mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
选题: Automating deployment strategies with Ansible
This commit is contained in:
parent
d383eca7a0
commit
08a416d51b
@ -0,0 +1,152 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automating deployment strategies with Ansible)
|
||||
[#]: via: (https://opensource.com/article/19/1/automating-deployment-strategies-ansible)
|
||||
[#]: author: (Jario da Silva Junior https://opensource.com/users/jairojunior)
|
||||
|
||||
Automating deployment strategies with Ansible
|
||||
======
|
||||
Use automation to eliminate time sinkholes due to repetitive tasks and unplanned work.
|
||||

|
||||
|
||||
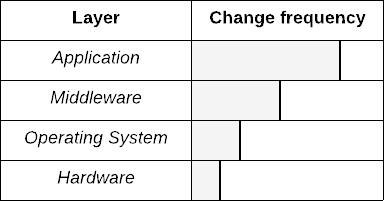
When you examine your technology stack from the bottom layer to the top—hardware, operating system (OS), middleware, and application—with their respective configurations, it's clear that changes are far more frequent as you go up in the stack. Your hardware will hardly change, your OS has a long lifecycle, and your middleware will keep up with the application's needs, but even if your release cycle is long (weeks or months), your applications will be the most volatile.
|
||||
|
||||
|
||||
|
||||
In [The Practice of System and Network Administration][1], the authors categorize the biggest "time sinkholes" in IT as manual/non-standard provisioning of OSes and application deployments. These time sinkholes will consume you with repetitive tasks or unplanned work.
|
||||
|
||||
How so? Let's say you provision a new server without Network Time Protocol (NTP) properly configured, and a small percentage of your requests—in a cluster of dozens of servers—start to behave strangely because an application uses some sort of scheduler that relies on correct time. When you look at it like this, it is an easy problem to fix, but how long it would it take your team figure it out? Incidents or unplanned work consume a lot of your time and, even worse, your greatest talents. Should you really be wasting time investigating production systems like this? Wouldn't it be better to set this server aside and automatically provision a new one from scratch?
|
||||
|
||||
What about manual deployment? Imagine 20 binaries deployed across a farm or nodes with their respective configuration files? How error-prone is this? Inevitably, it will eventually end up in unplanned work.
|
||||
|
||||
The [State of DevOps Report 2018][2] introduces the stages of DevOps adoption, and it's no surprise that Stage 0 includes deployment automation and reuse of deployment patterns, while Stage 1 and 2 focus on standardization of your infrastructure stack to reduce inconsistencies across your environment.
|
||||
|
||||
Note that, more than once, I have seen an ops team using this "standardization" as an excuse to limit a development team's ability to deliver, forcing them to use a hammer on something that is definitely not a nail. Don't do it; the price is extremely high.
|
||||
|
||||
The lesson to be learned here is that lack of automation not only increases your lead time but also the rate of problems in your process and the amount of unplanned work you face. If you've read [The Phoenix Project][3], you know this is the root of all evil in any value stream, and if you don't get rid of it, it will eventually kill your business.
|
||||
|
||||
When trying to fill the biggest time sinkholes, why not start with automating operating system installation? We could, but the results would take longer to appear since new virtual machines are not created as frequently as applications are deployed. In other words, this may not free up the time we need to power our initiative, so it could die prematurely.
|
||||
|
||||
Still not convinced? Smaller and more frequent releases are also extremely positive from the development side. Let's explain a little further…
|
||||
|
||||
### Deploy ≠ Release
|
||||
|
||||
The first thing to understand is that, although they're used interchangeably, deployment and release do **NOT** mean the same thing. Release refers to providing the user a new version, while deployment is the technical process of deploying the new version. Let's focus on the technical process of deployment.
|
||||
|
||||
### Tasks, groups, and Ansible
|
||||
|
||||
We need to understand the deployment process from the beginning to the end, including everything in the middle—the tasks, which servers are involved in the process, and which steps are executed—to avoid falling into the pitfalls described by Mattias Geniar in [Automating the unknown][4].
|
||||
|
||||
#### Tasks
|
||||
|
||||
The steps commonly executed in a regular deployment process include:
|
||||
|
||||
* Deploy application(s)/database(s) or database(s) change(s)
|
||||
* Stop/start services and monitoring
|
||||
* Add/remove the server from our load balancers
|
||||
* Verify application state—is it ready to serve requests?
|
||||
* Manual approval—is it necessary?
|
||||
|
||||
|
||||
|
||||
For some people, automating the deployment process but leaving a manual approval step is like riding a bike with training wheels. As someone once told me: "It's better to ride with training wheels than not ride at all."
