mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
0264cf2683
@ -1,16 +1,16 @@
|
||||
生日快乐,KDE:你从不知道的 11 个应用
|
||||
你从不知道的 11 个 KDE 应用
|
||||
======
|
||||
你今天需要哪种有趣或奇特的应用?
|
||||
|
||||
> 你今天需要哪种有趣或奇特的应用?
|
||||
|
||||
|
||||
|
||||
Linux 桌面环境 KDE 将于今年 10 月 14 日庆祝诞生 22 周年。KDE 社区用户创建了大量应用,它们很多都提供有趣和奇特的服务。我们仔细看了该列表,并挑选出了你可能想了解的 11 个应用。
|
||||
|
||||
没有很多,但[也有不少][1]。
|
||||
Linux 桌面环境 KDE 于今年 10 月 14 日庆祝诞生 22 周年。KDE 社区用户创建了海量应用(并没有很多,但[也有不少][1]),它们很多都提供有趣和奇特的服务。我们仔细看了该列表,并挑选出了你可能想了解的 11 个应用。
|
||||
|
||||
### 11 个你从没了解的 KDE 应用
|
||||
|
||||
1. [KTeaTime][2] 是一个泡茶计时器。选择你正在饮用的茶的类型 - 绿茶、红茶、凉茶等 - 当可以取出茶包来饮用时,计时器将会响。
|
||||
2. [KTux][3] 就是一个屏保程序......是么?Tux 用他的绿色飞船在外太空飞行。
|
||||
1. [KTeaTime][2] 是一个泡茶计时器。选择你正在饮用的茶的类型 —— 绿茶、红茶、凉茶等 —— 当可以取出茶包来饮用时,计时器将会响。
|
||||
2. [KTux][3] 就是一个屏保程序……是么?Tux 用它的绿色飞船在外太空飞行。
|
||||
3. [Blinken][4] 是一款基于 Simon Says 的记忆游戏,这是一个 1978 年发布的电子游戏。玩家们在记住长度增加的序列时会有挑战。
|
||||
4. [Tellico][5] 是一个收集管理器,用于组织你最喜欢的爱好。也许你还在收集棒球卡。也许你是红酒俱乐部的一员。也许你是一个严肃的书虫。也许三个都是!
|
||||
5. [KRecipes][6] **不是** 简单的食谱管理器。它还有很多其他功能!购物清单、营养素分析、高级搜索、菜谱评级、导入/导出各种格式等。
|
||||
@ -19,7 +19,7 @@ Linux 桌面环境 KDE 将于今年 10 月 14 日庆祝诞生 22 周年。KDE
|
||||
8. [KDiamond][9] 类似于宝石迷阵或其他单人益智游戏,其中游戏的目标是搭建一定数量的相同类型的宝石或物体的行。这里是钻石。
|
||||
9. [KolourPaint][10] 是一个非常简单的图像编辑工具,也可以用于创建简单的矢量图形。
|
||||
10. [Kiriki][11] 是一款类似于 Yahtzee 的 2-6 名玩家的骰子游戏。
|
||||
11. [RSIBreak][12] 没有以 K 开头。什么!?它以“RSI”开头代表“重复性劳损” (Repetitive Strain Injury),这会在日复一日长时间使用鼠标和键盘后发生。这个应用会提醒你休息,并可以个性化,以满足你的需求。
|
||||
11. [RSIBreak][12] 居然没有以 K 开头!?它以“RSI”开头代表“<ruby>重复性劳损<rt>Repetitive Strain Injury</rt></ruby>” ,这会在日复一日长时间使用鼠标和键盘后发生。这个应用会提醒你休息,并可以个性化定制,以满足你的需求。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -28,7 +28,7 @@ via: https://opensource.com/article/18/10/kde-applications
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -51,7 +51,7 @@ rule_translation_revised() {
|
||||
# 发布译文:发布多篇译文
|
||||
rule_translation_published() {
|
||||
[ "$TSL_D" -ge 1 ] && [ "$PUB_A" -ge 1 ] && [ "$TSL_D" -eq "$PUB_A" ] \
|
||||
&& [ "$TOTAL" -eq $(("$TSL_D" + "$PUB_A")) ] \
|
||||
&& [ "$TOTAL" -eq $(($TSL_D + $PUB_A)) ] \
|
||||
&& echo "匹配规则:发布译文 ${PUB_A} 篇"
|
||||
}
|
||||
|
||||
|
||||
69
sources/talk/20180623 The IBM 029 Card Punch.md
Normal file
69
sources/talk/20180623 The IBM 029 Card Punch.md
Normal file
@ -0,0 +1,69 @@
|
||||
The IBM 029 Card Punch
|
||||
======
|
||||
Lines of code longer than 80 characters drive me crazy. I appreciate that this is pedantic. I’ve seen people on the internet make good arguments for why the 80-character limit ought to be respected even on our modern Retina-display screens, but those arguments hardly justify the visceral hatred I feel for even that one protruding 81st character.
|
||||
|
||||
There was once a golden era in which it was basically impossible to go over the 80-character limit. The 80-character limit was a physical reality, because there was no 81st column for an 81st character to fit in. Any programmers attempting to name a function something horrendously long and awful would discover, in a moment of delicious, slow-dawning horror, that there literally isn’t room for their whole declaration.
|
||||
|
||||
This golden era was the era of punch card programming. By the 1960s, IBM’s punch cards had set the standard and the standard was that punch cards had 80 columns. The 80-column standard survived into the teletype and dumb terminal era and from there embedded itself into the nooks and crannies of our operating systems. Today, when you launch your terminal emulator and open a new window, odds are it will be 80 characters wide, even though we now have plenty of screen real estate and tend to favor longer identifiers over inscrutable nonsense like `iswcntrl()`.
|
||||
|
||||
If questions on Quora are any indication, many people have trouble imagining what it must have been like to program computers using punch cards. I will admit that for a long time I also didn’t understand how punch card programming could have worked, because it struck me as awfully labor-intensive to punch all those holes. This was a misunderstanding; programmers never punched holes in cards the same way a train conductor does. They had card punch machines (also known as key punches), which allowed them to punch holes in cards using a typewriter-style keyboard. And card punches were hardly new technology—they were around as early as the 1890s.
|
||||
|
||||
One of the most widely used card punch machines was the IBM 029. It is perhaps the best remembered card punch today.
|
||||
|
||||
![][1]
|
||||
|
||||
The IBM 029 was released in 1964 as part of IBM’s System/360 rollout. System/360 was a family of computing systems and peripherals that would go on to dominate the mainframe computing market in the late 1960s. Like many of the other System/360 machines, the 029 was big. This was an era when the distinction between computing machinery and furniture was blurry—the 029 was not something you put on a table but an entire table in itself. The 029 improved upon its predecessor, the 026, by supporting new characters like parentheses and by generally being quieter. It had cool electric blue highlights and was flat and angular whereas the 026 had a 1940s rounded, industrial look. Another of its big selling points was that it could automatically left-pad numeric fields with zeros, demonstrating that JavaScript programmers were not the first programmers too lazy to do their own left-padding.
|
||||
|
||||
But wait, you might say—IBM released a brand-new card punch in 1964? What about that photograph of the Unix gods at Bell Labs using teletype machines in, like, 1970? Weren’t card punching machines passé by the mid- to late-1960s? Well, it might surprise you to know that the 029 was available in IBM’s catalog until as late as 1984. In fact, most programmers programmed using punch cards until well into the 1970s. This doesn’t make much sense given that there were people using teletype machines during World War II. Indeed, the teletype is almost of the same vintage as the card punch. The limiting factor, it turns out, was not the availability of teletypes but the availability of computing time. What kept people from using teletypes was that teletypes assumed an interactive, “online” model of communication with the computer. Before Unix and the invention of timesharing operating systems, your interactive session with a computer would have stopped everyone else from using it, a delay potentially costing thousands of dollars. So programmers instead wrote their programs offline using card punch machines and then fed them into mainframe computers later as batch jobs. Punch cards had the added benefit of being a cheap data store in an era where cheap, reliable data storage was hard to come by. Your programs lived in stacks of cards on your shelves rather than in files on your hard drive.
|
||||
|
||||
So what was it actually like using an IBM 029 card punch? That’s hard to explain without first taking a look at the cards themselves. A typical punch card had 12 rows and 80 columns. The bottom nine rows were the digit rows, numbered one through nine. These rows had the appropriate digit printed in each column. The top three rows, called the “zone” rows, consisted of two blank rows and usually a zero row. Row 12 was at the very top of the card, followed by row 11, then rows zero through nine. This somewhat confusing ordering meant that the top edge of the card was called the 12 edge while the bottom was called the nine edge. A corner of each card was usually clipped to make it easier to keep a stack of cards all turned around the right way.
|
||||
|
||||
![][2]
|
||||
|
||||
When they were first invented, punch cards were meant to be punched with circular holes, but IBM eventually realized that they could fit more columns on a card if the holes were narrow rectangles. Different combinations of holes in a column represented different characters. For human convenience, card punches like the 029 would print each column’s character at the top of the card at the same time as punching the necessary holes. Digits were represented by one punched hole in the appropriate digit row. Alphabetical and symbolic characters were represented by a hole in a zone row and then a combination of one or two holes in the digit rows. The letter A, for example, was represented by a hole in the 12 zone row and another hole in the one row. This was an encoding of sorts, sometimes called the Hollerith code, after the original inventor of the punch card machine. The encoding allowed for only a relatively small character set; lowercase letters, for example, were not represented. Some clever engineer today might wonder why punch cards didn’t just use a binary encoding—after all, with 12 rows, you could encode over 4000 characters. The Hollerith code was used instead because it ensured that no more than three holes ever appeared in a single column. This preserved the structural integrity of the card. A binary encoding would have entailed so many holes that the card would have fallen apart.
|
||||
|
||||
Cards came in different flavors. By the 1960s, 80 columns was the standard, but those 80 columns could be used to represent different things. The basic punch card was unlabeled, but cards meant for COBOL programming, for example, divided the 80 columns into fields. On a COBOL card, the last eight columns were reserved for an identification number, which could be used to automatically sort a stack of cards if it were dropped (apparently a perennial hazard). Another column, column seven, could be used to indicate that the statement on this card was a continuation of a statement on a previous card. This meant that if you were truly desperate you could circumvent the 80-character limit, though whether a two-card statement counts as one long line or just two is unclear. FORTRAN cards were similar but had different fields. Universities often watermarked the punch cards handed out by their computing centers, while other kinds of designs were introduced for special occasions like the [1976 bicentennial][3].
|
||||
|
||||
Ultimately the cards had to be read and understood by a computer. IBM sold a System/360 peripheral called the IBM 2540 which could read up to 1000 cards per minute. The IBM 2540 ran electrical brushes across the surface of each card which made contact with a plate behind the cards wherever there was a hole. Once read, the System/360 family of computers represented the characters on each punch card using an 8-bit encoding called EBCDIC, which stood for Extended Binary Coded Decimal Interchange Code. EBCDIC was a proper binary encoding, but it still traced its roots back to the punch card via an earlier encoding called BCDIC, a 6-bit encoding which used the low four bits to represent a punch card’s digit rows and the high two bits to represent the zone rows. Punch card programmers would typically hand their cards to the actual computer operators, who would feed the cards into the IBM 2540 and then hand the printed results back to the programmer. The programmer usually didn’t see the computer at all.
|
||||
|
||||
What the programmer did see a lot of was the card punch. The 029 was not a computer, but that doesn’t mean that it wasn’t a complicated machine. The best way to understand what it was like using the 029 is to watch [this instructional video][4] made by the computing center at the University of Michigan in 1967. I’m going to do my best to summarize it here, but if you don’t watch the video you will miss out on all the wonderful clacking and whooshing.
|
||||
|
||||
The 029 was built around a U-shaped track that the punch cards traveled along. On the right-hand side, at the top of the U, was the card hopper, which you would typically load with a fresh stack of cards before using the machine. The IBM 029 worked primarily with 80-column cards, but the card hopper could accommodate smaller cards if needed. Your punch cards would start in the card hopper, travel along the line of the U, and then end up in the stacker, at the top of the U on the left-hand side. The cards would accumulate there in the order that you punched them.
|
||||
|
||||
To turn the machine on, you flipped a switch under the desk at about the height of your knees. You then pressed the “FEED” key twice to get cards loaded into the machine. The business part of the card track, the bottom of the U, was made up of three separate stations: On the right was a kind of waiting area, in the middle was the punching station, and on the left was the reading station. Pressing the “FEED” key twice loaded one card into the punching station and one card into the waiting area behind it. A column number indicator right above the punching station told you which column you were currently punching. With every keystroke, the machine would punch the requisite holes, print the appropriate character at the top of the card, and then advance the card through the punching station by one column. If you punched all 80 columns, the card would automatically be released to the reading station and a new card would be loaded into the punching station. If you wanted this to happen before you reached the 80th column, you could press the “REL” key (for “release”).
|
||||
|
||||
The printed characters made it easy to spot a mistake. But fixing a mistake, as the University of Michigan video warns, is not as easy as whiting out the printed character at the top of the card and writing in a new one. The holes are all that the computer will read. Nor is it as easy as backspacing one space and typing in a new character. The holes have already been punched in the column, after all, and cannot be unpunched. Punching more holes will only produce an invalid combination not associated with any character. The IBM 029 did have a backspace button that moved the punched card backward one column, but the button was placed on the face of the machine instead of on the keyboard. This was probably done to discourage its use, since backspacing was so seldom what the user actually wanted to do.
|
||||
|
||||
Instead, the only way to correct a mistake was scrap the incorrect card and punch a new one. This is where the reading station came in handy. Say you made a mistake in the 68th column of a card. To fix your mistake, you could carefully repunch the first 67 columns of a new card and then punch the correct character in the 68th column. Alternatively, you could release the incorrect card to the reading station, load a new card into the punching station, and hold down the “DUP” key (for duplicate) until the column number indicator reads 68. You could then correct your mistake by punching the correct character. The reading station and the “DUP” key together allowed IBM 029 operators to easily copy the contents of one card to the next. There were all sorts of reasons to do this, but correcting mistakes was the most common.
|
||||
|
||||
The “DUP” key allowed the 029’s operator to invoke the duplicate functionality manually. But the 029 could also duplicate automatically where necessary. This was particularly useful when punched cards were used to record data rather than programs. For example, you might be using each card to record information about a single undergraduate university student. On each card, you might have a field that contains the name of that student’s residence hall. Perhaps you find yourself entering data for all the students in one residence hall at one time. In that case, you’d want the 029 to automatically copy over the previous card’s residence hall field every time you reached the first column of the field.
|
||||
|
||||
Automated behavior like this could be programmed into the 029 by using the program drum. The drum sat upright in the middle of the U above the punching station. You programmed the 029 by punching holes in a card and wrapping that card around the program drum. The punched card allowed you to specify the automatic behavior you expected from the machine at each column of the card currently in the punching station. You could specify that a column should automatically be copied from the previous card, which is how an 029 operator might more quickly enter student records. You could also specify, say, that a particular field should contain numeric or alphabetic characters, or that a given field should be left blank and skipped altogether. The program drum made it much easier to punch schematized cards where certain column ranges had special meanings. There is another [“advanced” instructional video][5] produced by the University of Michigan that covers the program drum that is worth watching, provided, of course, that you have already mastered the basics.
|
||||
|
||||
Watching either of the University of Michigan videos today, what’s surprising is how easy the card punch is to operate. Correcting mistakes is tedious, but otherwise the machine seems to be less of an obstacle than I would have expected. Moving from one card to the next is so seamless that I can imagine COBOL or FORTRAN programmers forgetting that they are creating separate cards rather than one long continuous text file. On the other hand, it’s interesting to consider how card punches, even though they were only an input tool, probably limited how early programming languages evolved. Structured programming would eventually come along and encourage people to think of entire blocks of code as one unit, but I can see how punch card programming’s emphasis on each line made structured programming hard to conceive of. It’s no wonder that punch card programmers were not the ones that decided to enclose blocks with single curly braces entirely on their own lines. How wasteful that would have seemed!
|
||||
|
||||
So even though nobody programs using punch cards anymore, every programmer ought to [try it][6] at least once—if only to understand why COBOL and FORTRAN look the way they do, or how 80 characters somehow became everybody’s favorite character limit.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][7] on Twitter or subscribe to the [RSS feed][8] to make sure you know when a new post is out.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/06/23/ibm-029-card-punch.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twobithistory.org/images/ibm029_front.jpg
|
||||
[2]: https://twobithistory.org/images/card.png
|
||||
[3]: http://www.jkmscott.net/data/Punched%20card%20013.jpg
|
||||
[4]: https://www.youtube.com/watch?v=kaQmAybWn-w
|
||||
[5]: https://www.youtube.com/watch?v=SWD1PwNxpoU
|
||||
[6]: http://www.masswerk.at/keypunch/
|
||||
[7]: https://twitter.com/TwoBitHistory
|
||||
[8]: https://twobithistory.org/feed.xml
|
||||
@ -0,0 +1,126 @@
|
||||
Dawn of the Microcomputer: The Altair 8800
|
||||
======
|
||||
Subscribers to Popular Electronics were a sophisticated group. The magazine’s editor, Arthur Salsberg, felt compelled to point out as much in the editorial section of the [December 1974 issue][1]. The magazine had received letters complaining that a recent article, titled “How to Set Up a Home TV Service Shop,” would inspire a horde of amateur TV technicians to go out and undercut professional repairmen, doing great damage to everyone’s TVs in the process. Salsberg thought this concern was based on a misunderstanding about who read Popular Electronics. He explained that, according to the magazine’s own surveys, 52% of Popular Electronics subscribers were electronics professionals of some kind and 150,000 of them had repaired a TV in the last 60 days. Moreover, the average Popular Electronics subscriber had spent $470 on electronics equipment ($3578 in 2018) and possessed such necessities as VOMs, VTVMs, tube testers, transistor testers, r-f signal generators, and scopes. “Popular Electronics readers are not largely neophytes,” Salsberg concluded.
|
||||
|
||||
I am surprised that anyone familiar with Popular Electronics could ever have doubted its subscribers. I certainly haven’t repaired a TV in the last 60 days. My computer is a block of aluminum that I have never seen the inside of. Yet the December 1974 issue of Popular Electronics features articles such as “Standing Wave Ratio: What It Is and How to Deal with It” and “Test Scene: Uses for Your Multimeter.” Even the ads are intimidating. One of them, which seems to be for some kind of stereo system, boldly proclaims that “no piece of audio equipment is as eagerly awaited as the ‘one four-channel unit that does everything—i.e. the receiver with built-in circuitry for SQ, RM and CD-4 record decoding.’” The mere hobbyists subscribed to Popular Electronics, let alone the professionals, must have been very knowledgeable indeed.
|
||||
|
||||
But Popular Electronics readers were introduced to something in the [January 1975 issue][2] that they had never encountered before. Below a heading that read “PROJECT BREAKTHROUGH,” the magazine’s cover showed a large gray and black box whose front panel bore a complicated array of lights and toggles. This was the Altair 8800, the “world’s first minicomputer kit to rival commercial models,” available for under $400. Though advertised as a “minicomputer,” the Altair would actually be the first commercially successful member of a new class of computers, first known as “microcomputers” and then eventually as PCs. The Altair was small enough and cheap enough that the average family could have one at home. Its appearance in Popular Electronics magazine meant that, as Salsberg wrote in that issue, “the home computer age is here—finally.”
|
||||
|
||||
![January 1975 cover of Popular Electronics][3]
|
||||
|
||||
I have written briefly about [the Altair before][4], but I think the Altair is worth revisiting. It was not an especially powerful computer compared to others available at the time (though it cost significantly less money). Nor was it the first general-purpose computer to incorporate a microprocessor chip—at least three microprocessor-based computers preceded it. But the Altair was and is a kind of Ur-Computer for all of us. It was the first popular computer in a lineage that includes our own devices, whereas the mainframes and bulky minicomputers that predated the Altair were an entirely different kind of machine, programmed by punched card or else rarely interacted with directly. The Altair was also a radically simple computer, without any kind of operating system or even a bootloader. Unless you bought peripherals for it, the Altair was practically a bank of RAM with switches and lights on the front. The Altair’s simplicity makes learning about it a great way to reacquaint yourself with the basic concepts of computing, exactly as they were encountered by the denizens of the old analog world as they first ventured into our digital one.
|
||||
|
||||
### Roberts and Co.
|
||||
|
||||
The Altair was designed and manufactured by a company called Micro Instrumentation and Telemetry Systems (MITS), based in Albuquerque, New Mexico. MITS was run by a man named H. Edward Roberts. The company had started off making telemetry systems for model rocket kits before moving into the calculator market, which in the early 1970s was booming. Integrated circuits were bringing the cost of a calculator down dramatically and suddenly every working American professional had to have one. But the calculator market was ruthlessly competitive and, by the beginning of 1974, MITS was deeply in debt.
|
||||
|
||||
The year 1974 would prove to be an “annus mirabilis” in computing. In January, Hewlett-Packard introduced the HP-65, the world’s first programmable handheld calculator. In April, Intel released the Intel 8080, its second 8-bit microprocessor and the first microprocessor to become widely popular. Then, in July, Radio Electronics magazine advertised a build-it-yourself minicomputer called the Mark-8, which employed the Intel 8008 microprocessor that Intel had released in 1972. The Mark-8 was only the third computer ever built using a microprocessor and it was the first to be appear on the cover of a magazine. The Mark-8’s appearance in Radio Electronics pushed Popular Electronics to look for a minicomputer project of their own to feature.
|
||||
|
||||
Popular Electronics subscribers actually received their copies of the January 1975 issue in the mail in December of 1974. So the announcement of the Altair closed out the “annus mirabilis” that was that year. The Altair’s introduction was so momentous because never before had such a fully capable computer been offered to the public at an affordable price. The PDP-8, one the most popular minicomputers at the time, could only be bought for several thousand dollars. Yet the Intel 8080 chip at the heart of the Altair made it almost as capable as the PDP-8, if not more so; the 8080 supported a wider instruction set and the Altair could be expanded to have up to 64kb of memory, while the stock PDP-8 typically only had 4kb. The Altair was also more powerful than the Mark-8, which, because it was based on the Intel 8008, could only address 16kb of memory. And whereas the Mark-8 had to be built from scratch by customers with only a booklet and printed circuit boards to guide them, the Altair could be purchased fully assembled, though MITS soon became so inundated with orders that the only real way to get an Altair was to order the construction kit.
|
||||
|
||||
For many Popular Electronics readers, the Altair was their first window into the world of digital computing. The article introducing the Altair in the January 1975 issue was written by Roberts and the Altair’s co-designer, William Yates. Roberts and Yates took pains to explain, in terms familiar to the electricians and radio enthusiasts in their audience, the basic concepts underlying digital hardware and computer programming. “A computer,” they wrote, “is basically a piece of variable hardware. By changing the bit pattern stored in the memory, the hardware can be altered from one type of device to another.” Of programming, meanwhile, Roberts and Yates wrote that the basic concepts are “simple enough to master in a relatively short time,” but that becoming “an efficient programmer requires a lot of experience and a large amount of creativity,” which sounds about right to me. The article included a detailed diagram explaining all the constituent circuits of the Intel 8080 CPU, even though readers would receive at least that part fully assembled. It explained the difference between a CPU and a computer’s memory unit, the uses of a stack pointer, and the enormous advantages offered by assembly languages and higher-level languages like FORTRAN and BASIC over manual entry of machine code.
|
||||
|
||||
Popular Electronics had in fact been running a series written by Roberts for several issues before January 1975. The series was billed as a short course in “digital logic.” In the December 1974 issue, Roberts walked readers through building a “very low cost computer terminal,” which was basically an octal keypad that could input values into an 8-bit computer. In the course of describing the keypad, Roberts explained how transistor-to-transistor logic works and also how to construct a flip-flop, a kind of circuit capable of “remembering” digital values. The keypad, Roberts promised, could be used with the Altair computer, to be announced the following month.
|
||||
|
||||
It’s unclear how many Popular Electronics readers actually built the keypad, but it would have been a very useful thing to have. Without a keypad or some other input mechanism, the only way to input values into the Altair was through the switches on the front panel. The front panel had a row of 16 switches that could be used to set an address and a lower row of eight switches that could be used to control the operation of the computer. The eight right-most switches in the row of 16 could also be used to specify a value to be stored in memory. This made sense because the Intel 8080 used 16-bit values to address 8-bit words. The 16 switches on the front panel each represented a bit—the up position represented a one, while the down position represented a zero. Interacting with a computer this way is a revelation (more on that in a minute), because the Altair’s front panel is a true binary interface. It’s as close as you can get to the bare metal.
|
||||
|
||||
As alien as the Altair’s interface is to us today, it was not unusual for its time. The PDP-8, for example, had a similar binary input mechanism on its front panel, though the PDP-8’s switches were nicer and colored in that attractive orange and yellow color scheme that really ought to make a comeback. The PDP-8, however, was often paired with a paper-tape reader or a teletype machine, which made program entry much easier. These I/O devices were expensive, meaning that most Altair users in the early days were stuck with the front panel. As you might imagine, entering long programs via the switches was a chore. Eventually the Altair could be hooked up to a cassette recorder and programs could be loaded that way. Bill Gates and Paul Allen, in what would become Microsoft’s first ever commercial venture, also wrote a version of BASIC for the Altair that MITS licensed and released in the middle of 1975. Users that could afford a teletype could then [load BASIC into the Altair via paper tape][5] and interact with their Altair through text. BASIC, which had become everyone’s favorite introductory programming language in schools, would go on to become the standard interface to the machines produced in the early microcomputer era.
|
||||
|
||||
### z80pack
|
||||
|
||||
Thanks to the efforts of several internet people, in particular a person named Udo Munk, you can run a simulation of the Altair on your computer. The simulation is built on top of some software that emulates the Zilog Z80 CPU, a CPU designed to be software-compatible with the Intel 8080. The Altair simulation allows you to input programs entirely via the front panel switches like early users of the Altair had to do. Though clicking on switches does not offer the same tactile satisfaction as flipping real switches, playing with the Altair simulation is a great way to appreciate how a binary human/computer interface was both horribly inefficient and, at least in my opinion, charmingly straightforward.
|
||||
|
||||
z80pack, Udo Munk’s Z80 emulation package, can be downloaded from the z80pack website. There are instructions in [my last Altair post][4] explaining how to get it set up on Mac OS. If you are able to compile both the FrontPanel library and the `altairsim` executable, you should be able to run `altairsim` and see the following window:
|
||||
|
||||
![Simulated Altair Front Panel][6]
|
||||
|
||||
By default, at least with the version of z80pack that I am using (1.36), the Altair is configured with something called Tarbell boot ROM, which I think is used to load disk images. In practice, what this means is that you can’t write values into the first several words in RAM. If you edit the file `/altairsim/conf/system.conf`, you can instead set up a simple Altair that has 16 pages of RAM and no ROM or bootloader software at all. You can also use this configuration file to increase the size of the window the simulation runs in, which is handy.
|
||||
|
||||
The front panel of the Altair is intimidating, but in reality there isn’t that much going on. The [Altair manual][7] does a good job of explaining the many switches and status lights, as does this [YouTube video][8]. To enter and run a simple program, you only really need to know a few things. The lights labeled D0 through D7 near the top right of the Altair indicate the contents of the currently addressed word. The lights labeled A0 through A15 indicate the current address. The 16 switches below the address lights can be used to set a new address; when the “EXAMINE” switch is pressed upward, the data lights update to show the contents of the newly addressed word. In this way, you can “peek” at all the words in memory. You can also press the “EXAMINE” switch down to the “EXAMINE NEXT” position, which automatically examines the next memory address, which makes peeking at sequential words significantly easier.
|
||||
|
||||
To save a bit pattern to a word, you have to set the bit pattern using the right-most eight switches labeled 0 through 7. You then press the “DEPOSIT” switch upward.
|
||||
|
||||
In the [February 1975 issue][9] of Popular Electronics, Roberts and Yates walked Altair owners through inputting a small sample program to ensure that their Altair was functioning. The program loads two integers from memory, adds them, and saves the sum back into memory. The program consists of only six instructions, but those six instructions involve 14 words of memory altogether, which takes some time to input correctly. The sample program also appears in the Altair manual in table form, which I’ve reproduced here:
|
||||
|
||||
Address Mnemonic Bit Pattern Octal Equivalent 0 LDA 00 111 010 0 7 2 1 (address) 10 000 000 2 0 0 2 (address) 00 000 000 0 0 0 3 MOV B, A 01 000 111 1 0 7 4 LDA 00 111 010 0 7 2 5 (address) 10 000 001 2 0 1 6 (address) 00 000 000 0 0 0 7 ADD B 10 000 000 2 0 0 8 STA 00 110 010 0 6 2 9 (address) 10 000 010 2 0 2 10 (address) 00 000 000 0 0 0 11 JMP 11 000 011 3 0 3 12 (address) 00 000 000 0 0 0 13 (address) 00 000 000 0 0 0
|
||||
|
||||
If you input each word in the above table into the Altair via the switches, you end up with a program that loads the value in word 128, adds it to the value in the word 129, and finally saves it into word 130. The addresses that accompany each instruction taking an address are given with the least-significant bits first, which is why the second byte is always zeroed out (no addresses are higher than 255). Once you’ve input the program and entered some values into words 128 and 129, you can press the “RUN” switch into the down position briefly before pushing it into the “STOP” position. Since the program loops, it repeatedly adds those values and saves the sum thousands of times a second. The sum is always the same though, so if you peek at word 130 after stopping the program, you should find the correct answer.
|
||||
|
||||
I don’t know whether any regular users of the Altair ever had access to an assembler, but z80pack includes one. The z80pack assembler, `z80asm`, is meant for Z80 assembly, so it uses a different set of mnemonics altogether. But since the Z80 was designed to be compatible with software written for the Intel 8080, the opcodes are all the same, even if the mnemonics are different. So just to illustrate what it might have been like to write the same program in assembly, here is a version that can be assembled by `z80asm` and loaded into the Altair:
|
||||
|
||||
```
|
||||
ORG 0000H
|
||||
START: LD A,(80H) ;Load from address 128.
|
||||
LD B,A ;Move loaded value from accumulator (A) to reg B.
|
||||
LD A,(81H) ;Load from address 129.
|
||||
ADD A,B ;Add A and B.
|
||||
LD (82H),A ;Store A at address 130.
|
||||
JP START ;Jump to start.
|
||||
```
|
||||
|
||||
You can turn this into something called an Intel HEX file by invoking the assembler like so (after you have compiled it):
|
||||
|
||||
```
|
||||
$ ./z80asm -fh -oadd.hex add.asm
|
||||
```
|
||||
|
||||
The `-f` flag, here taking `h` as an argument, specifies that a HEX file should be output. You can then load the program into the Altair by passing the HEX file in using the `-x` flag:
|
||||
|
||||
```
|
||||
$ ./altairsim -x add.hex
|
||||
```
|
||||
|
||||
This sets up the first 14 words in memory as if you had input the values manually via the switches. Instead of doing all that again, you can just run the program by using the “RUN” switch as before. Much easier!
