mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
08eb10320b
@ -1,7 +1,7 @@
|
||||
language: c
|
||||
script:
|
||||
- sh ./scripts/check.sh
|
||||
- ./scripts/badge.sh
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then sh ./scripts/check.sh; fi'
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" = "false" ]; then sh ./scripts/badge.sh; fi'
|
||||
branches:
|
||||
only:
|
||||
- master
|
||||
|
||||
@ -1,38 +1,36 @@
|
||||
坚实的 React 基础:初学者指南
|
||||
============================================================
|
||||
============
|
||||
|
||||

|
||||
React.js crash course
|
||||
|
||||
*React.js crash course*
|
||||
|
||||
在过去的几个月里,我一直在使用 React 和 React-Native。我已经发布了两个作为产品的应用, [Kiven Aa][1](React)和 [Pollen Chat][2](React Native)。当我开始学习 React 时,我找了一些不仅仅是教我如何用 React 写应用的东西(一个博客,一个视频,一个课程,等等),我也想让它帮我做好面试准备。
|
||||
|
||||
我发现的大部分资料都集中在某一单一方面上。所以,这篇文章针对的是那些希望理论与实践完美结合的观众。我会告诉你一些理论,以便你了解幕后发生的事情,然后我会向你展示如何编写一些 React.js 代码。
|
||||
|
||||
如果你更喜欢视频形式,我在YouTube上传了整个课程,请去看看。
|
||||
|
||||
如果你更喜欢视频形式,我在 [YouTube][https://youtu.be/WJ6PgzI16I4] 上传了整个课程,请去看看。
|
||||
|
||||
让我们开始......
|
||||
|
||||
> React.js 是一个用于构建用户界面的 JavaScript 库
|
||||
|
||||
你可以构建各种单页应用程序。例如,你希望在用户界面上实时显示更改的聊天软件和电子商务门户。
|
||||
你可以构建各种单页应用程序。例如,你希望在用户界面上实时显示变化的聊天软件和电子商务门户。
|
||||
|
||||
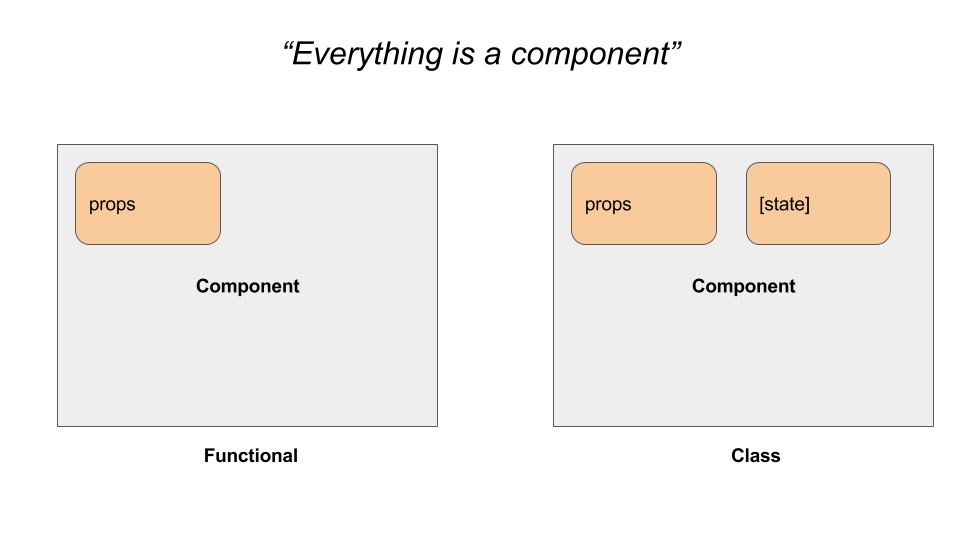
### 一切都是组件
|
||||
|
||||
React 应用由组件组成,数量多且互相嵌套。你或许会问:”可什么是组件呢?“
|
||||
React 应用由组件组成,数量繁多且互相嵌套。你或许会问:”可什么是组件呢?“
|
||||
|
||||
组件是可重用的代码段,它定义了某些功能在 UI 上的外观和行为。 比如,按钮就是一个组件。
|
||||
|
||||
让我们看看下面的计算器,当你尝试计算2 + 2 = 4 -1 = 3(简单的数学题)时,你会在Google上看到这个计算器。
|
||||
让我们看看下面的计算器,当你尝试计算 2 + 2 = 4 -1 = 3(简单的数学题)时,你会在 Google 上看到这个计算器。
|
||||
|
||||

|
||||
红色标记表示组件
|
||||
|
||||
|
||||
*红色标记表示组件*
|
||||
|
||||
如上图所示,这个计算器有很多区域,比如展示窗口和数字键盘。所有这些都可以是许多单独的组件或一个巨大的组件。这取决于在 React 中分解和抽象出事物的程度。你为所有这些组件分别编写代码,然后合并这些组件到一个容器中,而这个容器又是一个 React 组件。这样你就可以创建可重用的组件,最终的应用将是一组协同工作的单独组件。
|
||||
|
||||
|
||||
|
||||
以下是一个你践行了以上原则并可以用 React 编写计算器的方法。
|
||||
|
||||
```
|
||||
@ -47,7 +45,6 @@ React 应用由组件组成,数量多且互相嵌套。你或许会问:”
|
||||
<Key number={9}/>
|
||||
</NumPad>
|
||||
</Calculator>
|
||||
|
||||
```
|
||||
|
||||
没错!它看起来像HTML代码,然而并不是。我们将在后面的部分中详细探讨它。
|
||||
@ -56,7 +53,7 @@ React 应用由组件组成,数量多且互相嵌套。你或许会问:”
|
||||
|
||||
这篇教程专注于 React 的基础部分。它没有偏向 Web 或 React Native(开发移动应用)。所以,我们会用一个在线编辑器,这样可以在学习 React 能做什么之前避免 web 或 native 的具体配置。
|
||||
|
||||
我已经为读者在 [codepen.io][4] 设置好了开发环境。只需点开这个链接并且阅读所有 HTML 和 JavaScript 注释。
|
||||
我已经为读者在 [codepen.io][4] 设置好了开发环境。只需点开[该链接][4]并且阅读 HTML 和 JavaScript 中的所有注释。
|
||||
|
||||
### 控制组件
|
||||
|
||||
@ -70,8 +67,6 @@ React 应用由组件组成,数量多且互相嵌套。你或许会问:”
|
||||
|
||||
在 React 中,一个函数式组件通过 `props` 对象使用你传递给它的任意数据。它返回一个对象,该对象描述了 React 应渲染的 UI。函数式组件也称为无状态组件。
|
||||
|
||||
|
||||
|
||||
让我们编写第一个函数式组件。
|
||||
|
||||
```
|
||||
@ -80,14 +75,12 @@ function Hello(props) {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
就这么简单。我们只是将 `props` 作为参数传递给了一个普通的 JavaScript 函数并且有返回值。嗯?返回了什么?那个 `<div>{props.name}</div>`。它是 JSX(JavaScript Extended)。我们将在后面的部分中详细了解它。
|
||||
|
||||
上面这个函数将在浏览器中渲染出以下HTML。
|
||||
上面这个函数将在浏览器中渲染出以下 HTML。
|
||||
|
||||
```
|
||||
<!-- If the "props" object is: {name: 'rajat'} -->
|
||||
<!-- If the "props" object is: {name: 'rajat'} -->
|
||||
<div>
|
||||
rajat
|
||||
</div>
|
||||
@ -104,7 +97,7 @@ function Hello(props) {
|
||||
|
||||
属性 `name` 在上面的代码中变成了 `Hello` 组件里的 `props.name` ,属性 `age` 变成了 `props.age` 。
|
||||
|
||||
> 记住! 你可以将一个React组件嵌套在其他React组件中。
|
||||
> 记住! 你可以将一个 React 组件嵌套在其他 React 组件中。
|
||||
|
||||
让我们在 codepen playground 使用 `Hello` 组件。用我们的 `Hello` 组件替换 `ReactDOM.render()` 中的 `div`,并在底部窗口中查看更改。
|
||||
|
||||
@ -117,13 +110,15 @@ ReactDOM.render(<Hello name="rajat"/>, document.getElementById('root'));
|
||||
```
|
||||
|
||||
|
||||
> 但是如果你的组件有一些内部状态怎么办?例如,像下面的计数器组件一样,它有一个内部计数变量,它在 + 和 - 键按下时发生变化。
|
||||
> 但是如果你的组件有一些内部状态怎么办?例如,像下面的计数器组件一样,它有一个内部计数变量,它在 `+` 和 `-` 键按下时发生变化。
|
||||
|
||||
具有内部状态的 React 组件
|
||||
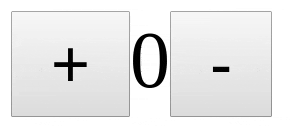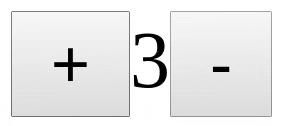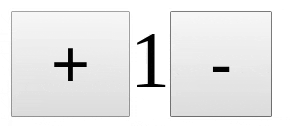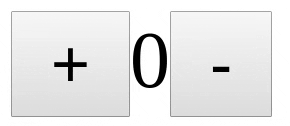
|
||||
|
||||
*具有内部状态的 React 组件*
|
||||
|
||||
#### b) 基于类的组件
|
||||
|
||||
基于类的组件有一个额外属性 `state` ,你可以用它存放组件的私有数据。我们可以用 class 表示法重写我们的 `Hello` 。由于这些组件具有状态,因此这些组件也称为有状态组件。
|
||||
基于类的组件有一个额外属性 `state` ,你可以用它存放组件的私有数据。我们可以用 `class` 表示法重写我们的 `Hello` 。由于这些组件具有状态,因此这些组件也称为有状态组件。
|
||||
|
||||
```
|
||||
class Counter extends React.Component {
|
||||
@ -138,9 +133,9 @@ class Counter extends React.Component {
|
||||
}
|
||||
```
|
||||
|
||||
我们继承了 React 库的 React.Component 类以在React中创建基于类的组件。在[这里][5]了解更多有关 JavaScript 类的东西。
|
||||
我们继承了 React 库的 `React.Component` 类以在 React 中创建基于类的组件。在[这里][5]了解更多有关 JavaScript 类的东西。
|
||||
|
||||
`render()` 方法必须存在于你的类中,因为React会查找此方法,用以了解它应在屏幕上渲染的 UI。为了使用这种内部状态,我们首先要在组件
|
||||
`render()` 方法必须存在于你的类中,因为 React 会查找此方法,用以了解它应在屏幕上渲染的 UI。为了使用这种内部状态,我们首先要在组件
|
||||
|
||||
要使用这种内部状态,我们首先必须按以下方式初始化组件类的构造函数中的状态对象。
|
||||
|
||||
@ -166,47 +161,47 @@ class Counter extends React.Component {
|
||||
// In your react app: <Counter />
|
||||
```
|
||||
|
||||
类似地,可以使用 this.props 对象在我们基于类的组件内访问 props。
|
||||
类似地,可以使用 `this.props` 对象在我们基于类的组件内访问 `props`。
|
||||
|
||||
要设置 state,请使用 `React.Component` 的 `setState()`。 在本教程的最后一部分中,我们将看到一个这样的例子。
|
||||
要设置 `state`,请使用 `React.Component` 的 `setState()`。 在本教程的最后一部分中,我们将看到一个这样的例子。
|
||||
|
||||
> 提示:永远不要在 `render()` 函数中调用 `setState()`,因为 `setState` 会导致组件重新渲染,这将导致无限循环。
|
||||
|
||||
|
||||
基于类的组件具有可选属性 “state”。
|
||||
|
||||
*基于类的组件具有可选属性 “state”。*
|
||||
|
||||
除了 `state` 以外,基于类的组件有一些声明周期方法比如 `componentWillMount()`。你可以利用这些去做初始化 `state`这样的事, 可是那将超出这篇文章的范畴。
|
||||
|
||||
### JSX
|
||||
|
||||
JSX 是 JavaScript Extended 的一种简短形式,它是一种编写 React components 的方法。使用 JSX,你可以在类 XML 标签中获得 JavaScript 的全部力量。
|
||||
JSX 是 JavaScript Extended 的缩写,它是一种编写 React 组件的方法。使用 JSX,你可以在类 XML 标签中获得 JavaScript 的全部力量。
|
||||
|
||||
你把 JavaScript 表达式放在`{}`里。下面是一些有效的 JSX 例子。
|
||||
你把 JavaScript 表达式放在 `{}` 里。下面是一些有效的 JSX 例子。
|
||||
|
||||
```
|
||||
<button disabled={true}>Press me!</button>
|
||||
|
||||
<button disabled={true}>Press me {3+1} times!</button>;
|
||||
|
||||
<div className='container'><Hello /></div>
|
||||
|
||||
```
|
||||
|
||||
它的工作方式是你编写 JSX 来描述你的 UI 应该是什么样子。像 Babel 这样的转码器将这些代码转换为一堆 `React.createElement()`调用。然后,React 库使用这些 `React.createElement()`调用来构造 DOM 元素的树状结构。对于 React 的网页视图或 React Native 的 Native 视图,它将保存在内存中。
|
||||
它的工作方式是你编写 JSX 来描述你的 UI 应该是什么样子。像 Babel 这样的转码器将这些代码转换为一堆 `React.createElement()` 调用。然后,React 库使用这些 `React.createElement()` 调用来构造 DOM 元素的树状结构。对于 React 的网页视图或 React Native 的 Native 视图,它将保存在内存中。
|
||||
|
||||
React 接着会计算它如何在存储展示给用户的 UI 的内存中有效地模仿这个树。此过程称为 [reconciliation][7]。完成计算后,React会对屏幕上的真正 UI 进行更改。
|
||||
React 接着会计算它如何在展示给用户的 UI 的内存中有效地模仿这个树。此过程称为 [reconciliation][7]。完成计算后,React 会对屏幕上的真正 UI 进行更改。
|
||||
|
||||
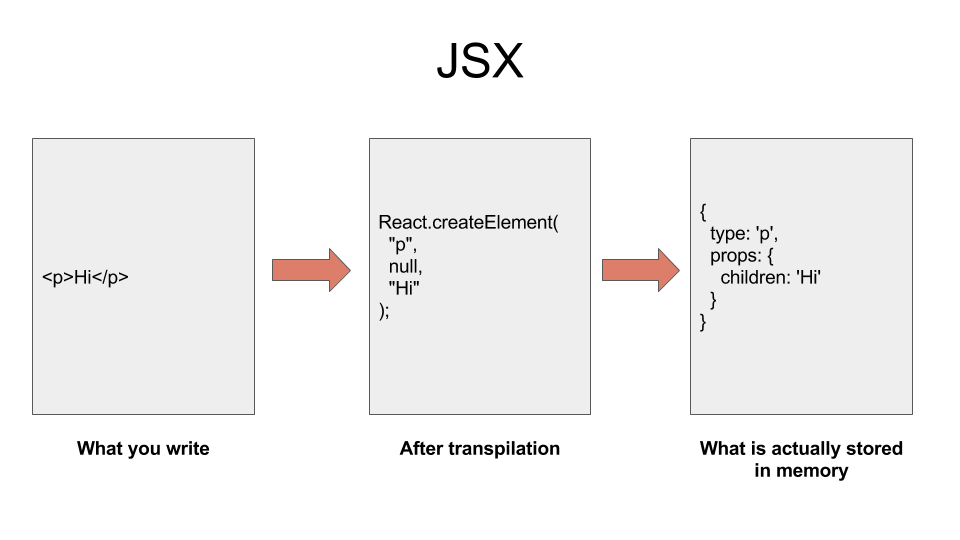
|
||||
React 如何将你的 JSX 转化为描述应用 UI 的树。
|
||||
|
||||
*React 如何将你的 JSX 转化为描述应用 UI 的树。*
|
||||
|
||||
你可以使用 [Babel 的在线 REPL][8] 查看当你写一些 JSX 的时候,React 的真正输出。
|
||||
|
||||
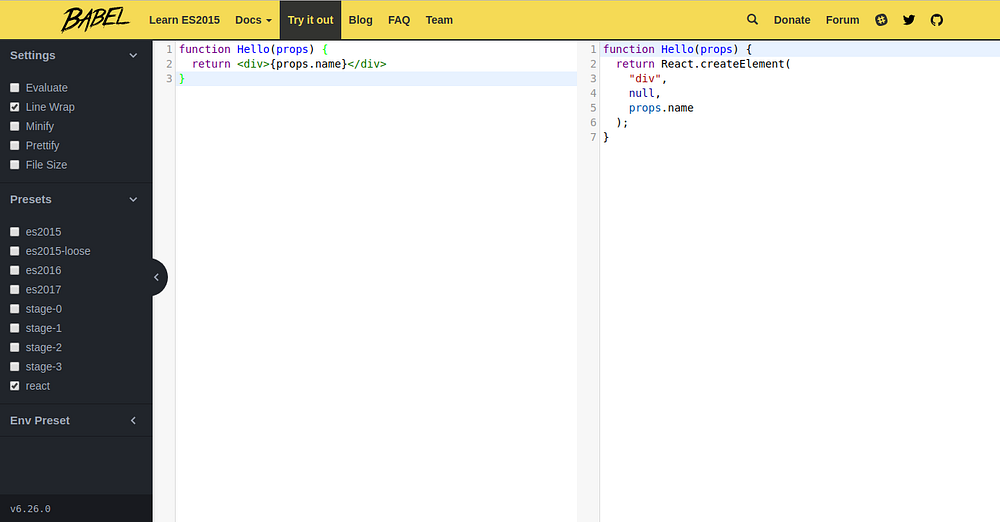
|
||||
使用Babel REPL 转换 JSX 为普通 JavaScript
|
||||
|
||||
*使用Babel REPL 转换 JSX 为普通 JavaScript*
|
||||
|
||||
> 由于 JSX 只是 `React.createElement()` 调用的语法糖,因此可以在没有 JSX 的情况下使用 React。
|
||||
|
||||
现在我们了解了所有的概念,所以我们已经准备好编写我们之前看到的作为GIF图的计数器组件。
|
||||
现在我们了解了所有的概念,所以我们已经准备好编写我们之前看到之前的 GIF 图中的计数器组件。
|
||||
|
||||
代码如下,我希望你已经知道了如何在我们的 playground 上渲染它。
|
||||
|
||||
@ -249,20 +244,19 @@ class Counter extends React.Component {
|
||||
以下是关于上述代码的一些重点。
|
||||
|
||||
1. JSX 使用 `驼峰命名` ,所以 `button` 的 属性是 `onClick`,不是我们在HTML中用的 `onclick`。
|
||||
|
||||
2. 绑定 `this` 是必要的,以便在回调时工作。 请参阅上面代码中的第8行和第9行。
|
||||
|
||||
最终的交互式代码位于[此处][9]。
|
||||
|
||||
有了这个,我们已经到了 React 速成课程的结束。我希望我已经阐明了 React 如何工作以及如何使用 React 来构建更大的应用程序,使用更小和可重用的组件。
|
||||
有了这个,我们已经到了 React 速成课程的结束。我希望我已经阐明了 React 如何工作,以及如何使用 React 来构建更大的应用程序,使用更小和可重用的组件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/rock-solid-react-js-foundations-a-beginners-guide-c45c93f5a923
|
||||
|
||||
作者:[Rajat Saxena ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Rajat Saxena][a]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,39 @@
|
||||
写给系统管理员的容器手册
|
||||
面向系统管理员的容器手册
|
||||
======
|
||||
> 你所需了解的容器如何工作的知识。
|
||||
|
||||

|
||||
|
||||
现在人们严重地过度使用“容器”这个术语。另外,对不同的人来说,它可能会有不同的含义,这取决于上下文。
|
||||
现在人们严重过度使用了“容器”这个术语。另外,对不同的人来说,它可能会有不同的含义,这取决于上下文。
|
||||
|
||||
传统的 Linux 容器只是系统上普通的进程组成的进程组。进程组之间是相互隔离的,实现方法包括:资源限制(控制组 [cgoups])、Linux 安全限制(文件权限,基于 Capability 的安全模块,SELinux,AppArmor,seccomp 等)还有名字空间(进程 ID,网络,挂载等)。
|
||||
传统的 Linux 容器只是系统上普通的进程。一组进程与另外一组进程是相互隔离的,实现方法包括:资源限制(控制组 [cgoups])、Linux 安全限制(文件权限,基于 Capability 的安全模块、SELinux、AppArmor、seccomp 等)还有名字空间(进程 ID、网络、挂载等)。
|
||||
|
||||
如果你启动一台现代 Linux 操作系统,使用 `cat /proc/PID/cgroup` 命令就可以看到该进程是属于一个控制组的。还可以从 `/proc/PID/status` 文件中查看进程的 Capability 信息,从 `/proc/self/attr/current` 文件中查看进程的 SELinux 标签信息,从 `/proc/PID/ns` 目录下的文件查看进程所属的名字空间。因此,如果把容器定义为带有资源限制、Linux 安全限制和名字空间的进程,那么按照这个定义,Linux 操作系统上的每一个进程都在容器里。因此我们常说 [Linux 就是容器,容器就是 Linux][1]。而**容器运行时**是这样一种工具,它调整上述资源限制、安全限制和名字空间,并启动容器。
|
||||
如果你启动一台现代 Linux 操作系统,使用 `cat /proc/PID/cgroup` 命令就可以看到该进程是属于一个控制组的。还可以从 `/proc/PID/status` 文件中查看进程的 Capability 信息,从 `/proc/self/attr/current` 文件中查看进程的 SELinux 标签信息,从 `/proc/PID/ns` 目录下的文件查看进程所属的名字空间。因此,如果把容器定义为带有资源限制、Linux 安全限制和名字空间的进程,那么按照这个定义,Linux 操作系统上的每一个进程都在一个容器里。因此我们常说 [Linux 就是容器,容器就是 Linux][1]。而**容器运行时**是这样一种工具,它调整上述资源限制、安全限制和名字空间,并启动容器。
|
||||
|
||||
Docker 引入了**容器镜像**的概念,镜像是一个普通的 TAR 包文件,包含了:
|
||||
|
||||
* **Rootfs(容器的根文件系统):**一个目录,看起来像是操作系统的普通根目录(/),例如,一个包含 `/usr`, `/var`, `/home` 等的目录。
|
||||
* **JSON 文件(容器的配置):**定义了如何运行 rootfs;例如,当容器启动的时候要在 rootfs 里运行什么 **command** 或者 **entrypoint**,给容器定义什么样的**环境变量**,容器的**工作目录**是哪个,以及其他一些设置。
|
||||
* **rootfs(容器的根文件系统)**:一个目录,看起来像是操作系统的普通根目录(`/`),例如,一个包含 `/usr`, `/var`, `/home` 等的目录。
|
||||
* **JSON 文件(容器的配置)**:定义了如何运行 rootfs;例如,当容器启动的时候要在 rootfs 里运行什么命令(`CMD`)或者入口(`ENTRYPOINT `),给容器定义什么样的环境变量(`ENV`),容器的工作目录(`WORKDIR `)是哪个,以及其他一些设置。
|
||||
|
||||
Docker 把 rootfs 和 JSON 配置文件打包成**基础镜像**。你可以在这个基础之上,给 rootfs 安装更多东西,创建新的 JSON 配置文件,然后把相对于原始镜像的不同内容打包到新的镜像。这种方法创建出来的是**分层的镜像**。
|
||||
|
||||
[Open Container Initiative(开放容器计划 OCI)][2] 标准组织最终把容器镜像的格式标准化了,也就是 [OCI Image Specification(OCI 镜像规范)][3]。
|
||||
<ruby>[开放容器计划][2]<rt>Open Container Initiative</rt></ruby>(OCI)标准组织最终把容器镜像的格式标准化了,也就是 <ruby>[镜像规范][3]<rt>OCI Image Specification</rt></ruby>(OCI)。
|
||||
|
||||
用来创建容器镜像的工具被称为**容器镜像构建器**。有时候容器引擎做这件事情,不过可以用一些独立的工具来构建容器镜像。
|
||||
|
||||
Docker 把这些容器镜像(**tar 包**)托管到 web 服务中,并开发了一种协议来支持从 web 拉取镜像,这个 web 服务就叫**容器仓库**。
|
||||
Docker 把这些容器镜像(**tar 包**)托管到 web 服务中,并开发了一种协议来支持从 web 拉取镜像,这个 web 服务就叫<ruby>容器仓库<rt>container registry</rt></ruby>。
|
||||
|
||||
**容器引擎**是能从镜像仓库拉取镜像并装载到**容器存储**上的程序。容器引擎还能启动**容器运行时**(见下图)。
|
||||
|
||||
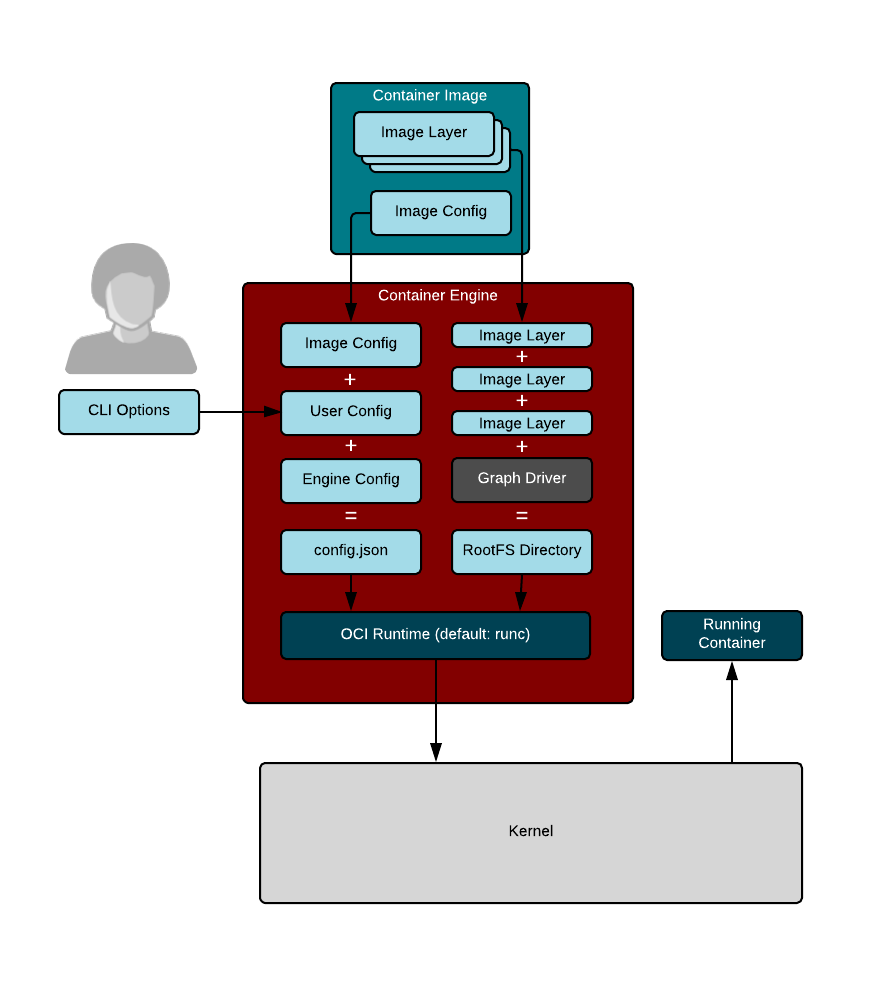
|
||||
|
||||
容器存储一般是**写入时复制**(COW)的分层文件系统。从容器仓库拉取一个镜像时,其中的 rootfs 首先被解压到磁盘。如果这个镜像是多层的,那么每一层都会被下载到 COW 文件系统的不同分层。 COW 文件系统保证了镜像的每一层独立存储,这最大化了多个分层镜像之间的文件共享程度。容器引擎通常支持多种容器存储类型,包括 `overlay`、`devicemapper`、`btrfs`、`aufs` 和 `zfs`。
|
||||
容器存储一般是<ruby>写入时复制<rt>copy-on-write</rt></ruby>(COW)的分层文件系统。从容器仓库拉取一个镜像时,其中的 rootfs 首先被解压到磁盘。如果这个镜像是多层的,那么每一层都会被下载到 COW 文件系统的不同分层。 COW 文件系统保证了镜像的每一层独立存储,这最大化了多个分层镜像之间的文件共享程度。容器引擎通常支持多种容器存储类型,包括 `overlay`、`devicemapper`、`btrfs`、`aufs` 和 `zfs`。
|
||||
|
||||
容器引擎将容器镜像下载到容器存储中之后,需要创建一份**容器运行时配置**,这份配置是用户/调用者的输入和镜像配置的合并。例如,容器的调用者可能会调整安全设置,添加额外的环境变量或者挂载一些卷到容器中。
|
||||
|
||||
容器运行时配置的格式,和解压出来的 rootfs 也都被开放容器计划 OCI 标准组织做了标准化,称为 [OCI 运行时规范][4]。
|
||||
|
||||
最终,容器引擎启动了一个**容器运行时**来读取运行时配置,修改 Linux 控制组、安全限制和名字空间,并执行容器命令来创建容器的 **PID 1**。至此,容器引擎已经可以把容器的标准输入/标准输出转给调用方,并控制容器了(例如,stop,start,attach)。
|
||||
最终,容器引擎启动了一个**容器运行时**来读取运行时配置,修改 Linux 控制组、安全限制和名字空间,并执行容器命令来创建容器的 **PID 1** 进程。至此,容器引擎已经可以把容器的标准输入/标准输出转给调用方,并控制容器了(例如,`stop`、`start`、`attach`)。
|
||||
|
||||
值得一提的是,现在出现了很多新的容器运行时,它们使用 Linux 的不同特性来隔离容器。可以使用 KVM 技术来隔离容器(想想迷你虚拟机),或者使用其他虚拟机监视器策略(例如拦截所有从容器内的进程发起的系统调用)。既然我们有了标准的运行时规范,这些工具都能被相同的容器引擎来启动。即使在 Windows 系统下,也可以使用 OCI 运行时规范来启动 Windows 容器。
|
||||
|
||||
@ -45,7 +46,7 @@ via: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[belitex](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
如何构建rpm包
|
||||
如何构建 RPM 包
|
||||
======
|
||||
|
||||
节省跨多个主机安装文件和脚本的时间和精力。
|
||||
> 节省跨多个主机安装文件和脚本的时间和精力。
|
||||
|
||||

|
||||
|
||||
自20多年前我开始使用 Linux 以来,我已经使用过基于 rpm 的软件包管理器在 Red Hat 和 Fedora Linux系统上安装软件。我使用过 **rpm** 程序本身,还有 **yum** 和 **DNF** ,用于在我的 Linux 主机上安装和更新软件包,DNF 是 yum 的一个紧密后代。 yum 和 DNF 工具是 rpm 实用程序的包装器,它提供了其他功能,例如查找和安装包依赖项的功能。
