mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge branch 'LCTT/master'
This commit is contained in:
commit
067ae02440
@ -0,0 +1,66 @@
|
||||
解决构建全球社区带来的挑战
|
||||
======
|
||||
|
||||
> 全球开源社区通常面临着语音壁垒、文化差异以及其它的挑战。如何去解决它们呢?
|
||||
|
||||

|
||||
|
||||
今天的开源组织参与人员来自于全世界。你能预见到组建在线社区可能遇到哪些困难吗?有没有什么办法能够克服这些困难呢?
|
||||
|
||||
为开源社区贡献力量的人共同合作推动软件的开发和发展。在过去,人们是面对面或者通过邮件和电话来交流的。今天,科技孕育出了在线交流——人们只需要进入一个聊天室或消息渠道就能一起工作了。比如,你可以早上跟摩洛哥的人一起工作,到了晚上又跟夏威夷的人一起工作。
|
||||
|
||||
### 全球社区的三个挑战
|
||||
|
||||
任何一个团队合作过的人都知道意见分歧是很难被克服的。对于在线社区来说,语言障碍、不同的时区,以及文化差异也带来了新的挑战。
|
||||
|
||||
#### 语言障碍
|
||||
|
||||
英语是开源社区中的主流语言,因此英语不好的人会很难看懂文档和修改意见。为了克服这个问题,吸引其他地区的社区成员,你需要邀请双语者参与到社区中来。问问周围的人——你会发现意想不到的精通其他语言的人。社区的双语成员可以帮助别人跨越语言障碍,并且可以通过翻译软件和文档来扩大项目的受众范围。
|
||||
|
||||
人们使用的编程语言也不一样。你可能喜欢用 Bash 而其他人则可能更喜欢 Python、Ruby、C 等其他语言。这意味着,人们可能由于编程语言的原因而难以为你的代码库做贡献。项目负责人为项目选择一门被软件社区广泛认可的语言至关重要。如果你选择了一门偏门的语言,则很少人能够参与其中。
|
||||
|
||||
#### 不同的时区
|
||||
|
||||
时区为开源社区带来了另一个挑战。比如,若你在芝加哥,想与一个在伦敦的成员安排一次视频会议,你需要调整 8 小时的时差。根据合作者的地理位置,你可能要在深夜或者清晨工作。
|
||||
|
||||
肉身转移,可以让你的团队在同一个时区工作可以帮助克服这个挑战,但这种方法只有极少数社区才能够负担的起。我们还可以定期举行虚拟会议讨论项目,建立一个固定的时间和地点以供所有人来讨论未决的事项,即将发布的版本等其他主题。
|
||||
|
||||
不同的时区也可以成为你的优势,因为团队成员可以全天候的工作。若你拥有一个类似 IRC 这样的实时交流平台,用户可以在任意时间都能找到人来回答问题。
|
||||
|
||||
#### 文化差异
|
||||
|
||||
文化差异是开源组织面临的最大挑战。世界各地的人都有不同的思考方式、计划以及解决问题的方法。政治环境也会影响工作环境并影响决策。
|
||||
|
||||
作为项目负责人,你应该努力构建一种能包容不同看法的环境。文化差异可以鼓励社区沟通。建设性的讨论总是对项目有益,因为它可以帮助社区成员从不同角度看待问题。不同意见也有助于解决问题。
|
||||
|
||||
要成功开源,团队必须学会拥抱差异。这不简单,但多样性最终会使社区收益。
|
||||
|
||||
### 加强在线沟通的其他方法
|
||||
|
||||
- **本地化:** 在线社区成员可能会发现位于附近的贡献者——去见个面并组织一个本地社区。只需要两个人就能组建一个社区了。可以邀请其他当地用户或雇员参与其中;他们甚至还能为以后的聚会提供场所呢。
|
||||
- **组织活动:** 组织活动是构建本地社区的好方法,而且费用也不高。你可以在当地的咖啡屋或者啤酒厂聚会,庆祝最新版本的发布或者某个核心功能的实现。组织的活动越多,人们参与的热情就越高(即使只是因为单纯的好奇心)。最终,可能会找到一家公司为你提供聚会的场地,或者为你提供赞助。
|
||||
- **保持联系:** 每次活动后,联系本地社区成员。收起电子邮箱地址或者其他联系方式并邀请他们参与到你的交流平台中。邀请他们为其他社区做贡献。你很可能会发现很多当地的人才,运气好的话,甚至可能发现新的核心开发人员!
|
||||
- **分享经验:** 本地社区是一种非常有价值的资源,对你,对其他社区来说都是。与可能受益的人分享你的发现和经验。如果你不清楚(LCTT 译注:这里原文是说 sure,但是根据上下文,这里应该是 not sure)如何策划一场活动或会议,可以咨询其他人的意见。也许能找到一些有经验的人帮你走到正轨。
|
||||
- **关注文化差异:** 记住,文化规范因地点和人而异,因此在清晨安排某项活动可能适用于一个地方的人,但是不合适另一个地方的人。当然,你可以(也应该)利用其他社区的参考资料来更好地理解这种差异性,但有时你也需要通过试错的方式来学习。不要忘了分享你所学到的东西,让别人也从中获益。
|
||||
- **检查个人观点:** 避免在工作场合提出带有很强主观色彩的观点(尤其是与政治相关的观点)。这会抑制开放式的沟通和问题的解决。相反,应该专注于鼓励与团队成员展开建设性讨论。如果你发现陷入了激烈的争论中,那么后退一步,冷静一下,然后再从更加积极的角度出发重新进行讨论。讨论必须是有建设性的,从多个角度讨论问题对社区有益。永远不要把自己的主观观念放在社区的总体利益之前。
|
||||
- **尝试异步沟通:** 这些天,实时通讯平台已经引起了大家的关注,但除此之外还别忘了电子邮件。如果没有在网络平台上找到人的话,可以给他们发送一封电子邮件。有可能你很快就能得到回复。考虑使用那些专注于异步沟通的平台,比如 [Twist][1],也不要忘了查看并更新论坛和维基。
|
||||
- **使用不同的解决方案:** 并不存在一个单一的完美的解决方法,学习最有效的方法还是通过经验来学习。从反复试验中你可以学到很多东西。不要害怕失败;你会从失败中学到很多东西从而不停地进步。
|
||||
|
||||
### 社区需要营养
|
||||
|
||||
将社区想象成是一颗植物的幼苗。你需要每天给它浇水,提供阳光和氧气。社区也是一样:倾听贡献者的声音,记住你在与活生生的人进行互动,他们需要以合适的方式进行持续的交流。如果社区缺少了人情味,人们会停止对它的贡献。
|
||||
|
||||
最后,请记住,每个社区都是不同的,没有一种单一的解决方法能够适用于所有社区。坚持不断地从社区中学习并适应这个社区。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/working-worldwide-communities
|
||||
|
||||
作者:[José Antonio Rey][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jose
|
||||
[1]:https://twistapp.com
|
||||
@ -2,66 +2,65 @@
|
||||
======
|
||||
|
||||

|
||||
Bittorrent 已经存在了很长时间,它可以从互联网上共享和下载数据。市场上有大量的 GUI 和 CLI 的 Bittorrent 客户端。有时,你不能坐下来等待你的下载完成。你可能想要立即观看内容。这就是 **BTFS**这个不起眼的文件系统派上用场的地方。使用 BTFS,你可以将种子文件或磁力链接挂载为目录,然后在文件树中作为只读目录。这些文件的内容将在程序读取时按需下载。由于 BTFS 在 FUSE 之上运行,因此不需要干预 Linux 内核。
|
||||
|
||||
## BTFS – 基于 FUSE 的 Bittorrent 文件系统
|
||||
Bittorrent 已经存在了很长时间,它可以从互联网上共享和下载数据。市场上有大量的 GUI 和 CLI 的 Bittorrent 客户端。有时,你不能坐下来等待你的下载完成。你可能想要立即观看内容。这就是 **BTFS** 这个不起眼的文件系统派上用场的地方。使用 BTFS,你可以将种子文件或磁力链接挂载为目录,然后在文件树中作为只读目录。这些文件的内容将在程序读取时按需下载。由于 BTFS 在 FUSE 之上运行,因此不需要干预 Linux 内核。
|
||||
|
||||
### 安装 BTFS
|
||||
|
||||
BTFS 存在于大多数 Linux 发行版的默认参仓库中。
|
||||
BTFS 存在于大多数 Linux 发行版的默认仓库中。
|
||||
|
||||
在 Arch Linux 及其变体上,运行以下命令来安装 BTFS。
|
||||
|
||||
```
|
||||
$ sudo pacman -S btfs
|
||||
|
||||
```
|
||||
|
||||
在Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install btfs
|
||||
|
||||
```
|
||||
|
||||
在 Gentoo 上:
|
||||
|
||||
```
|
||||
# emerge -av btfs
|
||||
|
||||
```
|
||||
|
||||
BTFS 也可以使用 [**Linuxbrew**][1] 包管理器进行安装。
|
||||
BTFS 也可以使用 [Linuxbrew][1] 包管理器进行安装。
|
||||
|
||||
```
|
||||
$ brew install btfs
|
||||
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
BTFS 的使用非常简单。你所要做的就是找到 .torrent 文件或磁力链接,并将其挂载到一个目录中。种子文件或磁力链接的内容将被挂载到你选择的目录内。当一个程序试图访问该文件进行读取时,实际的数据将按需下载。此外,像 **ls** 、**cat** 和 **cp**这样的工具能按照预期的方式来操作种子。像 **vlc** 和 **mplayer** 这样的程序也可以不加修改地工作。玩家甚至不知道实际内容并非物理存在于本地磁盘中,而是根据需要从 peer 中收集。
|
||||
BTFS 的使用非常简单。你所要做的就是找到 .torrent 文件或磁力链接,并将其挂载到一个目录中。种子文件或磁力链接的内容将被挂载到你选择的目录内。当一个程序试图访问该文件进行读取时,实际的数据将按需下载。此外,像 `ls` 、`cat` 和 `cp` 这样的工具能按照预期的方式来操作种子。像 `vlc` 和 `mplayer` 这样的程序也可以不加修改地工作。玩家甚至不知道实际内容并非物理存在于本地磁盘中,而是根据需要从 peer 中收集。
|
||||
|
||||
创建一个目录来挂载 torrent/magnet 链接:
|
||||
|
||||
```
|
||||
$ mkdir mnt
|
||||
|
||||
```
|
||||
|
||||
挂载 torrent/magnet 链接:
|
||||
|
||||
```
|
||||
$ btfs video.torrent mnt
|
||||
|
||||
```
|
||||
|
||||
[![][2]][3]
|
||||
![][3]
|
||||
|
||||
cd 到目录:
|
||||
|
||||
```
|
||||
$ cd mnt
|
||||
|
||||
```
|
||||
|
||||
然后,开始观看!
|
||||
|
||||
```
|
||||
$ vlc <path-to-video.mp4>
|
||||
|
||||
```
|
||||
|
||||
给 BTFS 一些时间来找到并获取网站 tracker。一旦加载了真实数据,BTFS 将不再需要 tracker。
|
||||
@ -69,9 +68,9 @@ $ vlc <path-to-video.mp4>
|
||||
![][4]
|
||||
|
||||
要卸载 BTFS 文件系统,只需运行以下命令:
|
||||
|
||||
```
|
||||
$ fusermount -u mnt
|
||||
|
||||
```
|
||||
|
||||
现在,挂载目录中的内容将消失。要再次访问内容,你需要按照上面的描述挂载 torrent。
|
||||
@ -82,8 +81,6 @@ BTFS 会将你的 VLC 或 Mplayer 变成爆米花时间。挂载你最喜爱的
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/btfs-a-bittorrent-filesystem-based-on-fuse/
|
||||
@ -91,7 +88,7 @@ via: https://www.ostechnix.com/btfs-a-bittorrent-filesystem-based-on-fuse/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
What is a Linux server and why does your business need one?
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,67 @@
|
||||
Intel and AMD Reveal New Processor Designs
|
||||
======
|
||||
|
||||

|
||||
|
||||
With this week's Computex show in Taipei and other recent events, processors are front and center in the tech news cycle. Intel made several announcements ranging from new Core processors to a cutting-edge technology for extending battery life. AMD, meanwhile, unveiled a second-gen, 32-core Threadripper CPU for high-end gaming and revealed some new Ryzen chips including some embedded friendly models.
|
||||
|
||||
Here’s a quick tour of major announcements from Intel and AMD, focusing on those processors of greatest interest to embedded Linux developers.
|
||||
|
||||
### Intel’s latest 8th Gen CPUs
|
||||
|
||||
In April, Intel announced that mass production of its 10nm fabricated Cannon Lake generation of Core processors would be delayed until 2019, which led to more grumbling about Moore’s Law finally running its course. Yet, there were plenty of consolation prizes in Intel’s [Computex showcase][1]. Intel revealed two power-efficient, 14nm 8th Gen Core product families, as well as its first 5GHz designs.
|
||||
|
||||
The Whiskey Lake U-series and Amber Lake Y-series Core chips will arrive in more than 70 different laptop and 2-in-1 models starting this fall. The chips will bring “double digit performance gains” compared to 7th Gen Kaby Lake Core CPUs, said Intel. The new product families are more power efficient than the [Coffee Lake][2] chips that are now starting to arrive in products.
|
||||
|
||||
Both Whiskey Lake and Amber Lake will provide Intel’s higher performance gigabit WiFi ((Intel 9560 AC), which is also appearing on the new [Gemini Lake][3] Pentium Silver and Celeron SoCs, the follow-ups to the Apollo Lake generation. Gigabit WiFi is essentially Intel’s spin on 802.11ac with 2×2 MU-MIMO and 160MHz channels.
|
||||
|
||||
Intel’s Whiskey Lake is a continuation of the 7th and 8th Gen Skylake U-series processors, which have been popular on embedded equipment. Intel had few details, but Whiskey Lake will presumably offer the same, relatively low 15W TDPs. It’s also likely that like the [Coffee Lake U-series chips][4] it will be available in quad-core models as well as the dual-core only Kaby Lake and Skylake U-Series chips.
|
||||
|
||||
The Amber Lake Y-series chips will primarily target 2-in-1s. Like the dual-core [Kaby Lake Y-Series][5] chips, Amber Lake will offer 4.5W TDPs, reports [PC World][6].
|
||||
|
||||
To celebrate Intel’s upcoming 50th anniversary, as well as the 40th anniversary of the first 8086 processor, Intel will launch a limited edition, 8th Gen [Core i7-8086K][7] CPU with a clock rate of 4GHz. The limited edition, 64-bit offering will be its first chip with 5GHz, single-core turbo boost speed, and the first 6-core, 12-thread processor with integrated graphics. Intel will be [giving away][8] 8,086 of the overclockable Core i7-8086K chips starting on June 7.
|
||||
|
||||
Intel also revealed plans to launch a new high-end Core X series with high core and thread counts by the end of the year. [AnandTech predicts][9] that this will use the Xeon-like Cascade Lake architecture. Later this year, it will announce new Core S-series models, which AnandTech projects will be octa-core Coffee Lake chips.
|
||||
|
||||
Intel also said that the first of its speedy Optane SSDs -- an M.2 form-factor product called the [905P][10] \-- is finally available. Due later this year is an Intel XMM 800 series modem that supports Sprint’s 5G cellular technology. Intel says 5G-enabled PCs will arrive in 2019.
|
||||
|
||||
### Intel promises all day laptop battery life
|
||||
|
||||
In other news, Intel says it will soon launch an Intel Low Power Display Technology that will provide all-day battery life on laptops. Co-developers Sharp and Innolux are using the technology for a late-2018 launch of a 1W display panel that can cut LCD power consumption in half.
|
||||
|
||||
### AMD keeps on ripping
|
||||
|
||||
At Computex, AMD unveiled a second generation Threadripper CPU with 32 cores and 64 threads. The high-end gaming processor will launch in the third quarter to go head to head with Intel’s unnamed 28-core monster. According to [Engadget][11], the new Threadripper adopts the same 12nm Zen+ architecture used by its Ryzen chips.
