mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-22 23:00:57 +08:00
commit
0366e2c23f
509
published/20150831 Linux workstation security checklist.md
Normal file
509
published/20150831 Linux workstation security checklist.md
Normal file
@ -0,0 +1,509 @@
|
||||
来自 Linux 基金会内部的《Linux 工作站安全检查清单》
|
||||
================================================================================
|
||||
|
||||
### 目标受众
|
||||
|
||||
这是一套 Linux 基金会为其系统管理员提供的推荐规范。
|
||||
|
||||
这个文档用于帮助那些使用 Linux 工作站来访问和管理项目的 IT 设施的系统管理员团队。
|
||||
|
||||
如果你的系统管理员是远程员工,你也许可以使用这套指导方针确保系统管理员的系统可以通过核心安全需求,降低你的IT 平台成为攻击目标的风险。
|
||||
|
||||
即使你的系统管理员不是远程员工,很多人也会在工作环境中通过便携笔记本完成工作,或者在家中设置系统以便在业余时间或紧急时刻访问工作平台。不论发生何种情况,你都能调整这个推荐规范来适应你的环境。
|
||||
|
||||
|
||||
### 限制
|
||||
|
||||
但是,这并不是一个详细的“工作站加固”文档,可以说这是一个努力避免大多数明显安全错误而不会导致太多不便的一组推荐基线(baseline)。你也许阅读这个文档后会认为它的方法太偏执,而另一些人也许会认为这仅仅是一些肤浅的研究。安全就像在高速公路上开车 -- 任何比你开的慢的都是一个傻瓜,然而任何比你开的快的人都是疯子。这个指南仅仅是一些列核心安全规则,既不详细又不能替代经验、警惕和常识。
|
||||
|
||||
我们分享这篇文档是为了[将开源协作的优势带到 IT 策略文献资料中][18]。如果你发现它有用,我们希望你可以将它用到你自己团体中,并分享你的改进,对它的完善做出你的贡献。
|
||||
|
||||
### 结构
|
||||
|
||||
每一节都分为两个部分:
|
||||
|
||||
- 核对适合你项目的需求
|
||||
- 形式不定的提示内容,解释了为什么这么做
|
||||
|
||||
#### 严重级别
|
||||
|
||||
在清单的每一个项目都包括严重级别,我们希望这些能帮助指导你的决定:
|
||||
|
||||
- **关键(ESSENTIAL)** 该项应该在考虑列表上被明确的重视。如果不采取措施,将会导致你的平台安全出现高风险。
|
||||
- **中等(NICE)** 该项将改善你的安全形势,但是会影响到你的工作环境的流程,可能会要求养成新的习惯,改掉旧的习惯。
|
||||
- **低等(PARANOID)** 留作感觉会明显完善我们平台安全、但是可能会需要大量调整与操作系统交互的方式的项目。
|
||||
|
||||
记住,这些只是参考。如果你觉得这些严重级别不能反映你的工程对安全的承诺,你应该调整它们为你所合适的。
|
||||
|
||||
## 选择正确的硬件
|
||||
|
||||
我们并不会要求管理员使用一个特殊供应商或者一个特殊的型号,所以这一节提供的是选择工作系统时的核心注意事项。
|
||||
|
||||
### 检查清单
|
||||
|
||||
- [ ] 系统支持安全启动(SecureBoot) _(关键)_
|
||||
- [ ] 系统没有火线(Firewire),雷电(thunderbolt)或者扩展卡(ExpressCard)接口 _(中等)_
|
||||
- [ ] 系统有 TPM 芯片 _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 安全启动(SecureBoot)
|
||||
|
||||
尽管它还有争议,但是安全引导能够预防很多针对工作站的攻击(Rootkits、“Evil Maid”,等等),而没有太多额外的麻烦。它并不能阻止真正专门的攻击者,加上在很大程度上,国家安全机构有办法应对它(可能是通过设计),但是有安全引导总比什么都没有强。
|
||||
|
||||
作为选择,你也许可以部署 [Anti Evil Maid][1] 提供更多健全的保护,以对抗安全引导所需要阻止的攻击类型,但是它需要更多部署和维护的工作。
|
||||
|
||||
#### 系统没有火线(Firewire),雷电(thunderbolt)或者扩展卡(ExpressCard)接口
|
||||
|
||||
火线是一个标准,其设计上允许任何连接的设备能够完全地直接访问你的系统内存(参见[维基百科][2])。雷电接口和扩展卡同样有问题,虽然一些后来部署的雷电接口试图限制内存访问的范围。如果你没有这些系统端口,那是最好的,但是它并不严重,它们通常可以通过 UEFI 关闭或内核本身禁用。
|
||||
|
||||
#### TPM 芯片
|
||||
|
||||
可信平台模块(Trusted Platform Module ,TPM)是主板上的一个与核心处理器单独分开的加密芯片,它可以用来增加平台的安全性(比如存储全盘加密的密钥),不过通常不会用于日常的平台操作。充其量,这个是一个有则更好的东西,除非你有特殊需求,需要使用 TPM 增加你的工作站安全性。
|
||||
|
||||
## 预引导环境
|
||||
|
||||
这是你开始安装操作系统前的一系列推荐规范。
|
||||
|
||||
### 检查清单
|
||||
|
||||
- [ ] 使用 UEFI 引导模式(不是传统 BIOS)_(关键)_
|
||||
- [ ] 进入 UEFI 配置需要使用密码 _(关键)_
|
||||
- [ ] 使用安全引导 _(关键)_
|
||||
- [ ] 启动系统需要 UEFI 级别密码 _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### UEFI 和安全引导
|
||||
|
||||
UEFI 尽管有缺点,还是提供了很多传统 BIOS 没有的好功能,比如安全引导。大多数现代的系统都默认使用 UEFI 模式。
|
||||
|
||||
确保进入 UEFI 配置模式要使用高强度密码。注意,很多厂商默默地限制了你使用密码长度,所以相比长口令你也许应该选择高熵值的短密码(关于密码短语请参考下面内容)。
|
||||
|
||||
基于你选择的 Linux 发行版,你也许需要、也许不需要按照 UEFI 的要求,来导入你的发行版的安全引导密钥,从而允许你启动该发行版。很多发行版已经与微软合作,用大多数厂商所支持的密钥给它们已发布的内核签名,因此避免了你必须处理密钥导入的麻烦。
|
||||
|
||||
作为一个额外的措施,在允许某人访问引导分区然后尝试做一些不好的事之前,让他们输入密码。为了防止肩窥(shoulder-surfing),这个密码应该跟你的 UEFI 管理密码不同。如果你经常关闭和启动,你也许不想这么麻烦,因为你已经必须输入 LUKS 密码了(LUKS 参见下面内容),这样会让你您减少一些额外的键盘输入。
|
||||
|
||||
## 发行版选择注意事项
|
||||
|
||||
很有可能你会坚持一个广泛使用的发行版如 Fedora,Ubuntu,Arch,Debian,或它们的一个类似发行版。无论如何,以下是你选择使用发行版应该考虑的。
|
||||
|
||||
### 检查清单
|
||||
|
||||
- [ ] 拥有一个强健的 MAC/RBAC 系统(SELinux/AppArmor/Grsecurity) _(关键)_
|
||||
- [ ] 发布安全公告 _(关键)_
|
||||
- [ ] 提供及时的安全补丁 _(关键)_
|
||||
- [ ] 提供软件包的加密验证 _(关键)_
|
||||
- [ ] 完全支持 UEFI 和安全引导 _(关键)_
|
||||
- [ ] 拥有健壮的原生全磁盘加密支持 _(关键)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### SELinux,AppArmor,和 GrSecurity/PaX
|
||||
|
||||
强制访问控制(Mandatory Access Controls,MAC)或者基于角色的访问控制(Role-Based Access Controls,RBAC)是一个用在老式 POSIX 系统的基于用户或组的安全机制扩展。现在大多数发行版已经捆绑了 MAC/RBAC 系统(Fedora,Ubuntu),或通过提供一种机制一个可选的安装后步骤来添加它(Gentoo,Arch,Debian)。显然,强烈建议您选择一个预装 MAC/RBAC 系统的发行版,但是如果你对某个没有默认启用它的发行版情有独钟,装完系统后应计划配置安装它。
|
||||
|
||||
应该坚决避免使用不带任何 MAC/RBAC 机制的发行版,像传统的 POSIX 基于用户和组的安全在当今时代应该算是考虑不足。如果你想建立一个 MAC/RBAC 工作站,通常认为 AppArmor 和 PaX 比 SELinux 更容易掌握。此外,在工作站上,很少有或者根本没有对外监听的守护进程,而针对用户运行的应用造成的最高风险,GrSecurity/PaX _可能_ 会比SELinux 提供更多的安全便利。
|
||||
|
||||
#### 发行版安全公告
|
||||
|
||||
大多数广泛使用的发行版都有一个给它们的用户发送安全公告的机制,但是如果你对一些机密感兴趣,去看看开发人员是否有见于文档的提醒用户安全漏洞和补丁的机制。缺乏这样的机制是一个重要的警告信号,说明这个发行版不够成熟,不能被用作主要管理员的工作站。
|
||||
|
||||
#### 及时和可靠的安全更新
|
||||
|
||||
多数常用的发行版提供定期安全更新,但应该经常检查以确保及时提供关键包更新。因此应避免使用附属发行版(spin-offs)和“社区重构”,因为它们必须等待上游发行版先发布,它们经常延迟发布安全更新。
|
||||
|
||||
现在,很难找到一个不使用加密签名、更新元数据或二者都不使用的发行版。如此说来,常用的发行版在引入这个基本安全机制就已经知道这些很多年了(Arch,说你呢),所以这也是值得检查的。
|
||||
|
||||
#### 发行版支持 UEFI 和安全引导
|
||||
|
||||
检查发行版是否支持 UEFI 和安全引导。查明它是否需要导入额外的密钥或是否要求启动内核有一个已经被系统厂商信任的密钥签名(例如跟微软达成合作)。一些发行版不支持 UEFI 或安全启动,但是提供了替代品来确保防篡改(tamper-proof)或防破坏(tamper-evident)引导环境([Qubes-OS][3] 使用 Anti Evil Maid,前面提到的)。如果一个发行版不支持安全引导,也没有防止引导级别攻击的机制,还是看看别的吧。
|
||||
|
||||
#### 全磁盘加密
|
||||
|
||||
全磁盘加密是保护静止数据的要求,大多数发行版都支持。作为一个选择方案,带有自加密硬盘的系统也可以用(通常通过主板 TPM 芯片实现),并提供了类似安全级别而且操作更快,但是花费也更高。
|
||||
|
||||
## 发行版安装指南
|
||||
|
||||
所有发行版都是不同的,但是也有一些一般原则:
|
||||
|
||||
### 检查清单
|
||||
|
||||
- [ ] 使用健壮的密码全磁盘加密(LUKS) _(关键)_
|
||||
- [ ] 确保交换分区也加密了 _(关键)_
|
||||
- [ ] 确保引导程序设置了密码(可以和LUKS一样) _(关键)_
|
||||
- [ ] 设置健壮的 root 密码(可以和LUKS一样) _(关键)_
|
||||
- [ ] 使用无特权账户登录,作为管理员组的一部分 _(关键)_
|
||||
- [ ] 设置健壮的用户登录密码,不同于 root 密码 _(关键)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 全磁盘加密
|
||||
|
||||
除非你正在使用自加密硬盘,配置你的安装程序完整地加密所有存储你的数据与系统文件的磁盘很重要。简单地通过自动挂载的 cryptfs 环(loop)文件加密用户目录还不够(说你呢,旧版 Ubuntu),这并没有给系统二进制文件或交换分区提供保护,它可能包含大量的敏感数据。推荐的加密策略是加密 LVM 设备,以便在启动过程中只需要一个密码。
|
||||
|
||||
`/boot`分区将一直保持非加密,因为引导程序需要在调用 LUKS/dm-crypt 前能引导内核自身。一些发行版支持加密的`/boot`分区,比如 [Arch][16],可能别的发行版也支持,但是似乎这样增加了系统更新的复杂度。如果你的发行版并没有原生支持加密`/boot`也不用太在意,内核镜像本身并没有什么隐私数据,它会通过安全引导的加密签名检查来防止被篡改。
|
||||
|
||||
#### 选择一个好密码
|
||||
|
||||
现代的 Linux 系统没有限制密码口令长度,所以唯一的限制是你的偏执和倔强。如果你要启动你的系统,你将大概至少要输入两个不同的密码:一个解锁 LUKS ,另一个登录,所以长密码将会使你老的更快。最好从丰富或混合的词汇中选择2-3个单词长度,容易输入的密码。
|
||||
|
||||
优秀密码例子(是的,你可以使用空格):
|
||||
|
||||
- nature abhors roombas
|
||||
- 12 in-flight Jebediahs
|
||||
- perdon, tengo flatulence
|
||||
|
||||
如果你喜欢输入可以在公开场合和你生活中能见到的句子,比如:
|
||||
|
||||
- Mary had a little lamb
|
||||
- you're a wizard, Harry
|
||||
- to infinity and beyond
|
||||
|
||||
如果你愿意的话,你也应该带上最少要 10-12个字符长度的非词汇的密码。
|
||||
|
||||
除非你担心物理安全,你可以写下你的密码,并保存在一个远离你办公桌的安全的地方。
|
||||
|
||||
#### Root,用户密码和管理组
|
||||
|
||||
我们建议,你的 root 密码和你的 LUKS 加密使用同样的密码(除非你共享你的笔记本给信任的人,让他应该能解锁设备,但是不应该能成为 root 用户)。如果你是笔记本电脑的唯一用户,那么你的 root 密码与你的 LUKS 密码不同是没有安全优势上的意义的。通常,你可以使用同样的密码在你的 UEFI 管理,磁盘加密,和 root 登录中 -- 知道这些任意一个都会让攻击者完全控制您的系统,在单用户工作站上使这些密码不同,没有任何安全益处。
|
||||
|
||||
你应该有一个不同的,但同样强健的常规用户帐户密码用来日常工作。这个用户应该是管理组用户(例如`wheel`或者类似,根据发行版不同),允许你执行`sudo`来提升权限。
|
||||
|
||||
换句话说,如果在你的工作站只有你一个用户,你应该有两个独特的、强健(robust)而强壮(strong)的密码需要记住:
|
||||
|
||||
**管理级别**,用在以下方面:
|
||||
|
||||
- UEFI 管理
|
||||
- 引导程序(GRUB)
|
||||
- 磁盘加密(LUKS)
|
||||
- 工作站管理(root 用户)
|
||||
|
||||
**用户级别**,用在以下:
|
||||
|
||||
- 用户登录和 sudo
|
||||
- 密码管理器的主密码
|
||||
|
||||
很明显,如果有一个令人信服的理由的话,它们全都可以不同。
|
||||
|
||||
## 安装后的加固
|
||||
|
||||
安装后的安全加固在很大程度上取决于你选择的发行版,所以在一个像这样的通用文档中提供详细说明是徒劳的。然而,这里有一些你应该采取的步骤:
|
||||
|
||||
### 检查清单
|
||||
|
||||
- [ ] 在全局范围内禁用火线和雷电模块 _(关键)_
|
||||
- [ ] 检查你的防火墙,确保过滤所有传入端口 _(关键)_
|
||||
- [ ] 确保 root 邮件转发到一个你可以收到的账户 _(关键)_
|
||||
- [ ] 建立一个系统自动更新任务,或更新提醒 _(中等)_
|
||||
- [ ] 检查以确保 sshd 服务默认情况下是禁用的 _(中等)_
|
||||
- [ ] 配置屏幕保护程序在一段时间的不活动后自动锁定 _(中等)_
|
||||
- [ ] 设置 logwatch _(中等)_
|
||||
- [ ] 安装使用 rkhunter _(中等)_
|
||||
- [ ] 安装一个入侵检测系统(Intrusion Detection System) _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 将模块列入黑名单
|
||||
|
||||
将火线和雷电模块列入黑名单,增加一行到`/etc/modprobe.d/blacklist-dma.conf`文件:
|
||||
|
||||
blacklist firewire-core
|
||||
blacklist thunderbolt
|
||||
|
||||
重启后的这些模块将被列入黑名单。这样做是无害的,即使你没有这些端口(但也不做任何事)。
|
||||
|
||||
#### Root 邮件
|
||||
|
||||
默认的 root 邮件只是存储在系统基本上没人读过。确保你设置了你的`/etc/aliases`来转发 root 邮件到你确实能读取的邮箱,否则你也许错过了重要的系统通知和报告:
|
||||
|
||||
# Person who should get root's mail
|
||||
root: bob@example.com
|
||||
|
||||
编辑后这些后运行`newaliases`,然后测试它确保能投递到,像一些邮件供应商将拒绝来自不存在的域名或者不可达的域名的邮件。如果是这个原因,你需要配置邮件转发直到确实可用。
|
||||
|
||||
#### 防火墙,sshd,和监听进程
|
||||
|
||||
默认的防火墙设置将取决于您的发行版,但是大多数都允许`sshd`端口连入。除非你有一个令人信服的合理理由允许连入 ssh,你应该过滤掉它,并禁用 sshd 守护进程。
|
||||
|
||||
systemctl disable sshd.service
|
||||
systemctl stop sshd.service
|
||||
|
||||
如果你需要使用它,你也可以临时启动它。
|
||||
|
||||
通常,你的系统不应该有任何侦听端口,除了响应 ping 之外。这将有助于你对抗网络级的零日漏洞利用。
|
||||
|
||||
#### 自动更新或通知
|
||||
|
||||
建议打开自动更新,除非你有一个非常好的理由不这么做,如果担心自动更新将使您的系统无法使用(以前发生过,所以这种担心并非杞人忧天)。至少,你应该启用自动通知可用的更新。大多数发行版已经有这个服务自动运行,所以你不需要做任何事。查阅你的发行版文档了解更多。
|
||||
|
||||
你应该尽快应用所有明显的勘误,即使这些不是特别贴上“安全更新”或有关联的 CVE 编号。所有的问题都有潜在的安全漏洞和新的错误,比起停留在旧的、已知的问题上,未知问题通常是更安全的策略。
|
||||
|
||||
#### 监控日志
|
||||
|
||||
你应该会对你的系统上发生了什么很感兴趣。出于这个原因,你应该安装`logwatch`然后配置它每夜发送在你的系统上发生的任何事情的活动报告。这不会预防一个专业的攻击者,但是一个不错的安全网络功能。
|
||||
|
||||
注意,许多 systemd 发行版将不再自动安装一个“logwatch”所需的 syslog 服务(因为 systemd 会放到它自己的日志中),所以你需要安装和启用“rsyslog”来确保在使用 logwatch 之前你的 /var/log 不是空的。
|
||||
|
||||
#### Rkhunter 和 IDS
|
||||
|
||||
安装`rkhunter`和一个类似`aide`或者`tripwire`入侵检测系统(IDS)并不是那么有用,除非你确实理解它们如何工作,并采取必要的步骤来设置正确(例如,保证数据库在外部介质,从可信的环境运行检测,记住执行系统更新和配置更改后要刷新散列数据库,等等)。如果你不愿在你的工作站执行这些步骤,并调整你如何工作的方式,这些工具只能带来麻烦而没有任何实在的安全益处。
|
||||
|
||||
我们建议你安装`rkhunter`并每晚运行它。它相当易于学习和使用,虽然它不会阻止一个复杂的攻击者,它也能帮助你捕获你自己的错误。
|
||||
|
||||
## 个人工作站备份
|
||||
|
||||
工作站备份往往被忽视,或偶尔才做一次,这常常是不安全的方式。
|
||||
|
||||
### 检查清单
|
||||
|
||||
- [ ] 设置加密备份工作站到外部存储 _(关键)_
|
||||
