-
-```
-
-I leave it as an exercise for you to carve out the sections for sidebar.tpl and footer.tpl.
-
-Note the lines in bold. I added them to facilitate a “login bar” at the top of every webpage. Once you’ve logged into the application, you will see the bar as so:
-
-![][17]
-
-This login bar works in conjunction with the GetSession code snippet we saw in activeContent(). The logic is, if the user is logged in (ie, there is a non-nil session), then we set the InSession parameter to a value (any value), which tells the templating engine to use the “Welcome” bar instead of “Login”. We also extract the user’s first name from the session so that we can present the friendly affectation “Welcome, Richard”.
-
-The home page, represented by index.tpl, uses the following snippet from index.html:
-```
-
-
-
-
Welcome to StarDust
- // to save space, I won't enter the remainder
- // of the snippet
-
-
-
-```
-
-#### Special Note
-
-The template files for the user module reside in the ‘user’ directory within ‘views’, just to keep things tidy. So, for example, the call to activeContent() for login is:
-```
-this.activeContent("user/login")
-
-```
-
-### Controller
-
-A controller handles requests by handing them off to the appropriate function or ‘method’. We only have one controller for our application and it’s defined in default.go. The default method Get() for handling a GET operation is associated with our home page:
-```
-func (this *MainController) Get() {
- this.activeContent("index")
-
-```
-```
- //bin //boot //dev //etc //home //lib //lib64 //media //mnt //opt //proc //root //run //sbin //speedup //srv //sys //tmp //usr //var This page requires login
- sess := this.GetSession("acme")
- if sess == nil {
- this.Redirect("/user/login/home", 302)
- return
- }
- m := sess.(map[string]interface{})
- fmt.Println("username is", m["username"])
- fmt.Println("logged in at", m["timestamp"])
-}
-
-```
-
-I’ve made login a requirement for accessing this page. Logging in means creating a session, which by default expires after 3600 seconds of inactivity. A session is typically maintained on the client side by a ‘cookie’.
-
-In order to support sessions in the application, the ‘SessionOn’ flag must be set to true. There are two ways to do this:
-
- 1. Insert ‘beego.SessionOn = true’ in the main program, main.go.
- 2. Insert ‘sessionon = true’ in the configuration file, app.conf, which can be found in the ‘conf’ directory.
-
-
-
-I chose #1. (But note that I used the configuration file to set ‘EnableAdmin’ to true: ‘enableadmin = true’. EnableAdmin allows you to use the Supervisor Module in Beego that keeps track of CPU, memory, Garbage Collector, threads, etc., via port 8088:
.)
-
-#### The Main Program
-
-The main program is also where we initialize the database to be used with the ORM (Object Relational Mapping) component. ORM makes it more convenient to perform database activities within our application. The main program’s init():
-```
-func init() {
- orm.RegisterDriver("sqlite", orm.DR_Sqlite)
- orm.RegisterDataBase("default", "sqlite3", "acme.db")
- name := "default"
- force := false
- verbose := false
- err := orm.RunSyncdb(name, force, verbose)
- if err != nil {
- fmt.Println(err)
- }
-}
-
-```
-
-To use SQLite, we must import ‘go-sqlite3', which can be installed with the command:
-```
-$ go get github.com/mattn/go-sqlite3
-
-```
-
-As you can see in the code snippet, the SQLite driver must be registered and ‘acme.db’ must be registered as our SQLite database.
-
-Recall in models.go, there was an init() function:
-```
-func init() {
- orm.RegisterModel(new(AuthUser))
-}
-
-```
-
-The database model has to be registered so that the appropriate table can be generated. To ensure that this init() function is executed, you must import ‘models’ without actually using it within the main program, as follows:
-```
-import _ "acme/models"
-
-```
-
-RunSyncdb() is used to autogenerate the tables when you start the program. (This is very handy for creating the database tables without having to **manually** do it in the database command line utility.) If you set ‘force’ to true, it will drop any existing tables and recreate them.
-
-#### The User Module
-
-User.go contains all the methods for handling login, registration, profile, etc. There are several third-party packages we need to import; they provide support for email, PBKDF2, and UUID. But first we must get them into our project…
-```
-$ go get github.com/alexcesaro/mail/gomail
-$ go get github.com/twinj/uuid
-
-```
-
-I originally got **github.com/gokyle/pbkdf2** , but this package was pulled from Github, so you can no longer get it. I’ve incorporated this package into my source under the ‘utilities’ folder, and the import is:
-```
-import pk "acme/utilities/pbkdf2"
-
-```
-
-The ‘pk’ is a convenient alias so that I don’t have to type the rather unwieldy ‘pbkdf2'.
-
-#### ORM
-
-It’s pretty straightforward to use ORM. The basic pattern is to create an ORM object, specify the ‘default’ database, and select which ORM operation you want, eg,
-```
-o := orm.NewOrm()
-o.Using("default")
-err := o.Insert(&user) // or
-err := o.Read(&user, "Email") // or
-err := o.Update(&user) // or
-err := o.Delete(&user)
-
-```
-
-#### Flash
-
-By the way, Beego provides a way to present notifications on your webpage through the use of ‘flash’. Basically, you create a ‘flash’ object, give it your notification message, store the flash in the controller, and then retrieve the message in the template file, eg,
-```
-flash := beego.NewFlash()
-flash.Error("You've goofed!") // or
-flash.Notice("Well done!")
-flash.Store(&this.Controller)
-
-```
-
-And in your template file, reference the Error flash with:
-```
-{{if .flash.error}}
-{{.flash.error}}
-
-{{end}}
-
-```
-
-#### Form Validation
-
-Once the user posts a request (by pressing the Submit button, for example), our handler must extract and validate the form input. So, first, check that we have a POST operation:
-```
-if this.Ctx.Input.Method() == "POST" {
-
-```
-
-Let’s get a form element, say, email:
-```
-email := this.GetString("email")
-
-```
-
-The string “email” is the same as in the HTML form:
-```
-
-
-```
-
-To validate it, we create a validation object, specify the type of validation, and then check to see if there are any errors:
-```
-valid := validation.Validation{}
-valid.Email(email, "email") // must be a proper email address
-if valid.HasErrors() {
- for _, err := range valid.Errors {
-
-```
-
-What you do with the errors is up to you. I like to present all of them at once to the user, so as I go through the range of valid.Errors, I add them to a map of errors that will eventually be used in the template file. Hence, the full snippet:
-```
-if this.Ctx.Input.Method() == "POST" {
- email := this.GetString("email")
- password := this.GetString("password")
- valid := validation.Validation{}
- valid.Email(email, "email")
- valid.Required(password, "password")
- if valid.HasErrors() {
- errormap := []string{}
- for _, err := range valid.Errors {
- errormap = append(errormap, "Validation failed on "+err.Key+": "+err.Message+"\n")
- }
- this.Data["Errors"] = errormap
- return
- }
-
-```
-
-### The User Management Methods
-
-We’ve looked at the major pieces of the controller. Now, we get to the meat of the application, the user management methods:
-
- * Login()
- * Logout()
- * Register()
- * Verify()
- * Profile()
- * Remove()
-
-
-
-Recall that we saw references to these functions in the router. The router associates each URL (and HTTP request) with the corresponding controller method.
-
-#### Login()
-
-Let’s look at the pseudocode for this method:
-```
-if the HTTP request is "POST" then
- Validate the form (extract the email address and password).
- Read the password hash from the database, keying on email.
- Compare the submitted password with the one on record.
- Create a session for this user.
-endif
-
-```
-
-In order to compare passwords, we need to give pk.MatchPassword() a variable with members ‘Hash’ and ‘Salt’ that are **byte slices**. Hence,
-```
-var x pk.PasswordHash
-
-```
-```
-x.Hash = make([]byte, 32)
-x.Salt = make([]byte, 16)
-// after x has the password from the database, then...
-
-```
-```
-if !pk.MatchPassword(password, &x) {
- flash.Error("Bad password")
- flash.Store(&this.Controller)
- return
-}
-
-```
-
-Creating a session is trivial, but we want to store some useful information in the session, as well. So we make a map and store first name, email address, and the time of login:
-```
-m := make(map[string]interface{})
-m["first"] = user.First
-m["username"] = email
-m["timestamp"] = time.Now()
-this.SetSession("acme", m)
-this.Redirect("/"+back, 302) // go to previous page after login
-
-```
-
-Incidentally, the name “acme” passed to SetSession is completely arbitrary; you just need to reference the same name to get the same session.
-
-#### Logout()
-
-This one is trivially easy. We delete the session and redirect to the home page.
-
-#### Register()
-```
-if the HTTP request is "POST" then
- Validate the form.
- Create the password hash for the submitted password.
- Prepare new user record.
- Convert the password hash to hexadecimal string.
- Generate a UUID and insert the user into database.
- Send a verification email.
- Flash a message on the notification page.
-endif
-
-```
-
-To send a verification email to the user, we use **gomail** …
-```
-link := "http://localhost:8080/user/verify/" + u // u is UUID
-host := "smtp.gmail.com"
-port := 587
-msg := gomail.NewMessage()
-msg.SetAddressHeader("From", "acmecorp@gmail.com", "ACME Corporation")
-msg.SetHeader("To", email)
-msg.SetHeader("Subject", "Account Verification for ACME Corporation")
-msg.SetBody("text/html", "To verify your account, please click on the link: "+link+"
Best Regards,
ACME Corporation")
-m := gomail.NewMailer(host, "youraccount@gmail.com", "YourPassword", port)
-if err := m.Send(msg); err != nil {
- return false
-}
-
-```
-
-I chose Gmail as my email relay (you will need to open your own account). Note that Gmail ignores the “From” address (in our case, “[acmecorp@gmail.com][18]”) because Gmail does not permit you to alter the sender address in order to prevent phishing.
-
-#### Notice()
-
-This special router method is for displaying a flash message on a notification page. It’s not really a user module function; it’s general enough that you can use it in many other places.
-
-#### Profile()
-
-We’ve already discussed all the pieces in this function. The pseudocode is:
-```
-Login required; check for a session.
-Get user record from database, keyed on email (or username).
-if the HTTP request is "POST" then
- Validate the form.
- if there is a new password then
- Validate the new password.
- Create the password hash for the new password.
- Convert the password hash to hexadecimal string.
- endif
- Compare submitted current password with the one on record.
- Update the user record.
- - update the username stored in session
-endif
-
-```
-
-#### Verify()
-
-The verification email contains a link which, when clicked by the recipient, causes Verify() to process the UUID. Verify() attempts to read the user record, keyed on the UUID or registration key, and if it’s found, then the registration key is removed from the database.
-
-#### Remove()
-
-Remove() is pretty much like Login(), except that instead of creating a session, you delete the user record from the database.
-
-### Exercise
-
-I left out one user management method: What if the user has forgotten his password? We should provide a way to reset the password. I leave this as an exercise for you. All the pieces you need are in this tutorial. (Hint: You’ll need to do it in a way similar to Registration verification. You should add a new Reset_key to the AuthUser table. And make sure the user email address exists in the database before you send the Reset email!)
-
-[Okay, so I’ll give you the [exercise solution][19]. I’m not cruel.]
-
-### Wrapping Up
-
-Let’s review what we’ve learned. We covered the mapping of URLs to request handlers in the router. We showed how to incorporate a CSS template design into our views. We discussed the ORM package, and how it’s used to perform database operations. We examined a number of third-party utilities useful in writing our application. The end result is a component useful in many scenarios.
-
-This is a great deal of material in a tutorial, but I believe it’s the best way to get started in writing a practical application.
-
-[For further material, look at the [sequel][20] to this article, as well as the [final edition][21].]
-
---------------------------------------------------------------------------------
-
-via: https://medium.com/@richardeng/a-word-from-the-beegoist-d562ff8589d7
-
-作者:[Richard Kenneth Eng][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://medium.com/@richardeng?source=post_header_lockup
-[1]:http://tour.golang.org/
-[2]:http://golang.org/
-[3]:http://beego.me/
-[4]:https://medium.com/@richardeng/in-the-beginning-61c7e63a3ea6
-[5]:http://www.mysql.com/
-[6]:http://www.sqlite.org/
-[7]:https://code.google.com/p/liteide/
-[8]:http://macromates.com/
-[9]:http://notepad-plus-plus.org/
-[10]:https://medium.com/@richardeng/back-to-the-future-9db24d6bcee1
-[11]:http://en.wikipedia.org/wiki/Acme_Corporation
-[12]:https://github.com/horrido/acme
-[13]:http://en.wikipedia.org/wiki/Regular_expression
-[14]:http://en.wikipedia.org/wiki/PBKDF2
-[15]:http://en.wikipedia.org/wiki/Universally_unique_identifier
-[16]:http://www.freewebtemplates.com/download/free-website-template/stardust-141989295/
-[17]:https://cdn-images-1.medium.com/max/1600/1*1OpYy1ISYGUaBy0U_RJ75w.png
-[18]:mailto:acmecorp@gmail.com
-[19]:https://github.com/horrido/acme-exercise
-[20]:https://medium.com/@richardeng/a-word-from-the-beegoist-ii-9561351698eb
-[21]:https://medium.com/@richardeng/a-word-from-the-beegoist-iii-dbd6308b2594
-[22]: http://golang.org/
-[23]: http://beego.me/
-[24]: http://revel.github.io/
-[25]: http://www.web2py.com/
-[26]: https://medium.com/@richardeng/the-zen-of-web2py-ede59769d084
-[27]: http://www.seaside.st/
-[28]: http://en.wikipedia.org/wiki/Object-relational_mapping
diff --git a/sources/tech/20151127 Research log- gene signatures and connectivity map.md b/sources/tech/20151127 Research log- gene signatures and connectivity map.md
new file mode 100644
index 0000000000..f4e7faa4bc
--- /dev/null
+++ b/sources/tech/20151127 Research log- gene signatures and connectivity map.md
@@ -0,0 +1,133 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Research log: gene signatures and connectivity map)
+[#]: via: (https://www.jtolio.com/2015/11/research-log-gene-signatures-and-connectivity-map)
+[#]: author: (jtolio.com https://www.jtolio.com/)
+
+Research log: gene signatures and connectivity map
+======
+
+Happy Thanksgiving everyone!
+
+### Context
+
+This is the third post in my continuing series on my attempts at research. Previously we talked about:
+
+ * [what I’m doing, cell states, and microarrays][1]
+ * and then [more about microarrays and R][2].
+
+
+
+By the end of last week we had discussed how to get a table of normalized gene expression intensities that looks like this:
+
+```
+ENSG00000280099_at 0.15484421
+ENSG00000280109_at 0.16881395
+ENSG00000280178_at -0.19621641
+ENSG00000280316_at 0.08622216
+ENSG00000280401_at 0.15966256
+ENSG00000281205_at -0.02085352
+...
+```
+
+The reason for doing this is to figure out which genes are related, and perhaps more importantly, what a cell is even doing.
+
+_Summary:_ new post, also, I’m bringing back the short section summaries.
+
+### Cell lines
+
+The first thing to do when trying to figure out what cells are doing is to choose a cell. There’s all sorts of cells. Healthy brain cells, cancerous blood cells, bruised skin cells, etc.
+
+For any experiment, you’ll need a control to eliminate noise and apply statistical tests for validity. If you don’t use a control, the effect you’re seeing may not even exist, and so for any experiment with cells, you will need a control cell.
+
+Cells often divide, which means that a cell, once chosen, will duplicate itself for you in the presence of the appropriate resources. Not all cells divide ad nauseam which provides some challenges, but many cells under study luckily do.
+
+So, a _cell line_ is simply a set of cells that have all replicated from a specific chosen initial cell. Any set of cells from a cell line will be as identical as possible (unless you screwed up! geez). They will be the same type of cell with the same traits and behaviors, at least, as much as possible.
+
+_Summary:_ a cell line is a large amount of cells that are as close to being the same as possible.
+
+### Perturbagens
+
+There are many things that might affect what a cell is doing. Drugs, agitation, temperature, disease, cancer, gene splicing, small molecules (maybe you give a cell more iron or calcium or something), hormones, light, Jello, ennui, etc. Given any particular cell line, giving a cell from that cell line one of these _perturbagens_, or, perturbing the cell in a specific way, when compared to a control will say what that cell does differently in the face of that perturbagen.
+
+If you’d like to find out what exactly a certain type of cell does when you give it lemon lime soda, then you choose the right cell line, leave out some control cells and give the rest of the cells soda.
+
+Then, you measure gene expression intensities for both the control cells and the perturbed cells. The _differential expression_ of genes between the perturbed cells and the controls cells is likely due to the introduction of the lemon lime soda.
+
+Genes that end up getting expressed _more_ in the presence of the soda are considered _up-regulated_, whereas genes that end up getting expressed _less_ are considered _down-regulated_. The degree to which a gene is up or down regulated constitutes how much of an effect the soda may have had on that gene.
+
+Of course, all of this has such a significant amount of experimental noise that you could find pretty much anything. You’ll need to replicate your experiment independently a few times before you publish that lemon lime soda causes increased expression in the [Sonic hedgehog gene][3].
+
+_Summary:_ A perturbagen is something you introduce/do to a cell to change its behavior, such as drugs or throwing it at a wall or something. The wall perturbagen.
+
+### Gene signature
+
+For a given change or perturbagen to a cell, we now have enough to compute lists of up-regulated and down-regulated genes and the magnitude change in expression for each gene.
+
+This gene expression pattern for some subset of important genes (perhaps the most changed in expression) is called a _gene signature_, and gene signatures are very useful. By comparing signatures, you can:
+
+ * identify or compare cell states
+ * find sets of positively or negatively correlated genes
+ * find similar disease signatures
+ * find similar drug signatures
+ * find drug signatures that might counteract opposite disease signatures.
+
+
+
+(That last bullet point is essentially where I’m headed with my research.)
+
+_Summary:_ a gene signature is a short summary of the most important gene expression differences a perturbagen causes in a cell.
+
+### Drugs!
+
+The pharmaceutical industry is constantly on the lookout for new breakthrough drugs that might represent huge windfalls in cash, and drugs don’t always work as planned. Many drugs spend years in research and development, only to ultimately find poor efficacy or adoption. Sometimes drugs even become known [much more for their side-effects than their originally intended therapy][4].
+
+The practical upshot is that there’s countless FDA-approved drugs that represent decades of work that are simply underused or even unused entirely. These drugs have already cleared many challenging regulatory hurdles, but are simply and quite literally cures looking for a disease.
+
+If even just one of these drugs can be given a new lease on life for some yet-to-be-cured disease, then perhaps we can give some people new leases on life!
+
+_Summary:_ instead of developing new drugs, there’s already lots of drugs that aren’t being used. Maybe we can find matching diseases!
+
+### The Connectivity Map project
+
+The [Broad Institute’s Connectivity Map project][5] isn’t particularly new anymore, but it represents a ground breaking and promising idea - we can dump a bunch of signatures into a database and construct all sorts of new hypotheses we might not even have thought to check before.
+
+To prove out the usefulness of this idea, the Connectivity Map (or cmap) project chose 5 different cell lines (all cancer cells, which are easy to get to replicate!) and a library of FDA approved drugs, and then gave some cells these drugs.
+
+They then constructed a database of all of the signatures they computed for each possible perturbagen they measured. Finally, they constructed a web interface where a user can upload a gene signature and get a result list back of all of the signatures they collected, ordered by the most to least similar. You can totally go sign up and [try it out][5].
+
+This simple tool is surprisingly powerful. It allows you to find similar drugs to a drug you know, but it also allows you to find drugs that might counteract a disease you’ve created a signature for.
+
+Ultimately, the project led to [a number of successful applications][6]. So useful was it that the Broad Institute has doubled down and created the much larger and more comprehensive [LINCS Project][7] that targets an order of magnitude more cell lines (77) and more perturbagens (42,532, compared to cmap’s 6100). You can sign up and use that one too!
+
+_Summary_: building a system that supports querying signature connections has already proved to be super useful.
+
+### Whew
+
+Alright, I wrote most of this on a plane yesterday but since I should now be spending time with family I’m going to cut it short here.
+
+Stay tuned for next week!
+
+--------------------------------------------------------------------------------
+
+via: https://www.jtolio.com/2015/11/research-log-gene-signatures-and-connectivity-map
+
+作者:[jtolio.com][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.jtolio.com/
+[b]: https://github.com/lujun9972
+[1]: https://www.jtolio.com/writing/2015/11/research-log-cell-states-and-microarrays/
+[2]: https://www.jtolio.com/writing/2015/11/research-log-r-and-more-microarrays/
+[3]: https://en.wikipedia.org/wiki/Sonic_hedgehog
+[4]: https://en.wikipedia.org/wiki/Sildenafil#History
+[5]: https://www.broadinstitute.org/cmap/
+[6]: https://www.broadinstitute.org/cmap/publications.jsp
+[7]: http://www.lincscloud.org/
diff --git a/sources/tech/20160302 Go channels are bad and you should feel bad.md b/sources/tech/20160302 Go channels are bad and you should feel bad.md
new file mode 100644
index 0000000000..0ad2a5ed97
--- /dev/null
+++ b/sources/tech/20160302 Go channels are bad and you should feel bad.md
@@ -0,0 +1,443 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Go channels are bad and you should feel bad)
+[#]: via: (https://www.jtolio.com/2016/03/go-channels-are-bad-and-you-should-feel-bad)
+[#]: author: (jtolio.com https://www.jtolio.com/)
+
+Go channels are bad and you should feel bad
+======
+
+_Update: If you’re coming to this blog post from a compendium titled “Go is not good,” I want to make it clear that I am ashamed to be on such a list. Go is absolutely the least worst programming language I’ve ever used. At the time I wrote this, I wanted to curb a trend I was seeing, namely, overuse of one of the more warty parts of Go. I still think channels could be much better, but overall, Go is wonderful. It’s like if your favorite toolbox had [this][1] in it; the tool can have uses (even if it could have had more uses), and it can still be your favorite toolbox!_
+
+_Update 2: I would be remiss if I didn’t point out this excellent survey of real issues: [Understanding Real-World Concurrency Bugs In Go][2]. A significant finding of this survey is that… Go channels cause lots of bugs._
+
+I’ve been using Google’s [Go programming language][3] on and off since mid-to-late 2010, and I’ve had legitimate product code written in Go for [Space Monkey][4] since January 2012 (before Go 1.0!). My initial experience with Go was back when I was researching Hoare’s [Communicating Sequential Processes][5] model of concurrency and the [π-calculus][6] under [Matt Might][7]’s [UCombinator research group][8] as part of my ([now redirected][9]) PhD work to better enable multicore development. Go was announced right then (how serendipitous!) and I immediately started kicking tires.
+
+It quickly became a core part of Space Monkey development. Our production systems at Space Monkey currently account for over 425k lines of pure Go (_not_ counting all of our vendored libraries, which would make it just shy of 1.5 million lines), so not the most Go you’ll ever see, but for the relatively young language we’re heavy users. We’ve [written about our Go usage][10] before. We’ve open-sourced some fairly heavily used libraries; many people seem to be fans of our [OpenSSL bindings][11] (which are faster than [crypto/tls][12], but please keep openssl itself up-to-date!), our [error handling library][13], [logging library][14], and [metric collection library/zipkin client][15]. We use Go, we love Go, we think it’s the least bad programming language for our needs we’ve used so far.
+
+Although I don’t think I can talk myself out of mentioning my widely avoided [goroutine-local-storage library][16] here either (which even though it’s a hack that you shouldn’t use, it’s a beautiful hack), hopefully my other experience will suffice as valid credentials that I kind of know what I’m talking about before I explain my deliberately inflamatory post title.
+
+![][17]
+
+### Wait, what?
+
+If you ask the proverbial programmer on the street what’s so special about Go, she’ll most likely tell you that Go is most known for channels and goroutines. Go’s theoretical underpinnings are heavily based in Hoare’s CSP model, which is itself incredibly fascinating and interesting and I firmly believe has much more to yield than we’ve appropriated so far.
+
+CSP (and the π-calculus) both use communication as the core synchronization primitive, so it makes sense Go would have channels. Rob Pike has been fascinated with CSP (with good reason) for a [considerable][18] [while][19] [now][20].
+
+But from a pragmatic perspective (which Go prides itself on), Go got channels wrong. Channels as implemented are pretty much a solid anti-pattern in my book at this point. Why? Dear reader, let me count the ways.
+
+#### You probably won’t end up using just channels.
+
+Hoare’s Communicating Sequential Processes is a computational model where essentially the only synchronization primitive is sending or receiving on a channel. As soon as you use a mutex, semaphore, or condition variable, bam, you’re no longer in pure CSP land. Go programmers often tout this model and philosophy through the chanting of the [cached thought][21] “[share memory by communicating][22].”
+
+So let’s try and write a small program using just CSP in Go! Let’s make a high score receiver. All we will do is keep track of the largest high score value we’ve seen. That’s it.
+
+First, we’ll make a `Game` struct.
+
+```
+type Game struct {
+ bestScore int
+ scores chan int
+}
+```
+
+`bestScore` isn’t going to be protected by a mutex! That’s fine, because we’ll simply have one goroutine manage its state and receive new scores over a channel.
+
+```
+func (g *Game) run() {
+ for score := range g.scores {
+ if g.bestScore < score {
+ g.bestScore = score
+ }
+ }
+}
+```
+
+Okay, now we’ll make a helpful constructor to start a game.
+
+```
+func NewGame() (g *Game) {
+ g = &Game{
+ bestScore: 0,
+ scores: make(chan int),
+ }
+ go g.run()
+ return g
+}
+```
+
+Next, let’s assume someone has given us a `Player` that can return scores. It might also return an error, cause hey maybe the incoming TCP stream can die or something, or the player quits.
+
+```
+type Player interface {
+ NextScore() (score int, err error)
+}
+```
+
+To handle the player, we’ll assume all errors are fatal and pass received scores down the channel.
+
+```
+func (g *Game) HandlePlayer(p Player) error {
+ for {
+ score, err := p.NextScore()
+ if err != nil {
+ return err
+ }
+ g.scores <- score
+ }
+}
+```
+
+Yay! Okay, we have a `Game` type that can keep track of the highest score a `Player` receives in a thread-safe way.
+
+You wrap up your development and you’re on your way to having customers. You make this game server public and you’re incredibly successful! Lots of games are being created with your game server.
+
+Soon, you discover people sometimes leave your game. Lots of games no longer have any players playing, but nothing stopped the game loop. You are getting overwhelmed by dead `(*Game).run` goroutines.
+
+**Challenge:** fix the goroutine leak above without mutexes or panics. For real, scroll up to the above code and come up with a plan for fixing this problem using just channels.
+
+I’ll wait.
+
+For what it’s worth, it totally can be done with channels only, but observe the simplicity of the following solution which doesn’t even have this problem:
+
+```
+type Game struct {
+ mtx sync.Mutex
+ bestScore int
+}
+
+func NewGame() *Game {
+ return &Game{}
+}
+
+func (g *Game) HandlePlayer(p Player) error {
+ for {
+ score, err := p.NextScore()
+ if err != nil {
+ return err
+ }
+ g.mtx.Lock()
+ if g.bestScore < score {
+ g.bestScore = score
+ }
+ g.mtx.Unlock()
+ }
+}
+```
+
+Which one would you rather work on? Don’t be deceived into thinking that the channel solution somehow makes this more readable and understandable in more complex cases. Teardown is very hard. This sort of teardown is just a piece of cake with a mutex, but the hardest thing to work out with Go-specific channels only. Also, if anyone replies that channels sending channels is easier to reason about here it will cause me an immediate head-to-desk motion.
+
+Importantly, this particular case might actually be _easily_ solved _with channels_ with some runtime assistance Go doesn’t provide! Unfortunately, as it stands, there are simply a surprising amount of problems that are solved better with traditional synchronization primitives than with Go’s version of CSP. We’ll talk about what Go could have done to make this case easier later.
+
+**Exercise:** Still skeptical? Try making both solutions above (channel-only vs. mutex-only) stop asking for scores from `Players` once `bestScore` is 100 or greater. Go ahead and open your text editor. This is a small, toy problem.
+
+The summary here is that you will be using traditional synchronization primitives in addition to channels if you want to do anything real.
+
+#### Channels are slower than implementing it yourself
+
+One of the things I assumed about Go being so heavily based in CSP theory is that there should be some pretty killer scheduler optimizations the runtime can make with channels. Perhaps channels aren’t always the most straightforward primitive, but surely they’re efficient and fast, right?
+
+![][23]
+
+As [Dustin Hiatt][24] points out on [Tyler Treat’s post about Go][25],
+
+> Behind the scenes, channels are using locks to serialize access and provide threadsafety. So by using channels to synchronize access to memory, you are, in fact, using locks; locks wrapped in a threadsafe queue. So how do Go’s fancy locks compare to just using mutex’s from their standard library `sync` package? The following numbers were obtained by using Go’s builtin benchmarking functionality to serially call Put on a single set of their respective types.
+
+```
+> BenchmarkSimpleSet-8 3000000 391 ns/op
+> BenchmarkSimpleChannelSet-8 1000000 1699 ns/o
+>
+```
+
+It’s a similar story with unbuffered channels, or even the same test under contention instead of run serially.
+
+Perhaps the Go scheduler will improve, but in the meantime, good old mutexes and condition variables are very good, efficient, and fast. If you want performance, you use the tried and true methods.
+
+#### Channels don’t compose well with other concurrency primitives
+
+Alright, so hopefully I have convinced you that you’ll at least be interacting with primitives besides channels sometimes. The standard library certainly seems to prefer traditional synchronization primitives over channels.
+
+Well guess what, it’s actually somewhat challenging to use channels alongside mutexes and condition variables correctly!
+
+One of the interesting things about channels that makes a lot of sense coming from CSP is that channel sends are synchronous. A channel send and channel receive are intended to be synchronization barriers, and the send and receive should happen at the same virtual time. That’s wonderful if you’re in well-executed CSP-land.
+
+![][26]
+
+Pragmatically, Go channels also come in a buffered variety. You can allocate a fixed amount of space to account for possible buffering so that sends and receives are disparate events, but the buffer size is capped. Go doesn’t provide a way to have arbitrarily sized buffers - you have to allocate the buffer size in advance. _This is fine_, I’ve seen people argue on the mailing list, _because memory is bounded anyway._
+
+Wat.
+
+This is a bad answer. There’s all sorts of reasons to use an arbitrarily buffered channel. If we knew everything up front, why even have `malloc`?
+
+Not having arbitrarily buffered channels means that a naive send on _any_ channel could block at any time. You want to send on a channel and update some other bookkeeping under a mutex? Careful! Your channel send might block!
+
+```
+// ...
+s.mtx.Lock()
+// ...
+s.ch <- val // might block!
+s.mtx.Unlock()
+// ...
+```
+
+This is a recipe for dining philosopher dinner fights. If you take a lock, you should quickly update state and release it and not do anything blocking under the lock if possible.
+
+There is a way to do a non-blocking send on a channel in Go, but it’s not the default behavior. Assume we have a channel `ch := make(chan int)` and we want to send the value `1` on it without blocking. Here is the minimum amount of typing you have to do to send without blocking:
+
+```
+select {
+case ch <- 1: // it sent
+default: // it didn't
+}
+```
+
+This isn’t what naturally leaps to mind for beginning Go programmers.
+
+The summary is that because many operations on channels block, it takes careful reasoning about philosophers and their dining to successfully use channel operations alongside and under mutex protection, without causing deadlocks.
+
+#### Callbacks are strictly more powerful and don’t require unnecessary goroutines.
+
+![][27]
+
+Whenever an API uses a channel, or whenever I point out that a channel makes something hard, someone invariably points out that I should just spin up a goroutine to read off the channel and make whatever translation or fix I need as it reads of the channel.
+
+Um, no. What if my code is in a hotpath? There’s very few instances that require a channel, and if your API could have been designed with mutexes, semaphores, and callbacks and no additional goroutines (because all event edges are triggered by API events), then using a channel forces me to add another stack of memory allocation to my resource usage. Goroutines are much lighter weight than threads, yes, but lighter weight doesn’t mean the lightest weight possible.
+
+As I’ve formerly [argued in the comments on an article about using channels][28] (lol the internet), your API can _always_ be more general, _always_ more flexible, and take drastically less resources if you use callbacks instead of channels. “Always” is a scary word, but I mean it here. There’s proof-level stuff going on.
+
+If someone provides a callback-based API to you and you need a channel, you can provide a callback that sends on a channel with little overhead and full flexibility.
+
+If, on the other hand, someone provides a channel-based API to you and you need a callback, you have to spin up a goroutine to read off the channel _and_ you have to hope that no one tries to send more on the channel when you’re done reading so you cause blocked goroutine leaks.
+
+For a super simple real-world example, check out the [context interface][29] (which incidentally is an incredibly useful package and what you should be using instead of [goroutine-local storage][16]):
+
+```
+type Context interface {
+ ...
+ // Done returns a channel that closes when this work unit should be canceled.
+ Done() <-chan struct{}
+
+ // Err returns a non-nil error when the Done channel is closed
+ Err() error
+ ...
+}
+```
+
+Imagine all you want to do is log the corresponding error when the `Done()` channel fires. What do you have to do? If you don’t have a good place you’re already selecting on a channel, you have to spin up a goroutine to deal with it:
+
+```
+go func() {
+ <-ctx.Done()
+ logger.Errorf("canceled: %v", ctx.Err())
+}()
+```
+
+What if `ctx` gets garbage collected without closing the channel `Done()` returned? Whoops! Just leaked a goroutine!
+
+Now imagine we changed `Done`’s signature:
+
+```
+// Done calls cb when this work unit should be canceled.
+Done(cb func())
+```
+
+First off, logging is so easy now. Check it out: `ctx.Done(func() { log.Errorf("canceled: %v", ctx.Err()) })`. But lets say you really do need some select behavior. You can just call it like this:
+
+```
+ch := make(chan struct{})
+ctx.Done(func() { close(ch) })
+```
+
+Voila! No expressiveness lost by using a callback instead. `ch` works like the channel `Done()` used to return, and in the logging case we didn’t need to spin up a whole new stack. I got to keep my stack traces (if our log package is inclined to use them); I got to avoid another stack allocation and another goroutine to give to the scheduler.
+
+Next time you use a channel, ask yourself if there’s some goroutines you could eliminate if you used mutexes and condition variables instead. If the answer is yes, your code will be more efficient if you change it. And if you’re trying to use channels just to be able to use the `range` keyword over a collection, I’m going to have to ask you to put your keyboard away or just go back to writing Python books.
+
+![more like Zooey De-channel, amirite][30]
+
+#### The channel API is inconsistent and just cray-cray
+
+Closing or sending on a closed channel panics! Why? If you want to close a channel, you need to either synchronize its closed state externally (with mutexes and so forth that don’t compose well!) so that other writers don’t write to or close a closed channel, or just charge forward and close or write to closed channels and expect you’ll have to recover any raised panics.
+
+This is such bizarre behavior. Almost every other operation in Go has a way to avoid a panic (type assertions have the `, ok =` pattern, for example), but with channels you just get to deal with it.
+
+Okay, so when a send will fail, channels panic. I guess that makes some kind of sense. But unlike almost everything else with nil values, sending to a nil channel won’t panic. Instead, it will block forever! That’s pretty counter-intuitive. That might be useful behavior, just like having a can-opener attached to your weed-whacker might be useful (and found in Skymall), but it’s certainly unexpected. Unlike interacting with nil maps (which do implicit pointer dereferences), nil interfaces (implicit pointer dereferences), unchecked type assertions, and all sorts of other things, nil channels exhibit actual channel behavior, as if a brand new channel was just instantiated for this operation.
+
+Receives are slightly nicer. What happens when you receive on a closed channel? Well, that works - you get a zero value. Okay that makes sense I guess. Bonus! Receives allow you to do a `, ok =`-style check if the channel was open when you received your value. Thank heavens we get `, ok =` here.
+
+But what happens if you receive from a nil channel? _Also blocks forever!_ Yay! Don’t try and use the fact that your channel is nil to keep track of if you closed it!
+
+### What are channels good for?
+
+Of course channels are good for some things (they are a generic container after all), and there are certain things you can only do with them (`select`).
+
+#### They are another special-cased generic datastructure
+
+Go programmers are so used to arguments about generics that I can feel the PTSD coming on just by bringing up the word. I’m not here to talk about it so wipe the sweat off your brow and let’s keep moving.
+
+Whatever your opinion of generics is, Go’s maps, slices, and channels are data structures that support generic element types, because they’ve been special-cased into the language.
+
+In a language that doesn’t allow you to write your own generic containers, _anything_ that allows you to better manage collections of things is valuable. Here, channels are a thread-safe datastructure that supports arbitrary value types.
+
+So that’s useful! That can save some boilerplate I suppose.
+
+I’m having trouble counting this as a win for channels.
+
+#### Select
+
+The main thing you can do with channels is the `select` statement. Here you can wait on a fixed number of inputs for events. It’s kind of like epoll, but you have to know upfront how many sockets you’re going to be waiting on.
+
+This is truly a useful language feature. Channels would be a complete wash if not for `select`. But holy smokes, let me tell you about the first time you decide you might need to select on multiple things but you don’t know how many and you have to use `reflect.Select`.
+
+### How could channels be better?
+
+It’s really tough to say what the most tactical thing the Go language team could do for Go 2.0 is (the Go 1.0 compatibility guarantee is good but hand-tying), but that won’t stop me from making some suggestions.
+
+#### Select on condition variables!
+
+We could just obviate the need for channels! This is where I propose we get rid of some sacred cows, but let me ask you this, how great would it be if you could select on any custom synchronization primitive? (A: So great.) If we had that, we wouldn’t need channels at all.
+
+#### GC could help us?
+
+In the very first example, we could easily solve the high score server cleanup with channels if we were able to use directionally-typed channel garbage collection to help us clean up.
+
+![][31]
+
+As you know, Go has directionally-typed channels. You can have a channel type that only supports reading (`<-chan`) and a channel type that only supports writing (`chan<-`). Great!
+
+Go also has garbage collection. It’s clear that certain kinds of book keeping are just too onerous and we shouldn’t make the programmer deal with them. We clean up unused memory! Garbage collection is useful and neat.
+
+So why not help clean up unused or deadlocked channel reads? Instead of having `make(chan Whatever)` return one bidirectional channel, have it return two single-direction channels (`chanReader, chanWriter := make(chan Type)`).
+
+Let’s reconsider the original example:
+
+```
+type Game struct {
+ bestScore int
+ scores chan<- int
+}
+
+func run(bestScore *int, scores <-chan int) {
+ // we don't keep a reference to a *Game directly because then we'd be holding
+ // onto the send side of the channel.
+ for score := range scores {
+ if *bestScore < score {
+ *bestScore = score
+ }
+ }
+}
+
+func NewGame() (g *Game) {
+ // this make(chan) return style is a proposal!
+ scoreReader, scoreWriter := make(chan int)
+ g = &Game{
+ bestScore: 0,
+ scores: scoreWriter,
+ }
+ go run(&g.bestScore, scoreReader)
+ return g
+}
+
+func (g *Game) HandlePlayer(p Player) error {
+ for {
+ score, err := p.NextScore()
+ if err != nil {
+ return err
+ }
+ g.scores <- score
+ }
+}
+```
+
+If garbage collection closed a channel when we could prove no more values are ever coming down it, this solution is completely fixed. Yes yes, the comment in `run` is indicative of the existence of a rather large gun aimed at your foot, but at least the problem is easily solveable now, whereas it really wasn’t before. Furthermore, a smart compiler could probably make appropriate proofs to reduce the damage from said foot-gun.
+
+#### Other smaller issues
+
+ * **Dup channels?** \- If we could use an equivalent of the `dup` syscall on channels, then we could also solve the multiple producer problem quite easily. Each producer could close their own `dup`-ed channel without ruining the other producers.
+ * **Fix the channel API!** \- Close isn’t idempotent? Send on closed channel panics with no way to avoid it? Ugh!
+ * **Arbitrarily buffered channels** \- If we could make buffered channels with no fixed buffer size limit, then we could make channels that don’t block.
+
+
+
+### What do we tell people about Go then?
+
+If you haven’t yet, please go take a look at my current favorite programming post: [What Color is Your Function][32]. Without being about Go specifically, this blog post much more eloquently than I could lays out exactly why goroutines are Go’s best feature (and incidentally one of the ways Go is better than Rust for some applications).
+
+If you’re still writing code in a programming language that forces keywords like `yield` on you to get high performance, concurrency, or an event-driven model, you are living in the past, whether or not you or anyone else knows it. Go is so far one of the best entrants I’ve seen of languages that implement an M:N threading model that’s not 1:1, and dang that’s powerful.
+
+So, tell folks about goroutines.
+
+If I had to pick one other leading feature of Go, it’s interfaces. Statically-typed [duck typing][33] makes extending and working with your own or someone else’s project so fun and amazing it’s probably worth me writing an entirely different set of words about it some other time.
+
+### So…
+
+I keep seeing people charge in to Go, eager to use channels to their full potential. Here’s my advice to you.
+
+**JUST STAHP IT**
+
+When you’re writing APIs and interfaces, as bad as the advice “never” can be, I’m pretty sure there’s never a time where channels are better, and every Go API I’ve used that used channels I’ve ended up having to fight. I’ve never thought “oh good, there’s a channel here;” it’s always instead been some variant of _**WHAT FRESH HELL IS THIS?**_
+
+So, _please, please use channels where appropriate and only where appropriate._
+
+In all of my Go code I work with, I can count on one hand the number of times channels were really the best choice. Sometimes they are. That’s great! Use them then. But otherwise just stop.
+
+![][34]
+
+_Special thanks for the valuable feedback provided by my proof readers Jeff Wendling, [Andrew Harding][35], [George Shank][36], and [Tyler Treat][37]._
+
+If you want to work on Go with us at Space Monkey, please [hit me up][38]!
+
+--------------------------------------------------------------------------------
+
+via: https://www.jtolio.com/2016/03/go-channels-are-bad-and-you-should-feel-bad
+
+作者:[jtolio.com][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.jtolio.com/
+[b]: https://github.com/lujun9972
+[1]: https://blog.codinghorror.com/content/images/uploads/2012/06/6a0120a85dcdae970b017742d249d5970d-800wi.jpg
+[2]: https://songlh.github.io/paper/go-study.pdf
+[3]: https://golang.org/
+[4]: http://www.spacemonkey.com/
+[5]: https://en.wikipedia.org/wiki/Communicating_sequential_processes
+[6]: https://en.wikipedia.org/wiki/%CE%A0-calculus
+[7]: http://matt.might.net
+[8]: http://www.ucombinator.org/
+[9]: https://www.jtolio.com/writing/2015/11/research-log-cell-states-and-microarrays/
+[10]: https://www.jtolio.com/writing/2014/04/go-space-monkey/
+[11]: https://godoc.org/github.com/spacemonkeygo/openssl
+[12]: https://golang.org/pkg/crypto/tls/
+[13]: https://godoc.org/github.com/spacemonkeygo/errors
+[14]: https://godoc.org/github.com/spacemonkeygo/spacelog
+[15]: https://godoc.org/gopkg.in/spacemonkeygo/monitor.v1
+[16]: https://github.com/jtolds/gls
+[17]: https://www.jtolio.com/images/wat/darth-helmet.jpg
+[18]: https://en.wikipedia.org/wiki/Newsqueak
+[19]: https://en.wikipedia.org/wiki/Alef_%28programming_language%29
+[20]: https://en.wikipedia.org/wiki/Limbo_%28programming_language%29
+[21]: https://lesswrong.com/lw/k5/cached_thoughts/
+[22]: https://blog.golang.org/share-memory-by-communicating
+[23]: https://www.jtolio.com/images/wat/jon-stewart.jpg
+[24]: https://twitter.com/HiattDustin
+[25]: http://bravenewgeek.com/go-is-unapologetically-flawed-heres-why-we-use-it/
+[26]: https://www.jtolio.com/images/wat/obama.jpg
+[27]: https://www.jtolio.com/images/wat/yael-grobglas.jpg
+[28]: http://www.informit.com/articles/article.aspx?p=2359758#comment-2061767464
+[29]: https://godoc.org/golang.org/x/net/context
+[30]: https://www.jtolio.com/images/wat/zooey-deschanel.jpg
+[31]: https://www.jtolio.com/images/wat/joel-mchale.jpg
+[32]: http://journal.stuffwithstuff.com/2015/02/01/what-color-is-your-function/
+[33]: https://en.wikipedia.org/wiki/Duck_typing
+[34]: https://www.jtolio.com/images/wat/michael-cera.jpg
+[35]: https://github.com/azdagron
+[36]: https://twitter.com/taterbase
+[37]: http://bravenewgeek.com
+[38]: https://www.jtolio.com/contact/
diff --git a/sources/tech/20170115 Magic GOPATH.md b/sources/tech/20170115 Magic GOPATH.md
new file mode 100644
index 0000000000..1d4cd16e24
--- /dev/null
+++ b/sources/tech/20170115 Magic GOPATH.md
@@ -0,0 +1,119 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Magic GOPATH)
+[#]: via: (https://www.jtolio.com/2017/01/magic-gopath)
+[#]: author: (jtolio.com https://www.jtolio.com/)
+
+Magic GOPATH
+======
+
+_**Update:** With the advent of Go 1.11 and [Go modules][1], this whole post is now useless. Unset your GOPATH entirely and switch to Go modules today!_
+
+Maybe someday I’ll start writing about things besides Go again.
+
+Go requires that you set an environment variable for your workspace called your `GOPATH`. The `GOPATH` is one of the most confusing aspects of Go to newcomers and even relatively seasoned developers alike. It’s not immediately clear what would be better, but finding a good `GOPATH` value has implications for your source code repository layout, how many separate projects you have on your computer, how default project installation instructions work (via `go get`), and even how you interoperate with other projects and libraries.
+
+It’s taken until Go 1.8 to decide to [set a default][2] and that small change was one of [the most talked about code reviews][3] for the 1.8 release cycle.
+
+After [writing about GOPATH himself][4], [Dave Cheney][5] [asked me][6] to write a blog post about what I do.
+
+### My proposal
+
+I set my `GOPATH` to always be the current working directory, unless a parent directory is clearly the `GOPATH`.
+
+Here’s the relevant part of my `.bashrc`:
+
+```
+# bash command to output calculated GOPATH.
+calc_gopath() {
+ local dir="$PWD"
+
+ # we're going to walk up from the current directory to the root
+ while true; do
+
+ # if there's a '.gopath' file, use its contents as the GOPATH relative to
+ # the directory containing it.
+ if [ -f "$dir/.gopath" ]; then
+ ( cd "$dir";
+ # allow us to squash this behavior for cases we want to use vgo
+ if [ "$(cat .gopath)" != "" ]; then
+ cd "$(cat .gopath)";
+ echo "$PWD";
+ fi; )
+ return
+ fi
+
+ # if there's a 'src' directory, the parent of that directory is now the
+ # GOPATH
+ if [ -d "$dir/src" ]; then
+ echo "$dir"
+ return
+ fi
+
+ # we can't go further, so bail. we'll make the original PWD the GOPATH.
+ if [ "$dir" == "/" ]; then
+ echo "$PWD"
+ return
+ fi
+
+ # now we'll consider the parent directory
+ dir="$(dirname "$dir")"
+ done
+}
+
+my_prompt_command() {
+ export GOPATH="$(calc_gopath)"
+
+ # you can have other neat things in here. I also set my PS1 based on git
+ # state
+}
+
+case "$TERM" in
+xterm*|rxvt*)
+ # Bash provides an environment variable called PROMPT_COMMAND. The contents
+ # of this variable are executed as a regular Bash command just before Bash
+ # displays a prompt. Let's only set it if we're in some kind of graphical
+ # terminal I guess.
+ PROMPT_COMMAND=my_prompt_command
+ ;;
+*)
+ ;;
+esac
+```
+
+The benefits are fantastic. If you want to quickly `go get` something and not have it clutter up your workspace, you can do something like:
+
+```
+cd $(mktemp -d) && go get github.com/the/thing
+```
+
+On the other hand, if you’re jumping between multiple projects (whether or not they have the full workspace checked in or are just library packages), the `GOPATH` is set accurately.
+
+More flexibly, if you have a tree where some parent directory is outside of the `GOPATH` but you want to set the `GOPATH` anyways, you can create a `.gopath` file and it will automatically set your `GOPATH` correctly any time your shell is inside that directory.
+
+The whole thing is super nice. I kinda can’t imagine doing something else anymore.
+
+### Fin.
+
+--------------------------------------------------------------------------------
+
+via: https://www.jtolio.com/2017/01/magic-gopath
+
+作者:[jtolio.com][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.jtolio.com/
+[b]: https://github.com/lujun9972
+[1]: https://golang.org/cmd/go/#hdr-Modules__module_versions__and_more
+[2]: https://rakyll.org/default-gopath/
+[3]: https://go-review.googlesource.com/32019/
+[4]: https://dave.cheney.net/2016/12/20/thinking-about-gopath
+[5]: https://dave.cheney.net/
+[6]: https://twitter.com/davecheney/status/811334240247812097
diff --git a/sources/tech/20170320 Whiteboard problems in pure Lambda Calculus.md b/sources/tech/20170320 Whiteboard problems in pure Lambda Calculus.md
new file mode 100644
index 0000000000..02200befe7
--- /dev/null
+++ b/sources/tech/20170320 Whiteboard problems in pure Lambda Calculus.md
@@ -0,0 +1,836 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Whiteboard problems in pure Lambda Calculus)
+[#]: via: (https://www.jtolio.com/2017/03/whiteboard-problems-in-pure-lambda-calculus)
+[#]: author: (jtolio.com https://www.jtolio.com/)
+
+Whiteboard problems in pure Lambda Calculus
+======
+
+My team at [Vivint][1], the [Space Monkey][2] group, stopped doing whiteboard interviews a while ago. We certainly used to do them, but we’ve transitioned to homework problems or actually just hiring a candidate as a short term contractor for a day or two to solve real work problems and see how that goes. Whiteboard interviews are kind of like [Festivus][3] but in a bad way: you get the feats of strength and then the airing of grievances. Unfortunately, modern programming is nothing like writing code in front of a roomful of strangers with only a whiteboard and a marker, so it’s probably not best to optimize for that.
+
+Nonetheless, [Kyle][4]’s recent (wonderful, amazing) post titled [acing the technical interview][5] got me thinking about fun ways to approach whiteboard problems as an interviewee. Kyle’s [Church-encodings][6] made me wonder how many “standard” whiteboard problems you could solve in pure lambda calculus. If this isn’t seen as a feat of strength by your interviewers, there will certainly be some airing of grievances.
+
+➡️️ **Update**: I’ve made a lambda calculus web playground so you can run lambda calculus right in your browser! I’ve gone through and made links to examples in this post with it. Check it out at
+
+### Lambda calculus
+
+Wait, what is lambda calculus? Did I learn that in high school?
+
+Big-C “Calculus” of course usually refers to derivatives, integrals, Taylor series, etc. You might have learned about Calculus in high school, but this isn’t that.
+
+More generally, a little-c “calculus” is really just any system of calculation. The [lambda calculus][7] is essentially a formalization of the smallest set of primitives needed to make a completely [Turing-complete][8] programming language. Expressions in the language can only be one of three things.
+
+ * An expression can define a function that takes exactly one argument (no more, no less) and then has another expression as the body.
+ * An expression can call a function by applying two subexpressions.
+ * An expression can reference a variable.
+
+
+
+Here is the entire grammar:
+
+```
+ ::=
+ | `λ` `.`
+ | `(` `)`
+```
+
+That’s it. There’s nothing else you can do. There are no numbers, strings, booleans, pairs, structs, anything. Every value is a function that takes one argument. All variables refer to these functions, and all functions can do is return another function, either directly, or by calling yet another function. There’s nothing else to help you.
+
+To be honest, it’s a little surprising that this is even Turing-complete. How do you do branches or loops or recursion? This seems too simple to work, right?
+
+A common whiteboard problem is the [fizz buzz problem][9]. The goal is to write a function that prints out all the numbers from 0 to 100, but instead of printing numbers divisible by 3 it prints “fizz”, and instead of printing numbers divisible by 5 it prints “buzz”, and in the case of both it prints “fizzbuzz”. It’s a simple toy problem but it’s touted as a good whiteboard problem because evidently many self-proclaimed programmers can’t solve it. Maybe part of that is cause whiteboard problems suck? I dunno.
+
+Anyway, here’s fizz buzz in pure lambda calculus:
+
+```
+(λU.(λY.(λvoid.(λ0.(λsucc.(λ+.(λ*.(λ1.(λ2.(λ3.(λ4.(λ5.(λ6.(λ7.(λ8.(λ9.(λ10.(λnum.(λtrue.(λfalse.(λif.(λnot.(λand.(λor.(λmake-pair.(λpair-first.(λpair-second.(λzero?.(λpred.(λ-.(λeq?.(λ/.(λ%.(λnil.(λnil?.(λcons.(λcar.(λcdr.(λdo2.(λdo3.(λdo4.(λfor.(λprint-byte.(λprint-list.(λprint-newline.(λzero-byte.(λitoa.(λfizzmsg.(λbuzzmsg.(λfizzbuzzmsg.(λfizzbuzz.(fizzbuzz (((num 1) 0) 1)) λn.((for n) λi.((do2 (((if (zero? ((% i) 3))) λ_.(((if (zero? ((% i) 5))) λ_.(print-list fizzbuzzmsg)) λ_.(print-list fizzmsg))) λ_.(((if (zero? ((% i) 5))) λ_.(print-list buzzmsg)) λ_.(print-list (itoa i))))) (print-newline nil)))) ((cons (((num 0) 7) 0)) ((cons (((num 1) 0) 5)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) ((cons (((num 0) 9) 8)) ((cons (((num 1) 1) 7)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) nil))))))))) ((cons (((num 0) 6) 6)) ((cons (((num 1) 1) 7)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) nil))))) ((cons (((num 0) 7) 0)) ((cons (((num 1) 0) 5)) ((cons (((num 1) 2) 2)) ((cons (((num 1) 2) 2)) nil))))) λn.(((Y λrecurse.λn.λresult.(((if (zero? n)) λ_.(((if (nil? result)) λ_.((cons zero-byte) nil)) λ_.result)) λ_.((recurse ((/ n) 10)) ((cons ((+ zero-byte) ((% n) 10))) result)))) n) nil)) (((num 0) 4) 8)) λ_.(print-byte (((num 0) 1) 0))) (Y λrecurse.λl.(((if (nil? l)) λ_.void) λ_.((do2 (print-byte (car l))) (recurse (cdr l)))))) PRINT_BYTE) λn.λf.((((Y λrecurse.λremaining.λcurrent.λf.(((if (zero? remaining)) λ_.void) λ_.((do2 (f current)) (((recurse (pred remaining)) (succ current)) f)))) n) 0) f)) λa.do3) λa.do2) λa.λb.b) λl.(pair-second (pair-second l))) λl.(pair-first (pair-second l))) λe.λl.((make-pair true) ((make-pair e) l))) λl.(not (pair-first l))) ((make-pair false) void)) λm.λn.((- m) ((* ((/ m) n)) n))) (Y λ/.λm.λn.(((if ((eq? m) n)) λ_.1) λ_.(((if (zero? ((- m) n))) λ_.0) λ_.((+ 1) ((/ ((- m) n)) n)))))) λm.λn.((and (zero? ((- m) n))) (zero? ((- n) m)))) λm.λn.((n pred) m)) λn.(((λn.λf.λx.(pair-second ((n λp.((make-pair (f (pair-first p))) (pair-first p))) ((make-pair x) x))) n) succ) 0)) λn.((n λ_.false) true)) λp.(p false)) λp.(p true)) λx.λy.λt.((t x) y)) λa.λb.((a true) b)) λa.λb.((a b) false)) λp.λt.λf.((p f) t)) λp.λa.λb.(((p a) b) void)) λt.λf.f) λt.λf.t) λa.λb.λc.((+ ((+ ((* ((* 10) 10)) a)) ((* 10) b))) c)) (succ 9)) (succ 8)) (succ 7)) (succ 6)) (succ 5)) (succ 4)) (succ 3)) (succ 2)) (succ 1)) (succ 0)) λm.λn.λx.(m (n x))) λm.λn.λf.λx.((((m succ) n) f) x)) λn.λf.λx.(f ((n f) x))) λf.λx.x) λx.(U U)) (U λh.λf.(f λx.(((h h) f) x)))) λf.(f f))
+```
+
+➡️️ [Try it out in your browser!][10]
+
+(This program expects a function to be defined called `PRINT_BYTE` which takes a Church-encoded numeral, turns it into a byte, writes it to `stdout`, and then returns the same Church-encoded numeral. Expecting a function that has side-effects might arguably disqualify this from being pure, but it’s definitely arguable.)
+
+Don’t be deceived! I said there were no native numbers or lists or control structures in lambda calculus and I meant it. `0`, `7`, `if`, and `+` are all _variables_ that represent _functions_ and have to be constructed before they can be used in the code block above.
+
+### What? What’s happening here?
+
+Okay let’s start over and build up to fizz buzz. We’re going to need a lot. We’re going to need to build up concepts of numbers, logic, and lists all from scratch. Ask your interviewers if they’re comfortable cause this might be a while.
+
+Here is a basic lambda calculus function:
+
+```
+λx.x
+```
+
+This is the identity function and it is equivalent to the following Javascript:
+
+```
+function(x) { return x; }
+```
+
+It takes an argument and returns it! We can call the identity function with another value. Function calling in many languages looks like `f(x)`, but in lambda calculus, it looks like `(f x)`.
+
+```
+(λx.x y)
+```
+
+This will return `y`. Once again, here’s equivalent Javascript:
+
+```
+function(x) { return x; }(y)
+```
+
+Aside: If you’re already familiar with lambda calculus, my formulation of precedence is such that `(λx.x y)` is not the same as `λx.(x y)`. `(λx.x y)` applies `y` to the identity function `λx.x`, and `λx.(x y)` is a function that applies `y` to its argument `x`. Perhaps not what you’re used to, but the parser was way more straightforward, and programming with it this way seems a bit more natural, believe it or not.
+
+Okay, great. We can call functions. What if we want to pass more than one argument?
+
+### Currying
+
+Imagine the following Javascript function:
+
+```
+let s1 = function(f, x) { return f(x); }
+```
+
+We want to call it with two arguments, another function and a value, and we want the function to then be called on the value, and have its result returned. Can we do this while using only one argument?
+
+[Currying][11] is a technique for dealing with this. Instead of taking two arguments, take the first argument and return another function that takes the second argument. Here’s the Javascript:
+
+```
+let s2 = function(f) {
+ return function(x) {
+ return f(x);
+ }
+};
+```
+
+Now, `s1(f, x)` is the same as `s2(f)(x)`. So the equivalent lambda calculus for `s2` is then
+
+```
+λf.λx.(f x)
+```
+
+Calling this function with `g` for `f` and `y` for `x` is like so:
+
+```
+((s2 g) y)
+```
+
+or
+
+```
+((λf.λx.(f x) g) y)
+```
+
+The equivalent Javascript here is:
+
+```
+function(f) {
+ return function(x) {
+ f(x)
+ }
+}(g)(y)
+```
+
+### Numbers
+
+Since everything is a function, we might feel a little stuck with what to do about numbers. Luckily, [Alonzo Church][12] already figured it out for us! When you have a number, often what you want to do is represent how many times you might do something.
+
+So let’s represent a number as how many times we’ll apply a function to a value. This is called a [Church numeral][13]. If we have `f` and `x`, `0` will mean we don’t call `f` at all, and just return `x`. `1` will mean we call `f` one time, `2` will mean we call `f` twice, and so on.
+
+Here are some definitions! (N.B.: assignment isn’t actually part of lambda calculus, but it makes writing down definitions easier)
+
+```
+0 = λf.λx.x
+```
+
+Here, `0` takes a function `f`, a value `x`, and never calls `f`. It just returns `x`. `f` is called 0 times.
+
+```
+1 = λf.λx.(f x)
+```
+
+Like `0`, `1` takes `f` and `x`, but here it calls `f` exactly once. Let’s see how this continues for other numbers.
+
+```
+2 = λf.λx.(f (f x))
+3 = λf.λx.(f (f (f x)))
+4 = λf.λx.(f (f (f (f x))))
+5 = λf.λx.(f (f (f (f (f x)))))
+```
+
+`5` is a function that takes `f`, `x`, and calls `f` 5 times!
+
+Okay, this is convenient, but how are we going to do math on these numbers?
+
+### Successor
+
+Let’s make a _successor_ function that takes a number and returns a new number that calls `f` just one more time.
+
+```
+succ = λn. λf.λx.(f ((n f) x))
+```
+
+`succ` is a function that takes a Church-encoded number, `n`. The spaces after `λn.` are ignored. I put them there to indicate that we expect to usually call `succ` with one argument, curried or no. `succ` then returns another Church-encoded number, `λf.λx.(f ((n f) x))`. What is it doing? Let’s break it down.
+
+ * `((n f) x)` looks like that time we needed to call a function that took two “curried” arguments. So we’re calling `n`, which is a Church numeral, with two arguments, `f` and `x`. This is going to call `f` `n` times!
+ * `(f ((n f) x))` This is calling `f` again, one more time, on the result of the previous value.
+
+
+
+So does `succ` work? Let’s see what happens when we call `(succ 1)`. We should get the `2` we defined earlier!
+
+```
+ (succ 1)
+-> (succ λf.λx.(f x)) # resolve the variable 1
+-> (λn.λf.λx.(f ((n f) x)) λf.λx.(f x)) # resolve the variable succ
+-> λf.λx.(f ((λf.λx.(f x) f) x)) # call the outside function. replace n
+ # with the argument
+
+let's sidebar and simplify the subexpression
+ (λf.λx.(f x) f)
+-> λx.(f x) # call the function, replace f with f!
+
+now we should be able to simplify the larger subexpression
+ ((λf.λx.(f x) f) x)
+-> (λx.(f x) x) # sidebar above
+-> (f x) # call the function, replace x with x!
+
+let's go back to the original now
+ λf.λx.(f ((λf.λx.(f x) f) x))
+-> λf.λx.(f (f x)) # subexpression simplification above
+```
+
+and done! That last line is identical to the `2` we defined originally! It calls `f` twice.
+
+### Math
+
+Now that we have the successor function, if your interviewers haven’t checked out, tell them that fizz buzz isn’t too far away now; we have [Peano Arithmetic][14]! They can then check their interview bingo cards and see if they’ve increased their winnings.
+
+No but for real, since we have the successor function, we can now easily do addition and multiplication, which we will need for fizz buzz.
+
+First, recall that a number `n` is a function that takes another function `f` and an initial value `x` and applies `f` _n_ times. So if you have two numbers _m_ and _n_, what you want to do is apply `succ` to `m` _n_ times!
+
+```
++ = λm.λn.((n succ) m)
+```
+
+Here, `+` is a variable. If it’s not a lambda expression or a function call, it’s a variable!
+
+Multiplication is similar, but instead of applying `succ` to `m` _n_ times, we’re going to add `m` to `0` `n` times.
+
+First, note that if `((+ m) n)` is adding `m` and `n`, then that means that `(+ m)` is a _function_ that adds `m` to its argument. So we want to apply the function `(+ m)` to `0` `n` times.
+
+```
+* = λm.λn.((n (+ m)) 0)
+```
+
+Yay! We have multiplication and addition now.
+
+### Logic
+
+We’re going to need booleans and if statements and logic tests and so on. So, let’s talk about booleans. Recall how with numbers, what we kind of wanted with a number `n` is to do something _n_ times. Similarly, what we want with booleans is to do one of two things, either/or, but not both. Alonzo Church to the rescue again.
+
+Let’s have booleans be functions that take two arguments (curried of course), where the `true` boolean will return the first option, and the `false` boolean will return the second.
+
+```
+true = λt.λf.t
+false = λt.λf.f
+```
+
+So that we can demonstrate booleans, we’re going to define a simple sample function called `zero?` that returns `true` if a number `n` is zero, and `false` otherwise:
+
+```
+zero? = λn.((n λ_.false) true)
+```
+
+To explain: if we have a Church numeral for 0, it will call the first argument it gets called with 0 times and just return the second argument. In other words, 0 will just return the second argument and that’s it. Otherwise, any other number will call the first argument at least once. So, `zero?` will take `n` and give it a function that throws away its argument and always returns `false` whenever it’s called, and start it off with `true`. Only zero values will return `true`.
+
+➡️️ [Try it out in your browser!][15]
+
+We can now write an `if'` function to make use of these boolean values. `if'` will take a predicate value `p` (the boolean) and two options `a` and `b`.
+
+```
+if' = λp.λa.λb.((p a) b)
+```
+
+You can use it like this:
+
+```
+((if' (zero? n)
+ (something-when-zero x))
+ (something-when-not-zero y))
+```
+
+One thing that’s weird about this construction is that the interpreter is going to evaluate both branches (my lambda calculus interpreter is [eager][16] instead of [lazy][17]). Both `something-when-zero` and `something-when-not-zero` are going to be called to determine what to pass in to `if'`. To make it so that we don’t actually call the function in the branch we don’t want to run, let’s protect the logic in another function. We’ll name the argument to the function `_` to indicate that we want to just throw it away.
+
+```
+((if (zero? n)
+ λ_. (something-when-zero x))
+ λ_. (something-when-not-zero y))
+```
+
+This means we’re going to have to make a new `if` function that calls the correct branch with a throwaway argument, like `0` or something.
+
+```
+if = λp.λa.λb.(((p a) b) 0)
+```
+
+Okay, now we have booleans and `if`!
+
+### Currying part deux
+
+At this point, you might be getting sick of how calling something with multiple curried arguments involves all these extra parentheses. `((f a) b)` is annoying, can’t we just do `(f a b)`?
+
+It’s not part of the strict grammar, but my interpreter makes this small concession. `(a b c)` will be expanded to `((a b) c)` by the parser. `(a b c d)` will be expanded to `(((a b) c) d)` by the parser, and so on.
+
+So, for the rest of the post, for ease of explanation, I’m going to use this [syntax sugar][18]. Observe how using `if` changes:
+
+```
+(if (zero? n)
+ λ_. (something-when-zero x)
+ λ_. (something-when-not-zero y))
+```
+
+It’s a little better.
+
+### More logic
+
+Let’s talk about `and`, `or`, and `not`!
+
+`and` returns true if and only if both `a` and `b` are true. Let’s define it!
+
+```
+and = λa.λb.
+ (if (a)
+ λ_. b
+ λ_. false)
+```
+
+`or` returns true if `a` is true or if `b` is true:
+
+```
+or = λa.λb.
+ (if (a)
+ λ_. true
+ λ_. b)
+```
+
+`not` just returns the opposite of whatever it was given:
+
+```
+not = λa.
+ (if (a)
+ λ_. false
+ λ_. true)
+```
+
+It turns out these can be written a bit more simply, but they’re basically doing the same thing:
+
+```
+and = λa.λb.(a b false)
+or = λa.λb.(a true b)
+not = λp.λt.λf.(p f t)
+```
+
+➡️️ [Try it out in your browser!][19]
+
+### Pairs!
+
+Sometimes it’s nice to keep data together. Let’s make a little 2-tuple type! We want three functions. We want a function called `make-pair` that will take two arguments and return a “pair”, we want a function called `pair-first` that will return the first element of the pair, and we want a function called `pair-second` that will return the second element. How can we achieve this? You’re almost certainly in the interview room alone, but now’s the time to yell “Alonzo Church”!
+
+```
+make-pair = λx.λy. λa.(a x y)
+```
+
+`make-pair` is going to take two arguments, `x` and `y`, and they will be the elements of the pair. The pair itself is a function that takes an “accessor” `a` that will be given `x` and `y`. All `a` has to do is take the two arguments and return the one it wants.
+
+Here is someone making a pair with variables `1` and `2`:
+
+```
+(make-pair 1 2)
+```
+
+This returns:
+
+```
+λa.(a 1 2)
+```
+
+There’s a pair! Now we just need to access the values inside.
+
+Remember how `true` takes two arguments and returns the first one and `false` takes two arguments and returns the second one?
+
+```
+pair-first = λp.(p true)
+pair-second = λp.(p false)
+```
+
+`pair-first` is going to take a pair `p` and give it `true` as the accessor `a`. `pair-second` is going to give the pair `false` as the accessor.
+
+Voilà, you can now store 2-tuples of values and recover the data from them.
+
+➡️️ [Try it out in your browser!][20]
+
+### Lists!
+
+We’re going to construct [linked lists][21]. Each list item needs two things: the value at the current position in the list and a reference to the rest of the list.
+
+One additional caveat is we want to be able to identify an empty list, so we’re going to store whether or not the current value is the end of a list as well. In [LISP][22]-based programming languages, the end of the list is the special value `nil`, and checking if we’ve hit the end of the list is accomplished with the `nil?` predicate.
+
+Because we want to distinguish `nil` from a list with a value, we’re going to store three things in each linked list item. Whether or not the list is empty, and if not, the value and the rest of the list. So we need a 3-tuple.
+
+Once we have pairs, other-sized tuples are easy. For instance, a 3-tuple is just one pair with another pair inside for one of the slots.
+
+For each list element, we’ll store:
+
+```
+[not-empty [value rest-of-list]]
+```
+
+As an example, a list element with a value of `1` would look like:
+
+```
+[true [1 remainder]]
+```
+
+whereas `nil` will look like
+
+```
+[false whatever]
+```
+
+That second part of `nil` just doesn’t matter.
+
+First, let’s define `nil` and `nil?`:
+
+```
+nil = (make-pair false false)
+nil? = λl. (not (pair-first l))
+```
+
+The important thing about `nil` is that the first element in the pair is `false`.
+
+Now that we have an empty list, let’s define how to add something to the front of it. In LISP-based languages, the operation to _construct_ a new list element is called `cons`, so we’ll call this `cons`, too.
+
+`cons` will take a value and an existing list and return a new list with the given value at the front of the list.
+
+```
+cons = λvalue.λlist.
+ (make-pair true (make-pair value list))
+```
+
+`cons` is returning a pair where, unlike `nil`, the first element of the pair is `true`. This represents that there’s something in the list here. The second pair element is what we wanted in our linked list: the value at the current position, and a reference to the rest of the list.
+
+So how do we access things in the list? Let’s define two functions called `head` and `tail`. `head` is going to return the value at the front of the list, and `tail` is going to return everything but the front of the list. In LISP-based languages, these functions are sometimes called `car` and `cdr` for surprisingly [esoteric reasons][23]. `head` and `tail` have undefined behavior here when called on `nil`, so let’s just assume `nil?` is false for the list and keep going.
+
+```
+head = λlist. (pair-first (pair-second list))
+tail = λlist. (pair-second (pair-second list))
+```
+
+Both `head` and `tail` first get `(pair-second list)`, which returns the tuple that has the value and reference to the remainder. Then, they use either `pair-first` or `pair-second` to get the current value or the rest of the list.
+
+Great, we have lists!
+
+➡️️ [Try it out in your browser!][24]
+
+### Recursion and loops
+
+Let’s make a simple function that sums up a list of numbers.
+
+```
+sum = λlist.
+ (if (nil? list)
+ λ_. 0
+ λ_. (+ (head list) (sum (tail list))))
+```
+
+If the list is empty, let’s return 0. If the list has an element, let’s add that element to the sum of the rest of the list. [Recursion][25] is a cornerstone tool of computer science, and being able to assume a solution to a subproblem to solve a problem is super neat!
+
+Okay, except, this doesn’t work like this in lambda calculus. Remember how I said assignment wasn’t something that exists in lambda calculus? If you have:
+
+```
+x = y
+
+```
+
+This really means you have:
+
+```
+(λx. y)
+```
+
+In the case of our sum definition, we have:
+
+```
+(λsum.
+
+
+ λlist.
+ (if (nil? list)
+ λ_. 0
+ λ_. (+ (head list) (sum (tail list)))))
+```
+
+What that means is `sum` doesn’t have any access to itself. It can’t call itself like we’ve written, because when it tries to call `sum`, it’s undefined!
+
+This is a pretty crushing blow, but it turns out there’s a mind bending and completely unexpected trick the universe has up its sleeve.
+
+Assume we wrote `sum` so that it takes two arguments. A reference to something like `sum` we’ll call `helper` and then the list. If we could figure out how to solve the recursion problem, then we could use this `sum`. Let’s do that.
+
+```
+sum = λhelper.λlist.
+ (if (nil? list)
+ λ_. 0
+ λ_. (+ (head list) (helper (tail list))))
+```
+
+But hey! When we call `sum`, we have a reference to `sum` then! Let’s just give `sum` itself before the list.
+
+```
+(sum sum list)
+```
+
+This seems promising, but unfortunately now the `helper` invocation inside of `sum` is broken. `helper` is just `sum` and `sum` expects a reference to itself. Let’s try again, changing the `helper` call:
+
+```
+sum = λhelper.λlist.
+ (if (nil? list)
+ λ_. 0
+ λ_. (+ (head list) (helper helper (tail list))))
+
+(sum sum list)
+```
+
+We did it! This actually works! We engineered recursion out of math! At no point does `sum` refer to itself inside of itself, and yet we managed to make a recursive function anyways!
+
+➡️️ [Try it out in your browser!][26]
+
+Despite the minor miracle we’ve just performed, we’ve now ruined how we program recursion to involve calling recursive functions with themselves. This isn’t the end of the world, but it’s a little annoying. Luckily for us, there’s a function that cleans this all right up called the [Y combinator][27].
+
+The _Y combinator_ is probably now more famously known as [a startup incubator][28], or perhaps even more so as the domain name for one of the most popular sites that has a different name than its URL, [Hacker News][29], but fixed point combinators such as the Y combinator have had a longer history.
+
+The Y combinator can be defined in different ways, but definition I’m using is:
+
+```
+Y = λf.(λx.(x x) λx.(f λy.((x x) y)))
+```
+
+You might consider reading more about how the Y combinator can be derived from an excellent tutorial such as [this one][30] or [this one][31].
+
+Anyway, `Y` will make our original `sum` work as expected.
+
+```
+sum = (Y λhelper.λlist.
+ (if (nil? list)
+ λ_. 0
+ λ_. (+ (head list) (helper (tail list)))))
+```
+
+We can now call `(sum list)` without any wacky doubling of the function name, either inside or outside of the function. Hooray!
+
+➡️️ [Try it out in your browser!][32]
+
+### More math
+
+“Get ready to do more math! We now have enough building blocks to do subtraction, division, and modulo, which we’ll need for fizz buzz,” you tell the security guards that are approaching you.
+
+Just like addition, before we define subtraction we’ll define a predecessor function. Unlike addition, the predecessor function `pred` is much more complicated than the successor function `succ`.
+
+The basic idea is we’re going to create a pair to keep track of the previous value. We’ll start from zero and build up `n` but also drag the previous value such that at `n` we also have `n - 1`. Notably, this solution does not figure out how to deal with negative numbers. The predecessor of 0 will be 0, and negatives will have to be dealt with some other time and some other way.
+
+First, we’ll make a helper function that takes a pair of numbers and returns a new pair where the first number in the old pair is the second number in the new pair, and the new first number is the successor of the old first number.
+
+```
+pred-helper = λpair.
+ (make-pair (succ (pair-first pair)) (pair-first pair))
+```
+
+Make sense? If we call `pred-helper` on a pair `[0 0]`, the result will be `[1 0]`. If we call it on `[1 0]`, the result will be `[2 1]`. Essentially this helper slides older numbers off to the right.
+
+Okay, so now we’re going to call `pred-helper` _n_ times, with a starting pair of `[0 0]`, and then get the _second_ value, which should be `n - 1` when we’re done, from the pair.
+
+```
+pred = λn.
+ (pair-second (n pred-helper (make-pair 0 0)))
+```
+
+We can combine these two functions now for the full effect:
+
+```
+pred = λn.
+ (pair-second
+ (n
+ λpair.(make-pair (succ (pair-first pair)) (pair-first pair))
+ (make-pair 0 0)))
+```
+
+➡️️ [Try it out in your browser!][33]
+
+Now that we have `pred`, subtraction is easy! To subtract `n` from `m`, we’re going to apply `pred` to `m` _n_ times.
+
+```
+- = λm.λn.(n pred m)
+```
+
+Keep in mind that if `n` is equal to _or greater than_ `m`, the result of `(- m n)` will be zero, since there are no negative numbers and the predecessor of `0` is `0`. This fact means we can implement some new logic tests. Let’s make `(ge? m n)` return `true` if `m` is greater than or equal to `n` and make `(le? m n)` return `true` if `m` is less than or equal to `n`.
+
+```
+ge? = λm.λn.(zero? (- n m))
+le? = λm.λn.(zero? (- m n))
+```
+
+If we have greater-than-or-equal-to and less-than-or-equal-to, then we can make equal!
+
+```
+eq? = λm.λn.(and (ge? m n) (le? m n))
+```
+
+Now we have enough for integer division! The idea for integer division of `n` and `m` is we will keep count of the times we can subtract `m` from `n` without going past zero.
+
+```
+/ = (Y λ/.λm.λn.
+ (if (eq? m n)
+ λ_. 1
+ λ_. (if (le? m n)
+ λ_. 0
+ λ_. (+ 1 (/ (- m n) n)))))
+```
+
+Once we have subtraction, multiplication, and integer division, we can create modulo.
+
+```
+% = λm.λn. (- m (* (/ m n) n))
+```
+
+➡️️ [Try it out in your browser!][34]
+
+### Aside about performance
+
+You might be wondering about performance at this point. Every time we subtract one from 100, we count up from 0 to 100 to generate 99. This effect compounds itself for division and modulo. The truth is that Church numerals and other encodings aren’t very performant! Just like how tapes in Turing machines aren’t a particularly efficient way to deal with data, Church encodings are most interesting from a theoretical perspective for proving facts about computation.
+
+That doesn’t mean we can’t make things faster though!
+
+Lambda calculus is purely functional and side-effect free, which means that all sorts of optimizations can applied. Functions can be aggressively memoized. In other words, once a specific function and its arguments have been computed, there’s no need to compute them ever again. The result of that function will always be the same anyways. Further, functions can be computed lazily and only if needed. What this means is if a branch of your program’s execution renders a result that’s never used, the compiler can decide to just not run that part of the program and end up with the exact same result.
+
+[My interpreter][35] does have side effects, since programs written in it can cause the system to write output to the user via the special built-in function `PRINT_BYTE`. As a result, I didn’t choose lazy evaluation. The only optimization I chose was aggressive memoization for all functions that are side-effect free. The memoization still has room for improvement, but the result is much faster than a naive implementation.
+
+### Output
+
+“We’re rounding the corner on fizz buzz!” you shout at the receptionist as security drags you around the corner on the way to the door. “We just need to figure out how to communicate results to the user!”
+
+Unfortunately, lambda calculus can’t communicate with your operating system kernel without some help, but a small concession is all we need. [Sheepda][35] provides a single built-in function `PRINT_BYTE`. `PRINT_BYTE` takes a number as its argument (a Church encoded numeral) and prints the corresponding byte to the configured output stream (usually `stdout`).
+
+With `PRINT_BYTE`, we’re going to need to reference a number of different [ASCII bytes][36], so we should make writing numbers in code easier. Earlier we defined numbers 0 - 5, so let’s start and define numbers 6 - 10.
+
+```
+6 = (succ 5)
+7 = (succ 6)
+8 = (succ 7)
+9 = (succ 8)
+10 = (succ 9)
+```
+
+Now let’s define a helper to create three digit decimal numbers.
+
+```
+num = λa.λb.λc.(+ (+ (* (* 10 10) a) (* 10 b)) c)
+```
+
+The newline byte is decimal 10. Here’s a function to print newlines!
+
+```
+print-newline = λ_.(PRINT_BYTE (num 0 1 0))
+```
+
+### Doing multiple things
+
+Now that we have this `PRINT_BYTE` function, we have functions that can cause side-effects. We want to call `PRINT_BYTE` but we don’t care about its return value. We need a way to call multiple functions in sequence.
+
+What if we make a function that takes two arguments and throws away the first one again?
+
+```
+do2 = λ_.λx.x
+```
+
+Here’s a function to print every value in a list:
+
+```
+print-list = (Y λrecurse.λlist.
+ (if (nil? list)
+ λ_. 0
+ λ_. (do2 (PRINT_BYTE (head list))
+ (recurse (tail list)))))
+```
+
+And here’s a function that works like a for loop. It calls `f` with every number from `0` to `n`. It uses a small helper function that continues to call itself until `i` is equal to `n`, and starts `i` off at `0`.
+
+```
+for = λn.λf.(
+ (Y λrecurse.λi.
+ (if (eq? i n)
+ λ_. void
+ λ_. (do2 (f i)
+ (recurse (succ i)))))
+ 0)
+```
+
+### Converting an integer to a string
+
+The last thing we need to complete fizz buzz is a function that turns a number into a string of bytes to print. You might have noticed the `print-num` calls in some of the web-based examples above. We’re going to see how to make it! Writing this function is sometimes a whiteboard problem in its own right. In C, this function is called `itoa`, for integer to ASCII.
+
+Here’s an example of how it works. Imagine the number we’re converting to bytes is `123`. We can get the `3` out by doing `(% 123 10)`, which will be `3`. Then we can divide by `10` to get `12`, and then start over. `(% 12 10)` is `2`. We’ll loop down until we hit zero.
+
+Once we have a number, we can convert it to ASCII by adding the value of the `'0'` ASCII byte. Then we can make a list of ASCII bytes for use with `print-list`.
+
+```
+zero-char = (num 0 4 8) # the ascii code for the byte that represents 0.
+
+itoa = λn.(
+ (Y λrecurse.λn.λresult.
+ (if (zero? n)
+ λ_. (if (nil? result)
+ λ_. (cons zero-char nil)
+ λ_. result)
+ λ_. (recurse (/ n 10) (cons (+ zero-char (% n 10)) result))))
+ n nil)
+
+print-num = λn.(print-list (itoa n))
+```
+
+### Fizz buzz
+
+“Here we go,” you shout at the building you just got kicked out of, “here’s how you do fizz buzz.”
+
+First, we need to define three strings: “Fizz”, “Buzz”, and “Fizzbuzz”.
+
+```
+fizzmsg = (cons (num 0 7 0) # F
+ (cons (num 1 0 5) # i
+ (cons (num 1 2 2) # z
+ (cons (num 1 2 2) # z
+ nil))))
+buzzmsg = (cons (num 0 6 6) # B
+ (cons (num 1 1 7) # u
+ (cons (num 1 2 2) # z
+ (cons (num 1 2 2) # z
+ nil))))
+fizzbuzzmsg = (cons (num 0 7 0) # F
+ (cons (num 1 0 5) # i
+ (cons (num 1 2 2) # z
+ (cons (num 1 2 2) # z
+ (cons (num 0 9 8) # b
+ (cons (num 1 1 7) # u
+ (cons (num 1 2 2) # z
+ (cons (num 1 2 2) # z
+ nil))))))))
+```
+
+Okay, now let’s define a function that will run from 0 to `n` and output numbers, fizzes, and buzzes:
+
+```
+fizzbuzz = λn.
+ (for n λi.
+ (do2
+ (if (zero? (% i 3))
+ λ_. (if (zero? (% i 5))
+ λ_. (print-list fizzbuzzmsg)
+ λ_. (print-list fizzmsg))
+ λ_. (if (zero? (% i 5))
+ λ_. (print-list buzzmsg)
+ λ_. (print-list (itoa i))))
+ (print-newline 0)))
+```
+
+Let’s do the first 20!
+
+```
+(fizzbuzz (num 0 2 0))
+```
+
+➡️️ [Try it out in your browser!][37]
+
+### Reverse a string
+
+“ENCORE!” you shout to no one as the last cars pull out of the company parking lot. Everyone’s gone home but this is your last night before the restraining order goes through.
+
+```
+reverse-list = λlist.(
+ (Y λrecurse.λold.λnew.
+ (if (nil? old)
+ λ_.new
+ λ_.(recurse (tail old) (cons (head old) new))))
+ list nil)
+```
+
+➡️️ [Try it out in your browser!][38]
+
+### Sheepda
+
+As I mentioned, I wrote a lambda calculus interpreter called [Sheepda][35] for playing around. By itself it’s pretty interesting if you’re interested in learning more about how to write programming language interpreters. Lambda calculus is as simple of a language as you can make, so the interpreter is very simple itself!
+
+It’s written in Go and thanks to [GopherJS][39] it’s what powers the [web playground][40].
+
+There are some fun projects if someone’s interested in getting more involved. Using the library to prune lambda expression trees and simplify expressions if possible would be a start! I’m sure my fizz buzz implementation isn’t as minimal as it could be, and playing [code golf][41] with it would be pretty neat!
+
+Feel free to fork , star it, bop it, twist it, or even pull it!
+
+--------------------------------------------------------------------------------
+
+via: https://www.jtolio.com/2017/03/whiteboard-problems-in-pure-lambda-calculus
+
+作者:[jtolio.com][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.jtolio.com/
+[b]: https://github.com/lujun9972
+[1]: https://www.vivint.com/
+[2]: https://www.spacemonkey.com/
+[3]: https://en.wikipedia.org/wiki/Festivus
+[4]: https://twitter.com/aphyr
+[5]: https://aphyr.com/posts/340-acing-the-technical-interview
+[6]: https://en.wikipedia.org/wiki/Church_encoding
+[7]: https://en.wikipedia.org/wiki/Lambda_calculus
+[8]: https://en.wikipedia.org/wiki/Turing_completeness
+[9]: https://imranontech.com/2007/01/24/using-fizzbuzz-to-find-developers-who-grok-coding/
+[10]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJvdXRwdXQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyKCVDRSVCQlUuKCVDRSVCQlkuKCVDRSVCQnZvaWQuKCVDRSVCQjAuKCVDRSVCQnN1Y2MuKCVDRSVCQiUyQi4oJUNFJUJCKi4oJUNFJUJCMS4oJUNFJUJCMi4oJUNFJUJCMy4oJUNFJUJCNC4oJUNFJUJCNS4oJUNFJUJCNi4oJUNFJUJCNy4oJUNFJUJCOC4oJUNFJUJCOS4oJUNFJUJCMTAuKCVDRSVCQm51bS4oJUNFJUJCdHJ1ZS4oJUNFJUJCZmFsc2UuKCVDRSVCQmlmLiglQ0UlQkJub3QuKCVDRSVCQmFuZC4oJUNFJUJCb3IuKCVDRSVCQm1ha2UtcGFpci4oJUNFJUJCcGFpci1maXJzdC4oJUNFJUJCcGFpci1zZWNvbmQuKCVDRSVCQnplcm8lM0YuKCVDRSVCQnByZWQuKCVDRSVCQi0uKCVDRSVCQmVxJTNGLiglQ0UlQkIlMkYuKCVDRSVCQiUyNS4oJUNFJUJCbmlsLiglQ0UlQkJuaWwlM0YuKCVDRSVCQmNvbnMuKCVDRSVCQmNhci4oJUNFJUJCY2RyLiglQ0UlQkJkbzIuKCVDRSVCQmRvMy4oJUNFJUJCZG80LiglQ0UlQkJmb3IuKCVDRSVCQnByaW50LWJ5dGUuKCVDRSVCQnByaW50LWxpc3QuKCVDRSVCQnByaW50LW5ld2xpbmUuKCVDRSVCQnplcm8tYnl0ZS4oJUNFJUJCaXRvYS4oJUNFJUJCZml6em1zZy4oJUNFJUJCYnV6em1zZy4oJUNFJUJCZml6emJ1enptc2cuKCVDRSVCQmZpenpidXp6LihmaXp6YnV6eiUyMCgoKG51bSUyMDEpJTIwMCklMjAxKSklMjAlQ0UlQkJuLigoZm9yJTIwbiklMjAlQ0UlQkJpLigoZG8yJTIwKCgoaWYlMjAoemVybyUzRiUyMCgoJTI1JTIwaSklMjAzKSkpJTIwJUNFJUJCXy4oKChpZiUyMCh6ZXJvJTNGJTIwKCglMjUlMjBpKSUyMDUpKSklMjAlQ0UlQkJfLihwcmludC1saXN0JTIwZml6emJ1enptc2cpKSUyMCVDRSVCQl8uKHByaW50LWxpc3QlMjBmaXp6bXNnKSkpJTIwJUNFJUJCXy4oKChpZiUyMCh6ZXJvJTNGJTIwKCglMjUlMjBpKSUyMDUpKSklMjAlQ0UlQkJfLihwcmludC1saXN0JTIwYnV6em1zZykpJTIwJUNFJUJCXy4ocHJpbnQtbGlzdCUyMChpdG9hJTIwaSkpKSkpJTIwKHByaW50LW5ld2xpbmUlMjBuaWwpKSkpJTIwKChjb25zJTIwKCgobnVtJTIwMCklMjA3KSUyMDApKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMCklMjA1KSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDIpJTIwMikpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAyKSUyMDIpKSUyMCgoY29ucyUyMCgoKG51bSUyMDApJTIwOSklMjA4KSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDEpJTIwNykpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAyKSUyMDIpKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMiklMjAyKSklMjBuaWwpKSkpKSkpKSklMjAoKGNvbnMlMjAoKChudW0lMjAwKSUyMDYpJTIwNikpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAxKSUyMDcpKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMiklMjAyKSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDIpJTIwMikpJTIwbmlsKSkpKSklMjAoKGNvbnMlMjAoKChudW0lMjAwKSUyMDcpJTIwMCkpJTIwKChjb25zJTIwKCgobnVtJTIwMSklMjAwKSUyMDUpKSUyMCgoY29ucyUyMCgoKG51bSUyMDEpJTIwMiklMjAyKSklMjAoKGNvbnMlMjAoKChudW0lMjAxKSUyMDIpJTIwMikpJTIwbmlsKSkpKSklMjAlQ0UlQkJuLigoKFklMjAlQ0UlQkJyZWN1cnNlLiVDRSVCQm4uJUNFJUJCcmVzdWx0LigoKGlmJTIwKHplcm8lM0YlMjBuKSklMjAlQ0UlQkJfLigoKGlmJTIwKG5pbCUzRiUyMHJlc3VsdCkpJTIwJUNFJUJCXy4oKGNvbnMlMjB6ZXJvLWJ5dGUpJTIwbmlsKSklMjAlQ0UlQkJfLnJlc3VsdCkpJTIwJUNFJUJCXy4oKHJlY3Vyc2UlMjAoKCUyRiUyMG4pJTIwMTApKSUyMCgoY29ucyUyMCgoJTJCJTIwemVyby1ieXRlKSUyMCgoJTI1JTIwbiklMjAxMCkpKSUyMHJlc3VsdCkpKSklMjBuKSUyMG5pbCkpJTIwKCgobnVtJTIwMCklMjA0KSUyMDgpKSUyMCVDRSVCQl8uKHByaW50LWJ5dGUlMjAoKChudW0lMjAwKSUyMDEpJTIwMCkpKSUyMChZJTIwJUNFJUJCcmVjdXJzZS4lQ0UlQkJsLigoKGlmJTIwKG5pbCUzRiUyMGwpKSUyMCVDRSVCQl8udm9pZCklMjAlQ0UlQkJfLigoZG8yJTIwKHByaW50LWJ5dGUlMjAoY2FyJTIwbCkpKSUyMChyZWN1cnNlJTIwKGNkciUyMGwpKSkpKSklMjBQUklOVF9CWVRFKSUyMCVDRSVCQm4uJUNFJUJCZi4oKCgoWSUyMCVDRSVCQnJlY3Vyc2UuJUNFJUJCcmVtYWluaW5nLiVDRSVCQmN1cnJlbnQuJUNFJUJCZi4oKChpZiUyMCh6ZXJvJTNGJTIwcmVtYWluaW5nKSklMjAlQ0UlQkJfLnZvaWQpJTIwJUNFJUJCXy4oKGRvMiUyMChmJTIwY3VycmVudCkpJTIwKCgocmVjdXJzZSUyMChwcmVkJTIwcmVtYWluaW5nKSklMjAoc3VjYyUyMGN1cnJlbnQpKSUyMGYpKSkpJTIwbiklMjAwKSUyMGYpKSUyMCVDRSVCQmEuZG8zKSUyMCVDRSVCQmEuZG8yKSUyMCVDRSVCQmEuJUNFJUJCYi5iKSUyMCVDRSVCQmwuKHBhaXItc2Vjb25kJTIwKHBhaXItc2Vjb25kJTIwbCkpKSUyMCVDRSVCQmwuKHBhaXItZmlyc3QlMjAocGFpci1zZWNvbmQlMjBsKSkpJTIwJUNFJUJCZS4lQ0UlQkJsLigobWFrZS1wYWlyJTIwdHJ1ZSklMjAoKG1ha2UtcGFpciUyMGUpJTIwbCkpKSUyMCVDRSVCQmwuKG5vdCUyMChwYWlyLWZpcnN0JTIwbCkpKSUyMCgobWFrZS1wYWlyJTIwZmFsc2UpJTIwdm9pZCkpJTIwJUNFJUJCbS4lQ0UlQkJuLigoLSUyMG0pJTIwKCgqJTIwKCglMkYlMjBtKSUyMG4pKSUyMG4pKSklMjAoWSUyMCVDRSVCQiUyRi4lQ0UlQkJtLiVDRSVCQm4uKCgoaWYlMjAoKGVxJTNGJTIwbSklMjBuKSklMjAlQ0UlQkJfLjEpJTIwJUNFJUJCXy4oKChpZiUyMCh6ZXJvJTNGJTIwKCgtJTIwbSklMjBuKSkpJTIwJUNFJUJCXy4wKSUyMCVDRSVCQl8uKCglMkIlMjAxKSUyMCgoJTJGJTIwKCgtJTIwbSklMjBuKSklMjBuKSkpKSkpJTIwJUNFJUJCbS4lQ0UlQkJuLigoYW5kJTIwKHplcm8lM0YlMjAoKC0lMjBtKSUyMG4pKSklMjAoemVybyUzRiUyMCgoLSUyMG4pJTIwbSkpKSklMjAlQ0UlQkJtLiVDRSVCQm4uKChuJTIwcHJlZCklMjBtKSklMjAlQ0UlQkJuLigoKCVDRSVCQm4uJUNFJUJCZi4lQ0UlQkJ4LihwYWlyLXNlY29uZCUyMCgobiUyMCVDRSVCQnAuKChtYWtlLXBhaXIlMjAoZiUyMChwYWlyLWZpcnN0JTIwcCkpKSUyMChwYWlyLWZpcnN0JTIwcCkpKSUyMCgobWFrZS1wYWlyJTIweCklMjB4KSkpJTIwbiklMjBzdWNjKSUyMDApKSUyMCVDRSVCQm4uKChuJTIwJUNFJUJCXy5mYWxzZSklMjB0cnVlKSklMjAlQ0UlQkJwLihwJTIwZmFsc2UpKSUyMCVDRSVCQnAuKHAlMjB0cnVlKSklMjAlQ0UlQkJ4LiVDRSVCQnkuJUNFJUJCdC4oKHQlMjB4KSUyMHkpKSUyMCVDRSVCQmEuJUNFJUJCYi4oKGElMjB0cnVlKSUyMGIpKSUyMCVDRSVCQmEuJUNFJUJCYi4oKGElMjBiKSUyMGZhbHNlKSklMjAlQ0UlQkJwLiVDRSVCQnQuJUNFJUJCZi4oKHAlMjBmKSUyMHQpKSUyMCVDRSVCQnAuJUNFJUJCYS4lQ0UlQkJiLigoKHAlMjBhKSUyMGIpJTIwdm9pZCkpJTIwJUNFJUJCdC4lQ0UlQkJmLmYpJTIwJUNFJUJCdC4lQ0UlQkJmLnQpJTIwJUNFJUJCYS4lQ0UlQkJiLiVDRSVCQmMuKCglMkIlMjAoKCUyQiUyMCgoKiUyMCgoKiUyMDEwKSUyMDEwKSklMjBhKSklMjAoKColMjAxMCklMjBiKSkpJTIwYykpJTIwKHN1Y2MlMjA5KSklMjAoc3VjYyUyMDgpKSUyMChzdWNjJTIwNykpJTIwKHN1Y2MlMjA2KSklMjAoc3VjYyUyMDUpKSUyMChzdWNjJTIwNCkpJTIwKHN1Y2MlMjAzKSklMjAoc3VjYyUyMDIpKSUyMChzdWNjJTIwMSkpJTIwKHN1Y2MlMjAwKSklMjAlQ0UlQkJtLiVDRSVCQm4uJUNFJUJCeC4obSUyMChuJTIweCkpKSUyMCVDRSVCQm0uJUNFJUJCbi4lQ0UlQkJmLiVDRSVCQnguKCgoKG0lMjBzdWNjKSUyMG4pJTIwZiklMjB4KSklMjAlQ0UlQkJuLiVDRSVCQmYuJUNFJUJCeC4oZiUyMCgobiUyMGYpJTIweCkpKSUyMCVDRSVCQmYuJUNFJUJCeC54KSUyMCVDRSVCQnguKFUlMjBVKSklMjAoVSUyMCVDRSVCQmguJUNFJUJCZi4oZiUyMCVDRSVCQnguKCgoaCUyMGgpJTIwZiklMjB4KSkpKSUyMCVDRSVCQmYuKGYlMjBmKSklNUNuJTIyJTdE
+[11]: https://en.wikipedia.org/wiki/Currying
+[12]: https://en.wikipedia.org/wiki/Alonzo_Church
+[13]: https://en.wikipedia.org/wiki/Church_encoding#Church_numerals
+[14]: https://en.wikipedia.org/wiki/Peano_axioms#Arithmetic
+[15]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTVDbjElMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjB4KSU1Q24yJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjB4KSklNUNuc3VjYyUyMCUzRCUyMCVDRSVCQm4uJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKChuJTIwZiklMjB4KSklNUNuJTVDbnRydWUlMjAlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYudCU1Q25mYWxzZSUyMCUzRCUyMCVDRSVCQnQuJUNFJUJCZi5mJTVDbiU1Q256ZXJvJTNGJTIwJTNEJTIwJUNFJUJCbi4oKG4lMjAlQ0UlQkJfLmZhbHNlKSUyMHRydWUpJTVDbiU1Q24lMjMlMjB0cnklMjBjaGFuZ2luZyUyMHRoZSUyMG51bWJlciUyMHplcm8lM0YlMjBpcyUyMGNhbGxlZCUyMHdpdGglNUNuKHplcm8lM0YlMjAwKSU1Q24lNUNuJTIzJTIwdGhlJTIwb3V0cHV0JTIwd2lsbCUyMGJlJTIwJTVDJTIyJUNFJUJCdC4lQ0UlQkJmLnQlNUMlMjIlMjBmb3IlMjB0cnVlJTIwYW5kJTIwJTVDJTIyJUNFJUJCdC4lQ0UlQkJmLmYlNUMlMjIlMjBmb3IlMjBmYWxzZS4lMjIlN0Q=
+[16]: https://en.wikipedia.org/wiki/Eager_evaluation
+[17]: https://en.wikipedia.org/wiki/Lazy_evaluation
+[18]: https://en.wikipedia.org/wiki/Syntactic_sugar
+[19]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTVDbjElMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjB4KSU1Q24yJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjB4KSklNUNuMyUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIwKGYlMjB4KSkpJTVDbnN1Y2MlMjAlM0QlMjAlQ0UlQkJuLiVDRSVCQmYuJUNFJUJCeC4oZiUyMCgobiUyMGYpJTIweCkpJTVDbiU1Q250cnVlJTIwJTIwJTNEJTIwJUNFJUJCdC4lQ0UlQkJmLnQlNUNuZmFsc2UlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYuZiU1Q24lNUNuemVybyUzRiUyMCUzRCUyMCVDRSVCQm4uKChuJTIwJUNFJUJCXy5mYWxzZSklMjB0cnVlKSU1Q24lNUNuaWYlMjAlM0QlMjAlQ0UlQkJwLiVDRSVCQmEuJUNFJUJCYi4oKChwJTIwYSklMjBiKSUyMDApJTVDbmFuZCUyMCUzRCUyMCVDRSVCQmEuJUNFJUJCYi4oYSUyMGIlMjBmYWxzZSklNUNub3IlMjAlM0QlMjAlQ0UlQkJhLiVDRSVCQmIuKGElMjB0cnVlJTIwYiklNUNubm90JTIwJTNEJTIwJUNFJUJCcC4lQ0UlQkJ0LiVDRSVCQmYuKHAlMjBmJTIwdCklNUNuJTVDbiUyMyUyMHRyeSUyMGNoYW5naW5nJTIwdGhpcyUyMHVwISU1Q24oaWYlMjAob3IlMjAoemVybyUzRiUyMDEpJTIwKHplcm8lM0YlMjAwKSklNUNuJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAyJTVDbiUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwMyklMjIlN0Q=
+[20]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTVDbjElMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjB4KSU1Q24yJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjB4KSklNUNuMyUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIwKGYlMjB4KSkpJTVDbiU1Q250cnVlJTIwJTIwJTNEJTIwJUNFJUJCdC4lQ0UlQkJmLnQlNUNuZmFsc2UlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYuZiU1Q24lNUNubWFrZS1wYWlyJTIwJTNEJTIwJUNFJUJCeC4lQ0UlQkJ5LiUyMCVDRSVCQmEuKGElMjB4JTIweSklNUNucGFpci1maXJzdCUyMCUzRCUyMCVDRSVCQnAuKHAlMjB0cnVlKSU1Q25wYWlyLXNlY29uZCUyMCUzRCUyMCVDRSVCQnAuKHAlMjBmYWxzZSklNUNuJTVDbiUyMyUyMHRyeSUyMGNoYW5naW5nJTIwdGhpcyUyMHVwISU1Q25wJTIwJTNEJTIwKG1ha2UtcGFpciUyMDIlMjAzKSU1Q24ocGFpci1zZWNvbmQlMjBwKSUyMiU3RA==
+[21]: https://en.wikipedia.org/wiki/Linked_list
+[22]: https://en.wikipedia.org/wiki/Lisp_%28programming_language%29
+[23]: https://en.wikipedia.org/wiki/CAR_and_CDR#Etymology
+[24]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBZmFsc2UlMkMlMjJvdXRwdXQlMjIlM0ElMjJyZXN1bHQlMjIlMkMlMjJjb2RlJTIyJTNBJTIyMCUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC54JTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwMSUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMHgpJTIwJTIwJTIwJTIwJTIwMiUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIweCkpJTIwJTIwJTIwJTIwMyUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMChmJTIwKGYlMjB4KSkpJTVDbnRydWUlMjAlMjAlM0QlMjAlQ0UlQkJ0LiVDRSVCQmYudCUyMCUyMCUyMCUyMGZhbHNlJTIwJTNEJTIwJUNFJUJCdC4lQ0UlQkJmLmYlNUNuJTVDbm1ha2UtcGFpciUyMCUzRCUyMCVDRSVCQnguJUNFJUJCeS4lMjAlQ0UlQkJhLihhJTIweCUyMHkpJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwcGFpci1maXJzdCUyMCUzRCUyMCVDRSVCQnAuKHAlMjB0cnVlKSUyMCUyMCUyMCUyMCUyMHBhaXItc2Vjb25kJTIwJTNEJTIwJUNFJUJCcC4ocCUyMGZhbHNlKSU1Q24lNUNubmlsJTIwJTNEJTIwKG1ha2UtcGFpciUyMGZhbHNlJTIwZmFsc2UpJTIwJTIwJTIwJTIwJTIwbmlsJTNGJTIwJTNEJTIwJUNFJUJCbC4lMjAobm90JTIwKHBhaXItZmlyc3QlMjBsKSklNUNuY29ucyUyMCUzRCUyMCVDRSVCQnZhbHVlLiVDRSVCQmxpc3QuKG1ha2UtcGFpciUyMHRydWUlMjAobWFrZS1wYWlyJTIwdmFsdWUlMjBsaXN0KSklNUNuJTVDbmhlYWQlMjAlM0QlMjAlQ0UlQkJsaXN0LiUyMChwYWlyLWZpcnN0JTIwKHBhaXItc2Vjb25kJTIwbGlzdCkpJTVDbnRhaWwlMjAlM0QlMjAlQ0UlQkJsaXN0LiUyMChwYWlyLXNlY29uZCUyMChwYWlyLXNlY29uZCUyMGxpc3QpKSU1Q24lNUNuJTIzJTIwdHJ5JTIwY2hhbmdpbmclMjB0aGlzJTIwdXAhJTVDbmwlMjAlM0QlMjAoY29ucyUyMDElMjAoY29ucyUyMDIlMjAoY29ucyUyMDMlMjBuaWwpKSklNUNuKGhlYWQlMjAodGFpbCUyMGwpKSUyMiU3RA==
+[25]: https://en.wikipedia.org/wiki/Recursion
+[26]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjJzdW0lMjAlM0QlMjAlQ0UlQkJoZWxwZXIuJUNFJUJCbGlzdC4lNUNuJTIwJTIwKGlmJTIwKG5pbCUzRiUyMGxpc3QpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwMCU1Q24lMjAlMjAlMjAlMjAlMjAlMjAlQ0UlQkJfLiUyMCglMkIlMjAoaGVhZCUyMGxpc3QpJTIwKGhlbHBlciUyMGhlbHBlciUyMCh0YWlsJTIwbGlzdCkpKSklNUNuJTVDbnJlc3VsdCUyMCUzRCUyMChzdW0lMjBzdW0lMjAoY29ucyUyMDElMjAoY29ucyUyMDIlMjAoY29ucyUyMDMlMjBuaWwpKSkpJTVDbiU1Q24lMjMlMjB3ZSdsbCUyMGV4cGxhaW4lMjBob3clMjBwcmludC1udW0lMjB3b3JrcyUyMGxhdGVyJTJDJTIwYnV0JTIwd2UlMjBuZWVkJTIwaXQlMjB0byUyMHNob3clMjB0aGF0JTIwc3VtJTIwaXMlMjB3b3JraW5nJTVDbihwcmludC1udW0lMjByZXN1bHQpJTIyJTdE
+[27]: https://en.wikipedia.org/wiki/Fixed-point_combinator#Fixed_point_combinators_in_lambda_calculus
+[28]: https://www.ycombinator.com/
+[29]: https://news.ycombinator.com/
+[30]: http://matt.might.net/articles/implementation-of-recursive-fixed-point-y-combinator-in-javascript-for-memoization/
+[31]: http://kestas.kuliukas.com/YCombinatorExplained/
+[32]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjJZJTIwJTNEJTIwJUNFJUJCZi4oJUNFJUJCeC4oeCUyMHgpJTIwJUNFJUJCeC4oZiUyMCVDRSVCQnkuKCh4JTIweCklMjB5KSkpJTVDbiU1Q25zdW0lMjAlM0QlMjAoWSUyMCVDRSVCQmhlbHBlci4lQ0UlQkJsaXN0LiU1Q24lMjAlMjAoaWYlMjAobmlsJTNGJTIwbGlzdCklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAwJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKCUyQiUyMChoZWFkJTIwbGlzdCklMjAoaGVscGVyJTIwKHRhaWwlMjBsaXN0KSkpKSklNUNuJTVDbiUyMyUyMHdlJ2xsJTIwZXhwbGFpbiUyMGhvdyUyMHRoaXMlMjB3b3JrcyUyMGxhdGVyJTJDJTIwYnV0JTIwd2UlMjBuZWVkJTIwaXQlMjB0byUyMHNob3clMjB0aGF0JTIwc3VtJTIwaXMlMjB3b3JraW5nJTVDbnByaW50LW51bSUyMCUzRCUyMCVDRSVCQm4uKHByaW50LWxpc3QlMjAoaXRvYSUyMG4pKSU1Q24lNUNuKHByaW50LW51bSUyMChzdW0lMjAoY29ucyUyMDElMjAoY29ucyUyMDIlMjAoY29ucyUyMDMlMjBuaWwpKSkpKSUyMiU3RA
+[33]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjIwJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LnglNUNuMSUyMCUzRCUyMCVDRSVCQmYuJUNFJUJCeC4oZiUyMHgpJTVDbjIlMjAlM0QlMjAlQ0UlQkJmLiVDRSVCQnguKGYlMjAoZiUyMHgpKSU1Q24zJTIwJTNEJTIwJUNFJUJCZi4lQ0UlQkJ4LihmJTIwKGYlMjAoZiUyMHgpKSklNUNuJTVDbnByZWQlMjAlM0QlMjAlQ0UlQkJuLiU1Q24lMjAlMjAocGFpci1zZWNvbmQlNUNuJTIwJTIwJTIwJTIwKG4lNUNuJTIwJTIwJTIwJTIwJTIwJUNFJUJCcGFpci4obWFrZS1wYWlyJTIwKHN1Y2MlMjAocGFpci1maXJzdCUyMHBhaXIpKSUyMChwYWlyLWZpcnN0JTIwcGFpcikpJTVDbiUyMCUyMCUyMCUyMCUyMChtYWtlLXBhaXIlMjAwJTIwMCkpKSU1Q24lNUNuJTIzJTIwd2UnbGwlMjBleHBsYWluJTIwaG93JTIwcHJpbnQtbnVtJTIwd29ya3MlMjBsYXRlciElNUNuKHByaW50LW51bSUyMChwcmVkJTIwMykpJTVDbiUyMiU3RA==
+[34]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjIlMkIlMjAlM0QlMjAlQ0UlQkJtLiVDRSVCQm4uKG0lMjBzdWNjJTIwbiklNUNuKiUyMCUzRCUyMCVDRSVCQm0uJUNFJUJCbi4obiUyMCglMkIlMjBtKSUyMDApJTVDbi0lMjAlM0QlMjAlQ0UlQkJtLiVDRSVCQm4uKG4lMjBwcmVkJTIwbSklNUNuJTJGJTIwJTNEJTIwKFklMjAlQ0UlQkIlMkYuJUNFJUJCbS4lQ0UlQkJuLiU1Q24lMjAlMjAoaWYlMjAoZXElM0YlMjBtJTIwbiklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAxJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKGlmJTIwKGxlJTNGJTIwbSUyMG4pJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwMCU1Q24lMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlQ0UlQkJfLiUyMCglMkIlMjAxJTIwKCUyRiUyMCgtJTIwbSUyMG4pJTIwbikpKSkpJTVDbiUyNSUyMCUzRCUyMCVDRSVCQm0uJUNFJUJCbi4lMjAoLSUyMG0lMjAoKiUyMCglMkYlMjBtJTIwbiklMjBuKSklNUNuJTVDbihwcmludC1udW0lMjAoJTI1JTIwNyUyMDMpKSUyMiU3RA==
+[35]: https://github.com/jtolds/sheepda/
+[36]: https://en.wikipedia.org/wiki/ASCII#Code_chart
+[37]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjIlMjMlMjBkZWZpbmUlMjB0aGUlMjBtZXNzYWdlcyU1Q25maXp6bXNnJTIwJTNEJTIwKGNvbnMlMjAobnVtJTIwMCUyMDclMjAwKSUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwNSklMjAoY29ucyUyMChudW0lMjAxJTIwMiUyMDIpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDIlMjAyKSUyMG5pbCkpKSklNUNuYnV6em1zZyUyMCUzRCUyMChjb25zJTIwKG51bSUyMDAlMjA2JTIwNiklMjAoY29ucyUyMChudW0lMjAxJTIwMSUyMDcpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDIlMjAyKSUyMChjb25zJTIwKG51bSUyMDElMjAyJTIwMiklMjBuaWwpKSkpJTVDbmZpenpidXp6bXNnJTIwJTNEJTIwKGNvbnMlMjAobnVtJTIwMCUyMDclMjAwKSUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwNSklMjAoY29ucyUyMChudW0lMjAxJTIwMiUyMDIpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDIlMjAyKSU1Q24lMjAlMjAlMjAlMjAoY29ucyUyMChudW0lMjAwJTIwOSUyMDgpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDElMjA3KSUyMChjb25zJTIwKG51bSUyMDElMjAyJTIwMiklMjAoY29ucyUyMChudW0lMjAxJTIwMiUyMDIpJTIwbmlsKSkpKSkpKSklNUNuJTVDbiUyMyUyMGZpenpidXp6JTVDbmZpenpidXp6JTIwJTNEJTIwJUNFJUJCbi4lNUNuJTIwJTIwKGZvciUyMG4lMjAlQ0UlQkJpLiU1Q24lMjAlMjAlMjAlMjAoZG8yJTVDbiUyMCUyMCUyMCUyMCUyMCUyMChpZiUyMCh6ZXJvJTNGJTIwKCUyNSUyMGklMjAzKSklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAoaWYlMjAoemVybyUzRiUyMCglMjUlMjBpJTIwNSkpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKHByaW50LWxpc3QlMjBmaXp6YnV6em1zZyklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAocHJpbnQtbGlzdCUyMGZpenptc2cpKSU1Q24lMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlMjAlQ0UlQkJfLiUyMChpZiUyMCh6ZXJvJTNGJTIwKCUyNSUyMGklMjA1KSklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4lMjAocHJpbnQtbGlzdCUyMGJ1enptc2cpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCVDRSVCQl8uJTIwKHByaW50LWxpc3QlMjAoaXRvYSUyMGkpKSkpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMChwcmludC1uZXdsaW5lJTIwbmlsKSkpJTVDbiU1Q24lMjMlMjBydW4lMjBmaXp6YnV6eiUyMDIwJTIwdGltZXMlNUNuKGZpenpidXp6JTIwKG51bSUyMDAlMjAyJTIwMCkpJTIyJTdE
+[38]: https://jtolds.github.io/sheepda/#JTdCJTIyc3RkbGliJTIyJTNBdHJ1ZSUyQyUyMm91dHB1dCUyMiUzQSUyMm91dHB1dCUyMiUyQyUyMmNvZGUlMjIlM0ElMjJoZWxsby13b3JsZCUyMCUzRCUyMChjb25zJTIwKG51bSUyMDAlMjA3JTIwMiklMjAoY29ucyUyMChudW0lMjAxJTIwMCUyMDEpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDAlMjA4KSUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwOCklMjAoY29ucyUyMChudW0lMjAxJTIwMSUyMDEpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMChjb25zJTIwKG51bSUyMDAlMjA0JTIwNCklMjAoY29ucyUyMChudW0lMjAwJTIwMyUyMDIpJTIwKGNvbnMlMjAobnVtJTIwMSUyMDElMjA5KSUyMChjb25zJTIwKG51bSUyMDElMjAxJTIwMSklMjAoY29ucyUyMChudW0lMjAxJTIwMSUyMDQpJTVDbiUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMCUyMChjb25zJTIwKG51bSUyMDElMjAwJTIwOCklMjAoY29ucyUyMChudW0lMjAxJTIwMCUyMDApJTIwKGNvbnMlMjAobnVtJTIwMCUyMDMlMjAzKSUyMG5pbCkpKSkpKSkpKSkpKSklNUNuJTVDbnJldmVyc2UtbGlzdCUyMCUzRCUyMCVDRSVCQmxpc3QuKCU1Q24lMjAlMjAoWSUyMCVDRSVCQnJlY3Vyc2UuJUNFJUJCb2xkLiVDRSVCQm5ldy4lNUNuJTIwJTIwJTIwJTIwKGlmJTIwKG5pbCUzRiUyMG9sZCklNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy5uZXclNUNuJTIwJTIwJTIwJTIwJTIwJTIwJTIwJTIwJUNFJUJCXy4ocmVjdXJzZSUyMCh0YWlsJTIwb2xkKSUyMChjb25zJTIwKGhlYWQlMjBvbGQpJTIwbmV3KSkpKSU1Q24lMjAlMjBsaXN0JTIwbmlsKSU1Q24lNUNuKGRvNCU1Q24lMjAlMjAocHJpbnQtbGlzdCUyMGhlbGxvLXdvcmxkKSU1Q24lMjAlMjAocHJpbnQtbmV3bGluZSUyMHZvaWQpJTVDbiUyMCUyMChwcmludC1saXN0JTIwKHJldmVyc2UtbGlzdCUyMGhlbGxvLXdvcmxkKSklNUNuJTIwJTIwKHByaW50LW5ld2xpbmUlMjB2b2lkKSklMjIlN0Q=
+[39]: https://github.com/gopherjs/gopherjs
+[40]: https://jtolds.github.io/sheepda/
+[41]: https://en.wikipedia.org/wiki/Code_golf
diff --git a/sources/tech/20180207 23 open source audio-visual production tools.md b/sources/tech/20180207 23 open source audio-visual production tools.md
index fd196200ce..b6b748ec39 100644
--- a/sources/tech/20180207 23 open source audio-visual production tools.md
+++ b/sources/tech/20180207 23 open source audio-visual production tools.md
@@ -1,3 +1,4 @@
+luming translating
23 open source audio-visual production tools
======
diff --git a/sources/tech/20180319 How to not be a white male asshole, by a former offender.md b/sources/tech/20180319 How to not be a white male asshole, by a former offender.md
new file mode 100644
index 0000000000..3478787ea1
--- /dev/null
+++ b/sources/tech/20180319 How to not be a white male asshole, by a former offender.md
@@ -0,0 +1,153 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to not be a white male asshole, by a former offender)
+[#]: via: (https://www.jtolio.com/2018/03/how-to-not-be-a-white-male-asshole-by-a-former-offender)
+[#]: author: (jtolio.com https://www.jtolio.com/)
+
+How to not be a white male asshole, by a former offender
+======
+
+_Huge thanks to Caitlin Jarvis for editing, contributing to, and proofreading to this post._
+
+First off, let’s start off with some assumptions. You, dear reader, don’t intend to cause anyone harm. You have good intentions, see yourself as a good person, and are interested in self improvement. That’s great!
+
+Second, I don’t actually know for sure if I’m not still a current offender. I might be! It’s certainly something I’ll never be done working on.
+
+### 1\. You don’t know what others are going through
+
+Unfortunately, your good intentions are not enough to make sure the experiences of others are, in fact, good because we live in a world of asymmetric information. If another person’s dog just died unbeknownst to you and you start talking excitedly about how great dogs are to try and cheer a sad person up, you may end up causing them to be even sadder. You know things other people don’t, and others know things you don’t.
+
+So when I say that if you are a white man, there is an invisible world of experiences happening all around you that you are inherently blind to, it’s because of asymmetric information. You can’t know what others are going through because you are not an impartial observer of a system. _You exist within the system._
+
+![][1]
+
+Let me show you what I mean: did you know a recent survey found that _[81 percent of women have experienced sexual harassment of some kind][2]_? Fully 1 out of every 2 women you know have had to deal specifically with _unwanted sexual touching_.
+
+What should have been most amazing about the [#MeToo movement][3] was not how many women reported harassment, but how many men were surprised.
+
+### 2\. You can inadvertently contribute to a racist, sexist, or prejudiced society
+
+I [previously wrote a lot about how small little interactions can add up][4], illustrating that even if you don’t intend to subject someone to racism, sexism, or some other prejudice, you might be doing it anyway. Intentions are meaningless when your actions amplify the negative experience of someone else.
+
+An example from [Maisha Johnson in Everyday Feminism][5]:
+
+> Black women deal with people touching our hair a lot. Now you know. Okay, there’s more to it than that: Black women deal with people touching our hair a _hell_ of a lot.
+>
+> If you approach a Black woman saying “I just have to feel your hair,” it’s pretty safe to assume this isn’t the first time she’s heard that.
+>
+> Everyone who asks me if they can touch follows a long line of people othering me – including strangers who touch my hair without asking. The psychological impact of having people constantly feel entitled my personal space has worn me down.
+
+Another example is that men frequently demand proof. Even though it makes sense in general to check your sources for something, the predominant response of men when confronted with claims of sexist treatment is to [ask for evidence][6]. Because this happens so frequently, this action _itself_ contributes to the sexist subjugation of women. The parallel universe women live in is so distinct from the experiences of men that men can’t believe their ears, and treat the report of a victim with skepticism.
+
+As you might imagine, this sort of effect is not limited to asking women for evidence or hair touching. Microaggressions are real and everywhere; the accumulation of lots of small things can be enormous.
+
+If you’re someone in charge of building things, this can be even more important and an even greater responsibility. If you build an app that is blind to the experiences of people who don’t look or act like you, you can significantly amplify negative experiences for others by causing systemic and system-wide issues.
+
+### 3\. The only way to stop contributing is to continually listen to others
+
+If you don’t already know what others are going through, and by not knowing what others are going through you may be subjecting them to prejudice even if you don’t mean to, what can you do to help others avoid prejudice? You can listen to them! People who are experiencing prejudice _don’t want to be experiencing prejudice_ and tend to be vocal about the experience. It is your job to really listen and then turn around and change the way you approach these situations in the future.
+
+### 4\. How do I listen?
+
+To listen to someone, you need to have empathy. You need to actually care about them. You need to process what they’re saying and not treat them with suspicion.
+
+Listening is very different from interjecting and arguing. Listening to others is different from making them do the work to educate you. It is your job to find the experiences of others you haven’t had and learn from them without demanding a curriculum.
+
+When people say you should just believe marginalized people, [no one is asking you to check your critical thinking at the door][7]. What you’re being asked to do is to be aware that your incredulity is a further reminder that you are not experiencing the same thing. Worse - white men acting incredulous is _so unbelievably common_ that it itself is a microaggression. Don’t be a sea lion:
+
+![][8]
+
+#### Aside about diversity of experience vs. diversity of thought.
+
+When trying to find others to listen to, who should you find? Recently, a growing number of people have echoed that all that’s really required of diversity is different viewpoints, and having diversity of thought is the ultimate goal.
+
+I want to point out that this is not the kind of diversity that will be useful to you. It’s easy to have a bunch of different opinions and then reject them when they complicate your life. What you want to be listening to is diversity of _experience_. Some experiences can’t be chosen. You can choose to be contrarian, but you can’t choose the color of your skin.
+
+### 5\. Where do I listen?
+
+What you need is a way to be a fly on the wall and observe the life experiences of others through their words and perspectives. Being friends and hanging out with people who are different from you is great. Getting out of monocultures is fantastic. Holding your company to diversity and inclusion initiatives is wonderful.
+
+But if you still need more or you live somewhere like Utah?
+
+What if there was a website where people from all walks of life opted in to talking about their day and what they’re feeling and experiencing from their viewpoint in a way you could read? It’d be almost like seeing the world through their eyes.
+
+Yep, this blog post is an unsolicited Twitter ad. Twitter definitely has its share of problems, but after [writing about how I finally figured out Twitter][9], in 2014 I decided to embark on a year-long effort to use Twitter (I wasn’t really using it before) to follow mostly women or people of color in my field and just see what the field is like for them on a day to day basis.
+
+Listening to others in this way blew my mind clean open. Suddenly I was aware of this invisible world around me, much of which is still invisible. Now, I’m looking for it, and I catch glimpses. I would challenge anyone and everyone to do this. Make sure the content you’re consuming is predominantly viewpoints from life experiences you haven’t had.
+
+If you need a start, here are some links to accounts to fill your Twitter feed up with:
+
+ * [200 Women of Color in Tech on Twitter][10]
+ * [Women Engineers on Twitter][11]
+
+
+
+You can also check out [who I follow][12], though I should warn I also follow a lot of political accounts, joke accounts, and my following of someone is not an endorsement.
+
+It’s also worth pointing out that no individual can possibly speak for an entire class of people, but if 38 out of 50 women are saying they’re dealing with something, you should listen.
+
+### 6\. Does this work?
+
+Listening to others works, but you don’t have to just take my word for it. Here are two specific and recent experience reports of people turning their worldview for the better by listening to others:
+
+ * [A professor at the University of New Brunswick][13]
+ * [A senior design developer at Microsoft][14]
+
+
+
+You can see how much of a profound and fast impact this had on me because by early 2015, only a few months into my Twitter experiment, I was worked up enough to write [my unicycle post][4] in response to what I was reading on Twitter.
+
+Having diverse perspectives in a workplace has even been shown to [increase productivity][15] and [increase creativity][16].
+
+### 7\. Don’t stop there!
+
+Not everyone is as growth-oriented as you. Just because you’re listening now doesn’t mean others are hearing the same distribution of experiences.
+
+If this is new to you, it’s not new to marginalized people. Imagine how tired they must be in trying to convince everyone their experiences are real, valid, and ongoing. Help get the word out! Repeat and retweet what women and minorities say. Give them credit. In meetings at your work, give credit to others for their ideas and amplify their voices.
+
+Did you know that [non-white or female bosses who push diversity are judged negatively by their peers and managers][17] but white male bosses are not? If you’re a white male, use your position where others can’t.
+
+If you need an example list of things your company can do, [here’s a list Susan Fowler wrote after her experience at Uber][18].
+
+Speak up, use your experiences to help others.
+
+### 8\. Am I not prejudiced now?
+
+The asymmetry of experiences we all have means we’re all inherently prejudiced to some degree and will likely continue to contribute to a prejudiced society. That said, the first step to fixing it is admitting it!
+
+There will always be work to do. You will always need to keep listening, keep learning, and work to improve every day.
+
+--------------------------------------------------------------------------------
+
+via: https://www.jtolio.com/2018/03/how-to-not-be-a-white-male-asshole-by-a-former-offender
+
+作者:[jtolio.com][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.jtolio.com/
+[b]: https://github.com/lujun9972
+[1]: https://www.jtolio.com/images/mrmouse.jpg
+[2]: https://www.npr.org/sections/thetwo-way/2018/02/21/587671849/a-new-survey-finds-eighty-percent-of-women-have-experienced-sexual-harassment
+[3]: https://en.wikipedia.org/wiki/Me_Too_movement
+[4]: https://www.jtolio.com/2015/03/what-riding-a-unicycle-can-teach-us-about-microaggressions/
+[5]: https://everydayfeminism.com/2015/09/dont-touch-black-womens-hair/
+[6]: https://twitter.com/ArielDumas/status/970692180766490630
+[7]: https://www.elle.com/culture/career-politics/a13977980/me-too-movement-false-accusations-believe-women/
+[8]: https://www.jtolio.com/images/sealion.png
+[9]: https://www.jtolio.com/2009/03/i-finally-figured-out-twitter/
+[10]: http://peopleofcolorintech.com/articles/a-list-of-200-women-of-color-on-twitter/
+[11]: https://github.com/ryanburgess/female-engineers-twitter
+[12]: https://twitter.com/jtolds/following
+[13]: https://www.theglobeandmail.com/opinion/ill-start-2018-by-recognizing-my-white-privilege/article37472875/
+[14]: https://micahgodbolt.com/blog/changing-your-worldview/
+[15]: http://edis.ifas.ufl.edu/hr022
+[16]: https://faculty.insead.edu/william-maddux/documents/PSPB-learning-paper.pdf
+[17]: https://digest.bps.org.uk/2017/07/12/non-white-or-female-bosses-who-push-diversity-are-judged-negatively-by-their-peers-and-managers/
+[18]: https://www.susanjfowler.com/blog/2017/5/20/five-things-tech-companies-can-do-better
diff --git a/sources/tech/20180330 Go on very small hardware Part 1.md b/sources/tech/20180330 Go on very small hardware Part 1.md
deleted file mode 100644
index 3ca498ada3..0000000000
--- a/sources/tech/20180330 Go on very small hardware Part 1.md
+++ /dev/null
@@ -1,506 +0,0 @@
-Go on very small hardware (Part 1)
-============================================================
-
-
-How low we can _Go_ and still do something useful?
-
-I recently bought this ridiculously cheap board:
-
- [][2]
-
-I bought it for three reasons. First, I have never dealt (as a programmer) with STM32F0 series. Second, the STM32F10x series is getting old. MCUs belonging to the STM32F0 family are just as cheap if not cheaper and has newer peripherals, with many improvements and bugs fixed. Thirdly, I chose the smallest member of the family for the purpose of this article, to make the whole thing a little more intriguing.
-
-### The Hardware
-
-The [STM32F030F4P6][3] is impresive piece of hardware:
-
-* CPU: [Cortex M0][1] 48 MHz (only 12000 logic gates, in minimal configuration),
-
-* RAM: 4 KB,
-
-* Flash: 16 KB,
-
-* ADC, SPI, I2C, USART and a couple of timers,
-
-all enclosed in TSSOP20 package. As you can see, it is very small 32-bit system.
-
-### The software
-
-If you hoped to see how to use [genuine Go][4] to program this board, you need to read the hardware specification one more time. You must face the truth: there is a negligible chance that someone will ever add support for Cortex-M0 to the Go compiler and this is just the beginning of work.
-
-I’ll use [Emgo][5], but don’t worry, you will see that it gives you as much Go as it can on such small system.
-
-There was no support for any F0 MCU in [stm32/hal][6] before this board arrived to me. After brief study of [RM][7], the STM32F0 series appeared to be striped down STM32F3 series, which made work on new port easier.
-
-If you want to follow subsequent steps of this post, you need to install Emgo
-
-```
-cd $HOME
-git clone https://github.com/ziutek/emgo/
-cd emgo/egc
-go install
-
-```
-
-and set a couple environment variables
-
-```
-export EGCC=path_to_arm_gcc # eg. /usr/local/arm/bin/arm-none-eabi-gcc
-export EGLD=path_to_arm_linker # eg. /usr/local/arm/bin/arm-none-eabi-ld
-export EGAR=path_to_arm_archiver # eg. /usr/local/arm/bin/arm-none-eabi-ar
-
-export EGROOT=$HOME/emgo/egroot
-export EGPATH=$HOME/emgo/egpath
-
-export EGARCH=cortexm0
-export EGOS=noos
-export EGTARGET=f030x6
-
-```
-
-A more detailed description can be found on the [Emgo website][8].
-
-Ensure that egc is on your PATH. You can use `go build` instead of `go install` and copy egc to your _$HOME/bin_ or _/usr/local/bin_ .
-
-Now create new directory for your first Emgo program and copy example linker script there:
-
-```
-mkdir $HOME/firstemgo
-cd $HOME/firstemgo
-cp $EGPATH/src/stm32/examples/f030-demo-board/blinky/script.ld .
-
-```
-
-### Minimal program
-
-Lets create minimal program in _main.go_ file:
-
-```
-package main
-
-func main() {
-}
-
-```
-
-It’s actually minimal and compiles witout any problem:
-
-```
-$ egc
-$ arm-none-eabi-size cortexm0.elf
- text data bss dec hex filename
- 7452 172 104 7728 1e30 cortexm0.elf
-
-```
-
-The first compilation can take some time. The resulting binary takes 7624 bytes of Flash (text+data), quite a lot for a program that does nothing. There are 8760 free bytes left to do something useful.
-
-What about traditional _Hello, World!_ code:
-
-```
-package main
-
-import "fmt"
-
-func main() {
- fmt.Println("Hello, World!")
-}
-
-```
-
-Unfortunately, this time it went worse:
-
-```
-$ egc
-/usr/local/arm/bin/arm-none-eabi-ld: /home/michal/P/go/src/github.com/ziutek/emgo/egpath/src/stm32/examples/f030-demo-board/blog/cortexm0.elf section `.text' will not fit in region `Flash'
-/usr/local/arm/bin/arm-none-eabi-ld: region `Flash' overflowed by 10880 bytes
-exit status 1
-
-```
-
- _Hello, World!_ requires at last STM32F030x6, with its 32 KB of Flash.
-
-The _fmt_ package forces to include whole _strconv_ and _reflect_ packages. All three are pretty big, even a slimmed-down versions in Emgo. We must forget about it. There are many applications that don’t require fancy formatted text output. Often one or more LEDs or seven segment display are enough. However, in Part 2, I’ll try to use _strconv_ package to format and print some numbers and text over UART.
-
-### Blinky
-
-Our board has one LED connected between PA4 pin and VCC. This time we need a bit more code:
-
-```
-package main
-
-import (
- "delay"
-
- "stm32/hal/gpio"
- "stm32/hal/system"
- "stm32/hal/system/timer/systick"
-)
-
-var led gpio.Pin
-
-func init() {
- system.SetupPLL(8, 1, 48/8)
- systick.Setup(2e6)
-
- gpio.A.EnableClock(false)
- led = gpio.A.Pin(4)
-
- cfg := &gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain}
- led.Setup(cfg)
-}
-
-func main() {
- for {
- led.Clear()
- delay.Millisec(100)
- led.Set()
- delay.Millisec(900)
- }
-}
-
-```
-
-By convention, the _init_ function is used to initialize the basic things and configure peripherals.
-
-`system.SetupPLL(8, 1, 48/8)` configures RCC to use PLL with external 8 MHz oscilator as system clock source. PLL divider is set to 1, multipler to 48/8 = 6 which gives 48 MHz system clock.
-
-`systick.Setup(2e6)` setups Cortex-M SYSTICK timer as system timer, which runs the scheduler every 2e6 nanoseconds (500 times per second).
-
-`gpio.A.EnableClock(false)` enables clock for GPIO port A. _False_ means that this clock should be disabled in low-power mode, but this is not implemented int STM32F0 series.
-
-`led.Setup(cfg)` setups PA4 pin as open-drain output.
-
-`led.Clear()` sets PA4 pin low, which in open-drain configuration turns the LED on.
-
-`led.Set()` sets PA4 to high-impedance state, which turns the LED off.
-
-Lets compile this code:
-
-```
-$ egc
-$ arm-none-eabi-size cortexm0.elf
- text data bss dec hex filename
- 9772 172 168 10112 2780 cortexm0.elf
-
-```
-
-As you can see, blinky takes 2320 bytes more than minimal program. There are still 6440 bytes left for more code.
-
-Let’s see if it works:
-
-```
-$ openocd -d0 -f interface/stlink.cfg -f target/stm32f0x.cfg -c 'init; program cortexm0.elf; reset run; exit'
-Open On-Chip Debugger 0.10.0+dev-00319-g8f1f912a (2018-03-07-19:20)
-Licensed under GNU GPL v2
-For bug reports, read
- http://openocd.org/doc/doxygen/bugs.html
-debug_level: 0
-adapter speed: 1000 kHz
-adapter_nsrst_delay: 100
-none separate
-adapter speed: 950 kHz
-target halted due to debug-request, current mode: Thread
-xPSR: 0xc1000000 pc: 0x0800119c msp: 0x20000da0
-adapter speed: 4000 kHz
-** Programming Started **
-auto erase enabled
-target halted due to breakpoint, current mode: Thread
-xPSR: 0x61000000 pc: 0x2000003a msp: 0x20000da0
-wrote 10240 bytes from file cortexm0.elf in 0.817425s (12.234 KiB/s)
-** Programming Finished **
-adapter speed: 950 kHz
-
-```
-
-For this article, the first time in my life, I converted short video to [animated PNG][9] sequence. I’m impressed, goodbye YouTube and sorry IE users. See [apngasm][10] for more info. I should study HTML5 based alternative, but for now, APNG is my preffered way for short looped videos.
-
-
-
-### More Go
-
-If you aren’t a Go programmer but you’ve heard something about Go language, you can say: “This syntax is nice, but not a significant improvement over C. Show me _Go language_ , give mi _channels_ and _goroutines!_ ”.
-
-Here you are:
-
-```
-import (
- "delay"
-
- "stm32/hal/gpio"
- "stm32/hal/system"
- "stm32/hal/system/timer/systick"
-)
-
-var led1, led2 gpio.Pin
-
-func init() {
- system.SetupPLL(8, 1, 48/8)
- systick.Setup(2e6)
-
- gpio.A.EnableClock(false)
- led1 = gpio.A.Pin(4)
- led2 = gpio.A.Pin(5)
-
- cfg := &gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain}
- led1.Setup(cfg)
- led2.Setup(cfg)
-}
-
-func blinky(led gpio.Pin, period int) {
- for {
- led.Clear()
- delay.Millisec(100)
- led.Set()
- delay.Millisec(period - 100)
- }
-}
-
-func main() {
- go blinky(led1, 500)
- blinky(led2, 1000)
-}
-
-```
-
-Code changes are minor: the second LED was added and the previous _main_ function was renamed to _blinky_ and now requires two parameters. _Main_ starts first _blinky_ in new goroutine, so both LEDs are handled _concurrently_ . It is worth mentioning that _gpio.Pin_ type supports concurrent access to different pins of the same GPIO port.
-
-Emgo still has several shortcomings. One of them is that you have to specify a maximum number of goroutines (tasks) in advance. It’s time to edit _script.ld_ :
-
-```
-ISRStack = 1024;
-MainStack = 1024;
-TaskStack = 1024;
-MaxTasks = 2;
-
-INCLUDE stm32/f030x4
-INCLUDE stm32/loadflash
-INCLUDE noos-cortexm
-
-```
-
-The size of the stacks are set by guess, and we’ll not care about them at the moment.
-
-```
-$ egc
-$ arm-none-eabi-size cortexm0.elf
- text data bss dec hex filename
- 10020 172 172 10364 287c cortexm0.elf
-
-```
-
-Another LED and goroutine costs 248 bytes of Flash.
-
-
-
-### Channels
-
-Channels are the [preffered way][11] in Go to communicate between goroutines. Emgo goes even further and allows to use _buffered_ channels by _interrupt handlers_ . The next example actually shows such case.
-
-```
-package main
-
-import (
- "delay"
- "rtos"
-
- "stm32/hal/gpio"
- "stm32/hal/irq"
- "stm32/hal/system"
- "stm32/hal/system/timer/systick"
- "stm32/hal/tim"
-)
-
-var (
- leds [3]gpio.Pin
- timer *tim.Periph
- ch = make(chan int, 1)
-)
-
-func init() {
- system.SetupPLL(8, 1, 48/8)
- systick.Setup(2e6)
-
- gpio.A.EnableClock(false)
- leds[0] = gpio.A.Pin(4)
- leds[1] = gpio.A.Pin(5)
- leds[2] = gpio.A.Pin(9)
-
- cfg := &gpio.Config{Mode: gpio.Out, Driver: gpio.OpenDrain}
- for _, led := range leds {
- led.Set()
- led.Setup(cfg)
- }
-
- timer = tim.TIM3
- pclk := timer.Bus().Clock()
- if pclk < system.AHB.Clock() {
- pclk *= 2
- }
- freq := uint(1e3) // Hz
- timer.EnableClock(true)
- timer.PSC.Store(tim.PSC(pclk/freq - 1))
- timer.ARR.Store(700) // ms
- timer.DIER.Store(tim.UIE)
- timer.CR1.Store(tim.CEN)
-
- rtos.IRQ(irq.TIM3).Enable()
-}
-
-func blinky(led gpio.Pin, period int) {
- for range ch {
- led.Clear()
- delay.Millisec(100)
- led.Set()
- delay.Millisec(period - 100)
- }
-}
-
-func main() {
- go blinky(leds[1], 500)
- blinky(leds[2], 500)
-}
-
-func timerISR() {
- timer.SR.Store(0)
- leds[0].Set()
- select {
- case ch <- 0:
- // Success
- default:
- leds[0].Clear()
- }
-}
-
-//c:__attribute__((section(".ISRs")))
-var ISRs = [...]func(){
- irq.TIM3: timerISR,
-}
-
-```
-
-Changes compared to the previous example:
-
-1. Thrid LED was added and connected to PA9 pin (TXD pin on UART header).
-
-2. The timer (TIM3) has been introduced as a source of interrupts.
-
-3. The new _timerISR_ function handles _irq.TIM3_ interrupt.
-
-4. The new buffered channel with capacity 1 is intended for communication between _timerISR_ and _blinky_ goroutines.
-
-5. The _ISRs_ array acts as _interrupt vector table_ , a part of bigger _exception vector table_ .
-
-6. The _blinky’s for statement_ was replaced with a _range statement_ .
-
-For convenience, all LEDs, or rather their pins, have been collected in the _leds_ array. Additionally, all pins have been set to a known initial state (high), just before they were configured as outputs.
-
-In this case, we want the timer to tick at 1 kHz. To configure TIM3 prescaler, we need to known its input clock frequency. According to RM the input clock frequency is equal to APBCLK when APBCLK = AHBCLK, otherwise it is equal to 2 x APBCLK.
-
-If the CNT register is incremented at 1 kHz, then the value of ARR register corresponds to the period of counter _update event_ (reload event) expressed in milliseconds. To make update event to generate interrupts, the UIE bit in DIER register must be set. The CEN bit enables the timer.
-
-Timer peripheral should stay enabled in low-power mode, to keep ticking when the CPU is put to sleep: `timer.EnableClock(true)`. It doesn’t matter in case of STM32F0 but it’s important for code portability.
-
-The _timerISR_ function handles _irq.TIM3_ interrupt requests. `timer.SR.Store(0)` clears all event flags in SR register to deassert the IRQ to [NVIC][12]. The rule of thumb is to clear the interrupt flags immedaitely at begining of their handler, because of the IRQ deassert latency. This prevents unjustified re-call the handler again. For absolute certainty, the clear-read sequence should be performed, but in our case, just clearing is enough.
-
-The following code:
-
-```
-select {
-case ch <- 0:
- // Success
-default:
- leds[0].Clear()
-}
-
-```
-
-is a Go way to non-blocking sending on a channel. No one interrupt handler can afford to wait for a free space in the channel. If the channel is full, the default case is taken, and the onboard LED is set on, until the next interrupt.
-
-The _ISRs_ array contains interrupt vectors. The `//c:__attribute__((section(".ISRs")))` causes that the linker will inserted it into .ISRs section.
-
-The new form of _blinky’s for_ loop:
-
-```
-for range ch {
- led.Clear()
- delay.Millisec(100)
- led.Set()
- delay.Millisec(period - 100)
-}
-
-```
-
-is the equivalent of:
-
-```
-for {
- _, ok := <-ch
- if !ok {
- break // Channel closed.
- }
- led.Clear()
- delay.Millisec(100)
- led.Set()
- delay.Millisec(period - 100)
-}
-
-```
-
-Note that in this case we aren’t interested in the value received from the channel. We’re interested only in the fact that there is something to receive. We can give it expression by declaring the channel’s element type as empty struct `struct{}` instead of _int_ and send `struct{}{}` values instead of 0, but it can be strange for newcomer’s eyes.
-
-Lets compile this code:
-
-```
-$ egc
-$ arm-none-eabi-size cortexm0.elf
- text data bss dec hex filename
- 11096 228 188 11512 2cf8 cortexm0.elf
-
-```
-
-This new example takes 11324 bytes of Flash, 1132 bytes more than the previous one.
-
-With the current timings, both _blinky_ goroutines consume from the channel much faster than the _timerISR_ sends to it. So they both wait for new data simultaneously and you can observe the randomness of _select_ , required by the [Go specification][13].
-
-
-
-The onboard LED is always off, so the channel overrun never occurs.
-
-Let’s speed up sending, by changing `timer.ARR.Store(700)` to `timer.ARR.Store(200)`. Now the _timerISR_ sends 5 messages per second but both recipients together can receive only 4 messages per second.
-
-
-
-As you can see, the _timerISR_ lights the yellow LED which means there is no space in the channel.
-
-This is where I finish the first part of this article. You should know that this part didn’t show you the most important thing in Go language, _interfaces_ .
-
-Goroutines and channels are only nice and convenient syntax. You can replace them with your own code - not easy but feasible. Interfaces are the essence of Go, and that’s what I will start with in the [second part][14] of this article.
-
-We still have some free space on Flash.
-
---------------------------------------------------------------------------------
-
-via: https://ziutek.github.io/2018/03/30/go_on_very_small_hardware.html
-
-作者:[ Michał Derkacz][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://ziutek.github.io/
-[1]:https://en.wikipedia.org/wiki/ARM_Cortex-M#Cortex-M0
-[2]:https://ziutek.github.io/2018/03/30/go_on_very_small_hardware.html
-[3]:http://www.st.com/content/st_com/en/products/microcontrollers/stm32-32-bit-arm-cortex-mcus/stm32-mainstream-mcus/stm32f0-series/stm32f0x0-value-line/stm32f030f4.html
-[4]:https://golang.org/
-[5]:https://github.com/ziutek/emgo
-[6]:https://github.com/ziutek/emgo/tree/master/egpath/src/stm32/hal
-[7]:http://www.st.com/resource/en/reference_manual/dm00091010.pdf
-[8]:https://github.com/ziutek/emgo
-[9]:https://en.wikipedia.org/wiki/APNG
-[10]:http://apngasm.sourceforge.net/
-[11]:https://blog.golang.org/share-memory-by-communicating
-[12]:http://infocenter.arm.com/help/topic/com.arm.doc.ddi0432c/Cihbecee.html
-[13]:https://golang.org/ref/spec#Select_statements
-[14]:https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html
diff --git a/sources/tech/20180507 Multinomial Logistic Classification.md b/sources/tech/20180507 Multinomial Logistic Classification.md
new file mode 100644
index 0000000000..01fb7b2e90
--- /dev/null
+++ b/sources/tech/20180507 Multinomial Logistic Classification.md
@@ -0,0 +1,215 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Multinomial Logistic Classification)
+[#]: via: (https://www.jtolio.com/2018/05/multinomial-logistic-classification)
+[#]: author: (jtolio.com https://www.jtolio.com/)
+
+Multinomial Logistic Classification
+======
+
+_This article was originally a problem I wrote for a coding competition I hosted, Vivint’s 2017 Game of Codes (now offline). The goal of this problem was not only to be a fun challenge but also to teach contestants almost everything they needed to know to build a neural network from scratch. I thought it might be neat to revive on my site! If machine learning is still scary sounding and foreign to you, you should feel much more at ease after working through this problem. I left out the details of [back-propagation][1], and a single-layer neural network isn’t really a neural network, but in this problem you can learn how to train and run a complete model! There’s lots of maybe scary-looking math but honestly if you can [multiply matrices][2] you should be fine._
+
+In this problem, you’re going to build and train a machine learning model… from scratch! Don’t be intimidated - it will be much easier than it sounds!
+
+### What is machine learning?
+
+_Machine learning_ is a broad and growing range of topics, but essentially the idea is to teach the computer how to find patterns in large amounts of data, then use those patterns to make predictions. Surprisingly, the techniques that have been developed allow computers to translate languages, drive cars, recognize cats, synthesize voice, understand your music tastes, cure diseases, and even adjust your thermostat!
+
+You might be surprised to learn that since about 2010, the entire artificial intelligence and machine learning community has reorganized around a surprisingly small and common toolbox for all of these problems. So, let’s dive in to this toolbox!
+
+### Classification
+
+One of the most fundamental ways of solving problems in machine learning is by recasting problems as _classification_ problems. In other words, if you can describe a problem as data that needs labels, you can use machine learning!
+
+Machine learning will go through a phase of _training_, where data and existing labels are provided to the system. As a motivating example, imagine you have a large collection of photos that either contain hot dogs or don’t. Some of your photos have already been labeled if they contain a hot dog or not, but the other photos we want to build a system that will automatically label them “hotdog” or “nothotdog.” During training, we attempt to build a model of what exactly the essence of each label is. In this case, we will run all of our existing labeled photos through the system so it can learn what makes a hot dog a hot dog.
+
+After training, we run the unseen photos through the model and use the model to generate classifications. If you provide a new photo to your hotdog/nothotdog model, your model should be able to tell you if the photo contains a hot dog, assuming your model had a good training data set and was able to capture the core concept of what a hot dog is.
+
+Many different types of problems can be described as classification problems. As an example, perhaps you want to predict which word comes next in a sequence. Given four input words, a classifier can label those four words as “likely the fourth word follows the last three words” or “not likely.” Alternatively, the classification label for three words could be the most likely word to follow those three.
+
+### How I learned to stop worrying and love multinomial logistic classification
+
+Okay, let’s do the simplest thing we can think of to take input data and classify it.
+
+Let’s imagine our data that we want to classify is a big list of values. If what we have is a 16 by 16 pixel picture, we’re going to just put all the pixels in one big row so we have 256 pixel values in a row. So we’ll say \\(\mathbf{x}\\) is a vector in 256 dimensions, and each dimension is the pixel value.
+
+We have two labels, “hotdog” and “nothotdog.” Just like any other machine learning system, our system will never be 100% confident with a classification, so we will need to output confidence probabilities. The output of our system will be a two-dimensional vector, \\(\mathbf{p}\\). \\(p_0\\) will represent the probability that the input should be labeled “hotdog” and \\(p_1\\) will represent the probability that the input should be labeled “nothotdog.”
+
+How do we take a vector in 256 (or \\(\dim(\mathbf{x})\\)) dimensions and make something in just 2 (or \\(\dim(\mathbf{p})\\)) dimensions? Why, [matrix multiplication][2] of course! If you have a matrix with 2 rows and 256 columns, multiplying it by a 256-dimensional vector will result in a 2-dimensional one.
+
+Surprisingly, this is actually really close to the final construction of our classifier, but there are two problems:
+
+ 1. If one of the input \\(\mathbf{x}\\)s is all zeros, the output will have to be zeros. But we need one of the output dimensions to not be zero!
+ 2. There’s nothing guaranteeing the probabilities in the output will be non-negative and all sum to 1.
+
+
+
+The first problem is easy, we add a bias vector \\(\mathbf{b}\\), turning our matrix multiplication into a standard linear equation of the form \\(\mathbf{W}\cdot\mathbf{x}+\mathbf{b}=\mathbf{y}\\).
+
+The second problem can be solved by using the [softmax function][3]. For a given vector \\(\mathbf{v}\\), softmax is defined as:
+
+In case the \\(\sum\\) scares you, \\(\sum_{j=0}^{n-1}\\) is basically a math “for loop.” All it’s saying is that we’re going to add together everything that comes after it (\\(e^{v_j}\\)) for every \\(j\\) value from 0 to \\(n-1\\).
+
+Softmax is a neat function! The output will be a vector where the largest dimension in the input will be the closest number to 1, no dimensions will be less than zero, and all dimensions sum to 1. Here are some examples:
+
+Unbelievably, these are all the building blocks you need for a linear model! Let’s put all the blocks together. If you already have \\(\mathbf{W}\cdot\mathbf{x}+\mathbf{b}=\mathbf{y}\\), your prediction \\(\mathbf{p}\\) can be found as \\(\text{softmax}\left(\mathbf{y}\right)\\). More fully, given an input \\(\mathbf{x}\\) and a trained model \\(\left(\mathbf{W},\mathbf{b}\right)\\), your prediction \\(\mathbf{p}\\) is:
+
+Once again, in this context, \\(p_0\\) is the probability given the model that the input should be labeled “hotdog” and \\(p_1\\) is the probability given the model that the input should be labeled “nothotdog.”
+
+It’s kind of amazing that all you need for good success with things even as complex as handwriting recognition is a linear model such as this one.
+
+### Scoring
+
+How do we find \\(\mathbf{W}\\) and \\(\mathbf{b}\\)? It might surprise you but we’re going to start off by guessing some random numbers and then changing them until we aren’t predicting things too badly (via a process known as [gradient descent][4]). But what does “too badly” mean?
+
+Recall that we have data that we’ve already labeled. We already have photos labeled “hotdog” and “nothotdog” in what’s called our _training set_. For each photo, we’re going to take whatever our current model is (\\(\mathbf{W}\\) and \\(\mathbf{b}\\)) and find \\(\mathbf{p}\\). Perhaps for one photo (that really is of a hot dog) our \\(\mathbf{p}\\) looks like this:
+
+This isn’t great! Our model says that the photo should be labeled “nothotdog” with 60% probability, but it is a hot dog.
+
+We need a bit more terminology. So far, we’ve only talked about one sample, one label, and one prediction at a time, but obviously we have lots of samples, lots of labels, and lots of predictions, and we want to score how our model does not just on one sample, but on all of our training samples. Assume we have \\(s\\) training samples, each sample has \\(d\\) dimensions, and there are \\(l\\) labels. In the case of our 16 by 16 pixel hot dog photos, \\(d = 256\\) and \\(l = 2\\). We’ll refer to sample \\(i\\) as \\(\mathbf{x}^{(i)}\\), our prediction for sample \\(i\\) as \\(\mathbf{p}^{(i)}\\), and the correct label vector for sample \\(i\\) as \\(\mathbf{L}^{(i)}\\). \\(\mathbf{L}^{(i)}\\) is a vector that is all zeros except for the dimension corresponding to the correct label, where that dimension is a 1. In other words, we have \\(\mathbf{W}\cdot\mathbf{x}^{(i)}+\mathbf{b} = \mathbf{p}^{(i)}\\) and we want \\(\mathbf{p}^{(i)}\\) to be as close to \\(\mathbf{L}^{(i)}\\) as possible, for all \\(s\\) samples.
+
+To score our model, we’re going to compute something called the _average cross entropy loss_. In general, [loss][5] is used to mean how off the mark a machine learning model is. While there are many ways of calculating loss, we’re going to use average [cross entropy][6] because it has some nice properties.
+
+Here’s the definition of the average cross entropy loss across all samples:
+
+All we need to do is find \\(\mathbf{W}\\) and \\(\mathbf{b}\\) that make this loss smallest. How do we do that?
+
+### Training
+
+As we said before, we will start \\(\mathbf{W}\\) and \\(\mathbf{b}\\) off with random values. For each value, choose a floating-point random number between -1 and 1.
+
+Of course, we’ll need to correct these values given the training data, and we now have enough information to describe how we will back-propagate corrections.
+
+The plan is to process all of the training data enough times that the loss drops to an “acceptable level.” Each time through the training data we’ll collect all of the predictions, and at the end we’ll update \\(\mathbf{W}\\) and \\(\mathbf{b}\\) with the information we’ve found.
+
+One problem that can occur is that your model might overcorrect after each run. A simple way to limit overcorrection some is to add a “learning rate”, usually designated \\(\alpha\\), which is some small fraction. You get to choose the learning rate! A good default choice for \\(\alpha\\) is 0.1.
+
+At the end of each run through all of the training data, here’s how you update \\(\mathbf{W}\\) and \\(\mathbf{b}\\):
+
+Just because this syntax is starting to get out of hand, let’s refresh what each symbol means.
+
+ * \\(W_{m,n}\\) is the cell in weight matrix \\(\mathbf{W}\\) at row \\(m\\) and column \\(n\\).
+ * \\(b_m\\) is the \\(m\\)-th dimension in the “bias” vector \\(\mathbf{b}\\).
+ * \\(\alpha\\) is again your learning rate, 0.1, and \\(s\\) is how many training samples you have.
+ * \\(x_n^{(i)}\\) is the \\(n\\)-th dimension of sample \\(i\\).
+ * Likewise, \\(p_m^{(i)}\\) and \\(L_m^{(i)}\\) are the \\(m\\)-th dimensions of our prediction and true labels for sample \\(i\\), respectively. Remember that for each sample \\(i\\), \\(L_m^{(i)}\\) is zero for all but the dimension corresponding to the correct label, where it is 1.
+
+
+
+If you’re curious how we got these equations, we applied the [chain rule][7] to calculate partial derivatives of the total loss. It’s hairy, and this problem description is already too long!
+
+Anyway, once you’ve updated your \\(\mathbf{W}\\) and \\(\mathbf{b}\\), you start the whole process over!
+
+### When do we stop?
+
+Knowing when to stop is a hard problem. How low your loss goes is a function of your learning rate, how many iterations you run over your training data, and a huge number of other factors. On the flip side, if you train your model so your loss is too low, you run the risk of overfitting your model to your training data, so it won’t work well on data it hasn’t seen before.
+
+One of the more common ways of deciding when to [stop training][8] is to have a separate validation set of samples we check our success on and stop when we stop improving. But for this problem, to keep things simple what we’re going to do is just keep track of how our loss changes and stop when the loss stops changing as much.
+
+After the first 10 iterations, your loss will have changed 9 times (there was no change from the first time since it was the first time). Take the average of those 9 changes and stop training when your loss change is less than a hundredth the average loss change.
+
+### Tie it all together
+
+Alright! If you’ve stuck with me this far, you’ve learned to implement a multinomial logistic classifier using gradient descent, [back-propagation][1], and [one-hot encoding][9]. Good job!
+
+You should now be able to write a program that takes labeled training samples, trains a model, then takes unlabeled test samples and predicts labels for them!
+
+### Your program
+
+As input your program should take vectors of floating-point values, followed by a label. Some of the labels will be question marks. Your program should output the correct label for all of the question marks it sees. The label your program should output will always be one it has seen training examples of.
+
+Your program will pass the tests if it labels 75% or more of the unlabeled data correctly.
+
+### Where to learn more
+
+If you want to learn more or dive deeper into optimizing your solution, you may be interested in the first section of [Udacity’s free course on Deep Learning][10], or [Dom Luma’s tutorial on building a mini-TensorFlow][11].
+
+### Example
+
+#### Input
+
+```
+ 0.93 -1.52 1.32 0.05 1.72 horse
+ 1.57 -1.74 0.92 -1.33 -0.68 staple
+ 0.18 1.24 -1.53 1.53 0.78 other
+ 1.96 -1.29 -1.50 -0.19 1.47 staple
+ 1.24 0.15 0.73 -0.22 1.15 battery
+ 1.41 -1.56 1.04 1.09 0.66 horse
+-0.70 -0.93 -0.18 0.75 0.88 horse
+ 1.12 -1.45 -1.26 -0.43 -0.05 staple
+ 1.89 0.21 -1.45 0.47 0.62 other
+-0.60 -1.87 0.82 -0.66 1.86 staple
+-0.80 -1.99 1.74 0.65 1.46 horse
+-0.03 1.35 0.11 -0.92 -0.04 battery
+-0.24 -0.03 0.58 1.32 -1.51 horse
+-0.60 -0.70 1.61 0.56 -0.66 horse
+ 1.29 -0.39 -1.57 -0.45 1.63 staple
+ 0.87 1.59 -1.61 -1.79 1.47 battery
+ 1.86 1.92 0.83 -0.34 1.06 battery
+-1.09 -0.81 1.47 1.82 0.06 horse
+-0.99 -1.00 -1.45 -1.02 -1.06 staple
+-0.82 -0.56 0.82 0.79 -1.02 horse
+-1.86 0.77 -0.58 0.82 -1.94 other
+ 0.15 1.18 -0.87 0.78 2.00 other
+ 1.18 0.79 1.08 -1.65 -0.73 battery
+ 0.37 1.78 0.01 0.06 -0.50 other
+-0.35 0.31 1.18 -1.83 -0.57 battery
+ 0.91 1.14 -1.85 0.39 0.07 other
+-1.61 0.28 -0.31 0.93 0.77 other
+-0.11 -1.75 -1.66 -1.55 -0.79 staple
+ 0.05 1.03 -0.23 1.49 1.66 other
+-1.99 0.43 -0.99 1.72 0.52 other
+-0.30 0.40 -0.70 0.51 0.07 other
+-0.54 1.92 -1.13 -1.53 1.73 battery
+-0.52 0.44 -0.84 -0.11 0.10 battery
+-1.00 -1.82 -1.19 -0.67 -1.18 staple
+-1.81 0.10 -1.64 -1.47 -1.86 battery
+-1.77 0.53 -1.28 0.55 -1.15 other
+ 0.29 -0.28 -0.41 0.70 1.80 horse
+-0.91 0.02 1.60 -1.44 -1.89 battery
+ 1.24 -0.42 -1.30 -0.80 -0.54 staple
+-1.98 -1.15 0.54 -0.14 -1.24 staple
+ 1.26 -1.02 -1.08 -1.27 1.65 ?
+ 1.97 1.14 0.51 0.96 -0.36 ?
+ 0.99 0.14 -0.97 -1.90 -0.87 ?
+ 1.54 -1.83 1.59 1.98 -0.41 ?
+-1.81 0.34 -0.83 0.90 -1.60 ?
+```
+
+#### Output
+
+```
+staple
+other
+battery
+horse
+other
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.jtolio.com/2018/05/multinomial-logistic-classification
+
+作者:[jtolio.com][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.jtolio.com/
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Backpropagation
+[2]: https://en.wikipedia.org/wiki/Matrix_multiplication
+[3]: https://en.wikipedia.org/wiki/Softmax_function
+[4]: https://en.wikipedia.org/wiki/Gradient_descent
+[5]: https://en.wikipedia.org/wiki/Loss_function
+[6]: https://en.wikipedia.org/wiki/Cross_entropy
+[7]: https://en.wikipedia.org/wiki/Chain_rule
+[8]: https://en.wikipedia.org/wiki/Early_stopping
+[9]: https://en.wikipedia.org/wiki/One-hot
+[10]: https://classroom.udacity.com/courses/ud730
+[11]: https://nbviewer.jupyter.org/github/domluna/labs/blob/master/Build%20Your%20Own%20TensorFlow.ipynb
diff --git a/sources/tech/20180708 Building a Messenger App- Conversations.md b/sources/tech/20180708 Building a Messenger App- Conversations.md
new file mode 100644
index 0000000000..1a5c7d251a
--- /dev/null
+++ b/sources/tech/20180708 Building a Messenger App- Conversations.md
@@ -0,0 +1,351 @@
+[#]: collector: (lujun9972)
+[#]: translator: (PsiACE)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building a Messenger App: Conversations)
+[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-conversations/)
+[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
+
+Building a Messenger App: Conversations
+======
+
+This post is the 3rd in a series:
+
+ * [Part 1: Schema][1]
+ * [Part 2: OAuth][2]
+
+
+
+In our messenger app, messages are stacked by conversations between two participants. You start a conversation providing the user you want to chat with, the conversations is created (if not exists already) and you can start sending messages to that conversations.
+
+On the front-end we’re interested in showing a list of the lastest conversations. There we’ll show the last message of it and the name and avatar of the other participant.
+
+In this post, we’ll code the endpoints to start a conversation, list the latest and find a single one.
+
+Inside the `main()` function add this routes.
+
+```
+router.HandleFunc("POST", "/api/conversations", requireJSON(guard(createConversation)))
+router.HandleFunc("GET", "/api/conversations", guard(getConversations))
+router.HandleFunc("GET", "/api/conversations/:conversationID", guard(getConversation))
+```
+
+These three endpoints require authentication so we use the `guard()` middleware. There is a new middleware that checks for the request content type JSON.
+
+### Require JSON Middleware
+
+```
+func requireJSON(handler http.HandlerFunc) http.HandlerFunc {
+ return func(w http.ResponseWriter, r *http.Request) {
+ if ct := r.Header.Get("Content-Type"); !strings.HasPrefix(ct, "application/json") {
+ http.Error(w, "Content type of application/json required", http.StatusUnsupportedMediaType)
+ return
+ }
+ handler(w, r)
+ }
+}
+```
+
+If the request isn’t JSON, it responds with a `415 Unsupported Media Type` error.
+
+### Create Conversation
+
+```
+type Conversation struct {
+ ID string `json:"id"`
+ OtherParticipant *User `json:"otherParticipant"`
+ LastMessage *Message `json:"lastMessage"`
+ HasUnreadMessages bool `json:"hasUnreadMessages"`
+}
+```
+
+So, a conversation holds a reference to the other participant and the last message. Also has a bool field to tell if it has unread messages.
+
+```
+type Message struct {
+ ID string `json:"id"`
+ Content string `json:"content"`
+ UserID string `json:"-"`
+ ConversationID string `json:"conversationID,omitempty"`
+ CreatedAt time.Time `json:"createdAt"`
+ Mine bool `json:"mine"`
+ ReceiverID string `json:"-"`
+}
+```
+
+Messages are for the next post, but I define the struct now since we are using it. Most of the fields are the same as the database table. We have `Mine` to tell if the message is owned by the current authenticated user and `ReceiverID` will be used to filter messanges once we add realtime capabilities.
+
+Lets write the HTTP handler then. It’s quite long but don’t be scared.
