mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
08a5d4afe8
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10639-1.html)
|
||||
[#]: subject: (Asynchronous rsync with Emacs,dired and tramp。)
|
||||
[#]: via: (https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp/)
|
||||
[#]: author: (cpbotha https://vxlabs.com/author/cpbotha/)
|
||||
@ -60,7 +60,7 @@ via: https://vxlabs.com/2018/03/30/asynchronous-rsync-with-emacs-dired-and-tramp
|
||||
作者:[cpbotha][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10640-1.html)
|
||||
[#]: subject: (SPEED TEST: x86 vs. ARM for Web Crawling in Python)
|
||||
[#]: via: (https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-in-python/)
|
||||
[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
|
||||
@ -12,7 +12,7 @@ x86 和 ARM 的 Python 爬虫速度对比
|
||||
|
||||
![][1]
|
||||
|
||||
如果你的老板给你的任务是不断地访问竞争对手的网站,把对方商品的价格记录下来,而且要纯手工操作,恐怕你会想要把整个办公室都烧掉。
|
||||
假如说,如果你的老板给你的任务是一次又一次地访问竞争对手的网站,把对方商品的价格记录下来,而且要纯手工操作,恐怕你会想要把整个办公室都烧掉。
|
||||
|
||||
之所以现在网络爬虫的影响力如此巨大,就是因为网络爬虫可以被用于追踪客户的情绪和趋向、搜寻空缺的职位、监控房地产的交易,甚至是获取 UFC 的比赛结果。除此以外,还有很多意想不到的用途。
|
||||
|
||||
@ -32,21 +32,21 @@ x86 和 ARM 的 Python 爬虫速度对比
|
||||
|
||||
ARM 是目前世界上最流行的 CPU 架构。
|
||||
|
||||
但 ARM 架构处理器在很多人眼中的地位只是作为一个节省成本的选择,而不是跑在生产环境中的处理器的首选。
|
||||
但 ARM 架构处理器在很多人眼中的地位只是作为一个省钱又省电的选择,而不是跑在生产环境中的处理器的首选。
|
||||
|
||||
然而,诞生于英国剑桥的 ARM CPU,最初是用于昂贵的 [Acorn Archimedes][4] 计算机上的,这是当时世界上最强大的计算机,它的运算速度甚至比最快的 386 还要快好几倍。
|
||||
然而,诞生于英国剑桥的 ARM CPU,最初是用于极其昂贵的 [Acorn Archimedes][4] 计算机上的,这是当时世界上最强大的桌面计算机,甚至在很长一段时间内,它的运算速度甚至比最快的 386 还要快好几倍。
|
||||
|
||||
Acorn 公司和 Commodore、Atari 的理念类似,他们认为一家伟大的计算机公司就应该制造出伟大的计算机,让人感觉有点目光短浅。而比尔盖茨的想法则有所不同,他力图在更多不同种类和价格的 x86 机器上使用他的 DOS 系统。
|
||||
|
||||
拥有大量用户基础的平台会让更多开发者开发出众多适应平台的软件,而软件资源丰富又让计算机更受用户欢迎。
|
||||
拥有大量用户基数的平台会成为第三方开发者开发软件的平台,而软件资源丰富又会让你的计算机更受用户欢迎。
|
||||
|
||||
即使是苹果公司也在这上面吃到了苦头,不得不在 x86 芯片上投入大量的财力。最终,这些芯片不再仅仅用于专业的计算任务,走进了人们的日常生活中。
|
||||
即使是苹果公司也几乎被打败。在 x86 芯片上投入大量的财力,最终,这些芯片被用于生产环境计算任务。
|
||||
|
||||
ARM 架构也并没有消失。基于 ARM 架构的芯片不仅运算速度快,同时也非常节能。因此诸如机顶盒、PDA、数码相机、MP3 播放器这些电子产品多数都会采用 ARM 架构的芯片,甚至在很多需要用电池、不配备大散热风扇的电子产品上,都可以见到 ARM 芯片的身影。
|
||||
但 ARM 架构也并没有消失。基于 ARM 架构的芯片不仅运算速度快,同时也非常节能。因此诸如机顶盒、PDA、数码相机、MP3 播放器这些电子产品多数都会采用 ARM 架构的芯片,甚至在很多需要用电池或不配备大散热风扇的电子产品上,都可以见到 ARM 芯片的身影。
|
||||
|
||||
而 ARM 则脱离 Acorn 成为了一种独立的商业模式,他们不生产实物芯片,仅仅是向芯片生产厂商出售相关的知识产权。
|
||||
而 ARM 则脱离 Acorn 成为了一种特殊的商业模式,他们不生产实物芯片,仅仅是向芯片生产厂商出售相关的知识产权。
|
||||
|
||||
因此,ARM 芯片被应用于很多手机和平板电脑上。当 Linux 被移植到这种架构的芯片上时,开源技术的大门就已经向它打开了,这才让我们今天得以在这些芯片上运行 web 爬虫程序。
|
||||
因此,这或多或少是 ARM 芯片被应用于如此之多的手机和平板电脑上的原因。当 Linux 被移植到这种架构的芯片上时,开源技术的大门就已经向它打开了,这才让我们今天得以在这些芯片上运行 web 爬虫程序。
|
||||
|
||||
#### 服务器端的 ARM
|
||||
|
||||
@ -64,11 +64,11 @@ ARM 架构也并没有消失。基于 ARM 架构的芯片不仅运算速度快
|
||||
|
||||
#### Scaleway
|
||||
|
||||
Scaleway 自身的定位是“专为开发者设计”。我觉得这个定位很准确,对于开发原型来说,Scaleway 提供的产品确实可以作为一个很好的沙盒环境。
|
||||
Scaleway 自身的定位是“专为开发者设计”。我觉得这个定位很准确,对于开发和原型设计来说,Scaleway 提供的产品确实可以作为一个很好的沙盒环境。
|
||||
|
||||
Scaleway 提供了一个简洁的页面,让用户可以快速地从主页进入 bash shell 界面。对于很多小企业、自由职业者或者技术顾问,如果想要运行 web 爬虫,这个产品毫无疑问是一个物美价廉的选择。
|
||||
Scaleway 提供了一个简洁的仪表盘页面,让用户可以快速地从主页进入 bash shell 界面。对于很多小企业、自由职业者或者技术顾问,如果想要运行 web 爬虫,这个产品毫无疑问是一个物美价廉的选择。
|
||||
|
||||
ARM 方面我们选择 [ARM64-2GB][10] 这一款服务器,每月只需要 3 欧元。它带有 4 个 Cavium ThunderX 核心,是在 2014 年推出的第一款服务器级的 ARMv8 处理器。但现在看来它已经显得有点落后了,并逐渐被更新的 ThunderX2 取代。
|
||||
ARM 方面我们选择 [ARM64-2GB][10] 这一款服务器,每月只需要 3 欧元。它带有 4 个 Cavium ThunderX 核心,这是在 2014 年推出的第一款服务器级的 ARMv8 处理器。但现在看来它已经显得有点落后了,并逐渐被更新的 ThunderX2 取代。
|
||||
|
||||
x86 方面我们选择 [1-S][11],每月的费用是 4 欧元。它拥有 2 个英特尔 Atom C3995 核心。英特尔的 Atom 系列处理器的特点是低功耗、单线程,最初是用在笔记本电脑上的,后来也被服务器所采用。
|
||||
|
||||
@ -76,43 +76,45 @@ x86 方面我们选择 [1-S][11],每月的费用是 4 欧元。它拥有 2 个
|
||||
|
||||
为了避免我不能熟练使用包管理器的尴尬局面,两方的操作系统我都会选择使用 Debian 9。
|
||||
|
||||
#### Amazon Web Services
|
||||
#### Amazon Web Services(AWS)
|
||||
|
||||
当你还在注册 AWS 账号的时候,使用 Scaleway 的用户可能已经把提交信用卡信息、启动 VPS 实例、添加sudoer、安装依赖包这一系列流程都完成了。AWS 的操作相对来说比较繁琐,甚至需要详细阅读手册才能知道你正在做什么。
|
||||
当你还在注册 AWS 账号的时候,使用 Scaleway 的用户可能已经把提交信用卡信息、启动 VPS 实例、添加 sudo 用户、安装依赖包这一系列流程都完成了。AWS 的操作相对来说比较繁琐,甚至需要详细阅读手册才能知道你正在做什么。
|
||||
|
||||
当然这也是合理的,对于一些需求复杂或者特殊的企业用户,确实需要通过详细的配置来定制合适的使用方案。
|
||||
|
||||
我们所采用的 AWS Graviton 处理器是 AWS EC2(Elastic Compute Cloud)的一部分,我会以按需实例的方式来运行,这也是最贵但最简捷的方式。AWS 同时也提供[竞价实例][12],这样可以用较低的价格运行实例,但实例的运行时间并不固定。如果实例需要长时间持续运行,还可以选择[预留实例][13]。
|
||||
我们所采用的 AWS Graviton 处理器是 AWS EC2(<ruby>弹性计算云<rt>Elastic Compute Cloud</rt></ruby>)的一部分,我会以按需实例的方式来运行,这也是最贵但最简捷的方式。AWS 同时也提供[竞价实例][12],这样可以用较低的价格运行实例,但实例的运行时间并不固定。如果实例需要长时间持续运行,还可以选择[预留实例][13]。
|
||||
|
||||
看,AWS 就是这么复杂……
|
||||
|
||||
我们分别选择 [a1.medium][14] 和 [t2.small][15] 两种型号的实例进行对比,两者都带有 2GB 内存。这个时候问题来了,手册中提到的 vCPU 又是什么?两种型号的不同之处就在于此。
|
||||
我们分别选择 [a1.medium][14] 和 [t2.small][15] 两种型号的实例进行对比,两者都带有 2GB 内存。这个时候问题来了,这里提到的 vCPU 又是什么?两种型号的不同之处就在于此。
|
||||
|
||||
对于 a1.medium 型号的实例,vCPU 是 AWS Graviton 芯片提供的单个计算核心。这个芯片由被亚马逊在 2015 收购的以色列厂商 Annapurna Labs 研发,是 AWS 独有的单线程 64 位 ARMv8 内核。它的按需价格为每小时 0.0255 美元。
|
||||
|
||||
而 t2.small 型号实例使用英特尔至强系列芯片,但我不确定具体是其中的哪一款。它每个核心有两个线程,但我们并不能用到整个核心,甚至整个线程。我们能用到的只是“20% 的基准性能,可以使用 CPU 积分突破这个基准”。这可能有一定的原因,但我没有弄懂。它的按需价格是每小时 0.023 美元。
|
||||
而 t2.small 型号实例使用英特尔至强系列芯片,但我不确定具体是其中的哪一款。它每个核心有两个线程,但我们并不能用到整个核心,甚至整个线程。
|
||||
|
||||
我们能用到的只是“20% 的基准性能,可以使用 CPU 积分突破这个基准”。这可能有一定的原因,但我没有弄懂。它的按需价格是每小时 0.023 美元。
|
||||
|
||||
在镜像库中没有 Debian 发行版的镜像,因此我选择了 Ubuntu 18.04。
|
||||
|
||||
### Beavis and Butthead Do Moz’s Top 500
|
||||
### 瘪四与大头蛋爬取 Moz 排行榜前 500 的网站
|
||||
|
||||
要测试这些 VPS 的 CPU 性能,就该使用爬虫了。一般来说都是对几个网站在尽可能短的时间里发出尽可能多的请求,但这种操作太暴力了,我的做法是只向大量网站发出少数几个请求。
|
||||
要测试这些 VPS 的 CPU 性能,就该使用爬虫了。一个方法是对几个网站在尽可能短的时间里发出尽可能多的请求,但这种操作不太礼貌,我的做法是只向大量网站发出少数几个请求。
|
||||
|
||||
为此,我编写了 `beavs.py` 这个爬虫程序(致敬我最喜欢的物理学家和制片人 Mike Judge)。这个程序会将 Moz 上排行前 500 的网站都爬取 3 层的深度,并计算 “wood” 和 “ass” 这两个单词在 HTML 文件中出现的次数。
|
||||
为此,我编写了 `beavis.py`(瘪四)这个爬虫程序(致敬我最喜欢的物理学家和制片人 Mike Judge)。这个程序会将 Moz 上排行前 500 的网站都爬取 3 层的深度,并计算 “wood” 和 “ass” 这两个单词在 HTML 文件中出现的次数。(LCTT 译注:beavis(瘪四)和 butt-head(大头蛋) 都是 Mike Judge 的动画片《瘪四与大头蛋》中的角色)
|
||||
|
||||
但我实际爬取的网站可能不足 500 个,因为我需要遵循网站的 `robot.txt` 协定,另外还有些网站需要提交 javascript 请求,也不一定会计算在内。但这已经是一个足以让 CPU 保持繁忙的爬虫任务了。
|
||||
|
||||
Python 的[全局解释器锁][16]机制会让我的程序只能用到一个 CPU 线程。为了测试多线程的性能,我需要启动多个独立的爬虫程序进程。
|
||||
|
||||
因此我还编写了 `butthead.py`,尽管 Butthead 很粗鲁,它也比 Beavis 要略胜一筹(译者注:beavis 和 butt-head 都是 Mike Judge 的动画片《Beavis and Butt-head》中的角色)。
|
||||
因此我还编写了 `butthead.py`,尽管大头蛋很粗鲁,它也总是比瘪四要略胜一筹。
|
||||
|
||||
我将整个爬虫任务拆分为多个部分,这可能会对爬取到的链接数量有一点轻微的影响。但无论如何,每次爬取都会有所不同,我们要关注的是爬取了多少个页面,以及耗时多长。
|
||||
|
||||
### 在 ARM 服务器上安装 Scrapy
|
||||
|
||||
安装 Scrapy 的过程与芯片的不同架构没有太大的关系,都是安装 pip 和相关的依赖包之后,再使用 pip 来安装Scrapy。
|
||||
安装 Scrapy 的过程与芯片的不同架构没有太大的关系,都是安装 `pip` 和相关的依赖包之后,再使用 `pip` 来安装 Scrapy。
|
||||
|
||||
据我观察,在使用 ARM 的机器上使用 pip 安装 Scrapy 确实耗时要长一点,我估计是由于需要从源码编译为二进制文件。
|
||||
据我观察,在使用 ARM 的机器上使用 `pip` 安装 Scrapy 确实耗时要长一点,我估计是由于需要从源码编译为二进制文件。
|
||||
|
||||
在 Scrapy 安装结束后,就可以通过 shell 来查看它的工作状态了。
|
||||
|
||||
@ -143,7 +145,7 @@ Scrapy 的官方文档建议[将爬虫程序的 CPU 使用率控制在 80% 到 9
|
||||
|
||||
我使用了 [top][18] 工具来查看爬虫程序运行期间的 CPU 使用率。在任务刚开始的时候,两者的 CPU 使用率都达到了 100%,但 ThunderX 大部分时间都达到了 CPU 的极限,无法看出来 Atom 的性能会比 ThunderX 超出多少。
|
||||
|
||||
通过 top 工具,我还观察了它们的内存使用情况。随着爬取任务的进行,ARM 机器的内存使用率最终达到了 14.7%,而 x86 则最终是 15%。
|
||||
通过 `top` 工具,我还观察了它们的内存使用情况。随着爬取任务的进行,ARM 机器的内存使用率最终达到了 14.7%,而 x86 则最终是 15%。
|
||||
|
||||
从运行日志还可以看出来,当 CPU 使用率到达极限时,会有大量的超时页面产生,最终导致页面丢失。这也是合理出现的现象,因为 CPU 过于繁忙会无法完整地记录所有爬取到的页面。
|
||||
|
||||
@ -156,19 +158,19 @@ Scrapy 的官方文档建议[将爬虫程序的 CPU 使用率控制在 80% 到 9
|
||||
| a1.medium | 100m 39.900s | 41,294 | 24,612.725 | 1.03605 |
|
||||
| t2.small | 78m 53.171s | 41,200 | 31,336.286 | 0.73397 |
|
||||
|
||||
为了方便比较,对于在 AWS 上跑的爬虫,我记录的指标和 Scaleway 上一致,但似乎没有达到预期的效果。这里我没有使用 top,而是使用了 AWS 提供的控制台来监控 CPU 的使用情况,从监控结果来看,我的爬虫程序并没有完全用到这两款服务器所提供的所有性能。
|
||||
为了方便比较,对于在 AWS 上跑的爬虫,我记录的指标和 Scaleway 上一致,但似乎没有达到预期的效果。这里我没有使用 `top`,而是使用了 AWS 提供的控制台来监控 CPU 的使用情况,从监控结果来看,我的爬虫程序并没有完全用到这两款服务器所提供的所有性能。
|
||||
|
||||
a1.medium 型号的机器尤为如此,在任务开始阶段,它的 CPU 使用率达到了峰值 45%,但随后一直在 20% 到 30% 之间。
|
||||
|
||||
让我有点感到意外的是,这个程序在 ARM 处理器上的运行速度相当慢,但却远未达到 Graviton CPU 能力的极限,而在 Inter 处理器上则可以在某些时候达到 CPU 能力的极限。它们运行的代码是完全相同的,处理器的不同架构可能导致了对代码的不同处理方式。
|
||||
让我有点感到意外的是,这个程序在 ARM 处理器上的运行速度相当慢,但却远未达到 Graviton CPU 能力的极限,而在 Intel Atom 处理器上则可以在某些时候达到 CPU 能力的极限。它们运行的代码是完全相同的,处理器的不同架构可能导致了对代码的不同处理方式。
|
||||
|
||||
个中原因无论是由于处理器本身的特性,还是而今是文件的编译,又或者是两者皆有,对我来说都是一个黑盒般的存在。我认为,既然在 AWS 机器上没有达到 CPU 处理能力的极限,那么只有在 Scaleway 机器上跑出来的性能数据是可以作为参考的。
|
||||
个中原因无论是由于处理器本身的特性,还是二进制文件的编译,又或者是两者皆有,对我来说都是一个黑盒般的存在。我认为,既然在 AWS 机器上没有达到 CPU 处理能力的极限,那么只有在 Scaleway 机器上跑出来的性能数据是可以作为参考的。
|
||||
|
||||
t2.small 型号的机器性能让人费解。CPU 利用率大概 20%,最高才达到 35%,是因为手册中说的“20% 的基准性能,可以使用 CPU 积分突破这个基准”吗?但在控制台中可以看到 CPU 积分并没有被消耗。
|
||||
|
||||
为了确认这一点,我安装了 [stress][19] 这个软件,然后运行了一段时间,这个时候发现居然可以把 CPU 使用率提高到 100% 了。
|
||||
|
||||
显然,我需要调整一下它们的配置文件。我将 CONCURRENT_REQUESTS 参数设置为 5000,将 REACTOR_THREADPOOL_MAXSIZE 参数设置为 120,将爬虫任务的负载调得更大。
|
||||
显然,我需要调整一下它们的配置文件。我将 `CONCURRENT_REQUESTS` 参数设置为 5000,将 `REACTOR_THREADPOOL_MAXSIZE` 参数设置为 120,将爬虫任务的负载调得更大。
|
||||
|
||||
| 机器种类 | 耗时 | 爬取页面数 | 每小时爬取页面数 | 每万页面费用(美元) |
|
||||
| ----------------------- | ----------- | ---------- | ---------------- | -------------------- |
|
||||
@ -182,7 +184,7 @@ a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升
|
||||
|
||||
现在我们看到它们的性能都差不多了。但至强处理器的线程持续跑满了 CPU,Graviton 处理器则只是有一段时间如此。可以认为 Graviton 略胜一筹。
|
||||
|
||||
然而,如果 CPU 积分耗尽了呢?这种情况下的对比可能更为公平。为了测试这种情况,我使用 stress 把所有的 CPU 积分用完,然后再次启动了爬虫任务。
|
||||
然而,如果 CPU 积分耗尽了呢?这种情况下的对比可能更为公平。为了测试这种情况,我使用 `stress` 把所有的 CPU 积分用完,然后再次启动了爬虫任务。
|
||||
|
||||
在没有 CPU 积分的情况下,CPU 使用率在 27% 就到达极限不再上升了,同时又出现了丢失页面的现象。这么看来,它的性能比负载较低的时候更差。
|
||||
|
||||
@ -190,7 +192,7 @@ a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升
|
||||
|
||||
将爬虫任务分散到不同的进程中,可以有效利用机器所提供的多个核心。
|
||||
|
||||
一开始,我将爬虫任务分布在 10 个不同的进程中并同时启动,结果发现比仅使用 1 个进程的时候还要慢。
|
||||
一开始,我将爬虫任务分布在 10 个不同的进程中并同时启动,结果发现比每个核心仅使用 1 个进程的时候还要慢。
|
||||
|
||||
经过尝试,我得到了一个比较好的方案。把爬虫任务分布在 10 个进程中,但每个核心只启动 1 个进程,在每个进程接近结束的时候,再从剩余的进程中选出 1 个进程启动起来。
|
||||
|
||||
@ -198,7 +200,7 @@ a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升
|
||||
|
||||
想要预估某个域名的页面量,一定程度上可以参考这个域名主页的链接数量。我用另一个程序来对这个数量进行了统计,然后按照降序排序。经过这样的预处理之后,只会额外增加 1 分钟左右的时间。
|
||||
|
||||
结果,爬虫运行的总耗时找过了两个小时!毕竟把链接最多的域名都堆在同一个进程中也存在一定的弊端。
|
||||
结果,爬虫运行的总耗时超过了两个小时!毕竟把链接最多的域名都堆在同一个进程中也存在一定的弊端。
|
||||
|
||||
针对这个问题,也可以通过调整各个进程爬取的域名数量来进行优化,又或者在排序之后再作一定的修改。不过这种优化可能有点复杂了。
|
||||
|
||||
@ -225,7 +227,9 @@ a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升
|
||||
|
||||
### 结论
|
||||
|
||||
从上面的数据来看,不同架构的 CPU 性能和它们的问世时间没有直接的联系,AWS Graviton 是单线程情况下性能最佳的。
|
||||
从上面的数据来看,对于性能而言,CPU 的架构并没有它们的问世时间重要,2018 年生产的 AWS Graviton 是单线程情况下性能最佳的。
|
||||
|
||||
你当然可以说按核心来比,Xeon 仍然赢了。但是,你不但需要计算美元的变化,甚至还要计算线程数。
|
||||
|
||||
另外在性能方面 2017 年生产的 Atom 轻松击败了 2014 年生产的 ThunderX,而 ThunderX 则在性价比方面占优。当然,如果你使用 AWS 的机器的话,还是使用 Graviton 吧。
|
||||
|
||||
@ -243,7 +247,7 @@ a1.medium 型号机器的 CPU 使用率在爬虫任务开始后 5 分钟飙升
|
||||
|
||||
要运行这些代码,需要预先安装 Scrapy,并且需要 [Moz 上排名前 500 的网站][21]的 csv 文件。如果要运行 `butthead.py`,还需要安装 [psutil][22] 这个库。
|
||||
|
||||
##### beavis.py
|
||||
*beavis.py*
|
||||
|
||||
```
|
||||
import scrapy
|
||||
@ -347,7 +351,7 @@ if __name__ == '__main__':
|
||||
print('Uh huhuhuhuh. It said wood ' + str(wood) + ' times.')