- [ ] 使用零认知(zero-knowledge)备份工具备份到站外或云上 _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 全加密的备份存到外部存储
|
||||
|
||||
把全部备份放到一个移动磁盘中比较方便,不用担心带宽和上行网速(在这个时代,大多数供应商仍然提供显著的不对称的上传/下载速度)。不用说,这个移动硬盘本身需要加密(再说一次,通过 LUKS),或者你应该使用一个备份工具建立加密备份,例如`duplicity`或者它的 GUI 版本 `deja-dup`。我建议使用后者并使用随机生成的密码,保存到离线的安全地方。如果你带上笔记本去旅行,把这个磁盘留在家,以防你的笔记本丢失或被窃时可以找回备份。
|
||||
|
||||
除了你的家目录外,你还应该备份`/etc`目录和出于取证目的的`/var/log`目录。
|
||||
|
||||
尤其重要的是,避免拷贝你的家目录到任何非加密存储上,即使是需要快速的在两个系统上移动文件时,一旦完成你肯定会忘了清除它,从而暴露个人隐私或者安全信息到监听者手中 -- 尤其是把这个存储介质跟你的笔记本放到同一个包里。
|
||||
|
||||
#### 有选择的零认知站外备份
|
||||
|
||||
站外备份(Off-site backup)也是相当重要的,是否可以做到要么需要你的老板提供空间,要么找一家云服务商。你可以建一个单独的 duplicity/deja-dup 配置,只包括重要的文件,以免传输大量你不想备份的数据(网络缓存、音乐、下载等等)。
|
||||
|
||||
作为选择,你可以使用零认知(zero-knowledge)备份工具,例如 [SpiderOak][5],它提供一个卓越的 Linux GUI工具还有更多的实用特性,例如在多个系统或平台间同步内容。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
下面是我们认为你应该采用的最佳实践列表。它当然不是非常详细的,而是试图提供实用的建议,来做到可行的整体安全性和可用性之间的平衡。
|
||||
|
||||
### 浏览
|
||||
|
||||
毫无疑问, web 浏览器将是你的系统上最大、最容易暴露的面临攻击的软件。它是专门下载和执行不可信、甚至是恶意代码的一个工具。它试图采用沙箱和代码清洁(code sanitization)等多种机制保护你免受这种危险,但是在之前它们都被击败了多次。你应该知道,在任何时候浏览网站都是你做的最不安全的活动。
|
||||
|
||||
有几种方法可以减少浏览器的影响,但这些真实有效的方法需要你明显改变操作您的工作站的方式。
|
||||
|
||||
#### 1: 使用两个不同的浏览器 _(关键)_
|
||||
|
||||
这很容易做到,但是只有很少的安全效益。并不是所有浏览器都可以让攻击者完全自由访问您的系统 -- 有时它们只能允许某人读取本地浏览器存储,窃取其它标签的活动会话,捕获浏览器的输入等。使用两个不同的浏览器,一个用在工作/高安全站点,另一个用在其它方面,有助于防止攻击者请求整个 cookie 存储的小问题。主要的不便是两个不同的浏览器会消耗大量内存。
|
||||
|
||||
我们建议:
|
||||
|
||||
##### 火狐用来访问工作和高安全站点
|
||||
|
||||
使用火狐登录工作有关的站点,应该额外关心的是确保数据如 cookies,会话,登录信息,击键等等,明显不应该落入攻击者手中。除了少数的几个网站,你不应该用这个浏览器访问其它网站。
|
||||
|
||||
你应该安装下面的火狐扩展:
|
||||
|
||||
- [ ] NoScript _(关键)_
|
||||
- NoScript 阻止活动内容加载,除非是在用户白名单里的域名。如果用于默认浏览器它会很麻烦(可是提供了真正好的安全效益),所以我们建议只在访问与工作相关的网站的浏览器上开启它。
|
||||
|
||||
- [ ] Privacy Badger _(关键)_
|
||||
- EFF 的 Privacy Badger 将在页面加载时阻止大多数外部追踪器和广告平台,有助于在这些追踪站点影响你的浏览器时避免跪了(追踪器和广告站点通常会成为攻击者的目标,因为它们能会迅速影响世界各地成千上万的系统)。
|
||||
|
||||
- [ ] HTTPS Everywhere _(关键)_
|
||||
- 这个 EFF 开发的扩展将确保你访问的大多数站点都使用安全连接,甚至你点击的连接使用的是 http://(可以有效的避免大多数的攻击,例如[SSL-strip][7])。
|
||||
|
||||
- [ ] Certificate Patrol _(中等)_
|
||||
- 如果你正在访问的站点最近改变了它们的 TLS 证书,这个工具将会警告你 -- 特别是如果不是接近失效期或者现在使用不同的证书颁发机构。它有助于警告你是否有人正尝试中间人攻击你的连接,不过它会产生很多误报。
|
||||
|
||||
你应该让火狐成为你打开连接时的默认浏览器,因为 NoScript 将在加载或者执行时阻止大多数活动内容。
|
||||
|
||||
##### 其它一切都用 Chrome/Chromium
|
||||
|
||||
Chromium 开发者在增加很多很好的安全特性方面走在了火狐前面(至少[在 Linux 上][6]),例如 seccomp 沙箱,内核用户空间等等,这会成为一个你访问的网站与你其它系统之间的额外隔离层。Chromium 是上游开源项目,Chrome 是 Google 基于它构建的专有二进制包(加一句偏执的提醒,如果你有任何不想让谷歌知道的事情都不要使用它)。
|
||||
|
||||
推荐你在 Chrome 上也安装**Privacy Badger** 和 **HTTPS Everywhere** 扩展,然后给它一个与火狐不同的主题,以让它告诉你这是你的“不可信站点”浏览器。
|
||||
|
||||
#### 2: 使用两个不同浏览器,一个在专用的虚拟机里 _(中等)_
|
||||
|
||||
这有点像上面建议的做法,除了您将添加一个通过快速访问协议运行在专用虚拟机内部 Chrome 的额外步骤,它允许你共享剪贴板和转发声音事件(如,Spice 或 RDP)。这将在不可信浏览器和你其它的工作环境之间添加一个优秀的隔离层,确保攻击者完全危害你的浏览器将必须另外打破 VM 隔离层,才能达到系统的其余部分。
|
||||
|
||||
这是一个鲜为人知的可行方式,但是需要大量的 RAM 和高速的处理器来处理多增加的负载。这要求作为管理员的你需要相应地调整自己的工作实践而付出辛苦。
|
||||
|
||||
#### 3: 通过虚拟化完全隔离你的工作和娱乐环境 _(低等)_
|
||||
|
||||
了解下 [Qubes-OS 项目][3],它致力于通过划分你的应用到完全隔离的 VM 中来提供高度安全的工作环境。
|
||||
|
||||
### 密码管理器
|
||||
|
||||
#### 检查清单
|
||||
|
||||
- [ ] 使用密码管理器 _(关键)_
|
||||
- [ ] 不相关的站点使用不同的密码 _(关键)_
|
||||
- [ ] 使用支持团队共享的密码管理器 _(中等)_
|
||||
- [ ] 给非网站类账户使用一个单独的密码管理器 _(低等)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
使用好的、唯一的密码对你的团队成员来说应该是非常关键的需求。凭证(credential)盗取一直在发生 — 通过被攻破的计算机、盗取数据库备份、远程站点利用、以及任何其它的方式。凭证绝不应该跨站点重用,尤其是关键的应用。
|
||||
|
||||
##### 浏览器中的密码管理器
|
||||
|
||||
每个浏览器有一个比较安全的保存密码机制,可以同步到供应商维护的,并使用用户的密码保证数据加密。然而,这个机制有严重的劣势:
|
||||
|
||||
1. 不能跨浏览器工作
|
||||
2. 不提供任何与团队成员共享凭证的方法
|
||||
|
||||
也有一些支持良好、免费或便宜的密码管理器,可以很好的融合到多个浏览器,跨平台工作,提供小组共享(通常是付费服务)。可以很容易地通过搜索引擎找到解决方案。
|
||||
|
||||
##### 独立的密码管理器
|
||||
|
||||
任何与浏览器结合的密码管理器都有一个主要的缺点,它实际上是应用的一部分,这样最有可能被入侵者攻击。如果这让你不放心(应该这样),你应该选择两个不同的密码管理器 -- 一个集成在浏览器中用来保存网站密码,一个作为独立运行的应用。后者可用于存储高风险凭证如 root 密码、数据库密码、其它 shell 账户凭证等。
|
||||
|
||||
这样的工具在团队成员间共享超级用户的凭据方面特别有用(服务器 root 密码、ILO密码、数据库管理密码、引导程序密码等等)。
|
||||
|
||||
这几个工具可以帮助你:
|
||||
|
||||
- [KeePassX][8],在第2版中改进了团队共享
|
||||
- [Pass][9],它使用了文本文件和 PGP,并与 git 结合
|
||||
- [Django-Pstore][10],它使用 GPG 在管理员之间共享凭据
|
||||
- [Hiera-Eyaml][11],如果你已经在你的平台中使用了 Puppet,在你的 Hiera 加密数据的一部分里面,可以便捷的追踪你的服务器/服务凭证。
|
||||
|
||||
### 加固 SSH 与 PGP 的私钥
|
||||
|
||||
个人加密密钥,包括 SSH 和 PGP 私钥,都是你工作站中最重要的物品 -- 这是攻击者最想得到的东西,这可以让他们进一步攻击你的平台或在其它管理员面前冒充你。你应该采取额外的步骤,确保你的私钥免遭盗窃。
|
||||
|
||||
#### 检查清单
|
||||
|
||||
- [ ] 用来保护私钥的强壮密码 _(关键)_
|
||||
- [ ] PGP 的主密码保存在移动存储中 _(中等)_
|
||||
- [ ] 用于身份验证、签名和加密的子密码存储在智能卡设备 _(中等)_
|
||||
- [ ] SSH 配置为以 PGP 认证密钥作为 ssh 私钥 _(中等)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
防止私钥被偷的最好方式是使用一个智能卡存储你的加密私钥,绝不要拷贝到工作站上。有几个厂商提供支持 OpenPGP 的设备:
|
||||
|
||||
- [Kernel Concepts][12],在这里可以采购支持 OpenPGP 的智能卡和 USB 读取器,你应该需要一个。
|
||||
- [Yubikey NEO][13],这里提供 OpenPGP 功能的智能卡还提供很多很酷的特性(U2F、PIV、HOTP等等)。
|
||||
|
||||
确保 PGP 主密码没有存储在工作站也很重要,仅使用子密码。主密钥只有在签名其它的密钥和创建新的子密钥时使用 — 不经常发生这种操作。你可以照着 [Debian 的子密钥][14]向导来学习如何将你的主密钥移动到移动存储并创建子密钥。
|
||||
|
||||
你应该配置你的 gnupg 代理作为 ssh 代理,然后使用基于智能卡 PGP 认证密钥作为你的 ssh 私钥。我们发布了一个[详尽的指导][15]如何使用智能卡读取器或 Yubikey NEO。
|
||||
|
||||
如果你不想那么麻烦,最少要确保你的 PGP 私钥和你的 SSH 私钥有个强健的密码,这将让攻击者很难盗取使用它们。
|
||||
|
||||
### 休眠或关机,不要挂起
|
||||
|
||||
当系统挂起时,内存中的内容仍然保留在内存芯片中,可以会攻击者读取到(这叫做冷启动攻击(Cold Boot Attack))。如果你离开你的系统的时间较长,比如每天下班结束,最好关机或者休眠,而不是挂起它或者就那么开着。
|
||||
|
||||
### 工作站上的 SELinux
|
||||
|
||||
如果你使用捆绑了 SELinux 的发行版(如 Fedora),这有些如何使用它的建议,让你的工作站达到最大限度的安全。
|
||||
|
||||
#### 检查清单
|
||||
|
||||
- [ ] 确保你的工作站强制(enforcing)使用 SELinux _(关键)_
|
||||
- [ ] 不要盲目的执行`audit2allow -M`,应该经常检查 _(关键)_
|
||||
- [ ] 绝不要 `setenforce 0` _(中等)_
|
||||
- [ ] 切换你的用户到 SELinux 用户`staff_u` _(中等)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
SELinux 是强制访问控制(Mandatory Access Controls,MAC),是 POSIX许可核心功能的扩展。它是成熟、强健,自从它推出以来已经有很长的路了。不管怎样,许多系统管理员现在仍旧重复过时的口头禅“关掉它就行”。
|
||||
|
||||
话虽如此,在工作站上 SELinux 会带来一些有限的安全效益,因为大多数你想运行的应用都是可以自由运行的。开启它有益于给网络提供足够的保护,也有可能有助于防止攻击者通过脆弱的后台服务提升到 root 级别的权限用户。
|
||||
|
||||
我们的建议是开启它并强制使用(enforcing)。
|
||||
|
||||
##### 绝不`setenforce 0`
|
||||
|
||||
使用`setenforce 0`临时把 SELinux 设置为许可(permissive)模式很有诱惑力,但是你应该避免这样做。当你想查找一个特定应用或者程序的问题时,实际上这样做是把整个系统的 SELinux 给关闭了。
|
||||
|
||||
你应该使用`semanage permissive -a [somedomain_t]`替换`setenforce 0`,只把这个程序放入许可模式。首先运行`ausearch`查看哪个程序发生问题:
|
||||
|
||||
ausearch -ts recent -m avc
|
||||
|
||||
然后看下`scontext=`(源自 SELinux 的上下文)行,像这样:
|
||||
|
||||
scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
|
||||
^^^^^^^^^^^^^^
|
||||
|
||||
这告诉你程序`gpg_pinentry_t`被拒绝了,所以你想排查应用的故障,应该增加它到许可域:
|
||||
|
||||
semange permissive -a gpg_pinentry_t
|
||||
|
||||
这将允许你使用应用然后收集 AVC 的其它数据,你可以结合`audit2allow`来写一个本地策略。一旦完成你就不会看到新的 AVC 的拒绝消息,你就可以通过运行以下命令从许可中删除程序:
|
||||
|
||||
semanage permissive -d gpg_pinentry_t
|
||||
|
||||
##### 用 SELinux 的用户 staff_r 使用你的工作站
|
||||
|
||||
SELinux 带有角色(role)的原生实现,基于用户帐户相关角色来禁止或授予某些特权。作为一个管理员,你应该使用`staff_r`角色,这可以限制访问很多配置和其它安全敏感文件,除非你先执行`sudo`。
|
||||
|
||||
默认情况下,用户以`unconfined_r`创建,你可以自由运行大多数应用,没有任何(或只有一点)SELinux 约束。转换你的用户到`staff_r`角色,运行下面的命令:
|
||||
|
||||
usermod -Z staff_u [username]
|
||||
|
||||
你应该退出然后登录新的角色,届时如果你运行`id -Z`,你将会看到:
|
||||
|
||||
staff_u:staff_r:staff_t:s0-s0:c0.c1023
|
||||
|
||||
在执行`sudo`时,你应该记住增加一个额外标志告诉 SELinux 转换到“sysadmin”角色。你需要用的命令是:
|
||||
|
||||
sudo -i -r sysadm_r
|
||||
|
||||
然后`id -Z`将会显示:
|
||||
|
||||
staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
|
||||
|
||||
**警告**:在进行这个切换前你应该能很顺畅的使用`ausearch`和`audit2allow`,当你以`staff_r`角色运行时你的应用有可能不再工作了。在写作本文时,已知以下流行的应用在`staff_r`下没有做策略调整就不会工作:
|
||||
|
||||
- Chrome/Chromium
|
||||
- Skype
|
||||
- VirtualBox
|
||||
|
||||
切换回`unconfined_r`,运行下面的命令:
|
||||
|
||||
usermod -Z unconfined_u [username]
|
||||
|
||||
然后注销再重新回到舒适区。
|
||||
|
||||
## 延伸阅读
|
||||
|
||||
IT 安全的世界是一个没有底的兔子洞。如果你想深入,或者找到你的具体发行版更多的安全特性,请查看下面这些链接:
|
||||
|
||||
- [Fedora 安全指南](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
|
||||
- [CESG Ubuntu 安全指南](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
|
||||
- [Debian 安全手册](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
|
||||
- [Arch Linux 安全维基](https://wiki.archlinux.org/index.php/Security)
|
||||
- [Mac OSX 安全](https://www.apple.com/support/security/guides/)
|
||||
|
||||
## 许可
|
||||
|
||||
这项工作在[创作共用授权4.0国际许可证][0]许可下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/lfit/itpol/blob/bbc17d8c69cb8eee07ec41f8fbf8ba32fdb4301b/linux-workstation-security.md
|
||||
|
||||
作者:[mricon][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mricon
|
||||
[0]: http://creativecommons.org/licenses/by-sa/4.0/
|
||||
[1]: https://github.com/QubesOS/qubes-antievilmaid
|
||||
[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
|
||||
[3]: https://qubes-os.org/
|
||||
[4]: https://xkcd.com/936/
|
||||
[5]: https://spideroak.com/
|
||||
[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
|
||||
[7]: http://www.thoughtcrime.org/software/sslstrip/
|
||||
[8]: https://keepassx.org/
|
||||
[9]: http://www.passwordstore.org/
|
||||
[10]: https://pypi.python.org/pypi/django-pstore
|
||||
[11]: https://github.com/TomPoulton/hiera-eyaml
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
[16]: http://www.pavelkogan.com/2014/05/23/luks-full-disk-encryption/
|
||||
[17]: https://en.wikipedia.org/wiki/Cold_boot_attack
|
||||
[18]: http://www.linux.com/news/featured-blogs/167-amanda-mcpherson/850607-linux-foundation-sysadmins-open-source-their-it-policies
|
||||
89
sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
Normal file → Executable file
89
sources/tech/20150917 A Repository with 44 Years of Unix Evolution.md
Normal file → Executable file
