以与标准的 Vim [filetype][5] 插件配合,所以它能理解一些编程语言并使用合适的方式来注释代码。
|
||||
|
||||
最易上手的方法是按 `Leader+Space` 组合键来切换注释当前行。Vim 默认的 Leader 键是 `\`。
|
||||
|
||||
在<ruby>可视化模式<rt>Visual mode</rt></ruby>中,你可以选择多行一并注释。NERD Commenter 也可以按计数注释,所以你可以加个数量 n 来注释 n 行。
|
||||
|
||||
还有个有用的特性 “Sexy Comment” 可以用 `Leader+cs` 来触发,它的块注释风格更漂亮一些。例如下面这段代码:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items {
|
||||
fmt.Println(i)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
选择 `main` 函数中的所有行然后按下 `Leader+cs` 会出来以下注释效果:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
/*
|
||||
* x := true
|
||||
* items := []string{"tv", "pc", "tablet"}
|
||||
*
|
||||
* if x {
|
||||
* for _, i := range items {
|
||||
* fmt.Println(i)
|
||||
* }
|
||||
* }
|
||||
*/
|
||||
}
|
||||
```
|
||||
|
||||
因为这些行都是在一个块中注释的,你可以用 `Leader+Space` 组合键一次去掉这里所有的注释。
|
||||
|
||||
NERD Commenter 是任何使用 Vim 写代码的开发者都必装的插件。
|
||||
|
||||
### 3、VIM Surround
|
||||
|
||||
[Vim Surround][6] 插件可以帮你“环绕”现有文本插入成对的符号(如括号或双引号)或标签(如 HTML 或 XML 标签)。它和 Auto Pairs 有点儿类似,但是用于处理已有文本,在编辑文本时更有用。
|
||||
|
||||
比如你有以下一个句子:
|
||||
|
||||
```
|
||||
"Vim plugins are awesome !"
|
||||
```
|
||||
|
||||
当你的光标处于引起来的句中任何位置时,你可以用 `ds"` 组合键删除句子两端的双引号。
|
||||
|
||||
```
|
||||
Vim plugins are awesome !
|
||||
```
|
||||
|
||||
你也可以用 `cs"'` 把双端的双引号换成单引号:
|
||||
|
||||
```
|
||||
'Vim plugins are awesome !'
|
||||
```
|
||||
|
||||
或者再用 `cs'[` 替换成中括号:
|
||||
|
||||
```
|
||||
[ Vim plugins are awesome ! ]
|
||||
```
|
||||
|
||||
它对编辑 HTML 或 XML 文本中的<ruby>标签<rt>tag</rt></ruby>尤其在行。假如你有以下一行 HTML 代码:
|
||||
|
||||
```
|
||||
<p>Vim plugins are awesome !</p>
|
||||
```
|
||||
|
||||
当光标在 “awesome” 这个单词的任何位置时,你可以按 `ysiw<em>` 直接给它加上着重标签(`<em>`):
|
||||
|
||||
```
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
```
|
||||
|
||||
注意它聪明地加上了 `</em>` 闭合标签。
|
||||
|
||||
Vim Surround 也可以用 `ySS` 缩进文本并加上标签。比如你有以下文本:
|
||||
|
||||
```
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
```
|
||||
|
||||
你可以用 `ySS<div class="normal">` 加上 `div` 标签,注意生成的段落是自动缩进的。
|
||||
|
||||
```
|
||||
<div class="normal">
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
Vim Surround 有很多其它选项,你可以参照 [GitHub][7] 上的说明尝试它们。
|
||||
|
||||
### 4、Vim Gitgutter
|
||||
|
||||
[Vim Gitgutter][8] 插件对使用 Git 作为版本控制工具的人来说非常有用。它会在 Vim 的行号列旁显示 `git diff` 的差异标记。假设你有如下已提交过的代码:
|
||||
|
||||
```
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
5 func main() {
|
||||
6 x := true
|
||||
7 items := []string{"tv", "pc", "tablet"}
|
||||
8
|
||||
9 if x {
|
||||
10 for _, i := range items {
|
||||
11 fmt.Println(i)
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
当你做出一些修改后,Vim Gitgutter 会显示如下标记:
|
||||
|
||||
```
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
`_` 标记表示在第 5 行和第 6 行之间删除了一行。`~` 表示第 8 行有修改,`+` 表示新增了第 11 行。
|
||||
|
||||
另外,Vim Gitgutter 允许你用 `[c` 和 `]c` 在多个有修改的块之间跳转,甚至可以用 `Leader+hs` 来暂存某个变更集。
|
||||
|
||||
这个插件提供了对变更的即时视觉反馈,如果你用 Git 的话,有了它简直是如虎添翼。
|
||||
|
||||
### 5、VIM Fugitive
|
||||
|
||||
[Vim Fugitive][9] 是另一个将 Git 工作流集成到 Vim 中的超棒插件。它对 Git 做了一些封装,可以让你在 Vim 里直接执行 Git 命令并将结果集成在 Vim 界面里。这个插件有超多的特性,更多信息请访问它的 [GitHub][10] 项目页面。
|
||||
|
||||
这里有一个使用 Vim Fugitive 的基础 Git 工作流示例。设想我们已经对下面的 Go 代码做出修改,你可以用 `:Gblame` 调用 `git blame` 来查看每行最后的提交信息:
|
||||
|
||||
```
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
|
||||
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
|
||||
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
|
||||
```
|
||||
|
||||
可以看到第 8 行和第 11 行显示还未提交。用 `:Gstatus` 命令检查仓库当前的状态:
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is up to date with 'origin/master'.
|
||||
3 #
|
||||
4 # Changes not staged for commit:
|
||||
5 # (use "git add <file>..." to update what will be committed)
|
||||
6 # (use "git checkout -- <file>..." to discard changes in working directory)
|
||||
7 #
|
||||
8 # modified: vim-5plugins/examples/test1.go
|
||||
9 #
|
||||
10 no changes added to commit (use "git add" and/or "git commit -a")
|
||||
--------------------------------------------------------------------------------------------------------
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
Vim Fugitive 在分割的窗口里显示 `git status` 的输出结果。你可以在该行按下 `-` 键用该文件的名字暂存这个文件的提交,再按一次 `-` 可以取消暂存。这个信息会随着你的操作自动更新:
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is up to date with 'origin/master'.
|
||||
3 #
|
||||
4 # Changes to be committed:
|
||||
5 # (use "git reset HEAD <file>..." to unstage)
|
||||
6 #
|
||||
7 # modified: vim-5plugins/examples/test1.go
|
||||
8 #
|
||||
--------------------------------------------------------------------------------------------------------
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
现在你可以用 `:Gcommit` 来提交修改了。Vim Fugitive 会打开另一个分割窗口让你输入提交信息:
|
||||
|
||||
```
|
||||
1 vim-5plugins: Updated test1.go example file
|
||||
2 # Please enter the commit message for your changes. Lines starting
|
||||
3 # with '#' will be ignored, and an empty message aborts the commit.
|
||||
4 #
|
||||
5 # On branch master
|
||||
6 # Your branch is up to date with 'origin/master'.
|
||||
7 #
|
||||
8 # Changes to be committed:
|
||||
9 # modified: vim-5plugins/examples/test1.go
|
||||
10 #
|
||||
```
|
||||
|
||||
按 `:wq` 保存文件完成提交:
|
||||
|
||||
```
|
||||
[master c3bf80f] vim-5plugins: Updated test1.go example file
|
||||
1 file changed, 2 insertions(+), 2 deletions(-)
|
||||
Press ENTER or type command to continue
|
||||
```
|
||||
|
||||
然后你可以再用 `:Gstatus` 检查结果并用 `:Gpush` 把新的提交推送到远程。
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is ahead of 'origin/master' by 1 commit.
|
||||
3 # (use "git push" to publish your local commits)
|
||||
4 #
|
||||
5 nothing to commit, working tree clean
|
||||
```
|
||||
|
||||
Vim Fugitive 的 GitHub 项目主页有很多屏幕录像展示了它的更多功能和工作流,如果你喜欢它并想多学一些,快去看看吧。
|
||||
|
||||
### 接下来?
|
||||
|
||||
这些 Vim 插件都是程序开发者的神器!还有另外两类开发者常用的插件:自动完成插件和语法检查插件。它些大都是和具体的编程语言相关的,以后我会在一些文章中介绍它们。
|
||||
|
||||
你在写代码时是否用到一些其它 Vim 插件?请在评论区留言分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/vim-plugins-developers
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[pityonline](https://github.com/pityonline)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgerardi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.vim.org/
|
||||
[2]: https://www.vim.org/scripts/script.php?script_id=3599
|
||||
[3]: https://github.com/jiangmiao/auto-pairs
|
||||
[4]: https://github.com/scrooloose/nerdcommenter
|
||||
[5]: http://vim.wikia.com/wiki/Filetype.vim
|
||||
[6]: https://www.vim.org/scripts/script.php?script_id=1697
|
||||
[7]: https://github.com/tpope/vim-surround
|
||||
[8]: https://github.com/airblade/vim-gitgutter
|
||||
[9]: https://www.vim.org/scripts/script.php?script_id=2975
|
||||
[10]: https://github.com/tpope/vim-fugitive
|
||||
@ -0,0 +1,230 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10568-1.html)
|
||||
[#]: subject: (The Evil-Twin Framework: A tool for improving WiFi security)
|
||||
[#]: via: (https://opensource.com/article/19/1/evil-twin-framework)
|
||||
[#]: author: (André Esser https://opensource.com/users/andreesser)
|
||||
|
||||
Evil-Twin 框架:一个用于提升 WiFi 安全性的工具
|
||||
======
|
||||
|
||||
> 了解一款用于对 WiFi 接入点安全进行渗透测试的工具。
|
||||
|
||||

|
||||
|
||||
越来越多的设备通过无线传输的方式连接到互联网,以及,大范围可用的 WiFi 接入点为攻击者攻击用户提供了很多机会。通过欺骗用户连接到[虚假的 WiFi 接入点][1],攻击者可以完全控制用户的网络连接,这将使得攻击者可以嗅探和篡改用户的数据包,将用户的连接重定向到一个恶意的网站,并通过网络发起其他的攻击。
|
||||
|
||||
为了保护用户并告诉他们如何避免线上的危险操作,安全审计人员和安全研究员必须评估用户的安全实践能力,用户常常在没有确认该 WiFi 接入点为安全的情况下就连接上了该网络,安全审计人员和研究员需要去了解这背后的原因。有很多工具都可以对 WiFi 的安全性进行审计,但是没有一款工具可以测试大量不同的攻击场景,也没有能和其他工具集成得很好的工具。
|
||||
|
||||
Evil-Twin Framework(ETF)用于解决 WiFi 审计过程中的这些问题。审计者能够使用 ETF 来集成多种工具并测试该 WiFi 在不同场景下的安全性。本文会介绍 ETF 的框架和功能,然后会提供一些案例来说明该如何使用这款工具。
|
||||
|
||||
### ETF 的架构
|
||||
|
||||
ETF 的框架是用 [Python][2] 写的,因为这门开发语言的代码非常易读,也方便其他开发者向这个项目贡献代码。除此之外,很多 ETF 的库,比如 [Scapy][3],都是为 Python 开发的,很容易就能将它们用于 ETF。
|
||||
|
||||
ETF 的架构(图 1)分为不同的彼此交互的模块。该框架的设置都写在一个单独的配置文件里。用户可以通过 `ConfigurationManager` 类里的用户界面来验证并修改这些配置。其他模块只能读取这些设置并根据这些设置进行运行。
|
||||
|
||||
![Evil-Twin Framework Architecture][5]
|
||||
|
||||
*图 1:Evil-Twin 的框架架构*
|
||||
|
||||
ETF 支持多种与框架交互的用户界面,当前的默认界面是一个交互式控制台界面,类似于 [Metasploit][6] 那种。正在开发用于桌面/浏览器使用的图形用户界面(GUI)和命令行界面(CLI),移动端界面也是未来的一个备选项。用户可以使用交互式控制台界面来修改配置文件里的设置(最终会使用 GUI)。用户界面可以与存在于这个框架里的每个模块进行交互。
|
||||
|
||||
WiFi 模块(AirCommunicator)用于支持多种 WiFi 功能和攻击类型。该框架确定了 Wi-Fi 通信的三个基本支柱:数据包嗅探、自定义数据包注入和创建接入点。三个主要的 WiFi 通信模块 AirScanner、AirInjector,和 AirHost,分别用于数据包嗅探、数据包注入,和接入点创建。这三个类被封装在主 WiFi 模块 AirCommunicator 中,AirCommunicator 在启动这些服务之前会先读取这些服务的配置文件。使用这些核心功能的一个或多个就可以构造任意类型的 WiFi 攻击。
|
||||
|
||||
要使用中间人(MITM)攻击(这是一种攻击 WiFi 客户端的常见手法),ETF 有一个叫做 ETFITM(Evil-Twin Framework-in-the-Middle)的集成模块,这个模块用于创建一个 web 代理,来拦截和修改经过的 HTTP/HTTPS 数据包。
|
||||
|
||||
许多其他的工具也可以利用 ETF 创建的 MITM。通过它的可扩展性,ETF 能够支持它们,而不必单独地调用它们,你可以通过扩展 Spawner 类来将这些工具添加到框架里。这使得开发者和安全审计人员可以使用框架里预先配置好的参数字符来调用程序。
|
||||
|
||||
扩展 ETF 的另一种方法就是通过插件。有两类插件:WiFi 插件和 MITM 插件。MITM 插件是在 MITM 代理运行时可以执行的脚本。代理会将 HTTP(s) 请求和响应传递给可以记录和处理它们的插件。WiFi 插件遵循一个更加复杂的执行流程,但仍然会给想参与开发并且使用自己插件的贡献者提供一个相对简单的 API。WiFi 插件还可以进一步地划分为三类,其中每个对应一个核心 WiFi 通信模块。
|
||||
|
||||
每个核心模块都有一些特定事件能触发响应的插件的执行。举个例子,AirScanner 有三个已定义的事件,可以对其响应进行编程处理。事件通常对应于服务开始运行之前的设置阶段、服务正在运行时的中间执行阶段、服务完成后的卸载或清理阶段。因为 Python 允许多重继承,所以一个插件可以继承多个插件类。
|
||||
|
||||
上面的图 1 是框架架构的摘要。从 ConfigurationManager 指出的箭头意味着模块会从中读取信息,指向它的箭头意味着模块会写入/修改配置。
|
||||
|
||||
### 使用 ETF 的例子
|
||||
|
||||
ETF 可以通过多种方式对 WiFi 的网络安全或者终端用户的 WiFi 安全意识进行渗透测试。下面的例子描述了这个框架的一些渗透测试功能,例如接入点和客户端检测、对使用 WPA 和 WEP 类型协议的接入点进行攻击,和创建 evil twin 接入点。
|
||||
|
||||
这些例子是使用 ETF 和允许进行 WiFi 数据捕获的 WiFi 卡设计的。它们也在 ETF 设置命令中使用了下面这些缩写:
|
||||
|
||||
* **APS** Access Point SSID
|
||||
* **APB** Access Point BSSID
|
||||
* **APC** Access Point Channel
|
||||
* **CM** Client MAC address
|
||||
|
||||
在实际的测试场景中,确保你使用了正确的信息来替换这些缩写。
|
||||
|
||||
#### 在解除认证攻击后捕获 WPA 四次握手的数据包。
|
||||
|
||||
这个场景(图 2)做了两个方面的考虑:<ruby>解除认证攻击<rt>de-authentication attack</rt></ruby>和捕获 WPA 四次握手数据包的可能性。这个场景从一个启用了 WPA/WPA2 的接入点开始,这个接入点有一个已经连上的客户端设备(在本例中是一台智能手机)。目的是通过常规的解除认证攻击(LCTT 译注:类似于 DoS 攻击)来让客户端断开和 WiFi 的网络,然后在客户端尝试重连的时候捕获 WPA 的握手包。重连会在断开连接后马上手动完成。
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][8]
|
||||
|
||||
*图 2:在解除认证攻击后捕获 WPA 握手包的场景*
|
||||
|
||||
在这个例子中需要考虑的是 ETF 的可靠性。目的是确认工具是否一直都能捕获 WPA 的握手数据包。每个工具都会用来多次复现这个场景,以此来检查它们在捕获 WPA 握手数据包时的可靠性。
|
||||
|
||||
使用 ETF 来捕获 WPA 握手数据包的方法不止一种。一种方法是使用 AirScanner 和 AirInjector 两个模块的组合;另一种方法是只使用 AirInjector。下面这个场景是使用了两个模块的组合。
|
||||
|
||||
ETF 启用了 AirScanner 模块并分析 IEEE 802.11 数据帧来发现 WPA 握手包。然后 AirInjecto 就可以使用解除认证攻击来强制客户端断开连接,以进行重连。必须在 ETF 上执行下面这些步骤才能完成上面的目标:
|
||||
|
||||
1. 进入 AirScanner 配置模式:`config airscanner`
|
||||
2. 设置 AirScanner 不跳信道:`config airscanner`
|
||||
3. 设置信道以嗅探经过 WiFi 接入点信道的数据(APC):`set fixed_sniffing_channel = <APC>`
|
||||
4. 使用 CredentialSniffer 插件来启动 AirScanner 模块:`start airscanner with credentialsniffer`
|
||||
5. 从已嗅探的接入点列表中添加目标接入点的 BSSID(APS):`add aps where ssid = <APS>`
|
||||
6. 启用 AirInjector 模块,在默认情况下,它会启用解除认证攻击:`start airinjector`
|
||||
|
||||
这些简单的命令设置能让 ETF 在每次测试时执行成功且有效的解除认证攻击。ETF 也能在每次测试的时候捕获 WPA 的握手数据包。下面的代码能让我们看到 ETF 成功的执行情况。
|
||||
|
||||
```
|
||||
███████╗████████╗███████╗
|
||||
██╔════╝╚══██╔══╝██╔════╝
|
||||
█████╗ ██║ █████╗
|
||||
██╔══╝ ██║ ██╔══╝
|
||||
███████╗ ██║ ██║
|
||||
╚══════╝ ╚═╝ ╚═╝
|
||||
|
||||
|
||||
[+] Do you want to load an older session? [Y/n]: n
|
||||
[+] Creating new temporary session on 02/08/2018
|
||||
[+] Enter the desired session name:
|
||||
ETF[etf/aircommunicator/]::> config airscanner
|
||||
ETF[etf/aircommunicator/airscanner]::> listargs
|
||||
sniffing_interface = wlan1; (var)
|
||||
probes = True; (var)
|
||||
beacons = True; (var)
|
||||
hop_channels = false; (var)
|
||||
fixed_sniffing_channel = 11; (var)
|
||||
ETF[etf/aircommunicator/airscanner]::> start airscanner with
|
||||
arpreplayer caffelatte credentialsniffer packetlogger selfishwifi
|
||||
ETF[etf/aircommunicator/airscanner]::> start airscanner with credentialsniffer
|
||||
[+] Successfully added credentialsniffer plugin.
|
||||
[+] Starting packet sniffer on interface 'wlan1'
|
||||
[+] Set fixed channel to 11
|
||||
ETF[etf/aircommunicator/airscanner]::> add aps where ssid = CrackWPA
|
||||
ETF[etf/aircommunicator/airscanner]::> start airinjector
|
||||
ETF[etf/aircommunicator/airscanner]::> [+] Starting deauthentication attack
|
||||
- 1000 bursts of 1 packets
|
||||
- 1 different packets
|
||||
[+] Injection attacks finished executing.
|
||||
[+] Starting post injection methods
|
||||
[+] Post injection methods finished
|
||||
[+] WPA Handshake found for client '70:3e:ac:bb:78:64' and network 'CrackWPA'
|
||||
```
|
||||
|
||||
#### 使用 ARP 重放攻击并破解 WEP 无线网络
|
||||
|
||||
下面这个场景(图 3)将关注[地址解析协议][9](ARP)重放攻击的效率和捕获包含初始化向量(IVs)的 WEP 数据包的速度。相同的网络可能需要破解不同数量的捕获的 IVs,所以这个场景的 IVs 上限是 50000。如果这个网络在首次测试期间,还未捕获到 50000 IVs 就崩溃了,那么实际捕获到的 IVs 数量会成为这个网络在接下来的测试里的新的上限。我们使用 `aircrack-ng` 对数据包进行破解。
|
||||
|
||||
测试场景从一个使用 WEP 协议进行加密的 WiFi 接入点和一台知道其密钥的离线客户端设备开始 —— 为了测试方便,密钥使用了 12345,但它可以是更长且更复杂的密钥。一旦客户端连接到了 WEP 接入点,它会发送一个不必要的 ARP 数据包;这是要捕获和重放的数据包。一旦被捕获的包含 IVs 的数据包数量达到了设置的上限,测试就结束了。
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][11]
|
||||
|
||||
*图 3:在进行解除认证攻击后捕获 WPA 握手包的场景*
|
||||
|
||||
ETF 使用 Python 的 Scapy 库来进行包嗅探和包注入。为了最大限度地解决 Scapy 里的已知的性能问题,ETF 微调了一些低级库,来大大加快包注入的速度。对于这个特定的场景,ETF 为了更有效率地嗅探,使用了 `tcpdump` 作为后台进程而不是 Scapy,Scapy 用于识别加密的 ARP 数据包。
|
||||
|
||||
这个场景需要在 ETF 上执行下面这些命令和操作:
|
||||
|
||||
1. 进入 AirScanner 设置模式:`config airscanner`
|
||||
2. 设置 AirScanner 不跳信道:`set hop_channels = false`
|
||||
3. 设置信道以嗅探经过接入点信道的数据(APC):`set fixed_sniffing_channel = <APC>`
|
||||
4. 进入 ARPReplayer 插件设置模式:`config arpreplayer`
|
||||
5. 设置 WEP 网络目标接入点的 BSSID(APB):`set target_ap_bssid <APB>`
|
||||
6. 使用 ARPReplayer 插件启动 AirScanner 模块:`start airscanner with arpreplayer`
|
||||
|
||||
在执行完这些命令后,ETF 会正确地识别加密的 ARP 数据包,然后成功执行 ARP 重放攻击,以此破坏这个网络。
|
||||
|
||||
#### 使用一款全能型蜜罐
|
||||
|
||||
图 4 中的场景使用相同的 SSID 创建了多个接入点,对于那些可以探测到但是无法接入的 WiFi 网络,这个技术可以发现网络的加密类型。通过启动具有所有安全设置的多个接入点,客户端会自动连接和本地缓存的接入点信息相匹配的接入点。
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][13]
|
||||
|
||||
*图 4:在解除认证攻击后捕获 WPA 握手包数据。*
|
||||
|
||||
使用 ETF,可以去设置 `hostapd` 配置文件,然后在后台启动该程序。`hostapd` 支持在一张无线网卡上通过设置虚拟接口开启多个接入点,并且因为它支持所有类型的安全设置,因此可以设置完整的全能蜜罐。对于使用 WEP 和 WPA(2)-PSK 的网络,使用默认密码,和对于使用 WPA(2)-EAP 的网络,配置“全部接受”策略。
|
||||
|
||||
对于这个场景,必须在 ETF 上执行下面的命令和操作:
|
||||
|
||||
1. 进入 APLauncher 设置模式:`config aplauncher`
|
||||
2. 设置目标接入点的 SSID(APS):`set ssid = <APS>`
|
||||
3. 设置 APLauncher 为全部接收的蜜罐:`set catch_all_honeypot = true`
|
||||
4. 启动 AirHost 模块:`start airhost`
|
||||
|
||||
使用这些命令,ETF 可以启动一个包含所有类型安全配置的完整全能蜜罐。ETF 同样能自动启动 DHCP 和 DNS 服务器,从而让客户端能与互联网保持连接。ETF 提供了一个更好、更快、更完整的解决方案来创建全能蜜罐。下面的代码能够看到 ETF 的成功执行。
|
||||
|
||||
```
|
||||
███████╗████████╗███████╗
|
||||
██╔════╝╚══██╔══╝██╔════╝
|
||||
█████╗ ██║ █████╗
|
||||
██╔══╝ ██║ ██╔══╝
|
||||
███████╗ ██║ ██║
|
||||
╚══════╝ ╚═╝ ╚═╝
|
||||
|
||||
|
||||
[+] Do you want to load an older session? [Y/n]: n
|
||||
[+] Creating ne´,cxzw temporary session on 03/08/2018
|
||||
[+] Enter the desired session name:
|
||||
ETF[etf/aircommunicator/]::> config aplauncher
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf ssid CatchMe
|
||||
ssid = CatchMe
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf catch_all_honeypot true
|
||||
catch_all_honeypot = true
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> start airhost
|
||||
[+] Killing already started processes and restarting network services
|
||||
[+] Stopping dnsmasq and hostapd services
|
||||
[+] Access Point stopped...
|
||||
[+] Running airhost plugins pre_start
|
||||
[+] Starting hostapd background process
|
||||
[+] Starting dnsmasq service
|
||||
[+] Running airhost plugins post_start
|
||||
[+] Access Point launched successfully
|
||||
[+] Starting dnsmasq service
|
||||
```
|
||||
|
||||
### 结论和以后的工作
|
||||
|
||||
这些场景使用常见和众所周知的攻击方式来帮助验证 ETF 测试 WIFI 网络和客户端的能力。这个结果同样证明了该框架的架构能在平台现有功能的优势上开发新的攻击向量和功能。这会加快新的 WiFi 渗透测试工具的开发,因为很多的代码已经写好了。除此之外,将 WiFi 技术相关的东西都集成到一个单独的工具里,会使 WiFi 渗透测试更加简单高效。
|
||||
|
||||
ETF 的目标不是取代现有的工具,而是为它们提供补充,并为安全审计人员在进行 WiFi 渗透测试和提升用户安全意识时,提供一个更好的选择。
|
||||
|
||||
ETF 是 [GitHub][14] 上的一个开源项目,欢迎社区为它的开发做出贡献。下面是一些您可以提供帮助的方法。
|
||||
|
||||
当前 WiFi 渗透测试的一个限制是无法在测试期间记录重要的事件。这使得报告已经识别到的漏洞更加困难且准确性更低。这个框架可以实现一个记录器,每个类都可以来访问它并创建一个渗透测试会话报告。
|
||||
|
||||
ETF 工具的功能涵盖了 WiFi 渗透测试的方方面面。一方面,它让 WiFi 目标侦察、漏洞挖掘和攻击这些阶段变得更加容易。另一方面,它没有提供一个便于提交报告的功能。增加了会话的概念和会话报告的功能,比如在一个会话期间记录重要的事件,会极大地增加这个工具对于真实渗透测试场景的价值。
|
||||
|
||||
另一个有价值的贡献是扩展该框架来促进 WiFi 模糊测试。IEEE 802.11 协议非常的复杂,考虑到它在客户端和接入点两方面都会有多种实现方式。可以假设这些实现都包含 bug 甚至是安全漏洞。这些 bug 可以通过对 IEEE 802.11 协议的数据帧进行模糊测试来进行发现。因为 Scapy 允许自定义的数据包创建和数据包注入,可以通过它实现一个模糊测试器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/evil-twin-framework
|
||||
|
||||
作者:[André Esser][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/andreesser
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Rogue_access_point
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://scapy.net
|
||||
[4]: /file/417776
|
||||
[5]: https://opensource.com/sites/default/files/uploads/pic1.png (Evil-Twin Framework Architecture)
|
||||
[6]: https://www.metasploit.com
|
||||
[7]: /file/417781
|
||||
[8]: https://opensource.com/sites/default/files/uploads/pic2.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[9]: https://en.wikipedia.org/wiki/Address_Resolution_Protocol
|
||||
[10]: /file/417786
|
||||
[11]: https://opensource.com/sites/default/files/uploads/pic3.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[12]: /file/417791
|
||||
[13]: https://opensource.com/sites/default/files/uploads/pic4.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[14]: https://github.com/Esser420/EvilTwinFramework
|
||||
@ -0,0 +1,393 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (luming)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10569-1.html)
|
||||
[#]: subject: (How To Copy A File/Folder From A Local System To Remote System In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
|
||||
如何在 Linux 上复制文件/文件夹到远程系统?
|
||||
======
|
||||
|
||||
从一个服务器复制文件到另一个服务器,或者从本地到远程复制是 Linux 管理员的日常任务之一。
|
||||
|
||||
我觉得不会有人不同意,因为无论在哪里这都是你的日常操作之一。有很多办法都能处理这个任务,我们试着加以概括。你可以挑一个喜欢的方法。当然,看看其他命令也能在别的地方帮到你。
|
||||
|
||||
我已经在自己的环境下测试过所有的命令和脚本了,因此你可以直接用到日常工作当中。
|
||||
|
||||
通常大家都倾向 `scp`,因为它是文件复制的<ruby>原生命令<rt>native command</rt></ruby>之一。但本文所列出的其它命令也很好用,建议你尝试一下。
|
||||
|
||||
文件复制可以轻易地用以下四种方法。
|
||||
|
||||
- `scp`:在网络上的两个主机之间复制文件,它使用 `ssh` 做文件传输,并使用相同的认证方式,具有相同的安全性。
|
||||
- `rsync`:是一个既快速又出众的多功能文件复制工具。它能本地复制、通过远程 shell 在其它主机之间复制,或者与远程的 `rsync` <ruby>守护进程<rt>daemon</rt></ruby> 之间复制。
|
||||
- `pscp`:是一个并行复制文件到多个主机上的程序。它提供了诸多特性,例如为 `scp` 配置免密传输,保存输出到文件,以及超时控制。
|
||||
- `prsync`:也是一个并行复制文件到多个主机上的程序。它也提供了诸多特性,例如为 `ssh` 配置免密传输,保存输出到 文件,以及超时控制。
|
||||
|
||||
### 方式 1:如何在 Linux 上使用 scp 命令从本地系统向远程系统复制文件/文件夹?
|
||||
|
||||
`scp` 命令可以让我们从本地系统复制文件/文件夹到远程系统上。
|
||||
|
||||
我会把 `output.txt` 文件从本地系统复制到 `2g.CentOS.com` 远程系统的 `/opt/backup` 文件夹下。
|
||||
|
||||
```
|
||||
# scp output.txt root@2g.CentOS.com:/opt/backup
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
```
|
||||
|
||||
从本地系统复制两个文件 `output.txt` 和 `passwd-up.sh` 到远程系统 `2g.CentOs.com` 的 `/opt/backup` 文件夹下。
|
||||
|
||||
```
|
||||
# scp output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
```
|
||||
|
||||
从本地系统复制 `shell-script` 文件夹到远程系统 `2g.CentOs.com` 的 `/opt/back` 文件夹下。
|
||||
|
||||
这会连同`shell-script` 文件夹下所有的文件一同复制到`/opt/back` 下。
|
||||
|
||||
```
|
||||
# scp -r /home/daygeek/2g/shell-script/ root@:/opt/backup/
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
ovh.sh 100% 76 0.1KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
passwd-up1.sh 100% 7 0.0KB/s 00:00
|
||||
server-list.txt 100% 23 0.0KB/s 00:00
|
||||
```
|
||||
|
||||
### 方式 2:如何在 Linux 上使用 scp 命令和 Shell 脚本复制文件/文件夹到多个远程系统上?
|
||||
|
||||
如果你想复制同一个文件到多个远程服务器上,那就需要创建一个如下面那样的小 shell 脚本。
|
||||
|
||||
并且,需要将服务器添加进 `server-list.txt` 文件。确保添加成功后,每个服务器应当单独一行。
|
||||
|
||||
最终,你想要的脚本就像下面这样:
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp /home/daygeek/2g/shell-script/output.txt root@$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
完成之后,给 `file-copy.sh` 文件设置可执行权限。
|
||||
|
||||
```
|
||||
# chmod +x file-copy.sh
|
||||
```
|
||||
|
||||
最后运行脚本完成复制。
|
||||
|
||||
```
|
||||
# ./file-copy.sh
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
```
|
||||
|
||||
使用下面的脚本可以复制多个文件到多个远程服务器上。
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp /home/daygeek/2g/shell-script/output.txt passwd-up.sh root@$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
下面结果显示所有的两个文件都复制到两个服务器上。
|
||||
|
||||
```
|
||||
# ./file-cp.sh
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
```
|
||||
|
||||
使用下面的脚本递归地复制文件夹到多个远程服务器上。
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp -r /home/daygeek/2g/shell-script/ root@$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
上述脚本的输出。
|
||||
|
||||
```
|
||||
# ./file-cp.sh
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
ovh.sh 100% 76 0.1KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
passwd-up1.sh 100% 7 0.0KB/s 00:00
|
||||
server-list.txt 100% 23 0.0KB/s 00:00
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
ovh.sh 100% 76 0.1KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
passwd-up1.sh 100% 7 0.0KB/s 00:00
|
||||
server-list.txt 100% 23 0.0KB/s 00:00
|
||||
```
|
||||
|
||||
### 方式 3:如何在 Linux 上使用 pscp 命令复制文件/文件夹到多个远程系统上?
|
||||
|
||||
`pscp` 命令可以直接让我们复制文件到多个远程服务器上。
|
||||
|
||||
使用下面的 `pscp` 命令复制单个文件到远程服务器。
|
||||
|
||||
```
|
||||
# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt /opt/backup
|
||||
|
||||
[1] 18:46:11 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
使用下面的 `pscp` 命令复制多个文件到远程服务器。
|
||||
|
||||
```
|
||||
# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt ovh.sh /opt/backup
|
||||
|
||||
[1] 18:47:48 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
使用下面的 `pscp` 命令递归地复制整个文件夹到远程服务器。
|
||||
|
||||
```
|
||||
# pscp.pssh -H 2g.CentOS.com -r /home/daygeek/2g/shell-script/ /opt/backup
|
||||
|
||||
[1] 18:48:46 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
使用下面的 `pscp` 命令使用下面的命令复制单个文件到多个远程服务器。
|
||||
|
||||
```
|
||||
# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt /opt/backup
|
||||
|
||||
[1] 18:49:48 [SUCCESS] 2g.CentOS.com
|
||||
[2] 18:49:48 [SUCCESS] 2g.Debian.com
|
||||
```
|
||||
|
||||
使用下面的 `pscp` 命令复制多个文件到多个远程服务器。
|
||||
|
||||
```
|
||||
# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt passwd-up.sh /opt/backup
|
||||
|
||||
[1] 18:50:30 [SUCCESS] 2g.Debian.com
|
||||
[2] 18:50:30 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
使用下面的命令递归地复制文件夹到多个远程服务器。
|
||||
|
||||
```
|
||||
# pscp.pssh -h server-list.txt -r /home/daygeek/2g/shell-script/ /opt/backup
|
||||
|
||||
[1] 18:51:31 [SUCCESS] 2g.Debian.com
|
||||
[2] 18:51:31 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
### 方式 4:如何在 Linux 上使用 rsync 命令复制文件/文件夹到多个远程系统上?
|
||||
|
||||
`rsync` 是一个即快速又出众的多功能文件复制工具。它能本地复制、通过远程 shell 在其它主机之间复制,或者在远程 `rsync` <ruby>守护进程<rt>daemon</rt></ruby> 之间复制。
|
||||
|
||||
使用下面的 `rsync` 命令复制单个文件到远程服务器。
|
||||
|
||||
```
|
||||
# rsync -avz /home/daygeek/2g/shell-script/output.txt root@2g.CentOS.com:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
output.txt
|
||||
|
||||
sent 598 bytes received 31 bytes 1258.00 bytes/sec
|
||||
total size is 2468 speedup is 3.92
|
||||
```
|
||||
|
||||
使用下面的 `rsync` 命令复制多个文件到远程服务器。
|
||||
|
||||
```
|
||||
# rsync -avz /home/daygeek/2g/shell-script/output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
output.txt
|
||||
passwd-up.sh
|
||||
|
||||
sent 737 bytes received 50 bytes 1574.00 bytes/sec
|
||||
total size is 2537 speedup is 3.22
|
||||
```
|
||||
|
||||
使用下面的 `rsync` 命令通过 `ssh` 复制单个文件到远程服务器。
|
||||
|
||||
```
|
||||
# rsync -avzhe ssh /home/daygeek/2g/shell-script/output.txt root@2g.CentOS.com:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
output.txt
|
||||
|
||||
sent 598 bytes received 31 bytes 419.33 bytes/sec
|
||||
total size is 2.47K speedup is 3.92
|
||||
```
|
||||
|
||||
使用下面的 `rsync` 命令通过 `ssh` 递归地复制文件夹到远程服务器。这种方式只复制文件不包括文件夹。
|
||||
|
||||
```
|
||||
# rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
./
|
||||
output.txt
|
||||
ovh.sh
|
||||
passwd-up.sh
|
||||
passwd-up1.sh
|
||||
server-list.txt
|
||||
|
||||
sent 3.85K bytes received 281 bytes 8.26K bytes/sec
|
||||
total size is 9.12K speedup is 2.21
|
||||
```
|
||||
|
||||
### 方式 5:如何在 Linux 上使用 rsync 命令和 Shell 脚本复制文件/文件夹到多个远程系统上?
|
||||
|
||||
如果你想复制同一个文件到多个远程服务器上,那也需要创建一个如下面那样的小 shell 脚本。
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
上面脚本的输出。
|
||||
|
||||
```
|
||||
# ./file-copy.sh
|
||||
|
||||
sending incremental file list
|
||||
./
|
||||
output.txt
|
||||
ovh.sh
|
||||
passwd-up.sh
|
||||
passwd-up1.sh
|
||||
server-list.txt
|
||||
|
||||
sent 3.86K bytes received 281 bytes 8.28K bytes/sec
|
||||
total size is 9.13K speedup is 2.21
|
||||
|
||||
sending incremental file list
|
||||
./
|
||||
output.txt
|
||||
ovh.sh
|
||||
passwd-up.sh
|
||||
passwd-up1.sh
|
||||
server-list.txt
|
||||
|
||||
sent 3.86K bytes received 281 bytes 2.76K bytes/sec
|
||||
total size is 9.13K speedup is 2.21
|
||||
```
|
||||
|
||||
### 方式 6:如何在 Linux 上使用 scp 命令和 Shell 脚本从本地系统向多个远程系统复制文件/文件夹?
|
||||
|
||||
在上面两个 shell 脚本中,我们需要事先指定好文件和文件夹的路径,这儿我做了些小修改,让脚本可以接收文件或文件夹作为输入参数。当你每天需要多次执行复制时,这将会非常有用。
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp -r $1 root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
输入文件名并运行脚本。
|
||||
|
||||
```
|
||||
# ./file-copy.sh output1.txt
|
||||
|
||||
output1.txt 100% 3558 3.5KB/s 00:00
|
||||
output1.txt 100% 3558 3.5KB/s 00:00
|
||||
```
|
||||
|
||||
### 方式 7:如何在 Linux 系统上用非标准端口复制文件/文件夹到远程系统?
|
||||
|
||||
如果你想使用非标准端口,使用下面的 shell 脚本复制文件或文件夹。
|
||||
|
||||
如果你使用了<ruby>非标准<rt>Non-Standard</rt></ruby>端口,确保像下面 `scp` 命令那样指定好了端口号。
|
||||
|
||||
```
|
||||
# file-copy-scp.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp -P 2222 -r $1 root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
运行脚本,输入文件名。
|
||||
|
||||
```
|
||||
# ./file-copy.sh ovh.sh
|
||||
|
||||
ovh.sh 100% 3558 3.5KB/s 00:00
|
||||
ovh.sh 100% 3558 3.5KB/s 00:00
|
||||
```
|
||||
|
||||
如果你使用了<ruby>非标准<rt>Non-Standard</rt></ruby>端口,确保像下面 `rsync` 命令那样指定好了端口号。
|
||||
|
||||
```
|
||||
# file-copy-rsync.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
rsync -avzhe 'ssh -p 2222' $1 root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
运行脚本,输入文件名。
|
||||
|
||||
```
|
||||
# ./file-copy-rsync.sh passwd-up.sh
|
||||
sending incremental file list
|
||||
passwd-up.sh
|
||||
|
||||
sent 238 bytes received 35 bytes 26.00 bytes/sec
|
||||
total size is 159 speedup is 0.58
|
||||
|
||||
sending incremental file list
|
||||
passwd-up.sh
|
||||
|
||||
sent 238 bytes received 35 bytes 26.00 bytes/sec
|
||||
total size is 159 speedup is 0.58
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mySoul8012)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10565-1.html)
|
||||
[#]: subject: (Book Review: Fundamentals of Linux)
|
||||
[#]: via: (https://itsfoss.com/fundamentals-of-linux-book-review)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
书评:《Linux 基础》
|
||||
======
|
||||
|
||||
介绍 Linux 的基础知识以及它的工作原理的书很多,今天,我们将会点评这样一本书。这次讨论的主题为 Oliver Pelz 所写的 《<ruby>[Linux 基础][1]<rt>Fundamentals of Linux</rt></ruby>》,由 [PacktPub][2] 出版。
|
||||
|
||||
[Oliver Pelz][3] 是一位拥有超过十年软件开发经验的开发者和系统管理员,拥有生物信息学学位证书。
|
||||
|
||||
### 《Linux 基础》
|
||||
|
||||
![Fundamental of Linux books][4]
|
||||
|
||||
正如可以从书名中猜到那样,《Linux 基础》的目标是为读者打下一个从了解 Linux 到学习 Linux 命令行的坚实基础。这本书一共有两百多页,因此它专注于教给用户日常任务和解决经常遇到的问题。本书是为想要成为 Linux 管理员的读者而写的。
|
||||
|
||||
第一章首先概述了虚拟化。本书作者指导了读者如何在 [VirtualBox][6] 中创建 [CentOS][5] 实例。如何克隆实例,如何使用快照。并且同时你也会学习到如何通过 SSH 命令连接到虚拟机。
|
||||
|
||||
第二章介绍了 Linux 命令行的基础知识,包括 shell 通配符,shell 展开,如何使用包含空格和特殊字符的文件名称。如何来获取命令手册的帮助页面。如何使用 `sed`、`awk` 这两个命令。如何浏览 Linux 的文件系统。
|
||||
|
||||
第三章更深入的介绍了 Linux 文件系统。你将了解如何在 Linux 中文件是如何链接的,以及如何搜索它们。你还将获得用户、组,以及文件权限的大概了解。由于本章的重点介绍了如何与文件进行交互。因此还将会介绍如何从命令行中读取文本文件,以及初步了解如何使用 vim 编辑器。
|
||||
|
||||
第四章重点介绍了如何使用命令行。以及涵盖的重要命令。如 `cat`、`sort`、`awk`、`tee`、`tar`、`rsync`、`nmap`、`htop` 等。你还将会了解到进程,以及它们如何彼此通讯。这一章还介绍了 Bash shell 脚本编程。
|
||||
|
||||
第五章同时也是本书的最后一章,将会介绍 Linux 和其他高级命令,以及网络的概念。本书的作者讨论了 Linux 是如何处理网络,并提供使用多个虚拟机的示例。同时还将会介绍如何安装新的程序,如何设置防火墙。
|
||||
|
||||
### 关于这本书的思考
|
||||
|
||||
Linux 的基础知识只有五章和少少的 200 来页可能看起来有些短,但是也涵盖了相当多的信息。同时也将会获得如何使用命令行所需要的知识的一切。
|
||||
|
||||
使用本书的时候,需要注意一件事情,即,本书专注于对命令行的关注,没有任何关于如何使用图形化的用户界面的任何教程。这是因为在 Linux 中有太多不同的桌面环境,以及很多的类似的系统应用,因此很难编写一本可以涵盖所有变种的书。此外,还有部分原因还因为本书的面向的用户群体为潜在的 Linux 管理员。
|
||||
|
||||
当我看到作者使用 Centos 教授 Linux 的时候有点惊讶。我原本以为他会使用更为常见的 Linux 的发行版本,例如 Ubuntu、Debian 或者 Fedora。原因在于 Centos 是为服务器设计的发行版本。随着时间的推移变化很小,能够为 Linux 的基础知识打下一个非常坚实的基础。
|
||||
|
||||
我自己使用 Linux 已经操作五年了。我大部分时间都在使用桌面版本的 Linux。我有些时候会使用命令行操作。但我并没有花太多的时间在那里。我使用鼠标完成了本书中涉及到的很多操作。现在呢。我同时也知道了如何通过终端做到同样的事情。这种方式不会改变我完成任务的方式,但是会有助于自己理解幕后发生的事情。
|
||||
|
||||
如果你刚刚使用 Linux,或者计划使用。我不会推荐你阅读这本书。这可能有点绝对化。但是如何你已经花了一些时间在 Linux 上。或者可以快速掌握某种技术语言。那么这本书很适合你。
|
||||
|
||||
如果你认为本书适合你的学习需求。你可以从以下链接获取到该书:
|
||||
|
||||
- [下载《Linux 基础》](https://www.packtpub.com/networking-and-servers/fundamentals-linux)
|
||||
|
||||
我们将在未来几个月内尝试点评更多 Linux 书籍,敬请关注我们。
|
||||
|
||||
你最喜欢的关于 Linux 的入门书籍是什么?请在下面的评论中告诉我们。
|
||||
|
||||
如果你发现这篇文章很有趣,请花一点时间在社交媒体、Hacker News或 [Reddit][8] 上分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/fundamentals-of-linux-book-review
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[mySoul8012](https://github.com/mySoul8012)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.packtpub.com/networking-and-servers/fundamentals-linux
|
||||
[2]: https://www.packtpub.com/
|
||||
[3]: http://www.oliverpelz.de/index.html
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/fundamentals-of-linux-book-review.jpeg?resize=800%2C450&ssl=1
|
||||
[5]: https://centos.org/
|
||||
[6]: https://www.virtualbox.org/
|
||||
[7]: https://www.centos.org/
|
||||
[8]: http://reddit.com/r/linuxusersgroup
|
||||
@ -1,47 +1,48 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10561-1.html)
|
||||
[#]: subject: (Get started with LogicalDOC, an open source document management system)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-logicaldoc)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
开始使用 LogicalDOC,一个开源文档管理系统
|
||||
开始使用 LogicalDOC 吧,一个开源文档管理系统
|
||||
======
|
||||
使用 LogicalDOC 更好地跟踪文档版本,这是我们开源工具系列中的第 12 个工具,它将使你在 2019 年更高效。
|
||||
|
||||
> 使用 LogicalDOC 更好地跟踪文档版本,这是我们开源工具系列中的第 12 个工具,它将使你在 2019 年更高效。
|
||||
|
||||

|
||||
|
||||
每年年初似乎都有疯狂的冲动,想方设法提高工作效率。新年的决议,开始一年的权利,当然,“与旧的,与新的”的态度都有助于实现这一目标。通常的一轮建议严重偏向封闭源和专有软件。它不一定是这样。
|
||||
每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
|
||||
|
||||
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 12 个工具来帮助你在 2019 年更有效率。
|
||||
|
||||
### LogicalDOC
|
||||
|
||||
高效的一部分是能够在你需要时找到你需要的东西。我们都看到过充满类似名称文件的目录, 这是每次更改文档时为跟踪所有版本而重命名这些文件的结果。例如,我的妻子是一名作家,她在将文档发送给审稿人之前,她经常使用新名称保存文档修订版。
|
||||
高效部分表现在能够在你需要时找到你所需的东西。我们都看到过塞满名称类似的文件的目录,这是每次更改文档时为了跟踪所有版本而重命名这些文件而导致的。例如,我的妻子是一名作家,她在将文档发送给审稿人之前,她经常使用新名称保存文档修订版。
|
||||
|
||||

|
||||
|
||||
程序员对此一个自然的解决方案是 Git 或者其他版本控制器,这个不适用于文档作者,因为用于代码的系统通常不能很好地兼容商业文本编辑器使用的格式。之前有人说,“只是更改格式”,[这不是每个人的选择][1]。同样,许多版本控制工具对于非技术人员来说并不是非常友好。在大型组织中,有一些工具可以解决此问题,但它们还需要大型组织的资源来运行、管理和支持它们。
|
||||
程序员对此一个自然的解决方案是 Git 或者其他版本控制器,但这个不适用于文档作者,因为用于代码的系统通常不能很好地兼容商业文本编辑器使用的格式。之前有人说,“改变格式就行”,[这不是适合每个人的选择][1]。同样,许多版本控制工具对于非技术人员来说并不是非常友好。在大型组织中,有一些工具可以解决此问题,但它们还需要大型组织的资源来运行、管理和支持它们。
|
||||
|
||||
|
||||
|
||||
[LogicalDOC CE][2] 是为解决此问题而编写的开源文档管理系统。它允许用户签入、签出、查看版本、搜索和锁定文档,并保留版本历史记录,类似于程序员使用的版本控制工具。
|
||||
|
||||
LogicalDOC 可在 Linux、MacOS 和 Windows 上[安装][3],使用基于 Java 的安装程序。在安装中,系统将提示你提供数据库存储文职,并提供仅限本地文件存储的选项。你将获得访问服务器的 URL 和默认用户名和密码,以及保存用于自动安装脚本选项。
|
||||
LogicalDOC 可在 Linux、MacOS 和 Windows 上[安装][3],使用基于 Java 的安装程序。在安装时,系统将提示你提供数据库存储位置,并提供只在本地文件存储的选项。你将获得访问服务器的 URL 和默认用户名和密码,以及保存用于自动安装脚本选项。
|
||||
|
||||
登录后,LogicalDOC 的默认页面会列出你已标记、签出的文档以及有关它们的最新说明。切换到“文档”选项卡将显示你有权访问的文件。你可以在界面中选择文件或使用拖放来上传文档。如果你上传 ZIP 文件,LogicalDOC 会解压它,并将其中的文件添加到仓库中。
|
||||
|
||||
|
||||
|
||||
右键单击文件将显示一个菜单选项,包括检出文件、锁定文件以防止更改,以及执行大量其他操作。签出文件会将其下载到用于编辑的本地计算机。在重新签入之前,其他任何人都无法修改签出文件。当重新签入文件时(使用相同的菜单),用户可以向版本添加标签,并且需要评论对其执行的操作。
|
||||
右键单击文件将显示一个菜单选项,包括检出文件、锁定文件以防止更改,以及执行大量其他操作。签出文件会将其下载到本地计算机以便编辑。在重新签入之前,其他任何人都无法修改签出的文件。当重新签入文件时(使用相同的菜单),用户可以向版本添加标签,并且需要备注对其执行的操作。
|
||||
|
||||
|
||||
|
||||
查看早期版本只需在“版本”页面下载就行。对于某些第三方服务,它还有导入和导出选项,内置 [Dropbox][4] 支持。
|
||||
|
||||
文档管理不仅仅是对能够负担得起昂贵解决方案的大公司。LogicalDOC 可帮助你追踪文档的版本历史,并为难以管理的文档提供了安全的仓库。
|
||||
文档管理不仅仅是能够负担得起昂贵解决方案的大公司才能有的。LogicalDOC 可帮助你追踪文档的版本历史,并为难以管理的文档提供了安全的仓库。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -50,7 +51,7 @@ via: https://opensource.com/article/19/1/productivity-tool-logicaldoc
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10567-1.html)
|
||||
[#]: subject: (Get started with gPodder, an open source podcast client)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-gpodder)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 gPodder 吧,一个开源播客客户端
|
||||
======
|
||||
|
||||
> 使用 gPodder 将你的播客同步到你的设备上,gPodder 是我们开源工具系列中的第 17 个工具,它将在 2019 年提高你的工作效率。
|
||||
|
||||

|
||||
|
||||
每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
|
||||
|
||||
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 17 个工具来帮助你在 2019 年更有效率。
|
||||
|
||||
### gPodder
|
||||
|
||||
我喜欢播客。哎呀,我非常喜欢它们,因此我录制了其中的三个(你可以在[我的个人资料][1]中找到它们的链接)。我从播客那里学到了很多东西,并在我工作时在后台播放它们。但是,如何在多台桌面和移动设备之间保持同步可能会有一些挑战。
|
||||
|
||||
[gPodder][2] 是一个简单的跨平台播客下载器、播放器和同步工具。它支持 RSS feed、[FeedBurner][3]、[YouTube][4] 和 [SoundCloud][5],它还有一个开源的同步服务,你可以根据需要运行它。gPodder 不直接播放播客。相反,它会使用你选择的音频或视频播放器。
|
||||
|
||||
|
||||
|
||||
安装 gPodder 非常简单。安装程序适用于 Windows 和 MacOS,同时也有用于主要的 Linux 发行版的软件包。如果你的发行版中没有它,你可以直接从 Git 下载运行。通过 “Add Podcasts via URL” 菜单,你可以输入播客的 RSS 源 URL 或其他服务的 “特殊” URL。gPodder 将获取节目列表并显示一个对话框,你可以在其中选择要下载的节目或在列表上标记旧节目。
|
||||
|
||||
|
||||
|
||||
它一个更好的功能是,如果 URL 已经在你的剪贴板中,gPodder 会自动将它放入播放 URL 中,这样你就可以很容易地将新的播客添加到列表中。如果你已有播客 feed 的 OPML 文件,那么可以上传并导入它。还有一个发现选项,让你可搜索 [gPodder.net][6] 上的播客,这是由编写和维护 gPodder 的人员提供的自由及开源的播客的列表网站。
|
||||
|
||||
|
||||
|
||||
[mygpo][7] 服务器在设备之间同步播客。gPodder 默认使用 [gPodder.net][8] 的服务器,但是如果你想要运行自己的服务器,那么可以在配置文件中更改它(请注意,你需要直接修改配置文件)。同步能让你在桌面和移动设备之间保持列表一致。如果你在多个设备上收听播客(例如,我在我的工作电脑、家用电脑和手机上收听),这会非常有用,因为这意味着无论你身在何处,你都拥有最近的播客和节目列表而无需一次又一次地设置。
|
||||
|
||||
|
||||
|
||||
单击播客节目将显示与其关联的文本,单击“播放”将启动设备的默认音频或视频播放器。如果要使用默认之外的其他播放器,可以在 gPodder 的配置设置中更改此设置。
|
||||
|
||||
通过 gPodder,你可以轻松查找、下载和收听播客,在设备之间同步这些播客,在易于使用的界面中访问许多其他功能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-gpodder
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/users/ksonney
|
||||
[2]: https://gpodder.github.io/
|
||||
[3]: https://feedburner.google.com/
|
||||
[4]: https://youtube.com
|
||||
[5]: https://soundcloud.com/
|
||||
[6]: http://gpodder.net
|
||||
[7]: https://github.com/gpodder/mygpo
|
||||
[8]: http://gPodder.net
|
||||
@ -0,0 +1,111 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10577-1.html)
|
||||
[#]: subject: (Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro)
|
||||
[#]: via: (https://itsfoss.com/olive-video-editor)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Olive:一款以 Final Cut Pro 为目标的开源视频编辑器
|
||||
======
|
||||
|
||||
[Olive][1] 是一个正在开发的新的开源视频编辑器。这个非线性视频编辑器旨在提供高端专业视频编辑软件的免费替代品。目标高么?我认为是的。
|
||||
|
||||
如果你读过我们的 [Linux 中的最佳视频编辑器][2]这篇文章,你可能已经注意到大多数“专业级”视频编辑器(如 [Lightworks][3] 或 DaVinciResolve)既不免费也不开源。
|
||||
|
||||
[Kdenlive][4] 和 Shotcut 也是此类,但它通常无法达到专业视频编辑的标准(这是许多 Linux 用户说的)。
|
||||
|
||||
爱好者级和专业级的视频编辑之间的这种差距促使 Olive 的开发人员启动了这个项目。
|
||||
|
||||
![Olive Video Editor][5]
|
||||
|
||||
*Olive 视频编辑器界面*
|
||||
|
||||
Libre Graphics World 中有一篇详细的[关于 Olive 的点评][6]。实际上,这是我第一次知道 Olive 的地方。如果你有兴趣了解更多信息,请阅读该文章。
|
||||
|
||||
### 在 Linux 中安装 Olive 视频编辑器
|
||||
|
||||
> 提醒你一下。Olive 正处于发展的早期阶段。你会发现很多 bug 和缺失/不完整的功能。你不应该把它当作你的主要视频编辑器。
|
||||
|
||||
如果你想测试 Olive,有几种方法可以在 Linux 上安装它。
|
||||
|
||||
#### 通过 PPA 在基于 Ubuntu 的发行版中安装 Olive
|
||||
|
||||
你可以在 Ubuntu、Mint 和其他基于 Ubuntu 的发行版使用官方 PPA 安装 Olive。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:olive-editor/olive-editor
|
||||
sudo apt-get update
|
||||
sudo apt-get install olive-editor
|
||||
```
|
||||
|
||||
#### 通过 Snap 安装 Olive
|
||||
|
||||
如果你的 Linux 发行版支持 Snap,则可以使用以下命令进行安装。
|
||||
|
||||
```
|
||||
sudo snap install --edge olive-editor
|
||||
```
|
||||
|
||||
#### 通过 Flatpak 安装 Olive
|
||||
|
||||
如果你的 [Linux 发行版支持 Flatpak][7],你可以通过 Flatpak 安装 Olive 视频编辑器。
|
||||
|
||||
- [Flatpak 地址](https://flathub.org/apps/details/org.olivevideoeditor.Olive)
|
||||
|
||||
#### 通过 AppImage 使用 Olive
|
||||
|
||||
不想安装吗?下载 [AppImage][8] 文件,将其设置为可执行文件并运行它。32 位和 64 位 AppImage 文件都有。你应该下载相应的文件。
|
||||
|
||||
- [下载 Olive 的 AppImage](https://github.com/olive-editor/olive/releases/tag/continuous)
|
||||
|
||||
Olive 也可用于 Windows 和 macOS。你可以从它的[下载页面][9]获得它。
|
||||
|
||||
### 想要支持 Olive 视频编辑器的开发吗?
|
||||
|
||||
如果你喜欢 Olive 尝试实现的功能,并且想要支持它,那么你可以通过以下几种方式。
|
||||
|
||||
如果你在测试 Olive 时发现一些 bug,请到它们的 GitHub 仓库中报告。
|
||||
|
||||
- [提交 bug 报告以帮助 Olive](https://github.com/olive-editor/olive/issues)
|
||||
|
||||
如果你是程序员,请浏览 Olive 的源代码,看看你是否可以通过编码技巧帮助项目。
|
||||
|
||||
- [Olive 的 GitHub 仓库](https://github.com/olive-editor/olive)
|
||||
|
||||
在经济上为项目做贡献是另一种可以帮助开发开源软件的方法。你可以通过成为赞助人来支持 Olive。
|
||||
|
||||
- [赞助 Olive](https://www.patreon.com/olivevideoeditor)
|
||||
|
||||
如果你没有支持 Olive 的金钱或编码技能,你仍然可以帮助它。在社交媒体或你经常访问的 Linux/软件相关论坛和群组中分享这篇文章或 Olive 的网站。一点微小的口碑都能间接地帮助它。
|
||||
|
||||
### 你如何看待 Olive?
|
||||
|
||||
评判 Olive 还为时过早。我希望能够持续快速开发,并且在年底之前发布 Olive 的稳定版(如果我没有过于乐观的话)。
|
||||
|
||||
你如何看待 Olive?你是否认同开发人员针对专业用户的目标?你希望 Olive 拥有哪些功能?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/olive-video-editor
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.olivevideoeditor.org/
|
||||
[2]: https://itsfoss.com/best-video-editing-software-linux/
|
||||
[3]: https://www.lwks.com/
|
||||
[4]: https://kdenlive.org/en/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?resize=800%2C450&ssl=1
|
||||
[6]: http://libregraphicsworld.org/blog/entry/introducing-olive-new-non-linear-video-editor
|
||||
[7]: https://itsfoss.com/flatpak-guide/
|
||||
[8]: https://itsfoss.com/use-appimage-linux/
|
||||
[9]: https://www.olivevideoeditor.org/download.php
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10566-1.html)
|
||||
[#]: subject: (Will quantum computing break security?)
|
||||
[#]: via: (https://opensource.com/article/19/1/will-quantum-computing-break-security)
|
||||
[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
|
||||
|
||||
量子计算会打破现有的安全体系吗?
|
||||
======
|
||||
|
||||
> 你会希望<ruby>[某黑客][6]<rt>J. Random Hacker</rt></ruby>假冒你的银行吗?
|
||||
|
||||