|
||||
|
||||
AMD also said it was sampling a 7nm Vega Instinct GPU designed for graphics cards with 32GB of expensive HBM2 memory rather than GDDR5X or GDDR6. The Vega Instinct will offer 35 percent greater performance and twice the power efficiency of the current 14nm Vega GPUs. New rendering capabilities will help it compete with Nvidia’s CUDA enabled GPUs in ray tracing, says [WCCFTech][12].
|
||||
|
||||
Some new Ryzen 2000-series processors recently showed up on an ASRock CPU chart that have the lowest power efficiency of the mainstream Ryzen chips. As detailed on [AnandTech][13], the 2.8GHz, octa-core, 16-thread Ryzen 7 2700E and 3.4GHz/3.9GHz, hexa-core, 12-thread Ryzen 5 2600E each have 45W TDPs. This is higher than the 12-54W TDPs of its [Ryzen Embedded V1000][2] SoCs, but lower than the 65W and up mainstream Ryzen chips. The new Ryzen-E models are aimed at SFF (small form factor) and fanless systems.
|
||||
|
||||
Join us at [Open Source Summit + Embedded Linux Conference Europe][14] in Edinburgh, UK on October 22-24, 2018, for 100+ sessions on Linux, Cloud, Containers, AI, Community, and more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/intel-amd-and-arm-reveal-new-processor-designs
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/ericstephenbrown
|
||||
[1]:https://newsroom.intel.com/editorials/pc-personal-contribution-platform-pushing-boundaries-modern-computers-computex/
|
||||
[2]:https://www.linux.com/news/elc-openiot/2018/3/hot-chips-face-mwc-and-embedded-world
|
||||
[3]:http://linuxgizmos.com/intel-launches-gemini-lake-socs-with-gigabit-wifi/
|
||||
[4]:http://linuxgizmos.com/intel-coffee-lake-h-series-debuts-in-congatec-and-seco-modules
|
||||
[5]:http://linuxgizmos.com/more-kaby-lake-chips-arrive-plus-four-nuc-mini-pcs/
|
||||
[6]:https://www.pcworld.com/article/3278091/components-processors/intel-computex-news-a-28-core-chip-a-5ghz-8086-two-new-architectures-and-more.html
|
||||
[7]:https://newsroom.intel.com/wp-content/uploads/sites/11/2018/06/intel-i7-8086k-launch-fact-sheet.pdf
|
||||
[8]:https://game.intel.com/8086sweepstakes/
|
||||
[9]:https://www.anandtech.com/show/12878/intel-discuss-whiskey-lake-amber-lake-and-cascade-lake
|
||||
[10]:https://www.intel.com/content/www/us/en/products/memory-storage/solid-state-drives/gaming-enthusiast-ssds/optane-905p-series.htm
|
||||
[11]:https://www.engadget.com/2018/06/05/amd-threadripper-32-cores/
|
||||
[12]:https://wccftech.com/amd-demos-worlds-first-7nm-gpu/
|
||||
[13]:https://www.anandtech.com/show/12841/amd-preps-new-ryzen-2000series-cpus-45w-ryzen-7-2700e-ryzen-5-2600e
|
||||
[14]:https://events.linuxfoundation.org/events/elc-openiot-europe-2018/
|
||||
@ -1,167 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
How To Downgrade A Package In Arch Linux
|
||||
======
|
||||
|
||||

|
||||
As you might know, Arch Linux is a rolling release and DIY (do-it-yourself) distribution. So you have to be bit careful while updating it often, especially installing or updating packages from the third party repositories like AUR. You might be end up with broken system if you don’t know what you are doing. It is your responsibility to make Arch Linux more stable. However, we all do mistakes. It is difficult to be careful all time. Sometimes, you want to update to most bleeding edge, and you might be stuck with broken packages. Don’t panic! In such cases, you can simply rollback to the old stable packages. This short tutorial describes how to downgrade a package in Arch Linux and its variants like Antergos, Manjaro Linux.
|
||||
|
||||
### Downgrade a package in Arch Linux
|
||||
|
||||
In Arch Linux, there is an utility called** “downgrade”** that helps you to downgrade an installed package to any available older version. This utility will check your local cache and the remote servers (Arch Linux repositories) for the old versions of a required package. You can pick any one of the old stable package from that list and install it.
|
||||
|
||||
This package is not available in the official repositories. You need to add the unofficial **archlinuxfr** repository.
|
||||
|
||||
To do so, edit **/etc/pacman.conf** file:
|
||||
```
|
||||
$ sudo nano /etc/pacman.conf
|
||||
|
||||
```
|
||||
|
||||
Add the following lines:
|
||||
```
|
||||
[archlinuxfr]
|
||||
SigLevel = Never
|
||||
Server = http://repo.archlinux.fr/$arch
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Update the repositories with command:
|
||||
```
|
||||
$ sudo pacman -Sy
|
||||
|
||||
```
|
||||
|
||||
Then install “Downgrade” utility using the following command from your Terminal:
|
||||
```
|
||||
$ sudo pacman -S downgrade
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (1) downgrade-5.2.3-1
|
||||
|
||||
Total Download Size: 0.01 MiB
|
||||
Total Installed Size: 0.10 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
|
||||
```
|
||||
|
||||
The typical usage of “downgrade” command is:
|
||||
```
|
||||
$ sudo downgrade [PACKAGE, ...] [-- [PACMAN OPTIONS]]
|
||||
|
||||
```
|
||||
|
||||
Let us say you want to downgrade **opera web browser** to any available old version.
|
||||
|
||||
To do so, run:
|
||||
```
|
||||
$ sudo downgrade opera
|
||||
|
||||
```
|
||||
|
||||
This command will list all available versions of opera package (both new and old) from your local cache and remote mirror.
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Available packages:
|
||||
|
||||
1) opera-37.0.2178.43-1-x86_64.pkg.tar.xz (local)
|
||||
2) opera-37.0.2178.43-1-x86_64.pkg.tar.xz (remote)
|
||||
3) opera-37.0.2178.32-1-x86_64.pkg.tar.xz (remote)
|
||||
4) opera-36.0.2130.65-2-x86_64.pkg.tar.xz (remote)
|
||||
5) opera-36.0.2130.65-1-x86_64.pkg.tar.xz (remote)
|
||||
6) opera-36.0.2130.46-2-x86_64.pkg.tar.xz (remote)
|
||||
7) opera-36.0.2130.46-1-x86_64.pkg.tar.xz (remote)
|
||||
8) opera-36.0.2130.32-2-x86_64.pkg.tar.xz (remote)
|
||||
9) opera-36.0.2130.32-1-x86_64.pkg.tar.xz (remote)
|
||||
10) opera-35.0.2066.92-1-x86_64.pkg.tar.xz (remote)
|
||||
11) opera-35.0.2066.82-1-x86_64.pkg.tar.xz (remote)
|
||||
12) opera-35.0.2066.68-1-x86_64.pkg.tar.xz (remote)
|
||||
13) opera-35.0.2066.37-2-x86_64.pkg.tar.xz (remote)
|
||||
14) opera-34.0.2036.50-1-x86_64.pkg.tar.xz (remote)
|
||||
15) opera-34.0.2036.47-1-x86_64.pkg.tar.xz (remote)
|
||||
16) opera-34.0.2036.25-1-x86_64.pkg.tar.xz (remote)
|
||||
17) opera-33.0.1990.115-2-x86_64.pkg.tar.xz (remote)
|
||||
18) opera-33.0.1990.115-1-x86_64.pkg.tar.xz (remote)
|
||||
19) opera-33.0.1990.58-1-x86_64.pkg.tar.xz (remote)
|
||||
20) opera-32.0.1948.69-1-x86_64.pkg.tar.xz (remote)
|
||||
21) opera-32.0.1948.25-1-x86_64.pkg.tar.xz (remote)
|
||||
22) opera-31.0.1889.174-1-x86_64.pkg.tar.xz (remote)
|
||||
23) opera-31.0.1889.99-1-x86_64.pkg.tar.xz (remote)
|
||||
24) opera-30.0.1835.125-1-x86_64.pkg.tar.xz (remote)
|
||||
25) opera-30.0.1835.88-1-x86_64.pkg.tar.xz (remote)
|
||||
26) opera-30.0.1835.59-1-x86_64.pkg.tar.xz (remote)
|
||||
27) opera-30.0.1835.52-1-x86_64.pkg.tar.xz (remote)
|
||||
28) opera-29.0.1795.60-1-x86_64.pkg.tar.xz (remote)
|
||||
29) opera-29.0.1795.47-1-x86_64.pkg.tar.xz (remote)
|
||||
30) opera-28.0.1750.51-1-x86_64.pkg.tar.xz (remote)
|
||||
31) opera-28.0.1750.48-1-x86_64.pkg.tar.xz (remote)
|
||||
32) opera-28.0.1750.40-1-x86_64.pkg.tar.xz (remote)
|
||||
33) opera-27.0.1689.76-1-x86_64.pkg.tar.xz (remote)
|
||||
34) opera-27.0.1689.69-1-x86_64.pkg.tar.xz (remote)
|
||||
35) opera-27.0.1689.66-1-x86_64.pkg.tar.xz (remote)
|
||||
36) opera-27.0.1689.54-2-x86_64.pkg.tar.xz (remote)
|
||||
37) opera-27.0.1689.54-1-x86_64.pkg.tar.xz (remote)
|
||||
38) opera-26.0.1656.60-1-x86_64.pkg.tar.xz (remote)
|
||||
39) opera-26.0.1656.32-1-x86_64.pkg.tar.xz (remote)
|
||||
40) opera-12.16.1860-2-x86_64.pkg.tar.xz (remote)
|
||||
41) opera-12.16.1860-1-x86_64.pkg.tar.xz (remote)
|
||||
|
||||
select a package by number:
|
||||
|
||||
```
|
||||
|
||||
Just type the package number of your choice, and hit enter to install it.
|
||||
|
||||
That’s it. The current installed package will be downgraded to the old version.
|
||||
|
||||
**Also Read:[How To Downgrade All Packages To A Specific Date In Arch Linux][1]**
|
||||
|
||||
##### So, how can avoid broken packages and make Arch Linux more stable?
|
||||
|
||||
Check [**Arch Linux news**][2] and [**forums**][3] before updating Arch Linux to find out if there have been any reported problem. I have been using Arch Linux as my main OS for the past few weeks. Here is some simple tips that I have found over a period of time to avoid installing unstable packages in Arch Linux.
|
||||
|
||||
1. Avoid partial upgrades. It means that never run “pacman -Sy <package-name>”. This command will partially upgrade your system while installing a package. Instead, first use “pacman -Syu” to update the system and then use “package -S <package-name>” to a install package.
|
||||
2. Avoid using “pacman -Syu –force” command. The –force flag will ignore the package and file conflicts and you might end-up with broken packages or broken system.
|
||||
3. Do not skip dependency check. It means that do not use “pacman -Rdd <package-name>”. This command will avoid dependency check while removing a package. If you run this command, a critical dependency which is needed by another important package could be removed too. Eventually, it will break your Arch Linux.
|
||||
4. It is always a good practice to make regular backup of important data and configuration files to avoid any data loss.
|
||||
5. Be careful while installing packages from third party and unofficial repositories like AUR. And do not install packages that are in heavy development.
|
||||
|
||||
|
||||
|
||||
For more details, check the [**Arch Linux maintenance guide**][4].
|
||||
|
||||
I am not an Arch Linux expert, and I am still learning to make it more stable. Please feel free to let me know If you have any tips to make Arch Linux stable and safe in the comment section below. I am all ears.
|
||||
|
||||
Hope this helps. That’s all for now. I will be here again with another interesting article soon. Until then, stay tuned with OSTechNix.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/downgrade-package-arch-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/downgrade-packages-specific-date-arch-linux/
|
||||
[2]:https://www.archlinux.org/news/
|
||||
[3]:https://bbs.archlinux.org/
|
||||
[4]:https://wiki.archlinux.org/index.php/System_maintenance
|
||||
@ -1,73 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Set up zsh on your Fedora system
|
||||
======
|
||||
|
||||

|
||||
|
||||
For some people, the terminal can be scary. But a terminal is more than just a black screen to type in. It usually runs a shell, so called because it wraps around the kernel. The shell is a text-based interface that lets you run commands on the system. It’s also sometimes called a command line interpreter or CLI. Fedora, like most Linux distributions, comes with bash as the default shell. However, it isn’t the only shell available; several other shells can be installed. This article focuses on the Z Shell, or zsh.
|
||||
|
||||
Bash is a rewrite of the old Bourne shell (sh) that shipped in UNIX. Zsh is intended to be friendlier than bash, through better interaction. Some of its useful features are:
|
||||
|
||||
* Programmable command line completion
|
||||
* Shared command history between running shell sessions
|
||||
* Spelling correction
|
||||
* Loadable modules
|
||||
* Interactive selection of files and folders
|
||||
|
||||
|
||||
|
||||
Zsh is available in the Fedora repositories. To install, run this command:
|
||||
```
|
||||
$ sudo dnf install zsh
|
||||
|
||||
```
|
||||
|
||||
### Using zsh
|
||||
|
||||
To start using it, just type zsh and the new shell prompts you with a first run wizard. This wizard helps you configure initial features, like history behavior and auto-completion. Or you can opt to keep the [rc file][1] empty:
|
||||
|
||||
![zsh First Run Wizzard][2]
|
||||
|
||||
If you type 1 the configuration wizard starts. The other options launch the shell immediately.
|
||||
|
||||
Note that the user prompt is **%** and not **$** as with bash. A significant feature here is the auto-completion that allows you to move among files and directories with the Tab key, much like a menu:
|
||||
|
||||
![zsh cd Feature][3]
|
||||
|
||||
Another interesting feature is spelling correction, which helps when writing filenames with mixed cases:
|
||||
|
||||
![zsh Auto Completion][4]
|
||||
|
||||
## Making zsh your default shell
|
||||
|
||||
Zsh offers a lot of plugins, like zsh-syntax-highlighting, and the famous “Oh my zsh” ([check out its page here][5]). You might want to make it the default, so it runs whenever you start a session or open a terminal. To do this, use the chsh (“change shell”) command:
|
||||
```
|
||||
$ chsh -s $(which zsh)
|
||||
|
||||
```
|
||||
|
||||
This command tells your system that you want to set (-s) your default shell to the correct location of the shell (which zsh).
|
||||
|
||||
Photo by [Kate Ter Haar][6] from [Flickr][7] (CC BY-SA).
