mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-19 22:51:41 +08:00
commit
05b6ddac75
@ -0,0 +1,293 @@
|
||||
完全指南之在 Ubuntu 操作系统中安装及卸载软件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
摘要:这篇文章详尽地说明了在 Ubuntu Linux 系统中安装及卸载软件的各种方法。
|
||||
|
||||
当你从 Windows 系统[转向 Linux 系统][14]的时候,刚开始的体验绝对是非比寻常的。在 Ubuntu 系统下就连最基本的事情,比如安装个应用程序都会让(刚从 Windows 世界来的)人感到无比困惑。
|
||||
|
||||
但是你也不用太担心。因为 Linux 系统提供了各种各样的方法来完成同一个任务,刚开始你感到困惑那也是正常的。你并不孤单,我们大家都是这么经历过来的。
|
||||
|
||||
在这篇初学者指南中,我将会教大家在 Ubuntu 系统里以最常用的方式来安装软件,以及如何卸载之前已安装的软件。
|
||||
|
||||
关于在 Ubuntu 上应使用哪种方法来安装软件,我也会提出自己的建议。请用心学习。这篇文章写得很长也很详细,你从中绝对能够学到东西。
|
||||
|
||||
### 在 Ubuntu 系统中安装和卸载软件
|
||||
|
||||
在这篇教程中我使用的是运行着 Unity 桌面环境的 Ubuntu 16.04 版本的系统。除了一些截图外,这篇教程也同样适用于其它版本的 Ubuntu 系统。
|
||||
|
||||
### 1.1 使用 Ubuntu 软件中心来安装软件 【推荐使用】
|
||||
|
||||
在 Ubuntu 系统中查找和安装软件最简单便捷的方法是使用 Ubuntu 软件中心。在 Ubuntu Unity 桌面里,你可以在 Dash 下搜索 Ubuntu 软件中心,然后选中打开即可:
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
你可以把 Ubuntu 软件中心想像成 Google 的 Play 商店或者是苹果的 App 商店。它包含 Ubuntu 系统下所有可用的软件。你可以通过应用程序的名称来搜索应用程序或者是通过浏览各种软件目录来进行查找软件。你还可以根据作者进行查询。这由你自己来选择。
|
||||
|
||||

|
||||
|
||||
一旦你找到自己想要的应用程序,选中它。软件中心将打开该应用程序的描述页面。你可以阅读关于这款软件的说明,评分等级和用户的评论。如果你愿意,也可以写一条评论。
|
||||
|
||||
一旦你确定想安装这款软件,你可以点击安装按钮来安装已选择的应用程序。在 Ubuntu 系统中,你需要输入 root 账号的密码才能安装该应用程序。
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
还有什么比这更简单的吗?我觉得应该没有了吧!
|
||||
|
||||
提示:正如我[在 Ubuntu 16.04 系统安装完成后你需要做的事情][17]这篇文章提到的那样,你应该启用 Canonical 合作伙伴仓库。默认情况下,Ubuntu 系统仅提供了那些源自自身软件库(Ubuntu 认证)的软件。
|
||||
|
||||
但是还有一个 Canonical 合伙伙伴软件库,它包含一些闭源专属软件,Ubuntu 并不直接管控它。启用该仓库后将让你能够访问更多的软件。[在 Ubuntu 系统下安装 Skype 软件][18]就是通过那种方式安装完成的。
|
||||
|
||||
在 Unity Dash 中,找到软件或更新工具。
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
如下图,打开其它软件标签面,勾选 Canonical 合作伙伴选项。
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
### 1.2 从 Ubuntu 软件中心卸载软件(推荐方式)
|
||||
|
||||
我们刚刚演示了如何在 Ubuntu 软件中心安装软件。那么如何使用同样的方法来卸载已安装的软件呢?
|
||||
|
||||
在 Ubuntu 软件中心卸载软件跟安装软件的步骤一样简单。
|
||||
|
||||
打开软件中心然后点击已安装的软件标签面。它将显示所有已安装的软件。或者,你也可以只搜索应用程序的名称。
|
||||
|
||||
要卸载 Ubuntu 系统中的应用程序,点击删除按钮即中。你同样需要输入 root 账号的密码。
|
||||
|
||||
[
|
||||

|
||||
][22]
|
||||
|
||||
### 2.1 在 Ubuntu 系统中使用 .DEB 文件来安装软件
|
||||
|
||||
.deb 文件跟 Windows 下的 .exe 文件很相似。这是一种安装软件的简易方式。很多软件开发商都会提供 .deb 格式的安装包。
|
||||
|
||||
Google Chrome 浏览器就是这样的。你可以下载从其官网下载 .deb 安装文件
|
||||
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
一旦你下载完成 .deb 安装文件之后,只需要双击运行即可。它将在 Ubuntu 软件中心打开,你就可以使用前面 1.1 节中同样的方式来安装软件。
|
||||
|
||||
或者,你也可以使用轻量级的安装程序 [在 Ubuntu 系统中使用 Gdebi 工具来安装 .deb 安装文件][24]。
|
||||
|
||||
软件安装完成后,你可以随意删除下载的 .deb 安装包。
|
||||
|
||||
提示:在使用 .deb 文件的过程中需要注意的一些问题:
|
||||
|
||||
* 确保你是从官网下载的 .deb 安装文件。仅使用官网或者 GitHub 上提供的软件包。
|
||||
* 确保你下载的 .deb 文件系统类型正确(32 位或是 64 位)。请阅读我们写的快速指南[如何查看你的 Ubuntu 系统是 32 位的还是 64 位的][8]
|
||||
|
||||
### 2.2 使用 .DEB 文件来删除已安装的软件
|
||||
|
||||
卸载 .deb 文件安装的软件跟我们在 1.2 节看到的步骤一样的。只需要打开 Ubuntu 软件中心,搜索应用程序名称,然后单击移除并卸载即可。
|
||||
|
||||
或者你也可以使用[新立得包管理器][25]。这也不是必须的,但是如果在 Ubuntu 软件中心找不到已安装的应用程序的情况下,就可以使用这个工具了。新立得软件包管理器会列出你系统里已安装的所有可用的软件。这是一个非常强大和有用的工具。
|
||||
|
||||
这个工具很强大非常有用。在 Ubuntu 软件中心被开发出来提供一种更友好的安装软件方式之前,新立得包管理器是 Ubuntu 系统中默认的安装和卸载软件的工具。
|
||||
|
||||
你可以单击下面的链接来安装新立得软件包管器(它将会在 Ubuntu 软件中心中打开)。
|
||||
|
||||
- [安装新立得包管理器][26]
|
||||
|
||||
打开新立得包管理器,然后找到你想卸载的软件。已安装的软件标记为绿色按钮。单击并选择“标记为删除”。然后单击“应用”来删除你所选择的软件。
|
||||
|
||||
[
|
||||

|
||||
][27]
|
||||
|
||||
### 3.1 在 Ubuntu 系统中使用 APT 命令来安装软件(推荐方式)
|
||||
|
||||
你应该看到过一些网站告诉你使用 `sudo apt-get install` 命令在 Ubuntu 系统下安装软件。
|
||||
|
||||
实际上这种命令行方式跟第 1 节中我们看到的安装方式一样。只是你没有使用 Ubuntu 软件中心来安装或卸载软件,而是使用的是命令行接口。别的没什么不同。
|
||||
|
||||
使用 `apt-get` 命令来安装软件超级简单。你只需要执行下面的命令:
|
||||
|
||||
```
|
||||
sudo apt-get install package_name
|
||||
```
|
||||
|
||||
上面使用 `sudo` 是为了获取“管理员”或 “root” (Linux 专用术语)账号权限。你可以替换 package_name 为你想要安装的软件包名。
|
||||
|
||||
`apt-get` 命令可以自动补全,你只需要输入一些字符并按 tab 键即可, `apt-get` 命令将会列出所有与该字符相匹配的程序。
|
||||
|
||||
### 3.2 在 Ubuntu 系统下使用 APT 命令来卸载软件(推荐方式)
|
||||
|
||||
在命令行下,你可以很轻易的卸载 Ubuntu 软件中心安装的软件,以及使用 `apt` 命令或是使用 .deb 安装包安装的各种软件。
|
||||
|
||||
你只需要使用下面的命令,替换 package-name 为你想要删除的软件名。
|
||||
|
||||
```
|
||||
sudo apt-get remove package_name
|
||||
```
|
||||
|
||||
同样地,你也可以通过按 tab 键来利用 `apt-get` 命令的自动补全功能。
|
||||
|
||||
使用 `apt-get` 命令来安装卸载或卸载并不算什么高深的技能。这实际上非常简便。通过这些简单命令的运用,你可以熟悉 Ubuntu Linux 系统的命令行操作,长期使用对你学习 Linux 系统的帮忙也很大。建议你看下我写的一篇很详细的[apt-get 命令使用指导][28]文章来进一步的了解该命令的使用。
|
||||
|
||||
- 建议阅读:[Linux 系统下 apt-get 命令初学者完全指南][29]
|
||||
|
||||
### 4.1 使用 PPA 命令在 Ubuntu 系统下安装应用程序
|
||||
|
||||
PPA 是[个人软件包归档( Personal Package Archive)][30]的缩写。这是开发者为 Ubuntu 用户提供软件的另一种方式。
|
||||
|
||||
在第 1 节中出现了一个叫做 ‘仓库(repository)’ 的术语。仓库本质上是一个软件集。 Ubuntu 官方仓库主要用于提供经过 Ubuntu 自己认证过的软件。 Canonical 合作伙伴仓库包含来自合作厂商提供的各种应用软件。
|
||||
|
||||
同时,PPA 允许开发者创建自己的 APT 仓库。当用户在系统里添加了一个仓库时(`sources.list` 中增加了该仓库),用户就可以使用开发者自己的仓库里提供的软件了。
|
||||
|
||||
现在你也许要问既然我们已经有 Ubuntu 的官方仓库了,还有什么必要使用 PPA 方式呢?
|
||||
|
||||
答案是并不是所有的软件都会自动添加到 Ubuntu 的官方仓库中。只有受信任的软件才会添加到其中。假设你开发出一款很棒的 Linux 应用程序,然后你想为用户提供定期的更新,但是在它被添加到 Ubuntu 仓库之前,这需要花费好几个月的时间(如果是在被允许的情况下)。 PPA 的出现就是为了解决这个问题。
|
||||
|
||||
除此之外, Ubuntu 官方仓库通常不会把最新版的软件添加进来。这会影响到 Ubuntu 系统的安全性及稳定性。新版本的软件或许会有影响到系统的[回退][31]。这就是为什么在新款软件进入到官方仓库前要花费一定的时间,有时候需要等待几个月。
|
||||
|
||||
但是,如果你不想等待最新版出现在 Ubuntu 仓库中呢?这个时候 PPA 就对你有帮助了。通过 PPA 方式,你可以获得该应用程序的最新版本。
|
||||
|
||||
通常情况下, PPA 通过这三个命令来进行使用。第一个命令添加 PPA 仓库到源列表中。第二个命令更新软件缓存列表,这样你的系统就可以获取到可用的新版本软件了。第三个命令用于从 PPA 安装软件。
|
||||
|
||||
我将演示使用 PPA 方式来安装 [Numix 主题][32]:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:numix/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install numix-gtk-theme numix-icon-theme-circle
|
||||
```
|
||||
|
||||
在上面的实例中,我们添加了一个[Numix 项目][33]提供的 PPA 。在更新软件信息之后,我们安装了两个 Numix PPA 中可用的应用程序。
|
||||
|
||||
如果你想使用带有图形界面的应用程序,你可以使用 [Y-PPA 应用程序][34]。通过它你可以很方便地查询 PPA,添加和删除软件。
|
||||
|
||||
注意:PPA 的安全性经常受到争议。我的建议是你应该从受信任的源添加 PPA,最好是从官方软件源添加。
|
||||
|
||||
### 4.2 卸载使用 PPA 方式安装的应用程序
|
||||
|
||||
在之前的文章[在 Ubuntu 系统下移除 PPA][35] 中我已经写得很详细了。你可以跳转到这篇文章去深入学习卸载 PPA 方式安装的软件。
|
||||
|
||||
这里简要提一下,你可以使用下面的两个命令来卸载:
|
||||
|
||||
```
|
||||
sudo apt-get remove numix-gtk-theme numix-icon-theme-circle
|
||||
|
||||
sudo add-apt-repository --remove ppa:numix/ppa
|
||||
```
|
||||
|
||||
第一个命令是卸载通过 PPA 方式安装的软件。第二个命令是从 `source.list` 中删除该 PPA。
|
||||
|
||||
### 5.1 在 Ubuntu Linux 系统中使用源代码来安装软件(不推荐使用)
|
||||
|
||||
我并不建议你使用[软件源代码][36]来安装该应用程序。这种方法很麻烦,容易出问题而且还非常地不方便。你得费尽周折去解决依赖包的问题。你还得保留源代码文件,以便将来卸载该应用程序。
|
||||
|
||||
但是还是有一些用户喜欢通过源代码编译的方式来安装软件,尽管他们自己本身并不会开发软件。实话告诉你,我曾经也经常使用这种方式来安装软件,不过那都是 5 年前的事了,那时候我还是一个实习生,我必须在 Ubuntu 系统下开发一款软件出来。但是,从那之后我更喜欢使用其它方式在 Ubuntu 系统中安装应用程序。我觉得,对于普通的 Linux 桌面用户,最好不要使用源代码的方式来安装软件。
|
||||
|
||||
在这一小节中我将简要地列出使用源代码方式来安装软件的几个步骤:
|
||||
* 下载你想要安装软件的源代码。
|
||||
* 解压下载的文件。
|
||||
* 进入到解压目录里并找到 `README` 或者 `INSTALL` 文件。一款开发完善的软件都会包含这样的文件,用于提供安装或卸载软件的指导方法。
|
||||
* 找到名为 `configure` 的配置文件。如果在当前目录下,使用这个命令来执行该文件:`./configure` 。它将会检查你的系统是否包含所有的必须的软件(在软件术语中叫做‘依赖包’)来安装该应用程序。(LCTT 译注:你可以先使用 `./configure --help` 来查看有哪些编译选项,包括安装的位置、可选的特性和模块等等。)注意并不是所有的软件都包括该配置文件,我觉得那些开发很糟糕的软件就没有这个配置文件。
|
||||
* 如果配置文件执行结果提示你缺少依赖包,你得先安装它们。
|
||||
* 一旦你安装完成所有的依赖包后,使用 `make` 命令来编译该应用程序。
|
||||
* 编译完成后,执行 `sudo make install` 命令来安装该应用程序。
|
||||
|
||||
注意有一些软件包会提供一个安装软件的脚本文件,你只需要运行这个文件即可安装完成。但是大多数情况下,你可没那么幸运。
|
||||
|
||||
还有,使用这种方式安装的软件并不会像使用 Ubuntu 软件库、 PPA 方式或者 .deb 安装方式那样安装的软件会自动更新。
|
||||
|
||||
如果你坚持使用源代码方式来安装软件,我建议你看下这篇很详细的文章[在 Ubuntu 系统中使用源代码安装软件][37]。
|
||||
|
||||
### 5.2 卸载使用源代码方式安装的软件(不推荐使用)
|
||||
|
||||
如果你觉得使用源代码安装软件的方式太难了,再想想看,当你卸载使用这种方式安装的软件将会更痛苦。
|
||||
|
||||
* 首先,你不能删除用于安装该软件的源代码。
|
||||
* 其次,你必须确保在安装的时候也有对应的方式来卸载它。一款设计上很糟糕的应用程序就不会提供卸载软件的方法,因此你不得不手动去删除那个软件包安装的所有文件。
|
||||
|
||||
正常情况下,你应该切换到源代码的解压目录下,使用下面的命令来卸载那个应用程序:
|
||||
|
||||
```
|
||||
sudo make uninstall
|
||||
```
|
||||
|
||||
但是,这也不能保证你每次都会很顺利地卸载完成。
|
||||
|
||||
看到了吧,使用源代码方式来安装软件实在是太麻烦了。这就是为什么我不推荐大家在 Ubuntu 系统中使用源代码来安装软件的原因。
|
||||
|
||||
### 其它一些在 Ubuntu 系统中安装软件的方法
|
||||
|
||||
另外,还有一些在 Ubuntu 系统下并不常用的安装软件的方法。由于这篇文章已经写得够长了,我就不再深入探讨了。下面我将把它们列出来:
|
||||
* Ubuntu 新推出的 [Snap 打包][9]方式
|
||||
* 使用 [dpkg][10] 命令
|
||||
* [AppImage][11] 方式
|
||||
* [pip][12] : 用于安装基于 Python 语言的应用程序
|
||||
|
||||
### 你是如何在 UBUNTU 系统中安装软件的呢?
|
||||
|
||||
如果你一直都在使用 Ubuntu 系统,那么你在 Ubuntu Linux 系统下最喜欢使用什么方式来安装软件呢?你觉得这篇文章对你有用吗?请分享你的一些观点,建议和提出相关的问题。
|
||||
|
||||
--------------------
|
||||
|
||||
作者简介:
|
||||

|
||||
|
||||
我叫 Abhishek Prakash ,F.O.S.S 开发者。我的工作是一名专业的软件开发人员。我是一名狂热的 Linux 系统及开源软件爱好者。我使用 Ubuntu 系统,并且相信分享是一种美德。除了 Linux 系统之外,我喜欢经典的侦探神秘小说。我是 Agatha Christie 作品的真爱粉。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/remove-install-software-ubuntu/
|
||||
|
||||
作者:[ABHISHEK PRAKASH][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/remove-install-software-ubuntu/#comments
|
||||
[3]:http://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fremove-install-software-ubuntu%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=How+To+Install+And+Remove+Software+In+Ubuntu+%5BComplete+Guide%5D&url=https://itsfoss.com/remove-install-software-ubuntu/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_pc
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fremove-install-software-ubuntu%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fremove-install-software-ubuntu%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:https://www.reddit.com/submit?url=https://itsfoss.com/remove-install-software-ubuntu/&title=How+To+Install+And+Remove+Software+In+Ubuntu+%5BComplete+Guide%5D
|
||||
[8]:https://itsfoss.com/32-bit-64-bit-ubuntu/
|
||||
[9]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[10]:https://help.ubuntu.com/lts/serverguide/dpkg.html
|
||||
[11]:http://appimage.org/
|
||||
[12]:https://pypi.python.org/pypi/pip
|
||||
[13]:https://itsfoss.com/remove-install-software-ubuntu/managing-software-in-ubuntu-1/
|
||||
[14]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2016/12/Ubuntu-Software-Center.png
|
||||
[16]:https://itsfoss.com/remove-install-software-ubuntu/install-software-ubuntu-linux-1/
|
||||
[17]:https://itsfoss.com/things-to-do-after-installing-ubuntu-16-04/
|
||||
[18]:https://itsfoss.com/install-skype-ubuntu-1404/
|
||||
[19]:https://itsfoss.com/ubuntu-notify-updates-frequently/software_update_ubuntu/
|
||||
[20]:https://itsfoss.com/things-to-do-after-installing-ubuntu-14-04/enable_canonical_partner/
|
||||
[21]:https://itsfoss.com/essential-linux-applications/
|
||||
[22]:https://itsfoss.com/remove-install-software-ubuntu/uninstall-software-ubuntu/
|
||||
[23]:https://itsfoss.com/remove-install-software-ubuntu/install-software-deb-package/
|
||||
[24]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[25]:http://www.nongnu.org/synaptic/
|
||||
[26]:apt://synaptic
|
||||
[27]:https://itsfoss.com/remove-install-software-ubuntu/uninstall-software-ubuntu-synaptic/
|
||||
[28]:https://itsfoss.com/apt-get-linux-guide/
|
||||
[29]:https://itsfoss.com/apt-get-linux-guide/
|
||||
[30]:https://help.launchpad.net/Packaging/PPA
|
||||
[31]:https://en.wikipedia.org/wiki/Software_regression
|
||||
[32]:https://itsfoss.com/install-numix-ubuntu/
|
||||
[33]:https://numixproject.org/
|
||||
[34]:https://itsfoss.com/easily-manage-ppas-ubuntu-1310-ppa-manager/
|
||||
[35]:https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
[36]:https://en.wikipedia.org/wiki/Source_code
|
||||
[37]:http://www.howtogeek.com/105413/how-to-compile-and-install-from-source-on-ubuntu/
|
||||
100
published/20170102 A Guide To Buying A Linux Laptop.md
Normal file
100
published/20170102 A Guide To Buying A Linux Laptop.md
Normal file
@ -0,0 +1,100 @@
|
||||
Linux 笔记本电脑选购指南
|
||||
============================================================
|
||||
|
||||
众所周知,如果你去电脑城[购买一个新的笔记本电脑][5],你所见到的尽是预安装了 Windows 或是 Mac 系统的笔记本电脑。无论怎样,你都会被迫支付一笔额外的费用—— 微软系统的许可费用或是苹果电脑背后的商标使用权费用。
|
||||
|
||||
当然,你也可以选择购买一款笔记本电脑,然后安装自己喜欢的操作系统。然而,最困难的可能是需要找到一款硬件跟你想安装的操作系统兼容性良好的笔记本电脑。
|
||||
|
||||
在此之上,我们还需要考虑硬件驱动程序的可用性。那么,你应该怎么办呢?答案很简单:[购买一款预安装了 Linux 系统的笔记本电脑][6]。
|
||||
|
||||
幸运的是,正好有几家值得依赖的公司提供质量好、有名气,并且预安装了 Linux 系统的笔记本电脑,这样你就不用再担心驱动程序的可用性了。
|
||||
|
||||
也就是说,在这篇文章中,我们将根据用户对笔记本电脑的用途列出 3 款可供用户选择的高性价比机器。
|
||||
|
||||
### 普通用户使用的 Linux 笔记本电脑
|
||||
|
||||
如果你正在寻找一款能够满足日常工作及娱乐需求的 Linux 笔记本电脑,它能够正常运行办公软件,有诸如 Firefox或是 Chrome 这样的 Web 浏览器,有局域网 / Wifi 连接功能,那么你可以考虑选择 [System76][7] 公司生产的 Linux 笔记本电脑,它可以根据用户的定制化需求选择处理器类型,内存及磁盘大小,以及其它配件。
|
||||
|
||||
除此之外, System76 公司为他们所有的 Ubuntu 系统的笔记本电脑提供终身技术支持。如果你觉得这听起来不错,并且也比较感兴趣,你可以考虑下 [Lemur][8] 或者 [Gazelle][9] 这两款笔记本电脑。
|
||||
|
||||

|
||||
|
||||
*Lemur Linux 笔记本电脑*
|
||||
|
||||
|
||||

|
||||
|
||||
*Gazelle Linux 笔记本电脑*
|
||||
|
||||
|
||||
### 开发者使用的 Linux 笔记本电脑
|
||||
|
||||
如果你想找一款坚固可靠,外观精美,并且性能强悍的笔记本电脑用于开发工作,你可以考虑一下 [Dell 的 XPS 13 笔记本电脑][10]。
|
||||
|
||||
这款 13 英寸的精美笔记本电脑,配置全高清 HD 显示器,触摸板,售价范围视其配置情况而定,CPU 代号/型号:Intel 的第 7 代处理器 i5 和 i7,固态硬盘大小:128 至 512 GB,内存大小:8 至 16 GB。
|
||||
|
||||
|
||||

|
||||
|
||||
*Dell XPS Linux 笔记本电脑*
|
||||
|
||||
这些都是你应该考虑在内的重要因素,Dell 已经做得很到位了。不幸的是,Dell ProSupport 为该型号的笔记本电脑仅提供 Ubuntu 16.04 LTS 系统的技术支持(在写本篇文章的时候 - 2016 年 12 月)。
|
||||
|
||||
### 系统管理员使用的 Linux 笔记本电脑
|
||||
|
||||
虽然系统管理员可以顺利搞定在裸机上安装 Linux 系统的工作,但是使用 System76 的产品,你可以避免寻找各种驱动并解决兼容性问题上的麻烦。
|
||||
|
||||
之后,你可以根据自己的需求来配置电脑特性,你可以提高笔记本电脑的性能,增加内存到 32 GB 以确保你可以运行虚拟化环境并进行各种系统管理相关的任务。
|
||||
|
||||
如果你对此比较感兴趣,你可以考虑购买 [Kudu][12] 或者是 [Oryx Pro][13] 笔记本电脑。
|
||||
|
||||

|
||||
|
||||
*Kudu Linux 笔记本电脑*
|
||||
|
||||
|
||||

|
||||
|
||||
*Oryx Pro 笔记本电脑*
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇文章中,我们探讨了对于普通用户、开发者及系统管理员来说,为什么购买一款预安装了 Linux 系统的笔记本是一个不错的选择。一旦你决定好,你就可以轻松自如的考虑下应该如何消费这笔省下来的钱了。
|
||||
|
||||
你觉得在购买一款 Linux 系统的笔记本电脑时还应该注意些什么?请在下面的评论区与大家分享。
|
||||
|
||||
像往常一样,如果你对这篇文章有什么意见和看法,请随时提出来。我们很期待看到你的回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Gabriel Cánepa 来自 Argentina,San Luis,Villa Mercedes ,他是一名 GNU/Linux 系统管理员和网站开发工程师。目前在一家世界领先的消费品公司工作,在日常工作中,他非常善于使用 FOSS 工具来提高公司在各个领域的生产率。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/buy-linux-laptops/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2016/11/Lemur-Laptop.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/11/Gazelle-Laptop.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/11/Kudu-Linux-Laptop.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/11/Oryx-Pro-Linux-Laptop.png
|
||||
[5]:http://amzn.to/2fPxTms
|
||||
[6]:http://amzn.to/2fPxTms
|
||||
[7]:https://system76.com/laptops
|
||||
[8]:https://system76.com/laptops/lemur
|
||||
[9]:https://system76.com/laptops/gazelle
|
||||
[10]:http://amzn.to/2fBLMGj
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/11/Dells-XPS-Laptops.png
|
||||
[12]:https://system76.com/laptops/kudu
|
||||
[13]:https://system76.com/laptops/oryx
|
||||
@ -0,0 +1,152 @@
|
||||
在 Linux 终端中自定义 Bash 配色和提示内容
|
||||
============================================================
|
||||
|
||||
现今,大多数(如果不是全部的话)现代 Linux 发行版的默认 shell 都是 Bash。然而,你可能已经注意到这样一个现象,在各个发行版中,其终端配色和提示内容都各不相同。
|
||||
|
||||
如果你一直都在考虑,或者只是一时好奇,如何定制可以使 Bash 更好用。不管怎样,请继续读下去 —— 本文将告诉你怎么做。
|
||||
|
||||
### PS1 Bash 环境变量
|
||||
|
||||
命令提示符和终端外观是通过一个叫 `PS1` 的变量来进行管理的。根据 **Bash** 手册页说明,**PS1** 代表了 shell 准备好读取命令时显示的主体的提示字符串。
|
||||
|
||||
**PS1** 所允许的内容包括一些反斜杠转义的特殊字符,可以查看手册页中 **PRMPTING** 部分的内容来了解它们的含义。
|
||||
|
||||
为了演示,让我们先来显示下我们系统中 `PS1` 的当前内容吧(这或许看上去和你们的有那么点不同):
|
||||
|
||||
```
|
||||
$ echo $PS1
|
||||
[\u@\h \W]\$
|
||||
```
|
||||
|
||||
现在,让我们来了解一下怎样自定义 PS1 吧,以满足我们各自的需求。
|
||||
|
||||
#### 自定义 PS1 格式
|
||||
|
||||
根据手册页 PROMPTING 章节的描述,下面对各个特殊字符的含义作如下说明:
|
||||
|
||||
- `\u:` 显示当前用户的 **用户名**。
|
||||
- `\h:` <ruby>完全限定域名 <rt>Fully-Qualified Domain Name</rt></ruby>(FQDN)中第一个点(.)之前的**主机名**。
|
||||
- `\W:` 当前工作目录的**基本名**,如果是位于 `$HOME` (家目录)通常使用波浪符号简化表示(`~`)。
|
||||
- `\$:` 如果当前用户是 root,显示为 `#`,否则为 `$`。
|
||||
|
||||
例如,如果我们想要显示当前命令的历史数量,可以考虑添加 `\!`;如果我们想要显示 FQDN 全称而不是短服务器名,那么可以考虑添加 `\H`。
|
||||
|
||||
在下面的例子中,我们同时将这两个特殊字符引入我们当前的环境中,命令如下:
|
||||
|
||||
```
|
||||
PS1="[\u@\H \W \!]\$"
|
||||
```
|
||||
|
||||
当按下回车键后,你将会看到提示内容会变成下面这样。可以对比执行命令修改前和修改后的提示内容:
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
*自定义 Linux 终端提示符 PS1*
|
||||
|
||||
现在,让我们再深入一点,修改命令提示符中的用户名和主机名 —— 同时修改文本和环境背景。
|
||||
|
||||
实际上,我们可以对提示符进行 3 个方面的自定义:
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<th>文本格式</th>
|
||||
<th>前景色(文本)</th>
|
||||
<th>背景色 </th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>0: 常规文本</th>
|
||||
<th>30: 黑色</th>
|
||||
<th>40: 黑色</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>1: 加粗</th>
|
||||
<th>31: 红色</th>
|
||||
<th>41: 红色</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>4: 下划线文本</th>
|
||||
<th> 32: 绿色</th>
|
||||
<th>42: 绿色</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th></th>
|
||||
<th>33: 黄色</th>
|
||||
<th>43: 黄色</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th></th>
|
||||
<th>34: 蓝色</th>
|
||||
<th>44: 蓝色</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th></th>
|
||||
<th>35: 紫色</th>
|
||||
<th>45: 紫色</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th></th>
|
||||
<th>36: 青色</th>
|
||||
<th>46: 青色</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<th></th>
|
||||
<th>37: 白色</th>
|
||||
<th>47: 白色</th>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
我们将在开头使用 `\e` 特殊字符,跟着颜色序列,在结尾使用 `m` 来表示结束。
|
||||
|
||||
在该序列中,三个值(**背景**,**格式**和**前景**)由分号分隔(如果不赋值,则假定为默认值)。
|
||||
|
||||
**建议阅读:** [在 Linux 中学习 Bash shell 脚本][2]。
|
||||
|
||||
此外,由于值的范围不同,指定背景,格式,或者前景的先后顺序没有关系。
|
||||
|
||||
例如,下面的 `PS1` 将导致提示符为黄色带下划线文本,并且背景为红色:
|
||||
|
||||
```
|
||||
PS1="\e[41;4;33m[\u@\h \W]$ "
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*修改 Linux 终端提示符配色 PS1*
|
||||
|
||||
虽然它看起来那么漂亮,但是这个自定义将只会持续到当前用户会话结束。如果你关闭终端,或者退出本次会话,所有修改都会丢失。
|
||||
|
||||
为了让修改永久生效,你必须将下面这行添加到 `~/.bashrc`或者 `~/.bash_profile`,这取决于你的版本。
|
||||
|
||||
```
|
||||
PS1="\e[41;4;33m[\u@\h \W]$ "
|
||||
```
|
||||
|
||||
尽情去玩耍吧,你可以尝试任何色彩,直到找出最适合你的。
|
||||
|
||||
##### 小结
|
||||
|
||||
在本文中,我们讲述了如何来自定义 Bash 提示符的配色和提示内容。如果你对本文还有什么问题或者建议,请在下面评论框中写下来吧。我们期待你们的声音。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:Aaron Kili 是一位 Linux 及 F.O.S.S 的狂热爱好者,一位未来的 Linux 系统管理员,web 开发者,而当前是 TechMint 的原创作者,他热爱计算机工作,并且信奉知识分享。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/customize-bash-colors-terminal-prompt-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/01/Customize-Linux-Terminal-Prompt.png
|
||||
[2]:http://www.tecmint.com/category/bash-shell/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/Change-Linux-Terminal-Color-Prompt.png
|
||||
@ -3,27 +3,27 @@ LXD 2.0 系列(五):镜像管理
|
||||
|
||||
这是 [LXD 2.0 系列介绍文章][0]的第五篇。
|
||||
|
||||
因为lxd容器管理有很多命令,因此这篇文章会很长。 如果你想要快速地浏览这些相同的命令,你可以[尝试下我们的在线演示][1]!
|
||||
因为 lxd 容器管理有很多命令,因此这篇文章会很长。 如果你想要快速地浏览这些相同的命令,你可以[尝试下我们的在线演示][1]!
|
||||
|
||||