|
||||
自20多年前我开始使用 Linux 以来,我已经使用过基于 rpm 的软件包管理器在 Red Hat 和 Fedora Linux 系统上安装软件。我使用过 `rpm` 程序本身,还有 `yum` 和 `dnf` ,用于在我的 Linux 主机上安装和更新软件包,`dnf` 是 `yum` 的一个近亲。 `yum` 和 `dnf` 工具是 `rpm` 实用程序的包装器,它提供了其他功能,例如查找和安装包依赖项的功能。
|
||||
|
||||
多年来,我创建了许多 Bash 脚本,其中一些脚本具有单独的配置文件,我希望在大多数新计算机和虚拟机上安装这些脚本。这也能解决安装所有这些软件包需要花费大量时间的难题,因此我决定通过创建一个 rpm 软件包来自动执行该过程,我可以将其复制到目标主机并将所有这些文件安装在适当的位置。虽然 **rpm** 工具以前用于构建 rpm 包,但该功能已被删除,并且创建了一个新工具来构建新的 rpm。
|
||||
多年来,我创建了许多 Bash 脚本,其中一些脚本具有单独的配置文件,我希望在大多数新计算机和虚拟机上安装这些脚本。这也能解决安装所有这些软件包需要花费大量时间的难题,因此我决定通过创建一个 rpm 软件包来自动执行该过程,我可以将其复制到目标主机并将所有这些文件安装在适当的位置。虽然 `rpm` 工具以前用于构建 rpm 包,但该功能已被删除,并且创建了一个新工具来构建新的 rpm。
|
||||
|
||||
当我开始这个项目时,我发现很少有关于创建 rpm 包的信息,但我找到了一本书,名为《Maximum RPM》,这本书才帮我弄明白了。这本书现在已经过时了,我发现的绝大多数信息都是如此。它也已经绝版,使用复印件需要花费数百美元。[Maximum RPM][1] 的在线版本是免费提供的,并保持最新。 [RPM 网站][2]还有其他网站的链接,这些网站上有很多关于 rpm 的文档。其他的信息往往是简短的,显然都是假设你已经对该过程有了很多了解。
|
||||
当我开始这个项目时,我发现很少有关于创建 rpm 包的信息,但我找到了一本书,名为《Maximum RPM》,这本书才帮我弄明白了。这本书现在已经过时了,我发现的绝大多数信息都是如此。它也已经绝版,用过的副本也需要花费数百美元。[Maximum RPM][1] 的在线版本是免费提供的,并保持最新。该 [RPM 网站][2]还有其他网站的链接,这些网站上有很多关于 rpm 的文档。其他的信息往往是简短的,显然都是假设你已经对该过程有了很多了解。
|
||||
|
||||
此外,我发现的每个文档都假定代码需要在开发环境中从源代码编译。我不是开发人员。我是一个系统管理员,我们系统管理员有不同的需求,因为我们不需要或者我们不应该为了管理任务而去编译代码;我们应该使用 shell 脚本。所以我们没有源代码,因为它需要被编译成二进制可执行文件。我们拥有的是一个也是可执行的源代码。
|
||||
此外,我发现的每个文档都假定代码需要在开发环境中从源代码编译。我不是开发人员。我是一个系统管理员,我们系统管理员有不同的需求,因为我们不需要或者我们不应该为了管理任务而去编译代码;我们应该使用 shell 脚本。所以我们没有源代码,因为它需要被编译成二进制可执行文件。我们拥有的源代码也应该是可执行的。
|
||||
|
||||
在大多数情况下,此项目应作为非 root 用户执行。 Rpm 包永远不应该由 root 用户构建,而只能由非特权普通用户构建。我将指出哪些部分应该以 root 身份执行,哪些部分应由非 root,非特权用户执行。
|
||||
在大多数情况下,此项目应作为非 root 用户执行。 rpm 包永远不应该由 root 用户构建,而只能由非特权普通用户构建。我将指出哪些部分应该以 root 身份执行,哪些部分应由非 root,非特权用户执行。
|
||||
|
||||
### 准备
|
||||
|
||||
@ -37,7 +37,7 @@ passwd: all authentication tokens updated successfully.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
构建 rpm 包需要 `rpm-build` 包,该包可能尚未安装。 现在以 root 身份安装它。 请注意,此命令还将安装多个依赖项。 数量可能会有所不同,具体取决于主机上已安装的软件包; 它在我的测试虚拟机上总共安装了17个软件包,这是非常小的。
|
||||
构建 rpm 包需要 `rpm-build` 包,该包可能尚未安装。 现在以 root 身份安装它。 请注意,此命令还将安装多个依赖项。 数量可能会有所不同,具体取决于主机上已安装的软件包; 它在我的测试虚拟机上总共安装了 17 个软件包,这是非常小的。
|
||||
|
||||
```
|
||||
dnf install -y rpm-build
|
||||
@ -49,15 +49,15 @@ dnf install -y rpm-build
|
||||
wget https://github.com/opensourceway/how-to-rpm/raw/master/utils.tar
|
||||
```
|
||||
|
||||
此 tar 包包含将由最终 rpm 程序安装的所有文件和 Bash 脚本。 还有一个完整的 spec 文件,你可以使用它来构建 rpm。 我们将详细介绍 spec 文件的每个部分。
|
||||
此 tar 包包含将由最终 `rpm` 程序安装的所有文件和 Bash 脚本。 还有一个完整的 spec 文件,你可以使用它来构建 rpm。 我们将详细介绍 spec 文件的每个部分。
|
||||
|
||||
作为普通学生 student,使用你的家目录作为当前工作目录(pwd),解压缩 tar 包。
|
||||
作为普通学生 student,使用你的家目录作为当前工作目录(`pwd`),解压缩 tar 包。
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ cd ; tar -xvf utils.tar
|
||||
```
|
||||
|
||||
使用 `tree` 命令验证~/development 的目录结构和包含的文件,如下所示:
|
||||
使用 `tree` 命令验证 `~/development` 的目录结构和包含的文件,如下所示:
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ tree development/
|
||||
@ -77,13 +77,13 @@ development/
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
`mymotd` 脚本创建一个发送到标准输出的“当日消息”数据流。 `create_motd` 脚本运行 `mymotd` 脚本并将输出重定向到 /etc/motd 文件。 此文件用于向使用SSH远程登录的用户显示每日消息。
|
||||
`mymotd` 脚本创建一个发送到标准输出的“当日消息”数据流。 `create_motd` 脚本运行 `mymotd` 脚本并将输出重定向到 `/etc/motd` 文件。 此文件用于向使用 SSH 远程登录的用户显示每日消息。
|
||||
|
||||
`die` 脚本是我自己的脚本,它将 `kill` 命令包装在一些代码中,这些代码可以找到与指定字符串匹配的运行程序并将其终止。 它使用 `kill -9` 来确保kill命令一定会执行。
|
||||
`die` 脚本是我自己的脚本,它将 `kill` 命令包装在一些代码中,这些代码可以找到与指定字符串匹配的运行程序并将其终止。 它使用 `kill -9` 来确保 `kill` 命令一定会执行。
|
||||
|
||||
`sysdata` 脚本可以显示有关计算机硬件,还有已安装的 Linux 版本,所有已安装的软件包以及硬盘驱动器元数据的数万行数据。 我用它来记录某个时间点的主机状态。 我以后可以用它作为参考。 我曾经这样做是为了维护我为客户安装的主机记录。
|
||||
`sysdata` 脚本可以显示有关计算机硬件,还有已安装的 Linux 版本,所有已安装的软件包以及硬盘驱动器元数据等数万行数据。 我用它来记录某个时间点的主机状态。 我以后可以用它作为参考。 我曾经这样做是为了维护我为客户安装的主机记录。
|
||||
|
||||
你可能需要将这些文件和目录的所有权更改为 student:student 。 如有必要,使用以下命令执行此操作:
|
||||
你可能需要将这些文件和目录的所有权更改为 `student:student` 。 如有必要,使用以下命令执行此操作:
|
||||
|
||||
```
|
||||
chown -R student:student development
|
||||
@ -104,11 +104,11 @@ chown -R student:student development
|
||||
└── SRPMS
|
||||
```
|
||||
|
||||
我们不会创建 rpmbuild/RPMS/X86_64 目录,因为对于64位编译的二进制文件这是特定于体系结构的。 我们有 shell 脚本,不是特定于体系结构的。 实际上,我们也不会使用 SRPMS 目录,它将包含编译器的源文件。
|
||||
我们不会创建 `rpmbuild/RPMS/X86_64` 目录,因为它是特定于体系结构编译的 64 位二进制文件。 我们有 shell 脚本,不是特定于体系结构的。 实际上,我们也不会使用 `SRPMS` 目录,它将包含编译器的源文件。
|
||||
|
||||
### 检查 spec 文件
|
||||
|
||||
每个 spec 文件都有许多部分,其中一些部分可能会被忽视或省略,取决于 rpm 构建的具体情况。 这个特定的 spec 文件不是工作所需的最小文件的示例,但它是一个很好的包含不需要编译的文件的中等复杂 spec 文件的例子。 如果需要编译,它将在`构建`部分中执行,该部分在此 spec 文件中省略掉了,因为它不是必需的。
|
||||
每个 spec 文件都有许多部分,其中一些部分可能会被忽视或省略,取决于 rpm 构建的具体情况。 这个特定的 spec 文件不是工作所需的最小文件的示例,但它是一个包含不需要编译的文件的中等复杂 spec 文件的很好例子。 如果需要编译,它将在 `%build` 部分中执行,该部分在此 spec 文件中省略掉了,因为它不是必需的。
|
||||
|
||||
#### 前言
|
||||
|
||||
@ -139,40 +139,46 @@ BuildRoot: ~/rpmbuild/
|
||||
# rpmbuild --target noarch -bb utils.spec
|
||||
```
|
||||
|
||||
`rpmbuild` 程序会忽略注释行。我总是喜欢在本节中添加注释,其中包含创建包所需的 `rpmbuild` 命令的确切语法。摘要标签是包的简短描述。 Name,Version 和 Release 标签用于创建 rpm 文件的名称,如utils-1.00-1.rpm 中所示。通过增加发行版号码和版本号,你可以创建 rpm 包去更新旧版本的。
|
||||
`rpmbuild` 程序会忽略注释行。我总是喜欢在本节中添加注释,其中包含创建包所需的 `rpmbuild` 命令的确切语法。
|
||||
|
||||
许可证标签定义了发布包的许可证。我总是使用 GPL 的一个变体。指定许可证对于澄清包中包含的软件是开源的这一事实非常重要。这也是我将许可证和 GPL 语句包含在将要安装的文件中的原因。
|
||||
`Summary` 标签是包的简短描述。
|
||||
|
||||
URL 通常是项目或项目所有者的网页。在这种情况下,它是我的个人网页。
|
||||
`Name`、`Version` 和 `Release` 标签用于创建 rpm 文件的名称,如 `utils-1.00-1.rpm`。通过增加发行版号码和版本号,你可以创建 rpm 包去更新旧版本的。
|
||||
|
||||
Group 标签很有趣,通常用于 GUI 应用程序。 Group 标签的值决定了应用程序菜单中的哪一组图标将包含此包中可执行文件的图标。与 Icon 标签(我们此处未使用)一起使用时,Group 标签允许添加图标和所需信息用于将程序启动到应用程序菜单结构中。
|
||||
`License` 标签定义了发布包的许可证。我总是使用 GPL 的一个变体。指定许可证对于澄清包中包含的软件是开源的这一事实非常重要。这也是我将 `License` 和 `GPL` 语句包含在将要安装的文件中的原因。
|
||||
|
||||
Packager 标签用于指定负责维护和创建包的人员或组织。
|
||||
`URL` 通常是项目或项目所有者的网页。在这种情况下,它是我的个人网页。
|
||||
|
||||
Requires 语句定义此 rpm 包的依赖项。每个都是包名。如果其中一个指定的软件包不存在,DNF 安装实用程序将尝试在 /etc/yum.repos.d 中定义的某个已定义的存储库中找到它,如果存在则安装它。如果 DNF 找不到一个或多个所需的包,它将抛出一个错误,指出哪些包丢失并终止。
|
||||
`Group` 标签很有趣,通常用于 GUI 应用程序。 `Group` 标签的值决定了应用程序菜单中的哪一组图标将包含此包中可执行文件的图标。与 `Icon` 标签(我们此处未使用)一起使用时,`Group` 标签允许在应用程序菜单结构中添加用于启动程序的图标和所需信息。
|
||||
|
||||
BuildRoot 行指定顶级目录,`rpmbuild` 工具将在其中找到 spec 文件,并在构建包时在其中创建临时目录。完成的包将存储在我们之前指定的noarch子目录中。注释显示了构建此程序包的命令语法,包括定义了目标体系结构的 `–target noarch` 选项。因为这些是Bash脚本,所以它们与特定的CPU架构无关。如果省略此选项,则构建将选用正在执行构建的CPU的体系结构。
|
||||
`Packager` 标签用于指定负责维护和创建包的人员或组织。
|
||||
|
||||
`Requires` 语句定义此 rpm 包的依赖项。每个都是包名。如果其中一个指定的软件包不存在,DNF 安装实用程序将尝试在 `/etc/yum.repos.d` 中定义的某个已定义的存储库中找到它,如果存在则安装它。如果 DNF 找不到一个或多个所需的包,它将抛出一个错误,指出哪些包丢失并终止。
|
||||
|
||||
`BuildRoot` 行指定顶级目录,`rpmbuild` 工具将在其中找到 spec 文件,并在构建包时在其中创建临时目录。完成的包将存储在我们之前指定的 `noarch` 子目录中。
|
||||
|
||||
注释显示了构建此程序包的命令语法,包括定义了目标体系结构的 `–target noarch` 选项。因为这些是 Bash 脚本,所以它们与特定的 CPU 架构无关。如果省略此选项,则构建将选用正在执行构建的 CPU 的体系结构。
|
||||
|
||||
`rpmbuild` 程序可以针对许多不同的体系结构,并且使用 `--target` 选项允许我们在不同的体系结构主机上构建特定体系结构的包,其具有与执行构建的体系结构不同的体系结构。所以我可以在 x86_64 主机上构建一个用于 i686 架构的软件包,反之亦然。
|
||||
|
||||
如果你有自己的网站,请将打包者的名称更改为你自己的网站。
|
||||
|
||||
#### 描述
|
||||
#### 描述部分(`%description`)
|
||||
|
||||
spec 文件的 `描述` 部分包含 rpm 包的描述。 它可以很短,也可以包含许多信息。 我们的 `描述` 部分相当简洁。
|
||||
spec 文件的 `%description` 部分包含 rpm 包的描述。 它可以很短,也可以包含许多信息。 我们的 `%description` 部分相当简洁。
|
||||
|
||||
```
|
||||
%description
|
||||
A collection of utility scripts for testing RPM creation.
|
||||
```
|
||||
|
||||
#### 准备
|
||||
#### 准备部分(`%prep`)
|
||||
|
||||
`准备` 部分是在构建过程中执行的第一个脚本。 在安装程序包期间不会执行此脚本。
|
||||
`%prep` 部分是在构建过程中执行的第一个脚本。 在安装程序包期间不会执行此脚本。
|
||||
|
||||
这个脚本只是一个 Bash shell 脚本。 它准备构建目录,根据需要创建用于构建的目录,并将相应的文件复制到各自的目录中。 这将包括完整编译作为构建的一部分所需的源。
|
||||
这个脚本只是一个 Bash shell 脚本。 它准备构建目录,根据需要创建用于构建的目录,并将相应的文件复制到各自的目录中。 这将包括作为构建的一部分的完整编译所需的源代码。
|
||||
|
||||
$RPM_BUILD_ROOT 目录表示已安装系统的根目录。 在 $RPM_BUILD_ROOT 目录中创建的目录是实时文件系统中的绝对路径,例如 /user/local/share/utils,/usr/local/bin 等。
|
||||
`$RPM_BUILD_ROOT` 目录表示已安装系统的根目录。 在 `$RPM_BUILD_ROOT` 目录中创建的目录是真实文件系统中的绝对路径,例如 `/user/local/share/utils`、`/usr/local/bin` 等。
|
||||
|
||||
对于我们的包,我们没有预编译源,因为我们的所有程序都是 Bash 脚本。 因此,我们只需将这些脚本和其他文件复制到已安装系统的目录中。
|
||||
|
||||
@ -193,11 +199,11 @@ cp /home/student/development/utils/spec/* $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
exit
|
||||
```
|
||||
|
||||
请注意,本节末尾的 exit 语句是必需的。
|
||||
请注意,本节末尾的 `exit` 语句是必需的。
|
||||
|
||||
#### 文件
|
||||
#### 文件部分(`%files`)
|
||||
|
||||
spec 文件的这一部分定义了要安装的文件及其在目录树中的位置。 它还指定了要安装的每个文件的文件属性以及所有者和组所有者。 文件权限和所有权是可选的,但我建议明确设置它们以消除这些属性在安装时不正确或不明确的任何可能性。 如果目录尚不存在,则会在安装期间根据需要创建目录。
|
||||
spec 文件的 `%files` 这一部分定义了要安装的文件及其在目录树中的位置。 它还指定了要安装的每个文件的文件属性(`%attr`)以及所有者和组所有者。 文件权限和所有权是可选的,但我建议明确设置它们以消除这些属性在安装时不正确或不明确的任何可能性。 如果目录尚不存在,则会在安装期间根据需要创建目录。
|
||||
|
||||
```
|
||||
%files
|
||||
@ -205,13 +211,13 @@ spec 文件的这一部分定义了要安装的文件及其在目录树中的位
|
||||
%attr(0644, root, root) /usr/local/share/utils/*
|
||||
```
|
||||
|
||||
#### 安装前
|
||||
#### 安装前(`%pre`)
|
||||
|
||||
在我们的实验室项目的 spec 文件中,此部分为空。 这将放置那些需要 rpm 安装前执行的脚本。
|
||||
在我们的实验室项目的 spec 文件中,此部分为空。 这应该放置那些需要 rpm 中的文件安装前执行的脚本。
|
||||
|
||||
#### 安装后
|
||||
#### 安装后(`%post`)
|
||||
|
||||
spec 文件的这一部分是另一个 Bash 脚本。 这个在安装文件后运行。 此部分几乎可以是你需要或想要的任何内容,包括创建文件,运行系统命令以及重新启动服务以在进行配置更改后重新初始化它们。 我们的 rpm 包的 `安装后` 脚本执行其中一些任务。
|
||||
spec 文件的这一部分是另一个 Bash 脚本。 这个在文件安装后运行。 此部分几乎可以是你需要或想要的任何内容,包括创建文件、运行系统命令以及重新启动服务以在进行配置更改后重新初始化它们。 我们的 rpm 包的 `%post` 脚本执行其中一些任务。
|
||||
|
||||
```
|
||||
%post
|
||||
@ -236,11 +242,11 @@ fi
|
||||
|
||||
此脚本中包含的注释应明确其用途。
|
||||
|
||||
#### 卸载后
|
||||
#### 卸载后(`%postun`)
|
||||
|
||||
此部分包含将在卸载 rpm 软件包后运行的脚本。 使用 rpm 或 DNF 删除包会删除文件部分中列出的所有文件,但它不会删除安装后部分创建的文件或链接,因此我们需要在本节中处理。
|
||||
此部分包含将在卸载 rpm 软件包后运行的脚本。 使用 `rpm` 或 `dnf` 删除包会删除文件部分中列出的所有文件,但它不会删除安装后部分创建的文件或链接,因此我们需要在本节中处理。
|
||||
|
||||
此脚本通常由清理任务组成,只是清除以前由rpm安装的文件,但rpm本身无法完成清除。 对于我们的包,它包括删除 `安装后` 脚本创建的链接并恢复 motd 文件的已保存原件。
|
||||
此脚本通常由清理任务组成,只是清除以前由 `rpm` 安装的文件,但 rpm 本身无法完成清除。 对于我们的包,它包括删除 `%post` 脚本创建的链接并恢复 motd 文件的已保存原件。
|
||||
|
||||
```
|
||||
%postun
|
||||
@ -254,9 +260,9 @@ then
|
||||
fi
|
||||
```
|
||||
|
||||
#### 清理
|
||||
#### 清理(`%clean`)
|
||||
|
||||
这个 Bash 脚本在 rpm 构建过程之后开始清理。 下面 `清理` 部分中的两行删除了 `rpm-build` 命令创建的构建目录。 在许多情况下,可能还需要额外的清理。
|
||||
这个 Bash 脚本在 rpm 构建过程之后开始清理。 下面 `%clean` 部分中的两行删除了 `rpm-build` 命令创建的构建目录。 在许多情况下,可能还需要额外的清理。
|
||||
|
||||
```
|
||||
%clean
|
||||
@ -264,9 +270,9 @@ rm -rf $RPM_BUILD_ROOT/usr/local/bin
|
||||
rm -rf $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
```
|
||||
|
||||
#### 更新日志
|
||||
#### 变更日志(`%changelog`)
|
||||
|
||||
此可选的文本部分包含 rpm 及其包含的文件的更改列表。 最新的更改记录在本部分顶部。
|
||||
此可选的文本部分包含 rpm 及其包含的文件的变更列表。最新的变更记录在本部分顶部。
|
||||
|
||||
```
|
||||
%changelog
|
||||
@ -280,20 +286,20 @@ rm -rf $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
|
||||
### 构建 rpm
|
||||
|
||||
spec 文件必须位于 rpmbuild 目录树的 SPECS 目录中。 我发现最简单的方法是创建一个指向该目录中实际 spec 文件的链接,以便可以在开发目录中对其进行编辑,而无需将其复制到 SPECS 目录。 将 SPECS 目录设为当前工作目录,然后创建链接。
|
||||
spec 文件必须位于 `rpmbuild` 目录树的 `SPECS` 目录中。 我发现最简单的方法是创建一个指向该目录中实际 spec 文件的链接,以便可以在开发目录中对其进行编辑,而无需将其复制到 `SPECS` 目录。 将 `SPECS` 目录设为当前工作目录,然后创建链接。
|
||||
|
||||
```
|
||||
cd ~/rpmbuild/SPECS/
|
||||
ln -s ~/development/spec/utils.spec
|
||||
```
|
||||
|
||||
运行以下命令以构建 rpm 。 如果没有错误发生,只需要花一点时间来创建 rpm 。
|
||||
运行以下命令以构建 rpm。 如果没有错误发生,只需要花一点时间来创建 rpm。
|
||||
|
||||
```
|
||||
rpmbuild --target noarch -bb utils.spec
|
||||
```
|
||||
|
||||
检查 ~/rpmbuild/RPMS/noarch 目录以验证新的 rpm 是否存在。
|
||||
检查 `~/rpmbuild/RPMS/noarch` 目录以验证新的 rpm 是否存在。
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ cd rpmbuild/RPMS/noarch/
|
||||
@ -305,7 +311,7 @@ total 24
|
||||
|
||||
### 测试 rpm
|
||||
|
||||
以 root 用户身份安装 rpm 以验证它是否正确安装并且文件是否安装在正确的目录中。 rpm 的确切名称将取决于你在 Preamble 部分中标签的值,但如果你使用了示例中的值,则 rpm 名称将如下面的示例命令所示:
|
||||
以 root 用户身份安装 rpm 以验证它是否正确安装并且文件是否安装在正确的目录中。 rpm 的确切名称将取决于你在前言部分中标签的值,但如果你使用了示例中的值,则 rpm 名称将如下面的示例命令所示:
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# cd /home/student/rpmbuild/RPMS/noarch/
|
||||
@ -318,9 +324,9 @@ Updating / installing...
|
||||
1:utils-1.0.0-1 ################################# [100%]
|
||||
```
|
||||
|
||||
检查 /usr/local/bin 以确保新文件存在。 你还应验证是否已创建 /etc/cron.daily 中的 create_motd 链接。
|
||||
检查 `/usr/local/bin` 以确保新文件存在。 你还应验证是否已创建 `/etc/cron.daily` 中的 `create_motd` 链接。
|
||||
|
||||
使用 `rpm -q --changelog utils` 命令查看更改日志。 使用 `rpm -ql utils` 命令(在 `ql`中为小写 L )查看程序包安装的文件。
|
||||
使用 `rpm -q --changelog utils` 命令查看更改日志。 使用 `rpm -ql utils` 命令(在 `ql` 中为小写 `L` )查看程序包安装的文件。
|
||||
|
||||
```
|
||||
[root@testvm1 noarch]# rpm -q --changelog utils
|
||||
@ -356,11 +362,11 @@ Requires: badrequire
|
||||
|
||||
构建包并尝试安装它。 显示什么消息?