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/set-zsh-fedora-system/
|
||||
|
||||
作者:[Eduard Lucena][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/x3mboy/
|
||||
[1]:https://en.wikipedia.org/wiki/Configuration_file
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshFirstRun.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshChangingFeature-1.gif
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshAutoCompletion.gif
|
||||
[5]:http://ohmyz.sh/
|
||||
[6]:https://www.flickr.com/photos/katerha/
|
||||
[7]:https://www.flickr.com/photos/katerha/34714051013/
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
Copying and renaming files on Linux
|
||||
======
|
||||

|
||||
|
||||
@ -0,0 +1,435 @@
|
||||
How To Add, Enable And Disable A Repository In Linux
|
||||
======
|
||||
Many of us using yum package manager to manage package installation, remove, update, search, etc, on RPM based system such as RHEL, CentOS, etc,.
|
||||
|
||||
Linux distributions gets most of its software from distribution official repositories. The official distribution repositories contain good amount of free and open source apps/software’s. It’s readily available to install and use.
|
||||
|
||||
RPM based distribution doesn’t offer some of the packages in their official distribution repository due to some limitation and proprietary issue. Also it won’t offer latest version of core packages due to stability.
|
||||
|
||||
To overcome this situation/issue, we need to install/enable the requires third party repository. There are many third party repositories are available for RPM based systems but only few of the repositories are advised to use because they didn’t replace large amount of base packages.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [YUM Command To Manage Packages on RHEL/CentOS Systems][1]
|
||||
**(#)** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][2]
|
||||
**(#)** [List of Command line Package Manager & Usage][3]
|
||||
**(#)** [A Graphical front-end tool for Linux Package Manager][4]
|
||||
|
||||
This can be done on RPM based system such as RHEL, CentOS, OEL, Fedora, etc,.
|
||||
|
||||
* Fedora system uses “dnf config-manager [options] [section …]”
|
||||
* Other RPM based system uses “yum-config-manager [options] [section …]”
|
||||
|
||||
|
||||
|
||||
### How To List Enabled Repositories
|
||||
|
||||
Just run the below command to check list of enabled repositories on your system.
|
||||
|
||||
For CentOS/RHEL/OLE systems
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
extras CentOS-6 - Extras 53
|
||||
updates CentOS-6 - Updates 1,255
|
||||
repolist: 8,014
|
||||
|
||||
```
|
||||
|
||||
For Fedora system
|
||||
```
|
||||
# dnf repolist
|
||||
|
||||
```
|
||||
|
||||
### How To Add A New Repository In System
|
||||
|
||||
Every repositories commonly provide their own `.repo` file. To add such a repository to your system, run the
|
||||
following command as root user. In our case, we are going to add `EPEL Repository` and `IUS Community Repo`, see below.
|
||||
|
||||
There is no `.repo` files are available for these repositories. Hence, we are installing by using below methods.
|
||||
|
||||
For **EPEL Repository** , since it’s available from CentOS extra repository so, run the below command to install it.
|
||||
```
|
||||
# yum install epel-release -y
|
||||
|
||||
```
|
||||
|
||||
For **IUS Community Repo** , run the below bash script to install it.
|
||||
```
|
||||
# curl 'https://setup.ius.io/' -o setup-ius.sh
|
||||
# sh setup-ius.sh
|
||||
|
||||
```
|
||||
|
||||
If you have `.repo` file, simple run the following command to add a repository on RHEL/CentOS/OEL.
|
||||
```
|
||||
# yum-config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
Loaded plugins: product-id, refresh-packagekit, subscription-manager
|
||||
adding repo from: http://www.example.com/example.repo
|
||||
grabbing file http://www.example.com/example.repo to /etc/yum.repos.d/example.repo
|
||||
example.repo | 413 B 00:00
|
||||
repo saved to /etc/yum.repos.d/example.repo
|
||||
|
||||
```
|
||||
|
||||
For Fedora system, run the below command to add a repository.
|
||||
```
|
||||
# dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
adding repo from: http://www.example.com/example.repo
|
||||
|
||||
```
|
||||
|
||||
If you run `yum repolist` command after adding these repositories, you can able to see newly added repositories. Yes, i saw that.
|
||||
|
||||
Make a note: whenever you run “yum repolist” command, that automatically fetch updates from corresponding repository and save the caches in local system.
|
||||
```
|
||||
# yum repolist
|
||||
|
||||
Loaded plugins: fastestmirror, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
epel/metalink | 6.1 kB 00:00
|
||||
* epel: epel.mirror.constant.com
|
||||
* ius: ius.mirror.constant.com
|
||||
ius | 2.3 kB 00:00
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
||||
extras CentOS-6 - Extras 53
|
||||
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
||||
updates CentOS-6 - Updates 1,255
|
||||
repolist: 20,909
|
||||
|
||||
```
|
||||
|
||||
Each repository has multiple channels such as Testing, Dev, Archive. You can understand this better by navigating to repository files location.
|
||||
```
|
||||
# ls -lh /etc/yum.repos.d
|
||||
total 64K
|
||||
-rw-r--r-- 1 root root 2.0K Apr 12 02:44 CentOS-Base.repo
|
||||
-rw-r--r-- 1 root root 647 Apr 12 02:44 CentOS-Debuginfo.repo
|
||||
-rw-r--r-- 1 root root 289 Apr 12 02:44 CentOS-fasttrack.repo
|
||||
-rw-r--r-- 1 root root 630 Apr 12 02:44 CentOS-Media.repo
|
||||
-rw-r--r-- 1 root root 916 May 18 11:07 CentOS-SCLo-scl.repo
|
||||
-rw-r--r-- 1 root root 892 May 18 10:36 CentOS-SCLo-scl-rh.repo
|
||||
-rw-r--r-- 1 root root 6.2K Apr 12 02:44 CentOS-Vault.repo
|
||||
-rw-r--r-- 1 root root 7.9K Apr 12 02:44 CentOS-Vault.repo.rpmnew
|
||||
-rw-r--r-- 1 root root 957 May 18 10:41 epel.repo
|
||||
-rw-r--r-- 1 root root 1.1K Nov 4 2012 epel-testing.repo
|
||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-archive.repo
|
||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-dev.repo
|
||||
-rw-r--r-- 1 root root 1.1K May 18 10:41 ius.repo
|
||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-testing.repo
|
||||
|
||||
```
|
||||
|
||||
### How To Enable A Repository In System
|
||||
|
||||
When you add a new repository by default it’s enable the their stable repository that’s why we are getting the repository information when we ran “yum repolist” command. In some cases if you want to enable their Testing or Dev or Archive repo, use the following command. Also, we can enable any disabled repo using this command.
|
||||
|
||||
To validate this, we are going to enable `epel-testing.repo` by running the below command.
|
||||
```
|
||||
# yum-config-manager --enable epel-testing
|
||||
|
||||
Loaded plugins: fastestmirror
|
||||
==================================================================================== repo: epel-testing =====================================================================================
|
||||
[epel-testing]
|
||||
bandwidth = 0
|
||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||
baseurl =
|
||||
cache = 0
|
||||
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
||||
cost = 1000
|
||||
enabled = 1
|
||||
enablegroups = True
|
||||
exclude =
|
||||
failovermethod = priority
|
||||
ftp_disable_epsv = False
|
||||
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
||||
gpgcakey =
|
||||
gpgcheck = True
|
||||
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
||||
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
||||
http_caching = all
|
||||
includepkgs =
|
||||
keepalive = True
|
||||
mdpolicy = group:primary
|
||||
mediaid =
|
||||
metadata_expire = 21600
|
||||
metalink =
|
||||
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
||||
mirrorlist_expire = 86400
|
||||
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
||||
old_base_cache_dir =
|
||||
password =
|
||||
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
||||
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
||||
proxy = False
|
||||
proxy_dict =
|
||||
proxy_password =
|
||||
proxy_username =
|
||||
repo_gpgcheck = False
|
||||
retries = 10
|
||||
skip_if_unavailable = False
|
||||
ssl_check_cert_permissions = True
|
||||
sslcacert =
|
||||
sslclientcert =
|
||||
sslclientkey =
|
||||
sslverify = True
|
||||
throttle = 0
|
||||
timeout = 30.0
|
||||
username =
|
||||
|
||||
```
|
||||
|
||||
Run the “yum repolist” command to check whether “epel-testing” is enabled or not. It’s enabled, i could able to see the repo.
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
Determining fastest mirrors
|
||||
epel/metalink | 18 kB 00:00
|
||||
epel-testing/metalink | 17 kB 00:00
|
||||
* epel: mirror.us.leaseweb.net
|
||||
* epel-testing: mirror.us.leaseweb.net
|
||||
* ius: mirror.team-cymru.com
|
||||
base | 3.7 kB 00:00
|
||||
centos-sclo-sclo | 2.9 kB 00:00
|
||||
epel | 4.7 kB 00:00
|
||||
epel/primary_db | 6.0 MB 00:00
|
||||
epel-testing | 4.7 kB 00:00
|
||||
epel-testing/primary_db | 368 kB 00:00
|
||||
extras | 3.4 kB 00:00
|
||||
ius | 2.3 kB 00:00
|
||||
ius/primary_db | 216 kB 00:00
|
||||
updates | 3.4 kB 00:00
|
||||
updates/primary_db | 8.1 MB 00:00 ...
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,509
|
||||
epel-testing Extra Packages for Enterprise Linux 6 - Testing - x86_64 809
|
||||
extras CentOS-6 - Extras 53
|
||||
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
||||
updates CentOS-6 - Updates 1,288
|
||||
repolist: 22,250
|
||||
|
||||
```
|
||||
|
||||
If you want to enable multiple repositories at once, use the below format. This command will enable epel, epel-testing, and ius repositories.
|
||||
```
|
||||
# yum-config-manager --enable epel epel-testing ius
|
||||
|
||||
```
|
||||
|
||||
For Fedora system, run the below command to enable a repository.
|
||||
```
|
||||
# dnf config-manager --set-enabled epel-testing
|
||||
|
||||
```
|
||||
|
||||
### How To Disable A Repository In System
|
||||
|
||||
Whenever you add a new repository by default it enables their stable repository that’s why we are getting the repository information when we ran “yum repolist” command. If you dont want to use the repository then disable that by running below command.
|
||||
|
||||
To validate this, we are going to disable `epel-testing.repo` & `ius.repo` by running below command.
|
||||
```
|
||||
# yum-config-manager --disable epel-testing ius
|
||||
|
||||
Loaded plugins: fastestmirror
|
||||
==================================================================================== repo: epel-testing =====================================================================================
|
||||
[epel-testing]
|
||||
bandwidth = 0
|
||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||
baseurl =
|
||||
cache = 0
|
||||
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
||||
cost = 1000
|
||||
enabled = 0
|
||||
enablegroups = True
|
||||
exclude =
|
||||
failovermethod = priority
|
||||
ftp_disable_epsv = False
|
||||
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
||||
gpgcakey =
|
||||
gpgcheck = True
|
||||
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
||||
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
||||
http_caching = all
|
||||
includepkgs =
|
||||
keepalive = True
|
||||
mdpolicy = group:primary
|
||||
mediaid =
|
||||
metadata_expire = 21600
|
||||
metalink =
|
||||
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
||||
mirrorlist_expire = 86400
|
||||
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
||||
old_base_cache_dir =
|
||||
password =
|
||||
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
||||
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
||||
proxy = False
|
||||
proxy_dict =
|
||||
proxy_password =
|
||||
proxy_username =
|
||||
repo_gpgcheck = False
|
||||
retries = 10
|
||||
skip_if_unavailable = False
|
||||
ssl_check_cert_permissions = True
|
||||
sslcacert =
|
||||
sslclientcert =
|
||||
sslclientkey =
|
||||
sslverify = True
|
||||
throttle = 0
|
||||
timeout = 30.0
|
||||
username =
|
||||
|
||||
========================================================================================= repo: ius =========================================================================================
|
||||
[ius]
|
||||
bandwidth = 0
|
||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||
baseurl =
|
||||
cache = 0
|
||||
cachedir = /var/cache/yum/x86_64/6/ius
|
||||
cost = 1000
|
||||
enabled = 0
|
||||
enablegroups = True
|
||||
exclude =
|
||||
failovermethod = priority
|
||||
ftp_disable_epsv = False
|
||||
gpgcadir = /var/lib/yum/repos/x86_64/6/ius/gpgcadir
|
||||
gpgcakey =
|
||||
gpgcheck = True
|
||||
gpgdir = /var/lib/yum/repos/x86_64/6/ius/gpgdir
|
||||
gpgkey = file:///etc/pki/rpm-gpg/IUS-COMMUNITY-GPG-KEY
|
||||
hdrdir = /var/cache/yum/x86_64/6/ius/headers
|
||||
http_caching = all
|
||||
includepkgs =
|
||||
keepalive = True
|
||||
mdpolicy = group:primary
|
||||
mediaid =
|
||||
metadata_expire = 21600
|
||||
metalink =
|
||||
mirrorlist = https://mirrors.iuscommunity.org/mirrorlist?repo=ius-centos6&arch=x86_64&protocol=http
|
||||
mirrorlist_expire = 86400
|
||||
name = IUS Community Packages for Enterprise Linux 6 - x86_64
|
||||
old_base_cache_dir =
|
||||
password =
|
||||
persistdir = /var/lib/yum/repos/x86_64/6/ius
|
||||
pkgdir = /var/cache/yum/x86_64/6/ius/packages
|
||||
proxy = False
|
||||
proxy_dict =
|
||||
proxy_password =
|
||||
proxy_username =
|
||||
repo_gpgcheck = False
|
||||
retries = 10
|
||||
skip_if_unavailable = False
|
||||
ssl_check_cert_permissions = True
|
||||
sslcacert =
|
||||
sslclientcert =
|
||||
sslclientkey =
|
||||
sslverify = True
|
||||
throttle = 0
|
||||
timeout = 30.0
|
||||
username =
|
||||
|
||||
```
|
||||
|
||||
Run the “yum repolist” command to check whether “epel-testing” & “ius” repositories are disabled or not. It’s disabled, i could not able to see those repo in the below list except “epel”.
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* epel: mirror.us.leaseweb.net
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
||||
extras CentOS-6 - Extras 53
|
||||
updates CentOS-6 - Updates 1,288
|
||||
repolist: 21,051
|
||||
|
||||
```
|
||||
|
||||
Alternatively, we can run the following command to see the details.
|
||||
```
|
||||
# yum repolist all | grep "epel*\|ius*"
|
||||
* epel: mirror.steadfast.net
|
||||
epel Extra Packages for Enterprise Linux 6 enabled: 12,509
|
||||
epel-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-source Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-testing Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-testing-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-testing-source Extra Packages for Enterprise Linux 6 disabled
|
||||
ius IUS Community Packages for Enterprise disabled
|
||||
ius-archive IUS Community Packages for Enterprise disabled
|
||||
ius-archive-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-archive-source IUS Community Packages for Enterprise disabled
|
||||
ius-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-dev IUS Community Packages for Enterprise disabled
|
||||
ius-dev-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-dev-source IUS Community Packages for Enterprise disabled
|
||||
ius-source IUS Community Packages for Enterprise disabled
|
||||
ius-testing IUS Community Packages for Enterprise disabled
|
||||
ius-testing-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-testing-source IUS Community Packages for Enterprise disabled
|
||||
|
||||
```
|
||||
|
||||
For Fedora system, run the below command to enable a repository.
|
||||
```
|
||||
# dnf config-manager --set-disabled epel-testing
|
||||
|
||||
```
|
||||
|
||||
Alternatively this can be done by editing the appropriate repo file manually. To do, open the corresponding repo file and change the value from `enabled=0`
|
||||
to `enabled=1` (To enable the repo) or from `enabled=1` to `enabled=0` (To disable the repo).
|
||||
|
||||
From:
|
||||
```
|
||||
[epel]
|
||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
||||
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
||||
failovermethod=priority
|
||||
enabled=0
|
||||
gpgcheck=1
|
||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
|
||||
```
|
||||
|
||||
To:
|
||||
```
|
||||
[epel]
|
||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
||||
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
||||
failovermethod=priority
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[2]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||
[4]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||
100
sources/tech/20180531 How To Disable Built-in Webcam In Linux.md
Normal file
100
sources/tech/20180531 How To Disable Built-in Webcam In Linux.md
Normal file
@ -0,0 +1,100 @@
|
||||
How To Disable Built-in Webcam In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, we’ll see how to disable built-in webcam or external webcam when it’s not used, and how to enable it back when it’s required in your Linux box. Disabling web cam can help you in many ways. You can prevent from the malware taking control of your integrated webcam and spy on you and your home. We have read countless stories in the past that some hackers can spy on you using your webcam without your knowledge. By hacking your webcam, the user can share your private photos and videos online. There could be many reasons. If you’re ever wondered how to disable the web cam in your Laptop or desktop, you’re in luck. This brief tutorial will show you how. Read on.
|
||||
|
||||
I tested this guide on Arch Linux and Ubuntu. It worked exactly as described below. I hope this will work on other Linux distributions as well.
|
||||
|
||||
### Disable Built-in webcam in Linux
|
||||
|
||||
First, find the web cam driver using command:
|
||||
```
|
||||
$ sudo lsmod | grep uvcvideo
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
uvcvideo 114688 1
|
||||
videobuf2_vmalloc 16384 1 uvcvideo
|
||||
videobuf2_v4l2 28672 1 uvcvideo
|
||||
videobuf2_common 53248 2 uvcvideo,videobuf2_v4l2
|
||||
videodev 208896 4 uvcvideo,videobuf2_common,videobuf2_v4l2
|
||||
media 45056 2 uvcvideo,videodev
|
||||
usbcore 286720 9 uvcvideo,usbhid,usb_storage,ehci_hcd,ath3k,btusb,uas,ums_realtek,ehci_pci
|
||||
|
||||
```
|
||||
|
||||
Here, **uvcvideo** is my web cam driver.
|
||||
|
||||
Now, let us disable webcam.
|
||||
|
||||
To do so, edit the following file (if the file is not exists, just create it):
|
||||
```
|
||||
$ sudo nano /etc/modprobe.d/blacklist.conf
|
||||
|
||||
```
|
||||
|
||||
Add the following lines:
|
||||
```
|
||||
##Disable webcam.