|
||||
|
||||
### 容器镜像
|
||||
|
||||
如果你以前使用过LXC,你可能还记得那些LXC“模板”,基本上都是导出一个容器文件系统以及一点配置的shell脚本。
|
||||
如果你以前使用过 LXC,你可能还记得那些 LXC “模板”,基本上都是导出一个容器文件系统以及一点配置的 shell 脚本。
|
||||
|
||||
大多数模板通过在本机上根据发行版自举来生成文件系统。这可能需要相当长的时间,并且无法在所有的发行版上可用,另外可能需要大量的网络带宽。
|
||||
大多数模板是通过在本机上执行一个完整的发行版自举来生成该文件系统。这可能需要相当长的时间,并且无法在所有的发行版上可用,另外可能需要大量的网络带宽。
|
||||
|
||||
回到LXC 1.0,我写了一个“下载”模板,它允许用户下载预先打包的容器镜像,在中央服务器上的模板脚本生成,接着高度压缩、签名并通过https分发。我们很多用户从旧版生成容器切换到使用这种新的,更快更可靠的创建容器的方法。
|
||||
回到 LXC 1.0,我写了一个“下载”模板,它允许用户下载预先打包的容器镜像,用模板脚本在中央服务器上生成,接着高度压缩、签名并通过 https 分发。我们很多用户从旧版的容器生成方式切换到了使用这种新的、更快更可靠的创建容器的方式。
|
||||
|
||||
使用LXD,我们通过全面的基于镜像的工作流程向前迈进了一步。所有容器都是从镜像创建的,我们在LXD中具有高级镜像缓存和预加载支持,以使镜像存储保持最新。
|
||||
使用 LXD,我们通过全面的基于镜像的工作流程向前迈进了一步。所有容器都是从镜像创建的,我们在 LXD 中具有高级镜像缓存和预加载支持,以使镜像存储保持最新。
|
||||
|
||||
### 与LXD镜像交互
|
||||
### 与 LXD 镜像交互
|
||||
|
||||
在更深入了解镜像格式之前,让我们快速了解下LXD可以让你做些什么。
|
||||
在更深入了解镜像格式之前,让我们快速了解下 LXD 可以让你做些什么。
|
||||
|
||||
#### 透明地导入镜像
|
||||
|
||||
所有的容器都是有镜像创建的。镜像可以来自一台远程服务器并使用它的完整hash、短hash或者别名拉取下来,但是最终每个LXD容器都是创建自一个本地镜像。
|
||||
所有的容器都是由镜像创建的。镜像可以来自一台远程服务器并使用它的完整 hash、短 hash 或者别名拉取下来,但是最终每个 LXD 容器都是创建自一个本地镜像。
|
||||
|
||||
这有个例子:
|
||||
|
||||
@ -33,9 +33,9 @@ lxc launch ubuntu:75182b1241be475a64e68a518ce853e800e9b50397d2f152816c24f038c94d
|
||||
lxc launch ubuntu:75182b1241be c3
|
||||
```
|
||||
|
||||
所有这些引用相同的远程镜像(在写这篇文章时)在第一次运行其中之一时,远程镜像将作为缓存镜像导入本地LXD镜像存储,接着从中创建容器。
|
||||
所有这些引用相同的远程镜像(在写这篇文章时),在第一次运行这些命令其中之一时,远程镜像将作为缓存镜像导入本地 LXD 镜像存储,接着从其创建容器。
|
||||
|
||||
下一次运行其中一个命令时,LXD将只检查镜像是否仍然是最新的(当不是由指纹引用时),如果是,它将创建容器而不下载任何东西。
|
||||
下一次运行其中一个命令时,LXD 将只检查镜像是否仍然是最新的(当不是由指纹引用时),如果是,它将创建容器而不下载任何东西。
|
||||
|
||||
现在镜像被缓存在本地镜像存储中,你也可以从那里启动它,甚至不检查它是否是最新的:
|
||||
|
||||
@ -49,13 +49,13 @@ lxc launch 75182b1241be c4
|
||||
lxc launch my-image c5
|
||||
```
|
||||
|
||||
如果你想要改变一些自动缓存或者过期行为,在本系列之前的文章中有一些命令。
|
||||
如果你想要改变一些自动缓存或者过期行为,在本系列之前的文章中有[一些命令](https://linux.cn/article-7687-1.html)。
|
||||
|
||||
#### 手动导入镜像
|
||||
|
||||
##### 从镜像服务器中复制
|
||||
|
||||
如果你想复制远程某个镜像到你本地镜像存储但不立即从它创建一个容器,你可以使用“lxc image copy”命令。它可以让你调整一些镜像标志,比如:
|
||||
如果你想复制远程的某个镜像到你本地镜像存储,但不立即从它创建一个容器,你可以使用`lxc image copy`命令。它可以让你调整一些镜像标志,比如:
|
||||
|
||||
```
|
||||
lxc image copy ubuntu:14.04 local:
|
||||
@ -63,28 +63,29 @@ lxc image copy ubuntu:14.04 local:
|
||||
|
||||
这只是简单地复制一个远程镜像到本地存储。
|
||||
|
||||
如果您想要通过比其指纹更容易的方式来记住你引用的镜像副本,则可以在复制时添加别名:
|
||||
|
||||
如果您想要通过比记住其指纹更容易的方式来记住你引用的镜像副本,则可以在复制时添加别名:
|
||||
|
||||
```
|
||||
lxc image copy ubuntu:12.04 local: --alias old-ubuntu
|
||||
lxc launch old-ubuntu c6
|
||||
```
|
||||
|
||||
如果你想要使用源服务器上设置的别名,你可以要求LXD复制下来:
|
||||
如果你想要使用源服务器上设置的别名,你可以要求 LXD 复制下来:
|
||||
|
||||
```
|
||||
lxc image copy ubuntu:15.10 local: --copy-aliases
|
||||
lxc launch 15.10 c7
|
||||
```
|
||||
|
||||
上面的副本都是一次性拷贝,也就是复制远程镜像的当前版本到本地镜像存储中。如果你想要LXD保持镜像最新,就像它缓存中存储的那样,你需要使用`–auto-update`标志:
|
||||
上面的副本都是一次性拷贝,也就是复制远程镜像的当前版本到本地镜像存储中。如果你想要 LXD 保持镜像最新,就像它在缓存中存储的那样,你需要使用 `–auto-update` 标志:
|
||||
|
||||
```
|
||||
lxc image copy images:gentoo/current/amd64 local: --alias gentoo --auto-update
|
||||
```
|
||||
|
||||
##### 导入tarball
|
||||
##### 导入 tarball
|
||||
|
||||
如果某人给你提供了一个单独的tarball,你可以用下面的命令导入:
|
||||
如果某人给你提供了一个单独的 tarball,你可以用下面的命令导入:
|
||||
|
||||
```
|
||||
lxc image import <tarball>
|
||||
@ -96,15 +97,15 @@ lxc image import <tarball>
|
||||
lxc image import <tarball> --alias random-image
|
||||
```
|
||||
|
||||
现在如果你被给了有两个tarball,识别哪个含有LXD的元数据。通常可以通过tarball名称,如果不行就选择最小的那个,元数据tarball包是很小的。 然后将它们一起导入:
|
||||
现在如果你被给了两个 tarball,要识别哪个是含有 LXD 元数据的。通常可以通过 tarball 的名称来识别,如果不行就选择最小的那个,元数据 tarball 包是很小的。 然后将它们一起导入:
|
||||
|
||||
```
|
||||
lxc image import <metadata tarball> <rootfs tarball>
|
||||
```
|
||||
|
||||
##### 从URL中导入
|
||||
##### 从 URL 中导入
|
||||
|
||||
“lxc image import”也可以与指定的URL一起使用。如果你的一台https网络服务器的某个路径中有LXD-Image-URL和LXD-Image-Hash的标头设置,那么LXD就会把这个镜像拉到镜像存储中。
|
||||
`lxc image import` 也可以与指定的 URL 一起使用。如果你的一台 https Web 服务器的某个路径中有 `LXD-Image-URL` 和 `LXD-Image-Hash` 的标头设置,那么 LXD 就会把这个镜像拉到镜像存储中。
|
||||
|
||||
可以参照例子这么做:
|
||||
|
||||
@ -112,18 +113,17 @@ lxc image import <metadata tarball> <rootfs tarball>
|
||||
lxc image import https://dl.stgraber.org/lxd --alias busybox-amd64
|
||||
```
|
||||
|
||||
当拉取镜像时,LXD还会设置一些标头,远程服务器可以检查它们以返回适当的镜像。 它们是LXD-Server-Architectures和LXD-Server-Version。
|
||||
|
||||
这意味着它可以是一个穷人的镜像服务器。 它可以使任何静态Web服务器提供一个用户友好的方式导入你的镜像。
|
||||
当拉取镜像时,LXD 还会设置一些标头,远程服务器可以检查它们以返回适当的镜像。 它们是 `LXD-Server-Architectures` 和 `LXD-Server-Version`。
|
||||
|
||||
这相当于一个简陋的镜像服务器。 它可以通过任何静态 Web 服务器提供一中用户友好的导入镜像的方式。
|
||||
|
||||
#### 管理本地镜像存储
|
||||
|
||||
现在我们本地已经有一些镜像了,让我们瞧瞧可以做些什么。我们已经涵盖了最主要的部分,从它们来创建容器,但是你还可以在本地镜像存储上做更多。
|
||||
现在我们本地已经有一些镜像了,让我们瞧瞧可以做些什么。我们已经介绍了最主要的部分,可以从它们来创建容器,但是你还可以在本地镜像存储上做更多。
|
||||
|
||||
##### 列出镜像
|
||||
|
||||
要列出所有的镜像,运行“lxc image list”:
|
||||
要列出所有的镜像,运行 `lxc image list`:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc image list
|
||||
@ -174,7 +174,7 @@ stgraber@dakara:~$ lxc image list os=ubuntu
|
||||
+-------------+--------------+--------+---------------------------------------------+--------+----------+------------------------------+
|
||||
```
|
||||
|
||||
要了解所有镜像的信息,你可以使用“lxc image info”:
|
||||
要了解镜像的所有信息,你可以使用`lxc image info`:
|
||||
|
||||
```
|
||||
stgraber@castiana:~$ lxc image info ubuntu
|
||||
@ -206,7 +206,7 @@ Source:
|
||||
|
||||
##### 编辑镜像
|
||||
|
||||
一个编辑镜像的属性和标志的简单方法是使用:
|
||||
编辑镜像的属性和标志的简单方法是使用:
|
||||
|
||||
```
|
||||
lxc image edit <alias or fingerprint>
|
||||
@ -228,7 +228,7 @@ properties:
|
||||
public: false
|
||||
```
|
||||
|
||||
你可以修改任何属性,打开或者关闭自动更新,后者标记一个镜像是公共的(以后还有更多)
|
||||
你可以修改任何属性,打开或者关闭自动更新,或者标记一个镜像是公共的(后面详述)。
|
||||
|
||||
##### 删除镜像
|
||||
|
||||
@ -238,11 +238,11 @@ public: false
|
||||
lxc image delete <alias or fingerprint>
|
||||
```
|
||||
|
||||
注意你不必移除缓存对象,它们会在过期后被LXD自动移除(默认上,在最后一次使用的10天后)。
|
||||
注意你不必移除缓存对象,它们会在过期后被 LXD 自动移除(默认上,在最后一次使用的 10 天后)。
|
||||
|
||||
##### 导出镜像
|
||||
|
||||
如果你想得到目前镜像的tarball,你可以使用“lxc image export”,像这样:
|
||||
如果你想得到目前镜像的 tarball,你可以使用`lxc image export`,像这样:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc image export old-ubuntu .
|
||||
@ -254,34 +254,34 @@ stgraber@dakara:~$ ls -lh *.tar.xz
|
||||
|
||||
#### 镜像格式
|
||||
|
||||
LXD现在支持两种镜像布局,unified或者split。这两者都是有效的LXD格式,虽然后者在与其他容器或虚拟机一起运行时更容易重新使用文件系统。
|
||||
LXD 现在支持两种镜像布局,unified 或者 split。这两者都是有效的 LXD 格式,虽然后者在与其他容器或虚拟机一起运行时更容易重用其文件系统。
|
||||
|
||||
LXD专注于系统容器,不支持任何应用程序容器的“标准”镜像格式,我们也不打算这么做。
|
||||
LXD 专注于系统容器,不支持任何应用程序容器的“标准”镜像格式,我们也不打算这么做。
|
||||
|
||||
我们的镜像很简单,它们是由容器文件系统,以及包含了镜像制作时间、到期时间、什么架构,以及可选的一堆文件模板的元数据文件组成。
|
||||
|
||||
有关[镜像格式][1]的最新详细信息,请参阅此文档。
|
||||
|
||||
##### unified镜像 (一个tarball)
|
||||
##### unified 镜像(一个 tarball)
|
||||
|
||||
unified镜像格式是LXD在生成镜像时使用的格式。它们是一个单独的大型tarball,包含“rootfs”目录的容器文件系统,在tarball根目录下有metadata.yaml文件,任何模板都进入“templates”目录。
|
||||
unified 镜像格式是 LXD 在生成镜像时使用的格式。它们是一个单独的大型 tarball,包含 `rootfs` 目录下的容器文件系统,在 tarball 根目录下有 `metadata.yaml` 文件,任何模板都放到 `templates` 目录。
|
||||
|
||||
tarball可以用任何方式压缩(或者不压缩)。镜像散列是压缩后的tarball的sha256。
|
||||
tarball 可以用任何方式压缩(或者不压缩)。镜像散列是压缩后的 tarball 的 sha256 。
|
||||
|
||||
|
||||
##### Split镜像 (两个tarball)
|
||||
##### Split 镜像(两个 tarball)
|
||||
|
||||
这种格式最常用于滚动更新镜像以及某人已经有了一个压缩文件系统tarball。
|
||||
这种格式最常用于滚动更新镜像并已经有了一个压缩文件系统 tarball 时。
|
||||
|
||||
它们由两个不同的tarball组成,第一个只包含LXD使用的元数据,因此metadata.yaml文件在根目录,任何模板都在“templates”目录。
|
||||
它们由两个不同的 tarball 组成,第一个只包含 LXD 使用的元数据, `metadata.yaml` 文件在根目录,任何模板都在 `templates` 目录。
|
||||
|
||||
第二个tarball只包含直接位于其根目录下的容器文件系统。大多数发行版已经有这样的tarball,因为它们常用于引导新机器。 此镜像格式允许不修改重新使用。
|
||||
第二个 tarball 只包含直接位于其根目录下的容器文件系统。大多数发行版已经有这样的 tarball,因为它们常用于引导新机器。 此镜像格式允许不经修改就重用。
|
||||
|
||||
两个tarball都可以压缩(或者不压缩),它们可以使用不同的压缩算法。 镜像散列是元数据和rootfs tarball结合的sha256。
|
||||
两个 tarball 都可以压缩(或者不压缩),它们可以使用不同的压缩算法。 镜像散列是元数据的 tarball 和 rootfs 的 tarball 结合的 sha256。
|
||||
|
||||
##### 镜像元数据
|
||||
|
||||
典型的metadata.yaml文件看起来像这样:
|
||||
典型的 `metadata.yaml` 文件看起来像这样:
|
||||
|
||||
```
|
||||
architecture: "i686"
|
||||
@ -336,31 +336,31 @@ templates:
|
||||
|
||||
##### 属性
|
||||
|
||||
两个唯一的必填字段是“creation date”(UNIX EPOCH)和“architecture”。 其他都可以保持未设置,镜像就可以正常地导入。
|
||||
两个唯一的必填字段是 `creation date`(UNIX 纪元时间)和 `architecture`。 其他都可以保持未设置,镜像就可以正常地导入。
|
||||
|
||||
额外的属性主要是帮助用户弄清楚镜像是什么。 例如“description”属性是在“lxc image list”中可见的。 用户可以使用其他属性的键/值对来搜索特定镜像。
|
||||
额外的属性主要是帮助用户弄清楚镜像是什么。 例如 `description` 属性是在 `lxc image list` 中可见的。 用户可以使用其它属性的键/值对来搜索特定镜像。
|
||||
|
||||
相反,这些属性用户可以通过“lxc image edit”来编辑,“creation date”和“architecture”字段是不可变的。
|
||||
相反,这些属性用户可以通过 `lxc image edit`来编辑,`creation date` 和 `architecture` 字段是不可变的。
|
||||
|
||||
##### 模板
|
||||
|
||||
模板机制允许在容器生命周期中的某一点生成或重新生成容器中的一些文件。
|
||||
|
||||
我们使用pongo2模板引擎来做这些,我们将所有我们知道的容器导出到模板。 这样,你可以使用用户定义的容器属性或常规LXD属性的自定义镜像来更改某些特定文件的内容。
|
||||
我们使用 [pongo2 模板引擎](https://github.com/flosch/pongo2)来做这些,我们将所有我们知道的容器信息都导出到模板。 这样,你可以使用用户定义的容器属性或常规 LXD 属性来自定义镜像,从而更改某些特定文件的内容。
|
||||
|
||||
正如你在上面的例子中看到的,我们使用在Ubuntu中的模板找出cloud-init并关闭一些init脚本。
|
||||
正如你在上面的例子中看到的,我们使用在 Ubuntu 中使用它们来进行 `cloud-init` 并关闭一些 init 脚本。
|
||||
|
||||
### 创建你的镜像
|
||||
|
||||
LXD专注于运行完整的Linux系统,这意味着我们期望大多数用户只使用干净的发行版镜像,而不是只用自己的镜像。
|
||||
LXD 专注于运行完整的 Linux 系统,这意味着我们期望大多数用户只使用干净的发行版镜像,而不是只用自己的镜像。
|
||||
|
||||
但是有一些情况下,你有自己的镜像是有用的。 例如生产服务器上的预配置镜像,或者构建那些我们没有构建的发行版或者架构的镜像。
|
||||
但是有一些情况下,你有自己的镜像是有必要的。 例如生产服务器上的预配置镜像,或者构建那些我们没有构建的发行版或者架构的镜像。
|
||||
|
||||
#### 将容器变成镜像
|
||||
|
||||
目前使用LXD构造镜像最简单的方法是将容器变成镜像。
|
||||
目前使用 LXD 构造镜像最简单的方法是将容器变成镜像。
|
||||
|
||||
可以这么做
|
||||
可以这么做:
|
||||
|
||||
```
|
||||
lxc launch ubuntu:14.04 my-container
|
||||
@ -369,7 +369,7 @@ lxc exec my-container bash
|
||||
lxc publish my-container --alias my-new-image
|
||||
```
|
||||
|
||||
你甚至可以将一个容器过去的snapshot变成镜像:
|
||||
你甚至可以将一个容器过去的快照变成镜像:
|
||||
|
||||
```
|
||||
lxc publish my-container/some-snapshot --alias some-image
|
||||
@ -379,25 +379,22 @@ lxc publish my-container/some-snapshot --alias some-image
|
||||
|
||||
构建你自己的镜像也很简单。
|
||||
|
||||
1.生成容器文件系统。 这完全取决于你使用的发行版。 对于Ubuntu和Debian,它将用于启动。
|
||||
2.配置容器中正常工作所需的任何东西(如果需要任何东西)。
|
||||
3.制作该容器文件系统的tarball,可选择压缩它。
|
||||
4.根据上面描述的内容写一个新的metadata.yaml文件。
|
||||
5.创建另一个包含metadata.yaml文件的压缩包。
|
||||
6.用下面的命令导入这两个tarball作为LXD镜像:
|
||||
```
|
||||
lxc image import <metadata tarball> <rootfs tarball> --alias some-name
|
||||
```
|
||||
1. 生成容器文件系统。这完全取决于你使用的发行版。对于 Ubuntu 和 Debian,它将用于启动。
|
||||
2. 配置容器中该发行版正常工作所需的任何东西(如果需要任何东西)。
|
||||
3. 制作该容器文件系统的 tarball,可选择压缩它。
|
||||
4. 根据上面描述的内容写一个新的 `metadata.yaml` 文件。
|
||||
5. 创建另一个包含 `metadata.yaml` 文件的 tarball。
|
||||
6. 用下面的命令导入这两个 tarball 作为 LXD 镜像:`lxc image import <metadata tarball> <rootfs tarball> --alias some-name`
|
||||
|
||||
正常工作前你可能需要经历几次这样的工作,调整这里或那里,可能会添加一些模板和属性。
|
||||
在一切都正常工作前你可能需要经历几次这样的工作,调整这里或那里,可能会添加一些模板和属性。
|
||||
|
||||
### 发布你的镜像
|
||||
|
||||
所有LXD守护程序都充当镜像服务器。除非另有说明,否则加载到镜像存储中的所有镜像都会被标记为私有,因此只有受信任的客户端可以检索这些镜像,但是如果要创建公共镜像服务器,你需要做的是将一些镜像标记为公开,并确保你的LXD守护进程监听网络。
|
||||
所有 LXD 守护程序都充当镜像服务器。除非另有说明,否则加载到镜像存储中的所有镜像都会被标记为私有,因此只有受信任的客户端可以检索这些镜像,但是如果要创建公共镜像服务器,你需要做的是将一些镜像标记为公开,并确保你的 LXD 守护进程监听网络。
|
||||
|
||||
#### 只运行LXD公共服务器
|
||||
#### 只运行 LXD 公共服务器
|
||||
|
||||
最简单的共享镜像的方式是运行一个公共的LXD守护进程。
|
||||
最简单的共享镜像的方式是运行一个公共的 LXD 守护进程。
|
||||
|
||||
你只要运行:
|
||||
|
||||
@ -411,35 +408,34 @@ lxc config set core.https_address "[::]:8443"
|
||||
lxc remote add <some name> <IP or DNS> --public
|
||||
```
|
||||
|
||||
他们就可以像任何默认的镜像服务器一样使用它们。 由于远程服务器添加了“-public”,因此不需要身份验证,并且客户端仅限于使用已标记为public的镜像。
|
||||
他们就可以像使用任何默认的镜像服务器一样使用它们。 由于远程服务器添加了 `-public` 选项,因此不需要身份验证,并且客户端仅限于使用已标记为 `public` 的镜像。
|
||||
|
||||
要将镜像设置成公共的,只需“lxc image edit”它们,并将public标志设置为true。
|
||||
要将镜像设置成公共的,只需使用 `lxc image edit` 编辑它们,并将 `public` 标志设置为 `true`。
|
||||
|
||||
#### 使用一台静态web服务器
|
||||
#### 使用一台静态 web 服务器
|
||||
|
||||
如上所述,“lxc image import”支持从静态http服务器下载。 基本要求是:
|
||||
如上所述,`lxc image import` 支持从静态 https 服务器下载。 基本要求是:
|
||||
|
||||
*服务器必须支持具有有效证书的HTTPS,TLS1.2和EC密钥
|
||||
*当点击“lxc image import”提供的URL时,服务器必须返回一个包含LXD-Image-Hash和LXD-Image-URL的HTTP标头。
|
||||
* 服务器必须支持具有有效证书的 HTTPS、TLS 1.2 和 EC 算法。
|
||||
* 当访问 `lxc image import` 提供的 URL 时,服务器必须返回一个包含 `LXD-Image-Hash` 和 `LXD-Image-URL` 的 HTTP 标头。
|
||||
|
||||
如果你想使它动态化,你可以让你的服务器查找LXD在请求镜像中发送的LXD-Server-Architectures和LXD-Server-Version的HTTP头。 这可以让你返回架构正确的镜像。
|
||||
如果你想使它动态化,你可以让你的服务器查找 LXD 在请求镜像时发送的 `LXD-Server-Architectures` 和 `LXD-Server-Version` 的 HTTP 标头,这可以让你返回符合该服务器架构的正确镜像。
|
||||
|
||||
#### 构建一个简单流服务器
|
||||
|
||||
“ubuntu:”和“ubuntu-daily:”在远端不使用LXD协议(“images:”是的),而是使用不同的协议称为简单流。
|
||||
`ubuntu:` 和 `ubuntu-daily:` 远端服务器不使用 LXD 协议(`images:` 使用),而是使用称为简单流(simplestreams)的不同协议。
|
||||
|
||||
简单流基本上是一个镜像服务器的描述格式,使用JSON来描述产品以及相关产品的文件列表。
|
||||
简单流基本上是一个镜像服务器的描述格式,使用 JSON 来描述产品以及相关产品的文件列表。
|
||||
|
||||
它被各种工具,如OpenStack,Juju,MAAS等用来查找,下载或者做镜像系统,LXD将它作为原生协议支持用于镜像检索。
|
||||
它被各种工具,如 OpenStack、Juju、MAAS 等用来查找、下载或者做镜像系统,LXD 将它作为用于镜像检索的原生协议。
|
||||
|
||||
虽然的确不是提供LXD镜像的最简单的方法,但是如果你的镜像也被其他一些工具使用,那这也许值得考虑一下。
|
||||
虽然这的确不是提供 LXD 镜像的最简单的方法,但是如果你的镜像也被其它一些工具使用,那这也许值得考虑一下。
|
||||
|
||||
更多信息可以在这里找到。
|
||||
关于简单流的更多信息可以在[这里](https://launchpad.net/simplestreams)找到。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望关于如何使用LXD管理镜像以及构建和发布镜像这点给你提供了一个好点子。对于以前的LXC而言可以在一组全球分布式系统上得到完全相同的镜像是一个很大的进步,并且让将来的道路更加可复制。
|
||||
|
||||
我希望这篇关于如何使用 LXD 管理镜像以及构建和发布镜像文章让你有所了解。对于以前的 LXC 而言,可以在一组全球分布式系统上得到完全相同的镜像是一个很大的进步,并且引导了更多可复制性的发展方向。
|
||||
|
||||
### 额外信息
|
||||
|
||||
@ -460,7 +456,7 @@ via: https://www.stgraber.org/2016/03/30/lxd-2-0-image-management-512/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
### Android 6.0 Marshmallow
|
||||
|
||||
In October 2015, Google brought Android 6.0 Marshmallow into the world. For the OS's launch, Google commissioned two new Nexus devices: the [Huawei Nexus 6P and LG Nexus 5X][39]. Rather than just the usual speed increase, the new phones also included a key piece of hardware: a fingerprint reader for Marshmallow's new fingerprint API. Marshmallow was also packing a crazy new search feature called "Google Now on Tap," user controlled app permissions, a new data backup system, and plenty of other refinements.
|
||||
|
||||
@ -0,0 +1,261 @@
|
||||
|
||||
beyondworld 翻译中
|
||||
|
||||
|
||||
Powerline – Adds Powerful Statuslines and Prompts to Vim Editor and Bash Terminal
|
||||
============================================================
|
||||
|
||||
Powerline is a great statusline plugin for [Vim editor][1], which is developed in Python and provides statuslines and prompts for many other applications such as bash, zsh, tmux and many more.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Add Power to Linux Terminal with Powerline Tool
|
||||
|
||||
#### Features
|
||||
|
||||
1. It is written in Python, which makes it extensible and feature rich.
|
||||
2. Stable and testable code base, which works well with Python 2.6+ and Python 3.
|
||||
3. It also supports prompts and statuslines in several Linux utilities and tools.
|
||||
4. It has configurations and decorator colors developed using JSON.
|
||||
5. Fast and lightweight, with daemon support, which provides even more better performance.
|
||||
|
||||
#### Powerline Screenshots
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Powerline Vim Statuslines
|
||||
|
||||
In this article, I will show you how to install Powerline and Powerline fonts and how to use with Bash and Vimunder RedHat and Debian based systems.
|
||||
|
||||
### Step 1: Installing Generic Requirements for Powerline
|
||||
|
||||
Due to a naming conflict with some other unrelated projects, powerline program is available on PyPI (Python Package Index) under the package name as powerline-status.
|
||||
|
||||
To install packages from PyPI, we need a ‘pip‘ (package management tool for installing Python packages). So, let’s first install pip tool under our Linux systems.
|
||||
|
||||
#### Install Pip on Debian, Ubuntu and Linux Mint
|
||||
|
||||
```
|
||||
# apt-get install python-pip
|
||||
```
|
||||
|
||||
##### Sample Output
|
||||
|
||||
```
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
Recommended packages:
|
||||
python-dev-all python-wheel
|
||||
The following NEW packages will be installed:
|
||||
python-pip
|
||||
0 upgraded, 1 newly installed, 0 to remove and 533 not upgraded.
|
||||
Need to get 97.2 kB of archives.
|
||||
After this operation, 477 kB of additional disk space will be used.
|
||||
Get:1 http://archive.ubuntu.com/ubuntu/ trusty-updates/universe python-pip all 1.5.4-1ubuntu3 [97.2 kB]
|
||||
Fetched 97.2 kB in 1s (73.0 kB/s)
|
||||
Selecting previously unselected package python-pip.
|
||||
(Reading database ... 216258 files and directories currently installed.)
|
||||
Preparing to unpack .../python-pip_1.5.4-1ubuntu3_all.deb ...
|
||||
Unpacking python-pip (1.5.4-1ubuntu3) ...
|
||||
Processing triggers for man-db (2.6.7.1-1ubuntu1) ...
|
||||
Setting up python-pip (1.5.4-1ubuntu3) ...
|
||||
```
|
||||
|
||||
#### Install Pip on CentOS, RHEL and Fedora
|
||||
|
||||
Under Fedora-based systems, you need to first [enable epel-repository][4] and then install pip package as shown.
|
||||
|
||||
```
|
||||
# yum install python-pip
|
||||
# dnf install python-pip [On Fedora 22+ versions]
|
||||
```
|
||||
|
||||
##### Sample Output
|
||||
|
||||
```
|
||||
Installing:
|
||||
python-pip noarch 7.1.0-1.el7 epel 1.5 M
|
||||
Transaction Summary
|
||||
=================================================================================
|
||||
Install 1 Package
|
||||
Total download size: 1.5 M
|
||||
Installed size: 6.6 M
|
||||
Is this ok [y/d/N]: y
|
||||
Downloading packages:
|
||||
python-pip-7.1.0-1.el7.noarch.rpm | 1.5 MB 00:00:01
|
||||
Running transaction check
|
||||
Running transaction test
|
||||
Transaction test succeeded
|
||||
Running transaction
|
||||
Installing : python-pip-7.1.0-1.el7.noarch 1/1
|
||||
Verifying : python-pip-7.1.0-1.el7.noarch 1/1
|
||||
Installed:
|
||||
python-pip.noarch 0:7.1.0-1.el7
|
||||
Complete!
|
||||
```
|
||||
|
||||
### Step 2: Installing Powerline Tool in Linux
|
||||
|
||||
Now it’s’ time to install Powerline latest development version from the Git repository. For this, your system must have git package installed in order to fetch the packages from Git.
|
||||
|
||||
```
|
||||
# apt-get install git
|
||||
# yum install git
|
||||
# dnf install git
|
||||
```
|
||||
|
||||
Next you can install Powerline with the help of pip command as shown.
|
||||
|
||||
```
|
||||
# pip install git+git://github.com/Lokaltog/powerline
|
||||
```
|
||||
|
||||
##### Sample Output
|
||||
|
||||
```
|
||||
Cloning git://github.com/Lokaltog/powerline to /tmp/pip-WAlznH-build
|
||||
Running setup.py (path:/tmp/pip-WAlznH-build/setup.py) egg_info for package from git+git://github.com/Lokaltog/powerline
|
||||
warning: no previously-included files matching '*.pyc' found under directory 'powerline/bindings'
|
||||
warning: no previously-included files matching '*.pyo' found under directory 'powerline/bindings'
|
||||
Installing collected packages: powerline-status
|
||||
Found existing installation: powerline-status 2.2
|
||||
Uninstalling powerline-status:
|
||||
Successfully uninstalled powerline-status
|
||||
Running setup.py install for powerline-status
|
||||
warning: no previously-included files matching '*.pyc' found under directory 'powerline/bindings'
|
||||
warning: no previously-included files matching '*.pyo' found under directory 'powerline/bindings'
|
||||
changing mode of build/scripts-2.7/powerline-lint from 644 to 755
|
||||
changing mode of build/scripts-2.7/powerline-daemon from 644 to 755
|
||||
changing mode of build/scripts-2.7/powerline-render from 644 to 755
|
||||
changing mode of build/scripts-2.7/powerline-config from 644 to 755
|
||||
changing mode of /usr/local/bin/powerline-config to 755
|
||||
changing mode of /usr/local/bin/powerline-lint to 755
|
||||
changing mode of /usr/local/bin/powerline-render to 755
|
||||
changing mode of /usr/local/bin/powerline-daemon to 755
|
||||
Successfully installed powerline-status
|
||||
Cleaning up...
|
||||
```
|
||||
|
||||
### Step 3: Installing Powerline Fonts in Linux
|
||||
|
||||
Powerline uses special glyphs to show special arrow effect and symbols for developers. For this, you must have a symbol font or a patched font installed on your systems.
|
||||
|
||||
Download the most recent version of the symbol font and fontconfig configuration file using following [wget command][5].
|
||||
|
||||
```
|
||||
# wget https://github.com/powerline/powerline/raw/develop/font/PowerlineSymbols.otf
|
||||
# wget https://github.com/powerline/powerline/raw/develop/font/10-powerline-symbols.conf
|
||||
```
|
||||
|
||||
Then you need to move the font to your fonts directory, /usr/share/fonts/ or /usr/local/share/fonts as follows or you can get the valid font paths by using command `xset q`.
|
||||
|
||||
```
|
||||
# mv PowerlineSymbols.otf /usr/share/fonts/
|
||||
```
|
||||
|
||||
Next, you need to update your system’s font cache as follows.
|
||||
|
||||
```
|
||||
# fc-cache -vf /usr/share/fonts/
|
||||
```
|
||||
|
||||
Now install the fontconfig file.
|
||||
|
||||
```
|
||||
# mv 10-powerline-symbols.conf /etc/fonts/conf.d/
|
||||
```
|
||||
|
||||
Note: If custom symbols doesn’t appear, then try to close all terminal sessions and restart X window for the changes to take effect.
|
||||
|
||||
### Step 4: Setting Powerline for Bash Shell and Vim Statuslines
|
||||
|
||||
In this section we shall look at configuring Powerline for bash shell and vim editor. First make your terminal to support 256color by adding the following line to ~/.bashrc file as follows.
|
||||
|
||||
```
|
||||
export TERM=”screen-256color”
|
||||
```
|
||||
|
||||
#### Enable Powerline on Bash Shell
|
||||
|
||||
To enable Powerline in bash shell by default, you need to add the following snippet to your ~/.bashrc file.
|
||||
|
||||
First get the location of installed powerline using following command.
|
||||
|
||||
```
|
||||
# pip show powerline-status
|
||||
Name: powerline-status
|
||||
Version: 2.2.dev9999-git.aa33599e3fb363ab7f2744ce95b7c6465eef7f08
|
||||
Location: /usr/local/lib/python2.7/dist-packages
|
||||
Requires:
|
||||
```
|
||||
|
||||
Once you know the actual location of powerline, make sure to replace the location in the below line as per your system suggested.
|
||||
|
||||
```
|
||||
powerline-daemon -q
|
||||
POWERLINE_BASH_CONTINUATION=1
|
||||
POWERLINE_BASH_SELECT=1
|
||||
. /usr/local/lib/python2.7/dist-packages/powerline/bindings/bash/powerline.sh
|
||||
```
|
||||
|
||||
Now try to logout and login back again, you will see powerline statuesline as shown below.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Try changing or switching to different directories and keep a eye on “breadcrumb” prompt changes to show your current location.
|
||||
|
||||
You will also be able to watch pending background jobs and if powerline is installed on a remote Linux machine, you can notice that the prompt adds the hostname when you connect via SSH.
|
||||
|
||||
#### Enable Powerline for Vim
|
||||
|
||||
If vim is your favorite editor, luckily there is a powerful plugin for vim, too. To enable this plugin, add these lines to `~/.vimrc` file.
|
||||
|
||||
```
|
||||
set rtp+=/usr/local/lib/python2.7/dist-packages/powerline/bindings/vim/
|
||||
set laststatus=2
|
||||
set t_Co=256
|
||||
```
|
||||
|
||||
Now you can launch vim and see a spiffy new status line:
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
### Summary
|
||||
|
||||
Powerline helps to set colorful and beautiful statuslines and prompts in several applications, good for coding environments. I hope you find this guide helpful and remember to post a comment if you need any help or have additional ideas.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I am Ravi Saive, creator of TecMint. A Computer Geek and Linux Guru who loves to share tricks and tips on Internet. Most Of My Servers runs on Open Source Platform called Linux. Follow Me: Twitter, Facebook and Google+
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/powerline-adds-powerful-statuslines-and-prompts-to-vim-and-bash/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/vi-editor-usage/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2015/10/Install-Powerline-Statuslines-in-Linux.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2015/10/Powerline-Vim-Statuslines.png
|
||||
[4]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[5]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2015/10/Bash-Powerline-Statuslines.gif
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2015/10/Vim-Powerline-Statuslines.gif
|
||||
@ -1,182 +0,0 @@
|
||||
Cathon is translating---
|
||||
|
||||
What is Docker?
|
||||
================
|
||||
|
||||