|
||||
|
||||
我们使用 `rpm` 命令来安装和删除 `utils` 包。 尝试使用 yum 或 DNF 安装软件包。 你必须与程序包位于同一目录中,或指定程序包的完整路径才能使其正常工作。
|
||||
我们使用 `rpm` 命令来安装和删除 `utils` 包。 尝试使用 `yum` 或 `dnf` 安装软件包。 你必须与程序包位于同一目录中,或指定程序包的完整路径才能使其正常工作。
|
||||
|
||||
### 总结
|
||||
|
||||
在这里看一下创建 rpm 包的基础知识,我们没有涉及很多标签和很多部分。 下面列出的资源可以提供更多信息。 构建 rpm 包并不困难;你只需要正确的信息。 我希望这对你有所帮助——我花了几个月的时间来自己解决问题。
|
||||
在这篇对创建 rpm 包的基础知识的概览中,我们没有涉及很多标签和很多部分。 下面列出的资源可以提供更多信息。 构建 rpm 包并不困难;你只需要正确的信息。 我希望这对你有所帮助——我花了几个月的时间来自己解决问题。
|
||||
|
||||
我们没有涵盖源代码构建,但如果你是开发人员,那么从这一点开始应该是一个简单的步骤。
|
||||
|
||||
@ -368,9 +374,9 @@ Requires: badrequire
|
||||
|
||||
### 资料
|
||||
|
||||
- Edward C. Baily,Maximum RPM,Sams著,于2000年,ISBN 0-672-31105-4
|
||||
- Edward C. Baily,[Maximum RPM][1],更新在线版本
|
||||
- [RPM文档][4]:此网页列出了 rpm 的大多数可用在线文档。 它包括许多其他网站的链接和有关 rpm 的信息。
|
||||
- Edward C. Baily,《Maximum RPM》,Sams 出版于 2000 年,ISBN 0-672-31105-4
|
||||
- Edward C. Baily,《[Maximum RPM][1]》,更新在线版本
|
||||
- [RPM 文档][4]:此网页列出了 rpm 的大多数可用在线文档。 它包括许多其他网站的链接和有关 rpm 的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -379,7 +385,7 @@ via: https://opensource.com/article/18/9/how-build-rpm-packages
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -387,4 +393,4 @@ via: https://opensource.com/article/18/9/how-build-rpm-packages
|
||||
[1]: http://ftp.rpm.org/max-rpm/
|
||||
[2]: http://rpm.org/index.html
|
||||
[3]: http://www.both.org/?p=960
|
||||
[4]: http://rpm.org/documentation.html
|
||||
[4]: http://rpm.org/documentation.html
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by bayar199468
|
||||
7 Best eBook Readers for Linux
|
||||
======
|
||||
**Brief:** In this article, we are covering some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Using Your Own Private Registry with Docker Enterprise Edition
|
||||
======
|
||||
|
||||
|
||||
@ -1,261 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
How To Find The Mounted Filesystem Type In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
As you may already know, the Linux supports numerous filesystems, such as Ext4, ext3, ext2, sysfs, securityfs, FAT16, FAT32, NTFS, and many. The most commonly used filesystem is Ext4. Ever wondered what type of filesystem are you currently using in your Linux system? No? Worry not! We got your back. This guide explains how to find the mounted filesystem type in Unix-like operating systems.
|
||||
|
||||
### Find The Mounted Filesystem Type In Linux
|
||||
|
||||
There can be many ways to find the filesystem type in Linux. Here, I have given 8 different methods. Let us get started, shall we?
|
||||
|
||||
#### Method 1 – Using findmnt command
|
||||
|
||||
This is the most commonly used method to find out the type of a filesystem. The **findmnt** command will list all mounted filesystems or search for a filesystem. The findmnt command can be able to search in **/etc/fstab** , **/etc/mtab** or **/proc/self/mountinfo**.
|
||||
|
||||
findmnt command comes pre-installed in most Linux distributions, because it is part of the package named **util-linux**. Just in case if it is not available, simply install this package and you’re good to go. For instance, you can install **util-linux** package in Debian-based systems using command:
|
||||
```
|
||||
$ sudo apt install util-linux
|
||||
|
||||
```
|
||||
|
||||
Let us go ahead and see how to use findmnt command to find out the mounted filesystems.
|
||||
|
||||
If you run it without any arguments/options, it will list all mounted filesystems in a tree-like format as shown below.
|
||||
```
|
||||
$ findmnt
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see, the findmnt command displays the target mount point (TARGET), source device (SOURCE), file system type (FSTYPE), and relevant mount options, like whether the filesystem is read/write or read-only. (OPTIONS). In my case, my root(/) filesystem type is EXT4.
|
||||
|
||||
If you don’t like/want to display the output in tree-like format, use **-l** flag to display in simple, plain format.
|
||||
```
|
||||
$ findmnt -l
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
You can also list a particular type of filesystem, for example **ext4** , using **-t** option.
|
||||
```
|
||||
$ findmnt -t ext4
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
/ /dev/sda2 ext4 rw,relatime,commit=360
|
||||
└─/boot /dev/sda1 ext4 rw,relatime,commit=360,data=ordered
|
||||
|
||||
```
|
||||
|
||||
Findmnt can produce df style output as well.
|
||||
```
|
||||
$ findmnt --df
|
||||
|
||||
```
|
||||
|
||||
Or
|
||||
```
|
||||
$ findmnt -D
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
SOURCE FSTYPE SIZE USED AVAIL USE% TARGET
|
||||
dev devtmpfs 3.9G 0 3.9G 0% /dev
|
||||
run tmpfs 3.9G 1.1M 3.9G 0% /run
|
||||
/dev/sda2 ext4 456.3G 342.5G 90.6G 75% /
|
||||
tmpfs tmpfs 3.9G 32.2M 3.8G 1% /dev/shm
|
||||
tmpfs tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
|
||||
bpf bpf 0 0 0 - /sys/fs/bpf
|
||||
tmpfs tmpfs 3.9G 8.4M 3.9G 0% /tmp
|
||||
/dev/loop0 squashfs 82.1M 82.1M 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 ext4 92.8M 55.7M 30.1M 60% /boot
|
||||
tmpfs tmpfs 788.8M 32K 788.8M 0% /run/user/1000
|
||||
gvfsd-fuse fuse.gvfsd-fuse 0 0 0 - /run/user/1000/gvfs
|
||||
|
||||
```
|
||||
|
||||
You can also display filesystems for a specific device, or mountpoint too.
|
||||
|
||||
Search for a device:
|
||||
```
|
||||
$ findmnt /dev/sda1
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
/boot /dev/sda1 ext4 rw,relatime,commit=360,data=ordered
|
||||
|
||||
```
|
||||
|
||||
Search for a mountpoint:
|
||||
```
|
||||
$ findmnt /
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
/ /dev/sda2 ext4 rw,relatime,commit=360
|
||||
|
||||
```
|
||||
|
||||
You can even find filesystems with specific label:
|
||||
```
|
||||
$ findmnt LABEL=Storage
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
$ man findmnt
|
||||
|
||||
```
|
||||
|
||||
The findmnt command is just enough to find the type of a mounted filesystem in Linux. It is created for that specific purpose only. However, there are also few other ways available to find out the filesystem type. If you’re interested to know, read on.
|
||||
|
||||
#### Method 2 – Using blkid command
|
||||
|
||||
The **blkid** command is used locate and print block device attributes. It is also part of the util-linux package, so you don’t bother to install it.
|
||||
|
||||
To find out the type of a filesystem using blkid command, run:
|
||||
```
|
||||
$ blkid /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
#### Method 3 – Using df command
|
||||
|
||||
The **df** command is used to report filesystem disk space usage in Unix-like operating systems. To find the type of all mounted filesystems, simply run:
|
||||
```
|
||||
$ df -T
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
![][4]
|
||||
|
||||
For details about df command, refer the following guide.
|
||||
|
||||
Also, check man pages.
|
||||
```
|
||||
$ man df
|
||||
|
||||
```
|
||||
|
||||
#### Method 4 – Using file command
|
||||
|
||||
The **file** command determines the type of a specified file. It works just fine for files with no file extension.
|
||||
|
||||
Run the following command to find the filesystem type of a partition:
|
||||
```
|
||||
$ sudo file -sL /dev/sda1
|
||||
[sudo] password for sk:
|
||||
/dev/sda1: Linux rev 1.0 ext4 filesystem data, UUID=83a1dbbf-1e15-4b45-94fe-134d3872af96 (needs journal recovery) (extents) (large files) (huge files)
|
||||
|
||||
```
|
||||
|
||||
Check man pages for more details:
|
||||
```
|
||||
$ man file
|
||||
|
||||
```
|
||||
|
||||
#### Method 5 – Using fsck command
|
||||
|
||||
The **fsck** command is used to check the integrity of a filesystem or repair it. You can find the type of a filesystem by passing the partition as an argument like below.
|
||||
```
|
||||
$ fsck -N /dev/sda1
|
||||
fsck from util-linux 2.32
|
||||
[/usr/bin/fsck.ext4 (1) -- /boot] fsck.ext4 /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man fsck
|
||||
|
||||
```
|
||||
|
||||
#### Method 6 – Using fstab Command
|
||||
|
||||
**fstab** is a file that contains static information about the filesystems. This file usually contains the mount point, filesystem type and mount options.
|
||||
|
||||
To view the type of a filesystem, simply run:
|
||||
```
|
||||
$ cat /etc/fstab
|
||||
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man fstab
|
||||
|
||||
```
|
||||
|
||||
#### Method 7 – Using lsblk command
|
||||
|
||||
The **lsblk** command displays the information about devices.
|
||||
|
||||
To display info about mounted filesystems, simply run:
|
||||
```
|
||||
$ lsblk -f
|
||||
NAME FSTYPE LABEL UUID MOUNTPOINT
|
||||
loop0 squashfs /var/lib/snapd/snap/core/4327
|
||||
sda
|
||||
├─sda1 ext4 83a1dbbf-1e15-4b45-94fe-134d3872af96 /boot
|
||||
├─sda2 ext4 4d25ddb0-5b20-40b4-ae35-ef96376d6594 /
|
||||
└─sda3 swap 1f8f5e2e-7c17-4f35-97e6-8bce7a4849cb [SWAP]
|
||||
sr0
|
||||
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man lsblk
|
||||
|
||||
```
|
||||
|
||||
#### Method 8 – Using mount command
|
||||
|
||||
The **mount** command is used to mount a local or remote filesystems in Unix-like systems.
|
||||
|
||||
To find out the type of a filesystem using mount command, do:
|
||||
```
|
||||
$ mount | grep "^/dev"
|
||||
/dev/sda2 on / type ext4 (rw,relatime,commit=360)
|
||||
/dev/sda1 on /boot type ext4 (rw,relatime,commit=360,data=ordered)
|
||||
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man mount
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now folks. You now know 8 different Linux commands to find out the type of a mounted Linux filesystems. If you know any other methods, feel free to let me know in the comment section below. I will check and update this guide accordingly.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-the-mounted-filesystem-type-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/07/findmnt-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/07/findmnt-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/07/df.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/07/fstab.png
|
||||
@ -1,94 +0,0 @@
|
||||
Translating by jlztan
|
||||
|
||||
Top 10 Raspberry Pi blogs to follow
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are plenty of great Raspberry Pi fan sites, tutorials, repositories, YouTube channels, and other resources on the web. Here are my top 10 favorite Raspberry Pi blogs, in no particular order.
|
||||
|
||||
### 1. Raspberry Pi Spy
|
||||
|
||||
Raspberry Pi fan Matt Hawkins has been writing a broad range of comprehensive and informative tutorials on his site, Raspberry Pi Spy, since the early days. I have learned a lot directly from this site, and Matt always seems to be the first to cover many topics. I have reached out for help many times in my first three years in the world of hacking and making with Raspberry Pi.
|
||||
|
||||
Fortunately for everyone, this early adopter site is still going strong. I hope to see it live on, giving new community members a helping hand when they need it.
|
||||
|
||||
### 2. Adafruit
|
||||
|
||||
Adafruit is one of the biggest names in hardware hacking. The company makes and sells beautiful hardware and provides excellent tutorials written by staff, community members, and even the wonderful Lady Ada herself.
|
||||
|
||||
As well as being a webshop, Adafruit also run a blog, which is full to the brim of great content from around the world. Check out the Raspberry Pi category, especially at the end of the work week, as [Friday is Pi Day][1] at Adafruit Towers.
|
||||
|
||||
### 3. Recantha's Raspberry Pi Pod
|
||||
|
||||
Mike Horne (Recantha) is a key Pi community member in the UK who runs the [CamJam and Potton Pi & Pint][2] (two Raspberry Jams in Cambridge) and [Pi Wars][3] (an annual Pi robotics competition). He gives advice to others setting up Jams and always has time to help beginners. With his co-organizer Tim Richardson, Horne developed the CamJam Edu Kit (a series of small and affordable kits for beginners to learn physical computing with Python).
|
||||
|
||||
On top of all this, he runs the Pi Pod, a blog full of anything and everything Pi-related from around the world. It's probably the most regularly updated Pi blog on this list, so it's a great way to keep your finger on the pulse of the Pi community.
|
||||
|
||||
### 4. Raspberry Pi blog
|
||||
|
||||
Not forgetting the official [Raspberry Pi Foundation][4], this blog covers a range of content from the Foundation's world of hardware, software, education, community, and charity and youth coding clubs. Big themes on the blog are digital making at home, empowerment through education, as well as official news on hardware releases and software updates.
|
||||
|
||||
The blog has been running [since 2011][5] and provides an [archive][6] of all 1800+ posts since that time. You can also follow [@raspberrypi_otd][7] on Twitter, which is a bot I created in [Python][8] (for an [Opensource.com tutorial][9], of course). The bot tweets links to blog posts from the current day in previous years from the Raspberry Pi blog archive.
|
||||
|
||||
### 5. RasPi.tv
|
||||
|
||||
Another seminal Raspberry Pi community member is Alex Eames, who got on board early on with his blog and YouTube channel, RasPi.tv. The site is packed with high-quality, well-produced video tutorials and written guides covering maker projects for all.
|
||||
|
||||
Alex makes a series of add-on boards and accessories for the Pi as [RasP.iO][10], including a handy GPIO port label, reference rulers, and more. His blog branches out into [Arduino][11], [WEMO][12], and other small boards too.
|
||||
|
||||
### 6. pyimagesearch
|
||||
|
||||
Though not strictly a Raspberry Pi blog (the "py" in the name is for "Python," not "Raspberry Pi"), this site features an extensive [Raspberry Pi category][13]. Adrian Rosebrock earned a PhD studying the fields of computer vision and machine learning. His blog aims to share the machine learning tricks he's picked up while studying and making his own computer vision projects.
|
||||
|
||||
If you want to learn about facial or object recognition using the Pi camera module, this is the place to be. Adrian's knowledge and practical application of deep learning and AI for image recognition is second to none—and he writes up his projects so that anyone can try.
|
||||
|
||||
### 7. Raspberry Pi Roundup
|
||||
|
||||
One of the UK's official Raspberry Pi resellers, The Pi Hut, maintains a blog curating the finds of the week. It's another great resource to keep up with what's on in the Pi world, and worth looking back through past issues.
|
||||
|
||||
### 8. Dave Akerman
|
||||
|
||||
A leading expert in high-altitude ballooning, Dave Akerman shares his knowledge and experience with balloon launches at minimal cost using Raspberry Pi. He publishes writeups of his launches with photos from the stratosphere and offers tips on how to launch a Pi balloon yourself.
|
||||
|
||||
Check out Dave's blogfor amazing photography from near space.
|
||||
|
||||
### 9. Pimoroni
|
||||
|
||||
A world-renowned Raspberry Pi reseller based in Sheffield in the UK, Pimoroni made the famous [Pibow Rainbow case][14] and followed it up with a host of incredible custom add-on boards and accessories.
|
||||
|
||||
Pimoroni's blog is laid out as beautifully as its hardware design and branding, and it provides great content for makers and hobbyists at home. The blog accompanies their entertaining YouTube channel [Bilge Tank][15].
|
||||
|
||||
### 10. Stuff About Code
|
||||
|
||||
Martin O'Hanlon is a Pi community member-turned-Foundation employee who started out hacking Minecraft on the Pi for fun and recently joined the Foundation as a content writer. Luckily, Martin's new job hasn't stopped him from updating his blog and sharing useful tidbits with the world. As well as lots on Minecraft, you'll find stuff on the Python libraries, [Blue Dot][16], and [guizero][17], along with general Raspberry Pi tips.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://blog.adafruit.com/category/raspberry-pi/
|
||||
[2]:https://camjam.me/?page_id=753
|
||||
[3]:https://piwars.org/
|
||||
[4]:https://www.raspberrypi-spy.co.uk/
|
||||
[5]:https://www.raspberrypi.org/blog/first-post/
|
||||
[6]:https://www.raspberrypi.org/blog/archive/
|
||||
[7]:https://twitter.com/raspberrypi_otd
|
||||
[8]:https://github.com/bennuttall/rpi-otd-bot/blob/master/src/bot.py
|
||||
[9]:https://opensource.com/article/17/8/raspberry-pi-twitter-bot
|
||||
[10]:https://rasp.io/
|
||||
[11]:https://www.arduino.cc/
|
||||
[12]:http://community.wemo.com/
|
||||
[13]:https://www.pyimagesearch.com/category/raspberry-pi/
|
||||
[14]:https://shop.pimoroni.com/products/pibow-for-raspberry-pi-3-b-plus
|
||||
[15]:https://www.youtube.com/channel/UCuiDNTaTdPTGZZzHm0iriGQ
|
||||
[16]:https://bluedot.readthedocs.io/en/latest/#
|
||||
[17]:https://lawsie.github.io/guizero/
|
||||
@ -1,160 +0,0 @@
|
||||
A Cross-platform High-quality GIF Encoder
|
||||
======
|
||||
|
||||

|
||||
|
||||
As a content writer, I needed to add images in my articles. Sometimes, it is better to add videos or gif images to explain the concept a bit easier. The readers can easily understand the guide much better by watching the output in video or gif format than the text. The day before, I have written about [**Flameshot**][1], a feature-rich and powerful screenshot tool for Linux. Today, I will show you how to make high quality gif images either from a video or set of images. Meet **Gifski** , a cross-platform, open source, command line High-quality GIF encoder based on **Pngquant**.
|
||||
|
||||
For those wondering, pngquant is a command line lossy PNG image compressor. Trust me, pngquant is one of the best loss-less PNG compressor that I ever use. It compresses PNG images **upto 70%** without losing the original quality and and preserves full alpha transparency. The compressed images are compatible with all web browsers and operating systems. Since Gifski is based on Pngquant, it uses pngquant’s features for creating efficient GIF animations. Gifski is capable of creating animated GIFs that use thousands of colors per frame. Gifski is also requires **ffmpeg** to convert video into PNG images.
|
||||
|
||||
### **Installing Gifski**
|
||||
|
||||
Make sure you have installed FFMpeg and Pngquant.
|
||||
|
||||
FFmpeg is available in the default repositories of most Linux distributions, so you can install it using the default package manager. For installation instructions, refer the following guide.
|
||||
|
||||
Pngquant is available in [**AUR**][2]. To install it in Arch-based systems, use any AUR helper programs like [**Yay**][3].
|
||||
```
|
||||
$ yay -S pngquant
|
||||
|
||||
```
|
||||
|
||||
On Debian-based systems, run:
|
||||
```
|
||||
$ sudo apt install pngquant
|
||||
|
||||
```
|
||||
|
||||
If pngquant is not available for your distro, compile and install it from source. You will need **`libpng-dev`** package installed with development headers.
|
||||
```
|
||||
$ git clone --recursive https://github.com/kornelski/pngquant.git
|
||||
|
||||
$ make
|
||||
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
After installing the prerequisites, install Gifski. You can install it using **cargo** if you have installed [**Rust**][4] programming language.
|
||||
```
|
||||
$ cargo install gifski
|
||||
|
||||
```
|
||||
|
||||
You can also get it with [**Linuxbrew**][5] package manager.
|
||||
```
|
||||
$ brew install gifski
|
||||
|
||||
```
|
||||
|
||||
If you don’t want to install cargo or Linuxbrew, download the latest binary executables from [**releases page**][6] and compile and install gifski manually.
|
||||
|
||||
### Create high-quality GIF animations using Gifski high-quality GIF encoder
|
||||
|
||||
Go to the location where you have kept the PNG images and run the following command to create GIF animation from the set of images:
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
|
||||
```
|
||||
|
||||
Here file.gif is the final output gif animation.
|
||||
|
||||
Gifski has also some other additional features, like;
|
||||
|
||||
* Create GIF animation with specific dimension
|
||||
* Show specific number of animations per second
|
||||
* Encode with a specific quality
|
||||
* Encode faster
|
||||
* Encode images exactly in the order given, rather than sorted
|
||||
|
||||
|
||||
|
||||
To create GIF animation with specific dimension, for example width=800 and height=400, use the following command:
|
||||
```
|
||||
$ gifski -o file.gif -W 800 -H 400 *.png
|
||||
|
||||
```
|
||||
|
||||
You can set how many number of animation frames per second you want in the gif animation. The default value is **20**. To do so, run:
|
||||
```
|
||||
$ gifski -o file.gif --fps 1 *.png
|
||||
|
||||
```
|
||||
|
||||
In the above example, I have used one animation frame per second.
|
||||
|
||||
We can encode with specific quality on the scale of 1-100. Obviously, the lower quality may give smaller file and higher quality give bigger seize gif animation.
|
||||
```
|
||||
$ gifski -o file.gif --quality 50 *.png
|
||||
|
||||
```
|
||||
|
||||
Gifski will take more time when you encode large number of images. To make the encoding process 3 times faster than usual speed, run:
|
||||
```
|
||||
$ gifski -o file.gif --fast *.png
|
||||
|
||||
```
|
||||
|
||||
Please note that it will reduce quality to 10% and create bigger animation file.
|
||||
|
||||
To encode images exactly in the order given (rather than sorted), use **`--nosort`** option.
|
||||
```
|
||||
$ gifski -o file.gif --nosort *.png
|
||||
|
||||
```
|
||||
|
||||
If you do not to loop the GIF, simple use **`--once`** option.
|
||||
```
|
||||
$ gifski -o file.gif --once *.png
|
||||
|
||||
```
|
||||
|
||||
**Create GIF animation from Video file**
|
||||
|
||||
Some times you might want to an animated file from a video. It is also possible. This is where FFmpeg comes in help. First convert the video into PNG frames first like below.
|
||||
```
|
||||
$ ffmpeg -i video.mp4 frame%04d.png
|
||||
|
||||
```
|
||||
|
||||
The above command makes image files namely “frame0001.png”, “frame0002.png”, “frame0003.png”…, etc. from video.mp4 (%04d makes the frame number) and save them in the current working directory.
|
||||
|
||||
After converting the image files, simply run the following command to make the animated GIF file.
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section.
|
||||
```
|
||||
$ gifski -h
|
||||
|
||||
```
|
||||
|
||||
Here is the sample animated file created using Gifski.
|
||||
|
||||
As you can see, the quality of the GIF file is really great.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/
|
||||
[2]: https://aur.archlinux.org/packages/pngquant/
|
||||
[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
|
||||
[5]: https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[6]: https://github.com/ImageOptim/gifski/releases
|
||||
@ -1,546 +0,0 @@
|
||||
[translating by jrg 20181014]
|
||||
|
||||
Using Grails with jQuery and DataTables
|
||||
======
|
||||
|
||||
Learn to build a Grails-based data browser that lets users visualize complex tabular data.
|
||||
|
||||

|
||||
|
||||
I’m a huge fan of [Grails][1]. Granted, I’m mostly a data person who likes to explore and analyze data using command-line tools. But even data people sometimes need to _look at_ the data, and sometimes using data means having a great data browser. With Grails, [jQuery][2], and the [DataTables jQuery plugin][3], we can make really nice tabular data browsers.
|
||||
|
||||
The [DataTables website][3] offers a lot of decent “recipe-style” documentation that shows how to put together some fine sample applications, and it includes the necessary JavaScript, HTML, and occasional [PHP][4] to accomplish some pretty spiffy stuff. But for those who would rather use Grails as their backend, a bit of interpretation is necessary. Also, the sample application data used is a single flat table of employees of a fictional company, so the complexity of dealing with table relations serves as an exercise for the reader.
|
||||
|
||||
In this article, we’ll fill those two gaps by creating a Grails application with a slightly more complex data structure and a DataTables browser. In doing so, we’ll cover Grails criteria, which are [Groovy][5] -fied Java Hibernate criteria. I’ve put the code for the application on [GitHub][6] , so this article is oriented toward explaining the nuances of the code.
|
||||
|
||||
For prerequisites, you will need Java, Groovy, and Grails environments set up. With Grails, I tend to use a terminal window and [Vim][7], so that’s what’s used here. To get a modern Java, I suggest downloading and installing the [Open Java Development Kit][8] (OpenJDK) provided by your Linux distro (which should be Java 8, 9, 10 or 11; at the time of writing, I’m working with Java 8). From my point of view, the best way to get up-to-date Groovy and Grails is to use [SDKMAN!][9].
|
||||
|
||||
Readers who have never tried Grails will probably need to do some background reading. As a starting point, I recommend [Creating Your First Grails Application][10].
|
||||
|
||||
### Getting the employee browser application
|
||||
|
||||
As mentioned above, I’ve put the source code for this sample employee browser application on [GitHub][6]. For further explanation, the application **embrow** was built using the following commands in a Linux terminal window:
|
||||
|
||||
```
|
||||
cd Projects
|
||||
grails create-app com.nuevaconsulting.embrow
|
||||
```
|
||||
|
||||
The domain classes and unit tests are created as follows:
|
||||
|
||||
```
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Position
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Office
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Employeecd embrowgrails createdomaincom.grails createdomaincom.grails createdomaincom.
|
||||
```
|
||||
|
||||
The domain classes built this way have no attributes, so they must be edited as follows:
|
||||
|
||||
The Position domain class:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Position {
|
||||
|
||||
String name
|
||||
int starting
|
||||
|
||||
static constraints = {
|
||||
name nullable: false, blank: false
|
||||
starting nullable: false
|
||||
}
|
||||
}com.Stringint startingstatic constraintsnullableblankstarting nullable
|
||||
```
|
||||
|
||||
The Office domain class:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Office {
|
||||
|
||||
String name
|
||||
String address
|
||||
String city
|
||||
String country
|
||||
|
||||
static constraints = {
|
||||
name nullable: false, blank: false
|
||||
address nullable: false, blank: false
|
||||
city nullable: false, blank: false
|
||||
country nullable: false, blank: false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And the Employee domain class:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Employee {
|
||||
|
||||
String surname
|
||||
String givenNames
|
||||
Position position
|
||||
Office office
|
||||
int extension
|
||||
Date hired
|
||||
int salary
|
||||
static constraints = {
|
||||
surname nullable: false, blank: false
|
||||
givenNames nullable: false, blank: false
|
||||
: false
|
||||
office nullable: false
|
||||
extension nullable: false
|
||||
hired nullable: false
|
||||
salary nullable: false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Note that whereas the Position and Office domain classes use predefined Groovy types String and int, the Employee domain class defines fields that are of type Position and Office (as well as the predefined Date). This causes the creation of the database table in which instances of Employee are stored to contain references, or foreign keys, to the tables in which instances of Position and Office are stored.
