mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
031955c2a3
@ -0,0 +1,203 @@
|
||||
Auditd - Tool for Security Auditing on Linux Server
|
||||
================================================================================
|
||||
First of all , we wish all our readers **Happy & Prosperous New YEAR 2015** from our Linoxide team. So lets start this new year explaining about Auditd tool.
|
||||
|
||||
Security is one of the main factor that we need to consider. We must maintain it because we don't want someone steal our data. Security includes many things. Audit, is one of it.
|
||||
|
||||
On Linux system, we know that we have a tool named **auditd**. This tool is by default exist in most of Linux operating system. What is auditd tool and how to use it? We will cover it below.
|
||||
|
||||
### What is auditd? ###
|
||||
|
||||
Auditd or audit daemon, is a userspace component to the Linux Auditing System. It’s responsible for writing audit records to the disk.
|
||||
|
||||

|
||||
|
||||
### Installing auditd ###
|
||||
|
||||
On Ubuntu based system , we can use [wajig][1] tool or **apt-get tool** to install auditd.
|
||||
|
||||

|
||||
|
||||
Just follow the instruction to get it done. Once it finish it will install some tools related to auditd tool. Here are the tools :
|
||||
|
||||
- **auditctl ;** is a tool to control the behaviour of the daemon on the fly, adding rules, etc
|
||||
- **/etc/audit/audit.rules ;** is the file that contains audit rules
|
||||
- **aureport ;** is tool to generate and view the audit report
|
||||
- **ausearch ;** is a tool to search various events
|
||||
- **auditspd ;** is a tool which can be used to relay event notifications to other applications instead of writing them to disk in the audit log
|
||||
- **autrace ;** is a command that can be used to trace a process
|
||||
- **/etc/audit/auditd.conf ;** is the configuration file of auditd tool
|
||||
- When the first time we install **auditd**, there will be no rules available yet.
|
||||
|
||||
We can check it using this command :
|
||||
|
||||
$ sudo auditctl -l
|
||||
|
||||

|
||||
|
||||
To add rules on auditd, let’s continue to the section below.
|
||||
|
||||
### How to use it ###
|
||||
|
||||
#### Audit files and directories access ####
|
||||
|
||||
One of the basic need for us to use an audit tool are, how can we know if someone change a file(s) or directories? Using auditd tool, we can do with those commands (please remember, we will need root privileges to configure auditd tool):
|
||||
|
||||
**Audit files**
|
||||
|
||||
$ sudo auditctl -w /etc/passwd -p rwxa
|
||||
|
||||

|
||||
|
||||
**With :**
|
||||
|
||||
- **-w path ;** this parameter will insert a watch for the file system object at path. On the example above, auditd will wacth /etc/passwd file
|
||||
- **-p ; **this parameter describes the permission access type that a file system watch will trigger on
|
||||
- **rwxa ;** are the attributes which bind to -p parameter above. r is read, w is write, x is execute and a is attribute
|
||||
|
||||
#### Audit directories ####
|
||||
|
||||
To audit directories, we will use a similar command. Let’s take a look at the command below :
|
||||
|
||||
$ sudo auditctl -w /production/
|
||||
|
||||

|
||||
|
||||
The above command will watch any access to the **/production folder**.
|
||||
|
||||
Now, if we run **auditctl -l** command again, we will see that new rules are added.
|
||||
|
||||

|
||||
|
||||
Now let’s see the audit log says.
|
||||
|
||||
### Viewing the audit log ###
|
||||
|
||||
After rules are added, now we can see how auditd in action. To view audit log, we can use **ausearch** tool.
|
||||
|
||||
We already add rule to watch /etc/passwd file. Now we will try to use **ausearch** tool to view the audit log.
|
||||
|
||||
$ sudo ausearch -f /etc/passwd
|
||||
|
||||
- **-f** parameter told ausearch to investigate /etc/passwd file
|
||||
- The result is shown below :
|
||||
> **time**->Mon Dec 22 09:39:16 2014
|
||||
> type=PATH msg=audit(1419215956.471:194): item=0 **name="/etc/passwd"** inode=142512 dev=08:01 mode=0100644 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419215956.471:194): **cwd="/home/pungki"**
|
||||
> type=SYSCALL msg=audit(1419215956.471:194): arch=40000003 **syscall=5** success=yes exit=3 a0=b779694b a1=80000 a2=1b6 a3=b8776aa8 items=1 ppid=2090 pid=2231 **auid=4294967295 uid=1000 gid=1000** euid=0 suid=0 fsuid=0 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=4294967295 **comm="sudo" exe="/usr/bin/sudo"** key=(null)
|
||||
|
||||
Now let’s we understand the result.
|
||||
|
||||
- **time ;** is when the audit is done
|
||||
- **name ;** is the object name to be audited
|
||||
- **cwd ;** is the current directory
|
||||
- **syscall ;** is related syscall
|
||||
- **auid ;** is the audit user ID
|
||||
- **uid and gid ;** are User ID and Group ID of the user who access the file
|
||||
- **comm ;** is the command that the user is used to access the file
|
||||
- **exe ;** is the location of the command of comm parameter above
|
||||
- The above audit log is the original file.
|
||||
|
||||
Next, we are going to add a new user, to see how the auditd record the activity to /etc/passwd file.
|
||||
|
||||
> **time->**Mon Dec 22 11:25:23 2014
|
||||
> type=PATH msg=audit(1419222323.628:510): item=1 **name="/etc/passwd.lock"** inode=143992 dev=08:01 mode=0100600 ouid=0 ogid=0 rdev=00:00 nametype=DELETE
|
||||
> type=PATH msg=audit(1419222323.628:510): item=0 **name="/etc/"** inode=131073 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=PARENT
|
||||
> type=CWD msg=audit(1419222323.628:510): **cwd="/root"**
|
||||
> type=SYSCALL msg=audit(1419222323.628:510): arch=40000003 **syscall=10** success=yes exit=0 a0=bfc0ceec a1=0 a2=bfc0ceec a3=897764c items=2 ppid=2978 pid=2994 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="chfn" exe="/usr/bin/chfn"** key=(null)
|
||||
|
||||
As we can see above, that on that particular time, **/etc/passwd was accessed** by user root (uid = 0 and gid = 0) **from** directory /root (cwd = /root). The /etc/passwd file was accessed using **chfn** command which located in **/usr/bin/chfn**
|
||||
|
||||
If we type **man chfn** on the console, we will see more detail about what is chfn.
|
||||
|
||||

|
||||
|
||||
Now we take a look at another example.
|
||||
|
||||
We already told auditd to watch directory /production/ . That is a new directory. So when we try to use ausearch tool at the first time, it found nothing.
|
||||
|
||||

|
||||
|
||||
Next, root account try to list the /production directory using ls command. The second time we use ausearch tool, it will show us some information.
|
||||
|
||||