|
||||
|
||||
As I said, I don’t think many Altair users wrote software this way. Once Altair BASIC became available, writing BASIC programs was probably the easiest way to program the Altair. z80pack also includes several HEX files containing different versions of Altair BASIC; the one I’ve been able to get working is version 4.0 of 4K BASIC, which you can load into the simulator like so:
|
||||
|
||||
```
|
||||
$ ./altairsim -x basic4k40.hex
|
||||
```
|
||||
|
||||
If you turn the simulated machine on and hit the “RUN” switch, you should see that BASIC has started talking to you in your terminal window. It first prompts you to enter the amount of memory you have available, which should be 4000 bytes. It then asks you a few more questions before presenting you with the “OK” prompt, which Gates and Allen used instead of the standard “READY” to save memory. From there, you can just use BASIC:
|
||||
|
||||
```
|
||||
OK
|
||||
PRINT 3 + 4
|
||||
7
|
||||
```
|
||||
|
||||
Though running BASIC with only 4kb of memory didn’t give you a lot of room, you can see how it would have been a significant step up from using the front panel.
|
||||
|
||||
The Altair, of course, was nowhere near as capable as the home desktops and laptops we have available to us today. Even something like the Macintosh, released less than a decade later, seems like a quantum leap forward over the spartan Altair. But to those first Popular Electronics readers that bought the kit and assembled it, the Altair was a real, fully capable computer that they could own for themselves, all for the low cost of $400 and half the surface space of the credenza. This would have been an amazing thing for people that had thus far only been able to interact with computers by handing [a stack of cards][10] or a roll of tape to another human being entrusted with the actual operation of the computer. Subsequent microcomputers would improve upon what the Altair offered and quickly become much easier to use, but they were all, in some sense, just more complicated Altairs. The Altair—almost Brutalist in its minimalism—was the bare-essentials blueprint for all that would follow.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][11] on Twitter or subscribe to the [RSS feed][12] to make sure you know when a new post is out.
|
||||
|
||||
Previously on TwoBitHistory…
|
||||
|
||||
> "I invite you to come along with me on an exciting journey and spend the next ten minutes of your life learning about a piece of software nobody has used in the last decade." <https://t.co/R9zA5ibFMs>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [July 7, 2018][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/07/22/dawn-of-the-microcomputer.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.americanradiohistory.com/Archive-Poptronics/70s/1974/Poptronics-1974-12.pdf
|
||||
[2]: https://www.americanradiohistory.com/Archive-Poptronics/70s/1975/Poptronics-1975-01.pdf
|
||||
[3]: https://twobithistory.org/images/jan1975-altair.jpg
|
||||
[4]: https://twobithistory.org/2017/12/02/simulating-the-altair.html
|
||||
[5]: https://www.youtube.com/watch?v=qv5b1Xowxdk
|
||||
[6]: https://www.autometer.de/unix4fun/z80pack/altair.png
|
||||
[7]: http://www.classiccmp.org/dunfield/altair/d/88opman.pdf
|
||||
[8]: https://www.youtube.com/watch?v=suyiMfzmZKs
|
||||
[9]: https://www.americanradiohistory.com/Archive-Poptronics/70s/1975/Poptronics-1975-02.pdf
|
||||
[10]: https://twobithistory.org/2018/06/23/ibm-029-card-punch.html
|
||||
[11]: https://twitter.com/TwoBitHistory
|
||||
[12]: https://twobithistory.org/feed.xml
|
||||
[13]: https://twitter.com/TwoBitHistory/status/1015647820353867776?ref_src=twsrc%5Etfw
|
||||
116
sources/talk/20180805 Where Vim Came From.md
Normal file
116
sources/talk/20180805 Where Vim Came From.md
Normal file
@ -0,0 +1,116 @@
|
||||
Where Vim Came From
|
||||
======
|
||||
I recently stumbled across a file format known as Intel HEX. As far as I can gather, Intel HEX files (which use the `.hex` extension) are meant to make binary images less opaque by encoding them as lines of hexadecimal digits. Apparently they are used by people who program microcontrollers or need to burn data into ROM. In any case, when I opened up a HEX file in Vim for the first time, I discovered something shocking. Here was this file format that, at least to me, was deeply esoteric, but Vim already knew all about it. Each line of a HEX file is a record divided into different fields—Vim had gone ahead and colored each of the fields a different color. `set ft?` I asked, in awe. `filetype=hex`, Vim answered, triumphant.
|
||||
|
||||
Vim is everywhere. It is used by so many people that something like HEX file support shouldn’t be a surprise. Vim comes pre-installed on Mac OS and has a large constituency in the Linux world. It is familiar even to people that hate it, because enough popular command line tools will throw users into Vim by default that the uninitiated getting trapped in Vim has become [a meme][1]. There are major websites, including Facebook, that will scroll down when you press the `j` key and up when you press the `k` key—the unlikely high-water mark of Vim’s spread through digital culture.
|
||||
|
||||
And yet Vim is also a mystery. Unlike React, for example, which everyone knows is developed and maintained by Facebook, Vim has no obvious sponsor. Despite its ubiquity and importance, there doesn’t seem to be any kind of committee or organization that makes decisions about Vim. You could spend several minutes poking around the [Vim website][2] without getting a better idea of who created Vim or why. If you launch Vim without giving it a file argument, then you will see Vim’s startup message, which says that Vim is developed by “Bram Moolenaar et al.” But that doesn’t tell you much. Who is Bram Moolenaar and who are his shadowy confederates?
|
||||
|
||||
Perhaps more importantly, while we’re asking questions, why does exiting Vim involve typing `:wq`? Sure, it’s a “write” operation followed by a “quit” operation, but that is not a particularly intuitive convention. Who decided that copying text should instead be called “yanking”? Why is `:%s/foo/bar/gc` short for “find and replace”? Vim’s idiosyncrasies seem too arbitrary to have been made up, but then where did they come from?
|
||||
|
||||
The answer, as is so often the case, begins with that ancient crucible of computing, Bell Labs. In some sense, Vim is only the latest iteration of a piece of software—call it the “wq text editor”—that has been continuously developed and improved since the dawn of the Unix epoch.
|
||||
|
||||
### Ken Thompson Writes a Line Editor
|
||||
|
||||
In 1966, Bell Labs hired Ken Thompson. Thompson had just completed a Master’s degree in Electrical Engineering and Computer Science at the University of California, Berkeley. While there, he had used a text editor called QED, written for the Berkeley Timesharing System between 1965 and 1966. One of the first things Thompson did after arriving at Bell Labs was rewrite QED for the MIT Compatible Time-Sharing System. He would later write another version of QED for the Multics project. Along the way, he expanded the program so that users could search for lines in a file and make substitutions using regular expressions.
|
||||
|
||||
The Multics project, which like the Berkeley Timesharing System sought to create a commercially viable time-sharing operating system, was a partnership between MIT, General Electric, and Bell Labs. AT&T eventually decided the project was going nowhere and pulled out. Thompson and fellow Bell Labs researcher Dennis Ritchie, now without access to a time-sharing system and missing the “feel of interactive computing” that such systems offered, set about creating their own version, which would eventually be known as Unix. In August 1969, while his wife and young son were away on vacation in California, Thompson put together the basic components of the new system, allocating “a week each to the operating system, the shell, the editor, and the assembler.”
|
||||
|
||||
The editor would be called `ed`. It was based on QED but was not an exact re-implementation. Thompson decided to ditch certain QED features. Regular expression support was pared back so that only relatively simple regular expressions would be understood. QED allowed users to edit several files at once by opening multiple buffers, but `ed` would only work with one buffer at a time. And whereas QED could execute a buffer containing commands, `ed` would do no such thing. These simplifications may have been called for. Dennis Ritchie has said that going without QED’s advanced regular expressions was “not much of a loss.”
|
||||
|
||||
`ed` is now a part of the POSIX specification, so if you have a POSIX-compliant system, you will have it installed on your computer. It’s worth playing around with, because many of the `ed` commands are today a part of Vim. In order to write a buffer to disk, for example, you have to use the `w` command. In order to quit the editor, you have to use the `q` command. These two commands can be specified on the same line at once—hence, `wq`. Like Vim, `ed` is a modal editor; to enter input mode from command mode you would use the insert command (`i`), the append command (`a`), or the change command (`c`), depending on how you are trying to transform your text. `ed` also introduced the `s/foo/bar/g` syntax for finding and replacing, or “substituting,” text.
|
||||
|
||||
Given all these similarities, you might expect the average Vim user to have no trouble using `ed`. But `ed` is not at all like Vim in another important respect. `ed` is a true line editor. It was written and widely used in the days of the teletype printer. When Ken Thompson and Dennis Ritchie were hacking away at Unix, they looked like this:
|
||||
|
||||
![Ken Thompson interacting with a PDP-11 via teletype.][3]
|
||||
|
||||
`ed` doesn’t allow you to edit lines in place among the other lines of the open buffer, or move a cursor around, because `ed` would have to reprint the entire file every time you made a change to it. There was no mechanism in 1969 for `ed` to “clear” the contents of the screen, because the screen was just a sheet of paper and everything that had already been output had been output in ink. When necessary, you can ask `ed` to print out a range of lines for you using the list command (`l`), but most of the time you are operating on text that you can’t see. Using `ed` is thus a little trying to find your way around a dark house with an underpowered flashlight. You can only see so much at once, so you have to try your best to remember where everything is.
|
||||
|
||||
Here’s an example of an `ed` session. I’ve added comments (after the `#` character) explaining the purpose of each line, though if these were actually entered `ed` wouldn’t recognize them as comments and would complain:
|
||||
|
||||
```
|
||||
[sinclairtarget 09:49 ~]$ ed
|
||||
i # Enter input mode
|
||||
Hello world!
|
||||
|
||||
Isn't it a nice day?
|
||||
. # Finish input
|
||||
1,2l # List lines 1 to 2
|
||||
Hello world!$
|
||||
$
|
||||
2d # Delete line 2
|
||||
,l # List entire buffer
|
||||
Hello world!$
|
||||
Isn't it a nice day?$
|
||||
s/nice/terrible/g # Substitute globally
|
||||
,l
|
||||
Hello world!$
|
||||
Isn't it a terrible day?$
|
||||
w foo.txt # Write to foo.txt
|
||||
38 # (bytes written)
|
||||
q # Quit
|
||||
[sinclairtarget 10:50 ~]$ cat foo.txt
|
||||
Hello world!
|
||||
Isn't it a terrible day?
|
||||
```
|
||||
|
||||
As you can see, `ed` is not an especially talkative program.
|
||||
|
||||
### Bill Joy Writes a Text Editor
|
||||
|
||||
`ed` worked well enough for Thompson and Ritchie. Others found it difficult to use and it acquired a reputation for being a particularly egregious example of Unix’s hostility toward the novice. In 1975, a man named George Coulouris developed an improved version of `ed` on the Unix system installed at Queen Mary’s College, London. Coulouris wrote his editor to take advantage of the video displays that he had available at Queen Mary’s. Unlike `ed`, Coulouris’ program allowed users to edit a single line in place on screen, navigating through the line keystroke by keystroke (imagine using Vim on one line at a time). Coulouris called his program `em`, or “editor for mortals,” which he had supposedly been inspired to do after Thompson paid a visit to Queen Mary’s, saw the program Coulouris had built, and dismissed it, saying that he had no need to see the state of a file while editing it.
|
||||
|
||||
In 1976, Coulouris brought `em` with him to UC Berkeley, where he spent the summer as a visitor to the CS department. This was exactly ten years after Ken Thompson had left Berkeley to work at Bell Labs. At Berkeley, Coulouris met Bill Joy, a graduate student working on the Berkeley Software Distribution (BSD). Coulouris showed `em` to Joy, who, starting with Coulouris’ source code, built out an improved version of `ed` called `ex`, for “extended `ed`.” Version 1.1 of `ex` was bundled with the first release of BSD Unix in 1978. `ex` was largely compatible with `ed`, but it added two more modes: an “open” mode, which enabled single-line editing like had been possible with `em`, and a “visual” mode, which took over the whole screen and enabled live editing of an entire file like we are used to today.
|
||||
|
||||
For the second release of BSD in 1979, an executable named `vi` was introduced that did little more than open `ex` in visual mode.
|
||||
|
||||
`ex`/`vi` (henceforth `vi`) established most of the conventions we now associate with Vim that weren’t already a part of `ed`. The video terminal that Joy was using was a Lear Siegler ADM-3A, which had a keyboard with no cursor keys. Instead, arrows were painted on the `h`, `j`, `k`, and `l` keys, which is why Joy used those keys for cursor movement in `vi`. The escape key on the ADM-3A keyboard was also where today we would find the tab key, which explains how such a hard-to-reach key was ever assigned an operation as common as exiting a mode. The `:` character that prefixes commands also comes from `vi`, which in regular mode (i.e. the mode entered by running `ex`) used `:` as a prompt. This addressed a long-standing complaint about `ed`, which, once launched, greets users with utter silence. In visual mode, saving and quitting now involved typing the classic `:wq`. “Yanking” and “putting,” marks, and the `set` command for setting options were all part of the original `vi`. The features we use in the course of basic text editing today in Vim are largely `vi` features.
|
||||
|
||||
![A Lear Siegler ADM-3A keyboard.][4]
|
||||
|
||||
`vi` was the only text editor bundled with BSD Unix other than `ed`. At the time, Emacs could cost hundreds of dollars (this was before GNU Emacs), so `vi` became enormously popular. But `vi` was a direct descendant of `ed`, which meant that the source code could not be modified without an AT&T source license. This motivated several people to create open-source versions of `vi`. STEVIE (ST Editor for VI Enthusiasts) appeared in 1987, Elvis appeared in 1990, and `nvi` appeared in 1994. Some of these clones added extra features like syntax highlighting and split windows. Elvis in particular saw many of its features incorporated into Vim, since so many Elvis users pushed for their inclusion.
|
||||
|
||||
### Bram Moolenaar Writes Vim
|
||||
|
||||
“Vim”, which now abbreviates “Vi Improved”, originally stood for “Vi Imitation.” Like many of the other `vi` clones, Vim began as an attempt to replicate `vi` on a platform where it was not available. Bram Moolenaar, a Dutch software engineer working for a photocopier company in Venlo, the Netherlands, wanted something like `vi` for his brand-new Amiga 2000. Moolenaar had grown used to using `vi` on the Unix systems at his university and it was now “in his fingers.” So in 1988, using the existing STEVIE `vi` clone as a starting point, Moolenaar began work on Vim.
|
||||
|
||||
Moolenaar had access to STEVIE because STEVIE had previously appeared on something called a Fred Fish disk. Fred Fish was an American programmer that mailed out a floppy disk every month with a curated selection of the best open-source software available for the Amiga platform. Anyone could request a disk for nothing more than the price of postage. Several versions of STEVIE were released on Fred Fish disks. The version that Moolenaar used had been released on Fred Fish disk 256. (Disappointingly, Fred Fish disks seem to have nothing to do with [Freddi Fish][5].)
|
||||
|
||||
Moolenaar liked STEVIE but quickly noticed that there were many `vi` commands missing. So, for the first release of Vim, Moolenaar made `vi` compatibility his priority. Someone else had written a series of `vi` macros that, when run through a properly `vi`-compatible editor, could solve a [randomly generated maze][6]. Moolenaar was able to get these macros working in Vim. In 1991, Vim was released for the first time on Fred Fish disk 591 as “Vi Imitation.” Moolenaar had added some features (including multi-level undo and a “quickfix” mode for compiler errors) that meant that Vim had surpassed `vi`. But Vim would remain “Vi Imitation” until Vim 2.0, released in 1993 via FTP.
|
||||
|
||||
Moolenaar, with the occasional help of various internet collaborators, added features to Vim at a steady clip. Vim 2.0 introduced support for the `wrap` option and for horizontal scrolling through long lines of text. Vim 3.0 added support for split windows and buffers, a feature inspired by the `vi` clone `nvi`. Vim also now saved each buffer to a swap file, so that edited text could survive a crash. Vimscript made its first appearance in Vim 5.0, along with support for syntax highlighting. All the while, Vim’s popularity was growing. It was ported to MS-DOS, to Windows, to Mac, and even to Unix, where it competed with the original `vi`.
|
||||
|
||||
In 2006, Vim was voted the most popular editor among Linux Journal readers. Today, according to Stack Overflow’s 2018 Developer Survey, Vim is the most popular text-mode (i.e. terminal emulator) editor, used by 25.8% of all software developers (and 40% of Sysadmin/DevOps people). For a while, during the late 1980s and throughout the 1990s, programmers waged the “Editor Wars,” which pitted Emacs users against `vi` (and eventually Vim) users. While Emacs certainly still has a following, some people think that the Editor Wars are over and that Vim won. The 2018 Stack Overflow Developer Survey suggests that this is true; only 4.1% of respondents used Emacs.
|
||||
|
||||
How did Vim become so successful? Obviously people like the features that Vim has to offer. But I would argue that the long history behind Vim illustrates that it had more advantages than just its feature set. Vim’s codebase dates back only to 1988, when Moolenaar began working on it. The “wq text editor,” on the other hand—the broader vision of how a Unix-y text editor should work—goes back a half-century. The “wq text editor” had a few different concrete expressions, but thanks in part to the unusual attention paid to backward compatibility by both Bill Joy and Bram Moolenaar, good ideas accumulated gradually over time. The “wq text editor,” in that sense, is one of the longest-running and most successful open-source projects, having enjoyed contributions from some of the greatest minds in the computing world. I don’t think the “startup-company-throws-away all-precedents-and-creates-disruptive-new-software” approach to development is necessarily bad, but Vim is a reminder that the collaborative and incremental approach can also yield wonders.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][7] on Twitter or subscribe to the [RSS feed][8] to make sure you know when a new post is out.
|
||||
|
||||
Previously on TwoBitHistory…
|
||||
|
||||
> New post! This time we're taking a look at the Altair 8800, the very first home computer, and how to simulate it on your modern PC.<https://t.co/s2sB5njrkd>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [July 22, 2018][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/08/05/where-vim-came-from.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stackoverflow.blog/wp-content/uploads/2017/05/meme.jpeg
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://upload.wikimedia.org/wikipedia/commons/8/8f/Ken_Thompson_%28sitting%29_and_Dennis_Ritchie_at_PDP-11_%282876612463%29.jpg
|
||||
[4]: https://vintagecomputer.ca/wp-content/uploads/2015/01/LSI-ADM3A-full-keyboard.jpg
|
||||
[5]: https://en.wikipedia.org/wiki/Freddi_Fish
|
||||
[6]: https://github.com/isaacs/.vim/tree/master/macros/maze
|
||||
[7]: https://twitter.com/TwoBitHistory
|
||||
[8]: https://twobithistory.org/feed.xml
|
||||
[9]: https://twitter.com/TwoBitHistory/status/1021058552352387074?ref_src=twsrc%5Etfw
|
||||
@ -0,0 +1,138 @@
|
||||
What Did Ada Lovelace's Program Actually Do?
|
||||
======
|
||||
The story of Microsoft’s founding is one of the most famous episodes in computing history. In 1975, Paul Allen flew out to Albuquerque to demonstrate the BASIC interpreter that he and Bill Gates had written for the Altair microcomputer. Because neither of them had a working Altair, Allen and Gates tested their interpreter using an emulator that they wrote and ran on Harvard’s computer system. The emulator was based on nothing more than the published specifications for the Intel 8080 processor. When Allen finally ran their interpreter on a real Altair—in front of the person he and Gates hoped would buy their software—he had no idea if it would work. But it did. The next month, Allen and Gates officially founded their new company.
|
||||
|
||||
Over a century before Allen and Gates wrote their BASIC interpreter, Ada Lovelace wrote and published a computer program. She, too, wrote a program for a computer that had only been described to her. But her program, unlike the Microsoft BASIC interpreter, was never run, because the computer she was targeting was never built.
|
||||
|
||||
Lovelace’s program is often called the world’s first computer program. Not everyone agrees that it should be called that. Lovelace’s legacy, it turns out, is one of computing history’s most hotly debated subjects. Walter Isaacson has written that the dispute about the extent and merit of her contributions constitutes a “minor academic specialty.” Inevitably, the fact that Lovelace was a woman has made this dispute a charged one. Historians have cited all kinds of primary evidence to argue that the credit given to Lovelace is either appropriate or undeserved. But they seem to spend less time explaining the technical details of her published writing, which is unfortunate, because the technical details are the most fascinating part of the story. Who wouldn’t want to know exactly how a program written in 1843 was supposed to work?
|
||||
|
||||
In fairness, Lovelace’s program is not easy to explain to the layperson without some hand-waving. It’s the intricacies of her program, though, that make it so remarkable. Whether or not she ought to be known as “the first programmer,” her program was specified with a degree of rigor that far surpassed anything that came before. She thought carefully about how operations could be organized into groups that could be repeated, thereby inventing the loop. She realized how important it was to track the state of variables as they changed, introducing a notation to illustrate those changes. As a programmer myself, I’m startled to see how much of what Lovelace was doing resembles the experience of writing software today.
|
||||
|
||||
So let’s take a closer look at Lovelace’s program. She designed it to calculate the Bernoulli numbers. To understand what those are, we have to go back a couple millennia to the genesis of one of mathematics’ oldest problems.
|
||||
|
||||
### Sums of Powers
|
||||
|
||||
The Pythagoreans lived on the shores of the Mediterranean and worshiped numbers. One of their pastimes was making triangles out of pebbles.
|
||||
|
||||
![][1]
|
||||
|
||||
One pebble followed by a row of two pebbles makes a triangle containing three pebbles. Add another row of three pebbles and you get a triangle containing six pebbles. You can continue like this, each time adding a row with one more pebble in it than the previous row. A triangle with six rows contains 21 pebbles. But how many pebbles does a triangle with 423 rows contain?
|
||||
|
||||
What the Pythagoreans were looking for was a way to calculate the following without doing all the addition:
|
||||
|
||||
They eventually realized that, if you place two triangles of the same size up against each other so that they form a rectangle, you can find the area of the rectangle and divide by two to get the number of pebbles in each of the triangles:
|
||||
|
||||
![][2]
|
||||
|
||||
Archimedes later explored a similar problem. He was interested in the following series:
|
||||
|
||||
You might visualize this series by imagining a stack of progressively larger squares (made out of tiny cubes), one on top of the other, forming a pyramid. Archimedes wanted to know if there was an easy way to tell how many cubes would be needed to construct a pyramid with, say, 423 levels. He recorded a solution that also permits a geometrical interpretation.
|
||||
|
||||
Three pyramids can be fit together to form a rectangular prism with a tiny, one-cube-high extrusion at one end. That little extrusion happens to be a triangle that obeys the same rules that the Pythagoreans used to make their pebble triangles. ([This video][3] might be a more helpful explanation of what I mean.) So the volume of the whole shape is given by the following equation:
|
||||
|
||||
By substituting the Pythagorean equation for the sum of the first n integers and doing some algebra, you get this:
|
||||
|
||||
In 499, the Indian mathematician and astronomer, Aryabhata, published a work known as the Aryabhatiya, which included a formula for calculating the sum of cubes:
|
||||
|
||||
A formula for the sum of the first n positive integers raised to the fourth power wasn’t published for another 500 years.
|
||||
|
||||
You might be wondering at this point if there is a general method for finding the sum of the first n integers raised to the kth power. Mathematicians were wondering too. Johann Faulhaber, a German mathematician and slightly kooky numerologist, was able to calculate formulas for sums of integers up to the 17th power, which he published in 1631. But this may have taken him years and he did not state a general solution. Blaise Pascal finally outlined a general method in 1665, though it depended on first knowing how to calculate the sum of integers raised to every lesser power. To calculate the sum of the first n positive integers raised to the sixth power, for example, you would first have to know how to calculate the sum of the first n positive integers raised to the fifth power.
|
||||
|
||||
A more practical general solution was stated in the posthumously published work of Swiss mathematician Jakob Bernoulli, who died in 1705. Bernoulli began by deriving the formulas for calculating the sums of the first n positive integers to the first, second, and third powers. These he gave in polynomial form, so they looked like the below:
|
||||
|
||||
Using Pascal’s Triangle, Bernoulli realized that these polynomials followed a predictable pattern. Essentially, Bernoulli broke the coefficients of each term down into two factors, one of which he could determine using Pascal’s Triangle and the other which he could derive from the interesting property that all the coefficients in the polynomial seemed to always add to one. Figuring out the exponent that should be attached to each term was no problem, because that also followed a predictable pattern. The factor of each coefficient that had to be calculated using the sums-to-one rule formed a sequence that became known as the Bernoulli numbers.
|
||||
|
||||
Bernoulli’s discovery did not mean that it was now trivial to calculate the sum of the first positive n integers to any given power. In order to calculate the sum of the first positive n integers raised to the kth power, you would need to know every Bernoulli number up to the kth Bernoulli number. Each Bernoulli number could only be calculated if the previous Bernoulli numbers were known. But calculating a long series of Bernoulli numbers was significantly easier than deriving each sum of powers formula in turn, so Bernoulli’s discovery was a big advance for mathematics.
|
||||
|
||||
### Babbage
|
||||
|
||||
Charles Babbage was born in 1791, nearly a century after Bernoulli died. I’ve always had some vague idea that Babbage designed but did not build a mechanical computer. But I’ve never entirely understood how that computer was supposed to work. The basic ideas, as it happens, are not that difficult to grasp, which is good news. Lovelace’s program was designed to run on one of Babbage’s machines, so we need to take another quick detour here to talk about how those machines worked.
|
||||
|
||||
Babbage designed two separate mechanical computing machines. His first machine was called the Difference Engine. Before the invention of the pocket calculator, people relied on logarithmic tables to calculate the product of large numbers. (There is a good [Numberphile video][4] on how this was done.) Large logarithmic tables are not difficult to create, at least conceptually, but the sheer number of calculations that need to be done in order to create them meant that in Babbage’s time they often contained errors. Babbage, frustrated by this, sought to create a machine that could tabulate logarithms mechanically and therefore without error.
|
||||
|
||||
The Difference Engine was not a computer, because all it did was add and subtract. It took advantage of a method devised by the French mathematician Gaspard de Prony that broke the process of tabulating logarithms down into small steps. These small steps involved only addition and subtraction, meaning that a small army of people without any special mathematical aptitude or training could be employed to produce a table. De Prony’s method, known as the method of divided differences, could be used to tabulate any polynomial. Polynomials, in turn, could be used to approximate logarithmic and trigonometric functions.
|
||||
|
||||
To get a sense of how this process worked, consider the following simple polynomial function:
|
||||
|
||||
The method of divided differences involves finding the difference between each successive value of y for different values of x. The differences between these differences are then found, and possibly the differences between those next differences themselves, until a constant difference appears. These differences can then be used to get the next value of the polynomial simply by adding.
|
||||
|
||||
Because the above polynomial is only a second-degree polynomial, we are able to find the constant difference after only two columns of differences:
|
||||
|
||||
x y Diff 1 Diff 2 1 2 2 5 3 3 10 5 2 4 17 7 2 5 ? ? 2 … … … …
|
||||
|
||||
Now, since we know that the constant difference is 2, we can find the value of y when x is 5 through addition only. If we add 2 to 7, the last entry in the “Diff 1” column, we get 9. If we add 9 to 17, the last entry in the y column, we get 26, our answer.
|
||||
|
||||
Babbage’s Difference Engine had, for each difference column in a table like the one above, a physical column of gears. Each gear was a decimal digit and one whole column was a decimal number. The Difference Engine had eight columns of gears, so it could tabulate a polynomial up to the seventh degree. The columns were initially set with values matching an early row in the difference table, worked out ahead of time. A human operator would then turn a crank shaft, causing the constant difference to propagate through the machine as the value stored on each column was added to the next.
|
||||
|
||||
Babbage was able to build a small section of the Difference Engine and use it to demonstrate his ideas at parties. But even after spending an amount of public money equal to the cost of two large warships, he never built the entire machine. Babbage could not find anyone in the early 1800s that could make the number of gears he needed with sufficient accuracy. A working Difference Engine would not be built until the 1990s, after the advent of precision machining. There is [a great video on YouTube][5] demonstrating a working Difference Engine on loan to the Computer History Museum in Mountain View, which is worth watching even just to listen to the marvelous sounds the machine makes while it runs.
|
||||
|
||||
Babbage eventually lost interest in the Difference Engine when he realized that a much more powerful and flexible machine could be built. His Analytical Engine was the machine that we know today as Babbage’s mechanical computer. The Analytical Engine was based on the same columns of gears used in the Difference Engine, but whereas the Difference Engine only had eight columns, the Analytical Engine was supposed to have many hundreds more. The Analytical Engine could be programmed using punched cards like a Jacquard Loom and could multiply and divide as well as add and subtract. In order to perform one of these operations, a section of the machine called the “mill” would rearrange itself into the appropriate configuration, read the operands off of other columns used for data storage, and then write the result back to another column.
|
||||
|
||||
Babbage called his new machine the Analytical Engine because it was powerful enough to do something resembling mathematical analysis. The Difference Engine could tabulate a polynomial, but the Analytical Engine would be able to calculate, for example, the coefficients of the polynomial expansion of another expression. It was an amazing machine, but the British government wisely declined to fund its construction. So Babbage went abroad to Italy to try to drum up support for his idea.
|
||||
|
||||
### Notes by The Translator
|
||||
|
||||
In Turin, Babbage met Italian engineer and future prime minister Luigi Menabrea. He persuaded Menabrea to write an outline of what the Analytical Engine could accomplish. In 1842, Menabrea published a paper on the topic in French. The following year, Lovelace published a translation of Menabrea’s paper into English.
|
||||
|
||||
Lovelace, then known as Ada Byron, first met Babbage at a party in 1833, when she was 17 and he was 41. Lovelace was fascinated with Babbage’s Difference Engine. She could also understand how it worked, because she had been extensively tutored in mathematics throughout her childhood. Her mother, Annabella Milbanke, had decided that a solid grounding in mathematics would ward off the wild, romantic sensibility that possessed Lovelace’s father, Lord Byron, the famous poet. After meeting in 1833, Lovelace and Babbage remained a part of the same social circle and wrote to each other frequently.
|
||||
|
||||
Ada Byron married William King in 1835. King later became the Earl of Lovelace, making Ada the Countess of Lovelace. Even after having three children, she continued her education in mathematics, employing Augustus de Morgan, who discovered De Morgan’s laws, as her tutor. Lovelace saw the potential of Babbage’s Analytical Machine immediately and was eager to work with him to promote the idea. A friend suggested that she translate Menabrea’s paper for an English audience.
|
||||
|
||||
Menabrea’s paper gave a brief overview of how the Difference Engine worked, then showed how the Analytical Engine would be a far superior machine. The Analytical Engine would be so powerful that it could “form the product of two numbers, each containing twenty figures, in three minutes” (emphasis in the original). Menabrea gave further examples of the machine’s capabilities, demonstrating how it could solve a simple system of linear equations and expand the product of two binomial expressions. In both cases, Menabrea provided what Lovelace called “diagrams of development,” which listed the sequence of operations that would need to be performed to calculate the correct answer. These were programs in the same sense that Lovelace’s own program was a program and they were originally published the year before. But as we will see, Menabrea’s programs were only simple examples of what was possible. All of them were trivial in the sense that they did not require any kind of branching or looping.