|
||||
|
||||
Now you can generate the controllers, views, and various other test components:
|
||||
|
||||
```
|
||||
-all com.nuevaconsulting.embrow.Position
|
||||
grails generate-all com.nuevaconsulting.embrow.Office
|
||||
grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.grails generateall com.grails generateall com.
|
||||
```
|
||||
|
||||
At this point, you have a basic create-read-update-delete (CRUD) application ready to go. I’ve included some base data in the **grails-app/init/com/nuevaconsulting/BootStrap.groovy** to populate the tables.
|
||||
|
||||
If you run the application with the command:
|
||||
|
||||
```
|
||||
grails run-app
|
||||
```
|
||||
|
||||
you will see the following screen in the browser at **<http://localhost:8080/:>**
|
||||
|
||||
![Embrow home screen][12]
|
||||
|
||||
The Embrow application home screen
|
||||
|
||||
Clicking on the link for the OfficeController gives you a screen that looks like this:
|
||||
|
||||
![Office list][14]
|
||||
|
||||
The office list
|
||||
|
||||
Note that this list is generated by the **OfficeController index** method and displayed by the view `office/index.gsp`.
|
||||
|
||||
Similarly, clicking on the **EmployeeController** gives a screen that looks like this:
|
||||
|
||||
![Employee controller][16]
|
||||
|
||||
The employee controller
|
||||
|
||||
Ok, that’s pretty ugly—what’s with the Position and Office links?
|
||||
|
||||
Well, the views generated by the `generate-all` commands above create an **index.gsp** file that uses the Grails <f:table/> tag that by default shows the class name ( **com.nuevaconsulting.embrow.Position** ) and the persistent instance identifier ( **30** ). This behavior can be customized to yield something better looking, and there is some pretty neat stuff with the autogenerated links, the autogenerated pagination, and the autogenerated sortable columns.
|
||||
|
||||
But even when it's fully cleaned up, this employee browser offers limited functionality. For example, what if you want to find all employees whose position includes the text “dev”? What if you want to combine columns for sorting so that the primary sort key is a surname and the secondary sort key is an office name? Or what if you want to export a sorted subset to a spreadsheet or PDF to email to someone who doesn’t have access to the browser?
|
||||
|
||||
The jQuery DataTables plugin provides this kind of extra functionality and allows you to create a full-fledged tabular data browser.
|
||||
|
||||
### Creating the employee browser view and controller methods
|
||||
|
||||
In order to create an employee browser based on jQuery DataTables, you must complete two tasks:
|
||||
|
||||
1. Create a Grails view that incorporates the HTML and JavaScript required to enable the DataTables
|
||||
|
||||
2. Add a method to the Grails controller to handle the new view
|
||||
|
||||
|
||||
|
||||
|
||||
#### The employee browser view
|
||||
|
||||
In the directory **embrow/grails-app/views/employee** , start by making a copy of the **index.gsp** file, calling it **browser.gsp** :
|
||||
|
||||
```
|
||||
cd Projects
|
||||
cd embrow/grails-app/views/employee
|
||||
cp gsp browser.gsp
|
||||
```
|
||||
|
||||
At this point, you want to customize the new **browser.gsp** file to add the relevant jQuery DataTables code.
|
||||
|
||||
As a rule, I like to grab my JavaScript and CSS from a content provider when feasible; to do so in this case, after the line:
|
||||
|
||||
```
|
||||
<title><g:message code="default.list.label" args="[entityName]" /></title>
|
||||
```
|
||||
|
||||
insert the following lines:
|
||||
|
||||
```
|
||||
<script src="https://code.jquery.com/jquery-2.2.4.min.js" integrity="sha256-BbhdlvQf/xTY9gja0Dq3HiwQF8LaCRTXxZKRutelT44=" crossorigin="anonymous"></script>
|
||||
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/1.10.16/css/jquery.dataTables.css">
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/1.10.16/js/jquery.dataTables.js"></script>
|
||||
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/scroller/1.4.4/css/scroller.dataTables.min.css">
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/scroller/1.4.4/js/dataTables.scroller.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/dataTables.buttons.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.flash.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.3/jszip.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/pdfmake.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/vfs_fonts.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.html5.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
|
||||
```
|
||||
|
||||
Next, remove the code that provided the data pagination in **index.gsp** :
|
||||
|
||||
```
|
||||
<div id="list-employee" class="content scaffold-list" role="main">
|
||||
<h1><g:message code="default.list.label" args="[entityName]" /></h1>
|
||||
<g:if test="${flash.message}">
|
||||
<div class="message" role="status">${flash.message}</div>
|
||||
</g:if>
|
||||
<f:table collection="${employeeList}" />
|
||||
|
||||
<div class="pagination">
|
||||
<g:paginate total="${employeeCount ?: 0}" />
|
||||
</div>
|
||||
</div>
|
||||
```
|
||||
|
||||
and insert the code that materializes the jQuery DataTables.
|
||||
|
||||
The first part to insert is the HTML that creates the basic tabular structure of the browser. For the application where DataTables talks to a database backend, provide only the table headers and footers; the DataTables JavaScript takes care of the table contents.
|
||||
|
||||
```
|
||||
<div id="employee-browser" class="content" role="main">
|
||||
<h1>Employee Browser</h1>
|
||||
<table id="employee_dt" class="display compact" style="width:99%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Surname</th>
|
||||
<th>Given name(s)</th>
|
||||
<th>Position</th>
|
||||
<th>Office</th>
|
||||
<th>Extension</th>
|
||||
<th>Hired</th>
|
||||
<th>Salary</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tfoot>
|
||||
<tr>
|
||||
<th>Surname</th>
|
||||
<th>Given name(s)</th>
|
||||
<th>Position</th>
|
||||
<th>Office</th>
|
||||
<th>Extension</th>
|
||||
<th>Hired</th>
|
||||
<th>Salary</th>
|
||||
</tr>
|
||||
</tfoot>
|
||||
</table>
|
||||
</div>
|
||||
```
|
||||
|
||||
Next, insert a JavaScript block, which serves three primary functions: It sets the size of the text boxes shown in the footer for column filtering, it establishes the DataTables table model, and it creates a handler to do the column filtering.
|
||||
|
||||
```
|
||||
<g:javascript>
|
||||
$('#employee_dt tfoot th').each( function() {javascript
|
||||
```
|
||||
|
||||
The code below handles sizing the filter boxes at the bottoms of the table columns:
|
||||
|
||||
```
|
||||
var title = $(this).text();
|
||||
if (title == 'Extension' || title == 'Hired')
|
||||
$(this).html('<input type="text" size="5" placeholder="' + title + '?" />');
|
||||
else
|
||||
$(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
|
||||
});titletitletitletitletitle
|
||||
```
|
||||
|
||||
Next, define the table model. This is where all the table options are provided, including the scrolling, rather than paginated, nature of the interface, the cryptic decorations to be provided according to the dom string, the ability to export data to CSV and other formats, as well as where the Ajax connection to the server is established. Note that the URL is created with a Groovy GString call to the Grails **createLink()** method, referring to the **browserLister** action in the **EmployeeController**. Also of interest is the definition of the columns of the table. This information is sent across to the back end, which queries the database and returns the appropriate records.
|
||||
|
||||
```
|
||||
var table = $('#employee_dt').DataTable( {
|
||||
"scrollY": 500,
|
||||
"deferRender": true,
|
||||
"scroller": true,
|
||||
"dom": "Brtip",
|
||||
"buttons": [ 'copy', 'csv', 'excel', 'pdf', 'print' ],
|
||||
"processing": true,
|
||||
"serverSide": true,
|
||||
"ajax": {
|
||||
"url": "${createLink(controller: 'employee', action: 'browserLister')}",
|
||||
"type": "POST",
|
||||
},
|
||||
"columns": [
|
||||
{ "data": "surname" },
|
||||
{ "data": "givenNames" },
|
||||
{ "data": "position" },
|
||||
{ "data": "office" },
|
||||
{ "data": "extension" },
|
||||
{ "data": "hired" },
|
||||
{ "data": "salary" }
|
||||
]
|
||||
});
|
||||
```
|
||||
|
||||
Finally, monitor the filter columns for changes and use them to apply the filter(s).
|
||||
|
||||
```
|
||||
table.columns().every(function() {
|
||||
var that = this;
|
||||
$('input', this.footer()).on('keyup change', function(e) {
|
||||
if (that.search() != this.value && 8 < e.keyCode && e.keyCode < 32)
|
||||
that.search(this.value).draw();
|
||||
});
|
||||
```
|
||||
|
||||
And that’s it for the JavaScript. This completes the changes to the view code.
|
||||
|
||||
```
|
||||
});
|
||||
</g:javascript>
|
||||
```
|
||||
|
||||
Here’s a screenshot of the UI this view creates:
|
||||
|
||||
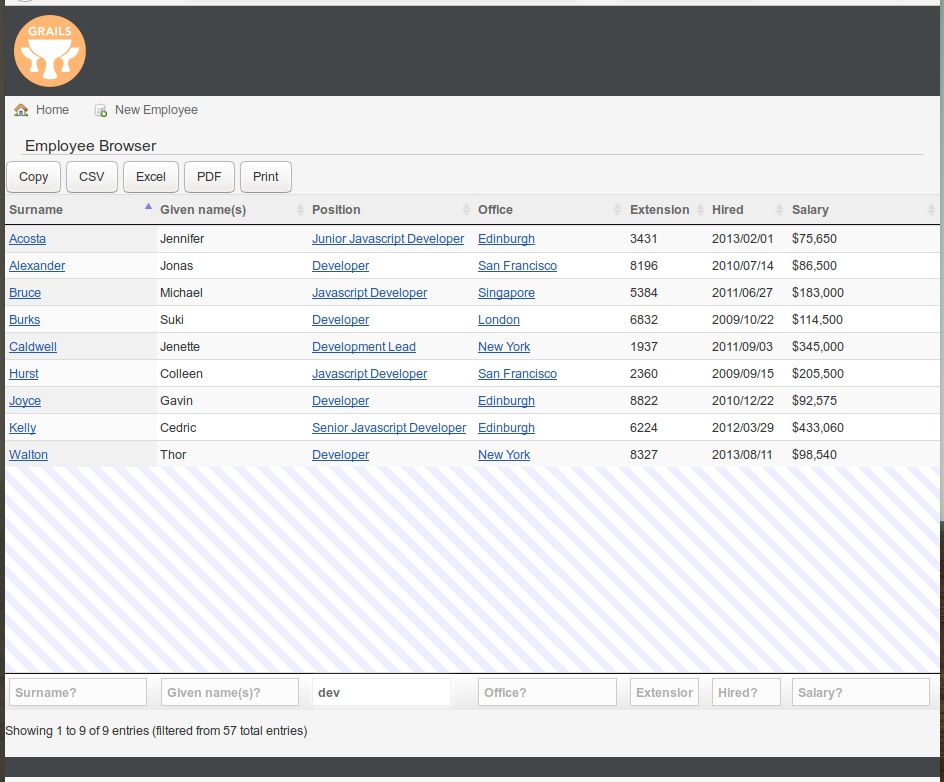
|
||||
|
||||
Here’s another screenshot showing the filtering and multi-column sorting at work (looking for employees whose positions include the characters “dev”, ordering first by office, then by surname):
|
||||
|
||||
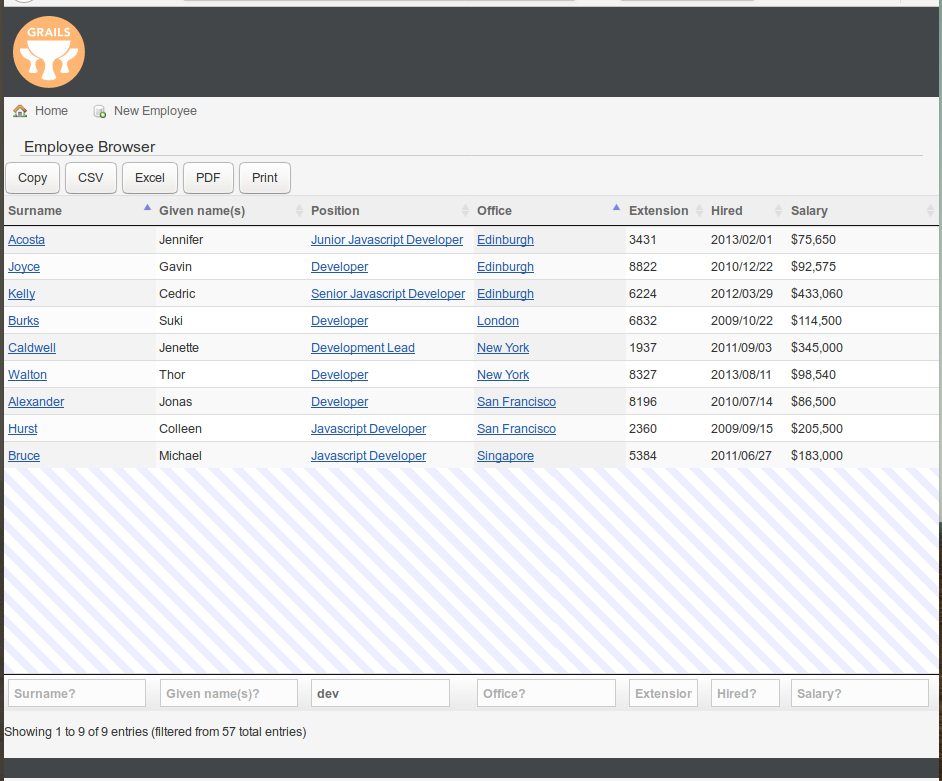
|
||||
|
||||
Here’s another screenshot, showing what happens when you click on the CSV button:
|
||||
|
||||
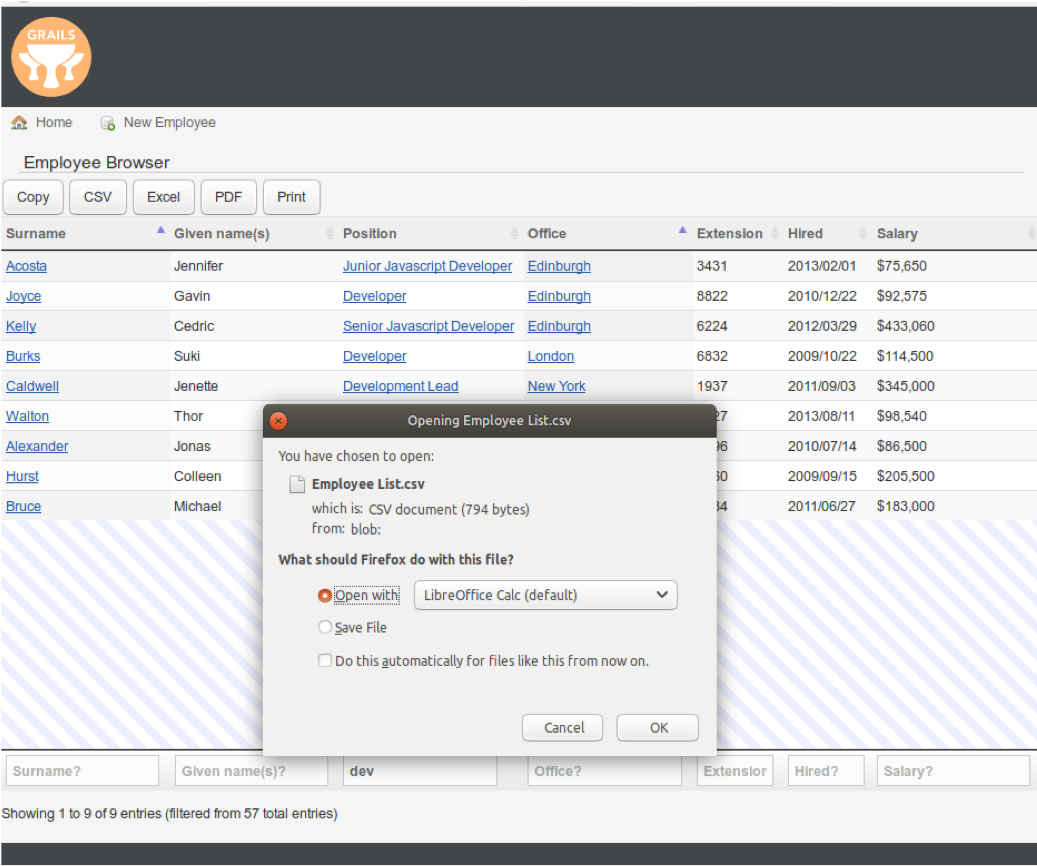
|
||||
|
||||
And finally, here’s a screenshot showing the CSV data opened in LibreOffice:
|
||||
|
||||
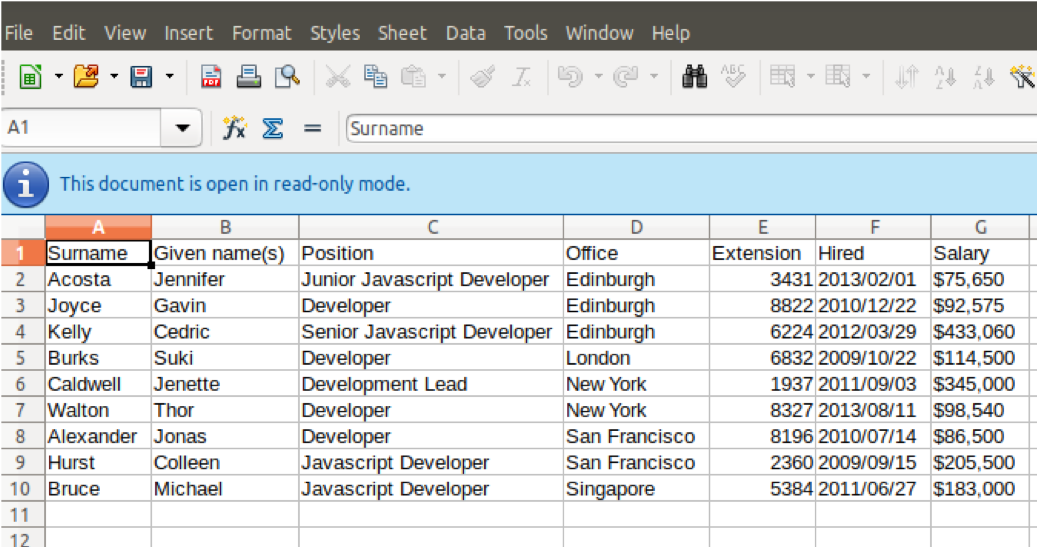
|
||||
|
||||
Ok, so the view part looked pretty straightforward; therefore, the controller action must do all the heavy lifting, right? Let’s see…
|
||||
|
||||
#### The employee controller browserLister action
|
||||
|
||||
Recall that we saw this string
|
||||
|
||||
```
|
||||
"${createLink(controller: 'employee', action: 'browserLister')}"
|
||||
```
|
||||
|
||||
as the URL used for the Ajax calls from the DataTables table model. [createLink() is the method][17] behind a Grails tag that is used to dynamically generate a link as the HTML is preprocessed on the Grails server. This ends up generating a link to the **EmployeeController** , located in
|
||||
|
||||
```
|
||||
embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy
|
||||
```
|
||||
|
||||
and specifically to the controller method **browserLister()**. I’ve left some print statements in the code so that the intermediate results can be seen in the terminal window where the application is running.
|
||||
|
||||
```
|
||||
def browserLister() {
|
||||
// Applies filters and sorting to return a list of desired employees
|
||||
```
|
||||
|
||||
First, print out the parameters passed to **browserLister()**. I usually start building controller methods with this code so that I’m completely clear on what my controller is receiving.
|
||||
|
||||
```
|
||||
println "employee browserLister params $params"
|
||||
println()
|
||||
```
|
||||
|
||||
Next, process those parameters to put them in a more usable shape. First, the jQuery DataTables parameters, a Groovy map called **jqdtParams** :
|
||||
|
||||
```
|
||||
def jqdtParams = [:]
|
||||
params.each { key, value ->
|
||||
def keyFields = key.replace(']','').split(/\[/)
|
||||
def table = jqdtParams
|
||||
for (int f = 0; f < keyFields.size() - 1; f++) {
|
||||
def keyField = keyFields[f]
|
||||
if (!table.containsKey(keyField))
|
||||
table[keyField] = [:]
|
||||
table = table[keyField]
|
||||
}
|
||||
table[keyFields[-1]] = value
|
||||
}
|
||||
println "employee dataTableParams $jqdtParams"
|
||||
println()
|
||||
```
|
||||
|
||||
Next, the column data, a Groovy map called **columnMap** :
|
||||
|
||||
```
|
||||
def columnMap = jqdtParams.columns.collectEntries { k, v ->
|
||||
def whereTerm = null
|
||||
switch (v.data) {
|
||||
case 'extension':
|
||||
case 'hired':
|
||||
case 'salary':
|
||||
if (v.search.value ==~ /\d+(,\d+)*/)
|
||||
whereTerm = v.search.value.split(',').collect { it as Integer }
|
||||
break
|
||||
default:
|
||||
if (v.search.value ==~ /[A-Za-z0-9 ]+/)
|
||||
whereTerm = "%${v.search.value}%" as String
|
||||
break
|
||||
}
|
||||
[(v.data): [where: whereTerm]]
|
||||
}
|
||||
println "employee columnMap $columnMap"
|
||||
println()
|
||||
```
|
||||
|
||||
Next, a list of all column names, retrieved from **columnMap** , and a corresponding list of how those columns should be ordered in the view, Groovy lists called **allColumnList** and **orderList** , respectively:
|
||||
|
||||
```
|
||||
def allColumnList = columnMap.keySet() as List
|
||||
println "employee allColumnList $allColumnList"
|
||||
def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as Integer], v.dir] }
|
||||
println "employee orderList $orderList"
|
||||
```
|
||||
|
||||
We’re going to use Grails’ implementation of Hibernate criteria to actually carry out the selection of elements to be displayed as well as their ordering and pagination. Criteria requires a filter closure; in most examples, this is given as part of the creation of the criteria instance itself, but here we define the filter closure beforehand. Note in this case the relatively complex interpretation of the “date hired” filter, which is treated as a year and applied to establish date ranges, and the use of **createAlias** to allow us to reach into related classes Position and Office:
|
||||
|
||||
```
|
||||
def filterer = {
|
||||
createAlias 'position', 'p'
|
||||
createAlias 'office', 'o'
|
||||
|
||||
if (columnMap.surname.where) ilike 'surname', columnMap.surname.where
|
||||
if (columnMap.givenNames.where) ilike 'givenNames', columnMap.givenNames.where
|
||||
if (columnMap.position.where) ilike 'p.name', columnMap.position.where
|
||||
if (columnMap.office.where) ilike 'o.name', columnMap.office.where
|
||||
if (columnMap.extension.where) inList 'extension', columnMap.extension.where
|
||||
if (columnMap.salary.where) inList 'salary', columnMap.salary.where
|
||||
if (columnMap.hired.where) {
|
||||
if (columnMap.hired.where.size() > 1) {
|
||||
or {
|
||||
columnMap.hired.where.each {
|
||||
between 'hired', Date.parse('yyyy/MM/dd',"${it}/01/01" as String),
|
||||
Date.parse('yyyy/MM/dd',"${it}/12/31" as String)
|
||||
}
|
||||
}
|
||||
} else {
|
||||
between 'hired', Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/01/01" as String),
|
||||
Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/12/31" as String)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
At this point, it’s time to apply the foregoing. The first step is to get a total count of all the Employee instances, required by the pagination code:
|
||||
|
||||
```
|
||||
def recordsTotal = Employee.count()
|
||||
println "employee recordsTotal $recordsTotal"
|
||||
```
|
||||
|
||||
Next, apply the filter to the Employee instances to get the count of filtered results, which will always be less than or equal to the total number (again, this is for the pagination code):
|
||||
|
||||
```
|
||||
def c = Employee.createCriteria()
|
||||
def recordsFiltered = c.count {
|
||||
filterer.delegate = delegate
|
||||
filterer()
|
||||
}
|
||||
println "employee recordsFiltered $recordsFiltered"
|
||||
|
||||
```
|
||||
|
||||
Once you have those two counts, you can get the actual filtered instances using the pagination and ordering information as well.
|
||||
|
||||
```
|
||||
def orderer = Employee.withCriteria {
|
||||
filterer.delegate = delegate
|
||||
filterer()
|
||||
orderList.each { oi ->
|
||||
switch (oi[0]) {
|
||||
case 'surname': order 'surname', oi[1]; break
|
||||
case 'givenNames': order 'givenNames', oi[1]; break
|
||||
case 'position': order 'p.name', oi[1]; break
|
||||
case 'office': order 'o.name', oi[1]; break
|
||||
case 'extension': order 'extension', oi[1]; break
|
||||
case 'hired': order 'hired', oi[1]; break
|
||||
case 'salary': order 'salary', oi[1]; break
|
||||
}
|
||||
}
|
||||
maxResults (jqdtParams.length as Integer)
|
||||
firstResult (jqdtParams.start as Integer)
|
||||
}
|
||||
```
|
||||
|
||||
To be completely clear, the pagination code in JTables manages three counts: the total number of records in the data set, the number resulting after the filters are applied, and the number to be displayed on the page (whether the display is scrolling or paginated). The ordering is applied to all the filtered records and the pagination is applied to chunks of those filtered records for display purposes.
|
||||
|
||||
Next, process the results returned by the orderer, creating links to the Employee, Position, and Office instance in each row so the user can click on these links to get all the detail on the relevant instance:
|
||||
|
||||
```
|
||||
def dollarFormatter = new DecimalFormat('$##,###.##')
|
||||
def employees = orderer.collect { employee ->
|
||||
['surname': "<a href='${createLink(controller: 'employee', action: 'show', id: employee.id)}'>${employee.surname}</a>",
|
||||
'givenNames': employee.givenNames,
|
||||
'position': "<a href='${createLink(controller: 'position', action: 'show', id: employee.position?.id)}'>${employee.position?.name}</a>",
|
||||
'office': "<a href='${createLink(controller: 'office', action: 'show', id: employee.office?.id)}'>${employee.office?.name}</a>",
|
||||
'extension': employee.extension,
|
||||
'hired': employee.hired.format('yyyy/MM/dd'),
|
||||
'salary': dollarFormatter.format(employee.salary)]
|
||||
}
|
||||
```
|
||||
|
||||
And finally, create the result you want to return and give it back as JSON, which is what jQuery DataTables requires.
|
||||
|
||||
```
|
||||
def result = [draw: jqdtParams.draw, recordsTotal: recordsTotal, recordsFiltered: recordsFiltered, data: employees]
|
||||
render(result as JSON)
|
||||
}
|
||||
```
|
||||
|
||||
That’s it.
|
||||
|
||||
If you’re familiar with Grails, this probably seems like more work than you might have originally thought, but there’s no rocket science here, just a lot of moving parts. However, if you haven’t had much exposure to Grails (or to Groovy), there’s a lot of new stuff to understand—closures, delegates, and builders, among other things.
|
||||
|
||||
In that case, where to start? The best place is to learn about Groovy itself, especially [Groovy closures][18] and [Groovy delegates and builders][19]. Then go back to the reading suggested above on Grails and Hibernate criteria queries.
|
||||
|
||||
### Conclusions
|
||||
|
||||
jQuery DataTables make awesome tabular data browsers for Grails. Coding the view isn’t too tricky, but the PHP examples provided in the DataTables documentation take you only so far. In particular, they aren’t written with Grails programmers in mind, nor do they explore the finer details of using elements that are references to other classes (essentially lookup tables).