|
||||
```
|
||||
|
||||
##### butthead.py
|
||||
*butthead.py*
|
||||
|
||||
```
|
||||
import scrapy, time, psutil
|
||||
@ -494,7 +498,7 @@ via: https://blog.dxmtechsupport.com.au/speed-test-x86-vs-arm-for-web-crawling-i
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,148 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (6 steps to stop ethical debt in AI product development)
|
||||
[#]: via: (https://opensource.com/article/19/3/ethical-debt-ai-product-development)
|
||||
[#]: author: (Lauren Maffeo https://opensource.com/users/lmaffeo)
|
||||
|
||||
6 steps to stop ethical debt in AI product development
|
||||
======
|
||||
|
||||
Machine bias in artificial intelligence is a known and unavoidable problem—but it is not unmanageable.
|
||||
|
||||
![old school calculator][1]
|
||||
|
||||
It's official: artificial intelligence (AI) isn't the unbiased genius we want it to be.
|
||||
|
||||
Alphabet (Google's parent company) used its latest annual report [to warn][2] that ethical concerns about its products might hurt future revenue. Entrepreneur Joy Buolamwini established the [Safe Face Pledge][3] to prevent abuse of facial analysis technology.
|
||||
|
||||
And years after St. George's Hospital Medical School in London was found to have used AI that inadvertently [screened out qualified female candidates][4], Amazon scrapped a recruiting tool last fall after machine learning (ML) specialists found it [doing the same thing][5].
|
||||
|
||||
We've learned the hard way that technologies built with AI are biased like people. Left unchecked, the datasets used to train such products can pose [life-or-death consequences][6] for their end users.
|
||||
|
||||
For example, imagine a self-driving car that can't recognize commands from people with certain accents. If the dataset used to train the technology powering that car isn't exposed to enough voice variations and inflections, it risks not recognizing all its users as fully human.
|
||||
|
||||
Here's the good news: Machine bias in AI is unavoidable—but it is _not_ unmanageable. Just like product and development teams work to reduce technical debt, you can [reduce the risk of ethical debt][7] as well.
|
||||
|
||||
Here are six steps that your technical team can start taking today:
|
||||
|
||||
### 1\. Document your priorities upfront
|
||||
|
||||
Reducing ethical debt within your product will require you to answer two key questions in the product specification phase:
|
||||
|
||||
* Which methods of fairness will you use?
|
||||
* How will you prioritize them?
|
||||
|
||||
|
||||
|
||||
If your team is building a product based on ML, it's not enough to reactively fix bugs or pull products from shelves. Instead, answer these questions [in your tech spec][8] so that they're included from the start of your product lifecycle.
|
||||
|
||||
### 2\. Train your data under fairness constraints
|
||||
|
||||
This step is tough because when you try to control or eliminate both direct and indirect bias, you'll find yourself in a Catch-22.
|
||||
|
||||
If you train exclusively on non-sensitive attributes, you eliminate direct discrimination but introduce or reinforce indirect bias.
|
||||
|
||||
However, if you train separate classifiers for each sensitive feature, you reintroduce direct discrimination.
|
||||
|
||||
Another challenge is that detection can occur only after you've trained your model. When this occurs, the only recourse is to scrap the model and retrain it from scratch.
|
||||
|
||||
To reduce these risks, don't just measure average strengths of acceptance and rejection across sensitive groups. Instead, use limits to determine what is or isn't included in the model you're training. When you do this, discrimination tests are expressed as restrictions and limitations on the learning process.
|
||||
|
||||
### 3\. Monitor your datasets throughout the product lifecycle
|
||||
|
||||
Developers build training sets based on data they hope the model will encounter. But many don't monitor the data their creations receive from the real world.
|
||||
|
||||
ML products are unique in that they're continuously taking in data. New data allows the algorithms powering these products to keep refining their results.
|
||||
|
||||
But such products often encounter data in deployment that differs from what they were trained on in production. It's also not uncommon for the algorithm to be updated without the model itself being revalidated.
|
||||
|
||||
This risk will decrease if you appoint someone to monitor the source, history, and context of the data in your algorithm. This person should conduct continuous audits to find unacceptable behavior.
|
||||
|
||||
Bias should be reduced as much as possible while maintaining an acceptable level of accuracy, as defined in the product specification. If unacceptable biases or behaviors are detected, the model should be rolled back to an earlier state prior to the first time you saw bias.
|
||||
|
||||
### 4\. Use tagged training data
|
||||
|
||||
We live in a world with trillions of images and videos at our fingertips, but most neural networks can't use this data for one reason: Most of it isn't tagged.
|
||||
|
||||
Tagging refers to which classes are present in an image and their locations. When you tag an image, you share which classes are present and where they're located.
|
||||
|
||||
This sounds simple—until you realize how much work it would take to draw shapes around every single person in a photo of a crowd or a box around every single person on a highway.
|
||||
|
||||
Even if you succeeded, you might rush your tagging and draw your shapes sloppily, leading to a poorly trained neural network.
|
||||
|
||||
The good news is that more products are coming to market so they can decrease the time and cost of tagging.
|
||||
|
||||
As one example, [Brain Builder][9] is a data annotation product from Neurala that uses open source frameworks like TensorFlow and Caffe. Its goal is to help users [manage and annotate their training data][10]. It also aims to bring diverse class examples to datasets—another key step in data training.
|
||||
|
||||
### 5\. Use diverse class examples
|
||||
|
||||
Training data needs positive and negative examples of classes. If you want specific classes of objects, you need negative examples as well. This (hopefully) mimics the data that the algorithm will encounter in the wild.
|
||||
|
||||
Consider the example of “homes” within a dataset. If the algorithm contains only images of homes in North America, it won't know to recognize homes in Japan, Morocco, or other international locations. Its concept of a “home” is thus limited.
|
||||
|
||||
Neurala warns, "Most AI applications require thousands of images to be tagged, and since data tagging cost is proportional to the time spent tagging, this step alone often costs tens to hundreds of thousands of dollars per project."
|
||||
|
||||
Luckily, 2018 saw a strong increase in the number of open source AI datasets. Synced has a helpful [roundup of 10 datasets][11]—from multi-label images to semantic parsing—that were open sourced last year. If you're looking for datasets by industry, GitHub [has a longer list][12].
|
||||
|
||||
### 6\. Focus on the subject, not the context
|
||||
|
||||
Tech leaders in monitoring ML datasets should aim to understand how the algorithm classifies data. That's because AI sometimes focuses on irrelevant attributes that are shared by several targets in the training set.
|
||||
|
||||
Let's start by looking at the biased training set below. Wolves were tagged standing in snow, but the model wasn't shown images of dogs. So, when dogs were introduced, the model started tagging them as wolves because both animals were standing in snow. In this case, the AI put too much emphasis on the context (a snowy backdrop).
|
||||
|
||||
![Wolves in snow][13]
|
||||
|
||||
Source: [Gartner][14] (full research available for clients)
|
||||
|
||||
By contrast, here is a training set from Brain Builder that is focused on the subject dogs. When monitoring your own training set, make sure the AI is giving more weight to the subject of each image. If you saw an image classifier state that one of the dogs below is a wolf, you would need to know which aspects of the input led to this misclassification. This is a sign to check your training set and confirm that the data is accurate.
|
||||
|
||||
![Dogs training set][15]
|
||||
|
||||
Source: [Brain Builder][16]
|
||||
|
||||
Reducing ethical debt isn't just the “right thing to do”—it also reduces _technical_ debt. Since programmatic bias is so tough to detect, working to reduce it, from the start of your lifecycle, will save you the need to retrain models from scratch.
|
||||
|
||||
This isn't an easy or perfect job; tech teams will have to make tradeoffs between fairness and accuracy. But this is the essence of product management: compromises based on what's best for the product and its end users.
|
||||
|
||||
Strategy is the soul of all strong products. If your team includes measures of fairness and algorithmic priorities from the start, you'll sail ahead of your competition.
|
||||
|
||||
* * *
|
||||
|
||||
_Lauren Maffeo will present_ [_Erase Unconscious Bias From Your AI Datasets_][17] _at[DrupalCon][18] in Seattle, April 8-12, 2019._
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/ethical-debt-ai-product-development
|
||||
|
||||
作者:[Lauren Maffeo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lmaffeo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/math_money_financial_calculator_colors.jpg?itok=_yEVTST1 (old school calculator)
|
||||
[2]: https://www.yahoo.com/news/google-warns-rise-ai-may-181710642.html?soc_src=mail&soc_trk=ma
|
||||
[3]: https://www.safefacepledge.org/
|
||||
[4]: https://futurism.com/ai-bias-black-box
|
||||
[5]: https://uk.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUKKCN1MK08G
|
||||
[6]: https://opensource.com/article/18/10/open-source-classifiers-ai-algorithms
|
||||
[7]: https://thenewstack.io/tech-ethics-new-years-resolution-dont-build-software-you-will-regret/
|
||||
[8]: https://eng.lyft.com/awesome-tech-specs-86eea8e45bb9
|
||||
[9]: https://www.neurala.com/tech
|
||||
[10]: https://www.roboticsbusinessreview.com/ai/brain-builder-neurala-video-annotation/
|
||||
[11]: https://medium.com/syncedreview/2018-in-review-10-open-sourced-ai-datasets-696b3b49801f
|
||||
[12]: https://github.com/awesomedata/awesome-public-datasets
|
||||
[13]: https://opensource.com/sites/default/files/uploads/wolves_in_snow.png (Wolves in snow)
|
||||
[14]: https://www.gartner.com/doc/3889586/control-bias-eliminate-blind-spots
|
||||
[15]: https://opensource.com/sites/default/files/uploads/ai_ml_canine_recognition.png (Dogs training set)
|
||||
[16]: https://www.neurala.com/
|
||||
[17]: https://events.drupal.org/seattle2019/sessions/erase-unconscious-bias-your-ai-datasets
|
||||
[18]: https://events.drupal.org/seattle2019
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
iWant – The Decentralized Peer To Peer File Sharing Commandline Application
|
||||
======
|
||||
|
||||
|
||||
@ -1,242 +0,0 @@
|
||||
tomjlw is translating
|
||||
Python ChatOps libraries: Opsdroid and Errbot
|
||||
======
|
||||
|
||||

|
||||
This article was co-written with [Lacey Williams Henschel][1].
|
||||
|
||||
ChatOps is conversation-driven development. The idea is you can write code that is executed in response to something typed in a chat window. As a developer, you could use ChatOps to merge pull requests from Slack, automatically assign a support ticket to someone from a received Facebook message, or check the status of a deployment through IRC.
|
||||
|
||||
In the Python world, the most widely used ChatOps libraries are Opsdroid and Errbot. In this month's Python column, let's chat about what it's like to use them, what each does well, and how to get started with them.
|
||||
|
||||
### Opsdroid
|
||||
|
||||
[Opsdroid][2] is a relatively young (since 2016) open source chatbot library written in Python. It has good documentation, a great tutorial, and includes plugins to help you connect to popular chat services.
|
||||
|
||||
#### What's built in
|
||||
|
||||
The library itself doesn't ship with everything you need to get started, but this is by design. The lightweight framework encourages you to enable its existing connectors (what Opsdroid calls the plugins that help you connect to chat services) or write your own, but it doesn't weigh itself down by shipping with connectors you may not need. You can easily enable existing Opsdroid connectors for:
|
||||
|
||||
|
||||
+ The command line
|
||||
+ Cisco Spark
|
||||
+ Facebook
|
||||
+ GitHub
|
||||
+ Matrix
|
||||
+ Slack
|
||||
+ Telegram
|
||||
+ Twitter
|
||||
+ Websockets
|
||||
|
||||
|
||||
Opsdroid calls the functions the chatbot performs "skills." Skills are `async` Python functions and use Opsdroid's matching decorators, called "matchers." You can configure your Opsdroid project to use skills from the same codebase your configuration file is in or import skills from outside public or private repositories.
|
||||
|
||||
You can enable some existing Opsdroid skills as well, including [seen][3], which tells you when a specific user was last seen by the bot, and [weather][4], which will report the weather to the user.
|
||||
|
||||
Finally, Opdroid allows you to configure databases using its existing database modules. Current databases with Opsdroid support include:
|
||||
|
||||
|
||||
+ Mongo
|
||||
+ Redis
|
||||
+ SQLite
|
||||
|
||||
|
||||
You configure databases, skills, and connectors in the `configuration.yaml` file in your Opsdroid project.
|
||||
|
||||
#### Opsdroid pros
|
||||
|
||||
**Docker support:** Opsdroid is meant to work well in Docker from the get-go. Docker instructions are part of its [installation documentation][5]. Using Opsdroid with Docker Compose is also simple: Set up Opsdroid as a service and when you run `docker-compose up`, your Opsdroid service will start and your chatbot will be ready to chat.
|
||||
```
|
||||
version: "3"
|
||||
|
||||
|
||||
|
||||
services:
|
||||
|
||||
opsdroid:
|
||||
|
||||
container_name: opsdroid
|
||||
|
||||
build:
|
||||
|
||||
context: .
|
||||
|
||||
dockerfile: Dockerfile
|
||||
|
||||
```
|
||||
|
||||
**Lots of connectors:** Opsdroid supports nine connectors to services like Slack and GitHub out of the box; all you need to do is enable those connectors in your configuration file and pass necessary tokens or API keys. For example, to enable Opsdroid to post in a Slack channel named `#updates`, add this to the `connectors` section of your configuration file:
|
||||
```
|
||||
- name: slack
|
||||
|
||||
api-token: "this-is-my-token"
|
||||
|
||||
default-room: "#updates"
|
||||
|
||||
```
|
||||
|
||||
You will have to [add a bot user][6] to your Slack workspace before configuring Opsdroid to connect to Slack.
|
||||
|
||||
If you need to connect to a service that Opsdroid does not support, there are instructions for adding your own connectors in the [docs][7].
|
||||
|
||||
**Pretty good docs.** Especially for a young-ish library in active development, Opsdroid's docs are very helpful. The docs include a [tutorial][8] that leads you through creating a couple of different basic skills. The Opsdroid documentation on [skills][9], [connectors][7], [databases][10], and [matchers][11] is also clear.
|
||||
|
||||
The repositories for its supported skills and connectors provide helpful example code for when you start writing your own custom skills and connectors.
|
||||
|
||||
**Natural language processing:** Opsdroid supports regular expressions for its skills, but also several NLP APIs, including [Dialogflow][12], [luis.ai][13], [Recast.AI][14], and [wit.ai][15].
|
||||
|
||||
#### Possible Opsdroid concern
|
||||
|
||||
Opsdroid doesn't yet enable the full features of some of its connectors. For example, the Slack API allows you to add color bars, images, and other "attachments" to your message. The Opsdroid Slack connector doesn't enable the "attachments" feature, so you would need to write a custom Slack connector if those features were important to you. If a connector is missing a feature you need, though, Opsdroid would welcome your [contribution][16]. The docs could use some more examples, especially of expected use cases.
|
||||
|
||||
#### Example usage
|
||||
|
||||
`hello/__init__.py`
|
||||
```
|
||||
from opsdroid.matchers import match_regex
|
||||
|
||||
import random
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@match_regex(r'hi|hello|hey|hallo')
|
||||
|
||||
async def hello(opsdroid, config, message):
|
||||
|
||||
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
|
||||
|
||||
await message.respond(text)
|
||||
|
||||
```
|
||||
|
||||
`configuration.yaml`
|
||||
```
|
||||
connectors:
|
||||
|
||||
- name: websocket
|
||||
|
||||
|
||||
|
||||
skills:
|
||||
|
||||
|
||||
|
||||
- name: hello
|
||||
|
||||
repo: "https://github.com/<user_id>/hello-skill"
|
||||
|
||||
```
|
||||
|
||||
### Errbot
|
||||
|
||||
[Errbot][17] is a batteries-included open source chatbot. Errbot was released in 2012 and has everything anyone would expect from a mature project, including good documentation, a great tutorial, and plenty of plugins to help you connect to existing popular chat services.