+
+```
+func createConversation(w http.ResponseWriter, r *http.Request) {
+ var input struct {
+ Username string `json:"username"`
+ }
+ defer r.Body.Close()
+ if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
+ http.Error(w, err.Error(), http.StatusBadRequest)
+ return
+ }
+
+ input.Username = strings.TrimSpace(input.Username)
+ if input.Username == "" {
+ respond(w, Errors{map[string]string{
+ "username": "Username required",
+ }}, http.StatusUnprocessableEntity)
+ return
+ }
+
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+
+ tx, err := db.BeginTx(ctx, nil)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not begin tx: %v", err))
+ return
+ }
+ defer tx.Rollback()
+
+ var otherParticipant User
+ if err := tx.QueryRowContext(ctx, `
+ SELECT id, avatar_url FROM users WHERE username = $1
+ `, input.Username).Scan(
+ &otherParticipant.ID,
+ &otherParticipant.AvatarURL,
+ ); err == sql.ErrNoRows {
+ http.Error(w, "User not found", http.StatusNotFound)
+ return
+ } else if err != nil {
+ respondError(w, fmt.Errorf("could not query other participant: %v", err))
+ return
+ }
+
+ otherParticipant.Username = input.Username
+
+ if otherParticipant.ID == authUserID {
+ http.Error(w, "Try start a conversation with someone else", http.StatusForbidden)
+ return
+ }
+
+ var conversationID string
+ if err := tx.QueryRowContext(ctx, `
+ SELECT conversation_id FROM participants WHERE user_id = $1
+ INTERSECT
+ SELECT conversation_id FROM participants WHERE user_id = $2
+ `, authUserID, otherParticipant.ID).Scan(&conversationID); err != nil && err != sql.ErrNoRows {
+ respondError(w, fmt.Errorf("could not query common conversation id: %v", err))
+ return
+ } else if err == nil {
+ http.Redirect(w, r, "/api/conversations/"+conversationID, http.StatusFound)
+ return
+ }
+
+ var conversation Conversation
+ if err = tx.QueryRowContext(ctx, `
+ INSERT INTO conversations DEFAULT VALUES
+ RETURNING id
+ `).Scan(&conversation.ID); err != nil {
+ respondError(w, fmt.Errorf("could not insert conversation: %v", err))
+ return
+ }
+
+ if _, err = tx.ExecContext(ctx, `
+ INSERT INTO participants (user_id, conversation_id) VALUES
+ ($1, $2),
+ ($3, $2)
+ `, authUserID, conversation.ID, otherParticipant.ID); err != nil {
+ respondError(w, fmt.Errorf("could not insert participants: %v", err))
+ return
+ }
+
+ if err = tx.Commit(); err != nil {
+ respondError(w, fmt.Errorf("could not commit tx to create conversation: %v", err))
+ return
+ }
+
+ conversation.OtherParticipant = &otherParticipant
+
+ respond(w, conversation, http.StatusCreated)
+}
+```
+
+For this endpoint you do a POST request to `/api/conversations` with a JSON body containing the username of the user you want to chat with.
+
+So first it decodes the request body into an struct with the username. Then it validates that the username is not empty.
+
+```
+type Errors struct {
+ Errors map[string]string `json:"errors"`
+}
+```
+
+This is the `Errors` struct. It’s just a map. If you enter an empty username you get this JSON with a `422 Unprocessable Entity` error.
+
+```
+{
+ "errors": {
+ "username": "Username required"
+ }
+}
+```
+
+Then, we begin an SQL transaction. We only received an username, but we need the actual user ID. So the first part of the transaction is to query for the id and avatar of that user (the other participant). If the user is not found, we respond with a `404 Not Found` error. Also, if the user happens to be the same as the current authenticated user, we respond with `403 Forbidden`. There should be two different users, not the same.
+
+Then, we try to find a conversation those two users have in common. We use `INTERSECT` for that. If there is one, we redirect to that conversation `/api/conversations/{conversationID}` and return there.
+
+If no common conversation was found, we continue by creating a new one and adding the two participants. Finally, we `COMMIT` the transaction and respond with the newly created conversation.
+
+### Get Conversations
+
+This endpoint `/api/conversations` is to get all the conversations of the current authenticated user.
+
+```
+func getConversations(w http.ResponseWriter, r *http.Request) {
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+
+ rows, err := db.QueryContext(ctx, `
+ SELECT
+ conversations.id,
+ auth_user.messages_read_at < messages.created_at AS has_unread_messages,
+ messages.id,
+ messages.content,
+ messages.created_at,
+ messages.user_id = $1 AS mine,
+ other_users.id,
+ other_users.username,
+ other_users.avatar_url
+ FROM conversations
+ INNER JOIN messages ON conversations.last_message_id = messages.id
+ INNER JOIN participants other_participants
+ ON other_participants.conversation_id = conversations.id
+ AND other_participants.user_id != $1
+ INNER JOIN users other_users ON other_participants.user_id = other_users.id
+ INNER JOIN participants auth_user
+ ON auth_user.conversation_id = conversations.id
+ AND auth_user.user_id = $1
+ ORDER BY messages.created_at DESC
+ `, authUserID)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not query conversations: %v", err))
+ return
+ }
+ defer rows.Close()
+
+ conversations := make([]Conversation, 0)
+ for rows.Next() {
+ var conversation Conversation
+ var lastMessage Message
+ var otherParticipant User
+ if err = rows.Scan(
+ &conversation.ID,
+ &conversation.HasUnreadMessages,
+ &lastMessage.ID,
+ &lastMessage.Content,
+ &lastMessage.CreatedAt,
+ &lastMessage.Mine,
+ &otherParticipant.ID,
+ &otherParticipant.Username,
+ &otherParticipant.AvatarURL,
+ ); err != nil {
+ respondError(w, fmt.Errorf("could not scan conversation: %v", err))
+ return
+ }
+
+ conversation.LastMessage = &lastMessage
+ conversation.OtherParticipant = &otherParticipant
+ conversations = append(conversations, conversation)
+ }
+
+ if err = rows.Err(); err != nil {
+ respondError(w, fmt.Errorf("could not iterate over conversations: %v", err))
+ return
+ }
+
+ respond(w, conversations, http.StatusOK)
+}
+```
+
+This handler just does a query to the database. It queries to the conversations table with some joins… First, to the messages table to get the last message. Then to the participants, but it adds a condition to a participant whose ID is not the one of the current authenticated user; this is the other participant. Then it joins to the users table to get his username and avatar. And finally joins with the participants again but with the contrary condition, so this participant is the current authenticated user. We compare `messages_read_at` with the message `created_at` to know whether the conversation has unread messages. And we use the message `user_id` to check if it’s “mine” or not.
+
+Note that this query assumes that a conversation has just two users. It only works for that scenario. Also, if you want to show a count of the unread messages, this design isn’t good. I think you could add a `unread_messages_count` `INT` field on the `participants` table and increment it each time a new message is created and reset it when the user read them.
+
+Then it iterates over the rows, scan each one to make an slice of conversations and respond with those at the end.
+
+### Get Conversation
+
+This endpoint `/api/conversations/{conversationID}` respond with a single conversation by its ID.
+
+```
+func getConversation(w http.ResponseWriter, r *http.Request) {
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+ conversationID := way.Param(ctx, "conversationID")
+
+ var conversation Conversation
+ var otherParticipant User
+ if err := db.QueryRowContext(ctx, `
+ SELECT
+ IFNULL(auth_user.messages_read_at < messages.created_at, false) AS has_unread_messages,
+ other_users.id,
+ other_users.username,
+ other_users.avatar_url
+ FROM conversations
+ LEFT JOIN messages ON conversations.last_message_id = messages.id
+ INNER JOIN participants other_participants
+ ON other_participants.conversation_id = conversations.id
+ AND other_participants.user_id != $1
+ INNER JOIN users other_users ON other_participants.user_id = other_users.id
+ INNER JOIN participants auth_user
+ ON auth_user.conversation_id = conversations.id
+ AND auth_user.user_id = $1
+ WHERE conversations.id = $2
+ `, authUserID, conversationID).Scan(
+ &conversation.HasUnreadMessages,
+ &otherParticipant.ID,
+ &otherParticipant.Username,
+ &otherParticipant.AvatarURL,
+ ); err == sql.ErrNoRows {
+ http.Error(w, "Conversation not found", http.StatusNotFound)
+ return
+ } else if err != nil {
+ respondError(w, fmt.Errorf("could not query conversation: %v", err))
+ return
+ }
+
+ conversation.ID = conversationID
+ conversation.OtherParticipant = &otherParticipant
+
+ respond(w, conversation, http.StatusOK)
+}
+```
+
+The query is quite similar. We’re not interested in showing the last message, so we omit those fields, but we need the message to know whether the conversation has unread messages. This time we do a `LEFT JOIN` instead of an `INNER JOIN` because the `last_message_id` is `NULLABLE`; in other case we won’t get any rows. We use an `IFNULL` in the `has_unread_messages` comparison for that reason too. Lastly, we filter by ID.
+
+If the query returns no rows, we respond with a `404 Not Found` error, otherwise `200 OK` with the found conversation.
+
+* * *
+
+Yeah, that concludes with the conversation endpoints.
+
+Wait for the next post to create and list messages 👋
+
+[Souce Code][3]
+
+--------------------------------------------------------------------------------
+
+via: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
+
+作者:[Nicolás Parada][a]
+选题:[lujun9972][b]
+译者:[PsiACE](https://github.com/PsiACE)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://nicolasparada.netlify.com/
+[b]: https://github.com/lujun9972
+[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
+[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
+[3]: https://github.com/nicolasparada/go-messenger-demo
diff --git a/sources/tech/20180710 Building a Messenger App- Messages.md b/sources/tech/20180710 Building a Messenger App- Messages.md
new file mode 100644
index 0000000000..55e596df64
--- /dev/null
+++ b/sources/tech/20180710 Building a Messenger App- Messages.md
@@ -0,0 +1,315 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building a Messenger App: Messages)
+[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-messages/)
+[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
+
+Building a Messenger App: Messages
+======
+
+This post is the 4th on a series:
+
+ * [Part 1: Schema][1]
+ * [Part 2: OAuth][2]
+ * [Part 3: Conversations][3]
+
+
+
+In this post we’ll code the endpoints to create a message and list them, also an endpoint to update the last time the participant read messages. Start by adding these routes in the `main()` function.
+
+```
+router.HandleFunc("POST", "/api/conversations/:conversationID/messages", requireJSON(guard(createMessage)))
+router.HandleFunc("GET", "/api/conversations/:conversationID/messages", guard(getMessages))
+router.HandleFunc("POST", "/api/conversations/:conversationID/read_messages", guard(readMessages))
+```
+
+Messages goes into conversations so the endpoint includes the conversation ID.
+
+### Create Message
+
+This endpoint handles POST requests to `/api/conversations/{conversationID}/messages` with a JSON body with just the message content and return the newly created message. It has two side affects: it updates the conversation `last_message_id` and updates the participant `messages_read_at`.
+
+```
+func createMessage(w http.ResponseWriter, r *http.Request) {
+ var input struct {
+ Content string `json:"content"`
+ }
+ defer r.Body.Close()
+ if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
+ http.Error(w, err.Error(), http.StatusBadRequest)
+ return
+ }
+
+ errs := make(map[string]string)
+ input.Content = removeSpaces(input.Content)
+ if input.Content == "" {
+ errs["content"] = "Message content required"
+ } else if len([]rune(input.Content)) > 480 {
+ errs["content"] = "Message too long. 480 max"
+ }
+ if len(errs) != 0 {
+ respond(w, Errors{errs}, http.StatusUnprocessableEntity)
+ return
+ }
+
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+ conversationID := way.Param(ctx, "conversationID")
+
+ tx, err := db.BeginTx(ctx, nil)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not begin tx: %v", err))
+ return
+ }
+ defer tx.Rollback()
+
+ isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not query participant existance: %v", err))
+ return
+ }
+
+ if !isParticipant {
+ http.Error(w, "Conversation not found", http.StatusNotFound)
+ return
+ }
+
+ var message Message
+ if err := tx.QueryRowContext(ctx, `
+ INSERT INTO messages (content, user_id, conversation_id) VALUES
+ ($1, $2, $3)
+ RETURNING id, created_at
+ `, input.Content, authUserID, conversationID).Scan(
+ &message.ID,
+ &message.CreatedAt,
+ ); err != nil {
+ respondError(w, fmt.Errorf("could not insert message: %v", err))
+ return
+ }
+
+ if _, err := tx.ExecContext(ctx, `
+ UPDATE conversations SET last_message_id = $1
+ WHERE id = $2
+ `, message.ID, conversationID); err != nil {
+ respondError(w, fmt.Errorf("could not update conversation last message ID: %v", err))
+ return
+ }
+
+ if err = tx.Commit(); err != nil {
+ respondError(w, fmt.Errorf("could not commit tx to create a message: %v", err))
+ return
+ }
+
+ go func() {
+ if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
+ log.Printf("could not update messages read at: %v\n", err)
+ }
+ }()
+
+ message.Content = input.Content
+ message.UserID = authUserID
+ message.ConversationID = conversationID
+ // TODO: notify about new message.
+ message.Mine = true
+
+ respond(w, message, http.StatusCreated)
+}
+```
+
+First, it decodes the request body into an struct with the message content. Then, it validates the content is not empty and has less than 480 characters.
+
+```
+var rxSpaces = regexp.MustCompile("\\s+")
+
+func removeSpaces(s string) string {
+ if s == "" {
+ return s
+ }
+
+ lines := make([]string, 0)
+ for _, line := range strings.Split(s, "\n") {
+ line = rxSpaces.ReplaceAllLiteralString(line, " ")
+ line = strings.TrimSpace(line)
+ if line != "" {
+ lines = append(lines, line)
+ }
+ }
+ return strings.Join(lines, "\n")
+}
+```
+
+This is the function to remove spaces. It iterates over each line, remove more than two consecutives spaces and returns with the non empty lines.
+
+After the validation, it starts an SQL transaction. First, it queries for the participant existance in the conversation.
+
+```
+func queryParticipantExistance(ctx context.Context, tx *sql.Tx, userID, conversationID string) (bool, error) {
+ if ctx == nil {
+ ctx = context.Background()
+ }
+ var exists bool
+ if err := tx.QueryRowContext(ctx, `SELECT EXISTS (
+ SELECT 1 FROM participants
+ WHERE user_id = $1 AND conversation_id = $2
+ )`, userID, conversationID).Scan(&exists); err != nil {
+ return false, err
+ }
+ return exists, nil
+}
+```
+
+I extracted it into a function because it’s reused later.
+
+If the user isn’t participant of the conversation, we return with a `404 Not Found` error.
+
+Then, it inserts the message and updates the conversation `last_message_id`. Since this point, `last_message_id` cannot by `NULL` because we don’t allow removing messages.
+
+Then it commits the transaction and we update the participant `messages_read_at` in a goroutine.
+
+```
+func updateMessagesReadAt(ctx context.Context, userID, conversationID string) error {
+ if ctx == nil {
+ ctx = context.Background()
+ }
+
+ if _, err := db.ExecContext(ctx, `
+ UPDATE participants SET messages_read_at = now()
+ WHERE user_id = $1 AND conversation_id = $2
+ `, userID, conversationID); err != nil {
+ return err
+ }
+ return nil
+}
+```
+
+Before responding with the new message, we must notify about it. This is for the realtime part we’ll code in the next post so I left a comment there.
+
+### Get Messages
+
+This endpoint handles GET requests to `/api/conversations/{conversationID}/messages`. It responds with a JSON array with all the messages in the conversation. It also has the same side affect of updating the participant `messages_read_at`.
+
+```
+func getMessages(w http.ResponseWriter, r *http.Request) {
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+ conversationID := way.Param(ctx, "conversationID")
+
+ tx, err := db.BeginTx(ctx, &sql.TxOptions{ReadOnly: true})
+ if err != nil {
+ respondError(w, fmt.Errorf("could not begin tx: %v", err))
+ return
+ }
+ defer tx.Rollback()
+
+ isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not query participant existance: %v", err))
+ return
+ }
+
+ if !isParticipant {
+ http.Error(w, "Conversation not found", http.StatusNotFound)
+ return
+ }
+
+ rows, err := tx.QueryContext(ctx, `
+ SELECT
+ id,
+ content,
+ created_at,
+ user_id = $1 AS mine
+ FROM messages
+ WHERE messages.conversation_id = $2
+ ORDER BY messages.created_at DESC
+ `, authUserID, conversationID)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not query messages: %v", err))
+ return
+ }
+ defer rows.Close()
+
+ messages := make([]Message, 0)
+ for rows.Next() {
+ var message Message
+ if err = rows.Scan(
+ &message.ID,
+ &message.Content,
+ &message.CreatedAt,
+ &message.Mine,
+ ); err != nil {
+ respondError(w, fmt.Errorf("could not scan message: %v", err))
+ return
+ }
+
+ messages = append(messages, message)
+ }
+
+ if err = rows.Err(); err != nil {
+ respondError(w, fmt.Errorf("could not iterate over messages: %v", err))
+ return
+ }
+
+ if err = tx.Commit(); err != nil {
+ respondError(w, fmt.Errorf("could not commit tx to get messages: %v", err))
+ return
+ }
+
+ go func() {
+ if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
+ log.Printf("could not update messages read at: %v\n", err)
+ }
+ }()
+
+ respond(w, messages, http.StatusOK)
+}
+```
+
+First, it begins an SQL transaction in readonly mode. Checks for the participant existance and queries all the messages. In each message, we use the current authenticated user ID to know whether the user owns the message (`mine`). Then it commits the transaction, updates the participant `messages_read_at` in a goroutine and respond with the messages.
+
+### Read Messages
+
+This endpoint handles POST requests to `/api/conversations/{conversationID}/read_messages`. Without any request or response body. In the frontend we’ll make this request each time a new message arrive in the realtime stream.
+
+```
+func readMessages(w http.ResponseWriter, r *http.Request) {
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+ conversationID := way.Param(ctx, "conversationID")
+
+ if err := updateMessagesReadAt(ctx, authUserID, conversationID); err != nil {
+ respondError(w, fmt.Errorf("could not update messages read at: %v", err))
+ return
+ }
+
+ w.WriteHeader(http.StatusNoContent)
+}
+```
+
+It uses the same function we’ve been using to update the participant `messages_read_at`.
+
+* * *
+
+That concludes it. Realtime messages is the only part left in the backend. Wait for it in the next post.
+
+[Souce Code][4]
+
+--------------------------------------------------------------------------------
+
+via: https://nicolasparada.netlify.com/posts/go-messenger-messages/
+
+作者:[Nicolás Parada][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://nicolasparada.netlify.com/
+[b]: https://github.com/lujun9972
+[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
+[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
+[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
+[4]: https://github.com/nicolasparada/go-messenger-demo
diff --git a/sources/tech/20180710 Building a Messenger App- Realtime Messages.md b/sources/tech/20180710 Building a Messenger App- Realtime Messages.md
new file mode 100644
index 0000000000..71479495b2
--- /dev/null
+++ b/sources/tech/20180710 Building a Messenger App- Realtime Messages.md
@@ -0,0 +1,175 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building a Messenger App: Realtime Messages)
+[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/)
+[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
+
+Building a Messenger App: Realtime Messages
+======
+
+This post is the 5th on a series:
+
+ * [Part 1: Schema][1]
+ * [Part 2: OAuth][2]
+ * [Part 3: Conversations][3]
+ * [Part 4: Messages][4]
+
+
+
+For realtime messages we’ll use [Server-Sent Events][5]. This is an open connection in which we can stream data. We’ll have and endpoint in which the user subscribes to all the messages sended to him.
+
+### Message Clients
+
+Before the HTTP part, let’s code a map to have all the clients listening for messages. Initialize this globally like so:
+
+```
+type MessageClient struct {
+ Messages chan Message
+ UserID string
+}
+
+var messageClients sync.Map
+```
+
+### New Message Created
+
+Remember in the [last post][4] when we created the message, we left a “TODO” comment. There we’ll dispatch a goroutine with this function.
+
+```
+go messageCreated(message)
+```
+
+Insert that line just where we left the comment.
+
+```
+func messageCreated(message Message) error {
+ if err := db.QueryRow(`
+ SELECT user_id FROM participants
+ WHERE user_id != $1 and conversation_id = $2
+ `, message.UserID, message.ConversationID).
+ Scan(&message.ReceiverID); err != nil {
+ return err
+ }
+
+ go broadcastMessage(message)
+
+ return nil
+}
+
+func broadcastMessage(message Message) {
+ messageClients.Range(func(key, _ interface{}) bool {
+ client := key.(*MessageClient)
+ if client.UserID == message.ReceiverID {
+ client.Messages <- message
+ }
+ return true
+ })
+}
+```
+
+The function queries for the recipient ID (the other participant ID) and sends the message to all the clients.
+
+### Subscribe to Messages
+
+Lets go to the `main()` function and add this route:
+
+```
+router.HandleFunc("GET", "/api/messages", guard(subscribeToMessages))
+```
+
+This endpoint handles GET requests on `/api/messages`. The request should be an [EventSource][6] connection. It responds with an event stream in which the data is JSON formatted.
+
+```
+func subscribeToMessages(w http.ResponseWriter, r *http.Request) {
+ if a := r.Header.Get("Accept"); !strings.Contains(a, "text/event-stream") {
+ http.Error(w, "This endpoint requires an EventSource connection", http.StatusNotAcceptable)
+ return
+ }
+
+ f, ok := w.(http.Flusher)
+ if !ok {
+ respondError(w, errors.New("streaming unsupported"))
+ return
+ }
+
+ ctx := r.Context()
+ authUserID := ctx.Value(keyAuthUserID).(string)
+
+ h := w.Header()
+ h.Set("Cache-Control", "no-cache")
+ h.Set("Connection", "keep-alive")
+ h.Set("Content-Type", "text/event-stream")
+
+ messages := make(chan Message)
+ defer close(messages)
+
+ client := &MessageClient{Messages: messages, UserID: authUserID}
+ messageClients.Store(client, nil)
+ defer messageClients.Delete(client)
+
+ for {
+ select {
+ case <-ctx.Done():
+ return
+ case message := <-messages:
+ if b, err := json.Marshal(message); err != nil {
+ log.Printf("could not marshall message: %v\n", err)
+ fmt.Fprintf(w, "event: error\ndata: %v\n\n", err)
+ } else {
+ fmt.Fprintf(w, "data: %s\n\n", b)
+ }
+ f.Flush()
+ }
+ }
+}
+```
+
+First it checks for the correct request headers and checks the server supports streaming. We create a channel of messages to make a client and store it in the clients map. Each time a new message is created, it will go in this channel, so we can read from it with a `for-select` loop.
+
+Server-Sent Events uses this format to send data:
+
+```
+data: some data here\n\n
+```
+
+We are sending it in JSON format:
+
+```
+data: {"foo":"bar"}\n\n
+```
+
+We are using `fmt.Fprintf()` to write to the response writter in this format and flushing the data in each iteration of the loop.
+
+This will loop until the connection is closed using the request context. We defered the close of the channel and the delete of the client, so when the loop ends, the channel will be closed and the client won’t receive more messages.
+
+Note aside, the JavaScript API to work with Server-Sent Events (EventSource) doesn’t support setting custom headers 😒 So we cannot set `Authorization: Bearer `. And that’s the reason why the `guard()` middleware reads the token from the URL query string also.
+
+* * *
+
+That concludes the realtime messages. I’d like to say that’s everything in the backend, but to code the frontend I’ll add one more endpoint to login. A login that will be just for development.
+
+[Souce Code][7]
+
+--------------------------------------------------------------------------------
+
+via: https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/
+
+作者:[Nicolás Parada][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://nicolasparada.netlify.com/
+[b]: https://github.com/lujun9972
+[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
+[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
+[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
+[4]: https://nicolasparada.netlify.com/posts/go-messenger-messages/
+[5]: https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events
+[6]: https://developer.mozilla.org/en-US/docs/Web/API/EventSource
+[7]: https://github.com/nicolasparada/go-messenger-demo
diff --git a/sources/tech/20180712 Building a Messenger App- Development Login.md b/sources/tech/20180712 Building a Messenger App- Development Login.md
new file mode 100644
index 0000000000..e12fb3c56a
--- /dev/null
+++ b/sources/tech/20180712 Building a Messenger App- Development Login.md
@@ -0,0 +1,145 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building a Messenger App: Development Login)
+[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-dev-login/)
+[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
+
+Building a Messenger App: Development Login
+======
+
+This post is the 6th on a series:
+
+ * [Part 1: Schema][1]
+ * [Part 2: OAuth][2]
+ * [Part 3: Conversations][3]
+ * [Part 4: Messages][4]
+ * [Part 5: Realtime Messages][5]
+
+
+
+We already implemented login through GitHub, but if we want to play around with the app, we need a couple of users to test it. In this post we’ll add an endpoint to login as any user just giving an username. This endpoint will be just for development.
+
+Start by adding this route in the `main()` function.
+
+```
+router.HandleFunc("POST", "/api/login", requireJSON(login))
+```
+
+### Login
+
+This function handles POST requests to `/api/login` with a JSON body with just an username and returns the authenticated user, a token and expiration date of it in JSON format.
+
+```
+func login(w http.ResponseWriter, r *http.Request) {
+ if origin.Hostname() != "localhost" {
+ http.NotFound(w, r)
+ return
+ }
+
+ var input struct {
+ Username string `json:"username"`
+ }
+ if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
+ http.Error(w, err.Error(), http.StatusBadRequest)
+ return
+ }
+ defer r.Body.Close()
+
+ var user User
+ if err := db.QueryRowContext(r.Context(), `
+ SELECT id, avatar_url
+ FROM users
+ WHERE username = $1
+ `, input.Username).Scan(
+ &user.ID,
+ &user.AvatarURL,
+ ); err == sql.ErrNoRows {
+ http.Error(w, "User not found", http.StatusNotFound)
+ return
+ } else if err != nil {
+ respondError(w, fmt.Errorf("could not query user: %v", err))
+ return
+ }
+
+ user.Username = input.Username
+
+ exp := time.Now().Add(jwtLifetime)
+ token, err := issueToken(user.ID, exp)
+ if err != nil {
+ respondError(w, fmt.Errorf("could not create token: %v", err))
+ return
+ }
+
+ respond(w, map[string]interface{}{
+ "authUser": user,
+ "token": token,
+ "expiresAt": exp,
+ }, http.StatusOK)
+}
+```
+
+First it checks we are on localhost or it responds with `404 Not Found`. It decodes the body skipping validation since this is just for development. Then it queries to the database for a user with the given username, if none is found, it returns with `404 Not Found`. Then it issues a new JSON web token using the user ID as Subject.
+
+```
+func issueToken(subject string, exp time.Time) (string, error) {
+ token, err := jwtSigner.Encode(jwt.Claims{
+ Subject: subject,
+ Expiration: json.Number(strconv.FormatInt(exp.Unix(), 10)),
+ })
+ if err != nil {
+ return "", err
+ }
+ return string(token), nil
+}
+```
+
+The function does the same we did [previously][2]. I just moved it to reuse code.
+
+After creating the token, it responds with the user, token and expiration date.
+
+### Seed Users
+
+Now you can add users to play with to the database.
+
+```
+INSERT INTO users (id, username) VALUES
+ (1, 'john'),
+ (2, 'jane');
+```
+
+You can save it to a file and pipe it to the Cockroach CLI.
+
+```
+cat seed_users.sql | cockroach sql --insecure -d messenger
+```
+
+* * *
+
+That’s it. Once you deploy the code to production and use your own domain this login function won’t be available.
+
+This post concludes the backend.
+
+[Souce Code][6]
+
+--------------------------------------------------------------------------------
+
+via: https://nicolasparada.netlify.com/posts/go-messenger-dev-login/
+
+作者:[Nicolás Parada][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://nicolasparada.netlify.com/
+[b]: https://github.com/lujun9972
+[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
+[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
+[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
+[4]: https://nicolasparada.netlify.com/posts/go-messenger-messages/
+[5]: https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/
+[6]: https://github.com/nicolasparada/go-messenger-demo
diff --git a/sources/tech/20180716 Building a Messenger App- Access Page.md b/sources/tech/20180716 Building a Messenger App- Access Page.md
new file mode 100644
index 0000000000..21671b92f6
--- /dev/null
+++ b/sources/tech/20180716 Building a Messenger App- Access Page.md
@@ -0,0 +1,459 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building a Messenger App: Access Page)
+[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-access-page/)
+[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
+
+Building a Messenger App: Access Page
+======
+
+This post is the 7th on a series:
+
+ * [Part 1: Schema][1]
+ * [Part 2: OAuth][2]
+ * [Part 3: Conversations][3]
+ * [Part 4: Messages][4]
+ * [Part 5: Realtime Messages][5]
+ * [Part 6: Development Login][6]
+
+
+
+Now that we’re done with the backend, lets move to the frontend. I will go with a single-page application.
+
+Lets start by creating a file `static/index.html` with the following content.
+
+```
+
+
+
+
+
+ Messenger
+
+
+
+
+
+
+```
+
+This HTML file must be server for every URL and JavaScript will take care of rendering the correct page.
+
+So lets go the the `main.go` for a moment and in the `main()` function add the following route:
+
+```
+router.Handle("GET", "/...", http.FileServer(SPAFileSystem{http.Dir("static")}))
+
+type SPAFileSystem struct {
+ fs http.FileSystem
+}
+
+func (spa SPAFileSystem) Open(name string) (http.File, error) {
+ f, err := spa.fs.Open(name)
+ if err != nil {
+ return spa.fs.Open("index.html")
+ }
+ return f, nil
+}
+```
+
+We use a custom file system so instead of returning `404 Not Found` for unknown URLs, it serves the `index.html`.
+
+### Router
+
+In the `index.html` we loaded two files: `styles.css` and `main.js`. I leave styling to your taste.
+
+Lets move to `main.js`. Create a `static/main.js` file with the following content:
+
+```
+import { guard } from './auth.js'
+import Router from './router.js'
+
+let currentPage
+const disconnect = new CustomEvent('disconnect')
+const router = new Router()
+
+router.handle('/', guard(view('home'), view('access')))
+router.handle('/callback', view('callback'))
+router.handle(/^\/conversations\/([^\/]+)$/, guard(view('conversation'), view('access')))
+router.handle(/^\//, view('not-found'))
+
+router.install(async result => {
+ document.body.innerHTML = ''
+ if (currentPage instanceof Node) {
+ currentPage.dispatchEvent(disconnect)
+ }
+ currentPage = await result
+ if (currentPage instanceof Node) {
+ document.body.appendChild(currentPage)
+ }
+})
+
+function view(pageName) {
+ return (...args) => import(`/pages/${pageName}-page.js`)
+ .then(m => m.default(...args))
+}
+```
+
+If you are follower of this blog, you already know how this works. That router is the one showed [here][7]. Just download it from [@nicolasparada/router][8] and save it to `static/router.js`.
+
+We registered four routes. At the root `/` we show the home or access page whether the user is authenticated. At `/callback` we show the callback page. On `/conversations/{conversationID}` we show the conversation or access page whether the user is authenticated and for every other URL, we show a not found page.
+
+We tell the router to render the result to the document body and dispatch a `disconnect` event to each page before leaving.
+
+We have each page in a different file and we import them with the new dynamic `import()`.
+
+### Auth
+
+`guard()` is a function that given two functions, executes the first one if the user is authenticated, or the sencond one if not. It comes from `auth.js` so lets create a `static/auth.js` file with the following content:
+
+```
+export function isAuthenticated() {
+ const token = localStorage.getItem('token')
+ const expiresAtItem = localStorage.getItem('expires_at')
+ if (token === null || expiresAtItem === null) {
+ return false
+ }
+
+ const expiresAt = new Date(expiresAtItem)
+ if (isNaN(expiresAt.valueOf()) || expiresAt <= new Date()) {
+ return false
+ }
+
+ return true
+}
+
+export function guard(fn1, fn2) {
+ return (...args) => isAuthenticated()
+ ? fn1(...args)
+ : fn2(...args)
+}
+
+export function getAuthUser() {
+ if (!isAuthenticated()) {
+ return null
+ }
+
+ const authUser = localStorage.getItem('auth_user')
+ if (authUser === null) {
+ return null
+ }
+
+ try {
+ return JSON.parse(authUser)
+ } catch (_) {
+ return null
+ }
+}
+```
+
+`isAuthenticated()` checks for `token` and `expires_at` from localStorage to tell if the user is authenticated. `getAuthUser()` gets the authenticated user from localStorage.
+
+When we login, we’ll save all the data to localStorage so it will make sense.
+
+### Access Page
+
+![access page screenshot][9]
+
+Lets start with the access page. Create a file `static/pages/access-page.js` with the following content:
+
+```
+const template = document.createElement('template')
+template.innerHTML = `
+ Messenger
+ Access with GitHub
+`
+
+export default function accessPage() {
+ return template.content
+}
+```
+
+Because the router intercepts all the link clicks to do its navigation, we must prevent the event propagation for this link in particular.
+
+Clicking on that link will redirect us to the backend, then to GitHub, then to the backend and then to the frontend again; to the callback page.
+
+### Callback Page
+
+Create the file `static/pages/callback-page.js` with the following content:
+
+```
+import http from '../http.js'
+import { navigate } from '../router.js'
+
+export default async function callbackPage() {
+ const url = new URL(location.toString())
+ const token = url.searchParams.get('token')
+ const expiresAt = url.searchParams.get('expires_at')
+
+ try {
+ if (token === null || expiresAt === null) {
+ throw new Error('Invalid URL')
+ }
+
+ const authUser = await getAuthUser(token)
+
+ localStorage.setItem('auth_user', JSON.stringify(authUser))
+ localStorage.setItem('token', token)
+ localStorage.setItem('expires_at', expiresAt)
+ } catch (err) {
+ alert(err.message)
+ } finally {
+ navigate('/', true)
+ }
+}
+
+function getAuthUser(token) {
+ return http.get('/api/auth_user', { authorization: `Bearer ${token}` })
+}
+```
+
+The callback page doesn’t render anything. It’s an async function that does a GET request to `/api/auth_user` using the token from the URL query string and saves all the data to localStorage. Then it redirects to `/`.
+
+### HTTP
+
+There is an HTTP module. Create a `static/http.js` file with the following content:
+
+```
+import { isAuthenticated } from './auth.js'
+
+async function handleResponse(res) {
+ const body = await res.clone().json().catch(() => res.text())
+
+ if (res.status === 401) {
+ localStorage.removeItem('auth_user')
+ localStorage.removeItem('token')
+ localStorage.removeItem('expires_at')
+ }
+
+ if (!res.ok) {
+ const message = typeof body === 'object' && body !== null && 'message' in body
+ ? body.message
+ : typeof body === 'string' && body !== ''
+ ? body
+ : res.statusText
+ throw Object.assign(new Error(message), {
+ url: res.url,
+ statusCode: res.status,
+ statusText: res.statusText,
+ headers: res.headers,
+ body,
+ })
+ }
+
+ return body
+}
+
+function getAuthHeader() {
+ return isAuthenticated()
+ ? { authorization: `Bearer ${localStorage.getItem('token')}` }
+ : {}
+}
+
+export default {
+ get(url, headers) {
+ return fetch(url, {
+ headers: Object.assign(getAuthHeader(), headers),
+ }).then(handleResponse)
+ },
+
+ post(url, body, headers) {
+ const init = {
+ method: 'POST',
+ headers: getAuthHeader(),
+ }
+ if (typeof body === 'object' && body !== null) {
+ init.body = JSON.stringify(body)
+ init.headers['content-type'] = 'application/json; charset=utf-8'
+ }
+ Object.assign(init.headers, headers)
+ return fetch(url, init).then(handleResponse)
+ },
+
+ subscribe(url, callback) {
+ const urlWithToken = new URL(url, location.origin)
+ if (isAuthenticated()) {
+ urlWithToken.searchParams.set('token', localStorage.getItem('token'))
+ }
+ const eventSource = new EventSource(urlWithToken.toString())
+ eventSource.onmessage = ev => {
+ let data
+ try {
+ data = JSON.parse(ev.data)
+ } catch (err) {
+ console.error('could not parse message data as JSON:', err)
+ return
+ }
+ callback(data)
+ }
+ const unsubscribe = () => {
+ eventSource.close()
+ }
+ return unsubscribe
+ },
+}
+```
+
+This module is a wrapper around the [fetch][10] and [EventSource][11] APIs. The most important part is that it adds the JSON web token to the requests.
+
+### Home Page
+
+![home page screenshot][12]
+
+So, when the user login, the home page will be shown. Create a `static/pages/home-page.js` file with the following content:
+
+```
+import { getAuthUser } from '../auth.js'
+import { avatar } from '../shared.js'
+
+export default function homePage() {
+ const authUser = getAuthUser()
+ const template = document.createElement('template')
+ template.innerHTML = `
+
+
+ ${avatar(authUser)}
+ ${authUser.username}
+
+
+
 `
+}
+```
+
+We use a small figure with the user’s initial in case the avatar URL is null.
+
+You can show the initial with a little of CSS using the `attr()` function.
+
+```
+.avatar[data-initial]::after {
+ content: attr(data-initial);
+}
+```
+
+### Development Login
+
+![access page with login form screenshot][13]
+
+In the previous post we coded a login for development. Lets add a form for that in the access page. Go to `static/pages/access-page.js` and modify it a little.
+
+```
+import http from '../http.js'
+
+const template = document.createElement('template')
+template.innerHTML = `
+
`
+}
+```
+
+We use a small figure with the user’s initial in case the avatar URL is null.
+
+You can show the initial with a little of CSS using the `attr()` function.
+
+```
+.avatar[data-initial]::after {
+ content: attr(data-initial);
+}
+```
+
+### Development Login
+
+![access page with login form screenshot][13]
+
+In the previous post we coded a login for development. Lets add a form for that in the access page. Go to `static/pages/access-page.js` and modify it a little.
+
+```
+import http from '../http.js'
+
+const template = document.createElement('template')
+template.innerHTML = `
+ Messenger
+
+ Access with GitHub
+`
+
+export default function accessPage() {
+ const page = template.content.cloneNode(true)
+ page.getElementById('login-form').onsubmit = onLoginSubmit
+ return page
+}
+
+async function onLoginSubmit(ev) {
+ ev.preventDefault()
+
+ const form = ev.currentTarget
+ const input = form.querySelector('input')
+ const submitButton = form.querySelector('button')
+
+ input.disabled = true
+ submitButton.disabled = true
+
+ try {
+ const payload = await login(input.value)
+ input.value = ''
+
+ localStorage.setItem('auth_user', JSON.stringify(payload.authUser))
+ localStorage.setItem('token', payload.token)
+ localStorage.setItem('expires_at', payload.expiresAt)
+
+ location.reload()
+ } catch (err) {
+ alert(err.message)
+ setTimeout(() => {
+ input.focus()
+ }, 0)
+ } finally {
+ input.disabled = false
+ submitButton.disabled = false
+ }
+}
+
+function login(username) {
+ return http.post('/api/login', { username })
+}
+```
+
+I added a login form. When the user submits the form. It does a POST requets to `/api/login` with the username. Saves all the data to localStorage and reloads the page.
+
+Remember to remove this form once you are done with the frontend.
+
+* * *
+
+That’s all for this post. In the next one, we’ll continue with the home page to add a form to start conversations and display a list with the latest ones.
+
+[Souce Code][14]
+
+--------------------------------------------------------------------------------
+
+via: https://nicolasparada.netlify.com/posts/go-messenger-access-page/
+
+作者:[Nicolás Parada][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://nicolasparada.netlify.com/
+[b]: https://github.com/lujun9972
+[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
+[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
+[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
+[4]: https://nicolasparada.netlify.com/posts/go-messenger-messages/
+[5]: https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/
+[6]: https://nicolasparada.netlify.com/posts/go-messenger-dev-login/
+[7]: https://nicolasparada.netlify.com/posts/js-router/
+[8]: https://unpkg.com/@nicolasparada/router
+[9]: https://nicolasparada.netlify.com/img/go-messenger-access-page/access-page.png
+[10]: https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API
+[11]: https://developer.mozilla.org/en-US/docs/Web/API/EventSource
+[12]: https://nicolasparada.netlify.com/img/go-messenger-access-page/home-page.png
+[13]: https://nicolasparada.netlify.com/img/go-messenger-access-page/access-page-v2.png
+[14]: https://github.com/nicolasparada/go-messenger-demo
diff --git a/sources/tech/20180719 Building a Messenger App- Home Page.md b/sources/tech/20180719 Building a Messenger App- Home Page.md
new file mode 100644
index 0000000000..ddec2c180f
--- /dev/null
+++ b/sources/tech/20180719 Building a Messenger App- Home Page.md
@@ -0,0 +1,255 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Building a Messenger App: Home Page)
+[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-home-page/)
+[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
+
+Building a Messenger App: Home Page
+======
+
+This post is the 8th on a series:
+
+ * [Part 1: Schema][1]
+ * [Part 2: OAuth][2]
+ * [Part 3: Conversations][3]
+ * [Part 4: Messages][4]
+ * [Part 5: Realtime Messages][5]
+ * [Part 6: Development Login][6]
+ * [Part 7: Access Page][7]
+
+
+
+Continuing the frontend, let’s finish the home page in this post. We’ll add a form to start conversations and a list with the latest ones.
+
+### Conversation Form
+
+![conversation form screenshot][8]
+
+In the `static/pages/home-page.js` file add some markup in the HTML view.
+
+```
+
+```
+
+Add that form just below the section in which we displayed the auth user and logout button.
+
+```
+page.getElementById('conversation-form').onsubmit = onConversationSubmit
+```
+
+Now we can listen to the “submit” event to create the conversation.
+
+```
+import http from '../http.js'
+import { navigate } from '../router.js'
+
+async function onConversationSubmit(ev) {
+ ev.preventDefault()
+
+ const form = ev.currentTarget
+ const input = form.querySelector('input')
+
+ input.disabled = true
+
+ try {
+ const conversation = await createConversation(input.value)
+ input.value = ''
+ navigate('/conversations/' + conversation.id)
+ } catch (err) {
+ if (err.statusCode === 422) {
+ input.setCustomValidity(err.body.errors.username)
+ } else {
+ alert(err.message)
+ }
+ setTimeout(() => {
+ input.focus()
+ }, 0)
+ } finally {
+ input.disabled = false
+ }
+}
+
+function createConversation(username) {
+ return http.post('/api/conversations', { username })
+}
+```
+
+On submit we do a POST request to `/api/conversations` with the username and redirect to the conversation page (for the next post).
+
+### Conversation List
+
+![conversation list screenshot][9]
+
+In the same file, we are going to make the `homePage()` function async to load the conversations first.
+
+```
+export default async function homePage() {
+ const conversations = await getConversations().catch(err => {
+ console.error(err)
+ return []
+ })
+ /*...*/
+}
+
+function getConversations() {
+ return http.get('/api/conversations')
+}
+```
+
+Then, add a list in the markup to render conversations there.
+
+```
+
+```
+
+Add it just below the current markup.
+
+```
+const conversationsOList = page.getElementById('conversations')
+for (const conversation of conversations) {
+ conversationsOList.appendChild(renderConversation(conversation))
+}
+```
+
+So we can append each conversation to the list.
+
+```
+import { avatar, escapeHTML } from '../shared.js'
+
+function renderConversation(conversation) {
+ const messageContent = escapeHTML(conversation.lastMessage.content)
+ const messageDate = new Date(conversation.lastMessage.createdAt).toLocaleString()
+
+ const li = document.createElement('li')
+ li.dataset['id'] = conversation.id
+ if (conversation.hasUnreadMessages) {
+ li.classList.add('has-unread-messages')
+ }
+ li.innerHTML = `
+
+
+ ${avatar(conversation.otherParticipant)}
+ ${conversation.otherParticipant.username}
+
+
+
${messageContent}
+
+
+
← Back
+ ${avatar(conversation.otherParticipant)}
+
${conversation.otherParticipant.username}
+
+```
+
+Now, add that list to the markup.
+
+```
+const messagesOList = page.getElementById('messages')
+for (const message of messages.reverse()) {
+ messagesOList.appendChild(renderMessage(message))
+}
+```
+
+So we can append messages to the list. We show them in reverse order.
+
+```
+function renderMessage(message) {
+ const messageContent = escapeHTML(message.content)
+ const messageDate = new Date(message.createdAt).toLocaleString()
+
+ const li = document.createElement('li')
+ if (message.mine) {
+ li.classList.add('owned')
+ }
+ li.innerHTML = `
+ ${messageContent}
+
+ `
+ return li
+}
+```
+
+Each message item displays the message content itself with its timestamp. Using `.mine` we can append a different class to the item so maybe you can show the message to the right.
+
+### Message Form
+
+![chat heading screenshot][11]
+
+```
+
+```
+
+Add that form to the current markup.
+
+```
+page.getElementById('message-form').onsubmit = messageSubmitter(conversationID)
+```
+
+Attach an event listener to the “submit” event.
+
+```
+function messageSubmitter(conversationID) {
+ return async ev => {
+ ev.preventDefault()
+
+ const form = ev.currentTarget
+ const input = form.querySelector('input')
+ const submitButton = form.querySelector('button')
+
+ input.disabled = true
+ submitButton.disabled = true
+
+ try {
+ const message = await createMessage(input.value, conversationID)
+ input.value = ''
+ const messagesOList = document.getElementById('messages')
+ if (messagesOList === null) {
+ return
+ }
+
+ messagesOList.appendChild(renderMessage(message))
+ } catch (err) {
+ if (err.statusCode === 422) {
+ input.setCustomValidity(err.body.errors.content)
+ } else {
+ alert(err.message)
+ }
+ } finally {
+ input.disabled = false
+ submitButton.disabled = false
+
+ setTimeout(() => {
+ input.focus()
+ }, 0)
+ }
+ }
+}
+
+function createMessage(content, conversationID) {
+ return http.post(`/api/conversations/${conversationID}/messages`, { content })
+}
+```
+
+We make use of [partial application][12] to have the conversation ID in the “submit” event handler. It takes the message content from the input and does a POST request to `/api/conversations/{conversationID}/messages` with it. Then prepends the newly created message to the list.
+
+### Messages Subscription
+
+To make it realtime we’ll subscribe to the message stream in this page also.
+
+```
+page.addEventListener('disconnect', subscribeToMessages(messageArriver(conversationID)))
+```
+
+Add that line in the `conversationPage()` function.
+
+```
+function subscribeToMessages(cb) {
+ return http.subscribe('/api/messages', cb)
+}
+
+function messageArriver(conversationID) {
+ return message => {
+ if (message.conversationID !== conversationID) {
+ return
+ }
+
+ const messagesOList = document.getElementById('messages')
+ if (messagesOList === null) {
+ return
+
+ }
+ messagesOList.appendChild(renderMessage(message))
+ readMessages(message.conversationID)
+ }
+}
+
+function readMessages(conversationID) {
+ return http.post(`/api/conversations/${conversationID}/read_messages`)
+}
+```
+
+We also make use of partial application to have the conversation ID here.
+When a new message arrives, first we check if it’s from this conversation. If it is, we go a prepend a message item to the list and do a POST request to `/api/conversations/{conversationID}/read_messages` to updated the last time the participant read messages.
+
+* * *
+
+That concludes this series. The messenger app is now functional.
+
+~~I’ll add pagination on the conversation and message list, also user searching before sharing the source code. I’ll updated once it’s ready along with a hosted demo 👨💻~~
+
+[Souce Code][13] • [Demo][14]
+
+--------------------------------------------------------------------------------
+
+via: https://nicolasparada.netlify.com/posts/go-messenger-conversation-page/
+
+作者:[Nicolás Parada][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://nicolasparada.netlify.com/
+[b]: https://github.com/lujun9972
+[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
+[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
+[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
+[4]: https://nicolasparada.netlify.com/posts/go-messenger-messages/
+[5]: https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/
+[6]: https://nicolasparada.netlify.com/posts/go-messenger-dev-login/
+[7]: https://nicolasparada.netlify.com/posts/go-messenger-access-page/
+[8]: https://nicolasparada.netlify.com/posts/go-messenger-home-page/
+[9]: https://nicolasparada.netlify.com/img/go-messenger-conversation-page/heading.png
+[10]: https://nicolasparada.netlify.com/img/go-messenger-conversation-page/list.png
+[11]: https://nicolasparada.netlify.com/img/go-messenger-conversation-page/form.png
+[12]: https://en.wikipedia.org/wiki/Partial_application
+[13]: https://github.com/nicolasparada/go-messenger-demo
+[14]: https://go-messenger-demo.herokuapp.com/
diff --git a/sources/tech/20180810 Use Plank On Multiple Monitors Without Creating Multiple Docks With autoplank.md b/sources/tech/20180810 Use Plank On Multiple Monitors Without Creating Multiple Docks With autoplank.md
deleted file mode 100644
index 29164e3510..0000000000
--- a/sources/tech/20180810 Use Plank On Multiple Monitors Without Creating Multiple Docks With autoplank.md
+++ /dev/null
@@ -1,77 +0,0 @@
-Use Plank On Multiple Monitors Without Creating Multiple Docks With autoplank
-======
-
-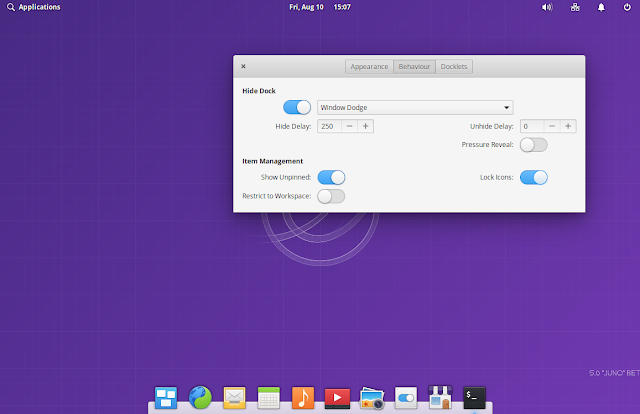
-
-**[autoplank][1] is a small tool written in Go which adds multi-monitor support to Plank dock without having to create [multiple][2] docks.**
-
-**When you move your mouse cursor to the bottom of a monitor, autoplank detect your mouse movement using** `xdotool` and it automatically moves Plank to that monitor. This tool **only works if Plank is set to run at the bottom of the screen** , at least for now.
-
-There's a slight delay until Plank actually shows up on the monitor where the mouse is though. The developer says this is intentional, to make sure you actually want to access Plank on that monitor. The time delay before showing plank is not currently configurable, but that may change in the future.
-
-autoplank should work with elementary OS, as well as any desktop environment or Linux distribution you use Plank dock on.
-
-Plank is a simple dock that shows icons of running applications / windows. The application allows pinning applications to the dock, and comes with a few built-in simple "docklets": a clipboard manager, clock, CPU monitor, show desktop and trash. To access its settings, hold down the `Ctrl` key while right clicking anywhere on the Plank dock, and then clicking on `Preferences` .
-
-Plank is used by default in elementary OS, but it can be used on any desktop environment or Linux distribution you wish.
-
-### Install autoplank
-
-On its GitHub page, it's mentioned that you need Go 1.8 or newer to build autoplank but I was able to successfully build it with Go 1.6 in Ubuntu 16.04 (elementary OS 0.4 Loki).
-
-The developer has said on
-
-**1\. Install required dependencies.**
-
-To build autoplank you'll need Go (`golang-go` in Debian, Ubuntu, elementary OS, etc.). To get the latest Git code you'll also need `git` , and for detecting the monitor on which you move the mose, you'll also need to install `xdotool` .
-
-Install these in Ubuntu, Debian, elementary OS and so on, by using this command:
-```
-sudo apt install git golang-go xdotool
-
-```
-
-**2\. Get the latest autoplank from[Git][1], build it, and install it in** `/usr/local/bin` :
-```
-git clone https://github.com/abiosoft/autoplank
-cd autoplank
-go build -o autoplank
-sudo mv autoplank /usr/local/bin/
-
-```
-
-You can remove the autoplank folder from your home directory now.
-
-When you want to uninstall autoplank, simply remove the `/usr/local/bin/autoplank` binary (`sudo rm /usr/local/bin/autoplank`).
-
-**3\. Add autoplank to startup.**
-
-If you want to try autoplank before adding it to startup or creating a systemd service for it, you can simply type `autoplank` in a terminal to start it.
-
-To have autoplank work between reboots, you'll need to add it to your startup applications. The exact steps for doing this depend on your desktop environments, so I won't tell you exactly how to do that for every desktop environment, but remember to use `/usr/local/bin/autoplank` as the executable in Startup Applications.
-
-In elementary OS, you can open `System Settings` , then in `Applications` , on the `Startup` tab, click the `+` button in the bottom left-hand side corner of the window, then add `/usr/local/bin/autoplank` in the `Type in a custom command` field:
-
-
-
-**Another way of using autoplank is by creating a systemd service for it, as explained[here][3].** Using a systemd service for autoplank has the advantage of restarting autoplank if it crashes for whatever reason. Use either the systemd service or add autoplank to your startup applications (don't use both).
-
-**4\. After you do this, logout, login and autoplank should be running so you can move the mouse at the bottom of a monitor to move Plank dock there.**
-
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxuprising.com/2018/08/use-plank-on-multiple-monitors-without.html
-
-作者:[Logix][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/118280394805678839070
-[1]:https://github.com/abiosoft/autoplank
-[2]:https://answers.launchpad.net/plank/+question/204593
-[3]:https://github.com/abiosoft/autoplank#optional-create-a-service
-[4]:https://www.reddit.com/r/elementaryos/comments/95a879/autoplank_use_plank_on_multimonitor_setup/e3r9saq/
diff --git a/sources/tech/20180906 What a shell dotfile can do for you.md b/sources/tech/20180906 What a shell dotfile can do for you.md
deleted file mode 100644
index 35593e1e32..0000000000
--- a/sources/tech/20180906 What a shell dotfile can do for you.md
+++ /dev/null
@@ -1,238 +0,0 @@
-What a shell dotfile can do for you
-======
-
-
-
-Ask not what you can do for your shell dotfile, but what a shell dotfile can do for you!
-
-I've been all over the OS map, but for the past several years my daily drivers have been Macs. For a long time, I used Bash, but when a few friends started proselytizing [zsh][1], I gave it a shot. It didn't take long for me to appreciate it, and several years later, I strongly prefer it for many of the little things that it does.
-
-I've been using zsh (provided via [Homebrew][2], not the system installed), and the [Oh My Zsh enhancement][3].
-
-The examples in this article are for my personal `.zshrc`. Most will work directly in Bash, and I don't believe that any rely on Oh My Zsh, but your mileage may vary. There was a period when I was maintaining a shell dotfile for both zsh and Bash, but I did eventually give up on my `.bashrc`.
-
-### We're all mad here
-
-If you want the possibility of using the same dotfile across OS's, you'll want to give your dotfile a little smarts.
-```
-### Mac Specifics
-if [[ "$OSTYPE" == "darwin"* ]]; then
- # Mac-specific stuff here.
-fi
-```
-
-For instance, I expect the Alt + arrow keys to move the cursor by the word rather than by a single space. To make this happen in [iTerm2][4] (my preferred shell), I add this snippet to the Mac-specific portion of my .zshrc:
-```
-### Mac Specifics
-if [[ "$OSTYPE" == "darwin"* ]]; then
- ### Mac cursor commands for iTerm2; map ctrl+arrows or alt+arrows to fast-move
- bindkey -e
- bindkey '^[[1;9C' forward-word
- bindkey '^[[1;9D' backward-word
- bindkey '\e\e[D' backward-word
- bindkey '\e\e[C' forward-word
-fi
-```
-
-### What about Bob?
-
-While I came to love my shell dotfile, I didn't always want the same things available on my home machines as on my work machines. One way to solve this is to have supplementary dotfiles to use at home but not at work. Here's how I accomplished this:
-```
-if [[ `egrep 'dnssuffix1|dnssuffix2' /etc/resolv.conf` ]]; then
- if [ -e $HOME/.work ]
- source $HOME/.work
- else
- echo "This looks like a work machine, but I can't find the ~/.work file"
- fi
-fi
-```
-
-In this case, I key off of my work dns suffix (or multiple suffixes, depending on your situation) and source a separate file that makes my life at work a little better.
-
-### That thing you do
-
-Now is probably a good time to quit using the tilde (`~`) to represent your home directory when writing scripts. You'll find that there are some contexts where it's not recognized. Getting in the habit of using the environment variable `$HOME` will save you a lot of troubleshooting time and headaches later on.
-
-The logical extension would be to have OS-specific dotfiles to include if you are so inclined.
-
-### Memory, all alone in the moonlight
-
-I've written embarrassing amounts of shell, and I've come to the conclusion that I really don't want to write more. It's not that shell can't do what I need most of the time, but I find that if I'm writing shell, I'm probably slapping together a duct-tape solution rather than permanently solving the problem.
-
-Likewise, I hate memorizing things, and throughout my career, I have had to do radical context shifting during the course of a day. The practical consequence is that I've had to re-learn many things several times over the years. ("Wait... which for-loop structure does this language use?")
-
-So, every so often I decide that I'm tired of looking up how to do something again. One way that I improve my life is by adding aliases.
-
-A common scenario for anyone who works with systems is finding out what's taking up all of the disk. Unfortunately, I have never been able to remember this incantation, so I made a shell alias, creatively called `bigdirs`:
-```
-alias bigdirs='du --max-depth=1 2> /dev/null | sort -n -r | head -n20'
-```
-
-While I could be less lazy and actually memorize it, well, that's just not the Unix way...
-
-### Typos, and the people who love them
-
-Another way that using shell aliases improves my life is by saving me from typos. I don't know why, but I've developed this nasty habit of typing a `w` after the sequence `ea`, so if I want to clear my terminal, I'll often type `cleawr`. Unfortunately, that doesn't mean anything to my shell. Until I add this little piece of gold:
-```
-alias cleawr='clear'
-```
-
-In one instance of Windows having an equivalent, but better, command, I find myself typing `cls`. It's frustrating to see your shell throw up its hands, so I add:
-```
-alias cls='clear'
-```
-
-Yes, I'm aware of `ctrl + l`, but I never use it.
-
-### Amuse yourself
-
-Work can be stressful. Sometimes you just need to have a little fun. If your shell doesn't know the command that it clearly should just do, maybe you want to shrug your shoulders right back at it! You can do this with a function:
-```
-shrug() { echo "¯\_(ツ)_/¯"; }
-```
-
-If that doesn't work, maybe you need to flip a table:
-```
-fliptable() { echo "(╯°□°)╯ ┻━┻"; } # Flip a table. Example usage: fsck -y /dev/sdb1 || fliptable
-```
-
-Imagine my chagrin and frustration when I needed to flip a desk and I couldn't remember what I had called it. So I added some more shell aliases:
-```
-alias flipdesk='fliptable'
-alias deskflip='fliptable'
-alias tableflip='fliptable'
-```
-
-And sometimes you need to celebrate:
-```
-disco() {
- echo "(•_•)"
- echo "<) )╯"
- echo " / \ "
- echo ""
- echo "\(•_•)"
- echo " ( (>"
- echo " / \ "
- echo ""
- echo " (•_•)"
- echo "<) )>"
- echo " / \ "
-}
-```
-
-Typically, I'll pipe the output of these commands to `pbcopy `and paste it into the relevant chat tool I'm using.
-
-I got this fun function from a Twitter account that I follow called "Command Line Magic:" [@climagic][5]. Since I live in Florida now, I'm very happy that this is the only snow in my life:
-```
-snow() {
- clear;while :;do echo $LINES $COLUMNS $(($RANDOM%$COLUMNS));sleep 0.1;done|gawk '{a[$3]=0;for(x in a) {o=a[x];a[x]=a[x]+1;printf "\033[%s;%sH ",o,x;printf "\033[%s;%sH*\033[0;0H",a[x],x;}}'
-}
-
-```
-
-### Fun with functions
-
-We've seen some examples of functions that I use. Since few of these examples require an argument, they could be done as aliases. I use functions out of personal preference when it's more than a single short statement.
-
-At various times in my career, I've run [Graphite][6], an open-source, scalable, time-series metrics solution. There have been enough instances where I needed to transpose a metric path (delineated with periods) to a filesystem path (delineated with slashes), or vice versa, that it became useful to have dedicated functions for these tasks:
-```
-# Useful for converting between Graphite metrics and file paths
-function dottoslash() {
- echo $1 | sed 's/\./\//g'
-}
-function slashtodot() {
- echo $1 | sed 's/\//\./g'
-}
-```
-
-During another time in my career, I was running a lot of Kubernetes. If you aren't familiar with running Kubernetes, you need to write a lot of YAML. Unfortunately, it's not hard to write invalid YAML. Worse, Kubernetes doesn't validate YAML before trying to apply it, so you won't find out it's invalid until you apply it. Unless you validate it first:
-```
-function yamllint() {
- for i in $(find . -name '*.yml' -o -name '*.yaml'); do echo $i; ruby -e "require 'yaml';YAML.load_file(\"$i\")"; done
-}
-```
-
-Because I got tired of embarrassing myself and occasionally breaking a customer's setup, I wrote this little snippet and added it as a pre-commit hook to all of my relevant repos. Something similar would be very helpful as part of your continuous integration process, especially if you're working as part of a team.
-
-### Oh, fingers, where art thou?
-
-I was once an excellent touch-typist. Those days are long gone. I typo more than I would have believed possible.
-
-At different times, I have used a fair amount of either Chef or Kubernetes. Fortunately for me, I never used both at the same time.
-
-Part of the Chef ecosystem is Test Kitchen, a suite of tools that facilitate testing, which is invoked with the commands `kitchen test`. Kubernetes is managed with a CLI tool `kubectl`. Both commands require several subcommands, and neither rolls off the fingers particularly fluidly.
-
-Rather than create a bunch of "typo aliases," I aliased those commands to `k`:
-```
-alias k='kitchen test $@'
-```
-
-or
-```
-alias k='kubectl $@'
-```
-
-### Timesplitters
-
-The last half of my career has involved writing more code with other people. I've worked in many environments where we have forked copies of repos on our account and use pull requests as part of the review process. When I want to make sure that my fork of a given repo is up to date with the parent, I use `fetchupstream`:
-```
-alias fetchupstream='git fetch upstream && git checkout master && git merge upstream/master && git push'
-```
-
-### Mine eyes have seen the glory of the coming of color
-
-I like color. It can make things like diffs easier to use.
-```
-alias diff='colordiff'
-```
-
-I thought that colorized man pages was a neat trick, so I incorporated this function:
-```
-# Colorized man pages, from:
-# http://boredzo.org/blog/archives/2016-08-15/colorized-man-pages-understood-and-customized
-man() {
- env \
- LESS_TERMCAP_md=$(printf "\e[1;36m") \
- LESS_TERMCAP_me=$(printf "\e[0m") \
- LESS_TERMCAP_se=$(printf "\e[0m") \
- LESS_TERMCAP_so=$(printf "\e[1;44;33m") \
- LESS_TERMCAP_ue=$(printf "\e[0m") \
- LESS_TERMCAP_us=$(printf "\e[1;32m") \
- man "$@"
-}
-```
-
-I love the command `which`. It simply tells you where in the filesystem the command you're running comes from—unless it's a shell function. After multiple cascading dotfiles, sometimes it's not clear where a function is defined or what it does. It turns out that the `whence` and `type` commands can help with that.
-```
-# Where is a function defined?
-whichfunc() {
- whence -v $1
- type -a $1
-}
-```
-
-### Conclusion
-
-I hope this article helps and inspires you to find ways to improve your daily shell-using experience. They don't need to be huge, novel, or complex. They might solve a minor but frequent bit of friction, create a shortcut, or even offer a solution to reducing common typos.
-
-You're welcome to look through my [dotfiles repo][7], but I warn you that it could use a lot of cleaning up. Feel free to use anything that you find helpful, and please be excellent to one another.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/9/shell-dotfile
-
-作者:[H.Waldo Grunenwald][a]
-选题:[lujun9972](https://github.com/lujun9972)
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/gwaldo
-[1]: http://www.zsh.org/
-[2]: https://brew.sh/
-[3]: https://github.com/robbyrussell/oh-my-zsh
-[4]: https://www.iterm2.com/
-[5]: https://twitter.com/climagic
-[6]: https://github.com/graphite-project/
-[7]: https://github.com/gwaldo/dotfiles
diff --git a/sources/tech/20181111 Some notes on running new software in production.md b/sources/tech/20181111 Some notes on running new software in production.md
new file mode 100644
index 0000000000..bfdfb66a44
--- /dev/null
+++ b/sources/tech/20181111 Some notes on running new software in production.md
@@ -0,0 +1,151 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Some notes on running new software in production)
+[#]: via: (https://jvns.ca/blog/2018/11/11/understand-the-software-you-use-in-production/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+Some notes on running new software in production
+======
+
+I’m working on a talk for kubecon in December! One of the points I want to get across is the amount of time/investment it takes to use new software in production without causing really serious incidents, and what that’s looked like for us in our use of Kubernetes.
+
+To start out, this post isn’t blanket advice. There are lots of times when it’s totally fine to just use software and not worry about **how** it works exactly. So let’s start by talking about when it’s important to invest.
+
+### when it matters: 99.99%
+
+If you’re running a service with a low SLO like 99% I don’t think it matters that much to understand the software you run in production. You can be down for like 2 hours a month! If something goes wrong, just fix it and it’s fine.
+
+At 99.99%, it’s different. That’s 45 minutes / year of downtime, and if you find out about a serious issue for the first time in production it could easily take you 20 minutes or to revert the change. That’s half your uptime budget for the year!
+
+### when it matters: software that you’re using heavily
+
+Also, even if you’re running a service with a 99.99% SLO, it’s impossible to develop a super deep understanding of every single piece of software you’re using. For example, a web service might use:
+
+ * 100 library dependencies
+ * the filesystem (so there’s linux filesystem code!)
+ * the network (linux networking code!)
+ * a database (like postgres)
+ * a proxy (like nginx/haproxy)
+
+
+
+If you’re only reading like 2 files from disk, you don’t need to do a super deep dive into Linux filesystems internals, you can just read the file from disk.
+
+What I try to do in practice is identify the components which we rely on the (or have the most unusual use cases for!), and invest time into understanding those. These are usually pretty easy to identify because they’re the ones which will cause the most problems :)
+
+### when it matters: new software
+
+Understanding your software especially matters for newer/less mature software projects, because it’s morely likely to have bugs & or just not have matured enough to be used by most people without having to worry. I’ve spent a bunch of time recently with Kubernetes/Envoy which are both relatively new projects, and neither of those are remotely in the category of “oh, it’ll just work, don’t worry about it”. I’ve spent many hours debugging weird surprising edge cases with both of them and learning how to configure them in the right way.
+
+### a playbook for understanding your software
+
+The playbook for understanding the software you run in production is pretty simple. Here it is:
+
+ 1. Start using it in production in a non-critical capacity (by sending a small percentage of traffic to it, on a less critical service, etc)
+ 2. Let that bake for a few weeks.
+ 3. Run into problems.
+ 4. Fix the problems. Go to step 3.
+
+
+
+Repeat until you feel like you have a good handle on this software’s failure modes and are comfortable running it in a more critical capacity. Let’s talk about that in a little more detail, though:
+
+### what running into bugs looks like
+
+For example, I’ve been spending a lot of time with Envoy in the last year. Some of the issues we’ve seen along the way are: (in no particular order)
+
+ * One of the default settings resulted in retry & timeout headers not being respected
+ * Envoy (as a client) doesn’t support TLS session resumption, so servers with a large amount of Envoy clients get DDOSed by TLS handshakes
+ * Envoy’s active healthchecking means that you services get healthchecked by every client. This is mostly okay but (again) services with many clients can get overwhelmed by it.
+ * Having every client independently healthcheck every server interacts somewhat poorly with services which are under heavy load, and can exacerbate performance issues by removing up-but-slow clients from the load balancer rotation.
+ * Envoy doesn’t retry failed connections by default
+ * it frequently segfaults when given incorrect configuration
+ * various issues with it segfaulting because of resource leaks / memory safety issues
+ * hosts running out of disk space between we didn’t rotate Envoy log files often enough
+
+
+
+A lot of these aren’t bugs – they’re just cases where what we expected the default configuration to do one thing, and it did another thing. This happens all the time, and it can result in really serious incidents. Figuring out how to configure a complicated piece of software appropriately takes a lot of time, and you just have to account for that.
+
+And Envoy is great software! The maintainers are incredibly responsive, they fix bugs quickly and its performance is good. It’s overall been quite stable and it’s done well in production. But just because something is great software doesn’t mean you won’t also run into 10 or 20 relatively serious issues along the way that need to be addressed in one way or another. And it’s helpful to understand those issues **before** putting the software in a really critical place.
+
+### try to have each incident only once
+
+My view is that running new software in production inevitably results in incidents. The trick:
+
+ 1. Make sure the incidents aren’t too serious (by making ‘production’ a less critical system first)
+ 2. Whenever there’s an incident (even if it’s not that serious!!!), spend the time necessary to understand exactly why it happened and how to make sure it doesn’t happen again
+
+
+
+My experience so far has been that it’s actually relatively possible to pull off “have every incident only once”. When we investigate issues and implement remediations, usually that issue **never comes back**. The remediation can either be:
+
+ * a configuration change
+ * reporting a bug upstream and either fixing it ourselves or waiting for a fix
+ * a workaround (“this software doesn’t work with 10,000 clients? ok, we just won’t use it with in cases where there are that many clients for now!“, “oh, a memory leak? let’s just restart it every hour”)
+
+
+
+Knowledge-sharing is really important here too – it’s always unfortunate when one person finds an incident in production, fixes it, but doesn’t explain the issue to the rest of the team so somebody else ends up causing the same incident again later because they didn’t hear about the original incident.
+
+### Understand what is ok to break and isn’t
+
+Another huge part of understanding the software I run in production is understanding which parts are OK to break (aka “if this breaks, it won’t result in a production incident”) and which aren’t. This lets me **focus**: I can put big boxes around some components and decide “ok, if this breaks it doesn’t matter, so I won’t pay super close attention to it”.
+
+For example, with Kubernetes:
+
+ok to break:
+
+ * any stateless control plane component can crash or be cycled out or go down for 5 minutes at any time. If we had 95% uptime for the kubernetes control plane that would probably be fine, it just needs to be working most of the time.
+ * kubernetes networking (the system where you give every pod an IP addresses) can break as much as it wants because we decided not to use it to start
+
+
+
+not ok:
+
+ * for us, if etcd goes down for 10 minutes, that’s ok. If it goes down for 2 hours, it’s not
+ * containers not starting or crashing on startup (iam issues, docker not starting containers, bugs in the scheduler, bugs in other controllers) is serious and needs to be looked at immediately
+ * containers not having access to the resources they need (because of permissions issues, etc)
+ * pods being terminated unexpectedly by Kubernetes (if you configure kubernetes wrong it can terminate your pods!)
+
+
+
+with Envoy, the breakdown is pretty different:
+
+ok to break:
+
+ * if the envoy control plane goes down for 5 minutes, that’s fine (it’ll keep working with stale data)
+ * segfaults on startup due to configuration errors are sort of okay because they manifest so early and they’re unlikely to surprise us (if the segfault doesn’t happen the 1st time, it shouldn’t happen the 200th time)
+
+
+
+not ok:
+
+ * Envoy crashes / segfaults are not good – if it crashes, network connections don’t happen
+ * if the control server serves incorrect or incomplete data that’s extremely dangerous and can result in serious production incidents. (so downtime is fine, but serving incorrect data is not!)
+
+
+
+Neither of these lists are complete at all, but they’re examples of what I mean by “understand your sofware”.
+
+### sharing ok to break / not ok lists is useful
+
+I think these “ok to break” / “not ok” lists are really useful to share, because even if they’re not 100% the same for every user, the lessons are pretty hard won. I’d be curious to hear about your breakdown of what kinds of failures are ok / not ok for software you’re using!
+
+Figuring out all the failure modes of a new piece of software and how they apply to your situation can take months. (this is is why when you ask your database team “hey can we just use NEW DATABASE” they look at you in such a pained way). So anything we can do to help other people learn faster is amazing
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/11/11/understand-the-software-you-use-in-production/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
diff --git a/sources/tech/20181118 An example of how C-- destructors are useful in Envoy.md b/sources/tech/20181118 An example of how C-- destructors are useful in Envoy.md
new file mode 100644
index 0000000000..f95f17db01
--- /dev/null
+++ b/sources/tech/20181118 An example of how C-- destructors are useful in Envoy.md
@@ -0,0 +1,130 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (An example of how C++ destructors are useful in Envoy)
+[#]: via: (https://jvns.ca/blog/2018/11/18/c---destructors---really-useful/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+An example of how C++ destructors are useful in Envoy
+======
+
+For a while now I’ve been working with a C++ project (Envoy), and sometimes I need to contribute to it, so my C++ skills have gone from “nonexistent” to “really minimal”. I’ve learned what an initializer list is and that a method starting with `~` is a destructor. I almost know what an lvalue and an rvalue are but not quite.
+
+But the other day when writing some C++ code I figured out something exciting about how to use destructors that I hadn’t realized! (the tl;dr of this post for people who know C++ is “julia finally understands what RAII is and that it is useful” :))
+
+### what’s a destructor?
+
+C++ has objects. When an C++ object goes out of scope, the compiler inserts a call to its destructor. So if you have some code like
+
+```
+function do_thing() {
+ Thing x{}; // this calls the Thing constructor
+ return 2;
+}
+```
+
+there will be a call to x’s destructor at the end of the `do_thing` function. so the code c++ generates looks something like:
+
+ * make new thing
+ * call the new thing’s destructor
+ * return 2
+
+
+
+Obviously destructors are way more complicated like this. They need to get called when there are exceptions! And sometimes they get called manually. And for lots of other reasons too. But there are 10 million things to know about C++ and that is not what we’re doing today, we are just talking about one thing.
+
+### what happens in a destructor?
+
+A lot of the time memory gets freed, which is how you avoid having memory leaks. But that’s not what we’re talking about in this post! We are talking about something more interesting.
+
+### the thing we’re interested in: Envoy circuit breakers
+
+So I’ve been working with Envoy a lot. 3 second Envoy refresher: it’s a HTTP proxy, your application makes requests to Envoy, which then proxies the request to the servers the application wants to talk to.
+
+One very useful feature Envoy has is this thing called “circuit breakers”. Basically the idea with is that if your application makes 50 billion connections to a service, that will probably overwhelm the service. So Envoy keeps track how many TCP connections you’ve made to a service, and will stop you from making new requests if you hit the limit. The default `max_connection` limit
+
+### how do you track connection count?
+
+To maintain a circuit breaker on the number of TCP connections, that means you need to keep an accurate count of how many TCP connections are currently open! How do you do that? Well, the way it works is to maintain a `connections` counter and:
+
+ * every time a connection is opened, increment the counter
+ * every time a connection is destroyed (because of a reset / timeout / whatever), decrement the counter
+ * when creating a new connection, check that the `connections` counter is not over the limit
+
+
+
+that’s all! And incrementing the counter when creating a new connection is pretty easy. But how do you make sure that the counter gets _decremented_ wheh the connection is destroyed? Connections can be destroyed in a lot of ways (they can time out! they can be closed by Envoy! they can be closed by the server! maybe something else I haven’t thought of could happen!) and it seems very easy to accidentally miss a way of closing them.
+
+### destructors to the rescue
+
+The way Envoy solves this problem is to create a connection object (called `ActiveClient` in the HTTP connection pool) for every connection.
+
+Then it:
+
+ * increments the counter in the constructor ([code][1])
+ * decrements the counter in the destructor ([code][2])
+ * checks the counter when a new connection is created ([code][3])
+
+
+
+The beauty of this is that now you don’t need to make sure that the counter gets decremented in all the right places, you now just need to organize your code so that the `ActiveClient` object’s destructor gets called when the connection has closed.
+
+Where does the `ActiveClient` destructor get called in Envoy? Well, Envoy maintains 2 lists of clients (`ready_clients` and `busy_clients`), and when a connection gets closed, Envoy removes the client from those lists. And when it does that, it doesn’t need to do any extra cleanup!! In C++, anytime a object is removed from a list, its destructor is called. So `client.removeFromList(ready_clients_);` takes care of all the cleanup. And there’s no chance of forgetting to decrement the counter!! It will definitely always happen unless you accidentally leave the object on one of these lists, which would be a bug anyway because the connection is closed :)
+
+### RAII
+
+This pattern Envoy is using here is an extremely common C++ programming pattern called “resource acquisition is initialization”. I find that name very confusing but that’s what it’s called. basically the way it works is:
+
+ * identify a resource (like “connection”) where a lot of things need to happen when the connection is initialized / finished
+ * make a class for that connection
+ * put all the initialization / finishing code in the constructor / destructor
+ * make sure the object’s destructor method gets called when appropriate! (by removing it from a vector / having it go out of scope)
+
+
+
+Previously I knew about using this pattern for kind of obvious things (make sure all the memory gets freed in the destructor, or make sure file descriptors get closed). But I didn’t realize it was also useful for cases that are slightly less obviously a resource like “decrement a counter”.
+
+The reason this pattern works is because the C++ compiler/standard library does a bunch of work to make sure that destructors get called when you’re done with an object – the compiler inserts destructor calls at the end of each block of code, after exceptions, and many standard library collections make sure destructors are called when you remove an object from a collection.
+
+### RAII gives you prompt, deterministic, and hard-to-screw-up cleanup of resources
+
+The exciting thing here is that this programming pattern gives you a way to schedule cleaning up resources that’s:
+
+ * easy to ensure always happens (when the object goes away, it always happens, even if there was an exception!)
+ * prompt & determinstic (it happens right away and it’s guaranteed to happen!)
+
+
+
+### what languages have RAII?
+
+C++ and Rust have RAII. Probably other languages too. Java, Python, Go, and garbage collected languages in general do not. In a garbage collected language you can often set up destructors to be run when the object is GC’d. But often (like in this case, which the connection count) you want things to be cleaned up **right away** when the object is no longer in use, not some indeterminate period later whenever GC happens to run.
+
+Python context managers are a related idea, you could do something like:
+
+```
+with conn_pool.connection() as conn:
+ do stuff
+```
+
+### that’s all for now!
+
+Hopefully this explanation of RAII is interesting and mostly correct. Thanks to Kamal for clarifying some RAII things for me!
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/11/18/c---destructors---really-useful/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://github.com/envoyproxy/envoy/blob/200b0e41641be46471c2ce3d230aae395fda7ded/source/common/http/http1/conn_pool.cc#L301
+[2]: https://github.com/envoyproxy/envoy/blob/200b0e41641be46471c2ce3d230aae395fda7ded/source/common/http/http1/conn_pool.cc#L315
+[3]: https://github.com/envoyproxy/envoy/blob/200b0e41641be46471c2ce3d230aae395fda7ded/source/common/http/http1/conn_pool.cc#L97
diff --git a/sources/tech/20181209 How do you document a tech project with comics.md b/sources/tech/20181209 How do you document a tech project with comics.md
new file mode 100644
index 0000000000..02d4981875
--- /dev/null
+++ b/sources/tech/20181209 How do you document a tech project with comics.md
@@ -0,0 +1,100 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How do you document a tech project with comics?)
+[#]: via: (https://jvns.ca/blog/2018/12/09/how-do-you-document-a-tech-project-with-comics/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+How do you document a tech project with comics?
+======
+
+Every so often I get email from people saying basically “hey julia! we have an open source project! we’d like to use comics / zines / art to document our project! Can we hire you?“.
+
+spoiler: the answer is “no, you can’t hire me” – I don’t do commissions. But I do think this is a cool idea and I’ve often wished I had something more useful to say to people than “no”, so if you’re interested in this, here are some ideas about how to accomplish it!
+
+### zine != drawing
+
+First, a terminology distinction. One weird thing I’ve noticed is that people frequently refer to individual tech drawings as “zines”. I think this is due to me communicating poorly somehow, but – drawings are not zines! A zine is a **printed booklet**, like a small maga**zine**. You wouldn’t call a photo of a model in Vogue a magazine! The magazine has like a million pages! An individual drawing is a drawing/comic/graphic/whatever. Just clarifying this because I think it causes a bit of unnecessary confusion.
+
+### comics without good information are useless
+
+Usually when folks ask me “hey, could we make a comic explaining X”, it doesn’t seem like they have a clear idea of what information exactly they want to get across, they just have a vague idea that maybe it would be cool to draw some comics. This makes sense – figuring out what information would be useful to tell people is very hard!! It’s 80% of what I spend my time on when making comics.
+
+You should think about comics the same way as any kind of documentation – start with the information you want to convey, who your target audience is, and how you want to distribute it (twitter? on your website? in person?), and figure out how to illustrate it after :). The information is the main thing, not the art!
+
+Once you have a clear story about what you want to get across, you can start trying to think about how to represent it using illustrations!
+
+### focus on concepts that don’t change
+
+Drawing comics is a much bigger investment than writing documentation (it takes me like 5x longer to convey the same information in a comic than in writing). So use it wisely! Because it’s not that easy to edit, if you’re going to make something a comic you want to focus on concepts that are very unlikely to change. So talk about the core ideas in your project instead of the exact command line arguments it takes!
+
+Here are a couple of options for how you could use comics/illustrations to document your project!
+
+### option 1: a single graphic
+
+One format you might want to try is a single, small graphic explaining what your project is about and why folks might be interested in it. For example: [this zulip comic][1]
+
+This is a short thing, you could post it on Twitter or print it as a pamphlet to give out. The information content here would probably be basically what’s on your project homepage, but presented in a more fun/exciting way :)
+
+You can put a pretty small amount of information in a single comic. With that Zulip comic, the things I picked out were:
+
+ * zulip is sort of like slack, but it has threads
+ * it’s easy to keep track of threads even if the conversation takes place over several days
+ * you can much more easily selectively catch up with Zulip
+ * zulip is open source
+ * there’s an open zulip server you can try out
+
+
+
+That’s not a lot of information! It’s 50 words :). So to do this effectively you need to distill your project down to 50 words in a way that’s still useful. It’s not easy!
+
+### option 2: many comics
+
+Another approach you can take is to make a more in depth comic / illustration, like [google’s guide to kubernetes][2] or [the children’s illustrated guide to kubernetes][3].
+
+To do this, you need a much stronger concept than “uh, I want to explain our project” – you want to have a clear target audience in mind! For example, if I were drawing a set of Docker comics, I’d probably focus on folks who want to use Docker in production. so I’d want to discuss:
+
+ * publishing your containers to a public/private registry
+ * some best practices for tagging your containers
+ * how to make sure your hosts don’t run out of disk space from downloading too many containers
+ * how to use layers to save on disk space / download less stuff
+ * whether it’s reasonable to run the same containers in production & in dev
+
+
+
+That’s totally different from the set of comics I’d write for folks who just want to use Docker to develop locally!
+
+### option 3: a printed zine
+
+The main thing that differentiates this from “many comics” is that zines are printed! Because of that, for this to make sense you need to have a place to give out the printed copies! Maybe you’re going present your project at a major conference? Maybe you give workshops about your project and want to give our the zine to folks in the workshop as notes? Maybe you want to mail it to people?
+
+### how to hire someone to help you
+
+There are basically 3 ways to hire someone:
+
+ 1. Hire someone who both understands (or can quickly learn) the technology you want to document and can illustrate well. These folks are tricky to find and probably expensive (I certainly wouldn’t do a project like this for less than $10,000 even if I did do commissions), just because programmers can usually charge a pretty high consulting rate. I’d guess that the main failure mode here is that it might be impossible/very hard to find someone, and it might be expensive.
+ 2. Collaborate with an illustrator to draw it for you. The main failure mode here is that if you don’t give the illustrator clear explanations of your tech to work with, you.. won’t end up with a clear and useful explanation. From what I’ve seen, **most folks underinvest in writing clear explanations for their illustrators** – I’ve seen a few really adorable tech comics that I don’t find useful or clear at all. I’d love to see more people do a better job of this. What’s the point of having an adorable illustration if it doesn’t teach anyone anything? :)
+ 3. Draw it yourself :). This is what I do, obviously. stick figures are okay!
+
+
+
+Most people seem to use method #2 – I’m not actually aware of any tech folks who have done commissioned comics (though I’m sure it’s happened!). I think method #2 is a great option and I’d love to see more folks do it. Paying illustrators is really fun!
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/12/09/how-do-you-document-a-tech-project-with-comics/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://twitter.com/b0rk/status/986444234365521920
+[2]: https://cloud.google.com/kubernetes-engine/kubernetes-comic/
+[3]: https://thenewstack.io/kubernetes-gets-childrens-book/
diff --git a/sources/tech/20181215 New talk- High Reliability Infrastructure Migrations.md b/sources/tech/20181215 New talk- High Reliability Infrastructure Migrations.md
new file mode 100644
index 0000000000..93755329c7
--- /dev/null
+++ b/sources/tech/20181215 New talk- High Reliability Infrastructure Migrations.md
@@ -0,0 +1,78 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (New talk: High Reliability Infrastructure Migrations)
+[#]: via: (https://jvns.ca/blog/2018/12/15/new-talk--high-reliability-infrastructure-migrations/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+New talk: High Reliability Infrastructure Migrations
+======
+
+On Tuesday I gave a talk at KubeCon called [High Reliability Infrastructure Migrations][1]. The abstract was:
+
+> For companies with high availability requirements (99.99% uptime or higher), running new software in production comes with a lot of risks. But it’s possible to make significant infrastructure changes while maintaining the availability your customers expect! I’ll give you a toolbox for derisking migrations and making infrastructure changes with confidence, with examples from our Kubernetes & Envoy experience at Stripe.
+
+### video
+
+#### slides
+
+Here are the slides:
+
+since everyone always asks, I drew them in the Notability app on an iPad. I do this because it’s faster than trying to use regular slides software and I can make better slides.
+
+### a few notes
+
+Here are a few links & notes about things I mentioned in the talk
+
+#### skycfg: write functions, not YAML
+
+I talked about how my team is working on non-YAML interfaces for configuring Kubernetes. The demo is at [skycfg.fun][2], and it’s [on GitHub here][3]. It’s based on [Starlark][4], a configuration language that’s a subset of Python.
+
+My coworker [John][5] has promised that he’ll write a blog post about it at some point, and I’m hoping that’s coming soon :)
+
+#### no haunted forests
+
+I mentioned a deploy system rewrite we did. John has a great blog post about when rewrites are a good idea and how he approached that rewrite called [no haunted forests][6].
+
+#### ignore most kubernetes ecosystem software
+
+One small point that I made in the talk was that on my team we ignore almost all software in the Kubernetes ecosystem so that we can focus on a few core pieces (Kubernetes & Envoy, plus some small things like kiam). I wanted to mention this because I think often in Kubernetes land it can seem like everyone is using Cool New Things (helm! istio! knative! eep!). I’m sure those projects are great but I find it much simpler to stay focused on the basics and I wanted people to know that it’s okay to do that if that’s what works for your company.
+
+I think the reality is that actually a lot of folks are still trying to work out how to use this new software in a reliable and secure way.
+
+#### other talks
+
+I haven’t watched other Kubecon talks yet, but here are 2 links:
+
+I heard good things about [this keynote from melanie cebula about kubernetes at airbnb][7], and I’m excited to see [this talk about kubernetes security][8]. The [slides from that security talk look useful][9]
+
+Also I’m very excited to see Kelsey Hightower’s keynote as always, but that recording isn’t up yet. If you have other Kubecon talks to recommend I’d love to know what they are.
+
+#### my first work talk I’m happy with
+
+I usually give talks about debugging tools, or side projects, or how I approach my job at a high level – not on the actual work that I do at my job. What I talked about in this talk is basically what I’ve been learning how to do at work for the last ~2 years. Figuring out how to make big infrastructure changes safely took me a long time (and I’m not done!), and so I hope this talk helps other folks do the same thing.
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/12/15/new-talk--high-reliability-infrastructure-migrations/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://www.youtube.com/watch?v=obB2IvCv-K0
+[2]: http://skycfg.fun
+[3]: https://github.com/stripe/skycfg
+[4]: https://github.com/bazelbuild/starlark
+[5]: https://john-millikin.com/
+[6]: https://john-millikin.com/sre-school/no-haunted-forests
+[7]: https://www.youtube.com/watch?v=ytu3aUCwlSg&index=127&t=0s&list=PLj6h78yzYM2PZf9eA7bhWnIh_mK1vyOfU
+[8]: https://www.youtube.com/watch?v=a03te8xEjUg&index=65&list=PLj6h78yzYM2PZf9eA7bhWnIh_mK1vyOfU&t=0s
+[9]: https://schd.ws/hosted_files/kccna18/1c/KubeCon%20NA%20-%20This%20year%2C%20it%27s%20about%20security%20-%2020181211.pdf
diff --git a/sources/tech/20181227 Linux commands for measuring disk activity.md b/sources/tech/20181227 Linux commands for measuring disk activity.md
deleted file mode 100644
index badda327dd..0000000000
--- a/sources/tech/20181227 Linux commands for measuring disk activity.md
+++ /dev/null
@@ -1,252 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Linux commands for measuring disk activity)
-[#]: via: (https://www.networkworld.com/article/3330497/linux/linux-commands-for-measuring-disk-activity.html)
-[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
-
-Linux commands for measuring disk activity
-======
-
-Linux systems provide a handy suite of commands for helping you see how busy your disks are, not just how full. In this post, we examine five very useful commands for looking into disk activity. Two of the commands (iostat and ioping) may have to be added to your system, and these same two commands require you to use sudo privileges, but all five commands provide useful ways to view disk activity.
-
-Probably one of the easiest and most obvious of these commands is **dstat**.
-
-### dtstat
-
-In spite of the fact that the **dstat** command begins with the letter "d", it provides stats on a lot more than just disk activity. If you want to view just disk activity, you can use the **-d** option. As shown below, you’ll get a continuous list of disk read/write measurements until you stop the display with a ^c. Note that after the first report, each subsequent row in the display will report disk activity in the following time interval, and the default is only one second.
-
-```
-$ dstat -d
--dsk/total-
- read writ
- 949B 73k
- 65k 0 <== first second
- 0 24k <== second second
- 0 16k
- 0 0 ^C
-```
-
-Including a number after the -d option will set the interval to that number of seconds.
-
-```
-$ dstat -d 10
--dsk/total-
- read writ
- 949B 73k
- 65k 81M <== first five seconds
- 0 21k <== second five second
- 0 9011B ^C
-```
-
-Notice that the reported data may be shown in a number of different units — e.g., M (megabytes), k (kilobytes), and B (bytes).
-
-Without options, the dstat command is going to show you a lot of other information as well — indicating how the CPU is spending its time, displaying network and paging activity, and reporting on interrupts and context switches.
-
-```
-$ dstat
-You did not select any stats, using -cdngy by default.
---total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
-usr sys idl wai stl| read writ| recv send| in out | int csw
- 0 0 100 0 0| 949B 73k| 0 0 | 0 3B| 38 65
- 0 0 100 0 0| 0 0 | 218B 932B| 0 0 | 53 68
- 0 1 99 0 0| 0 16k| 64B 468B| 0 0 | 64 81 ^C
-```
-
-The dstat command provides valuable insights into overall Linux system performance, pretty much replacing a collection of older tools, such as vmstat, netstat, iostat, and ifstat, with a flexible and powerful command that combines their features. For more insight into the other information that the dstat command can provide, refer to this post on the [dstat][1] command.
-
-### iostat
-
-The iostat command helps monitor system input/output device loading by observing the time the devices are active in relation to their average transfer rates. It's sometimes used to evaluate the balance of activity between disks.
-
-```
-$ iostat
-Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
-
-avg-cpu: %user %nice %system %iowait %steal %idle
- 0.07 0.01 0.03 0.05 0.00 99.85
-
-Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
-loop0 0.00 0.00 0.00 1048 0
-loop1 0.00 0.00 0.00 365 0
-loop2 0.00 0.00 0.00 1056 0
-loop3 0.00 0.01 0.00 16169 0
-loop4 0.00 0.00 0.00 413 0
-loop5 0.00 0.00 0.00 1184 0
-loop6 0.00 0.00 0.00 1062 0
-loop7 0.00 0.00 0.00 5261 0
-sda 1.06 0.89 72.66 2837453 232735080
-sdb 0.00 0.02 0.00 48669 40
-loop8 0.00 0.00 0.00 1053 0
-loop9 0.01 0.01 0.00 18949 0
-loop10 0.00 0.00 0.00 56 0
-loop11 0.00 0.00 0.00 7090 0
-loop12 0.00 0.00 0.00 1160 0
-loop13 0.00 0.00 0.00 108 0
-loop14 0.00 0.00 0.00 3572 0
-loop15 0.01 0.01 0.00 20026 0
-loop16 0.00 0.00 0.00 24 0
-```
-
-Of course, all the stats provided on Linux loop devices can clutter the display when you want to focus solely on your disks. The command, however, does provide the **-p** option, which allows you to just look at your disks — as shown in the commands below.
-
-```
-$ iostat -p sda
-Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
-
-avg-cpu: %user %nice %system %iowait %steal %idle
- 0.07 0.01 0.03 0.05 0.00 99.85
-
-Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
-sda 1.06 0.89 72.54 2843737 232815784
-sda1 1.04 0.88 72.54 2821733 232815784
-```
-
-Note that **tps** refers to transfers per second.
-
-You can also get iostat to provide repeated reports. In the example below, we're getting measurements every five seconds by using the **-d** option.
-
-```
-$ iostat -p sda -d 5
-Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
-
-Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
-sda 1.06 0.89 72.51 2843749 232834048
-sda1 1.04 0.88 72.51 2821745 232834048
-
-Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
-sda 0.80 0.00 11.20 0 56
-sda1 0.80 0.00 11.20 0 56
-```
-
-If you prefer to omit the first (stats since boot) report, add a **-y** to your command.
-
-```
-$ iostat -p sda -d 5 -y
-Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
-
-Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
-sda 0.80 0.00 11.20 0 56
-sda1 0.80 0.00 11.20 0 56
-```
-
-Next, we look at our second disk drive.
-
-```
-$ iostat -p sdb
-Linux 4.18.0-041800-generic (butterfly) 12/26/2018 _x86_64_ (2 CPU)
-
-avg-cpu: %user %nice %system %iowait %steal %idle
- 0.07 0.01 0.03 0.05 0.00 99.85
-
-Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
-sdb 0.00 0.02 0.00 48669 40
-sdb2 0.00 0.00 0.00 4861 40
-sdb1 0.00 0.01 0.00 35344 0
-```
-
-### iotop
-
-The **iotop** command is top-like utility for looking at disk I/O. It gathers I/O usage information provided by the Linux kernel so that you can get an idea which processes are most demanding in terms in disk I/O. In the example below, the loop time has been set to 5 seconds. The display will update itself, overwriting the previous output.
-
-```
-$ sudo iotop -d 5
-Total DISK READ: 0.00 B/s | Total DISK WRITE: 1585.31 B/s
-Current DISK READ: 0.00 B/s | Current DISK WRITE: 12.39 K/s
- TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
-32492 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.12 % [kworker/u8:1-ev~_power_efficient]
- 208 be/3 root 0.00 B/s 1585.31 B/s 0.00 % 0.11 % [jbd2/sda1-8]
- 1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init splash
- 2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
- 3 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_gp]
- 4 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_par_gp]
- 8 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [mm_percpu_wq]
-```
-
-### ioping
-
-The **ioping** command is an altogether different type of tool, but it can report disk latency — how long it takes a disk to respond to requests — and can be helpful in diagnosing disk problems.
-
-```
-$ sudo ioping /dev/sda1
-4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=1 time=960.2 us (warmup)
-4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=2 time=841.5 us
-4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=3 time=831.0 us
-4 KiB <<< /dev/sda1 (block device 111.8 GiB): request=4 time=1.17 ms
-^C
---- /dev/sda1 (block device 111.8 GiB) ioping statistics ---
-3 requests completed in 2.84 ms, 12 KiB read, 1.05 k iops, 4.12 MiB/s
-generated 4 requests in 3.37 s, 16 KiB, 1 iops, 4.75 KiB/s
-min/avg/max/mdev = 831.0 us / 947.9 us / 1.17 ms / 158.0 us
-```
-
-### atop
-
-The **atop** command, like **top** provides a lot of information on system performance, including some stats on disk activity.
-
-```
-ATOP - butterfly 2018/12/26 17:24:19 37d3h13m------ 10ed
-PRC | sys 0.03s | user 0.01s | #proc 179 | #zombie 0 | #exit 6 |
-CPU | sys 1% | user 0% | irq 0% | idle 199% | wait 0% |
-cpu | sys 1% | user 0% | irq 0% | idle 99% | cpu000 w 0% |
-CPL | avg1 0.00 | avg5 0.00 | avg15 0.00 | csw 677 | intr 470 |
-MEM | tot 5.8G | free 223.4M | cache 4.6G | buff 253.2M | slab 394.4M |
-SWP | tot 2.0G | free 2.0G | | vmcom 1.9G | vmlim 4.9G |
-DSK | sda | busy 0% | read 0 | write 7 | avio 1.14 ms |
-NET | transport | tcpi 4 | tcpo stall 8 | udpi 1 | udpo 0swout 2255 |
-NET | network | ipi 10 | ipo 7 | ipfrw 0 | deliv 60.67 ms |
-NET | enp0s25 0% | pcki 10 | pcko 8 | si 1 Kbps | so 3 Kbp0.73 ms |
-
- PID SYSCPU USRCPU VGROW RGROW ST EXC THR S CPUNR CPU CMD 1/1673e4 |
- 3357 0.01s 0.00s 672K 824K -- - 1 R 0 0% atop
- 3359 0.01s 0.00s 0K 0K NE 0 0 E - 0%
- 3361 0.00s 0.01s 0K 0K NE 0 0 E - 0%
- 3363 0.01s 0.00s 0K 0K NE 0 0 E - 0%
-31357 0.00s 0.00s 0K 0K -- - 1 S 1 0% bash
- 3364 0.00s 0.00s 8032K 756K N- - 1 S 1 0% sleep
- 2931 0.00s 0.00s 0K 0K -- - 1 I 1 0% kworker/u8:2-e
- 3356 0.00s 0.00s 0K 0K -E 0 0 E - 0%
- 3360 0.00s 0.00s 0K 0K NE 0 0 E - 0%
- 3362 0.00s 0.00s 0K 0K NE 0 0 E - 0%
-```
-
-If you want to look at _just_ the disk stats, you can easily manage that with a command like this:
-
-```
-$ atop | grep DSK
-$ atop | grep DSK
-DSK | sda | busy 0% | read 122901 | write 3318e3 | avio 0.67 ms |
-DSK | sdb | busy 0% | read 1168 | write 103 | avio 0.73 ms |
-DSK | sda | busy 2% | read 0 | write 92 | avio 2.39 ms |
-DSK | sda | busy 2% | read 0 | write 94 | avio 2.47 ms |
-DSK | sda | busy 2% | read 0 | write 99 | avio 2.26 ms |
-DSK | sda | busy 2% | read 0 | write 94 | avio 2.43 ms |
-DSK | sda | busy 2% | read 0 | write 94 | avio 2.43 ms |
-DSK | sda | busy 2% | read 0 | write 92 | avio 2.43 ms |
-^C
-```
-
-### Being in the know with disk I/O
-
-Linux provides enough commands to give you good insights into how hard your disks are working and help you focus on potential problems or slowdowns. Hopefully, one of these commands will tell you just what you need to know when it's time to question disk performance. Occasional use of these commands will help ensure that especially busy or slow disks will be obvious when you need to check them.
-
-Join the Network World communities on [Facebook][2] and [LinkedIn][3] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3330497/linux/linux-commands-for-measuring-disk-activity.html
-
-作者:[Sandra Henry-Stocker][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
-[b]: https://github.com/lujun9972
-[1]: https://www.networkworld.com/article/3291616/linux/examining-linux-system-performance-with-dstat.html
-[2]: https://www.facebook.com/NetworkWorld/
-[3]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20181229 Some nonparametric statistics math.md b/sources/tech/20181229 Some nonparametric statistics math.md
new file mode 100644
index 0000000000..452c295781
--- /dev/null
+++ b/sources/tech/20181229 Some nonparametric statistics math.md
@@ -0,0 +1,178 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Some nonparametric statistics math)
+[#]: via: (https://jvns.ca/blog/2018/12/29/some-initial-nonparametric-statistics-notes/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+Some nonparametric statistics math
+======
+
+I’m trying to understand nonparametric statistics a little more formally. This post may not be that intelligible because I’m still pretty confused about nonparametric statistics, there is a lot of math, and I make no attempt to explain any of the math notation. I’m working towards being able to explain this stuff in a much more accessible way but first I would like to understand some of the math!
+
+There’s some MathJax in this post so the math may or may not render in an RSS reader.
+
+Some questions I’m interested in:
+
+ * what is nonparametric statistics exactly?
+ * what guarantees can we make? are there formulas we can use?
+ * why do methods like the bootstrap method work?
+
+
+
+since these notes are from reading a math book and math books are extremely dense this is basically going to be “I read 7 pages of this math book and here are some points I’m confused about”
+
+### what’s nonparametric statistics?
+
+Today I’m looking at “all of nonparametric statistics” by Larry Wasserman. He defines nonparametric inference as:
+
+> a set of modern statistical methods that aim to keep the number of underlying assumptions as weak as possible
+
+Basically my interpretation of this is that – instead of assuming that your data comes from a specific family of distributions (like the normal distribution) and then trying to estimate the paramters of that distribution, you don’t make many assumptions about the distribution (“this is just some data!!“). Not having to make assumptions is nice!
+
+There aren’t **no** assumptions though – he says
+
+> we assume that the distribution $F$ lies in some set $\mathfrak{F}$ called a **statistical model**. For example, when estimating a density $f$, we might assume that $$ f \in \mathfrak{F} = \left\\{ g : \int(g^{\prime\prime}(x))^2dx \leq c^2 \right\\}$$ which is the set of densities that are not “too wiggly”.
+
+I have not too much intuition for the condition $\int(g^{\prime\prime}(x))^2dx \leq c^2$. I calculated that integral for [the normal distribution on wolfram alpha][1] and got 4, which is a good start. (4 is not infinity!)
+
+some questions I still have about this definition:
+
+ * what’s an example of a probability density function that _doesn’t_ satisfy that $\int(g^{\prime\prime}(x))^2dx \leq c^2$ condition? (probably something with an infinite number of tiny wiggles, and I don’t think any distribution i’m interested in in practice would have an infinite number of tiny wiggles?)
+ * why does the density function being “too wiggly” cause problems for nonparametric inference? very unclear as yet.
+
+
+
+### we still have to assume independence
+
+One assumption we **won’t** get away from is that the samples in the data we’re dealing with are independent. Often data in the real world actually isn’t really independent, but I think the what people do a lot of the time is to make a good effort at something approaching independence and then close your eyes and pretend it is?
+
+### estimating the density function
+
+Okay! Here’s a useful section! Let’s say that I have 100,000 data points from a distribution. I can draw a histogram like this of those data points:
+
+![][2]
+
+If I have 100,000 data points, it’s pretty likely that that histogram is pretty close to the actual distribution. But this is math, so we should be able to make that statement precise, right?
+
+For example suppose that 5% of the points in my sample are more than 100. Is the probability that a point is greater than 100 **actually** 0.05? The book gives a nice formula for this:
+
+$$ \mathbb{P}(|\widehat{P}_n(A) - P(A)| > \epsilon ) \leq 2e^{-2n\epsilon^2} $$
+
+(by [“Hoeffding’s inequality”][3] which I’ve never heard of before). Fun aside about that inequality: here’s a nice jupyter notebook by henry wallace using it to [identify the most common Boggle words][4].
+
+here, in our example:
+
+ * n is 1000 (the number of data points we have)
+ * $A$ is the set of points more than 100
+ * $\widehat{P}_n(A)$ is the empirical probability that a point is more than 100 (0.05)
+ * $P(A)$ is the actual probability
+ * $\epsilon$ is how certain we want to be that we’re right
+
+
+
+So, what’s the probability that the **real** probability is between 0.04 and 0.06? $\epsilon = 0.01$, so it’s $2e^{-2 \times 100,000 \times (0.01)^2} = 4e^{-9} $ ish (according to wolfram alpha)
+
+here is a table of how sure we can be:
+
+ * 100,000 data points: 4e-9 (TOTALLY CERTAIN that 4% - 6% of points are more than 100)
+ * 10,000 data points: 0.27 (27% probability that we’re wrong! that’s… not bad?)
+ * 1,000 data points: 1.6 (we know the probability we’re wrong is less than.. 160%? that’s not good!)
+ * 100 data points: lol
+
+
+
+so basically, in this case, using this formula: 100,000 data points is AMAZING, 10,000 data points is pretty good, and 1,000 is much less useful. If we have 1000 data points and we see that 5% of them are more than 100, we DEFINITELY CANNOT CONCLUDE that 4% to 6% of points are more than 100. But (using the same formula) we can use $\epsilon = 0.04$ and conclude that with 92% probability 1% to 9% of points are more than 100. So we can still learn some stuff from 1000 data points!
+
+This intuitively feels pretty reasonable to me – like it makes sense to me that if you have NO IDEA what your distribution that with 100,000 points you’d be able to make quite strong inferences, and that with 1000 you can do a lot less!
+
+### more data points are exponentially better?
+
+One thing that I think is really cool about this estimating the density function formula is that how sure you can be of your inferences scales **exponentially** with the size of your dataset (this is the $e^{-n\epsilon^2}$). And also exponentially with the square of how sure you want to be (so wanting to be sure within 0.01 is VERY DIFFERENT than within 0.04). So 100,000 data points isn’t 10x better than 10,000 data points, it’s actually like 10000000000000x better.
+
+Is that true in other places? If so that seems like a super useful intuition! I still feel pretty uncertain about this, but having some basic intuition about “how much more useful is 10,000 data points than 1,000 data points?“) feels like a really good thing.
+
+### some math about the bootstrap
+
+The next chapter is about the bootstrap! Basically the way the bootstrap works is:
+
+ 1. you want to estimate some statistic (like the median) of your distribution
+ 2. the bootstrap lets you get an estimate and also the variance of that estimate
+ 3. you do this by repeatedly sampling with replacement from your data and then calculating the statistic you want (like the median) on your samples
+
+
+
+I’m not going to go too much into how to implement the bootstrap method because it’s explained in a lot of place on the internet. Let’s talk about the math!
+
+I think in order to say anything meaningful about bootstrap estimates I need to learn a new term: a **consistent estimator**.
+
+### What’s a consistent estimator?
+
+Wikipedia says:
+
+> In statistics, a **consistent estimator** or **asymptotically consistent estimator** is an estimator — a rule for computing estimates of a parameter $\theta_0$ — having the property that as the number of data points used increases indefinitely, the resulting sequence of estimates converges in probability to $\theta_0$.
+
+This includes some terms where I forget what they mean (what’s “converges in probability” again?). But this seems like a very good thing! If I’m estimating some parameter (like the median), I would DEFINITELY LIKE IT TO BE TRUE that if I do it with an infinite amount of data then my estimate works. An estimator that is not consistent does not sound very useful!
+
+### why/when are bootstrap estimators consistent?
+
+spoiler: I have no idea. The book says the following:
+
+> Consistency of the boostrap can now be expressed as follows.
+>
+> **3.19 Theorem**. Suppose that $\mathbb{E}(X_1^2) < \infty$. Let $T_n = g(\overline{X}_n)$ where $g$ is continuously differentiable at $\mu = \mathbb{E}(X_1)$ and that $g\prime(\mu) \neq 0$. Then,
+>
+> $$ \sup_u | \mathbb{P}_{\widehat{F}_n} \left( \sqrt{n} (T( \widehat{F}_n*) - T( \widehat{F}_n) \leq u \right) - \mathbb{P}_{\widehat{F}} \left( \sqrt{n} (T( \widehat{F}_n) - T( \widehat{F}) \leq u \right) | \rightarrow^\text{a.s.} 0 $$
+>
+> **3.21 Theorem**. Suppose that $T(F)$ is Hadamard differentiable with respect to $d(F,G)= sup_x|F(x)-G(x)|$ and that $0 < \int L^2_F(x) dF(x) < \infty$. Then,
+>
+> $$ \sup_u | \mathbb{P}_{\widehat{F}_n} \left( \sqrt{n} (T( \widehat{F}_n*) - T( \widehat{F}_n) \leq u \right) - \mathbb{P}_{\widehat{F}} \left( \sqrt{n} (T( \widehat{F}_n) - T( \widehat{F}) \leq u \right) | \rightarrow^\text{P} 0 $$
+
+things I understand about these theorems:
+
+ * the two formulas they’re concluding are the same, except I think one is about convergence “almost surely” and one about “convergence in probability”. I don’t remember what either of those mean.
+ * I think for our purposes of doing Regular Boring Things we can replace “Hadamard differentiable” with “differentiable”
+ * I think they don’t actually show the consistency of the bootstrap, they’re actually about consistency of the bootstrap confidence interval estimate (which is a different thing)
+
+
+
+I don’t really understand how they’re related to consistency, and in particular the $\sup_u$ thing is weird, like if you’re looking at $\mathbb{P}(something < u)$, wouldn’t you want to minimize $u$ and not maximize it? Maybe it’s a typo and it should be $\inf_u$?
+
+it concludes:
+
+> there is a tendency to treat the bootstrap as a panacea for all problems. But the bootstrap requires regularity conditions to yield valid answers. It should not be applied blindly.
+
+### this book does not seem to explain why the bootstrap is consistent
+
+In the appendix (3.7) it gives a sketch of a proof for showing that estimating the **median** using the bootstrap is consistent. I don’t think this book actually gives a proof anywhere that bootstrap estimates in general are consistent, which was pretty surprising to me. It gives a bunch of references to papers. Though I guess bootstrap confidence intervals are the most important thing?
+
+### that’s all for now
+
+This is all extremely stream of consciousness and I only spent 2 hours trying to work through this, but some things I think I learned in the last couple hours are:
+
+ 1. maybe having more data is exponentially better? (is this true??)
+ 2. “consistency” of an estimator is a thing, not all estimators are consistent
+ 3. understanding when/why nonparametric bootstrap estimators are consistent in general might be very hard (the proof that the bootstrap median estimator is consistent already seems very complicated!)
+ 4. boostrap confidence intervals are not the same thing as bootstrap estimators. Maybe I’ll learn the difference next!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/12/29/some-initial-nonparametric-statistics-notes/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://www.wolframalpha.com/input/?i=integrate+(d%2Fdx(d%2Fdx(exp(-x%5E2))))%5E2++dx+from+x%3D-infinity+to+infinity
+[2]: https://jvns.ca/images/nonpar-histogram.png
+[3]: https://en.wikipedia.org/wiki/Hoeffding%27s_inequality
+[4]: https://nbviewer.jupyter.org/github/henrywallace/games/blob/master/boggle/boggle.ipynb#Estimating-Word-Probabilities
diff --git a/sources/tech/20190129 A few early marketing thoughts.md b/sources/tech/20190129 A few early marketing thoughts.md
new file mode 100644
index 0000000000..79cc6b1b1d
--- /dev/null
+++ b/sources/tech/20190129 A few early marketing thoughts.md
@@ -0,0 +1,164 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (A few early marketing thoughts)
+[#]: via: (https://jvns.ca/blog/2019/01/29/marketing-thoughts/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+A few early marketing thoughts
+======
+
+At some point last month I said I might write more about business, so here are some very early marketing thoughts for my zine business (!). The question I’m trying to make some progress on in this post is: “how to do marketing in a way that feels good?”
+
+### what’s the point of marketing?
+
+Okay! What’s marketing? What’s the point? I think the ideal way marketing works is:
+
+ 1. you somehow tell a person about a thing
+ 2. you explain somehow why the thing will be useful to them / why it is good
+ 3. they buy it and they like the thing because it’s what they expected
+
+
+
+(or, when you explain it they see that they don’t want it and don’t buy it which is good too!!)
+
+So basically as far as I can tell good marketing is just explaining what the thing is and why it is good in a clear way.
+
+### what internet marketing techniques do people use?
+
+I’ve been thinking a bit about internet marketing techniques I see people using on me recently. Here are a few examples of internet marketing techniques I’ve seen:
+
+ 1. word of mouth (“have you seen this cool new thing?!”)
+ 2. twitter / instagram marketing (build a twitter/instagram account)
+ 3. email marketing (“build a mailing list with a bajillion people on it and sell to them”)
+ 4. email marketing (“tell your existing users about features that they already have that they might want to use”)
+ 5. social proof marketing (“jane from georgia bought a sweater”), eg fomo.com
+ 6. cart notifications (“you left this sweater in your cart??! did you mean to buy it? maybe you should buy it!“)
+ 7. content marketing (which is fine but whenever people refer to my writing as ‘content’ I get grumpy :))
+
+
+
+### you need _some_ way to tell people about your stuff
+
+Something that is definitely true about marketing is that you need some way to tell new people about the thing you are doing. So for me when I’m thinking about running a business it’s less about “should i do marketing” and more like “well obviously i have to do marketing, how do i do it in a way that i feel good about?”
+
+### what’s up with email marketing?
+
+I feel like every single piece of internet marketing advice I read says “you need a mailing list”. This is advice that I haven’t really taken to heart – technically I have 2 mailing lists:
+
+ 1. the RSS feed for this blog, which sends out new blog posts to a mailing list for folks who don’t use RSS (which 3000 of you get)
+ 2. ’s list, for comics / new zine announcements (780 people subscribe to that! thank you!)
+
+
+
+but definitely neither of them is a Machine For Making Sales and I’ve put in almost no efforts in that direction yet.
+
+here are a few things I’ve noticed about marketing mailing lists:
+
+ * most marketing mailing lists are boring but some marketing mailing lists are actually interesting! For example I kind of like [amy hoy][1]’s emails.
+ * Someone told me recently that they have 200,000 people on their mailing list (?!!) which made the “a mailing list is a machine for making money” concept make a lot more sense to me. I wonder if people who make a lot of money from their mailing lists all have huge 10k+ person mailing lists like this?
+
+
+
+### what works for me: twitter
+
+Right now for my zines business I’d guess maybe 70% of my sales come from Twitter. The main thing I do is tweet pages from zines I’m working on (for example: yesterday’s [comic about ss][2]). The comics are usually good and fun so invariably they get tons of retweets, which means that I end up with lots of followers, which means that when I later put up the zine for sale lots of people will buy it.
+
+And of course people don’t _have_ to buy the zines, I post most of what ends up in my zines on twitter for free, so it feels like a nice way to do it. Everybody wins, I think.
+
+(side note: when I started getting tons of new followers from my comics I was actually super worried that it would make my experience of Twitter way worse. That hasn’t happened! the new followers all seem totally reasonable and I still get a lot of really interesting twitter replies which is wonderful ❤)
+
+I don’t try to hack/optimize this really: I just post comics when I make them and I try to make them good.
+
+### a small Twitter innovation: putting my website on the comics
+
+Here’s one small marketing change that I made that I think makes sense!
+
+In the past, I didn’t put anything about how to buy my comics on the comics I posted on Twitter, just my Twitter username. Like this:
+
+![][3]
+
+After a while, I realized people were asking me all the time “hey, can I buy a book/collection? where do these come from? how do I get more?“! I think a marketing secret is “people actually want to buy things that are good, it is useful to tell people where they can buy things that are good”.
+
+So just recently I’ve started adding my website and a note about my current project on the comics I post on Twitter. It doesn’t say much: just “❤ these comics? buy a collection! wizardzines.com” and “page 11 of my upcoming bite size networking zine”. Here’s what it looks like:
+
+![][4]
+
+I feel like this strikes a pretty good balance between “julia you need to tell people what you’re doing otherwise how are they supposed to buy things from you” and “omg too many sales pitches everywhere”? I’ve only started doing this recently so we’ll see how it goes.
+
+### should I work on a mailing list?
+
+It seems like the same thing that works on twitter would work by email if I wanted to put in the time (email people comics! when a zine comes out, email them about the zine and they can buy it if they want!).
+
+One thing I LOVE about Twitter though is that people always reply to the comics I post with their own tips and tricks that they love and I often learn something new. I feel like email would be nowhere near as fun :)
+
+But I still think this is a pretty good idea: keeping up with twitter can be time consuming and I bet a lot of people would like to get occasional email with programming drawings. (would you?)
+
+One thing I’m not sure about is – a lot of marketing mailing lists seem to use somewhat aggressive techniques to get new emails (a lot of popups on a website, or adding everyone who signs up to their service / buys a thing to a marketing list) and while I’m basically fine with that (unsubscribing is easy!), I’m not sure that it’s what I’d want to do, and maybe less aggressive techniques will work just as well? We’ll see.
+
+### should I track conversion rates?
+
+A piece of marketing advice I assume people give a lot is “be data driven, figure out what things convert the best, etc”. I don’t do this almost at all – gumroad used to tell me that most of my sales came from Twitter which was good to know, but right now I have basically no idea how it works.
+
+Doing a bunch of work to track conversion rates feels bad to me: it seems like it would be really easy to go down a dumb rabbit hole of “oh, let’s try to increase conversion by 5%” instead of just focusing on making really good and cool things.
+
+My guess is that what will work best for me for a while is to have some data that tells me in broad strokes how the business works (like “about 70% of sales come from twitter”) and just leave it at that.
+
+### should I do advertising?
+
+I had a conversation with Kamal about this post that went:
+
+ * julia: “hmm, maybe I should talk about ads?”
+ * julia: “wait, are ads marketing?”
+ * kamal: “yes ads are marketing”
+
+
+
+So, ads! I don’t know anything about advertising except that you can advertise on Facebook or Twitter or Google. Some non-ethical questions I have about advertising:
+
+ * how do you choose what keywords to advertise on?
+ * are there actually cheap keywords, like is ‘file descriptors’ cheap?
+ * how much do you need to pay per click? (for some weird linux keywords, google estimated 20 cents a click?)
+ * can you use ads effectively for something that costs $10?
+
+
+
+This seems nontrivial to learn about and I don’t think I’m going to try soon.
+
+### other marketing things
+
+a few other things I’ve thought about:
+
+ * I learned about “social proof marketing” sites like fomo.com yesterday which makes popups on your site like “someone bought COOL THING 3 hours ago”. This seems like it has some utility (people are actually buying things from me all the time, maybe that’s useful to share somehow?) but those popups feel a bit cheap to me and I don’t really think it’s something I’d want to do right now.
+ * similarly a lot of sites like to inject these popups like “HELLO PLEASE SIGN UP FOR OUR MAILING LIST”. similar thoughts. I’ve been putting an email signup link in the footer which seems like a good balance between discoverable and annoying. As an example of a popup which isn’t too intrusive, though: nate berkopec has [one on his site][5] which feels really reasonable! (scroll to the bottom to see it)
+
+
+
+Maybe marketing is all about “make your things discoverable without being annoying”? :)
+
+### that’s all!
+
+Hopefully some of this was interesting! Obviously the most important thing in all of this is to make cool things that are useful to people, but I think cool useful writing does not actually sell itself!
+
+If you have thoughts about what kinds of marketing have worked well for you / you’ve felt good about I would love to hear them!
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/01/29/marketing-thoughts/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://stackingthebricks.com/
+[2]: https://twitter.com/b0rk/status/1090058524137345025
+[3]: https://jvns.ca/images/kill.jpeg
+[4]: https://jvns.ca/images/ss.jpeg
+[5]: https://www.speedshop.co/2019/01/10/three-activerecord-mistakes.html
diff --git a/sources/tech/20190129 Create an online store with this Java-based framework.md b/sources/tech/20190129 Create an online store with this Java-based framework.md
deleted file mode 100644
index 6fb9bc5a6b..0000000000
--- a/sources/tech/20190129 Create an online store with this Java-based framework.md
+++ /dev/null
@@ -1,235 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (laingke)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Create an online store with this Java-based framework)
-[#]: via: (https://opensource.com/article/19/1/scipio-erp)
-[#]: author: (Paul Piper https://opensource.com/users/madppiper)
-
-Create an online store with this Java-based framework
-======
-Scipio ERP comes with a large range of applications and functionality.
-
-
-So you want to sell products or services online, but either can't find a fitting software or think customization would be too costly? [Scipio ERP][1] may just be what you are looking for.
-
-Scipio ERP is a Java-based open source e-commerce framework that comes with a large range of applications and functionality. The project was forked from [Apache OFBiz][2] in 2014 with a clear focus on better customization and a more modern appeal. The e-commerce component is quite extensive and works in a multi-store setup, internationally, and with a wide range of product configurations, and it's also compatible with modern HTML frameworks. The software also provides standard applications for many other business cases, such as accounting, warehouse management, or sales force automation. It's all highly standardized and therefore easy to customize, which is great if you are looking for more than a virtual cart.
-
-The system makes it very easy to keep up with modern web standards, too. All screens are constructed using the system's "[templating toolkit][3]," an easy-to-learn macro set that separates HTML from all applications. Because of it, every application is already standardized to the core. Sounds confusing? It really isn't—it all looks a lot like HTML, but you write a lot less of it.
-
-### Initial setup
-
-Before you get started, make sure you have Java 1.8 (or greater) SDK and a Git client installed. Got it? Great! Next, check out the master branch from GitHub:
-
-```
-git clone https://github.com/ilscipio/scipio-erp.git
-cd scipio-erp
-git checkout master
-```
-
-To set up the system, simply run **./install.sh** and select either option from the command line. Throughout development, it is best to stick to an **installation for development** (Option 1), which will also install a range of demo data. For professional installations, you can modify the initial config data ("seed data") so it will automatically set up the company and catalog data for you. By default, the system will run with an internal database, but it [can also be configured][4] with a wide range of relational databases such as PostgreSQL and MariaDB.
-
-![Setup wizard][6]
-
-Follow the setup wizard to complete your initial configuration,
-
-Start the system with **./start.sh** and head over to **** to complete the configuration. If you installed with demo data, you can log in with username **admin** and password **scipio**. During the setup wizard, you can set up a company profile, accounting, a warehouse, your product catalog, your online store, and additional user profiles. Keep the website entries on the product store configuration screen for now. The system allows you to run multiple webstores with different underlying code; unless you want to do that, it is easiest to stick to the defaults.
-
-Congratulations, you just installed Scipio ERP! Play around with the screens for a minute or two to get a feel for the functionality.
-
-### Shortcuts
-
-Before you jump into the customization, here are a few handy commands that will help you along the way:
-
- * Create a shop-override: **./ant create-component-shop-override**
- * Create a new component: **./ant create-component**
- * Create a new theme component: **./ant create-theme**
- * Create admin user: **./ant create-admin-user-login**
- * Various other utility functions: **./ant -p**
- * Utility to install & update add-ons: **./git-addons help**
-
-
-
-Also, make a mental note of the following locations:
-
- * Scripts to run Scipio as a service: **/tools/scripts/**
- * Log output directory: **/runtime/logs**
- * Admin application: ****
- * E-commerce application: ****
-
-
-
-Last, Scipio ERP structures all code in the following five major directories:
-
- * Framework: framework-related sources, the application server, generic screens, and configurations
- * Applications: core applications
- * Addons: third-party extensions
- * Themes: modifies the look and feel
- * Hot-deploy: your own components
-
-
-
-Aside from a few configurations, you will be working within the hot-deploy and themes directories.
-
-### Webstore customizations
-
-To really make the system your own, start thinking about [components][7]. Components are a modular approach to override, extend, and add to the system. Think of components as self-contained web modules that capture information on databases ([entity][8]), functions ([services][9]), screens ([views][10]), [events and actions][11], and web applications. Thanks to components, you can add your own code while remaining compatible with the original sources.
-
-Run **./ant create-component-shop-override** and follow the steps to create your webstore component. A new directory will be created inside of the hot-deploy directory, which extends and overrides the original e-commerce application.
-
-![component directory structure][13]
-
-A typical component directory structure.
-
-Your component will have the following directory structure:
-
- * config: configurations
- * data: seed data
- * entitydef: database table definitions
- * script: Groovy script location
- * servicedef: service definitions
- * src: Java classes
- * webapp: your web application
- * widget: screen definitions
-
-
-
-Additionally, the **ivy.xml** file allows you to add Maven libraries to the build process and the **ofbiz-component.xml** file defines the overall component and web application structure. Apart from the obvious, you will also find a **controller.xml** file inside the web apps' **WEB-INF** directory. This allows you to define request entries and connect them to events and screens. For screens alone, you can also use the built-in CMS functionality, but stick to the core mechanics first. Familiarize yourself with **/applications/shop/** before introducing changes.
-
-#### Adding custom screens
-
-Remember the [templating toolkit][3]? You will find it used on every screen. Think of it as a set of easy-to-learn macros that structure all content. Here's an example:
-
-```
-<@section title="Title">
- <@heading id="slider">Slider
- <@row>
- <@cell columns=6>
- <@slider id="" class="" controls=true indicator=true>
- <@slide link="#" image="https://placehold.it/800x300">Just some content…
- <@slide title="This is a title" link="#" image="https://placehold.it/800x300">
-
-
- <@cell columns=6>Second column
-
-
-```
-
-Not too difficult, right? Meanwhile, themes contain the HTML definitions and styles. This hands the power over to your front-end developers, who can define the output of each macro and otherwise stick to their own build tools for development.
-
-Let's give it a quick try. First, define a request on your own webstore. You will modify the code for this. A built-in CMS is also available at **** , which allows you to create new templates and screens in a much more efficient way. It is fully compatible with the templating toolkit and comes with example templates that can be adopted to your preferences. But since we are trying to understand the system here, let's go with the more complicated way first.
-
-Open the **[controller.xml][14]** file inside of your shop's webapp directory. The controller keeps track of request events and performs actions accordingly. The following will create a new request under **/shop/test** :
-
-```
-
-
-
-
-
-```
-
-You can define multiple responses and, if you want, you could use an event or a service call inside the request to determine which response you may want to use. I opted for a response of type "view." A view is a rendered response; other types are request-redirects, forwards, and alike. The system comes with various renderers and allows you to determine the output later; to do so, add the following:
-
-```
-
-
-```
-
-Replace **my-component** with your own component name. Then you can define your very first screen by adding the following inside the tags within the **widget/CommonScreens.xml** file:
-
-```
-
-
-
-```
-
-Screens are actually quite modular and consist of multiple elements ([widgets, actions, and decorators][15]). For the sake of simplicity, leave this as it is for now, and complete the new webpage by adding your very first templating toolkit file. For that, create a new **webapp/mycomponent/test/test.ftl** file and add the following:
-
-```
-<@alert type="info">Success!
-```
-
-![Custom screen][17]
-
-A custom screen.
-
-Open **** and marvel at your own accomplishments.
-
-#### Custom themes
-
-Modify the look and feel of the shop by creating your very own theme. All themes can be found as components inside of the themes folder. Run **./ant create-theme** to add your own.
-
-![theme component layout][19]
-
-A typical theme component layout.
-
-Here's a list of the most important directories and files:
-
- * Theme configuration: **data/*ThemeData.xml**
- * Theme-specific wrapping HTML: **includes/*.ftl**
- * Templating Toolkit HTML definition: **includes/themeTemplate.ftl**
- * CSS class definition: **includes/themeStyles.ftl**
- * CSS framework: **webapp/theme-title/***
-
-
-
-Take a quick look at the Metro theme in the toolkit; it uses the Foundation CSS framework and makes use of all the things above. Afterwards, set up your own theme inside your newly constructed **webapp/theme-title** directory and start developing. The Foundation-shop theme is a very simple shop-specific theme implementation that you can use as a basis for your own work.
-
-Voila! You have set up your own online store and are ready to customize!
-
-![Finished Scipio ERP shop][21]
-
-A finished shop based on Scipio ERP.
-
-### What's next?
-
-Scipio ERP is a powerful framework that simplifies the development of complex e-commerce applications. For a more complete understanding, check out the project [documentation][7], try the [online demo][22], or [join the community][23].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/1/scipio-erp
-
-作者:[Paul Piper][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/madppiper
-[b]: https://github.com/lujun9972
-[1]: https://www.scipioerp.com
-[2]: https://ofbiz.apache.org/
-[3]: https://www.scipioerp.com/community/developer/freemarker-macros/
-[4]: https://www.scipioerp.com/community/developer/installation-configuration/configuration/#database-configuration
-[5]: /file/419711
-[6]: https://opensource.com/sites/default/files/uploads/setup_step5_sm.jpg (Setup wizard)
-[7]: https://www.scipioerp.com/community/developer/architecture/components/
-[8]: https://www.scipioerp.com/community/developer/entities/
-[9]: https://www.scipioerp.com/community/developer/services/
-[10]: https://www.scipioerp.com/community/developer/views-requests/
-[11]: https://www.scipioerp.com/community/developer/events-actions/
-[12]: /file/419716
-[13]: https://opensource.com/sites/default/files/uploads/component_structure.jpg (component directory structure)
-[14]: https://www.scipioerp.com/community/developer/views-requests/request-controller/
-[15]: https://www.scipioerp.com/community/developer/views-requests/screen-widgets-decorators/
-[16]: /file/419721
-[17]: https://opensource.com/sites/default/files/uploads/success_screen_sm.jpg (Custom screen)
-[18]: /file/419726
-[19]: https://opensource.com/sites/default/files/uploads/theme_structure.jpg (theme component layout)
-[20]: /file/419731
-[21]: https://opensource.com/sites/default/files/uploads/finished_shop_1_sm.jpg (Finished Scipio ERP shop)
-[22]: https://www.scipioerp.com/demo/
-[23]: https://forum.scipioerp.com/
diff --git a/sources/tech/20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md b/sources/tech/20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md
deleted file mode 100644
index 3b9af595d6..0000000000
--- a/sources/tech/20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md
+++ /dev/null
@@ -1,103 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (The Earliest Linux Distros: Before Mainstream Distros Became So Popular)
-[#]: via: (https://itsfoss.com/earliest-linux-distros/)
-[#]: author: (Avimanyu Bandyopadhyay https://itsfoss.com/author/avimanyu/)
-
-The Earliest Linux Distros: Before Mainstream Distros Became So Popular
-======
-
-In this throwback history article, we’ve tried to look back into how some of the earliest Linux distributions evolved and came into being as we know them today.
-
-![][1]
-
-In here we have tried to explore how the idea of popular distros such as Red Hat, Debian, Slackware, SUSE, Ubuntu and many others came into being after the first Linux kernel became available.
-
-As Linux was initially released in the form of a kernel in 1991, the distros we know today was made possible with the help of numerous collaborators throughout the world with the creation of shells, libraries, compilers and related packages to make it a complete Operating System.
-
-### 1\. The first known “distro” by HJ Lu
-
-The way we know Linux distributions today goes back to 1992, when the first known distro-like tools to get access to Linux were released by HJ Lu. It consisted of two 5.25” floppy diskettes:
-
-![Linux 0.12 Boot and Root Disks | Photo Credit][2]
-
- * **LINUX 0.12 BOOT DISK** : The “boot” disk was used to boot the system first.
- * **LINUX 0.12 ROOT DISK** : The second “root” disk for getting a command prompt for access to the Linux file system after booting.
-
-
-
-To install 0.12 on a hard drive, one had to use a hex editor to edit its master boot record (MBR) and that was quite a complex process, especially during that era.
-
-Feeling too nostalgic?
-
-You can [install cool-retro-term application][3] that gives you a Linux terminal in the vintage looks of the 90’s computers.
-
-### 2\. MCC Interim Linux
-
-![MCC Linux 0.99.14, 1993 | Image Credit][4]
-
-Initially released in the same year as “LINUX 0.12” by Owen Le Blanc of Manchester Computing Centre in England, MCC Interim Linux was the first Linux distribution for novice users with a menu driven installer and end user/programming tools. Also in the form of a collection of diskettes, it could be installed on a system to provide a basic text-based environment.
-
-MCC Interim Linux was much more user-friendly than 0.12 and the installation process on a hard drive was much easier and similar to modern ways. It did not require using a hex editor to edit the MBR.
-
-Though it was first released in February 1992, it was also available for download through FTP since November that year.
-
-### 3\. TAMU Linux
-
-![TAMU Linux | Image Credit][5]
-
-TAMU Linux was developed by Aggies at Texas A&M with the Texas A&M Unix & Linux Users Group in May 1992 and was called TAMU 1.0A. It was the first Linux distribution to offer the X Window System instead of just a text based operating system.
-
-### 4\. Softlanding Linux System (SLS)
-
-![SLS Linux 1.05, 1994 | Image Credit][6]
-
-“Gentle Touchdowns for DOS Bailouts” was their slogan! SLS was released by Peter McDonald in May 1992. SLS was quite widely used and popular during its time and greatly promoted the idea of Linux. But due to a decision by the developers to change the executable format in the distro, users stopped using it.
-
-Many of the popular distros the present community is most familiar with, evolved via SLS. Two of them are:
-
- * **Slackware** : One of the earliest Linux distros, Slackware was created by Patrick Volkerding in 1993. Slackware is based on SLS and was one of the very first Linux distributions.
- * **Debian** : An initiative by Ian Murdock, Debian was also released in 1993 after moving on from the SLS model. The very popular Ubuntu distro we know today is based on Debian.
-
-
-
-### 5\. Yggdrasil
-
-![LGX Yggdrasil Fall 1993 | Image Credit][7]
-
-Released on December 1992, Yggdrasil was the first distro to give birth to the idea of Live Linux CDs. It was developed by Yggdrasil Computing, Inc., founded by Adam J. Richter in Berkeley, California. It could automatically configure itself on system hardware as “Plug-and-Play”, which is a very regular and known feature in today’s time. The later versions of Yggdrasil included a hack for running any proprietary MS-DOS CD-ROM driver within Linux.
-
-![Yggdrasil’s Plug-and-Play Promo | Image Credit][8]
-
-Their motto was “Free Software For The Rest of Us”.
-
-In the late 90s, one very popular distro was [Mandriva][9], first released in 1998, by unifying the French _Mandrake Linux_ distribution with the Brazilian _Conectiva Linux_ distribution. It had a release lifetime of 18 months for updates related to Linux and system software and desktop based updates were released every year. It also had server versions with 5 years of support. Now we have [Open Mandriva][10].
-
-If you have more nostalgic distros to share from the earliest days of Linux release, please share with us in the comments below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/earliest-linux-distros/
-
-作者:[Avimanyu Bandyopadhyay][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/avimanyu/
-[b]: https://github.com/lujun9972
-[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/earliest-linux-distros.png?resize=800%2C450&ssl=1
-[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-0.12-Floppies.jpg?ssl=1
-[3]: https://itsfoss.com/cool-retro-term/
-[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/MCC-Interim-Linux-0.99.14-1993.jpg?fit=800%2C600&ssl=1
-[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/TAMU-Linux.jpg?ssl=1
-[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/SLS-1.05-1994.jpg?ssl=1
-[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/LGX_Yggdrasil_CD_Fall_1993.jpg?fit=781%2C800&ssl=1
-[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Yggdrasil-Linux-Summer-1994.jpg?ssl=1
-[9]: https://en.wikipedia.org/wiki/Mandriva_Linux
-[10]: https://www.openmandriva.org/
diff --git a/sources/tech/20190217 Organizing this blog into categories.md b/sources/tech/20190217 Organizing this blog into categories.md
new file mode 100644
index 0000000000..e8a03f1bdd
--- /dev/null
+++ b/sources/tech/20190217 Organizing this blog into categories.md
@@ -0,0 +1,155 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Organizing this blog into categories)
+[#]: via: (https://jvns.ca/blog/2019/02/17/organizing-this-blog-into-categories/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+Organizing this blog into categories
+======
+
+Today I organized the front page of this blog ([jvns.ca][1]) into CATEGORIES! Now it is actually possible to make some sense of what is on here!! There are 28 categories (computer networking! learning! “how things work”! career stuff! many more!) I am so excited about this.
+
+How it works: Every post is in only 1 category. Obviously the categories aren’t “perfect” (there is a “how things work” category and a “kubernetes” category and a “networking” category, and so for a “how container networking works in kubernetes” I need to just pick one) but I think it’s really nice and I’m hoping that it’ll make the blog easier for folks to navigate.
+
+If you’re interested in more of the story of how I’m thinking about this: I’ve been a little dissatisfied for a long time with how this blog is organized. Here’s where I started, in 2013, with a pretty classic blog layout (this is Octopress, which was a Jekyll Wordpress-lookalike theme that was cool back then and which served me very well for a long time):
+
+![][2]
+
+### problem with “show the 5 most recent posts”: you don’t know what the person’s writing is about!
+
+This is a super common way to organize a blog: on the homepage of your blog, you display maybe the 5 most recent posts, and then maybe have a “previous” link.
+
+The thing I find tricky about this (as a blog reader) is that
+
+ 1. it’s hard to hunt through their back catalog to find cool things they’ve written
+ 2. it’s SO HARD to get an overall sense for the body of a person’s work by reading 1 blog post at a time
+
+
+
+### next attempt: show every post in chronological order
+
+My next attempt at blog organization was to show every post on the homepage in chronological order. This was inspired by [Dan Luu’s blog][3], which takes a super minimal approach. I switched to this (according to the internet archive) sometime in early 2016. Here’s what it looked like (with some CSS issues :))
+
+![][4]
+
+The reason I like this “show every post in chronological order” approach more is that when I discover a new blog, I like to obsessively binge read through the whole thing to see all the cool stuff the person has written. [Rachel by the bay][5] also organizes her writing this way, and when I found her blog I was like OMG WOW THIS IS AMAZING I MUST READ ALL OF THIS NOW and being able to look through all the entries quickly and start reading ones that caught my eye was SO FUN.
+
+[Will Larson’s blog][6] also has a “list of all posts” page which I find useful because it’s a good blog, and sometimes I want to refer back to something he wrote months ago and can’t remember what it was called, and being able to scan through all the titles makes it easier to do that.
+
+I was pretty happy with this and that’s how it’s been for the last 3 years.
+
+### problem: a chronological list of 390 posts still kind of sucks
+
+As of today, I have 390 posts here (360,000 words! that’s, like, 4 300-page books! eep!). This is objectively a lot of writing and I would like people new to the blog to be able to navigate it and actually have some idea what’s going on.
+
+And this blog is not actually just a totally disorganized group of words! I have a lot of specific interests: I’ve written probably 30 posts about computer networking, 15ish on ML/statistics, 20ish career posts, etc. And when I write a new Kubernetes post or whatever, it’s usually at least sort of related to some ongoing train of thought I have about Kubernetes. And it’s totally obvious to _me_ what other posts that post is related to, but obviously to a new person it’s not at all clear what the trains of thought are in this blog.
+
+### solution for now: assign every post 1 (just 1) category
+
+My new plan is to assign every post a single category. I got this idea from [Itamar Turner-Trauring’s site][7].
+
+Here are the initial categories:
+
+ * Cool computer tools / features / ideas
+ * Computer networking
+ * How a computer thing works
+ * Kubernetes / containers
+ * Zines / comics
+ * On writing comics / zines
+ * Conferences
+ * Organizing conferences
+ * Businesses / marketing
+ * Statistics / machine learning / data analysis
+ * Year in review
+ * Infrastructure / operations engineering
+ * Career / work
+ * Working with others / communication
+ * Remote work
+ * Talks transcripts / podcasts
+ * On blogging / speaking
+ * On learning
+ * Rust
+ * Linux debugging / tracing tools
+ * Debugging stories
+ * Fan posts about awesome work by other people
+ * Inclusion
+ * rbspy
+ * Performance
+ * Open source
+ * Linux systems stuff
+ * Recurse Center (my daily posts during my RC batch)
+
+
+
+I guess you can tell this is a systems-y blog because there are 8 different systems-y categories (kubernetes, infrastructure, linux debugging tools, rust, debugging stories, performance, and linux systems stuff, how a computer thing works) :).
+
+But it was nice to see that I also have this huge career / work category! And that category is pretty meaningful to me, it includes a lot of things that I struggled with and were hard for me to learn. And I get to put all my machine learning posts together, which is an area I worked in for 3 years and am still super interested in and every so often learn a new thing about!
+
+### How I assign the categories: a big text file
+
+I came up with a scheme for assigning the categories that I thought was really fun! I knew immediately that coming up with categories in advance would be impossible (how was I supposed to know that “fan posts about awesome work by other people” was a substantial category?)
+
+So instead, I took kind of a Marie Kondo approach: I wrote a script to just dump all the titles of every blog post into a text file, and then I just used vim to organize them roughly into similar sections. Seeing everything in one place (a la marie kondo) really helped me see the patterns and figure out what some categories were.
+
+[Here’s the final result of that text file][8]. I think having a lightweight way of organizing the posts all in one file made a huge difference and that it would have been impossible for me to seen the patterns otherwise.
+
+### How I implemented it: a hugo taxonomy
+
+Once I had that big text file, I wrote [a janky python script][9] to assign the categories in that text file to the actual posts.
+
+I use Hugo for this blog, and so I also needed to tell Hugo about the categories. This blog already technically has tags (though they’re woefully underused, I didn’t want to delete them). I use Hugo, and it turns out that in Hugo you can define arbitrary taxonomies. So I defined a new taxonomy for these sections (right now it’s called, unimaginitively, `juliasections`).
+
+The details of how I did this are pretty boring but [here’s the hugo template that makes it display on the homepage][10]. I used this [Hugo documentation page on taxonomies a lot][11].
+
+### organizing my site is cool! reverse chronology maybe isn’t the best possible thing!
+
+Amy Hoy has this interesting article called [how the blog broke the web][12] about how the rise of blog software made people adopt a site format that maybe didn’t serve what they were writing the best.
+
+I don’t personally feel that mad about the blog / reverse chronology organization: I like blogging! I think it was nice for the first 6 years or whatever to be able to just write things that I think are cool without thinking about where they “fit”. It’s worked really well for me.
+
+But today, 360,000 words in, I think it makes sense to add a little more structure :).
+
+### what it looks like now!
+
+Here’s what the new front page organization looks like! These are the blogging / learning / rust sections! I think it’s cool how you can see the evolution of some of my thinking (I sure have written a lot of posts about asking questions :)).
+
+![][13]
+
+### I ❤ the personal website
+
+This is also part of why I love having a personal website that I can organize any way I want: for both of my main sites ([jvns.ca][1] and now [wizardzines.com][14]) I have total control over how they appear! And I can evolve them over time at my own pace if I decide something a little different will work better for me. I’ve gone from a jekyll blog to octopress to a custom-designed octopress blog to Hugo and made a ton of little changes over time. It’s so nice.
+
+I think it’s fun that these 3 screenshots are each 3 years apart – what I wanted in 2013 is not the same as 2016 is not the same as 2019! This is okay!
+
+And I really love seeing how other people choose to organize their personal sites! Please keep making cool different personal sites.
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/02/17/organizing-this-blog-into-categories/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://jvns.ca
+[2]: https://jvns.ca/images/website-2013.png
+[3]: https://danluu.com
+[4]: https://jvns.ca/images/website-2016.png
+[5]: https://rachelbythebay.com/w/
+[6]: https://lethain.com/all-posts/
+[7]: https://codewithoutrules.com/worklife/
+[8]: https://github.com/jvns/jvns.ca/blob/2f7b2723994628a5348069dd87b3df68c2f0285c/scripts/titles.txt
+[9]: https://github.com/jvns/jvns.ca/blob/2f7b2723994628a5348069dd87b3df68c2f0285c/scripts/parse_titles.py
+[10]: https://github.com/jvns/jvns.ca/blob/25d239a3ba36c1bae1d055d2b7d50a4f1d0489ef/themes/orange/layouts/index.html#L39-L59
+[11]: https://gohugo.io/templates/taxonomy-templates/
+[12]: https://stackingthebricks.com/how-blogs-broke-the-web/
+[13]: https://jvns.ca/images/website-2019.png
+[14]: https://wizardzines.com
diff --git a/sources/tech/20190301 Guide to Install VMware Tools on Linux.md b/sources/tech/20190301 Guide to Install VMware Tools on Linux.md
deleted file mode 100644
index e6a43bcde1..0000000000
--- a/sources/tech/20190301 Guide to Install VMware Tools on Linux.md
+++ /dev/null
@@ -1,143 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Guide to Install VMware Tools on Linux)
-[#]: via: (https://itsfoss.com/install-vmware-tools-linux)
-[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-
-Guide to Install VMware Tools on Linux
-======
-
-**VMware Tools enhances your VM experience by allowing you to share clipboard and folder among other things. Learn how to install VMware tools on Ubuntu and other Linux distributions.**
-
-In an earlier tutorial, you learned to [install VMware Workstation on Ubuntu][1]. You can further enhance the functionality of your virtual machines by installing VMware Tools.
-
-If you have already installed a guest OS on VMware, you must have noticed the requirement for [VMware tools][2] – even though not completely aware of what it is needed for.
-
-In this article, we will highlight the importance of VMware tools, the features it offers, and the method to install VMware tools on Ubuntu or any other Linux distribution.
-
-### VMware Tools: Overview & Features
-
-![Installing VMware Tools on Ubuntu][3]Installing VMware Tools on Ubuntu
-
-For obvious reasons, the virtual machine (your Guest OS) will not behave exactly like the host. There will be certain limitations in terms of its performance and operationg. And, that is why a set of utilities (VMware Tools) was introduced.
-
-VMware tools help in managing the guest OS in an efficient manner while also improving its performance.
-
-#### What exactly is VMware tool responsible for?
-
-![How to Install VMware tools on Linux][4]
-
-You have got a vague idea of what it does – but let us talk about the details:
-
- * Synchronize the time between the guest OS and the host to make things easier.
- * Unlocks the ability to pass messages from host OS to guest OS. For example, you copy a text on the host to your clipboard and you can easily paste it to your guest OS.
- * Enables sound in guest OS.
- * Improves video resolution.
- * Improves the cursor movement.
- * Fixes incorrect network speed data.
- * Eliminates inadequate color depth.
-
-
-
-These are the major changes that happen when you install VMware tools on Guest OS. But, what exactly does it contain / feature in order to unlock/enhance these functionalities? Let’s see..
-
-#### VMware tools: Core Feature Details
-
-![Sharing clipboard between guest and host OS with VMware Tools][5]Sharing clipboard between guest and host OS with VMware Tools
-
-If you do not want to know what it includes to enable the functionalities, you can skip this part. But, for the curious readers, let us briefly discuss about it:
-
-**VMware device drivers:** It really depends on the OS. Most of the major operating systems do include device drivers by default. So, you do not have to install it separately. This generally involves – memory control driver, mouse driver, audio driver, NIC driver, VGA driver and so on.
-
-**VMware user process:** This is where things get really interesting. With this, you get the ability to copy-paste and drag-drop between the host and the guest OS. You can basically copy and paste the text from the host to the virtual machine or vice versa.
-
-You get to drag and drop files as well. In addition, it enables the pointer release/lock when you do not have an SVGA driver installed.
-
-**VMware tools lifecycle management** : Well, we will take a look at how to install VMware tools below – but this feature helps you easily install/upgrade VMware tools in the virtual machine.
-
-**Shared Folders** : In addition to these, VMware tools also allow you to have shared folders between the guest OS and the host.
-
-![Sharing folder between guest and host OS using VMware Tools in Linux][6]Sharing folder between guest and host OS using VMware Tools in Linux
-
-Of course, what it does and facilitates also depends on the host OS. For example, on Windows, you get a Unity mode on VMware to run programs on virtual machine and operate it from the host OS.
-
-### How to install VMware Tools on Ubuntu & other Linux distributions
-
-**Note:** For Linux guest operating systems, you should already have “Open VM Tools” suite installed, eliminating the need of installing VMware tools separately, most of the time.
-
-Most of the time, when you install a guest OS, you will get a prompt as a software update or a popup telling you to install VMware tools if the operating system supports [Easy Install][7].
-
-Windows and Ubuntu does support Easy Install. So, even if you are using Windows as your host OS or trying to install VMware tools on Ubuntu, you should first get an option to install the VMware tools easily as popup message. Here’s how it should look like:
-
-![Pop-up to install VMware Tools][8]Pop-up to install VMware Tools
-
-This is the easiest way to get it done. So, make sure you have an active network connection when you setup the virtual machine.
-
-If you do not get any of these pop ups – or options to easily install VMware tools. You have to manually install it. Here’s how to do that:
-
-1\. Launch VMware Workstation Player.
-
-2\. From the menu, navigate through **Virtual Machine - > Install VMware tools**. If you already have it installed, and want to repair the installation, you will observe the same option to appear as “ **Re-install VMware tools** “.
-
-3\. Once you click on that, you will observe a virtual CD/DVD mounted in the guest OS.
-
-4\. Open that and copy/paste the **tar.gz** file to any location of your choice and extract it, here we choose the **Desktop**.
-
-![][9]
-
-5\. After extraction, launch the terminal and navigate to the folder inside by typing in the following command:
-
-```
-cd Desktop/VMwareTools-10.3.2-9925305/vmware-tools-distrib
-```
-
-You need to check the name of the folder and path in your case – depending on the version and where you extracted – it might vary.
-
-![][10]
-
-Replace **Desktop** with your storage location (such as cd Downloads) and the rest should remain the same if you are installing **10.3.2 version**.
-
-6\. Now, simply type in the following command to start the installation:
-
-```
-sudo ./vmware-install.pl -d
-```
-
-![][11]
-
-You will be asked the password for permission to install, type it in and you should be good to go.
-
-That’s it. You are done. These set of steps should be applicable to almost any Ubuntu-based guest operating system. If you want to install VMware tools on Ubuntu Server, or any other OS.
-
-**Wrapping Up**
-
-Installing VMware tools on Ubuntu Linux is pretty easy. In addition to the easy method, we have also explained the manual method to do it. If you still need help, or have a suggestion regarding the installation, let us know in the comments down below.
-
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/install-vmware-tools-linux
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
-[2]: https://kb.vmware.com/s/article/340
-[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-downloading.jpg?fit=800%2C531&ssl=1
-[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/install-vmware-tools-linux.png?resize=800%2C450&ssl=1
-[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-features.gif?resize=800%2C500&ssl=1
-[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-shared-folder.jpg?fit=800%2C660&ssl=1
-[7]: https://docs.vmware.com/en/VMware-Workstation-Player-for-Linux/15.0/com.vmware.player.linux.using.doc/GUID-3F6B9D0E-6CFC-4627-B80B-9A68A5960F60.html
-[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools.jpg?fit=800%2C481&ssl=1
-[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-extraction.jpg?fit=800%2C564&ssl=1
-[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-folder.jpg?fit=800%2C487&ssl=1
-[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-installation-ubuntu.jpg?fit=800%2C492&ssl=1
diff --git a/sources/tech/20190315 New zine- Bite Size Networking.md b/sources/tech/20190315 New zine- Bite Size Networking.md
new file mode 100644
index 0000000000..cd47c5619a
--- /dev/null
+++ b/sources/tech/20190315 New zine- Bite Size Networking.md
@@ -0,0 +1,100 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (New zine: Bite Size Networking!)
+[#]: via: (https://jvns.ca/blog/2019/03/15/new-zine--bite-size-networking-/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+New zine: Bite Size Networking!
+======
+
+Last week I released a new zine: Bite Size Networking! It’s the third zine in the “bite size” series:
+
+ 1. [Bite Size Linux][1]
+ 2. [Bite Size Command Line][2]
+ 3. [Bite Size Networking][3]
+
+
+
+You can get it for $10 at ! (or $150/$250/$600 for the corporate rate).
+
+Here’s the cover and table of contents!
+
+[![][4]][5]
+
+A few people have asked for a 3-pack with all 3 “bite size” zines which is coming soon!
+
+### why this zine?
+
+In last few years I’ve been doing a lot of networking at work, and along the way I’ve gone from “uh, what even is tcpdump” to “yes I can just type in `sudo tcpdump -c 200 -n port 443 -i lo`” without even thinking twice about it. As usual this zine is the resource I wish I had 4 years ago. There are so many things it took me a long time to figure out how to do like:
+
+ * inspect SSL certificates
+ * make DNS queries
+ * figure out what server is using that port
+ * find out whether the firewall is causing you problems or not
+ * capture / search network traffic on a machine
+
+
+
+and as often happens with computers none of them are really that hard!! But the man pages for the tols you need to do these things are Very Long and as usual don’t differentiate between “everybody always uses this option and you 10000% need to know it” and “you will never use this option it does not matter”. So I spent a long time staring sadly at the tcpdump man page.
+
+the pitch for this zine is:
+
+> It’s Thursday afternoon and your users are reporting SSL errors in production and you don’t know why. Or a HTTP header isn’t being set correctly and it’s breaking the site. Or you just got a notification that your site’s SSL certificate is expiring in 2 days. Or you need to update DNS to point to a new server. Or a server suddenly isn’t able to connect to a service. And networking maybe isn’t your full time job, but you still need to get the problem fixed.
+
+Kamal (my partner) proofreads all my zines and we hit an exciting milestone with this one: this is the first zine where he was like “wow, I really did not know a lot of the stuff in this zine”. This is of course because I’ve spent a lot more time than him debugging weird networking things, and when you practice something you get better at it :)
+
+### a couple of example pages
+
+Here are a couple of example pages, to give you an idea of what’s in the zine:
+
+![][6] ![][7]
+
+### next thing to get better at: getting feedback!
+
+One thing I’ve realized that while I get a ton of help from people while writing these zines (I read probably a thousand tweets from people suggesting ideas for things to include in the zine), I don’t get as much feedback from people about the final product as I’d like!
+
+I often hear positive things (“I love them!”, “thank you so much!”, “this helped me in my job!”) but I’d really love to hear more about which bits specifically helped the most and what didn’t make as much sense or what you would have liked to see more of. So I’ll probably be asking a few questions about that to people who buy this zine!
+
+### selling zines is going well
+
+When I made the switch about a year ago from “every zine I release is free” to “the old zines are free but all the new ones are not free” it felt scary! It’s been startlingly totally fine and a very positive thing. Sales have been really good, people take the work more seriously, I can spend more time on them, and I think the quality has gone up.
+
+And I’ve been doing occasional [giveaways][8] for people who can’t afford a $10 zine, which feels like a nice way to handle “some people legitimately can’t afford $10 and I would like to get them information too”.
+
+### what’s next?
+
+I’m not sure yet! A few options:
+
+ * kubernetes
+ * more about linux concepts (bite size linux part II)
+ * how to do statistics using simulations
+ * something else!
+
+
+
+We’ll see what I feel most inspired by :)
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/03/15/new-zine--bite-size-networking-/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://wizardzines.com/zines/bite-size-linux/
+[2]: https://wizardzines.com/zines/bite-size-command-line/
+[3]: https://wizardzines.com/zines/bite-size-networking/
+[4]: https://jvns.ca/images/bite-size-networking-cover.png
+[5]: https://gum.co/bite-size-networking
+[6]: https://jvns.ca/images/ngrep.png
+[7]: https://jvns.ca/images/ping.png
+[8]: https://twitter.com/b0rk/status/1104368319816220674
diff --git a/sources/tech/20190320 Move your dotfiles to version control.md b/sources/tech/20190320 Move your dotfiles to version control.md
deleted file mode 100644
index 7d070760c7..0000000000
--- a/sources/tech/20190320 Move your dotfiles to version control.md
+++ /dev/null
@@ -1,130 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Move your dotfiles to version control)
-[#]: via: (https://opensource.com/article/19/3/move-your-dotfiles-version-control)
-[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
-
-Move your dotfiles to version control
-======
-Back up or sync your custom configurations across your systems by sharing dotfiles on GitLab or GitHub.
-
-
-
-There is something truly exciting about customizing your operating system through the collection of hidden files we call dotfiles. In [What a Shell Dotfile Can Do For You][1], H. "Waldo" Grunenwald goes into excellent detail about the why and how of setting up your dotfiles. Let's dig into the why and how of sharing them.
-
-### What's a dotfile?
-
-"Dotfiles" is a common term for all the configuration files we have floating around our machines. These files usually start with a **.** at the beginning of the filename, like **.gitconfig** , and operating systems often hide them by default. For example, when I use **ls -a** on MacOS, it shows all the lovely dotfiles that would otherwise not be in the output.
-
-```
-dotfiles on master
-➜ ls
-README.md Rakefile bin misc profiles zsh-custom
-
-dotfiles on master
-➜ ls -a
-. .gitignore .oh-my-zsh README.md zsh-custom
-.. .gitmodules .tmux Rakefile
-.gemrc .global_ignore .vimrc bin
-.git .gvimrc .zlogin misc
-.gitconfig .maid .zshrc profiles
-```
-
-If I take a look at one, **.gitconfig** , which I use for Git configuration, I see a ton of customization. I have account information, terminal color preferences, and tons of aliases that make my command-line interface feel like mine. Here's a snippet from the **[alias]** block:
-
-```
-87 # Show the diff between the latest commit and the current state
-88 d = !"git diff-index --quiet HEAD -- || clear; git --no-pager diff --patch-with-stat"
-89
-90 # `git di $number` shows the diff between the state `$number` revisions ago and the current state
-91 di = !"d() { git diff --patch-with-stat HEAD~$1; }; git diff-index --quiet HEAD -- || clear; d"
-92
-93 # Pull in remote changes for the current repository and all its submodules
-94 p = !"git pull; git submodule foreach git pull origin master"
-95
-96 # Checkout a pull request from origin (of a github repository)
-97 pr = !"pr() { git fetch origin pull/$1/head:pr-$1; git checkout pr-$1; }; pr"
-```
-
-Since my **.gitconfig** has over 200 lines of customization, I have no interest in rewriting it on every new computer or system I use, and either does anyone else. This is one reason sharing dotfiles has become more and more popular, especially with the rise of the social coding site GitHub. The canonical article advocating for sharing dotfiles is Zach Holman's [Dotfiles Are Meant to Be Forked][2] from 2008. The premise is true to this day: I want to share them, with myself, with those new to dotfiles, and with those who have taught me so much by sharing their customizations.
-
-### Sharing dotfiles
-
-Many of us have multiple systems or know hard drives are fickle enough that we want to back up our carefully curated customizations. How do we keep these wonderful files in sync across environments?
-
-My favorite answer is distributed version control, preferably a service that will handle the heavy lifting for me. I regularly use GitHub and continue to enjoy GitLab as I get more experienced with it. Either one is a perfect place to share your information. To set yourself up:
-
- 1. Sign into your preferred Git-based service.
- 2. Create a repository called "dotfiles." (Make it public! Sharing is caring.)
- 3. Clone it to your local environment.*
- 4. Copy your dotfiles into the folder.
- 5. Symbolically link (symlink) them back to their target folder (most often **$HOME** ).
- 6. Push them to the remote repository.
-
-
-
-* You may need to set up your Git configuration commands to clone the repository. Both GitHub and GitLab will prompt you with the commands to run.
-
-
-
-Step 4 above is the crux of this effort and can be a bit tricky. Whether you use a script or do it by hand, the workflow is to symlink from your dotfiles folder to the dotfiles destination so that any updates to your dotfiles are easily pushed to the remote repository. To do this for my **.gitconfig** file, I would enter:
-
-```
-$ cd dotfiles/
-$ ln -nfs .gitconfig $HOME/.gitconfig
-```
-
-The flags added to the symlinking command offer a few additional benefits:
-
- * **-s** creates a symbolic link instead of a hard link
- * **-f** continues with other symlinking when an error occurs (not needed here, but useful in loops)
- * **-n** avoids symlinking a symlink (same as **-h** for other versions of **ln** )
-
-
-
-You can review the IEEE and Open Group [specification of **ln**][3] and the version on [MacOS 10.14.3][4] if you want to dig deeper into the available parameters. I had to look up these flags since I pulled them from someone else's dotfiles.
-
-You can also make updating simpler with a little additional code, like the [Rakefile][5] I forked from [Brad Parbs][6]. Alternatively, you can keep it incredibly simple, as Jeff Geerling does [in his dotfiles][7]. He symlinks files using [this Ansible playbook][8]. Keeping everything in sync at this point is easy: you can cron job or occasionally **git push** from your dotfiles folder.
-
-### Quick aside: What not to share
-
-Before we move on, it is worth noting what you should not add to a shared dotfile repository—even if it starts with a dot. Anything that is a security risk, like files in your **.ssh/** folder, is not a good choice to share using this method. Be sure to double-check your configuration files before publishing them online and triple-check that no API tokens are in your files.
-
-### Where should I start?
-
-If Git is new to you, my [article about the terminology][9] and [a cheat sheet][10] of my most frequently used commands should help you get going.
-
-There are other incredible resources to help you get started with dotfiles. Years ago, I came across [dotfiles.github.io][11] and continue to go back to it for a broader look at what people are doing. There is a lot of tribal knowledge hidden in other people's dotfiles. Take the time to scroll through some and don't be shy about adding them to your own.
-
-I hope this will get you started on the joy of having consistent dotfiles across your computers.
-
-What's your favorite dotfile trick? Add a comment or tweet me [@mbbroberg][12].
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/3/move-your-dotfiles-version-control
-
-作者:[Matthew Broberg][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mbbroberg
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/article/18/9/shell-dotfile
-[2]: https://zachholman.com/2010/08/dotfiles-are-meant-to-be-forked/
-[3]: http://pubs.opengroup.org/onlinepubs/9699919799/utilities/ln.html
-[4]: https://www.unix.com/man-page/FreeBSD/1/ln/
-[5]: https://github.com/mbbroberg/dotfiles/blob/master/Rakefile
-[6]: https://github.com/bradp/dotfiles
-[7]: https://github.com/geerlingguy/dotfiles
-[8]: https://github.com/geerlingguy/mac-dev-playbook
-[9]: https://opensource.com/article/19/2/git-terminology
-[10]: https://opensource.com/downloads/cheat-sheet-git
-[11]: http://dotfiles.github.io/
-[12]: https://twitter.com/mbbroberg?lang=en
diff --git a/sources/tech/20190326 Why are monoidal categories interesting.md b/sources/tech/20190326 Why are monoidal categories interesting.md
new file mode 100644
index 0000000000..37aaef753a
--- /dev/null
+++ b/sources/tech/20190326 Why are monoidal categories interesting.md
@@ -0,0 +1,134 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Why are monoidal categories interesting?)
+[#]: via: (https://jvns.ca/blog/2019/03/26/what-are-monoidal-categories/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+Why are monoidal categories interesting?
+======
+
+Hello! Someone on Twitter asked a question about tensor categories recently and I remembered “oh, I know something about that!! These are a cool thing!“. Monoidal categories are also called “tensor categories” and I think that term feels a little more concrete: one of the biggest examples of a tensor category is the category of vector spaces with the tensor product as the way you combine vectors / functions. “Monoidal” means “has an associative binary operation with an identity”, and with vector spaces the tensor product is the “associative binary operation” it’s referring to. So I’m going to mostly use “tensor categories” in this post instead.
+
+So here’s a quick stab at explaining why tensor categories are cool. I’m going to make a lot of oversimplifications which I figure is better than trying to explain category theory from the ground up. I’m not a category theorist (though I spent 2 years in grad school doing a bunch of category theory) and I will almost certainly say wrong things about category theory.
+
+In this post I’m going to try to talk about [Seven Sketches in Compositionality: An Invitation to Applied Category Theory][1] using mostly plain English.
+
+### tensor categories aren’t monads
+
+If you have been around functional programming for a bit, you might see the word “monoid” and “categories” and wonder “oh, is julia writing about monads, like in Haskell”? I am not!!
+
+There is a sentence “monads are a monoid in the category of endofunctors” which includes both the word “monoid” and “category” but that is not what I am talking about at all. We’re not going to talk about types or Haskell or monads or anything.
+
+#### tensor categories are about proving (or defining) things with pictures
+
+Here’s what I think is a really nice example from this [“seven sketches in compositionality”](() PDF (on page 47):
+
+![][2]
+
+The idea here is that you have 3 inequalities
+
+ 1. `t <= v + w`
+ 2. `w + u <= x + z`
+ 3. `v + x <= y`,
+
+
+
+and you want to prove that `t + u <= y + z`.
+
+You can do this algebraically pretty easily.
+
+But in this diagram they’ve done something really different! They’ve sort of drawn the inequalities as boxes with lines coming out of them for each variable, and then you can see that you end up with a `t` and a `u` on the left and a `y` and a `z` on the right, and so maybe that means that `t + u <= y + z`.
+
+The first time I saw something like this in a math class I felt like – what? what is happening? you can’t just draw PICTURES to prove things?!! And of course you can’t _just_ draw pictures to prove things.