@ -1,33 +1,32 @@
|
||||
translating wi-cuckoo
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
一个涵盖 Unix 44 年进化史的仓库
|
||||
=============================================================================
|
||||
### 摘要 ###
|
||||
|
||||
The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
|
||||
Unix 操作系统的进化历史,可以从一个版本控制的仓库中窥见,时间跨越从 1972 年以 5000 行内核代码的出现,到 2015 年成为一个含有 26,000,000 行代码的被广泛使用的系统。该仓库包含 659,000 条提交,和 2306 次合并。仓库部署被普遍采用的 Git 系统储存其代码,并且在时下流行的 GitHub 上建立了档案。它综合了系统定制软件的 24 个快照,都是开发自贝尔实验室,伯克利大学,386BSD 团队,两个传统的仓库 和 开源 FreeBSD 系统的仓库。总的来说,850 位个人贡献者已经确认,更早些时候的一批人主要做基础研究。这些数据可以用于一些经验性的研究,在软件工程,信息系统和软件考古学领域。
|
||||
|
||||
### 1 Introduction ###
|
||||
### 1 介绍 ###
|
||||
|
||||
The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
|
||||
Unix 操作系统作为一个主要的工程上的突破而脱颖而出,得益于其模范的设计,大量的技术贡献,它的开发模型和广泛的使用。Unix 编程环境的设计已经被标榜为一个能提供非常简洁,功能强大并且优雅的设计[[1][1]]。在技术方面,许多对 Unix 有直接贡献的,或者因 Unix 而流行的特性就包括[[2][2]]:用高级语言编写的可移植部署的内核;一个分层式设计的文件系统;兼容的文件,设备,网络和进程间 I/O;管道和过滤架构;虚拟文件系统;和用户可选的 shell。很早的时候,就有一个庞大的社区为 Unix 贡献软件[[3][3]],[[4][4]],pp. 65-72]。随时间流走,这个社区不断壮大,并且以现在称为开源软件开发的方式在工作着[[5][5],pp. 440-442]。Unix 和其睿智的晚辈们也将 C 和 C++ 编程语言,分析程序和词法分析生成器(*yacc,lex*),发扬光大了,文档编制工具(*troff,eqn,tbl*),脚本语言(*awk,sed,Perl*),TCP/IP 网络,和配置管理系统(*SCSS,RCS,Subversion,Git*)发扬广大了,同时也形成了大部分的现代互联网基础设施和网络。
|
||||
|
||||
Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
|
||||
幸运的是,一些重要的具有历史意义的 Unix 材料已经保存下来了,现在保持对外开放。尽管 Unix 最初是由相对严格的协议发行,但在早期的开发中,很多重要的部分是通过 Unix 的某个版权拥有者以一个自由的协议发行。然后将这些部分再结合开发的软件或者以开源发行的软件,Berkeley,Californai 大学和 FreeBSD 项目组从 1972 年六月二十日开始到现在,提供了涵盖整个系统的开发。
|
||||
|
||||
Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
|
||||
|
||||
### 2 Data Overview ###
|
||||
### 2. 数据概览 ###
|
||||
|
||||
The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
|
||||
这 1GB 的 Unix 仓库可以从 [GitHub][9] 克隆。[1][10]如今[2][11],这个仓库包含来自 850 个贡献者的 659,000 个提交和 2306 个合并。贡献者有来自 Bell 实验室的 23 个员工,Berkeley 计算机系统研究组(CSRG)的 158 个人,和 FreeBSD 项目的 660 个成员。
|
||||
|
||||
The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
|
||||
这个仓库的生命始于一个 *Epoch* 的标签,这里面只包含了证书信息和现在的 README 文件。其后各种各样的标签和分支记录了很多重要的时刻。
|
||||
|
||||
- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
|
||||
- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
|
||||
- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
|
||||
- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
|
||||
- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
|
||||
- *Research-VX* 标签对应来自 Bell 实验室六次的研究版本。从 *Research-V1* (PDP-11 4768 行汇编代码)开始,到以 *Research-V7* (大约 324,000 行代码,1820 个 C 文件)结束。
|
||||
- *Bell-32V* 是 DEC/VAX 架构的 Unix 第七个版本的一部分。
|
||||
- *BSD-X* 标签对应 Berkeley 释出的 15 个快照。
|
||||
- *386BSD-X* 标签对应系统的两个开源版本,主要是 Lynne 和 William Jolitz 写的 适用于 Intel 386 架构的内核代码。
|
||||
- *FreeBSD-release/X* 标签和分支标记了来自 FreeBSD 项目的 116 个发行版。
|
||||
|
||||
In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
|
||||
另外,以 *-Snapshot-Development* 为后缀的分支,表示一个被综合的以时间排序的快照文件序列的一些提交,而以一个 *-VCS-Development* 为后缀的标签,标记了有特别发行版出现的历史分支的时刻。
|
||||
|
||||
The repository's history includes commits from the earliest days of the system's development, such as the following.
|
||||
仓库的历史包含从系统开发早期的一些提交,比如下面这些。
|
||||
|
||||
commit c9f643f59434f14f774d61ee3856972b8c3905b1
|
||||
Author: Dennis Ritchie <research!dmr>
|
||||
@ -35,69 +34,69 @@ The repository's history includes commits from the earliest days of the system's
|
||||
Research V5 development
|
||||
Work on file usr/sys/dmr/kl.c
|
||||
|
||||
Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
|
||||
释出间隙的合并随着系统进化而发生,比如 从 BSD 2 到 BSD 3 的开发,Unix 32/V 也是正确地代表了 Git 仓库里带两个父节点的图形节点。(这太莫名其妙了)
|
||||
|
||||
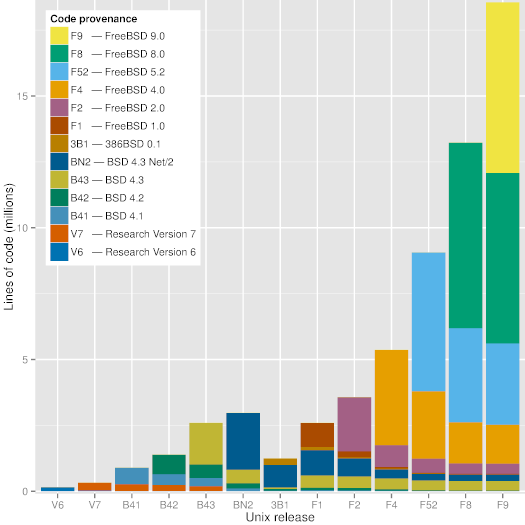
More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
|
||||
更为重要的是,该仓库的构造方式允许 **git blame**,就是可以给源代码加上注释,如版本,日期和它们第一次出现相关联的作者,这样可以知道任何代码的起源。比如说 **BSD-4** 这个标签,在内核的 *pipe.c* 文件上运行一下 git blame,就会显示代码行由 Ken Thompson 写于 1974,1975 和 1979年,Bill Joy 写于 1980 年。这就可以自动(尽管计算上比较费事)检测出任何时刻出现的代码。
|
||||
|
||||
|
||||
|
||||
Figure 1: Code provenance across significant Unix releases.
|
||||
|
||||
As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
|
||||
如上图[12]所示,现代版本的 Unix(FreeBSD 9)依然有来自 BSD 4.3,BSD 4.3 Net/2 和 BSD 2.0 的代码块。有趣的是,这图片显示有部分代码好像没有保留下来,当时激进地要创造一个脱离于 Berkeyel(386BSD 和 FreeBSD 1.0)释出代码的开源操作系统,其所开发的代码。FreeBSD 9 中最古老的代码是一个 18 行的队列,在 C 库里面的 timezone.c 文件里,该文件也可以在第七版的 Unix 文件里找到,同样的名字,时间戳是 1979 年一月十日 - 36 年前。
|
||||
|
||||
### 3 Data Collection and Processing ###
|
||||
### 数据收集和处理 ###
|
||||
|
||||
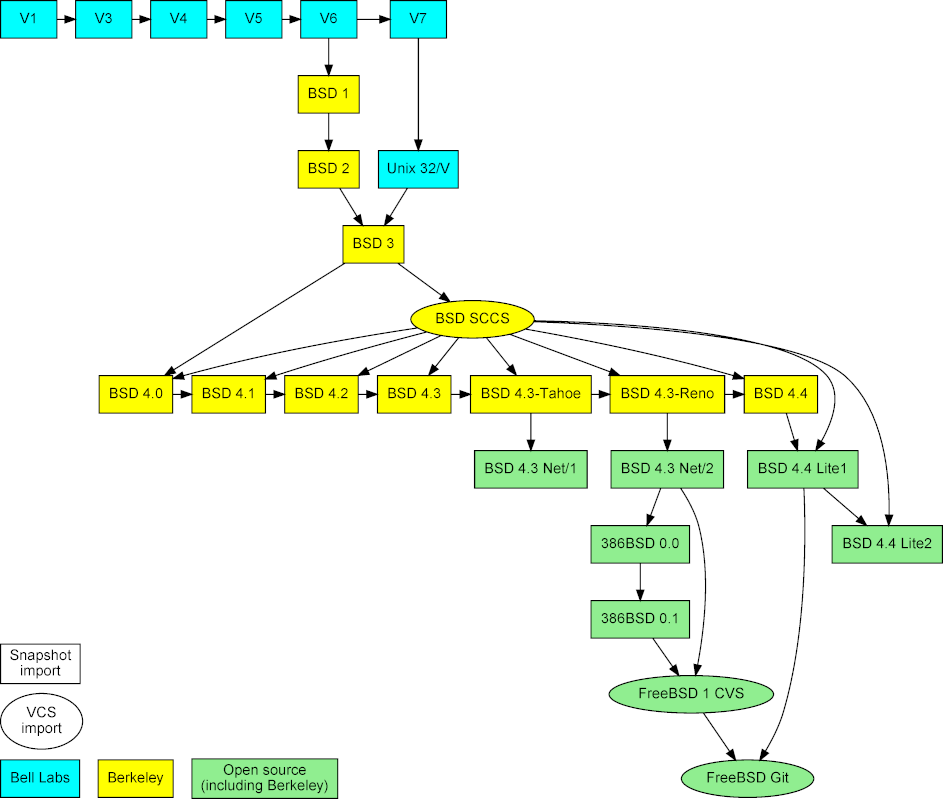
The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
|
||||
这个项目的目的是以某种方式巩固从数据方面说明 Unix 的进化,通过将其并入一个现代的修订仓库,帮助人们对系统进化的研究。项目工作包括收录数据,分类并综合到一个单独的 Git 仓库里。
|
||||
|
||||
|
||||
|
||||
Figure 2: Imported Unix snapshots, repositories, and their mergers.
|
||||
|
||||
The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
|
||||
项目以三种数据类型为基础(见 Figure [2][13])。首先,早些发布的版本快照,是从 [Unix Heritage Society archive][14] 中获得,[2][15] 在 [CD-ROM 镜像][16] 中包括 CSRG 全部的源包,[4][17] [Oldlinux site],[5][19] 和 [FreeBSD 包][20]。[6][21] 其次,以前的,现在的仓库,也就是 CSRG SCCS [[6][22]] 仓库,FreeBSD 1 CVS 仓库,和[现代 FreeBSD 开发的 Git 镜像][23]。[7][24]前两个都是从相同的源获得而作为对应的快照。
|
||||
|
||||
The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
|
||||
最后,也是最费力的数据源是 **primary research**。释出的快照并没有提供关于它们的源头和每个文件贡献者的信息。因此,这些信息片段需要通过 primary research 验证。至于作者信息主要通过作者的自传,研究论文,内部备忘录和旧文档扫描;通过阅读并且自动处理源代码和帮助页面补充;通过与那个年代的人用电子邮件交流;在 *StackExchange* 网站上贴出疑问;查看文件的位置(在早期的内核源代码版本中,分为 `usr/sys/dmr` 和 `/usr/sys/ken`);从研究论文和帮助手册到源代码,从一个发行版到另一个发行版地宣传中获取。(有趣的是,第一和第二的研究版帮助页面都有一个 “owner” 部分,列出了作者(比如,*Ken*)与对应的系统命令,文件,系统调用,或者功能库。在第四版中这个部分就没了,而在 BSD 发行版中又浮现了 “Author” 部分。)关于作者信息更为详细地写在了项目的文件中,这些文件被用于匹配源代码文件和它们的作者和对应的提交信息。最后,information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26](不好组织这个语言)
|
||||
|
||||
The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
|
||||
作为该项目的一部分而开发的软件和数据文件,现在可以[在线获取][27],[9][28],并且,如果有合适的网络环境,CPU 和磁盘资源,可以用来从头构建这样一个仓库。关于主要发行版的所有者信息,都存储在该项目 `author-path` 目录下的文件里。These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author.(这句单词都认识,但是不理解具体意思)也可以制定多个作者。正则表达式是按线性处理的,所以一个文件末尾的匹配一切的表达式可以指定一个发行版的默认作者。为避免重复,一个以 `.au` 后缀的独立文件专门用于映射作者身份到他们的名字和 email。这样一个文件为每个社区建立了一个,以关联系统的进化:Bell 实验室,Berkeley,386BSD 和 FreeBSD。为了真实性的需要,早期 Bell 实验室发行版的 emails 都以 UUCP 注释列出了(e.g. `research!ken`)。FreeBSD 作者的鉴定人图谱,需要导入早期的 CVS 仓库,通过从如今项目的 Git 仓库里解压对应的数据构建。总的来说,注释作者信息的文件(828 rules)包含 1107 行,并且另外 640 映射作者鉴定人到名字。
|
||||
|
||||
The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
|
||||
现在项目的数据源被编码成了一个 168 行的 `Makefile`。它包括下面的步骤。
|
||||
|
||||
**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
|
||||
**Fetching** 从远程站点复制和克隆大约 11GB 的镜像,档案和仓库。
|
||||
|
||||
**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
|
||||
**Tooling** 从 2.9 BSD 中为旧的 PDP-11 档案获取一个归档器,并作出调整来在现代的 Unix 版本下编译;编译 4.3 BSD *compress* 程序来解压 386BSD 发行版,这个程序不再是现代 Unix 系统的组成部分了。
|
||||
|
||||
**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
|
||||
**Organizing** 用 tar 和 *cpio* 解压缩包;结合第六版的三个目录;用旧的 PDP-11 归档器解压所有的 1 BSD 档案;挂载 CD-ROM 镜像,这样可以作为文件系统处理;组合 8 和 62 386BSD 散乱的磁盘镜像为两个独立的文件。
|
||||
|
||||
**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
|
||||
**Cleaning** 重新存储第一版的内核源代码文件,这个可以通过合适的字符识别从打印输出用获取;给第七版的源代码文件打补丁;移除一个发行版后被添加进来的元数据和其他文件,为避免得到错误的时间戳信息;修复毁坏的 SCCS 文件;通过移除 CVS symbols assigned to multiple revisions with a custom Perl script,删除 CVS *Attr* 文件和用 *cvs2svn* 将 CVS 仓库转换为 Git 仓库,来处理早期的 FreeBSD CVS 仓库。
|
||||
|
||||
An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
|
||||
在仓库表述中有一个很有意思的部分就是,如何导入那些快照,并以一种方式联系起来,使得 *git blame* 可以发挥它的魔力。快照导入到仓库是作为一系列的提交实现的,根据每个文件的时间戳。当所有文件导入后,就被用对应发行版的名字给标记了。在这点上,一个人可以删除那些文件,并开始导入下一个快照。注意 *git blame* 命令是通过回溯一个仓库的历史来工作的,并使用启发法来检测文件之间或内部的代码移动和复制。因此,删除掉的快照间会产生中断,防止它们之间的代码被追踪。
|
||||
|
||||
Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
|
||||
相反,在下一个快照导入之前,之前快照的所有文件都被移动到了一个隐藏的后备目录里,叫做 `.ref`(引用)。它们保存在那,直到下个快照的所有文件都被导入了,这时候它们就会被删掉。因为 `.ref` 目录下的每个文件都完全配对一个原始文件,*git blame* 可以知道多少源代码通过 `.ref` 文件从一个版本移到了下一个,而不用显示出 `.ref` 文件。为了更进一步帮助检测代码起源,同时增加表述的真实性,每个发行版都被表述成了一个合并,介于有增加文件的分支(*-Development*)与之前发行版之间的合并。
|
||||
|
||||
For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
|
||||
上世纪 80 年代这个时期,只有 Berkeley 开发文件的一个子集是用 SCCS 版本控制的。整个时期内,我们统一的仓库里包含了来自 SCCS 的提交和快照增加的文件。在每个发行版的时间点上,可以发现 SCCS 最近的提交,被标记成一个发行版中增加的导入分支的合并。这些合并可以在 Figure [2][29] 中间看到。
|
||||
|
||||
The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
|
||||
将各种数据资源综合到一个仓库的工作,主要是用两个脚本来完成的。一个 780 行的 Perl 脚本(`import-dir.pl`)可以从一个单独的数据源(快照目录,SCCS 仓库,或者 Git 仓库)中,以 *Git fast export* 格式导出(真实的或者综合的)提交历史。输出是一个简单的文本格式,Git 工具用这个来导入和导出提交。其他方面,这个脚本以一些东西为参数,如文件到贡献者的映射,贡献者登录名和他们的全名间的映射,导入的提交会被合并,哪些文件要处理,哪些文件要忽略,和“引用”文件的处理。一个 450 行的 Shell 脚本创建 Git 仓库,并调用带适当参数的 Perl 脚本,导入 27 个可用的历史数据资源。Shell 脚本也会跑 30 遍测试,比较特定标签的仓库和对应的数据源,确认出现的和没出现的备用目录,并查看分支树和合并的数量,*git blame* 和 *git log* 的输出中的退化。最后,*git* 被调用来作垃圾收集和压缩仓库,从最初的 6GB 降到发行的 1GB。
|
||||
|
||||
### 4 Data Uses ###
|
||||
### 4 数据使用 ###
|
||||
|
||||
The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
|
||||
数据可以用于软件工程,信息系统和软件考古学领域的经验性研究。鉴于它从不间断而独一无二的存在了超过了 40 年,可以供软件的进化和代代更迭参考。伴随那个时代以来在处理速度千倍地增长,存储容量百万倍的扩大,数据同样可以用于软件和硬件技术交叉进化的研究。软件开发从研究中心到大学,到开源社区的转移,可以用来研究组织文化对于软件开发的影响。仓库也可以用于学习开发者编程的影响力,比如 Turing 奖获得者(Dennis Ritchie 和 Ken Thompson)和 IT 产业的大佬(Bill Joy 和 Eric Schmidt)。另一个值得学习的现象是代码的长寿,无论是单行的水平,或是作为那个时代随 Unix 发行的完整的系统(Ingres, Lisp, Pascal, Ratfor, Snobol, TMP),和导致代码存活或消亡的因素。最后,因为数据使 Git 底层软件仓库存储技术感到压力,到了它的限度,这会加速修正管理系统领域的工程进度。
|
||||
|
||||
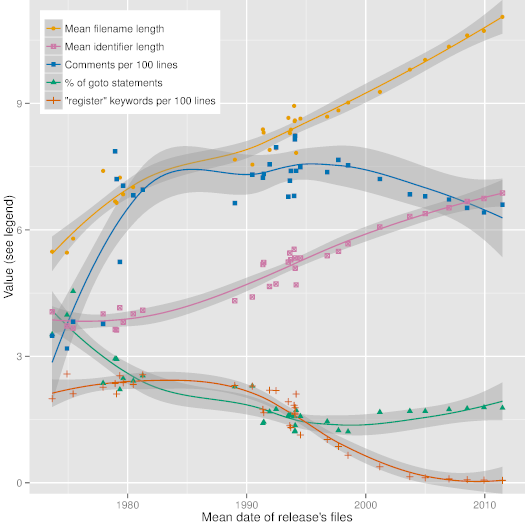
|
||||
|
||||
Figure 3: Code style evolution along Unix releases.