|
||||
|
||||
近年来,<ruby>量子计算机<rt>quantum computer</rt></ruby>已经出现在大众的视野当中。量子计算机被认为是第六类计算机,这六类计算机包括:
|
||||
|
||||
1. <ruby>人力<rt>Humans</rt></ruby>:在人造的计算工具出现之前,人类只能使用人力去进行计算。而承担计算工作的人,只能被称为“计算者”。
|
||||
2. <ruby>模拟计算工具<rt>Mechanical analogue</rt></ruby>:由人类制造的一些模拟计算过程的小工具,例如<ruby>[安提凯希拉装置][1]<rt>Antikythera mechanism</rt></ruby>、<ruby>星盘<rt>astrolabe</rt></ruby>、<ruby>计算尺<rt>slide rule</rt></ruby>等等。
|
||||
3. <ruby>机械工具<rt>Mechanical digital</rt></ruby>:在这一个类别中包括了运用到离散数学但未使用电子技术进行计算的工具,例如<ruby>算盘<rt>abacus</rt></ruby>、Charles Babbage 的<ruby>差分机<rt>Difference Engine</rt></ruby>等等。
|
||||
4. <ruby>电子模拟计算工具<rt>Electronic analogue</rt></ruby>:这一个类别的计算机多数用于军事方面的用途,例如炸弹瞄准器、枪炮瞄准装置等等。
|
||||
5. <ruby>电子计算机<rt>Electronic digital</rt></ruby>:我在这里会稍微冒险一点,我觉得 Colossus 是第一台电子计算机,[^1] :这一类几乎包含现代所有的电子设备,从移动电话到超级计算机,都在这个类别当中。
|
||||
6. <ruby>量子计算机<rt>Quantum computer</rt></ruby>:即将进入我们的生活,而且与之前的几类完全不同。
|
||||
|
||||
### 什么是量子计算?
|
||||
|
||||
<ruby>量子计算<rt>Quantum computing</rt></ruby>的概念来源于<ruby>量子力学<rt>quantum mechanics</rt></ruby>,使用的计算方式和我们平常使用的普通计算非常不同。如果想要深入理解,建议从参考[维基百科上的定义][2]开始。对我们来说,最重要的是理解这一点:量子计算机使用<ruby>量子位<rt>qubit</rt></ruby>进行计算。在这样的前提下,对于很多数学算法和运算操作,量子计算机的计算速度会比普通计算机要快得多。
|
||||
|
||||
这里的“快得多”是按数量级来说的“快得多”。在某些情况下,一个计算任务如果由普通计算机来执行,可能要耗费几年或者几十年才能完成,但如果由量子计算机来执行,就只需要几秒钟。这样的速度甚至令人感到可怕。因为量子计算机会非常擅长信息的加密解密计算,即使在没有密钥的情况下,也能快速完成繁重的计算任务。
|
||||
|
||||
这意味着,如果拥有足够强大的量子计算机,那么你的所有信息都会被一览无遗,任何被加密的数据都可以被正确解密出来,甚至伪造数字签名也会成为可能。这确实是一个严重的问题。谁也不想被某个黑客冒充成自己在用的银行,更不希望自己在区块链上的交易被篡改得面目全非。
|
||||
|
||||
### 好消息
|
||||
|
||||
尽管上面的提到的问题非常可怕,但也不需要太担心。
|
||||
|
||||
首先,如果要实现上面提到的能力,一台可以操作大量量子位的量子计算机是必不可少的,而这个硬件上的要求就是一个很高的门槛。[^4] 目前普遍认为,规模大得足以有效破解经典加密算法的量子计算机在最近几年还不可能出现。
|
||||
|
||||
其次,除了攻击现有的加密算法需要大量的量子位以外,还需要很多量子位来保证容错性。
|
||||
|
||||
还有,尽管确实有一些理论上的模型阐述了量子计算机如何对一些现有的算法作出攻击,但是要让这样的理论模型实际运作起来的难度会比我们[^5] 想象中大得多。事实上,有一些攻击手段也是未被完全确认是可行的,又或者这些攻击手段还需要继续耗费很多年的改进才能到达如斯恐怖的程度。
|
||||
|
||||
最后,还有很多专业人士正在研究能够防御量子计算的算法(这样的算法也被称为“<ruby>后量子算法<rt>post-quantum algorithms</rt></ruby>”)。如果这些防御算法经过测试以后投入使用,我们就可以使用这些算法进行加密,来对抗量子计算了。
|
||||
|
||||
总而言之,很多专家都认为,我们现有的加密方式在未来 5 年甚至未来 10 年内都是安全的,不需要过分担心。
|
||||
|
||||
### 也有坏消息
|
||||
|
||||
但我们也并不是高枕无忧了,以下两个问题就值得我们关注:
|
||||
|
||||
1. 人们在设计应用系统的时候仍然没有对量子计算作出太多的考量。如果设计的系统可能会使用 10 年以上,又或者数据加密和签名的时间跨度在 10 年以上,那么就必须考虑量子计算在未来会不会对系统造成不利的影响。
|
||||
2. 新出现的防御量子计算的算法可能会是专有的。也就是说,如果基于这些防御量子计算的算法来设计系统,那么在系统落地的时候,可能会需要为此付费。尽管我是支持开源的,尤其是[开源密码学][3],但我最担心的就是无法开源这方面的内容。而且最糟糕的是,在建立新的协议标准时(不管是事实标准还是通过标准组织建立的标准),无论是故意的,还是无意忽略,或者是没有好的开源替代品,他们都很可能使用专有算法而排除使用开源算法。
|
||||
|
||||
### 我们要怎样做?
|
||||
|
||||
幸运的是,针对上述两个问题,我们还是有应对措施的。首先,在整个系统的设计阶段,就需要考虑到它是否会受到量子计算的影响,并作出相应的规划。当然了,不需要现在就立即采取行动,因为当前的技术水平也没法实现有效的方案,但至少也要[在加密方面保持敏捷性][4],以便在任何需要的时候为你的协议和系统更换更有效的加密算法。[^7]
|
||||
|
||||
其次是参与开源运动。尽可能鼓励密码学方面的有识之士团结起来,支持开放标准,并投入对非专有的防御量子计算的算法研究当中去。这一点也算是当务之急,因为号召更多的人重视起来并加入研究,比研究本身更为重要。
|
||||
|
||||
本文首发于《[Alice, Eve, and Bob][5]》,并在作者同意下重新发表。
|
||||
|
||||
[^1]: 我认为把它称为第一台电子可编程计算机是公平的。我知道有早期的非可编程的,也有些人声称是 ENIAC,但我没有足够的空间或精力在这里争论这件事。
|
||||
[^2]: No。
|
||||
[^3]: See 2. Don't get me wrong, by the way—I grew up near Weston-super-Mare, and it's got things going for it, but it's not Mayfair.
|
||||
[^4]: 如果量子物理学家说很难,那么在我看来,就很难。
|
||||
[^5]: 而且我假设我们都不是量子物理学家或数学家。
|
||||
[^6]: I'm definitely not.
|
||||
[^7]: 而且不仅仅是出于量子计算的原因:我们现有的一些经典算法很可能会陷入其他非量子攻击,例如新的数学方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/will-quantum-computing-break-security
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mikecamel
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Antikythera_mechanism
|
||||
[2]: https://en.wikipedia.org/wiki/Quantum_computing
|
||||
[3]: https://opensource.com/article/17/10/many-eyes
|
||||
[4]: https://aliceevebob.com/2017/04/04/disbelieving-the-many-eyes-hypothesis/
|
||||
[5]: https://aliceevebob.com/2019/01/08/will-quantum-computing-break-security/
|
||||
[6]: https://www.techopedia.com/definition/20225/j-random-hacker
|
||||
@ -0,0 +1,228 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (leommxj)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10571-1.html)
|
||||
[#]: subject: (How to determine how much memory is installed, used on Linux systems)
|
||||
[#]: via: (https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何在 Linux 系统中判断安装、使用了多少内存
|
||||
======
|
||||
|
||||
> 有几个命令可以报告在 Linux 系统上安装和使用了多少内存。根据你使用的命令,你可能会被细节淹没,也可能获得快速简单的答案。
|
||||
|
||||

|
||||
|
||||
在 Linux 系统中有很多种方法获取有关安装了多少内存的信息及查看多少内存正在被使用。有些命令提供了大量的细节,而其他命令提供了简洁但不一定易于理解的答案。在这篇文章中,我们将介绍一些查看内存及其使用状态的有用的工具。
|
||||
|
||||
在我们开始之前,让我们先来回顾一些基础知识。物理内存和虚拟内存并不是一回事。后者包括配置为交换空间的磁盘空间。交换空间可能包括为此目的特意留出来的分区,以及在创建新的交换分区不可行时创建的用来增加可用交换空间的文件。有些 Linux 命令会提供关于两者的信息。
|
||||
|
||||
当物理内存占满时,交换空间通过提供可以用来存放内存中非活动页的磁盘空间来扩展内存。
|
||||
|
||||
`/proc/kcore` 是在内存管理中起作用的一个文件。这个文件看上去是个普通文件(虽然非常大),但它并不占用任何空间。它就像其他 `/proc` 下的文件一样是个虚拟文件。
|
||||
|
||||
```
|
||||
$ ls -l /proc/kcore
|
||||
-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
|
||||
```
|
||||
|
||||
有趣的是,下面查询的两个系统并没有安装相同大小的内存,但 `/proc/kcore` 的大小却是相同的。第一个系统安装了 4 GB 的内存,而第二个系统安装了 6 GB。
|
||||
|
||||
```
|
||||
system1$ ls -l /proc/kcore
|
||||
-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
|
||||
system2$ ls -l /proc/kcore
|
||||
-r-------- 1 root root 140737477881856 Feb 5 13:00 /proc/kcore
|
||||
```
|
||||
|
||||
一种不靠谱的解释说这个文件代表可用虚拟内存的大小(没准要加 4 KB),如果这样,这些系统的虚拟内存可就是 128TB 了!这个数字似乎代表了 64 位系统可以寻址多少内存,而不是当前系统有多少可用内存。在命令行中计算 128 TB 和这个文件大小加上 4 KB 很容易。
|
||||
|
||||
```
|
||||
$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128
|
||||
140737488355328
|
||||
$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128 + 4096
|
||||
140737488359424
|
||||
```
|
||||
|
||||
另一个用来检查内存的更人性化的命令是 `free`。它会给出一个易于理解的内存报告。
|
||||
|
||||
```
|
||||
$ free
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812244 4090752 13112 1199480 4984140
|
||||
Swap: 2097148 0 2097148
|
||||
```
|
||||
|
||||
使用 `-g` 选项,`free` 会以 GB 为单位返回结果。
|
||||
|
||||
```
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 5 0 3 0 1 4
|
||||
Swap: 1 0 1
|
||||
```
|
||||
|
||||
使用 `-t` 选项,`free` 会显示与无附加选项时相同的值(不要把 `-t` 选项理解成 TB),并额外在输出的底部添加一行总计数据。
|
||||
|
||||
```
|
||||
$ free -t
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812408 4090612 13112 1199456 4983984
|
||||
Swap: 2097148 0 2097148
|
||||
Total: 8199624 812408 6187760
|
||||
```
|
||||
|
||||
当然,你也可以选择同时使用两个选项。
|
||||
|
||||
```
|
||||
$ free -tg
|
||||
total used free shared buff/cache available
|
||||
Mem: 5 0 3 0 1 4
|
||||
Swap: 1 0 1
|
||||
Total: 7 0 5
|
||||
```
|
||||
|
||||
如果你尝试用这个报告来解释“这个系统安装了多少内存?”,你可能会感到失望。上面的报告就是在前文说的装有 6 GB 内存的系统上运行的结果。这并不是说这个结果是错的,这就是系统对其可使用的内存的看法。
|
||||
|
||||
`free` 命令也提供了每隔 X 秒刷新显示的选项(下方示例中 X 为 10)。
|
||||
|
||||
```
|
||||
$ free -s 10
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812280 4090704 13112 1199492 4984108
|
||||
Swap: 2097148 0 2097148
|
||||
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812260 4090712 13112 1199504 4984120
|
||||
Swap: 2097148 0 2097148
|
||||
```
|
||||
|
||||
使用 `-l` 选项,`free` 命令会提供高低内存使用信息。
|
||||
|
||||
```
|
||||
$ free -l
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102476 812376 4090588 13112 1199512 4984000
|
||||
Low: 6102476 2011888 4090588
|
||||
High: 0 0 0
|
||||
Swap: 2097148 0 2097148
|
||||
```
|
||||
|
||||
查看内存的另一个选择是 `/proc/meminfo` 文件。像 `/proc/kcore` 一样,这也是一个虚拟文件,它可以提供关于安装或使用了多少内存以及可用内存的报告。显然,空闲内存和可用内存并不是同一回事。`MemFree` 看起来代表未使用的 RAM。`MemAvailable` 则是对于启动新程序时可使用的内存的一个估计。
|
||||
|
||||
```
|
||||
$ head -3 /proc/meminfo
|
||||
MemTotal: 6102476 kB
|
||||
MemFree: 4090596 kB
|
||||
MemAvailable: 4984040 kB
|
||||
```
|
||||
|
||||
如果只想查看内存总计,可以使用下面的命令之一:
|
||||
|
||||
```
|
||||
$ awk '/MemTotal/ {print $2}' /proc/meminfo
|
||||
6102476
|
||||
$ grep MemTotal /proc/meminfo
|
||||
MemTotal: 6102476 kB
|
||||
```
|
||||
|
||||
`DirectMap` 将内存信息分为几类。
|
||||
|
||||
```
|
||||
$ grep DirectMap /proc/meminfo
|
||||
DirectMap4k: 213568 kB
|
||||
DirectMap2M: 6076416 kB
|
||||
```
|
||||
|
||||
`DirectMap4k` 代表被映射成标准 4 k 页的内存大小,`DirectMap2M` 则显示了被映射为 2 MB 的页的内存大小。
|
||||
|
||||
`getconf` 命令将会提供比我们大多数人想要看到的更多的信息。
|
||||
|
||||
```
|
||||
$ getconf -a | more
|
||||
LINK_MAX 65000
|
||||
_POSIX_LINK_MAX 65000
|
||||
MAX_CANON 255
|
||||
_POSIX_MAX_CANON 255
|
||||
MAX_INPUT 255
|
||||
_POSIX_MAX_INPUT 255
|
||||
NAME_MAX 255
|
||||
_POSIX_NAME_MAX 255
|
||||
PATH_MAX 4096
|
||||
_POSIX_PATH_MAX 4096
|
||||
PIPE_BUF 4096
|
||||
_POSIX_PIPE_BUF 4096
|
||||
SOCK_MAXBUF
|
||||
_POSIX_ASYNC_IO
|
||||
_POSIX_CHOWN_RESTRICTED 1
|
||||
_POSIX_NO_TRUNC 1
|
||||
_POSIX_PRIO_IO
|
||||
_POSIX_SYNC_IO
|
||||
_POSIX_VDISABLE 0
|
||||
ARG_MAX 2097152
|
||||
ATEXIT_MAX 2147483647
|
||||
CHAR_BIT 8
|
||||
CHAR_MAX 127
|
||||
--More--
|
||||
```
|
||||
|
||||
使用类似下面的命令来将其输出精简为指定的内容,你会得到跟前文提到的其他命令相同的结果。
|
||||
|
||||
```
|
||||
$ getconf -a | grep PAGES | awk 'BEGIN {total = 1} {if (NR == 1 || NR == 3) total *=$NF} END {print total / 1024" kB"}'
|
||||
6102476 kB
|
||||
```
|
||||
|
||||
上面的命令通过将下方输出的第一行和最后一行的值相乘来计算内存。
|
||||
|
||||
```
|
||||
PAGESIZE 4096 <==
|
||||
_AVPHYS_PAGES 1022511
|
||||
_PHYS_PAGES 1525619 <==
|
||||
```
|
||||
|
||||
自己动手计算一下,我们就知道这个值是怎么来的了。
|
||||
|
||||
```
|
||||
$ expr 4096 \* 1525619 / 1024
|
||||
6102476
|
||||
```
|
||||
|
||||
显然值得为以上的指令之一设置个 `alias`。
|
||||
|
||||
另一个具有非常易于理解的输出的命令是 `top` 。在 `top` 输出的前五行,你可以看到一些数字显示多少内存正被使用。
|
||||
|
||||
```
|
||||
$ top
|
||||
top - 15:36:38 up 8 days, 2:37, 2 users, load average: 0.00, 0.00, 0.00
|
||||
Tasks: 266 total, 1 running, 265 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.2 us, 0.4 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
MiB Mem : 3244.8 total, 377.9 free, 1826.2 used, 1040.7 buff/cache
|
||||
MiB Swap: 3536.0 total, 3535.7 free, 0.3 used. 1126.1 avail Mem
|
||||
```
|
||||
|
||||
最后一个命令将会以一个非常简洁的方式回答“系统安装了多少内存?”:
|
||||
|
||||
```
|
||||
$ sudo dmidecode -t 17 | grep "Size.*MB" | awk '{s+=$2} END {print s / 1024 "GB"}'
|
||||
6GB
|
||||
```
|
||||
|
||||
取决于你想要获取多少细节,Linux 系统提供了许多用来查看系统安装内存以及使用/空闲内存的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[leommxj](https://github.com/leommxj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10576-1.html)
|
||||
[#]: subject: (How To Grant And Remove Sudo Privileges To Users On Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何在 Ubuntu 上为用户授予和移除 sudo 权限
|
||||
======
|
||||
|
||||

|
||||
|
||||
如你所知,用户可以在 Ubuntu 系统上使用 sudo 权限执行任何管理任务。在 Linux 机器上创建新用户时,他们无法执行任何管理任务,直到你将其加入 `sudo` 组的成员。在这个简短的教程中,我们将介绍如何将普通用户添加到 `sudo` 组以及移除给定的权限,使其成为普通用户。
|
||||
|
||||
### 在 Linux 上向普通用户授予 sudo 权限
|
||||
|
||||
通常,我们使用 `adduser` 命令创建新用户,如下所示。
|
||||
|
||||
```
|
||||
$ sudo adduser ostechnix
|
||||
```
|
||||
|
||||
如果你希望新创建的用户使用 `sudo` 执行管理任务,只需使用以下命令将它添加到 `sudo` 组:
|
||||
|
||||
```
|
||||
$ sudo usermod -a -G sudo hduser
|
||||
```
|
||||
|
||||
上面的命令将使名为 `ostechnix` 的用户成为 `sudo` 组的成员。
|
||||
|
||||
你也可以使用此命令将用户添加到 `sudo` 组。
|
||||
|
||||
```
|
||||
$ sudo adduser ostechnix sudo
|
||||
```
|
||||
|
||||
现在,注销并以新用户身份登录,以使此更改生效。此时用户已成为管理用户。
|
||||
|
||||
要验证它,只需在任何命令中使用 `sudo` 作为前缀。
|
||||
|
||||
```
|
||||
$ sudo mkdir /test
|
||||
[sudo] password for ostechnix:
|
||||
```
|
||||
|
||||
### 移除用户的 sudo 权限
|
||||
|
||||
有时,你可能希望移除特定用户的 `sudo` 权限,而不用在 Linux 中删除它。要将任何用户设为普通用户,只需将其从 `sudo` 组中删除即可。
|
||||
|
||||
比如说如果要从 `sudo` 组中删除名为 `ostechnix` 的用户,只需运行:
|
||||
|
||||
```
|
||||
$ sudo deluser ostechnix sudo
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Removing user `ostechnix' from group `sudo' ...
|
||||
Done.
|
||||
```
|
||||
|
||||
此命令仅从 `sudo` 组中删除用户 `ostechnix`,但不会永久地从系统中删除用户。现在,它成为了普通用户,无法像 `sudo` 用户那样执行任何管理任务。
|
||||
|
||||
此外,你可以使用以下命令撤消用户的 `sudo` 访问权限:
|
||||
|
||||
```
|
||||
$ sudo gpasswd -d ostechnix sudo
|
||||
```
|
||||
|
||||
从 `sudo` 组中删除用户时请小心。不要从 `sudo` 组中删除真正的管理员。
|
||||
|
||||
使用命令验证用户 `ostechnix` 是否已从 `sudo` 组中删除:
|
||||
|
||||
```
|
||||
$ sudo -l -U ostechnix
|
||||
User ostechnix is not allowed to run sudo on ubuntuserver.
|
||||
```
|
||||
|
||||
是的,用户 `ostechnix` 已从 `sudo` 组中删除,他无法执行任何管理任务。
|
||||
|
||||
从 `sudo` 组中删除用户时请小心。如果你的系统上只有一个 `sudo` 用户,并且你将他从 `sudo` 组中删除了,那么就无法执行任何管理操作,例如在系统上安装、删除和更新程序。所以,请小心。在我们的下一篇教程中,我们将解释如何恢复用户的 `sudo` 权限。
|
||||
|
||||
就是这些了。希望这篇文章有用。还有更多好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-grant-and-remove-sudo-privileges-to-users-on-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10573-1.html)
|
||||
[#]: subject: (3 tools for viewing files at the command line)
|
||||
[#]: via: (https://opensource.com/article/19/2/view-files-command-line)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
在命令行查看文件的 3 个工具
|
||||
======
|
||||
|
||||
> 看一下 `less`、Antiword 和 `odt2xt` 这三个实用程序,它们都可以在终端中查看文件。
|
||||
|
||||