+
+What’s actually happening in pictures like this is that when you put 2 things next to each other in the picture (like `t` and `u`), that actually represents the “tensor product” of `t` and `u`. In this case the “tensor product” is defined to be addition. And the tensor product (addition in this case) has some special properties –
+
+ 1. it’s associative
+ 2. if `a <= b` and `c <= d` then `a + c <= b + d`
+
+
+
+so saying that this picture proves that `t + u <= y + z` **actually** means that you can read a proof off the diagram in a straightforward way:
+
+```
+ t + u
+<= (v + w) + u
+= v + (w + u)
+<= v + (x + z)
+= (v + x) + z
+<= y + z
+```
+
+So all the things that “look like they would work” according to the picture actually do work in practice because our tensor product thing is associative and because addition works nicely with the `<=` relationship. The book explains all this in a lot more detail.
+
+### draw vector spaces with “string diagrams”
+
+Proving this simple inequality is kind of boring though! We want to do something more interesting, so let’s talk about vector spaces! Here’s a diagram that includes some vector spaces (U1, U2, V1, V2) and some functions (f,g) between them.
+
+![][3]
+
+Again, here what it means to have U1 stacked on top of U2 is that we’re taking a tensor product of U1 and U2. And the tensor product is associative, so there’s no ambiguity if we stack 3 or 4 vector spaces together!
+
+This is all explained in a lot more detail in this nice blog post called [introduction to string diagrams][4] (which I took that picture from).
+
+### define the trace of a matrix with a picture
+
+So far this is pretty boring! But in a [follow up blog post][5], they talk about something more outrageous: you can (using vector space duality) take the lines in one of these diagrams and move them **backwards** and make loops. So that lets us define the trace of a function `f : V -> V` like this:
+
+![][6]
+
+This is a really outrageous thing! We’ve said, hey, we have a function and we want to get a number in return right? Okay, let’s just… draw a circle around it so that there are no lines left coming out of it, and then that will be a number! That seems a lot more natural and prettier than the usual way of defining the trace of a matrix (“sum up the numbers on the diagonal”)!
+
+When I first saw this I thought it was super cool that just drawing a circle is actually a legitimate way of defining a mathematical concept!
+
+### how are tensor category diagrams different from regular category theory diagrams?
+
+If you see “tensor categories let you prove things with pictures” you might think “well, the whole point of category theory is to prove things with pictures, so what?“. I think there are a few things that are different in tensor category diagrams:
+
+ 1. with string diagrams, the lines are objects and the boxes are functions which is the opposite of how usual category theory diagrams are
+ 2. putting things next to each other in the diagram has a specific meaning (“take the tensor product of those 2 things”) where as in usual category theory diagrams it doesn’t. being able to combine things in this way is powerful!
+ 3. half circles have a specific meaning (“take the dual”)
+ 4. you can use specific elements of a (eg vector space) in a diagram which usually you wouldn’t do in a category theory diagram (the objects would be the whole vector space, not one element of that vector space)
+
+
+
+### what does this have to do with programming?
+
+Even though this is usually a programming blog I don’t know whether this particular thing really has anything to do with programming, I just remembered I thought it was cool. I wrote my [master’s thesis][7] (which i will link to even though it’s not very readable) on topological quantum computing which involves a bunch of monoidal categories.
+
+Some of the diagrams in this post are sort of why I got interested in that area in the first place – I thought it was really cool that you could formally define / prove things with pictures. And useful things, like the trace of a matrix!
+
+### edit: some ways this might be related to programming
+
+Someone pointed me to a couple of twitter threads (coincidentally from this week!!) that relate tensor categories & diagrammatic methods to programming:
+
+ 1. [this thread from @KenScambler][8] (“My best kept secret* is that string & wiring diagrams–plucked straight out of applied category theory–are _fabulous_ for software and system design.)
+ 2. [this other thread by him of 31 interesting related things to this topic][9]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/03/26/what-are-monoidal-categories/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://arxiv.org/pdf/1803.05316.pdf
+[2]: https://jvns.ca/images/monoidal-preorder.png
+[3]: https://jvns.ca/images/tensor-vector.png
+[4]: https://qchu.wordpress.com/2012/11/05/introduction-to-string-diagrams/
+[5]: https://qchu.wordpress.com/2012/11/06/string-diagrams-duality-and-trace/
+[6]: https://jvns.ca/images/trace.png
+[7]: https://github.com/jvns/masters-thesis/raw/master/thesis.pdf
+[8]: https://twitter.com/KenScambler/status/1108738366529400832
+[9]: https://twitter.com/KenScambler/status/1109474342822244353
diff --git a/sources/tech/20190403 Use Git as the backend for chat.md b/sources/tech/20190403 Use Git as the backend for chat.md
deleted file mode 100644
index e564bbc6e7..0000000000
--- a/sources/tech/20190403 Use Git as the backend for chat.md
+++ /dev/null
@@ -1,141 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Use Git as the backend for chat)
-[#]: via: (https://opensource.com/article/19/4/git-based-chat)
-[#]: author: (Seth Kenlon https://opensource.com/users/seth)
-
-Use Git as the backend for chat
-======
-GIC is a prototype chat application that showcases a novel way to use Git.
-![Team communication, chat][1]
-
-[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at GIC, a Git-based chat application
-
-### Meet GIC
-
-While the authors of Git probably expected frontends to be created for Git, they undoubtedly never expected Git would become the backend for, say, a chat client. Yet, that's exactly what developer Ephi Gabay did with his experimental proof-of-concept [GIC][3]: a chat client written in [Node.js][4] using Git as its backend database.
-
-GIC is by no means intended for production use. It's purely a programming exercise, but it's one that demonstrates the flexibility of open source technology. What's astonishing is that the client consists of just 300 lines of code, excluding the Node libraries and Git itself. And that's one of the best things about the chat client and about open source; the ability to build upon existing work. Seeing is believing, so you should give GIC a look for yourself.
-
-### Get set up
-
-GIC uses Git as its engine, so you need an empty Git repository to serve as its chatroom and logger. The repository can be hosted anywhere, as long as you and anyone who needs access to the chat service has access to it. For instance, you can set up a Git repository on a free Git hosting service like GitLab and grant chat users contributor access to the Git repository. (They must be able to make commits to the repository, because each chat message is a literal commit.)
-
-If you're hosting it yourself, create a centrally located bare repository. Each user in the chat must have an account on the server where the bare repository is located. You can create accounts specific to Git with Git hosting software like [Gitolite][5] or [Gitea][6], or you can give them individual user accounts on your server, possibly using **git-shell** to restrict their access to Git.
-
-Performance is best on a self-hosted instance. Whether you host your own or you use a hosting service, the Git repository you create must have an active branch, or GIC won't be able to make commits as users chat because there is no Git HEAD. The easiest way to ensure that a branch is initialized and active is to commit a README or license file upon creation. If you don't do that, you can create and commit one after the fact:
-
-```
-$ echo "chat logs" > README
-$ git add README
-$ git commit -m 'just creating a HEAD ref'
-$ git push -u origin HEAD
-```
-
-### Install GIC
-
-Since GIC is based on Git and written in Node.js, you must first install Git, Node.js, and the Node package manager, npm (which should be bundled with Node). The command to install these differs depending on your Linux or BSD distribution, but here's an example command on Fedora:
-
-```
-$ sudo dnf install git nodejs
-```
-
-If you're not running Linux or BSD, follow the installation instructions on [git-scm.com][7] and [nodejs.org][8].
-
-There's no install process, as such, for GIC. Each user (Alice and Bob, in this example) must clone the repository to their hard drive:
-
-```
-$ git cone https://github.com/ephigabay/GIC GIC
-```
-
-Change directory into the GIC directory and install the Node.js dependencies with **npm** :
-
-```
-$ cd GIC
-$ npm install
-```
-
-Wait for the Node modules to download and install.
-
-### Configure GIC
-
-The only configuration GIC requires is the location of your Git chat repository. Edit the **config.js** file:
-
-```
-module.exports = {
-gitRepo: '[seth@example.com][9]:/home/gitchat/chatdemo.git',
-messageCheckInterval: 500,
-branchesCheckInterval: 5000
-};
-```
-
-
-Test your connection to the Git repository before trying GIC, just to make sure your configuration is sane:
-
-```
-$ git clone --quiet seth@example.com:/home/gitchat/chatdemo.git > /dev/null
-```
-
-Assuming you receive no errors, you're ready to start chatting.
-
-### Chat with Git
-
-From within the GIC directory, start the chat client:
-
-```
-$ npm start
-```
-
-When the client first launches, it must clone the chat repository. Since it's nearly an empty repository, it won't take long. Type your message and press Enter to send a message.
-
-![GIC][10]
-
-A Git-based chat client. What will they think of next?
-
-As the greeting message says, a branch in Git serves as a chatroom or channel in GIC. There's no way to create a new branch from within the GIC UI, but if you create one in another terminal session or in a web UI, it shows up immediately in GIC. It wouldn't take much to patch some IRC-style commands into GIC.
-
-After chatting for a while, take a look at your Git repository. Since the chat happens in Git, the repository itself is also a chat log:
-
-```
-$ git log --pretty=format:"%p %cn %s"
-4387984 Seth Kenlon Hey Chani, did you submit a talk for All Things Open this year?
-36369bb Chani No I didn't get a chance. Did you?
-[...]
-```
-
-### Exit GIC
-
-Not since Vim has there been an application as difficult to stop as GIC. You see, there is no way to stop GIC. It will continue to run until it is killed. When you're ready to stop GIC, open another terminal tab or window and issue this command:
-
-```
-$ kill `pgrep npm`
-```
-
-GIC is a novelty. It's a great example of how an open source ecosystem encourages and enables creativity and exploration and challenges us to look at applications from different angles. Try GIC out. Maybe it will give you ideas. At the very least, it's a great excuse to spend an afternoon with Git.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/4/git-based-chat
-
-作者:[Seth Kenlon (Red Hat, Community Moderator)][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
-[2]: https://git-scm.com/
-[3]: https://github.com/ephigabay/GIC
-[4]: https://nodejs.org/en/
-[5]: http://gitolite.com
-[6]: http://gitea.io
-[7]: http://git-scm.com
-[8]: http://nodejs.org
-[9]: mailto:seth@example.com
-[10]: https://opensource.com/sites/default/files/uploads/gic.jpg (GIC)
diff --git a/sources/tech/20190404 How writers can get work done better with Git.md b/sources/tech/20190404 How writers can get work done better with Git.md
deleted file mode 100644
index 1da47fd69f..0000000000
--- a/sources/tech/20190404 How writers can get work done better with Git.md
+++ /dev/null
@@ -1,266 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How writers can get work done better with Git)
-[#]: via: (https://opensource.com/article/19/4/write-git)
-[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/noreplyhttps://opensource.com/users/seth)
-
-How writers can get work done better with Git
-======
-If you're a writer, you could probably benefit from using Git. Learn how
-in our series about little-known uses of Git.
-![Writing Hand][1]
-
-[Git][2] is one of those rare applications that has managed to encapsulate so much of modern computing into one program that it ends up serving as the computational engine for many other applications. While it's best-known for tracking source code changes in software development, it has many other uses that can make your life easier and more organized. In this series leading up to Git's 14th anniversary on April 7, we'll share seven little-known ways to use Git. Today, we'll look at ways writers can use Git to get work done.
-
-### Git for writers
-
-Some people write fiction; others write academic papers, poetry, screenplays, technical manuals, or articles about open source. Many do a little of each. The common thread is that if you're a writer, you could probably benefit from using Git. While Git is famously a highly technical tool used by computer programmers, it's ideal for the modern author, and this article will demonstrate how it can change the way you write—and why you'd want it to.
-
-Before talking about Git, though, it's important to talk about what _copy_ (or _content_ , for the digital age) really is, and why it's different from your delivery _medium_. It's the 21 st century, and the tool of choice for most writers is a computer. While computers are deceptively good at combining processes like copy editing and layout, writers are (re)discovering that separating content from style is a good idea, after all. That means you should be writing on a computer like it's a typewriter, not a word processor. In computer lingo, that means writing in _plaintext_.
-
-### Writing in plaintext
-
-It used to be a safe assumption that you knew what market you were writing for. You wrote content for a book, or a website, or a software manual. These days, though, the market's flattened: you might decide to use content you write for a website in a printed book project, and the printed book might release an EPUB version later. And in the case of digital editions of your content, the person reading your content is in ultimate control: they may read your words on the website where you published them, or they might click on Firefox's excellent [Reader View][3], or they might print to physical paper, or they could dump the web page to a text file with Lynx, or they may not see your content at all because they use a screen reader.
-
-It makes sense to write your words as words, leaving the delivery to the publishers. Even if you are also your own publisher, treating your words as a kind of source code for your writing is a smarter and more efficient way to work, because when it comes time to publish, you can use the same source (your plaintext) to generate output appropriate to your target (PDF for print, EPUB for e-books, HTML for websites, and so on).
-
-Writing in plaintext not only means you don't have to worry about layout or how your text is styled, but you also no longer require specialized tools. Anything that can produce text becomes a valid "word processor" for you, whether it's a basic notepad app on your mobile or tablet, the text editor that came bundled with your computer, or a free editor you download from the internet. You can write on practically any device, no matter where you are or what you're doing, and the text you produce integrates perfectly with your project, no modification required.
-
-And, conveniently, Git specializes in managing plaintext.
-
-### The Atom editor
-
-When you write in plaintext, a word processor is overkill. Using a text editor is easier because text editors don't try to "helpfully" restructure your input. It lets you type the words in your head onto the screen, no interference. Better still, text editors are often designed around a plugin architecture, such that the application itself is woefully basic (it edits text), but you can build an environment around it to meet your every need.
-
-A great example of this design philosophy is the [Atom][4] editor. It's a cross-platform text editor with built-in Git integration. If you're new to working in plaintext and new to Git, Atom is the easiest way to get started.
-
-#### Install Git and Atom
-
-First, make sure you have Git installed on your system. If you run Linux or BSD, Git is available in your software repository or ports tree. The command you use will vary depending on your distribution; on Fedora, for instance:
-
-
-```
-`$ sudo dnf install git`
-```
-
-You can also download and install Git for [Mac][5] and [Windows][6].
-
-You won't need to use Git directly, because Atom serves as your Git interface. Installing Atom is the next step.
-
-If you're on Linux, install Atom from your software repository through your software installer or the appropriate command, such as:
-
-
-```
-`$ sudo dnf install atom`
-```
-
-Atom does not currently build on BSD. However, there are very good alternatives available, such as [GNU Emacs][7]. For Mac and Windows users, you can find installers on the [Atom website][4].
-
-Once your installs are done, launch the Atom editor.
-
-#### A quick tour
-
-If you're going to live in plaintext and Git, you need to get comfortable with your editor. Atom's user interface may be more dynamic than what you are used to. You can think of it more like Firefox or Chrome than as a word processor, in fact, because it has tabs and panels that can be opened and closed as they are needed, and it even has add-ons that you can install and configure. It's not practical to try to cover all of Atom's many features, but you can at least get familiar with what's possible.
-
-When Atom opens, it displays a welcome screen. If nothing else, this screen is a good introduction to Atom's tabbed interface. You can close the welcome screens by clicking the "close" icons on the tabs at the top of the Atom window and create a new file using **File > New File**.
-
-Working in plaintext is a little different than working in a word processor, so here are some tips for writing content in a way that a human can connect with and that Git and computers can parse, track, and convert.
-
-#### Write in Markdown
-
-These days, when people talk about plaintext, mostly they mean Markdown. Markdown is more of a style than a format, meaning that it intends to provide a predictable structure to your text so computers can detect natural patterns and convert the text intelligently. Markdown has many definitions, but the best technical definition and cheatsheet is on [CommonMark's website][8].
-
-
-```
-# Chapter 1
-
-This is a paragraph with an *italic* word and a **bold** word in it.
-And it can even reference an image.
-
-
-```
-
-As you can tell from the example, Markdown isn't meant to read or feel like code, but it can be treated as code. If you follow the expectations of Markdown defined by CommonMark, then you can reliably convert, with just one click of a button, your writing from Markdown to .docx, .epub, .html, MediaWiki, .odt, .pdf, .rtf, and a dozen other formats _without_ loss of formatting.
-
-You can think of Markdown a little like a word processor's styles. If you've ever written for a publisher with a set of styles that govern what chapter titles and section headings look like, this is basically the same thing, except that instead of selecting a style from a drop-down menu, you're adding little notations to your text. These notations look natural to any modern reader who's used to "txt speak," but are swapped out with fancy text stylings when the text is rendered. It is, in fact, what word processors secretly do behind the scenes. The word processor shows bold text, but if you could see the code generated to make your text bold, it would be a lot like Markdown (actually it's the far more complex XML). With Markdown, that barrier is removed, which looks scarier on the one hand, but on the other hand, you can write Markdown on literally anything that generates text without losing any formatting information.
-
-The popular file extension for Markdown files is .md. If you're on a platform that doesn't know what a .md file is, you can associate the extension to Atom manually or else just use the universal .txt extension. The file extension doesn't change the nature of the file; it just changes how your computer decides what to do with it. Atom and some platforms are smart enough to know that a file is plaintext no matter what extension you give it.
-
-#### Live preview
-
-Atom features the **Markdown Preview** plugin, which shows you both the plain Markdown you're writing and the way it will (commonly) render.
-
-![Atom's preview screen][9]
-
-To activate this preview pane, select **Packages > Markdown Preview > Toggle Preview** or press **Ctrl+Shift+M**.
-
-This view provides you with the best of both worlds. You get to write without the burden of styling your text, but you also get to see a common example of what your text will look like, at least in a typical digital format. Of course, the point is that you can't control how your text is ultimately rendered, so don't be tempted to adjust your Markdown to force your render preview to look a certain way.
-
-#### One sentence per line
-
-Your high school writing teacher doesn't ever have to see your Markdown.
-
-It won't come naturally at first, but maintaining one sentence per line makes more sense in the digital world. Markdown ignores single line breaks (when you've pressed the Return or Enter key) and only creates a new paragraph after a single blank line.
-
-![Writing in Atom][10]
-
-The advantage of writing one sentence per line is that your work is easier to track. That is, if you've changed one word at the start of a paragraph, then it's easy for Atom, Git, or any application to highlight that change in a meaningful way if the change is limited to one line rather than one word in a long paragraph. In other words, a change to one sentence should only affect that sentence, not the whole paragraph.
-
-You might be thinking, "many word processors track changes, too, and they can highlight a single word that's changed." But those revision trackers are bound to the interface of that word processor, which means you can't look through revisions without being in front of that word processor. In a plaintext workflow, you can review revisions in plaintext, which means you can make or approve edits no matter what you have on hand, as long as that device can deal with plaintext (and most of them can).
-
-Writers admittedly don't usually think in terms of line numbers, but it's a useful tool for computers, and ultimately a great reference point in general. Atom numbers the lines of your text document by default. A _line_ is only a line once you have pressed the Enter or Return key.
-
-![Writing in Atom][11]
-
-If a line has a dot instead of a number, that means it's part of the previous line wrapped for you because it couldn't fit on your screen.
-
-#### Theme it
-
-If you're a visual person, you might be very particular about the way your writing environment looks. Even if you are writing in plain Markdown, it doesn't mean you have to write in a programmer's font or in a dark window that makes you look like a coder. The simplest way to modify what Atom looks like is to use [theme packages][12]. It's conventional for theme designers to differentiate dark themes from light themes, so you can search with the keyword Dark or Light, depending on what you want.
-
-To install a theme, select **Edit > Preferences**. This opens a new tab in the Atom interface. Yes, tabs are used for your working documents _and_ for configuration and control panels. In the **Settings** tab, click on the **Install** category.
-
-In the **Install** panel, search for the name of the theme you want to install. Click the **Themes** button on the right of the search field to search only for themes. Once you've found your theme, click its **Install** button.
-
-![Atom's themes][13]
-
-To use a theme you've installed or to customize a theme to your preference, navigate to the **Themes** category in your **Settings** tab. Pick the theme you want to use from the drop-down menu. The changes take place immediately, so you can see exactly how the theme affects your environment.
-
-You can also change your working font in the **Editor** category of the **Settings** tab. Atom defaults to monospace fonts, which are generally preferred by programmers. But you can use any font on your system, whether it's serif or sans or gothic or cursive. Whatever you want to spend your day staring at, it's entirely up to you.
-
-On a related note, by default Atom draws a vertical marker down its screen as a guide for people writing code. Programmers often don't want to write long lines of code, so this vertical line is a reminder to them to simplify things. The vertical line is meaningless to writers, though, and you can remove it by disabling the **wrap-guide** package.
-
-To disable the **wrap-guide** package, select the **Packages** category in the **Settings** tab and search for **wrap-guide**. When you've found the package, click its **Disable** button.
-
-#### Dynamic structure
-
-When creating a long document, I find that writing one chapter per file makes more sense than writing an entire book in a single file. Furthermore, I don't name my chapters in the obvious syntax **chapter-1.md** or **1.example.md** , but by chapter titles or keywords, such as **example.md**. To provide myself guidance in the future about how the book is meant to be assembled, I maintain a file called **toc.md** (for "Table of Contents") where I list the (current) order of my chapters.
-
-I do this because, no matter how convinced I am that chapter 6 just couldn't possibly happen before chapter 1, there's rarely a time that I don't swap the order of one or two chapters or sections before I'm finished with a book. I find that keeping it dynamic from the start helps me avoid renaming confusion, and it also helps me treat the material less rigidly.
-
-### Git in Atom
-
-Two things every writer has in common is that they're writing for keeps and their writing is a journey. You don't sit down to write and finish with a final draft; by definition, you have a first draft. And that draft goes through revisions, each of which you carefully save in duplicate and triplicate just in case one of your files turns up corrupted. Eventually, you get to what you call a final draft, but more than likely you'll be going back to it one day, either to resurrect the good parts or to fix the bad.
-
-The most exciting feature in Atom is its strong Git integration. Without ever leaving Atom, you can interact with all of the major features of Git, tracking and updating your project, rolling back changes you don't like, integrating changes from a collaborator, and more. The best way to learn it is to step through it, so here's how to use Git within the Atom interface from the beginning to the end of a writing project.
-
-First thing first: Reveal the Git panel by selecting **View > Toggle Git Tab**. This causes a new tab to open on the right side of Atom's interface. There's not much to see yet, so just keep it open for now.
-
-#### Starting a Git project
-
-You can think of Git as being bound to a folder. Any folder outside a Git directory doesn't know about Git, and Git doesn't know about it. Folders and files within a Git directory are ignored until you grant Git permission to keep track of them.
-
-You can create a Git project by creating a new project folder in Atom. Select **File > Add Project Folder** and create a new folder on your system. The folder you create appears in the left **Project Panel** of your Atom window.
-
-#### Git add
-
-Right-click on your new project folder and select **New File** to create a new file in your project folder. If you have files you want to import into your new project, right-click on the folder and select **Show in File Manager** to open the folder in your system's file viewer (Dolphin or Nautilus on Linux, Finder on Mac, Explorer on Windows), and then drag-and-drop your files.
-
-With a project file (either the empty one you created or one you've imported) open in Atom, click the **Create Repository** button in the **Git** tab. In the pop-up dialog box, click **Init** to initialize your project directory as a local Git repository. Git adds a **.git** directory (invisible in your system's file manager, but visible to you in Atom) to your project folder. Don't be fooled by this: The **.git** directory is for Git to manage, not you, so you'll generally stay out of it. But seeing it in Atom is a good reminder that you're working in a project actively managed by Git; in other words, revision history is available when you see a **.git** directory.
-
-In your empty file, write some stuff. You're a writer, so type some words. It can be any set of words you please, but remember the writing tips above.
-
-Press **Ctrl+S** to save your file and it will appear in the **Unstaged Changes** section of the **Git** tab. That means the file exists in your project folder but has not yet been committed over to Git's purview. Allow Git to keep track of your file by clicking on the **Stage All** button in the top-right of the **Git** tab. If you've used a word processor with revision history, you can think of this step as permitting Git to record changes.
-
-#### Git commit
-
-Your file is now staged. All that means is Git is aware that the file exists and is aware that it has been changed since the last time Git was made aware of it.
-
-A Git commit sends your file into Git's internal and eternal archives. If you're used to word processors, this is similar to naming a revision. To create a commit, enter some descriptive text in the **Commit** message box at the bottom of the **Git** tab. You can be vague or cheeky, but it's more useful if you enter useful information for your future self so that you know why the revision was made.
-
-The first time you make a commit, you must create a branch. Git branches are a little like alternate realities, allowing you to switch from one timeline to another to make changes that you may or may not want to keep forever. If you end up liking the changes, you can merge one experimental branch into another, thereby unifying different versions of your project. It's an advanced process that's not worth learning upfront, but you still need an active branch, so you have to create one for your first commit.
-
-Click on the **Branch** icon at the very bottom of the **Git** tab to create a new branch.
-
-![Creating a branch][14]
-
-It's customary to name your first branch **master**. You don't have to; you can name it **firstdraft** or whatever you like, but adhering to the local customs can sometimes make talking about Git (and looking up answers to questions) a little easier because you'll know that when someone mentions **master** , they really mean **master** and not **firstdraft** or whatever you called your branch.
-
-On some versions of Atom, the UI may not update to reflect that you've created a new branch. Don't worry; the branch will be created (and the UI updated) once you make your commit. Press the **Commit** button, whether it reads **Create detached commit** or **Commit to master**.
-
-Once you've made a commit, the state of your file is preserved forever in Git's memory.
-
-#### History and Git diff
-
-A natural question is how often you should make a commit. There's no one right answer to that. Saving a file with **Ctrl+S** and committing to Git are two separate processes, so you will continue to do both. You'll probably want to make commits whenever you feel like you've done something significant or are about to try out a crazy new idea that you may want to back out of.
-
-To get a feel for what impact a commit has on your workflow, remove some text from your test document and add some text to the top and bottom. Make another commit. Do this a few times until you have a small history at the bottom of your **Git** tab, then click on a commit to view it in Atom.
-
-![Viewing differences][15]
-
-When viewing a past commit, you see three elements:
-
- 1. Text in green was added to a document when the commit was made.
- 2. Text in red was removed from the document when the commit was made.
- 3. All other text was untouched.
-
-
-
-#### Remote backup
-
-One of the advantages of using Git is that, by design, it is distributed, meaning you can commit your work to your local repository and push your changes out to any number of servers for backup. You can also pull changes in from those servers so that whatever device you happen to be working on always has the latest changes.
-
-For this to work, you must have an account on a Git server. There are several free hosting services out there, including GitHub, the company that produces Atom but oddly is not open source, and GitLab, which is open source. Preferring open source to proprietary, I'll use GitLab in this example.
-
-If you don't already have a GitLab account, sign up for one and start a new project. The project name doesn't have to match your project folder in Atom, but it probably makes sense if it does. You can leave your project private, in which case only you and anyone you give explicit permissions to can access it, or you can make it public if you want it to be available to anyone on the internet who stumbles upon it.
-
-Do not add a README to the project.
-
-Once the project is created, it provides you with instructions on how to set up the repository. This is great information if you decide to use Git in a terminal or with a separate GUI, but Atom's workflow is different.
-
-Click the **Clone** button in the top-right of the GitLab interface. This reveals the address you must use to access the Git repository. Copy the **SSH** address (not the **https** address).
-
-In Atom, click on your project's **.git** directory and open the **config**. Add these configuration lines to the file, adjusting the **seth/example.git** part of the **url** value to match your unique address.
-
-* * *
-
-
-```
-[remote "origin"]
-url = [git@gitlab.com][16]:seth/example.git
-fetch = +refs/heads/*:refs/remotes/origin/*
-[branch "master"]
-remote = origin
-merge = refs/heads/master
-```
-
-At the bottom of the **Git** tab, a new button has appeared, labeled **Fetch**. Since your server is brand new and therefore has no data for you to fetch, right-click on the button and select **Push**. This pushes your changes to your Gitlab account, and now your project is backed up on a Git server.
-
-Pushing changes to a server is something you can do after each commit. It provides immediate offsite backup and, since the amount of data is usually minimal, it's practically as fast as a local save.
-
-### Writing and Git
-
-Git is a complex system, useful for more than just revision tracking and backups. It enables asynchronous collaboration and encourages experimentation. This article has covered the basics, but there are many more articles—and entire books—on Git and how to use it to make your work more efficient, more resilient, and more dynamic. It all starts with using Git for small tasks. The more you use it, the more questions you'll find yourself asking, and eventually the more tricks you'll learn.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/4/write-git
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sethhttps://opensource.com/users/noreplyhttps://opensource.com/users/seth
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/write-hand_0.jpg?itok=Uw5RJD03 (Writing Hand)
-[2]: https://git-scm.com/
-[3]: https://support.mozilla.org/en-US/kb/firefox-reader-view-clutter-free-web-pages
-[4]: http://atom.io
-[5]: https://git-scm.com/download/mac
-[6]: https://git-scm.com/download/win
-[7]: http://gnu.org/software/emacs
-[8]: https://commonmark.org/help/
-[9]: https://opensource.com/sites/default/files/uploads/atom-preview.jpg (Atom's preview screen)
-[10]: https://opensource.com/sites/default/files/uploads/atom-para.jpg (Writing in Atom)
-[11]: https://opensource.com/sites/default/files/uploads/atom-linebreak.jpg (Writing in Atom)
-[12]: https://atom.io/themes
-[13]: https://opensource.com/sites/default/files/uploads/atom-theme.jpg (Atom's themes)
-[14]: https://opensource.com/sites/default/files/uploads/atom-branch.jpg (Creating a branch)
-[15]: https://opensource.com/sites/default/files/uploads/git-diff.jpg (Viewing differences)
-[16]: mailto:git@gitlab.com
diff --git a/sources/tech/20190404 Why blockchain (might be) coming to an IoT implementation near you.md b/sources/tech/20190404 Why blockchain (might be) coming to an IoT implementation near you.md
deleted file mode 100644
index f5915aebe7..0000000000
--- a/sources/tech/20190404 Why blockchain (might be) coming to an IoT implementation near you.md
+++ /dev/null
@@ -1,79 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Why blockchain (might be) coming to an IoT implementation near you)
-[#]: via: (https://www.networkworld.com/article/3386881/why-blockchain-might-be-coming-to-an-iot-implementation-near-you.html#tk.rss_all)
-[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
-
-Why blockchain (might be) coming to an IoT implementation near you
-======
-
-![MF3D / Getty Images][1]
-
-Companies have found that IoT partners well with a host of other popular enterprise computing technologies of late, and blockchain – the innovative system of distributed trust most famous for underpinning cryptocurrencies – is no exception. Yet while the two phenomena can be complementary in certain circumstances, those expecting an explosion of blockchain-enabled IoT technologies probably shouldn’t hold their breath.
-
-Blockchain technology can be counter-intuitive to understand at a basic level, but it’s probably best thought of as a sort of distributed ledger keeping track of various transactions. Every “block” on the chain contains transactional records or other data to be secured against tampering, and is linked to the previous one by a cryptographic hash, which means that any tampering with the block will invalidate that connection. The nodes – which can be largely anything with a CPU in it – communicate via a decentralized, peer-to-peer network to share data and ensure the validity of the data in the chain.
-
-**[ Also see[What is edge computing?][2] and [How edge networking and IoT will reshape data centers][3].]**
-
-The system works because all the blocks have to agree with each other on the specifics of the data that they’re safeguarding, according to Nir Kshetri, a professor of management at the University of North Carolina – Greensboro. If someone attempts to alter a previous transaction on a given node, the rest of the data on the network pushes back. “The old record of the data is still there,” said Kshetri.
-
-That’s a powerful security technique – absent a bad actor successfully controlling all of the nodes on a given blockchain (the [famous “51% attack][4]”), the data protected by that blockchain can’t be falsified or otherwise fiddled with. So it should be no surprise that the use of blockchain is an attractive option to companies in some corners of the IoT world.
-
-Part of the reason for that, over and above the bare fact of blockchain’s ability to securely distribute trusted information across a network, is its place in the technology stack, according to Jay Fallah, CTO and co-founder of NXMLabs, an IoT security startup.
-
-“Blockchain stands at a very interesting intersection. Computing has accelerated in the last 15 years [in terms of] storage, CPU, etc, but networking hasn’t changed that much until recently,” he said. “[Blockchain]’s not a network technology, it’s not a data technology, it’s both.”
-
-### Blockchain and IoT**
-
-**
-
-Where blockchain makes sense as a part of the IoT world depends on who you speak to and what they are selling, but the closest thing to a general summation may have come from Allison Clift-Jenning, CEO of enterprise blockchain vendor Filament.
-
-“Anywhere where you've got people who are kind of wanting to trust each other, and have very archaic ways of doing it, that is usually a good place to start with use cases,” she said.
-
-One example, culled directly from Filament’s own customer base, is used car sales. Filament’s working with “a major Detroit automaker” to create a trusted-vehicle history platform, based on a device that plugs into the diagnostic port of a used car, pulls information from there, and writes that data to a blockchain. Just like that, there’s an immutable record of a used car’s history, including whether its airbags have ever been deployed, whether it’s been flooded, and so on. No unscrupulous used car lot or duplicitous former owner could change the data, and even unplugging the device would mean that there’s a suspicious blank period in the records.
-
-Most of present-day blockchain IoT implementation is about trust and the validation of data, according to Elvira Wallis, senior vice president and global head of IoT at SAP.
-
-“Most of the use cases that we have come across are in the realm of tracking and tracing items,” she said, giving the example of a farm-to-fork tracking system for high-end foodstuffs, using blockchain nodes mounted on crates and trucks, allowing for the creation of an un-fudgeable record of an item’s passage through transport infrastructure. (e.g., how long has this steak been refrigerated at such-and-such a temperature, how far has it traveled today, and so on.)
-
-### **Is using blockchain with IoT a good idea?**
-
-Different vendors sell different blockchain-based products for different use cases, which use different implementations of blockchain technology, some of which don’t bear much resemblance to the classic, linear, mined-transaction blockchain used in cryptocurrency.
-
-That means it’s a capability that you’d buy from a vendor for a specific use case, at this point. Few client organizations have the in-house expertise to implement a blockchain security system, according to 451 Research senior analyst Csilla Zsigri.
-
-The idea with any intelligent application of blockchain technology is to play to its strengths, she said, creating a trusted platform for critical information.
-
-“That’s where I see it really adding value, just in adding a layer of trust and validation,” said Zsigri.
-
-Yet while the basic idea of blockchain-enabled IoT applications is fairly well understood, it’s not applicable to every IoT use case, experts agree. Applying blockchain to non-transactional systems – although there are exceptions, including NXM Labs’ blockchain-based configuration product for IoT devices – isn’t usually the right move.
-
-If there isn’t a need to share data between two different parties – as opposed to simply moving data from sensor to back-end – blockchain doesn’t generally make sense, since it doesn’t really do anything for the key value-add present in most IoT implementations today: data analysis.
-
-“We’re still in kind of the early dial-up era of blockchain today,” said Clift-Jennings. “It’s slower than a typical database, it often isn't even readable, it often doesn't have a query engine tied to it. You don't really get privacy, by nature of it.”
-
-Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3386881/why-blockchain-might-be-coming-to-an-iot-implementation-near-you.html#tk.rss_all
-
-作者:[Jon Gold][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.networkworld.com/author/Jon-Gold/
-[b]: https://github.com/lujun9972
-[1]: https://images.idgesg.net/images/article/2019/02/chains_binary_data_blockchain_security_by_mf3d_gettyimages-941175690_2400x1600-100788434-large.jpg
-[2]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
-[3]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
-[4]: https://bitcoinist.com/51-percent-attack-hackers-steals-18-million-bitcoin-gold-btg-tokens/
-[5]: https://www.facebook.com/NetworkWorld/
-[6]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20190505 Blockchain 2.0 - What Is Ethereum -Part 9.md b/sources/tech/20190505 Blockchain 2.0 - What Is Ethereum -Part 9.md
deleted file mode 100644
index a4669a2eb0..0000000000
--- a/sources/tech/20190505 Blockchain 2.0 - What Is Ethereum -Part 9.md
+++ /dev/null
@@ -1,83 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Blockchain 2.0 – What Is Ethereum [Part 9])
-[#]: via: (https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/)
-[#]: author: (editor https://www.ostechnix.com/author/editor/)
-
-Blockchain 2.0 – What Is Ethereum [Part 9]
-======
-
-![Ethereum][1]
-
-In the previous guide of this series, we discussed about [**Hyperledger Project (HLP)**][2], a fastest growing product developed by **Linux Foundation**. In this guide, we are going to discuss about what is **Ethereum** and its features in detail. Many researchers opine that the future of the internet will be based on principles of decentralized computing. Decentralized computing was in fact among one of the broader objectives of having the internet in the first place. However, the internet took another turn owing to differences in computing capabilities available. While modern server capabilities make the case for server-side processing and execution, lack of decent mobile networks in large parts of the world make the case for the same on the client side. Modern smartphones now have **SoCs** (system on a chip or system on chip) capable of handling many such operations on the client side itself, however, limitations owing to retrieving and storing data securely still pushes developers to have server-side computing and data management. Hence, a bottleneck in regards to data transfer capabilities is currently observed.
-
-All of that might soon change because of advancements in distributed data storage and program execution platforms. [**The blockchain**][3], for the first time in the history of the internet, basically allows for secure data management and program execution on a distributed network of users as opposed to central servers.
-
-**Ethereum** is one such blockchain platform that gives developers access to frameworks and tools used to build and run applications on such a decentralized network. Though more popularly known in general for its cryptocurrency, Ethereum is more than just **ethers** (the cryptocurrency). It’s a full **Turing complete programming language** that is designed to develop and deploy **DApps** or **Distributed APPlications** [1]. We’ll look at DApps in more detail in one of the upcoming posts.
-
-Ethereum is an open-source, supports by default a public (non-permissioned) blockchain, and features an extensive smart contract platform **(Solidity)** underneath. Ethereum provides a virtual computing environment called the **Ethereum virtual machine** to run applications and [**smart contracts**][4] as well[2]. The Ethereum virtual machine runs on thousands of participating nodes all over the world, meaning the application data while being secure, is almost impossible to be tampered with or lost.
-
-### Getting behind Ethereum: What sets it apart
-
-In 2017, a 30 plus group of the who’s who of the tech and financial world got together to leverage the Ethereum blockchain’s capabilities. Thus, the **Ethereum Enterprise Alliance (EEA)** was formed by a long list of supporting members including _Microsoft_ , _JP Morgan_ , _Cisco Systems_ , _Deloitte_ , and _Accenture_. JP Morgan already has **Quorum** , a decentralized computing platform for financial services based on Ethereum currently in operation, while Microsoft has Ethereum based cloud services it markets through its Azure cloud business[3].
-
-### What is ether and how is it related to Ethereum
-
-Ethereum creator **Vitalik Buterin** understood the true value of a decentralized processing platform and the underlying blockchain tech that powered bitcoin. He failed to gain majority agreement for his idea of proposing that Bitcoin should be developed to support running distributed applications (DApps) and programs (now referred to as smart contracts).
-
-Hence in 2013, he proposed the idea of Ethereum in a white paper he published. The original white paper is still maintained and available for readers **[here][5]**. The idea was to develop a blockchain based platform to run smart contracts and applications designed to run on nodes and user devices instead of servers.
-
-The Ethereum system is often mistaken to just mean the cryptocurrency ether, however, it has to be reiterated that Ethereum is a full stack platform for developing applications and executing them as well and has been so since inception whereas bitcoin isn’t. **Ether is currently the second biggest cryptocurrency** by market capitalization and trades at an average of $170 per ether at the time of writing this article[4].
-
-### Features and technicalities of the platform[5]
-
- * As we’ve already mentioned, the cryptocurrency called ether is simply one of the things the platform features. The purpose of the system is more than taking care of financial transactions. In fact, the key difference between the Ethereum platform and Bitcoin is in their scripting capabilities. Ethereum is developed in a Turing complete programming language which means it has scripting and application capabilities similar to other major programming languages. Developers require this feature to create DApps and complex smart contracts on the platform, a feature that bitcoin misses on.
- * The “mining” process of ether is more stringent and complex. While specialized ASICs may be used to mine bitcoin, the basic hashing algorithm used by Ethereum **(EThash)** reduces the advantage that ASICs have in this regard.
- * The transaction fees itself to be paid as an incentive to miners and node operators for running the network is calculated using a computational token called **Gas**. Gas improves the system’s resilience and resistance to external hacks and attacks by requiring the initiator of the transaction to pay ethers proportionate to the number of computational resources that are required to carry out that transaction. This is in contrast to other platforms such as Bitcoin where the transaction fee is measured in tandem with the transaction size. As such, the average transaction costs in Ethereum is radically less than Bitcoin. This also implies that running applications running on the Ethereum virtual machine will require a fee depending straight up on the computational problems that the application is meant to solve. Basically, the more complex an execution, the more the fee.
- * The block time for Ethereum is estimated to be around _**10-15 seconds**_. The block time is the average time that is required to timestamp and create a block on the blockchain network. Compared to the 10+ minutes the same transaction will take on the bitcoin network, it becomes apparent that _**Ethereum is much faster**_ with respect to transactions and verification of blocks.
- * _It is also interesting to note that there is no hard cap on the amount of ether that can be mined or the rate at which ether can be mined leading to less radical system design than bitcoin._
-
-
-
-### Conclusion
-
-While Ethereum is comparable and far outpaces similar platforms, the platform itself lacked a definite path for development until the Ethereum enterprise alliance started pushing it. While the definite push for enterprise developments are made by the Ethereum platform, it has to be noted that Ethereum also caters to small-time developers and individuals as well. As such developing the platform for end users and enterprises leave a lot of specific functionality out of the loop for Ethereum. Also, the blockchain model proposed and developed by the Ethereum foundation is a public model whereas the one proposed by projects such as the Hyperledger project is private and permissioned.
-
-While only time can tell which platform among the ones put forward by Ethereum, Hyperledger, and R3 Corda among others will find the most fans in real-world use cases, such systems do prove the validity behind the claim of a blockchain powered future.
-
-**References:**
-
- * [1] [**Gabriel Nicholas, “Ethereum Is Coding’s New Wild West | WIRED,” Wired , 2017**][6].
- * [2] [**What is Ethereum? — Ethereum Homestead 0.1 documentation**][7].
- * [3] [**Ethereum, a Virtual Currency, Enables Transactions That Rival Bitcoin’s – The New York Times**][8].
- * [4] [**Cryptocurrency Market Capitalizations | CoinMarketCap**][9].
- * [5] [**Introduction — Ethereum Homestead 0.1 documentation**][10].
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/
-
-作者:[editor][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/editor/
-[b]: https://github.com/lujun9972
-[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Ethereum-720x340.png
-[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
-[3]: https://www.ostechnix.com/blockchain-2-0-an-introduction/
-[4]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
-[5]: https://github.com/ethereum/wiki/wiki/White-Paper
-[6]: https://www.wired.com/story/ethereum-is-codings-new-wild-west/
-[7]: http://www.ethdocs.org/en/latest/introduction/what-is-ethereum.html#ethereum-virtual-machine
-[8]: https://www.nytimes.com/2016/03/28/business/dealbook/ethereum-a-virtual-currency-enables-transactions-that-rival-bitcoins.html
-[9]: https://coinmarketcap.com/
-[10]: http://www.ethdocs.org/en/latest/introduction/index.html
diff --git a/sources/tech/20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md b/sources/tech/20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md
deleted file mode 100644
index c685af487c..0000000000
--- a/sources/tech/20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md
+++ /dev/null
@@ -1,81 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Blockchain 2.0 – Introduction To Hyperledger Fabric [Part 10])
-[#]: via: (https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/)
-[#]: author: (sk https://www.ostechnix.com/author/sk/)
-
-Blockchain 2.0 – Introduction To Hyperledger Fabric [Part 10]
-======
-
-![Hyperledger Fabric][1]
-
-### Hyperledger Fabric
-
-The [**Hyperledger project**][2] is an umbrella organization of sorts featuring many different modules and systems under development. Among the most popular among these individual sub-projects is the **Hyperledger Fabric**. This post will explore the features that would make the Fabric almost indispensable in the near future once blockchain systems start proliferating into main stream use. Towards the end we will also take a quick look at what developers and enthusiasts need to know regarding the technicalities of the Hyperledger Fabric.
-
-### Inception
-
-In the usual fashion for the Hyperledger project, Fabric was “donated” to the organization by one of its core members, **IBM** , who was previously the principle developer of the same. The technology platform shared by IBM was put to joint development at the Hyperledger project with contributions from over a 100 member companies and institutions.
-
-Currently running on **v1.4** of the LTS version, Fabric has come a long way and is currently seen as the go to enterprise solution for managing business data. The core vision that surrounds the Hyperledger project inevitably permeates into the Fabric as well. The Hyperledger Fabric system carries forward all the enterprise ready and scalable features that are hard coded into all projects under the Hyperledger organization.
-
-### Highlights Of Hyperledger Fabric
-
-Hyperledger Fabric offers a wide variety of features and standards that are built around the mission of supporting fast development and modular architectures. Furthermore, compared to its competitors (primarily **Ripple** and [**Ethereum**][3]), Fabric takes an explicit stance toward closed and [**permissioned blockchains**][4]. Their core objective here is to develop a set of tools which will aid blockchain developers in creating customized solutions and not to create a standalone ecosystem or a product.
-
-Some of the highlights of the Hyperledger Fabric are given below:
-
- * **Permissioned blockchain systems**
-
-
-
-This is a category where other platforms such as Ethereum and Ripple differ quite a lot with Hyperledger Fabric. The Fabric by default is a tool designed to implement a private permissioned blockchain. Such blockchains cannot be accessed by everyone and the nodes working to offer consensus or to verify transactions are chosen by a central authority. This might be important for some applications such as banking and insurance, where transactions have to be verified by the central authority rather than participants.
-
- * **Confidential and controlled information flow**
-
-
-
-The Fabric has built in permission systems that will restrict information flow within a specific group or certain individuals as the case may be. Unlike a public blockchain where anyone and everyone who runs a node will have a copy and selective access to data stored in the blockchain, the admin of the system can choose how to and who to share access to the information. There are also subsystems which will encrypt the stored data at better security standards compared to existing competition.
-
- * **Plug and play architecture**
-
-
-
-Hyperledger Fabric has a plug and play type architecture. Individual components of the system may be chosen to be implemented and components of the system that developers don’t see a use for maybe discarded. The Fabric takes a highly modular and customizable route to development rather than a one size fits all approach taken by its competitors. This is especially attractive for firms and companies looking to build a lean system fast. This combined with the interoperability of the Fabric with other Hyperledger components implies that developers and designers now have access to a diverse set of standardized tools instead of having to pull code from different sources and integrate them afterwards. It also presents a rather fail-safe way to build robust modular systems.
-
- * **Smart contracts and chaincode**
-
-
-
-A distributed application running on a blockchain is called a [**Smart contract**][5]. While the smart contract term is more or less associated with the Ethereum platform, chaincode is the name given to the same in the Hyperledger camp. Apart from possessing all the benefits of **DApps** being present in chaincode applications, what sets Hyperledger apart is the fact that the code for the same may be written in multiple high-level programming language. It supports [**Go**][6] and **JavaScript** out of the box and supports many other after integration with appropriate compiler modules as well. Though this fact might not mean much at this point, the fact remains that if existing talent can be used for ongoing projects involving blockchain that has the potential to save companies billions of dollars in personnel training and management in the long run. Developers can code in languages they’re comfortable in to start building applications on the Hyperledger Fabric and need not learn nor train in platform specific languages and syntax. This presents flexibility which current competitors of the Hyperledger Fabric do not offer.
-
- * The Hyperledger Fabric is a back-end driver platform and is mainly aimed at integration projects where a blockchain or another distributed ledger technology is required. As such it does not provide any user facing services except for minor scripting capabilities. (Think of it to be more like a scripting language.)
- * Hyperledger Fabric supports building sidechains for specific use-cases. In case, the developer wishes to isolate a set of users or participants to a specific part or functionality of the application, they may do so by implementing side-chains. Side-chains are blockchains that derive from a main parent, but form a different chain after their initial block. This block which gives rise to the new chain will stay immune to further changes in the new chain and the new chain remains immutable even if new information is added to the original chain. This functionality will aid in scaling the platform being developed and usher in user specific and case specific processing capabilities.
- * The previous feature also means that not all users will have an “exact” copy of all the data in the blockchain as is expected usually from public chains. Participating nodes will have a copy of data that is only relevant to them. For instance, consider an application similar to PayTM in India. The app has wallet functionality as well as an e-commerce end. However, not all its wallet users use PayTM to shop online. In this scenario, only active shoppers will have the corresponding chain of transactions on the PayTM e-commerce site, whereas the wallet users will just have a copy of the chain that stores wallet transactions. This flexible architecture for data storage and retrieval is important while scaling, since massive singular blockchains have been shown to increase lead times for processing transactions. The chain can be kept lean and well categorised this way.
-
-
-
-We will look at other modules under the Hyperledger Project in detail in upcoming posts.
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/
-
-作者:[sk][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.ostechnix.com/author/sk/
-[b]: https://github.com/lujun9972
-[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
-[3]: https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/
-[4]: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
-[5]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
-[6]: https://www.ostechnix.com/install-go-language-linux/
diff --git a/sources/tech/20190528 A Quick Look at Elvish Shell.md b/sources/tech/20190528 A Quick Look at Elvish Shell.md
deleted file mode 100644
index 82927332a7..0000000000
--- a/sources/tech/20190528 A Quick Look at Elvish Shell.md
+++ /dev/null
@@ -1,107 +0,0 @@
-Translating by name1e5s
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (A Quick Look at Elvish Shell)
-[#]: via: (https://itsfoss.com/elvish-shell/)
-[#]: author: (John Paul https://itsfoss.com/author/john/)
-
-A Quick Look at Elvish Shell
-======
-
-Everyone who comes to this site has some knowledge (no matter how slight) of the Bash shell that comes default of so many systems. There have been several attempts to create shells that solve some of the shortcomings of Bash that have appeared over the years. One such shell is Elvish, which we will look at today.
-
-### What is Elvish Shell?
-
-![Pipelines In Elvish][1]
-
-[Elvish][2] is more than just a shell. It is [also][3] “an expressive programming language”. It has a number of interesting features including:
-
- * Written in Go
- * Built-in file manager, inspired by the [Ranger file manager][4] (`Ctrl + N`)
- * Searchable command history (`Ctrl + R`)
- * History of directories visited (`Ctrl + L`)
- * Powerful pipelines that support structured data, such as lists, maps, and functions
- * Includes a “standard set of control structures: conditional control with `if`, loops with `for` and `while`, and exception handling with `try`“
- * Support for [third-party modules via a package manager to extend Elvish][5]
- * Licensed under the BSD 2-Clause license
-
-
-
-“Why is it named Elvish?” I hear you shout. Well, according to [their website][6], they chose their current name because:
-
-> In roguelikes, items made by the elves have a reputation of high quality. These are usually called elven items, but “elvish” was chosen because it ends with “sh”, a long tradition of Unix shells. It also rhymes with fish, one of the shells that influenced the philosophy of Elvish.
-
-### How to Install Elvish Shell
-
-Elvish is available in several mainstream distributions.
-
-Note that the software is very young. The most recent version is 0.12. According to the project’s [GitHub page][3]: “Despite its pre-1.0 status, it is already suitable for most daily interactive use.”
-
-![Elvish Control Structures][7]
-
-#### Debian and Ubuntu
-
-Elvish packages were introduced into Debian Buster and Ubuntu 17.10. Unfortunately, those packages are out of date and you will need to use a [PPA][8] to install the latest version. You will need to use the following commands:
-
-```
-sudo add-apt-repository ppa:zhsj/elvish
-sudo apt update
-sudo apt install elvish
-```
-
-#### Fedora
-
-Elvish is not available in the main Fedora repos. You will need to add the [FZUG Repository][9] to install Evlish. To do so, you will need to use these commands:
-
-```
-sudo dnf config-manager --add-repo=http://repo.fdzh.org/FZUG/FZUG.repol
-sudo dnf install elvish
-```
-
-#### Arch
-
-Elvish is available in the [Arch User Repository][10].
-
-I believe you know [how to change shell in Linux][11] so after installing you can switch to Elvish to use it.
-
-### Final Thoughts on Elvish Shell
-
-Personally, I have no reason to install Elvish on any of my systems. I can get most of its features by installing a couple of small command line programs or using already installed programs.
-
-For example, the search past commands feature already exists in Bash and it works pretty well. If you want to improve your ability to search past commands, I would recommend installing [fzf][12] instead. Fzf uses fuzzy search, so you don’t need to remember the exact command you are looking for. Fzf also allows you to preview and open files.
-
-I do think that the fact that Elvish is also a programming language is neat, but I’ll stick with Bash shell scripting until Elvish matures a little more.
-
-Have you every used Elvish? Do you think it would be worthwhile to install Elvish? What is your favorite Bash replacement? Please let us know in the comments below.
-
-If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][13].
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/elvish-shell/
-
-作者:[John Paul][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/john/
-[b]: https://github.com/lujun9972
-[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/pipelines-in-elvish.png?fit=800%2C421&ssl=1
-[2]: https://elv.sh/
-[3]: https://github.com/elves/elvish
-[4]: https://ranger.github.io/
-[5]: https://github.com/elves/awesome-elvish
-[6]: https://elv.sh/ref/name.html
-[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/Elvish-control-structures.png?fit=800%2C425&ssl=1
-[8]: https://launchpad.net/%7Ezhsj/+archive/ubuntu/elvish
-[9]: https://github.com/FZUG/repo/wiki/Add-FZUG-Repository
-[10]: https://aur.archlinux.org/packages/elvish/
-[11]: https://linuxhandbook.com/change-shell-linux/
-[12]: https://github.com/junegunn/fzf
-[13]: http://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20190614 What is a Java constructor.md b/sources/tech/20190614 What is a Java constructor.md
deleted file mode 100644
index 66cd30110d..0000000000
--- a/sources/tech/20190614 What is a Java constructor.md
+++ /dev/null
@@ -1,158 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (What is a Java constructor?)
-[#]: via: (https://opensource.com/article/19/6/what-java-constructor)
-[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/ashleykoree)
-
-What is a Java constructor?
-======
-Constructors are powerful components of programming. Use them to unlock
-the full potential of Java.
-![][1]
-
-Java is (disputably) the undisputed heavyweight in open source, cross-platform programming. While there are many [great][2] [cross-platform][2] [frameworks][3], few are as unified and direct as [Java][4].
-
-Of course, Java is also a pretty complex language with subtleties and conventions all its own. One of the most common questions about Java relates to **constructors** : What are they and what are they used for?
-
-Put succinctly: a constructor is an action performed upon the creation of a new **object** in Java. When your Java application creates an instance of a class you have written, it checks for a constructor. If a constructor exists, Java runs the code in the constructor while creating the instance. That's a lot of technical terms crammed into a few sentences, but it becomes clearer when you see it in action, so make sure you have [Java installed][5] and get ready for a demo.
-
-### Life without constructors
-
-If you're writing Java code, you're already using constructors, even though you may not know it. All classes in Java have a constructor because even if you haven't created one, Java does it for you when the code is compiled. For the sake of demonstration, though, ignore the hidden constructor that Java provides (because a default constructor adds no extra features), and take a look at life without an explicit constructor.
-
-Suppose you're writing a simple Java dice-roller application because you want to produce a pseudo-random number for a game.
-
-First, you might create your dice class to represent a physical die. Knowing that you play a lot of [Dungeons and Dragons][6], you decide to create a 20-sided die. In this sample code, the variable **dice** is the integer 20, representing the maximum possible die roll (a 20-sided die cannot roll more than 20). The variable **roll** is a placeholder for what will eventually be a random number, and **rand** serves as the random seed.
-
-
-```
-import java.util.Random;
-
-public class DiceRoller {
-private int dice = 20;
-private int roll;
-private [Random][7] rand = new [Random][7]();
-```
-
-Next, create a function in the **DiceRoller** class to execute the steps the computer must take to emulate a die roll: Take an integer from **rand** and assign it to the **roll** variable, add 1 to account for the fact that Java starts counting at 0 but a 20-sided die has no 0 value, then print the results.
-
-
-```
-public void Roller() {
-roll = rand.nextInt(dice);
-roll += 1;
-[System][8].out.println (roll);
-}
-```
-
-Finally, spawn an instance of the **DiceRoller** class and invoke its primary function, **Roller** :
-
-
-```
-// main loop
-public static void main ([String][9][] args) {
-[System][8].out.printf("You rolled a ");
-
-DiceRoller App = new DiceRoller();
-App.Roller();
-}
-}
-```
-
-As long as you have a Java development environment installed (such as [OpenJDK][10]), you can run your application from a terminal:
-
-
-```
-$ java dice.java
-You rolled a 12
-```
-
-In this example, there is no explicit constructor. It's a perfectly valid and legal Java application, but it's a little limited. For instance, if you set your game of Dungeons and Dragons aside for the evening to play some Yahtzee, you would need 6-sided dice. In this simple example, it wouldn't be that much trouble to change the code, but that's not a realistic option in complex code. One way you could solve this problem is with a constructor.
-
-### Constructors in action
-
-The **DiceRoller** class in this example project represents a virtual dice factory: When it's called, it creates a virtual die that is then "rolled." However, by writing a custom constructor, you can make your Dice Roller application ask what kind of die you'd like to emulate.
-
-Most of the code is the same, with the exception of a constructor accepting some number of sides. This number doesn't exist yet, but it will be created later.
-
-
-```
-import java.util.Random;
-
-public class DiceRoller {
-private int dice;
-private int roll;
-private [Random][7] rand = new [Random][7]();
-
-// constructor
-public DiceRoller(int sides) {
-dice = sides;
-}
-```
-
-The function emulating a roll remains unchanged:
-
-
-```
-public void Roller() {
-roll = rand.nextInt(dice);
-roll += 1;
-[System][8].out.println (roll);
-}
-```
-
-The main block of code feeds whatever arguments you provide when running the application. Were this a complex application, you would parse the arguments carefully and check for unexpected results, but for this sample, the only precaution taken is converting the argument string to an integer type:
-
-
-```
-public static void main ([String][9][] args) {
-[System][8].out.printf("You rolled a ");
-DiceRoller App = new DiceRoller( [Integer][11].parseInt(args[0]) );
-App.Roller();
-}
-}
-```
-
-Launch the application and provide the number of sides you want your die to have:
-
-
-```
-$ java dice.java 20
-You rolled a 10
-$ java dice.java 6
-You rolled a 2
-$ java dice.java 100
-You rolled a 44
-```
-
-The constructor has accepted your input, so when the class instance is created, it is created with the **sides** variable set to whatever number the user dictates.
-
-Constructors are powerful components of programming. Practice using them to unlock the full potential of Java.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/6/what-java-constructor
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/seth/users/ashleykoree
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/build_structure_tech_program_code_construction.png?itok=nVsiLuag
-[2]: https://opensource.com/resources/python
-[3]: https://opensource.com/article/17/4/pyqt-versus-wxpython
-[4]: https://opensource.com/resources/java
-[5]: https://openjdk.java.net/install/index.html
-[6]: https://opensource.com/article/19/5/free-rpg-day
-[7]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+random
-[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
-[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
-[10]: https://openjdk.java.net/
-[11]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+integer
diff --git a/sources/tech/20190623 What does debugging a program look like.md b/sources/tech/20190623 What does debugging a program look like.md
new file mode 100644
index 0000000000..7cc7c1432e
--- /dev/null
+++ b/sources/tech/20190623 What does debugging a program look like.md
@@ -0,0 +1,184 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What does debugging a program look like?)
+[#]: via: (https://jvns.ca/blog/2019/06/23/a-few-debugging-resources/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+What does debugging a program look like?
+======
+
+I was debugging with a friend who’s a relatively new programmer yesterday, and showed them a few debugging tips. Then I was thinking about how to teach debugging this morning, and [mentioned on Twitter][1] that I’d never seen a really good guide to debugging your code. (there are a ton of really great replies by Anne Ogborn to that tweet if you are interested in debugging tips)
+
+As usual, I got a lot of helpful answers and now I have a few ideas about how to teach debugging skills / describe the process of debugging.
+
+### a couple of debugging resources
+
+I was hoping for more links to debugging books/guides, but here are the 2 recommendations I got:
+
+**“Debugging” by David Agans**: Several people recommended the book [Debugging][2], which looks like a nice and fairly short book that explains a debugging strategy. I haven’t read it yet (though I ordered it to see if I should be recommending it) and the rules laid out in the book (“understand the system”, “make it fail”, “quit thinking and look”, “divide and conquer”, “change one thing at a time”, “keep an audit trail”, “check the plug”, “get a fresh view”, and “if you didn’t fix it, it ain’t fixed”) seem extremely resaonable :). He also has a charming [debugging poster][3].
+
+**“How to debug” by John Regehr**: [How to Debug][4] is a very good blog post based on Regehr’s experience teaching a university embedded systems course. Lots of good advice. He also has a [blog post reviewing 4 books about debugging][5], including Agans’ book.
+
+### reproduce your bug (but how do you do that?)
+
+The rest of this post is going to be an attempt to aggregate different ideas about debugging people tweeted at me.
+
+Somewhat obviously, everybody agrees that being able to consistently reproduce a bug is important if you want to figure out what’s going on. I have an intuitive sense for how to do this but I’m not sure how to **explain** how to go from “I saw this bug twice” to “I can consistently reproduce this bug on demand on my laptop”, and I wonder whether the techniques you use to do this depend on the domain (backend web dev, frontend, mobile, games, C++ programs, embedded etc).
+
+### reproduce your bug _quickly_
+
+Everybody also agrees that it’s extremely useful be able to reproduce the bug quickly (if it takes you 3 minutes to check if every change helped, iterating is VERY SLOW).
+
+A few suggested approaches:
+
+ * for something that requires clicking on a bunch of things in a browser to reproduce, recording what you clicked on with [Selenium][6] and getting Selenium to replay the UI interactions (suggested [here][7])
+ * writing a unit test that reproduces the bug (if you can). bonus: you can add this to your test suite later if it makes sense
+ * writing a script / finding a command line incantation that does it (like `curl MY_APP.local/whatever`)
+
+
+
+### accept that it’s probably your code’s fault
+
+Sometimes I see a problem and I’m like “oh, library X has a bug”, “oh, it’s DNS”, “oh, SOME OTHER THING THAT IS NOT MY CODE is broken”. And sometimes it’s not my code! But in general between an established library and my code that I wrote last month, usually it’s my code that I wrote last month that’s the problem :).
+
+### start doing experiments
+
+@act_gardner gave a [nice, short explanation of what you have to do after you reproduce your bug][8]
+
+> I try to encourage people to first fully understand the bug - What’s happening? What do you expect to happen? When does it happen? When does it not happen? Then apply their mental model of the system to guess at what could be breaking and come up with experiments.
+>
+> Experiments could be changing or removing code, making API calls from a REPL, trying new inputs, poking at memory values with a debugger or print statements.
+
+I think the loop here may be:
+
+ * make guess about one aspect about what might be happening (“this variable is set to X where it should be Y”, “the server is being sent the wrong request”, “this code is never running at all”)
+ * do experiment to check that guess
+ * repeat until you understand what’s going on
+
+
+
+### change one thing at a time
+
+Everybody definitely agrees that it is important to change one thing a time when doing an experiment to verify an assumption.
+
+### check your assumptions
+
+A lot of debugging is realizing that something you were **sure** was true (“wait this request is going to the new server, right, not the old one???“) is actually… not true. I made an attempt to [list some common incorrect assumptions][9]. Here are some examples:
+
+ * this variable is set to X (“that filename is definitely right”)
+ * that variable’s value can’t possibly have changed between X and Y
+ * this code was doing the right thing before
+ * this function does X
+ * I’m editing the right file
+ * there can’t be any typos in that line I wrote it is just 1 line of code
+ * the documentation is correct
+ * the code I’m looking at is being executed at some point
+ * these two pieces of code execute sequentially and not in parallel
+ * the code does the same thing when compiled in debug / release mode (or with -O2 and without, or…)
+ * the compiler is not buggy (though this is last on purpose, the compiler is only very rarely to blame :))
+
+
+
+### weird methods to get information
+
+There are a lot of normal ways to do experiments to check your assumptions / guesses about what the code is doing (print out variable values, use a debugger, etc). Sometimes, though, you’re in a more difficult environment where you can’t print things out and don’t have access to a debugger (or it’s inconvenient to do those things, maybe because there are too many events). Some ways to cope:
+
+ * [adding sounds on mobile][10]: “In the mobile world, I live on this advice. Xcode can play a sound when you hit a breakpoint (and continue without stopping). I place them certain places in the code, and listen for buzzing Tink to indicate tight loops or Morse/Pop pairs to catch unbalanced events” (also [this tweet][11])
+ * there’s a very cool talk about [using XCode to play sound for iOS debugging here][12]
+ * [adding LEDs][13]: “When I did embedded dev ages ago on grids of transputers, we wired up an LED to an unused pin on each chip. It was surprisingly effective for diagnosing parallelism issues.”
+ * [string][14]: “My networks prof told me about a hack he saw at Xerox in the early days of Ethernet: a tap in the coax with an amp and motor and piece of string. The busier the network was, the faster the string twirled.”
+ * [peep][15] is a “network auralizer” that translates what’s happening on your system into sounds. I spent 10 minutes trying to get it to compile and failed so far but it looks very fun and I want to try it!!
+
+
+
+The point here is that information is the most important thing and you need to do whatever’s necessary to get information.
+
+### write your code so it’s easier to debug
+
+Another point a few people brought up is that you can improve your program to make it easier to debug. tef has a nice post about this: [Write code that’s easy to delete, and easy to debug too.][16] here. I thought this was very true:
+
+> Debuggable code isn’t necessarily clean, and code that’s littered with checks or error handling rarely makes for pleasant reading.
+
+I think one interpretation of “easy to debug” is “every single time there’s an error, the program reports to you exactly what happened in an easy to understand way”. Whenever my program has a problem and says sometihng “error: failure to connect to SOME_IP port 443: connection timeout” I’m like THANK YOU THAT IS THE KIND OF THING I WANTED TO KNOW and I can check if I need to fix a firewall thing or if I got the wrong IP for some reason or what.
+
+One simple example of this recently: I was making a request to a server I wrote and the reponse I got was “upstream connect error or disconnect/reset before headers”. This is an nginx error which basically in this case boiled down to “your program crashed before it sent anything in response to the request”. Figuring out the cause of the crash was pretty easy, but having better error handling (returning an error instead of crashing) would have saved me a little time because instead of having to go check the cause of the crash, I could have just read the error message and figured out what was going on right away.
+
+### error messages are better than silently failing
+
+To get closer to the dream of “every single time there’s an error, the program reports to you exactly what happened in an easy to understand way” you also need to be disciplined about immediately returning an error message instead of silently writing incorrect data / passing a nonsense value to another function which will do WHO KNOWS WHAT with it and cause you a gigantic headache. This means adding code like this:
+
+```
+if UNEXPECTED_THING:
+ raise "oh no THING happened"
+```
+
+This isn’t easy to get right (it’s not always obvious where you should be raising errors!“) but it really helps a lot.
+
+### failure: print out a stack of errors, not just one error.
+
+Related to returning helpful errors that make it easy to debug: Rust has a really incredible error handling library [called failure][17] which basicaly lets you return a chain of errors instead of just one error, so you can print out a stack of errors like:
+
+```
+"error starting server process" caused by
+"error initializing logging backend" caused by
+"connection failure: timeout connecting to 1.2.3.4 port 1234".
+```
+
+This is SO MUCH MORE useful than just `connection failure: timeout connecting to 1.2.3.4 port 1234` by itself because it tells you the significance of 1.2.3.4 (it’s something to do with the logging backend!). And I think it’s also more useful than `connection failure: timeout connecting to 1.2.3.4 port 1234` with a stack trace, because it summarizes at a high level the parts that went wrong instead of making you read all the lines in the stack trace (some of which might not be relevant!).
+
+tools like this in other languages:
+
+ * Go: the idiom to do this seems to be to just concatenate your stack of errors together as a big string so you get “error: thing one: error: thing two : error: thing three” which works okay but is definitely a lot less structured than `failure`’s system
+ * Java: I hear you can give exceptions causes but haven’t used that myself
+ * Python 3: you can use `raise ... from` which sets the `__cause__` attribute on the exception and then your exceptions will be separated by `The above exception was the direct cause of the following exception:..`
+
+
+
+If you know how to do this in other languages I’d be interested to hear!
+
+### understand what the error messages mean
+
+One sub debugging skill that I take for granted a lot of the time is understanding what error messages mean! I came across this nice graphic explaining [common Python errors and what they mean][18], which breaks down things like `NameError`, `IOError`, etc.
+
+I think a reason interpreting error messages is hard is that understanding a new error message might mean learning a new concept – `NameError` can mean “Your code uses a variable outside the scope where it’s defined”, but to really understand that you need to understand what variable scope is! I ran into this a lot when learning Rust – the Rust compiler would be like “you have a weird lifetime error” and I’d like be “ugh ok Rust I get it I will go actually learn about how lifetimes work now!“.
+
+And a lot of the time error messages are caused by a problem very different from the text of the message, like how “upstream connect error or disconnect/reset before headers” might mean “julia, your server crashed!“. The skill of understanding what error messages mean is often not transferable when you switch to a new area (if I started writing a lot of React or something tomorrow, I would probably have no idea what any of the error messages meant!). So this definitely isn’t just an issue for beginner programmers.
+
+### that’s all for now!
+
+I feel like the big thing I’m missing when talking about debugging skills is a stronger understanding of where people get stuck with debugging – it’s easy to say “well, you need to reproduce the problem, then make a more minimal reproduction, then start coming up with guesses and verifying them, and improve your mental model of the system, and then figure it out, then fix the problem and hopefully write a test to make it not come back”, but – where are people actually getting stuck in practice? What are the hardest parts? I have some sense of what the hardest parts usually are for me but I’m still not sure what the hardest parts usually are for someone newer to debugging their code.
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/06/23/a-few-debugging-resources/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://twitter.com/b0rk/status/1142825259546140673
+[2]: http://debuggingrules.com/
+[3]: http://debuggingrules.com/?page_id=40
+[4]: https://blog.regehr.org/archives/199
+[5]: https://blog.regehr.org/archives/849
+[6]: https://www.seleniumhq.org/
+[7]: https://twitter.com/AnnieTheObscure/status/1142843984642899968
+[8]: https://twitter.com/act_gardner/status/1142838587437830144
+[9]: https://twitter.com/b0rk/status/1142812831420768257
+[10]: https://twitter.com/cocoaphony/status/1142847665690030080
+[11]: https://twitter.com/AnnieTheObscure/status/1142842421954244608
+[12]: https://qnoid.com/2013/06/08/Sound-Debugging.html
+[13]: https://twitter.com/wombatnation/status/1142887843963867136
+[14]: https://twitter.com/irvingreid/status/1142887472441040896
+[15]: http://peep.sourceforge.net/intro.html
+[16]: https://programmingisterrible.com/post/173883533613/code-to-debug
+[17]: https://github.com/rust-lang-nursery/failure
+[18]: https://pythonforbiologists.com/29-common-beginner-errors-on-one-page/
diff --git a/sources/tech/20190627 RPM packages explained.md b/sources/tech/20190627 RPM packages explained.md
deleted file mode 100644
index 3fb3cee6b2..0000000000
--- a/sources/tech/20190627 RPM packages explained.md
+++ /dev/null
@@ -1,339 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (RPM packages explained)
-[#]: via: (https://fedoramagazine.org/rpm-packages-explained/)
-[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
-
-RPM packages explained
-======
-
-![][1]
-
-Perhaps the best known way the Fedora community pursues its [mission of promoting free and open source software and content][2] is by developing the [Fedora software distribution][3]. So it’s not a surprise at all that a very large proportion of our community resources are spent on this task. This post summarizes how this software is “packaged” and the underlying tools such as _rpm_ that make it all possible.
-
-### RPM: the smallest unit of software
-
-The editions and flavors ([spins][4]/[labs][5]/[silverblue][6]) that users get to choose from are all very similar. They’re all composed of various software that is mixed and matched to work well together. What differs between them is the exact list of tools that goes into each. That choice depends on the use case that they target. The basic unit of all of these is an RPM package file.
-
-RPM files are archives that are similar to ZIP files or tarballs. In fact, they uses compression to reduce the size of the archive. However, along with files, RPM archives also contain metadata about the package. This can be queried using the _rpm_ tool:
-```
-
-```
-
-$ rpm -q fpaste
-fpaste-0.3.9.2-2.fc30.noarch
-
-$ rpm -qi fpaste
-Name : fpaste
-Version : 0.3.9.2
-Release : 2.fc30
-Architecture: noarch
-Install Date: Tue 26 Mar 2019 08:49:10 GMT
-Group : Unspecified
-Size : 64144
-License : GPLv3+
-Signature : RSA/SHA256, Thu 07 Feb 2019 15:46:11 GMT, Key ID ef3c111fcfc659b9
-Source RPM : fpaste-0.3.9.2-2.fc30.src.rpm
-Build Date : Thu 31 Jan 2019 20:06:01 GMT
-Build Host : buildhw-07.phx2.fedoraproject.org
-Relocations : (not relocatable)
-Packager : Fedora Project
-Vendor : Fedora Project
-URL :
-Bug URL :
-Summary : A simple tool for pasting info onto sticky notes instances
-Description :
-It is often useful to be able to easily paste text to the Fedora
-Pastebin at and this simple script
-will do that and return the resulting URL so that people may
-examine the output. This can hopefully help folks who are for
-some reason stuck without X, working remotely, or any other
-reason they may be unable to paste something into the pastebin
-
-$ rpm -ql fpaste
-/usr/bin/fpaste
-/usr/share/doc/fpaste
-/usr/share/doc/fpaste/README.rst
-/usr/share/doc/fpaste/TODO
-/usr/share/licenses/fpaste
-/usr/share/licenses/fpaste/COPYING
-/usr/share/man/man1/fpaste.1.gz
-```
-
-```
-
-When an RPM package is installed, the _rpm_ tools know exactly what files were added to the system. So, removing a package also removes these files, and leaves the system in a consistent state. This is why installing software using _rpm_ is preferred over installing software from source whenever possible.
-
-### Dependencies
-
-Nowadays, it is quite rare for software to be completely self-contained. Even [fpaste][7], a simple one file Python script, requires that the Python interpreter be installed. So, if the system does not have Python installed (highly unlikely, but possible), _fpaste_ cannot be used. In packager jargon, we say that “Python is a **run-time dependency** of _fpaste_“.
-
-When RPM packages are built (the process of building RPMs is not discussed in this post), the generated archive includes all of this metadata. That way, the tools interacting with the RPM package archive know what else must must be installed so that fpaste works correctly:
-```
-
-```
-
-$ rpm -q --requires fpaste
-/usr/bin/python3
-python3
-rpmlib(CompressedFileNames) <= 3.0.4-1
-rpmlib(FileDigests) <= 4.6.0-1
-rpmlib(PayloadFilesHavePrefix) <= 4.0-1
-rpmlib(PayloadIsXz) <= 5.2-1
-
-$ rpm -q --provides fpaste
-fpaste = 0.3.9.2-2.fc30
-
-$ rpm -qi python3
-Name : python3
-Version : 3.7.3
-Release : 3.fc30
-Architecture: x86_64
-Install Date: Thu 16 May 2019 18:51:41 BST
-Group : Unspecified
-Size : 46139
-License : Python
-Signature : RSA/SHA256, Sat 11 May 2019 17:02:44 BST, Key ID ef3c111fcfc659b9
-Source RPM : python3-3.7.3-3.fc30.src.rpm
-Build Date : Sat 11 May 2019 01:47:35 BST
-Build Host : buildhw-05.phx2.fedoraproject.org
-Relocations : (not relocatable)
-Packager : Fedora Project
-Vendor : Fedora Project
-URL :
-Bug URL :
-Summary : Interpreter of the Python programming language
-Description :
-Python is an accessible, high-level, dynamically typed, interpreted programming
-language, designed with an emphasis on code readability.
-It includes an extensive standard library, and has a vast ecosystem of
-third-party libraries.
-
-The python3 package provides the "python3" executable: the reference
-interpreter for the Python language, version 3.
-The majority of its standard library is provided in the python3-libs package,
-which should be installed automatically along with python3.
-The remaining parts of the Python standard library are broken out into the
-python3-tkinter and python3-test packages, which may need to be installed
-separately.
-
-Documentation for Python is provided in the python3-docs package.
-
-Packages containing additional libraries for Python are generally named with
-the "python3-" prefix.
-
-$ rpm -q --provides python3
-python(abi) = 3.7
-python3 = 3.7.3-3.fc30
-python3(x86-64) = 3.7.3-3.fc30
-python3.7 = 3.7.3-3.fc30
-python37 = 3.7.3-3.fc30
-```
-
-```
-
-### Resolving RPM dependencies
-
-While _rpm_ knows the required dependencies for each archive, it does not know where to find them. This is by design: _rpm_ only works on local files and must be told exactly where they are. So, if you try to install a single RPM package, you get an error if _rpm_ cannot find the package’s run-time dependencies. This example tries to install a package downloaded from the Fedora package set:
-```
-
-```
-
-$ ls
-python3-elephant-0.6.2-3.fc30.noarch.rpm
-
-$ rpm -qpi python3-elephant-0.6.2-3.fc30.noarch.rpm
-Name : python3-elephant
-Version : 0.6.2
-Release : 3.fc30
-Architecture: noarch
-Install Date: (not installed)
-Group : Unspecified
-Size : 2574456
-License : BSD
-Signature : (none)
-Source RPM : python-elephant-0.6.2-3.fc30.src.rpm
-Build Date : Fri 14 Jun 2019 17:23:48 BST
-Build Host : buildhw-02.phx2.fedoraproject.org
-Relocations : (not relocatable)
-Packager : Fedora Project
-Vendor : Fedora Project
-URL :
-Bug URL :
-Summary : Elephant is a package for analysis of electrophysiology data in Python
-Description :
-Elephant - Electrophysiology Analysis Toolkit Elephant is a package for the
-analysis of neurophysiology data, based on Neo.
-
-$ rpm -qp --requires python3-elephant-0.6.2-3.fc30.noarch.rpm
-python(abi) = 3.7
-python3.7dist(neo) >= 0.7.1
-python3.7dist(numpy) >= 1.8.2
-python3.7dist(quantities) >= 0.10.1
-python3.7dist(scipy) >= 0.14.0
-python3.7dist(six) >= 1.10.0
-rpmlib(CompressedFileNames) <= 3.0.4-1
-rpmlib(FileDigests) <= 4.6.0-1
-rpmlib(PartialHardlinkSets) <= 4.0.4-1
-rpmlib(PayloadFilesHavePrefix) <= 4.0-1
-rpmlib(PayloadIsXz) <= 5.2-1
-
-$ sudo rpm -i ./python3-elephant-0.6.2-3.fc30.noarch.rpm
-error: Failed dependencies:
- python3.7dist(neo) >= 0.7.1 is needed by python3-elephant-0.6.2-3.fc30.noarch
- python3.7dist(quantities) >= 0.10.1 is needed by python3-elephant-0.6.2-3.fc30.noarch
-```
-
-```
-
-In theory, one could download all the packages that are required for _python3-elephant_, and tell _rpm_ where they all are, but that isn’t convenient. What if _python3-neo_ and _python3-quantities_ have other run-time requirements and so on? Very quickly, the **dependency chain** can get quite complicated.
-
-#### Repositories
-
-Luckily, _dnf_ and friends exist to help with this issue. Unlike _rpm_, _dnf_ is aware of **repositories**. Repositories are collections of packages, with metadata that tells _dnf_ what these repositories contain. All Fedora systems come with the default Fedora repositories enabled by default:
-```
-
-```
-
-$ sudo dnf repolist
-repo id repo name status
-fedora Fedora 30 - x86_64 56,582
-fedora-modular Fedora Modular 30 - x86_64 135
-updates Fedora 30 - x86_64 - Updates 8,573
-updates-modular Fedora Modular 30 - x86_64 - Updates 138
-updates-testing Fedora 30 - x86_64 - Test Updates 8,458
-```
-
-```
-
-There’s more information on [these repositories][8], and how they [can be managed][9] on the Fedora quick docs.
-
-_dnf_ can be used to query repositories for information on the packages they contain. It can also search them for software, or install/uninstall/upgrade packages from them:
-```
-
-```
-
-$ sudo dnf search elephant
-Last metadata expiration check: 0:05:21 ago on Sun 23 Jun 2019 14:33:38 BST.
-============================================================================== Name & Summary Matched: elephant ==============================================================================
-python3-elephant.noarch : Elephant is a package for analysis of electrophysiology data in Python
-python3-elephant.noarch : Elephant is a package for analysis of electrophysiology data in Python
-
-$ sudo dnf list \\*elephant\\*
-Last metadata expiration check: 0:05:26 ago on Sun 23 Jun 2019 14:33:38 BST.
-Available Packages
-python3-elephant.noarch 0.6.2-3.fc30 updates-testing
-python3-elephant.noarch 0.6.2-3.fc30 updates
-```
-
-```
-
-#### Installing dependencies
-
-When installing the package using _dnf_ now, it _resolves_ all the required dependencies, then calls _rpm_ to carry out the _transaction_:
-```
-
-```
-
-$ sudo dnf install python3-elephant
-Last metadata expiration check: 0:06:17 ago on Sun 23 Jun 2019 14:33:38 BST.
-Dependencies resolved.
-==============================================================================================================================================================================================
- Package Architecture Version Repository Size
-==============================================================================================================================================================================================
-Installing:
- python3-elephant noarch 0.6.2-3.fc30 updates-testing 456 k
-Installing dependencies:
- python3-neo noarch 0.8.0-0.1.20190215git49b6041.fc30 fedora 753 k
- python3-quantities noarch 0.12.2-4.fc30 fedora 163 k
-Installing weak dependencies:
- python3-igor noarch 0.3-5.20150408git2c2a79d.fc30 fedora 63 k
-
-Transaction Summary
-==============================================================================================================================================================================================
-Install 4 Packages
-
-Total download size: 1.4 M
-Installed size: 7.0 M
-Is this ok [y/N]: y
-Downloading Packages:
-(1/4): python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch.rpm 222 kB/s | 63 kB 00:00
-(2/4): python3-elephant-0.6.2-3.fc30.noarch.rpm 681 kB/s | 456 kB 00:00
-(3/4): python3-quantities-0.12.2-4.fc30.noarch.rpm 421 kB/s | 163 kB 00:00
-(4/4): python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch.rpm 840 kB/s | 753 kB 00:00
-\----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-Total 884 kB/s | 1.4 MB 00:01
-Running transaction check
-Transaction check succeeded.
-Running transaction test
-Transaction test succeeded.
-Running transaction
- Preparing : 1/1
- Installing : python3-quantities-0.12.2-4.fc30.noarch 1/4
- Installing : python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch 2/4
- Installing : python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch 3/4
- Installing : python3-elephant-0.6.2-3.fc30.noarch 4/4
- Running scriptlet: python3-elephant-0.6.2-3.fc30.noarch 4/4
- Verifying : python3-elephant-0.6.2-3.fc30.noarch 1/4
- Verifying : python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch 2/4
- Verifying : python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch 3/4
- Verifying : python3-quantities-0.12.2-4.fc30.noarch 4/4
-
-Installed:
- python3-elephant-0.6.2-3.fc30.noarch python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch python3-quantities-0.12.2-4.fc30.noarch
-
-Complete!
-```
-
-```
-
-Notice how dnf even installed _python3-igor_, which isn’t a direct dependency of _python3-elephant_.
-
-### DnfDragora: a graphical interface to DNF
-
-While technical users may find _dnf_ straightforward to use, it isn’t for everyone. [Dnfdragora][10] addresses this issue by providing a graphical front end to _dnf_.
-
-![dnfdragora \(version 1.1.1-2 on Fedora 30\) listing all the packages installed on a system.][11]
-
-From a quick look, dnfdragora appears to provide all of _dnf_‘s main functions.
-
-There are other tools in Fedora that also manage packages. GNOME Software, and Discover are two examples. GNOME Software is focused on graphical applications only. You can’t use the graphical front end to install command line or terminal tools such as _htop_ or _weechat_. However, GNOME Software does support the installation of [Flatpaks][12] and Snap applications which _dnf_ does not. So, they are different tools with different target audiences, and so provide different functions.
-
-This post only touches the tip of the iceberg that is the life cycle of software in Fedora. This article explained what RPM packages are, and the main differences between using _rpm_ and using _dnf_.
-
-In future posts, we’ll speak more about:
-
- * The processes that are needed to create these packages
- * How the community tests them to ensure that they are built correctly
- * The infrastructure that the community uses to get them to community users in future posts.
-
-
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/rpm-packages-explained/
-
-作者:[Ankur Sinha "FranciscoD"][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/ankursinha/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
-[2]: https://docs.fedoraproject.org/en-US/project/#_what_is_fedora_all_about
-[3]: https://getfedora.org
-[4]: https://spins.fedoraproject.org/
-[5]: https://labs.fedoraproject.org/
-[6]: https://silverblue.fedoraproject.org/
-[7]: https://src.fedoraproject.org/rpms/fpaste
-[8]: https://docs.fedoraproject.org/en-US/quick-docs/repositories/
-[9]: https://docs.fedoraproject.org/en-US/quick-docs/adding-or-removing-software-repositories-in-fedora/
-[10]: https://src.fedoraproject.org/rpms/dnfdragora
-[11]: https://fedoramagazine.org/wp-content/uploads/2019/06/dnfdragora-1024x558.png
-[12]: https://fedoramagazine.org/getting-started-flatpak/
diff --git a/sources/tech/20190628 Get your work recognized- write a brag document.md b/sources/tech/20190628 Get your work recognized- write a brag document.md
new file mode 100644
index 0000000000..e13dd2a07b
--- /dev/null
+++ b/sources/tech/20190628 Get your work recognized- write a brag document.md
@@ -0,0 +1,256 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get your work recognized: write a brag document)
+[#]: via: (https://jvns.ca/blog/brag-documents/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+Get your work recognized: write a brag document
+======
+
+There’s this idea that, if you do great work at your job, people will (or should!) automatically recognize that work and reward you for it with promotions / increased pay. In practice, it’s often more complicated than that – some kinds of important work are more visible/memorable than others. It’s frustrating to have done something really important and later realize that you didn’t get rewarded for it just because the people making the decision didn’t understand or remember what you did. So I want to talk about a tactic that I and lots of people I work with have used!
+
+This blog post isn’t just about being promoted or getting raises though. The ideas here have actually been more useful to me to help me reflect on themes in my work, what’s important to me, what I’m learning, and what I’d like to be doing differently. But they’ve definitely helped with promotions!
+
+You can also [skip to the brag document template at the end][1].
+
+### you don’t remember everything you did
+
+One thing I’m always struck by when it comes to performance review time is a feeling of “wait, what _did_ I do in the last 6 months?“. This is a kind of demoralizing feeling and it’s usually not based in reality, more in “I forgot what cool stuff I actually did”.
+
+I invariably end up having to spend a bunch of time looking through my pull requests, tickets, launch emails, design documents, and more. I always end up finding small (and sometimes not-so-small) things that I completely forgot I did, like:
+
+ * mentored an intern 5 months ago
+ * did a small-but-important security project
+ * spent a few weeks helping get an important migration over the line
+ * helped X put together this design doc
+ * etcetera!
+
+
+
+### your manager doesn’t remember everything you did
+
+And if you don’t remember everything important you did, your manager (no matter how great they are!) probably doesn’t either. And they need to explain to other people why you should be promoted or given an evaluation like “exceeds expectations” (“X’s work is so awesome!!!!” doesn’t fly).
+
+So if your manager is going to effectively advocate for you, they need help.
+
+### here’s the tactic: write a document listing your accomplishments
+
+The tactic is pretty simple! Instead of trying to remember everything you did with your brain, maintain a “brag document” that lists everything so you can refer to it when you get to performance review season! This is a pretty common tactic – when I started doing this I mentioned it to more experienced people and they were like “oh yeah, I’ve been doing that for a long time, it really helps”.
+
+Where I work we call this a “brag document” but I’ve heard other names for the same concept like “hype document” or “list of stuff I did” :).
+
+There’s a basic template for a brag document at the end of this post.
+
+### share your brag document with your manager
+
+When I first wrote a brag document I was kind of nervous about sharing it with my manager. It felt weird to be like “hey, uh, look at all the awesome stuff I did this year, I wrote a long document listing everything”. But my manager was really thankful for it – I think his perspective was “this makes my job way easier, now I can look at the document when writing your perf review instead of trying to remember what happened”.
+
+Giving them a document that explains your accomplishments will really help your manager advocate for you in discussions about your performance and come to any meetings they need to have prepared.
+
+Brag documents also **really** help with manager transitions – if you get a new manager 3 months before an important performance review that you want to do well on, giving them a brag document outlining your most important work & its impact will help them understand what you’ve been doing even though they may not have been aware of any of your work before.
+
+### share it with your peer reviewers
+
+Similarly, if your company does peer feedback as part of the promotion/perf process – share your brag document with your peer reviewers!! Every time someone shares their doc with me I find it SO HELPFUL with writing their review for much the same reasons it’s helpful to share it with your manager – it reminds me of all the amazing things they did, and when they list their goals in their brag document it also helps me see what areas they might be most interested in feedback on.
+
+On some teams at work it’s a team norm to share a brag document with peer reviewers to make it easier for them.
+
+### explain the big picture
+
+In addition to just listing accomplishments, in your brag document you can write the narrative explaining the big picture of your work. Have you been really focused on security? On building your product skills & having really good relationships with your users? On building a strong culture of code review on the team?
+
+In my brag document, I like to do this by making a section for areas that I’ve been focused on (like “security”) and listing all the work I’ve done in that area there. This is especially good if you’re working on something fuzzy like “building a stronger culture of code review” where all the individual actions you do towards that might be relatively small and there isn’t a big shiny ship.
+
+### use your brag document to notice patterns
+
+In the past I’ve found the brag document useful not just to hype my accomplishments, but also to reflect on the work I’ve done. Some questions it’s helped me with:
+
+ * What work do I feel most proud of?
+ * Are there themes in these projects I should be thinking about? What’s the big picture of what I’m working on? (am I working a lot on security? localization?).
+ * What do I wish I was doing more / less of?
+ * Which of my projects had the effect I wanted, and which didn’t? Why might that have been?
+ * What could have gone better with project X? What might I want to do differently next time?
+
+
+
+### you can write it all at once or update it every 2 weeks
+
+Many people have told me that it works best for them if they take a few minutes to update their brag document every 2 weeks ago. For me it actually works better to do a single marathon session every 6 months or every year where I look through everything I did and reflect on it all at once. Try out different approaches and see what works for you!
+
+### don’t forget to include the fuzzy work
+
+A lot of us work on fuzzy projects that can feel hard to quantify, like:
+
+ * improving code quality on the team / making code reviews a little more in depth
+ * making on call easier
+ * building a more fair interview process / performance review system
+ * refactoring / driving down technical debt
+
+
+
+A lot of people will leave this kind of work out because they don’t know how to explain why it’s important. But I think this kind of work is especially important to put into your brag document because it’s the most likely to fall under the radar! One way to approach this is to, for each goal:
+
+ 1. explain your goal for the work (why do you think it’s important to refactor X piece of code?)
+ 2. list some things you’ve done towards that goal
+ 3. list any effects you’ve seen of the work, even if they’re a little indirect
+
+
+
+If you tell your coworkers this kind of work is important to you and tell them what you’ve been doing, maybe they can also give you ideas about how to do it more effectively or make the effects of that work more obvious!
+
+### encourage each other to celebrate accomplishments
+
+One nice side effect of having a shared idea that it’s normal/good to maintain a brag document at work is that I sometimes see people encouraging each other to record & celebrate their accomplishments (“hey, you should put that in your brag doc, that was really good!”). It can be hard to see the value of your work sometimes, especially when you’re working on something hard, and an outside perspective from a friend or colleague can really help you see why what you’re doing is important.
+
+Brag documents are good when you use them on your own to advocate for yourself, but I think they’re better as a collaborative effort to recognize where people are excelling.
+
+Next, I want to talk about a couple of structures that we’ve used to help people recognize their accomplishments.
+
+### the brag workshop: help people list their accomplishments
+
+The way this “brag document” practice started in the first place is that my coworker [Karla][2] and I wanted to help other women in engineering advocate for themselves more in the performance review process. The idea is that some people undersell their accomplishments more than they should, so we wanted to encourage those people to “brag” a little bit and write down what they did that was important.
+
+We did this by running a “brag workshop” just before performance review season. The format of the workshop is like this:
+
+**Part 1: write the document: 1-2 hours**. Everybody sits down with their laptop, starts looking through their pull requests, tickets they resolved, design docs, etc, and puts together a list of important things they did in the last 6 months.
+
+**Part 2: pair up and make the impact of your work clearer: 1 hour**. The goal of this part is to pair up, review each other’s documents, and identify places where people haven’t bragged “enough” – maybe they worked on an extremely critical project to the company but didn’t highlight how important it was, maybe they improved test performance but didn’t say that they made the tests 3 times faster and that it improved everyone’s developer experience. It’s easy to accidentally write “I shipped $feature” and miss the follow up (“… which caused $thing to happen”). Another person reading through your document can help you catch the places where you need to clarify the impact.
+
+### biweekly brag document writing session
+
+Another approach to helping people remember their accomplishments: my friend Dave gets some friends together every couple of weeks or so for everyone to update their brag documents. It’s a nice way for people to talk about work that they’re happy about & celebrate it a little bit, and updating your brag document as you go can be easier than trying to remember everything you did all at once at the end of the year.
+
+These don’t have to be people in the same company or even in the same city – that group meets over video chat and has people from many different companies doing this together from Portland, Toronto, New York, and Montreal.
+
+In general, especially if you’re someone who really cares about your work, I think it’s really positive to share your goals & accomplishments (and the things that haven’t gone so well too!) with your friends and coworkers. It makes it feel less like you’re working alone and more like everyone is supporting each other in helping them accomplish what they want.
+
+### thanks
+
+Thanks to Karla Burnett who I worked with on spreading this idea at work, to Dave Vasilevsky for running brag doc writing sessions, to Will Larson who encouraged me to start one [of these][3] in the first place, to my manager Jay Shirley for always being encouraging & showing me that this is a useful way to work with a manager, and to Allie, Dan, Laura, Julian, Kamal, Stanley, and Vaibhav for reading a draft of this.
+
+I’d also recommend the blog post [Hype Yourself! You’re Worth It!][4] by Aashni Shah which talks about a similar approach.
+
+## Appendix: brag document template
+
+Here’s a template for a brag document! Usually I make one brag document per year. (“Julia’s 2017 brag document”). I think it’s okay to make it quite long / comprehensive – 5-10 pages or more for a year of work doesn’t seem like too much to me, especially if you’re including some graphs/charts / screenshots to show the effects of what you did.
+
+One thing I want to emphasize, for people who don’t like to brag, is – **you don’t have to try to make your work sound better than it is**. Just make it sound **exactly as good as it is**! For example “was the primary contributor to X new feature that’s now used by 60% of our customers and has gotten Y positive feedback”.
+
+### Goals for this year:
+
+ * List your major goals here! Sharing your goals with your manager & coworkers is really nice because it helps them see how they can support you in accomplishing those goals!
+
+
+
+### Goals for next year
+
+ * If it’s getting towards the end of the year, maybe start writing down what you think your goals for next year might be.
+
+
+
+### Projects
+
+For each one, go through:
+
+ * What your contributions were (did you come up with the design? Which components did you build? Was there some useful insight like “wait, we can cut scope and do what we want by doing way less work” that you came up with?)
+ * The impact of the project – who was it for? Are there numbers you can attach to it? (saved X dollars? shipped new feature that has helped sell Y big deals? Improved performance by X%? Used by X internal users every day?). Did it support some important non-numeric company goal (required to pass an audit? helped retain an important user?)
+
+
+
+Remember: don’t forget to explain what the results of you work actually were! It’s often important to go back a few months later and fill in what actually happened after you launched the project.
+
+### Collaboration & mentorship
+
+Examples of things in this category:
+
+ * Helping others in an area you’re an expert in (like “other engineers regularly ask me for one-off help solving weird bugs in their CSS” or “quoting from the C standard at just the right moment”)
+ * Mentoring interns / helping new team members get started
+ * Writing really clear emails/meeting notes
+ * Foundational code that other people built on top of
+ * Improving monitoring / dashboards / on call
+ * Any code review that you spent a particularly long time on / that you think was especially important
+ * Important questions you answered (“helped Risha from OTHER_TEAM with a lot of questions related to Y”)
+ * Mentoring someone on a project (“gave Ben advice from time to time on leading his first big project”)
+ * Giving an internal talk or workshop
+
+
+
+### Design & documentation
+
+List design docs & documentation that you worked on
+
+ * Design docs: I usually just say “wrote design for X” or “reviewed design for X”
+ * Documentation: maybe briefly explain the goal behind this documentation (for example “we were getting a lot of questions about X, so I documented it and now we can answer the questions more quickly”)
+
+
+
+### Company building
+
+This is a category we have at work – it basically means “things you did to help the company overall, not just your project / team”. Some things that go in here:
+
+ * Going above & beyond with interviewing or recruiting (doing campus recruiting, etc)
+ * Improving important processes, like the interview process or writing better onboarding materials
+
+
+
+### What you learned
+
+My friend Julian suggested this section and I think it’s a great idea – try listing important things you learned or skills you’ve acquired recently! Some examples of skills you might be learning or improving:
+
+ * how to do performance analysis & make code run faster
+ * internals of an important piece of software (like the JVM or Postgres or Linux)
+ * how to use a library (like React)
+ * how to use an important tool (like the command line or Firefox dev tools)
+ * about a specific area of programming (like localization or timezones)
+ * an area like product management / UX design
+ * how to write a clear design doc
+ * a new programming language
+
+
+
+It’s really easy to lose track of what skills you’re learning, and usually when I reflect on this I realize I learned a lot more than I thought and also notice things that I’m _not_ learning that I wish I was.
+
+### Outside of work
+
+It’s also often useful to track accomplishments outside of work, like:
+
+ * blog posts
+ * talks/panels
+ * open source work
+ * Industry recognition
+
+
+
+I think this can be a nice way to highlight how you’re thinking about your career outside of strictly what you’re doing at work.
+
+This can also include other non-career-related things you’re proud of, if that feels good to you! Some people like to keep a combined personal + work brag document.
+
+### General prompts
+
+If you’re feeling stuck for things to mention, try:
+
+ * If you were trying to convince a friend to come join your company/team, what would you tell them about your work?
+ * Did anybody tell you you did something well recently?
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/brag-documents/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: tmp.nd0Dg3RXQE#template
+[2]: https://karla.io/
+[3]: https://lethain.com/career-narratives/
+[4]: http://blog.aashni.me/2019/01/hype-yourself-youre-worth-it/
diff --git a/sources/tech/20190718 What you need to know to be a sysadmin.md b/sources/tech/20190718 What you need to know to be a sysadmin.md
index bd482f3ca4..55947b8456 100644
--- a/sources/tech/20190718 What you need to know to be a sysadmin.md
+++ b/sources/tech/20190718 What you need to know to be a sysadmin.md
@@ -1,5 +1,5 @@
[#]: collector: (lujun9972)
-[#]: translator: (WangYueScream )
+[#]: translator: ( )
[#]: reviewer: ( )
[#]: publisher: ( )
[#]: url: ( )
diff --git a/sources/tech/20190719 Buying a Linux-ready laptop.md b/sources/tech/20190719 Buying a Linux-ready laptop.md
deleted file mode 100644
index f63f9276e4..0000000000
--- a/sources/tech/20190719 Buying a Linux-ready laptop.md
+++ /dev/null
@@ -1,80 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Buying a Linux-ready laptop)
-[#]: via: (https://opensource.com/article/19/7/linux-laptop)
-[#]: author: (Ricardo Berlasso https://opensource.com/users/rgb-eshttps://opensource.com/users/greg-phttps://opensource.com/users/chrisodhttps://opensource.com/users/victorhckhttps://opensource.com/users/hankghttps://opensource.com/users/noplanman)
-
-Buying a Linux-ready laptop
-======
-Tuxedo makes it easy to buy an out-of-the-box "penguin-ready" laptop.
-![Penguin with green background][1]
-
-Recently, I bought and started using a Tuxedo Book BC1507, a Linux laptop computer. Ten years ago, if someone had told me that, by the end of the decade, I could buy top-quality, "penguin-ready" laptops from companies such as [System76][2], [Slimbook][3], and [Tuxedo][4], I probably would have laughed. Well, now I'm laughing, but with joy!
-
-Going beyond designing computers for free/libre open source software (FLOSS), all three companies recently [announced][5] they are trying to eliminate proprietary BIOS software by switching to [Coreboot][6].
-
-### Buying it
-
-Tuxedo Computers is a German company that builds Linux-ready laptops. In fact, if you want a different operating system, it costs more.
-
-Buying the computer was incredibly easy. Tuxedo offers many payment methods: not only credit cards but also PayPal and even bank transfers. Just fill out the bank transfer form on Tuxedo's web page, and the company will send you the bank coordinates.
-
-Tuxedo builds every computer on demand, and picking exactly what you want is as easy as selecting the basic model and exploring the drop-down menus to select different components. There is a lot of information on the page to guide you in the purchase.
-
-If you pick a different Linux distribution from the recommended one, Tuxedo does a "net install," so have a network cable ready to finish the installation, or you can burn your preferred image onto a USB key. I used a DVD with the openSUSE Leap 15.1 installer through an external DVD reader instead, but you get the idea.
-
-The model I chose accepts up to two disks: one SSD and the other either an SSD or a conventional hard drive. As I was already over budget, I decided to pick a conventional 1TB disk and increase the RAM to 16GB. The processor is an 8th Generation i5 with four cores. I selected a back-lit Spanish keyboard, a 1920×1080/96dpi screen, and an SD card reader—all in all, a great system.
-
-If you're fine with the default English or German keyboard, you can even ask for a penguin icon on the Meta key! I needed a Spanish keyboard, which doesn't offer this option.
-
-### Receiving and using it
-
-The perfectly packaged computer arrived in total safety to my door just six working days after the payment was registered. After unpacking the computer and unlocking the battery, I was ready to roll.
-
-![Tuxedo Book BC1507][7]
-
-The new toy on top of my (physical) desktop.
-
-The computer's design is really nice and feels solid. Even though the chassis on this model is not aluminum, it stays cool. The fan is really quiet, and the airflow goes to the back edge, not to the sides, as in many other laptops. The battery provides several hours of autonomy from an electrical outlet. An option in the BIOS called FlexiCharger stops charging the battery after it reaches a certain percentage, so you don't need to remove the battery when you work for a long time while plugged in.
-
-The keyboard is really comfortable and surprisingly quiet. Even the touchpad keys are quiet! Also, you can easily adjust the light intensity on the back-lit keyboard.
-
-Finally, it's easy to access every component in the laptop so the computer can be updated or repaired without problems. Tuxedo even sends spare screws!
-
-### Conclusion
-
-After a month of heavy use, I'm really happy with the system. I got exactly what I asked for, and everything works perfectly.
-
-Because they are usually high-end systems, Linux-included computers tend to be on the expensive side of the spectrum. If you compare the price of a Tuxedo or Slimbook computer with something with similar specifications from a more established brand, the prices are not that different. If you are after a powerful system to use with free software, don't hesitate to support these companies: What they offer is worth the price.
-
-Let's us know in the comments about your experience with Tuxedo and other "penguin-friendly" companies.
-
-* * *
-
-_This article is based on "[My new 'penguin ready' laptop: Tuxedo-Book-BC1507][8]," published on Ricardo's blog, [From Mind to Type][9]._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/7/linux-laptop
-
-作者:[Ricardo Berlasso][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/rgb-eshttps://opensource.com/users/greg-phttps://opensource.com/users/chrisodhttps://opensource.com/users/victorhckhttps://opensource.com/users/hankghttps://opensource.com/users/noplanman
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
-[2]: https://system76.com/
-[3]: https://slimbook.es/en/
-[4]: https://www.tuxedocomputers.com/
-[5]: https://www.tuxedocomputers.com/en/Infos/News/Tuxedo-Computers-stands-for-Free-Software-and-Security-.tuxedo
-[6]: https://coreboot.org/
-[7]: https://opensource.com/sites/default/files/uploads/tuxedo-600_0.jpg (Tuxedo Book BC1507)
-[8]: https://frommindtotype.wordpress.com/2019/06/17/my-new-penguin-ready-laptop-tuxedo-book-bc1507/
-[9]: https://frommindtotype.wordpress.com/
diff --git a/sources/tech/20190801 Linux permissions 101.md b/sources/tech/20190801 Linux permissions 101.md
deleted file mode 100644
index cfbc3d0a29..0000000000
--- a/sources/tech/20190801 Linux permissions 101.md
+++ /dev/null
@@ -1,346 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Linux permissions 101)
-[#]: via: (https://opensource.com/article/19/8/linux-permissions-101)
-[#]: author: (Alex Juarez https://opensource.com/users/mralexjuarezhttps://opensource.com/users/marcobravohttps://opensource.com/users/greg-p)
-
-Linux permissions 101
-======
-Knowing how to control users' access to files is a fundamental system
-administration skill.
-![Penguins][1]
-
-Understanding Linux permissions and how to control which users have access to files is a fundamental skill for systems administration.
-
-This article will cover standard Linux file systems permissions, dig further into special permissions, and wrap up with an explanation of default permissions using **umask**.
-
-### Understanding the ls command output
-
-Before we can talk about how to modify permissions, we need to know how to view them. The **ls** command with the long listing argument (**-l**) gives us a lot of information about a file.
-
-
-```
-$ ls -lAh
-total 20K
--rwxr-xr--+ 1 root root 0 Mar 4 19:39 file1
--rw-rw-rw-. 1 root root 0 Mar 4 19:39 file10
--rwxrwxr--+ 1 root root 0 Mar 4 19:39 file2
--rw-rw-rw-. 1 root root 0 Mar 4 19:39 file8
--rw-rw-rw-. 1 root root 0 Mar 4 19:39 file9
-drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir
-```
-
-To understand what this means, let's break down the output regarding the permissions into individual sections. It will be easier to reference each section individually.
-
-Take a look at each component of the final line in the output above:
-
-
-```
-`drwxrwxrwx. 2 root root 4.0K Mar 4 20:04 testdir`
-```
-
-Section 1 | Section 2 | Section 3 | Section 4 | Section 5 | Section 6 | Section 7
----|---|---|---|---|---|---
-d | rwx | rwx | rwx | . | root | root
-
-Section 1 (on the left) reveals what type of file it is.
-
-d | Directory
----|---
-- | Regular file
-l | A soft link
-
-The [info page][2] for **ls** has a full listing of the different file types.
-
-Each file has three modes of access:
-
- * the owner
- * the group
- * all others
-
-
-
-Sections 2, 3, and 4 refer to the user, group, and "other users" permissions. And each section can include a combination of **r** (read), **w** (write), and **x** (executable) permissions.
-
-Each of the permissions is also assigned a numerical value, which is important when talking about the octal representation of permissions.
-
-Permission | Octal Value
----|---
-Read | 4
-Write | 2
-Execute | 1
-
-Section 5 details any alternative access methods, such as SELinux or File Access Control List (FACL).
-
-Method | Character
----|---
-No other method | -
-SELinux | .
-FACLs | +
-Any combination of methods | +
-
-Sections 6 and 7 are the names of the owner and the group, respectively.
-
-### Using chown and chmod
-
-#### The chown command
-
-The **chown** (change ownership) command is used to change a file's user and group ownership.
-
-To change both the user and group ownership of the file **foo** to **root**, we can use these commands:
-
-
-```
-$ chown root:root foo
-$ chown root: foo
-```
-
-Running the command with the user followed by a colon (**:**) sets both the user and group ownership.
-
-To set only the user ownership of the file **foo** to the **root** user, enter:
-
-
-```
-`$ chown root foo`
-```
-
-To change only the group ownership of the file **foo**, precede the group with a colon:
-
-
-```
-`$ chown :root foo`
-```
-
-#### The chmod command
-
-The **chmod** (change mode) command controls file permissions for the owner, group, and all other users who are neither the owner nor part of the group associated with the file.
-
-The **chmod** command can set permissions in both octal (e.g., 755, 644, etc.) and symbolic (e.g., u+rwx, g-rwx, o=rw) formatting.
-
-Octal notation assigns 4 "points" to **read**, 2 to **write**, and 1 to **execute**. If we want to assign the user **read** permissions, we assign 4 to the first slot, but if we want to add **write** permissions, we must add 2. If we want to add **execute**, then we add 1. We do this for each permission type: owner, group, and others.
-
-For example, if we want to assign **read**, **write**, and **execute** to the owner of the file, but only **read** and **execute** to group members and all other users, we would use 755 in octal formatting. That's all permission bits for the owner (4+2+1), but only a 4 and 1 for the group and others (4+1).
-
-> The breakdown for that is: 4+2+1=7; 4+1=5; and 4+1=5.
-
-If we wanted to assign **read** and **write** to the owner of the file but only **read** to members of the group and all other users, we could use **chmod** as follows:
-
-
-```
-`$ chmod 644 foo_file`
-```
-
-In the examples below, we use symbolic notation in different groupings. Note the letters **u**, **g**, and **o** represent **user**, **group**, and **other**. We use **u**, **g**, and **o** in conjunction with **+**, **-**, or **=** to add, remove, or set permission bits.
-
-To add the **execute** bit to the ownership permission set:
-
-
-```
-`$ chmod u+x foo_file`
-```
-
-To remove **read**, **write**, and **execute** from members of the group:
-
-
-```
-`$ chmod g-rwx foo_file`
-```
-
-To set the ownership for all other users to **read** and **write**:
-
-
-```
-`$ chmod o=rw`
-```
-
-### The special bits: Set UID, set GID, and sticky bits
-
-In addition to the standard permissions, there are a few special permission bits that have some useful benefits.
-
-#### Set user ID (suid)
-
-When **suid** is set on a file, an operation executes as the owner of the file, not the user running the file. A [good example][3] of this is the **passwd** command. It needs the **suid** bit to be set so that changing a password runs with root permissions.
-
-
-```
-$ ls -l /bin/passwd
--rwsr-xr-x. 1 root root 27832 Jun 10 2014 /bin/passwd
-```
-
-An example of setting the **suid** bit would be:
-
-
-```
-`$ chmod u+s /bin/foo_file_name`
-```
-
-#### Set group ID (sgid)
-
-The **sgid** bit is similar to the **suid** bit in the sense that the operations are done under the group ownership of the directory instead of the user running the command.
-
-An example of using **sgid** would be if multiple users are working out of the same directory, and every file created in the directory needs to have the same group permissions. The example below creates a directory called **collab_dir**, sets the **sgid** bit, and changes the group ownership to **webdev**.
-
-
-```
-$ mkdir collab_dir
-$ chmod g+s collab_dir
-$ chown :webdev collab_dir
-```
-
-Now any file created in the directory will have the group ownership of **webdev** instead of the user who created the file.
-
-
-```
-$ cd collab_dir
-$ touch file-sgid
-$ ls -lah file-sgid
--rw-r--r--. 1 root webdev 0 Jun 12 06:04 file-sgid
-```
-
-#### The "sticky" bit
-
-The sticky bit denotes that only the owner of a file can delete the file, even if group permissions would otherwise allow it. This setting usually makes the most sense on a common or collaborative directory such as **/tmp**. In the example below, the **t** in the **execute** column of the **all others** permission set indicates that the sticky bit has been applied.
-
-
-```
-$ ls -ld /tmp
-drwxrwxrwt. 8 root root 4096 Jun 12 06:07 /tmp/
-```
-
-Keep in mind this does not prevent somebody from editing the file; it just keeps them from deleting the contents of a directory.
-
-We set the sticky bit with:
-
-
-```
-`$ chmod o+t foo_dir`
-```
-
-On your own, try setting the sticky bit on a directory and give it full group permissions so that multiple users can read, write and execute on the directory because they are in the same group.
-
-From there, create files as each user and then try to delete them as the other.
-
-If everything is configured correctly, one user should not be able to delete users from the other user.
-
-Note that each of these bits can also be set in octal format with SUID=4, SGID=2, and Sticky=1.
-
-
-```
-$ chmod 4744
-$ chmod 2644
-$ chmod 1755
-```
-
-#### Uppercase or lowercase?
-
-If you are setting the special bits and see an uppercase **S** or **T** instead of lowercase (as we've seen until this point), it is because the underlying execute bit is not present. To demonstrate, the following example creates a file with the sticky bit set. We can then add/remove the execute bit to demonstrate the case change.
-
-
-```
-$ touch file cap-ST-demo
-$ chmod 1755 cap-ST-demo
-$ ls -l cap-ST-demo
--rwxr-xr-t. 1 root root 0 Jun 12 06:16 cap-ST-demo
-
-$ chmod o-x cap-X-demo
-$ ls -l cap-X-demo
--rwxr-xr-T. 1 root root 0 Jun 12 06:16 cap-ST-demo
-```
-
-#### Setting the execute bit conditionally
-
-To this point, we've set the **execute** bit using a lowercase **x**, which sets it without asking any questions. We have another option: using an uppercase **X** instead of lowercase will set the **execute** bit only if it is already present somewhere in the permission group. This can be a difficult concept to explain, but the demo below will help illustrate it. Notice here that after trying to add the **execute** bit to the group privileges, it is not applied.
-
-
-```
-$ touch cap-X-file
-$ ls -l cap-X-file
--rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
-$ chmod g+X cap-X-file
-$ ls -l cap-X-file
--rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
-```
-
-In this similar example, we add the execute bit first to the group permissions using the lowercase **x** and then use the uppercase **X** to add permissions for all other users. This time, the uppercase **X** sets the permissions.
-
-
-```
-$ touch cap-X-file
-$ ls -l cap-X-file
--rw-r--r--. 1 root root 0 Jun 12 06:31 cap-X-file
-$ chmod g+x cap-X-file
-$ ls -l cap-X-file
--rw-r-xr--. 1 root root 0 Jun 12 06:31 cap-X-file
-$ chmod g+x cap-X-file
-$ chmod o+X cap-X-file
-ls -l cap-X-file
--rw-r-xr-x. 1 root root 0 Jun 12 06:31 cap-X-file
-```
-
-### Understanding umask
-
-The **umask** masks (or "blocks off") bits from the default permission set in order to define permissions for a file or directory. For example, a 2 in the **umask** output indicates it is blocking the **write** bit from a file, at least by default.
-
-Using the **umask** command without any arguments allows us to see the current **umask** setting. There are four columns: the first is reserved for the special suid, sgid, or sticky bit, and the remaining three represent the owner, group, and other permissions.
-
-
-```
-$ umask
-0022
-```
-
-To understand what this means, we can execute **umask** with a **-S** (as shown below) to get the result of masking the bits. For instance, because of the **2** value in the third column, the **write** bit is masked off from the group and other sections; only **read** and **execute** can be assigned for those.
-
-
-```
-$ umask -S
-u=rwx,g=rx,o=rx
-```
-
-To see what the default permission set is for files and directories, let's set our **umask** to all zeros. This means that we are not masking off any bits when we create a file.
-
-
-```
-$ umask 000
-$ umask -S
-u=rwx,g=rwx,o=rwx
-
-$ touch file-umask-000
-$ ls -l file-umask-000
--rw-rw-rw-. 1 root root 0 Jul 17 22:03 file-umask-000
-```
-
-Now when we create a file, we see the default permissions are **read** (4) and **write** (2) for all sections, which would equate to 666 in octal representation.
-
-We can do the same for a directory and see its default permissions are 777. We need the **execute** bit on directories so we can traverse through them.
-
-
-```
-$ mkdir dir-umask-000
-$ ls -ld dir-umask-000
-drwxrwxrwx. 2 root root 4096 Jul 17 22:03 dir-umask-000/
-```
-
-### Conclusion
-
-There are many other ways an administrator can control access to files on a system. These permissions are basic to Linux, and we can build upon these fundamental aspects. If your work takes you into FACLs or SELinux, you will see that they also build upon these first rules of file access.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/linux-permissions-101
-
-作者:[Alex Juarez][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mralexjuarezhttps://opensource.com/users/marcobravohttps://opensource.com/users/greg-p
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux-penguins.png?itok=yKOpaJM_ (Penguins)
-[2]: https://www.gnu.org/software/texinfo/manual/info-stnd/info-stnd.html
-[3]: https://www.theurbanpenguin.com/using-a-simple-c-program-to-explain-the-suid-permission/
diff --git a/sources/tech/20190804 Learn how to Install LXD - LXC Containers in Ubuntu.md b/sources/tech/20190804 Learn how to Install LXD - LXC Containers in Ubuntu.md
new file mode 100644
index 0000000000..b4e1a2667b
--- /dev/null
+++ b/sources/tech/20190804 Learn how to Install LXD - LXC Containers in Ubuntu.md
@@ -0,0 +1,508 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Learn how to Install LXD / LXC Containers in Ubuntu)
+[#]: via: (https://www.linuxtechi.com/install-lxd-lxc-containers-from-scratch/)
+[#]: author: (Shashidhar Soppin https://www.linuxtechi.com/author/shashidhar/)
+
+Learn how to Install LXD / LXC Containers in Ubuntu
+======
+
+Let me start by explaining what a container is, it is normal process on the host machine (any Linux based m/c) with following characteristics,
+
+ * It feels like a VM, but it is not.
+ * Uses the host Kernel.
+ * Cannot boot a different Operating System.
+ * Can’t have its own modules.
+ * Does not need “**init”** as PID (Process id) as “1”
+
+
+
+[![Learn-LXD-LXC-Containers][1]][2]
+
+LXC (**LinuX Containers**) technology was developed long ago and is an Operating System level virtualization technology. This was existing from the days of BSD and System-V Release 4 (Popular Unix flavors during 1980-90’s). But until recently, no one new how much it can help us in saving in terms of resource utilization. Because of this technology change, all enterprises are moving towards adoption of virtualization (be it Cloud or be it Docker containers). This also helped in better management of **OpEX(Operational expenditures)** and **CaPEX(Captial expenditures)** costs. Using this technique, we can create and run multiple and isolated Linux virtual environments on a single Linux host machine (called control host). LXC mainly uses Linux’s cgroups and namespaces functionalities, which were introduced in version 2.6.24(kernel version) onwards. In parallel many advancements in hypervisors happened like that of **KVM**, **QEMU**, **Hyper-V**, **ESXi** etc. Especially KVM (Kernel Virtual Machine) which is core of Linux OS, helped in this kind of advancement.
+
+Difference between LXC and LXD is that LXC is the original and older way to manage containers but it is still supported, all commands of LXC starts with “**lxc-“** like “**lxc-create**” & “**lxc-info**“, whereas LXD is a new way to manage containers and lxc command is used for all containers operations and management.
+
+All of us know that “**Docker**” utilizes LXC and was developed using Go language, cgroups, namespaces and finally the Linux Kernel itself. Complete Docker has been built and developed using LXC as the basic foundation block. Docker is completely dependent on underlying infrastructure & hardware and using the Operating System as the medium. However, Docker is a portable and easily deployable container engine; all its dependencies are run using a virtual container on most of the Linux based servers. Groups, and Namespaces are the building block concepts for both LXC and Docker containers. Following are the brief description of these concepts.
+
+### C Groups (Control Groups)
+
+With Cgroups each resource will have its own hierarchy.
+
+ * CPU, Memory, I/O etc will have their own control group hierarchy. Following are various characterics of Cgroups,
+ * Each process is in each node
+ * Each hierarchy starts with one node
+ * Initially all processes start at the root node. Therefore “each node” is equivalent to “group of processes”.
+ * Hierarchies are independent, ex: CPU, Block I/O, memory etc
+
+
+
+As explained earlier there are various Cgroup types as listed below,
+
+1) **Memory Cgroups**
+
+a) Keeps track of pages used by each group.
+
+b) File read/write/mmap from block devices
+
+c) Anonymous memory(stack, heap etc)
+
+d) Each memory page is charged to a group
+
+e) Pages can be shared across multiple groups
+
+2) **CPU Cgroups**
+
+a) Track users/system cpu time
+
+b) Track usage per CPU
+
+c) Allows set to weights
+
+d) Can’t set cpu limits
+
+3) **Block IO Cgroup**
+
+a) Keep track of read/write(I/O’s)
+
+b) Set throttle (limits) for each group (per block device)
+
+c) Set real weights for each group (per block device)
+
+4) **Devices Cgroup**
+
+a) Controls what the group can do on device nodes
+
+b) Permission include /read/write/mknode
+
+5) **Freezer Cgroup**
+
+a) Allow to freeze/thaw a group of processes
+
+b) Similar to SIGSTOP/SIGCONT
+
+c) Cannot be detected by processes
+
+### NameSpaces
+
+Namespaces provide processes with their own system view. Each process is in name space of each type.
+
+There are multiple namespaces like,
+
+ * PID – Process within a PID name space only see processes in the same PID name space
+ * Net – Processes within a given network namespace get their own private network stack.
+ * Mnt – Processes can have their own “root” and private “mount” points.
+ * Uts – Have container its own hostname
+ * IPC – Allows processes to have own IPC semaphores, IPC message queues and shared memory
+ * USR – Allows to map UID/GID
+
+
+
+### Installation and configuration of LXD containers
+
+To have LXD installed on Ubuntu system (18.04 LTS) , we can start with LXD installation using below apt command
+
+```
+root@linuxtechi:~$ sudo apt update
+root@linuxtechi:~$ sudo apt install lxd -y
+```
+
+Once the LXD is installed, we can start with its initialization as below, (most of the times use the default options)
+
+```
+root@linuxtechi:~$ sudo lxd init
+```
+
+![lxc-init-ubuntu-system][1]
+
+Once the LXD is initialized successfully, run the below command to verify information
+
+```
+root@linuxtechi:~$ sudo lxc info | more
+```
+
+![lxc-info-command][1]
+
+Use below command to list if there is any container is downloaded on our host,
+
+```
+root@linuxtechi:~$ sudo lxc image list
++-------+-------------+--------+-------------+------+------+-------------+
+| ALIAS | FINGERPRINT | PUBLIC | DESCRIPTION | ARCH | SIZE | UPLOAD DATE |
++-------+-------------+--------+-------------+------+------+-------------+
+root@linuxtechi:~$
+```
+
+Quick and easy way to start the first container on Ubuntu 18.04 (or any supported Ubuntu flavor) use the following command. The container name we have provided is “shashi”
+
+```
+root@linuxtechi:~$ sudo lxc launch ubuntu:18.04 shashi
+Creating shashi
+Starting shashi
+root@linuxtechi:~$
+```
+
+To list out what are the LXC containers that are in the system
+
+```
+root@linuxtechi:~$ sudo lxc list
++--------+---------+-----------------------+-----------------------------------------------+------------+-----------+
+| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
++--------+---------+-----------------------+-----------------------------------------------+------------+-----------+
+| shashi | RUNNING | 10.122.140.140 (eth0) | fd42:49da:7c44:cebe:216:3eff:fea4:ea06 (eth0) | PERSISTENT | 0 |
++--------+---------+-----------------------+-----------------------------------------------+------------+-----------+
+root@linuxtechi:~$
+```
+
+Other Container management commands for LXD are listed below :
+
+**Note:** In below examples, shashi is my container name
+
+**How to take bash shell of your LXD Container?**
+
+```
+root@linuxtechi:~$ sudo lxc exec shashi bash
+root@linuxtechi:~#
+```
+
+**How Stop, Start & Restart LXD Container?**
+
+```
+root@linuxtechi:~$ sudo lxc stop shashi
+root@linuxtechi:~$ sudo lxc list
++--------+---------+------+------+------------+-----------+
+| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
++--------+---------+------+------+------------+-----------+
+| shashi | STOPPED | | | PERSISTENT | 0 |
++--------+---------+------+------+------------+-----------+
+root@linuxtechi:~$
+root@linuxtechi:~$ sudo lxc start shashi
+root@linuxtechi:~$ sudo lxc restart shashi
+```
+
+**How to delete a LXD Container?**
+
+```
+root@linuxtechi:~$ sudo lxc stop shashi
+root@linuxtechi:~$ sudo lxc delete shashi
+root@linuxtechi:~$ sudo lxc list
++------+-------+------+------+------+-----------+
+| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
++------+-------+------+------+------+-----------+
+root@linuxtechi:~$
+```
+
+**How to take snapshot of LXD container and then restore it?**
+
+Let’s assume we have pkumar container based on centos7 image, so to take the snapshot use the following,
+
+```
+root@linuxtechi:~$ sudo lxc snapshot pkumar pkumar_snap0
+```
+
+Use below command to verify the snapshot
+
+```
+root@linuxtechi:~$ sudo lxc info pkumar | grep -i Snapshots -A2
+Snapshots:
+ pkumar_snap0 (taken at 2019/08/02 19:39 UTC) (stateless)
+root@linuxtechi:~$
+```
+
+Use below command to restore the LXD container from their snapshot
+
+Syntax:
+
+$ lxc restore {container_name} {snapshot_name}
+
+```
+root@linuxtechi:~$ sudo lxc restore pkumar pkumar_snap0
+root@linuxtechi:~$
+```
+
+**How to delete LXD container snapshot?**
+
+```
+$ sudo lxc delete
+```
+
+**How to set Memory, CPU and Disk Limit on LXD container?**
+
+Syntax to set Memory limit:
+
+# lxc config set <container_name> limits.memory <Memory_Size>KB/MB/GB
+
+Syntax to set CPU limit:
+
+# lxc config set <container_name> limits.cpu {Number_of_CPUs}
+
+Syntax to Set Disk limit:
+
+# lxc config device set <container_name> root size <Size_MB/GB>
+
+**Note:** To set a disk limit (it requires btrfs or ZFS filesystem)
+
+Let’s set limit on Memory and CPU on container shashi using the following commands,
+
+```
+root@linuxtechi:~$ sudo lxc config set shashi limits.memory 256MB
+root@linuxtechi:~$ sudo lxc config set shashi limits.cpu 2
+```
+
+### Install and configure LXC container (commands and operations)
+
+To install lxc on your ubuntu system, use the beneath apt command,
+
+```
+root@linuxtechi:~$ sudo apt install lxc -y
+```
+
+In earlier version of LXC, the command “**lxc-clone**” was used and later it was deprecated. Now, “**lxc-copy**” command is widely used for cloning operation.
+
+**Note:** To get “lxc-copy” command working, use the following installation steps,
+
+```
+root@linuxtechi:~$ sudo apt install lxc1 -y
+```
+
+**Creating Linux Containers using the templates**
+
+LXC provides ready-made templates for easy installation of Linux containers. Templates are usually found in the directory path /usr/share/lxc/templates, but in fresh installation we will not get the templates, so to download the templates in your local system , run the beneath command,
+
+```
+root@linuxtechi:~$ sudo apt install lxc-templates -y
+```
+
+Once the lxc-templates are installed successfully then templates will be available,
+
+```
+root@linuxtechi:~$ sudo ls /usr/share/lxc/templates/
+lxc-alpine lxc-centos lxc-fedora lxc-oci lxc-plamo lxc-sparclinux lxc-voidlinux
+lxc-altlinux lxc-cirros lxc-fedora-legacy lxc-openmandriva lxc-pld lxc-sshd
+lxc-archlinux lxc-debian lxc-gentoo lxc-opensuse lxc-sabayon lxc-ubuntu
+lxc-busybox lxc-download lxc-local lxc-oracle lxc-slackware lxc-ubuntu-cloud
+root@linuxtechi:~$
+```
+
+Let’s Launch a container using template,
+
+Syntax: lxc-create -n <container_name> lxc -t <template_name>
+
+```
+root@linuxtechi:~$ sudo lxc-create -n shashi_lxc -t ubuntu
+………………………
+invoke-rc.d: could not determine current runlevel
+invoke-rc.d: policy-rc.d denied execution of start.
+Current default time zone: 'Etc/UTC'
+Local time is now: Fri Aug 2 11:46:42 UTC 2019.
+Universal Time is now: Fri Aug 2 11:46:42 UTC 2019.
+
+##
+# The default user is 'ubuntu' with password 'ubuntu'!
+# Use the 'sudo' command to run tasks as root in the container.
+##
+………………………………………
+root@linuxtechi:~$
+```
+
+Once the complete template is created, we can login into this console using the following steps
+
+```
+root@linuxtechi:~$ sudo lxc-start -n shashi_lxc -d
+root@linuxtechi:~$ sudo lxc-console -n shashi_lxc
+
+Connected to tty 1
+Type to exit the console, to enter Ctrl+a itself
+
+Ubuntu 18.04.2 LTS shashi_lxc pts/0
+
+shashi_lxc login: ubuntu
+Password:
+Last login: Fri Aug 2 12:00:35 UTC 2019 on pts/0
+Welcome to Ubuntu 18.04.2 LTS (GNU/Linux 4.15.0-20-generic x86_64)
+To run a command as administrator (user "root"), use "sudo ".
+See "man sudo_root" for details.
+
+root@linuxtechi_lxc:~$ free -h
+ total used free shared buff/cache available
+Mem: 3.9G 23M 3.8G 112K 8.7M 3.8G
+Swap: 1.9G 780K 1.9G
+root@linuxtechi_lxc:~$ grep -c processor /proc/cpuinfo
+1
+root@linuxtechi_lxc:~$ df -h /
+Filesystem Size Used Avail Use% Mounted on
+/dev/sda1 40G 7.4G 31G 20% /
+root@linuxtechi_lxc:~$
+```
+
+Now logout or exit from the container and go back to host machine login window. With the lxc-ls command we can see that shashi-lxc container is created.
+
+```
+root@linuxtechi:~$ sudo lxc-ls
+shashi_lxc
+root@linuxtechi:~$
+```
+
+“**lxc-ls -f**” command provides details with ip address of the container and the same is as below,
+
+```
+root@linuxtechi:~$ sudo lxc-ls -f
+NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
+shashi_lxc RUNNING 0 - 10.0.3.190 - false
+root@linuxtechi:~$
+```
+
+“**lxc-info -n <container_name>**” command provides with all the required details along with State, ip address etc.
+
+```
+root@linuxtechi:~$ sudo lxc-info -n shashi_lxc
+Name: shashi_lxc
+State: RUNNING
+PID: 6732
+IP: 10.0.3.190
+CPU use: 2.38 seconds
+BlkIO use: 240.00 KiB
+Memory use: 27.75 MiB
+KMem use: 5.04 MiB
+Link: vethQ7BVGU
+ TX bytes: 2.01 KiB
+ RX bytes: 9.52 KiB
+ Total bytes: 11.53 KiB
+root@linuxtechi:~$
+```
+
+**How to Start, Stop, Restart and Delete LXC containers**
+
+```
+$ lxc-start -n
+$ lxc-stop -n
+$ lxc-destroy -n
+```
+
+**LXC Cloning operation**
+
+Now the main cloning operation to be performed on the LXC container. The following steps are followed
+
+As described earlier LXC offers a feature of cloning a container from the existing container, by running the following command to clone an existing “shashi_lxc” container to a new container “shashi_lxc_clone”.
+
+**Note:** We have to make sure that before starting the cloning operation, first we have to stop the existing container using the “**lxc-stop**” command.
+
+```
+root@linuxtechi:~$ sudo lxc-stop -n shashi_lxc
+root@linuxtechi:~$ sudo lxc-copy -n shashi_lxc -N shashi_lxc_clone
+root@linuxtechi:~$ sudo lxc-ls
+shashi_lxc shashi_lxc_clone
+root@linuxtechi:~$
+```
+
+Now start the cloned container
+
+```
+root@linuxtechi:~$ sudo lxc-start -n shashi_lxc_clone
+root@linuxtechi:~$ sudo lxc-ls -f
+NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
+shashi_lxc STOPPED 0 - - - false
+shashi_lxc_clone RUNNING 0 - 10.0.3.201 - false
+root@linuxtechi:~$
+```
+
+With the above set of commands, cloning operation is done and the new clone “shashi_lxc_clone” got created. We can login into this lxc container console with below steps,
+
+```
+root@linuxtechi:~$ sudo lxc-console -n shashi_lxc_clone
+
+Connected to tty 1
+Type to exit the console, to enter Ctrl+a itself
+Ubuntu 18.04.2 LTS shashi_lxc pts/0
+
+shashi_lxc login:
+```
+
+**LXC Network configuration and commands**
+
+We can attach to the newly created container, but to remotely login into this container using SSH or any other means, we have to do some minimal configuration changes as explained below,
+
+```
+root@linuxtechi:~$ sudo lxc-attach -n shashi_lxc_clone
+root@linuxtechi_lxc:/#
+root@linuxtechi_lxc:/# useradd -m shashi
+root@linuxtechi_lxc:/# passwd shashi
+Enter new UNIX password:
+Retype new UNIX password:
+passwd: password updated successfully
+root@linuxtechi_lxc:/#
+```
+
+First install the ssh server using the following command so that smooth “ssh” connect can be established.
+
+```
+root@linuxtechi_lxc:/# apt install openssh-server -y
+```
+
+Now get the IP address of the existing lxc container using the following command,
+
+```
+root@linuxtechi_lxc:/# ip addr show eth0|grep inet
+ inet 10.0.3.201/24 brd 10.0.3.255 scope global dynamic eth0
+ inet6 fe80::216:3eff:fe82:e251/64 scope link
+root@linuxtechi_lxc:/#
+```
+
+From the host machine with a new console window, use the following command to connect to this container over ssh
+
+```
+root@linuxtechi:~$ ssh 10.0.3.201
+root@linuxtechi's password:
+$
+```
+
+Now, we have logged in a container using ssh session.
+
+**LXC process related commands**
+
+```
+root@linuxtechi:~$ ps aux|grep lxc|grep -v grep
+```
+
+![lxc-process-ubuntu-system][1]
+
+**LXC snapshot operation**
+
+Snapshotting is one of the main operations which will help in taking point in time snapshot of the lxc container images. These same snapshot images can be used later for further use.
+
+```
+root@linuxtechi:~$ sudo lxc-stop -n shashi_lxc
+root@linuxtechi:~$ sudo lxc-snapshot -n shashi_lxc
+root@linuxtechi:~$
+```
+
+The snapshot path can be located using the following command.
+
+```
+root@linuxtechi:~$ sudo lxc-snapshot -L -n shashi_lxc
+snap0 (/var/lib/lxc/shashi_lxc/snaps) 2019:08:02 20:28:49
+root@linuxtechi:~$
+```
+
+**Conclusion:**
+
+LXC, LinuX containers is one of the early container technologies. Understanding the concepts and learning about LXC will help in deeper understanding of any other containers like Docker Containers. This article has provided deeper insights on Cgroup and Namespaces which are also very much required concepts for better understanding of Containers and like. Many of the LXC operations like cloning, snapshotting, network operation etc are covered with command line examples.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/install-lxd-lxc-containers-from-scratch/
+
+作者:[Shashidhar Soppin][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linuxtechi.com/author/shashidhar/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Learn-LXD-LXC-Containers.jpg
diff --git a/sources/tech/20190805 How to Install and Configure PostgreSQL on Ubuntu.md b/sources/tech/20190805 How to Install and Configure PostgreSQL on Ubuntu.md
deleted file mode 100644
index 8b9677ba83..0000000000
--- a/sources/tech/20190805 How to Install and Configure PostgreSQL on Ubuntu.md
+++ /dev/null
@@ -1,267 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Install and Configure PostgreSQL on Ubuntu)
-[#]: via: (https://itsfoss.com/install-postgresql-ubuntu/)
-[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
-
-How to Install and Configure PostgreSQL on Ubuntu
-======
-
-_**In this tutorial, you’ll learn how to install and use the open source database PostgreSQL on Ubuntu Linux.**_
-
-[PostgreSQL][1] (or Postgres) is a powerful, free and open-source relational database management system ([RDBMS][2]) that has a strong reputation for reliability, feature robustness, and performance. It is designed to handle various tasks, of any size. It is cross-platform, and the default database for [macOS Server][3].
-
-PostgreSQL might just be the right tool for you if you’re a fan of a simple to use SQL database manager. It supports SQL standards and offers additional features, while also being heavily extendable by the user as the user can add data types, functions, and do many more things.
-
-Earlier I discussed [installing MySQL on Ubuntu][4]. In this article, I’ll show you how to install and configure PostgreSQL, so that you are ready to use it to suit whatever your needs may be.
-
-![][5]
-
-### Installing PostgreSQL on Ubuntu
-
-PostgreSQL is available in Ubuntu main repository. However, like many other development tools, it may not be the latest version.
-
-First check the PostgreSQL version available in [Ubuntu repositories][6] using this [apt command][7] in the terminal:
-
-```
-apt show postgresql
-```
-
-In my Ubuntu 18.04, it showed that the available version of PostgreSQL is version 10 (10+190 means version 10) whereas PostgreSQL version 11 is already released.
-
-```
-Package: postgresql
-Version: 10+190
-Priority: optional
-Section: database
-Source: postgresql-common (190)
-Origin: Ubuntu
-```
-
-Based on this information, you can make your mind whether you want to install the version available from Ubuntu or you want to get the latest released version of PostgreSQL.
-
-I’ll show both methods to you.
-
-#### Method 1: Install PostgreSQL from Ubuntu repositories
-
-In the terminal, use the following command to install PostgreSQL
-
-```
-sudo apt update
-sudo apt install postgresql postgresql-contrib
-```
-
-Enter your password when asked and you should have it installed in a few seconds/minutes depending on your internet speed. Speaking of that, feel free to check various [network bandwidth in Ubuntu][8].
-
-What is postgresql-contrib?
-
-The postgresql-contrib or the contrib package consists some additional utilities and functionalities that are not part of the core PostgreSQL package. In most cases, it’s good to have the contrib package installed along with the PostgreSQL core.
-
-[][9]
-
-Suggested read Fix gvfsd-smb-browse Taking 100% CPU In Ubuntu 16.04
-
-#### Method 2: Installing the latest version 11 of PostgreSQL in Ubuntu
-
-To install PostgreSQL 11, you need to add the official PostgreSQL repository in your sources.list, add its certificate and then install it from there.
-
-Don’t worry, it’s not complicated. Just follow these steps.
-
-Add the GPG key first:
-
-```
-wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
-```
-
-Now add the repository with the below command. If you are using Linux Mint, you’ll have to manually replace the `lsb_release -cs` the Ubuntu version your Mint release is based on.
-
-```
-sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
-```
-
-Everything is ready now. Install PostgreSQL with the following commands:
-
-```
-sudo apt update
-sudo apt install postgresql postgresql-contrib
-```
-
-PostgreSQL GUI application
-
-You may also install a GUI application (pgAdmin) for managing PostgreSQL databases:
-
-_sudo apt install pgadmin4_
-
-### Configuring PostgreSQL
-
-You can check if **PostgreSQL** is running by executing:
-
-```
-service postgresql status
-```
-
-Via the **service** command you can also **start**, **stop** or **restart** **postgresql**. Typing in **service postgresql** and pressing **Enter** should output all options. Now, onto the users.
-
-By default, PostgreSQL creates a special user postgres that has all rights. To actually use PostgreSQL, you must first log in to that account:
-
-```
-sudo su postgres
-```
-
-Your prompt should change to something similar to:
-
-```
-[email protected]:/home/ubuntu$
-```
-
-Now, run the **PostgreSQL Shell** with the utility **psql**:
-
-```
-psql
-```
-
-You should be prompted with:
-
-```
-postgress=#
-```
-
-You can type in **\q** to **quit** and **\?** for **help**.
-
-To see all existing tables, enter:
-
-```
-\l
-```
-
-The output will look similar to this (Hit the key **q** to exit this view):
-
-![PostgreSQL Tables][10]
-
-With **\du** you can display the **PostgreSQL users**:
-
-![PostgreSQLUsers][11]
-
-You can change the password of any user (including **postgres**) with:
-
-```
-ALTER USER postgres WITH PASSWORD 'my_password';
-```
-
-**Note:** _Replace **postgres** with the name of the user and **my_password** with the wanted password._ Also, don’t forget the **;** (**semicolumn**) after every statement.
-
-It is recommended that you create another user (it is bad practice to use the default **postgres** user). To do so, use the command:
-
-```
-CREATE USER my_user WITH PASSWORD 'my_password';
-```
-
-If you run **\du**, you will see, however, that **my_user** has no attributes yet. Let’s add **Superuser** to it:
-
-```
-ALTER USER my_user WITH SUPERUSER;
-```
-
-You can **remove users** with:
-
-```
-DROP USER my_user;
-```
-
-To **log in** as another user, quit the prompt (**\q**) and then use the command:
-
-```
-psql -U my_user
-```
-
-You can connect directly to a database with the **-d** flag:
-
-```
-psql -U my_user -d my_db
-```
-
-You should call the PostgreSQL user the same as another existing user. For example, my use is **ubuntu**. To log in, from the terminal I use:
-
-```
-psql -U ubuntu -d postgres
-```
-
-**Note:** _You must specify a database (by default it will try connecting you to the database named the same as the user you are logged in as)._
-
-If you have a the error:
-
-```
-psql: FATAL: Peer authentication failed for user "my_user"
-```
-
-Make sure you are logging as the correct user and edit **/etc/postgresql/11/main/pg_hba.conf** with administrator rights:
-
-```
-sudo vim /etc/postgresql/11/main/pg_hba.conf
-```
-
-**Note:** _Replace **11** with your version (e.g. **10**)._
-
-Here, replace the line:
-
-```
-local all postgres peer
-```
-
-With:
-
-```
-local all postgres md5
-```
-
-Then restart **PostgreSQL**:
-
-```
-sudo service postgresql restart
-```
-
-Using **PostgreSQL** is the same as using any other **SQL** type database. I won’t go into the specific commands, since this article is about getting you started with a working setup. However, here is a [very useful gist][12] to reference! Also, the man page (**man psql**) and the [documentation][13] are very helpful.
-
-[][14]
-
-Suggested read [How To] Share And Sync Any Folder With Dropbox in Ubuntu
-
-**Wrapping Up**
-
-Reading this article has hopefully guided you through the process of installing and preparing PostgreSQL on an Ubuntu system. If you are new to SQL, you should read this article to know the [basic SQL commands][15]:
-
-[Basic SQL Commands][15]
-
-If you have any issues or questions, please feel free to ask in the comment section.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/install-postgresql-ubuntu/
-
-作者:[Sergiu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/sergiu/
-[b]: https://github.com/lujun9972
-[1]: https://www.postgresql.org/
-[2]: https://www.codecademy.com/articles/what-is-rdbms-sql
-[3]: https://www.apple.com/in/macos/server/
-[4]: https://itsfoss.com/install-mysql-ubuntu/
-[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-postgresql-ubuntu.png?resize=800%2C450&ssl=1
-[6]: https://itsfoss.com/ubuntu-repositories/
-[7]: https://itsfoss.com/apt-command-guide/
-[8]: https://itsfoss.com/network-speed-monitor-linux/
-[9]: https://itsfoss.com/fix-gvfsd-smb-high-cpu-ubuntu/
-[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/postgresql_tables.png?fit=800%2C303&ssl=1
-[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/postgresql_users.png?fit=800%2C244&ssl=1
-[12]: https://gist.github.com/Kartones/dd3ff5ec5ea238d4c546
-[13]: https://www.postgresql.org/docs/manuals/
-[14]: https://itsfoss.com/sync-any-folder-with-dropbox/
-[15]: https://itsfoss.com/basic-sql-commands/
diff --git a/sources/tech/20190809 Mutation testing is the evolution of TDD.md b/sources/tech/20190809 Mutation testing is the evolution of TDD.md
deleted file mode 100644
index 766d2a4285..0000000000
--- a/sources/tech/20190809 Mutation testing is the evolution of TDD.md
+++ /dev/null
@@ -1,285 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Mutation testing is the evolution of TDD)
-[#]: via: (https://opensource.com/article/19/8/mutation-testing-evolution-tdd)
-[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
-
-Mutation testing is the evolution of TDD
-======
-Since test-driven development is modeled on how nature works, mutation
-testing is the natural next step in the evolution of DevOps.
-![Ants and a leaf making the word "open"][1]
-
-In "[Failure is a feature in blameless DevOps][2]," I discussed the central role of failure in delivering quality by soliciting feedback. This is the failure agile DevOps teams rely on to guide them and drive development. [Test-driven development (TDD)][3] is the _[conditio sine qua non][4]_ of any agile DevOps value stream delivery. Failure-centric TDD methodology only works if it is paired with measurable tests.
-
-TDD methodology is modeled on how nature works and how nature produces winners and losers in the evolutionary game.
-
-### Natural selection
-
-![Charles Darwin][5]
-
-In 1859, [Charles Darwin][6] proposed the theory of evolution in his book _[On the Origin of Species][7]_. Darwin's thesis was that natural variability is caused by the combination of spontaneous mutations in individual organisms and environmental pressures. These pressures eliminate less-adapted organisms while favoring other, more fit organisms. Each and every living being mutates its chromosomes, and those spontaneous mutations are carried to the next generation (the offspring). The newly emerged variability is then tested under natural selection—the environmental pressures that exist due to the variability of environmental conditions.
-
-This simplified diagram illustrates the process of adjusting to environmental conditions.
-
-![Environmental pressures on fish][8]
-
-Fig. 1. Different environmental pressures result in different outcomes governed by natural selection. Image screenshot from a [video by Richard Dawkins][9].
-
-This illustration shows a school of fish in their natural habitat. The habitat varies (darker or lighter gravel at the bottom of the sea or riverbed), as does each fish (darker or lighter body patterns and colors).
-
-It also shows two situations (i.e., two variations of the environmental pressure):
-
- 1. The predator is present
- 2. The predator is absent
-
-
-
-In the first situation, fish that are easier to spot against the gravel shade are at higher risk of being picked off by predators. When the gravel is darker, the lighter portion of the fish population is thinned out. And vice versa—when the gravel is a lighter shade, the darker portion of the fish population suffers the thinning out scenario.
-
-In the second situation, fish are sufficiently relaxed to engage in mating. In the absence of predators and in the presence of the mating ritual, the opposite results can be expected: The fish that stand out against the background have a better chance of being picked for mating and transferring their characteristics to offspring.
-
-### Selection criteria
-
-When selecting among variability, the process is never arbitrary, capricious, whimsical, nor random. The decisive factor is always measurable. That decisive factor is usually called a _test_ or a _goal_.
-
-A simple mathematical example can illustrate this process of decision making. (Only in this case it won't be governed by natural selection, but by artificial selection.) Suppose someone asks you to build a little function that will take a positive number and calculate that number's square root. How would you go about doing that?
-
-The agile DevOps way is to _fail fast_. Start with humility, admitting upfront that you don't really know how to develop that function. All you know, at this point, is how to _describe_ what you'd like to do. In technical parlance, you are ready to engage in crafting a _unit test_.
-
-"Unit test" describes your specific expectation. It could simply be formulated as "given the number 16, I expect the square root function to return number 4." You probably know that the square root of 16 is 4. However, you don't know the square root for some larger numbers (such as 533).
-
-At the very least, you have formulated your selection criteria, your test or goal.
-
-### Implement the failing test
-
-The [.NET Core][10] platform can illustrate the implementation. .NET typically uses [xUnit.net][11] as a unit-testing framework. (To follow the coding examples, please install .NET Core and xUnit.net.)
-
-Open the command line and create a folder where your square root solution will be implemented. For example, type:
-
-
-```
-`mkdir square_root`
-```
-
-Then type:
-
-
-```
-`cd square_root`
-```
-
-Create a separate folder for unit tests:
-
-
-```
-`mkdir unit_tests`
-```
-
-Move into the **unit_tests** folder (**cd unit_tests**) and initiate the xUnit framework:
-
-
-```
-`dotnet new xunit`
-```
-
-Now, move one folder up to the **square_root** folder, and create the **app** folder:
-
-
-```
-mkdir app
-cd app
-```
-
-Create the scaffold necessary for the C# code:
-
-
-```
-`dotnet new classlib`
-```
-
-Now open your favorite editor and start cracking!
-
-In your code editor, navigate to the **unit_tests** folder and open **UnitTest1.cs**.
-
-Replace auto-generated code in **UnitTest1.cs** with:
-
-
-```
-using System;
-using Xunit;
-using app;
-
-namespace unit_tests{
-
- public class UnitTest1{
- Calculator calculator = new Calculator();
-
- [Fact]
- public void GivenPositiveNumberCalculateSquareRoot(){
- var expected = 4;
- var actual = calculator.CalculateSquareRoot(16);
- Assert.Equal(expected, actual);
- }
- }
-}
-```
-
-This unit test describes the expectation that the variable **expected** should be 4. The next line describes the **actual** value. It proposes to calculate the **actual** value by sending a message to the component called **calculator**. This component is described as capable of handling the **CalculateSquareRoot** message by accepting a numeric value. That component hasn't been developed yet. But it doesn't really matter, because this merely describes the expectations.
-
-Finally, it describes what happens when the message is triggered to be sent. At that point, it asserts whether the **expected** value is equal to the **actual** value. If it is, the test passed and the goal is reached. If the **expected** value isn't equal to the **actual value**, the test fails.
-
-Next, to implement the component called **calculator**, create a new file in the **app** folder and call it **Calculator.cs**. To implement a function that calculates the square root of a number, add the following code to this new file:
-
-
-```
-namespace app {
- public class Calculator {
- public double CalculateSquareRoot(double number) {
- double bestGuess = number;
- return bestGuess;
- }
- }
-}
-```
-
-Before you can test this implementation, you need to instruct the unit test how to find this new component (**Calculator**). Navigate to the **unit_tests** folder and open the **unit_tests.csproj** file. Add the following line in the **<ItemGroup>** code block:
-
-
-```
-``
-```
-
-Save the **unit_test.csproj** file. Now you are ready for your first test run.
-
-Go to the command line and **cd** into the **unit_tests** folder. Run the following command:
-
-
-```
-`dotnet test`
-```
-
-Running the unit test will produce the following output:
-
-![xUnit output after the unit test run fails][12]
-
-Fig. 2. xUnit output after the unit test run fails.
-
-As you can see, the unit test failed. It expected that sending number 16 to the **calculator** component would result in the number 4 as the output, but the output (the **actual** value) was the number 16.
-
-Congratulations! You have created your first failure. Your unit test provided strong, immediate feedback urging you to fix the failure.
-
-### Fix the failure
-
-To fix the failure, you must improve **bestGuess**. Right now, **bestGuess** merely takes the number the function receives and returns it. Not good enough.
-
-But how do you figure out a way to calculate the square root value? I have an idea—how about looking at how Mother Nature solves problems.
-
-### Emulate Mother Nature by iterating
-
-It is extremely hard (pretty much impossible) to guess the correct value from the first (and only) attempt. You must allow for several attempts at guessing to increase your chances of solving the problem. And one way to allow for multiple attempts is to _iterate_.
-
-To iterate, store the **bestGuess** value in the **previousGuess** variable, transform the **bestGuess** value, and compare the difference between the two values. If the difference is 0, you solved the problem. Otherwise, keep iterating.
-
-Here is the body of the function that produces the correct value for the square root of any positive number:
-
-
-```
-double bestGuess = number;
-double previousGuess;
-
-do {
- previousGuess = bestGuess;
- bestGuess = (previousGuess + (number/previousGuess))/2;
-} while((bestGuess - previousGuess) != 0);
-
-return bestGuess;
-```
-
-This loop (iteration) converges bestGuess values to the desired solution. Now your carefully crafted unit test passes!
-
-![Unit test successful][13]
-
-Fig. 3. Unit test successful, 0 tests failed.
-
-### The iteration solves the problem
-
-Just like Mother Nature's approach, in this exercise, iteration solves the problem. An incremental approach combined with stepwise refinement is the guaranteed way to arrive at a satisfactory solution. The decisive factor in this game is having a measurable goal and test. Once you have that, you can keep iterating until you hit the mark.
-
-### Now the punchline!
-
-OK, this was an amusing experiment, but the more interesting discovery comes from playing with this newly minted solution. Until now, your starting **bestGuess** was always equal to the number the function receives as the input parameter. What happens if you change the initial **bestGuess**?
-
-To test that, you can run a few scenarios. First, observe the stepwise refinement as the iteration loops through a series of guesses as it tries to calculate the square root of 25:
-
-![Code iterating for the square root of 25][14]
-
-Fig. 4. Iterating to calculate the square root of 25.
-
-Starting with 25 as the **bestGuess**, it takes eight iterations for the function to calculate the square root of 25. But what would happen if you made a comical, ridiculously wrong stab at the **bestGuess**? What if you started with a clueless second guess, that 1 million might be the square root of 25? What would happen in such an obviously erroneous situation? Would your function be able to deal with such idiocy?
-
-Take a look at the horse's mouth. Rerun the scenario, this time starting from 1 million as the **bestGuess**:
-
-![Stepwise refinement][15]
-
-Fig. 5. Stepwise refinement when calculating the square root of 25 by starting with 1 million as the initial **bestGuess**.
-
-Oh wow! Starting with a ludicrously large number, the number of iterations only tripled (from eight iterations to 23). Not nearly as dramatic an increase as you might intuitively expect.
-
-### The moral of the story
-
-The _Aha!_ moment arrives when you realize that, not only is iteration guaranteed to solve the problem, but it doesn't matter whether your search for the solution begins with a good or a terribly botched initial guess. However erroneous your initial understanding, the process of iteration, coupled with a measurable test/goal, puts you on the right track and delivers the solution. Guaranteed.
-
-Figures 4 and 5 show a steep and dramatic burndown. From a wildly incorrect starting point, the iteration quickly burns down to an absolutely correct solution.
-
-This amazing methodology, in a nutshell, is the essence of agile DevOps.
-
-### Back to some high-level observations
-
-Agile DevOps practice stems from the recognition that we live in a world that is fundamentally based on uncertainty, ambiguity, incompleteness, and a healthy dose of confusion. From the scientific/philosophical point of view, these traits are well documented and supported by [Heisenberg's Uncertainty Principle][16] (covering the uncertainty part), [Wittgenstein's Tractatus Logico-Philosophicus][17] (the ambiguity part), [Gödel's incompleteness theorems][18] (the incompleteness aspect), and the [Second Law of Thermodynamics][19] (the confusion caused by relentless entropy).
-
-In a nutshell, no matter how hard you try, you can never get complete information when trying to solve any problem. It is, therefore, more profitable to abandon an arrogant stance and adopt a more humble approach to solving problems. Humility pays big dividends in rewarding you—not only with the hoped-for solution but also with the byproduct of a well-structured solution.
-
-### Conclusion
-
-Nature works incessantly—it's a continuous flow. Nature has no master plan; everything happens as a response to what happened earlier. The feedback loops are very tight, and apparent progress/regress is piecemeal. Everywhere you look in nature, you see stepwise refinement, in one shape or form or another.
-
-Agile DevOps is a very interesting outcome of the engineering model's gradual maturation. DevOps is based on the recognition that the information you have available is always incomplete, so you'd better proceed cautiously. Obtain a measurable test (e.g., a hypothesis, a measurable expectation), make a humble attempt at satisfying it, most likely fail, then collect the feedback, fix the failure, and continue. There is no plan other than agreeing that, with each step of the way, there must be a measurable hypothesis/test.
-
-In the next article in this series, I'll take a closer look at how mutation testing provides much-needed feedback that drives value.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/mutation-testing-evolution-tdd
-
-作者:[Alex Bunardzic][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/alex-bunardzic
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_520X292_openanttrail-2.png?itok=xhD3WmUd (Ants and a leaf making the word "open")
-[2]: https://opensource.com/article/19/7/failure-feature-blameless-devops
-[3]: https://en.wikipedia.org/wiki/Test-driven_development
-[4]: https://www.merriam-webster.com/dictionary/conditio%20sine%20qua%20non
-[5]: https://opensource.com/sites/default/files/uploads/darwin.png (Charles Darwin)
-[6]: https://en.wikipedia.org/wiki/Charles_Darwin
-[7]: https://en.wikipedia.org/wiki/On_the_Origin_of_Species
-[8]: https://opensource.com/sites/default/files/uploads/environmentalconditions2.png (Environmental pressures on fish)
-[9]: https://www.youtube.com/watch?v=MgK5Rf7qFaU
-[10]: https://dotnet.microsoft.com/
-[11]: https://xunit.net/
-[12]: https://opensource.com/sites/default/files/uploads/xunit-output.png (xUnit output after the unit test run fails)
-[13]: https://opensource.com/sites/default/files/uploads/unit-test-success.png (Unit test successful)
-[14]: https://opensource.com/sites/default/files/uploads/iterating-square-root.png (Code iterating for the square root of 25)
-[15]: https://opensource.com/sites/default/files/uploads/bestguess.png (Stepwise refinement)
-[16]: https://en.wikipedia.org/wiki/Uncertainty_principle
-[17]: https://en.wikipedia.org/wiki/Tractatus_Logico-Philosophicus
-[18]: https://en.wikipedia.org/wiki/G%C3%B6del%27s_incompleteness_theorems
-[19]: https://en.wikipedia.org/wiki/Second_law_of_thermodynamics
diff --git a/sources/tech/20190812 Cloud-native Java, open source security, and more industry trends.md b/sources/tech/20190812 Cloud-native Java, open source security, and more industry trends.md
deleted file mode 100644
index cbc42dbbbd..0000000000
--- a/sources/tech/20190812 Cloud-native Java, open source security, and more industry trends.md
+++ /dev/null
@@ -1,88 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Cloud-native Java, open source security, and more industry trends)
-[#]: via: (https://opensource.com/article/19/8/cloud-native-java-and-more)
-[#]: author: (Tim Hildred https://opensource.com/users/thildred)
-
-Cloud-native Java, open source security, and more industry trends
-======
-A weekly look at open source community and industry trends.
-![Person standing in front of a giant computer screen with numbers, data][1]
-
-As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
-
-## [Why is modern web development so complicated?][2]
-
-> Modern frontend web development is a polarizing experience: many love it, others despise it.
->
-> I am a huge fan of modern web development, though I would describe it as "magical"—and magic has its upsides and downsides... Recently I’ve been needing to explain “modern web development workflows” to folks who only have a cursory of vanilla web development workflows and… It is a LOT to explain! Even a hasty explanation ends up being pretty long. So in the effort of writing more of my explanations down, here is the beginning of a long yet hasty explanation of the evolution of web development..
-
-**The impact:** Specific enough to be useful to (especially new) frontend developers, but simple and well explained enough to help non-developers understand better some of the frontend developer problems. By the end, you'll (kinda) know the difference between Javascript and WebAPIs and how 2019 Javascript is different than 2006 Javascript.
-
-## [Open sourcing the Kubernetes security audit][3]
-
-> Last year, the Cloud Native Computing Foundation (CNCF) began the process of performing and open sourcing third-party security audits for its projects in order to improve the overall security of our ecosystem. The idea was to start with a handful of projects and gather feedback from the CNCF community as to whether or not this pilot program was useful. The first projects to undergo this process were [CoreDNS][4], [Envoy][5] and [Prometheus][6]. These first public audits identified security issues from general weaknesses to critical vulnerabilities. With these results, project maintainers for CoreDNS, Envoy and Prometheus have been able to address the identified vulnerabilities and add documentation to help users.
->
-> The main takeaway from these initial audits is that a public security audit is a great way to test the quality of an open source project along with its vulnerability management process and more importantly, how resilient the open source project’s security practices are. With CNCF [graduated projects][7] especially, which are used widely in production by some of the largest companies in the world, it is imperative that they adhere to the highest levels of security best practices.
-
-**The impact:** A lot of companies are placing big bets on Kubernetes being to the cloud what Linux is to that data center. Seeing 4 of those companies working together to make sure the project is doing what it should be from a security perspective inspires confidence. Sharing that research shows that open source is so much more than code in a repository; it is the capturing and sharing of expert opinions in a way that benefits the community at large rather than the interests of a few.
-
-## [Quarkus—what's next for the lightweight Java framework?][8]
-
-> What does “container first” mean? What are the strengths of Quarkus? What’s new in 0.20.0? What features can we look forward to in the future? When will version 1.0.0 be released? We have so many questions about Quarkus and Alex Soto was kind enough to answer them all. _With the release of Quarkus 0.20.0, we decided to get in touch with [JAX London speaker][9], Java Champion, and Director of Developer Experience at Red Hat – Alex Soto. He was kind enough to answer all our questions about the past, present, and future of Quarkus. It seems like we have a lot to look forward to with this exciting lightweight framework!_
-
-**The impact**: Someone clever recently told me that Quarkus has the potential to make Java "possibly one of the best languages for containers and serverless environments". That made me do a double-take; while Java is one of the most popular programming languages ([if not the most popular][10]) it probably isn't the first one that jumps to mind when you hear the words "cloud native." Quarkus could extend and grow the value of the skills held by a huge chunk of the developer workforce by allowing them to apply their experience to new challenges.
-
-## [Julia programming language: Users reveal what they love and hate the most about it][11]
-
-> The most popular technical feature of Julia is speed and performance followed by ease of use, while the most popular non-technical feature is that users don't have to pay to use it.
->
-> Users also report their biggest gripes with the language. The top one is that packages for add-on features aren't sufficiently mature or well maintained to meet their needs.
-
-**The impact:** The Julia 1.0 release has been out for a year now, and has seen impressive growth in a bunch of relevant metrics (downloads, GitHub stars, etc). It is a language aimed squarely at some of our biggest current and future challenges ("scientific computing, machine learning, data mining, large-scale linear algebra, distributed and parallel computing") so finding out how it's users are feeling about it gives an indirect read on how well those challenges are being addressed.
-
-## [Multi-cloud by the numbers: 11 interesting stats][12]
-
-> If you boil our recent dive into [interesting stats about Kubernetes][13] down to its bottom line, it looks something like this: [Kubernetes'][14] popularity will continue for the foreseeable future.
->
-> Spoiler alert: When you dig up recent numbers about [multi-cloud][15] usage, they tell a similar story: Adoption is soaring.
->
-> This congruity makes sense. Perhaps not every organization will use Kubernetes to manage its multi-cloud and/or [hybrid cloud][16] infrastructure, but the two increasingly go hand-in-hand. Even when they don’t, they both reflect a general shift toward more distributed and heterogeneous IT environments, as well as [cloud-native development][17] and other overlapping trends.
-
-**The impact**: Another explanation of increasing adoption of "multi-cloud strategies" is they retroactively legitimize decisions taken in separate parts of an organization without consultation as "strategic." "Wait, so you bought hours from who? And you bought hours from the other one? Why wasn't that in the meeting minutes? I guess we're a multi-cloud company now!" Of course I'm joking, I'm sure most big companies are a lot better coordinated than that, right?
-
-_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/cloud-native-java-and-more
-
-作者:[Tim Hildred][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/thildred
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
-[2]: https://www.vrk.dev/2019/07/11/why-is-modern-web-development-so-complicated-a-long-yet-hasty-explanation-part-1/
-[3]: https://www.cncf.io/blog/2019/08/06/open-sourcing-the-kubernetes-security-audit/
-[4]: https://coredns.io/2018/03/15/cure53-security-assessment/
-[5]: https://github.com/envoyproxy/envoy/blob/master/docs/SECURITY_AUDIT.pdf
-[6]: https://cure53.de/pentest-report_prometheus.pdf
-[7]: https://www.cncf.io/projects/
-[8]: https://jaxenter.com/quarkus-whats-next-for-the-lightweight-java-framework-160793.html
-[9]: https://jaxlondon.com/cloud-kubernetes-serverless/java-particle-acceleration-using-quarkus/
-[10]: https://opensource.com/article/19/8/possibly%20one%20of%20the%20best%20languages%20for%20containers%20and%20serverless%20environments.