|
||||
|
||||
Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
|
||||
Figure [3][30] 描述了一些有趣的代码统计,根据 36 个主要 Unix 发行版,验证了代码风格和编程语言的使用在很长的时间尺度上的进化。这种进化是软硬件技术的需求和支持驱动的,软件构筑理论,甚至社会力量。图片中的数据已经计算了在一个所给发行版中出现的文件的平均时间。正如可以从中看到,在过去的 40 年中,验证器和文件名字的长度已经稳定从 4 到 6 个字符增长到 7 到 11 个字符。我们也可以看到在评论数量的少量稳定增加,和 *goto* 表达的使用量减少,同时 *register* 这个类型修改器的消失。
|
||||
|
||||
### 5 Further Work ###
|
||||
### 5 未来的工作 ###
|
||||
|
||||
Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
|
||||
可以做很多事情去提高仓库的正确性和有效性。创建进程作为源代码开源了,通过 GitHub 的拉取请求,可以很容易地贡献更多代码和修复。最有用的社区贡献会使得导入的快照文件的覆盖增长,这曾经是隶属于一个具体的作者。现在,大约 90,000 个文件(在 160,000 总量之外)被指定了作者,根据一个默认的规则。类似地,大约有 250 个作者(最初 FreeBSD 那些)是验证器确认的。两个都列在了 build 仓库无配对的目录里,也欢迎贡献数据。进一步,BSD SCCS 和 FreeBSD CVS 的提交,共享相同的作者和时间戳,这些可以结合成一个单独的 Git 提交。导入 SCCS 文件提交的支持会被添加进来,为了引入仓库对应的元数据。最后,最重要的,开源系统的更多分支会添加进来,比如 NetBSD OpenBSD, DragonFlyBSD 和 *illumos*。理想地,其他重要的历史上的 Unix 发行版,它们的版权拥有者,如 System III, System V, NeXTSTEP 和 SunOS,也会在一个协议下释出他们的系统,允许他们的合作伙伴使用仓库用于研究。
|
||||
|
||||
#### Acknowledgements ####
|
||||
### 鸣谢 ###
|
||||
|
||||
The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
|
||||
本人感谢很多付出努力的人们。 Brian W. Kernighan, Doug McIlroy 和 Arnold D. Robbins 帮助 Bell 实验室开发了登录验证器。 Clem Cole, Era Erikson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze 和 Anatole Shaw 开发了 BSD 的登录验证器。BSD SCCS 导入了 H. Merijn Brand 和 Jonathan Gray 的开发工作的代码。
|
||||
|
||||
This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
|
||||
这次研究通过 National Strategic Reference Framework (NSRF) 的 Operational Program " Education and Lifelong Learning" - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform,由 European Union ( European Social Fund - ESF) 和 Greek national funds 出资赞助。
|
||||
|
||||
### References ###
|
||||
### 引用 ###
|
||||
|
||||
[[1]][31]
|
||||
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
|
||||
@ -143,7 +142,7 @@ This research has been co-financed by the European Union (European Social Fund -
|
||||
|
||||
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by NearTan
|
||||
How to Install Laravel PHP Framework on CentOS 7 / Ubuntu 15.04
|
||||
================================================================================
|
||||
Hi All, In this article we are going to setup Laravel on CentOS 7 and Ubuntu 15.04. If you are a PHP web developer then you don't need to worry about of all modern PHP frameworks, Laravel is the easiest to get up and running that saves your time and effort and makes web development a joy. Laravel embraces a general development philosophy that sets a high priority on creating maintainable code by following some simple guidelines, you should be able to keep a rapid pace of development and be free to change your code with little fear of breaking existing functionality.
|
||||
@ -172,4 +173,4 @@ via: http://linoxide.com/linux-how-to/install-laravel-php-centos-7-ubuntu-15-04/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
|
||||
@ -1,452 +0,0 @@
|
||||
su-kaiyao translating
|
||||
|
||||
Getting started with Docker by Dockerizing this Blog
|
||||
======================
|
||||
>This article covers the basic concepts of Docker and how to Dockerize an application by creating a custom Dockerfile
|
||||
>Written by Benjamin Cane on 2015-12-01 10:00:00
|
||||
|
||||
Docker is an interesting technology that over the past 2 years has gone from an idea, to being used by organizations all over the world to deploy applications. In today's article I am going to cover how to get started with Docker by "Dockerizing" an existing application. The application in question is actually this very blog!
|
||||
|
||||
## What is Docker
|
||||
|
||||
Before we dive into learning the basics of Docker let's first understand what Docker is and why it is so popular. Docker, is an operating system container management tool that allows you to easily manage and deploy applications by making it easy to package them within operating system containers.
|
||||
|
||||
### Containers vs. Virtual Machines
|
||||
|
||||
Containers may not be as familiar as virtual machines but they are another method to provide **Operating System Virtualization**. However, they differ quite a bit from standard virtual machines.
|
||||
|
||||
Standard virtual machines generally include a full Operating System, OS Packages and eventually an Application or two. This is made possible by a Hypervisor which provides hardware virtualization to the virtual machine. This allows for a single server to run many standalone operating systems as virtual guests.
|
||||
|
||||
Containers are similar to virtual machines in that they allow a single server to run multiple operating environments, these environments however, are not full operating systems. Containers generally only include the necessary OS Packages and Applications. They do not generally contain a full operating system or hardware virtualization. This also means that containers have a smaller overhead than traditional virtual machines.
|
||||
|
||||
Containers and Virtual Machines are often seen as conflicting technology, however, this is often a misunderstanding. Virtual Machines are a way to take a physical server and provide a fully functional operating environment that shares those physical resources with other virtual machines. A Container is generally used to isolate a running process within a single host to ensure that the isolated processes cannot interact with other processes within that same system. In fact containers are closer to **BSD Jails** and `chroot`'ed processes than full virtual machines.
|
||||
|
||||
### What Docker provides on top of containers
|
||||
|
||||
Docker itself is not a container runtime environment; in fact Docker is actually container technology agnostic with efforts planned for Docker to support [Solaris Zones](https://blog.docker.com/2015/08/docker-oracle-solaris-zones/) and [BSD Jails](https://wiki.freebsd.org/Docker). What Docker provides is a method of managing, packaging, and deploying containers. While these types of functions may exist to some degree for virtual machines they traditionally have not existed for most container solutions and the ones that existed, were not as easy to use or fully featured as Docker.
|
||||
|
||||
Now that we know what Docker is, let's start learning how Docker works by first installing Docker and deploying a public pre-built container.
|
||||
|
||||
## Starting with Installation
|
||||
As Docker is not installed by default step 1 will be to install the Docker package; since our example system is running Ubuntu 14.0.4 we will do this using the Apt package manager.
|
||||
|
||||
```
|
||||
# apt-get install docker.io
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following extra packages will be installed:
|
||||
aufs-tools cgroup-lite git git-man liberror-perl
|
||||
Suggested packages:
|
||||
btrfs-tools debootstrap lxc rinse git-daemon-run git-daemon-sysvinit git-doc
|
||||
git-el git-email git-gui gitk gitweb git-arch git-bzr git-cvs git-mediawiki
|
||||
git-svn
|
||||
The following NEW packages will be installed:
|
||||
aufs-tools cgroup-lite docker.io git git-man liberror-perl
|
||||
0 upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 7,553 kB of archives.
|
||||
After this operation, 46.6 MB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
```
|
||||
|
||||
To check if any containers are running we can execute the `docker` command using the `ps` option.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
The `ps` function of the `docker` command works similar to the Linux `ps `command. It will show available Docker containers and their current status. Since we have not started any Docker containers yet, the command shows no running containers.
|
||||
|
||||
## Deploying a pre-built nginx Docker container
|
||||
One of my favorite features of Docker is the ability to deploy a pre-built container in the same way you would deploy a package with `yum` or `apt-get`. To explain this better let's deploy a pre-built container running the nginx web server. We can do this by executing the `docker` command again, however, this time with the `run` option.
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
The `run` function of the `docker` command tells Docker to find a specified Docker image and start a container running that image. By default, Docker containers run in the foreground, meaning when you execute `docker run` your shell will be bound to the container's console and the process running within the container. In order to launch this Docker container in the background I included the `-d` (**detach**) flag.
|
||||
|
||||
By executing `docker ps` again we can see the nginx container running.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 nginx:latest nginx -g 'daemon off 4 seconds ago Up 3 seconds 443/tcp, 80/tcp desperate_lalande
|
||||
```
|
||||
|
||||
In the above output we can see the running container `desperate_lalande` and that this container has been built from the `nginx:latest image`.
|
||||
|
||||
### Docker Images
|
||||
Images are one of Docker's key features and is similar to a virtual machine image. Like virtual machine images, a Docker image is a container that has been saved and packaged. Docker however, doesn't just stop with the ability to create images. Docker also includes the ability to distribute those images via Docker repositories which are a similar concept to package repositories. This is what gives Docker the ability to deploy an image like you would deploy a package with `yum`. To get a better understanding of how this works let's look back at the output of the `docker run` execution.
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
```
|
||||
|
||||
The first message we see is that `docker` could not find an image named nginx locally. The reason we see this message is that when we executed `docker run` we told Docker to startup a container, a container based on an image named **nginx**. Since Docker is starting a container based on a specified image it needs to first find that image. Before checking any remote repository Docker first checks locally to see if there is a local image with the specified name.
|
||||
|
||||
Since this system is brand new there is no Docker image with the name nginx, which means Docker will need to download it from a Docker repository.
|
||||
|
||||
```
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
This is exactly what the second part of the output is showing us. By default, Docker uses the [Docker Hub](https://hub.docker.com/) repository, which is a repository service that Docker (the company) runs.
|
||||
|
||||
Like GitHub, Docker Hub is free for public repositories but requires a subscription for private repositories. It is possible however, to deploy your own Docker repository, in fact it is as easy as `docker run registry`. For this article we will not be deploying a custom registry service.
|
||||
|
||||
### Stopping and Removing the Container
|
||||
Before moving on to building a custom Docker container let's first clean up our Docker environment. We will do this by stopping the container from earlier and removing it.
|
||||
|
||||
To start a container we executed `docker` with the `run` option, in order to stop this same container we simply need to execute the `docker` with the `kill` option specifying the container name.
|
||||
|
||||
```
|
||||
# docker kill desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
If we execute `docker ps` again we will see that the container is no longer running.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
However, at this point we have only stopped the container; while it may no longer be running it still exists. By default, `docker ps` will only show running containers, if we add the `-a` (all) flag it will show all containers running or not.
|
||||
|
||||
```
|
||||
# docker ps -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 5c82215b03d1 nginx -g 'daemon off 4 weeks ago Exited (-1) About a minute ago desperate_lalande
|
||||
```
|
||||
|
||||
In order to fully remove the container we can use the `docker` command with the `rm` option.
|
||||
|
||||
```
|
||||
# docker rm desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
While this container has been removed; we still have a **nginx** image available. If we were to re-run `docker run -d nginx` again the container would be started without having to fetch the nginx image again. This is because Docker already has a saved copy on our local system.
|
||||
|
||||
To see a full list of local images we can simply run the `docker` command with the `images` option.
|
||||
|
||||
```
|
||||
# docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
nginx latest 9fab4090484a 5 days ago 132.8 MB
|
||||
```
|
||||
|
||||
## Building our own custom image
|
||||
At this point we have used a few basic Docker commands to start, stop and remove a common pre-built image. In order to "Dockerize" this blog however, we are going to have to build our own Docker image and that means creating a **Dockerfile**.
|
||||
|
||||
With most virtual machine environments if you wish to create an image of a machine you need to first create a new virtual machine, install the OS, install the application and then finally convert it to a template or image. With Docker however, these steps are automated via a Dockerfile. A Dockerfile is a way of providing build instructions to Docker for the creation of a custom image. In this section we are going to build a custom Dockerfile that can be used to deploy this blog.
|
||||
|
||||
### Understanding the Application
|
||||
Before we can jump into creating a Dockerfile we first need to understand what is required to deploy this blog.
|
||||
|
||||
The blog itself is actually static HTML pages generated by a custom static site generator that I wrote named; **hamerkop**. The generator is very simple and more about getting the job done for this blog specifically. All the code and source files for this blog are available via a public [GitHub](https://github.com/madflojo/blog) repository. In order to deploy this blog we simply need to grab the contents of the GitHub repository, install **Python** along with some **Python** modules and execute the `hamerkop` application. To serve the generated content we will use **nginx**; which means we will also need **nginx** to be installed.
|
||||
|
||||
So far this should be a pretty simple Dockerfile, but it will show us quite a bit of the [Dockerfile Syntax](https://docs.docker.com/v1.8/reference/builder/). To get started we can clone the GitHub repository and creating a Dockerfile with our favorite editor; `vi` in my case.
|
||||
|
||||
```
|
||||
# git clone https://github.com/madflojo/blog.git
|
||||
Cloning into 'blog'...
|
||||
remote: Counting objects: 622, done.
|
||||
remote: Total 622 (delta 0), reused 0 (delta 0), pack-reused 622
|
||||
Receiving objects: 100% (622/622), 14.80 MiB | 1.06 MiB/s, done.
|
||||
Resolving deltas: 100% (242/242), done.
|
||||
Checking connectivity... done.
|
||||
# cd blog/
|
||||
# vi Dockerfile
|
||||
```
|
||||
|
||||
### FROM - Inheriting a Docker image
|
||||
The first instruction of a Dockerfile is the `FROM` instruction. This is used to specify an existing Docker image to use as our base image. This basically provides us with a way to inherit another Docker image. In this case we will be starting with the same **nginx** image we were using before, if we wanted to start with a blank slate we could use the **Ubuntu** Docker image by specifying `ubuntu:latest`.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
```
|
||||
|
||||
In addition to the `FROM` instruction, I also included a `MAINTAINER` instruction which is used to show the Author of the Dockerfile.
|
||||
|
||||
As Docker supports using `#` as a comment marker, I will be using this syntax quite a bit to explain the sections of this Dockerfile.
|
||||
|
||||
### Running a test build
|
||||
Since we inherited the **nginx** Docker image our current Dockerfile also inherited all the instructions within the [Dockerfile](https://github.com/nginxinc/docker-nginx/blob/08eeb0e3f0a5ee40cbc2bc01f0004c2aa5b78c15/Dockerfile) used to build that **nginx** image. What this means is even at this point we are able to build a Docker image from this Dockerfile and run a container from that image. The resulting image will essentially be the same as the **nginx** image but we will run through a build of this Dockerfile now and a few more times as we go to help explain the Docker build process.
|
||||
|
||||
In order to start the build from a Dockerfile we can simply execute the `docker` command with the **build** option.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 23.6 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Running in c97f36450343
|
||||
---> 60a44f78d194
|
||||
Removing intermediate container c97f36450343
|
||||
Successfully built 60a44f78d194
|
||||
```
|
||||
|
||||
In the above example I used the `-t` (**tag**) flag to "tag" the image as "blog". This essentially allows us to name the image, without specifying a tag the image would only be callable via an **Image ID** that Docker assigns. In this case the **Image ID** is `60a44f78d194` which we can see from the `docker` command's build success message.