|
||||
|
||||
我常说,你不需要使用命令行也可以高效使用 Linux —— 我知道许多 Linux 用户从不打开终端窗口,并且也用的挺好。然而,即使我不认为自己是一名技术人员,我也会在命令行上花费大约 20% 的计算时间,包括操作文件、处理文本和使用实用程序。
|
||||
|
||||
我经常在终端窗口中做的一件事是查看文件,无论是文本还是需要用到文字处理器的文件。有时使用命令行实用程序比启动文本编辑器或文字处理器更容易。
|
||||
|
||||
下面是我在命令行中用来查看文件的三个实用程序。
|
||||
|
||||
### less
|
||||
|
||||
[less][1] 的美妙之处在于它易于使用,它将你正在查看的文件分解为块(或页面),这使得它们更易于阅读。你可以使用它在命令行查看文本文件,例如 README、HTML 文件、LaTeX 文件或其他任何纯文本文件。我在[上一篇文章][2]中介绍了 `less`。
|
||||
|
||||
要使用 `less`,只需输入:
|
||||
|
||||
```
|
||||
less file_name
|
||||
```
|
||||
|
||||
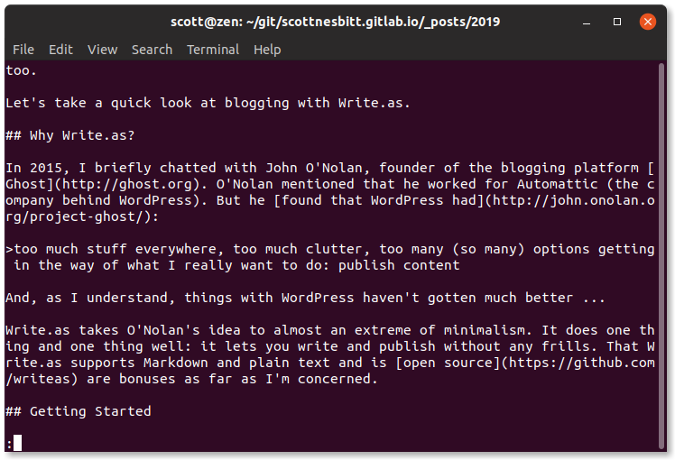
|
||||
|
||||
通过按键盘上的空格键或 `PgDn` 键向下滚动文件,按 `PgUp` 键向上移动文件。要停止查看文件,按键盘上的 `Q` 键。
|
||||
|
||||
### Antiword
|
||||
|
||||
[Antiword][3] 是一个很好地实用小程序,你可以使用它将 Word 文档转换为纯文本。只要你想,还可以将它们转换为 [PostScript][4] 或 [PDF][5]。在本文中,让我们继续使用文本转换。
|
||||
|
||||
Antiword 可以读取和转换 Word 2.0 到 2003 版本创建的文件(LCTT 译注:此处疑为 Word 2000,因为 Word 2.0 for DOS 发布于 1984 年,而 WinWord 2.0 发布于 1991 年,都似乎太老了)。它不能读取 DOCX 文件 —— 如果你尝试这样做,Antiword 会显示一条错误消息,表明你尝试读取的是一个 ZIP 文件。这在技术上说是正确的,但仍然令人沮丧。
|
||||
|
||||
要使用 Antiword 查看 Word 文档,输入以下命令:
|
||||
|
||||
```
|
||||
antiword file_name.doc
|
||||
```
|
||||
|
||||
Antiword 将文档转换为文本并显示在终端窗口中。不幸的是,它不能在终端中将文档分解成页面。不过,你可以将 Antiword 的输出重定向到 `less` 或 [more][6] 之类的实用程序,一遍对其进行分页。通过输入以下命令来执行此操作:
|
||||
|
||||
```
|
||||
antiword file_name.doc | less
|
||||
```
|
||||
|
||||
如果你是命令行的新手,那么我告诉你 `|` 称为管道。这就是重定向。
|
||||
|
||||
|
||||
|
||||
### odt2txt
|
||||
|
||||
作为一个优秀的开源公民,你会希望尽可能多地使用开放格式。对于你的文字处理需求,你可能需要处理 [ODT][7] 文件(由诸如 LibreOffice Writer 和 AbiWord 等文字处理器使用)而不是 Word 文件。即使没有,也可能会遇到 ODT 文件。而且,即使你的计算机上没有安装 Writer 或 AbiWord,也很容易在命令行中查看它们。
|
||||
|
||||
怎样做呢?用一个名叫 [odt2txt][8] 的实用小程序。正如你猜到的那样,`odt2txt` 将 ODT 文件转换为纯文本。要使用它,运行以下命令:
|
||||
|
||||
```
|
||||
odt2txt file_name.odt
|
||||
```
|
||||
|
||||
与 Antiword 一样,`odt2txt` 将文档转换为文本并在终端窗口中显示。和 Antiword 一样,它不会对文档进行分页。但是,你也可以使用以下命令将 `odt2txt` 的输出管道传输到 `less` 或 `more` 这样的实用程序中:
|
||||
|
||||
```
|
||||
odt2txt file_name.odt | more
|
||||
```
|
||||
|
||||
|
||||
|
||||
你有一个最喜欢的在命令行中查看文件的实用程序吗?欢迎留下评论与社区分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/view-files-command-line
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnu.org/software/less/
|
||||
[2]: https://opensource.com/article/18/4/using-less-view-text-files-command-line
|
||||
[3]: http://www.winfield.demon.nl/
|
||||
[4]: http://en.wikipedia.org/wiki/PostScript
|
||||
[5]: http://en.wikipedia.org/wiki/Portable_Document_Format
|
||||
[6]: https://opensource.com/article/19/1/more-text-files-linux
|
||||
[7]: http://en.wikipedia.org/wiki/OpenDocument
|
||||
[8]: https://github.com/dstosberg/odt2txt
|
||||
@ -1,60 +1,70 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (guevaraya)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10562-1.html)
|
||||
[#]: subject: (How to List Installed Packages on Ubuntu and Debian [Quick Tip])
|
||||
[#]: via: (https://itsfoss.com/list-installed-packages-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何索引 Ubuntu 和 Debian 上已安装的软件包 [快速提示]
|
||||
如何列出 Ubuntu 和 Debian 上已安装的软件包
|
||||
======
|
||||
|
||||
当你安装了 [Ubuntu 并想好好用一用][1]。但在将来某个时候,你肯定会遇到忘记曾经安装了那些软件包。
|
||||
|
||||
这个是完全正常。没有人要求你把系统里所有已安装的软件包都记住。但是问题是,如何才能知道已经安装了哪些软件包?如何查看安装过的软件包呢?
|
||||
|
||||
### 索引 Ubuntu 和 Debian 上已安装的软件包
|
||||
### 列出 Ubuntu 和 Debian 上已安装的软件包
|
||||
|
||||
![索引已安装的软件包][2]
|
||||
![列出已安装的软件包][2]
|
||||
|
||||
如果你经常用 [apt 命令][3],你可能会注意到 apt 可以索引已安装的软件包。这里说对了一点。
|
||||
如果你经常用 [apt 命令][3],你可能觉得会有个命令像 `apt` 一样可以列出已安装的软件包。不算全错。
|
||||
|
||||
[apt-get 命令][4] 没有类似列出已安装软件包的简单的选项,但是 `apt` 有一个这样的命令:
|
||||
|
||||
[apt-get 命令] 没有类似索引已安装软件包的简单的选项,但是 apt 有一个这样的命令:
|
||||
```
|
||||
apt list --installed
|
||||
```
|
||||
这个会显示 apt 命令安装的所有的软件包。同时也会包含由于依赖被安装的软件包。也就是说不仅会包含你曾经安装的程序,而且会包含大量库文件和间接安装的软件包。
|
||||
|
||||
![用 atp 命令索引显示已安装的软件包][5] 用 atp 命令索引显示已安装的软件包
|
||||
这个会显示使用 `apt` 命令安装的所有的软件包。同时也会包含由于依赖而被安装的软件包。也就是说不仅会包含你曾经安装的程序,而且会包含大量库文件和间接安装的软件包。
|
||||
|
||||
![用 atp 命令列出显示已安装的软件包][5]
|
||||
|
||||
*用 atp 命令列出显示已安装的软件包*
|
||||
|
||||
由于列出出来的已安装的软件包太多,用 `grep` 过滤特定的软件包是一个比较好的办法。
|
||||
|
||||
由于索引出来的已安装的软件包太多,用 grep 过滤特定的软件包是一个比较好的办法。
|
||||
```
|
||||
apt list --installed | grep program_name
|
||||
```
|
||||
|
||||
如上命令也可以检索出 .deb 格式的软件包文件。是不是很酷?不是吗?
|
||||
如上命令也可以检索出使用 .deb 软件包文件安装的软件。是不是很酷?
|
||||
|
||||
如果你阅读过 [apt 与 apt-get 对比][7]的文章,你可能已经知道 apt 和 apt-get 命令都是基于 [dpkg][8]。也就是说用 dpkg 命令可以索引 Debian 系统的所有已经安装的软件包。
|
||||
如果你阅读过 [apt 与 apt-get 对比][7]的文章,你可能已经知道 `apt` 和 `apt-get` 命令都是基于 [dpkg][8]。也就是说用 `dpkg` 命令可以列出 Debian 系统的所有已经安装的软件包。
|
||||
|
||||
```
|
||||
dpkg-query -l
|
||||
```
|
||||
你可以用 grep 命令检索指定的软件包。
|
||||
|
||||
![用 dpkg 命令索引显示已经安装的软件包][9]![用 dpkg 命令索引显示已经安装的软件包][9]用 dpkg 命令索引显示已经安装的软件包
|
||||
你可以用 `grep` 命令检索指定的软件包。
|
||||
|
||||
![用 dpkg 命令列出显示已经安装的软件包][9]!
|
||||
|
||||
现在你可以搞定索引 Debian 的软件包管理器安装的应用了。那 Snap 和 Flatpak 这个两种应用呢?如何索引他们?因为他们不能被 apt 和 dpkg 访问。
|
||||
*用 dpkg 命令列出显示已经安装的软件包*
|
||||
|
||||
现在你可以搞定列出 Debian 的软件包管理器安装的应用了。那 Snap 和 Flatpak 这个两种应用呢?如何列出它们?因为它们不能被 `apt` 和 `dpkg` 访问。
|
||||
|
||||
显示系统里所有已经安装的 [Snap 软件包][10],可以这个命令:
|
||||
|
||||
```
|
||||
snap list
|
||||
```
|
||||
Snap 可以用绿色勾号索引显示经过认证的发布者。
|
||||
![索引已经安装的 Snap 软件包][11]索引已经安装的 Snap 软件包
|
||||
|
||||
Snap 可以用绿色勾号标出哪个应用来自经过认证的发布者。
|
||||
|
||||
![列出已经安装的 Snap 软件包][11]
|
||||
|
||||
*列出已经安装的 Snap 软件包*
|
||||
|
||||
显示系统里所有已安装的 [Flatpak 软件包][12],可以用这个命令:
|
||||
|
||||
@ -65,37 +75,45 @@ flatpak list
|
||||
让我来个汇总:
|
||||
|
||||
|
||||
用 apt 命令显示已安装软件包:
|
||||
用 `apt` 命令显示已安装软件包:
|
||||
|
||||
**apt** **list –installed**
|
||||
```
|
||||
apt list –installed
|
||||
```
|
||||
|
||||
用 dpkg 命令显示已安装软件包:
|
||||
用 `dpkg` 命令显示已安装软件包:
|
||||
|
||||
**dpkg-query -l**
|
||||
```
|
||||
dpkg-query -l
|
||||
```
|
||||
|
||||
索引系统里 Snap 已安装软件包:
|
||||
列出系统里 Snap 已安装软件包:
|
||||
|
||||
**snap list**
|
||||
```
|
||||
snap list
|
||||
```
|
||||
|
||||
索引系统里 Flatpak 已安装软件包:
|
||||
列出系统里 Flatpak 已安装软件包:
|
||||
|
||||
**flatpak list**
|
||||
```
|
||||
flatpak list
|
||||
```
|
||||
|
||||
### 显示最近安装的软件包
|
||||
|
||||
现在你已经看过以字母顺序索引的已经安装软件包了。如何显示最近已经安装的软件包?
|
||||
现在你已经看过以字母顺序列出的已经安装软件包了。如何显示最近已经安装的软件包?
|
||||
|
||||
幸运的是,Linux 系统保存了所有发生事件的日志。你可以参考最近安装软件包的日志。
|
||||
|
||||
有两个方法可以来做。用 dpkg 命令的日志或者 apt 命令的日志。
|
||||
有两个方法可以来做。用 `dpkg` 命令的日志或者 `apt` 命令的日志。
|
||||
|
||||
你仅仅需要用 grep 命令过滤已经安装的软件包日志。
|
||||
你仅仅需要用 `grep` 命令过滤已经安装的软件包日志。
|
||||
|
||||
```
|
||||
grep " install " /var/log/dpkg.log
|
||||
```
|
||||
|
||||
这会显示所有的软件安装包,其中包括最近安装的过程中被依赖的软件包。
|
||||
这会显示所有的软件安装包,其中包括最近安装的过程中所依赖的软件包。
|
||||
|
||||
```
|
||||
2019-02-12 12:41:42 install ubuntu-make:all 16.11.1ubuntu1
|
||||
@ -108,13 +126,13 @@ grep " install " /var/log/dpkg.log
|
||||
2019-02-14 11:49:10 install qml-module-qtgraphicaleffects:amd64 5.9.5-0ubuntu1
|
||||
```
|
||||
|
||||
你也可以查看 apt历史命令日志。这个仅会显示用 apt 命令安装的的程序。但不会显示被依赖安装的软件包,详细的日志在日志里可以看到。有时你只是想看看对吧?
|
||||
你也可以查看 `apt` 历史命令日志。这个仅会显示用 `apt` 命令安装的的程序。但不会显示被依赖安装的软件包,详细的日志在日志里可以看到。有时你只是想看看对吧?
|
||||
|
||||
```
|
||||
grep " install " /var/log/apt/history.log
|
||||
```
|
||||
|
||||
具体的显示如下:
|
||||
具体的显示如下:
|
||||
|
||||
```
|
||||
Commandline: apt install pinta
|
||||
@ -128,28 +146,30 @@ Commandline: apt install cool-retro-term
|
||||
Commandline: apt install ubuntu-software
|
||||
```
|
||||
|
||||
![显示最近已安装的软件包][13]显示最近已安装的软件包
|
||||
![显示最近已安装的软件包][13]
|
||||
|
||||
apt 的历史日志非常有用。因为他显示了什么时候执行了 apt 命令,哪个用户执行的命令以及安装的软件包名
|
||||
*显示最近已安装的软件包*
|
||||
|
||||
### 小贴士: 在软件中心显示已安装的程序包名
|
||||
`apt` 的历史日志非常有用。因为他显示了什么时候执行了 `apt` 命令,哪个用户执行的命令以及安装的软件包名。
|
||||
|
||||
如果你觉得终端和命令行交互不友好,可以有一个方法查看系统的程序名。
|
||||
### 小技巧:在软件中心显示已安装的程序包名
|
||||
|
||||
如果你觉得终端和命令行交互不友好,还有一个方法可以查看系统的程序名。
|
||||
|
||||
可以打开软件中心,然后点击已安装标签。你可以看到系统上已经安装的程序包名
|
||||
|
||||
![Ubuntu 软件中心显示已安装的软件包][14] 在软件中心显示已安装的软件包
|
||||
![Ubuntu 软件中心显示已安装的软件包][14]
|
||||
|
||||
这个不会显示库和其他命令行的东西,有可能你也不想看到他们,因为你是大量交互都是在 GUI,相反你可以一直用 Synaptic 软件包管理器。
|
||||
*在软件中心显示已安装的软件包*
|
||||
|
||||
**结束语**
|
||||
这个不会显示库和其他命令行的东西,有可能你也不想看到它们,因为你的大量交互都是在 GUI。此外,你也可以用 Synaptic 软件包管理器。
|
||||
|
||||
我希望这个简易的教程可以帮你查看 Ubuntu 和 基于 Debian 的发行版的已安装软件包。
|
||||
### 结束语
|
||||
|
||||
我希望这个简易的教程可以帮你查看 Ubuntu 和基于 Debian 的发行版的已安装软件包。
|
||||
|
||||
如果你对本文有什么问题或建议,请在下面留言。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/list-installed-packages-ubuntu
|
||||
@ -157,7 +177,7 @@ via: https://itsfoss.com/list-installed-packages-ubuntu
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
296
sources/talk/20160921 lawyer The MIT License, Line by Line.md
Normal file
296
sources/talk/20160921 lawyer The MIT License, Line by Line.md
Normal file
@ -0,0 +1,296 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Amanda0212)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (lawyer The MIT License, Line by Line)
|
||||
[#]: via: (https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html)
|
||||
[#]: author: (Kyle E. Mitchell https://kemitchell.com/)
|
||||
|
||||
lawyer The MIT License, Line by Line
|
||||
======
|
||||
|
||||
### The MIT License, Line by Line
|
||||
|
||||
[The MIT License][1] is the most popular open-source software license. Here’s one read of it, line by line.
|
||||
|
||||
#### Read the License
|
||||
|
||||
If you’re involved in open-source software and haven’t taken the time to read the license from top to bottom—it’s only 171 words—you need to do so now. Especially if licenses aren’t your day-to-day. Make a mental note of anything that seems off or unclear, and keep trucking. I’ll repeat every word again, in chunks and in order, with context and commentary. But it’s important to have the whole in mind.
|
||||
|
||||
> The MIT License (MIT)
|
||||
>
|
||||
> Copyright (c) <year> <copyright holders>
|
||||
>
|
||||
> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||
>
|
||||
> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
>
|
||||
> The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the Software.
|
||||
|
||||
The license is arranged in five paragraphs, but breaks down logically like this:
|
||||
|
||||
* **Header**
|
||||
* **License Title** : “The MIT License”
|
||||
* **Copyright Notice** : “Copyright (c) …”
|
||||
* **License Grant** : “Permission is hereby granted …”
|
||||
* **Grant Scope** : “… to deal in the Software …”
|
||||
* **Conditions** : “… subject to …”
|
||||
* **Attribution and Notice** : “The above … shall be included …”
|
||||
* **Warranty Disclaimer** : “The software is provided ‘as is’ …”
|
||||
* **Limitation of Liability** : “In no event …”
|
||||
|
||||
|
||||
|
||||
Here we go:
|
||||
|
||||
#### Header
|
||||
|
||||
##### License Title
|
||||
|
||||
> The MIT License (MIT)
|
||||
|
||||
“The MIT License” is a not a single license, but a family of license forms derived from language prepared for releases from the Massachusetts Institute of Technology. It has seen a lot of changes over the years, both for the original projects that used it, and also as a model for other projects. The Fedora Project maintains a [kind of cabinet of MIT license curiosities][2], with insipid variations preserved in plain text like anatomical specimens in formaldehyde, tracing a wayward kind of evolution.
|
||||
|
||||
Fortunately, the [Open Source Initiative][3] and [Software Package Data eXchange][4] groups have standardized a generic MIT-style license form as “The MIT License”. OSI in turn has adopted SPDX’ standardized [string identifiers][5] for common open-source licenses, with `MIT` pointing unambiguously to the standardized form “MIT License”. If you want MIT-style terms for a new project, use [the standardized form][1].
|
||||
|
||||
Even if you include “The MIT License” or “SPDX:MIT” in a `LICENSE` file, any responsible reviewer will still run a comparison of the text against the standard form, just to be sure. While various license forms calling themselves “MIT License” vary only in minor details, the looseness of what counts as an “MIT License” has tempted some authors into adding bothersome “customizations”. The canonical horrible, no good, very bad example of this is [the JSON license][6], an MIT-family license plus “The Software shall be used for Good, not Evil.”. This kind of thing might be “very Crockford”. It is definitely a pain in the ass. Maybe the joke was supposed to be on the lawyers. But they laughed all the way to the bank.
|
||||
|
||||
Moral of the story: “MIT License” alone is ambiguous. Folks probably have a good idea what you mean by it, but you’re only going to save everyone—yourself included—time by copying the text of the standard MIT License form into your project. If you use metadata, like the `license` property in package manager metadata files, to designate the `MIT` license, make sure your `LICENSE` file and any header comments use the standard form text. All of this can be [automated][7].
|
||||
|
||||
##### Copyright Notice
|
||||
|
||||
> Copyright (c) <year> <copyright holders>
|
||||
|
||||
Until the 1976 Copyright Act, United States copyright law required specific actions, called “formalities”, to secure copyright in creative works. If you didn’t follow those formalities, your rights to sue others for unauthorized use of your work were limited, often completely lost. One of those formalities was “notice”: Putting marks on your work and otherwise making it known to the market that you were claiming copyright. The © is a standard symbol for marking copyrighted works, to give notice of copyright. The ASCII character set doesn’t have the © symbol, but `Copyright (c)` gets the same point across.
|
||||
|
||||
The 1976 Copyright Act, which “implemented” many requirements of the international Berne Convention, eliminated formalities for securing copyright. At least in the United States, copyright holders still need to register their copyrighted works before suing for infringement, with potentially higher damages if they register before infringement begins. In practice, however, many register copyright right before bringing suit against someone in particular. You don’t lose your copyright just by failing to put notices on it, registering, sending a copy to the Library of Congress, and so on.
|
||||
|
||||
Even if copyright notices aren’t as absolutely necessary as they used to be, they are still plenty useful. Stating the year a work was authored and who the copyright belonged to give some sense of when copyright in the work might expire, bringing the work into the public domain. The identity of the author or authors is also useful: United States law calculates copyright terms differently for individual and “corporate” authors. Especially in business use, it may also behoove a company to think twice about using software from a known competitor, even if the license terms give very generous permission. If you’re hoping others will see your work and want to license it from you, copyright notices serve nicely for attribution.
|
||||
|
||||
As for “copyright holder”: Not all standard form licenses have a space to write this out. More recent license forms, like [Apache 2.0][8] and [GPL 3.0][9], publish `LICENSE` texts that are meant to be copied verbatim, with header comments and separate files elsewhere to indicate who owns copyright and is giving the license. Those approaches neatly discourage changes to the “standard” texts, accidental or intentional. They also make automated license identification more reliable.
|
||||
|
||||
The MIT License descends from language written for releases of code by institutions. For institutional releases, there was just one clear “copyright holder”, the institution releasing the code. Other institutions cribbed these licenses, replacing “MIT” with their own names, leading eventually to the generic forms we have now. This process repeated for other short-form institutional licenses of the era, notably the [original four-clause BSD License][10] for the University of California, Berkeley, now used in [three-clause][11] and [two-clause][12] variants, as well as [The ISC License][13] for the Internet Systems Consortium, an MIT variant.
|
||||
|
||||
In each case, the institution listed itself as the copyright holder in reliance on rules of copyright ownership, called “[works made for hire][14]” rules, that give employers and clients ownership of copyright in some work their employees and contractors do on their behalf. These rules don’t usually apply to distributed collaborators submitting code voluntarily. This poses a problem for project-steward foundations, like the Apache Foundation and Eclipse Foundation, that accept contributions from a more diverse group of contributors. The usual foundation approach thus far has been to use a house license that states a single copyright holder—[Apache 2.0][8] and [EPL 1.0][15]—backed up by contributor license agreements—[Apache CLAs][16] and [Eclipse CLAs][17]—to collect rights from contributors. Collecting copyright ownership in one place is even more important under “copyleft” licenses like the GPL, which rely on copyright owners to enforce license conditions to promote software-freedom values.
|
||||
|
||||
These days, loads of projects without any kind of institutional or business steward use MIT-style license terms. SPDX and OSI have helped these use cases by standardizing forms of licenses like MIT and ISC that don’t refer to a specific entity or institutional copyright holder. Armed with those forms, the prevailing practice of project authors is to fill their own name in the copyright notice of the form very early on … and maybe bump the year here and there. At least under United States copyright law, the resulting copyright notice doesn’t give a full picture.
|
||||
|
||||
The original owner of a piece of software retains ownership of their work. But while MIT-style license terms give others rights to build on and change the software, creating what the law calls “derivative works”, they don’t give the original author ownership of copyright in others’ contributions. Rather, each contributor has copyright in any [even marginally creative][18] work they make using the existing code as a starting point.
|
||||
|
||||
Most of these projects also balk at the idea of taking contributor license agreements, to say nothing of signed copyright assignments. That’s both naive and understandable. Despite the assumption of some newer open-source developers that sending a pull request on GitHub “automatically” licenses the contribution for distribution on the terms of the project’s existing license, United States law doesn’t recognize any such rule. Strong copyright protection, not permissive licensing, is the default.
|
||||
|
||||
Update: GitHub later changed its site-wide terms of service to include an attempt to flip this default, at least on GitHub.com. I’ve written up some thoughts on that development, not all of them positive, in [another post][19].
|
||||
|
||||
To fill the gap between legally effective, well-documented grants of rights in contributions and no paper trail at all, some projects have adopted the [Developer Certificate of Origin][20], a standard statement contributors allude to using `Signed-Off-By` metadata tags in their Git commits. The Developer Certificate of Origin was developed for Linux kernel development in the wake of the infamous SCO lawsuits, which alleged that chunks of Linux’ code derived from SCO-owned Unix source. As a means of creating a paper trail showing that each line of Linux came from a contributor, the Developer Certificate of Origin functions nicely. While the Developer Certificate of Origin isn’t a license, it does provide lots of good evidence that those submitting code expected the project to distribute their code, and for others to use it under the kernel’s existing license terms. The kernel also maintains a machine-readable `CREDITS` file listing contributors with name, affiliation, contribution area, and other metadata. I’ve done [some][21] [experiments][22] adapting that approach for projects that don’t use the kernel’s development flow.
|
||||
|
||||
#### License Grant
|
||||
|
||||
> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”),
|
||||
|
||||
The meat of The MIT License is, you guessed it, a license. In general terms, a license is permission that one person or legal entity—the “licensor”—gives another—the “licensee”—to do something the law would otherwise let them sue for. The MIT License is a promise not to sue.
|
||||
|
||||
The law sometimes distinguishes licenses from promises to give licenses. If someone breaks a promise to give a license, you may be able to sue them for breaking their promise, but you may not end up with a license. “Hereby” is one of those hokey, archaic-sounding words lawyers just can’t get rid of. It’s used here to show that the license text itself gives the license, and not just a promise of a license. It’s a legal [IIFE][23].
|
||||
|
||||
While many licenses give permission to a specific, named licensee, The MIT License is a “public license”. Public licenses give everybody—the public at large—permission. This is one of the three great ideas in open-source licensing. The MIT License captures this idea by giving a license “to any person obtaining a copy of … the Software”. As we’ll see later, there is also a condition to receiving this license that ensures others will learn about their permission, too.
|
||||
|
||||
The parenthetical with a capitalized term in quotation marks (a “Definition”), is the standard way to give terms specific meanings in American-style legal documents. Courts will reliably look back to the terms of the definition when they see a defined, capitalized term used elsewhere in the document.
|
||||
|
||||
##### Grant Scope
|
||||
|
||||
> to deal in the Software without restriction,
|
||||
|
||||
From the licensee’s point of view, these are the seven most important words in The MIT License. The key legal concerns are getting sued for copyright infringement and getting sued for patent infringement. Neither copyright law nor patent law uses “to deal in” as a term of art; it has no specific meaning in court. As a result, any court deciding a dispute between a licensor and a licensee would ask what the parties meant and understood by this language. What the court will see is that the language is intentionally broad and open-ended. It gives licensees a strong argument against any claim by a licensor that they didn’t give permission for the licensee to do that specific thing with the software, even if the thought clearly didn’t occur to either side when the license was given.
|
||||
|
||||
> including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
|
||||
|
||||
No piece of legal writing is perfect, “fully settled in meaning”, or unmistakably clear. Beware anyone who pretends otherwise. This is the least perfect part of The MIT License. There are three main issues:
|
||||
|
||||
First, “including without limitation” is a legal antipattern. It crops up in any number of flavors:
|
||||
|
||||
* “including, without limitation”
|
||||
* “including, without limiting the generality of the foregoing”
|
||||
* “including, but not limited to”
|
||||
* many, many pointless variations
|
||||
|
||||
|
||||
|
||||
All of these share a common purpose, and they all fail to achieve it reliably. Fundamentally, drafters who use them try to have their cake and eat it, too. In The MIT License, that means introducing specific examples of “dealing in the Software”—“use, copy, modify” and so on—without implying that licensee action has to be something like the examples given to count as “dealing in”. The trouble is that, if you end up needing a court to review and interpret the terms of a license, the court will see its job as finding out what those fighting meant by the language. If the court needs to decide what “deal in” means, it cannot “unsee” the examples, even if you tell it to. I’d argue that “deal in the Software without restriction” alone would be better for licensees. Also shorter.
|
||||
|
||||
Second, the verbs given as examples of “deal in” are a hodgepodge. Some have specific meanings under copyright or patent law, others almost do or just plain don’t:
|
||||
|
||||
* use appears in [United States Code title 35, section 271(a)][24], the patent law’s list of what patent owners can sue others for doing without permission.
|
||||
|
||||
* copy appears in [United States Code title 17, section 106][25], the copyright law’s list of what copyright owners can sue others for doing without permission.
|
||||
|
||||
* modify doesn’t appear in either copyright or patent statute. It is probably closest to “prepare derivative works” under the copyright statute, but may also implicate improving or otherwise derivative inventions.
|
||||
|
||||
* merge doesn’t appear in either copyright or patent statute. “Merger” has a specific meaning in copyright, but that’s clearly not what’s intended here. Rather, a court would probably read “merge” according to its meaning in industry, as in “to merge code”.
|
||||
|
||||
* publish doesn’t appear in either copyright or patent statute. Since “the Software” is what’s being published, it probably hews closest to “distribute” under the [copyright statute][25]. That statute also covers rights to perform and display works “publicly”, but those rights apply only to specific kinds of copyrighted work, like plays, sound recordings, and motion pictures.
|
||||
|
||||
* distribute appears in the [copyright statute][25].
|
||||
|
||||
* sublicense is a general term of intellectual property law. The right to sublicense means the right to give others licenses of their own, to do some or all of what you have permission to do. The MIT License’s right to sublicense is actually somewhat unusual in open-source licenses generally. The norm is what Heather Meeker calls a “direct licensing” approach, where everyone who gets a copy of the software and its license terms gets a license direct from the owner. Anyone who might get a sublicense under the MIT License will probably end up with a copy of the license telling them they have a direct license, too.
|
||||
|
||||
* sell copies of is a mongrel. It is close to “offer to sell” and “sell” in the [patent statute][24], but refers to “copies”, a copyright concept. On the copyright side, it seems close to “distribute”, but the [copyright statute][25] makes no mention of sales.
|
||||
|
||||
* permit persons to whom the Software is furnished to do so seems redundant of “sublicense”. It’s also unnecessary to the extent folks who get copies also get a direct license.
|
||||
|
||||
|
||||
|
||||
|
||||
Lastly, as a result of this mishmash of legal, industry, general-intellectual-property, and general-use terms, it isn’t clear whether The MIT License includes a patent license. The general language “deal in” and some of the example verbs, especially “use”, point toward a patent license, albeit a very unclear one. The fact that the license comes from the copyright holder, who may or may not have patent rights in inventions in the software, as well as most of the example verbs and the definition of “the Software” itself, all point strongly toward a copyright license. More recent permissive open-source licenses, like [Apache 2.0][8], address copyright, patent, and even trademark separately and specifically.
|
||||
|
||||
##### Three License Conditions
|
||||
|
||||
> subject to the following conditions:
|
||||
|
||||
There’s always a catch! MIT has three!
|
||||
|
||||
If you don’t follow The MIT License’s conditions, you don’t get the permission the license offers. So failing to do what the conditions say at least theoretically leaves you open to a lawsuit, probably a copyright lawsuit.
|
||||
|
||||
Using the value of the software to the licensee to motivate compliance with conditions, even though the licensee paid nothing for the license, is the second great idea of open-source licensing. The last, not found in The MIT License, builds off license conditions: “Copyleft” licenses like the [GNU General Public License][9] use license conditions to control how those making changes can license and distribute their changed versions.
|
||||
|
||||
##### Notice Condition
|
||||
|
||||
> The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
|
||||
If you give someone a copy of the software, you need to include the license text and any copyright notice. This serves a few critical purposes:
|
||||
|
||||
1. Gives others notice that they have permission for the software under the public license. This is a key part of the direct-licensing model, where each user gets a license direct from the copyright holder.
|
||||
|
||||
2. Makes known who’s behind the software, so they can be showered in praises, glory, and cold, hard cash donations.
|
||||
|
||||
3. Ensures the warranty disclaimer and limitation of liability (coming up next) follow the software around. Everyone who gets a copy should get a copy of those licensor protections, too.
|
||||
|
||||
|
||||
|
||||
|
||||
There’s nothing to stop you charging for providing a copy, or even a copy in compiled form, without source code. But when you do, you can’t pretend that the MIT code is your own proprietary code, or provided under some other license. Those receiving get to know their rights under the “public license”.
|
||||
|
||||
Frankly, compliance with this condition is breaking down. Nearly every open-source license has such an “attribution” condition. Makers of system and installed software often understand they’ll need to compile a notices file or “license information” screen, with copies of license texts for libraries and components, for each release of their own. The project-steward foundations have been instrumental in teaching those practices. But web developers, as a whole, haven’t got the memo. It can’t be explained away by a lack of tooling—there is plenty—or the highly modular nature of packages from npm and other repositories—which uniformly standardize metadata formats for license information. All the good JavaScript minifiers have command-line flags for preserving license header comments. Other tools will concatenate `LICENSE` files from package trees. There’s really no excuse.
|
||||
|
||||
##### Warranty Disclaimer
|
||||
|
||||
> The Software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement.
|
||||
|
||||
Nearly every state in the United States has enacted a version of the Uniform Commercial Code, a model statute of laws governing commercial transactions. Article 2 of the UCC—“Division 2” in California—governs contracts for sales of goods, from used automobiles bought off the lot to large shipments of industrial chemicals to manufacturing plants.
|
||||
|
||||
Some of the UCC’s rules about sales contracts are mandatory. These rules always apply, whether those buying and selling like them or not. Others are just “defaults”. Unless buyers and sellers opt out in writing, the UCC implies that they want the baseline rule found in the UCC’s text for their deal. Among the default rules are implied “warranties”, or promises by sellers to buyers about the quality and usability of the goods being sold.
|
||||
|
||||
There is a big theoretical debate about whether public licenses like The MIT License are contracts—enforceable agreements between licensors and licensees—or just licenses, which go one way, but may come with strings attached, their conditions. There is less debate about whether software counts as “goods”, triggering the UCC’s rules. There is no debate among licensors on liability: They don’t want to get sued for lots of money if the software they give away for free breaks, causes problems, doesn’t work, or otherwise causes trouble. That’s exactly the opposite of what three default rules for “implied warranties” do:
|
||||
|
||||
1. The implied warranty of “merchantability” under [UCC section 2-314][26] is a promise that “the goods”—the Software—are of at least average quality, properly packaged and labeled, and fit for the ordinary purposes they are intended to serve. This warranty applies only if the one giving the software is a “merchant” with respect to the software, meaning they deal in software and hold themselves out as skilled in software.
|
||||
|
||||
2. The implied warranty of “fitness for a particular purpose” under [UCC section 2-315][27] kicks in when the seller knows the buyer is relying on them to provide goods for a particular purpose. The goods need to actually be “fit” for that purpose.
|
||||
|
||||
3. The implied warranty of “noninfringement” is not part of the UCC, but is a common feature of general contract law. This implied promise protects the buyer if it turns out the goods they received infringe somebody else’s intellectual property rights. That would be the case if the software under The MIT License didn’t actually belong to the one trying to license it, or if it fell under a patent owned by someone else.
|
||||
|
||||
|
||||
|
||||
|
||||
[Section 2-316(3)][28] of the UCC requires language opting out of, or “excluding”, implied warranties of merchantability and fitness for a particular purpose to be conspicuous. “Conspicuous” in turn means written or formatted to call attention to itself, the opposite of microscopic fine print meant to slip past unwary consumers. State law may impose a similar attention-grabbing requirement for disclaimers of noninfringement.
|
||||
|
||||
Lawyers have long suffered under the delusion that writing anything in `ALL-CAPS` meets the conspicuous requirement. That isn’t true. Courts have criticized the Bar for pretending as much, and most everyone agrees all-caps does more to discourage reading than compel it. All the same, most open-source-license forms set their warranty disclaimers in all-caps, in part because that’s the only obvious way to make it stand out in plain-text `LICENSE` files. I’d prefer to use asterisks or other ASCII art, but that ship sailed long, long ago.
|
||||
|
||||
##### Limitation of Liability
|
||||
|
||||
> In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the Software or the use or other dealings in the Software.
|
||||
|
||||
The MIT License gives permission for software “free of charge”, but the law does not assume that folks receiving licenses free of charge give up their rights to sue when things go wrong and the licensor is to blame. “Limitations of liability”, often paired with “damages exclusions”, work a lot like licenses, as promises not to sue. But these are protections for the licensor against lawsuits by licensees.
|
||||
|
||||
In general, courts read limitations of liability and damages exclusions warily, since they can shift an incredible amount of risk from one side to another. To protect the community’s vital interest in giving folks a way to redress wrongs done in court, they “strictly construe” language limiting liability, reading it against the one protected by it where possible. Limitations of liability have to be specific to stand up. Especially in “consumer” contracts and other situations where those giving up the right to sue lack sophistication or bargaining power, courts have sometimes refused to honor language that seemed buried out of sight. Partly for that reason, partly by sheer force of habit, lawyers tend to give limits of liability the all-caps treatment, too.
|
||||
|
||||
Drilling down a bit, the “limitation of liability” part is a cap on the amount of money a licensee can sue for. In open-source licenses, that limit is always no money at all, $0, “not liable”. By contrast, in commercial licenses, it’s often a multiple of license fees paid in the last 12-month period, though it’s often negotiated.
|
||||
|
||||
The “exclusion” part lists, specifically, kinds of legal claims—reasons to sue for damages—the licensor cannot use. Like many, many legal forms, The MIT License mentions actions “of contract”—for breaching a contract—and “of tort”. Tort rules are general rules against carelessly or maliciously harming others. If you run someone down on the road while texting, you have committed a tort. If your company sells faulty headphones that burn peoples’ ears off, your company has committed a tort. If a contract doesn’t specifically exclude tort claims, courts sometimes read exclusion language in a contract to prevent only contract claims. For good measure, The MIT License throws in “or otherwise”, just to catch the odd admiralty law or other, exotic kind of legal claim.
|
||||
|
||||
The phrase “arising from, out of or in connection with” is a recurring tick symptomatic of the legal draftsman’s inherent, anxious insecurity. The point is that any lawsuit having anything to do with the software is covered by the limitation and exclusions. On the off chance something can “arise from”, but not “out of”, or “in connection with”, it feels better to have all three in the form, so pack ‘em in. Never mind that any court forced to split hairs in this part of the form will have to come up with different meanings for each, on the assumption that a professional drafter wouldn’t use different words in a row to mean the same thing. Never mind that in practice, where courts don’t feel good about a limitation that’s disfavored to begin with, they’ll be more than ready to read the scope trigger narrowly. But I digress. The same language appears in literally millions of contracts.
|
||||
|
||||
#### Overall
|
||||
|
||||
All these quibbles are a bit like spitting out gum on the way into church. The MIT License is a legal classic. The MIT License works. It is by no means a panacea for all software IP ills, in particular the software patent scourge, which it predates by decades. But MIT-style licenses have served admirably, fulfilling a narrow purpose—reversing troublesome default rules of copyright, sales, and contract law—with a minimal combination of discreet legal tools. In the greater context of computing, its longevity is astounding. The MIT License has outlasted and will outlast the vast majority of software licensed under it. We can only guess how many decades of faithful legal service it will have given when it finally loses favor. It’s been especially generous to those who couldn’t have afforded their own lawyer.
|
||||
|
||||
We’ve seen how the The MIT License we know today is a specific, standardized set of terms, bringing order at long last to a chaos of institution-specific, haphazard variations.
|
||||
|
||||
We’ve seen how its approach to attribution and copyright notice informed intellectual property management practices for academic, standards, commercial, and foundation institutions.
|
||||
|
||||
We’ve seen how The MIT Licenses grants permission for software to all, for free, subject to conditions that protect licensors from warranties and liability.
|
||||
|
||||
We’ve seen that despite some crusty verbiage and lawyerly affectation, one hundred and seventy one little words can get a hell of a lot of legal work done, clearing a path for open-source software through a dense underbrush of intellectual property and contract.
|
||||
|
||||
I’m so grateful for all who’ve taken the time to read this rather long post, to let me know they found it useful, and to help improve it. As always, I welcome your comments via [e-mail][29], [Twitter][30], and [GitHub][31].
|
||||
|
||||
A number of folks have asked where they can read more, or find run-downs of other licenses, like the GNU General Public License or the Apache 2.0 license. No matter what your particular continuing interest may be, I heartily recommend the following books:
|
||||
|
||||
* Andrew M. St. Laurent’s [Understanding Open Source & Free Software Licensing][32], from O’Reilly.
|
||||
|
||||
I start with this one because, while it’s somewhat dated, its approach is also closest to the line-by-line approach used above. O’Reilly has made it [available online][33].
|
||||
|
||||
* Heather Meeker’s [Open (Source) for Business][34]
|
||||
|
||||
In my opinion, by far the best writing on the GNU General Public License and copyleft more generally. This book covers the history, the licenses, their development, as well as compatibility and compliance. It’s the book I lend to clients considering or dealing with the GPL.
|
||||
|
||||
* Larry Rosen’s [Open Source Licensing][35], from Prentice Hall.
|
||||
|
||||
A great first book, also available for free [online][36]. This is the best introduction to open-source licensing and related law for programmers starting from scratch. This one is also a bit dated in some specific details, but Larry’s taxonomy of licenses and succinct summary of open-source business models stand the test of time.
|
||||
|
||||
|
||||
|
||||
|
||||
All of these were crucial to my own education as an open-source licensing lawyer. Their authors are professional heroes of mine. Have a read! — K.E.M
|
||||
|
||||
I license this article under a [Creative Commons Attribution-ShareAlike 4.0 license][37].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://writing.kemitchell.com/2016/09/21/MIT-License-Line-by-Line.html
|
||||
|
||||
作者:[Kyle E. Mitchell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kemitchell.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://spdx.org/licenses/MIT
|
||||
[2]: https://fedoraproject.org/wiki/Licensing:MIT?rd=Licensing/MIT
|
||||
[3]: https://opensource.org
|
||||
[4]: https://spdx.org
|
||||
[5]: http://spdx.org/licenses/
|
||||
[6]: https://spdx.org/licenses/JSON
|
||||
[7]: https://www.npmjs.com/package/licensor
|
||||
[8]: https://www.apache.org/licenses/LICENSE-2.0
|
||||
[9]: https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[10]: http://spdx.org/licenses/BSD-4-Clause
|
||||
[11]: https://spdx.org/licenses/BSD-3-Clause
|
||||
[12]: https://spdx.org/licenses/BSD-2-Clause
|
||||
[13]: http://www.isc.org/downloads/software-support-policy/isc-license/
|
||||
[14]: http://worksmadeforhire.com/
|
||||
[15]: https://www.eclipse.org/legal/epl-v10.html
|
||||
[16]: https://www.apache.org/licenses/#clas
|
||||
[17]: https://wiki.eclipse.org/ECA
|
||||
[18]: https://en.wikipedia.org/wiki/Feist_Publications,_Inc.,_v._Rural_Telephone_Service_Co.
|
||||
[19]: https://writing.kemitchell.com/2017/02/16/Against-Legislating-the-Nonobvious.html
|
||||
[20]: http://developercertificate.org/
|
||||
[21]: https://github.com/berneout/berneout-pledge
|
||||
[22]: https://github.com/berneout/authors-certificate
|
||||
[23]: https://en.wikipedia.org/wiki/Immediately-invoked_function_expression
|
||||
[24]: https://www.govinfo.gov/app/details/USCODE-2017-title35/USCODE-2017-title35-partIII-chap28-sec271
|
||||
[25]: https://www.govinfo.gov/app/details/USCODE-2017-title17/USCODE-2017-title17-chap1-sec106
|
||||
[26]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2314.&lawCode=COM
|
||||
[27]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2315.&lawCode=COM
|
||||
[28]: https://leginfo.legislature.ca.gov/faces/codes_displaySection.xhtml?sectionNum=2316.&lawCode=COM
|
||||
[29]: mailto:kyle@kemitchell.com
|
||||
[30]: https://twitter.com/kemitchell
|
||||
[31]: https://github.com/kemitchell/writing/tree/master/_posts/2016-09-21-MIT-License-Line-by-Line.md
|
||||
[32]: https://lccn.loc.gov/2006281092
|
||||
[33]: http://www.oreilly.com/openbook/osfreesoft/book/
|
||||
[34]: https://www.amazon.com/dp/1511617772
|
||||
[35]: https://lccn.loc.gov/2004050558
|
||||
[36]: http://www.rosenlaw.com/oslbook.htm
|
||||
[37]: https://creativecommons.org/licenses/by-sa/4.0/legalcode
|
||||
@ -1,3 +1,4 @@
|
||||
name1e5s translating
|
||||
The Rise and Demise of RSS
|
||||
======
|
||||
There are two stories here. The first is a story about a vision of the web’s future that never quite came to fruition. The second is a story about how a collaborative effort to improve a popular standard devolved into one of the most contentious forks in the history of open-source software development.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
acyanbird translating
|
||||
A Short History of Chaosnet
|
||||
======
|
||||
If you fire up `dig` and run a DNS query for `google.com`, you will get a response somewhat like the following:
|
||||
|
||||
@ -1,136 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (jdh8383)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 CI/CD tools for sysadmins)
|
||||
[#]: via: (https://opensource.com/article/18/12/cicd-tools-sysadmins)
|
||||
[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
|
||||
|
||||
7 CI/CD tools for sysadmins
|
||||
======
|
||||
An easy guide to the top open source continuous integration, continuous delivery, and continuous deployment tools.
|
||||