|
||||
|
||||
Lovelace appended a series of notes to her translation of Menabrea’s paper that together ran much longer than the original work. It was here that she made her major contributions to computing. In Note A, which Lovelace attached to Menabrea’s initial description of the Analytical Engine, Lovelace explained at some length and often in lyrical language the promise of a machine that could perform arbitrary mathematical operations. She foresaw that a machine like the Analytical Engine wasn’t just limited to numbers and could in fact act on any objects “whose mutual fundamental relations could be expressed by those of the abstract science of operations, and which should be also susceptible of adaptations to the action of the operating notation and mechanism of the engine.” She added that the machine might one day, for example, compose music. This insight was all the more remarkable given that Menabrea saw the Analytical Engine primarily as a tool for automating “long and arid computation,” which would free up the intellectual capacities of brilliant scientists for more advanced thinking. The miraculous foresight that Lovelace demonstrated in Note A is one major reason that she is celebrated today.
|
||||
|
||||
The other famous note is Note G. Lovelace begins Note G by arguing that, despite its impressive powers, the Analytical Machine cannot really be said to “think.” This part of Note G is what Alan Turing would later refer to as “Lady Lovelace’s Objection.” Nevertheless, Lovelace continues, the machine can do extraordinary things. To illustrate its ability to handle even more complex problems, Lovelace provides her program calculating the Bernoulli numbers.
|
||||
|
||||
The full program, in the expanded “diagram of development” format that Lovelace explains in Note D, can be seen [here][6]. The program is essentially a list of operations, specified using the usual mathematical symbols. It doesn’t appear that Babbage or Lovelace got as far as developing anything like a set of op codes for the Analytical Engine.
|
||||
|
||||
Though Lovelace was describing a method for computing the entire sequence of Bernoulli numbers up to some limit, the program she provided only illustrated one step of that process. Her program calculated a number that she called B7, which modern mathematicians know as the eighth Bernoulli number. Her program thus sought to solve the following equation:
|
||||
|
||||
In the above, each term represents a coefficient in the polynomial formula for the sum of integers to a particular power. Here that power is eight, since the eighth Bernoulli number first appears in the formula for the sum of positive integers to the eighth power. The B and A numbers represent the two kinds of factors that Bernoulli discovered. B1 through B7 are all different Bernoulli numbers, indexed according to Lovelace’s indexing. A0 through A5 represent the factors of the coefficients that Bernoulli could calculate using Pascal’s Triangle. The values of A0, A1, A3, and A5 appear below. Here n represents the index of the Bernoulli number in the sequence of odd-numbered Bernoulli numbers starting with the first. Lovelace’s program used n = 4.
|
||||
|
||||
I’ve created a [translation][7] of Lovelace’s program into C, which may be easier to follow. Lovelace’s program first calculates A0 and the product B1A1. It then enters a loop that repeats twice to calculate B3A3 and B5A5, since those are formed according to an identical pattern. After each product is calculated, it is added with all the previous products, so that by the end of the program the full sum has been obtained.
|
||||
|
||||
Obviously the C translation is not an exact recreation of Lovelace’s program. It declares variables on the stack, for example, whereas Lovelace’s variables were more like registers. But it makes obvious the parts of Lovelace’s program that were so prescient. The C program contains two `while` loops, one nested inside the other. Lovelace’s program did not have `while` loops exactly, but she made groups of operations and in the text of her note specified when they should repeat. The variable `v10`, in the original program and in the C translation, functions as a counter variable that decrements with each loop, a construct any programmer would be familiar with. In fact, aside from the profusion of variables with unhelpful names, the C translation of Lovelace’s program doesn’t look that alien at all.
|
||||
|
||||
The other thing worth mentioning quickly is that translating Lovelace’s program into C was not that difficult, thanks to the detail present in her diagram. Unlike Menabrea’s tables, her table includes a column labeled “Indication of change in the value on any Variable,” which makes it much easier to follow the mutation of state throughout the program. She adds a superscript index here to each variable to indicate the successive values they hold. A superscript of two, for example, means that the value being used here is the second value that has been assigned to the variable since the beginning of the program.
|
||||
|
||||
### The First Programmer?
|
||||
|
||||
After I had translated Lovelace’s program into C, I was able to run it on my own computer. To my frustration, I kept getting the wrong result. After some debugging, I finally realized that the problem wasn’t the code that I had written. The bug was in the original!
|
||||
|
||||
In her “diagram of development,” Lovelace gives the fourth operation as `v5 / v4`. But the correct ordering here is `v4 / v5`. This may well have been a typesetting error and not an error in the program that Lovelace devised. All the same, this must be the oldest bug in computing. I marveled that, for ten minutes or so, unknowingly, I had wrestled with this first ever bug.
|
||||
|
||||
Jim Randall, another blogger that has [translated Lovelace’s program into Python][8], has noted this division bug and two other issues. What does it say about Ada Lovelace that her published program contains minor bugs? Perhaps it shows that she was attempting to write not just a demonstration but a real program. After all, can you really be writing anything more than toy programs if you aren’t also writing lots of bugs?
|
||||
|
||||
One Wikipedia article calls Lovelace the first to publish a “complex program.” Maybe that’s the right way to think about Lovelace’ accomplishment. Menabrea published “diagrams of development” in his paper a year before Lovelace published her translation. Babbage also wrote more than twenty programs that he never published. So it’s not quite accurate to say that Lovelace wrote or published the first program, though there’s always room to quibble about what exactly constitutes a “program.” Even so, Lovelace’s program was miles ahead of anything else that had been published before. The longest program that Menabrea presented was 11 operations long and contained no loops or branches; Lovelace’s program contains 25 operations and a nested loop (and thus branching). Menabrea wrote the following toward the end of his paper:
|
||||
|
||||
> When once the engine shall have been constructed, the difficulty will be reduced to the making of the cards; but as these are merely the translation of algebraic formulae, it will, by means of some simple notation, be easy to consign the execution of them to a workman.
|
||||
|
||||
Neither Babbage nor Menabrea were especially interested in applying the Analytical Engine to problems beyond the immediate mathematical challenges that first drove Babbage to construct calculating machines. Lovelace saw that the Analytical Engine was capable of much more than Babbage or Menabrea could imagine. Lovelace also grasped that “the making of the cards” would not be a mere afterthought and that it could be done well or done poorly. This is hard to appreciate without understanding her program from Note G and seeing for oneself the care she put into designing it. But having done that, you might agree that Lovelace, even if she was not the very first programmer, was the first programmer to deserve the title.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][9] on Twitter or subscribe to the [RSS feed][10] to make sure you know when a new post is out.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/08/18/ada-lovelace-note-g.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twobithistory.org/images/triangular_numbers1.png
|
||||
[2]: https://twobithistory.org/images/triangular_numbers2.png
|
||||
[3]: https://www.youtube.com/watch?v=aXbT37IlyZQ
|
||||
[4]: https://youtu.be/VRzH4xB0GdM
|
||||
[5]: https://www.youtube.com/watch?v=BlbQsKpq3Ak
|
||||
[6]: https://upload.wikimedia.org/wikipedia/commons/c/cf/Diagram_for_the_computation_of_Bernoulli_numbers.jpg
|
||||
[7]: https://gist.github.com/sinclairtarget/ad18ac65d277e453da5f479d6ccfc20e
|
||||
[8]: https://enigmaticcode.wordpress.com/tag/bernoulli-numbers/
|
||||
[9]: https://twitter.com/TwoBitHistory
|
||||
[10]: https://twobithistory.org/feed.xml
|
||||
@ -1,516 +0,0 @@
|
||||
fuowang 翻译中
|
||||
|
||||
9 Best Free Video Editing Software for Linux In 2017
|
||||
======
|
||||
**Brief: Here are best video editors for Linux, their feature, pros and cons and how to install them on your Linux distributions.**
|
||||
|
||||
![Best Video editors for Linux][1]
|
||||
|
||||
![Best Video editors for Linux][2]
|
||||
|
||||
We have discussed [best photo management applications for Linux][3], [best code editors for Linux][4] in similar articles in the past. Today we shall see the **best video editing software for Linux**.
|
||||
|
||||
When asked about free video editing software, Windows Movie Maker and iMovie is what most people often suggest.
|
||||
|
||||
Unfortunately, both of them are not available for GNU/Linux. But you don't need to worry about it, we have pooled together a list of **best free video editors** for you.
|
||||
|
||||
## Best Video Editors for Linux
|
||||
|
||||
Let's have a look at the best free video editing software for Linux below. Here's a quick summary if you think the article is too long to read. You can click on the links to jump to the relevant section of the article:
|
||||
|
||||
Video Editors Main Usage Type Kdenlive General purpose video editing Free and Open Source OpenShot General purpose video editing Free and Open Source Shotcut General purpose video editing Free and Open Source Flowblade General purpose video editing Free and Open Source Lightworks Professional grade video editing Freemium Blender Professional grade 3D editing Free and Open Source Cinelerra General purpose video editing Free and Open Source DaVinci Resolve Professional grade video editing Freemium VidCutter Simple video split and merge Free and Open Source
|
||||
|
||||
### 1\. Kdenlive
|
||||
|
||||
![Kdenlive-free video editor on ubuntu][1]
|
||||
|
||||
![Kdenlive-free video editor on ubuntu][5]
|
||||
[Kdenlive][6] is a free and [open source][7] video editing software from [KDE][8] that provides support for dual video monitors, a multi-track timeline, clip list, customizable layout support, basic effects, and basic transitions.
|
||||
|
||||
It supports a wide variety of file formats and a wide range of camcorders and cameras including Low resolution camcorder (Raw and AVI DV editing), Mpeg2, mpeg4 and h264 AVCHD (small cameras and camcorders), High resolution camcorder files, including HDV and AVCHD camcorders, Professional camcorders, including XDCAM-HD™ streams, IMX™ (D10) streams, DVCAM (D10) , DVCAM, DVCPRO™, DVCPRO50™ streams and DNxHD™ streams.
|
||||
|
||||
If you are looking for an iMovie alternative for Linux, Kdenlive would be your best bet.
|
||||
|
||||
#### Kdenlive features
|
||||
|
||||
* Multi-track video editing
|
||||
* A wide range of audio and video formats
|
||||
* Configurable interface and shortcuts
|
||||
* Easily create tiles using text or images
|
||||
* Plenty of effects and transitions
|
||||
* Audio and video scopes make sure the footage is correctly balanced
|
||||
* Proxy editing
|
||||
* Automatic save
|
||||
* Wide hardware support
|
||||
* Keyframeable effects
|
||||
|
||||
|
||||
|
||||
#### Pros
|
||||
|
||||
* All-purpose video editor
|
||||
* Not too complicated for those who are familiar with video editing
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* It may still be confusing if you are looking for something extremely simple
|
||||
* KDE applications are infamous for being bloated
|
||||
|
||||
|
||||
|
||||
#### Installing Kdenlive
|
||||
|
||||
Kdenlive is available for all major Linux distributions. You can simply search for it in your software center. Various packages are available in the [download section of Kdenlive website][9].
|
||||
|
||||
Command line enthusiasts can install it from the terminal by running the following command in Debian and Ubuntu-based Linux distributions:
|
||||
```
|
||||
sudo apt install kdenlive
|
||||
```
|
||||
|
||||
### 2\. OpenShot
|
||||
|
||||
![Openshot-free-video-editor-on-ubuntu][1]
|
||||
|
||||
![Openshot-free-video-editor-on-ubuntu][10]
|
||||
|
||||
[OpenShot][11] is another multi-purpose video editor for Linux. OpenShot can help you create videos with transitions and effects. You can also adjust audio levels. Of course, it support of most formats and codecs.
|
||||
|
||||
You can also export your film to DVD, upload to YouTube, Vimeo, Xbox 360, and many common video formats. OpenShot is a tad bit simpler than Kdenlive. So if you need a video editor with a simple UI OpenShot is a good choice.
|
||||
|
||||
There is also a neat documentation to [get you started with OpenShot][12].
|
||||
|
||||
#### OpenShot features
|
||||
|
||||
* Cross-platform, available on Linux, macOS, and Windows
|
||||
* Support for a wide range of video, audio, and image formats
|
||||
* Powerful curve-based Keyframe animations
|
||||
* Desktop integration with drag and drop support
|
||||
* Unlimited tracks or layers
|
||||
* Clip resizing, scaling, trimming, snapping, rotation, and cutting
|
||||
* Video transitions with real-time previews
|
||||
* Compositing, image overlays and watermarks
|
||||
* Title templates, title creation, sub-titles
|
||||
* Support for 2D animation via image sequences
|
||||
* 3D animated titles and effects
|
||||
* SVG friendly for creating and including vector titles and credits
|
||||
* Scrolling motion picture credits
|
||||
* Frame accuracy (step through each frame of video)
|
||||
* Time-mapping and speed changes on clips
|
||||
* Audio mixing and editing
|
||||
* Digital video effects, including brightness, gamma, hue, greyscale, chroma key etc
|
||||
|
||||
|
||||
|
||||
#### Pros
|
||||
|
||||
* All-purpose video editor for average video editing needs
|
||||
* Available on Windows and macOS along with Linux
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* It may be simple but if you are extremely new to video editing, there is definitely a learning curve involved here
|
||||
* You may still not find up to the mark of a professional-grade, movie making editing software
|
||||
|
||||
|
||||
|
||||
#### Installing OpenShot
|
||||
|
||||
OpenShot is also available in the repository of all major Linux distributions. You can simply search for it in your software center. You can also get it from its [official website][13].
|
||||
|
||||
My favorite way is to use the following command in Debian and Ubuntu-based Linux distributions:
|
||||
```
|
||||
sudo apt install openshot
|
||||
```
|
||||
|
||||
### 3\. Shotcut
|
||||
|
||||
![Shotcut Linux video editor][1]
|
||||
|
||||
![Shotcut Linux video editor][14]
|
||||
|
||||
[Shotcut][15] is another video editor for Linux that can be put in the same league as Kdenlive and OpenShot. While it does provide similar features as the other two discussed above, Shotcut is a bit advanced with support for 4K videos.
|
||||
|
||||
Support for a number of audio, video format, transitions and effects are some of the numerous features of Shotcut. External monitor is also supported here.
|
||||
|
||||
There is a collection of video tutorials to [get you started with Shotcut][16]. It is also available for Windows and macOS so you can use your learning on other operating systems as well.
|
||||
|
||||
#### Shotcut features
|
||||
|
||||
* Cross-platform, available on Linux, macOS, and Windows
|
||||
* Support for a wide range of video, audio, and image formats
|
||||
* Native timeline editing
|
||||
* Mix and match resolutions and frame rates within a project
|
||||
* Audio filters, mixing and effects
|
||||
* Video transitions and filters
|
||||
* Multitrack timeline with thumbnails and waveforms
|
||||
* Unlimited undo and redo for playlist edits including a history view
|
||||
* Clip resizing, scaling, trimming, snapping, rotation, and cutting
|
||||
* Trimming on source clip player or timeline with ripple option
|
||||
* External monitoring on an extra system display/monitor
|
||||
* Hardware support
|
||||
|
||||
|
||||
|
||||
You can read about more features [here][17].
|
||||
|
||||
#### Pros
|
||||
|
||||
* All-purpose video editor for common video editing needs
|
||||
* Support for 4K videos
|
||||
* Available on Windows and macOS along with Linux
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Too many features reduce the simplicity of the software
|
||||
|
||||
|
||||
|
||||
#### Installing Shotcut
|
||||
|
||||
Shotcut is available in [Snap][18] format. You can find it in Ubuntu Software Center. For other distributions, you can get the executable file from its [download page][19].
|
||||
|
||||
### 4\. Flowblade
|
||||
|
||||
![Flowblade movie editor on ubuntu][1]
|
||||
|
||||
![Flowblade movie editor on ubuntu][20]
|
||||
|
||||
[Flowblade][21] is a multitrack non-linear video editor for Linux. Like the above-discussed ones, this too is a free and open source software. It comes with a stylish and modern user interface.
|
||||
|
||||
Written in Python, it is designed to provide a fast, and precise. Flowblade has focused on providing the best possible experience on Linux and other free platforms. So there's no Windows and OS X version for now. Feels good to be a Linux exclusive.
|
||||
|
||||
You also get a decent [documentation][22] to help you use all of its features.
|
||||
|
||||
#### Flowblade features
|
||||
|
||||
* Lightweight application
|
||||
* Provide simple interface for simple tasks like split, merge, overwrite etc
|
||||
* Plenty of audio and video effects and filters
|
||||
* Supports [proxy editing][23]
|
||||
* Drag and drop support
|
||||
* Support for a wide range of video, audio, and image formats
|
||||
* Batch rendering
|
||||
* Watermarks
|
||||
* Video transitions and filters
|
||||
* Multitrack timeline with thumbnails and waveforms
|
||||
|
||||
|
||||
|
||||
You can read about more [Flowblade features][24] here.
|
||||
|
||||
#### Pros
|
||||
|
||||
* Lightweight
|
||||
* Good for general purpose video editing
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Not available on other platforms
|
||||
|
||||
|
||||
|
||||
#### Installing Flowblade
|
||||
|
||||
Flowblade should be available in the repositories of all major Linux distributions. You can install it from the software center. More information is available on its [download page][25].
|
||||
|
||||
Alternatively, you can install Flowblade in Ubuntu and other Ubuntu based systems, using the command below:
|
||||
```
|
||||
sudo apt install flowblade
|
||||
```
|
||||
|
||||
### 5\. Lightworks
|
||||
|
||||
![Lightworks running on ubuntu 16.04][1]
|
||||
|
||||
![Lightworks running on ubuntu 16.04][26]
|
||||
|
||||
If you looking for a video editor software that has more feature, this is the answer. [Lightworks][27] is a cross-platform professional video editor, available for Linux, Mac OS X and Windows.
|
||||
|
||||
It is an award-winning professional [non-linear editing][28] (NLE) software that supports resolutions up to 4K as well as video in SD and HD formats.
|
||||
|
||||
Lightworks is available for Linux, however, it is not open source.
|
||||
|
||||
This application has two versions:
|
||||
|
||||
* Lightworks Free
|
||||
* Lightworks Pro
|
||||
|
||||
|
||||
|
||||
Pro version has more features such as higher resolution support, 4K and Blue Ray support etc.
|
||||
|
||||
Extensive documentation is available on its [website][29]. You can also refer to videos at [Lightworks video tutorials page][30]
|
||||
|
||||
#### Lightworks features
|
||||
|
||||
* Cross-platform
|
||||
* Simple & intuitive User Interface
|
||||
* Easy timeline editing & trimming
|
||||
* Real-time ready to use audio & video FX
|
||||
* Access amazing royalty-free audio & video content
|
||||
* Lo-Res Proxy workflows for 4K
|
||||
* Export video for YouTube/Vimeo, SD/HD, up to 4K
|
||||
* Drag and drop support
|
||||
* Wide variety of audio and video effects and filters
|
||||
|
||||
|
||||
|
||||
#### Pros
|
||||
|
||||
* Professional, feature-rich video editor
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Limited free version
|
||||
|
||||
|
||||
|
||||
#### Installing Lightworks
|
||||
|
||||
Lightworks provides DEB packages for Debian and Ubuntu-based Linux distributions and RPM packages for Fedora-based Linux distributions. You can find the packages on its [download page][31].
|
||||
|
||||
### 6\. Blender
|
||||
|
||||
![Blender running on Ubuntu 16.04][1]
|
||||
|
||||
![Blender running on Ubuntu 16.04][32]
|
||||
|
||||
[Blender][33] is a professional, industry-grade open source, cross-platform video editor. It is popular for 3D works. Blender has been used in several Hollywood movies including Spider Man series.
|
||||
|
||||
Although originally designed for produce 3D modeling, but it can also be used for video editing and input capabilities with a variety of formats.
|
||||
|
||||
#### Blender features
|
||||
|
||||
* Live preview, luma waveform, chroma vectorscope and histogram displays
|
||||
* Audio mixing, syncing, scrubbing and waveform visualization
|
||||
* Up to 32 slots for adding video, images, audio, scenes, masks and effects
|
||||
* Speed control, adjustment layers, transitions, keyframes, filters and more
|
||||
|
||||
|
||||
|
||||
You can read about more features [here][34].
|
||||
|
||||
#### Pros
|
||||
|
||||
* Cross-platform
|
||||
* Professional grade editing
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Complicated
|
||||
* Mainly for 3D animation, not focused on regular video editing
|
||||
|
||||
|
||||
|
||||
#### Installing Blender
|
||||
|
||||
The latest version of Blender can be downloaded from its [download page][35].
|
||||
|
||||
### 7\. Cinelerra
|
||||
|
||||
![Cinelerra video editor for Linux][1]
|
||||
|
||||
![Cinelerra video editor for Linux][36]
|
||||
|
||||
[Cinelerra][37] has been available since 1998 and has been downloaded over 5 million times. It was the first video editor to provide non-linear editing on 64-bit systems back in 2003. It was a go-to video editor for Linux users at that time but it lost its sheen afterward as some developers abandoned the project.
|
||||
|
||||
Good thing is that its back on track and is being developed actively again.
|
||||
|
||||
There is some [interesting backdrop story][38] about how and why Cinelerra was started if you care to read.
|
||||
|
||||
#### Cinelerra features
|
||||
|
||||
* Non-linear editing
|
||||
* Support for HD videos
|
||||
* Built-in frame renderer
|
||||
* Various video effects
|
||||
* Unlimited layers
|
||||
* Split pane editing
|
||||
|
||||
|
||||
|
||||
#### Pros
|
||||
|
||||
* All-purpose video editor
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Not suitable for beginners
|
||||
* No packages available
|
||||
|
||||
|
||||
|
||||
#### Installing Cinelerra
|
||||
|
||||
You can download the source code from [SourceForge][39]. More information on its [download page][40].
|
||||
|
||||
### 8\. DaVinci Resolve
|
||||
|
||||
![DaVinci Resolve video editor][1]
|
||||
|
||||
![DaVinci Resolve video editor][41]
|
||||
|
||||
If you want Hollywood level video editing, use the tool the professionals use in Hollywood. [DaVinci Resolve][42] from Blackmagic is what professionals are using for editing movies and tv shows.
|
||||
|
||||
DaVinci Resolve is not your regular video editor. It's a full-fledged editing tool that provides editing, color correction and professional audio post-production in a single application.
|
||||
|
||||
DaVinci Resolve is not open source. Like LightWorks, it too provides a free version for Linux. The pro version costs $300.
|
||||
|
||||
#### DaVinci Resolve features
|
||||
|
||||
* High-performance playback engine
|
||||
* All kind of edit types such as overwrite, insert, ripple overwrite, replace, fit to fill, append at end
|
||||
* Advanced Trimming
|
||||
* Audio Overlays
|
||||
* Multicam Editing allows editing footage from multiple cameras in real-time
|
||||
* Transition and filter-effects
|
||||
* Speed effects
|
||||
* Timeline curve editor
|
||||
* Non-linear editing for VFX
|
||||
|
||||
|
||||
|
||||
#### Pros
|
||||
|
||||
* Cross-platform
|
||||
* Professional grade video editor
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Not suitable for average editing
|
||||
* Not open source
|
||||
* Some features are not available in the free version
|
||||
|
||||
|
||||
|
||||
#### Installing DaVinci Resolve
|
||||
|
||||
You can download DaVinci Resolve for Linux from [its website][42]. You'll have to register, even for the free version.
|
||||
|
||||
### 9\. VidCutter
|
||||
|
||||
![VidCutter video editor for Linux][1]
|
||||
|
||||
![VidCutter video editor for Linux][43]
|
||||
|
||||
Unlike all the other video editors discussed here, [VidCutter][44] is utterly simple. It doesn't do much except splitting videos and merging. But at times you just need this and VidCutter gives you just that.
|
||||
|
||||
#### VidCutter features
|
||||
|
||||
* Cross-platform app available for Linux, Windows and MacOS
|
||||
* Supports most of the common video formats such as: AVI, MP4, MPEG 1/2, WMV, MP3, MOV, 3GP, FLV etc
|
||||
* Simple interface
|
||||
* Trims and merges the videos, nothing more than that
|
||||
|
||||
|
||||
|
||||
#### Pros
|
||||
|
||||
* Cross-platform
|
||||
* Good for simple split and merge
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Not suitable for regular video editing
|
||||
* Crashes often
|
||||
|
||||
|
||||
|
||||
#### Installing VidCutter
|
||||
|
||||
If you are using Ubuntu-based Linux distributions, you can use the official PPA:
|
||||
```
|
||||
sudo add-apt-repository ppa:ozmartian/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install vidcutter
|
||||
```
|
||||
|
||||
It is available in AUR so Arch Linux users can also install it easily. For other Linux distributions, you can find the installation files on its [GitHub page][45].
|
||||
|
||||
### Which is the best video editing software for Linux?
|
||||
|
||||
A number of video editors mentioned here use [FFmpeg][46]. You can use FFmpeg on your own as well. It's a command line only tool so I didn't include it in the main list but it would have been unfair to not mention it at all.
|
||||
|
||||
If you need an editor for simply cutting and joining videos, go with VidCutter.
|
||||
|
||||
If you need something more than that, **OpenShot** or **Kdenlive** is a good choice. These are suitable for beginners and a system with standard specification.
|
||||
|
||||
If you have a high-end computer and need advanced features you can go out with **Lightworks** or **DaVinci Resolve**. If you are looking for more advanced features for 3D works, **Blender** has got your back.
|
||||
|
||||
So that's all I can write about the ** best video editing software for Linux** such as Ubuntu, Linux Mint, Elementary, and other Linux distributions. Share with us which video editor you like the most.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-video-editing-software-linux/
|
||||
|
||||
作者:[It'S Foss Team][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/itsfoss/
|
||||
[1]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[2]:https://itsfoss.com/wp-content/uploads/2016/06/best-Video-editors-Linux-800x450.png
|
||||
[3]:https://itsfoss.com/linux-photo-management-software/
|
||||
[4]:https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2016/06/kdenlive-free-video-editor-on-ubuntu.jpg
|
||||
[6]:https://kdenlive.org/
|
||||
[7]:https://itsfoss.com/tag/open-source/
|
||||
[8]:https://www.kde.org/
|
||||
[9]:https://kdenlive.org/download/
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2016/06/openshot-free-video-editor-on-ubuntu.jpg
|
||||
[11]:http://www.openshot.org/
|
||||
[12]:http://www.openshot.org/user-guide/
|
||||
[13]:http://www.openshot.org/download/
|
||||
[14]:https://itsfoss.com/wp-content/uploads/2016/06/shotcut-video-editor-linux-800x503.jpg
|
||||
[15]:https://www.shotcut.org/
|
||||
[16]:https://www.shotcut.org/tutorials/
|
||||
[17]:https://www.shotcut.org/features/
|
||||
[18]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[19]:https://www.shotcut.org/download/
|
||||
[20]:https://itsfoss.com/wp-content/uploads/2016/06/flowblade-movie-editor-on-ubuntu.jpg
|
||||
[21]:http://jliljebl.github.io/flowblade/
|
||||
[22]:https://jliljebl.github.io/flowblade/webhelp/help.html
|
||||
[23]:https://jliljebl.github.io/flowblade/webhelp/proxy.html
|
||||
[24]:https://jliljebl.github.io/flowblade/features.html
|
||||
[25]:https://jliljebl.github.io/flowblade/download.html
|
||||
[26]:https://itsfoss.com/wp-content/uploads/2016/06/lightworks-running-on-ubuntu-16.04.jpg
|
||||
[27]:https://www.lwks.com/
|
||||
[28]:https://en.wikipedia.org/wiki/Non-linear_editing_system
|
||||
[29]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206&tab=4
|
||||
[30]:https://www.lwks.com/videotutorials
|
||||
[31]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206&tab=1
|
||||
[32]:https://itsfoss.com/wp-content/uploads/2016/06/blender-running-on-ubuntu-16.04.jpg
|
||||
[33]:https://www.blender.org/
|
||||
[34]:https://www.blender.org/features/
|
||||
[35]:https://www.blender.org/download/
|
||||
[36]:https://itsfoss.com/wp-content/uploads/2016/06/cinelerra-screenshot.jpeg
|
||||
[37]:http://cinelerra.org/
|
||||
[38]:http://cinelerra.org/our-story
|
||||
[39]:https://sourceforge.net/projects/heroines/files/cinelerra-6-src.tar.xz/download
|
||||
[40]:http://cinelerra.org/download
|
||||
[41]:https://itsfoss.com/wp-content/uploads/2016/06/davinci-resolve-vdeo-editor-800x450.jpg
|
||||
[42]:https://www.blackmagicdesign.com/products/davinciresolve/
|
||||
[43]:https://itsfoss.com/wp-content/uploads/2016/06/vidcutter-screenshot-800x585.jpeg
|
||||
[44]:https://itsfoss.com/vidcutter-video-editor-linux/
|
||||
[45]:https://github.com/ozmartian/vidcutter/releases
|
||||
[46]:https://www.ffmpeg.org/
|
||||
@ -1,3 +1,4 @@
|
||||
translating by dianbanjiu
|
||||
Manage Your Games Using Lutris In Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,158 +0,0 @@
|
||||
The 5 Best Linux Distributions for Development
|
||||
============================================================
|
||||
|
||||

|
||||
Jack Wallen looks at some of the best LInux distributions for development efforts.[Creative Commons Zero][6]
|
||||
|
||||
When considering Linux, there are so many variables to take into account. What package manager do you wish to use? Do you prefer a modern or old-standard desktop interface? Is ease of use your priority? How flexible do you want your distribution? What task will the distribution serve?
|
||||
|
||||
It is that last question which should often be considered first. Is the distribution going to work as a desktop or a server? Will you be doing network or system audits? Or will you be developing? If you’ve spent much time considering Linux, you know that for every task there are several well-suited distributions. This certainly holds true for developers. Even though Linux, by design, is an ideal platform for developers, there are certain distributions that rise above the rest, to serve as great operating systems to serve developers.
|
||||
|
||||
I want to share what I consider to be some of the best distributions for your development efforts. Although each of these five distributions can be used for general purpose development (with maybe one exception), they each serve a specific purpose. You may or may not be surprised by the selections.
|
||||
|
||||
With that said, let’s get to the choices.
|
||||
|
||||
### Debian
|
||||
|
||||
The [Debian][14] distribution winds up on the top of many a Linux list. With good reason. Debian is that distribution from which so many are based. It is this reason why many developers choose Debian. When you develop a piece of software on Debian, chances are very good that package will also work on [Ubuntu][15], [Linux Mint][16], [Elementary OS][17], and a vast collection of other distributions.
|
||||
|
||||
Beyond that obvious answer, Debian also has a very large amount of applications available, by way of the default repositories (Figure 1).
|
||||
|
||||

|
||||
Figure 1: Available applications from the standard Debian repositories.[Used with permission][1]
|
||||
|
||||
To make matters even programmer-friendly, those applications (and their dependencies) are simple to install. Take, for instance, the build-essential package (which can be installed on any distribution derived from Debian). This package includes the likes of dkpg-dev, g++, gcc, hurd-dev, libc-dev, and make—all tools necessary for the development process. The build-essential package can be installed with the command sudo apt install build-essential.
|
||||
|
||||
There are hundreds of other developer-specific applications available from the standard repositories, tools such as:
|
||||
|
||||
* Autoconf—configure script builder
|
||||
|
||||
* Autoproject—creates a source package for a new program
|
||||
|
||||
* Bison—general purpose parser generator
|
||||
|
||||
* Bluefish—powerful GUI editor, targeted towards programmers
|
||||
|
||||
* Geany—lightweight IDE
|
||||
|
||||
* Kate—powerful text editor
|
||||
|
||||
* Eclipse—helps builders independently develop tools that integrate with other people’s tools
|
||||
|
||||
The list goes on and on.