-[11]: https://www.zdnet.com/article/julia-programming-language-users-reveal-what-they-love-and-hate-the-most-about-it/#ftag=RSSbaffb68
-[12]: https://enterprisersproject.com/article/2019/8/multi-cloud-statistics
-[13]: https://enterprisersproject.com/article/2019/7/kubernetes-statistics-13-compelling
-[14]: https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=701f2000000tjyaAAA
-[15]: https://www.redhat.com/en/topics/cloud-computing/what-is-multicloud?intcmp=701f2000000tjyaAAA
-[16]: https://enterprisersproject.com/hybrid-cloud
-[17]: https://enterprisersproject.com/article/2018/10/how-explain-cloud-native-apps-plain-english
diff --git a/sources/tech/20190822 11 Essential Keyboard Shortcuts Google Chrome-Chromium Users Should Know.md b/sources/tech/20190822 11 Essential Keyboard Shortcuts Google Chrome-Chromium Users Should Know.md
deleted file mode 100644
index 4e2693f079..0000000000
--- a/sources/tech/20190822 11 Essential Keyboard Shortcuts Google Chrome-Chromium Users Should Know.md
+++ /dev/null
@@ -1,141 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (11 Essential Keyboard Shortcuts Google Chrome/Chromium Users Should Know)
-[#]: via: (https://itsfoss.com/google-chrome-shortcuts/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-
-11 Essential Keyboard Shortcuts Google Chrome/Chromium Users Should Know
-======
-
-_**Brief: Master these Google Chrome keyboard shortcuts for a better, smoother and more productive web browsing experience. Downloadable cheatsheet is also included.**_
-
-Google Chrome is the [most popular web browser][1] and there is no denying it. It’s open source version [Chromium][2] is also getting popularity and some Linux distributions now include it as the default web browser.
-
-If you use it on desktop a lot, you can improve your browsing experience by using Google Chrome keyboard shortcuts. No need to go up to your mouse and spend time finding your way around. Just master these shortcuts and you’ll even save some time and be more productive.
-
-I am using the term Google Chrome but these shortcuts are equally applicable to the Chromium browser.
-
-### 11 Cool Chrome Keyboard shortcuts you should be using
-
-If you are a pro, you might know a few of these Chrome shortcuts already but the chances are that you may still find some hidden gems here. Let’s see.
-
-**Keyboard Shortcuts** | **Action**
----|---
-Ctrl+T | Open a new tab
-Ctrl+N | Open a new window
-Ctrl+Shift+N | Open incognito window
-Ctrl+W | Close current tab
-Ctrl+Shift+T | Reopen last closed tab
-Ctrl+Shift+W | Close the window
-Ctrl+Tab and Ctrl+Shift+Tab | Switch to right or left tab
-Ctrl+L | Go to search/address bar
-Ctrl+D | Bookmark the website
-Ctrl+H | Access browsing history
-Ctrl+J | Access downloads history
-Shift+Esc | Open Chrome task manager
-
-You can [download this list of useful Chrome keyboard shortcut for quick reference][3].
-
-#### 1\. Open a new tab with Ctrl+T
-
-Need to open a new tab? Just press Ctrl and T keys together and you’ll have a new tab opened.
-
-#### 2\. Open a new window with Ctrl+N
-
-Too many tabs opened already? Time to open a fresh new window. Use Ctrl and N keys to open a new browser window.
-
-#### 3\. Go incognito with Ctrl+Shift+N
-
-Checking flight or hotel prices online? Going incognito might help. Open an incognito window in Chrome with Ctrl+Shift+N.
-
-[][4]
-
-Suggested read Best Text Editors for Linux Command Line
-
-#### 4\. Close a tab with Ctrl+W
-
-Close the current tab with Ctrl and W key. No need to take the mouse to the top and look for the x button.
-
-#### 5\. Accidentally closed a tab? Reopen it with Ctrl+Shift+T
-
-This is my favorite Google Chrome shortcut. No more ‘oh crap’ when you close a tab you didn’t mean to. Use the Ctrl+Shift+T and it will open the last closed tab. Keep hitting this key combination and it will keep on bringing the closed tabs.
-
-#### 6\. Close the entire browser window with Ctrl+Shift+W
-
-Done with you work? Time to close the entire browser window with all the tabs. Use the keys Ctrl+Shift+W and the browser window will disappear like it never existed.
-
-#### 7\. Switch between tabs with Ctrl+Tab
-
-Too many tabs open? You can move to right tab with Ctrl+Tab. Want to move left? Use Ctrl+Shift+Tab. Press these keys repeatedly and you can move between all the open tabs in the current browser window.
-
-You can also use Ctrl+0 till Ctrl+9 to go to one of the first 10 tabs. But this Chrome keyboard shortcut doesn’t work for the 11th tabs onward.
-
-#### 8\. Go to the search/address bar with Ctrl+L
-
-Want to type a new URL or search something quickly. You can use Ctrl+L and it will highlight the address bar on the top.
-
-#### 9\. Bookmark the current website with Ctrl+D
-
-Found something interesting? Save it in your bookmarks with Ctrl+D keys combination.
-
-#### 10\. Go back in history with Ctrl+H
-
-You can open up your browser history with Ctrl+H keys. Search through the history if you are looking for a page visited some time ago or delete something that you don’t want to be seen anymore.
-
-#### 11\. See your downloads with Ctrl+J
-
-Pressing the Ctrl+J keys in Chrome will take you to the Downloads page. This page will show you all the downloads action you performed.
-
-[][5]
-
-Suggested read Get Rid Of Two Google Chrome Icons From Dock In Elementary OS Freya [Quick Tip]
-
-#### Bonus shortcut: Open Chrome task manager with Shift+Esc
-
-Many people doesn’t even know that there is a task manager in Chrome browser. Chrome is infamous for eating up your system’s RAM. And when you have plenty of tabs opened, finding the culprit is not easy.
-
-With Chrome task manager, you can see all the open tabs and their system utilization stats. You can also see various hidden processes such as Chrome extensions and other services.
-
-![Google Chrome Task Manager][6]
-
-I am going to this table here for a quick reference.
-
-### Download Chrome shortcut cheatsheet
-
-I know that mastering keyboard shortcuts depends on habit and you can make it a habit by using it again and again. To help you in this task, I have created this Google Chrome keyboard shortcut cheatsheet.
-
-You can download the below image in PDF form, print it and put it on your desk. This way you can use practice the shortcuts all the time.
-
-![Google Chrome Keyboard Shortcuts Cheat Sheet][7]
-
-[Download Chrome Shortcut Cheatsheet][8]
-
-If you are interested in mastering shortcuts, you may also have a look at [Ubuntu keyboard shortcuts][9].
-
-By the way, what’s your favorite Chrome shortcut?
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/google-chrome-shortcuts/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://en.wikipedia.org/wiki/Usage_share_of_web_browsers
-[2]: https://www.chromium.org/Home
-[3]: tmp.3qZNXSy2FC#download-cheatsheet
-[4]: https://itsfoss.com/command-line-text-editors-linux/
-[5]: https://itsfoss.com/rid-google-chrome-icons-dock-elementary-os-freya/
-[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/google-chrome-task-manager.png?resize=800%2C300&ssl=1
-[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/google-chrome-keyboard-shortcuts-cheat-sheet.png?ssl=1
-[8]: https://drive.google.com/open?id=1lZ4JgRuFbXrnEXoDQqOt7PQH6femIe3t
-[9]: https://itsfoss.com/ubuntu-shortcuts/
diff --git a/sources/tech/20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md b/sources/tech/20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md
deleted file mode 100644
index ab12c95ddd..0000000000
--- a/sources/tech/20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md
+++ /dev/null
@@ -1,82 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (A Raspberry Pi Based Open Source Tablet is in Making and it’s Called CutiePi)
-[#]: via: (https://itsfoss.com/cutiepi-open-source-tab/)
-[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-
-A Raspberry Pi Based Open Source Tablet is in Making and it’s Called CutiePi
-======
-
-CutiePie is an 8-inch open-source tablet built on top of Raspberry Pi. For now, it is just a working prototype which they announced on [Raspberry Pi forums][1].
-
-In this article, you’ll get to know more details on the specifications, price, and availability of CutiePi.
-
-They have made the Tablet using a custom-designed Compute Model (CM3) carrier board. The [official website][2] mentions the purpose of a custom CM3 carrier board as:
-
-> A custom CM3/CM3+ carrier board designed for portable use, with enhanced power management and Li-Po battery level monitoring features; works with selected HDMI or MIPI DSI displays.
-
-So, this is what makes the Tablet thin enough while being portable.
-
-### CutiePi Specifications
-
-![CutiePi Board][3]
-
-I was surprised to know that it rocks an 8-inch IPS LCD display – which is a good thing for starters. However, you won’t be getting a true HD screen because the resolution is 1280×800 – as mentioned officially.
-
-It is also planned to come packed with Li-Po 4800 mAh battery (the prototype had a 5000 mAh battery). Well, for a Tablet, that isn’t bad at all.
-
-Connectivity options include the support for Wi-Fi and Bluetooth 4.0. In addition to this, a USB Type-A, 6x GPIO pins, and a microSD card slot is present.
-
-![CutiePi Specifications][4]
-
-The hardware is officially compatible with [Raspbian OS][5] and the user interface is built with [Qt][6] for a fast and intuitive user experience. Also, along with the in-built apps, it is expected to support Raspbian PIXEL apps via XWayland.
-
-### CutiePi Source Code
-
-You can second-guess the pricing of this tablet by analyzing the bill for the materials used. CutiePi follows a 100% open-source hardware design for this project. So, if you are curious, you can check out their GitHub page for more information on the hardware design and stuff.
-
-[CutiePi on GitHub][7]
-
-### CutiePi Pricing, Release Date & Availability
-
-CutiePi plans to work on [DVT][8] batch PCBs in August (this month). And, they target to launch the final product by the end of 2019.
-
-Officially, they expect it to launch it at around $150-$250. This is just an approximate for the range and should be taken with a pinch of salt.
-
-Obviously, the price will be a major factor in order to make it a success – even though the product itself sounds promising.
-
-**Wrapping Up**
-
-CutiePi is not the first project to use a [single board computer like Raspberry Pi][9] to make a tablet. We have the upcoming [PineTab][10] which is based on Pine64 single board computer. Pine also has a laptop called [Pinebook][11] based on the same.
-
-Judging by the prototype – it is indeed a product that we can expect to work. However, the pre-installed apps and the apps that it will support may turn the tide. Also, considering the price estimate – it sounds promising.
-
-What do you think about it? Let us know your thoughts in the comments below or just play this interactive poll.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/cutiepi-open-source-tab/
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://www.raspberrypi.org/forums/viewtopic.php?t=247380
-[2]: https://cutiepi.io/
-[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/cutiepi-board.png?ssl=1
-[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/cutiepi-specifications.jpg?ssl=1
-[5]: https://itsfoss.com/raspberry-pi-os-desktop/
-[6]: https://en.wikipedia.org/wiki/Qt_%28software%29
-[7]: https://github.com/cutiepi-io/cutiepi-board
-[8]: https://en.wikipedia.org/wiki/Engineering_validation_test#Design_verification_test
-[9]: https://itsfoss.com/raspberry-pi-alternatives/
-[10]: https://www.pine64.org/pinetab/
-[11]: https://itsfoss.com/pinebook-pro/
diff --git a/sources/tech/20190822 How to move a file in Linux.md b/sources/tech/20190822 How to move a file in Linux.md
deleted file mode 100644
index c38f9445e1..0000000000
--- a/sources/tech/20190822 How to move a file in Linux.md
+++ /dev/null
@@ -1,286 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to move a file in Linux)
-[#]: via: (https://opensource.com/article/19/8/moving-files-linux-depth)
-[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/doni08521059)
-
-How to move a file in Linux
-======
-Whether you're new to moving files in Linux or experienced, you'll learn
-something in this in-depth writeup.
-![Files in a folder][1]
-
-Moving files in Linux can seem relatively straightforward, but there are more options available than most realize. This article teaches beginners how to move files in the GUI and on the command line, but also explains what’s actually happening under the hood, and addresses command line options that many experience users have rarely explored.
-
-### Moving what?
-
-Before delving into moving files, it’s worth taking a closer look at what actually happens when _moving_ file system objects. When a file is created, it is assigned to an _inode_, which is a fixed point in a file system that’s used for data storage. You can what inode maps to a file with the [ls][2] command:
-
-
-```
-$ ls --inode example.txt
-7344977 example.txt
-```
-
-When you move a file, you don’t actually move the data from one inode to another, you only assign the file object a new name or file path. In fact, a file retains its permissions when it’s moved, because moving a file doesn’t change or re-create it.
-
-File and directory inodes never imply inheritance and are dictated by the filesystem itself. Inode assignment is sequential based on when the file was created and is entirely independent of how you organize your computer. A file "inside" a directory may have a lower inode number than its parent directory, or a higher one. For example:
-
-
-```
-$ mkdir foo
-$ mv example.txt foo
-$ ls --inode
-7476865 foo
-$ ls --inode foo
-7344977 example.txt
-```
-
-When moving a file from one hard drive to another, however, the inode is very likely to change. This happens because the new data has to be written onto a new filesystem. For this reason, in Linux the act of moving and renaming files is literally the same action. Whether you move a file to another directory or to the same directory with a new name, both actions are performed by the same underlying program.
-
-This article focuses on moving files from one directory to another.
-
-### Moving with a mouse
-
-The GUI is a friendly and, to most people, familiar layer of abstraction on top of a complex collection of binary data. It’s also the first and most intuitive way to move files on Linux. If you’re used to the desktop experience, in a generic sense, then you probably already know how to move files around your hard drive. In the GNOME desktop, for instance, the default action when dragging and dropping a file from one window to another is to move the file rather than to copy it, so it’s probably one of the most intuitive actions on the desktop:
-
-![Moving a file in GNOME.][3]
-
-The Dolphin file manager in the KDE Plasma desktop defaults to prompting the user for an action. Holding the **Shift** key while dragging a file forces a move action:
-
-![Moving a file in KDE.][4]
-
-### Moving on the command line
-
-The shell command intended for moving files on Linux, BSD, Illumos, Solaris, and MacOS is **mv**. A simple command with a predictable syntax, **mv <source> <destination>** moves a source file to the specified destination, each defined by either an [absolute][5] or [relative][6] file path. As mentioned before, **mv** is such a common command for [POSIX][7] users that many of its additional modifiers are generally unknown, so this article brings a few useful modifiers to your attention whether you are new or experienced.
-
-Not all **mv** commands were written by the same people, though, so you may have GNU **mv**, BSD **mv**, or Sun **mv**, depending on your operating system. Command options differ from implementation to implementation (BSD **mv** has no long options at all) so refer to your **mv** man page to see what’s supported, or install your preferred version instead (that’s the luxury of open source).
-
-#### Moving a file
-
-To move a file from one folder to another with **mv**, remember the syntax **mv <source> <destination>**. For instance, to move the file **example.txt** into your **Documents** directory:
-
-
-```
-$ touch example.txt
-$ mv example.txt ~/Documents
-$ ls ~/Documents
-example.txt
-```
-
-Just like when you move a file by dragging and dropping it onto a folder icon, this command doesn’t replace **Documents** with **example.txt**. Instead, **mv** detects that **Documents** is a folder, and places the **example.txt** file into it.
-
-You can also, conveniently, rename the file as you move it:
-
-
-```
-$ touch example.txt
-$ mv example.txt ~/Documents/foo.txt
-$ ls ~/Documents
-foo.txt
-```
-
-That’s important because it enables you to rename a file even when you don’t want to move it to another location, like so:
-
-
-```
-`$ touch example.txt $ mv example.txt foo2.txt $ ls foo2.txt`
-```
-
-#### Moving a directory
-
-The **mv** command doesn’t differentiate a file from a directory the way [**cp**][8] does. You can move a directory or a file with the same syntax:
-
-
-```
-$ touch file.txt
-$ mkdir foo_directory
-$ mv file.txt foo_directory
-$ mv foo_directory ~/Documents
-```
-
-#### Moving a file safely
-
-If you copy a file to a directory where a file of the same name already exists, the **mv** command replaces the destination file with the one you are moving, by default. This behavior is called _clobbering_, and sometimes it’s exactly what you intend. Other times, it is not.
-
-Some distributions _alias_ (or you might [write your own][9]) **mv** to **mv --interactive**, which prompts you for confirmation. Some do not. Either way, you can use the **\--interactive** or **-i** option to ensure that **mv** asks for confirmation in the event that two files of the same name are in conflict:
-
-
-```
-$ mv --interactive example.txt ~/Documents
-mv: overwrite '~/Documents/example.txt'?
-```
-
-If you do not want to manually intervene, use **\--no-clobber** or **-n** instead. This flag silently rejects the move action in the event of conflict. In this example, a file named **example.txt** already exists in **~/Documents**, so it doesn't get moved from the current directory as instructed:
-
-
-```
-$ mv --no-clobber example.txt ~/Documents
-$ ls
-example.txt
-```
-
-#### Moving with backups
-
-If you’re using GNU **mv**, there are backup options offering another means of safe moving. To create a backup of any conflicting destination file, use the **-b** option:
-
-
-```
-$ mv -b example.txt ~/Documents
-$ ls ~/Documents
-example.txt example.txt~
-```
-
-This flag ensures that **mv** completes the move action, but also protects any pre-existing file in the destination location.
-
-Another GNU backup option is **\--backup**, which takes an argument defining how the backup file is named:
-
- * **existing**: If numbered backups already exist in the destination, then a numbered backup is created. Otherwise, the **simple** scheme is used.
- * **none**: Does not create a backup even if **\--backup** is set. This option is useful to override a **mv** alias that sets the backup option.
- * **numbered**: Appends the destination file with a number.
- * **simple**: Appends the destination file with a **~**, which can conveniently be hidden from your daily view with the **\--ignore-backups** option for **[ls][2]**.
-
-
-
-For example:
-
-
-```
-$ mv --backup=numbered example.txt ~/Documents
-$ ls ~/Documents
--rw-rw-r--. 1 seth users 128 Aug 1 17:23 example.txt
--rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
-```
-
-A default backup scheme can be set with the environment variable VERSION_CONTROL. You can set environment variables in your **~/.bashrc** file or dynamically before your command:
-
-
-```
-$ VERSION_CONTROL=numbered mv --backup example.txt ~/Documents
-$ ls ~/Documents
--rw-rw-r--. 1 seth users 128 Aug 1 17:23 example.txt
--rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
--rw-rw-r--. 1 seth users 128 Aug 1 17:22 example.txt.~2~
-```
-
-The **\--backup** option still respects the **\--interactive** or **-i** option, so it still prompts you to overwrite the destination file, even though it creates a backup before doing so:
-
-
-```
-$ mv --backup=numbered example.txt ~/Documents
-mv: overwrite '~/Documents/example.txt'? y
-$ ls ~/Documents
--rw-rw-r--. 1 seth users 128 Aug 1 17:24 example.txt
--rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
--rw-rw-r--. 1 seth users 128 Aug 1 17:22 example.txt.~2~
--rw-rw-r--. 1 seth users 128 Aug 1 17:23 example.txt.~3~
-```
-
-You can override **-i** with the **\--force** or **-f** option.
-
-
-```
-$ mv --backup=numbered --force example.txt ~/Documents
-$ ls ~/Documents
--rw-rw-r--. 1 seth users 128 Aug 1 17:26 example.txt
--rw-rw-r--. 1 seth users 128 Aug 1 17:20 example.txt.~1~
--rw-rw-r--. 1 seth users 128 Aug 1 17:22 example.txt.~2~
--rw-rw-r--. 1 seth users 128 Aug 1 17:24 example.txt.~3~
--rw-rw-r--. 1 seth users 128 Aug 1 17:25 example.txt.~4~
-```
-
-The **\--backup** option is not available in BSD **mv**.
-
-#### Moving many files at once
-
-When moving multiple files, **mv** treats the final directory named as the destination:
-
-
-```
-$ mv foo bar baz ~/Documents
-$ ls ~/Documents
-foo bar baz
-```
-
-If the final item is not a directory, **mv** returns an error:
-
-
-```
-$ mv foo bar baz
-mv: target 'baz' is not a directory
-```
-
-The syntax of GNU **mv** is fairly flexible. If you are unable to provide the **mv** command with the destination as the final argument, use the **\--target-directory** or **-t** option:
-
-
-```
-$ mv --target-directory=~/Documents foo bar baz
-$ ls ~/Documents
-foo bar baz
-```
-
-This is especially useful when constructing **mv** commands from the output of some other command, such as the **find** command, **xargs**, or [GNU Parallel][10].
-
-#### Moving based on mtime
-
-With GNU **mv**, you can define a move action based on whether the file being moved is newer than the destination file it would replace. This option is possible with the **\--update** or **-u** option, and is not available in BSD **mv**:
-
-
-```
-$ ls -l ~/Documents
--rw-rw-r--. 1 seth users 128 Aug 1 17:32 example.txt
-$ ls -l
--rw-rw-r--. 1 seth users 128 Aug 1 17:42 example.txt
-$ mv --update example.txt ~/Documents
-$ ls -l ~/Documents
--rw-rw-r--. 1 seth users 128 Aug 1 17:42 example.txt
-$ ls -l
-```
-
-This result is exclusively based on the files’ modification time, not on a diff of the two files, so use it with care. It’s easy to fool **mv** with a mere **touch** command:
-
-
-```
-$ cat example.txt
-one
-$ cat ~/Documents/example.txt
-one
-two
-$ touch example.txt
-$ mv --update example.txt ~/Documents
-$ cat ~/Documents/example.txt
-one
-```
-
-Obviously, this isn’t the most intelligent update function available, but it offers basic protection against overwriting recent data.
-
-### Moving
-
-There are more ways to move data than just the **mv** command, but as the default program for the job, **mv** is a good universal option. Now that you know what options you have available, you can use **mv** smarter than ever before.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/moving-files-linux-depth
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sethhttps://opensource.com/users/doni08521059
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
-[2]: https://opensource.com/article/19/7/master-ls-command
-[3]: https://opensource.com/sites/default/files/uploads/gnome-mv.jpg (Moving a file in GNOME.)
-[4]: https://opensource.com/sites/default/files/uploads/kde-mv.jpg (Moving a file in KDE.)
-[5]: https://opensource.com/article/19/7/understanding-file-paths-and-how-use-them
-[6]: https://opensource.com/article/19/7/navigating-filesystem-relative-paths
-[7]: https://opensource.com/article/19/7/what-posix-richard-stallman-explains
-[8]: https://opensource.com/article/19/7/copying-files-linux
-[9]: https://opensource.com/article/19/7/bash-aliases
-[10]: https://opensource.com/article/18/5/gnu-parallel
diff --git a/sources/tech/20190823 The Linux kernel- Top 5 innovations.md b/sources/tech/20190823 The Linux kernel- Top 5 innovations.md
deleted file mode 100644
index 95e35bc309..0000000000
--- a/sources/tech/20190823 The Linux kernel- Top 5 innovations.md
+++ /dev/null
@@ -1,105 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (The Linux kernel: Top 5 innovations)
-[#]: via: (https://opensource.com/article/19/8/linux-kernel-top-5-innovations)
-[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/mhaydenhttps://opensource.com/users/mralexjuarez)
-
-The Linux kernel: Top 5 innovations
-======
-Want to know what the actual (not buzzword) innovations are when it
-comes to the Linux kernel? Read on.
-![Penguin with green background][1]
-
-The word _innovation_ gets bandied about in the tech industry almost as much as _revolution_, so it can be difficult to differentiate hyperbole from something that’s actually exciting. The Linux kernel has been called innovative, but then again it’s also been called the biggest hack in modern computing, a monolith in a micro world.
-
-Setting aside marketing and modeling, Linux is arguably the most popular kernel of the open source world, and it’s introduced some real game-changers over its nearly 30-year life span.
-
-### Cgroups (2.6.24)
-
-Back in 2007, Paul Menage and Rohit Seth got the esoteric [_control groups_ (cgroups)][2] feature added to the kernel (the current implementation of cgroups is a rewrite by Tejun Heo.) This new technology was initially used as a way to ensure, essentially, quality of service for a specific set of tasks.
-
-For example, you could create a control group definition (cgroup) for all tasks associated with your web server, another cgroup for routine backups, and yet another for general operating system requirements. You could then control a percentage of resources for each cgroup, such that your OS and web server gets the bulk of system resources while your backup processes have access to whatever is left.
-
-What cgroups has become most famous for, though, is its role as the technology driving the cloud today: containers. In fact, cgroups were originally named [process containers][3]. It was no great surprise when they were adopted by projects like [LXC][4], [CoreOS][5], and Docker.
-
-The floodgates being opened, the term _containers_ justly became synonymous with Linux, and the concept of microservice-style cloud-based “apps” quickly became the norm. These days, it’s hard to get away from cgroups, they’re so prevalent. Every large-scale infrastructure (and probably your laptop, if you run Linux) takes advantage of cgroups in a meaningful way, making your computing experience more manageable and more flexible than ever.
-
-For example, you might already have installed [Flathub][6] or [Flatpak][7] on your computer, or maybe you’ve started using [Kubernetes][8] and/or [OpenShift][9] at work. Regardless, if the term “containers” is still hazy for you, you can gain a hands-on understanding of containers from [Behind the scenes with Linux containers][10].
-
-### LKMM (4.17)
-
-In 2018, the hard work of Jade Alglave, Alan Stern, Andrea Parri, Luc Maranget, Paul McKenney, and several others, got merged into the mainline Linux kernel to provide formal memory models. The Linux Kernel Memory [Consistency] Model (LKMM) subsystem is a set of tools describing the Linux memory coherency model, as well as producing _litmus tests_ (**klitmus**, specifically) for testing.
-
-As systems become more complex in physical design (more CPU cores added, cache and RAM grow, and so on), the harder it is for them to know which address space is required by which CPU, and when. For example, if CPU0 needs to write data to a shared variable in memory, and CPU1 needs to read that value, then CPU0 must write before CPU1 attempts to read. Similarly, if values are written in one order to memory, then there’s an expectation that they are also read in that same order, regardless of which CPU or CPUs are doing the reading.
-
-Even on a single CPU, memory management requires a specific task order. A simple action such as **x = y** requires a CPU to load the value of **y** from memory, and then store that value in **x**. Placing the value stored in **y** into the **x** variable cannot occur _before_ the CPU has read the value from memory. There are also address dependencies: **x[n] = 6** requires that **n** is loaded before the CPU can store the value of six.
-
-LKMM helps identify and trace these memory patterns in code. It does this in part with a tool called **herd**, which defines the constraints imposed by a memory model (in the form of logical axioms), and then enumerates all possible outcomes consistent with these constraints.
-
-### Low-latency patch (2.6.38)
-
-Long ago, in the days before 2011, if you wanted to do "serious" [multimedia work on Linux][11], you had to obtain a low-latency kernel. This mostly applied to [audio recording][12] while adding lots of real-time effects (such as singing into a microphone and adding reverb, and hearing your voice in your headset with no noticeable delay). There were distributions, such as [Ubuntu Studio][13], that reliably provided such a kernel, so in practice it wasn't much of a hurdle, just a significant caveat when choosing your distribution as an artist.
-
-However, if you weren’t using Ubuntu Studio, or you had some need to update your kernel before your distribution got around to it, you had to go to the rt-patches web page, download the kernel patches, apply them to your kernel source code, compile, and install manually.
-
-And then, with the release of kernel version 2.6.38, this process was all over. The Linux kernel suddenly, as if by magic, had low-latency code (according to benchmarks, latency decreased by a factor of 10, at least) built-in by default. No more downloading patches, no more compiling. Everything just worked, and all because of a small 200-line patch implemented by Mike Galbraith.
-
-For open source multimedia artists the world over, it was a game-changer. Things got so good from 2011 on that in 2016, I challenged myself to [build a Digital Audio Workstation (DAW) on a Raspberry Pi v1 (model B)][14] and found that it worked surprisingly well.
-
-### RCU (2.5)
-
-RCU, or Read-Copy-Update, is a system defined in computer science that allows multiple processor threads to read from shared memory. It does this by deferring updates, but also marking them as updated, to ensure that the data’s consumers read the latest version. Effectively, this means that reads happen concurrently with updates.
-
-The typical RCU cycle is a little like this:
-
- 1. Remove pointers to data to prevent other readers from referencing it.
- 2. Wait for readers to complete their critical processes.
- 3. Reclaim the memory space.
-
-
-
-Dividing the update stage into removal and reclamation phases means the updater performs the removal immediately while deferring reclamation until all active readers are complete (either by blocking them or by registering a callback to be invoked upon completion).
-
-While the concept of read-copy-update was not invented for the Linux kernel, its implementation in Linux is a defining example of the technology.
-
-### Collaboration (0.01)
-
-The final answer to the question of what the Linux kernel innovated will always be, above all else, collaboration. Call it good timing, call it technical superiority, call it hackability, or just call it open source, but the Linux kernel and the many projects that it enabled is a glowing example of collaboration and cooperation.
-
-And it goes well beyond just the kernel. People from all walks of life have contributed to open source, arguably _because_ of the Linux kernel. The Linux was, and remains to this day, a major force of [Free Software][15], inspiring users to bring their code, art, ideas, or just themselves, to a global, productive, and diverse community of humans.
-
-### What’s your favorite innovation?
-
-This list is biased toward my own interests: containers, non-uniform memory access (NUMA), and multimedia. I’ve surely left your favorite kernel innovation off the list. Tell me about it in the comments!
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/linux-kernel-top-5-innovations
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sethhttps://opensource.com/users/mhaydenhttps://opensource.com/users/mralexjuarez
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
-[2]: https://en.wikipedia.org/wiki/Cgroups
-[3]: https://lkml.org/lkml/2006/10/20/251
-[4]: https://linuxcontainers.org
-[5]: https://coreos.com/
-[6]: http://flathub.org
-[7]: http://flatpak.org
-[8]: http://kubernetes.io
-[9]: https://www.redhat.com/sysadmin/learn-openshift-minishift
-[10]: https://opensource.com/article/18/11/behind-scenes-linux-containers
-[11]: http://slackermedia.info
-[12]: https://opensource.com/article/17/6/qtractor-audio
-[13]: http://ubuntustudio.org
-[14]: https://opensource.com/life/16/3/make-music-raspberry-pi-milkytracker
-[15]: http://fsf.org
diff --git a/sources/tech/20190823 The lifecycle of Linux kernel testing.md b/sources/tech/20190823 The lifecycle of Linux kernel testing.md
deleted file mode 100644
index 65bab32536..0000000000
--- a/sources/tech/20190823 The lifecycle of Linux kernel testing.md
+++ /dev/null
@@ -1,78 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (The lifecycle of Linux kernel testing)
-[#]: via: (https://opensource.com/article/19/8/linux-kernel-testing)
-[#]: author: (Major Hayden https://opensource.com/users/mhaydenhttps://opensource.com/users/mhaydenhttps://opensource.com/users/marcobravohttps://opensource.com/users/mhayden)
-
-The lifecycle of Linux kernel testing
-======
-The Continuous Kernel Integration (CKI) project aims to prevent bugs
-from entering the Linux kernel.
-![arrows cycle symbol for failing faster][1]
-
-In _[Continuous integration testing for the Linux kernel][2]_, I wrote about the [Continuous Kernel Integration][3] (CKI) project and its mission to change how kernel developers and maintainers work. This article is a deep dive into some of the more technical aspects of the project and how all the pieces fit together.
-
-### It all starts with a change
-
-Every exciting feature, improvement, and bug in the kernel starts with a change proposed by a developer. These changes appear on myriad mailing lists for different kernel repositories. Some repositories focus on certain subsystems in the kernel, such as storage or networking, while others focus on broad aspects of the kernel. The CKI project springs into action when developers propose a change, or patchset, to the kernel or when a maintainer makes changes in the repository itself.
-
-The CKI project maintains triggers that monitor these patchsets and take action. Software projects such as [Patchwork][4] make this process much easier by collating multi-patch contributions into a single patch series. This series travels as a unit through the CKI system and allows for publishing a single report on the series.
-
-Other triggers watch the repository for changes. This occurs when kernel maintainers merge patchsets, revert patches, or create new tags. Testing these critical changes ensures that developers always have a solid baseline to use as a foundation for writing new patches.
-
-All of these changes make their way into a GitLab pipeline and pass through multiple stages and multiple systems.
-
-### Prepare the build
-
-Everything starts with getting the source ready for compile time. This requires cloning the repository, applying the patchset proposed by the developer, and generating a kernel config file. These config files have thousands of options that turn features on or off, and config files differ incredibly between different system architectures. For example, a fairly standard x86_64 system may have a ton of options available in its config file, but an s390x system (IBM zSeries mainframes) likely has much fewer options. Some options might make sense on that mainframe but they have no purpose on a consumer laptop.
-
-The kernel moves forward and transforms into a source artifact. The artifact contains the entire repository, with patches applied, and all kernel configuration files required for compiling. Upstream kernels move on as a tarball, while Red Hat kernels become a source RPM for the next step.
-
-### Piles of compiles
-
-Compiling the kernel turns the source code into something that a computer can boot up and use. The config file describes what to build, scripts in the kernel describe how to build it, and tools on the system (like GCC and glibc) do the building. This process takes a while to complete, but the CKI project needs it done quickly for four architectures: aarch64 (64-bit ARM), ppc64le (POWER), s390x (IBM zSeries), and x86_64. It's important that we compile kernels quickly so that we keep our backlog manageable and developers receive prompt feedback.
-
-Adding more CPUs provides plenty of speed improvements, but every system has its limits. The CKI project compiles kernels within containers in an OpenShift deployment; although OpenShift allows for tons of scalability, the deployment still has a finite number of CPUs available. The CKI team allocates 20 virtual CPUs for compiling each kernel. With four architectures involved, this balloons to 80 CPUs!
-
-Another speed increase comes from a tool called [ccache][5]. Kernel development moves quickly, but a large amount of the kernel remains unchanged even between multiple releases. The ccache tool caches the built objects (small pieces of the overall kernel) during the compile on a disk. When another kernel compile comes along later, ccache looks for unchanged pieces of the kernel that it saw before. Ccache pulls the cached object from the disk and reuses it. This allows for faster compiles and lower overall CPU usage. Kernels that took 20 minutes to compile now race to the finish line in less than a few minutes.
-
-### Testing time
-
-The kernel moves onto its last step: testing on real hardware. Each kernel boots up on its native architecture using Beaker, and myriad tests begin poking it to find problems. Some tests look for simple problems, such as issues with containers or error messages on boot-up. Other tests dive deep into various kernel subsystems to find regressions in system calls, memory allocation, and threading.
-
-Large testing frameworks, such as the [Linux Test Project][6] (LTP), contain tons of tests that look for troublesome regressions in the kernel. Some of these regressions could roll back critical security fixes, and there are tests to ensure those improvements remain in the kernel.
-
-One critical step remains when tests finish: reporting. Kernel developers and maintainers need a concise report that tells them exactly what worked, what did not work, and how to get more information. Each CKI report contains details about the source code used, the compile parameters, and the testing output. That information helps developers know where to begin looking to fix an issue. Also, it helps maintainers know when a patchset needs to be held for another look before a bug makes its way into their kernel repository.
-
-### Summary
-
-The CKI project team strives to prevent bugs from entering the Linux kernel by providing timely, automated feedback to kernel developers and maintainers. This work makes their job easier by finding the low-hanging fruit that leads to kernel bugs, security issues, and performance problems.
-
-* * *
-
-_To learn more, you can attend the [CKI Hackfest][7] on September 12-13 following the [Linux Plumbers Conference][8] September 9-11 in Lisbon, Portugal._
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/linux-kernel-testing
-
-作者:[Major Hayden][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/mhaydenhttps://opensource.com/users/mhaydenhttps://opensource.com/users/marcobravohttps://opensource.com/users/mhayden
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
-[2]: https://opensource.com/article/19/6/continuous-kernel-integration-linux
-[3]: https://cki-project.org/
-[4]: https://github.com/getpatchwork/patchwork
-[5]: https://ccache.dev/
-[6]: https://linux-test-project.github.io
-[7]: https://cki-project.org/posts/hackfest-agenda/
-[8]: https://www.linuxplumbersconf.org/
diff --git a/sources/tech/20190824 How to compile a Linux kernel in the 21st century.md b/sources/tech/20190824 How to compile a Linux kernel in the 21st century.md
deleted file mode 100644
index 0740c0b3a0..0000000000
--- a/sources/tech/20190824 How to compile a Linux kernel in the 21st century.md
+++ /dev/null
@@ -1,225 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to compile a Linux kernel in the 21st century)
-[#]: via: (https://opensource.com/article/19/8/linux-kernel-21st-century)
-[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/greg-p)
-
-How to compile a Linux kernel in the 21st century
-======
-You don't have to compile the Linux kernel but you can with this quick
-tutorial.
-![and old computer and a new computer, representing migration to new software or hardware][1]
-
-In computing, a kernel is the low-level software that handles communication with hardware and general system coordination. Aside from some initial firmware built into your computer's motherboard, when you start your computer, the kernel is what provides awareness that it has a hard drive and a screen and a keyboard and a network card. It's also the kernel's job to ensure equal time (more or less) is given to each component so that your graphics and audio and filesystem and network all run smoothly, even though they're running concurrently.
-
-The quest for hardware support, however, is ongoing, because the more hardware that gets released, the more stuff a kernel must adopt into its code to make the hardware work as expected. It's difficult to get accurate numbers, but the Linux kernel is certainly among the top kernels for hardware compatibility. Linux operates innumerable computers and mobile phones, embedded system on a chip (SoC) boards for hobbyist and industrial uses, RAID cards, sewing machines, and much more.
-
-Back in the 20th century (and even in the early years of the 21st), it was not unreasonable for a Linux user to expect that when they purchased a very new piece of hardware, they would need to download the very latest kernel source code, compile it, and install it so that they could get support for the device. Lately, though, you'd be hard-pressed to find a Linux user who compiles their own kernel except for fun or profit by way of highly specialized custom hardware. It generally isn't required these days to compile the Linux kernel yourself.
-
-Here are the reasons why, plus a quick tutorial on how to compile a kernel when you need to.
-
-### Update your existing kernel
-
-Whether you've got a brand new laptop featuring a fancy new graphics card or WiFi chipset or you've just brought home a new printer, your operating system (called either GNU+Linux or just Linux, which is also the name of the kernel) needs a driver to open communication channels to that new component (graphics card, WiFi chip, printer, or whatever). It can be deceptive, sometimes, when you plug in a new device and your computer _appears_ to acknowledge it. But don't let that fool you. Sometimes that _is_ all you need, but other times your OS is just using generic protocols to probe a device that's attached.
-
-For instance, your computer may be able to identify your new network printer, but sometimes that's only because the network card in the printer is programmed to identify itself to a network so it can gain a DHCP address. It doesn't necessarily mean that your computer knows what instructions to send to the printer to produce a page of printed text. In fact, you might argue that the computer doesn't even really "know" that the device is a printer; it may only display that there's a device on the network at a specific address and the device identifies itself with the series of characters _p-r-i-n-t-e-r_. The conventions of human language are meaningless to a computer; what it needs is a driver.
-
-Kernel developers, hardware manufacturers, support technicians, and hobbyists all know that new hardware is constantly being released. Many of them contribute drivers, submitted straight to the kernel development team for inclusion in Linux. For example, Nvidia graphic card drivers are often written into the [Nouveau][2] kernel module and, because Nvidia cards are common, the code is usually included in any kernel distributed for general use (such as the kernel you get when you download [Fedora][3] or [Ubuntu][4]. Where Nvidia is less common, for instance in embedded systems, the Nouveau module is usually excluded. Similar modules exist for many other devices: printers benefit from [Foomatic][5] and [CUPS][6], wireless cards have [b43, ath9k, wl][7] modules, and so on.
-
-Distributions tend to include as much as they reasonably can in their Linux kernel builds because they want you to be able to attach a device and start using it immediately, with no driver installation required. For the most part, that's what happens, especially now that many device vendors are now funding Linux driver development for the hardware they sell and submitting those drivers directly to the kernel team for general distribution.
-
-Sometimes, however, you're running a kernel you installed six months ago with an exciting new device that just hit the stores a week ago. In that case, your kernel may not have a driver for that device. The good news is that very often, a driver for that device may exist in a very recent edition of the kernel, meaning that all you have to do is update what you're running.
-
-Generally, this is done through a package manager. For instance, on RHEL, CentOS, and Fedora:
-
-
-```
-`$ sudo dnf update kernel`
-```
-
-On Debian and Ubuntu, first get your current kernel version:
-
-
-```
-$ uname -r
-4.4.186
-```
-
-Search for newer versions:
-
-
-```
-$ sudo apt update
-$ sudo apt search linux-image
-```
-
-Install the latest version you find. In this example, the latest available is 5.2.4:
-
-
-```
-`$ sudo apt install linux-image-5.2.4`
-```
-
-After a kernel upgrade, you must [reboot][8] (unless you're using kpatch or kgraft). Then, if the device driver you need is in the latest kernel, your hardware will work as expected.
-
-### Install a kernel module
-
-Sometimes a distribution doesn't expect that its users often use a device (or at least not enough that the device driver needs to be in the Linux kernel). Linux takes a modular approach to drivers, so distributions can ship separate driver packages that can be loaded by the kernel even though the driver isn't compiled into the kernel itself. This is useful, although it can get complicated when a driver isn't included in a kernel but is needed during boot, or when the kernel gets updated out from under the modular driver. The first problem is solved with an **initrd** (initial RAM disk) and is out of scope for this article, and the second is solved by a system called **kmod**.
-
-The kmod system ensures that when a kernel is updated, all modular drivers installed alongside it are also updated. If you install a driver manually, you miss out on the automation that kmod provides, so you should opt for a kmod package whenever it is available. For instance, while Nvidia drivers are built into the kernel as the Nouveau driver, the official Nvidia drivers are distributed only by Nvidia. You can install Nvidia-branded drivers manually by going to the website, downloading the **.run** file, and running the shell script it provides, but you must repeat that same process after you install a new kernel, because nothing tells your package manager that you manually installed a kernel driver. Because Nvidia drives your graphics, updating the Nvidia driver manually usually means you have to perform the update from a terminal, because you have no graphics without a functional graphics driver.
-
-![Nvidia configuration application][9]
-
-However, if you install the Nvidia drivers as a kmod package, updating your kernel also updates your Nvidia driver. On Fedora and related:
-
-
-```
-`$ sudo dnf install kmod-nvidia`
-```
-
-On Debian and related:
-
-
-```
-$ sudo apt update
-$ sudo apt install nvidia-kernel-common nvidia-kernel-dkms nvidia-glx nvidia-xconfig nvidia-settings nvidia-vdpau-driver vdpau-va-driver
-```
-
-This is only an example, but if you're installing Nvidia drivers in real life, you must also blacklist the Nouveau driver. See your distribution's documentation for the best steps.
-
-### Download and install a driver
-
-Not everything is included in the kernel, and not everything _else_ is available as a kernel module. In some cases, you have to download a special driver written and bundled by the hardware vendor, and other times, you have the driver but not the frontend to configure driver options.
-
-Two common examples are HP printers and [Wacom][10] illustration tablets. If you get an HP printer, you probably have generic drivers that can communicate with your printer. You might even be able to print. But the generic driver may not be able to provide specialized options specific to your model, such as double-sided printing, collation, paper tray choices, and so on. [HPLIP][11] (the HP Linux Imaging and Printing system) provides options to manage jobs, adjust printing options, select paper trays where applicable, and so on.
-
-HPLIP is usually bundled in package managers; just search for "hplip."
-
-![HPLIP in action][12]
-
-Similarly, drivers for Wacom tablets, the leading illustration tablet for digital artists, are usually included in your kernel, but options to fine-tune settings, such as pressure sensitivity and button functionality, are only accessible through the graphical control panel included by default with GNOME but installable as the extra package **kde-config-tablet** on KDE.
-
-There are likely some edge cases that don't have drivers in the kernel but offer kmod versions of driver modules as an RPM or DEB file that you can download and install through your package manager.
-
-### Patching and compiling your own kernel
-
-Even in the futuristic utopia that is the 21st century, there are vendors that don't understand open source enough to provide installable drivers. Sometimes, such companies provide source code for a driver but expect you to download the code, patch a kernel, compile, and install manually.
-
-This kind of distribution model has the same disadvantages as installing packaged drivers outside of the kmod system: an update to your kernel breaks the driver because it must be re-integrated into your kernel manually each time the kernel is swapped out for a new one.
-
-This has become rare, happily, because the Linux kernel team has done an excellent job of pleading loudly for companies to communicate with them, and because companies are finally accepting that open source isn't going away any time soon. But there are still novelty or hyper-specialized devices out there that provide only kernel patches.
-
-Officially, there are distribution-specific preferences for how you should compile a kernel to keep your package manager involved in upgrading such a vital part of your system. There are too many package managers to cover each; as an example, here is what happens behind the scenes when you use tools like **rpmdev** on Fedora or **build-essential** and **devscripts** on Debian.
-
-First, as usual, find out which kernel version you're running:
-
-
-```
-`$ uname -r`
-```
-
-In most cases, it's safe to upgrade your kernel if you haven't already. After all, it's possible that your problem will be solved in the latest release. If you tried that and it didn't work, then you should download the source code of the kernel you are running. Most distributions provide a special command for that, but to do it manually, you can find the source code on [kernel.org][13].
-
-You also must download whatever patch you need for your kernel. Sometimes, these patches are specific to the kernel release, so choose carefully.
-
-It's traditional, or at least it was back when people regularly compiled their own kernels, to place the source code and patches in **/usr/src/linux**.
-
-Unarchive the kernel source and the patch files as needed:
-
-
-```
-$ cd /usr/src/linux
-$ bzip2 --decompress linux-5.2.4.tar.bz2
-$ cd linux-5.2.4
-$ bzip2 -d ../patch*bz2
-```
-
-The patch file may have instructions on how to do the patch, but often they're designed to be executed from the top level of your tree:
-
-
-```
-`$ patch -p1 < patch*example.patch`
-```
-
-Once the kernel code is patched, you can use your old configuration to prepare the patched kernel config:
-
-
-```
-`$ make oldconfig`
-```
-
-The **make oldconfig** command serves two purposes: it inherits your current kernel's configuration, and it allows you to configure new options introduced by the patch.
-
-You may need to run the **make menuconfig** command, which launches an ncurses-based, menu-driven list of possible options for your new kernel. The menu can be overwhelming, but since it starts with your old config as a foundation, you can look through the menu and disable modules for hardware that you know you do not have and do not anticipate needing. Alternately, if you know that you have some piece of hardware and see it is not included in your current configuration, you may choose to build it, either as a module or directly into the kernel. In theory, this isn't necessary because presumably, your current kernel was treating you well but for the missing patch, and probably the patch you applied has activated all the necessary options required by whatever device prompted you to patch your kernel in the first place.
-
-Next, compile the kernel and its modules:
-
-
-```
-$ make bzImage
-$ make modules
-```
-
-This leaves you with a file named **vmlinuz**, which is a compressed version of your bootable kernel. Save your old version and place the new one in your **/boot** directory:
-
-
-```
-$ sudo mv /boot/vmlinuz /boot/vmlinuz.nopatch
-$ sudo cat arch/x86_64/boot/bzImage > /boot/vmlinuz
-$ sudo mv /boot/System.map /boot/System.map.stock
-$ sudo cp System.map /boot/System.map
-```
-
-So far, you've patched and built a kernel and its modules, you've installed the kernel, but you haven't installed any modules. That's the final build step:
-
-
-```
-`$ sudo make modules_install`
-```
-
-The new kernel is in place, and its modules are installed.
-
-The final step is to update your bootloader so that the part of your computer that loads before the kernel knows where to find Linux. The GRUB bootloader makes this process relatively simple:
-
-
-```
-`$ sudo grub2-mkconfig`
-```
-
-### Real-world compiling
-
-Of course, nobody runs those manual commands now. Instead, refer to your distribution for instructions on modifying a kernel using the developer toolset that your distribution's maintainers use. This toolset will probably create a new installable package with all the patches incorporated, alert the package manager of the upgrade, and update your bootloader for you.
-
-### Kernels
-
-Operating systems and kernels are mysterious things, but it doesn't take much to understand what components they're built upon. The next time you get a piece of tech that appears to not work on Linux, take a deep breath, investigate driver availability, and go with the path of least resistance. Linux is easier than ever—and that includes the kernel.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/linux-kernel-21st-century
-
-作者:[Seth Kenlon][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/sethhttps://opensource.com/users/greg-p
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/migration_innovation_computer_software.png?itok=VCFLtd0q (and old computer and a new computer, representing migration to new software or hardware)
-[2]: https://nouveau.freedesktop.org/wiki/
-[3]: http://fedoraproject.org
-[4]: http://ubuntu.com
-[5]: https://wiki.linuxfoundation.org/openprinting/database/foomatic
-[6]: https://www.cups.org/
-[7]: https://wireless.wiki.kernel.org/en/users/drivers
-[8]: https://opensource.com/article/19/7/reboot-linux
-[9]: https://opensource.com/sites/default/files/uploads/nvidia.jpg (Nvidia configuration application)
-[10]: https://linuxwacom.github.io
-[11]: https://developers.hp.com/hp-linux-imaging-and-printing
-[12]: https://opensource.com/sites/default/files/uploads/hplip.jpg (HPLIP in action)
-[13]: https://www.kernel.org/
diff --git a/sources/tech/20190826 How RPM packages are made- the source RPM.md b/sources/tech/20190826 How RPM packages are made- the source RPM.md
deleted file mode 100644
index 4629db3580..0000000000
--- a/sources/tech/20190826 How RPM packages are made- the source RPM.md
+++ /dev/null
@@ -1,238 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How RPM packages are made: the source RPM)
-[#]: via: (https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/)
-[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
-
-How RPM packages are made: the source RPM
-======
-
-![][1]
-
-In a [previous post, we looked at what RPM packages are][2]. They are archives that contain files and metadata. This metadata tells RPM where to create or remove files from when an RPM is installed or uninstalled. The metadata also contains information on “dependencies”, which you will remember from the previous post, can either be “runtime” or “build time”.
-
-As an example, we will look at _fpaste_. You can download the RPM using _dnf_. This will download the latest version of _fpaste_ that is available in the Fedora repositories. On Fedora 30, this is currently 0.3.9.2:
-
-```
-$ dnf download fpaste
-
-...
-fpaste-0.3.9.2-2.fc30.noarch.rpm
-```
-
-Since this is the built RPM, it contains only files needed to use _fpaste_:
-
-```
-$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.noarch.rpm
-/usr/bin/fpaste
-/usr/share/doc/fpaste
-/usr/share/doc/fpaste/README.rst
-/usr/share/doc/fpaste/TODO
-/usr/share/licenses/fpaste
-/usr/share/licenses/fpaste/COPYING
-/usr/share/man/man1/fpaste.1.gz
-```
-
-### Source RPMs
-
-The next link in the chain is the source RPM. All software in Fedora must be built from its source code. We do not include pre-built binaries. So, for an RPM file to be made, RPM (the tool) needs to be:
-
- * given the files that have to be installed,
- * told how to generate these files, if they are to be compiled, for example,
- * told where these files must be installed,
- * what other dependencies this particular software needs to work properly.
-
-
-
-The source RPM holds all of this information. Source RPMs are similar archives to RPM, but as the name suggests, instead of holding the built binary files, they contain the source files for a piece of software. Let’s download the source RPM for _fpaste_:
-
-```
-$ dnf download fpaste --source
-...
-fpaste-0.3.9.2-2.fc30.src.rpm
-```
-
-Notice how the file ends with “src.rpm”. All RPMs are built from source RPMs. You can easily check what source RPM a “binary” RPM comes from using dnf too:
-
-```
-$ dnf repoquery --qf "%{SOURCERPM}" fpaste
-fpaste-0.3.9.2-2.fc30.src.rpm
-```
-
-Also, since this is the source RPM, it does not contain built files. Instead, it contains the sources and instructions on how to build the RPM from them:
-
-```
-$ rpm -qpl ./fpaste-0.3.9.2-2.fc30.src.rpm
-fpaste-0.3.9.2.tar.gz
-fpaste.spec
-```
-
-Here, the first file is simply the source code for _fpaste_. The second is the “spec” file. The spec file is the recipe that tells RPM (the tool) how to create the RPM (the archive) using the sources contained in the source RPM—all the information that RPM (the tool) needs to build RPMs (the archives) are contained in spec files. When we package maintainers add software to Fedora, most of our time is spent writing and perfecting the individual spec files. When a software package needs an update, we go back and tweak the spec file. You can see the spec files for ALL packages in Fedora at our source repository at
-
-Note that one source RPM may contain the instructions to build multiple RPMs. _fpaste_ is a very simple piece of software, where one source RPM generates one “binary” RPM. Python, on the other hand is more complex. While there is only one source RPM, it generates multiple binary RPMs:
-
-```
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-devel
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-libs
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-idle
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-
-$ sudo dnf repoquery --qf "%{SOURCERPM}" python3-tkinter
-python3-3.7.3-1.fc30.src.rpm
-python3-3.7.4-1.fc30.src.rpm
-```
-
-In RPM jargon, “python3” is the “main package”, and so the spec file will be called “python3.spec”. All the other packages are “sub-packages”. You can download the source RPM for python3 and see what’s in it too. (Hint: patches are also part of the source code):
-
-```
-$ dnf download --source python3
-python3-3.7.4-1.fc30.src.rpm
-
-$ rpm -qpl ./python3-3.7.4-1.fc30.src.rpm
-00001-rpath.patch
-00102-lib64.patch
-00111-no-static-lib.patch
-00155-avoid-ctypes-thunks.patch
-00170-gc-assertions.patch
-00178-dont-duplicate-flags-in-sysconfig.patch
-00189-use-rpm-wheels.patch
-00205-make-libpl-respect-lib64.patch
-00251-change-user-install-location.patch
-00274-fix-arch-names.patch
-00316-mark-bdist_wininst-unsupported.patch
-Python-3.7.4.tar.xz
-check-pyc-timestamps.py
-idle3.appdata.xml
-idle3.desktop
-python3.spec
-```
-
-### Building an RPM from a source RPM
-
-Now that we have the source RPM, and know what’s in it, we can rebuild our RPM from it. Before we do so, though, we should set our system up to build RPMs. First, we install the required tools:
-
-```
-$ sudo dnf install fedora-packager
-```
-
-This will install the rpmbuild tool. rpmbuild requires a default layout so that it knows where each required component of the source rpm is. Let’s see what they are:
-
-```
-# Where should the spec file go?
-$ rpm -E %{_specdir}
-/home/asinha/rpmbuild/SPECS
-
-# Where should the sources go?
-$ rpm -E %{_sourcedir}
-/home/asinha/rpmbuild/SOURCES
-
-# Where is temporary build directory?
-$ rpm -E %{_builddir}
-/home/asinha/rpmbuild/BUILD
-
-# Where is the buildroot?
-$ rpm -E %{_buildrootdir}
-/home/asinha/rpmbuild/BUILDROOT
-
-# Where will the source rpms be?
-$ rpm -E %{_srcrpmdir}
-/home/asinha/rpmbuild/SRPMS
-
-# Where will the built rpms be?
-$ rpm -E %{_rpmdir}
-/home/asinha/rpmbuild/RPMS
-```
-
-I have all of this set up on my system already:
-
-```
-$ cd
-$ tree -L 1 rpmbuild/
-rpmbuild/
-├── BUILD
-├── BUILDROOT
-├── RPMS
-├── SOURCES
-├── SPECS
-└── SRPMS
-
-6 directories, 0 files
-```
-
-RPM provides a tool that sets it all up for you too:
-
-```
-$ rpmdev-setuptree
-```
-
-Then we ensure that we have all the build dependencies for _fpaste_ installed:
-
-```
-sudo dnf builddep fpaste-0.3.9.2-3.fc30.src.rpm
-```
-
-For _fpaste_ you only need Python and that must already be installed on your system (dnf uses Python too). The builddep command can also be given a spec file instead of an source RPM. Read more in the man page:
-
-```
-$ man dnf.plugin.builddep
-```
-
-Now that we have all that we need, building an RPM from a source RPM is as simple as:
-
-```
-$ rpmbuild --rebuild fpaste-0.3.9.2-3.fc30.src.rpm
-..
-..
-
-$ tree ~/rpmbuild/RPMS/noarch/
-/home/asinha/rpmbuild/RPMS/noarch/
-└── fpaste-0.3.9.2-3.fc30.noarch.rpm
-
-0 directories, 1 file
-```
-
-rpmbuild will install the source RPM and build your RPM from it. You can now install the RPM to use it as you do–using dnf. Of course, as said before, if you want to change anything in the RPM, you must modify the spec file—we’ll cover spec files in next post.
-
-### Summary
-
-To summarise this post in two short points:
-
- * the RPMs we generally install to use software are “binary” RPMs that contain built versions of the software
- * these are built from source RPMs that include the source code and the spec file that are needed to generate the binary RPMs.
-
-
-
-If you’d like to get started with building RPMs, and help the Fedora community maintain the massive amount of software we provide, you can start here:
-
-For any queries, post to the [Fedora developers mailing list][3]—we’re always happy to help!
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/
-
-作者:[Ankur Sinha "FranciscoD"][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/ankursinha/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
-[2]: https://fedoramagazine.org/rpm-packages-explained/
-[3]: https://lists.fedoraproject.org/archives/list/devel@lists.fedoraproject.org/
diff --git a/sources/tech/20190826 Introduction to the Linux chown command.md b/sources/tech/20190826 Introduction to the Linux chown command.md
deleted file mode 100644
index cb79c6fec6..0000000000
--- a/sources/tech/20190826 Introduction to the Linux chown command.md
+++ /dev/null
@@ -1,138 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Introduction to the Linux chown command)
-[#]: via: (https://opensource.com/article/19/8/linux-chown-command)
-[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdosshttps://opensource.com/users/sethhttps://opensource.com/users/alanfdosshttps://opensource.com/users/sethhttps://opensource.com/users/greg-phttps://opensource.com/users/alanfdoss)
-
-Introduction to the Linux chown command
-======
-Learn how to change a file or directory's ownership with chown.
-![Hand putting a Linux file folder into a drawer][1]
-
-Every file and directory on a Linux system is owned by someone, and the owner has complete control to change or delete the files they own. In addition to having an owning _user_, a file has an owning _group_.
-
-You can view the ownership of a file using the **ls -l** command:
-
-
-```
-[pablo@workstation Downloads]$ ls -l
-total 2454732
--rw-r--r--. 1 pablo pablo 1934753792 Jul 25 18:49 Fedora-Workstation-Live-x86_64-30-1.2.iso
-```
-
-The third and fourth columns of the output are the owning user and group, which together are referred to as _ownership_. Both are **pablo** for the ISO file above.
-
-The ownership settings, set by the [**chmod** command][2], control who is allowed to perform read, write, or execute actions. You can change ownership (one or both) with the **chown** command.
-
-It is often necessary to change ownership. Files and directories can live a long time on a system, but users can come and go. Ownership may also need to change when files and directories are moved around the system or from one system to another.
-
-The ownership of the files and directories in my home directory are my user and my primary group, represented in the form **user:group**. Suppose Susan is managing the Delta group, which needs to edit a file called **mynotes**. You can use the **chown** command to change the user to **susan** and the group to **delta**:
-
-
-```
-$ chown susan:delta mynotes
-ls -l
--rw-rw-r--. 1 susan delta 0 Aug 1 12:04 mynotes
-```
-
-Once the Delta group is finished with the file, it can be assigned back to me:
-
-
-```
-$ chown alan mynotes
-$ ls -l mynotes
--rw-rw-r--. 1 alan delta 0 Aug 1 12:04 mynotes
-```
-
-Both the user and group can be assigned back to me by appending a colon (**:**) to the user:
-
-
-```
-$ chown alan: mynotes
-$ ls -l mynotes
--rw-rw-r--. 1 alan alan 0 Aug 1 12:04 mynotes
-```
-
-By prepending the group with a colon, you can change just the group. Now members of the **gamma** group can edit the file:
-
-
-```
-$ chown :gamma mynotes
-$ ls -l
--rw-rw-r--. 1 alan gamma 0 Aug 1 12:04 mynotes
-```
-
-A few additional arguments to chown can be useful at both the command line and in a script. Just like many other Linux commands, chown has a recursive argument ****(**-R**) which tells the command to descend into the directory to operate on all files inside. Without the **-R** flag, you change permissions of the folder only, leaving the files inside it unchanged. In this example, assume that the intent is to change permissions of a directory and all its contents. Here I have added the **-v** (verbose) argument so that chown reports what it is doing:
-
-
-```
-$ ls -l . conf
-.:
-drwxrwxr-x 2 alan alan 4096 Aug 5 15:33 conf
-
-conf:
--rw-rw-r-- 1 alan alan 0 Aug 5 15:33 conf.xml
-
-$ chown -vR susan:delta conf
-changed ownership of 'conf/conf.xml' from alan:alan to susan:delta
-changed ownership of 'conf' from alan:alan to susan:delta
-```
-
-Depending on your role, you may need to use **sudo** to change ownership of a file.
-
-You can use a reference file (**\--reference=RFILE**) when changing the ownership of files to match a certain configuration or when you don't know the ownership (as might be the case when running a script). You can duplicate the user and group of another file (**RFILE**, known as a reference file), for example, to undo the changes made above. Recall that a dot (**.**) refers to the present working directory.
-
-
-```
-`$ chown -vR --reference=. conf`
-```
-
-### Report Changes
-
-Most commands have arguments for controlling their output. The most common is **-v** (-**-verbose**) to enable verbose, but chown also has a **-c** (**\--changes**) argument to instruct chown to only report when a change is made. Chown still reports other things, such as when an operation is not permitted.
-
-The argument **-f** (**\--silent**, **\--quiet**) is used to suppress most error messages. I will use **-f** and the **-c** in the next section so that only actual changes are shown.
-
-### Preserve Root
-
-The root (**/**) of the Linux filesystem should be treated with great respect. If a mistake is made at this level, the consequences could leave a system completely useless. Particularly when you are running a recursive command that makes any kind of change or worse: deletions. The chown command has an argument that can be used to protect and preserve the root. The argument is **\--preserve-root**. If this argument is used with a recursive chown command on the root, nothing is done and a message appears instead.
-
-
-```
-$ chown -cfR --preserve-root alan /
-chown: it is dangerous to operate recursively on '/'
-chown: use --no-preserve-root to override this failsafe
-```
-
-The option has no effect when not used in conjunction with **\--recursive**. However, if the command is run by the root user, the permissions of the **/** itself will be changed, but not of other files or directories within.
-
-
-```
-$ chown -c --preserve-root alan /
-chown: changing ownership of '/': Operation not permitted
-[root@localhost /]# chown -c --preserve-root alan /
-changed ownership of '/' from root to alan
-```
-
-### Ownership is security
-
-File and directory ownership is part of good information security, so it's important to occasionally check and maintain file ownership to prevent unwanted access. The chown command is one of the most common and important in the set of Linux security commands.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/linux-chown-command
-
-作者:[Alan Formy-Duval][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/alanfdosshttps://opensource.com/users/sethhttps://opensource.com/users/alanfdosshttps://opensource.com/users/sethhttps://opensource.com/users/greg-phttps://opensource.com/users/alanfdoss
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
-[2]: https://opensource.com/article/19/8/introduction-linux-chmod-command
diff --git a/sources/tech/20190827 curl exercises.md b/sources/tech/20190827 curl exercises.md
new file mode 100644
index 0000000000..36eae2743b
--- /dev/null
+++ b/sources/tech/20190827 curl exercises.md
@@ -0,0 +1,84 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (curl exercises)
+[#]: via: (https://jvns.ca/blog/2019/08/27/curl-exercises/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+curl exercises
+======
+
+Recently I’ve been interested in how people learn things. I was reading Kathy Sierra’s great book [Badass: Making Users Awesome][1]. It talks about the idea of _deliberate practice_.
+
+The idea is that you find a small micro-skill that can be learned in maybe 3 sessions of 45 minutes, and focus on learning that micro-skill. So, as an exercise, I was trying to think of a computer skill that I thought could be learned in 3 45-minute sessions.
+
+I thought that making HTTP requests with `curl` might be a skill like that, so here are some curl exercises as an experiment!
+
+### what’s curl?
+
+curl is a command line tool for making HTTP requests. I like it because it’s an easy way to test that servers or APIs are doing what I think, but it’s a little confusing at first!
+
+Here’s a drawing explaining curl’s most important command line arguments (which is page 6 of my [Bite Size Networking][2] zine). You can click to make it bigger.
+
+
+
+### fluency is valuable
+
+With any command line tool, I think having fluency is really helpful. It’s really nice to be able to just type in the thing you need. For example recently I was testing out the Gumroad API and I was able to just type in:
+
+```
+curl https://api.gumroad.com/v2/sales \
+ -d "access_token=" \
+ -X GET -d "before=2016-09-03"
+```
+
+and get things working from the command line.
+
+### 21 curl exercises
+
+These exercises are about understanding how to make different kinds of HTTP requests with curl. They’re a little repetitive on purpose. They exercise basically everything I do with curl.
+
+To keep it simple, we’re going to make a lot of our requests to the same website: . httpbin is a service that accepts HTTP requests and then tells you what request you made.
+
+ 1. Request
+ 2. Request . httpbin.org/anything will look at the request you made, parse it, and echo back to you what you requested. curl’s default is to make a GET request.
+ 3. Make a POST request to
+ 4. Make a GET request to , but this time add some query parameters (set `value=panda`).
+ 5. Request google’s robots.txt file ([www.google.com/robots.txt][3])
+ 6. Make a GET request to and set the header `User-Agent: elephant`.
+ 7. Make a DELETE request to
+ 8. Request and also get the response headers
+ 9. Make a POST request to with the JSON body `{"value": "panda"}`
+ 10. Make the same POST request as the previous exercise, but set the Content-Type header to `application/json` (because POST requests need to have a content type that matches their body). Look at the `json` field in the response to see the difference from the previous one.
+ 11. Make a GET request to and set the header `Accept-Encoding: gzip` (what happens? why?)
+ 12. Put a bunch of a JSON in a file and then make a POST request to with the JSON in that file as the body
+ 13. Make a request to and set the header ‘Accept: image/png’. Save the output to a PNG file and open the file in an image viewer. Try the same thing with with different `Accept:` headers.
+ 14. Make a PUT request to
+ 15. Request , save it to a file, and open that file in your image editor.
+ 16. Request . You’ll get an empty response. Get curl to show you the response headers too, and try to figure out why the response was empty.
+ 17. Make any request to and just set some nonsense headers (like `panda: elephant`)
+ 18. Request and . Request them again and get curl to show the response headers.
+ 19. Request and set a username and password (with `-u username:password`)
+ 20. Download the Twitter homepage () in Spanish by setting the `Accept-Language: es-ES` header.
+ 21. Make a request to the Stripe API with curl. (see for how, they give you a test API key). Try making exactly the same request to .
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/08/27/curl-exercises/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://www.amazon.com/Badass-Making-Awesome-Kathy-Sierra/dp/1491919019
+[2]: https://wizardzines.com/zines/bite-size-networking
+[3]: http://www.google.com/robots.txt
diff --git a/sources/tech/20190828 Managing Ansible environments on MacOS with Conda.md b/sources/tech/20190828 Managing Ansible environments on MacOS with Conda.md
deleted file mode 100644
index 7aa3a4181b..0000000000
--- a/sources/tech/20190828 Managing Ansible environments on MacOS with Conda.md
+++ /dev/null
@@ -1,174 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Managing Ansible environments on MacOS with Conda)
-[#]: via: (https://opensource.com/article/19/8/using-conda-ansible-administration-macos)
-[#]: author: (James Farrell https://opensource.com/users/jamesf)
-
-Managing Ansible environments on MacOS with Conda
-======
-Conda corrals everything you need for Ansible into a virtual environment
-and keeps it separate from your other projects.
-![CICD with gears][1]
-
-If you are a Python developer using MacOS and involved with Ansible administration, you may want to use the Conda package manager to keep your Ansible work separate from your core OS and other local projects.
-
-Ansible is based on Python. Conda is not required to make Ansible work on MacOS, but it does make managing Python versions and package dependencies easier. This allows you to use an upgraded Python version on MacOS and keep Python package dependencies separate between your system, Ansible, and other programming projects.
-
-There are other ways to install Ansible on MacOS. You could use [Homebrew][2], but if you are into Python development (or Ansible development), you might find managing Ansible in a Python virtual environment reduces some confusion. I find this to be simpler; rather than trying to load a Python version and dependencies into the system or in **/usr/local**, Conda helps me corral everything I need for Ansible into a virtual environment and keep it all completely separate from other projects.
-
-This article focuses on using Conda to manage Ansible as a Python project to keep it clean and separated from other projects. Read on to learn how to install Conda, create a new virtual environment, install Ansible, and test it.
-
-### Prelude
-
-Recently, I wanted to learn [Ansible][3], so I needed to figure out the best way to install it.
-
-I am generally wary of installing things into my daily use workstation. I especially dislike applying manual updates to the vendor's default OS installation (a preference I developed from years of Unix system administration). I really wanted to use Python 3.7, but MacOS packages the older 2.7, and I was not going to install any global Python packages that might interfere with the core MacOS system.
-
-So, I started my Ansible work using a local Ubuntu 18.04 virtual machine. This provided a real level of safe isolation, but I soon found that managing it was tedious. I set out to see how to get a flexible but isolated Ansible system on native MacOS.
-
-Since Ansible is based on Python, Conda seemed to be the ideal solution.
-
-### Installing Conda
-
-Conda is an open source utility that provides convenient package- and environment-management features. It can help you manage multiple versions of Python, install package dependencies, perform upgrades, and maintain project isolation. If you are manually managing Python virtual environments, Conda will help streamline and manage your work. Surf on over to the [Conda documentation][4] for all the details.
-
-I chose the [Miniconda][5] Python 3.7 installation for my workstation because I wanted the latest Python version. Regardless of which version you select, you can always install new virtual environments with other versions of Python.
-
-To install Conda, download the PKG format file, do the usual double-click, and select the "Install for me only" option. The install took about 158MB of space on my system.
-
-After the installation, bring up a terminal to see what you have. You should see:
-
- * A new **miniconda3** directory in your **home**
- * The shell prompt modified to prepend the word "(base)"
- * **.bash_profile** updated with Conda-specific settings
-
-
-
-Now that the base is installed, you have your first Python virtual environment. Running the usual Python version check should prove this, and your PATH will point to the new location:
-
-
-```
-(base) $ which python
-/Users/jfarrell/miniconda3/bin/python
-(base) $ python --version
-Python 3.7.1
-```
-
-Now that Conda is installed, the next step is to set up a virtual environment, then get Ansible installed and running.
-
-### Creating a virtual environment for Ansible
-
-I want to keep Ansible separate from my other Python projects, so I created a new virtual environment and switched over to it:
-
-
-```
-(base) $ conda create --name ansible-env --clone base
-(base) $ conda activate ansible-env
-(ansible-env) $ conda env list
-```
-
-The first command clones the Conda base into a new virtual environment called **ansible-env**. The clone brings in the Python 3.7 version and a bunch of default Python modules that you can add to, remove, or upgrade as needed.
-
-The second command changes the shell context to this new **ansible-env** environment. It sets the proper paths for Python and the modules it contains. Notice that your shell prompt changes after the **conda activate ansible-env** command.
-
-The third command is not required; it lists what Python modules are installed with their version and other data.
-
-You can always switch out of a virtual environment and into another with Conda's **activate** command. This will bring you back to the base: **conda activate base**.
-
-### Installing Ansible
-
-There are various ways to install Ansible, but using Conda keeps the Ansible version and all desired dependencies packaged in one place. Conda provides the flexibility both to keep everything separated and to add in other new environments as needed (as I'll demonstrate later).
-
-To install a relatively recent version of Ansible, use:
-
-
-```
-(base) $ conda activate ansible-env
-(ansible-env) $ conda install -c conda-forge ansible
-```
-
-Since Ansible is not part of Conda's default channels, the **-c** is used to search and install from an alternate channel. Ansible is now installed into the **ansible-env** virtual environment and is ready to use.
-
-### Using Ansible
-
-Now that you have installed a Conda virtual environment, you're ready to use it. First, make sure the node you want to control has your workstation's SSH key installed to the right user account.
-
-Bring up a new shell and run some basic Ansible commands:
-
-
-```
-(base) $ conda activate ansible-env
-(ansible-env) $ ansible --version
-ansible 2.8.1
- config file = None
- configured module search path = ['/Users/jfarrell/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
- ansible python module location = /Users/jfarrell/miniconda3/envs/ansibleTest/lib/python3.7/site-packages/ansible
- executable location = /Users/jfarrell/miniconda3/envs/ansibleTest/bin/ansible
- python version = 3.7.1 (default, Dec 14 2018, 13:28:58) [Clang 4.0.1 (tags/RELEASE_401/final)]
-(ansible-env) $ ansible all -m ping -u ansible
-192.168.99.200 | SUCCESS => {
- "ansible_facts": {
- "discovered_interpreter_python": "/usr/bin/python"
- },
- "changed": false,
- "ping": "pong"
-}
-```
-
-Now that Ansible is working, you can pull your playbooks out of source control and start using them from your MacOS workstation.
-
-### Cloning the new Ansible for Ansible development
-
-This part is purely optional; it's only needed if you want additional virtual environments to modify Ansible or to safely experiment with questionable Python modules. You can clone your main Ansible environment into a development copy with:
-
-
-```
-(ansible-env) $ conda create --name ansible-dev --clone ansible-env
-(ansible-env) $ conda activte ansible-dev
-(ansible-dev) $
-```
-
-### Gotchas to look out for
-
-Occasionally you may get into trouble with Conda. You can usually delete a bad environment with:
-
-
-```
-$ conda activate base
-$ conda remove --name ansible-dev --all
-```
-
-If you get errors that you cannot resolve, you can usually delete the environment directly by finding it in **~/miniconda3/envs** and removing the entire directory. If the base becomes corrupt, you can remove the entire **~/miniconda3** directory and reinstall it from the PKG file. Just be sure to preserve any desired environments you have in **~/miniconda3/envs**, or use the Conda tools to dump the environment configuration and recreate it later.
-
-The **sshpass** program is not included on MacOS. It is needed only if your Ansible work requires you to supply Ansible with an SSH login password. You can find the current [sshpass source][6] on SourceForge.
-
-Finally, the base Conda Python module list may lack some Python modules you need for your work. If you need to install one, the **conda install <package>** command is preferred, but **pip** can be used where needed, and Conda will recognize the install modules.
-
-### Conclusion
-
-Ansible is a powerful automation utility that's worth all the effort to learn. Conda is a simple and effective Python virtual environment management tool.
-
-Keeping software installs separated on your MacOS environment is a prudent approach to maintain stability and sanity with your daily work environment. Conda can be especially helpful to upgrade your Python version, separate Ansible from your other projects, and safely hack on Ansible.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/8/using-conda-ansible-administration-macos
-
-作者:[James Farrell][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/jamesf
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cicd_continuous_delivery_deployment_gears.png?itok=kVlhiEkc (CICD with gears)
-[2]: https://brew.sh/
-[3]: https://docs.ansible.com/?extIdCarryOver=true&sc_cid=701f2000001OH6uAAG
-[4]: https://conda.io/projects/conda/en/latest/index.html
-[5]: https://docs.conda.io/en/latest/miniconda.html
-[6]: https://sourceforge.net/projects/sshpass/
diff --git a/sources/tech/20190830 How to Install Linux on Intel NUC.md b/sources/tech/20190830 How to Install Linux on Intel NUC.md
deleted file mode 100644
index 86d73c5ddc..0000000000
--- a/sources/tech/20190830 How to Install Linux on Intel NUC.md
+++ /dev/null
@@ -1,191 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Install Linux on Intel NUC)
-[#]: via: (https://itsfoss.com/install-linux-on-intel-nuc/)
-[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
-
-How to Install Linux on Intel NUC
-======
-
-The previous week, I got myself an [Intel NUC][1]. Though it is a tiny device, it is equivalent to a full-fledged desktop CPU. Most of the [Linux-based mini PCs][2] are actually built on top of the Intel NUC devices.
-
-I got the ‘barebone’ NUC with 8th generation Core i3 processor. Barebone means that the device has no RAM, no hard disk and obviously, no operating system. I added an [8GB RAM from Crucial][3] (around $33) and a [240 GB Western Digital SSD][4] (around $45).
-
-Altogether, I had a desktop PC ready in under $400. I already have a screen and keyboard-mouse pair so I am not counting them in the expense.
-
-![A brand new Intel NUC NUC8i3BEH at my desk with Raspberry Pi 4 lurking behind][5]
-
-The main reason why I got Intel NUC is that I want to test and review various Linux distributions on real hardware. I have a [Raspberry Pi 4][6] which works as an entry-level desktop but it’s an [ARM][7] device and thus there are only a handful of Linux distributions available for Raspberry Pi.
-
-_The Amazon links in the article are affiliate links. Please read our [affiliate policy][8]._
-
-### Installing Linux on Intel NUC
-
-I started with Ubuntu 18.04 LTS version because that’s what I had available at the moment. You can follow this tutorial for other distributions as well. The steps should remain the same at least till the partition step which is the most important one in the entire procedure.
-
-#### Step 1: Create a live Linux USB
-
-Download Ubuntu 18.04 from its website. Use another computer to [create a live Ubuntu USB][9]. You can use a tool like [Rufus][10] or [Etcher][11]. On Ubuntu, you can use the default Startup Disk Creator tool.
-
-#### Step 2: Make sure the boot order is correct
-
-Insert your USB and power on the NUC. As soon as you see the Intel NUC written on the screen, press F2 to go to BIOS settings.
-
-![BIOS Settings in Intel NUC][12]
-
-In here, just make sure that boot order is set to boot from USB first. If not, change the boot order.
-
-If you had to make any changes, press F10 to save and exit. Else, use Esc to exit the BIOS.
-
-#### Step 3: Making the correct partition to install Linux
-
-Now when it boots again, you’ll see the familiar Grub screen that allows you to try Ubuntu live or install it. Choose to install it.
-
-[][13]
-
-Suggested read 3 Ways to Check Linux Kernel Version in Command Line
-
-First few installation steps are simple. You choose the keyboard layout, and the network connection (if any) and other simple steps.
-
-![Choose the keyboard layout while installing Ubuntu Linux][14]
-
-You may go with the normal installation that has a handful of useful applications installed by default.
-
-![][15]
-
-The interesting screen comes next. You have two options:
-
- * **Erase disk and install Ubuntu**: Simplest option that will install Ubuntu on the entire disk. If you want to use only one operating system on the Intel NUC, choose this option and Ubuntu will take care of the rest.
- * **Something Else**: This is the advanced option if you want to take control of things. In my case, I want to install multiple Linux distribution on the same SSD. So I am opting for this advanced option.
-
-
-
-![][16]
-
-_**If you opt for “Erase disk and install Ubuntu”, click continue and go to the step 4.**_
-
-If you are going with the advanced option, follow the rest of the step 3.
-
-Select the SSD disk and click on New Partition Table.
-
-![][17]
-
-It will show you a warning. Just hit Continue.
-
-![][18]
-
-Now you’ll see a free space of the size of your SSD disk. My idea is to create an EFI System Partition for the EFI boot loader, a root partition and a home partition. I am not creating a [swap partition][19]. Ubuntu creates a swap file on its own and if the need be, I can extend the swap by creating additional swap files.
-
-I’ll leave almost 200 GB of free space on the disk so that I could install other Linux distributions here. You can utilize all of it for your home partitions. Keeping separate root and home partitions help you when you want to save reinstall the system
-
-Select the free space and click on the plus sign to add a partition.
-
-![][20]
-
-Usually 100 MB is sufficient for the EFI but some distributions may need more space so I am going with 500 MB of EFI partition.
-
-![][21]
-
-Next, I am using 20 GB of root space. If you are going to use only one distributions, you can increase it to 40 GB easily.
-
-Root is where the system files are kept. Your program cache and installed applications keep some files under the root directory. I recommend [reading about the Linux filesystem hierarchy][22] to get more knowledge on this topic.
-
-[][23]
-
-Suggested read Share Folders On Local Network Between Ubuntu And Windows
-
-Provide the size, choose Ext4 file system and use / as the mount point.
-
-![][24]
-
-The next is to create a home partition. Again, if you want to use only one Linux distribution, go for the remaining free space. Else, choose a suitable disk space for the Home partition.
-
-Home is where your personal documents, pictures, music, download and other files are stored.
-
-![][25]
-
-Now that you have created EFI, root and home partitions, you are ready to install Ubuntu Linux. Hit the Install Now button.
-
-![][26]
-
-It will give you a warning about the new changes being written to the disk. Hit continue.
-
-![][27]
-
-#### Step 4: Installing Ubuntu Linux
-
-Things are pretty straightforward from here onward. Choose your time zone right now or change it later.
-
-![][28]
-
-On the next screen, choose a username, hostname and the password.
-
-![][29]
-
-It’s a wait an watch game for next 7-8 minutes.
-
-![][30]
-
-Once the installation is over, you’ll be prompted for a restart.
-
-![][31]
-
-When you restart, you should remove the live USB otherwise you’ll boot into the installation media again.
-
-That’s all you need to do to install Linux on an Intel NUC device. Quite frankly, you can use the same procedure on any other system.
-
-**Intel NUC and Linux: how do you use it?**
-
-I am loving the Intel NUC. It doesn’t take space on the desk and yet it is powerful enough to replace the regular bulky desktop CPU. You can easily upgrade it to 32GB of RAM. You can install two SSD on it. Altogether, it provides some scope of configuration and upgrade.
-
-If you are looking to buy a desktop computer, I highly recommend [Intel NUC][1] mini PC. If you are not comfortable installing the OS on your own, you can [buy one of the Linux-based mini PCs][2].
-
-Do you own an Intel NUC? How’s your experience with it? Do you have any tips to share it with us? Do leave a comment below.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/install-linux-on-intel-nuc/
-
-作者:[Abhishek Prakash][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/abhishek/
-[b]: https://github.com/lujun9972
-[1]: https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW (Intel NUC)
-[2]: https://itsfoss.com/linux-based-mini-pc/
-[3]: https://www.amazon.com/Crucial-Single-PC4-19200-SODIMM-260-Pin/dp/B01BIWKP58?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01BIWKP58 (8GB RAM from Crucial)
-[4]: https://www.amazon.com/Western-Digital-240GB-Internal-WDS240G1G0B/dp/B01M9B2VB7?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01M9B2VB7 (240 GB Western Digital SSD)
-[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/intel-nuc.jpg?resize=800%2C600&ssl=1
-[6]: https://itsfoss.com/raspberry-pi-4/
-[7]: https://en.wikipedia.org/wiki/ARM_architecture
-[8]: https://itsfoss.com/affiliate-policy/
-[9]: https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/
-[10]: https://rufus.ie/
-[11]: https://www.balena.io/etcher/
-[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/boot-screen-nuc.jpg?ssl=1
-[13]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
-[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-1_tutorial.jpg?ssl=1
-[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-2_tutorial.jpg?ssl=1
-[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-3_tutorial.jpg?ssl=1
-[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-4_tutorial.jpg?ssl=1
-[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-5_tutorial.jpg?ssl=1
-[19]: https://itsfoss.com/swap-size/
-[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-6_tutorial.jpg?ssl=1
-[21]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-7_tutorial.jpg?ssl=1
-[22]: https://linuxhandbook.com/linux-directory-structure/
-[23]: https://itsfoss.com/share-folders-local-network-ubuntu-windows/
-[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-8_tutorial.jpg?ssl=1
-[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-9_tutorial.jpg?ssl=1
-[26]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-10_tutorial.jpg?ssl=1
-[27]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-11_tutorial.jpg?ssl=1
-[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-12_tutorial.jpg?ssl=1
-[29]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-13_tutorial.jpg?ssl=1
-[30]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-14_tutorial.jpg?ssl=1
-[31]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-15_tutorial.jpg?ssl=1
diff --git a/sources/tech/20190901 Best Linux Distributions For Everyone in 2019.md b/sources/tech/20190901 Best Linux Distributions For Everyone in 2019.md
deleted file mode 100644
index 6959b35d60..0000000000
--- a/sources/tech/20190901 Best Linux Distributions For Everyone in 2019.md
+++ /dev/null
@@ -1,392 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Best Linux Distributions For Everyone in 2019)
-[#]: via: (https://itsfoss.com/best-linux-distributions/)
-[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-
-Best Linux Distributions For Everyone in 2019
-======
-
-_**Brief: Which is the best Linux distribution? There is no definite answer to that question. This is why we have compiled this list of best Linux in various categories.**_
-
-There are a lot of Linux distributions. I can’t even think of coming up with an exact number because you would find loads of Linux distros that differ from one another in one way or the other.
-
-Some of them just turn out to be a clone of one another while some of them tend to be unique. So, it’s kind of a mess – but that is the beauty of Linux.
-
-Fret not, even though there are thousands of distributions around, in this article, I have compiled a list of the best Linux distros available right now. Of course, the list can be subjective. But, here, we try to categorize the distros – so there’s something for everyone.
-
- * [Best distribution for new Linux users][1]
- * [Best Linux distros for servers][2]
- * [Best Linux distros that can run on old computers][3]
- * [Best distributions for advanced Linux users][4]
- * [Best evergreen Linux distributions][5]
-
-
-
-**Note:** _The list is in no particular order of ranking._
-
-### Best Linux Distributions for Beginners
-
-In this category, we aim to list the distros which are easy-to-use out of the box. You do not need to dig deeper, you can just start using it right away after installation without needing to know any commands or tips.
-
-#### Ubuntu
-
-![][6]
-
-Ubuntu is undoubtedly one of the most popular Linux distributions. You can even find it pre-installed on a lot of laptops available.
-
-The user interface is easy to get comfortable with. If you play around, you can easily customize the look of it as per your requirements. In either case, you can opt to install a theme as well. You can learn more about [how to install themes in Ubuntu][7] to get started.
-
-In addition to what it offers, you will find a huge online community of Ubuntu users. So, if you face an issue – head to any of the forums (or a subreddit) to ask for help. If you are looking for direct solutions in no time, you should check out our coverage on [Ubuntu][8] (where we have a lot of tutorials and recommendations for Ubuntu).
-
-[Ubuntu][9]
-
-#### Linux Mint
-
-![Linux Mint 19 Cinnamon desktop screenshot][10]
-
-Linux Mint Cinnamon is another popular Linux distribution among beginners. The default Cinnamon desktop resembles Windows XP and this is why many users opted for it when Windows XP was discontinued.
-
-Linux Mint is based on Ubuntu and thus it has all the applications available for Ubuntu. The simplicity and ease of use is why it has become a prominent choice for new Linux users.
-
-[Linux Mint][11]
-
-#### elementary OS
-
-![][12]
-
-elementary OS is one of the most beautiful Linux distros I’ve ever used. The UI resembles that of Mac OS – so if you have already used a Mac-powered system, it’s easy to get comfortable with.
-
-This distribution is based on Ubuntu and focuses to deliver a user-friendly Linux environment which looks as pretty as possible while keeping the performance in mind. If you choose to install elementary OS, a list of [11 things to do after installing elementary OS][13] should come in handy.
-
-[elementary OS][14]
-
-#### MX Linux
-
-![][15]
-
-MX Linux came in the limelight almost a year ago. Now (at the time of publishing this), it is the most popular Linux distro on [DistroWatch.com][16]. If you haven’t used it yet – you will be surprised when you get to use it.
-
-Unlike Ubuntu, MX Linux is a [rolling release distribution][17] based on Debian with Xfce as its desktop environment. In addition to its impeccable stability – it comes packed with a lot of GUI tools which makes it easier for any user comfortable with Windows/Mac originally.
-
-Also, the package manager is perfectly tailored to facilitate one-click installations. You can even search for [Flatpak][18] packages and install it in no time (Flathub is available by default in the package manager as one of the sources).
-
-[MX Linux][19]
-
-#### Zorin OS
-
-![][20]
-
-Zorin OS is yet another Ubuntu-based distribution which happens to be one of the most good-looking and intuitive OS for desktop. Especially, after [Zorin OS 15 release][21] – I would definitely recommend it for users without any Linux background. A lot of GUI-based applications comes baked in as well.
-
-You can also install it on older PCs – however, make sure to choose the “Lite” edition. In addition, you have “Core”, “Education” & “Ultimate” editions. You can choose to install the Core edition for free – but if you want to support the developers and help improve Zorin, consider getting the Ultimate edition.
-
-Zorin OS was started by two teenagers based in Ireland. You may [read their story here][22].
-
-[Zorin OS][23]
-
-**Other Options**
-
-[Deepin][24] and other flavors of Ubuntu (like Kubuntu, Xubuntu) could also be some of the preferred choices for beginners. You can take a look at them if you want to explore more options.
-
-If you want a challenge, you can indeed try Fedora over Ubuntu – but make sure to follow our article on [Ubuntu vs Fedora][25] to make a better decision from the desktop point of view.
-
-### Best Linux Server Distributions
-
-For servers, the choice of a Linux distro comes down to stability, performance, and enterprise support. If you are just experimenting, you can try any distro you want.
-
-But, if you are installing it for a web server or anything vital – you should take a look at some of our recommendations.
-
-#### Ubuntu Server
-
-Depending on where you want it, Ubuntu provides different options for your server. If you are looking for an optimized solution to run on AWS, Azure, Google Cloud Platform, etc., [Ubuntu Cloud][26] is the way to go.
-
-In either case, you can opt for Ubuntu Server packages and have it installed on your server. Nevertheless, Ubuntu is the most popular Linux distro when it comes to deployment on the cloud (judging by the numbers – [source 1][27], [source 2][28]).
-
-Do note that we recommend you to go for the LTS editions – unless you have specific requirements.
-
-[Ubuntu Server][29]
-
-#### Red Hat Enterprise Linux
-
-Red Hat Enterprise Linux is a top-notch Linux platform for businesses and organizations. If we go by the numbers, Red Hat may not be the most popular choice for servers. But, there’s a significant group of enterprise users who rely on RHEL (like Lenovo).
-
-Technically, Fedora and Red Hat are related. Whatever Red Hat supports – gets tested on Fedora before making it available for RHEL. I’m not an expert on server distributions for tailored requirements – so you should definitely check out their [official documentation][30] to know if it’s suitable for you.
-
-[Red Hat Enterprise Linux][31]
-
-#### SUSE Linux Enterprise Server
-
-![Suse Linux Enterprise \(Image: Softpedia\)][32]
-
-Fret not, do not confuse this with OpenSUSE. Everything comes under a common brand “SUSE” – but OpenSUSE is an open-source distro targeted and yet, maintained by the community.
-
-SUSE Linux Enterprise Server is one of the most popular solutions for cloud-based servers. You will have to opt for a subscription in order to get priority support and assistance to manage your open source solution.
-
-[SUSE Linux Enterprise Server][33]
-
-#### CentOS
-
-![][34]
-
-As I mentioned, you need a subscription for RHEL. But, CentOS is more like a community edition of RHEL because it has been derived from the sources of Red Hat Enterprise Linux. And, it is open source and free as well. Even though the number of hosting providers using CentOS is significantly less compared to the last few years – it still is a great choice.
-
-CentOS may not come loaded with the latest software packages – but it is considered as one of the most stable distros. You should find CentOS images on a variety of cloud platforms. If you don’t, you can always opt for the self-hosted image that CentOS provides.
-
-[CentOS][35]
-
-**Other Options**
-
-You can also try exploring [Fedora Server][36] or [Debian][37] as alternatives to some of the distros mentioned above.
-
-![Coding][38]
-
-![Coding][38]
-
-If you are into programming and software development check out the list of
-
-[Best Linux Distributions for Programmers][39]
-
-![Hacking][40]
-
-![Hacking][40]
-
-Interested in learning and practicing cyber security? Check out the list of
-
-[Best Linux Distribution for Hacking and Pen-Testing][41]
-
-### Best Linux Distributions for Older Computers
-
-If you have an old PC laying around or if you didn’t really need to upgrade your system – you can still try some of the best Linux distros available.
-
-We’ve already talked about some of the [best lightweight Linux distributions][42] in details. Here, we shall only mention what really stands out from that list (and some new additions).
-
-#### Puppy Linux
-
-![][43]
-
-Puppy Linux is literally one of the smallest distribution there is. When I first started to explore Linux, my friend recommended me to experiment with Puppy Linux because it can run on older hardware configurations with ease.
-
-It’s worth checking it out if you want a snappy experience on your good old PC. Over the years, the user experience has improved along with the addition of several new useful features.
-
-[Puppy Linux][44]
-
-#### Solus Budgie
-
-![][45]
-
-After a recent major release – [Solus 4 Fortitude][46] – it is an impressive lightweight desktop OS. You can opt for desktop environments like GNOME or MATE. However, Solus Budgie happens to be one of my favorites as a full-fledged Linux distro for beginners while being light on system resources.
-
-[Solus][47]
-
-#### Bodhi
-
-![][48]
-
-Bodhi Linux is built on top of Ubuntu. However, unlike Ubuntu – it does run well on older configurations.
-
-The main highlight of this distro is its [Moksha Desktop][49] (which is a continuation of Enlightenment 17 desktop). The user experience is intuitive and screaming fast. Even though it’s not something for my personal use – you should give it a try on your older systems.
-
-[Bodhi Linux][50]
-
-#### antiX
-
-![][51]
-
-antiX – which is also partially responsible for MX Linux is a lightweight Linux distribution tailored for old and new computers. The UI isn’t impressive – but it works as expected.
-
-It is based on Debian and can be utilized as a live CD distribution without needing to install it. antiX also provides live bootloaders. In contrast to some other distros, you get to save the settings so that you don’t lose it with every reboot. Not just that, you can also save changes to the root directory with its “Live persistence” feature.
-
-So, if you are looking for a live-USB distro to provide a snappy user experience on old hardware – antiX is the way to go.
-
-[antiX][52]
-
-#### Sparky Linux
-
-![][53]
-
-Sparky Linux is based on Debian which turns out to be a perfect Linux distro for low-end systems. Along with a screaming fast experience, Sparky Linux offers several special editions (or varieties) for different users.
-
-For example, it provides a stable release (with varieties) and rolling releases specific to a group of users. Sparky Linux GameOver edition is quite popular for gamers because it includes a bunch of pre-installed games. You can check out our list of [best Linux Gaming distributions][54] – if you also want to play games on your system.
-
-#### Other Options
-
-You can also try [Linux Lite][55], [Lubuntu][56], and [Peppermint][57] as some of the lightweight Linux distributions.
-
-### Best Linux Distro for Advanced Users
-
-Once you get comfortable with the variety of package managers and commands to help troubleshoot your way to resolve any issue, you can start exploring Linux distros which are tailored for Advanced users only.
-
-Of course, if you are a professional – you will have a set of specific requirements. However, if you’ve been using Linux for a while as a common user – these distros are worth checking out.
-
-#### Arch Linux
-
-![Image Credits: Samiuvic / Deviantart][58]
-
-Arch Linux is itself a simple yet powerful distribution with a huge learning curve. Unlike others, you won’t have everything pre-installed in one go. You have to configure the system and add packages as needed.
-
-Also, when installing Arch Linux, you will have to follow a set of commands (without GUI). To know more about it, you can follow our guide on [how to install Arch Linux][59]. If you are going to install it, you should also know about some of the [essential things to do after installing Arch Linux][60]. It will help you get a jump start.
-
-In addition to all the versatility and simplicity, it’s worth mentioning that the community behind Arch Linux is very active. So, if you run into a problem, you don’t have to worry.
-
-[Arch Linux][61]
-
-#### Gentoo
-
-![Gentoo Linux][62]
-
-If you know how to compile the source code, Gentoo Linux is a must-try for you. It is also a lightweight distribution – however, you need to have the required technical knowledge to make it work.
-
-Of course, the [official handbook][63] provides a lot of information that you need to know. But, if you aren’t sure what you’re doing – it will take a lot of your time to figure out how to make the most out of it.
-
-[Gentoo Linux][64]
-
-#### Slackware
-
-![Image Credits: thundercr0w / Deviantart][65]
-
-Slackware is one of the oldest Linux distribution that still matters. If you are willing to compile or develop software to set up a perfect environment for yourself – Slackware is the way to go.
-
-In case you’re curious about some of the oldest Linux distros, we have an article on the [earliest linux distributions][66] – go check it out.
-
-Even though the number of users/developers utilizing it has significantly decreased, it is still a fantastic choice for advanced users. Also, with the recent news of [Slackware getting a Patreon page][67] – we hope that Slackware continues to exist as one of the best Linux distros out there.
-
-[Slackware][68]
-
-### Best Multi-purpose Linux Distribution
-
-There are certain Linux distros which you can utilize as a beginner-friendly / advanced OS for both desktops and servers. Hence, we thought of compiling a separate section for such distributions.
-
-If you don’t agree with us (or have suggestions to add here) – feel free to let us know in the comments. Here’s what we think could come in handy for every user:
-
-#### Fedora
-
-![][69]
-
-Fedora offers two separate editions – one for desktops/laptops and the other for servers (Fedora Workstation and Fedora Server respectively).
-
-So, if you are looking for a snappy desktop OS – with a potential learning curve while being user-friendly – Fedora is an option. In either case, if you are looking for a Linux OS for your server – that’s a good choice as well.
-
-[Fedora][70]
-
-#### Manjaro
-
-![][71]
-
-Manjaro is based on [Arch Linux][72]. Fret not, while Arch Linux is tailored for advanced users, Manjaro makes it easy for a newcomer. It is a simple and beginner-friendly Linux distro. The user interface is good enough and offers a bunch of useful GUI applications built-in.
-
-You get options to choose a [desktop environment][73] for Manjaro while downloading it. Personally, I like the KDE desktop for Manjaro.
-
-[Manjaro Linux][74]
-
-### Debian
-
-![Image Credits: mrneilypops / Deviantart][75]
-
-Well, Ubuntu’s based on Debian – so it must be a darn good distribution itself. Debian is an ideal choice for both desktop and servers.
-
-It may not be the best beginner-friendly OS – but you can easily get started by going through the [official documentation][76]. The recent release of [Debian 10 Buster][77] introduces a lot of changes and necessary improvements. So, you must give it a try!
-
-**Wrapping Up**
-
-Overall, these are the best Linux distributions that we recommend you to try. Yes, there are a lot of other Linux distributions that deserve the mention – but to each of their own, depending on personal preferences – the choices will be subjective.
-
-But, we also have a separate list of distros for [Windows users][78], [hackers and pen testers][41], [gamers][54], [programmers][39], and [privacy buffs.][79] So, if that interest you – do go through them.
-
-If you think we missed listing one of your favorites that deserves as one of the best Linux distributions out there, let us know your thoughts in the comments below and we’ll keep the article up-to-date accordingly.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/best-linux-distributions/
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: tmp.NoRXbIWHkg#for-beginners
-[2]: tmp.NoRXbIWHkg#for-servers
-[3]: tmp.NoRXbIWHkg#for-old-computers
-[4]: tmp.NoRXbIWHkg#for-advanced-users
-[5]: tmp.NoRXbIWHkg#general-purpose
-[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-10.jpg?ssl=1
-[7]: https://itsfoss.com/install-themes-ubuntu/
-[8]: https://itsfoss.com/tag/ubuntu/
-[9]: https://ubuntu.com/download/desktop
-[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/linux-Mint-19-desktop.jpg?ssl=1
-[11]: https://www.linuxmint.com/
-[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/elementary-os-juno-feat.jpg?ssl=1
-[13]: https://itsfoss.com/things-to-do-after-installing-elementary-os-5-juno/
-[14]: https://elementary.io/
-[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/mx-linux.jpg?ssl=1
-[16]: https://distrowatch.com/
-[17]: https://en.wikipedia.org/wiki/Linux_distribution#Rolling_distributions
-[18]: https://flatpak.org/
-[19]: https://mxlinux.org/
-[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/zorin-os-15.png?ssl=1
-[21]: https://itsfoss.com/zorin-os-15-release/
-[22]: https://itsfoss.com/zorin-os-interview/
-[23]: https://zorinos.com/
-[24]: https://www.deepin.org/en/
-[25]: https://itsfoss.com/ubuntu-vs-fedora/
-[26]: https://ubuntu.com/download/cloud
-[27]: https://w3techs.com/technologies/details/os-linux/all/all
-[28]: https://thecloudmarket.com/stats
-[29]: https://ubuntu.com/download/server
-[30]: https://developers.redhat.com/products/rhel/docs-and-apis
-[31]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
-[32]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/SUSE-Linux-Enterprise.jpg?ssl=1
-[33]: https://www.suse.com/products/server/
-[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/centos.png?ssl=1
-[35]: https://www.centos.org/
-[36]: https://getfedora.org/en/server/
-[37]: https://www.debian.org/distrib/
-[38]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/coding.jpg?ssl=1
-[39]: https://itsfoss.com/best-linux-distributions-progammers/
-[40]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/hacking.jpg?ssl=1
-[41]: https://itsfoss.com/linux-hacking-penetration-testing/
-[42]: https://itsfoss.com/lightweight-linux-beginners/
-[43]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/puppy-linux-bionic.jpg?ssl=1
-[44]: http://puppylinux.com/
-[45]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/03/solus-4-featured.jpg?resize=800%2C450&ssl=1
-[46]: https://itsfoss.com/solus-4-release/
-[47]: https://getsol.us/home/
-[48]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/bodhi-linux.png?fit=800%2C436&ssl=1
-[49]: http://www.bodhilinux.com/moksha-desktop/
-[50]: http://www.bodhilinux.com/
-[51]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/10/antix-linux-screenshot.jpg?ssl=1
-[52]: https://antixlinux.com/
-[53]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/sparky-linux.jpg?ssl=1
-[54]: https://itsfoss.com/linux-gaming-distributions/
-[55]: https://www.linuxliteos.com/
-[56]: https://lubuntu.me/
-[57]: https://peppermintos.com/
-[58]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/arch_linux_screenshot.jpg?ssl=1
-[59]: https://itsfoss.com/install-arch-linux/
-[60]: https://itsfoss.com/things-to-do-after-installing-arch-linux/
-[61]: https://www.archlinux.org
-[62]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/gentoo-linux.png?ssl=1
-[63]: https://wiki.gentoo.org/wiki/Handbook:Main_Page
-[64]: https://www.gentoo.org
-[65]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/slackware-screenshot.jpg?ssl=1
-[66]: https://itsfoss.com/earliest-linux-distros/
-[67]: https://distrowatch.com/dwres.php?resource=showheadline&story=8743
-[68]: http://www.slackware.com/
-[69]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/fedora-overview.png?ssl=1
-[70]: https://getfedora.org/
-[71]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/manjaro-gnome.jpg?ssl=1
-[72]: https://www.archlinux.org/
-[73]: https://itsfoss.com/glossary/desktop-environment/
-[74]: https://manjaro.org/
-[75]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/debian-screenshot.png?ssl=1
-[76]: https://www.debian.org/releases/stable/installmanual
-[77]: https://itsfoss.com/debian-10-buster/
-[78]: https://itsfoss.com/windows-like-linux-distributions/
-[79]: https://itsfoss.com/privacy-focused-linux-distributions/
diff --git a/sources/tech/20190901 Different Ways to Configure Static IP Address in RHEL 8.md b/sources/tech/20190901 Different Ways to Configure Static IP Address in RHEL 8.md
deleted file mode 100644
index 2f8f6ba711..0000000000
--- a/sources/tech/20190901 Different Ways to Configure Static IP Address in RHEL 8.md
+++ /dev/null
@@ -1,250 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Different Ways to Configure Static IP Address in RHEL 8)
-[#]: via: (https://www.linuxtechi.com/configure-static-ip-address-rhel8/)
-[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
-
-Different Ways to Configure Static IP Address in RHEL 8
-======
-
-While Working on **Linux Servers**, assigning Static IP address on NIC / Ethernet cards is one of the common tasks that every Linux engineer do. If one configures the **Static IP address** correctly on a Linux server then he/she can access it remotely over network. In this article we will demonstrate what are different ways to assign Static IP address on RHEL 8 Server’s NIC.
-
-[![Configure-Static-IP-RHEL8][1]][2]
-
-Following are the ways to configure Static IP on a NIC,
-
- * nmcli (command line tool)
- * Network Scripts files(ifcfg-*)
- * nmtui (text based user interface)
-
-
-
-### Configure Static IP Address using nmcli command line tool
-
-Whenever we install RHEL 8 server then ‘**nmcli**’, a command line tool is installed automatically, nmcli is used by network manager and allows us to configure static ip address on Ethernet cards.
-
-Run the below ip addr command to list Ethernet cards on your RHEL 8 server
-
-```
-[root@linuxtechi ~]# ip addr
-```
-
-![ip-addr-command-rhel8][1]
-
-As we can see in above command output, we have two NICs enp0s3 & enp0s8. Currently ip address assigned to the NIC is via dhcp server.
-
-Let’s assume we want to assign the static IP address on first NIC (enp0s3) with the following details,
-
- * IP address = 192.168.1.4
- * Netmask = 255.255.255.0
- * Gateway= 192.168.1.1
- * DNS = 8.8.8.8
-
-
-
-Run the following nmcli commands one after the another to configure static ip,
-
-List currently active Ethernet cards using “**nmcli connection**” command,
-
-```
-[root@linuxtechi ~]# nmcli connection
-NAME UUID TYPE DEVICE
-enp0s3 7c1b8444-cb65-440d-9bf6-ea0ad5e60bae ethernet enp0s3
-virbr0 3020c41f-6b21-4d80-a1a6-7c1bd5867e6c bridge virbr0
-[root@linuxtechi ~]#
-```
-
-Use beneath nmcli command to assign static ip on enp0s3,
-
-**Syntax:**
-
-# nmcli connection modify <interface_name> ipv4.address <ip/prefix>
-
-**Note:** In short form, we usually replace connection with ‘con’ keyword and modify with ‘mod’ keyword in nmcli command.
-
-Assign ipv4 (192.168.1.4) to enp0s3 interface,
-
-```
-[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.addresses 192.168.1.4/24
-[root@linuxtechi ~]#
-```
-
-Set the gateway using below nmcli command,
-
-```
-[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.gateway 192.168.1.1
-[root@linuxtechi ~]#
-```
-
-Set the manual configuration (from dhcp to static),
-
-```
-[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.method manual
-[root@linuxtechi ~]#
-```
-
-Set DNS value as “8.8.8.8”,
-
-```
-[root@linuxtechi ~]# nmcli con mod enp0s3 ipv4.dns "8.8.8.8"
-[root@linuxtechi ~]#
-```
-
-To save the above changes and to reload the interface execute the beneath nmcli command,
-
-```
-[root@linuxtechi ~]# nmcli con up enp0s3
-Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/4)
-[root@linuxtechi ~]#
-```
-
-Above command output confirms that interface enp0s3 has been configured successfully.Whatever the changes we have made using above nmcli commands, those changes is saved permanently under the file “etc/sysconfig/network-scripts/ifcfg-enp0s3”
-
-```
-[root@linuxtechi ~]# cat /etc/sysconfig/network-scripts/ifcfg-enp0s3
-```
-
-![ifcfg-enp0s3-file-rhel8][1]
-
-To Confirm whether IP address has been to enp0s3 interface use the below ip command,
-
-```
-[root@linuxtechi ~]#ip addr show enp0s3
-```
-
-### Configure Static IP Address manually using network-scripts (ifcfg-) files
-
-We can configure the static ip address to an ethernet card using its network-script or ‘ifcfg-‘ files. Let’s assume we want to assign the static ip address on our second Ethernet card ‘enp0s8’.
-
- * IP= 192.168.1.91
- * Netmask / Prefix = 24
- * Gateway=192.168.1.1
- * DNS1=4.2.2.2
-
-
-
-Go to the directory “/etc/sysconfig/network-scripts” and look for the file ‘ifcfg- enp0s8’, if it does not exist then create it with following content,
-
-```
-[root@linuxtechi ~]# cd /etc/sysconfig/network-scripts/
-[root@linuxtechi network-scripts]# vi ifcfg-enp0s8
-TYPE="Ethernet"
-DEVICE="enp0s8"
-BOOTPROTO="static"
-ONBOOT="yes"
-NAME="enp0s8"
-IPADDR="192.168.1.91"
-PREFIX="24"
-GATEWAY="192.168.1.1"
-DNS1="4.2.2.2"
-```
-
-Save and exit the file and then restart network manager service to make above changes into effect,
-
-```
-[root@linuxtechi network-scripts]# systemctl restart NetworkManager
-[root@linuxtechi network-scripts]#
-```
-
-Now use below ip command to verify whether ip address is assigned to nic or not,
-
-```
-[root@linuxtechi ~]# ip add show enp0s8
-3: enp0s8: mtu 1500 qdisc fq_codel state UP group default qlen 1000
- link/ether 08:00:27:7c:bb:cb brd ff:ff:ff:ff:ff:ff
- inet 192.168.1.91/24 brd 192.168.1.255 scope global noprefixroute enp0s8
- valid_lft forever preferred_lft forever
- inet6 fe80::a00:27ff:fe7c:bbcb/64 scope link
- valid_lft forever preferred_lft forever
-[root@linuxtechi ~]#
-```
-
-Above output confirms that static ip address has been configured successfully on the NIC ‘enp0s8’
-
-### Configure Static IP Address using ‘nmtui’ utility
-
-nmtui is a text based user interface for controlling network manager, when we execute nmtui, it will open a text base user interface through which we can add, modify and delete connections. Apart from this nmtui can also be used to set hostname of your system.
-
-Let’s assume we want to assign static ip address to interface enp0s3 with following details,
-
- * IP address = 10.20.0.72
- * Prefix = 24
- * Gateway= 10.20.0.1
- * DNS1=4.2.2.2
-
-
-
-Run nmtui and follow the screen instructions, example is show
-
-```
-[root@linuxtechi ~]# nmtui
-```
-
-[![nmtui-rhel8][1]][3]
-
-Select the first option ‘**Edit a connection**‘ and then choose the interface as ‘enp0s3’
-
-[![Choose-interface-nmtui-rhel8][1]][4]
-
-Choose Edit and then specify the IP address, Prefix, Gateway and DNS Server ip,
-
-[![set-ip-nmtui-rhel8][1]][5]
-
-Choose OK and hit enter. In the next window Choose ‘**Activate a connection**’
-
-[![Activate-option-nmtui-rhel8][1]][6]
-
-Select **enp0s3**, Choose **Deactivate** & hit enter
-
-[![Deactivate-interface-nmtui-rhel8][1]][7]
-
-Now choose **Activate** & hit enter,
-
-[![Activate-interface-nmtui-rhel8][1]][8]
-
-Select Back and then select Quit,
-
-[![Quit-Option-nmtui-rhel8][1]][9]
-
-Use below IP command to verify whether ip address has been assigned to interface enp0s3
-
-```
-[root@linuxtechi ~]# ip add show enp0s3
-2: enp0s3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
- link/ether 08:00:27:53:39:4d brd ff:ff:ff:ff:ff:ff
- inet 10.20.0.72/24 brd 10.20.0.255 scope global noprefixroute enp0s3
- valid_lft forever preferred_lft forever
- inet6 fe80::421d:5abf:58bd:c47e/64 scope link noprefixroute
- valid_lft forever preferred_lft forever
-[root@linuxtechi ~]#
-```
-
-Above output confirms that we have successfully assign the static IP address to interface enp0s3 using nmtui utility.
-
-That’s all from this tutorial, we have covered three different ways to configure ipv4 address to an Ethernet card on RHEL 8 system. Please do not hesitate to share feedback and comments in comments section below.
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxtechi.com/configure-static-ip-address-rhel8/
-
-作者:[Pradeep Kumar][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linuxtechi.com/author/pradeep/
-[b]: https://github.com/lujun9972
-[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Configure-Static-IP-RHEL8.jpg
-[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/nmtui-rhel8.jpg
-[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Choose-interface-nmtui-rhel8.jpg
-[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/set-ip-nmtui-rhel8.jpg
-[6]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Activate-option-nmtui-rhel8.jpg
-[7]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Deactivate-interface-nmtui-rhel8.jpg
-[8]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Activate-interface-nmtui-rhel8.jpg
-[9]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Quit-Option-nmtui-rhel8.jpg
diff --git a/sources/tech/20190901 How to write zines with simple tools.md b/sources/tech/20190901 How to write zines with simple tools.md
new file mode 100644
index 0000000000..05b21f047e
--- /dev/null
+++ b/sources/tech/20190901 How to write zines with simple tools.md
@@ -0,0 +1,138 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to write zines with simple tools)
+[#]: via: (https://jvns.ca/blog/2019/09/01/ways-to-write-zines-without-fancy-tools/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+How to write zines with simple tools
+======
+
+People often ask me what tools I use to write my zines ([the answer is here][1]). Answering this question as written has always felt slightly off to me, though, and I couldn’t figure out why for a long time.
+
+I finally realized last week that instead of “what tools do you use to write zines?” some people may have actually wanted to know “how can I do this myself?”! And “buy a $500 iPad” is not a terribly useful answer to that question – it’s not how I got started, iPads are kind of a weird fancy way to write zines, and most people don’t have them.
+
+So this blog post is about more traditional (and easier to get started with) ways to write zines.
+
+We’re going to start out by talking about the mechanics of how to write the zine, and then talk about how to assemble it into a booklet.
+
+### Way 1: Write it on paper
+
+This is how I made my first zine (spying on your programs with strace) which you can see here: .
+
+Here’s an example of a page I drew on paper this morning pretty quickly. It looks kind of bad because I scanned it with my phone, but if you use a real scanner (like I did with the strace PDF above), the scanned version comes out better.
+
+
+
+### Way 2: Use a Google doc
+
+The next option is to use a Google doc (or whatever other word processor you prefer). [Here’s the Google doc I wrote for the below image][2], and here’s what it looks like:
+
+
+
+They key thing about this Google doc approach is to apply some “less is more”. It’s intended to be printed as part of a booklet on **half** a sheet of letter paper, which means everything needs to be twice as big for it to look good.
+
+### Way 3: Use an iPad
+
+This is what I do (use the Notability app on iPad). I’m not going to talk about this method much because this post is about using more readily available tools.
+
+
+
+### Way 4: Use a single sheet of paper
+
+This is a subset of “Write it on paper” – the [Wikibooks page on zine making][3] has a great guide that shows how to write out a tiny zine on 1 piece of paper and then fold it up to make a little booklet. Here are the pictures of the steps from the Wikibooks page:
+
+
+
+Sumana Harihareswara’s [Playing with python][4] zine is a nice example of a zine that’s intended to be folded up in that way.
+
+### Way 5: Adobe Illustrator
+
+I’ve never used Adobe Illustrator so I’m not going to pretend that I know anything about it or put together an example using it, but I hear it’s a way people do book layout.
+
+### booklets: the photocopier method
+
+So you’ve written a bunch of pages and want to assemble them into a booklet. One way to do this (and what I did for my first zine about strace!) is the photocopier method. There’s a great guide by Julia Gfrörer in [this tweet][5], which I’m going to reproduce here:
+
+![][6]
+![][7]
+![][8]
+![][9]
+
+That explanation is excellent and I don’t have anything to add. I did it that way and it worked great.
+
+If you want to buy a print copy of that how-to-make-zines zine from Thruban Press, you can [get it here on Etsy][10].
+
+### booklets: the computer method
+
+If you’ve made your zine in Google Docs or in another computery way, you probably want a more computery way of assembling the pages into a booklet.
+
+**what I use: pdflatex**
+
+I do this using the `pdfpages` LaTeX extension. This sounds complicated but it’s not really, you don’t need to learn latex or anything. You just need to have pdflatex on your system, which is a `sudo apt install texlive-base` away on Ubuntu. The steps are:
+
+ 1. Get a PDF with the pages from your zine (pages need to be a multiple of 4)
+ 2. Get the latex file from [this gist][11]
+ 3. Replace `/home/bork/http-zine.pdf` with the path to your PDF and `1-28` with `1-however many pages are in your zine`.
+ 4. run `pdflatex formatted-zine.tex`
+ 5. Tweak the parameters until it looks the way you want. The [documentation for the pdfpages package is here][12]
+
+
+
+I like using this relatively complicated method because there are always small tweaks I want to make like “oh, the right margin is too big, crop it a little bit” and the pdfpages package has tons of options that let me make those tweaks.
+
+**other methods**
+
+ 1. On Linux you can use the `pdfjam` bash script, which is just a wrapper around the pdfpages latex package. This is what I used to do but today I find it simpler to use the pdfpages latex package directly.
+ 2. There’s a program called [Booklet Creator][13] for Mac and Windows that [@mrfb uses][14]. It looks pretty simple to use.
+ 3. If you convert your PDF to a ps file (with `pdf2ps` for instance), `psnup` can do this. I tried `cat file.ps | psbook | psnup -2 > booklet.ps` and it worked, though the resulting PDFs are a little slow to load in my PDF viewer for some reason.
+ 4. there are probably a ton more ways to do this, if you know more let me know
+
+
+
+### making zines is easy and low tech
+
+That’s all! I mostly wanted to explain that zines are an easy low tech thing to do and if you think making them sounds fun, you definitely 100% do not need to use any fancy expensive tools to do it, you can literally use some sheets of paper, a Sharpie, a pen, and spend $3 at your local print shop to use the photocopier.
+
+### resources
+
+summary of the resources I linked to:
+
+ * Guide to putting together zines with a photocopier by Julia Gfrörer: [this tweet][5], [get it on Etsy][10]
+ * [Wikibooks page on zine making][3]
+ * Notes on making zines using Google Docs: [this twitter thread][14]
+ * [Stolen Sharpie Revolution][15] (the first book I read about making zines). You can also get it on Amazon if you want but it’s probably better to buy directly from their site.
+ * [Booklet Creator][13]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/09/01/ways-to-write-zines-without-fancy-tools/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://twitter.com/b0rk/status/1160171769833185280
+[2]: https://docs.google.com/document/d/1byzfXC0h6hNFlWXaV9peJpX-GamJOrJ70x9nu1dZ-m0/edit?usp=sharing
+[3]: https://en.m.wikibooks.org/wiki/Zine_Making/Putting_pages_together
+[4]: https://www.harihareswara.net/pix/playing-with-python-zine/playing-with-python-zine.pdf
+[5]: https://twitter.com/thorazos/status/1158556879485906944
+[6]: https://pbs.twimg.com/media/EBQFUC0X4AAPTU1?format=jpg&name=small
+[7]: https://pbs.twimg.com/media/EBQFUC0XsAEBhHf?format=jpg&name=small
+[8]: https://pbs.twimg.com/media/EBQFUC1XUAAKDIB?format=jpg&name=small
+[9]: https://pbs.twimg.com/media/EBQFUDRX4AMkIAr?format=jpg&name=small
+[10]: https://www.etsy.com/thorazos/listing/693692176/thuban-press-guide-to-analog-self?utm_source=Copy&utm_medium=ListingManager&utm_campaign=Share&utm_term=so.lmsm&share_time=1565113962419
+[11]: https://gist.github.com/jvns/b3de1d658e2b44aebb485c35fb1a7a0f
+[12]: http://texdoc.net/texmf-dist/doc/latex/pdfpages/pdfpages.pdf
+[13]: https://www.bookletcreator.com/
+[14]: https://twitter.com/mrfb/status/1159478532545888258
+[15]: http://www.stolensharpierevolution.org/
diff --git a/sources/tech/20190902 How RPM packages are made- the spec file.md b/sources/tech/20190902 How RPM packages are made- the spec file.md
deleted file mode 100644
index c5dace0332..0000000000
--- a/sources/tech/20190902 How RPM packages are made- the spec file.md
+++ /dev/null
@@ -1,299 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How RPM packages are made: the spec file)
-[#]: via: (https://fedoramagazine.org/how-rpm-packages-are-made-the-spec-file/)
-[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
-
-How RPM packages are made: the spec file
-======
-
-![][1]
-
-In the [previous article on RPM package building][2], you saw that source RPMS include the source code of the software, along with a “spec” file. This post digs into the spec file, which contains instructions on how to build the RPM. Again, this article uses _fpaste_ as an example.
-
-### Understanding the source code
-
-Before you can start writing a spec file, you need to have some idea of the software that you’re looking to package. Here, you’re looking at fpaste, a very simple piece of software. It is written in Python, and is a one file script. When a new version is released, it’s provided here on Pagure:
-
-The current version, as the archive shows, is 0.3.9.2. Download it so you can see what’s in the archive:
-
-```
-$ wget https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz
-$ tar -tvf fpaste-0.3.9.2.tar.gz
-drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/
--rw-rw-r-- root/root 25 2018-07-25 02:58 fpaste-0.3.9.2/.gitignore
--rw-rw-r-- root/root 3672 2018-07-25 02:58 fpaste-0.3.9.2/CHANGELOG
--rw-rw-r-- root/root 35147 2018-07-25 02:58 fpaste-0.3.9.2/COPYING
--rw-rw-r-- root/root 444 2018-07-25 02:58 fpaste-0.3.9.2/Makefile
--rw-rw-r-- root/root 1656 2018-07-25 02:58 fpaste-0.3.9.2/README.rst
--rw-rw-r-- root/root 658 2018-07-25 02:58 fpaste-0.3.9.2/TODO
-drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/
-drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/
-drwxrwxr-x root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/
--rw-rw-r-- root/root 3867 2018-07-25 02:58 fpaste-0.3.9.2/docs/man/en/fpaste.1
--rwxrwxr-x root/root 24884 2018-07-25 02:58 fpaste-0.3.9.2/fpaste
-lrwxrwxrwx root/root 0 2018-07-25 02:58 fpaste-0.3.9.2/fpaste.py -> fpaste
-```
-
-The files you want to install are:
-
- * _fpaste.py_: which should go be installed to /usr/bin/.
- * _docs/man/en/fpaste.1_: the manual, which should go to /usr/share/man/man1/.
- * _COPYING_: the license text, which should go to /usr/share/license/fpaste/.
- * _README.rst, TODO_: miscellaneous documentation that goes to /usr/share/doc/fpaste.
-
-
-
-Where these files are installed depends on the Filesystem Hierarchy Standard. To learn more about it, you can either read here: or look at the man page on your Fedora system:
-
-```
-$ man hier
-```
-
-#### Part 1: What are we building?
-
-Now that we know what files we have in the source, and where they are to go, let’s look at the spec file. You can see the full file here:
-
-Here is the first part of the spec file:
-
-```
-Name: fpaste
-Version: 0.3.9.2
-Release: 3%{?dist}
-Summary: A simple tool for pasting info onto sticky notes instances
-BuildArch: noarch
-License: GPLv3+
-URL: https://pagure.io/fpaste
-Source0: https://pagure.io/releases/fpaste/fpaste-0.3.9.2.tar.gz
-
-Requires: python3
-
-%description
-It is often useful to be able to easily paste text to the Fedora
-Pastebin at http://paste.fedoraproject.org and this simple script
-will do that and return the resulting URL so that people may
-examine the output. This can hopefully help folks who are for
-some reason stuck without X, working remotely, or any other
-reason they may be unable to paste something into the pastebin
-```
-
-_Name_, _Version_, and so on are called _tags_, and are defined in RPM. This means you can’t just make up tags. RPM won’t understand them if you do! The tags to keep an eye out for are:
-
- * _Source0_: tells RPM where the source archive for this software is located.
- * _Requires_: lists run-time dependencies for the software. RPM can automatically detect quite a few of these, but in some cases they must be mentioned manually. A run-time dependency is a capability (often a package) that must be on the system for this package to function. This is how _[dnf][3]_ detects whether it needs to pull in other packages when you install this package.
- * _BuildRequires_: lists the build-time dependencies for this software. These must generally be determined manually and added to the spec file.
- * _BuildArch_: the computer architectures that this software is being built for. If this tag is left out, the software will be built for all supported architectures. The value _noarch_ means the software is architecture independent (like fpaste, which is written purely in Python).
-
-
-
-This section provides general information about fpaste: what it is, which version is being made into an RPM, its license, and so on. If you have fpaste installed, and look at its metadata, you can see this information included in the RPM:
-
-```
-$ sudo dnf install fpaste
-$ rpm -qi fpaste
-Name : fpaste
-Version : 0.3.9.2
-Release : 2.fc30
-...
-```
-
-RPM adds a few extra tags automatically that represent things that it knows.
-
-At this point, we have the general information about the software that we’re building an RPM for. Next, we start telling RPM what to do.
-
-#### Part 2: Preparing for the build
-
-The next part of the spec is the preparation section, denoted by _%prep_:
-
-```
-%prep
-%autosetup
-```
-
-For fpaste, the only command here is %autosetup. This simply extracts the tar archive into a new folder and keeps it ready for the next section where we build it. You can do more here, like apply patches, modify files for different purposes, and so on. If you did look at the contents of the source rpm for Python, you would have seen lots of patches there. These are all applied in this section.
-
-Typically anything in a spec file with the **%** prefix is a macro or label that RPM interprets in a special way. Often these will appear with curly braces, such as _%{example}_.
-
-#### Part 3: Building the software
-
-The next section is where the software is built, denoted by “%build”. Now, since fpaste is a simple, pure Python script, it doesn’t need to be built. So, here we get:
-
-```
-%build
-#nothing required
-```
-
-Generally, though, you’d have build commands here, like:
-
-```
-configure; make
-```
-
-The build section is often the hardest section of the spec, because this is where the software is being built from source. This requires you to know what build system the tool is using, which could be one of many: Autotools, CMake, Meson, Setuptools (for Python) and so on. Each has its own commands and style. You need to know these well enough to get the software to build correctly.
-
-#### Part 4: Installing the files
-
-Once the software is built, it needs to be installed in the _%install_ section:
-
-```
-%install
-mkdir -p %{buildroot}%{_bindir}
-make install BINDIR=%{buildroot}%{_bindir} MANDIR=%{buildroot}%{_mandir}
-```
-
-RPM doesn’t tinker with your system files when building RPMs. It’s far too risky to add, remove, or modify files to a working installation. What if something breaks? So, instead RPM creates an artificial file system and works there. This is referred to as the _buildroot_. So, here in the buildroot, we create _/usr/bin_, represented by the macro _%{_bindir}_, and then install the files to it using the provided Makefile.
-
-At this point, we have a built version of fpaste installed in our artificial buildroot.
-
-#### Part 5: Listing all files to be included in the RPM
-
-The last section of the spec file is the files section, _%files_. This is where we tell RPM what files to include in the archive it creates from this spec file. The fpaste file section is quite simple:
-
-```
-%files
-%{_bindir}/%{name}
-%doc README.rst TODO
-%{_mandir}/man1/%{name}.1.gz
-%license COPYING
-```
-
-Notice how, here, we do not specify the buildroot. All of these paths are relative to it. The _%doc_ and _%license_ commands simply do a little more—they create the required folders and remember that these files must go there.
-
-RPM is quite smart. If you’ve installed files in the _%install_ section, but not listed them, it’ll tell you this, for example.
-
-#### Part 6: Document all changes in the change log
-
-Fedora is a community based project. Lots of contributors maintain and co-maintain packages. So it is imperative that there’s no confusion about what changes have been made to a package. To ensure this, the spec file contains the last section, the Changelog, _%changelog_:
-
-```
-%changelog
-* Thu Jul 25 2019 Fedora Release Engineering < ...> - 0.3.9.2-3
-- Rebuilt for https://fedoraproject.org/wiki/Fedora_31_Mass_Rebuild
-
-* Thu Jan 31 2019 Fedora Release Engineering < ...> - 0.3.9.2-2
-- Rebuilt for https://fedoraproject.org/wiki/Fedora_30_Mass_Rebuild
-
-* Tue Jul 24 2018 Ankur Sinha - 0.3.9.2-1
-- Update to 0.3.9.2
-
-* Fri Jul 13 2018 Fedora Release Engineering < ...> - 0.3.9.1-4
-- Rebuilt for https://fedoraproject.org/wiki/Fedora_29_Mass_Rebuild
-
-* Wed Feb 07 2018 Fedora Release Engineering < ..> - 0.3.9.1-3
-- Rebuilt for https://fedoraproject.org/wiki/Fedora_28_Mass_Rebuild
-
-* Sun Sep 10 2017 Vasiliy N. Glazov < ...> - 0.3.9.1-2
-- Cleanup spec
-
-* Fri Sep 08 2017 Ankur Sinha - 0.3.9.1-1
-- Update to latest release
-- fixes rhbz 1489605
-...
-....
-```
-
-There must be a changelog entry for _every_ change to the spec file. As you see here, while I’ve updated the spec as the maintainer, others have too. Having the changes documented clearly helps everyone know what the current status of the spec is. For all packages installed on your system, you can use rpm to see their changelogs:
-
-```
-$ rpm -q --changelog fpaste
-```
-
-### Building the RPM
-
-Now we are ready to build the RPM. If you want to follow along and run the commands below, please ensure that you followed the steps [in the previous post][2] to set your system up for building RPMs.
-
-We place the fpaste spec file in _~/rpmbuild/SPECS_, the source code archive in _~/rpmbuild/SOURCES/_ and can now create the source RPM:
-
-```
-$ cd ~/rpmbuild/SPECS
-$ wget https://src.fedoraproject.org/rpms/fpaste/raw/master/f/fpaste.spec
-
-$ cd ~/rpmbuild/SOURCES
-$ wget https://pagure.io/fpaste/archive/0.3.9.2/fpaste-0.3.9.2.tar.gz
-
-$ cd ~/rpmbuild/SOURCES
-$ rpmbuild -bs fpaste.spec
-Wrote: /home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
-```
-
-Let’s have a look at the results:
-
-```
-$ ls ~/rpmbuild/SRPMS/fpaste*
-/home/asinha/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
-
-$ rpm -qpl ~/rpmbuild/SRPMS/fpaste-0.3.9.2-3.fc30.src.rpm
-fpaste-0.3.9.2.tar.gz
-fpaste.spec
-```
-
-There we are — the source rpm has been built. Let’s build both the source and binary rpm together:
-
-```
-$ cd ~/rpmbuild/SPECS
-$ rpmbuild -ba fpaste.spec
-..
-..
-..
-```
-
-RPM will show you the complete build output, with details on what it is doing in each section that we saw before. This “build log” is extremely important. When builds do not go as expected, we packagers spend lots of time going through them, tracing the complete build path to see what went wrong.
-
-That’s it really! Your ready-to-install RPMs are where they should be:
-
-```
-$ ls ~/rpmbuild/RPMS/noarch/
-fpaste-0.3.9.2-3.fc30.noarch.rpm
-```
-
-### Recap
-
-We’ve covered the basics of how RPMs are built from a spec file. This is by no means an exhaustive document. In fact, it isn’t documentation at all, really. It only tries to explain how things work under the hood. Here’s a short recap:
-
- * RPMs are of two types: _source_ and _binary_.
- * Binary RPMs contain the files to be installed to use the software.
- * Source RPMs contain the information needed to build the binary RPMs: the complete source code, and the instructions on how to build the RPM in the spec file.
- * The spec file has various sections, each with its own purpose.
-
-
-
-Here, we’ve built RPMs locally, on our Fedora installations. While this is the basic process, the RPMs we get from repositories are built on dedicated servers with strict configurations and methods to ensure correctness and security. This Fedora packaging pipeline will be discussed in a future post.
-
-Would you like to get started with building packages, and help the Fedora community maintain the massive amount of software we provide? You can [start here by joining the package collection maintainers][4].
-
-For any queries, post to the [Fedora developers mailing list][5]—we’re always happy to help!
-
-### References
-
-Here are some useful references to building RPMs:
-
- *
- *
- *
- *
-
-
-
-* * *
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/how-rpm-packages-are-made-the-spec-file/
-
-作者:[Ankur Sinha "FranciscoD"][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/ankursinha/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
-[2]: https://fedoramagazine.org/how-rpm-packages-are-made-the-source-rpm/
-[3]: https://fedoramagazine.org/managing-packages-fedora-dnf/
-[4]: https://fedoraproject.org/wiki/Join_the_package_collection_maintainers
-[5]: https://lists.fedoraproject.org/archives/list/devel@lists.fedoraproject.org/
diff --git a/sources/tech/20190905 Building CI-CD pipelines with Jenkins.md b/sources/tech/20190905 Building CI-CD pipelines with Jenkins.md
deleted file mode 100644
index 44b4d6cd24..0000000000
--- a/sources/tech/20190905 Building CI-CD pipelines with Jenkins.md
+++ /dev/null
@@ -1,255 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Building CI/CD pipelines with Jenkins)
-[#]: via: (https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins)
-[#]: author: (Bryant Son https://opensource.com/users/brson)
-
-Building CI/CD pipelines with Jenkins
-======
-Build continuous integration and continuous delivery (CI/CD) pipelines
-with this step-by-step Jenkins tutorial.
-![pipelines][1]
-
-In my article [_A beginner's guide to building DevOps pipelines with open source tools_][2], I shared a story about building a DevOps pipeline from scratch. The core technology driving that initiative was [Jenkins][3], an open source tool to build continuous integration and continuous delivery (CI/CD) pipelines.
-
-At Citi, there was a separate team that provided dedicated Jenkins pipelines with a stable master-slave node setup, but the environment was only used for quality assurance (QA), staging, and production environments. The development environment was still very manual, and our team needed to automate it to gain as much flexibility as possible while accelerating the development effort. This is the reason we decided to build a CI/CD pipeline for DevOps. And the open source version of Jenkins was the obvious choice due to its flexibility, openness, powerful plugin-capabilities, and ease of use.
-
-In this article, I will share a step-by-step walkthrough on how you can build a CI/CD pipeline using Jenkins.
-
-### What is a pipeline?
-
-Before jumping into the tutorial, it's helpful to know something about CI/CD pipelines.
-
-To start, it is helpful to know that Jenkins itself is not a pipeline. Just creating a new Jenkins job does not construct a pipeline. Think about Jenkins like a remote control—it's the place you click a button. What happens when you do click a button depends on what the remote is built to control. Jenkins offers a way for other application APIs, software libraries, build tools, etc. to plug into Jenkins, and it executes and automates the tasks. On its own, Jenkins does not perform any functionality but gets more and more powerful as other tools are plugged into it.
-
-A pipeline is a separate concept that refers to the groups of events or jobs that are connected together in a sequence:
-
-> A **pipeline** is a sequence of events or jobs that can be executed.
-
-The easiest way to understand a pipeline is to visualize a sequence of stages, like this:
-
-![Pipeline example][4]
-
-Here, you should see two familiar concepts: _Stage_ and _Step_.
-
- * **Stage:** A block that contains a series of steps. A stage block can be named anything; it is used to visualize the pipeline process.
- * **Step:** A task that says what to do. Steps are defined inside a stage block.
-
-
-
-In the example diagram above, Stage 1 can be named "Build," "Gather Information," or whatever, and a similar idea is applied for the other stage blocks. "Step" simply says what to execute, and this can be a simple print command (e.g., **echo "Hello, World"**), a program-execution command (e.g., **java HelloWorld**), a shell-execution command (e.g., **chmod 755 Hello**), or any other command—as long as it is recognized as an executable command through the Jenkins environment.
-
-The Jenkins pipeline is provided as a _codified script_ typically called a **Jenkinsfile**, although the file name can be different. Here is an example of a simple Jenkins pipeline file.
-
-
-```
-// Example of Jenkins pipeline script
-
-pipeline {
- stages {
- stage("Build") {
- steps {
- // Just print a Hello, Pipeline to the console
- echo "Hello, Pipeline!"
- // Compile a Java file. This requires JDKconfiguration from Jenkins
- javac HelloWorld.java
- // Execute the compiled Java binary called HelloWorld. This requires JDK configuration from Jenkins
- java HelloWorld
- // Executes the Apache Maven commands, clean then package. This requires Apache Maven configuration from Jenkins
- mvn clean package ./HelloPackage
- // List the files in current directory path by executing a default shell command
- sh "ls -ltr"
- }
- }
- // And next stages if you want to define further...
- } // End of stages
-} // End of pipeline
-```
-
-It's easy to see the structure of a Jenkins pipeline from this sample script. Note that some commands, like **java**, **javac**, and **mvn**, are not available by default, and they need to be installed and configured through Jenkins. Therefore:
-
-> A **Jenkins pipeline** is the way to execute a Jenkins job sequentially in a defined way by codifying it and structuring it inside multiple blocks that can include multiple steps containing tasks.
-
-OK. Now that you understand what a Jenkins pipeline is, I'll show you how to create and execute a Jenkins pipeline. At the end of the tutorial, you will have built a Jenkins pipeline like this:
-
-![Final Result][5]
-
-### How to build a Jenkins pipeline
-
-To make this tutorial easier to follow, I created a sample [GitHub repository][6] and a video tutorial.
-
-Before starting this tutorial, you'll need:
-
- * **Java Development Kit:** If you don't already have it, install a JDK and add it to the environment path so a Java command (like **java jar**) can be executed through a terminal. This is necessary to leverage the Java Web Archive (WAR) version of Jenkins that is used in this tutorial (although you can use any other distribution).
- * **Basic computer operations:** You should know how to type some code, execute basic Linux commands through the shell, and open a browser.
-
-
-
-Let's get started.
-
-#### Step 1: Download Jenkins
-
-Navigate to the [Jenkins download page][7]. Scroll down to **Generic Java package (.war)** and click on it to download the file; save it someplace where you can locate it easily. (If you choose another Jenkins distribution, the rest of tutorial steps should be pretty much the same, except for Step 2.) The reason to use the WAR file is that it is a one-time executable file that is easily executable and removable.
-
-![Download Jenkins as Java WAR file][8]
-
-#### Step 2: Execute Jenkins as a Java binary
-
-Open a terminal window and enter the directory where you downloaded Jenkins with **cd <your path>**. (Before you proceed, make sure JDK is installed and added to the environment path.) Execute the following command, which will run the WAR file as an executable binary:
-
-
-```
-`java -jar ./jenkins.war`
-```
-
-If everything goes smoothly, Jenkins should be up and running at the default port 8080.
-
-![Execute as an executable JAR binary][9]
-
-#### Step 3: Create a new Jenkins job
-
-Open a web browser and navigate to **localhost:8080**. Unless you have a previous Jenkins installation, it should go straight to the Jenkins dashboard. Click **Create New Jobs**. You can also click **New Item** on the left.
-
-![Create New Job][10]
-
-#### Step 4: Create a pipeline job
-
-In this step, you can select and define what type of Jenkins job you want to create. Select **Pipeline** and give it a name (e.g., TestPipeline). Click **OK** to create a pipeline job.
-
-![Create New Pipeline Job][11]
-
-You will see a Jenkins job configuration page. Scroll down to find** Pipeline section**. There are two ways to execute a Jenkins pipeline. One way is by _directly writing a pipeline script_ on Jenkins, and the other way is by retrieving the _Jenkins file from SCM_ (source control management). We will go through both ways in the next two steps.
-
-#### Step 5: Configure and execute a pipeline job through a direct script
-
-To execute the pipeline with a direct script, begin by copying the contents of the [sample Jenkinsfile][6] from GitHub. Choose **Pipeline script** as the **Destination** and paste the **Jenkinsfile** contents in **Script**. Spend a little time studying how the Jenkins file is structured. Notice that there are three Stages: Build, Test, and Deploy, which are arbitrary and can be anything. Inside each Stage, there are Steps; in this example, they just print some random messages.
-
-Click **Save** to keep the changes, and it should automatically take you back to the Job Overview.
-
-![Configure to Run as Jenkins Script][12]
-
-To start the process to build the pipeline, click **Build Now**. If everything works, you will see your first pipeline (like the one below).
-
-![Click Build Now and See Result][13]
-
-To see the output from the pipeline script build, click any of the Stages and click **Log**. You will see a message like this.
-
-![Visit sample GitHub with Jenkins get clone link][14]
-
-#### Step 6: Configure and execute a pipeline job with SCM
-
-Now, switch gears: In this step, you will Deploy the same Jenkins job by copying the **Jenkinsfile** from a source-controlled GitHub. In the same [GitHub repository][6], pick up the repository URL by clicking **Clone or download** and copying its URL.
-
-![Checkout from GitHub][15]
-
-Click **Configure** to modify the existing job. Scroll to the **Advanced Project Options** setting, but this time, select the **Pipeline script from SCM** option in the **Destination** dropdown. Paste the GitHub repo's URL in the **Repository URL**, and type **Jenkinsfile** in the **Script Path**. Save by clicking the **Save** button.
-
-![Change to Pipeline script from SCM][16]
-
-To build the pipeline, once you are back to the Task Overview page, click **Build Now** to execute the job again. The result will be the same as before, except you have one additional stage called **Declaration: Checkout SCM**.
-
-![Build again and verify][17]
-
-To see the pipeline's output from the SCM build, click the Stage and view the **Log** to check how the source control cloning process went.
-
-![Verify Checkout Procedure][18]
-
-### Do more than print messages
-
-Congratulations! You've built your first Jenkins pipeline!
-
-"But wait," you say, "this is very limited. I cannot really do anything with it except print dummy messages." That is OK. So far, this tutorial provided just a glimpse of what a Jenkins pipeline can do, but you can extend its capabilities by integrating it with other tools. Here are a few ideas for your next project:
-
- * Build a multi-staged Java build pipeline that takes from the phases of pulling dependencies from JAR repositories like Nexus or Artifactory, compiling Java codes, running the unit tests, packaging into a JAR/WAR file, and deploying to a cloud server.
- * Implement the advanced code testing dashboard that will report back the health of the project based on the unit test, load test, and automated user interface test with Selenium.
- * Construct a multi-pipeline or multi-user pipeline automating the tasks of executing Ansible playbooks while allowing for authorized users to respond to task in progress.
- * Design a complete end-to-end DevOps pipeline that pulls the infrastructure resource files and configuration files stored in SCM like GitHub and executing the scripts through various runtime programs.
-
-
-
-Follow any of the tutorials at the end of this article to get into these more advanced cases.
-
-#### Manage Jenkins
-
-From the main Jenkins dashboard, click **Manage Jenkins**.
-
-![Manage Jenkins][19]
-
-#### Global tool configuration
-
-There are many options available, including managing plugins, viewing the system log, etc. Click **Global Tool Configuration**.
-
-![Global Tools Configuration][20]
-
-#### Add additional capabilities
-
-Here, you can add the JDK path, Git, Gradle, and so much more. After you configure a tool, it is just a matter of adding the command into your Jenkinsfile or executing it through your Jenkins script.
-
-![See Various Options for Plugin][21]
-
-### Where to go from here?
-
-This article put you on your way to creating a CI/CD pipeline using Jenkins, a cool open source tool. To find out about many of the other things you can do with Jenkins, check out these other articles on Opensource.com:
-
- * [Getting started with Jenkins X][22]
- * [Install an OpenStack cloud with Jenkins][23]
- * [Running Jenkins builds in containers][24]
- * [Getting started with Jenkins pipelines][25]
- * [How to run JMeter with Jenkins][26]
- * [Integrating OpenStack into your Jenkins workflow][27]
-
-
-
-You may be interested in some of the other articles I've written to supplement your open source journey:
-
- * [9 open source tools for building a fault-tolerant system][28]
- * [Understanding software design patterns][29]
- * [A beginner's guide to building DevOps pipelines with open source tools][2]
-
-
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins
-
-作者:[Bryant Son][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/brson
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/pipe-pipeline-grid.png?itok=kkpzKxKg (pipelines)
-[2]: https://opensource.com/article/19/4/devops-pipeline
-[3]: https://jenkins.io/
-[4]: https://opensource.com/sites/default/files/uploads/diagrampipeline.jpg (Pipeline example)
-[5]: https://opensource.com/sites/default/files/uploads/0_endresultpreview_0.jpg (Final Result)
-[6]: https://github.com/bryantson/CICDPractice
-[7]: https://jenkins.io/download/
-[8]: https://opensource.com/sites/default/files/uploads/2_downloadwar.jpg (Download Jenkins as Java WAR file)
-[9]: https://opensource.com/sites/default/files/uploads/3_runasjar.jpg (Execute as an executable JAR binary)
-[10]: https://opensource.com/sites/default/files/uploads/4_createnewjob.jpg (Create New Job)
-[11]: https://opensource.com/sites/default/files/uploads/5_createpipeline.jpg (Create New Pipeline Job)
-[12]: https://opensource.com/sites/default/files/uploads/6_runaspipelinescript.jpg (Configure to Run as Jenkins Script)
-[13]: https://opensource.com/sites/default/files/uploads/7_buildnow4script.jpg (Click Build Now and See Result)
-[14]: https://opensource.com/sites/default/files/uploads/8_seeresult4script.jpg (Visit sample GitHub with Jenkins get clone link)
-[15]: https://opensource.com/sites/default/files/uploads/9_checkoutfromgithub.jpg (Checkout from GitHub)
-[16]: https://opensource.com/sites/default/files/uploads/10_runsasgit.jpg (Change to Pipeline script from SCM)
-[17]: https://opensource.com/sites/default/files/uploads/11_seeresultfromgit.jpg (Build again and verify)
-[18]: https://opensource.com/sites/default/files/uploads/12_verifycheckout.jpg (Verify Checkout Procedure)
-[19]: https://opensource.com/sites/default/files/uploads/13_managingjenkins.jpg (Manage Jenkins)
-[20]: https://opensource.com/sites/default/files/uploads/14_globaltoolsconfiguration.jpg (Global Tools Configuration)
-[21]: https://opensource.com/sites/default/files/uploads/15_variousoptions4plugin.jpg (See Various Options for Plugin)
-[22]: https://opensource.com/article/18/11/getting-started-jenkins-x
-[23]: https://opensource.com/article/18/4/install-OpenStack-cloud-Jenkins
-[24]: https://opensource.com/article/18/4/running-jenkins-builds-containers
-[25]: https://opensource.com/article/18/4/jenkins-pipelines-with-cucumber
-[26]: https://opensource.com/life/16/7/running-jmeter-jenkins-continuous-delivery-101
-[27]: https://opensource.com/business/15/5/interview-maish-saidel-keesing-cisco
-[28]: https://opensource.com/article/19/3/tools-fault-tolerant-system
-[29]: https://opensource.com/article/19/7/understanding-software-design-patterns
diff --git a/sources/tech/20190905 How to Change Themes in Linux Mint.md b/sources/tech/20190905 How to Change Themes in Linux Mint.md
deleted file mode 100644
index 6f1c1ce3da..0000000000
--- a/sources/tech/20190905 How to Change Themes in Linux Mint.md
+++ /dev/null
@@ -1,103 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (qfzy1233)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Change Themes in Linux Mint)
-[#]: via: (https://itsfoss.com/install-themes-linux-mint/)
-[#]: author: (It's FOSS Community https://itsfoss.com/author/itsfoss/)
-
-How to Change Themes in Linux Mint
-======
-
-Using Linux Mint is, from the start, a unique experience for its main Desktop Environment: Cinnamon. This is one of the main [features why I love Linux Mint][1].
-
-Since Mint’s dev team [started to take design more serious][2], “Themes” applet became an important way not only to choose new themes, icons, buttons, window borders and mouse pointers, but also to install new themes directly from it. Interested? Let’s jump into it.
-
-### How to change themes in Linux Mint
-
-Search for themes in the Menu and open the Themes applet.
-
-![Theme Applet provides an easy way of installing and changing themes][3]
-
-At the applet there’s a “Add/Remove” button, pretty simple, huh? And, clicking on it, you and I can see Cinnamon Spices (Cinnamon’s official addons repository) themes ordered first by popularity.
-
-![Installing new themes in Linux Mint Cinnamon][4]
-
-To install one, all it’s needed to do is click on yours preferred one and wait for it to download. After that, the theme will be available at the “Desktop” option on the first page of the applet. Just double click on one of the installed themes to start using it.
-
-![Changing themes in Linux Mint Cinnamon][5]
-
-Here’s the default Linux Mint look:
-
-![Linux Mint Default Theme][6]
-
-And here’s after I change the theme:
-
-![Linux Mint with Carta Theme][7]
-
-All the themes are also available at the Cinnamon Spices site for more information and bigger screenshots so you can take a better look on how your system will look.
-
-[Browse Cinnamon Themes][8]
-
-### Installing third party themes in Linux Mint
-
-_“I saw this amazing theme on another site and it is not available at Cinnamon Spices…”_
-
-Cinnamon Spices has a good collection of themes but you’ll still find that the theme you saw some place else is not available on the official Cinnamon website.
-
-Well, it would be nice if there was another way, huh? You might imagine that there is (I’m mean…obviously there is). So, first things first, there are other websites where you and I can find new cool themes.
-
-I’ll recommend going to Cinnamon Look and browse themes there. If you like something download it.
-
-[Get more themes at Cinnamon Look][9]
-
-After the preferred theme is downloaded, you will have a compressed file now with all you need for the installation. Extract it and save at ~/.themes. Confused? The “~” file path is actually your home folder: /home/{YOURUSER}/.themes.
-
-[][10]
-
-Suggested read Fix "Failed To Start Session" At Login In Ubuntu 16.04
-
-So go to the your Home directory. Press Ctrl+H to [show hidden files in Linux][11]. If you don’t see a .themes folder, create a new folder and name .themes. Remember that the dot at the beginning of the folder name is important.
-
-Copy the extracted theme folder from your Downloads directory to the .themes folder in your Home.
-
-After that, look for the installed theme at the applet above mentioned.
-
-Note
-
-Remember that the themes must be made to work on Cinnamon, even though it is a fork from GNOME, not all themes made for GNOME works at Cinnamon.
-
-Changing theme is one part of Cinnamon customization. You can also [change the looks of Linux Mint by changing the icons][12].
-
-I hope you now you know how to change themes in Linux Mint. Which theme are you going to use?
-
-### João Gondim
-
-Linux enthusiast from Brasil.
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/install-themes-linux-mint/
-
-作者:[It's FOSS Community][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/itsfoss/
-[b]: https://github.com/lujun9972
-[1]: https://itsfoss.com/tiny-features-linux-mint-cinnamon/
-[2]: https://itsfoss.com/linux-mint-new-design/
-[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/install-theme-linux-mint-1.jpg?resize=800%2C625&ssl=1
-[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/install-theme-linux-mint-2.jpg?resize=800%2C625&ssl=1
-[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/install-theme-linux-mint-3.jpg?resize=800%2C450&ssl=1
-[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/linux-mint-default-theme.jpg?resize=800%2C450&ssl=1
-[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/linux-mint-carta-theme.jpg?resize=800%2C450&ssl=1
-[8]: https://cinnamon-spices.linuxmint.com/themes
-[9]: https://www.cinnamon-look.org/
-[10]: https://itsfoss.com/failed-to-start-session-ubuntu-14-04/
-[11]: https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
-[12]: https://itsfoss.com/install-icon-linux-mint/
diff --git a/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md b/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md
deleted file mode 100644
index d1523f33c3..0000000000
--- a/sources/tech/20190906 6 Open Source Paint Applications for Linux Users.md
+++ /dev/null
@@ -1,234 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (6 Open Source Paint Applications for Linux Users)
-[#]: via: (https://itsfoss.com/open-source-paint-apps/)
-[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
-
-6 Open Source Paint Applications for Linux Users
-======
-
-As a child, when I started using computer (with Windows XP), my favorite application was Paint. I spent hours doodling on it. Surprisingly, children still love the paint apps. And not just children, the simple paint app comes handy in a number of situations.
-
-You will find a bunch of applications that let you draw/paint or manipulate images. However, some of them are proprietary. While you’re a Linux user – why not focus on open source paint applications?
-
-In this article, we are going to list some of the best open source paint applications which are worthy alternatives to proprietary painting software available on Linux.
-
-### Open Source paint & drawing applications
-
-![][1]
-
-**Note:** _The list is in no particular order of ranking._
-
-#### 1\. Pinta
-
-![][2]
-
-Key Highlights:
-
- * Great alternative to Paint.NET / MS Paint
- * Add-on support (WebP Image support available)
- * Layer Support
-
-
-
-[Pinta][3] is an impressive open-source paint application which is perfect for drawing and basic image editing. In other words, it is a simple paint application with some fancy features.
-
-You may consider [Pinta][4] as an alternative to MS Paint on Linux – but with layer support and more. Not just MS Paint, but it acts as a Linux replacement for Paint.NET software available for Windows. Even though Paint.NET is better – Pinta seems to be a decent alternative to it.
-
-A couple of add-ons can be utilized to enhance the functionality, like the [support for WebP images on Linux][5]. In addition to the layer support, you can easily resize the images, add effects, make adjustments (brightness, contrast, etc.), and also adjust the quality when exporting the image.
-
-#### How to install Pinta?
-
-You should be able to easily find it in the Software Center / App Center / Package Manager. Just type in “**Pinta**” and get started installing it. In either case, try the [Flatpak][6] package.
-
-Or, you can enter the following command in the terminal (Ubuntu/Debian):
-
-```
-sudo apt install pinta
-```
-
-For more information on the download packages and installation instructions, refer the [official download page][7].
-
-#### 2\. Krita
-
-![][8]
-
-Key Highlights:
-
- * HDR Painting
- * PSD Support
- * Layer Support
- * Brush stabilizers
- * 2D Animation
-
-
-
-Krita is one of the most advanced open source paint applications for Linux. Of course, for this article, it helps you draw sketches and wreak havoc upon the canvas. But, in addition to that, it offers a whole lot of features.
-
-[][9]
-
-Suggested read Things To Do After Installing Fedora 24
-
-For instance, if you have a shaky hand, it can help you stabilize the brush strokes. You also get built-in vector tools to create comic panels and other interesting things. If you are looking for a full-fledged color management support, drawing assistants, and layer management, Krita should be your preferred choice.
-
-#### How to install Krita?
-
-Similar to pinta, you should be able to find it listed in the Software Center/App Center or the package manager. It’s also available in the [Flatpak repository][10].
-
-Thinking to install it via terminal? Type in the following command:
-
-```
-sudo apt install krita
-```
-
-In either case, you can head down to their [official download page][11] to get the **AppImage** file and run it.
-
-If you have no idea on AppImage files, check out our guide on – [how to use AppImage][12].
-
-#### 3\. Tux Paint
-
-![][13]
-
-Key Highlights:
-
- * A no-nonsense paint application for kids
-
-
-
-I’m not kidding, Tux Paint is one of the best open-source paint applications for kids between 3-12 years of age. Of course, you do not want options when you want to just scribble. So, Tux Paint seems to be the best option in that case (even for adults!).
-
-#### How to install Tuxpaint?
-
-Tuxpaint can be downloaded from the Software Center or Package manager. In either case, to install it on Ubuntu/Debian, type in the following command in the terminal:
-
-```
-sudo apt install tuxpaint
-```
-
-For more information on it, head to the [official site][14].
-
-#### 4\. Drawpile
-
-![][15]
-
-Key Highlights:
-
- * Collaborative Drawing
- * Built-in chat to interact with other users
- * Layer support
- * Record drawing sessions
-
-
-
-Drawpile is an interesting open-source paint application where you get to collaborate with other users in real-time. To be precise, you can simultaneously draw in a single canvas. In addition to this unique feature, you have the layer support, ability to record your drawing session, and even a chat facility to interact with the users collaborating.
-
-You can host/join a public session or start a private session with your friend which requires a code. By default, the server will be your computer. But, if you want a remote server, you can select it as well.
-
-Do note, that you will need to [sign up for a Drawpile account][16] in order to collaborate.
-
-#### How to install Drawpile?
-
-As far as I’m aware of, you can only find it listed in the [Flatpak repository][17].
-
-[][18]
-
-Suggested read OCS Store: One Stop Shop All of Your Linux Software Customization Needs
-
-#### 5\. MyPaint
-
-![][19]
-
-Key Highlights:
-
- * Easy-to-use tool for digital painters
- * Layer management support
- * Lots of options to tweak your brush and drawing
-
-
-
-[MyPaint][20] is a simple yet powerful tool for digital painters. It features a lot of options to tweak in order to make the perfect digital brush stroke. I’m not much of a digital artist (but a scribbler) but I observed quite a few options to adjust the brush, the colors, and an option to add a scratchpad panel.
-
-It also supports layer management – in case you want that. The latest stable version hasn’t been updated for a few years now, but the recent alpha build (which I tested) works just fine. If you are looking for an open source paint application on Linux – do give this a try.
-
-#### How to install MyPaint?
-
-MyPaint is available in the official repository. However, that’s the old version. If you still want to proceed, you can search for it in the Software Center or type the following command in the terminal:
-
-```
-sudo apt install mypaint
-```
-
-You can head to its official [GitHub release page][21] for the latest alpha build and get the [AppImage file][12] (any version) to make it executable and launch the app.
-
-#### 6\. KolourPaint
-
-![][22]
-
-Key Highlights:
-
- * A simple alternative to MS Paint on Linux
- * No layer management support
-
-
-
-If you aren’t looking for any Layer management support and just want an open source paint application to draw stuff – this is it.
-
-[KolourPaint][23] is originally tailored for KDE desktop environments but it works flawlessly on others too.
-
-#### How to install KolourPaint?
-
-You can install KolourPaint right from the Software Center or via the terminal using the following command:
-
-```
-sudo apt install kolourpaint4
-```
-
-In either case, you can utilize [Flathub][24] as well.
-
-**Wrapping Up**
-
-If you are wondering about applications like GIMP/Inkscape, we have those listed in another separate article on the [best Linux Tools for digital artists][25]. If you’re curious about more options, I recommend you to check that out.
-
-Here, we try to compile a list of best open source paint applications available for Linux. If you think we missed something, feel free to tell us about it in the comments section below!
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/open-source-paint-apps/
-
-作者:[Ankush Das][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://itsfoss.com/author/ankush/
-[b]: https://github.com/lujun9972
-[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/open-source-paint-apps.png?resize=800%2C450&ssl=1
-[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/pinta.png?ssl=1
-[3]: https://pinta-project.com/pintaproject/pinta/
-[4]: https://itsfoss.com/pinta-1-6-ubuntu-linux-mint/
-[5]: https://itsfoss.com/webp-ubuntu-linux/
-[6]: https://www.flathub.org/apps/details/com.github.PintaProject.Pinta
-[7]: https://pinta-project.com/pintaproject/pinta/releases
-[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/krita-paint.png?ssl=1
-[9]: https://itsfoss.com/things-to-do-after-installing-fedora-24/
-[10]: https://www.flathub.org/apps/details/org.kde.krita
-[11]: https://krita.org/en/download/krita-desktop/
-[12]: https://itsfoss.com/use-appimage-linux/
-[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/tux-paint.jpg?ssl=1
-[14]: http://www.tuxpaint.org/
-[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/drawpile.png?ssl=1
-[16]: https://drawpile.net/accounts/signup/
-[17]: https://flathub.org/apps/details/net.drawpile.drawpile
-[18]: https://itsfoss.com/ocs-store/
-[19]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/mypaint.png?ssl=1
-[20]: https://mypaint.org/
-[21]: https://github.com/mypaint/mypaint/releases
-[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/09/kolourpaint.png?ssl=1
-[23]: http://kolourpaint.org/
-[24]: https://flathub.org/apps/details/org.kde.kolourpaint
-[25]: https://itsfoss.com/best-linux-graphic-design-software/
diff --git a/sources/tech/20190909 How to Setup Multi Node Elastic Stack Cluster on RHEL 8 - CentOS 8.md b/sources/tech/20190909 How to Setup Multi Node Elastic Stack Cluster on RHEL 8 - CentOS 8.md
deleted file mode 100644
index f56e708426..0000000000
--- a/sources/tech/20190909 How to Setup Multi Node Elastic Stack Cluster on RHEL 8 - CentOS 8.md
+++ /dev/null
@@ -1,476 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Setup Multi Node Elastic Stack Cluster on RHEL 8 / CentOS 8)
-[#]: via: (https://www.linuxtechi.com/setup-multinode-elastic-stack-cluster-rhel8-centos8/)
-[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
-
-How to Setup Multi Node Elastic Stack Cluster on RHEL 8 / CentOS 8
-======
-
-Elastic stack widely known as **ELK stack**, it is a group of opensource products like **Elasticsearch**, **Logstash** and **Kibana**. Elastic Stack is developed and maintained by Elastic company. Using elastic stack, one can feed system’s logs to Logstash, it is a data collection engine which accept the logs or data from all the sources and normalize logs and then it forwards the logs to Elasticsearch for **analyzing**, **indexing**, **searching** and **storing** and finally using Kibana one can represent the visualize data, using Kibana we can also create interactive graphs and diagram based on user’s queries.
-
-[![Elastic-Stack-Cluster-RHEL8-CentOS8][1]][2]
-
-In this article we will demonstrate how to setup multi node elastic stack cluster on RHEL 8 / CentOS 8 servers. Following are details for my Elastic Stack Cluster:
-
-### Elasticsearch:
-
- * Three Servers with Minimal RHEL 8 / CentOS 8
- * IPs & Hostname – 192.168.56.40 (elasticsearch1.linuxtechi. local), 192.168.56.50 (elasticsearch2.linuxtechi. local), 192.168.56.60 (elasticsearch3.linuxtechi. local)
-
-
-
-### Logstash:
-
- * Two Servers with minimal RHEL 8 / CentOS 8
- * IPs & Hostname – 192.168.56.20 (logstash1.linuxtechi. local) , 192.168.56.30 (logstash2.linuxtechi. local)
-
-
-
-### Kibana:
-
- * One Server with minimal RHEL 8 / CentOS 8
- * Hostname – kibana.linuxtechi.local
- * IP – 192.168.56.10
-
-
-
-### Filebeat:
-
- * One Server with minimal CentOS 7
- * IP & hostname – 192.168.56.70 (web-server)
-
-
-
-Let’s start with Elasticsearch cluster setup,
-
-#### Setup 3 node Elasticsearch cluster
-
-As I have already stated that I have kept nodes for Elasticsearch cluster, login to each node, set the hostname and configure yum/dnf repositories.
-
-Use the below hostnamectl command to set the hostname on respective nodes,
-
-```
-[root@linuxtechi ~]# hostnamectl set-hostname "elasticsearch1.linuxtechi. local"
-[root@linuxtechi ~]# exec bash
-[root@linuxtechi ~]#
-[root@linuxtechi ~]# hostnamectl set-hostname "elasticsearch2.linuxtechi. local"
-[root@linuxtechi ~]# exec bash
-[root@linuxtechi ~]#
-[root@linuxtechi ~]# hostnamectl set-hostname "elasticsearch3.linuxtechi. local"
-[root@linuxtechi ~]# exec bash
-[root@linuxtechi ~]#
-```
-
-For CentOS 8 System we don’t need to configure any OS package repository and for RHEL 8 Server, if you have valid subscription and then subscribed it with Red Hat for getting package repository. In Case you want to configure local yum/dnf repository for OS packages then refer the below url:
-
-[How to Setup Local Yum/DNF Repository on RHEL 8 Server Using DVD or ISO File][3]
-
-Configure Elasticsearch package repository on all the nodes, create a file elastic.repo file under /etc/yum.repos.d/ folder with the following content
-
-```
-~]# vi /etc/yum.repos.d/elastic.repo
-[elasticsearch-7.x]
-name=Elasticsearch repository for 7.x packages
-baseurl=https://artifacts.elastic.co/packages/7.x/yum
-gpgcheck=1
-gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
-enabled=1
-autorefresh=1
-type=rpm-md
-```
-
-save & exit the file
-
-Use below rpm command on all three nodes to import Elastic’s public signing key
-
-```
-~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
-```
-
-Add the following lines in /etc/hosts file on all three nodes,
-
-```
-192.168.56.40 elasticsearch1.linuxtechi.local
-192.168.56.50 elasticsearch2.linuxtechi.local
-192.168.56.60 elasticsearch3.linuxtechi.local
-```
-
-Install Java on all three Nodes using yum / dnf command,
-
-```
-[root@linuxtechi ~]# dnf install java-openjdk -y
-[root@linuxtechi ~]# dnf install java-openjdk -y
-[root@linuxtechi ~]# dnf install java-openjdk -y
-```
-
-Install Elasticsearch using beneath dnf command on all three nodes,
-
-```
-[root@linuxtechi ~]# dnf install elasticsearch -y
-[root@linuxtechi ~]# dnf install elasticsearch -y
-[root@linuxtechi ~]# dnf install elasticsearch -y
-```
-
-**Note:** In case OS firewall is enabled and running in each Elasticsearch node then allow following ports using beneath firewall-cmd command,
-
-```
-~]# firewall-cmd --permanent --add-port=9300/tcp
-~]# firewall-cmd --permanent --add-port=9200/tcp
-~]# firewall-cmd --reload
-```
-
-Configure Elasticsearch, edit the file “**/etc/elasticsearch/elasticsearch.yml**” on all the three nodes and add the followings,
-
-```
-~]# vim /etc/elasticsearch/elasticsearch.yml
-…………………………………………
-cluster.name: opn-cluster
-node.name: elasticsearch1.linuxtechi.local
-network.host: 192.168.56.40
-http.port: 9200
-discovery.seed_hosts: ["elasticsearch1.linuxtechi.local", "elasticsearch2.linuxtechi.local", "elasticsearch3.linuxtechi.local"]
-cluster.initial_master_nodes: ["elasticsearch1.linuxtechi.local", "elasticsearch2.linuxtechi.local", "elasticsearch3.linuxtechi.local"]
-……………………………………………
-```
-
-**Note:** on Each node, add the correct hostname in node.name parameter and ip address in network.host parameter and other parameters will remain the same.