|
||||
|
||||
I’ve used this approach to make a couple of data browsers that allow the user to select which columns to view and accumulate record counts, or just to browse the data. The performance is good even in million-row tables on a relatively modest VPS.
|
||||
|
||||
One caveat: I have stumbled upon some problems with the various Hibernate criteria mechanisms exposed in Grails (see my other GitHub repositories), so care and experimentation is required. If all else fails, the alternative approach is to build SQL strings on the fly and execute them instead. As of this writing, I prefer to work with Grails criteria, unless I get into messy subqueries, but that may just reflect my relative lack of experience with subqueries in Hibernate.
|
||||
|
||||
I hope you Grails programmers out there find this interesting. Please feel free to leave comments or suggestions below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://grails.org/
|
||||
[2]: https://jquery.com/
|
||||
[3]: https://datatables.net/
|
||||
[4]: http://php.net/
|
||||
[5]: http://groovy-lang.org/
|
||||
[6]: https://github.com/monetschemist/grails-datatables
|
||||
[7]: https://www.vim.org/
|
||||
[8]: http://openjdk.java.net/
|
||||
[9]: http://sdkman.io/
|
||||
[10]: http://guides.grails.org/creating-your-first-grails-app/guide/index.html
|
||||
[11]: https://opensource.com/file/410061
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screen_1.png (Embrow home screen)
|
||||
[13]: https://opensource.com/file/410066
|
||||
[14]: https://opensource.com/sites/default/files/uploads/screen_2.png (Office list screenshot)
|
||||
[15]: https://opensource.com/file/410071
|
||||
[16]: https://opensource.com/sites/default/files/uploads/screen3.png (Employee controller screenshot)
|
||||
[17]: https://gsp.grails.org/latest/ref/Tags/createLink.html
|
||||
[18]: http://groovy-lang.org/closures.html
|
||||
[19]: http://groovy-lang.org/dsls.html
|
||||
@ -1,78 +0,0 @@
|
||||
fuowang 翻译中
|
||||
|
||||
4 open source invoicing tools for small businesses
|
||||
======
|
||||
Manage your billing and get paid with easy-to-use, web-based invoicing software.
|
||||
|
||||

|
||||
|
||||
No matter what your reasons for starting a small business, the key to keeping that business going is getting paid. Getting paid usually means sending a client an invoice.
|
||||
|
||||
It's easy enough to whip up an invoice using LibreOffice Writer or LibreOffice Calc, but sometimes you need a bit more. A more professional look. A way of keeping track of your invoices. Reminders about when to follow up on the invoices you've sent.
|
||||
|
||||
There's a wide range of commercial and closed-source invoicing tools out there. But the offerings on the open source side of the fence are just as good, and maybe even more flexible, than their closed source counterparts.
|
||||
|
||||
Let's take a look at four web-based open source invoicing tools that are great choices for freelancers and small businesses on a tight budget. I reviewed two of them in 2014, in an [earlier version][1] of this article. These four picks are easy to use and you can use them on just about any device.
|
||||
|
||||
### Invoice Ninja
|
||||
|
||||
I've never been a fan of the term ninja. Despite that, I like [Invoice Ninja][2]. A lot. It melds a simple interface with a set of features that let you create, manage, and send invoices to clients and customers.
|
||||
|
||||
You can easily configure multiple clients, track payments and outstanding invoices, generate quotes, and email invoices. What sets Invoice Ninja apart from its competitors is its [integration with][3] over 40 online popular payment gateways, including PayPal, Stripe, WePay, and Apple Pay.
|
||||
|
||||
[Download][4] a version that you can install on your own server or get an account with the [hosted version][5] of Invoice Ninja. There's a free version and a paid tier that will set you back US$ 8 a month.
|
||||
|
||||
### InvoicePlane
|
||||
|
||||
Once upon a time, there was a nifty open source invoicing tool called FusionInvoice. One day, its creators took the latest version of the code proprietary. That didn't end happily, as FusionInvoice's doors were shut for good in 2018. But that wasn't the end of the application. An old version of the code stayed open source and morphed into [InvoicePlane][6], which packs all of FusionInvoice's goodness.
|
||||
|
||||
Creating an invoice takes just a couple of clicks. You can make them as minimal or detailed as you need. When you're ready, you can email your invoices or output them as PDFs. You can also create recurring invoices for clients or customers you regularly bill.
|
||||
|
||||
InvoicePlane does more than generate and track invoices. You can also create quotes for jobs or goods, track products you sell, view and enter payments, and run reports on your invoices.
|
||||
|
||||
[Grab the code][7] and install it on your web server. Or, if you're not quite ready to do that, [take the demo][8] for a spin.
|
||||
|
||||
### OpenSourceBilling
|
||||
|
||||
Described by its developer as "beautifully simple billing software," [OpenSourceBilling][9] lives up to the description. It has one of the cleanest interfaces I've seen, which makes configuring and using the tool a breeze.
|
||||
|
||||
OpenSourceBilling stands out because of its dashboard, which tracks your current and past invoices, as well as any outstanding amounts. Your information is broken up into graphs and tables, which makes it easy to follow.
|
||||
|
||||
You do much of the configuration on the invoice itself. You can add items, tax rates, clients, and even payment terms with a click and a few keystrokes. OpenSourceBilling saves that information across all of your invoices, both new and old.
|
||||
|
||||
As with some of the other tools we've looked at, OpenSourceBilling has a [demo][10] you can try.
|
||||
|
||||
### BambooInvoice
|
||||
|
||||
When I was a full-time freelance writer and consultant, I used [BambooInvoice][11] to bill my clients. When its original developer stopped working on the software, I was a bit disappointed. But BambooInvoice is back, and it's as good as ever.
|
||||
|
||||
What attracted me to BambooInvoice is its simplicity. It does one thing and does it well. You can create and edit invoices, and BambooInvoice keeps track of them by client and by the invoice numbers you assign to them. It also lets you know which invoices are open or overdue. You can email the invoices from within the application or generate PDFs. You can also run reports to keep tabs on your income.
|
||||
|
||||
To [install][12] and use BambooInvoice, you'll need a web server running PHP 5 or newer as well as a MySQL database. Chances are you already have access to one, so you're good to go.
|
||||
|
||||
Do you have a favorite open source invoicing tool? Feel free to share it by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/open-source-invoicing-tools
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: https://opensource.com/business/14/9/4-open-source-invoice-tools
|
||||
[2]: https://www.invoiceninja.org/
|
||||
[3]: https://www.invoiceninja.com/integrations/
|
||||
[4]: https://github.com/invoiceninja/invoiceninja
|
||||
[5]: https://www.invoiceninja.com/invoicing-pricing-plans/
|
||||
[6]: https://invoiceplane.com/
|
||||
[7]: https://wiki.invoiceplane.com/en/1.5/getting-started/installation
|
||||
[8]: https://demo.invoiceplane.com/
|
||||
[9]: http://www.opensourcebilling.org/
|
||||
[10]: http://demo.opensourcebilling.org/
|
||||
[11]: https://www.bambooinvoice.net/
|
||||
[12]: https://sourceforge.net/projects/bambooinvoice/
|
||||
@ -1,331 +0,0 @@
|
||||
translating---cyleft
|
||||
====
|
||||
|
||||
6 Commands To Shutdown And Reboot The Linux System From Terminal
|
||||
======
|
||||
Linux administrator performing many tasks in their routine work. The system Shutdown and Reboot task also included in it.
|
||||
|
||||
It’s one of the risky task for them because some times it wont come back due to some reasons and they need to spend more time on it to troubleshoot.
|
||||
|
||||
These task can be performed through CLI in Linux. Most of the time Linux administrator prefer to perform these kind of tasks via CLI because they are familiar on this.
|
||||
|
||||
There are few commands are available in Linux to perform these tasks and user needs to choose appropriate command to perform the task based on the requirement.
|
||||
|
||||
All these commands has their own feature and allow Linux admin to use it.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [11 Methods To Find System/Server Uptime In Linux][1]
|
||||
**(#)** [Tuptime – A Tool To Report The Historical And Statistical Running Time Of Linux System][2]
|
||||
|
||||
When the system is initiated for Shutdown or Reboot. It will be notified to all logged-in users and processes. Also, it wont allow any new logins if the time argument is used.
|
||||
|
||||
I would suggest you to double check before you perform this action because you need to follow few prerequisites to make sure everything is fine.
|
||||
|
||||
Those steps are listed below.
|
||||
|
||||
* Make sure you should have a console access to troubleshoot further in case any issues arise. VMWare access for VMs and IPMI/iLO/iDRAC access for physical servers.
|
||||
* You have to create a ticket as per your company procedure either Incident or Change ticket and get approval
|
||||
* Take the important configuration files backup and move to other servers for safety
|
||||
* Verify the log files (Perform the pre-check)
|
||||
* Communicate about your activity with other dependencies teams like DBA, Application, etc
|
||||
* Ask them to bring down their Database service or Application service and get a confirmation from them.
|
||||
* Validate the same from your end using the appropriate command to double confirm this.
|
||||
* Finally reboot the system
|
||||
* Verify the log files (Perform the post-check), If everything is good then move to next step. If you found something is wrong then troubleshoot accordingly.
|
||||
* If it’s back to up and running, ask the dependencies team to bring up their applications.
|
||||
* Monitor for some time, and communicate back to them saying everything is working fine as expected.
|
||||
|
||||
|
||||
|
||||
This task can be performed using following commands.
|
||||
|
||||
* **`shutdown Command:`** shutdown command used to halt, power-off or reboot the machine.
|
||||
* **`halt Command:`** halt command used to halt, power-off or reboot the machine.
|
||||
* **`poweroff Command:`** poweroff command used to halt, power-off or reboot the machine.
|
||||
* **`reboot Command:`** reboot command used to halt, power-off or reboot the machine.
|
||||
* **`init Command:`** init (short for initialization) is the first process started during booting of the computer system.
|
||||
* **`systemctl Command:`** systemd is a system and service manager for Linux operating systems.
|
||||
|
||||
|
||||
|
||||
### Method-1: How To Shutdown And Reboot The Linux System Using Shutdown Command
|
||||
|
||||
shutdown command used to power-off or reboot a Linux remote machine or local host. It’s offering
|
||||
multiple options to perform this task effectively. If the time argument is used, 5 minutes before the system goes down the /run/nologin file is created to ensure that further logins shall not be allowed.
|
||||
|
||||
The general syntax is
|
||||
|
||||
```
|
||||
# shutdown [OPTION] [TIME] [MESSAGE]
|
||||
|
||||
```
|
||||
|
||||
Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
|
||||
|
||||
```
|
||||
# shutdown -h now
|
||||
|
||||
```
|
||||
|
||||
* **`-h:`** Equivalent to –poweroff, unless –halt is specified.
|
||||
|
||||
|
||||
|
||||
Alternatively we can use the shutdown command with `halt` option to bring down the machine immediately.
|
||||
|
||||
```
|
||||
# shutdown --halt now
|
||||
or
|
||||
# shutdown -H now
|
||||
|
||||
```
|
||||
|
||||
* **`-H, --halt:`** Halt the machine.
|
||||
|
||||
|
||||
|
||||
Alternatively we can use the shutdown command with `poweroff` option to bring down the machine immediately.
|
||||
|
||||
```
|
||||
# shutdown --poweroff now
|
||||
or
|
||||
# shutdown -P now
|
||||
|
||||
```
|
||||
|
||||
* **`-P, --poweroff:`** Power-off the machine (the default).
|
||||
|
||||
|
||||
|
||||
Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
|
||||
|
||||
```
|
||||
# shutdown -h now
|
||||
|
||||
```
|
||||
|
||||
* **`-h:`** Equivalent to –poweroff, unless –halt is specified.
|
||||
|
||||
|
||||
|
||||
If you run the below commands without time parameter, it will wait for a minute then execute the given command.
|
||||
|
||||
```
|
||||
# shutdown -h
|
||||
Shutdown scheduled for Mon 2018-10-08 06:42:31 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
|
||||
|
||||
```
|
||||
|
||||
All other logged in users can see a broadcast message in their terminal like below.
|
||||
|
||||
```
|
||||
[[email protected] ~]$
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
|
||||
|
||||
```
|
||||
|
||||
for Halt option.
|
||||
|
||||
```
|
||||
# shutdown -H
|
||||
Shutdown scheduled for Mon 2018-10-08 06:37:53 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:36:53 EDT):
|
||||
|
||||
The system is going down for system halt at Mon 2018-10-08 06:37:53 EDT!
|
||||
|
||||
```
|
||||
|
||||
for Poweroff option.
|
||||
|
||||
```
|
||||
# shutdown -P
|
||||
Shutdown scheduled for Mon 2018-10-08 06:40:07 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:39:07 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:40:07 EDT!
|
||||
|
||||
```
|
||||
|
||||
This can be cancelled by hitting `shutdown -c` option on your terminal.
|
||||
|
||||
```
|
||||
# shutdown -c
|
||||
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:39:09 EDT):
|
||||
|
||||
The system shutdown has been cancelled at Mon 2018-10-08 06:40:09 EDT!
|
||||
|
||||
```
|
||||
|
||||
All other logged in users can see a broadcast message in their terminal like below.
|
||||
|
||||
```
|
||||
[[email protected] ~]$
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:35 EDT):
|
||||
|
||||
The system shutdown has been cancelled at Mon 2018-10-08 06:42:35 EDT!
|
||||
|
||||
```
|
||||
|
||||
Add a time parameter, if you want to perform shutdown or reboot in `N` seconds. Here you can add broadcast a custom message to logged-in users. In this example, we are rebooting the machine in another 5 minutes.
|
||||
|
||||
```
|
||||
# shutdown -r +5 "To activate the latest Kernel"
|
||||
Shutdown scheduled for Mon 2018-10-08 07:13:16 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[[email protected] ~]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 07:08:16 EDT):
|
||||
|
||||
To activate the latest Kernel
|
||||
The system is going down for reboot at Mon 2018-10-08 07:13:16 EDT!
|
||||
|
||||
```
|
||||
|
||||
Run the below command to reboot a Linux machine immediately. It will kill all the processes immediately and will reboot the system.
|
||||
|
||||
```
|
||||
# shutdown -r now
|
||||
|
||||
```
|
||||
|
||||
* **`-r, --reboot:`** Reboot the machine.
|
||||
|
||||
|
||||
|
||||
### Method-2: How To Shutdown And Reboot The Linux System Using reboot Command
|
||||
|
||||
reboot command used to power-off or reboot a Linux remote machine or local host. Reboot command comes with two useful options.
|
||||
|
||||
It will perform a graceful shutdown and restart of the machine (This is similar to your restart option which is available in your system menu).
|
||||
|
||||
Run “reboot’ command without any option to reboot Linux machine.
|
||||
|
||||
```
|
||||
# reboot
|
||||
|
||||
```
|
||||
|
||||
Run the “reboot” command with `-p` option to power-off or shutdown the Linux machine.
|
||||
|
||||
```
|
||||
# reboot -p
|
||||
|
||||
```
|
||||
|
||||
* **`-p, --poweroff:`** Power-off the machine, either halt or poweroff commands is invoked.
|
||||
|
||||
|
||||
|
||||
Run the “reboot” command with `-f` option to forcefully reboot the Linux machine (This is similar to pressing the power button on the CPU).
|
||||
|
||||
```
|
||||
# reboot -f
|
||||
|
||||
```
|
||||
|
||||
* **`-f, --force:`** Force immediate halt, power-off, or reboot.
|
||||
|
||||
|
||||
|
||||
### Method-3: How To Shutdown And Reboot The Linux System Using init Command
|
||||
|
||||
init (short for initialization) is the first process started during booting of the computer system.
|
||||
|
||||
It will check the /etc/inittab file to decide the Linux run level. Also, allow users to perform shutdown and reboot the Linux machine. There are seven runlevels exist, from zero to six.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How To Check All Running Services In Linux][3]
|
||||
|
||||
Run the below init command to shutdown the system .
|
||||
|
||||
```
|
||||
# init 0
|
||||
|
||||
```
|
||||
|
||||
* **`0:`** Halt – to shutdown the system.
|
||||
|
||||
|
||||
|
||||
Run the below init command to reboot the system .
|
||||
|
||||
```
|
||||
# init 6
|
||||
|
||||
```
|
||||
|
||||
* **`6:`** Reboot – to reboot the system.
|
||||
|
||||
|
||||
|
||||
### Method-4: How To Shutdown The Linux System Using halt Command
|
||||
|
||||
halt command used to power-off or shutdown a Linux remote machine or local host.
|
||||
halt terminates all processes and shuts down the cpu.
|
||||
|
||||
```
|
||||
# halt
|
||||
|
||||
```
|
||||
|
||||
### Method-5: How To Shutdown The Linux System Using poweroff Command
|
||||
|
||||
poweroff command used to power-off or shutdown a Linux remote machine or local host. Poweroff is exactly like halt, but it also turns off the unit itself (lights and everything on a PC). It sends an ACPI command to the board, then to the PSU, to cut the power.
|
||||
|
||||
```
|
||||
# poweroff
|
||||
|
||||
```
|
||||
|
||||
### Method-6: How To Shutdown And Reboot The Linux System Using systemctl Command
|
||||
|
||||
Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
|
||||
|
||||
systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the first process get started by kernel and holding PID 1.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][4]
|
||||
|
||||
It’s a parent process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart.
|
||||
|
||||
systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
|
||||
|
||||
systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and you can see the system hierarchy by exploring /cgroup/systemd file.
|
||||
|
||||
```
|
||||
# systemctl halt
|
||||
# systemctl poweroff
|
||||
# systemctl reboot
|
||||
# systemctl suspend
|
||||
# systemctl hibernate
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
|
||||