|
||||
|
||||
Debian is also as rock-solid a distribution as you’ll find, so there’s very little concern you’ll lose precious work, by way of the desktop crashing. As a bonus, all programs included with Debian have met the [Debian Free Software Guidelines][18], which adheres to the following “social contract”:
|
||||
|
||||
* Debian will remain 100% free.
|
||||
|
||||
* We will give back to the free software community.
|
||||
|
||||
* We will not hide problems.
|
||||
|
||||
* Our priorities are our users and free software
|
||||
|
||||
* Works that do not meet our free software standards are included in a non-free archive.
|
||||
|
||||
Also, if you’re new to developing on Linux, Debian has a handy [Programming section in their user manual][19].
|
||||
|
||||
### openSUSE Tumbleweed
|
||||
|
||||
If you’re looking to develop with a cutting-edge, rolling release distribution, [openSUSE][20] offers one of the best in [Tumbleweed][21]. Not only will you be developing with the most up to date software available, you’ll be doing so with the help of openSUSE’s amazing administrator tools … of which includes YaST. If you’re not familiar with YaST (Yet another Setup Tool), it’s an incredibly powerful piece of software that allows you to manage the whole of the platform, from one convenient location. From within YaST, you can also install using RPM Groups. Open YaST, click on RPM Groups (software grouped together by purpose), and scroll down to the Development section to see the large amount of groups available for installation (Figure 2).
|
||||
|
||||
|
||||

|
||||
Figure 2: Installing package groups in openSUSE Tumbleweed.[Creative Commons Zero][2]
|
||||
|
||||
openSUSE also allows you to quickly install all the necessary devtools with the simple click of a weblink. Head over to the [rpmdevtools install site][22] and click the link for Tumbleweed. This will automatically add the necessary repository and install rpmdevtools.
|
||||
|
||||
By developing with a rolling release distribution, you know you’re working with the most recent releases of installed software.
|
||||
|
||||
### CentOS
|
||||
|
||||
Let’s face it, [Red Hat Enterprise Linux][23] (RHEL) is the de facto standard for enterprise businesses. If you’re looking to develop for that particular platform, and you can’t afford a RHEL license, you cannot go wrong with [CentOS][24]—which is, effectively, a community version of RHEL. You will find many of the packages found on CentOS to be the same as in RHEL—so once you’re familiar with developing on one, you’ll be fine on the other.
|
||||
|
||||
If you’re serious about developing on an enterprise-grade platform, you cannot go wrong starting with CentOS. And because CentOS is a server-specific distribution, you can more easily develop for a web-centric platform. Instead of developing your work and then migrating it to a server (hosted on a different machine), you can easily have CentOS setup to serve as an ideal host for both developing and testing.
|
||||
|
||||
Looking for software to meet your development needs? You only need open up the CentOS Application Installer, where you’ll find a Developer section that includes a dedicated sub-section for Integrated Development Environments (IDEs - Figure 3).
|
||||
|
||||

|
||||
Figure 3: Installing a powerful IDE is simple in CentOS.[Used with permission][3]
|
||||
|
||||
CentOS also includes Security Enhanced Linux (SELinux), which makes it easier for you to test your software’s ability to integrate with the same security platform found in RHEL. SELinux can often cause headaches for poorly designed software, so having it at the ready can be a real boon for ensuring your applications work on the likes of RHEL. If you’re not sure where to start with developing on CentOS 7, you can read through the [RHEL 7 Developer Guide][25].
|
||||
|
||||
### Raspbian
|
||||
|
||||
Let’s face it, embedded systems are all the rage. One easy means of working with such systems is via the Raspberry Pi—a tiny footprint computer that has become incredibly powerful and flexible. In fact, the Raspberry Pi has become the hardware used by DIYers all over the planet. Powering those devices is the [Raspbian][26] operating system. Raspbian includes tools like [BlueJ][27], [Geany][28], [Greenfoot][29], [Sense HAT Emulator][30], [Sonic Pi][31], and [Thonny Python IDE][32], [Python][33], and [Scratch][34], so you won’t want for the necessary development software. Raspbian also includes a user-friendly desktop UI (Figure 4), to make things even easier.
|
||||
|
||||

|
||||
Figure 4: The Raspbian main menu, showing pre-installed developer software.[Used with permission][4]
|
||||
|
||||
For anyone looking to develop for the Raspberry Pi platform, Raspbian is a must have. If you’d like to give Raspbian a go, without the Raspberry Pi hardware, you can always install it as a VirtualBox virtual machine, by way of the ISO image found [here][35].
|
||||
|
||||
### Pop!_OS
|
||||
|
||||
Don’t let the name full you, [System76][36]’s [Pop!_OS][37] entry into the world of operating systems is serious. And although what System76 has done to this Ubuntu derivative may not be readily obvious, it is something special.
|
||||
|
||||
The goal of System76 is to create an operating system specific to the developer, maker, and computer science professional. With a newly-designed GNOME theme, Pop!_OS is beautiful (Figure 5) and as highly functional as you would expect from both the hardware maker and desktop designers.
|
||||
|
||||
### [devel_5.jpg][11]
|
||||
|
||||

|
||||
Figure 5: The Pop!_OS Desktop.[Used with permission][5]
|
||||
|
||||
But what makes Pop!_OS special is the fact that it is being developed by a company dedicated to Linux hardware. This means, when you purchase a System76 laptop, desktop, or server, you know the operating system will work seamlessly with the hardware—on a level no other company can offer. I would predict that, with Pop!_OS, System76 will become the Apple of Linux.
|
||||
|
||||
### Time for work
|
||||
|
||||
In their own way, each of these distributions. You have a stable desktop (Debian), a cutting-edge desktop (openSUSE Tumbleweed), a server (CentOS), an embedded platform (Raspbian), and a distribution to seamless meld with hardware (Pop!_OS). With the exception of Raspbian, any one of these distributions would serve as an outstanding development platform. Get one installed and start working on your next project with confidence.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][13]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/5-best-linux-distributions-development
|
||||
|
||||
作者:[JACK WALLEN ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/devel1jpg
|
||||
[8]:https://www.linux.com/files/images/devel2jpg
|
||||
[9]:https://www.linux.com/files/images/devel3jpg
|
||||
[10]:https://www.linux.com/files/images/devel4jpg
|
||||
[11]:https://www.linux.com/files/images/devel5jpg
|
||||
[12]:https://www.linux.com/files/images/king-penguins1920jpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:https://www.debian.org/
|
||||
[15]:https://www.ubuntu.com/
|
||||
[16]:https://linuxmint.com/
|
||||
[17]:https://elementary.io/
|
||||
[18]:https://www.debian.org/social_contract
|
||||
[19]:https://www.debian.org/doc/manuals/debian-reference/ch12.en.html
|
||||
[20]:https://www.opensuse.org/
|
||||
[21]:https://en.opensuse.org/Portal:Tumbleweed
|
||||
[22]:https://software.opensuse.org/download.html?project=devel%3Atools&package=rpmdevtools
|
||||
[23]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[24]:https://www.centos.org/
|
||||
[25]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/pdf/developer_guide/Red_Hat_Enterprise_Linux-7-Developer_Guide-en-US.pdf
|
||||
[26]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[27]:https://www.bluej.org/
|
||||
[28]:https://www.geany.org/
|
||||
[29]:https://www.greenfoot.org/
|
||||
[30]:https://www.raspberrypi.org/blog/sense-hat-emulator/
|
||||
[31]:http://sonic-pi.net/
|
||||
[32]:http://thonny.org/
|
||||
[33]:https://www.python.org/
|
||||
[34]:https://scratch.mit.edu/
|
||||
[35]:http://rpf.io/x86iso
|
||||
[36]:https://system76.com/
|
||||
[37]:https://system76.com/pop
|
||||
312
sources/tech/20180707 Version Control Before Git with CVS.md
Normal file
312
sources/tech/20180707 Version Control Before Git with CVS.md
Normal file
@ -0,0 +1,312 @@
|
||||
Version Control Before Git with CVS
|
||||
======
|
||||
Github was launched in 2008. If your software engineering career, like mine, is no older than Github, then Git may be the only version control software you have ever used. While people sometimes grouse about its steep learning curve or unintuitive interface, Git has become everyone’s go-to for version control. In Stack Overflow’s 2015 developer survey, 69.3% of respondents used Git, almost twice as many as used the second-most-popular version control system, Subversion. After 2015, Stack Overflow stopped asking developers about the version control systems they use, perhaps because Git had become so popular that the question was uninteresting.
|
||||
|
||||
Git itself is not much older than Github. Linus Torvalds released the first version of Git in 2005. Though today younger developers might have a hard time conceiving of a world where the term “version control software” didn’t more or less just mean Git, such a world existed not so long ago. There were lots of alternatives to choose from. Open source developers preferred Subversion, enterprises and video game companies used Perforce (some still do), while the Linux kernel project famously relied on a version control system called BitKeeper.
|
||||
|
||||
Some of these systems, particularly BitKeeper, might feel familiar to a young Git user transported back in time. Most would not. BitKeeper aside, the version control systems that came before Git worked according to a fundamentally different paradigm. In a taxonomy offered by Eric Sink, author of Version Control by Example, Git is a third-generation version control system, while most of Git’s predecessors, the systems popular in the 1990s and early 2000s, are second-generation version control systems. Where third-generation version control systems are distributed, second-generation version control systems are centralized. You have almost certainly heard Git described as a “distributed” version control system before. I never quite understood the distributed/centralized distinction, at least not until I installed and experimented with a centralized second-generation version control system myself.
|
||||
|
||||
The system I installed was CVS. CVS, short for Concurrent Versions System, was the very first second-generation version control system. It was also the most popular version control system for about a decade until it was replaced in 2000 by Subversion. Even then, Subversion was supposed to be “CVS but better,” which only underscores how dominant CVS had become throughout the 1990s.
|
||||
|
||||
CVS was first developed in 1986 by a Dutch computer scientist named Dick Grune, who was looking for a way to collaborate with his students on a compiler project. CVS was initially little more than a collection of shell scripts wrapping RCS (Revision Control System), a first-generation version control system that Grune wanted to improve. RCS works according to a pessimistic locking model, meaning that no two programmers can work on a single file at once. In order to edit a file, you have to first ask RCS for an exclusive lock on the file, which you keep until you are finished editing. If someone else is already editing a file you need to edit, you have to wait. CVS improved on RCS and ushered in the second generation of version control systems by trading the pessimistic locking model for an optimistic one. Programmers could now edit the same file at the same time, merging their edits and resolving any conflicts later. (Brian Berliner, an engineer who later took over the CVS project, wrote a very readable [paper][1] about CVS’ innovations in 1990.)
|
||||
|
||||
In that sense, CVS wasn’t all that different from Git, which also works according to an optimistic model. But that’s where the similarities end. In fact, when Linus Torvalds was developing Git, one of his guiding principles was WWCVSND, or “What Would CVS Not Do.” Whenever he was in doubt about a decision, he strove to choose the option that had not been chosen in the design of CVS. So even though CVS predates Git by over a decade, it influenced Git as a kind of negative template.
|
||||
|
||||
I’ve really enjoyed playing around with CVS. I think there’s no better way to understand why Git’s distributed nature is such an improvement on what came before. So I invite you to come along with me on an exciting journey and spend the next ten minutes of your life learning about a piece of software nobody has used in the last decade. (See correction.)
|
||||
|
||||
### Getting Started with CVS
|
||||
|
||||
Instructions for installing CVS can be found on the [project’s homepage][2]. On MacOS, you can install CVS using Homebrew.
|
||||
|
||||
Since CVS is centralized, it distinguishes between the client-side universe and the server-side universe in a way that something like Git does not. The distinction is not so pronounced that there are different executables. But in order to start using CVS, even on your own machine, you’ll have to set up the CVS backend.
|
||||
|
||||
The CVS backend, the central store for all your code, is called the repository. Whereas in Git you would typically have a repository for every project, in CVS the repository holds all of your projects. There is one central repository for everything, though there are ways to work with only a project at a time.
|
||||
|
||||
To create a local repository, you run the `init` command. You would do this somewhere global like your home directory.
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox init
|
||||
```
|
||||
|
||||
CVS allows you to pass options to either the `cvs` command itself or to the `init` subcommand. Options that appear after the `cvs` command are global in nature, while options that appear after the subcommand are specific to the subcommand. In this case, the `-d` flag is global. Here it happens to tell CVS where we want to create our repository, but in general the `-d` flag points to the location of the repository we want to use for any given action. It can be tedious to supply the `-d` flag all the time, so the `CVSROOT` environment variable can be set instead.
|
||||
|
||||
Since we’re working locally, we’ve just passed a path for our `-d` argument, but we could also have included a hostname.
|
||||
|
||||
The command creates a directory called `sandbox` in your home directory. If you list the contents of `sandbox`, you’ll find that it contains another directory called `CVSROOT`. This directory, not to be confused with the environment variable, holds administrative files for the repository.
|
||||
|
||||
Congratulations! You’ve just created your first CVS repository.
|
||||
|
||||
### Checking In Code
|
||||
|
||||
Let’s say that you’ve decided to keep a list of your favorite colors. You are an artistically inclined but extremely forgetful person. You type up your list of colors and save it as a file called `favorites.txt`:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
Let’s also assume that you’ve saved your file in a new directory called `colors`. Now you’d like to put your favorite color list under version control, because fifty years from now it will be interesting to look back and see how your tastes changed through time.
|
||||
|
||||
In order to do that, you will have to import your directory as a new CVS project. You can do that using the `import` command:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox import -m "" colors colors initial
|
||||
N colors/favorites.txt
|
||||
|
||||
No conflicts created by this import
|
||||
```
|
||||
|
||||
Here we are specifying the location of our repository with the `-d` flag again. The remaining arguments are passed to the `import` subcommand. We have to provide a message, but here we don’t really need one, so we’ve left it blank. The next argument, `colors`, specifies the name of our new directory in the repository; here we’ve just used the same name as the directory we are in. The last two arguments specify the vendor tag and the release tag respectively. We’ll talk more about tags in a minute.
|
||||
|
||||
You’ve just pulled your “colors” project into the CVS repository. There are a couple different ways to go about bringing code into CVS, but this is the method recommended by [Pragmatic Version Control Using CVS][3], the Pragmatic Programmer book about CVS. What makes this method a little awkward is that you then have to check out your work fresh, even though you’ve already got an existing `colors` directory. Instead of using that directory, you’re going to delete it and then check out the version that CVS already knows about:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox co colors
|
||||
cvs checkout: Updating colors
|
||||
U colors/favorites.txt
|
||||
```
|
||||
|
||||
This will create a new directory, also called `colors`. In this directory you will find your original `favorites.txt` file along with a directory called `CVS`. The `CVS` directory is basically CVS’ equivalent of the `.git` directory in every Git repository.
|
||||
|
||||
### Making Changes
|
||||
|
||||
Get ready for a trip.
|
||||
|
||||
Just like Git, CVS has a `status` subcommand:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
|
||||
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: fD7GYxt035GNg8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
This is where things start to look alien. CVS doesn’t have commit objects. In the above, there is something called a “Commit Identifier,” but this might be only a relatively recent edition—no mention of a “Commit Identifier” appears in Pragmatic Version Control Using CVS, which was published in 2003. (The last update to CVS was released in 2008.)
|
||||
|
||||
Whereas with Git you’d talk about the version of a file associated with commit `45de392`, in CVS files are versioned separately. The first version of your file is version 1.1, the next version is 1.2, and so on. When branches are involved, extra numbers are appended, so you might end up with something like the `1.1.1.1` above, which appears to be the default in our case even though we haven’t created any branches.
|
||||
|
||||
If you were to run `cvs log` (equivalent to `git log`) in a project with lots of files and commits, you’d see an individual history for each file. You might have a file at version 1.2 and a file at version 1.14 in the same project.
|
||||
|
||||
Let’s go ahead and make a change to version 1.1 of our `favorites.txt` file:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
+cyan
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
Once we’ve made the change, we can run `cvs diff` to see what CVS thinks we’ve done:
|
||||
|
||||
```
|
||||
$ cvs diff
|
||||
cvs diff: Diffing .
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.1.1.1
|
||||
diff -r1.1.1.1 favorites.txt
|
||||
3a4
|
||||
> cyan
|
||||
```
|
||||
|
||||
CVS recognizes that we added a new line containing the color “cyan” to the file. (Actually, it says we’ve made changes to the “RCS” file; you can see that CVS never fully escaped its original association with RCS.) The diff we are being shown is the diff between the copy of `favorites.txt` in our working directory and the 1.1.1.1 version stored in the repository.
|
||||
|
||||
In order to update the version stored in the repository, we have to commit the change. In Git, this would be a multi-step process. We’d have to stage the change so that it appears in our index. Then we’d commit the change. Finally, to make the change visible to anyone else, we’d have to push the commit up to the origin repository.
|
||||
|
||||
In CVS, all of these things happen when you run `cvs commit`. CVS just bundles up all the changes it can find and puts them in the repository:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Add cyan to favorites."
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.2; previous revision: 1.1
|
||||
```
|
||||
|
||||
I’m so used to Git that this strikes me as terrifying. Without an opportunity to stage changes, any old thing that you’ve touched in your working directory might end up as part of the public repository. Did you passive-aggressively rewrite a coworker’s poorly implemented function out of cathartic necessity, never intending for him to know? Too bad, he now thinks you’re a dick. You also can’t edit your commits before pushing them, since a commit is a push. Do you enjoy spending 40 minutes repeatedly running `git rebase -i` until your local commit history flows like the derivation of a mathematical proof? Sorry, you can’t do that here, and everyone is going to find out that you don’t actually write your tests first.
|
||||
|
||||
But I also now understand why so many people find Git needlessly complicated. If `cvs commit` is what you were used to, then I’m sure staging and pushing changes would strike you as a pointless chore.
|
||||
|
||||
When people talk about Git being a “distributed” system, this is primarily the difference they mean. In CVS, you can’t make commits locally. A commit is a submission of code to the central repository, so it’s not something you can do without a connection. All you’ve got locally is your working directory. In Git, you have a full-fledged local repository, so you can make commits all day long even while disconnected. And you can edit those commits, revert, branch, and cherry pick as much as you want, without anybody else having to know.
|
||||
|
||||
Since commits were a bigger deal, CVS users often made them infrequently. Commits would contain as many changes as today we might expect to see in a ten-commit pull request. This was especially true if commits triggered a CI build and an automated test suite.
|
||||
|
||||
If we now run `cvs status`, we can see that we have a new version of our file:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.2 2018-07-06 21:18:59 -0400
|
||||
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: pQx5ooyNk90wW8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
### Merging
|
||||
|
||||
As mentioned above, in CVS you can edit a file that someone else is already editing. That was CVS’ big improvement on RCS. What happens when you need to bring your changes back together?
|
||||
|
||||
Let’s say that you have invited some friends to add their favorite colors to your list. While they are adding their colors, you decide that you no longer like the color green and remove it from the list.
|
||||
|
||||
When you go to commit your changes, you might discover that CVS notices a problem:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Remove green"
|
||||
cvs commit: Examining .
|
||||
cvs commit: Up-to-date check failed for `favorites.txt'
|
||||
cvs [commit aborted]: correct above errors first!
|
||||
```
|
||||
|
||||
It looks like your friends committed their changes first. So your version of `favorites.txt` is not up-to-date with the version in the repository. If you run `cvs status`, you’ll see that your local copy of `favorites.txt` is version 1.2 with some local changes, but the repository version is 1.3:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Needs Merge
|
||||
|
||||
Working revision: 1.2 2018-07-07 10:42:43 -0400
|
||||
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: 2oZ6n0G13bDaldJA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
You can run `cvs diff` to see exactly what the differences between 1.2 and 1.3 are:
|
||||
|
||||
```
|
||||
$ cvs diff -r HEAD favorites.txt
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.3
|
||||
diff -r1.3 favorites.txt
|
||||
3d2
|
||||
< green
|
||||
7,10d5
|
||||
<
|
||||
< pink
|
||||
< hot pink
|
||||
< bubblegum pink
|
||||
```
|
||||
|
||||
It seems that our friends really like pink. In any case, they’ve edited a different part of the file than we have, so the changes are easy to merge. CVS can do that for us when we run `cvs update`, which is similar to `git pull`:
|
||||
|
||||
```
|
||||
$ cvs update
|
||||
cvs update: Updating .
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.2
|
||||
retrieving revision 1.3
|
||||
Merging differences between 1.2 and 1.3 into favorites.txt
|
||||
M favorites.txt
|
||||
```
|
||||
|
||||
If you now take a look at `favorites.txt`, you’ll find that it has been modified to include the changes that your friends made to the file. Your changes are still there too. Now you are free to commit the file:
|
||||
|
||||
```
|
||||
$ cvs commit
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.4; previous revision: 1.3
|
||||
```
|
||||
|
||||
The end result is what you’d get in Git by running `git pull --rebase`. Your changes have been added on top of your friends’ changes. There is no “merge commit.”
|
||||
|
||||
Sometimes, changes to the same file might be incompatible. If your friends had changed “green” to “olive,” for example, that would have conflicted with your change removing “green” altogether. In the early days of CVS, this was exactly the kind of case that caused people to worry that CVS wasn’t safe; RCS’ pessimistic locking ensured that such a case could never arise. But CVS guarantees safety by making sure that nobody’s changes get overwritten automatically. You have to tell CVS which change you want to keep going forward, so when you run `cvs update`, CVS marks up the file with both changes in the same way that Git does when Git detects a merge conflict. You then have to manually edit the file and pick the change you want to keep.
|
||||
|
||||
The interesting thing to note here is that merge conflicts have to be fixed before you can commit. This is another consequence of CVS’ centralized nature. In Git, you don’t have to worry about resolving merges until you push the commits you’ve got locally.
|
||||
|
||||
Since CVS doesn’t have easily addressable commit objects, the only way to group a collection of changes is to mark a particular working directory state with a tag.
|
||||
|
||||
Creating a tag is easy:
|
||||
|
||||
```
|
||||
$ cvs tag VERSION_1_0
|
||||
cvs tag: Tagging .
|
||||
T favorites.txt
|
||||
```
|
||||
|
||||
You’ll later be able to return files to this state by running `cvs update` and passing the tag to the `-r` flag:
|
||||
|
||||
```
|
||||
$ cvs update -r VERSION_1_0
|
||||
cvs update: Updating .
|
||||
U favorites.txt
|
||||
```
|
||||
|
||||
Because you need a tag to rewind to an earlier working directory state, CVS encourages a lot of preemptive tagging. Before major refactors, for example, you might create a `BEFORE_REFACTOR_01` tag that you could later use if the refactor went wrong. People also used tags if they wanted to generate project-wide diffs. Basically, all the things we routinely do today with commit hashes have to be anticipated and planned for with CVS, since you needed to have the tags available already.
|
||||
|
||||
Branches can be created in CVS, sort of. Branches are just a special kind of tag:
|
||||
|
||||
```
|
||||
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
|
||||
cvs rtag: Tagging colors
|
||||
```
|
||||
|
||||
That only creates the branch (in full view of everyone, by the way), so you still need to switch to it using `cvs update`:
|
||||
|
||||
```
|
||||
$ cvs update -r TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
The above commands switch onto the new branch in your current working directory, but Pragmatic Version Control Using CVS actually advises that you create a new directory to hold your new branch. Presumably its authors found switching directories easier than switching branches in CVS.
|
||||
|
||||
Pragmatic Version Control Using CVS also advises against creating branches off of an existing branch. They recommend only creating branches off of the mainline branch, which in Git is known as `master`. In general, branching was considered an “advanced” CVS skill. In Git, you might start a new branch for almost any trivial reason, but in CVS branching was typically used only when really necessary, such as for releases.
|
||||
|
||||
A branch could later be merged back into the mainline using `cvs update` and the `-j` flag:
|
||||
|
||||
```
|
||||
$ cvs update -j TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
### Thanks for the Commit Histories
|
||||
|
||||
In 2007, Linus Torvalds gave [a talk][4] about Git at Google. Git was very new then, so the talk was basically an attempt to persuade a roomful of skeptical programmers that they should use Git, even though Git was so different from anything then available. If you haven’t already seen the talk, I highly encourage you to watch it. Linus is an entertaining speaker, even if he never fails to be his brash self. He does an excellent job of explaining why the distributed model of version control is better than the centralized one. A lot of his criticism is reserved for CVS in particular.
|
||||
|
||||
Git is a [complex tool][5]. Learning it can be a frustrating experience. But I’m also continually amazed at the things that Git can do. In comparison, CVS is simple and straightforward, though often unable to do many of the operations we now take for granted. Going back and using CVS for a while is an excellent way to find yourself with a new appreciation for Git’s power and flexibility. It illustrates well why understanding the history of software development can be so beneficial—picking up and re-examining obsolete tools will teach you volumes about the why behind the tools we use today.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][6] on Twitter or subscribe to the [RSS feed][7] to make sure you know when a new post is out.
|
||||
|
||||
#### Correction
|
||||
|
||||
I’ve been told that there are many organizations, particularly risk-adverse organizations that do things like make medical device software, that still use CVS. Programmers in these organizations have developed little tricks for working around CVS’ limitations, such as making a new branch for almost every change to avoid committing directly to `HEAD`. (Thanks to Michael Kohne for pointing this out.)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/07/07/cvs.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf
|
||||
[2]: https://www.nongnu.org/cvs/
|
||||
[3]: http://shop.oreilly.com/product/9780974514000.do
|
||||
[4]: https://www.youtube.com/watch?v=4XpnKHJAok8
|
||||
[5]: https://xkcd.com/1597/
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
@ -1,145 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
How To Remove Or Disable Ubuntu Dock
|
||||
======
|
||||
|
||||

|
||||
|
||||
**If you want to replace the Ubuntu Dock in Ubuntu 18.04 with some other dock (like Plank dock for example) or panel, and you want to remove or disable the Ubuntu Dock, here's what you can do and how.**
|
||||
|
||||
Ubuntu Dock - the bar on the left-hand side of the screen which can be used to pin applications and access installed applications -
|
||||
|
||||
|
||||
### How to access the Activities Overview without Ubuntu Dock
|
||||
|
||||
Without Ubuntu Dock, you may have no way of accessing the Activities / installed application list (which can be accessed from Ubuntu Dock by clicking on Show Applications button at the bottom of the dock). For example if you want to use Plank dock.
|
||||
|
||||
Obviously, that's not the case if you install Dash to Panel extension to use it instead Ubuntu Dock, because Dash to Panel provides a button to access the Activities Overview / installed applications.
|
||||
|
||||
Depending on what you plan to use instead of Ubuntu Dock, if there's no way of accessing the Activities Overview, you can enable the Activities Overview Hot Corner option and simply move your mouse to the upper left corner of the screen to open the Activities. Another way of accessing the installed application list is using a keyboard shortcut: `Super + A` .
|
||||
|
||||
If you want to enable the Activities Overview hot corner, use this command:
|
||||
```
|
||||
gsettings set org.gnome.shell enable-hot-corners true
|
||||
|
||||
```
|
||||
|
||||
If later you want to undo this and disable the hot corners, you need to use this command:
|
||||
```
|
||||
gsettings set org.gnome.shell enable-hot-corners false
|
||||
|
||||
```
|
||||
|
||||
You can also enable or disable the Activities Overview Hot Corner option by using the Gnome Tweaks application (the option is in the `Top Bar` section of Gnome Tweaks), which can be installed by using this command:
|
||||
```
|
||||
sudo apt install gnome-tweaks
|
||||
|
||||
```
|
||||
|
||||
### How to remove or disable Ubuntu Dock
|
||||
|
||||
Below you'll find 4 ways of getting rid of Ubuntu Dock which work in Ubuntu 18.04.
|
||||
|
||||
**Option 1: Remove the Gnome Shell Ubuntu Dock package.**
|
||||
|
||||
The easiest way of getting rid of the Ubuntu Dock is to remove the package.
|
||||
|
||||
This completely removes the Ubuntu Dock extension from your system, but it also removes the `ubuntu-desktop` meta package. There's no immediate issue if you remove the `ubuntu-desktop` meta package because does nothing by itself. The `ubuntu-meta` package depends on a large number of packages which make up the Ubuntu Desktop. Its dependencies won't be removed and nothing will break. The issue is that if you want to upgrade to a newer Ubuntu version, any new `ubuntu-desktop` dependencies won't be installed.
|
||||
|
||||
As a way around this, you can simply install the `ubuntu-desktop` meta package before upgrading to a newer Ubuntu version (for example if you want to upgrade from Ubuntu 18.04 to 18.10).
|
||||
|
||||
If you're ok with this and want to remove the Ubuntu Dock extension package from your system, use the following command:
|
||||
```
|
||||
sudo apt remove gnome-shell-extension-ubuntu-dock
|
||||
|
||||
```
|
||||
|
||||
If later you want to undo the changes, simply install the extension back using this command:
|
||||
```
|
||||
sudo apt install gnome-shell-extension-ubuntu-dock
|
||||
|
||||
```
|
||||
|
||||
Or to install the `ubuntu-desktop` meta package back (this will install any ubuntu-desktop dependencies you may have removed, including Ubuntu Dock), you can use this command:
|
||||
```
|
||||
sudo apt install ubuntu-desktop
|
||||
|
||||
```
|
||||
|
||||
**Option 2: Install and use the vanilla Gnome session instead of the default Ubuntu session.**
|
||||
|
||||
Another way to get rid of Ubuntu Dock is to install and use the vanilla Gnome session. Installing the vanilla Gnome session will also install other packages this session depends on, like Gnome Documents, Maps, Music, Contacts, Photos, Tracker and more.
|
||||
|
||||
By installing the vanilla Gnome session, you'll also get the default Gnome GDM login / lock screen theme instead of the Ubuntu defaults as well as Adwaita Gtk theme and icons. You can easily change the Gtk and icon theme though, by using the Gnome Tweaks application.
|
||||
|
||||
Furthermore, the AppIndicators extension will be disabled by default (so applications that make use of the AppIndicators tray won't show up on the top panel), but you can enable this by using Gnome Tweaks (under Extensions, enable the Ubuntu appindicators extension).
|
||||
|
||||
In the same way, you can also enable or disable Ubuntu Dock from the vanilla Gnome session, which is not possible if you use the Ubuntu session (disabling Ubuntu Dock from Gnome Tweaks when using the Ubuntu session does nothing).
|
||||
|
||||
If you don't want to install these extra packages required by the vanilla Gnome session, this option of removing Ubuntu Dock is not for you so check out the other options.
|
||||
|
||||
If you are ok with this though, here's what you need to do. To install the vanilla Gnome session in Ubuntu, use this command:
|
||||
```
|
||||
sudo apt install vanilla-gnome-desktop
|
||||
|
||||
```
|
||||
|
||||
After the installation finishes, reboot your system and on the login screen, after you click on your username, click the gear icon next to the `Sign in` button, and select `GNOME` instead of `Ubuntu` , then proceed to login:
|
||||
|
||||
|
||||
|
||||
In case you want to undo this and remove the vanilla Gnome session, you can purge the vanilla Gnome package and then remove the dependencies it installed (second command) using the following commands:
|
||||
```
|
||||
sudo apt purge vanilla-gnome-desktop
|
||||
sudo apt autoremove
|
||||
|
||||
```
|
||||
|
||||
Then reboot and select Ubuntu in the same way, from the GDM login screen.