|
||||
|
||||
#### What's built in
|
||||
|
||||
Unlike Opsdroid, which takes a more lightweight approach, Errbot ships with everything you need to build a customized bot safely.
|
||||
|
||||
Errbot includes support for XMPP, IRC, Slack, Hipchat, and Telegram services natively. It lists support for 10 other services through community-supplied backends.
|
||||
|
||||
#### Errbot pros
|
||||
|
||||
**Good docs:** Errbot's docs are mature and easy to use.
|
||||
|
||||
**Dynamic plugin architecture:** Errbot allow you to securely install, uninstall, update, enable, and disable plugins by chatting with the bot. This makes development and adding features easy. For the security conscious, this can all be locked down thanks to Errbot's granular permission system.
|
||||
|
||||
Errbot uses your plugin docstrings to generate documentation for available commands when someone types `!help`, which makes it easier to know what each command does.
|
||||
|
||||
**Built-in administration and security:** Errbot allows you to restrict lists of users who have administrative rights and even has fine-grained access controls. For example, you can restrict which commands may be called by specific users and/or specific rooms.
|
||||
|
||||
**Extensive plugin framework:** Errbot supports hooks, callbacks, subcommands, webhooks, polling, and many [more features][18]. If those aren't enough, you can even write [Dynamic plugins][19]. This feature is useful if you want to enable chat commands based on what commands are available on a remote server.
|
||||
|
||||
**Ships with a testing framework:** Errbot supports [pytest][20] and ships with some useful utilities that make testing your plugins easy and possible. Its "[testing your plugins][21]" docs are well thought out and provide enough to get started.
|
||||
|
||||
#### Possible Errbot concerns
|
||||
|
||||
**Initial !:** By default, Errbot commands are issued starting with an exclamation mark (`!help` and `!hello`). Some people may like this, but others may find it annoying. Thankfully, this is easy to turn off.
|
||||
|
||||
**Plugin metadata:** At first, Errbot's [Hello World][22] plugin example seems easy to use. However, I couldn't get my plugin to load until I read further into the tutorial and discovered that I also needed a `.plug` file, a file Errbot uses to load plugins. This is a pretty minor nitpick, but it wasn't obvious to me until I dug further into the docs.
|
||||
|
||||
#### Example usage
|
||||
|
||||
`hello.py`
|
||||
```
|
||||
import random
|
||||
|
||||
from errbot import BotPlugin, botcmd
|
||||
|
||||
|
||||
|
||||
class Hello(BotPlugin):
|
||||
|
||||
|
||||
|
||||
@botcmd
|
||||
|
||||
def hello(self, msg, args):
|
||||
|
||||
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
|
||||
|
||||
return text
|
||||
|
||||
```
|
||||
|
||||
`hello.plug`
|
||||
```
|
||||
[Core]
|
||||
|
||||
Name = Hello
|
||||
|
||||
Module = hello
|
||||
|
||||
|
||||
|
||||
[Python]
|
||||
|
||||
Version = 2+
|
||||
|
||||
|
||||
|
||||
[Documentation]
|
||||
|
||||
Description = Example "Hello" plugin
|
||||
|
||||
```
|
||||
|
||||
Have you used Errbot or Opsdroid? If so, please leave a comment with your impressions on these tools.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/python-chatops-libraries-opsdroid-and-errbot
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laceynwilliams
|
||||
[1]:https://opensource.com/users/laceynwilliams
|
||||
[2]:https://opsdroid.github.io/
|
||||
[3]:https://github.com/opsdroid/skill-seen
|
||||
[4]:https://github.com/opsdroid/skill-weather
|
||||
[5]:https://opsdroid.readthedocs.io/en/stable/#docker
|
||||
[6]:https://api.slack.com/bot-users
|
||||
[7]:https://opsdroid.readthedocs.io/en/stable/extending/connectors/
|
||||
[8]:https://opsdroid.readthedocs.io/en/stable/tutorials/introduction/
|
||||
[9]:https://opsdroid.readthedocs.io/en/stable/extending/skills/
|
||||
[10]:https://opsdroid.readthedocs.io/en/stable/extending/databases/
|
||||
[11]:https://opsdroid.readthedocs.io/en/stable/matchers/overview/
|
||||
[12]:https://opsdroid.readthedocs.io/en/stable/matchers/dialogflow/
|
||||
[13]:https://opsdroid.readthedocs.io/en/stable/matchers/luis.ai/
|
||||
[14]:https://opsdroid.readthedocs.io/en/stable/matchers/recast.ai/
|
||||
[15]:https://opsdroid.readthedocs.io/en/stable/matchers/wit.ai/
|
||||
[16]:https://opsdroid.readthedocs.io/en/stable/contributing/
|
||||
[17]:http://errbot.io/en/latest/
|
||||
[18]:http://errbot.io/en/latest/features.html#extensive-plugin-framework
|
||||
[19]:http://errbot.io/en/latest/user_guide/plugin_development/dynaplugs.html
|
||||
[20]:http://pytest.org/
|
||||
[21]:http://errbot.io/en/latest/user_guide/plugin_development/testing.html
|
||||
[22]:http://errbot.io/en/latest/index.html#simple-to-build-upon
|
||||
@ -1,58 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Cypht, an open source email client)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-cypht-email)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Cypht, an open source email client
|
||||
======
|
||||
Integrate your email and news feeds into one view with Cypht, the fourth in our series on 19 open source tools that will make you more productive in 2019.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the fourth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Cypht
|
||||
|
||||
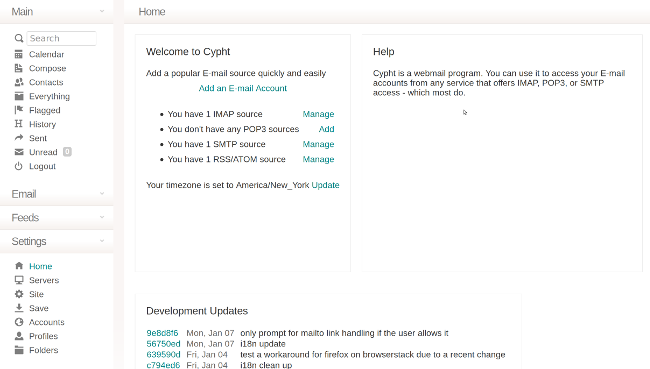
We spend a lot of time dealing with email, and effectively [managing your email][1] can make a huge impact on your productivity. Programs like Thunderbird, Kontact/KMail, and Evolution all seem to have one thing in common: they seek to duplicate the functionality of Microsoft Outlook, which hasn't really changed in the last 10 years or so. Even the [console standard-bearers][2] like Mutt and Cone haven't changed much in the last decade.
|
||||
|
||||
|
||||
|
||||
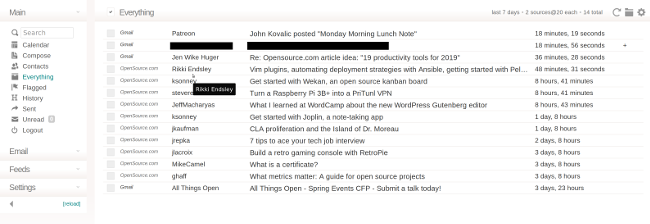
[Cypht][3] is a simple, lightweight, and modern webmail client that aggregates several accounts into a single view. Along with email accounts, it includes Atom/RSS feeds. It makes reading items from these different sources very simple by using an "Everything" screen that shows not just the mail from your inbox, but also the newest articles from your news feeds.
|
||||
|
||||
|
||||
|
||||
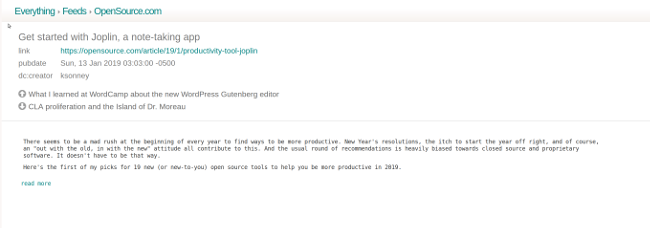
It uses a simplified version of HTML messages to display mail or you can set it to view a plain-text version. Since Cypht doesn't load images from remote sources (to help maintain security), HTML rendering can be a little rough, but it does enough to get the job done. You'll get plain-text views with most rich-text mail—meaning lots of links and hard to read. I don't fault Cypht, since this is really the email senders' doing, but it does detract a little from the reading experience. Reading news feeds is about the same, but having them integrated with your email accounts makes it much easier to keep up with them (something I sometimes have issues with).
|
||||
|
||||
|
||||
|
||||
Users can use a preconfigured mail server and add any additional servers they use. Cypht's customization options include plain-text vs. HTML mail display, support for multiple profiles, and the ability to change the theme (and make your own). You have to remember to click the "Save" button on the left navigation bar, though, or your custom settings will disappear after that session. If you log out and back in without saving, all your changes will be lost and you'll end up with the settings you started with. This does make it easy to experiment, and if you need to reset things, simply logging out without saving will bring back the previous setup when you log back in.
|
||||
|
||||
|
||||
|
||||
[Installing Cypht][4] locally is very easy. While it is not in a container or similar technology, the setup instructions were very clear and easy to follow and didn't require any changes on my part. On my laptop, it took about 10 minutes from starting the installation to logging in for the first time. A shared installation on a server uses the same steps, so it should be about the same.
|
||||
|
||||
In the end, Cypht is a fantastic alternative to desktop and web-based email clients with a simple interface to help you handle your email quickly and efficiently.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-cypht-email
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/7/email-alternatives-thunderbird
|
||||
[2]: https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
|
||||
[3]: https://cypht.org/
|
||||
[4]: https://cypht.org/install.html
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
331
sources/tech/20190318 10 Python image manipulation tools.md
Normal file
331
sources/tech/20190318 10 Python image manipulation tools.md
Normal file
@ -0,0 +1,331 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (10 Python image manipulation tools)
|
||||
[#]: via: (https://opensource.com/article/19/3/python-image-manipulation-tools)
|
||||
[#]: author: (Parul Pandey https://opensource.com/users/parul-pandey)
|
||||
|
||||
10 Python image manipulation tools
|
||||
======
|
||||
|
||||
These Python libraries provide an easy and intuitive way to transform images and make sense of the underlying data.
|
||||
|
||||
![][1]
|
||||
|
||||
Today's world is full of data, and images form a significant part of this data. However, before they can be used, these digital images must be processed—analyzed and manipulated in order to improve their quality or extract some information that can be put to use.
|
||||
|
||||
Common image processing tasks include displays; basic manipulations like cropping, flipping, rotating, etc.; image segmentation, classification, and feature extractions; image restoration; and image recognition. Python is an excellent choice for these types of image processing tasks due to its growing popularity as a scientific programming language and the free availability of many state-of-the-art image processing tools in its ecosystem.
|
||||
|
||||
This article looks at 10 of the most commonly used Python libraries for image manipulation tasks. These libraries provide an easy and intuitive way to transform images and make sense of the underlying data.
|
||||
|
||||
### 1\. scikit-image
|
||||
|
||||
**[**scikit** -image][2]** is an open source Python package that works with [NumPy][3] arrays. It implements algorithms and utilities for use in research, education, and industry applications. It is a fairly simple and straightforward library, even for those who are new to Python's ecosystem. The code is high-quality, peer-reviewed, and written by an active community of volunteers.
|
||||
|
||||
#### Resources
|
||||
|
||||
scikit-image is very well [documented][4] with a lot of examples and practical use cases.
|
||||
|
||||
#### Usage
|
||||
|
||||
The package is imported as **skimage** , and most functions are found within the submodules.
|
||||
|
||||
Image filtering:
|
||||
|
||||
```
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
from skimage import data,filters
|
||||
|
||||
image = data.coins() # ... or any other NumPy array!
|
||||
edges = filters.sobel(image)
|
||||
plt.imshow(edges, cmap='gray')
|
||||
```
|
||||
|
||||
![Image filtering in scikit-image][6]
|
||||
|
||||
Template matching using the [match_template][7] function:
|
||||
|
||||
![Template matching in scikit-image][9]
|
||||
|
||||
You can find more examples in the [gallery][10].
|
||||
|
||||
### 2\. NumPy
|
||||
|
||||
[**NumPy**][11] is one of the core libraries in Python programming and provides support for arrays. An image is essentially a standard NumPy array containing pixels of data points. Therefore, by using basic NumPy operations, such as slicing, masking, and fancy indexing, you can modify the pixel values of an image. The image can be loaded using **skimage** and displayed using Matplotlib.
|
||||
|
||||
#### Resources
|
||||
|
||||
A complete list of resources and documentation is available on NumPy's [official documentation page][11].
|
||||
|
||||
#### Usage
|
||||
|
||||
Using Numpy to mask an image:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
from skimage import data
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
image = data.camera()
|
||||
type(image)
|
||||
numpy.ndarray #Image is a NumPy array:
|
||||
|
||||
mask = image < 87
|
||||
image[mask]=255
|
||||
plt.imshow(image, cmap='gray')
|
||||
```
|
||||
|
||||
![NumPy][13]
|
||||
|
||||
### 3\. SciPy
|
||||
|
||||
**[SciPy][14]** is another of Python's core scientific modules (like NumPy) and can be used for basic image manipulation and processing tasks. In particular, the submodule [**scipy.ndimage**][15] (in SciPy v1.1.0) provides functions operating on n-dimensional NumPy arrays. The package currently includes functions for linear and non-linear filtering, binary morphology, B-spline interpolation, and object measurements.
|
||||
|
||||
#### Resources
|
||||
|
||||
For a complete list of functions provided by the **scipy.ndimage** package, refer to the [documentation][16].
|
||||
|
||||
#### Usage
|
||||
|
||||
Using SciPy for blurring using a [Gaussian filter][17]:
|
||||
```
|
||||
from scipy import misc,ndimage
|
||||
|
||||
face = misc.face()
|
||||
blurred_face = ndimage.gaussian_filter(face, sigma=3)
|
||||
very_blurred = ndimage.gaussian_filter(face, sigma=5)
|
||||
|
||||
#Results
|
||||
plt.imshow(<image to be displayed>)
|
||||
```
|
||||
|
||||
![Using a Gaussian filter in SciPy][19]
|
||||
|
||||
### 4\. PIL/Pillow
|
||||
|
||||
**PIL** (Python Imaging Library) is a free library for the Python programming language that adds support for opening, manipulating, and saving many different image file formats. However, its development has stagnated, with its last release in 2009. Fortunately, there is [**Pillow**][20], an actively developed fork of PIL, that is easier to install, runs on all major operating systems, and supports Python 3. The library contains basic image processing functionality, including point operations, filtering with a set of built-in convolution kernels, and color-space conversions.
|
||||
|
||||
#### Resources
|
||||
|
||||
The [documentation][21] has instructions for installation as well as examples covering every module of the library.
|
||||
|
||||
#### Usage
|
||||
|
||||
Enhancing an image in Pillow using ImageFilter:
|
||||
|
||||
```
|
||||
from PIL import Image,ImageFilter
|
||||
#Read image
|
||||
im = Image.open('image.jpg')
|
||||
#Display image
|
||||
im.show()
|
||||
|
||||
from PIL import ImageEnhance
|
||||
enh = ImageEnhance.Contrast(im)
|
||||
enh.enhance(1.8).show("30% more contrast")
|
||||
```
|
||||
|
||||
![Enhancing an image in Pillow using ImageFilter][23]
|
||||
|
||||
[Image source code][24]
|
||||
|
||||
### 5\. OpenCV-Python
|
||||
|
||||
**OpenCV** (Open Source Computer Vision Library) is one of the most widely used libraries for computer vision applications. [**OpenCV-Python**][25] is the Python API for OpenCV. OpenCV-Python is not only fast, since the background consists of code written in C/C++, but it is also easy to code and deploy (due to the Python wrapper in the foreground). This makes it a great choice to perform computationally intensive computer vision programs.
|
||||
|
||||
#### Resources
|
||||
|
||||
The [OpenCV2-Python-Guide][26] makes it easy to get started with OpenCV-Python.
|
||||
|
||||
#### Usage
|
||||
|
||||
Using _Image Blending using Pyramids_ in OpenCV-Python to create an "Orapple":
|
||||
|
||||
|
||||
![Image blending using Pyramids in OpenCV-Python][28]
|
||||
|
||||
[Image source code][29]
|
||||
|
||||
### 6\. SimpleCV
|
||||
|
||||
[**SimpleCV**][30] is another open source framework for building computer vision applications. It offers access to several high-powered computer vision libraries such as OpenCV, but without having to know about bit depths, file formats, color spaces, etc. Its learning curve is substantially smaller than OpenCV's, and (as its tagline says), "it's computer vision made easy." Some points in favor of SimpleCV are:
|
||||
|
||||
* Even beginning programmers can write simple machine vision tests
|
||||
* Cameras, video files, images, and video streams are all interoperable
|
||||
|
||||
|
||||
|
||||
#### Resources
|
||||
|
||||
The official [documentation][31] is very easy to follow and has tons of examples and use cases to follow.
|
||||
|
||||
#### Usage
|
||||
|
||||
### [7-_simplecv.png][32]
|
||||
|
||||
![SimpleCV][33]
|
||||
|
||||
### 7\. Mahotas
|
||||
|
||||
**[Mahotas][34]** is another computer vision and image processing library for Python. It contains traditional image processing functions such as filtering and morphological operations, as well as more modern computer vision functions for feature computation, including interest point detection and local descriptors. The interface is in Python, which is appropriate for fast development, but the algorithms are implemented in C++ and tuned for speed. Mahotas' library is fast with minimalistic code and even minimum dependencies. Read its [official paper][35] for more insights.
|
||||
|
||||
#### Resources
|
||||
|
||||
The [documentation][36] contains installation instructions, examples, and even some tutorials to help you get started using Mahotas easily.
|
||||
|
||||
#### Usage
|
||||
|
||||
The Mahotas library relies on simple code to get things done. For example, it does a good job with the [Finding Wally][37] problem with a minimum amount of code.
|
||||
|
||||
Solving the Finding Wally problem:
|
||||
|
||||
![Finding Wally problem in Mahotas][39]
|
||||
|
||||
[Image source code][40]
|
||||
|
||||
![Finding Wally problem in Mahotas][42]
|
||||
|
||||
[Image source code][40]
|
||||
|
||||
### 8\. SimpleITK
|
||||
|
||||
[**ITK**][43] (Insight Segmentation and Registration Toolkit) is an "open source, cross-platform system that provides developers with an extensive suite of software tools for image analysis. **[SimpleITK][44]** is a simplified layer built on top of ITK, intended to facilitate its use in rapid prototyping, education, [and] interpreted languages." It's also an image analysis toolkit with a [large number of components][45] supporting general filtering operations, image segmentation, and registration. SimpleITK is written in C++, but it's available for a large number of programming languages including Python.
|
||||
|
||||
#### Resources
|
||||
|
||||
There are a large number of [Jupyter Notebooks][46] illustrating the use of SimpleITK for educational and research activities. The notebooks demonstrate using SimpleITK for interactive image analysis using the Python and R programming languages.
|
||||
|
||||
#### Usage
|
||||
|
||||
Visualization of a rigid CT/MR registration process created with SimpleITK and Python:
|
||||
|
||||
![SimpleITK animation][48]
|
||||
|
||||
[Image source code][49]
|
||||
|
||||
### 9\. pgmagick
|
||||
|
||||
[**pgmagick**][50] is a Python-based wrapper for the GraphicsMagick library. The [**GraphicsMagick**][51] image processing system is sometimes called the Swiss Army Knife of image processing. Its robust and efficient collection of tools and libraries supports reading, writing, and manipulating images in over 88 major formats including DPX, GIF, JPEG, JPEG-2000, PNG, PDF, PNM, and TIFF.