|
||||
blacklist uvcvideo
|
||||
|
||||
```
|
||||
|
||||
The line **“##Disable webcam”** is not necessary. I have added it for the sake of easy understanding.
|
||||
|
||||
Save and exit the file. Reboot your system to take effect the changes.
|
||||
|
||||
To verify, whether Webcam is really disabled or not, open any instant messenger applications or web cam software such as Cheese or Guvcview. You will see a blank screen like below.
|
||||
|
||||
**Cheese output:**
|
||||
|
||||
![][2]
|
||||
|
||||
**Guvcview output:**
|
||||
|
||||
![][3]
|
||||
|
||||
See? The web cam is disabled and is not working.
|
||||
|
||||
To enable it back, edit:
|
||||
```
|
||||
$ sudo nano /etc/modprobe.d/blacklist.conf
|
||||
|
||||
```
|
||||
|
||||
Comment the lines which you have added earlier.
|
||||
```
|
||||
##Disable webcam.
|
||||
#blacklist uvcvideo
|
||||
|
||||
```
|
||||
|
||||
Save and close the file. Then, reboot your Computer to enable your Webcam.
|
||||
|
||||
Does it enough? No. Why? If someone can remotely access your system, they can easily enable the webcam back. So, It is always a good idea to cover it up with a tape or unplug the camera or disable it in the BIOS when it’s not used. This method is not just for disabling the built-in webcam, but also for external web camera.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-disable-built-in-webcam-in-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2015/08/cheese.jpg
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2015/08/guvcview.jpg
|
||||
131
sources/tech/20180531 How to create shortcuts in vi.md
Normal file
131
sources/tech/20180531 How to create shortcuts in vi.md
Normal file
@ -0,0 +1,131 @@
|
||||
How to create shortcuts in vi
|
||||
======
|
||||
|
||||

|
||||
|
||||
Learning the [vi text editor][1] takes some effort, but experienced vi users know that after a while, using basic commands becomes second nature. It's a form of what is known as muscle memory, which in this case might well be called finger memory.
|
||||
|
||||
After you get a grasp of the main approach and basic commands, you can make editing with vi even more powerful and streamlined by using its customization options to create shortcuts. I hope that the techniques described below will facilitate your writing, programming, and data manipulation.
|
||||
|
||||
Before proceeding, I'd like to thank Chris Hermansen (who recruited me to write this article) for checking my draft with [Vim][2], as I use another version of vi. I'm also grateful for Chris's helpful suggestions, which I incorporated here.
|
||||
|
||||
First, let's review some conventions. I'll use <RET> to designate pressing the RETURN or ENTER key, and <SP> for the space bar. CTRL-x indicates simultaneously pressing the Control key and the x key (whatever x happens to be).
|
||||
|
||||
Set up your own command abbreviations with the `map` command. My first example involves the `write` command, used to save the current state of the file you're working on:
|
||||
```
|
||||
:w<RET>
|
||||
|
||||
```
|
||||
|
||||
This is only three keystrokes, but since I do it so frequently, I'd rather use only one. The key I've chosen for this purpose is the comma, which is not part of the standard vi command set. The command to set this up is:
|
||||
```
|
||||
:map , :wCTRL-v<RET>
|
||||
|
||||
```
|
||||
|
||||
The CTRL-v is essential since without it the <RET> would signal the end of the map, and we want to include the <RET> as part of the mapped comma. In general, CTRL-v is used to enter the keystroke (or control character) that follows rather than being interpreted literally.
|
||||
|
||||
In the above map, the part on the right will display on the screen as `:w^M`. The caret (`^`) indicates a control character, in this case CTRL-m, which is the system's form of <RET>.
|
||||
|
||||
So far so good—sort of. If I write my current file about a dozen times while creating and/or editing it, this map could result in a savings of 2 x 12 keystrokes. But that doesn't account for the keystrokes needed to set up the map, which in the above example is 11 (counting CTRL-v and the shifted character `:` as one stroke each). Even with a net savings, it would be a bother to set up the map each time you start a vi session.
|
||||
|
||||
Fortunately, there's a way to put maps and other abbreviations in a startup file that vi reads each time it is invoked: the `.exrc` file, or in Vim, the `.vimrc` file. Simply create this file in your home directory with a list of maps, one per line—without the colon—and the abbreviation is defined for all subsequent vi sessions until you delete or change it.
|
||||
|
||||
Before going on to a variation of the `map` command and another type of abbreviation method, here are a few more examples of maps that I've found useful for streamlining my text editing:
|
||||
```
|
||||
Displays as
|
||||
|
||||
|
||||
|
||||
:map X :xCTRL-v<RET> :x^M
|
||||
|
||||
|
||||
|
||||
or
|
||||
|
||||
|
||||
|
||||
:map X ,:qCTRL-v<RET> ,:q^M
|
||||
|
||||
```
|
||||
|
||||
The above equivalent maps write and quit (exit) the file. The `:x` is the standard vi command for this, and the second version illustrates that a previously defined map may be used in a subsequent map.
|
||||
```
|
||||
:map v :e<SP> :e
|
||||
|
||||
```
|
||||
|
||||
The above starts the command to move to another file while remaining within vi; when using this, just follow the "v" with a filename, followed by <RET>.
|
||||
```
|
||||
:map CTRL-vCTRL-e :e<SP>#CTRL-v<RET> :e #^M
|
||||
|
||||
```
|
||||
|
||||
The `#` here is the standard vi symbol for "the alternate file," which means the filename last used, so this shortcut is handy for switching back and forth between two files. Here's an example of how I use this:
|
||||
```
|
||||
map CTRL-vCTRL-r :!spell %>err &CTRL-v<RET> :!spell %>err&^M
|
||||
|
||||
```
|
||||
|
||||
(Note: The first CTRL-v in both examples above is not needed in some versions of vi.) The `:!` is a way to run an external (non-vi) command. In this case (`spell`), `%` is the vi symbol denoting the current file, the `>` redirects the output of the spell-check to a file called `err`, and the `&` says to run this in the background so I can continue editing while `spell` completes its task. I can then type `verr<RET>` (using my previous shortcut, `v`, followed by `err`) to go the file of potential errors flagged by the `spell` command, then back to the file I'm working on with CTRL-e. After running the spell-check the first time, I can use CTRL-r repeatedly and return to the `err` file with just CTRL-e.
|
||||
|
||||
A variation of the `map` command may be used to abbreviate text strings while inputting. For example,
|
||||
```
|
||||
:map! CTRL-o \fI
|
||||
|
||||
:map! CTRL-k \fP
|
||||
|
||||
```
|
||||
|
||||
This will allow you to use CTRL-o as a shortcut for entering the `groff` command to italicize the word that follows, and this will allow you to use CTRL-k for the `groff` command reverts to the previous font.
|
||||
|
||||
Here are two other examples of this technique:
|
||||
```
|
||||
:map! rh rhinoceros
|
||||
|
||||
:map! hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
The above may instead be accomplished using the `ab` command, as follows (if you're trying these out in order, first use `unmap! rh` and `umap! hi`):
|
||||
```
|
||||
:ab rh rhinoceros
|
||||
|
||||
:ab hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
In the `map!` method above, the abbreviation immediately expands to the defined word when typed (in Vim), whereas with the `ab` method, the expansion occurs when the abbreviation is followed by a space or punctuation mark (in both Vim and my version of vi, where the expansion also works like this for the `map!` method).
|
||||
|
||||
To reverse any `map`, `map!`, or `ab` within a vi session, use `:unmap`, `:unmap!`, or `:unab`.
|
||||
|
||||
In my version of vi, undefined letters that are good candidates for mapping include g, K, q, v, V, and Z; undefined control characters are CTRL-a, CTRL-c, CTRL-k, CTRL-n, CTRL-o, CTRL-p, and CTRL-x; some other undefined characters are `#` and `*`. You can also redefine characters that have meaning in vi but that you consider obscure and of little use; for example, the X that I chose for two examples in this article is a built-in vi command to delete the character to the immediate left of the current character (easily accomplished by the two-key command `hx`).
|
||||
|
||||
Finally, the commands
|
||||
```
|
||||
:map<RET>
|
||||
|
||||
:map!<RET>
|
||||
|
||||
:ab
|
||||
|
||||
```
|
||||
|
||||
will show all the currently defined mappings and abbreviations.
|
||||
|
||||
I hope that all of these tips will help you customize vi and make it easier and more efficient to use.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
|
||||
|
||||
作者:[Dan Sonnenschein][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dannyman
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://www.vim.org/
|
||||
@ -0,0 +1,268 @@
|
||||
You don't know Bash: An introduction to Bash arrays
|
||||
======
|
||||
|
||||

|
||||
|
||||
Although software engineers regularly use the command line for many aspects of development, arrays are likely one of the more obscure features of the command line (although not as obscure as the regex operator `=~`). But obscurity and questionable syntax aside, [Bash][1] arrays can be very powerful.
|
||||
|
||||
### Wait, but why?
|
||||
|
||||
Writing about Bash is challenging because it's remarkably easy for an article to devolve into a manual that focuses on syntax oddities. Rest assured, however, the intent of this article is to avoid having you RTFM.
|
||||
|
||||
#### A real (actually useful) example
|
||||
|
||||
To that end, let's consider a real-world scenario and how Bash can help: You are leading a new effort at your company to evaluate and optimize the runtime of your internal data pipeline. As a first step, you want to do a parameter sweep to evaluate how well the pipeline makes use of threads. For the sake of simplicity, we'll treat the pipeline as a compiled C++ black box where the only parameter we can tweak is the number of threads reserved for data processing: `./pipeline --threads 4`.
|
||||
|
||||
### The basics
|
||||
|
||||
`--threads` parameter that we want to test:
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
```
|
||||
|
||||
The first thing we'll do is define an array containing the values of theparameter that we want to test:
|
||||
|
||||
In this example, all the elements are numbers, but it need not be the case—arrays in Bash can contain both numbers and strings, e.g., `myArray=(1 2 "three" 4 "five")` is a valid expression. And just as with any other Bash variable, make sure to leave no spaces around the equal sign. Otherwise, Bash will treat the variable name as a program to execute, and the `=` as its first parameter!
|
||||
|
||||
Now that we've initialized the array, let's retrieve a few of its elements. You'll notice that simply doing `echo $allThreads` will output only the first element.
|
||||
|
||||
To understand why that is, let's take a step back and revisit how we usually output variables in Bash. Consider the following scenario:
|
||||
```
|
||||
type="article"
|
||||
|
||||
echo "Found 42 $type"
|
||||
|
||||
```
|
||||
|
||||
Say the variable `$type` is given to us as a singular noun and we want to add an `s` at the end of our sentence. We can't simply add an `s` to `$type` since that would turn it into a different variable, `$types`. And although we could utilize code contortions such as `echo "Found 42 "$type"s"`, the best way to solve this problem is to use curly braces: `echo "Found 42 ${type}s"`, which allows us to tell Bash where the name of a variable starts and ends (interestingly, this is the same syntax used in JavaScript/ES6 to inject variables and expressions in [template literals][2]).
|
||||
|
||||
So as it turns out, although Bash variables don't generally require curly brackets, they are required for arrays. In turn, this allows us to specify the index to access, e.g., `echo ${allThreads[1]}` returns the second element of the array. Not including brackets, e.g.,`echo $allThreads[1]`, leads Bash to treat `[1]` as a string and output it as such.
|
||||
|
||||
Yes, Bash arrays have odd syntax, but at least they are zero-indexed, unlike some other languages (I'm looking at you, `R`).
|
||||
|
||||
### Looping through arrays
|
||||
|
||||
Although in the examples above we used integer indices in our arrays, let's consider two occasions when that won't be the case: First, if we wanted the `$i`-th element of the array, where `$i` is a variable containing the index of interest, we can retrieve that element using: `echo ${allThreads[$i]}`. Second, to output all the elements of an array, we replace the numeric index with the `@` symbol (you can think of `@` as standing for `all`): `echo ${allThreads[@]}`.
|
||||
|
||||
#### Looping through array elements
|
||||
|
||||
With that in mind, let's loop through `$allThreads` and launch the pipeline for each value of `--threads`:
|
||||
```
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
./pipeline --threads $t
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### Looping through array indices
|
||||
|
||||
Next, let's consider a slightly different approach. Rather than looping over array elements, we can loop over array indices:
|
||||
```
|
||||
for i in ${!allThreads[@]}; do
|
||||
|
||||
./pipeline --threads ${allThreads[$i]}
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
Let's break that down: As we saw above, `${allThreads[@]}` represents all the elements in our array. Adding an exclamation mark to make it `${!allThreads[@]}` will return the list of all array indices (in our case 0 to 7). In other words, the `for` loop is looping through all indices `$i` and reading the `$i`-th element from `$allThreads` to set the value of the `--threads` parameter.
|
||||
|
||||
This is much harsher on the eyes, so you may be wondering why I bother introducing it in the first place. That's because there are times where you need to know both the index and the value within a loop, e.g., if you want to ignore the first element of an array, using indices saves you from creating an additional variable that you then increment inside the loop.
|
||||
|
||||
### Populating arrays
|
||||
|
||||
So far, we've been able to launch the pipeline for each `--threads` of interest. Now, let's assume the output to our pipeline is the runtime in seconds. We would like to capture that output at each iteration and save it in another array so we can do various manipulations with it at the end.
|
||||
|
||||
#### Some useful syntax
|
||||
|
||||
But before diving into the code, we need to introduce some more syntax. First, we need to be able to retrieve the output of a Bash command. To do so, use the following syntax: `output=$( ./my_script.sh )`, which will store the output of our commands into the variable `$output`.
|
||||
|
||||
The second bit of syntax we need is how to append the value we just retrieved to an array. The syntax to do that will look familiar:
|
||||
```
|
||||
myArray+=( "newElement1" "newElement2" )
|
||||
|
||||
```
|
||||
|
||||
#### The parameter sweep
|
||||
|
||||
Putting everything together, here is our script for launching our parameter sweep:
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
|
||||
allRuntimes=()
|
||||
|
||||
for t in ${allThreads[@]}; do
|
||||
|
||||
runtime=$(./pipeline --threads $t)
|
||||
|
||||
allRuntimes+=( $runtime )
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
And voilà!
|
||||
|
||||
### What else you got?
|
||||
|
||||
In this article, we covered the scenario of using arrays for parameter sweeps. But I promise there are more reasons to use Bash arrays—here are two more examples.
|
||||
|
||||
#### Log alerting
|
||||
|
||||
In this scenario, your app is divided into modules, each with its own log file. We can write a cron job script to email the right person when there are signs of trouble in certain modules:``
|
||||
```
|
||||
# List of logs and who should be notified of issues
|
||||
|
||||
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
|
||||
|
||||
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
|
||||
|
||||
|
||||
|
||||
# Look for signs of trouble in each log
|
||||
|
||||
for i in ${!logPaths[@]};
|
||||
|
||||
do
|
||||
|
||||
log=${logPaths[$i]}
|
||||
|
||||
stakeholder=${logEmails[$i]}
|
||||
|
||||
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
|
||||
|
||||
|
||||
|
||||
# Warn stakeholders if recently saw > 5 errors
|
||||
|
||||
if [[ "$numErrors" -gt 5 ]];
|
||||
|
||||
then
|
||||
|
||||
emailRecipient="$stakeholder"
|
||||
|
||||
emailSubject="WARNING: ${log} showing unusual levels of errors"
|
||||
|
||||
emailBody="${numErrors} errors found in log ${log}"
|
||||
|
||||
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
|
||||
|
||||
fi
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
#### API queries
|
||||
|
||||
Say you want to generate some analytics about which users comment the most on your Medium posts. Since we don't have direct database access, SQL is out of the question, but we can use APIs!