-
-Now Start and enable the Elasticsearch service on all three nodes using following systemctl command,
-
-```
-~]# systemctl daemon-reload
-~]# systemctl enable elasticsearch.service
-~]# systemctl start elasticsearch.service
-```
-
-Use below ‘ss’ command to verify whether elasticsearch node is start listening on 9200 port,
-
-```
-[root@linuxtechi ~]# ss -tunlp | grep 9200
-tcp LISTEN 0 128 [::ffff:192.168.56.40]:9200 *:* users:(("java",pid=2734,fd=256))
-[root@linuxtechi ~]#
-```
-
-Use following curl commands to verify the Elasticsearch cluster status
-
-```
-[root@linuxtechi ~]# curl http://elasticsearch1.linuxtechi.local:9200
-[root@linuxtechi ~]# curl -X GET http://elasticsearch2.linuxtechi.local:9200/_cluster/health?pretty
-```
-
-Output above command would be something like below,
-
-![Elasticsearch-cluster-status-rhel8][1]
-
-Above output confirms that we have successfully created 3 node Elasticsearch cluster and status of cluster is also green.
-
-**Note:** If you want to modify JVM heap size then you have edit the file “**/etc/elasticsearch/jvm.options**” and change the below parameters that suits to your environment,
-
- * -Xms1g
- * -Xmx1g
-
-
-
-Now let’s move to Logstash nodes,
-
-#### Install and Configure Logstash
-
-Perform the following steps on both Logstash nodes,
-
-Login to both the nodes set the hostname using following hostnamectl command,
-
-```
-[root@linuxtechi ~]# hostnamectl set-hostname "logstash1.linuxtechi.local"
-[root@linuxtechi ~]# exec bash
-[root@linuxtechi ~]#
-[root@linuxtechi ~]# hostnamectl set-hostname "logstash2.linuxtechi.local"
-[root@linuxtechi ~]# exec bash
-[root@linuxtechi ~]#
-```
-
-Add the following entries in /etc/hosts file in both logstash nodes
-
-```
-~]# vi /etc/hosts
-192.168.56.40 elasticsearch1.linuxtechi.local
-192.168.56.50 elasticsearch2.linuxtechi.local
-192.168.56.60 elasticsearch3.linuxtechi.local
-```
-
-Save and exit the file
-
-Configure Logstash repository on both the nodes, create a file **logstash.repo** under the folder /ete/yum.repos.d/ with following content,
-
-```
-~]# vi /etc/yum.repos.d/logstash.repo
-[elasticsearch-7.x]
-name=Elasticsearch repository for 7.x packages
-baseurl=https://artifacts.elastic.co/packages/7.x/yum
-gpgcheck=1
-gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
-enabled=1
-autorefresh=1
-type=rpm-md
-```
-
-Save and exit the file, run the following rpm command to import the signing key
-
-```
-~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
-```
-
-Install Java OpenJDK on both the nodes using following dnf command,
-
-```
-~]# dnf install java-openjdk -y
-```
-
-Run the following dnf command from both the nodes to install logstash,
-
-```
-[root@linuxtechi ~]# dnf install logstash -y
-[root@linuxtechi ~]# dnf install logstash -y
-```
-
-Now configure logstash, perform below steps on both logstash nodes,
-
-Create a logstash conf file, for that first we have copy sample logstash file under ‘/etc/logstash/conf.d/’
-
-```
-# cd /etc/logstash/
-# cp logstash-sample.conf conf.d/logstash.conf
-```
-
-Edit conf file and update the following content,
-
-```
-# vi conf.d/logstash.conf
-
-input {
- beats {
- port => 5044
- }
-}
-
-output {
- elasticsearch {
- hosts => ["http://elasticsearch1.linuxtechi.local:9200", "http://elasticsearch2.linuxtechi.local:9200", "http://elasticsearch3.linuxtechi.local:9200"]
- index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
- #user => "elastic"
- #password => "changeme"
- }
-}
-```
-
-Under output section, in hosts parameter specify FQDN of all three Elasticsearch nodes, other parameters leave as it is.
-
-Allow logstash port “5044” in OS firewall using following firewall-cmd command,
-
-```
-~ # firewall-cmd --permanent --add-port=5044/tcp
-~ # firewall-cmd –reload
-```
-
-Now start and enable Logstash service, run the following systemctl commands on both the nodes
-
-```
-~]# systemctl start logstash
-~]# systemctl eanble logstash
-```
-
-Use below ss command to verify whether logstash service start listening on 5044,
-
-```
-[root@linuxtechi ~]# ss -tunlp | grep 5044
-tcp LISTEN 0 128 *:5044 *:* users:(("java",pid=2416,fd=96))
-[root@linuxtechi ~]#
-```
-
-Above output confirms that logstash has been installed and configured successfully. Let’s move to Kibana installation.
-
-#### Install and Configure Kibana
-
-Login to Kibana node, set the hostname with **hostnamectl** command,
-
-```
-[root@linuxtechi ~]# hostnamectl set-hostname "kibana.linuxtechi.local"
-[root@linuxtechi ~]# exec bash
-[root@linuxtechi ~]#
-```
-
-Edit /etc/hosts file and add the following lines
-
-```
-192.168.56.40 elasticsearch1.linuxtechi.local
-192.168.56.50 elasticsearch2.linuxtechi.local
-192.168.56.60 elasticsearch3.linuxtechi.local
-```
-
-Setup the Kibana repository using following,
-
-```
-[root@linuxtechi ~]# vi /etc/yum.repos.d/kibana.repo
-[elasticsearch-7.x]
-name=Elasticsearch repository for 7.x packages
-baseurl=https://artifacts.elastic.co/packages/7.x/yum
-gpgcheck=1
-gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
-enabled=1
-autorefresh=1
-type=rpm-md
-
-[root@linuxtechi ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
-```
-
-Execute below dnf command to install kibana,
-
-```
-[root@linuxtechi ~]# yum install kibana -y
-```
-
-Configure Kibana by editing the file “**/etc/kibana/kibana.yml**”
-
-```
-[root@linuxtechi ~]# vim /etc/kibana/kibana.yml
-…………
-server.host: "kibana.linuxtechi.local"
-server.name: "kibana.linuxtechi.local"
-elasticsearch.hosts: ["http://elasticsearch1.linuxtechi.local:9200", "http://elasticsearch2.linuxtechi.local:9200", "http://elasticsearch3.linuxtechi.local:9200"]
-…………
-```
-
-Start and enable kibana service
-
-```
-[root@linuxtechi ~]# systemctl start kibana
-[root@linuxtechi ~]# systemctl enable kibana
-```
-
-Allow Kibana port ‘5601’ in OS firewall,
-
-```
-[root@linuxtechi ~]# firewall-cmd --permanent --add-port=5601/tcp
-success
-[root@linuxtechi ~]# firewall-cmd --reload
-success
-[root@linuxtechi ~]#
-```
-
-Access Kibana portal / GUI using the following URL:
-
-
-
-[![Kibana-Dashboard-rhel8][1]][4]
-
-From dashboard, we can also check our Elastic Stack cluster status
-
-[![Stack-Monitoring-Overview-RHEL8][1]][5]
-
-This confirms that we have successfully setup multi node Elastic Stack cluster on RHEL 8 / CentOS 8.
-
-Now let’s send some logs to logstash nodes via filebeat from other Linux servers, In my case I have one CentOS 7 Server, I will push all important logs of this server to logstash via filebeat.
-
-Login to CentOS 7 server and install filebeat package using following rpm command,
-
-```
-[root@linuxtechi ~]# rpm -ivh https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-x86_64.rpm
-Retrieving https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.1-x86_64.rpm
-Preparing... ################################# [100%]
-Updating / installing...
- 1:filebeat-7.3.1-1 ################################# [100%]
-[root@linuxtechi ~]#
-```
-
-Edit the /etc/hosts file and add the following entries,
-
-```
-192.168.56.20 logstash1.linuxtechi.local
-192.168.56.30 logstash2.linuxtechi.local
-```
-
-Now configure the filebeat so that it can send logs to logstash nodes using load balancing technique, edit the file “**/etc/filebeat/filebeat.yml**” and add the following parameters,
-
-Under the ‘**filebeat.inputs:**’ section change ‘**enabled: false**‘ to ‘**enabled: true**‘ and under the “**paths**” parameter specify the location log files that we can send to logstash, In output Elasticsearch section comment out “**output.elasticsearch**” and **host** parameter. In Logstash output section, remove the comments for “**output.logstash:**” and “**hosts:**” and add the both logstash nodes in hosts parameters and also “**loadbalance: true**”.
-
-```
-[root@linuxtechi ~]# vi /etc/filebeat/filebeat.yml
-……………………….
-filebeat.inputs:
-- type: log
- enabled: true
- paths:
- - /var/log/messages
- - /var/log/dmesg
- - /var/log/maillog
- - /var/log/boot.log
-#output.elasticsearch:
- # hosts: ["localhost:9200"]
-
-output.logstash:
- hosts: ["logstash1.linuxtechi.local:5044", "logstash2.linuxtechi.local:5044"]
- loadbalance: true
-………………………………………
-```
-
-Start and enable filebeat service using beneath systemctl commands,
-
-```
-[root@linuxtechi ~]# systemctl start filebeat
-[root@linuxtechi ~]# systemctl enable filebeat
-```
-
-Now go to Kibana GUI, verify whether new indices are visible or not,
-
-Choose Management option from Left side bar and then click on Index Management under Elasticsearch,
-
-[![Elasticsearch-index-management-Kibana][1]][6]
-
-As we can see above, indices are visible now, let’s create index pattern,
-
-Click on “Index Patterns” from Kibana Section, it will prompt us to create a new pattern, click on “**Create Index Pattern**” and specify the pattern name as “**filebeat**”
-
-[![Define-Index-Pattern-Kibana-RHEL8][1]][7]
-
-Click on Next Step
-
-Choose “**Timestamp**” as time filter for index pattern and then click on “Create index pattern”
-
-[![Time-Filter-Index-Pattern-Kibana-RHEL8][1]][8]
-
-[![filebeat-index-pattern-overview-Kibana][1]][9]
-
-Now Click on Discover to see real time filebeat index pattern,
-
-[![Discover-Kibana-REHL8][1]][10]
-
-This confirms that Filebeat agent has been configured successfully and we are able to see real time logs on Kibana dashboard.
-
-That’s all from this article, please don’t hesitate to share your feedback and comments in case these steps help you to setup multi node Elastic Stack Cluster on RHEL 8 / CentOS 8 system.
-
---------------------------------------------------------------------------------
-
-via: https://www.linuxtechi.com/setup-multinode-elastic-stack-cluster-rhel8-centos8/
-
-作者:[Pradeep Kumar][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.linuxtechi.com/author/pradeep/
-[b]: https://github.com/lujun9972
-[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Elastic-Stack-Cluster-RHEL8-CentOS8.jpg
-[3]: https://www.linuxtechi.com/setup-local-yum-dnf-repository-rhel-8/
-[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Kibana-Dashboard-rhel8.jpg
-[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Stack-Monitoring-Overview-RHEL8.jpg
-[6]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Elasticsearch-index-management-Kibana.jpg
-[7]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Define-Index-Pattern-Kibana-RHEL8.jpg
-[8]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Time-Filter-Index-Pattern-Kibana-RHEL8.jpg
-[9]: https://www.linuxtechi.com/wp-content/uploads/2019/09/filebeat-index-pattern-overview-Kibana.jpg
-[10]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Discover-Kibana-REHL8.jpg
diff --git a/sources/tech/20190909 How to use Terminator on Linux to run multiple terminals in one window.md b/sources/tech/20190909 How to use Terminator on Linux to run multiple terminals in one window.md
deleted file mode 100644
index 6ee0820fdf..0000000000
--- a/sources/tech/20190909 How to use Terminator on Linux to run multiple terminals in one window.md
+++ /dev/null
@@ -1,118 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to use Terminator on Linux to run multiple terminals in one window)
-[#]: via: (https://www.networkworld.com/article/3436784/how-to-use-terminator-on-linux-to-run-multiple-terminals-in-one-window.html)
-[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
-
-How to use Terminator on Linux to run multiple terminals in one window
-======
-Providing an option for multiple GNOME terminals within a single window frame, Terminator lets you flexibly align your workspace to suit your needs.
-Sandra Henry-Stocker
-
-If you’ve ever wished that you could line up multiple terminal windows and organize them in a single window frame, we may have some good news for you. The Linux **Terminator** can do this for you. No problemo!
-
-### Splitting windows
-
-Terminator will initially open like a terminal window with a single window. Once you mouse click within that window, however, it will bring up an options menu that gives you the flexibility to make changes. You can choose “**split horizontally**” or “**split vertically**” to split the window you are currently position in into two smaller windows. In fact, with these menu choices, complete with tiny illustrations of the resultant split (resembling **=** and **||**), you can split windows repeatedly if you like. Of course, if you split the overall window into more than six or nine sections, you might just find that they're too small to be used effectively.
-
-**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][1] ]**
-
-Using ASCII art to illustrate the process of splitting windows, you might see something like this:
-
-```
-+-------------------+ +-------------------+ +-------------------+
-| | | | | |
-| | | | | |
-| | ==> |-------------------| ==> |-------------------|
-| | | | | | |
-| | | | | | |
-+-------------------+ +-------------------+ +-------------------+
- Original terminal Split horizontally Split vertically
-```
-
-Another option for splitting windows is to use control sequences like **Ctrl+Shift+e** to split a window vertically and **Ctrl+Shift+o** (“o" as in “open”) to split the screen horizontally.
-
-Once Terminator has split into smaller windows for you, you can click in any window to use it and move from window to window as your work dictates.
-
-### Maximizing a window
-
-If you want to ignore all but one of your windows for a while and focus on just one, you can click in that window and select the "**Maximize**" option from the menu. That window will then grow to claim all of the space. Click again and select "**Restore all terminals**" to return to the multi-window display. **Ctrl+Shift+x** will toggle between the normal and maximized settings.
-
-The window size indicators (e.g., 80x15) on window labels display the number of characters per line and the number of lines per window that each window provides.
-
-### Closing windows
-
-To close any window, bring up the Terminator menu and select **Close**. Other windows will adjust themselves to take up the space until you close the last remaining window.
-
-### Saving your customized setup(s)
-
-Setting up your customized terminator settings as your default once you've split your overall window into multiple segments is quite easy. Select **Preferences** from the pop-up menu and then **Layouts** from the tab along the top of the window that opens. You should then see **New Layout** listed. Just click on the **Save** option at the bottom and **Close** on the bottom right. Terminator will save your settings in **~/.config/terminator/config** and will then use this file every time you use it.
-
-You can also enlarge your overall window by stretching it with your mouse. Again, if you want to retain the changes, select **Preferences** from the menu, **Layouts** and then **Save** and **Close** again.
-
-### Choosing between saved configurations
-
-If you like, you can set up multiple options for your Terminator window arrangements by maintaining a number of config files, renaming each afterwards (e.g., config-1, config-2) and then moving your choice into place as **~/.config/terminator/config** when you want to use that layout. Here's an example script for doing something like this script. It lets you choose between three pre-configured window arrangements:
-
-```
-#!/bin/bash
-
-PS3='Terminator options: '
-options=("Split 1" "Split 2" "Split 3" "Quit")
-select opt in "${options[@]}"
-do
- case $opt in
- "Split 1")
- config=config-1
- break
- ;;
- "Split 2")
- config=config-2
- break
- ;;
- "Split 3")
- config=config-3
- break
- ;;
- *)
- exit
- ;;
- esac
-done
-
-cd ~/.config/terminator
-cp config config-
-cp $config config
-cd
-terminator &
-```
-
-You could give the options more meaningful names than "config-1" if that helps.
-
-### Wrap-up
-
-Terminator is a good choice for setting up multiple windows to work on related tasks. If you've never used it, you'll probably need to install it first with a command such as "sudo apt install terminator" or "sudo yum install -y terminator".
-
-Hopefully, you will enjoy using Terminator. And, as another character of the same name might say, "I'll be back!"
-
-Join the Network World communities on [Facebook][2] and [LinkedIn][3] to comment on topics that are top of mind.
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3436784/how-to-use-terminator-on-linux-to-run-multiple-terminals-in-one-window.html
-
-作者:[Sandra Henry-Stocker][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
-[b]: https://github.com/lujun9972
-[1]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
-[2]: https://www.facebook.com/NetworkWorld/
-[3]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20190911 4 open source cloud security tools.md b/sources/tech/20190911 4 open source cloud security tools.md
deleted file mode 100644
index 5d14a725df..0000000000
--- a/sources/tech/20190911 4 open source cloud security tools.md
+++ /dev/null
@@ -1,90 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (4 open source cloud security tools)
-[#]: via: (https://opensource.com/article/19/9/open-source-cloud-security)
-[#]: author: (Alison NaylorAaron Rinehart https://opensource.com/users/asnaylorhttps://opensource.com/users/ansilvahttps://opensource.com/users/sethhttps://opensource.com/users/bretthunoldtcomhttps://opensource.com/users/aaronrineharthttps://opensource.com/users/marcobravo)
-
-4 open source cloud security tools
-======
-Find and eliminate vulnerabilities in the data you store in AWS and
-GitHub.
-![Tools in a cloud][1]
-
-If your day-to-day as a developer, system administrator, full-stack engineer, or site reliability engineer involves Git pushes, commits, and pulls to and from GitHub and deployments to Amazon Web Services (AWS), security is a persistent concern. Fortunately, open source tools are available to help your team avoid common mistakes that could cost your organization thousands of dollars.
-
-This article describes four open source tools that can help improve your security practices when you're developing on GitHub and AWS. Also, in the spirit of open source, I've joined forces with three security experts—[Travis McPeak][2], senior cloud security engineer at Netflix; [Rich Monk][3], senior principal information security analyst at Red Hat; and [Alison Naylor][4], principal information security analyst at Red Hat—to contribute to this article.
-
-We've separated each tool by scenario, but they are not mutually exclusive.
-
-### 1\. Find sensitive data with Gitrob
-
-You need to find any potentially sensitive information present in your team's Git repos so you can remove it. It may make sense for you to use tools that are focused towards attacking an application or a system using a red/blue team model, in which an infosec team is divided in two: an attack team (a.k.a. a red team) and a defense team (a.k.a. a blue team). Having a red team to try to penetrate your systems and applications is lots better than waiting for an adversary to do so. Your red team might try using [Gitrob][5], a tool that can clone and crawl through your Git repositories looking for credentials and sensitive files.
-
-Even though tools like Gitrob could be used for harm, the idea here is for your infosec team to use it to find inadvertently disclosed sensitive data that belongs to your organization (such as AWS keypairs or other credentials that were committed by mistake). That way, you can get your repositories fixed and sensitive data expunged—hopefully before an adversary finds them. Remember to remove not only the affected files but [also their history][6]!
-
-### 2\. Avoid committing sensitive data with git-secrets
-
-While it's important to find and remove sensitive information in your Git repos, wouldn't it be better to avoid committing those secrets in the first place? Mistakes happen, but you can protect yourself from public embarrassment by using [git-secrets][7]. This tool allows you to set up hooks that scan your commits, commit messages, and merges looking for common patterns for secrets. Choose patterns that match the credentials your team uses, such as AWS access keys and secret keys. If it finds a match, your commit is rejected and a potential crisis averted.
-
-It's simple to set up git-secrets for your existing repos, and you can apply a global configuration to protect all future repositories you initialize or clone. You can also use git-secrets to scan your repos (and all previous revisions) to search for secrets before making them public.
-
-### 3\. Create temporary credentials with Key Conjurer
-
-It's great to have a little extra insurance to prevent inadvertently publishing stored secrets, but maybe we can do even better by not storing credentials at all. Keeping track of credentials generally—including who has access to them, where they are stored, and when they were last rotated—is a hassle. However, programmatically generating temporary credentials can avoid a lot of those issues altogether, neatly side-stepping the issue of storing secrets in Git repos. Enter [Key Conjurer][8], which was created to address this need. For more on why Riot Games created Key Conjurer and how they developed it, read _[Key conjurer: our policy of least privilege][9]_.
-
-### 4\. Apply least privilege automatically with Repokid
-
-Anyone who has taken a security 101 course knows that least privilege is the best practice for role-based access control configuration. Sadly, outside school, it becomes prohibitively difficult to apply least-privilege policies manually. An application's access requirements change over time, and developers are too busy to trim back their permissions manually. [Repokid][10] uses data that AWS provides about identity and access management (IAM) use to automatically right-size policies. Repokid helps even the largest organizations apply least privilege automatically in AWS.
-
-### Tools, not silver bullets
-
-These tools are by no means silver bullets, but they are just that: tools! So, make sure you work with the rest of your organization to understand the use cases and usage patterns for your cloud services before trying to implement any of these tools or other controls.
-
-Becoming familiar with the best practices documented by all your cloud and code repository services should be taken seriously as well. The following articles will help you do so.
-
-**For AWS:**
-
- * [Best practices for managing AWS access keys][11]
- * [AWS security audit guidelines][12]
-
-
-
-**For GitHub:**
-
- * [Introducing new ways to keep your code secure][13]
- * [GitHub Enterprise security best practices][14]
-
-
-
-Last but not least, reach out to your infosec team; they should be able to provide you with ideas, recommendations, and guidelines for your team's success. Always remember: security is everyone's responsibility, not just theirs.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/9/open-source-cloud-security
-
-作者:[Alison NaylorAaron Rinehart][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/asnaylorhttps://opensource.com/users/ansilvahttps://opensource.com/users/sethhttps://opensource.com/users/bretthunoldtcomhttps://opensource.com/users/aaronrineharthttps://opensource.com/users/marcobravo
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cloud_tools_hardware.png?itok=PGjJenqT (Tools in a cloud)
-[2]: https://twitter.com/travismcpeak?lang=en
-[3]: https://github.com/rmonk
-[4]: https://www.linkedin.com/in/alperkins/
-[5]: https://github.com/michenriksen/gitrob
-[6]: https://help.github.com/en/articles/removing-sensitive-data-from-a-repository
-[7]: https://github.com/awslabs/git-secrets
-[8]: https://github.com/RiotGames/key-conjurer
-[9]: https://technology.riotgames.com/news/key-conjurer-our-policy-least-privilege
-[10]: https://github.com/Netflix/repokid
-[11]: https://docs.aws.amazon.com/general/latest/gr/aws-access-keys-best-practices.html
-[12]: https://docs.aws.amazon.com/general/latest/gr/aws-security-audit-guide.html
-[13]: https://github.blog/2019-05-23-introducing-new-ways-to-keep-your-code-secure/
-[14]: https://github.blog/2015-10-09-github-enterprise-security-best-practices/
diff --git a/sources/tech/20190911 How to set up a TFTP server on Fedora.md b/sources/tech/20190911 How to set up a TFTP server on Fedora.md
deleted file mode 100644
index e85eae976c..0000000000
--- a/sources/tech/20190911 How to set up a TFTP server on Fedora.md
+++ /dev/null
@@ -1,181 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (amwps290 )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to set up a TFTP server on Fedora)
-[#]: via: (https://fedoramagazine.org/how-to-set-up-a-tftp-server-on-fedora/)
-[#]: author: (Curt Warfield https://fedoramagazine.org/author/rcurtiswarfield/)
-
-How to set up a TFTP server on Fedora
-======
-
-![][1]
-
-**TFTP**, or Trivial File Transfer Protocol, allows users to transfer files between systems using the [UDP protocol][2]. By default, it uses UDP port 69. The TFTP protocol is extensively used to support remote booting of diskless devices. So, setting up a TFTP server on your own local network can be an interesting way to do [Fedora installations][3], or other diskless operations.
-
-TFTP can only read and write files to or from a remote system. It doesn’t have the capability to list files or make any changes on the remote server. There are also no provisions for user authentication. Because of security implications and the lack of advanced features, TFTP is generally only used on a local area network (LAN).
-
-### TFTP server installation
-
-The first thing you will need to do is install the TFTP client and server packages:
-
-```
-dnf install tftp-server tftp -y
-```
-
-This creates a _tftp_ service and socket file for [systemd][4] under _/usr/lib/systemd/system_.
-
-```
-/usr/lib/systemd/system/tftp.service
-/usr/lib/systemd/system/tftp.socket
-```
-
-Next, copy and rename these files to _/etc/systemd/system_:
-
-```
-cp /usr/lib/systemd/system/tftp.service /etc/systemd/system/tftp-server.service
-
-cp /usr/lib/systemd/system/tftp.socket /etc/systemd/system/tftp-server.socket
-```
-
-### Making local changes
-
-You need to edit these files from the new location after you’ve copied and renamed them, to add some additional parameters. Here is what the _tftp-server.service_ file initially looks like:
-
-```
-[Unit]
-Description=Tftp Server
-Requires=tftp.socket
-Documentation=man:in.tftpd
-
-[Service]
-ExecStart=/usr/sbin/in.tftpd -s /var/lib/tftpboot
-StandardInput=socket
-
-[Install]
-Also=tftp.socket
-```
-
-Make the following changes to the _[Unit]_ section:
-
-```
-Requires=tftp-server.socket
-```
-
-Make the following changes to the _ExecStart_ line:
-
-```
-ExecStart=/usr/sbin/in.tftpd -c -p -s /var/lib/tftpboot
-```
-
-Here are what the options mean:
-
- * The _**-c**_ option allows new files to be created.
- * The _**-p**_ option is used to have no additional permissions checks performed above the normal system-provided access controls.
- * The _**-s**_ option is recommended for security as well as compatibility with some boot ROMs which cannot be easily made to include a directory name in its request.
-
-
-
-The default upload/download location for transferring the files is _/var/lib/tftpboot_.
-
-Next, make the following changes to the _[Install]_ section:
-
-```
-[Install]
-WantedBy=multi-user.target
-Also=tftp-server.socket
-```
-
-Don’t forget to save your changes!
-
-Here is the completed _/etc/systemd/system/tftp-server.service_ file:
-
-```
-[Unit]
-Description=Tftp Server
-Requires=tftp-server.socket
-Documentation=man:in.tftpd
-
-[Service]
-ExecStart=/usr/sbin/in.tftpd -c -p -s /var/lib/tftpboot
-StandardInput=socket
-
-[Install]
-WantedBy=multi-user.target
-Also=tftp-server.socket
-```
-
-### Starting the TFTP server
-
-Reload the systemd daemon:
-
-```
-systemctl daemon-reload
-```
-
-Now start and enable the server:
-
-```
-systemctl enable --now tftp-server
-```
-
-To change the permissions of the TFTP server to allow upload and download functionality, use this command. Note TFTP is an inherently insecure protocol, so this may not be advised on a network you share with other people.
-
-```
-chmod 777 /var/lib/tftpboot
-```
-
-Configure your firewall to allow TFTP traffic:
-
-```
-firewall-cmd --add-service=tftp --perm
-firewall-cmd --reload
-```
-
-### Client Configuration
-
-Install the TFTP client:
-
-```
-yum install tftp -y
-```
-
-Run the _tftp_ command to connect to the TFTP server. Here is an example that enables the verbose option:
-
-```
-[client@thinclient:~ ]$ tftp 192.168.1.164
-tftp> verbose
-Verbose mode on.
-tftp> get server.logs
-getting from 192.168.1.164:server.logs to server.logs [netascii]
-Received 7 bytes in 0.0 seconds [inf bits/sec]
-tftp> quit
-[client@thinclient:~ ]$
-```
-
-Remember, TFTP does not have the ability to list file names. So you’ll need to know the file name before running the _get_ command to download any files.
-
-* * *
-
-_Photo by _[_Laika Notebooks_][5]_ on [Unsplash][6]_.
-
---------------------------------------------------------------------------------
-
-via: https://fedoramagazine.org/how-to-set-up-a-tftp-server-on-fedora/
-
-作者:[Curt Warfield][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://fedoramagazine.org/author/rcurtiswarfield/
-[b]: https://github.com/lujun9972
-[1]: https://fedoramagazine.org/wp-content/uploads/2019/09/tftp-server-816x345.jpg
-[2]: https://en.wikipedia.org/wiki/User_Datagram_Protocol
-[3]: https://docs.fedoraproject.org/en-US/fedora/f30/install-guide/advanced/Network_based_Installations/
-[4]: https://fedoramagazine.org/systemd-getting-a-grip-on-units/
-[5]: https://unsplash.com/@laikanotebooks?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
-[6]: https://unsplash.com/search/photos/file-folders?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
diff --git a/sources/tech/20190912 An introduction to Markdown.md b/sources/tech/20190912 An introduction to Markdown.md
deleted file mode 100644
index df13f64f6d..0000000000
--- a/sources/tech/20190912 An introduction to Markdown.md
+++ /dev/null
@@ -1,166 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (An introduction to Markdown)
-[#]: via: (https://opensource.com/article/19/9/introduction-markdown)
-[#]: author: (Juan Islas https://opensource.com/users/xislashttps://opensource.com/users/mbbroberghttps://opensource.com/users/scottnesbitthttps://opensource.com/users/scottnesbitthttps://opensource.com/users/f%C3%A1bio-emilio-costahttps://opensource.com/users/don-watkinshttps://opensource.com/users/greg-phttps://opensource.com/users/marcobravohttps://opensource.com/users/alanfdosshttps://opensource.com/users/scottnesbitthttps://opensource.com/users/jamesf)
-
-An introduction to Markdown
-======
-Write once and convert your text into multiple formats. Here's how to
-get started with Markdown.
-![Woman programming][1]
-
-For a long time, I thought all the files I saw on GitLab and GitHub with an **.md** extension were written in a file type exclusively for developers. That changed a few weeks ago when I started using Markdown. It quickly became the most important tool in my daily work.
-
-Markdown makes my life easier. I just need to add a few symbols to what I'm already writing and, with the help of a browser extension or an open source program, I can transform my text into a variety of commonly used formats such as ODT, email (more on that later), PDF, and EPUB.
-
-### What is Markdown?
-
-A friendly reminder from [Wikipedia][2]:
-
-> Markdown is a lightweight markup language with plain text formatting syntax.
-
-What this means to you is that by using just a few extra symbols in your text, Markdown helps you create a document with an explicit structure. When you take notes in plain text (in a notepad application, for example), there's nothing to indicate which text is meant to be bold or italic. In ordinary text, you might write a link as **** one time, then as just **example.com**, and later **go to the website (example.com)**. There's no internal consistency.
-
-But if you write the way Markdown prescribes, your text has internal consistency. Computers like consistency because it enables them to follow strict instructions without worrying about exceptions.
-
-Trust me; once you learn to use Markdown, every writing task will be, in some way, easier and better than before. So let's learn it.
-
-### Markdown basics
-
-The following rules are the basics for writing in Markdown.
-
- 1. Create a text file with an **.md** extension (for example, **example.md**.) You can use any text editor (even a word processor like LibreOffice or Microsoft Word), as long as you remember to save it as a _text_ file.
-
-
-
-![Names of Markdown files][3]
-
- 2. Write whatever you want, just as you usually do:
-
-
-```
-Lorem ipsum
-
-Consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
-Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
-Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
-
-De Finibus Bonorum et Malorum
-
-Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo.
-Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt.
-
- Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem.
-```
-
- 3. Make sure to place an empty line between paragraphs. That might feel unnatural if you're used to writing business letters or traditional prose, where paragraphs have only one new line and maybe even an indentation before the first word. For Markdown, an empty line (some word processors mark this with **¶**, called a Pilcrow symbol) guarantees a new paragraph is created when you convert it to another format like HTML.
-
- 4. Designate titles and subtitles. For the document's title, add a pound or hash (**#**) symbol and a space before the text (e.g., **# Lorem ipsum**). The first subtitle level uses two (**## De Finibus Bonorum et Malorum**), the next level gets three (**### Third Subtitle**), and so on. Note that there is a space between the pound sign and the first word.
-
-
-```
-# Lorem ipsum
-
-Consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
-Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
-Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
-
-## De Finibus Bonorum et Malorum
-
-Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo.
-Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt.
-
- Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem.
-```
-
- 5. If you want **bold** letters, just place the letters between two asterisks (stars) with no spaces: ****This will be in bold****.
-
-
-
-
-![Bold text in Markdown][4]
-
- 6. For _italics_, put the text between underline symbols with no spaces: **_I want this text to be in italics_**.
-
-
-
-![Italics text in Markdown][5]
-
- 7. To insert a link (like [Markdown Tutorial][6]), put the text you want to link in brackets and the URL in parentheses with no spaces between them:
-**[Markdown Tutorial]()**.
-
-
-
-![Hyperlinks in Markdown][7]
-
- 8. Blockquotes are written with a greater-than (**>**) symbol and a space before the text you want to quote: **> A famous quote**.
-
-
-
-![Blockquote text in Markdown][8]
-
-### Markdown tutorials and tip sheets
-
-These tips will get you started writing in Markdown, but it has a lot more functions than just bold and italics and links. The best way to learn Markdown is to use it, but I recommend investing 15 minutes stepping through the simple [Markdown Tutorial][6] to practice these rules and learn a couple more.
-
-Because modern Markdown is an amalgamation of many different interpretations of the idea of structured text, the [CommonMark][9] project defines a spec with a rigid set of rules to bring clarity to Markdown. It might be helpful to keep a [CommonMark-compliant cheatsheet][10] on hand when writing.
-
-### What you can do with Markdown
-
-Markdown lets you write anything you want—once—and transform it into almost any kind of format you want to use. The following examples show how to turn simple text written in MD into different formats. You don't need multiple formats of your text—you can start from a single source and then… rule the world!
-
- 1. **Simple note-taking:** You can write your notes in Markdown and, the moment you save them, the open source note application [Turtl][11] interprets your text file and shows you the formatted result. You can have your notes anywhere!
-
-
-
-![Turtl application][12]
-
- 2. **PDF files:** With the [Pandoc][13] application, you can convert your Markdown into a PDF with one simple command: **pandoc <file.md> -o <file.pdf>**.
-
-
-
-![Markdown text converted to PDF with Pandoc][14]
-
- 3. **Email:** You can also convert Markdown text into an HTML-formatted email by installing the browser extension [Markdown Here][15]. To use it, just select your Markdown text, use Markdown Here to translate it into HTML, and send your message using your favorite email client.
-
-
-
-![Markdown text converted to email with Markdown Here][16]
-
-### Start using it
-
-You don't need a special application to use Markdown—you just need a text editor and the tips above. It's compatible with how you already write; all you need to do is use it, so give it a try.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/9/introduction-markdown
-
-作者:[Juan Islas][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/xislashttps://opensource.com/users/mbbroberghttps://opensource.com/users/scottnesbitthttps://opensource.com/users/scottnesbitthttps://opensource.com/users/f%C3%A1bio-emilio-costahttps://opensource.com/users/don-watkinshttps://opensource.com/users/greg-phttps://opensource.com/users/marcobravohttps://opensource.com/users/alanfdosshttps://opensource.com/users/scottnesbitthttps://opensource.com/users/jamesf
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop-music-headphones.png?itok=EQZ2WKzy (Woman programming)
-[2]: https://en.wikipedia.org/wiki/Markdown
-[3]: https://opensource.com/sites/default/files/uploads/markdown_names_md-1.png (Names of Markdown files)
-[4]: https://opensource.com/sites/default/files/uploads/markdown_bold.png (Bold text in Markdown)
-[5]: https://opensource.com/sites/default/files/uploads/markdown_italic.png (Italics text in Markdown)
-[6]: https://www.markdowntutorial.com/
-[7]: https://opensource.com/sites/default/files/uploads/markdown_link.png (Hyperlinks in Markdown)
-[8]: https://opensource.com/sites/default/files/uploads/markdown_blockquote.png (Blockquote text in Markdown)
-[9]: https://commonmark.org/help/
-[10]: https://opensource.com/downloads/cheat-sheet-markdown
-[11]: https://turtlapp.com/
-[12]: https://opensource.com/sites/default/files/uploads/markdown_turtl_02.png (Turtl application)
-[13]: https://opensource.com/article/19/5/convert-markdown-to-word-pandoc
-[14]: https://opensource.com/sites/default/files/uploads/markdown_pdf.png (Markdown text converted to PDF with Pandoc)
-[15]: https://markdown-here.com/
-[16]: https://opensource.com/sites/default/files/uploads/markdown_mail_02.png (Markdown text converted to email with Markdown Here)
diff --git a/sources/tech/20190912 Bash Script to Send a Mail About New User Account Creation.md b/sources/tech/20190912 Bash Script to Send a Mail About New User Account Creation.md
deleted file mode 100644
index e8e4d27a2c..0000000000
--- a/sources/tech/20190912 Bash Script to Send a Mail About New User Account Creation.md
+++ /dev/null
@@ -1,126 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: (geekpi)
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (Bash Script to Send a Mail About New User Account Creation)
-[#]: via: (https://www.2daygeek.com/linux-shell-script-to-monitor-user-creation-send-email/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-Bash Script to Send a Mail About New User Account Creation
-======
-
-For some purposes you may need to keep track of new user creation details on Linux.
-
-Also, you may need to send the details by mail.
-
-This may be part of the audit objective or the security team may wish to monitor this for the tracking purposes.
-
-We can do this in other way, as we have already described in the previous article.
-
- * **[Bash script to send a mail when new user account is created in system][1]**
-
-
-
-There are many open source monitoring tools are available for Linux.
-
-But I don’t think they have a way to track the new user creation process and alert the administrator when that happens.
-
-So how can we achieve this?
-
-We can write our own Bash script to achieve this.
-
-We have added many useful shell scripts in the past. If you want to check them out, go to the link below.
-
- * **[How to automate day to day activities using shell scripts?][2]**
-
-
-
-### What does this script really do?
-
-This will take a backup of the “/etc/passwd” file twice a day (beginning of the day and end of the day), which will enable you to get new user creation details for the specified date.
-
-We need to add the below two cronjobs to copy the “/etc/passwd” file.
-
-```
-# crontab -e
-
-1 0 * * * cp /etc/passwd /opt/scripts/passwd-start-$(date +"%Y-%m-%d")
-59 23 * * * cp /etc/passwd /opt/scripts/passwd-end-$(date +"%Y-%m-%d")
-```
-
-It uses the “difference” command to detect the difference between files, and if any difference is found to yesterday’s date, the script will send an email alert to the email id given with new user details.
-
-We can’t run this script often because user creation is not happening frequently. However, we plan to run this script once a day.
-
-Therefore, you can get a consolidated report on new user creation.
-
-**Note:** We used our email id in the script for demonstration purpose. So we ask you to use your email id instead.
-
-```
-# vi /opt/scripts/new-user-detail.sh
-
-#!/bin/bash
-mv /opt/scripts/passwd-start-$(date --date='yesterday' '+%Y-%m-%d') /opt/scripts/passwd-start
-mv /opt/scripts/passwd-end-$(date --date='yesterday' '+%Y-%m-%d') /opt/scripts/passwd-end
-ucount=$(diff /opt/scripts/passwd-start /opt/scripts/passwd-end | grep ">" | cut -d":" -f6 | cut -d"/" -f3 | wc -l)
-if [ $ucount -gt 0 ]
-then
-SUBJECT="ATTENTION: New User Account is created on server : `date --date='yesterday' '+%b %e'`"
-MESSAGE="/tmp/new-user-logs.txt"
-TO="[email protected]"
-echo "Hostname: `hostname`" >> $MESSAGE
-echo -e "\n" >> $MESSAGE
-echo "The New User Details are below." >> $MESSAGE
-echo "+------------------------------+" >> $MESSAGE
-diff /opt/scripts/passwd-start /opt/scripts/passwd-end | grep ">" | cut -d":" -f6 | cut -d"/" -f3 >> $MESSAGE
-echo "+------------------------------+" >> $MESSAGE
-mail -s "$SUBJECT" "$TO" < $MESSAGE
-rm $MESSAGE
-fi
-```
-
-Set an executable permission to "new-user-detail.sh" file.
-
-```
-$ chmod +x /opt/scripts/new-user-detail.sh
-```
-
-Finally add a cronjob to automate this. It runs daily at 7AM.
-
-```
-# crontab -e
-
-0 7 * * * /bin/bash /opt/scripts/new-user.sh
-```
-
-**Note:** You will receive an email alert at 7AM every day, which is for yesterday's date details.
-
-**Output:** The output will be the same as the one below.
-
-```
-# cat /tmp/new-user-logs.txt
-
-Hostname: CentOS.2daygeek.com
-
-The New User Details are below.
-+------------------------------+
-tuser3
-+------------------------------+
-```
-
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/linux-shell-script-to-monitor-user-creation-send-email/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
-[1]: https://www.2daygeek.com/linux-bash-script-to-monitor-user-creation-send-email/
-[2]: https://www.2daygeek.com/category/shell-script/
diff --git a/sources/tech/20190912 New zine- HTTP- Learn your browser-s language.md b/sources/tech/20190912 New zine- HTTP- Learn your browser-s language.md
new file mode 100644
index 0000000000..85e3a6428a
--- /dev/null
+++ b/sources/tech/20190912 New zine- HTTP- Learn your browser-s language.md
@@ -0,0 +1,197 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (New zine: HTTP: Learn your browser's language!)
+[#]: via: (https://jvns.ca/blog/2019/09/12/new-zine-on-http/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+New zine: HTTP: Learn your browser's language!
+======
+
+Hello! I’ve released a new zine! It’s called “HTTP: Learn your browsers language!”
+
+You can get it for $12 at . If you buy it, you’ll get a PDF that you can either read on your computer or print out.
+
+Here’s the cover and table of contents:
+
+[![][1]][2]
+
+### why http?
+
+I got the idea for this zine from talking to [Marco Rogers][3] – he mentioned that he thought that new web developers / mobile developers would really benefit from understanding the fundamentals of HTTP better, I thought “OOH I LOVE TALKING ABOUT HTTP”, wrote a few pages about HTTP, saw they were helping people, and decided to write a whole zine about HTTP.
+
+HTTP is important to understand because it runs the entire web – if you understand how HTTP requests and responses work, then it makes it WAY EASIER to debug why your web application isn’t working properly. Caching, cookies, and a lot of web security are implemented using HTTP headers, so if you don’t understand HTTP headers those things seem kind of like impenetrable magic. But actually the HTTP protocol is fundamentally pretty simple – there are a lot of complicated details but the basics are pretty easy to understand.
+
+So the goal of this zine is to teach you the basics so you can easily look up and understand the details when you need them.
+
+### what it looks like printed out
+
+All of my zines are best printed out (though you get a PDF you can read on your computer too!), so here are a couple of pictures of what it looks like when printed. I always ask my illustrator to make both a black and white version and a colour version of the cover so that it looks great when printed on a black and white printer.
+
+[![][4]][2]
+
+(if you click on that “same origin policy” image, you can make it bigger)
+
+The zine comes with 4 print PDFs in addition to a PDF you can just read on your computer/phone:
+
+ * letter / colour
+ * letter / b&w
+ * a4 / colour
+ * a4 / b&w
+
+
+
+### zines for your team
+
+You can also buy this zine for your team members at work to help them learn HTTP!
+
+I’ve been trying to get the pricing right for this for a while – I used to do it based on size of company, but that didn’t seem quite right because sometimes people would want to buy the zine for a small team at a big company. So I’ve switched to pricing based on the number of copies you want to distribute at your company.
+
+Here’s the link: [zines for your team!][5].
+
+### the tweets
+
+When I started writing zines, I would just sit down, write down the things I thought were important, and be done with it.
+
+In the last year and a half or so I’ve taken a different approach – instead of writing everything and then releasing it, instead I write a page at a time, post the page to Twitter, and then improve it and decide what page to write next based on the questions/comments I get on Twitter. If someone replies to the tweet and asks a question that shows that what I wrote is unclear, I can improve it! (I love getting replies on twitter asking clarifiying questions!).
+
+Here are all the initial drafts of the pages I wrote and posted on twitter, in chronological order. Some of the pages didn’t make it into the zine at all, and I needed to do a lot of editing at the end to figure out the right order and make them all work coherently together in a zine instead of being a bunch of independent tweets.
+
+ * Jul 1: [http status codes][6]
+ * Jul 2: [anatomy of a HTTP response][7]
+ * Jul 2: [POST requests][8]
+ * Jul 2: [an example POST request][9]
+ * Jul 28: [the same origin policy][10]
+ * Jul 28: [what’s HTTP?][11]
+ * Jul 30: [the most important HTTP request headers][12]
+ * Jun 30: [anatomy of a HTTP request][13]
+ * Aug 4: [content delivery networks][14]
+ * Aug 6: [caching headers][15]
+ * Aug 6: [how cookies work][16]
+ * Aug 7: [redirects][17]
+ * Aug 8: [45 seconds on the Accept-Language HTTP header][18]
+ * Aug 9: [HTTPS: HTTP + security][19]
+ * Aug 9: [today in 45 second video experiments: the Range header][20]
+ * Aug 9: [some HTTP exercises to try][21]
+ * Aug 10: [some security headers][22]
+ * Aug 12: [using HTTP APIs][23]
+ * Aug 13: [what’s with those headers that start with x-?][24]
+ * Aug 13: [important HTTP response headers][25]
+ * Aug 14: [HTTP request methods (part 1)][26]
+ * Aug 14: [HTTP request methods (part 2)][27]
+ * Aug 15: [how URLs work][28]
+ * Aug 16: [CORS][29]
+ * Aug 19: [why the same origin policy matters][30]
+ * Aug 21: [HTTP headers][31]
+ * Aug 24: [how to learn more about HTTP][32]
+ * Aug 25: [HTTP/2][33]
+ * Aug 27: [certificates][34]
+
+
+
+Writing zines one tweet at a time has been really fun. I think it improves the quality a lot, because I get a ton of feedback along the way that I can use to make the zine better. There are also some experimental 45 second tiny videos in that list, which are definitely not part of the zine, but which were fun to make and which I might expand on in the future.
+
+### examplecat.com
+
+One tiny easter egg in the zine: I have a lot of examples of HTTP requests, and I wasn’t sure for a long time what domain I should use for the examples. I used example.com a bunch, and google.com and twitter.com sometimes, but none of those felt quite right.
+
+A couple of days before publishing the zine I finally had an epiphany – my example on the cover was requesting a picture of a cat, so I registered which just has a single picture of a cat. It also has an ASCII cat if you’re browsing in your terminal.
+
+```
+$ curl https://examplecat.com/cat.txt -i
+HTTP/2 200
+accept-ranges: bytes
+cache-control: public, max-age=0, must-revalidate
+content-length: 33
+content-type: text/plain; charset=UTF-8
+date: Thu, 12 Sep 2019 16:48:16 GMT
+etag: "ac5affa59f554a1440043537ae973790-ssl"
+strict-transport-security: max-age=31536000
+age: 5
+server: Netlify
+x-nf-request-id: c5060abc-0399-4b44-94bf-c481e22c2b50-1772748
+
+\ /\
+ ) ( ')
+( / )
+ \(__)|
+```
+
+### more zines at wizardzines.com
+
+If you’re interested in the idea of programming zines and haven’t seen my zines before, I have a bunch more at . There are 6 free zines there:
+
+ * [so you want to be a wizard][35]
+ * [let’s learn tcpdump!][36]
+ * [spying on your programs with strace][37]
+ * [networking! ACK!][38]
+ * [linux debugging tools you’ll love][39]
+ * [profiling and tracing with perf][40]
+
+
+
+### next zine: not sure yet!
+
+Some things I’m considering for the next zine:
+
+ * debugging skills (I started writing a bunch of pages about debugging but switched gears to the HTTP zine because I got really excited about that. but debugging is my favourite thing so I’d like to get this done at some point)
+ * gdb (a short zine in the spirit of [let’s learn tcpdump][36])
+ * relational databases (what’s up with transactions?)
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/09/12/new-zine-on-http/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://jvns.ca/images/http-zine-cover.png
+[2]: https://gum.co/http-zine
+[3]: https://twitter.com/polotek
+[4]: https://jvns.ca/images/http-zine-cover.jpeg
+[5]: https://wizardzines.com/zines-team/
+[6]: https://twitter.com/b0rk/status/1145824140462608387
+[7]: https://twitter.com/b0rk/status/1145896193077256197
+[8]: https://twitter.com/b0rk/status/1146054159214567424
+[9]: https://twitter.com/b0rk/status/1146065212560179202
+[10]: https://twitter.com/b0rk/status/1155493682885341184
+[11]: https://twitter.com/b0rk/status/1155318552129396736
+[12]: https://twitter.com/b0rk/status/1156048630220017665
+[13]: https://twitter.com/b0rk/status/1145362860136177664
+[14]: https://twitter.com/b0rk/status/1158012032651862017
+[15]: https://twitter.com/b0rk/status/1158726129508868097
+[16]: https://twitter.com/b0rk/status/1158848054142873603
+[17]: https://twitter.com/b0rk/status/1159163613938167808
+[18]: https://twitter.com/b0rk/status/1159492669384658944
+[19]: https://twitter.com/b0rk/status/1159812119099060224
+[20]: https://twitter.com/b0rk/status/1159829608595804160
+[21]: https://twitter.com/b0rk/status/1159839824594915335
+[22]: https://twitter.com/b0rk/status/1160185182323970050
+[23]: https://twitter.com/b0rk/status/1160933788949655552
+[24]: https://twitter.com/b0rk/status/1161283690925834241
+[25]: https://twitter.com/b0rk/status/1161262574031265793
+[26]: https://twitter.com/b0rk/status/1161679906415218690
+[27]: https://twitter.com/b0rk/status/1161680137865367553
+[28]: https://twitter.com/b0rk/status/1161997141876903936
+[29]: https://twitter.com/b0rk/status/1162392625057583104
+[30]: https://twitter.com/b0rk/status/1163460967067541504
+[31]: https://twitter.com/b0rk/status/1164181027469832196
+[32]: https://twitter.com/b0rk/status/1165277002791829510
+[33]: https://twitter.com/b0rk/status/1165623594917007362
+[34]: https://twitter.com/b0rk/status/1166466933912494081
+[35]: https://wizardzines.com/zines/wizard/
+[36]: https://wizardzines.com/zines/tcpdump/
+[37]: https://wizardzines.com/zines/strace/
+[38]: https://wizardzines.com/zines/networking/
+[39]: https://wizardzines.com/zines/debugging/
+[40]: https://wizardzines.com/zines/perf/
diff --git a/sources/tech/20190913 An introduction to Virtual Machine Manager.md b/sources/tech/20190913 An introduction to Virtual Machine Manager.md
deleted file mode 100644
index 9c2ae81643..0000000000
--- a/sources/tech/20190913 An introduction to Virtual Machine Manager.md
+++ /dev/null
@@ -1,102 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (An introduction to Virtual Machine Manager)
-[#]: via: (https://opensource.com/article/19/9/introduction-virtual-machine-manager)
-[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdosshttps://opensource.com/users/alanfdosshttps://opensource.com/users/bgamrathttps://opensource.com/users/marcobravo)
-
-An introduction to Virtual Machine Manager
-======
-Virt-manager provides a full range of options for spinning up virtual
-machines on Linux.
-![A person programming][1]
-
-In my [series][2] about [GNOME Boxes][3], I explained how Linux users can quickly spin up virtual machines on their desktop without much fuss. Boxes is ideal for creating virtual machines in a pinch when a simple configuration is all you need.
-
-But if you need to configure more detail in your virtual machine, you need a tool that provides a full range of options for disks, network interface cards (NICs), and other hardware. This is where [Virtual Machine Manager][4] (virt-manager) comes in. If you don't see it in your applications menu, you can install it from your package manager or via the command line:
-
- * On Fedora: **sudo dnf install virt-manager**
- * On Ubuntu: **sudo apt install virt-manager**
-
-
-
-Once it's installed, you can launch it from its application menu icon or from the command line by entering **virt-manager**.
-
-![Virtual Machine Manager's main screen][5]
-
-To demonstrate how to create a virtual machine using virt-manager, I'll go through the steps to set one up for Red Hat Enterprise Linux 8.
-
-To start, click **File** then **New Virtual Machine**. Virt-manager's developers have thoughtfully titled each step of the process (e.g., Step 1 of 5) to make it easy. Click **Local install media** and **Forward**.
-
-![Step 1 virtual machine creation][6]
-
-On the next screen, browse to select the ISO file for the operating system you want to install. (My RHEL 8 image is located in my Downloads directory.) Virt-manager automatically detects the operating system.
-
-![Step 2 Choose the ISO File][7]
-
-In Step 3, you can specify the virtual machine's memory and CPU. The defaults are 1,024MB memory and one CPU.
-
-![Step 3 Set CPU and Memory][8]
-
-I want to give RHEL ample room to run—and the hardware I'm using can accommodate it—so I'll increase them (respectively) to 4,096MB and two CPUs.
-
-The next step configures storage for the virtual machine; the default setting is a 10GB disk image. (I'll keep this setting, but you can adjust it for your needs.) You can also choose an existing disk image or create one in a custom location.
-
-![Step 4 Configure VM Storage][9]
-
-Step 5 is the place to name your virtual machine and click Finish. This is equivalent to creating a virtual machine or a Box in GNOME Boxes. While it's technically the last step, you have several options (as you can see in the screenshot below). Since the advantage of virt-manager is the ability to customize a virtual machine, I'll check the box labeled **Customize configuration before install** before I click **Finish**.
-
-Since I chose to customize the configuration, virt-manager opens a screen displaying a bunch of devices and settings. This is the fun part!
-
-Here you have another chance to name the virtual machine. In the list on the left, you can view details on various aspects, such as CPU, memory, disks, controllers, and many other items. For example, I can click on **CPUs** to verify the change I made in Step 3.
-
-![Changing the CPU count][10]
-
-I can also confirm the amount of memory I set.
-
-When installing a VM to run as a server, I usually disable or remove its sound capability. To do so, select **Sound** and click **Remove** or right-click on **Sound** and choose **Remove Hardware**.
-
-You can also add hardware with the **Add Hardware** button at the bottom. This brings up the **Add New Virtual Hardware** screen where you can add additional storage devices, memory, sound, etc. It's like having access to a very well-stocked (if virtual) computer hardware warehouse.
-
-![The Add New Hardware screen][11]
-
-Once you are happy with your VM configuration, click **Begin Installation**, and the system will boot and begin installing your specified operating system from the ISO.
-
-![Begin installing the OS][12]
-
-Once it completes, it reboots, and your new VM is ready for use.
-
-![Red Hat Enterprise Linux 8 running in VMM][13]
-
-Virtual Machine Manager is a powerful tool for desktop Linux users. It is open source and an excellent alternative to proprietary and closed virtualization products.
-
-Learn how Vagrant and Ansible can be used to provision virtual machines for web development.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/19/9/introduction-virtual-machine-manager
-
-作者:[Alan Formy-Duval][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://opensource.com/users/alanfdosshttps://opensource.com/users/alanfdosshttps://opensource.com/users/bgamrathttps://opensource.com/users/marcobravo
-[b]: https://github.com/lujun9972
-[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
-[2]: https://opensource.com/sitewide-search?search_api_views_fulltext=GNOME%20Box
-[3]: https://wiki.gnome.org/Apps/Boxes
-[4]: https://virt-manager.org/
-[5]: https://opensource.com/sites/default/files/1-vmm_main_0.png (Virtual Machine Manager's main screen)
-[6]: https://opensource.com/sites/default/files/2-vmm_step1_0.png (Step 1 virtual machine creation)
-[7]: https://opensource.com/sites/default/files/3-vmm_step2.png (Step 2 Choose the ISO File)
-[8]: https://opensource.com/sites/default/files/4-vmm_step3default.png (Step 3 Set CPU and Memory)
-[9]: https://opensource.com/sites/default/files/6-vmm_step4.png (Step 4 Configure VM Storage)
-[10]: https://opensource.com/sites/default/files/9-vmm_customizecpu.png (Changing the CPU count)
-[11]: https://opensource.com/sites/default/files/11-vmm_addnewhardware.png (The Add New Hardware screen)
-[12]: https://opensource.com/sites/default/files/12-vmm_rhelbegininstall.png
-[13]: https://opensource.com/sites/default/files/13-vmm_rhelinstalled_0.png (Red Hat Enterprise Linux 8 running in VMM)
diff --git a/sources/tech/20190913 How to Find and Replace a String in File Using the sed Command in Linux.md b/sources/tech/20190913 How to Find and Replace a String in File Using the sed Command in Linux.md
deleted file mode 100644
index bfb85529d4..0000000000
--- a/sources/tech/20190913 How to Find and Replace a String in File Using the sed Command in Linux.md
+++ /dev/null
@@ -1,352 +0,0 @@
-[#]: collector: (lujun9972)
-[#]: translator: ( )
-[#]: reviewer: ( )
-[#]: publisher: ( )
-[#]: url: ( )
-[#]: subject: (How to Find and Replace a String in File Using the sed Command in Linux)
-[#]: via: (https://www.2daygeek.com/linux-sed-to-find-and-replace-string-in-files/)
-[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
-
-How to Find and Replace a String in File Using the sed Command in Linux
-======
-
-When you are working on text files you may need to find and replace a string in the file.
-
-Sed command is mostly used to replace the text in a file.
-
-This can be done using the sed command and awk command in Linux.
-
-In this tutorial, we will show you how to do this using the sed command and then show about the awk command.
-
-### What is sed Command
-
-Sed command stands for Stream Editor, It is used to perform basic text manipulation in Linux. It could perform various functions such as search, find, modify, insert or delete files.
-
-Also, it’s performing complex regular expression pattern matching.
-
-It can be used for the following purpose.
-
- * To find and replace matches with a given format.
- * To find and replace specific lines that match a given format.
- * To find and replace the entire line that matches the given format.
- * To search and replace two different patterns simultaneously.
-
-
-
-The fifteen examples listed in this article will help you to master in the sed command.
-
-If you want to remove a line from a file using the Sed command, go to the following article.
-
-**`Note:`** Since this is a demonstration article, we use the sed command without the `-i` option, which removes lines and prints the contents of the file in the Linux terminal.
-
-But if you want to remove lines from the source file in the real environment, use the `-i` option with the sed command.
-
-Common Syntax for sed to replace a string.
-
-```
-sed -i 's/Search_String/Replacement_String/g' Input_File
-```
-
-First we need to understand sed syntax to do this. See details about it.
-
- * `sed:` It’s a Linux command.
- * `-i:` It’s one of the option for sed and what it does? By default sed print the results to the standard output. When you add this option with sed then it will edit files in place. A backup of the original file will be created when you add a suffix (For ex, -i.bak
- * `s:` The s is the substitute command.
- * `Search_String:` To search a given string or regular expression.
- * `Replacement_String:` The replacement string.
- * `g:` Global replacement flag. By default, the sed command replaces the first occurrence of the pattern in each line and it won’t replace the other occurrence in the line. But, all occurrences will be replaced when the replacement flag is provided
- * `/` Delimiter character.
- * `Input_File:` The filename that you want to perform the action.
-
-
-
-Let us look at some examples of commonly used with sed command to search and convert text in files.
-
-We have created the below file for demonstration purposes.
-
-```
-# cat sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 1) How to Find and Replace the “first” Event of the Pattern on a Line
-
-The below sed command replaces the word **unix** with **linux** in the file. This only changes the first instance of the pattern on each line.
-
-```
-# sed 's/unix/linux/' sed-test.txt
-
-1 Unix linux unix 23
-2 linux Linux 34
-3 linuxlinux UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 2) How to Find and Replace the “Nth” Occurrence of the Pattern on a Line
-
-Use the /1,/2,../n flags to replace the corresponding occurrence of a pattern in a line.
-
-The below sed command replaces the second instance of the “unix” pattern with “linux” in a line.
-
-```
-# sed 's/unix/linux/2' sed-test.txt
-
-1 Unix unix linux 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 3) How to Search and Replace all Instances of the Pattern in a Line
-
-The below sed command replaces all instances of the “unix” format with “Linux” on the line because “g” means a global replacement.
-
-```
-# sed 's/unix/linux/g' sed-test.txt
-
-1 Unix linux linux 23
-2 linux Linux 34
-3 linuxlinux UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 4) How to Find and Replace the Pattern for all Instances in a Line from the “Nth” Event
-
-The below sed command replaces all the patterns from the “Nth” instance of a pattern in a line.
-
-```
-# sed 's/unix/linux/2g' sed-test.txt
-
-1 Unix unix linux 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 5) Search and Replace the pattern on a specific line number
-
-You can able to replace the string on a specific line number. The below sed command replaces the pattern “unix” with “linux” only on the 3rd line.
-
-```
-# sed '3 s/unix/linux/' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 linuxlinux UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 6) How to Find and Replace Pattern in a Range of Lines
-
-You can specify the range of line numbers to replace the string.
-
-The below sed command replaces the “Unix” pattern with “Linux” with lines 1 through 3.
-
-```
-# sed '1,3 s/unix/linux/' sed-test.txt
-
-1 Unix linux unix 23
-2 linux Linux 34
-3 linuxlinux UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 7) How to Find and Change the pattern in the Last Line
-
-The below sed command allows you to replace the matching string only in the last line.
-
-The below sed command replaces the “Linux” pattern with “Unix” only on the last line.
-
-```
-# sed '$ s/Linux/Unix/' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /bin/bash CentOS Linux OS
-Unix is free and opensource operating system
-```
-
-### 8) How to Find and Replace the Pattern with only Right Word in a Line
-
-As you might have noticed, the substring “linuxunix” is replaced with “linuxlinux” in the 6th example. If you want to replace only the right matching word, use the word-boundary expression “\b” on both ends of the search string.
-
-```
-# sed '1,3 s/\bunix\b/linux/' sed-test.txt
-
-1 Unix linux unix 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 9) How to Search and Replaces the pattern with case insensitive
-
-Everyone knows that Linux is case sensitive. To make the pattern match with case insensitive, use the I flag.
-
-```
-# sed 's/unix/linux/gI' sed-test.txt
-
-1 linux linux linux 23
-2 linux Linux 34
-3 linuxlinux linuxLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 10) How to Find and Replace a String that Contains the Delimiter Character
-
-When you search and replace for a string with the delimiter character, we need to use the backslash “\” to escape the slash.
-
-In this example, we are going to replaces the “/bin/bash” with “/usr/bin/fish”.
-
-```
-# sed 's/\/bin\/bash/\/usr\/bin\/fish/g' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /usr/bin/fish CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-The above sed command works as expected, but it looks bad. To simplify this, most of the people will use the vertical bar “|”. So, I advise you to go with it.
-
-```
-# sed 's|/bin/bash|/usr/bin/fish/|g' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /usr/bin/fish/ CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 11) How to Find and Replaces Digits with a Given Pattern
-
-Similarly, digits can be replaced with pattern. The below sed command replaces all digits with “[0-9]” “number” pattern.
-
-```
-# sed 's/[0-9]/number/g' sed-test.txt
-
-number Unix unix unix numbernumber
-number linux Linux numbernumber
-number linuxunix UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 12) How to Find and Replace only two Digit Numbers with Pattern
-
-If you want to replace the two digit numbers with the pattern, use the sed command below.
-
-```
-# sed 's/\b[0-9]\{2\}\b/number/g' sed-test.txt
-
-1 Unix unix unix number
-2 linux Linux number
-3 linuxunix UnixLinux
-linux /bin/bash CentOS Linux OS
-Linux is free and opensource operating system
-```
-
-### 13) How to Print only Replaced Lines with the sed Command
-
-If you want to display only the changed lines, use the below sed command.
-
- * p – It prints the replaced line twice on the terminal.
- * n – It suppresses the duplicate rows generated by the “p” flag.
-
-
-
-```
-# sed -n 's/Unix/Linux/p' sed-test.txt
-
-1 Linux unix unix 23
-3 linuxunix LinuxLinux
-```
-
-### 14) How to Run Multiple sed Commands at Once
-
-The following sed command detect and replaces two different patterns simultaneously.
-
-The below sed command searches for “linuxunix” and “CentOS” pattern, replacing them with “LINUXUNIX” and “RHEL8” at a time.
-
-```
-# sed -e 's/linuxunix/LINUXUNIX/g' -e 's/CentOS/RHEL8/g' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 LINUXUNIX UnixLinux
-linux /bin/bash RHEL8 Linux OS
-Linux is free and opensource operating system
-```
-
-The following sed command search for two different patterns and replaces them with one string at a time.
-
-The below sed command searches for “linuxunix” and “CentOS” pattern, replacing them with “Fedora30” at a time.
-
-```
-# sed -e 's/\(linuxunix\|CentOS\)/Fedora30/g' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 Fedora30 UnixLinux
-linux /bin/bash Fedora30 Linux OS
-Linux is free and opensource operating system
-```
-
-### 15) How to Find and Replace the Entire Line if the Given Pattern Matches
-
-If the pattern matches, you can use the sed command to replace the entire line with the new line. This can be done using the “C” flag.
-
-```
-# sed '/OS/ c New Line' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-New Line
-Linux is free and opensource operating system
-```
-
-### 16) How to Search and Replace lines that Matches a Pattern
-
-You can specify a pattern for the sed command to fit on a line. In the event of pattern matching, the sed command searches for the string to be replaced.
-
-The below sed command first looks for lines that have the “OS” pattern, then replaces the word “Linux” with “ArchLinux”.
-
-```
-# sed '/OS/ s/Linux/ArchLinux/' sed-test.txt
-
-1 Unix unix unix 23
-2 linux Linux 34
-3 linuxunix UnixLinux
-linux /bin/bash CentOS ArchLinux OS
-Linux is free and opensource operating system
-```
---------------------------------------------------------------------------------
-
-via: https://www.2daygeek.com/linux-sed-to-find-and-replace-string-in-files/
-
-作者:[Magesh Maruthamuthu][a]
-选题:[lujun9972][b]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: https://www.2daygeek.com/author/magesh/
-[b]: https://github.com/lujun9972
diff --git a/sources/tech/20190915 How to Configure SFTP Server with Chroot in Debian 10.md b/sources/tech/20190915 How to Configure SFTP Server with Chroot in Debian 10.md
new file mode 100644
index 0000000000..877845b87a
--- /dev/null
+++ b/sources/tech/20190915 How to Configure SFTP Server with Chroot in Debian 10.md
@@ -0,0 +1,197 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Configure SFTP Server with Chroot in Debian 10)
+[#]: via: (https://www.linuxtechi.com/configure-sftp-chroot-debian10/)
+[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
+
+How to Configure SFTP Server with Chroot in Debian 10
+======
+
+**SFTP** stands for Secure File Transfer Protocol / SSH File Transfer Protocol, it is one of the most common method which is used to transfer files securely over ssh from our local system to remote server and vice-versa. The main advantage of sftp is that we don’t need to install any additional package except ‘**openssh-server**’, in most of the Linux distributions ‘openssh-server’ package is the part of default installation. Other benefit of sftp is that we can allow user to use sftp only not ssh.
+
+[![Configure-sftp-debian10][1]][2]
+
+Recently Debian 10, Code name ‘Buster’ has been released, in this article we will demonstrate how to configure sftp with Chroot ‘Jail’ like environment in Debian 10 System. Here Chroot Jail like environment means that user’s cannot go beyond from their respective home directories or users cannot change directories from their home directories. Following are the lab details:
+
+ * OS = Debian 10
+ * IP Address = 192.168.56.151
+
+
+
+Let’s jump into SFTP Configuration Steps,
+
+### Step:1) Create a Group for sftp using groupadd command
+
+Open the terminal, create a group with a name “**sftp_users**” using below groupadd command,
+
+```
+root@linuxtechi:~# groupadd sftp_users
+```
+
+### Step:2) Add Users to Group ‘sftp_users’ and set permissions
+
+In case you want to create new user and want to add that user to ‘sftp_users’ group, then run the following command,
+
+**Syntax:** # useradd -m -G sftp_users <user_name>
+
+Let’s suppose user name is ’Jonathan’
+
+```
+root@linuxtechi:~# useradd -m -G sftp_users jonathan
+```
+
+set the password using following chpasswd command,
+
+```
+root@linuxtechi:~# echo "jonathan:" | chpasswd
+```
+
+In case you want to add existing users to ‘sftp_users’ group then run beneath usermod command, let’s suppose already existing user name is ‘chris’
+
+```
+root@linuxtechi:~# usermod -G sftp_users chris
+```
+
+Now set the required permissions on Users,
+
+```
+root@linuxtechi:~# chown root /home/jonathan /home/chris/
+```
+
+Create an upload folder in both the user’s home directory and set the correct ownership,
+
+```
+root@linuxtechi:~# mkdir /home/jonathan/upload
+root@linuxtechi:~# mkdir /home/chris/upload
+root@linuxtechi:~# chown jonathan /home/jonathan/upload
+root@linuxtechi:~# chown chris /home/chris/upload
+```
+
+**Note:** User like Jonathan and Chris can upload files and directories to upload folder from their local systems.
+
+### Step:3) Edit sftp configuration file (/etc/ssh/sshd_config)
+
+As we have already stated that sftp operations are done over the ssh, so it’s configuration file is “**/etc/ssh/sshd_config**“, Before making any changes I would suggest first take the backup and then edit this file and add the following content,
+
+```
+root@linuxtechi:~# cp /etc/ssh/sshd_config /etc/ssh/sshd_config-org
+root@linuxtechi:~# vim /etc/ssh/sshd_config
+………
+#Subsystem sftp /usr/lib/openssh/sftp-server
+Subsystem sftp internal-sftp
+
+Match Group sftp_users
+ X11Forwarding no
+ AllowTcpForwarding no
+ ChrootDirectory %h
+ ForceCommand internal-sftp
+…………
+```
+
+Save & exit the file.
+
+To make above changes into the affect, restart ssh service using following systemctl command
+
+```
+root@linuxtechi:~# systemctl restart sshd
+```
+
+In above ‘sshd_config’ file we have commented out the line which starts with “Subsystem” and added new entry “Subsystem sftp internal-sftp” and new lines like,
+
+“**Match Group sftp_users”** –> It means if a user is a part of ‘sftp_users’ group then apply rules which are mentioned below to this entry.
+
+“**ChrootDierctory %h**” –> It means users can only change directories within their respective home directories, they cannot go beyond their home directories, or in other words we can say users are not permitted to change directories, they will get jai like environment within their directories and can’t access any other user’s and system’s directories.
+
+“**ForceCommand internal-sftp**” –> It means users are limited to sftp command only.
+
+### Step:4) Test and Verify sftp
+
+Login to any other Linux system which is on the same network of your sftp server and then try to ssh sftp server via the users that we have mapped in ‘sftp_users’ group.
+
+```
+[root@linuxtechi ~]# ssh root@linuxtechi
+root@linuxtechi's password:
+Write failed: Broken pipe
+[root@linuxtechi ~]# ssh root@linuxtechi
+root@linuxtechi's password:
+Write failed: Broken pipe
+[root@linuxtechi ~]#
+```
+
+Above confirms that users are not allowed to SSH , now try sftp using following commands,
+
+```
+[root@linuxtechi ~]# sftp root@linuxtechi
+root@linuxtechi's password:
+Connected to 192.168.56.151.
+sftp> ls -l
+drwxr-xr-x 2 root 1001 4096 Sep 14 07:52 debian10-pkgs
+-rw-r--r-- 1 root 1001 155 Sep 14 07:52 devops-actions.txt
+drwxr-xr-x 2 1001 1002 4096 Sep 14 08:29 upload
+```
+
+Let’s try to download a file using sftp ‘**get**‘ command
+
+```
+sftp> get devops-actions.txt
+Fetching /devops-actions.txt to devops-actions.txt
+/devops-actions.txt 100% 155 0.2KB/s 00:00
+sftp>
+sftp> cd /etc
+Couldn't stat remote file: No such file or directory
+sftp> cd /root
+Couldn't stat remote file: No such file or directory
+sftp>
+```
+
+Above output confirms that we are able to download file from our sftp server to local machine and apart from this we have also tested that users cannot change directories.
+
+Let’s try to upload a file under “**upload**” folder,
+
+```
+sftp> cd upload/
+sftp> put metricbeat-7.3.1-amd64.deb
+Uploading metricbeat-7.3.1-amd64.deb to /upload/metricbeat-7.3.1-amd64.deb
+metricbeat-7.3.1-amd64.deb 100% 38MB 38.4MB/s 00:01
+sftp> ls -l
+-rw-r--r-- 1 1001 1002 40275654 Sep 14 09:18 metricbeat-7.3.1-amd64.deb
+sftp>
+```
+
+This confirms that we have successfully uploaded a file from our local system to sftp server.
+
+Now test the SFTP server with winscp tool, enter the sftp server ip address along user’s credentials,
+
+[![Winscp-sftp-debian10][1]][3]
+
+Click on Login and then try to download and upload files
+
+[![Download-file-winscp-debian10-sftp][1]][4]
+
+Now try to upload files in upload folder,
+
+[![Upload-File-using-winscp-Debian10-sftp][1]][5]
+
+Above window confirms that uploading is also working fine, that’s all from this article. If these steps help you to configure SFTP server with chroot environment in Debian 10 then please do share your feedback and comments.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/configure-sftp-chroot-debian10/
+
+作者:[Pradeep Kumar][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linuxtechi.com/author/pradeep/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Configure-sftp-debian10.jpg
+[3]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Winscp-sftp-debian10.jpg
+[4]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Download-file-winscp-debian10-sftp.jpg
+[5]: https://www.linuxtechi.com/wp-content/uploads/2019/09/Upload-File-using-winscp-Debian10-sftp.jpg
diff --git a/sources/tech/20190916 Constraint programming by example.md b/sources/tech/20190916 Constraint programming by example.md
new file mode 100644
index 0000000000..c434913c5e
--- /dev/null
+++ b/sources/tech/20190916 Constraint programming by example.md
@@ -0,0 +1,163 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Constraint programming by example)
+[#]: via: (https://opensource.com/article/19/9/constraint-programming-example)
+[#]: author: (Oleksii Tsvietnov https://opensource.com/users/oleksii-tsvietnovhttps://opensource.com/users/oleksii-tsvietnov)
+
+Constraint programming by example
+======
+Understand constraint programming with an example application that
+converts a character's case and ASCII codes.
+![Math formulas in green writing][1]
+
+There are many different ways to solve problems in computing. You might "brute force" your way to a solution by calculating as many possibilities as you can, or you might take a procedural approach and carefully establish the known factors that influence the correct answer. In [constraint programming][2], a problem is viewed as a series of limitations on what could possibly be a valid solution. This paradigm can be applied to effectively solve a group of problems that can be translated to variables and constraints or represented as a mathematic equation. In this way, it is related to the Constraint Satisfaction Problem ([CSP][3]).
+
+Using a declarative programming style, it describes a general model with certain properties. In contrast to the imperative style, it doesn't tell _how_ to achieve something, but rather _what_ to achieve. Instead of defining a set of instructions with only one obvious way to compute values, constraint programming declares relationships between variables within constraints. A final model makes it possible to compute the values of variables regardless of direction or changes. Thus, any change in the value of one variable affects the whole system (i.e., all other variables), and to satisfy defined constraints, it leads to recomputing the other values.
+
+As an example, let's take Pythagoras' theorem: **a² + b² = c²**. The _constraint_ is represented by this equation, which has three _variables_ (a, b, and c), and each has a _domain_ (non-negative). Using the imperative programming style, to compute any of the variables if we have the other two, we would need to create three different functions (because each variable is computed by a different equation):
+
+ * c = √(a² + b²)
+ * a = √(c² - b²)
+ * b = √(c² - a²)
+
+
+
+These functions satisfy the main constraint, and to check domains, each function should validate the input. Moreover, at least one more function would be needed for choosing an appropriate function according to the provided variables. This is one of the possible solutions:
+
+
+```
+def pythagoras(*, a=None, b=None, c=None):
+ ''' Computes a side of a right triangle '''
+
+ # Validate
+ if len([i for i in (a, b, c) if i is None or i <= 0]) != 1:
+ raise SystemExit("ERROR: you need to define any of two non-negative variables")
+
+ # Compute
+ if a is None:
+ return (c**2 - b**2)**0.5
+ elif b is None:
+ return (c**2 - a**2)**0.5
+ else:
+ return (a**2 + b**2)**0.5
+```
+
+To see the difference with the constraint programming approach, I'll show an example of a "problem" with four variables and a constraint that is not represented by a straight mathematic equation. This is a converter that can change characters' cases (lower-case to/from capital/upper-case) and return the ASCII codes for each. Hence, at any time, the converter is aware of all four values and reacts immediately to any changes. The idea of creating this example was fully inspired by John DeNero's [Fahrenheit-Celsius converter][4].
+
+Here is a diagram of a constraint system:
+
+![Constraint system model][5]
+
+The represented "problem" is translated into a constraint system that consists of nodes (constraints) and connectors (variables). Connectors provide an interface for getting and setting values. They also check the variables' domains. When one value changes, that particular connector notifies all its connected nodes about the change. Nodes, in turn, satisfy constraints, calculate new values, and propagate them to other connectors across the system by "asking" them to set a new value. Propagation is done using the message-passing technique that means connectors and nodes get messages (synchronously) and react accordingly. For instance, if the system gets the **A** letter on the "capital letter" connector, the other three connectors provide an appropriate result according to the defined constraint on the nodes: 97, a, and 65. It's not allowed to set any other lower-case letters (e.g., b) on that connector because each connector has its own domain.
+
+When all connectors are linked to nodes, which are defined by constraints, the system is fully set and ready to get values on any of four connectors. Once it's set, the system automatically calculates and sets values on the rest of the connectors. There is no need to check what variable was set and which functions should be called, as is required in the imperative approach—that is relatively easy to achieve with a few variables but gets interesting in case of tens or more.
+
+### How it works
+
+The full source code is available in my [GitHub repo][6]. I'll dig a little bit into the details to explain how the system is built.
+
+First, define the connectors by giving them names and setting domains as a function of one argument:
+
+
+```
+import constraint_programming as cp
+
+small_ascii = cp.connector('Small Ascii', lambda x: x >= 97 and x <= 122)
+small_letter = cp.connector('Small Letter', lambda x: x >= 'a' and x <= 'z')
+capital_ascii = cp.connector('Capital Ascii', lambda x: x >= 65 and x <= 90)
+capital_letter = cp.connector('Capital Letter', lambda x: x >= 'A' and x <= 'Z')
+```
+
+Second, link these connectors to nodes. There are two types: _code_ (translates letters back and forth to ASCII codes) and _aA_ (translates small letters to capital and back):
+
+
+```
+code(small_letter, small_ascii)
+code(capital_letter, capital_ascii)
+aA(small_letter, capital_letter)
+```
+
+These two nodes differ in which functions should be called, but they are derived from a general constraint function:
+
+
+```
+def code(conn1, conn2):
+ return cp.constraint(conn1, conn2, ord, chr)
+
+def aA(conn1, conn2):
+ return cp.constraint(conn1, conn2, str.upper, str.lower)
+```
+
+Each node has only two connectors. If there is an update on a first connector, then a first function is called to calculate the value of another connector (variable). The same happens if a second connector's value changes. For example, if the _code_ node gets **A** on the **conn1** connector, then the function **ord** will be used to get its ASCII code. And, the other way around, if the _aA_ node gets **A** on the **conn2** connector, then it needs to use the **str.lower** function to get the correct small letter on the **conn1**. Every node is responsible for computing new values and "sending" a message to another connector that there is a new value to set. This message is conveyed with the name of a node that is asking to set a new value and also a new value.
+
+
+```
+def set_value(src_constr, value):
+ if (not domain is None) and (not domain(value)):
+ raise ValueOutOfDomain(link, value)
+ link['value'] = value
+ for constraint in constraints:
+ if constraint is not src_constr:
+ constraint['update'](link)
+```
+
+When a connector receives the **set** message, it runs the **set_value** function to check a domain, sets a new value, and sends the "update" message to another node. It is just a notification that the value on that connector has changed.
+
+
+```
+def update(src_conn):
+ if src_conn is conn1:
+ conn2['set'](node, constr1(conn1['value']))
+ else:
+ conn1['set'](node, constr2(conn2['value']))
+```
+
+Then, the notified node requests this new value on the connector, computes a new value for another connector, and so on until the whole system changes. That's how the propagation works.
+
+But how does the message passing happen? It is implemented as accessing keys of dictionaries. Both functions (connector and constraint) return a _dispatch dictionary_. Such a dictionary contains _messages_ as keys and _closures_ as values. By accessing a key, let's say, **set**, a dictionary returns the function **set_value** (closure) that has access to all local names of the "connector" function.
+
+
+```
+# A dispatch dictionary
+link = { 'name': name,
+ 'value': None,
+ 'connect': connect,
+ 'set': set_value,
+ 'constraints': get_constraints }
+
+return link
+```
+
+Having a dictionary as a return value makes it possible to create multiple closures (functions) with access to the same local state to operate on. Then these closures are callable by using keys as a type of message.
+
+### Why use Constraint programming?
+
+Constraint programming can give you a new perspective to difficult problems. It's not something you can use in every situation, but it may well open new opportunities for solutions in certain situations. If you find yourself up against an equation that seems difficult to reliably solve in code, try looking at it from a different angle. If the angle that seems to work best is constraint programming, you now have an example of how it can be implemented.
+
+* * *
+
+_This article was originally published on [Oleksii Tsvietnov's blog][7] and is reprinted with his permission._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/constraint-programming-example
+
+作者:[Oleksii Tsvietnov][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/oleksii-tsvietnovhttps://opensource.com/users/oleksii-tsvietnov
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/edu_math_formulas.png?itok=B59mYTG3 (Math formulas in green writing)
+[2]: https://en.wikipedia.org/wiki/Constraint_programming
+[3]: https://vorakl.com/articles/csp/
+[4]: https://composingprograms.com/pages/24-mutable-data.html#propagating-constraints
+[5]: https://opensource.com/sites/default/files/uploads/constraint-system.png (Constraint system model)
+[6]: https://github.com/vorakl/composingprograms.com/tree/master/char_converter
+[7]: https://vorakl.com/articles/char-converter/
diff --git a/sources/tech/20190916 The Emacs Series Exploring ts.el.md b/sources/tech/20190916 The Emacs Series Exploring ts.el.md
new file mode 100644
index 0000000000..06e724d4ab
--- /dev/null
+++ b/sources/tech/20190916 The Emacs Series Exploring ts.el.md
@@ -0,0 +1,366 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Emacs Series Exploring ts.el)
+[#]: via: (https://opensourceforu.com/2019/09/the-emacs-series-exploring-ts-el/)
+[#]: author: (Shakthi Kannan https://opensourceforu.com/author/shakthi-kannan/)
+
+The Emacs Series Exploring ts.el
+======
+
+[![][1]][2]
+
+_In this article, the author reviews the ts.el date and time library for Emacs. Written by Adam Porter, ts.el is still in the development phase and has been released under the GNU General Public License v3.0._
+
+The ts.el package uses intuitive names for date and time functions. It internally uses UNIX timestamps and depends on both the ‘dash’ and ‘s’ Emacs libraries. The parts of the date are computed lazily and also cached for performance. The source code is available at __. In this article, we will explore the API functions available from the ts.el library.
+
+**Installation**
+The package does not have a tagged release yet; hence, you should download it from and add it to your Emacs load path to use it. You should also have the ‘dash’ and ‘s’ libraries installed and loaded in your Emacs environment. You can then load the library using the following command:
+
+```
+(require ‘ts)
+```
+
+**Usage**
+Let us explore the various functions available to retrieve parts of the date from the ts.el library. When the examples were executed, the date was ‘Friday July 5, 2019’. The ts-dow function can be used to obtain the day of the week, as shown below:
+
+```
+(ts-dow (ts-now))
+5
+```
+
+_ts-now_ is a Lisp construct that returns a timestamp set. It is defined in ts.el as follows:
+
+```
+(defsubst ts-now ()
+“Return `ts’ struct set to now.”
+(make-ts :unix (float-time)))
+```
+
+The day of the week starts from Monday (1) and hence Friday has the value of 5. An abbreviated form of the day can be fetched using the _ts-day-abbr_ function. In the following example, ‘Friday’ is shortened to‘Fri’.
+
+```
+(ts-day-abbr (ts-now))
+"Fri"
+```
+
+The day of the week in full form can be obtained using the _ts-day-name_ function, as shown below:
+
+```
+(ts-day-name (ts-now))
+“Friday”
+```
+
+The twelve months from January to December are numbered from 1 to 12 respectively. Hence, for the month of July, the index number is 7. This numeric value for the month can be retrieved using the ‘ts-month’ API. For example:
+
+```
+(ts-month (ts-now))
+7
+```
+
+If you want a three-character abbreviation for the month’s name, you can use the ts-month-abbr function as shown below:
+
+```
+(ts-month-abbr (ts-now))
+“Jul”
+```
+
+The _ts-month-name_ function can be used to obtain the full name of the month. For example:
+
+```
+(ts-month-name (ts-now))
+“July”
+```
+
+The day of the week starts from Monday and has an index 1, while Sunday has an index 7. If you need the numeric value for the day of the week, use the ts-day function as indicated below:
+
+```
+(ts-day (ts-now))
+5
+```
+
+The _ts-year_ API returns the year. In our example, it is ‘2019’ as shown below:
+
+```
+(ts-year (ts-now))
+2019
+```
+
+The hour, minute and seconds can be retrieved using the _ts-hour, ts-minute_ and _ts-second_ functions, respectively. Examples of these functions are given below:
+
+```
+(ts-hour (ts-now))
+18
+
+(ts-minute (ts-now))
+19
+
+(ts-second (ts-now))
+5
+```
+
+The UNIX timestamps are in UTC, by default. The _ts-tz-offset_ function returns the offset from UTC. The Indian Standard Time (IST) is five-and-a-half-hours ahead of UTC and hence this function returns ‘+0530’ as shown below:
+
+```
+(ts-tz-offset (ts-now))
+"+0530"
+```
+
+The _ts-tz-abbr_ API returns an abbreviated form of the time zone. In our case, ‘IST’ is returned for the Indian Standard Time.
+
+```
+(ts-tz-abbr (ts-now))
+"IST"
+```
+
+The _ts-adjustf_ function applies the time adjustments passed to the timestamp and the _ts-format_ function formats the timestamp as a string. A couple of examples are given below:
+
+```
+(let ((ts (ts-now)))
+(ts-adjustf ts ‘day 1)
+(ts-format nil ts))
+“2019-07-06 18:23:24 +0530”
+
+(let ((ts (ts-now)))
+(ts-adjustf ts ‘year 1 ‘month 3 ‘day 5)
+(ts-format nil ts))
+“2020-10-10 18:24:07 +0530”
+```
+
+You can use the _ts-dec_ function to decrement the timestamp. For example:
+
+```
+(ts-day-name (ts-dec ‘day 1 (ts-now)))
+“Thursday”
+```
+
+The threading macro syntax can also be used with the ts-dec function as shown below:
+
+```
+(->> (ts-now) (ts-dec ‘day 2) ts-day-name)
+“Wednesday”
+```
+
+The UNIX epoch is the number of seconds that have elapsed since January 1, 1970 (midnight UTC/GMT). The ts-unix function returns an epoch UNIX timestamp as illustrated below:
+
+```
+(ts-unix (ts-adjust ‘day -2 (ts-now)))
+1562158551.0 ;; Wednesday, July 3, 2019 6:25:51 PM GMT+05:30
+```
+
+An hour has 3600 seconds and a day has 86400 seconds. You can compare epoch timestamps as shown in the following example:
+
+```
+(/ (- (ts-unix (ts-now))
+(ts-unix (ts-adjust ‘day -4 (ts-now))))
+86400)
+4
+```
+
+The _ts-difference_ function returns the difference between two timestamps, while the _ts-human-duration_ function returns the property list (_plist_) values of years, days, hours, minutes and seconds. For example:
+
+```
+(ts-human-duration
+(ts-difference (ts-now)
+(ts-dec ‘day 3 (ts-now))))
+(:years 0 :days 3 :hours 0 :minutes 0 :seconds 0)
+```
+
+A number of aliases are available for the hour, minute, second, year, month and day format string constructors. A few examples are given below:
+
+```
+(ts-hour (ts-now))
+18
+(ts-H (ts-now))
+18
+
+
+(ts-minute (ts-now))
+46
+(ts-min (ts-now))
+46
+(ts-M (ts-now))
+46
+
+(ts-second (ts-now))
+16
+(ts-sec (ts-now))
+16
+(ts-S (ts-now))
+16
+
+(ts-year (ts-now))
+2019
+(ts-Y (ts-now))
+2019
+
+(ts-month (ts-now))
+7
+(ts-m (ts-now))
+7
+
+(ts-day (ts-now))
+5
+(ts-d (ts-now))
+5
+```
+
+You can parse a string into a timestamp object using the ts-parse function. For example:
+
+```
+(ts-format nil (ts-parse “Fri Dec 6 2019 18:48:00”))
+“2019-12-06 18:48:00 +0530”
+```
+
+You can also format the difference between two timestamps in a human readable format as shown in the following example:
+
+```
+(ts-human-format-duration
+(ts-difference (ts-now)
+(ts-adjust ‘day -1 ‘hour -3 ‘minute -2 ‘second -4 (ts-now))))
+“1 days, 3 hours, 2 minutes, 4 seconds”
+```
+
+The timestamp comparator operations are also defined in ts.el. The ts< function compares if one epoch UNIX timestamp is less than the other. Its definition is as follows:
+
+```
+(defun ts< (a b)
+“Return non-nil if timestamp A is less than timestamp B.”
+(< (ts-unix a) (ts-unix b)))
+```
+
+In the example given below, the current timestamp is not less than the previous day and hence it returns nil.
+
+```
+(ts< (ts-now) (ts-adjust ‘day -1 (ts-now)))
+nil
+```
+
+Similarly, we have other comparator functions like ts>, ts=, ts>= and ts<=. A few examples of these function use cases are given below:
+
+```
+(ts> (ts-now) (ts-adjust ‘day -1 (ts-now)))
+t
+
+(ts= (ts-now) (ts-now))
+nil
+
+(ts>= (ts-now) (ts-adjust ‘day -1 (ts-now)))
+t
+
+(ts<= (ts-now) (ts-adjust ‘day -2 (ts-now)))
+nil
+```
+
+**Benchmarking**
+A few performance tests can be conducted to compare the Emacs internal time values versus the UNIX timestamps. The benchmarking tests can be executed by including the bench-multi macro and bench-multi-process-results function available from __ in your Emacs environment.
+You will also need to load the dash-functional library to use the -on function.
+
+```
+(require ‘dash-functional)
+```
+
+The following tests have been executed on an Intel(R) Core(TM) i7-3740QM CPU at 2.70GHz with eight cores, 16GB RAM and running Ubuntu 18.04 LTS.
+
+**Formatting**
+The first benchmarking exercise is to compare the formatting of the UNIX timestamp and the Emacs internal time. The Emacs Lisp code to run the test is shown below:
+
+```
+(let ((format “%Y-%m-%d %H:%M:%S”))
+(bench-multi :times 100000
+:forms ((“Unix timestamp” (format-time-string format 1544311232))
+(“Internal time” (format-time-string format ‘(23564 20962 864324 108000))))))
+```
+
+The output appears as an s-expression:
+
+```
+((“Form” “x faster than next” “Total runtime” “# of GCs” “Total GC runtime”)
+hline
+
+(“Internal time” “1.11” “2.626460” 13 “0.838733”)
+(“Unix timestamp” “slowest” “2.921408” 13 “0.920814”))
+```
+
+The abbreviation ‘GC’ refers to garbage collection. A tabular representation of the above results is given below:
+
+[![][3]][4]
+
+We observe that formatting the internal time is slightly faster.
+
+**Getting the current time**
+The functions to obtain the current time can be compared using the following test:
+
+```
+(bench-multi :times 100000
+:forms ((“Unix timestamp” (float-time))
+(“Internal time” (current-time))))
+```
+
+The results are shown below:
+
+[![][5]][6]
+
+We observe that using the Unix timestamp is faster.
+
+**Parsing**
+The third benchmarking exercise is to compare parsing functions on a date timestamp string. The corresponding test code is given below:
+
+```
+(let* ((s “Wed 10 Jul 2019”))
+(bench-multi :times 100000
+:forms ((“ts-parse” (ts-parse s))
+(“ts-parse ts-unix” (ts-unix (ts-parse s))))))
+```
+
+The _ts-parse_ function is slightly faster than the ts-parse _ts-unix_ function, as seen in the results:
+
+[![][7]][8]
+
+**A new timestamp versus blanking fields**
+The last performance comparison is between creating a new timestamp and blanking the fields. The relevant test code is as follows:
+
+```
+(let* ((a (ts-now)))
+(bench-multi :times 100000
+:ensure-equal t
+:forms ((“New” (let ((ts (copy-ts a)))
+(setq ts (ts-fill ts))
+(make-ts :unix (ts-unix ts))))
+(“Blanking” (let ((ts (copy-ts a)))
+(setq ts (ts-fill ts))
+(ts-reset ts))))))
+```
+
+The output of the benchmarking exercise is given below:
+
+[![][9]][10]
+
+We observe that creating a new timestamp is slightly faster than blanking the fields.
+You are encouraged to read the ts.el README and notes.org from the GitHub repository __ for more information.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/09/the-emacs-series-exploring-ts-el/
+
+作者:[Shakthi Kannan][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/shakthi-kannan/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/GPL-emacs-1.jpg?resize=696%2C435&ssl=1 (GPL emacs)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/GPL-emacs-1.jpg?fit=800%2C500&ssl=1
+[3]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/1-1.png?resize=350%2C151&ssl=1
+[4]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/1-1.png?ssl=1
+[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/2-1.png?resize=350%2C191&ssl=1
+[6]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/2-1.png?ssl=1
+[7]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/3.png?resize=350%2C144&ssl=1
+[8]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/3.png?ssl=1
+[9]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/4.png?resize=350%2C149&ssl=1
+[10]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/4.png?ssl=1
diff --git a/sources/tech/20190917 Talking to machines- Lisp and the origins of AI.md b/sources/tech/20190917 Talking to machines- Lisp and the origins of AI.md
new file mode 100644
index 0000000000..795f4c731b
--- /dev/null
+++ b/sources/tech/20190917 Talking to machines- Lisp and the origins of AI.md
@@ -0,0 +1,115 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Talking to machines: Lisp and the origins of AI)
+[#]: via: (https://opensource.com/article/19/9/command-line-heroes-lisp)
+[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberg)
+
+Talking to machines: Lisp and the origins of AI
+======
+The Command Line Heroes podcast explores the invention of Lisp and the
+rise of thinking computers powered by open source software.
+![Listen to the Command Line Heroes Podcast][1]
+
+Artificial intelligence (AI) is all the rage today, and its massive impact on the world is still to come, says the[ Association for the Advancement of Artificial Intelligence][2] (AAAI). According to an article on [Nanalyze][3]:
+
+> "The vast majority of nearly 2,000 experts polled by the Pew Research Center in 2014 said they anticipate robotics and artificial intelligence will permeate wide segments of daily life by 2025. A 2015 study covering 17 countries found that artificial intelligence and related technologies added an estimated 0.4 percentage point on average to those countries' annual GDP growth between 1993 and 2007, accounting for just over one-tenth of those countries' overall GDP growth during that time."
+
+However, this is the second time has AI garnered so much attention. When was AI first popular, and what does that have to do with the obscure-but-often-loved programming language Lisp?
+
+The second-to-last podcast of [Command Line Heroes][4]' third season dives into these topics and leaves us thinking about open source at the core of AI.
+
+### Before the term AI
+
+Thinking machines have been a curiosity for centuries, long before they could be realized. In the 1800s, computer science pioneers Charles Babbage and Ada Lovelace imagined an analytical engine capable of predictions far beyond human skills, such as correctly selecting the winning horse in a race.
+
+In the 1940s and '50s, Alan Turing defined what it would look like for intelligent machines to emulate human intelligence; that's what we now call the Turing Test. In his 1950 [research paper][5], Turing's "imitation game" set out to convince someone they were communicating with a human in another room when, in reality, it was a machine.
+
+While these theories inspired imaginative debate, they became less theoretical as computer hardware began providing enough power to begin experimenting.
+
+### Why Lisp is at the heart of AI theory
+
+John McCarthy, the person to coin the term "artificial intelligence," is also the person who reinvented how we program to create thinking machines. His reimagined approach was codified into the Lisp programming language. As [Paul Graham][6] wrote:
+
+> "In 1960, [John McCarthy][7] published a remarkable paper in which he did for programming something like what Euclid did for geometry. He showed how, given a handful of simple operators and a notation for functions, you can build a whole programming language. He called this language Lisp, for 'List Processing,' because one of his key ideas was to use a simple data structure called a list for both code and data.
+>
+> "It's worth understanding what McCarthy discovered, not just as a landmark in the history of computers, but as a model for what programming is tending to become in our own time. It seems to me that there have been two really clean, consistent models of programming so far: the C model and the Lisp model. These two seem points of high ground, with swampy lowlands between them. As computers have grown more powerful, the new languages being developed have been [moving steadily][8] toward the Lisp model. A popular recipe for new programming languages in the past 20 years has been to take the C model of computing and add to it, piecemeal, parts taken from the Lisp model, like runtime typing and garbage collection."
+
+I remember when I first wrote Lisp for a computer science class. After wrapping my head around its seemingly infinite number of parentheses, I uncovered a beautiful pattern of thought: Can I think through what I want this software to do?
+
+![The elegance of Lisp programming is timeless][9]
+
+That sounds silly: computers process what we code them to do, but there's something about recursion that made me think in a wildly different light. It's exciting to learn that 15 years ago, I may have been tapping into the big-picture changes McCarthy was describing.
+
+### Why the slowdown in AI?
+
+By the mid-to-late 1960s, McCarthy's work made way to a new field of research, where AI, machine learning (ML), and deep learning all became possibilities. And Lisp became the accepted standard in this emerging field. It's said that in 1968, McCarthy made a wager with David Levy, a Scottish chess master, that in 10 years a computer would be able to beat Levy in a chess match. Why did it take nearly 30 years to get to the famous [Deep Blue vs. Garry Kasparov][10] match?
+
+Command Line Heroes explores one theory: that for-profit investment in AI pulled essential talent from academia, where they were advancing the science, and pushed them onto a different path. Whether or not this was the reason, the world of AI fell into a "winter," where the people pursuing it were considered unrealistic.
+
+This AI winter lasted for quite some time. In 2005, The [_New York Times_ reported][11] that AI had become so stigmatized that "some computer scientists and software engineers avoided the term artificial intelligence for fear of being viewed as wild-eyed dreamers."
+
+### Where is AI now?
+
+Fast forward to today, when talking about AI or ML is a fast pass to getting people's attention—but that attention isn't always positive. Many are concerned that AI will remove millions of jobs from the world. Others say it will [create][12] millions of more jobs than are lost.
+
+The verdict is still out. [McKinsey's research][13] on the job loss vs. job gain debate is fascinating. When you take into account growing world consumption, aging populations, "marketization" of previously unpaid domestic work, and other factors, you find that the answer depends on your outlook.
+
+One thing is for sure: AI will be a significant part of our lives, and it will have much wider implications than other areas of tech. For this reason (among others), examining the [misconceptions around ethics and bias in AI][14] is essential.
+
+### Open source and AI
+
+McCarthy had a dream that machines could have common sense. His AI goals included open source from the very beginning; this is visualized on Red Hat's beautifully animated webpage on the [origins of AI and its open source roots][15].
+
+[![Origins of AI and open source screenshot][16]][15]
+
+If we are to achieve the goals of McCarthy, Turing, or other AI pioneers, I believe it will be because of the open source community behind the technology. Part of the reason AI's popularity bounced back is because of open source: languages, frameworks, and the datasets we analyze are increasingly open. Here are a handful of things to explore:
+
+ * [Learn enough Python and R][17] to be part of this future
+ * [Explore Python libraries][18] that will bulk up your skills
+ * Understand how [AI and ML are related][19]
+ * Explore [free and open datasets][20]
+ * Use modern implementations of Lisp, [available under open source licenses][21]
+
+
+
+It's possible that early AI explored the right ideas in the wrong decade. World-class computers back then weren't even as powerful as today's cellphones, and each one was shared by dozens of individuals. Today, many of us own multiple supercomputers and carry them with us all the time. For this reason, among others, the future of AI is strong and its highest achievements are yet to come.
+
+_Command Line Heroes has covered programming languages for all of Season 3. [Subscribe so that you don't miss the last episode of the season][4], and I would love to hear your thoughts in the comments below._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/command-line-heroes-lisp
+
+作者:[Matthew Broberg][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberghttps://opensource.com/users/mbbroberg
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command_line_hereoes_ep7_blog-header-292x521.png?itok=lI4DXvq2 (Listen to the Command Line Heroes Podcast)
+[2]: http://aaai.org/
+[3]: https://www.nanalyze.com/2016/11/artificial-intelligence-definition/
+[4]: https://www.redhat.com/en/command-line-heroes
+[5]: https://www.csee.umbc.edu/courses/471/papers/turing.pdf
+[6]: http://www.paulgraham.com/rootsoflisp.html
+[7]: http://www-formal.stanford.edu/jmc/index.html
+[8]: http://www.paulgraham.com/diff.html
+[9]: https://opensource.com/sites/default/files/uploads/lisp_cycles.png (The elegance of Lisp programming is timeless)
+[10]: https://en.wikipedia.org/wiki/Deep_Blue_versus_Garry_Kasparov
+[11]: https://www.nytimes.com/2005/10/14/technology/behind-artificial-intelligence-a-squadron-of-bright-real-people.html
+[12]: https://singularityhub.com/2019/01/01/ai-will-create-millions-more-jobs-than-it-will-destroy-heres-how/
+[13]: https://www.mckinsey.com/featured-insights/future-of-work/jobs-lost-jobs-gained-what-the-future-of-work-will-mean-for-jobs-skills-and-wages
+[14]: https://opensource.com/article/19/8/4-misconceptions-ethics-and-bias-ai
+[15]: https://www.redhat.com/en/open-source-stories/ai-revolutionaries/origins-ai-open-source
+[16]: https://opensource.com/sites/default/files/uploads/origins_aiopensource.png (Origins of AI and open source screenshot)
+[17]: https://opensource.com/article/19/5/learn-python-r-data-science
+[18]: https://opensource.com/article/18/5/top-8-open-source-ai-technologies-machine-learning
+[19]: https://opensource.com/tags/ai-and-machine-learning
+[20]: https://opensource.com/article/19/2/learn-data-science-ai
+[21]: https://www.cliki.net/Common+Lisp+implementation
diff --git a/sources/tech/20190917 What-s Good About TensorFlow 2.0.md b/sources/tech/20190917 What-s Good About TensorFlow 2.0.md
new file mode 100644
index 0000000000..a00306d6c5
--- /dev/null
+++ b/sources/tech/20190917 What-s Good About TensorFlow 2.0.md
@@ -0,0 +1,328 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What’s Good About TensorFlow 2.0?)
+[#]: via: (https://opensourceforu.com/2019/09/whats-good-about-tensorflow-2-0/)
+[#]: author: (Siva Rama Krishna Reddy B https://opensourceforu.com/author/siva-krishna/)
+
+What’s Good About TensorFlow 2.0?
+======
+
+[![][1]][2]
+
+_Version 2.0 of TensorFlow is focused on simplicity and ease of use. It has been strengthened with updates like eager execution and intuitive higher level APIs accompanied by flexible model building. It is platform agnostic, and makes APIs more consistent, while removing those that are redundant._
+
+Machine learning and artificial intelligence are experiencing a revolution these days, primarily due to three major factors. The first is the increased computing power available within small form factors such as GPUs, NPUs and TPUs. The second is the breakthrough in machine learning algorithms. State-of-art algorithms and hence models are available to infer faster. Finally, huge amounts of labelled data is essential for deep learning models to perform better, and this is now available.
+
+TensorFlow is an open source AI framework from Google which arms researchers and developers with the right tools to build novel models. It was made open source in 2015 and, in the past few years, has evolved with various enhancements covering operator support, programming languages, hardware support, data sets, official models, and distributed training and deployment strategies.
+
+TensorFlow 2.0 was released recently at the TensorFlow Developer Summit. It has major changes across the stack, some of which will be discussed from the developers’ point of view.
+
+TensorFlow 2.0 is primarily focused on the ease-of-use, power and scalability aspects. Ease is ensured in terms of simplified APIs, Keras being the main high level API interface; eager execution is available by default. Version 2.0 is powerful in the sense of being flexible and running much faster than earlier, with more optimisation. Finally, it is more scalable since it can be deployed on high-end distributed environments as well as on small edge devices.
+
+This new release streamlines the various components involved, from data preparation all the way up to deployment on various targets. High speed data processing pipelines are offered by tf.data, high level APIs are offered by tf.keras, and there are simplified APIs to access various distribution strategies on targets like the CPU, GPU and TPU. TensorFlow 2.0 offers a unique packaging format called SavedModel that can be deployed over the cloud through a TensorFlow Serving. Edge devices can be deployed through TensorFlow Lite, and Web applications through the newly introduced TensorFlow.js and various other language bindings that are also available.
+
+![Figure 1: The evolution of TensorFlow][3]
+
+TensorFlow.js was announced at the developer summit with off-the-shelf pretrained models for the browser, node, desktop and mobile native applications. The inclusion of Swift was also announced. Looking at some of the performance improvements since last year, the latest release claims a training speedup of 1.8x on NVIDIA Tesla V100, a 1.6x training speedup on Google Cloud TPUv2 and a 3.3.x inference speedup on Intel Skylake.
+
+**Upgrade to 2.0**
+The new release offers a utility _tf_upgrade_v2_ to convert a 1.x Python application script to a 2.0 compatible script. It does most of the job in converting the 1.x deprecated API to a newer compatibility API. An example of the same can be seen below:
+
+```
+test-pc:~$cat test-infer-v1.py
+
+# Tensorflow imports
+import tensorflow as tf
+
+save_path = ‘checkpoints/dev’
+with tf.gfile.FastGFile(“./trained-graph.pb”, ‘rb’) as f:
+graph_def = tf.GraphDef()
+graph_def.ParseFromString(f.read())
+tf.import_graph_def(graph_def, name=’’)
+
+with tf.Session(graph=tf.get_default_graph()) as sess:
+input_data = sess.graph.get_tensor_by_name(“DecodeJPGInput:0”)
+output_data = sess.graph.get_tensor_by_name(“final_result:0”)
+
+image = ‘elephant-299.jpg’
+if not tf.gfile.Exists(image):
+tf.logging.fatal(‘File does not exist %s’, image)
+image_data = tf.gfile.FastGFile(image, ‘rb’).read()
+
+result = sess.run(output_data, {‘DecodeJPGInput:0’: image_data})
+print(result)
+
+test-pc:~$ tf_upgrade_v2 --infile test-infer-v1.py --outfile test-infer-v2.py
+
+INFO line 5:5: Renamed ‘tf.gfile.FastGFile’ to ‘tf.compat.v1.gfile.FastGFile’
+INFO line 6:16: Renamed ‘tf.GraphDef’ to ‘tf.compat.v1.GraphDef’
+INFO line 10:9: Renamed ‘tf.Session’ to ‘tf.compat.v1.Session’
+INFO line 10:26: Renamed ‘tf.get_default_graph’ to ‘tf.compat.v1.get_default_graph’
+INFO line 15:15: Renamed ‘tf.gfile.Exists’ to ‘tf.io.gfile.exists’
+INFO line 16:12: Renamed ‘tf.logging.fatal’ to ‘tf.compat.v1.logging.fatal’
+INFO line 17:21: Renamed ‘tf.gfile.FastGFile’ to ‘tf.compat.v1.gfile.FastGFile’
+TensorFlow 2.0 Upgrade Script
+-----------------------------
+Converted 1 files
+Detected 0 issues that require attention
+-------------------------------------------------------------
+Make sure to read the detailed log ‘report.txt’
+
+test-pc:~$ cat test-infer-v2.py
+
+# Tensorflow imports
+import tensorflow as tf
+
+save_path = ‘checkpoints/dev’
+with tf.compat.v1.gfile.FastGFile(“./trained-graph.pb”, ‘rb’) as f:
+graph_def = tf.compat.v1.GraphDef()
+graph_def.ParseFromString(f.read())
+tf.import_graph_def(graph_def, name=’’)
+
+with tf.compat.v1.Session(graph=tf.compat.v1.get_default_graph()) as sess:
+input_data = sess.graph.get_tensor_by_name(“DecodeJPGInput:0”)
+output_data = sess.graph.get_tensor_by_name(“final_result:0”)
+
+image = ‘elephant-299.jpg’
+if not tf.io.gfile.exists(image):
+tf.compat.v1.logging.fatal(‘File does not exist %s’, image)
+image_data = tf.compat.v1.gfile.FastGFile(image, ‘rb’).read()
+
+result = sess.run(output_data, {‘DecodeJPGInput:0’: image_data})
+print(result)
+```
+
+As we can see here, the _tf_upgrade_v2_ utility converts all the deprecated APIs to compatible v1 APIs, to make them work with 2.0.
+
+**Eager execution:** Eager execution allows real-time evaluation of Tensors without calling _session.run_. A major advantage with eager execution is that we can print the Tensor values any time for debugging.
+With TensorFlow 1.x, the code is:
+
+```
+test-pc:~$python3
+Python 3.6.7 (default, Oct 22 2018, 11:32:17)
+[GCC 8.2.0] on linux
+Type “help”, “copyright”, “credits” or “license” for more information.
+>>> import tensorflow as tf
+>>> print(tf.__version__)
+1.14.0
+>>> tf.add(2,3)
+
+```
+
+TensorFlow 2.0, on the other hand, evaluates the result that we call the API:
+
+```
+test-pc:~$python3
+Python 3.6.7 (default, Oct 22 2018, 11:32:17)
+[GCC 8.2.0] on linux
+Type “help”, “copyright”, “credits” or “license” for more information.
+>>> import tensorflow as tf
+>>> print(tf.__version__)
+2.0.0-beta1
+>>> tf.add(2,3)
+
+```
+
+In v1.x, the resulting Tensor doesn’t display the value and we need to execute the graph under a session to get the value, but in v2.0 the values are implicitly computed and available for debugging.
+
+**Keras**
+Keras (_tf.keras_) is now the official high level API. It has been enhanced with many compatible low level APIs. The redundancy across Keras and TensorFlow is removed, and most of the APIs are now available with Keras. The low level operators are still accessible through tf.raw_ops.
+We can now save the Keras model directly as a Tensorflow SavedModel, as shown below:
+
+```
+# Save Model to SavedModel
+saved_model_path = tf.keras.experimental.export_saved_model(model, ‘/path/to/model’)
+
+# Load the SavedModel
+new_model = tf.keras.experimental.load_from_saved_model(saved_model_path)
+
+# new_model is now keras Model object.
+new_model.summary()
+```
+
+Earlier, APIs related to various layers, optimisers, metrics and loss functions were distributed across Keras and native TensorFlow. Latest enhancements unify them as _tf.keras.optimizer.*, tf.keras.metrics.*, tf.keras.losses.* and tf.keras.layers.*._
+The RNN layers are now much more simplified compared to v 1.x.
+With TensorFlow 1.x, the commands given are:
+
+```
+if tf.test.is_gpu_available():
+model.add(tf.keras.layers.CudnnLSTM(32))
+else
+model.add(tf.keras.layers.LSTM(32))
+```
+
+With TensorFlow 2.0, the commands given are:
+
+```
+# This will use Cudnn kernel when the GPU is available.
+model.add(tf.keras.layer.LSTM(32))
+```
+
+TensorBoard integration is now a simple call back, as shown below:
+
+```
+tb_callbaclk = tf.keras.callbacks.TensorBoard(log_dir=log_dir)
+
+model.fit(
+x_train, y_train, epocha=5,
+validation_data = [x_test, y_test],
+Callbacks = [tb_callbacks])
+```
+
+With this simple call back addition, TensorBoard is up on the browser to look for all the statistics in real-time.
+Keras offers unified distribution strategies, and a few lines of code can enable the required strategy as shown below:
+
+```
+strategy = tf.distribute.MirroredStrategy()
+
+with strategy.scope()
+model = tf.keras.models.Sequential([
+tf.keras.layers.Dense(64, input_shape=[10]),
+tf.keras.layers.Dense(64, activation=’relu’),
+tf.keras.layers.Dense(10, activation=’softmax’)])
+
+model.compile(optimizer=’adam’,
+loss=’categorical_crossentropy’,
+metrics=[‘accuracy’])
+```
+
+As shown above, the model definition under the desired scope is all we need to apply the desired strategy. Very soon, there will be support for multi-node synchronous and TPU strategy, and later, for parameter server strategy.
+
+![Figure 2: Coral products with edge TPU][4]
+
+**TensorFlow function**
+Function is a major upgrade that impacts the way we write TensorFlow applications. The new version introduces tf.function, which simplifies the applications and makes it very close to writing a normal Python application.
+A sample _tf.function_ definition looks like what’s shown in the code snippet below. Here the _tf.function_ declaration makes the user define a function as a TensorFlow operator, and all optimisation is applied automatically. Also, the function is faster than eager execution. APIs like _tf.control_dependencies_, _tf.global_variable_initializer_, and _tf.cond, tf.while_loop_ are no longer needed with _tf.function_. The user defined functions are polymorphic by default, i.e., we may pass mixed type tensors.
+
+```
+test-pc:~$ cat tf-test.py
+import tensorflow as tf
+
+print(tf.__version__)
+
+@tf.function
+def add(a, b):
+return (a+b)
+
+print(add(tf.ones([2,2]), tf.ones([2,2])))
+
+test-pc:~$ python3 tf-test.py
+2.0.0-beta1
+tf.Tensor(
+[[2. 2.]
+[2. 2.]], shape=(2, 2), dtype=float32)
+```
+
+Here is another example to demonstrate automatic control flows and Autograph in action. Autograph automatically converts the conditions, while it loops Python to TensorFlow operators.
+
+```
+test-pc:~$ cat tf-test-control.py
+import tensorflow as tf
+
+print(tf.__version__)
+
+@tf.function
+def f(x):
+while tf.reduce_sum(x) > 1:
+x = tf.tanh(x)
+return x
+
+print(f(tf.random.uniform([10])))
+
+test-pc:~$ python3 tf-test-control.py
+
+2.0.0-beta1
+tf.Tensor(
+[0.10785562 0.11102211 0.11347286 0.11239681 0.03989326 0.10335539
+0.11030331 0.1135259 0.11357211 0.07324989], shape=(10,), dtype=float32)
+```
+
+We can see Autograph in action with the following API over the function.
+
+```
+print(tf.autograph.to_code(f)) # f is the function name
+```
+
+**TensorFlow Lite**
+The latest advancements in edge devices add neural network accelerators. Google has released EdgeTPU, Intel has the edge inference platform Movidius, Huawei mobile devices have the Kirin based NPU, Qualcomm has come up with NPE SDK to accelerate on the Snapdragon chipsets using Hexagon power and, recently, Samsung released Exynos 9 with NPU. An edge device optimised framework is necessary to support these hardware ecosystems.
+
+Unlike TensorFlow, which is widely used in high power-consuming server infrastructure, edge devices are challenging in terms of reduced computing power, limited memory and battery constraints. TensorFlow Lite is aimed at bringing in TensorFlow models directly onto the edge with minimal effort. The TF Lite model format is different from TensorFlow. A TF Lite converter is available to convert a TensorFlow SavedBundle to a TF Lite model.
+
+Though TensorFlow Lite is evolving, there are limitations too, such as in the number of operations supported, and the unsupported semantics like control-flows and RNNs. In its early days, TF Lite used a TOCO converter and there were a few challenges for the developer community. A brand new 2.0 converter is planned to be released soon. There are claims that using TF Lite results in huge improvements across the CPU, GPU and TPU.
+
+TF Lite introduces delegates to accelerate parts of the graph on an accelerator. We may choose a specific delegate for a specific sub-graph, if needed.
+
+```
+#import “tensorflow/lite/delegates/gpu/metal_delegate.h”
+
+// Initialize interpreter with GPU delegate
+std::unique_ptr interpreter;
+InterpreterBuilder(*model, resolver)(&interpreter);
+auto* delegate = NewGpuDelegate(nullptr); // default config
+if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
+
+// Run inference
+while (true) {
+WriteToInputTensor(interpreter->typed_input_tensor(0));
+if (interpreter->Invoke() != kTfLiteOk) return false;
+ReadFromOutputTensor(interpreter->typed_output_tensor(0));
+}
+
+// Clean up
+interpreter = nullptr;
+DeleteGpuDelegate(delegate);
+```
+
+As shown above, we can choose GPUDelegate, and modify the graph with the respective kernel’s runtime. TF Lite is going to support the Android NNAPI delegate, in order to support all the hardware that is supported by NNAPI. For edge devices, CPU optimisation is also important, as not all edge devices are equipped with accelerators; hence, there is a plan to support further optimisations for ARM and x86.
+
+Optimisations based on quantisation and pruning are evolving to reduce the size and processing demands of models. Quantisation generally can reduce model size by 4x (i.e., 32-bit to 8-bit). Models with more convolution layers may get faster by 10 to 50 per cent on the CPU. Fully connected and RNN layers may speed up operation by 3x.
+
+TF Lite now supports post-training quantisation, which reduces the size along with compute demands greatly. TensorFlow 2.0 offers simplified APIs to build models with quantisation and by pruning optimisations.
+A normal dense layer without quantisation looks like what follows:
+
+```
+tf.keras.layers.Dense(512, activation=’relu’)
+```
+
+Whereas a quality dense layer looks like what’s shown below:
+
+```
+quantize.Quantize(tf.keras.layers.Dense(512, activation=’relu’))
+```
+
+Pruning is a technique used to drop connections that are ineffective. In general, ‘dense’ layers contain lots of connections which don’t influence the output. Such connections can be dropped by making the weight zero. Tensors with lots of zeros may be represented as ‘sparse’ and can be compressed. Also, the number of operations in a sparse tensor is less.
+Building a layer with _prune_ is as simple as using the following command:
+
+```
+prune.Prune(tf.keras.layers.Dense(512, activation=’relu’))
+```
+
+In a pipeline, there is Keras based quantised training and Keras based connection pruning. These optimisations may push TF Lite further ahead of the competition, with regard to other frameworks.
+
+**Coral**
+Coral is a new platform for creating products with on-device ML acceleration. The first product here features Google’s Edge TPU in SBC and USB form factors. TensorFlow Lite is officially supported on this platform, with the salient features being very fast inference speed, privacy and no reliance on network connection.
+
+More details related to hardware specifications, pricing, and a getting started guide can be found at __.
+
+With these advances as well as a wider ecosystem, it’s very evident that TensorFlow may become the leading framework for artificial intelligence and machine learning, similar to how Android evolved in the mobile world.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/09/whats-good-about-tensorflow-2-0/
+
+作者:[Siva Rama Krishna Reddy B][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/siva-krishna/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2018/09/ML-with-tensorflow.jpg?resize=696%2C328&ssl=1 (ML with tensorflow)
+[2]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2018/09/ML-with-tensorflow.jpg?fit=1200%2C565&ssl=1
+[3]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-1-The-evolution-of-TensorFlow.jpg?resize=350%2C117&ssl=1
+[4]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-2-Coral-products-with-edge-TPU.jpg?resize=350%2C198&ssl=1
diff --git a/sources/tech/20190919 An introduction to audio processing and machine learning using Python.md b/sources/tech/20190919 An introduction to audio processing and machine learning using Python.md
new file mode 100644
index 0000000000..67b4779680
--- /dev/null
+++ b/sources/tech/20190919 An introduction to audio processing and machine learning using Python.md
@@ -0,0 +1,162 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (An introduction to audio processing and machine learning using Python)
+[#]: via: (https://opensource.com/article/19/9/audio-processing-machine-learning-python)
+[#]: author: (Jyotika Singh https://opensource.com/users/jyotika-singhhttps://opensource.com/users/jroakeshttps://opensource.com/users/don-watkinshttps://opensource.com/users/clhermansenhttps://opensource.com/users/greg-p)
+
+An introduction to audio processing and machine learning using Python
+======
+The pyAudioProcessing library classifies audio into different categories
+and genres.
+![abstract illustration with black background][1]
+
+At a high level, any machine learning problem can be divided into three types of tasks: data tasks (data collection, data cleaning, and feature formation), training (building machine learning models using data features), and evaluation (assessing the model). Features, [defined][2] as "individual measurable propert[ies] or characteristic[s] of a phenomenon being observed," are very useful because they help a machine understand the data and classify it into categories or predict a value.
+
+![Machine learning at a high level][3]
+
+Different data types use very different processing techniques. Take the example of an image as a data type: it looks like one thing to the human eye, but a machine sees it differently after it is transformed into numerical features derived from the image's pixel values using different filters (depending on the application).
+
+![Data types and feature formation in images][4]
+
+[Word2vec][5] works great for processing bodies of text. It represents words as vectors of numbers, and the distance between two word vectors determines how similar the words are. If we try to apply Word2vec to numerical data, the results probably will not make sense.
+
+![Word2vec for analyzing a corpus of text][6]
+
+So, there are processing techniques specific to the audio data type that works well with audio.
+
+### What are audio signals?
+
+Audio signals are signals that vibrate in the audible frequency range. When someone talks, it generates air pressure signals; the ear takes in these air pressure differences and communicates with the brain. That's how the brain helps a person recognize that the signal is speech and understand what someone is saying.
+
+There are a lot of MATLAB tools to perform audio processing, but not as many exist in Python. Before we get into some of the tools that can be used to process audio signals in Python, let's examine some of the features of audio that apply to audio processing and machine learning.
+
+![Examples of audio terms to learn][7]
+
+Some data features and transformations that are important in speech and audio processing are Mel-frequency cepstral coefficients ([MFCCs][8]), Gammatone-frequency cepstral coefficients (GFCCs), Linear-prediction cepstral coefficients (LFCCs), Bark-frequency cepstral coefficients (BFCCs), Power-normalized cepstral coefficients (PNCCs), spectrum, cepstrum, spectrogram, and more.
+
+We can use some of these features directly and extract features from some others, like spectrum, to train a machine learning model.
+
+### What are spectrum and cepstrum?
+
+Spectrum and cepstrum are two particularly important features in audio processing.
+
+![Spectrum and cepstrum][9]
+
+Mathematically, a spectrum is the [Fourier transform][10] of a signal. A Fourier transform converts a time-domain signal to the frequency domain. In other words, a spectrum is the frequency domain representation of the input audio's time-domain signal.
+
+A [cepstrum][11] is formed by taking the log magnitude of the spectrum followed by an inverse Fourier transform. This results in a signal that's neither in the frequency domain (because we took an inverse Fourier transform) nor in the time domain (because we took the log magnitude prior to the inverse Fourier transform). The domain of the resulting signal is called the quefrency.
+
+### What does this have to do with hearing?
+
+The reason we care about the signal in the frequency domain relates to the biology of the ear. Many things must happen before we can process and interpret a sound. One happens in the cochlea, a fluid-filled part of the ear with thousands of tiny hairs that are connected to nerves. Some of the hairs are short, and some are relatively longer. The shorter hairs resonate with higher sound frequencies, and the longer hairs resonate with lower sound frequencies. Therefore, the ear is like a natural Fourier transform analyzer!
+
+![How the ear works][12]
+
+Another fact about human hearing is that as the sound frequency increases above 1kHz, our ears begin to get less selective to frequencies. This corresponds well with something called the Mel filter bank.
+
+![MFCC][13]
+
+Passing a spectrum through the Mel filter bank, followed by taking the log magnitude and a [discrete cosine transform][14] (DCT) produces the Mel cepstrum. DCT extracts the signal's main information and peaks. It is also widely used in JPEG and MPEG compressions. The peaks are the gist of the audio information. Typically, the first 13 coefficients extracted from the Mel cepstrum are called the MFCCs. These hold very useful information about audio and are often used to train machine learning models.
+
+Another filter inspired by human hearing is the Gammatone filter bank. This filter bank is used as a front-end simulation of the cochlea. Thus, it has many applications in speech processing because it aims to replicate how we hear.
+
+![GFCC][15]
+
+GFCCs are formed by passing the spectrum through Gammatone filter bank, followed by loudness compression and DCT. The first (approximately) 22 features are called GFCCs. GFCCs have a number of applications in speech processing, such as speaker identification.
+
+Other features useful in audio processing tasks (especially speech) include LPCC, BFCC, PNCC, and spectral features like spectral flux, entropy, roll off, centroid, spread, and energy entropy.
+
+### Building a classifier
+
+As a quick experiment, let's try building a classifier with spectral features and MFCC, GFCC, and a combination of MFCCs and GFCCs using an open source Python-based library called [pyAudioProcessing][16].
+
+To start, we want pyAudioProcessing to classify audio into three categories: speech, music, or birds.
+
+![Segmenting audio into speech, music, and birds][17]
+
+Using a small dataset (50 samples for training per class) and without any fine-tuning, we can gauge the potential of this classification model to identify audio categories.
+
+![MFCC of speech, music, and bird signals][18]
+
+Next, let's try pyAudioProcessing on a music genre classification problem using the [GZTAN][19] audio dataset and audio features: MFCC and spectral features.
+
+![Music genre classification][20]
+
+Some genres do well while others have room for improvement. Some things that can be explored from this data include:
+
+ * Data quality check: Is more data needed?
+ * Features around the beat and other aspects of music audio
+ * Features other than audio, like transcription and text
+ * Would a different classifier be better? There has been research on using neural networks to classify music genres.
+
+
+
+Regardless of the results of this quick test, it is evident that these features get useful information out of the signal, a machine can work with them, and they form a good baseline to work with.
+
+### Learn more
+
+Here are some useful resources that can help in your journey with Python audio processing and machine learning:
+
+ * [pyAudioAnalysis][21]
+ * [pyAudioProcessing][16]
+ * [Power-normalized cepstral coefficients (PNCC) for robust speech recognition][22]
+ * [LPCC features][23]
+ * [Speech recognition using MFCC][24]
+ * [Speech/music classification using block-based MFCC features][25]
+ * [Musical genre classification of audio signals][26]
+ * Libraries for reading audio in Python: [SciPy][27], [pydub][28], [libROSA][29], pyAudioAnalysis
+ * Libraries for getting features: libROSA, pyAudioAnalysis (for MFCC); pyAudioProcessing (for MFCC and GFCC)
+ * Basic machine learning models to use on audio: sklearn, hmmlearn, pyAudioAnalysis, pyAudioProcessing
+
+
+
+* * *
+
+_This article is based on Jyotika Singh's presentation "[Audio processing and ML using Python][30]" from PyBay 2019._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/audio-processing-machine-learning-python
+
+作者:[Jyotika Singh][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jyotika-singhhttps://opensource.com/users/jroakeshttps://opensource.com/users/don-watkinshttps://opensource.com/users/clhermansenhttps://opensource.com/users/greg-p
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/FeedbackLoop.png?itok=l7Sa9fHt (abstract illustration with black background)
+[2]: https://en.wikipedia.org/wiki/Feature_(machine_learning)
+[3]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_1.png (Machine learning at a high level)
+[4]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_1a.png (Data types and feature formation in images)
+[5]: https://en.wikipedia.org/wiki/Word2vec
+[6]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_2b.png (Word2vec for analyzing a corpus of text)
+[7]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_4.png (Examples of audio terms to learn)
+[8]: https://en.wikipedia.org/wiki/Mel-frequency_cepstrum
+[9]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_5.png (Spectrum and cepstrum)
+[10]: https://en.wikipedia.org/wiki/Fourier_transform
+[11]: https://en.wikipedia.org/wiki/Cepstrum
+[12]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_6.png (How the ear works)
+[13]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_7.png (MFCC)
+[14]: https://en.wikipedia.org/wiki/Discrete_cosine_transform
+[15]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_8.png (GFCC)
+[16]: https://github.com/jsingh811/pyAudioProcessing
+[17]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_10.png (Segmenting audio into speech, music, and birds)
+[18]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_11.png (MFCC of speech, music, and bird signals)
+[19]: http://marsyas.info/downloads/datasets.html
+[20]: https://opensource.com/sites/default/files/uploads/audioprocessing-ml_12.png (Music genre classification)
+[21]: https://github.com/tyiannak/pyAudioAnalysis
+[22]: http://www.cs.cmu.edu/~robust/Papers/OnlinePNCC_V25.pdf
+[23]: https://link.springer.com/content/pdf/bbm%3A978-3-319-17163-0%2F1.pdf
+[24]: https://pdfs.semanticscholar.org/3439/454a00ef811b3a244f2b0ce770e80f7bc3b6.pdf
+[25]: https://pdfs.semanticscholar.org/031b/84fb7ae3fae3fe51a0a40aed4a0dcb55a8e3.pdf
+[26]: https://pdfs.semanticscholar.org/4ccb/0d37c69200dc63d1f757eafb36ef4853c178.pdf
+[27]: https://www.scipy.org/
+[28]: https://github.com/jiaaro/pydub
+[29]: https://librosa.github.io/librosa/
+[30]: https://pybay.com/speaker/jyotika-singh/
diff --git a/sources/tech/20190919 Why it-s time to embrace top-down cybersecurity practices.md b/sources/tech/20190919 Why it-s time to embrace top-down cybersecurity practices.md
new file mode 100644
index 0000000000..2a8d17b1b1
--- /dev/null
+++ b/sources/tech/20190919 Why it-s time to embrace top-down cybersecurity practices.md
@@ -0,0 +1,101 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Why it's time to embrace top-down cybersecurity practices)
+[#]: via: (https://opensource.com/article/19/9/cybersecurity-practices)
+[#]: author: (Matt ShealyAnderson Silva https://opensource.com/users/mshealyhttps://opensource.com/users/asnaylorhttps://opensource.com/users/ansilvahttps://opensource.com/users/bexelbiehttps://opensource.com/users/mkalindepauleduhttps://opensource.com/users/alanfdoss)
+
+Why it's time to embrace top-down cybersecurity practices
+======
+An open culture doesn't mean being light on security practices. Having
+executives on board with cybersecurity, including funding it adequately,
+is critical for protecting and securing company data.
+![Two different business organization charts][1]
+
+Cybersecurity is no longer just the domain of the IT staff putting in firewalls and backing up servers. It takes a commitment from the top and a budget to match. The stakes are high when it comes to keeping your customers' information safe.
+
+The average cost of a data breach in 2018 was $148 for each compromised record. That equals an average cost of [$3.86 million per breach][2]. Because it takes organizations more than six months—196 days on average—to detect breaches, a lot of remediation must happen after discovery.
+
+With compliance regulations in most industries tightening and stricter security rules, such as the [General Data Protection Regulation][3] (GDPR) becoming law, breaches can lead to large fines as well as loss of reputation.
+
+To build a cybersecurity solution from the top down, you need to build a solid foundation. This foundation should be viewed not as a technology problem but as a governance issue. Tech solutions will play a role, but it takes more than that—it starts with building a culture of safety.
+
+### Build a cybersecurity culture
+
+"A chain is no stronger than its weakest link," Thomas Reid wrote back in 1786. The message still applies when it comes to cybersecurity today. Your systems are only as secure as your least safety-conscious team member. One lapse, by one person, can compromise your data.
+
+It's important to build a culture where all team members understand the importance of cybersecurity. Security is not just the IT department's job. It is everyone's responsibility.
+
+Training is a continuous responsibility. When new team members are on-boarded, they need to be trained in security best practices. When team members leave, their access must be restricted immediately. As team members get comfortable in their positions, there should be [strong policies, procedures, and training][4] to keep them safety conscious.
+
+### Maintain secure systems
+
+Corporate policies and procedures will establish a secure baseline for your systems. It's important to maintain strict adherence as systems expand or evolve. Secure network design must match these policies.
+
+A secure system will be able to filter all incoming traffic at the network perimeter. Only traffic required to support your organization should be allowed to get through this perimeter. Unfortunately, threats sometimes still get in.
+
+Zero-day attacks are increasing in number, and more threat actors are exploiting known defects in software. In 2018, more than [three-quarters of successful endpoint attacks exploited zero-day flaws][5]. While it's difficult to guard against unknown threats, you can minimize your exposure by strictly applying updates and patches immediately when they're released.
+
+### Manage user privileges
+
+By limiting each individual user's access and privileges, companies can utilize micro-segmenting to minimize potential damage done by a possible attack. If an attack does get through your secure perimeter, this will limit the number of areas the attacker has access to.
+
+User access should be limited to only the privileges they need to do their jobs, especially when it comes to sensitive data. Most breaches start with email phishing. Unsuspecting employees click on a malicious link or are tricked into giving up their login credentials. The less access employees have, the less damage a hacker can do.
+
+Identity and access management (IAM) systems can deploy single sign-on (SSO) to reduce the number of passwords users need to access systems by using an authentication token accepted by different apps. Multi-factor authentication practices combined with reducing privileges can lower risk to the entire system.
+
+### Implement continuous monitoring
+
+Your security needs [continuous monitoring across your enterprise][6] to detect and prevent intrusion. This includes servers, networks, Software-as-a-Service (SaaS), cloud services, mobile users, third-party applications, and much more. In reality, it is imperative that every entry point and connection are continuously monitored.
+
+Your employees are working around the clock, especially if you are a global enterprise. They are working from home and working on the road. This means multiple devices, internet accesses, and servers, all of which need to be monitored.
+
+Likewise, hackers are working continuously to find any flaw in your system that could lead to a possible cyberattack. Don't wait for your next IT audit to worry about finding the flaws; this should be a continual process and high priority.
+
+### Conduct regular risk assessments
+
+Even with continuous monitoring, chief information security officers (CISOs) and IT managers should regularly conduct risk assessments. New devices, hardware, third-party apps, and cloud services are being added all the time. It's easy to forget how all these individual pieces, added one at a time, all fit into the big picture.
+
+The regularly scheduled, formal risk assessment should take an exhaustive look at infrastructure and access points. It should include penetration testing to identify potential threats.
+
+Your risk assessment should also analyze backups and data-recovery planning in case a breach occurs. Don't just set up your security and hope it works. Have a plan for what you will do if access is breached, know who will be responsible for what, and establish an expected timeline to implement your plan.
+
+### Pay attention to remote teams and BYOD users
+
+More team members than ever work remotely. Whether they are working on the road, at a remote location, or from home, they pose a cybersecurity risk. They are connecting remotely, which can [leave channels open for intrusion or data interception][7].
+
+Team members often mix company devices and personal devices almost seamlessly. The advent of BYOD (bring your own device) means company assets may also be vulnerable to apps and software installed on personal devices. While you can manage what's on company devices, when employees check their company email from their personal phone or connect to a company server from their personal laptop, you've increased your overall risk.
+
+Personal devices and remote connections should always utilize a virtual private network (VPN). A VPN uses encrypted connections to the internet that create a private tunnel that masks the user's IP address. As Douglas Crawford, resident security expert at ProPrivacy.com, [explains][8], "Until the Edward Snowden revelations, people assumed that 128-bit encryption was in practice uncrackable through brute force. They believed it would be so for around another 100 years (taking Moore's Law into account). In theory, this still holds true. However, the scale of resources that the NSA seems willing to throw at cracking encryption has shaken many experts' faith in these predictions. Consequently, system administrators the world over are scrambling to upgrade cipher key lengths."
+
+### A top-down cybersecurity strategy is essential
+
+When it comes to cybersecurity, a top-down strategy is essential to providing adequate protection. Building a culture of cybersecurity throughout the organization, maintaining secure systems, and continuous monitoring are essential to safeguarding your systems and your data.
+
+A top-down approach means your IT department is not solely focused on your company's tech stack while management is solely focused on the company mission and objectives. These are no longer siloed departments; they are interwoven and dependent on each other to ensure success.
+
+Ultimately, success is defined as keeping your customer information safe and secure. Continuous monitoring and protection of sensitive information are critical to the success of the entire company. With top management on board with funding cybersecurity adequately, IT can ensure optimum security practices.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/cybersecurity-practices
+
+作者:[Matt ShealyAnderson Silva][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mshealyhttps://opensource.com/users/asnaylorhttps://opensource.com/users/ansilvahttps://opensource.com/users/bexelbiehttps://opensource.com/users/mkalindepauleduhttps://opensource.com/users/alanfdoss
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_orgchart2.png?itok=R_cnshU2 (Two different business organization charts)
+[2]: https://securityintelligence.com/ponemon-cost-of-a-data-breach-2018/
+[3]: https://ec.europa.eu/info/law/law-topic/data-protection_en
+[4]: https://us.norton.com/internetsecurity-how-to-cyber-security-best-practices-for-employees.html
+[5]: https://www.ponemon.org/news-2/82
+[6]: https://digitalguardian.com/blog/what-continuous-security-monitoring
+[7]: https://www.chamberofcommerce.com/business-advice/ransomeware-the-terrifying-threat-to-small-business
+[8]: https://proprivacy.com/guides/the-ultimate-privacy-guide
diff --git a/sources/tech/20190920 Deep Learning Based Chatbots are Smarter.md b/sources/tech/20190920 Deep Learning Based Chatbots are Smarter.md
new file mode 100644
index 0000000000..f75089648b
--- /dev/null
+++ b/sources/tech/20190920 Deep Learning Based Chatbots are Smarter.md
@@ -0,0 +1,113 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Deep Learning Based Chatbots are Smarter)
+[#]: via: (https://opensourceforu.com/2019/09/deep-learning-based-chatbots-are-smarter/)
+[#]: author: (Dharmendra Patel https://opensourceforu.com/author/dharmendra-patel/)
+
+Deep Learning Based Chatbots are Smarter
+======
+
+[![][1]][2]
+
+_Contemporary chatbots extensively use machine learning, natural language processing, artificial intelligence and deep learning. They are typically used in the customer service space for almost all domains. Chatbots based on deep learning are far better than traditional variants. Here’s why._
+
+Chatbots are currently being used extensively to change customer behaviour. Usually, traditional artificial intelligence (AI) concepts are used in designing chatbots. However, modern applications generate such vast volumes of data that it becomes arduous to process this with traditional AI algorithms.
+Deep learning is a subset of AI and is the most suitable technique to process large quantities of data. Deep learning based systems learn from copious data points. Systems like chatbots are the right contenders for deep learning as they require abundant data points to train the system to reach precise levels of performance. The main purpose of chatbots is to offer the most appropriate reply to any question or message that it receives. The ideal response from a chatbot has multiple aspects to it, such as:
+
+ * It should be able to chat in a pragmatic manner
+ * Respond to the caller’s query
+ * Provide the corresponding, relevant information
+ * Raise follow up questions like in a real conversation
+
+
+
+Deep learning simulates the human mind for processing information. It works like the human brain by categorising a variety of information, and automatically discovers the features to be used to classify this information in a way that is perfect for chatbot systems.
+
+![Figure 1: Steps for designing chatbots using deep learning][3]
+
+**Steps for designing chatbots using deep learning**
+The goal while designing chatbots using deep learning is to entirely automate the system to lessen the need for human management as much as possible. To achieve this, we need to completely replace all human experts with a chatbot, eradicating the need for client service representatives entirely. Figure 1 depicts the steps for designing chatbots using deep learning.
+
+The first step when designing a chatbot is to collect the existing interactions between clients and service representatives, in order to teach the machine the phrases that are important while interacting with customers. This is called ontology creation.
+
+The data preparation or data preprocessing is the next step in designing the chatbot. This consists of several steps such as tokenisation, stemming and lemmatising. This phase integrates grammar into machine understanding.
+
+The third step involves deciding on the appropriate model of the chatbot. There are two prominent models — retrieval based and generative. Retrieval models apply the repository of predefined responses while generative models are advanced versions of the retrieval model that use deep learning concepts.
+
+The next step is to decide on the appropriate technique to handle client interactions efficiently.
+Now you are ready to design and implement the chatbot. Use the appropriate programming language for the implementation. Once it is implemented successfully, test it to uncover any bugs or errors.
+
+**Deep learning based models for chatbots**
+Generative models are based on deep learning. They are the smartest models for chatbots but are very complicated to build and operate. They give the best response for any query as they use semantic similarity, which identifies the terms that have common characteristics.
+
+The Recurrent Neural Network (RNN) encoder-decoder is the ultimate generative model for chatbots, and consists of two RNNs. As an input, the encoder takes a sentence and processes one word at a time. It translates the series of the words into a predetermined size feature vector. It takes only significant words and removes the unnecessary ones. The encoder consists of a number of hidden layers in which one layer influences the other. The final hidden layer acts as a summary layer for the entire sentence.
+The decoder, on the other hand, generates another series, one word at a time. The decoder is influenced by the context and by previously generated words.
+
+Generally, this model is best suited to fixed length sequences; however, before applying the training to the model, padding concepts are used to convert variable length series into fixed length series. For example:
+
+```
+Query : [P P P P P P “What” “About” “Placement” “ ?” ]
+// Assume that the fixed length is 10.P is Padding
+Response : [ SD “ It” “is” “Almost” “100%” END P P P P ]
+// SD means start decoding. END means response is over. P is Padding
+```
+
+Word embedding is another important aspect of deep learning based chatbots. It captures the context of the word in the sentence, the semantic and syntactic similarities, as well as the relationship with other words. Word2Vec is a famous method to construct word embedding. There are two main techniques in Word2Vec and both are based on neural networks — continuous bag-of-words (CBOW) and continuous skip-gram.
+
+The continuous bag-of-words method is generally used as a tool of feature generation. A sentence is first converted into a bag of words. After that, various measures are calculated to characterise the sentence.
+
+The frequency is the main measure of the CBOW. It provides better accuracy for frequent words. The skip-gram method achieves the reverse of the CBOW method. It tries to predict the source context words from the target. It works well for fewer training data sets.
+
+The logic for the chatbots that use deep learning is as follows:
+_Step 1:_ Build the corpus vocabulary.
+_Step 2:_ Map a unique numeric identifier with each word.
+_Step 3:_ Padding is done to the context words to keep their size fixed.
+_Step 4:_ Make a pair of target words and surround the context words.
+_Step 5:_ Build the deep learning architecture for the CBOW model. This involves the following sequence:
+
+ * Input as context words
+ * Initialised with random weights
+ * Arrange the word embeddings
+ * Create a dense softmax layer
+ * Predict target word
+ * Match with actual target word
+ * Compute the loss
+ * Perform back propagation to update embedding layer
+_Step 6:_ Train the model.
+_Step 7:_ Test the model.
+
+
+
+![Figure 2: Encoder layers][4]
+
+![Figure 3: Decoder functioning][5]
+
+**Deep learning tools for chatbots**
+TensorFlow is a great tool that uses deep learning. It uses linear regression to achieve effective conversation. We first need to develop a TensorFlow model by using JSON to recognise patterns. The next step is loading this framework and contextualising the data. TensorFlow makes chatbots realistic and very effective.
+
+Microsoft conversational AI tools are another important resource to design effective chatbots. These tools can be used to design, link, install and accomplish intelligent bots. The Microsoft Bot Builder software development kit (SDK) is ideal for the quick, free and easy development of chatbots with intelligence.
+
+Pytorch is an excellent open source library based on Python for applications like chatbots. The Optim module implements various algorithms based on neural networks, which are essential for the designing of efficient chatbots. It also provides the power of Tensors and so has the same functionalities as TensorFlow.
+Chatbots are essential if organisations aim to deal with customers without any human intervention. As discussed, deep learning based chatbots are the better option compared to the traditional variants, as the former handle abundant data efficiently. And generative models for building chatbots are more appropriate in the modern context.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/09/deep-learning-based-chatbots-are-smarter/
+
+作者:[Dharmendra Patel][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/dharmendra-patel/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Screenshot-from-2019-09-20-16-23-04.png?resize=696%2C472&ssl=1 (Screenshot from 2019-09-20 16-23-04)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Screenshot-from-2019-09-20-16-23-04.png?fit=706%2C479&ssl=1
+[3]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/1DL.png?resize=350%2C248&ssl=1
+[4]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/2DL.png?resize=350%2C72&ssl=1
+[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/3DL.png?resize=350%2C67&ssl=1
diff --git a/sources/tech/20190920 Euler-s Identity Really is a Miracle, Too.md b/sources/tech/20190920 Euler-s Identity Really is a Miracle, Too.md
new file mode 100644
index 0000000000..2340130aaa
--- /dev/null
+++ b/sources/tech/20190920 Euler-s Identity Really is a Miracle, Too.md
@@ -0,0 +1,138 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Euler's Identity Really is a Miracle, Too)
+[#]: via: (https://theartofmachinery.com/2019/09/20/euler_formula_miracle.html)
+[#]: author: (Simon Arneaud https://theartofmachinery.com)
+
+Euler's Identity Really is a Miracle, Too
+======
+
+[A post about the exponential function being a miracle][1] did the rounds recently, and [the Hacker News comment thread][2] brought up some debate about the miracle of Euler’s famous identity:
+
+[e^{\pi i} + 1 = 0]
+
+A while back I used to make a living teaching this stuff to high school students and university undergrads. Let me give my personal take on what’s so special about Euler’s identity.
+
+### Complex numbers are already a miracle
+
+Let’s start with complex numbers.
+
+The first introduction to complex numbers is usually something like, “We don’t know what (\sqrt{- 1}) is, so let’s try calling it (i).” As it turns out, it works. [It works unreasonably well.][3] To see what I mean, imagine we tried to do the same thing with (\frac{1}{0}). We’ll let’s just make up a value for it called, say, (v). Now consider this old teaser:
+
+[\begin{matrix} {x = 2} & {,y = 2} \ {\therefore x} & {= y} \ {\text{(multiply\ by\ y)}\therefore{xy}} & {= y^{2}} \ {\text{(subtract\ x\ squared)}\therefore{xy} - x^{2}} & {= y^{2} - x^{2}} \ {\text{(factorise)}\therefore x(y - x)} & {= (y + x)(y - x)} \ {\text{(divide\ common\ factor)}\therefore x} & {= y + x} \ {\text{(subtract\ x)}\therefore 0} & {= y} \ {\therefore 0} & {= 2} \ \end{matrix}]
+
+(If you’re not sure about the factorisation, try expanding it.) Obviously (0 \neq 2), so where does this “proof” go wrong? At the point it assumes dividing by the (y - x) factor obeys the normal rules of algebra — it doesn’t because (y - x = 0). We can’t just quietly add (v) to our number system and expect any of our existing maths to work with it. On the other hand, it turns out we _can_ (for example) write quadratic equations using (i) and treat them just like quadratic equations using real numbers (even solving them with the same old quadratic formula).
+
+It gets better. As anyone who’s studied complex numbers knows, after we take the plunge and say (\sqrt{- 1} = i), we don’t need to invent new numbers for, e.g., (\sqrt{i}) (it’s (\frac{\pm (1 + i)}{2})). In fact, instead of going “[turtles all the way down][4]” naming new numbers, we discover that complex numbers actually fill more gaps in the real number system. In many ways, complex numbers work better than real numbers.
+
+### (e^{\pi i}) isn’t just a made up thing
+
+I’ve met a few engineers who think that (e^{\pi i} = - 1) and its generalisation (e^{\theta i} = \cos\theta + i\sin\theta) are just notation made up by mathematicians for conveniently modelling things like rotations. I think that’s a shame because Euler’s formula is a lot more surprising than just notation.
+
+Let’s look at some ways to calculate (e^{x}) for real numbers. With a bit of calculus, you can figure out this Taylor series expansion around zero (also known as a Maclaurin series):
+
+[\begin{matrix} e^{x} & {= 1 + x + \frac{x^{2}}{2} + \frac{x^{3}}{2 \times 3} + \frac{x^{4}}{2 \times 3 \times 4} + \ldots} \ & {= \sum\limits_{n = 0}^{\infty}\frac{x^{n}}{n!}} \ \end{matrix}]
+
+A neat thing about this series is that it’s easy to compare with [the series for sin and cos][5]. If you assume they work just as well for complex numbers as real numbers, it only takes simple algebra to show (e^{\theta i} = \cos\theta + i\sin\theta), so it’s the classic textbook proof.
+
+Unfortunately, if you try evaluating the series on a computer, you hit numerical stability problems. Here’s another way to calculate (e^{x}):
+
+[e^{x} = \lim\limits_{n\rightarrow\infty}\left( 1 + \frac{x}{n} \right)^{n}]
+
+Or, translated naïvely into a stupid approximation algorithm in computer code [1][6]:
+
+```
+import std.algorithm;
+import std.range;
+
+double approxExp(double x, int n) pure
+{
+ return (1 + x / n).repeat(n).reduce!"a * b";
+}
+```
+
+Try plugging some numbers into this function, and you’ll see it calculates approximate values for (e^{x}) (though you might need `n` in the thousands to get good results).
+
+Now for a little leap of faith: That function only uses addition, division and multiplication, which can all be defined and implemented for complex numbers without assuming Euler’s formula. So what if you replace `double` with [a complex number type][7], assume everything’s okay mathematically, and try plugging in some numbers like (3.141593i)? Try it for yourself. Somehow everything starts cancelling out as (n) gets bigger and (x) gets closer to (\pi i), and you get something closer and closer to (- 1 + 0i).
+
+### (e) and (\pi) are miracles, too
+
+Because mathematicians prefer to write these constants symbolically, it’s easy to forget what they really are. Imagine the real number line stretching from minus infinity to infinity. There’s one notch slightly below 3, and another notch just above 3, and for deeper reasons, these two notches are special and keep turning up in seemingly unrelated places in maths.
+
+For example, take the series sum (\frac{1}{1} + \frac{1}{2} + \frac{1}{3} + \ldots). It doesn’t converge, but the sum to (n) terms (called the Harmonic function, or (H(n))) approximates (\log_{e}n). If you square the terms, the series converges, but this time (\pi) appears instead of (e): (\frac{1}{1^{2}} + \frac{1}{2^{2}} + \frac{1}{3^{2}} + \ldots = \frac{\pi^{2}}{6}).
+
+Here’s some more context for why the ubiquity of (e) and (\pi) is special. “The ratio of a circle’s circumference to its diameter” and “the square root of 2” are both numbers that can’t be written down as exact decimals, but at least we can describe them well enough to _define_ them exactly. Imagine some immortal creature tried listing all the numbers that can be mathematically defined. The list could start with all numbers that can be defined in under 10 characters, then all the numbers that can be defined in 10-20 characters, and so on. Obviously, that list never ends, but every definable number will appear on it somewhere, at some finite position. That’s what Georg Cantor called countably infinite, and he went on to prove ([using a simple diagonalisation argument][8]) that the set of real numbers is somehow infinitely bigger than that. That means most real numbers aren’t even definable.
+
+In other words, you could say maths with numbers is based on a sea of literally indescribable chaos. Thinking of it that way, it’s amazing that the five constants in Euler’s formula get us as far as they do.
+
+### Yes, the exponential function is a miracle
+
+I hinted that we can’t just assume that the Taylor series expansion for (e^{x}) works for complex numbers. Here are some examples that show what I mean. First, take the series expansion of (e^{- x^{2}}), the shape of the bell curve famous in statistics:
+
+[e^{- x^{2}} = 1 - x^{2} + \frac{x^{4}}{2} - \frac{x^{6}}{3!} + \frac{x^{8}}{4!} - \ldots]
+
+Of course, we can’t calculate the whole infinite sum, but we can approximate it by taking the first (n) terms. Here’s a plot of approximations taking successively more terms. We can see the bell shape after a few dozen terms, and the more terms we add, the better it gets:
+
+![][9]
+
+Okay, that’s a Taylor series doing what it’s supposed to. How about we try the same thing with another hump-shaped curve, (\frac{1}{1 + x^{2}})?
+
+![][10]
+
+This time it’s like there’s an invisible brick wall at (x = \pm 1). By adding more terms, we can get as close to perfect an approximation as we like, until (x) hits (\pm 1), then the approximation stops converging. The series just won’t work beyond that. But if Taylor expansion doesn’t always work for the whole real number line, can we take it for granted that the series for (e^{x}), (\sin x) and (\cos x) work for complex numbers?
+
+To get some more insight, we can colour in the places in the complex plane where the Taylor series for (\frac{1}{1 + x^{2}}) converges. It turns out we get a perfect circle of radius 1 centred at 0:
+
+![][11]
+
+There are two special points on the plane: (i) and (- i). At these points, (\frac{1}{1 + x^{2}}) turns into a (\frac{1}{0}) singularity, and the series expansion simply can’t work. It’s as if the convergence region expands out from 0 until it hits these singularity points and gets stuck. The funny thing is, these singularities in the complex plane limit how far the Taylor series can work, even when if we derive it using nothing but real analysis.
+
+It turns out that (e^{x}), (\sin x) and (\cos x) don’t have any problematic points in the complex plane, and that’s why we can easily use Taylor series to explore them beyond real numbers.
+
+This is yet another example of things making more sense when analysed with complex numbers, which only makes “real” numbers look like the odd ones out. Which raises another question: if [complex numbers are apparently fundamental to explaining the universe][12][2][13], why do we only experience real values? Obviously, the world would be a very different place if we could eat (i) slices of pizza, or if the flow of time had real and imaginary parts. But why the heck _not_?
+
+### Provably true things can still be surprising
+
+Of course, philosophy about the physical world aside, none of this is just luck. Maths is maths and there’s no alternative universe where things work differently. That’s because there are logical reasons why all this is true.
+
+But I don’t think that makes it less special. Arthur C. Clarke famously said that any sufficiently advanced technology is indistinguishable from magic, and I don’t think it should lose all magic as soon as someone, somewhere is smart enough to figure out how to make it work. Likewise, I don’t think mathematical theory becomes less special just because someone figures out a proof. On the contrary, it’s thanks to people wondering about these miraculous patterns that we have the calculus and complex analysis needed to understand how it all works.
+
+ 1. A less-stupid version uses squaring instead of naïve exponentiation: `return (1 + z / (1< “A bridge is a network connection that combines multiple network adapters.”
+
+One excellent example for a bridge is combining the physical NIC with a virtual interface, like the one created and used for KVM virtualization. [Leif Madsen’s blog][13] has an excellent article on how to achieve this in the CLI. This can also be accomplished in Cockpit with just a few clicks. The example below will accomplish the first part of Leif’s blog using the web UI. We’ll bridge the enp9s0 interface with the virbr0 virtual interface.
+
+Click the **Add Bridge** button to launch the settings box. Provide a name and select the interfaces you would like to bridge. To enable **Spanning Tree Protocol (STP)**, click the box to the right of the label. Click the **Apply** button to finalize the configuration.
+
+As is consistent with teaming and bonding, selecting the bridge from the main screen will display the details of the interface. As seen in the example below, the physical device takes control and the virtual interface will adopt that device’s IP address.
+
+Select the individual interface in the bridge’s detail screen for more options. And once again, click the **Delete** button to remove the bridge.
+
+![][14]
+
+#### Adding VLANs
+
+Cockpit allows admins to create VLANs, or virtual networks, using any of the interfaces on the system. Click the **Add VLAN** button and select an interface. Furthermore, in the **Parent** drop-down list, assign the VLAN ID, and if you like, give it a new name. By default the name will be the same as the parent followed by a dot and the ID. For example, interface _enp11s0_ with VLAN ID _9_ will result in _enp11s0.9_). Click **Apply** to save the settings and to return to the networking main screen. Click the VLAN interface for further configuration. As always, click the **Delete** button to remove the VLAN.
+
+![][15]
+
+As we can see, Cockpit can help admins with common network configurations when managing the system’s connectivity. In the next article, we’ll explore how Cockpit handles user management and peek into the add-on 389 Directory Servers.
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/managing-network-interfaces-and-firewalld-in-cockpit/
+
+作者:[Shaun Assam][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/sassam/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-networking-816x345.jpg
+[2]: https://fedoramagazine.org/performing-storage-management-tasks-in-cockpit/
+[3]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-network-main-screen-1024x687.png
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-add-zone.gif
+[5]: https://github.com/cockpit-project/cockpit/wiki/Feature:-Firewall
+[6]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-add_remove-services.gif
+[7]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-interfaces-overview-1.gif
+[8]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-interface-bonding.gif
+[9]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/networking_guide/sec-comparison_of_network_teaming_to_bonding
+[10]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/networking_guide/ch-configure_network_teaming
+[11]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-interface-teaming.gif
+[12]: https://fedoramagazine.org/build-network-bridge-fedora
+[13]: http://blog.leifmadsen.com/blog/2016/12/01/create-network-bridge-with-nmcli-for-libvirt/
+[14]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-interface-bridging.gif
+[15]: https://fedoramagazine.org/wp-content/uploads/2019/09/cockpit-interface-vlans.gif
diff --git a/sources/tech/20190921 Top Open Source Video Players for Linux.md b/sources/tech/20190921 Top Open Source Video Players for Linux.md
new file mode 100644
index 0000000000..df23a92668
--- /dev/null
+++ b/sources/tech/20190921 Top Open Source Video Players for Linux.md
@@ -0,0 +1,295 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Top Open Source Video Players for Linux)
+[#]: via: (https://itsfoss.com/video-players-linux/)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Top Open Source Video Players for Linux
+======
+
+_**Wondering which video player should you use on Linux? Here’s a list of top open source video players available for Linux distributions.**_
+
+You can watch Hulu, Prime Video and/or [Netflix on Linux][1]. You can also [download videos from YouTube][2] and watch them later or if you are in a country where you cannot get Netflix and other streaming services, you may have to rely on torrent services like [Popcorn Time in Linux][3].
+
+Watching movies/TV series or other video contents on computers is not an ‘ancient tradition’ yet. Usually, you go with the default video player that comes baked in with your Linux distribution (that could be anything).
+
+You won’t have an issue utilizing the default player – however, if you specifically want more open-source video player choices (or alternatives to the default one), you should keep reading.
+
+### Best Linux video players
+
+![][4]
+
+I have included the installation steps for Ubuntu but that shouldn’t make it the list of Ubuntu video players. These open source software should be available in any Linux distribution you are using.
+
+Installing the software
+
+Another note for Ubuntu users. You should have [universe repository enabled][5] in order to find and install these video players from the software center or by using command line. I have mentioned the commands but if you like, you can also install them from the Software Center.
+
+_Please keep in mind that the list is in no particular order of ranking._
+
+#### 1\. VLC Media Player
+
+![][6]
+
+Key Highlights:
+
+ * Built-in codecs
+ * Customization options
+ * Cross-platform
+ * Every video file format supported
+ * Extensions available for added functionalities
+
+
+
+[VLC Media Player][7] is unquestionably the most popular open source video player. Not just limited to Linux – but it’s a must-have video player for every platform (including Windows).
+
+It is a quite powerful video player capable of handling a variety of file formats and codecs. You can customize the look of it by using skins and enhance the functionalities with the help of certain extensions. Other features like [subtitle synchronization][8], audio/video filters, etc, exist as well.
+
+[VLC Media Player][7]
+
+#### How to install VLC?
+
+You can easily [install VLC in Ubuntu][9] from the Software Center or download it from the [official website][7].
+
+If you’re utilizing the terminal, you will have to separately install the components as per your requirements by following the [official resource][10]. To install the player, just type in:
+
+```
+sudo apt install vlc
+```
+
+#### 2\. MPlayer
+
+![][11]
+
+Key Highlights:
+
+ * Wide range of output drivers supported
+ * Major file formats supported
+ * Cross-platform
+ * Command-line based
+
+
+
+Yet another impressive open-source video player (technically, a video player engine). [MPlayer][12] may not offer you an intuitive user experience but it supports a wide range of output drivers and subtitle files.
+
+Unlike others, MPlayer does not offer a working GUI (it has one, but it doesn’t work as expected). So, you will have to utilize the terminal in order to play a video. Even though this isn’t a popular choice – it works and a couple of video players that I’ll be listing below are inspired (or based) from MPlayer but with a GUI.
+
+[MPlayer][12]
+
+#### How to install MPlayer?
+
+We already have an article on [installing MPlayer on Ubuntu and other Linux distros][13]. If you’re interested to install this, you should check it out.
+
+```
+sudo apt install mplayer mplayer-gui
+```
+
+#### 3\. SMPlayer
+
+![][14]
+
+Key Highlights:
+
+ * Supports all major video formats
+ * Built-in codecs
+ * Cross-platform (Windows & Linux)
+ * Play ad-free YouTube video
+ * Opensubtitles integration
+ * UI Customization available
+ * Based on MPlayer
+
+
+
+As mentioned, SMPlayer uses MPlayer as the playback engine. So, it supports a wide range of file formats. In addition to all the basic features, it also lets you play YouTube videos from within the video player (by getting rid of the annoying ads).
+
+If you want to know about SMPlayer a bit more – we have a separate article here: [SMPlayer in Linux][15].
+
+Similar to VLC, it also comes baked in with codecs, so you don’t have to worry about finding codecs and installing them to make it work unless there’s something specific you need.
+
+[SMPlayer][16]
+
+#### How to install SMPlayer?
+
+SMPlayer should be available in your Software Center. However, if you want to utilize the terminal, type in this:
+
+```
+sudo apt install smplayer
+```
+
+#### 4\. MPV Player
+
+![][17]
+
+Key Highlights:
+
+ * Minimalist GUI
+ * Video codecs built in
+ * High-quality video output by video scaling
+ * Cross-platform
+ * YouTube Videos supported via CLI
+
+
+
+If you are looking for a video player with a streamlined/minimal UI, this is for you. Similar to the above-mentioned video players, we also have a separate article on [MPV Player][18] with installation instructions (if you’re interested to know more about it).
+
+Keeping that aside, it offers what you would expect from a standard video player. You can even try it on your Windows/Mac systems.
+
+[MPV Player][19]
+
+#### How to install MPV Player?
+
+You will find it listed in the Software Center or Package Manager. In either case, you can download the required package for your distro from the [official download page][20].
+
+If you’re on Ubuntu, you can type in this in the terminal:
+
+```
+sudo apt install mpv
+```
+
+#### 5\. Dragon Player
+
+![][21]
+
+Key Highlights:
+
+ * Simple UI
+ * Tailored for KDE
+ * Supports playing CDs and DVDs
+
+
+
+This has been specifically tailored for KDE desktop users. It is a dead-simple video player with all the basic features needed. You shouldn’t expect anything fancy out of it – but it does support the major file formats.
+
+[Dragon Player][22]
+
+#### How to install Dragon Player?
+
+You will find it listed in the official repo. In either case, you can type in the following command to install it via terminal:
+
+```
+sudo apt install dragonplayer
+```
+
+#### 6\. GNOME Videos
+
+![Totem Video Player][23]
+
+Key Highlights:
+
+ * A simple video player for GNOME Desktop
+ * Plugins supported
+ * Ability to sort/access separate video channels
+
+
+
+The default video player for distros with GNOME desktop environment (previously known as Totem). It supports all the major file formats and also lets you take a snap while playing a video. Similar to some of the others, it is a very simple and useful video player. You can try it out if you want.