|
||||
|
||||
#### Resources
|
||||
|
||||
pgmagick's [GitHub repository][52] has installation instructions and requirements. There is also a detailed [user guide][53].
|
||||
|
||||
#### Usage
|
||||
|
||||
Image scaling:
|
||||
|
||||
![Image scaling in pgmagick][55]
|
||||
|
||||
[Image source code][56]
|
||||
|
||||
Edge extraction:
|
||||
|
||||
![Edge extraction in pgmagick][58]
|
||||
|
||||
[Image source code][59]
|
||||
|
||||
### 10\. Pycairo
|
||||
|
||||
[**Pycairo**][60] is a set of Python bindings for the [Cairo][61] graphics library. Cairo is a 2D graphics library for drawing vector graphics. Vector graphics are interesting because they don't lose clarity when resized or transformed. Pycairo can call Cairo commands from Python.
|
||||
|
||||
#### Resources
|
||||
|
||||
The Pycairo [GitHub repository][62] is a good resource with detailed instructions on installation and usage. There is also a [getting started guide][63], which has a brief tutorial on Pycairo.
|
||||
|
||||
#### Usage
|
||||
|
||||
Drawing lines, basic shapes, and radial gradients with Pycairo:
|
||||
|
||||
![Pycairo][65]
|
||||
|
||||
[Image source code][66]
|
||||
|
||||
### Conclusion
|
||||
|
||||
These are some of the useful and freely available image processing libraries in Python. Some are well known and others may be new to you. Try them out to get to know more about them!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/python-image-manipulation-tools
|
||||
|
||||
作者:[Parul Pandey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/parul-pandey
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/daisy_gimp_art_design.jpg?itok=6kCxAKWO
|
||||
[2]: https://scikit-image.org/
|
||||
[3]: http://docs.scipy.org/doc/numpy/reference/index.html#module-numpy
|
||||
[4]: http://scikit-image.org/docs/stable/user_guide.html
|
||||
[5]: /file/426206
|
||||
[6]: https://opensource.com/sites/default/files/uploads/1-scikit-image.png (Image filtering in scikit-image)
|
||||
[7]: http://scikit-image.org/docs/dev/auto_examples/features_detection/plot_template.html#sphx-glr-auto-examples-features-detection-plot-template-py
|
||||
[8]: /file/426211
|
||||
[9]: https://opensource.com/sites/default/files/uploads/2-scikit-image.png (Template matching in scikit-image)
|
||||
[10]: https://scikit-image.org/docs/dev/auto_examples
|
||||
[11]: http://www.numpy.org/
|
||||
[12]: /file/426216
|
||||
[13]: https://opensource.com/sites/default/files/uploads/3-numpy.png (NumPy)
|
||||
[14]: https://www.scipy.org/
|
||||
[15]: https://docs.scipy.org/doc/scipy/reference/ndimage.html#module-scipy.ndimage
|
||||
[16]: https://docs.scipy.org/doc/scipy/reference/tutorial/ndimage.html#correlation-and-convolution
|
||||
[17]: https://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.gaussian_filter.html
|
||||
[18]: /file/426221
|
||||
[19]: https://opensource.com/sites/default/files/uploads/4-scipy.png (Using a Gaussian filter in SciPy)
|
||||
[20]: https://python-pillow.org/
|
||||
[21]: https://pillow.readthedocs.io/en/3.1.x/index.html
|
||||
[22]: /file/426226
|
||||
[23]: https://opensource.com/sites/default/files/uploads/5-pillow.png (Enhancing an image in Pillow using ImageFilter)
|
||||
[24]: http://sipi.usc.edu/database/
|
||||
[25]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_setup/py_intro/py_intro.html
|
||||
[26]: https://github.com/abidrahmank/OpenCV2-Python-Tutorials
|
||||
[27]: /file/426236
|
||||
[28]: https://opensource.com/sites/default/files/uploads/6-opencv.jpeg (Image blending using Pyramids in OpenCV-Python)
|
||||
[29]: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_pyramids/py_pyramids.html#pyramids
|
||||
[30]: http://simplecv.org/
|
||||
[31]: http://examples.simplecv.org/en/latest/
|
||||
[32]: /file/426241
|
||||
[33]: https://opensource.com/sites/default/files/uploads/7-_simplecv.png (SimpleCV)
|
||||
[34]: https://mahotas.readthedocs.io/en/latest/
|
||||
[35]: https://openresearchsoftware.metajnl.com/articles/10.5334/jors.ac/
|
||||
[36]: https://mahotas.readthedocs.io/en/latest/install.html
|
||||
[37]: https://blog.clarifai.com/wheres-waldo-using-machine-learning-to-find-all-the-waldos
|
||||
[38]: /file/426246
|
||||
[39]: https://opensource.com/sites/default/files/uploads/8-mahotas.png (Finding Wally problem in Mahotas)
|
||||
[40]: https://mahotas.readthedocs.io/en/latest/wally.html
|
||||
[41]: /file/426251
|
||||
[42]: https://opensource.com/sites/default/files/uploads/9-mahotas.png (Finding Wally problem in Mahotas)
|
||||
[43]: https://itk.org/
|
||||
[44]: http://www.simpleitk.org/
|
||||
[45]: https://itk.org/ITK/resources/resources.html
|
||||
[46]: http://insightsoftwareconsortium.github.io/SimpleITK-Notebooks/
|
||||
[47]: /file/426256
|
||||
[48]: https://opensource.com/sites/default/files/uploads/10-simpleitk.gif (SimpleITK animation)
|
||||
[49]: https://github.com/InsightSoftwareConsortium/SimpleITK-Notebooks/blob/master/Utilities/intro_animation.py
|
||||
[50]: https://pypi.org/project/pgmagick/
|
||||
[51]: http://www.graphicsmagick.org/
|
||||
[52]: https://github.com/hhatto/pgmagick
|
||||
[53]: https://pgmagick.readthedocs.io/en/latest/
|
||||
[54]: /file/426261
|
||||
[55]: https://opensource.com/sites/default/files/uploads/11-pgmagick.png (Image scaling in pgmagick)
|
||||
[56]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#scaling-a-jpeg-image
|
||||
[57]: /file/426266
|
||||
[58]: https://opensource.com/sites/default/files/uploads/12-pgmagick.png (Edge extraction in pgmagick)
|
||||
[59]: https://pgmagick.readthedocs.io/en/latest/cookbook.html#edge-extraction
|
||||
[60]: https://pypi.org/project/pycairo/
|
||||
[61]: https://cairographics.org/
|
||||
[62]: https://github.com/pygobject/pycairo
|
||||
[63]: https://pycairo.readthedocs.io/en/latest/tutorial.html
|
||||
[64]: /file/426271
|
||||
[65]: https://opensource.com/sites/default/files/uploads/13-pycairo.png (Pycairo)
|
||||
[66]: http://zetcode.com/gfx/pycairo/basicdrawing/
|
||||
@ -0,0 +1,162 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 Ways To Check Whether A Port Is Open On The Remote Linux System?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
3 Ways To Check Whether A Port Is Open On The Remote Linux System?
|
||||
======
|
||||
|
||||
This is an important topic, which is not only for Linux administrator and it will be very helpful for all.
|
||||
|
||||
I mean to say. It’s very useful for users who are working in IT Infra.
|
||||
|
||||
They have to check whether the port is open or not on Linux server before proceeding to next steps.
|
||||
|
||||
If it’s not open then they can directly ask the Linux admin to check on this.
|
||||
|
||||
If it’s open then we need to check with application team, etc,.
|
||||
|
||||
In this article, we will show you, how to check this using three methods.
|
||||
|
||||
It can be done using the following Linux commands.
|
||||
|
||||
* **`nc:`** Netcat is a simple Unix utility which reads and writes data across network connections, using TCP or UDP protocol.
|
||||
* **`nmap:`** Nmap (“Network Mapper”) is an open source tool for network exploration and security auditing. It was designed to rapidly scan large networks.
|
||||
* **`telnet:`** The telnet command is used for interactive communication with another host using the TELNET protocol.
|
||||
|
||||
|
||||
|
||||
### How To Check Whether A Port Is Open On The Remote Linux System Using nc (netcat) Command?
|
||||
|
||||
nc stands for netcat. Netcat is a simple Unix utility which reads and writes data across network connections, using TCP or UDP protocol.
|
||||
|
||||
It is designed to be a reliable “back-end” tool that can be used directly or easily driven by other programs and scripts.
|
||||
|
||||
At the same time, it is a feature-rich network debugging and exploration tool, since it can create almost any kind of connection you would need and has several interesting built-in capabilities.
|
||||
|
||||
Netcat has three main modes of functionality. These are the connect mode, the listen mode, and the tunnel mode.
|
||||
|
||||
**Common Syntax for nc (netcat):**
|
||||
|
||||
```
|
||||
$ nc [-options] [HostName or IP] [PortNumber]
|
||||
```
|
||||
|
||||
In this example, we are going to check whether the port 22 is open or not on the remote Linux system.
|
||||
|
||||
If it’s success then you will be getting the following output.
|
||||
|
||||
```
|
||||
# nc -zvw3 192.168.1.8 22
|
||||
Connection to 192.168.1.8 22 port [tcp/ssh] succeeded!
|
||||
```
|
||||
|
||||
**Details:**
|
||||
|
||||
* **`nc:`** It’s a command.
|
||||
* **`z:`** zero-I/O mode (used for scanning).
|
||||
* **`v:`** For verbose.
|
||||
* **`w3:`** timeout wait seconds
|
||||
* **`192.168.1.8:`** Destination system IP.
|
||||
* **`22:`** Port number needs to be verified.
|
||||
|
||||
|
||||
|
||||
If it’s fail then you will be getting the following output.
|
||||
|
||||
```
|
||||
# nc -zvw3 192.168.1.95 22
|
||||
nc: connect to 192.168.1.95 port 22 (tcp) failed: Connection refused
|
||||
```
|
||||
|
||||
### How To Check Whether A Port Is Open On The Remote Linux System Using nmap Command?
|
||||
|
||||
Nmap (“Network Mapper”) is an open source tool for network exploration and security auditing. It was designed to rapidly scan large networks, although it works fine against single hosts.
|
||||
|
||||
Nmap uses raw IP packets in novel ways to determine what hosts are available on the network, what services (application name and version) those hosts are offering, what operating systems (and OS versions) they are running, what type of packet filters/firewalls are in use, and dozens of other characteristics.
|
||||
|
||||
While Nmap is commonly used for security audits, many systems and network administrators find it useful for routine tasks such as network inventory, managing service upgrade schedules, and monitoring host or service uptime.
|
||||
|
||||
**Common Syntax for nmap:**
|
||||
|
||||
```
|
||||
$ nmap [-options] [HostName or IP] [-p] [PortNumber]
|
||||
```
|
||||
|
||||
If it’s success then you will be getting the following output.
|
||||
|
||||
```
|
||||
# nmap 192.168.1.8 -p 22
|
||||
|
||||
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 03:37 IST Nmap scan report for 192.168.1.8 Host is up (0.00031s latency).
|
||||
|
||||
PORT STATE SERVICE
|
||||
|
||||
22/tcp open ssh
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 13.06 seconds
|
||||
```
|
||||
|
||||
If it’s fail then you will be getting the following output.
|
||||
|
||||
```
|
||||
# nmap 192.168.1.8 -p 80
|
||||
Starting Nmap 7.70 ( https://nmap.org ) at 2019-03-16 04:30 IST
|
||||
Nmap scan report for 192.168.1.8
|
||||
Host is up (0.00036s latency).
|
||||
|
||||
PORT STATE SERVICE
|
||||
80/tcp closed http
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 13.07 seconds
|
||||
```
|
||||
|
||||
### How To Check Whether A Port Is Open On The Remote Linux System Using telnet Command?
|
||||
|
||||
The telnet command is used for interactive communication with another host using the TELNET protocol.
|
||||
|
||||
**Common Syntax for telnet:**
|
||||
|
||||
```
|
||||
$ telnet [HostName or IP] [PortNumber]
|
||||
```
|
||||
|
||||
If it’s success then you will be getting the following output.
|
||||
|
||||
```
|
||||
$ telnet 192.168.1.9 22
|
||||
Trying 192.168.1.9...
|
||||
Connected to 192.168.1.9.
|
||||
Escape character is '^]'.
|
||||
SSH-2.0-OpenSSH_5.3
|
||||
^]
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
||||
If it’s fail then you will be getting the following output.
|
||||
|
||||
```
|
||||
$ telnet 192.168.1.9 80
|
||||
Trying 192.168.1.9...
|
||||
telnet: Unable to connect to remote host: Connection refused
|
||||
```
|
||||
|
||||
We had found only the above three methods. If you found any other ways, please let us know by updating your query in the comments section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-whether-a-port-is-open-on-the-remote-linux-system-server/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,176 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Building and augmenting libraries by calling Rust from JavaScript)
|
||||
[#]: via: (https://opensource.com/article/19/3/calling-rust-javascript)
|
||||
[#]: author: (Ryan Levick https://opensource.com/users/ryanlevick)
|
||||
|
||||
Building and augmenting libraries by calling Rust from JavaScript
|
||||
======
|
||||
|
||||
Explore how to use WebAssembly (Wasm) to embed Rust inside JavaScript.
|
||||
|
||||
![JavaScript in Vim][1]
|
||||
|
||||
In _[Why should you use Rust in WebAssembly?][2]_ , I looked at why you might want to write WebAssembly (Wasm), and why you might choose Rust as the language to do it in. Now I'll share what that looks like by exploring ways to embed Rust inside JavaScript.
|
||||
|
||||
This is something that separates Rust from Go, C#, and other languages with large runtimes that can compile to Wasm. Rust has a minimal runtime (basically just an allocator), making it easy to use Rust from JavaScript libraries. C and C++ have similar stories, but what sets Rust apart is its tooling, which we'll take a look at now.
|
||||
|
||||
### The basics
|
||||
|
||||
If you've never used Rust before, you'll first want to get that set up. It's pretty easy. First download [**Rustup**][3], which is a way to control versions of Rust and different toolchains for cross-compilation. This will give you access to [**Cargo**][4], which is the Rust build tool and package manager.
|
||||
|
||||
Now we have a decision to make. We can easily write Rust code that runs in the browser through WebAssembly, but if we want to do anything other than make people's CPU fans spin, we'll probably at some point want to interact with the Document Object Model (DOM) or use some JavaScript API. In other words: _we need JavaScript interop_ (aka the JavaScript interoperability API).
|
||||
|
||||
### The problem and the solutions
|
||||
|
||||
WebAssembly is an extremely simple machine language. If we want to be able to communicate with JavaScript, Wasm gives us only four data types to do it with: 32- and 64-bit floats and integers. Wasm doesn't have a concept of strings, arrays, objects, or any other rich data type. Basically, we can only pass around pointers between Rust and JavaScript. Needless to say, this is less than ideal.
|
||||
|
||||
The good news is there are two libraries that facilitate communication between Rust-based Wasm and JavaScript: [**wasm-bindgen**][5] and [**stdweb**][6]. The bad news, however, is these two libraries are unfortunately incompatible with each other. **wasm-bindgen** is lower-level than **stdweb** and attempts to provide full control over how JavaScript and Rust interact. In fact, there is even talk of [rewriting **stdweb** using **wasm-bindgen**][7], which would get rid of the issue of incompatibility.
|
||||
|
||||
Because **wasm-bindgen** is the lighter-weight option (and the option officially worked on by the official [Rust WebAssembly working group][8]), we'll focus at that.
|
||||
|
||||
### wasm-bindgen and wasm-pack
|
||||
|
||||
We're going to create a function that takes a string from JavaScript, makes it uppercase and prepends "HELLO, " to it, and returns it back to JavaScript. We'll call this function **excited_greeting**!
|
||||
|
||||
First, let's create our Rust library that will house this fabulous function:
|
||||
|
||||
```
|
||||
$ cargo new my-wasm-library --lib
|
||||
$ cd my-wasm-library
|
||||
```
|
||||
|
||||
Now we'll want to replace the contents of **src/lib.rs** with our exciting logic. I think it's best to write the code out instead of copy/pasting.
|
||||
|
||||
```
|
||||
// Include the `wasm_bindgen` attribute into the current namespace.
|
||||
use wasm_bindgen::prelude::wasm_bindgen;
|
||||
|
||||
// This attribute makes calling Rust from JavaScript possible.
|
||||
// It generates code that can convert the basic types wasm understands
|
||||
// (integers and floats) into more complex types like strings and
|
||||
// vice versa. If you're interested in how this works, check this out:
|
||||
// <https://blog.ryanlevick.com/posts/wasm-bindgen-interop/>
|
||||
#[wasm_bindgen]
|
||||
// This is pretty plain Rust code. If you've written Rust before this
|
||||
// should look extremely familiar. If not, why wait?! Check this out:
|
||||
// <https://doc.rust-lang.org/book/>
|
||||
pub fn excited_greeting(original: &str) -> String {
|
||||
format!("HELLO, {}", original.to_uppercase())
|
||||
}
|
||||
```
|
||||
|
||||
Second, we'll have to make two changes to our **Cargo.toml** configuration file:
|
||||
|
||||
* Add **wasm_bindgen** as a dependency.
|
||||
* Configure the type of library binary to be a **cdylib** or dynamic system library. In this case, our system is **wasm** , and setting this option is how we produce **.wasm** binary files.
|
||||
|
||||
|
||||
```
|
||||
[package]
|
||||
name = "my-wasm-library"
|
||||
version = "0.1.0"
|
||||
authors = ["$YOUR_INFO"]
|
||||
edition = "2018"
|
||||
|
||||
[lib]
|
||||
crate-type = ["cdylib", "rlib"]
|
||||
|
||||
[dependencies]
|
||||
wasm-bindgen = "0.2.33"
|
||||
```
|
||||
|
||||
Now let's build! If we just use **cargo build** , we'll get a **.wasm** binary, but in order to make it easy to call our Rust code from JavaScript, we'd like to have some JavaScript code that converts rich JavaScript types like strings and objects to pointers and passes these pointers to the Wasm module on our behalf. Doing this manually is tedious and prone to bugs.
|
||||
|
||||
Luckily, in addition to being a library, **wasm-bindgen** also has the ability to create this "glue" JavaScript for us. This means in our code we can interact with our Wasm module using normal JavaScript types, and the generated code from **wasm-bindgen** will do the dirty work of converting these rich types into the pointer types that Wasm actually understands.
|
||||
|
||||
We can use the awesome **wasm-pack** to build our Wasm binary, invoke the **wasm-bindgen** CLI tool, and package all of our JavaScript (and any optional generated TypeScript types) into one nice and neat package. Let's do that now!
|
||||
|
||||
First we'll need to install **wasm-pack** :
|
||||
|
||||
```
|
||||
$ cargo install wasm-pack
|
||||
```
|
||||
|
||||
By default, **wasm-bindgen** produces ES6 modules. We'll use our code from a simple script tag, so we just want it to produce a plain old JavaScript object that gives us access to our Wasm functions. To do this, we'll pass it the **\--target no-modules** option.