[2]: https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/
|
||||
[3]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
[4]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
@ -0,0 +1,236 @@
|
||||
如何在 Linux 中查看已挂载的文件系统类型
|
||||
======
|
||||
|
||||

|
||||
|
||||
如你所知,Linux 支持非常多的文件系统,例如 Ext4、ext3、ext2、sysfs、securityfs、FAT16、FAT32、NTFS 等等,当前被使用最多的文件系统是 Ext4。你曾经疑惑过你的 Linux 系统使用的是什么类型的文件系统吗?没有疑惑过?不用担心!我们将帮助你。本指南将解释如何在类 Unix 的操作系统中查看已挂载的文件系统类型。
|
||||
|
||||
### 在 Linux 中查看已挂载的文件系统类型
|
||||
|
||||
有很多种方法可以在 Linux 中查看已挂载的文件系统类型,下面我将给出 8 种不同的方法。那现在就让我们开始吧!
|
||||
|
||||
#### 方法 1 – 使用 `findmnt` 命令
|
||||
|
||||
这是查出文件系统类型最常使用的方法。**findmnt** 命令将列出所有已挂载的文件系统或者搜索出某个文件系统。`findmnt` 命令能够在 `/etc/fstab`、`/etc/mtab` 或 `/proc/self/mountinfo` 这几个文件中进行搜索。
|
||||
|
||||
`findmnt` 预装在大多数的 Linux 发行版中,因为它是 **util-linux** 包的一部分。为了防止 `findmnt` 命令不可用,你可以安装这个软件包。例如,你可以使用下面的命令在基于 Debian 的系统中安装 **util-linux** 包:
|
||||
```
|
||||
$ sudo apt install util-linux
|
||||
```
|
||||
|
||||
下面让我们继续看看如何使用 `findmnt` 来找出已挂载的文件系统。
|
||||
|
||||
假如你只敲 `findmnt` 命令而不带任何的参数或选项,它将像下面展示的那样以树状图形式列举出所有已挂载的文件系统。
|
||||
```
|
||||
$ findmnt
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
![][2]
|
||||
|
||||
正如你看到的那样,`findmnt` 展示出了目标挂载点(TARGET)、源设备(SOURCE)、文件系统类型(FSTYPE)以及相关的挂载选项(OPTIONS),例如文件系统是否是可读可写或者只读的。以我的系统为例,我的根(`/`)文件系统的类型是 EXT4 。
|
||||
|
||||
假如你不想以树状图的形式来展示输出,可以使用 **-l** 选项来以简单平凡的形式来展示输出:
|
||||
```
|
||||
$ findmnt -l
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
你还可以使用 **-t** 选项来列举出特定类型的文件系统,例如下面展示的 **ext4** 文件系统类型:
|
||||
```
|
||||
$ findmnt -t ext4
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
/ /dev/sda2 ext4 rw,relatime,commit=360
|
||||
└─/boot /dev/sda1 ext4 rw,relatime,commit=360,data=ordered
|
||||
```
|
||||
|
||||
`findmnt` 还可以生成 `df` 类型的输出,使用命令
|
||||
```
|
||||
$ findmnt --df
|
||||
```
|
||||
或
|
||||
```
|
||||
$ findmnt -D
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
SOURCE FSTYPE SIZE USED AVAIL USE% TARGET
|
||||
dev devtmpfs 3.9G 0 3.9G 0% /dev
|
||||
run tmpfs 3.9G 1.1M 3.9G 0% /run
|
||||
/dev/sda2 ext4 456.3G 342.5G 90.6G 75% /
|
||||
tmpfs tmpfs 3.9G 32.2M 3.8G 1% /dev/shm
|
||||
tmpfs tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
|
||||
bpf bpf 0 0 0 - /sys/fs/bpf
|
||||
tmpfs tmpfs 3.9G 8.4M 3.9G 0% /tmp
|
||||
/dev/loop0 squashfs 82.1M 82.1M 0 100% /var/lib/snapd/snap/core/4327
|
||||
/dev/sda1 ext4 92.8M 55.7M 30.1M 60% /boot
|
||||
tmpfs tmpfs 788.8M 32K 788.8M 0% /run/user/1000
|
||||
gvfsd-fuse fuse.gvfsd-fuse 0 0 0 - /run/user/1000/gvfs
|
||||
```
|
||||
|
||||
你还可以展示某个特定设备或者挂载点的文件系统类型。
|
||||
|
||||
查看某个特定的设备:
|
||||
```
|
||||
$ findmnt /dev/sda1
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
/boot /dev/sda1 ext4 rw,relatime,commit=360,data=ordered
|
||||
```
|
||||
|
||||
查看某个特定的挂载点:
|
||||
```
|
||||
$ findmnt /
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
/ /dev/sda2 ext4 rw,relatime,commit=360
|
||||
```
|
||||
|
||||
你甚至还可以查看某个特定标签的文件系统的类型:
|
||||
```
|
||||
$ findmnt LABEL=Storage
|
||||
```
|
||||
|
||||
更多详情,请参考其 man 手册。
|
||||
```
|
||||
$ man findmnt
|
||||
```
|
||||
|
||||
`findmnt` 命令已足够完成在 Linux 中查看已挂载文件系统类型的任务,这个命令就是为了这个特定任务而生的。然而,还存在其他方法来查看文件系统的类型,假如你感兴趣的话,请接着让下看。
|
||||
|
||||
#### 方法 2 – 使用 `blkid` 命令
|
||||
|
||||
**blkid** 命令被用来查找和打印块设备的属性。它也是 **util-linux** 包的一部分,所以你不必再安装它。
|
||||
|
||||
为了使用 `blkid` 命令来查看某个文件系统的类型,可以运行:
|
||||
```
|
||||
$ blkid /dev/sda1
|
||||
```
|
||||
|
||||
#### 方法 3 – 使用 `df` 命令
|
||||
|
||||
在类 Unix 的操作系统中, **df** 命令被用来报告文件系统的磁盘空间使用情况。为了查看所有已挂载文件系统的类型,只需要运行:
|
||||
```
|
||||
$ df -T
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
![][4]
|
||||
|
||||
关于 `df` 命令的更多细节,可以参考下面的指南。
|
||||
|
||||
- [针对新手的 df 命令教程](https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/)
|
||||
|
||||
同样也可以参考其 man 手册:
|
||||
```
|
||||
$ man df
|
||||
```
|
||||
|
||||
#### 方法 4 – 使用 `file` 命令
|
||||
|
||||
**file** 命令可以判读出某个特定文件的类型,即便该文件没有文件后缀名也同样适用。
|
||||
|
||||
运行下面的命令来找出某个特定分区的文件系统类型:
|
||||
```
|
||||
$ sudo file -sL /dev/sda1
|
||||
[sudo] password for sk:
|
||||
/dev/sda1: Linux rev 1.0 ext4 filesystem data, UUID=83a1dbbf-1e15-4b45-94fe-134d3872af96 (needs journal recovery) (extents) (large files) (huge files)
|
||||
```
|
||||
|
||||
查看其 man 手册可以知晓更多细节:
|
||||
```
|
||||
$ man file
|
||||
```
|
||||
|
||||
#### 方法 5 – 使用 `fsck` 命令
|
||||
|
||||
**fsck** 命令被用来检查某个文件系统是否健全或者修复它。你可以像下面那样通过将分区名字作为 `fsck` 的参数来查看该分区的文件系统类型:
|
||||
|
||||
```
|
||||
$ fsck -N /dev/sda1
|
||||
fsck from util-linux 2.32
|
||||
[/usr/bin/fsck.ext4 (1) -- /boot] fsck.ext4 /dev/sda1
|
||||
```
|
||||
|
||||
如果想知道更多的内容,请查看其 man 手册:
|
||||
```
|
||||
$ man fsck
|
||||
```
|
||||
|
||||
#### 方法 6 – 使用 `fstab` 命令
|
||||
|
||||
**fstab** 是一个包含文件系统静态信息的文件。这个文件通常包含了挂载点、文件系统类型和挂载选项等信息。
|
||||
|
||||
要查看某个文件系统的类型,只需要运行:
|
||||
```
|
||||
$ cat /etc/fstab
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
更多详情,请查看其 man 手册:
|
||||
```
|
||||
$ man fstab
|
||||
```
|
||||
|
||||
#### 方法 7 – 使用 `lsblk` 命令
|
||||
|
||||
**lsblk** 命令可以展示设备的信息。
|
||||
|
||||
要展示已挂载文件系统的信息,只需运行:
|
||||
```
|
||||
$ lsblk -f
|
||||
NAME FSTYPE LABEL UUID MOUNTPOINT
|
||||
loop0 squashfs /var/lib/snapd/snap/core/4327
|
||||
sda
|
||||
├─sda1 ext4 83a1dbbf-1e15-4b45-94fe-134d3872af96 /boot
|
||||
├─sda2 ext4 4d25ddb0-5b20-40b4-ae35-ef96376d6594 /
|
||||
└─sda3 swap 1f8f5e2e-7c17-4f35-97e6-8bce7a4849cb [SWAP]
|
||||
sr0
|
||||
```
|
||||
|
||||
更多细节,可以参考它的 man 手册:
|
||||
```
|
||||
$ man lsblk
|
||||
```
|
||||
|
||||
#### 方法 8 – 使用 `mount` 命令
|
||||
|
||||
**mount** 被用来在类 Unix 系统中挂载本地或远程的文件系统。
|
||||
|
||||
要使用 `mount` 命令查看文件系统的类型,可以像下面这样做:
|
||||
```
|
||||
$ mount | grep "^/dev"
|
||||
/dev/sda2 on / type ext4 (rw,relatime,commit=360)
|
||||
/dev/sda1 on /boot type ext4 (rw,relatime,commit=360,data=ordered)
|
||||
```
|
||||
|
||||
更多详情,请参考其 man 手册的内容:
|
||||
```
|
||||
$ man mount
|
||||
```
|
||||
|
||||
好了,上面便是今天的全部内容了。现在你知道了 8 种不同的 Linux 命令来查看已挂载的 Linux 文件系统的类型。假如你知道其他的命令来完成同样的任务,请在下面的评论部分让我们知晓,我将确认并相应地升级本教程。
|
||||
|
||||
更过精彩内容即将呈现,请保持关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-the-mounted-filesystem-type-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/07/findmnt-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/07/findmnt-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/07/df.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/07/fstab.png
|
||||
@ -1,305 +1,245 @@
|
||||
|
||||
命令行:增强版
|
||||
======
|
||||
|
||||
我不确定有多少Web 开发者能完全逃避使用命令行。就我来说,我从1997年上大学就开始使用命令行了,那时的l33t-hacker 让我着迷,同时我也觉得它很难掌握。
|
||||
|
||||
过去这些年我的命令行本领在逐步加强,我经常会去搜寻在我工作中能使用的更好的命令行工具。下面就是我现在使用的用于增强原有命令行工具的列表。
|
||||
我不确定有多少 Web 开发者能完全避免使用命令行。就我来说,我从 1997 年上大学就开始使用命令行了,那时的 l33t-hacker 让我着迷,同时我也觉得它很难掌握。
|
||||
|
||||
过去这些年我的命令行本领在逐步加强,我经常会去搜寻工作中能用的更好的命令行工具。下面就是我现在使用的用于增强原有命令行工具的列表。
|
||||
|
||||
### 怎么忽略我所做的命令行增强
|
||||
|
||||
通常情况下我会用别名将新的或者增强的命令行工具链接到原来的命令行(如`cat`和`ping`)。
|
||||
|
||||
|
||||
如果我需要运行原来的命令的话(有时我确实需要这么做),我会像下面这样来运行未加修改的原来的命令行。(我用的是Mac,你的输出可能不一样)
|
||||
通常情况下我会用别名将新的增强的命令行工具链接到原来的命令(如 `cat` 和 `ping`)。
|
||||
|
||||
如果我需要运行原来的命令的话(有时我确实需要这么做),我会像下面这样来运行未加修改的原始命令。(我用的是 Mac,你的用法可能不一样)
|
||||
|
||||
```
|
||||
$ \cat # 忽略叫 "cat" 的别名 - 具体解释: https://stackoverflow.com/a/16506263/22617
|
||||
$ command cat # 忽略函数和别名
|
||||
|
||||
```
|
||||
|
||||
### bat > cat
|
||||
|
||||
`cat`用于打印文件的内容,如果你在命令行上要花很多时间的话,例如语法高亮之类的功能会非常有用。我首先发现了[ccat][3]这个有语法高亮功能的的工具,然后我发现了[bat][4],它的功能有语法高亮,分页,行号和git集成。
|
||||
|
||||
|
||||
`bat`命令也能让我在输出里(只要输出比屏幕的高度长)
|
||||
使用`/`关键字绑定来搜索(和用`less`搜索功能一样)。
|
||||
`cat` 用于打印文件的内容,如果你平时用命令行很多的话,例如语法高亮之类的功能会非常有用。我首先发现了 [ccat][3] 这个有语法高亮功能的工具,然后我发现了 [bat][4],它的功能有语法高亮,分页,行号和 git 集成。
|
||||
|
||||
`bat` 命令也能让我在输出里(多于一屏时)使用 `/` 搜索(和用 `less` 搜索功能一样)。
|
||||
|
||||
![Simple bat output][5]
|
||||
|
||||
我将别名`cat`链接到了`bat`命令:
|
||||
|
||||
|
||||
我将别名 `cat` 链接到了 `bat` 命令:
|
||||
|
||||
```
|
||||
alias cat='bat'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][4]
|
||||
💾 [安装指引][4]
|
||||
|
||||
### prettyping > ping
|
||||
|
||||
`ping`非常有用,当我碰到“糟了,是不是什么服务挂了?/我的网不通了?”这种情况下我最先想到的工具就是它了。但是`prettyping`(“prettyping” 可不是指"pre typing")(译注:英文字面意思是'预打印')在`ping`上加上了友好的输出,这可让我感觉命令行友好了很多呢。
|
||||
|
||||
`ping` 非常有用,当我碰到“糟了,是不是 X 挂了?/我的网不通了?”这种情况下我最先想到的工具就是它了。但是 `prettyping`(“prettyping” 可不是指“pre typing”)在 `ping` 的基础上加了友好的输出,这可让我感觉命令行友好了很多呢。
|
||||
|
||||
![/images/cli-improved/ping.gif][6]
|
||||
|
||||
我也将`ping`用别名链接到了`prettyping`命令:
|
||||
|
||||
我也将 `ping` 用别名链接到了 `prettyping` 命令:
|
||||
|
||||
```
|
||||
alias ping='prettyping --nolegend'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][7]
|
||||
💾 [安装指引][7]
|
||||
|
||||
### fzf > ctrl+r
|
||||
|
||||
在命令行上使用`ctrl+r`将允许你在命令历史里[反向搜索][8]使用过的命令,这是个挺好的小技巧,但是它需要你给出非常精确的输入才能正常运行。
|
||||
在命令行上使用 `ctrl+r` 将允许你在命令历史里[反向搜索][8]使用过的命令,这是个挺好的小技巧,但是它需要你给出非常精确的输入才能正常运行。
|
||||
|
||||
`fzf`这个工具相比于`ctrl+r`有了**巨大的**进步。它能针对命令行历史进行模糊查询,并且提供了对可能的合格结果进行全面交互式预览。
|
||||
`fzf` 这个工具相比于 `ctrl+r` 有了**巨大的**进步。它能针对命令行历史进行模糊查询,并且提供了对可能的合格结果进行全面交互式预览。
|
||||
|
||||
除了搜索命令历史,`fzf` 还能预览和打开文件,我在下面的视频里展示了这些功能。
|
||||
|
||||
除了搜索命令历史,`fzf`还能预览和打开文件,我在下面的视频里展示了这些功能。
|
||||
|
||||
|
||||
为了这个预览的效果,我创建了一个叫`preview`的别名,它将`fzf`和前文提到的`bat`组合起来完成预览功能,还给上面绑定了一个定制的热键Ctrl+o来打开 VS Code:
|
||||
|
||||
为了这个预览的效果,我创建了一个叫 `preview` 的别名,它将 `fzf` 和前文提到的 `bat` 组合起来完成预览功能,还给上面绑定了一个定制的热键 `ctrl+o` 来打开 VS Code:
|
||||
|
||||
```
|
||||
alias preview="fzf --preview 'bat --color \"always\" {}'"
|
||||
# 支持在 VS Code 里用ctrl+o 来打开选择的文件
|
||||
# 支持在 VS Code 里用 ctrl+o 来打开选择的文件
|
||||
export FZF_DEFAULT_OPTS="--bind='ctrl-o:execute(code {})+abort'"
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][9]
|
||||
💾 [安装指引][9]
|
||||
|
||||
### htop > top
|
||||
|
||||
`top`是当我想快速诊断为什么机器上的CPU跑的那么累或者风扇为什么突然呼呼大做的时候首先会想到的工具。我在产品环境也会使用这个工具。讨厌的是Mac上的`top`和 Linux 上的`top`有着极大的不同(恕我直言,应该是差的多)。
|
||||
`top` 是当我想快速诊断为什么机器上的 CPU 跑的那么累或者风扇为什么突然呼呼大做的时候首先会想到的工具。我在生产环境也会使用这个工具。讨厌的是 Mac 上的 `top` 和 Linux 上的 `top` 有着极大的不同(恕我直言,应该是差的多)。
|
||||
|
||||
不过,`htop` 是对 Linux 上的 `top` 和 Mac 上蹩脚的 `top` 的极大改进。它增加了包括颜色输出,键盘热键绑定以及不同的视图输出,这对理解进程之间的父子关系有极大帮助。
|
||||
|
||||
不过,`htop`是对 Linux 上的`top`和 Mac 上蹩脚的`top`的极大改进。它增加了包括颜色输出编码,键盘热键绑定以及不同的视图输出,这极大的帮助了我来理解进程之间的父子关系。
|
||||
|
||||
|
||||
方便的热键绑定包括:
|
||||
|
||||
* P - CPU使用率排序
|
||||
* M - 内存使用排序
|
||||
* F4 - 用字符串过滤进程(例如只看包括"node"的进程)
|
||||
* space - 锚定一个单独进程,这样我能观察它是否有尖峰状态
|
||||
一些很容易上手的热键:
|
||||
|
||||
* P - 按 CPU 使用率排序
|
||||
* M - 按内存使用排序
|
||||
* F4 - 用字符串过滤进程(例如只看包括 node 的进程)
|
||||
* space - 锚定一个单独进程,这样我能观察它是否有尖峰状态
|
||||
|
||||
![htop output][10]
|
||||
|
||||
在Mac Sieera 上htop 有个奇怪的bug,不过这个bug可以通过以root运行来绕过(我实在记不清这个bug 是什么,但是这个别名能搞定它,有点讨厌的是我得每次都输入root密码。):
|
||||
|
||||
在 Mac Sierra 上 htop 有个奇怪的 bug,不过这个 bug 可以通过以 root 运行来绕过(我实在记不清这个 bug 是什么,但是这个别名能搞定它,有点讨厌的是我得每次都输入 root 密码。):
|
||||
|
||||
```
|
||||
alias top="sudo htop" # 给top加上别名并且绕过 Sieera 上的bug
|
||||
alias top="sudo htop" # 给 top 加上别名并且绕过 Sierra 上的 bug
|
||||
```
|
||||
|
||||
💾 [Installation directions][11]
|
||||
💾 [安装指引][11]
|
||||
|
||||
### diff-so-fancy > diff
|
||||
|
||||
我非常确定我是一些年前从 Paul Irish 那儿学来的这个技巧,尽管我很少直接使用`diff`,但我的git命令行会一直使用`diff`。`diff-so-fancy`给了我代码语法颜色和更改字符高亮的功能。
|
||||
|
||||
我非常确定我是几年前从 Paul Irish 那儿学来的这个技巧,尽管我很少直接使用 `diff`,但我的 git 命令行会一直使用 `diff`。`diff-so-fancy` 给了我代码语法颜色和更改字符高亮的功能。
|
||||
|
||||
![diff so fancy][12]
|
||||
|
||||
在我的`~/.gitconfig`文件里我有下面的选项来打开`git diff`和`git show`的`diff-so-fancy`功能。
|
||||
|
||||
在我的 `~/.gitconfig` 文件里我用了下面的选项来打开 `git diff` 和 `git show` 的 `diff-so-fancy` 功能。
|
||||
|
||||
```
|
||||
[pager]
|
||||
diff = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
show = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
|
||||
diff = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
show = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
```
|
||||
|
||||
💾 [Installation directions][13]
|
||||
💾 [安装指引][13]
|
||||
|
||||
### fd > find
|
||||
|
||||
尽管我使用 Mac, 但我从来不是一个Spotlight的拥趸,我觉得它的性能很差,关键字也难记,加上更新它自己的数据库时会拖慢CPU,简直一无是处。我经常使用[Alfred][14],但是它的搜索功能也工作的不是很好。
|
||||
尽管我使用 Mac,但我绝不是 Spotlight 的粉丝,我觉得它的性能很差,关键字也难记,加上更新它自己的数据库时会拖慢 CPU,简直一无是处。我经常使用 [Alfred][14],但是它的搜索功能也不是很好。
|
||||
|
||||
我倾向于在命令行中搜索文件,但是 `find` 的难用在于很难去记住那些合适的表达式来描述我想要的文件。(而且 Mac 上的 `find` 命令和非 Mac 的 `find` 命令还有些许不同,这更加深了我的失望。)
|
||||
|
||||
我倾向于在命令行中搜索文件,但是`find`的难用在于很难去记住那些合适的表达式来描述我想要的文件。(而且 Mac 上的 find 命令和非Mac的find命令还有些许不同,这更加深了我的失望。)
|
||||
`fd` 是一个很好的替代品(它的作者和 `bat` 的作者是同一个人)。它非常快而且对于我经常要搜索的命令非常好记。
|
||||
|
||||
`fd`是一个很好的替代品(它的作者和`bat`的作者是同一个人)。它非常快而且对于我经常要搜索的命令非常好记。
|
||||
|
||||
|
||||
|
||||
几个使用方便的例子:
|
||||
几个上手的例子:
|
||||
|
||||
```
|
||||
$ fd cli # 所有包含"cli"的文件名
|
||||
$ fd -e md # 所有以.md作为扩展名的文件
|
||||
$ fd cli -x wc -w # 搜索"cli"并且在每个搜索结果上运行`wc -w`
|
||||
|
||||
|
||||
$ fd cli # 所有包含 "cli" 的文件名
|
||||
$ fd -e md # 所有以 .md 作为扩展名的文件
|
||||
$ fd cli -x wc -w # 搜索 "cli" 并且在每个搜索结果上运行 `wc -w`
|
||||
```
|
||||
|
||||
![fd output][15]
|
||||
|
||||
💾 [Installation directions][16]
|
||||
💾 [安装指引][16]
|
||||
|
||||
### ncdu > du
|
||||
|
||||
对我来说,知道当前的磁盘空间使用是非常重要的任务。我用过 Mac 上的[Dish Daisy][17],但是我觉得那个程序产生结果有点慢。
|
||||
对我来说,知道当前磁盘空间被什么占用了非常重要。我用过 Mac 上的 [DaisyDisk][17],但是我觉得那个程序产生结果有点慢。
|
||||
|
||||
`du -sh` 命令是我经常会跑的命令(`-sh` 是指结果以“汇总”和“人类可读”的方式显示),我经常会想要深入挖掘那些占用了大量磁盘空间的目录,看看到底是什么在占用空间。
|
||||
|
||||
`du -sh`命令是我经常会跑的命令(`-sh`是指结果以`总结`和`人类可读`的方式显示),我经常会想要深入挖掘那些占用了大量磁盘空间的目录,看看到底是什么在占用空间。
|
||||
|
||||
`ncdu`是一个非常棒的替代品。它提供了一个交互式的界面并且允许快速的扫描那些占用了大量磁盘空间的目录和文件,它又快又准。(尽管不管在哪个工具的情况下,扫描我的home目录都要很长时间,它有550G)
|
||||
|
||||
|
||||
一旦当我找到一个目录我想要“处理”一下(如删除,移动或压缩文件),我都会使用命令+点击屏幕[iTerm2][18]上部的目录名字来对那个目录执行搜索。
|
||||
`ncdu` 是一个非常棒的替代品。它提供了一个交互式的界面并且允许快速的扫描那些占用了大量磁盘空间的目录和文件,它又快又准。(尽管不管在哪个工具的情况下,扫描我的 home 目录都要很长时间,它有 550G)
|
||||
|
||||
一旦当我找到一个目录我想要“处理”一下(如删除,移动或压缩文件),我会使用 `commond+` 点击 [iTerm2][18] 上部的目录名字的方法在 Finder 中打开它。
|
||||
|
||||
![ncdu output][19]
|
||||
|
||||
还有另外一个选择[一个叫nnn的另外选择][20],它提供了一个更漂亮的界面,它也提供文件尺寸和使用情况,实际上它更像一个全功能的文件管理器。
|
||||
还有另外一个选择[一个叫 nnn 的另外选择][20],它提供了一个更漂亮的界面,它也提供文件尺寸和使用情况,实际上它更像一个全功能的文件管理器。
|
||||
|
||||
|
||||
我的`ncdu`使用下面的别名链接:
|
||||
我的 `ncdu` 使用下面的别名:
|
||||
|
||||
```
|
||||
alias du="ncdu --color dark -rr -x --exclude .git --exclude node_modules"
|
||||
|
||||
```
|
||||
|
||||
选项说明:
|
||||
|
||||
选项有:
|
||||
* `--color dark` 使用颜色方案
|
||||
* `-rr` 只读模式(防止误删和运行新的登陆程序)
|
||||
* `--exclude` 忽略不想操作的目录
|
||||
|
||||
* `--color dark` 使用颜色方案
|
||||
* `-rr` 只读模式(防止误删和运行新的登陆程序)
|
||||
* `--exclude` 忽略不想操作的目录
|
||||
|
||||
|
||||
|
||||
💾 [Installation directions][21]
|
||||
💾 [安装指引][21]
|
||||
|
||||
### tldr > man
|
||||
|
||||
几乎所有的单独命令行工具都有一个相伴的手册,其可以被`man <命令名>`来调出,但是在`man`的输出里找到东西可有点让人困惑,而且在一个包含了所有的技术细节的输出里找东西也挺可怕的。
|
||||
|
||||
|
||||
这就是TL;DR(译注:英文里`文档太长,没空去读`的缩写)项目创建的初衷。这是一个由社区驱动的文档系统,而且针对的是命令行。就我现在用下来,我还没碰到过一个命令它没有相应的文档,你[也可以做贡献][22]。
|
||||
几乎所有的命令行工具都有一个相伴的手册,它可以被 `man <命令名>` 来调出,但是在 `man` 的输出里找到东西可有点让人困惑,而且在一个包含了所有的技术细节的输出里找东西也挺可怕的。
|
||||
|
||||
这就是 TL;DR(译注:英文里“文档太长,没空去读”的缩写)项目创建的初衷。这是一个由社区驱动的文档系统,而且针对的是命令行。就我现在用下来,我还没碰到过一个命令没有它相应的文档,你[也可以做贡献][22]。
|
||||
|
||||
![TLDR output for 'fd'][23]
|
||||
|
||||
作为一个小技巧,我将`tldr`的别名链接到`help`(这样输入会快一点。。。)
|
||||
一个小技巧,我将 `tldr` 的别名链接到 `help`(这样输入会快一点……)
|
||||
|
||||
```
|
||||
alias help='tldr'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][24]
|
||||
💾 [安装指引][24]
|
||||
|
||||
### ack || ag > grep
|
||||
|
||||
`grep`毫无疑问是一个命令行上的强力工具,但是这些年来它已经被一些工具超越了,其中两个叫`ack`和`ag`。
|
||||
`grep` 毫无疑问是一个强力的命令行工具,但是这些年来它已经被一些工具超越了,其中两个叫 `ack` 和 `ag`。
|
||||
|
||||
我个人对 `ack` 和 `ag` 都尝试过,而且没有非常明显的个人偏好,(那也就是说它们都很棒,并且很相似)。我倾向于默认只使用 `ack`,因为这三个字符就在指尖,很好打。并且 `ack` 有大量的 `ack --` 参数可以使用!(你一定会体会到这一点。)
|
||||
|
||||
我个人对`ack`和`ag`都尝试过,而且没有非常明显的个人偏好,(那也就是说他们都很棒,并且很相似)。我倾向于默认只使用`ack`,因为这三个字符就在指尖,很好打。并且,`ack`有大量的`ack --`参数可以使用,(你一定会体会到这一点。)
|
||||
|
||||
|
||||
`ack`和`ag`都将使用正则表达式来表达搜索,这非常契合我的工作,我能指定搜索的文件类型而不用使用类似于`--js`或`--html`的文件标识(尽管`ag`比`ack`在文件类型过滤器里包括了更多的文件类型。)
|
||||
|
||||
|
||||
两个工具都支持常见的`grep`选项,如`-B`和`-A`用于在搜索的上下文里指代`之前`和`之后`。
|
||||
`ack` 和 `ag` 都使用正则表达式来搜索,这非常契合我的工作,我能指定文件类型搜索,类似于 `--js` 或 `--html` 这种文件标识。(尽管 `ag` 比 `ack` 在文件类型过滤器里包括了更多的文件类型。)
|
||||
|
||||
两个工具都支持常见的 `grep` 选项,如 `-B` 和 `-A` 用于在搜索的上下文里指代“之前”和“之后”。
|
||||
|
||||
![ack in action][25]
|
||||
|
||||
因为`ack`不支持markdown(而我又恰好写了很多markdown), 我在我的`~/.ackrc`文件里放了如下的定制语句:
|
||||
|
||||
|
||||
因为 `ack` 不支持 markdown(而我又恰好写了很多 markdown),我在我的 `~/.ackrc` 文件里加了以下定制语句:
|
||||
|
||||
```
|
||||
--type-set=md=.md,.mkd,.markdown
|
||||
--pager=less -FRX
|
||||
|
||||
```
|
||||
|
||||
💾 Installation directions: [ack][26], [ag][27]
|
||||
💾 安装指引: [ack][26], [ag][27]
|
||||
|
||||
[Futher reading on ack & ag][28]
|
||||
[关于 ack & ag 的更多信息][28]
|
||||
|
||||
### jq > grep et al
|
||||
### jq > grep 及其它
|
||||
|
||||
我是[jq][29]的粉丝之一。当然一开始我也在它的语法里苦苦挣扎,好在我对查询语言还算有些使用心得,现在我对`jq`可以说是每天都要用。(不过从前我要么使用grep 或者使用一个叫[json][30]的工具,相比而言后者的功能就非常基础了。)
|
||||
我是 [jq][29] 的忠实粉丝之一。当然一开始我也在它的语法里苦苦挣扎,好在我对查询语言还算有些使用心得,现在我对 `jq` 可以说是每天都要用。(不过从前我要么使用 `grep` 或者使用一个叫 [json][30] 的工具,相比而言后者的功能就非常基础了。)
|
||||
|
||||
我甚至开始撰写一个 `jq` 的教程系列(有 2500 字并且还在增加),我还发布了一个[网页工具][31]和一个 Mac 上的应用(这个还没有发布。)
|
||||
|
||||
我甚至开始撰写一个`jq`的教程系列(有2500字并且还在增加),我还发布了一个[web tool][31]和一个Mac 上的应用(这个还没有发布。)
|
||||
|
||||
|
||||
`jq`允许我传入一个 JSON 并且能非常简单的将其转变为一个 使用JSON格式的结果,这正是我想要的。下面这个例子允许我用一个命令更新我的所有节点依赖(为了阅读方便,我将其分成为多行。)
|
||||
|
||||
`jq` 允许我传入一个 JSON 并且能非常简单的将其转变为一个使用 JSON 格式的结果,这正是我想要的。下面这个例子允许我用一个命令更新我的所有 node 依赖。(为了阅读方便,我将其分成为多行。)
|
||||
|
||||
```
|
||||
$ npm i $(echo $(\
|
||||
npm outdated --json | \
|
||||
jq -r 'to_entries | .[] | "\(.key)@\(.value.latest)"' \
|
||||
npm outdated --json | \
|
||||
jq -r 'to_entries | .[] | "\(.key)@\(.value.latest)"' \
|
||||
))
|
||||
|
||||
```
|
||||
上面的命令将使用npm 的 JSON 输出格式来列出所有的过期节点依赖,然后将下面的源JSON转换为:
|
||||
|
||||
上面的命令将使用 npm 的 JSON 输出格式来列出所有过期的 node 依赖,然后将下面的源 JSON 转换为:
|
||||
|
||||
```
|
||||
{
|
||||
"node-jq": {
|
||||
"current": "0.7.0",
|
||||
"wanted": "0.7.0",
|
||||
"latest": "1.2.0",
|
||||
"location": "node_modules/node-jq"
|
||||
},
|
||||
"uuid": {
|
||||
"current": "3.1.0",
|
||||
"wanted": "3.2.1",
|
||||
"latest": "3.2.1",
|
||||
"location": "node_modules/uuid"
|
||||
}
|
||||
"node-jq": {
|
||||
"current": "0.7.0",
|
||||
"wanted": "0.7.0",
|
||||
"latest": "1.2.0",
|
||||
"location": "node_modules/node-jq"
|
||||
},
|
||||
"uuid": {
|
||||
"current": "3.1.0",
|
||||
"wanted": "3.2.1",
|
||||
"latest": "3.2.1",
|
||||
"location": "node_modules/uuid"
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
转换结果为:(译注:原文此处并未给出结果)
|
||||
|
||||
上面的结果会被作为`npm install`的输入,你瞧,我的升级就这样全部搞定了。(当然,这里有点小题大做了。)
|
||||
上面的结果会被作为 `npm install` 的输入,你瞧,我的升级就这样全部搞定了。(当然,这里有点小题大做了。)
|
||||
|
||||
### 很荣幸提及一些其它的工具
|
||||
|
||||
### 很荣幸提及一些其他的工具
|
||||
|
||||
我也在开始尝试一些别的工具,但我还没有完全掌握他们。(除了`ponysay`,当我新启动一个命令行会话时,它就会出现。)
|
||||
|
||||
|
||||
* [ponysay][32] > cowsay
|
||||
* [csvkit][33] > awk et al
|
||||
* [noti][34] > `display notification`
|
||||
* [entr][35] > watch
|
||||
|
||||
我也在开始尝试一些别的工具,但我还没有完全掌握它们。(除了 `ponysay`,当我打开一个新的终端会话时,它就会出现。)