+
+[Gnome Videos][24]
+
+#### How to install Totem (GNOME Videos)?
+
+You can just type in “totem” to find the video player for GNOME listed in the software center. If not, you can also try utilizing the terminal with the following command:
+
+```
+sudo apt install totem
+```
+
+#### 7\. Deepin Movie
+
+![][25]
+
+If you are using [Deepin OS][26], you will find this as your default video player for Deepin Desktop Environment. It features all the basic functionalities that you would normally look in a video player. You can try compiling the source to install it if you aren’t using Deepin.
+
+[Deepin Movie][27]
+
+#### How to Install Deepin?
+
+You can find it in the Software Center. If you’d want to compile, the source code is available at [GitHub][28]. In either case, type in the following command in the terminal:
+
+```
+sudo apt install deepin-movie
+```
+
+#### 8\. Xine Multimedia Engine
+
+![][29]
+
+Key Higlights:
+
+ * Customization available
+ * Subtitles supported
+ * Major file formats supported
+ * Streaming playback support
+
+
+
+Xine is an interesting portable media player. You can either choose to utilize the GUI or call the xine library from other applications to make use of the features available.
+
+It supports a wide range of file formats. You can customize the skin of the GUI. It supports all kinds of subtitles (even from the DVDs). In addition to this, you can take a snapshot while playing the video, which comes handy.
+
+[Xine Multimedia][30]
+
+#### How to install Xine Multimedia?
+
+You probably won’t find this in your Software Center. So, you can try typing this in your terminal to get it installed:
+
+```
+sudo apt install xine-ui
+```
+
+In addition to that, you can also check for available binary packages on their [official website][31].
+
+**Wrapping Up**
+
+We would recommend you to try out these open source video players over anything else. In addition to all these, you can also try [Miro Player][32] which is no more being actively maintained but works – so you can give it a try, if nothing else works for you.
+
+However, if you think we missed one of your favorite Linux video player that deserves a mentioned, let us know about it in the comments down below!
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/video-players-linux/
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/watch-netflix-in-ubuntu-linux/
+[2]: https://itsfoss.com/download-youtube-linux/
+[3]: https://itsfoss.com/popcorn-time-ubuntu-linux/
+[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/Video-Players-for-Linux.png?ssl=1
+[5]: https://itsfoss.com/ubuntu-repositories/
+[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/vlc-media-player.jpg?ssl=1
+[7]: https://www.videolan.org/vlc/
+[8]: https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/
+[9]: https://itsfoss.com/install-latest-vlc/
+[10]: https://wiki.videolan.org/Debian/#Debian
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2015/10/mplayer-video.jpg?ssl=1
+[12]: http://www.mplayerhq.hu/design7/news.html
+[13]: https://itsfoss.com/mplayer/
+[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/SMPlayer-coco.jpg?ssl=1
+[15]: https://itsfoss.com/smplayer/
+[16]: https://www.smplayer.info/en/info
+[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/08/mpv-player-interface.png?ssl=1
+[18]: https://itsfoss.com/mpv-video-player/
+[19]: https://mpv.io/
+[20]: https://mpv.io/installation/
+[21]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/dragon-player.jpg?ssl=1
+[22]: https://kde.org/applications/multimedia/org.kde.dragonplayer
+[23]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/totem-video-player.png?ssl=1
+[24]: https://wiki.gnome.org/Apps/Videos
+[25]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/deepin-movie.jpg?ssl=1
+[26]: https://www.deepin.org/en/
+[27]: https://www.deepin.org/en/original/deepin-movie/
+[28]: https://github.com/linuxdeepin/deepin-movie-reborn
+[29]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/xine-multilmedia.jpg?ssl=1
+[30]: https://www.xine-project.org/home
+[31]: https://www.xine-project.org/releases
+[32]: http://www.getmiro.com/
diff --git a/sources/tech/20190924 A human approach to reskilling in the age of AI.md b/sources/tech/20190924 A human approach to reskilling in the age of AI.md
new file mode 100644
index 0000000000..8eaeb099f1
--- /dev/null
+++ b/sources/tech/20190924 A human approach to reskilling in the age of AI.md
@@ -0,0 +1,121 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (A human approach to reskilling in the age of AI)
+[#]: via: (https://opensource.com/open-organization/19/9/claiming-human-age-of-AI)
+[#]: author: (Jen Kelchner https://opensource.com/users/jenkelchnerhttps://opensource.com/users/jenkelchner)
+
+A human approach to reskilling in the age of AI
+======
+Investing in learning agility and core capabilities is as important for
+the individual worker as it is for the decision-making executive.
+Thinking openly can get us there.
+![Person on top of a mountain, arm raise][1]
+
+[The age of AI is upon us][2]. Emerging technologies give humans some relief from routine tasks and allow us to get back to the creative, adaptable creatures many of us prefer being.
+
+So a shift to developing _human_ skills in the workplace should be a critical focus for organizations. In this part of my series on learning agility, we'll take a look at some reasons for a sense of urgency over reskilling our workforce and reconnecting to our humanness.
+
+### The clock is ticking
+
+If you don't believe AI conversations affect you, then I suggest reviewing this 2018 McKinsey Report on [reskilling in the age of automation][3], which provides some interesting statistics. Here are a few applicable nuggets:
+
+ * 62% of executives believe they need to **retrain or replace more than a quarter** of their workforce **by 2023** due to advancing digitization
+ * The **US and Europe face a larger threat** on reskilling than the rest of the world
+ * 70% of execs in companies with more than $500 million in annual revenue state this **will affect more than 25%** of their employees
+
+
+
+No matter where you fall on an organizational chart, automation (and digitalization more generally) is an important topic for you—because the need for reskilling that it introduces will most likely affect you.
+
+But what does this reskilling conversation have to do with core capability development?
+
+To answer _that_ question, let's take a look at a few statistics curated in a [2019 LinkedIn Global Talent Report][4].
+
+When surveyed on the topic of ~~soft skills~~ core human capabilities, global companies had this to say:
+
+ * **92%** agree that they matter as much or more than "hard skills"
+ * **80%** said these skills are increasingly important to company success
+ * Only **41%** have a formal process to identify these skills
+
+
+
+Before panicking at the thought of what these stats could mean to you or your company, let's actually dig into these core capabilities that you already have but may need to brush up on and strengthen.
+
+### Core human capabilities
+
+_What the heck does all this have to do with learning agility_, you may be asking, _and why should I care_?
+
+What many call "soft skills" are really human skills—core capabilities anyone can cultivate.
+
+I recommend catching up with this introduction to [learning agility][5]. There, I define learning agility as "the capacity for adapting to situations and applying knowledge from prior experience—even when you don't know what to do [...], a willingness to learn from all your experiences and then apply that knowledge to tackle new challenges in new situations." In that piece, we also discussed reasons why characteristics associated with learning agility are among the most sought after skills on the planet today.
+
+Too often, [these skills go by the name "soft skills."][6] Explanations usually go something like this: "hard skills" are more like engineering- or science-based skills and, well, "non-peopley" related things. But what many call "soft skills" are really _human skills_—core capabilities anyone can cultivate. As leaders, we need to continue to change the narrative concerning these core capabilities (for many reasons, not least of which is the fact that the distinction frequently re-entrenches a [gender bias][7], as if skills somehow fit on a spectrum from "soft to hard.")
+
+For two decades, I've heard decision makers choose not to invest in people or leadership development because "there isn't money in soft skills" and "there's no way to track the ROI" on developing them. Fortunately, we're moving out of this tragic mindset, as leaders recognize how digital transformation has reshaped how we connect, build community, and organize for work. Perhaps this has something to do with increasingly pervasive reports (and blowups) we see across ecosystems regarding [toxic work culture][8] or broken leadership styles. Top consulting firms doing [global talent surveys][9] continue to identify crucial breakdowns in talent development pointing right back to our topic at hand.
+
+For two decades, I've heard decision makers choose not to invest in people or leadership development because "there isn't money in soft skills" and "there's no way to track the ROI" on developing them. Fortunately, we're moving out of this tragic mindset.
+
+We all have access to these capabilities, but often we've lacked examples to learn by or have had little training on how to put them to work. Let's look at the list of the most-needed human skills right now, shall we?
+
+Topping the leaderboard moving into 2020:
+
+ * Communication
+ * Relationship building
+ * Emotional intelligence (EQ)
+ * Critical thinking and problem-solving (CQ)
+ * [Learning agility][5] and adaptability quotient (AQ)
+ * Creativity
+
+
+
+If we were to take the items on this list and generalize them into three categories of importance for the future of work, it would look like:
+
+ 1. Emotional Quotient
+ 2. Adaptability Quotient
+ 3. Creativity Quotient
+
+
+
+Some of us have been conditioned to think we're "not creative" because the term "creativity" refers only to things like art, design, or music. However, in this case, "creativity" means the ability to combine ideas, things, techniques, or approaches in new ways—and it's [crucial to innovation][10]. Solving problems in new ways is the [most important skill][11] companies look for when trying to solve their skill-gap problems. (_Spoiler alert: This is learning agility!_) Obviously, our generalized list ignores many nuances (not to mention additional skills we might develop in our people and organizations as contexts shift); however, this is a really great place to start.
+
+### Where do we go from here?
+
+In order to accommodate the demands of tomorrow's organizations, we must:
+
+ * look at retraining and reskilling from early education models to organizational talent development programs, and
+ * adjust our organizational culture and internal frameworks to support being human and innovative.
+
+
+
+This means exploring [open principles][12], agile methodologies, collaborative work models, and continuous states of learning across all aspects of your organization. Digital transformation and reskilling on core capabilities leaves no one—and _no department_—behind.
+
+In our next installment, we'll begin digging into these core capabilities and examine the five dimensions of learning agility with simple ways to apply them.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/open-organization/19/9/claiming-human-age-of-AI
+
+作者:[Jen Kelchner][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jenkelchnerhttps://opensource.com/users/jenkelchner
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/developer_mountain_cloud_top_strong_win.jpg?itok=axK3EX-q (Person on top of a mountain, arm raise)
+[2]: https://appinventiv.com/blog/ai-technology-trends/
+[3]: https://www.mckinsey.com/featured-insights/future-of-work/retraining-and-reskilling-workers-in-the-age-of-automation
+[4]: https://app.box.com/s/c5scskbsz9q6lb0hqb7euqeb4fr8m0bl/file/388525098383
+[5]: https://opensource.com/open-organization/19/8/introduction-learning-agility
+[6]: https://enterprisersproject.com/article/2019/9/6-soft-skills-for-ai-age
+[7]: https://enterprisersproject.com/article/2019/8/why-soft-skills-core-to-IT
+[8]: https://ldr21.com/how-ubers-workplace-crisis-can-save-your-organization-money/
+[9]: https://www.inc.com/scott-mautz/new-deloitte-study-of-10455-millennials-says-employers-are-failing-to-help-young-people-develop-4-crucial-skills.html
+[10]: https://velites.nl/en/2018/11/12/creative-quotient/
+[11]: https://learning.linkedin.com/blog/top-skills/why-creativity-is-the-most-important-skill-in-the-world
+[12]: https://opensource.com/open-organization/resources/open-org-definition
diff --git a/sources/tech/20190924 An advanced look at Python interfaces using zope.interface.md b/sources/tech/20190924 An advanced look at Python interfaces using zope.interface.md
new file mode 100644
index 0000000000..16b4780710
--- /dev/null
+++ b/sources/tech/20190924 An advanced look at Python interfaces using zope.interface.md
@@ -0,0 +1,132 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (An advanced look at Python interfaces using zope.interface)
+[#]: via: (https://opensource.com/article/19/9/zopeinterface-python-package)
+[#]: author: (Moshe Zadka https://opensource.com/users/moshezhttps://opensource.com/users/lauren-pritchetthttps://opensource.com/users/sethhttps://opensource.com/users/drmjg)
+
+An advanced look at Python interfaces using zope.interface
+======
+Zope.interface helps declare what interfaces exist, which objects
+provide them, and how to query for that information.
+![Snake charmer cartoon with a yellow snake and a blue snake][1]
+
+The **zope.interface** library is a way to overcome ambiguity in Python interface design. Let's take a look at it.
+
+### Implicit interfaces are not zen
+
+The [Zen of Python][2] is loose enough and contradicts itself enough that you can prove anything from it. Let's meditate upon one of its most famous principles: "Explicit is better than implicit."
+
+One thing that traditionally has been implicit in Python is the expected interface. Functions have been documented to expect a "file-like object" or a "sequence." But what is a file-like object? Does it support **.writelines**? What about **.seek**? What is a "sequence"? Does it support step-slicing, such as **a[1:10:2]**?
+
+Originally, Python's answer was the so-called "duck-typing," taken from the phrase "if it walks like a duck and quacks like a duck, it's probably a duck." In other words, "try it and see," which is possibly the most implicit you could possibly get.
+
+In order to make those things explicit, you need a way to express expected interfaces. One of the first big systems written in Python was the [Zope][3] web framework, and it needed those things desperately to make it obvious what rendering code, for example, expected from a "user-like object."
+
+Enter **zope.interface**, which is developed by Zope but published as a separate Python package. **Zope.interface** helps declare what interfaces exist, which objects provide them, and how to query for that information.
+
+Imagine writing a simple 2D game that needs various things to support a "sprite" interface; e.g., indicate a bounding box, but also indicate when the object intersects with a box. Unlike some other languages, in Python, attribute access as part of the public interface is a common practice, instead of implementing getters and setters. The bounding box should be an attribute, not a method.
+
+A method that renders the list of sprites might look like:
+
+
+```
+def render_sprites(render_surface, sprites):
+ """
+ sprites should be a list of objects complying with the Sprite interface:
+ * An attribute "bounding_box", containing the bounding box.
+ * A method called "intersects", that accepts a box and returns
+ True or False
+ """
+ pass # some code that would actually render
+```
+
+The game will have many functions that deal with sprites. In each of them, you would have to specify the expected contract in a docstring.
+
+Additionally, some functions might expect a more sophisticated sprite object, maybe one that has a Z-order. We would have to keep track of which methods expect a Sprite object, and which expect a SpriteWithZ object.
+
+Wouldn't it be nice to be able to make what a sprite is explicit and obvious so that methods could declare "I need a sprite" and have that interface strictly defined? Enter **zope.interface**.
+
+
+```
+from zope import interface
+
+class ISprite(interface.Interface):
+
+ bounding_box = interface.Attribute(
+ "The bounding box"
+ )
+
+ def intersects(box):
+ "Does this intersect with a box"
+```
+
+This code looks a bit strange at first glance. The methods do not include a **self**, which is a common practice, and it has an **Attribute** thing. This is the way to declare interfaces in **zope.interface**. It looks strange because most people are not used to strictly declaring interfaces.
+
+The reason for this practice is that the interface shows how the method will be called, not how it is defined. Because interfaces are not superclasses, they can be used to declare data attributes.
+
+One possible implementation of the interface can be with a circular sprite:
+
+
+```
+@implementer(ISprite)
+@attr.s(auto_attribs=True)
+class CircleSprite:
+ x: float
+ y: float
+ radius: float
+
+ @property
+ def bounding_box(self):
+ return (
+ self.x - self.radius,
+ self.y - self.radius,
+ self.x + self.radius,
+ self.y + self.radius,
+ )
+
+ def intersects(self, box):
+ # A box intersects a circle if and only if
+ # at least one corner is inside the circle.
+ top_left, bottom_right = box[:2], box[2:]
+ for choose_x_from (top_left, bottom_right):
+ for choose_y_from (top_left, bottom_right):
+ x = choose_x_from[0]
+ y = choose_y_from[1]
+ if (((x - self.x) ** 2 + (y - self.y) ** 2) <=
+ self.radius ** 2):
+ return True
+ return False
+```
+
+This _explicitly_ declares that the **CircleSprite** class implements the interface. It even enables us to verify that the class implements it properly:
+
+
+```
+from zope.interface import verify
+
+def test_implementation():
+ sprite = CircleSprite(x=0, y=0, radius=1)
+ verify.verifyObject(ISprite, sprite)
+```
+
+This is something that can be run by **pytest**, **nose**, or another test runner, and it will verify that the sprite created complies with the interface. The test is often partial: it will not test anything only mentioned in the documentation, and it will not even test that the methods can be called without exceptions! However, it does check that the right methods and attributes exist. This is a nice addition to the unit test suite and—at a minimum—prevents simple misspellings from passing the tests.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/zopeinterface-python-package
+
+作者:[Moshe Zadka][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/moshezhttps://opensource.com/users/lauren-pritchetthttps://opensource.com/users/sethhttps://opensource.com/users/drmjg
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/getting_started_with_python.png?itok=MFEKm3gl (Snake charmer cartoon with a yellow snake and a blue snake)
+[2]: https://en.wikipedia.org/wiki/Zen_of_Python
+[3]: http://zope.org
diff --git a/sources/tech/20190924 CodeReady Containers- complex solutions on OpenShift - Fedora.md b/sources/tech/20190924 CodeReady Containers- complex solutions on OpenShift - Fedora.md
new file mode 100644
index 0000000000..f3522e9717
--- /dev/null
+++ b/sources/tech/20190924 CodeReady Containers- complex solutions on OpenShift - Fedora.md
@@ -0,0 +1,165 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (CodeReady Containers: complex solutions on OpenShift + Fedora)
+[#]: via: (https://fedoramagazine.org/codeready-containers-complex-solutions-on-openshift-fedora/)
+[#]: author: (Marc Chisinevski https://fedoramagazine.org/author/mchisine/)
+
+CodeReady Containers: complex solutions on OpenShift + Fedora
+======
+
+![][1]
+
+Want to experiment with (complex) solutions on [OpenShift][2] 4.1+? CodeReady Containers (CRC) on a physical Fedora server is a great choice. It lets you:
+
+ * Configure the RAM available to CRC / OpenShift (this is key as we’ll deploy Machine Learning, Change Data Capture, Process Automation and other solutions with significant memory requirements)
+ * Avoid installing anything on your laptop
+ * Standardize (on Fedora 30) so that you get the same results every time
+
+
+
+Start by installing CRC and Ansible Agnostic Deployer (AgnosticD) on a Fedora 30 physical server. Then, you’ll use AgnosticD to deploy Open Data Hub on the OpenShift 4.1 environment created by CRC. Let’s get started!
+
+### Set up CodeReady Containers
+
+```
+$ dnf config-manager --set-enabled fedora
+$ su -c 'dnf -y install git wget tar qemu-kvm libvirt NetworkManager jq libselinux-python'
+$ sudo systemctl enable --now libvirtd
+```
+
+Let’s also add a user.
+
+```
+$ sudo adduser demouser
+$ sudo passwd demouser
+$ sudo usermod -aG wheel demouser
+```
+
+Download and extract CodeReady Containers:
+
+```
+$ su demouser
+$ cd /home/demouser
+$ wget https://mirror.openshift.com/pub/openshift-v4/clients/crc/1.0.0-beta.3/crc-linux-amd64.tar.xz
+$ tar -xvf crc-linux-amd64.tar.xz
+$ cd crc-linux-1.0.0-beta.3-amd64/
+$ sudo cp ./crc /usr/bin
+```
+
+Set the memory available to CRC according to what you have on your physical server. For example, on a physical server with around 100GB you can allocate 80G to CRC as follows:
+
+```
+$ crc config set memory 81920
+$ crc setup
+```
+
+You’ll need your pull secret from .
+
+```
+$ crc start
+```
+
+That’s it — you can now login to your OpenShift environment:
+
+```
+eval $(crc oc-env) && oc login -u kubeadmin -p https://api.crc.testing:6443
+```
+
+### Set up Ansible Agnostic Deployer
+
+[github.com/redhat-cop/agnosticd][3] is a fully automated two-phase deployer. Let’s deploy it!
+
+```
+$ su demouser
+$ cd /home/demouser
+$ git clone https://github.com/redhat-cop/agnosticd.git
+$ cd agnosticd/ansible
+$ python -m pip install --upgrade --trusted-host files.pythonhosted.org -r requirements.txt
+$ python3 -m pip install --upgrade --trusted-host files.pythonhosted.org -r requirements.txt
+$ pip3 install kubernetes
+$ pip3 install openshift
+$ pip install kubernetes
+$ pip install openshift
+```
+
+### Set up Open Data Hub on Code Ready Containers
+
+[Open Data Hub][4] is a machine-learning-as-a-service platform built on OpenShift and Kafka/Strimzi. It integrates a collection of open source projects.
+
+First, create an Ansible inventory file with the following content.
+
+```
+$ cat inventory
+$ 127.0.0.1 ansible_connection=local
+```
+
+Set up the WORKLOAD environment variable so that Ansible Agnostic Deployer knows that we want to deploy Open Data Hub.
+
+```
+$ export WORKLOAD="ocp4-workload-open-data-hub"
+$ sudo cp /usr/local/bin/ansible-playbook /usr/bin/ansible-playbook
+```
+
+We are only deploying one Open Data Hub project, so set _user_count_ to 1. You can set up workshops for many students by setting _user_count_.
+
+An OpenShift project (with Open Data Hub in our case) will be created for each student.
+
+```
+$ eval $(crc oc-env) && oc login -u kubeadmin -p https://api.crc.testing:6443
+$ ansible-playbook -i inventory ./configs/ocp-workloads/ocp-workload.yml -e"ocp_workload=${WORKLOAD}" -e"ACTION=create" -e"user_count=1" -e"ocp_username=kubeadmin" -e"ansible_become_pass=" -e"silent=False"
+$ oc project open-data-hub-user1
+$ oc get route
+NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
+jupyterhub jupyterhub-open-data-hub-user1.apps-crc.testing jupyterhub 8080-tcp edge/Redirect None
+```
+
+On your laptop, add _jupyterhub-open-data-hub-user1.apps-crc.testing_ to your _/etc/hosts_ file. For example:
+
+```
+127.0.0.1 localhost fedora30 console-openshift-console.apps-crc.testing oauth-openshift.apps-crc.testing mapit-app-management.apps-crc.testing mapit-spring-pipeline-demo.apps-crc.testing jupyterhub-open-data-hub-user1.apps-crc.testing jupyterhub-open-data-hub-user1.apps-crc.testing
+```
+
+On your laptop:
+
+```
+$ sudo ssh marc@fedora30 -L 443:jupyterhub-open-data-hub-user1.apps-crc.testing:443
+```
+
+You can now browse to [https://jupyterhub-open-data-hub-user1.apps-crc.testing][5].
+
+Now that we have Open Data Hub ready, you could deploy something interesting on it. For example, you could deploy IBM’s Qiskit open source framework for quantum computing. For more information, refer to Video no. 9 at [this YouTube playlist][6], and the [Github repo here][7].
+
+You could also deploy plenty of other useful tools for Process Automation, Change Data Capture, Camel Integration, and 3scale API Management. You don’t have to wait for articles on these, though. Step-by-step short videos are already [available on YouTube][6].
+
+The corresponding step-by-step instructions are [also on YouTube][6]. You can also follow along with this article using the [GitHub repo][8].
+
+* * *
+
+_Photo by _[_Marta Markes_][9]_ on _[_Unsplash_][10]_._
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/codeready-containers-complex-solutions-on-openshift-fedora/
+
+作者:[Marc Chisinevski][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/mchisine/
+[b]: https://github.com/lujun9972
+[1]: https://fedoramagazine.org/wp-content/uploads/2019/09/codeready-containers-816x345.jpg
+[2]: https://fedoramagazine.org/run-openshift-locally-minishift/
+[3]: https://github.com/redhat-cop/agnosticd
+[4]: https://opendatahub.io/
+[5]: https://jupyterhub-open-data-hub-user1.apps-crc.testing/
+[6]: https://www.youtube.com/playlist?list=PLg1pvyPzFye2UtQjZTSjoXhFdqkGK6exw
+[7]: https://github.com/marcredhat/crcdemos/blob/master/IBMQuantum-qiskit
+[8]: https://github.com/marcredhat/crcdemos/tree/master/fedora
+[9]: https://unsplash.com/@vnevremeni?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
+[10]: https://unsplash.com/s/photos/container?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
diff --git a/sources/tech/20190924 Integrate online documents editors, into a Python web app using ONLYOFFICE.md b/sources/tech/20190924 Integrate online documents editors, into a Python web app using ONLYOFFICE.md
new file mode 100644
index 0000000000..35c101ed2c
--- /dev/null
+++ b/sources/tech/20190924 Integrate online documents editors, into a Python web app using ONLYOFFICE.md
@@ -0,0 +1,381 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Integrate online documents editors, into a Python web app using ONLYOFFICE)
+[#]: via: (https://opensourceforu.com/2019/09/integrate-online-documents-editors-into-a-python-web-app-using-onlyoffice/)
+[#]: author: (Aashima Sharma https://opensourceforu.com/author/aashima-sharma/)
+
+Integrate online documents editors, into a Python web app using ONLYOFFICE
+======
+
+[![][1]][2]
+
+_[ONLYOFFICE][3] is an open-source collaborative office suite distributed under the terms of GNU AGPL v.3 license. It contains three editors for text documents, spreadsheets, and presentations and features the following:_
+
+ * Viewing, editing and co-editing docx, .xlsx, pptx files. OOXML as a core format ensures high compatibility with Microsoft Word, Excel and PowerPoint files.
+ * Editing other popular formats (.odt, .rtf, .txt, .html, .ods., .csv, .odp) with inner conversion to OOXML.
+ * Familiar tabbed interface.
+ * Collaboration tools: two co-editing modes (fast and strict), track changes, comments and integrated chat.
+ * Flexible access rights management: full access, read only, review, form filling and comment.
+ * Building your own add-ons using the API.
+ * 250 languages available and hieroglyphic alphabets.
+
+
+
+API allowing the developers integrate ONLYOFFICE editors into their own web sites and apps written in any programming language and setup and manage the editors.
+
+To integrate ONLYOFFICE editors, we will need an integration app connecting the editors (ONLYOFFICE Document Server) and your service. To use editors within your interface, it should grant to ONLYOFFICE the following permissions :
+
+ * Adding and executing custom code.
+ * Anonymous access for downloading and saving files. It means that the editors only communicate with your service on the server side without involving any user authorization data from the client side (browser cookies).
+ * Adding new buttons to UI (for example, “Open in ONLYOFFICE”, “Edit in ONLYOFFICE”).
+ * Оpening a new page where ONLYOFFICE can execute the script to add an editor.
+ * Ability to specify Document Server connection settings.
+
+
+
+There are several cases of successful integration with popular collaboration solutions such as Nextcloud, ownCloud, Alfresco, Confluence and SharePoint, via official ready-to-use connectors offered by ONLYOFFICE.
+
+One of the most actual integration cases is the integration of ONLYOFFICE editors with its open-source collaboration platform written in C#. This platform features document and project management, CRM, email aggregator, calendar, user database, blogs, forums, polls, wiki, and instant messenger.
+
+Integrating online editors with CRM and Projects modules, you can:
+
+ * Attach documents to CRM opportunities and cases, or to project tasks and discussions, or even create a separate folder with documents, spreadsheets, and presentations related to the project.
+ * Create new docs, sheets, and presentations right in CRM or in the Project module.
+ * Open and edit attached documents, or download and delete them.
+ * Import contacts to your CRM in bulk from a CSV file as well as export the customer database as a CSV file.
+
+
+
+In the Mail module, you can attach files stored in the Documents module or insert a link to the needed document into the message body. When ONLYOFFICE users receive a message with an attached document, they are able to: download the attachment, view the file in the browser, open the file for editing or save it to the Documents module. As mentioned above, if the format differs from OOXML, the file will be automatically converted to .docx/.xlsx/.pptx and its copy will be saved in the original format as well.
+
+In this article, you will see the integration process of ONLYOFFICE into the Document Management System written in Python, one of the most popular programming languages. The following steps will show you how to create all the necessary elements to make possible work and collaboration on documents within DMS interface: viewing, editing, co-editing, saving files and users access management and may serve as an example of integration into your Python app.
+
+**1\. What you will need**
+
+Let’s start off by creating key components of the integration process: [_ONLYOFFICE Document Server_][4] and DMS written in Python.
+
+1.1 To install ONLYOFFICE Document Server you can choose from multiple installation options: compile the source code available on GitHub, use .deb or .rpm packages or the Docker image.
+We recommend installing Document Server and all the necessary dependencies with only one command using the Docker image. Please note, that choosing this method, you need the latest Docker version installed.
+
+```
+docker run -itd -p 80:80 onlyoffice/documentserver-de
+```
+
+1.2 We need to develop DMS in Python. If you have one already, please, check if it meets the following conditions:
+
+ * Has a list of files you need to open for viewing/editing
+ * Allows downloading files
+
+
+
+For the app, we will use a Bottle framework. We will install it in the working directory using the following command:
+
+```
+pip install bottle
+```
+
+Then we create the app’s code * main.py* and the template _index.tpl_ .
+We add the following code into this * main.py* file:
+
+```
+from bottle import route, run, template, get, static_file # connecting the framework and the necessary components
+@route('/') # setting up routing for requests for /
+def index():
+return template('index.tpl') # showing template in response to request
+run(host="localhost", port=8080) # running the application on port 8080
+```
+
+Once we run the app, an empty page will be rendered on .
+
+In order, the Document Server to be able to create new docs, add default files and form a list of their names in the template, we should create a folder _files_ , and put 3 files (.docx, .xlsx and .pptx) in there.
+
+To read these files’ names, we use the _listdir_ component.
+
+```
+from os import listdir
+```
+
+Now let’s create a variable for all the file names from the files folder:
+
+```
+sample_files = [f for f in listdir('files')]
+```
+
+To use this variable in the template, we need to pass it through the _template_ method:
+
+```
+def index():
+return template('index.tpl', sample_files=sample_files)
+
+Here’s this variable in the template:
+%for file in sample_files:
+
+{{file}}
+
+% end
+```
+
+We restart the application to see the list of filenames on the page.
+Here’s the method to make these files available for all the app users:
+
+```
+@get("/files/")
+def show_sample_files(filepath):
+return static_file(filepath, root="files")
+```
+
+**2\. How to view docs in ONLYOFFICE within the Python App**
+Once all the components are ready, let’s add functions to make editors operational within the app interface.
+
+The first option enables users to open and view docs. Connect document editors API in the template:
+
+```
+
+```
+
+_editor_url_ is a link to document editors.
+
+A button to open each file for viewing:
+
+```
+
+```
+
+Now we need to add a div with _id_ , in which the document editor will be opened:
+
+```
+
+```
+
+To open the editor, we have to call a function:
+
+```
+
+```
+
+There are two arguments for the DocEditor function: id of the element where the editors will be opened and a JSON with the editors’ settings.
+In this example, the following mandatory parameters are used:
+
+ * _documentType_ is identified by its format (.docx, .xlsx, .pptx for texts, spreadsheets and presentations accordingly)
+ * _document.url_ is the link to the file you are going to open.
+ * _editorConfig.mode_.
+
+
+
+We can also add _title_ that will be displayed in the editors.
+
+So, now we have everything to view docs in our Python app.
+
+**3\. How to edit docs in ONLYOFFICE within the Python App**
+First of all, add the “Edit” button:
+
+```
+
+```
+
+Then create a new function that will open files for editing. It is similar to the View function.
+Now we have 3 functions:
+
+```
+
+```
+
+_destroyEditor_ is called to close an open editor.
+As you might notice, the _editorConfig_ parameter is absent from the _edit()_ function, because it has by default the value * {“mode”: “edit”}.*
+
+Now we have everything to open docs for co-editing in your Python app.
+
+**4\. How to co-edit docs in ONLYOFFICE within the Python App**
+Co-editing is implemented by using the same document.key for the same document in the editors’ settings. Without this key, the editors will create the editing session each time you open the file.
+
+Set unique keys for each doc to make users connect to the same editing session for co-editing. The format of the key should be the following: _filename + “_key”_. The next step is to add it to all of the configs where document is present.
+
+```
+document: {
+url: "host_url" + '/' + filepath,
+title: filename,
+key: filename + '_key'
+},
+```
+
+**5\. How to save docs in ONLYOFFICE within the Python App**
+Every time we change and save the file, ONLYOFFICE stores all its versions. Let’s see closely how it works. After we close the editor, Document Server builds the file version to be saved and sends the request to callbackUrl address. This request contains document.key and the link to the just built file.
+document.key is used to find the old version of the file and replace it with the new one. As we do not have any database here, we just send the filename using callbackUrl.
+Specify _callbackUrl_ parameter in the setting in _editorConfig.callbackUrl_ and add it to the _edit()method_:
+
+```
+function edit(filename) {
+const filepath = 'files/' + filename;
+if (editor) {
+editor.destroyEditor()
+}
+editor = new DocsAPI.DocEditor("editor",
+{
+documentType: get_file_type(filepath),
+document: {
+url: "host_url" + '/' + filepath,
+title: filename,
+key: filename + '_key'
+}
+,
+editorConfig: {
+mode: 'edit',
+callbackUrl: "host_url" + '/callback' + '&filename=' + filename // add file name as a request parameter
+}
+});
+}
+```
+
+Write a method that will save file after getting the POST request to* /callback* address:
+
+```
+@post("/callback") # processing post requests for /callback
+def callback():
+if request.json['status'] == 2:
+file = requests.get(request.json['url']).content
+with open('files/' + request.query['filename'], 'wb') as f:
+f.write(file)
+return "{\"error\":0}"
+```
+
+* # status 2* is the built file.
+
+When we close the editor, the new version of the file will be saved to storage.
+
+**6\. How to manage users in ONLYOFFICE within the Python App**
+If there are users in your app, and you need to see who exactly is editing a doc, write their identifiers (id and name) in the editors’ configuration.
+Add the ability to select a user in the interface:
+
+```
+
+```
+
+If you add the call of the function *pick_user()*at the beginning of the tag _<script>_, it will initialize, in the function itself, the variables responsible for the id and the user name.
+
+```
+function pick_user() {
+const user_selector = document.getElementById("user_selector");
+this.current_user_name = user_selector.options[user_selector.selectedIndex].text;
+this.current_user_id = user_selector.options[user_selector.selectedIndex].value;
+}
+```
+
+Make use of _editorConfig.user.id_ and _editorConfig.user.name_ to configure user’s settings. Add these parameters to the editors’ configuration in the file editing function.
+
+```
+function edit(filename) {
+const filepath = 'files/' + filename;
+if (editor) {
+editor.destroyEditor()
+}
+editor = new DocsAPI.DocEditor("editor",
+{
+documentType: get_file_type(filepath),
+document: {
+url: "host_url" + '/' + filepath,
+title: filename
+},
+editorConfig: {
+mode: 'edit',
+callbackUrl: "host_url" + '/callback' + '?filename=' + filename,
+user: {
+id: this.current_user_id,
+name: this.current_user_name
+}
+}
+});
+}
+```
+
+Using this approach, you can integrate ONLYOFFICE editors into your app written in Python and get all the necessary tools for working and collaborating on docs. For more integration examples (Java, Node.js, PHP, Ruby), please, refer to the official [_API documentation_][5].
+
+**By: Maria Pashkina**
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/09/integrate-online-documents-editors-into-a-python-web-app-using-onlyoffice/
+
+作者:[Aashima Sharma][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/aashima-sharma/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2016/09/Typist-composing-text-in-laptop.jpg?resize=696%2C420&ssl=1 (Typist composing text in laptop)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2016/09/Typist-composing-text-in-laptop.jpg?fit=900%2C543&ssl=1
+[3]: https://www.onlyoffice.com/en/
+[4]: https://www.onlyoffice.com/en/developer-edition.aspx
+[5]: https://api.onlyoffice.com/editors/basic
diff --git a/sources/tech/20190925 Debugging in Emacs- The Grand Unified Debugger.md b/sources/tech/20190925 Debugging in Emacs- The Grand Unified Debugger.md
new file mode 100644
index 0000000000..f1a7fe8060
--- /dev/null
+++ b/sources/tech/20190925 Debugging in Emacs- The Grand Unified Debugger.md
@@ -0,0 +1,97 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Debugging in Emacs: The Grand Unified Debugger)
+[#]: via: (https://opensourceforu.com/2019/09/debugging-in-emacs-the-grand-unified-debugger/)
+[#]: author: (Vineeth Kartha https://opensourceforu.com/author/vineeth-kartha/)
+
+Debugging in Emacs: The Grand Unified Debugger
+======
+
+[![][1]][2]
+
+_This article briefly explores the features of the Grand Unified Debugger, a debugging tool for Emacs._
+
+If you are a C/C++ developer, it is highly likely that you have crossed paths with GDB (the GNU debugger) which is, without doubt, one of the most powerful and unrivalled debuggers out there. Its only drawback is that it is command line based, and though that offers a lot of power, it is sometimes a bit restrictive as well. This is why smart people started coming up with IDEs to integrate editors and debuggers, and give them a GUI. There are still developers who believe that using the mouse reduces productivity and that mouse-click based GUIs are temptations by the devil.
+Since Emacs is one of the coolest text editors out there, I am going to show you how to write, compile and debug code without having to touch the mouse or move out of Emacs.
+
+![Figure 1: Compile command in Emacs’ mini buffer][3]
+
+![Figure 2: Compilation status][4]
+
+The Grand Unified Debugger, or GUD as it is commonly known, is an Emacs mode in which GDB can be run from within Emacs. This provides all the features of Emacs in GDB. The user does not have to move out of the editor to debug the code written.
+
+**Setting the stage for the Grand Unified Debugger**
+If you are using a Linux machine, then it is likely you will have GDB and gcc already installed. The next step is to ensure that Emacs is also installed. I am assuming that the readers are familiar with GDB and have used it at least for basic debugging. If not, please do check out some quick introductions to GDB that are widely available on the Internet.
+
+For people who are new to Emacs, let me introduce you to some basic terminology. Throughout this article, you will see shortcut commands such as C-c, M-x, etc. C means the Ctrl key and M means the Alt key. C-c means the Ctrl + c keys are pressed. If you see C-c c, it means Ctrl + c is pressed followed by c. Also, in Emacs, the main area where you edit the text is called the main buffer, and the area at the bottom of the Emacs window, where commands are entered, is called the mini buffer.
+Start Emacs and to create a new file, press _C-x C-f_. This will prompt you to enter a file name. Let us call our file ‘buggyFactorial.cpp’. Once the file is open, type in the code shown below:
+
+```
+#include
+#include
+int factorial(int num) {
+int product = 1;
+while(num--) {
+product *= num;
+}
+return product;
+}
+int main() {
+int result = factorial(5);
+assert(result == 120);
+}
+```
+
+Save the file with _C-x C-s_. Once the file is saved, it’s time to compile the code. Press _M-x_ and in the prompt that comes up, type in compile and hit Enter. Then, in the prompt, replace whatever is there with _g++ -g buggyFactorial.cpp_ and again hit _Enter_.
+
+This will open up another buffer in Emacs that will show the status of the compile and, hopefully, if the code typed in is correct, you will get a buffer like the one shown in Figure 2.
+
+To hide this compilation status buffer, make sure your cursor is in the compilation buffer (you can do this without the mouse using _C-x o_-this is used to move the cursor from one open buffer to the other), and then press _C-x 0_. The next step is to run the code and see if it works fine. Press M-! and in the mini buffer prompt, type _./a.out._
+
+See the mini buffer that says the assertion is failed. Clearly, something is wrong with the code, because the factorial (5) is 120. So let’s debug the code now.
+
+![Figure 3: Output of the code in the mini buffer][5]
+
+![Figure 4: The GDB buffer in Emacs][6]
+
+**Debugging the code using GUD**
+Now, since we have the code compiled, it’s time to see what is wrong with it. Press M-x and in the prompt, enter _gdb._ In the next prompt that appears, write _gdb -i=mi a.out_, which will start GDB in the Emacs buffer and if everything goes well, you should get the window that’s shown in Figure 4.
+At the gdb prompt, type break main and then r to run the program. This should start running the program and should break at the _main()_.
+
+As soon as GDB hits the break point at main, a new buffer will open up showing the code that you are debugging. Notice the red dot on the left side, which is where your breakpoint was set. There will be a small indicator that shows which line of the code you are on. Currently, this will be the same as the break point itself (Figure 5).
+
+![Figure 5: GDB and the code in split windows][7]
+
+![Figure 6: Show the local variables in a separate frame in Emacs][8]
+
+To debug the factorial function, we need to step into it. For this, you can either use the _gdb_ prompt and the gdb command step, or you can use the Emacs shortcut _C-c C-s_. There are other similar shortcuts, but I prefer using the GDB commands. So I will use them in the rest of this article.
+Let us keep an eye on the local variables while stepping through the factorial number. Check out Figure 6 for how to get an Emacs frame to show the local variables.
+
+Step through the code in the GDB prompt and watch the value of the local variable change. In the first iteration of the loop itself, we see a problem. The value of the product should have been 5 and not 4.
+
+This is where I leave you and now it’s up to the readers to explore and discover the magic land called GUD mode. Every gdb command works in the GUD mode as well. I leave the fix to this code as an exercise to readers. Explore and see how you can customise things to make your workflow simpler and become more productive while debugging.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/09/debugging-in-emacs-the-grand-unified-debugger/
+
+作者:[Vineeth Kartha][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/vineeth-kartha/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Screenshot-from-2019-09-25-15-39-46.png?resize=696%2C440&ssl=1 (Screenshot from 2019-09-25 15-39-46)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Screenshot-from-2019-09-25-15-39-46.png?fit=800%2C506&ssl=1
+[3]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure_1.png?resize=350%2C228&ssl=1
+[4]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure_2.png?resize=350%2C228&ssl=1
+[5]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure_3.png?resize=350%2C228&ssl=1
+[6]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure_4.png?resize=350%2C227&ssl=1
+[7]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure_5.png?resize=350%2C200&ssl=1
+[8]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure_6.png?resize=350%2C286&ssl=1
diff --git a/sources/tech/20190925 Mutation testing by example- Execute the test.md b/sources/tech/20190925 Mutation testing by example- Execute the test.md
new file mode 100644
index 0000000000..2706e6dae1
--- /dev/null
+++ b/sources/tech/20190925 Mutation testing by example- Execute the test.md
@@ -0,0 +1,163 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Mutation testing by example: Execute the test)
+[#]: via: (https://opensource.com/article/19/9/mutation-testing-example-execute-test)
+[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
+
+Mutation testing by example: Execute the test
+======
+Use the logic created so far in this series to implement functioning
+code, then use failure and unit testing to make it better.
+![A cat.][1]
+
+The [second article][2] in this series demonstrated how to implement the logic for determining whether it's daylight or nighttime in a home automation system (HAS) application that controls locking and unlocking a cat door. This third article explains how to write code to use that logic in an application that locks a door at night and unlocks it during daylight hours.
+
+As a reminder, set yourself up to follow along using the .NET xUnit.net testing framework by following the [instructions here][3].
+
+### Disable the cat trap door during nighttime
+
+Assume the cat door is a sophisticated Internet of Things (IoT) product that has an IP address and can be accessed by sending a request to its API. For the sake of brevity, this series doesn't go into how to program an IoT device; rather, it simulates the service to keep the focus on test-driven development (TDD) and mutation testing.
+
+Start by writing a failing unit test:
+
+
+```
+[Fact]
+public void GivenNighttimeDisableTrapDoor() {
+ var expected = "Cat trap door disabled";
+ var timeOfDay = dayOrNightUtility.GetDayOrNight(nightHour);
+ var actual = catTrapDoor.Control(timeOfDay);
+ Assert.Equal(expected, actual);
+}
+```
+
+This describes a brand new component or service (**catTrapDoor**). That component (or service) has the capability to control the trap door given the current time. Now it's time to implement **catTrapDoor**.
+
+To simulate this service, you must first describe its capabilities by using the interface. Create a new file in the app folder and name it **ICatTrapDoor.cs** (by convention, an interface name starts with an uppercase letter **I**). Add the following code to that file:
+
+
+```
+namespace app{
+ public interface ICatTrapDoor {
+ string Control(string dayOrNight);
+ }
+}
+```
+
+This interface is not capable of functioning. It merely describes your intention when building the **CatTrapDoor** service. Interfaces are a nice way to create abstractions of the services you are working with. In a way, you could regard this interface as an API of the **CatTrapDoor** service.
+
+To implement the API, create a new file in the app folder and name it **FakeCatTrapDoor.cs**. Enter the following code into the class file:
+
+
+```
+namespace app{
+ public class FakeCatTrapDoor : ICatTrapDoor {
+ public string Control(string dayOrNight) {
+ string trapDoorStatus = "Undetermined";
+ if(dayOrNight == "Nighttime") {
+ trapDoorStatus = "Cat trap door disabled";
+ }
+
+ return trapDoorStatus;
+ }
+ }
+}
+```
+
+This new **FakeCatTrapDoor** class implements the interface **ICatTrapDoor**. Its method **Control** accepts string value **dayOrNight** and checks whether the value passed in is "Nighttime." If it is, it modifies **trapDoorStatus** from "Undetermined" to "Cat trap door disabled" and returns that value to the calling client.
+
+Why is it called **FakeCatTrapDoor**? Because it's not a representation of the real cat trap door. The fake just helps you work out the processing logic. Once your logic is airtight, the fake service is replaced with the real service (this topic is reserved for the discipline of integration testing).
+
+With everything implemented, all the unit tests pass when they run:
+
+
+```
+Starting test execution, please wait...
+
+Total tests; 3. Passed: 3. failed: 0. Skipped: 0.
+Test Run Successful.
+Test execution time: 1.3913 Seconds
+```
+
+### Enable the cat trap door during daytime
+
+It's time to look at the next scenario in our user story:
+
+> _Scenario #2: Enable cat trap door during daylight_
+>
+> * Given that the clock detects the daylight
+> * When the clock notifies the HAS
+> * Then the HAS enables the cat trap door
+>
+
+
+This should be easy, just the flip side of the first scenario. First, write the failing test. Add the following unit test to your **UnitTest1.cs** file in the **unittest** folder:
+
+
+```
+[Fact]
+public void GivenDaylightEnableTrapDoor() {
+ var expected = "Cat trap door enabled";
+ var timeOfDay = dayOrNightUtility.GetDayOrNight(dayHour);
+ var actual = catTrapDoor.Control(timeOfDay);
+ Assert.Equal(expected, actual);
+}
+```
+
+You can expect to receive a "Cat trap door enabled" notification when sending the "Daylight" status to **catTrapDoor** service. When you run unit tests, you see the result you expect, which fails as expected:
+
+
+```
+Starting test execution, please wait...
+[Xunit unittest.UnitTest1.UnitTest1.GivenDaylightEnableTrapDoor [FAIL]
+Failed unittest.UnitTest1.UnitTest1.GivenDaylightEnableTrapDoor
+[...]
+```
+
+The unit test expected to receive a "Cat trap door enabled" notification but instead was notified that the cat trap door status is "Undetermined." Cool; now's the time to fix this minor failure.
+
+Adding three lines of code to the **FakeCatTrapDoor** does the trick:
+
+
+```
+if(dayOrNight == "Daylight") {
+ trapDoorStatus = "Cat trap door enabled";
+}
+```
+
+Run the unit tests again, and all tests pass:
+
+
+```
+Starting test execution, please wait...
+
+Total tests: 4. Passed: 4. Failed: 0. Skipped: 0.
+Test Run Successful.
+Test execution time: 2.4888 Seconds
+```
+
+Awesome! Everything looks good, all the unit tests are in green, you have a rock-solid solution. Thank you, TDD!
+
+### Not so fast!
+
+Experienced engineers would not be convinced that the solution is rock-solid. Why? Because the solution hasn't been mutated yet. To dive deeply into what mutation is and why it's important, be sure to read the final article in this series.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/mutation-testing-example-execute-test
+
+作者:[Alex Bunardzic][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/alex-bunardzic
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cat_pet_animal.jpg?itok=HOrVTfBZ (A cat.)
+[2]: https://opensource.com/article/19/9/mutation-testing-example-part-2-failure-experimentation
+[3]: https://opensource.com/article/19/8/mutation-testing-evolution-tdd
diff --git a/sources/tech/20190926 3 open source social platforms to consider.md b/sources/tech/20190926 3 open source social platforms to consider.md
new file mode 100644
index 0000000000..dddde6dc77
--- /dev/null
+++ b/sources/tech/20190926 3 open source social platforms to consider.md
@@ -0,0 +1,76 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (3 open source social platforms to consider)
+[#]: via: (https://opensource.com/article/19/9/open-source-social-networks)
+[#]: author: (Jaouhari Youssef https://opensource.com/users/jaouharihttps://opensource.com/users/danarelhttps://opensource.com/users/osmomjianhttps://opensource.com/users/dff)
+
+3 open source social platforms to consider
+======
+A photo-sharing platform, a privacy-friendly social network, and a web
+application for building and sharing portfolios.
+![Hands holding a mobile phone with open on the screen][1]
+
+It is no mystery why modern social media platforms were designed to be addictive: the more we consult them, the more data they have to fuel them—which enables them to grow smarter and bigger and more powerful.
+
+The massive, global interest in these platforms has created the attention economy, and people's focused mental engagement is the new gold in the age of information abundance. As economist, political scientist, and cognitive psychologist Herbert A. Simon said in [_Designing organizations for an information-rich world_][2], "the wealth of information means a dearth of something else: a scarcity of whatever it is that information consumes." And information consumes our attention, a resource we only have so much of it.
+
+According to [GlobalWebIndex][3], we are now spending an average of 142 minutes on social media and messaging platforms daily, 63% more than the 90 minutes we spent on these platforms just seven years ago. This can be explained by the fact that these platforms have grown more intelligent over time by studying the minds and behaviors of users and applying those findings to boost their appeal.
+
+Of relevance here is the psychological concept [variable-ratio schedule][4], which gives rewards after an average number of responses but on an unpredictable schedule. One example is slot machines, which may provide a reward an average of every five games, but the players don't know the specific number of games (one, two, seven, or even 15) they must play before obtaining a reward. This schedule leads to a high response rate and strong engagement.
+
+Knowing all of this, what can we do to make things better and loosen the grip social networks have on us and our data? I suggest the answer is migrating to open source social platforms, which I believe consider the humane aspect of technology more than private companies do. Here are three open source social platforms to consider.
+
+### Pixelfed
+
+[Pixelfed][5] is a photo-sharing platform that is ad-free and privacy-focused, which means no third party is making a profit from your data. Posts are in chronological order, which means there is no algorithm making distinctions between content.
+
+To join the network, you can pick one of the servers on the [list of instances][6], or you can [install and run][7] your own Pixelfed instance.
+
+Once you are set up, you can connect with other Pixelfed instances. This is known as federation, which means many instances of a software (in this case, Pixelfed) share data (in this case, pictures). When you federate with another instance of Pixelfed, you can see and interact with pictures posted to other accounts.
+
+The project is ongoing and needs the community's support to grow. Check [Pixelfed's GitHub][8] page for more information about contributing.
+
+### Okuna
+
+[Okuna][9] is an open source, privacy-friendly social network. It is committed to being a positive influence on society and the environment, plus it donates 30% of its profits to worthy causes.
+
+### Mahara
+
+[Mahara][10] is an open source web application for building and sharing electronic portfolios. (The word _mahara_ is Māori for _memory_ or _thoughtful consideration_.) With Mahara, you can create a meaningful and verifiable professional profile, but all your data belongs to you rather than a corporate sponsor. It is customizable and can be integrated into other web services.
+
+You can try Mahara on its [demo site][11].
+
+### Engage for change
+
+If you want to know more about the impact of the attention economy on our lives and engage for positive change, take a look at the [Center for Humane Technology][12], an organization trying to temper the attention economy and make technology more humane. Its aim is to spur change that will protect human vulnerabilities from being exploited and therefore build a better society.
+
+As Sonya Parker said, "whatever you focus your attention on will become important to you even if it's unimportant." So let's focus our attention on building a better world for all.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/open-source-social-networks
+
+作者:[Jaouhari Youssef][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jaouharihttps://opensource.com/users/danarelhttps://opensource.com/users/osmomjianhttps://opensource.com/users/dff
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003588_01_rd3os.combacktoschoolserieshe_rh_041x_0.png?itok=tfg6_I78 (Hands holding a mobile phone with open on the screen)
+[2]: https://digitalcollections.library.cmu.edu/awweb/awarchive?type=file&item=33748
+[3]: https://www.digitalinformationworld.com/2019/01/how-much-time-do-people-spend-social-media-infographic.html
+[4]: https://dictionary.apa.org/variable-ratio-schedule
+[5]: https://pixelfed.org/
+[6]: https://pixelfed.org/join
+[7]: https://docs.pixelfed.org/installing-pixelfed/
+[8]: https://github.com/pixelfed/pixelfed
+[9]: https://www.okuna.io/en/home
+[10]: https://mahara.org/
+[11]: https://demo.mahara.org/
+[12]: https://humanetech.com/problem/
diff --git a/sources/tech/20190926 Mutation testing by example- Evolving from fragile TDD.md b/sources/tech/20190926 Mutation testing by example- Evolving from fragile TDD.md
new file mode 100644
index 0000000000..4ce6e23232
--- /dev/null
+++ b/sources/tech/20190926 Mutation testing by example- Evolving from fragile TDD.md
@@ -0,0 +1,258 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Mutation testing by example: Evolving from fragile TDD)
+[#]: via: (https://opensource.com/article/19/9/mutation-testing-example-definition)
+[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzichttps://opensource.com/users/alex-bunardzichttps://opensource.com/users/marcobravo)
+
+Mutation testing by example: Evolving from fragile TDD
+======
+Test-driven development is not enough for delivering lean code that
+works exactly to expectations. Mutation testing is a powerful step
+forward. Here's what that looks like.
+![Binary code on a computer screen][1]
+
+The [third article][2] in this series demonstrated how to use failure and unit testing to develop better code.
+
+While it seemed that the journey was over with a successful sample Internet of Things (IoT) application to control a cat door, experienced programmers know that solutions need _mutation_.
+
+### What's mutation testing?
+
+Mutation testing is the process of iterating through each line of implemented code, mutating that line, then running unit tests and checking if the mutation broke the expectations. If it hasn't, you have created a surviving mutant.
+
+Surviving mutants are always an alarming issue that points to potentially risky areas in a codebase. As soon as you catch a surviving mutant, you must kill it. And the only way to kill a surviving mutant is to create additional descriptions—new unit tests that describe your expectations regarding the output of your function or module. In the end, you deliver a lean, mean solution that is airtight and guarantees no pesky bugs or defects are lurking in your codebase.
+
+If you leave surviving mutants to kick around and proliferate, live long, and prosper, then you are creating the much dreaded technical debt. On the other hand, if any unit test complains that the temporarily mutated line of code produces output that's different from the expected output, the mutant has been killed.
+
+### Installing Stryker
+
+The quickest way to try mutation testing is to leverage a dedicated framework. This example uses [Stryker][3].
+
+To install Stryker, go to the command line and run:
+
+
+```
+`$ dotnet tool install -g dotnet-stryker`
+```
+
+To run Stryker, navigate to the **unittest** folder and type:
+
+
+```
+`$ dotnet-stryker`
+```
+
+Here is Stryker's report on the quality of our solution:
+
+
+```
+14 mutants have been created. Each mutant will now be tested, this could take a while.
+
+Tests progress | 14/14 | 100% | ~0m 00s |
+Killed : 13
+Survived : 1
+Timeout : 0
+
+All mutants have been tested, and your mutation score has been calculated
+\- \app [13/14 (92.86%)]
+[...]
+```
+
+The report says:
+
+ * Stryker created 14 mutants
+ * Stryker saw 13 mutants were killed by the unit tests
+ * Stryker saw one mutant survive the onslaught of the unit tests
+ * Stryker calculated that the existing codebase contains 92.86% of code that serves the expectations
+ * Stryker calculated that 7.14% of the codebase contains code that does not serve the expectations
+
+
+
+Overall, Stryker claims that the application assembled in the first three articles in this series failed to produce a reliable solution.
+
+### How to kill a mutant
+
+When software developers encounter surviving mutants, they typically reach for the implemented code and look for ways to modify it. For example, in the case of the sample application for cat door automation, change the line:
+
+
+```
+`string trapDoorStatus = "Undetermined";`
+```
+
+to:
+
+
+```
+`string trapDoorStatus = "";`
+```
+
+and run Stryker again. A mutant has survived:
+
+
+```
+All mutants have been tested, and your mutation score has been calculated
+\- \app [13/14 (92.86%)]
+[...]
+[Survived] String mutation on line 4: '""' ==> '"Stryker was here!"'
+[...]
+```
+
+This time, you can see that Stryker mutated the line:
+
+
+```
+`string trapDoorStatus = "";`
+```
+
+into:
+
+
+```
+`string trapDoorStatus = ""Stryker was here!";`
+```
+
+This is a great example of how Stryker works: it mutates every line of our code, in a smart way, in order to see if there are further test cases we have yet to think about. It's forcing us to consider our expectations in greater depth.
+
+Defeated by Stryker, you can attempt to improve the implemented code by adding more logic to it:
+
+
+```
+public string Control(string dayOrNight) {
+ string trapDoorStatus = "Undetermined";
+ if(dayOrNight == "Nighttime") {
+ trapDoorStatus = "Cat trap door disabled";
+ } else if(dayOrNight == "Daylight") {
+ trapDoorStatus = "Cat trap door enabled";
+ } else {
+ trapDoorStatus = "Undetermined";
+ }
+ return trapDoorStatus;
+}
+```
+
+But after running Stryker again, you see this attempt created a new mutant:
+
+
+```
+ll mutants have been tested, and your mutation score has been calculated
+\- \app [13/15 (86.67%)]
+[...]
+[Survived] String mutation on line 4: '"Undetermined"' ==> '""'
+[...]
+[Survived] String mutation on line 10: '"Undetermined"' ==> '""'
+[...]
+```
+
+![Stryker report][4]
+
+You cannot wiggle out of this tight spot by modifying the implemented code. It turns out the only way to kill surviving mutants is to _describe additional expectations_. And how do you describe expectations? By writing unit tests.
+
+### Unit testing for success
+
+It's time to add a new unit test. Since the surviving mutant is located on line 4, you realize you have not specified expectations for the output with value "Undetermined."
+
+Let's add a new unit test:
+
+
+```
+[Fact]
+public void GivenIncorrectTimeOfDayReturnUndetermined() {
+ var expected = "Undetermined";
+ var actual = catTrapDoor.Control("Incorrect input");
+ Assert.Equal(expected, actual);
+}
+```
+
+The fix worked! Now all mutants are killed:
+
+
+```
+All mutants have been tested, and your mutation score has been calculated
+\- \app [14/14 (100%)]
+[Killed] [...]
+```
+
+You finally have a complete solution, including a description of what is expected as output if the system receives incorrect input values.
+
+### Mutation testing to the rescue
+
+Suppose you decide to over-engineer a solution and add this method to the **FakeCatTrapDoor**:
+
+
+```
+private string getTrapDoorStatus(string dayOrNight) {
+ string status = "Everything okay";
+ if(dayOrNight != "Nighttime" || dayOrNight != "Daylight") {
+ status = "Undetermined";
+ }
+ return status;
+}
+```
+
+Then replace the line 4 statement:
+
+
+```
+`string trapDoorStatus = "Undetermined";`
+```
+
+with:
+
+
+```
+`string trapDoorStatus = getTrapDoorStatus(dayOrNight);`
+```
+
+When you run unit tests, everything passes:
+
+
+```
+Starting test execution, please wait...
+
+Total tests: 5. Passed: 5. Failed: 0. Skipped: 0.
+Test Run Successful.
+Test execution time: 2.7191 Seconds
+```
+
+The test has passed without an issue. TDD has worked. But bring Stryker to the scene, and suddenly the picture looks a bit grim:
+
+
+```
+All mutants have been tested, and your mutation score has been calculated
+\- \app [14/20 (70%)]
+[...]
+```
+
+Stryker created 20 mutants; 14 mutants were killed, while six mutants survived. This lowers the success score to 70%. This means only 70% of our code is there to fulfill the described expectations. The other 30% of the code is there for no clear reason, which puts us at risk of misuse of that code.
+
+In this case, Stryker helps fight the bloat. It discourages the use of unnecessary and convoluted logic because it is within the crevices of such unnecessary complex logic where bugs and defects breed.
+
+### Conclusion
+
+As you've seen, mutation testing ensures that no uncertain fact goes unchecked.
+
+You could compare Stryker to a chess master who is thinking of all possible moves to win a match. When Stryker is uncertain, it's telling you that winning is not yet a guarantee. The more unit tests we record as facts, the further we are in our match, and the more likely Stryker can predict a win. In any case, Stryker helps detect losing scenarios even when everything looks good on the surface.
+
+It is always a good idea to engineer code properly. You've seen how TDD helps in that regard. TDD is especially useful when it comes to keeping your code extremely modular. However, TDD on its own is not enough for delivering lean code that works exactly to expectations. Developers can add code to an already implemented codebase without first describing the expectations. That puts the entire code base at risk. Mutation testing is especially useful in catching breaches in the regular test-driven development (TDD) cadence. You need to mutate every line of implemented code to be certain no line of code is there without a specific reason.
+
+Now that you understand how mutation testing works, you should look into how to leverage it. Next time, I'll show you how to put mutation testing to good use when tackling more complex scenarios. I will also introduce more agile concepts to see how DevOps culture can benefit from maturing technology.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/mutation-testing-example-definition
+
+作者:[Alex Bunardzic][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/alex-bunardzichttps://opensource.com/users/alex-bunardzichttps://opensource.com/users/marcobravo
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/binary_code_computer_screen.png?itok=7IzHK1nn (Binary code on a computer screen)
+[2]: https://opensource.com/article/19/9/mutation-testing-example-part-3-execute-test
+[3]: https://stryker-mutator.io/
+[4]: https://opensource.com/sites/default/files/uploads/strykerreport.png (Stryker report)
diff --git a/sources/tech/20190927 5 tips for GNU Debugger.md b/sources/tech/20190927 5 tips for GNU Debugger.md
new file mode 100644
index 0000000000..faedf4240d
--- /dev/null
+++ b/sources/tech/20190927 5 tips for GNU Debugger.md
@@ -0,0 +1,230 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (5 tips for GNU Debugger)
+[#]: via: (https://opensource.com/article/19/9/tips-gnu-debugger)
+[#]: author: (Tim Waugh https://opensource.com/users/twaugh)
+
+5 tips for GNU Debugger
+======
+Learn how to use some of the lesser-known features of gdb to inspect and
+fix your code.
+![Bug tracking magnifying glass on computer screen][1]
+
+The [GNU Debugger][2] (gdb) is an invaluable tool for inspecting running processes and fixing problems while you're developing programs.
+
+You can set breakpoints at specific locations (by function name, line number, and so on), enable and disable those breakpoints, display and alter variable values, and do all the standard things you would expect any debugger to do. But it has many other features you might not have experimented with. Here are five for you to try.
+
+### Conditional breakpoints
+
+Setting a breakpoint is one of the first things you'll learn to do with the GNU Debugger. The program stops when it reaches a breakpoint, and you can run gdb commands to inspect it or change variables before allowing the program to continue.
+
+For example, you might know that an often-called function crashes sometimes, but only when it gets a certain parameter value. You could set a breakpoint at the start of that function and run the program. The function parameters are shown each time it hits the breakpoint, and if the parameter value that triggers the crash is not supplied, you can continue until the function is called again. When the troublesome parameter triggers a crash, you can step through the code to see what's wrong.
+
+
+```
+(gdb) break sometimes_crashes
+Breakpoint 1 at 0x40110e: file prog.c, line 5.
+(gdb) run
+[...]
+Breakpoint 1, sometimes_crashes (f=0x7fffffffd1bc) at prog.c:5
+5 fprintf(stderr,
+(gdb) continue
+Breakpoint 1, sometimes_crashes (f=0x7fffffffd1bc) at prog.c:5
+5 fprintf(stderr,
+(gdb) continue
+```
+
+To make this more repeatable, you could count how many times the function is called before the specific call you are interested in, and set a counter on that breakpoint (for example, "continue 30" to make it ignore the next 29 times it reaches the breakpoint).
+
+But where breakpoints get really powerful is in their ability to evaluate expressions at runtime, which allows you to automate this kind of testing. Enter: conditional breakpoints.
+
+
+```
+break [LOCATION] if CONDITION
+
+(gdb) break sometimes_crashes if !f
+Breakpoint 1 at 0x401132: file prog.c, line 5.
+(gdb) run
+[...]
+Breakpoint 1, sometimes_crashes (f=0x0) at prog.c:5
+5 fprintf(stderr,
+(gdb)
+```
+
+Instead of having gdb ask what to do every time the function is called, a conditional breakpoint allows you to make gdb stop at that location only when a particular expression evaluates as true. If the execution reaches the conditional breakpoint location, but the expression evaluates as false, the
+
+debugger automatically lets the program continue without asking the user what to do.
+
+### Breakpoint commands
+
+An even more sophisticated feature of breakpoints in the GNU Debugger is the ability to script a response to reaching a breakpoint. Breakpoint commands allow you to write a list of GNU Debugger commands to run whenever it reaches a breakpoint.
+
+We can use this to work around the bug we already know about in the **sometimes_crashes** function and make it return from that function harmlessly when it provides a null pointer.
+
+We can use **silent** as the first line to get more control over the output. Without this, the stack frame will be displayed each time the breakpoint is hit, even before our breakpoint commands run.
+
+
+```
+(gdb) break sometimes_crashes
+Breakpoint 1 at 0x401132: file prog.c, line 5.
+(gdb) commands 1
+Type commands for breakpoint(s) 1, one per line.
+End with a line saying just "end".
+>silent
+>if !f
+ >frame
+ >printf "Skipping call\n"
+ >return 0
+ >continue
+ >end
+>printf "Continuing\n"
+>continue
+>end
+(gdb) run
+Starting program: /home/twaugh/Documents/GDB/prog
+warning: Loadable section ".note.gnu.property" outside of ELF segments
+Continuing
+Continuing
+Continuing
+#0 sometimes_crashes (f=0x0) at prog.c:5
+5 fprintf(stderr,
+Skipping call
+[Inferior 1 (process 9373) exited normally]
+(gdb)
+```
+
+### Dump binary memory
+
+GNU Debugger has built-in support for examining memory using the **x** command in various formats, including octal, hexadecimal, and so on. But I like to see two formats side by side: hexadecimal bytes on the left, and ASCII characters represented by those same bytes on the right.
+
+When I want to view the contents of a file byte-by-byte, I often use **hexdump -C** (hexdump comes from the [util-linux][3] package). Here is gdb's **x** command displaying hexadecimal bytes:
+
+
+```
+(gdb) x/33xb mydata
+0x404040 <mydata>: 0x02 0x01 0x00 0x02 0x00 0x00 0x00 0x01
+0x404048 <mydata+8>: 0x01 0x47 0x00 0x12 0x61 0x74 0x74 0x72
+0x404050 <mydata+16>: 0x69 0x62 0x75 0x74 0x65 0x73 0x2d 0x63
+0x404058 <mydata+24>: 0x68 0x61 0x72 0x73 0x65 0x75 0x00 0x05
+0x404060 <mydata+32>: 0x00
+```
+
+What if you could teach gdb to display memory just like hexdump does? You can, and in fact, you can use this method for any format you prefer.
+
+By combining the **dump** command to store the bytes in a file, the **shell** command to run hexdump on the file, and the **define** command, we can make our own new **hexdump** command to use hexdump to display the contents of memory.
+
+
+```
+(gdb) define hexdump
+Type commands for definition of "hexdump".
+End with a line saying just "end".
+>dump binary memory /tmp/dump.bin $arg0 $arg0+$arg1
+>shell hexdump -C /tmp/dump.bin
+>end
+```
+
+Those commands can even go in the **~/.gdbinit** file to define the hexdump command permanently. Here it is in action:
+
+
+```
+(gdb) hexdump mydata sizeof(mydata)
+00000000 02 01 00 02 00 00 00 01 01 47 00 12 61 74 74 72 |.........G..attr|
+00000010 69 62 75 74 65 73 2d 63 68 61 72 73 65 75 00 05 |ibutes-charseu..|
+00000020 00 |.|
+00000021
+```
+
+### Inline disassembly
+
+Sometimes you want to understand more about what happened leading up to a crash, and the source code is not enough. You want to see what's going on at the CPU instruction level.
+
+The **disassemble** command lets you see the CPU instructions that implement a function. But sometimes the output can be hard to follow. Usually, I want to see what instructions correspond to a certain section of source code in the function. To achieve this, use the **/s** modifier to include source code lines with the disassembly.
+
+
+```
+(gdb) disassemble/s main
+Dump of assembler code for function main:
+prog.c:
+11 {
+ 0x0000000000401158 <+0>: push %rbp
+ 0x0000000000401159 <+1>: mov %rsp,%rbp
+ 0x000000000040115c <+4>: sub $0x10,%rsp
+
+12 int n = 0;
+ 0x0000000000401160 <+8>: movl $0x0,-0x4(%rbp)
+
+13 sometimes_crashes(&n);
+ 0x0000000000401167 <+15>: lea -0x4(%rbp),%rax
+ 0x000000000040116b <+19>: mov %rax,%rdi
+ 0x000000000040116e <+22>: callq 0x401126 <sometimes_crashes>
+[...snipped...]
+```
+
+This, along with **info registers** to see the current values of all the CPU registers and commands like **stepi** to step one instruction at a time, allow you to have a much more detailed understanding of the program.
+
+### Reverse debug
+
+Sometimes you wish you could turn back time. Imagine you've hit a watchpoint on a variable. A watchpoint is like a breakpoint, but instead of being set at a location in the program, it is set on an expression (using the **watch** command). Whenever the value of the expression changes, execution stops, and the debugger takes control.
+
+So imagine you've hit this watchpoint, and the memory used by a variable has changed value. This can turn out to be caused by something that occurred much earlier; for example, the memory was freed and is now being re-used. But when and why was it freed?
+
+The GNU Debugger can solve even this problem because you can run your program in reverse!
+
+It achieves this by carefully recording the state of the program at each step so that it can restore previously recorded states, giving the illusion of time flowing backward.
+
+To enable this state recording, use the **target record-full** command. Then you can use impossible-sounding commands, such as:
+
+ * **reverse-step**, which rewinds to the previous source line
+ * **reverse-next**, which rewinds to the previous source line, stepping backward over function calls
+ * **reverse-finish**, which rewinds to the point when the current function was about to be called
+ * **reverse-continue**, which rewinds to the previous state in the program that would (now) trigger a breakpoint (or anything else that causes it to stop)
+
+
+
+Here is an example of reverse debugging in action:
+
+
+```
+(gdb) b main
+Breakpoint 1 at 0x401160: file prog.c, line 12.
+(gdb) r
+Starting program: /home/twaugh/Documents/GDB/prog
+[...]
+
+Breakpoint 1, main () at prog.c:12
+12 int n = 0;
+(gdb) target record-full
+(gdb) c
+Continuing.
+
+Program received signal SIGSEGV, Segmentation fault.
+0x0000000000401154 in sometimes_crashes (f=0x0) at prog.c:7
+7 return *f;
+(gdb) reverse-finish
+Run back to call of #0 0x0000000000401154 in sometimes_crashes (f=0x0)
+ at prog.c:7
+0x0000000000401190 in main () at prog.c:16
+16 sometimes_crashes(0);
+```
+
+These are just a handful of useful things the GNU Debugger can do. There are many more to discover. Which hidden, little-known, or just plain amazing feature of gdb is your favorite? Please share it in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/tips-gnu-debugger
+
+作者:[Tim Waugh][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/twaugh
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bug_software_issue_tracking_computer_screen.jpg?itok=6qfIHR5y (Bug tracking magnifying glass on computer screen)
+[2]: https://www.gnu.org/software/gdb/
+[3]: https://en.wikipedia.org/wiki/Util-linux
diff --git a/sources/tech/20190928 Microsoft open sourcing its C-- library, Cloudera-s open source data platform, new tools to remove leaked passwords on GitHub and combat ransomware, and more open source news.md b/sources/tech/20190928 Microsoft open sourcing its C-- library, Cloudera-s open source data platform, new tools to remove leaked passwords on GitHub and combat ransomware, and more open source news.md
new file mode 100644
index 0000000000..cb803113ab
--- /dev/null
+++ b/sources/tech/20190928 Microsoft open sourcing its C-- library, Cloudera-s open source data platform, new tools to remove leaked passwords on GitHub and combat ransomware, and more open source news.md
@@ -0,0 +1,83 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Microsoft open sourcing its C++ library, Cloudera's open source data platform, new tools to remove leaked passwords on GitHub and combat ransomware, and more open source news)
+[#]: via: (https://opensource.com/article/19/9/news-september-28)
+[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
+
+Microsoft open sourcing its C++ library, Cloudera's open source data platform, new tools to remove leaked passwords on GitHub and combat ransomware, and more open source news
+======
+Catch up on the biggest open source headlines from the past two weeks.
+![Weekly news roundup with TV][1]
+
+In this edition of our open source news roundup, we take a look Cloudera's open source data platform, Microsoft open sourcing its C++ library, new tools to beef up digital security, and more!
+
+### Cloudera releases open source cloud data platform
+
+It was only a few months ago that data processing software vendor Cloudera went [all in on open source][2]. The results of that shift have started to appear, with the company releasing "[an integrated data platform made up entirely of open-source elements.][3]"
+
+Called Cloudera Data Platform, it combines "a cloud-native data warehouse, machine learning service and data hub, each running as instances within the self-contained operating environments." Cloudera's chief product officer Arun Murthy said that by using "existing components in the cloud, the platform cuts deployment times from weeks to hours." The speed of open source adoption is a great industry proof point. One can image the next step is Cloudera's participation in the underlying open source communities they now depend on.
+
+### Microsoft open sources its C++ standard library
+
+When you think of open source software, programming language libraries probably aren't the first things that come to mind. But they're often an essential part of the software that we use. A team at Microsoft recognized the importance of the company's implementation of the C++ Standard Library (STL) and it's been [released as open source][4].
+
+By making the library open source, users get "easy access to all the latest developments in C++" and enables them to participate "in the STL’s development by reporting issues and commenting on pull requests." The library, which is under an Apache License, is [available on GitHub][5].
+
+### Two new open source security tools
+
+Nowadays, more than ever it seems, digital security is important to anyone using a computer — from average users to system administrators to software developers. Open source has been playing its part in helping make systems more secure, and two new open source tools to help secure an organization's code and its computers have been released.
+
+If you, or someone in your company, has ever accidentally published sensitive information to a public GitHub repository, then [Shhgit is for you][6]. The tool, which you can [find on GitHub][7], is designed to detect passwords, connection strings, and access keys that wind up being exposed. Unlike similar tools, you don't need to point Shhgit at a particular repository. Instead, it "taps into the GitHub firehose to automatically flag up leaked secrets".
+
+Ransomware attacks are no joke, and defending against them is serious business. Cameyo, a company specializing in virtualization, has released an [open source monitoring tool][8] that "any organization can use to identify attacks taking place over RDP (Remote Desktop Protocol) in their environment." Called [RDPmon][9], the software enables users to "monitor and identify brute force attacks and to help protect against ransomware". It does this by watching the number of attempted RDP connections, along with the number of users and which programs those users are running.
+
+### New foundation to develop open source data processing engine
+
+There's a new open source foundation in town. Tech firms Alibaba, Facebook, Twitter, and Uber have [teamed up][10] to further develop Presto, a database search engine and processing tool originally crafted by Facebook.
+
+The Presto Foundation, which operates under the Linux Foundation's umbrella, aims to make Presto the "fastest and most reliable SQL engine for massively distributed data processing." One of the foundation members, Alibaba, already has plans for the tool. According to an [article in CX Tech][11], Alibaba intends to refine Presto to more efficiently "sift through the mountains of data generated by its e-commerce platforms."
+
+#### In other news
+
+ * [Scientists Create World’s First Open Source Tool for 3D Analysis of Advanced Biomaterials][12]
+ * [Percona announces Percona Distribution for PostgreSQL to support open source databases][13]
+ * [Sage gets cloudy, moves towards open source and microservices][14]
+ * [Compliance monitoring of EU’s Common Agricultural Policy made more transparent and efficient with Open Source][15]
+ * [WebLinc is taking its in-house ecommerce platform open source][16]
+
+
+
+_Thanks, as always, to Opensource.com staff members and moderators for their help this week._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/9/news-september-28
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
+[2]: https://opensource.com/19/7/news-july-20#cloudera
+[3]: https://siliconangle.com/2019/09/24/cloudera-debuts-open-source-integrated-cloud-data-platform/
+[4]: https://devclass.com/2019/09/18/microsoft-turns-to-github-to-open-source-c-stl/
+[5]: https://github.com/microsoft/STL
+[6]: https://portswigger.net/daily-swig/open-source-tool-for-bug-hunters-searches-for-leaked-secrets-in-github-commits
+[7]: https://github.com/eth0izzle/shhgit/
+[8]: https://betanews.com/2019/09/18/tool-prevents-brute-force-ransomware/
+[9]: https://github.com/cameyo/rdpmon
+[10]: https://sdtimes.com/data/the-presto-foundation-launches-under-the-linux-foundation/
+[11]: https://www.caixinglobal.com/2019-09-24/alibaba-global-tech-giants-form-foundation-for-open-source-database-tool-101465449.html
+[12]: https://sputniknews.com/science/201909111076763585-russian-german-scientists-create-worlds-first-open-source-tool-for-3d-analysis-of-advanced/
+[13]: https://hub.packtpub.com/percona-announces-percona-distribution-for-postgresql-to-support-open-source-databases/
+[14]: https://www.itworldcanada.com/article/sage-gets-cloudy-moves-towards-open-source-and-microservices/421771
+[15]: https://joinup.ec.europa.eu/node/702122
+[16]: https://technical.ly/philly/2019/09/24/weblinc-ecommerce-platform-open-source-workarea/
diff --git a/sources/tech/20190929 Open Source Voice Chat Mumble Makes a Big Release After 10 Years.md b/sources/tech/20190929 Open Source Voice Chat Mumble Makes a Big Release After 10 Years.md
new file mode 100644
index 0000000000..3205c22a0a
--- /dev/null
+++ b/sources/tech/20190929 Open Source Voice Chat Mumble Makes a Big Release After 10 Years.md
@@ -0,0 +1,117 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Open Source Voice Chat Mumble Makes a Big Release After 10 Years)
+[#]: via: (https://itsfoss.com/mumble-voice-chat/)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+
+Open Source Voice Chat Mumble Makes a Big Release After 10 Years
+======
+
+The greatest power of the Internet is its ability to connect people anywhere in the world. Voice chat applications are just one category of tools uniting us. Recently, one of the biggest open-source voice chat apps made a new release, 10 years after its previous release.
+
+### Mumble: Open Source, Low Latency, High Quality Voice Chat
+
+![Mumble][1]
+
+[Mumble][2] is a “free, open source, low latency, high quality voice chat application”. It was originally created to be used by gamers, but it is also used to record podcasts. Several [Linux podcasts][3] use Mumble to record hosts located at different places in the world, including Late Nite Linux. To give you an idea of how powerful Mumble is, it has been used to connect “Eve Online players with huge communities of over 100 simultaneous voice participants”.
+
+Here are some of the features that make Mumble interesting:
+
+ * Low-latency (ideal for gamers)
+ * Connections always encrypted and secured
+ * Connect with friends across servers
+ * Extensive user permission system
+ * Extendable through Ice and GRPC protocols
+ * Automatable administration through Ice middleware
+ * Low resource cost for hosting
+ * Free choice between official and third-party server software
+ * Provide users with channel viewer data (CVP) without giving control away
+
+
+
+It’s a powerful software with a lot of features. If you are new to it and want to start using it, I suggest [going through its documentation][4].
+
+### What’s New in Mumble 1.3.0?
+
+![Mumble 1.30 Interface with Lite Theme][5]
+
+The team behind Mumble released [version 1.3.0][6] in early August. This is the first major release in ten years and it contains over 3,000 changes. Here are just a few of the new features in Mumble 1.3.0:
+
+ * UI redesign
+ * New lite and dark themes
+ * Individual user volume adjustment
+ * New bindable shortcut for changing transmission modes
+ * Quickly filter channels
+ * Multichannel recordings are synchronous even after several hours
+ * PulseAudio monitor devices can be used as input devices
+ * An optional clock (current time) in the overlay
+ * Improved user management, including searchable ban list
+ * Added support for systemd
+ * Option to disable public server list
+ * Lower volume of other users when “Priority Speaker” talks
+ * New interface allows renaming users as well as (batch) deletions
+ * Mumble client can be controlled through SocketRPC
+ * Support for Logitech G-keys has been added
+
+
+
+### Installing Mumble on Linux
+
+![Mumble 1.30 Interface Dark Theme][7]
+
+The Mumble team has installers available for Linux, Windows (32 and 64 bit), and macOS. You can find and download them from the [project’s website][8]. You can also browse its [source code on GitHub][9].
+
+They have a [PPA available for Ubuntu][10]. Which means you can easily install it on Ubuntu and Ubuntu-based distributions like Linux Mint, elementary OS. To install, just enter these commands, one by one, in the terminal:
+
+```
+sudo add-apt-repository ppa:mumble/release
+sudo apt update
+sudo apt install mumble
+```
+
+The Snap community also created a [snap app for Mumble][11]. This makes installing Mumble easier in any Linux distribution that supports Snap. You can install it with the following command:
+
+```
+sudo snap install mumble
+```
+
+There are also _third-party clients_ for Android and iOS on the download page.
+
+[Download Mumble for other platforms][8]
+
+**Final Thoughts**
+
+I have never used Mumble or any other voice chat app. I just never had the need. That being said, I’m glad that there is a powerful FOSS option available and so widely used.
+
+Have you ever used Mumble? What is your favorite voice chat app? Please let us know in the comments below.
+
+If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][12].
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/mumble-voice-chat/
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/09/mumble-voice-chat-logo.png?ssl=1
+[2]: https://www.mumble.info/
+[3]: https://itsfoss.com/linux-podcasts/
+[4]: https://wiki.mumble.info/wiki/Main_Page
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/mumble-1.30-interface.jpg?ssl=1
+[6]: https://www.mumble.info/blog/mumble-1.3.0-release-announcement/
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/09/mumble-1.30-interface-1.png?resize=800%2C529&ssl=1
+[8]: https://www.mumble.info/downloads/
+[9]: https://github.com/mumble-voip/mumble
+[10]: https://itsfoss.com/ppa-guide/
+[11]: https://snapcraft.io/mumble
+[12]: https://reddit.com/r/linuxusersgroup
diff --git a/sources/tech/20190930 Cacoo- A Lightweight Online Tool for Modelling AWS Architecture.md b/sources/tech/20190930 Cacoo- A Lightweight Online Tool for Modelling AWS Architecture.md
new file mode 100644
index 0000000000..428c68007a
--- /dev/null
+++ b/sources/tech/20190930 Cacoo- A Lightweight Online Tool for Modelling AWS Architecture.md
@@ -0,0 +1,72 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Cacoo: A Lightweight Online Tool for Modelling AWS Architecture)
+[#]: via: (https://opensourceforu.com/2019/09/cacoo-a-lightweight-online-tool-for-modelling-aws-architecture/)
+[#]: author: (Magesh Kasthuri https://opensourceforu.com/author/magesh-kasthuri/)
+
+Cacoo: A Lightweight Online Tool for Modelling AWS Architecture
+======
+
+[![AWS][1]][2]
+
+_Cacoo is a simple and efficient online tool that can be used to model diagrams for AWS architecture. It is not specific to AWS architecture and can be used for UML modelling, cloud architecture for GCP, Azure, network architecture, etc. However, this open source tool is one of the most efficient in architecture modelling for AWS solutions._
+
+For a cloud architect, representing the solution’s design as an architecture diagram is much more helpful in explaining the details visually to target audiences like the IT manager, the development team, business stakeholders and the application owner. Though there are many tools like Sparkx Enterprise Architect, Rational Software Modeler and Visual Paradigm, to name a few, these are not so sophisticated and flexible enough for cloud architecture modelling. Cacoo is an advanced and lightweight tool that has many features to support AWS cloud modelling, as can be seen in Figures 1 and 2.
+
+![Figure 1: Template options for AWS architecture diagram][3]
+
+![Figure 2: Sample AWS architecture diagram in Cacoo][4]
+
+![Figure 3: AWS diagram options in Cacoo][5]
+
+Though AWS provides developer tools, there is no built-in tool provided for solution modelling and hence we have to choose an external tool like Cacoo for the design preparation.
+
+We can start with solution modelling in Cacoo either by using the AWS diagram templates, which list pre-built templates for standard architecture diagrams like the network diagram, DevOps solutions, etc. If you want to develop a custom solution from the list of shapes available in the Cacoo online editor, you can choose AWS components like compute, storage, network, analytics, AI tools, etc, and prepare custom architecture to suit your solution, as shown in Figure 2.
+
+There are connectors available to relate the components (for example, how network communication happens, and how ELB or elastic load balancing branches to EC2 storage). Figure 3 lists sample diagram shapes available for AWS architecture diagrams in Cacoo.
+
+![Figure 4: Create an IAM role to connect to Cacoo][6]
+
+![Figure 5: Add the policy to the IAM role to enable Cacoo to import from the AWS account][7]
+
+**Integrating Cacoo with an AWS account to import architecture**
+One of the biggest advantages of Cacoo compared to other cloud modelling tools is that it can import architecture from an AWS account. We can connect to an AWS account, and Cacoo selects the services created in the account with the role attached and prepares an architecture diagram, on the fly.
+
+For this, we need to first create an IAM (Identity and Access Management) role in the AWS account with the account ID and external ID as given in the Cacoo Import AWS Architecture account (Figure 4).
+
+Then we need to add a policy to the IAM role in order to access the components attached to this role from Cacoo. For policy creation, we have sample policies available in Cacoo’s Import AWS Architecture wizard. We just need to copy and paste the policy as shown in Figure 5.
+
+Once this is done, the IAM role is created in the AWS account. Now we need to copy the role ARN (Amazon Resource Name) from the new role created and paste it in Cacoo’s Import AWS Architecture wizard as shown in Figure 6. This imports the architecture of the services created in the account, which is attached to the IAM role we have created and displays it as an architecture diagram.
+
+![Figure 6: Cacoo’s AWS Architecture Import wizard][8]
+
+![Figure 7: Cacoo’ worksheet with AWS imported architecture][9]
+
+Once this is done, we can see the architecture in Cacoo’s worksheet (Figure 7). We can print or export the architecture diagram into PPT, PNG, SVG, PDF, etc, for an architecture document, or for poster printing and other technical discussion purposes, as needed.
+Cacoo is one of the most powerful cloud architecture modelling tools and can be used for visual designs for AWS architecture, on the fly, using online tools without installing any software. The online account is accessible from anywhere and can be used for quick architecture presentation.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/09/cacoo-a-lightweight-online-tool-for-modelling-aws-architecture/
+
+作者:[Magesh Kasthuri][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/magesh-kasthuri/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/07/AWS.jpg?resize=696%2C427&ssl=1 (AWS)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/07/AWS.jpg?fit=750%2C460&ssl=1
+[3]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-1-Template-options-for-AWS-architecture-diagram.jpg?resize=350%2C262&ssl=1
+[4]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-2-Sample-AWS-architecture-diagram-in-Cacoo.jpg?resize=350%2C186&ssl=1
+[5]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-3-AWS-diagram-options-in-Cacoo.jpg?resize=350%2C337&ssl=1
+[6]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-4-Create-an-IAM-role-to-connect-to-Cacoo.jpg?resize=350%2C228&ssl=1
+[7]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-5-Add-the-policy-to-the-IAM-role-to-enable-Cacoo-to-import-from-the-AWS-account.jpg?resize=350%2C221&ssl=1
+[8]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-6-Cacoo%E2%80%99s-AWS-Architecture-Import-wizard.jpg?resize=350%2C353&ssl=1
+[9]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-7-Cacoo%E2%80%99s-worksheet-with-AWS-imported-architecture.jpg?resize=350%2C349&ssl=1
diff --git a/sources/tech/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md b/sources/tech/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md
new file mode 100644
index 0000000000..5de0f02b79
--- /dev/null
+++ b/sources/tech/20190930 How the Linux screen tool can save your tasks - and your sanity - if SSH is interrupted.md
@@ -0,0 +1,119 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How the Linux screen tool can save your tasks – and your sanity – if SSH is interrupted)
+[#]: via: (https://www.networkworld.com/article/3441777/how-the-linux-screen-tool-can-save-your-tasks-and-your-sanity-if-ssh-is-interrupted.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+How the Linux screen tool can save your tasks – and your sanity – if SSH is interrupted
+======
+The Linux screen command can be a life-saver when you need to ensure long-running tasks don't get killed when an SSH session is interrupted. Here's how to use it.
+Sandra Henry-Stocker
+
+If you’ve ever had to restart a time-consuming process because your SSH session was disconnected, you might be very happy to learn about an interesting tool that you can use to avoid this problem – the **screen** tool.
+
+Screen, which is a terminal multiplexor, allows you to run many terminal sessions within a single ssh session, detaching from them and reattaching them as needed. The process for doing this is surprising simple and involves only a handful of commands.
+
+**[ Two-Minute Linux Tips: [Learn how to master a host of Linux commands in these 2-minute video tutorials][1] ]**
+
+To start a screen session, you simply type **screen** within your ssh session. You then start your long-running process, type **Ctrl+A Ctrl+D** to detach from the session and **screen -r** to reattach when the time is right.
+
+[][2]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][2]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+If you’re going to run more than one screen session, a better option is to give each session a meaningful name that will help you remember what task is being handled in it. Using this approach, you would name each session when you start it by using a command like this:
+
+```
+$ screen -S slow-build
+```
+
+Once you have multiple sessions running, reattaching to one then requires that you pick it from the list. In the commands below, we list the currently running sessions before reattaching one of them. Notice that initially both sessions are marked as being detached.
+
+Advertisement
+
+```
+$ screen -ls
+There are screens on:
+ 6617.check-backups (09/26/2019 04:35:30 PM) (Detached)
+ 1946.slow-build (09/26/2019 02:51:50 PM) (Detached)
+2 Sockets in /run/screen/S-shs
+```
+
+Reattaching to the session then requires that you supply the assigned name. For example:
+
+```
+$ screen -r slow-build
+```
+
+The process you left running should have continued processing while it was detached and you were doing some other work. If you ask about your screen sessions while using one of them, you should see that the session you’re currently reattached to is once again “attached.”
+
+```
+$ screen -ls
+There are screens on:
+ 6617.check-backups (09/26/2019 04:35:30 PM) (Attached)
+ 1946.slow-build (09/26/2019 02:51:50 PM) (Detached)
+2 Sockets in /run/screen/S-shs.
+```
+
+You can ask what version of screen you’re running with the **-version** option.
+
+```
+$ screen -version
+Screen version 4.06.02 (GNU) 23-Oct-17
+```
+
+### Installing screen
+
+If “which screen” doesn’t provide information on screen, it probably isn't installed on your system.
+
+```
+$ which screen
+/usr/bin/screen
+```
+
+If you need to install it, one of the following commands is probably right for your system:
+
+```
+sudo apt install screen
+sudo yum install screen
+```
+
+The screen tool comes in handy whenever you need to run time-consuming processes that could be interrupted if your SSH session for any reason disconnects. And, as you've just seen, it’s very easy to use and manage.
+
+Here's a recap of the commands used above:
+
+```
+screen -S start a session
+Ctrl+A Ctrl+D detach from a session
+screen -ls list sessions
+screen -r reattach a session
+```
+
+While there is more to know about **screen**, including additional ways that you can maneuver between screen sessions, this should get you started using this handy tool.
+
+Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3441777/how-the-linux-screen-tool-can-save-your-tasks-and-your-sanity-if-ssh-is-interrupted.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
+[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[3]: https://www.facebook.com/NetworkWorld/
+[4]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20191001 How to create the data structure for a Corteza Low Code application.md b/sources/tech/20191001 How to create the data structure for a Corteza Low Code application.md
new file mode 100644
index 0000000000..6e065ac302
--- /dev/null
+++ b/sources/tech/20191001 How to create the data structure for a Corteza Low Code application.md
@@ -0,0 +1,225 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to create the data structure for a Corteza Low Code application)
+[#]: via: (https://opensource.com/article/19/10/corteza-low-code-data-structure)
+[#]: author: (Lenny Horstink https://opensource.com/users/lenny-horstink)
+
+How to create the data structure for a Corteza Low Code application
+======
+Corteza is an open source alternative to Salesforce. Learn how to use it
+in this series.
+![Green graph of measurements][1]
+
+In the [first article][2] in this series, I showed how to create a custom application to track donations using Corteza Low-Code, a graphical user interface- (GUI) and web-based development environment that serves as an alternative to Salesforce. So far, the Donations application merely exists, but this article explains how to make it do something by populating it with a data structure using modules and fields.
+
+Modules and fields exist inside your application. (In programming terminology, they are "locally defined.") Modules and fields define places where data is stored in your application. Without modules and fields, your application has no memory nor anything to work with, so defining them is the next step when creating a new app.
+
+The [Donations application][3] is available on the Corteza community server. You need to be logged in or create a free Corteza community server account to check it out.
+
+### Enter the application's admin area
+
+To enter the admin area of an application, you first need to open the application inside Corteza Low-Code. To enter the Donations application created in the first part of this series:
+
+ 1. Enter Corteza. (Read [_Intro to Corteza, an open source alternative to Salesforce_][4] if you need some background on this.)
+ 2. Click on the **+** button to create a new tab.
+ 3. Select Corteza Low-Code.
+ 4. Click on the Donations namespace to enter the Donations application.
+
+
+
+Since the Donations application doesn't have any modules or pages yet, the only thing you see is an **Admin panel** link on the right. If the applications had pages, it would show the main menu and the **Admin panel** link on the far right.
+
+![Open Corteza Low Code admin panel][5]
+
+Click on it to enter the application's admin area. There are four menu items:
+
+![Corteza Low Code admin panel menu][6]
+
+ * **Modules:** Create or edit modules and fields
+ * **Pages:** Define the visual part of your application
+ * **Charts:** Create charts to add to pages
+ * **Automation:** Add automation rules to automate business processes and workflows
+
+
+
+The **Public pages** link takes you back to your application.
+
+### Create modules and fields
+
+Modules and fields define what data you need to store in your application and how that data links to other data. If you've ever built a database with [LibreOffice Base][7], Filemaker Pro, or a similar application, this might feel familiar—but you don't need any database experience to work with Corteza.
+
+#### Modules
+
+A module is like a table in a database. A simple application typically has a few modules, while bigger applications have many more. Corteza CRM, for example, has over 35. The number of modules an application can have is unlimited.
+
+A new application does not have any modules. You can create one by using the form on top or by importing an existing module from a different application using an export file. You can import and export individual modules or all modules at the same time.
+
+When you create a module, best practice is to give it a descriptive name without spaces and using capital letters on different words, e.g., _Lead_, _Account_, or _CaseUpdate_.
+
+The Donations application includes the following modules:
+
+ * **Contact:** To store the donor's contact data
+ * **ContactDonation:** To track a contact's donation(s)
+ * **Project:** To store a project you can assign donations to
+ * **Note:** To store notes related to a project
+
+
+
+![Donations application modules][8]
+
+#### Fields
+
+Each module consists of a set of fields that define what data you want to store and in what format.
+
+You can add new fields to a module by using the **Add new field** button. This adds a new row with the following fields:
+
+ * **Name:** It must be unique and cannot have spaces, e.g., "firstname." This is not shown to the end user.
+ * **Title:** This is the field's label—the field name the end users see when they view or edit a record. It can contain any character, including spaces. Although it's best practice to keep this title unique, it's not mandatory. An example is "First name."
+ * **Type:** This is where you set the field type. The wrench icon on the right allows you to set more detailed data for the field type.
+ * **Multiple values:** This checkbox is available when you want a field type to allow multiple value entries.
+ * **Required:** This makes the field mandatory for the end user when creating or editing a record.
+ * **Sensitive:** This allows you to mark data that is sensitive, such as name, email, or telephone number, so your application is compliant with privacy regulations such as the [GDPR][9].
+
+
+
+At the end of the row, you can find a **Delete** button (to remove a field) and a **Permission** button (to set read permissions and update field permissions per role).
+
+### Field types
+
+You can select from the following field types. The wrench icon beside the field type provides further options for each case.
+
+ * **Checkbox (Y/N):** This field shows a checkbox to the end user when editing a record. When you click on the wrench icon, you can select what checked and unchecked represent. For example: Yes/No, Active/Inactive, etc.
+ * **DateTime:** This makes a date field. You can select:
+ * Date only
+ * Time only
+ * Past values only
+ * Future value only
+ * Output relative value (e.g., three days ago)
+ * Custom output format (see [Moment.js][10] for formatting options)
+ * **Email:** This field auto-validates whether the input is an email and turns it into a clickable email link in record-viewing mode. You can select the **Don't turn email into a link** option to remove the auto-link feature.
+ * **Select:** When you click on the wrench icon, you can use the **Add** button to add as many Select options as you need. You can also set whether the end user can select multiple values at once.
+ * **Number:** This field gives you the option to add a prefix (for example a $ for values in dollars), a suffix (for example % for a number that represents a percentage), and the decimal precision (e.g., zero for whole numbers or two for values like 1.13, 2.44, 3.98), and you can use the **Format Input** field to create more complex formats.
+ * **Record:** This field allows you to link the current module to another module. It will show as a Select to the end user. You can select the module in the **Module name** field and choose the field to use to load the Select options. In **Query fields on search**, you can define what fields you want the user to be able to search on. As with the **Select** field type, you can set whether the user can select multiple values at once.
+ * **String:** By default, a String field is a single-line text-input field, but you can choose to make it multi-line or even a rich text editor.
+ * **URL:** The URL field automatically validates whether the field is a link to a site. You can select the following options for this field:
+ * Trim # from the URL
+ * Trim ? from the URL
+ * Only allow SSL (HTTPS) URLs
+ * Don't turn URL into a link
+ * **User:** This creates a Select field that loads with all users in Corteza. You can preset the value to the current user.
+ * **File:** This creates a **File Upload** button for the end user.
+
+
+
+#### Field types in the Donations application
+
+The Donations application includes the following fields in its four modules.
+
+##### 1\. Contact
+
+![Contact module][11]
+
+ * Name (String)
+ * Email (Email)
+ * Phone (String)
+ * Address (String; _Multi-line_)
+
+
+
+##### 2\. ContactDonation
+
+![Corteza Donations app modules][12]
+
+ * Contact (Record; link to **Contact**)
+ * Donation (Number; _Prefix $_ and _Precision 2_)
+ * Project (Record; link to **Project**)
+
+
+
+##### 3\. Project
+
+![Project module][13]
+
+ * Name (String)
+ * Description (String; _Multi-line_ and _Use rich text editor_)
+ * Status (Select; with options _Planning_, _Active_, and _Finished_)
+ * Start date (DateTime; _Date only_)
+ * Website link (URL)
+ * Donations total (Number; _Prefix $_ and _Precision 2_)
+ * Project owner (User; _Multiple select_ and _Preset with current user_)
+
+
+
+##### 4\. Notes
+
+![Notes module][14]
+
+ * Project (Record; link to **Project**)
+ * Subject (String)
+ * Note (String; _Multi-line_ and _Use rich text editor_)
+ * File (File; _Single image_)
+
+
+
+### Create relationships between modules
+
+Practically every Corteza Low Code application consists of multiple modules that are linked together. For example, projects can have notes or donations can be assigned to different projects. The **Record** field type creates relationships between modules.
+
+The **Record** field type's basic function is to link from module B back to module A. Records in module B are children of records in module A (you could say it's a 1-N relationship).
+
+For example, in the Donations application, the module **Note** has a **Record** field that links to the module **Project**. The end user will see a **Select** field in a **Note** record with the value of the **Project** that the note pertains to.
+
+To create this relationship in the Donations application, select the wrench icon in the **projectId** row:
+
+![Wrench icon][15]
+
+In the popup that opens, select the module the field will link to, the label end users will see, and which fields the end user can search on.
+
+![Setting query fields for search][16]
+
+This creates a simple relationship that allows the **Project** to have **Notes**. A many-to-many relationship between modules is more complex. For example, the Donations application needs to support contacts who make multiple donations and donations that are assigned to different projects. The **ContactDonation** module sits in the middle to manage this.
+
+This module has two fields of the **Record** type. For each, we need to select the correct module and set the label and query fields the user can search on. The Donations application needs the following to be set for the **Contact** and **Project** modules:
+
+![Contact module field settings][17]
+
+![Project module field settings][18]
+
+This creates a many-to-many relationship between modules.
+
+You've now set up a structure for the data in your application. The next step is to create the visual side of your app using Corteza's **Pages** feature. It's easier than you might expect, as you'll see in the third article in this series.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/corteza-low-code-data-structure
+
+作者:[Lenny Horstink][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/lenny-horstink
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_lead-steps-measure.png?itok=DG7rFZPk (Green graph of measurements)
+[2]: https://opensource.com/article/19/9/how-build-application-corteza-low-code-open-source-alternative-salesforce
+[3]: https://latest.cortezaproject.org/compose/ns/donations/
+[4]: https://opensource.com/article/19/8/corteza-open-source-alternative-salesforce
+[5]: https://opensource.com/sites/default/files/uploads/corteza_donationsadminpanel.png (Open Corteza Low Code admin panel)
+[6]: https://opensource.com/sites/default/files/uploads/corteza_donationsmenuadminpanel.png (Corteza Low Code admin panel menu)
+[7]: https://www.libreoffice.org/discover/base/
+[8]: https://opensource.com/sites/default/files/uploads/corteza_donationstmodules.png (Donations application modules)
+[9]: https://eugdpr.org/
+[10]: https://momentjs.com/docs/#/displaying/format/
+[11]: https://opensource.com/sites/default/files/uploads/corteza_contactmodulefields.png (Contact module)
+[12]: https://opensource.com/sites/default/files/uploads/corteza_contactdonationmodule.png (Corteza Donations app modules)
+[13]: https://opensource.com/sites/default/files/uploads/corteza_projectmodule.png (Project module)
+[14]: https://opensource.com/sites/default/files/uploads/corteza_notesmodule.png (Notes module)
+[15]: https://opensource.com/sites/default/files/uploads/corteza_createrelationshipicon.png (Wrench icon)
+[16]: https://opensource.com/sites/default/files/uploads/corteza_queryfieldsonsearch.png (Setting query fields for search)
+[17]: https://opensource.com/sites/default/files/uploads/corteza_modulefieldsettings-contact.png (Contact module field settings)
+[18]: https://opensource.com/sites/default/files/uploads/corteza_modulefieldsettings-project.png (Project module field settings)
diff --git a/sources/tech/20191001 The Best Android Apps for Protecting Privacy and Keeping Information Secure.md b/sources/tech/20191001 The Best Android Apps for Protecting Privacy and Keeping Information Secure.md
new file mode 100644
index 0000000000..6e47df1e3a
--- /dev/null
+++ b/sources/tech/20191001 The Best Android Apps for Protecting Privacy and Keeping Information Secure.md
@@ -0,0 +1,134 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Best Android Apps for Protecting Privacy and Keeping Information Secure)
+[#]: via: (https://opensourceforu.com/2019/10/the-best-android-apps-for-protecting-privacy-and-keeping-information-secure/)
+[#]: author: (Magimai Prakash https://opensourceforu.com/author/magimai-prakash/)
+
+The Best Android Apps for Protecting Privacy and Keeping Information Secure
+======
+
+[![][1]][2]
+
+_Privacy violations and data theft occur every day, making it necessary for all of us to safeguard our data. We trust our smartphones way too much and tend to store personal data on them, ignoring the fact that these devices could easily be compromised. However, there are a few open source apps that can ensure the data on your phone is not compromised. This article lists the best ones._
+
+Everyone is becoming aware about information security. There are plenty of privacy and security apps available in the Google Play store too, but it is not easy to select the right one. Most users prefer free apps, but some of these offer only limited functionality and force users to upgrade to a premium membership, which many cannot afford.
+
+This article sheds light on some FOSS Android apps that will really help in safeguarding your privacy.
+
+![Figure 1: Safe Notes][3]
+
+![Figure 2: Exodus Privacy][4]
+
+**Safe Notes**
+Safe Notes is a companion app for the Protected Text website (__). It is an online encrypted notepad which offers space on a separate site for users to store their notes. To use this service, you do not need to sign up with the website. Instead, you need to choose a site name and a password to protect it.
+
+You have two options to use Safe Notes — you can either use this app to save your notes locally, or you can import your existing Protected Text site in the app. In the latter case, you can synchronise your notes between the app as well as in the Protected Text website.
+
+By default, all the notes will be in an unlocked state. After you have saved your notes, if you want to encrypt them, click on the key icon beside your note and you will be prompted to give a password. After entering the password of your choice, your note will be encrypted and instead of the key icon, you will see an unlocked icon in its place, which means that your note is not locked. To lock your note, click the ‘Unlocked’ icon beside your note — your note will get locked and the password will be removed from your device.
+
+Passwords that you are using are not transmitted anywhere. Even if you are using an existing Protected Text site, your passwords are not transmitted. Only your encrypted notes get sent to the Protected Text servers, so you are in total control. But this also means that you cannot recover your password if you lose it.
+
+Your notes are encrypted by the AES algorithm and SHA 12 for hashing, while SSL is used for data transmission.
+
+![Figure 3: Net Guard][5]
+
+**Exodus Privacy**
+Have you ever wondered how many permissions you are granting to an Android app? While you can see these in the Google Play store, you may not know that some of those permissions are impacting your privacy more severely than you realise.
+
+While permissions are taking control of your device with or without your knowledge, third party trackers also compromise your privacy by stealthily collecting data without your consent. And the worst part is that you have no clue as to how many trackers you have in your Android app.
+
+To view the permissions for an Android app and the trackers in it, use Exodus Privacy.
+
+Exodus Privacy is an Android app that has been created and maintained by a French non-profit organisation. While the app is not capable of any analysis, it will fetch reports from the Exodus Platform for the apps that are installed in your device.
+
+These reports are auto-generated by using the static analysis method and, currently, the Exodus platform contains 58,392 reports. Each report gives you information about the number of trackers and permissions.
+
+Permissions are evaluated using the three levels of Google Permission Classification. These are ‘Normal’, ‘Signature’ and ‘Dangerous’. We should be concerned about the ‘Dangerous’ level because such permissions can access the user’s private and other stored sensitive data.
+
+Trackers are also listed in this app. When you click on a tracker, you will be taken to a page which shows you the other Android apps that have that particular tracker. This can be really useful to know if the same tracker has been used in the other apps that you have installed.
+
+In addition, the reports will contain information such as ‘Fingerprint’ and other geographical details about the app publisher such as ‘Country’, ‘State’ and ‘Locality’.
+
+![Figure 4: xBrowserSync][6]
+
+![Figure 5: Scrambled Exif][7]
+
+**Net Guard**
+Most Android apps need network access to function properly, but offline apps don’t need this to operate. Yet some of these offline apps continue to run in the background and use network access for some reason or the other. As a result, your battery gets drained very quickly and the data plan on your phone gets exhausted faster than you think.
+
+Net Guard solves this problem by blocking the network access to selected apps. Net Guard will only block the outgoing traffic from apps, not what’s incoming.
+
+The Net Guard main window displays all the installed apps. For every app you will see the ‘mobile network’ icon and the ‘Wi-Fi’ icon. When they are both green, it means that Net Guard will allow the app to have network access via the mobile network and Wi-Fi. Alternatively, you can enable any one of them; for example, you can allow the app to use the Internet only via the mobile network by clicking on the ‘Mobile network’ icon to turn it green while the ‘Wi-Fi’ icon is red.
+
+When both the ‘Mobile network’ and ‘Wi-Fi’ icons are red, the app’s outgoing traffic is blocked.
+Also, when ‘Lockdown’ mode is enabled, it will block the network access for all apps except those that are configured to have network access in the ‘Lockdown’ mode too. This is useful when you have very little battery and your data plan is about to expire.
+
+Net Guard can also block network access to the system apps, but please be cautious about this because sometimes, when the user blocks Internet access to some critical system apps, it could result in a malfunction of other apps.
+
+**xBrowserSync**
+xBrowserSync is a free and open source service that helps to sync bookmarks across your devices. Most of the sync services require you to sign up and keep your data with them.
+
+xBrowserSync is an anonymous and secure service, for which you need not sign up. To use this service you need to know your sync ID and have a strong password for it.
+
+Currently, xBrowserSync supports the Mozilla and Chrome browsers; so if you’re using either one of them, you can proceed further. Also, if you have to transfer a huge number of bookmarks from your existing service to xBrowserSync, it is advised that you have a backup of all your bookmarks before you create your first sync.
+
+You can create your first sync by entering a strong password for it. After your sync is created, a unique sync ID will be shown to you, which can be used to sync your bookmarks across your devices.
+
+xBrowserSync encrypts all your data locally before it is synced. It also uses PBKDF2 with 250,000 iterations of SHA-256 for the key derivation to combat brute force attacks. Apart from that, It uses PBKDF2 with 250,000 iterations of SHA-256 for the key derivation to combat brute force attacks. And it uses AES-GCM with a random 16 byte IV (Initialization Vector- a random number that is used with secret key to encrypt the data) with 32-bit char sync ID of the user as a salt value. All of these are in place to ensure that your data cannot be decrypted without your password.
+
+The app provides you with a sleek interface that makes it easy for you to add bookmarks, and share and edit them by adding descriptions and tags to them.
+
+xBrowserSync is currently hosted by four providers, including the official one. So to accommodate all the users, the synced data that isn’t accessed for a long time is removed. If you don’t want to be dependent on other providers, you can host xBrowserSync for yourself.
+
+![Figure 6: Riseup VPN][8]
+
+**Scrambled Exif**
+When we share our photos on social media, sometimes we share the metadata on those photos accidentally. Metadata can be useful for some situations but it can also pose a serious threat to your privacy. A typical photo may consist of the following pieces of data such as ‘date and time’, ‘make and model of the camera’, ‘phone name’ and ‘location’. When all these pieces of data are put together by a system or by a group of people, they are able to determine your location at that particular time.
+
+So if you want to share your photos with your friends as well as on social media without divulging metadata, you can use Scrambled Exif.
+
+Scrambled Exif is a free and open source tool which removes the Exif data from your photos, after installing the app. So when you want to share a photo, you have to click on the ‘Share’ button from the photo, and it will show you the available options for sharing — choose ‘Scrambled Exif’. Once you have done that, all your metadata is removed from that photo, and you will again be shown the share list. From there on, you can share your photos normally.
+
+**Riseup VPN**
+Riseup VPN (Virtual Private Network) is a tool that enables you to protect your identity, as well as bypass the censorship that is imposed on your network and the encryption of your Internet traffic. Some VPN service providers log your IP address and quietly betray your trust.
+
+Riseup VPN is a personal VPN service offered by the Riseup Organization, which is a non-profit that fights for a free Internet by providing tools and other resources for anyone who wants to enjoy the Internet without being restrained.
+
+To use the Riseup VPN, you do not need to register, nor do you need to configure the settings — it is all prepped for you. All you need is to click on the ‘Turn on’ button and within a few moments, you can see that your traffic is routed through the Riseup networks. By default, Riseup does not log your IP address.
+
+At present, Riseup VPN supports the Riseup networks in Hong Kong and Amsterdam.
+
+![Figure 7: Secure Photo Viewer][9]
+
+**Secure Photo Viewer**
+When you want to show a cool picture of yours to your friends by giving your phone to them, some of them may get curious and go to your gallery to view all your photos. Once you unlock the gallery, you cannot control what should be shown and what ought to be hidden, as long as your phone is with them.
+
+Secure Photo Viewer fixes this problem. After installing it, choose the photos or videos you want to show to a friend and click ‘share’. This will show ‘Secure Photo Viewer’ in the available options. Once you click on it, a new window will open and it will instruct you to lock your device. Within a few seconds the photo you have chosen will show up on the screen. Now you can show your friends just that photo, and they can’t get into your gallery and view the rest of your private photos.
+
+Most of the apps listed here are available on F-Droid as well as on Google Play. I recommend using F-Droid because every app has been compiled via its source code by F-Droid itself, so it is unlikely to have malicious code injected in it.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/the-best-android-apps-for-protecting-privacy-and-keeping-information-secure/
+
+作者:[Magimai Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/magimai-prakash/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Android-Apps-security.jpg?resize=696%2C658&ssl=1 (Android Apps security)
+[2]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Android-Apps-security.jpg?fit=890%2C841&ssl=1
+[3]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-1-Safe-Notes.jpg?resize=211%2C364&ssl=1
+[4]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-2-Exodus-Privacy.jpg?resize=225%2C386&ssl=1
+[5]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-3-Net-Guard.jpg?resize=226%2C495&ssl=1
+[6]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-4-xBrowserSync.jpg?resize=251%2C555&ssl=1
+[7]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-5-Scrambled-Exif-350x535.jpg?resize=235%2C360&ssl=1
+[8]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-6-Riseup-VPN.jpg?resize=242%2C536&ssl=1
+[9]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/09/Figure-7-Secure-Photo-Viewer.jpg?resize=228%2C504&ssl=1
diff --git a/sources/tech/20191002 How to create the user interface for your Corteza Low Code application.md b/sources/tech/20191002 How to create the user interface for your Corteza Low Code application.md
new file mode 100644
index 0000000000..52056a29ac
--- /dev/null
+++ b/sources/tech/20191002 How to create the user interface for your Corteza Low Code application.md
@@ -0,0 +1,240 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to create the user interface for your Corteza Low Code application)
+[#]: via: (https://opensource.com/article/19/10/corteza-low-code-user-interface)
+[#]: author: (Lenny Horstink https://opensource.com/users/lenny-horstink)
+
+How to create the user interface for your Corteza Low Code application
+======
+Add a user-friendly interface to your application built in Corteza Low
+Code, an open source alternative to Salesforce.
+![metrics and data shown on a computer screen][1]
+
+In the first two articles in this series, I explained how to use Corteza Low Code to [create an application][2] to track donations and [set up its data structure][3] with modules and fields. In the third article, I will explain how to create the graphical part of the Donations application.
+
+**Pages** is the HTTP web layer of Corteza Low Code. For comfort of design and to ensure your application is responsive and mobile-ready by default, Pages are built-in blocks. Each block can be resized and dragged wherever you desire. In all blocks, you can define the title, the description, and the layout.
+
+There are two types of pages: **Record** pages (which show data for or related to a single record) and **List** pages (which show a searchable list of multiple records). Each type is described below.
+
+### Record pages
+
+A module without a Record page cannot do anything. To store data inside a module, you need to create a Record page and add it to a module by selecting the appropriate **Page builder** button on the **Modules** page. This opens the drag-and-drop page editor.
+
+The Donations application has four modules, and each one has the **Page builder** link:
+
+![Page Builder Link][4]
+
+First, create the record page for the **Contact** module. When you click on the **Page builder** link, an empty record page opens. Add blocks with the **\+ Add block** button.
+
+![Add block button][5]
+
+There are multiple block types available.
+
+![Block types][6]
+
+The "Contact" record page in the "Donations" application uses two block types: **Record** and **Record list**.
+
+#### Record blocks
+
+The **Record** block is the most important block for a Record page. You can select the block's layout and the fields you want to show. The **Contact** record page needs to show: _Name_, _Email_, _Phone,_ and _Address_. Select those fields and hit **Save and close**, and the block will be added.
+
+![Form to change Record block][7]
+
+When you view a record, the values of these fields are shown as strings, and when you add or edit a record, these fields turn into form-input fields.
+
+Tip: You can drag-and-drop the fields and place them in any order you prefer.
+
+#### Record list blocks
+
+The **Contact** page will show the list of donation each contact has given. Create a list of records by selecting the **Record list** block.
+
+Make **Donations** the title, and select the **ContactDonation** module in the **Module** field. After selecting a module, the columns that are available are populated automatically, and you can select the columns you want to show in the **Record list**: _Donation_, _Project_, and the system field _Created at_.
+
+If you saved the **Record list** block right now, you would see all donations from all contacts. Because you want to show the donations related to a single contact record, you need to add a **prefilter**.
+
+The **Prefilter records** field allows simplified SQL "Where" conditions, and variables like **${recordID}**, **${ownerID}**, and **${userID}** are evaluated (when available). For the **Record list**, you want to filter **ContactDonation** records by contact, so you need to fill in: **${recordID} = contactId**. Note: **contactId** is a **Record** field in the module **ContactDonation**. Take a look back at the [second article][3] in this series for more info about linking modules.
+
+You also want to be able to sort a contact's donations by date. This can be done in the **Presort records** field by inserting **createdAt DESC**. This field supports simplified SQL _Order by_ condition syntax.
+
+You can also select to hide or show the **New record** button and Search box, and you can define the number of records shown. A best practice is to adjust this number to the size of the block.
+
+![Form to change Record list block][8]
+
+To save the block and add it to the page, hit **Save and close**. Now the second block has been added to the page.
+
+#### Other block types
+
+Other block types are:
+
+ * **Content:** This block allows you to add fixed text, which you can create with a rich text editor. This is ideal for "help" texts or links to resources, such as the sales handbook on an intranet.
+ * **Chart:** Inserts charts that have been created with the chart builder. This is very useful when you are creating dashboards.
+ * **Social media feed:** You can show live content from Twitter here—either a fixed Twitter feed (which is shown in all records) or from a Module field that represents a Twitter link (which enables each record to have his own feed).
+ * **Automation:** In this block, you can add automation rules that have a manual trigger and that are available for the module, as well as automation rules with no primary module. They are shown to end users as buttons. You can format the automation rule buttons by inserting custom text and selecting a style, and you can change the order of them (when you have multiple buttons) with a drag-and-drop.
+ * **Calendar:** This block inserts a calendar, which can be shown in the following formats:
+ * Month
+ * Month agenda
+ * Week agenda
+ * Day agenda
+ * Month list
+ * Week list
+ * Day list The source of the calendar is a list of records from one or multiple modules. For each source, you can select which field represents the title, start date, and end date of the event.
+ * **File:** You can upload a file and show it on the page. Just like the **Content** block, the content of this block will be the same for all records. To have files that are related to a record, you need to use the **File** field type when creating fields in a module.
+
+
+
+Next, add the Record pages for the other modules in the Donations application. Once that is done, you will see the following list under **Pages**:
+
+![List of pages][9]
+
+### Change the page layout
+
+After adding blocks to pages, such as the **Contact Details** and **Donations** blocks in the **Contact** module's Record page, you can resize and position them to create the layout you want.
+
+![Moving blocks around][10]
+
+The end result is:
+
+![Corteza layout][11]
+
+Corteza Low-Code is responsive by default, so the blocks will resize and reposition automatically on devices with small screens.
+
+### List pages
+
+List pages are not related to any single record; rather, they show lists of records. This page type is used to create a home page, list of contacts, list of projects, dashboards, etc. List pages are important because you can't enter new records without viewing a list because the **Add new record** button is shown on lists.
+
+For the Donations application, create the following list pages: _Home_, _Contacts_, and _Projects_.
+
+To create a List page, you need to go to the **Pages** administrative page and enter a title in the **Create a new page** box at the top. When you submit this form, it opens the **Edit page** form, which allows you to add a page description (for internal use; the end user will not see it), and you can set the page to **Enabled** so it can be accessed.
+
+Your list of pages will now look like:
+
+![List of pages][12]
+
+You can drag-and-drop to rearrange this to:
+
+![List of pages][13]
+
+Rearranging pages makes it easier to maintain the application. It also allows you to generate the application menu structure because List pages (but not Record pages) are shown as menu items.
+
+Adding content to each List page is exactly the same as adding blocks to Record pages. The only difference is that you cannot select the **Record** block type (because it is related to a single record).
+
+### Create a menu
+
+The menu in a Corteza Low-Code application is automatically generated by the tree of pages on the admin page **Pages**. It only shows List pages and ignores Record pages.
+
+To reorder the menu, simply drag-and-drop the pages in the desired order within the tree of pages.
+
+### Add charts
+
+Everybody loves charts and graphs. If pictures are worth 1,000 words, then you can create a priceless application in Corteza.
+
+Corteza Low-Code comes with a chart builder that allows you to build line, bar, pie, and donut charts:
+
+![Chart types available in Corteza Low Code][14]
+
+As an example, add a chart that shows how many donations have been made to each Project. To begin, enter the **Charts** page in the admin menu.
+
+![Corteza charts admin page][15]
+
+To create a new chart, use the **Create a new chart** field.
+
+Inside the chart builder, you will find the following fields:
+
+ * **Name:** Enter a name for the chart; e.g., _Donations_.
+ * **Module:** This is the module that provides the data to the chart.
+ * **Filters:** You can select one of the predefined filters, such as **Records created this year**, or add any custom filter (such as **status = "Active"**).
+ * **Dimensions:** These can be **Datetime** and **Select** fields. Datetime fields allow grouping (e.g., by day, by week, by month). The **Skip missing values** option is handy to remove values that would return null (e.g., records with incomplete data), and **Calculate how many labels can be shown** can avoid overlapping labels (which is useful for charts with many dates on the X-axis).
+ * **Metrics:** Metrics are numeric fields and have a predefined _count_ option. You can add multiple metric blocks and give each a different label, field (source), function (COUNTD, SUM, MAX, MIN, AVG, or STD, if possible), output (line or bar), and color.
+
+
+
+This sample chart uses the **ContactDonation** module and shows total donations per day.
+
+![Chart of donations per day][16]
+
+The final step is to add a chart to a page. To add this chart to the home page:
+
+ * Enter **Pages** in the admin menu.
+ * Click on the **Page builder** link of the **Home** page.
+ * Add a page block of the type **Chart**, add a block title, and select the chart.
+ * Resize and reposition the block (or blocks) to make the layout look nice.
+
+
+
+![Chart added][17]
+
+When you save the page and enter your Donation application (via the **Public pages** link on the top right), you will see the home page with the chart.
+
+![Chart displayed on Corteza UI][18]
+
+### Add automation
+
+Automation can make your Corteza Low Code application more efficient. With the Automation tool, you can create business logic that evaluates records automatically when they are created, updated, or deleted, or you can execute a rule manually.
+
+Triggers are written in JavaScript, one of the most used programming languages in the world, enabling you to write simple code that can evaluate, calculate, and transform data (such as numbers, strings, or dates). Corteza Low Code comes with extra functions that allow you to access, create, save, or delete records; find users; send notifications via email; use Corteza Messaging; and more.
+
+[Corteza CRM][19] has an extensive set of automation rules that can be used as examples. Some of them are:
+
+ * Account: Create new case
+ * Account: Create new opportunity
+ * Case: Insert case number
+ * Contract: Send contract to custom email
+ * Lead: Convert a lead into an account and opportunity
+ * Opportunity: Apply price book
+ * Opportunity: Generate new quote
+ * Quote: Submit quote for approval
+
+
+
+A complete manual on how to use the automation module, together with code examples, is in development.
+
+### Deploy an application
+
+Deploying a Corteza Low Code application is very simple. As soon as it's Enabled, it's deployed and available in the Corteza Low Code Namespaces menu. Once deployed, you can start using your application!
+
+### For more information
+
+As I mentioned in parts 1 and 2 of this series, the complete Donations application created in this series is available on the [Corteza community server][20]. You need to be logged in or create a free Corteza community server account to check it out.
+
+Also, check out the documentation on the [Corteza website][21] for other, up-to-date user and admin tutorials.
+
+If you have any questions—or would like to contribute—please join the [Corteza Community][22]. After you log in, please introduce yourself in the #Welcome channel.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/corteza-low-code-user-interface
+
+作者:[Lenny Horstink][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/lenny-horstink
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
+[2]: https://opensource.com/article/19/9/how-build-application-corteza-low-code-open-source-alternative-salesforce
+[3]: https://opensource.com/article/19/9/creating-data-structure-corteza-low-code
+[4]: https://opensource.com/sites/default/files/uploads/corteza_donationspagebuilderlink.png (Page Builder Link)
+[5]: https://opensource.com/sites/default/files/uploads/corteza_addblock.png (Add block button)
+[6]: https://opensource.com/sites/default/files/uploads/corteza_blocktypes.png (Block types)
+[7]: https://opensource.com/sites/default/files/uploads/corteza_changerecordblock.png (Form to change Record block)
+[8]: https://opensource.com/sites/default/files/uploads/corteza_changerecordlistblock.png (Form to change Record list block)
+[9]: https://opensource.com/sites/default/files/uploads/corteza_pageslist.png (List of pages)
+[10]: https://opensource.com/sites/default/files/uploads/corteza_movingblocks.png (Moving blocks around)
+[11]: https://opensource.com/sites/default/files/uploads/corteza_layoutresult.png (Corteza layout)
+[12]: https://opensource.com/sites/default/files/uploads/corteza_pageslist2.png (List of pages)
+[13]: https://opensource.com/sites/default/files/uploads/corteza_pageslist3.png (List of pages)
+[14]: https://opensource.com/sites/default/files/uploads/corteza_charttypes.png (Chart types available in Corteza Low Code)
+[15]: https://opensource.com/sites/default/files/uploads/corteza_createachart.png (Corteza charts admin page)
+[16]: https://opensource.com/sites/default/files/uploads/corteza_chartdonationsperday.png (Chart of donations per day)
+[17]: https://opensource.com/sites/default/files/uploads/corteza_addchartpreview.png (Chart added)
+[18]: https://opensource.com/sites/default/files/uploads/corteza_pageshowingchart.png (Chart displayed on Corteza UI)
+[19]: https://cortezaproject.org/technology/core/corteza-crm/
+[20]: https://latest.cortezaproject.org/compose/ns/donations/
+[21]: https://www.cortezaproject.org/
+[22]: https://latest.cortezaproject.org/
diff --git a/sources/tech/20191003 4 open source eBook readers for Android.md b/sources/tech/20191003 4 open source eBook readers for Android.md
new file mode 100644
index 0000000000..f2c6638bc4
--- /dev/null
+++ b/sources/tech/20191003 4 open source eBook readers for Android.md
@@ -0,0 +1,174 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (4 open source eBook readers for Android)
+[#]: via: (https://opensource.com/article/19/10/open-source-ereaders-android)
+[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
+
+4 open source eBook readers for Android
+======
+Looking for a new eBook app? Check out these four solid, open source
+eBook readers for Android.
+![Computer browser with books on the screen][1]
+
+Who doesn't like a good read? Instead of frittering away your time on social media or a [messaging app][2], you can enjoy a book, magazine, or another document on your Android-powered phone or tablet.
+
+To do that, all you need is the right eBook reader app. So let's take a look at four solid, open source eBook readers for Android.
+
+### Book Reader
+
+Let's start off with my favorite open source Android eBook reader: [Book Reader][3]. It's based on the older, open source version of the now-proprietary FBReader app. Like earlier versions of its progenitor, Book Reader is simple and minimal, but it does a great job.
+
+**Pros of Book Reader:**
+
+ * It's easy to use.
+ * The app's interface follows Android's [Material Design guidelines][4], so it's very clean.
+ * You can add bookmarks to an eBook and share text with other apps on your device.
+ * There's growing support for languages other than English.
+
+
+
+**Cons of Book Reader:**
+
+ * Book Reader has a limited number of configuration options.
+ * There's no built-in dictionary or support for an external dictionary.
+
+
+
+**Supported eBook formats:**
+
+Book Reader supports EPUB, .mobi, PDF, [DjVu][5], HTML, plain text, Word documents, RTF, and [FictionBook][6].
+
+![Book Reader Android app][7]
+
+Book Reader's source code is licensed under the GNU General Public License version 3.0, and you can find it on [GitLab][8].
+
+### Cool Reader
+
+[Cool Reader][9] is a zippy and easy-to-use eBook app. While I think the app's icons are reminiscent of those found in Windows Vista, Cool Reader does have several useful features.
+
+**Pros of Cool Reader:**
+
+ * It's highly configurable. You can change fonts, line and paragraph spacing, hyphenation, font sizes, margins, and background colors.
+ * You can override the stylesheet in a book. I found this useful with two or three books that set all text in small capital letters.
+ * It automatically scans your device for new books when you start it up. You can also access books on [Project Gutenberg][10] and the [Internet Archive][11].
+
+
+
+**Cons of Cool Reader:**
+
+ * Cool Reader doesn't have the cleanest or most modern interface.
+ * While it's usable out of the box, you really need to do a bit of configuration to make Cool Reader comfortable to use.
+ * The app's default dictionary is proprietary, although you can swap it out for [an open one][12].
+
+
+
+**Supported eBook formats:**
+
+You can use Cool Reader to browse EPUB, FictionBook, plain text, RTF, HTML, [Compiled HTML Help][13] (.chm), and TCR (the eBook format for the Psion series of handheld computers) files.
+
+![Cool Reader Android app][14]
+
+Cool Reader's source code is licensed under the GNU General Public License version 2, and you can find it on [Sourceforge][15].
+
+### KOReader
+
+[KOReader][16] was originally created for [E Ink][17] eBook readers but found its way to Android. While testing it, I found KOReader to be both useful and frustrating in equal measures. It's definitely not a bad app, but it's not my first choice.
+
+**Pros of KOReader:**
+
+ * It's highly configurable.
+ * It supports multiple languages.
+ * It allows you to look up words using a [dictionary][18] (if you have one installed) or Wikipedia (if you're connected to the internet).
+
+
+
+**Cons of KOReader:**
+
+ * You need to change the settings for each book you read. KOReader doesn't remember settings when you open a new book.
+ * The interface is reminiscent of a dedicated eBook reader. The app doesn't have that Android look and feel.
+
+
+
+**Supported eBook formats:**
+
+You can view PDF, DjVu, CBT, and [CBZ][5] eBooks. It also supports EPUB, FictionBook, .mobi, Word documents, text files, and [Compiled HTML Help][13] (.chm) files.
+
+![KOReader Android app][19]
+
+KOReader's source code is licensed under the GNU Affero General Public License version 3.0, and you can find it on [GitHub][20].
+
+### Booky McBookface
+
+Yes, that really is the name of [this eBook reader][21]. It's the most basic of the eBook readers in this article but don't let that (or the goofy name) put you off. Booky McBookface is easy to use and does the one thing it does quite well.
+
+**Pros of Booky McBookface:**
+
+ * There are no frills. It's just you and your eBook.
+ * The interface is simple and clean.
+ * Long-tapping the app's icon in the Android Launcher pops up a menu from which you can open the last book you were reading, get a list of unread books, or find and open a book on your device.
+
+
+
+**Cons of Booky McBookface:**
+
+ * The app has few configuration options—you can change the size of the font and the brightness, and that's about it.
+ * You need to use the buttons at the bottom of the screen to navigate through an eBook. Tapping the edges of the screen doesn't work.
+ * You can't add bookmarks to an eBook.
+
+
+
+**Supported eBook formats:**
+
+You can read eBooks in EPUB, HTML, or plain text formats with Booky McBookface.
+
+![Booky McBookface Android app][22]
+
+Booky McBookface's source code is available under the GNU General Public License version 3.0, and you can find it [on GitHub][23].
+
+Do you have a favorite open source eBook reader for Android? Share it with the community by leaving a comment.
+
+Have you ever downloaded an Android app only to find that it wants access to all your phone's...
+
+There is a rich and growing ecosystem of open source applications for mobile devices, just like the...
+
+With these seven open source apps, you can play chess against your phone or an online opponent,...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/open-source-ereaders-android
+
+作者:[Scott Nesbitt][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/scottnesbitt
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_browser_program_books_read.jpg?itok=iNMWe8Bu (Computer browser with books on the screen)
+[2]: https://opensource.com/article/19/3/open-messenger-client
+[3]: https://f-droid.org/en/packages/com.github.axet.bookreader/
+[4]: https://material.io/design/
+[5]: https://opensource.com/article/19/3/comic-book-archive-djvu
+[6]: https://en.wikipedia.org/wiki/FictionBook
+[7]: https://opensource.com/sites/default/files/uploads/book_reader-book-list.png (Book Reader Android app)
+[8]: https://gitlab.com/axet/android-book-reader/tree/HEAD
+[9]: https://f-droid.org/en/packages/org.coolreader/
+[10]: https://www.gutenberg.org/
+[11]: https://archive.org
+[12]: http://aarddict.org/
+[13]: https://fileinfo.com/extension/chm
+[14]: https://opensource.com/sites/default/files/uploads/cool_reader-icons.png (Cool Reader Android app)
+[15]: https://sourceforge.net/projects/crengine/
+[16]: https://f-droid.org/en/packages/org.koreader.launcher/
+[17]: https://en.wikipedia.org/wiki/E_Ink
+[18]: https://github.com/koreader/koreader/wiki/Dictionary-support
+[19]: https://opensource.com/sites/default/files/uploads/koreader-lookup.png (KOReader Android app)
+[20]: https://github.com/koreader/koreader
+[21]: https://f-droid.org/en/packages/com.quaap.bookymcbookface/
+[22]: https://opensource.com/sites/default/files/uploads/booky_mcbookface-menu.png (Booky McBookface Android app)
+[23]: https://github.com/quaap/BookyMcBookface
diff --git a/sources/tech/20191003 Creating a perfect landing page for free.md b/sources/tech/20191003 Creating a perfect landing page for free.md
new file mode 100644
index 0000000000..877e133f50
--- /dev/null
+++ b/sources/tech/20191003 Creating a perfect landing page for free.md
@@ -0,0 +1,74 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Creating a perfect landing page for free)
+[#]: via: (https://opensourceforu.com/2019/10/creating-a-perfect-landing-page-for-free/)
+[#]: author: (Jagoda Glowacka https://opensourceforu.com/author/jagoda-glowacka/)
+
+Creating a perfect landing page for free
+======
+
+[![][1]][2]
+
+_Nowadays running an online business has become more popular than doing it in a traditional way. Entrepreneurs are lured by the lack of barriers of entry, simplicity of reaching wide ranges of customers and endless possibilities of growing. With Internet and new technologies it is far easier today to become an online businessman than a traditional one. However, one thing is to become an entrepreneur and another is to keep oneself on the market._
+
+Since the digital business world is in constant expansion the competition is getting fiercer and the quality of products and services offered increases. It makes it more troublesome to be noticed in the crowd of alike ambitious online businessmen offering similar products. In order to survive you need to use all the cards you have and even if you have already done that you should always think about improvement and innovation.
+
+One of this card should definitely be a decent nice-looking and attention-grabbing landing page that boosts your conversions and build trust among your potential customers. Since today you can easily [_create landing page_][3] for free you should never deprive your business of one. As it is a highly powerful tool than can move your business off the ground and gain a lot of new leads. However, in order to do all of this it has to be a high quality landing page that will be impeccable for your targeted audience.
+
+**A landing page is a must for every online business**
+
+The concept of landing pages arrived a few years back but these few years were enough to settle down and become the necessity of every online business. At the beginning loads of businessmen decided to ignore their existence and preferred to persuade themselves that a homepage is already enough. Well, sorry to break it for them – but it’s not.
+
+**Homepage should never equal landing page**
+
+Obviously, a homepage is also a must for every online business and without it the business can only exist in entrepreneur’s imagination ;-) However, an essence of a homepage is not the same what an essence of a landing page is. And even the most state-of-the-art business website does not replace a good piece of landing page.
+
+Homepages do serve multiple purposes but none of them is focused on attracting new clients as they don’t clearly encourage visitors to take an action such as subscribing or filling out a contact form. Homepages’ primary focus is the company itself – its full offer, history or founder and it makes them full of distracting information and links. And last but not least, the information on them is not put in order that would make the visitors desire the product instantly.
+
+**Landing pages impose action**
+
+Landing page is a standalone website and serves as a first-impression maker among the visitors. It is the place where your new potential customers land and in order to keep them you need to show them instantly that your solution is something they need. It should quickly grab attention of the visitors, engage them in an action and make them interested in your product or service. And it should do all of that as quickly as possible.
+
+Therefore, landing pages are a great tool which helps you increase your conversion rate, getting information about your visitors, engage new potential leads into action (such as subscribing for a free trial or a newsletter what provide you with personal information about them) and make them believe your product or service is worthwhile. However, in order to fulfill all these functions it needs to have all the necessary landing page elements and it has to be a landing page of high quality.
+
+**Every landing page needs some core features**
+In order to create a perfectly converting landing page you need to plan its structure and put all the essential elements on it that will help you achieve your goals. The core elements that should be placed on every landing page are:
+
+ * headlines which should be catchy, keywords focused and eye-catching. It is the first, and sometimes only, element that visitors read so it has to be well-thought and a little intriguing,
+ * subheadlines which should be completion of headlines, a little bit more descriptive but still keywords focused and catchy,
+ * benefits of your solution clearly outlined and demonstrating high value and absolute necessity of purchasing it for your potential leads,
+ * call-to-action in a visible place and allowing the visitors to subscribe for a free trial, coupons, a newsletter or purchase right away.
+
+
+
+All of these features put together in a right order enable you to boost your conversions and make your product or service absolutely desirable for your customers. They are all the core elements of every landing page and without any of them there is a higher risk of landing page failure.
+
+However, putting all the elements is one thing but designing a landing page is another. When planning its structure you should always have in mind who your target is and adjust your landing page look accordingly. You should always keep up with landing page trends which make your landing page up-to-date and appealing for the customers.
+
+If it all sounds quite confusing and you are a landing page newbie or still don’t really feel confident in landing page creation you may facilitate this task and use a highly powerful tool the landing page savvies have prepared for you. And that is a [_free landing page creator_][4] which help you create a high quality and eye-catching landing page in less than an hour.
+
+**Creating a free landing page is a piece of cake**
+Today the digital marketing world is full of bad quality landing pages that don’t truly work miracles for businesses. In order to give you all the bonanza the quality of landing page is crucial and choosing a landing page builder designed by landing page experts is one of the most secure options to create a landing page of excellence.
+
+They are online tools which slightly guide you through the whole creation process making it effortless and quick. They are full of pre-installed features such as landing page layouts and templates, drag and drop function, simple copying and moving or tailoring your landing page to every type of device. You can use these builders up to 14 days for free thanks to a free trial period. Quite nice, huh? ;-)
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/creating-a-perfect-landing-page-for-free/
+
+作者:[Jagoda Glowacka][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/jagoda-glowacka/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/09/Long-wait-open-for-webpage-in-broser-using-laptop.jpg?resize=696%2C405&ssl=1 (Long wait open for webpage in broser using laptop)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2017/09/Long-wait-open-for-webpage-in-broser-using-laptop.jpg?fit=1996%2C1162&ssl=1
+[3]: https://landingi.com/blog/how-to-create-landing-page
+[4]: https://landingi.com/free-landing-page
diff --git a/sources/tech/20191003 SQL queries don-t start with SELECT.md b/sources/tech/20191003 SQL queries don-t start with SELECT.md
new file mode 100644
index 0000000000..18fb43d437
--- /dev/null
+++ b/sources/tech/20191003 SQL queries don-t start with SELECT.md
@@ -0,0 +1,144 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (SQL queries don't start with SELECT)
+[#]: via: (https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/)
+[#]: author: (Julia Evans https://jvns.ca/)
+
+SQL queries don't start with SELECT
+======
+
+Okay, obviously many SQL queries do start with `SELECT` (and actually this post is only about `SELECT` queries, not `INSERT`s or anything).
+
+But! Yesterday I was working on an [explanation of window functions][1], and I found myself googling “can you filter based on the result of a window function”. As in – can you filter the result of a window function in a WHERE or HAVING or something?
+
+Eventually I concluded “window functions must run after WHERE and GROUP BY happen, so you can’t do it”. But this led me to a bigger question – **what order do SQL queries actually run in?**.
+
+This was something that I felt like I knew intuitively (“I’ve written at least 10,000 SQL queries, some of them were really complicated! I must know this!“) but I struggled to actually articulate what the order was.
+
+### SQL queries happen in this order
+
+I looked up the order, and here it is! (SELECT isn’t the first thing, it’s like the 5th thing!) ([here it is in a tweet][2]).
+
+(I really want to find a more accurate way of phrasing this than “sql queries happen/run in this order” but I haven’t figured it out yet)
+
+
+
+In a non-image format, the order is:
+
+ * `FROM/JOIN` and all the `ON` conditions
+ * `WHERE`
+ * `GROUP BY`
+ * `HAVING`
+ * `SELECT` (including window functions)
+ * `ORDER BY`
+ * `LIMIT`
+
+
+
+### questions this diagram helps you answer
+
+This diagram is about the _semantics_ of SQL queries – it lets you reason through what a given query will return and answers questions like:
+
+ * Can I do `WHERE` on something that came from a `GROUP BY`? (no! WHERE happens before GROUP BY!)
+ * Can I filter based on the results of a window function? (no! window functions happen in `SELECT`, which happens after both `WHERE` and `GROUP BY`)
+ * Can I `ORDER BY` based on something I did in GROUP BY? (yes! `ORDER BY` is basically the last thing, you can `ORDER BY` based on anything!)
+ * When does `LIMIT` happen? (at the very end!)
+
+
+
+**Database engines don’t actually literally run queries in this order** because they implement a bunch of optimizations to make queries run faster – we’ll get to that a little later in the post.
+
+So:
+
+ * you can use this diagram when you just want to understand which queries are valid and how to reason about what results of a given query will be
+ * you _shouldn’t_ use this diagram to reason about query performance or anything involving indexes, that’s a much more complicated thing with a lot more variables
+
+
+
+### confounding factor: column aliases
+
+Someone on Twitter pointed out that many SQL implementations let you use the syntax:
+
+```
+SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*)
+FROM table
+GROUP BY full_name
+```
+
+This query makes it _look_ like GROUP BY happens after SELECT even though GROUP BY is first, because the GROUP BY references an alias from the SELECT. But it’s not actually necessary for the GROUP BY to run after the SELECT for this to work – the database engine can just rewrite the query as
+
+```
+SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*)
+FROM table
+GROUP BY CONCAT(first_name, ' ', last_name)
+```
+
+and run the GROUP BY first.
+
+Your database engine also definitely does a bunch of checks to make sure that what you put in SELECT and GROUP BY makes sense together before it even starts to run the query, so it has to look at the query as a whole anyway before it starts to come up with an execution plan.
+
+### queries aren’t actually run in this order (optimizations!)
+
+Database engines in practice don’t actually run queries by joining, and then filtering, and then grouping, because they implement a bunch of optimizations reorder things to make the query run faster as long as reordering things won’t change the results of the query.
+
+One simple example of a reason why need to run queries in a different order to make them fast is that in this query:
+
+```
+SELECT * FROM
+owners LEFT JOIN cats ON owners.id = cats.owner
+WHERE cats.name = 'mr darcy'
+```
+
+it would be silly to do the whole left join and match up all the rows in the 2 tables if you just need to look up the 3 cats named ‘mr darcy’ – it’s way faster to do some filtering first for cats named ‘mr darcy’. And in this case filtering first doesn’t change the results of the query!
+
+There are lots of other optimizations that database engines implement in practice that might make them run queries in a different order but there’s no room for that and honestly it’s not something I’m an expert on.
+
+### LINQ starts queries with `FROM`
+
+LINQ (a querying syntax in C# and VB.NET) uses the order `FROM ... WHERE ... SELECT`. Here’s an example of a LINQ query:
+
+```
+var teenAgerStudent = from s in studentList
+ where s.Age > 12 && s.Age < 20
+ select s;
+```
+
+pandas (my [favourite data wrangling tool][3]) also basically works like this, though you don’t need to use this exact order – I’ll often write pandas code like this:
+
+```
+df = thing1.join(thing2) # like a JOIN
+df = df[df.created_at > 1000] # like a WHERE
+df = df.groupby('something', num_yes = ('yes', 'sum')) # like a GROUP BY
+df = df[df.num_yes > 2] # like a HAVING, filtering on the result of a GROUP BY
+df = df[['num_yes', 'something1', 'something']] # pick the columns I want to display, like a SELECT
+df.sort_values('sometthing', ascending=True)[:30] # ORDER BY and LIMIT
+df[:30]
+```
+
+This isn’t because pandas is imposing any specific rule on how you have to write your code, though. It’s just that it often makes sense to write code in the order JOIN / WHERE / GROUP BY / HAVING. (I’ll often put a `WHERE` first to improve performance though, and I think most database engines will also do a WHERE first in practice)
+
+`dplyr` in R also lets you use a different syntax for querying SQL databases like Postgres, MySQL and SQLite, which is also in a more logical order.
+
+### I was really surprised that I didn’t know this
+
+I’m writing a blog post about this because when I found out the order I was SO SURPRISED that I’d never seen it written down that way before – it explains basically everything that I knew intuitively about why some queries are allowed and others aren’t. So I wanted to write it down in the hopes that it will help other people also understand how to write SQL queries.
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/
+
+作者:[Julia Evans][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://jvns.ca/
+[b]: https://github.com/lujun9972
+[1]: https://twitter.com/b0rk/status/1179419244808851462?s=20
+[2]: https://twitter.com/b0rk/status/1179449535938076673
+[3]: https://github.com/jvns/pandas-cookbook
diff --git a/sources/tech/20191006 Use internal packages to reduce your public API surface.md b/sources/tech/20191006 Use internal packages to reduce your public API surface.md
new file mode 100644
index 0000000000..eef43ae560
--- /dev/null
+++ b/sources/tech/20191006 Use internal packages to reduce your public API surface.md
@@ -0,0 +1,54 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Use internal packages to reduce your public API surface)
+[#]: via: (https://dave.cheney.net/2019/10/06/use-internal-packages-to-reduce-your-public-api-surface)
+[#]: author: (Dave Cheney https://dave.cheney.net/author/davecheney)
+
+Use internal packages to reduce your public API surface
+======
+
+In the beginning, before the `go` tool, before Go 1.0, the Go distribution stored the standard library in a subdirectory called `pkg/` and the commands which built upon it in `cmd/`. This wasn’t so much a deliberate taxonomy but a by product of the original `make` based build system. In [September 2014][1], the Go distribution dropped the `pkg/` subdirectory, but then this tribal knowledge had set root in large Go projects and continues to this day.
+
+I tend to view empty directories inside a Go project with suspicion. Often they are a hint that the module’s author may be trying to create a taxonomy of packages rather than ensuring each package’s name, and thus its enclosing directory, [uniquely describes its purpose][2]. While the symmetry with `cmd/` for `package main` commands is appealing, a directory that exists only to hold other packages is a potential design smell.
+
+More importantly, the boilerplate of an empty `pkg/` directory distracts from the more useful idiom of an `internal/` directory. `internal/` is a special directory name recognised by the `go` tool which will prevent one package from being imported by another unless both share a common ancestor. Packages within an `internal/` directory are therefore said to be _internal packages_.
+
+To create an internal package, place it within a directory named `internal/`. When the `go` command sees an import of a package with `internal/` in the import path, it verifies that the importing package is within the tree rooted at the _parent_ of the `internal/` directory.
+
+For example, a package `/a/b/c/internal/d/e/f` can only be imported by code in the directory tree rooted at `/a/b/c`. It cannot be imported by code in `/a/b/g` or in any other repository.
+
+If your project contains multiple packages you may find you have some exported symbols which are intended to be used by other packages in your project, but are not intended to be part of your project’s public API. Although Go has limited visibility modifiers–public, exported, symbols and private, non exported, symbols–internal packages provide a useful mechanism for controlling visibility to parts of your project which would otherwise be considered part of its public versioned API.
+
+You can, of course, promote internal packages later if you want to commit to supporting that API; just move them up a directory level or two. The key is this process is _opt-in_. As the author, internal packages give you control over which symbols in your project’s public API without being forced to glob concepts together into unwieldy mega packages to avoid exporting them.
+
+### Related posts:
+
+ 1. [Stress test your Go packages][3]
+ 2. [Practical public speaking for Nerds][4]
+ 3. [Five suggestions for setting up a Go project][5]
+ 4. [Automatically fetch your project’s dependencies with gb][6]
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://dave.cheney.net/2019/10/06/use-internal-packages-to-reduce-your-public-api-surface
+
+作者:[Dave Cheney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://dave.cheney.net/author/davecheney
+[b]: https://github.com/lujun9972
+[1]: https://groups.google.com/forum/m/#!msg/golang-dev/c5AknZg3Kww/OFLmvGyfNR0J
+[2]: https://dave.cheney.net/2019/01/08/avoid-package-names-like-base-util-or-common
+[3]: https://dave.cheney.net/2013/06/19/stress-test-your-go-packages (Stress test your Go packages)
+[4]: https://dave.cheney.net/2015/02/17/practical-public-speaking-for-nerds (Practical public speaking for Nerds)
+[5]: https://dave.cheney.net/2014/12/01/five-suggestions-for-setting-up-a-go-project (Five suggestions for setting up a Go project)
+[6]: https://dave.cheney.net/2016/06/26/automatically-fetch-your-projects-dependencies-with-gb (Automatically fetch your project’s dependencies with gb)
diff --git a/sources/tech/20191007 7 Java tips for new developers.md b/sources/tech/20191007 7 Java tips for new developers.md
new file mode 100644
index 0000000000..8ad9a70f8a
--- /dev/null
+++ b/sources/tech/20191007 7 Java tips for new developers.md
@@ -0,0 +1,222 @@
+[#]: collector: (lujun9972)
+[#]: translator: (robsean)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (7 Java tips for new developers)
+[#]: via: (https://opensource.com/article/19/10/java-basics)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+7 Java tips for new developers
+======
+If you're just getting started with Java programming, here are seven
+basics you need to know.
+![Coffee and laptop][1]
+
+Java is a versatile programming language used, in some way, in nearly every industry that touches a computer. Java's greatest power is that it runs in a Java Virtual Machine (JVM), a layer that translates Java code into bytecode compatible with your operating system. As long as a JVM exists for your operating system, whether that OS is on a server (or [serverless][2], for that matter), desktop, laptop, mobile device, or embedded device, then a Java application can run on it.
+
+This makes Java a popular language for both programmers and users. Programmers know that they only have to write one version of their software to end up with an application that runs on any platform, and users know that an application will run on their computer regardless of what operating system they use.
+
+Many languages and frameworks are cross-platform, but none deliver the same level of abstraction. With Java, you target the JVM, not the OS. For programmers, that's the path of least resistance when faced with several programming challenges, but it's only useful if you know how to program Java. If you're just getting started with Java programming, here are seven basic tips you need to know.
+
+But first, if you're not sure whether you have Java installed, you can find out in a terminal (such as [Bash][3] or [PowerShell][4]) by running:
+
+
+```
+$ java --version
+openjdk 12.0.2 2019-07-16
+OpenJDK Runtime Environment 19.3 (build 12.0.2+9)
+OpenJDK 64-Bit Server VM 19.3 (build 12.0.2+9, mixed mode, sharing)
+```
+
+If you get an error or nothing in return, then you should install the [Java Development Kit][5] (JDK) to get started with Java development. Or install a Java Runtime Environment ****(JRE) if you just need to run Java applications.
+
+### 1\. Java packages
+
+In Java, related classes are grouped into a _package_. The basic Java libraries you get when you download the JDK are grouped into packages starting with **java** or **javax**. Packages serve a similar function as folders on your computer: they provide structure and definition for related elements (in programming terminology, a _namespace_). Additional packages can be obtained from independent coders, open source projects, and commercial vendors, just as libraries can be obtained for any programming language.
+
+When you write a Java program, you should declare a package name at the top of your code. If you're just writing a simple application to get started with Java, your package name can be as simple as the name of your project. If you're using a Java integrated development environment (IDE), like [Eclipse][6], it generates a sane package name for you when you start a new project.
+
+
+```
+package helloworld;
+
+/**
+ * @author seth
+ * An application written in Java.
+ */
+```
+
+Otherwise, you can determine the name of your package by looking at its path in relation to the broad definition of your project. For instance, if you're writing a set of classes to assist in game development and the collection is called **jgamer**, then you might have several unique classes within it.
+
+
+```
+package jgamer.avatar;
+
+/**
+ * @author seth
+ * An imaginary game library.
+ */
+```
+
+The top level of your package is **jgamer**, and each package inside it is a descendant, such as **jgamer.avatar** and **jgamer.score** and so on. In your filesystem, the structure reflects this, with **jgamer** being the top directory containing the files **avatar.java** and **score.java**.
+
+### 2\. Java imports
+
+The most fun you'll ever have as a polyglot programmer is trying to keep track of whether you **include**, **import**, **use**, **require**, or **some other term** a library in whatever programming language you're writing in. Java, for the record, uses the **import** keyword when importing libraries needed for your code.
+
+
+```
+package helloworld;
+
+import javax.swing.*;
+import java.awt.*;
+import java.awt.event.*;
+
+/**
+ * @author seth
+ * A GUI hello world.
+ */
+```
+
+Imports work based on an environment's Java path. If Java doesn't know where Java libraries are stored on a system, then an import cannot be successful. As long as a library is stored in a system's Java path, then an import can succeed, and a library can be used to build and run a Java application.
+
+If a library is not expected to be in the Java path (because, for instance, you are writing the library yourself), then the library can be bundled with your application (license permitting) so that the import works as expected.
+
+### 3\. Java classes
+
+A Java class is declared with the keywords **public class** along with a unique class name mirroring its file name. For example, in a file **Hello.java** in project **helloworld**:
+
+
+```
+package helloworld;
+
+import javax.swing.*;
+import java.awt.*;
+import java.awt.event.*;
+
+/**
+ * @author seth
+ * A GUI hello world.
+ */
+
+public class Hello {
+ // this is an empty class
+}
+```
+
+You can declare variables and functions inside a class. In Java, variables within a class are called _fields_.
+
+### 4\. Java methods
+
+Java methods are, essentially, functions within an object. They are defined as being **public** (meaning they can be accessed by any other class) or **private** (limiting their use) based on the expected type of returned data, such as **void**, **int**, **float**, and so on.
+
+
+```
+ public void helloPrompt([ActionEvent][7] event) {
+ [String][8] salutation = "Hello %s";
+
+ string helloMessage = "World";
+ message = [String][8].format(salutation, helloMessage);
+ [JOptionPane][9].showMessageDialog(this, message);
+ }
+
+ private int someNumber (x) {
+ return x*2;
+ }
+```
+
+When calling a method directly, it is referenced by its class and method name. For instance, **Hello.someNumber** refers to the **someNumber** method in the **Hello** class.
+
+### 5\. Static
+
+The **static** keyword in Java makes a member in your code accessible independently of the object that contains it.
+
+In object-oriented programming, you write code that serves as a template for "objects" that get spawned as the application runs. You don't code a specific window, for instance, but an _instance_ of a window based upon a window class in Java (and modified by your code). Since nothing you are coding "exists" until the application generates an instance of it, most methods and variables (and even nested classes) cannot be used until the object they depend upon has been created.
+
+However, sometimes you need to access or use data in an object before it is created by the application (for example, an application can't generate a red ball without first knowing that the ball is meant to be red). For those cases, there's the **static** keyword.
+
+### 6\. Try and catch
+
+Java is excellent at catching errors, but it can only recover gracefully if you tell it what to do. The cascading hierarchy of attempting to perform an action in Java starts with **try**, falls back to **catch**, and ends with **finally**. Should the **try** clause fail, then **catch** is invoked, and in the end, there's always **finally** to perform some sensible action regardless of the results. Here's an example:
+
+
+```
+try {
+ cmd = parser.parse(opt, args);
+
+ if(cmd.hasOption("help")) {
+ HelpFormatter helper = new HelpFormatter();
+ helper.printHelp("Hello <options>", opt);
+ [System][10].exit(0);
+ }
+ else {
+ if(cmd.hasOption("shell") || cmd.hasOption("s")) {
+ [String][8] target = cmd.getOptionValue("tgt");
+ } // else
+ } // fi
+} catch ([ParseException][11] err) {
+ [System][10].out.println(err);
+ [System][10].exit(1);
+ } //catch
+ finally {
+ new Hello().helloWorld(opt);
+ } //finally
+} //try
+```
+
+It's a robust system that attempts to avoid irrecoverable errors or, at least, to provide you with the option to give useful feedback to the user. Use it often, and your users will thank you!
+
+### 7\. Running a Java application
+
+Java files, usually ending in **.java**, theoretically can be run with the **java** command. If an application is complex, however, whether running a single file results in anything meaningful is another question.
+
+To run a **.java** file directly:
+
+
+```
+`$ java ./Hello.java`
+```
+
+Usually, Java applications are distributed as Java Archives (JAR) files, ending in **.jar**. A JAR file contains a manifest file specifying the main class, some metadata about the project structure, and all the parts of your code required to run the application.
+
+To run a JAR file, you may be able to double-click its icon (depending on how you have your OS set up), or you can launch it from a terminal:
+
+
+```
+`$ java -jar ./Hello.jar`
+```
+
+### Java for everyone
+
+Java is a powerful language, and thanks to the [OpenJDK][12] project and other initiatives, it's an open specification that allows projects like [IcedTea][13], [Dalvik][14], and [Kotlin][15] to thrive. Learning Java is a great way to prepare to work in a wide variety of industries, and what's more, there are plenty of [great reasons to use it][16].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/java-basics
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_cafe_brew_laptop_desktop.jpg?itok=G-n1o1-o (Coffee and laptop)
+[2]: https://www.redhat.com/en/resources/building-microservices-eap-7-reference-architecture
+[3]: https://www.gnu.org/software/bash/
+[4]: https://docs.microsoft.com/en-us/powershell/scripting/install/installing-powershell?view=powershell-6
+[5]: http://openjdk.java.net/
+[6]: http://www.eclipse.org/
+[7]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+actionevent
+[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
+[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+joptionpane
+[10]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
+[11]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+parseexception
+[12]: https://openjdk.java.net/
+[13]: https://icedtea.classpath.org/wiki/Main_Page
+[14]: https://source.android.com/devices/tech/dalvik/
+[15]: https://kotlinlang.org/
+[16]: https://opensource.com/article/19/9/why-i-use-java
diff --git a/sources/tech/20191007 Introduction to open source observability on Kubernetes.md b/sources/tech/20191007 Introduction to open source observability on Kubernetes.md
new file mode 100644
index 0000000000..acd1bc1331
--- /dev/null
+++ b/sources/tech/20191007 Introduction to open source observability on Kubernetes.md
@@ -0,0 +1,202 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Introduction to open source observability on Kubernetes)
+[#]: via: (https://opensource.com/article/19/10/open-source-observability-kubernetes)
+[#]: author: (Yuri Grinshteyn https://opensource.com/users/yuri-grinshteyn)
+
+Introduction to open source observability on Kubernetes
+======
+In the first article in this series, learn the signals, mechanisms,
+tools, and platforms you can use to observe services running on
+Kubernetes.
+![Looking back with binoculars][1]
+
+With the advent of DevOps, engineering teams are taking on more and more ownership of the reliability of their services. While some chafe at the increased operational burden, others welcome the opportunity to treat service reliability as a key feature, invest in the necessary capabilities to measure and improve reliability, and deliver the best possible customer experiences.
+
+This change is measured explicitly in the [2019 Accelerate State of DevOps Report][2]. One of its most interesting conclusions (as written in the summary) is:
+
+> "Delivering software quickly, **reliably** _[emphasis mine]_, and safely is at the heart of technology transformation and organizational performance. We see continued evidence that software speed, stability, and **availability** _[emphasis mine]_ contribute to organizational performance (including profitability, productivity, and customer satisfaction). Our highest performers are twice as likely to meet or exceed their organizational performance goals."
+
+The full [report][3] says:
+
+> "**Low performers use more proprietary software than high and elite performers**: The cost to maintain and support proprietary software can be prohibitive, prompting high and elite performers to use open source solutions. This is in line with results from previous reports. In fact, the 2018 Accelerate State of DevOps Report found that elite performers were 1.75 times more likely to make extensive use of open source components, libraries, and platforms."
+
+This is a strong testament to the value of open source as a general accelerator of performance. Combining these two conclusions leads to the rather obvious thesis for this series:
+
+> Reliability is a critical feature, observability is a necessary component of reliability, and open source tooling is at least _A_ right approach, if not _THE_ right approach.
+
+This article, the first in a series, will introduce the types of signals engineers typically rely on and the mechanisms, tools, and platforms that you can use to instrument services running on Kubernetes to emit these signals, ingest and store them, and use and interpret them.
+
+From there, the series will continue with hands-on tutorials, where I will walk through getting started with each of the tools and technologies. By the end, you should be well-equipped to start improving the observability of your own systems!
+
+### What is observability?
+
+While observability as a general [concept in control theory][4] has been around since at least 1960, its applicability to digital systems and services is rather new and in some ways an evolution of how these systems have been monitored for the last two decades. You are likely familiar with the necessity of monitoring services to ensure you know about issues before your users are impacted. You are also likely familiar with the idea of using metric data to better understand the health and state of a system, especially in the context of troubleshooting during an incident or debugging.
+
+The key differentiation between monitoring and observability is that observability is an inherent property of a system or service, rather than something someone does to the system, which is what monitoring fundamentally is. [Cindy Sridharan][5], author of a free [e-book][6] on observability in distributed systems, does a great job of explaining the difference in an excellent [Medium article][7].
+
+It is important to distinguish between these two terms because observability, as a property of the service you build, is your responsibility. As a service developer and owner, you have full control over the signals your system emits, how and where those signals are ingested and stored, and how they're utilized. This is in contrast to "monitoring," which may be done by others (and by you) to measure the availability and performance of your service and generate alerts to let you know that service reliability has degraded.
+
+### Signals
+
+Now that you understand the idea of observability as a property of a system that you control and that is explicitly manifested as the signals you instruct your system to emit, it's important to understand and describe the kinds of signals generally considered in this context.
+
+#### What are metrics?
+
+A metric is a fundamental type of signal that can be emitted by a service or the infrastructure it's running on. At its most basic, it is the combination of:
+
+ 1. Some identifier, hopefully descriptive, that indicates what the metric represents
+ 2. A series of data points, each of which contains two elements:
+a. The timestamp at which the data point was generated (or ingested)
+b. A numeric value representing the state of the thing you're measuring at that time
+
+
+
+Time-series metrics have been and remain the key data structure used in monitoring and observability practice and are the primary way that the state and health of a system are represented over time. They are also the primary mechanism for alerting, but that practice and others (like incident management, on-call, and postmortems) are outside the scope here. For now, the focus is on how to instrument systems to emit metrics, how to store them, and how to use them for charts and dashboards to help you visualize the current and historical state of your system.
+
+Metrics are used for two primary purposes: health and insight.
+
+Understanding the health and state of your infrastructure, platform, and service is essential to keeping them available to users. Generally, these are emitted by the various components chosen to build services, and it's just a matter of setting up the right collection and storage infrastructure to be able to use them. Metrics from the simple (node CPU utilization) to the esoteric (garbage collection statistics) fall into this category.
+
+Metrics are also essential to understanding what is happening in the system to avoid interruptions to your services. From this perspective, a service can emit custom telemetry that precisely describes specific aspects of how the service is functioning and performing. This will require you to instrument the code itself, usually by including specific libraries, and specify an export destination.
+
+#### What are logs?
+
+Unlike metrics that represent numeric values that change over time, logs represent discrete events. Log entries contain both the log payload—the message emitted by a component of the service or the code—and often metadata, such as the timestamp, label, tag, or other identifiers. Therefore, this is by far the largest volume of data you need to store, and you should carefully consider your log ingestion and storage strategies as you look to take on increasing user traffic.
+
+#### What are traces?
+
+Distributed tracing is a relatively new addition to the observability toolkit and is specifically relevant to microservice architectures to allow you to understand latency and how various backend service calls contribute to it. Ted Young published an [excellent article on the concept][8] that includes its origins with Google's [Dapper paper][9] and subsequent evolution. This series will be specifically concerned with the various implementations available.
+
+### Instrumentation
+
+Once you identify the signals you want to emit, store, and analyze, you need to instruct your system to create the signals and build a mechanism to store and analyze them. Instrumentation refers to those parts of your code that are used to generate metrics, logs, and traces. In this series, we'll discuss open source instrumentation options and introduce the basics of their use through hands-on tutorials.