|
||||
|
||||
Continuous integration, continuous delivery, and continuous deployment (CI/CD) have all existed in the developer community for many years. Some organizations have involved their operations counterparts, but many haven't. For most organizations, it's imperative for their operations teams to become just as familiar with CI/CD tools and practices as their development compatriots are.
|
||||
|
||||
CI/CD practices can equally apply to infrastructure and third-party applications and internally developed applications. Also, there are many different tools but all use similar models. And possibly most importantly, leading your company into this new practice will put you in a strong position within your company, and you'll be a beacon for others to follow.
|
||||
|
||||
Some organizations have been using CI/CD practices on infrastructure, with tools like [Ansible][1], [Chef][2], or [Puppet][3], for several years. Other tools, like [Test Kitchen][4], allow tests to be performed on infrastructure that will eventually host applications. In fact, those tests can even deploy the application into a production-like environment and execute application-level tests with production loads in more advanced configurations. However, just getting to the point of being able to test the infrastructure individually is a huge feat. Terraform can also use Test Kitchen for even more [ephemeral][5] and [idempotent][6] infrastructure configurations than some of the original configuration-management tools. Add in Linux containers and Kubernetes, and you can now test full infrastructure and application deployments with prod-like specs and resources that come and go in hours rather than months or years. Everything is wiped out before being deployed and tested again.
|
||||
|
||||
However, you can also focus on getting your network configurations or database data definition language (DDL) files into version control and start running small CI/CD pipelines on them. Maybe it just checks syntax or semantics or some best practices. Actually, this is how most development pipelines started. Once you get the scaffolding down, it will be easier to build on. You'll start to find all kinds of use cases for pipelines once you get started.
|
||||
|
||||
For example, I regularly write a newsletter within my company, and I maintain it in version control using [MJML][7]. I needed to be able to host a web version, and some folks liked being able to get a PDF, so I built a [pipeline][8]. Now when I create a new newsletter, I submit it for a merge request in GitLab. This automatically creates an index.html with links to HTML and PDF versions of the newsletter. The HTML and PDF files are also created in the pipeline. None of this is published until someone comes and reviews these artifacts. Then, GitLab Pages publishes the website and I can pull down the HTML to send as a newsletter. In the future, I'll automatically send the newsletter when the merge request is merged or after a special approval step. This seems simple, but it has saved me a lot of time. This is really at the core of what these tools can do for you. They will save you time.
|
||||
|
||||
The key is creating tools to work in the abstract so that they can apply to multiple problems with little change. I should also note that what I created required almost no code except [some light HTML templating][9], some [node to loop through the HTML files][10], and some more [node to populate the index page with all the HTML pages and PDFs][11].
|
||||
|
||||
Some of this might look a little complex, but most of it was taken from the tutorials of the different tools I'm using. And many developers are happy to work with you on these types of things, as they might also find them useful when they're done. The links I've provided are to a newsletter we plan to start for [DevOps KC][12], and all the code for creating the site comes from the work I did on our internal newsletter.
|
||||
|
||||
Many of the tools listed below can offer this type of interaction, but some offer a slightly different model. The emerging model in this space is that of a declarative description of a pipeline in something like YAML with each stage being ephemeral and idempotent. Many of these systems also ensure correct sequencing by creating a [directed acyclic graph][13] (DAG) over the different stages of the pipeline.
|
||||
|
||||
These stages are often run in Linux containers and can do anything you can do in a container. Some tools, like [Spinnaker][14], focus only on the deployment component and offer some operational features that others don't normally include. [Jenkins][15] has generally kept pipelines in an XML format and most interactions occur within the GUI, but more recent implementations have used a [domain specific language][16] (DSL) using [Groovy][17]. Further, Jenkins jobs normally execute on nodes with a special Java agent installed and consist of a mix of plugins and pre-installed components.
|
||||
|
||||
Jenkins introduced pipelines in its tool, but they were a bit challenging to use and contained several caveats. Recently, the creator of Jenkins decided to move the community toward a couple different initiatives that will hopefully breathe new life into the project—which is the one that really brought CI/CD to the masses. I think its most interesting initiative is creating a Cloud Native Jenkins that can turn a Kubernetes cluster into a Jenkins CI/CD platform.
|
||||
|
||||
As you learn more about these tools and start bringing these practices into your company or your operations division, you'll quickly gain followers. You will increase your own productivity as well as that of others. We all have years of backlog to get to—how much would your co-workers love if you could give them enough time to start tackling that backlog? Not only that, but your customers will start to see increased application reliability, and your management will see you as a force multiplier. That certainly can't hurt during your next salary negotiation or when interviewing with all your new skills.
|
||||
|
||||
Let's dig into the tools a bit more. We'll briefly cover each one and share links to more information.
|
||||
|
||||
### GitLab CI
|
||||
|
||||
GitLab is a fairly new entrant to the CI/CD space, but it's already achieved the top spot in the [Forrester Wave for Continuous Integration Tools][20]. That's a huge achievement in such a crowded and highly qualified field. What makes GitLab CI so great? It uses a YAML file to describe the entire pipeline. It also has a functionality called Auto DevOps that allows for simpler projects to have a pipeline built automatically with multiple tests built-in. This system uses [Herokuish buildpacks][21] to determine the language and how to build the application. Some languages can also manage databases, which is a real game-changer for building new applications and getting them deployed to production from the beginning of the development process. The system has native integrations into Kubernetes and will deploy your application automatically into a Kubernetes cluster using one of several different deployment methodologies, like percentage-based rollouts and blue-green deployments.
|
||||
|
||||
In addition to its CI functionality, GitLab offers many complementary features like operations and monitoring with Prometheus deployed automatically with your application; portfolio and project management using GitLab Issues, Epics, and Milestones; security checks built into the pipeline with the results provided as an aggregate across multiple projects; and the ability to edit code right in GitLab using the WebIDE, which can even provide a preview or execute part of a pipeline for faster feedback.
|
||||
|
||||
### GoCD
|
||||
|
||||
GoCD comes from the great minds at Thoughtworks, which is testimony enough for its capabilities and efficiency. To me, GoCD's main differentiator from the rest of the pack is its [Value Stream Map][22] (VSM) feature. In fact, pipelines can be chained together with one pipeline providing the "material" for the next pipeline. This allows for increased independence for different teams with different responsibilities in the deployment process. This may be a useful feature when introducing this type of system in older organizations that intend to keep these teams separate—but having everyone using the same tool will make it easier later to find bottlenecks in the VSM and reorganize the teams or work to increase efficiencies.
|
||||
|
||||
It's incredibly valuable to have a VSM for each product in a company; that GoCD allows this to be [described in JSON or YAML][23] in version control and presented visually with all the data around wait times makes this tool even more valuable to an organization trying to understand itself better. Start by installing GoCD and mapping out your process with only manual approval gates. Then have each team use the manual approvals so you can start collecting data on where bottlenecks might exist.
|
||||
|
||||
### Travis CI
|
||||
|
||||
Travis CI was my first experience with a Software as a Service (SaaS) CI system, and it's pretty awesome. The pipelines are stored as YAML with your source code, and it integrates seamlessly with tools like GitHub. I don't remember the last time a pipeline failed because of Travis CI or the integration—Travis CI has a very high uptime. Not only can it be used as SaaS, but it also has a version that can be hosted. I haven't run that version—there were a lot of components, and it looked a bit daunting to install all of it. I'm guessing it would be much easier to deploy it all to Kubernetes with [Helm charts provided by Travis CI][26]. Those charts don't deploy everything yet, but I'm sure it will grow even more in the future. There is also an enterprise version if you don't want to deal with the hassle.
|
||||
|
||||
However, if you're developing open source code, you can use the SaaS version of Travis CI for free. That is an awesome service provided by an awesome team! This alleviates a lot of overhead and allows you to use a fairly common platform for developing open source code without having to run anything.
|
||||
|
||||
### Jenkins
|
||||
|
||||
Jenkins is the original, the venerable, de facto standard in CI/CD. If you haven't already, you need to read "[Jenkins: Shifting Gears][27]" from Kohsuke, the creator of Jenkins and CTO of CloudBees. It sums up all of my feelings about Jenkins and the community from the last decade. What he describes is something that has been needed for several years, and I'm happy CloudBees is taking the lead on this transformation. Jenkins will be a bit overwhelming to most non-developers and has long been a burden on its administrators. However, these are items they're aiming to fix.
|
||||
|
||||
[Jenkins Configuration as Code][28] (JCasC) should help fix the complex configuration issues that have plagued admins for years. This will allow for a zero-touch configuration of Jenkins masters through a YAML file, similar to other CI/CD systems. [Jenkins Evergreen][29] aims to make this process even easier by providing predefined Jenkins configurations based on different use cases. These distributions should be easier to maintain and upgrade than the normal Jenkins distribution.
|
||||
|
||||
Jenkins 2 introduced native pipeline functionality with two types of pipelines, which [I discuss][30] in a LISA17 presentation. Neither is as easy to navigate as YAML when you're doing something simple, but they're quite nice for doing more complex tasks.
|
||||
|
||||
[Jenkins X][31] is the full transformation of Jenkins and will likely be the implementation of Cloud Native Jenkins (or at least the thing most users see when using Cloud Native Jenkins). It will take JCasC and Evergreen and use them at their best natively on Kubernetes. These are exciting times for Jenkins, and I look forward to its innovation and continued leadership in this space.
|
||||
|
||||
### Concourse CI
|
||||
|
||||
I was first introduced to Concourse through folks at Pivotal Labs when it was an early beta version—there weren't many tools like it at the time. The system is made of microservices, and each job runs within a container. One of its most useful features that other tools don't have is the ability to run a job from your local system with your local changes. This means you can develop locally (assuming you have a connection to the Concourse server) and run your builds just as they'll run in the real build pipeline. Also, you can rerun failed builds from your local system and inject specific changes to test your fixes.
|
||||
|
||||
Concourse also has a simple extension system that relies on the fundamental concept of resources. Basically, each new feature you want to provide to your pipeline can be implemented in a Docker image and included as a new resource type in your configuration. This keeps all functionality encapsulated in a single, immutable artifact that can be upgraded and modified independently, and breaking changes don't necessarily have to break all your builds at the same time.
|
||||
|
||||
### Spinnaker
|
||||
|
||||
Spinnaker comes from Netflix and is more focused on continuous deployment than continuous integration. It can integrate with other tools, including Travis and Jenkins, to kick off test and deployment pipelines. It also has integrations with monitoring tools like Prometheus and Datadog to make decisions about deployments based on metrics provided by these systems. For example, the canary deployment uses a judge concept and the metrics being collected to determine if the latest canary deployment has caused any degradation in pertinent metrics and should be rolled back or if deployment can continue.
|
||||
|
||||
A couple of additional, unique features related to deployments cover an area that is often overlooked when discussing continuous deployment, and might even seem antithetical, but is critical to success: Spinnaker helps make continuous deployment a little less continuous. It will prevent a stage from running during certain times to prevent a deployment from occurring during a critical time in the application lifecycle. It can also enforce manual approvals to ensure the release occurs when the business will benefit the most from the change. In fact, the whole point of continuous integration and continuous deployment is to be ready to deploy changes as quickly as the business needs to change.
|
||||
|
||||
### Screwdriver
|
||||
|
||||
Screwdriver is an impressively simple piece of engineering. It uses a microservices approach and relies on tools like Nomad, Kubernetes, and Docker to act as its execution engine. There is a pretty good [deployment tutorial][34] for deploying to AWS and Kubernetes, but it could be improved once the in-progress [Helm chart][35] is completed.
|
||||
|
||||
Screwdriver also uses YAML for its pipeline descriptions and includes a lot of sensible defaults, so there's less boilerplate configuration for each pipeline. The configuration describes an advanced workflow that can have complex dependencies among jobs. For example, a job can be guaranteed to run after or before another job. Jobs can run in parallel and be joined afterward. You can also use logical operators to run a job, for example, if any of its dependencies are successful or only if all are successful. Even better is that you can specify certain jobs to be triggered from a pull request. Also, dependent jobs won't run when this occurs, which allows easy segregation of your pipeline for when an artifact should go to production and when it still needs to be reviewed.
|
||||
|
||||
This is only a brief description of these CI/CD tools—each has even more cool features and differentiators you can investigate. They are all open source and free to use, so go deploy them and see which one fits your needs best.
|
||||
|
||||
### What to read next
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/cicd-tools-sysadmins
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ansible.com/
|
||||
[2]: https://www.chef.io/
|
||||
[3]: https://puppet.com/
|
||||
[4]: https://github.com/test-kitchen/test-kitchen
|
||||
[5]: https://www.merriam-webster.com/dictionary/ephemeral
|
||||
[6]: https://en.wikipedia.org/wiki/Idempotence
|
||||
[7]: https://mjml.io/
|
||||
[8]: https://gitlab.com/devopskc/newsletter/blob/master/.gitlab-ci.yml
|
||||
[9]: https://gitlab.com/devopskc/newsletter/blob/master/index/index.html
|
||||
[10]: https://gitlab.com/devopskc/newsletter/blob/master/html-to-pdf.js
|
||||
[11]: https://gitlab.com/devopskc/newsletter/blob/master/populate-index.js
|
||||
[12]: https://devopskc.com/
|
||||
[13]: https://en.wikipedia.org/wiki/Directed_acyclic_graph
|
||||
[14]: https://www.spinnaker.io/
|
||||
[15]: https://jenkins.io/
|
||||
[16]: https://martinfowler.com/books/dsl.html
|
||||
[17]: http://groovy-lang.org/
|
||||
[18]: https://about.gitlab.com/product/continuous-integration/
|
||||
[19]: https://gitlab.com/gitlab-org/gitlab-ce/
|
||||
[20]: https://about.gitlab.com/2017/09/27/gitlab-leader-continuous-integration-forrester-wave/
|
||||
[21]: https://github.com/gliderlabs/herokuish
|
||||
[22]: https://www.gocd.org/getting-started/part-3/#value_stream_map
|
||||
[23]: https://docs.gocd.org/current/advanced_usage/pipelines_as_code.html
|
||||
[24]: https://docs.travis-ci.com/
|
||||
[25]: https://github.com/travis-ci/travis-ci
|
||||
[26]: https://github.com/travis-ci/kubernetes-config
|
||||
[27]: https://jenkins.io/blog/2018/08/31/shifting-gears/
|
||||
[28]: https://jenkins.io/projects/jcasc/
|
||||
[29]: https://github.com/jenkinsci/jep/blob/master/jep/300/README.adoc
|
||||
[30]: https://danbarker.codes/talk/lisa17-becoming-plumber-building-deployment-pipelines/
|
||||
[31]: https://jenkins-x.io/
|
||||
[32]: https://concourse-ci.org/
|
||||
[33]: https://github.com/concourse/concourse
|
||||
[34]: https://docs.screwdriver.cd/cluster-management/kubernetes
|
||||
[35]: https://github.com/screwdriver-cd/screwdriver-chart
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (alim0x)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Linux testing has changed and what matters today)
|
||||
[#]: via: (https://opensource.com/article/19/2/phoronix-michael-larabel)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
How Linux testing has changed and what matters today
|
||||
======
|
||||
Michael Larabel, the founder of Phoronix, shares his insights on the evolution of Linux and open hardware.
|
||||

|
||||
|
||||
If you've ever wondered how your Linux computer stacks up against other Linux, Windows, and MacOS machines or searched for reviews of Linux-compatible hardware, you're probably familiar with [Phoronix][1]. Along with its website, which attracts more than 250 million visitors a year to its Linux reviews and news, the company also offers the [Phoronix Test Suite][2], an open source hardware benchmarking tool, and [OpenBenchmarking.org][3], where test result data is stored.
|
||||
|
||||
According to [Michael Larabel][4], who started Phoronix in 2004, the site "is frequently cited as being the leading source for those interested in computer hardware and Linux. It offers insights regarding the development of the Linux kernel, product reviews, interviews, and news regarding free and open source software."
|
||||
|
||||
I recently had the opportunity to interview Michael about Phoronix and his work.
|
||||
|
||||
The questions and answers have been edited for length and clarity.
|
||||
|
||||
**Don Watkins:** What inspired you to start Phoronix?
|
||||
|
||||
**Michael Larabel:** When I started [Phoronix.com][5] in June 2004, it was still challenging to get a mouse or other USB peripherals working on the popular distributions of the time, like Mandrake, Yoper, MEPIS, and others. So, I set out to work on reviewing different hardware components and their compatibility with Linux. Over time, that shifted more from "does the basic device work?" to how well they perform and what features are supported or unsupported under Linux.
|
||||
|
||||
It's been interesting to see the evolution and the importance of Linux on hardware rise. Linux was very common to LAMP/web servers, but Linux has also become synonymous with high-performance computing (HPC), Android smartphones, cloud software, autonomous vehicles, edge computing, digital signage, and related areas. While Linux hasn't quite dominated the desktop, it's doing great practically everywhere else.
|
||||
|
||||
I also developed the Phoronix Test Suite, with its initial 1.0 public release in 2008, to increase the viability of testing on Linux, engage with more hardware and software vendors on best practices for testing, and just get more test cases running on Linux. At the time, there weren't any really shiny benchmarks on Linux like there were on Windows.
|
||||
|
||||
**DW:** Who are your website's readers?
|
||||
|
||||
**ML:** Phoronix's audience is as diverse as the content. Initially, it was quite desktop/gamer/enthusiast oriented, but as Linux's dominance has grown in HPC, cloud, embedded, etc., my testing has expanded in those areas and thus so has the readership. Readers tend to be interested in open source/Linux ecosystem advancements, performance, and a slight bent towards graphics processor and hardware driver interests.
|
||||
|
||||
**DW:** How important is testing in the Linux world and how has it changed from when you started?
|
||||
|
||||
**ML:** Testing has changed radically since 2004. Back then, many open source projects weren't carrying out any continuous integration (CI) or testing for regressions—both functional issues and performance problems. The hardware vendors supporting Linux were mostly trying to get things working and maintained while being less concerned about performance or scratching away at catching up to Mac, Solaris, and Windows. With time, we've seen the desktop reach close parity with (or exceed, depending upon your views) alternative operating systems. Most PC hardware now works out-of-the-box on Linux, most open source projects engage in some form of CI or testing, and more time and resources are afforded to advancing Linux performance. With high-frequency trading and cloud platforms relying on Linux, performance has become of utmost importance.
|
||||
|
||||
Most of my testing at Phoronix.com is focused on benchmarking processors, graphics cards, storage devices, and other areas of interest to gamers and enthusiasts, but also interesting server platforms. Readers are also quite interested in testing of software components like the Linux kernel, code compilers, and filesystems. But in terms of the Phoronix Test Suite, its scope is rather limitless, with a framework in which new tests can be easily added and automated. There are currently more than 1,000 different profiles/suites, and new ones are routinely added—from machine learning tests to traditional benchmarks.
|
||||
|
||||
**DW:** How important is open source hardware? Where do you see it going?
|
||||
|
||||
**ML:** Open hardware is of increasing importance, especially in light of all the security vulnerabilities and disclosures in recent years. Facebook's work on the [Open Compute Project][6] can be commended, as can Google leveraging [Coreboot][7] in its Chromebook devices, and [Raptor Computing Systems][8]' successful, high-performance, open source POWER9 desktops/workstations/servers. [Intel][9] potentially open sourcing its firmware support package this year is also incredibly tantalizing and will hopefully spur more efforts in this space.
|
||||
|
||||
Outside of that, open source hardware has had a really tough time cracking the consumer space due to the sheer amount of capital necessary and the complexities of designing a modern chip, etc., not to mention competing with the established hardware vendors' marketing budgets and other resources. So, while I would love for 100% open source hardware to dominate—or even compete in features and performance with proprietary hardware—in most segments, that is sadly unlikely to happen, especially with open hardware generally being much more expensive due to economies of scale.
|
||||
|
||||
Software efforts like [OpenBMC][10], Coreboot/[Libreboot][11], and [LinuxBoot][12] are opening up hardware much more. Those efforts at liberating hardware have proven successful and will hopefully continue to be endorsed by more organizations.
|
||||
|
||||
As for [OSHWA][13], I certainly applaud their efforts and the enthusiasm they bring to open source hardware. Certainly, for niche and smaller-scale devices, open source hardware can be a great fit. It will certainly be interesting to see what comes about with OSHWA and some of its partners like Lulzbot, Adafruit, and System76.
|
||||
|
||||
**DW:** Can people install Phoronix Test Suite on their own computers?
|
||||
|
||||
ML: The Phoronix Test Suite benchmarking software is open source under the GPL and can be downloaded from [Phoronix-Test-Suite.com][2] and [GitHub][14]. The benchmarking software works on not only Linux systems but also MacOS, Solaris, BSD, and Windows 10/Windows Server. The Phoronix Test Suite works on x86/x86_64, ARM/AArch64, POWER, RISC-V, and other architectures.
|
||||
|
||||
**DW:** How does [OpenBenchmarking.org][15] work with the Phoronix Test Suite?
|
||||
|
||||
**ML:** OpenBenchmarking.org is, in essence, the "cloud" component to the Phoronix Test Suite. It stores test profiles/test suites in a package manager-like fashion, allows users to upload their own benchmarking results, and offers related functionality around our benchmarking software.
|
||||
|
||||
OpenBenchmarking.org is seamlessly integrated into the Phoronix Test Suite, but from the web interface, it is also where anyone can see the public benchmark results, inspect the open source test profiles to understand their methodology, research hardware and software data, and use similar functionality.
|
||||
|
||||
Another component developed as part of the Phoronix Test Suite is [Phoromatic][16], which effectively allows anyone to deploy their own OpenBenchmarking-like environment within their own private intranet/LAN. This allows organizations to archive their benchmark results locally (and privately), orchestrate benchmarks automatically against groups of systems, manage the benchmark systems, and develop new test cases.
|
||||
|
||||
**DW:** How can people stay up to date on Phoronix?
|
||||
|
||||
**ML:** You can follow [me][17], [Phoronix][18], [Phoronix Test Suite][19], and [OpenBenchMarking.org][20] on Twitter.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/phoronix-michael-larabel
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.phoronix.com/
|
||||
[2]: https://www.phoronix-test-suite.com/
|
||||
[3]: https://openbenchmarking.org/
|
||||
[4]: https://www.michaellarabel.com/
|
||||
[5]: http://Phoronix.com
|
||||
[6]: https://www.opencompute.org/
|
||||
[7]: https://www.coreboot.org/
|
||||
[8]: https://www.raptorcs.com/
|
||||
[9]: https://www.phoronix.com/scan.php?page=news_item&px=Intel-Open-Source-FSP-Likely
|
||||
[10]: https://en.wikipedia.org/wiki/OpenBMC
|
||||
[11]: https://libreboot.org/
|
||||
[12]: https://linuxboot.org/
|
||||
[13]: https://www.oshwa.org/
|
||||
[14]: https://github.com/phoronix-test-suite/
|
||||
[15]: http://OpenBenchmarking.org
|
||||
[16]: http://www.phoronix-test-suite.com/index.php?k=phoromatic
|
||||
[17]: https://twitter.com/michaellarabel
|
||||
[18]: https://twitter.com/phoronix
|
||||
[19]: https://twitter.com/Phoromatic
|
||||
[20]: https://twitter.com/OpenBenchmark
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Do Linux distributions still matter with containers?)
|
||||
[#]: via: (https://opensource.com/article/19/2/linux-distributions-still-matter-containers)
|
||||
[#]: author: (Scott McCarty https://opensource.com/users/fatherlinux)
|
||||
|
||||
Do Linux distributions still matter with containers?
|
||||
======
|
||||
There are two major trends in container builds: using a base image and building from scratch. Each has engineering tradeoffs.
|
||||