|
||||
|
||||
> **time->**Mon Dec 22 14:18:28 2014
|
||||
> type=PATH msg=audit(1419232708.344:527): item=0 **name="/production/"** inode=797104 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419232708.344:527): cwd="/root"
|
||||
> type=SYSCALL msg=audit(1419232708.344:527): arch=40000003 syscall=295 success=yes exit=3 a0=ffffff9c a1=95761e8 a2=98800 a3=0 items=1 ppid=3033 pid=3444 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="ls" exe="/bin/ls"** key=(null)
|
||||
|
||||
Similar with the previous one, we can determine that **/production folder was looked** by root account (uid=0 gid=0) **using ls command** (comm = ls) and the ls command is **located in /bin/ls folder**.
|
||||
|
||||
### Viewing the audit reports ###
|
||||
|
||||
Once we put the audit rules, it will run automatically. And after a period of time, we want to see how auditd can help us to track them.
|
||||
|
||||
Auditd comes with another tool called **aureport**. As we can guess from its name, **aureport** is a tool that produces summary reports of the audit system log.
|
||||
|
||||
We already told auditd to track /etc/passwd before. And a moment after the auditd parameter is developed, the audit.log file is created.
|
||||
|
||||
To generate the report of audit, we can use aureport tool. Without any parameters, aureport will generate a summary report of audit activity.
|
||||
|
||||
$ sudo aureport
|
||||
|
||||

|
||||
|
||||
As we can see, there are some information available which cover most important area.
|
||||
|
||||
On the picture above we see there are **3 times failed authentication**. Using aureport, we can drill down to that information.
|
||||
|
||||
We can use this command to look deeper on failed authentication :
|
||||
|
||||
$ sudo aureport -au
|
||||
|
||||

|
||||
|
||||
As we can see on the picture above, there are two users which at the particular time are failed to authenticated
|
||||
|
||||
If we want to see all events related to account modification, we can use -m parameter.
|
||||
|
||||
$ sudo aureport -m
|
||||
|
||||

|
||||
|
||||
### Auditd configuration file ###
|
||||
|
||||
Previously we already added :
|
||||
|
||||
- $ sudo auditctl -w /etc/passwd -p rwxa
|
||||
- $ sudo auditctl -w /production/
|
||||
- Now, if we sure the rules are OK, we can add it into
|
||||
|
||||
**/etc/audit/audit.rules** to make them permanently.Here’s how to put them into the /etc/audit/audit.rules fileSample of audit rule file
|
||||
|
||||

|
||||
|
||||
**Then don’t forget to restart auditd daemon.**
|
||||
|
||||
# /etc/init.d/auditd restart
|
||||
|
||||
OR
|
||||
|
||||
# service auditd restart
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Auditd is one of the audit tool that available on Linux system. You can explore more detail about auditd and its related tools by reading its manual page. For example, just type **man auditd** to see more detail about auditd. Or type **man ausearch** to see more detail about ausearch tool.
|
||||
|
||||
**Please be careful before creating rules**. It will increase your log file size significantly if too much information to record.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/auditd-tool-security-auditing/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
123
sources/tech/20150104 How To Install Websvn In CentOS 7.md
Normal file
123
sources/tech/20150104 How To Install Websvn In CentOS 7.md
Normal file
@ -0,0 +1,123 @@
|
||||
How To Install Websvn In CentOS 7
|
||||
================================================================================
|
||||
**WebSVN** offers a view onto your subversion repositories that’s been designed to reflect the Subversion methodology. You can view the log of any file or directory and see a list of all the files changed, added or deleted in any given revision. You can also view the differences between two versions of a file so as to see exactly what was changed in a particular revision.
|
||||
|
||||
### Features ###
|
||||
|
||||
WebSVN offers the following features:
|
||||
|
||||
- Easy to use interface;
|
||||
- Customisable templating system;
|
||||
- Colourisation of file listings;
|
||||
- Blame view;
|
||||
- Log message searching;
|
||||
- RSS feed support.
|
||||
|
||||
### Installation ###
|
||||
|
||||
I use the following link to install Subversion on CentOS 7.
|
||||
|
||||
- [How To install Subversion On CentOS 7][1]
|
||||
|
||||
**1 – Download the websvn to /var/www/html.**
|
||||
|
||||
cd /var/www/html
|
||||
|
||||
----------
|
||||
|
||||
wget http://websvn.tigris.org/files/documents/1380/49057/websvn-2.3.3.zip
|
||||
|
||||
**2 – Extract the zip package.**
|
||||
|
||||
unzip websvn-2.3.3.zip
|
||||
|
||||
----------
|
||||
|
||||
mv websvn-2.3.3 websvn
|
||||
|
||||
**3 – Installl php to your system.**
|
||||
|
||||
yum install php
|
||||
|
||||
**4 – Edit web svn config.**
|
||||
|
||||
cd /var/www/html/websvn/include
|
||||
|
||||
----------
|
||||
|
||||
cp distconfig.php config.php
|
||||
|
||||
----------
|
||||
|
||||
vi config.php
|
||||
|
||||
----------
|
||||
|
||||
// Configure these lines if your commands aren't on your path.
|
||||
//
|
||||
$config->setSVNCommandPath('/usr/bin'); // e.g. c:\\program files\\subversion\\bin
|
||||
$config->setDiffPath('/usr/bin');
|
||||
----------
|
||||
// For syntax colouring, if option enabled...
|
||||
$config->setEnscriptPath('/usr/bin');
|
||||
$config->setSedPath('/bin');
|
||||
----------
|
||||
// For delivered tarballs, if option enabled...
|
||||
$config->setTarPath('/bin');
|
||||
----------
|
||||
// For delivered GZIP'd files and tarballs, if option enabled...
|
||||
$config->setGZipPath('/bin');
|
||||
----------
|
||||
//
|
||||
$config->parentPath('/svn/');
|
||||
----------
|
||||
$extEnscript[".pl"] = "perl";
|
||||
$extEnscript[".py"] = "python";
|
||||
$extEnscript[".sql"] = "sql";
|
||||
$extEnscript[".java"] = "java";
|
||||
$extEnscript[".html"] = "html";
|
||||
$extEnscript[".xml"] = "html";
|
||||
$extEnscript[".thtml"] = "html";
|
||||
$extEnscript[".tpl"] = "html";
|
||||
$extEnscript[".sh"] = "bash";
|
||||
~
|
||||
|
||||
save and exit.
|
||||
|
||||
**6 – Reload apache and start websvn link http://ip/websvn.**
|
||||
|
||||