|
||||
|
||||
In addition to the `-t` flag, I also specified the directory `/root/blog`. This directory is the "build directory", which is the directory that contains the Dockerfile and any other files necessary to build this container.
|
||||
|
||||
Now that we have run through a successful build, let's start customizing this image.
|
||||
|
||||
### Using RUN to execute apt-get
|
||||
The static site generator used to generate the HTML pages is written in **Python** and because of this the first custom task we should perform within this `Dockerfile` is to install Python. To install the Python package we will use the Apt package manager. This means we will need to specify within the Dockerfile that `apt-get update` and `apt-get install python-dev` are executed; we can do this with the `RUN` instruction.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
```
|
||||
|
||||
In the above we are simply using the `RUN` instruction to tell Docker that when it builds this image it will need to execute the specified `apt-get` commands. The interesting part of this is that these commands are only executed within the context of this container. What this means is even though `python-dev` and `python-pip` are being installed within the container, they are not being installed for the host itself. Or to put it simplier, within the container the `pip` command will execute, outside the container, the `pip` command does not exist.
|
||||
|
||||
It is also important to note that the Docker build process does not accept user input during the build. This means that any commands being executed by the `RUN` instruction must complete without user input. This adds a bit of complexity to the build process as many applications require user input during installation. For our example, none of the commands executed by `RUN` require user input.
|
||||
|
||||
### Installing Python modules
|
||||
With **Python** installed we now need to install some Python modules. To do this outside of Docker, we would generally use the `pip` command and reference a file within the blog's Git repository named `requirements.txt`. In an earlier step we used the `git` command to "clone" the blog's GitHub repository to the `/root/blog` directory; this directory also happens to be the directory that we have created the `Dockerfile`. This is important as it means the contents of the Git repository are accessible to Docker during the build process.
|
||||
|
||||
When executing a build, Docker will set the context of the build to the specified "build directory". This means that any files within that directory and below can be used during the build process, files outside of that directory (outside of the build context), are inaccessible.
|
||||
|
||||
In order to install the required Python modules we will need to copy the `requirements.txt` file from the build directory into the container. We can do this using the `COPY` instruction within the `Dockerfile`.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
```
|
||||
|
||||
Within the `Dockerfile` we added 3 instructions. The first instruction uses `RUN` to create a `/build/` directory within the container. This directory will be used to copy any application files needed to generate the static HTML pages. The second instruction is the `COPY` instruction which copies the `requirements.txt` file from the "build directory" (`/root/blog`) into the `/build` directory within the container. The third is using the `RUN` instruction to execute the `pip` command; installing all the modules specified within the `requirements.txt` file.
|
||||
|
||||
`COPY` is an important instruction to understand when building custom images. Without specifically copying the file within the Dockerfile this Docker image would not contain the requirements.txt file. With Docker containers everything is isolated, unless specifically executed within a Dockerfile a container is not likely to include required dependencies.
|
||||
|
||||
### Re-running a build
|
||||
Now that we have a few customization tasks for Docker to perform let's try another build of the blog image again.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Running in bde05cf1e8fe
|
||||
---> f4b66e09fa61
|
||||
Removing intermediate container bde05cf1e8fe
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
Removing intermediate container 9aa8ff43f4b0
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Running in c50b15ddd8b1
|
||||
Downloading/unpacking jinja2 (from -r /build/requirements.txt (line 1))
|
||||
Downloading/unpacking PyYaml (from -r /build/requirements.txt (line 2))
|
||||
<truncated to reduce noise>
|
||||
Successfully installed jinja2 PyYaml mistune markdown MarkupSafe
|
||||
Cleaning up...
|
||||
---> abab55c20962
|
||||
Removing intermediate container c50b15ddd8b1
|
||||
Successfully built abab55c20962
|
||||
```
|
||||
|
||||
From the above build output we can see the build was successful, but we can also see another interesting message;` ---> Using cache`. What this message is telling us is that Docker was able to use its build cache during the build of this image.
|
||||
|
||||
#### Docker build cache
|
||||
|
||||
When Docker is building an image, it doesn't just build a single image; it actually builds multiple images throughout the build processes. In fact we can see from the above output that after each "Step" Docker is creating a new image.
|
||||
|
||||
```
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
```
|
||||
|
||||
The last line from the above snippet is actually Docker informing us of the creating of a new image, it does this by printing the **Image ID**; `cef11c3fb97c`. The useful thing about this approach is that Docker is able to use these images as cache during subsequent builds of the **blog** image. This is useful because it allows Docker to speed up the build process for new builds of the same container. If we look at the example above we can actually see that rather than installing the `python-dev` and `python-pip` packages again, Docker was able to use a cached image. However, since Docker was unable to find a build that executed the `mkdir` command, each subsequent step was executed.
|
||||
|
||||
The Docker build cache is a bit of a gift and a curse; the reason for this is that the decision to use cache or to rerun the instruction is made within a very narrow scope. For example, if there was a change to the `requirements.txt` file Docker would detect this change during the build and start fresh from that point forward. It does this because it can view the contents of the `requirements.txt` file. The execution of the `apt-get` commands however, are another story. If the **Apt** repository that provides the Python packages were to contain a newer version of the python-pip package; Docker would not be able to detect the change and would simply use the build cache. This means that an older package may be installed. While this may not be a major issue for the `python-pip` package it could be a problem if the installation was caching a package with a known vulnerability.
|
||||
|
||||
For this reason it is useful to periodically rebuild the image without using Docker's cache. To do this you can simply specify `--no-cache=True` when executing a Docker build.
|
||||
|
||||
## Deploying the rest of the blog
|
||||
With the Python packages and modules installed this leaves us at the point of copying the required application files and running the `hamerkop` application. To do this we will simply use more `COPY` and `RUN` instructions.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
|
||||
## Add blog code nd required files
|
||||
COPY static /build/static
|
||||
COPY templates /build/templates
|
||||
COPY hamerkop /build/
|
||||
COPY config.yml /build/
|
||||
COPY articles /build/articles
|
||||
|
||||
## Run Generator
|
||||
RUN /build/hamerkop -c /build/config.yml
|
||||
```
|
||||
|
||||
Now that we have the rest of the build instructions, let's run through another build and verify that the image builds successfully.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog/
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Using cache
|
||||
---> f4b66e09fa61
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> Using cache
|
||||
---> cef11c3fb97c
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Using cache
|
||||
---> abab55c20962
|
||||
Step 7 : COPY static /build/static
|
||||
---> 15cb91531038
|
||||
Removing intermediate container d478b42b7906
|
||||
Step 8 : COPY templates /build/templates
|
||||
---> ecded5d1a52e
|
||||
Removing intermediate container ac2390607e9f
|
||||
Step 9 : COPY hamerkop /build/
|
||||
---> 59efd1ca1771
|
||||
Removing intermediate container b5fbf7e817b7
|
||||
Step 10 : COPY config.yml /build/
|
||||
---> bfa3db6c05b7
|
||||
Removing intermediate container 1aebef300933
|
||||
Step 11 : COPY articles /build/articles
|
||||
---> 6b61cc9dde27
|
||||
Removing intermediate container be78d0eb1213
|
||||
Step 12 : RUN /build/hamerkop -c /build/config.yml
|
||||
---> Running in fbc0b5e574c5
|
||||
Successfully created file /usr/share/nginx/html//2011/06/25/checking-the-number-of-lwp-threads-in-linux
|
||||
Successfully created file /usr/share/nginx/html//2011/06/checking-the-number-of-lwp-threads-in-linux
|
||||
<truncated to reduce noise>
|
||||
Successfully created file /usr/share/nginx/html//archive.html
|
||||
Successfully created file /usr/share/nginx/html//sitemap.xml
|
||||
---> 3b25263113e1
|
||||
Removing intermediate container fbc0b5e574c5
|
||||
Successfully built 3b25263113e1
|
||||
```
|
||||
|
||||
### Running a custom container
|
||||
With a successful build we can now start our custom container by running the `docker` command with the `run` option, similar to how we started the nginx container earlier.
|
||||
|
||||
```
|
||||
# docker run -d -p 80:80 --name=blog blog
|
||||
5f6c7a2217dcdc0da8af05225c4d1294e3e6bb28a41ea898a1c63fb821989ba1
|
||||
```
|
||||
|
||||
Once again the `-d` (**detach**) flag was used to tell Docker to run the container in the background. However, there are also two new flags. The first new flag is `--name`, which is used to give the container a user specified name. In the earlier example we did not specify a name and because of that Docker randomly generated one. The second new flag is `-p`, this flag allows users to map a port from the host machine to a port within the container.
|
||||
|
||||
The base **nginx** image we used exposes port 80 for the HTTP service. By default, ports bound within a Docker container are not bound on the host system as a whole. In order for external systems to access ports exposed within a container the ports must be mapped from a host port to a container port using the `-p` flag. The command above maps port 80 from the host, to port 80 within the container. If we wished to map port 8080 from the host, to port 80 within the container we could do so by specifying the ports in the following syntax `-p 8080:80`.
|
||||
|
||||
From the above command it appears that our container was started successfully, we can verify this by executing `docker ps`.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
d264c7ef92bd blog:latest nginx -g 'daemon off 3 seconds ago Up 3 seconds 443/tcp, 0.0.0.0:80->80/tcp blog
|
||||
```
|
||||
|
||||
## Wrapping up
|
||||
|
||||