|
||||
|
||||
This is an excerpt from [Docker: Up and Running][3] by Karl Matthias and Sean P. Kane. It may contain references to unavailable content that is part of the larger resource.
|
||||
|
||||
|
||||
Docker was first introduced to the world—with no pre-announcement and little fanfare—by Solomon Hykes, founder and CEO of dotCloud, in a five-minute [lightning talk][4] at the Python Developers Conference in Santa Clara, California, on March 15, 2013\. At the time of this announcement, only about 40 people outside dotCloud been given the opportunity to play with Docker.
|
||||
|
||||
Within a few weeks of this announcement, there was a surprising amount of press. The project was quickly open-sourced and made publicly available on [GitHub][5], where anyone could download and contribute to the project. Over the next few months, more and more people in the industry started hearing about Docker and how it was going to revolutionize the way software was built, delivered, and run. And within a year, almost no one in the industry was unaware of Docker, but many were still unsure what it was exactly, and why people were so excited about.
|
||||
|
||||
Docker is a tool that promises to easily encapsulate the process of creating a distributable artifact for any application, deploying it at scale into any environment, and streamlining the workflow and responsiveness of agile software organizations.
|
||||
|
||||
|
||||
|
||||
### The Promise of Docker
|
||||
|
||||
While ostensibly viewed as a virtualization platform, Docker is far more than that. Docker’s domain spans a few crowded segments of the industry that include technologies like KVM, Xen, OpenStack, Mesos, Capistrano, Fabric, Ansible, Chef, Puppet, SaltStack, and so on. There is something very telling about the list of products that Docker competes with, and maybe you’ve spotted it already. For example, most engineers would not say that virtualization products compete with configuration management tools, yet both technologies are being disrupted by Docker. The technologies in that list are also generally acclaimed for their ability to improve productivity and that’s what is causing a great deal of the buzz. Docker sits right in the middle of some of the most enabling technologies of the last decade.
|
||||
|
||||
If you were to do a feature-by-feature comparison of Docker and the reigning champion in any of these areas, Docker would very likely look like a middling competitor. It’s stronger in some areas than others, but what Docker brings to the table is a feature set that crosses a broad range of workflow challenges. By combining the ease of application deployment tools like Capistrano and Fabric, with the ease of administrating virtualization systems, and then providing hooks that make workflow automation and orchestration easy to implement, Docker provides a very enabling feature set.
|
||||
|
||||
Lots of new technologies come and go, and a dose of skepticism about the newest rage is always healthy. Without digging deeper, it would be easy to dismiss Docker as just another technology that solves a few very specific problems for developers or operations teams. If you look at Docker as a virtualization or deployment technology alone, it might not seem very compelling. But Docker is much more than it seems on the surface.
|
||||
|
||||
It is hard and often expensive to get communication and processes right between teams of people, even in smaller organizations. Yet we live in a world where the communication of detailed information between teams is increasingly required to be successful. A tool that reduces the complexity of that communication while aiding in the production of more robust software would be a big win. And that’s exactly why Docker merits a deeper look. It’s no panacea, and implementing Docker well requires some thought, but Docker is a good approach to solving some real-world organizational problems and helping enable companies to ship better software faster. Delivering a well-designed Docker workflow can lead to happier technical teams and real money for the organization’s bottom line.
|
||||
|
||||
So where are companies feeling the most pain? Shipping software at the speed expected in today’s world is hard to do well, and as companies grow from one or two developers to many teams of developers, the burden of communication around shipping new releases becomes much heavier and harder to manage. Developers have to understand a lot of complexity about the environment they will be shipping software into, and production operations teams need to increasingly understand the internals of the software they ship. These are all generally good skills to work on because they lead to a better understanding of the environment as a whole and therefore encourage the designing of robust software, but these same skills are very difficult to scale effectively as an organization’s growth accelerates.
|
||||
|
||||
The details of each company’s environment often require a lot of communication that doesn’t directly build value in the teams involved. For example, requiring developers to ask an operations team for _release 1.2.1_ of a particular library slows them down and provides no direct business value to the company. If developers could simply upgrade the version of the library they use, write their code, test with the new version, and ship it, the delivery time would be measurably shortened. If operations people could upgrade software on the host system without having to coordinate with multiple teams of application developers, they could move faster. Docker helps to build a layer of isolation in software that reduces the burden of communication in the world of humans.
|
||||
|
||||
Beyond helping with communication issues, Docker is opinionated about software architecture in a way that encourages more robustly crafted applications. Its architectural philosophy centers around atomic or throwaway containers. During deployment, the whole running environment of the old application is thrown away with it. Nothing in the environment of the application will live longer than the application itself and that’s a simple idea with big repercussions. It means that applications are not likely to accidentally rely on artifacts left by a previous release. It means that ephemeral debugging changes are less likely to live on in future releases that picked them up from the local filesystem. And it means that applications are highly portable between servers because all state has to be included directly into the deployment artifact and be immutable, or sent to an external dependency like a database, cache, or file server.
|
||||
|
||||
This leads to applications that are not only more scalable, but more reliable. Instances of the application container can come and go with little repercussion on the uptime of the frontend site. These are proven architectural choices that have been successful for non-Docker applications, but the design choices included in Docker’s own design mean that Dockerized applications will follow these best practices by requirement and that’s a good thing.
|
||||
|
||||
|
||||
|
||||
### Benefits of the Docker Workflow
|
||||
|
||||
It’s hard to cohesively group into categories all of the things Docker brings to the table. When implemented well, it benefits organizations, teams, developers, and operations engineers in a multitude of ways. It makes architectural decisions simpler because all applications essentially look the same on the outside from the hosting system’s perspective. It makes tooling easier to write and share between applications. Nothing in this world comes with benefits and no challenges, but Docker is surprisingly skewed toward the benefits. Here are some more of the things you get with Docker:
|
||||
|
||||
|
||||
|
||||
Packaging software in a way that leverages the skills developers already have.
|
||||
|
||||
|
||||
|
||||
Many companies have had to create positions for release and build engineers in order to manage all the knowledge and tooling required to create software packages for their supported platforms. Tools like rpm, mock, dpkg, and pbuilder can be complicated to use, and each one must be learned independently. Docker wraps up all your requirements together into one package that is defined in a single file.
|
||||
|
||||
|
||||
|
||||
Bundling application software and required OS filesystems together in a single standardized image format.
|
||||
|
||||
|
||||
|
||||
In the past, you typically needed to package not only your application, but many of the dependencies that it relied on, including libraries and daemons. However, you couldn’t ever ensure that 100 percent of the execution environment was identical. All of this made packaging difficult to master, and hard for many companies to accomplish reliably. Often someone running Scientific Linux would resort to trying to deploy a community package tested on Red Hat Linux, hoping that the package was close enough to what they needed. With Docker you deploy your application along with every single file required to run it. Docker’s layered images make this an efficient process that ensures that your application is running in the expected environment.
|
||||
|
||||
|
||||
|
||||
Using packaged artifacts to test and deliver the exact same artifact to all systems in all environments.
|
||||
|
||||
|
||||
|
||||
When developers commit changes to a version control system, a new Docker image can be built, which can go through the whole testing process and be deployed to production without any need to recompile or repackage at any step in the process.
|
||||
|
||||
|
||||
|
||||
Abstracting software applications from the hardware without sacrificing resources.
|
||||
|
||||
|
||||
|
||||
Traditional enterprise virtualization solutions like VMware are typically used when people need to create an abstraction layer between the physical hardware and the software applications that run on it, at the cost of resources. The hypervisors that manage the VMs and each VM’s running kernel use a percentage of the hardware system’s resources, which are then no longer available to the hosted applications. A container, on the other hand, is just another process that talks directly to the Linux kernel and therefore can utilize more resources, up until the system or quota-based limits are reached.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
When Docker was first released, Linux containers had been around for quite a few years, and many of the other technologies that it is built on are not entirely new. However, Docker’s unique mix of strong architectural and workflow choices combine together into a whole that is much more powerful than the sum of its parts. Docker finally makes Linux containers, which have been around for more than a decade, approachable to the average technologist. It fits containers relatively easily into the existing workflow and processes of real companies. And the problems discussed above have been felt by so many people that interest in the Docker project has been accelerating faster than anyone could have reasonably expected.
|
||||
|
||||
In the first year, newcomers to the project were surprised to find out that Docker wasn’t already production-ready, but a steady stream of commits from the open source Docker community has moved the project forward at a very brisk pace. That pace seems to only pick up steam as time goes on. As Docker has now moved well into the 1.x release cycle, stability is good, production adoption is here, and many companies are looking to Docker as a solution to some of the serious complexity issues that they face in their application delivery processes.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### What Docker Isn’t
|
||||
|
||||
Docker can be used to solve a wide breadth of challenges that other categories of tools have traditionally been enlisted to fix; however, Docker’s breadth of features often means that it lacks depth in specific functionality. For example, some organizations will find that they can completely remove their configuration management tool when they migrate to Docker, but the real power of Docker is that although it can replace some aspects of more traditional tools, it is usually compatible with them or even augmented by combining with them, as well. In the following list, we explore some of the tool categories that Docker doesn’t directly replace but that can often be used in conjunction to achieve great results:
|
||||
|
||||
|
||||
|
||||
Enterprise Virtualization Platform (VMware, KVM, etc.)
|
||||
|
||||
|
||||
|
||||
A container is not a virtual machine in the traditional sense. Virtual machines contain a complete operating system, running on top of the host operating system. The biggest advantage is that it is easy to run many virtual machines with radically different operating systems on a single host. With containers, both the host and the containers share the same kernel. This means that containers utilize fewer system resources, but must be based on the same underlying operating system (i.e., Linux).
|
||||
|
||||
|
||||
|
||||
Cloud Platform (Openstack, CloudStack, etc.)
|
||||
|
||||
|
||||
|
||||
Like Enterprise virtualization, the container workflow shares a lot of similarities on the surface with cloud platforms. Both are traditionally leveraged to allow applications to be horizontally scaled in response to changing demand. Docker, however, is not a cloud platform. It only handles deploying, running, and managing containers on pre-existing Docker hosts. It doesn’t allow you to create new host systems (instances), object stores, block storage, and the many other resources that are typically associated with a cloud platform.
|
||||
|
||||
|
||||
|
||||
Configuration Management (Puppet, Chef, etc.)
|
||||
|
||||
|
||||
|
||||
Although Docker can significantly improve an organization’s ability to manage applications and their dependencies, it does not directly replace more traditional configuration management. Dockerfiles are used to define how a container should look at build time, but they do not manage the container’s ongoing state, and cannot be used to manage the Docker host system.
|
||||
|
||||
|
||||
|
||||
Deployment Framework (Capistrano, Fabric, etc.)
|
||||
|
||||
|
||||
|
||||
Docker eases many aspects of deployment by creating self-contained container images that encapsulate all the dependencies of an application and can be deployed, in all environments, without changes. However, Docker can’t be used to automate a complex deployment process by itself. Other tools are usually still needed to stitch together the larger workflow automation.
|
||||
|
||||
|
||||
|
||||
Workload Management Tool (Mesos, Fleet, etc.)
|
||||
|
||||
|
||||
|
||||
The Docker server does not have any internal concept of a cluster. Additional orchestration tools (including Docker’s own Swarm tool) must be used to coordinate work intelligently across a pool of Docker hosts, and track the current state of all the hosts and their resources, and keep an inventory of running containers.
|
||||
|
||||
|
||||
|
||||
Development Environment (Vagrant, etc.)
|
||||
|
||||
|
||||
|
||||
Vagrant is a virtual machine management tool for developers that is often used to simulate server stacks that closely resemble the production environment in which an application is destined to be deployed. Among other things, Vagrant makes it easy to run Linux software on Mac OS X and Windows-based workstations. Since the Docker server only runs on Linux, Docker originally provided a tool called Boot2Docker to allow developers to quickly launch Linux-based Docker machines on various platforms. Boot2Docker is sufficient for many standard Docker workflows, but it doesn’t provide the breadth of features found in Docker Machine and Vagrant.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Wrapping your head around Docker can be challenging when you are coming at it without a strong frame of reference. In the next chapter we will lay down a broad overview of Docker, what it is, how it is intended to be used, and what advantages it brings to the table when implemented with all of this in mind.
|
||||
|
||||
|
||||
-----------------
|
||||
作者简介:
|
||||
|
||||
#### [Karl Matthias][1]
|
||||
|
||||
Karl Matthias has worked as a developer, systems administrator, and network engineer for everything from startups to Fortune 500 companies. After working for startups overseas for a few years in Germany and the UK, he has recently returned with his family to Portland, Oregon to work as Lead Site Reliability Engineer at New Relic. When not devoting his time to things digital, he can be found herding his two daughters, shooting film with vintage cameras, or riding one of his bicycles.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### [Sean Kane][2]
|
||||
|
||||
Sean Kane is currently a Lead Site Reliability Engineer for the Shared Infrastructure Team at New Relic. He has had a long career in production operations, with many diverse roles, in a broad range of industries. He has spoken about subjects like alerting fatigue and hardware automation at various meet-ups and technical conferences, including Velocity. Sean spent most of his youth living overseas, and exploring what life has to offer, including graduating from the Ringling Brother & Barnum & Bailey Clown College, completing 2 summer internship...
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/learning/what-is-docker
|
||||
|
||||
作者:[Karl Matthias ][a],[Sean Kane][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/5abbf-karl-matthias
|
||||
[b]:https://www.oreilly.com/people/d5ce6-sean-kane
|
||||
[1]:https://www.oreilly.com/people/5abbf-karl-matthias
|
||||
[2]:https://www.oreilly.com/people/d5ce6-sean-kane
|
||||
[3]:http://shop.oreilly.com/product/0636920036142.do?intcmp=il-security-books-videos-update-na_new_site_what_is_docker_text_cta
|
||||
[4]:http://youtu.be/wW9CAH9nSLs
|
||||
[5]:https://github.com/docker/docker
|
||||
[6]:https://commons.wikimedia.org/wiki/File:2009_3962573662_card_catalog.jpg
|
||||
@ -1,3 +1,5 @@
|
||||
Translated by Yoo-4x
|
||||
|
||||
Building a data science portfolio: Storytelling with data
|
||||
========
|
||||
|
||||
|
||||
@ -1,150 +0,0 @@
|
||||
|
||||
beyondworld 翻译中
|
||||
|
||||
# Suspend to Idle
|
||||
|
||||
### Introduction
|
||||
|
||||
The Linux kernel supports a variety of sleep states. These states provide power savings by placing the various parts of the system into low power modes. The four sleep states are suspend to idle, power-on standby (standby), suspend to ram, and suspend to disk. These are also referred to sometimes by their ACPI state: S0, S1, S3, and S4, respectively. Suspend to idle is purely software driven and involves keeping the CPUs in their deepest idle state as much as possible. Power-on standby involves placing devices in low power states and powering off all non-boot CPUs. Suspend to ram takes this further by powering off all CPUs and putting the memory into self-refresh. Lastly, suspend to disk gets the greatest power savings through powering off as much of the system as possible, including the memory. The contents of memory are written to disk, and on resume this is read back into memory.
|
||||
|
||||
This blog post focuses on the implementation of suspend to idle. As described above, suspend to idle is a software implemented sleep state. The system goes through a normal platform suspend where it freezes the user space and puts peripherals into low-power states. However, instead of powering off and hotplugging out CPUs, the system is quiesced and forced into an idle cpu state. With peripherals in low power mode, no IRQs should occur, aside from wake related irqs. These wake irqs could be timers set to wake the system (RTC, generic timers, etc), or other sources like power buttons, USB, and other peripherals.
|
||||
|
||||
During freeze, a special cpuidle function is called as processors enter idle. This enter_freeze() function can be as simple as calling the cpuidle enter() function, or can be much more complex. The complexity of the function is dependent on the SoCs requirements and methods for placing the SoC into lower power modes.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
### Platform suspend_ops
|
||||
|
||||
Typically, to support S2I, a system must implement a platform_suspend_ops and provide at least minimal suspend support. This meant filling in at least the valid() function in the platform_suspend_ops. If suspend-to-idle and suspend-to-ram was to be supported, the suspend_valid_only_mem would be used for the valid function.
|
||||
|
||||
Recently, however, automatic support for S2I was added to the kernel. Sudeep Holla proposed a change that would provide S2I support on systems without requiring the implementation of platform_suspend_ops. This patch set was accepted and will be part of the 4.9 release. The patch can be found at: [https://lkml.org/lkml/2016/8/19/474][1]
|
||||
|
||||
With suspend_ops defined, the system will report the valid platform suspend states when the /sys/power/state is read.
|
||||
|
||||
```
|
||||
# cat /sys/power/state
|
||||
```
|
||||
|
||||
freeze mem_
|
||||
|
||||
This example shows that both S0 (suspend to idle) and S3 (suspend to ram) are supported on this platform. With Sudeep’s change, only freeze will show up for platforms which do not implement platform_suspend_ops.
|
||||
|
||||
### Wake IRQ support
|
||||
|
||||
Once the system is placed into a sleep state, the system must receive wake events which will resume the system. These wake events are generated from devices on the system. It is important to make sure that device drivers utilize wake irqs and configure themselves to generate wake events upon receiving wake irqs. If wake devices are not identified properly, the system will take the interrupt and then go back to sleep and will not resume.
|
||||
|
||||
Once devices implement proper wake API usage, they can be used to generate wake events. Make sure DT files also specify wake sources properly. An example of configuring a wakeup-source is the following (arch/arm/boot/dst/am335x-evm.dts):
|
||||
|
||||
```
|
||||
gpio_keys: volume_keys@0 {__
|
||||
compatible = “gpio-keys”;
|
||||
#address-cells = <1>;
|
||||
#size-cells = <0>;
|
||||
autorepeat;
|
||||
|
||||
switch@9 {
|
||||
label = “volume-up”;
|
||||
linux,code = <115>;
|
||||
gpios = <&gpio0 2 GPIO_ACTIVE_LOW>;
|
||||
wakeup-source;
|
||||
};
|
||||
|
||||
switch@10 {
|
||||
label = “volume-down”;
|
||||
linux,code = <114>;
|
||||
gpios = <&gpio0 3 GPIO_ACTIVE_LOW>;
|
||||
wakeup-source;
|
||||
};
|
||||
};
|
||||
```
|
||||
|
||||
As you can see, two gpio keys are defined to be wakeup-sources. Either of these keys, when pressed, would generate a wake event during suspend.
|
||||
|
||||
An alternative to DT configuration is if the device driver itself configures wake support in the code using the typical wakeup facilities.
|
||||
|
||||
### Implementation
|
||||
|
||||
### Freeze function
|
||||
|
||||
Systems should define a enter_freeze() function in their cpuidle driver if they want to take full advantage of suspend to idle. The enter_freeze() function uses a slightly different function prototype than the enter() function. As such, you can’t just specify the enter() for both enter and enter_freeze. At a minimum, it will directly call the enter() function. If no enter_freeze() is specified, the suspend will occur, but the extra things that would have occurred if enter_freeze() was present, like tick_freeze() and stop_critical_timings(), will not occur. This results in timer IRQs waking up the system. This will not result in a resume, as the system will go back into suspend after handling the IRQ.
|
||||
|
||||
During suspend, minimal interrupts should occur (ideally none).
|
||||
|
||||
The picture below shows a plot of power usage vs time. The two spikes on the graph are the suspend and the resume. The small periodic spikes before and after the suspend are the system exiting idle to do bookkeeping operations, scheduling tasks, and handling timers. It takes a certain period of time for the system to go back into the deeper idle state due to latency.
|
||||
|
||||

|
||||
Power Usage Time Progression
|
||||
|
||||
The ftrace capture shown below displays the activity on the 4 CPUs before, during, and after the suspend/resume operation. As you can see, during the suspend, no IPIs or IRQs are handled.
|
||||
|
||||

|
||||
|
||||
Ftrace capture of Suspend/Resume
|
||||
|
||||
### Idle State Support
|
||||
|
||||
You must determine which idle states support freeze. During freeze, the power code will determine the deepest idle state that supports freeze. This is done by iterating through the idle states and looking for which states have defined enter_freeze(). The cpuidle driver or SoC specific suspend code must determine which idle states should implement freeze and it must configure them by specifying the freeze function for all applicable idle states for each cpu.
|
||||
|
||||
As an example, the Qualcomm platform will set the enter_freeze function during the suspend init function in the platform suspend code. This is done after the cpuidle driver is initialized so that all structures are defined and in place.
|
||||
|
||||
### Driver support for Suspend/Resume
|
||||
|
||||
You may encounter buggy drivers during your first successful suspend operation. Many drivers have not had robust testing of suspend/resume paths. You may even find that suspend may not have much to do because pm_runtime has already done everything you would have done in the suspend. Because the user space is frozen, the devices should already be idled and pm_runtime disabled.
|
||||
|
||||
### Testing
|
||||
|
||||
Testing for suspend to idle can be done either manually, or through using something that does an auto suspend (script/process/etc), auto sleep or through something like Android where if a wakelock is not held the system continuously tried to suspend. If done manually, the following will place the system in freeze:
|
||||
|
||||
```
|
||||
/ # echo freeze > /sys/power/state
|
||||
[ 142.580832] PM: Syncing filesystems … done.
|
||||
[ 142.583977] Freezing user space processes … (elapsed 0.001 seconds) done.
|
||||
[ 142.591164] Double checking all user space processes after OOM killer disable… (elapsed 0.000 seconds)
|
||||
[ 142.600444] Freezing remaining freezable tasks … (elapsed 0.001 seconds) done._
|
||||
_[ 142.608073] Suspending console(s) (use no_console_suspend to debug)
|
||||
[ 142.708787] mmc1: Reset 0x1 never completed.
|
||||
[ 142.710608] msm_otg 78d9000.phy: USB in low power mode
|
||||
[ 142.711379] PM: suspend of devices complete after 102.883 msecs
|
||||
[ 142.712162] PM: late suspend of devices complete after 0.773 msecs
|
||||
[ 142.712607] PM: noirq suspend of devices complete after 0.438 msecs
|
||||
< system suspended >
|
||||
….
|
||||
< wake irq triggered >
|
||||
[ 147.700522] PM: noirq resume of devices complete after 0.216 msecs
|
||||
[ 147.701004] PM: early resume of devices complete after 0.353 msecs
|
||||
[ 147.701636] msm_otg 78d9000.phy: USB exited from low power mode
|
||||
[ 147.704492] PM: resume of devices complete after 3.479 msecs
|
||||
[ 147.835599] Restarting tasks … done.
|
||||
/ #
|
||||
```
|
||||
|
||||
In the above example, it should be noted that the MMC driver was responsible for 100ms of that 102.883ms. Some device drivers will still have work to do when suspending. This may be flushing of data out to disk or other tasks which take some time.
|
||||
|
||||
If the system has freeze defined, it will try to suspend the system. If it does not have freeze capabilities, you will see the following:
|
||||
|
||||
```
|
||||
/ # echo freeze > /sys/power/state
|
||||
sh: write error: Invalid argument
|
||||
/ #
|
||||
```
|
||||
|
||||
### Future Developments
|
||||
|
||||
There are two areas where work is currently being done on Suspend to Idle on ARM platforms. The first area was mentioned earlier in the platform_suspend_ops prerequisite section. The work to always allow for the freeze state was accepted and will be part of the 4.9 kernel. The other area that is being worked on is the freeze_function support.
|
||||
|
||||
The freeze_function implementation is currently required if you want the best response/performance. However, since most SoCs will use the ARM cpuidle driver, it makes sense for the ARM cpuidle driver to implement its own generic freeze_function. And in fact, ARM is working to add this generic support. A SoC vendor should only have to implement specialized freeze_functions if they implement their own cpuidle driver or require additional provisioning before entering their deepest freezable idle state.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linaro.org/blog/suspend-to-idle/
|
||||
|
||||
作者:[Andy Gross][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linaro.org/author/andygross/
|
||||
[1]:https://lkml.org/lkml/2016/8/19/474
|
||||
@ -1,111 +0,0 @@
|
||||
translating by ypingcn.
|
||||
|
||||
CLOUD FOCUSED LINUX DISTROS FOR PEOPLE WHO BREATHE ONLINE
|
||||
============================================================
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
_Brief: We list some _Cloud centric_ Linux distributions that might be termed as real Linux alternatives to Chrome OS._
|
||||
|
||||
The world is moving to cloud-based services and we all know the kind of love that Chrome OS got. Well, it does deserve respect. It’s super fast, light, power-efficient, minimalistic, beautifully designed and utilizes the full potential of cloud that technology permits today.
|
||||
|
||||
Although [Chrome OS][7] is exclusively available only for Google’s hardware, there are other means to experience the potential of cloud computing right on your laptop or desktop.
|
||||
|
||||
As I have repeatedly said, there is always something for everybody in the Linux domain, be it [Linux distributions that look like Windows][8] or Mac OS. Linux is all about sharing, love and some really bleeding edge computing experience. Let’s crack this list right away!
|
||||
|
||||
### 1\. CUB LINUX
|
||||
|
||||

|
||||
|
||||
It is not Chrome OS. But the above image is featuring the desktop of [Cub Linux][9]. Say what?
|
||||
|
||||
Cub Linux is no news for Linux users. But if you already did not know, Cub Linux is the web focused Linux distro that is inspired from mainstream Chrome OS. It is also the open source brother of Chrome OS from mother Linux.
|
||||
|
||||
Chrome OS has the Chrome Browser as it’s primary component. Not so long ago, a project by name [Chromixium OS][10] was started to recreate Chrome OS like experience by using the Chromium Browser in place of Chrome Browser. Due to some legal issues, the name was later changed to Cub Linux (Chromium+Ubuntu).
|
||||
|
||||

|
||||
|
||||
Well, history apart, as the name hints, Cub Linux is based on Ubuntu, features the lightweight Openbox Desktop Environment. The Desktop is customized to give a Chrome OS impression and looks really neat.
|
||||
|
||||
In the apps department, you can install the web applications from the Chrome web store and all the Ubuntu software. Yup, with all the snappy apps of the Chrome OS, You’ll still get the Ubuntu goodies.
|
||||
|
||||
As far as the performance is concerned, the operating system is super fast thanks to its Openbox Desktop Environment. Based on Ubuntu Linux, the stability of Cub Linux is unquestionable. The desktop itself is a treat to the eyes with all its smooth animations and beautiful UI.
|
||||
|
||||
[Suggested Read[Year 2013 For Linux] 2 Linux Distributions Discontinued][11]
|
||||
|
||||
I suggest Cub Linux to anybody who spends most their times on a browser and do some home tasks now and then. Well, a browser is all you need and a browser is exactly what you’ll get.
|
||||
|
||||
### 2\. PEPPERMINT OS
|
||||
|
||||
A good number of people look towards Linux because they want a no-BS computing experience. Some people do not really like the hassle of an anti-virus, a defragmenter, a cleaner etcetera as they want an operating system and not a baby. And I must say Peppermint OS is really good at being no-BS. [Peppermint OS][12] developers have put a good amount of effort in understanding the user requirements and needs.
|
||||
|
||||

|
||||
|
||||
There is a very small number of selected software included by default. The traditional ideology of including a couple apps from every software category is ditched here for good. The power to customize the computer as per needs has been given to the user. By the way, do we really need to install so many applications when we can get web alternatives for almost all the applications?
|
||||
|
||||
Ice
|
||||
|
||||
Ice is a utile little tool that converts your favorite and most used websites into desktop applications that you can directly launch from your desktop or the menu. It’s what we call a site-specific browser.
|
||||
|
||||

|
||||
|
||||
Love facebook? Why not make a facebook web app on your desktop for quick launch? While there are people complaining about a decent Google drive application for Linux, Ice allows you to access Drive with just a click. Not just Drive, the functionality of Ice is limited only by your imagination.
|
||||
|
||||
Peppermint OS 7 is based on Ubuntu 16.04\. It not only provides a smooth, rock solid performance but also a very swift response. A heavily customizes LXDE will be your home screen. And the customization I’m speaking about is driven to achieve both a snappy performance as well as visual appeal.
|
||||
|
||||
Peppermint OS hits more of a middle ground in the cloud-native operating system types. Although the skeleton of the OS is designed to support the speedy cloudy apps, the native Ubuntu application play well too. If you are someone like me who wants an OS that is balanced in online-offline capabilities, [Peppermint OS is for you][13].
|
||||
|
||||
[Suggested ReadPennsylvania High School Distributes 1,700 Ubuntu Laptops to Students][14]
|
||||
|
||||
### 3.APRICITY OS
|
||||
|
||||
[Apricity OS][15] stole the show for being one of the top aesthetically pleasing Linux distros out there. It’s just gorgeous. It’s like the Mona Lisa of the Linux domain. But, there’s more to it than just the looks.
|
||||
|
||||

|
||||
|
||||
The prime reason [Apricity OS][16] makes this list is because of its simplicity. While OS desktop design is getting chaotic and congested with elements (and I’m not talking only about non-Linux operating systems), Apricity de-clutters everything and simplifies the very basic human-desktop interaction. Gnome desktop environment is customized beautifully here. They made it really simpler.
|
||||
|
||||
The pre-installed software list is really small. Almost all Linux distros have the same pre-installed software. But Apricity OS has a completely new set of software. Chrome instead of Firefox. I was really waiting for this. I mean why not give us what’s rocking out there?
|
||||
|
||||
Apricity OS also features the Ice tool that we discussed in the last segment. But instead of Firefox, Chrome browser is used in website-desktop integration. Apricity OS has Numix Circle icons by default and everytime you add a popular webapp, there will be a beautiful icon placed on your Dock.
|
||||
|
||||

|
||||
|
||||
See what I mean?
|
||||
|
||||
Apricity OS is based on Arch Linux. (So anybody looking for a quick start with Arch, and a beautiful at that one, download that Apricity ISO [here][17]) Apricity fully upholds the Arch principle of freedom of choice. Within just 10 minutes on the Ice, and you’ll have all your favorite webapps set up.
|
||||
|
||||
Gorgeous backgrounds, minimalistic desktop and a great functionality. These make Apricity OS a really great choice for setting up an amazing cloud-centric system. It’ll take 5 mins for Apricity OS to make you fall in love with it. I mean it.
|
||||
|
||||
There you have it, people. Cloud-centric Linux distros for online dwellers. Do give us your take on the webapp-native app topic. Don’t forget to share.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cloud-focused-linux-distros/
|
||||
|
||||
作者:[Aquil Roshan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/author/aquil/
|
||||
[2]:https://itsfoss.com/cloud-focused-linux-distros/#comments
|
||||
[3]:https://twitter.com/share?original_referer=https%3A%2F%2Fitsfoss.com%2F&source=tweetbutton&text=Cloud+Focused+Linux+Distros+For+People+Who+Breathe+Online&url=https%3A%2F%2Fitsfoss.com%2Fcloud-focused-linux-distros%2F&via=%40itsfoss
|
||||
[4]:https://www.linkedin.com/cws/share?url=https://itsfoss.com/cloud-focused-linux-distros/
|
||||
[5]:http://pinterest.com/pin/create/button/?url=https://itsfoss.com/cloud-focused-linux-distros/&description=Cloud+Focused+Linux+Distros+For+People+Who+Breathe+Online&media=https://itsfoss.com/wp-content/uploads/2016/11/cloud-centric-Linux-distributions.jpg
|
||||
[6]:https://itsfoss.com/wp-content/uploads/2016/11/cloud-centric-Linux-distributions.jpg
|
||||
[7]:https://en.wikipedia.org/wiki/Chrome_OS
|
||||
[8]:https://itsfoss.com/windows-like-linux-distributions/
|
||||
[9]:https://cublinux.com/
|
||||
[10]:https://itsfoss.com/chromixiumos-released/
|
||||
[11]:https://itsfoss.com/year-2013-linux-2-linux-distributions-discontinued/
|
||||
[12]:https://peppermintos.com/
|
||||
[13]:https://peppermintos.com/
|
||||
[14]:https://itsfoss.com/pennsylvania-high-school-ubuntu/
|
||||
[15]:https://apricityos.com/
|
||||
[16]:https://itsfoss.com/apricity-os/
|
||||
[17]:https://apricityos.com/
|
||||
@ -1,174 +0,0 @@
|
||||
Translating by firstadream
|
||||
|
||||
### [Can Linux containers save IoT from a security meltdown?][28]
|
||||
|
||||

|
||||
In this final IoT series post, Canonical and Resin.io champion Linux container technology as a solution to IoT security and interoperability challenges.
|
||||
|
||||
|
|
||||

|
||||
|
||||
**Artik 7** |
|
||||
|
||||
Despite growing security threats, the Internet of Things hype shows no sign of abating. Feeling the FoMo, companies are busily rearranging their roadmaps for IoT. The transition to IoT runs even deeper and broader than the mobile revolution. Everything gets swallowed in the IoT maw, including smartphones, which are often our windows on the IoT world, and sometimes our hubs or sensor endpoints.
|
||||
|
||||
New IoT focused processors and embedded boards continue to reshape the tech landscape. Since our [Linux and Open Source Hardware for IoT][5] story in September, we’ve seen [Intel Atom E3900][6] “Apollo Lake” SoCs aimed at IoT gateways, as well as [new Samsung Artik modules][7], including a Linux-driven, 64-bit Artik 7 COM for gateways and an RTOS-ready, Cortex-M4 Artik 0\. ARM announced [Cortex-M23 and Cortex-M33][8] cores for IoT endpoints featuring ARMv8-M and TrustZone security.
|
||||
|
||||
Security is a selling point for these products, and for good reason. The Mirai botnet that recently attacked the Dyn service and blacked out much of the U.S. Internet for a day brought Linux-based IoT into the forefront — and not in a good way. Just as IoT devices can be turned to the dark side via DDoS, the devices and their owners can also be the victimized directly by malicious attacks.
|
||||
|
||||
|
|
||||

|
||||
|
||||
**Cortex-M33 and -M23** |
|
||||
|
||||
The Dyn attack reinforced the view that IoT will more confidently move forward in more controlled and protected industrial environments rather than the home. It’s not that consumer [IoT security technology][9] is unavailable, but unless products are designed for security from scratch, as are many of the solutions in our [smart home hub story][10], security adds cost and complexity.
|
||||
|
||||
In this final, future-looking segment of our IoT series, we look at two Linux-based, Docker-oriented container technologies that are being proposed as solutions to IoT security. Containers might also help solve the ongoing issues of development complexity and barriers to interoperability that we explored in our story on [IoT frameworks][11].
|
||||
|
||||
We spoke with Canonical’s Oliver Ries, VP Engineering Ubuntu Client Platform about his company’s Ubuntu Core and its Docker-friendly, container-like Snaps package management technology. We also interviewed Resin.io CEO and co-founder Alexandros Marinos about his company’s new Docker-based ResinOS for IoT.
|
||||
|
||||
**Ubuntu Core Snaps to**
|
||||
|
||||
Canonical’s IoT-oriented [Snappy Ubuntu Core][12] version of Ubuntu is built around a container-like snap package management mechanism, and offers app store support. The snaps technology was recently [released on its own][13] for other Linux distributions. On November 3, Canonical released [Ubuntu Core 16][14], which improves white label app store and update control services.
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][15]
|
||||
**Classic Ubuntu (left) architecture vs. Ubuntu Core 16**
|
||||
(click image to enlarge)
|
||||
</center>
|
||||
|
||||
The snap mechanism offers automatic updates, and helps block unauthorized updates. Using transactional systems management, snaps ensure that updates either deploy as intended or not at all. In Ubuntu Core, security is further strengthened with AppArmor, and the fact that all application files are kept in separate silos, and are read-only.
|
||||
|
||||
|
|
||||

|
||||
|
||||
**LimeSDR** |
|
||||
|
||||
Ubuntu Core, which was part of our recent [survey of open source IoT OSes][16], now runs on Gumstix boards, Erle Robotics drones, Dell Edge Gateways, the [Nextcloud Box][17], LimeSDR, the Mycroft home hub, Intel’s Joule, and SBCs compliant with Linaro’s 96Boards spec. Canonical is also collaborating with the Linaro IoT and Embedded (LITE) Segment Group on its [96Boards IoT Edition][18]Initially, 96Boards IE is focused on Zephyr-driven Cortex-M4 boards like Seeed’s [BLE Carbon][19], but it will expand to gateway boards that can run Ubuntu Core.
|
||||
|
||||
“Ubuntu Core and snaps have relevance from edge to gateway to the cloud,” says Canonical’s Ries. “The ability to run snap packages on any major distribution, including Ubuntu Server and Ubuntu for Cloud, allows us to provide a coherent experience. Snaps can be upgraded in a failsafe manner using transactional updates, which is important in an IoT world moving to continuous updates for security, bug fixes, or new features.”
|
||||
|
||||
|
|
||||

|
||||
|
||||
**Nextcloud Box** |
|
||||
|
||||
Security and reliability are key points of emphasis, says Ries. “Snaps can run completely isolated from one another and from the OS, making it possible for two applications to securely run on a single gateway,” he says. “Snaps are read-only and authenticated, guaranteeing the integrity of the code.”
|
||||
|
||||
Ries also touts the technology for reducing development time. “Snap packages allow a developer to deliver the same binary package to any platform that supports it, thereby cutting down on development and testing costs, deployment time, and update speed,” says Ries. “With snap packages, the developer is in full control of the lifecycle, and can update immediately. Snap packages provide all required dependencies, so developers can choose which components they use.”
|
||||
|
||||
**ResinOS: Docker for IoT**
|
||||
|
||||
Resin.io, which makes the commercial IoT framework of the same name, recently spun off the framework’s Yocto Linux based [ResinOS 2.0][20]” target=”new”>ResinOS 2.0 as an open source project. Whereas Ubuntu Core runs Docker container engines within snap packages, ResinOS runs Docker on the host. The minimalist ResinOS abstracts the complexity of working with Yocto code, enabling developers to quickly deploy Docker containers.
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][21]
|
||||
**ResinOS 2.0 architecture**
|
||||
(click image to enlarge)
|
||||
</center>
|
||||
|
||||
Like the Linux-based CoreOS, ResinOS integrates systemd control services and a networking stack, enabling secure rollouts of updated applications over a heterogeneous network. However, it’s designed to run on resource constrained devices such as ARM hacker boards, whereas CoreOS and other Docker-oriented OSes like the Red Hat based Project Atomic are currently x86 only and prefer a resource-rich server platform. ResinOS can run on 20 Linux devices and counting, including the Raspberry Pi, BeagleBone, and Odroid-C1.
|
||||
|
||||
“We believe that Linux containers are even more important for embedded than for the cloud,” says Resin.io’s Marinos. “In the cloud, containers represent an optimization over previous processes, but in embedded they represent the long-delayed arrival of generic virtualization.”
|
||||
|
||||
|
|
||||

|
||||
|
||||
**BeagleBone
|
||||
Black** |
|
||||
|
||||
When applied to IoT, full enterprise virtual machines have performance issues and restrictions on direct hardware access, says Marinos. Mobile VMs like OSGi and Android’s Dalvik can been used for IoT, but they require Java among other limitations.
|
||||
|
||||
Using Docker may seem natural for enterprise developers, but how do you convince embedded hackers to move to an entirely new paradigm? “Rather than transferring practices from the cloud wholesale, ResinOS is optimized for embedded,” answers Marinos. In addition, he says, containers are better than typical IoT technologies at containing failure. “If there’s a software defect, the host OS can remain functional and even connected. To recover, you can either restart the container or push an update. The ability to update a device without rebooting it further removes failure opportunities.”
|
||||
|
||||
According to Marinos, other benefits accrue from better alignment with the cloud, such as access to a broader set of developers. Containers provide “a uniform paradigm across data center and edge, and a way to easily transfer technology, workflows, infrastructure, and even applications to the edge,” he adds.
|
||||
|
||||
The inherent security benefits in containers are being augmented with other technologies, says Marinos. “As the Docker community pushes to implement signed images and attestation, these naturally transfer to ResinOS,” he says. “Similar benefits accrue when the Linux kernel is hardened to improve container security, or gains the ability to better manage resources consumed by a container.”
|
||||
|
||||
Containers also fit in well with open source IoT frameworks, says Marinos. “Linux containers are easy to use in combination with an almost endless variety of protocols, applications, languages and libraries,” says Marinos. “Resin.io has participated in the AllSeen Alliance, and we have worked with partners who use IoTivity and Thread.”
|
||||
|
||||
**Future IoT: Smarter Gateways and Endpoints**
|
||||
|
||||
Marinos and Canonical’s Ries agree on several future trends in IoT. First, the original conception of IoT, in which MCU-based endpoints communicate directly with the cloud for processing, is quickly being replaced with a fog computing architecture. That calls for more intelligent gateways that do a lot more than aggregate data and translate between ZigBee and WiFi.
|
||||
|
||||
Second, gateways and smart edge devices are increasingly running multiple apps. Third, many of these devices will provide onboard analytics, which we’re seeing in the latest [smart home hubs][22]. Finally, rich media will soon become part of the IoT mix.
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][23] [
|
||||

|
||||
][24]
|
||||
**Some recent IoT gateways: Eurotech’s [ReliaGate 20-26][1] and Advantech’s [UBC-221][2]**
|
||||
(click images to enlarge)
|
||||
</center>
|
||||
|
||||
“Intelligent gateways are taking over a lot of the processing and control functions that were originally envisioned for the cloud,” says Marinos. “Accordingly, we’re seeing an increased push for containerization, so feature- and security-related improvements can be deployed with a cloud-like workflow. The decentralization is driven by factors such as the mobile data crunch, an evolving legal framework, and various physical limitations.”
|
||||
|
||||
Platforms like Ubuntu Core are enabling an “explosion of software becoming available for gateways,” says Canonical’s Ries. “The ability to run multiple applications on a single device is appealing both for users annoyed with the multitude of single-function devices, and for device owners, who can now generate ongoing software revenues.”
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][25] [
|
||||