|
||||
|
||||
Some people say Linux distributions no longer matter with containers. Alternative approaches, like distroless and scratch containers, seem to be all the rage. It appears we are considering and making technology decisions based more on fashion sense and immediate emotional gratification than thinking through the secondary effects of our choices. We should be asking questions like: How will these choices affect maintenance six months down the road? What are the engineering tradeoffs? How does this paradigm shift affect our build systems at scale?
|
||||
|
||||
It's frustrating to watch. If we forget that engineering is a zero-sum game with measurable tradeoffs—advantages and disadvantages, with costs and benefits of different approaches— we do ourselves a disservice, we do our employers a disservice, and we do our colleagues who will eventually maintain our code a disservice. Finally, we do all of the maintainers ([hail the maintainers!][1]) a disservice by not appreciating the work they do.
|
||||
|
||||
### Understanding the problem
|
||||
|
||||
To understand the problem, we have to investigate why we started using Linux distributions in the first place. I would group the reasons into two major buckets: kernels and other packages. Compiling kernels is actually fairly easy. Slackware and Gentoo (I still have a soft spot in my heart) taught us that.
|
||||
|
||||
On the other hand, the tremendous amount of development and runtime software that needs to be packaged for a usable Linux system can be daunting. Furthermore, the only way you can ensure that millions of permutations of packages can be installed and work together is by using the old paradigm: compile it and ship it together as a thing (i.e., a Linux distribution). So, why do Linux distributions compile kernels and all the packages together? Simple: to make sure things work together.
|
||||
|
||||
First, let's talk about kernels. The kernel is special. Booting a Linux system without a compiled kernel is a bit of a challenge. It's the core of a Linux operating system, and it's the first thing we rely on when a system boots. Kernels have a lot of different configuration options when they're being compiled that can have a tremendous effect on how hardware and software run on one. A secondary problem in this bucket is that system software, like compilers, C libraries, and interpreters, must be tuned for the options you built into the kernel. Gentoo taught us this in a visceral way, which turned everyone into a miniature distribution maintainer.
|
||||
|
||||
Embarrassingly (because I have worked with containers for the last five years), I must admit that I have compiled kernels quite recently. I had to get nested KVM working on RHEL 7 so that I could run [OpenShift on OpenStack][2] virtual machines, in a KVM virtual machine on my laptop, as well as [our Container Development Kit (CDK][3]). #justsayin Suffice to say, I fired RHEL7 up on a brand new 4.X kernel at the time. Like any good sysadmin, I was a little worried that I missed some important configuration options and patches. And, of course, I had missed some things. Sleep mode stopped working right, my docking station stopped working right, and there were numerous other small, random errors. But it did work well enough for a live demo of OpenShift on OpenStack, in a single KVM virtual machine on my laptop. Come on, that's kinda' fun, right? But I digress…
|
||||
|
||||
Now, let's talk about all the other packages. While the kernel and associated system software can be tricky to compile, the much, much bigger problem from a workload perspective is compiling thousands and thousands of packages to give us a useable Linux system. Each package requires subject matter expertise. Some pieces of software require running only three commands: **./configure** , **make** , and **make install**. Others require a lot of subject matter expertise ranging from adding users and configuring specific defaults in **etc** to running post-install scripts and adding systemd unit files. The set of skills necessary for the thousands of different pieces of software you might use is daunting for any single person. But, if you want a usable system with the ability to try new software whenever you want, you have to learn how to compile and install the new software before you can even begin to learn to use it. That's Linux without a Linux distribution. That's the engineering problem you are agreeing to when you forgo a Linux distribution.
|
||||
|
||||
The point is that you have to build everything together to ensure it works together with any sane level of reliability, and it takes a ton of knowledge to build a usable cohort of packages. This is more knowledge than any single developer or sysadmin is ever going to reasonably learn and retain. Every problem I described applies to your [container host][4] (kernel and system software) and [container image][5] (system software and all other packages)—notice the overlap; there are compilers, C libraries, interpreters, and JVMs in the container image, too.
|
||||
|
||||
### The solution
|
||||
|
||||
You already know this, but Linux distributions are the solution. Stop reading and send your nearest package maintainer (again, hail the maintainers!) an e-card (wait, did I just give my age away?). Seriously though, these people do a ton of work, and it's really underappreciated. Kubernetes, Istio, Prometheus, and Knative: I am looking at you. Your time is coming too, when you will be in maintenance mode, overused, and underappreciated. I will be writing this same article again, probably about Kubernetes, in about seven to 10 years.
|
||||
|
||||
### First principles with container builds
|
||||
|
||||
There are tradeoffs to building from scratch and building from base images.
|
||||
|
||||
#### Building from base images
|
||||
|
||||
Building from base images has the advantage that most build operations are nothing more than a package install or update. It relies on a ton of work done by package maintainers in a Linux distribution. It also has the advantage that a patching event six months—or even 10 years—from now (with RHEL) is an operations/systems administrator event (yum update), not a developer event (that requires picking through code to figure out why some function argument no longer works).
|
||||
|
||||
Let's double-click on that a bit. Application code relies on a lot of libraries ranging from JSON munging libraries to object-relational mappers. Unlike the Linux kernel and Glibc, these types of libraries change with very little regard to breaking API compatibility. That means that three years from now your patching event likely becomes a code-changing event, not a yum update event. Got it, let that sink in. Developers, you are getting paged at 2 AM if the security team can't find a firewall hack to block the exploit.
|
||||
|
||||
Building from a base image is not perfect; there are disadvantages, like the size of all the dependencies that get dragged in. This will almost always make your container images larger than building from scratch. Another disadvantage is you will not always have access to the latest upstream code. This can be frustrating for developers, especially when you just want to get something out the door, but not as frustrating as being paged to look at a library you haven't thought about in three years that the upstream maintainers have been changing the whole time.
|
||||
|
||||
If you are a web developer and rolling your eyes at me, I have one word for you: DevOps. That means you are carrying a pager, my friend.
|
||||
|
||||
#### Building from scratch
|
||||
|
||||
Scratch builds have the advantage of being really small. When you don't rely on a Linux distribution in the container, you have a lot of control, which means you can customize everything for your needs. This is a best-of-breed model, and it's valid in certain use cases. Another advantage is you have access to the latest packages. You don't have to wait for a Linux distro to update anything. You are in control, so you choose when to spend the engineering work to incorporate new software.
|
||||
|
||||
Remember, there is a cost to controlling everything. Often, updating to new libraries with new features drags in unwanted API changes, which means fixing incompatibilities in code (in other words, [shaving yaks][6]). Shaving yaks at 2 AM when the application doesn't work is not fun. Luckily, with containers, you can roll back and shave the yaks the next business day, but it will still eat into your time for delivering new value to the business, new features to your applications. Welcome to the life of a sysadmin.
|
||||
|
||||
OK, that said, there are times that building from scratch makes sense. I will completely concede that statically compiled Golang programs and C programs are two decent candidates for scratch/distroless builds. With these types of programs, every container build is a compile event. You still have to worry about API breakage three years from now, but if you are a Golang shop, you should have the skillset to fix things over time.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Basically, Linux distributions do a ton of work to save you time—on a regular Linux system or with containers. The knowledge that maintainers have is tremendous and leveraged so much without really being appreciated. The adoption of containers has made the problem even worse because it's even further abstracted.
|
||||
|
||||
With container hosts, a Linux distribution offers you access to a wide hardware ecosystem, ranging from tiny ARM systems, to giant 128 CPU x86 boxes, to cloud-provider VMs. They offer working container engines and container runtimes out of the box, so you can just fire up your containers and let somebody else worry about making things work.
|
||||
|
||||
For container images, Linux distributions offer you easy access to a ton of software for your projects. Even when you build from scratch, you will likely look at how a package maintainer built and shipped things—a good artist is a good thief—so, don't undervalue this work.
|
||||
|
||||
So, thank you to all of the maintainers in Fedora, RHEL (Frantisek, you are my hero), Debian, Gentoo, and every other Linux distribution. I appreciate the work you do, even though I am a "container guy."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/linux-distributions-still-matter-containers
|
||||
|
||||
作者:[Scott McCarty][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/fatherlinux
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://aeon.co/essays/innovation-is-overvalued-maintenance-often-matters-more
|
||||
[2]: https://blog.openshift.com/openshift-on-openstack-delivering-applications-better-together/
|
||||
[3]: https://developers.redhat.com/blog/2018/02/13/red-hat-cdk-nested-kvm/
|
||||
[4]: https://developers.redhat.com/blog/2018/02/22/container-terminology-practical-introduction/#h.8tyd9p17othl
|
||||
[5]: https://developers.redhat.com/blog/2018/02/22/container-terminology-practical-introduction/#h.dqlu6589ootw
|
||||
[6]: https://en.wiktionary.org/wiki/yak_shaving
|
||||
@ -1,160 +0,0 @@
|
||||
tomjlw is translating
|
||||
Annoying Experiences Every Linux Gamer Never Wanted!
|
||||
============================================================
|
||||
|
||||
|
||||
[][10]
|
||||
|
||||
[Gaming on Linux][12] has come a long way. There are dedicated [Linux gaming distributions][13] now. But this doesn’t mean that gaming experience on Linux is as smooth as on Windows.
|
||||
|
||||
What are the obstacles that should be thought about to ensure that we enjoy games as much as Windows users do?
|
||||
|
||||
[Wine][14], [PlayOnLinux][15] and other similar tools are not always able to play every popular Windows game. In this article, I would like to discuss various factors that must be dealt with in order to have the best possible Linux gaming experience.
|
||||
|
||||
### #1 SteamOS is Open Source, Steam for Linux is NOT
|
||||
|
||||
As stated on the [SteamOS page][16], even though SteamOS is open source, Steam for Linux continues to be proprietary. Had it also been open source, the amount of support from the open source community would have been tremendous! Since it is not, [the birth of Project Ascension was inevitable][17]:
|
||||
|
||||
[video](https://youtu.be/07UiS5iAknA)
|
||||
|
||||
Project Ascension is an open source game launcher designed to launch games that have been bought and downloaded from anywhere – they can be Steam games, [Origin games][18], Uplay games, games downloaded directly from game developer websites or from DVD/CD-ROMs.
|
||||
|
||||
Here is how it all began: [Sharing The Idea][19] resulted in a very interesting discussion with readers all over from the gaming community pitching in their own opinions and suggestions.
|
||||
|
||||
### #2 Performance compared to Windows
|
||||
|
||||
Getting Windows games to run on Linux is not always an easy task. But thanks to a feature called [CSMT][20] (command stream multi-threading), PlayOnLinux is now better equipped to deal with these performance issues, though it’s still a long way to achieve Windows level outcomes.
|
||||
|
||||
Native Linux support for games has not been so good for past releases.
|
||||
|
||||
Last year, it was reported that SteamOS performed [significantly worse][21] than Windows. Tomb Raider was released on SteamOS/Steam for Linux last year. However, benchmark results were [not at par][22] with performance on Windows.
|
||||
|
||||
[video](https://youtu.be/nkWUBRacBNE)
|
||||
|
||||
This was much obviously due to the fact that the game had been developed with [DirectX][23] in mind and not [OpenGL][24].
|
||||
|
||||
Tomb Raider is the [first Linux game that uses TressFX][25]. This video includes TressFX comparisons:
|
||||
|
||||
[video](https://youtu.be/-IeY5ZS-LlA)
|
||||
|
||||
Here is another interesting comparison which shows Wine+CSMT performing much better than the native Linux version itself on Steam! This is the power of Open Source!
|
||||
|
||||
[Suggested readA New Linux OS "OSu" Vying To Be Ubuntu Of Arch Linux World][26]
|
||||
|
||||
[video](https://youtu.be/sCJkC6oJ08A)
|
||||
|
||||
TressFX has been turned off in this case to avoid FPS loss.
|
||||
|
||||
Here is another Linux vs Windows comparison for the recently released “[Life is Strange][27]” on Linux:
|
||||
|
||||
[video](https://youtu.be/Vlflu-pIgIY)
|
||||
|
||||
It’s good to know that [_Steam for Linux_][28] has begun to show better improvements in performance for this new Linux game.
|
||||
|
||||
Before launching any game for Linux, developers should consider optimizing them especially if it’s a DirectX game and requires OpenGL translation. We really do hope that [Deus Ex: Mankind Divided on Linux][29] gets benchmarked well, upon release. As its a DirectX game, we hope it’s being ported well for Linux. Here’s [what the Executive Game Director had to say][30].
|
||||
|
||||
### #3 Proprietary NVIDIA Drivers
|
||||
|
||||
[AMD’s support for Open Source][31] is definitely commendable when compared to [NVIDIA][32]. Though [AMD][33] driver support is [pretty good on Linux][34] now due to its better open source driver, NVIDIA graphic card owners will still have to use the proprietary NVIDIA drivers because of the limited capabilities of the open-source version of NVIDIA’s graphics driver called Nouveau.
|
||||
|
||||
In the past, legendary Linus Torvalds has also shared his thoughts about Linux support from NVIDIA to be totally unacceptable:
|
||||
|
||||
[video](https://youtu.be/O0r6Pr_mdio)
|
||||
|
||||
You can watch the complete talk [here][35]. Although NVIDIA responded with [a commitment for better linux support][36], the open source graphics driver still continues to be weak as before.
|
||||
|
||||
### #4 Need for Uplay and Origin DRM support on Linux
|
||||
|
||||
[video](https://youtu.be/rc96NFwyxWU)
|
||||
|
||||
The above video describes how to install the [Uplay][37] DRM on Linux. The uploader also suggests that the use of wine as the main tool of games and applications is not recommended on Linux. Rather, preference to native applications should be encouraged instead.
|
||||
|
||||
The following video is a guide about installing the [Origin][38] DRM on Linux:
|
||||
|
||||
[video](https://youtu.be/ga2lNM72-Kw)
|
||||
|
||||
Digital Rights Management Software adds another layer for game execution and hence it adds up to the already challenging task to make a Windows game run well on Linux. So in addition to making the game execute, W.I.N.E has to take care of running the DRM software such as Uplay or Origin as well. It would have been great if, like Steam, Linux could have got its own native versions of Uplay and Origin.
|
||||
|
||||
[Suggested readLinux Foundation Head Calls 2017 'Year of the Linux Desktop'... While Running Apple's macOS Himself][39]
|
||||
|
||||
### #5 DirectX 11 support for Linux
|
||||
|
||||
Even though we have tools on Linux to run Windows applications, every game comes with its own set of tweak requirements for it to be playable on Linux. Though there was an announcement about [DirectX 11 support for Linux][40] last year via Code Weavers, it’s still a long way to go to make playing newly launched titles on Linux a possibility. Currently, you can
|
||||
|
||||
Currently, you can [buy Crossover from Codeweavers][41] to get the best DirectX 11 support available. This [thread][42] on the Arch Linux forums clearly shows how much more effort is required to make this dream a possibility. Here is an interesting [find][43] from a [Reddit thread][44], which mentions Wine getting [DirectX 11 patches from Codeweavers][45]. Now that’s definitely some good news.
|
||||
|
||||
### #6 100% of Steam games are not available for Linux
|
||||
|
||||
This is an important point to ponder as Linux gamers continue to miss out on every major game release since most of them land up on Windows. Here is a guide to [install Steam for Windows on Linux][46].
|
||||
|
||||
### #7 Better Support from video game publishers for OpenGL
|
||||
|
||||
Currently, developers and publishers focus primarily on DirectX for video game development rather than OpenGL. Now as Steam is officially here for Linux, developers should start considering development in OpenGL as well.
|
||||
|
||||
[Direct3D][47] is made solely for the Windows platform. The OpenGL API is an open standard, and implementations exist for not only Windows but a wide variety of other platforms.
|
||||
|
||||
Though quite an old article, [this valuable resource][48] shares a lot of thoughtful information on the realities of OpenGL and DirectX. The points made are truly very sensible and enlightens the reader about the facts based on actual chronological events.
|
||||
|
||||
Publishers who are launching their titles on Linux should definitely not leave out the fact that developing the game on OpenGL would be a much better deal than translating it from DirectX to OpenGL. If conversion has to be done, the translations must be well optimized and carefully looked into. There might be a delay in releasing the games but still it would definitely be worth the wait.
|
||||
|
||||
Have more annoyances to share? Do let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-gaming-problems/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay ][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[1]:https://itsfoss.com/author/avimanyu/
|
||||
[2]:https://itsfoss.com/linux-gaming-problems/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21&url=https://itsfoss.com/linux-gaming-problems/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg&url=https://itsfoss.com/linux-gaming-problems/&is_video=false&description=Linux%20gamer%27s%20problem
|
||||
[12]:https://itsfoss.com/linux-gaming-guide/
|
||||
[13]:https://itsfoss.com/linux-gaming-distributions/
|
||||
[14]:https://itsfoss.com/use-windows-applications-linux/
|
||||
[15]:https://www.playonlinux.com/en/
|
||||
[16]:http://store.steampowered.com/steamos/
|
||||
[17]:http://www.ibtimes.co.uk/reddit-users-want-replace-steam-open-source-game-launcher-project-ascension-1498999
|
||||
[18]:https://www.origin.com/
|
||||
[19]:https://www.reddit.com/r/pcmasterrace/comments/33xcvm/we_hate_valves_monopoly_over_pc_gaming_why/
|
||||
[20]:https://github.com/wine-compholio/wine-staging/wiki/CSMT
|
||||
[21]:http://arstechnica.com/gaming/2015/11/ars-benchmarks-show-significant-performance-hit-for-steamos-gaming/
|
||||
[22]:https://www.gamingonlinux.com/articles/tomb-raider-benchmark-video-comparison-linux-vs-windows-10.7138
|
||||
[23]:https://en.wikipedia.org/wiki/DirectX
|
||||
[24]:https://en.wikipedia.org/wiki/OpenGL
|
||||
[25]:https://www.gamingonlinux.com/articles/tomb-raider-released-for-linux-video-thoughts-port-report-included-the-first-linux-game-to-use-tresfx.7124
|
||||
[26]:https://itsfoss.com/osu-new-linux/
|
||||
[27]:http://lifeisstrange.com/
|
||||
[28]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[29]:https://itsfoss.com/deus-ex-mankind-divided-linux/
|
||||
[30]:http://wccftech.com/deus-ex-mankind-divided-director-console-ports-on-pc-is-disrespectful/
|
||||
[31]:http://developer.amd.com/tools-and-sdks/open-source/
|
||||
[32]:http://nvidia.com/
|
||||
[33]:http://amd.com/
|
||||
[34]:http://www.makeuseof.com/tag/open-source-amd-graphics-now-awesome-heres-get/
|
||||
[35]:https://youtu.be/MShbP3OpASA
|
||||
[36]:https://itsfoss.com/nvidia-optimus-support-linux/
|
||||
[37]:http://uplay.com/
|
||||
[38]:http://origin.com/
|
||||
[39]:https://itsfoss.com/linux-foundation-head-uses-macos/
|
||||
[40]:http://www.pcworld.com/article/2940470/hey-gamers-directx-11-is-coming-to-linux-thanks-to-codeweavers-and-wine.html
|
||||
[41]:https://itsfoss.com/deal-run-windows-software-and-games-on-linux-with-crossover-15-66-off/
|
||||
[42]:https://bbs.archlinux.org/viewtopic.php?id=214771
|
||||
[43]:https://ghostbin.com/paste/sy3e2
|
||||
[44]:https://www.reddit.com/r/linux_gaming/comments/3ap3uu/directx_11_support_coming_to_codeweavers/
|
||||
[45]:https://www.codeweavers.com/about/blogs/caron/2015/12/10/directx-11-really-james-didnt-lie
|
||||
[46]:https://itsfoss.com/linux-gaming-guide/
|
||||
[47]:https://en.wikipedia.org/wiki/Direct3D
|
||||
[48]:http://blog.wolfire.com/2010/01/Why-you-should-use-OpenGL-and-not-DirectX
|
||||
121
sources/tech/20170519 zsh shell inside Emacs on Windows.md
Normal file
121
sources/tech/20170519 zsh shell inside Emacs on Windows.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (zsh shell inside Emacs on Windows)
|
||||
[#]: via: (https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html)
|
||||
[#]: author: (Peter Mosmans https://www.onwebsecurity.com/)
|
||||
|
||||
zsh shell inside Emacs on Windows
|
||||
======
|
||||
|
||||
![zsh shell inside Emacs on Windows][5]
|
||||
|
||||
The most obvious advantage of running a cross-platform shell (for example Bash or zsh) is that you can use the same syntax and scripts on multiple platforms. Setting up (alternative) shells on Windows can be pretty tricky, but the small investment is well worth the reward.
|
||||
|
||||
The MSYS2 subsystem allows you to run shells like Bash or zsh on Windows. An important part of MSYS2 is making sure that the search paths are all pointing to the MSYS2 subsystem: There are a lot of dependencies.
|
||||
|
||||
Bash is the default shell once MSYS2 is installed; zsh can be installed using the package manager:
|
||||
|
||||
```
|
||||
pacman -Sy zsh
|
||||
```
|
||||
|
||||
Setting zsh as default shell can be done by modifying the ` /etc/passwd` file, for instance:
|
||||
|
||||
```
|
||||
mkpasswd -c | sed -e 's/bash/zsh/' | tee -a /etc/passwd
|
||||
```
|
||||
|
||||
This will change the default shell from bash to zsh.
|
||||
|
||||
Running zsh under Emacs on Windows can be done by modifying the ` shell-file-name` variable, and pointing it to the zsh binary from the MSYS2 subsystem. The shell binary has to be somewhere in the Emacs ` exec-path` variable.
|
||||
|
||||
```
|
||||
(setq shell-file-name (executable-find "zsh.exe"))
|
||||
```
|
||||
|
||||
Don't forget to modify the PATH environment variable for Emacs, as the MSYS2 paths should be resolved before Windows paths. Using the same example, where MSYS2 is installed under
|
||||
|
||||
```
|
||||
c:\programs\msys2
|
||||
```
|
||||
|
||||
:
|
||||
|
||||
```
|
||||
(setenv "PATH" "C:\\programs\\msys2\\mingw64\\bin;C:\\programs\\msys2\\usr\\local\\bin;C:\\programs\\msys2\\usr\\bin;C:\\Windows\\System32;C:\\Windows")
|
||||
```
|
||||
|
||||
After setting these two variables in the Emacs configuration file, running
|
||||
|
||||
```
|
||||
M-x shell
|
||||
```
|
||||
|
||||
in Emacs should bring up the familiar zsh prompt.
|
||||
|
||||
Emacs' terminal settings (eterm) are different than MSYS2' standard terminal settings (xterm-256color). This means that some plugins or themes (prompts) might not work - especially when using oh-my-zsh.
|
||||
|
||||
Detecting whether zsh is started under Emacs is easy, using the variable
|
||||
|
||||
```
|
||||
$INSIDE_EMACS
|
||||
```
|
||||
|
||||
. This codesnippet in
|
||||
|
||||
```
|
||||
.zshrc
|
||||
```
|
||||
|
||||
(which will be sourced for interactive shells) only enables the git plugin when being run in Emacs, and changes the theme
|
||||
|
||||
```
|
||||
# Disable some plugins while running in Emacs
|
||||
if [[ -n "$INSIDE_EMACS" ]]; then
|
||||
plugins=(git)
|
||||
ZSH_THEME="simple"
|
||||
else
|
||||
ZSH_THEME="compact-grey"
|
||||
fi
|
||||
```
|
||||
|
||||
. This codesnippet in(which will be sourced for interactive shells) only enables the git plugin when being run in Emacs, and changes the theme
|
||||
|
||||
By adding the ` INSIDE_EMACS` variable to the local ` ~/.ssh/config` as ` SendEnv` variable...
|
||||
|
||||
```
|
||||
Host myhost
|
||||
SendEnv INSIDE_EMACS
|
||||
```
|
||||
|
||||
... and to a ssh server as ` AcceptEnv` variable in ` /etc/ssh/sshd_config` ...
|
||||
|
||||
```
|
||||
AcceptEnv LANG LC_* INSIDE_EMACS
|
||||
```
|
||||
|
||||
... this even works when ssh'ing inside an Emacs shell session to another ssh server, running zsh. When ssh'ing in the zsh shell inside Emacs on Windows, using the parameters ` -t -t` forces pseudo-tty allocation (which is necessary, as Emacs on Windows don't have a true tty).
|
||||
|
||||
Cross-platform, open-source goodyness...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.onwebsecurity.com/configuration/zsh-shell-inside-emacs-on-windows.html
|
||||
|
||||
作者:[Peter Mosmans][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.onwebsecurity.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.onwebsecurity.com/category/configuration.html
|
||||
[2]: https://www.onwebsecurity.com/tag/emacs.html
|
||||
[3]: https://www.onwebsecurity.com/tag/msys2.html
|
||||
[4]: https://www.onwebsecurity.com/tag/zsh.html
|
||||
[5]: https://www.onwebsecurity.com//images/zsh-shell-inside-emacs-on-windows.png
|
||||
@ -1,3 +1,4 @@
|
||||
tomjlw is translatting
|
||||
Toplip – A Very Strong File Encryption And Decryption CLI Utility
|
||||
======
|
||||
There are numerous file encryption tools available on the market to protect
|
||||
@ -260,7 +261,7 @@ Cheers!
|
||||
via: https://www.ostechnix.com/toplip-strong-file-encryption-decryption-cli-utility/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,97 +0,0 @@
|
||||
8 KDE Plasma Tips and Tricks to Improve Your Productivity
|
||||
======
|
||||
|
||||
[#] leon-shi is translating
|
||||

|
||||
|
||||
KDE's Plasma is easily one of the most powerful desktop environments available for Linux. It's highly configurable, and it looks pretty good, too. That doesn't amount to a whole lot unless you can actually get things done.
|
||||
|
||||
You can easily configure Plasma and make use of a lot of its convenient and time-saving features to boost your productivity and have a desktop that empowers you, rather than getting in your way.
|
||||
|
||||
These tips aren't in any particular order, so you don't need to prioritize. Pick the ones that best fit your workflow.
|
||||
|
||||
**Related** : [10 of the Best KDE Plasma Applications You Should Try][1]
|
||||
|
||||
### 1. Multimedia Controls
|
||||
|
||||
This isn't so much of a tip as it is something that's good to keep in mind. Plasma keeps multimedia controls everywhere. You don't need to open your media player every time you need to pause, resume, or skip a song; you can mouse over the minimized window or even control it via the lock screen. There's no need to scramble to log in to change a song or because you forgot to pause one.
|
||||
|
||||
### 2. KRunner
|
||||
|
||||
![KDE Plasma KRunner][2]
|
||||
|
||||
KRunner is an often under-appreciated feature of the Plasma desktop. Most people are used to digging through the application launcher menu to find the program that they're looking to launch. That's not necessary with KRunner.
|
||||
|
||||
To use KRunner, make sure that your focus is on the desktop itself. (Click on it instead of a window.) Then, start typing the name of the program that you want. KRunner will automatically drop down from the top of your screen with suggestions. Click or press Enter on the one you're looking for. It's much faster than remembering which category your program is under.
|
||||
|
||||
### 3. Jump Lists
|
||||
|
||||
![KDE Plasma Jump Lists][3]
|
||||
|
||||
Jump lists are a fairly recent addition to the Plasma desktop. They allow you to launch an application directly to a specific section or feature.
|
||||
|
||||
So if you have a launcher on a menu bar, you can right-click and get a list of places to jump to. Select where you want to go, and you're off.
|
||||
|
||||
### 4. KDE Connect
|
||||
|
||||
![KDE Connect Menu Android][4]
|
||||
|
||||
[KDE Connect][5] is a massive help if you have an Android phone. It connects the phone to your desktop so you can share things seamlessly between the devices.
|
||||
|
||||
With KDE Connect, you can see your [Android device's notification][6] on your desktop in real time. It also enables you to send and receive text messages from Plasma without ever picking up your phone.
|
||||
|
||||
KDE Connect also lets you send files and share web pages between your phone and your computer. You can easily move from one device to the other without a lot of hassle or losing your train of thought.
|
||||
|
||||
### 5. Plasma Vaults
|
||||
|
||||
![KDE Plasma Vault][7]
|
||||
|
||||
Plasma Vaults are another new addition to the Plasma desktop. They are KDE's simple solution to encrypted files and folders. If you don't work with encrypted files, this one won't really save you any time. If you do, though, vaults are a much simpler approach.
|
||||
|
||||
Plasma Vaults let you create encrypted directories as a regular user without root and manage them from your task bar. You can mount and unmount the directories on the fly without the need for external programs or additional privileges.
|
||||
|
||||
### 6. Pager Widget
|
||||
|
||||
![KDE Plasma Pager][8]
|
||||
|
||||
Configure your desktop with the pager widget. It allows you to easily access three additional workspaces for even more screen room.
|
||||
|
||||
Add the widget to your menu bar, and you can slide between multiple workspaces. These are all the size of your screen, so you gain multiple times the total screen space. That lets you lay out more windows without getting confused by a minimized mess or disorganization.
|
||||
|
||||
### 7. Create a Dock
|
||||
|
||||
![KDE Plasma Dock][9]
|
||||
|
||||
Plasma is known for its flexibility and the room it allows for configuration. Use that to your advantage. If you have programs that you're always using, consider setting up an OS X style dock with your most used applications. You'll be able to get them with a single click rather than going through a menu or typing in their name.
|
||||
|
||||
### 8. Add a File Tree to Dolphin
|
||||
|
||||
![Plasma Dolphin Directory][10]
|
||||
|
||||
It's much easier to navigate folders in a directory tree. Dolphin, Plasma's default file manager, has built-in functionality to display a directory listing in the form of a tree on the side of the folder window.
|
||||
|
||||
To enable the directory tree, click on the "Control" tab, then "Configure Dolphin," "View Modes," and "Details." Finally, select "Expandable Folders."
|
||||
|
||||
Remember that these tips are just tips. Don't try to force yourself to do something that's getting in your way. You may hate using file trees in Dolphin. You may never use Pager. That's alright. There may even be something that you personally like that's not listed here. Do what works for you. That said, at least a few of these should shave some serious time out of your work day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/kde-plasma-tips-tricks-improve-productivity/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/10-best-kde-plasma-applications/ (10 of the Best KDE Plasma Applications You Should Try)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-krunner.jpg (KDE Plasma KRunner)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-jumplist.jpg (KDE Plasma Jump Lists)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/05/kde-connect-menu-e1494899929112.jpg (KDE Connect Menu Android)
|
||||
[5]:https://www.maketecheasier.com/send-receive-sms-linux-kde-connect/
|
||||
[6]:https://www.maketecheasier.com/android-notifications-ubuntu-kde-connect/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-vault.jpg (KDE Plasma Vault)
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-pager.jpg (KDE Plasma Pager)
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dock.jpg (KDE Plasma Dock)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dolphin.jpg (Plasma Dolphin Directory)
|
||||
@ -1,75 +0,0 @@
|
||||
Ick: a continuous integration system
|
||||
======
|
||||
**TL;DR:** Ick is a continuous integration or CI system. See <http://ick.liw.fi/> for more information.
|
||||
|
||||
More verbose version follows.
|
||||
|
||||
### First public version released
|
||||
|
||||
The world may not need yet another continuous integration system (CI), but I do. I've been unsatisfied with the ones I've tried or looked at. More importantly, I am interested in a few things that are more powerful than what I've ever even heard of. So I've started writing my own.
|
||||
|
||||
My new personal hobby project is called ick. It is a CI system, which means it can run automated steps for building and testing software. The home page is at <http://ick.liw.fi/>, and the [download][1] page has links to the source code and .deb packages and an Ansible playbook for installing it.
|
||||
|
||||
I have now made the first publicly advertised release, dubbed ALPHA-1, version number 0.23. It is of alpha quality, and that means it doesn't have all the intended features and if any of the features it does have work, you should consider yourself lucky.
|
||||
|
||||
### Invitation to contribute
|
||||
|
||||
Ick has so far been my personal project. I am hoping to make it more than that, and invite contributions. See the [governance][2] page for the constitution, the [getting started][3] page for tips on how to start contributing, and the [contact][4] page for how to get in touch.
|
||||
|
||||
### Architecture
|
||||
|
||||
Ick has an architecture consisting of several components that communicate over HTTPS using RESTful APIs and JSON for structured data. See the [architecture][5] page for details.
|
||||
|
||||
### Manifesto
|
||||
|
||||
Continuous integration (CI) is a powerful tool for software development. It should not be tedious, fragile, or annoying. It should be quick and simple to set up, and work quietly in the background unless there's a problem in the code being built and tested.
|
||||
|
||||
A CI system should be simple, easy, clear, clean, scalable, fast, comprehensible, transparent, reliable, and boost your productivity to get things done. It should not be a lot of effort to set up, require a lot of hardware just for the CI, need frequent attention for it to keep working, and developers should never have to wonder why something isn't working.
|
||||
|
||||
A CI system should be flexible to suit your build and test needs. It should support multiple types of workers, as far as CPU architecture and operating system version are concerned.
|
||||
|
||||
Also, like all software, CI should be fully and completely free software and your instance should be under your control.
|
||||
|
||||
(Ick is little of this yet, but it will try to become all of it. In the best possible taste.)
|
||||
|
||||
### Dreams of the future
|
||||
|
||||
In the long run, I would ick to have features like ones described below. It may take a while to get all of them implemented.
|
||||
|
||||
* A build may be triggered by a variety of events. Time is an obvious event, as is source code repository for the project changing. More powerfully, any build dependency changing, regardless of whether the dependency comes from another project built by ick, or a package from, say, Debian: ick should keep track of all the packages that get installed into the build environment of a project, and if any of their versions change, it should trigger the project build and tests again.
|
||||
|
||||
* Ick should support building in (or against) any reasonable target, including any Linux distribution, any free operating system, and any non-free operating system that isn't brain-dead.
|
||||
|
||||
* Ick should manage the build environment itself, and be able to do builds that are isolated from the build host or the network. This partially works: one can ask ick to build a container and run a build in the container. The container is implemented using systemd-nspawn. This can be improved upon, however. (If you think Docker is the only way to go, please contribute support for that.)
|
||||
|
||||
* Ick should support any workers that it can control over ssh or a serial port or other such neutral communication channel, without having to install an agent of any kind on them. Ick won't assume that it can have, say, a full Java run time, so that the worker can be, say, a micro controller.
|
||||
|
||||
* Ick should be able to effortlessly handle very large numbers of projects. I'm thinking here that it should be able to keep up with building everything in Debian, whenever a new Debian source package is uploaded. (Obviously whether that is feasible depends on whether there are enough resources to actually build things, but ick itself should not be the bottleneck.)
|
||||
|
||||
* Ick should optionally provision workers as needed. If all workers of a certain type are busy, and ick's been configured to allow using more resources, it should do so. This seems like it would be easy to do with virtual machines, containers, cloud providers, etc.
|
||||
|
||||
* Ick should be flexible in how it can notify interested parties, particularly about failures. It should allow an interested party to ask to be notified over IRC, Matrix, Mastodon, Twitter, email, SMS, or even by a phone call and speech syntethiser. "Hello, interested party. It is 04:00 and you wanted to be told when the hello package has been built for RISC-V."
|
||||
|
||||
|
||||
|
||||
|
||||
### Please give feedback
|
||||
|
||||
If you try ick, or even if you've just read this far, please share your thoughts on it. See the [contact][4] page for where to send it. Public feedback is preferred over private, but if you prefer private, that's OK too.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.liw.fi/posts/2018/01/22/ick_a_continuous_integration_system/
|
||||
|
||||
作者:[Lars Wirzenius][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.liw.fi/
|
||||
[1]:http://ick.liw.fi/download/
|
||||
[2]:http://ick.liw.fi/governance/
|
||||
[3]:http://ick.liw.fi/getting-started/
|
||||
[4]:http://ick.liw.fi/contact/
|
||||
[5]:http://ick.liw.fi/architecture/
|
||||
@ -1,158 +0,0 @@
|
||||
The 5 Best Linux Distributions for Development
|
||||
============================================================
|
||||
|
||||

|
||||
Jack Wallen looks at some of the best LInux distributions for development efforts.[Creative Commons Zero][6]
|
||||
|
||||
When considering Linux, there are so many variables to take into account. What package manager do you wish to use? Do you prefer a modern or old-standard desktop interface? Is ease of use your priority? How flexible do you want your distribution? What task will the distribution serve?
|
||||
|
||||
It is that last question which should often be considered first. Is the distribution going to work as a desktop or a server? Will you be doing network or system audits? Or will you be developing? If you’ve spent much time considering Linux, you know that for every task there are several well-suited distributions. This certainly holds true for developers. Even though Linux, by design, is an ideal platform for developers, there are certain distributions that rise above the rest, to serve as great operating systems to serve developers.
|
||||
|
||||
I want to share what I consider to be some of the best distributions for your development efforts. Although each of these five distributions can be used for general purpose development (with maybe one exception), they each serve a specific purpose. You may or may not be surprised by the selections.
|
||||
|
||||
With that said, let’s get to the choices.
|
||||
|
||||
### Debian
|
||||
|
||||
The [Debian][14] distribution winds up on the top of many a Linux list. With good reason. Debian is that distribution from which so many are based. It is this reason why many developers choose Debian. When you develop a piece of software on Debian, chances are very good that package will also work on [Ubuntu][15], [Linux Mint][16], [Elementary OS][17], and a vast collection of other distributions.
|
||||
|
||||
Beyond that obvious answer, Debian also has a very large amount of applications available, by way of the default repositories (Figure 1).
|
||||
|
||||

|
||||
Figure 1: Available applications from the standard Debian repositories.[Used with permission][1]
|
||||
|
||||
To make matters even programmer-friendly, those applications (and their dependencies) are simple to install. Take, for instance, the build-essential package (which can be installed on any distribution derived from Debian). This package includes the likes of dkpg-dev, g++, gcc, hurd-dev, libc-dev, and make—all tools necessary for the development process. The build-essential package can be installed with the command sudo apt install build-essential.
|
||||
|
||||
There are hundreds of other developer-specific applications available from the standard repositories, tools such as:
|
||||
|
||||
* Autoconf—configure script builder
|
||||
|
||||
* Autoproject—creates a source package for a new program
|
||||
|
||||
* Bison—general purpose parser generator
|
||||
|
||||
* Bluefish—powerful GUI editor, targeted towards programmers
|
||||
|
||||
* Geany—lightweight IDE
|
||||
|
||||
* Kate—powerful text editor
|
||||
|
||||
* Eclipse—helps builders independently develop tools that integrate with other people’s tools
|
||||
|
||||
The list goes on and on.
|
||||
|
||||
Debian is also as rock-solid a distribution as you’ll find, so there’s very little concern you’ll lose precious work, by way of the desktop crashing. As a bonus, all programs included with Debian have met the [Debian Free Software Guidelines][18], which adheres to the following “social contract”:
|
||||
|
||||
* Debian will remain 100% free.
|
||||
|
||||
* We will give back to the free software community.
|
||||
|
||||
* We will not hide problems.
|
||||
|
||||
* Our priorities are our users and free software
|
||||
|
||||
* Works that do not meet our free software standards are included in a non-free archive.
|
||||
|
||||
Also, if you’re new to developing on Linux, Debian has a handy [Programming section in their user manual][19].
|
||||
|
||||
### openSUSE Tumbleweed
|
||||
|
||||
If you’re looking to develop with a cutting-edge, rolling release distribution, [openSUSE][20] offers one of the best in [Tumbleweed][21]. Not only will you be developing with the most up to date software available, you’ll be doing so with the help of openSUSE’s amazing administrator tools … of which includes YaST. If you’re not familiar with YaST (Yet another Setup Tool), it’s an incredibly powerful piece of software that allows you to manage the whole of the platform, from one convenient location. From within YaST, you can also install using RPM Groups. Open YaST, click on RPM Groups (software grouped together by purpose), and scroll down to the Development section to see the large amount of groups available for installation (Figure 2).
|
||||
|
||||
|
||||

|
||||
Figure 2: Installing package groups in openSUSE Tumbleweed.[Creative Commons Zero][2]
|
||||
|
||||
openSUSE also allows you to quickly install all the necessary devtools with the simple click of a weblink. Head over to the [rpmdevtools install site][22] and click the link for Tumbleweed. This will automatically add the necessary repository and install rpmdevtools.
|
||||
|
||||
By developing with a rolling release distribution, you know you’re working with the most recent releases of installed software.
|
||||
|
||||
### CentOS
|
||||
|
||||
Let’s face it, [Red Hat Enterprise Linux][23] (RHEL) is the de facto standard for enterprise businesses. If you’re looking to develop for that particular platform, and you can’t afford a RHEL license, you cannot go wrong with [CentOS][24]—which is, effectively, a community version of RHEL. You will find many of the packages found on CentOS to be the same as in RHEL—so once you’re familiar with developing on one, you’ll be fine on the other.
|
||||
|
||||
If you’re serious about developing on an enterprise-grade platform, you cannot go wrong starting with CentOS. And because CentOS is a server-specific distribution, you can more easily develop for a web-centric platform. Instead of developing your work and then migrating it to a server (hosted on a different machine), you can easily have CentOS setup to serve as an ideal host for both developing and testing.
|
||||
|
||||
Looking for software to meet your development needs? You only need open up the CentOS Application Installer, where you’ll find a Developer section that includes a dedicated sub-section for Integrated Development Environments (IDEs - Figure 3).
|
||||
|
||||

|
||||
Figure 3: Installing a powerful IDE is simple in CentOS.[Used with permission][3]
|
||||
|
||||
CentOS also includes Security Enhanced Linux (SELinux), which makes it easier for you to test your software’s ability to integrate with the same security platform found in RHEL. SELinux can often cause headaches for poorly designed software, so having it at the ready can be a real boon for ensuring your applications work on the likes of RHEL. If you’re not sure where to start with developing on CentOS 7, you can read through the [RHEL 7 Developer Guide][25].
|
||||
|
||||
### Raspbian
|
||||
|
||||
Let’s face it, embedded systems are all the rage. One easy means of working with such systems is via the Raspberry Pi—a tiny footprint computer that has become incredibly powerful and flexible. In fact, the Raspberry Pi has become the hardware used by DIYers all over the planet. Powering those devices is the [Raspbian][26] operating system. Raspbian includes tools like [BlueJ][27], [Geany][28], [Greenfoot][29], [Sense HAT Emulator][30], [Sonic Pi][31], and [Thonny Python IDE][32], [Python][33], and [Scratch][34], so you won’t want for the necessary development software. Raspbian also includes a user-friendly desktop UI (Figure 4), to make things even easier.
|
||||
|
||||

|
||||
Figure 4: The Raspbian main menu, showing pre-installed developer software.[Used with permission][4]
|
||||
|
||||
For anyone looking to develop for the Raspberry Pi platform, Raspbian is a must have. If you’d like to give Raspbian a go, without the Raspberry Pi hardware, you can always install it as a VirtualBox virtual machine, by way of the ISO image found [here][35].
|
||||
|
||||
### Pop!_OS
|
||||
|
||||
Don’t let the name full you, [System76][36]’s [Pop!_OS][37] entry into the world of operating systems is serious. And although what System76 has done to this Ubuntu derivative may not be readily obvious, it is something special.
|
||||
|
||||
The goal of System76 is to create an operating system specific to the developer, maker, and computer science professional. With a newly-designed GNOME theme, Pop!_OS is beautiful (Figure 5) and as highly functional as you would expect from both the hardware maker and desktop designers.
|
||||
|
||||
### [devel_5.jpg][11]
|
||||
|
||||

|
||||
Figure 5: The Pop!_OS Desktop.[Used with permission][5]
|
||||
|
||||
But what makes Pop!_OS special is the fact that it is being developed by a company dedicated to Linux hardware. This means, when you purchase a System76 laptop, desktop, or server, you know the operating system will work seamlessly with the hardware—on a level no other company can offer. I would predict that, with Pop!_OS, System76 will become the Apple of Linux.
|
||||
|
||||
### Time for work
|
||||
|
||||
In their own way, each of these distributions. You have a stable desktop (Debian), a cutting-edge desktop (openSUSE Tumbleweed), a server (CentOS), an embedded platform (Raspbian), and a distribution to seamless meld with hardware (Pop!_OS). With the exception of Raspbian, any one of these distributions would serve as an outstanding development platform. Get one installed and start working on your next project with confidence.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][13]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/5-best-linux-distributions-development
|
||||
|
||||
作者:[JACK WALLEN ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/devel1jpg
|
||||
[8]:https://www.linux.com/files/images/devel2jpg
|
||||
[9]:https://www.linux.com/files/images/devel3jpg
|
||||
[10]:https://www.linux.com/files/images/devel4jpg
|
||||
[11]:https://www.linux.com/files/images/devel5jpg
|
||||
[12]:https://www.linux.com/files/images/king-penguins1920jpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:https://www.debian.org/
|
||||
[15]:https://www.ubuntu.com/
|
||||
[16]:https://linuxmint.com/
|
||||
[17]:https://elementary.io/
|
||||
[18]:https://www.debian.org/social_contract
|
||||
[19]:https://www.debian.org/doc/manuals/debian-reference/ch12.en.html
|
||||
[20]:https://www.opensuse.org/
|
||||
[21]:https://en.opensuse.org/Portal:Tumbleweed
|
||||
[22]:https://software.opensuse.org/download.html?project=devel%3Atools&package=rpmdevtools
|
||||
[23]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[24]:https://www.centos.org/
|
||||
[25]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/pdf/developer_guide/Red_Hat_Enterprise_Linux-7-Developer_Guide-en-US.pdf
|
||||
[26]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[27]:https://www.bluej.org/
|
||||
[28]:https://www.geany.org/
|
||||
[29]:https://www.greenfoot.org/
|
||||
[30]:https://www.raspberrypi.org/blog/sense-hat-emulator/
|
||||
[31]:http://sonic-pi.net/
|
||||
[32]:http://thonny.org/
|
||||
[33]:https://www.python.org/
|
||||
[34]:https://scratch.mit.edu/
|
||||
[35]:http://rpf.io/x86iso
|
||||
[36]:https://system76.com/
|
||||
[37]:https://system76.com/pop
|
||||
@ -1,78 +0,0 @@
|
||||
3 open source tools for scientific publishing
|
||||
======
|
||||
|
||||
|
||||
One industry that lags behind others in the adoption of digital or open source tools is the competitive and lucrative world of scientific publishing. Worth over £19B ($26B) annually, according to figures published by Stephen Buranyi in [The Guardian][1] last year, the system for selecting, publishing, and sharing even the most important scientific research today still bears many of the constraints of print media. New digital-era technologies present a huge opportunity to accelerate discovery, make science collaborative instead of competitive, and redirect investments from infrastructure development into research that benefits society.
|
||||
|
||||
The non-profit [eLife initiative][2] was established by the funders of research, in part to encourage the use of these technologies to this end. In addition to publishing an open-access journal for important advances in life science and biomedical research, eLife has made itself into a platform for experimentation and showcasing innovation in research communication—with most of this experimentation based around the open source ethos.
|
||||
|
||||
Working on open publishing infrastructure projects gives us the opportunity to accelerate the reach and adoption of the types of technology and user experience (UX) best practices that we consider important to the advancement of the academic publishing industry. Speaking very generally, the UX of open source products is often left undeveloped, which can in some cases dissuade people from using it. As part of our investment in OSS development, we place a strong emphasis on UX in order to encourage users to adopt these products.
|
||||
|
||||
All of our code is open source, and we actively encourage community involvement in our projects, which to us means faster iteration, more experimentation, greater transparency, and increased reach for our work.
|
||||
|
||||
The projects that we are involved in, such as the development of Libero (formerly known as [eLife Continuum][3]) and the [Reproducible Document Stack][4], along with our recent collaboration with [Hypothesis][5], show how OSS can be used to bring about positive changes in the assessment, publication, and communication of new discoveries.
|
||||
|
||||
### Libero
|
||||
|
||||
Libero is a suite of services and applications available to publishers that includes a post-production publishing system, a full front-end user interface pattern suite, Libero's Lens Reader, an open API, and search and recommendation engines.
|
||||
|
||||
Last year, we took a user-driven approach to redesigning the front end of Libero, resulting in less distracting site “furniture” and a greater focus on research articles. We tested and iterated all the key functional areas of the site with members of the eLife community to ensure the best possible reading experience for everyone. The site’s new API also provides simpler access to content for machine readability, including text mining, machine learning, and online application development.
|
||||
|
||||
The content on our website and the patterns that drive the new design are all open source to encourage future product development for both eLife and other publishers that wish to use it.
|
||||
|
||||
### The Reproducible Document Stack
|
||||
|
||||
In collaboration with [Substance][6] and [Stencila][7], eLife is also engaged in a project to create a Reproducible Document Stack (RDS)—an open stack of tools for authoring, compiling, and publishing computationally reproducible manuscripts online.
|
||||
|
||||
Today, an increasing number of researchers are able to document their computational experiments through languages such as [R Markdown][8] and [Python][9]. These can serve as important parts of the experimental record, and while they can be shared independently from or alongside the resulting research article, traditional publishing workflows tend to relegate these assets as a secondary class of content. To publish papers, researchers using these languages often have little option but to submit their computational results as “flattened” outputs in the form of figures, losing much of the value and reusability of the code and data references used in the computation. And while electronic notebook solutions such as [Jupyter][10] can enable researchers to publish their code in an easily reusable and executable form, that’s still in addition to, rather than as an integral part of, the published manuscript.
|
||||
|
||||
The [Reproducible Document Stack][11] project aims to address these challenges through development and publication of a working prototype of a reproducible manuscript that treats code and data as integral parts of the document, demonstrating a complete end-to-end technology stack from authoring through to publication. It will ultimately allow authors to submit their manuscripts in a format that includes embedded code blocks and computed outputs (statistical results, tables, or graphs), and have those assets remain both visible and executable throughout the publication process. Publishers will then be able to preserve these assets directly as integral parts of the published online article.
|
||||
|
||||
### Open annotation with Hypothesis
|
||||
|
||||
Most recently, we introduced open annotation in collaboration with [Hypothesis][12] to enable users of our website to make comments, highlight important sections of articles, and engage with the reading public online.
|
||||
|
||||
Through this collaboration, the open source Hypothesis software was customized with new moderation features, single sign-on authentication, and user-interface customization options, giving publishers more control over its implementation on their sites. These enhancements are already driving higher-quality discussions around published scholarly content.
|
||||
|
||||
The tool can be integrated seamlessly into publishers’ websites, with the scholarly publishing platform [PubFactory][13] and content solutions provider [Ingenta][14] already taking advantage of its improved feature set. [HighWire][15] and [Silverchair][16] are also offering their publishers the opportunity to implement the service.
|
||||
|
||||
### Other industries and open source
|
||||
|
||||
Over time, we hope to see more publishers adopt Hypothesis, Libero, and other projects to help them foster the discovery and reuse of important scientific research. But the opportunities for innovation eLife has been able to leverage because of these and other OSS technologies are also prevalent in other industries.
|
||||
|
||||
The world of data science would be nowhere without the high-quality, well-supported open source software and the communities built around it; [TensorFlow][17] is a leading example of this. Thanks to OSS and its communities, all areas of AI and machine learning have seen rapid acceleration and advancement compared to other areas of computing. Similar is the explosion in usage of Linux as a cloud web host, followed by containerization with Docker, and now the growth of Kubernetes, one of the most popular open source projects on GitHub.
|
||||
|
||||
All of these technologies enable organizations to do more with less and focus on innovation instead of reinventing the wheel. And in the end, that’s the real benefit of OSS: It lets us all learn from each other’s failures while building on each other's successes.
|
||||
|
||||
We are always on the lookout for opportunities to engage with the best emerging talent and ideas at the interface of research and technology. Find out more about some of these engagements on [eLife Labs][18], or contact [innovation@elifesciences.org][19] for more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/scientific-publishing-software
|
||||
|
||||
作者:[Paul Shanno][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pshannon
|
||||
[1]:https://www.theguardian.com/science/2017/jun/27/profitable-business-scientific-publishing-bad-for-science
|
||||
[2]:https://elifesciences.org/about
|
||||
[3]:https://elifesciences.org/inside-elife/33e4127f/elife-introduces-continuum-a-new-open-source-tool-for-publishing
|
||||
[4]:https://elifesciences.org/for-the-press/e6038800/elife-supports-development-of-open-technology-stack-for-publishing-reproducible-manuscripts-online
|
||||
[5]:https://elifesciences.org/for-the-press/81d42f7d/elife-enhances-open-annotation-with-hypothesis-to-promote-scientific-discussion-online
|
||||
[6]:https://github.com/substance
|
||||
[7]:https://github.com/stencila/stencila
|
||||
[8]:https://rmarkdown.rstudio.com/
|
||||
[9]:https://www.python.org/
|
||||
[10]:http://jupyter.org/
|
||||
[11]:https://elifesciences.org/labs/7dbeb390/reproducible-document-stack-supporting-the-next-generation-research-article
|
||||
[12]:https://github.com/hypothesis
|
||||
[13]:http://www.pubfactory.com/
|
||||
[14]:http://www.ingenta.com/
|
||||
[15]:https://github.com/highwire
|
||||
[16]:https://www.silverchair.com/community/silverchair-universe/hypothesis/
|
||||
[17]:https://www.tensorflow.org/
|
||||
[18]:https://elifesciences.org/labs
|
||||
[19]:mailto:innovation@elifesciences.org
|
||||
@ -0,0 +1,76 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Modularity in Fedora 28 Server Edition)
|
||||
[#]: via: (https://fedoramagazine.org/wp-content/uploads/2018/05/f28-server-modularity-816x345.jpg)
|
||||
[#]: author: (Stephen Gallagher https://fedoramagazine.org/author/sgallagh/)
|
||||
|
||||
Modularity in Fedora 28 Server Edition
|
||||
======
|
||||
|
||||