At this point we now have a running custom Docker container. While we touched on a few Dockerfile instructions within this article we have yet to discuss all the instructions. For a full list of Dockerfile instructions you can checkout [Docker's reference page](https://docs.docker.com/v1.8/reference/builder/), which explains the instructions very well.
|
||||
|
||||
Another good resource is their [Dockerfile Best Practices page](https://docs.docker.com/engine/articles/dockerfile_best-practices/) which contains quite a few best practices for building custom Dockerfiles. Some of these tips are very useful such as strategically ordering the commands within the Dockerfile. In the above examples our Dockerfile has the `COPY` instruction for the `articles` directory as the last `COPY` instruction. The reason for this is that the `articles` directory will change quite often. It's best to put instructions that will change oftenat the lowest point possible within the Dockerfile to optimize steps that can be cached.
|
||||
|
||||
In this article we covered how to start a pre-built container and how to build, then deploy a custom container. While there is quite a bit to learn about Docker this article should give you a good idea on how to get started. Of course, as always if you think there is anything that should be added drop it in the comments below.
|
||||
|
||||
--------------------------------------
|
||||
via:http://bencane.com/2015/12/01/getting-started-with-docker-by-dockerizing-this-blog/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+bencane%2FSAUo+%28Benjamin+Cane%29
|
||||
|
||||
作者:Benjamin Cane
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by bianjp
|
||||
|
||||
How to enable Software Collections (SCL) on CentOS
|
||||
================================================================================
|
||||
Red Hat Enterprise Linux (RHEL) and its community fork, CentOS, offer 10-year life cycle, meaning that each version of RHEL/CentOS is updated with security patches for up to 10 years. While such long life cycle guarantees much needed system compatibility and reliability for enterprise users, a downside is that core applications and run-time environments grow antiquated as the underlying RHEL/CentOS version becomes close to end-of-life (EOF). For example, CentOS 6.5, whose EOL is dated to November 30th 2020, comes with python 2.6.6 and MySQL 5.1.73, which are already pretty old by today's standard.
|
||||
@ -14,7 +16,7 @@ The latest SCL offers:
|
||||
- Ruby 1.9.3
|
||||
- Perl 5.16.3
|
||||
- MariaDB and MySQL 5.5
|
||||
- Apache httpd 2.4.6
|
||||
- Apache httpd 2.4.6
|
||||
|
||||
In the rest of the tutorial, let me show you how to set up the SCL repository and how to install and enable the packages from the SCL.
|
||||
|
||||
|
||||
@ -1,3 +1,7 @@
|
||||
translating by ezio
|
||||
|
||||
|
||||
|
||||
Securi-Pi: Using the Raspberry Pi as a Secure Landing Point
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -1,503 +0,0 @@
|
||||
Linux 基金会内部的 Linux 工作站安全检查清单
|
||||
================================================================================
|
||||
|
||||
### 目标受众
|
||||
|
||||
这是一套 Linux 基金会为其系统管理员提供的推荐规范。
|
||||
|
||||
这个文档用于帮助那些使用 Linux 工作站来访问和管理项目的 IT 设施的系统管理员团队。
|
||||
|
||||
如果你的系统管理员是远程员工,你也许可以使用这套指导方针确保系统管理员的系统可以通过核心安全需求,降低你的IT 平台成为攻击目标的风险。
|
||||
|
||||
即使你的系统管理员不是远程员工,很多人也会在工作环境中通过便携笔记本完成工作,或者在家中设置系统以便在业余时间或紧急时刻访问工作平台。不论发生何种情况,你都能调整这个推荐规范来适应你的环境。
|
||||
|
||||
|
||||
### 限制
|
||||
|
||||
但是,这并不是一个详细的“工作站加固”文档,可以说这是一个努力避免大多数明显安全错误而不会导致太多不便的一组推荐基线(baseline)。你也许阅读这个文档后会认为它的方法太偏执,而另一些人也许会认为这仅仅是一些肤浅的研究。安全就像在高速公路上开车 -- 任何比你开的慢的都是一个傻瓜,然而任何比你开的快的人都是疯子。这个指南仅仅是一些列核心安全规则,既不详细又不能替代经验、警惕和常识。
|
||||
|
||||
我们分享这篇文档是为了[将开源协作的优势带到 IT 策略文献资料中][18]。如果你发现它有用,我们希望你可以将它用到你自己团体中,并分享你的改进,对它的完善做出你的贡献。
|
||||
|
||||
### 结构
|
||||
|
||||
每一节都分为两个部分:
|
||||
|
||||
- 核对适合你项目的需求
|
||||
- 形式不定的提示内容,解释了为什么这么做
|
||||
|
||||
#### 严重级别
|
||||
|
||||
在清单的每一个项目都包括严重级别,我们希望这些能帮助指导你的决定:
|
||||
|
||||
- **关键(ESSENTIAL)** 该项应该在考虑列表上被明确的重视。如果不采取措施,将会导致你的平台安全出现高风险。
|
||||
- **中等(NICE)** 该项将改善你的安全形势,但是会影响到你的工作环境的流程,可能会要求养成新的习惯,改掉旧的习惯。
|
||||
- **可疑(PARANOID)** 留作感觉会明显完善我们平台安全、但是可能会需要大量调整与操作系统交互的方式的项目。
|
||||
|
||||
记住,这些只是参考。如果你觉得这些严重级别不能反映你的工程对安全的承诺,你应该调整它们为你所合适的。
|
||||
|
||||
## 选择正确的硬件
|
||||
|
||||
我们并不会要求管理员使用一个特殊供应商或者一个特殊的型号,所以这一节提供的是选择工作系统时的核心注意事项。
|
||||
|
||||
### 检查清单
|
||||
|
||||
- [ ] 系统支持安全启动(SecureBoot) _(关键)_
|
||||
- [ ] 系统没有火线(Firewire),雷电(thunderbolt)或者扩展卡(ExpressCard)接口 _(中等)_
|
||||
- [ ] 系统有 TPM 芯片 _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 安全启动(SecureBoot)
|
||||
|
||||
尽管它还有争议,但是安全引导能够预防很多针对工作站的攻击(Rootkits、“Evil Maid”,等等),而没有太多额外的麻烦。它并不能阻止真正专门的攻击者,加上在很大程度上,国家安全机构有办法应对它(可能是通过设计),但是有安全引导总比什么都没有强。
|
||||
|
||||
作为选择,你也许可以部署 [Anti Evil Maid][1] 提供更多健全的保护,以对抗安全引导所需要阻止的攻击类型,但是它需要更多部署和维护的工作。
|
||||
|
||||
#### 系统没有火线(Firewire),雷电(thunderbolt)或者扩展卡(ExpressCard)接口
|
||||
|
||||
火线是一个标准,其设计上允许任何连接的设备能够完全地直接访问你的系统内存(参见[维基百科][2])。雷电接口和扩展卡同样有问题,虽然一些后来部署的雷电接口试图限制内存访问的范围。如果你没有这些系统端口,那是最好的,但是它并不严重,它们通常可以通过 UEFI 关闭或内核本身禁用。
|
||||
|
||||
#### TPM 芯片
|
||||
|
||||
可信平台模块(Trusted Platform Module ,TPM)是主板上的一个与核心处理器单独分开的加密芯片,它可以用来增加平台的安全性(比如存储全盘加密的密钥),不过通常不会用于日常的平台操作。充其量,这个是一个有则更好的东西,除非你有特殊需求,需要使用 TPM 增加你的工作站安全性。
|
||||
|
||||
## 预引导环境
|
||||
|
||||
这是你开始安装操作系统前的一系列推荐规范。
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 使用 UEFI 引导模式(不是传统 BIOS)_(关键)_
|
||||
- [ ] 进入 UEFI 配置需要使用密码 _(关键)_
|
||||
- [ ] 使用安全引导 _(关键)_
|
||||
- [ ] 启动系统需要 UEFI 级别密码 _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### UEFI 和安全引导
|
||||
|
||||
UEFI 尽管有缺点,还是提供很多传统 BIOS 没有的好功能,比如安全引导。大多数现代的系统都默认使用 UEFI 模式。
|
||||
|
||||
确保进入 UEFI 配置模式要使用高强度密码。注意,很多厂商默默地限制了你使用密码长度,所以相比长口令你也许应该选择高熵值的短密码(关于密码短语请参考下面内容)。
|
||||
|
||||
基于你选择的 Linux 发行版,你也许需要、也许不需要按照 UEFI 的要求,来导入你的发行版的安全引导密钥,从而允许你启动该发行版。很多发行版已经与微软合作,用大多数厂商所支持的密钥给它们已发布的内核签名,因此避免了你必须处理密钥导入的麻烦。
|
||||
|
||||
作为一个额外的措施,在允许某人访问引导分区然后尝试做一些不好的事之前,让他们输入密码。为了防止肩窥(shoulder-surfing),这个密码应该跟你的 UEFI 管理密码不同。如果你经常关闭和启动,你也许不想这么麻烦,因为你已经必须输入 LUKS 密码了(LUKS 参见下面内容),这样会让你您减少一些额外的键盘输入。
|
||||
|
||||
## 发行版选择注意事项
|
||||
|
||||
很有可能你会坚持一个广泛使用的发行版如 Fedora,Ubuntu,Arch,Debian,或它们的一个类似分支。无论如何,以下是你选择使用发行版应该考虑的。
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 拥有一个强健的 MAC/RBAC 系统(SELinux/AppArmor/Grsecurity) _(关键)_
|
||||
- [ ] 发布安全公告 _(关键)_
|
||||
- [ ] 提供及时的安全补丁 _(关键)_
|
||||
- [ ] 提供软件包的加密验证 _(关键)_
|
||||
- [ ] 完全支持 UEFI 和安全引导 _(关键)_
|
||||
- [ ] 拥有健壮的原生全磁盘加密支持 _(关键)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### SELinux,AppArmor,和 GrSecurity/PaX
|
||||
|
||||
强制访问控制(Mandatory Access Controls,MAC)或者基于角色的访问控制(Role-Based Access Controls,RBAC)是一个用在老式 POSIX 系统的基于用户或组的安全机制扩展。现在大多数发行版已经捆绑了 MAC/RBAC 系统(Fedora,Ubuntu),或通过提供一种机制一个可选的安装后步骤来添加它(Gentoo,Arch,Debian)。显然,强烈建议您选择一个预装 MAC/RBAC 系统的发行版,但是如果你对某个没有默认启用它的发行版情有独钟,装完系统后应计划配置安装它。
|
||||
|
||||
应该坚决避免使用不带任何 MAC/RBAC 机制的发行版,像传统的 POSIX 基于用户和组的安全在当今时代应该算是考虑不足。如果你想建立一个 MAC/RBAC 工作站,通常认为 AppArmor 和 PaX 比 SELinux 更容易掌握。此外,在工作站上,很少有或者根本没有对外监听的守护进程,而针对用户运行的应用造成的最高风险,GrSecurity/PaX _可能_ 会比SELinux 提供更多的安全便利。
|
||||
|
||||
#### 发行版安全公告
|
||||
|
||||
大多数广泛使用的发行版都有一个给它们的用户发送安全公告的机制,但是如果你对一些机密感兴趣,去看看开发人员是否有见于文档的提醒用户安全漏洞和补丁的机制。缺乏这样的机制是一个重要的警告信号,说明这个分支不够成熟,不能被用作主要管理员的工作站。
|
||||
|
||||
#### 及时和可靠的安全更新
|
||||
|
||||
多数常用的发行版提供定期安全更新,但应该经常检查以确保及时提供关键包更新。因此应避免使用附属发行版(spin-offs)和“社区重构”,因为它们必须等待上游分支先发布,它们经常延迟发布安全更新。
|
||||
|
||||
现在,很难找到一个不使用加密签名、更新元数据或二者都不使用的发行版。如此说来,常用的发行版在引入这个基本安全机制就已经知道这些很多年了(Arch,我正在看你),所以这也是值得检查的。
|
||||
|
||||
#### 发行版支持 UEFI 和安全引导
|
||||
|
||||
检查发行版是否支持 UEFI 和安全引导。查明它是否需要导入额外的密钥或是否要求启动内核有一个已经被系统厂商信任的密钥签名(例如跟微软达成合作)。一些发行版不支持 UEFI 或安全启动,但是提供了替代品来确保防篡改(tamper-proof)或防破坏(tamper-evident)引导环境([Qubes-OS][3] 使用 Anti Evil Maid,前面提到的)。如果一个发行版不支持安全引导,也没有防止引导级别攻击的机制,还是看看别的吧。
|
||||
|
||||
#### 全磁盘加密
|
||||
|
||||
全磁盘加密是保护静止数据的要求,大多数发行版都支持。作为一个选择方案,带有自加密硬盘的系统也可以用(通常通过主板 TPM 芯片实现),并提供了类似安全级别而且操作更快,但是花费也更高。
|
||||
|
||||
## 发行版安装指南
|
||||
|
||||
所有发行版都是不同的,但是也有一些一般原则:
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 使用健壮的密码全磁盘加密(LUKS) _(关键)_
|
||||
- [ ] 确保交换分区也加密了 _(关键)_
|
||||
- [ ] 确保引导程序设置了密码(可以和LUKS一样) _(关键)_
|
||||
- [ ] 设置健壮的root密码(可以和LUKS一样) _(关键)_
|
||||
- [ ] 使用无特权账户登录,管理员组的一部分 _(关键)_
|
||||
- [ ] 设置强壮的用户登录密码,不同于root密码 _(关键)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 全磁盘加密
|
||||
|
||||
除非你正在使用自加密硬件设备,配置你的安装程序给磁盘完整加密用来存储你的数据与你的系统文件很重要。通过自动安装的cryptfs循环文件加密用户目录还不够简单(我正在看你,老版Ubuntu),这并没有给系统二进制文件或交换分区提供保护,它可能包含大量的敏感数据。推荐的加密策略是加密LVM设备,所以在启动过程中只需要一个密码。
|
||||
|
||||
`/boot`分区将一直保持非加密,当引导程序需要引导内核前,调用LUKS/dm-crypt。内核映像本身应该用安全引导加密签名检查防止被篡改。
|
||||
|
||||
换句话说,`/boot`应该是你系统上唯一没有加密的分区。
|
||||
|
||||
#### 选择好密码
|
||||
|
||||
现代的Linux系统没有限制密码口令长度,所以唯一的限制是你的偏执和倔强。如果你要启动你的系统,你将大概至少要输入两个不同的密码:一个解锁LUKS,另一个登陆,所以长密码将会使你老的很快。最好从丰富或混合的词汇中选择2-3个单词长度,容易输入的密码。
|
||||
|
||||
优秀密码例子(是的,你可以使用空格):
|
||||
- nature abhors roombas
|
||||
- 12 in-flight Jebediahs
|
||||
- perdon, tengo flatulence
|
||||
|
||||
如果你更喜欢输入口令句,你也可以坚持使用无词汇密码但最少要10-12个字符长度。
|
||||
|
||||
除非你有人身安全的担忧,写下你的密码,并保存在一个远离你办公桌的安全的地方才合适。
|
||||
|
||||
#### Root,用户密码和管理组
|
||||
|
||||
我们建议,你的root密码和你的LUKS加密使用同样的密码(除非你共享你的笔记本给可信的人,它应该能解锁设备,但是不应该能成为root用户)。如果你是笔记本电脑的唯一用户,那么你的root密码与你的LUKS密码不同是没有意义的安全优势。通常,你可以使用同样的密码在你的UEFI管理,磁盘加密,和root登陆 -- 知道这些任意一个都会让攻击者完全控制您的系统,在单用户工作站上使这些密码不同,没有任何安全益处。
|
||||
|
||||
你应该有一个不同的,但同样强健的常规用户帐户密码用来每天工作。这个用户应该是管理组用户(例如`wheel`或者类似,根据分支),允许你执行`sudo`来提升权限。
|
||||
|
||||
换句话说,如果在你的工作站只有你一个用户,你应该有两个独特的,强健的,同样的强壮的密码需要记住:
|
||||
|
||||
**管理级别**,用在以下区域:
|
||||
|
||||
- UEFI管理
|
||||
- 引导程序(GRUB)
|
||||
- 磁盘加密(LUKS)
|
||||
- 工作站管理(root用户)
|
||||
|
||||
**User-level**, used for the following:
|
||||
**用户级别**,用在以下:
|
||||
|
||||
- 用户登陆和sudo
|
||||
- 密码管理器的主密码
|
||||
|
||||
很明显,如果有一个令人信服的理由它们所有可以不同。
|
||||
|
||||
## 安装后的加强
|
||||
|
||||
安装后的安全性加强在很大程度上取决于你选择的分支,所以在一个通用的文档中提供详细说明是徒劳的,例如这一个。然而,这里有一些你应该采取的步骤:
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 在全体范围内禁用火线和雷电模块 _(关键)_
|
||||
- [ ] 检查你的防火墙,确保过滤所有传入端口 _(关键)_
|
||||
- [ ] 确保root邮件转发到一个你可以查看到的账户 _(关键)_
|
||||
- [ ] 检查以确保sshd服务默认情况下是禁用的 _(中等)_
|
||||
- [ ] 建立一个系统自动更新任务,或更新提醒 _(中等)_
|
||||
- [ ] 配置屏幕保护程序在一段时间的不活动后自动锁定 _(中等)_
|
||||
- [ ] 建立日志监控 _(中等)_
|
||||
- [ ] 安装使用rkhunter _(低等)_
|
||||
- [ ] 安装一个入侵检测系统 _(偏执)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 黑名单模块
|
||||
|
||||
将火线和雷电模块列入黑名单,增加一行到`/etc/modprobe.d/blacklist-dma.conf`文件:
|
||||
|
||||
blacklist firewire-core
|
||||
blacklist thunderbolt
|
||||
|
||||
重启后的模块将被列入黑名单。这样做是无害的,即使你没有这些端口(但也不做任何事)。
|
||||
|
||||
#### Root邮件
|
||||
|
||||
默认的root邮件只是存储在系统基本上没人读过。确保你设置了你的`/etc/aliases`来转发root邮件到你确实能读取的邮箱,否则你也许错过了重要的系统通知和报告:
|
||||
|
||||
# Person who should get root's mail
|
||||
root: bob@example.com
|
||||
|
||||
编辑后这些后运行`newaliases`,然后测试它确保已投递,像一些邮件供应商将拒绝从没有或者不可达的域名的邮件。如果是这个原因,你需要配置邮件转发直到确实可用。
|
||||
|
||||
#### 防火墙,sshd,和监听进程
|
||||
|
||||
默认的防火墙设置将取决于您的发行版,但是大多数都允许`sshd`端口连入。除非你有一个令人信服的合理理由允许连入ssh,你应该过滤出来,禁用sshd守护进程。
|
||||
|
||||
systemctl disable sshd.service
|
||||
systemctl stop sshd.service
|
||||
|
||||
如果你需要使用它,你也可以临时启动它。
|
||||
|
||||
通常,你的系统不应该有任何侦听端口除了响应ping。这将有助于你对抗网络级别的零日漏洞利用。
|
||||
|
||||
#### 自动更新或通知
|
||||
|
||||
建议打开自动更新,除非你有一个非常好的理由不这么做,如担心自动更新将使您的系统无法使用(这是发生在过去,所以这种恐惧并非杞人忧天)。至少,你应该启用自动通知可用的更新。大多数发行版已经有这个服务自动运行,所以你不需要做任何事。查阅你的发行版文档查看更多。
|
||||
|
||||
你应该尽快应用所有明显的勘误,即使这些不是特别贴上“安全更新”或有关联的CVE代码。所有错误都潜在的安全漏洞和新的错误,比起坚持旧的,已知的错误,未知错误通常是更安全的策略。
|
||||
|
||||
#### 监控日志
|
||||
|
||||
你应该对你的系统上发生了什么很感兴趣。出于这个原因,你应该安装`logwatch`然后配置它每夜发送在你的系统上发生的任何事情的活动报告。这不会预防一个专业的攻击者,但是一个好安全网功能。
|
||||
|
||||
注意,许多systemd发行版将不再自动安装一个“logwatch”需要的syslog服务(由于systemd依靠自己的分类),所以你需要安装和启用“rsyslog”来确保使用logwatch之前你的/var/log不是空。
|
||||
|
||||
#### Rkhunter和IDS
|
||||
|
||||
安装`rkhunter`和一个入侵检测系统(IDS)像`aide`或者`tripwire`将不会有用,除非你确实理解它们如何工作采取必要的步骤来设置正确(例如,保证数据库在额外的媒介,从可信的环境运行检测,记住执行系统更新和配置更改后要刷新数据库散列,等等)。如果你不愿在你的工作站执行这些步骤调整你如何工作,这些工具将带来麻烦没有任何实在的安全益处。