|
||||
|
||||
What if a tool doesn't include an API or a command-line interface (CLI) to enable task automation? Well, maybe it's time to think about changing tools. There are many open source application servers, databases, monitoring systems, and load balancers that are easily automated—thanks in large part to the [Unix way][5]. When adopting a new technology, eliminate options that are not automated and use your creativity to support your legacy technologies. For example, I've seen people versioning network appliance configuration files and updating them using FTP.
|
||||
|
||||
And guess what? It's a wonderful time to adopt open source tools. The recent [Accelerate: State of DevOps][6] report found that open source technologies are in predominant use in high-performance organizations. The logic is pretty simple: open source projects function in a "Darwinist" model, where those that do not adapt and evolve will die for lack of a user base or contributions. Feedback is paramount to software evolution.
|
||||
|
||||
#### Groups
|
||||
|
||||
To identify groups of servers to target for automation, think about the most tasks you want to automate, such as those that:
|
||||
|
||||
* Deploy application(s)/database(s) or database change(s)
|
||||
* Stop/start services and monitoring
|
||||
* Add/remove server(s) from load balancer(s)
|
||||
* Verify application state—is it ready to serve requests?
|
||||
|
||||
|
||||
|
||||
#### The playbook
|
||||
|
||||
A high-level deployment process could be:
|
||||
|
||||
1. Stop monitoring (to avoid false-positives)
|
||||
2. Remove server from the load balancer (to prevent the user from receiving an error code)
|
||||
3. Stop the service (to enable a graceful shutdown)
|
||||
4. Deploy the new version of the application
|
||||
5. Wait for the application to be ready to receive new requests
|
||||
6. Execute steps 3, 2, and 1.
|
||||
7. Do the same for the next N servers.
|
||||
|
||||
|
||||
|
||||
Having documentation of your process is nice, but having an executable documenting your deployment is better! Here's what steps 1–5 would look like in Ansible for a fully open source stack:
|
||||
|
||||
```
|
||||
- name: Disable alerts
|
||||
nagios:
|
||||
action: disable_alerts
|
||||
host: "{{ inventory_hostname }}"
|
||||
services: webserver
|
||||
delegate_to: "{{ item }}"
|
||||
loop: "{{ groups.monitoring }}"
|
||||
|
||||
- name: Disable servers in the LB
|
||||
haproxy:
|
||||
host: "{{ inventory_hostname }}"
|
||||
state: disabled
|
||||
backend: app
|
||||
delegate_to: "{{ item }}"
|
||||
loop: " {{ groups.lbserver }}"
|
||||
|
||||
- name: Stop the service
|
||||
service: name=httpd state=stopped
|
||||
|
||||
- name: Deploy a new version
|
||||
unarchive: src=app.tar.gz dest=/var/www/app
|
||||
|
||||
- name: Verify application state
|
||||
uri:
|
||||
url: "http://{{ inventory_hostname }}/app/healthz"
|
||||
status_code: 200
|
||||
retries: 5
|
||||
```
|
||||
|
||||
### Why Ansible?
|
||||
|
||||
There are other alternatives for application deployment, but the things that make Ansible an excellent choice include:
|
||||
|
||||
* Multi-tier orchestration (i.e., **delegate_to** ) allowing you to orderly target different groups of servers: monitoring, load balancer, application server, database, etc.
|
||||
* Rolling upgrade (i.e., serial) to control how changes are made (e.g., 1 by 1, N by N, X% at a time, etc.)
|
||||
* Error control, **max_fail_percentage** and **any_errors_fatal** , is my process all-in or will it tolerate fails?
|
||||
* A vast library of modules for:
|
||||
* Monitoring (e.g., Nagios, Zabbix, etc.)
|
||||
* Load balancers (e.g., HAProxy, F5, Netscaler, Cisco, etc.)
|
||||
* Services (e.g., service, command, file)
|
||||
* Deployment (e.g., copy, unarchive)
|
||||
* Programmatic verifications (e.g., command, Uniform Resource Identifier)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
|
||||
|
||||
作者:[Jario da Silva Junior][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jairojunior
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.amazon.com/Practice-System-Network-Administration-Enterprise/dp/0321919165/ref=dp_ob_title_bk
|
||||
[2]: https://puppet.com/resources/whitepaper/state-of-devops-report
|
||||
[3]: https://www.amazon.com/Phoenix-Project-DevOps-Helping-Business/dp/0988262592
|
||||
[4]: https://ma.ttias.be/automating-unknown/
|
||||
[5]: https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
[6]: https://cloudplatformonline.com/2018-state-of-devops.html
|
||||
Loading…
Reference in New Issue
Block a user