|
||||
|
||||
### What is Modularity?
|
||||
|
||||
A classic conundrum that all open-source distributions have faced is the “too fast/too slow” problem. Users install an operating system in order to enable the use of their applications. A comprehensive distribution like Fedora has an advantage and a disadvantage to the large amount of available software. While the package the user wants may be available, it might not be available in the version needed. Here’s how Modularity can help solve that problem.
|
||||
|
||||
Fedora sometimes moves too fast for some users. Its rapid release cycle and desire to carry the latest stable software can result in breaking compatibility with applications. If a user can’t run a web application because Fedora upgraded a web framework to an incompatible version, it can be very frustrating. The classic answer to the “too fast” problem has been “Fedora should have an LTS release.” However, this approach only solves half the problem and makes the flip side of this conundrum worse.
|
||||
|
||||
There are also times when Fedora moves too slowly for some of its users. For example, a Fedora release may be poorly-timed alongside the release of other desirable software. Once a Fedora release is declared stable, packagers must abide by the [Stable Updates Policy][1] and not introduce incompatible changes into the system.
|
||||
|
||||
Fedora Modularity addresses both sides of this problem. Fedora will still ship a standard release under its traditional policy. However, it will also ship a set of modules that define alternative versions of popular software. Those in the “too fast” camp still have the benefit of Fedora’s newer kernel and other general platform enhancements. In addition, they still have access to older frameworks or toolchains that support their applications.
|
||||
|
||||
In addition, those users who like to live closer to the edge can access newer software than was available at release time.
|
||||
|
||||
### What is Modularity not?
|
||||
|
||||
Modularity is not a drop-in replacement for [Software Collections][2]. These two technologies try to solve many of the same problems, but have distinct differences.
|
||||
|
||||
Software Collections install different versions of packages in parallel on the system. However, their downside is that each installation exists in its own namespaced portion of the filesystem. Furthermore, each application that relies on them needs to be told where to find them.
|
||||
|
||||
With Modularity, only one version of a package exists on the system, but the user can choose which one. The advantage is that this version lives in a standard location on the system. The package requires no special changes to applications that rely on it. Feedback from user studies shows most users don’t actually rely on parallel installation. Containerization and virtualization solve that problem.
|
||||
|
||||
### Why not just use containers?
|
||||
|
||||
This is another common question. Why would a user want modules when they could just use containers? The answer is, someone still has to maintain the software in the containers. Modules provide pre-packaged content for those containers that users don’t need to maintain, update and patch on their own. This is how Fedora takes the traditional value of a distribution and moves it into the new, containerized world.
|
||||
|
||||
Here’s an example of how Modularity solves problems for users of Node.js and Review Board.
|
||||
|
||||
### Node.js
|
||||
|
||||
Many readers may be familiar with Node.js, a popular server-side JavaScript runtime. Node.js has an even/odd release policy. Its community supports even-numbered releases (6.x, 8.x, 10.x, etc.) for around 30 months. Meanwhile, they support odd-numbered releases that are essentially developer previews for 9 months.
|
||||
|
||||
Due to this cycle, Fedora carried only the most recent even-numbered version of Node.js in its stable repositories. It avoided the odd-numbered versions entirely since their lifecycle was shorter than Fedora, and generally not aligned with a Fedora release. This didn’t sit well with some Fedora users, who wanted access to the latest and greatest enhancements.
|
||||
|
||||
Thanks to Modularity, Fedora 28 shipped with not just one, but three versions of Node.js to satisfy both developers and stable deployments. Fedora 28’s traditional repository shipped with Node.js 8.x. This version was the most recent long-term stable version at release time. The Modular repositories (available by default on Fedora 28 Server edition) also made the older Node.js 6.x release and the newer Node.js 9.x development release available.
|
||||
|
||||
Additionally, Node.js released 10.x upstream just days after Fedora 28\. In the past, users who wanted to deploy that version had to wait until Fedora 29, or use sources from outside Fedora. However, thanks again to Modularity, Node.js 10.x is already [available][3] in the Modular Updates-Testing repository for Fedora 28.
|
||||
|
||||
### Review Board
|
||||
|
||||
Review Board is a popular Django application for performing code reviews. Fedora included Review Board from Fedora 13 all the way until Fedora 21\. At that point, Fedora moved to Django 1.7\. Review Board was unable to keep up, due to backwards-incompatible changes in Django’s database support. It remained alive in EPEL for RHEL/CentOS 7, simply because those releases had fortunately frozen on Django 1.6\. Nevertheless, its time in Fedora was apparently over.
|
||||
|
||||
However, with the advent of Modularity, Fedora could again ship the older Django as a non-default module stream. As a result, Review Board has been restored to Fedora as a module. Fedora carries both supported releases from upstream: 2.5.x and 3.0.x.
|
||||
|
||||
### Putting the pieces together
|
||||
|
||||
Fedora has always provided users with a wide range of software to use. Fedora Modularity now provides them with deeper choices for which versions of the software they need. The next few years will be very exciting for Fedora, as developers and users start putting together their software in new and exciting (or old and exciting) ways.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/wp-content/uploads/2018/05/f28-server-modularity-816x345.jpg
|
||||
|
||||
作者:[Stephen Gallagher][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sgallagh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoraproject.org/wiki/Updates_Policy#Stable_Releases
|
||||
[2]: https://www.softwarecollections.org
|
||||
[3]: https://bodhi.fedoraproject.org/updates/FEDORA-MODULAR-2018-2b0846cb86
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Flowsnow)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (An introduction to the Pyramid web framework for Python)
|
||||
|
||||
@ -1,125 +0,0 @@
|
||||
Qalculate! – The Best Calculator Application in The Entire Universe
|
||||
======
|
||||
I have been a GNU-Linux user and a [Debian][1] user for more than a decade. As I started using the desktop more and more, it seemed to me that apart from few web-based services most of my needs were being met with [desktop applications][2] within Debian itself.
|
||||
|
||||
One of such applications was the need for me to calculate between different measurements of units. While there are and were many web-services which can do the same, I wanted something which could do all this and more on my desktop for both privacy reasons as well as not having to hunt for a web service for doing one thing or the other. My search ended when I found Qalculate!.
|
||||
|
||||
### Qalculate! The most versatile calculator application
|
||||
|
||||
![Qalculator is the best calculator app][3]
|
||||
|
||||
This is what aptitude says about [Qalculate!][4] and I cannot put it in better terms:
|
||||
|
||||
> Powerful and easy to use desktop calculator – GTK+ version
|
||||
>
|
||||
> Qalculate! is small and simple to use but with much power and versatility underneath. Features include customizable functions, units, arbitrary precision, plotting, and a graphical interface that uses a one-line fault-tolerant expression entry (although it supports optional traditional buttons).
|
||||
|
||||
It also did have a KDE interface as well as in its previous avatar, but at least in Debian testing, it just shows only the GTK+ version which can be seen from the github [repo][5] as well.
|
||||
|
||||
Needless to say that Qalculate! is available in Debian repository and hence can easily be installed [using apt command][6] or through software center in Debian based distributions like Ubuntu. It is also availale for Windows and macOS.
|
||||
|
||||
#### Features of Qalculate!
|
||||
|
||||
Now while it would be particularly long to go through the whole list of functionality it allows – allow me to list some of the functionality to be followed by a few screenshots of just a couple of functionalities that Qalculate! provides. The idea is basically to familiarize you with a couple of basic methods and then leave it up to you to enjoy exploring what all Qalculate! can do.
|
||||
|
||||
* Algebra
|
||||
* Calculus
|
||||
* Combinatorics
|
||||
* Complex_Numbers
|
||||
* Data_Sets
|
||||
* Date_&_Time
|
||||
* Economics
|
||||
* Exponents_&_Logarithms
|
||||
* Geometry
|
||||
* Logical
|
||||
* Matrices_&_Vectors
|
||||
* Miscellaneous
|
||||
* Number_Theory
|
||||
* Statistics
|
||||
* Trigonometry
|
||||
|
||||
|
||||
|
||||
#### Using Qalculate!
|
||||
|
||||
Using Qalculate! is not complicated. You can even write in the simple natural language. However, I recommend [reading the manual][7] to utilize the full potential of Qalculate!
|
||||
|
||||
![qalculate byte to gibibyte conversion ][8]
|
||||
|
||||
![conversion from celcius degrees to fahreneit][9]
|
||||
|
||||
#### qalc is the command line version of Qalculate!
|
||||
|
||||
You can achieve the same results as Qalculate! with its command-line brethren qalc
|
||||
```
|
||||
$ qalc 62499836 byte to gibibyte
|
||||
62499836 * byte = approx. 0.058207508 gibibyte
|
||||
|
||||
$ qalc 40 degree celsius to fahrenheit
|
||||
(40 * degree) * celsius = 104 deg*oF
|
||||
|
||||
```
|
||||
|
||||
I shared the command-line interface so that people who don’t like GUI interfaces and prefer command-line (CLI) or have headless nodes (no GUI) could also use qalculate, pretty common in server environments.
|
||||
|
||||
If you want to use it in scripts, I guess libqalculate would be the way to go and seeing how qalculate-gtk, qalc depend on it seems it should be good enough.
|
||||
|
||||
Just to share, you could also explore how to use plotting of series data but that and other uses will leave to you. Don’t forget to check the /usr/share/doc/qalculate/index.html to see all the different functionalities that Qalculate! has.
|
||||
|
||||
Note:- Do note that though Debian prefers [gnuplot][10] to showcase the pretty graphs that can come out of it.
|
||||
|
||||
#### Bonus Tip: You can thank the developer via command line in Debian
|
||||
|
||||
If you use Debian and like any package, you can quickly thank the Debian Developer or maintainer maintaining the said package using:
|
||||
```
|
||||
reportbug --kudos $PACKAGENAME
|
||||
|
||||
```
|
||||
|
||||
Since I liked QaIculate!, I would like to give a big shout-out to the Debian developer and maintainer Vincent Legout for the fantastic work he has done.
|
||||
```
|
||||
reportbug --kudos qalculate
|
||||
|
||||
```
|
||||
|
||||
I would also suggest reading my detailed article on using reportbug tool for [bug reporting in Debian][11].
|
||||
|
||||
#### The opinion of a Polymer Chemist on Qalculate!
|
||||
|
||||
Through my fellow author [Philip Prado][12], we contacted a Mr. Timothy Meyers, currently a student working in a polymer lab as a Polymer Chemist.
|
||||
|
||||
His professional opinion on Qaclulate! is –
|
||||
|
||||
> This looks like almost any scientist to use as any type of data calculations statistics could use this program issue would be do you know the commands and such to make it function
|
||||
>
|
||||
> I feel like there’s some Physics constants that are missing but off the top of my head I can’t think of what they are but I feel like there’s not very many [fluid dynamics][13] stuff in there and also some different like [light absorption][14] coefficients for different compounds but that’s just a chemist in me I don’t know if those are super necessary. [Free energy][15] might be one
|
||||
|
||||
In the end, I just want to share this is a mere introduction to what Qalculate! can do and is limited by what you want to get done and your imagination. I hope you like Qalculate!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/qalculate/
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/shirish/
|
||||
[1]:https://www.debian.org/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/qalculate-app-featured-1-800x450.jpeg
|
||||
[4]:https://qalculate.github.io/
|
||||
[5]:https://github.com/Qalculate
|
||||
[6]:https://itsfoss.com/apt-command-guide/
|
||||
[7]:https://qalculate.github.io/manual/index.html
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/qalculate-byte-conversion.png
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/qalculate-gtk-weather-conversion.png
|
||||
[10]:http://www.gnuplot.info/
|
||||
[11]:https://itsfoss.com/bug-report-debian/
|
||||
[12]:https://itsfoss.com/author/phillip/
|
||||
[13]:https://en.wikipedia.org/wiki/Fluid_dynamics
|
||||
[14]:https://en.wikipedia.org/wiki/Absorption_(electromagnetic_radiation)
|
||||
[15]:https://en.wikipedia.org/wiki/Gibbs_free_energy
|
||||
@ -1,3 +1,11 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (runningwater)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What a shell dotfile can do for you)
|
||||
[#]: via: (https://opensource.com/article/18/9/shell-dotfile)
|
||||
[#]: author: (H.Waldo Grunenwald https://opensource.com/users/gwaldo)
|
||||
What a shell dotfile can do for you
|
||||
======
|
||||
|
||||
@ -223,7 +231,7 @@ via: https://opensource.com/article/18/9/shell-dotfile
|
||||
|
||||
作者:[H.Waldo Grunenwald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,176 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Three SSH GUI Tools for Linux)
|
||||
[#]: via: (https://www.linux.com/blog/learn/intro-to-linux/2018/11/three-ssh-guis-linux)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
[#]: url: ( )
|
||||
|
||||
Three SSH GUI Tools for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
At some point in your career as a Linux administrator, you’re going to use Secure Shell (SSH) to remote into a Linux server or desktop. Chances are, you already have. In some instances, you’ll be SSH’ing into multiple Linux servers at once. In fact, Secure Shell might well be one of the most-used tools in your Linux toolbox. Because of this, you’ll want to make the experience as efficient as possible. For many admins, nothing is as efficient as the command line. However, there are users out there who do prefer a GUI tool, especially when working from a desktop machine to remote into and work on a server.
|
||||
|
||||
If you happen to prefer a good GUI tool, you’ll be happy to know there are a couple of outstanding graphical tools for SSH on Linux. Couple that with a unique terminal window that allows you to remote into multiple machines from the same window, and you have everything you need to work efficiently. Let’s take a look at these three tools and find out if one (or more) of them is perfectly apt to meet your needs.
|
||||
|
||||
I’ll be demonstrating these tools on [Elementary OS][1], but they are all available for most major distributions.
|
||||
|
||||
### PuTTY
|
||||
|
||||
Anyone that’s been around long enough knows about [PuTTY][2]. In fact, PuTTY is the de facto standard tool for connecting, via SSH, to Linux servers from the Windows environment. But PuTTY isn’t just for Windows. In fact, from withing the standard repositories, PuTTY can also be installed on Linux. PuTTY’s feature list includes:
|
||||
|
||||
* Saved sessions.
|
||||
|
||||
* Connect via IP address or hostname.
|
||||
|
||||
* Define alternative SSH port.
|
||||
|
||||
* Connection type definition.
|
||||
|
||||
* Logging.
|
||||
|
||||
* Options for keyboard, bell, appearance, connection, and more.
|
||||
|
||||
* Local and remote tunnel configuration
|
||||
|
||||
* Proxy support
|
||||
|
||||
* X11 tunneling support
|
||||
|
||||
|
||||
|
||||
|
||||
The PuTTY GUI is mostly a way to save SSH sessions, so it’s easier to manage all of those various Linux servers and desktops you need to constantly remote into and out of. Once you’ve connected, from PuTTY to the Linux server, you will have a terminal window in which to work. At this point, you may be asking yourself, why not just work from the terminal window? For some, the convenience of saving sessions does make PuTTY worth using.
|
||||
|
||||
Installing PuTTY on Linux is simple. For example, you could issue the command on a Debian-based distribution:
|
||||
|
||||
```
|
||||
sudo apt-get install -y putty
|
||||
```
|
||||
|
||||
Once installed, you can either run the PuTTY GUI from your desktop menu or issue the command putty. In the PuTTY Configuration window (Figure 1), type the hostname or IP address in the HostName (or IP address) section, configure the port (if not the default 22), select SSH from the connection type, and click Open.
|
||||
|
||||
![PuTTY Connection][4]
|
||||
|
||||
Figure 1: The PuTTY Connection Configuration Window.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Once the connection is made, you’ll then be prompted for the user credentials on the remote server (Figure 2).
|
||||
|
||||
![log in][7]
|
||||
|
||||
Figure 2: Logging into a remote server with PuTTY.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
To save a session (so you don’t have to always type the remote server information), fill out the IP address (or hostname), configure the port and connection type, and then (before you click Open), type a name for the connection in the top text area of the Saved Sessions section, and click Save. This will then save the configuration for the session. To then connect to a saved session, select it from the saved sessions window, click Load, and then click Open. You should then be prompted for the remote credentials on the remote server.
|
||||
|
||||
### EasySSH
|
||||
|
||||
Although [EasySSH][8] doesn’t offer the amount of configuration options found in PuTTY, it’s (as the name implies) incredibly easy to use. One of the best features of EasySSH is that it offers a tabbed interface, so you can have multiple SSH connections open and quickly switch between them. Other EasySSH features include:
|
||||
|
||||
* Groups (so you can group tabs for an even more efficient experience).
|
||||
|
||||
* Username/password save.
|
||||
|
||||
* Appearance options.
|
||||
|
||||
* Local and remote tunnel support.
|
||||
|
||||
|
||||
|
||||
|
||||
Install EasySSH on a Linux desktop is simple, as the app can be installed via flatpak (which does mean you must have Flatpak installed on your system). Once flatpak is installed, add EasySSH with the commands:
|
||||
|
||||
```
|
||||
sudo flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
|
||||
sudo flatpak install flathub com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
Run EasySSH with the command:
|
||||
|
||||
```
|
||||
flatpak run com.github.muriloventuroso.easyssh
|
||||
```
|
||||
|
||||
The EasySSH app will open, where you can click the + button in the upper left corner. In the resulting window (Figure 3), configure your SSH connection as required.
|
||||
|
||||
![Adding a connection][10]
|
||||
|
||||
Figure 3: Adding a connection in EasySSH is simple.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Once you’ve added the connection, it will appear in the left navigation of the main window (Figure 4).
|
||||
|
||||
![EasySSH][12]
|
||||
|
||||
Figure 4: The EasySSH main window.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
To connect to a remote server in EasySSH, select it from the left navigation and then click the Connect button (Figure 5).
|
||||
|
||||
![Connecting][14]
|
||||
|
||||
Figure 5: Connecting to a remote server with EasySSH.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
The one caveat with EasySSH is that you must save the username and password in the connection configuration (otherwise the connection will fail). This means anyone with access to the desktop running EasySSH can remote into your servers without knowing the passwords. Because of this, you must always remember to lock your desktop screen any time you are away (and make sure to use a strong password). The last thing you want is to have a server vulnerable to unwanted logins.
|
||||
|
||||
### Terminator
|
||||
|
||||
Terminator is not actually an SSH GUI. Instead, Terminator functions as a single window that allows you to run multiple terminals (and even groups of terminals) at once. Effectively you can open Terminator, split the window vertical and horizontally (until you have all the terminals you want), and then connect to all of your remote Linux servers by way of the standard SSH command (Figure 6).
|
||||
|
||||
![Terminator][16]
|
||||
|
||||
Figure 6: Terminator split into three different windows, each connecting to a different Linux server.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
To install Terminator, issue a command like:
|
||||
|
||||
### sudo apt-get install -y terminator
|
||||
|
||||
Once installed, open the tool either from your desktop menu or from the command terminator. With the window opened, you can right-click inside Terminator and select either Split Horizontally or Split Vertically. Continue splitting the terminal until you have exactly the number of terminals you need, and then start remoting into those servers.
|
||||
The caveat to using Terminator is that it is not a standard SSH GUI tool, in that it won’t save your sessions or give you quick access to those servers. In other words, you will always have to manually log into your remote Linux servers. However, being able to see your remote Secure Shell sessions side by side does make administering multiple remote machines quite a bit easier.
|
||||
|
||||
Few (But Worthwhile) Options
|
||||
|
||||
There aren’t a lot of SSH GUI tools available for Linux. Why? Because most administrators prefer to simply open a terminal window and use the standard command-line tools to remotely access their servers. However, if you have a need for a GUI tool, you have two solid options and one terminal that makes logging into multiple machines slightly easier. Although there are only a few options for those looking for an SSH GUI tool, those that are available are certainly worth your time. Give one of these a try and see for yourself.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/11/three-ssh-guis-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://elementary.io/
|
||||
[2]: https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
|
||||
[3]: https://www.linux.com/files/images/sshguis1jpg
|
||||
[4]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_1.jpg?itok=DiNTz_wO (PuTTY Connection)
|
||||
[5]: https://www.linux.com/licenses/category/used-permission
|
||||
[6]: https://www.linux.com/files/images/sshguis2jpg
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_2.jpg?itok=4ORsJlz3 (log in)
|
||||
[8]: https://github.com/muriloventuroso/easyssh
|
||||
[9]: https://www.linux.com/files/images/sshguis3jpg
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_3.jpg?itok=bHC2zlda (Adding a connection)
|
||||
[11]: https://www.linux.com/files/images/sshguis4jpg
|
||||
[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_4.jpg?itok=hhJzhRIg (EasySSH)
|
||||
[13]: https://www.linux.com/files/images/sshguis5jpg
|
||||
[14]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_5.jpg?itok=piFEFYTQ (Connecting)
|
||||
[15]: https://www.linux.com/files/images/sshguis6jpg
|
||||
[16]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ssh_guis_6.jpg?itok=-kYl6iSE (Terminator)
|
||||
@ -1,62 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Schedule a visit with the Emacs psychiatrist)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-eliza)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Schedule a visit with the Emacs psychiatrist
|
||||
======
|
||||
Eliza is a natural language processing chatbot hidden inside of one of Linux's most popular text editors.
|
||||
|
||||
|
||||
Welcome to another day of the 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
|
||||
Today's selection is a hidden gem inside of Emacs: Eliza, the Rogerian psychotherapist, a terminal toy ready to listen to everything you have to say.
|
||||
|
||||
A brief aside: While this toy is amusing, your health is no laughing matter. Please take care of yourself this holiday season, physically and mentally, and if stress and anxiety from the holidays are having a negative impact on your wellbeing, please consider seeing a professional for guidance. It really can help.
|
||||
|
||||
To launch [Eliza][1], first, you'll need to launch Emacs. There's a good chance Emacs is already installed on your system, but if it's not, it's almost certainly in your default repositories.
|
||||
|
||||
Since I've been pretty fastidious about keeping this series in the terminal, launch Emacs with the **-nw** flag to keep in within your terminal emulator.
|
||||
|
||||
```
|
||||
$ emacs -nw
|
||||
```
|
||||
|
||||
Inside of Emacs, type M-x doctor to launch Eliza. For those of you like me from a Vim background who have no idea what this means, just hit escape, type x and then type doctor. Then, share all of your holiday frustrations.
|
||||
|
||||
Eliza goes way back, all the way to the mid-1960s a the MIT Artificial Intelligence Lab. [Wikipedia][2] has a rather fascinating look at her history.
|
||||
|
||||
Eliza isn't the only amusement inside of Emacs. Check out the [manual][3] for a whole list of fun toys.
|
||||
|
||||
|
||||
![Linux toy: eliza animated][5]
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? We're running out of time, but I'd still love to hear your suggestions. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
|
||||
|
||||
Be sure to check out yesterday's toy, [Head to the arcade in your Linux terminal with this Pac-man clone][6], and come back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-eliza
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.emacswiki.org/emacs/EmacsDoctor
|
||||
[2]: https://en.wikipedia.org/wiki/ELIZA
|
||||
[3]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Amusements.html
|
||||
[4]: /file/417326
|
||||
[5]: https://opensource.com/sites/default/files/uploads/linux-toy-eliza-animated.gif (Linux toy: eliza animated)
|
||||
[6]: https://opensource.com/article/18/12/linux-toy-myman
|
||||
@ -1,110 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Midori: A Lightweight Open Source Web Browser)
|
||||
[#]: via: (https://itsfoss.com/midori-browser)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Midori: A Lightweight Open Source Web Browser
|
||||
======
|
||||
|
||||
**Here’s a quick review of the lightweight, fast, open source web browser Midori, which has returned from the dead.**
|
||||
|
||||
If you are looking for a lightweight [alternative web browser][1], try Midori.
|
||||
|
||||
[Midori][2] is an open source web browser that focuses more on being lightweight than on providing a ton of features.
|
||||
|
||||
If you have never heard of Midori, you might think that it is a new application but Midori was first released in 2007.
|
||||
|
||||
Because it focused on speed, Midori soon gathered a niche following and became the default browser in lightweight Linux distributions like Bodhi Linux, SilTaz etc.
|
||||
|
||||
Other distributions like [elementary OS][3] also used Midori as its default browser. But the development of Midori stalled around 2016 and its fans started wondering if Midori was dead already. elementary OS dropped it from its latest release, I believe, for this reason.
|
||||
|
||||
The good news is that Midori is not dead. After almost two years of inactivity, the development resumed in the last quarter of 2018. A few extensions including an ad-blocker were added in the later releases.
|
||||
|
||||
### Features of Midori web browser
|
||||
|
||||
![Midori web browser][4]
|
||||
|
||||
Here are some of the main features of the Midori browser
|
||||
|
||||
* Written in Vala with GTK+3 and WebKit rendering engine.
|
||||
* Tabs, windows and session management
|
||||
* Speed dial
|
||||
* Saves tab for the next session by default
|
||||
* Uses DuckDuckGo as a default search engine. It can be changed to Google or Yahoo.
|
||||
* Bookmark management
|
||||
* Customizable and extensible interface
|
||||
* Extension modules can be written in C and Vala
|
||||
* Supports HTML5
|
||||
* An extremely limited set of extensions include an ad-blocker, colorful tabs etc. No third-party extensions.
|
||||
* Form history
|
||||
* Private browsing
|
||||
* Available for Linux and Windows
|
||||
|
||||
|
||||
|
||||
Trivia: Midori is a Japanese word that means green. The Midori developer is not Japanese if you were guessing something along that line.
|
||||
|
||||
### Experiencing Midori
|
||||
|
||||
![Midori web browser in Ubuntu 18.04][5]
|
||||
|
||||
I have been using Midori for the past few days. The experience is mostly fine. It supports HTML5 and renders the websites quickly. The ad-blocker is okay. The browsing experience is more or less smooth as you would expect in any standard web browser.
|
||||
|
||||
The lack of extensions has always been a weak point of Midori so I am not going to talk about that.
|
||||
|
||||
What I did notice is that it doesn’t support international languages. I couldn’t find a way to add new language support. It could not render the Hindi fonts at all and I am guessing it’s the same with many other non-[Romance languages][6].
|
||||
|
||||
I also had my fair share of troubles with YouTube videos. Some videos would throw playback error while others would run just fine.
|
||||
|
||||
Midori didn’t eat my RAM like Chrome so that’s a big plus here.
|
||||
|
||||
If you want to try out Midori, let’s see how can you get your hands on it.
|
||||
|
||||
### Install Midori on Linux
|
||||
|
||||
Midori is no longer available in the Ubuntu 18.04 repository. However, the newer versions of Midori can be easily installed using the [Snap packages][7].
|
||||
|
||||
If you are using Ubuntu, you can find Midori (Snap version) in the Software Center and install it from there.
|
||||
|
||||
![Midori browser is available in Ubuntu Software Center][8]Midori browser is available in Ubuntu Software Center
|
||||
|
||||
For other Linux distributions, make sure that you have [Snap support enabled][9] and then you can install Midori using the command below:
|
||||
|
||||
```
|
||||
sudo snap install midori
|
||||
```
|
||||
|
||||
You always have the option to compile from the source code. You can download the source code of Midori from its website.
|
||||
|
||||
If you like Midori and want to help this open source project, please donate to them or [buy Midori merchandise from their shop][10].
|
||||
|
||||
Do you use Midori or have you ever tried it? How’s your experience with it? What other web browser do you prefer to use? Please share your views in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/midori-browser
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/open-source-browsers-linux/
|
||||
[2]: https://www.midori-browser.org/
|
||||
[3]: https://itsfoss.com/elementary-os-juno-features/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?resize=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-browser-linux.jpeg?resize=800%2C491&ssl=1
|
||||
[6]: https://en.wikipedia.org/wiki/Romance_languages
|
||||
[7]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-ubuntu-software-center.jpeg?ssl=1
|
||||
[9]: https://itsfoss.com/install-snap-linux/
|
||||
[10]: https://www.midori-browser.org/shop
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,254 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Three Ways To Reset And Change Forgotten Root Password on RHEL 7/CentOS 7 Systems)
|
||||
[#]: via: (https://www.2daygeek.com/linux-reset-change-forgotten-root-password-in-rhel-7-centos-7/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
|
||||
Three Ways To Reset And Change Forgotten Root Password on RHEL 7/CentOS 7 Systems
|
||||
======
|
||||
|
||||
If you are forget to remember your root password for RHEL 7 and CentOS 7 systems and want to reset the forgotten root password?
|
||||
|
||||
If so, don’t worry we are here to help you out on this.
|
||||
|
||||
Navigate to the following link if you want to **[reset forgotten root password on RHEL 6/CentOS 6][1]**.
|
||||
|
||||
This is generally happens when you use different password in vast environment or if you are not maintaining the proper inventory.
|
||||
|
||||
Whatever it is. No issues, we will help you through this article.
|
||||
|
||||
It can be done in many ways but we are going to show you the best three methods which we tried many times for our clients.
|
||||
|
||||
In Linux servers there are three different users are available. These are, Normal User, System User and Super User.
|
||||
|
||||
As everyone knows the Root user is known as super user in Linux and Administrator is in Windows.
|
||||
|
||||
We can’t perform any major activity without root password so, make sure you should have the right root password when you perform any major tasks.
|
||||
|
||||
If you don’t know or don’t have it, try to reset using one of the below method.
|
||||
|
||||
* Reset Forgotten Root Password By Booting into Single User Mode using `rd.break`
|
||||
* Reset Forgotten Root Password By Booting into Single User Mode using `init=/bin/bash`
|
||||
* Reset Forgotten Root Password By Booting into Rescue Mode
|
||||
|
||||
|
||||
|
||||
### Method-1: Reset Forgotten Root Password By Booting into Single User Mode
|
||||
|
||||
Just follow the below procedure to reset the forgotten root password in RHEL 7/CentOS 7 systems.
|
||||
|
||||
To do so, reboot your system and follow the instructions carefully.
|
||||
|
||||
**`Step-1:`** Reboot your system and interrupt at the boot menu by hitting **`e`** key to modify the kernel arguments.
|
||||
![][3]
|
||||
|
||||
**`Step-2:`** In the GRUB options, find `linux16` word and add the `rd.break` word in the end of the file then press `Ctrl+x` or `F10` to boot into single user mode.
|
||||
![][4]
|
||||
|
||||
**`Step-3:`** At this point of time, your root filesystem will be mounted in Read only (RO) mode to /sysroot. Run the below command to confirm this.
|
||||
|
||||
```
|
||||
# mount | grep root
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
**`Step-4:`** Based on the above output, i can say that i’m in single user mode and my root file system is mounted in read only mode.
|
||||
|
||||
It won’t allow you to make any changes on your system until you mount the root filesystem with Read and write (RW) mode to /sysroot. To do so, use the following command.
|
||||
|
||||
```
|
||||
# mount -o remount,rw /sysroot
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
**`Step-5:`** Currently your file systems are mounted as a temporary partition. Now, your command prompt shows **switch_root:/#**.
|
||||
|
||||
Run the following command to get into a chroot jail so that /sysroot is used as the root of the file system.
|
||||
|
||||
```
|
||||
# chroot /sysroot
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
**`Step-6:`** Now you can able to reset the root password with help of `passwd` command.
|
||||
|
||||
```
|
||||
# echo "CentOS7$#123" | passwd --stdin root
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
**`Step-7:`** By default CentOS 7/RHEL 7 use SELinux in enforcing mode, so create a following hidden file which will automatically perform a relabel of all files on next boot.
|
||||
|
||||
It allow us to fix the context of the **/etc/shadow** file.
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
**`Step-8:`** Issue `exit` twice to exit from the chroot jail environment and reboot the system.
|
||||
![][10]
|
||||
|
||||
**`Step-9:`** Now you can login to your system with your new password.
|
||||
![][11]
|
||||
|
||||
### Method-2: Reset Forgotten Root Password By Booting into Single User Mode
|
||||
|
||||
Alternatively we can use the below procedure to reset the forgotten root password in RHEL 7/CentOS 7 systems.
|
||||
|
||||
**`Step-1:`** Reboot your system and interrupt at the boot menu by hitting **`e`** key to modify the kernel arguments.
|
||||
![][3]
|
||||
|
||||
**`Step-2:`** In the GRUB options, find `rhgb quiet` word and replace with the `init=/bin/bash` or `init=/bin/sh` word then press `Ctrl+x` or `F10` to boot into single user mode.
|
||||
|
||||
Screenshot for **`init=/bin/bash`**.
|
||||
![][12]
|
||||
|
||||
Screenshot for **`init=/bin/sh`**.
|
||||
![][13]
|
||||
|
||||
**`Step-3:`** At this point of time, your root system will be mounted in Read only mode to /. Run the below command to confirm this.
|
||||
|
||||
```
|
||||
# mount | grep root
|
||||
```
|
||||
|
||||
![][14]
|
||||
|
||||
**`Step-4:`** Based on the above ouput, i can say that i’m in single user mode and my root file system is mounted in read only (RO) mode.
|
||||
|
||||
It won’t allow you to make any changes on your system until you mount the root file system with Read and write (RW) mode. To do so, use the following command.
|
||||
|
||||
```
|
||||
# mount -o remount,rw /
|
||||
```
|
||||
|
||||
![][15]
|
||||
|
||||
**`Step-5:`** Now you can able to reset the root password with help of `passwd` command.
|
||||
|
||||
```
|
||||
# echo "RHEL7$#123" | passwd --stdin root
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
**`Step-6:`** By default CentOS 7/RHEL 7 use SELinux in enforcing mode, so create a following hidden file which will automatically perform a relabel of all files on next boot.
|
||||
|
||||
It allow us to fix the context of the **/etc/shadow** file.
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
![][17]
|
||||
|
||||
**`Step-7:`** Finally `Reboot` the system.
|
||||
|
||||
```
|
||||
# exec /sbin/init 6
|
||||
```
|
||||
|
||||
![][18]
|
||||
|
||||
**`Step-9:`** Now you can login to your system with your new password.
|
||||
![][11]
|
||||
|
||||
### Method-3: Reset Forgotten Root Password By Booting into Rescue Mode
|
||||
|
||||
Alternatively, we can reset the forgotten Root password for RHEL 7 and CentOS 7 systems using Rescue mode.
|
||||
|
||||
**`Step-1:`** Insert the bootable media through USB or DVD drive which is compatible for you and reboot your system. It will take to you to the below screen.
|
||||
|
||||
Hit `Troubleshooting` to launch the `Rescue` mode.
|
||||
![][19]
|
||||
|
||||
**`Step-2:`** Choose `Rescue a CentOS system` and hit `Enter` button.
|
||||
![][20]
|
||||
|
||||
**`Step-3:`** Here choose `1` and the rescue environment will now attempt to find your Linux installation and mount it under the directory `/mnt/sysimage`.
|
||||
![][21]
|
||||
|
||||
**`Step-4:`** Simple hit `Enter` to get a shell.
|
||||
![][22]
|
||||
|
||||
**`Step-5:`** Run the following command to get into a chroot jail so that /mnt/sysimage is used as the root of the file system.
|
||||
|
||||
```
|
||||
# chroot /mnt/sysimage
|
||||
```
|
||||
|
||||
![][23]
|
||||
|
||||
**`Step-6:`** Now you can able to reset the root password with help of **passwd** command.
|
||||
|
||||
```
|
||||
# echo "RHEL7$#123" | passwd --stdin root
|
||||
```
|
||||
|
||||
![][24]
|
||||
|
||||
**`Step-7:`** By default CentOS 7/RHEL 7 use SELinux in enforcing mode, so create a following hidden file which will automatically perform a relabel of all files on next boot.
|
||||
It allow us to fix the context of the /etc/shadow file.
|
||||
|
||||
```
|
||||
# touch /.autorelabel
|
||||
```
|
||||
|
||||
![][25]
|
||||
|
||||
**`Step-8:`** Remove the bootable media then initiate the reboot.
|
||||
|
||||
**`Step-9:`** Issue `exit` twice to exit from the chroot jail environment and reboot the system.
|
||||
![][26]
|
||||
|
||||
**`Step-10:`** Now you can login to your system with your new password.
|
||||
![][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-reset-change-forgotten-root-password-in-rhel-7-centos-7/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-reset-change-forgotten-root-password-in-rhel-6-centos-6/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-2.png
|
||||
[4]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-3.png
|
||||
[5]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-5.png
|
||||
[6]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-6.png
|
||||
[7]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-8.png
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-10.png
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-10a.png
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-11.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/12/reset-forgotten-root-password-on-rhel-7-centos-7-12.png
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2018/12/method-reset-forgotten-root-password-on-rhel-7-centos-7-1.png
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2018/12/method-reset-forgotten-root-password-on-rhel-7-centos-7-1a.png
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2018/12/method-reset-forgotten-root-password-on-rhel-7-centos-7-3.png
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2018/12/method-reset-forgotten-root-password-on-rhel-7-centos-7-4.png
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2018/12/method-reset-forgotten-root-password-on-rhel-7-centos-7-5.png
|
||||
[17]: https://www.2daygeek.com/wp-content/uploads/2018/12/method-reset-forgotten-root-password-on-rhel-7-centos-7-6.png
|
||||
[18]: https://www.2daygeek.com/wp-content/uploads/2018/12/method-reset-forgotten-root-password-on-rhel-7-centos-7-7.png
|
||||
[19]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-1.png
|
||||
[20]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-2.png
|
||||
[21]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-3.png
|
||||
[22]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-4.png
|
||||
[23]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-5.png
|
||||
[24]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-6.png
|
||||
[25]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-7.png
|
||||
[26]: https://www.2daygeek.com/wp-content/uploads/2018/12/rescue-reset-forgotten-root-password-on-rhel-7-centos-7-8.png
|
||||
@ -1,133 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How ASLR protects Linux systems from buffer overflow attacks)
|
||||
[#]: via: (https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How ASLR protects Linux systems from buffer overflow attacks
|
||||
======
|
||||
|
||||