|
||||
|
||||
我们强烈建议你安装`rkhunter`并每晚运行它。它相当易于学习和使用,虽然它不会阻止一个复杂的攻击者,它也能帮助你捕获你自己的错误。
|
||||
|
||||
## 个人工作站备份
|
||||
|
||||
工作站备份往往被忽视,或无计划的做,常常是不安全的方式。
|
||||
|
||||
### 清单
|
||||
|
||||
- [ ] 设置加密备份工作站到外部存储 _(关键)_
|
||||
- [ ] 使用零认知云备份的备份工具 _(中等)_
|
||||
|
||||
### 注意事项
|
||||
|
||||
#### 全加密备份存到外部存储
|
||||
|
||||
把全部备份放到一个移动磁盘中比较方便,不用担心带宽和流速(在这个时代,大多数供应商仍然提供显著的不对称的上传/下载速度)。不用说,这个移动硬盘本身需要加密(又一次,通过LIKS),或者你应该使用一个备份工具建立加密备份,例如`duplicity`或者它的GUI版本,`deja-dup`。我建议使用后者并使用随机生成的密码,保存到你的密码管理器中。如果你带上笔记本去旅行,把这个磁盘留在家,以防你的笔记本丢失或被窃时可以找回备份。
|
||||
|
||||
除了你的家目录外,你还应该备份`/etc`目录和处于鉴定目的的`/var/log`目录。
|
||||
|
||||
首先是,避免拷贝你的家目录到任何非加密存储上,甚至是快速的在两个系统上移动文件,一旦完成你肯定会忘了清除它,暴露个人隐私或者安全信息到监听者手中 -- 尤其是把这个存储跟你的笔记本防盗同一个包里。
|
||||
|
||||
#### 零认知站外备份选择性
|
||||
|
||||
站外备份也是相当重要的,是否可以做到要么需要你的老板提供空间,要么找一家云服务商。你可以建一个单独的duplicity/deja-dup配置,只包括重要的文件,以免传输大量你不想备份的数据(网络缓存,音乐,下载等等)。
|
||||
|
||||
作为选择,你可以使用零认知备份工具,例如[SpiderOak][5],它提供一个卓越的Linux GUI工具还有实用的特性,例如在多个系统或平台间同步内容。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
下面是我们认为你应该采用的最佳实践列表。它当然不是非常详细的,而是试图提供实用的建议,一个可行的整体安全性和可用性之间的平衡
|
||||
|
||||
### 浏览
|
||||
|
||||
毫无疑问,在你的系统上web浏览器将是最大、最容易暴露的攻击层面的软件。它是专门下载和执行不可信,恶意代码的一个工具。它试图采用沙箱和代码卫生处理等多种机制保护你免受这种危险,但是在之前多个场合它们都被击败了。你应该学到浏览网站是最不安全的活动在你参与的任何一天。
|
||||
|
||||
有几种方法可以减少浏览器的影响,但真正有效的方法需要你操作您的工作站将发生显著的变化。
|
||||
|
||||
#### 1: 实用两个不同的浏览器
|
||||
|
||||
这很容易做到,但是只有很少的安全效益。并不是所有浏览器都妥协给攻击者完全自由访问您的系统 -- 有时它们只能允许一个读取本地浏览器存储,窃取其它标签的活动会话,捕获输入浏览器,例如,实用两个不同的浏览器,一个用在工作/高安全站点,另一个用在其它,有助于防止攻击者请求整个饼干罐的小妥协。主要的不便是两个不同的浏览器消耗内存大量。
|
||||
|
||||
我们建议:
|
||||
|
||||
##### 火狐用来工作和高安全站点
|
||||
|
||||
使用火狐登陆工作有关的站点,应该额外关心的是确保数据如cookies,会话,登陆信息,打键次数等等,明显不应该落入攻击者手中。除了少数的几个网站,你不应该用这个浏览器访问其它网站。
|
||||
|
||||
你应该安装下面的火狐扩展:
|
||||
|
||||
- [ ] NoScript _(关键)_
|
||||
- NoScript阻止活动内容加载,除非在用户白名单里的域名。跟你默认浏览器比它使用起来很麻烦(可是提供了真正好的安全效益),所以我们建议只在开启了它的浏览器上访问与工作相关的网站。
|
||||
|
||||
- [ ] Privacy Badger _(关键)_
|
||||
- EFF的Privacy Badger将在加载时预防大多数外部追踪器和广告平台,在这些追踪站点影响你的浏览器时将有助于避免妥协(追踪着和广告站点通常会成为攻击者的目标,因为它们会迅速影响世界各地成千上万的系统)。
|
||||
|
||||
- [ ] HTTPS Everywhere _(关键)_
|
||||
- 这个EFF开发的扩展将确保你访问的大多数站点都在安全连接上,甚至你点击的连接使用的是http://(有效的避免大多数的攻击,例如[SSL-strip][7])。
|
||||
|
||||
- [ ] Certificate Patrol _(中等)_
|
||||
- 如果你正在访问的站点最近改变了它们的TLS证书 -- 特别是如果不是接近失效期或者现在使用不同的证书颁发机构,这个工具将会警告你。它有助于警告你是否有人正尝试中间人攻击你的连接,但是产生很多无害的假的类似情况。
|
||||
|
||||
你应该让火狐成为你的默认打开连接的浏览器,因为NoScript将在加载或者执行时阻止大多数活动内容。
|
||||
|
||||
##### 其它一切都用Chrome/Chromium
|
||||
|
||||
Chromium开发者在增加很多很好的安全特性方面比火狐强(至少[在Linux上][6])),例如seccomp沙箱,内核用户名空间等等,这担当一个你访问网站和你其它系统间额外的隔离层。Chromium是流开源项目,Chrome是Google所有的基于它构建的包(使用它输入时要非常谨慎任,何你不想让谷歌知道的事情都不要使用它)。
|
||||
|
||||
有人推荐你在Chrome上也安装**Privacy Badger**和**HTTPS Everywhere**扩展,然后给它一个不同的主题,从火狐指出这是你浏览器“不信任的站点”。
|
||||
|
||||
#### 2: 使用两个不同浏览器,一个在专用的虚拟机里
|
||||
|
||||
这有点像上面建议的做法,除了您将添加一个额外的步骤,通过快速访问协议运行专用虚拟机内部Chrome,允许你共享剪贴板和转发声音事件(如,Spice或RDP)。这将在不可信的浏览器和你其它的工作环境之间添加一个优秀的隔离层,确保攻击者完全危害你的浏览器将不得不另外打破VM隔离层,以达到系统的其余部分。
|
||||
|
||||
这是一个出奇可行的结构,但是需要大量的RAM和高速处理器可以处理增加的负载。这还需要一个重要的奉献的管理员需要相应地调整自己的工作实践。
|
||||
|
||||
#### 3: 通过虚拟化完全隔离你的工作和娱乐环境
|
||||
|
||||
看[Qubes-OS项目][3],它致力于通过划分你的应用到完全独立分开的VM中,提供高安全工作环境。
|
||||
|
||||
### 密码管理器
|
||||
|
||||
#### 清单
|
||||
|
||||
- [ ] 使用密码管理器 _(关键)_
|
||||
- [ ] 不相关的站点使用不同的密码 _(关键)_
|
||||
- [ ] 使用支持团队共享的密码管理器 _(中等)_
|
||||
- [ ] 给非网站用户使用一个单独的密码管理器 _(偏执)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
使用好的,唯一的密码对你的团队成员来说应该是非常关键的需求。证书盗取一直在发生 — 要么通过中间计算机,盗取数据库备份,远程站点利用,要么任何其它的打算。证书从不应该通过站点被重用,尤其是关键的应用。
|
||||
|
||||
|
||||
##### 浏览器中的密码管理器
|
||||
|
||||
每个浏览器有一个比较安全的保存密码机制,通过供应商的机制可以同步到云存储同事用户提供密码保证数据加密。无论如何,这个机制有严重的劣势:
|
||||
|
||||
|
||||
1. 不能跨浏览器工作
|
||||
2. 不提供任何与团队成员共享凭证的方法
|
||||
|
||||
也有一些良好的支持,免费或便宜的密码管理器,很好的融合到多个浏览器,跨平台工作,提供小组共享(通常是支付服务)。可以很容易地通过搜索引擎找到解决方案。
|
||||
|
||||
##### 独立的密码管理器
|
||||
|
||||
任何密码管理器都有一个主要的缺点,与浏览器结合,事实上是应用的一部分,这样最有可能被入侵者攻击。如果这让你不舒服(应该这样),你应该选择两个不同的密码管理器 -- 一个集成在浏览器中用来保存网站密码,一个作为独立运行的应用。后者可用于存储高风险凭证如root密码,数据库密码,其它shell账户凭证等。
|
||||
|
||||
有这样的工具可以特别有效的在团腿成员间共享超级用户的凭据(服务器根密码,ILO密码,数据库管理密码,引导装载程序密码等等)。
|
||||
|
||||
这几个工具可以帮助你:
|
||||
|
||||
- [KeePassX][8],2版中改善了团队共享
|
||||
- [Pass][9],它使用了文本文件和PGP并与git结合
|
||||
- [Django-Pstore][10],它是用GPG在管理员之间共享凭据
|
||||
- [Hiera-Eyaml][11],如果你已经在你的平台中使用了Puppet,可以便捷的追踪你的服务器/服务凭证,像你的Hiera加密数据的一部分。
|
||||
|
||||
### 加固SSH和PGP私钥
|
||||
|
||||
个人加密密钥,包括SSH和PGP私钥,都是你工作站中最重要的物品 -- 攻击将在获取到感兴趣的东西,这将允许它们进一步攻击你的平台或冒充你为其它管理员。你应该采取额外的步骤,确保你的私钥免遭盗窃。
|
||||
|
||||
#### 清单
|
||||
|
||||
- [ ] 强壮的密码用来保护私钥 _(关键)_
|
||||
- [ ] PGP的主密码保存在移动存储中 _(中等)_
|
||||
- [ ] 身份验证、签名和加密注册表子项存储在智能卡设备 _(中等)_
|
||||
- [ ] SSH配置为使用PGP认证密钥作为ssh私钥 _(中等)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
防止私钥被偷的最好方式是使用一个智能卡存储你的加密私钥,不要拷贝到工作平台上。有几个厂商提供支持OpenPGP的设备:
|
||||
|
||||
- [Kernel Concepts][12],在这里可以采购支持OpenPGP的智能卡和USB读取器,你应该需要一个。
|
||||
- [Yubikey NEO][13],这里提供OpenPGP功能的智能卡还提供很多很酷的特性(U2F, PIV, HOTP等等)。
|
||||
|
||||
确保PGP主密码没有存储在工作平台也很重要,只有子密码在使用。主密钥只有在登陆其它的密钥和创建子密钥时使用 — 不经常发生这种操作。你可以照着[Debian的子密钥][14]向导来学习如何移动你的主密钥到移动存储和创建子密钥。
|
||||
|
||||
你应该配置你的gnupg代理作为ssh代理然后使用基于智能卡PGP认证密钥作为你的ssh私钥。我们公布了一个细节向导如何使用智能卡读取器或Yubikey NEO。
|
||||
|
||||
如果你不想那么麻烦,最少要确保你的PGP私钥和你的SSH私钥有个强健的密码,这将让攻击者很难盗取使用它们。
|
||||
|
||||
### 工作站上的SELinux
|
||||
|
||||
如果你使用的发行版绑定了SELinux(如Fedora),这有些如何使用它的建议,让你的工作站达到最大限度的安全。
|
||||
|
||||
#### 清单
|
||||
|
||||
- [ ] 确保你的工作站强制使用SELinux _(关键)_
|
||||
- [ ] 不要盲目的执行`audit2allow -M`,经常检查 _(关键)_
|
||||
- [ ] 从不 `setenforce 0` _(中等)_
|
||||
- [ ] 切换你的用户到SELinux用户`staff_u` _(中等)_
|
||||
|
||||
#### 注意事项
|
||||
|
||||
SELinux是一个强制访问控制(MAC)为POSIX许可核心功能扩展。它是成熟,强健,自从它推出以来已经有很长的路了。不管怎样,许多系统管理员现在重复过时的口头禅“关掉它就行。”
|
||||
|
||||
话虽如此,在工作站上SELinux还是限制了安全效益,像很多应用都要作为一个用户自由的运行。开启它有益于给网络提供足够的保护,有可能有助于防止攻击者通过脆弱的后台服务提升到root级别的权限用户。
|
||||
|
||||
我们的建议是开启它并强制使用。
|
||||
|
||||
##### 从不`setenforce 0`
|
||||
|
||||
使用`setenforce 0`短时间内把SELinux设置为许可模式,但是你应该避免这样做。其实你是想查找一个特定应用或者程序的问题,实际上这样是把全部系统的SELinux关闭了。
|
||||
|
||||
你应该使用`semanage permissive -a [somedomain_t]`替换`setenforce 0`,只把这个程序放入许可模式。首先运行`ausearch`查看那个程序发生问题:
|
||||
|
||||
ausearch -ts recent -m avc
|
||||
|
||||
然后看下`scontext=`(SELinux的上下文)行,像这样:
|
||||
|
||||
scontext=staff_u:staff_r:gpg_pinentry_t:s0-s0:c0.c1023
|
||||
^^^^^^^^^^^^^^
|
||||
|
||||
这告诉你程序`gpg_pinentry_t`被拒绝了,所以你想查看应用的故障,应该增加它到许可模式:
|
||||
|
||||
semange permissive -a gpg_pinentry_t
|
||||
|
||||
这将允许你使用应用然后收集AVC的其它部分,你可以连同`audit2allow`写一个本地策略。一旦完成你就不会看到新的AVC的拒绝,你可以从许可中删除程序,运行:
|
||||
|
||||
semanage permissive -d gpg_pinentry_t
|
||||
|
||||
##### 用SELinux的用户staff_r,使用你的工作站
|
||||
|
||||
SELinux附带的本地角色实现基于角色的用户帐户禁止或授予某些特权。作为一个管理员,你应该使用`staff_r`角色,这可以限制访问很多配置和其它安全敏感文件,除非你先执行`sudo`。
|
||||
|
||||
默认,用户作为`unconfined_r`被创建,你可以运行大多数应用,没有任何(或只有一点)SELinux约束。转换你的用户到`staff_r`角色,运行下面的命令:
|
||||
|
||||
usermod -Z staff_u [username]
|
||||
|
||||
你应该退出然后登陆激活新角色,届时如果你运行`id -Z`,你将会看到:
|
||||
|
||||
staff_u:staff_r:staff_t:s0-s0:c0.c1023
|
||||
|
||||
在执行`sudo`时,你应该记住增加一个额外的标准告诉SELinux转换到"sysadmin"角色。你想要的命令是:
|
||||
|
||||
sudo -i -r sysadm_r
|
||||
|
||||
届时`id -Z`将会显示:
|
||||
|
||||
staff_u:sysadm_r:sysadm_t:s0-s0:c0.c1023
|
||||
|
||||
**警告**:在进行这个切换前你应该舒服的使用`ausearch`和`audit2allow`,当你作为`staff_r`角色运行时你的应用有可能不再工作了。写到这里时,以下流行的应用已知在`staff_r`下没有做策略调整就不会工作:
|
||||
|
||||
- Chrome/Chromium
|
||||
- Skype
|
||||
- VirtualBox
|
||||
|
||||
切换回`unconfined_r`,运行下面的命令:
|
||||
|
||||
usermod -Z unconfined_u [username]
|
||||
|
||||
然后注销再重新回到舒服的区域。
|
||||
|
||||
## 延伸阅读
|
||||
|
||||
IT安全的世界是一个没有底的兔子洞。如果你想深入,或者找到你的具体发行版更多的安全特性,请查看下面这些链接:
|
||||
|
||||
- [Fedora Security Guide](https://docs.fedoraproject.org/en-US/Fedora/19/html/Security_Guide/index.html)
|
||||
- [CESG Ubuntu Security Guide](https://www.gov.uk/government/publications/end-user-devices-security-guidance-ubuntu-1404-lts)
|
||||
- [Debian Security Manual](https://www.debian.org/doc/manuals/securing-debian-howto/index.en.html)
|
||||
- [Arch Linux Security Wiki](https://wiki.archlinux.org/index.php/Security)
|
||||
- [Mac OSX Security](https://www.apple.com/support/security/guides/)
|
||||
|
||||
## 许可
|
||||
|
||||
这项工作在[创作共用授权4.0国际许可证][0]许可下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/lfit/itpol/blob/bbc17d8c69cb8eee07ec41f8fbf8ba32fdb4301b/linux-workstation-security.md
|
||||
|
||||
作者:[mricon][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/mricon
|
||||
[0]: http://creativecommons.org/licenses/by-sa/4.0/
|
||||
[1]: https://github.com/QubesOS/qubes-antievilmaid
|
||||
[2]: https://en.wikipedia.org/wiki/IEEE_1394#Security_issues
|
||||
[3]: https://qubes-os.org/
|
||||
[4]: https://xkcd.com/936/
|
||||
[5]: https://spideroak.com/
|
||||
[6]: https://code.google.com/p/chromium/wiki/LinuxSandboxing
|
||||
[7]: http://www.thoughtcrime.org/software/sslstrip/
|
||||
[8]: https://keepassx.org/
|
||||
[9]: http://www.passwordstore.org/
|
||||
[10]: https://pypi.python.org/pypi/django-pstore
|
||||
[11]: https://github.com/TomPoulton/hiera-eyaml
|
||||
[12]: http://shop.kernelconcepts.de/
|
||||
[13]: https://www.yubico.com/products/yubikey-hardware/yubikey-neo/
|
||||
[14]: https://wiki.debian.org/Subkeys
|
||||
[15]: https://github.com/lfit/ssh-gpg-smartcard-config
|
||||
[16]: http://www.pavelkogan.com/2014/05/23/luks-full-disk-encryption/
|
||||
[17]: https://en.wikipedia.org/wiki/Cold_boot_attack
|
||||
[18]: http://www.linux.com/news/featured-blogs/167-amanda-mcpherson/850607-linux-foundation-sysadmins-open-source-their-it-policies
|
||||
@ -0,0 +1,464 @@
|
||||
通过Dockerize这篇博客来开启我们的Docker之旅
|
||||
===
|
||||
>这篇文章将包含Docker的基本概念,以及如何通过创建一个定制的Dockerfile来Dockerize一个应用
|
||||
>作者:Benjamin Cane,2015-12-01 10:00:00
|
||||
|
||||
Docker是2年前从某个idea中孕育而生的有趣技术,世界各地的公司组织都积极使用它来部署应用。在今天的文章中,我将教你如何通过"Dockerize"一个现有的应用,来开始我们的Docker运用。问题中的应用指的就是这篇博客!
|
||||
|
||||
## 什么是Docker?
|
||||
|
||||
当我们开始学习Docker基本概念时,让我们先去搞清楚什么是Docker以及它为什么这么流行。Docker是一个操作系统容器管理工具,它通过将应用打包在操作系统容器中,来方便我们管理和部署应用。
|
||||
|
||||
### 容器 vs. 虚拟机
|
||||
|
||||
容器虽和虚拟机并不完全相似,但它也是一种提供**操作系统虚拟化**的方式。但是,它和标准的虚拟机还是有不同之处的。
|
||||
|
||||
标准虚拟机一般会包括一个完整的操作系统,操作系统包,最后还有一至两个应用。这都得益于为虚拟机提供硬件虚拟化的管理程序。这样一来,一个单一的服务器就可以将许多独立的操作系统作为虚拟客户机运行了。
|
||||
|
||||
容器和虚拟机很相似,它们都支持在单一的服务器上运行多个操作环境,只是,在容器中,这些环境并不是一个个完整的操作系统。容器一般只包含必要的操作系统包和一些应用。它们通常不会包含一个完整的操作系统或者硬件虚拟化程序。这也意味着容器比传统的虚拟机开销更少。
|
||||
|
||||
容器和虚拟机常被误认为是两种抵触的技术。虚拟机采用同一个物理服务器,来提供全功能的操作环境,该环境会和其余虚拟机一起共享这些物理资源。容器一般用来隔离运行中的应用进程,运行进程将在单独的主机中运行,以保证隔离后的进程之间不能相互影响。事实上,容器和**BSD Jails**以及`chroot`进程的相似度,超过了和完整虚拟机的相似度。
|
||||
|
||||
### Docker在容器的上层提供了什么
|
||||
|
||||
Docker不是一个容器运行环境,事实上,只是一个容器技术,并不包含那些帮助Docker支持[Solaris Zones](https://blog.docker.com/2015/08/docker-oracle-solaris-zones/)和[BSD Jails](https://wiki.freebsd.org/Docker)的技术。Docker提供管理,打包和部署容器的方式。虽然一定程度上,虚拟机多多少少拥有这些类似的功能,但虚拟机并没有完整拥有绝大多数的容器功能,即使拥有,这些功能用起来都并没有Docker来的方便。
|
||||
|
||||
现在,我们应该知道Docker是什么了,然后,我们将从安装Docker,并部署一个公共的预构建好的容器开始,学习Docker是如何工作的。
|
||||
|
||||
## 从安装开始
|
||||
|
||||
默认情况下,Docker并不会自动被安装在您的计算机中,所以,第一步就是安装Docker包;我们的教学机器系统是Ubuntu 14.0.4,所以,我们将使用Apt包管理器,来执行安装操作。
|
||||
|
||||
```
|
||||
# apt-get install docker.io
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following extra packages will be installed:
|
||||
aufs-tools cgroup-lite git git-man liberror-perl
|
||||
Suggested packages:
|
||||
btrfs-tools debootstrap lxc rinse git-daemon-run git-daemon-sysvinit git-doc
|
||||
git-el git-email git-gui gitk gitweb git-arch git-bzr git-cvs git-mediawiki
|
||||
git-svn
|
||||
The following NEW packages will be installed:
|
||||
aufs-tools cgroup-lite docker.io git git-man liberror-perl
|
||||
0 upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 7,553 kB of archives.