|
||||
|
||||
* [ponysay][32] > `cowsay`
|
||||
* [csvkit][33] > `awk 及其它`
|
||||
* [noti][34] > `display notification`
|
||||
* [entr][35] > `watch`
|
||||
|
||||
### 你有什么好点子吗?
|
||||
|
||||
|
||||
上面是我的命令行清单。能告诉我们你的吗?你有没有试着去增强一些你每天都会用到的命令呢?请告诉我,我非常乐意知道。
|
||||
|
||||
|
||||
上面是我的命令行清单。你的呢?你有没有试着去增强一些你每天都会用到的命令呢?请告诉我,我非常乐意知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -307,8 +247,8 @@ via: https://remysharp.com/2018/08/23/cli-improved
|
||||
|
||||
作者:[Remy Sharp][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:DavidChenLiang(https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -335,7 +275,7 @@ via: https://remysharp.com/2018/08/23/cli-improved
|
||||
[20]: https://github.com/jarun/nnn
|
||||
[21]: https://dev.yorhel.nl/ncdu
|
||||
[22]: https://github.com/tldr-pages/tldr#contributing
|
||||
[23]: https://remysharp.com/images/cli-improved/tldr.png (Sample tldr output for 'fd')
|
||||
[23]: https://remysharp.com/images/cli-improved/tldr.png (Sample tldr output for fd)
|
||||
[24]: http://tldr-pages.github.io/
|
||||
[25]: https://remysharp.com/images/cli-improved/ack.png (Sample ack output with grep args)
|
||||
[26]: https://beyondgrep.com
|
||||
|
||||
@ -0,0 +1,94 @@
|
||||
# 10个最值得关注的树莓派博客
|
||||
|
||||

|
||||
|
||||
网上有很多很棒的树莓派爱好者网站,教程,代码仓库,YouTube 频道和其他资源。以下是我最喜欢的十大树莓派博客,排名不分先后。
|
||||
|
||||
### 1. Raspberry Pi Spy
|
||||
|
||||
树莓派粉丝 Matt Hawkins 从很早开始就在他的网站 Raspberry Pi Spy 上撰写了大量全面且信息丰富的教程。我从这个网站上直接学到了很多东西,而且 Matt 似乎也总是第一个涵盖很多主题的人。在我学习使用树莓派的前三年里,多次在这个网站得到帮助。
|
||||
|
||||
让每个人感到幸运的是,这个不断采用新技术的网站仍然很强大。我希望看到它继续存在下去,让新社区成员在需要时得到帮助。
|
||||
|
||||
### 2. Adafruit
|
||||
|
||||
Adafruit 是硬件黑客中最知名的品牌之一。该公司制作和销售漂亮的硬件,并提供由员工、社区成员,甚至 Lady Ada 女士自己编写的优秀教程。
|
||||
|
||||
除了网上商店,Adafruit 还经营一个博客,这个博客充满了来自世界各地的精彩内容。在博客上可以查看树莓派的类别,特别是在工作日的最后一天,会在 Adafruit Towers 举办名为 [Friday is Pi Day][1] 的活动。
|
||||
|
||||
### 3. Recantha's Raspberry Pi Pod
|
||||
|
||||
Mike Horne(Recantha)是英国一位重要的树莓派社区成员,负责 [CamJam 和 Potton Pi&Pint][2](剑桥的两个树莓派社团)以及 [Pi Wars][3] (一年一度的树莓派机器人竞赛)。他为其他人建立树莓派社团提供建议,并且总是有时间帮助初学者。Horne和他的共同组织者 Tim Richardson 一起开发了 CamJam Edu Kit (一系列小巧且价格合理的套件,适合初学者使用 Python 学习物理计算)。
|
||||
|
||||
除此之外,他还运营着 Pi Pod,这是一个包含了世界各地树莓派相关内容的博客。它可能是这个列表中更新最频繁的树莓派博客,所以这是一个把握树莓派社区动向的极好方式。
|
||||
|
||||
### 4. Raspberry Pi blog
|
||||
|
||||
必须提一下树莓派的官方博客:[Raspberry Pi Foundation][4],这个博客涵盖了基金会的硬件,软件,教育,社区,慈善和青年编码俱乐部的一系列内容。博客上的大型主题是家庭数字化,教育授权,以及硬件版本和软件更新的官方新闻。
|
||||
|
||||
该博客自 [2011 年][5] 运行至今,并提供了自那时以来所有 1800 多个帖子的 [存档][6] 。你也可以在Twitter上关注[@raspberrypi_otd][7],这是我用 [Python][8] 创建的机器人(教程在这里:[Opensource.com][9])。Twitter 机器人推送来自博客存档的过去几年同一天的树莓派帖子。
|
||||
|
||||
### 5. RasPi.tv
|
||||
|
||||
另一位开创性的树莓派社区成员是 Alex Eames,通过他的博客和 YouTube 频道 RasPi.tv,他很早就加入了树莓派社区。他的网站为很多创客项目提供高质量、精心制作的视频教程和书面指南。
|
||||
|
||||
Alex 的网站 [RasP.iO][10] 制作了一系列树莓派附加板和配件,包括方便的 GPIO 端口引脚,电路板测量尺等等。他的博客也拓展到了 [Arduino][11],[WEMO][12] 以及其他小网站。
|
||||
|
||||
### 6. pyimagesearch
|
||||
|
||||
虽然不是严格的树莓派博客(名称中的“py”是“Python”,而不是“树莓派”),但该网站有着大量的 [树莓派种类][13]。 Adrian Rosebrock 获得了计算机视觉和机器学习领域的博士学位,他的博客旨在分享他在学习和制作自己的计算机视觉项目时所学到的机器学习技巧。
|
||||
|
||||
如果你想使用树莓派的相机模块学习面部或物体识别,来这个网站就对了。Adrian 在图像识别领域的深度学习和人工智能知识和实际应用是首屈一指的,而且他编写了自己的项目,这样任何人都可以进行尝试。
|
||||
|
||||
### 7. Raspberry Pi Roundup
|
||||
|
||||
这个博客由英国官方树莓派经销商之一 The Pi Hut 进行维护,会有每周的树莓派新闻。这是另一个很好的资源,可以紧跟树莓派社区的最新资讯,而且之前的文章也值得回顾。
|
||||
|
||||
### 8. Dave Akerman
|
||||
|
||||
Dave Akerman 是研究高空热气球的一流专家,他分享使用树莓派以最低的成本进行热气球发射方面的知识和经验。他会在一张由热气球拍摄的平流层照片下面对本次发射进行评论,也会对个人发射树莓派热气球给出自己的建议。
|
||||
|
||||
查看 Dave 的博客,了解精彩的临近空间摄影作品。
|
||||
|
||||
### 9. Pimoroni
|
||||
|
||||
Pimoroni 是一家世界知名的树莓派经销商,其总部位于英国谢菲尔德。这家经销商制作了著名的 [树莓派彩虹保护壳][14],并推出了许多极好的定制附加板和配件。
|
||||
|
||||
Pimoroni 的博客布局与其硬件设计和品牌推广一样精美,博文内容非常适合创客和业余爱好者在家进行创作,并且可以在有趣的 YouTube 频道 [Bilge Tank][15] 上找到。
|
||||
|
||||
### 10. Stuff About Code
|
||||
|
||||
Martin O'Hanlon 以树莓派社区成员的身份转为了基金会的员工,他起初出于乐趣在树莓派上开发我的世界作弊器,最近作为内容编辑加入了基金会。幸运的是,马丁的新工作并没有阻止他更新博客并与世界分享有益的趣闻。
|
||||
|
||||
除了我的世界的很多内容,你还可以在 Python 库,[Blue Dot][16] 和 [guizero][17] 上找到 Martin O'Hanlon 的贡献,以及一些总结性的树莓派技巧。
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[1]: https://blog.adafruit.com/category/raspberry-pi/
|
||||
[2]: https://camjam.me/?page_id=753
|
||||
[3]: https://piwars.org/
|
||||
[4]: https://www.raspberrypi-spy.co.uk/
|
||||
[5]: https://www.raspberrypi.org/blog/first-post/
|
||||
[6]: https://www.raspberrypi.org/blog/archive/
|
||||
[7]: https://twitter.com/raspberrypi_otd
|
||||
[8]: https://github.com/bennuttall/rpi-otd-bot/blob/master/src/bot.py
|
||||
[9]: https://opensource.com/article/17/8/raspberry-pi-twitter-bot
|
||||
[10]: https://rasp.io/
|
||||
[11]: https://www.arduino.cc/
|
||||
[12]: http://community.wemo.com/
|
||||
[13]: https://www.pyimagesearch.com/category/raspberry-pi/
|
||||
[14]: https://shop.pimoroni.com/products/pibow-for-raspberry-pi-3-b-plus
|
||||
[15]: https://www.youtube.com/channel/UCuiDNTaTdPTGZZzHm0iriGQ
|
||||
[16]: https://bluedot.readthedocs.io/en/latest/#
|
||||
[17]: https://lawsie.github.io/guizero/
|
||||
|
||||
@ -0,0 +1,147 @@
|
||||
Gifski – 一个跨平台的高质量 GIF 编码器
|
||||
======
|
||||
|
||||

|
||||
|
||||
作为一名文字工作者,我需要在我的文章中添加图片。有时为了更容易讲清楚某个概念,我还会添加视频或者 gif 动图,相比于文字,通过视频或者 gif 格式的输出,读者可以更容易地理解我的指导。前些天,我已经写了篇文章来介绍针对 Linux 的功能丰富的强大截屏工具 [**Flameshot**][1]。今天,我将向你展示如何从一段视频或者一些图片来制作高质量的 gif 动图。这个工具就是 **Gifski**,一个跨平台、开源、基于 **Pngquant** 的高质量命令行 GIF 编码器。
|
||||
|
||||
对于那些好奇 pngquant 是什么的读者,简单来说 pngquant 是一个针对 PNG 图片的无损压缩命令行工具。相信我,pngquant 是我使用过的最好的 PNG 无损压缩工具。它可以将 PNG 图片最高压缩 **70%** 而不会损失图片的原有质量并保存了所有的阿尔法透明度。经过压缩的图片可以在所有的网络浏览器和系统中使用。而 Gifski 是基于 Pngquant 的,它使用 pngquant 的功能来创建高质量的 GIF 动图。Gifski 能够创建每帧包含上千种颜色的 GIF 动图。Gifski 也需要 **ffmpeg** 来将视频转换为 PNG 图片。
|
||||
|
||||
### **安装 Gifski**
|
||||
|
||||
首先需要确保你安装了 FFMpeg 和 Pngquant。
|
||||
|
||||
FFmpeg 在大多数的 Linux 发行版的默认软件仓库中都可以获取到,所以你可以使用默认的包管理器来安装它。具体的安装过程,请参考下面链接中的指导。
|
||||
|
||||
- [在 Linux 中如何安装 FFmpeg](https://www.ostechnix.com/install-ffmpeg-linux/)
|
||||
|
||||
Pngquant 可以从 [**AUR**][2] 中获取到。要在基于 Arch 的系统安装它,使用任意一个 AUR 帮助程序即可,例如下面示例中的 [**Yay**][3]:
|
||||
```
|
||||
$ yay -S pngquant
|
||||
```
|
||||
|
||||
在基于 Debian 的系统中,运行:
|
||||
```
|
||||
$ sudo apt install pngquant
|
||||
```
|
||||
|
||||
假如在你使用的发行版中没有 pngquant,你可以从源码编译并安装它。为此你还需要安装 **`libpng-dev`** 包。
|
||||
```
|
||||
$ git clone --recursive https://github.com/kornelski/pngquant.git
|
||||
|
||||
$ make
|
||||
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
安装完上述依赖后,再安装 Gifski。假如你已经安装了 [**Rust**][4] 编程语言,你可以使用 **cargo** 来安装它:
|
||||
```
|
||||
$ cargo install gifski
|
||||
```
|
||||
|
||||
另外,你还可以使用 [**Linuxbrew**][5] 包管理器来安装它:
|
||||
```
|
||||
$ brew install gifski
|
||||
```
|
||||
|
||||
假如你不想安装 cargo 或 Linuxbrew,可以从它的 [发布页面][6] 下载最新的二进制程序,或者手动从源码编译并安装 gifski 。
|
||||
|
||||
### 使用 Gifski 来创建高质量的 GIF 动图
|
||||
|
||||
进入你保存 PNG 图片的目录,然后运行下面的命令来从这些图片创建 GIF 动图:
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
```
|
||||
|
||||
上面的 `file.gif` 为最后输出的 gif 动图。
|
||||
|
||||
Gifski 还有其他的特性,例如:
|
||||
|
||||
* 创建特定大小的 GIF 动图
|
||||
* 在每秒钟展示特定数目的动图
|
||||
* 以特定的质量编码
|
||||
* 更快速度的编码
|
||||
* 以给定顺序来编码图片,而不是以排序的结果来编码
|
||||
|
||||
为了创建特定大小的 GIF 动图,例如宽为 800,高为 400,可以使用下面的命令:
|
||||
```
|
||||
$ gifski -o file.gif -W 800 -H 400 *.png
|
||||
|
||||
```
|
||||
|
||||
你可以设定 GIF 动图在每秒钟展示多少帧,默认值是 **20**。为此,可以运行下面的命令:
|
||||
```
|
||||
$ gifski -o file.gif --fps 1 *.png
|
||||
```
|
||||
|
||||
在上面的例子中,我指定每秒钟展示 1 帧。
|
||||
|
||||
我们还能够以特定质量(1-100 范围内)来编码。显然,更低的质量将生成更小的文件,更高的质量将生成更大的 GIF 动图文件。
|
||||
```
|
||||
$ gifski -o file.gif --quality 50 *.png
|
||||
```
|
||||
|
||||
当需要编码大量图片时,Gifski 将会花费更多时间。如果想要编码过程加快到通常速度的 3 倍左右,可以运行:
|
||||
```
|
||||
$ gifski -o file.gif --fast *.png
|
||||
```
|
||||
|
||||
请注意上面的命令产生的 GIF 动图文件将减少 10% 的质量并且文件大小也会更大。
|
||||
|
||||
如果想让图片以某个给定的顺序(而不是通过排序)精确地被编码,可以使用 **`--nosort`** 选项。
|
||||
```
|
||||
$ gifski -o file.gif --nosort *.png
|
||||
```
|
||||
|
||||
假如你不想让 GIF 循环播放,只需要使用 **`--once`** 选项即可:
|
||||
```
|
||||
$ gifski -o file.gif --once *.png
|
||||
```
|
||||
|
||||
**从视频创建 GIF 动图**
|
||||
|
||||
有时或许你想从一个视频创建 GIF 动图。这也是可以做到的,这时候 FFmpeg 便能提供帮助。首先像下面这样,将视频转换成一系列的 PNG 图片:
|
||||
```
|
||||
$ ffmpeg -i video.mp4 frame%04d.png
|
||||
```
|
||||
|
||||
上面的命令将会从 `video.mp4` 这个视频文件创建名为“frame0001.png”、“frame0002.png”、“frame0003.png”等等形式的图片(其中的 `%04d` 代表帧数),然后将这些图片保存在当前的工作目录。
|
||||
|
||||
转换好图片后,只需要运行下面的命令便可以制作 GIF 动图了:
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
```
|
||||
|
||||
想知晓更多的细节,请参考它的帮助部分:
|
||||
```
|
||||
$ gifski -h
|
||||
```
|
||||
|
||||
下面是使用 Gifski 创建的示例 GIF 动图文件。
|
||||
|
||||

|
||||
|
||||
正如你看到的那样,GIF 动图的质量看起来是非常好的。
|
||||
|
||||
好了,这就是全部内容了。希望这篇指南对你有所帮助。更多精彩内容即将呈现,请保持关注!
|
||||
|
||||
干杯吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/
|
||||
[2]: https://aur.archlinux.org/packages/pngquant/
|
||||
[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
|
||||
[5]: https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[6]: https://github.com/ImageOptim/gifski/releases
|
||||
@ -0,0 +1,538 @@
|
||||
将 Grails 与 jQuery 和 DataTables 一起使用
|
||||
======
|
||||
|
||||
本文介绍如何构建一个基于 Grails 的数据浏览器来可视化复杂的表格数据。
|
||||
|
||||

|
||||
|
||||
我是 [Grails][1] 的忠实粉丝。当然,我主要是热衷于利用命令行工具来探索和分析数据的数据人。数据人经常需要_查看_数据,这也意味着他们通常拥有优秀的数据浏览器。利用 Grails,[jQuery][2],以及 [DataTables jQuery 插件][3],我们可以制作出非常友好的表格数据浏览器。
|
||||
|
||||
[DataTables 网站][3]提供了许多“食谱风格”的教程文档,展示了如何组合一些优秀的示例应用程序,这些程序包含了完成一些非常漂亮的东西所必要的 JavaScript,HTML,以及偶尔出现的 [PHP][4]。但对于那些宁愿使用 Grails 作为后端的人来说,有必要进行一些说明示教。此外,样本程序中使用的数据是虚构公司的员工的单个平面表数据,因此处理这些复杂的表关系可以作为读者的一个练习项目。
|
||||
|
||||
本文中,我们将创建具有略微复杂的数据结构和 DataTables 浏览器的 Grails 应用程序。我们将介绍 Grails 标准 [Groovy][5]-fied Java Hibernate 标准。我已将代码托管在 [GitHub][6] 上方便大家访问,因此本文主要是对代码细节的解读。
|
||||
|
||||
首先,你需要配置 Java,Groovy,Grails 的使用环境。对于 Grails,我倾向于使用终端窗口和 [Vim][7],本文也使用它们。为获得现代 Java,建议下载并安装 Linux 发行版提供的 [Open Java Development Kit][8] (OpenJDK)(应该是 Java 8,9,10或11,撰写本文时,我正在使用 Java 8)。从我的角度来看,获取最新的 Groovy 和 Grails 的最佳方法是使用 [SKDMAN!][9]。
|
||||
|
||||
从未尝试过 Grails 的读者可能需要做一些背景资料阅读。作为初学者,推荐文章 [创建你的第一个 Grails 应用程序][10]。
|
||||
|
||||
### 获取员工信息浏览器应用程序
|
||||
|
||||
正如上文所提,我将本文中员工信息浏览器的源代码托管在 [GitHub][6]上。进一步讲,应用程序 **embrow** 是在 Linux 终端中用如下命令构建的:
|
||||
|
||||
```
|
||||
cd Projects
|
||||
grails create-app com.nuevaconsulting.embrow
|
||||
```
|
||||
|
||||
域类和单元测试创建如下:
|
||||
|
||||
```
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Position
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Office
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Employeecd embrowgrails createdomaincom.grails createdomaincom.grails createdomaincom.
|
||||
```
|
||||
|
||||
这种方式构建的域类没有属性,因此必须按如下方式编辑它们:
|
||||
|
||||
Position 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Position {
|
||||
|
||||
String name
|
||||
int starting
|
||||
|
||||
static constraints = {
|
||||
name nullable: false, blank: false
|
||||
starting nullable: false
|
||||
}
|
||||
}com.Stringint startingstatic constraintsnullableblankstarting nullable
|
||||
```
|
||||
|
||||
Office 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Office {
|
||||
|
||||
String name
|
||||
String address
|
||||
String city
|
||||
String country
|
||||
|
||||
static constraints = {
|
||||
name nullable: false, blank: false
|
||||
address nullable: false, blank: false
|
||||
city nullable: false, blank: false
|
||||
country nullable: false, blank: false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Enployee 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Employee {
|
||||
|
||||
String surname
|
||||
String givenNames
|
||||
Position position
|
||||
Office office
|
||||
int extension
|
||||
Date hired
|
||||
int salary
|
||||
static constraints = {
|
||||
surname nullable: false, blank: false
|
||||
givenNames nullable: false, blank: false
|
||||
: false
|
||||
office nullable: false
|
||||
extension nullable: false
|
||||
hired nullable: false
|
||||
salary nullable: false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
请注意,虽然 Position 和 Office 域类使用了预定义的 Groovy 类型 String 以及 int,但 Employee 域类定义了 Position 和 Office 字段(以及预定义的 Date)。这会导致创建数据库表,其中存储的 Employee 实例中包含了指向存储 Position 和 Office 实例表的引用或者外键。
|
||||
|
||||
现在你可以生成控制器,视图,以及其他各种测试组件:
|
||||
|
||||
```
|
||||
-all com.nuevaconsulting.embrow.Position
|
||||
grails generate-all com.nuevaconsulting.embrow.Office
|
||||
grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.grails generateall com.grails generateall com.
|
||||
```
|
||||
|
||||
此时,你已经准备好基本的 create-read-update-delete(CRUD)应用程序。我在**grails-app/init/com/nuevaconsulting/BootStrap.groovy**中包含了一些基础数据来填充表格。
|
||||
|
||||
如果你用如下命令来启动应用程序:
|
||||
|
||||
```
|
||||
grails run-app
|
||||
```
|
||||
|
||||
在浏览器输入**<http://localhost:8080/:>**,你将会看到如下界面:
|
||||
|
||||
![Embrow home screen][12]
|
||||
|
||||
Embrow 应用程序主界面。
|
||||
|
||||
单击 OfficeController,会跳转到如下界面:
|
||||
|
||||
![Office list][14]
|
||||
|
||||
Office 列表
|
||||
|
||||
注意,此表由 **OfficeController index** 生成,并由视图 `office/index.gsp` 显示。
|
||||
|
||||
同样,单击 **EmployeeController** 跳转到如下界面:
|
||||
|
||||
![Employee controller][16]
|
||||
|
||||
employee controller
|
||||
|
||||
好吧,这很丑陋: Position 和 Office 链接是什么?
|
||||
|
||||
上面的命令 `generate-all` 生成的视图创建了一个叫 **index.gsp** 的文件,它使用 Grails <f:table/> 标签,该标签默认会显示类名(**com.nuevaconsulting.embrow.Position**)和持久化示例标识符(**30**)。这个操作可以自定义用来产生更好看的东西,并且自动生成链接,自动生成分页以及自动生成可拍序列的一些非常简洁直观的东西。
|
||||
|
||||
但该员工信息浏览器功能也是有限的。例如,如果想查找 position 信息中包含 “dev” 的员工该怎么办?如果要组合排序,以姓氏为主排序关键字,office 为辅助排序关键字,该怎么办?或者,你需要将已排序的数据导出到电子表格或 PDF 文档以便通过电子邮件发送给无法访问浏览器的人,该怎么办?