|
||||
][26]
|
||||
**Two more IoT gateways: [MyOmega MYNXG IC2 Controller (left) and TechNexion’s ][3][LS1021A-IoT Gateway][4]**
|
||||
(click images to enlarge)
|
||||
</center>
|
||||
|
||||
It’s not only gateways — endpoints are getting smarter, too. “Reading a lot of IoT coverage, you get the impression that all endpoints run on microcontrollers,” says Marinos. “But we were surprised by the large amount of Linux endpoints out there like digital signage, drones, and industrial machinery, that perform tasks rather than operate as an intermediary. We call this the shadow IoT.”
|
||||
|
||||
Canonical’s Ries agrees that a single-minded focus on minimalist technology misses out on the emerging IoT landscape. “The notion of ‘lightweight’ is very short lived in an industry that’s developing as fast as IoT,” says Ries. “Today’s premium consumer hardware will be powering endpoints in a matter of months.”
|
||||
|
||||
While much of the IoT world will remain lightweight and “headless,” with sensors like accelerometers and temperature sensors communicating in whisper thin data streams, many of the newer IoT applications use rich media. “Media input/output is simply another type of peripheral,” says Marinos. “There’s always the issue of multiple containers competing for a limited resource, but it’s not much different than with sensor or Bluetooth antenna access.”
|
||||
|
||||
Ries sees a trend of “increasing smartness at the edge” in both industrial and home gateways. “We are seeing a large uptick in AI, machine learning, computer vision, and context awareness,” says Ries. “Why run face detection software in the cloud and incur delays and bandwidth and computing costs, when the same software could run at the edge?”
|
||||
|
||||
As we explored in our [opening story][27] of this IoT series, there are IoT issues related to security such as loss of privacy and the tradeoffs from living in a surveillance culture. There are also questions about the wisdom of relinquishing one’s decisions to AI agents that may be controlled by someone else. These won’t be fully solved by containers, snaps, or any other technology.
|
||||
|
||||
Perhaps we’d be happier if Alexa handled the details of our lives while we sweat the big stuff, and maybe there’s a way to balance privacy and utility. For now, we’re still exploring, and that’s all for the good.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
[1]:http://hackerboards.com/atom-based-gateway-taps-new-open-source-iot-cloud-platform/
|
||||
[2]:http://hackerboards.com/compact-iot-gateway-runs-yocto-linux-on-quark/
|
||||
[3]:http://hackerboards.com/wireless-crazed-customizable-iot-gateway-uses-arm-or-x86-coms/
|
||||
[4]:http://hackerboards.com/iot-gateway-runs-linux-on-qoriq-accepts-arduino-shields/
|
||||
[5]:http://hackerboards.com/linux-and-open-source-hardware-for-building-iot-devices/
|
||||
[6]:http://hackerboards.com/intel-launches-14nm-atom-e3900-and-spins-an-automotive-version/
|
||||
[7]:http://hackerboards.com/samsung-adds-first-64-bit-and-cortex-m4-based-artik-modules/
|
||||
[8]:http://hackerboards.com/new-cortex-m-chips-add-armv8-and-trustzone/
|
||||
[9]:http://hackerboards.com/exploring-security-challenges-in-linux-based-iot-devices/
|
||||
[10]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[11]:http://hackerboards.com/open-source-projects-for-the-internet-of-things-from-a-to-z/
|
||||
[12]:http://hackerboards.com/lightweight-snappy-ubuntu-core-os-targets-iot/
|
||||
[13]:http://hackerboards.com/canonical-pushes-snap-as-a-universal-linux-package-format/
|
||||
[14]:http://hackerboards.com/ubuntu-core-16-gets-smaller-goes-all-snaps/
|
||||
[15]:http://hackerboards.com/files/canonical_ubuntucore16_diagram.jpg
|
||||
[16]:http://hackerboards.com/open-source-oses-for-the-internet-of-things/
|
||||
[17]:http://hackerboards.com/private-cloud-server-and-iot-gateway-runs-ubuntu-snappy-on-rpi/
|
||||
[18]:http://hackerboards.com/linaro-beams-lite-at-internet-of-things-devices/
|
||||
[19]:http://hackerboards.com/96boards-goes-cortex-m4-with-iot-edition-and-carbon-sbc/
|
||||
[20]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/%3Ca%20href=
|
||||
[21]:http://hackerboards.com/files/resinio_resinos_arch.jpg
|
||||
[22]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[23]:http://hackerboards.com/files/eurotech_reliagate2026.jpg
|
||||
[24]:http://hackerboards.com/files/advantech_ubc221.jpg
|
||||
[25]:http://hackerboards.com/files/myomega_mynxg.jpg
|
||||
[26]:http://hackerboards.com/files/technexion_ls1021aiot_front.jpg
|
||||
[27]:http://hackerboards.com/an-open-source-perspective-on-the-internet-of-things-part-1/
|
||||
[28]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
@ -1,3 +1,5 @@
|
||||
OneNewLife translating
|
||||
|
||||
The truth about traditional JavaScript benchmarks
|
||||
============================================================
|
||||
|
||||
@ -9,7 +11,7 @@ That raises the question, why is JavaScript so popular/successful? There is no o
|
||||
Back in the days, these speed-ups were measured with what is now called _traditional JavaScript benchmarks_, starting with Apple’s [SunSpider benchmark][24], the mother of all JavaScript micro-benchmarks, followed by Mozilla’s [Kraken benchmark][25] and Google’s V8 benchmark. Later the V8 benchmark was superseded by the[Octane benchmark][26] and Apple released its new [JetStream benchmark][27]. These traditional JavaScript benchmarks drove amazing efforts to bring a level of performance to JavaScript that noone would have expected at the beginning of the century. Speed-ups up to a factor of 1000 were reported, and all of a sudden using `<script>` within a website was no longer a dance with the devil, and doing work client-side was not only possible, but even encouraged.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][28]
|
||||
|
||||
|
||||
@ -18,20 +20,20 @@ Now in 2016, all (relevant) JavaScript engines reached a level of performance th
|
||||
The vast majority of these accomplishments were due to the presence of these micro-benchmarks and static performance test suites, and the vital competition that resulted from having these traditional JavaScript benchmarks. You can say what you want about SunSpider, but it’s clear that without SunSpider, JavaScript performance would likely not be where it is today. Okay, so much for the praise… now on to the flip side of the coin: Any kind of static performance test - be it a micro-benchmark or a large application macro-benchmark - is doomed to become irrelevant over time! Why? Because the benchmark can only teach you so much before you start gaming it. Once you get above (or below) a certain threshold, the general applicability of optimizations that benefit a particular benchmark will decrease exponentially. For example we built Octane as a proxy for performance of real world web applications, and it probably did a fairly good job at that for quite some time, but nowadays the distribution of time in Octane vs. real world is quite different, so optimizing for Octane beyond where it is currently, is likely not going to yield any significant improvements in the real world (neither general web nor Node.js workloads).
|
||||
|
||||
[
|
||||

|
||||

|
||||
][32]
|
||||
|
||||
|
||||
Since it became more and more obvious that all the traditional benchmarks for measuring JavaScript performance, including the most recent versions of JetStream and Octane, might have outlived their usefulness, we started investigating new ways to measure real-world performance beginning of the year, and added a lot of new profiling and tracing hooks to V8 and Chrome. We especially added mechanisms to see where exactly we spend time when browsing the web, i.e. whether it’s script execution, garbage collection, compilation, etc., and the results of these investigations were highly interesting and surprising. As you can see from the slide above, running Octane spends more than 70% of the time executing JavaScript and collecting garbage, while browsing the web you always spend less than 30% of the time actually executing JavaScript, and never more than 5% collecting garbage. Instead a significant amount of time goes to parsing and compiling, which is not reflected in Octane. So spending a lot of time to optimize JavaScript execution will boost your score on Octane, but won’t have any positive impact on loading [youtube.com][33]. In fact, spending more time on optimizing JavaScript execution might even hurt your real-world performance since the compiler takes more time, or you need to track additional feedback, thus eventually adding more time to the Compile, IC and Runtime buckets.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][34]
|
||||
|
||||
There’s another set of benchmarks, which try to measure overall browser performance, including JavaScript **and** DOM performance, with the most recent addition being the [Speedometer benchmark][35]. The benchmark tries to capture real world performance more realistically by running a simple [TodoMVC][36] application implemented with different popular web frameworks (it’s a bit outdated now, but a new version is in the makings). The various tests are included in the slide above next to octane (angular, ember, react, vanilla, flight and backbone), and as you can see these seem to be a better proxy for real world performance at this point in time. Note however that this data is already six months old at the time of this writing and things might have changed as we optimized more real world patterns (for example we are refactoring the IC system to reduce overhead significantly, and the [parser is being redesigned][37]). Also note that while this looks like it’s only relevant in the browser space, we have very strong evidence that traditional peak performance benchmarks are also not a good proxy for real world Node.js application performance.
|
||||
|
||||
[
|
||||

|
||||

|
||||
][38]
|
||||
|
||||
|
||||
@ -42,7 +44,7 @@ All of this is probably already known to a wider audience, so I’ll use the res
|
||||
A blog post on traditional JavaScript benchmarks wouldn’t be complete without pointing out the obvious SunSpider problems. So let’s start with the prime example of performance test that has limited applicability in real world: The [`bitops-bitwise-and.js`][39] performance test.
|
||||
|
||||
[
|
||||
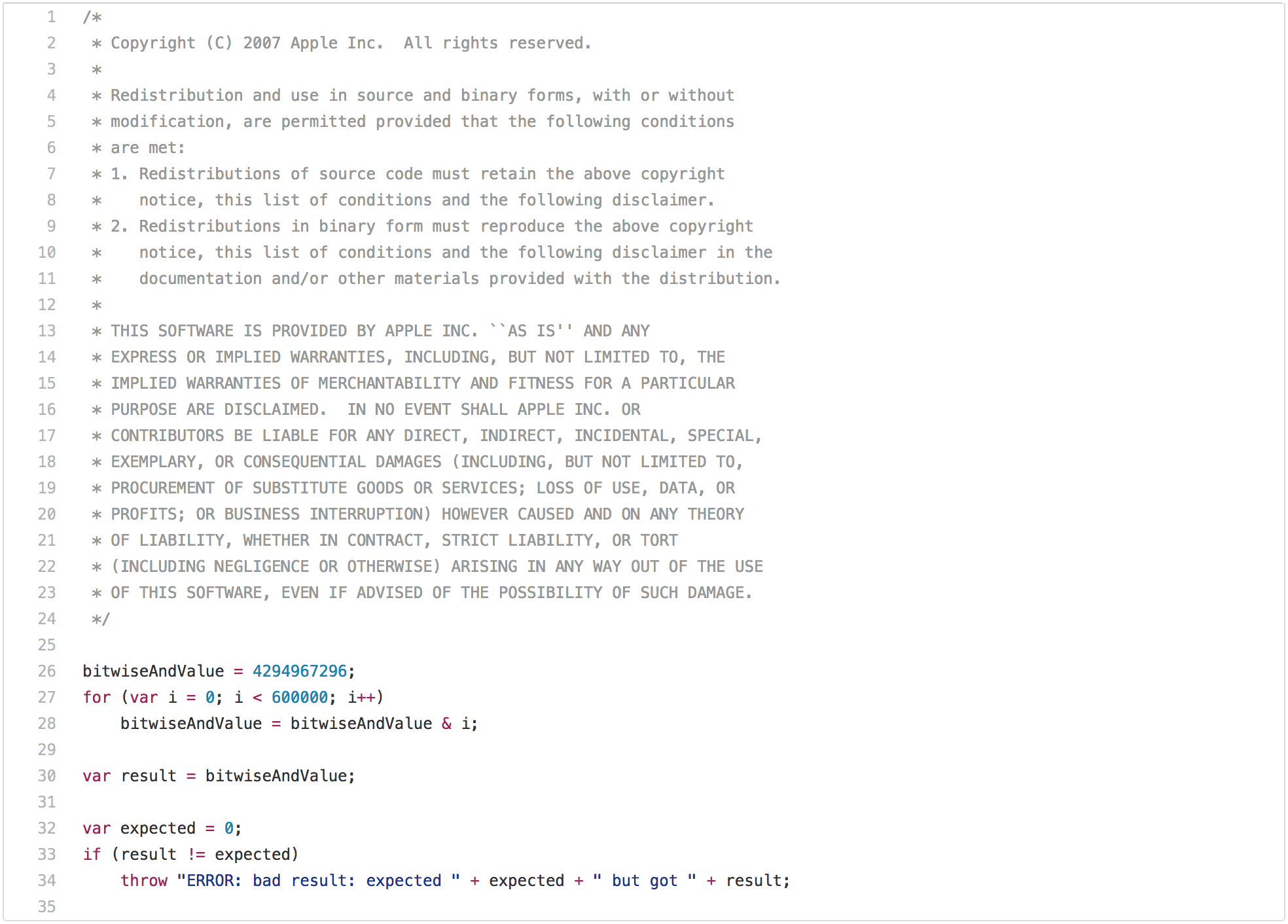
|
||||

|
||||
][40]
|
||||
|
||||
There are a couple of algorithms that need fast bitwise and, especially in the area of code transpiled from C/C++ to JavaScript, so it does indeed make some sense to be able to perform this operation quickly. However real world web pages will probably not care whether an engine can execute bitwise and in a loop 2x faster than another engine. But staring at this code for another couple of seconds, you’ll probably notice that `bitwiseAndValue` will be `0` after the first loop iteration and will remain `0` for the next 599999 iterations. So once you get this to good performance, i.e. anything below 5ms on decent hardware, you can start gaming this benchmark by trying to recognize that only the first iteration of the loop is necessary, while the remaining iterations are a waste of time (i.e. dead code after [loop peeling][41]). This needs some machinery in JavaScript to perform this transformation, i.e. you need to check that `bitwiseAndValue` is either a regular property of the global object or not present before you execute the script, there must be no interceptor on the global object or it’s prototypes, etc., but if you really want to win this benchmark, and you are willing to go all in, then you can execute this test in less than 1ms. However this optimization would be limited to this special case, and slight modifications of the test would probably no longer trigger it.
|
||||
@ -50,7 +52,7 @@ There are a couple of algorithms that need fast bitwise and, especially in the a
|
||||
Ok, so that [`bitops-bitwise-and.js`][42] test was definitely the worst example of a micro-benchmark. Let’s move on to something more real worldish in SunSpider, the [`string-tagcloud.js`][43] test, which essentially runs a very early version of the `json.js` polyfill. The test arguably looks a lot more reasonable that the bitwise and test, but looking at the profile of the benchmark for some time immediately reveals that a lot of time is spent on a single `eval` expression (up to 20% of the overall execution time for parsing and compiling plus up to 10% for actually executing the compiled code):
|
||||
|
||||
[
|
||||
|
||||

|
||||
][44]
|
||||
|
||||
Looking closer reveals that this `eval` is executed exactly once, and is passed a JSONish string, that contains an array of 2501 objects with `tag` and `popularity` fields:
|
||||
@ -118,7 +120,7 @@ $ node string-tagcloud.js
|
||||
Time (string-tagcloud): 26 ms.
|
||||
$ node -v
|
||||
v8.0.0-pre
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
This is a common problem with static benchmarks and performance test suites. Today noone would seriously use `eval` to parse JSON data (also for obvious security reaons, not only for the performance issues), but rather stick to [`JSON.parse`][46] for all code written in the last five years. In fact using `eval` to parse JSON would probably be considered a bug in production code today! So the engine writers effort of focusing on performance of newly written code is not reflected in this ancient benchmark, instead it would be beneficial to make `eval`unnecessarily ~~smart~~complex to win on `string-tagcloud.js`.
|
||||
@ -126,13 +128,13 @@ This is a common problem with static benchmarks and performance test suites. Tod
|
||||
Ok, so let’s look at yet another example: the [`3d-cube.js`][47]. This benchmark does a lot of matrix operations, where even the smartest compiler can’t do a lot about it, but just has to execute it. Essentially the benchmark spends a lot of time executing the `Loop` function and functions called by it.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][48]
|
||||
|
||||
One interesting observation here is that the `RotateX`, `RotateY` and `RotateZ` functions are always called with the same constant parameter `Phi`.
|
||||
|
||||
[
|
||||
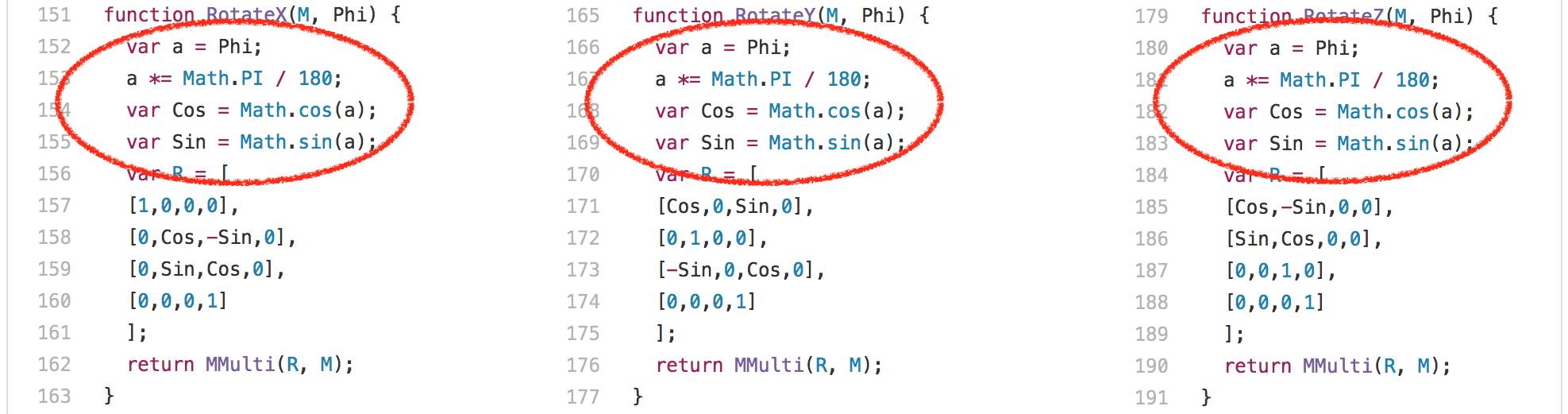
|
||||

|
||||
][49]
|
||||
|
||||
This means that we basically always compute the same values for [`Math.sin`][50] and [`Math.cos`][51], 204 times each. There are only three different inputs,
|
||||
@ -144,7 +146,7 @@ This means that we basically always compute the same values for [`Math.sin`][50
|
||||
obviously. So, one thing you could do here to avoid recomputing the same sine and cosine values all the time is to cache the previously computed values, and in fact, that’s what V8 used to do in the past, and other engines like SpiderMonkey still do. We removed the so-called _transcendental cache_ from V8 because the overhead of the cache was noticable in actual workloads where you don’t always compute the same values in a row, which is unsurprisingly very common in the wild. We took serious hits on the SunSpider benchmark when we removed this benchmark specific optimizations back in 2013 and 2014, but we totally believe that it doesn’t make sense to optimize for a benchmark while at the same time penalizing the real world use case in such a way.
|
||||
|
||||
[
|
||||
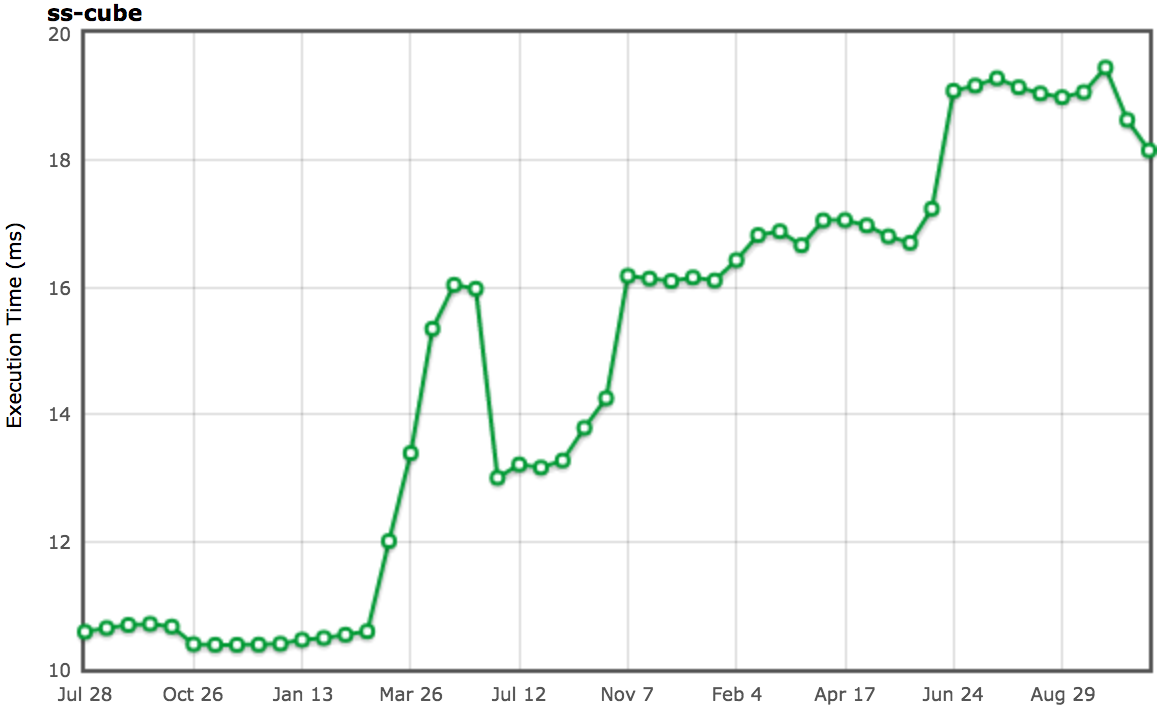
|
||||

|
||||
][52]
|
||||
|
||||
|
||||
@ -155,7 +157,7 @@ Obviously a better way to deal with the constant sine/cosine inputs is a sane in
|
||||
Besides these very test specific issues, there’s another fundamental problem with the SunSpider benchmark: The overall execution time. V8 on decent Intel hardware runs the whole benchmark in roughly 200ms currently (with the default configuration). A minor GC can take anything between 1ms and 25ms currently (depending on live objects in new space and old space fragmentation), while a major GC pause can easily take 30ms (not even taking into account the overhead from incremental marking), that’s more than 10% of the overall execution time of the whole SunSpider suite! So any engine that doesn’t want to risk a 10-20% slowdown due to a GC cycle has to somehow ensure it doesn’t trigger GC while running SunSpider.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][54]
|
||||
|
||||
There are different tricks to accomplish this, none of which has any positive impact in real world as far as I can tell. V8 uses a rather simple trick: Since every SunSpider test is run in a new `<iframe>`, which corresponds to a new _native context_ in V8 speak, we just detect rapid `<iframe>` creation and disposal (all SunSpider tests take less than 50ms each), and in that case perform a garbage collection between the disposal and creation, to ensure that we never trigger a GC while actually running a test. This trick works pretty well, and in 99.9% of the cases doesn’t clash with real uses; except every now and then, it can hit you hard if for whatever reason you do something that makes you look like you are the SunSpider test driver to V8, then you can get hit hard by forced GCs, and that can have a negative effect on your application. So rule of thumb: **Don’t let your application look like SunSpider!**
|
||||
@ -163,7 +165,7 @@ There are different tricks to accomplish this, none of which has any positive im
|
||||
I could go on with more SunSpider examples here, but I don’t think that’d be very useful. By now it should be clear that optimizing further for SunSpider above the threshold of good performance will not reflect any benefits in real world. In fact the world would probably benefit a lot from not having SunSpider any more, as engines could drop weird hacks that are only useful for SunSpider and can even hurt real world use cases. Unfortunately SunSpider is still being used heavily by the (tech) press to compare what they think is browser performance, or even worse compare phones! So there’s a certain natural interest from phone makers and also from Android in general to have Chrome look somewhat decent on SunSpider (and other nowadays meaningless benchmarks FWIW). The phone makers generate money by selling phones, so getting good reviews is crucial for the success of the phone division or even the whole company, and some of them even went as far as shipping old versions of V8 in their phones that had a higher score on SunSpider, exposing their users to all kinds of unpatched security holes that had long been fixed, and shielding their users from any real world performance benefits that come with more recent V8 versions!
|
||||
|
||||
[
|
||||
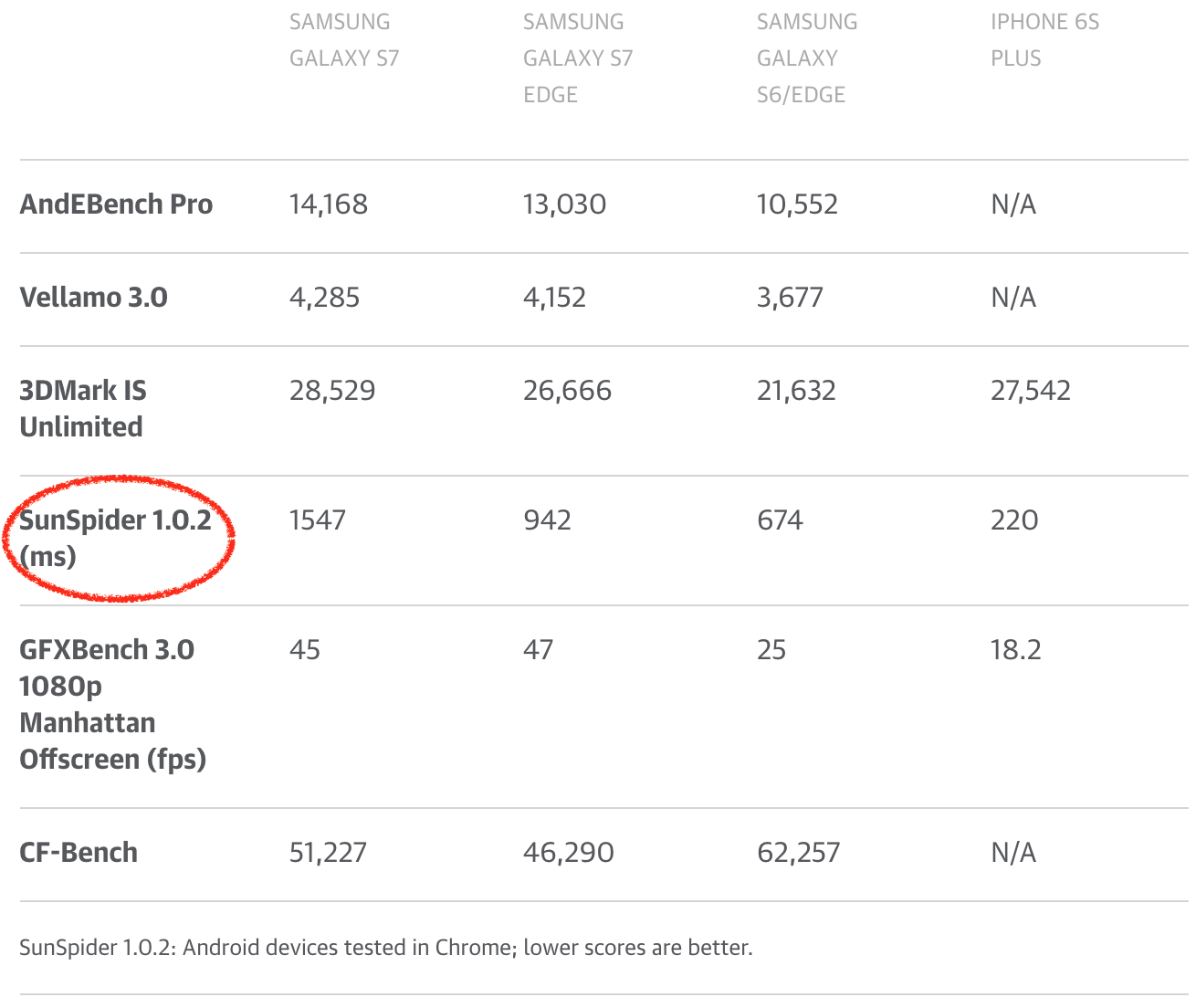
|
||||

|
||||
][55]
|
||||
|
||||
|
||||
@ -172,7 +174,7 @@ If we as the JavaScript community really want to be serious about real world per
|
||||
### Cuteness break!
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
I always loved this in [Myles Borins][57]’ talks, so I had to shamelessly steal his idea. So now that we recovered from the SunSpider rant, let’s go on to check the other classic benchmarks…
|
||||
@ -182,19 +184,19 @@ I always loved this in [Myles Borins][57]’ talks, so I had to shamelessly ste
|
||||
The Kraken benchmark was [released by Mozilla in September 2010][58], and it was said to contain snippets/kernels of real world applications, and be less of a micro-benchmark compared to SunSpider. I don’t want to spend too much time on Kraken, because I think it wasn’t as influential on JavaScript performance as SunSpider and Octane, so I’ll highlight one particular example from the [`audio-oscillator.js`][59] test.
|
||||
|
||||
[
|
||||
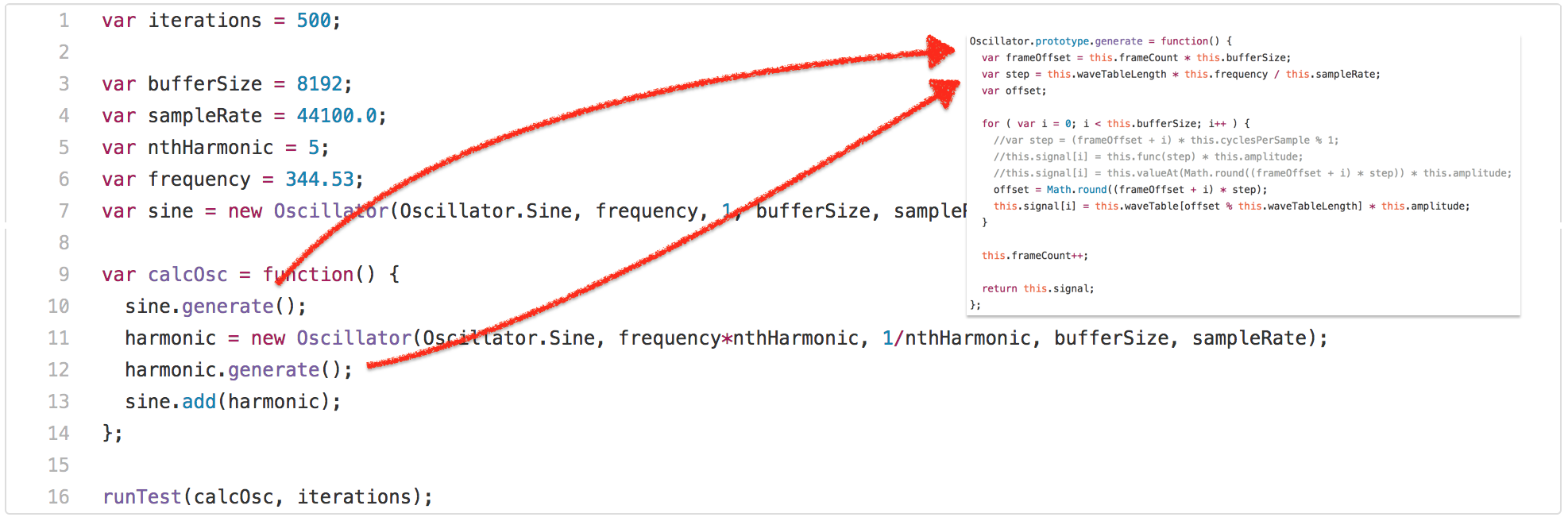
|
||||

|
||||
][60]
|
||||
|
||||
So the test invokes the `calcOsc` function 500 times. `calcOsc` first calls `generate` on the global `sine``Oscillator`, then creates a new `Oscillator`, calls `generate` on that and adds it to the global `sine` oscillator. Without going into detail why the test is doing this, let’s have a look at the `generate` method on the `Oscillator` prototype.
|
||||
|
||||
[
|
||||
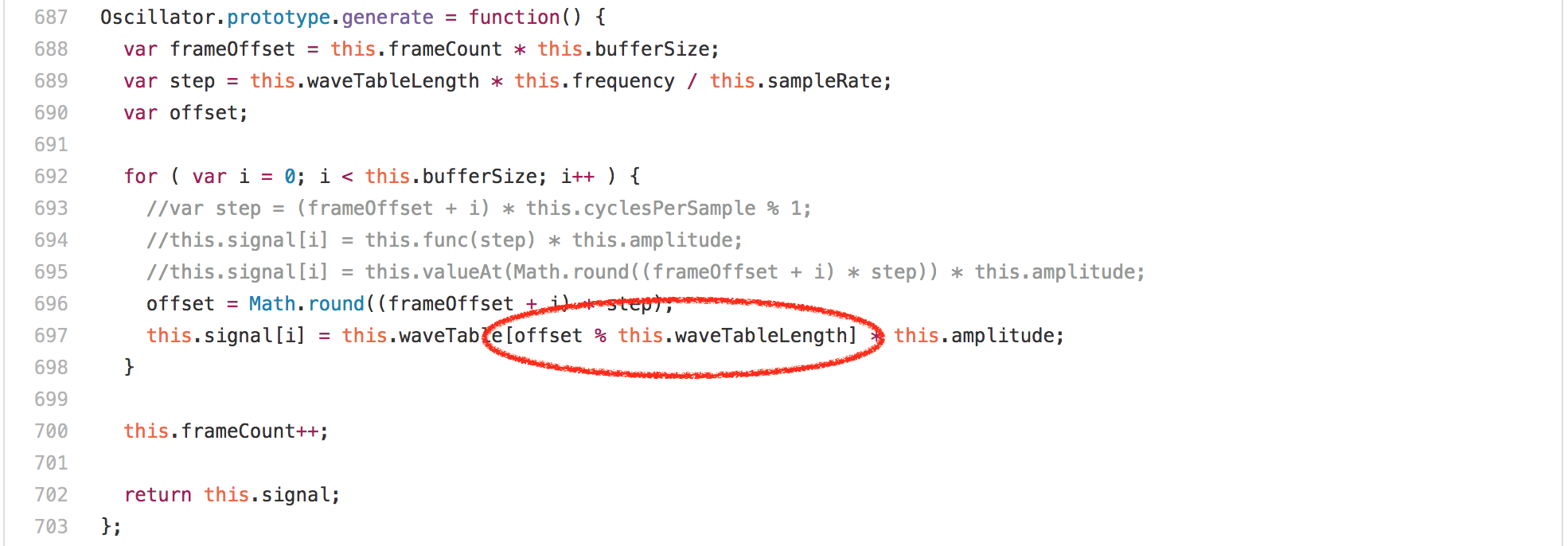
|
||||