|
||||
|
||||
**Option 3: Permanently hide the Ubuntu Dock from your desktop instead of removing it.**
|
||||
|
||||
If you prefer to permanently hide the Ubuntu Dock from showing up on your desktop instead of uninstalling it or using the vanilla Gnome session, you can easily do this using Dconf Editor. The drawback to this is that Ubuntu Dock will still use some system resources even though you're not using in on your desktop, but you'll also be able to easily revert this without installing or removing any packages.
|
||||
|
||||
Ubuntu Dock is only hidden from your desktop though. When you go in overlay mode (Activities), you'll still see and be able to use Ubuntu Dock from there.
|
||||
|
||||
To permanently hide Ubuntu Dock, use Dconf Editor to navigate to `/org/gnome/shell/extensions/dash-to-dock` and disable (set them to false) the following options: `autohide` , `dock-fixed` and `intellihide` .
|
||||
|
||||
You can achieve this from the command line if you wish, buy running the commands below:
|
||||
```
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock autohide false
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed false
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide false
|
||||
|
||||
```
|
||||
In case you change your mind and you want to undo this, you can either use Dconf Editor and re-enable (set them to true) autohide, dock-fixed and intellihide from `/org/gnome/shell/extensions/dash-to-dock` , or you can use these commands:
|
||||
```
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock autohide true
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed true
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide true
|
||||
|
||||
```
|
||||
|
||||
**Option 4: Use Dash to Panel extension.**
|
||||
|
||||
You can install Dash to Panel from
|
||||
|
||||
If you change your mind and you want Ubuntu Dock back, you can either disable Dash to Panel by using Gnome Tweaks app, or completely remove Dash to Panel by clicking the X button next to it from here:
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/how-to-remove-or-disable-ubuntu-dock.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://bugs.launchpad.net/ubuntu/+source/gnome-tweak-tool/+bug/1713020
|
||||
[2]:https://www.linuxuprising.com/2018/05/gnome-shell-dash-to-panel-v14-brings.html
|
||||
[3]:https://extensions.gnome.org/extension/1160/dash-to-panel/
|
||||
184
sources/tech/20180902 Learning BASIC Like It-s 1983.md
Normal file
184
sources/tech/20180902 Learning BASIC Like It-s 1983.md
Normal file
@ -0,0 +1,184 @@
|
||||
Learning BASIC Like It's 1983
|
||||
======
|
||||
I was not yet alive in 1983. This is something that I occasionally regret. I am especially sorry that I did not experience the 8-bit computer era as it was happening, because I think the people that first encountered computers when they were relatively simple and constrained have a huge advantage over the rest of us.
|
||||
|
||||
Today, (almost) everyone knows how to use a computer, but very few people, even in the computing industry, grasp all of what is going on inside of any single machine. There are now [so many layers of software][1] doing so many different things that one struggles to identify the parts that are essential. In 1983, though, home computers were unsophisticated enough that a diligent person could learn how a particular computer worked through and through. That person is today probably less mystified than I am by all the abstractions that modern operating systems pile on top of the hardware. I expect that these layers of abstractions were easy to understand one by one as they were introduced; today, new programmers have to try to understand them all by working top to bottom and backward in time.
|
||||
|
||||
Many famous programmers, particularly in the video game industry, started programming games in childhood on 8-bit computers like the Apple II and the Commodore 64. John Romero, Richard Garriott, and Chris Roberts are all examples. It’s easy to see how this happened. In the 8-bit computer era, many games were available only as printed BASIC listings in computer magazines and [books][2]. If you wanted to play one of those games, you had to type in the whole program by hand. Inevitably, you would get something wrong, so you would have to debug your program. By the time you got it working, you knew enough about how the program functioned to start modifying it yourself. If you were an avid gamer, you became a good programmer almost by necessity.
|
||||
|
||||
I also played computer games throughout my childhood. But the games I played came on CD-ROMs. I sometimes found myself having to google how to fix a crashing installer, which would involve editing the Windows Registry or something like that. This kind of minor troubleshooting may have made me comfortable enough with computers to consider studying computer science in college. But it never taught me anything crucial about how computers worked or how to control them.
|
||||
|
||||
Now, of course, I tell computers what to do for a living. All the same, I can’t help feeling that I missed out on some fundamental insight afforded only to those that grew up programming simpler computers. What would it have been like to encounter computers for the first time in the early 1980s? How would that have been different from the experience of using a computer today?
|
||||
|
||||
This post is going to be a little different from the usual Two-Bit History post because I’m going to try to imagine an answer to these questions.
|
||||
|
||||
### 1983
|
||||
|
||||
It was just last week that you saw [the Commodore 64 ad][3] on TV. Now that M*A*S*H was over, you were in the market for something new to do on Monday nights. This Commodore 64 thing looked even better than the Apple II that Rudy’s family had in their basement. Plus, the ad promised that the new computer would soon bring friends “knocking down” your door. You knew several people at school that would rather be hanging out at your house than Rudy’s anyway, if only they could play Zork there.
|
||||
|
||||
So you persuaded your parents to buy one. Your mother said that they would consider it only if having a home computer meant that you stayed away from the arcade. You reluctantly agreed. Your father thought he would start tracking the family’s finances in MultiPlan, the spreadsheet program he had heard about, which is why the computer got put in the living room. A year later, though, you would be the only one still using it. You were finally allowed to put it on the desk in your bedroom, right under your Police poster.
|
||||
|
||||
(Your sister protested this decision, but it was 1983 and computers [weren’t for her][4].)
|
||||
|
||||
Dad picked it up from [ComputerLand][5] on the way home from work. The two of you laid the box down next to the TV and opened it. “WELCOME TO THE WORLD OF FRIENDLY COMPUTING,” said the packaging. Twenty minutes later, you weren’t convinced—the two of you were still trying to connect the Commodore to the TV set and wondering whether the TV’s antenna cable was the 75-ohm or 300-ohm coax type. But eventually you were able to turn your TV to channel 3 and see a grainy, purple image.
|
||||
|
||||
![Commodore 64 startup screen][6]
|
||||
|
||||
`READY`, the computer reported. Your father pushed the computer toward you, indicating that you should be the first to give it a try. `HELLO`, you typed, carefully hunting for each letter. The computer’s response was baffling.
|
||||
|
||||
![Commodore 64 syntax error][7]
|
||||
|
||||
You tried typing in a few different words, but the response was always the same. Your father said that you had better read through the rest of the manual. That would be no mean feat—[the manual that came with the Commodore 64][8] was a small book. But that didn’t bother you, because the introduction to the manual foreshadowed wonders.
|
||||
|
||||
The Commodore 64, it claimed, had “the most advanced picture maker in the microcomputer industry,” which would allow you “to design your own pictures in four different colors, just like the ones you see on arcade type video games.” The Commodore 64 also had “built-in music and sound effects that rival many well known music synthesizers.” All of these tools would be put in your hands, because the manual would walk you through it all:
|
||||
|
||||
> Just as important as all the available hardware is the fact that this USER’S GUIDE will help you develop your understanding of computers. It won’t tell you everything there is to know about computers, but it will refer you to a wide variety of publications for more detailed information about the topics presented. Commodore wants you to really enjoy your new COMMODORE 64. And to have fun, remember: programming is not the kind of thing you can learn in a day. Be patient with yourself as you go through the USER’S GUIDE.
|
||||
|
||||
That night, in bed, you read through the entire first three chapters—”Setup,” “Getting Started,” and “Beginning BASIC Programming”—before finally succumbing to sleep with the manual splayed across your chest.
|
||||
|
||||
### Commodore BASIC
|
||||
|
||||
Now, it’s Saturday morning and you’re eager to try out what you’ve learned. One of the first things the manual teaches you how to do is change the colors on the display. You follow the instructions, pressing `CTRL-9` to enter reverse type mode and then holding down the space bar to create long lines. You swap between colors using `CTRL-1` through `CTRL-8`, reveling in your sudden new power over the TV screen.
|
||||
|
||||
![Commodore 64 color bands][9]
|
||||
|
||||
As cool as this is, you realize it doesn’t count as programming. In order to program the computer, you learned last night, you have to speak to it in a language called BASIC. To you, BASIC seems like something out of Star Wars, but BASIC is, by 1983, almost two decades old. It was invented by two Dartmouth professors, John Kemeny and Tom Kurtz, who wanted to make computing accessible to undergraduates in the social sciences and humanities. It was widely available on minicomputers and popular in college math classes. It then became standard on microcomputers after Bill Gates and Paul Allen wrote the MicroSoft BASIC interpreter for the Altair. But the manual doesn’t explain any of this and you won’t learn it for many years.
|
||||
|
||||
One of the first BASIC commands the manual suggests you try is the `PRINT` command. You type in `PRINT "COMMODORE 64"`, slowly, since it takes you a while to find the quotation mark symbol above the `2` key. You hit `RETURN` and this time, instead of complaining, the computer does exactly what you told it to do and displays “COMMODORE 64” on the next line.
|
||||
|
||||
Now you try using the `PRINT` command on all sorts of different things: two numbers added together, two numbers multiplied together, even several decimal numbers. You stop typing out `PRINT` and instead use `?`, since the manual has advised you that `?` is an abbreviation for `PRINT` often used by expert programmers. You feel like an expert already, but then you remember that you haven’t even made it to chapter three, “Beginning BASIC Programming.”
|
||||
|
||||
You get there soon enough. The chapter begins by prompting you to write your first real BASIC program. You type in `NEW` and hit `RETURN`, which gives you a clean slate. You then type your program in:
|
||||
|
||||
```
|
||||
10 ?"COMMODORE 64"
|
||||
20 GOTO 10
|
||||
```
|
||||
|
||||
The 10 and the 20, the manual explains, are line numbers. They order the statements for the computer. They also allow the programmer to refer to other lines of the program in certain commands, just like you’ve done here with the `GOTO` command, which directs the program back to line 10. “It is good programming practice,” the manual opines, “to number lines in increments of 10—in case you need to insert some statements later on.”
|
||||
|
||||
You type `RUN` and stare as the screen clogs with “COMMODORE 64,” repeated over and over.
|
||||
|
||||
![Commodore 64 showing result of printing "Commodore 64" repeatedly][10]
|
||||
|
||||
You’re not certain that this isn’t going to blow up your computer. It takes you a second to remember that you are supposed to hit the `RUN/STOP` key to break the loop.
|
||||
|
||||
The next few sections of the manual teach you about variables, which the manual tells you are like “a number of boxes within the computer that can each hold a number or a string of text characters.” Variables that end in a `%` symbol are whole numbers, while variables ending in a `$` symbol are strings of characters. All other variables are something called “floating point” variables. The manual warns you to be careful with variable names because only the first two letters of the name are actually recognized by the computer, even though nothing stops you from making a name as long as you want it to be. (This doesn’t particularly bother you, but you could see how 30 years from now this might strike someone as completely insane.)
|
||||
|
||||
You then learn about the `IF... THEN...` and `FOR... NEXT...` constructs. With all these new tools, you feel equipped to tackle the next big challenge the manual throws at you. “If you’re the ambitious type,” it goads, “type in the following program and see what happens.” The program is longer and more complicated than any you have seen so far, but you’re dying to know what it does:
|
||||
|
||||
```
|
||||
10 REM BOUNCING BALL
|
||||
20 PRINT "{CLR/HOME}"
|
||||
25 FOR X = 1 TO 10 : PRINT "{CRSR/DOWN}" : NEXT
|
||||
30 FOR BL = 1 TO 40
|
||||
40 PRINT " ●{CRSR LEFT}";:REM (● is a Shift-Q)
|
||||
50 FOR TM = 1 TO 5
|
||||
60 NEXT TM
|
||||
70 NEXT BL
|
||||
75 REM MOVE BALL RIGHT TO LEFT
|
||||
80 FOR BL = 40 TO 1 STEP -1
|
||||
90 PRINT " {CRSR LEFT}{CRSR LEFT}●{CRSR LEFT}";
|
||||
100 FOR TM = 1 TO 5
|
||||
110 NEXT TM
|
||||
120 NEXT BL
|
||||
130 GOTO 20
|
||||
```
|
||||
|
||||
The program above takes advantage of one of the Commodore 64’s coolest features. Non-printable command characters, when passed to the `PRINT` command as part of a string, just do the action they usually perform instead of printing to the screen. This allows you to replay arbitrary chains of commands by printing strings from within your programs.
|
||||
|
||||
It takes you a long time to type in the above program. You make several mistakes and have to re-enter some of the lines. But eventually you are able to type `RUN` and behold a masterpiece:
|
||||
|
||||
![Commodore 64 bouncing ball][11]
|
||||
|
||||
You think that this is a major contender for the coolest thing you have ever seen. You forget about it almost immediately though, because once you’ve learned about BASIC’s built-in functions like `RND` (which returns a random number) and `CHR$` (which returns the character matching a given number code), the manual shows you a program that many years from now will still be famous enough to be made the title of an [essay anthology][12]:
|
||||
|
||||
```
|
||||
10 PRINT "{CLR/HOME}"
|
||||
20 PRINT CHR$(205.5 + RND(1));
|
||||
40 GOTO 20
|
||||
```
|
||||
|
||||
When run, the above program produces a random maze:
|
||||
|
||||
![Commodore 64 maze program][13]
|
||||
|
||||
This is definitely the coolest thing you have ever seen.
|
||||
|
||||
### PEEK and POKE
|
||||
|
||||
You’ve now made it through the first four chapters of the Commodore 64 manual, including the chapter titled “Advanced BASIC,” so you’re feeling pretty proud of yourself. You’ve learned a lot this Saturday morning. But this afternoon (after a quick lunch break), you’re going to learn something that will make this magical machine in your living room much less mysterious.
|
||||
|
||||
The next chapter in the manual is titled “Advanced Color and Graphic Commands.” It starts off by revisiting the colored bars that you were able to type out first thing this morning and shows you how you can do the same thing from a program. It then teaches you how to change the background colors of the screen.
|
||||
|
||||
In order to do this, you need to use the BASIC `PEEK` and `POKE` commands. Those commands allow you to, respectively, examine and write to a memory address. The Commodore 64 has a main background color and a border color. Each is controlled by a specially designated memory address. You can write any color value you would like to those addresses to make the background or border that color.
|
||||
|
||||
The manual explains:
|
||||
|
||||
> Just as variables can be thought of as a representation of “boxes” within the machine where you placed your information, you can also think of some specially defined “boxes” within the computer that represent specific memory locations.
|
||||
>
|
||||
> The Commodore 64 looks at these memory locations to see what the screen’s background and border color should be, what characters are to be displayed on the screen—and where—and a host of other tasks.
|
||||
|
||||
You write a program to cycle through all the available combinations of background and border color:
|
||||
|
||||
```
|
||||
10 FOR BA = 0 TO 15
|
||||
20 FOR BO = 0 TO 15
|
||||
30 POKE 53280, BA
|
||||
40 POKE 53281, BO
|
||||
50 FOR X = 1 TO 500 : NEXT X
|
||||
60 NEXT BO : NEXT BA
|
||||
```
|
||||
|
||||
While the `POKE` commands, with their big operands, looked intimidating at first, now you see that the actual value of the number doesn’t matter that much. Obviously, you have to get the number right, but all the number represents is a “box” that Commodore just happened to store at address 53280. This box has a special purpose: Commodore uses it to determine what color the screen’s background should be.
|
||||
|
||||
![Commodore 64 changing background colors][14]
|
||||
|
||||
You think this is pretty neat. Just by writing to a special-purpose box in memory, you can control a fundamental property of the computer. You aren’t sure how the Commodore 64’s circuitry takes the value you write in memory and changes the color of the screen, but you’re okay not knowing that. At least you understand everything up to that point.
|
||||
|
||||
### Special Boxes
|
||||
|
||||
You don’t get through the entire manual that Saturday, since you are now starting to run out of steam. But you do eventually read all of it. In the process, you learn about many more of the Commodore 64’s special-purpose boxes. There are boxes you can write to control what is on screen—one box, in fact, for every place a character might appear. In chapter six, “Sprite Graphics,” you learn about the special-purpose boxes that allow you to define images that can be moved around and even scaled up and down. In chapter seven, “Creating Sound,” you learn about the boxes you can write to in order to make your Commodore 64 sing “Michael Row the Boat Ashore.” The Commodore 64, it turns out, has very little in the way of what you would later learn is called an API. Controlling the Commodore 64 mostly involves writing to memory addresses that have been given special meaning by the circuitry.
|
||||
|
||||
The many years you ultimately spend writing to those special boxes stick with you. Even many decades later, when you find yourself programming a machine with an extensive graphics or sound API, you know that, behind the curtain, the API is ultimately writing to those boxes or something like them. You will sometimes wonder about younger programmers that have only ever used APIs, and wonder what they must think the API is doing for them. Maybe they think that the API is calling some other, hidden API. But then what do think that hidden API is calling? You will pity those younger programmers, because they must be very confused indeed.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][15] on Twitter or subscribe to the [RSS feed][16] to make sure you know when a new post is out.
|
||||
|
||||
Previously on TwoBitHistory…
|
||||
|
||||
> Have you ever wondered what a 19th-century computer program would look like translated into C?
|
||||
>
|
||||
> This week's post: A detailed look at how Ada Lovelace's famous program worked and what it was trying to do.<https://t.co/BizR2Zu7nt>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [August 19, 2018][17]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/09/02/learning-basic.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/watch?v=kZRE7HIO3vk
|
||||
[2]: https://en.wikipedia.org/wiki/BASIC_Computer_Games
|
||||
[3]: https://www.youtube.com/watch?v=ZekAbt2o6Ms
|
||||
[4]: https://www.npr.org/sections/money/2014/10/21/357629765/when-women-stopped-coding
|
||||
[5]: https://www.youtube.com/watch?v=MA_XtT3VAVM
|
||||
[6]: https://twobithistory.org/images/c64_startup.png
|
||||
[7]: https://twobithistory.org/images/c64_error.png
|
||||
[8]: ftp://www.zimmers.net/pub/cbm/c64/manuals/C64_Users_Guide.pdf
|
||||
[9]: https://twobithistory.org/images/c64_colors.png
|
||||
[10]: https://twobithistory.org/images/c64_print_loop.png
|
||||
[11]: https://twobithistory.org/images/c64_ball.gif
|
||||
[12]: http://10print.org/
|
||||
[13]: https://twobithistory.org/images/c64_maze.gif
|
||||
[14]: https://twobithistory.org/images/c64_background.gif
|
||||
[15]: https://twitter.com/TwoBitHistory
|
||||
[16]: https://twobithistory.org/feed.xml
|
||||
[17]: https://twitter.com/TwoBitHistory/status/1030974776821665793?ref_src=twsrc%5Etfw
|
||||
@ -1,525 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Lab 3: User Environments
|
||||
======
|
||||
### Lab 3: User Environments
|
||||
|
||||
#### Introduction
|
||||
|
||||
In this lab you will implement the basic kernel facilities required to get a protected user-mode environment (i.e., "process") running. You will enhance the JOS kernel to set up the data structures to keep track of user environments, create a single user environment, load a program image into it, and start it running. You will also make the JOS kernel capable of handling any system calls the user environment makes and handling any other exceptions it causes.
|
||||
|
||||
**Note:** In this lab, the terms _environment_ and _process_ are interchangeable - both refer to an abstraction that allows you to run a program. We introduce the term "environment" instead of the traditional term "process" in order to stress the point that JOS environments and UNIX processes provide different interfaces, and do not provide the same semantics.
|
||||
|
||||
##### Getting Started
|
||||
|
||||
Use Git to commit your changes after your Lab 2 submission (if any), fetch the latest version of the course repository, and then create a local branch called `lab3` based on our lab3 branch, `origin/lab3`:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
Lab 3 contains a number of new source files, which you should browse:
|
||||
|
||||
```
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
```
|
||||
|
||||
In addition, a number of the source files we handed out for lab2 are modified in lab3. To see the differences, you can type:
|
||||
|
||||
```
|
||||
$ git diff lab2
|
||||
|
||||
```
|
||||
|
||||
You may also want to take another look at the [lab tools guide][1], as it includes information on debugging user code that becomes relevant in this lab.
|
||||
|
||||
##### Lab Requirements
|
||||
|
||||
This lab is divided into two parts, A and B. Part A is due a week after this lab was assigned; you should commit your changes and make handin your lab before the Part A deadline, making sure your code passes all of the Part A tests (it is okay if your code does not pass the Part B tests yet). You only need to have the Part B tests passing by the Part B deadline at the end of the second week.
|
||||
|
||||
As in lab 2, you will need to do all of the regular exercises described in the lab and _at least one_ challenge problem (for the entire lab, not for each part). Write up brief answers to the questions posed in the lab and a one or two paragraph description of what you did to solve your chosen challenge problem in a file called `answers-lab3.txt` in the top level of your `lab` directory. (If you implement more than one challenge problem, you only need to describe one of them in the write-up.) Do not forget to include the answer file in your submission with git add answers-lab3.txt.
|
||||
|
||||
##### Inline Assembly
|
||||
|
||||
In this lab you may find GCC's inline assembly language feature useful, although it is also possible to complete the lab without using it. At the very least, you will need to be able to understand the fragments of inline assembly language ("`asm`" statements) that already exist in the source code we gave you. You can find several sources of information on GCC inline assembly language on the class [reference materials][2] page.
|
||||
|
||||
#### Part A: User Environments and Exception Handling
|
||||
|
||||
The new include file `inc/env.h` contains basic definitions for user environments in JOS. Read it now. The kernel uses the `Env` data structure to keep track of each user environment. In this lab you will initially create just one environment, but you will need to design the JOS kernel to support multiple environments; lab 4 will take advantage of this feature by allowing a user environment to `fork` other environments.
|
||||
|
||||
As you can see in `kern/env.c`, the kernel maintains three main global variables pertaining to environments:
|
||||
|
||||
```
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
|
||||
```
|
||||
|
||||
Once JOS gets up and running, the `envs` pointer points to an array of `Env` structures representing all the environments in the system. In our design, the JOS kernel will support a maximum of `NENV` simultaneously active environments, although there will typically be far fewer running environments at any given time. (`NENV` is a constant `#define`'d in `inc/env.h`.) Once it is allocated, the `envs` array will contain a single instance of the `Env` data structure for each of the `NENV` possible environments.
|
||||
|
||||
The JOS kernel keeps all of the inactive `Env` structures on the `env_free_list`. This design allows easy allocation and deallocation of environments, as they merely have to be added to or removed from the free list.
|
||||
|
||||
The kernel uses the `curenv` symbol to keep track of the _currently executing_ environment at any given time. During boot up, before the first environment is run, `curenv` is initially set to `NULL`.
|
||||
|
||||
##### Environment State
|
||||
|
||||
The `Env` structure is defined in `inc/env.h` as follows (although more fields will be added in future labs):
|
||||
|
||||
```
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
```
|
||||
|
||||
Here's what the `Env` fields are for:
|
||||
|
||||
* **env_tf** :
|
||||
This structure, defined in `inc/trap.h`, holds the saved register values for the environment while that environment is _not_ running: i.e., when the kernel or a different environment is running. The kernel saves these when switching from user to kernel mode, so that the environment can later be resumed where it left off.
|
||||
* **env_link** :
|
||||
This is a link to the next `Env` on the `env_free_list`. `env_free_list` points to the first free environment on the list.
|
||||
* **env_id** :
|
||||
The kernel stores here a value that uniquely identifiers the environment currently using this `Env` structure (i.e., using this particular slot in the `envs` array). After a user environment terminates, the kernel may re-allocate the same `Env` structure to a different environment - but the new environment will have a different `env_id` from the old one even though the new environment is re-using the same slot in the `envs` array.
|
||||
* **env_parent_id** :
|
||||
The kernel stores here the `env_id` of the environment that created this environment. In this way the environments can form a “family tree,” which will be useful for making security decisions about which environments are allowed to do what to whom.
|
||||
* **env_type** :
|
||||
This is used to distinguish special environments. For most environments, it will be `ENV_TYPE_USER`. We'll introduce a few more types for special system service environments in later labs.
|
||||
* **env_status** :
|
||||
This variable holds one of the following values:
|
||||
* `ENV_FREE`:
|
||||
Indicates that the `Env` structure is inactive, and therefore on the `env_free_list`.
|
||||
* `ENV_RUNNABLE`:
|
||||
Indicates that the `Env` structure represents an environment that is waiting to run on the processor.
|
||||
* `ENV_RUNNING`:
|
||||
Indicates that the `Env` structure represents the currently running environment.
|
||||
* `ENV_NOT_RUNNABLE`:
|
||||
Indicates that the `Env` structure represents a currently active environment, but it is not currently ready to run: for example, because it is waiting for an interprocess communication (IPC) from another environment.
|
||||
* `ENV_DYING`:
|
||||
Indicates that the `Env` structure represents a zombie environment. A zombie environment will be freed the next time it traps to the kernel. We will not use this flag until Lab 4.
|
||||
* **env_pgdir** :
|
||||
This variable holds the kernel _virtual address_ of this environment's page directory.
|
||||
|
||||
|
||||
|
||||
Like a Unix process, a JOS environment couples the concepts of "thread" and "address space". The thread is defined primarily by the saved registers (the `env_tf` field), and the address space is defined by the page directory and page tables pointed to by `env_pgdir`. To run an environment, the kernel must set up the CPU with _both_ the saved registers and the appropriate address space.
|
||||
|
||||
Our `struct Env` is analogous to `struct proc` in xv6. Both structures hold the environment's (i.e., process's) user-mode register state in a `Trapframe` structure. In JOS, individual environments do not have their own kernel stacks as processes do in xv6. There can be only one JOS environment active in the kernel at a time, so JOS needs only a _single_ kernel stack.
|
||||
|
||||
##### Allocating the Environments Array
|
||||
|
||||
In lab 2, you allocated memory in `mem_init()` for the `pages[]` array, which is a table the kernel uses to keep track of which pages are free and which are not. You will now need to modify `mem_init()` further to allocate a similar array of `Env` structures, called `envs`.
|
||||
|
||||
```
|
||||
Exercise 1. Modify `mem_init()` in `kern/pmap.c` to allocate and map the `envs` array. This array consists of exactly `NENV` instances of the `Env` structure allocated much like how you allocated the `pages` array. Also like the `pages` array, the memory backing `envs` should also be mapped user read-only at `UENVS` (defined in `inc/memlayout.h`) so user processes can read from this array.
|
||||
```
|
||||
|
||||
You should run your code and make sure `check_kern_pgdir()` succeeds.
|
||||
|
||||
##### Creating and Running Environments
|
||||
|
||||
You will now write the code in `kern/env.c` necessary to run a user environment. Because we do not yet have a filesystem, we will set up the kernel to load a static binary image that is _embedded within the kernel itself_. JOS embeds this binary in the kernel as a ELF executable image.
|
||||
|
||||
The Lab 3 `GNUmakefile` generates a number of binary images in the `obj/user/` directory. If you look at `kern/Makefrag`, you will notice some magic that "links" these binaries directly into the kernel executable as if they were `.o` files. The `-b binary` option on the linker command line causes these files to be linked in as "raw" uninterpreted binary files rather than as regular `.o` files produced by the compiler. (As far as the linker is concerned, these files do not have to be ELF images at all - they could be anything, such as text files or pictures!) If you look at `obj/kern/kernel.sym` after building the kernel, you will notice that the linker has "magically" produced a number of funny symbols with obscure names like `_binary_obj_user_hello_start`, `_binary_obj_user_hello_end`, and `_binary_obj_user_hello_size`. The linker generates these symbol names by mangling the file names of the binary files; the symbols provide the regular kernel code with a way to reference the embedded binary files.
|
||||
|
||||
In `i386_init()` in `kern/init.c` you'll see code to run one of these binary images in an environment. However, the critical functions to set up user environments are not complete; you will need to fill them in.
|
||||
|
||||
```
|
||||
Exercise 2. In the file `env.c`, finish coding the following functions:
|
||||
|
||||
* `env_init()`
|
||||
Initialize all of the `Env` structures in the `envs` array and add them to the `env_free_list`. Also calls `env_init_percpu`, which configures the segmentation hardware with separate segments for privilege level 0 (kernel) and privilege level 3 (user).
|
||||
* `env_setup_vm()`
|
||||
Allocate a page directory for a new environment and initialize the kernel portion of the new environment's address space.
|
||||
* `region_alloc()`
|
||||
Allocates and maps physical memory for an environment
|
||||
* `load_icode()`
|
||||
You will need to parse an ELF binary image, much like the boot loader already does, and load its contents into the user address space of a new environment.
|
||||
* `env_create()`
|
||||
Allocate an environment with `env_alloc` and call `load_icode` to load an ELF binary into it.
|
||||
* `env_run()`
|
||||
Start a given environment running in user mode.
|
||||
|
||||
|
||||
|
||||
As you write these functions, you might find the new cprintf verb `%e` useful -- it prints a description corresponding to an error code. For example,
|
||||
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
|
||||
will panic with the message "env_alloc: out of memory".
|
||||
```
|
||||
|
||||
Below is a call graph of the code up to the point where the user code is invoked. Make sure you understand the purpose of each step.
|
||||
|
||||
* `start` (`kern/entry.S`)
|
||||
* `i386_init` (`kern/init.c`)
|
||||
* `cons_init`
|
||||
* `mem_init`
|
||||
* `env_init`
|
||||
* `trap_init` (still incomplete at this point)
|
||||
* `env_create`
|
||||
* `env_run`
|
||||
* `env_pop_tf`
|
||||
|
||||
|
||||
|
||||
Once you are done you should compile your kernel and run it under QEMU. If all goes well, your system should enter user space and execute the `hello` binary until it makes a system call with the `int` instruction. At that point there will be trouble, since JOS has not set up the hardware to allow any kind of transition from user space into the kernel. When the CPU discovers that it is not set up to handle this system call interrupt, it will generate a general protection exception, find that it can't handle that, generate a double fault exception, find that it can't handle that either, and finally give up with what's known as a "triple fault". Usually, you would then see the CPU reset and the system reboot. While this is important for legacy applications (see [this blog post][3] for an explanation of why), it's a pain for kernel development, so with the 6.828 patched QEMU you'll instead see a register dump and a "Triple fault." message.
|
||||
|
||||
We'll address this problem shortly, but for now we can use the debugger to check that we're entering user mode. Use make qemu-gdb and set a GDB breakpoint at `env_pop_tf`, which should be the last function you hit before actually entering user mode. Single step through this function using si; the processor should enter user mode after the `iret` instruction. You should then see the first instruction in the user environment's executable, which is the `cmpl` instruction at the label `start` in `lib/entry.S`. Now use b *0x... to set a breakpoint at the `int $0x30` in `sys_cputs()` in `hello` (see `obj/user/hello.asm` for the user-space address). This `int` is the system call to display a character to the console. If you cannot execute as far as the `int`, then something is wrong with your address space setup or program loading code; go back and fix it before continuing.