|
||||
|
||||
That’s it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-websvn-centos-7/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
[1]:http://www.unixmen.com/install-subversion-centos-7/
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,207 @@
|
||||
How to configure fail2ban to protect Apache HTTP server
|
||||
================================================================================
|
||||
An Apache HTTP server in production environments can be under attack in various different ways. Attackers may attempt to gain access to unauthorized or forbidden directories by using brute-force attacks or executing evil scripts. Some malicious bots may scan your websites for any security vulnerability, or collect email addresses or web forms to send spams to.
|
||||
|
||||
Apache HTTP server comes with comprehensive logging capabilities capturing various abnormal events indicative of such attacks. However, it is still non-trivial to systematically parse detailed Apache logs and react to potential attacks quickly (e.g., ban/unban offending IP addresses) as they are perpetrated in the wild. That is when `fail2ban` comes to the rescue, making a sysadmin's life easier.
|
||||
|
||||
`fail2ban` is an open-source intrusion prevention tool which detects various attacks based on system logs and automatically initiates prevention actions e.g., banning IP addresses with `iptables`, blocking connections via /etc/hosts.deny, or notifying the events via emails. fail2ban comes with a set of predefined "jails" which use application-specific log filters to detect common attacks. You can also write custom jails to deter any specific attack on an arbitrary application.
|
||||
|
||||
In this tutorial, I am going to demonstrate how you can configure fail2ban to protect your Apache HTTP server. I assume that you have Apache HTTP server and fail2ban already installed. Refer to [another tutorial][1] for fail2ban installation.
|
||||
|
||||
### What is a Fail2ban Jail ###
|
||||
|
||||
Let me go over more detail on fail2ban jails. A jail defines an application-specific policy under which fail2ban triggers an action to protect a given application. fail2ban comes with several jails pre-defined in /etc/fail2ban/jail.conf, for popular applications such as Apache, Dovecot, Lighttpd, MySQL, Postfix, [SSH][2], etc. Each jail relies on application-specific log filters (found in /etc/fail2ban/fileter.d) to detect common attacks. Let's check out one example jail: SSH jail.
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry = 6
|
||||
banaction = iptables-multiport
|
||||
|
||||
This SSH jail configuration is defined with several parameters:
|
||||
|
||||
- **[ssh]**: the name of a jail with square brackets.
|
||||
- **enabled**: whether the jail is activated or not.
|
||||
- **port**: a port number to protect (either numeric number of well-known name).
|
||||
- **filter**: a log parsing rule to detect attacks with.
|
||||
- **logpath**: a log file to examine.
|
||||
- **maxretry**: maximum number of failures before banning.
|
||||
- **banaction**: a banning action.
|
||||
|
||||
Any parameter defined in a jail configuration will override a corresponding `fail2ban-wide` default parameter. Conversely, any parameter missing will be assgined a default value defined in [DEFAULT] section.
|
||||
|
||||
Predefined log filters are found in /etc/fail2ban/filter.d, and available actions are in /etc/fail2ban/action.d.
|
||||
|
||||
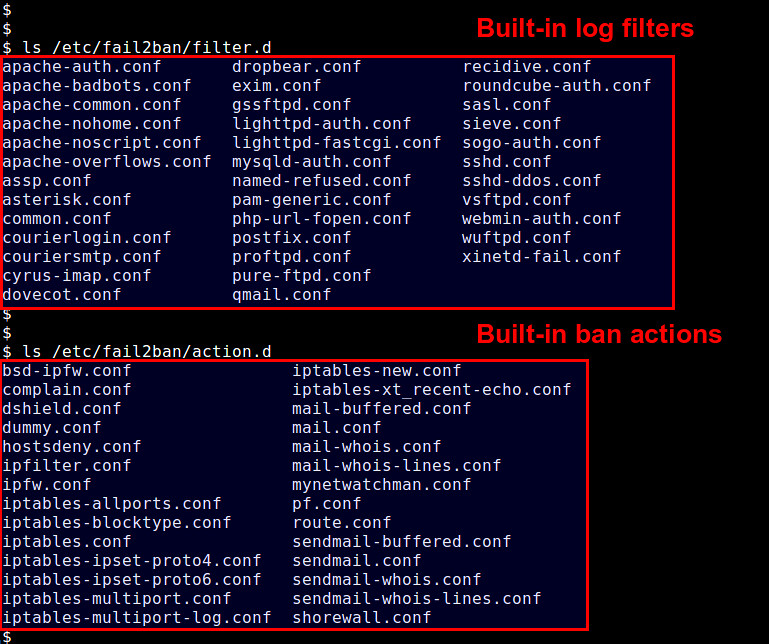
|
||||
|
||||
If you want to overwrite `fail2ban` defaults or define any custom jail, you can do so by creating **/etc/fail2ban/jail.local** file. In this tutorial, I am going to use /etc/fail2ban/jail.local.
|
||||
|
||||
### Enable Predefined Apache Jails ###
|
||||
|
||||
Default installation of `fail2ban` offers several predefined jails and filters for Apache HTTP server. I am going to enable those built-in Apache jails. Due to slight differences between Debian and Red Hat configurations, let me provide fail2ban jail configurations for them separately.
|
||||
|
||||
#### Enable Apache Jails on Debian or Ubuntu ####
|
||||
|
||||
To enable predefined Apache jails on a Debian-based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect potential search for exploits and php vulnerabilities
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
Since none of the jails above specifies an action, all of these jails will perform a default action when triggered. To find out the default action, look for "banaction" under [DEFAULT] section in /etc/fail2ban/jail.conf.
|
||||
|
||||
banaction = iptables-multiport
|
||||
|
||||
In this case, the default action is iptables-multiport (defined in /etc/fail2ban/action.d/iptables-multiport.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails.
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
#### Enable Apache Jails on CentOS/RHEL or Fedora ####
|
||||
|
||||
To enable predefined Apache jails on a Red Hat based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect spammer robots crawling email addresses
|
||||
[apache-badbots]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-badbots
|
||||
logpath = /var/log/httpd/*access_log
|
||||
bantime = 172800
|
||||
maxretry = 1
|
||||
|
||||
# detect potential search for exploits and php <a href="http://xmodulo.com/recommend/penetrationbook" style="" target="_blank" rel="nofollow" >vulnerabilities</a>
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to execute non-existing scripts that
|
||||
# are associated with several popular web services
|
||||
# e.g. webmail, phpMyAdmin, WordPress
|
||||
port = http,https
|
||||
filter = apache-botsearch
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
Note that the default action for all these jails is iptables-multiport (defined as "banaction" under [DEFAULT] in /etc/fail2ban/jail.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails in fail2ban.
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo systemctl restart fail2ban
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
### Check and Manage Fail2ban Banning Status ###
|
||||
|
||||
Once jails are activated, you can monitor current banning status with fail2ban-client command-line tool.
|
||||
|
||||
To see a list of active jails:
|
||||
|
||||
$ sudo fail2ban-client status
|
||||
|
||||
To see the status of a particular jail (including banned IP list):
|
||||
|
||||
$ sudo fail2ban-client status [name-of-jail]
|
||||
|
||||
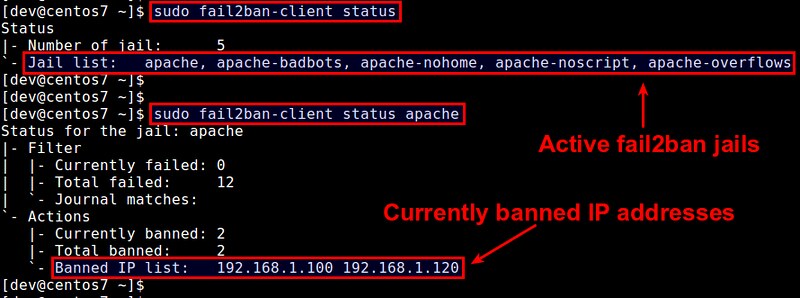
|
||||
|
||||
You can also manually ban or unban IP addresses.
|
||||
|
||||
To ban an IP address with a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] banip [ip-address]
|
||||
|
||||
To unban an IP address blocked by a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] unbanip [ip-address]
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial explains how a fail2ban jail works and how to protect an Apache HTTP server using built-in Apache jails. Depending on your environments and types of web services you need to protect, you may need to adapt existing jails, or write custom jails and log filters. Check outfail2ban's [official Github page][3] for more up-to-date examples of jails and filters.
|
||||
|
||||
Are you using fail2ban in any production environment? Share your experience.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[2]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[3]:https://github.com/fail2ban/fail2ban
|
||||
@ -0,0 +1,109 @@
|
||||
How to debug a C/C++ program with Nemiver debugger
|
||||
================================================================================
|
||||
If you read [my post on GDB][1], you know how important and useful a debugger I think can be for a C/C++ program. However, if a command line debugger like GDB sounds more like a problem than a solution to you, you might be more interested in Nemiver. [Nemiver][2] is a GTK+-based standalone graphical debugger for C/C++ programs, using GDB as its back-end. Admirable for its speed and stability, Nemiver is a very reliable debugger filled with goodies.
|
||||
|
||||
### Installation of Nemiver ###
|
||||
|
||||
For Debian based distributions, it should be pretty straightforward:
|
||||
|
||||
$ sudo apt-get install nemiver
|
||||
|
||||
For Arch Linux:
|
||||
|
||||
$ sudo pacman -S nemiver
|
||||
|
||||
For Fedora:
|
||||
|
||||
$ sudo yum install nemiver
|
||||
|
||||
If you prefer compiling yourself, the latest sources are available from [GNOME website][3].
|
||||
|
||||
As a bonus, it integrates very well with the GNOME environment.
|
||||
|
||||
### Basic Usage of Nemiver ###
|
||||
|
||||
Start Nemiver with the command:
|
||||
|
||||
$ nemiver
|
||||
|
||||
You can also summon it with an executable with:
|
||||
|
||||
$ nemiver [path to executable to debug]
|
||||
|
||||
Note that Nemiver will be much more helpful if the executable is compiled in debug mode (the -g flag with GCC).
|
||||
|
||||
A good thing is that Nemiver is really fast to load, so you should instantly see the main screen in the default layout.
|
||||
|
||||
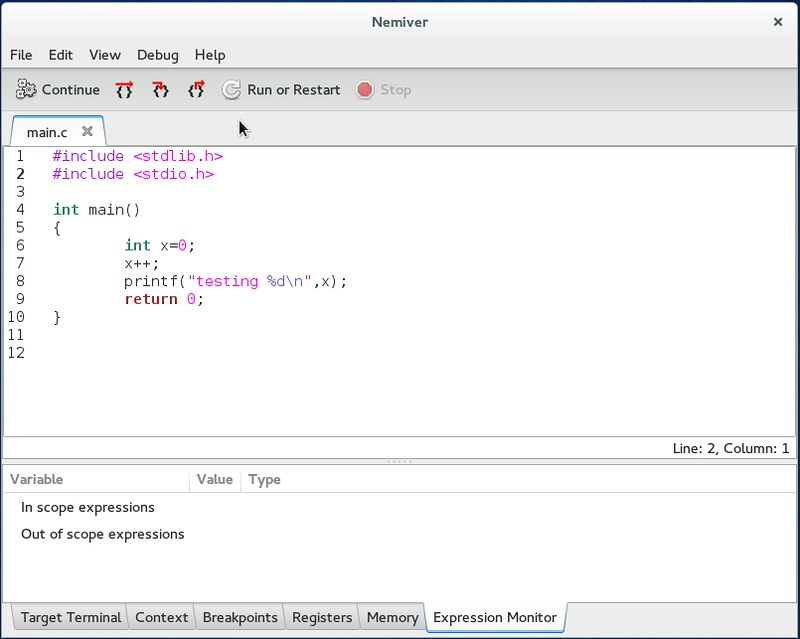
|
||||
|
||||
By default, a breakpoint has been placed in the first line of the main function. This gives you the time to recognize the basic debugger functions:
|
||||
|
||||