|
||||
|
||||
jQuery DataTables 插件提供了这些所需的功能。允许你创建一个完成的表格数据浏览器。
|
||||
|
||||
### 创建员工信息浏览器视图和控制器的方法
|
||||
|
||||
要基于 jQuery DataTables 创建员工信息浏览器,你必须先完成以下两个任务:
|
||||
1. 创建 Grails 视图,其中包含启用 DataTable 所需的 HTML 和 JavaScript
|
||||
|
||||
|
||||
#### 员工信息浏览器视图
|
||||
|
||||
在目录 **embrow/grails-app/views/employee** 中,首先复制 **index.gsp** 文件,重命名为 **browser.gsp**:
|
||||
|
||||
```
|
||||
cd Projects
|
||||
cd embrow/grails-app/views/employee
|
||||
cp gsp browser.gsp
|
||||
```
|
||||
|
||||
此刻,你自定义新的 **browser.gsp** 文件来添加相关的 jQuery DataTables 代码。
|
||||
|
||||
通常,在可能的时候,我喜欢从内容提供商处获得 JavaScript 和 CSS;在下面这行后面:
|
||||
|
||||
```
|
||||
<title><g:message code="default.list.label" args="[entityName]" /></title>
|
||||
```
|
||||
|
||||
插入如下代码:
|
||||
|
||||
```
|
||||
<script src="https://code.jquery.com/jquery-2.2.4.min.js" integrity="sha256-BbhdlvQf/xTY9gja0Dq3HiwQF8LaCRTXxZKRutelT44=" crossorigin="anonymous"></script>
|
||||
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/1.10.16/css/jquery.dataTables.css">
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/1.10.16/js/jquery.dataTables.js"></script>
|
||||
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/scroller/1.4.4/css/scroller.dataTables.min.css">
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/scroller/1.4.4/js/dataTables.scroller.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/dataTables.buttons.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.flash.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.3/jszip.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/pdfmake.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/vfs_fonts.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.html5.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
|
||||
```
|
||||
|
||||
然后删除 **index.gsp** 中提供数据分页的代码:
|
||||
|
||||
```
|
||||
<div id="list-employee" class="content scaffold-list" role="main">
|
||||
<h1><g:message code="default.list.label" args="[entityName]" /></h1>
|
||||
<g:if test="${flash.message}">
|
||||
<div class="message" role="status">${flash.message}</div>
|
||||
</g:if>
|
||||
<f:table collection="${employeeList}" />
|
||||
|
||||
<div class="pagination">
|
||||
<g:paginate total="${employeeCount ?: 0}" />
|
||||
</div>
|
||||
</div>
|
||||
```
|
||||
|
||||
并插入实现 jQuery DataTables 的代码。
|
||||
|
||||
要插入的第一部分是 HTML,它将创建浏览器的基本表格结构。DataTables 与后端通信的应用程序来说,它们只提供表格页眉和页脚;DataTables JavaScript 则负责表中内容。
|
||||
|
||||
```
|
||||
<div id="employee-browser" class="content" role="main">
|
||||
<h1>Employee Browser</h1>
|
||||
<table id="employee_dt" class="display compact" style="width:99%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Surname</th>
|
||||
<th>Given name(s)</th>
|
||||
<th>Position</th>
|
||||
<th>Office</th>
|
||||
<th>Extension</th>
|
||||
<th>Hired</th>
|
||||
<th>Salary</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tfoot>
|
||||
<tr>
|
||||
<th>Surname</th>
|
||||
<th>Given name(s)</th>
|
||||
<th>Position</th>
|
||||
<th>Office</th>
|
||||
<th>Extension</th>
|
||||
<th>Hired</th>
|
||||
<th>Salary</th>
|
||||
</tr>
|
||||
</tfoot>
|
||||
</table>
|
||||
</div>
|
||||
```
|
||||
|
||||
接下来,插入一个 JavaScript 块,它主要提供三个功能:它设置页脚中显示的文本框的大小,以进行列过滤,建立 DataTables 表模型,并创建一个处理程序来进行列过滤。
|
||||
|
||||
```
|
||||
<g:javascript>
|
||||
$('#employee_dt tfoot th').each( function() {javascript
|
||||
```
|
||||
|
||||
下面的代码处理表格列底部的过滤器框的大小:
|
||||
|
||||
```
|
||||
var title = $(this).text();
|
||||
if (title == 'Extension' || title == 'Hired')
|
||||
$(this).html('<input type="text" size="5" placeholder="' + title + '?" />');
|
||||
else
|
||||
$(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
|
||||
});titletitletitletitletitle
|
||||
```
|
||||
|
||||
接下来,定义表模型。 这是提供所有表选项的地方,包括界面的滚动,而不是分页,根据 dom 字符串提供的装饰,将数据导出为 CSV 和其他格式的能力,以及建立与服务器的 Ajax 连接。 请注意,使用 Groovy GString 调用 Grails **createLink()** 的方法创建 URL,在 **EmployeeController** 中指向 **browserLister** 操作。同样有趣的是表格列的定义。此信息将发送到后端,后端查询数据库并返回相应的记录。
|
||||
|
||||
```
|
||||
var table = $('#employee_dt').DataTable( {
|
||||
"scrollY": 500,
|
||||
"deferRender": true,
|
||||
"scroller": true,
|
||||
"dom": "Brtip",
|
||||
"buttons": [ 'copy', 'csv', 'excel', 'pdf', 'print' ],
|
||||
"processing": true,
|
||||
"serverSide": true,
|
||||
"ajax": {
|
||||
"url": "${createLink(controller: 'employee', action: 'browserLister')}",
|
||||
"type": "POST",
|
||||
},
|
||||
"columns": [
|
||||
{ "data": "surname" },
|
||||
{ "data": "givenNames" },
|
||||
{ "data": "position" },
|
||||
{ "data": "office" },
|
||||
{ "data": "extension" },
|
||||
{ "data": "hired" },
|
||||
{ "data": "salary" }
|
||||
]
|
||||
});
|
||||
```
|
||||
|
||||
最后,监视过滤器列以进行更改,并使用它们来应用过滤器。
|
||||
|
||||
```
|
||||
table.columns().every(function() {
|
||||
var that = this;
|
||||
$('input', this.footer()).on('keyup change', function(e) {
|
||||
if (that.search() != this.value && 8 < e.keyCode && e.keyCode < 32)
|
||||
that.search(this.value).draw();
|
||||
});
|
||||
```
|
||||
|
||||
这就是 JavaScript,这样就完成了对视图代码的更改。
|
||||
|
||||
```
|
||||
});
|
||||
</g:javascript>
|
||||
```
|
||||
|
||||
以下是此视图创建的UI的屏幕截图:
|
||||
|
||||

|
||||
|
||||
这是另一个屏幕截图,显示了过滤和多列排序(寻找 position 包括字符 “dev” 的员工,先按 office 排序,然后按姓氏排序):
|
||||
|
||||

|
||||
|
||||
这是另一个屏幕截图,显示单击 CSV 按钮时会发生什么:
|
||||
|
||||

|
||||
|
||||
最后,这是一个截图,显示在 LibreOffice 中打开的 CSV 数据:
|
||||
|
||||

|
||||
|
||||
好的,视图部分看起来非常简单; 因此,控制器必须做所有繁重的工作,对吧? 让我们来看看…
|
||||
|
||||
#### 控制器 browserLister 操作
|
||||
|
||||
回想一下,我们看到过这个字符串
|
||||
|
||||
```
|
||||
"${createLink(controller: 'employee', action: 'browserLister')}"
|
||||
```
|
||||
|
||||
对于从 DataTables 模型中调用 Ajax 的 URL,是在 Grails 服务器上动态创建 HTML 链接,其 Grails 标记背后通过调用 [createLink()][17] 的方法实现的。这会最终产生一个指向 **EmployeeController** 的链接,位于:
|
||||
|
||||
```
|
||||
embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy
|
||||
```
|
||||
|
||||
特别是控制器方法 **browserLister()**。我在代码中留了一些 print 语句,以便在运行时能够在终端看到中间结果。
|
||||
|
||||
```
|
||||
def browserLister() {
|
||||
// Applies filters and sorting to return a list of desired employees
|
||||
```
|
||||
|
||||
首先,打印出传递给 **browserLister()** 的参数。我通常使用此代码开始构建控制器方法,以便我完全清楚我的控制器正在接收什么。
|
||||
|
||||
```
|
||||
println "employee browserLister params $params"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,处理这些参数以使它们更加有用。首先,jQuery DataTables 参数,一个名为 **jqdtParams**的 Groovy 映射:
|
||||
|
||||
```
|
||||
def jqdtParams = [:]
|
||||
params.each { key, value ->
|
||||
def keyFields = key.replace(']','').split(/\[/)
|
||||
def table = jqdtParams
|
||||
for (int f = 0; f < keyFields.size() - 1; f++) {
|
||||
def keyField = keyFields[f]
|
||||
if (!table.containsKey(keyField))
|
||||
table[keyField] = [:]
|
||||
table = table[keyField]
|
||||
}
|
||||
table[keyFields[-1]] = value
|
||||
}
|
||||
println "employee dataTableParams $jqdtParams"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,列数据,一个名为 **columnMap**的 Groovy 映射:
|
||||
|
||||
```
|
||||
def columnMap = jqdtParams.columns.collectEntries { k, v ->
|
||||
def whereTerm = null
|
||||
switch (v.data) {
|
||||
case 'extension':
|
||||
case 'hired':
|
||||
case 'salary':
|
||||
if (v.search.value ==~ /\d+(,\d+)*/)
|
||||
whereTerm = v.search.value.split(',').collect { it as Integer }
|
||||
break
|
||||
default:
|
||||
if (v.search.value ==~ /[A-Za-z0-9 ]+/)
|
||||
whereTerm = "%${v.search.value}%" as String
|
||||
break
|
||||
}
|
||||
[(v.data): [where: whereTerm]]
|
||||
}
|
||||
println "employee columnMap $columnMap"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,从 **columnMap** 中检索的所有列表,以及在视图中应如何排序这些列表,Groovy 列表分别称为 **allColumnList**和 **orderList**:
|
||||
|
||||
```
|
||||
def allColumnList = columnMap.keySet() as List
|
||||
println "employee allColumnList $allColumnList"
|
||||
def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as Integer], v.dir] }
|
||||
println "employee orderList $orderList"
|
||||
```
|
||||
|
||||
我们将使用 Grails 的 Hibernate 标准实现来实际选择要显示的元素以及它们的排序和分页。标准要求过滤器关闭; 在大多数示例中,这是作为标准实例本身的创建的一部分给出的,但是在这里我们预先定义过滤器闭包。请注意,在这种情况下,“date hired” 过滤器的相对复杂的解释被视为一年并应用于建立日期范围,并使用 **createAlias** 以允许我们进入相关类别 Position 和 Office:
|
||||
|
||||
```
|
||||
def filterer = {
|
||||
createAlias 'position', 'p'
|
||||
createAlias 'office', 'o'
|
||||
|
||||
if (columnMap.surname.where) ilike 'surname', columnMap.surname.where
|
||||
if (columnMap.givenNames.where) ilike 'givenNames', columnMap.givenNames.where
|
||||
if (columnMap.position.where) ilike 'p.name', columnMap.position.where
|
||||
if (columnMap.office.where) ilike 'o.name', columnMap.office.where
|
||||
if (columnMap.extension.where) inList 'extension', columnMap.extension.where
|
||||
if (columnMap.salary.where) inList 'salary', columnMap.salary.where
|
||||
if (columnMap.hired.where) {
|
||||
if (columnMap.hired.where.size() > 1) {
|
||||
or {
|
||||
columnMap.hired.where.each {
|
||||
between 'hired', Date.parse('yyyy/MM/dd',"${it}/01/01" as String),
|
||||
Date.parse('yyyy/MM/dd',"${it}/12/31" as String)
|
||||
}
|
||||
}
|
||||
} else {
|
||||
between 'hired', Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/01/01" as String),
|
||||
Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/12/31" as String)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
是时候应用上述内容了。第一步是获取分页代码所需的所有 Employee 实例的总数:
|
||||
|
||||
```
|
||||
def recordsTotal = Employee.count()
|
||||
println "employee recordsTotal $recordsTotal"
|
||||
```
|
||||
|
||||
接下来,将过滤器应用于 Employee 实例以获取过滤结果的计数,该结果将始终小于或等于总数(同样,这是针对分页代码):
|
||||
|
||||
```
|
||||
def c = Employee.createCriteria()
|
||||
def recordsFiltered = c.count {
|
||||
filterer.delegate = delegate
|
||||
filterer()
|
||||
}
|
||||
println "employee recordsFiltered $recordsFiltered"
|
||||
|
||||
```
|
||||
|
||||
获得这两个计数后,你还可以使用分页和排序信息获取实际过滤的实例。
|
||||
|
||||
```
|
||||
def orderer = Employee.withCriteria {
|
||||
filterer.delegate = delegate
|
||||
filterer()
|
||||
orderList.each { oi ->
|
||||
switch (oi[0]) {
|
||||
case 'surname': order 'surname', oi[1]; break
|
||||
case 'givenNames': order 'givenNames', oi[1]; break
|
||||
case 'position': order 'p.name', oi[1]; break
|
||||
case 'office': order 'o.name', oi[1]; break
|
||||
case 'extension': order 'extension', oi[1]; break
|
||||
case 'hired': order 'hired', oi[1]; break
|
||||
case 'salary': order 'salary', oi[1]; break
|
||||
}
|
||||
}
|
||||
maxResults (jqdtParams.length as Integer)
|
||||
firstResult (jqdtParams.start as Integer)
|
||||
}
|
||||
```
|
||||
|
||||
要完全清楚,JTable 中的分页代码管理三个计数:数据集中的记录总数,应用过滤器后得到的数字,以及要在页面上显示的数字(显示是滚动还是分页)。 排序应用于所有过滤的记录,并且分页应用于那些过滤的记录的块以用于显示目的。
|
||||
|
||||
接下来,处理命令返回的结果,在每行中创建指向 Employee,Position 和 Office 实例的链接,以便用户可以单击这些链接以获取相关实例的所有详细信息:
|
||||
|
||||
```
|
||||
def dollarFormatter = new DecimalFormat('$##,###.##')
|
||||
def employees = orderer.collect { employee ->
|
||||
['surname': "<a href='${createLink(controller: 'employee', action: 'show', id: employee.id)}'>${employee.surname}</a>",
|
||||
'givenNames': employee.givenNames,
|
||||
'position': "<a href='${createLink(controller: 'position', action: 'show', id: employee.position?.id)}'>${employee.position?.name}</a>",
|
||||
'office': "<a href='${createLink(controller: 'office', action: 'show', id: employee.office?.id)}'>${employee.office?.name}</a>",
|
||||
'extension': employee.extension,
|
||||
'hired': employee.hired.format('yyyy/MM/dd'),
|
||||
'salary': dollarFormatter.format(employee.salary)]
|
||||
}
|
||||
```
|
||||
|
||||
最后,创建要返回的结果并将其作为 JSON 返回,这是 jQuery DataTables 所需要的。
|
||||
|
||||
```
|
||||
def result = [draw: jqdtParams.draw, recordsTotal: recordsTotal, recordsFiltered: recordsFiltered, data: employees]
|
||||
render(result as JSON)
|
||||
}
|
||||
```
|
||||
|
||||
大功告成
|
||||
如果你熟悉 Grails,这可能看起来比你原先想象的要多,但这里没有火箭式的一步到位方法,只是很多分散的操作步骤。但是,如果你没有太多接触 Grails(或 Groovy),那么需要了解很多新东西 - 闭包,代理和构建器等等。
|
||||
|
||||
在那种情况下,从哪里开始? 最好的地方是了解 Groovy 本身,尤其是 [Groovy closures][18] 和 [Groovy delegates and builders][19]。然后再去阅读上面关于 Grails 和 Hibernate 条件查询的建议阅读文章。
|
||||
|
||||
### 结语
|
||||
|
||||
jQuery DataTables 为 Grails 制作了很棒的表格数据浏览器。对视图进行编码并不是太棘手,但DataTables 文档中提供的 PHP 示例提供的功能仅到此位置。特别是,它们不是用 Grails 程序员编写的,也不包含探索使用引用其他类(实质上是查找表)的元素的更精细的细节。
|
||||
|
||||
我使用这种方法制作了几个数据浏览器,允许用户选择要查看和累积记录计数的列,或者只是浏览数据。即使在相对适度的 VPS 上的百万行表中,性能也很好。
|
||||
|
||||
一个警告:我偶然发现了 Grails 中暴露的各种 Hibernate 标准机制的一些问题(请参阅我的其他 GitHub 代码库),因此需要谨慎和实验。如果所有其他方法都失败了,另一种方法是动态构建 SQL 字符串并执行它们。在撰写本文时,我更喜欢使用 Grails 标准,除非我遇到杂乱的子查询,但这可能只反映了我在 Hibernate 中对子查询的相对缺乏经验。
|
||||
|
||||
我希望 Grails 程序员发现本文的有趣性。请随时在下面留下评论或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://grails.org/
|
||||
[2]: https://jquery.com/
|
||||
[3]: https://datatables.net/
|
||||
[4]: http://php.net/
|
||||
[5]: http://groovy-lang.org/
|
||||
[6]: https://github.com/monetschemist/grails-datatables
|
||||
[7]: https://www.vim.org/
|
||||
[8]: http://openjdk.java.net/
|
||||
[9]: http://sdkman.io/
|
||||
[10]: http://guides.grails.org/creating-your-first-grails-app/guide/index.html
|
||||
[11]: https://opensource.com/file/410061
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screen_1.png "Embrow home screen"
|
||||
[13]: https://opensource.com/file/410066
|
||||
[14]: https://opensource.com/sites/default/files/uploads/screen_2.png "Office list screenshot"
|
||||
[15]: https://opensource.com/file/410071
|
||||
[16]: https://opensource.com/sites/default/files/uploads/screen3.png "Employee controller screenshot"
|
||||
[17]: https://gsp.grails.org/latest/ref/Tags/createLink.html
|
||||
[18]: http://groovy-lang.org/closures.html
|
||||
[19]: http://groovy-lang.org/dsls.html
|
||||
@ -0,0 +1,76 @@
|
||||
适用于小型企业的 4 个开源发票工具
|
||||
======
|
||||
用基于 web 的发票软件管理你的账单,完成收款,十分简单。
|
||||
|
||||

|
||||
|
||||
无论您开办小型企业的原因是什么,保持业务发展的关键是可以盈利。收款也就意味着向客户提供发票。
|
||||
|
||||
使用 LibreOffice Writer 或 LibreOffice Calc 提供发票很容易,但有时候你需要的不止这些。从更专业的角度看。一种跟进发票的方法。提醒你何时跟进你发出的发票。
|
||||
|
||||
在这里有各种各样的商业闭源发票管理工具。但是开源界的产品和相对应的闭源商业工具比起来,并不差,没准还更灵活。
|
||||
|
||||
让我们一起了解这 4 款基于 web 的开源发票工具,它们很适用于预算紧张的自由职业者和小型企业。2014 年,我在本文的[早期版本][1]中提到了其中两个工具。这 4 个工具用起来都很简单,并且你可以在任何设备上使用它们。
|
||||
|
||||
### Invoice Ninja
|
||||
|
||||
我不是很喜欢 ninja 这个词。尽管如此,我喜欢 [Invoice Ninja][2]。非常喜欢。它将功能融合在一个简单的界面,其中包含一组功能,可让创建,管理和向客户、消费者发送发票。
|
||||
|
||||
您可以轻松配置多个客户端,跟进付款和未结清的发票,生成报价并用电子邮件发送发票。Invoice Ninja 与其竞争对手不同,它[集成][3]了超过 40 个流行支付方式,包括 PayPal,Stripe,WePay 以及 Apple Pay。
|
||||
|
||||
[下载][4]一个可以安装到自己服务器上的版本,或者获取一个[托管版][5]的账户,都可以使用 Invoice Ninja。它有免费版,也有每月 8 美元的收费版。
|
||||
|
||||
### InvoicePlane
|
||||
|
||||
以前,有一个叫做 FusionInvoice 的漂亮的开源发票工具。有一天,FusionInvoice 的开发者将最新版本的代码设为了专有。这件事结局并不完美,因为 FusionInvoice 从 2018 年起再也不开源了。但这不代表这个工具完蛋了。它旧版本的代码依然是开源的,并且再次开发为包括 FusionInvoice 所有优点的新工具 [InvoicePlane][6]。
|
||||
|
||||
只需点几下鼠标即可制作发票。你可以根据需要将它们设为最简或者最详细。一切准备就绪时,你可以用电子邮件发送发票或者输出为 PDF 文件。你还可以为经常开发票的客户或消费者制作定期发票。
|
||||
|
||||
InvoicePlane 不仅可以生成或跟进发票。你还可以为任务或商品创制报价,跟进你销售的产品,查看确认付款,并在发票上生成报告。
|
||||
|
||||
[获取代码][7]并将其安装在你的 Web 服务器上。或者,如果你还没准备好安装它,可以[拿小样][8]试用以下。
|
||||
|
||||
### OpenSourceBilling
|
||||
|
||||
[OpenSourceBilling][9] 被它的开发者称赞为“非常简单的计费软件”,当之无愧。它拥有最简洁的交互界面,配置使用起来轻而易举。
|
||||
|
||||
OpenSourceBilling 因它的商业智能仪表盘脱颖而出,它可以跟进跟进你当前和以前的发票,以及任何没有支付的款项。它以图表的形式整理信息,使之很容易阅读。
|
||||
|
||||
你可以在发票上配置很多信息。只需点几下鼠标按几下键盘,即可添加项目、税率、客户名称以及付款条件。OpenSourceBilling 将这些信息保存在你所有的发票当中,不管新发票还是旧发票。
|
||||
|
||||
与我们之前讨论过的工具一样,OpenSourceBilling 也有可以试用的[程序小样][10]。
|
||||
|
||||
### BambooInvoice
|
||||
|
||||
当我是一个全职自由作家和顾问时,我通过 [BambooInvoice][11] 向客户收费。当它最初的开发者停止维护此软件时,我有点失望。但是 BambooInvoice 又回来了,并一如既往的好。
|
||||
|
||||
BambooInvoice 的简洁很吸引我。它只做一件事并做的很好。你可以创建并修改发票,BambooInvoice 会根据客户和分配的发票编号负责跟进。它会告诉你哪些发票是开放的或过期的。你可以在程序中通过电子邮件发送发票或者导出为 PDF 文件。你还可以生成报告密切关注收入。
|
||||
|
||||
要[安装][12]并使用 BambooInvoice,你需要一个运行 PHP 5 或更高版本的 web 服务器,并运行 MySQL 数据库。机会就在你面前,所以你很乐意去用它。
|
||||
|
||||
你又最喜欢的开源发票工具吗?请自由分享评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/open-source-invoicing-tools
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: https://opensource.com/business/14/9/4-open-source-invoice-tools
|
||||
[2]: https://www.invoiceninja.org/
|
||||
[3]: https://www.invoiceninja.com/integrations/
|
||||
[4]: https://github.com/invoiceninja/invoiceninja
|
||||
[5]: https://www.invoiceninja.com/invoicing-pricing-plans/
|
||||
[6]: https://invoiceplane.com/
|
||||
[7]: https://wiki.invoiceplane.com/en/1.5/getting-started/installation
|
||||
[8]: https://demo.invoiceplane.com/
|
||||
[9]: http://www.opensourcebilling.org/
|
||||
[10]: http://demo.opensourcebilling.org/
|
||||
[11]: https://www.bambooinvoice.net/
|
||||
[12]: https://sourceforge.net/projects/bambooinvoice/
|
||||
@ -0,0 +1,307 @@
|
||||
重启和关闭 Linux 系统的 6 个终端命令
|
||||
======
|
||||
在 Linux 管理员的日程当中, 有很多需要执行的任务, 系统的重启和关闭就被包含其中.
|
||||
|
||||
对于 Linux 管理员来说, 重启和关闭系统是其诸多风险操作中的一例, 有时候, 由于某些原因, 这些操作可能无法挽回, 他们需要更多的时间来排查问题.
|
||||
|
||||
在 Linux 命令行模式下我们可以执行这些任务. 很多时候, 由于熟悉命令行, Linux 管理员更倾向于在命令行下完成这些任务.
|
||||
|
||||
重启和关闭系统的 Linux 命令并不多, 用户需要根据需要, 选择合适的命令来完成任务.
|
||||
|
||||
以下所有命令都有其自身特点, 并允许被 Linux 管理员使用.
|
||||
|
||||
**建议阅读 :**
|
||||
|
||||
**(#)** [查看系统/服务器正常运行时间的 11 个方法][1]
|
||||
|
||||
**(#)** [Tuptime 一款为 Linux 系统保存历史记录, 统计运行时间工具][2]
|
||||
|
||||
系统重启和关闭之始, 会通知所有已登录的用户和已注册的进程. 当然, 如果会造成冲突, 系统不会允许新的用户登入.
|
||||
|
||||
执行此类操作之前, 我建议您坚持复查, 因为您只能得到很少的提示来确保这一切顺利.
|
||||
|
||||
下面陈列了一些步骤.
|
||||
|
||||
* 确保您拥有一个可以处理故障的终端, 以防之后可能会发生的问题. VMWare 可以访问物理服务器的虚拟机, IPMI, iLO 和 iDRAC.
|
||||
* 您需要通过公司的流程, 申请修改或故障的执行权直到得到许可.
|
||||
* 为安全着想, 备份重要的配置文件, 并保存到其他服务器上.
|
||||
* 验证日志文件(提前检查)
|
||||
* 和相关团队交流, 比如数据库管理团队, 应用团队等.
|
||||
* 通知数据库和应用服务人员关闭服务, 并得到确定.
|
||||
* 使用适当的命令复盘操作, 验证工作.
|
||||
* 最后, 重启系统
|
||||
* 验证日志文件, 如果一切顺利, 执行下一步操作, 如果发现任何问题, 对症排查.
|
||||
* 无论是回退版本还是运行程序, 通知相关团队提出申请.
|
||||
* 对操作做适当守候, 并将预期的一切正常的反馈给团队
|
||||
|
||||
使用下列命令执行这项任务.
|
||||
|
||||
* **`shutdown 命令:`** shutdown 命令用来为中止, 重启或切断电源
|
||||
* **`halt 命令:`** halt 命令用来为中止, 重启或切断电源
|
||||
* **`poweroff 命令:`** poweroff 命令用来为中止, 重启或切断电源
|
||||
* **`reboot 命令:`** reboot 命令用来为中止, 重启或切断电源
|
||||
* **`init 命令:`** init(initialization 的简称) 是系统启动的第一个进程.
|
||||
* **`systemctl 命令:`** systemd 是 Linux 系统和服务器的管理程序.
|
||||
|
||||
|
||||
### 方案 - 1: 如何使用 Shutdown 命令关闭和重启 Linux 系统
|
||||
|
||||
shutdown 命令用户关闭或重启本地和远程的 Linux 设备. 它为高效完成作业提供多个选项. 如果使用了 time 参数, 系统关闭的 5 分钟之前, /run/nologin 文件会被创建, 以确保后续的登录会被拒绝.
|
||||
|
||||
通用语法如下
|
||||
|
||||
```
|
||||
# shutdown [OPTION] [TIME] [MESSAGE]
|
||||
|
||||
```
|
||||
|
||||
运行下面的命令来立即关闭 Linux 设备. 它会立刻杀死所有进程, 并关闭系统.
|
||||
|
||||
```
|
||||
# shutdown -h now
|
||||
|
||||
```
|
||||
|
||||
* **`-h:`** 如果不特指 -halt 选项, 这等价于 -poweroff 选项.
|
||||
|
||||
另外我们可以使用带有 `poweroff` 选项的 `shutdown` 命令来立即关闭设备.
|
||||
|
||||
```
|
||||
# shutdown --halt now
|
||||
或者
|
||||
# shutdown -H now
|
||||
|
||||
```
|
||||
|
||||
* **`-H, --halt:`** 停止设备运行
|
||||
|
||||
另外我们可以使用带有 `poweroff` 选项的 `shutdown` 命令来立即关闭设备.
|
||||
|
||||
```
|
||||
# shutdown --poweroff now
|
||||
或者
|
||||
# shutdown -P now
|
||||
|
||||
```
|
||||
|
||||
* **`-P, --poweroff:`** 切断电源 (默认).
|
||||
|
||||
运行以下命令立即关闭 Linux 设备. 它将会立即杀死所有的进程并关闭系统.
|
||||
|
||||
```
|
||||
# shutdown -h now
|
||||
|
||||
```
|
||||
|
||||
* **`-h:`** 如果不特指 -halt 选项, 这等价于 -poweroff 选项.
|
||||
|
||||
如果您没有使用 time 选项运行下面的命令, 它将会在一分钟后执行给出的命令
|
||||
|
||||
```
|
||||
# shutdown -h
|
||||
Shutdown scheduled for Mon 2018-10-08 06:42:31 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
|
||||
|
||||
```
|
||||
|
||||
其他的登录用户都能在中断中看到如下的广播消息:
|
||||
|
||||
```
|
||||
[[email protected] ~]$
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
|
||||
|
||||
```
|
||||
|
||||
对于使用了 Halt 选项.
|
||||
|
||||
```
|
||||
# shutdown -H
|
||||
Shutdown scheduled for Mon 2018-10-08 06:37:53 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:36:53 EDT):
|
||||
|
||||
The system is going down for system halt at Mon 2018-10-08 06:37:53 EDT!
|
||||
|
||||
```
|
||||
|
||||
对于使用了 Poweroff 选项.
|
||||
|
||||
```
|
||||
# shutdown -P
|
||||
Shutdown scheduled for Mon 2018-10-08 06:40:07 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:39:07 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:40:07 EDT!
|
||||
|
||||
```
|
||||
|
||||
可以在您的终端上敲击 `Shutdown -c` 选项取消操作.
|
||||
|
||||
```
|
||||
# shutdown -c
|
||||
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:39:09 EDT):
|
||||
|
||||
The system shutdown has been cancelled at Mon 2018-10-08 06:40:09 EDT!
|
||||
|
||||
```
|
||||
|
||||
其他的登录用户都能在中断中看到如下的广播消息:
|
||||
|
||||
```
|
||||
[[email protected] ~]$
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:35 EDT):
|
||||
|
||||
The system shutdown has been cancelled at Mon 2018-10-08 06:42:35 EDT!
|
||||
|
||||
```
|
||||
|
||||
添加 time 参数, 如果你想在 `N` 秒之后执行关闭或重启操作. 这里, 您可以为所有登录用户添加自定义广播消息. 例如, 我们将在五分钟后重启设备.
|
||||
|
||||
```
|
||||
# shutdown -r +5 "To activate the latest Kernel"
|
||||
Shutdown scheduled for Mon 2018-10-08 07:13:16 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[[email protected] ~]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 07:08:16 EDT):
|
||||
|
||||
To activate the latest Kernel
|
||||
The system is going down for reboot at Mon 2018-10-08 07:13:16 EDT!
|
||||
|
||||
```
|
||||
|
||||
运行下面的命令立即重启 Linux 设备. 它会立即杀死所有进程并且重新启动系统.
|
||||
|
||||
```
|
||||
# shutdown -r now
|
||||
|
||||
```
|
||||
|
||||
* **`-r, --reboot:`** 重启设备.
|
||||
|
||||
### 方案 - 2: 如何通过 reboot 命令关闭和重启 Linux 系统
|
||||
|
||||
reboot 命令用于关闭和重启本地或远程设备. Reboot 命令拥有两个实用的选项.
|
||||
|
||||
它能够优雅的关闭和重启设备(就好像在系统菜单中惦记重启选项一样简单).
|
||||
|
||||
执行不带任何参数的 `reboot` 命令来重启 Linux 设备
|
||||
|
||||
```
|
||||
# reboot
|
||||
|
||||
```
|
||||
|
||||
执行带 `-p` 参数的 `reboot` 命令来关闭 Linux 设备或切断电源
|
||||
|
||||
```
|
||||
# reboot -p
|
||||
|
||||
```
|
||||
|
||||
* **`-p, --poweroff:`** 调用 halt 或 poweroff 命令, 切断设备电源.
|
||||
|
||||
|
||||
执行带 `-f` 参数的 `reboot` 命令来强制重启 Linux 设备(这类似按压 CPU 上的电源键)
|
||||
|
||||
```
|
||||
# reboot -f
|
||||
|
||||
```
|
||||
|
||||
* **`-f, --force:`** 立刻强制中断, 切断电源或重启
|
||||
|
||||
### 方案 - 3: 如何通过 init 命令关闭和重启 Linux 系统
|
||||
|
||||
init(initialization 的简写) 是系统启动的第一个进程.
|
||||
|
||||
他将会检查 /etc/inittab 文件并决定 linux 运行级别. 同时, 授权用户在 Linux 设备上执行关机或重启 操作. 这里存在从 0 到 6 的七个运行等级.
|
||||
|
||||
**建议阅读 :**
|
||||
**(#)** [如何检查 Linux 上所有运行的服务][3]
|
||||
|
||||
执行一下 init 命令关闭系统.
|
||||
```
|
||||
# init 0
|
||||
|
||||
```
|
||||
|
||||
* **`0:`** 中断 – 关闭系统.
|
||||
|
||||
运行下面的 init 命令重启设备
|
||||
```
|
||||
# init 6
|
||||
|
||||
```
|
||||
|
||||
* **`6:`** 重启 – 重启设备.
|
||||
|
||||
### 方案 - 4: 如何通过 halt 命令关闭和重启 Linux 系统
|
||||
|
||||
halt 命令用来切断电源或关闭远程 Linux 设备或本地主机.
|
||||
中断所有进程并关闭 cpu
|
||||
```
|
||||
# halt
|
||||
|
||||
```
|
||||
|
||||
### 方案 - 5: 如何通过 poweroff 命令关闭和重启 Linux 系统
|
||||
|
||||
poweroff 命令用来切断电源或关闭远程 Linux 设备或本地主机. Poweroff 很像 halt, 但是它可以关闭设备自身的单元(等和其他 PC 上的任何事物). 它会为 PSU 发送 ACPI 指令, 切断电源.
|
||||
|
||||
```
|
||||
# poweroff
|
||||
|
||||
```
|
||||
|
||||
### 方案 - 6: 如何通过 systemctl 命令关闭和重启 Linux 系统
|
||||
|
||||
Systemd 是一款适用于所有主流 Linux 发型版的全新 init 系统和系统管理器, 而不是传统的 SysV init 系统.
|
||||
|
||||
systemd 兼容与 SysV 和 LSB 脚本. 它能够替代 sysvinit 系统. systemd 是内核启动的第一个进程, 并持有序号为 1 的进程 PID.
|
||||
|
||||
**建议阅读 :**
|
||||
**(#)** [chkservice – 一款终端下系统单元管理工具][4]
|
||||
|
||||
它是一切进程的父进程, Fedora 15 是第一个适配安装 systemd 的发行版.
|
||||
It’s a parent process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart.
|
||||
|
||||
systemctl 是命令行下管理系统, 守护进程, 开启服务(如 start, restart, stop, enable, disable, reload & status)的主要工具.
|
||||
|
||||
systemd 使用 .service 文件而不是 bash 脚本(SysVinit 用户使用的). systemd 将所有守护进程归与自身的 Linux cgroups 用户组下, 您可以浏览 /cgroup/systemd 文件查看系统层次等级
|
||||
|
||||
```
|
||||
# systemctl halt
|
||||
# systemctl poweroff
|
||||
# systemctl reboot
|
||||
# systemctl suspend
|
||||
# systemctl hibernate
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cyleft](https://github.com/cyleft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
|
||||
[2]: https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/
|
||||
[3]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
[4]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
Loading…
Reference in New Issue
Block a user