|
||||
|
||||
To avoid getting into a long discussion about API authentication and tokens, we'll instead use [JSONPlaceholder][3], a public-facing API testing service, as our endpoint. Once we query each post and retrieve the emails of everyone who commented, we can append those emails to our results array:
|
||||
```
|
||||
endpoint="https://jsonplaceholder.typicode.com/comments"
|
||||
|
||||
allEmails=()
|
||||
|
||||
|
||||
|
||||
# Query first 10 posts
|
||||
|
||||
for postId in {1..10};
|
||||
|
||||
do
|
||||
|
||||
# Make API call to fetch emails of this posts's commenters
|
||||
|
||||
response=$(curl "${endpoint}?postId=${postId}")
|
||||
|
||||
|
||||
|
||||
# Use jq to parse the JSON response into an array
|
||||
|
||||
allEmails+=( $( jq '.[].email' <<< "$response" ) )
|
||||
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
Note here that I'm using the [`jq` tool][4] to parse JSON from the command line. The syntax of `jq` is beyond the scope of this article, but I highly recommend you look into it.
|
||||
|
||||
As you might imagine, there are countless other scenarios in which using Bash arrays can help, and I hope the examples outlined in this article have given you some food for thought. If you have other examples to share from your own work, please leave a comment below.
|
||||
|
||||
### But wait, there's more!
|
||||
|
||||
Since we covered quite a bit of array syntax in this article, here's a summary of what we covered, along with some more advanced tricks we did not cover:
|
||||
|
||||
Syntax Result `arr=()` Create an empty array `arr=(1 2 3)` Initialize array `${arr[2]}` Retrieve third element `${arr[@]}` Retrieve all elements `${!arr[@]}` Retrieve array indices `${#arr[@]}` Calculate array size `arr[0]=3` Overwrite 1st element `arr+=(4)` Append value(s) `str=$(ls)` Save `ls` output as a string `arr=( $(ls) )` Save `ls` output as an array of files `${arr[@]:s:n}` Retrieve elements at indices `n` to `s+n`
|
||||
|
||||
### One last thought
|
||||
|
||||
As we've discovered, Bash arrays sure have strange syntax, but I hope this article convinced you that they are extremely powerful. Once you get the hang of the syntax, you'll find yourself using Bash arrays quite often.
|
||||
|
||||
#### Bash or Python?
|
||||
|
||||
Which begs the question: When should you use Bash arrays instead of other scripting languages such as Python?
|
||||
|
||||
To me, it all boils down to dependencies—if you can solve the problem at hand using only calls to command-line tools, you might as well use Bash. But for times when your script is part of a larger Python project, you might as well use Python.
|
||||
|
||||
For example, we could have turned to Python to implement the parameter sweep, but we would have ended up just writing a wrapper around Bash:
|
||||
```
|
||||
import subprocess
|
||||
|
||||
|
||||
|
||||
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
|
||||
|
||||
all_runtimes = []
|
||||
|
||||
|
||||
|
||||
# Launch pipeline on each number of threads
|
||||
|
||||
for t in all_threads:
|
||||
|
||||
cmd = './pipeline --threads {}'.format(t)
|
||||
|
||||
|
||||
|
||||
# Use the subprocess module to fetch the return output
|
||||
|
||||
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
|
||||
|
||||
output = p.communicate()[0]
|
||||
|
||||
all_runtimes.append(output)
|
||||
|
||||
```
|
||||
|
||||
Since there's no getting around the command line in this example, using Bash directly is preferable.
|
||||
|
||||
#### Time for a shameless plug
|
||||
|
||||
If you enjoyed this article, there's more where that came from! [Register here to attend OSCON][5], where I'll be presenting the live-coding workshop [You Don't Know Bash][6] on July 17, 2018. No slides, no clickers—just you and me typing away at the command line, exploring the wondrous world of Bash.
|
||||
|
||||
This article originally appeared on [Medium][7] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays
|
||||
|
||||
作者:[Robert Aboukhalil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/robertaboukhalil
|
||||
[1]:https://opensource.com/article/17/7/bash-prompt-tips-and-tricks
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals
|
||||
[3]:https://github.com/typicode/jsonplaceholder
|
||||
[4]:https://stedolan.github.io/jq/
|
||||
[5]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[6]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67166
|
||||
[7]:https://medium.com/@robaboukhalil/the-weird-wondrous-world-of-bash-arrays-a86e5adf2c69
|
||||
99
sources/tech/20180601 Download an OS with GNOME Boxes.md
Normal file
99
sources/tech/20180601 Download an OS with GNOME Boxes.md
Normal file
@ -0,0 +1,99 @@
|
||||
Download an OS with GNOME Boxes
|
||||
======
|
||||
|
||||

|
||||
|
||||
Boxes is the GNOME application for running virtual machines. Recently Boxes added a new feature that makes it easier to run different Linux distributions. You can now automatically install these distros in Boxes, as well as operating systems like FreeBSD and FreeDOS. The list even includes Red Hat Enterprise Linux. The Red Hat Developer Program includes a [no-cost subscription to Red Hat Enterprise Linux][1]. With a [Red Hat Developer][2] account, Boxes can automatically set up a RHEL virtual machine entitled to the Developer Suite subscription. Here’s how it works.
|
||||
|
||||
### Red Hat Enterprise Linux
|
||||
|
||||
To create a Red Hat Enterprise Linux virtual machine, launch Boxes and click New. Select Download an OS from the source selection list. At the top, pick Red Hat Enterprise Linux. This opens a web form at [developers.redhat.com][2]. Sign in with an existing Red Hat Developer Account, or create a new one.
|
||||
|
||||
![][3]
|
||||
|
||||
If this is a new account, Boxes requires some additional information before continuing. This step is required to enable the Developer Subscription on the account. Be sure to [accept the Terms & Conditions][4] now too. This saves a step later during registration.
|
||||
|
||||
![][5]
|
||||
|
||||
Click Submit and the installation disk image starts to download. The download can take a while, depending on your Internet connection. This is a great time to go fix a cup of tea or coffee!
|
||||
|
||||
![][6]
|
||||
|
||||
Once the media has downloaded (conveniently to ~/Downloads), Boxes offers to perform an Express Install. Fill in the account and password information and click Continue. Click Create after you verify the virtual machine details. The Express Install automatically performs the entire installation! (Now is a great time to enjoy a second cup of tea or coffee, if so inclined.)
|
||||
|
||||
![][7]
|
||||
|
||||
![][8]
|
||||
|
||||
![][9]
|
||||
|
||||
Once the installation is done, the virtual machine reboots and logs directly into the desktop. Inside the virtual machine, launch the Red Hat Subscription Manager via the Applications menu, under System Tools. Enter the root password to launch the utility.
|
||||
|
||||
![][10]
|
||||
|
||||
Click the Register button and follow the steps through the registration assistant. Log in with your Red Hat Developers account when prompted.
|
||||
|
||||
![][11]
|
||||
|
||||
![][12]
|
||||
|
||||
Now you can download and install updates through any normal update method, such as yum or GNOME Software.
|
||||
|
||||
![][13]
|
||||
|
||||
### FreeDOS anyone?
|
||||
|
||||
Boxes can install a lot more than just Red Hat Enterprise Linux, too. As a front end to KVM and qemu, Boxes supports a wide variety of operating systems. Using [libosinfo][14], Boxes can automatically download (and in some cases, install) quite a few different ones.
|
||||
|
||||
![][15]
|
||||
|
||||
To install an OS from the list, select it and finish creating the new virtual machine. Some OSes, like FreeDOS, do not support an Express Install. In those cases the virtual machine boots from the installation media. You can then manually install.
|
||||
|
||||
![][16]
|
||||
|
||||
![][17]
|
||||
|
||||
### Popular operating systems on Boxes
|
||||
|
||||
These are just a few of the popular choices available in Boxes today.
|
||||
|
||||
![][18]![][19]![][20]![][21]![][22]![][23]
|
||||
|
||||
Fedora updates its osinfo-db package regularly. Be sure to check back frequently for new OS options.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/download-os-gnome-boxes/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/linkdupont/
|
||||
[1]:https://developers.redhat.com/blog/2016/03/31/no-cost-rhel-developer-subscription-now-available/
|
||||
[2]:http://developers.redhat.com
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-33-13.png
|
||||
[4]:https://www.redhat.com/wapps/tnc/termsack?event%5B%5D=signIn
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-34-37.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-14-37-27.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-09-11.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-15-19-1024x815.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-21-53-1024x815.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-26-29-1024x815.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-30-48-1024x815.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-31-17-1024x815.png
|
||||
[13]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-32-29-1024x815.png
|
||||
[14]:https://libosinfo.org
|
||||
[15]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-20-02-56.png
|
||||
[16]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-40-25.png
|
||||
[17]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-15-43-02-1024x815.png
|
||||
[18]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-55-20-1024x815.png
|
||||
[19]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-28-28-1024x815.png
|
||||
[20]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-11-43-1024x815.png
|
||||
[21]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-16-58-09-1024x815.png
|
||||
[22]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-17-46-38-1024x815.png
|
||||
[23]:https://fedoramagazine.org/wp-content/uploads/2018/05/Screenshot-from-2018-05-25-18-34-11-1024x815.png
|
||||
@ -0,0 +1,123 @@
|
||||
How To Test A Package Without Installing It In Linux
|
||||
======
|
||||

|
||||
For some reason, you might want to test a package before installing it in your Linux system. If so, you’re lucky! Today, I will show you how to do it in Linux using **Nix** package manager. One of the notable feature of Nix package manager is it allows the users to test the packages without having to install them first. This can be helpful when you want to use a particular application temporarily.
|
||||
|
||||
### Test A Package Without Installing It In Linux
|
||||
|
||||
Make sure you have installed Nix package manager first. If you haven’t installed it yet, refer the following guide.
|
||||
|
||||
For instance, let us say you want to test your C++ code. You don’t have to install GCC. Just run the following command:
|
||||
```
|
||||
$ nix-shell -p gcc
|
||||
|
||||
```
|
||||
|
||||
This command builds or downloads gcc package and its dependencies, then drops you into a Bash shell where the **gcc** command is present, all without affecting your normal environment.
|
||||
```
|
||||
LANGUAGE = (unset),
|
||||
LC_ALL = (unset),
|
||||
LANG = "en_US.UTF-8"
|
||||
are supported and installed on your system.
|
||||
perl: warning: Falling back to the standard locale ("C").
|
||||
download-using-manifests.pl: perl: warning: Setting locale failed.
|
||||
download-using-manifests.pl: perl: warning: Please check that your locale settings:
|
||||
download-using-manifests.pl: LANGUAGE = (unset),
|
||||
download-using-manifests.pl: LC_ALL = (unset),
|
||||
download-using-manifests.pl: LANG = "en_US.UTF-8"
|
||||
download-using-manifests.pl: are supported and installed on your system.
|
||||
download-using-manifests.pl: perl: warning: Falling back to the standard locale ("C").
|
||||
download-from-binary-cache.pl: perl: warning: Setting locale failed.
|
||||
download-from-binary-cache.pl: perl: warning: Please check that your locale settings:
|
||||
download-from-binary-cache.pl: LANGUAGE = (unset),
|
||||
download-from-binary-cache.pl: LC_ALL = (unset),
|
||||
download-from-binary-cache.pl: LANG = "en_US.UTF-8"
|
||||
|
||||
[...]
|
||||
|
||||
fetching path ‘/nix/store/6mk1s81va81dl4jfbhww86cwkl4gyf4j-stdenv’...
|
||||
perl: warning: Setting locale failed.
|
||||
perl: warning: Please check that your locale settings:
|
||||
LANGUAGE = (unset),
|
||||
LC_ALL = (unset),
|
||||
LANG = "en_US.UTF-8"
|
||||
are supported and installed on your system.
|
||||
perl: warning: Falling back to the standard locale ("C").
|
||||
|
||||
*** Downloading ‘https://cache.nixos.org/nar/0aznfg1g17a8jdzvnp3pqszs9rq2wiwf2rcgczyg5b3k6d0iricl.nar.xz’ to ‘/nix/store/6mk1s81va81dl4jfbhww86cwkl4gyf4j-stdenv’...
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 8324 100 8324 0 0 6353 0 0:00:01 0:00:01 --:--:-- 6373
|
||||
|
||||
[nix-shell:~]$
|
||||
|
||||
```
|
||||
|
||||
Check the GCC version:
|
||||
```
|
||||
[nix-shell:~]$ gcc -v
|
||||
Using built-in specs.
|
||||
COLLECT_GCC=/nix/store/dyj2k6ch35r1ips4vr97md2i0yvl4r5c-gcc-5.4.0/bin/gcc
|
||||
COLLECT_LTO_WRAPPER=/nix/store/dyj2k6ch35r1ips4vr97md2i0yvl4r5c-gcc-5.4.0/libexec/gcc/x86_64-unknown-linux-gnu/5.4.0/lto-wrapper
|
||||
Target: x86_64-unknown-linux-gnu
|
||||
Configured with:
|
||||
Thread model: posix
|
||||
gcc version 5.4.0 (GCC)
|
||||
|
||||
```
|
||||
|
||||
Now, go ahead and test the code. Once you are done, type **exit** to return back to your console.
|
||||
```
|
||||
[nix-shell:~]$ exit
|
||||
exit
|
||||
|
||||
```
|
||||
|
||||
Once you are exit from the nix-shell, you can’t use GCC.
|
||||
|
||||
Here is another example.
|
||||
```
|
||||
$ nix-shell -p hello
|
||||
|
||||
```
|
||||
|
||||
This builds or downloads GNU Hello and its dependencies, then drops you into a Bash shell where the **hello** command is present, all without affecting your normal environment:
|
||||
```
|
||||
[nix-shell:~]$ hello
|
||||
Hello, world!
|
||||
|
||||
```
|
||||
|
||||
Type exit to return back to the console.
|
||||
```
|
||||
[nix-shell:~]$ exit
|
||||
|
||||
```
|
||||
|
||||
Now test if hello program is available or not.
|
||||
```
|
||||
$ hello
|
||||
hello: command not found
|
||||
|
||||
```
|
||||
|
||||
For more details about Nix package manager, refer the following guide.
|
||||
|
||||
Hope this helps! More good stuffs to come. Stay tuned!!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-test-a-package-without-installing-it-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,122 @@
|
||||
A friendly alternative to the find tool in Linux
|
||||
======
|
||||

|
||||
|
||||
[fd][1] is a super fast, [Rust][2]-based alternative to the Unix/Linux `find` command. It does not mirror all of `find`'s powerful functionality; however, it does provide just enough features to cover 80% of the use cases you might run into. Features like a well thought-out and convenient syntax, colorized output, smart case, regular expressions, and parallel command execution make `fd` a more than capable successor.
|
||||
|
||||
### Installation
|
||||
|
||||
Head over the [fd][1] GitHub page and check out the section on installation. It covers how to install the application on [macOS,][3] [Debian/Ubuntu][4] [Red Hat][5] , and [Arch Linux][6] . Once installed, you can get a complete overview of all available command-line options by runningfor concise help, or `fd -h` for concise help, or `fd --help` for more detailed help.
|
||||
|
||||
### Simple search
|
||||
|
||||
`fd` is designed to help you easily find files and folders in your operating system's filesystem. The simplest search you can perform is to run `fd` with a single argument, that argument being whatever it is that you're searching for. For example, let's assume that you want to find a Markdown document that has the word `services` as part of the filename:
|
||||
```
|
||||
$ fd services
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
If called with just a single argument, `fd` searches the current directory recursively for any files and/or directories that match your argument. The equivalent search using the built-in `find` command looks something like this:
|
||||
```
|
||||
$ find . -name 'services'
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
As you can see, `fd` is much simpler and requires less typing. Getting more done with less typing is always a win in my book.
|
||||
|
||||
### Files and folders
|
||||
|
||||
You can restrict your search to files or directories by using the `-t` argument, followed by the letter that represents what you want to search for. For example, to find all files in the current directory that have `services` in the filename, you would use:
|
||||
```
|
||||
$ fd -tf services
|
||||
|
||||
downloads/services.md
|
||||
|
||||
```
|
||||
|
||||
And to find all directories in the current directory that have `services` in the filename:
|
||||
```
|
||||
$ fd -td services
|
||||
|
||||
applications/services
|
||||
|
||||
library/services
|
||||
|
||||
```
|
||||
|
||||
How about listing all documents with the `.md` extension in the current folder?
|
||||
```
|
||||
$ fd .md
|
||||
|
||||
administration/administration.md
|
||||
|
||||
development/elixir/elixir_install.md
|
||||
|
||||
readme.md
|
||||
|
||||
sidebar.md
|
||||
|
||||
linux.md
|
||||
|
||||
```
|
||||
|
||||
As you can see from the output, `fd` not only found and listed files from the current folder, but it also found files in subfolders. Pretty neat. You can even search for hidden files using the `-H` argument:
|
||||
```
|
||||
fd -H sessions .