|
||||
|
||||
- Next line (mapped to F6)
|
||||
- Step inside a function (F7)
|
||||
- Step out of a function (Shift+F7)
|
||||
|
||||
But maybe my personal favorite is the option "Run to cursor" which makes the program run until a precise line under your cursor, and is by default mapped to F11.
|
||||
|
||||
Next, the breakpoints are also easy to use. The quick way to lay a breakpoint at a line is using F8. But Nemiver also has a more complex menu under "Debug" which allows you to set up a breakpoint at a particular function, line number, location of binary file, or even at an event like an exception, a fork, or an exec.
|
||||
|
||||
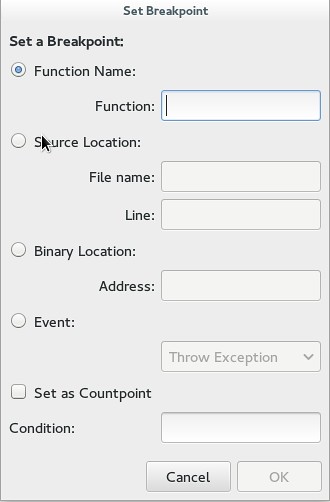
|
||||
|
||||
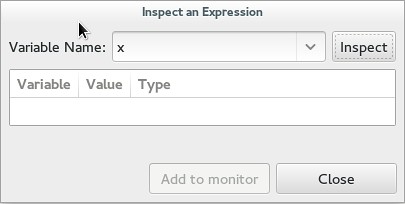
You can also watch a variable by tracking it. In "Debug" you can inspect an expression by giving its name and examining it. It is then possible to add it to the list of controlled variable for easy access. This is probably one of the most useful aspects as I have never been a huge fan of hovering over a variable to get its value. Note that hovering does work though. And to make it even better, Nemiver is capable of watching a struct, and giving you the values of all the member variables.
|
||||
|
||||
|
||||
|
||||
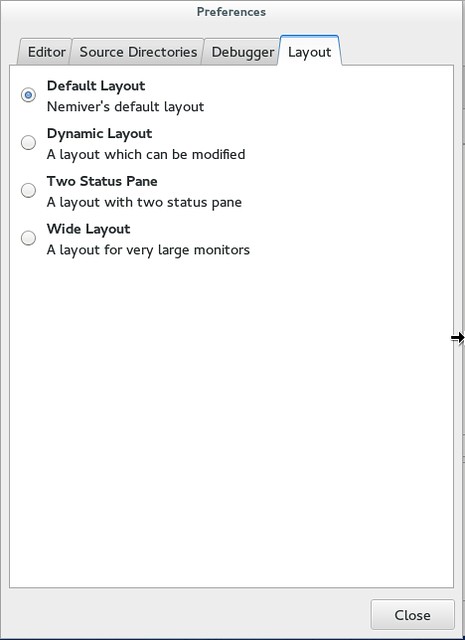
Talking about easy access to information, I also really appreciate the layout of the program. By default, the code is in the upper half and the tabs in the lower part. This grants you access to a terminal for output, a context tracker, a breakpoints list, register addresses, memory map, and variable control. But note that under "Edit" "Preferences" "Layout" you can select different layouts, including a dynamic one for you to modify.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
And naturally, once you set up all your breakpoints, watch-points, and layout, you can save your session under “File” for easy retrieval in case you close Nemiver.
|
||||
|
||||
### Advanced Usage of Nemiver ###
|
||||
|
||||
So far, we talked about the basic features of Nemiver, i.e., what you need to get started and debug simple programs immediately. If you have more advanced needs, and especially more complex programs, you might be more interested in some of these features mentioned here.
|
||||
|
||||
#### Debugging a running process ####
|
||||
|
||||
Nemiver allows you to attach to a running process for debugging. Under the "File" menu, you can filter the list of running processes, and connect to a process.
|
||||
|
||||