|
||||
|
||||
```
|
||||
$ wasm-pack build --target no-modules
|
||||
```
|
||||
|
||||
We now have a **pkg** directory in our project. If we look at the contents, we'll see the following:
|
||||
|
||||
* **package.json** : useful if we want to package this up as an NPM module
|
||||
* **my_wasm_library_bg.wasm** : our actual Wasm code
|
||||
* **my_wasm_library.js** : the JavaScript "glue" code
|
||||
* Some TypeScript definition files
|
||||
|
||||
|
||||
|
||||
Now we can create an **index.html** file that will make use of our JavaScript and Wasm:
|
||||
|
||||
```
|
||||
<[html][9]>
|
||||
<[head][10]>
|
||||
<[meta][11] content="text/html;charset=utf-8" http-equiv="Content-Type" />
|
||||
</[head][10]>
|
||||
<[body][12]>
|
||||
<!-- Include our glue code -->
|
||||
<[script][13] src='./pkg/my_wasm_library.js'></[script][13]>
|
||||
<!-- Include our glue code -->
|
||||
<[script][13]>
|
||||
window.addEventListener('load', async () => {
|
||||
// Load the wasm file
|
||||
await wasm_bindgen('./pkg/my_wasm_library_bg.wasm');
|
||||
// Once it's loaded the `wasm_bindgen` object is populated
|
||||
// with the functions defined in our Rust code
|
||||
const greeting = wasm_bindgen.excited_greeting("Ryan")
|
||||
console.log(greeting)
|
||||
});
|
||||
</[script][13]>
|
||||
</[body][12]>
|
||||
</[html][9]>
|
||||
```
|
||||
|
||||
You may be tempted to open the HTML file in your browser, but unfortunately, this is not possible. For security reasons, Wasm files have to be served from the same domain as the HTML file. You'll need an HTTP server. If you have a favorite static HTTP server that can serve files from your filesystem, feel free to use that. I like to use [**basic-http-server**][14], which you can install and run like so:
|
||||
|
||||
```
|
||||
$ cargo install basic-http-server
|
||||
$ basic-http-server
|
||||
```
|
||||
|
||||
Now open the **index.html** file through the web server by going to **<http://localhost:4000/index.html>** and check your JavaScript console. You should see a very exciting greeting there!
|
||||
|
||||
If you have any questions, please [let me know][15]. Next time, we'll take a look at how we can use various browser and JavaScript APIs from within our Rust code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/calling-rust-javascript
|
||||
|
||||
作者:[Ryan Levick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ryanlevick
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/javascript_vim.jpg?itok=mqkAeakO (JavaScript in Vim)
|
||||
[2]: https://opensource.com/article/19/2/why-use-rust-webassembly
|
||||
[3]: https://rustup.rs/
|
||||
[4]: https://doc.rust-lang.org/cargo/
|
||||
[5]: https://github.com/rustwasm/wasm-bindgen
|
||||
[6]: https://github.com/koute/stdweb
|
||||
[7]: https://github.com/koute/stdweb/issues/318
|
||||
[8]: https://www.rust-lang.org/governance/wgs/wasm
|
||||
[9]: http://december.com/html/4/element/html.html
|
||||
[10]: http://december.com/html/4/element/head.html
|
||||
[11]: http://december.com/html/4/element/meta.html
|
||||
[12]: http://december.com/html/4/element/body.html
|
||||
[13]: http://december.com/html/4/element/script.html
|
||||
[14]: https://github.com/brson/basic-http-server
|
||||
[15]: https://twitter.com/ryan_levick
|
||||
107
sources/tech/20190318 How to host your own webfonts.md
Normal file
107
sources/tech/20190318 How to host your own webfonts.md
Normal file
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to host your own webfonts)
|
||||
[#]: via: (https://opensource.com/article/19/3/webfonts)
|
||||
[#]: author: (Seth Kenlon (Red Hat, Community Moderator) https://opensource.com/users/seth)
|
||||
|
||||
How to host your own webfonts
|
||||
======
|
||||
|
||||
### Customize your website by self-hosting openly licensed fonts.
|
||||
|
||||
![Open source fonts][1]
|
||||
|
||||
Fonts are often a mystery to many computer users. For example, have you designed a cool flyer and, when you take the file somewhere for printing, find all the titles rendered in Arial because the printer doesn't have the fancy font you used in your design? There are ways to prevent this, of course: you can convert words in special fonts into paths, bundle fonts into a PDF, bundle open source fonts with your design files, or—at least—list the fonts required. And yet it's still a problem because we're human and we're forgetful.
|
||||
|
||||
The web has the same sort of problem. If you have even a basic understanding of CSS, you've probably seen this kind of declaration:
|
||||
|
||||
```
|
||||
h1 { font-family: "Times New Roman", Times, serif; }
|
||||
```
|
||||
|
||||
This is a designer's attempt to define a specific font, provide a fallback if a user doesn't have Times New Roman installed, and offer yet another fallback if the user doesn't have Times either. It's better than using a graphic instead of text, but it's still an awkward, inelegant method of font non-management, However, in the early-ish days of the web, it's all we had to work with.
|
||||
|
||||
### Webfonts
|
||||
|
||||
Then webfonts happened, moving font management from the client to the server. Fonts on websites were rendered for the client by the server, rather than requiring the web browser to find a font on the user's system. Google and other providers even host openly licensed fonts, which designers can include on their sites with a simple CSS rule.
|
||||
|
||||
The problem with this free convenience, of course, is that it doesn't come without cost. It's $0 to use, but major sites like Google love to keep track of who references their data, fonts included. If you don't see a need to assist Google in building a record of everyone's activity on the web, the good news is you can host your own webfonts, and it's as simple as uploading fonts to your host and using one easy CSS rule. As a side benefit, your site may load faster, as you'll be making one fewer external call upon loading each page.
|
||||
|
||||
### Self-hosted webfonts
|
||||
|
||||
The first thing you need is an openly licensed font. This can be confusing if you're not used to thinking or caring about obscure software licenses, especially since it seems like all fonts are free. Very few of us have consciously paid for a font, and yet most people have high-priced fonts on their computers. Thanks to licensing deals, your computer may have shipped with fonts that [you aren't legally allowed to copy and redistribute][2]. Fonts like Arial, Verdana, Calibri, Georgia, Impact, Lucida and Lucida Grande, Times and Times New Roman, Trebuchet, Geneva, and many others are owned by Microsoft, Apple, and Adobe. If you purchased a computer preloaded with Windows or MacOS, you paid for the right to use the bundled fonts, but you don't own those fonts and are not permitted to upload them to a web server (unless otherwise stated).
|
||||
|
||||
Fortunately, the open source craze hit the font world long ago, and there are excellent collections of openly licensed fonts from collectives and projects like [The League of Moveable Type][3], [Font Library][4], [Omnibus Type][5], and even [Google][6] and [Adobe][7].
|
||||
|
||||
You can use most common font file formats, including TTF, OTF, WOFF, EOT, and so on. Since Sorts Mill Goudy includes a WOFF (Web Open Font Format, developed in part by Mozilla) version, I'll use it in this example. However, other formats work the same way.
|
||||
|
||||
Assuming you want to use [Sorts Mill Goudy][8] on your web page:
|
||||
|
||||
1. Upload the **GoudyStM-webfont.woff** file to your web server:
|
||||
|
||||
```
|
||||
scp GoudyStM-webfont.woff seth@example.com:~/www/fonts/
|
||||
```
|
||||
|
||||
Your host may also provide a graphical upload tool through cPanel or a similar web control panel.
|
||||
|
||||
|
||||
|
||||
2. In your site's CSS file, add an **@font-face** rule, similar to this:
|
||||
|
||||
|
||||
```
|
||||
@font-face {
|
||||
font-family: "titlefont";
|
||||
src: url("../fonts/GoudyStM-webfont.woff");
|
||||
}
|
||||
```
|
||||
|
||||
The **font-family** value is something you make up. It's a human-friendly name for whatever the font face represents. I am using "titlefont" in this example because I imagine this font will be used for the main titles on an imaginary site. You could just as easily use "officialfont" or "myfont."
|
||||
|
||||
The **src** value is the path to the font file. The path to the font must be appropriate for your server's file structure; in this example, I have the **fonts** directory alongside a **css** directory. You may not have your site structured that way, so adjust the paths as needed, remembering that a single dot means _this folder_ and two dots mean _a folder back_.
|
||||
|
||||
|
||||
|
||||
3. Now that you've defined the font face name and the location, you can call it for any given CSS class or ID you desire. For example, if you want **< h1>** to render in the Sorts Mill Goudy font, then make its CSS rule use your custom font name:
|
||||
|
||||
```
|
||||
h1 { font-family: "titlefont", serif; }
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
You're now hosting and using your own fonts.
|
||||
|
||||
|
||||
![Web fonts on a website][10]
|
||||
|
||||
_Thanks to Alexandra Kanik for teaching me about @font-face and most everything else I know about good web design._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/webfonts
|
||||
|
||||
作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life_typography_fonts.png?itok=Q1jMys5G (Open source fonts)
|
||||
[2]: https://docs.microsoft.com/en-us/typography/fonts/font-faq
|
||||
[3]: https://www.theleagueofmoveabletype.com/
|
||||
[4]: https://fontlibrary.org/
|
||||
[5]: https://www.omnibus-type.com
|
||||
[6]: https://github.com/googlefonts
|
||||
[7]: https://github.com/adobe-fonts
|
||||
[8]: https://www.theleagueofmoveabletype.com/sorts-mill-goudy
|
||||
[9]: /file/426056
|
||||
[10]: https://opensource.com/sites/default/files/uploads/webfont.jpg (Web fonts on a website)
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Solus 4 ‘Fortitude’ Released with Significant Improvements)
|
||||
[#]: via: (https://itsfoss.com/solus-4-release)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Solus 4 ‘Fortitude’ Released with Significant Improvements
|
||||
======
|
||||
|
||||
Finally, after a year of work, the much anticipated Solus 4 is here. It’s a significant release not just because this is a major upgrade, but also because this is the first major release after [Ikey Doherty (the founder of Solus) left the project][1] a few months ago.
|
||||
|
||||
Now that everything’s under control with the new _management_ , **Solus 4 Fortitude** with updated Budgie desktop and other significant improvements has officially released.
|
||||
|
||||
### What’s New in Solus 4
|
||||
|
||||
![Solus 4 Fortitude][2]
|
||||
|
||||
#### Core Improvements
|
||||
|
||||
Solus 4 comes loaded with **[Linux Kernel 4.20.16][3]** which enables better hardware support (like Touchpad support, improved support for Intel Coffee Lake and Ice Lake CPUs, and for AMD Picasso & Raven2 APUs).
|
||||
|
||||
This release also ships with the latest [FFmpeg 4.1.1][4]. Also, they have enabled the support for [dav1d][5] in [VLC][6] – which is an open source AV1 decoder. So, you can consider these upgrades to significantly improve the Multimedia experience.
|
||||
|
||||
It also includes some minor fixes to the Software Center – if you were encountering any issues while finding an application or viewing the description.
|
||||
|
||||
In addition, WPS Office has been removed from the listing.
|
||||
|
||||
#### UI Improvements
|
||||
|
||||
![Budgie 10.5][7]
|
||||
|
||||
The Budgie desktop update includes some minor changes and also comes baked in with the [Plata (Noir) GTK Theme.][8]
|
||||
|
||||
You will no longer observe same applications multiple times in the menu, they’ve fixed this. They have also introduced a “ **Caffeine** ” mode as applet which prevents the system from suspending, locking the screen or changing the brightness while you are working. You can schedule the time accordingly.
|
||||
|
||||
![Caffeine Mode][9]
|
||||
|
||||
The new Budgie desktop experience also adds quick actions to the app icons on the task bar, dubbed as “ **Icon Tasklist** “. It makes it easy to manage the active tabs on a browser or the actions to minimize and move it to a new workplace (as shown in the image below).
|
||||
|
||||
![Icon Tasklist][10]
|
||||
|
||||
As the [change log][11] mentions, the above pop over design lets you do more:
|
||||
|
||||
* _Close all instances of the selected application_
|
||||
* _Easily access per-window controls for marking it always on top, maximizing / unmaximizing, minimizing, and moving it to various workspaces._
|
||||
* _Quickly favorite / unfavorite apps_
|
||||
* _Quickly launch a new instance of the selected application_
|
||||
* _Scroll up or down on an IconTasklist button when a single window is open to activate and bring it into focus, or minimize it, based on the scroll direction._
|
||||
* _Toggle to minimize and unminimize various application windows_
|
||||
|
||||
|
||||
|
||||
The notification area now groups the notifications from specific applications instead of piling it all up. So, that’s a good improvement.
|
||||
|
||||
In addition to these, the sound widget got some cool improvements while letting you personalize the look and feel of your desktop in an efficient manner.
|
||||
|
||||
To know about all the nitty-gritty details, do refer the official [release note][11]s.
|
||||
|
||||
### Download Solus 4
|
||||
|
||||
You can get the latest version of Solus from its download page below. It is available in the default Budgie, GNOME and MATE desktop flavors.
|
||||
|
||||
[Get Solus 4][12]
|
||||
|
||||
### Wrapping Up**
|
||||
|
||||
Solus 4 is definitely an impressive upgrade – without introducing any unnecessary fancy features but by adding only the useful ones, subtle changes.
|
||||
|
||||
What do you think about the latest Solus 4 Fortitude? Have you tried it yet?
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/solus-4-release
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/ikey-leaves-solus/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/solus-4-featured.jpg?fit=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/kernel-4-20-release/
|
||||
[4]: https://www.ffmpeg.org/
|
||||
[5]: https://code.videolan.org/videolan/dav1d
|
||||
[6]: https://www.videolan.org/index.html
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/Budgie-desktop.jpg?resize=800%2C450&ssl=1
|
||||
[8]: https://gitlab.com/tista500/plata-theme
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/caffeine-mode.jpg?ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/IconTasklistPopover.jpg?ssl=1
|
||||
[11]: https://getsol.us/2019/03/17/solus-4-released/
|
||||
[12]: https://getsol.us/download/
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/Budgie-desktop.jpg?fit=800%2C450&ssl=1
|
||||
[14]: https://www.facebook.com/sharer.php?t=Solus%204%20%E2%80%98Fortitude%E2%80%99%20Released%20with%20Significant%20Improvements&u=https%3A%2F%2Fitsfoss.com%2Fsolus-4-release%2F
|
||||
[15]: https://twitter.com/intent/tweet?text=Solus+4+%E2%80%98Fortitude%E2%80%99+Released+with+Significant+Improvements&url=https%3A%2F%2Fitsfoss.com%2Fsolus-4-release%2F&via=itsfoss2
|
||||
[16]: https://www.linkedin.com/shareArticle?title=Solus%204%20%E2%80%98Fortitude%E2%80%99%20Released%20with%20Significant%20Improvements&url=https%3A%2F%2Fitsfoss.com%2Fsolus-4-release%2F&mini=true
|
||||
[17]: https://www.reddit.com/submit?title=Solus%204%20%E2%80%98Fortitude%E2%80%99%20Released%20with%20Significant%20Improvements&url=https%3A%2F%2Fitsfoss.com%2Fsolus-4-release%2F
|
||||
121
sources/tech/20190320 4 cool terminal multiplexers.md
Normal file
121
sources/tech/20190320 4 cool terminal multiplexers.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 cool terminal multiplexers)
|
||||
[#]: via: (https://fedoramagazine.org/4-cool-terminal-multiplexers/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
4 cool terminal multiplexers
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
The Fedora OS is comfortable and easy for lots of users. It has a stunning desktop that makes it easy to get everyday tasks done. Under the hood is all the power of a Linux system, and the terminal is the easiest way for power users to harness it. By default terminals are simple and somewhat limited. However, a _terminal multiplexer_ allows you to turn your terminal into an even more incredible powerhouse. This article shows off some popular terminal multiplexers and how to install them.
|
||||
|
||||
Why would you want to use one? Well, for one thing, it lets you logout of your system while _leaving your terminal session undisturbed_. It’s incredibly useful to logout of your console, secure it, travel somewhere else, then remotely login with SSH and continue where you left off. Here are some utilities to check out.
|
||||
|
||||
One of the oldest and most well-known terminal multiplexers is _screen._ However, because the code is no longer maintained, this article focuses on more recent apps. (“Recent” is relative — some of these have been around for years!)
|
||||
|
||||
### Tmux
|
||||
|
||||
The _tmux_ utility is one of the most widely used replacements for _screen._ It has a highly configurable interface. You can program tmux to start up specific kinds of sessions based on your needs. You’ll find a lot more about tmux in this article published earlier:
|
||||
|
||||
> [Use tmux for a more powerful terminal][2]
|
||||
|
||||
Already a tmux user? You might like [this additional article on making your tmux sessions more effective][3].
|
||||
|
||||
To install tmux, use the _sudo_ command along with _dnf_ , since you’re probably in a terminal already:
|
||||
|
||||
```
|
||||
$ sudo dnf install tmux
|
||||
```
|
||||
|
||||
To start learning, run the _tmux_ command. A single pane window starts with your default shell. Tmux uses a _modifier key_ to signal that a command is coming next. This key is **Ctrl+B** by default. If you enter **Ctrl+B, C** you’ll create a new window with a shell in it.
|
||||
|
||||
Here’s a hint: Use **Ctrl+B, ?** to enter a help mode that lists all the keys you can use. To keep things simple, look for the lines starting with _bind-key -T prefix_ at first. These are keys you can use right after the modifier key to configure your tmux session. You can hit **Ctrl+C** to exit the help mode back to tmux.
|
||||
|
||||
To completely exit tmux, use the standard _exit_ command or _Ctrl+D_ keystroke to exit all the shells.
|
||||
|
||||
### Dvtm
|
||||
|
||||
You might have recently seen the Magazine article on [dwm, a dynamic window manager][4]. Like dwm, _dvtm_ is for tiling window management — but in a terminal. It’s designed to adhere to the legacy UNIX philosophy of “do one thing well” — in this case managing windows in a terminal.
|
||||
|
||||
Installing dvtm is easy as well. However, if you want the logout functionality mentioned earlier, you’ll also need the _abduco_ package which handles session management for dvtm.
|
||||
|
||||
```
|
||||
$ sudo dnf install dvtm abduco
|
||||
```
|
||||
|
||||
The dvtm utility has many keystrokes already mapped to allow you to manage windows in the terminal. By default, it uses **Ctrl+G** as its modifier key. This keystroke tells dvtm that the following character is going to be a command it should process. For instance, **Ctrl+G, C** creates a new window and **Ctrl+G, X** removes it.
|
||||
|
||||
For more information on using dvtm, check out the dvtm [home page][5] which includes numerous tips and get-started information.
|
||||
|
||||
### Byobu
|
||||
|
||||
While _byobu_ isn’t truly a multiplexer on its own — it wraps _tmux_ or even the older _screen_ to add functions — it’s worth covering here too. Byobu makes terminal multiplexers better for novices, by adding a help menu and window tabs that are slightly easier to navigate.
|
||||
|
||||
Of course it’s available in the Fedora repos as well. To install, use this command:
|
||||
|
||||
```
|
||||
$ sudo dnf install byobu
|
||||
```
|
||||
|
||||
By default the _byobu_ command runs _screen_ underneath, so you might want to run _byobu-tmux_ to wrap _tmux_ instead. You can then use the **F9** key to open up a help menu for more information to help you get started.
|
||||
|
||||
### Mtm
|
||||
|
||||
The _mtm_ utility is one of the smallest multiplexers you’ll find. In fact, it’s only about 1000 lines of code! You might find it helpful if you’re in a limited environment such as old hardware, a minimal container, and so forth. To get started, you’ll need a couple packages.
|
||||
|
||||
```
|
||||
$ sudo dnf install git ncurses-devel make gcc
|
||||
```
|
||||
|
||||
Then clone the repository where mtm lives:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/deadpixi/mtm.git
|
||||
```
|
||||
|
||||
Change directory into the _mtm_ folder and build the program:
|
||||
|
||||
```
|
||||
$ make
|
||||
```
|
||||
|
||||
You might receive a few warnings, but when you’re done, you’ll have the very small _mtm_ utility. Run it with this command:
|
||||
|
||||
```
|
||||
$ ./mtm
|
||||
```
|
||||
|
||||
You can find all the documentation for the utility [on its GitHub page][6].
|
||||
|
||||
These are just some of the terminal multiplexers out there. Got one you’d like to recommend? Leave a comment below with your tips and enjoy building windows in your terminal!