|
||||
|
||||
##### Handling Interrupts and Exceptions
|
||||
|
||||
At this point, the first `int $0x30` system call instruction in user space is a dead end: once the processor gets into user mode, there is no way to get back out. You will now need to implement basic exception and system call handling, so that it is possible for the kernel to recover control of the processor from user-mode code. The first thing you should do is thoroughly familiarize yourself with the x86 interrupt and exception mechanism.
|
||||
|
||||
```
|
||||
Exercise 3. Read Chapter 9, Exceptions and Interrupts in the 80386 Programmer's Manual (or Chapter 5 of the IA-32 Developer's Manual), if you haven't already.
|
||||
```
|
||||
|
||||
In this lab we generally follow Intel's terminology for interrupts, exceptions, and the like. However, terms such as exception, trap, interrupt, fault and abort have no standard meaning across architectures or operating systems, and are often used without regard to the subtle distinctions between them on a particular architecture such as the x86. When you see these terms outside of this lab, the meanings might be slightly different.
|
||||
|
||||
##### Basics of Protected Control Transfer
|
||||
|
||||
Exceptions and interrupts are both "protected control transfers," which cause the processor to switch from user to kernel mode (CPL=0) without giving the user-mode code any opportunity to interfere with the functioning of the kernel or other environments. In Intel's terminology, an _interrupt_ is a protected control transfer that is caused by an asynchronous event usually external to the processor, such as notification of external device I/O activity. An _exception_ , in contrast, is a protected control transfer caused synchronously by the currently running code, for example due to a divide by zero or an invalid memory access.
|
||||
|
||||
In order to ensure that these protected control transfers are actually _protected_ , the processor's interrupt/exception mechanism is designed so that the code currently running when the interrupt or exception occurs _does not get to choose arbitrarily where the kernel is entered or how_. Instead, the processor ensures that the kernel can be entered only under carefully controlled conditions. On the x86, two mechanisms work together to provide this protection:
|
||||
|
||||
1. **The Interrupt Descriptor Table.** The processor ensures that interrupts and exceptions can only cause the kernel to be entered at a few specific, well-defined entry-points _determined by the kernel itself_ , and not by the code running when the interrupt or exception is taken.
|
||||
|
||||
The x86 allows up to 256 different interrupt or exception entry points into the kernel, each with a different _interrupt vector_. A vector is a number between 0 and 255. An interrupt's vector is determined by the source of the interrupt: different devices, error conditions, and application requests to the kernel generate interrupts with different vectors. The CPU uses the vector as an index into the processor's _interrupt descriptor table_ (IDT), which the kernel sets up in kernel-private memory, much like the GDT. From the appropriate entry in this table the processor loads:
|
||||
|
||||
* the value to load into the instruction pointer (`EIP`) register, pointing to the kernel code designated to handle that type of exception.
|
||||
* the value to load into the code segment (`CS`) register, which includes in bits 0-1 the privilege level at which the exception handler is to run. (In JOS, all exceptions are handled in kernel mode, privilege level 0.)
|
||||
2. **The Task State Segment.** The processor needs a place to save the _old_ processor state before the interrupt or exception occurred, such as the original values of `EIP` and `CS` before the processor invoked the exception handler, so that the exception handler can later restore that old state and resume the interrupted code from where it left off. But this save area for the old processor state must in turn be protected from unprivileged user-mode code; otherwise buggy or malicious user code could compromise the kernel.
|
||||
|
||||
For this reason, when an x86 processor takes an interrupt or trap that causes a privilege level change from user to kernel mode, it also switches to a stack in the kernel's memory. A structure called the _task state segment_ (TSS) specifies the segment selector and address where this stack lives. The processor pushes (on this new stack) `SS`, `ESP`, `EFLAGS`, `CS`, `EIP`, and an optional error code. Then it loads the `CS` and `EIP` from the interrupt descriptor, and sets the `ESP` and `SS` to refer to the new stack.
|
||||
|
||||
Although the TSS is large and can potentially serve a variety of purposes, JOS only uses it to define the kernel stack that the processor should switch to when it transfers from user to kernel mode. Since "kernel mode" in JOS is privilege level 0 on the x86, the processor uses the `ESP0` and `SS0` fields of the TSS to define the kernel stack when entering kernel mode. JOS doesn't use any other TSS fields.
|
||||
|
||||
|
||||
|
||||
|
||||
##### Types of Exceptions and Interrupts
|
||||
|
||||
All of the synchronous exceptions that the x86 processor can generate internally use interrupt vectors between 0 and 31, and therefore map to IDT entries 0-31. For example, a page fault always causes an exception through vector 14. Interrupt vectors greater than 31 are only used by _software interrupts_ , which can be generated by the `int` instruction, or asynchronous _hardware interrupts_ , caused by external devices when they need attention.
|
||||
|
||||
In this section we will extend JOS to handle the internally generated x86 exceptions in vectors 0-31. In the next section we will make JOS handle software interrupt vector 48 (0x30), which JOS (fairly arbitrarily) uses as its system call interrupt vector. In Lab 4 we will extend JOS to handle externally generated hardware interrupts such as the clock interrupt.
|
||||
|
||||
##### An Example
|
||||
|
||||
Let's put these pieces together and trace through an example. Let's say the processor is executing code in a user environment and encounters a divide instruction that attempts to divide by zero.
|
||||
|
||||
1. The processor switches to the stack defined by the `SS0` and `ESP0` fields of the TSS, which in JOS will hold the values `GD_KD` and `KSTACKTOP`, respectively.
|
||||
|
||||
2. The processor pushes the exception parameters on the kernel stack, starting at address `KSTACKTOP`:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
|
||||
```
|
||||
|
||||
3. Because we're handling a divide error, which is interrupt vector 0 on the x86, the processor reads IDT entry 0 and sets `CS:EIP` to point to the handler function described by the entry.
|
||||
|
||||
4. The handler function takes control and handles the exception, for example by terminating the user environment.
|
||||
|
||||
|
||||
|
||||
|
||||
For certain types of x86 exceptions, in addition to the "standard" five words above, the processor pushes onto the stack another word containing an _error code_. The page fault exception, number 14, is an important example. See the 80386 manual to determine for which exception numbers the processor pushes an error code, and what the error code means in that case. When the processor pushes an error code, the stack would look as follows at the beginning of the exception handler when coming in from user mode:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
##### Nested Exceptions and Interrupts
|
||||
|
||||
The processor can take exceptions and interrupts both from kernel and user mode. It is only when entering the kernel from user mode, however, that the x86 processor automatically switches stacks before pushing its old register state onto the stack and invoking the appropriate exception handler through the IDT. If the processor is _already_ in kernel mode when the interrupt or exception occurs (the low 2 bits of the `CS` register are already zero), then the CPU just pushes more values on the same kernel stack. In this way, the kernel can gracefully handle _nested exceptions_ caused by code within the kernel itself. This capability is an important tool in implementing protection, as we will see later in the section on system calls.
|
||||
|
||||
If the processor is already in kernel mode and takes a nested exception, since it does not need to switch stacks, it does not save the old `SS` or `ESP` registers. For exception types that do not push an error code, the kernel stack therefore looks like the following on entry to the exception handler:
|
||||
|
||||
```
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
For exception types that push an error code, the processor pushes the error code immediately after the old `EIP`, as before.
|
||||
|
||||
There is one important caveat to the processor's nested exception capability. If the processor takes an exception while already in kernel mode, and _cannot push its old state onto the kernel stack_ for any reason such as lack of stack space, then there is nothing the processor can do to recover, so it simply resets itself. Needless to say, the kernel should be designed so that this can't happen.
|
||||
|
||||
##### Setting Up the IDT
|
||||
|
||||
You should now have the basic information you need in order to set up the IDT and handle exceptions in JOS. For now, you will set up the IDT to handle interrupt vectors 0-31 (the processor exceptions). We'll handle system call interrupts later in this lab and add interrupts 32-47 (the device IRQs) in a later lab.
|
||||
|
||||
The header files `inc/trap.h` and `kern/trap.h` contain important definitions related to interrupts and exceptions that you will need to become familiar with. The file `kern/trap.h` contains definitions that are strictly private to the kernel, while `inc/trap.h` contains definitions that may also be useful to user-level programs and libraries.
|
||||
|
||||
Note: Some of the exceptions in the range 0-31 are defined by Intel to be reserved. Since they will never be generated by the processor, it doesn't really matter how you handle them. Do whatever you think is cleanest.
|
||||
|
||||
The overall flow of control that you should achieve is depicted below:
|
||||
|
||||
```
|
||||
IDT trapentry.S trap.c
|
||||
|
||||
+----------------+
|
||||
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
+----------------+
|
||||
| &handler2 |--------> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
.
|
||||
.
|
||||
.
|
||||
+----------------+
|
||||
| &handlerX |--------> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
```
|
||||
|
||||
Each exception or interrupt should have its own handler in `trapentry.S` and `trap_init()` should initialize the IDT with the addresses of these handlers. Each of the handlers should build a `struct Trapframe` (see `inc/trap.h`) on the stack and call `trap()` (in `trap.c`) with a pointer to the Trapframe. `trap()` then handles the exception/interrupt or dispatches to a specific handler function.
|
||||
|
||||
```
|
||||
Exercise 4. Edit `trapentry.S` and `trap.c` and implement the features described above. The macros `TRAPHANDLER` and `TRAPHANDLER_NOEC` in `trapentry.S` should help you, as well as the T_* defines in `inc/trap.h`. You will need to add an entry point in `trapentry.S` (using those macros) for each trap defined in `inc/trap.h`, and you'll have to provide `_alltraps` which the `TRAPHANDLER` macros refer to. You will also need to modify `trap_init()` to initialize the `idt` to point to each of these entry points defined in `trapentry.S`; the `SETGATE` macro will be helpful here.
|
||||
|
||||
Your `_alltraps` should:
|
||||
|
||||
1. push values to make the stack look like a struct Trapframe
|
||||
2. load `GD_KD` into `%ds` and `%es`
|
||||
3. `pushl %esp` to pass a pointer to the Trapframe as an argument to trap()
|
||||
4. `call trap` (can `trap` ever return?)
|
||||
|
||||
|
||||
|
||||
Consider using the `pushal` instruction; it fits nicely with the layout of the `struct Trapframe`.
|
||||
|
||||
Test your trap handling code using some of the test programs in the `user` directory that cause exceptions before making any system calls, such as `user/divzero`. You should be able to get make grade to succeed on the `divzero`, `softint`, and `badsegment` tests at this point.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! You probably have a lot of very similar code right now, between the lists of `TRAPHANDLER` in `trapentry.S` and their installations in `trap.c`. Clean this up. Change the macros in `trapentry.S` to automatically generate a table for `trap.c` to use. Note that you can switch between laying down code and data in the assembler by using the directives `.text` and `.data`.
|
||||
```
|
||||
|
||||
```
|
||||
Questions
|
||||
|
||||
Answer the following questions in your `answers-lab3.txt`:
|
||||
|
||||
1. What is the purpose of having an individual handler function for each exception/interrupt? (i.e., if all exceptions/interrupts were delivered to the same handler, what feature that exists in the current implementation could not be provided?)
|
||||
2. Did you have to do anything to make the `user/softint` program behave correctly? The grade script expects it to produce a general protection fault (trap 13), but `softint`'s code says `int $14`. _Why_ should this produce interrupt vector 13? What happens if the kernel actually allows `softint`'s `int $14` instruction to invoke the kernel's page fault handler (which is interrupt vector 14)?
|
||||
```
|
||||
|
||||
|
||||
This concludes part A of the lab. Don't forget to add `answers-lab3.txt`, commit your changes, and run make handin before the part A deadline.
|
||||
|
||||
#### Part B: Page Faults, Breakpoints Exceptions, and System Calls
|
||||
|
||||
Now that your kernel has basic exception handling capabilities, you will refine it to provide important operating system primitives that depend on exception handling.
|
||||
|
||||
##### Handling Page Faults
|
||||
|
||||
The page fault exception, interrupt vector 14 (`T_PGFLT`), is a particularly important one that we will exercise heavily throughout this lab and the next. When the processor takes a page fault, it stores the linear (i.e., virtual) address that caused the fault in a special processor control register, `CR2`. In `trap.c` we have provided the beginnings of a special function, `page_fault_handler()`, to handle page fault exceptions.
|
||||
|
||||
```
|
||||
Exercise 5. Modify `trap_dispatch()` to dispatch page fault exceptions to `page_fault_handler()`. You should now be able to get make grade to succeed on the `faultread`, `faultreadkernel`, `faultwrite`, and `faultwritekernel` tests. If any of them don't work, figure out why and fix them. Remember that you can boot JOS into a particular user program using make run- _x_ or make run- _x_ -nox. For instance, make run-hello-nox runs the _hello_ user program.
|
||||
```
|
||||
|
||||
You will further refine the kernel's page fault handling below, as you implement system calls.
|
||||
|
||||
##### The Breakpoint Exception
|
||||
|
||||
The breakpoint exception, interrupt vector 3 (`T_BRKPT`), is normally used to allow debuggers to insert breakpoints in a program's code by temporarily replacing the relevant program instruction with the special 1-byte `int3` software interrupt instruction. In JOS we will abuse this exception slightly by turning it into a primitive pseudo-system call that any user environment can use to invoke the JOS kernel monitor. This usage is actually somewhat appropriate if we think of the JOS kernel monitor as a primitive debugger. The user-mode implementation of `panic()` in `lib/panic.c`, for example, performs an `int3` after displaying its panic message.
|
||||
|
||||
```
|
||||
Exercise 6. Modify `trap_dispatch()` to make breakpoint exceptions invoke the kernel monitor. You should now be able to get make grade to succeed on the `breakpoint` test.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Modify the JOS kernel monitor so that you can 'continue' execution from the current location (e.g., after the `int3`, if the kernel monitor was invoked via the breakpoint exception), and so that you can single-step one instruction at a time. You will need to understand certain bits of the `EFLAGS` register in order to implement single-stepping.
|
||||
|
||||
Optional: If you're feeling really adventurous, find some x86 disassembler source code - e.g., by ripping it out of QEMU, or out of GNU binutils, or just write it yourself - and extend the JOS kernel monitor to be able to disassemble and display instructions as you are stepping through them. Combined with the symbol table loading from lab 1, this is the stuff of which real kernel debuggers are made.
|
||||
```
|
||||
|
||||
```
|
||||
Questions
|
||||
|
||||
3. The break point test case will either generate a break point exception or a general protection fault depending on how you initialized the break point entry in the IDT (i.e., your call to `SETGATE` from `trap_init`). Why? How do you need to set it up in order to get the breakpoint exception to work as specified above and what incorrect setup would cause it to trigger a general protection fault?
|
||||
4. What do you think is the point of these mechanisms, particularly in light of what the `user/softint` test program does?
|
||||
```
|
||||
|
||||
|
||||
##### System calls
|
||||
|
||||
User processes ask the kernel to do things for them by invoking system calls. When the user process invokes a system call, the processor enters kernel mode, the processor and the kernel cooperate to save the user process's state, the kernel executes appropriate code in order to carry out the system call, and then resumes the user process. The exact details of how the user process gets the kernel's attention and how it specifies which call it wants to execute vary from system to system.
|
||||
|
||||
In the JOS kernel, we will use the `int` instruction, which causes a processor interrupt. In particular, we will use `int $0x30` as the system call interrupt. We have defined the constant `T_SYSCALL` to 48 (0x30) for you. You will have to set up the interrupt descriptor to allow user processes to cause that interrupt. Note that interrupt 0x30 cannot be generated by hardware, so there is no ambiguity caused by allowing user code to generate it.
|
||||
|
||||
The application will pass the system call number and the system call arguments in registers. This way, the kernel won't need to grub around in the user environment's stack or instruction stream. The system call number will go in `%eax`, and the arguments (up to five of them) will go in `%edx`, `%ecx`, `%ebx`, `%edi`, and `%esi`, respectively. The kernel passes the return value back in `%eax`. The assembly code to invoke a system call has been written for you, in `syscall()` in `lib/syscall.c`. You should read through it and make sure you understand what is going on.
|
||||
|
||||
```
|
||||
Exercise 7. Add a handler in the kernel for interrupt vector `T_SYSCALL`. You will have to edit `kern/trapentry.S` and `kern/trap.c`'s `trap_init()`. You also need to change `trap_dispatch()` to handle the system call interrupt by calling `syscall()` (defined in `kern/syscall.c`) with the appropriate arguments, and then arranging for the return value to be passed back to the user process in `%eax`. Finally, you need to implement `syscall()` in `kern/syscall.c`. Make sure `syscall()` returns `-E_INVAL` if the system call number is invalid. You should read and understand `lib/syscall.c` (especially the inline assembly routine) in order to confirm your understanding of the system call interface. Handle all the system calls listed in `inc/syscall.h` by invoking the corresponding kernel function for each call.
|
||||
|
||||
Run the `user/hello` program under your kernel (make run-hello). It should print "`hello, world`" on the console and then cause a page fault in user mode. If this does not happen, it probably means your system call handler isn't quite right. You should also now be able to get make grade to succeed on the `testbss` test.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Implement system calls using the `sysenter` and `sysexit` instructions instead of using `int 0x30` and `iret`.
|
||||
|
||||
The `sysenter/sysexit` instructions were designed by Intel to be faster than `int/iret`. They do this by using registers instead of the stack and by making assumptions about how the segmentation registers are used. The exact details of these instructions can be found in Volume 2B of the Intel reference manuals.
|
||||
|
||||
The easiest way to add support for these instructions in JOS is to add a `sysenter_handler` in `kern/trapentry.S` that saves enough information about the user environment to return to it, sets up the kernel environment, pushes the arguments to `syscall()` and calls `syscall()` directly. Once `syscall()` returns, set everything up for and execute the `sysexit` instruction. You will also need to add code to `kern/init.c` to set up the necessary model specific registers (MSRs). Section 6.1.2 in Volume 2 of the AMD Architecture Programmer's Manual and the reference on SYSENTER in Volume 2B of the Intel reference manuals give good descriptions of the relevant MSRs. You can find an implementation of `wrmsr` to add to `inc/x86.h` for writing to these MSRs [here][4].
|
||||
|
||||
Finally, `lib/syscall.c` must be changed to support making a system call with `sysenter`. Here is a possible register layout for the `sysenter` instruction:
|
||||
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
|
||||
GCC's inline assembler will automatically save registers that you tell it to load values directly into. Don't forget to either save (push) and restore (pop) other registers that you clobber, or tell the inline assembler that you're clobbering them. The inline assembler doesn't support saving `%ebp`, so you will need to add code to save and restore it yourself. The return address can be put into `%esi` by using an instruction like `leal after_sysenter_label, %%esi`.
|
||||
|
||||
Note that this only supports 4 arguments, so you will need to leave the old method of doing system calls around to support 5 argument system calls. Furthermore, because this fast path doesn't update the current environment's trap frame, it won't be suitable for some of the system calls we add in later labs.
|
||||
|
||||
You may have to revisit your code once we enable asynchronous interrupts in the next lab. Specifically, you'll need to enable interrupts when returning to the user process, which `sysexit` doesn't do for you.
|
||||
```
|
||||
|
||||
##### User-mode startup
|
||||
|
||||
A user program starts running at the top of `lib/entry.S`. After some setup, this code calls `libmain()`, in `lib/libmain.c`. You should modify `libmain()` to initialize the global pointer `thisenv` to point at this environment's `struct Env` in the `envs[]` array. (Note that `lib/entry.S` has already defined `envs` to point at the `UENVS` mapping you set up in Part A.) Hint: look in `inc/env.h` and use `sys_getenvid`.
|
||||
|
||||
`libmain()` then calls `umain`, which, in the case of the hello program, is in `user/hello.c`. Note that after printing "`hello, world`", it tries to access `thisenv->env_id`. This is why it faulted earlier. Now that you've initialized `thisenv` properly, it should not fault. If it still faults, you probably haven't mapped the `UENVS` area user-readable (back in Part A in `pmap.c`; this is the first time we've actually used the `UENVS` area).
|
||||
|
||||
```
|
||||
Exercise 8. Add the required code to the user library, then boot your kernel. You should see `user/hello` print "`hello, world`" and then print "`i am environment 00001000`". `user/hello` then attempts to "exit" by calling `sys_env_destroy()` (see `lib/libmain.c` and `lib/exit.c`). Since the kernel currently only supports one user environment, it should report that it has destroyed the only environment and then drop into the kernel monitor. You should be able to get make grade to succeed on the `hello` test.
|
||||
```
|
||||
|
||||
##### Page faults and memory protection
|
||||
|
||||
Memory protection is a crucial feature of an operating system, ensuring that bugs in one program cannot corrupt other programs or corrupt the operating system itself.
|
||||
|
||||
Operating systems usually rely on hardware support to implement memory protection. The OS keeps the hardware informed about which virtual addresses are valid and which are not. When a program tries to access an invalid address or one for which it has no permissions, the processor stops the program at the instruction causing the fault and then traps into the kernel with information about the attempted operation. If the fault is fixable, the kernel can fix it and let the program continue running. If the fault is not fixable, then the program cannot continue, since it will never get past the instruction causing the fault.
|
||||
|
||||
As an example of a fixable fault, consider an automatically extended stack. In many systems the kernel initially allocates a single stack page, and then if a program faults accessing pages further down the stack, the kernel will allocate those pages automatically and let the program continue. By doing this, the kernel only allocates as much stack memory as the program needs, but the program can work under the illusion that it has an arbitrarily large stack.
|
||||
|
||||
System calls present an interesting problem for memory protection. Most system call interfaces let user programs pass pointers to the kernel. These pointers point at user buffers to be read or written. The kernel then dereferences these pointers while carrying out the system call. There are two problems with this:
|
||||
|
||||
1. A page fault in the kernel is potentially a lot more serious than a page fault in a user program. If the kernel page-faults while manipulating its own data structures, that's a kernel bug, and the fault handler should panic the kernel (and hence the whole system). But when the kernel is dereferencing pointers given to it by the user program, it needs a way to remember that any page faults these dereferences cause are actually on behalf of the user program.
|
||||
2. The kernel typically has more memory permissions than the user program. The user program might pass a pointer to a system call that points to memory that the kernel can read or write but that the program cannot. The kernel must be careful not to be tricked into dereferencing such a pointer, since that might reveal private information or destroy the integrity of the kernel.
|
||||
|
||||
|
||||
|
||||
For both of these reasons the kernel must be extremely careful when handling pointers presented by user programs.
|
||||
|
||||
You will now solve these two problems with a single mechanism that scrutinizes all pointers passed from userspace into the kernel. When a program passes the kernel a pointer, the kernel will check that the address is in the user part of the address space, and that the page table would allow the memory operation.
|
||||
|
||||
Thus, the kernel will never suffer a page fault due to dereferencing a user-supplied pointer. If the kernel does page fault, it should panic and terminate.
|
||||
|
||||
```
|
||||
Exercise 9. Change `kern/trap.c` to panic if a page fault happens in kernel mode.
|
||||
|
||||
Hint: to determine whether a fault happened in user mode or in kernel mode, check the low bits of the `tf_cs`.
|
||||
|
||||
Read `user_mem_assert` in `kern/pmap.c` and implement `user_mem_check` in that same file.
|
||||
|
||||
Change `kern/syscall.c` to sanity check arguments to system calls.
|
||||
|
||||
Boot your kernel, running `user/buggyhello`. The environment should be destroyed, and the kernel should _not_ panic. You should see:
|
||||
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
Finally, change `debuginfo_eip` in `kern/kdebug.c` to call `user_mem_check` on `usd`, `stabs`, and `stabstr`. If you now run `user/breakpoint`, you should be able to run backtrace from the kernel monitor and see the backtrace traverse into `lib/libmain.c` before the kernel panics with a page fault. What causes this page fault? You don't need to fix it, but you should understand why it happens.
|
||||
```
|
||||
|
||||
Note that the same mechanism you just implemented also works for malicious user applications (such as `user/evilhello`).
|
||||
|
||||
```
|
||||
Exercise 10. Boot your kernel, running `user/evilhello`. The environment should be destroyed, and the kernel should not panic. You should see:
|
||||
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
```
|
||||
|
||||
**This completes the lab.** Make sure you pass all of the make grade tests and don't forget to write up your answers to the questions and a description of your challenge exercise solution in `answers-lab3.txt`. Commit your changes and type make handin in the `lab` directory to submit your work.
|
||||
|
||||
Before handing in, use git status and git diff to examine your changes and don't forget to git add answers-lab3.txt. When you're ready, commit your changes with git commit -am 'my solutions to lab 3', then make handin and follow the directions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab3/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/labguide.html
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labs/reference.html
|
||||
[3]: http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx
|
||||
[4]: http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c
|
||||
@ -1,281 +0,0 @@
|
||||
How to set up WordPress on a Raspberry Pi
|
||||
======
|
||||
|
||||
Run your WordPress website on your Raspberry Pi with this simple tutorial.
|
||||
|
||||

|
||||
|
||||
WordPress is a popular open source blogging platform and content management system (CMS). It's easy to set up and has a thriving community of developers building websites and creating themes and plugins for others to use.
|
||||
|
||||
Although getting hosting packages with a "one-click WordPress setup" is easy, it's also simple to set up your own on a Linux server with only command-line access, and the [Raspberry Pi][1] is a perfect way to try it out and learn something along the way.
|
||||
|
||||
The four components of a commonly used web stack are Linux, Apache, MySQL, and PHP. Here's what you need to know about each.
|
||||
|
||||
### Linux
|
||||
|
||||
The Raspberry Pi runs Raspbian, which is a Linux distribution based on Debian and optimized to run well on Raspberry Pi hardware. It comes with two options to start: Desktop or Lite. The Desktop version boots to a familiar-looking desktop and comes with lots of educational software and programming tools, as well as the LibreOffice suite, Minecraft, and a web browser. The Lite version has no desktop environment, so it's command-line only and comes with only the essential software.
|
||||
|
||||
This tutorial will work with either version, but if you use the Lite version you'll have to use another computer to access your website.
|
||||
|
||||
### Apache
|
||||
|
||||
Apache is a popular web server application you can install on the Raspberry Pi to serve web pages. On its own, Apache can serve static HTML files over HTTP. With additional modules, it can serve dynamic web pages using scripting languages such as PHP.
|
||||
|
||||
Installing Apache is very simple. Open a terminal window and type the following command:
|
||||
|
||||
```
|
||||
sudo apt install apache2 -y
|
||||
```
|
||||
|
||||
By default, Apache puts a test HTML file in a web folder you can view from your Pi or another computer on your network. Just open the web browser and enter the address **<http://localhost>**. Alternatively (particularly if you're using Raspbian Lite), enter the Pi's IP address instead of **localhost**. You should see this in your browser window:
|
||||
|
||||
|
||||
|
||||
This means you have Apache working!
|
||||
|
||||
This default webpage is just an HTML file on the filesystem. It is located at **/var/www/html/index.html**. You can try replacing this file with some HTML of your own using the [Leafpad][2] text editor:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo leafpad index.html
|
||||
```
|
||||
|
||||
Save and close Leafpad then refresh the browser to see your changes.
|
||||
|
||||
### MySQL
|
||||
|
||||
MySQL (pronounced "my S-Q-L" or "my sequel") is a popular database engine. Like PHP, it's widely used on web servers, which is why projects like WordPress use it and why those projects are so popular.
|
||||
|
||||
Install MySQL Server by entering the following command into the terminal window:
|
||||
|
||||
```
|
||||
sudo apt-get install mysql-server -y
|
||||
```
|
||||
|
||||
WordPress uses MySQL to store posts, pages, user data, and lots of other content.
|
||||
|
||||
### PHP
|
||||
|
||||
PHP is a preprocessor: it's code that runs when the server receives a request for a web page via a web browser. It works out what needs to be shown on the page, then sends that page to the browser. Unlike static HTML, PHP can show different content under different circumstances. PHP is a very popular language on the web; huge projects like Facebook and Wikipedia are written in PHP.
|
||||
|
||||
Install PHP and the MySQL extension:
|
||||
|
||||
```
|
||||
sudo apt-get install php php-mysql -y
|
||||
```
|
||||
|
||||
Delete the **index.html** file and create **index.php** :
|
||||
|
||||
```
|
||||
sudo rm index.html
|
||||
sudo leafpad index.php
|
||||
```
|
||||
|
||||
Add the following line:
|
||||
|
||||
```
|
||||
<?php phpinfo(); ?>
|
||||
```
|
||||
|
||||
Save, exit, and refresh your browser. You'll see the PHP status page:
|
||||
|
||||
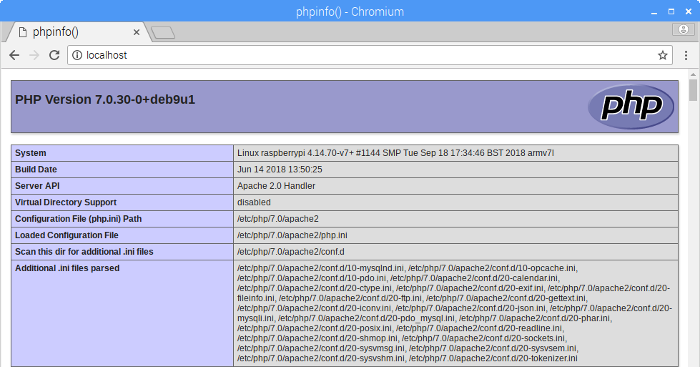
|
||||
|
||||
### WordPress
|
||||
|
||||
You can download WordPress from [wordpress.org][3] using the **wget** command. Helpfully, the latest version of WordPress is always available at [wordpress.org/latest.tar.gz][4], so you can grab it without having to look it up on the website. As I'm writing, this is version 4.9.8.
|
||||
|
||||
Make sure you're in **/var/www/html** and delete everything in it:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo rm *
|
||||
```
|
||||
|
||||
Download WordPress using **wget** , then extract the contents and move the WordPress files to the **html** directory:
|
||||
|
||||
```
|
||||
sudo wget http://wordpress.org/latest.tar.gz
|
||||
sudo tar xzf latest.tar.gz
|
||||
sudo mv wordpress/* .
|
||||
```
|
||||
|
||||
Tidy up by removing the tarball and the now-empty **wordpress** directory:
|
||||
|
||||
```
|
||||
sudo rm -rf wordpress latest.tar.gz
|
||||
```
|
||||
|
||||
Running the **ls** or **tree -L 1** command will show the contents of a WordPress project:
|
||||
|
||||
```
|
||||
.
|
||||
├── index.php
|
||||
├── license.txt
|
||||
├── readme.html
|
||||
├── wp-activate.php
|
||||
├── wp-admin
|
||||
├── wp-blog-header.php
|
||||
├── wp-comments-post.php
|
||||
├── wp-config-sample.php
|
||||
├── wp-content
|
||||
├── wp-cron.php
|
||||
├── wp-includes
|
||||
├── wp-links-opml.php
|
||||
├── wp-load.php
|
||||
├── wp-login.php
|
||||
├── wp-mail.php
|
||||
├── wp-settings.php
|
||||
├── wp-signup.php
|
||||
├── wp-trackback.php
|
||||
└── xmlrpc.php
|
||||
|
||||
3 directories, 16 files
|
||||
```
|
||||
|
||||
This is the source of a default WordPress installation. The files you edit to customize your installation belong in the **wp-content** folder.
|
||||
|
||||
You should now change the ownership of all these files to the Apache user:
|
||||
|
||||
```
|
||||
sudo chown -R www-data: .