|
||||
|
||||
Address Space Layout Randomization (ASLR) is a memory-protection process for operating systems that guards against buffer-overflow attacks. It helps to ensure that the memory addresses associated with running processes on systems are not predictable, thus flaws or vulnerabilities associated with these processes will be more difficult to exploit.
|
||||
|
||||
ASLR is used today on Linux, Windows, and MacOS systems. It was first implemented on Linux in 2005. In 2007, the technique was deployed on Microsoft Windows and MacOS. While ASLR provides the same function on each of these operating systems, it is implemented differently on each one.
|
||||
|
||||
The effectiveness of ASLR is dependent on the entirety of the address space layout remaining unknown to the attacker. In addition, only executables that are compiled as Position Independent Executable (PIE) programs will be able to claim the maximum protection from ASLR technique because all sections of the code will be loaded at random locations. PIE machine code will execute properly regardless of its absolute address.
|
||||
|
||||
**[ Also see:[Invaluable tips and tricks for troubleshooting Linux][1] ]**
|
||||
|
||||
### ASLR limitations
|
||||
|
||||
In spite of ASLR making exploitation of system vulnerabilities more difficult, its role in protecting systems is limited. It's important to understand that ASLR:
|
||||
|
||||
* Doesn't _resolve_ vulnerabilities, but makes exploiting them more of a challenge
|
||||
* Doesn't track or report vulnerabilities
|
||||
* Doesn't offer any protection for binaries that are not built with ASLR support
|
||||
* Isn't immune to circumvention
|
||||
|
||||
|
||||
|
||||
### How ASLR works
|
||||
|
||||
ASLR increases the control-flow integrity of a system by making it more difficult for an attacker to execute a successful buffer-overflow attack by randomizing the offsets it uses in memory layouts.
|
||||
|
||||
ASLR works considerably better on 64-bit systems, as these systems provide much greater entropy (randomization potential).
|
||||
|
||||
### Is ASLR working on your Linux system?
|
||||
|
||||
Either of the two commands shown below will tell you whether ASLR is enabled on your system.
|
||||
|
||||
```
|
||||
$ cat /proc/sys/kernel/randomize_va_space
|
||||
2
|
||||
$ sysctl -a --pattern randomize
|
||||
kernel.randomize_va_space = 2
|
||||
```
|
||||
|
||||
The value (2) shown in the commands above indicates that ASLR is working in full randomization mode. The value shown will be one of the following:
|
||||
|
||||
```
|
||||
0 = Disabled
|
||||
1 = Conservative Randomization
|
||||
2 = Full Randomization
|
||||
```
|
||||
|
||||
If you disable ASLR and run the commands below, you should notice that the addresses shown in the **ldd** output below are all the same in the successive **ldd** commands. The **ldd** command works by loading the shared objects and showing where they end up in memory.
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=0 <== disable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 0
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffff7fd1000) <== same addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007ffff7c69000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffff7c63000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7a79000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fd3000)
|
||||
```
|
||||
|
||||
If the value is set back to **2** to enable ASLR, you will see that the addresses will change each time you run the command.
|
||||
|
||||
```
|
||||
$ sudo sysctl -w kernel.randomize_va_space=2 <== enable
|
||||
[sudo] password for shs:
|
||||
kernel.randomize_va_space = 2
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007fff47d0e000) <== first set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007f1cb7ce0000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f1cb7cda000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f1cb7af0000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007f1cb8045000)
|
||||
$ ldd /bin/bash
|
||||
linux-vdso.so.1 (0x00007ffe1cbd7000) <== second set of addresses
|
||||
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007fed59742000)
|
||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fed5973c000)
|
||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fed59552000)
|
||||
/lib64/ld-linux-x86-64.so.2 (0x00007fed59aa7000)
|
||||
```
|
||||
|
||||
### Attempting to bypass ASLR
|
||||
|
||||
In spite of its advantages, attempts to bypass ASLR are not uncommon and seem to fall into several categories:
|
||||
|
||||
* Using address leaks
|
||||
* Gaining access to data relative to particular addresses
|
||||
* Exploiting implementation weaknesses that allow attackers to guess addresses when entropy is low or when the ASLR implementation is faulty
|
||||
* Using side channels of hardware operation
|
||||
|
||||
|
||||
|
||||
### Wrap-up
|
||||
|
||||
ASLR is of great value, especially when run on 64 bit systems and implemented properly. While not immune from circumvention attempts, it does make exploitation of system vulnerabilities considerably more difficult. Here is a reference that can provide a lot more detail [on the Effectiveness of Full-ASLR on 64-bit Linux][2], and here is a paper on one circumvention effort to [bypass ASLR][3] using branch predictors.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3331199/linux/what-does-aslr-do-for-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[2]: https://cybersecurity.upv.es/attacks/offset2lib/offset2lib-paper.pdf
|
||||
[3]: http://www.cs.ucr.edu/~nael/pubs/micro16.pdf
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -1,369 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (pityonline)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 useful Vim plugins for developers)
|
||||
[#]: via: (https://opensource.com/article/19/1/vim-plugins-developers)
|
||||
[#]: author: (Ricardo Gerardi https://opensource.com/users/rgerardi)
|
||||
|
||||
5 useful Vim plugins for developers
|
||||
======
|
||||
Expand Vim's capabilities and improve your workflow with these five plugins for writing code.
|
||||

|
||||
|
||||
I have used [Vim][1] as a text editor for over 20 years, but about two years ago I decided to make it my primary text editor. I use Vim to write code, configuration files, blog articles, and pretty much everything I can do in plaintext. Vim has many great features and, once you get used to it, you become very productive.
|
||||
|
||||
I tend to use Vim's robust native capabilities for most of what I do, but there are a number of plugins developed by the open source community that extend Vim's capabilities, improve your workflow, and make you even more productive.
|
||||
|
||||
Following are five plugins that are useful when using Vim to write code in any programming language.
|
||||
|
||||
### 1. Auto Pairs
|
||||
|
||||
The [Auto Pairs][2] plugin helps insert and delete pairs of characters, such as brackets, parentheses, or quotation marks. This is very useful for writing code, since most programming languages use pairs of characters in their syntax—such as parentheses for function calls or quotation marks for string definitions.
|
||||
|
||||
In its most basic functionality, Auto Pairs inserts the corresponding closing character when you type an opening character. For example, if you enter a bracket **[** , Auto-Pairs automatically inserts the closing bracket **]**. Conversely, if you use the Backspace key to delete the opening bracket, Auto Pairs deletes the corresponding closing bracket.
|
||||
|
||||
If you have automatic indentation on, Auto Pairs inserts the paired character in the proper indented position when you press Return/Enter, saving you from finding the correct position and typing the required spaces or tabs.
|
||||
|
||||
Consider this Go code block for instance:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Inserting an opening curly brace **{** after **items** and pressing Return/Enter produces this result:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items {
|
||||
| (cursor here)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Auto Pairs offers many other options (which you can read about on [GitHub][3]), but even these basic features will save time.
|
||||
|
||||
### 2. NERD Commenter
|
||||
|
||||
The [NERD Commenter][4] plugin adds code-commenting functions to Vim, similar to the ones found in an integrated development environment (IDE). With this plugin installed, you can select one or several lines of code and change them to comments with the press of a button.
|
||||
|
||||
NERD Commenter integrates with the standard Vim [filetype][5] plugin, so it understands several programming languages and uses the appropriate commenting characters for single or multi-line comments.
|
||||
|
||||
The easiest way to get started is by pressing **Leader+Space** to toggle the current line between commented and uncommented. The standard Vim Leader key is the **\** character.
|
||||
|
||||
In Visual mode, you can select multiple lines and toggle their status at the same time. NERD Commenter also understands counts, so you can provide a count n followed by the command to change n lines together.
|
||||
|
||||
Other useful features are the "Sexy Comment," triggered by **Leader+cs** , which creates a fancy comment block using the multi-line comment character. For example, consider this block of code:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
x := true
|
||||
items := []string{"tv", "pc", "tablet"}
|
||||
|
||||
if x {
|
||||
for _, i := range items {
|
||||
fmt.Println(i)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Selecting all the lines in **function main** and pressing **Leader+cs** results in the following comment block:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
/*
|
||||
* x := true
|
||||
* items := []string{"tv", "pc", "tablet"}
|
||||
*
|
||||
* if x {
|
||||
* for _, i := range items {
|
||||
* fmt.Println(i)
|
||||
* }
|
||||
* }
|
||||
*/
|
||||
}
|
||||
```
|
||||
|
||||
Since all the lines are commented in one block, you can uncomment the entire block by toggling any of the lines of the block with **Leader+Space**.
|
||||
|
||||
NERD Commenter is a must-have for any developer using Vim to write code.
|
||||
|
||||
### 3. VIM Surround
|
||||
|
||||
The [Vim Surround][6] plugin helps you "surround" existing text with pairs of characters (such as parentheses or quotation marks) or tags (such as HTML or XML tags). It's similar to Auto Pairs but, instead of working while you're inserting text, it's more useful when you're editing text.
|
||||
|
||||
For example, if you have the following sentence:
|
||||
|
||||
```
|
||||
"Vim plugins are awesome !"
|
||||
```
|
||||
|
||||
You can remove the quotation marks around the sentence by pressing the combination **ds"** while your cursor is anywhere between the quotation marks:
|
||||
|
||||
```
|
||||
Vim plugins are awesome !
|
||||
```
|
||||
|
||||
You can also change the double quotation marks to single quotation marks with the command **cs"'** :
|
||||
|
||||
```
|
||||
'Vim plugins are awesome !'
|
||||
```
|
||||
|
||||
Or replace them with brackets by pressing **cs'[**
|
||||
|
||||
```
|
||||
[ Vim plugins are awesome ! ]
|
||||
```
|
||||
|
||||
While it's a great help for text objects, this plugin really shines when working with HTML or XML tags. Consider the following HTML line:
|
||||
|
||||
```
|
||||
<p>Vim plugins are awesome !</p>
|
||||
```
|
||||
|
||||
You can emphasize the word "awesome" by pressing the combination **ysiw <em>** while the cursor is anywhere on that word:
|
||||
|
||||
```
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
```
|
||||
|
||||
Notice that the plugin is smart enough to use the proper closing tag **< /em>**.
|
||||
|
||||
Vim Surround can also indent text and add tags in their own lines using **ySS**. For example, if you have:
|
||||
|
||||
```
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
```
|
||||
|
||||
Add a **div** tag with this combination: **ySS <div class="normal">**, and notice that the paragraph line is indented automatically.
|
||||
|
||||
```
|
||||
<div class="normal">
|
||||
<p>Vim plugins are <em>awesome</em> !</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
Vim Surround has many other options. Give it a try—and consult [GitHub][7] for additional information.
|
||||
|
||||
### 4\. Vim Gitgutter
|
||||
|
||||
The [Vim Gitgutter][8] plugin is useful for anyone using Git for version control. It shows the output of **Git diff** as symbols in the "gutter"—the sign column where Vim presents additional information, such as line numbers. For example, consider the following as the committed version in Git:
|
||||
|
||||
```
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
5 func main() {
|
||||
6 x := true
|
||||
7 items := []string{"tv", "pc", "tablet"}
|
||||
8
|
||||
9 if x {
|
||||
10 for _, i := range items {
|
||||
11 fmt.Println(i)
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
After making some changes, Vim Gitgutter displays the following symbols in the gutter:
|
||||
|
||||
```
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
The **-** symbol shows that a line was deleted between lines 5 and 6. The **~** symbol shows that line 8 was modified, and the symbol **+** shows that line 11 was added.
|
||||
|
||||
In addition, Vim Gitgutter allows you to navigate between "hunks"—individual changes made in the file—with **[c** and **]c** , or even stage individual hunks for commit by pressing **Leader+hs**.
|
||||
|
||||
This plugin gives you immediate visual feedback of changes, and it's a great addition to your toolbox if you use Git.
|
||||
|
||||
### 5\. VIM Fugitive
|
||||
|
||||
[Vim Fugitive][9] is another great plugin for anyone incorporating Git into the Vim workflow. It's a Git wrapper that allows you to execute Git commands directly from Vim and integrates with Vim's interface. This plugin has many features—check its [GitHub][10] page for more information.
|
||||
|
||||
Here's a basic Git workflow example using Vim Fugitive. Considering the changes we've made to the Go code block on section 4, you can use **git blame** by typing the command **:Gblame** :
|
||||
|
||||
```
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
|
||||
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
|
||||
00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
|
||||
e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
|
||||
```
|
||||
|
||||
You can see that lines 8 and 11 have not been committed. Check the repository status by typing **:Gstatus** :
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is up to date with 'origin/master'.
|
||||
3 #
|
||||
4 # Changes not staged for commit:
|
||||
5 # (use "git add <file>..." to update what will be committed)
|
||||
6 # (use "git checkout -- <file>..." to discard changes in working directory)
|
||||
7 #
|
||||
8 # modified: vim-5plugins/examples/test1.go
|
||||
9 #
|
||||
10 no changes added to commit (use "git add" and/or "git commit -a")
|
||||
--------------------------------------------------------------------------------------------------------
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
Vim Fugitive opens a split window with the result of **git status**. You can stage a file for commit by pressing the **-** key on the line with the name of the file. You can reset the status by pressing **-** again. The message updates to reflect the new status:
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is up to date with 'origin/master'.
|
||||
3 #
|
||||
4 # Changes to be committed:
|
||||
5 # (use "git reset HEAD <file>..." to unstage)
|
||||
6 #
|
||||
7 # modified: vim-5plugins/examples/test1.go
|
||||
8 #
|
||||
--------------------------------------------------------------------------------------------------------
|
||||
1 package main
|
||||
2
|
||||
3 import "fmt"
|
||||
4
|
||||
_ 5 func main() {
|
||||
6 items := []string{"tv", "pc", "tablet"}
|
||||
7
|
||||
~ 8 if len(items) > 0 {
|
||||
9 for _, i := range items {
|
||||
10 fmt.Println(i)
|
||||
+ 11 fmt.Println("------")
|
||||
12 }
|
||||
13 }
|
||||
14 }
|
||||
```
|
||||
|
||||
Now you can use the command **:Gcommit** to commit the changes. Vim Fugitive opens another split that allows you to enter a commit message:
|
||||
|
||||
```
|
||||
1 vim-5plugins: Updated test1.go example file
|
||||
2 # Please enter the commit message for your changes. Lines starting
|
||||
3 # with '#' will be ignored, and an empty message aborts the commit.
|
||||
4 #
|
||||
5 # On branch master
|
||||
6 # Your branch is up to date with 'origin/master'.
|
||||
7 #
|
||||
8 # Changes to be committed:
|
||||
9 # modified: vim-5plugins/examples/test1.go
|
||||
10 #
|
||||
```
|
||||
|
||||
Save the file with **:wq** to complete the commit:
|
||||
|
||||
```
|
||||
[master c3bf80f] vim-5plugins: Updated test1.go example file
|
||||
1 file changed, 2 insertions(+), 2 deletions(-)
|
||||
Press ENTER or type command to continue
|
||||
```
|
||||
|
||||
You can use **:Gstatus** again to see the result and **:Gpush** to update the remote repository with the new commit.
|
||||
|
||||
```
|
||||
1 # On branch master
|
||||
2 # Your branch is ahead of 'origin/master' by 1 commit.
|
||||
3 # (use "git push" to publish your local commits)
|
||||
4 #
|
||||
5 nothing to commit, working tree clean
|
||||
```
|
||||
|
||||
If you like Vim Fugitive and want to learn more, the GitHub repository has links to screencasts showing additional functionality and workflows. Check it out!
|
||||
|
||||
### What's next?
|
||||
|
||||
These Vim plugins help developers write code in any programming language. There are two other categories of plugins to help developers: code-completion plugins and syntax-checker plugins. They are usually related to specific programming languages, so I will cover them in a follow-up article.
|
||||
|
||||
Do you have another Vim plugin you use when writing code? Please share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/vim-plugins-developers
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[pityonline](https://github.com/pityonline)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgerardi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.vim.org/
|
||||
[2]: https://www.vim.org/scripts/script.php?script_id=3599
|
||||
[3]: https://github.com/jiangmiao/auto-pairs
|
||||
[4]: https://github.com/scrooloose/nerdcommenter
|
||||
[5]: http://vim.wikia.com/wiki/Filetype.vim
|
||||
[6]: https://www.vim.org/scripts/script.php?script_id=1697
|
||||
[7]: https://github.com/tpope/vim-surround
|
||||
[8]: https://github.com/airblade/vim-gitgutter
|
||||
[9]: https://www.vim.org/scripts/script.php?script_id=2975
|
||||
[10]: https://github.com/tpope/vim-fugitive
|
||||
514
sources/tech/20190115 Linux Desktop Setup - HookRace Blog.md
Normal file
514
sources/tech/20190115 Linux Desktop Setup - HookRace Blog.md
Normal file
@ -0,0 +1,514 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Desktop Setup · HookRace Blog)
|
||||
[#]: via: (https://hookrace.net/blog/linux-desktop-setup/)
|
||||
[#]: author: (Dennis Felsing http://felsin9.de/nnis/)
|
||||
|
||||
Linux Desktop Setup
|
||||
======
|
||||
|
||||
|
||||
My software setup has been surprisingly constant over the last decade, after a few years of experimentation since I initially switched to Linux in 2006. It might be interesting to look back in another 10 years and see what changed. A quick overview of what’s running as I’m writing this post:
|
||||
|
||||
[![htop overview][1]][2]
|
||||
|
||||
### Motivation
|
||||
|
||||
My software priorities are, in no specific order:
|
||||
|
||||
* Programs should run on my local system so that I’m in control of them, this excludes cloud solutions.
|
||||
* Programs should run in the terminal, so that they can be used consistently from anywhere, including weak computers or a phone.
|
||||
* Keyboard focused is nearly automatic by using terminal software. I prefer to use the mouse where it makes sense only, reaching for the mouse all the time during typing feels like a waste of time. Occasionally it took me an hour to notice that the mouse wasn’t even plugged in.
|
||||
* Ideally use fast and efficient software, I don’t like hearing the fan and feeling the room heat up. I can also keep running older hardware for much longer, my 10 year old Thinkpad x200s is still fine for all the software I use.
|
||||
* Be composable. I don’t want to do every step manually, instead automate more when it makes sense. This naturally favors the shell.
|
||||
|
||||
|
||||
|
||||
### Operating Systems
|
||||
|
||||
I had a hard start with Linux 12 years ago by removing Windows, armed with just the [Gentoo Linux][3] installation CD and a printed manual to get a functioning Linux system. It took me a few days of compiling and tinkering, but in the end I felt like I had learnt a lot.
|
||||
|
||||
I haven’t looked back to Windows since then, but I switched to [Arch Linux][4] on my laptop after having the fan fail from the constant compilation stress. Later I also switched all my other computers and private servers to Arch Linux. As a rolling release distribution you get package upgrades all the time, but the most important breakages are nicely reported in the [Arch Linux News][5].
|
||||
|
||||
One annoyance though is that Arch Linux removes the old kernel modules once you upgrade it. I usually notice that once I try plugging in a USB flash drive and the kernel fails to load the relevant module. Instead you’re supposed to reboot after each kernel upgrade. There are a few [hacks][6] around to get around the problem, but I haven’t been bothered enough to actually use them.
|
||||
|
||||
Similar problems happen with other programs, commonly Firefox, cron or Samba requiring a restart after an upgrade, but annoyingly not warning you that that’s the case. [SUSE][7], which I use at work, nicely warns about such cases.
|
||||
|
||||
For the [DDNet][8] production servers I prefer [Debian][9] over Arch Linux, so that I have a lower chance of breakage on each upgrade. For my firewall and router I used [OpenBSD][10] for its clean system, documentation and great [pf firewall][11], but right now I don’t have a need for a separate router anymore.
|
||||
|
||||
### Window Manager
|
||||
|
||||
Since I started out with Gentoo I quickly noticed the huge compile time of KDE, which made it a no-go for me. I looked around for more minimal solutions, and used [Openbox][12] and [Fluxbox][13] initially. At some point I jumped on the tiling window manager train in order to be more keyboard-focused and picked up [dwm][14] and [awesome][15] close to their initial releases.
|
||||
|
||||
In the end I settled on [xmonad][16] thanks to its flexibility, extendability and being written and configured in pure [Haskell][17], a great functional programming language. One example of this is that at home I run a single 40” 4K screen, but often split it up into four virtual screens, each displaying a workspace on which my windows are automatically arranged. Of course xmonad has a [module][18] for that.
|
||||
|
||||
[dzen][19] and [conky][20] function as a simple enough status bar for me. My entire conky config looks like this:
|
||||
|
||||
```
|
||||
out_to_console yes
|
||||
update_interval 1
|
||||
total_run_times 0
|
||||
|
||||
TEXT
|
||||
${downspeed eth0} ${upspeed eth0} | $cpu% ${loadavg 1} ${loadavg 2} ${loadavg 3} $mem/$memmax | ${time %F %T}
|
||||
```
|
||||
|
||||
And gets piped straight into dzen2 with `conky | dzen2 -fn '-xos4-terminus-medium-r-normal-*-12-*-*-*-*-*-*-*' -bg '#000000' -fg '#ffffff' -p -e '' -x 1000 -w 920 -xs 1 -ta r`.
|
||||
|
||||
One important feature for me is to make the terminal emit a beep sound once a job is done. This is done simply by adding a `\a` character to the `PR_TITLEBAR` variable in zsh, which is shown whenever a job is done. Of course I disable the actual beep sound by blacklisting the `pcspkr` kernel module with `echo "blacklist pcspkr" > /etc/modprobe.d/nobeep.conf`. Instead the sound gets turned into an urgency by urxvt’s `URxvt.urgentOnBell: true` setting. Then xmonad has an urgency hook to capture this and I can automatically focus the currently urgent window with a key combination. In dzen I get the urgent windowspaces displayed with a nice and bright `#ff0000`.
|
||||
|
||||
The final result in all its glory on my Laptop:
|
||||
|
||||
[![Laptop screenshot][21]][22]
|
||||
|
||||
I hear that [i3][23] has become quite popular in the last years, but it requires more manual window alignment instead of specifying automated methods to do it.
|
||||
|
||||
I realize that there are also terminal multiplexers like [tmux][24], but I still require a few graphical applications, so in the end I never used them productively.
|
||||
|
||||
### Terminal Persistency
|
||||
|
||||
In order to keep terminals alive I use [dtach][25], which is just the detach feature of screen. In order to make every terminal on my computer detachable I wrote a [small wrapper script][26]. This means that even if I had to restart my X server I could keep all my terminals running just fine, both local and remote.
|
||||
|
||||
### Shell & Programming
|
||||
|
||||
Instead of [bash][27] I use [zsh][28] as my shell for its huge number of features.
|
||||
|
||||
As a terminal emulator I found [urxvt][29] to be simple enough, support Unicode and 256 colors and has great performance. Another great feature is being able to run the urxvt client and daemon separately, so that even a large number of terminals barely takes up any memory (except for the scrollback buffer).
|
||||
|
||||
There is only one font that looks absolutely clean and perfect to me: [Terminus][30]. Since i’s a bitmap font everything is pixel perfect and renders extremely fast and at low CPU usage. In order to switch fonts on-demand in each terminal with `CTRL-WIN-[1-7]` my ~/.Xdefaults contains:
|
||||
|
||||
```
|
||||
URxvt.font: -xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*
|
||||
dzen2.font: -xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*
|
||||
|
||||
URxvt.keysym.C-M-1: command:\033]50;-xos4-terminus-medium-r-normal-*-12-*-*-*-*-*-*-*\007
|
||||
URxvt.keysym.C-M-2: command:\033]50;-xos4-terminus-medium-r-normal-*-14-*-*-*-*-*-*-*\007
|
||||
URxvt.keysym.C-M-3: command:\033]50;-xos4-terminus-medium-r-normal-*-18-*-*-*-*-*-*-*\007
|
||||
URxvt.keysym.C-M-4: command:\033]50;-xos4-terminus-medium-r-normal-*-22-*-*-*-*-*-*-*\007
|
||||
URxvt.keysym.C-M-5: command:\033]50;-xos4-terminus-medium-r-normal-*-24-*-*-*-*-*-*-*\007
|
||||
URxvt.keysym.C-M-6: command:\033]50;-xos4-terminus-medium-r-normal-*-28-*-*-*-*-*-*-*\007
|
||||
URxvt.keysym.C-M-7: command:\033]50;-xos4-terminus-medium-r-normal-*-32-*-*-*-*-*-*-*\007
|
||||
|
||||
URxvt.keysym.C-M-n: command:\033]10;#ffffff\007\033]11;#000000\007\033]12;#ffffff\007\033]706;#00ffff\007\033]707;#ffff00\007
|
||||
URxvt.keysym.C-M-b: command:\033]10;#000000\007\033]11;#ffffff\007\033]12;#000000\007\033]706;#0000ff\007\033]707;#ff0000\007
|
||||
```
|
||||
|
||||
For programming and writing I use [Vim][31] with syntax highlighting and [ctags][32] for indexing, as well as a few terminal windows with grep, sed and the other usual suspects for search and manipulation. This is probably not at the same level of comfort as an IDE, but allows me more automation.
|
||||
|
||||
One problem with Vim is that you get so used to its key mappings that you’ll want to use them everywhere.
|
||||
|
||||
[Python][33] and [Nim][34] do well as scripting languages where the shell is not powerful enough.
|
||||
|
||||
### System Monitoring
|
||||
|
||||
[htop][35] (look at the background of that site, it’s a live view of the server that’s hosting it) works great for getting a quick overview of what the software is currently doing. [lm_sensors][36] allows monitoring the hardware temperatures, fans and voltages. [powertop][37] is a great little tool by Intel to find power savings. [ncdu][38] lets you analyze disk usage interactively.
|
||||
|
||||
[nmap][39], iptraf-ng, [tcpdump][40] and [Wireshark][41] are essential tools for analyzing network problems.
|
||||
|
||||
There are of course many more great tools.
|
||||
|
||||
### Mails & Synchronization
|
||||
|
||||
On my home server I have a [fetchmail][42] daemon running for each email acccount that I have. Fetchmail just retrieves the incoming emails and invokes [procmail][43]:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
for i in /home/deen/.fetchmail/*; do
|
||||
FETCHMAILHOME=$i /usr/bin/fetchmail -m 'procmail -d %T' -d 60
|
||||
done
|
||||
```
|
||||
|
||||
The configuration is as simple as it could be and waits for the server to inform us of fresh emails:
|
||||
|
||||
```
|
||||
poll imap.1und1.de protocol imap timeout 120 user "dennis@felsin9.de" password "XXX" folders INBOX keep ssl idle
|
||||
```
|
||||
|
||||
My `.procmailrc` config contains a few rules to backup all mails and sort them into the correct directories, for example based on the mailing list id or from field in the mail header:
|
||||
|
||||
```
|
||||
MAILDIR=/home/deen/shared/Maildir
|
||||
LOGFILE=$HOME/.procmaillog
|
||||
LOGABSTRACT=no
|
||||
VERBOSE=off
|
||||
FORMAIL=/usr/bin/formail
|
||||
NL="
|
||||
"
|
||||
|
||||
:0wc
|
||||
* ! ? test -d /media/mailarchive/`date +%Y`
|
||||
| mkdir -p /media/mailarchive/`date +%Y`
|
||||
|
||||
# Make backups of all mail received in format YYYY/YYYY-MM
|
||||
:0c
|
||||
/media/mailarchive/`date +%Y`/`date +%Y-%m`
|
||||
|
||||
:0
|
||||
* ^From: .*(.*@.*.kit.edu|.*@.*.uka.de|.*@.*.uni-karlsruhe.de)
|
||||
$MAILDIR/.uni/
|
||||
|
||||
:0
|
||||
* ^list-Id:.*lists.kit.edu
|
||||
$MAILDIR/.uni-ml/
|
||||
|
||||
[...]
|
||||
```
|
||||
|
||||
To send emails I use [msmtp][44], which is also great to configure:
|
||||
|
||||
```
|
||||
account default
|
||||
host smtp.1und1.de
|
||||
tls on
|
||||
tls_trust_file /etc/ssl/certs/ca-certificates.crt
|
||||
auth on
|
||||
from dennis@felsin9.de
|
||||
user dennis@felsin9.de
|
||||
password XXX
|
||||
|
||||
[...]
|
||||
```
|
||||
|
||||
But so far the emails are still on the server. My documents are all stored in a directory that I synchronize between all computers using [Unison][45]. Think of Unison as a bidirectional interactive [rsync][46]. My emails are part of this documents directory and thus they end up on my desktop computers.
|
||||
|
||||
This also means that while the emails reach my server immediately, I only fetch them on deman instead of getting instant notifications when an email comes in.
|
||||
|
||||
From there I read the mails with [mutt][47], using the sidebar plugin to display my mail directories. The `/etc/mailcap` file is essential to display non-plaintext mails containing HTML, Word or PDF:
|
||||
|
||||
```
|
||||
text/html;w3m -I %{charset} -T text/html; copiousoutput
|
||||
application/msword; antiword %s; copiousoutput
|
||||
application/pdf; pdftotext -layout /dev/stdin -; copiousoutput
|
||||
```
|
||||
|
||||
### News & Communication
|
||||
|
||||
[Newsboat][48] is a nice little RSS/Atom feed reader in the terminal. I have it running on the server in a `tach` session with about 150 feeds. Filtering feeds locally is also possible, for example:
|
||||
|
||||
```
|
||||
ignore-article "https://forum.ddnet.tw/feed.php" "title =~ \"Map Testing •\" or title =~ \"Old maps •\" or title =~ \"Map Bugs •\" or title =~ \"Archive •\" or title =~ \"Waiting for mapper •\" or title =~ \"Other mods •\" or title =~ \"Fixes •\""
|
||||
```
|
||||
|
||||
I use [Irssi][49] the same way for communication via IRC.
|
||||
|
||||
### Calendar
|
||||
|
||||
[remind][50] is a calendar that can be used from the command line. Setting new reminders is done by editing the `rem` files:
|
||||
|
||||
```
|
||||
# One time events
|
||||
REM 2019-01-20 +90 Flight to China %b
|
||||
|
||||
# Recurring Holidays
|
||||
REM 1 May +90 Holiday "Tag der Arbeit" %b
|
||||
REM [trigger(easterdate(year(today()))-2)] +90 Holiday "Karfreitag" %b
|
||||
|
||||
# Time Change
|
||||
REM Nov Sunday 1 --7 +90 Time Change (03:00 -> 02:00) %b
|
||||
REM Apr Sunday 1 --7 +90 Time Change (02:00 -> 03:00) %b
|
||||
|
||||
# Birthdays
|
||||
FSET birthday(x) "'s " + ord(year(trigdate())-x) + " birthday is %b"
|
||||
REM 16 Apr +90 MSG Andreas[birthday(1994)]
|
||||
|
||||
# Sun
|
||||
SET $LatDeg 49
|
||||
SET $LatMin 19
|
||||
SET $LatSec 49
|
||||
SET $LongDeg -8
|
||||
SET $LongMin -40
|
||||
SET $LongSec -24
|
||||
|
||||
MSG Sun from [sunrise(trigdate())] to [sunset(trigdate())]
|
||||
[...]
|
||||
```
|
||||
|
||||
Unfortunately there is no Chinese Lunar calendar function in remind yet, so Chinese holidays can’t be calculated easily.
|
||||
|
||||
I use two aliases for remind:
|
||||
|
||||
```
|
||||
rem -m -b1 -q -g
|
||||
```
|
||||
|
||||
to see a list of the next events in chronological order and
|
||||
|
||||
```
|
||||
rem -m -b1 -q -cuc12 -w$(($(tput cols)+1)) | sed -e "s/\f//g" | less
|
||||
```
|
||||
|
||||
to show a calendar fitting just the width of my terminal:
|
||||
|
||||
![remcal][51]
|
||||
|
||||
### Dictionary
|
||||
|
||||
[rdictcc][52] is a little known dictionary tool that uses the excellent dictionary files from [dict.cc][53] and turns them into a local database:
|
||||
|
||||
```
|
||||
$ rdictcc rasch
|
||||
====================[ A => B ]====================
|
||||
rasch:
|
||||
- apace
|
||||
- brisk [speedy]
|
||||
- cursory
|
||||
- in a timely manner
|
||||
- quick
|
||||
- quickly
|
||||
- rapid
|
||||
- rapidly
|
||||
- sharpish [Br.] [coll.]
|
||||
- speedily
|
||||
- speedy
|
||||
- swift
|
||||
- swiftly
|
||||
rasch [gehen]:
|
||||
- smartly [quickly]
|
||||
Rasch {n} [Zittergras-Segge]:
|
||||
- Alpine grass [Carex brizoides]
|
||||
- quaking grass sedge [Carex brizoides]
|
||||
Rasch {m} [regional] [Putzrasch]:
|
||||
- scouring pad
|
||||
====================[ B => A ]====================
|
||||
Rasch model:
|
||||
- Rasch-Modell {n}
|
||||
```
|
||||
|
||||
### Writing and Reading
|
||||
|
||||
I have a simple todo file containing my tasks, that is basically always sitting open in a Vim session. For work I also use the todo file as a “done” file so that I can later check what tasks I finished on each day.
|
||||
|
||||
For writing documents, letters and presentations I use [LaTeX][54] for its superior typesetting. A simple letter in German format can be set like this for example:
|
||||
|
||||
```
|
||||
\documentclass[paper = a4, fromalign = right]{scrlttr2}
|
||||
\usepackage{german}
|
||||
\usepackage{eurosym}
|
||||
\usepackage[utf8]{inputenc}
|
||||
\setlength{\parskip}{6pt}
|
||||
\setlength{\parindent}{0pt}
|
||||
|
||||
\setkomavar{fromname}{Dennis Felsing}
|
||||
\setkomavar{fromaddress}{Meine Str. 1\\69181 Leimen}
|
||||
\setkomavar{subject}{Titel}
|
||||
|
||||
\setkomavar*{enclseparator}{Anlagen}
|
||||
|
||||
\makeatletter
|
||||
\@setplength{refvpos}{89mm}
|
||||
\makeatother
|
||||
|
||||
\begin{document}
|
||||
\begin{letter} {Herr Soundso\\Deine Str. 2\\69121 Heidelberg}
|
||||
\opening{Sehr geehrter Herr Soundso,}
|
||||
|
||||
Sie haben bei mir seit dem Bla Bla Bla.
|
||||
|
||||
Ich fordere Sie hiermit zu Bla Bla Bla auf.
|
||||
|
||||
\closing{Mit freundlichen Grüßen}
|
||||
|
||||
\end{letter}
|
||||
\end{document}
|
||||
```
|
||||
|
||||
Further example documents and presentations can be found over at [my private site][55].
|
||||
|
||||
To read PDFs [Zathura][56] is fast, has Vim-like controls and even supports two different PDF backends: Poppler and MuPDF. [Evince][57] on the other hand is more full-featured for the cases where I encounter documents that Zathura doesn’t like.
|
||||
|
||||
### Graphical Editing
|
||||
|
||||
[GIMP][58] and [Inkscape][59] are easy choices for photo editing and interactive vector graphics respectively.
|
||||
|
||||
In some cases [Imagemagick][60] is good enough though and can be used straight from the command line and thus automated to edit images. Similarly [Graphviz][61] and [TikZ][62] can be used to draw graphs and other diagrams.
|
||||
|
||||
### Web Browsing
|
||||
|
||||
As a web browser I’ve always used [Firefox][63] for its extensibility and low resource usage compared to Chrome.
|
||||
|
||||
Unfortunately the [Pentadactyl][64] extension development stopped after Firefox switched to Chrome-style extensions entirely, so I don’t have satisfying Vim-like controls in my browser anymore.
|
||||
|
||||
### Media Players
|
||||
|
||||
[mpv][65] with hardware decoding allows watching videos at 5% CPU load using the `vo=gpu` and `hwdec=vaapi` config settings. `audio-channels=2` in mpv seems to give me clearer downmixing to my stereo speakers / headphones than what PulseAudio does by default. A great little feature is exiting with `Shift-Q` instead of just `Q` to save the playback location. When watching with someone with another native tongue you can use `--secondary-sid=` to show two subtitles at once, the primary at the bottom, the secondary at the top of the screen
|
||||
|
||||
My wirelss mouse can easily be made into a remote control with mpv with a small `~/.config/mpv/input.conf`:
|
||||
|
||||
```
|
||||
MOUSE_BTN5 run "mixer" "pcm" "-2"
|
||||
MOUSE_BTN6 run "mixer" "pcm" "+2"
|
||||
MOUSE_BTN1 cycle sub-visibility
|
||||
MOUSE_BTN7 add chapter -1
|
||||
MOUSE_BTN8 add chapter 1
|
||||
```
|
||||
|
||||
[youtube-dl][66] works great for watching videos hosted online, best quality can be achieved with `-f bestvideo+bestaudio/best --all-subs --embed-subs`.
|
||||
|
||||
As a music player [MOC][67] hasn’t been actively developed for a while, but it’s still a simple player that plays every format conceivable, including the strangest Chiptune formats. In the AUR there is a [patch][68] adding PulseAudio support as well. Even with the CPU clocked down to 800 MHz MOC barely uses 1-2% of a single CPU core.
|
||||
|
||||
![moc][69]
|
||||
|
||||
My music collection sits on my home server so that I can access it from anywhere. It is mounted using [SSHFS][70] and automount in the `/etc/fstab/`:
|
||||
|
||||
```
|
||||
root@server:/media/media /mnt/media fuse.sshfs noauto,x-systemd.automount,idmap=user,IdentityFile=/root/.ssh/id_rsa,allow_other,reconnect 0 0
|
||||
```
|
||||
|
||||
### Cross-Platform Building
|
||||
|
||||
Linux is great to build packages for any major operating system except Linux itself! In the beginning I used [QEMU][71] to with an old Debian, Windows and Mac OS X VM to build for these platforms.
|
||||
|
||||
Nowadays I switched to using chroot for the old Debian distribution (for maximum Linux compatibility), [MinGW][72] to cross-compile for Windows and [OSXCross][73] to cross-compile for Mac OS X.
|
||||
|
||||
The script used to [build DDNet][74] as well as the [instructions for updating library builds][75] are based on this.
|
||||
|
||||
### Backups
|
||||
|
||||
As usual, we nearly forgot about backups. Even if this is the last chapter, it should not be an afterthought.
|
||||
|
||||
I wrote [rrb][76] (reverse rsync backup) 10 years ago to wrap rsync so that I only need to give the backup server root SSH rights to the computers that it is backing up. Surprisingly rrb needed 0 changes in the last 10 years, even though I kept using it the entire time.
|
||||
|
||||
The backups are stored straight on the filesystem. Incremental backups are implemented using hard links (`--link-dest`). A simple [config][77] defines how long backups are kept, which defaults to:
|
||||
|
||||
```
|
||||
KEEP_RULES=( \
|
||||
7 7 \ # One backup a day for the last 7 days
|
||||
31 8 \ # 8 more backups for the last month
|
||||
365 11 \ # 11 more backups for the last year
|
||||
1825 4 \ # 4 more backups for the last 5 years
|
||||
)
|
||||
```
|
||||
|
||||
Since some of my computers don’t have a static IP / DNS entry and I still want to back them up using rrb I use a reverse SSH tunnel (as a systemd service) for them:
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Reverse SSH Tunnel
|
||||
After=network.target
|
||||
|
||||
[Service]
|
||||
ExecStart=/usr/bin/ssh -N -R 27276:localhost:22 -o "ExitOnForwardFailure yes" server
|
||||
KillMode=process
|
||||
Restart=always
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
Now the server can reach the client through `ssh -p 27276 localhost` while the tunnel is running to perform the backup, or in `.ssh/config` format:
|
||||
|
||||
```
|
||||
Host cr-remote
|
||||
HostName localhost
|
||||
Port 27276
|
||||
```
|
||||
|
||||
While talking about SSH hacks, sometimes a server is not easily reachable thanks to some bad routing. In that case you can route the SSH connection through another server to get better routing, in this case going through the USA to reach my Chinese server which had not been reliably reachable from Germany for a few weeks:
|
||||
|
||||
```
|
||||
Host chn.ddnet.tw
|
||||
ProxyCommand ssh -q usa.ddnet.tw nc -q0 chn.ddnet.tw 22
|
||||
Port 22
|
||||
```
|
||||
|
||||
### Final Remarks
|
||||
|
||||
Thanks for reading my random collection of tools. I probably forgot many programs that I use so naturally every day that I don’t even think about them anymore. Let’s see how stable my software setup stays in the next years. If you have any questions, feel free to get in touch with me at [dennis@felsin9.de][78].
|
||||
|
||||
Comments on [Hacker News][79].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hookrace.net/blog/linux-desktop-setup/
|
||||
|
||||
作者:[Dennis Felsing][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://felsin9.de/nnis/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://hookrace.net/public/linux-desktop/htop_small.png
|
||||
[2]: https://hookrace.net/public/linux-desktop/htop.png
|
||||
[3]: https://gentoo.org/
|
||||
[4]: https://www.archlinux.org/
|
||||
[5]: https://www.archlinux.org/news/
|
||||
[6]: https://www.reddit.com/r/archlinux/comments/4zrsc3/keep_your_system_fully_functional_after_a_kernel/
|
||||
[7]: https://www.suse.com/
|
||||
[8]: https://ddnet.tw/
|
||||
[9]: https://www.debian.org/
|
||||
[10]: https://www.openbsd.org/
|
||||
[11]: https://www.openbsd.org/faq/pf/
|
||||
[12]: http://openbox.org/wiki/Main_Page
|
||||
[13]: http://fluxbox.org/
|
||||
[14]: https://dwm.suckless.org/
|
||||
[15]: https://awesomewm.org/
|
||||
[16]: https://xmonad.org/
|
||||
[17]: https://www.haskell.org/
|
||||
[18]: http://hackage.haskell.org/package/xmonad-contrib-0.15/docs/XMonad-Layout-LayoutScreens.html
|
||||
[19]: http://robm.github.io/dzen/
|
||||
[20]: https://github.com/brndnmtthws/conky
|
||||
[21]: https://hookrace.net/public/linux-desktop/laptop_small.png
|
||||
[22]: https://hookrace.net/public/linux-desktop/laptop.png
|
||||
[23]: https://i3wm.org/
|
||||
[24]: https://github.com/tmux/tmux/wiki
|
||||
[25]: http://dtach.sourceforge.net/
|
||||
[26]: https://github.com/def-/tach/blob/master/tach
|
||||
[27]: https://www.gnu.org/software/bash/
|
||||
[28]: http://www.zsh.org/
|
||||
[29]: http://software.schmorp.de/pkg/rxvt-unicode.html
|
||||
[30]: http://terminus-font.sourceforge.net/
|
||||
[31]: https://www.vim.org/
|
||||
[32]: http://ctags.sourceforge.net/
|
||||
[33]: https://www.python.org/
|
||||
[34]: https://nim-lang.org/
|
||||
[35]: https://hisham.hm/htop/
|
||||
[36]: http://lm-sensors.org/
|
||||
[37]: https://01.org/powertop/
|
||||
[38]: https://dev.yorhel.nl/ncdu
|
||||
[39]: https://nmap.org/
|
||||
[40]: https://www.tcpdump.org/
|
||||
[41]: https://www.wireshark.org/
|
||||
[42]: http://www.fetchmail.info/
|
||||
[43]: http://www.procmail.org/
|
||||
[44]: https://marlam.de/msmtp/
|
||||
[45]: https://www.cis.upenn.edu/~bcpierce/unison/
|
||||
[46]: https://rsync.samba.org/
|
||||
[47]: http://www.mutt.org/
|
||||
[48]: https://newsboat.org/
|
||||
[49]: https://irssi.org/
|
||||
[50]: https://www.roaringpenguin.com/products/remind
|
||||
[51]: https://hookrace.net/public/linux-desktop/remcal.png
|
||||
[52]: https://github.com/tsdh/rdictcc
|
||||
[53]: https://www.dict.cc/
|
||||
[54]: https://www.latex-project.org/
|
||||
[55]: http://felsin9.de/nnis/research/
|
||||
[56]: https://pwmt.org/projects/zathura/
|
||||
[57]: https://wiki.gnome.org/Apps/Evince
|
||||
[58]: https://www.gimp.org/
|
||||
[59]: https://inkscape.org/
|
||||
[60]: https://imagemagick.org/Usage/
|
||||
[61]: https://www.graphviz.org/
|
||||
[62]: https://sourceforge.net/projects/pgf/
|
||||
[63]: https://www.mozilla.org/en-US/firefox/new/
|
||||
[64]: https://github.com/5digits/dactyl
|
||||
[65]: https://mpv.io/
|
||||
[66]: https://rg3.github.io/youtube-dl/
|
||||
[67]: http://moc.daper.net/
|
||||
[68]: https://aur.archlinux.org/packages/moc-pulse/
|
||||
[69]: https://hookrace.net/public/linux-desktop/moc.png
|
||||
[70]: https://github.com/libfuse/sshfs
|
||||
[71]: https://www.qemu.org/
|
||||
[72]: http://www.mingw.org/
|
||||
[73]: https://github.com/tpoechtrager/osxcross
|
||||
[74]: https://github.com/ddnet/ddnet-scripts/blob/master/ddnet-release.sh
|
||||
[75]: https://github.com/ddnet/ddnet-scripts/blob/master/ddnet-lib-update.sh
|
||||
[76]: https://github.com/def-/rrb/blob/master/rrb
|
||||
[77]: https://github.com/def-/rrb/blob/master/config.example
|
||||
[78]: mailto:dennis@felsin9.de
|
||||
[79]: https://news.ycombinator.com/item?id=18979731
|
||||
@ -1,236 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Evil-Twin Framework: A tool for improving WiFi security)
|
||||
[#]: via: (https://opensource.com/article/19/1/evil-twin-framework)
|
||||
[#]: author: (André Esser https://opensource.com/users/andreesser)
|
||||
|
||||
The Evil-Twin Framework: A tool for improving WiFi security
|
||||
======
|
||||
Learn about a pen-testing tool intended to test the security of WiFi access points for all types of threats.
|
||||

|
||||
|
||||
The increasing number of devices that connect over-the-air to the internet over-the-air and the wide availability of WiFi access points provide many opportunities for attackers to exploit users. By tricking users to connect to [rogue access points][1], hackers gain full control over the users' network connection, which allows them to sniff and alter traffic, redirect users to malicious sites, and launch other attacks over the network..
|
||||
|
||||
To protect users and teach them to avoid risky online behaviors, security auditors and researchers must evaluate users' security practices and understand the reasons they connect to WiFi access points without being confident they are safe. There are a significant number of tools that can conduct WiFi audits, but no single tool can test the many different attack scenarios and none of the tools integrate well with one another.
|
||||
|
||||
The **Evil-Twin Framework** (ETF) aims to fix these problems in the WiFi auditing process by enabling auditors to examine multiple scenarios and integrate multiple tools. This article describes the framework and its functionalities, then provides some examples to show how it can be used.
|
||||
|
||||
### The ETF architecture
|
||||
|
||||
The ETF framework was written in [Python][2] because the development language is very easy to read and make contributions to. In addition, many of the ETF's libraries, such as **[Scapy][3]** , were already developed for Python, making it easy to use them for ETF.
|
||||
|
||||
The ETF architecture (Figure 1) is divided into different modules that interact with each other. The framework's settings are all written in a single configuration file. The user can verify and edit the settings through the user interface via the **ConfigurationManager** class. Other modules can only read these settings and run according to them.
|
||||
|
||||
![Evil-Twin Framework Architecture][5]
|
||||
|
||||
Figure 1: Evil-Twin framework architecture
|
||||
|
||||
The ETF supports multiple user interfaces that interact with the framework. The current default interface is an interactive console, similar to the one on [Metasploit][6]. A graphical user interface (GUI) and a command line interface (CLI) are under development for desktop/browser use, and mobile interfaces may be an option in the future. The user can edit the settings in the configuration file using the interactive console (and eventually with the GUI). The user interface can interact with every other module that exists in the framework.
|
||||
|
||||
The WiFi module ( **AirCommunicator** ) was built to support a wide range of WiFi capabilities and attacks. The framework identifies three basic pillars of Wi-Fi communication: **packet sniffing** , **custom packet injection** , and **access point creation**. The three main WiFi communication modules are **AirScanner** , **AirInjector** , and **AirHost** , which are responsible for packet sniffing, packet injection, and access point creation, respectively. The three classes are wrapped inside the main WiFi module, AirCommunicator, which reads the configuration file before starting the services. Any type of WiFi attack can be built using one or more of these core features.
|
||||
|
||||
To enable man-in-the-middle (MITM) attacks, which are a common way to attack WiFi clients, the framework has an integrated module called ETFITM (Evil-Twin Framework-in-the-Middle). This module is responsible for the creation of a web proxy used to intercept and manipulate HTTP/HTTPS traffic.
|
||||
|
||||
There are many other tools that can leverage the MITM position created by the ETF. Through its extensibility, ETF can support them—and, instead of having to call them separately, you can add the tools to the framework just by extending the Spawner class. This enables a developer or security auditor to call the program with a preconfigured argument string from within the framework.
|
||||
|
||||
The other way to extend the framework is through plugins. There are two categories of plugins: **WiFi plugins** and **MITM plugins**. MITM plugins are scripts that can run while the MITM proxy is active. The proxy passes the HTTP(S) requests and responses through to the plugins where they can be logged or manipulated. WiFi plugins follow a more complex flow of execution but still expose a fairly simple API to contributors who wish to develop and use their own plugins. WiFi plugins can be further divided into three categories, one for each of the core WiFi communication modules.
|
||||
|
||||
Each of the core modules has certain events that trigger the execution of a plugin. For instance, AirScanner has three defined events to which a response can be programmed. The events usually correspond to a setup phase before the service starts running, a mid-execution phase while the service is running, and a teardown or cleanup phase after a service finishes. Since Python allows multiple inheritance, one plugin can subclass more than one plugin class.
|
||||
|
||||
Figure 1 above is a summary of the framework's architecture. Lines pointing away from the ConfigurationManager mean that the module reads information from it and lines pointing towards it mean that the module can write/edit configurations.
|
||||
|
||||
### Examples of using the Evil-Twin Framework
|
||||
|
||||
There are a variety of ways ETF can conduct penetration testing on WiFi network security or work on end users' awareness of WiFi security. The following examples describe some of the framework's pen-testing functionalities, such as access point and client detection, WPA and WEP access point attacks, and evil twin access point creation.
|
||||
|
||||
These examples were devised using ETF with WiFi cards that allow WiFi traffic capture. They also utilize the following abbreviations for ETF setup commands:
|
||||
|
||||
* **APS** access point SSID
|
||||
* **APB** access point BSSID
|
||||
* **APC** access point channel
|
||||
* **CM** client MAC address
|
||||
|
||||
|
||||
|
||||
In a real testing scenario, make sure to replace these abbreviations with the correct information.
|
||||
|
||||
#### Capturing a WPA 4-way handshake after a de-authentication attack
|
||||
|
||||
This scenario (Figure 2) takes two aspects into consideration: the de-authentication attack and the possibility of catching a 4-way WPA handshake. The scenario starts with a running WPA/WPA2-enabled access point with one connected client device (in this case, a smartphone). The goal is to de-authenticate the client with a general de-authentication attack then capture the WPA handshake once it tries to reconnect. The reconnection will be done manually immediately after being de-authenticated.
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][8]
|
||||
|
||||
Figure 2: Scenario for capturing a WPA handshake after a de-authentication attack
|
||||
|
||||
The consideration in this example is the ETF's reliability. The goal is to find out if the tools can consistently capture the WPA handshake. The scenario will be performed multiple times with each tool to check its reliability when capturing the WPA handshake.
|
||||
|
||||
There is more than one way to capture a WPA handshake using the ETF. One way is to use a combination of the AirScanner and AirInjector modules; another way is to just use the AirInjector. The following scenario uses a combination of both modules.
|
||||
|
||||
The ETF launches the AirScanner module and analyzes the IEEE 802.11 frames to find a WPA handshake. Then the AirInjector can launch a de-authentication attack to force a reconnection. The following steps must be done to accomplish this on the ETF:
|
||||
|
||||
1. Enter the AirScanner configuration mode: **config airscanner**
|
||||
2. Configure the AirScanner to not hop channels: **config airscanner**
|
||||
3. Set the channel to sniff the traffic on the access point channel (APC): **set fixed_sniffing_channel = <APC>**
|
||||
4. Start the AirScanner module with the CredentialSniffer plugin: **start airscanner with credentialsniffer**
|
||||
5. Add a target access point BSSID (APS) from the sniffed access points list: **add aps where ssid = <APS>**
|
||||
6. Start the AirInjector, which by default lauches the de-authentication attack: **start airinjector**
|
||||
|
||||
|
||||
|
||||
This simple set of commands enables the ETF to perform an efficient and successful de-authentication attack on every test run. The ETF can also capture the WPA handshake on every test run. The following code makes it possible to observe the ETF's successful execution.
|
||||
|
||||
```
|
||||
███████╗████████╗███████╗
|
||||
██╔════╝╚══██╔══╝██╔════╝
|
||||
█████╗ ██║ █████╗
|
||||
██╔══╝ ██║ ██╔══╝
|
||||
███████╗ ██║ ██║
|
||||
╚══════╝ ╚═╝ ╚═╝
|
||||
|
||||
|
||||
[+] Do you want to load an older session? [Y/n]: n
|
||||
[+] Creating new temporary session on 02/08/2018
|
||||
[+] Enter the desired session name:
|
||||
ETF[etf/aircommunicator/]::> config airscanner
|
||||
ETF[etf/aircommunicator/airscanner]::> listargs
|
||||
sniffing_interface = wlan1; (var)
|
||||
probes = True; (var)
|
||||
beacons = True; (var)
|
||||
hop_channels = false; (var)
|
||||
fixed_sniffing_channel = 11; (var)
|
||||
ETF[etf/aircommunicator/airscanner]::> start airscanner with
|
||||
arpreplayer caffelatte credentialsniffer packetlogger selfishwifi
|
||||
ETF[etf/aircommunicator/airscanner]::> start airscanner with credentialsniffer
|
||||
[+] Successfully added credentialsniffer plugin.
|
||||
[+] Starting packet sniffer on interface 'wlan1'
|
||||
[+] Set fixed channel to 11
|
||||
ETF[etf/aircommunicator/airscanner]::> add aps where ssid = CrackWPA
|
||||
ETF[etf/aircommunicator/airscanner]::> start airinjector
|
||||
ETF[etf/aircommunicator/airscanner]::> [+] Starting deauthentication attack
|
||||
- 1000 bursts of 1 packets
|
||||
- 1 different packets
|
||||
[+] Injection attacks finished executing.
|
||||
[+] Starting post injection methods
|
||||
[+] Post injection methods finished
|
||||
[+] WPA Handshake found for client '70:3e:ac:bb:78:64' and network 'CrackWPA'
|
||||
```
|
||||
|
||||
#### Launching an ARP replay attack and cracking a WEP network
|
||||
|
||||
The next scenario (Figure 3) will also focus on the [Address Resolution Protocol][9] (ARP) replay attack's efficiency and the speed of capturing the WEP data packets containing the initialization vectors (IVs). The same network may require a different number of caught IVs to be cracked, so the limit for this scenario is 50,000 IVs. If the network is cracked during the first test with less than 50,000 IVs, that number will be the new limit for the following tests on the network. The cracking tool to be used will be **aircrack-ng**.
|
||||
|
||||
The test scenario starts with an access point using WEP encryption and an offline client that knows the key—the key for testing purposes is 12345, but it can be a larger and more complex key. Once the client connects to the WEP access point, it will send out a gratuitous ARP packet; this is the packet that's meant to be captured and replayed. The test ends once the limit of packets containing IVs is captured.
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][11]
|
||||
|
||||
Figure 3: Scenario for capturing a WPA handshake after a de-authentication attack
|
||||
|
||||
ETF uses Python's Scapy library for packet sniffing and injection. To minimize known performance problems in Scapy, ETF tweaks some of its low-level libraries to significantly speed packet injection. For this specific scenario, the ETF uses **tcpdump** as a background process instead of Scapy for more efficient packet sniffing, while Scapy is used to identify the encrypted ARP packet.
|
||||
|
||||
This scenario requires the following commands and operations to be performed on the ETF:
|
||||
|
||||
1. Enter the AirScanner configuration mode: **config airscanner**
|
||||
2. Configure the AirScanner to not hop channels: **set hop_channels = false**
|
||||
3. Set the channel to sniff the traffic on the access point channel (APC): **set fixed_sniffing_channel = <APC>**
|
||||
4. Enter the ARPReplayer plugin configuration mode: **config arpreplayer**
|
||||
5. Set the target access point BSSID (APB) of the WEP network: **set target_ap_bssid <APB>**
|
||||
6. Start the AirScanner module with the ARPReplayer plugin: **start airscanner with arpreplayer**
|
||||
|
||||
|
||||
|
||||
After executing these commands, ETF correctly identifies the encrypted ARP packet, then successfully performs an ARP replay attack, which cracks the network.
|
||||
|
||||
#### Launching a catch-all honeypot
|
||||
|
||||
The scenario in Figure 4 creates multiple access points with the same SSID. This technique discovers the encryption type of a network that was probed for but out of reach. By launching multiple access points with all security settings, the client will automatically connect to the one that matches the security settings of the locally cached access point information.
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][13]
|
||||
|
||||
Figure 4: Scenario for capturing a WPA handshake after a de-authentication attack
|
||||
|
||||
Using the ETF, it is possible to configure the **hostapd** configuration file then launch the program in the background. Hostapd supports launching multiple access points on the same wireless card by configuring virtual interfaces, and since it supports all types of security configurations, a complete catch-all honeypot can be set up. For the WEP and WPA(2)-PSK networks, a default password is used, and for the WPA(2)-EAP, an "accept all" policy is configured.
|
||||
|
||||
For this scenario, the following commands and operations must be performed on the ETF:
|
||||
|
||||
1. Enter the APLauncher configuration mode: **config aplauncher**
|
||||
2. Set the desired access point SSID (APS): **set ssid = <APS>**
|
||||
3. Configure the APLauncher as a catch-all honeypot: **set catch_all_honeypot = true**
|
||||
4. Start the AirHost module: **start airhost**
|
||||
|
||||
|
||||
|
||||
With these commands, the ETF can launch a complete catch-all honeypot with all types of security configurations. ETF also automatically launches the DHCP and DNS servers that allow clients to stay connected to the internet. ETF offers a better, faster, and more complete solution to create catch-all honeypots. The following code enables the successful execution of the ETF to be observed.
|
||||
|
||||
```
|
||||
███████╗████████╗███████╗
|
||||
██╔════╝╚══██╔══╝██╔════╝
|
||||
█████╗ ██║ █████╗
|
||||
██╔══╝ ██║ ██╔══╝
|
||||
███████╗ ██║ ██║
|
||||
╚══════╝ ╚═╝ ╚═╝
|
||||
|
||||
|
||||
[+] Do you want to load an older session? [Y/n]: n
|
||||
[+] Creating ne´,cxzw temporary session on 03/08/2018
|
||||
[+] Enter the desired session name:
|
||||
ETF[etf/aircommunicator/]::> config aplauncher
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf ssid CatchMe
|
||||
ssid = CatchMe
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf catch_all_honeypot true
|
||||
catch_all_honeypot = true
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> start airhost
|
||||
[+] Killing already started processes and restarting network services
|
||||
[+] Stopping dnsmasq and hostapd services
|
||||
[+] Access Point stopped...
|
||||
[+] Running airhost plugins pre_start
|
||||
[+] Starting hostapd background process
|
||||
[+] Starting dnsmasq service
|
||||
[+] Running airhost plugins post_start
|
||||
[+] Access Point launched successfully
|
||||
[+] Starting dnsmasq service
|
||||
```
|
||||
|
||||
### Conclusions and future work
|
||||
|
||||
These scenarios use common and well-known attacks to help validate the ETF's capabilities for testing WiFi networks and clients. The results also validate that the framework's architecture enables new attack vectors and features to be developed on top of it while taking advantage of the platform's existing capabilities. This should accelerate development of new WiFi penetration-testing tools, since a lot of the code is already written. Furthermore, the fact that complementary WiFi technologies are all integrated in a single tool will make WiFi pen-testing simpler and more efficient.
|
||||
|
||||
The ETF's goal is not to replace existing tools but to complement them and offer a broader choice to security auditors when conducting WiFi pen-testing and improving user awareness.
|
||||
|
||||
The ETF is an open source project [available on GitHub][14] and community contributions to its development are welcomed. Following are some of the ways you can help.
|
||||
|
||||
One of the limitations of current WiFi pen-testing is the inability to log important events during tests. This makes reporting identified vulnerabilities both more difficult and less accurate. The framework could implement a logger that can be accessed by every class to create a pen-testing session report.
|
||||
|
||||
The ETF tool's capabilities cover many aspects of WiFi pen-testing. On one hand, it facilitates the phases of WiFi reconnaissance, vulnerability discovery, and attack. On the other hand, it doesn't offer a feature that facilitates the reporting phase. Adding the concept of a session and a session reporting feature, such as the logging of important events during a session, would greatly increase the value of the tool for real pen-testing scenarios.
|
||||
|
||||
Another valuable contribution would be extending the framework to facilitate WiFi fuzzing. The IEEE 802.11 protocol is very complex, and considering there are multiple implementations of it, both on the client and access point side, it's safe to assume these implementations contain bugs and even security flaws. These bugs could be discovered by fuzzing IEEE 802.11 protocol frames. Since Scapy allows custom packet creation and injection, a fuzzer can be implemented through it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/evil-twin-framework
|
||||
|
||||
作者:[André Esser][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/andreesser
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Rogue_access_point
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://scapy.net
|
||||
[4]: /file/417776
|
||||
[5]: https://opensource.com/sites/default/files/uploads/pic1.png (Evil-Twin Framework Architecture)
|
||||
[6]: https://www.metasploit.com
|
||||
[7]: /file/417781
|
||||
[8]: https://opensource.com/sites/default/files/uploads/pic2.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[9]: https://en.wikipedia.org/wiki/Address_Resolution_Protocol
|
||||
[10]: /file/417786
|
||||
[11]: https://opensource.com/sites/default/files/uploads/pic3.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[12]: /file/417791
|
||||
[13]: https://opensource.com/sites/default/files/uploads/pic4.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[14]: https://github.com/Esser420/EvilTwinFramework
|
||||
@ -1,398 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Copy A File/Folder From A Local System To Remote System In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
|
||||
How To Copy A File/Folder From A Local System To Remote System In Linux?
|
||||
======
|
||||
|
||||
Copying a file from one server to another server or local to remote is one of the routine task for Linux administrator.
|
||||
|
||||
If anyone says no, i won’t accept because this is one of the regular activity wherever you go.
|
||||
|
||||
It can be done in many ways and we are trying to cover all the possible options.
|
||||
|
||||
You can choose the one which you would prefer. Also, check other commands as well that may help you for some other purpose.
|
||||
|
||||
I have tested all these commands and script in my test environment so, you can use this for your routine work.
|
||||
|
||||
By default every one go with SCP because it’s one of the native command that everyone use for file copy. But commands which is listed in this article are be smart so, give a try if you would like to try new things.
|
||||
|
||||
This can be done in below four ways easily.
|
||||
|
||||
* **`SCP:`** scp copies files between hosts on a network. It uses ssh for data transfer, and uses the same authentication and provides the same security as ssh.
|
||||
* **`RSYNC:`** rsync is a fast and extraordinarily versatile file copying tool. It can copy locally, to/from another host over any remote shell, or to/from a remote rsync daemon.
|
||||
* **`PSCP:`** pscp is a program for copying files in parallel to a number of hosts. It provides features such as passing a password to scp, saving output to files, and timing out.
|
||||
* **`PRSYNC:`** prsync is a program for copying files in parallel to a number of hosts. It provides features such as passing a password to ssh, saving output to files, and timing out.
|
||||
|
||||
|
||||
|
||||
### Method-1: Copy Files/Folders From A Local System To Remote System In Linux Using SCP Command?
|
||||
|
||||
scp command allow us to copy files/folders from a local system to remote system.
|
||||
|
||||
We are going to copy the `output.txt` file from my local system to `2g.CentOS.com` remote system under `/opt/backup` directory.
|
||||
|
||||
```
|
||||
# scp output.txt root@2g.CentOS.com:/opt/backup
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
```
|
||||
|
||||
We are going to copy two files `output.txt` and `passwd-up.sh` files from my local system to `2g.CentOS.com` remote system under `/opt/backup` directory.
|
||||
|
||||
```
|
||||
# scp output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
```
|
||||
|
||||
We are going to copy the `shell-script` directory from my local system to `2g.CentOS.com` remote system under `/opt/backup` directory.
|
||||
|
||||
This will copy the `shell-script` directory and associated files under `/opt/backup` directory.
|
||||
|
||||
```
|
||||
# scp -r /home/daygeek/2g/shell-script/ [email protected]:/opt/backup/
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
ovh.sh 100% 76 0.1KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
passwd-up1.sh 100% 7 0.0KB/s 00:00
|
||||
server-list.txt 100% 23 0.0KB/s 00:00
|
||||
```
|
||||
|
||||
### Method-2: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using Shell Script with scp Command?
|
||||
|
||||
If you would like to copy the same file into multiple remote servers then create the following small shell script to achieve this.
|
||||
|
||||
To do so, get the servers list and add those into `server-list.txt` file. Make sure you have to update the servers list into `server-list.txt` file. Each server should be in separate line.
|
||||
|
||||
Finally mention the file location which you want to copy like below.
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp /home/daygeek/2g/shell-script/output.txt [email protected]$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
Once you done, set an executable permission to password-update.sh file.
|
||||
|
||||
```
|
||||
# chmod +x file-copy.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# ./file-copy.sh
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
```
|
||||
|
||||
Use the following script to copy the multiple files into multiple remote servers.
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp /home/daygeek/2g/shell-script/output.txt passwd-up.sh [email protected]$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
The below output shows all the files twice as this copied into two servers.
|
||||
|
||||
```
|
||||
# ./file-cp.sh
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
```
|
||||
|
||||
Use the following script to copy the directory recursively into multiple remote servers.
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp -r /home/daygeek/2g/shell-script/ [email protected]$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
Output for the above script.
|
||||
|
||||
```
|
||||
# ./file-cp.sh
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
ovh.sh 100% 76 0.1KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
passwd-up1.sh 100% 7 0.0KB/s 00:00
|
||||
server-list.txt 100% 23 0.0KB/s 00:00
|
||||
|
||||
output.txt 100% 2468 2.4KB/s 00:00
|
||||
ovh.sh 100% 76 0.1KB/s 00:00
|
||||
passwd-up.sh 100% 877 0.9KB/s 00:00
|
||||
passwd-up1.sh 100% 7 0.0KB/s 00:00
|
||||
server-list.txt 100% 23 0.0KB/s 00:00
|
||||
```
|
||||
|
||||
### Method-3: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using PSCP Command?
|
||||
|
||||
pscp command directly allow us to perform the copy to multiple remote servers.
|
||||
|
||||
Use the following pscp command to copy a single file to remote server.
|
||||
|
||||
```
|
||||
# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt /opt/backup
|
||||
|
||||
[1] 18:46:11 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
Use the following pscp command to copy a multiple files to remote server.
|
||||
|
||||
```
|
||||
# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt ovh.sh /opt/backup
|
||||
|
||||
[1] 18:47:48 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
Use the following pscp command to copy a directory recursively to remote server.
|
||||
|
||||
```
|
||||
# pscp.pssh -H 2g.CentOS.com -r /home/daygeek/2g/shell-script/ /opt/backup
|
||||
|
||||
[1] 18:48:46 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
Use the following pscp command to copy a single file to multiple remote servers.
|
||||
|
||||
```
|
||||
# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt /opt/backup
|
||||
|
||||
[1] 18:49:48 [SUCCESS] 2g.CentOS.com
|
||||
[2] 18:49:48 [SUCCESS] 2g.Debian.com
|
||||
```
|
||||
|
||||
Use the following pscp command to copy a multiple files to multiple remote servers.
|
||||
|
||||
```
|
||||
# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt passwd-up.sh /opt/backup
|
||||
|
||||
[1] 18:50:30 [SUCCESS] 2g.Debian.com
|
||||
[2] 18:50:30 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
Use the following pscp command to copy a directory recursively to multiple remote servers.
|
||||
|
||||
```
|
||||
# pscp.pssh -h server-list.txt -r /home/daygeek/2g/shell-script/ /opt/backup
|
||||
|
||||
[1] 18:51:31 [SUCCESS] 2g.Debian.com
|
||||
[2] 18:51:31 [SUCCESS] 2g.CentOS.com
|
||||
```
|
||||
|
||||
### Method-4: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using rsync Command?
|
||||
|
||||
Rsync is a fast and extraordinarily versatile file copying tool. It can copy locally, to/from another host over any remote shell, or to/from a remote rsync daemon.
|
||||
|
||||
Use the following rsync command to copy a single file to remote server.
|
||||
|
||||
```
|
||||
# rsync -avz /home/daygeek/2g/shell-script/output.txt [email protected]:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
output.txt
|
||||
|
||||
sent 598 bytes received 31 bytes 1258.00 bytes/sec
|
||||
total size is 2468 speedup is 3.92
|
||||
```
|
||||
|
||||
Use the following pscp command to copy a multiple files to remote server.
|
||||
|
||||
```
|
||||
# rsync -avz /home/daygeek/2g/shell-script/output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
output.txt
|
||||
passwd-up.sh
|
||||
|
||||
sent 737 bytes received 50 bytes 1574.00 bytes/sec
|
||||
total size is 2537 speedup is 3.22
|
||||
```
|
||||
|
||||
Use the following rsync command to copy a single file to remote server overh ssh.
|
||||
|
||||
```
|
||||
# rsync -avzhe ssh /home/daygeek/2g/shell-script/output.txt root@2g.CentOS.com:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
output.txt
|
||||
|
||||
sent 598 bytes received 31 bytes 419.33 bytes/sec
|
||||
total size is 2.47K speedup is 3.92
|
||||
```
|
||||
|
||||
Use the following pscp command to copy a directory recursively to remote server over ssh. This will copy only files not the base directory.
|
||||
|
||||
```
|
||||
# rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com:/opt/backup
|
||||
|
||||
sending incremental file list
|
||||
./
|
||||
output.txt
|
||||
ovh.sh
|
||||
passwd-up.sh
|
||||
passwd-up1.sh
|
||||
server-list.txt
|
||||
|
||||
sent 3.85K bytes received 281 bytes 8.26K bytes/sec
|
||||
total size is 9.12K speedup is 2.21
|
||||
```
|
||||
|
||||
### Method-5: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using Shell Script with rsync Command?
|
||||
|
||||
If you would like to copy the same file into multiple remote servers then create the following small shell script to achieve this.
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
Output for the above shell script.
|
||||
|
||||
```
|
||||
# ./file-copy.sh
|
||||
|
||||
sending incremental file list
|
||||
./
|
||||
output.txt
|
||||
ovh.sh
|
||||
passwd-up.sh
|
||||
passwd-up1.sh
|
||||
server-list.txt
|
||||
|
||||
sent 3.86K bytes received 281 bytes 8.28K bytes/sec
|
||||
total size is 9.13K speedup is 2.21
|
||||
|
||||
sending incremental file list
|
||||
./
|
||||
output.txt
|
||||
ovh.sh
|
||||
passwd-up.sh
|
||||
passwd-up1.sh
|
||||
server-list.txt
|
||||
|
||||
sent 3.86K bytes received 281 bytes 2.76K bytes/sec
|
||||
total size is 9.13K speedup is 2.21
|
||||
```
|
||||
|
||||
### Method-6: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using Shell Script with scp Command?
|
||||
|
||||
In the above two shell script, we need to mention the file and folder location as a prerequiesties but here i did a small modification that allow the script to get a file or folder as a input. It could be very useful when you want to perform the copy multiple times in a day.
|
||||
|
||||
```
|
||||
# file-copy.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp -r $1 root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
Run the shell script and give the file name as a input.
|
||||
|
||||
```
|
||||
# ./file-copy.sh output1.txt
|
||||
|
||||
output1.txt 100% 3558 3.5KB/s 00:00
|
||||
output1.txt 100% 3558 3.5KB/s 00:00
|
||||
```
|
||||
|
||||
### Method-7: Copy Files/Folders From A Local System To Multiple Remote System In Linux With Non-Standard Port Number?
|
||||
|
||||
Use the below shell script to copy a file or folder if you are using Non-Standard port.
|
||||
|
||||
If you are using `Non-Standard` port, make sure you have to mention the port number as follow for SCP command.
|
||||
|
||||
```
|
||||
# file-copy-scp.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
scp -P 2222 -r $1 root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
Run the shell script and give the file name as a input.
|
||||
|
||||
```
|
||||
# ./file-copy.sh ovh.sh
|
||||
|
||||
ovh.sh 100% 3558 3.5KB/s 00:00
|
||||
ovh.sh 100% 3558 3.5KB/s 00:00
|
||||
```
|
||||
|
||||
If you are using `Non-Standard` port, make sure you have to mention the port number as follow for rsync command.
|
||||
|
||||
```
|
||||
# file-copy-rsync.sh
|
||||
|
||||
#!/bin/sh
|
||||
for server in `more server-list.txt`
|
||||
do
|
||||
rsync -avzhe 'ssh -p 2222' $1 root@2g.CentOS.com$server:/opt/backup
|
||||
done
|
||||
```
|
||||
|
||||
Run the shell script and give the file name as a input.
|
||||
|
||||
```
|
||||
# ./file-copy-rsync.sh passwd-up.sh
|
||||
sending incremental file list
|
||||
passwd-up.sh
|
||||
|
||||
sent 238 bytes received 35 bytes 26.00 bytes/sec
|
||||
total size is 159 speedup is 0.58
|
||||
|
||||
sending incremental file list
|
||||
passwd-up.sh
|
||||
|
||||
sent 238 bytes received 35 bytes 26.00 bytes/sec
|
||||
total size is 159 speedup is 0.58
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,81 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Mind map yourself using FreeMind and Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
Mind map yourself using FreeMind and Fedora
|
||||
======
|
||||