|
||||
|
||||
#### Debugging a program remotely over a TCP connection ####
|
||||
|
||||
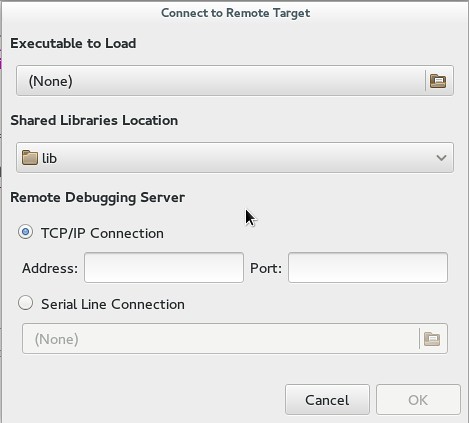
Nemiver supports remote-debugging, where you set up a lightweight debug server on a remote machine, and launch Nemiver from another machine to debug a remote target hosted by the debug server. Remote debugging can be useful if you cannot run full-fledged Nemiver or GDB on the remote machine for some reason. Under the "File" menu, specify the binary, shared library location, and the address and port.
|
||||
|
||||
|
||||
|
||||
#### Using your own GDB binary to debug ####
|
||||
|
||||
In case you compiled Nemiver yourself, you can specify a new location for GDB under "Edit" "Preferences" "Debug". This option can be useful if you want to use a custom version of GDB in Nemiver for some reason.
|
||||
|
||||
#### Follow a child or parent process ####
|
||||
|
||||
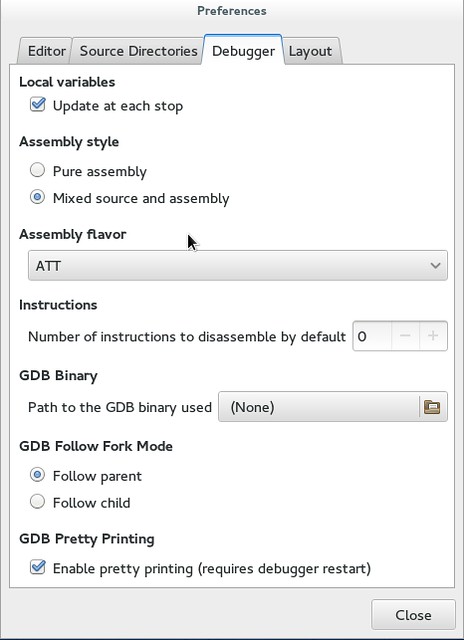
Nemiver is capable of following a child or parent process in case your program forks. To enable this feature, go to "Preferences" under "Debugger" tab.
|
||||
|
||||
|
||||
|
||||
To conclude, Nemiver is probably my favorite program for debugging without an IDE. It even beats GDB in my opinion, and [command line][4] programs generally have a good grip on me. So if you have never used it, I really recommend it. I can only congratulate the team behind it for giving us such a reliable and stable program.
|
||||
|
||||
What do you think of Nemiver? Would you consider it for standalone debugging? Or do you still stick to an IDE? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/gdb-command-line-debugger.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
@ -0,0 +1,134 @@
|
||||
How to set up a cross-platform backup server on Linux with BackupPC
|
||||
================================================================================
|
||||
Just in case you haven't been able to tell from my earlier posts on [backupninja][1] and [backup-manager][2], I am a big backup fan. When it comes to backup, I'd rather have too much than not enough, because if the need arises, you will be grateful that you took the time and effort to generate extra copies of your important data.
|
||||
|
||||
In this post, I will introduce you to [BackupPC][3], a cross-platform backup server software which can perform pull backup of Linux, Windows and MacOS client hosts over network. BackupPC adds a number of features that make managing backups an almost fun thing to do.
|
||||
|
||||
### Features of BackupPC ###
|
||||
|
||||
BackupPC comes with a robust web interface that allows you to collect and manage backups of other remote client hosts in a centralized fashion. Using the web interface, you can examine logs and configuration files, start/cancel/schedule backups of other remote hosts, and visualize current status of backup tasks. You can also browse through archived files and restore individual files or entire jobs from backup archives very easily. To restore individual single files, you can download them from any previous backup directly from the web interface. As if this weren't enough, no special client-side software is needed for client hosts. On Windows clients, the native SMB protocol is used, whereas on *nix clients, you will use `rsync` or tar over SSH, RSH or NFS.
|
||||
|
||||
### Installing BackupPC ###
|
||||
|
||||
On Debian, Ubuntu and their derivatives, run the following command.
|
||||
|
||||
# aptitude install backuppc
|
||||
|
||||
On Fedora, use `yum` command. Note the case sensitive package name.
|
||||
|
||||
On CentOS/RHEL 6, first enable [EPEL repository][4]. On CentOS/RHEL 7, enable [Nux Dextop][5] repository instead. Then go ahead with `yum` command:
|
||||
|
||||
# yum install BackupPC
|
||||
|
||||
As usual, both package management systems will take care of dependency resolution automatically. In addition, as part of the installation process, you may be asked to configure, or reconfigure the web server that will be used for the graphical user interface. The following screenshot is from a Debian system:
|
||||
|
||||