|
||||
][61]
|
||||
|
||||
Looking at the code, you’d expect this to be dominated by the array accesses or the multiplications or the[`Math.round`][62] calls in the loop, but surprisingly what’s completely dominating the runtime of `Oscillator.prototype.generate` is the `offset % this.waveTableLength` expression. Running this benchmark in a profiler on any Intel machine reveals that more than 20% of the ticks are attributed to the `idiv`instruction that we generate for the modulus. One interesting observation however is that the `waveTableLength` field of the `Oscillator` instances always contains the same value 2048, as it’s only assigned once in the `Oscillator` constructor.
|
||||
|
||||
[
|
||||
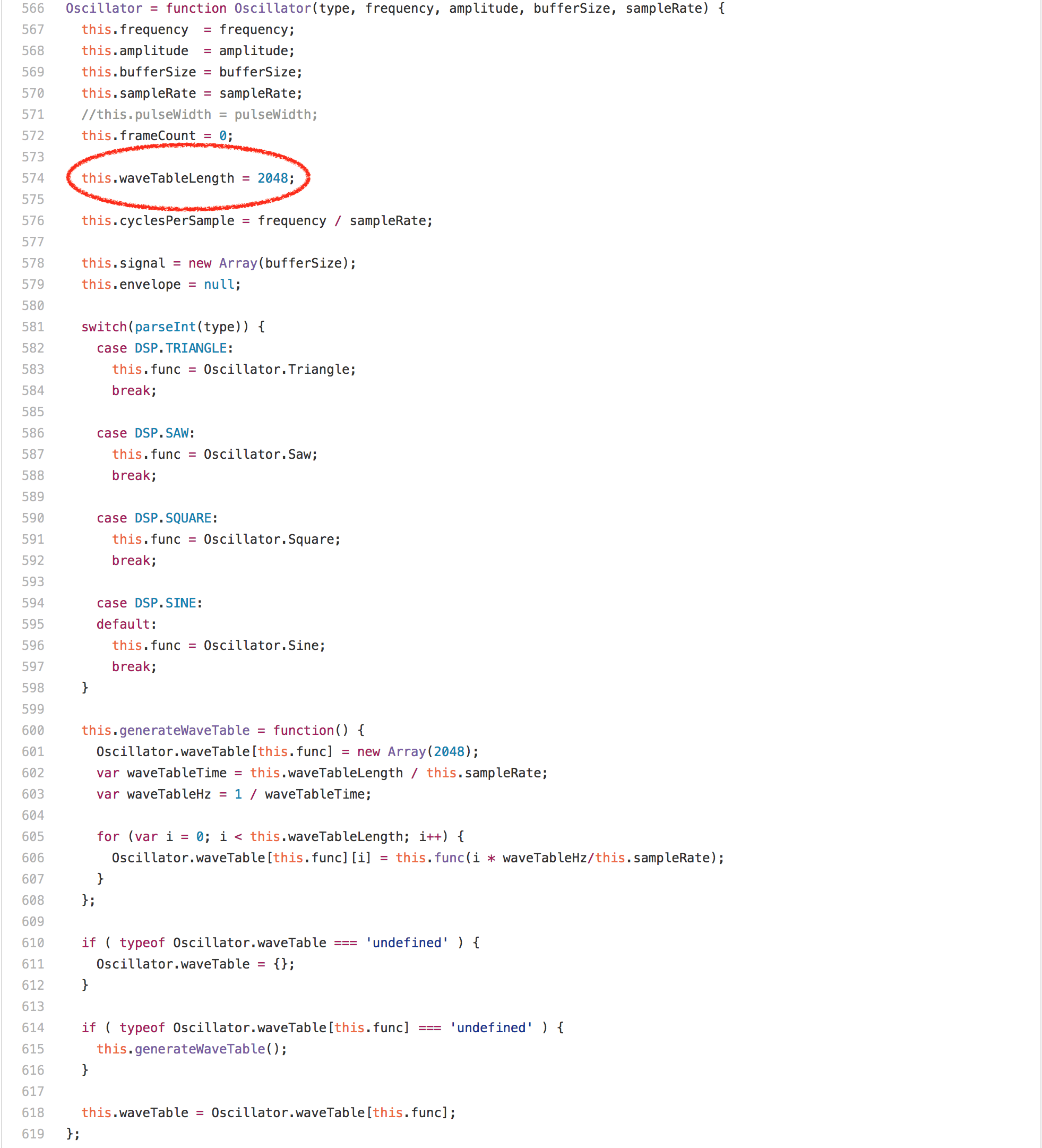
|
||||

|
||||
][63]
|
||||
|
||||
If we know that the right hand side of an integer modulus operation is a power of two, we can generate [way better code][64] obviously and completely avoid the `idiv` instruction on Intel. So what we needed was a way to get the information that `this.waveTableLength` is always 2048 from the `Oscillator` constructor to the modulus operation in `Oscillator.prototype.generate`. One obvious way would be to try to rely on inlining of everything into the `calcOsc` function and let load/store elimination do the constant propagation for us, but this would not work for the `sine` oscillator, which is allocated outside the `calcOsc` function.
|
||||
@ -206,7 +208,7 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
|
||||
[...SNIP...]
|
||||
[BinaryOpIC(MOD:None*None->None) => (MOD:Smi*2048->Smi) @ ~Oscillator.generate+598 at audio-oscillator.js:697]
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
shows that the `BinaryOpIC` is picking up the proper constant feedback for the right hand side of the modulus, and properly tracks that the left hand side was always a small integer (a `Smi` in V8 speak), and we also always produced a small integer result. Looking at the generated code using `--print-opt-code --code-comments` quickly reveals that Crankshaft utilizes the feedback to generate an efficient code sequence for the integer modulus in `Oscillator.prototype.generate`:
|
||||
@ -261,7 +263,7 @@ $ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
|
||||
Time (audio-oscillator-once): 64 ms.
|
||||
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
|
||||
Time (audio-oscillator-once): 81 ms.
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
This is an example for a pretty terrible performance cliff: Let’s say a developer writes code for a library and does careful tweaking and optimizations using certain sample input values, and the performance is decent. Now a user starts using that library reading through the performance notes, but somehow falls off the performance cliff, because she/he is using the library in a slightly different way, i.e. somehow polluting type feedback for a certain `BinaryOpIC`, and is hit by a 20% slowdown (compared to the measurements of the library author) that neither the library author nor the user can explain, and that seems rather arbitrary.
|
||||
@ -292,7 +294,7 @@ $ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
|
||||
Time (audio-oscillator-once): 69 ms.
|
||||
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
|
||||
Time (audio-oscillator-once): 69 ms.
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
The problem with benchmarks and over-specialization is that the benchmark can give you hints where to look and what to do, but it doesn’t tell you how far you have to go and doesn’t protect the optimization properly. For example, all JavaScript engines use benchmarks as a way to guard against performance regressions, but running Kraken for example wouldn’t protect the general approach that we have in TurboFan, i.e. we could _degrade_ the modulus optimization in TurboFan to the over-specialized version of Crankshaft and the benchmark wouldn’t tell us that we regressed, because from the point of view of the benchmark it’s fine! Now you could extend the benchmark, maybe in the same way that I did above, and try to cover everything with benchmarks, which is what engine implementors do to a certain extent, but that approach doesn’t scale arbitrarily. Even though benchmarks are convenient and easy to use for communication and competition, you’ll also need to leave space for common sense, otherwise over-specialization will dominate everything and you’ll have a really, really fine line of acceptable performance and big performance cliffs.
|
||||
@ -361,7 +363,7 @@ function(t) {
|
||||
More precisely the time is not spent in this function itself, but rather operations and builtin library functions triggered by this. As it turned out we spent 4-7% of the overall execution time of the benchmark calling into the [`Compare` runtime function][76], which implements the general case for the [abstract relational comparison][77].
|
||||
|
||||
|
||||
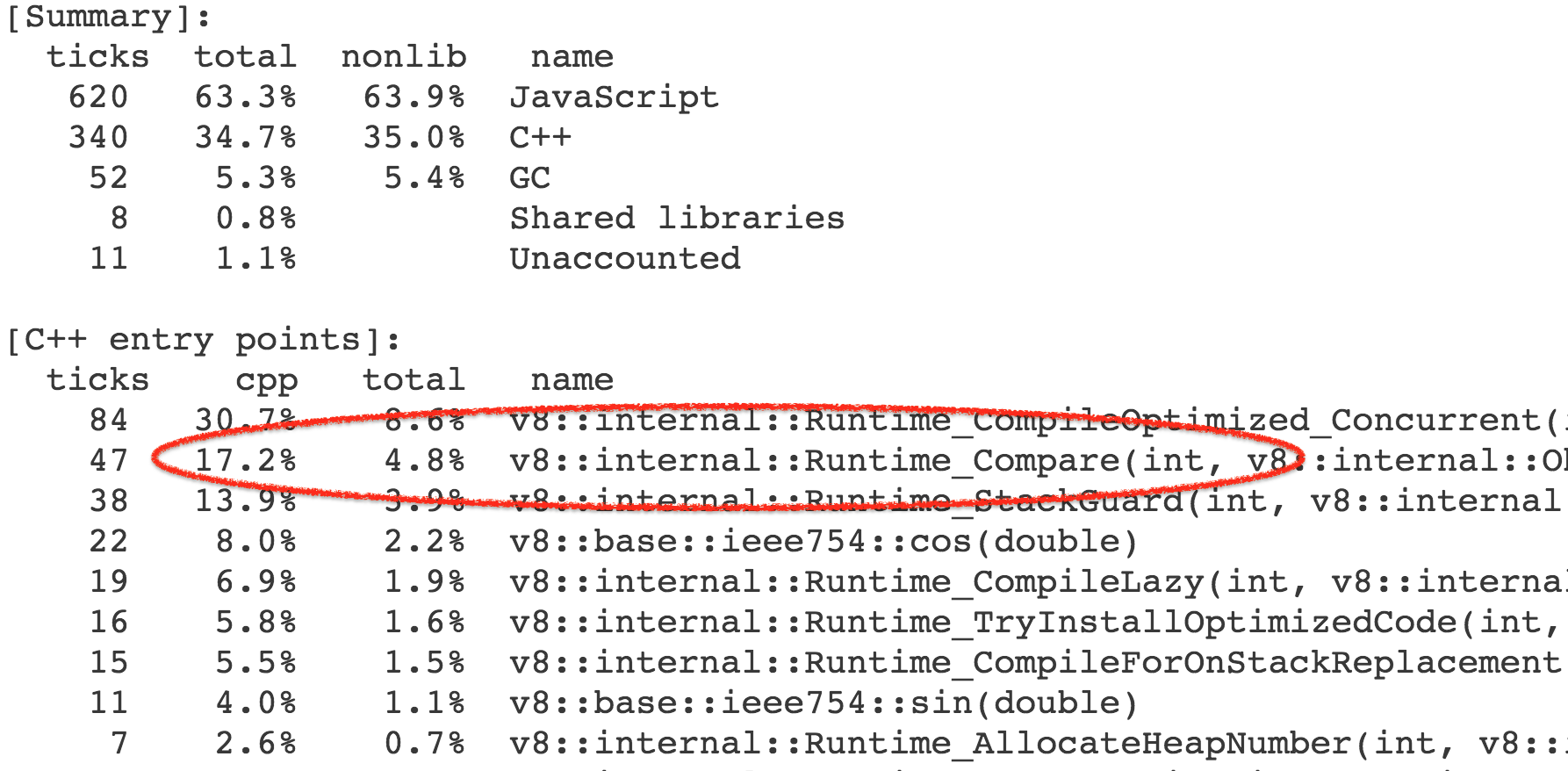
|
||||

|
||||
|
||||
|
||||
Almost all the calls to the runtime function came from the [`CompareICStub`][78], which is used for the two relational comparisons in the inner function:
|
||||
@ -408,7 +410,7 @@ $ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
|
||||
Score (Box2D): 48063
|
||||
$ ~/Projects/v8/out/Release/d8 octane-box2d.js
|
||||
Score (Box2D): 55359
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
So how did we do that? As it turned out we already had a mechanism for tracking the shape of objects that are being compared in the `CompareIC`, the so-called _known receiver_ map tracking (where _map_ is V8 speak for object shape+prototype), but that was limited to abstract and strict equality comparisons. But I could easily extend the tracking to also collect the feedback for abstract relational comparison:
|
||||
@ -419,18 +421,18 @@ $ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
|
||||
[CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1]
|
||||
[CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1]
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
Here the `CompareIC` used in the baseline code tells us that for the LT (less than) and the GTE (greather than or equal) comparisons in the function we’re looking at, it had only seen `RECEIVER`s so far (which is V8 speak for JavaScript objects), and all these receivers had the same map `0x1d5a860493a1`, which corresponds to the map of `L` instances. So in optimized code, we can constant-fold these operations to `false` and `true`respectively as long as we know that both sides of the comparison are instances with the map `0x1d5a860493a1` and noone messed with `L`s prototype chain, i.e. the `Symbol.toPrimitive`, `"valueOf"` and `"toString"` methods are the default ones, and noone installed a `Symbol.toStringTag` accessor property. The rest of the story is _black voodoo magic_ in Crankshaft, with a lot of cursing and initially forgetting to check `Symbol.toStringTag` properly:
|
||||
|
||||
[
|
||||
|
||||

|
||||
][80]
|
||||
|
||||
And in the end there was a rather huge performance boost on this particular benchmark:
|
||||
|
||||
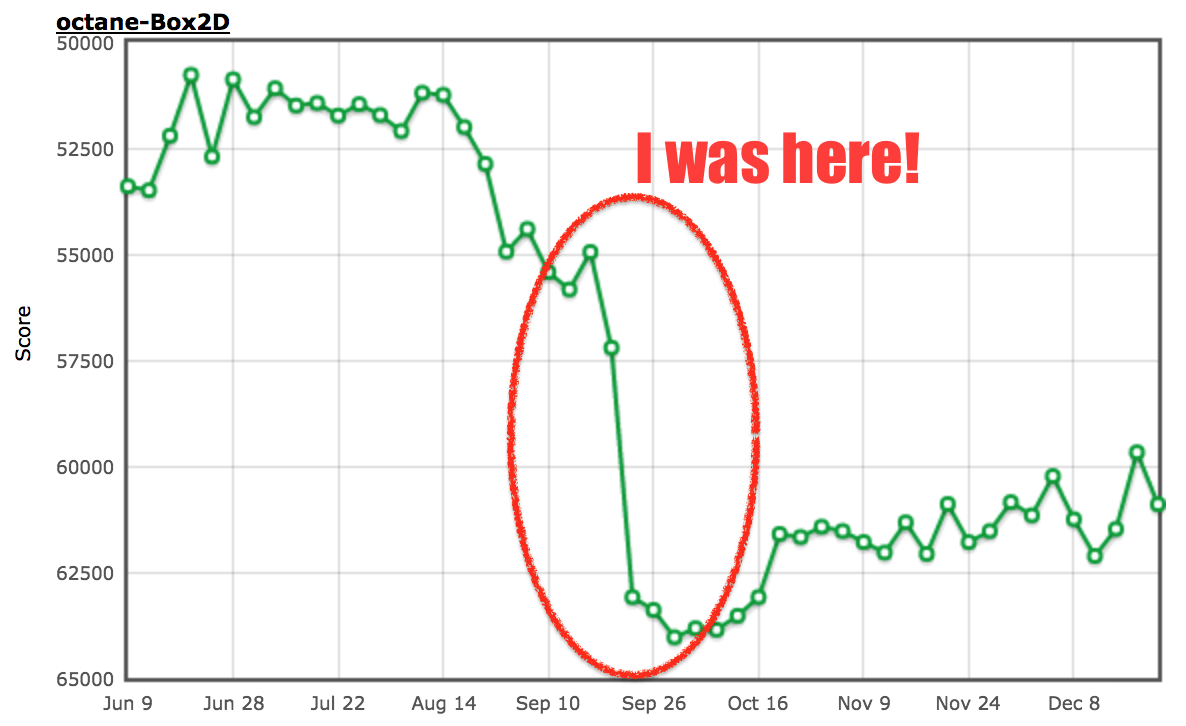
|
||||

|
||||
|
||||
|
||||
To my defense, back then I was not convinced that this particular behavior would always point to a bug in the original code, so I was even expecting that code in the wild might hit this case fairly often, also because I was assuming that JavaScript developers wouldn’t always care about these kinds of potential bugs. However, I was so wrong, and here I stand corrected! I have to admit that this particular optimization is purely a benchmark thing, and will not help any real code (unless the code is written to benefit from this optimization, but then you could as well write `true` or `false` directly in your code instead of using an always-constant relational comparison). You might wonder why we slightly regressed soon after my patch. That was the period where we threw the whole team at implementing ES2015, which was really a dance with the devil to get all the new stuff in (ES2015 is a monster!) without seriously regressing the traditional benchmarks.
|
||||
@ -438,13 +440,13 @@ To my defense, back then I was not convinced that this particular behavior would
|
||||
Enough said about Box2D, let’s have a look at the Mandreel benchmark. Mandreel was a compiler for compiling C/C++ code to JavaScript, it didn’t use the [asm.js][81] subset of JavaScript that is being used by the more recent [Emscripten][82] compiler, and has been deprecated (and more or less disappeared from the internet) since roughly three years now. Nevertheless, Octane still has a version of the [Bullet physics engine][83] compiled via [Mandreel][84]. An interesting test here is the MandreelLatency test, which instruments the Mandreel benchmark with frequent time measurement checkpoints. The idea here was that since Mandreel stresses the VM’s compiler, this test provides an indication of the latency introduced by the compiler, and long pauses between measurement checkpoints lower the final score. In theory that sounds very reasonable, and it does indeed make some sense. However as usual vendors figured out ways to cheat on this benchmark.
|
||||
|
||||
[
|
||||
|
||||

|
||||
][85]
|
||||
|
||||
Mandreel contains a huge initialization function `global_init` that takes an incredible amount of time just parsing this function, and generating baseline code for it. Since engines usually parse various functions in scripts multiple times, one so-called pre-parse step to discover functions inside the script, and then as the function is invoked for the first time a full parse step to actually generate baseline code (or bytecode) for the function. This is called [_lazy parsing_][86] in V8 speak. V8 has some heuristics in place to detect functions that are invoked immediately where pre-parsing is actually a waste of time, but that’s not clear for the `global_init`function in the Mandreel benchmark, thus we’d would have an incredible long pause for pre-parsing + parsing + compiling the big function. So we [added an additional heuristic][87] that would also avoids the pre-parsing for this `global_init` function.
|
||||
|
||||
[
|
||||
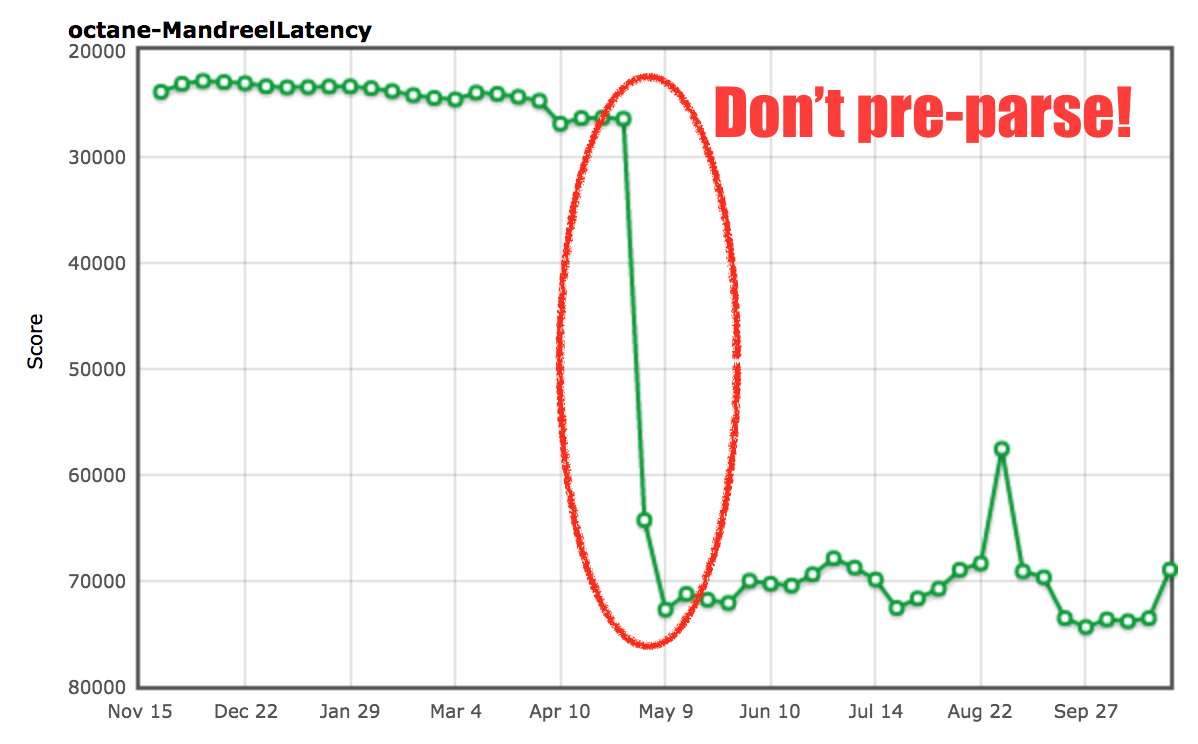
|
||||

|
||||
][88]
|
||||
|
||||
So we saw an almost 200% improvement just by detecting `global_init` and avoiding the expensive pre-parse step. We are somewhat certain that this should not negatively impact real world use cases, but there’s no guarantee that this won’t bite you on large functions where pre-parsing would be beneficial (because they aren’t immediately executed).
|
||||
@ -452,7 +454,7 @@ So we saw an almost 200% improvement just by detecting `global_init` and avoid
|
||||
So let’s look into another slightly less controversial benchmark: the [`splay.js`][89] test, which is meant to be a data manipulation benchmark that deals with splay trees and exercises the automatic memory management subsystem (aka the garbage collector). It comes bundled with a latency test that instruments the Splay code with frequent measurement checkpoints, where a long pause between checkpoints is an indication of high latency in the garbage collector. This test measures the frequency of latency pauses, classifies them into buckets and penalizes frequent long pauses with a low score. Sounds great! No GC pauses, no jank. So much for the theory. Let’s have a look at the benchmark, here’s what’s at the core of the whole splay tree business:
|
||||
|
||||
[
|
||||

|
||||

|
||||
][90]
|
||||
|
||||
This is the core of the splay tree construction, and despite what you might think looking at the full benchmark, this is more or less all that matters for the SplayLatency score. How come? Actually what the benchmark does is to construct huge splay trees, so that the majority of nodes survive, thus making it to old space. With a generational garbage collector like the one in V8 this is super expensive if a program violates the [generational hypothesis][91] leading to extreme pause times for essentially evacuating everything from new space to old space. Running V8 in the old configuration clearly shows this problem:
|
||||
@ -535,7 +537,7 @@ $ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
|
||||
[20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure
|
||||
[20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
So the key observation here is that allocating the splay tree nodes in old space directly would avoid essentially all the overhead of copying objects around and reduce the number of minor GC cycles to the bare minimum (thereby reducing the pauses caused by the GC). So we came up with a mechanism called [_Allocation Site Pretenuring_][92] that would try to dynamically gather feedback at allocation sites when run in baseline code to decide whether a certain percent of the objects allocated here survives, and if so instrument the optimized code to allocate objects in old space directly - i.e. _pretenure the objects_.
|
||||
@ -562,13 +564,13 @@ $ out/Release/d8 --trace-gc octane-splay.js
|
||||
[20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested
|
||||
[20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure
|
||||
[...SNIP...]
|
||||
$
|
||||
$
|
||||
```
|
||||
|
||||
And indeed that essentially fixed the problem for the SplayLatency benchmark completely and boosted our score by over 250%!
|
||||
|
||||
[
|
||||
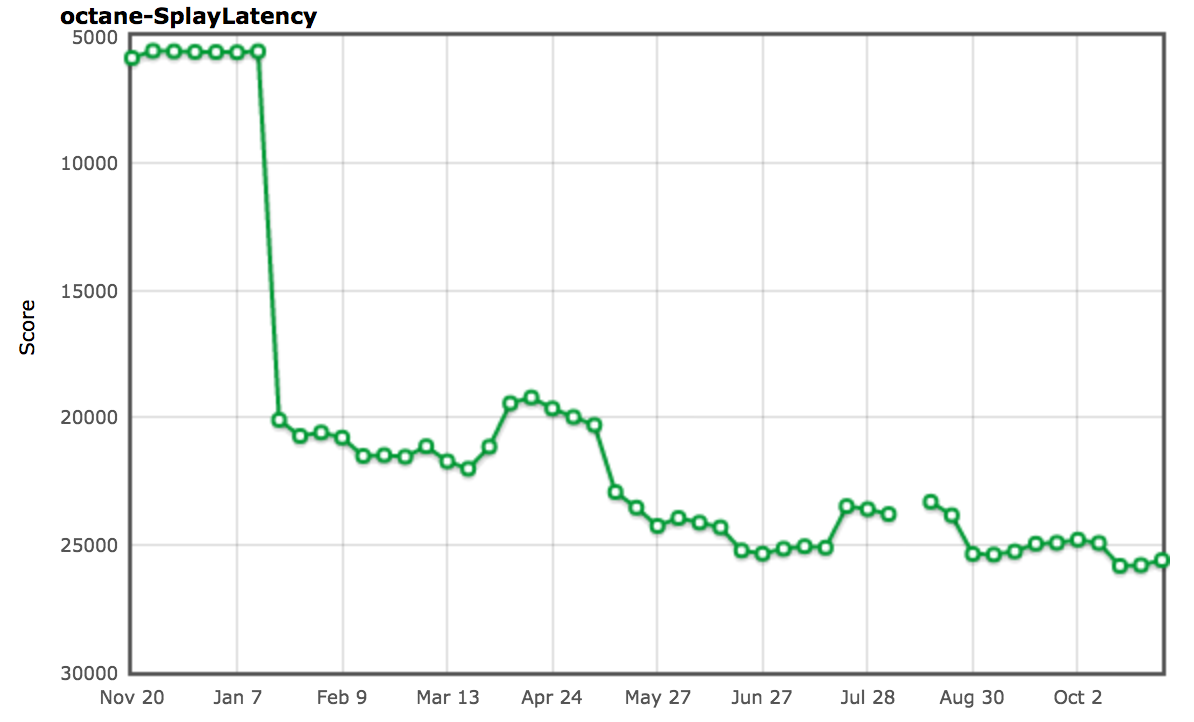
|
||||

|
||||
][93]
|
||||
|
||||
As mentioned in the [SIGPLAN paper][94] we had good reasons to believe that allocation site pretenuring might be a win for real world applications, and were really looking forward to seeing improvements and extending the mechanism to cover more than just object and array literals. But it didn’t take [long][95] [to][96] [realize][97] that allocation site pretenuring can have a pretty serious negative impact on real world application performance. We actually got a lot of negative press, including a shit storm from Ember.js developers and users, not only because of allocation site pretenuring, but that was big part of the story.
|
||||
@ -590,13 +592,13 @@ Ok, I think that should be sufficient to underline the point. I could go on poin
|
||||
I hope it should be clear by now why benchmarks are generally a good idea, but are only useful to a certain level, and once you cross the line of _useful competition_, you’ll start wasting the time of your engineers or even start hurting your real world performance! If we are serious about performance for the web, we need to start judging browser by real world performance and not their ability to game four year old benchmarks. We need to start educating the (tech) press, or failing that, at least ignore them.
|
||||
|
||||
[
|
||||
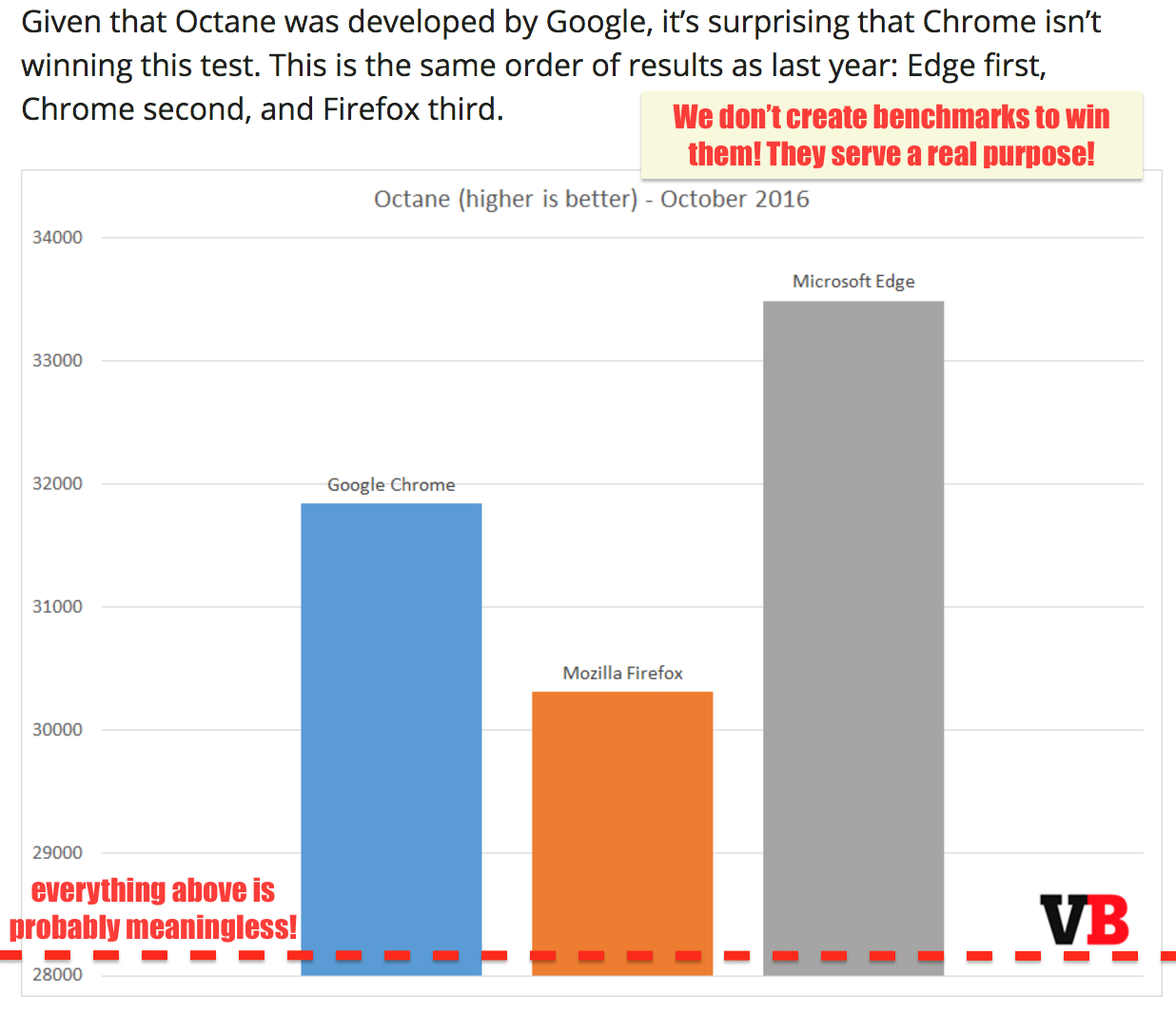
|
||||

|
||||
][99]
|
||||
|
||||
Noone is afraid of competition, but gaming potentially broken benchmarks is not really useful investment of engineering time. We can do a lot more, and take JavaScript to the next level. Let’s work on meaningful performance tests that can drive competition on areas of interest for the end user and the developer. Additionally let’s also drive meaningful improvements for server and tooling side code running in Node.js (either on V8 or ChakraCore)!
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
One closing comment: Don’t use traditional JavaScript benchmarks to compare phones. It’s really the most useless thing you can do, as the JavaScript performance often depends a lot on the software and not necessarily on the hardware, and Chrome ships a new version every six weeks, so whatever you measure in March maybe irrelevant already in April. And if there’s no way to avoid running something in a browser that assigns a number to a phone, then at least use a recent full browser benchmark that has at least something to do with what people will do with their browsers, i.e. consider [Speedometer benchmark][100].
|
||||
|
||||
@ -1,302 +0,0 @@
|
||||
rusking translating
|
||||
|
||||
HOW TO INSTALL AND REMOVE SOFTWARE IN UBUNTU [COMPLETE GUIDE]
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
_Brief: This detailed guide shows you various ways to install software_ _in Ubuntu Linux and it also demonstrates how to remove installed software in Ubuntu._
|
||||
|
||||
When you [switch to Linux][14], the experience could be overwhelming at the start. Even the basic things like installing applications in Ubuntu could seem confusing.
|
||||
|
||||
Don’t worry. Linux provides so many ways to do the same task that it is only natural that you may seem lost, at least in the beginning. You are not alone. We have all been to that stage.
|
||||
|
||||
In this beginner’s guide, I’ll show most popular ways to install software in Ubuntu. I’ll also show you how to uninstall the software you had installed earlier.
|
||||
|
||||
I’ll also provide my recommendation about which method you should be using for installing software in Ubuntu. Sit tight and pay attention. This is a long article, a detailed one which is surely going to add to your knowledge.
|
||||
|
||||
### INSTALLING AND UNINSTALLING SOFTWARE IN UBUNTU
|
||||
|
||||
I am using Ubuntu 16.04 running with Unity desktop environment in this guide. Apart from a couple of screenshots, this guide is applicable to all other flavors of Ubuntu.
|
||||
|
||||
### 1.1 INSTALL SOFTWARE USING UBUNTU SOFTWARE CENTER [RECOMMENDED]
|
||||
|
||||
The easiest and most convenient way to find and install software in Ubuntu is by using Ubuntu Software Center. In Ubuntu Unity, you can search for Ubuntu Software Center in Dash and click on it to open it:
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
|
||||
You can think of Ubuntu Software Center as Google’s Play Store or Apple’s App Store. It showcases all the software available for your Ubuntu system. You can either search for an application by its name or just browse through various categories of software. You can also opt for the editor’s pick. Your choice mainly.
|
||||
|
||||

|
||||
|
||||
Once you have found the application you are looking for, simply click on it. This will open a page inside Software Center with a description of the application. You can read the description, see its raiting and also read reviews. You can also write a review if you want.
|
||||
|
||||
Once you are convinced that you want the application, you can click on the install button to install the selected application. You’ll have to enter your password in order to install applications in Ubuntu.
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
Can it be any easier than this? I doubt that.
|
||||
|
||||
Tip: As I had mentioned in [things to do after installing Ubuntu 16.04][17], you should enable Canonical partner repository. By default, Ubuntu provides only those softwares that come from its own repository (verified by Ubuntu).
|
||||
|
||||
But there is also a Canonical Partner repository which is not directly controlled by Ubuntu and includes closed source proprietary software. Enabling this repository gives you access to more software. [Installing Skype in Ubuntu][18] is achieved by this method.
|
||||
|
||||
In Unity Dash, look for Software & Updates.
|
||||
|
||||
[
|
||||

|
||||
][19]
|
||||
|
||||
And in here, under Other Software tab, check the options of Canonical Partners.
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
|
||||
|
||||
### 1.2 REMOVE SOFTWARE USING UBUNTU SOFTWARE CENTER [RECOMMENDED]
|
||||
|
||||
We just saw how to install software using Ubuntu Software Center. How about removing software that you had installed using this method?
|
||||
|
||||
Uninstalling software with Ubuntu Software Center is as easy as the installation process itself.
|
||||
|
||||
Open the Software Center and click on the Installed tab. It will show you all the installed software. Alternatively, you can just search for the application by its name.
|
||||
|
||||
To remove the application from Ubuntu, simply click on Remove button. Again you will have to provide your password here.
|
||||
|
||||
[
|
||||

|
||||
][22]
|
||||
|
||||
### 2.1 INSTALL SOFTWARE IN UBUNTU USING .DEB FILES
|
||||
|
||||
.deb files are similar to the .exe files in Windows. This is an easy way to provide software installation. Many software vendors provide their software in .deb format. Google Chrome is such an example.
|
||||
|
||||
You can download .deb file from the official website.
|
||||
|
||||
[
|
||||

|
||||
][23]
|
||||
|
||||
Once you have downloaded the .deb file, just double click on it to run it. It will open in Ubuntu Software Center and you can install it in the same way as we saw in section 1.1.
|
||||
|
||||
Alternatively, you can use a lightweight program [Gdebi to install .deb files in Ubuntu][24].
|
||||
|
||||
Once you have installed the software, you are free to delete the downloaded .deb file.
|
||||
|
||||
Tip: A few things to keep in mind while dealing with .deb file.
|
||||
|
||||
* Make sure that you are downloading the .deb file from the official source. Only rely on the official website or GitHub pages.
|
||||
* Make sure that you are downloading the .deb file for correct system type (32 bit or 64 bit). Read our quick guide to [know if your Ubuntu system is 32 bit or 64 bit][8].
|
||||
|
||||
### 2.2 REMOVE SOFTWARE THAT WAS INSTALLED USING .DEB
|
||||
|
||||
Removing software that was installed by a .deb file is the same as we saw earlier in section 1.2\. Just go to Ubuntu Software Center, search for the application name and click on remove to uninstall it.
|
||||
|
||||
Alternatively, you can use [Synaptic Package Manager][25]. Not necessarily but this may happen that the installed application is not visible in Ubuntu Software Center. Synaptic Package Manager is lists all the software that are available for your system and all the software that are already installed on your system.This is a very powerful and very useful tool.
|
||||
|
||||
This is a very powerful and very useful tool. Before Ubuntu Software Center came into existence to provide a more user-friendly approach to software installation, Synaptic was the default program for installing and uninstalling software in Ubuntu.
|
||||
|
||||
You can install Synaptic package manager by clicking on the link below (it will open Ubuntu Software Center).
|
||||
|
||||
[Install Synaptic Package Manager][26]
|
||||
|
||||
Open Synaptic Manager and then search for the software you want to uninstall. Installed softwares are marked with a green button. Click on it and select “mark for removal”. Once you do that, click on “apply” to remove the selected software.
|
||||
|
||||
[
|
||||

|
||||
][27]
|
||||
|
||||
### 3.1 INSTALL SOFTWARE IN UBUNTU USING APT COMMANDS [RECOMMENDED]
|
||||
|
||||
You might have noticed a number of websites giving you a command like “sudo apt-get install” to install software in Ubuntu.
|
||||
|
||||
This is actually the command line equivalent of what we saw in section 1\. Basically, instead of using the graphical interface of Ubuntu Software Center, you are using the command line interface. Nothing else changes.
|
||||
|
||||
Using the apt-get command to install software is extremely easy. All you need to do is to use a command like:
|
||||
|
||||
```
|
||||
sudo apt-get install package_name
|
||||
```
|
||||
|
||||
Here sudo gives ‘admin’ or ‘root’ (in Linux term) privileges. You can replace package_name with the desired software name.
|
||||
|
||||
apt-get commands have auto-completion so if you type a few letters and hit tab, it will provide all the programs matching with those letters.
|
||||
|
||||
### 3.2 REMOVE SOFTWARE IN UBUNTU USING APT COMMANDS [RECOMMENDED]
|
||||
|
||||
You can easily remove softwares that were installed using Ubuntu Software Center, apt command or .deb file using the command line.
|
||||
|
||||
All you have to do is to use the following command, just replace the package_name with the software name you want to delete.
|
||||
|
||||
```
|
||||
sudo apt-get remove package_name
|
||||
```
|
||||
|
||||
Here again, you can benefit from auto completion by pressing the tab key.
|
||||
|
||||
Using apt-get commands is not rocket science. This is in fact very convenient. With these simple commands, you get acquainted with the command line part of Ubuntu Linux and it does help in long run. I recommend reading my detailed [guide on using apt-get commands][28] to learn in detail about it.
|
||||
|
||||
[Suggested ReadUsing apt-get Commands In Linux [Complete Beginners Guide]][29]
|
||||
|
||||
### 4.1 INSTALL APPLICATIONS IN UBUNTU USING PPA
|
||||
|
||||
PPA stands for [Personal Package Archive][30]. This is another way that developers use to provide their software to Ubuntu users.
|
||||
|
||||
In section 1, you came across a term called ‘repository’. Repository basically contains a collection of software. Ubuntu’s official repository has the softwares that are approved by Ubuntu. Canonical partner repository contains the softwares from partnered vendors.
|
||||
|
||||
In the same way, PPA enables a developer to create its own APT repository. When an end user (i.e you) adds this repository to the system (sources.list is modified with this entry), software provided by the developer in his/her repository becomes available for the user.
|
||||
|
||||
Now you may ask what’s the need of PPA when we already have the official Ubuntu repository?
|
||||
|
||||
The answer is that not all software automatically get added to Ubuntu’s official repository. Only the trusted software make it to that list. Imagine that you developed a cool Linux application and you want to provide regular updates to your users but it will take months before it could be added to Ubuntu’s repository (if it could). PPA comes handy in those cases.
|
||||
|
||||
Apart from that, Ubuntu’s official repository often doesn’t include the latest version of a software. This is done to secure the stability of the Ubuntu system. A brand new software version might have a [regression][31] that could impact the system. This is why it takes some time before a new version makes it to the official repository, sometimes it takes months.
|
||||
|
||||
But what if you do not want to wait till the latest version comes to the Ubuntu’s official repository? This is where PPA saves your day. By using PPA, you get the newer version.
|
||||
|
||||
Typically PPA are used in three commands. First to add the PPA repository to the sources list. Second to update the cache of software list so that your system could be aware of the new available software. And third to install the software from the PPA.
|
||||
|
||||
I’ll show you an example by using [Numix theme][32] PPA:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:numix/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install numix-gtk-theme numix-icon-theme-circle
|
||||
```
|
||||
|
||||
In the above example, we added a PPA provided [Numix project][33]. And after updating the software information, we add two programs available in Numix PPA.
|
||||
|
||||
If you want a GUI application, you can use [Y-PPA application][34]. It lets you search for PPA, add and remove software in a better way.
|
||||
|
||||
Tip: Security of PPA has often debated. My advice is that you should add PPA from a trusted source, preferably from the official sources.
|
||||
|
||||
### 4.2 REMOVE APPLICATIONS INSTALLED USING PPA
|
||||
|
||||
I have discussed [removing PPA in Ubuntu][35] in detail earlier. You should refer to that article to get more insights about handling PPA removal.
|
||||
|
||||
To quickly discuss it here, you can use the following two commands.
|
||||
|
||||
```
|
||||
sudo apt-get remove numix-gtk-theme numix-icon-theme-circle
|
||||
```
|
||||
|
||||
```
|
||||
sudo add-apt-repository --remove ppa:numix/ppa
|
||||
```
|
||||
|
||||
First command removes the software installed via the PPA. Second command removes the PPA from sources.list.
|
||||
|
||||
### 5.1 INSTALLING SOFTWARE USING SOURCE CODE IN UBUNTU LINUX [NOT RECOMMENDED]
|
||||
|
||||
Installing a software using the [source code][36] is not something I would recommend to you. It’s tedious, troublesome and not very convenient. You’ll have to fight your way through dependencies and what not. You’ll have to keep the source code files else you won’t be able to uninstall it later.
|
||||
|
||||
But building from source code is still liked by a few, even if they are not developing software of their own. To tell you the truth, last I used source code extensively was 5 years ago when I was an intern and I had to develop a software in Ubuntu. I have preferred the other ways to install applications in Ubuntu since then. For normal desktop Linux user, installing from source code should be best avoided.
|
||||
|
||||
I’ll be short in this section and just list out the steps to install a software from source code:
|
||||
|
||||
* Download the source code of the program you want to install.
|
||||
* Extract the downloaded file.
|
||||
* Go to extracted directory and look for a README or INSTALL file. A well-developed software may include such a file to provide installation and/or removal instructions.
|
||||
* Look for a file called configure. If it’s present, run the file using the command: ./configure This will check if your system has all the required softwares (called ‘dependencies’ in software term) to install the program. Note that not all software include configure file which is, in my opinion, bad development practice.
|
||||
* If configure notifies you of missing dependencies, install them.
|
||||
* Once you have everything, use the command make to compile the program.
|
||||
* Once the program is compiled, run the command sudo make install to install the software.
|
||||
|
||||
Do note that some softwares provide you with an install script and just running that files will install the software for you. But you won’t be that lucky most of the time.
|
||||
|
||||
Also note that the program you installed using this way won’t be updated automatically like programs installed from Ubuntu’s repository or PPAs or .deb.
|
||||
|
||||
I recommend reading this detailed article on [using the source code in Ubuntu][37] if you insist on using source code.
|
||||
|
||||
### 5.2 REMOVING SOFTWARE INSTALLED USING SOURCE CODE [NOT RECOMMENDED]
|
||||
|
||||
If you thought installing software from source code was difficult, think again. Removing the software installed using source code could be a bigger pain.
|
||||
|
||||
* First, you should not delete the source code you used to install the program.
|
||||
* Second, you should make sure at the installation time that there is a way to uninstall the program. A badly configured program might not provide a way to uninstall the program and then you’ll have to manually remove all the files installed by the software.
|
||||
|
||||
Normally, you should be able to uninstall the program by going to its extracted directory and using this command:
|
||||
|
||||
```
|
||||
sudo make uninstall
|
||||
```
|
||||
|
||||
But this is not a guarantee that you’ll get this uninstall all the time.
|
||||
|
||||
You see, there are lots of ifs and buts attached with source code and not that many advantages. This is the reason why I do not recommend using the source code to install the software in Ubuntu.
|
||||
|
||||
### FEW MORE WAYS TO INSTALL APPLICATIONS IN UBUNTU
|
||||
|
||||
There are a few more (not so popular) ways you can install software in Ubuntu. Since this article is already way too long, I won’t cover them. I am just going to list them here:
|
||||
|
||||
* Ubuntu’s new [Snap packaging][9].
|
||||
* [dpkg][10] commands
|
||||
* [AppImage][11]
|
||||
* [pip][12] : used for installing Python based programs
|
||||
|
||||
### HOW DO YOU INSTALL APPLICATIONS IN UBUNTU?
|
||||
|
||||
If you have already been using Ubuntu, what’s your favorite way to install software in Ubuntu Linux? Did you find this guide useful? Do share your views, suggestions and questions.
|
||||
|
||||
--------------------
|
||||
|
||||
作者简介:
|
||||