+
+### Observability on Kubernetes
+
+Kubernetes is the dominant platform today for deploying and maintaining containers. As it rose to the top of the industry's consciousness, so did new technologies to provide effective observability tooling around it. Here is a short list of these essential technologies; they will be covered in greater detail in future articles in this series.
+
+#### Metrics
+
+Once you select your preferred approach for instrumenting your service with metrics, the next decision is where to store those metrics and what set of services will support your effort to monitor your environment.
+
+##### Prometheus
+
+[Prometheus][10] is the best place to start when looking to monitor both your Kubernetes infrastructure and the services running in the cluster. It provides everything you'll need, including client instrumentation libraries, the [storage backend][11], a visualization UI, and an alerting framework. Running Prometheus also provides a wealth of infrastructure metrics right out of the box. It further provides [integrations][12] with third-party providers for storage, although the data exchange is not bi-directional in every case, so be sure to read the documentation if you want to store metric data in multiple locations.
+
+Later in this series, I will walk through setting up Prometheus in a cluster for basic infrastructure monitoring and adding custom telemetry to an application using the Prometheus client libraries.
+
+##### Graphite
+
+[Graphite][13] grew out of an in-house development effort at Orbitz and is now positioned as an enterprise-ready monitoring tool. It provides metrics storage and retrieval mechanisms, but no instrumentation capabilities. Therefore, you will still need to implement Prometheus or OpenCensus instrumentation to collect metrics. Later in this series, I will walk through setting up Graphite and sending metrics to it.
+
+##### InfluxDB
+
+[InfluxDB][14] is another open source database purpose-built for storing and retrieving time-series metrics. Unlike Graphite, InfluxDB is supported by a company called InfluxData, which provides both the InfluxDB software and a cloud-hosted version called InfluxDB Cloud. Later in this series, I will walk through setting up InfluxDB in a cluster and sending metrics to it.
+
+##### OpenTSDB
+
+[OpenTSDB][15] is also an open source purpose-built time-series database. One of its advantages is the ability to use [HBase][16] as the storage layer, which allows integration with a cloud managed service like Google's Cloud Bigtable. Google has published a [reference guide][17] on setting up OpenTSDB to monitor your Kubernetes cluster (assuming it's running in Google Kubernetes Engine, or GKE). Since it's a great introduction, I recommend following Google's tutorial if you're interested in learning more about OpenTSDB.
+
+##### OpenCensus
+
+[OpenCensus][18] is the open source version of the [Census library][19] developed at Google. It provides both metric and tracing instrumentation capabilities and supports a number of backends to [export][20] the metrics to—including Prometheus! Note that OpenCensus does not monitor your infrastructure, and you will still need to determine the best approach if you choose to use OpenCensus for custom metric telemetry.
+
+We'll revisit this library later in this series, and I will walk through creating metrics in a service and exporting them to a backend.
+
+#### Logging for observability
+
+If metrics provide "what" is happening, logging tells part of the story of "why." Here are some common options for consistently gathering and analyzing logs.
+
+##### Collecting with fluentd
+
+In the Kubernetes ecosystem, [fluentd][21] is the de-facto open source standard for collecting logs emitted in the cluster and forwarding them to a specified backend. You can use config maps to modify fluentd's behavior, and later in the series, I'll walk through deploying it in a cluster and modifying the associated config map to parse unstructured logs and convert them to structured for better and easier analysis. In the meantime, you can read my post "[Customizing Kubernetes logging (Part 1)][22]" on how to do that on GKE.
+
+##### Storing and analyzing with ELK
+
+The most common storage mechanism for logs is provided by [Elastic][23] in the form of the "ELK" stack. As Elastic says:
+
+> "'ELK' is the acronym for three open source projects: Elasticsearch, Logstash, and Kibana. Elasticsearch is a search and analytics engine. Logstash is a server‑side data processing pipeline that ingests data from multiple sources simultaneously, transforms it, and then sends it to a 'stash' like Elasticsearch. Kibana lets users visualize data with charts and graphs in Elasticsearch."
+
+Later in the series, I'll walk through setting up Elasticsearch, Kibana, and Logstash in
+a cluster to store and analyze logs being collected by fluentd.
+
+#### Distributed traces and observability
+
+When asking "why" in analyzing service issues, logs can only provide the information that applications are designed to share with it. The way to go even deeper is to gather traces. As the [OpenTracing initiative][24] says:
+
+> "Distributed tracing, also called distributed request tracing, is a method used to profile and monitor applications, especially those built using a microservices architecture. Distributed tracing helps pinpoint where failures occur and what causes poor performance."
+
+##### Istio
+
+The [Istio][25] open source service mesh provides multiple benefits for microservice architectures, including traffic control, security, and observability capabilities. It does not combine multiple spans into a single trace to assemble a full picture of what happens when a user call traverses a distributed system, but it can nevertheless be useful as an easy first step toward distributed tracing. It also provides other observability benefits—it's the easiest way to get ["golden signal"][26] metrics for each service, and it also adds logging for each request, which can be very useful for calculating error rates. You can read my post on [using it with Google's Stackdriver][27]. I'll revisit it in this series and show how to install it in a cluster and configure it to export observability data to a backend.
+
+##### OpenCensus
+
+I described [OpenCensus][28] in the Metrics section above, and that's one of the main reasons for choosing it for distributed tracing: Using a single library for both metrics and traces is a great option to reduce your instrumentation work—with the caveat that you must be working in a language that supports both the traces and stats exporters. I'll come back to OpenCensus and show how to get started instrumenting code for distributed tracing. Note that OpenCensus provides only the instrumentation library, and you'll still need to use a storage and visualization layer like Zipkin, Jaeger, Stackdriver (on GCP), or X-Ray (on AWS).
+
+##### Zipkin
+
+[Zipkin][29] is a full, distributed tracing solution that includes instrumentation, storage, and visualization. It's a tried and true set of tools that's been around for years and has a strong user and developer community. It can also be used as a backend for other instrumentation options like OpenCensus. In a future tutorial, I'll show how to set up the Zipkin server and instrument your code.
+
+##### Jaeger
+
+[Jaeger][30] is another open source tracing solution that includes all the components you'll need. It's a newer project that's being incubated at the Cloud Native Computing Foundation (CNCF). Whether you choose to use Zipkin or Jaeger may ultimately depend on your experience with them and their support for the language you're writing your service in. In this series, I'll walk through setting up Jaeger and instrumenting code for tracing.
+
+### Visualizing observability data
+
+The final piece of the toolkit for using metrics is the visualization layer. There are basically two options here: the "native" visualization that your persistence layers enable (e.g., the Prometheus UI or Flux with InfluxDB) or a purpose-built visualization tool.
+
+[Grafana][31] is currently the de facto standard for open source visualization. I'll walk through setting it up and using it to visualize data from various backends later in this series.
+
+### Looking ahead
+
+Observability on Kubernetes has many parts and many options for each type of need. Metric, logging, and tracing instrumentation provide the bedrock of information needed to make decisions about services. Instrumenting, storing, and visualizing data are also essential. Future articles in this series will dive into all of these options with hands-on tutorials for each.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/open-source-observability-kubernetes
+
+作者:[Yuri Grinshteyn][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/yuri-grinshteyn
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/look-binoculars-sight-see-review.png?itok=NOw2cm39 (Looking back with binoculars)
+[2]: https://cloud.google.com/blog/products/devops-sre/the-2019-accelerate-state-of-devops-elite-performance-productivity-and-scaling
+[3]: https://services.google.com/fh/files/misc/state-of-devops-2019.pdf
+[4]: https://en.wikipedia.org/wiki/Observability
+[5]: https://twitter.com/copyconstruct
+[6]: https://t.co/0gOgZp88Jn?amp=1
+[7]: https://medium.com/@copyconstruct/monitoring-and-observability-8417d1952e1c
+[8]: https://opensource.com/article/18/5/distributed-tracing
+[9]: https://research.google.com/pubs/pub36356.html
+[10]: https://prometheus.io/
+[11]: https://prometheus.io/docs/prometheus/latest/storage/
+[12]: https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
+[13]: https://graphiteapp.org/
+[14]: https://www.influxdata.com/get-influxdb/
+[15]: http://opentsdb.net/
+[16]: https://hbase.apache.org/
+[17]: https://cloud.google.com/solutions/opentsdb-cloud-platform
+[18]: https://opencensus.io/
+[19]: https://opensource.googleblog.com/2018/03/how-google-uses-opencensus-internally.html
+[20]: https://opencensus.io/exporters/#exporters
+[21]: https://www.fluentd.org/
+[22]: https://medium.com/google-cloud/customizing-kubernetes-logging-part-1-a1e5791dcda8
+[23]: https://www.elastic.co/
+[24]: https://opentracing.io/docs/overview/what-is-tracing
+[25]: http://istio.io/
+[26]: https://landing.google.com/sre/sre-book/chapters/monitoring-distributed-systems/
+[27]: https://medium.com/google-cloud/istio-and-stackdriver-59d157282258
+[28]: http://opencensus.io/
+[29]: https://zipkin.io/
+[30]: https://www.jaegertracing.io/
+[31]: https://grafana.com/
diff --git a/sources/tech/20191007 Understanding Joins in Hadoop.md b/sources/tech/20191007 Understanding Joins in Hadoop.md
new file mode 100644
index 0000000000..ea0025a9d2
--- /dev/null
+++ b/sources/tech/20191007 Understanding Joins in Hadoop.md
@@ -0,0 +1,66 @@
+[#]: collector: (lujun9972)
+[#]: translator: (heguangzhi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Understanding Joins in Hadoop)
+[#]: via: (https://opensourceforu.com/2019/10/understanding-joins-in-hadoop/)
+[#]: author: (Bhaskar Narayan Das https://opensourceforu.com/author/bhaskar-narayan/)
+
+Understanding Joins in Hadoop
+======
+
+[![Hadoop big data career opportunities][1]][2]
+
+_Those who have just begun the study of Hadoop might have come across different types of joins. This article briefly discusses normal joins, map side joins and reduce side joins. The differences between map side joins and reduce side joins, as well as their pros and cons, are also discussed._
+
+Normally, the term join is used to refer to the combination of the record-sets of two tables. Thus when we run a query, tables are joined and we get the data from two tables in the joined format, as is the case in SQL joins. Joins find maximum usage in Hadoop processing. They should be used when large data sets are encountered and there is no urgency to generate the outcome. In case of Hadoop common joins, Hadoop distributes all the rows on all the nodes based on the join key. Once this is achieved, all the keys that have the same values end up on the same node and then, finally, the join at the reducer happens. This scenario is perfect when both the tables are huge, but when one table is small and the other is quite big, common joins become inefficient and take more time to distribute the row.
+
+While processing data using Hadoop, we generally do it over the map phase and the reduce phase. Thus there are mappers and reducers that do the job for the map phase and the reduce phase. We use map reduce joins when we encounter a large data set that is too big to use data-sharing techniques.
+
+**Map side joins**
+Map side join is the term used when the record sets of two tables are joined within the mapper. In this case, the reduce phase is not involved. In the map side join, the record sets of the tables are loaded into memory, ensuring a faster join operation. Map side join is convenient for small tables and not recommended for large tables. In situations where you have queries running too frequently with small table joins you could experience a very significant reduction in query computation time.
+
+**Reduce side joins**
+Reduce side joins happen at the reduce side of Hadoop processing. They are also known as repartitioned sort merge joins, or simply, repartitioned joins or distributed joins or common joins. They are the most widely used joins. Reduce side joins happen when both the tables are so big that they cannot fit into the memory. The process flow of reduce side joins is as follows:
+
+ 1. The input data is read by the mapper, which needs to be combined on the basis of the join key or common column.
+ 2. Once the input data is processed by the mapper, it adds a tag to the processed input data in order to distinguish the input origin sources.
+ 3. The mapper returns the intermediate key-value pair, where the key is also the join key.
+ 4. For the reducer, a key and a list of values is generated once the sorting and shuffling phase is complete.
+ 5. The reducer joins the values that are present in the generated list along with the key to produce the final outcome.
+
+
+
+The join at the reduce side combines the output of two mappers based on a common key. This scenario is quite synonymous with SQL joins, where the data sets of two tables are joined based on a primary key. In this case we have to decide which field is the primary key.
+There are a few terms associated with reduce side joins:
+1\. _Data source:_ This is nothing but the input files.
+2\. _Tag:_ This is basically used to distinguish each input data on the basis of its origin.
+3\. _Group key:_ This refers to the common column that is used as a join key to combine the output of two mappers.
+
+**Difference between map side joins and reduce side joins**
+
+ 1. A map side join, as explained earlier, happens on the map side whereas a reduce side join happens on the reduce side.
+ 2. A map side join happens in the memory whereas a reduce side join happens off the memory.
+ 3. Map side joins are effective when one data set is big while the other is small, whereas reduce side joins work effectively for big size data sets.
+ 4. Map side joins are expensive, whereas reduce side joins are cheap.
+
+
+
+Opt for map side joins when the table size is small and fits in memory, and you require the job to be completed in a short span of time. Use the reduce side join when dealing with large data sets, which cannot fit into the memory. Reduce side joins are easy to implement and have the advantage of their inbuilt sorting and shuffling algorithms. Besides this, there is no requirement to strictly follow any formatting rule for input in case of reduce side joins, and these could also be performed on unstructured data sets.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/understanding-joins-in-hadoop/
+
+作者:[Bhaskar Narayan Das][a]
+选题:[lujun9972][b]
+译者:[heguangzhi](https://github.com/heguangzhi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/bhaskar-narayan/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2017/06/Hadoop-big-data.jpg?resize=696%2C441&ssl=1 (Hadoop big data career opportunities)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2017/06/Hadoop-big-data.jpg?fit=750%2C475&ssl=1
diff --git a/sources/tech/20191007 Using the Java Persistence API.md b/sources/tech/20191007 Using the Java Persistence API.md
new file mode 100644
index 0000000000..e911428044
--- /dev/null
+++ b/sources/tech/20191007 Using the Java Persistence API.md
@@ -0,0 +1,273 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Using the Java Persistence API)
+[#]: via: (https://opensource.com/article/19/10/using-java-persistence-api)
+[#]: author: (Stephon Brown https://opensource.com/users/stephb)
+
+Using the Java Persistence API
+======
+Learn how to use the JPA by building an example app for a bike store.
+![Coffee beans][1]
+
+The Java Persistence API (JPA) is an important Java functionality for application developers to understand. It translates exactly how Java developers turn method calls on objects into accessing, persisting, and managing data stored in NoSQL and relational databases.
+
+This article examines the JPA in detail through a tutorial example of building a bicycle loaning service. This example will create a create, read, update, and delete (CRUD) layer for a larger application using the Spring Boot framework, the MongoDB database (which is [no longer open source][2]), and the Maven package manager. I also use NetBeans 11 as my IDE of choice.
+
+This tutorial focuses on the open source angle of the Java Persistence API, rather than the tools, to show how it works. This is all about learning the pattern of programming applications, but it's still smart to understand the software. You can access the full code in my [GitHub repository][3].
+
+### Java: More than 'beans'
+
+Java is an object-oriented language that has gone through many changes since the Java Development Kit (JDK) was released in 1996. Understanding the language's various pathways and its virtual machine is a history lesson in itself; in brief, the language has forked in many directions, similar to the Linux kernel, since its release. There are standard editions that are free to the community, enterprise editions for business, and an open source alternatives contributed to by multiple vendors. Major versions are released at six-month intervals; since there are often major differences in features, you may want to do some research before choosing a version.
+
+All and all, Java is steeped in history. This tutorial focuses on [JDK 11][4], which is the open source implementation of Java 11, because it is one of the long-term-support versions that is still active.
+
+ * **Spring Boot: **Spring Boot is a module from the larger Spring framework developed by Pivotal. Spring is a very popular framework for working with Java. It allows for a variety of architectures and configurations. Spring also offers support for web applications and security. Spring Boot offers basic configurations for bootstrapping various types of Java projects quickly. This tutorial uses Spring Boot to quickly write a console application and test functionality against the database.
+ * **Maven:** Maven is a project/package manager developed by Apache. Maven allows for the management of packages and various dependencies within its POM.xml file. If you have used NPM, you may be familiar with how package managers function. Maven also manages build and reporting functionality.
+ * **Lombok:** Lombok is a library that allows the creation of object getters/setters through annotation within the object file. This is already present in languages like C#, and Lombok introduces this functionality into Java.
+ * **NetBeans: **NetBeans is a popular open source IDE that focuses specifically on Java development. Many of its tools provide an implementation for the latest Java SE and EE updates.
+
+
+
+This group of tools will be used to create a simple application for a fictional bike store. It will implement functionality for inserting collections for "Customer" and "Bike" objects.
+
+### Brewed to perfection
+
+Navigate to the [Spring Initializr][5]. This website enables you to generate basic project needs for Spring Boot and the dependencies you will need for the project. Select the following options:
+
+ 1. **Project:** Maven Project
+ 2. **Language:** Java
+ 3. **Spring Boot:** 2.1.8 (or the most stable release)
+ 4. **Project Metadata:** Whatever your naming conventions are (e.g., **com.stephb**)
+ * You can keep Artifact as "Demo"
+ 5. **Dependencies:** Add:
+ * Spring Data MongoDB
+ * Lombok
+
+
+
+Click **Download** and open the new project in your chosen IDE (e.g., NetBeans).
+
+#### Model outline
+
+The models represent information collected about specific objects in the program that will be persisted in your database. Focus on two objects: **Customer** and **Bike**. First, create a **dto** folder within the **src** folder. Then, create the two Java class objects named **Customer.java** and **Bike.java**. They will be structured in the program as follows:
+
+**Customer. Java**
+
+
+```
+ 1 package com.stephb.JavaMongo.dto;
+ 2
+ 3 import lombok.Getter;
+ 4 import lombok.Setter;
+ 5 import org.springframework.data.annotation.Id;
+ 6
+ 7 /**
+ 8 *
+ 9 * @author stephon
+10 */
+11 @Getter @Setter
+12 public class Customer {
+13
+14 private @Id [String][6] id;
+15 private [String][6] emailAddress;
+16 private [String][6] firstName;
+17 private [String][6] lastName;
+18 private [String][6] address;
+19
+20 }
+```
+
+**Bike.java**
+
+
+```
+ 1 package com.stephb.JavaMongo.dto;
+ 2
+ 3 import lombok.Getter;
+ 4 import lombok.Setter;
+ 5 import org.springframework.data.annotation.Id;
+ 6
+ 7 /**
+ 8 *
+ 9 * @author stephon
+10 */
+11 @Getter @Setter
+12 public class Bike {
+13 private @Id [String][6] id;
+14 private [String][6] modelNumber;
+15 private [String][6] color;
+16 private [String][6] description;
+17
+18 @Override
+19 public [String][6] toString() {
+20 return "This bike model is " + this.modelNumber + " is the color " + this.color + " and is " + description;
+21 }
+22 }
+```
+
+As you can see, Lombok annotation is used within the object to generate the getters/setters for the properties/attributes. Properties can specifically receive the annotations if you do not want all of the attributes to have getters/setters within that class. These two classes will form the container carrying your data to wherever you want to display information.
+
+#### Set up a database
+
+I used a [Mongo Docker][7] container for testing. If you have MongoDB installed on your system, you do not have to run an instance in Docker. You can install MongoDB from its website by selecting your system information and following the installation instructions.
+
+After installing, you can interact with your new MongoDB server through the command line, a GUI such as MongoDB Compass, or IDE drivers for connecting to data sources. Now you can define your data layer to pull, transform, and persist your data. To set your database access properties, navigate to the **applications.properties** file in your application and provide the following:
+
+
+```
+ 1 spring.data.mongodb.host=localhost
+ 2 spring.data.mongodb.port=27017
+ 3 spring.data.mongodb.database=BikeStore
+```
+
+#### Define the data access object/data access layer
+
+The data access objects (DAO) in the data access layer (DAL) will define how you will interact with data in the database. The awesome thing about using a **spring-boot-starter** is that most of the work for querying the database is already done.
+
+Start with the **Customer** DAO. Create an interface in a new **dao** folder within the **src** folder, then create another Java class name called **CustomerRepository.java**. The class should look like:
+
+
+```
+ 1 package com.stephb.JavaMongo.dao;
+ 2
+ 3 import com.stephb.JavaMongo.dto.Customer;
+ 4 import java.util.List;
+ 5 import org.springframework.data.mongodb.repository.MongoRepository;
+ 6
+ 7 /**
+ 8 *
+ 9 * @author stephon
+10 */
+11 public interface CustomerRepository extends MongoRepository<Customer, String>{
+12 @Override
+13 public List<Customer> findAll();
+14 public List<Customer> findByFirstName([String][6] firstName);
+15 public List<Customer> findByLastName([String][6] lastName);
+16 }
+```
+
+This class is an interface that extends or inherits from the **MongoRepository** class with your DTO (**Customer.java**) and a string because they will be used for querying with your custom functions. Because you have inherited from this class, you have access to many functions that allow persistence and querying of your object without having to implement or reference your own functions. For example, after you instantiate the **CustomerRepository** object, you can use the **Save** function immediately. You can also override these functions if you need more extended functionality. I created a few custom queries to search my collection, given specific elements of my object.
+
+The **Bike** object also has a repository for interacting with the database. Implement it very similarly to the **CustomerRepository**. It should look like:
+
+
+```
+ 1 package com.stephb.JavaMongo.dao;
+ 2
+ 3 import com.stephb.JavaMongo.dto.Bike;
+ 4 import java.util.List;
+ 5 import org.springframework.data.mongodb.repository.MongoRepository;
+ 6
+ 7 /**
+ 8 *
+ 9 * @author stephon
+10 */
+11 public interface BikeRepository extends MongoRepository<Bike,String>{
+12 public Bike findByModelNumber([String][6] modelNumber);
+13 @Override
+14 public List<Bike> findAll();
+15 public List<Bike> findByColor([String][6] color);
+16 }
+```
+
+#### Run your program
+
+Now that you have a way to structure your data and a way to pull, transform, and persist it, run your program!
+
+Navigate to your **Application.java** file (it may have a different name, depending on what you named your application, but it should include "application"). Where the class is defined, include an **implements CommandLineRunner** afterward. This will allow you to implement a **run** method to create a command-line application. Override the **run** method provided by the **CommandLineRunner** interface and include the following to test the **BikeRepository**:
+
+
+```
+ 1 package com.stephb.JavaMongo;
+ 2
+ 3 import com.stephb.JavaMongo.dao.BikeRepository;
+ 4 import com.stephb.JavaMongo.dao.CustomerRepository;
+ 5 import com.stephb.JavaMongo.dto.Bike;
+ 6 import java.util.Scanner;
+ 7 import org.springframework.beans.factory.annotation.Autowired;
+ 8 import org.springframework.boot.CommandLineRunner;
+ 9 import org.springframework.boot.SpringApplication;
+10 import org.springframework.boot.autoconfigure.SpringBootApplication;
+11
+12
+13 @SpringBootApplication
+14 public class JavaMongoApplication implements CommandLineRunner {
+15 @Autowired
+16 private BikeRepository bikeRepo;
+17 private CustomerRepository custRepo;
+18
+19 public static void main([String][6][] args) {
+20 SpringApplication.run(JavaMongoApplication.class, args);
+21 }
+22 @Override
+23 public void run([String][6]... args) throws [Exception][8] {
+24 Scanner scan = new Scanner([System][9].in);
+25 [String][6] response = "";
+26 boolean running = true;
+27 while(running){
+28 [System][9].out.println("What would you like to create? \n C: The Customer \n B: Bike? \n X:Close");
+29 response = scan.nextLine();
+30 if ("B".equals(response.toUpperCase())) {
+31 [String][6][] bikeInformation = new [String][6][3];
+32 [System][9].out.println("Enter the information for the Bike");
+33 [System][9].out.println("Model Number");
+34 bikeInformation[0] = scan.nextLine();
+35 [System][9].out.println("Color");
+36 bikeInformation[1] = scan.nextLine();
+37 [System][9].out.println("Description");
+38 bikeInformation[2] = scan.nextLine();
+39
+40 Bike bike = new Bike();
+41 bike.setModelNumber(bikeInformation[0]);
+42 bike.setColor(bikeInformation[1]);
+43 bike.setDescription(bikeInformation[2]);
+44
+45 bike = bikeRepo.save(bike);
+46 [System][9].out.println(bike.toString());
+47
+48
+49 } else if ("X".equals(response.toUpperCase())) {
+50 [System][9].out.println("Bye");
+51 running = false;
+52 } else {
+53 [System][9].out.println("Sorry nothing else works right now!");
+54 }
+55 }
+56
+57 }
+58 }
+```
+
+The **@Autowired** annotation allows automatic dependency injection of the **BikeRepository** and **CustomerRepository** beans. You will use these classes to persist and gather data from the database.
+
+There you have it! You have created a command-line application that connects to a database and is able to perform CRUD operations with minimal code on your part.
+
+### Conclusion
+
+Translating from programming language concepts like objects and classes into calls to store, retrieve, or change data in a database is essential to building an application. The Java Persistence API (JPA) is an important tool in the Java developer's toolkit to solve that challenge. What databases are you exploring in Java? Please share in the comments.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/using-java-persistence-api
+
+作者:[Stephon Brown][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/stephb
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-beans.jpg?itok=3hkjX5We (Coffee beans)
+[2]: https://www.techrepublic.com/article/mongodb-ceo-tells-hard-truths-about-commercial-open-source/
+[3]: https://github.com/StephonBrown/SpringMongoJava
+[4]: https://openjdk.java.net/projects/jdk/11/
+[5]: https://start.spring.io/
+[6]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
+[7]: https://hub.docker.com/_/mongo
+[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+exception
+[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
diff --git a/sources/tech/20191008 Bringing Some Order into a Collection of Photographs.md b/sources/tech/20191008 Bringing Some Order into a Collection of Photographs.md
new file mode 100644
index 0000000000..b3c2dee08e
--- /dev/null
+++ b/sources/tech/20191008 Bringing Some Order into a Collection of Photographs.md
@@ -0,0 +1,119 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Bringing Some Order into a Collection of Photographs)
+[#]: via: (https://opensourceforu.com/2019/10/bringing-some-order-into-a-collection-of-photographs/)
+[#]: author: (Dr Anil Seth https://opensourceforu.com/author/anil-seth/)
+
+Bringing Some Order into a Collection of Photographs
+======
+
+[![][1]][2]
+
+_In this article, the author shares tips on managing photographs using different Internet resources and Python programming._
+
+These days, it is very easy to let Google Photos or similar cloud based services manage your photos. You can keep clicking on the smartphone and the photos get saved. The tools for helping you find photos, especially based on the content, keep getting better. There is no cost to keeping all your photos as long as you are an amateur and not taking very high resolution images. And it is far easier to let the dozens of photos clicked by accident remain on the cloud, than to remove them!
+
+Even if you are willing to delegate the task of managing photos to AI tools, there is still the challenge of what to do with the photos taken before the smartphone era. Broadly, the photos can be divided into two groups — those taken with digital cameras and the physical photo prints.
+Each of the two categories will need to be handled and managed differently. First, consider the older physical photos.
+
+**Managing physical photos in the digital era**
+
+Photos can deteriorate over time. So, the sooner you digitise them, the better you will preserve your memories. Besides, it is far easier to share a memory digitally when the family members are scattered across the globe.
+
+The first hard decision is related to the physical albums. Should you take photos out of albums for scanning and risk damaging the albums, or scan the album pages and then crop individual photos from the album pages? Scanning or imaging tools can help with the cropping of photos.
+In this article, we assume that you are ready to deal with a collection of individual photos.
+
+One of the great features of photo management software, both on the cloud and the desktop, is that they organise the photos by date. However, the only date associated with scanned photos is the date of scanning! It will be a while before the AI software will place the photos on a timeline by examining the age of the people in the photos. Currently, you will need to handle this aspect manually.
+
+One would like to be able to store a date in the metadata of the image so every tool can use it.
+Python has a number of packages to help you do this. A pretty easy one to use is pyexiv2. Here is a snippet of sample code to modify the date of an image:
+
+```
+import datetime
+import pyexiv2
+EXIF_DATE = ‘Exif.Image.DateTime’
+EXIF_ORIG_DATE = ‘Exif.Photo.DateTimeOriginal’
+def update_exif(filename,date):
+try:
+metadata=pyexiv2.ImageMetadata(filename)
+metadata.read()
+metadata[EXIF_DATE]=date
+metadata[EXIF_ORIG_DATE]=date
+metadata.write()
+except:
+print(“Error “ + f)
+```
+
+Most photo management software seem to use either of the two dates, whichever is available. While you are setting the date, you might as well set both! There can be various ways in which the date for the photo may be specified. You may find the following scheme convenient.
+Sort the photos manually into directories, each with the name _yy-mm-dd_. If the date is not known, you might as well select an approximate date. If the month also is not known, set it to 01. Now, you can use the _os.walk_ function to iterate over the directories and files, and set the date for each file as just suggested above.
+
+You may further divide the files into event based sub-directories, event_label, and use that to label photos, as follows:
+
+```
+LABEL = ‘Xmp.xmp.Label’
+metadata[LABEL] = pyexiv2.XmpTag(LABEL,event_label)
+```
+
+This is only for illustration purposes. You can decide on how you would like to organise the photos and use what seems most convenient for you.
+
+**Digital photos**
+Digital photos have different challenges. It is so easy to keep taking photos that you are likely to have a lot of them. Unless you have been careful, you are likely to find that you have used different tools for downloading photos from digital cameras and smartphones, so the file names and directory names are not consistent. A convenient option is to use the date and time of an image from the metadata and rename files accordingly. An example code follows:
+
+```
+import os
+import datetime
+import pyexiv2
+EXIF_DATE = ‘Exif.Image.DateTime’
+EXIF_ORIG_DATE = ‘Exif.Photo.DateTimeOriginal’
+def rename_file(p,f,fpref,ctr):
+fold,fext = f.rsplit(‘.’,1) # separate the ext, e.g. jpg
+fname = fpref + “-%04i”%ctr # add a serial number to ensure uniqueness
+fnew = ‘.’.join((fname,fext))
+os.rename(‘/’.join((p,f)),’/’.join((p,fnew)))
+
+def process_files(path, files):
+ctr = 0
+for f in files:
+try:
+metadata=pyexiv2.ImageMetadata(‘/’.join((path,f)))
+metadata.read()
+if EXIF_ORIG_DATE in metadata.exif_keys:
+datestamp = metadata[EXIF_ORIG_DATE].human_value
+else:
+datestamp = metadata[EXIF_DATE].human_value
+datepref = ‘_’.join([ x.replace(‘:’,’-’) for x in datestamp.split(‘ ‘)])
+rename_file(path,f,datepref,ctr)
+ctr += 1
+except:
+print(‘Error in %s/%s’%(path,f))
+for path, dirs, files in os.walk(‘.’): # work with current directory for convenience
+if len(files) > 0:
+process_files(path, files)
+```
+
+All the file names now have a consistent file name. Since the photo managing software provides a way to view the photos by time, it seems that organising the files into directories that have meaningful names may be preferable. You can move photos into directories/albums that are meaningful. The photo management software will let you view photos either by albums or by dates.
+
+**Reducing clutter and duplicates**
+Over time, my collection included multiple copies of the same photos. In the old days, to share photos easily, I used to even keep low resolution copies. Digikam has an excellent option of identifying similar photos. However, each photo needs to be handled individually. A very convenient tool for finding the duplicate files and managing them programmatically is *. The output of this program contains each set of duplicate files on a separate line.
+
+You can use the Python Pillow and Matplotlib packages to display the images. Use the image’s size to select the image with the highest resolution among the duplicates, retain that and delete the rest.
+One thing is certain, though. After all the work is done, it is a pleasure to look at the photographs and relive all those old memories.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/bringing-some-order-into-a-collection-of-photographs/
+
+作者:[Dr Anil Seth][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/anil-seth/
+[b]: https://github.com/lujun9972
+[1]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Gimp-6-Souping-up-photos.jpg?resize=696%2C492&ssl=1 (Gimp-6 Souping up photos)
+[2]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Gimp-6-Souping-up-photos.jpg?fit=900%2C636&ssl=1
diff --git a/sources/tech/20191009 Start developing in the cloud with Eclipse Che IDE.md b/sources/tech/20191009 Start developing in the cloud with Eclipse Che IDE.md
new file mode 100644
index 0000000000..e3ddcf5e07
--- /dev/null
+++ b/sources/tech/20191009 Start developing in the cloud with Eclipse Che IDE.md
@@ -0,0 +1,124 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Start developing in the cloud with Eclipse Che IDE)
+[#]: via: (https://opensource.com/article/19/10/cloud-ide-che)
+[#]: author: (Bryant Son https://opensource.com/users/brson)
+
+Start developing in the cloud with Eclipse Che IDE
+======
+Eclipse Che offers Java developers an Eclipse IDE in a container-based
+cloud environment.
+![Tools in a cloud][1]
+
+In the many, many technical interviews I've gone through in my professional career, I've noticed that I'm rarely asked questions that have definitive answers. Most of the time, I'm asked open-ended questions that do not have an absolutely correct answer but evaluate my prior experiences and how well I can explain things.
+
+One interesting open-ended question that I've been asked several times is:
+
+> "As you start your first day on a project, what five tools do you install first and why?"
+
+There is no single definitely correct answer to this question. But as a programmer who codes, I know the must-have tools that I cannot live without. And as a Java developer, I always include an interactive development environment (IDE)—and my two favorites are Eclipse IDE and IntelliJ IDEA.
+
+### My Java story
+
+When I was a student at the University of Texas at Austin, most of my computer science courses were taught in Java. And as an enterprise developer working for different companies, I have mostly worked with Java to build various enterprise-level applications. So, I know Java, and most of the time I've developed with Eclipse. I have also used the Spring Tools Suite (STS), which is a variation of the Eclipse IDE that is installed with Spring Framework plugins, and IntelliJ, which is not exactly open source, since I prefer its paid edition, but some Java developers favor it due to its faster performance and other fancy features.
+
+Regardless of which IDE you use, installing your own developer IDE presents one common, big problem: _"It works on my computer, and I don't know why it doesn't work on your computer."_
+
+[![xkcd comic][2]][3]
+
+Because a developer tool like Eclipse can be highly dependent on the runtime environment, library configuration, and operating system, the task of creating a unified sharing environment for everyone can be quite a challenge.
+
+But there is a perfect solution to this. We are living in the age of cloud computing, and Eclipse Che provides an open source solution to running an Eclipse-based IDE in a container-based cloud environment.
+
+### From local development to a cloud environment
+
+I want the benefits of a cloud-based development environment with the familiarity of my local system. That's a difficult balance to find.
+
+When I first heard about Eclipse Che, it looked like the cloud-based development environment I'd been looking for, but I got busy with technology I needed to learn and didn't follow up with it. Then a new project came up that required a remote environment, and I had the perfect excuse to use Che. Although I couldn't fully switch to the cloud-based IDE for my daily work, I saw it as a chance to get more familiar with it.
+
+![Eclipse Che interface][4]
+
+Eclipse Che IDE has a lot of excellent [features][5], but what I like most is that it is an open source framework that offers exactly what I want to achieve:
+
+ 1. Scalable workspaces leveraging the power of cloud
+ 2. Extensible and customizable plugins for different runtimes
+ 3. A seamless onboarding experience to enable smooth collaboration between members
+
+
+
+### Getting started with Eclipse Che
+
+Eclipse Che can be installed on any container-based environment. I run both [Code Ready Workspace 1.2][6] and [Eclipse Che 7][7] on [OpenShift][8], but I've also tried it on top of [Minikube][9] and [Minishift][10].
+
+![Eclipse Che on OpenShift][11]
+
+Read the requirement guides to ensure your runtime is compatible with Che:
+
+ * [Che on Kubernetes][12]
+ * [Che on OpenShift-compatible OSS environments like OKD][13]
+
+
+
+For instance, you can quickly install Eclipse Che if you launch OKD locally through Minishift, but make sure to have at least 5GB RAM to have a smooth experience.
+
+There are various ways to install Eclipse Che; I recommend leveraging the Che command-line interface, [chectl][14]. Although it is still in an incubator stage, it is my preferred way because it gives multiple configuration and management options. You can also run the installation as [an Operator][15], which you can [read more about][16]. I decided to go with chectl since I did not want to take on both concepts at the same time. Che's quick-start provides [installation steps for many scenarios][17].
+
+### Why cloud works best for me
+
+Although the local installation of Eclipse Che works, I found the most painless way is to install it on one of the common public cloud vendors.
+
+I like to collaborate with others in my IDE; working collaboratively is essential if you want your application to be something more than a hobby project. And when you are working at a company, there will be enterprise considerations around the application lifecycle of develop, test, and deploy for your application.
+
+Eclipse Che's multi-user capability means each person owns an isolated workspace that does not interfere with others' workspaces, yet team members can still collaborate on application development by working in the same cluster. And if you are considering moving to Eclipse Che for something more than a hobby or testing, the cloud environment's multi-user features will enable a faster development cycle. This includes [resource management][18] to ensure resources are allocated to each environment, as well as security considerations like [authentication and authorization][19] (or specific needs like [OpenID][20]) that are important to maintaining the environment.
+
+Therefore, moving Eclipse Che to the cloud early will be a good choice if your development experience is like mine. By moving to the cloud, you can take advantage of cloud-based scalability and resource flexibility while on the road.
+
+### Use Che and give back
+
+I really enjoy this new development configuration that enables me to regularly code in the cloud. Open source enables me to do so in an easy way, so it's important for me to consider how to give back. All of Che's components are open source under the Eclipse Public License 2.0 and available on GitHub at the following links:
+
+ * [Eclipse Che GitHub][21]
+ * [Eclipse Che Operator][15]
+ * [chectl (Eclipse Che CLI)][14]
+
+
+
+Consider using Che and giving back—either as a user by filing bug reports or as a developer to help enhance the project.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/cloud-ide-che
+
+作者:[Bryant Son][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/brson
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cloud_tools_hardware.png?itok=PGjJenqT (Tools in a cloud)
+[2]: https://opensource.com/sites/default/files/uploads/1_xkcd.jpg (xkcd comic)
+[3]: https://xkcd.com/1316
+[4]: https://opensource.com/sites/default/files/uploads/0_banner.jpg (Eclipse Che interface)
+[5]: https://www.eclipse.org/che/features
+[6]: https://developers.redhat.com/products/codeready-workspaces/overview
+[7]: https://che.eclipse.org/eclipse-che-7-is-now-available-40ae07120b38
+[8]: https://www.openshift.com/
+[9]: https://kubernetes.io/docs/tutorials/hello-minikube/
+[10]: https://www.okd.io/minishift/
+[11]: https://opensource.com/sites/default/files/uploads/2_openshiftresources.jpg (Eclipse Che on OpenShift)
+[12]: https://www.eclipse.org/che/docs/che-6/kubernetes-single-user.html
+[13]: https://www.eclipse.org/che/docs/che-6/openshift-single-user.html
+[14]: https://github.com/che-incubator/chectl
+[15]: https://github.com/eclipse/che-operator
+[16]: https://opensource.com/article/19/6/kubernetes-potential-run-anything
+[17]: https://www.eclipse.org/che/docs/che-7/che-quick-starts.html#running-che-locally_che-quick-starts
+[18]: https://www.eclipse.org/che/docs/che-6/resource-management.html
+[19]: https://www.eclipse.org/che/docs/che-6/user-management.html
+[20]: https://www.eclipse.org/che/docs/che-6/authentication.html
+[21]: https://github.com/eclipse/che
diff --git a/sources/tech/20191009 The Emacs Series ht.el- The Hash Table Library for Emacs.md b/sources/tech/20191009 The Emacs Series ht.el- The Hash Table Library for Emacs.md
new file mode 100644
index 0000000000..84e5a46acb
--- /dev/null
+++ b/sources/tech/20191009 The Emacs Series ht.el- The Hash Table Library for Emacs.md
@@ -0,0 +1,414 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Emacs Series ht.el: The Hash Table Library for Emacs)
+[#]: via: (https://opensourceforu.com/2019/10/the-emacs-series-ht-el-the-hash-table-library-for-emacs/)
+[#]: author: (Shakthi Kannan https://opensourceforu.com/author/shakthi-kannan/)
+
+The Emacs Series ht.el: The Hash Table Library for Emacs
+======
+
+[![][1]][2]
+
+_In this article, we explore the various hash table functions and macros provided by the ht.el library._
+
+The ht.el hash table library for Emacs has been written by Wilfred Hughes. The latest tagged release is version 2.2 and the software is released under the GNU General Public License v3. The source code is available at __. It provides a comprehensive list of hash table operations and a very consistent API. For example, any mutation function will always return nil.
+
+**Installation**
+The Milkypostman’s Emacs Lisp Package Archive (MELPA) and Marmalade repositories have ht.el available for installation. You can add the following command to your Emacs init.el configuration file:
+
+```
+(require ‘package)
+(add-to-list ‘package-archives ‘(“melpa” . “https://melpa.org/packages/”) t)
+```
+
+You can then run _M-x package <RET> ht <RET>_ to install the _ht.el_ library. If you are using Cask, then you simply add the following code to your Cask file:
+
+```
+(depends-on “ht”)
+```
+
+You will need the ht library in your Emacs environment before using the API functions.
+
+```
+(require ‘ht)
+```
+
+**Usage**
+Let us now explore the various API functions provided by the _ht.el_ library. The _ht-create_ function will return a hash table that can be assigned to a hash table variable. You can also verify that the variable is a hash table using the type-of function as shown below:
+
+```
+(let ((greetings (ht-create)))
+(type-of greetings))
+
+hash-table
+```
+
+You can add an item to the hash table using the ht-set! function, which takes the hash table, key and value as arguments. The entries in the hash table can be listed using the _ht-items_ function as illustrated below:
+
+```
+(ht-set! hash-table key value) ;; Syntax
+(ht-items hash-table) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-items greetings))
+
+((“Adam” “Hello Adam!”))
+```
+
+The keys present in a hash table can be retrieved using the _ht-keys_ function, while the values in a hash table can be obtained using the _ht-values_ function, as shown in the following examples:
+
+```
+(ht-keys hash-table) ;; Syntax
+(ht-values hash-table) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-keys greetings))
+
+(“Adam”)
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-values greetings))
+
+(“Hello Adam!”)
+```
+
+The “ht-clear!” function can be used to clear all the items in a hash-table. For example:
+
+```
+(ht-clear! hash-table) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-clear! greetings)
+(ht-items greetings))
+
+nil
+```
+
+An entire hash table can be copied to another hash table using the _ht-copy_ API as shown below:
+
+```
+(ht-copy hash-table) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-items (ht-copy greetings)))
+
+((“Adam” “Hello Adam!”))
+```
+
+The _ht-merge_ function can combine two different hash tables into one. In the following example, the items in the _english_ and _numbers_ hash tables are merged together.
+
+```
+(ht-merge hash-table1 hash-table2) ;; Syntax
+
+(let ((english (ht-create))
+(numbers (ht-create)))
+(ht-set! english “a” “A”)
+(ht-set! numbers “1” “One”)
+(ht-items (ht-merge english numbers)))
+
+((“1” “One”) (“a” “A”))
+```
+
+You can make modifications to an existing hash table. For example, you can remove an item in the hash table using the _ht-remove!_ function, which takes as input a hash table and a key as shown below:
+
+```
+(ht-remove hash-table key) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-set! greetings “Eve” “Hello Eve!”)
+(ht-remove! greetings “Eve”)
+(ht-items greetings))
+
+((“Adam” “Hello Adam!”))
+```
+
+You can do an in-place modification to an item in the hash table using the _ht-update!_ function. An example is given below:
+
+```
+(ht-update! hash-table key value) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-update! greetings (ht (“Adam” “Howdy Adam!”)))
+(ht-items greetings))
+
+((“Adam” “Howdy Adam!”))
+```
+
+A number of predicate functions are available in _ht.el_ that can be used to check for conditions in a hash table. The _ht_? function checks to see if the input argument is a hash table. It returns t if the argument is a hash table and _nil_ otherwise.
+
+```
+(ht? hash-table) ;; Syntax
+
+(ht? nil)
+
+nil
+
+(let ((greetings (ht-create)))
+(ht? greetings))
+
+t
+```
+
+You can verify if a key is present in a hash table using the _ht-contains_? API, which takes a hash table and key as arguments. It returns t if the item exists in the hash table. Otherwise, it simply returns _nil_.
+
+```
+(ht-contains? hash-table key) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-contains? greetings “Adam”))
+
+t
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-contains? greetings “Eve”))
+
+nil
+```
+
+The _ht-empty?_ function can be used to check if the input hash-table is empty or not. A couple of examples are shown below:
+
+```
+(ht-empty? hash-table) ;; Syntax
+
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-empty? greetings))
+
+nil
+
+(let ((greetings (ht-create)))
+(ht-empty? greetings))
+
+t
+```
+
+The equality check can be used on a couple of hash tables to verify if they are the same, using the _ht-equal_? function as illustrated below:
+
+```
+(ht-equal? hash-table1 hash-table2) ;; Syntax
+
+(let ((english (ht-create))
+(numbers (ht-create)))
+(ht-set! english “a” “A”)
+(ht-set! numbers “1” “One”)
+(ht-equal? english numbers))
+
+nil
+```
+
+A few of the ht.el library functions accept a function as an argument and apply it to the items of the list. For example, the ht-map function takes a function with a key and value as arguments, and applies the function to each item in the hash table. For example:
+
+```
+(ht-map function hash-table) ;; Syntax
+
+(let ((numbers (ht-create)))
+(ht-set! numbers 1 “One”)
+(ht-map (lambda (x y) (* x 2)) numbers))
+
+(2)
+```
+
+You can also use the _ht-each_ API to iterate through each item in the hash-table. In the following example, the sum of all the values is calculated and finally printed in the output.
+
+```
+(ht-each function hash-table) ;; Syntax
+
+(let ((numbers (ht-create))
+(sum 0))
+(ht-set! numbers “A” 1)
+(ht-set! numbers “B” 2)
+(ht-set! numbers “C” 3)
+(ht-each (lambda (key value) (setq sum (+ sum value))) numbers)
+(print sum))
+
+6
+```
+
+The _ht-select_ function can be used to match and pick a specific set of items in the list. For example:
+
+```
+(ht-select function hash-table) ;; Syntax
+
+(let ((numbers (ht-create)))
+(ht-set! numbers 1 “One”)
+(ht-set! numbers 2 “Two”)
+(ht-items (ht-select (lambda (x y) (= x 2)) numbers)))
+
+((“2” “Two”))
+```
+
+You can also reject a set of values by passing a filter function to the _ht-reject API_, and retrieve those items from the hash table that do not match the predicate function. In the following example, key 2 is rejected and the item with key 1 is returned.
+
+```
+(ht-reject function hash-table) ;; Syntax
+
+(let ((numbers (ht-create)))
+(ht-set! numbers 1 “One”)
+(ht-set! numbers 2 “Two”)
+(ht-items (ht-reject (lambda (x y) (= x 2)) numbers)))
+
+((“1” “One”))
+```
+
+If you want to mutate the existing hash table and remove the items that match a filter function, you can use the _ht-reject_! function as shown below:
+
+```
+(ht-reject! function hash-table) ;; Syntax
+
+(let ((numbers (ht-create)))
+(ht-set! numbers 1 “One”)
+(ht-set! numbers 2 “Two”)
+(ht-reject! (lambda (x y) (= x 2)) numbers)
+(ht-items numbers))
+
+((“1” “One”))
+```
+
+The _ht-find_ function accepts a function and a hash table, and returns the items that satisfy the input function. For example:
+
+```
+(ht-find function hash-table) ;; Syntax
+
+(let ((numbers (ht-create)))
+(ht-set! numbers 1 “One”)
+(ht-set! numbers 2 “Two”)
+(ht-find (lambda (x y) (= x 2)) numbers))
+
+(2 “Two”)
+```
+
+You can retrieve the items in the hash table using a specific set of keys with the _ht-select-keys_ API, as illustrated below:
+
+```
+(ht-select-keys hash-table keys) ;; Syntax
+
+(let ((numbers (ht-create)))
+(ht-set! numbers 1 “One”)
+(ht-set! numbers 2 “Two”)
+(ht-items (ht-select-keys numbers ‘(1))))
+
+((1 “One”))
+```
+
+The following two examples are more comprehensive in using the hash table library functions. The _say-hello_ function returns a greeting based on the name as shown below:
+
+```
+(defun say-hello (name)
+(let ((greetings (ht-create)))
+(ht-set! greetings “Adam” “Hello Adam!”)
+(ht-set! greetings “Eve” “Hello Eve!”)
+(ht-get greetings name “Hello stranger!”)))
+
+(say-hello “Adam”)
+“Hello Adam!”
+
+(say-hello “Eve”)
+“Hello Eve!”
+
+(say-hello “Bob”)
+“Hello stranger!”
+```
+
+The _ht_ macro returns a hash table and we create nested hash tables in the following example:
+
+```
+(let ((alphabets (ht (“Greek” (ht (1 (ht (‘letter “α”)
+(‘name “alpha”)))
+(2 (ht (‘letter “β”)
+(‘name “beta”)))))
+(“English” (ht (1 (ht (‘letter “a”)
+(‘name “A”)))
+(2 (ht (‘letter “b”)
+(‘name “B”))))))))
+(ht-get* alphabets “Greek” 1 ‘letter))
+
+“α”
+```
+
+**Testing**
+The _ht.el_ library has built-in tests that you can execute to validate the API functions. You first need to clone the repository using the following commands:
+
+```
+$ git clone git@github.com:Wilfred/ht.el.git
+
+Cloning into ‘ht.el’...
+remote: Enumerating objects: 1, done.
+remote: Counting objects: 100% (1/1), done.
+Receiving objects: 100% (471/471), 74.58 KiB | 658.00 KiB/s, done.
+remote: Total 471 (delta 0), reused 1 (delta 0), pack-reused 470
+Resolving deltas: 100% (247/247), done.
+```
+
+If you do not have Cask, install the same using the instructions provided in the _README_ file at __.
+You can then change the directory into the cloned ‘_ht.el_’ folder and run _cask install_. This will locally install the required dependencies for running the tests.
+
+```
+$ cd ht.el/
+$ cask install
+Loading package information... Select coding system (default utf-8):
+done
+Package operations: 4 installs, 0 removals
+- Installing [ 1/4] dash (2.12.0)... done
+- Installing [ 2/4] ert-runner (latest)... done
+- Installing [ 3/4] cl-lib (latest)... already present
+- Installing [ 4/4] f (latest)... already present
+```
+
+A _Makefile_ exists in the top-level directory and you can simply run ‘make’ to run the tests, as shown below:
+
+```
+$ make
+rm -f ht.elc
+make unit
+make[1]: Entering directory ‘/home/guest/ht.el’
+cask exec ert-runner
+.........................................
+
+Ran 41 tests in 0.016 seconds
+make[1]: Leaving directory ‘/home/guest/ht.el’
+make compile
+make[1]: Entering directory ‘/home/guest/ht.el’
+cask exec emacs -Q -batch -f batch-byte-compile ht.el
+make[1]: Leaving directory ‘/home/guest/ht.el’
+make unit
+make[1]: Entering directory ‘/home/guest/ht.el’
+cask exec ert-runner
+.........................................
+
+Ran 41 tests in 0.015 seconds
+make[1]: Leaving directory ‘/home/guest/ht.el’
+make clean-elc
+make[1]: Entering directory ‘/home/guest/ht.el’
+rm -f ht.elc
+make[1]: Leaving directory ‘/home/guest/ht.el’
+```
+
+You are encouraged to read the ht.el _README_ file from the GitHub repository at __ for more information.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/the-emacs-series-ht-el-the-hash-table-library-for-emacs/
+
+作者:[Shakthi Kannan][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/shakthi-kannan/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/GPL-3.jpg?resize=696%2C351&ssl=1 (GPL 3)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/GPL-3.jpg?fit=998%2C503&ssl=1
diff --git a/sources/tech/20191010 Achieve high-scale application monitoring with Prometheus.md b/sources/tech/20191010 Achieve high-scale application monitoring with Prometheus.md
new file mode 100644
index 0000000000..dc5ecedfff
--- /dev/null
+++ b/sources/tech/20191010 Achieve high-scale application monitoring with Prometheus.md
@@ -0,0 +1,301 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Achieve high-scale application monitoring with Prometheus)
+[#]: via: (https://opensource.com/article/19/10/application-monitoring-prometheus)
+[#]: author: (Paul Brebner https://opensource.com/users/paul-brebner)
+
+Achieve high-scale application monitoring with Prometheus
+======
+Prometheus' prowess as a monitoring system and its ability to achieve
+high-scalability make it a strong choice for monitoring applications and
+servers.
+![Tall building with windows][1]
+
+[Prometheus][2] is an increasingly popular—for good reason—open source tool that provides monitoring and alerting for applications and servers. Prometheus' great strength is in monitoring server-side metrics, which it stores as [time-series data][3]. While Prometheus doesn't lend itself to application performance management, active control, or user experience monitoring (although a GitHub extension does make user browser metrics available to Prometheus), its prowess as a monitoring system and ability to achieve high-scalability through a [federation of servers][4] make Prometheus a strong choice for a wide variety of use cases.
+
+In this article, we'll take a closer look at Prometheus' architecture and functionality and then examine a detailed instance of the tool in action.
+
+### Prometheus architecture and components
+
+Prometheus consists of the Prometheus server (handling service discovery, metrics retrieval and storage, and time-series data analysis through the PromQL query language), a data model for metrics, a graphing GUI, and native support for [Grafana][5]. There is also an optional alert manager that allows users to define alerts via the query language and an optional push gateway for short-term application monitoring. These components are situated as shown in the following diagram.
+
+![Promethius architecture][6]
+
+Prometheus can automatically capture standard metrics by using agents to execute general-purpose code in the application environment. It can also capture custom metrics through instrumentation, placing custom code within the source code of the monitored application. Prometheus officially supports [client libraries][7] for Go, Python, Ruby, and Java/Scala and also enables users to write their own libraries. Additionally, many unofficial libraries for other languages are available.
+
+Developers can also utilize third-party [exporters][8] to automatically activate instrumentation for many popular software solutions they might be using. For example, users of JVM-based applications like open source [Apache Kafka][9] and [Apache Cassandra][10] can easily collect metrics by leveraging the existing [JMX exporter][11]. In other cases, an exporter won't be needed because the application will [expose metrics][12] that are already in the Prometheus format. Those on Cassandra might also find Instaclustr's freely available [Cassandra Exporter for Prometheus][13] to be helpful, as it integrates Cassandra metrics from a self-managed cluster into Prometheus application monitoring.
+
+Also important: Developers can leverage an available [node exporter][14] to monitor kernel metrics and host hardware. Prometheus offers a [Java client][15] as well, with a number of features that can be registered either piecemeal or at once through a single **DefaultExports.initialize();** command—including memory pools, garbage collection, JMX, classloading, and thread counts.
+
+### Prometheus data modeling and metrics
+
+Prometheus provides four metric types:
+
+ * **Counter:** Counts incrementing values; a restart can return these values to zero
+ * **Gauge:** Tracks metrics that can go up and down
+ * **Histogram:** Observes data according to specified response sizes or durations and counts the sums of observed values along with counts in configurable buckets
+ * **Summary:** Counts observed data similar to a histogram and offers configurable quantiles that are calculated over a sliding time window
+
+
+
+Prometheus time-series data metrics each include a string name, which follows a naming convention to include the name of the monitored data subject, the logical type, and the units of measure used. Each metric includes streams of 64-bit float value that are timestamped down to the millisecond, and a set of key:value pairs labeling the dimensions it measures. Prometheus automatically adds **Job** and **Instance** labels to each metric to keep track of the configured job name of the data target and the **<host>:<port>** piece of the scraped target URL, respectively.
+
+### Prometheus example: the Anomalia Machina anomaly detection experiment
+
+Before moving into the example, download and begin using open source Prometheus by following this [getting started][16] guide.
+
+To demonstrate how to put Prometheus into action and perform application monitoring at a high scale, let's take a look at a recent [experimental Anomalia Machina project][17] we completed at Instaclustr. This project—just a test case, not a commercially available solution—leverages Kafka and Cassandra in an application deployed by Kubernetes, which performs anomaly detection on streaming data. (Such detection is critical to use cases including IoT applications and digital ad fraud, among other areas.) The experimental application relies heavily on Prometheus to collect application metrics across distributed instances and make them readily available to view.
+
+This diagram displays the experiment's architecture:
+
+![Anomalia Machina Architecture][18]
+
+Our goals in utilizing Prometheus included monitoring the application's more generic metrics, such as throughput, as well as the response times delivered by the Kafka load generator (the Kafka producer), the Kafka consumer, and the Cassandra client tasked with detecting any anomalies in the data. Prometheus monitors the system's hardware metrics as well, such as the CPU for each AWS EC2 instance running the application. The project also counts on Prometheus to monitor application-specific metrics such as the total number of rows each Cassandra read returns and, crucially, the number of anomalies it detects. All of this monitoring is centralized for simplicity.
+
+In practice, this means forming a test pipeline with producer, consumer, and detector methods, as well as the following three metrics:
+
+ * A counter metric, called **prometheusTest_requests_total**, increments each time that each pipeline stage executes without incident, while a **stage** label allows for tracking the successful execution of each stage, and a **total** label tracks the total pipeline count.
+ * Another counter metric, called **prometheusTest_anomalies_total**, counts any detected anomalies.
+ * Finally, a gauge metric called **prometheusTest_duration_seconds** tracks the seconds of duration for each stage (again using a **stage** label and a **total** label).
+
+
+
+The code behind these measurements increments counter metrics using the **inc()** method and sets the time value of the gauge metric with the **setToTime()** method. This is demonstrated in the following annotated example code:
+
+
+```
+import java.io.IOException;
+import io.prometheus.client.Counter;
+import io.prometheus.client.Gauge;
+import io.prometheus.client.exporter.HTTPServer;
+import io.prometheus.client.hotspot.DefaultExports;
+
+//
+// Demo of how we plan to use Prometheus Java client to instrument Anomalia Machina.
+// Note that the Anomalia Machina application will have Kafka Producer and Kafka consumer and rest of pipeline running in multiple separate processes/instances.
+// So metrics from each will have different host/port combinations.
+public class PrometheusBlog {
+static String appName = "prometheusTest";
+// counters can only increase in value (until process restart)
+// Execution count. Use a single Counter for all stages of the pipeline, stages are distinguished by labels
+static final Counter pipelineCounter = Counter.build()
+ .name(appName + "_requests_total").help("Count of executions of pipeline stages")
+ .labelNames("stage")
+ .register();
+// in theory could also use pipelineCounter to count anomalies found using another label
+// but less potential for confusion having another counter. Doesn't need a label
+static final Counter anomalyCounter = Counter.build()
+ .name(appName + "_anomalies_total").help("Count of anomalies detected")
+ .register();
+// A Gauge can go up and down, and is used to measure current value of some variable.
+// pipelineGauge will measure duration in seconds of each stage using labels.
+static final Gauge pipelineGauge = Gauge.build()
+ .name(appName + "_duration_seconds").help("Gauge of stage durations in seconds")
+ .labelNames("stage")
+ .register();
+
+public static void main(String[] args) {
+// Allow default JVM metrics to be exported
+ DefaultExports.initialize();
+
+ // Metrics are pulled by Prometheus, create an HTTP server as the endpoint
+ // Note if there are multiple processes running on the same server need to change port number.
+ // And add all IPs and port numbers to the Prometheus configuration file.
+HTTPServer server = null;
+try {
+server = new HTTPServer(1234);
+} catch (IOException e) {
+e.printStackTrace();
+}
+// now run 1000 executions of the complete pipeline with random time delays and increasing rate
+int max = 1000;
+for (int i=0; i < max; i++)
+{
+// total time for complete pipeline, and increment anomalyCounter
+pipelineGauge.labels("total").setToTime(() -> {
+producer();
+consumer();
+if (detector())
+anomalyCounter.inc();
+});
+// total pipeline count
+pipelineCounter.labels("total").inc();
+System.out.println("i=" + i);
+
+// increase the rate of execution
+try {
+Thread.sleep(max-i);
+} catch (InterruptedException e) {
+e.printStackTrace();
+}
+}
+server.stop();
+}
+// the 3 stages of the pipeline, for each we increase the stage counter and set the Gauge duration time
+public static void producer() {
+class Local {};
+String name = Local.class.getEnclosingMethod().getName();
+pipelineGauge.labels(name).setToTime(() -> {
+try {
+Thread.sleep(1 + (long)(Math.random()*20));
+} catch (InterruptedException e) {
+e.printStackTrace();
+}
+});
+pipelineCounter.labels(name).inc();
+ }
+public static void consumer() {
+class Local {};
+String name = Local.class.getEnclosingMethod().getName();
+pipelineGauge.labels(name).setToTime(() -> {
+try {
+Thread.sleep(1 + (long)(Math.random()*10));
+} catch (InterruptedException e) {
+e.printStackTrace();
+}
+});
+pipelineCounter.labels(name).inc();
+ }
+// detector returns true if anomaly detected else false
+public static boolean detector() {
+class Local {};
+String name = Local.class.getEnclosingMethod().getName();
+pipelineGauge.labels(name).setToTime(() -> {
+try {
+Thread.sleep(1 + (long)(Math.random()*200));
+} catch (InterruptedException e) {
+e.printStackTrace();
+}
+});
+pipelineCounter.labels(name).inc();
+return (Math.random() > 0.95);
+ }
+}
+```
+
+Prometheus collects metrics by polling ("scraping") instrumented code (unlike some other monitoring solutions that receive metrics via push methods). The code example above creates a required HTTP server on port 1234 so that Prometheus can scrape metrics as needed.
+
+The following sample code addresses Maven dependencies:
+
+
+```
+<!-- The client -->
+<dependency>
+<groupId>io.prometheus</groupId>
+<artifactId>simpleclient</artifactId>
+<version>LATEST</version>
+</dependency>
+<!-- Hotspot JVM metrics-->
+<dependency>
+<groupId>io.prometheus</groupId>
+<artifactId>simpleclient_hotspot</artifactId>
+<version>LATEST</version>
+</dependency>
+<!-- Exposition HTTPServer-->
+<dependency>
+<groupId>io.prometheus</groupId>
+<artifactId>simpleclient_httpserver</artifactId>
+<version>LATEST</version>
+</dependency>
+<!-- Pushgateway exposition-->
+<dependency>
+<groupId>io.prometheus</groupId>
+<artifactId>simpleclient_pushgateway</artifactId>
+<version>LATEST</version>
+</dependency>
+```
+
+The code example below tells Prometheus where it should look to scrape metrics. This code can simply be added to the configuration file (default: Prometheus.yml) for basic deployments and tests.
+
+
+```
+global:
+ scrape_interval: 15s # By default, scrape targets every 15 seconds.
+
+# scrape_configs has jobs and targets to scrape for each.
+scrape_configs:
+# job 1 is for testing prometheus instrumentation from multiple application processes.
+ # The job name is added as a label job=<job_name> to any timeseries scraped from this config.
+ - job_name: 'testprometheus'
+
+ # Override the global default and scrape targets from this job every 5 seconds.
+ scrape_interval: 5s
+
+ # this is where to put multiple targets, e.g. for Kafka load generators and detectors
+ static_configs:
+ - targets: ['localhost:1234', 'localhost:1235']
+
+ # job 2 provides operating system metrics (e.g. CPU, memory etc).
+ - job_name: 'node'
+
+ # Override the global default and scrape targets from this job every 5 seconds.
+ scrape_interval: 5s
+
+ static_configs:
+ - targets: ['localhost:9100']
+```
+
+Note the job named "node" that uses port 9100 in this configuration file; this job offers node metrics and requires running the [Prometheus node exporter][14] on the same server where the application is running. Polling for metrics should be done with care: doing it too often can overload applications, too infrequently can result in lag. Where application metrics can't be polled, Prometheus also offers a [push gateway][19].
+
+### Viewing Prometheus metrics and results
+
+Our experiment initially used [expressions][20], and later [Grafana][5], to visualize data and overcome Prometheus' lack of default dashboards. Using the Prometheus interface (or [http://localhost:][21]9[090/metrics][21]), select metrics by name and then enter them in the expression box for execution. (Note that it's common to experience error messages at this stage, so don't be discouraged if you encounter a few issues.) With correctly functioning expressions, results will be available for display in tables or graphs as appropriate.
+
+Using the **[irate][22]** or **[rate][23]** function on a counter metric will produce a useful rate graph:
+
+![Rate graph][24]
+
+Here is a similar graph of a gauge metric:
+
+![Gauge graph][25]
+
+Grafana provides much more robust graphing capabilities and built-in Prometheus support with graphs able to display multiple metrics:
+
+![Grafana graph][26]
+
+To enable Grafana, install it, navigate to , create a Prometheus data source, and add a Prometheus graph using an expression. A note here: An empty graph often points to a time range issue, which can usually be solved by using the "Last 5 minutes" setting.
+
+Creating this experimental application offered an excellent opportunity to build our knowledge of what Prometheus is capable of and resulted in a high-scale experimental production application that can monitor 19 billion real-time data events for anomalies each day. By following this guide and our example, hopefully, more developers can successfully put Prometheus into practice.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/application-monitoring-prometheus
+
+作者:[Paul Brebner][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/paul-brebner
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/windows_building_sky_scale.jpg?itok=mH6CAX29 (Tall building with windows)
+[2]: https://prometheus.io/
+[3]: https://prometheus.io/docs/concepts/data_model
+[4]: https://prometheus.io/docs/prometheus/latest/federation
+[5]: https://grafana.com/
+[6]: https://opensource.com/sites/default/files/uploads/prometheus_architecture.png (Promethius architecture)
+[7]: https://prometheus.io/docs/instrumenting/clientlibs/
+[8]: https://prometheus.io/docs/instrumenting/exporters/
+[9]: https://kafka.apache.org/
+[10]: http://cassandra.apache.org/
+[11]: https://github.com/prometheus/jmx_exporter
+[12]: https://prometheus.io/docs/instrumenting/exporters/#software-exposing-prometheus-metrics
+[13]: https://github.com/instaclustr/cassandra-exporter
+[14]: https://prometheus.io/docs/guides/node-exporter/
+[15]: https://github.com/prometheus/client_java
+[16]: https://prometheus.io/docs/prometheus/latest/getting_started/
+[17]: https://github.com/instaclustr/AnomaliaMachina
+[18]: https://opensource.com/sites/default/files/uploads/anomalia_machina_architecture.png (Anomalia Machina Architecture)
+[19]: https://prometheus.io/docs/instrumenting/pushing/
+[20]: https://prometheus.io/docs/prometheus/latest/querying/basics/
+[21]: http://localhost:9090/metrics
+[22]: https://prometheus.io/docs/prometheus/latest/querying/functions/#irate
+[23]: https://prometheus.io/docs/prometheus/latest/querying/functions/#rate
+[24]: https://opensource.com/sites/default/files/uploads/rate_graph.png (Rate graph)
+[25]: https://opensource.com/sites/default/files/uploads/gauge_graph.png (Gauge graph)
+[26]: https://opensource.com/sites/default/files/uploads/grafana_graph.png (Grafana graph)
diff --git a/sources/tech/20191013 Sugarizer- The Taste of Sugar on Any Device.md b/sources/tech/20191013 Sugarizer- The Taste of Sugar on Any Device.md
new file mode 100644
index 0000000000..749ff78037
--- /dev/null
+++ b/sources/tech/20191013 Sugarizer- The Taste of Sugar on Any Device.md
@@ -0,0 +1,59 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Sugarizer: The Taste of Sugar on Any Device)
+[#]: via: (https://opensourceforu.com/2019/10/sugarizer-the-taste-of-sugar-on-any-device/)
+[#]: author: (Dr Anil Seth https://opensourceforu.com/author/anil-seth/)
+
+Sugarizer: The Taste of Sugar on Any Device
+======
+
+[![][1]][2]
+
+_Sugar is a learning platform that was initially developed for the OLPC project. The Sugar Learning Environment can be downloaded and installed on any Linux-compatible hardware. Sugarizer mimics the UI of Sugar using HTML5 and CSS3._
+
+The One Laptop Per Child (OLPC) project was launched less than 12 years ago. The goal of bringing down the cost of a laptop to US$ 100 was never really achieved. The project also did not turn out to be as much of a success as anticipated. However, the goal was not really about the laptop, but to educate as many children as possible.
+The interactive learning environment of the OLPC project was equally critical. This became a separate project under Sugar Labs, [_https://wiki.sugarlabs.org/_][3], and continues to be active. The Sugar Learning Environment is available as a Fedora spin, and can be downloaded and installed on any Linux-compatible hardware. It would be a good option to install it on an old system, which could then be donated. The US$ 90 Pinebook, [_https://www.pine64.org/,_][4] with Sugar installed on it would also make a memorable and useful gift.
+The Sugar Environment can happily coexist with other desktop environments on Linux. So, the computer does not have to be dedicated to Sugar. On Fedora, you may add it to your existing desktop as follows:
+
+```
+$ sudo dnf group install ‘Sugar Desktop Environment’
+```
+
+I have not tried it on Ubuntu. However, the following command should work:
+
+```
+$ sudo apt install sucrose
+```
+
+However, Sugar remains, by and large, an unknown entity. This is especially disappointing considering that the need to _learn to learn_ has never been greater.
+Hence, the release of Sugarizer is a pleasant surprise. It allows you to use the Sugar environment on any device, with the help of Web technologies. Sugarizer mimics the UI of Sugar using HTML5 and CSS3. It runs activities that have been written in HTML5/JavaScript. The current release includes a number of Sugar activities written initially in Python, which have been ported to HTML5/JavaScript.
+You may try the new release at _sugarizer.org_. Better still, install it from Google Play on your Android tablet or from App Store on an Apple device. It works well even on a two-year-old, low-end tablet. Hence, you may easily put your old tablet to good use by gifting it to a child after installing Sugarizer on it. In this way, you could even rationalise your desire to buy the replacement tablet you have been eyeing.
+
+**Does it work?**
+My children are too old and grandchildren too young. Reason tells me that it should work. Experience also tells me that it will most likely NOT improve school grades. I did not like school. I was bored most of the time. If I was studying in today’s schools, I would have had ulcers or a nervous breakdown!
+When I think of schools, I recall the frustration of a child long ago (just 20 years) who got an answer wrong. The book and the teacher said that a mouse has two buttons. The mouse he used at home had three!
+So, can you risk leaving the education of children you care about to the schools? Think about the skills you may be using today. Could these have been taught at schools a mere five years ago?
+I never took JavaScript seriously and never made an effort to learn it. Today, I see Sugarizer and Snap! (a clone of Scratch in JavaScript) and am acutely aware of my foolishness. However, having learnt programming outside the classroom, I am confident that I can learn to program in JavaScript, should the need arise.
+The intention at the start was to write about the activities in Sugarizer and, maybe, explore the source code. My favourite activities include TamTam, Turtle Blocks, Maze, etc. From the food chain activity, I discovered that some animals that I had believed to be carnivores, were not. I have also seen children get excited by the Speak activity.
+However, once I started writing after the heading ‘Does it work?’, my mind took a radical turn. Now, I am convinced that Sugarizer will work only if you try it out.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/sugarizer-the-taste-of-sugar-on-any-device/
+
+作者:[Dr Anil Seth][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/anil-seth/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2017/05/Technology-Development-in-Computers-Innovation-eLearning-1.jpg?resize=696%2C696&ssl=1 (Technology Development in Computers (Innovation), eLearning)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2017/05/Technology-Development-in-Computers-Innovation-eLearning-1.jpg?fit=900%2C900&ssl=1
+[3]: https://wiki.sugarlabs.org/
+[4]: https://www.pine64.org/,
diff --git a/sources/tech/20191014 How to make a Halloween lantern with Inkscape.md b/sources/tech/20191014 How to make a Halloween lantern with Inkscape.md
new file mode 100644
index 0000000000..0f15fae6e6
--- /dev/null
+++ b/sources/tech/20191014 How to make a Halloween lantern with Inkscape.md
@@ -0,0 +1,188 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to make a Halloween lantern with Inkscape)
+[#]: via: (https://opensource.com/article/19/10/how-make-halloween-lantern-inkscape)
+[#]: author: (Jess Weichler https://opensource.com/users/cyanide-cupcake)
+
+How to make a Halloween lantern with Inkscape
+======
+Use open source tools to make a spooky and fun decoration for your
+favorite Halloween haunt.
+![Halloween - backlit bat flying][1]
+
+The spooky season is almost here! This year, decorate your haunt with a unique Halloween lantern made with open source!
+
+Typically, a portion of a lantern's structure is opaque to block the light from within. What makes a lantern a lantern are the parts that are missing: windows cut from the structure so that light can escape. While it's impractical for lighting, a lantern with windows in spooky shapes and lurking silhouettes can be atmospheric and a lot of fun to create.
+
+This article demonstrates how to create your own lantern using [Inkscape][2]. If you don't have Inkscape, you can install it from your software repository on Linux or download it from the [Inkscape website][3] on MacOS and Windows.
+
+### Supplies
+
+ * Template ([A4][4] or [Letter][5] size)
+ * Cardstock (black is traditional)
+ * Tracing paper (optional)
+ * Craft knife, ruler, and cutting mat (a craft cutting machine/laser cutter can be used instead)
+ * Craft glue
+ * LED tea-light "candle"
+_Safety note:_ Only use battery-operated candles for this project.
+
+
+
+### Understanding the template
+
+To begin, download the correct template for your region (A4 or Letter) from the links above and open it in Inkscape.
+
+* * *
+
+* * *
+
+* * *
+
+**![Lantern template screen][6]**
+
+The gray-and-white checkerboard background is see-through (in technical terms, it's an _alpha channel_.)
+
+The black base forms the lantern. Right now, there are no windows for light to shine through; the lantern is a solid black base. You will use the **Union** and **Difference** options in Inkscape to design the windows digitally.
+
+The dotted blue lines represent fold scorelines. The solid orange lines represent guides. Windows for light should not be placed outside the orange boxes.
+
+To the left of the template are a few pre-made objects you can use in your design.
+
+### To create a window or shape
+
+ 1. Create an object that looks like the window style you want. Objects can be created using any of the shape tools in Inkscape's left toolbar. Alternately, you can download Creative Commons- or Public Domain-licensed clipart and import the PNG file into your project.
+ 2. When you are happy with the shape of the object, turn it into a **Path** (rather than a **Shape**, which Inkscape sees as two different kinds of objects) by selecting **Object > Object to Path** in the top menu.
+
+
+
+![Object to path menu][7]
+
+ 3. Place the object on top of the base shape.
+ 4. Select both the object and the black base by clicking one, pressing and holding the Shift key, then selecting the other.
+ 5. Select **Object > Difference** from the top menu to remove the shape of the object from the base. This creates what will become a window in your lantern.
+
+
+
+![Object > Difference menu][8]
+
+### To add an object to a window
+
+After making a window, you can add objects to it to create a scene.
+
+**Tips:**
+
+ * All objects, including text, must be connected to the base of the lantern. If not, they will fall out after cutting and leave a blank space.
+ * Avoid small, intricate details. These are difficult to cut, even when using a machine like a laser cutter or a craft plotter.
+
+
+ 1. Create or import an object.
+ 2. Place the object inside the window so that it is touching at least two sides of the base.
+ 3. With the object selected, choose **Object > Object to Path** from the top menu.
+
+
+
+![Object to path menu][9]
+
+ 4. Select the object and the black base by clicking on each one while holding the Shift key).
+ 5. Select **Object > Union** to join the object and the base.
+
+
+
+### Add text
+
+Text can either be cut out from the base to create a window (as I did with the stars) or added to a window (which blocks the light from within the lantern). If you're creating a window, only follow steps 1 and 2 below, then use **Difference** to remove the text from the base layer.
+
+ 1. Select the Text tool from the left sidebar to create text. Thick, bold fonts work best.
+
+![Text tool][10]
+
+ 2. Select your text, then choose **Path > Object to Path** from the top menu. This converts the text object to a path. Note that this step means you can no longer edit the text, so perform this step _only after_ you're sure you have the word or words you want.
+
+ 3. After you have converted the text, you can press **F2** on your keyboard to activate the **Node Editor** tool to clearly show the nodes of the text when it is selected with this tool.
+
+
+
+
+![Text selected with Node editor][11]
+
+ 4. Ungroup the text.
+ 5. Adjust each letter so that it slightly overlaps its neighboring letter or the base.
+
+
+
+![Overlapping the text][12]
+
+ 6. To connect all of the letters to one another and to the base, re-select all the text and the base, then select **Path > Union**.
+
+![Connecting letters and base with Path > Union][13]
+
+
+
+
+### Prepare for printing
+
+The following instructions are for hand-cutting your lantern. If you're using a laser cutter or craft plotter, follow the techniques required by your hardware to prepare your files.
+
+ 1. In the **Layer** panel, click the **Eye** icon beside the **Safety** layer to hide the safety lines. If you don't see the Layer panel, reveal it by selecting **Layer > Layers** from the top menu.
+ 2. Select the black base. In the **Fill and Stroke** panel, set the fill to **X** (meaning _no fill_) and the **Stroke** to solid black (that's #000000ff to fans of hexes).
+
+
+
+![Setting fill and stroke][14]
+
+ 3. Print your pattern with **File > Print**.
+
+ 4. Using a craft knife and ruler, carefully cut around each black line. Lightly score the dotted blue lines, then fold.
+
+![Cutting out the lantern][15]
+
+ 5. To finish off the windows, cut tracing paper to the size of each window and glue it to the inside of the lantern.
+
+![Adding tracing paper][16]
+
+ 6. Glue the lantern together at the tabs.
+
+ 7. Turn on a battery-powered LED candle and place it inside your lantern.
+
+
+
+
+![Completed lantern][17]
+
+Now your lantern is complete and ready to light up your haunt. Happy Halloween!
+
+How to make Halloween bottle labels with Inkscape, GIMP, and items around the house.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/how-make-halloween-lantern-inkscape
+
+作者:[Jess Weichler][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/cyanide-cupcake
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/halloween_bag_bat_diy.jpg?itok=24M0lX25 (Halloween - backlit bat flying)
+[2]: https://opensource.com/article/18/1/inkscape-absolute-beginners
+[3]: http://inkscape.org
+[4]: https://www.dropbox.com/s/75qzjilg5ak2oj1/papercraft_lantern_A4_template.svg?dl=0
+[5]: https://www.dropbox.com/s/8fswdge49jwx91n/papercraft_lantern_letter_template%20.svg?dl=0
+[6]: https://opensource.com/sites/default/files/uploads/lanterntemplate_screen.png (Lantern template screen)
+[7]: https://opensource.com/sites/default/files/uploads/lantern1.png (Object to path menu)
+[8]: https://opensource.com/sites/default/files/uploads/lantern2.png (Object > Difference menu)
+[9]: https://opensource.com/sites/default/files/uploads/lantern3.png (Object to path menu)
+[10]: https://opensource.com/sites/default/files/uploads/lantern4.png (Text tool)
+[11]: https://opensource.com/sites/default/files/uploads/lantern5.png (Text selected with Node editor)
+[12]: https://opensource.com/sites/default/files/uploads/lantern6.png (Overlapping the text)
+[13]: https://opensource.com/sites/default/files/uploads/lantern7.png (Connecting letters and base with Path > Union)
+[14]: https://opensource.com/sites/default/files/uploads/lantern8.png (Setting fill and stroke)
+[15]: https://opensource.com/sites/default/files/uploads/lantern9.jpg (Cutting out the lantern)
+[16]: https://opensource.com/sites/default/files/uploads/lantern10.jpg (Adding tracing paper)
+[17]: https://opensource.com/sites/default/files/uploads/lantern11.jpg (Completed lantern)
diff --git a/sources/tech/20191014 My Linux story- I grew up on PC Magazine not candy.md b/sources/tech/20191014 My Linux story- I grew up on PC Magazine not candy.md
new file mode 100644
index 0000000000..d3f967357f
--- /dev/null
+++ b/sources/tech/20191014 My Linux story- I grew up on PC Magazine not candy.md
@@ -0,0 +1,48 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (My Linux story: I grew up on PC Magazine not candy)
+[#]: via: (https://opensource.com/article/19/10/linux-journey-newb-ninja)
+[#]: author: (Michael Zamot https://opensource.com/users/mzamot)
+
+My Linux story: I grew up on PC Magazine not candy
+======
+This Linux story begins with a kid reading about Linux in issues of PC
+Magazine from his childhood home in Costa Rica. Today, he's a passionate
+member of the global Linux community.
+![The back of a kid head][1]
+
+In 1998, the movie _Titanic_ was released, mobile phones were just a luxury, and pagers were still in use. This was also the year I got my first computer. I can remember the details as if it were yesterday: Pentium 133MHz and just 16MB of memory. Back in that time (while running nothing less than Windows 95), this was a good machine. I can still hear in my mind the old spinning hard drive noise when I powered that computer on, and see the Windows 95 flag. It never crossed my mind, though (especially as an 8-year-old kid), that I would dedicate every minute of my life to Linux and open source.
+
+Being just a kid, I always asked my mom to buy me every issue of PC Magazine instead of candies. I never skipped a single issue, and all of those dusty old magazines are still there in Costa Rica. It was in these magazines that I discovered the essential technology that changed my life. An issue in the year 2000 talked extensively about Linux and the advantages of free and open-source software. That issue also included a review of one of the most popular Linux distributions back then: Corel Linux. Unfortunately, the disc was not included. Without internet at home, I was out of luck, but that issue still lit a spark within me.
+
+In 2003, I asked my mom to take me to a Richard Stallman talk. I couldn’t believe he was in the country. I was the only kid in that room, and I was laser-focused on everything he was saying, though I didn’t understand anything about patents, licenses, or the jokes about him with an old hard drive over his head.
+
+Despite my attempts, I couldn’t make Linux work on my computer. One rainy afternoon in the year 2003, with the heavy smell of recently brewed coffee, my best friend and I were able to get a local magazine with a two-disk bundle: Mandrake Linux 7.1 (if my memory doesn’t fail) on one and StarOffice on the other. My friend poured more coffee into our mugs while I inserted the Mandrake disk into the computer with my shaking, excited hands. Linux was finally running—the same Linux I had been obsessed with since I read about it 3 years earlier.
+
+We were lucky enough to get broadband internet in 2006 (at the lightning speed of 128/64Kbps), so I was able to use an old Pentium II computer under my bed and run it 24x7 with Debian, Apache, and my own mail server (my personal server, I told myself). This old machine was my playground to experiment on and put into practice all of the knowledge and reading I had been doing (and also to make the electricity bill more expensive).
+
+As soon as I discovered there were open source communities in the country, I started attending their meetings. Eventually, I was helping in their events, and not long after I was organizing and giving talks. We used to host two annual events for many years: Festival Latinoamericano de Software Libre (Latin American Free Software Installation Fest) and Software Freedom Day.
+
+Thanks to what I learned from my reading, but more importantly from the people in these local communities that guided and mentored me, I was able to land my first Linux job in 2011, even without college. I kept growing from there, working for many companies and learning more about open source and Linux at each one. Eventually, I felt that I had an obligation (or a social debt) to give back to the community so that other people like the younger me could also learn. Not long after, I started teaching classes and meeting wonderful and passionate people, many of whom are now as devoted to Linux and open source as I am. I can definitely say: Mission accomplished!
+
+Eventually, what I learned about open source, Linux, OpenStack, Docker, and every other technology I played with sent me overseas, allowing me to work (doesn’t feel like it) for the most amazing company I’ve ever worked for, doing what I love. Because of open source and Linux, I became a part of something bigger than me. I was a member of a community, and I experienced what I consider the most significant impact on my life: Meeting and learning from so many masterminds and amazing people that today I can call friends. Without them and these communities, I wouldn’t be the person I am today.
+
+How could I know when I was 10 years old and reading a magazine that Linux and open source would connect me to the greatest people, and change my life forever?
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/linux-journey-newb-ninja
+
+作者:[Michael Zamot][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mzamot
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/idea_innovation_kid_education.png?itok=3lRp6gFa (The back of a kid head)
diff --git a/sources/tech/20191015 Formatting NFL data for doing data science with Python.md b/sources/tech/20191015 Formatting NFL data for doing data science with Python.md
new file mode 100644
index 0000000000..67f15777ad
--- /dev/null
+++ b/sources/tech/20191015 Formatting NFL data for doing data science with Python.md
@@ -0,0 +1,235 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Formatting NFL data for doing data science with Python)
+[#]: via: (https://opensource.com/article/19/10/formatting-nfl-data-python)
+[#]: author: (Christa Hayes https://opensource.com/users/cdhayes2)
+
+Formatting NFL data for doing data science with Python
+======
+In part 1 of this series on machine learning with Python, learn how to
+prepare a National Football League dataset for training.
+![A football field.][1]
+
+No matter what medium of content you consume these days (podcasts, articles, tweets, etc.), you'll probably come across some reference to data. Whether it's to back up a talking point or put a meta-view on how data is everywhere, data and its analysis are in high demand.
+
+As a programmer, I've found data science to be more comparable to wizardry than an exact science. I've coveted the ability to get ahold of raw data and glean something useful and concrete from it. What a useful talent!
+
+This got me thinking about the difference between data scientists and programmers. Aren't data scientists just statisticians who can code? Look around and you'll see any number of tools aimed at helping developers become data scientists. AWS has a full-on [machine learning course][2] geared specifically towards turning developers into experts. [Visual Studio][3] has built-in Python projects that—with the click of a button—will create an entire template for classification problems. And scores of programmers are writing tools designed to make data science easier for anyone to pick up.
+
+I thought I'd lean into the clear message of recruiting programmers to the data (or dark) side and give it a shot with a fun project: training a machine learning model to predict plays using a National Football League (NFL) dataset.
+
+### Set up the environment
+
+Before I can dig into the data, I need to set up my [virtual environment][4]. This is important because, without an environment, I'll have nowhere to work. Fortunately, Opensource.com has [some great resources][5] for installing and configuring the setup.
+
+Any of the code you see here, I was able to look up through existing documentation. If there is one thing programmers are familiar with, it's navigating foreign (and sometimes very sparse) documentation.
+
+### Get the data
+
+As with any modern problem, the first step is to make sure you have quality data. Luckily, I came across a set of [NFL tracking data][6] from 2017 that was used for the NFL Big Data Bowl. Even the NFL is trying its best to attract the brightest stars in the data realm.
+
+Everything I need to know about the schema is in the README. This exercise will train a machine learning model to predict run (in which the ball carrier keeps the football and runs downfield) and pass (in which the ball is passed to a receiving player) plays using the plays.csv [data file][7]. I won't use player tracking data in this exercise, but it could be fun to explore later.
+
+First things first, I need to get access to my data by importing it into a dataframe. The [Pandas][8] library is an open source Python library that provides algorithms for easy analysis of data structures. The structure in the sample NFL data happens to be a two-dimensional array (or in simpler terms, a table), which data scientists often refer to as a dataframe. The Pandas function dealing with dataframes is [pandas.DataFrame][9]. I'll also import several other libraries that I will use later.
+
+
+```
+import pandas as pd
+import numpy as np
+import seaborn as sns
+import matplotlib.pyplot as plt
+import xgboost as xgb
+
+from sklearn import metrics
+
+df = pd.read_csv('data/plays.csv')
+
+print(len(df))
+print(df.head())
+```
+
+### Format the data
+
+The NFL data dump does not explicitly indicate which plays are runs (also called rushes) and which are passes. Therefore, I have to classify the offensive play types through some football savvy and reasoning.
+
+Right away, I can get rid of special teams plays in the **isSTPLAY** column. Special teams are neither offense nor defense, so they are irrelevant to my objective.
+
+
+```
+#drop st plays
+df = df[~df['isSTPlay']]
+print(len(df))
+```
+
+Skimming the **playDescription** column, I see some plays where the quarterback kneels, which effectively ends a play. This is usually called a "victory formation" because the intent is to run out the clock. These are significantly different than normal running plays, so I can drop them as well.
+
+
+```
+#drop kneels
+df = df[~df['playDescription'].str.contains("kneels")]
+print (len(df))
+```
+
+The data reports time in terms of the quarters in which a game is normally played (as well as the time on the game clock in each quarter). Is this the most intuitive in terms of trying to predict a sequence? One way to answer this is to consider how gameplay differs between time splits.
+
+When a team has the ball with a minute left in the first quarter, will it act the same as if it has the ball with a minute left in the second quarter? Probably not. Will it act the same with a minute to go at the end of both halves? All else remaining equal, the answer is likely yes in most scenarios.
+
+I'll convert the **quarter** and **GameClock** columns from quarters to halves, denoted in seconds rather than minutes. I'll also create a **half** column from the **quarter** values. There are some fifth quarter values, which I take to be overtime. Since overtime rules are different than normal gameplay, I can drop them.
+
+
+```
+#drop overtime
+df = df[~(df['quarter'] == 5)]
+print(len(df))
+
+#convert time/quarters
+def translate_game_clock(row):
+ raw_game_clock = row['GameClock']
+ quarter = row['quarter']
+ minutes, seconds_raw = raw_game_clock.partition(':')[::2]
+
+ seconds = seconds_raw.partition(':')[0]
+
+ total_seconds_left_in_quarter = int(seconds) + (int(minutes) * 60)
+
+ if quarter == 3 or quarter == 1:
+ return total_seconds_left_in_quarter + 900
+ elif quarter == 4 or quarter == 2:
+ return total_seconds_left_in_quarter
+
+if 'GameClock' in list (df.columns):
+ df['secondsLeftInHalf'] = df.apply(translate_game_clock, axis=1)
+
+if 'quarter' in list(df.columns):
+ df['half'] = df['quarter'].map(lambda q: 2 if q > 2 else 1)
+```
+
+The **yardlineNumber** column also needs to be transformed. The data currently lists the yard line as a value from one to 50. Again, this is unhelpful because a team would not act the same on its own 20-yard line vs. its opponent's 20-yard line. I will convert it to represent a value from one to 99, where the one-yard line is nearest the possession team's endzone, and the 99-yard line is nearest the opponent's end zone.
+
+
+```
+def yards_to_endzone(row):
+ if row['possessionTeam'] == row['yardlineSide']:
+ return 100 - row['yardlineNumber']
+ else :
+ return row['yardlineNumber']
+
+df['yardsToEndzone'] = df.apply(yards_to_endzone, axis = 1)
+```
+
+The personnel data would be extremely useful if I could get it into a format for the machine learning algorithm to take in. Personnel identifies the different types of skill positions on the field at a given time. The string value currently shown in **personnel.offense** is not conducive to input, so I'll convert each personnel position to its own column to indicate the number present on the field during the play. Defense personnel might be interesting to include later to see if it has any outcome on prediction. For now, I'll just stick with offense.
+
+
+```
+def transform_off_personnel(row):
+
+ rb_count = 0
+ te_count = 0
+ wr_count = 0
+ ol_count = 0
+ dl_count = 0
+ db_count = 0
+
+ if not pd.isna(row['personnel.offense']):
+ personnel = row['personnel.offense'].split(', ')
+ for p in personnel:
+ if p[2:4] == 'RB':
+ rb_count = int(p[0])
+ elif p[2:4] == 'TE':
+ te_count = int(p[0])
+ elif p[2:4] == 'WR':
+ wr_count = int(p[0])
+ elif p[2:4] == 'OL':
+ ol_count = int(p[0])
+ elif p[2:4] == 'DL':
+ dl_count = int(p[0])
+ elif p[2:4] == 'DB':
+ db_count = int(p[0])
+
+ return pd.Series([rb_count,te_count,wr_count,ol_count,dl_count, db_count])
+
+df[['rb_count','te_count','wr_count','ol_count','dl_count', 'db_count']] = df.apply(transform_off_personnel, axis=1)
+```
+
+Now the offense personnel values are represented by individual columns.
+
+![Result of reformatting offense personnel][10]
+
+Formations describe how players are positioned on the field, and this is also something that would seemingly have value in predicting play outcomes. Once again, I'll convert the string values into integers.
+
+
+```
+df['offenseFormation'] = df['offenseFormation'].map(lambda f : 'EMPTY' if pd.isna(f) else f)
+
+def formation(row):
+ form = row['offenseFormation'].strip()
+ if form == 'SHOTGUN':
+ return 0
+ elif form == 'SINGLEBACK':
+ return 1
+ elif form == 'EMPTY':
+ return 2
+ elif form == 'I_FORM':
+ return 3
+ elif form == 'PISTOL':
+ return 4
+ elif form == 'JUMBO':
+ return 5
+ elif form == 'WILDCAT':
+ return 6
+ elif form=='ACE':
+ return 7
+ else:
+ return -1
+
+df['numericFormation'] = df.apply(formation, axis=1)
+
+print(df.yardlineNumber.unique())
+```
+
+Finally, it's time to classify the play types. The **PassResult** column has four distinct values: I, C, S, and null, which represent Incomplete passing plays, Complete passing plays, Sacks (classified as passing plays), and a null value. Since I've already eliminated all special teams plays, I can assume the null values are running plays. So I'll convert the play outcome into a single column called **play_type** represented by either a 0 for running or a 1 for passing. This will be the column (or _label_, as the data scientists say) I want my algorithm to predict.
+
+
+```
+def play_type(row):
+ if row['PassResult'] == 'I' or row['PassResult'] == 'C' or row['PassResult'] == 'S':
+ return 'Passing'
+ else:
+ return 'Rushing'
+
+df['play_type'] = df.apply(play_type, axis = 1)
+df['numericPlayType'] = df['play_type'].map(lambda p: 1 if p == 'Passing' else 0)
+```
+
+### Take a break
+
+Is it time to start predicting things yet? Most of my work so far has been trying to understand the data and what format it needs to be in—before I even get started on predicting anything. Anyone else need a minute?
+
+In part two, I'll do some analysis and visualization of the data before feeding it into a machine learning algorithm, and then I'll score the model's results to see how accurate they are. Stay tuned!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/formatting-nfl-data-python
+
+作者:[Christa Hayes][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/cdhayes2
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_LIFE_football__520x292.png?itok=5hPbxQF8 (A football field.)
+[2]: https://aws.amazon.com/training/learning-paths/machine-learning/developer/
+[3]: https://docs.microsoft.com/en-us/visualstudio/python/overview-of-python-tools-for-visual-studio?view=vs-2019
+[4]: https://opensource.com/article/19/9/get-started-data-science-python
+[5]: https://opensource.com/article/17/10/python-101
+[6]: https://github.com/nfl-football-ops/Big-Data-Bowl
+[7]: https://github.com/nfl-football-ops/Big-Data-Bowl/tree/master/Data
+[8]: https://pandas.pydata.org/
+[9]: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
+[10]: https://opensource.com/sites/default/files/uploads/nfl-python-7_personneloffense.png (Result of reformatting offense personnel)
diff --git a/sources/tech/20191016 Open source interior design with Sweet Home 3D.md b/sources/tech/20191016 Open source interior design with Sweet Home 3D.md
new file mode 100644
index 0000000000..bc5a17c51c
--- /dev/null
+++ b/sources/tech/20191016 Open source interior design with Sweet Home 3D.md
@@ -0,0 +1,142 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Open source interior design with Sweet Home 3D)
+[#]: via: (https://opensource.com/article/19/10/interior-design-sweet-home-3d)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Open source interior design with Sweet Home 3D
+======
+Try out furniture layouts, color schemes, and more in virtual reality
+before you go shopping in the real world.
+![Several houses][1]
+
+There are three schools of thought on how to go about decorating a room:
+
+ 1. Buy a bunch of furniture and cram it into the room
+ 2. Take careful measurements of each item of furniture, calculate the theoretical capacity of the room, then cram it all in, ignoring the fact that you've placed a bookshelf on top of your bed
+ 3. Use a computer for pre-visualization
+
+
+
+Historically, I practiced the little-known fourth principle: don't have furniture. However, since I became a remote worker, I've found that a home office needs conveniences like a desk and a chair, a bookshelf for reference books and tech manuals, and so on. Therefore, I have been formulating a plan to populate my living and working space with actual furniture, made of actual wood rather than milk crates (or glue and sawdust, for that matter), with an emphasis on _plan_. The last thing I want is to bring home a great find from a garage sale to discover that it doesn't fit through the door or that it's oversized compared to another item of furniture.
+
+It was time to do what the professionals do. It was time to pre-viz.
+
+### Open source interior design
+
+[Sweet Home 3D][2] is an open source (GPLv2) interior design application that helps you draw your home's floor plan and then define, resize, and arrange furniture. You can do all of this with precise measurements, down to fractions of a centimeter, without having to do any math and with the ease of basic drag-and-drop operations. And when you're done, you can view the results in 3D. If you can create a basic table (not the furniture kind) in a word processor, you can plan the interior design of your home in Sweet Home 3D.
+
+### Installing
+
+Sweet Home 3D is a [Java][3] application, so it's universal. It runs on any operating system that can run Java, which includes Linux, Windows, MacOS, and BSD. Regardless of your OS, you can [download][4] the application from the website.
+
+ * On Linux, [untar][5] the archive. Right-click on the SweetHome3D file and select **Properties**. In the **Permission** tab, grant the file executable permission.
+ * On MacOS and Windows, expand the archive and launch the application. You must grant it permission to run on your system when prompted.
+
+
+
+![Sweet Home 3D permissions][6]
+
+On Linux, you can also install Sweet Home 3D as a Snap package, provided you have **snapd** installed and enabled.
+
+### Measures of success
+
+First thing first: Break out your measuring tape. To get the most out of Sweet Home 3D, you must know the actual dimensions of the living space you're planning for. You may or may not need to measure down to the millimeter or 16th of an inch; you know your own tolerance for variance. But you must get the basic dimensions, including measuring walls and windows and doors.
+
+Use your best judgment for common sense. For instance, When measuring doors, include the door frame; while it's not technically part of the _door_ itself, it is part of the wall space that you probably don't want to cover with furniture.
+
+![Measure twice, execute once][7]
+
+CC-SA-BY opensource.com
+
+### Creating a room
+
+When you first launch Sweet Home 3D, it opens a blank canvas in its default viewing mode, a blueprint view in the top panel, and a 3D rendering in the bottom panel. On my [Slackware][8] desktop computer, this works famously, but my desktop is also my video editing and gaming computer, so it's got a great graphics card for 3D rendering. On my laptop, this view was a lot slower. For best performance (especially on a computer not dedicated to 3D rendering), go to the **3D View** menu at the top of the window and select **Virtual Visit**. This view mode renders your work from a ground-level point of view based on the position of a virtual visitor. That means you get to control what is rendered and when.
+
+It makes sense to switch to this view regardless of your computer's power because an aerial 3D rendering doesn't provide you with much more detail than what you have in your blueprint plan. Once you have changed the view mode, you can start designing.
+
+The first step is to define the walls of your home. This is done with the **Create Walls** tool, found to the right of the **Hand** icon in the top toolbar. Drawing walls is simple: Click where you want a wall to begin, click to anchor it, and continue until your room is complete.
+
+![Drawing walls in Sweet Home 3D][9]
+
+Once you close the walls, press **Esc** to exit the tool.
+
+#### Defining a room
+
+Sweet Home 3D is flexible on how you create walls. You can draw the outer boundary of your house first, and then subdivide the interior, or you can draw each room as conjoined "containers" that ultimately form the footprint of your house. This flexibility is possible because, in real life and in Sweet Home 3D, walls don't always define a room. To define a room, use the **Create Rooms** button to the right of the **Create Walls** button in the top toolbar.
+
+If the room's floor space is defined by four walls, then all you need to do to define that enclosure as a room is double-click within the four walls. Sweet Home 3D defines the space as a room and provides you with its area in feet or meters, depending on your preference.
+
+For irregular rooms, you must manually define each corner of the room with a click. Depending on the complexity of the room shape, you may have to experiment to find whether you need to work clockwise or counterclockwise from your origin point to avoid quirky Möbius-strip flooring. Generally, however, defining the floor space of a room is straightforward.
+
+![Defining rooms in Sweet Home 3D][10]
+
+After you give the room a floor, you can change to the **Arrow** tool and double-click on the room to give it a name. You can also set the color and texture of the flooring, walls, ceiling, and baseboards.
+
+![Modifying room floors, ceilings, etc. in Sweet Home 3D][11]
+
+None of this is rendered in your blueprint view by default. To enable room rendering in your blueprint panel, go to the **File** menu and select **Preferences**. In the **Preferences** panel, set **Room rendering in plan** to **Floor color or texture**.
+
+### Doors and windows
+
+Once you've finished the basic floor plan, you can switch permanently to the **Arrow** tool.
+
+You can find doors and windows in the left column of Sweet Home 3D, in the **Doors and Windows** category. You have many choices, so choose whatever is closest to what you have in your home.
+
+![Moving a door in Sweet Home 3D][12]
+
+To place a door or window into your plan, drag-and-drop it on the appropriate wall in your blueprint panel. To adjust its position and size, double-click the door or window.
+
+### Adding furniture
+
+With the base plan complete, the part of the job that feels like _work_ is over! From this point onward, you can play with furniture arrangements and other décor.
+
+You can find furniture in the left column, organized by the room for which each is intended. You can drag-and-drop any item into your blueprint plan and control orientation and size with the tools visible when you hover your mouse over the item's corners. Double-click on any item to adjust its color and finish.
+
+### Visiting and exporting
+
+To see what your future home will look like, drag the "person" icon in your blueprint view into a room.
+
+![Sweet Home 3D rendering][13]
+
+You can strike your own balance between realism and just getting a feel for space, but your imagination is your only limit. You can get additional assets to add to your home from the Sweet Home 3D [download page][4]. You can even create your own furniture and textures with the **Library Editor** applications, which are optional downloads from the project site.
+
+Sweet Home 3D can export your blueprint plan to SVG format for use in [Inkscape][14], and it can export your 3D model to OBJ format for use in [Blender][15]. To export your blueprint, go to the **Plan** menu and select **Export to SVG format**. To export a 3D model, go to the **3D View** menu and select **Export to OBJ format**.
+
+You can also take "snapshots" of your home so that you can refer to your ideas without opening Sweet Home 3D. To create a snapshot, go to the **3D View** menu and select **Create Photo**. The snapshot is rendered from the perspective of the person icon in the blueprint view, so adjust as required, then click the **Create** button in the **Create Photo** window. If you're happy with the photo, click **Save**.
+
+### Home sweet home
+
+There are many more features in Sweet Home 3D. You can add a sky and a lawn, position lights for your photos, set ceiling height, add another level to your house, and much more. Whether you're planning for a flat you're renting or a house you're buying—or a house that doesn't even exist (yet), Sweet Home 3D is an engaging and easy application that can entertain and help you make better purchasing choices when scurrying around for furniture, so you can finally stop eating breakfast at the kitchen counter and working while crouched on the floor.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/interior-design-sweet-home-3d
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LIFE_housing.png?itok=s7i6pQL1 (Several houses)
+[2]: http://www.sweethome3d.com/
+[3]: https://opensource.com/resources/java
+[4]: http://www.sweethome3d.com/download.jsp
+[5]: https://opensource.com/article/17/7/how-unzip-targz-file
+[6]: https://opensource.com/sites/default/files/uploads/sweethome3d-permissions.png (Sweet Home 3D permissions)
+[7]: https://opensource.com/sites/default/files/images/life/sweethome3d-measure.jpg (Measure twice, execute once)
+[8]: http://www.slackware.com/
+[9]: https://opensource.com/sites/default/files/uploads/sweethome3d-walls.jpg (Drawing walls in Sweet Home 3D)
+[10]: https://opensource.com/sites/default/files/uploads/sweethome3d-rooms.jpg (Defining rooms in Sweet Home 3D)
+[11]: https://opensource.com/sites/default/files/uploads/sweethome3d-rooms-modify.jpg (Modifying room floors, ceilings, etc. in Sweet Home 3D)
+[12]: https://opensource.com/sites/default/files/uploads/sweethome3d-move.jpg (Moving a door in Sweet Home 3D)
+[13]: https://opensource.com/sites/default/files/uploads/sweethome3d-view.jpg (Sweet Home 3D rendering)
+[14]: http://inkscape.org
+[15]: http://blender.org
diff --git a/sources/tech/20191017 How to type emoji on Linux.md b/sources/tech/20191017 How to type emoji on Linux.md
new file mode 100644
index 0000000000..ff85c55938
--- /dev/null
+++ b/sources/tech/20191017 How to type emoji on Linux.md
@@ -0,0 +1,146 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to type emoji on Linux)
+[#]: via: (https://opensource.com/article/19/10/how-type-emoji-linux)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+How to type emoji on Linux
+======
+The GNOME desktop makes it easy to use emoji in your communications.
+![A cat under a keyboard.][1]
+
+Emoji are those fanciful pictograms that snuck into the Unicode character space. They're all the rage online, and people use them for all kinds of surprising things, from signifying reactions on social media to serving as visual labels for important file names. There are many ways to enter Unicode characters on Linux, but the GNOME desktop makes it easy to find and type an emoji.
+
+![Emoji in Emacs][2]
+
+### Requirements
+
+For this easy method, you must be running Linux with the [GNOME][3] desktop.
+
+You must also have an emoji font installed. There are many to choose from, so do a search for _emoji_ using your favorite software installer application or package manager.
+
+For example, on Fedora:
+
+
+```
+$ sudo dnf search emoji
+emoji-picker.noarch : An emoji selection tool
+unicode-emoji.noarch : Unicode Emoji Data Files
+eosrei-emojione-fonts.noarch : A color emoji font
+twitter-twemoji-fonts.noarch : Twitter Emoji for everyone
+google-android-emoji-fonts.noarch : Android Emoji font released by Google
+google-noto-emoji-fonts.noarch : Google “Noto Emoji” Black-and-White emoji font
+google-noto-emoji-color-fonts.noarch : Google “Noto Color Emoji” colored emoji font
+[...]
+```
+
+On Ubuntu or Debian, use **apt search** instead.
+
+I'm using [Google Noto Color Emoji][4] in this article.
+
+### Get set up
+
+To get set up, launch GNOME's Settings application.
+
+ 1. In Settings, click the **Region & Language** category in the left column.
+ 2. Click the plus symbol (**+**) under the **Input Sources** heading to bring up the **Add an Input Source** panel.
+
+
+
+![Add a new input source][5]
+
+ 3. In the **Add an Input Source** panel, click the hamburger menu at the bottom of the input list.
+
+
+
+![Add an Input Source panel][6]
+
+ 4. Scroll to the bottom of the list and select **Other**.
+ 5. In the **Other** list, find **Other (Typing Booster)**. (You can type **boost** in the search field at the bottom to filter the list.)
+
+
+
+![Find Other \(Typing Booster\) in inputs][7]
+
+ 6. Click the **Add** button in the top-right corner of the panel to add the input source to GNOME.
+
+
+
+Once you've done that, you can close the Settings window.
+
+#### Switch to Typing Booster
+
+You now have a new icon in the top-right of your GNOME desktop. By default, it's set to the two-letter abbreviation of your language (**en** for English, **eo** for Esperanto, **es** for Español, and so on). If you press the **Super** key (the key with a Linux penguin, Windows logo, or Mac Command symbol) and the **Spacebar** together on your keyboard, you will switch input sources from your default source to the next on your input list. In this example, you only have two input sources: your default language and Typing Booster.
+
+Try pressing **Super**+**Spacebar** together and watch the input name and icon change.
+
+#### Configure Typing Booster
+
+With the Typing Booster input method active, click the input sources icon in the top-right of your screen, select **Unicode symbols and emoji predictions**, and set it to **On**.
+
+![Set Unicode symbols and emoji predictions to On][8]
+
+This makes Typing Booster dedicated to typing emoji, which isn't all Typing Booster is good for, but in the context of this article it's exactly what is needed.
+
+### Type emoji
+
+With Typing Booster still active, open a text editor like Gedit, a web browser, or anything that you know understands Unicode characters, and type "_thumbs up_." As you type, Typing Booster searches for matching emoji names.
+
+![Typing Booster searching for emojis][9]
+
+To leave emoji mode, press **Super**+**Spacebar** again, and your input source goes back to your default language.
+
+### Switch the switcher
+
+If the **Super**+**Spacebar** keyboard shortcut is not natural for you, then you can change it to a different combination. In GNOME Settings, navigate to **Devices** and select **Keyboard**.
+
+In the top bar of the **Keyboard** window, search for **Input** to filter the list. Set **Switch to next input source** to a key combination of your choice.
+
+![Changing keystroke combination in GNOME settings][10]
+
+### Unicode input
+
+The fact is, keyboards were designed for a 26-letter (or thereabouts) alphabet along with as many numerals and symbols. ASCII has more characters than what you find on a typical keyboard, to say nothing of the millions of characters within Unicode. If you want to type Unicode characters into a modern Linux application but don't want to switch to Typing Booster, then you can use the Unicode input shortcut.
+
+ 1. With your default language active, open a text editor like Gedit, a web browser, or any application you know accepts Unicode.
+ 2. Press **Ctrl**+**Shift**+**U** on your keyboard to enter Unicode entry mode. Release the keys.
+ 3. You are currently in Unicode entry mode, so type a number of a Unicode symbol. For instance, try **1F44D** for a 👍 symbol, or **2620** for a ☠ symbol. To get the number code of a Unicode symbol, you can search the internet or refer to the [Unicode specification][11].
+
+
+
+### Pragmatic emoji-ism
+
+Emoji are fun and expressive. They can make your text unique to you. They can also be utilitarian. Because emoji are Unicode characters, they can be used anywhere a font can be used, and they can be used the same way any alphabetic character can be used. For instance, if you want to mark a series of files with a special symbol, you can add an emoji to the name, and you can filter by that emoji in Search.
+
+![Labeling a file with emoji][12]
+
+Use emoji all you want because Linux is a Unicode-friendly environment, and it's getting friendlier with every release.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/how-type-emoji-linux
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead_cat-keyboard.png?itok=fuNmiGV- (A cat under a keyboard.)
+[2]: https://opensource.com/sites/default/files/uploads/emacs-emoji.jpg (Emoji in Emacs)
+[3]: https://www.gnome.org/
+[4]: https://www.google.com/get/noto/help/emoji/
+[5]: https://opensource.com/sites/default/files/uploads/gnome-setting-region-add.png (Add a new input source)
+[6]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-list.png (Add an Input Source panel)
+[7]: https://opensource.com/sites/default/files/uploads/gnome-setting-input-other-typing-booster.png (Find Other (Typing Booster) in inputs)
+[8]: https://opensource.com/sites/default/files/uploads/emoji-input-on.jpg (Set Unicode symbols and emoji predictions to On)
+[9]: https://opensource.com/sites/default/files/uploads/emoji-input.jpg (Typing Booster searching for emojis)
+[10]: https://opensource.com/sites/default/files/uploads/gnome-setting-keyboard-switch-input.jpg (Changing keystroke combination in GNOME settings)
+[11]: http://unicode.org/emoji/charts/full-emoji-list.html
+[12]: https://opensource.com/sites/default/files/uploads/file-label.png (Labeling a file with emoji)
diff --git a/sources/tech/20191017 Intro to the Linux useradd command.md b/sources/tech/20191017 Intro to the Linux useradd command.md
new file mode 100644
index 0000000000..b2befd4650
--- /dev/null
+++ b/sources/tech/20191017 Intro to the Linux useradd command.md
@@ -0,0 +1,218 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Intro to the Linux useradd command)
+[#]: via: (https://opensource.com/article/19/10/linux-useradd-command)
+[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
+
+Intro to the Linux useradd command
+======
+Add users (and customize their accounts as needed) with the useradd
+command.
+![people in different locations who are part of the same team][1]
+
+Adding a user is one of the most fundamental exercises on any computer system; this article focuses on how to do it on a Linux system.
+
+Before getting started, I want to mention three fundamentals to keep in mind. First, like with most operating systems, Linux users need an account to be able to log in. This article specifically covers local accounts, not network accounts such as LDAP. Second, accounts have both a name (called a username) and a number (called a user ID). Third, users are typically placed into a group. Groups also have a name and group ID.
+
+As you'd expect, Linux includes a command-line utility for adding users; it's called **useradd**. You may also find the command **adduser**. Many distributions have added this symbolic link to the **useradd** command as a matter of convenience.
+
+
+```
+$ file `which adduser`
+/usr/sbin/adduser: symbolic link to useradd
+```
+
+Let's take a look at **useradd**.
+
+> Note: The defaults described in this article reflect those in Red Hat Enterprise Linux 8.0. You may find subtle differences in these files and certain defaults on other Linux distributions or other Unix operating systems such as FreeBSD or Solaris.
+
+### Default behavior
+
+The basic usage of **useradd** is quite simple: A user can be added just by providing their username.
+
+
+```
+`$ sudo useradd sonny`
+```
+
+In this example, the **useradd** command creates an account called _sonny_. A group with the same name is also created, and _sonny_ is placed in it to be used as the primary group. There are other parameters, such as language and shell, that are applied according to defaults and values set in the configuration files **/etc/default/useradd** and **/etc/login.defs**. This is generally sufficient for a single, personal system or a small, one-server business environment.
+
+While the two files above govern the behavior of **useradd**, user information is stored in other files found in the **/etc** directory, which I will refer to throughout this article.
+
+File | Description | Fields (bold—set by useradd)
+---|---|---
+passwd | Stores user account details | **username**:unused:**uid**:**gid**:**comment**:**homedir**:**shell**
+shadow | Stores user account security details | **username**:password:lastchange:minimum:maximum:warn:**inactive**:**expire**:unused
+group | Stores group details | **groupname**:unused:**gid**:**members**
+
+### Customizable behavior
+
+The command line allows customization for times when an administrator needs finer control, such as to specify a user's ID number.
+
+#### User and group ID numbers
+
+By default, **useradd** tries to use the same number for the user ID (UID) and primary group ID (GID), but there are no guarantees. Although it's not necessary for the UID and GID to match, it's easier for administrators to manage them when they do.
+
+I have just the scenario to explain. Suppose I add another account, this time for Timmy. Comparing the two users, _sonny_ and _timmy_, shows that both users and their respective primary groups were created by using the **getent** command.
+
+
+```
+$ getent passwd sonny timmy
+sonny❌1001:1002:Sonny:/home/sonny:/bin/bash
+timmy❌1002:1003::/home/timmy:/bin/bash
+
+$ getent group sonny timmy
+sonny❌1002:
+timmy❌1003:
+```
+
+Unfortunately, neither users' UID nor primary GID match. This is because the default behavior is to assign the next available UID to the user and then attempt to assign the same number to the primary group. However, if that number is already used, the next available GID is assigned to the group. To explain what happened, I hypothesize that a group with GID 1001 already exists and enter a command to confirm.
+
+
+```
+$ getent group 1001
+book❌1001:alan
+```
+
+The group _book_ with the ID _1001_ has caused the GIDs to be off by one. This is an example where a system administrator would need to take more control of the user-creation process. To resolve this issue, I must first determine the next available user and group ID that will match. The commands **getent group** and **getent passwd** will be helpful in determining the next available number. This number can be passed with the **-u** argument.
+
+
+```
+$ sudo useradd -u 1004 bobby
+
+$ getent passwd bobby; getent group bobby
+bobby❌1004:1004::/home/bobby:/bin/bash
+bobby❌1004:
+```
+
+Another good reason to specify the ID is for users that will be accessing files on a remote system using the Network File System (NFS). NFS is easier to administer when all client and server systems have the same ID configured for a given user. I cover this in a bit more detail in my article on [using autofs to mount NFS shares][2].
+
+### More customization
+
+Very often though, other account parameters need to be specified for a user. Here are brief examples of the most common customizations you may need to use.
+
+#### Comment
+
+The comment option is a plain-text field for providing a short description or other information using the **-c** argument.
+
+
+```
+$ sudo useradd -c "Bailey is cool" bailey
+$ getent passwd bailey
+bailey❌1011:1011:Bailey is cool:/home/bailey:/bin/bash
+```
+
+#### Groups
+
+A user can be assigned one primary group and multiple secondary groups. The **-g** argument specifies the name or GID of the primary group. If it's not specified, **useradd** creates a primary group with the user's same name (as demonstrated above). The **-G** (uppercase) argument is used to pass a comma-separated list of groups that the user will be placed into; these are known as secondary groups.
+
+
+```
+$ sudo useradd -G tgroup,fgroup,libvirt milly
+$ id milly
+uid=1012(milly) gid=1012(milly) groups=1012(milly),981(libvirt),4000(fgroup),3000(tgroup)
+```
+
+#### Home directory
+
+The default behavior of **useradd** is to create the user's home directory in **/home**. However, different aspects of the home directory can be overridden with the following arguments. The **-b** sets another directory where user homes can be placed. For example, **/home2** instead of the default **/home**.
+
+
+```
+$ sudo useradd -b /home2 vicky
+$ getent passwd vicky
+vicky❌1013:1013::/home2/vicky:/bin/bash
+```
+
+The **-d** lets you specify a home directory with a different name from the user.
+
+
+```
+$ sudo useradd -d /home/ben jerry
+$ getent passwd jerry
+jerry❌1014:1014::/home/ben:/bin/bash
+```
+
+#### The skeleton directory
+
+The **-k** instructs the new user's new home directory to be populated with any files in the **/etc/skel** directory. These are usually shell configuration files, but they can be anything that a system administrator would like to make available to all new users.
+
+#### Shell
+
+The **-s** argument can be used to specify the shell. The default is used if nothing else is specified. For example, in the following, shell **bash** is defined in the default configuration file, but Wally has requested **zsh**.
+
+
+```
+$ grep SHELL /etc/default/useradd
+SHELL=/bin/bash
+
+$ sudo useradd -s /usr/bin/zsh wally
+$ getent passwd wally
+wally❌1004:1004::/home/wally:/usr/bin/zsh
+```
+
+#### Security
+
+Security is an essential part of user management, so there are several options available with the **useradd** command. A user account can be given an expiration date, in the form YYYY-MM-DD, using the **-e** argument.
+
+
+```
+$ sudo useradd -e 20191231 sammy
+$ sudo getent shadow sammy
+sammy:!!:18171:0:99999:7::20191231:
+```
+
+An account can also be disabled automatically if the password expires. The **-f** argument will set the number of days after the password expires before the account is disabled. Zero is immediate.
+
+
+```
+$ sudo useradd -f 30 willy
+$ sudo getent shadow willy
+willy:!!:18171:0:99999:7:30::
+```
+
+### A real-world example
+
+In practice, several of these arguments may be used when creating a new user account. For example, if I need to create an account for Perry, I might use the following command:
+
+
+```
+$ sudo useradd -u 1020 -c "Perry Example" \
+-G tgroup -b /home2 \
+-s /usr/bin/zsh \
+-e 20201201 -f 5 perry
+```
+
+Refer to the sections above to understand each option. Verify the results with:
+
+
+```
+$ getent passwd perry; getent group perry; getent shadow perry; id perry
+perry❌1020:1020:Perry Example:/home2/perry:/usr/bin/zsh
+perry❌1020:
+perry:!!:18171:0:99999:7:5:20201201:
+uid=1020(perry) gid=1020(perry) groups=1020(perry),3000(tgroup)
+```
+
+### Some final advice
+
+The **useradd** command is a "must-know" for any Unix (not just Linux) administrator. It is important to understand all of its options since user creation is something that you want to get right the first time. This means having a well-thought-out naming convention that includes a dedicated UID/GID range reserved for your users across your enterprise, not just on a single system—particularly when you're working in a growing organization.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/linux-useradd-command
+
+作者:[Alan Formy-Duval][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/alanfdoss
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/connection_people_team_collaboration.png?itok=0_vQT8xV (people in different locations who are part of the same team)
+[2]: https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
diff --git a/sources/tech/20191017 Using multitail on Linux.md b/sources/tech/20191017 Using multitail on Linux.md
new file mode 100644
index 0000000000..3b6fc7ca78
--- /dev/null
+++ b/sources/tech/20191017 Using multitail on Linux.md
@@ -0,0 +1,132 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wenwensnow)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Using multitail on Linux)
+[#]: via: (https://www.networkworld.com/article/3445228/using-multitail-on-linux.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+Using multitail on Linux
+======
+
+[Glen Bowman][1] [(CC BY-SA 2.0)][2]
+
+The **multitail** command can be very helpful whenever you want to watch activity on a number of files at the same time – especially log files. It works like a multi-windowed **tail -f** command. That is, it displays the bottoms of files and new lines as they are being added. While easy to use in general, **multitail** does provide some command-line and interactive options that you should be aware of before you start to use it routinely.
+
+### Basic multitail-ing
+
+The simplest use of **multitail** is to list the names of the files that you wish to watch on the command line. This command splits the screen horizontally (i.e., top and bottom), displaying the bottom of each of the files along with updates.
+
+[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
+
+```
+$ multitail /var/log/syslog /var/log/dmesg
+```
+
+The display will be split like this:
+
+[][4]
+
+BrandPost Sponsored by HPE
+
+[Take the Intelligent Route with Consumption-Based Storage][4]
+
+Combine the agility and economics of HPE storage with HPE GreenLake and run your IT department with efficiency.
+
+```
++-----------------------+
+| |
+| |
++-----------------------|
+| |
+| |
++-----------------------+
+```
+
+The lines displayed from each of the files would be followed by a single line per file that includes the assigned file number (starting with 00), the file name, the file size, and the date and time the most recent content was added. Each of the files will be allotted half the space available regardless of its size or activity. For example:
+
+```
+content lines from my1.log
+more content
+more lines
+
+00] my1.log 59KB - 2019/10/14 12:12:09
+content lines from my2.log
+more content
+more lines
+
+01] my2.log 120KB - 2019/10/14 14:22:29
+```
+
+Note that **multitail** will not complain if you ask it to display non-text files or files that you have no permission to view; you just won't see the contents.
+
+You can also use wild cards to specify the files that you want to watch:
+
+```
+$ multitail my*.log
+```
+
+One thing to keep in mind is that **multitail** is going to split the screen evenly. If you specify too many files, you will see only a few lines from each and you will only see the first seven or so of the requested files if you list too many unless you take extra steps to view the later files (see the scrolling option described below). The exact result depends on the how many lines are available in your terminal window.
+
+Press **q** to quit **multitail** and return to your normal screen view.
+
+### Dividing the screen
+
+**Multitail** will split your terminal window vertically (i.e., left and right) if you prefer. For this, use the **-s** option. If you specify three files, the right side of your screen will be divided horizontally as well. With four, you'll have four equal-sized windows.
+
+```
++-----------+-----------+ +-----------+-----------+ +-----------+-----------+
+| | | | | | | | |
+| | | | | | | | |
+| | | | +-----------+ +-----------+-----------+
+| | | | | | | | |
+| | | | | | | | |
++-----------+-----------+ +-----------+-----------+ +-----------+-----------+
+ 2 files 3 files 4 files
+```
+
+Use **multitail -s 3 file1 file2 file3** if you want to split the screen into three columns.
+
+```
++-------+-------+-------+
+| | | |
+| | | |
+| | | |
+| | | |
+| | | |
++-------+-------+-------+
+ 3 files with -s 3
+```
+
+### Scrolling
+
+You can scroll up and down through displayed files, but you need to press **b** to bring up a selection menu and then use the up and arrow buttons to select the file you wish to scroll through. Then press the **enter** key. You can then scroll through the lines in an enlarged area, again using the up and down arrows. Press **q** when you're done to go back to the normal view.
+
+### Getting Help
+
+Pressing **h** in **multitail** will open a help menu describing some of the basic operations, though the man page provides quite a bit more information and is worth perusing if you want to learn even more about using this tool.
+
+**Multitail** will not likely be installed on your system by default, but using **apt-get** or **yum** should get you to an easy install. The tool provides a lot of functionality, but with its character-based display, window borders will just be strings of **q**'s and **x**'s. It's a very handy when you need to keep an eye on file updates.
+
+Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3445228/using-multitail-on-linux.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.flickr.com/photos/glenbowman/7992498919/in/photolist-dbgDtv-gHfRRz-5uRM4v-gHgFnz-6sPqTZ-5uaP7H-USFPqD-pbtRUe-fiKiYn-nmgWL2-pQNepR-q68p8d-dDsUxw-dbgFKG-nmgE6m-DHyqM-nCKA4L-2d7uFqH-Kbqzk-8EwKg-8Vy72g-2X3NSN-78Bv84-buKWXF-aeM4ok-yhweWf-4vwpyX-9hu8nq-9zCoti-v5nzP5-23fL48r-24y6pGS-JhWDof-6zF75k-24y6nHS-9hr19c-Gueh6G-Guei7u-GuegFy-24y6oX5-26qu5iX-wKrnMW-Gueikf-24y6oYh-27y4wwA-x4z19F-x57yP4-24BY6gc-24y6nPo-QGwbkf
+[2]: https://creativecommons.org/licenses/by-sa/2.0/legalcode
+[3]: https://www.networkworld.com/newsletters/signup.html
+[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE20773&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
+[5]: https://www.facebook.com/NetworkWorld/
+[6]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20191018 How to use Protobuf for data interchange.md b/sources/tech/20191018 How to use Protobuf for data interchange.md
new file mode 100644
index 0000000000..4de9e2120a
--- /dev/null
+++ b/sources/tech/20191018 How to use Protobuf for data interchange.md
@@ -0,0 +1,516 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to use Protobuf for data interchange)
+[#]: via: (https://opensource.com/article/19/10/protobuf-data-interchange)
+[#]: author: (Marty Kalin https://opensource.com/users/mkalindepauledu)
+
+How to use Protobuf for data interchange
+======
+Protobuf encoding increases efficiency when exchanging data between
+applications written in different languages and running on different
+platforms.
+![metrics and data shown on a computer screen][1]
+
+Protocol buffers ([Protobufs][2]), like XML and JSON, allow applications, which may be written in different languages and running on different platforms, to exchange data. For example, a sending application written in Go could encode a Go-specific sales order in Protobuf, which a receiver written in Java then could decode to get a Java-specific representation of the received order. Here is a sketch of the architecture over a network connection:
+
+
+```
+`Go sales order--->Pbuf-encode--->network--->Pbuf-decode--->Java sales order`
+```
+
+Protobuf encoding, in contrast to its XML and JSON counterparts, is binary rather than text, which can complicate debugging. However, as the code examples in this article confirm, the Protobuf encoding is significantly more efficient in size than either XML or JSON encoding.
+
+Protobuf is efficient in another way. At the implementation level, Protobuf and other encoding systems serialize and deserialize structured data. Serialization transforms a language-specific data structure into a bytestream, and deserialization is the inverse operation that transforms a bytestream back into a language-specific data structure. Serialization and deserialization may become the bottleneck in data interchange because these operations are CPU-intensive. Efficient serialization and deserialization is another Protobuf design goal.
+
+Recent encoding technologies, such as Protobuf and FlatBuffers, derive from the [DCE/RPC][3] (Distributed Computing Environment/Remote Procedure Call) initiative of the early 1990s. Like DCE/RPC, Protobuf contributes to both the [IDL][4] (interface definition language) and the encoding layer in data interchange.
+
+This article will look at these two layers then provide code examples in Go and Java to flesh out Protobuf details and show that Protobuf is easy to use.
+
+### Protobuf as an IDL and encoding layer
+
+DCE/RPC, like Protobuf, is designed to be language- and platform-neutral. The appropriate libraries and utilities allow any language and platform to play in the DCE/RPC arena. Furthermore, the DCE/RPC architecture is elegant. An IDL document is the contract between the remote procedure on the one side and callers on the other side. Protobuf, too, centers on an IDL document.
+
+An IDL document is text and, in DCE/RPC, uses basic C syntax along with syntactic extensions for metadata (square brackets) and a few new keywords such as **interface**. Here is an example:
+
+
+```
+[uuid (2d6ead46-05e3-11ca-7dd1-426909beabcd), version(1.0)]
+interface echo {
+ const long int ECHO_SIZE = 512;
+ void echo(
+ [in] handle_t h,
+ [in, string] idl_char from_client[ ],
+ [out, string] idl_char from_service[ECHO_SIZE]
+ );
+}
+```
+
+This IDL document declares a procedure named **echo**, which takes three arguments: the **[in]** arguments of type **handle_t** (implementation pointer) and **idl_char** (array of ASCII characters) are passed to the remote procedure, whereas the **[out]** argument (also a string) is passed back from the procedure. In this example, the **echo** procedure does not explicitly return a value (the **void** to the left of **echo**) but could do so. A return value, together with one or more **[out]** arguments, allows the remote procedure to return arbitrarily many values. The next section introduces a Protobuf IDL, which differs in syntax but likewise serves as a contract in data interchange.
+
+The IDL document, in both DCE/RPC and Protobuf, is the input to utilities that create the infrastructure code for exchanging data:
+
+
+```
+`IDL document--->DCE/PRC or Protobuf utilities--->support code for data interchange`
+```
+
+As relatively straightforward text, the IDL is likewise human-readable documentation about the specifics of the data interchange—in particular, the number of data items exchanged and the data type of each item.
+
+Protobuf can used in a modern RPC system such as [gRPC][5]; but Protobuf on its own provides only the IDL layer and the encoding layer for messages passed from a sender to a receiver. Protobuf encoding, like the DCE/RPC original, is binary but more efficient.
+
+At present, XML and JSON encodings still dominate in data interchange through technologies such as web services, which make use of in-place infrastructure such as web servers, transport protocols (e.g., TCP, HTTP), and standard libraries and utilities for processing XML and JSON documents. Moreover, database systems of various flavors can store XML and JSON documents, and even legacy relational systems readily generate XML encodings of query results. Every general-purpose programming language now has libraries that support XML and JSON. What, then, recommends a return to a _binary_ encoding system such as Protobuf?
+
+Consider the negative decimal value **-128**. In the 2's complement binary representation, which dominates across systems and languages, this value can be stored in a single 8-bit byte: 10000000. The text encoding of this integer value in XML or JSON requires multiple bytes. For example, UTF-8 encoding requires four bytes for the string, literally **-128**, which is one byte per character (in hex, the values are 0x2d, 0x31, 0x32, and 0x38). XML and JSON also add markup characters, such as angle brackets and braces, to the mix. Details about Protobuf encoding are forthcoming, but the point of interest now is a general one: Text encodings tend to be significantly less compact than binary ones.
+
+### A code example in Go using Protobuf
+
+My code examples focus on Protobuf rather than RPC. Here is an overview of the first example:
+
+ * The IDL file named _dataitem.proto_ defines a Protobuf **message** with six fields of different types: integer values with different ranges, floating-point values of a fixed size, and strings of two different lengths.
+ * The Protobuf compiler uses the IDL file to generate a Go-specific version (and, later, a Java-specific version) of the Protobuf **message** together with supporting functions.
+ * A Go app populates the native Go data structure with randomly generated values and then serializes the result to a local file. For comparison, XML and JSON encodings also are serialized to local files.
+ * As a test, the Go application reconstructs an instance of its native data structure by deserializing the contents of the Protobuf file.
+ * As a language-neutrality test, the Java application also deserializes the contents of the Protobuf file to get an instance of a native data structure.
+
+
+
+This IDL file and two Go and one Java source files are available as a ZIP file on [my website][6].
+
+The all-important Protobuf IDL document is shown below. The document is stored in the file _dataitem.proto_, with the customary _.proto_ extension.
+
+#### Example 1. Protobuf IDL document
+
+
+```
+syntax = "proto3";
+
+package main;
+
+message DataItem {
+ int64 oddA = 1;
+ int64 evenA = 2;
+ int32 oddB = 3;
+ int32 evenB = 4;
+ float small = 5;
+ float big = 6;
+ string short = 7;
+ string long = 8;
+}
+```
+
+The IDL uses the current proto3 rather than the earlier proto2 syntax. The package name (in this case, **main**) is optional but customary; it is used to avoid name conflicts. The structured **message** contains eight fields, each of which has a Protobuf data type (e.g., **int64**, **string**), a name (e.g., **oddA**, **short**), and a numeric tag (aka key) after the equals sign **=**. The tags, which are 1 through 8 in this example, are unique integer identifiers that determine the order in which the fields are serialized.
+
+Protobuf messages can be nested to arbitrary levels, and one message can be the field type in the other. Here's an example that uses the **DataItem** message as a field type:
+
+
+```
+message DataItems {
+ repeated DataItem item = 1;
+}
+```
+
+A single **DataItems** message consists of repeated (none or more) **DataItem** messages.
+
+Protobuf also supports enumerated types for clarity:
+
+
+```
+enum PartnershipStatus {
+ reserved "FREE", "CONSTRAINED", "OTHER";
+}
+```
+
+The **reserved** qualifier ensures that the numeric values used to implement the three symbolic names cannot be reused.
+
+To generate a language-specific version of one or more declared Protobuf **message** structures, the IDL file containing these is passed to the _protoc_ compiler (available in the [Protobuf GitHub repository][7]). For the Go code, the supporting Protobuf library can be installed in the usual way (with **%** as the command-line prompt):
+
+
+```
+`% go get github.com/golang/protobuf/proto`
+```
+
+The command to compile the Protobuf IDL file _dataitem.proto_ into Go source code is:
+
+
+```
+`% protoc --go_out=. dataitem.proto`
+```
+
+The flag **\--go_out** directs the compiler to generate Go source code; there are similar flags for other languages. The result, in this case, is a file named _dataitem.pb.go_, which is small enough that the essentials can be copied into a Go application. Here are the essentials from the generated code:
+
+
+```
+var _ = proto.Marshal
+
+type DataItem struct {
+ OddA int64 `protobuf:"varint,1,opt,name=oddA" json:"oddA,omitempty"`
+ EvenA int64 `protobuf:"varint,2,opt,name=evenA" json:"evenA,omitempty"`
+ OddB int32 `protobuf:"varint,3,opt,name=oddB" json:"oddB,omitempty"`
+ EvenB int32 `protobuf:"varint,4,opt,name=evenB" json:"evenB,omitempty"`
+ Small float32 `protobuf:"fixed32,5,opt,name=small" json:"small,omitempty"`
+ Big float32 `protobuf:"fixed32,6,opt,name=big" json:"big,omitempty"`
+ Short string `protobuf:"bytes,7,opt,name=short" json:"short,omitempty"`
+ Long string `protobuf:"bytes,8,opt,name=long" json:"long,omitempty"`
+}
+
+func (m *DataItem) Reset() { *m = DataItem{} }
+func (m *DataItem) String() string { return proto.CompactTextString(m) }
+func (*DataItem) ProtoMessage() {}
+func init() {}
+```
+
+The compiler-generated code has a Go structure **DataItem**, which exports the Go fields—the names are now capitalized—that match the names declared in the Protobuf IDL. The structure fields have standard Go data types: **int32**, **int64**, **float32**, and **string**. At the end of each field line, as a string, is metadata that describes the Protobuf types, gives the numeric tags from the Protobuf IDL document, and provides information about JSON, which is discussed later.
+
+There are also functions; the most important is **proto.Marshal** for serializing an instance of the **DataItem** structure into Protobuf format. The helper functions include **Reset**, which clears a **DataItem** structure, and **String**, which produces a one-line string representation of a **DataItem**.
+
+The metadata that describes Protobuf encoding deserves a closer look before analyzing the Go program in more detail.
+
+### Protobuf encoding
+
+A Protobuf message is structured as a collection of key/value pairs, with the numeric tag as the key and the corresponding field as the value. The field names, such as **oddA** and **small**, are for human readability, but the _protoc_ compiler does use the field names in generating language-specific counterparts. For example, the **oddA** and **small** names in the Protobuf IDL become the fields **OddA** and **Small**, respectively, in the Go structure.
+
+The keys and their values both get encoded, but with an important difference: some numeric values have a fixed-size encoding of 32 or 64 bits, whereas others (including the **message** tags) are _varint_ encoded—the number of bits depends on the integer's absolute value. For example, the integer values 1 through 15 require 8 bits to encode in _varint_, whereas the values 16 through 2047 require 16 bits. The _varint_ encoding, similar in spirit (but not in detail) to UTF-8 encoding, favors small integer values over large ones. (For a detailed analysis, see the Protobuf [encoding guide][8].) The upshot is that a Protobuf **message** should have small integer values in fields, if possible, and as few keys as possible, but one key per field is unavoidable.
+
+Table 1 below gives the gist of Protobuf encoding:
+
+**Table 1. Protobuf data types**
+
+Encoding | Sample types | Length
+---|---|---
+varint | int32, uint32, int64 | Variable length
+fixed | fixed32, float, double | Fixed 32-bit or 64-bit length
+byte sequence | string, bytes | Sequence length
+
+Integer types that are not explicitly **fixed** are _varint_ encoded; hence, in a _varint_ type such as **uint32** (**u** for unsigned), the number 32 describes the integer's range (in this case, 0 to 232 \- 1) rather than its bit size, which differs depending on the value. For fixed types such as **fixed32** or **double**, by contrast, the Protobuf encoding requires 32 and 64 bits, respectively. Strings in Protobuf are byte sequences; hence, the size of the field encoding is the length of the byte sequence.
+
+Another efficiency deserves mention. Recall the earlier example in which a **DataItems** message consists of repeated **DataItem** instances:
+
+
+```
+message DataItems {
+ repeated DataItem item = 1;
+}
+```
+
+The **repeated** means that the **DataItem** instances are _packed_: the collection has a single tag, in this case, 1. A **DataItems** message with repeated **DataItem** instances is thus more efficient than a message with multiple but separate **DataItem** fields, each of which would require a tag of its own.
+
+With this background in mind, let's return to the Go program.
+
+### The dataItem program in detail
+
+The _dataItem_ program creates a **DataItem** instance and populates the fields with randomly generated values of the appropriate types. Go has a **rand** package with functions for generating pseudo-random integer and floating-point values, and my **randString** function generates pseudo-random strings of specified lengths from a character set. The design goal is to have a **DataItem** instance with field values of different types and bit sizes. For example, the **OddA** and **EvenA** values are 64-bit non-negative integer values of odd and even parity, respectively; but the **OddB** and **EvenB** variants are 32 bits in size and hold small integer values between 0 and 2047. The random floating-point values are 32 bits in size, and the strings are 16 (**Short**) and 32 (**Long**) characters in length. Here is the code segment that populates the **DataItem** structure with random values:
+
+
+```
+// variable-length integers
+n1 := rand.Int63() // bigger integer
+if (n1 & 1) == 0 { n1++ } // ensure it's odd
+...
+n3 := rand.Int31() % UpperBound // smaller integer
+if (n3 & 1) == 0 { n3++ } // ensure it's odd
+
+// fixed-length floats
+...
+t1 := rand.Float32()
+t2 := rand.Float32()
+...
+// strings
+str1 := randString(StrShort)
+str2 := randString(StrLong)
+
+// the message
+dataItem := &DataItem {
+ OddA: n1,
+ EvenA: n2,
+ OddB: n3,
+ EvenB: n4,
+ Big: f1,
+ Small: f2,
+ Short: str1,
+ Long: str2,
+}
+```
+
+Once created and populated with values, the **DataItem** instance is encoded in XML, JSON, and Protobuf, with each encoding written to a local file:
+
+
+```
+func encodeAndserialize(dataItem *DataItem) {
+ bytes, _ := xml.MarshalIndent(dataItem, "", " ") // Xml to dataitem.xml
+ ioutil.WriteFile(XmlFile, bytes, 0644) // 0644 is file access permissions
+
+ bytes, _ = json.MarshalIndent(dataItem, "", " ") // Json to dataitem.json
+ ioutil.WriteFile(JsonFile, bytes, 0644)
+
+ bytes, _ = proto.Marshal(dataItem) // Protobuf to dataitem.pbuf
+ ioutil.WriteFile(PbufFile, bytes, 0644)
+}
+```
+
+The three serializing functions use the term _marshal_, which is roughly synonymous with _serialize_. As the code indicates, each of the three **Marshal** functions returns an array of bytes, which then are written to a file. (Possible errors are ignored for simplicity.) On a sample run, the file sizes were:
+
+
+```
+dataitem.xml: 262 bytes
+dataitem.json: 212 bytes
+dataitem.pbuf: 88 bytes
+```
+
+The Protobuf encoding is significantly smaller than the other two. The XML and JSON serializations could be reduced slightly in size by eliminating indentation characters, in this case, blanks and newlines.
+
+Below is the _dataitem.json_ file resulting eventually from the **json.MarshalIndent** call, with added comments starting with **##**:
+
+
+```
+{
+ "oddA": 4744002665212642479, ## 64-bit >= 0
+ "evenA": 2395006495604861128, ## ditto
+ "oddB": 57, ## 32-bit >= 0 but < 2048
+ "evenB": 468, ## ditto
+ "small": 0.7562016, ## 32-bit floating-point
+ "big": 0.85202795, ## ditto
+ "short": "ClH1oDaTtoX$HBN5", ## 16 random chars
+ "long": "xId0rD3Cri%3Wt%^QjcFLJgyXBu9^DZI" ## 32 random chars
+}
+```
+
+Although the serialized data goes into local files, the same approach would be used to write the data to the output stream of a network connection.
+
+### Testing serialization/deserialization
+
+The Go program next runs an elementary test by deserializing the bytes, which were written earlier to the _dataitem.pbuf_ file, into a **DataItem** instance. Here is the code segment, with the error-checking parts removed:
+
+
+```
+filebytes, err := ioutil.ReadFile(PbufFile) // get the bytes from the file
+...
+testItem.Reset() // clear the DataItem structure
+err = proto.Unmarshal(filebytes, testItem) // deserialize into a DataItem instance
+```
+
+The **proto.Unmarshal** function for deserializing Protbuf is the inverse of the **proto.Marshal** function. The original **DataItem** and the deserialized clone are printed to confirm an exact match:
+
+
+```
+Original:
+2041519981506242154 3041486079683013705 1192 1879
+0.572123 0.326855
+boPb#T0O8Xd&Ps5EnSZqDg4Qztvo7IIs 9vH66AiGSQgCDxk&
+
+Deserialized:
+2041519981506242154 3041486079683013705 1192 1879
+0.572123 0.326855
+boPb#T0O8Xd&Ps5EnSZqDg4Qztvo7IIs 9vH66AiGSQgCDxk&
+```
+
+### A Protobuf client in Java
+
+The example in Java is to confirm Protobuf's language neutrality. The original IDL file could be used to generate the Java support code, which involves nested classes. To suppress warnings, however, a slight addition can be made. Here is the revision, which specifies a **DataMsg** as the name for the outer class, with the inner class automatically named **DataItem** after the Protobuf message:
+
+
+```
+syntax = "proto3";
+
+package main;
+
+option java_outer_classname = "DataMsg";
+
+message DataItem {
+...
+```
+
+With this change in place, the _protoc_ compilation is the same as before, except the desired output is now Java rather than Go:
+
+
+```
+`% protoc --java_out=. dataitem.proto`
+```
+
+The resulting source file (in a subdirectory named _main_) is _DataMsg.java_ and about 1,120 lines in length: Java is not terse. Compiling and then running the Java code requires a JAR file with the library support for Protobuf. This file is available in the [Maven repository][9].
+
+With the pieces in place, my test code is relatively short (and available in the ZIP file as _Main.java_):
+
+
+```
+package main;
+import java.io.FileInputStream;
+
+public class Main {
+ public static void main(String[] args) {
+ String path = "dataitem.pbuf"; // from the Go program's serialization
+ try {
+ DataMsg.DataItem deserial =
+ DataMsg.DataItem.newBuilder().mergeFrom(new FileInputStream(path)).build();
+
+ System.out.println(deserial.getOddA()); // 64-bit odd
+ System.out.println(deserial.getLong()); // 32-character string
+ }
+ catch(Exception e) { System.err.println(e); }
+ }
+}
+```
+
+Production-grade testing would be far more thorough, of course, but even this preliminary test confirms the language-neutrality of Protobuf: the _dataitem.pbuf_ file results from the Go program's serialization of a Go **DataItem**, and the bytes in this file are deserialized to produce a **DataItem** instance in Java. The output from the Java test is the same as that from the Go test.
+
+### Wrapping up with the numPairs program
+
+Let's end with an example that highlights Protobuf efficiency but also underscores the cost involved in any encoding technology. Consider this Protobuf IDL file:
+
+
+```
+syntax = "proto3";
+package main;
+
+message NumPairs {
+ repeated NumPair pair = 1;
+}
+
+message NumPair {
+ int32 odd = 1;
+ int32 even = 2;
+}
+```
+
+A **NumPair** message consists of two **int32** values together with an integer tag for each field. A **NumPairs** message is a sequence of embedded **NumPair** messages.
+
+The _numPairs_ program in Go (below) creates 2 million **NumPair** instances, with each appended to the **NumPairs** message. This message can be serialized and deserialized in the usual way.
+
+#### Example 2. The numPairs program
+
+
+```
+package main
+
+import (
+ "math/rand"
+ "time"
+ "encoding/xml"
+ "encoding/json"
+ "io/ioutil"
+ "github.com/golang/protobuf/proto"
+)
+
+// protoc-generated code: start
+var _ = proto.Marshal
+type NumPairs struct {
+ Pair []*NumPair `protobuf:"bytes,1,rep,name=pair" json:"pair,omitempty"`
+}
+
+func (m *NumPairs) Reset() { *m = NumPairs{} }
+func (m *NumPairs) String() string { return proto.CompactTextString(m) }
+func (*NumPairs) ProtoMessage() {}
+func (m *NumPairs) GetPair() []*NumPair {
+ if m != nil { return m.Pair }
+ return nil
+}
+
+type NumPair struct {
+ Odd int32 `protobuf:"varint,1,opt,name=odd" json:"odd,omitempty"`
+ Even int32 `protobuf:"varint,2,opt,name=even" json:"even,omitempty"`
+}
+
+func (m *NumPair) Reset() { *m = NumPair{} }
+func (m *NumPair) String() string { return proto.CompactTextString(m) }
+func (*NumPair) ProtoMessage() {}
+func init() {}
+// protoc-generated code: finish
+
+var numPairsStruct NumPairs
+var numPairs = &numPairsStruct
+
+func encodeAndserialize() {
+ // XML encoding
+ filename := "./pairs.xml"
+ bytes, _ := xml.MarshalIndent(numPairs, "", " ")
+ ioutil.WriteFile(filename, bytes, 0644)
+
+ // JSON encoding
+ filename = "./pairs.json"
+ bytes, _ = json.MarshalIndent(numPairs, "", " ")
+ ioutil.WriteFile(filename, bytes, 0644)
+
+ // ProtoBuf encoding
+ filename = "./pairs.pbuf"
+ bytes, _ = proto.Marshal(numPairs)
+ ioutil.WriteFile(filename, bytes, 0644)
+}
+
+const HowMany = 200 * 100 * 100 // two million
+
+func main() {
+ rand.Seed(time.Now().UnixNano())
+
+ // uncomment the modulus operations to get the more efficient version
+ for i := 0; i < HowMany; i++ {
+ n1 := rand.Int31() // % 2047
+ if (n1 & 1) == 0 { n1++ } // ensure it's odd
+ n2 := rand.Int31() // % 2047
+ if (n2 & 1) == 1 { n2++ } // ensure it's even
+
+ next := &NumPair {
+ Odd: n1,
+ Even: n2,
+ }
+ numPairs.Pair = append(numPairs.Pair, next)
+ }
+ encodeAndserialize()
+}
+```
+
+The randomly generated odd and even values in each **NumPair** range from zero to 2 billion and change. In terms of raw rather than encoded data, the integers generated in the Go program add up to 16MB: two integers per **NumPair** for a total of 4 million integers in all, and each value is four bytes in size.
+
+For comparison, the table below has entries for the XML, JSON, and Protobuf encodings of the 2 million **NumPair** instances in the sample **NumsPairs** message. The raw data is included, as well. Because the _numPairs_ program generates random values, output differs across sample runs but is close to the sizes shown in the table.
+
+**Table 2. Encoding overhead for 16MB of integers**
+
+Encoding | File | Byte size | Pbuf/other ratio
+---|---|---|---
+None | pairs.raw | 16MB | 169%
+Protobuf | pairs.pbuf | 27MB | —
+JSON | pairs.json | 100MB | 27%
+XML | pairs.xml | 126MB | 21%
+
+As expected, Protobuf shines next to XML and JSON. The Protobuf encoding is about a quarter of the JSON one and about a fifth of the XML one. But the raw data make clear that Protobuf incurs the overhead of encoding: the serialized Protobuf message is 11MB larger than the raw data. Any encoding, including Protobuf, involves structuring the data, which unavoidably adds bytes.
+
+Each of the serialized 2 million **NumPair** instances involves _four_ integer values: one apiece for the **Even** and **Odd** fields in the Go structure, and one tag per each field in the Protobuf encoding. As raw rather than encoded data, this would come to 16 bytes per instance, and there are 2 million instances in the sample **NumPairs** message. But the Protobuf tags, like the **int32** values in the **NumPair** fields, use _varint_ encoding and, therefore, vary in byte length; in particular, small integer values (which include the tags, in this case) require fewer than four bytes to encode.
+
+If the _numPairs_ program is revised so that the two **NumPair** fields hold values less than 2048, which have encodings of either one or two bytes, then the Protobuf encoding drops from 27MB to 16MB—the very size of the raw data. The table below summarizes the new encoding sizes from a sample run.
+
+**Table 3. Encoding with 16MB of integers < 2048**
+
+Encoding | File | Byte size | Pbuf/other ratio
+---|---|---|---
+None | pairs.raw | 16MB | 100%
+Protobuf | pairs.pbuf | 16MB | —
+JSON | pairs.json | 77MB | 21%
+XML | pairs.xml | 103MB | 15%
+
+In summary, the modified _numPairs_ program, with field values less than 2048, reduces the four-byte size for each integer value in the raw data. But the Protobuf encoding still requires tags, which add bytes to the Protobuf message. Protobuf encoding does have a cost in message size, but this cost can be reduced by the _varint_ factor if relatively small integer values, whether in fields or keys, are being encoded.
+
+For moderately sized messages consisting of structured data with mixed types—and relatively small integer values—Protobuf has a clear advantage over options such as XML and JSON. In other cases, the data may not be suited for Protobuf encoding. For example, if two applications need to share a huge set of text records or large integer values, then compression rather than encoding technology may be the way to go.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/protobuf-data-interchange
+
+作者:[Marty Kalin][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mkalindepauledu
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
+[2]: https://developers.google.com/protocol-buffers/
+[3]: https://en.wikipedia.org/wiki/DCE/RPC
+[4]: https://en.wikipedia.org/wiki/Interface_description_language
+[5]: https://grpc.io/
+[6]: http://condor.depaul.edu/mkalin
+[7]: https://github.com/protocolbuffers/protobuf
+[8]: https://developers.google.com/protocol-buffers/docs/encoding
+[9]: https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java
diff --git a/sources/tech/20191018 Perceiving Python programming paradigms.md b/sources/tech/20191018 Perceiving Python programming paradigms.md
new file mode 100644
index 0000000000..9a0027d61d
--- /dev/null
+++ b/sources/tech/20191018 Perceiving Python programming paradigms.md
@@ -0,0 +1,122 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Perceiving Python programming paradigms)
+[#]: via: (https://opensource.com/article/19/10/python-programming-paradigms)
+[#]: author: (Jigyasa Grover https://opensource.com/users/jigyasa-grover)
+
+Perceiving Python programming paradigms
+======
+Python supports imperative, functional, procedural, and object-oriented
+programming; here are tips on choosing the right one for a specific use
+case.
+![A python with a package.][1]
+
+Early each year, TIOBE announces its Programming Language of The Year. When its latest annual [TIOBE index][2] report came out, I was not at all surprised to see [Python again winning the title][3], which was based on capturing the most search engine ranking points (especially on Google, Bing, Yahoo, Wikipedia, Amazon, YouTube, and Baidu) in 2018.
+
+![Python data from TIOBE Index][4]
+
+Adding weight to TIOBE's findings, earlier this year, nearly 90,000 developers took Stack Overflow's annual [Developer Survey][5], which is the largest and most comprehensive survey of people who code around the world. The main takeaway from this year's results was:
+
+> "Python, the fastest-growing major programming language, has risen in the ranks of programming languages in our survey yet again, edging out Java this year and standing as the second most loved language (behind Rust)."
+
+Ever since I started programming and exploring different languages, I have seen admiration for Python soaring high. Since 2003, it has consistently been among the top 10 most popular programming languages. As TIOBE's report stated:
+
+> "It is the most frequently taught first language at universities nowadays, it is number one in the statistical domain, number one in AI programming, number one in scripting and number one in writing system tests. Besides this, Python is also leading in web programming and scientific computing (just to name some other domains). In summary, Python is everywhere."
+
+There are several reasons for Python's rapid rise, bloom, and dominance in multiple domains, including web development, scientific computing, testing, data science, machine learning, and more. The reasons include its readable and maintainable code; extensive support for third-party integrations and libraries; modular, dynamic, and portable structure; flexible programming; learning ease and support; user-friendly data structures; productivity and speed; and, most important, community support. The diverse application of Python is a result of its combined features, which give it an edge over other languages.
+
+But in my opinion, the comparative simplicity of its syntax and the staggering flexibility it provides developers coming from many other languages win the cake. Very few languages can match Python's ability to conform to a developer's coding style rather than forcing him or her to code in a particular way. Python lets more advanced developers use the style they feel is best suited to solve a particular problem.
+
+While working with Python, you are like a snake charmer. This allows you to take advantage of Python's promise to offer a non-conforming environment for developers to code in the style best suited for a particular situation and to make the code more readable, testable, and coherent.
+
+## Python programming paradigms
+
+Python supports four main [programming paradigms][6]: imperative, functional, procedural, and object-oriented. Whether you agree that they are valid or even useful, Python strives to make all four available and working. Before we dive in to see which programming paradigm is most suitable for specific use cases, it is a good time to do a quick review of them.
+
+### Imperative programming paradigm
+
+The [imperative programming paradigm][7] uses the imperative mood of natural language to express directions. It executes commands in a step-by-step manner, just like a series of verbal commands. Following the "how-to-solve" approach, it makes direct changes to the state of the program; hence it is also called the stateful programming model. Using the imperative programming paradigm, you can quickly write very simple yet elegant code, and it is super-handy for tasks that involve data manipulation. Owing to its comparatively slower and sequential execution strategy, it cannot be used for complex or parallel computations.
+
+[![Linus Torvalds quote][8]][9]
+
+Consider this example task, where the goal is to take a list of characters and concatenate it to form a string. A way to do it in an imperative programming style would be something like:
+
+
+```
+>>> sample_characters = ['p','y','t','h','o','n']
+>>> sample_string = ''
+>>> sample_string
+''
+>>> sample_string = sample_string + sample_characters[0]
+>>> sample_string
+'p'
+>>> sample_string = sample_string + sample_characters[1]
+>>> sample_string
+'py'
+>>> sample_string = sample_string + sample_characters[2]
+>>> sample_string
+'pyt'
+>>> sample_string = sample_string + sample_characters[3]
+>>> sample_string
+'pyth'
+>>> sample_string = sample_string + sample_characters[4]
+>>> sample_string
+'pytho'
+>>> sample_string = sample_string + sample_characters[5]
+>>> sample_string
+'python'
+>>>
+```
+
+Here, the variable **sample_string** is also like a state of the program that is getting changed after executing the series of commands, and it can be easily extracted to track the progress of the program. The same can be done using a **for** loop (also considered imperative programming) in a shorter version of the above code:
+
+
+```
+>>> sample_characters = ['p','y','t','h','o','n']
+>>> sample_string = ''
+>>> sample_string
+>>> for c in sample_characters:
+... sample_string = sample_string + c
+... print(sample_string)
+...
+p
+py
+pyt
+pyth
+pytho
+python
+>>>
+```
+
+### Functional programming paradigm
+
+The [functional programming paradigm][10] treats program computation as the evaluation of mathematical functions based on [lambda calculus][11]. Lambda calculus is a formal system in mathematical logic for expressing computation based on function abstraction and application using variable binding and substitution. It follows the "what-to-solve" approach—that is, it expresses logic without describing its control flow—hence it is also classified as the declarative programming model.
+
+The functional programming paradigm promotes stateless functions, but it's important to note that Python's implementation of functional programming deviates from standard implementation. Python is said to be an _impure_ functional language because it is possible to maintain state and create side effects if you are not careful. That said, functional programming is handy for parallel processing and is super-efficient for tasks requiring recursion and concurrent execution.
+
+
+```
+>>> sample_characters = ['p','y','t','h','o','n']
+>>> import functools
+>>> sample_string = functools.reduce(lambda s,c: s + c, sample_characters)
+>>> sample_string
+'python'
+>>>
+```
+
+Using the same example, the functional way of concatenating a list of characters to form a string would be the same as above. Since the computation happens in a single line, there is no explicit way to obtain the state of the program with **sample_string** and track the progress. The functional programming implementation of this example is fascinating, as it reduces the lines of code and simply does its job in a single line, with the exception of using the **functools** module and the **reduce** method. The three keywords—**functools**, **reduce**, and **lambda**—are defined as follows:
+
+ * **functools** is a module for higher-order functions and provides for functions that act on or return other functions. It encourages writing reusable code, as it is easier to replicate existing functions with some arguments already passed and create a new version of a function in a well-documented manner.
+ * **reduce** is a method that applies a function of two arguments cumulatively to the items in sequence, from left to right, to reduce the sequence to a single value. For example: [code] >>> sample_list = [1,2,3,4,5]
+>>> import functools
+>>> sum = functools.reduce(lambda x,y: x + y, sample_list)
+>>> sum
+15
+>>> ((((1+2)+3)+4)+5)
+15
+>>>
+```
+ * **lambda functions** are small, anonymized (i.e., nameless) functions that can take any number of arguments but spit out only one value. They are useful when they are used as an argu
\ No newline at end of file
diff --git a/sources/tech/20191020 14 SCP Command Examples to Securely Transfer Files in Linux.md b/sources/tech/20191020 14 SCP Command Examples to Securely Transfer Files in Linux.md
new file mode 100644
index 0000000000..e34b1d825c
--- /dev/null
+++ b/sources/tech/20191020 14 SCP Command Examples to Securely Transfer Files in Linux.md
@@ -0,0 +1,241 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (14 SCP Command Examples to Securely Transfer Files in Linux)
+[#]: via: (https://www.linuxtechi.com/scp-command-examples-in-linux/)
+[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
+
+14 SCP Command Examples to Securely Transfer Files in Linux
+======
+
+**SCP** (Secure Copy) is command line tool in Linux and Unix like systems which is used to transfer files and directories across the systems securely over the network. When we use scp command to copy files and directories from our local system to remote system then in the backend it makes **ssh connection** to remote system. In other words, we can say scp uses the same **SSH security mechanism** in the backend, it needs either password or keys for authentication.
+
+[![scp-command-examples-linux][1]][2]
+
+In this tutorial we will discuss 14 useful Linux scp command examples.
+
+**Syntax of scp command:**
+
+### scp <options> <files_or_directories> [root@linuxtechi][3]_host:/<folder>
+
+### scp <options> [root@linuxtechi][3]_host:/files <folder_local_system>
+
+First syntax of scp command demonstrate how to copy files or directories from local system to target host under the specific folder.
+
+Second syntax of scp command demonstrate how files from target host is copied into local system.
+
+Some of the most widely used options in scp command are listed below,
+
+ * -C Enable Compression
+ * -i identity File or private key
+ * -l limit the bandwidth while copying
+ * -P ssh port number of target host
+ * -p Preserves permissions, modes and access time of files while copying
+ * -q Suppress warning message of SSH
+ * -r Copy files and directories recursively
+ * -v verbose output
+
+
+
+Let’s jump into the examples now!!!!
+
+###### Example:1) Copy a file from local system to remote system using scp
+
+Let’s assume we want to copy jdk rpm package from our local Linux system to remote system (172.20.10.8) using scp command, use the following command,
+
+```
+[root@linuxtechi ~]$ scp jdk-linux-x64_bin.rpm root@linuxtechi:/opt
+root@linuxtechi's password:
+jdk-linux-x64_bin.rpm 100% 10MB 27.1MB/s 00:00
+[root@linuxtechi ~]$
+```
+
+Above command will copy jdk rpm package file to remote system under /opt folder.
+
+###### Example:2) Copy a file from remote System to local system using scp
+
+Let’s suppose we want to copy a file from remote system to our local system under the /tmp folder, execute the following scp command,
+
+```
+[root@linuxtechi ~]$ scp root@linuxtechi:/root/Technical-Doc-RHS.odt /tmp
+root@linuxtechi's password:
+Technical-Doc-RHS.odt 100% 1109KB 31.8MB/s 00:00
+[root@linuxtechi ~]$ ls -l /tmp/Technical-Doc-RHS.odt
+-rwx------. 1 pkumar pkumar 1135521 Oct 19 11:12 /tmp/Technical-Doc-RHS.odt
+[root@linuxtechi ~]$
+```
+
+###### Example:3) Verbose Output while transferring files using scp (-v)
+
+In scp command, we can enable the verbose output using -v option, using verbose output we can easily find what exactly is happening in the background. This becomes very useful in **debugging connection**, **authentication** and **configuration problems**.
+
+```
+root@linuxtechi ~]$ scp -v jdk-linux-x64_bin.rpm root@linuxtechi:/opt
+Executing: program /usr/bin/ssh host 172.20.10.8, user root, command scp -v -t /opt
+OpenSSH_7.8p1, OpenSSL 1.1.1 FIPS 11 Sep 2018
+debug1: Reading configuration data /etc/ssh/ssh_config
+debug1: Reading configuration data /etc/ssh/ssh_config.d/05-redhat.conf
+debug1: Reading configuration data /etc/crypto-policies/back-ends/openssh.config
+debug1: /etc/ssh/ssh_config.d/05-redhat.conf line 8: Applying options for *
+debug1: Connecting to 172.20.10.8 [172.20.10.8] port 22.
+debug1: Connection established.
+…………
+debug1: Next authentication method: password
+root@linuxtechi's password:
+```
+
+###### Example:4) Transfer multiple files to remote system
+
+Multiple files can be copied / transferred to remote system using scp command in one go, in scp command specify the multiple files separated by space, example is shown below
+
+```
+[root@linuxtechi ~]$ scp install.txt index.html jdk-linux-x64_bin.rpm root@linuxtechi:/mnt
+root@linuxtechi's password:
+install.txt 100% 0 0.0KB/s 00:00
+index.html 100% 85KB 7.2MB/s 00:00
+jdk-linux-x64_bin.rpm 100% 10MB 25.3MB/s 00:00
+[root@linuxtechi ~]$
+```
+
+###### Example:5) Transfer files across two remote hosts
+
+Using scp command we can copy files and directories between two remote hosts, let’s suppose we have a local Linux system which can connect to two remote Linux systems, so from my local linux system I can use scp command to copy files across these two systems,
+
+Syntax:
+
+### scp [root@linuxtechi][3]_hosts1:/<files_to_transfer> [root@linuxtechi][3]_host2:/<folder>
+
+Example is shown below,
+
+```
+# scp root@linuxtechi:~/backup-Oct.zip root@linuxtechi:/tmp
+# ssh root@linuxtechi "ls -l /tmp/backup-Oct.zip"
+-rwx------. 1 root root 747438080 Oct 19 12:02 /tmp/backup-Oct.zip
+```
+
+###### Example:6) Copy files and directories recursively (-r)
+
+Use -r option in scp command to recursively copy the entire directory from one system to another, example is shown below,
+
+```
+[root@linuxtechi ~]$ scp -r Downloads root@linuxtechi:/opt
+```
+
+Use below command to verify whether Download folder is copied to remote system or not,
+
+```
+[root@linuxtechi ~]$ ssh root@linuxtechi "ls -ld /opt/Downloads"
+drwxr-xr-x. 2 root root 75 Oct 19 12:10 /opt/Downloads
+[root@linuxtechi ~]$
+```
+
+###### Example:7) Increase transfer speed by enabling compression (-C)
+
+In scp command, we can increase the transfer speed by enabling the compression using -C option, it will automatically enable compression at source and decompression at destination host.