|
||||
```
|
||||
|
||||
### WordPress database
|
||||
|
||||
To get your WordPress site set up, you need a database. This is where MySQL comes in!
|
||||
|
||||
Run the MySQL secure installation command in the terminal window:
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
You will be asked a series of questions. There's no password set up initially, but you should set one in the second step. Make sure you enter a password you will remember, as you'll need it to connect to WordPress. Press Enter to say Yes to each question that follows.
|
||||
|
||||
When it's complete, you will see the messages "All done!" and "Thanks for using MariaDB!"
|
||||
|
||||
Run **mysql** in the terminal window:
|
||||
|
||||
```
|
||||
sudo mysql -uroot -p
|
||||
```
|
||||
|
||||
Enter the root password you created. You will be greeted by the message "Welcome to the MariaDB monitor." Create the database for your WordPress installation at the **MariaDB [(none)] >** prompt using:
|
||||
|
||||
```
|
||||
create database wordpress;
|
||||
```
|
||||
|
||||
Note the semicolon at the end of the statement. If the command is successful, you should see this:
|
||||
|
||||
```
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
```
|
||||
|
||||
Grant database privileges to the root user, entering your password at the end of the statement:
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';
|
||||
```
|
||||
|
||||
For the changes to take effect, you will need to flush the database privileges:
|
||||
|
||||
```
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Exit the MariaDB prompt with **Ctrl+D** to return to the Bash shell.
|
||||
|
||||
### WordPress configuration
|
||||
|
||||
Open the web browser on your Raspberry Pi and open **<http://localhost>**. You should see a WordPress page asking you to pick your language. Select your language and click **Continue**. You will be presented with the WordPress welcome screen. Click the **Let's go!** button.
|
||||
|
||||
Fill out the basic site information as follows:
|
||||
|
||||
```
|
||||
Database Name: wordpress
|
||||
User Name: root
|
||||
Password: <YOUR PASSWORD>
|
||||
Database Host: localhost
|
||||
Table Prefix: wp_
|
||||
```
|
||||
|
||||
Click **Submit** to proceed, then click **Run the install**.
|
||||
|
||||
|
||||
|
||||
Fill in the form: Give your site a title, create a username and password, and enter your email address. Hit the **Install WordPress** button, then log in using the account you just created. Now that you're logged in and your site is set up, you can see your website by visiting **<http://localhost/wp-admin>**.
|
||||
|
||||
### Permalinks
|
||||
|
||||
It's a good idea to change your permalink settings to make your URLs more friendly.
|
||||
|
||||
To do this, log into WordPress and go to the dashboard. Go to **Settings** , then **Permalinks**. Select the **Post name** option and click **Save Changes**. You'll need to enable Apache's **rewrite** module:
|
||||
|
||||
```
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
|
||||
You'll also need to tell the virtual host serving the site to allow requests to be overwritten. Edit the Apache configuration file for your virtual host:
|
||||
|
||||
```
|
||||
sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
```
|
||||
|
||||
Add the following lines after line 1:
|
||||
|
||||
```
|
||||
<Directory "/var/www/html">
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
```
|
||||
|
||||
Ensure it's within the **< VirtualHost *:80>** like so:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
<Directory "/var/www/html">
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
...
|
||||
```
|
||||
|
||||
Save the file and exit, then restart Apache:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
### What's next?
|
||||
|
||||
WordPress is very customizable. By clicking your site name in the WordPress banner at the top of the page (when you're logged in), you'll be taken to the Dashboard. From there, you can change the theme, add pages and posts, edit the menu, add plugins, and do lots more.
|
||||
|
||||
Here are some interesting things you can try on the Raspberry Pi's web server.
|
||||
|
||||
* Add pages and posts to your website
|
||||
* Install different themes from the Appearance menu
|
||||
* Customize your website's theme or create your own
|
||||
* Use your web server to display useful information for people on your network
|
||||
|
||||
|
||||
|
||||
Don't forget, the Raspberry Pi is a Linux computer. You can also follow these instructions to install WordPress on a server running Debian or Ubuntu.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/setting-wordpress-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sitewide-search?search_api_views_fulltext=raspberry%20pi
|
||||
[2]: https://en.wikipedia.org/wiki/Leafpad
|
||||
[3]: http://wordpress.org/
|
||||
[4]: https://wordpress.org/latest.tar.gz
|
||||
@ -0,0 +1,520 @@
|
||||
2017 年 Linux 上最好的 9 个免费视频编辑软件
|
||||
======
|
||||
**概要:这里介绍 Linux 上几个最好的视频编辑器,介绍他们的特性、利与弊,以及如何在你的 Linux 发行版上安装它们。**
|
||||
|
||||
![Linux 上最好的视频编辑器][1]
|
||||
|
||||
![Linux 上最好的视频编辑器][2]
|
||||
|
||||
我们曾经在一篇短文中讨论过[ Linux 上最好的照片管理应用][3],[Linux 上最好的代码编辑器][4]。今天我们将讨论 **Linux 上最好的视频编辑软件**。
|
||||
|
||||
当谈到免费视频编辑软件,Windows Movie Maker 和 iMovie 是大部分人经常推荐的。
|
||||
|
||||
很不幸,上述两者在 GNU/Linux 上都不可用。但是不必担心,我们为你汇集了一个**最好的视频编辑器**清单。
|
||||
|
||||
## Linux 上最好的视频编辑器
|
||||
|
||||
接下来让我们一起看看这些最好的视频编辑软件。如果你觉得文章读起来太长,这里有一个快速摘要。你可以点击链接跳转到文章的相关章节:
|
||||
|
||||
视频编辑器 主要用途 类型
|
||||
Kdenlive 通用视频编辑 免费开源
|
||||
OpenShot 通用视频编辑 免费开源
|
||||
Shotcut 通用视频编辑 免费开源
|
||||
Flowblade 通用视频编辑 免费开源
|
||||
Lightworks 专业级视频编辑 免费增值
|
||||
Blender 专业级三维编辑 免费开源
|
||||
Cinelerra 通用视频编辑 免费开源
|
||||
DaVinci 专业级视频处理编辑 免费增值
|
||||
VidCutter 简单视频拆分合并 免费开源
|
||||
|
||||
### 1\. Kdenlive
|
||||
|
||||
![Kdenlive - Ubuntu 上的免费视频编辑器][1]
|
||||
|
||||
![Kdenlive - Ubuntu 上的免费视频编辑器][5]
|
||||
[Kdenlive][6] 是 [KDE][8] 上的一个免费且[开源][7]的视频编辑软件,支持双视频监控,多轨时间线,剪辑列表,支持自定义布局,基本效果,以及基本过渡。
|
||||
|
||||
它支持多种文件格式和多种摄像机、相机,包括低分辨率摄像机(Raw 和 AVI DV 编辑),Mpeg2,mpeg4 和 h264 AVCHD(小型相机和便携式摄像机),高分辨率摄像机文件,包括 HDV 和 AVCHD 摄像机,专业摄像机,包括 XDCAM-HD™ 流, IMX™ (D10) 流,DVCAM (D10),DVCAM,DVCPRO™,DVCPRO50™ 流以及 DNxHD™ 流。
|
||||
|
||||
如果你正寻找 Linux 上 iMovie 的替代品,Kdenlive 会是你最好的选择。
|
||||
|
||||
#### Kdenlive 特性
|
||||
|
||||
* 多轨视频编辑
|
||||
* 多种音视频格式支持
|
||||
* 可配置的界面和快捷方式
|
||||
* 使用文本或图像轻松创建切片
|
||||
* 丰富的效果和过渡
|
||||
* 音频和视频示波器可确保镜头绝对平衡
|
||||
* 代理编辑
|
||||
* 自动保存
|
||||
* 广泛的硬件支持
|
||||
* 关键帧效果
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
|
||||
* 通用视频编辑器
|
||||
* 对于那些熟悉视频编辑的人来说并不太复杂
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
* 如果你想找的是极致简单的编辑软件,它可能还是令你有些困惑
|
||||
* KDE 应用程序以臃肿而臭名昭著
|
||||
|
||||
|
||||
|
||||
#### 安装 Kdenlive
|
||||
|
||||
Kdenlive 适用于所有主要的 Linux 发行版。你只需在软件中心搜索即可。[Kdenlive 网站的下载部分][9]提供了各种软件包。
|
||||
|
||||
命令行爱好者可以通过在 Debian 和基于 Ubuntu 的 Linux 发行版中运行以下命令从终端安装它:
|
||||
```
|
||||
sudo apt install kdenlive
|
||||
```
|
||||
|
||||
### 2\. OpenShot
|
||||
|
||||
![Openshot - ubuntu 上的免费视频编辑器][1]
|
||||
|
||||
![Openshot - ubuntu 上的免费视频编辑器][10]
|
||||
|
||||
[OpenShot][11] 是 Linux 上的另一个多用途视频编辑器。OpenShot 可以帮助你创建具有过渡和效果的视频。你还可以调整声音大小。当然,它支持大多数格式和编解码器。
|
||||
|
||||
你还可以将视频导出至 DVD,上传至 YouTube,Vimeo,Xbox 360 以及许多常见的视频格式。OpenShot 比 Kdenlive 要简单一些。因此,如果你需要界面简单的视频编辑器,OpenShot 是一个不错的选择。
|
||||
|
||||
它还有个简洁的[开始使用 Openshot][12] 文档。
|
||||
|
||||
#### OpenShot 特性
|
||||
|
||||
* 跨平台,可在Linux,macOS 和 Windows 上使用
|
||||
* 支持多种视频,音频和图像格式
|
||||
* 强大的基于曲线的关键帧动画
|
||||
* 桌面集成与拖放支持
|
||||
* 不受限制的音视频轨道或图层
|
||||
* 可剪辑调整大小,缩放,修剪,捕捉,旋转和剪切
|
||||
* 视频转换可实时预览
|
||||
* 合成,图像层叠和水印
|
||||
* 标题模板,标题创建,子标题
|
||||
* 利用图像序列支持2D动画
|
||||
* 3D 动画标题和效果
|
||||
* 支持保存为 SVG 格式以及矢量标题和可信证
|
||||
* 滚动动态图片
|
||||
* 帧精度(逐步浏览每一帧视频)
|
||||
* 剪辑的时间映射和速度更改
|
||||
* 音频混合和编辑
|
||||
* 数字视频效果,包括亮度,伽玛,色调,灰度,色度键等
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
|
||||
* 用于一般视频编辑需求的通用视频编辑器
|
||||
* 可在 Windows 和 macOS 以及 Linux 上使用
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 软件用起来可能很简单,但如果你对视频编辑非常陌生,那么肯定需要一个曲折学习的过程
|
||||
* 你可能仍然没有达到专业级电影制作编辑软件的水准
|
||||
|
||||
|
||||
|
||||
#### 安装 OpenShot
|
||||
|
||||
OpenShot 也可以在所有主流 Linux 发行版的软件仓库中使用。你只需在软件中心搜索即可。你也可以从[官方页面][13]中获取它。
|
||||
|
||||
在 Debian 和基于 Ubuntu 的 Linux 发行版中,我最喜欢运行以下命令来安装它:
|
||||
```
|
||||
sudo apt install openshot
|
||||
```
|
||||
|
||||
### 3\. Shotcut
|
||||
|
||||
![Shotcut Linux 视频编辑器][1]
|
||||
|
||||
![Shotcut Linux 视频编辑器][14]
|
||||
|
||||
[Shotcut][15] 是 Linux 上的另一个编辑器,可以和 Kdenlive 与 OpenShot 归为同一联盟。虽然它确实与上面讨论的其他两个软件有类似的功能,但 Shotcut 更先进的地方是支持4K视频。
|
||||
|
||||
支持许多音频,视频格式,过渡和效果是 Shotcut 的众多功能中的一部分。它也支持外部监视器。
|
||||
|
||||
这里有一系列视频教程让你[轻松上手 Shotcut][16]。它也可在 Windows 和 macOS 上使用,因此你也可以在其他操作系统上学习。
|
||||
|
||||
#### Shotcut 特性
|
||||
|
||||
* 跨平台,可在 Linux,macOS 和 Windows 上使用
|
||||
* 支持各种视频,音频和图像格式
|
||||
* 原生时间线编辑
|
||||
* 混合并匹配项目中的分辨率和帧速率
|
||||
* 音频滤波,混音和效果
|
||||
* 视频转换和过滤
|
||||
* 具有缩略图和波形的多轨时间轴
|
||||
* 无限制撤消和重做播放列表编辑,包括历史记录视图
|
||||
* 剪辑调整大小,缩放,修剪,捕捉,旋转和剪切
|
||||
* 使用纹波选项修剪源剪辑播放器或时间轴
|
||||
* 在额外系统显示/监视器上的外部监察
|
||||
* 硬件支持
|
||||
|
||||
|
||||
|
||||
你可以在[这里][17]阅它的更多特性。
|
||||
|
||||
#### 优点
|
||||
|
||||
* 用于常见视频编辑需求的通用视频编辑器
|
||||
* 支持 4K 视频
|
||||
* 可在 Windows,macOS 以及 Linux 上使用
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 功能太多降低了软件的易用性
|
||||
|
||||
|
||||
|
||||
#### 安装 Shotcut
|
||||
|
||||
Shotcut 以 [Snap][18] 格式提供。你可以在 Ubuntu 软件中心找到它。对于其他发行版,你可以从此[下载页面][19]获取可执行文件来安装。
|
||||
|
||||
### 4\. Flowblade
|
||||
|
||||
![Flowblade ubuntu 上的视频编辑器][1]
|
||||
|
||||
![Flowblade ubuntu 上的视频编辑器][20]
|
||||
|
||||
[Flowblade][21] 是 Linux 上的一个多轨非线性视频编辑器。与上面讨论的一样,这也是一个免费开源的软件。它具有时尚和现代化的用户界面。
|
||||
|
||||
用 Python 编写,它的设计初衷是快速且准确。Flowblade 专注于在 Linux 和其他免费平台上提供最佳体验。所以它没有在 Windows 和 OS X 上运行的版本。Linux 用户专享其实感觉也不错的。
|
||||
|
||||
你也可以查看这个不错的[文档][22]来帮助你使用它的所有功能。
|
||||
|
||||
#### Flowblade 特性
|
||||
|
||||
* 轻量级应用
|
||||
* 为简单的任务提供简单的界面,如拆分,合并,覆盖等
|
||||
* 大量的音视频效果和过滤器
|
||||
* 支持[代理编辑][23]
|
||||
* 支持拖拽
|
||||
* 支持多种视频、音频和图像格式
|
||||
* 批量渲染
|
||||
* 水印
|
||||
* 视频转换和过滤器
|
||||
* 具有缩略图和波形的多轨时间轴
|
||||
|
||||
|
||||
|
||||
你可以在 [Flowblade 特性][24]里阅读关于它的更多信息。
|
||||
|
||||
#### 优点
|
||||
|
||||
* 轻量
|
||||
* 适用于通用视频编辑
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 不支持其他平台
|
||||
|
||||
|
||||
|
||||
#### 安装 Flowblade
|
||||
|
||||
Flowblade 应当在所有主流 Linux 发行版的软件仓库中都可以找到。你可以从软件中心安装它。也可以在[下载页面][25]查看更多信息。
|
||||
|
||||
另外,你可以在 Ubuntu 和基于 Ubuntu 的系统中使用一下命令安装 Flowblade:
|
||||
```
|
||||
sudo apt install flowblade
|
||||
```
|
||||
|
||||
### 5\. Lightworks
|
||||
|
||||
![Lightworks 运行在 ubuntu 16.04][1]
|
||||
|
||||
![Lightworks 运行在 ubuntu 16.04][26]
|
||||
|
||||
如果你在寻找一个具有更多特性的视频编辑器,这就是你想要的。[Lightworks][27] 是一个跨平台的专业视频编辑器,可以在 Linux,Mac OS X 以及 Windows上使用。
|
||||
|
||||
它是一款屡获殊荣的专业[非线性编辑][28](NLE)软件,支持高达 4K 的分辨率以及 SD 和 HD 格式的视频。
|
||||
|
||||
Lightworks 可以在 Linux 上使用,然而它不开源。
|
||||
|
||||
Lightwokrs 有两个版本:
|
||||
|
||||
* Lightworks 免费版
|
||||
* Lightworks 专业版
|
||||
|
||||
|
||||
|
||||
专业版有更多功能,比如支持更高的分辨率,支持 4K 和 蓝光视频等。
|
||||
|
||||
这个[页面][29]有广泛的可用文档。你也可以参考 [Lightworks 视频向导页][30]的视频。
|
||||
|
||||
#### Lightworks 特性
|
||||
|
||||
* 跨平台
|
||||
* 简单直观的用户界面
|
||||
* 简明的时间线编辑和修剪
|
||||
* 实时可用的音频和视频FX
|
||||
* 可用精彩的免版税音频和视频内容
|
||||
* 适用于 4K 的 Lo-Res 代理工作流程
|
||||
* 支持导出 YouTube/Vimeo,SD/HD视频,最高可达4K
|
||||
* 支持拖拽
|
||||
* 各种音频和视频效果和滤镜
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
|
||||
* 专业,功能丰富的视频编辑器
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 免费版有使用限制
|
||||
|
||||
|
||||
|
||||
#### 安装 Lightworks
|
||||
|
||||
Lightworks 为 Debian 和基于 Ubuntu 的 Linux 提供了 DEB 安装包,为基于 Fedora 的 Linux 发行版提供了RPM 安装包。你可以在[下载页面][31]找到安装包。
|
||||
|
||||
### 6\. Blender
|
||||
|
||||
![Blender 运行在 Ubuntu 16.04][1]
|
||||
|
||||
![Blender 运行在 Ubuntu 16.04][32]
|
||||
|
||||
[Blender][33] 是一个专业的,工业级的开源跨平台视频编辑器。它在制作 3D 作品的工具当中较为流行。Blender 已被用于制作多部好莱坞电影,包括蜘蛛侠系列。
|
||||
|
||||
虽然最初设计用于制作 3D 模型,但它也具有多种格式视频的编辑功能。
|
||||
|
||||
#### Blender 特性
|
||||
|
||||
* 实时预览,亮度波形,色度矢量显示和直方图显示
|
||||
* 音频混合,同步,擦洗和波形可视化
|
||||
* 最多32个轨道,用于添加视频,图像,音频,场景,面具和效果
|
||||
* 速度控制,调整图层,过渡,关键帧,过滤器等
|
||||
|
||||
|
||||
|
||||
你可以在[这里][34]阅读更多相关特性。
|
||||
|
||||
#### 优点
|
||||
|
||||
* 跨平台
|
||||
* 专业级视频编辑
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 复杂
|
||||
* 主要用于制作 3D 动画,不专门用于常规视频编辑
|
||||
|
||||
|
||||
|
||||
#### 安装 Blender
|
||||
|
||||
Blender 的最新版本可以从[下载页面][35]下载。
|
||||
|
||||
### 7\. Cinelerra
|
||||
|
||||
![Cinelerra Linux 上的视频编辑器][1]
|
||||
|
||||
![Cinelerra Linux 上的视频编辑器][36]
|
||||
|
||||
[Cinelerra][37] 从 1998 年发布以来,已被下载超过500万次。它是 2003 年第一个在 64 位系统上提供非线性编辑的视频编辑器。当时它是Linux用户的首选视频编辑器,但随后一些开发人员丢弃了此项目,它也随之失去了光彩。
|
||||
|
||||
好消息是它正回到正轨并且良好地再次发展。
|
||||
|
||||
如果你想了解关于 Cinelerra 项目是如何开始的,这里有些[有趣的背景故事][38]。
|
||||
|
||||
#### Cinelerra 特性
|
||||
|
||||
* 非线性编辑
|
||||
* 支持 HD 视频
|
||||
* 内置框架渲染器
|
||||
* 各种视频效果
|
||||
* 不受限制的图层数量
|
||||
* 拆分窗格编辑
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
* 通用视频编辑器
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 不适用于新手
|
||||
* 没有可用的安装包
|
||||
|
||||
|
||||
|
||||
#### 安装 Cinelerra
|
||||
|
||||
你可以从 [SourceForge][39] 下载源码。更多相关信息请看[下载页面][40]。
|
||||
|
||||
### 8\. DaVinci Resolve
|
||||
|
||||
![DaVinci Resolve 视频编辑器][1]
|
||||
|
||||
![DaVinci Resolve 视频编辑器][41]
|
||||
|
||||
如果你想要好莱坞级别的视频编辑器,那就用好莱坞正在使用的专业工具。来自 Blackmagic 公司的 [DaVinci Resolve][42] 就是专业人士用于编辑电影和电视节目的专业工具。
|
||||
|
||||
DaVinci Resolve 不是常规的视频编辑器。它是一个成熟的编辑工具,在这一个应用程序中提供编辑,色彩校正和专业音频后期制作功能。
|
||||
|
||||
DaVinci Resolve 不开源。类似于 LightWorks,它也为 Linux 提供一个免费版本。专业版售价是 $300。
|
||||
|
||||
#### DaVinci Resolve 特性
|
||||
|
||||
* 高性能播放引擎
|
||||
* 支持所有类型的编辑类型,如覆盖,插入,波纹覆盖,替换,适合填充,末尾追加
|
||||
* 高级修剪
|
||||
* 音频叠加
|
||||
* Multicam Editing 可实现实时编辑来自多个摄像机的镜头
|
||||
* 过渡和过滤效果
|
||||
* 速度效果
|
||||
* 时间轴曲线编辑器
|
||||
* VFX 的非线性编辑
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
* 跨平台
|
||||
* 专业级视频编辑器
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 不适用于通用视频编辑
|
||||
* 不开源
|
||||
* 免费版本中有些功能无法使用
|
||||
|
||||
|
||||
|
||||
#### 安装 DaVinci Resolve
|
||||
|
||||
你可以从[这个页面][42]下载 DaVinci Resolve。你需要注册,哪怕仅仅下载免费版。
|
||||
|
||||
### 9\. VidCutter
|
||||
|
||||
![VidCutter Linux 上的视频编辑器][1]
|
||||
|
||||
![VidCutter Linux 上的视频编辑器][43]
|
||||
|
||||
不像这篇文章讨论的其他视频编辑器,[VidCutter][44] 非常简单。除了分割和合并视频之外,它没有其他太多功能。但有时你正好需要 VidCutter 提供的这些功能。
|
||||
|
||||
#### VidCutter 特性
|
||||
|
||||
* 适用于Linux,Windows 和 MacOS 的跨平台应用程序
|
||||
* 支持绝大多数常见视频格式,例如:AVI,MP4,MPEG 1/2,WMV,MP3,MOV,3GP,FLV 等等
|
||||
* 界面简单
|
||||
* 修剪和合并视频,仅此而已
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
|
||||
* 跨平台
|
||||
* 很适合做简单的视频分割和合并
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
|
||||
* 不适合用于通用视频编辑
|
||||
* 经常崩溃
|
||||
|
||||
|
||||
|
||||
#### 安装 VidCutter
|
||||
|
||||
如果你使用的是基于 Ubuntu 的 Linux 发行版,你可以使用这个官方 PPA(译者注:PPA,个人软件包档案,PersonalPackageArchives):
|
||||
```
|
||||
sudo add-apt-repository ppa:ozmartian/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install vidcutter
|
||||
```
|
||||
|
||||
Arch Linux 用户可以轻松的使用 AUR 安装它。对于其他 Linux 发行版的用户,你可以从这个 [Github 页面][45]上查找安装文件。
|
||||
|
||||
### 哪个是 Linux 上最好的视频编辑软件?
|
||||
|
||||
文章里提到的一些视频编辑器使用 [FFmpeg][46]。你也可以自己使用 FFmpeg。它只是一个命令行工具,所以我没有在上文的列表中提到,但一句也不提又不公平。
|
||||
|
||||
如果你需要一个视频编辑器来简单的剪切和拼接视频,请使用 VidCutter。
|
||||
|
||||
如果你需要的不止这些,**OpenShot** 或者 **Kdenlive** 是不错的选择。他们有规格标准的系统,适用于初学者。
|
||||
|
||||
如果你拥有一台高端计算机并且需要高级功能,可以使用 **Lightworks** 或者 **DaVinci Resolve**。如果你在寻找更高级的工具用于制作 3D 作品,If you are looking for more advanced features for 3D works,**Blender** 就得到了你的支持。
|
||||
|
||||
这就是关于 **Linux 上最好的视频编辑软件**我所能表达的全部内容,像Ubuntu,Linux Mint,Elementary,以及其他 Linux 发行版。向我们分享你最喜欢的视频编辑器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-video-editing-software-linux/
|
||||
|
||||
作者:[It'S Foss Team][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/itsfoss/
|
||||
[1]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
|
||||
[2]:https://itsfoss.com/wp-content/uploads/2016/06/best-Video-editors-Linux-800x450.png
|
||||
[3]:https://itsfoss.com/linux-photo-management-software/
|
||||
[4]:https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2016/06/kdenlive-free-video-editor-on-ubuntu.jpg
|
||||
[6]:https://kdenlive.org/
|
||||
[7]:https://itsfoss.com/tag/open-source/
|
||||
[8]:https://www.kde.org/
|
||||
[9]:https://kdenlive.org/download/
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2016/06/openshot-free-video-editor-on-ubuntu.jpg
|
||||
[11]:http://www.openshot.org/
|
||||
[12]:http://www.openshot.org/user-guide/
|
||||
[13]:http://www.openshot.org/download/
|
||||
[14]:https://itsfoss.com/wp-content/uploads/2016/06/shotcut-video-editor-linux-800x503.jpg
|
||||
[15]:https://www.shotcut.org/
|
||||
[16]:https://www.shotcut.org/tutorials/
|
||||
[17]:https://www.shotcut.org/features/
|
||||
[18]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[19]:https://www.shotcut.org/download/
|
||||
[20]:https://itsfoss.com/wp-content/uploads/2016/06/flowblade-movie-editor-on-ubuntu.jpg
|
||||
[21]:http://jliljebl.github.io/flowblade/
|
||||
[22]:https://jliljebl.github.io/flowblade/webhelp/help.html
|
||||
[23]:https://jliljebl.github.io/flowblade/webhelp/proxy.html
|
||||
[24]:https://jliljebl.github.io/flowblade/features.html
|
||||
[25]:https://jliljebl.github.io/flowblade/download.html
|
||||
[26]:https://itsfoss.com/wp-content/uploads/2016/06/lightworks-running-on-ubuntu-16.04.jpg
|
||||
[27]:https://www.lwks.com/
|
||||
[28]:https://en.wikipedia.org/wiki/Non-linear_editing_system
|
||||
[29]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206&tab=4
|
||||
[30]:https://www.lwks.com/videotutorials
|
||||
[31]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206&tab=1
|
||||
[32]:https://itsfoss.com/wp-content/uploads/2016/06/blender-running-on-ubuntu-16.04.jpg
|
||||
[33]:https://www.blender.org/
|
||||
[34]:https://www.blender.org/features/
|
||||
[35]:https://www.blender.org/download/
|
||||
[36]:https://itsfoss.com/wp-content/uploads/2016/06/cinelerra-screenshot.jpeg
|
||||
[37]:http://cinelerra.org/
|
||||
[38]:http://cinelerra.org/our-story
|
||||
[39]:https://sourceforge.net/projects/heroines/files/cinelerra-6-src.tar.xz/download
|
||||
[40]:http://cinelerra.org/download
|
||||
[41]:https://itsfoss.com/wp-content/uploads/2016/06/davinci-resolve-vdeo-editor-800x450.jpg
|
||||
[42]:https://www.blackmagicdesign.com/products/davinciresolve/
|
||||
[43]:https://itsfoss.com/wp-content/uploads/2016/06/vidcutter-screenshot-800x585.jpeg
|
||||
[44]:https://itsfoss.com/vidcutter-video-editor-linux/
|
||||
[45]:https://github.com/ozmartian/vidcutter/releases
|
||||
[46]:https://www.ffmpeg.org/
|
||||
@ -0,0 +1,102 @@
|
||||
对于开发者来说5个最好的Linux发行版
|
||||
============================================================
|
||||

|
||||
Jack Wallen介绍了一些非常适合用来做开发工作的Linux发行版本.[Creative Commons Zero][6]
|
||||
在考虑使用Linux时,需要做很多的考量。你希望使用什么包管理器?你更喜欢现代还是比较旧的桌面界面?易用性是你使用Linux的首选吗?你希望分发的灵活性?发行版的服务性任务是什么?
|
||||
这是你在开始使用Linux之前必须考虑的问题。发行版是作为桌面还是服务器运行?你会做网络或者系统审计吗?或者你会开发?如果你花了很多时间考虑Linux,你知道每个任务都有非常合适的Linux发行版。这当然非常适用于开发人员。尽管Linux在设计上对于开发人员来说是一个理想的平台,但某些发行版高于其他的发行版,可以作为最好的开发人员的操作系统去服务开发人员。
|
||||
我想来分享我自己认为是你在做开发工作当中的最佳Linux发行版。虽然这五个发行版的每一个都可以用来通用开发(可能有一个是例外),但是它们都有各自的特定目的,你看会或不会对这些选择感觉到惊讶
|
||||
话虽如此,让我们做出选择
|
||||
### Debian
|
||||
在[Debian][14]的发行版中许多Linux列表中排名靠前。 有充分的理由。 Debian是许多人所依赖的发行版. 这就是为什么更多的开发人员去选择debian的理由。 当你在Debian上开发一个软件的时候,很有可能该软件包可以适用于[Ubuntu][15], [Linux Mint][16], [Elementary OS][17],以及大量的其他Debian发行版。
|
||||
除了这个非常明显的答案之外,Debian还通过默认存储库提供了大量可用的应用程序(图1)。
|
||||

|
||||
图 1: 标准的Debian存储库里面可用的应用程序。[Used with permission][1]
|
||||
为了让程序员友好,这些应用程序 (以及它们的依赖项) 易于安装.例如,构建必需的包(可以安装在Debian的任何衍生发行版上)。该软件包包括dkpg-dev,g ++,gcc,hurd-dev,libc-dev以及开发过程所需的make-all工具。可以使用命令sudo apt install build-essential安装build-essential软件包。
|
||||
标准存储库当中提供了数百种的特定于开发人员的应用程序,例如:
|
||||
* Autoconf—配置构建脚本的软件
|
||||
* Autoproject—为新程序创建源码包
|
||||
* Bison—通用的解析生成器
|
||||
* Bluefish—面向程序员的强大GUI编辑器
|
||||
* Geany—轻量化的IDE
|
||||
* Kate—强大的文本编辑器
|
||||
* Eclipse—帮助构建者独立开发与其他工具的集成性软件
|
||||
这个清单一直在继续更新.
|
||||
Debian也是你能找到的坚于磐石的发行版,因此很少有人担心因为桌面崩溃而让你失去宝贵的工作。作为奖励,Debian的所有应用程序都必须符合[Debian自由软件指南][18], 该指南遵守以下 “社会契约”:
|
||||
* Debian 保持完全免费.
|
||||
* 我们将无偿回馈自由软件社区.
|
||||
* 我们不会隐藏问题.
|
||||
* 我们的首要任务是我们的用户和自由软件
|
||||
* 不符合我们的免费软件标准的作品在非免费档案中..