|
||||
|
||||
I am Abhishek Prakash, 'creator' of It's F.O.S.S. Working as a software professional. I am an avid Linux lover and Open Source enthusiast. I use Ubuntu and believe in sharing knowledge. Apart from Linux, I love classic detective mystery. Huge fan of Agatha Christie work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/remove-install-software-ubuntu/
|
||||
|
||||
作者:[ABHISHEK PRAKASH][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/remove-install-software-ubuntu/#comments
|
||||
[3]:http://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fremove-install-software-ubuntu%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=How+To+Install+And+Remove+Software+In+Ubuntu+%5BComplete+Guide%5D&url=https://itsfoss.com/remove-install-software-ubuntu/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_pc
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fremove-install-software-ubuntu%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fremove-install-software-ubuntu%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:https://www.reddit.com/submit?url=https://itsfoss.com/remove-install-software-ubuntu/&title=How+To+Install+And+Remove+Software+In+Ubuntu+%5BComplete+Guide%5D
|
||||
[8]:https://itsfoss.com/32-bit-64-bit-ubuntu/
|
||||
[9]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[10]:https://help.ubuntu.com/lts/serverguide/dpkg.html
|
||||
[11]:http://appimage.org/
|
||||
[12]:https://pypi.python.org/pypi/pip
|
||||
[13]:https://itsfoss.com/remove-install-software-ubuntu/managing-software-in-ubuntu-1/
|
||||
[14]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[15]:https://itsfoss.com/wp-content/uploads/2016/12/Ubuntu-Software-Center.png
|
||||
[16]:https://itsfoss.com/remove-install-software-ubuntu/install-software-ubuntu-linux-1/
|
||||
[17]:https://itsfoss.com/things-to-do-after-installing-ubuntu-16-04/
|
||||
[18]:https://itsfoss.com/install-skype-ubuntu-1404/
|
||||
[19]:https://itsfoss.com/ubuntu-notify-updates-frequently/software_update_ubuntu/
|
||||
[20]:https://itsfoss.com/things-to-do-after-installing-ubuntu-14-04/enable_canonical_partner/
|
||||
[21]:https://itsfoss.com/essential-linux-applications/
|
||||
[22]:https://itsfoss.com/remove-install-software-ubuntu/uninstall-software-ubuntu/
|
||||
[23]:https://itsfoss.com/remove-install-software-ubuntu/install-software-deb-package/
|
||||
[24]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[25]:http://www.nongnu.org/synaptic/
|
||||
[26]:apt://synaptic
|
||||
[27]:https://itsfoss.com/remove-install-software-ubuntu/uninstall-software-ubuntu-synaptic/
|
||||
[28]:https://itsfoss.com/apt-get-linux-guide/
|
||||
[29]:https://itsfoss.com/apt-get-linux-guide/
|
||||
[30]:https://help.launchpad.net/Packaging/PPA
|
||||
[31]:https://en.wikipedia.org/wiki/Software_regression
|
||||
[32]:https://itsfoss.com/install-numix-ubuntu/
|
||||
[33]:https://numixproject.org/
|
||||
[34]:https://itsfoss.com/easily-manage-ppas-ubuntu-1310-ppa-manager/
|
||||
[35]:https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
[36]:https://en.wikipedia.org/wiki/Source_code
|
||||
[37]:http://www.howtogeek.com/105413/how-to-compile-and-install-from-source-on-ubuntu/
|
||||
@ -1,3 +1,6 @@
|
||||
|
||||
Translating by fristadream
|
||||
|
||||
Will Android do for the IoT what it did for mobile?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,66 +0,0 @@
|
||||
The Do’s and Don’ts of Writing Test cases in Android.
|
||||
============================================================
|
||||
|
||||
In this post, I will try to explain the best practices of writing the test cases based on my experience. I will use Espresso code in this post, but these practices will apply on both unit and instrumentation tests. For the purpose of explaining, I will consider a news application.
|
||||
|
||||
> The features and conditions of the application mentioned below are purely fictitious and are meant purely for the purpose of explaining the best practices and have no resemblance to any application active or removed from Play Store. :P
|
||||
|
||||
The news application will have the following activities.
|
||||
|
||||
* LanguageSelection- When the user launches the application for the very first time, he has to select at least one language. On selecting one or more than one language, the selection will be saved in the shared preferences and the user will be redirected to NewsList activity.
|
||||
* NewsList - When the user lands on the NewsList activity, a request is sent to the server along with the language parameter and the response is shown in the recycler view (which has id _news_list_). In case the language is not present in the shared preference or server does not give a successful response, an error screen will become visible to the user and the recycler view will be gone. The NewsList activity has a button which has the text “Change your Language” if the user had selected only one language and “Change your Languages” if the user had selected more than one language which will always be visible. ( I swear to God that this is a fictional app)
|
||||
* NewsDetail- As the name suggests, this activity is launched when the user clicks on any news list item.
|
||||
|
||||
|
||||
Enough about the great features of the app. Let’s dive into the test cases written for NewsList activity. This is the code which I wrote the very first time.
|
||||
|
||||
|
||||
#### Decide carefully what the test case is about.
|
||||
|
||||
In the first test case_ testClickOnAnyNewsItem()_, if the server does not send a successful response, the test case will fail because the visibility of the recycler view is GONE. But that is not what the test case is about. For this test case to PASS or FAIL, the minimum requirement is that the recycler view should be present and if due to any reason, it is not present, then the test case should not be considered FAILED. The correct code for this test should be something like this.
|
||||
|
||||
|
||||
#### A test case should be complete in itself
|
||||
|
||||
When I started testing, I always tested the activities in the following sequence
|
||||
|
||||
* LanguageSelection
|
||||
* NewsList
|
||||
* NewsDetail
|
||||
|
||||
Since I tested the LanguageSelection activity first, a language was always getting set before the tests for NewsList activity began. But when I tested NewsList activity first, the tests started to fail. The reason for the failure was simple- language was not selected and because of that, the recycler view was not present. Thus, the order of execution of the test cases should not affect the outcome of the test. Therefore before running the test, the language should be saved in the shared preferences. In this case, the test case now becomes independent from LanguageSelection activity test.
|
||||
|
||||
|
||||
#### Avoid conditional coding in test cases.
|
||||
|
||||
Now in the second test case _testChangeLanguageFeature()_, we get the count of the languages selected by the user and based on the count, we write an if-else condition for testing. But the if-else conditions should be written inside your actual code, not in the testing code. Each and every condition should be tested separately. So, in this case, instead of writing only a single test case, we should have written two test cases as follows.
|
||||
|
||||
|
||||
#### The Test cases should be independent of external factors
|
||||
|
||||
In most of the applications, we interact with external agents like network and database. A test case can invoke a request to the server during its execution and the response can be either successful or failed. But due to the failed response from the server, the test case should not be considered failed. Think of it as this way- If a test case fails, then we make some changes in the client code so that the test code works. But in this case, are we going to make any changes in the client code?- NO.
|
||||
|
||||
But you should also not completely avoid testing the network request and response. Since the server is an external agent, there can be a scenario when it can send some wrong response which might result in crashing of the application. Therefore, you should write test cases and cover all the possible responses from the server, even the responses which the server will never send. In this way, all the code will be covered and you make sure that the application handles all the responses gracefully and never crashes down.
|
||||
|
||||
> Writing the test cases in a correct way is as important as writing the code for which the tests are written.
|
||||
|
||||
|
||||
Thanks for reading the article. I hope it helps you write better test cases. You can connect with me on [LinkedIn][1]. You can check out my other medium articles [here][2].
|
||||
|
||||
_For more about programming, follow _[_Mindorks_][3]_ , so you’ll get notified when we write new posts._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.mindorks.com/the-dos-and-don-ts-of-writing-test-cases-in-android-70f1b5dab3e1#.lfilq9k5e
|
||||
|
||||
作者:[Anshul Jain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.mindorks.com/@anshuljain?source=post_header_lockup
|
||||
[1]:http://www.linkedin.com/in/anshul-jain-b7082573
|
||||
[2]:https://medium.com/@anshuljain
|
||||
[3]:https://blog.mindorks.com/
|
||||
@ -1,107 +0,0 @@
|
||||
#rusking translating
|
||||
|
||||
A Guide To Buying A Linux Laptop
|
||||
============================================================
|
||||
|
||||
It goes without saying that if you go to a computer store downtown to [buy a new laptop][5], you will be offered a notebook with Windows preinstalled, or a Mac. Either way, you’ll be forced to pay an extra fee – either for a Microsoft license or for the Apple logo on the back.
|
||||
|
||||
On the other hand, you have the option to buy a laptop and install a distribution of your choice. However, the hardest part may be to find the right hardware that will get along nicely with the operating system.
|
||||
|
||||
On top of that, we also need to consider the availability of drivers for the hardware. So what do you do? The answer is simple: [buy a laptop with Linux preinstalled][6].
|
||||
|
||||
Fortunately, there are several respectable vendors that offer high-quality, well-known brands and distributions and ensure you will not have to worry about the availability of drivers.
|
||||
|
||||
That said, in this article we will list the top 3 machines of our choice based on the intended usage.
|
||||
|
||||
#### Linux Laptops For Home Users
|
||||
|
||||
If you are looking for a laptop that can run an office suite, a modern web browser such as Firefox or Chrome, and has Ethernet/Wifi connectivity, [System76][7] allows you to design your future laptop by choosing the processor type, RAM / storage size, and accessories.
|
||||
|
||||
On top of that, System76 provides Ubuntu lifetime support for all of their laptop models. If this sounds like something that sparks some interest in you, checkout the [Lemur][8] or [Gazelle][9] laptops.
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
Lemur Laptop for Linux
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Gazelle Laptop for Linux
|
||||
|
||||
#### Linux Laptops For Developers
|
||||
|
||||
If you are looking for a reliable, nice-looking, and robust laptop for development tasks, you may want to consider [Dell’s XPS 13 Laptops][10].
|
||||
|
||||
This 13-inch beauty features a full HD display and a touchscreen Prices vary depending on the processor generation / model (Intel’s 7th generation i5 and i7), the solid state drive size (128 to 512 GB), and the RAM size (8 to 16 GB).
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Dells XPS Laptop for Linux
|
||||
|
||||
These are very important considerations to take into account and Dell has gotten you covered. Unfortunately, the only Linux distribution that is backed by Dell ProSupport on this model is Ubuntu 16.04 LTS (at the time of this writing – December 2016).
|
||||
|
||||
#### Linux Laptops for System Administrators
|
||||
|
||||
Although system administrators can safely undertake the task of installing a distribution on bare-metal hardware, you can avoid the hassle of searching for available drivers by checking out other offers by System76.
|
||||
|
||||
Since you can choose the features of your laptop, being able to add processing power and up to 32 GB of RAM will ensure you can run virtualized environments on and perform all imaginable system administration tasks with it.
|
||||
|
||||
If this sounds like something that sparks some interest in you, checkout the [Kudu][12] or [Oryx Pro][13] laptops.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Kudu Linux Laptop
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Oryx Pro Linux Laptop
|
||||
|
||||
##### Summary
|
||||
|
||||
In this article we have discussed why buying a laptop with Linux preinstalled is a good option for both home users, developers, and system administrators. Once you have made your choice, feel free to relax and think about what you are going to do with the money you saved.
|
||||
|
||||
Can you think of other tips for buying a Linux laptop? Please let us know using the comment form below.
|
||||
|
||||
As always, don’t hesitate to contact us using the form below if you have questions or comments about this article. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Gabriel Cánepa is a GNU/Linux sysadmin and web developer from Villa Mercedes, San Luis, Argentina. He works for a worldwide leading consumer product company and takes great pleasure in using FOSS tools to increase productivity in all areas of his daily work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/buy-linux-laptops/
|
||||
|
||||
作者:[ Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2016/11/Lemur-Laptop.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2016/11/Gazelle-Laptop.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2016/11/Kudu-Linux-Laptop.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2016/11/Oryx-Pro-Linux-Laptop.png
|
||||
[5]:http://amzn.to/2fPxTms
|
||||
[6]:http://amzn.to/2fPxTms
|
||||
[7]:https://system76.com/laptops
|
||||
[8]:https://system76.com/laptops/lemur
|
||||
[9]:https://system76.com/laptops/gazelle
|
||||
[10]:http://amzn.to/2fBLMGj
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2016/11/Dells-XPS-Laptops.png
|
||||
[12]:https://system76.com/laptops/kudu
|
||||
[13]:https://system76.com/laptops/oryx
|
||||
@ -1,105 +0,0 @@
|
||||
5 things to watch in Go programming in 2017
|
||||
============================================================
|
||||
|
||||
### What will innovations like dynamic plugins, serverless Go, and HTTP/2 Push mean for your development this year?
|
||||
|
||||
Go 1.8 is due to be released next month and it’s slated to have several new features, including:
|
||||
|
||||
* [HTTP/2 Push][1]
|
||||
* [HTTP Server Graceful Shutdown][2]
|
||||
* [Plugins][3]
|
||||
* [Default GOPATH][4]
|
||||
|
||||
Which of these new features will have the most impact probably depends on how you and your development team use Go. Since Go 1.0 released in 2012, its emphasis on simplicity, concurrency, and built-in support has kept its [popularity][9] pointed up and to the right, so the answers to “_What is Go good for?_” keep multiplying.
|
||||
|
||||
Here I’ll offer some thoughts on a few things from the upcoming release and elsewhere in the Go world that have caught my eye recently. It’s hardly an exhaustive list, so [let me know][10] what else you think is going to be important in Go for 2017.
|
||||
|
||||
### Go’s super deployability + plugins = containers, anyone?
|
||||
|
||||
The [1.8 release][11] planned for next month has several folks I’ve talked with wondering how the addition of dynamic plugins — for loading shared libraries with code that wasn’t part of the program when it was compiled — will affect things like containers. Dynamic plugins should make it simpler to use high-concurrency microservices in containers. You’ll be able to easily load plugins as external processes, with all the added benefits of microservices in containers: protecting your main process from crashes and not having anything messing around in your memory space. Dynamic support for plugins should really be a boon for using containers in Go.
|
||||
|
||||
_For some expert live Go training, sign up for _[_Go Beyond the Basics_][12]_._
|
||||
|
||||
### Cross-platform support will keep pulling in developers
|
||||
|
||||
In the 7 years since Go was open-sourced, it has been adopted across the globe. [Daniel Whitenack][13], a data scientist and engineer who maintains the Go kernel for Jupyter, told me he recently [gave a data science and Go training in Siberia][14], (yes, Siberia! And, yes data science and Go — more on that in a bit . . .) and “was amazed to see how vibrant and active the Go community was there.” Another big reason folks will continue to adopt Go for their projects is cross compilation, which, as several Go experts have explained, [got even easier with the 1.5 release][15]. Developers from other languages such as Python should find the ability to build a bundled, ready-to-deploy application for multiple operating systems with no VM on target platforms a key draw for working in Go.
|
||||
|
||||
Pair this cross-platform support with projected [15% speed improvements in compile time][16] in the 1.8 release, and you can see why Go is a favorite language for startups.
|
||||
|
||||
_Interested in the basics of Go? Check out the _[_Go Fundamentals Learning Path_][17]_ for guidance from O’Reilly experts to get you started._
|
||||
|
||||
### A Go interpreter is in the works; goodbye Read-Eval-Print-Loop
|
||||
|
||||
Some really smart people are working on a [Go Interpreter][18], and I will definitely be watching this. As many of you know too well, there are several Read-Eval-Print-Loop (REPL) solutions out there that can evaluate expressions and make sure your code works as expected, but these methods often mean tolerating inconvenient caveats, or slogging through several to find the one that fits your use case. A robust, consistent interpreter would be great, and as soon as I hear more, I’ll let you know.
|
||||
|
||||
_Working with Go complexities in your development? Watch the _[_Intermediate Go_][19]_ video training from O’Reilly._
|
||||
|
||||
### Serverless for Go — what will that look like?
|
||||
|
||||
Yes, there’s a lot of hype right now around serverless architecture, a.k.a. function as a service (FaaS). But sometimes where there’s smoke there’s fire, so what’s happening in the Go space around serverless? Could we see a serverless service with native support for Go this year?
|
||||
|
||||
AWS Lambda is the most well-known serverless provider, but Google also recently launched [Google Cloud Functions][20]. Both of these FaaS solutions let you run code without managing servers; your code is stored on a cluster of servers managed for you and run only when a triggering event calls it. AWS Lambda currently supports JavaScript, Python, and Java, plus you can launch Go, Ruby, and bash processes. Google Cloud Functions only supports JavaScript, but it seems likely that both Java and Python will soon be supported, too. A lot of IoT devices already make use of a serverless approach, and with Go’s growing adoption by startups, serverless seems a likely spot for growth, so I’m watching what develops to support Go in these serverless solutions.
|
||||
|
||||
There are already [several frameworks that have Go support][21] underway for AWS Lambdas:
|
||||
|
||||
* [λ Gordon][5] — Create, wire and deploy AWS Lambdas using CloudFormation
|
||||
* [Apex][6] — Build, deploy, and manage AWS Lambda functions
|
||||
* [Sparta][7] — A Go framework for AWS Lambda microservices
|
||||
|
||||
There’s also an AWS Lambda alternative that supports Go:
|
||||
|
||||
* [Iron.io][8]: Built on top of Docker and Go; language agnostic; supports Golang, Python, Ruby, PHP, and .NET
|
||||
|
||||
_For more on serverless architecture, watch Mike Roberts’ keynote from the O’Reilly Software Architecture Conference in San Francisco: _[_An Introduction to Serverless_][22]_._
|
||||
|
||||
### Go for Data — no really!
|
||||
|
||||
I hinted at this at the beginning of this article: perhaps surprisingly, a lot of people are using Go for data science and machine learning. There’s some debate about whether this is a good fit, but based on things like the annual Advent Posts for [Gopher Academy for December 2016][23], where you’ll note at least 4 of the 30 posts are on ML or distributed data processing of some kind, it’s happening.
|
||||
|
||||
My earlier point about Go’s easy deployability is probably one key reason data scientists are working with Go: they can more easily show their data models to others in a readable and productionable application. Pair this with the broad adoption of Go (as I mentioned earlier, its popularity is pointed up and to the right!), and you have data folks creating applications that “work and play well with others.” Any applications data scientists build in Go will speak the same language as the rest of the company, or at least fit very well with modern architectures.
|
||||
|
||||
_For more on Go for data science, Daniel Whitenack has written an excellent overview that explains more about how it’s being used: _[_Data Science Gophers_][24]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Supervising Editor at O’Reilly Media, works with an editorial team that covers a wide variety of programming topics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@sconant/5-things-to-watch-in-go-programming-in-2017-39cd7a7e58e3#.8t4to5jr1
|
||||
|
||||
作者:[Susan Conant][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@sconant?source=footer_card
|
||||
[1]:https://beta.golang.org/doc/go1.8#h2push
|
||||
[2]:https://beta.golang.org/doc/go1.8#http_shutdown
|
||||
[3]:https://beta.golang.org/doc/go1.8#plugin
|
||||
[4]:https://beta.golang.org/doc/go1.8#gopath
|
||||
[5]:https://github.com/jorgebastida/gordon
|
||||
[6]:https://github.com/apex/apex
|
||||
[7]:http://gosparta.io/
|
||||
[8]:https://www.iron.io/
|
||||
[9]:https://github.com/golang/go/wiki/GoUsers
|
||||
[10]:https://twitter.com/SuConant
|
||||
[11]:https://beta.golang.org/doc/go1.8
|
||||
[12]:https://www.safaribooksonline.com/live-training/courses/go-beyond-the-basics/0636920065357/
|
||||
[13]:https://www.oreilly.com/people/1ea0c-daniel-whitenack
|
||||
[14]:https://devfest.gdg.org.ru/en/
|
||||
[15]:https://medium.com/@rakyll/go-1-5-cross-compilation-488092ba44ec#.7s7sxmc4h
|
||||
[16]:https://beta.golang.org/doc/go1.8#compiler
|
||||
[17]:http://shop.oreilly.com/category/learning-path/go-fundamentals.do
|
||||
[18]:https://github.com/go-interpreter
|
||||
[19]:http://shop.oreilly.com/product/0636920047513.do
|
||||
[20]:https://cloud.google.com/functions/docs/
|
||||
[21]:https://github.com/SerifAndSemaphore/go-serverless-list
|
||||
[22]:https://www.safaribooksonline.com/library/view/oreilly-software-architecture/9781491976142/video288473.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=5-things-to-watch-in-go-programming-body-text-cta
|
||||
[23]:https://blog.gopheracademy.com/series/advent-2016/
|
||||
[24]:https://www.oreilly.com/ideas/data-science-gophers
|
||||
@ -1,3 +1,4 @@
|
||||
翻译中--by zky001
|
||||
Top 8 systems operations and engineering trends for 2017
|
||||
=================
|
||||
|
||||
|
||||
114
translated/tech/20160510 What is Docker.md
Normal file
114
translated/tech/20160510 What is Docker.md
Normal file
@ -0,0 +1,114 @@
|
||||
Docker 是什么?
|
||||
================
|
||||
|
||||