|
||||
|
||||
.bash_sessions
|
||||
|
||||
```
|
||||
|
||||
### Specifying a directory
|
||||
|
||||
If you want to search a specific directory, the name of the directory can be given as a second argument to `fd`:
|
||||
```
|
||||
$ fd passwd /etc
|
||||
|
||||
/etc/default/passwd
|
||||
|
||||
/etc/pam.d/passwd
|
||||
|
||||
/etc/passwd
|
||||
|
||||
```
|
||||
|
||||
In this example, we're telling `fd` that we want to search for all instances of the word `passwd` in the `etc` directory.
|
||||
|
||||
### Global searches
|
||||
|
||||
What if you know part of the filename but not the folder? Let's say you downloaded a book on Linux network administration but you have no idea where it was saved. No problem:
|
||||
```
|
||||
fd Administration /
|
||||
|
||||
/Users/pmullins/Documents/Books/Linux/Mastering Linux Network Administration.epub
|
||||
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
The `fd` utility is an excellent replacement for the `find` command, and I'm sure you'll find it just as useful as I do. To learn more about the command, simply explore the rather extensive man page.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/friendly-alternative-find
|
||||
|
||||
作者:[Patrick H. Mullins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pmullins
|
||||
[1]:https://github.com/sharkdp/fd
|
||||
[2]:https://www.rust-lang.org/en-US/
|
||||
[3]:https://en.wikipedia.org/wiki/MacOS
|
||||
[4]:https://www.ubuntu.com/community/debian
|
||||
[5]:https://www.redhat.com/en
|
||||
[6]:https://www.archlinux.org/
|
||||
341
sources/tech/20180606 Getting started with Buildah.md
Normal file
341
sources/tech/20180606 Getting started with Buildah.md
Normal file
@ -0,0 +1,341 @@
|
||||
Getting started with Buildah
|
||||
======
|
||||

|
||||
|
||||
[Buildah][1] is a command-line tool for building [Open Container Initiative][2]-compatible (that means Docker- and Kubernetes-compatible, too) images quickly and easily. It can act as a drop-in replacement for the Docker daemon’s `docker build` command (i.e., building images with a traditional Dockerfile) but is flexible enough to allow you to build images with whatever tools you prefer to use. Buildah is easy to incorporate into scripts and build pipelines, and best of all, it doesn’t require a running container daemon to build its image.
|
||||
|
||||
### A drop-in replacement for docker build
|
||||
|
||||
You can get started with Buildah immediately, dropping it into place where images are currently built using a Dockerfile and `docker build`. Buildah’s `build-using-dockerfile`, or `bud` argument makes it behave just like `docker build` does, so it's easy to incorporate into existing scripts or build pipelines.
|
||||
|
||||
As with [previous articles I’ve written about Buildah][3], I like to use the example of installing "GNU Hello" from source. Consider this Dockerfile:
|
||||
```
|
||||
FROM fedora:28
|
||||
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
|
||||
|
||||
RUN dnf install -y tar gzip gcc make \
|
||||
|
||||
&& dnf clean all
|
||||
|
||||
|
||||
|
||||
ADD http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
|
||||
|
||||
|
||||
|
||||
RUN tar xvzf /tmp/hello-2.10.tar.gz -C /opt
|
||||
|
||||
|
||||
|
||||
WORKDIR /opt/hello-2.10
|
||||
|
||||
|
||||
|
||||
RUN ./configure
|
||||
|
||||
RUN make
|
||||
|
||||
RUN make install
|
||||
|
||||
RUN hello -v
|
||||
|
||||
ENTRYPOINT "/usr/local/bin/hello"
|
||||
|
||||
```
|
||||
|
||||
Buildah can create an image from this Dockerfile as easily as `buildah bud -t hello .`, replacing `docker build -t hello .`:
|
||||
```
|
||||
[chris@krang] $ sudo buildah bud -t hello .
|
||||
|
||||
STEP 1: FROM fedora:28
|
||||
|
||||
Getting image source signatures
|
||||
|
||||
Copying blob sha256:e06fd16225608e5b92ebe226185edb7422c3f581755deadf1312c6b14041fe73
|
||||
|
||||
81.48 MiB / 81.48 MiB [====================================================] 8s
|
||||
|
||||
Copying config sha256:30190780b56e33521971b0213810005a69051d720b73154c6e473c1a07ebd609
|
||||
|
||||
2.29 KiB / 2.29 KiB [======================================================] 0s
|
||||
|
||||
Writing manifest to image destination
|
||||
|
||||
Storing signatures
|
||||
|
||||
STEP 2: LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
STEP 3: RUN dnf install -y tar gzip gcc make && dnf clean all
|
||||
|
||||
|
||||
|
||||
<snip>
|
||||
|
||||
```
|
||||
|
||||
Once the build is complete, you can see the new image with the `buildah images` command:
|
||||
```
|
||||
[chris@krang] $ sudo buildah images
|
||||
|
||||
IMAGE ID IMAGE NAME CREATED AT SIZE
|
||||
|
||||
30190780b56e docker.io/library/fedora:28 Mar 7, 2018 16:53 247 MB
|
||||
|
||||
6d54bef73e63 docker.io/library/hello:latest May 3, 2018 15:24 391.8 MB
|
||||
|
||||
```
|
||||
|
||||
The new image, tagged `hello:latest`, can be pushed to a remote image registry or run using [CRI-O][4] or other Kubernetes CRI-compatible runtimes, or pushed to a remote registry. If you’re testing it as a replacement for Docker build, you will probably want to copy the image to the docker daemon’s local image storage so it can be run by Docker. This is easily accomplished with the `buildah push` command:
|
||||
```
|
||||
[chris@krang] $ sudo buildah push hello:latest docker-daemon:hello:latest
|
||||
|
||||
Getting image source signatures
|
||||
|
||||
Copying blob sha256:72fcdba8cff9f105a61370d930d7f184702eeea634ac986da0105d8422a17028
|
||||
|
||||
247.02 MiB / 247.02 MiB [==================================================] 2s
|
||||
|
||||
Copying blob sha256:e567905cf805891b514af250400cc75db3cb47d61219750e0db047c5308bd916
|
||||
|
||||
144.75 MiB / 144.75 MiB [==================================================] 1s
|
||||
|
||||
Copying config sha256:6d54bef73e638f2e2dd8b7bf1c4dfa26e7ed1188f1113ee787893e23151ff3ff
|
||||
|
||||
1.59 KiB / 1.59 KiB [======================================================] 0s
|
||||
|
||||
Writing manifest to image destination
|
||||
|
||||
Storing signatures
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ sudo docker images | head -n2
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
docker.io/hello latest 6d54bef73e63 2 minutes ago 398 MB
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ sudo docker run -t hello:latest
|
||||
|
||||
Hello, world!
|
||||
|
||||
```
|
||||
|
||||
### A few differences
|
||||
|
||||
Unlike Docker build, Buildah doesn’t commit changes to a layer automatically for every instruction in the Dockerfile—it builds everything from top to bottom, every time. On the positive side, this means non-cached builds (for example, those you would do with automation or build pipelines) end up being somewhat faster than their Docker build counterparts, especially if there are a lot of instructions. This is great for getting new changes into production quickly from an automated deployment or continuous delivery standpoint.
|
||||
|
||||
Practically speaking, however, the lack of caching may not be quite as useful for image development, where caching layers can save significant time when doing builds over and over again. This applies only to the `build-using-dockerfile` command, however. When using Buildah native commands, as we’ll see below, you can choose when to commit your changes to disk, allowing for more flexible development.
|
||||
|
||||
### Buildah native commands
|
||||
|
||||
Where Buildah _really_ shines is in its native commands, which you can use to interact with container builds. Rather than using `build-using-dockerfile/bud` for each build, Buildah has commands to actually interact with the temporary container created during the build process. (Docker uses temporary, or _intermediate_ containers, too, but you don’t really interact with them while the image is being built.)
|
||||
|
||||
Using the "GNU Hello" example again, consider this image build using Buildah commands:
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
|
||||
|
||||
set -o errexit
|
||||
|
||||
|
||||
|
||||
# Create a container
|
||||
|
||||
container=$(buildah from fedora:28)
|
||||
|
||||
|
||||
|
||||
# Labels are part of the "buildah config" command
|
||||
|
||||
buildah config --label maintainer="Chris Collins <collins.christopher@gmail.com>" $container
|
||||
|
||||
|
||||
|
||||
# Grab the source code outside of the container
|
||||
|
||||
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz -o hello-2.10.tar.gz
|
||||
|
||||
|
||||
|
||||
buildah copy $container hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
|
||||
|
||||
|
||||
|
||||
buildah run $container dnf install -y tar gzip gcc make
|
||||
|
||||
Buildah run $container dnf clean all
|
||||
|
||||
buildah run $container tar xvzf /tmp/hello-2.10.tar.gz -C /opt
|
||||
|
||||
|
||||
|
||||
# Workingdir is also a "buildah config" command
|
||||
|
||||
buildah config --workingdir /opt/hello-2.10 $container
|
||||
|
||||
|
||||
|
||||
buildah run $container ./configure
|
||||
|
||||
buildah run $container make
|
||||
|
||||
buildah run $container make install
|
||||
|
||||
buildah run $container hello -v
|
||||
|
||||
|
||||
|
||||
# Entrypoint, too, is a “buildah config” command
|
||||
|
||||
buildah config --entrypoint /usr/local/bin/hello $container
|
||||
|
||||
|
||||
|
||||
# Finally saves the running container to an image
|
||||
|
||||
buildah commit --format docker $container hello:latest
|
||||
|
||||
```
|
||||
|
||||
One thing that should be immediately obvious is the fact that this is a Bash script rather than a Dockerfile. Using Buildah’s native commands makes it easy to script, in whatever language or automation context you like to use. This could be a makefile, a Python script, or whatever tools you like to use.
|
||||
|
||||
So what is going on here? The first Buildah command `container=$(buildah from fedora:28)`, creates a running container from the fedora:28 image, and stores the container name (the output of the command) as a variable for later use. All the rest of the Buildah commands use the `$container` variable to say what container to act upon. For the most part those commands are self-explanatory: `buildah copy` moves a file into the container, `buildah run` executes a command in the container. It is easy to match them to their Dockerfile equivalents.
|
||||
|
||||
The final command, `buildah commit`, commits the container to an image on disk. When building images with Buildah commands rather than from a Dockerfile, you can use the `commit` command to decide when to save your changes. In the example above, all of the changes are committed at once, but intermediate commits could be included too, allowing you to choose cache points from which to start. (For example, it would be particularly useful to cache to disk after the `dnf install`, as that can take a long time, but is also reliably the same each time.)
|
||||
|
||||
### Mountpoints, install directories, and chroots
|
||||
|
||||
Another useful Buildah command opens the door to a lot of flexibility in building images. `buildah mount` mounts the root directory of a container to a mountpoint on your host. For example:
|
||||
```
|
||||
[chris@krang] $ container=$(sudo buildah from fedora:28)
|
||||
|
||||
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
|
||||
|
||||
[chris@krang] $ echo $mountpoint
|
||||
|
||||
/var/lib/containers/storage/overlay2/463eda71ec74713d8cebbe41ee07da5f6df41c636f65139a7bd17b24a0e845e3/merged
|
||||
|
||||
[chris@krang] $ cat ${mountpoint}/etc/redhat-release
|
||||
|
||||
Fedora release 28 (Twenty Eight)
|
||||
|
||||
[chris@krang] $ ls ${mountpoint}
|
||||
|
||||
bin dev home lib64 media opt root sbin sys usr
|
||||
|
||||
boot etc lib lost+found mnt proc run srv tmp var
|
||||
|
||||
```
|
||||
|
||||
This is great because now you can interact with the mountpoint to make changes to your container image. This allows you to use tools on your host to build and install software, rather than including those tools in the container image itself. For example, in the Bash script above, we needed to install the tar, Gzip, GCC, and make packages to compile "GNU Hello" inside the container. Using a mountpoint, we can build an image with the same software, but the downloaded tarball and tar, Gzip, etc., RPMs are all on the host machine rather than in the container and resulting image:
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
|
||||
|
||||
set -o errexit
|
||||
|
||||
|
||||
|
||||
# Create a container
|
||||
|
||||
container=$(buildah from fedora:28)
|
||||
|
||||
mountpoint=$(buildah mount $container)
|
||||
|
||||
|
||||
|
||||
buildah config --label maintainer="Chris Collins <collins.christopher@gmail.com>" $container
|
||||
|
||||
|
||||
|
||||
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz \
|
||||
|
||||
-o /tmp/hello-2.10.tar.gz
|
||||
|
||||
tar xvzf src/hello-2.10.tar.gz -C ${mountpoint}/opt
|
||||
|
||||
|
||||
|
||||
pushd ${mountpoint}/opt/hello-2.10
|
||||
|
||||
./configure
|
||||
|
||||
make
|
||||
|
||||
make install DESTDIR=${mountpoint}
|
||||
|
||||
popd
|
||||
|
||||
|
||||
|
||||
chroot $mountpoint bash -c "/usr/local/bin/hello -v"
|
||||
|
||||
|
||||
|
||||
buildah config --entrypoint "/usr/local/bin/hello" $container
|
||||
|
||||
buildah commit --format docker $container hello
|
||||
|
||||
buildah unmount $container
|
||||
|
||||
```
|
||||
|
||||
Take note of a few things in the script above:
|
||||
|
||||
1. The `curl` command downloads the tarball to the host, not the image
|
||||
|
||||
2. The `tar` command (running from the host itself) extracts the source code from the tarball into `/opt` inside the container.
|
||||
|
||||
3. `Configure`, `make`, and `make install` are all running from a directory inside the mountpoint, mounted to the host rather than running inside the container itself.
|
||||
|
||||
4. The `chroot` command here is used to change root into the mountpoint itself and test that "hello" is working, similar to the `buildah run` command used in the previous example.
|
||||
|
||||
|
||||
|
||||
|
||||
This script is shorter, it uses tools most Linux folks are already familiar with, and the resulting image is smaller (no tarball, no extra packages, etc). You could even use the package manager for the host system to install software into the container. For example, let’s say you wanted to install [NGINX][5] into the container with GNU Hello (for whatever reason):
|
||||
```
|
||||
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
|
||||
|
||||
[chris@krang] $ sudo dnf install nginx --installroot $mountpoint
|
||||
|
||||
[chris@krang] $ sudo chroot $mountpoint nginx -v
|
||||
|
||||
nginx version: nginx/1.12.1
|
||||
|
||||
```
|
||||
|
||||
In the example above, DNF is used with the `--installroot` flag to install NGINX into the container, which can be verified with chroot.
|
||||
|
||||
### Try it out!
|
||||
|
||||
Buildah is a lightweight and flexible way to create container images without running a full Docker daemon on your host. In addition to offering out-of-the-box support for building from Dockerfiles, Buildah is easy to use with scripts or build tools of your choice and can help build container images using existing tools on the build host. The result is leaner images that use less bandwidth to ship around, require less storage space, and have a smaller surface area for potential attackers. Give it a try!
|
||||
|
||||
**[See our related story,[Creating small containers with Buildah][6]]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/getting-started-buildah
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://github.com/projectatomic/buildah
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:http://chris.collins.is/2017/08/17/buildah-a-new-way-to-build-container-images/
|
||||
[4]:http://cri-o.io/
|
||||
[5]:https://www.nginx.com/
|
||||
[6]:https://opensource.com/article/18/5/containers-buildah
|
||||
139
sources/tech/20180606 Working with modules in Fedora 28.md
Normal file
139
sources/tech/20180606 Working with modules in Fedora 28.md
Normal file
@ -0,0 +1,139 @@
|
||||
Working with modules in Fedora 28
|
||||
======
|
||||

|
||||
The recent Fedora Magazine article entitled [Modularity in Fedora 28 Server Edition][1] did a great job of explaining Modularity in Fedora 28. It also pointed out a few example modules and explained the problems they solve. This article puts one of those modules to practical use, covering installation and setup of Review Board 3.0 using modules.