|
||||
|
||||
A mind map of yourself sounds a little far-fetched at first. Is this process about neural pathways? Or telepathic communication? Not at all. Instead, a mind map of yourself is a way to describe yourself to others visually. It also shows connections among the characteristics you use to describe yourself. It’s a useful way to share information with others in a clever but also controllable way. You can use any mind map application for this purpose. This article shows you how to get started using [FreeMind][1], available in Fedora.
|
||||
|
||||
### Get the application
|
||||
|
||||
The FreeMind application has been around a while. While the UI is a bit dated and could use a refresh, it’s a powerful app that offers many options for building mind maps. And of course it’s 100% open source. There are other mind mapping apps available for Fedora and Linux users, as well. Check out [this previous article that covers several mind map options][2].
|
||||
|
||||
Install FreeMind from the Fedora repositories using the Software app if you’re running Fedora Workstation. Or use this [sudo][3] command in a terminal:
|
||||
|
||||
```
|
||||
$ sudo dnf install freemind
|
||||
```
|
||||
|
||||
You can launch the app from the GNOME Shell Overview in Fedora Workstation. Or use the application start service your desktop environment provides. FreeMind shows you a new, blank map by default:
|
||||
|
||||
![][4]
|
||||
FreeMind initial (blank) mind map
|
||||
|
||||
A map consists of linked items or descriptions — nodes. When you think of something related to a node you want to capture, simply create a new node connected to it.
|
||||
|
||||
### Mapping yourself
|
||||
|
||||
Click in the initial node. Replace it with your name by editing the text and hitting **Enter**. You’ve just started your mind map.
|
||||
|
||||
What would you think of if you had to fully describe yourself to someone? There are probably many things to cover. How do you spend your time? What do you enjoy? What do you dislike? What do you value? Do you have a family? All of this can be captured in nodes.
|
||||
|
||||
To add a node connection, select the existing node, and hit **Insert** , or use the “light bulb” icon for a new child node. To add another node at the same level as the new child, use **Enter**.
|
||||
|
||||
Don’t worry if you make a mistake. You can use the **Delete** key to remove an unwanted node. There’s no rules about content. Short nodes are best, though. They allow your mind to move quickly when creating the map. Concise nodes also let viewers scan and understand the map easily later.
|
||||
|
||||
This example uses nodes to explore each of these major categories:
|
||||
|
||||
![][5]
|
||||
Personal mind map, first level
|
||||
|
||||
You could do another round of iteration for each of these areas. Let your mind freely connect ideas to generate the map. Don’t worry about “getting it right.” It’s better to get everything out of your head and onto the display. Here’s what a next-level map might look like.
|
||||
|
||||
![][6]
|
||||
Personal mind map, second level
|
||||
|
||||
You could expand on any of these nodes in the same way. Notice how much information you can quickly understand about John Q. Public in the example.
|
||||
|
||||
### How to use your personal mind map
|
||||
|
||||
This is a great way to have team or project members introduce themselves to each other. You can apply all sorts of formatting and color to the map to give it personality. These are fun to do on paper, of course. But having one on your Fedora system means you can always fix mistakes, or even make changes as you change.
|
||||
|
||||
Have fun exploring your personal mind map!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://freemind.sourceforge.net/wiki/index.php/Main_Page
|
||||
[2]: https://fedoramagazine.org/three-mind-mapping-tools-fedora/
|
||||
[3]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-17-04-1024x736.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-32-38-1024x736.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-38-00-1024x736.png
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user