|
||||
After this operation, 46.6 MB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
```
|
||||
|
||||
为了检查当前是否有容器运行,我们可以执行`docker`命令,加上`ps`选项
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
`docker`命令中的`ps`功能类似于Linux的`ps`命令。它将显示可找到的Docker容器以及各自的状态。由于我们并没有开启任何Docker容器,所以命令没有显示任何正在运行的容器。
|
||||
|
||||
## 部署一个预构建好的nginx Docker容器
|
||||
|
||||
我比较喜欢的Docker特性之一就是Docker部署预先构建好的容器的方式,就像`yum`和`apt-get`部署包一样。为了更好地解释,我们来部署一个运行着nginx web服务器的预构建容器。我们可以继续使用`docker`命令,这次选择`run`选项。
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
`docker`命令的`run`选项,用来通知Docker去寻找一个指定的Docker镜像,然后开启运行着该镜像的容器。默认情况下,Docker容器在前台运行,这意味着当你运行`docker run`命令的时候,你的shell会被绑定到容器的控制台以及运行在容器中的进程。为了能在后台运行该Docker容器,我们可以使用`-d` (**detach**)标志。
|
||||
|
||||
再次运行`docker ps`命令,可以看到nginx容器正在运行。
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 nginx:latest nginx -g 'daemon off 4 seconds ago Up 3 seconds 443/tcp, 80/tcp desperate_lalande
|
||||
```
|
||||
|
||||
从上面的打印信息中,我们可以看到正在运行的名为`desperate_lalande`的容器,它是由`nginx:latest image`(译者注:nginx最新版本的镜像)构建而来得。
|
||||
|
||||
### Docker镜像
|
||||
|
||||
镜像是Docker的核心特征之一,类似于虚拟机镜像。和虚拟机镜像一样,Docker镜像是一个被保存并打包的容器。当然,Docker不只是创建镜像,它还可以通过Docker仓库发布这些镜像,Docker仓库和包仓库的概念差不多,它让Docker能够模仿`yum`部署包的方式来部署镜像。为了更好地理解这是怎么工作的,我们来回顾`docker run`执行后的输出。
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
```
|
||||
|
||||
我们可以看到第一条信息是,Docker不能在本地找到名叫nginx的镜像。这是因为当我们执行`docker run`命令时,告诉Docker运行一个基于nginx镜像的容器。既然Docker要启动一个基于特定镜像的容器,那么Docker首先需要知道那个指定镜像。在检查远程仓库之前,Docker首先检查本地是否存在指定名称的本地镜像。
|
||||
|
||||
因为系统是崭新的,不存在nginx镜像,Docker将选择从Docker仓库下载之。
|
||||
|
||||
```
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
这就是第二部分打印信息显示给我们的内容。默认,Docker会使用[Docker Hub](https://hub.docker.com/)仓库,该仓库由Docker公司维护。
|
||||
|
||||
和Github一样,在Docker Hub创建公共仓库是免费的,私人仓库就需要缴纳费用了。当然,部署你自己的Docker仓库也是可以实现的,事实上只需要简单地运行`docker run registry`命令就行了。但在这篇文章中,我们的重点将不是讲解如何部署一个定制的注册服务。
|
||||
|
||||
### 关闭并移除容器
|
||||
|
||||
在我们继续构建定制容器之前,我们先清理Docker环境,我们将关闭先前的容器,并移除它。
|
||||
|
||||
我们利用`docker`命令和`run`选项运行一个容器,所以,为了停止该相同的容器,我们简单地在执行`docker`命令时,使用`kill`选项,并指定容器名。
|
||||
|
||||
```
|
||||
# docker kill desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
当我们再次执行`docker ps`,就不再有容器运行了
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
但是,此时,我们这是停止了容器;虽然它不再运行,但仍然存在。默认情况下,`docker ps`只会显示正在运行的容器,如果我们附加`-a` (all) 标识,它会显示所有运行和未运行的容器。
|
||||
|
||||
```
|
||||
# docker ps -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 5c82215b03d1 nginx -g 'daemon off 4 weeks ago Exited (-1) About a minute ago desperate_lalande
|
||||
```
|
||||
|
||||
为了能完整地移除容器,我们在用`docker`命令时,附加`rm`选项。
|
||||
|
||||
```
|
||||
# docker rm desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
虽然容器被移除了;但是我们仍拥有可用的**nginx**镜像(译者注:镜像缓存)。如果我们重新运行`docker run -d nginx`,Docker就无需再次拉取nginx镜像,即可启动容器。这是因为我们本地系统中已经保存了一个副本。
|
||||
|
||||
为了列出系统中所有的本地镜像,我们运行`docker`命令,附加`images`选项。
|
||||
|
||||
```
|
||||
# docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
nginx latest 9fab4090484a 5 days ago 132.8 MB
|
||||
```
|
||||
|
||||
## 构建我们自己的镜像
|
||||
|
||||
截至目前,我们已经使用了一些基础的Docker命令来开启,停止和移除一个预构建好的普通镜像。为了"Dockerize"这篇博客,我们需要构建我们自己的镜像,也就是创建一个**Dockerfile**。
|
||||
|
||||
在大多数虚拟机环境中,如果你想创建一个机器镜像,首先,你需要建立一个新的虚拟机,安装操作系统,安装应用,最后将其转换为一个模板或者镜像。但在Docker中,所有这些步骤都可以通过Dockerfile实现全自动。Dockerfile是向Docker提供构建指令去构建定制镜像的方式。在这一章节,我们将编写能用来部署这篇博客的定制Dockerfile。
|
||||
|
||||
### 理解应用
|
||||
|
||||
我们开始构建Dockerfile之前,第一步要搞明白,我们需要哪些东西来部署这篇博客。
|
||||
|
||||
博客本质上是由静态站点生成器生成的静态HTML页面,这个静态站点是我编写的,名为**hamerkop**。这个生成器很简单,它所做的就是生成该博客站点。所有的博客源码都被我放在了一个公共的[Github仓库](https://github.com/madflojo/blog)。为了部署这篇博客,我们要先从Github仓库把博客内容拉取下来,然后安装**Python**和一些**Python**模块,最后执行`hamerkop`应用。我们还需要安装**nginx**,来运行生成后的内容。
|
||||
|
||||
截止目前,这些还是一个简单的Dockerfile,但它却给我们展示了相当多的[Dockerfile语法]((https://docs.docker.com/v1.8/reference/builder/))。我们需要克隆Github仓库,然后使用你最喜欢的编辑器编写Dockerfile;我选择`vi`
|
||||
|
||||
```
|
||||
# git clone https://github.com/madflojo/blog.git
|
||||
Cloning into 'blog'...
|
||||
remote: Counting objects: 622, done.
|
||||
remote: Total 622 (delta 0), reused 0 (delta 0), pack-reused 622
|
||||
Receiving objects: 100% (622/622), 14.80 MiB | 1.06 MiB/s, done.
|
||||
Resolving deltas: 100% (242/242), done.
|
||||
Checking connectivity... done.
|
||||
# cd blog/
|
||||
# vi Dockerfile
|
||||
```
|
||||
|
||||
### FROM - 继承一个Docker镜像
|
||||
|
||||
第一条Dockerfile指令是`FROM`指令。这将指定一个现存的镜像作为我们的基础镜像。这也从根本上给我们提供了继承其他Docker镜像的途径。在本例中,我们还是从刚刚我们使用的**nginx**开始,如果我们想重新开始,我们可以通过指定`ubuntu:latest`来使用**Ubuntu** Docker镜像。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
```
|
||||
|
||||
除了`FROM`指令,我还使用了`MAINTAINER`,它用来显示Dockerfile的作者。
|
||||
|
||||
Docker支持使用`#`作为注释,我将经常使用该语法,来解释Dockerfile的部分内容。
|
||||
|
||||
### 运行一次测试构建
|
||||
|
||||
因为我们继承了**nginx** Docker镜像,我们现在的Dockerfile也就包括了用来构建**nginx**镜像的[Dockerfile](https://github.com/nginxinc/docker-nginx/blob/08eeb0e3f0a5ee40cbc2bc01f0004c2aa5b78c15/Dockerfile)中所有指令。这意味着,此时我们可以从该Dockerfile中构建出一个Docker镜像,然后从该镜像中运行一个容器。虽然,最终的镜像和**nginx**镜像本质上是一样的,但是我们这次是通过构建Dockerfile的形式,然后我们将讲解Docker构建镜像的过程。
|
||||
|
||||
想要从Dockerfile构建镜像,我们只需要在运行`docker`命令的时候,加上**build**选项。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 23.6 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Running in c97f36450343
|
||||
---> 60a44f78d194
|
||||
Removing intermediate container c97f36450343
|
||||
Successfully built 60a44f78d194
|
||||
```
|
||||
|
||||
上面的例子,我们使用了`-t` (**tag**)标识给镜像添加"blog"的标签。本质上我们只是在给镜像命名,如果我们不指定标签,就只能通过Docker分配的**Image ID**来访问镜像了。本例中,从Docker构建成功的信息可以看出,**Image ID**值为`60a44f78d194`。
|
||||
|
||||
除了`-t`标识外,我还指定了目录`/root/blog`。该目录被称作"构建目录",它将包含Dockerfile,以及其他需要构建该容器的文件。
|
||||
|
||||
现在我们构建成功,下面我们开始定制该镜像。
|
||||
|
||||
### 使用RUN来执行apt-get
|
||||
|
||||
用来生成HTML页面的静态站点生成器是用**Python**语言编写的,所以,在Dockerfile中需要做的第一件定制任务是安装Python。我们将使用Apt包管理器来安装Python包,这意味着在Dockerfile中我们要指定运行`apt-get update`和`apt-get install python-dev`;为了完成这一点,我们可以使用`RUN`指令。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
```
|
||||
|
||||
如上所示,我们只是简单地告知Docker构建镜像的时候,要去执行指定的`apt-get`命令。比较有趣的是,这些命令只会在该容器的上下文中执行。这意味着,即使容器中安装了`python-dev`和`python-pip`,但主机本身并没有安装这些。说的更简单点,`pip`命令将只在容器中执行,出了容器,`pip`命令不存在。
|
||||
|
||||
还有一点比较重要的是,Docker构建过程中不接受用户输入。这说明任何被`RUN`指令执行的命令必须在没有用户输入的时候完成。由于很多应用在安装的过程中需要用户的输入信息,所以这增加了一点难度。我们例子,`RUN`命令执行的命令都不需要用户输入。
|
||||
|
||||
### 安装Python模块
|
||||
|
||||
**Python**安装完毕后,我们现在需要安装Python模块。如果在Docker外做这些事,我们通常使用`pip`命令,然后参考博客Git仓库中名叫`requirements.txt`的文件。在之前的步骤中,我们已经使用`git`命令成功地将Github仓库"克隆"到了`/root/blog`目录;这个目录碰巧也是我们创建`Dockerfile`的目录。这很重要,因为这意味着Dokcer在构建过程中可以访问Git仓库中的内容。
|
||||
|
||||
当我们执行构建后,Docker将构建的上下文环境设置为指定的"构建目录"。这意味着目录中的所有文件都可以在构建过程中被使用,目录之外的文件(构建环境之外)是不能访问的。
|
||||
|
||||
为了能安装需要的Python模块,我们需要将`requirements.txt`从构建目录拷贝到容器中。我们可以在`Dockerfile`中使用`COPY`指令完成这一需求。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
```
|
||||
|
||||
在`Dockerfile`中,我们增加了3条指令。第一条指令使用`RUN`在容器中创建了`/build/`目录。该目录用来拷贝生成静态HTML页面需要的一切应用文件。第二条指令是`COPY`指令,它将`requirements.txt`从"构建目录"(`/root/blog`)拷贝到容器中的`/build/`目录。第三条使用`RUN`指令来执行`pip`命令;安装`requirements.txt`文件中指定的所有模块。
|
||||
|
||||
当构建定制镜像时,`COPY`是条重要的指令。如果在Dockerfile中不指定拷贝文件,Docker镜像将不会包含requirements.txt文件。在Docker容器中,所有东西都是隔离的,除非在Dockerfile中指定执行,否则容器中不会包括需要的依赖。
|
||||
|
||||
### 重新运行构建
|
||||
|
||||
现在,我们让Docker执行了一些定制任务,现在我们尝试另一次blog镜像的构建。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Running in bde05cf1e8fe
|
||||
---> f4b66e09fa61
|
||||
Removing intermediate container bde05cf1e8fe
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
Removing intermediate container 9aa8ff43f4b0
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Running in c50b15ddd8b1
|
||||
Downloading/unpacking jinja2 (from -r /build/requirements.txt (line 1))
|
||||
Downloading/unpacking PyYaml (from -r /build/requirements.txt (line 2))
|
||||
<truncated to reduce noise>
|
||||
Successfully installed jinja2 PyYaml mistune markdown MarkupSafe
|
||||
Cleaning up...
|
||||
---> abab55c20962
|
||||
Removing intermediate container c50b15ddd8b1
|
||||
Successfully built abab55c20962
|
||||
```
|
||||
|
||||
上述输出所示,我们可以看到构建成功了,我们还可以看到另外一个有趣的信息` ---> Using cache`。这条信息告诉我们,Docker在构建该镜像时使用了它的构建缓存。
|
||||
|
||||
### Docker构建缓存
|
||||
|
||||
当Docker构建镜像时,它不仅仅构建一个单独的镜像;事实上,在构建过程中,它会构建许多镜像。从上面的输出信息可以看出,在每一"步"执行后,Docker都在创建新的镜像。
|
||||
|
||||
```
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
```
|
||||
|
||||
上面片段的最后一行可以看出,Docker在告诉我们它在创建一个新镜像,因为它打印了**Image ID**;`cef11c3fb97c`。这种方式有用之处在于,Docker能在随后构建**blog**镜像时将这些镜像作为缓存使用。这很有用处,因为这样,Docker就能加速同一个容器中新构建任务的构建流程。从上面的例子中,我们可以看出,Docker没有重新安装`python-dev`和`python-pip`包,Docker则使用了缓存镜像。但是由于Docker并没有找到执行`mkdir`命令的构建缓存,随后的步骤就被一一执行了。
|
||||
|
||||
Docker构建缓存一定程度上是福音,但有时也是噩梦。这是因为使用缓存或者重新运行指令的决定在一个很狭窄的范围内执行。比如,如果`requirements.txt`文件发生了修改,Docker会在构建时检测到该变化,然后Docker会重新执行该执行那个点往后的所有指令。这得益于Docker能查看`requirements.txt`的文件内容。但是,`apt-get`命令的执行就是另一回事了。如果提供Python包的**Apt** 仓库包含了一个更新的python-pip包;Docker不会检测到这个变化,转而去使用构建缓存。这会导致之前旧版本的包将被安装。虽然对`python-pip`来说,这不是主要的问题,但对使用了某个致命攻击缺陷的包缓存来说,这是个大问题。
|
||||
|
||||
出于这个原因,抛弃Docker缓存,定期地重新构建镜像是有好处的。这时,当我们执行Docker构建时,我简单地指定`--no-cache=True`即可。
|
||||
|
||||
## 部署博客的剩余部分
|
||||
|
||||
Python包和模块安装后,接下来我们将拷贝需要用到的应用文件,然后运行`hamerkop`应用。我们只需要使用更多的`COPY` and `RUN`指令就可完成。
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
|
||||
## Add blog code nd required files
|
||||
COPY static /build/static
|
||||
COPY templates /build/templates
|
||||
COPY hamerkop /build/
|
||||
COPY config.yml /build/
|
||||
COPY articles /build/articles
|
||||
|
||||
## Run Generator
|
||||
RUN /build/hamerkop -c /build/config.yml
|
||||
```
|
||||
|
||||
现在我们已经写出了剩余的构建指令,我们再次运行另一次构建,并确保镜像构建成功。
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog/
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Using cache
|
||||
---> f4b66e09fa61
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> Using cache
|
||||
---> cef11c3fb97c
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Using cache
|
||||
---> abab55c20962
|
||||
Step 7 : COPY static /build/static
|
||||
---> 15cb91531038
|
||||
Removing intermediate container d478b42b7906
|
||||
Step 8 : COPY templates /build/templates
|
||||
---> ecded5d1a52e
|
||||
Removing intermediate container ac2390607e9f
|
||||
Step 9 : COPY hamerkop /build/
|
||||
---> 59efd1ca1771
|
||||
Removing intermediate container b5fbf7e817b7
|
||||
Step 10 : COPY config.yml /build/
|
||||
---> bfa3db6c05b7
|
||||
Removing intermediate container 1aebef300933
|
||||
Step 11 : COPY articles /build/articles
|
||||
---> 6b61cc9dde27
|
||||
Removing intermediate container be78d0eb1213
|
||||
Step 12 : RUN /build/hamerkop -c /build/config.yml
|
||||
---> Running in fbc0b5e574c5
|
||||
Successfully created file /usr/share/nginx/html//2011/06/25/checking-the-number-of-lwp-threads-in-linux
|
||||
Successfully created file /usr/share/nginx/html//2011/06/checking-the-number-of-lwp-threads-in-linux
|
||||
<truncated to reduce noise>
|
||||
Successfully created file /usr/share/nginx/html//archive.html
|
||||
Successfully created file /usr/share/nginx/html//sitemap.xml
|
||||
---> 3b25263113e1
|
||||
Removing intermediate container fbc0b5e574c5
|
||||
Successfully built 3b25263113e1
|
||||
```
|
||||
|
||||
### 运行定制的容器
|
||||
|
||||
成功的一次构建后,我们现在就可以通过运行`docker`命令和`run`选项来运行我们定制的容器,和之前我们启动nginx容器一样。
|
||||
|
||||
```
|
||||
# docker run -d -p 80:80 --name=blog blog
|
||||
5f6c7a2217dcdc0da8af05225c4d1294e3e6bb28a41ea898a1c63fb821989ba1
|
||||
```
|
||||
|
||||
我们这次又使用了`-d` (**detach**)标识来让Docker在后台运行。但是,我们也可以看到两个新标识。第一个新标识是`--name`,这用来给容器指定一个用户名称。之前的例子,我们没有指定名称,因为Docker随机帮我们生成了一个。第二个新标识是`-p`,这个标识允许用户从主机映射一个端口到容器中的一个端口。
|
||||
|
||||
之前我们使用的基础**nginx**镜像分配了80端口给HTTP服务。默认情况下,容器内的端口通道并没有绑定到主机系统。为了让外部系统能访问容器内部端口,我们必须使用`-p`标识将主机端口映射到容器内部端口。上面的命令,我们通过`-p 8080:80`语法将主机80端口映射到容器内部的80端口。
|
||||
|
||||
经过上面的命令,我们的容器似乎成功启动了,我们可以通过执行`docker ps`核实。
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
d264c7ef92bd blog:latest nginx -g 'daemon off 3 seconds ago Up 3 seconds 443/tcp, 0.0.0.0:80->80/tcp blog
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
截止目前,我们拥有了正在运行的定制Docker容器。虽然在这篇文章中,我们只接触了一些Dockerfile指令用法,但是我们还是要讨论所有的指令。我们可以检查[Docker's reference page](https://docs.docker.com/v1.8/reference/builder/)来获取所有的Dockerfile指令用法,那里对指令的用法说明得很详细。
|
||||
|
||||
另一个比较好的资源是[Dockerfile Best Practices page](https://docs.docker.com/engine/articles/dockerfile_best-practices/),它有许多构建定制Dockerfile的最佳练习。有些技巧非常有用,比如战略性地组织好Dockerfile中的命令。上面的例子中,我们将`articles`目录的`COPY`指令作为Dockerfile中最后的`COPY`指令。这是因为`articles`目录会经常变动。所以,将那些经常变化的指令尽可能地放在最后面的位置,来最优化那些可以被缓存的步骤。
|
||||
|
||||
通过这篇文章,我们涉及了如何运行一个预构建的容器,以及如何构建,然后部署定制容器。虽然关于Docker你还有许多需要继续学习的地方,但我想这篇文章给了你如何继续开始的好建议。当然,如果你认为还有一些需要继续补充的内容,在下面评论即可。
|
||||
|
||||
--------------------------------------
|
||||
via:http://bencane.com/2015/12/01/getting-started-with-docker-by-dockerizing-this-blog/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+bencane%2FSAUo+%28Benjamin+Cane%29
|
||||
|
||||
作者:Benjamin Cane
|
||||
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
Loading…
Reference in New Issue
Block a user