|
||||
|
||||
### Getting started
|
||||
|
||||
To follow along with this article and use modules, you need a system running [Fedora 28 Server Edition][2] along with [sudo administrative privileges][3]. Also, run this command to make sure all the packages on the system are current:
|
||||
```
|
||||
sudo dnf -y update
|
||||
|
||||
```
|
||||
|
||||
While you can use modules on Fedora 28 non-server editions, be aware of the [caveats described in the comments of the previous article][4].
|
||||
|
||||
### Examining modules
|
||||
|
||||
First, take a look at what modules are available for Fedora 28. Run the following command:
|
||||
```
|
||||
dnf module list
|
||||
|
||||
```
|
||||
|
||||
The output lists a collection of modules that shows the associated stream, version, and available installation profiles for each. A [d] next to a particular module stream indicates the default stream used if the named module is installed.
|
||||
|
||||
The output also shows most modules have a profile named default. That’s not a coincidence, since default is the name used for the default profile.
|
||||
|
||||
To see where all those modules are coming from, run:
|
||||
```
|
||||
dnf repolist
|
||||
|
||||
```
|
||||
|
||||
Along with the usual [fedora and updates package repositories][5], the output shows the fedora-modular and updates-modular repositories.
|
||||
|
||||
The introduction stated you’d be setting up Review Board 3.0. Perhaps a module named reviewboard caught your attention in the earlier output. Next, to get some details about that module, run this command:
|
||||
```
|
||||
dnf module info reviewboard
|
||||
|
||||
```
|
||||
|
||||
The description confirms it is the Review Board module, but also says it’s the 2.5 stream. However, you want 3.0. Look at the available reviewboard modules:
|
||||
```
|
||||
dnf module list reviewboard
|
||||
|
||||
```
|
||||
|
||||
The [d] next to the 2.5 stream means it is configured as the default stream for reviewboard. Therefore, be explicit about the stream you want:
|
||||
```
|
||||
dnf module info reviewboard:3.0
|
||||
|
||||
```
|
||||
|
||||
Now for even more details about the reviewboard:3.0 module, add the verbose option:
|
||||
```
|
||||
dnf module info reviewboard:3.0 -v
|
||||
|
||||
```
|
||||
|
||||
### Installing the Review Board 3.0 module
|
||||
|
||||
Now that you’ve tracked down the module you want, install it with this command:
|
||||
```
|
||||
sudo dnf -y module install reviewboard:3.0
|
||||
|
||||
```
|
||||
|
||||
The output shows the ReviewBoard package was installed, along with several other dependent packages, including several from the django:1.6 module. The installation also enabled the reviewboard:3.0 module and the dependent django:1.6 module.
|
||||
|
||||
Next, to see enabled modules, use this command:
|
||||
```
|
||||
dnf module list --enabled
|
||||
|
||||
```
|
||||
|
||||
The output shows [e] for enabled streams, and [i] for installed profiles. In the case of the reviewboard:3.0 module, the default profile was installed. You could have specified a different profile when installing the module. In fact, you still can — and this time you don’t need to specify the 3.0 stream since it was already enabled:
|
||||
```
|
||||
sudo dnf -y module install reviewboard/server
|
||||
|
||||
```
|
||||
|
||||
However, installation of the reviewboard:3.0/server profile is rather uneventful. The reviewboard:3.0 module’s server profile is the same as the default profile — so there’s nothing more to install.
|
||||
|
||||
### Spin up a Review Board site
|
||||
|
||||
Now that the Review Board 3.0 module and its dependent packages are installed, [create a Review Board site][6] running on the local system. Without further ado or explanation, copy and paste the following commands to do that:
|
||||
```
|
||||
sudo rb-site install --noinput \
|
||||
--domain-name=localhost --db-type=sqlite3 \
|
||||
--db-name=/var/www/rev.local/data/reviewboard.db \
|
||||
--admin-user=rbadmin --admin-password=secret \
|
||||
/var/www/rev.local
|
||||
sudo chown -R apache /var/www/rev.local/htdocs/media/uploaded \
|
||||
/var/www/rev.local/data
|
||||
sudo ln -s /var/www/rev.local/conf/apache-wsgi.conf \
|
||||
/etc/httpd/conf.d/reviewboard-localhost.conf
|
||||
sudo setsebool -P httpd_can_sendmail=1 httpd_can_network_connect=1 \
|
||||
httpd_can_network_memcache=1 httpd_unified=1
|
||||
sudo systemctl enable --now httpd
|
||||
|
||||
```
|
||||
|
||||
Now fire up a web browser on the system, point it at <http://localhost>, and enjoy the shiny new Review Board site! To login as the Review Board admin, use the userid and password seen in the rb-site command above.
|
||||
|
||||
### Module cleanup
|
||||
|
||||
It’s good practice to clean up after yourself. To do that, remove the Review Board module and the site directory:
|
||||
```
|
||||
sudo dnf -y module remove reviewboard:3.0
|
||||
sudo rm -rf /var/www/rev.local
|
||||
|
||||
```
|
||||
|
||||
### Closing remarks
|
||||
|
||||
Now that you’ve explored how to examine and administer the Review Board module, go experiment with the other modules available in Fedora 28.
|
||||
|
||||
Learn more about using modules in Fedora 28 on the [Fedora Modularity][7] web site. The dnf manual page’s Module Command section also contains useful information.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/working-modules-fedora-28/
|
||||
|
||||
作者:[Merlin Mathesius][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/merlinm/
|
||||
[1]:https://fedoramagazine.org/modularity-fedora-28-server-edition/
|
||||
[2]:https://getfedora.org/server/
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]:https://fedoramagazine.org/modularity-fedora-28-server-edition/#comment-476696
|
||||
[5]:https://fedoraproject.org/wiki/Repositories
|
||||
[6]:https://www.reviewboard.org/docs/manual/dev/admin/installation/creating-sites/
|
||||
[7]:https://docs.pagure.org/modularity/
|
||||
@ -0,0 +1,68 @@
|
||||
3 journaling applications for the Linux desktop
|
||||
======
|
||||
|
||||

|
||||
Keeping a journal, even irregularly, can have many benefits. It's not only therapeutic and cathartic, it's also a good record of where you are and where you've been. It can help show your progress in life and remind you of what you've done right and what you've done wrong.
|
||||
|
||||
No matter what your reasons are for keeping a journal or a diary, there are a variety of ways in which to do that. You could go old school and use pen and paper. You could use a web-based application. Or you could turn to the [humble text file][1].
|
||||
|
||||
Another option is to use a dedicated journaling application. There are several very flexible and very useful journaling tools for the Linux desktop. Let's take a look at three of them.
|
||||
|
||||
### RedNotebook
|
||||
|
||||
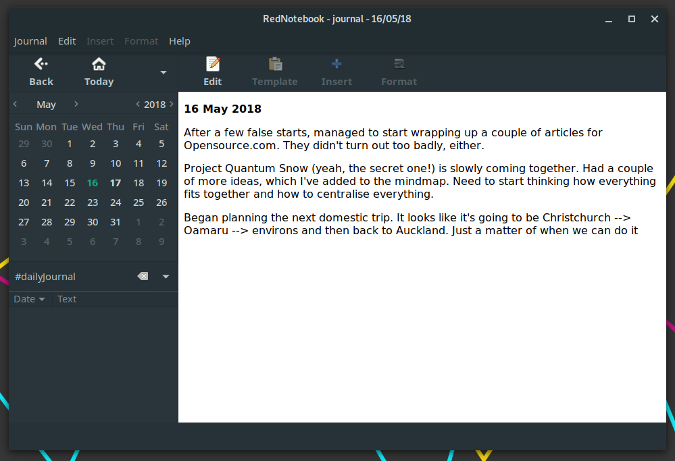
|
||||
|
||||
Of the three journaling applications described here, [RedNotebook][2] is the most flexible. Much of that flexibility comes from its templates. Those templates let you record personal thoughts or meeting minutes, plan a journey, or log a phone call. You can also edit existing templates or create your own.
|
||||
|
||||
You format your journal entries using markup that's very much like Markdown. You can also add tags to your journal entries to make them easier to find. Just click or type a tag in the left pane of the application, and a list of corresponding journal entries appears in the right pane.
|
||||
|
||||
On top of that, you can export all or some or just one of your journal entries to plain text, HTML, LaTeX, or PDF. Before you do that, you can get an idea of how an entry will look as a PDF or HTML file by clicking the Preview button on the toolbar.
|
||||
|
||||
Overall, RedNotebook is an easy to use, yet flexible application. It does take a bit of getting used to, but once you do, it's a useful tool.
|
||||
|
||||
### Lifeograph
|
||||
|
||||
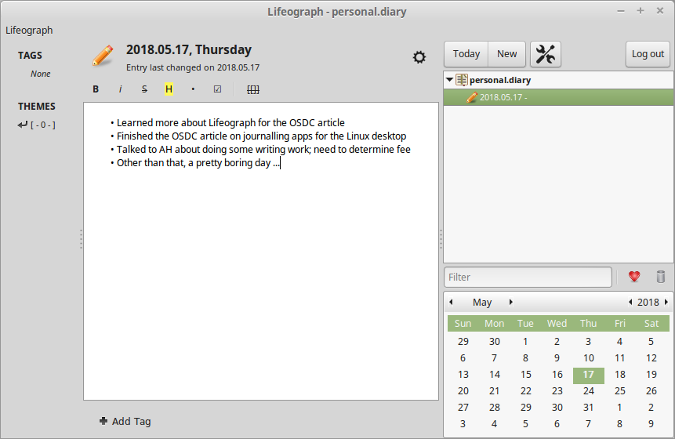
|
||||
|
||||
[Lifeograph][3] has a similar look and feel to RedNotebook. It doesn't have as many features, but Lifeograph gets the job done.
|
||||
|
||||
The application makes journaling easy by keeping things simple and uncluttered. You have a large area in which to write, and you can add some basic formatting to your journal entries. That includes the usual bold and italics, along with bullets and highlighting. You can add tags to your journal entries to better organize and find them.
|
||||
|
||||
Lifeograph has a pair of features I find especially useful. First, you can create multiple journals—for example, a work journal and a personal journal. Second is the ability to password protect your journals. While the website states that Lifeograph uses "real encryption," there are no details about what that is. Still, setting a password will keep most snoopers at bay.
|
||||
|
||||
### Almanah Diary
|
||||
|
||||
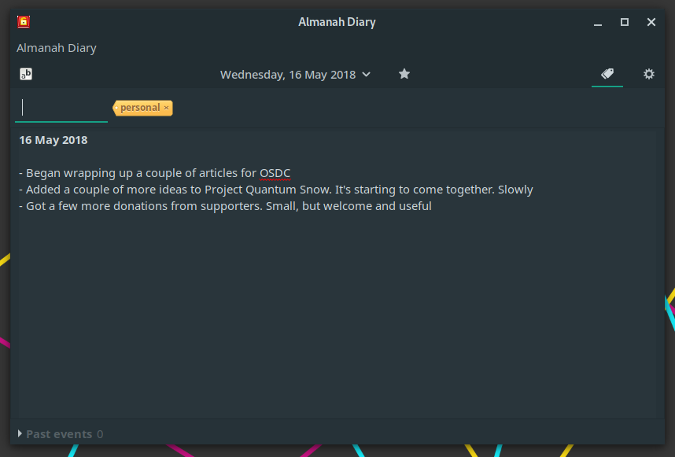
|
||||
|
||||
[Almanah Diary][4] is another very simple journaling tool. But don't let its lack of features put you off. It's simple, but it gets the job done.
|
||||
|
||||
How simple? It's pretty much an area for entering your journal entries and a calendar. You can do a bit more than that—like adding some basic formatting (bold, italics, and underline) and convert text to a hyperlink. Almanah also enables you to encrypt your journal.
|
||||
|
||||
While there is a feature to import plaintext files into the application, I couldn't get it working. Still, if you like your software simple and need a quick and dirty journal, then Almanah Diary is worth a look.
|
||||
|
||||
### What about the command line?
|
||||
|
||||
You don't have to go GUI if you don't want to. The command line is a great option for keeping a journal.
|
||||
|
||||
One that I've tried and liked is [jrnl][5]. Or you can use [this solution][6], which uses a command line alias to format and save your journal entries into a text file.
|
||||
|
||||
Do you have a favorite journaling application? Feel free to share it by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/linux-journaling-applications
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://plaintextproject.online/2017/07/19/journal.html
|
||||
[2]:http://rednotebook.sourceforge.net
|
||||
[3]:http://lifeograph.sourceforge.net/wiki/Main_Page
|
||||
[4]:https://wiki.gnome.org/Apps/Almanah_Diary
|
||||
[5]:http://maebert.github.com/jrnl/
|
||||
[6]:http://tamilinux.wordpress.com/2007/07/27/writing-short-notes-and-diaries-from-the-cli/
|
||||
@ -0,0 +1,157 @@
|
||||
如何在 Arch Linux 中降级软件包
|
||||
=====
|
||||
|
||||

|
||||
正如你了解的,Arch Linux 是一个滚动版本和 DIY(自己动手)发行版。因此,在经常更新时必须小心,特别是从 AUR 等第三方存储库安装或更新软件包。如果你不知道自己在做什么,那么最终很可能会破坏系统。你有责任使 Arch Linux 更加稳定。但是,我们都会犯错误,要时刻小心是很难的。有时候,你想更新到最新的版本,但你可能会被破损的包卡住。不要惊慌!在这种情况下,你可以简单地回滚到旧的稳定包。这个简短的教程描述了如何在 Arch Linux 中以及它的变体,如 Antergos,Manjaro Linux 中降级一个包,
|
||||
|
||||
### 在 Arch Linux 中降级一个包
|
||||
|
||||
在 Arch Linux 中,有一个名为 **“downgrade”** 的实用程序,可帮助你将安装的软件包降级为任何可用的旧版本。此实用程序将检查你的本地缓存和远程服务器(Arch Linux 仓库)以查找所需软件包的旧版本。你可以从该列表中选择任何一个旧的稳定的软件包并进行安装。
|
||||
|
||||
该软件包在官方仓库中不可用,你需要添加非官方的 **archlinuxfr** 仓库。
|
||||
|
||||
为此,请编辑 **/etc/pacman.conf** 文件:
|
||||
```
|
||||
$ sudo nano /etc/pacman.conf
|
||||
```
|
||||
|
||||
添加以下行:
|
||||
```
|
||||
[archlinuxfr]
|
||||
SigLevel = Never
|
||||
Server = http://repo.archlinux.fr/$arch
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
使用以下命令来更新仓库:
|
||||
```
|
||||
$ sudo pacman -Sy
|
||||
```
|
||||
|
||||
然后在终端中使用以下命令安装 “Downgrade” 实用程序:
|
||||
```
|
||||
$ sudo pacman -S downgrade
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
```
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (1) downgrade-5.2.3-1
|
||||
|
||||
Total Download Size: 0.01 MiB
|
||||
Total Installed Size: 0.10 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
|
||||
```
|
||||
|
||||
“downgrade” 命令的典型用法是:
|
||||
|
||||
```
|
||||
$ sudo downgrade [PACKAGE, ...] [-- [PACMAN OPTIONS]]
|
||||
```
|
||||
|
||||
让我们假设你想要将** opera web 浏览器 **降级到任何可用的旧版本。
|
||||
|
||||
为此,运行:
|
||||
```
|
||||
$ sudo downgrade opera
|
||||
|
||||
```
|
||||
|
||||
此命令将从本地缓存和远程镜像列出所有可用的 opera 包(新旧两种版本)。
|
||||
|
||||
**示例输出:**
|
||||
```
|
||||
Available packages:
|
||||
|
||||
1) opera-37.0.2178.43-1-x86_64.pkg.tar.xz (local)
|
||||
2) opera-37.0.2178.43-1-x86_64.pkg.tar.xz (remote)
|
||||
3) opera-37.0.2178.32-1-x86_64.pkg.tar.xz (remote)
|
||||
4) opera-36.0.2130.65-2-x86_64.pkg.tar.xz (remote)
|
||||
5) opera-36.0.2130.65-1-x86_64.pkg.tar.xz (remote)
|
||||
6) opera-36.0.2130.46-2-x86_64.pkg.tar.xz (remote)
|
||||
7) opera-36.0.2130.46-1-x86_64.pkg.tar.xz (remote)
|
||||
8) opera-36.0.2130.32-2-x86_64.pkg.tar.xz (remote)
|
||||
9) opera-36.0.2130.32-1-x86_64.pkg.tar.xz (remote)
|
||||
10) opera-35.0.2066.92-1-x86_64.pkg.tar.xz (remote)
|
||||
11) opera-35.0.2066.82-1-x86_64.pkg.tar.xz (remote)
|
||||
12) opera-35.0.2066.68-1-x86_64.pkg.tar.xz (remote)
|
||||
13) opera-35.0.2066.37-2-x86_64.pkg.tar.xz (remote)
|
||||
14) opera-34.0.2036.50-1-x86_64.pkg.tar.xz (remote)
|
||||
15) opera-34.0.2036.47-1-x86_64.pkg.tar.xz (remote)
|
||||
16) opera-34.0.2036.25-1-x86_64.pkg.tar.xz (remote)
|
||||
17) opera-33.0.1990.115-2-x86_64.pkg.tar.xz (remote)
|
||||
18) opera-33.0.1990.115-1-x86_64.pkg.tar.xz (remote)
|
||||
19) opera-33.0.1990.58-1-x86_64.pkg.tar.xz (remote)
|
||||
20) opera-32.0.1948.69-1-x86_64.pkg.tar.xz (remote)
|
||||
21) opera-32.0.1948.25-1-x86_64.pkg.tar.xz (remote)
|
||||
22) opera-31.0.1889.174-1-x86_64.pkg.tar.xz (remote)
|
||||
23) opera-31.0.1889.99-1-x86_64.pkg.tar.xz (remote)
|
||||
24) opera-30.0.1835.125-1-x86_64.pkg.tar.xz (remote)
|
||||
25) opera-30.0.1835.88-1-x86_64.pkg.tar.xz (remote)
|
||||
26) opera-30.0.1835.59-1-x86_64.pkg.tar.xz (remote)
|
||||
27) opera-30.0.1835.52-1-x86_64.pkg.tar.xz (remote)
|
||||
28) opera-29.0.1795.60-1-x86_64.pkg.tar.xz (remote)
|
||||
29) opera-29.0.1795.47-1-x86_64.pkg.tar.xz (remote)
|
||||
30) opera-28.0.1750.51-1-x86_64.pkg.tar.xz (remote)
|
||||
31) opera-28.0.1750.48-1-x86_64.pkg.tar.xz (remote)
|
||||
32) opera-28.0.1750.40-1-x86_64.pkg.tar.xz (remote)
|
||||
33) opera-27.0.1689.76-1-x86_64.pkg.tar.xz (remote)
|
||||
34) opera-27.0.1689.69-1-x86_64.pkg.tar.xz (remote)
|
||||
35) opera-27.0.1689.66-1-x86_64.pkg.tar.xz (remote)
|
||||
36) opera-27.0.1689.54-2-x86_64.pkg.tar.xz (remote)
|
||||
37) opera-27.0.1689.54-1-x86_64.pkg.tar.xz (remote)
|
||||
38) opera-26.0.1656.60-1-x86_64.pkg.tar.xz (remote)
|
||||
39) opera-26.0.1656.32-1-x86_64.pkg.tar.xz (remote)
|
||||
40) opera-12.16.1860-2-x86_64.pkg.tar.xz (remote)
|
||||
41) opera-12.16.1860-1-x86_64.pkg.tar.xz (remote)
|
||||
|
||||
select a package by number:
|
||||
|
||||
```
|
||||
|
||||
只需输入你选择的包号码,然后按回车即可安装。
|
||||
|
||||
就这样。当前安装的软件包将被降级为旧版本。
|
||||
|
||||
**另外阅读:[在 Arch Linux 中如何将所有软件包降级到特定日期][1]**
|
||||
|
||||
##### 那么,如何避免已损坏的软件包并使 Arch Linux 更加稳定?
|
||||
|
||||
在更新 Arch Linux 之前查看[** Arch Linux 新闻**][2]和[**论坛**][3],看看是否有任何已报告的问题。过去几周我一直在使用 Arch Linux 作为我的主要操作系统,以下是我在这段时间内发现的一些简单提示,以避免在 Arch Linux 中安装不稳定的软件包。
|
||||
|
||||
1. 避免部分升级。这意味着永远不会运行 “pacman -Sy <软件包名称>”。此命令将在安装软件包时部分升级你的系统。相反,优先使用 “pacman -Syu” 来更新系统,然后使用 “package -S <软件包名称>” 安装软件包。
|
||||
2. 避免使用 “pacman -Syu -force” 命令。-force 标志将忽略程序包和文件冲突,并且可能会以破损的程序包或损坏的系统结束。
|
||||
3. 不要跳过依赖性检查。这意味着不要使用 “pacman -Rdd <软件包名称>”。此命令将在删除软件包时避免依赖性检查。如果你运行这个命令,另一个重要的包所需的关键依赖也可以被删除。最终,它会损坏你的 Arch Linux。
|
||||
4. 定期备份重要数据和配置文件以避免数据丢失总是一个好习惯。
|
||||
5. 安装第三方软件包和 AUR 等非官方软件包时要小心。不要安装那些正在经历重大发展的软件包。
|
||||
|
||||
有关更多详细信息,请查看[** Arch Linux维护指南**][4]。
|
||||
|
||||
我不是 Arch Linux 专家,我仍然在学习如何使它更稳定。如果你有任何技巧让 Arch Linux 保持稳定和安全,请在下面的评论部分保持稳定和安全告诉我,我将洗耳恭听。
|
||||
|
||||
希望这可以有帮助。目前为止这就是全部了。我很快会再次在这里与另一篇有趣的文章。在此之前,请继续关注 OSTechNix。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/downgrade-package-arch-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/downgrade-packages-specific-date-arch-linux/
|
||||
[2]:https://www.archlinux.org/news/
|
||||
[3]:https://bbs.archlinux.org/
|
||||
[4]:https://wiki.archlinux.org/index.php/System_maintenance
|
||||
@ -1,70 +0,0 @@
|
||||
构建全球社区带来的挑战
|
||||
======
|
||||

|
||||
|
||||
今天的开源组织参与人员来自于全世界。你能预见到组建在线社区可能遇到哪些困难吗?有没有什么办法能够克服这些困难呢?
|
||||
|
||||
为开源社区贡献力量的人共同合作推动软件的开发和发展 (People contributing to an open source community share a commitment to the software they're helping to develop)。在过去,人们是面对面或者通过邮件和电话来交流的。今天,科技孕育出了在线交流--人们只需要进入一个聊天室或消息渠道就能一起工作了。比如,你可以早上跟摩洛哥的人一起工作,到了晚上又跟夏威夷的人一起工作。
|
||||
|
||||
## 全球社区的三个挑战
|
||||
|
||||
任何一个团队合作过的人都知道意见分歧是很难被克服的。对于在线社区来说,语言障碍,不同的时区,以及文化差异也带来了新的挑战。
|
||||
|
||||
### 语言障碍
|
||||
|
||||
英语是开源社区中的主流语言,因此英语不好的人会很难看懂文档和修改意见。为了克服这个问题,吸引其他地区的社区成员,你需要邀请双语者参与到社区中来。问问周围的人--你会发现意想不到的精通其他语言的人。社区的双语成员可以帮助别人跨越语言障碍,并且可以通过翻译软件和文档来扩大项目的受众范围。
|
||||
|
||||
人们使用的编程语言也不一样。你可能喜欢用 Bash 而其他人则可能更喜欢 Python,Ruby,C 等其他语言。这意味着,人们可能由于编程语言的原因而难以为你的代码库做贡献。项目负责人为项目选择一门被软件社区广泛认可的语言至关重要。如果你选择了一门偏门的语言,则很少人能够参与其中。
|
||||
|
||||
### 不同的时区
|
||||
|
||||
时区为开源社区带来了另一个挑战。比如,若你在芝加哥,想与一个在伦敦的成员安排一次视频会议,你需要调整 8 小时的时差。根据合作者的地理位置,你可能要在深夜或者清晨工作。
|
||||
|
||||
肉体转移 (Physical sprints),让你的团队在同一个时区工作可以帮助克服这个挑战,但这中方法只有极少数社区才能够负担的起。我们还可以定期举行虚拟会议讨论项目,建立一个固定的时间和地点以供所有人来讨论未决的事项,即将发布的版本等其他主题。
|
||||
|
||||
不同的时区也可以成为你的优势,因为团队成员可以全天候的工作。若你拥有一个类似 IRC 这样的实时交流平台,用户可以在任意时间都能找到人来回答问题。
|
||||
|
||||
### 文化差异
|
||||
|
||||
文化差异是开源组织面临的最大挑战。世界各地的人都有不同的思考方式,计划以及解决问题的方法。政治环境也会影响工作环境并影响决策。
|
||||
|
||||
作为项目负责人,你应该努力构建一种能包容不同看法的环境。文化差异可以鼓励社区沟通。建设性的讨论总是对项目有益,因为它可以帮助社区成员从不同角度看待问题。不同意见也有助于解决问题。
|
||||
|
||||
要成功开源,团队必须学会拥抱差异。这不简单,但多样性最终会使社区收益。
|
||||
|
||||
## 加强在线沟通的其他方法
|
||||
|
||||
**本地化:** 在线社区成员可能会发现位于附近的贡献者--去见个面并组织一个本地社区。只需要两个人就能组建一个社区了。可以邀请其他当地用户或雇员参与其中; 他们甚至还能为以后的聚会提供场所呢。
|
||||
|
||||
**组织活动:** 组织活动是构建本地社区的好方法,而且费用也不高。你可以在当地的咖啡屋或者啤酒厂聚会,庆祝最新版本的发布或者某个核心功能的实现。组织的活动越多,人们参与的热情就越高(即使只是因为单纯的好奇心)。最终,可能会找到一家公司为你提供聚会的场地,或者为你提供赞助。
|
||||
|
||||
**保持联系:** 每次活动后,联系本地社区成员。收起电子邮箱地址或者其他联系方式并邀请他们参与到你的交流平台中。邀请他们为其他社区做贡献。你很可能会发现很多当地的人才,运气好的话,甚至可能发现新的核心开发人员!
|
||||
|
||||
**分享经验:** 本地社区是一种非常有价值的资源,对你,对其他社区来说都是。与可能受益的人分享你的发现和经验。如果你不清楚(译者注:这里原文是说 sure,但是根据上下文,这里应该是 not sure) 如何策划一场活动或会议,可以咨询其他人的意见。也许能找到一些有经验的人帮你走到正轨。
|
||||
|
||||
**关注文化差异:** 记住,文化规范因地点和人口而异,因此在清晨安排某项活动可能适用于一个地方的人,但是不合适另一个地方的人。当然,你可以--也应该--利用其他社区的参考资料来更好地理解这种差异性,但有时你也需要通过试错的方式来学习。不要忘了分享你所学到的东西,让别人也从中获益。
|
||||
|
||||
**检查个人观点:** 避免在工作场合提出带有很强主观色彩的观点(尤其是与政治相关的观点)。这会抑制开放式的沟通和问题的解决。相反,应该专注于鼓励与团队成员展开建设性讨论。如果你发现陷入了激烈的争论中,那么后退一步,冷静一下,然后再从更加积极的角度出发重新进行讨论。讨论必须是有建设性的,从多个角度讨论问题对社区有益。永远不要把自己的主观观念放在社区的总体利益之前。
|
||||
|
||||
**尝试异步沟通:** 这些天,实时通讯平台已经引起了大家的关注,但除此之外还别忘了电子邮件。如果没有在网络平台上找到人的话,可以给他们发送一封电子邮件。有可能你很快就能得到回复。考虑使用那些专注于异步沟通的平台,比如 [Twist][1],也不要忘了查看并更新论坛和维基。
|
||||
|
||||
**使用不同的解决方案:** 并不存在一个单一的完美的解决方法,学习最有效的方法还是通过经验来学习。从反复试验中你可以学到很多东西。不要害怕失败; 你慧聪失败中学到很多东西从而不停地进步。
|
||||
|
||||
## 社区需要营养
|
||||
|
||||
将社区想象成是一颗植物的幼苗。你需要每天给它浇水,提供阳光和氧气。社区也是一样:倾听贡献者的声音,记住你在与活生生的人进行互动,他们需要以合适的方式进行持续的交流。如果社区缺少了人情味,人们会停止对它的贡献。
|
||||
|
||||
最后,请记住,每个社区都是不同的,没有一种单一的解决方法能够适用于所有社区。坚持不断地从社区中学习并适应这个社区。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/working-worldwide-communities
|
||||
|
||||
作者:[José Antonio Rey][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jose
|
||||
[1]:https://twistapp.com
|
||||
71
translated/tech/20180523 Set up zsh on your Fedora system.md
Normal file
71
translated/tech/20180523 Set up zsh on your Fedora system.md
Normal file
@ -0,0 +1,71 @@
|
||||
在 Fedora 系统上设置 zsh
|
||||
======
|
||||
|
||||

|
||||
|
||||
对于一些人来说,终端可能会很吓人。但终端不仅仅是在黑屏中输入。它通常运行一个 shell,因为它围绕着内核调用。shell 是一个基于文本的界面,可让你在系统上运行命令。它有时也被称为命令行解释器或 CLI。与大多数Linux发行版一样,Fedora带有bash作为默认shell。但是,它不是唯一可用的 shell,你可以安装其他的 shell。本文重点介绍 Z Shell 或 zsh。
|
||||
|
||||
Bash 是对 UNIX 中提供的旧 Bourne shell(sh)的重写。通过更好的交互,zsh 旨在比 bash 更友善。它的一些有用功能是:
|
||||
|
||||
* 可编程的命令行补全
|
||||
* 在运行的 shell 会话之间共享命令历史
|
||||
* 拼写纠正
|
||||
* 可加载模块
|
||||
* 交互选择文件和文件夹
|
||||
|
||||
|
||||
|
||||
zsh 在 Fedora 仓库中存在。要安装,请运行以下命令:
|
||||
```
|
||||
$ sudo dnf install zsh
|
||||
|
||||
```
|
||||
|
||||
### 使用 zsh
|
||||
|
||||
要开始使用它,只需输入 zsh,新的 shell 在第一次运行时显示向导。该向导可帮助你配置初始功能,如历史记录行为和自动补全。或者你可以选择保持[ rc 文件][1] 为空:
|
||||
|
||||
![zsh First Run Wizzard][2]
|
||||
|
||||
如果输入 1,则启动配置向导。其他选项立即启动 shell。
|
||||
|
||||
请注意,与 bash 相同,用户提示符是 **%** 而不是 **$**。这里的一个重要功能是自动补全功能,它允许你使用 Tab 键在文件和目录之间移动,非常类似于菜单:
|
||||
|
||||
![zsh cd Feature][3]
|
||||
|
||||
另一个有趣的功能是拼写纠正,这有助于在混合大小写的情况下输入文件名:
|
||||
|
||||
![zsh Auto Completion][4]
|
||||
|
||||
## 使用 zsh 成为你的默认 shell
|
||||
|
||||
zsh 提供了很多插件,如 zsh-syntax-highlighting 和著名的 “Oh my zsh”([在此查看其页面][5])。也许你希望将其设为默认 shell,以便在你在开始会话或打开终端时运行。为此,请使用 chsh(“更改 shell”)命令:
|
||||
```
|
||||
$ chsh -s $(which zsh)
|
||||
|
||||
```
|
||||
|
||||
这个命令告诉你的系统你要设置(-s)默认shell 的正确位置(which zsh)。
|
||||
|
||||
图片来自 [Flickr][7] 由 [Kate Ter Haar][6] 提供(CC BY-SA)。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/set-zsh-fedora-system/
|
||||
|
||||
作者:[Eduard Lucena][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/x3mboy/
|
||||
[1]:https://en.wikipedia.org/wiki/Configuration_file
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshFirstRun.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshChangingFeature-1.gif
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/zshAutoCompletion.gif
|
||||
[5]:http://ohmyz.sh/
|
||||
[6]:https://www.flickr.com/photos/katerha/
|
||||
[7]:https://www.flickr.com/photos/katerha/34714051013/
|
||||
Loading…
Reference in New Issue
Block a user