|
||||
|
||||
Select your choice by pressing the space bar, and then move to Ok with the tab key and hit ENTER.
|
||||
|
||||
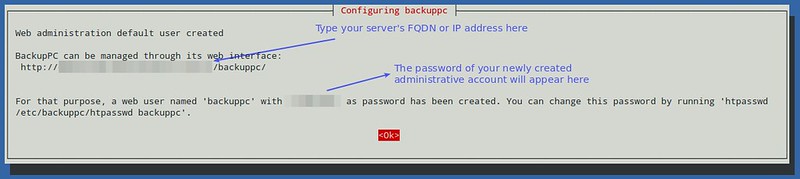
You will then be presented with the following screen informing you that an administrative user account 'backuppc', along with its corresponding password (which can be changed later if desired), has been created to manage BackupPC. Note that both a HTTP user account and a regular Linux account of the same name 'backuppc' will be created with an identical password. The former is needed to access BackupPC's protected web interface, while the latter is needed to perform backup using rsync over SSH.
|
||||
|
||||
|
||||
|
||||
You can change the default password for the HTTP user 'backuppc' with the following command:
|
||||
|
||||
# htpasswd /path/to/hash/file backuppc
|
||||
|
||||
As for a regular 'backuppc' [Linux][6] user account, use passwd command to change its default password.
|
||||
|
||||
# passwd backuppc
|
||||
|
||||
Note that the installation process creates the web and the program's configuration files automatically.
|
||||
|
||||
### Launching BackupPC and Configuring Backups ###
|
||||
|
||||
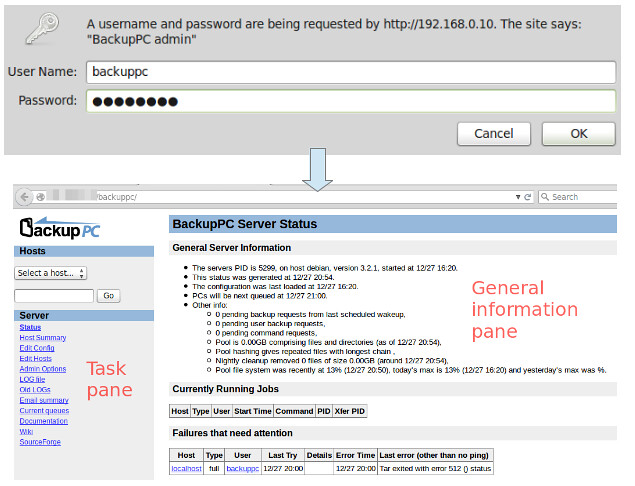
To start, open a browser window and point to http://<server's FQDN or IP address>/backuppc/. When prompted, enter the default HTTP user credentials that were supplied to you earlier. If the authentication succeeds, you will be taken to the main page of the web interface.
|
||||
|
||||
|
||||
|
||||
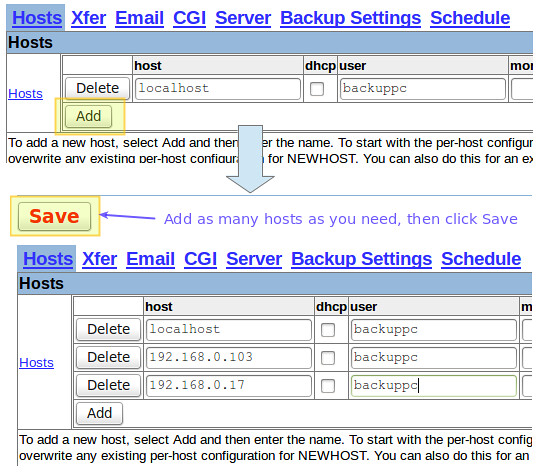
Most likely the first thing that you will want to do is add a new client host to back up. Go to "Edit Hosts" in the Task pane. We will add two client hosts:
|
||||
|
||||
- Host #1: CentOS 7 [IP 192.168.0.17]
|
||||
- Host #2: Windows 7 [IP 192.168.0.103]
|
||||
|
||||
We will back up the CentOS host using rsync over SSH and the Windows host using SMB. Prior to performing the backup, we need to set up [key-based authentication][7] to our CentOS host and a shared folder in our Windows machine.
|
||||
|
||||
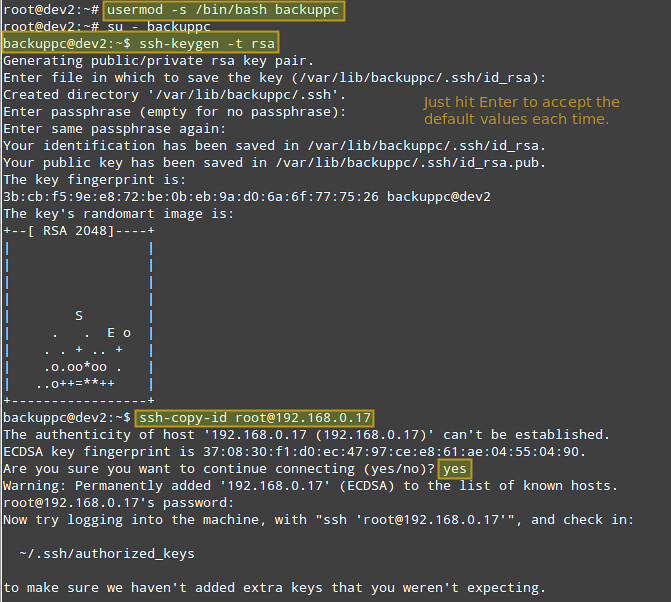
Here are the instructions for setting up key-based authentication for a remote CentOS host. We create the 'backuppc' user's RSA key pair, and transfer its public key to the root account of the CentOS host.
|
||||
|
||||
# usermod -s /bin/bash backuppc
|
||||
# su - backuppc
|
||||
# ssh-keygen -t rsa
|
||||
# ssh-copy-id root@192.168.0.17
|
||||
|
||||
When prompted, type yes and enter root's password for 192.168.0.17.
|
||||
|
||||
|
||||
|
||||
You will need root access for a remote CentOS host to grant write access to all its file system in case of restoring a backup of files or directories owned by root.
|
||||
|
||||
Once the CentOS and Windows hosts are ready, add them to BackupPC using the web interface:
|
||||
|
||||
|
||||
|
||||
The next step consists of modifying each host's backup settings:
|
||||
|
||||
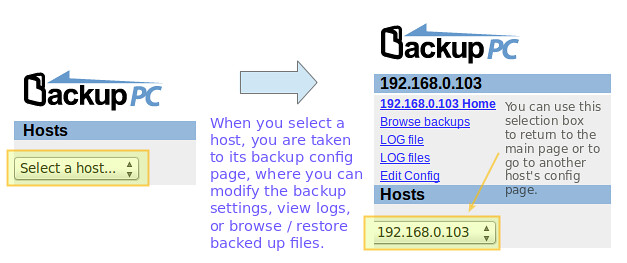
|
||||
|
||||
The following image shows the configuration for the backup of the Windows machine:
|
||||
|
||||
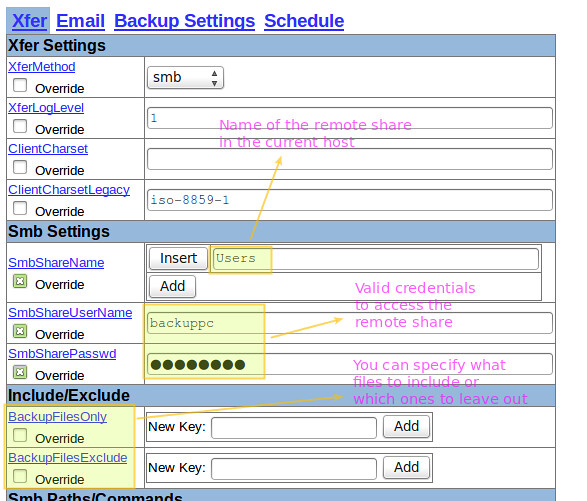
|
||||
|
||||
And the following screenshot shows the settings for the backup of the CentOS box:
|
||||
|
||||
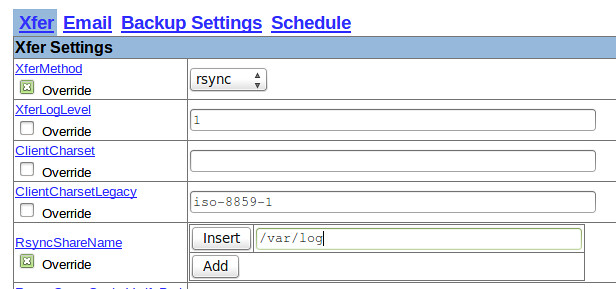
|
||||
|
||||
### Starting a Backup ###
|
||||
|
||||
To start each backup, go to each host's settings, and then click "Start Full Backup":
|
||||
|
||||
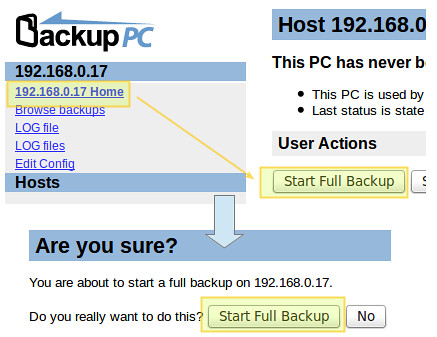
|
||||
|
||||
At any time, you can view the status of the process by clicking on the host's home as shown in the image above. If it fails for some reason, a link to a page with the error message(s) will appear in the host menu as well. When a backup completes successfully, a directory with the host's name or IP address is created under /var/lib/backuppc/pc in the server:
|
||||
|
||||