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _Michael_][7]_ on [Unsplash][8]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-terminal-multiplexers/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/08/tmuxers-4-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[3]: https://fedoramagazine.org/4-tips-better-tmux-sessions/
|
||||
[4]: https://fedoramagazine.org/lets-try-dwm-dynamic-window-manger/
|
||||
[5]: http://www.brain-dump.org/projects/dvtm/#why
|
||||
[6]: https://github.com/deadpixi/mtm
|
||||
[7]: https://unsplash.com/photos/48yI_ZyzuLo?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/search/photos/windows?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Choosing an open messenger client: Alternatives to WhatsApp)
|
||||
[#]: via: (https://opensource.com/article/19/3/open-messenger-client)
|
||||
[#]: author: (Chris Hermansen (Community Moderator) https://opensource.com/users/clhermansen)
|
||||
|
||||
Choosing an open messenger client: Alternatives to WhatsApp
|
||||
======
|
||||
|
||||
Keep in touch with far-flung family, friends, and colleagues without sacrificing your privacy.
|
||||
|
||||
![Team communication, chat][1]
|
||||
|
||||
Like many families, mine is inconveniently spread around, and I have many colleagues in North and South America. So, over the years, I've relied more and more on WhatsApp to stay in touch with people. The claimed end-to-end encryption appeals to me, as I prefer to maintain some shreds of privacy, and moreover to avoid forcing those with whom I communicate to use an insecure mechanism. But all this [WhatsApp/Facebook/Instagram "convergence"][2] has led our family to decide to vote with our feet. We no longer use WhatsApp for anything except communicating with others who refuse to use anything else, and we're working on them.
|
||||
|
||||
So what do we use instead? Before I spill the beans, I'd like to explain what other options we looked at and how we chose.
|
||||
|
||||
### Options we considered and how we evaluated them
|
||||
|
||||
There is an absolutely [crazy number of messaging apps out there][3], and we spent a good deal of time thinking about what we needed for a replacement. We started by reading Dan Arel's article on [five social media alternatives to protect privacy][4].
|
||||
|
||||
Then we came up with our list of core needs:
|
||||
|
||||
* Our entire family uses Android phones.
|
||||
* One of us has a Windows desktop; the rest use Linux.
|
||||
* Our main interest is something we can use to chat, both individually and as a group, on our phones, but it would be nice to have a desktop client available.
|
||||
* It would also be nice to have voice and video calling as well.
|
||||
* Our privacy is important. Ideally, the code should be open source to facilitate security reviews. If the operation is not pure peer-to-peer, then the organization operating the server components should not operate a business based on the commercialization of our personal information.
|
||||
|
||||
|
||||
|
||||
At that point, we narrowed the long list down to [Viber][5], [Line][6], [Signal][7], [Threema][8], [Wire][9], and [Riot.im][10]. While I lean strongly to open source, we wanted to include some closed source and paid solutions to make sure we weren't missing something important. Here's how those six alternatives measured up.
|
||||
|
||||
### Line
|
||||
|
||||
[Line][11] is a popular messaging application, and it's part of a larger Line "ecosystem"—online gaming, Taxi (an Uber-like service in Japan), Wow (a food delivery service), Today (a news hub), shopping, and others. For us, Line checks a few too many boxes with all those add-on features. Also, I could not determine its current security quality, and it's not open source. The business model seems to be to build a community and figure out how to make money through that community.
|
||||
|
||||
### Riot.im
|
||||
|
||||
[Riot.im][12] operates on top of the Matrix protocol and therefore lets the user choose a Matrix provider. It also appears to check all of our "needs" boxes, although in operation it looks more like Slack, with a room-oriented and interoperable/federated design. It offers desktop clients, and it's open source. Since the Matrix protocol can be hosted anywhere, any business model would be particular to the Matrix provider.
|
||||
|
||||
### Signal
|
||||
|
||||
[Signal][13] offers a similar user experience to WhatsApp. It checks all of our "needs" boxes, with solid security validated by external audit. It is open source, and it is developed and operated by a not-for-profit foundation, in principle similar to the Mozilla Foundation. Interestingly, Signal's communications protocol appears to be used by other messaging apps, [including WhatsApp][14].
|
||||
|
||||
### Threema
|
||||
|
||||
[Threema][15] is extremely privacy-focused. It checks some of our "needs" boxes, with decent external audit results of its security. It doesn't offer a desktop client, and it [isn't fully open source][16] though some of its core components are. Threema's business model appears to be to offer paid secure communications.
|
||||
|
||||
### Viber
|
||||
|
||||
[Viber][17] is a very popular messaging application. It checks most of our "needs" boxes; however, it doesn't seem to have solid proof of its security—it seems to use a proprietary encryption mechanism, and as far as I could determine, its current security mechanisms are not externally audited. It's not open source. The owner, Rakuten, seems to be planning for a paid subscription as a business model.
|
||||
|
||||
### Wire
|
||||
|
||||
[Wire][18] was started and is built by some ex-Skype people. It appears to check all of our "needs" boxes, although I am not completely comfortable with its security profile since it stores client data that apparently is not encrypted on its servers. It offers desktop clients and is open source. The developer and operator, Wire Swiss, appears to have a [pay-for-service track][9] as its future business model.
|
||||
|
||||
### The final verdict
|
||||
|
||||
In the end, we picked Signal. We liked its open-by-design approach, its serious and ongoing [privacy and security stance][7] and having a Signal app on our GNOME (and Windows) desktops. It performs very well on our Android handsets and our desktops. Moreover, it wasn't a big surprise to our small user community; it feels much more like WhatsApp than, for example, Riot.im, which we also tried extensively. Having said that, if we were trying to replace Slack, we'd probably move to Riot.im.
|
||||
|
||||
_Have a favorite messenger? Tell us about it in the comments below._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/open-messenger-client
|
||||
|
||||
作者:[Chris Hermansen (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://www.cnbc.com/2018/03/28/facebook-new-privacy-settings-dont-address-instagram-whatsapp.html
|
||||
[3]: https://en.wikipedia.org/wiki/Comparison_of_instant_messaging_clients
|
||||
[4]: https://opensource.com/article/19/1/open-source-social-media-alternatives
|
||||
[5]: https://en.wikipedia.org/wiki/Viber
|
||||
[6]: https://en.wikipedia.org/wiki/Line_(software)
|
||||
[7]: https://en.wikipedia.org/wiki/Signal_(software)
|
||||
[8]: https://en.wikipedia.org/wiki/Threema
|
||||
[9]: https://en.wikipedia.org/wiki/Wire_(software)
|
||||
[10]: https://en.wikipedia.org/wiki/Riot.im
|
||||
[11]: https://line.me/en/
|
||||
[12]: https://about.riot.im/
|
||||
[13]: https://signal.org/
|
||||
[14]: https://en.wikipedia.org/wiki/Signal_Protocol
|
||||
[15]: https://threema.ch/en
|
||||
[16]: https://threema.ch/en/faq/source_code
|
||||
[17]: https://www.viber.com/
|
||||
[18]: https://wire.com/en/
|
||||
130
sources/tech/20190320 Move your dotfiles to version control.md
Normal file
130
sources/tech/20190320 Move your dotfiles to version control.md
Normal file
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Move your dotfiles to version control)
|
||||
[#]: via: (https://opensource.com/article/19/3/move-your-dotfiles-version-control)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||
|
||||
Move your dotfiles to version control
|
||||
======
|
||||
Back up or sync your custom configurations across your systems by sharing dotfiles on GitLab or GitHub.
|
||||
|
||||

|
||||
|
||||
There is something truly exciting about customizing your operating system through the collection of hidden files we call dotfiles. In [What a Shell Dotfile Can Do For You][1], H. "Waldo" Grunenwald goes into excellent detail about the why and how of setting up your dotfiles. Let's dig into the why and how of sharing them.
|
||||
|
||||
### What's a dotfile?
|
||||
|
||||
"Dotfiles" is a common term for all the configuration files we have floating around our machines. These files usually start with a **.** at the beginning of the filename, like **.gitconfig** , and operating systems often hide them by default. For example, when I use **ls -a** on MacOS, it shows all the lovely dotfiles that would otherwise not be in the output.
|
||||
|
||||
```
|
||||
dotfiles on master
|
||||
➜ ls
|
||||
README.md Rakefile bin misc profiles zsh-custom
|
||||
|
||||
dotfiles on master
|
||||
➜ ls -a
|
||||
. .gitignore .oh-my-zsh README.md zsh-custom
|
||||
.. .gitmodules .tmux Rakefile
|
||||
.gemrc .global_ignore .vimrc bin
|
||||
.git .gvimrc .zlogin misc
|
||||
.gitconfig .maid .zshrc profiles
|
||||
```
|
||||
|
||||
If I take a look at one, **.gitconfig** , which I use for Git configuration, I see a ton of customization. I have account information, terminal color preferences, and tons of aliases that make my command-line interface feel like mine. Here's a snippet from the **[alias]** block:
|
||||
|
||||
```
|
||||
87 # Show the diff between the latest commit and the current state
|
||||
88 d = !"git diff-index --quiet HEAD -- || clear; git --no-pager diff --patch-with-stat"
|
||||
89
|
||||
90 # `git di $number` shows the diff between the state `$number` revisions ago and the current state
|
||||
91 di = !"d() { git diff --patch-with-stat HEAD~$1; }; git diff-index --quiet HEAD -- || clear; d"
|
||||
92
|
||||
93 # Pull in remote changes for the current repository and all its submodules
|
||||
94 p = !"git pull; git submodule foreach git pull origin master"
|
||||
95
|
||||
96 # Checkout a pull request from origin (of a github repository)
|
||||
97 pr = !"pr() { git fetch origin pull/$1/head:pr-$1; git checkout pr-$1; }; pr"
|
||||
```
|
||||
|
||||
Since my **.gitconfig** has over 200 lines of customization, I have no interest in rewriting it on every new computer or system I use, and either does anyone else. This is one reason sharing dotfiles has become more and more popular, especially with the rise of the social coding site GitHub. The canonical article advocating for sharing dotfiles is Zach Holman's [Dotfiles Are Meant to Be Forked][2] from 2008. The premise is true to this day: I want to share them, with myself, with those new to dotfiles, and with those who have taught me so much by sharing their customizations.
|
||||
|
||||
### Sharing dotfiles
|
||||
|
||||
Many of us have multiple systems or know hard drives are fickle enough that we want to back up our carefully curated customizations. How do we keep these wonderful files in sync across environments?
|
||||
|
||||
My favorite answer is distributed version control, preferably a service that will handle the heavy lifting for me. I regularly use GitHub and continue to enjoy GitLab as I get more experienced with it. Either one is a perfect place to share your information. To set yourself up:
|
||||
|
||||
1. Sign into your preferred Git-based service.
|
||||
2. Create a repository called "dotfiles." (Make it public! Sharing is caring.)
|
||||
3. Clone it to your local environment.*
|
||||
4. Copy your dotfiles into the folder.
|
||||
5. Symbolically link (symlink) them back to their target folder (most often **$HOME** ).
|
||||
6. Push them to the remote repository.
|
||||
|
||||
|
||||
|
||||
* You may need to set up your Git configuration commands to clone the repository. Both GitHub and GitLab will prompt you with the commands to run.
|
||||
|
||||
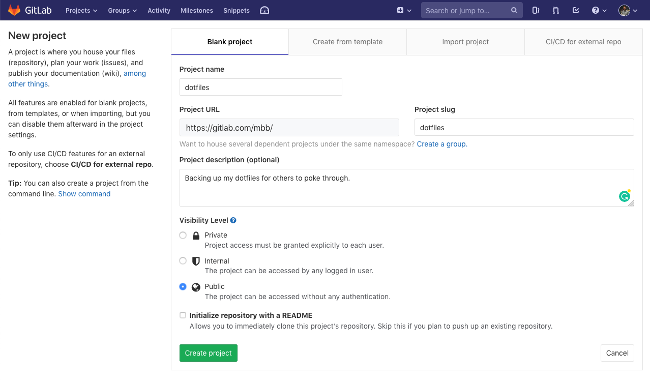
|
||||
|
||||
Step 4 above is the crux of this effort and can be a bit tricky. Whether you use a script or do it by hand, the workflow is to symlink from your dotfiles folder to the dotfiles destination so that any updates to your dotfiles are easily pushed to the remote repository. To do this for my **.gitconfig** file, I would enter:
|
||||
|
||||
```
|
||||
$ cd dotfiles/
|
||||
$ ln -nfs .gitconfig $HOME/.gitconfig
|
||||
```
|
||||
|
||||
The flags added to the symlinking command offer a few additional benefits:
|
||||
|
||||
* **-s** creates a symbolic link instead of a hard link
|
||||
* **-f** continues with other symlinking when an error occurs (not needed here, but useful in loops)
|
||||
* **-n** avoids symlinking a symlink (same as **-h** for other versions of **ln** )
|
||||
|
||||
|
||||
|
||||
You can review the IEEE and Open Group [specification of **ln**][3] and the version on [MacOS 10.14.3][4] if you want to dig deeper into the available parameters. I had to look up these flags since I pulled them from someone else's dotfiles.
|
||||
|
||||
You can also make updating simpler with a little additional code, like the [Rakefile][5] I forked from [Brad Parbs][6]. Alternatively, you can keep it incredibly simple, as Jeff Geerling does [in his dotfiles][7]. He symlinks files using [this Ansible playbook][8]. Keeping everything in sync at this point is easy: you can cron job or occasionally **git push** from your dotfiles folder.
|
||||
|
||||
### Quick aside: What not to share
|
||||
|
||||
Before we move on, it is worth noting what you should not add to a shared dotfile repository—even if it starts with a dot. Anything that is a security risk, like files in your **.ssh/** folder, is not a good choice to share using this method. Be sure to double-check your configuration files before publishing them online and triple-check that no API tokens are in your files.
|
||||
|
||||
### Where should I start?
|
||||
|
||||
If Git is new to you, my [article about the terminology][9] and [a cheat sheet][10] of my most frequently used commands should help you get going.
|
||||
|
||||
There are other incredible resources to help you get started with dotfiles. Years ago, I came across [dotfiles.github.io][11] and continue to go back to it for a broader look at what people are doing. There is a lot of tribal knowledge hidden in other people's dotfiles. Take the time to scroll through some and don't be shy about adding them to your own.
|
||||
|
||||
I hope this will get you started on the joy of having consistent dotfiles across your computers.
|
||||
|
||||
What's your favorite dotfile trick? Add a comment or tweet me [@mbbroberg][12].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/move-your-dotfiles-version-control
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/9/shell-dotfile
|
||||
[2]: https://zachholman.com/2010/08/dotfiles-are-meant-to-be-forked/
|
||||
[3]: http://pubs.opengroup.org/onlinepubs/9699919799/utilities/ln.html
|
||||
[4]: https://www.unix.com/man-page/FreeBSD/1/ln/
|
||||
[5]: https://github.com/mbbroberg/dotfiles/blob/master/Rakefile
|
||||
[6]: https://github.com/bradp/dotfiles
|
||||
[7]: https://github.com/geerlingguy/dotfiles
|
||||
[8]: https://github.com/geerlingguy/mac-dev-playbook
|
||||
[9]: https://opensource.com/article/19/2/git-terminology
|
||||
[10]: https://opensource.com/downloads/cheat-sheet-git
|
||||
[11]: http://dotfiles.github.io/
|
||||
[12]: https://twitter.com/mbbroberg?lang=en
|
||||
@ -0,0 +1,186 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Nuvola: Desktop Music Player for Streaming Services)
|
||||
[#]: via: (https://itsfoss.com/nuvola-music-player)
|
||||
[#]: author: (Atharva Lele https://itsfoss.com/author/atharva/)
|
||||
|
||||
Nuvola: Desktop Music Player for Streaming Services
|
||||
======
|
||||
|
||||
[Nuvola][1] is not like your usual music players. It’s different because it allows you to play a number of streaming services in a desktop music player.
|
||||
|
||||
Nuvola provides a runtime called [Nuvola Apps Runtime][2] which runs web apps. This is why Nuvola can support a host of streaming services. Some of the major players it supports are:
|
||||
|
||||
* Spotify
|
||||
* Google Play Music
|
||||
* YouTube, YouTube Music
|
||||
* [Pandora][3]
|
||||
* [SoundCloud][4]
|
||||
* and many many more.
|
||||
|
||||
|
||||
|
||||
You can find the full list [here][1] in the Music streaming services section. Apple Music is not supported, if you were wondering.
|
||||
|
||||
Why would you use a streaming music service in a different desktop player when you can run it in a web browser? The advantage with Nuvola is that it provides tight integration with many [desktop environments][5].
|
||||
|
||||
Ideally it should work with all DEs, but the officially supported ones are GNOME, Unity, and Pantheon (elementary OS).
|
||||
|
||||
### Features of Nuvola Music Player
|
||||
|
||||
Let’s see some of the main features of the open source project Nuvola:
|
||||
|
||||
* Supports a wide variety of music streaming services
|
||||
* Desktop integration with GNOME, Unity, and Pantheon.
|
||||
* Keyboard shortcuts with the ability to customize them
|
||||
* Support for keyboard’s multimedia keys (paid feature)
|
||||
* Background play with notifications
|
||||
* [GNOME Media Player][6] extension support
|
||||
* App Tray indicator
|
||||
* Dark and Light themes
|
||||
* Enable or disable features
|
||||
* Password Manager for web services
|
||||
* Remote control over internet (paid feature)
|
||||
* Available for a lot of distros ([Flatpak][7] packages)
|
||||
|
||||
|
||||
|
||||
Complete list of features is available [here][8].
|
||||
|
||||
### How to install Nuvola on Ubuntu & other Linux distributions
|
||||
|
||||
Installing Nuvola consists of a few more steps than simply adding a PPA and then installing the software. Since it is based on [Flatpak][7], you have to set up Flatpak first and then you can install Nuvola.
|
||||
|
||||
[Enable Flatpak Support][9]
|
||||
|
||||
The steps are pretty simple. You can follow the guide [here][10] if you want to install using the GUI, however I prefer terminal commands since they’re easier and faster.
|
||||
|
||||
**Warning: If already installed, remove the older version of Nuvola (Click to expand)**
|
||||
|
||||
If you have ever installed Nuvola before, you need to uninstall it to avoid issues. Run these commands in the terminal to do so.
|
||||
|
||||
```
|
||||
sudo apt remove nuvolaplayer*
|
||||
```
|
||||
|
||||
```
|
||||
rm -rf ~/.cache/nuvolaplayer3 ~/.local/share/nuvolaplayer ~/.config/nuvolaplayer3 ~/.local/share/applications/nuvolaplayer3*
|
||||
```
|
||||
|
||||
Once you have made sure that your system has Flatpak, you can install Nuvola using this command:
|
||||
|
||||
```
|
||||
flatpak remote-add --if-not-exists flathub https://dl.flathub.org/repo/flathub.flatpakrepo
|
||||
flatpak remote-add --if-not-exists nuvola https://dl.tiliado.eu/flatpak/nuvola.flatpakrepo
|
||||
```
|
||||
|
||||
This is an optional step but I recommend you install this since the service allows you to commonly configure settings like shortcuts for each of the streaming service that you might use.