|
||||
|
||||
这是一段摘录,取自于 Karl Matthias 和 Sean P. Kane 撰写的书籍 [Docker: Up and Running][3]。其中或许包含一些其他资源的引用,您可以点击其中的链接。
|
||||
|
||||
2013 年 3 月 15 日,在加利福尼亚州圣克拉拉召开的 Python 开发者大会上,dotCloud 的创始人兼首席执行官 Solomon Hvkes 在一场仅五分钟的[微型演讲][4]中,首次提出了 Docker 这一概念。当时,仅约 40 人(除 dotCloud 内部人员)获得了使用 Docker 的机会。
|
||||
|
||||
这在之后的几周内,有关 Docker 的新闻铺天盖地。随后这个项目很快在 [Github][5] 上开源,任何人都可以下载它并为其做出贡献。在之后的几个月中,越来越多的业界人士开始听说 Docker 以及它是如何彻底地改变了软件开发,交付和运行的方式。一年之内,Docker 的名字几乎无人不知无人不晓,但还是有很多人不太明白 Docker 究竟是什么,人们为何如此兴奋。
|
||||
|
||||
Docker 是一个工具,它致力于为任何应用程序创建易于分发的构建产物,将其部署到任何环境中,并简化敏捷软件组织的工作流程,降低响应速度。
|
||||
|
||||
### Docker 带来的希望
|
||||
|
||||
虽然表面上被视为一个虚拟化平台,但 Docker 远远不止如此。Docker 涉及的领域横跨了业界多个方面,包括 KVM, Xen, OpenStack, Mesos, Capistrano, Fabric, Ansible, Chef, Puppet, SaltStack 等技术。或许你已经发现了,在 Docker 的竞争产品列表中有一个值得一提的事儿。例如,大多数工程师不会说,虚拟化产品会和配置管理工具是竞争关系,但 Docker 和这两种技术都有点关系。前面列举的一些技术常常因其提高了工作效率而获得称赞,这就导致了大量的探讨。而现在 Docker 正处在这些过去十年间最广泛使用的技术之中。
|
||||
|
||||
如果你要拿 Docker 分别与这些领域的卫冕冠军按照功能逐项比较,那么 Docker 看上去可能只是个一般的竞争对手。Docker 在某些领域表现的更好,但它带来的是一个跨越广泛的解决工作流程中众多挑战的功能集合。通过结合应用程序部署工具(如 Capistrano, Fabric)的易用性和易于管理的虚拟化系统,提供使工作流程自动化和业务流程易于实施的钩子,Docker 提供了一个非常强大的功能集合。
|
||||
|
||||
大量的新技术来来去去,因此对这些新事物保持一定的怀疑总是好的。如果不深入研究,人们很容易误以为 Docker 只是另一种为开发者和运营团队解决一些具体问题的技术。如果只是把 Docker 看作一种虚拟化技术或者部署技术,这似乎并不能令人信服。不过 Docker 可比表面上看起来的强大得多。
|
||||
|
||||
即使在小型团队中,团队内部的沟通和相处也往往是困难的。然而在我们生活的这个世界里,团队内部对于细节的沟通是迈向成功越来越不可或缺的因素。而一个能够降低沟通复杂性,协助开发更为强健软件的工具,无疑是一个巨大的成功。这正是 Docker 值得我们深入了解的原因。当然 Docker 也不是什么灵丹妙药,它的正确使用还需深思熟虑,不过 Docker 确实能够解决一些组织层面的现实问题,还能够帮助公司更好更快地发布软件。使用精心设计的 Docker 工作流程能够让技术团队更加和谐,为组织创造实实在在的收益。
|
||||
|
||||
那么,最让公司感到头疼的问题是什么呢?现如今,很难按照预期的速度发布软件,而随着公司从只有一两个开发人员成长到拥有若干开发团队的时候,发布新版本时的沟通负担将越来越重,难以管理。开发者不能不去了解软件所处环境的复杂性,生产运营团队也需要不断地理解所发布软件的内部细节。通常这些都是不错的工作技能,因为它们有利于更好地从整体上理解发布环境,从而促进软件的鲁棒性设计。但是随着团队的壮大,需要掌握的技能也越来越多。
|
||||
|
||||
充分了解所用的环境细节往往需要团队之间大量的沟通,而这并不能直接为团队创造值。例如,为了发布版本1.2.1, 开发人员要求运维团队升级特定的库,这个过程就降低了开发效率,也没有为公司创造价值。如果开发人员能够直接升级他们所使的库,然后编写代码,测试新版本,最后发布软件,那么整个交付过程所用的时间将会明显缩短。如果运维人员无需与多个应用开发团队相协调,就能够在宿主系统上升级软件,那么效率将大大提高。Docker 有助于在软件层面建立一层隔离,从而减轻团队的沟通负担。
|
||||
|
||||
除了有助于解决沟通问题,在某种程度上 Docker 的软件架构还鼓励开发出更多精致的应用程序。这种架构哲学的核心是一次性的小型容器。在新版本部署的时候,会将旧版本应用的整个运行环境全部丢弃。在应用所处的环境中,任何东西的存在时间都不会超过应用程序本身。这是一个简单却影响深远的想法。这就意味着,应用程序不会意外地依赖于之前版本的遗留产物; 对应用的短暂调试和修改也不会存在于未来的版本中; 应用程序具有高度的可移植性,因为应用的所有状态要么直接包含于用于部署的构建产物中,且不可修改,要么存储于数据库、缓存或文件服务器等外部依赖中。
|
||||
|
||||
因此,应用程序不仅具有更好的可扩展性,而且更加可靠。存储应用的容器实例数量的增减,对于前端网站的影响很小。事实证明,这种架构对于非 Docker 化的应用程序已然成功,但是 Docker 自身包含了这种架构方式,使得 Docker 化的应用程序始终遵循这些最佳实践,这也是一件好事。
|
||||
|
||||
### Docker 工作流程的好处
|
||||
|
||||
我们很难把 Docker 的好处一一举例。如果用得好,Docker 能在多个方面为组织,团队,开发者和运营工程师带来帮助。从宿主系统的角度看,所有应用程序的本质是一样的,因此这就决定了 Docker 让架构的选择更加简单。这也让工具的编写和应用程序之间的分享变得更加容易。这世上没有什么只有好处却没有挑战的东西,但是 Docker 似乎就是一个例外。以下是一些我们使用 Docker 能够得到的好处:
|
||||
|
||||
**使用开发人员已经掌握的技能打包软件**
|
||||
|
||||
> 许多公司为了管理各种工具来为它们的平台构建软件包,不得不提供一些软件发布和构建工程师的岗位。像 rpm, mock, dpkg 和 pbuilder 等工具使用起来并不容易,每一种工具都需要单独学习。而 Docker 则把你所有需要的东西全部打包起来,定义为一个文件。
|
||||
|
||||
**使用标准化的镜像格式打包应用软件及其所需的文件系统**
|
||||
|
||||
> 过去,不仅需要打包应用程序,还需要包含一些依赖库和守护进程等。然而,我们永远不能百分之百地保证,软件运行的环境是完全一致的。这就使得软件的打包很难掌握,许多公司也不能可靠地完成这项工作。使用 Scientific Linux 的用户经常会试图部署一个来自社区的,仅在 Red Hat Linux 上经过测试的软件包,希望这个软件包足够接近他们的需求。如果使用 Dokcer, 只需将应用程序和其所依赖的每个文件一起部署即可。Docker 的分层镜像使得这个过程更加高效,确保应用程序运行在预期的环境中。
|
||||
|
||||
**测试打包好的构建产物并将其部署到运行任意系统的生产环境**
|
||||
|
||||
> 当开发者将更改提交到版本控制系统的时候,可以构建一个新的 Docker,然后通过测试,部署到生产环境,整个过程中无需任何的重新编译和重新打包。
|
||||
|
||||
**将应用软件从硬件中抽象出来,无需牺牲资源**
|
||||
|
||||
> 传统的企业级虚拟化解决方案,例如 VMware,以消耗资源为代价在物理硬件和运行其上的应用软件之间建立抽象层。虚拟机管理程序和每一个虚拟机中运行的内核都要占用一定的硬件系统资源,而这部分资源将不能够被宿主系统的应用程序使用。而容器仅仅是一个能够与 Linux 内核直接通信的进程,因此它可以使用更多的资源,直到系统资源耗尽或者配额达到上限为止。
|
||||
|
||||
Docker 出现之前,Linux 容器技术已经存在了很多年,Docker 使用的技术也不是全新的。但是这个独一无二的集强大架构和工作流程于一身的 Docker 要比各个技术加在一起还要强大的多。Docker 终于让已经存在了十余年的 Linux 容器走进了普通技术人员的生活中。Docker 让容器更加轻易地融入到公司现有的工作流程中。以上讨论到的问题是被很多人所关注的,以至于 Docker 项目的快速发展超出了所有人的合理预期。
|
||||
|
||||
Docker 发布的第一年,许多刚接触的新人惊讶地发现,尽管 Docker 还不能在生产环境中使用,但是来自 Docker 开源社区源源不断的提交,飞速推动着这个项目向前发展。随着时间的推移,这一速度似乎越来越快。现在 Docker 进入了 1.x 发布周期,稳定性好了,可以在生产环境中使用。因此,许多公司使用 Docker 来解决它们在应用程序交付过程中面对的棘手问题。
|
||||
|
||||
### Docker 不是什么
|
||||
|
||||
Docker 可以解决很多问题,这些问题是其他类型的传统工具专门解决的。那么 Docker 在功能上的广度就意味着它在特定的功能上缺乏深度。例如,一些组织认为,使用 Docker 之后可以完全摈弃配置管理工具,但 Docker 真正强大之处在于,它虽然能够取代某些传统的工具,但通常与它们是兼容的,甚至与它们结合使用还能增强更加自身的功能。下面将列举一些 Docker 还未能完全取代的工具,如果与它们结合起来使用,往往能取得更好的效果。
|
||||
|
||||
**企业级虚拟化平台(VMware, KVM 等)**
|
||||
|
||||
> 容器并不是传统意义上的虚拟机。虚拟机包含完整的操作系统,运行在宿主操作系统之上。虚拟化平台最大的优点是,一台宿主机上可以使用虚拟机运行多个完全不同的操作系统。而容器是和主机共用同一个内核,这就意味着容器使用更少的系统资源,但必须基于同一个底层操作系统(如 Linux)。
|
||||
|
||||
**云平台(Openstack, CloudStack 等)**
|
||||
|
||||
> 与企业级虚拟化平台一样,容器和云平台的工作流程表面上有大量的相似之处。从传统意义上看,二者都可以按需横向扩展。但是,Docker 并不是云平台,它只能在预先安装 Docker 的宿主机中部署,运行和管理容器,并能创建新的宿主系统(实例),对象存储,数据块存储以及其他与云平台相关的资源。
|
||||
|
||||
**配置管理工具(Puppet,Chef 等)**
|
||||
|
||||
> 尽管 Docker 能够显著提高一个组织管理应用程序及其依赖的能力,但不能完全取代传统的配置管理工具。Dockerfile 文件用于定义一个容器构建时内容,但不能持续管理容器运行时的状态和 Docker 的宿主系统。
|
||||
|
||||
**部署框架(Capistrano,Fabric等)**
|
||||
|
||||
> Docker 通过创建自成一体的容器镜像,简化了应用程序在所有环境上的部署过程。这些用于部署的容器镜像封装了应用程序的全部依赖。然而 Docker 本身不无法执行复杂的自动化部署任务。我们通常使用其他工具一起实现较大的工作流程自动化。
|
||||
|
||||
**工作负载管理工具(Mesos,Fleet等)**
|
||||
|
||||
> Docker 服务器没有集群的概念。我们必须使用其他的业务流程工具(如 Docker 自己开发的 Swarm)智能地协调多个 Docker 主机的任务,跟踪所有主机的状态及其资源使用情况,确保运行着足够的容器。
|
||||
|
||||
**虚拟化开发环境(Vagrant等)**
|
||||
|
||||
> 对开发者来说,Vagrant 是一个虚拟机管理工具,经常用来模拟与实际生产环境尽量一致的服务器软件栈。此外,Vagrant 可以很容易地让 Mac OS X 和基于 Windows 的工作站运行 Linux 软件。由于 Docker 服务器只能运行在 Linux 上,于是它提供了一个名为 Boot2Docker 的工具允许开发人员在不同的平台上快速运行基于 Linux 的 Docker 容器。Boot2Docker 足以满足很多标准的 Docker 工作流程,但仍然无法支持 Docker Machine 和 Vagrant 的所有功能。
|
||||
|
||||
如果没有参考标准,很难理解 Docker 的作用。下一章我们将简要介绍,什么是 Docker,它的目标使用场景,以及 它的优势。
|
||||
|
||||
-----------------
|
||||
作者简介:
|
||||
|
||||
#### [Karl Matthias][1]
|
||||
|
||||
Karl Matthias 曾先在创业公司和世界 500 强企业中担任过开发人员,系统管理员和网络工程师。在德国和英国的初创公司工作了若干年后,他和家人回到了美国俄勒冈州波特兰,在 New Relic 公司担任首席网站可靠性工程师。业余时间,他会和他的两个女儿玩,用他那老式相机摄摄影,或者骑骑自行车。
|
||||
|
||||
#### [Sean Kane][2]
|
||||
|
||||
Sean Kane 目前在 New Relic 公司的共享基础设施团队中担任首席网站可靠性工程师。他在生产运维领域有很长的职业生涯,在不同的行业中工作过,有许多不同的头衔。他在各类聚会和技术论坛做过演讲,涉及过疲劳预警和硬件自动化等话题。他的青年阶段大部分在海外度过,毕业于林林兄弟及巴纳姆和贝利小丑学院,在美国中央情报局做过两次实习等等,他一直在探索生活的真谛。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/learning/what-is-docker
|
||||
|
||||
作者:[Karl Matthias ][a],[Sean Kane][b]
|
||||
译者:[译者ID](https://github.com/Cathon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/5abbf-karl-matthias
|
||||
[b]:https://www.oreilly.com/people/d5ce6-sean-kane
|
||||
[1]:https://www.oreilly.com/people/5abbf-karl-matthias
|
||||
[2]:https://www.oreilly.com/people/d5ce6-sean-kane
|
||||
[3]:http://shop.oreilly.com/product/0636920036142.do?intcmp=il-security-books-videos-update-na_new_site_what_is_docker_text_cta
|
||||
[4]:http://youtu.be/wW9CAH9nSLs
|
||||
[5]:https://github.com/docker/docker
|
||||
[6]:https://commons.wikimedia.org/wiki/File:2009_3962573662_card_catalog.jpg
|
||||
147
translated/tech/20161018 Suspend to Idle.md
Normal file
147
translated/tech/20161018 Suspend to Idle.md
Normal file
@ -0,0 +1,147 @@
|
||||
|
||||
# Suspend to Idle
|
||||
|
||||
### 简介
|
||||
|
||||
Linux内核提供了多种睡眠状态,各个状态通过设置系统中的不同部件进入低耗电模式来节约能源。目前总共有四种状态,分别是:suspend to idle,power-on standby,suspend to ram和suspend to disk。这些状态分别对应ACPI的4种状态:S0,S1,S3和S4。suspend to idle是纯软件实现的,主要用于尽量保持CPU处于睡眠状态。powder-on standby则使设备处于低耗电状态,并且停止non-boot CPU运行。suspend to ram则会更进一步处理关闭部件节约能源,包括停止CPU运行,只保持内存自刷新工作,保证内存中的内容仍然存在。suspend to disk则是尽最大努力关闭部件进行节能,包括关闭内存。然后内存中的内容会被写到硬盘,待唤醒计算机的时候将硬盘中的内容重新恢复到内存中。
|
||||
|
||||
这篇博文主要介绍挂起suspend to idle的实现。如上所说,suspend to idle主要通过软件实现。一般平台的挂起过程包括冻结用户空间并将外围设备调至低耗电模式。但是系统并不是直接关闭和拔掉运行中的cpu,而是静静地强制将CPU进入休眠状态。随着外围设备进入了低耗电模式,除了唤醒相关的中断外不会有其他中断产生。唤醒中断包括那些设置用于唤醒系统的计时器(比如RTC,普通计时器等)、或者电源开关、USB和其它外围设备。
|
||||
|
||||
在冻结过程中,当系统进入休眠状态时会调用一个特殊的cpu休眠函数。这个enter_freeze()函数可以简单得和调用cpu进入休眠的enter()函数相同,也可以更复杂。复杂的程度由将SoCs置为低耗电模式的条件和方法决定。
|
||||
|
||||
### 先决条件
|
||||
|
||||
### 平台挂起条件
|
||||
|
||||
一般情况,为了支持S2I,系统必须实现platform_suspend_ops并提供最低限度的挂起支持。这意味着至少要实现platform_suspend_ops中的所有必要函数的功能。如果suspend to idle 和suspend to ram都支持,那么至少要实现suspend_valid_only_men。
|
||||
|
||||
最近,内核开始支持支持S2I。Sudeep Holla表示无须满足platform_suspend_ops条件也会支持S2I。这个分支已经被接收并将在4.9版本被合并,该分支的路径在[https://lkml.org/lkml/2016/8/19/474][1]
|
||||
|
||||
如果定义了suspend_ops。那么可以通过查看/sys/power/state文件得知系统具体支持哪些挂起状态。如下操作:
|
||||
|
||||
```
|
||||
# cat /sys/power/state
|
||||
```
|
||||
|
||||
freeze mem_
|
||||
|
||||
这个示例的结果显示该平台支持S0(suspend to idle)和S3(suspend to ram)。随着Sudeep's的发展,只有那些没有实现platform_suspend_ops的平台才会显示freeze的结果。
|
||||
|
||||
### 唤醒中断
|
||||
|
||||
一旦系统处于某种睡眠状态,系统必须要接收某个唤醒事件才能恢复系统。这些唤醒事件一般由系统的设备产生。因此确保这些设备的驱动实现了唤醒中断,并且在接收这些中断的基础上产生了唤醒事件。如果唤醒设备没有正确配置,那么系统收到中断后只能继续保持睡眠状态而不会恢复。
|
||||
|
||||
一旦设备正确实现了唤醒接口的调用,那么该设备就能产生唤醒事件。确保DT正确配置了唤醒源。下面是一个示例唤醒源配置,该文件来自(arch/arm/boot/dst/am335x-evm.dts):
|
||||
|
||||
```
|
||||
gpio_keys: volume_keys@0 {__
|
||||
compatible = “gpio-keys”;
|
||||
#address-cells = <1>;
|
||||
#size-cells = <0>;
|
||||
autorepeat;
|
||||
|
||||
switch@9 {
|
||||
label = “volume-up”;
|
||||
linux,code = <115>;
|
||||
gpios = <&gpio0 2 GPIO_ACTIVE_LOW>;
|
||||
wakeup-source;
|
||||
};
|
||||
|
||||
switch@10 {
|
||||
label = “volume-down”;
|
||||
linux,code = <114>;
|
||||
gpios = <&gpio0 3 GPIO_ACTIVE_LOW>;
|
||||
wakeup-source;
|
||||
};
|
||||
};
|
||||
```
|
||||
如上所示,有两个gpio键被配置为了唤醒源,在系统挂起期间按下其中任何一个键都会产生一个唤醒事件。
|
||||
|
||||
相对与DT文件配置的另一个唤醒源配置就是设备驱动配置自身,如果设备驱动在代码里面配置了唤醒支持,那么就会使用该默认唤醒配置。
|
||||
|
||||
### 补充
|
||||
|
||||
### freeze功能
|
||||
|
||||
如果系统希望能够充分使用suspend to idle,那么应该在cpu空闲驱动代码中定义enter_freeze()函数。enter_freeze()与enter()的使用方式完全不同,因此不能给enter和enter_freeze实现相同的enter()功能。如果没有定义enter_freeze(),虽然系统会挂起,但是不会触发那些只有当enter_freeze()定义了才会触发的函数,比如tick_freeze()和stop_critical_timing()都不会发生。虽然这也会导致中断唤醒系统,但不会导致系统恢复,系统处理完中断后会继续睡眠。在该最低限度情况下,系统会直接调用enter()。
|
||||
|
||||
在挂起过程中,越少中断产生越好(最好一个也没有)。
|
||||
|
||||
下图显示了能耗和时间的对比。图中的两个尖刺分别是挂起和恢复阶段。挂起前后的能耗尖刺是系统退出空闲态正在进行的记录操作,进程调度,计时器处理等。由于潜在的原因系统进入更深层次休眠状态进行的默认操作需要花很多时间。
|
||||
|
||||

|
||||
Power Usage Time Progression
|
||||
|
||||
下面的跟踪时序图显示了4核CPU在系统挂起和恢复操作这段时间内的活动。如图所示,在挂起这段时间没有请求或者中断被处理。
|
||||
|
||||

|
||||
|
||||
Ftrace capture of Suspend/Resume
|
||||
|
||||
### 空闲状态
|
||||
|
||||
你必须确定哪个空闲状态支持冻结,在冻结期间,电源相关代码会决定用哪个空闲状态来实现冻结。这个过程是通过在每个空闲状态中查找谁定义了enter_freeze()来决定的。cpu空闲驱动代码或者SoC挂起相关代码必须实现冻结相关操作,并通过指定冻结功能给所有CPU的可应用空闲状态进行配置。
|
||||
|
||||
比如Qualcomm会在平台的挂起功能中的初始化代码处定义enter_freeze函数。这个工作是在cpu空闲驱动已经初始化并且所有数据结构已经定义就位的情况下进行的。
|
||||
|
||||
### 挂起/恢复相关驱动支持
|
||||
|
||||
你可能会在第一次成功挂起操作后碰到驱动相关的bug。很多驱动开发者没有精力完全测试挂起和恢复相关的代码。由于用户空间已经被冻结,唤醒设备此时已经处于休眠状态并且pm_runtime已经被禁止。你可能会发现挂起操作并没有多少工作可做,因为pm_runtime已经做好了挂起相关的准备。
|
||||
|
||||
### 测试相关
|
||||
|
||||
测试suspend to idle可以手动进行,也可以用(脚本或程序)自动挂起,使用自动睡眠或者Android中的wakelock来让系统挂起。如果手动测试,下面的操作会直接将系统冻结。
|
||||
|
||||
```
|
||||
/ # echo freeze > /sys/power/state
|
||||
[ 142.580832] PM: Syncing filesystems … done.
|
||||
[ 142.583977] Freezing user space processes … (elapsed 0.001 seconds) done.
|
||||
[ 142.591164] Double checking all user space processes after OOM killer disable… (elapsed 0.000 seconds)
|
||||
[ 142.600444] Freezing remaining freezable tasks … (elapsed 0.001 seconds) done._
|
||||
_[ 142.608073] Suspending console(s) (use no_console_suspend to debug)
|
||||
[ 142.708787] mmc1: Reset 0x1 never completed.
|
||||
[ 142.710608] msm_otg 78d9000.phy: USB in low power mode
|
||||
[ 142.711379] PM: suspend of devices complete after 102.883 msecs
|
||||
[ 142.712162] PM: late suspend of devices complete after 0.773 msecs
|
||||
[ 142.712607] PM: noirq suspend of devices complete after 0.438 msecs
|
||||
< system suspended >
|
||||
….
|
||||
< wake irq triggered >
|
||||
[ 147.700522] PM: noirq resume of devices complete after 0.216 msecs
|
||||
[ 147.701004] PM: early resume of devices complete after 0.353 msecs
|
||||
[ 147.701636] msm_otg 78d9000.phy: USB exited from low power mode
|
||||
[ 147.704492] PM: resume of devices complete after 3.479 msecs
|
||||
[ 147.835599] Restarting tasks … done.
|
||||
/ #
|
||||
```
|
||||
|
||||
在上面的例子中,需要注意MMC驱动的操作占了102.883ms中的100ms。有些设备驱动在挂起的时候有很多工作要做,比如将数据刷出到硬盘,或者其他耗时的操作等。
|
||||
|
||||
如果系统定义了freeze。那么系统将尝试挂起操作,如果没有freeze功能,那么你会看到下面的提示:
|
||||
|
||||
```
|
||||
/ # echo freeze > /sys/power/state
|
||||
sh: write error: Invalid argument
|
||||
/ #
|
||||
```
|
||||
|
||||
### 未来的发展
|
||||
|
||||
目前在ARM平台上的suspend to idle有两方面的工作需要做。第一方面是前面提到的需要准备好platform_suspend_ops相关工作,该工作致力于冻结状态的合法化并将并到4.9版本的内核中。另一方面是关于冻结功能方面的支持。
|
||||
|
||||
如果你希望设备有更好的响应及表现那么应该继续完善冻结相关功能的实现。然而很多SoCs会使用ARM的cpu空闲驱动,这使得ARM能够完善自己独特的冻结功能。而事实上,ARM正在尝试添加自己特有的支持。如果SoCs供应商希望实现他们自己的cpu空闲驱动或者需要在进入更深层次的冻结休眠状态时提供额外的支持,那么只有实现自己的冻结功能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linaro.org/blog/suspend-to-idle/
|
||||
|
||||
作者:[Andy Gross][a]
|
||||
|
||||
译者:[beyondworld](https://github.com/beyondworld)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linaro.org/author/andygross/
|
||||
[1]:https://lkml.org/lkml/2016/8/19/474
|
||||
@ -0,0 +1,110 @@
|
||||
|
||||
为了畅游网络的人们、专注于云端的 Linux 发行版
|
||||
============================================================
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
概述:我们列举几款以云端为中心的 Linux 发行版,它们被视为真正能替代 Chrome OS 的 Linux 发行版。
|
||||
|
||||
这个世界正在向云端服务转变,而且我们都知道 Chrome OS 倍受人们喜爱。嗯,它确实值得尊重。它超级快、轻盈、省电、简约、设计精美而且充分发挥了当今科技所能提供的云端潜能。
|
||||
|
||||
虽然 [Chrome OS][7] 只能在谷歌的硬件上使用,但是,就只是在你的台式机或者笔记本上,还是有其他的方法来体验云计算的潜能。
|
||||
|
||||
正如我重复所说的,在 Linux 领域中,人们总能参与其中。有那些看起来像 Windows 或者 Mac OS 的Linux 发行版。Linux 汇集了分享,爱和计算体验的最前沿。让我们马上看看这份列表吧!
|
||||
|
||||
### 1\. CUB LINUX
|
||||
|
||||

|
||||
|
||||
这不是 Chrome OS ,上述图片描绘的是 Cub Linux 的桌面。不清楚我说的什么?
|
||||
|
||||
Cub Linux 对于 Linux 用户来说不再新鲜,但是如果你确实不知道的话,(我来解释下,)Cub Linux 灵感来源于主流的 Chrome OS ,是一款专注于网页的 Linux 发行版。从母亲 Linux 来讲,它也是 Chrome OS 的开源兄弟。
|
||||
|
||||
Chrome OS 内置了 Chrome 浏览器。不久之前,一个名为 [Chromixium OS][10] 的项目启动,旨在用 Chromium 浏览器取代 Chrome 浏览器,来提供与 Chrome OS 同样的体验。因为一些法律上的争论,项目名字后来改为 Cub Linux (取自 Chromium 和 Ubuntu 两个词)。
|
||||
|
||||

|
||||
|
||||
在历史部分,如名字提示的那样,Cub Linux 基于 Ubuntu ,使用了轻量的 Openbox 桌面环境。定制桌面来给人以 Chrome OS 的印象,而且看起来很整洁。
|
||||
|
||||
在应用部分,你能安装 Chrome 网上商店的网络应用和所有的 Ubuntu 应用。对,有 Chrome OS 的精美应用,你仍能体会到 Ubuntu 的好处。
|
||||
|
||||
就表现而言,这操作系统相当快多亏了它自身的 Openbox 桌面环境。基于 Ubuntu ,Cub Linux 的稳定性是毋庸置疑的。这桌面流畅的动画和漂亮的用户界面,对于眼睛是一种享受,
|
||||
|
||||
[Suggested Read[Year 2013 For Linux] 2 Linux Distributions Discontinued][11]
|
||||
|
||||
我向花费大部分时间在浏览器,时不时做些家务的人推荐 Cub Linux 。嗯,一个浏览器就是你所需要的全部,而且,一个浏览器正是你将会得到的全部。
|
||||
|
||||
### 2\. PEPPERMINT OS
|
||||
|
||||
不少人把目光投向 Linux 因为他们想要一个良好的使用计算机的体验。一些人是真的不喜欢防病毒软件、磁盘整理程序、清理工具的打扰,他们只是想要一个操作系统而不是个孩子。我必须说 Peppermint OS 真的不会打扰用户。[Peppermint OS][12] 的开发者在理解用户需求上花费了大量的时间精力。
|
||||
|
||||

|
||||
|
||||
系统默认内置了很少的软件。内置从每一个软件类别挑选的一些应用,这传统的想法没有被开发者所采纳,这为了良好的用户体验。个性化定制电脑的权力已经移交给用户。顺便说一句,当能用网页替代几乎大部分应用时,我们真的需要安装那么多的应用吗?
|
||||
|
||||
Ice
|
||||
|
||||
Ice 是一个有用的小工具,它能将你最喜爱和经常用到的网页转化成桌面应用,这样你就能直接从你的桌面或菜单启动。这就是我们所说的特定页浏览器。
|
||||
|
||||

|
||||
|
||||
喜欢 facebook ?为了快速启动,为什么不弄一个 facebook 的网页应用在你的桌面上?当人们抱怨 Linux 上不知如何正确安装 Google Drive 应用时,Ice 能让你在一次单击就能访问
|
||||
|
||||
Peppermint OS 7 是基于 Ubuntu 16.04 。它不仅有流畅、稳固的表现,而且反应很快。一个深度定制的 LXDE 将会是你的首页。我所说的定制是为了实现华丽的表现和视觉吸引力。
|
||||
|
||||
Peppermint OS 介于云操作系统和本地操作系统。虽然这操作系统的框架被设计来支持快速的云端应用,但是本地的 Ubuntu 应用运行得也不错。如果你是像我那样,想要一个能在在线和离线之间保持平衡的操作系统的话,[Peppermint OS 很适合你][13]。
|
||||
|
||||
[Suggested ReadPennsylvania High School Distributes 1,700 Ubuntu Laptops to Students][14]
|
||||
|
||||
### 3.APRICITY OS
|
||||
|
||||
[Apricity OS][15] 在这里是极具美感的 Linux 发行版之一。它就像是 Linux 里的蒙娜丽莎。但是,不止外观优美,它还有更多优点。
|
||||
|
||||

|
||||
|
||||
将 [Apricity OS][16] 加入这名单中的基本理由是它的简洁。当桌面操作系统设计变得越来越乱、堆砌元素时(我只是在讨论 Linux 操作系统),Apricity 除去所有杂项,简化最基本的人机交互。在这,Gnome 桌面环境被定制得非常优美。他们使其变得更简单。
|
||||
|
||||
预装的软件真的很少。几乎所有的 Linux 发行版有同样的预装软件。但是 Apricity OS 有一个全新的软件集合。Chrome 而不是 Firefox 。我真的很期待这点。我是说为什么不在外面告诉我们改变了什么?
|
||||
|
||||
Apricity OS 也展现了我们在上一段讨论的 Ice 工具。但不是 Firefox ,Chrome 浏览器被用在网页-桌面一体化里。Apricity OS 默认内置了 Numix Circle 图标。。每一次你添加一个网页应用,那就会有一个优美的图标放在你的底栏上。
|
||||
|
||||

|
||||
|
||||
看见我所说的了吗?
|
||||
|
||||
Apricity OS 基于 Arch Linux 。(所以任何想要快速上手 Arch ,想要优美发行版的人,来[这里][17]下载 Apricity 的 ISO 文件。) Apricity 完全保持了 Arch 选择自由的原则。
|
||||
|
||||
华丽的背景,极简主义的桌面和一大堆的功能。这些特性使得 Apricity OS 在建立一个很棒的云端系统上成为一个极佳选择。在 Apricity OS 花上5分钟来使你完全爱上它。我是认真的。
|
||||
|
||||
到此你就看完了全部。给网上居住者的云端 Linux 发行版。给我们关于网页应用和本地应用话题的看法。别忘了分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cloud-focused-linux-distros/
|
||||
|
||||
作者:[Aquil Roshan ][a]
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/author/aquil/
|
||||
[2]:https://itsfoss.com/cloud-focused-linux-distros/#comments
|
||||
[3]:https://twitter.com/share?original_referer=https%3A%2F%2Fitsfoss.com%2F&source=tweetbutton&text=Cloud+Focused+Linux+Distros+For+People+Who+Breathe+Online&url=https%3A%2F%2Fitsfoss.com%2Fcloud-focused-linux-distros%2F&via=%40itsfoss
|
||||
[4]:https://www.linkedin.com/cws/share?url=https://itsfoss.com/cloud-focused-linux-distros/
|
||||
[5]:http://pinterest.com/pin/create/button/?url=https://itsfoss.com/cloud-focused-linux-distros/&description=Cloud+Focused+Linux+Distros+For+People+Who+Breathe+Online&media=https://itsfoss.com/wp-content/uploads/2016/11/cloud-centric-Linux-distributions.jpg
|
||||
[6]:https://itsfoss.com/wp-content/uploads/2016/11/cloud-centric-Linux-distributions.jpg
|
||||
[7]:https://en.wikipedia.org/wiki/Chrome_OS
|
||||
[8]:https://itsfoss.com/windows-like-linux-distributions/
|
||||
[9]:https://cublinux.com/
|
||||
[10]:https://itsfoss.com/chromixiumos-released/
|
||||
[11]:https://itsfoss.com/year-2013-linux-2-linux-distributions-discontinued/
|
||||
[12]:https://peppermintos.com/
|
||||
[13]:https://peppermintos.com/
|
||||
[14]:https://itsfoss.com/pennsylvania-high-school-ubuntu/
|
||||
[15]:https://apricityos.com/
|
||||
[16]:https://itsfoss.com/apricity-os/
|
||||
[17]:https://apricityos.com/
|
||||
@ -0,0 +1,167 @@
|
||||
|
||||
###[Linux容器能否弥补IoT的安全短板?][28]
|
||||
|
||||

|
||||
在这个最后的物联网系列文章中,Canonical和Resin.io向以Linux容器技术作为物联网安全性和互操作性的解决方案发起挑战。
|
||||
|
||||

|
||||
|
||||
**Artik 7** |
|
||||
|
||||
尽管受到日益增长的安全威胁,物联网炒作没有显示减弱的迹象。为了刷存在感,公司正忙于重新安排物联网的路线图。物联网大潮迅猛异常,比移动互联网革命渗透地更加深入和广泛。IoT像黑洞一样,吞噬一切,包括智能手机,它通常是我们在物联网世界中的窗口,有时作为我们的集线器或传感器端点。
|
||||
|
||||
新的物联网处理器和嵌入式主板继续重塑技术版图。自从9月份推出[Linux和开源硬件IoT] [5]系列文章之后,我们看到了面向物联网网关的“Apollo Lake]”SoC [Intel Atom E3900] [6]以及[新三星Artik模块][7],包括用于网关并由Linux驱动的64位Artik 7 COM及自带RTOS的Cortex-M4 Artik。 ARM为具有ARMv8-M和TrustZone安全性的IoT终端发布了[Cortex-M23和Cortex-M33] [8]内核。
|
||||
|
||||
安全是这些产品的卖点。最近攻击Dyn服务并在一天内摧毁了美国大部分互联网的未来僵尸网络将基于Linux的物联网推到台前 - 当然这种方式似乎不太体面。通过DDoS攻击可以黑掉物联网设备,其设备所有者同样可能直接遭受恶意攻击。
|
||||
|
||||

|
||||
|
||||
**Cortex-M33 和 -M23**
|
||||
|
||||
Dyn攻击让我们更加笃定,物联网将更加自信地在受控制和受保护的工业环境而不是家用环境中向前发展。这不是因为消费者[物联网安全技术] [9]不可用,但除非产品设计之初就以安全为目标,否则如我们的[智能家居集线器系列] [10]中的许多解决方案,后期再考虑安全就会增加成本和复杂性。
|
||||
|
||||
在物联网系列的最后一个未来展望的部分,我们将探讨两种基于Linux的面向Docker的容器技术,这些技术被提出作为物联网安全解决方案。容器还可以帮助解决在[物联网框架] [11]中探讨的开发复杂性和互操作性障碍的问题。
|
||||
|
||||
我们与Canonical的Ubuntu客户平台工程副总裁Oliver Ries讨论了Ubuntu Core和Docker友好的容器式Snaps包管理技术。我们还就新的基于Docker的物联网方案ResinO采访了Resin.io首席执行官和联合创始人Alexandros Marinos。
|
||||
|
||||
**Ubuntu Core 与快照管理**
|
||||
|
||||
Canonical面向物联网的[Snappy Ubuntu Core] [12]版本的Ubuntu是围绕一个类似容器的快照包管理机制构建,并提供应用商店支持。 snap技术最近[自行发布] [13]用于其他Linux发行版。 11月3日,Canonical发布了[Ubuntu Core 16] [14],该版本改进了白标应用商店和更新控制服务。
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][15]
|
||||
**传统Ubuntu(左)架构 与 Ubuntu Core 16**
|
||||
(点击图片放大)
|
||||
</center>
|
||||
|
||||
快照机制提供自动更新,并有助于阻止未经授权的更新。 使用事务系统管理,快照可确保更新按预期部署或根本不部署。 在Ubuntu Core中,使用AppArmor进一步加强了安全性,并且所有应用程序文件都只读且保存在隔离的孤岛中。
|
||||

|
||||
|
||||
**LimeSDR** |
|
||||
|
||||
Ubuntu Core是我们最近展开的[开源物联网操作系统调查] [16]的一部分,现在运行在Gumstix主板,Erle机器人无人机,Dell Edge网关,[Nextcloud Box] [17],LimeSDR,Mycroft家庭集线器 ,英特尔的Joule和符合Linaro的96Boards规范的SBC上。 Canonical公司还与Linaro物联网和嵌入式(LITE)部门集团[96Boards物联网版] [18]合作。最初,96Boards IE专注于Zephyr驱动的Cortex-M4板卡,如Seeed的[BLE Carbon] [19] 它将扩展到可以运行Ubuntu Core的网关板卡。
|
||||
|
||||
“Ubuntu Core和快照具有从边缘到网关到云的相关性,”Canonical的Ries说。 “能够在任何主要发行版(包括Ubuntu Server和Ubuntu for Cloud)上运行快照包,使我们能够提供一致的体验。 Snaps可以使用事务更新以故障安全方式升级,可用于安全性,错误修复或新功能的持续更新,这在物联网环境中非常重要。
|
||||
|
||||

|
||||
|
||||
**Nextcloud盒子** |
|
||||
|
||||
安全性和可靠性是关注的重点,Ries说。 “Snaps可以完全独立于彼此和操作系统运行,使得两个应用程序可以安全地在单个网关上运行,”他说。 “Snaps是只读的和经过认证的,可以保证代码的完整性。
|
||||
|
||||
Ries还采用了减少开发时间的技术。 “Snap软件包允许开发人员向支持它的任何平台提供相同的二进制包,从而降低开发和测试成本,减少部署时间和提高更新速度。 “使用snap包,开发人员完全控制开发生命周期,并可以立即更新。 Snap包提供所有必需的依赖项,因此开发人员可以选择定制他们使用的组件。
|
||||
|
||||
**ResinOS: 为IoT而生的Docker**
|
||||
|
||||
Resin.io公司,与其商用IoT框架同名,最近剥离了该框架的Yocto Linux [ResinOS 2.0] [20],ResinOS 2.0将作为一个独立的开源项目运营。 Ubuntu Core在snap包中运行Docker容器引擎,ResinOS在主机上运行Docker。 极致简约的ResinOS抽离了使用Yocto代码的复杂性,使开发人员能够快速部署Docker容器。
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][21]
|
||||
**ResinOS 2.0 架构**
|
||||
(点击图片放大)
|
||||
</center>
|
||||
|
||||
与基于Linux的CoreOS一样,ResinOS集成了系统控制服务和网络协议栈,可通过异构网络安全地部署更新的应用程序。 但是,它为在资源受限的设备(如ARM黑客板)上运行而设计,与之相反,CoreOS和其他基于Docker的操作系统(例如基于Red Hat的Project Atomic)目前仅能运行在x86上,并且更喜欢资源丰富的服务器平台。 ResinOS可以在20个Linux设备上运行,包括Raspberry Pi,BeagleBone和Odroid-C1等。
|
||||
|
||||
“我们认为Linux容器对嵌入式系统比对于云更重要,”Resin.io的Marinos说。 “在云中,容器代表了对之前进程的优化,但在嵌入式中,它们代表了姗姗来迟的通用虚拟化“
|
||||
|
||||

|
||||
|
||||
**BeagleBone Black** |
|
||||
|
||||
当应用于物联网时,完整的企业虚拟机有直接硬件访问的性能问题和限制,Marinos说。像OSGi和Android的Dalvik这样的移动虚拟机可以用于IoT,但是它们依赖Java并有其他限制。
|
||||
|
||||
对于企业开发人员来说,使用Docker似乎很自然,但是你如何说服嵌入式黑客转向全新的范式呢? “Marinos解释说,”ResinOS不是把云技术的实践经验照单全收,而是针对嵌入式进行了优化。”此外,他说,容器比典型的物联网技术更好地包容故障。 “如果有软件缺陷,主机操作系统可以继续正常工作,甚至保持连接。要恢复,您可以重新启动容器或推送更新。更新设备而不重新启动它的能力进一步消除了故障引发问题的机率。”
|
||||
|
||||
根据Marinos,其他好处源自与云技术的一致性,例如拥有更广泛的开发人员。容器提供了“跨数据中心和边缘的统一范式,以及一种方便地将技术,工作流,基础设施,甚至应用程序转移到边缘(终端)的方式。
|
||||
|
||||
Marinos说,容器中的固有安全性优势正在被其他技术增强。 “随着Docker社区推动实现签名的图像和证据,这些自然转移并应用到ResinOS,”他说。 “当Linux内核被强化以提高容器安全性时,或者获得更好地管理容器所消耗的资源的能力时,会产生类似的好处。
|
||||
|
||||
容器也适合开源IoT框架,Marinos说。 “Linux容器很容易与几乎各种协议,应用程序,语言和库结合使用,”Marinos说。 “Resin.io参加了AllSeen联盟,我们与使用IoTivity和Thread的伙伴合作。
|
||||
|
||||
**IoT的未来:智能网关与智能终端**
|
||||
|
||||
Marinos和Canonical的Ries对未来物联网的几个发展趋势具有一致的看法。 首先,物联网的最初概念(其中基于MCU的端点直接与云进行通信以进行处理)正在迅速被雾化计算架构取代。 这需要更智能的网关,也需要比仅仅在ZigBee和WiFi之间聚合和转换数据更多的功能。
|
||||
|
||||
第二,网关和智能边缘设备越来越多地运行多个应用程序。 第三,许多这些设备将提供板载分析,这些在最新的[智能家居集线器] [22]上都有体现。 最后,富媒体将很快成为物联网组合的一部分。
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][23] [
|
||||

|
||||
][24]
|
||||
**最新设备网关: Eurotech’s [ReliaGate 20-26][1] 和 Advantech’s [UBC-221][2]**
|
||||
(点击图片放大)
|
||||
</center>
|
||||
|
||||
“智能网关正在接管最初为云服务设计的许多处理和控制功能,”Marinos说。 “因此,我们看到对容器化的推动力在增加,可以在IoT设备中使用类似云工作流程来部署与功能和安全相关的优化。 去中心化是由移动数据紧缩,不断发展的法律框架和各种物理限制等因素驱动的。
|
||||
|
||||
Ubuntu Core等平台正在使“可用于网关的软件爆炸式增长”,Canonical的Ries说。 “在单个设备上运行多个应用程序的能力吸引了众多单一功能设备的用户,以及现在可以产生持续的软件收入的设备所有者。
|
||||
|
||||
<center>
|
||||
[
|
||||