|
||||
|
||||
Feel free to browse those directories for the files from the command line, but there is an easier way to look for those files and restore them.
|
||||
|
||||
### Restoring Backup ###
|
||||
|
||||
To view the files that have been saved, go to "Browse backups" under each host's main menu. You can visualize the directories and files at a glance, and select those that you want to restore. Alternatively, you can click on files to open them with the default program, or right click and choose Save link as to download it to the machine where you're working at the time:
|
||||
|
||||
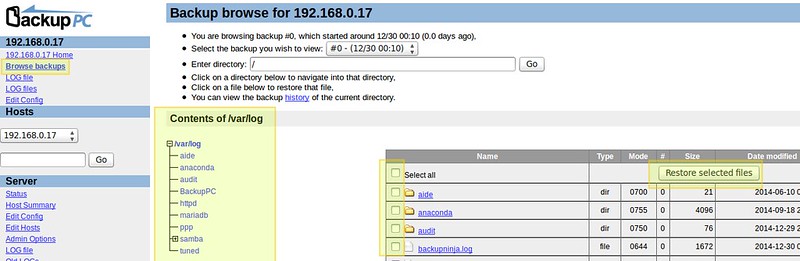
|
||||
|
||||
If you want, you can download a zip or tar file containing the backup's contents:
|
||||
|
||||
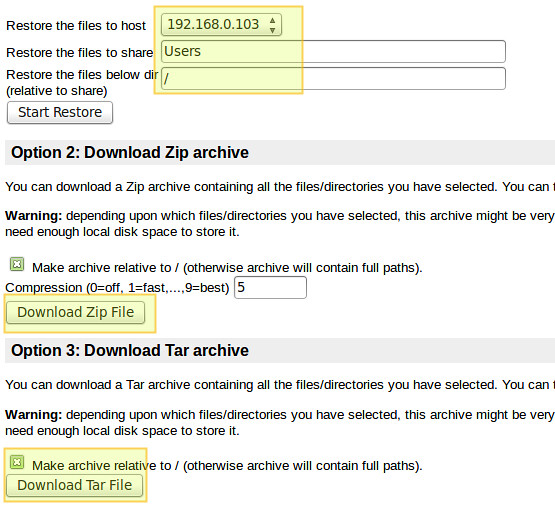
|
||||
|
||||
or just restore the file(s):
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There is a saying that goes, "the simpler, the better", and that is just what BackupPC has to offer. In BackupPC, you will not only find a backup tool but also a very versatile interface to manage your backups of several operating systems without needing any client-side application. I believe that's more than reason enough for you to give it at least a try.
|
||||
|
||||
Feel free to leave your comments and questions, if you have any, using the form below. I am always happy to hear what readers have to say!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/backuppc-cross-platform-backup-server-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/backup-debian-system-backupninja.html
|
||||
[2]:http://xmodulo.com/linux-backup-manager.html
|
||||
[3]:http://backuppc.sourceforge.net/
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
|
||||
[6]:http://xmodulo.com/recommend/linuxguide
|
||||
[7]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
@ -0,0 +1,146 @@
|
||||
How to Configure Chroot Environment in Ubuntu 14.04
|
||||
================================================================================
|
||||
There are many instances when you may wish to isolate certain applications, user, or environments within a Linux system. Different operating systems have different methods of achieving isolation, and in Linux, a classic way is through a `chroot` environment.
|
||||
|
||||
In this guide, we'll show you step wise on how to setup an isolated environment using chroot in order to create a barrier between your regular operating system and a contained environment. This is mainly useful for testing purposes. We will teach you the steps on an **Ubuntu 14.04** VPS instance.
|
||||
|
||||
Most system administrators will benefit from knowing how to accomplish a quick and easy chroot environment and it is a valuable skill to have.
|
||||
|
||||
### The chroot environment ###
|
||||
|
||||
A chroot environment is an operating system call that will change the root location temporarily to a new folder. Typically, the operating system's conception of the root directory is the actual root located at "/". However, with `chroot`, you can specify another directory to serve as the top-level directory for the duration of a chroot.
|
||||
|
||||
Any applications that are run from within the `chroot` will be unable to see the rest of the operating system in principle.
|
||||
|
||||
#### Advantages of Chroot Environment ####
|
||||
|
||||
> - Test applications without the risk of compromising the entire host system.
|
||||
>
|
||||
> - From the security point of view, whatever happens in the chroot environment won't affect the host system (not even under root user).
|
||||
>
|
||||
> - A different operating system running in the same hardware.
|
||||
|
||||
For instance, it allows you to build, install, and test software in an environment that is separated from your normal operating system. It could also be used as a method of **running 32-bit applications in a 64-bit environment**.
|
||||
|
||||
But while chroot environments will certainly make additional work for an unprivileged user, they should be considered a hardening feature instead of a security feature, meaning that they attempt to reduce the number of attack vectors instead of creating a full solution. If you need full isolation, consider a more complete solution, such as Linux containers, Docker, vservers, etc.
|
||||
|
||||
### Debootstrap and Schroot ###
|
||||
|
||||
The necessary packages to setup the chroot environment are **debootstrap** and **schroot**, which are available in the ubuntu repository. The schroot command is used to setup the chroot environment.
|
||||
|
||||
**Debootstrap** allows you to install a new fresh copy of any Debian (or debian-based) system from a repository in a directory with all the basic commands and binaries needed to run a basic instance of the operating system.
|
||||
|
||||
The **schroot** allows access to chroots for normal users using the same mechanism, but with permissions checking and allowing additional automated setup of the chroot environment, such as mounting additional filesystems and other configuration tasks.
|
||||
|
||||
These are the steps to implement this functionality in Ubuntu 14.04 LTS:
|
||||
|
||||
### 1. Installing the Packages ###
|
||||
|
||||
Firstly, We're gonna install debootstrap and schroot in our host Ubuntu 14.04 LTS.
|
||||
|
||||
$ sudo apt-get install debootstrap
|
||||
$ sudo apt-get install schroot
|
||||
|
||||
### 2. Configuring Schroot ###
|
||||
|
||||
Now that we have the appropriate tools, we just need to specify a directory that we want to use as our chroot environment. We will create a directory called linoxide in our root directory to setup chroot there:
|
||||
|
||||
sudo mkdir /linoxide
|
||||
|
||||
We have to configure schroot to suit our needs in the configuration file .we will modify the schroot configuration file with the information we require to get configured.
|
||||
|
||||
sudo nano /etc/schroot/schroot.conf
|
||||
|
||||
We are on an Ubuntu 14.04 LTS (Trusty Tahr) system currently, but let's say that we want to test out some packages available on Ubuntu 13.10, code named "Saucy Salamander". We can do that by creating an entry that looks like this:
|
||||
|
||||
[saucy]
|
||||
description=Ubuntu Saucy
|
||||
location=/linoxide
|
||||
priority=3
|
||||
users=arun
|
||||
root-groups=root
|
||||
|
||||