|
||||
|
||||
```
|
||||
flatpak install nuvola eu.tiliado.Nuvola
|
||||
```
|
||||
|
||||
Nuvola supports 29 streaming services. To get them, you need to add those services individually. You can find all the supported music services are available on this [page][10].
|
||||
|
||||
For the purpose of this tutorial, I’m going to go with [YouTube Music][11].
|
||||
|
||||
```
|
||||
flatpak install nuvola eu.tiliado.NuvolaAppYoutubeMusic
|
||||
```
|
||||
|
||||
After this, you should have the app installed and should be able to see the icon if you search for it.
|
||||
|
||||
![Nuvola App specific icons][12]
|
||||
|
||||
Clicking on the icon will pop-up the first time setup. You’ll have to accept the Privacy Policy and then continue.
|
||||
|
||||
![Terms and Conditions page][13]
|
||||
|
||||
After accepting terms and conditions, you should launch into the web app of the respective streaming service, YouTube Music in this case.
|
||||
|
||||
![YouTube Music web app running on Nuvola Runtime][14]
|
||||
|
||||
In case of installation on other distributions, specific guidelines are available on the [Nuvola website][15].
|
||||
|
||||
### My experience with Nuvola Music Player
|
||||
|
||||
Initially I thought that it wouldn’t be too different than simply running the web app in [Firefox][16], since many desktop environments like KDE support media controls and shortcuts for media playing in Firefox.
|
||||
|
||||
However, this isn’t the case with many other desktops environments and that’s where Nuvola comes in handy. Often, it’s also faster to access than loading the website on the browser.
|
||||
|
||||
Once loaded, it behaves pretty much like a normal web app with the benefit of keyboard shortcuts. Speaking of shortcuts, you should check out the list of must know [Ubuntu shortcuts][17].
|
||||
|
||||
![Viewing an Artist’s page][18]
|
||||
|
||||
Integration with the DE comes in handy when you quickly want to change a song or play/pause your music without leaving your current application. Nuvola gives you access in GNOME notifications as well as provides an app tray icon.
|
||||
|
||||
* ![Notification music controls][19]
|
||||
|
||||
* ![App tray music controls][20]
|
||||
|
||||
|
||||
|
||||
|
||||
Keyboard shortcuts work well, globally as well as in-app. You get a notification when the song changes. Whether you do it yourself or it automatically switches to the next song.
|
||||
|
||||
![][21]
|
||||
|
||||
By default, very few keyboard shortcuts are provided. However you can enable them for almost everything you can do with the app. For example I set the song change shortcuts to Ctrl + Arrow keys as you can see in the screenshot.
|
||||
|
||||
![Keyboard Shortcuts][22]
|
||||
|
||||
All in all, it works pretty well and it’s fast and responsive. Definitely more so than your usual Snap app.
|
||||
|
||||
**Some criticism**
|
||||
|
||||
Some thing that did not please me as much was the installation size. Since it requires a browser back-end and GNOME integration it essentially installs a browser and necessary GNOME libraries for Flatpak, so that results in having to install almost 350MB in dependencies.
|
||||
|
||||
After that, you install individual apps. The individual apps themselves are not heavy at all. But if you just use one streaming service, having a 300+ MB installation might not be ideal if you’re concerned about disk space.
|
||||
|
||||
Nuvola also does not support local music, at least as far as I could find.
|
||||
|
||||
**Conclusion**
|
||||
|
||||
Hope this article helped you to know more about Nuvola Music Player and its features. If you like such different applications, why not take a look at some of the [lesser known music players for Linux][23]?
|
||||
|
||||
As always, if you have any suggestions or questions, I look forward to reading your comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/nuvola-music-player
|
||||
|
||||
作者:[Atharva Lele][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/atharva/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nuvola.tiliado.eu/
|
||||
[2]: https://nuvola.tiliado.eu/#fn:1
|
||||
[3]: https://itsfoss.com/install-pandora-linux-client/
|
||||
[4]: https://itsfoss.com/install-soundcloud-linux/
|
||||
[5]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[6]: https://extensions.gnome.org/extension/55/media-player-indicator/
|
||||
[7]: https://flatpak.org/
|
||||
[8]: http://tiliado.github.io/nuvolaplayer/documentation/4/explore.html
|
||||
[9]: https://itsfoss.com/flatpak-guide/
|
||||
[10]: https://nuvola.tiliado.eu/nuvola/ubuntu/bionic/
|
||||
[11]: https://nuvola.tiliado.eu/app/youtube_music/ubuntu/bionic/
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_youtube_music_icon.png?resize=800%2C450&ssl=1
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_eula.png?resize=800%2C450&ssl=1
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_youtube_music.png?resize=800%2C450&ssl=1
|
||||
[15]: https://nuvola.tiliado.eu/index/
|
||||
[16]: https://itsfoss.com/why-firefox/
|
||||
[17]: https://itsfoss.com/ubuntu-shortcuts/
|
||||
[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_web_player.png?resize=800%2C449&ssl=1
|
||||
[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_music_controls.png?fit=800%2C450&ssl=1
|
||||
[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_web_player2.png?fit=800%2C450&ssl=1
|
||||
[21]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_song_change_notification-e1553077619208.png?ssl=1
|
||||
[22]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/nuvola_shortcuts.png?resize=800%2C450&ssl=1
|
||||
[23]: https://itsfoss.com/lesser-known-music-players-linux/
|
||||
@ -0,0 +1,268 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Setup Linux Media Server Using Jellyfin)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Setup Linux Media Server Using Jellyfin
|
||||
======
|
||||
|
||||
![Setup Linux Media Server Using Jellyfin][1]
|
||||
|
||||
We’ve already written about setting up your own streaming media server on Linux using [**Streama**][2]. Today, we will going to setup yet another media server using **Jellyfin**. Jellyfin is a free, cross-platform and open source alternative to propriety media streaming applications such as **Emby** and **Plex**. The main developer of Jellyfin forked it from Emby after the announcement of Emby transitioning to a proprietary model. Jellyfin doesn’t include any premium features, licenses or membership plans. It is completely free and open source project supported by hundreds of community members. Using jellyfin, we can instantly setup Linux media server in minutes and access it via LAN/WAN from any devices using multiple apps.
|
||||
|
||||
### Setup Linux Media Server Using Jellyfin
|
||||
|
||||
Jellyfin supports GNU/Linux, Mac OS and Microsoft Windows operating systems. You can install it on your Linux distribution as described below.
|
||||
|
||||
##### Install Jellyfin On Linux
|
||||
|
||||
As of writing this guide, Jellyfin packages are available for most popular Linux distributions, such as Arch Linux, Debian, CentOS, Fedora and Ubuntu.
|
||||
|
||||
On **Arch Linux** and its derivatives like **Antergos** , **Manjaro Linux** , you can install Jellyfin using any AUR helper tools, for example [**YaY**][3].
|
||||
|
||||
```
|
||||
$ yay -S jellyfin-git
|
||||
```
|
||||
|
||||
On **CentOS/RHEL** :
|
||||
|
||||
Download the latest Jellyfin rpm package from [**here**][4] and install it as shown below.
|
||||
|
||||
```
|
||||
$ wget https://repo.jellyfin.org/releases/server/centos/jellyfin-10.2.2-1.el7.x86_64.rpm
|
||||
|
||||
$ sudo yum localinstall jellyfin-10.2.2-1.el7.x86_64.rpm
|
||||
```
|
||||
|
||||
On **Fedora** :
|
||||
|
||||
Download Jellyfin for Fedora from [**here**][5].
|
||||
|
||||
```
|
||||
$ wget https://repo.jellyfin.org/releases/server/fedora/jellyfin-10.2.2-1.fc29.x86_64.rpm
|
||||
|
||||
$ sudo dnf install jellyfin-10.2.2-1.fc29.x86_64.rpm
|
||||
```
|
||||
|
||||
On **Debian** :
|
||||
|
||||
Install HTTPS transport for APT if it is not installed already:
|
||||
|
||||
```
|
||||
$ sudo apt install apt-transport-https
|
||||
```
|
||||
|
||||
Import Jellyfin GPG signing key:``
|
||||
|
||||
```
|
||||
$ wget -O - https://repo.jellyfin.org/debian/jellyfin_team.gpg.key | sudo apt-key add -
|
||||
```
|
||||
|
||||
Add Jellyfin repository:
|
||||
|
||||
```
|
||||
$ sudo touch /etc/apt/sources.list.d/jellyfin.list
|
||||
|
||||
$ echo "deb [arch=amd64] https://repo.jellyfin.org/debian $( lsb_release -c -s ) main" | sudo tee /etc/apt/sources.list.d/jellyfin.list
|
||||
```
|
||||
|
||||
Finally, update Jellyfin repository and install Jellyfin using commands:``
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt install jellyfin
|
||||
```
|
||||
|
||||
On **Ubuntu 18.04 LTS** :
|
||||
|
||||
Install HTTPS transport for APT if it is not installed already:
|
||||
|
||||
```
|
||||
$ sudo apt install apt-transport-https
|
||||
```
|
||||
|
||||
Import and add Jellyfin GPG signing key:``
|
||||
|
||||
```
|
||||
$ wget -O - https://repo.jellyfin.org/debian/jellyfin_team.gpg.key | sudo apt-key add -
|
||||
```
|
||||
|
||||
Add the Jellyfin repository:
|
||||
|
||||
```
|
||||
$ sudo touch /etc/apt/sources.list.d/jellyfin.list
|
||||
|
||||
$ echo "deb https://repo.jellyfin.org/ubuntu bionic main" | sudo tee /etc/apt/sources.list.d/jellyfin.list
|
||||
```
|
||||
|
||||
For Ubuntu 16.04, just replace **bionic** with **xenial** in the above URL.
|
||||
|
||||
Finally, update Jellyfin repository and install Jellyfin using commands:``
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt install jellyfin
|
||||
```
|
||||
|
||||
##### Start Jellyfin service
|
||||
|
||||
Run the following commands to enable and start jellyfin service on every reboot:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable jellyfin
|
||||
|
||||
$ sudo systemctl start jellyfin
|
||||
```
|
||||
|
||||
To check if the service has been started or not, run:
|
||||
|
||||
```
|
||||
$ sudo systemctl status jellyfin
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
● jellyfin.service - Jellyfin Media Server
|
||||
Loaded: loaded (/lib/systemd/system/jellyfin.service; enabled; vendor preset: enabled)
|
||||
Drop-In: /etc/systemd/system/jellyfin.service.d
|
||||
└─jellyfin.service.conf
|
||||
Active: active (running) since Wed 2019-03-20 12:20:19 UTC; 1s ago
|
||||
Main PID: 4556 (jellyfin)
|
||||
Tasks: 11 (limit: 2320)
|
||||
CGroup: /system.slice/jellyfin.service
|
||||
└─4556 /usr/bin/jellyfin --datadir=/var/lib/jellyfin --configdir=/etc/jellyfin --logdir=/var/log/jellyfin --cachedir=/var/cache/jellyfin --r
|
||||
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading Emby.Photos, Version=10.2.2.0, Culture=neutral, PublicKeyToken=null
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading Emby.Server.Implementations, Version=10.2.2.0, Culture=neutral, PublicKeyToken=nu
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading MediaBrowser.MediaEncoding, Version=10.2.2.0, Culture=neutral, PublicKeyToken=nul
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading Emby.Dlna, Version=10.2.2.0, Culture=neutral, PublicKeyToken=null
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading MediaBrowser.LocalMetadata, Version=10.2.2.0, Culture=neutral, PublicKeyToken=nul
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading Emby.Notifications, Version=10.2.2.0, Culture=neutral, PublicKeyToken=null
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading MediaBrowser.XbmcMetadata, Version=10.2.2.0, Culture=neutral, PublicKeyToken=null
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Loading jellyfin, Version=10.2.2.0, Culture=neutral, PublicKeyToken=null
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Sqlite version: 3.26.0
|
||||
Mar 20 12:20:21 ubuntuserver jellyfin[4556]: [12:20:21] [INF] Sqlite compiler options: COMPILER=gcc-5.4.0 20160609,DEFAULT_FOREIGN_KEYS,ENABLE_COLUMN_M
|
||||
```
|
||||
|
||||
If you see an output something, congratulations! Jellyfin service has been started.
|
||||
|
||||
Next, we should do some initial configuration.
|
||||
|
||||
##### Configure Jellyfin
|
||||
|
||||
Once jellyfin is installed, open the browser and navigate to – **http:// <domain-name>:8096** or **http:// <IP-Address>:8096** URL.
|
||||
|
||||
You will see the following welcome screen. Select your preferred language and click Next.
|
||||
|
||||
![][6]
|
||||
|
||||
Enter your user details. You can add more users later from the Jellyfin Dashboard.
|
||||
|
||||
![][7]
|
||||
|
||||
The next step is to select media files which we want to stream. To do so, click “Add media Library” button:
|
||||
|
||||
![][8]
|
||||
|
||||
Choose the content type (i.e audio, video, movies etc.,), display name and click plus (+) sign next to the Folders icon to choose the location where you kept your media files. You can further choose other library settings such as the preferred download language, country etc. Click Ok after choosing the preferred options.
|
||||
|
||||
![][9]
|
||||
|
||||
Similarly, add all of the media files. Once you have chosen everything to stream, click Next.
|
||||
|
||||
![][10]
|
||||
|
||||
Choose the Metadata language and click Next:
|
||||
|
||||
![][11]
|
||||
|
||||
Next, you need to configure whether you want to allow remote connections to this media server. Make sure you have allowed the remote connections. Also, enable automatic port mapping and click Next:
|
||||
|
||||
![][12]
|
||||
|
||||
You’re all set! Click Finish to complete Jellyfin configuration.
|
||||
|
||||
![][13]
|
||||
|
||||
You will now be redirected to Jellyfin login page. Click on the username and enter it’s password which we setup earlier.
|
||||
|
||||
![][14]
|
||||
|
||||
This is how Jellyfin dashboard looks like.
|
||||
|
||||
![][15]
|
||||
|
||||
As you see in the screenshot, all of your media files are shown in the dashboard itself under My Media section. Just click on the any media file of your choice and start watching it!!
|
||||
|
||||
![][16]
|
||||
|
||||
You can access this Jellyfin media server from any systems on the network using URL – <http://ip-address:8096>. You need not to install any extra apps. All you need is a modern web browser.
|
||||
|
||||
If you want to change anything or reconfigure, click on the three horizontal bars from the Home screen. Here, you can add users, media files, change playback settings, add TV/DVR, install plugins, change default port no and a lot more settings.
|
||||
|
||||
![][17]
|
||||
|
||||
For more details, check out [**Jellyfin official documentation**][18] page.
|
||||
|
||||
And, that’s all for now. As you can see setting up a streaming media server on Linux is no big-deal. I tested it on my Ubuntu 18.04 LTS VM. It worked fine out of the box. I can be able to watch the movies from other systems in my LAN. If you’re looking for easy, quick and free solution for hosting a media server, Jellyfin is a good choice.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.ostechnix.com/streama-setup-your-own-streaming-media-server-in-minutes/
|
||||
[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]: https://repo.jellyfin.org/releases/server/centos/
|
||||
[5]: https://repo.jellyfin.org/releases/server/fedora/
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-1.png
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-2-1.png
|
||||
[8]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-3-1.png
|
||||
[9]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-4-1.png
|
||||
[10]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-5-1.png
|
||||
[11]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-6.png
|
||||
[12]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-7.png
|
||||
[13]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-8-1.png
|
||||
[14]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-9.png
|
||||
[15]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-10.png
|
||||
[16]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-11.png
|
||||
[17]: http://www.ostechnix.com/wp-content/uploads/2019/03/jellyfin-12.png
|
||||
[18]: https://jellyfin.readthedocs.io/en/latest/
|
||||
[19]: https://github.com/jellyfin/jellyfin
|
||||
[20]: http://feedburner.google.com/fb/a/mailverify?uri=ostechnix (Subscribe to our Email newsletter)
|
||||
[21]: https://www.paypal.me/ostechnix (Donate Via PayPal)
|
||||
[22]: http://ostechnix.tradepub.com/category/information-technology/1207/
|
||||
[23]: https://www.facebook.com/ostechnix/
|
||||
[24]: https://twitter.com/ostechnix
|
||||
[25]: https://plus.google.com/+SenthilkumarP/
|
||||
[26]: https://www.linkedin.com/in/ostechnix
|
||||
[27]: http://feeds.feedburner.com/Ostechnix
|
||||
[28]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/?share=reddit (Click to share on Reddit)
|
||||
[29]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/?share=twitter (Click to share on Twitter)
|
||||
[30]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/?share=facebook (Click to share on Facebook)
|
||||
[31]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/?share=linkedin (Click to share on LinkedIn)
|
||||
[32]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/?share=pocket (Click to share on Pocket)
|
||||
[33]: https://api.whatsapp.com/send?text=How%20To%20Setup%20Linux%20Media%20Server%20Using%20Jellyfin%20https%3A%2F%2Fwww.ostechnix.com%2Fhow-to-setup-linux-media-server-using-jellyfin%2F (Click to share on WhatsApp)
|
||||
[34]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/?share=telegram (Click to share on Telegram)
|
||||
[35]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/?share=email (Click to email this to a friend)
|
||||
[36]: https://www.ostechnix.com/how-to-setup-linux-media-server-using-jellyfin/#print (Click to print)
|
||||
151
sources/tech/20190321 How to add new disk in Linux.md
Normal file
151
sources/tech/20190321 How to add new disk in Linux.md
Normal file
@ -0,0 +1,151 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to add new disk in Linux)
|
||||
[#]: via: (https://kerneltalks.com/hardware-config/how-to-add-new-disk-in-linux/)
|
||||
[#]: author: (kerneltalks https://kerneltalks.com)
|
||||
|
||||
How to add new disk in Linux
|
||||
======
|
||||
|
||||
* * *
|
||||
|
||||
_Step by step procedure to add disk in Linux machine_
|
||||
|
||||
![New disk addition in Linux][1]
|
||||
|
||||
In this article we will walk you through steps to add new disk in Linux machine. Adding raw disk to linux machine may very depending upon the type of server you have but once disk is presented to machine, procedure of getting it to mount points is almost same.
|
||||
|
||||
**Objective** : Add new 10GB disk to server and create 5GB mount point out of it using LVM and newly created volume group.
|
||||
|
||||
* * *
|
||||
|
||||
### Adding raw disk to Linux machine
|
||||
|
||||
If you are using AWS EC2 Linux server, you may [follow these steps][2] to add raw disk. If you are on VMware Linux VM you will have different set of steps to follow to add disk. If you are running physical rack mount/blade server then adding disk will be a physical task.
|
||||
|
||||
Now once the disk is attached to Linux machine physically/virtually, it will be identified by kernel and then our rally starts.
|
||||
|
||||
* * *
|
||||
|
||||
### Identifying newly added disk in Linux
|
||||
|
||||
After attachment of raw disk, you need to ask kernel to [scan new disk][3]. Mostly its done now automatically by kernel in new versions.
|
||||
|
||||
First thing is to identify newly added disk and its name in kernel. There are numerous ways to achieve this. I will list few –
|
||||
|
||||
* You can observer `lsblk` output before and after adding/scanning disk to get new disk name.
|
||||
* Check newly created disk files in `/dev` filesystem. Match timestamp of file and disk addition time.
|
||||
* Observer `fdisk -l` output before and after adding/scanning disk to get new disk name.
|
||||
|
||||
|
||||
|
||||
For our example I am using AWS EC2 server and I added 5GB disk to my server. here is my lsblk output –
|
||||
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
xvda 202:0 0 10G 0 disk
|
||||
├─xvda1 202:1 0 1M 0 part
|
||||
└─xvda2 202:2 0 10G 0 part /
|
||||
xvdf 202:80 0 10G 0 disk
|
||||
```
|
||||
|
||||
You can see xvdf is our newly added disk. Full path for disk is `/dev/xvdf`.
|
||||
|
||||
* * *
|
||||
|
||||
### Add new disk in LVM
|
||||
|
||||
We are using LVM here since its widely used and flexible volume manager on Linux plateform. Make sure you have `lvm` or `lvm2` [package installed on your system][4]. If not, [install lvm/lvm2 package][5].
|
||||
|
||||
Now, we are going to add this RAW disk in Logical Volume Manager and create 10GB of mount point out of it. List of commands you need to follow are –
|
||||
|
||||
* [pvcreate][6]
|
||||
* [vgcreate][7]
|
||||
* [lvcreate][8]
|
||||
|
||||
|
||||
|
||||
If you are willing to add disk to existing mount point and use its space to [extend mount point][9] then `vgcreate` should be replaced by `vgextend`.
|
||||
|
||||
Sample outputs from my session –
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# pvcreate /dev/xvdf
|
||||
Physical volume "/dev/xvdf" successfully created.
|
||||
[root@kerneltalks ~]# vgcreate vgdata /dev/xvdf
|
||||
Volume group "vgdata" successfully created
|
||||
[root@kerneltalks ~]# lvcreate -L 5G -n lvdata vgdata
|
||||
Logical volume "lvdata" created.
|
||||
```
|
||||
|
||||
Now, you have logical volume created. You need to format it with filesystem on your choice and mount it. We are choosing ext4 filesystem here and formatting using `mkfs.ext4` .