|
||||
][25] [
|
||||

|
||||
][26]
|
||||
**两种IoT网关: [MyOmega MYNXG IC2 Controller (左) 和TechNexion’s ][3][LS1021A-IoT Gateway][4]**
|
||||
(点击图片放大)
|
||||
</center>
|
||||
|
||||
不仅是网关 - 终端也变得更聪明。 “阅读大量的物联网新闻报道,你得到的印象是所有终端都运行在微控制器上,”Marinos说。 “但是我们对大量的Linux终端,如数字标牌,无人机和工业机械等直接执行任务,而不是作为操作中介(数据转发)感到惊讶。我们称之为影子IoT。
|
||||
|
||||
Canonical的Ries同意,对简约技术的专注使他们忽视了新兴物联网领域。 “轻量化的概念在一个发展速度与物联网一样快的行业中初现端倪,”Ries说。 “今天的高级消费硬件可以持续为终端供电数月。“
|
||||
|
||||
虽然大多数物联网设备将保持轻量和“无头”(一种配置方式,比如物联网设备缺少显示器,键盘等),它们装备有传感器如加速度计和温度传感器并通过低速率的数据流通信,但是许多较新的物联网应用已经使用富媒体。 “媒体输入/输出只是另一种类型的外设,”Marinos说。 “总是存在多个容器竞争有限资源的问题,但它与传感器或蓝牙竞争天线资源没有太大区别。”
|
||||
|
||||
Ries看到了工业和家庭网关中“提高边缘智能”的趋势。 “我们看到人工智能,机器学习,计算机视觉和上下文意识的大幅上升,”Ries说。 “为什么要在云中运行面部检测软件,如果相同的软件可以在边缘设备运行而又没有网络延迟和带宽及计算成本?“
|
||||
|
||||
当我们在这个物联网系列的[开篇故事] [27]中探索时,我们发现存在与安全相关的物联网问题,例如隐私丧失和生活在监视文化中的权衡。还有一些问题如把个人决策交给可能由他人操控的AI裁定。这些不会被容器,快照或任何其他技术完全解决。
|
||||
|
||||
Perhaps we’d be happier if Alexa handled the details of our lives while we sweat the big stuff, and maybe there’s a way to balance privacy and utility. For now, we’re still exploring, and that’s all for the good.
|
||||
如果Alexa可以处理生活琐碎,而我们专注在要事上,也许我们会更快乐。或许有一个方法来平衡隐私和效用,现在,我们仍在探索,如此甚好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
[1]:http://hackerboards.com/atom-based-gateway-taps-new-open-source-iot-cloud-platform/
|
||||
[2]:http://hackerboards.com/compact-iot-gateway-runs-yocto-linux-on-quark/
|
||||
[3]:http://hackerboards.com/wireless-crazed-customizable-iot-gateway-uses-arm-or-x86-coms/
|
||||
[4]:http://hackerboards.com/iot-gateway-runs-linux-on-qoriq-accepts-arduino-shields/
|
||||
[5]:http://hackerboards.com/linux-and-open-source-hardware-for-building-iot-devices/
|
||||
[6]:http://hackerboards.com/intel-launches-14nm-atom-e3900-and-spins-an-automotive-version/
|
||||
[7]:http://hackerboards.com/samsung-adds-first-64-bit-and-cortex-m4-based-artik-modules/
|
||||
[8]:http://hackerboards.com/new-cortex-m-chips-add-armv8-and-trustzone/
|
||||
[9]:http://hackerboards.com/exploring-security-challenges-in-linux-based-iot-devices/
|
||||
[10]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[11]:http://hackerboards.com/open-source-projects-for-the-internet-of-things-from-a-to-z/
|
||||
[12]:http://hackerboards.com/lightweight-snappy-ubuntu-core-os-targets-iot/
|
||||
[13]:http://hackerboards.com/canonical-pushes-snap-as-a-universal-linux-package-format/
|
||||
[14]:http://hackerboards.com/ubuntu-core-16-gets-smaller-goes-all-snaps/
|
||||
[15]:http://hackerboards.com/files/canonical_ubuntucore16_diagram.jpg
|
||||
[16]:http://hackerboards.com/open-source-oses-for-the-internet-of-things/
|
||||
[17]:http://hackerboards.com/private-cloud-server-and-iot-gateway-runs-ubuntu-snappy-on-rpi/
|
||||
[18]:http://hackerboards.com/linaro-beams-lite-at-internet-of-things-devices/
|
||||
[19]:http://hackerboards.com/96boards-goes-cortex-m4-with-iot-edition-and-carbon-sbc/
|
||||
[20]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/%3Ca%20href=
|
||||
[21]:http://hackerboards.com/files/resinio_resinos_arch.jpg
|
||||
[22]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[23]:http://hackerboards.com/files/eurotech_reliagate2026.jpg
|
||||
[24]:http://hackerboards.com/files/advantech_ubc221.jpg
|
||||
[25]:http://hackerboards.com/files/myomega_mynxg.jpg
|
||||
[26]:http://hackerboards.com/files/technexion_ls1021aiot_front.jpg
|
||||
[27]:http://hackerboards.com/an-open-source-perspective-on-the-internet-of-things-part-1/
|
||||
[28]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
@ -0,0 +1,170 @@
|
||||
编写android测试单元应该做的和不应该做的.
|
||||
============================================================
|
||||
|
||||
在本文中, 根据我的实际经验我将为大家阐述一个测试用例.在本文中我将使用Espresso编码, 但是它们可以用到单元测试当中. 基于以上目的, 我们来研究一个新闻程序.
|
||||
|
||||
> 以下内容纯属虚构,如有雷同纯属巧合:P
|
||||
|
||||
一个新闻APP应该会有以下几个工作流.
|
||||
|
||||
|
||||
* 语言选择页面- 当用户第一次打开软件, 他必须至少选择一种语言. 当选择一个或者多个语言, 用shared preferences保存选项,用户跳转到新闻列表页面.
|
||||
* 新闻列表页面- 当用户来到新闻列表页面, 将发送一个包含语言参数的请求到服务器,并将服务器返回的内容显示在recycler view上(包含有新闻列表的 id?_news_list_). 如果语言参数不存在在shared preferences或者服务器没有返回一个成功消息, 就会弹出一个错误对话框并且recycler view将不可见. 新闻列表页面有个名叫 “Change your Language” 的按钮,如果用户选择了一种语言 或者用户选择多种语言“Change your Languages” 永远是可见的. ( 我对天发誓这是一个虚构的APP软件)
|
||||
* 新闻详细内容-如同名字所述, 当用户点选新闻列表项将启动这个页面.
|
||||
|
||||
|
||||
这个APP已经研究的足够了,让我们深入新闻列表页面编写测试用例. 这是我第一次写的代码.
|
||||
|
||||
|
||||
```
|
||||
/*
|
||||
Click on the first news item.
|
||||
It should open NewsDetailActivity
|
||||
*/
|
||||
@Test
|
||||
public void testClickOnAnyNewsItem() {
|
||||
onView(allOf(withId(R.id.news_list), isDisplayed())).perform(RecyclerViewActions
|
||||
.actionOnItemAtPosition(1, click()));
|
||||
intended(hasComponent(NewsDetailsActivity.class.getName()));
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* To test the correct text on the button
|
||||
*/
|
||||
@Test
|
||||
public void testChangeLanguageFeature() {
|
||||
int count = UserPreferenceUtil.getSelectedLanguagesCount();
|
||||
if (count == 1) {
|
||||
onView(withText("Choose your Language")).check(matches(isDisplayed()));
|
||||
} else if (count > 1) {
|
||||
onView(withText("Choose your Languages")).check(matches(isDisplayed()));
|
||||
}
|
||||
?}
|
||||
```
|
||||
#### 仔细想想测试什么.
|
||||
|
||||
我们首先来测试新闻列表项的点击_?testClickOnAnyNewsItem()_, 如果服务器没有返回成功信息, 测试用例将会返回失败,因为recycler view是不可见的. 但是这个测试用例的通过或者失败并不是我们所期望的结果, 它要求不管什么原因recycler view都是可见的, 如果recycler view不可见,将返回失败信息. 正确的测试代码应该像下面这个样子.
|
||||
|
||||
```
|
||||
/*
|
||||
Click on any news item.
|
||||
It should open NewsDetailActivity
|
||||
*/
|
||||
@Test
|
||||
public void testClickOnAnyNewsItem() {
|
||||
try {
|
||||
/*To test this case, we need to have recyclerView present. If we don't have the
|
||||
recyclerview present either due to the presence of error_screen, then we should consider
|
||||
this test case successful. The test case should be unsuccesful only when we click on a
|
||||
news item and it doesn't open NewsDetail activity
|
||||
*/
|
||||
ViewInteraction viewInteraction = onView(withId(R.id.news_list));
|
||||
viewInteraction.check(matches(isDisplayed()));
|
||||
} catch (NoMatchingViewException e) {
|
||||
return;
|
||||
} catch (AssertionFailedError e) {
|
||||
return;
|
||||
}
|
||||
//Here we are sure, that the news_list recyclerview is visible to the user.
|
||||
onView(allOf(withId(R.id.news_list), isDisplayed())).perform(RecyclerViewActions
|
||||
.actionOnItemAtPosition(1, click()));
|
||||
intended(hasComponent(NewsDetailsActivity.class.getName()));
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
#### 一个测试用例本身应该是完整的
|
||||
|
||||
当我开始测试, 我通常按如下顺序测试
|
||||
|
||||
* 语音选择页面
|
||||
* 新闻列表页面
|
||||
* 新闻详细内容
|
||||
|
||||
当我开始测试语音选择页面, 总有一种语音已经是选择好了的. 但是当我测试新闻列表页面, 测试用例开始返回错误信息. 原因很简单- 没有选择语音,recycler view讲不会显示出来.因此, 测试用例的执行顺序不能影响测试结果. 因此在运行测试用例之前, 语言选项必须是保存的. 在本例中,测试用例独立与语言选择页面单独运行.
|
||||
|
||||
```
|
||||
@Rule
|
||||
public ActivityTestRule activityTestRule =
|
||||
new ActivityTestRule(TopicsActivity.class, false, false);
|
||||
|
||||
/*
|
||||
Click on any news item.
|
||||
It should open NewsDetailActivity
|
||||
*/
|
||||
@Test
|
||||
public void testClickOnAnyNewsItem() {
|
||||
UserPreferenceUtil.saveUserPrimaryLanguage("english");
|
||||
Intent intent = new Intent();
|
||||
activityTestRule.launchActivity(intent);
|
||||
try {
|
||||
ViewInteraction viewInteraction = onView(withId(R.id.news_list));
|
||||
viewInteraction.check(matches(isDisplayed()));
|
||||
} catch (NoMatchingViewException e) {
|
||||
return;
|
||||
} catch (AssertionFailedError e) {
|
||||
return;
|
||||
}
|
||||
onView(allOf(withId(R.id.news_list), isDisplayed())).perform(RecyclerViewActions
|
||||
.actionOnItemAtPosition(1, click()));
|
||||
intended(hasComponent(NewsDetailsActivity.class.getName()));
|
||||
?}
|
||||
```
|
||||
#### 在测试用例中避免使用条件代码.
|
||||
|
||||
现在在第二个测试用例_testChangeLanguageFeature()_, 我们获取到用户选择语言个数, 我们写了if-else条件来进行测试 . 但是 if-else 条件应该写在你的代码当中, 不是测试代码里. 每一个条件应该单独测试. 因此, 在本例中, 我们将写如下两个测试用例.
|
||||
|
||||
```
|
||||
/**
|
||||
* To test the correct text on the button when only one language is selected.
|
||||
*/
|
||||
@Test
|
||||
public void testChangeLanguageFeatureForSingeLanguage() {
|
||||
//Other initializations
|
||||
UserPreferenceUtil.saveSelectedLanguagesCount(1);
|
||||
Intent intent = new Intent();
|
||||
activityTestRule.launchActivity(intent);
|
||||
onView(withText("Choose your Language")).check(matches(isDisplayed()));
|
||||
}
|
||||
|
||||
/**
|
||||
* To test the correct text on the button when more than one language is selected.
|
||||
*/
|
||||
@Test
|
||||
public void testChangeLanguageFeatureForMultipleLanguages() {
|
||||
//Other initializations
|
||||
UserPreferenceUtil.saveSelectedLanguagesCount(5); //Write anything greater than 1.
|
||||
Intent intent = new Intent();
|
||||
activityTestRule.launchActivity(intent);
|
||||
onView(withText("Choose your Languages")).check(matches(isDisplayed()));
|
||||
}
|
||||
|
||||
```
|
||||
#### 测试用例应该独立于外部因素
|
||||
|
||||
在大多数APP中, 我们与外部网络或者数据库进行交互.一个测试用例可以向服务器发送一个请求并获取返回信息. 但是当获取失败信息以后, 我们不能认为测试用例没有通过.试想一下如果测试用例没有通过, 然后我们修改客户端代码,测试用例通过. 但是在本文中, 我们有在客户端进行任何更改吗?-没有.
|
||||
|
||||
但是你应该也无法避免要测试网络请求和响应. 由于服务器是一个外部代理, 我们可以设想一个场景,发送一些可能导致程序崩溃的错误请求. 因此, 你写的测试用例应该覆盖所有可能来自服务器的响应,通过这种方式来保证你的代码不会崩溃.
|
||||
|
||||
> 正确的编写测试用例非常重要的.
|
||||
|
||||
感谢你阅读此文章。你可以联系我[LinkedIn][1]. 你还可以阅读我的其他文章[here][2].
|
||||
|
||||
获取更多资讯请关注?_[_Mindorks_][3]_?, 你将获得我们的最新信息.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.mindorks.com/the-dos-and-don-ts-of-writing-test-cases-in-android-70f1b5dab3e1#.lfilq9k5e
|
||||
|
||||
作者:[Anshul Jain][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.mindorks.com/@anshuljain?source=post_header_lockup
|
||||
[1]:http://www.linkedin.com/in/anshul-jain-b7082573
|
||||
[2]:https://medium.com/@anshuljain
|
||||
[3]:https://blog.mindorks.com/
|
||||
@ -0,0 +1,192 @@
|
||||
嗨,本教程中,我们将学习如何使用 docker 部署 golang web 应用程序。 你可能已经知道,由于 golang 的高性能和可靠性,docker是完全是用 golang 写的。在我们详细介绍之前,请确保你已经安装了 docker 以及 golang 并对它们有基本了解。
|
||||
|
||||
|
||||
### 关于 docker
|
||||
|
||||
Docker 是一个开源程序,它使一个 Linux 应用程序捆绑完整的依赖并打包为容器来共享主机操作系统的相同内核。 另一方面,像 VMware 这样的基于 hypervisor 的虚拟化操作系统容器提供了高级别的隔离和安全性,由于客户机和主机之间的通信是通过 hypervisor 来实现的,因为它们不共享内核空间。这也导致了由于硬件仿真带来的性能开销。 所以容器虚拟化诞生了以确保一个轻量级的虚拟环境,它将一组进程和资源与主机以及其他容器分组及隔离。因此,容器内部的进程无法看到容器外部的进程或资源。
|
||||
|
||||
### 用 Go 语言创建一个 "Hello World" web 应用
|
||||
|
||||
让我们创建一个 Go 应用的目录,它会在浏览器中显示“Hello World”。创建一个 web 应用目录并使它成为当前页面。进入 web 应用目录并编辑一个 “main.go”。
|
||||
|
||||
root@demohost:~# mkdir web-app
|
||||
root@demohost:~# cd web-app/
|
||||
root@demohost:~/web-app# vim.tiny main.go
|
||||
|
||||
package main
|
||||
import (
|
||||
"fmt"
|
||||
"net/http"
|
||||
)
|
||||
|
||||
func handler(w http.ResponseWriter, r *http.Request) {
|
||||
fmt.Fprintf(w, "Hello %s", r.URL.Path[1:])
|
||||
}
|
||||
|
||||
func main() {
|
||||
http.HandleFunc("/World", handler)
|
||||
http.ListenAndServe(":8080", nil)
|
||||
}
|
||||
|
||||
使用下面的命令运行上面的 “Hello World” Go 程序。在浏览器中输入 http://127.0.0.1:8080/World 测试,你会在浏览器中看到“Hello World”。
|
||||
|
||||
root@demohost:~/web-app# PORT=8080 go run main.go
|
||||
|
||||
下一步是将上面的应用容器化。因此我们会创建一个 dockerfile 文件,它会告诉 docker 如何容器化我们的 web 应用。
|
||||
|
||||
root@demohost:~/web-app# vim.tiny Dockerfile
|
||||
|
||||
# 得到最新的golang docker 镜像
|
||||
FROM golang:latest
|
||||
|
||||
# 在容器内部创建一个目录来存储我们的 web 应用,接着使它称为工作目录。
|
||||
RUN mkdir -p /go/src/web-app
|
||||
WORKDIR /go/src/web-app
|
||||
|
||||
# 复制 web 目录到容器中
|
||||
COPY . /go/src/web-app
|
||||
|
||||
# 下载并安装第三方依赖到容器中
|
||||
RUN go-wrapper download
|
||||
RUN go-wrapper install
|
||||
|
||||
# 设置 PORT 环境变量
|
||||
ENV PORT 8080
|
||||
|
||||
# 给主机暴露 8080 端口,这样外部网络可以访问你的应用
|
||||
EXPOSE 8080
|
||||
|
||||
# 告诉 Docker 启动容器运行的命令
|
||||
CMD ["go-wrapper", "run"]
|
||||
|
||||
### 构建/运行容器
|
||||
|
||||
使用下面的命令构建你的 Go web 应用,你会在成功构建后获得确认。
|
||||
|
||||
root@demohost:~/web-app# docker build --rm -t web-app .
|
||||
Sending build context to Docker daemon 3.584 kB
|
||||
Step 1 : FROM golang:latest
|
||||
latest: Pulling from library/golang
|
||||
386a066cd84a: Already exists
|
||||
75ea84187083: Pull complete
|
||||
88b459c9f665: Pull complete
|
||||
a31e17eb9485: Pull complete
|
||||
1b272d7ab8a4: Pull complete
|
||||
eca636a985c1: Pull complete
|
||||
08158782d330: Pull complete
|
||||
Digest: sha256:02718aef869a8b00d4a36883c82782b47fc01e774d0ac1afd434934d8ccfee8c
|
||||
Status: Downloaded newer image for golang:latest
|
||||
---> 9752d71739d2
|
||||
Step 2 : RUN mkdir -p /go/src/web-app
|
||||
---> Running in 9aef92fff9e8
|
||||
---> 49936ff4f50c
|
||||
Removing intermediate container 9aef92fff9e8
|
||||
Step 3 : WORKDIR /go/src/web-app
|
||||
---> Running in 58440a93534c
|
||||
---> 0703574296dd
|
||||
Removing intermediate container 58440a93534c
|
||||
Step 4 : COPY . /go/src/web-app
|
||||
---> 82be55bc8e9f
|
||||
Removing intermediate container cae309ac7757
|
||||
Step 5 : RUN go-wrapper download
|
||||
---> Running in 6168e4e96ab1
|
||||
+ exec go get -v -d
|
||||
---> 59664b190fee
|
||||
Removing intermediate container 6168e4e96ab1
|
||||
Step 6 : RUN go-wrapper install
|
||||
---> Running in e56f093b6f03
|
||||
+ exec go install -v
|
||||
web-app
|
||||
---> 584cd410fdcd
|
||||
Removing intermediate container e56f093b6f03
|
||||
Step 7 : ENV PORT 8080
|
||||
---> Running in 298e2a415819
|
||||
---> c87fd2b43977
|
||||
Removing intermediate container 298e2a415819
|
||||
Step 8 : EXPOSE 8080
|
||||
---> Running in 4f639a3790a7
|
||||
---> 291167229d6f
|
||||
Removing intermediate container 4f639a3790a7
|
||||
Step 9 : CMD go-wrapper run
|
||||
---> Running in 6cb6bc28e406
|
||||
---> b32ca91bdfe0
|
||||
Removing intermediate container 6cb6bc28e406
|
||||
Successfully built b32ca91bdfe0
|
||||
|
||||
现在可以运行我们的 Go 应用了,可以执行下面的命令。
|
||||
|
||||
root@demohost:~/web-app# docker run -p 8080:8080 --name="test" -d web-app
|
||||
7644606b9af28a3ef1befd926f216f3058f500ffad44522c1d4756c576cfa85b
|
||||
|
||||
进入 http://localhost:8080/World 浏览你的 web 应用。你已经成功容器化了一个可重复的/确定性的容器化 Go web 应用。使用下面的命令来启动、停止并检查容器的状态。
|
||||
|
||||
列出所有容器
|
||||
root@demohost:~/ docker ps -a
|
||||
|
||||
使用 id 启动容器
|
||||
root@demohost:~/ docker start CONTAINER_ID_OF_WEB_APP
|
||||
|
||||
使用 id 停止容器
|
||||
root@demohost:~/ docker stop CONTAINER_ID_OF_WEB_APP
|
||||
|
||||
### 重新构建镜像
|
||||
|
||||
假设你正在开发 web 应用程序并在更改代码。现在要在更新代码后查看结果,你需要重新生成 docker 镜像、停止旧镜像并运行新镜像,并且每次更改代码时都会继续。为了使这个过程自动化,我们将使用 docker 卷在主机和容器之间共享一个目录。这意味着你不必重新构建镜像以在容器内进行更改。容器如何检测你是否对 web 程序的源码进行了更改?答案是有一个名为 “Gin” 的好工具[https://github.com/codegangsta/gin][1],它能检测是否对源码进行了任何更改、重建镜像/二进制文件并在容器内运行更新过代码的进程。
|
||||
|
||||
要使这个过程自动化,我们将编辑 Dockerfile 并安装 Gin 将其作为 entry 命令执行。我们将开放 3030 端口(Gin代理),而不是 8080。 Gin 代理将转发流量到 8080 端口的 web 程序。
|
||||
|
||||
root@demohost:~/web-app# vim.tiny Dockerfile
|
||||
|
||||
# 得到最新的 golang docker 镜像
|
||||
FROM golang:latest
|
||||
|
||||
# 在容器内部创建一个目录来存储我们的 web 应用,接着使它称为工作目录。
|
||||
RUN mkdir -p /go/src/web-app
|
||||
WORKDIR /go/src/web-app
|
||||
|
||||
# 复制 web 程序到容器中
|
||||
COPY . /go/src/web-app
|
||||
|
||||
# 下载并安装第三方依赖到容器中
|
||||
RUN go get github.com/codegangsta/gin
|
||||
RUN go-wrapper download
|
||||
RUN go-wrapper install
|
||||
|
||||
# 设置 PORT 环境变量
|
||||
ENV PORT 8080
|
||||
|
||||
# 给主机暴露 8080 端口,这样外部网络可以访问你的应用
|
||||
EXPOSE 3030
|
||||
|
||||
# 启动容器时运行 Gin
|
||||
CMD gin run
|
||||
|
||||
# 告诉 Docker 启动容器运行的命令
|
||||
CMD ["go-wrapper", "run"]
|
||||
|
||||
现在构建镜像并启动容器:
|
||||
|
||||
root@demohost:~/web-app# docker build --rm -t web-app .
|
||||
|
||||
我们会在当前 web 程序的根目录下运行 docker 并通过暴露的 3030 端口链接 CWD 到容器中的应用目录下。
|
||||
|
||||
root@demohost:~/web-app# docker run -p 3030:3030 -v `pwd`:/go/src/web-app --name="test" -d web-app
|
||||
|
||||
打开 http://localhost:3030/World, 你就能看到你的 web 程序了。现在如果你改变了任何代码,它会在刷新后反应在你的浏览器中。
|
||||
|
||||
### 总结
|
||||
|
||||
就是这样,我们的 Go web 应用已经运行在 Ubuntu 16.04 Docker 容器中运行了!你可以通过使用 Go 框架来快速开发 API、网络应用和后端服务,从而扩展当前的网络应用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/containers/setup-go-docker-deploy-application/
|
||||
|
||||
作者:[Dwijadas Dey][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/dwijadasd/
|
||||
[1]:https://github.com/codegangsta/gin
|
||||
@ -0,0 +1,107 @@
|
||||
2017 年 Go 语言编程值得关注的 5 点
|
||||
============================================================
|
||||
|
||||
### 今年像动态插件,serverless 的 Go 以及 HTTP/2 这些创新对你的开发意味着什么?
|
||||
|
||||
Go 1.8 将于下个月发布,它将有几个新功能,包括:
|
||||
|
||||
* [HTTP/2 Push] [1]
|
||||
* [HTTP 服务器平滑关闭] [2]
|
||||
* [插件] [3]
|
||||
* [缺省 GOPATH] [4]
|
||||
|
||||
这些新功能的影响力取决于你和开发团队如何使用 Go。 自从 Go 1.0 于 2012 年发布以来,其简单性、并发性和内置支持使其保持[普及度][9]不断增长,所以“Go 擅长什么”的答案一直在增长。
|
||||
|
||||
这里我会提供一些想法,从即将到来的版本及 Go 世界最近其它吸引我的地方。这不是一个详尽的列表,所以请[让我知道][10]你认为在 2017 年 Go 还会发生哪些重要的事。
|
||||
|
||||
### Go 的超级可部署性 + 插件 = 容器、任何东西?
|
||||
|
||||
下个月计划发布的 [1.8 版本][11],我已经与几个人交谈过添加动态插件 - 这是为了加载在编译时不是程序一部分的共享库的代码 - 会如何影响像容器之类的事物。 动态插件使容器中的高并发微服务变得更加简单。 你可以轻松地加载插件作为外部进程,同时具备在容器中微服务的所有好处:保护你的主进程不会崩溃,并且没有任何东西会搞乱你的内存空间。 对插件的动态支持应该是在 Go 中使用容器的福音。
|
||||
|
||||
_关于专家现场 Go 培训,请注册_[ _Go Beyond the Basics_][12]_。_
|
||||
|
||||
### 跨平台支持仍在吸引开发人员
|
||||
|
||||
在 Go 开源之后的 7 年里,它已被全球采用。[Daniel Whitenack][13] 是一名数据科学家和工程师,他为 Jupyter 维护 Go 内核,告诉我最近他[在西伯利亚做数据科学和 Go 语言培训][14],(是的,在西伯利亚!数据科学和Go - 之后再细讲一下...)并 “很惊讶地看到那里 Go 社区是如此活跃和积极。” 人们将继续采取 Go 用于项目的另一个很大的原因是交叉编译,对此,几个 Go 专家解释说[这在 Go 1.5 版本中更容易了][15]。来自其他语言(如 Python)的开发人员应该发现,在没有 VM 的目标平台上,能够为多个操作系统构建捆绑的、可以部署的应用程序是在 Go 中工作的关键。
|
||||
|
||||
在 1.8 版本中对跨平台的支持,再加上[编译时间 15% 的速度提高][16],你就可以看到为什么 Go 是初创公司最喜欢的语言。
|
||||
|
||||
*有兴趣了解 Go 的基础知识吗?查看 [Go 基础学习路径][17] 让 O’Reilly 专家来带你开始。*
|
||||
|
||||
### Go 解释器在开发中:再见 Read-Eval-Print-Loop
|
||||
|
||||
有一些真正的聪明人正在做一个 [Go 解释器][18],我一定会持续关注它。如你所知的那样,有几个 Read-Eval-Print-Loop(REPL)的解决方案可以用来评估表达式并确保代码按预期工作,但这些方法通常意味着容忍不便的事项,或费力从几个方案中找到一个适合你的案例。有一个健壮、一致的解释器就太好了,一旦我了解到更多,我会告诉你们。
|
||||
|
||||
|
||||
*在开发中使用 Go 复杂特性?观看 O'Reilly 的视频训练 [中级 Go ][19]*。
|
||||
|
||||
### Go 的 serverless - 会是什么样子?
|
||||
|
||||
是的,现在围绕 serverless 架构有很多炒作,也就是功能即服务(FaaS)。但有时候也有些模糊,那么关于 Go 的 serverless 发生了什么?我们能在今年看到一个 Go 语言原生支持的 serverless 服务么?
|
||||
|
||||
AWS Lambda 是最知名的 serverless 提供商,但 Google 最近还推出了 [Google Cloud Functions][20]。这两个 FaaS 解决方案使你可以在不管理服务器的情况下运行代码,你的代码存储在别人为你管理的服务器集群上,并且仅在触发事件调用它时运行。AWS Lambda 目前支持 JavaScript、Python 和 Java,还可以启动 Go、Ruby 和 bash 进程。 Google Cloud Functions 只支持 JavaScript,但很可能不久将支持 Java 和 Python。许多物联网设备已经使用 serverless 方案,随着 Go 越来越多地被创业公司采用,serverless 似乎是一个可能的增长点,所以我在关注这些 serverless 解决方案中 Go 的开发情况。
|
||||
|
||||
已经有[几个框架][25]可以支持 AWS Lambdas:
|
||||
|
||||
* [λGordon][5] - 使用 CloudFormation 创建、连接及部署 AWS Lambdas
|
||||
* [Apex][6] - 构建、部署及管理 AWS Lambda 函数
|
||||
* [Sparta][7] - AWS Lambda 微服务的 Go 框架
|
||||
|
||||
还有一个 AWS Lambda 替代品支持 Go:
|
||||
|
||||
* [Iron.io][8]:建立在 Docker 和 Go 之上;语言不可知;支持 Golang、Python、Ruby、PHP 和 .NET
|
||||
|
||||
*有关 serverless 架构的更多信息,请观看 Mike Roberts 在旧金山 O'Reilly 软件架构会议上的演讲主题:[_serverless介绍_][22]。*
|
||||
|
||||
### 数据科学中的 Go
|
||||
|
||||
我在本文开头暗示了这一点:也许令人惊讶的是很多人都在使用 Go 进行数据科学和机器学习。关于它是否适合还有一些争论,但基于像[ Gopher 学院在 2016 年 12月][23]的年度文章那样,你会注意到 30 篇文章中至少有 4 篇是关于机器学习或分布式数据处理,这些都在发生。
|
||||
|
||||
我之前关于 Go 的易部署性的观点可能是数据科学家使用 Go 的一个关键原因:他们可以更轻松地在可读以及可用于生产的应用程序中向他人展示数据模型。与此相结合的是 Go 的广泛使用(正如我前面提到的,它正变得越来越流行!),而且有数据专家创建“可用并且与其它程序兼容”的程序。任何使用 Go 构建的应用数据科学家会在公司其他部分使用相同的语言,或者至少非常适合现代架构。
|
||||
|
||||
*更多关于 Go 的数据科学,Daniel Whitenack 写了一个很好的概述,解释了如何使用它: [Data Science Gophers][24]。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
O'Reilly Media 的监督编辑,与编辑团队合作,涵盖各种各样的编程主题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@sconant/5-things-to-watch-in-go-programming-in-2017-39cd7a7e58e3#.8t4to5jr1
|
||||
|
||||
作者:[Susan Conant][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@sconant?source=footer_card
|
||||
[1]:https://beta.golang.org/doc/go1.8#h2push
|
||||
[2]:https://beta.golang.org/doc/go1.8#http_shutdown
|
||||
[3]:https://beta.golang.org/doc/go1.8#plugin
|
||||
[4]:https://beta.golang.org/doc/go1.8#gopath
|
||||
[5]:https://github.com/jorgebastida/gordon
|
||||
[6]:https://github.com/apex/apex
|
||||
[7]:http://gosparta.io/
|
||||
[8]:https://www.iron.io/
|
||||
[9]:https://github.com/golang/go/wiki/GoUsers
|
||||
[10]:https://twitter.com/SuConant
|
||||
[11]:https://beta.golang.org/doc/go1.8
|
||||
[12]:https://www.safaribooksonline.com/live-training/courses/go-beyond-the-basics/0636920065357/
|
||||
[13]:https://www.oreilly.com/people/1ea0c-daniel-whitenack
|
||||
[14]:https://devfest.gdg.org.ru/en/
|
||||
[15]:https://medium.com/@rakyll/go-1-5-cross-compilation-488092ba44ec#.7s7sxmc4h
|
||||
[16]:https://beta.golang.org/doc/go1.8#compiler
|
||||
[17]:http://shop.oreilly.com/category/learning-path/go-fundamentals.do
|
||||
[18]:https://github.com/go-interpreter
|
||||
[19]:http://shop.oreilly.com/product/0636920047513.do
|
||||
[20]:https://cloud.google.com/functions/docs/
|
||||
[21]:https://github.com/SerifAndSemaphore/go-serverless-list
|
||||
[22]:https://www.safaribooksonline.com/library/view/oreilly-software-architecture/9781491976142/video288473.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=5-things-to-watch-in-go-programming-body-text-cta
|
||||
[23]:https://blog.gopheracademy.com/series/advent-2016/
|
||||
[24]:https://www.oreilly.com/ideas/data-science-gophers
|
||||
[25]:https://github.com/SerifAndSemaphore/go-serverless-list
|
||||
@ -1,109 +0,0 @@
|
||||
在 Linux 终端中自定义 Bash 配色和提示内容
|
||||
============================================================
|
||||
|
||||
现今,(如果不是全部的话)大多数现代 Linux 发行版的默认 shell 都是 Bash。然而,你可能已经注意到这样一个现象,在各个发行版中,其终端配色和 提示内容都各不相同。
|
||||
|
||||
如果你一直都在考虑怎样来定制以使它更好用,当然,你也可能只是心血来潮。不管怎样,继续读下去——本文将告诉你怎么做。
|
||||
### PS1 Bash 环境变量
|
||||
|
||||
命令提示符和终端外观是通过一个叫`PS1`的变量来进行管理的。根据 Bash 手册页说明,PS1 表现了 shell 准备好读取命令时显示的基本提示字符串。
|
||||
|
||||
PS1 所允许的内容由一些反斜杠转义的特殊字符组成,可以查看手册页中 PRMPTING 章节的内容来了解它们的含义。
|
||||
|
||||
为了演示,让我们先来显示以下我们系统中`PS1`的当前内容吧(这或许看上去和你们的有那么点不同):
|
||||
|
||||
```
|
||||
$ echo $PS1
|
||||
[\u@\h \W]\$
|
||||
```
|
||||
|
||||
现在,让我们来了解一下怎样自定义 PS1 吧,以满足我们各自的需求。
|
||||
#### 自定义 PS1 格式
|
||||
|
||||
根据手册页 PROMPTING 章节的描述,下面对各个特殊字符的含义作如下说明:
|
||||
1. `\u:` 显示当前用户的用户名。
|
||||
2. `\h:` 完全合格域名中第一个点(.)之前的主机名。
|
||||
3. `\W:` 当前工作目录的基本名,对于 $HOME 通常简化使用波浪符号表示(~)。
|
||||
$$
|
||||
4. `\$:` 如果当前用户是 root,显示为 #,否则为 $。
|
||||
|
||||
例如,如果我们想要显示当前命令的历史数量,可以考虑添加`\!`;如果我们想要显示 FQDN 而不是短服务器名,那么可以考虑添加`\H`。
|
||||
|
||||
在下面的例子中,我们将同时将这两个特殊字符引入我们当前的环境中,命令如下:
|
||||
|
||||
```
|
||||
PS1="[\u@\H \W \!]\$"
|
||||
```
|
||||
|
||||
当你按下 Enter 键时,你将会看到提示内容会变成下面这样。你可以通过下面的命令来对比修改前和修改后的提示内容:
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
自定义 Linux 终端提示符 PS1
|
||||
|
||||
现在,让我们再深入一点,修改命令提示符中的用户名和主机名——同时修改文本和环境背景。
|
||||
|
||||
实际上,我们可以对提示符进行 3 个方面的自定义:
|
||||
|
||||
| 文本格式 | 前景色(文本) | 背景色 |
|
||||
| 0: 常规文本 | 30: 黑色 | 40: 黑色|
|
||||
| 1: 加粗 | 31: 红色 | 41: 红色 |
|
||||
| 4: 下划线文本 | 32: 绿色 | 42: 绿色 |
|
||||
| | 33: 黄色 | 43: 黄色 |
|
||||
| | 34: 蓝色 | 44: 蓝色 |
|
||||
| | 35: 紫色 | 45: 紫色 |
|
||||
| | 36: 青色 | 46: 青色 |
|
||||
| | 37: 白色 | 47: 白色 |
|
||||
|
||||
我们将在开头使用`\e`特殊字符以及在结尾使用`m`来后面跟着的是颜色序列。
|
||||
|
||||
在该序列中,三个值(背景,格式和前景)由逗号分隔(如果不赋值,则假定为默认值)。
|
||||
**建议阅读:** [在 Linux 中学习 Bash shell 脚本][2]
|
||||
|
||||
此外,由于值的范围不同,指定(背景,格式,或者前景)的先后顺序没有关系。
|
||||
For example, the following `PS1` will cause the prompt to appear in yellow underlined text with red background:
|
||||
例如,下面的`PS1`将导致提示符出现黄色带下划线,并且背景为红色的文本:
|
||||
|
||||
```
|
||||
PS1="\e[41;4;33m[\u@\h \W]$ "
|
||||
```
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
修改 Linux 终端提示符配色 PS1
|
||||
|
||||
虽然它看起来那么好,但是这个自定义将只会持续到当前用户会话结束。如果你关闭终端,或者退出本次会话,所有修改都会丢失。
|
||||
|
||||
为了让修改永久生效,你必须将下面这行添加到`~/.bashrc`或者`~/.bash_profile`,这取决于你的版本。
|
||||
|
||||
```
|
||||
PS1="\e[41;4;33m[\u@\h \W]$ "
|
||||
```
|
||||
|
||||
尽情去玩耍吧,你可以尝试任何色彩,直到找出最适合你的。
|
||||
##### 小结
|
||||
|
||||
在本文中,我们讲述了如何来自定义 Bash 提示符的配色和提示内容。如果你对本文还有什么问题或者建议,请在下面评论框中写下来吧。我们期待你们的声音。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:Aaron Kili 是一位 Linux 及 F.O.S.S 的狂热爱好者,一位未来的 Linux 系统管理员,web 开发者,而当前是 TechMint 的内容创建者,他热爱计算机工作,并且信奉知识分享。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/customize-bash-colors-terminal-prompt-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2017/01/Customize-Linux-Terminal-Prompt.png
|
||||
[2]:http://www.tecmint.com/category/bash-shell/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/01/Change-Linux-Terminal-Color-Prompt.png
|
||||
Loading…
Reference in New Issue
Block a user