|
||||
|
||||
Modify the values of the configuration parameters in the above example to fit your system:
|
||||
|
||||
### 3. Installing 32 bit Ubuntu with debootstrap ###
|
||||
|
||||
Debootstrap downloads and installs a minimal operating system inside your **chroot environment**. You can install any debian-based distro of your choice, as long as you have a repository available.
|
||||
|
||||
Above, we placed the chroot environment under the directory **/linoxide** and this is the root directory of the chroot environment. So we'll need to run debootstrap inside that directory which we have already created:
|
||||
|
||||
cd /linoxide
|
||||
sudo debootstrap --variant=buildd --arch amd64 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
sudo chroot /linoxide /debootstrap/debootstrap --second-stage
|
||||
|
||||
You can replace amd64 in --arch as i386 or other bit OS you wanna setup available in the repository. You can replace the mirror http://archive.ubuntu.com/ubuntu/ above as the one closest, you can get the closest one from the official [Ubuntu Mirror Page][1].
|
||||
|
||||
**Note: You will need to add --foreign above 3rd line command if you choose to setup i386 bit OS choot in your 64 bit Host Ubuntu as:**
|
||||
|
||||
sudo debootstrap --variant=buildd --foreign --arch i386 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
|
||||
It takes some time (depending on your bandwidth) to download, install and configure the complete system. It takes about 500 MBs for a minimal installation.
|
||||
|
||||
### 4. Finallizing the chroot environment ###
|
||||
|
||||
After the system is installed, we'll need to do some final configurations to make sure the system functions correctly. First, we'll want to make sure our host `fstab` is aware of some pseudo-systems in our guest.
|
||||
|
||||
sudo nano /etc/fstab
|
||||
|
||||
Add the below lines like these to the bottom of your fstab:
|
||||
|
||||
proc /linoxide/proc proc defaults 0 0
|
||||
sysfs /linoxide/sys sysfs defaults 0 0
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Now, we're going to need to mount these filesystems within our guest:
|
||||
|
||||
$ sudo mount proc /linoxide/proc -t proc
|
||||
$sudo mount sysfs /linoxide/sys -t sysfs
|
||||
|
||||
We'll also want to copy our /etc/hosts file so that we will have access to the correct network information:
|
||||
|
||||
$ sudo cp /etc/hosts /linoxide/etc/hosts
|
||||
|
||||
Finally, You can list the available chroot environments using the schroot command.
|
||||
|
||||
$ schroot -l
|
||||
|
||||
We can enter the chroot environment through a command like this:
|
||||
|
||||
$ sudo chroot /linoxide/ /bin/bash
|
||||
|
||||
You can test the chroot environment by checking the version of distributions installed.
|
||||
|
||||
# lsb_release -a
|
||||
# uname -a
|
||||
|
||||
To finish this tutorial, in order to run a graphic application from the chroot, you have to export the DISPLAY environment variable.
|
||||
|
||||
$ DISPLAY=:0.0 ./apps
|
||||
|
||||
Here, we have successfully installed Chrooted Ubuntu 13.10(Saucy Salamander) in your host Ubuntu 14.04 LTS (Trusty Tahr).
|
||||
|
||||
You can exit chroot environment successfully by running the commands below:
|
||||
|
||||
# exit
|
||||
|
||||
Afterwards, we need to unmount our proc and sys filesystems:
|
||||
|
||||
$ sudo umount /test/proc
|
||||
$ sudo umount /test/sys
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-chroot-environment-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
Loading…
Reference in New Issue
Block a user