+
+```
+root@linuxtechi ~]$ scp -r -C Downloads root@linuxtechi:/mnt
+```
+
+In the above example we are transferring the Download directory with compression enabled.
+
+###### Example:8) Limit bandwidth while copying ( -l )
+
+Use ‘-l’ option in scp command to put limit on bandwidth usage while copying. Bandwidth is specified in Kbit/s, example is shown below,
+
+```
+[root@linuxtechi ~]$ scp -l 500 jdk-linux-x64_bin.rpm root@linuxtechi:/var
+```
+
+###### Example:9) Specify different ssh port while scp ( -P)
+
+There can be some scenario where ssh port is changed on destination host, so while using scp command we can specify the ssh port number using ‘-P’ option.
+
+```
+[root@linuxtechi ~]$ scp -P 2022 jdk-linux-x64_bin.rpm root@linuxtechi:/var
+```
+
+In above example, ssh port for remote host is “2022”
+
+###### Example:10) Preserves permissions, modes and access time of files while copying (-p)
+
+Use “-p” option in scp command to preserve permissions, access time and modes while copying from source to destination
+
+```
+[root@linuxtechi ~]$ scp -p jdk-linux-x64_bin.rpm root@linuxtechi:/var/tmp
+jdk-linux-x64_bin.rpm 100% 10MB 13.5MB/s 00:00
+[root@linuxtechi ~]$
+```
+
+###### Example:11) Transferring files in quiet mode ( -q) in scp
+
+Use ‘-q’ option in scp command to suppress transfer progress, warning and diagnostic messages of ssh. Example is shown below,
+
+```
+[root@linuxtechi ~]$ scp -q -r Downloads root@linuxtechi:/var/tmp
+[root@linuxtechi ~]$
+```
+
+###### Example:12) Use Identify file in scp while transferring ( -i )
+
+In most of the Linux environments, keys-based authentication is preferred. In scp command we specify the identify file or private key file using ‘-i’ option, example is shown below,
+
+```
+[root@linuxtechi ~]$ scp -i my_key.pem -r Downloads root@linuxtechi:/root
+```
+
+In above example, “my_key.pem” is the identity file or private key file.
+
+###### Example:13) Use different ‘ssh_config’ file in scp ( -F)
+
+There are some scenarios where you use different networks to connect to Linux systems, may be some network is behind proxy servers, so in that case we must have different **ssh_config** file.
+
+Different ssh_config file in scp command is specified via ‘-F’ option, example is shown below
+
+```
+[root@linuxtechi ~]$ scp -F /home/pkumar/new_ssh_config -r Downloads root@linuxtechi:/root
+root@linuxtechi's password:
+jdk-linux-x64_bin.rpm 100% 10MB 16.6MB/s 00:00
+backup-Oct.zip 100% 713MB 41.9MB/s 00:17
+index.html 100% 85KB 6.6MB/s 00:00
+[root@linuxtechi ~]$
+```
+
+###### Example:14) Use Different Cipher in scp command (-c)
+
+By default, scp uses ‘AES-128’ cipher to encrypt the files. If you want to use another cipher in scp command then use ‘-c’ option followed by cipher name,
+
+Let’s suppose we want to use ‘3des-cbc’ cipher in scp command while transferring the files, run the following scp command
+
+```
+[root@linuxtechi ~]# scp -c 3des-cbc -r Downloads root@linuxtechi:/root
+```
+
+Use the below command to list ssh and scp ciphers,
+
+```
+[root@linuxtechi ~]# ssh -Q cipher localhost | paste -d , -s -
+3des-cbc,aes128-cbc,aes192-cbc,aes256-cbc,root@linuxtechi,aes128-ctr,aes192-ctr,aes256-ctr,root@linuxtechi,root@linuxtechi,root@linuxtechi
+[root@linuxtechi ~]#
+```
+
+That’s all from this tutorial, to get more details about scp command, kindly refer its man page. Please do share your feedback and comments in comments section below.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/scp-command-examples-in-linux/
+
+作者:[Pradeep Kumar][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linuxtechi.com/author/pradeep/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: https://www.linuxtechi.com/wp-content/uploads/2019/10/scp-command-examples-linux.jpg
+[3]: https://www.linuxtechi.com/cdn-cgi/l/email-protection
diff --git a/sources/tech/20191021 How to build a Flatpak.md b/sources/tech/20191021 How to build a Flatpak.md
new file mode 100644
index 0000000000..94bbb65036
--- /dev/null
+++ b/sources/tech/20191021 How to build a Flatpak.md
@@ -0,0 +1,320 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to build a Flatpak)
+[#]: via: (https://opensource.com/article/19/10/how-build-flatpak-packaging)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+How to build a Flatpak
+======
+A universal packaging format with a decentralized means of distribution.
+Plus, portability and sandboxing.
+![][1]
+
+A long time ago, a Linux distribution shipped an operating system along with _all_ the software available for it. There was no concept of “third party” software because everything was a part of the distribution. Applications weren’t so much installed as they were enabled from a great big software repository that you got on one of the many floppy disks or, later, CDs you purchased or downloaded.
+
+This evolved into something even more convenient as the internet became ubiquitous, and the concept of what is now the “app store” was born. Of course, Linux distributions tend to call this a _software repository_ or just _repo_ for short, with some variations for “branding”, such as _Ubuntu Software Center_ or, with typical GNOME minimalism, simply _Software_.
+
+This model worked well back when open source software was still a novelty and the number of open source applications was a number rather than a _theoretical_ number. In today’s world of GitLab and GitHub and Bitbucket (and [many][2] [many][3] more), it’s hardly possible to count the number of open source projects, much less package them up in a repository. No Linux distribution today, even [Debian][4] and its formidable group of package maintainers, can claim or hope to have a package for every installable open source project.
+
+Of course, a Linux package doesn’t have to be in a repository to be installable. Any programmer can package up their software and distribute it from their own website. However, because repositories are seen as an integral part of a distribution, there isn’t a universal packaging format, meaning that a programmer must decide whether to release a `.deb` or `.rpm`, or an AUR build script, or a Nix or Guix package, or a Homebrew script, or just a mostly-generic `.tgz` archive for `/opt`. It’s overwhelming for a developer who lives and breathes Linux every day, much less for a developer just trying to make a best-effort attempt at supporting a free and open source target.
+
+### Why Flatpak?
+
+The Flatpak project provides a universal packaging format along with a decentralized means of distribution, plus portability, and sandboxing.
+
+ * **Universal** Install the Flatpak system, and you can run Flatpaks, regardless of your distribution. No daemon or systemd required. The same Flatpak runs on Fedora, Ubuntu, Mageia, Pop OS, Arch, Slackware, and more.
+ * **Decentralized** Developers can create and sign their own Flatpak packages and repositories. There’s no repository to petition in order to get a package included.
+ * **Portability** If you have a Flatpak on your system and want to hand it to a friend so they can run the same application, you can export the Flatpak to a USB thumbdrive.
+ * **Sandboxed** Flatpaks use a container-based model, allowing multiple versions of libraries and applications to exist on one system. Yes, you can easily install the latest version of an app to test out while maintaining the old version you rely on.
+
+
+
+### Building a Flatpak
+
+To build a Flatpak, you must first install Flatpak (the subsystem that enables you to use Flatpak packages) and the Flatpak-builder application.
+
+On Fedora, CentOS, RHEL, and similar:
+
+
+```
+`$ sudo dnf install flatpak flatpak-builder`
+```
+
+On Debian, Ubuntu, and similar:
+
+
+```
+`$ sudo apt install flatpak flatpak-builder`
+```
+
+You must also install the development tools required to build the application you are packaging. By nature of developing the application you’re now packaging, you may already have a development environment installed, so you might not notice that these components are required, but should you start building Flatpaks with Jenkins or from inside containers, then you must ensure that your build tools are a part of your toolchain.
+
+For the first example build, this article assumes that your application uses [GNU Autotools][5], but Flatpak itself supports other build systems, such as `cmake`, `cmake-ninja`, `meson`, `ant`, as well as custom commands (a `simple` build system, in Flatpak terminology, but by no means does this imply that the build itself is actually simple).
+
+#### Project directory
+
+Unlike the strict RPM build infrastructure, Flatpak doesn’t impose a project directory structure. I prefer to create project directories based on the **dist** packages of software, but there’s no technical reason you can’t instead integrate your Flatpak build process with your source directory. It is technically easier to build a Flatpak from your **dist** package, though, and it’s an easier demo too, so that’s the model this article uses. Set up a project directory for GNU Hello, serving as your first Flatpak:
+
+
+```
+$ mkdir hello_flatpak
+$ mkdir src
+```
+
+Download your distributable source. For this example, the source code is located at `https://ftp.gnu.org/gnu/hello/hello-2.10.tar.gz`.
+
+
+```
+$ cd hello_flatpak
+$ wget
+```
+
+#### Manifest
+
+A Flatpak is defined by a manifest, which describes how to build and install the application it is delivering. A manifest is atomic and reproducible. A Flatpak exists in a “sandbox” container, though, so the manifest is based on a mostly empty environment with a root directory call `/app`.
+
+The first two attributes are the ID of the application you are packaging and the command provided by it. The application ID must be unique to the application you are packaging. The canonical way of formulating a unique ID is to use a triplet value consisting of the entity responsible for the code followed by the name of the application, such as `org.gnu.Hello`. The command provided by the application is whatever you type into a terminal to run the application. This does not imply that the application is intended to be run from a terminal instead of a `.desktop` file in the Activities or Applications menu.
+
+In a file called `org.gnu.Hello.yaml`, enter this text:
+
+
+```
+id: org.gnu.Hello
+command: hello
+```
+
+A manifest can be written in [YAML][6] or in JSON. This article uses YAML.
+
+Next, you must define each “module” delivered by this Flatpak package. You can think of a module as a dependency or a component. For GNU Hello, there is only one module: GNU Hello. More complex applications may require a specific library or another application entirely.
+
+
+```
+modules:
+ - name: hello
+ buildsystem: autotools
+ no-autogen: true
+ sources:
+ - type: archive
+ path: src/hello-2.10.tar.gz
+```
+
+The `buildsystem` value identifies how Flatpak must build the module. Each module can use its own build system, so one Flatpak can have several build systems defined.
+
+The `no-autogen` value tells Flatpak not to run the setup commands for `autotools`, which aren’t necessary because the GNU Hello source code is the product of `make dist`. If the code you’re building isn’t in a easily buildable form, then you may need to install `autogen` and `autoconf` to prepare the source for `autotools`. This option doesn’t apply at all to projects that don’t use `autotools`.
+
+The `type` value tells Flatpak that the source code is in an archive, which triggers the requisite unarchival tasks before building. The `path` points to the source code. In this example, the source exists in the `src` directory on your local build machine, but you could instead define the source as a remote location:
+
+
+```
+modules:
+ - name: hello
+ buildsystem: autotools
+ no-autogen: true
+ sources:
+ - type: archive
+ url:
+```
+
+Finally, you must define the platform required for the application to run and build. The Flatpak maintainers supply runtimes and SDKs that include common libraries, including `freedesktop`, `gnome`, and `kde`. The basic requirement is the `freedesk` runtime and SDK, although this may be superseded by GNOME or KDE, depending on what your code needs to run. For this GNU Hello example, only the basics are required.
+
+
+```
+runtime: org.freedesktop.Platform
+runtime-version: '18.08'
+sdk: org.freedesktop.Sdk
+```
+
+The entire GNU Hello flatpak manifest:
+
+
+```
+id: org.gnu.Hello
+runtime: org.freedesktop.Platform
+runtime-version: '18.08'
+sdk: org.freedesktop.Sdk
+command: hello
+modules:
+ - name: hello
+ buildsystem: autotools
+ no-autogen: true
+ sources:
+ - type: archive
+ path: src/hello-2.10.tar.gz
+```
+
+#### Building a Flatpak
+
+Now that the package is defined, you can build it. The build process prompts Flatpak-builder to parse the manifest and to resolve each requirement: it ensures that the necessary Platform and SDK are available (if they aren’t, then you’ll have to install them with the `flatpak` command), it unarchives the source code, and executes the `buildsystem` specified.
+
+The command to start:
+
+
+```
+`$ flatpak-builder build-dir org.gnu.Hello.yaml`
+```
+
+The directory `build-dir` is created if it does not already exist. The name `build-dir` is arbitrary; you could call it `build` or `bld` or `penguin`, and you can have more than one build destination in the same project directory. However, the term `build-dir` is a frequent value used in documentation, so using it as the literal value can be helpful.
+
+#### Testing your application
+
+You can test your application before or after it has been built by running the build command along with the `--run` option, and endingi the command with the command provided by the Flatpak:
+
+
+```
+$ flatpak-builder --run build-dir \
+org.gnu.Hello.yaml hello
+Hello, world!
+```
+
+### Packaging GUI apps with Flatpak
+
+Packaging up a simple self-contained _hello world_ application is trivial, and fortunately packaging up a GUI application isn’t much harder. The most difficult applications to package are those that don’t rely on common libraries and frameworks (in the context of packaging, “common” means anything _not_ already packaged by someone else). The Flatpak community provides SDKs and SDK Extensions for many components you might otherwise have had to package yourself. For instance, when packaging the pure Java implementation of `pdftk`, I use the OpenJDK SDK extension I found in the Flatpak Github repository:
+
+
+```
+runtime: org.freedesktop.Platform
+runtime-version: '18.08'
+sdk: org.freedesktop.Sdk
+sdk-extensions:
+ - org.freedesktop.Sdk.Extension.openjdk11
+```
+
+The Flatpak community does a lot of work on the foundations required for applications to run upon in order to make the packaging process easy for developers. For instance, the Kblocks game from the KDE community requires the KDE platform to run, and that’s already available from Flatpak. The additional `libkdegames` library is not included, but it’s as easy to add it to your list of `modules` as `kblocks` itself.
+
+Here’s a manifest for the Kblocks game:
+
+
+```
+id: org.kde.kblocks
+command: kblocks
+modules:
+\- buildsystem: cmake-ninja
+ name: libkdegames
+ sources:
+ type: archive
+ path: src/libkdegames-19.08.2.tar.xz
+\- buildsystem: cmake-ninja
+ name: kblocks
+ sources:
+ type: archive
+ path: src/kblocks-19.08.2.tar.xz
+runtime: org.kde.Platform
+runtime-version: '5.13'
+sdk: org.kde.Sdk
+```
+
+As you can see, the manifest is still straight-forward and relatively intuitive. The build system is different, and the runtime and SDK point to KDE instead of the Freedesktop, but the structure and requirements are basically the same.
+
+Because it’s a GUI application, however, there are some new options required. First, it needs an icon so that when it’s listed in the Activities or Application menu, it looks nice and recognizable. Kblocks includes an icon in its sources, but the names of files exported by a Flatpak must be prefixed using the application ID (such as `org.kde.Kblocks.desktop`). The easiest way to do this is to rename the file directly in the application source, which Flatpak can do for you as long as you include this directive in your manifest:
+
+
+```
+`rename-icon: kblocks`
+```
+
+Another unique trait of GUI applications is that they often require integration with common desktop services, like the graphics server (X11 or Wayland) itself, a sound server such as [Pulse Audio][7], and the Inter-Process Communication (IPC) subsystem.
+
+In the case of Kblocks, the requirements are:
+
+
+```
+finish-args:
+\- --share=ipc
+\- --socket=x11
+\- --socket=wayland
+\- --socket=pulseaudio
+\- --device=dri
+\- --filesystem=xdg-config/kdeglobals:ro
+```
+
+Here’s the final, complete manifest, using URLs for the sources so you can try this on your own system easily:
+
+
+```
+command: kblocks
+finish-args:
+\- --share=ipc
+\- --socket=x11
+\- --socket=wayland
+\- --socket=pulseaudio
+\- --device=dri
+\- --filesystem=xdg-config/kdeglobals:ro
+id: org.kde.kblocks
+modules:
+\- buildsystem: cmake-ninja
+ name: libkdegames
+ sources:
+ - sha256: 83456cec44502a1f79c0be00c983090e32fd8aea5fec1461fbfbd37b5f8866ac
+ type: archive
+ url:
+\- buildsystem: cmake-ninja
+ name: kblocks
+ sources:
+ - sha256: 8b52c949e2d446a4ccf81b09818fc90234f2f55d8722c385491ee67e1f2abf93
+ type: archive
+ url:
+rename-icon: kblocks
+runtime: org.kde.Platform
+runtime-version: '5.13'
+sdk: org.kde.Sdk
+```
+
+To build the application, you must have the KDE Platform and SDK Flatpaks (version 5.13 as of this writing) installed. Once the application has been built, you can run it using the `--run` method, but to see the application icon, you must install it.
+
+#### Distributing and installing a Flatpak you have built
+
+Distributing flatpaks happen through repositories.
+
+You can list your apps on [Flathub.org][8], a community website meant as a _technically_ decentralised (but central in spirit) location for Flatpaks. To submit your Flatpak, [place your manifest into a Git repository][9] and [submit a pull request on Github][10].
+
+Alternately, you can create your own repository using the `flatpak build-export` command.
+
+You can also just install locally:
+
+
+```
+`$ flatpak-builder --force-clean --install build-dir org.kde.Kblocks.yaml`
+```
+
+Once installed, open your Activities or Applications menu and search for Kblocks.
+
+![The Activities menu in GNOME][11]
+
+### Learning more
+
+The [Flatpak documentation site][12] has a good walkthrough on building your first Flatpak. It’s worth reading even if you’ve followed along with this article. Besides that, the docs provide details on what Platforms and SDKs are available.
+
+For those who enjoy learning from examples, there are manifests for _every application_ available on [Flathub][13].
+
+The resources to build and use Flatpaks are plentiful, and Flatpak, along with containers and sandboxed apps, are arguably [the future][14], so get familiar with them, start integrating them with your Jenkins pipelines, and enjoy easy and universal Linux app packaging.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/how-build-flatpak-packaging
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/flatpak-lead-image.png?itok=J93RG_fi
+[2]: http://notabug.org
+[3]: http://savannah.nongnu.org/
+[4]: http://debian.org
+[5]: https://opensource.com/article/19/7/introduction-gnu-autotools
+[6]: https://www.redhat.com/sysadmin/yaml-tips
+[7]: https://opensource.com/article/17/1/linux-plays-sound
+[8]: http://flathub.org
+[9]: https://opensource.com/resources/what-is-git
+[10]: https://opensource.com/life/16/3/submit-github-pull-request
+[11]: https://opensource.com/sites/default/files/gnome-activities-kblocks.jpg (The Activities menu in GNOME)
+[12]: http://docs.flatpak.org/en/latest/introduction.html
+[13]: https://github.com/flathub
+[14]: https://silverblue.fedoraproject.org/
diff --git a/sources/tech/20191022 Beginner-s Guide to Handle Various Update Related Errors in Ubuntu.md b/sources/tech/20191022 Beginner-s Guide to Handle Various Update Related Errors in Ubuntu.md
new file mode 100644
index 0000000000..381ee4c9dd
--- /dev/null
+++ b/sources/tech/20191022 Beginner-s Guide to Handle Various Update Related Errors in Ubuntu.md
@@ -0,0 +1,261 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Beginner’s Guide to Handle Various Update Related Errors in Ubuntu)
+[#]: via: (https://itsfoss.com/ubuntu-update-error/)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Beginner’s Guide to Handle Various Update Related Errors in Ubuntu
+======
+
+_**Who hasn’t come across an error while doing an update in Ubuntu? Update errors are common and plenty in Ubuntu and other Linux distributions based on Ubuntu. Here are some common Ubuntu update errors and their fixes.**_
+
+This article is part of Ubuntu beginner series that explains the know-how of Ubuntu so that a new user could understand the things better.
+
+In an earlier article, I discussed [how to update Ubuntu][1]. In this tutorial, I’ll discuss some common errors you may encounter while updating [Ubuntu][2]. It usually happens because you tried to add software or repositories on your own and that probably caused an issue.
+
+There is no need to panic if you see the errors while updating your system.The errors are common and the fix is easy. You’ll learn how to fix those common update errors.
+
+_**Before you begin, I highly advise reading these two articles to have a better understanding of the repository concept in Ubuntu.**_
+
+![Understand Ubuntu repositories][3]
+
+![Understand Ubuntu repositories][3]
+
+###### **Understand Ubuntu repositories**
+
+Learn what are various repositories in Ubuntu and how they enable you to install software in your system.
+
+[Read More][4]
+
+![Understanding PPA in Ubuntu][5]
+
+![Understanding PPA in Ubuntu][5]
+
+###### **Understanding PPA in Ubuntu**
+
+Further improve your concept of repositories and package handling in Ubuntu with this detailed guide on PPA.
+
+[Read More][6]
+
+### Error 0: Failed to download repository information
+
+Many Ubuntu desktop users update their system through the graphical software updater tool. You are notified that updates are available for your system and you can click one button to start downloading and installing the updates.
+
+Well, that’s what usually happens. But sometimes you’ll see an error like this:
+
+![][7]
+
+_**Failed to download repository information. Check your internet connection.**_
+
+That’s a weird error because your internet connection is most likely working just fine and it still says to check the internet connection.
+
+Did you note that I called it ‘error 0’? It’s because it’s not an error in itself. I mean, most probably, it has nothing to do with the internet connection. But there is no useful information other than this misleading error message.
+
+If you see this error message and your internet connection is working fine, it’s time to put on your detective hat and [use your grey cells][8] (as [Hercule Poirot][9] would say).
+
+You’ll have to use the command line here. You can [use Ctrl+Alt+T keyboard shortcut to open the terminal in Ubuntu][10]. In the terminal, use this command:
+
+```
+sudo apt update
+```
+
+Let the command finish. Observe the last three-four lines of its output. That will give you the real reason why sudo apt-get update fails. Here’s an example:
+
+![][11]
+
+Rest of the tutorial here shows how to handle the errors that you just saw in the last few lines of the update command output.
+
+### Error 1: Problem With MergeList
+
+When you run update in terminal, you may see an error “[problem with MergeList][12]” like below:
+
+```
+E:Encountered a section with no Package: header,
+E:Problem with MergeList /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_precise_universe_binary-i386_Packages,
+E:The package lists or status file could not be parsed or opened.’
+```
+
+For some reasons, the file in /var/lib/apt/lists directory got corrupted. You can delete all the files in this directory and run the update again to regenerate everything afresh. Use the following commands one by one:
+
+```
+sudo rm -r /var/lib/apt/lists/*
+sudo apt-get clean && sudo apt-get update
+```
+
+Your problem should be fixed.
+
+### Error 2: Hash Sum mismatch
+
+If you find an error that talks about [Hash Sum mismatch][13], the fix is the same as the one in the previous error.
+
+```
+W:Failed to fetch bzip2:/var/lib/apt/lists/partial/in.archive.ubuntu.com_ubuntu_dists_oneiric_restricted_binary-i386_Packages Hash Sum mismatch,
+W:Failed to fetch bzip2:/var/lib/apt/lists/partial/in.archive.ubuntu.com_ubuntu_dists_oneiric_multiverse_binary-i386_Packages Hash Sum mismatch,
+E:Some index files failed to download. They have been ignored, or old ones used instead
+```
+
+The error occurs possibly because of a mismatched metadata cache between the server and your system. You can use the following commands to fix it:
+
+```
+sudo rm -rf /var/lib/apt/lists/*
+sudo apt update
+```
+
+### Error 3: Failed to fetch with error 404 not found
+
+If you try adding a PPA repository that is not available for your current [Ubuntu version][14], you’ll see that it throws a 404 not found error.
+
+```
+W: Failed to fetch http://ppa.launchpad.net/venerix/pkg/ubuntu/dists/raring/main/binary-i386/Packages 404 Not Found
+E: Some index files failed to download. They have been ignored, or old ones used instead.
+```
+
+You added a PPA hoping to install an application but it is not available for your Ubuntu version and you are now stuck with the update error. This is why you should check beforehand if a PPA is available for your Ubuntu version or not. I have discussed how to check the PPA availability in the detailed [PPA guide][6].
+
+Anyway, the fix here is that you remove the troublesome PPA from your list of repositories. Note the PPA name from the error message. Go to _Software & Updates_ tool:
+
+![Open Software & Updates][15]
+
+In here, move to _Other Software_ tab and look for that PPA. Uncheck the box to [remove the PPA][16] from your system.
+
+![Remove PPA Using Software & Updates In Ubuntu][17]
+
+Your software list will be updated when you do that. Now if you run the update again, you shouldn’t see the error.
+
+### Error 4: Failed to download package files error
+
+A similar error is **[failed to download package files error][18] **like this:
+
+![][19]
+
+In this case, a newer version of the software is available but it’s not propagated to all the mirrors. If you are not using a mirror, easily fixed by changing the software sources to Main server. Please read this article for more details on [failed to download package error][18].
+
+Go to _Software & Updates_ and in there changed the download server to Main server:
+
+![][20]
+
+### Error 5: GPG error: The following signatures couldn’t be verified
+
+Adding a PPA may also result in the following [GPG error: The following signatures couldn’t be verified][21] when you try to run an update in terminal:
+
+```
+W: GPG error: http://repo.mate-desktop.org saucy InRelease: The following signatures couldn’t be verified because the public key is not available: NO_PUBKEY 68980A0EA10B4DE8
+```
+
+All you need to do is to fetch this public key in the system. Get the key number from the message. In the above message, the key is 68980A0EA10B4DE8.
+
+This key can be used in the following manner:
+
+```
+sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 68980A0EA10B4DE8
+```
+
+Once the key has been added, run the update again and it should be fine.
+
+### Error 6: BADSIG error
+
+Another signature related Ubuntu update error is [BADSIG error][22] which looks something like this:
+
+```
+W: A error occurred during the signature verification. The repository is not updated and the previous index files will be used. GPG error: http://extras.ubuntu.com precise Release: The following signatures were invalid: BADSIG 16126D3A3E5C1192 Ubuntu Extras Archive Automatic Signing Key
+W: GPG error: http://ppa.launchpad.net precise Release:
+The following signatures were invalid: BADSIG 4C1CBC1B69B0E2F4 Launchpad PPA for Jonathan French W: Failed to fetch http://extras.ubuntu.com/ubuntu/dists/precise/Release
+```
+
+All the repositories are signed with the GPG and for some reason, your system finds them invalid. You’ll need to update the signature keys. The easiest way to do that is by regenerating the apt packages list (with their signature keys) and it should have the correct key.
+
+Use the following commands one by one in the terminal:
+
+```
+cd /var/lib/apt
+sudo mv lists oldlist
+sudo mkdir -p lists/partial
+sudo apt-get clean
+sudo apt-get update
+```
+
+### Error 7: Partial upgrade error
+
+Running updates in terminal may throw this partial upgrade error:
+
+![][23]
+
+```
+Not all updates can be installed
+Run a partial upgrade, to install as many updates as possible
+```
+
+Run the following command in terminal to fix this error:
+
+```
+sudo apt-get install -f
+```
+
+### Error 8: Could not get lock /var/cache/apt/archives/lock
+
+This error happens when another program is using APT. Suppose you are installing some thing in Ubuntu Software Center and at the same time, trying to run apt in terminal.
+
+```
+E: Could not get lock /var/cache/apt/archives/lock – open (11: Resource temporarily unavailable)
+E: Unable to lock directory /var/cache/apt/archives/
+```
+
+Check if some other program might be using apt. It could be a command running terminal, Software Center, Software Updater, Software & Updates or any other software that deals with installing and removing applications.
+
+If you can close other such programs, close them. If there is a process in progress, wait for it to finish.
+
+If you cannot find any such programs, use the following [command to kill all such running processes][24]:
+
+```
+sudo killall apt apt-get
+```
+
+This is a tricky problem and if the problem still persists, please read this detailed tutorial on [fixing the unable to lock the administration directory error in Ubuntu][25].
+
+_**Any other update error you encountered?**_
+
+That compiles the list of frequent Ubuntu update errors you may encounter. I hope this helps you to get rid of these errors.
+
+Have you encountered any other update error in Ubuntu recently that hasn’t been covered here? Do mention it in comments and I’ll try to do a quick tutorial on it.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/ubuntu-update-error/
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/update-ubuntu/
+[2]: https://ubuntu.com/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/03/ubuntu-repositories.png?ssl=1
+[4]: https://itsfoss.com/ubuntu-repositories/
+[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/what-is-ppa.png?ssl=1
+[6]: https://itsfoss.com/ppa-guide/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2013/04/Failed-to-download-repository-information-Ubuntu-13.04.png?ssl=1
+[8]: https://idioms.thefreedictionary.com/little+grey+cells
+[9]: https://en.wikipedia.org/wiki/Hercule_Poirot
+[10]: https://itsfoss.com/ubuntu-shortcuts/
+[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2013/11/Ubuntu-Update-error.jpeg?ssl=1
+[12]: https://itsfoss.com/how-to-fix-problem-with-mergelist/
+[13]: https://itsfoss.com/solve-ubuntu-error-failed-to-download-repository-information-check-your-internet-connection/
+[14]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
+[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/05/software-updates-ubuntu-gnome.jpeg?ssl=1
+[16]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
+[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/10/remove_ppa_using_software_updates_in_ubuntu.jpg?ssl=1
+[18]: https://itsfoss.com/fix-failed-download-package-files-error-ubuntu/
+[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2014/09/Ubuntu_Update_error.jpeg?ssl=1
+[20]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2014/09/Change_server_Ubuntu.jpeg?ssl=1
+[21]: https://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
+[22]: https://itsfoss.com/solve-badsig-error-quick-tip/
+[23]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2013/09/Partial_Upgrade_error_Elementary_OS_Luna.png?ssl=1
+[24]: https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/
+[25]: https://itsfoss.com/could-not-get-lock-error/
diff --git a/sources/tech/20191022 How collaboration fueled a development breakthrough at Greenpeace.md b/sources/tech/20191022 How collaboration fueled a development breakthrough at Greenpeace.md
new file mode 100644
index 0000000000..6d236a3ab7
--- /dev/null
+++ b/sources/tech/20191022 How collaboration fueled a development breakthrough at Greenpeace.md
@@ -0,0 +1,108 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How collaboration fueled a development breakthrough at Greenpeace)
+[#]: via: (https://opensource.com/open-organization/19/10/collaboration-breakthrough-greenpeace)
+[#]: author: (Laura Hilliger https://opensource.com/users/laurahilliger)
+
+How collaboration fueled a development breakthrough at Greenpeace
+======
+We're building an innovative platform to connect environmental
+advocates—but system complexity threatened to slow us down. Opening up
+was the answer.
+![The Open Organization at Greenpeace][1]
+
+Activists really don't like feeling stuck.
+
+We thrive on forward momentum and the energy it creates. When that movement grinds to a halt, even for a moment, our ability to catalyze passion in others stalls too.
+
+And my colleagues and I at Greenpeace International were feeling stuck.
+
+We'd managed to launch a prototype of Planet 4, [Greenpeace's new, open engagement platform][2] for activists and communities. It's live in more than 38 countries (with many more sites). More than 1.75 million people are using it. We've topped more than 3.1 million pageviews.
+
+To get here, we [spent more than 650 hours in meetings, drank 1,478 litres of coffee, and fixed more than 300 bugs][3]. But it fell short of our vision; it _still_ wasn't [the minimum lovable product][4] we wanted and we didn't know how to move it forward.
+
+We were stuck.
+
+Planet 4's complexity was daunting. We didn't always have the right people to address the numerous challenges the project raised. We didn't know if we'd ever realize our vision. Yet a commitment to openness had gotten us here, and I knew a commitment to openness would get us through this, too.
+
+As [the story of Planet 4][5] continues, I'll explain how it did.
+
+### An opportunity
+
+By 2016, my work helping Greenpeace International become a more open organization—[which I described in the first part of this series][6]—was beginning to bear fruit. We were holding regular [community calls][7]. We were releasing project updates frequently and publicly. We were networking with global stakeholders across the organization to define what Planet 4 needed to be. We were [architecting the project with participation in mind][8].
+
+Becoming open is an organic process. There's no standard "game plan" for implementing process and practices in an organization. Success depends on the people, the tools, the project, the very fabric of the culture you're working inside.
+
+Inside Greenpeace, we were beginning to see that success.
+
+A commitment to openness had gotten us here, and I knew a commitment to openness would get us through this, too.
+
+For some, this open way of working was inspiring and engaging. For others it was terrifying. Some thought asking for everyone's input was ridiculous. Some thought only "experts" should be part of the conversations, a viewpoint that doesn't mesh well with [the principle of inclusivity][9]. I appreciate expertise—don't get me wrong—but the problem with only asking for "expert" opinions is that you exclude people who might have more interest, passion, and knowledge than someone with a formal title.
+
+Planet 4 was a vision—not just of a new and open engagement platform, but of an organization that could make _use_ of this platform. And it raised problems on both those fronts:
+
+ * **Data and systems integration:** As a network of 28 independent offices all over the world, Greenpeace has a complex technical landscape. While Greenpeace International provides system _recommendations_ and _support_, individual National and Regional Offices are free to make their own systems choices, even if they aren't the supported ones. This is a good thing; different tools better address different needs for different offices. But it's challenging, too, because the absence of standardization means a lack of expertise in all those systems.
+ * **Organizational culture and work styles:** Planet 4 devoured many of Greenpeace's internal strategies and visions, then spit them out into a way that promised to move toward the type of organization we wanted to be. It was challenging the organizational status quo.
+
+
+
+Our team was too small, our work too big, and the landscape of working in a global non-profit too complex. The team was struggling, and we needed help.
+
+Then, in 2018, I saw an opportunity.
+
+As an [Open Organization Ambassador][10], I'd been to Red Hat Summit to speak on a panel about open organizational principles. There I noticed a session exploring what [Red Hat had done to help UNICEF][11], another global non-profit, with its digital transformation efforts. Surely, I thought, Red Hat and Greenpeace could work together, too.
+
+So I did something that shouldn't seem so revolutionary or audacious: I found the Red Hatter responsible for the company's collaboration with UNICEF, Alexandra Machado, and I _said hello_. I wasn't just introducing myself; I was approaching Alexandra on behalf of a global community of open-minded advocates.
+
+And it worked.
+
+### Accelerating
+
+Together, Alexandra and I spent more than a year coordinating a collaboration that could help Greenpeace move forward. Earlier this year, we started to succeed.
+
+Planet 4 was a vision—not just of a new and open engagement platform, but of an organization that could make use of this platform. And it raised problems on both those fronts.
+
+In late May, members of the Planet 4 project and a team from Red Hat's App Dev Center of Excellence met in Amsterdam. The goal: Accelerate us.
+
+We'd spend an entire week together in a design sprint aimed at helping us chart a speedy path toward making our vision for the Planet 4 engagement platform a reality, beginning with navigating its technical complexity. And in the process, we'd lean heavily on the open way of working we'd learned to embrace.
+
+At the sprint, our teams got to know each other. We dumped everything on the table. In a radically open and honest way, the Greenpeace team helped the Red Hat team from Waterford understand the technical and cultural hurdles we faced. We explained our organization and our tech stack, our vision and our dreams. Red Hatters noticed our passion and worked alongside us to explore possible technologies that could make our vision a reality.
+
+Through a series of exercises—including a particularly helpful session of [event storming][12]—we confirmed that our dream was not only the right one to have but also fully realizable. We talked through the dynamics of the systems we are addressing, and, in the end, the Red Hat team helped us envision a prototype for integrated systems that the Greenpeace team could take forward. We've already begun user testing.
+
+_Listen to Patrick Carney of Red Hat Open Innovation Labs explain event storming._
+
+On top of that, our new allies wrote a technical report that laid out the complexities we could _see_ but not _address_—and in a way that spurred internal conversations forward. We found ourselves, a few weeks after the event, moving forward at speed.
+
+Finally, we were unstuck.
+
+In the final chapter of Planet 4's story, I'll explain what the experience taught us about the power of openness.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/open-organization/19/10/collaboration-breakthrough-greenpeace
+
+作者:[Laura Hilliger][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/laurahilliger
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/images/open-org/open-org-greenpeace-article-2-blog-thumbnail-520x292.png?itok=YNEKRAxS (The Open Organization at Greenpeace)
+[2]: http://greenpeace.org/international
+[3]: https://medium.com/planet4/p4-in-2018-3bec1cc12be8
+[4]: https://medium.com/planet4/past-the-prototype-d3e0a4d3a171
+[5]: https://opensource.com/tags/open-organization-greenpeace
+[6]: https://opensource.com/open-organization/19/10/open-platform-greenpeace-1
+[7]: https://opensource.com/open-organization/16/1/community-calls-will-increase-participation-your-open-organization
+[8]: https://opensource.com/open-organization/16/8/best-results-design-participation
+[9]: https://opensource.com/open-organization/resources/open-org-definition
+[10]: https://opensource.com/open-organization/resources/meet-ambassadors
+[11]: https://www.redhat.com/en/proof-of-concept-series
+[12]: https://openpracticelibrary.com/practice/event-storming/
diff --git a/sources/tech/20191022 How to Go About Linux Boot Time Optimisation.md b/sources/tech/20191022 How to Go About Linux Boot Time Optimisation.md
new file mode 100644
index 0000000000..9e99bcdb7c
--- /dev/null
+++ b/sources/tech/20191022 How to Go About Linux Boot Time Optimisation.md
@@ -0,0 +1,227 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Go About Linux Boot Time Optimisation)
+[#]: via: (https://opensourceforu.com/2019/10/how-to-go-about-linux-boot-time-optimisation/)
+[#]: author: (B Thangaraju https://opensourceforu.com/author/b-thangaraju/)
+
+How to Go About Linux Boot Time Optimisation
+======
+
+[![][1]][2]
+
+_Booting an embedded device or a piece of telecommunication equipment quickly is crucial for time-critical applications and also plays a very major role in improving the user experience. This article gives some important tips on how to enhance the boot-up time of any device._
+
+Fast booting or fast rebooting plays a crucial role in various situations. It is critical for an embedded system to boot up fast in order to maintain the high availability and better performance of all the services. Imagine a telecommunications device running a Linux operating system that does not have fast booting enabled. All the systems, services and the users dependent on that particular embedded device might be affected. It is really important that devices maintain high availability in their services, for which fast booting and rebooting play a crucial role.
+
+A small failure or shutdown of a telecom device, even for a few seconds, can play havoc with countless users working on the Internet. Thus, it is really important for a lot of time-dependent devices and telecommunication devices to incorporate fast booting in their devices to help them get back to work quicker. Let us understand the Linux boot-up procedure from Figure 1.
+
+![Figure 1: Boot-up procedure][3]
+
+![Figure 2: Boot chart][4]
+
+**Monitoring tools and the boot-up procedure**
+A user should take note of a number of factors before making changes to a machine. These include the current booting speed of the machine and also the services, processes or applications that are taking up resources and increasing the boot-up time.
+
+**Boot chart:** To monitor the boot-up speed and the various services that start while booting up, the user can install the boot chart using the following command:
+
+```
+sudo apt-get install pybootchartgui.
+```
+
+Each time you boot up, the boot chart saves a _.png_ (portable network graphics) file in the log, which enables the user to view the _png_ files to get an understanding about the system’s boot-up process and services. Use the following command for this purpose:
+
+```
+cd /var/log/bootchart
+```
+
+The user might need an application to view the _.png_ files. Feh is an X11 image viewer that targets console users. It doesn’t have a fancy GUI, unlike most other image viewers, but it simply displays pictures. Feh can be used to view the _.png_ files. You can install it using the following command:
+
+```
+sudo apt-get install feh
+```
+
+You can view the _png_ files using _feh xxxx.png_.
+Figure 2 shows the boot chart when a boot chart _png_ file is viewed.
+However, a boot chart is not necessary for Ubuntu versions later than 15.10. To get very brief information regarding boot up speed, use the following command:
+
+```
+systemd-analyze
+```
+
+![Figure 3: Output of systemd-analyze][5]
+
+Figure 3 shows the output of the command _systemd-analyze_.
+The command _systemd-analyze_ blame is used to print a list of all running units based on the time they took to initialise. This information is very helpful and can be used to optimise boot-up times. systemd-analyze blame doesn’t display results for services with _Type=simple_, because systemd considers such services to be started immediately; hence, no measurement of the initialisation delays can be done.
+
+![Figure 4: Output of systemd-analyze blame][6]
+
+Figure 4 shows the output of _systemd-analyze_ blame.
+The following command prints a tree of the time-critical chain of units:
+
+```
+command systemd-analyze critical-chain
+```
+
+Figure 5 shows the output of the command _systemd-analyze critical-chain_.
+
+![Figure 5: Output of systemd-analyze critical-chain][7]
+
+**Steps to reduce the boot-up time**
+Shown below are the various steps that can be taken to reduce boot-up time.
+
+**BUM (Boot-Up-Manager):** BUM is a run level configuration editor that allows the configuration of _init_ services when the system boots up or reboots. It displays a list of every service that can be started at boot. The user can toggle individual services on and off. BUM has a very clean GUI and is very easy to use.
+
+BUM can be installed in Ubuntu 14.04 using the following command:
+
+```
+sudo apt-get install bum
+```
+
+To install it in versions later than 15.10, download the packages from the link _ 13_.
+
+Start with basic things and disable services related to the scanner and printer. You can also disable Bluetooth and all other unwanted devices and services if you are not using any of them. I strongly recommend that you study the basics about the services before disabling them, as it might affect the machine or operating system. Figure 6 shows the GUI of BUM.
+
+![Figure 6: BUM][8]
+
+**Editing the rc file:** To edit the rc file, you need to go to the rc directory. This can be done using the following command:
+
+```
+cd /etc/init.d.
+```
+
+However, root privileges are needed to access _init.d_, which basically contains start/stop scripts that are used to control (start, stop, reload, restart) the daemon while the system is running or during boot.
+
+The _rc_ file in _init.d_ is called a run control script. During booting, init executes the _rc_ script and plays its role. To improve the booting speed, we make changes to the _rc_ file. Open the _rc_ file (once you are in the _init.d_ directory) using any file editor.
+
+For example, by entering _vim rc_, you can change the value of _CONCURRENCY=none_ to _CONCURRENCY=shell_. The latter allows certain startup scripts to be executed simultaneously, rather than serially.
+
+In the latest versions of the kernel, the value should be changed to _CONCURRENCY=makefile_.
+Figures 7 and 8 show the comparison of boot-up times before and after editing the rc file. The improvement in the boot-up speed can be noticed. The time to boot before editing the rc file was 50.98 seconds, whereas the time to boot after making the changes to the rc file is 23.85 seconds.
+However, the above-mentioned changes don’t work on operating systems later than the Ubuntu version 15.10, since the operating systems with the latest kernel use the systemd file and not the _init.d_ file any more.
+
+![Figure 7: Boot speed before making changes to the rc file][9]
+
+![Figure 8: Boot speed after making changes to the rc file][10]
+
+**E4rat:** E4rat stands for e4 ‘reduced access time’ (ext4 file system only). It is a project developed by Andreas Rid and Gundolf Kiefer. E4rat is an application that helps in achieving a fast boot with the help of defragmentation. It also accelerates application startups. E4rat eliminates both seek times and rotational delays using physical file reallocation. This leads to a high disk transfer rate.
+E4rat is available as a .deb package and you can download it from its official website __.
+
+Ubuntu’s default ureadahead package conflicts with e4rat. So a few packages have to be installed using the following command:
+
+```
+sudo dpkg purge ureadahead ubuntu-minimal
+```
+
+Now install the dependencies for e4rat using the following command:
+
+```
+sudo apt-get install libblkid1 e2fslibs
+```
+
+Open the downloaded _.deb_ file and install it. Boot data is now needed to be gathered properly to work with e4rat.
+
+Follow the steps given below to get e4rat running properly and to increase the boot-up speed.
+
+ * Access the Grub menu while booting. This can be done by holding the shift button when the system is booting.
+ * Choose the option (kernel version) that is normally used to boot and press ‘e’.
+ * Look for the line starting with _linux /boot/vmlinuz_ and add the following code at the end of the line (hit space after the last letter of the sentence):
+
+
+
+```
+- init=/sbin/e4rat-collect or try - quiet splash vt.handsoff =7 init=/sbin/e4rat-collect
+```
+
+ * Now press _Ctrl+x_ to continue booting. This lets e4rat collect data after booting. Work on the machine, open and close applications for the next two minutes.
+ * Access the log file by going to the e4rat folder and using the following command:
+
+
+
+```
+cd /var/log/e4rat
+```
+
+ * If you do not find any log file, repeat the above mentioned process. Once the log file is there, access the Grub menu again and press ‘e’ as your option.
+ * Enter ‘single’ at the end of the same line that you have edited before. This will help you access the command line. If a different menu appears asking for anything, choose Resume normal boot. If you don’t get to the command prompt for some reason, hit Ctrl+Alt+F1.
+ * Enter your details once you see the login prompt.
+ * Now enter the following command:
+
+
+
+```
+sudo e4rat-realloc /var/lib/e4rat/startup.log
+```
+
+This process takes a while, depending on the machine’s disk speed.
+
+ * Now restart your machine using the following command:
+
+
+
+```
+sudo shutdown -r now
+```
+
+ * Now, we need to configure Grub to run e4rat at every boot.
+ * Access the grub file using any editor. For example, _gksu gedit /etc/default/grub._
+ * Look for a line starting with _GRUB CMDLINE LINUX DEFAULT=_, and add the following line in between the quotes and before whatever options there are:
+
+
+
+```
+init=/sbin/e4rat-preload 18
+```
+
+ * It should look like this:
+
+
+
+```
+GRUB CMDLINE LINUX DEFAULT = init=/sbin/e4rat- preload quiet splash
+```
+
+ * Save and close the Grub menu and update Grub using _sudo update-grub_.
+ * Reboot the system and you will find noticeable changes in boot speed.
+
+
+
+Figures 9 and 10 show the differences between the boot-up time before and after installing e4rat. The improvement in the boot-up speed can be noticed. The time taken to boot before using e4rat was 22.32 seconds, whereas the time taken to boot after using e4rat is 9.065 seconds
+
+![Figure 9: Boot speed before using e4rat][11]
+
+![Figure 10: Boot speed after using e4rat][12]
+
+**A few simple tweaks**
+A good boot-up speed can also be achieved using very small tweaks, two of which are listed below.
+**SSD:** Using solid-state devices rather than normal hard disks or other storage devices will surely improve your booting speed. SSDs also help in achieving great speeds in transferring files and running applications.
+
+**Disabling GUI:** The graphical user interface, desktop graphics and window animations take up a lot of resources. Disabling the GUI is another good way to achieve great boot-up speed.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/how-to-go-about-linux-boot-time-optimisation/
+
+作者:[B Thangaraju][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/b-thangaraju/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Screenshot-from-2019-10-07-13-16-32.png?resize=696%2C496&ssl=1 (Screenshot from 2019-10-07 13-16-32)
+[2]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Screenshot-from-2019-10-07-13-16-32.png?fit=700%2C499&ssl=1
+[3]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-1.png?resize=350%2C302&ssl=1
+[4]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-2.png?resize=350%2C412&ssl=1
+[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-3.png?resize=350%2C69&ssl=1
+[6]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-4.png?resize=350%2C535&ssl=1
+[7]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-5.png?resize=350%2C206&ssl=1
+[8]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-6.png?resize=350%2C449&ssl=1
+[9]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-7.png?resize=350%2C85&ssl=1
+[10]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-8.png?resize=350%2C72&ssl=1
+[11]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-9.png?resize=350%2C61&ssl=1
+[12]: https://i0.wp.com/opensourceforu.com/wp-content/uploads/2019/10/fig-10.png?resize=350%2C61&ssl=1
diff --git a/sources/tech/20191022 How to program with Bash- Logical operators and shell expansions.md b/sources/tech/20191022 How to program with Bash- Logical operators and shell expansions.md
new file mode 100644
index 0000000000..024af38122
--- /dev/null
+++ b/sources/tech/20191022 How to program with Bash- Logical operators and shell expansions.md
@@ -0,0 +1,498 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to program with Bash: Logical operators and shell expansions)
+[#]: via: (https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions)
+[#]: author: (David Both https://opensource.com/users/dboth)
+
+How to program with Bash: Logical operators and shell expansions
+======
+Learn about logical operators and shell expansions, in the second
+article in this three-part series on programming with Bash.
+![Women in computing and open source v5][1]
+
+Bash is a powerful programming language, one perfectly designed for use on the command line and in shell scripts. This three-part series (which is based on my [three-volume Linux self-study course][2]) explores using Bash as a programming language on the command-line interface (CLI).
+
+The [first article][3] explored some simple command-line programming with Bash, including using variables and control operators. This second article looks into the types of file, string, numeric, and miscellaneous logical operators that provide execution-flow control logic and different types of shell expansions in Bash. The third and final article in the series will explore the **for**, **while**, and **until** loops that enable repetitive operations.
+
+Logical operators are the basis for making decisions in a program and executing different sets of instructions based on those decisions. This is sometimes called flow control.
+
+### Logical operators
+
+Bash has a large set of logical operators that can be used in conditional expressions. The most basic form of the **if** control structure tests for a condition and then executes a list of program statements if the condition is true. There are three types of operators: file, numeric, and non-numeric operators. Each operator returns true (0) if the condition is met and false (1) if the condition is not met.
+
+The functional syntax of these comparison operators is one or two arguments with an operator that are placed within square braces, followed by a list of program statements that are executed if the condition is true, and an optional list of program statements if the condition is false:
+
+
+```
+if [ arg1 operator arg2 ] ; then list
+or
+if [ arg1 operator arg2 ] ; then list ; else list ; fi
+```
+
+The spaces in the comparison are required as shown. The single square braces, **[** and **]**, are the traditional Bash symbols that are equivalent to the **test** command:
+
+
+```
+`if test arg1 operator arg2 ; then list`
+```
+
+There is also a more recent syntax that offers a few advantages and that some sysadmins prefer. This format is a bit less compatible with different versions of Bash and other shells, such as ksh (the Korn shell). It looks like:
+
+
+```
+`if [[ arg1 operator arg2 ]] ; then list`
+```
+
+#### File operators
+
+File operators are a powerful set of logical operators within Bash. Figure 1 lists more than 20 different operators that Bash can perform on files. I use them quite frequently in my scripts.
+
+Operator | Description
+---|---
+-a filename | True if the file exists; it can be empty or have some content but, so long as it exists, this will be true
+-b filename | True if the file exists and is a block special file such as a hard drive like **/dev/sda** or **/dev/sda1**
+-c filename | True if the file exists and is a character special file such as a TTY device like **/dev/TTY1**
+-d filename | True if the file exists and is a directory
+-e filename | True if the file exists; this is the same as **-a** above
+-f filename | True if the file exists and is a regular file, as opposed to a directory, a device special file, or a link, among others
+-g filename | True if the file exists and is **set-group-id**, **SETGID**
+-h filename | True if the file exists and is a symbolic link
+-k filename | True if the file exists and its "sticky'" bit is set
+-p filename | True if the file exists and is a named pipe (FIFO)
+-r filename | True if the file exists and is readable, i.e., has its read bit set
+-s filename | True if the file exists and has a size greater than zero; a file that exists but that has a size of zero will return false
+-t fd | True if the file descriptor **fd** is open and refers to a terminal
+-u filename | True if the file exists and its **set-user-id** bit is set
+-w filename | True if the file exists and is writable
+-x filename | True if the file exists and is executable
+-G filename | True if the file exists and is owned by the effective group ID
+-L filename | True if the file exists and is a symbolic link
+-N filename | True if the file exists and has been modified since it was last read
+-O filename | True if the file exists and is owned by the effective user ID
+-S filename | True if the file exists and is a socket
+file1 -ef file2 | True if file1 and file2 refer to the same device and iNode numbers
+file1 -nt file2 | True if file1 is newer (according to modification date) than file2, or if file1 exists and file2 does not
+file1 -ot file2 | True if file1 is older than file2, or if file2 exists and file1 does not
+
+_**Fig. 1: The Bash file operators**_
+
+As an example, start by testing for the existence of a file:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; if [ -e $File ] ; then echo "The file $File exists." ; else echo "The file $File does not exist." ; fi
+The file TestFile1 does not exist.
+[student@studentvm1 testdir]$
+```
+
+Next, create a file for testing named **TestFile1**. For now, it does not need to contain any data:
+
+
+```
+`[student@studentvm1 testdir]$ touch TestFile1`
+```
+
+It is easy to change the value of the **$File** variable rather than a text string for the file name in multiple locations in this short CLI program:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; if [ -e $File ] ; then echo "The file $File exists." ; else echo "The file $File does not exist." ; fi
+The file TestFile1 exists.
+[student@studentvm1 testdir]$
+```
+
+Now, run a test to determine whether a file exists and has a non-zero length, which means it contains data. You want to test for three conditions: 1. the file does not exist; 2. the file exists and is empty; and 3. the file exists and contains data. Therefore, you need a more complex set of tests—use the **elif** stanza in the **if-elif-else** construct to test for all of the conditions:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; if [ -s $File ] ; then echo "$File exists and contains data." ; fi
+[student@studentvm1 testdir]$
+```
+
+In this case, the file exists but does not contain any data. Add some data and try again:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is file $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; fi
+TestFile1 exists and contains data.
+[student@studentvm1 testdir]$
+```
+
+That works, but it is only truly accurate for one specific condition out of the three possible ones. Add an **else** stanza so you can be somewhat more accurate, and delete the file so you can fully test this new code:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; rm $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
+TestFile1 does not exist or is empty.
+```
+
+Now create an empty file to test:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; touch $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
+TestFile1 does not exist or is empty.
+```
+
+Add some content to the file and test again:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is file $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; else echo "$File does not exist or is empty." ; fi
+TestFile1 exists and contains data.
+```
+
+Now, add the **elif** stanza to discriminate between a file that does not exist and one that is empty:
+
+
+```
+[student@studentvm1 testdir]$ File="TestFile1" ; touch $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; elif [ -e $File ] ; then echo "$File exists and is empty." ; else echo "$File does not exist." ; fi
+TestFile1 exists and is empty.
+[student@studentvm1 testdir]$ File="TestFile1" ; echo "This is $File" > $File ; if [ -s $File ] ; then echo "$File exists and contains data." ; elif [ -e $File ] ; then echo "$File exists and is empty." ; else echo "$File does not exist." ; fi
+TestFile1 exists and contains data.
+[student@studentvm1 testdir]$
+```
+
+Now you have a Bash CLI program that can test for these three different conditions… but the possibilities are endless.
+
+It is easier to see the logic structure of the more complex compound commands if you arrange the program statements more like you would in a script that you can save in a file. Figure 2 shows how this would look. The indents of the program statements in each stanza of the **if-elif-else** structure help to clarify the logic.
+
+
+```
+File="TestFile1"
+echo "This is $File" > $File
+if [ -s $File ]
+ then
+ echo "$File exists and contains data."
+elif [ -e $File ]
+ then
+ echo "$File exists and is empty."
+else
+ echo "$File does not exist."
+fi
+```
+
+_**Fig. 2: The command line program rewritten as it would appear in a script**_
+
+Logic this complex is too lengthy for most CLI programs. Although any Linux or Bash built-in commands may be used in CLI programs, as the CLI programs get longer and more complex, it makes more sense to create a script that is stored in a file and can be executed at any time, now or in the future.
+
+#### String comparison operators
+
+String comparison operators enable the comparison of alphanumeric strings of characters. There are only a few of these operators, which are listed in Figure 3.
+
+Operator | Description
+---|---
+-z string | True if the length of string is zero
+-n string | True if the length of string is non-zero
+string1 == string2
+or
+string1 = string2 | True if the strings are equal; a single **=** should be used with the test command for POSIX conformance. When used with the **[[** command, this performs pattern matching as described above (compound commands).
+string1 != string2 | True if the strings are not equal
+string1 < string2 | True if string1 sorts before string2 lexicographically (refers to locale-specific sorting sequences for all alphanumeric and special characters)
+string1 > string2 | True if string1 sorts after string2 lexicographically
+
+_**Fig. 3: Bash string logical operators**_
+
+First, look at string length. The quotes around **$MyVar** in the comparison must be there for the comparison to work. (You should still be working in **~/testdir**.)
+
+
+```
+[student@studentvm1 testdir]$ MyVar="" ; if [ -z "" ] ; then echo "MyVar is zero length." ; else echo "MyVar contains data" ; fi
+MyVar is zero length.
+[student@studentvm1 testdir]$ MyVar="Random text" ; if [ -z "" ] ; then echo "MyVar is zero length." ; else echo "MyVar contains data" ; fi
+MyVar is zero length.
+```
+
+You could also do it this way:
+
+
+```
+[student@studentvm1 testdir]$ MyVar="Random text" ; if [ -n "$MyVar" ] ; then echo "MyVar contains data." ; else echo "MyVar is zero length" ; fi
+MyVar contains data.
+[student@studentvm1 testdir]$ MyVar="" ; if [ -n "$MyVar" ] ; then echo "MyVar contains data." ; else echo "MyVar is zero length" ; fi
+MyVar is zero length
+```
+
+Sometimes you may need to know a string's exact length. This is not a comparison, but it is related. Unfortunately, there is no simple way to determine the length of a string. There are a couple of ways to do it, but I think using the **expr** (evaluate expression) command is easiest. Read the man page for **expr** for more about what it can do. Note that quotes are required around the string or variable you're testing.
+
+
+```
+[student@studentvm1 testdir]$ MyVar="" ; expr length "$MyVar"
+0
+[student@studentvm1 testdir]$ MyVar="How long is this?" ; expr length "$MyVar"
+17
+[student@studentvm1 testdir]$ expr length "We can also find the length of a literal string as well as a variable."
+70
+```
+
+Regarding comparison operators, I use a lot of testing in my scripts to determine whether two strings are equal (i.e., identical). I use the non-POSIX version of this comparison operator:
+
+
+```
+[student@studentvm1 testdir]$ Var1="Hello World" ; Var2="Hello World" ; if [ "$Var1" == "$Var2" ] ; then echo "Var1 matches Var2" ; else echo "Var1 and Var2 do not match." ; fi
+Var1 matches Var2
+[student@studentvm1 testdir]$ Var1="Hello World" ; Var2="Hello world" ; if [ "$Var1" == "$Var2" ] ; then echo "Var1 matches Var2" ; else echo "Var1 and Var2 do not match." ; fi
+Var1 and Var2 do not match.
+```
+
+Experiment some more on your own to try out these operators.
+
+#### Numeric comparison operators
+
+Numeric operators make comparisons between two numeric arguments. Like the other operator classes, most are easy to understand.
+
+Operator | Description
+---|---
+arg1 -eq arg2 | True if arg1 equals arg2
+arg1 -ne arg2 | True if arg1 is not equal to arg2
+arg1 -lt arg2 | True if arg1 is less than arg2
+arg1 -le arg2 | True if arg1 is less than or equal to arg2
+arg1 -gt arg2 | True if arg1 is greater than arg2
+arg1 -ge arg2 | True if arg1 is greater than or equal to arg2
+
+_**Fig. 4: Bash numeric comparison logical operators**_
+
+Here are some simple examples. The first instance sets the variable **$X** to 1, then tests to see if **$X** is equal to 1. In the second instance, **X** is set to 0, so the comparison is not true.
+
+
+```
+[student@studentvm1 testdir]$ X=1 ; if [ $X -eq 1 ] ; then echo "X equals 1" ; else echo "X does not equal 1" ; fi
+X equals 1
+[student@studentvm1 testdir]$ X=0 ; if [ $X -eq 1 ] ; then echo "X equals 1" ; else echo "X does not equal 1" ; fi
+X does not equal 1
+[student@studentvm1 testdir]$
+```
+
+Try some more experiments on your own.
+
+#### Miscellaneous operators
+
+These miscellaneous operators show whether a shell option is set or a shell variable has a value, but it does not discover the value of the variable, just whether it has one.
+
+Operator | Description
+---|---
+-o optname | True if the shell option optname is enabled (see the list of options under the description of the **-o** option to the Bash set builtin in the Bash man page)
+-v varname | True if the shell variable varname is set (has been assigned a value)
+-R varname | True if the shell variable varname is set and is a name reference
+
+_**Fig. 5: Miscellaneous Bash logical operators**_
+
+Experiment on your own to try out these operators.
+
+### Expansions
+
+Bash supports a number of types of expansions and substitutions that can be quite useful. According to the Bash man page, Bash has seven forms of expansions. This article looks at five of them: tilde expansion, arithmetic expansion, pathname expansion, brace expansion, and command substitution.
+
+#### Brace expansion
+
+Brace expansion is a method for generating arbitrary strings. (This tool is used below to create a large number of files for experiments with special pattern characters.) Brace expansion can be used to generate lists of arbitrary strings and insert them into a specific location within an enclosing static string or at either end of a static string. This may be hard to visualize, so it's best to just do it.
+
+First, here's what a brace expansion does:
+
+
+```
+[student@studentvm1 testdir]$ echo {string1,string2,string3}
+string1 string2 string3
+```
+
+Well, that is not very helpful, is it? But look what happens when you use it just a bit differently:
+
+
+```
+[student@studentvm1 testdir]$ echo "Hello "{David,Jen,Rikki,Jason}.
+Hello David. Hello Jen. Hello Rikki. Hello Jason.
+```
+
+That looks like something useful—it could save a good deal of typing. Now try this:
+
+
+```
+[student@studentvm1 testdir]$ echo b{ed,olt,ar}s
+beds bolts bars
+```
+
+I could go on, but you get the idea.
+
+#### Tilde expansion
+
+Arguably, the most common expansion is the tilde (**~**) expansion. When you use this in a command like **cd ~/Documents**, the Bash shell expands it as a shortcut to the user's full home directory.
+
+Use these Bash programs to observe the effects of the tilde expansion:
+
+
+```
+[student@studentvm1 testdir]$ echo ~
+/home/student
+[student@studentvm1 testdir]$ echo ~/Documents
+/home/student/Documents
+[student@studentvm1 testdir]$ Var1=~/Documents ; echo $Var1 ; cd $Var1
+/home/student/Documents
+[student@studentvm1 Documents]$
+```
+
+#### Pathname expansion
+
+Pathname expansion is a fancy term expanding file-globbing patterns, using the characters **?** and *****, into the full names of directories that match the pattern. File globbing refers to special pattern characters that enable significant flexibility in matching file names, directories, and other strings when performing various actions. These special pattern characters allow matching single, multiple, or specific characters in a string.
+
+ * **?** — Matches only one of any character in the specified location within the string
+ * ***** — Matches zero or more of any character in the specified location within the string
+
+
+
+This expansion is applied to matching directory names. To see how this works, ensure that **testdir** is the present working directory (PWD) and start with a plain listing (the contents of my home directory will be different from yours):
+
+
+```
+[student@studentvm1 testdir]$ ls
+chapter6 cpuHog.dos dmesg1.txt Documents Music softlink1 testdir6 Videos
+chapter7 cpuHog.Linux dmesg2.txt Downloads Pictures Templates testdir
+testdir cpuHog.mac dmesg3.txt file005 Public testdir tmp
+cpuHog Desktop dmesg.txt link3 random.txt testdir1 umask.test
+[student@studentvm1 testdir]$
+```
+
+Now list the directories that start with **Do**, **testdir/Documents**, and **testdir/Downloads**:
+
+
+```
+Documents:
+Directory01 file07 file15 test02 test10 test20 testfile13 TextFiles
+Directory02 file08 file16 test03 test11 testfile01 testfile14
+file01 file09 file17 test04 test12 testfile04 testfile15
+file02 file10 file18 test05 test13 testfile05 testfile16
+file03 file11 file19 test06 test14 testfile09 testfile17
+file04 file12 file20 test07 test15 testfile10 testfile18
+file05 file13 Student1.txt test08 test16 testfile11 testfile19
+file06 file14 test01 test09 test18 testfile12 testfile20
+
+Downloads:
+[student@studentvm1 testdir]$
+```
+
+Well, that did not do what you wanted. It listed the contents of the directories that begin with **Do**. To list only the directories and not their contents, use the **-d** option.
+
+
+```
+[student@studentvm1 testdir]$ ls -d Do*
+Documents Downloads
+[student@studentvm1 testdir]$
+```
+
+In both cases, the Bash shell expands the **Do*** pattern into the names of the two directories that match the pattern. But what if there are also files that match the pattern?
+
+
+```
+[student@studentvm1 testdir]$ touch Downtown ; ls -d Do*
+Documents Downloads Downtown
+[student@studentvm1 testdir]$
+```
+
+This shows the file, too. So any files that match the pattern are also expanded to their full names.
+
+#### Command substitution
+
+Command substitution is a form of expansion that allows the STDOUT data stream of one command to be used as the argument of another command; for example, as a list of items to be processed in a loop. The Bash man page says: "Command substitution allows the output of a command to replace the command name." I find that to be accurate if a bit obtuse.
+
+There are two forms of this substitution, **`command`** and **$(command)**. In the older form using back tics (**`**), using a backslash (**\**) in the command retains its literal meaning. However, when it's used in the newer parenthetical form, the backslash takes on its meaning as a special character. Note also that the parenthetical form uses only single parentheses to open and close the command statement.
+
+I frequently use this capability in command-line programs and scripts where the results of one command can be used as an argument for another command.
+
+Start with a very simple example that uses both forms of this expansion (again, ensure that **testdir** is the PWD):
+
+
+```
+[student@studentvm1 testdir]$ echo "Todays date is `date`"
+Todays date is Sun Apr 7 14:42:46 EDT 2019
+[student@studentvm1 testdir]$ echo "Todays date is $(date)"
+Todays date is Sun Apr 7 14:42:59 EDT 2019
+[student@studentvm1 testdir]$
+```
+
+The **-w** option to the **seq** utility adds leading zeros to the numbers generated so that they are all the same width, i.e., the same number of digits regardless of the value. This makes it easier to sort them in numeric sequence.
+
+The **seq** utility is used to generate a sequence of numbers:
+
+
+```
+[student@studentvm1 testdir]$ seq 5
+1
+2
+3
+4
+5
+[student@studentvm1 testdir]$ echo `seq 5`
+1 2 3 4 5
+[student@studentvm1 testdir]$
+```
+
+Now you can do something a bit more useful, like creating a large number of empty files for testing:
+
+
+```
+`[student@studentvm1 testdir]$ for I in $(seq -w 5000) ; do touch file-$I ; done`
+```
+
+In this usage, the statement **seq -w 5000** generates a list of numbers from one to 5,000. By using command substitution as part of the **for** statement, the list of numbers is used by the **for** statement to generate the numerical part of the file names.
+
+#### Arithmetic expansion
+
+Bash can perform integer math, but it is rather cumbersome (as you will soon see). The syntax for arithmetic expansion is **$((arithmetic-expression))**, using double parentheses to open and close the expression.
+
+Arithmetic expansion works like command substitution in a shell program or script; the value calculated from the expression replaces the expression for further evaluation by the shell.
+
+Once again, start with something simple:
+
+
+```
+[student@studentvm1 testdir]$ echo $((1+1))
+2
+[student@studentvm1 testdir]$ Var1=5 ; Var2=7 ; Var3=$((Var1*Var2)) ; echo "Var 3 = $Var3"
+Var 3 = 35
+```
+
+The following division results in zero because the result would be a decimal value of less than one:
+
+
+```
+[student@studentvm1 testdir]$ Var1=5 ; Var2=7 ; Var3=$((Var1/Var2)) ; echo "Var 3 = $Var3"
+Var 3 = 0
+```
+
+Here is a simple calculation I often do in a script or CLI program that tells me how much total virtual memory I have in a Linux host. The **free** command does not provide that data:
+
+
+```
+[student@studentvm1 testdir]$ RAM=`free | grep ^Mem | awk '{print $2}'` ; Swap=`free | grep ^Swap | awk '{print $2}'` ; echo "RAM = $RAM and Swap = $Swap" ; echo "Total Virtual memory is $((RAM+Swap))" ;
+RAM = 4037080 and Swap = 6291452
+Total Virtual memory is 10328532
+```
+
+I used the **`** character to delimit the sections of code used for command substitution.
+
+I use Bash arithmetic expansion mostly for checking system resource amounts in a script and then choose a program execution path based on the result.
+
+### Summary
+
+This article, the second in this series on Bash as a programming language, explored the Bash file, string, numeric, and miscellaneous logical operators that provide execution-flow control logic and the different types of shell expansions.
+
+The third article in this series will explore the use of loops for performing various types of iterative operations.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/programming-bash-logical-operators-shell-expansions
+
+作者:[David Both][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_5.png?itok=YHpNs_ss (Women in computing and open source v5)
+[2]: http://www.both.org/?page_id=1183
+[3]: https://opensource.com/article/19/10/programming-bash-part-1
diff --git a/sources/tech/20191022 NGT- A library for high-speed approximate nearest neighbor search.md b/sources/tech/20191022 NGT- A library for high-speed approximate nearest neighbor search.md
new file mode 100644
index 0000000000..5922064511
--- /dev/null
+++ b/sources/tech/20191022 NGT- A library for high-speed approximate nearest neighbor search.md
@@ -0,0 +1,258 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (NGT: A library for high-speed approximate nearest neighbor search)
+[#]: via: (https://opensource.com/article/19/10/ngt-open-source-library)
+[#]: author: (Masajiro Iwasaki https://opensource.com/users/masajiro-iwasaki)
+
+NGT: A library for high-speed approximate nearest neighbor search
+======
+NGT is a high-performing, open source deep learning library for
+large-scale and high-dimensional vectors.
+![Houses in a row][1]
+
+Approximate nearest neighbor ([ANN][2]) search is used in deep learning to make a best guess at the point in a given set that is most similar to another point. This article explains the differences between ANN search and traditional search methods and introduces [NGT][3], a top-performing open source ANN library developed by [Yahoo! Japan Research][4].
+
+### Nearest neighbor search for high-dimensional data
+
+Different search methods are used for different data types. For example, full-text search is for text data, content-based image retrieval is for images, and relational databases are for data relationships. Deep learning models can easily generate vectors from various kinds of data so that the vector space has embedded relationships among source data. This means that if two source data are similar, the two vectors from the data will be located near each other in the vector space. Therefore, all you have to do is search the vectors instead of the source data.
+
+Moreover, the vectors not only represent the text and image characteristics of the source data, but they also represent products, human beings, organizations, and so forth. Therefore, you can search for similar documents and images as well as products with similar attributes, human beings with similar skills, clothing with similar features, and so on. For example, [Yahoo! Japan][5] provides a similarity-based fashion-item search using NGT.
+
+![Nearest neighbour search][6]
+
+Since the number of dimensions in deep learning models tends to increase, ANN search methods are indispensable when searching for more than several million high-dimensional vectors. ANN search methods allow you to search for neighbors to the specified query vector in high-dimensional space.
+
+There are many nearest-neighbor search methods to choose from. [ANN Benchmarks][7] evaluates the best-known ANN search methods, including Faiss (Facebook), Flann, and Hnswlib. According to this benchmark, NGT achieves top-level performance.
+
+### NGT algorithms
+
+The NGT index combines a graph and a tree. This result is a very good search performance, with the graph's vertices representing searchable objects. Neighboring vertices are connected by edges.
+
+This animation shows how a graph is constructed.
+
+![NGT graph construction][8]
+
+In the search procedure, neighboring vertices to the specified query can be found descending the graph. Densely connected vertices enable users to explore the graph effectively.
+
+![NGT graph][9]
+
+NGT provides a command-line tool, along with C, C++, and Python APIs. This article focuses on the command-line tool and the Python API.
+
+### Using NGT with the command-line tool
+
+#### Linux installation
+
+Download the [latest version of NGT][10] as a ZIP file and install it on Linux with:
+
+
+```
+unzip NGT-x.x.x.zip
+cd NGT-x.x.x
+mkdir build
+cd build
+cmake ..
+make
+make install
+```
+
+Since NGT libraries are installed in **/usr/local/lib(64)** by default, add the directory to the search path:
+
+
+```
+export PATH="$PATH:/opt/local/bin"
+export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/lib"
+```
+
+#### Sample dataset generation
+
+Before you can search for a large-scale dataset, you must generate an NGT dataset. As an example, [download the][11] [fastText][11] [dataset][11] from the [fastText website][12], then convert it to the NGT registration format with:
+
+
+```
+curl -O
+unzip wiki-news-300d-1M-subword.vec.zip
+tail -n +2 wiki-news-300d-1M-subword.vec | cut -d " " -f 2- > objects.ssv
+```
+
+**Objects.ssv** is a registration file that has 1 million objects. One object in the file is extracted as a query:
+
+
+```
+`head -10000 objects.ssv | tail -1 > query.ssv`
+```
+
+#### Index construction
+
+An **ngt_index** can be constructed using the following command:
+
+
+```
+`ngt create -d 300 -D c index objects.ssv`
+```
+
+_-d_ specifies the number of dimensions of the vector. _-D c_ means using cosine similarity.
+
+#### Approximate nearest neighbor search
+
+The **ngt_index** can be searched for with the queries using:
+
+
+```
+`ngt search -n 10 index query.ssv`
+```
+
+**-n** specifies the number of resulting objects.
+
+The search results are:
+
+
+```
+Query No.1
+Rank ID Distance
+1 10000 0
+2 21516 0.184495
+3 201860 0.240375
+4 71865 0.241284
+5 339589 0.267265
+6 485158 0.280977
+7 7961 0.283865
+8 924513 0.286571
+9 28870 0.286654
+10 395274 0.290466
+Query Time= 0.000972628 (sec), 0.972628 (msec)
+Average Query Time= 0.000972628 (sec), 0.972628 (msec), (0.000972628/1)
+```
+
+Please see the [NGT command-line README][13] for more information.
+
+### Using NGT from Python
+
+Although NGT has C and C++ APIs, the [ngtpy][14] Python binding for NGT is the simplest option for programming.
+
+#### Installing ngtpy
+
+Install the Python binding (ngtpy) through PyPI with:
+
+
+```
+`pip3 install ngt`
+```
+
+#### Sample dataset generation
+
+Generate data files for Python sample programs from the sample data set you downloaded by using this code:
+
+
+```
+dataset_path = 'wiki-news-300d-1M-subword.vec'
+with open(dataset_path, 'r') as fi, open('objects.tsv', 'w') as fov,
+open('words.tsv', 'w') as fow:
+ n, dim = map(int, fi.readline().split())
+ fov.write('{0}¥t{1}¥n'.format(n, dim))
+ for line in fi:
+ tokens = line.rstrip().split(' ')
+ fow.write(tokens[0] + '¥n')
+ fov.write('{0}¥n'.format('¥t'.join(tokens[1:])))
+```
+
+#### Index construction
+
+Construct the NGT index with:
+
+
+```
+import ngtpy
+
+index_path = 'index'
+with open('objects.tsv', 'r') as fin:
+ n, dim = map(int, fin.readline().split())
+ ngtpy.create(index_path, dim, distance_type='Cosine') # create an index
+ index = ngtpy.Index(index_path) # open the index
+ print('inserting objects...')
+ for line in fin:
+ object = list(map(float, line.rstrip().split('¥t')))
+ index.insert(object) # insert objects
+print('building objects...')
+index.build_index()
+print('saving the index...')
+index.save()
+```
+
+#### Approximate nearest neighbor search
+
+Here is an example ANN search program:
+
+
+```
+import ngtpy
+
+print('loading words...')
+with open('words.tsv', 'r') as fin:
+ words = list(map(lambda x: x.rstrip('¥n'), fin.readlines()))
+
+index = ngtpy.Index('index', zero_based_numbering = False) # open index
+query_id = 10000
+query_object = index.get_object(query_id) # get the object for a query
+
+result = index.search(query_object) # aproximate nearest neighbor search
+print('Query={}'.format(words[query_id - 1]))
+print('Rank¥tID¥tDistance¥tWord')
+for rank, object in enumerate(result):
+ print('{}¥t{}¥t{:.6f}¥t{}'.format(rank + 1, object[0], object[1], words[object[0] - 1]))
+```
+
+And here are the search results, which are the same as the NGT command-line option's results:
+
+
+```
+loading words...
+Query=Horse
+Rank ID Distance Word
+1 10000 0.000000 Horse
+2 21516 0.184495 Horses
+3 201860 0.240375 Horseback
+4 71865 0.241284 Horseman
+5 339589 0.267265 Prancing
+6 485158 0.280977 Horsefly
+7 7961 0.283865 Dog
+8 924513 0.286571 Horsing
+9 28870 0.286654 Pony
+10 395274 0.290466 Blood-Horse
+```
+
+For more information, please see [ngtpy README][14].
+
+Approximate nearest neighbor (ANN) principles are important features for analyzing data. Learning how to use it in your own projects, or to make sense of data that you're analyzing, is a powerful way to make correlations and interpret information. With NGT, you can use ANN in whatever way you require, or build upon it to add custom features.
+
+Introduction to Apache Hadoop, an open source software framework for storage and large scale...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/ngt-open-source-library
+
+作者:[Masajiro Iwasaki][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/masajiro-iwasaki
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/house_home_colors_live_building.jpg?itok=HLpsIfIL (Houses in a row)
+[2]: https://en.wikipedia.org/wiki/Nearest_neighbor_search#Approximate_nearest_neighbor
+[3]: https://github.com/yahoojapan/NGT
+[4]: https://research-lab.yahoo.co.jp/en/
+[5]: https://www.yahoo.co.jp/
+[6]: https://opensource.com/sites/default/files/browser-visual-search_new.jpg (Nearest neighbour search)
+[7]: https://github.com/erikbern/ann-benchmarks
+[8]: https://opensource.com/sites/default/files/uploads/ngt_movie2.gif (NGT graph construction)
+[9]: https://opensource.com/sites/default/files/uploads/ngt_movie1.gif (NGT graph)
+[10]: https://github.com/yahoojapan/NGT/releases/latest
+[11]: https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M-subword.vec.zip
+[12]: https://fasttext.cc/
+[13]: https://github.com/yahoojapan/NGT/blob/master/bin/ngt/README.md
+[14]: https://github.com/yahoojapan/NGT/blob/master/python/README-ngtpy.md
diff --git a/sources/tech/20191023 Best practices in test-driven development.md b/sources/tech/20191023 Best practices in test-driven development.md
new file mode 100644
index 0000000000..47f025a111
--- /dev/null
+++ b/sources/tech/20191023 Best practices in test-driven development.md
@@ -0,0 +1,206 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Best practices in test-driven development)
+[#]: via: (https://opensource.com/article/19/10/test-driven-development-best-practices)
+[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
+
+Best practices in test-driven development
+======
+Ensure you're producing very high-quality code by following these TDD
+best practices.
+![magnifying glass on computer screen][1]
+
+In my previous series on [test-driven development (TDD) and mutation testing][2], I demonstrated the benefits of relying on examples when building a solution. That begs the question: What does "relying on examples" mean?
+
+In that series, I described one of my expectations when building a solution to determine whether it's daytime or nighttime. I provided an example of a specific hour of the day that I consider to fall in the daytime category. I created a **DateTime** variable named **dayHour** and gave it the specific value of **August 8, 2019, 7 hours, 0 minutes, 0 seconds**.
+
+My logic (or way of reasoning) was: "When the system is notified that the time is exactly 7am on August 8, 2019, I expect that the system will perform the necessary calculations and return the value **Daylight**."
+
+Armed with such a specific example, it was very easy to create a unit test (**Given7amReturnDaylight**). I then ran the tests and watched my unit test fail, which gave me the opportunity to work on fixing this early failure.
+
+### Iteration is the solution
+
+One very important aspect of TDD (and, by proxy, of agile) is the fact that it is impossible to arrive at an acceptable solution unless you are iterating. TDD is a professional discipline based on the process of relentless iterating. It is very important to note that it mandates that each iteration must begin with a micro-failure. That micro-failure has only one purpose: to solicit immediate feedback. And that immediate feedback ensures we can rapidly close the gap between _wanting_ a solution and _getting_ a solution.
+
+Iteration provides an opportunity to solicit immediate feedback by failing as early as possible. Because that failure is fast (i.e., it is a micro-failure), it is not alarming; even when we fail, we can remain calm, knowing that it will be easy to fix the failure. And the feedback from that failure will guide us toward fixing the failure.
+
+Rinse, repeat, until we completely close the gap and deliver the solution that fully meets the expectation (but keep in mind that the expectation must also be a micro-expectation).
+
+### Why micro?
+
+This approach often feels very unambitious. In TDD (and in agile), it's best to pick a tiny, almost trivial challenge, and then do the TDD song-and-dance by failing first, then iterating until we solve that trivial challenge. People who are used to more substantial, beefy engineering and problem solving tend to feel that such an exercise is beneath their level of competence.
+
+One of the cornerstones of agile philosophy relies on reducing the problem space to multiple, smallest-possible surface areas. As Robert C. Martin puts it:
+
+> _"Agile is a small idea about the small problems of small programming teams doing small things"_
+
+But how can making an unimpressive series of such pedestrian, minuscule, and almost insignificant micro-victories ever enable us to reach the big-scale solution?
+
+Here is where sophisticated and elaborate systems thinking comes into play. When building a system, there's always the risk of ending up with a dreaded "monolith." A monolith is a system built on the principle of tight coupling. Any part of the monolith is highly dependent on many other parts of the same monolith. That arrangement makes the monolith very brittle, unreliable, and difficult to operate, maintain, troubleshoot, and fix.
+
+The only way to avoid this trap is to minimize or, better yet, completely remove coupling. Instead of investing heroic efforts into building elaborate parts that will be assembled into a system, it is much better to take humble, baby steps toward building tiny, micro parts. These micro parts have very little capability on their own, and will, by virtue of such arrangement, not be dependent on other components. This will minimize and even remove any coupling.
+
+The desired end game in building a useful, elaborate system is to compose it from a collection of generic, completely independent components. The more generic each component is, the more robust, resilient, and flexible the resulting system will be. Also, having a collection of generic components enables them to be repurposed to build brand new systems by reconfiguring those components.
+
+Consider a toy castle made out of Lego blocks. If we pick almost any block from that castle and examine it in isolation, we won't be able to find anything on that block that specifies it is a Lego block meant for building a castle. The block itself is sufficiently generic, which makes it suitable for building other contraptions, such as toy cars, toy airplanes, toy boats, etc. That's the power of having generic components.
+
+TDD is a proven discipline for delivering generic, independent, and autonomous components that can be safely used to assemble large, sophisticated systems expediently. As in agile, TDD is focused on micro-activities. And because agile is based on the fundamental principle known as "the Whole Team," the humble approach illustrated here is also important when specifying business examples. If the example used for building a component is not modest, it will be difficult to meet the expectations. Therefore, the expectations must be humble, which makes the resulting examples equally humble.
+
+For instance, if a member of the Whole Team (a requester) provides the developer with an expectation and an example that reads:
+
+> _"When processing an order, make sure to apply appropriate discount for orders made by loyal customers, or for orders over certain monetary value, or both."_
+
+The developer should recognize that this example is too ambitious. That's not a humble expectation. It is not sufficiently micro, if you will. The developer should always strive to guide a requester in being more specific and micro-level when crafting examples. Paradoxically, the more specific the example, the more generic the resulting solution will be.
+
+A much better, more effective expectation and example would be:
+
+> _"Discount made for an order greater than $100.00 is $18.00."_
+
+Or:
+
+> _"Discount made for an order greater than $100.00 that was made by a customer who already placed three orders is $25.00."_
+
+Such micro-examples make it easy to turn them into automated micro-expectations (read: unit tests). Such expectations will make us fail, and then we will pick ourselves up and iterate until we deliver the solution—a robust, generic component that knows how to calculate discounts based on the micro-examples supplied by the Whole Team.
+
+### Writing quality unit tests
+
+Merely writing unit tests without any concern about their quality is a fool's errand. Shoddily written unit tests will result in bloated, tightly coupled code. Such code is brittle, difficult to reason about, and often nearly impossible to fix.
+
+We need to lay down some ground rules for writing quality unit tests. These ground rules will help us make swift progress in building robust, reliable solutions. The easiest way to do that is to introduce a mnemonic in the form of an acronym: **FIRST**, which says unit tests must be:
+
+ * **F** = Fast
+ * **I** = Independent
+ * **R** = Repeatable
+ * **S** = Self-validating
+ * **T** = Thorough
+
+
+
+#### Fast
+
+Since a unit test describes a micro-example, it should expect very simple processing from the implemented code. This means that each unit test should be very fast to run.
+
+#### Independent
+
+Since a unit test describes a micro-example, it should describe a very simple process that does not depend on any other unit test.
+
+#### Repeatable
+
+Since a unit test does not depend on any other unit test, it must be fully repeatable. What that means is that each time a certain unit test runs, it produces the same results as the previous time it ran. Neither the number of times the unit tests run nor the order in which they run should ever affect the expected output.
+
+#### Self-validating
+
+When unit tests run, the outcome of the testing should be instantly visible. Developers should not be expected to reach for some other source(s) of information to find out whether their unit tests failed or passed.
+
+#### Thorough
+
+Unit tests should describe all the expectations as defined in the micro-examples.
+
+### Well-structured unit tests
+
+Unit tests are code. And the same as any other code, unit tests need to be well-structured. It is unacceptable to deliver sloppy, messy unit tests. All the principles that apply to the rules governing clean implementation code apply with equal force to unit tests.
+
+A time-tested and proven methodology for writing reliable quality code is based on the clean code principle known as **SOLID**. This acronym that helps us remember five very important principles:
+
+ * **S** = Single responsibility principle
+ * **O** = Open–closed principle
+ * **L** = Liskov substitution principle
+ * **I** = Interface segregation principle
+ * **D** = Dependency inversion principle
+
+
+
+#### Single responsibility principle
+
+Each component must be responsible for performing only one operation. This principle is illustrated in this meme
+
+![Sign illustrating single-responsibility principle][3]
+
+Pumping septic tanks is an operation that must be kept separate from filling swimming pools.
+
+Applied to unit tests, this principle ensures that each unit test verifies one—and only one—expectation. From a technical standpoint, this means each unit test must have one and only one **Assert** statement.
+
+#### Open–closed principle
+
+This principle states that a component should be open for extensions, but closed for any modifications.
+
+![Open-closed principle][4]
+
+Applied to unit tests, this principle ensures that we will not implement a change to an existing unit test in that unit test. Instead, we must write a brand new unit test that will implement the changes.
+
+#### Liskov substitution principle
+
+This principle provides a guide for deciding which level of abstraction may be appropriate for the solution.
+
+![Liskov substitution principle][5]
+
+Applied to unit tests, this principle guides us to avoid tight coupling with dependencies that depend on the underlying computing environment (such as databases, disks, network, etc.).
+
+#### Interface segregation principle
+
+This principle reminds us not to bloat APIs. When subsystems need to collaborate to complete a task, they should communicate via interfaces. But those interfaces must not be bloated. If a new capability becomes necessary, don't add it to the already defined interface; instead, craft a brand new interface.
+
+![Interface segregation principle][6]
+
+Applied to unit tests, removing the bloat from interfaces helps us craft more specific unit tests, which, in turn, results in more generic components.
+
+#### Dependency inversion principle
+
+This principle states that we should control our dependencies, instead of dependencies controlling us. If there is a need to use another component's services, instead of being responsible for instantiating that component within the component we are building, it must instead be injected into our component.
+
+![Dependency inversion principle][7]
+
+Applied to the unit tests, this principle helps separate the intention from the implementation. We must strive to inject only those dependencies that have been sufficiently abstracted. That approach is important for ensuring unit tests are not mixed with integration tests.
+
+### Testing the tests
+
+Finally, even if we manage to produce well-structured unit tests that fulfill the FIRST principles, it does not guarantee that we have delivered a solid solution. TDD best practices rely on the proper sequence of events when building components/services; we are always and invariably expected to provide a description of our expectations (supplied in the micro-examples). Only after those expectations are described in the unit test can we move on to writing the implementation code. However, two unwanted side effects can, and often do, happen while writing implementation code:
+
+ 1. Implemented code enables the unit tests to pass, but they are written in a convoluted way, using unnecessarily complex logic
+ 2. Implemented code gets tagged on AFTER the unit tests have been written
+
+
+
+In the first case, even if all unit tests pass, mutation testing uncovers that some mutants have survived. As I explained in _[Mutation testing by example: Evolving from fragile TDD][8]_, that is an extremely undesirable situation because it means that the solution is unnecessarily complex and, therefore, unmaintainable.
+
+In the second case, all unit tests are guaranteed to pass, but a potentially large portion of the codebase consists of implemented code that hasn't been described anywhere. This means we are dealing with mysterious code. In the best-case scenario, we could treat that mysterious code as deadwood and safely remove it. But more likely than not, removing this not-described, implemented code will cause some serious breakages. And such breakages indicate that our solution is not well engineered.
+
+### Conclusion
+
+TDD best practices stem from the time-tested methodology called [extreme programming][9] (XP for short). One of the cornerstones of XP is based on the **three C's**:
+
+ 1. **Card:** A small card briefly specifies the intent (e.g., "Review customer request").
+ 2. **Conversation:** The card becomes a ticket to conversation. The whole team gets together and talks about "Review customer request." What does that mean? Do we have enough information/knowledge to ship the "review customer request" functionality in this increment? If not, how do we further slice this card?
+ 3. **Concrete confirmation examples:** This includes all the specific values plugged in (e.g., concrete names, numeric values, specific dates, whatever else is pertinent to the use case) plus all values expected as an output of the processing.
+
+
+
+Starting from such micro-examples, we write unit tests. We watch unit tests fail, then make them pass. And while doing that, we observe and respect the best software engineering practices: the **FIRST** principles, the **SOLID** principles, and the mutation testing discipline (i.e., kill all surviving mutants).
+
+This ensures that our components and services are delivered with solid quality built in. And what is the measure of that quality? Simple—**the cost of change**. If the delivered code is costly to change, it is of shoddy quality. Very high-quality code is structured so well that it is simple and inexpensive to change and, at the same time, does not incur any change-management risks.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/test-driven-development-best-practices
+
+作者:[Alex Bunardzic][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/alex-bunardzic
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/search_find_code_issue_bug_programming.png?itok=XPrh7fa0 (magnifying glass on computer screen)
+[2]: https://opensource.com/users/alex-bunardzic
+[3]: https://opensource.com/sites/default/files/uploads/single-responsibility.png (Sign illustrating single-responsibility principle)
+[4]: https://opensource.com/sites/default/files/uploads/openclosed_cc.jpg (Open-closed principle)
+[5]: https://opensource.com/sites/default/files/uploads/liskov_substitution_cc.jpg (Liskov substitution principle)
+[6]: https://opensource.com/sites/default/files/uploads/interface_segregation_cc.jpg (Interface segregation principle)
+[7]: https://opensource.com/sites/default/files/uploads/dependency_inversion_cc.jpg (Dependency inversion principle)
+[8]: https://opensource.com/article/19/9/mutation-testing-example-definition
+[9]: https://en.wikipedia.org/wiki/Extreme_programming
diff --git a/sources/tech/20191023 How to program with Bash- Loops.md b/sources/tech/20191023 How to program with Bash- Loops.md
new file mode 100644
index 0000000000..e582bda447
--- /dev/null
+++ b/sources/tech/20191023 How to program with Bash- Loops.md
@@ -0,0 +1,352 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to program with Bash: Loops)
+[#]: via: (https://opensource.com/article/19/10/programming-bash-loops)
+[#]: author: (David Both https://opensource.com/users/dboth)
+
+How to program with Bash: Loops
+======
+Learn how to use loops for performing iterative operations, in the final
+article in this three-part series on programming with Bash.
+![arrows cycle symbol for failing faster][1]
+
+Bash is a powerful programming language, one perfectly designed for use on the command line and in shell scripts. This three-part series, based on my [three-volume Linux self-study course][2], explores using Bash as a programming language on the command-line interface (CLI).
+
+The [first article][3] in this series explored some simple command-line programming with Bash, including using variables and control operators. The [second article][4] looked into the types of file, string, numeric, and miscellaneous logical operators that provide execution-flow control logic and different types of shell expansions in Bash. This third (and final) article examines the use of loops for performing various types of iterative operations and ways to control those loops.
+
+### Loops
+
+Every programming language I have ever used has at least a couple types of loop structures that provide various capabilities to perform repetitive operations. I use the for loop quite often but I also find the while and until loops useful.
+
+#### for loops
+
+Bash's implementation of the **for** command is, in my opinion, a bit more flexible than most because it can handle non-numeric values; in contrast, for example, the standard C language **for** loop can deal only with numeric values.
+
+The basic structure of the Bash version of the **for** command is simple:
+
+
+```
+`for Var in list1 ; do list2 ; done`
+```
+
+This translates to: "For each value in list1, set the **$Var** to that value and then perform the program statements in list2 using that value; when all of the values in list1 have been used, it is finished, so exit the loop." The values in list1 can be a simple, explicit string of values, or they can be the result of a command substitution (described in the second article in the series). I use this construct frequently.
+
+To try it, ensure that **~/testdir** is still the present working directory (PWD). Clean up the directory, then look at a trivial example of the **for** loop starting with an explicit list of values. This list is a mix of alphanumeric values—but do not forget that all variables are strings and can be treated as such.
+
+
+```
+[student@studentvm1 testdir]$ rm *
+[student@studentvm1 testdir]$ for I in a b c d 1 2 3 4 ; do echo $I ; done
+a
+b
+c
+d
+1
+2
+3
+4
+```
+
+Here is a bit more useful version with a more meaningful variable name:
+
+
+```
+[student@studentvm1 testdir]$ for Dept in "Human Resources" Sales Finance "Information Technology" Engineering Administration Research ; do echo "Department $Dept" ; done
+Department Human Resources
+Department Sales
+Department Finance
+Department Information Technology
+Department Engineering
+Department Administration
+Department Research
+```
+
+Make some directories (and show some progress information while doing so):
+
+
+```
+[student@studentvm1 testdir]$ for Dept in "Human Resources" Sales Finance "Information Technology" Engineering Administration Research ; do echo "Working on Department $Dept" ; mkdir "$Dept" ; done
+Working on Department Human Resources
+Working on Department Sales
+Working on Department Finance
+Working on Department Information Technology
+Working on Department Engineering
+Working on Department Administration
+Working on Department Research
+[student@studentvm1 testdir]$ ll
+total 28
+drwxrwxr-x 2 student student 4096 Apr 8 15:45 Administration
+drwxrwxr-x 2 student student 4096 Apr 8 15:45 Engineering
+drwxrwxr-x 2 student student 4096 Apr 8 15:45 Finance
+drwxrwxr-x 2 student student 4096 Apr 8 15:45 'Human Resources'
+drwxrwxr-x 2 student student 4096 Apr 8 15:45 'Information Technology'
+drwxrwxr-x 2 student student 4096 Apr 8 15:45 Research
+drwxrwxr-x 2 student student 4096 Apr 8 15:45 Sales
+```
+
+The **$Dept** variable must be enclosed in quotes in the **mkdir** statement; otherwise, two-part department names (such as "Information Technology") will be treated as two separate departments. That highlights a best practice I like to follow: all file and directory names should be a single word. Although most modern operating systems can deal with spaces in names, it takes extra work for sysadmins to ensure that those special cases are considered in scripts and CLI programs. (They almost certainly should be considered, even if they're annoying because you never know what files you will have.)
+
+So, delete everything in **~/testdir**—again—and do this one more time:
+
+
+```
+[student@studentvm1 testdir]$ rm -rf * ; ll
+total 0
+[student@studentvm1 testdir]$ for Dept in Human-Resources Sales Finance Information-Technology Engineering Administration Research ; do echo "Working on Department $Dept" ; mkdir "$Dept" ; done
+Working on Department Human-Resources
+Working on Department Sales
+Working on Department Finance
+Working on Department Information-Technology
+Working on Department Engineering
+Working on Department Administration
+Working on Department Research
+[student@studentvm1 testdir]$ ll
+total 28
+drwxrwxr-x 2 student student 4096 Apr 8 15:52 Administration
+drwxrwxr-x 2 student student 4096 Apr 8 15:52 Engineering
+drwxrwxr-x 2 student student 4096 Apr 8 15:52 Finance
+drwxrwxr-x 2 student student 4096 Apr 8 15:52 Human-Resources
+drwxrwxr-x 2 student student 4096 Apr 8 15:52 Information-Technology
+drwxrwxr-x 2 student student 4096 Apr 8 15:52 Research
+drwxrwxr-x 2 student student 4096 Apr 8 15:52 Sales
+```
+
+Suppose someone asks for a list of all RPMs on a particular Linux computer and a short description of each. This happened to me when I worked for the State of North Carolina. Since open source was not "approved" for use by state agencies at that time, and I only used Linux on my desktop computer, the pointy-haired bosses (PHBs) needed a list of each piece of software that was installed on my computer so that they could "approve" an exception.
+
+How would you approach that? Here is one way, starting with the knowledge that the **rpm –qa** command provides a complete description of an RPM, including the two items the PHBs want: the software name and a brief summary.
+
+Build up to the final result one step at a time. First, list all RPMs:
+
+
+```
+[student@studentvm1 testdir]$ rpm -qa
+perl-HTTP-Message-6.18-3.fc29.noarch
+perl-IO-1.39-427.fc29.x86_64
+perl-Math-Complex-1.59-429.fc29.noarch
+lua-5.3.5-2.fc29.x86_64
+java-11-openjdk-headless-11.0.ea.28-2.fc29.x86_64
+util-linux-2.32.1-1.fc29.x86_64
+libreport-fedora-2.9.7-1.fc29.x86_64
+rpcbind-1.2.5-0.fc29.x86_64
+libsss_sudo-2.0.0-5.fc29.x86_64
+libfontenc-1.1.3-9.fc29.x86_64
+<snip>
+```
+
+Add the **sort** and **uniq** commands to sort the list and print the unique ones (since it's possible that some RPMs with identical names are installed):
+
+
+```
+[student@studentvm1 testdir]$ rpm -qa | sort | uniq
+a2ps-4.14-39.fc29.x86_64
+aajohan-comfortaa-fonts-3.001-3.fc29.noarch
+abattis-cantarell-fonts-0.111-1.fc29.noarch
+abiword-3.0.2-13.fc29.x86_64
+abrt-2.11.0-1.fc29.x86_64
+abrt-addon-ccpp-2.11.0-1.fc29.x86_64
+abrt-addon-coredump-helper-2.11.0-1.fc29.x86_64
+abrt-addon-kerneloops-2.11.0-1.fc29.x86_64
+abrt-addon-pstoreoops-2.11.0-1.fc29.x86_64
+abrt-addon-vmcore-2.11.0-1.fc29.x86_64
+<snip>
+```
+
+Since this gives the correct list of RPMs you want to look at, you can use this as the input list to a loop that will print all the details of each RPM:
+
+
+```
+`[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done`
+```
+
+This code produces way more data than you want. Note that the loop is complete. The next step is to extract only the information the PHBs requested. So, add an **egrep** command, which is used to select **^Name** or **^Summary**. The carat (**^**) specifies the beginning of the line; thus, any line with Name or Summary at the beginning of the line is displayed.
+
+
+```
+[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done | egrep -i "^Name|^Summary"
+Name : a2ps
+Summary : Converts text and other types of files to PostScript
+Name : aajohan-comfortaa-fonts
+Summary : Modern style true type font
+Name : abattis-cantarell-fonts
+Summary : Humanist sans serif font
+Name : abiword
+Summary : Word processing program
+Name : abrt
+Summary : Automatic bug detection and reporting tool
+<snip>
+```
+
+You can try **grep** instead of **egrep** in the command above, but it will not work. You could also pipe the output of this command through the **less** filter to explore the results. The final command sequence looks like this:
+
+
+```
+`[student@studentvm1 testdir]$ for RPM in `rpm -qa | sort | uniq` ; do rpm -qi $RPM ; done | egrep -i "^Name|^Summary" > RPM-summary.txt`
+```
+
+This command-line program uses pipelines, redirection, and a **for** loop—all on a single line. It redirects the output of your little CLI program to a file that can be used in an email or as input for other purposes.
+
+This process of building up the program one step at a time allows you to see the results of each step and ensure that it is working as you expect and provides the desired results.
+
+From this exercise, the PHBs received a list of over 1,900 separate RPM packages. I seriously doubt that anyone read that list. But I gave them exactly what they asked for, and I never heard another word from them about it.
+
+### Other loops
+
+There are two more types of loop structures available in Bash: the **while** and **until** structures, which are very similar to each other in both syntax and function. The basic syntax of these loop structures is simple:
+
+
+```
+`while [ expression ] ; do list ; done`
+```
+
+and
+
+
+```
+`until [ expression ] ; do list ; done`
+```
+
+The logic of the first reads: "While the expression evaluates as true, execute the list of program statements. When the expression evaluates as false, exit from the loop." And the second: "Until the expression evaluates as true, execute the list of program statements. When the expression evaluates as true, exit from the loop."
+
+#### While loop
+
+The **while** loop is used to execute a series of program statements while (so long as) the logical expression evaluates as true. Your PWD should still be **~/testdir**.
+
+The simplest form of the **while** loop is one that runs forever. The following form uses the true statement to always generate a "true" return code. You could also use a simple "1"—and that would work just the same—but this illustrates the use of the true statement:
+
+
+```
+[student@studentvm1 testdir]$ X=0 ; while [ true ] ; do echo $X ; X=$((X+1)) ; done | head
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+[student@studentvm1 testdir]$
+```
+
+This CLI program should make more sense now that you have studied its parts. First, it sets **$X** to zero in case it has a value left over from a previous program or CLI command. Then, since the logical expression **[ true ]** always evaluates to 1, which is true, the list of program instructions between **do** and **done** is executed forever—or until you press **Ctrl+C** or otherwise send a signal 2 to the program. Those instructions are an arithmetic expansion that prints the current value of **$X** and then increments it by one.
+
+One of the tenets of [_The Linux Philosophy for Sysadmins_][5] is to strive for elegance, and one way to achieve elegance is simplicity. You can simplify this program by using the variable increment operator, **++**. In the first instance, the current value of the variable is printed, and then the variable is incremented. This is indicated by placing the **++** operator after the variable:
+
+
+```
+[student@studentvm1 ~]$ X=0 ; while [ true ] ; do echo $((X++)) ; done | head
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+```
+
+Now delete **| head** from the end of the program and run it again.
+
+In this version, the variable is incremented before its value is printed. This is specified by placing the **++** operator before the variable. Can you see the difference?
+
+
+```
+[student@studentvm1 ~]$ X=0 ; while [ true ] ; do echo $((++X)) ; done | head
+1
+2
+3
+4
+5
+6
+7
+8
+9
+```
+
+You have reduced two statements into a single one that prints the value of the variable and increments that value. There is also a decrement operator, **\--**.
+
+You need a method for stopping the loop at a specific number. To accomplish that, change the true expression to an actual numeric evaluation expression. Have the program loop to 5 and stop. In the example code below, you can see that **-le** is the logical numeric operator for "less than or equal to." This means: "So long as **$X** is less than or equal to 5, the loop will continue. When **$X** increments to 6, the loop terminates."
+
+
+```
+[student@studentvm1 ~]$ X=0 ; while [ $X -le 5 ] ; do echo $((X++)) ; done
+0
+1
+2
+3
+4
+5
+[student@studentvm1 ~]$
+```
+
+#### Until loop
+
+The **until** command is very much like the **while** command. The difference is that it will continue to loop until the logical expression evaluates to "true." Look at the simplest form of this construct:
+
+
+```
+[student@studentvm1 ~]$ X=0 ; until false ; do echo $((X++)) ; done | head
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+[student@studentvm1 ~]$
+```
+
+It uses a logical comparison to count to a specific value:
+
+
+```
+[student@studentvm1 ~]$ X=0 ; until [ $X -eq 5 ] ; do echo $((X++)) ; done
+0
+1
+2
+3
+4
+[student@studentvm1 ~]$ X=0 ; until [ $X -eq 5 ] ; do echo $((++X)) ; done
+1
+2
+3
+4
+5
+[student@studentvm1 ~]$
+```
+
+### Summary
+
+This series has explored many powerful tools for building Bash command-line programs and shell scripts. But it has barely scratched the surface on the many interesting things you can do with Bash; the rest is up to you.
+
+I have discovered that the best way to learn Bash programming is to do it. Find a simple project that requires multiple Bash commands and make a CLI program out of them. Sysadmins do many tasks that lend themselves to CLI programming, so I am sure that you will easily find tasks to automate.
+
+Many years ago, despite being familiar with other shell languages and Perl, I made the decision to use Bash for all of my sysadmin automation tasks. I have discovered that—sometimes with a bit of searching—I have been able to use Bash to accomplish everything I need.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/programming-bash-loops
+
+作者:[David Both][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
+[2]: http://www.both.org/?page_id=1183
+[3]: https://opensource.com/article/19/10/programming-bash-part-1
+[4]: https://opensource.com/article/19/10/programming-bash-part-2
+[5]: https://www.apress.com/us/book/9781484237298
diff --git a/sources/tech/20191024 Get sorted with sort at the command line.md b/sources/tech/20191024 Get sorted with sort at the command line.md
new file mode 100644
index 0000000000..ff291f39bc
--- /dev/null
+++ b/sources/tech/20191024 Get sorted with sort at the command line.md
@@ -0,0 +1,250 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get sorted with sort at the command line)
+[#]: via: (https://opensource.com/article/19/10/get-sorted-sort)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+Get sorted with sort at the command line
+======
+Reorganize your data in a format that makes sense to you—right from the
+Linux, BSD, or Mac terminal—with the sort command.
+![Coding on a computer][1]
+
+If you've ever used a spreadsheet application, then you know that rows can be sorted by the contents of a column. For instance, if you have a list of expenses, you might want to sort them by date or by ascending price or by category, and so on. If you're comfortable using a terminal, you may not want to have to use a big office application just to sort text data. And that's exactly what the [**sort**][2] command is for.
+
+### Installing
+
+You don't need to install **sort** because it's invariably included on any [POSIX][3] system. On most Linux systems, the **sort** command is bundled in a collection of utilities from the GNU organization. On other POSIX systems, such as BSD and Mac, the default **sort** command is not from GNU, so some options may differ. I'll attempt to account for both GNU and BSD implementations in this article.
+
+### Sort lines alphabetically
+
+The **sort** command, by default, looks at the first character of each line of a file and outputs each line in ascending alphabetic order. In the event that two characters on multiple lines are the same, it considers the next character. For example:
+
+
+```
+$ cat distro.list
+Slackware
+Fedora
+Red Hat Enterprise Linux
+Ubuntu
+Arch
+1337
+Mint
+Mageia
+Debian
+$ sort distro.list
+1337
+Arch
+Debian
+Fedora
+Mageia
+Mint
+Red Hat Enterprise Linux
+Slackware
+Ubuntu
+```
+
+Using **sort** doesn't change the original file. Sort is a filter, so if you want to preserve your data in its sorted form, you must redirect the output using either **>** or **tee**:
+
+
+```
+$ sort distro.list | tee distro.sorted
+1337
+Arch
+Debian
+[...]
+$ cat distro.sorted
+1337
+Arch
+Debian
+[...]
+```
+
+### Sort by column
+
+Complex data sets sometimes need to be sorted by something other than the first letter of each line. Imagine, for instance, a list of animals and each one's species and genus, and each "field" (a "cell" in a spreadsheet) is defined by a predictable delimiter character. This is such a common data format for spreadsheet exports that the CSV (comma-separated values) file extension exists to identify such files (although a CSV file doesn't have to be comma-separated, nor does a delimited file have to use the CSV extension to be valid and usable). Consider this example data set:
+
+
+```
+Aptenodytes;forsteri;Miller,JF;1778;Emperor
+Pygoscelis;papua;Wagler;1832;Gentoo
+Eudyptula;minor;Bonaparte;1867;Little Blue
+Spheniscus;demersus;Brisson;1760;African
+Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
+Eudyptes;chrysocome;Viellot;1816;Southern Rockhopper
+Torvaldis;linux;Ewing,L;1996;Tux
+```
+
+Given this sample data set, you can use the **\--field-separator** (use **-t** on BSD and Mac—or on GNU to reduce typing) option to set the delimiting character to a semicolon (because this example uses semicolons instead of commas, but it could use any character), and use the **\--key** (**-k** on BSD and Mac or on GNU to reduce typing) option to define which field to sort by. For example, to sort by the second field (starting at 1, not 0) of each line:
+
+
+```
+sort --field-separator=";" --key=2
+Megadyptes;antipodes;Milne-Edwards;1880;Yellow-eyed
+Eudyptes;chrysocome;Viellot;1816;Sothern Rockhopper
+Spheniscus;demersus;Brisson;1760;African
+Aptenodytes;forsteri;Miller,JF;1778;Emperor
+Torvaldis;linux;Ewing,L;1996;Tux
+Eudyptula;minor;Bonaparte;1867;Little Blue
+Pygoscelis;papua;Wagler;1832;Gentoo
+```
+
+That's somewhat difficult to read, but Unix is famous for its _pipe_ method of constructing commands, so you can use the **column** command to "prettify" the output. Using GNU **column**:
+
+
+```
+$ sort --field-separator=";" \
+\--key=2 penguins.list | \
+column --table --separator ";"
+Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
+Eudyptes chrysocome Viellot 1816 Southern Rockhopper
+Spheniscus demersus Brisson 1760 African
+Aptenodytes forsteri Miller,JF 1778 Emperor
+Torvaldis linux Ewing,L 1996 Tux
+Eudyptula minor Bonaparte 1867 Little Blue
+Pygoscelis papua Wagler 1832 Gentoo
+```
+
+Slightly more cryptic to the new user (but shorter to type), the command options on BSD and Mac:
+
+
+```
+$ sort -t ";" \
+-k2 penguins.list | column -t -s ";"
+Megadyptes antipodes Milne-Edwards 1880 Yellow-eyed
+Eudyptes chrysocome Viellot 1816 Southern Rockhopper
+Spheniscus demersus Brisson 1760 African
+Aptenodytes forsteri Miller,JF 1778 Emperor
+Torvaldis linux Ewing,L 1996 Tux
+Eudyptula minor Bonaparte 1867 Little Blue
+Pygoscelis papua Wagler 1832 Gentoo
+```
+
+The **key** definition doesn't have to be set to **2**, of course. Any existing field may be used as the sorting key.
+
+### Reverse sort
+
+You can reverse the order of a sorted list with the **\--reverse** (**-r** on BSD or Mac or GNU for brevity):
+
+
+```
+$ sort --reverse alphabet.list
+z
+y
+x
+w
+[...]
+```
+
+You can achieve the same result by piping the output of a normal sort through [tac][4].
+
+### Sorting by month (GNU only)
+
+In a perfect world, everyone would write dates according to the ISO 8601 standard: year, month, day. It's a logical method of specifying a unique date, and it's easy for computers to understand. And yet quite often, humans use other means of identifying dates, including months with pretty arbitrary names.
+
+Fortunately, the GNU **sort** command accounts for this and is able to sort correctly by month name. Use the **\--month-sort** (**-M**) option:
+
+
+```
+$ cat month.list
+November
+October
+September
+April
+[...]
+$ sort --month-sort month.list
+January
+February
+March
+April
+May
+[...]
+November
+December
+```
+
+Months may be identified by their full name or some portion of their names.
+
+### Human-readable numeric sort (GNU only)
+
+Another common point of confusion between humans and computers is groups of numbers. For instance, humans often write "1024 kilobytes" as "1KB" because it's easier and quicker for the human brain to parse "1KB" than "1024" (and it gets easier the larger the number becomes). To a computer, though, a string such as 9KB is larger than, for instance, 1MB (even though 9KB is only a fraction of a megabyte). The GNU **sort** command provides the **\--human-numeric-sort** (**-h**) option to help parse these values correctly.
+
+
+```
+$ cat sizes.list
+2M
+12MB
+1k
+9k
+900
+7000
+$ sort --human-numeric-sort
+900
+7000
+1k
+9k
+2M
+12MB
+```
+
+There are some inconsistencies. For example, 16,000 bytes is greater than 1KB, but **sort** fails to recognize that:
+
+
+```
+$ cat sizes0.list
+2M
+12MB
+16000
+1k
+$ sort -h sizes0.list
+16000
+1k
+2M
+12MB
+```
+
+Logically, 16,000 should be written 16KB in this context, so GNU **sort** is not entirely to blame. As long as you are sure that your numbers are consistent, the **\--human-numeric-sort** can help parse human-readable numbers in a computer-friendly way.
+
+### Randomized sort (GNU only)
+
+Sometimes utilities provide the option to do the opposite of what they're meant to do. In a way, it makes no sense for a **sort** command to have the ability to "sort" a file randomly. Then again, the workflow of the command makes it a convenient feature to have. You _could_ use a different command, like [**shuf**][5], or you could just add an option to the command you're using. Whether it's bloat or ingenious UX design, the GNU **sort** command provides the means to sort a file arbitrarily.
+
+The purest form of arbitrary sorting is the **\--random-sort** or **-R** option (not to be confused with the **-r** option, which is short for **\--reverse**).
+
+
+```
+$ sort --random-sort alphabet.list
+d
+m
+p
+a
+[...]
+```
+
+You can run a random sort multiple times on a file for different results each time.
+
+### Sorted
+
+There are many more features available with the **sort** GNU and BSD commands, so spend some time getting to know the options. You'll be surprised at how flexible **sort** can be, especially when it's combined with other Unix utilities.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/get-sorted-sort
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_laptop_hack_work.png?itok=aSpcWkcl (Coding on a computer)
+[2]: https://en.wikipedia.org/wiki/Sort_(Unix)
+[3]: https://en.wikipedia.org/wiki/POSIX
+[4]: https://opensource.com/article/19/9/tac-command
+[5]: https://www.gnu.org/software/coreutils/manual/html_node/shuf-invocation.html
diff --git a/sources/tech/20191024 The Five Most Popular Operating Systems for the Internet of Things.md b/sources/tech/20191024 The Five Most Popular Operating Systems for the Internet of Things.md
new file mode 100644
index 0000000000..89d6ef1acf
--- /dev/null
+++ b/sources/tech/20191024 The Five Most Popular Operating Systems for the Internet of Things.md
@@ -0,0 +1,147 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Five Most Popular Operating Systems for the Internet of Things)
+[#]: via: (https://opensourceforu.com/2019/10/the-five-most-popular-operating-systems-for-the-internet-of-things/)
+[#]: author: (K S Kuppusamy https://opensourceforu.com/author/ks-kuppusamy/)
+
+The Five Most Popular Operating Systems for the Internet of Things
+======
+
+[![][1]][2]
+
+_Connecting every ‘thing’ that we see around us to the Internet is the fundamental idea of the Internet of Things (IoT). There are many operating systems to get the best out of the things that are connected to the Internet. This article explores four popular operating systems for IoT — Ubuntu Core, RIOT, Contiki and TinyOS._
+
+To say that life is running on the Internet these days is not an exaggeration due to the number and variety of services that we consume on the Net. These services span multiple domains such as information, financial services, social networking and entertainment. As this list grows longer, it becomes imperative that we do not restrict the types of devices that can connect to the Internet. The Internet of Things (IoT) facilitates connecting various types of ‘things’ to the Internet infrastructure. By connecting a device or thing to the Internet, these things get the ability to not only interact with the user but also between themselves. This feature of a variety of things interacting among themselves to assist users in a pervasive manner constitutes an interesting phenomenon called ambient intelligence.
+
+![Figure 1: IoT application domains][3]
+
+IoT is becoming increasingly popular as the types of devices that can be connected to it are becoming more diverse. The nature of applications is also evolving. Some of the popular domains in which IoT is getting used increasingly are listed below (Figure 1):
+
+ * Smart homes
+ * Smart cities
+ * Smart agriculture
+ * Connected automobiles
+ * Smart shopping
+ * Connected health
+
+
+
+![Figure 2: IoT operating system features][4]
+
+As the application domains become diverse, the need to manage the IoT infrastructure efficiently is also becoming more important. The operating systems in normal computers perform the primary functions such as resource management, user interaction, etc. The requirements of IoT operating systems are specialised due to the nature and size of the devices involved in the process. Some of the important characteristics/requirements of IoT operating systems are listed below (Figure 2):
+
+ * A tiny memory footprint
+ * Energy efficiency
+ * Connectivity features
+ * Hardware-agnostic operations
+ * Real-time processing requirements
+ * Security requirements
+ * Application development ecosystem
+
+
+
+As of 2019, there is a spectrum of choices for selecting the operating system (OS) for the Internet of Things. Some of these OSs are shown in Figure 3.
+
+![Figure 3: IoT operating systems][5]
+
+**Ubuntu Core**
+As Ubuntu is a popular Linux distribution, the Ubuntu Core IoT offering has also become popular. Ubuntu Core is a secure and lightweight OS for IoT, and is designed with a ‘security first’ philosophy. According to the official documentation, the entire system has been redesigned to focus on security from the first boot. There is a detailed white paper available on Ubuntu Core’s security features. It can be accessed at _ -ubuntu-core-security-whitepaper.pdf?_ga=2.74563154.1977628533. 1565098475-2022264852.1565098475_.
+
+Ubuntu Core has been made tamper-resistant. As the applications may be from diverse sources, they are given privileges for only their own data. This has been done so that one poorly designed app does not make the entire system vulnerable. Ubuntu Core is ‘built for business’, which means that the developers can focus directly on the application at hand, while the other requirements are supported by the default operating system.
+
+Another important feature of Ubuntu Core is the availability of a secure app store, which you can learn more about at __. There is a ready-to-go software ecosystem that makes using Ubuntu Core simple.
+
+The official documentation lists various successful case studies about how Ubuntu Core has been successfully used.
+
+**RIOT**
+RIOT is a user-friendly OS for the Internet of Things. This FOSS OS has been developed by a number of people from around the world.
+RIOT supports many low-power IoT devices. It has support for various microcontroller architectures. The official documentation lists the following reasons for using the RIOT OS.
+
+ * _**It is developer friendly:**_ It supports the standard environments and tools so that developers need not go through a steep learning curve. Standard programming languages such as C or C++ are supported. The hardware dependent code is very minimal. Developers can code once and then run their code on 8-bit, 16-bit and 32-bit platforms.
+ * _**RIOT is resource friendly:**_ One of the important features of RIOT is its ability to support lightweight devices. It enables maximum energy efficiency. It supports multi-threading with very little overhead for threading.
+ * _**RIOT is IoT friendly:**_ The common system support provided by RIOT makes it a very important choice for IoT. It has support for CoAP, CBOR, high resolution and long-term timers.
+
+
+
+**Contiki**
+Contiki is an important OS for IoT. It facilitates connecting tiny, low-cost and low-energy devices to the Internet.
+The prominent reasons for choosing the Contiki OS are as follows.
+
+ * _**Internet standards:**_ The Contiki OS supports the IPv6 and IPv4 standards, in addition to the low-power 6lowpan, RPL and CoAP standards.
+ * _**Support for a variety of hardware:**_ Contiki can be run on a variety of low-power devices, which are easily available online.
+ * _**Large community support:**_ One of the important advantages of using Contiki is the availability of an active community of developers. So when you have some technical issues to be solved, these community members make the problem solving process simple and effective.
+
+
+
+The major features of Contiki are listed below.
+
+ * _**Memory allocation:**_ Even the tiny systems with only a few kilobytes of memory can also use Contiki. Its memory efficiency is an important feature.
+ * _**Full IP networking:**_ The Contiki OS offers a full IP network stack. This includes major standard protocols such as UDP, TCP, HTTP, 6lowpan, RPL, CoAP, etc.
+ * _**Power awareness:**_ The ability to assess the power requirements and to use them in an optimal minimal manner is an important feature of Contiki.
+ * The Cooja network simulator makes the process of developing and debugging software easier.
+ * The availability of the Coffee Flash file system and the Contiki shell makes the file handling and command execution simpler and more effective.
+
+
+
+**TinyOS**
+TinyOS is an open source operating system designed for low-power wireless devices. It has a vibrant community of users spread across the world from both academia and industry. The popularity of TinyOS can be understood from the fact that it gets downloaded more than 35,000 times in a year.
+TinyOS is very effectively used in various scenarios such as sensor networks, smart buildings, smart meters, etc. The main repository of TinyOS is available at .
+TinyOS is written in nesC which is a dialect of C. A sample code snippet is shown below:
+
+```
+configuration Led {
+provides {
+interface LedControl;
+}
+uses {
+interface Gpio;
+}
+}
+implementation {
+
+command void LedControl.turnOn() {
+call Gpio.set();
+}
+
+command void LedControl.turnOff() {
+call Gpio.clear();
+}
+
+}
+```
+
+**Zephyr**
+Zephyr is a real-time OS that supports multiple architectures and is optimised for resource-constrained environments. Security is also given importance in the Zephyr design.
+
+The prominent features of Zephyr are listed below:
+
+ * Support for 150+ boards.
+ * Complete flexibility and freedom of choice.
+ * Can handle small footprint IoT devices.
+ * Can develop products with built-in security features.
+
+
+
+This article has introduced readers to a list of four OSs for the IoT, from which they can select the ideal one, based on individual requirements.
+
+--------------------------------------------------------------------------------
+
+via: https://opensourceforu.com/2019/10/the-five-most-popular-operating-systems-for-the-internet-of-things/
+
+作者:[K S Kuppusamy][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensourceforu.com/author/ks-kuppusamy/
+[b]: https://github.com/lujun9972
+[1]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/OS-for-IoT.jpg?resize=696%2C647&ssl=1 (OS for IoT)
+[2]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/OS-for-IoT.jpg?fit=800%2C744&ssl=1
+[3]: https://i2.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-1-IoT-application-domains.jpg?resize=350%2C107&ssl=1
+[4]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-2-IoT-operating-system-features.jpg?resize=350%2C93&ssl=1
+[5]: https://i1.wp.com/opensourceforu.com/wp-content/uploads/2019/10/Figure-3-IoT-operating-systems.jpg?resize=350%2C155&ssl=1
diff --git a/sources/tech/20191025 How I used the wget Linux command to recover lost images.md b/sources/tech/20191025 How I used the wget Linux command to recover lost images.md
new file mode 100644
index 0000000000..08dd80f053
--- /dev/null
+++ b/sources/tech/20191025 How I used the wget Linux command to recover lost images.md
@@ -0,0 +1,132 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How I used the wget Linux command to recover lost images)
+[#]: via: (https://opensource.com/article/19/10/how-community-saved-artwork-creative-commons)
+[#]: author: (Seth Kenlon https://opensource.com/users/seth)
+
+How I used the wget Linux command to recover lost images
+======
+The story of the rise and fall of the Open Clip Art Library and the
+birth of FreeSVG.org, a new library of communal artwork.
+![White shoes on top of an orange tribal pattern][1]
+
+In 2004, the Open Clip Art Library (OCAL) was launched as a source of free illustrations for anyone to use, for any purpose, without requiring attribution or anything in return. This site was the open source world’s answer to the big stacks of clip art CDs on the shelf of every home office in the 1990s, and to the art dumps provided by the closed-source office and artistic software titles.
+
+In the beginning, the clip art library consisted mostly of work by a few contributors, but in 2010 it went live with a brand new interactive website, allowing anyone to create and contribute clip art with a vector illustration application. The site immediately garnered contributions from around the globe, and from all manner of free software and free culture projects. A special importer for this library was even included in [Inkscape][2].
+
+However, in early 2019, the website hosting the Open Clip Art Library went offline with no warning or explanation. Its community, which had grown to number in the thousands, assumed at first that this was a temporary glitch. The site remained offline, however, for over six months without any clear explanation of what had happened.
+
+Rumors started to swell. The site was being updated ("There is years of technical debt to pay off," said site developer Jon Philips in an email). The site had fallen to rampant DDOS attacks, claimed a Twitter account. The maintainer had fallen prey to identity theft, another Twitter account claimed. Today, as of this writing, the site’s one and only remaining page declares that it is in "maintenance and protected mode," the meaning of which is unclear, except that users cannot access its content.
+
+### Recovering the commons
+
+Sites appear and disappear over the course of time, but the loss of the Open Clip Art Library was particularly surprising to its community because it was seen as a community project. Few community members understood that the site hosting the library had fallen into the hands of a single maintainer, so while the artwork in the library was owned by everyone due to its [Creative Commons 0 License][3], access to it was functionally owned by a single maintainer. And, because the site’s community kept in touch with one another through the site, that same maintainer effectively owned the community.
+
+When the site failed, the community lost access to its artwork as well as each other. And without the site, there was no community.
+
+Initially, everything on the site was blocked when it went down. After several months, though, users started recognizing that the site’s database was still online, which meant that a user could access an individual art file by entering its exact URL. In other words, you couldn’t navigate to the art file through clicking around a website, but if you already knew the address, then you could bring it up in your browser. Similarly, technical (or lazy) users realized it was also possible to "scrape" the site with an automated web browser like **wget**.
+
+The **wget** Linux command is _technically_ a web browser, although it doesn’t let you browse interactively the way you do with Firefox. Instead, **wget** goes out onto the internet and retrieves a file or a collection of files and downloads them to your hard drive. You can then open those files in Firefox or a text editor, or whatever application is most appropriate, and view the content.
+
+Usually, **wget** needs to know a specific file to fetch. If you’re on Linux or macOS with **wget** installed, you can try this process by downloading the index page for [example.com][4]:
+
+
+```
+$ wget example.org/index.html
+[...]
+$ tail index.html
+
+<body><div>
+ <h1>Example Domain</h1>
+ <p>This domain is for illustrative examples in documents.
+ You may use this domain in examples without permission.</p>
+ <p><a href="[http://www.iana.org/domains/example"\>More][5] info</a></p>
+</div></body></html>
+```
+
+To scrape the Open Clip Art Library, I used the **\--mirror** option, so that I could point **wget** to just the directory containing the artwork so it could download everything within that directory. This action resulted in four straight days (96 hours) of constant downloading, ending with an excess of 100,000 SVG files that had been contributed by over 5,000 community members. Unfortunately, the author of any file that did not have proper metadata was irrecoverable because this information was locked in inaccessible files in the database, but the CC0 license meant that this issue _technically_ didn’t matter (because no attribution is required with CC0 files).
+
+A casual analysis of the downloaded files also revealed that nearly 45,000 of them were copies of the same single file (the site’s logo). This was caused by redirects pointing to the site's logo (for reasons unknown), and careful parsing could extract the original destination. Another 96 hours, and all clip art posted on OCAL up to its last day was recovered: **a total of about 156,000 images.**
+
+SVG files tend to be small, but this is still an enormous amount of work that poses a few very real problems. First of all, several gigabytes of online storage would be needed so the artwork could be made available to its former community. Secondly, a means of searching the artwork would be necessary, because it’s just not realistic to browse through 55,000 files manually.
+
+It became apparent that what the community really needed was a platform.
+
+### Building a new platform
+
+For some time, the site [Public Domain Vectors][6] had been publishing vector art that was in the public domain. While it remains a popular site, open source users often used it only as a secondary source of art because most of the files there were in the EPS and AI formats, both of which are associated with Adobe. Both file formats can generally be converted to SVG but at a loss of features.
+
+When the Public Domain Vectors site’s maintainers (Vedran and Boris) heard about the loss of the Open Clip Art Library, they decided to create a site oriented toward the open source community. True to form, they chose the open source [Laravel][7] framework as the backend, which provided the site with an admin dashboard and user access. The framework, being robust and well-developed, also allowed them to respond quickly to bug reports and feature requests, and to upgrade the site as needed. The site they are building is called [FreeSVG.org][8], and is already a robust and thriving library of communal artwork.
+
+Since then they have been uploading all of the clip art from the Open Clip Art Library, and they're even diligently tagging and categorizing the art as they go. As creators of Public Domain Vectors, they are also contributing their own images in SVG format. Their aim is to become the primary resource for SVG images with a CC0 license on the internet.
+
+### Contributing
+
+The maintainers of [FreeSVG.org][8] are aware that they have inherited significant stewardship. They are working to title and describe all images on the site so that users can easily find artwork, and will provide this file to the community once it is ready, believing strongly that the metadata about the art belongs to the people that create and use the art as much as the art itself does. They're also aware that unforeseen circumstances can arise, so they create regular backups of their site and content, and intend to make the most recent backup available to the public, should their site fail.
+
+If you want to add to the Creative Commons content of [FreeSVG.org][9], then download [Inkscape][10] and start drawing. There’s plenty of public domain artwork out there in the world, like [historical advertisements][11], [tarot cards][12], and [storybooks][13] just waiting to be converted to SVG, so you can contribute even if you aren’t confident in your drawing skills. Visit the [FreeSVG forum][14] to connect with and support other contributors.
+
+The concept of the _commons_ is important. [Creative Commons benefits everyone][15], whether you’re a student, teacher, librarian, small business owner, or CEO. If you don’t contribute directly, then you can always help promote it.
+
+That’s a strength of free culture: It doesn’t just scale, it gets better when more people participate.
+
+### Hard lessons learned
+
+From the demise of the Open Clip Art Library to the rise of FreeSVG.org, the open culture community has learned several hard lessons. For posterity, here are the ones that I believe are most important.
+
+#### Maintain your metadata
+
+If you’re a content creator, help the archivists of the future and add metadata to your files. Most image, music, font, and video file formats can have EXIF data embedded into them, and others have metadata entry interfaces in the applications that create them. Be diligent in tagging your work with your name, website or public email, and license.
+
+#### Make copies
+
+Don’t assume that somebody else is doing backups. If you care about communal digital content, then back it up yourself, or else don’t count on having it available forever. The trope that _whatever’s uploaded to the internet is forever_ may be true, but that doesn’t mean it’s _available to you_ forever. If the Open Clip Art Library files hadn’t become secretly available again, it’s unlikely that anyone would have ever successfully uncovered all 55,000 images from random places on the web, or from personal stashes on people’s hard drives around the globe.
+
+#### Create external channels
+
+If a community is defined by a single website or physical location, then that community is as good as dissolved should it lose access to that space. If you’re a member of a community that’s driven by a single organization or site, you owe it to yourselves to share contact information with those you care about and to establish a channel for communication even when that site is not available.
+
+For example, [Opensource.com][16] itself maintains mailing lists and other off-site channels for its authors and correspondents to communicate with one another, with or without the intervention or even existence of the website.
+
+#### Free culture is worth working for
+
+The internet is sometimes seen as a lazy person’s social club. You can log on when you want and turn it off when you’re tired, and you can wander into whatever social circle you want.
+
+But in reality, free culture can be hard work. It’s not hard in the sense that it’s difficult to be a part of, but it’s something you have to work to maintain. If you ignore the community you’re in, then the community may wither and fade before you realize it.
+
+Take a moment to look around you and identify what communities you’re a part of, and if nothing else, tell someone that you appreciate what they bring to your life. And just as importantly, keep in mind that you’re contributing to the lives of your communities, too.
+
+Creative Commons held its Gl obal Summit a few weeks ago in Warsaw, with amazing international...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/how-community-saved-artwork-creative-commons
+
+作者:[Seth Kenlon][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tribal_pattern_shoes.png?itok=e5dSf2hS (White shoes on top of an orange tribal pattern)
+[2]: https://opensource.com/article/18/1/inkscape-absolute-beginners
+[3]: https://creativecommons.org/share-your-work/public-domain/cc0/
+[4]: http://example.com
+[5]: http://www.iana.org/domains/example"\>More
+[6]: http://publicdomainvectors.org
+[7]: https://github.com/viralsolani/laravel-adminpanel
+[8]: https://freesvg.org
+[9]: http://freesvg.org
+[10]: http://inkscape.org
+[11]: https://freesvg.org/drinking-coffee-vector-drawing
+[12]: https://freesvg.org/king-of-swords-tarot-card
+[13]: https://freesvg.org/space-pioneers-135-scene-vector-image
+[14]: http://forum.freesvg.org/
+[15]: https://opensource.com/article/18/1/creative-commons-real-world
+[16]: http://Opensource.com
diff --git a/sources/tech/20191026 How to Backup Configuration Files on a Remote System Using the Bash Script.md b/sources/tech/20191026 How to Backup Configuration Files on a Remote System Using the Bash Script.md
new file mode 100644
index 0000000000..c2d3b4397f
--- /dev/null
+++ b/sources/tech/20191026 How to Backup Configuration Files on a Remote System Using the Bash Script.md
@@ -0,0 +1,550 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Backup Configuration Files on a Remote System Using the Bash Script)
+[#]: via: (https://www.2daygeek.com/linux-bash-script-backup-configuration-files-remote-linux-system-server/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+How to Backup Configuration Files on a Remote System Using the Bash Script
+======
+
+It is a good practice to backup configuration files before performing any activity on a Linux system.
+
+You can use this script if you are restarting the server after several days.
+
+If you are really concerned about the backup of your configuration files, it is advisable to use this script at least once a month.
+
+If something goes wrong, you can restore the system to normal by comparing configuration files based on the error message.
+
+Three **[bash scripts][1]** are included in this article, and each **[shell script][2]** is used for specific purposes.
+
+You can choose one based on your requirements.
+
+Everything in Linux is a file. If you make some wrong changes in the configuration file, it will cause the associated service to crash.
+
+So it is a good idea to take a backup of configuration files, and you do not have to worry about disk usage as this not consume much space.
+
+### What does this script do?
+
+This script backs up specific configuration files, moves them to another server, and finally deletes the backup on the remote machine.
+
+This script has six parts, and the details are below.
+
+ * **Part-1:** Backup a General Configuration Files
+ * **Part-2:** Backup a wwn/wwpn number if the server is physical.
+ * **Part-3:** Backup an oracle related files if the system has an oracle user account.
+ * **Part-4:** Create a tar archive of backup configuration files.
+ * **Part-5:** Copy the tar archive to other server.
+ * **Part-6:** Remove Backup of configuration files on the remote system.
+
+
+
+**System details are as follows:**
+
+ * **Server-A:** Local System/ JUMP System (local.2daygeek.com)
+ * **Server-B:** Remote System-1 (CentOS6.2daygeek.com)
+ * **Server-C:** Remote System-2 (CentOS7.2daygeek.com)
+
+
+
+### 1) Bash Script to Backup Configuration files on Remote Server
+
+Two scripts are included in this example, which allow you to back up important configurations files from one server to another (that is, from a remote server to a local server).
+
+For example, if you want to back up important configuration files from **“Server-B”** to **“Server-A”**. Use the following script.
+
+This is a real bash script that takes backup of configuration files on the remote server.
+
+```
+# vi /home/daygeek/shell-script/config-file.sh
+
+#!/bin/bash
+mkdir /tmp/conf-bk-$(date +%Y%m%d)
+cd /tmp/conf-bk-$(date +%Y%m%d)
+
+For General Configuration Files
+hostname > hostname.out
+uname -a > uname.out
+uptime > uptime.out
+cat /etc/hosts > hosts.out
+/bin/df -h>df-h.out
+pvs > pvs.out
+vgs > vgs.out
+lvs > lvs.out
+/bin/ls -ltr /dev/mapper>mapper.out
+fdisk -l > fdisk.out
+cat /etc/fstab > fstab.out
+cat /etc/exports > exports.out
+cat /etc/crontab > crontab.out
+cat /etc/passwd > passwd.out
+ip link show > ip.out
+/bin/netstat -in>netstat-in.out
+/bin/netstat -rn>netstat-rn.out
+/sbin/ifconfig -a>ifconfig-a.out
+cat /etc/sysctl.conf > sysctl.out
+sleep 10s
+
+#For Physical Server
+vserver=$(lscpu | grep vendor | wc -l)
+if [ $vserver -gt 0 ]
+then
+echo "$(hostname) is a VM"
+else
+systool -c fc_host -v | egrep "(Class Device path | port_name |port_state)" > systool.out
+fi
+sleep 10s
+
+#For Oracle DB Servers
+if id oracle >/dev/null 2>&1; then
+/usr/sbin/oracleasm listdisks>asm.out
+/sbin/multipath -ll > mpath.out
+/bin/ps -ef|grep pmon > pmon.out
+else
+echo "oracle user does not exist on server"
+fi
+sleep 10s
+
+#Create a tar archive
+tar -cvf /tmp/$(hostname)-date +%Y%m%d.tar /tmp/conf-bk-$(date +%Y%m%d)
+sleep 10s
+
+#Copy a tar archive to other server
+sshpass -p 'password' scp /tmp/$(hostname)-date +%Y%m%d.tar Server-A:/home/daygeek/backup/
+
+#Remove the backup config folder
+cd ..
+rm -Rf conf-bk-$(date +%Y%m%d)
+rm $(hostname)-date +%Y%m%d.tar
+rm config-file.sh
+exit
+```
+
+This is a sub-script that pushes the above script to the target server.
+
+```
+# vi /home/daygeek/shell-script/conf-remote.sh
+
+#!/bin/bash
+echo -e "Enter the Remote Server Name: \c"
+read server
+scp /home/daygeek/shell-script/config-file.sh $server:/tmp/
+ssh [email protected]${server} sh /home/daygeek/shell-script/config-file.sh
+sleep 10s
+exit
+```
+
+Finally run the bash script to achieve this.
+
+```
+# sh /home/daygeek/shell-script/conf-remote.sh
+
+Enter the Remote Server Name: CentOS6.2daygeek.com
+config-file.sh 100% 1446 647.8KB/s 00:00
+CentOS6.2daygeek.com is a VM
+oracle user does not exist on server
+tar: Removing leading `/' from member names
+/tmp/conf-bk-20191024/
+/tmp/conf-bk-20191024/pvs.out
+/tmp/conf-bk-20191024/vgs.out
+/tmp/conf-bk-20191024/ip.out
+/tmp/conf-bk-20191024/netstat-in.out
+/tmp/conf-bk-20191024/fstab.out
+/tmp/conf-bk-20191024/ifconfig-a.out
+/tmp/conf-bk-20191024/hostname.out
+/tmp/conf-bk-20191024/crontab.out
+/tmp/conf-bk-20191024/netstat-rn.out
+/tmp/conf-bk-20191024/uptime.out
+/tmp/conf-bk-20191024/uname.out
+/tmp/conf-bk-20191024/mapper.out
+/tmp/conf-bk-20191024/lvs.out
+/tmp/conf-bk-20191024/exports.out
+/tmp/conf-bk-20191024/df-h.out
+/tmp/conf-bk-20191024/sysctl.out
+/tmp/conf-bk-20191024/hosts.out
+/tmp/conf-bk-20191024/passwd.out
+/tmp/conf-bk-20191024/fdisk.out
+```
+
+Once you run the above script, use the ls command to check the copied tar archive file.
+
+```
+# ls -ltrh /home/daygeek/backup/*.tar
+
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 11:01 /home/daygeek/backup/CentOS6.2daygeek.com-20191024.tar
+```
+
+If it is moved successfully, you can find the contents of it without extracting it using the following tar command.
+
+```
+# tar -tvf /home/daygeek/backup/CentOS6.2daygeek.com-20191024.tar
+
+drwxr-xr-x root/root 0 2019-10-25 11:00 tmp/conf-bk-20191024/
+-rw-r--r-- root/root 96 2019-10-25 11:00 tmp/conf-bk-20191024/pvs.out
+-rw-r--r-- root/root 92 2019-10-25 11:00 tmp/conf-bk-20191024/vgs.out
+-rw-r--r-- root/root 413 2019-10-25 11:00 tmp/conf-bk-20191024/ip.out
+-rw-r--r-- root/root 361 2019-10-25 11:00 tmp/conf-bk-20191024/netstat-in.out
+-rw-r--r-- root/root 785 2019-10-25 11:00 tmp/conf-bk-20191024/fstab.out
+-rw-r--r-- root/root 1375 2019-10-25 11:00 tmp/conf-bk-20191024/ifconfig-a.out
+-rw-r--r-- root/root 21 2019-10-25 11:00 tmp/conf-bk-20191024/hostname.out
+-rw-r--r-- root/root 457 2019-10-25 11:00 tmp/conf-bk-20191024/crontab.out
+-rw-r--r-- root/root 337 2019-10-25 11:00 tmp/conf-bk-20191024/netstat-rn.out
+-rw-r--r-- root/root 62 2019-10-25 11:00 tmp/conf-bk-20191024/uptime.out
+-rw-r--r-- root/root 116 2019-10-25 11:00 tmp/conf-bk-20191024/uname.out
+-rw-r--r-- root/root 210 2019-10-25 11:00 tmp/conf-bk-20191024/mapper.out
+-rw-r--r-- root/root 276 2019-10-25 11:00 tmp/conf-bk-20191024/lvs.out
+-rw-r--r-- root/root 0 2019-10-25 11:00 tmp/conf-bk-20191024/exports.out
+-rw-r--r-- root/root 236 2019-10-25 11:00 tmp/conf-bk-20191024/df-h.out
+-rw-r--r-- root/root 1057 2019-10-25 11:00 tmp/conf-bk-20191024/sysctl.out
+-rw-r--r-- root/root 115 2019-10-25 11:00 tmp/conf-bk-20191024/hosts.out
+-rw-r--r-- root/root 2194 2019-10-25 11:00 tmp/conf-bk-20191024/passwd.out
+-rw-r--r-- root/root 1089 2019-10-25 11:00 tmp/conf-bk-20191024/fdisk.out
+```
+
+### 2) Bash Script to Backup Configuration files on Remote Server
+
+There are two scripts added in this example, which do the same as the above script, but this can be very useful if you have a JUMP server in your environment.
+
+This script allows you to copy important configuration files from your client system into the JUMP box
+
+For example, since we have already set up a password-less login, you have ten clients that can be accessed from the JUMP server. If so, use this script.
+
+This is a real bash script that takes backup of configuration files on the remote server.
+
+```
+# vi /home/daygeek/shell-script/config-file-1.sh
+
+#!/bin/bash
+mkdir /tmp/conf-bk-$(date +%Y%m%d)
+cd /tmp/conf-bk-$(date +%Y%m%d)
+
+For General Configuration Files
+hostname > hostname.out
+uname -a > uname.out
+uptime > uptime.out
+cat /etc/hosts > hosts.out
+/bin/df -h>df-h.out
+pvs > pvs.out
+vgs > vgs.out
+lvs > lvs.out
+/bin/ls -ltr /dev/mapper>mapper.out
+fdisk -l > fdisk.out
+cat /etc/fstab > fstab.out
+cat /etc/exports > exports.out
+cat /etc/crontab > crontab.out
+cat /etc/passwd > passwd.out
+ip link show > ip.out
+/bin/netstat -in>netstat-in.out
+/bin/netstat -rn>netstat-rn.out
+/sbin/ifconfig -a>ifconfig-a.out
+cat /etc/sysctl.conf > sysctl.out
+sleep 10s
+
+#For Physical Server
+vserver=$(lscpu | grep vendor | wc -l)
+if [ $vserver -gt 0 ]
+then
+echo "$(hostname) is a VM"
+else
+systool -c fc_host -v | egrep "(Class Device path | port_name |port_state)" > systool.out
+fi
+sleep 10s
+
+#For Oracle DB Servers
+if id oracle >/dev/null 2>&1; then
+/usr/sbin/oracleasm listdisks>asm.out
+/sbin/multipath -ll > mpath.out
+/bin/ps -ef|grep pmon > pmon.out
+else
+echo "oracle user does not exist on server"
+fi
+sleep 10s
+
+#Create a tar archieve
+tar -cvf /tmp/$(hostname)-date +%Y%m%d.tar /tmp/conf-bk-$(date +%Y%m%d)
+sleep 10s
+
+#Remove the backup config folder
+cd ..
+rm -Rf conf-bk-$(date +%Y%m%d)
+rm config-file.sh
+exit
+```
+
+This is a sub-script that pushes the above script to the target server.
+
+```
+# vi /home/daygeek/shell-script/conf-remote-1.sh
+
+#!/bin/bash
+echo -e "Enter the Remote Server Name: \c"
+read server
+scp /home/daygeek/shell-script/config-file-1.sh $server:/tmp/
+ssh [email protected]${server} sh /home/daygeek/shell-script/config-file-1.sh
+sleep 10s
+echo -e "Re-Enter the Remote Server Name: \c"
+read server
+scp $server:/tmp/$server-date +%Y%m%d.tar /home/daygeek/backup/
+exit
+```
+
+Finally run the bash script to achieve this.
+
+```
+# sh /home/daygeek/shell-script/conf-remote-1.sh
+
+Enter the Remote Server Name: CentOS6.2daygeek.com
+config-file.sh 100% 1446 647.8KB/s 00:00
+CentOS6.2daygeek.com is a VM
+oracle user does not exist on server
+tar: Removing leading `/' from member names
+/tmp/conf-bk-20191025/
+/tmp/conf-bk-20191025/pvs.out
+/tmp/conf-bk-20191025/vgs.out
+/tmp/conf-bk-20191025/ip.out
+/tmp/conf-bk-20191025/netstat-in.out
+/tmp/conf-bk-20191025/fstab.out
+/tmp/conf-bk-20191025/ifconfig-a.out
+/tmp/conf-bk-20191025/hostname.out
+/tmp/conf-bk-20191025/crontab.out
+/tmp/conf-bk-20191025/netstat-rn.out
+/tmp/conf-bk-20191025/uptime.out
+/tmp/conf-bk-20191025/uname.out
+/tmp/conf-bk-20191025/mapper.out
+/tmp/conf-bk-20191025/lvs.out
+/tmp/conf-bk-20191025/exports.out
+/tmp/conf-bk-20191025/df-h.out
+/tmp/conf-bk-20191025/sysctl.out
+/tmp/conf-bk-20191025/hosts.out
+/tmp/conf-bk-20191025/passwd.out
+/tmp/conf-bk-20191025/fdisk.out
+Enter the Server Name Once Again: CentOS6.2daygeek.com
+CentOS6.2daygeek.com-20191025.tar
+```
+
+Once you run the above script, use the ls command to check the copied tar archive file.
+
+```
+# ls -ltrh /home/daygeek/backup/*.tar
+
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 11:44 /home/daygeek/backup/CentOS6.2daygeek.com-20191025.tar
+```
+
+If it is moved successfully, you can find the contents of it without extracting it using the following tar command.
+
+```
+# tar -tvf /home/daygeek/backup/CentOS6.2daygeek.com-20191025.tar
+
+drwxr-xr-x root/root 0 2019-10-25 11:43 tmp/conf-bk-20191025/
+-rw-r--r-- root/root 96 2019-10-25 11:43 tmp/conf-bk-20191025/pvs.out
+-rw-r--r-- root/root 92 2019-10-25 11:43 tmp/conf-bk-20191025/vgs.out
+-rw-r--r-- root/root 413 2019-10-25 11:43 tmp/conf-bk-20191025/ip.out
+-rw-r--r-- root/root 361 2019-10-25 11:43 tmp/conf-bk-20191025/netstat-in.out
+-rw-r--r-- root/root 785 2019-10-25 11:43 tmp/conf-bk-20191025/fstab.out
+-rw-r--r-- root/root 1375 2019-10-25 11:43 tmp/conf-bk-20191025/ifconfig-a.out
+-rw-r--r-- root/root 21 2019-10-25 11:43 tmp/conf-bk-20191025/hostname.out
+-rw-r--r-- root/root 457 2019-10-25 11:43 tmp/conf-bk-20191025/crontab.out
+-rw-r--r-- root/root 337 2019-10-25 11:43 tmp/conf-bk-20191025/netstat-rn.out
+-rw-r--r-- root/root 61 2019-10-25 11:43 tmp/conf-bk-20191025/uptime.out
+-rw-r--r-- root/root 116 2019-10-25 11:43 tmp/conf-bk-20191025/uname.out
+-rw-r--r-- root/root 210 2019-10-25 11:43 tmp/conf-bk-20191025/mapper.out
+-rw-r--r-- root/root 276 2019-10-25 11:43 tmp/conf-bk-20191025/lvs.out
+-rw-r--r-- root/root 0 2019-10-25 11:43 tmp/conf-bk-20191025/exports.out
+-rw-r--r-- root/root 236 2019-10-25 11:43 tmp/conf-bk-20191025/df-h.out
+-rw-r--r-- root/root 1057 2019-10-25 11:43 tmp/conf-bk-20191025/sysctl.out
+-rw-r--r-- root/root 115 2019-10-25 11:43 tmp/conf-bk-20191025/hosts.out
+-rw-r--r-- root/root 2194 2019-10-25 11:43 tmp/conf-bk-20191025/passwd.out
+-rw-r--r-- root/root 1089 2019-10-25 11:43 tmp/conf-bk-20191025/fdisk.out
+```
+
+### 3) Bash Script to Backup Configuration files on Multiple Linux Remote Systems
+
+This script allows you to copy important configuration files from multiple remote Linux systems into the JUMP box at the same time.
+
+This is a real bash script that takes backup of configuration files on the remote server.
+
+```
+# vi /home/daygeek/shell-script/config-file-2.sh
+
+#!/bin/bash
+mkdir /tmp/conf-bk-$(date +%Y%m%d)
+cd /tmp/conf-bk-$(date +%Y%m%d)
+
+For General Configuration Files
+hostname > hostname.out
+uname -a > uname.out
+uptime > uptime.out
+cat /etc/hosts > hosts.out
+/bin/df -h>df-h.out
+pvs > pvs.out
+vgs > vgs.out
+lvs > lvs.out
+/bin/ls -ltr /dev/mapper>mapper.out
+fdisk -l > fdisk.out
+cat /etc/fstab > fstab.out
+cat /etc/exports > exports.out
+cat /etc/crontab > crontab.out
+cat /etc/passwd > passwd.out
+ip link show > ip.out
+/bin/netstat -in>netstat-in.out
+/bin/netstat -rn>netstat-rn.out
+/sbin/ifconfig -a>ifconfig-a.out
+cat /etc/sysctl.conf > sysctl.out
+sleep 10s
+
+#For Physical Server
+vserver=$(lscpu | grep vendor | wc -l)
+if [ $vserver -gt 0 ]
+then
+echo "$(hostname) is a VM"
+else
+systool -c fc_host -v | egrep "(Class Device path | port_name |port_state)" > systool.out
+fi
+sleep 10s
+
+#For Oracle DB Servers
+if id oracle >/dev/null 2>&1; then
+/usr/sbin/oracleasm listdisks>asm.out
+/sbin/multipath -ll > mpath.out
+/bin/ps -ef|grep pmon > pmon.out
+else
+echo "oracle user does not exist on server"
+fi
+sleep 10s
+
+#Create a tar archieve
+tar -cvf /tmp/$(hostname)-date +%Y%m%d.tar /tmp/conf-bk-$(date +%Y%m%d)
+sleep 10s
+
+#Remove the backup config folder
+cd ..
+rm -Rf conf-bk-$(date +%Y%m%d)
+rm config-file.sh
+exit
+```
+
+This is a sub-script that pushes the above script to the target servers.
+
+```
+# vi /home/daygeek/shell-script/conf-remote-2.sh
+
+#!/bin/bash
+for server in CentOS6.2daygeek.com CentOS7.2daygeek.com
+do
+scp /home/daygeek/shell-script/config-file-2.sh $server:/tmp/
+ssh [email protected]${server} sh /tmp/config-file-2.sh
+sleep 10s
+scp $server:/tmp/$server-date +%Y%m%d.tar /home/daygeek/backup/
+done
+exit
+```
+
+Finally run the bash script to achieve this.
+
+```
+# sh /home/daygeek/shell-script/conf-remote-2.sh
+
+config-file-1.sh 100% 1444 416.5KB/s 00:00
+CentOS6.2daygeek.com is a VM
+oracle user does not exist on server
+tar: Removing leading `/' from member names
+/tmp/conf-bk-20191025/
+/tmp/conf-bk-20191025/pvs.out
+/tmp/conf-bk-20191025/vgs.out
+/tmp/conf-bk-20191025/ip.out
+/tmp/conf-bk-20191025/netstat-in.out
+/tmp/conf-bk-20191025/fstab.out
+/tmp/conf-bk-20191025/ifconfig-a.out
+/tmp/conf-bk-20191025/hostname.out
+/tmp/conf-bk-20191025/crontab.out
+/tmp/conf-bk-20191025/netstat-rn.out
+/tmp/conf-bk-20191025/uptime.out
+/tmp/conf-bk-20191025/uname.out
+/tmp/conf-bk-20191025/mapper.out
+/tmp/conf-bk-20191025/lvs.out
+/tmp/conf-bk-20191025/exports.out
+/tmp/conf-bk-20191025/df-h.out
+/tmp/conf-bk-20191025/sysctl.out
+/tmp/conf-bk-20191025/hosts.out
+/tmp/conf-bk-20191025/passwd.out
+/tmp/conf-bk-20191025/fdisk.out
+CentOS6.2daygeek.com-20191025.tar
+config-file-1.sh 100% 1444 386.2KB/s 00:00
+CentOS7.2daygeek.com is a VM
+oracle user does not exist on server
+/tmp/conf-bk-20191025/
+/tmp/conf-bk-20191025/hostname.out
+/tmp/conf-bk-20191025/uname.out
+/tmp/conf-bk-20191025/uptime.out
+/tmp/conf-bk-20191025/hosts.out
+/tmp/conf-bk-20191025/df-h.out
+/tmp/conf-bk-20191025/pvs.out
+/tmp/conf-bk-20191025/vgs.out
+/tmp/conf-bk-20191025/lvs.out
+/tmp/conf-bk-20191025/mapper.out
+/tmp/conf-bk-20191025/fdisk.out
+/tmp/conf-bk-20191025/fstab.out
+/tmp/conf-bk-20191025/exports.out
+/tmp/conf-bk-20191025/crontab.out
+/tmp/conf-bk-20191025/passwd.out
+/tmp/conf-bk-20191025/ip.out
+/tmp/conf-bk-20191025/netstat-in.out
+/tmp/conf-bk-20191025/netstat-rn.out
+/tmp/conf-bk-20191025/ifconfig-a.out
+/tmp/conf-bk-20191025/sysctl.out
+tar: Removing leading `/' from member names
+CentOS7.2daygeek.com-20191025.tar
+```
+
+Once you run the above script, use the ls command to check the copied tar archive file.
+
+```
+# ls -ltrh /home/daygeek/backup/*.tar
+
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 12:37 /home/daygeek/backup/CentOS6.2daygeek.com-20191025.tar
+-rw-r--r-- 1 daygeek daygeek 30K Oct 25 12:38 /home/daygeek/backup/CentOS7.2daygeek.com-20191025.tar
+```
+
+If it is moved successfully, you can find the contents of it without extracting it using the following tar command.
+
+```
+# tar -tvf /home/daygeek/backup/CentOS7.2daygeek.com-20191025.tar
+
+drwxr-xr-x root/root 0 2019-10-25 12:23 tmp/conf-bk-20191025/
+-rw-r--r-- root/root 21 2019-10-25 12:23 tmp/conf-bk-20191025/hostname.out
+-rw-r--r-- root/root 115 2019-10-25 12:23 tmp/conf-bk-20191025/uname.out
+-rw-r--r-- root/root 62 2019-10-25 12:23 tmp/conf-bk-20191025/uptime.out
+-rw-r--r-- root/root 228 2019-10-25 12:23 tmp/conf-bk-20191025/hosts.out
+-rw-r--r-- root/root 501 2019-10-25 12:23 tmp/conf-bk-20191025/df-h.out
+-rw-r--r-- root/root 88 2019-10-25 12:23 tmp/conf-bk-20191025/pvs.out
+-rw-r--r-- root/root 84 2019-10-25 12:23 tmp/conf-bk-20191025/vgs.out
+-rw-r--r-- root/root 252 2019-10-25 12:23 tmp/conf-bk-20191025/lvs.out
+-rw-r--r-- root/root 197 2019-10-25 12:23 tmp/conf-bk-20191025/mapper.out
+-rw-r--r-- root/root 1088 2019-10-25 12:23 tmp/conf-bk-20191025/fdisk.out
+-rw-r--r-- root/root 465 2019-10-25 12:23 tmp/conf-bk-20191025/fstab.out
+-rw-r--r-- root/root 0 2019-10-25 12:23 tmp/conf-bk-20191025/exports.out
+-rw-r--r-- root/root 451 2019-10-25 12:23 tmp/conf-bk-20191025/crontab.out
+-rw-r--r-- root/root 2748 2019-10-25 12:23 tmp/conf-bk-20191025/passwd.out
+-rw-r--r-- root/root 861 2019-10-25 12:23 tmp/conf-bk-20191025/ip.out
+-rw-r--r-- root/root 455 2019-10-25 12:23 tmp/conf-bk-20191025/netstat-in.out
+-rw-r--r-- root/root 505 2019-10-25 12:23 tmp/conf-bk-20191025/netstat-rn.out
+-rw-r--r-- root/root 2072 2019-10-25 12:23 tmp/conf-bk-20191025/ifconfig-a.out
+-rw-r--r-- root/root 449 2019-10-25 12:23 tmp/conf-bk-20191025/sysctl.out
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-bash-script-backup-configuration-files-remote-linux-system-server/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/category/bash-script/
+[2]: https://www.2daygeek.com/category/shell-script/
diff --git a/sources/tech/20191028 Enterprise JavaBeans, infrastructure predictions, and more industry trends.md b/sources/tech/20191028 Enterprise JavaBeans, infrastructure predictions, and more industry trends.md
new file mode 100644
index 0000000000..f1d2b48d0d
--- /dev/null
+++ b/sources/tech/20191028 Enterprise JavaBeans, infrastructure predictions, and more industry trends.md
@@ -0,0 +1,69 @@
+[#]: collector: (lujun9972)
+[#]: translator: (warmfrog)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Enterprise JavaBeans, infrastructure predictions, and more industry trends)
+[#]: via: (https://opensource.com/article/19/10/enterprise-javabeans-and-more-industry-trends)
+[#]: author: (Tim Hildred https://opensource.com/users/thildred)
+
+Enterprise JavaBeans, infrastructure predictions, and more industry trends
+======
+A weekly look at open source community and industry trends.
+![Person standing in front of a giant computer screen with numbers, data][1]
+
+As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
+
+## [Gartner: 10 infrastructure trends you need to know][2]
+
+> Corporate network infrastructure is only going to get more involved over the next two to three years as automation, network challenges, and hybrid cloud become more integral to the enterprise.
+
+**The impact:** The theme running through all these predictions is the impact of increased complexity. As consumers of technology, we expect things to get easier and easier. As producers of technology, we know what's going on behind the curtains to make that simplicity possible is its opposite.
+
+## [Jakarta EE: What's in store for Enterprise JavaBeans?][3]
+
+> [Enterprise JavaBeans (EJB)][4] has been very important to the Java EE ecosystem and promoted many robust solutions to enterprise problems. Besides that, in the past when integration techniques were not so advanced, EJB did great work with remote EJB, integrating many Java EE applications. However, remote EJB is not necessary anymore, and we have many techniques and tools that are better for doing that. So, does EJB still have a place in this new cloud-native world?
+
+**The impact:** This offers some insights into how programming languages and frameworks evolve and change over time. Respond to changes in developer affinity by identifying the good stuff in a language and getting it landed somewhere else. Ideally that "somewhere else" should be an open standard so that no single vendor gets to control your technology destiny.
+
+## [From virtualization to containerization][5]
+
+> Before the telecom industry has got to grips with "step one" virtualization, many industry leaders are already moving on to the next level—containerization. This is a key part of making network software cloud-native i.e. designed, developed, and optimized to exploit cloud technology such as distributed processing and data stores.
+
+**The impact:** There are certain industries that make big technology decisions on long time horizons; I can only imagine the FOMO that the fast-moving world of infrastructure technology could cause when you've picked something and it starts to look a bit crufty next to the new hotness.
+
+## [How do you rollback deployments in Kubernetes?][6]
+
+> There are several strategies when it comes to deploying apps into production. In Kubernetes, rolling updates are the default strategy to update the running version of your app. The rolling update cycles previous Pod out and bring newer Pod in incrementally.
+
+**The impact:** What is the cloud-native distributed equivalent to **ctrl+z**? And aren't you glad there is one?
+
+## [What's a Trusted Compute Base?][7]
+
+> A few months ago, in an article called [Turtles—and chains of trust][8], I briefly mentioned Trusted Compute Bases, or TCBs, but then didn’t go any deeper. I had a bit of a search across the articles on this blog, and realised that I’ve never gone into this topic in much detail, which feels like a mistake, so I’m going to do it now.
+
+**The impact:** The issue of to what extent you can trust the computer systems that power your whole life is only going to become more prevalent and more vexing. That turns out to be a great argument for open source from the bottom turtle (hardware) all the way up.
+
+_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/10/enterprise-javabeans-and-more-industry-trends
+
+作者:[Tim Hildred][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/thildred
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
+[2]: https://www.networkworld.com/article/3447397/gartner-10-infrastructure-trends-you-need-to-know.html
+[3]: https://developers.redhat.com/blog/2019/10/22/jakarta-ee-whats-in-store-for-enterprise-javabeans/
+[4]: https://docs.oracle.com/cd/E13222_01/wls/docs100/ejb/deploy.html
+[5]: https://www.lightreading.com/nfv/from-virtualization-to-containerization/a/d-id/755016
+[6]: https://learnk8s.io/kubernetes-rollbacks/
+[7]: https://aliceevebob.com/2019/10/22/whats-a-trusted-compute-base/
+[8]: https://aliceevebob.com/2019/07/02/turtles-and-chains-of-trust/
diff --git a/sources/tech/20191028 How to remove duplicate lines from files with awk.md b/sources/tech/20191028 How to remove duplicate lines from files with awk.md
new file mode 100644
index 0000000000..0282a26768
--- /dev/null
+++ b/sources/tech/20191028 How to remove duplicate lines from files with awk.md
@@ -0,0 +1,243 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to remove duplicate lines from files with awk)
+[#]: via: (https://opensource.com/article/19/10/remove-duplicate-lines-files-awk)
+[#]: author: (Lazarus Lazaridis https://opensource.com/users/iridakos)
+
+How to remove duplicate lines from files with awk
+======
+Learn how to use awk '!visited[$0]++' without sorting or changing their
+order.
+![Coding on a computer][1]
+
+Suppose you have a text file and you need to remove all of its duplicate lines.
+
+### TL;DR
+
+To remove the duplicate lines while _preserving their order in the file_, use:
+
+
+```
+`awk '!visited[$0]++' your_file > deduplicated_file`
+```
+
+### How it works
+
+The script keeps an associative array with _indices_ equal to the unique lines of the file and _values_ equal to their occurrences. For each line of the file, if the line occurrences are zero, then it increases them by one and _prints the line_, otherwise, it just increases the occurrences _without printing the line_.
+
+I was not familiar with **awk**, and I wanted to understand how this can be accomplished with such a short script (**awk**ward). I did my research, and here is what is going on:
+
+ * The awk "script" **!visited[$0]++** is executed for _each line_ of the input file.
+ * **visited[]** is a variable of type [associative array][2] (a.k.a. [Map][3]). We don't have to initialize it because **awk** will do it the first time we access it.
+ * The **$0** variable holds the contents of the line currently being processed.
+ * **visited[$0]** accesses the value stored in the map with a key equal to **$0** (the line being processed), a.k.a. the occurrences (which we set below).
+ * The **!** negates the occurrences' value:
+ * In awk, [any nonzero numeric value or any nonempty string value is true][4].
+ * By default, [variables are initialized to the empty string][5], which is zero if converted to a number.
+ * That being said:
+ * If **visited[$0]** returns a number greater than zero, this negation is resolved to **false**.
+ * If **visited[$0]** returns a number equal to zero or an empty string, this negation is resolved to **true**.
+ * The **++** operation increases the variable's value (**visited[$0]**) by one.
+ * If the value is empty, **awk** converts it to **0** (number) automatically and then it gets increased.
+ * **Note:** The operation is executed after we access the variable's value.
+
+
+
+Summing up, the whole expression evaluates to:
+
+ * **true** if the occurrences are zero/empty string
+ * **false** if the occurrences are greater than zero
+
+
+
+**awk** statements consist of a [_pattern-expression_ and an _associated action_][6].
+
+
+```
+` {