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# mkfs.ext4 /dev/vgdata/lvdata
|
||||
mke2fs 1.42.9 (28-Dec-2013)
|
||||
Filesystem label=
|
||||
OS type: Linux
|
||||
Block size=4096 (log=2)
|
||||
Fragment size=4096 (log=2)
|
||||
Stride=0 blocks, Stripe width=0 blocks
|
||||
327680 inodes, 1310720 blocks
|
||||
65536 blocks (5.00%) reserved for the super user
|
||||
First data block=0
|
||||
Maximum filesystem blocks=1342177280
|
||||
40 block groups
|
||||
32768 blocks per group, 32768 fragments per group
|
||||
8192 inodes per group
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376, 294912, 819200, 884736
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (32768 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Mounting volume from new disk on mount point
|
||||
|
||||
Lets mount the logical volume of 5GB which we created and formatted on /data mount point using `mount` command.
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# mount /dev/vgdata/lvdata /data
|
||||
[root@kerneltalks ~]# df -Ph /data
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vgdata-lvdata 4.8G 20M 4.6G 1% /data
|
||||
```
|
||||
|
||||
Verify your mount point with df command as above and you are all done! You can always add an entry in [/etc/fstab][10] to make this mount persistent over reboots.
|
||||
|
||||
You have attached 10GB disk to Linux machine and created 5GB mount point out of it!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/hardware-config/how-to-add-new-disk-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://kerneltalks.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/kerneltalks.com/wp-content/uploads/2019/03/How-to-add-new-disk-in-Linux.png?ssl=1
|
||||
[2]: https://kerneltalks.com/cloud-services/how-to-add-ebs-disk-on-aws-linux-server/
|
||||
[3]: https://kerneltalks.com/disk-management/howto-scan-new-lun-disk-linux-hpux/
|
||||
[4]: https://kerneltalks.com/tools/check-package-installed-linux/
|
||||
[5]: https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[6]: https://kerneltalks.com/disk-management/lvm-command-tutorials-pvcreate-pvdisplay/
|
||||
[7]: https://kerneltalks.com/disk-management/lvm-commands-tutorial-vgcreate-vgdisplay-vgscan/
|
||||
[8]: https://kerneltalks.com/disk-management/lvm-commands-tutorial-lvcreate-lvdisplay-lvremove/
|
||||
[9]: https://kerneltalks.com/disk-management/extend-file-system-online-lvm/
|
||||
[10]: https://kerneltalks.com/config/understanding-etcfstab-file/
|
||||
@ -0,0 +1,235 @@
|
||||
Python ChatOps 库: Opsdroid 和 Errbot
|
||||
======
|
||||
|
||||

|
||||
这篇文章由笔者和 [Lacey Williams Henschel][1] 共同编写。
|
||||
|
||||
ChatOps 是基于会话导向而进行的开发。它的想法是你可以编写能够对聊天窗口中的某些输入进行回复的可执行代码。作为一个开发者,你能够用 ChatOps 从 Slack 合并拉取请求,自动从收到的 Facebook 消息中给某人分配支持票或者通过 IRC 检查开发状态。
|
||||
|
||||
在 Python 世界,最为广泛使用的 ChatOps 库是 Opsdroid 和 Errbot。在这个月的 Python 专栏,让我们一起聊聊使用它们是怎样的体验,它们各自适用于什么方面以及如何着手使用它们。
|
||||
|
||||
### Opsdroid
|
||||
|
||||
[Opsdroid][2] 是一个相对年轻的(始于 2016)Python 开源聊天机器人库。它有着良好的开发文档,不错的教程并且包含能够帮助你对接流行的聊天服务的插件。
|
||||
|
||||
#### 它内建了什么
|
||||
|
||||
库本身并没有自带所有你需要上手的东西,但这是故意的。轻量级的框架鼓励你去运用它现存的连接器(Opsdroid 所谓的帮你接入聊天服务的插件)或者去编写你自己的,但是它并不会因自带你所不需要的的连接器而自贬身价。你可以轻松使用现有的 Opsdroid 连接器来接入:
|
||||
|
||||
+ 命令行
|
||||
+ Cisco Spark
|
||||
+ Facebook
|
||||
+ GitHub
|
||||
+ Matrix
|
||||
+ Slack
|
||||
+ Telegram
|
||||
+ Twitter
|
||||
+ Websockets
|
||||
|
||||
Opsdroid 引用使聊天机器人能够展现它们的技能的函数。这些技能其实是 `异步` Python 函数并使用 Opsdroid 叫做“匹配器”的匹配装饰器。你可以设置你的 Opsdroid 项目,来使用同样从你设置文件所在的代码基地来的技能。你也可以从外面的公共或私人仓库调用这些技能。
|
||||
|
||||
你同样可以激活一些现存的 Opsdroid 技能包括 [seen][3],它会告诉你什么时候一个特定用户被聊天机器人所看到以及 [weather][4],会将天气报告给用户。
|
||||
|
||||
最后,Opdroid 允许你使用现存的数据库模块设置数据库。现在 Opdroid 支持的数据库包括:
|
||||
|
||||
+ Mongo
|
||||
+ Redis
|
||||
+ SQLite
|
||||
|
||||
你可以在你的 Opdroid 项目中的 `configuration.yaml` 文件设置数据库、技能和连接器。
|
||||
|
||||
#### Opsdroid 的优势
|
||||
|
||||
**Docker 支持:**从一开始 Opsdroid 就打算在 Docker 中良好运行。Docker 指导是它 [安装文档][5] 中的一部分。使用 Opsdroid 和 Docker Copmose 也很简单:将 Opsdroid 设置成一种服务,当你运行 `docker-compose up` 时,你的 Opsdroid 服务将会开启你的聊天机器人也将就绪。
|
||||
```
|
||||
version: "3"
|
||||
|
||||
|
||||
|
||||
services:
|
||||
|
||||
opsdroid:
|
||||
|
||||
container_name: opsdroid
|
||||
|
||||
build:
|
||||
|
||||
context: .
|
||||
|
||||
dockerfile: Dockerfile
|
||||
|
||||
```
|
||||
|
||||
**丰富的连接器:** Opsdroid 支持九种从外部接入像 Slack 和 Github 等服务的连接器。你所要做的一切就是在你的设置文件中激活那些连接器然后把必须的口令或者 API 密匙传过去。比如为了激活 Opsdroid 以在一个叫做 `#updates` 的 Slack 频道发帖,你需要将以下代码加入你设置文件的 `connectors` 部分:
|
||||
```
|
||||
- name: slack
|
||||
|
||||
api-token: "this-is-my-token"
|
||||
|
||||
default-room: "#updates"
|
||||
|
||||
```
|
||||
|
||||
在设置 Opsdroid 以接入 Slack 之前你需要[添加一个机器人用户][6]。
|
||||
|
||||
如果你需要接入一个 Opsdroid 不支持的服务,在[文档][7]里有有添加你自己的连接器的教程。
|
||||
|
||||
**相当不错的文档:** 特别是对于一个在积极开发中的新兴库来说,Opsdroid 的文档十分有帮助。这些文档包括一篇带你创建几个不同的基本技能的[教程][8]。Opsdroid 在[技能][9],[连接器][7],[数据库][10],以及[匹配器][11]方面的文档也十分清晰。
|
||||
|
||||
**自然语言处理:**它所支持的技能和连接器的仓库为它的技能提供了富有帮助的示范代码。它同样提供了几个包括 [Dialogflow][12],[luis.ai][13],[Recast.AI][14] 以及 [wit.ai][15] 的 NLP API。
|
||||
|
||||
#### 对 Opsdroid 可能的考虑
|
||||
|
||||
Opsdroid 对它的一部分连接器还没有激活全部的特性。比如说,Slack API 允许你向你的消息添加颜色柱,图片以及其他的“附件”。Opsdroid Slack 连接器并没有激活“附件”特性,所以如果那些特性对你来说很重要的话,你需要编写一个自定义的 Slack 连接器。如果连接器缺少一个你需要的特性,Opsdroid 将欢迎你的[贡献][16]。文档中可以使用更多的例子,特别是对于预料到的使用场景。
|
||||
|
||||
#### 示例用法
|
||||
|
||||
`hello/__init__.py`
|
||||
```
|
||||
from opsdroid.matchers import match_regex
|
||||
|
||||
import random
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@match_regex(r'hi|hello|hey|hallo')
|
||||
|
||||
async def hello(opsdroid, config, message):
|
||||
|
||||
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
|
||||
|
||||
await message.respond(text)
|
||||
|
||||
```
|
||||
|
||||
`configuration.yaml`
|
||||
```
|
||||
connectors:
|
||||
|
||||
- name: websocket
|
||||
|
||||
|
||||
|
||||
skills:
|
||||
|
||||
|
||||
|
||||
- name: hello
|
||||
|
||||
repo: "https://github.com/<user_id>/hello-skill"
|
||||
|
||||
```
|
||||
|
||||
### Errbot
|
||||
|
||||
[Errbot][17] 是一个功能齐全的开源聊天机器人。Errbot 发行于2012年并且拥有人们从一个成熟的项目能期待的一切,包括良好的文档,优秀的教程以及许多帮你连入现存的流行聊天服务的插件。
|
||||
|
||||
#### 它内建了什么
|
||||
|
||||
不像采用了一个较轻量级途径的 Opsdroid,Errbot 安全地自带了你需要创建一个自定义机器人的一切东西。
|
||||
|
||||
Errbot 包括了对于本地 XMPP, IRC, Slack, Hipchat 以及 Telegram 服务的支持。它通过社区支持的后端列出了另外十种服务。
|
||||
|
||||
#### Errbot 的优势
|
||||
|
||||
**良好的文档:** Errbot 的文档成熟易读。
|
||||
|
||||
**动态插件架构:** Errbot 允许你通过和聊天机器人交谈安全安装,卸载,更新,激活以及禁用插件。这使得开发和添加特性十分简便。感谢 Errbot 的颗粒性授权系统,出于安全意识这所有的一切都可以被锁闭。
|
||||
|
||||
当某个人输入 `!help`,Errbot 使用你的插件文档字符串来为可获取的命令生成文档,这使得了解每行命令的作用更加简便。
|
||||
|
||||
**內建的管理和安全特性:** Errbot 允许你限制拥有管理员权限甚至细粒度访问控制用户列表。比如说你可以限制特定用户或房间访问特定命令。
|
||||
|
||||
**额外的插件框架:** Errbot 支持钩子,回调,子命令,webhook,轮询以及其它[多得多的特性][18]。如果那些还不够,你甚至可以编写[动态插件][19]。当你需要基于在远程服务器上什么命令可以获取来激活聊天命令时,这个特性十分有用。
|
||||
|
||||
**自带测试框架:** Errbot 支持 [pytest][20] 同时也自带一些能使测试插件变的可能且简便的有用设施。它“[测试你的插件][21]”的文档出于深思熟虑并提供足够的资料让你上手。
|
||||
|
||||
#### 对 Errbot 可能的考虑
|
||||
|
||||
**首先 !:** 默认情况下,Errbot 命令发出时以一个惊叹号打头(`!help` 以及 `!hello`)。一些人可能会喜欢这样,但是另一些人可能认为这让人烦恼。谢天谢地,这很容易关掉。
|
||||
|
||||
**插件元数据** 首先,Errbot 的 [Hello World][22] 插件示例看上去易于使用。然而我无法加载我的插件直到我进一步阅读了教程并发现我还需要一个 `.plug` 文档,一个 Errbot 用来加载插件的文档。这可能比较吹毛求疵了,但是在我深挖文档之前,这对我来说都不是显而易见的。
|
||||
|
||||
### 示例用法
|
||||
|
||||
`hello.py`
|
||||
```
|
||||
import random
|
||||
|
||||
from errbot import BotPlugin, botcmd
|
||||
|
||||
|
||||
|
||||
class Hello(BotPlugin):
|
||||
|
||||
|
||||
|
||||
@botcmd
|
||||
|
||||
def hello(self, msg, args):
|
||||
|
||||
text = random.choice(["Hi {}", "Hello {}", "Hey {}"]).format(message.user)
|
||||
|
||||
return text
|
||||
|
||||
```
|
||||
|
||||
`hello.plug`
|
||||
```
|
||||
[Core]
|
||||
|
||||
Name = Hello
|
||||
|
||||
Module = hello
|
||||
|
||||
|
||||
|
||||
[Python]
|
||||
|
||||
Version = 2+
|
||||
|
||||
|
||||
|
||||
[Documentation]
|
||||
|
||||
Description = Example "Hello" plugin
|
||||
|
||||
```
|
||||
|
||||
你用过 Errbot 或 Opsdroid 吗?如果用过请留下关于你对于这些工具印象的留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/python-chatops-libraries-opsdroid-and-errbot
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laceynwilliams
|
||||
[1]:https://opensource.com/users/laceynwilliams
|
||||
[2]:https://opsdroid.github.io/
|
||||
[3]:https://github.com/opsdroid/skill-seen
|
||||
[4]:https://github.com/opsdroid/skill-weather
|
||||
[5]:https://opsdroid.readthedocs.io/en/stable/#docker
|
||||
[6]:https://api.slack.com/bot-users
|
||||
[7]:https://opsdroid.readthedocs.io/en/stable/extending/connectors/
|
||||
[8]:https://opsdroid.readthedocs.io/en/stable/tutorials/introduction/
|
||||
[9]:https://opsdroid.readthedocs.io/en/stable/extending/skills/
|
||||
[10]:https://opsdroid.readthedocs.io/en/stable/extending/databases/
|
||||
[11]:https://opsdroid.readthedocs.io/en/stable/matchers/overview/
|
||||
[12]:https://opsdroid.readthedocs.io/en/stable/matchers/dialogflow/
|
||||
[13]:https://opsdroid.readthedocs.io/en/stable/matchers/luis.ai/
|
||||
[14]:https://opsdroid.readthedocs.io/en/stable/matchers/recast.ai/
|
||||
[15]:https://opsdroid.readthedocs.io/en/stable/matchers/wit.ai/
|
||||
[16]:https://opsdroid.readthedocs.io/en/stable/contributing/
|
||||
[17]:http://errbot.io/en/latest/
|
||||
[18]:http://errbot.io/en/latest/features.html#extensive-plugin-framework
|
||||
[19]:http://errbot.io/en/latest/user_guide/plugin_development/dynaplugs.html
|
||||
[20]:http://pytest.org/
|
||||
[21]:http://errbot.io/en/latest/user_guide/plugin_development/testing.html
|
||||
[22]:http://errbot.io/en/latest/index.html#simple-to-build-upon
|
||||
@ -0,0 +1,57 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Cypht, an open source email client)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-cypht-email)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Cypht,一个开源的电子邮件客户端
|
||||
======
|
||||
使用 Cypht 将你的电子邮件和新闻源集成到一个界面中,这是我们 19 个开源工具系列中的第 4 个,它将使你在 2019 年更高效。
|
||||

|
||||
|
||||
每年年初似乎都有疯狂的冲动,想方设法提高工作效率。新年的决议,开始一年的权利,当然,“与旧的,与新的”的态度都有助于实现这一目标。通常的一轮建议严重偏向封闭源和专有软件。它不一定是这样。
|
||||
|
||||
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第 4 个工具来帮助你在 2019 年更有效率。
|
||||
|
||||
### Cypht
|
||||
|
||||
我们花了很多时间来处理电子邮件,有效地[管理你的电子邮件][1]可以对你的工作效率产生巨大影响。像 Thunderbird、Kontact/KMail 和 Evolution 这样的程序似乎都有一个共同点:它们试图复制 Microsoft Outlook 的功能,这在过去 10 年左右并没有真正改变。在过去十年中,甚至像 Mutt 和 Cone 这样的[著名控制台程序][2]也没有太大变化。
|
||||
|
||||

|
||||
|
||||
[Cypht][3] 是一个简单、轻量级和现代的 Webmail 客户端,它将多个帐户聚合到一个界面中。除了电子邮件帐户,它还包括 Atom/RSS 源。在 “Everything” 中,不仅可以显示收件箱中的邮件,还可以显示新闻源中的最新文章,从而使得阅读不同来源的内容变得简单。
|
||||
|
||||

|
||||
|
||||
它使用简化的 HTML 消息来显示邮件,或者你也可以将其设置为查看纯文本版本。由于 Cypht 不会加载远程图像(以帮助维护安全性),HTML 渲染可能有点粗糙,但它足以完成工作。你将看到包含大量富文本邮件的纯文本视图 - 这意味着很多链接并且难以阅读。我不会说是 Cypht 的问题,因为这确实是发件人所做的,但它确实降低了阅读体验。阅读新闻源大致相同,但它们与你的电子邮件帐户集成,这意味着可以轻松获取最新的(我有时会遇到问题)。
|
||||
|
||||

|
||||
|
||||
用户可以使用预配置的邮件服务器并添加他们使用的任何其他服务器。Cypht 的自定义选项包括纯文本与 HTML 邮件显示,它支持多个配置文件以及更改主题(并自行创建)。你要记得单击左侧导航栏上的“保存”按钮,否则你的自定义设置将在该会话后消失。如果你在不保存的情况下注销并重新登录,那么所有更改都将丢失,你将获得开始时的设置。因此可以轻松地实验,如果你需要重置,只需在不保存的情况下注销,那么在再次登录时就会看到之前的配置。
|
||||
|
||||

|
||||
|
||||
本地[安装 Cypht][4] 非常容易。虽然它不适用容器或类似技术,但安装说明非常清晰且易于遵循,并且不需要我做任何更改。在我的笔记本上,从安装开始到首次登录大约需要 10 分钟。服务器上的共享安装使用相同的步骤,因此它应该大致相同。
|
||||
|
||||
最后,Cypht 是桌面和基于 Web 的电子邮件客户端的绝佳替代方案,它有简单的界面,可帮助你快速有效地处理电子邮件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-cypht-email
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/7/email-alternatives-thunderbird
|
||||
[2]: https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
|
||||
[3]: https://cypht.org/
|
||||
[4]: https://cypht.org/install.html
|
||||
Loading…
Reference in New Issue
Block a user