|
||||
此外,你不熟悉在Linux上进行开发,Debian在其[用户手册][19]中有一个方便编程的部分。
|
||||
### openSUSE Tumbleweed (滚动更新版)
|
||||
如果你希望开发出最前沿的滚动发行版本, [openSUSE][20] 将提供最好的[Tumbleweed][21]之一。 还可以借助openSUSE当中令人惊叹的管理员工具(其中包括YaST)来实现这一目标。如果你不熟悉YaST(又一个设置工具)的话,它是一个非常强大的软件,允许您从一个方便的位置来管理整个平台。在YaST中,您还可以使用RPM组进行安装。打开YaST,单击RPM Groups(按目的分组的软件),然后向下滚动到Development部分以查看可安装的大量组(图2)
|
||||

|
||||
图 2: 在openSUSE Tumbleweed中安装软件包组.[Creative Commons Zero][2]
|
||||
openSUSE还允许您通过简单的单击链接快速安装所有必需的devtools [rpmdevtools安装页面][22], 然后单击Tumbleweed的链接。这将自动添加必要的存储库并安装rpmdevtools
|
||||
对于开发者来说,通过滚动版本进行开发,你可以知道你已安装的软件是最新版本。
|
||||
### CentOS
|
||||
让我们来看一下, [红帽企业版Linux][23] (RHEL) 是企业事务的事实标准. 如果你正在寻找针对特定平台进行开发,并且你有点担心无法承担RHEL的许可证,那么[CentOS][24]就是你不错的选择— 实际上,它是RHEL的社区版本。你会发现CentOS上的许多软件包与RHEL中的软件包相同 - 所以一旦熟悉了一个软件包,你就可以使用其他的软件包。
|
||||
如果你认真考虑在企业级平台上进行开发,那么CentOS就是不错的选择。而且由于CentOS是特定于服务器的发行版,因此您可以更轻松地以Web为中心的平台进行开发。您可以轻松地将CentOS作为开发和测试的理想主机,而不是开发您的工作然后将其迁移到服务器(托管在不同的计算机上).
|
||||
寻找满足你开发需求的软件? 你只需要打开CentOS软件中心, 其中包含了集成开发环境(IDE - 图3)的专用子部分
|
||||

|
||||
图 3: 在CentOS中安装功能强大的IDE很简单。.[Used with permission][3]
|
||||
Centos还包括安全增强性的Linux(SElinux),它使你可以更加轻松的去测试你的软件与RHEL中的同一安全平台的集成功能,SElinux经常会让设计不佳的软件感到头疼,因此准备了它可以真正有利于确保你的应用程序在RHEL之类的应用程序上面运行。如果你不确定如何在Centos上进行开发工作。你可以阅读[RHEL 7 开发人员指南][25].
|
||||
### Raspbian
|
||||
让我们来看一下, 嵌入式操作系统风靡一时. 使用这种 操作系统最简单的一种方法就是通过Raspberry Pi——一种极小的单片机(也可以称为小型计算机). 事实上,Raspberry Pi 已经成为了全球喜爱DIY用户使用的硬件. 为这些 设备供电的是 [Raspbian][26]操作系统. Raspbian包含[BlueJ][27], [Geany][28], [Greenfoot][29], [Sense HAT Emulator][30], [Sonic Pi][31], 和 [Thonny Python IDE][32], [Python][33], 和 [Scratch][34]等一些工具, 因此你不需要开发软件。Raspbian还包括一个用户友好的桌面UI(图4),使事情变得更加容易。
|
||||

|
||||
图 4: Raspbian主菜单,显示预安装的开发人员软件.[Used with permission][4]
|
||||
对于任何想要对Raspberry Pi平台开发的人来说,Raspbian是必要的。如果你想在不使用Raspberry Pi硬件的情况下使用Raspbian系统,您可以通过下载[此处][35]的ISO映像将其安装在VirtualBox虚拟机中
|
||||
### Pop!_OS
|
||||
不要让这个名字迷惑你,,不要让这个名字迷惑你, 进入[System76][36]的 [Pop!_OS][37]操作系统世界是非常严格的. 虽然System76对这个Ubuntu衍生产品做了很多修改但不是很明显,但这是特别的。
|
||||
System76的目标是创建一个特定于开发人员,制造商和计算机科学专业人员的操作系统。通过新设计的GNOME主题,Pop!_OS非常漂亮(图5),并且功能与硬件制造商使桌面设计人员一样强大。
|
||||
### [devel_5.jpg][11]
|
||||

|
||||
图 5: Pop!_OS 桌面.[Used with permission][5]
|
||||
但是,Pop!_OS的特殊之处在于它是由一家致力于Linux硬件的公司开发的。这意味着,当您购买System76笔记本电脑,台式机或服务器时,您就会知道操作系统将与硬件无缝协作 - 这是其他公司无法提供的。我预测,Pop!_OS将使System76将成为Linux界Apple。
|
||||
### 工作时间
|
||||
以他们自己的方式,每个发行版。你有一个稳定的桌面(Debian),一个尖端的桌面(openSUSE Tumbleweed),一个服务器(CentOS),一个嵌入式平台(Raspbian),以及一个与硬件无缝融合的发行版(Pop!_OS)。除了Raspbian之外,这些发行版中的任何一个都将成为一个出色的开发平台。安装一个并开始自信地开展下一个项目。
|
||||
可以通过Linux Foundation和edX 免费提供的["Linux简介" ][13]来了解更多的有关Linux信息
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/5-best-linux-distributions-development
|
||||
作者:[JACK WALLEN ][a]
|
||||
译者:[geekmar](https://github.com/geekmar)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/devel1jpg
|
||||
[8]:https://www.linux.com/files/images/devel2jpg
|
||||
[9]:https://www.linux.com/files/images/devel3jpg
|
||||
[10]:https://www.linux.com/files/images/devel4jpg
|
||||
[11]:https://www.linux.com/files/images/devel5jpg
|
||||
[12]:https://www.linux.com/files/images/king-penguins1920jpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:https://www.debian.org/
|
||||
[15]:https://www.ubuntu.com/
|
||||
[16]:https://linuxmint.com/
|
||||
[17]:https://elementary.io/
|
||||
[18]:https://www.debian.org/social_contract
|
||||
[19]:https://www.debian.org/doc/manuals/debian-reference/ch12.en.html
|
||||
[20]:https://www.opensuse.org/
|
||||
[21]:https://en.opensuse.org/Portal:Tumbleweed
|
||||
[22]:https://software.opensuse.org/download.html?project=devel%3Atools&package=rpmdevtools
|
||||
[23]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[24]:https://www.centos.org/
|
||||
[25]:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/pdf/developer_guide/Red_Hat_Enterprise_Linux-7-Developer_Guide-en-US.pdf
|
||||
[26]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[27]:https://www.bluej.org/
|
||||
[28]:https://www.geany.org/
|
||||
[29]:https://www.greenfoot.org/
|
||||
[30]:https://www.raspberrypi.org/blog/sense-hat-emulator/
|
||||
[31]:http://sonic-pi.net/
|
||||
[32]:http://thonny.org/
|
||||
[33]:https://www.python.org/
|
||||
[34]:https://scratch.mit.edu/
|
||||
[35]:http://rpf.io/x86iso
|
||||
[36]:https://system76.com/
|
||||
[37]:https://system76.com/pop
|
||||
143
translated/tech/20180810 How To Remove Or Disable Ubuntu Dock.md
Normal file
143
translated/tech/20180810 How To Remove Or Disable Ubuntu Dock.md
Normal file
@ -0,0 +1,143 @@
|
||||
如何移除或禁用 Ubuntu Dock
|
||||
======
|
||||
|
||||

|
||||
|
||||
**如果你想用其它 dock(例如 Plank dock)或面板来替换 Ubuntu 18.04 中的 Dock,或者你想要移除或禁用 Ubuntu Dock,本文会告诉你如何做。**
|
||||
|
||||
Ubuntu Dock - 屏幕左侧栏,可用于固定应用程序或访问已安装的应用程序。使用默认的 Ubuntu 会话时,[无法][1]使用 Gnome Tweaks 禁用它。如果你需要,还是有几种方法来摆脱它的。下面我将列出 4 种方法可以移除或禁用 Ubuntu Dock,以及每个方法的缺点(如果有的话),还有如何撤销每个方法的更改。本文还包括在没有 Ubuntu Dock 的情况下访问多任务视图和已安装应用程序列表的其它方法。
|
||||
(to 校正:Activities Overview 在本文翻译为多任务视图,如有不妥,请改正)
|
||||
### 如何在没有 Ubuntu Dock 的情况下访问多任务试图
|
||||
|
||||
如果没有 Ubuntu Dock,你可能无法访问活动的或已安装的应用程序列表(但是可以通过单击 Dock 底部的“显示应用程序”按钮从 Ubuntu Dock 访问)。例如,如果你想使用 Plank Dock。(to 校正:这里是什么意思呢)
|
||||
|
||||
显然,如果你安装了 Dash to Panel 扩展来使用它而不是 Ubuntu Dock,那么情况并非如此。因为 Dash to Panel 提供了一个按钮来访问多任务视图或已安装的应用程序。
|
||||
|
||||
根据你计划使用的 Dock 而不是 Ubuntu Dock,如果无法访问多任务视图,那么你可以启用 Activities Overview Hot Corner 选项,只需将鼠标移动到屏幕的左上角即可打开 Activities。访问已安装的应用程序列表的另一种方法是使用快捷键:`Super + A`。
|
||||
|
||||
如果要启用 Activities Overview hot corner,使用以下命令:
|
||||
```
|
||||
gsettings set org.gnome.shell enable-hot-corners true
|
||||
|
||||
```
|
||||
|
||||
如果以后要撤销此操作并禁用 hot corners,那么你需要使用以下命令:
|
||||
```
|
||||
gsettings set org.gnome.shell enable-hot-corners false
|
||||
|
||||
```
|
||||
|
||||
你可以使用 Gnome Tweaks 应用程序(该选项位于 Gnome Tweaks 的 `Top Bar` 部分)启用或禁用 Activities Overview Hot Corner 选项,可以使用以下命令进行安装:
|
||||
```
|
||||
sudo apt install gnome-tweaks
|
||||
|
||||
```
|
||||
|
||||
### 如何移除或禁用 Ubuntu Dock
|
||||
|
||||
下面你将找到 4 种摆脱 Ubuntu Dock 的方法,环境在 Ubuntu 18.04 下。
|
||||
|
||||
**方法 1: 移除 Gnome Shell Ubuntu Dock 包。**
|
||||
|
||||
摆脱 Ubuntu Dock 的最简单方法就是删除包。
|
||||
|
||||
这将会从你的系统中完全移除 Ubuntu Dock 扩展,但同时也移除了 `ubuntu-desktop` 元数据包。如果你移除 `ubuntu-desktop` 元数据包,不会马上出现问题,因为它本身没有任何作用。`ubuntu-meta` 包依赖于组成 Ubuntu 桌面的大量包。它的依赖关系不会被删除,也不会被破坏。问题是如果你以后想升级到新的 Ubuntu 版本,那么将不会安装任何新的 `ubuntu-desktop` 依赖项。
|
||||
|
||||
为了解决这个问题,你可以在升级到较新的 Ubuntu 版本之前安装 `ubuntu-desktop` 元包(例如,如果你想从 Ubuntu 18.04 升级到 18.10)。
|
||||
|
||||
如果你对此没有意见,并且想要从系统中删除 Ubuntu Dock 扩展包,使用以下命令:
|
||||
```
|
||||
sudo apt remove gnome-shell-extension-ubuntu-dock
|
||||
|
||||
```
|
||||
|
||||
如果以后要撤消更改,只需使用以下命令安装扩展:
|
||||
```
|
||||
sudo apt install gnome-shell-extension-ubuntu-dock
|
||||
|
||||
```
|
||||
|
||||
或者重新安装 `ubuntu-desktop` 元数据包(这将会安装你可能已删除的任何 ubuntu-desktop 依赖项,包括 Ubuntu Dock),你可以使用以下命令:
|
||||
```
|
||||
sudo apt install ubuntu-desktop
|
||||
|
||||
```
|
||||
|
||||
**选项2:安装并使用 vanilla Gnome 会话而不是默认的 Ubuntu 会话。**
|
||||
|
||||
摆脱 Ubuntu Dock 的另一种方法是安装和使用 vanilla Gnome 会话。安装 vanilla Gnome 会话还将安装此会话所依赖的其它软件包,如 Gnome 文档,地图,音乐,联系人,照片,跟踪器等。
|
||||
|
||||
通过安装 vanilla Gnome 会话,你还将获得默认 Gnome GDM 登录和锁定屏幕主题,而不是 Ubuntu 默认值,另外还有 Adwaita Gtk 主题和图标。你可以使用 Gnome Tweaks 应用程序轻松更改 Gtk 和图标主题。
|
||||
|
||||
此外,默认情况下将禁用 AppIndicators 扩展(因此使用 AppIndicators 托盘的应用程序不会显示在顶部面板上),但你可以使用 Gnome Tweaks 启用此功能(在扩展中,启用 Ubuntu appindicators 扩展)。
|
||||
|
||||
同样,你也可以从 vanilla Gnome 会话启用或禁用 Ubuntu Dock,这在 Ubuntu 会话中是不可能的(使用 Ubuntu 会话时无法从 Gnome Tweaks 禁用 Ubuntu Dock)。
|
||||
|
||||
如果你不想安装 vanilla Gnome 会话所需的这些额外软件包,那么这个移除 Ubuntu Dock 的这个选项不适合你,请查看其它选项。
|
||||
|
||||
如果你对此没有意见,以下是你需要做的事情。要在 Ubuntu 中安装普通的 Gnome 会话,使用以下命令:
|
||||
```
|
||||
sudo apt install vanilla-gnome-desktop
|
||||
|
||||
```
|
||||
|
||||
安装完成后,重启系统。在登录屏幕上,单击用户名,单击 `Sign in` 按钮旁边的齿轮图标,然后选择 `GNOME` 而不是 `Ubuntu`,之后继续登录。
|
||||
|
||||

|
||||
|
||||
如果要撤销此操作并移除 vanilla Gnome 会话,可以使用以下命令清除 vanilla Gnome 软件包,然后删除它安装的依赖项(第二条命令):
|
||||
```
|
||||
sudo apt purge vanilla-gnome-desktop
|
||||
sudo apt autoremove
|
||||
|
||||
```
|
||||
|
||||
然后重新启动,并以相同的方式从 GDM 登录屏幕中选择 Ubuntu。
|
||||
|
||||
**选项 3:从桌面上永久隐藏 Ubuntu Dock,而不是将其移除。**
|
||||
|
||||
如果你希望永久隐藏 Ubuntu Dock,不让它显示在桌面上,但不移除它或使用 vanilla Gnome 会话,你可以使用 Dconf 编辑器轻松完成此操作。这样做的缺点是 Ubuntu Dock 仍然会使用一些系统资源,即使你没有在桌面上使用它,但你也可以轻松恢复它而无需安装或移除任何包。
|
||||
|
||||
Ubuntu Dock 只对你的桌面隐藏,当你进入叠加模式(Activities)时,你仍然可以看到并从那里使用 Ubuntu Dock。
|
||||
|
||||
要永久隐藏 Ubuntu Dock,使用 Dconf 编辑器导航到 `/org/gnome/shell/extensions/dash-to-dock` 并禁用以下选项(将它们设置为 false):`autohide`, `dock-fixed` 和 `intellihide`。
|
||||
|
||||
如果你愿意,可以从命令行实现此目的,运行以下命令:
|
||||
```
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock autohide false
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed false
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide false
|
||||
|
||||
```
|
||||
|
||||
如果你改变主意了并想撤销此操作,你可以使用 Dconf 编辑器从 `/org/gnome/shell/extensions/dash-to-dock` 中启动 `autohide`, `dock-fixed` 和 `intellihide`(将它们设置为 true),或者你可以使用以下这些命令:
|
||||
```
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock autohide true
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock dock-fixed true
|
||||
gsettings set org.gnome.shell.extensions.dash-to-dock intellihide true
|
||||
|
||||
```
|
||||
|
||||
**选项 4:使用 Dash to Panel 扩展。**
|
||||
|
||||
[Dash to Panel][2] 是 Gnome Shell 的一个高度可配置面板,是 Ubuntu Dock 或 Dash to Dock 的一个很好的替代品(Ubuntu Dock 是从 Dash to Dock 克隆而来的)。安装和启动 Dash to Panel 扩展会禁用 Ubuntu Dock,因此你无需执行其它任何操作。
|
||||
|
||||
你可以从 [extensions.gnome.org][3] 来安装 Dash to Panel。
|
||||
|
||||
如果你改变主意并希望重新使用 Ubuntu Dock,那么你可以使用 Gnome Tweaks 应用程序禁用 Dash to Panel,或者通过单击以下网址旁边的 X 按钮完全移除 Dash to Panel: https://extensions.gnome.org/local/。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/how-to-remove-or-disable-ubuntu-dock.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://bugs.launchpad.net/ubuntu/+source/gnome-tweak-tool/+bug/1713020
|
||||
[2]:https://www.linuxuprising.com/2018/05/gnome-shell-dash-to-panel-v14-brings.html
|
||||
[3]:https://extensions.gnome.org/extension/1160/dash-to-panel/
|
||||
524
translated/tech/20181004 Lab 3- User Environments.md
Normal file
524
translated/tech/20181004 Lab 3- User Environments.md
Normal file
@ -0,0 +1,524 @@
|
||||
实验 3:用户环境
|
||||
======
|
||||
### 实验 3:用户环境
|
||||
|
||||
#### 简介
|
||||
|
||||
在本实验中,你将要实现一个基本的内核功能,要求它能够保护运行的用户模式环境(即:进程)。你将去增强这个 JOS 内核,去配置数据结构以便于保持对用户环境的跟踪、创建一个单一用户环境、将程序镜像加载到用户环境中、并将它启动运行。你也要写出一些 JOS 内核的函数,用来处理任何用户环境生成的系统调用,以及处理由用户环境引进的各种异常。
|
||||
|
||||
**注意:** 在本实验中,术语**_“环境”_** 和**_“进程”_** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
|
||||
|
||||
##### 预备知识
|
||||
|
||||
使用 Git 去提交你自实验 2 以后的更改(如果有的话),获取课程仓库的最新版本,以及创建一个命名为 `lab3` 的本地分支,指向到我们的 lab3 分支上 `origin/lab3` :
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
实验 3 包含一些你将探索的新源文件:
|
||||
|
||||
```c
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
```
|
||||
|
||||
另外,一些在实验 2 中的源文件在实验 3 中将被修改。如果想去查看有什么更改,可以运行:
|
||||
|
||||
```
|
||||
$ git diff lab2
|
||||
|
||||
```
|
||||
|
||||
你也可以另外去看一下 [实验工具指南][1],它包含了与本实验有关的调试用户代码方面的信息。
|
||||
|
||||
##### 实验要求
|
||||
|
||||
本实验分为两部分:Part A 和 Part B。Part A 在本实验完成后一周内提交;你将要提交你的更改和完成的动手实验,在提交之前要确保你的代码通过了 Part A 的所有检查(如果你的代码未通过 Part B 的检查也可以提交)。只需要在第二周提交 Part B 的期限之前代码检查通过即可。
|
||||
|
||||
由于在实验 2 中,你需要做实验中描述的所有正则表达式练习,并且至少通过一个挑战(是指整个实验,不是每个部分)。写出详细的问题答案并张贴在实验中,以及一到两个段落的关于你如何解决你选择的挑战问题的详细描述,并将它放在一个名为 `answers-lab3.txt` 的文件中,并将这个文件放在你的 `lab` 目标的根目录下。(如果你做了多个问题挑战,你仅需要提交其中一个即可)不要忘记使用 `git add answers-lab3.txt` 提交这个文件。
|
||||
|
||||
##### 行内汇编语言
|
||||
|
||||
在本实验中你可能找到使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言("`asm`" 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料][2] 的页面上找到 GCC 行内汇编语言有关的信息。
|
||||
|
||||
#### Part A:用户环境和异常处理
|
||||
|
||||
新文件 `inc/env.h` 中包含了在 JOS 中关于用户环境的基本定义。现在就去阅读它。内核使用数据结构 `Env` 去保持对每个用户环境的跟踪。在本实验的开始,你将只创建一个环境,但你需要去设计 JOS 内核支持多环境;实验 4 将带来这个高级特性,允许用户环境去 `fork` 其它环境。
|
||||
|
||||
正如你在 `kern/env.c` 中所看到的,内核维护了与环境相关的三个全局变量:
|
||||
|
||||
```
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
|
||||
```
|
||||
|
||||
一旦 JOS 启动并运行,`envs` 指针指向到一个数组,即数据结构 `Env`,它保存了系统中全部的环境。在我们的设计中,JOS 内核将同时支持最大值为 `NENV` 个的活动的环境,虽然在一般情况下,任何给定时刻运行的环境很少。(`NENV` 是在 `inc/env.h` 中用 `#define` 定义的一个常量)一旦它被分配,对于每个 `NENV` 可能的环境,`envs` 数组将包含一个数据结构 `Env` 的单个实例。
|
||||
|
||||
JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动的环境。这样的设计使得环境的分配和回收很容易,因为这只不过是添加或删除空闲列表的问题而已。
|
||||
|
||||
内核使用符号 `curenv` 来保持对任意给定时刻的 _当前正在运行的环境_ 进行跟踪。在系统引导期间,在第一个环境运行之前,`curenv` 被初始化为 `NULL`。
|
||||
|
||||
##### 环境状态
|
||||
|
||||
数据结构 `Env` 被定义在文件 `inc/env.h` 中,内容如下:(在后面的实验中将添加更多的字段):
|
||||
|
||||
```c
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
```
|
||||
|
||||
以下是数据结构 `Env` 中的字段简介:
|
||||
|
||||
* **env_tf**:
|
||||
这个结构定义在 `inc/trap.h` 中,它用于在那个环境不运行时保持它保存在寄存器中的值,即:当内核或一个不同的环境在运行时。当从用户模式切换到内核模式时,内核将保存这些东西,以便于那个环境能够在稍后重新运行时回到中断运行的地方。
|
||||
* **env_link**:
|
||||
这是一个链接,它链接到在 `env_free_list` 上的下一个 `Env` 上。`env_free_list` 指向到列表上第一个空闲的环境。
|
||||
* **env_id**:
|
||||
内核在数据结构 `Env` 中保存了一个唯一标识当前环境的值(即:使用数组 `envs` 中的特定槽位)。在一个用户环境终止之后,内核可能给另外的环境重新分配相同的数据结构 `Env` —— 但是新的环境将有一个与已终止的旧的环境不同的 `env_id`,即便是新的环境在数组 `envs` 中复用了同一个槽位。
|
||||
* **env_parent_id**:
|
||||
内核使用它来保存创建这个环境的父级环境的 `env_id`。通过这种方式,环境就可以形成一个“家族树”,这对于做出“哪个环境可以对谁做什么”这样的安全决策非常有用。
|
||||
* **env_type**:
|
||||
它用于去区分特定的环境。对于大多数环境,它将是 `ENV_TYPE_USER` 的。在稍后的实验中,针对特定的系统服务环境,我们将引入更多的几种类型。
|
||||
* **env_status**:
|
||||
这个变量持有以下几个值之一:
|
||||
* `ENV_FREE`:
|
||||
表示那个 `Env` 结构是非活动的,并且因此它还在 `env_free_list` 上。
|
||||
* `ENV_RUNNABLE`:
|
||||
表示那个 `Env` 结构所代表的环境正等待被调度到处理器上去运行。
|
||||
* `ENV_RUNNING`:
|
||||
表示那个 `Env` 结构所代表的环境当前正在运行中。
|
||||
* `ENV_NOT_RUNNABLE`:
|
||||
表示那个 `Env` 结构所代表的是一个当前活动的环境,但不是当前准备去运行的:例如,因为它正在因为一个来自其它环境的进程间通讯(IPC)而处于等待状态。
|
||||
* `ENV_DYING`:
|
||||
表示那个 `Env` 结构所表示的是一个僵尸环境。一个僵尸环境将在下一次被内核捕获后被释放。我们在实验 4 之前不会去使用这个标志。
|
||||
* **env_pgdir**:
|
||||
这个变量持有这个环境的内核虚拟地址的页目录。
|
||||
|
||||
|
||||
|
||||
就像一个 Unix 进程一样,一个 JOS 环境耦合了“线程”和“地址空间”的概念。线程主要由保存的寄存器来定义(`env_tf` 字段),而地址空间由页目录和 `env_pgdir` 所指向的页表所定义。为运行一个环境,内核必须使用保存的寄存器值和相关的地址空间去设置 CPU。
|
||||
|
||||
我们的 `struct Env` 与 xv6 中的 `struct proc` 类似。它们都在一个 `Trapframe` 结构中持有环境(即进程)的用户模式寄存器状态。在 JOS 中,单个的环境并不能像 xv6 中的进程那样拥有它们自己的内核栈。在这里,内核中任意时间只能有一个 JOS 环境处于活动中,因此,JOS 仅需要一个单个的内核栈。
|
||||
|
||||
##### 为环境分配数组
|
||||
|
||||
在实验 2 的 `mem_init()` 中,你为数组 `pages[]` 分配了内存,它是内核用于对页面分配与否的状态进行跟踪的一个表。你现在将需要去修改 `mem_init()`,以便于后面使用它分配一个与结构 `Env` 类似的数组,这个数组被称为 `envs`。
|
||||
|
||||
```markdown
|
||||
练习 1、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
|
||||
```
|
||||
|
||||
你应该去运行你的代码,并确保 `check_kern_pgdir()` 是没有问题的。
|
||||
|
||||
##### 创建和运行环境
|
||||
|
||||
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
|
||||
|
||||
在实验 3 中,`GNUmakefile` 将在 `obj/user/` 目录中生成一些二进制镜像。如果你看到 `kern/Makefrag`,你将注意到一些奇怪的的东西,它们“链接”这些二进制直接进入到内核中运行,就像 `.o` 文件一样。在链接器命令行上的 `-b binary` 选项,将因此把它们链接为“原生的”不解析的二进制文件,而不是由编译器产生的普通的 `.o` 文件。(就链接器而言,这些文件压根就不是 ELF 镜像文件 —— 它们可以是任何东西,比如,一个文本文件或图片!)如果你在内核构建之后查看 `obj/kern/kernel.sym` ,你将会注意到链接器很奇怪的生成了一些有趣的、命名很费解的符号,比如像 `_binary_obj_user_hello_start`、`_binary_obj_user_hello_end`、以及 `_binary_obj_user_hello_size`。链接器通过改编二进制文件的命令来生成这些符号;这种符号为普通内核代码使用一种引入嵌入式二进制文件的方法。
|
||||
|
||||
在 `kern/init.c` 的 `i386_init()` 中,你将写一些代码在环境中运行这些二进制镜像中的一种。但是,设置用户环境的关键函数还没有实现;将需要你去完成它们。
|
||||
|
||||
```markdown
|
||||
练习 2、在文件 `env.c` 中,写完以下函数的代码:
|
||||
|
||||
* `env_init()`
|
||||
初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
|
||||
* `env_setup_vm()`
|
||||
为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
|
||||
* `region_alloc()`
|
||||
为一个新环境分配和映射物理内存
|
||||
* `load_icode()`
|
||||
你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
|
||||
* `env_create()`
|
||||
使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
|
||||
* `env_run()`
|
||||
在用户模式中开始运行一个给定的环境
|
||||
|
||||
|
||||
|
||||
在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 -- 它可以输出一个错误代码的相关描述。比如:
|
||||
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
|
||||
中 panic 将输出消息 "env_alloc: out of memory"。
|
||||
```
|
||||
|
||||
下面是用户代码相关的调用图。确保你理解了每一步的用途。
|
||||
|
||||
* `start` (`kern/entry.S`)
|
||||
* `i386_init` (`kern/init.c`)
|
||||
* `cons_init`
|
||||
* `mem_init`
|
||||
* `env_init`
|
||||
* `trap_init`(到目前为止还未完成)
|
||||
* `env_create`
|
||||
* `env_run`
|
||||
* `env_pop_tf`
|
||||
|
||||
|
||||
|
||||
在完成以上函数后,你应该去编译内核并在 QEMU 下运行它。如果一切正常,你的系统将进入到用户空间并运行二进制的 `hello` ,直到使用 `int` 指令生成一个系统调用为止。在那个时刻将存在一个问题,因为 JOS 尚未设置硬件去允许从用户空间到内核空间的各种转换。当 CPU 发现没有系统调用中断的服务程序时,它将生成一个一般保护异常,找到那个异常并去处理它,还将生成一个双重故障异常,同样也找到它并处理它,并且最后会出现所谓的“三重故障异常”。通常情况下,你将随后看到 CPU 复位以及系统重引导。虽然对于传统的应用程序(在 [这篇博客文章][3] 中解释了原因)这是重大的问题,但是对于内核开发来说,这是一个痛苦的过程,因此,在打了 6.828 补丁的 QEMU 上,你将可以看到转储的寄存器内容和一个“三重故障”的信息。
|
||||
|
||||
我们马上就会去处理这些问题,但是现在,我们可以使用调试器去检查我们是否进入了用户模式。使用 `make qemu-gdb` 并在 `env_pop_tf` 处设置一个 GDB 断点,它是你进入用户模式之前到达的最后一个函数。使用 `si` 单步进入这个函数;处理器将在 `iret` 指令之后进入用户模式。然后你将会看到在用户环境运行的第一个指令,它将是在 `lib/entry.S` 中的标签 `start` 的第一个指令 `cmpl`。现在,在 `hello` 中的 `sys_cputs()` 的 `int $0x30` 处使用 `b *0x...`(关于用户空间的地址,请查看 `obj/user/hello.asm` )设置断点。这个指令 `int` 是系统调用去显示一个字符到控制台。如果到 `int` 还没有运行,那么可能在你的地址空间设置或程序加载代码时发生了错误;返回去找到问题并解决后重新运行。
|
||||
|
||||
##### 处理中断和异常
|
||||
|
||||
到目前为止,在用户空间中的第一个系统调用指令 `int $0x30` 已正式寿终正寝了:一旦处理器进入用户模式,将无法返回。因此,现在,你需要去实现基本的异常和系统调用服务程序,因为那样才有可能让内核从用户模式代码中恢复对处理器的控制。你所做的第一件事情就是彻底地掌握 x86 的中断和异常机制的使用。
|
||||
|
||||
```
|
||||
练习 3、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
|
||||
```
|
||||
|
||||
在这个实验中,对于中断、异常、以其它类似的东西,我们将遵循 Intel 的术语习惯。由于如<ruby>异常<rt>exception</rt></ruby>、<ruby>陷阱<rt>trap</rt></ruby>、<ruby>中断<rt>interrupt</rt></ruby>、<ruby>故障<rt>fault</rt></ruby>和<ruby>中止<rt>abort</rt></ruby>这些术语在不同的架构和操作系统上并没有一个统一的标准,我们经常在特定的架构下(如 x86)并不去考虑它们之间的细微差别。当你在本实验以外的地方看到这些术语时,它们的含义可能有细微的差别。
|
||||
|
||||
##### 受保护的控制转移基础
|
||||
|
||||
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(CPL=0)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
|
||||
|
||||
为了确保这些受保护的控制转移是真正地受到保护,处理器的中断/异常机制设计是:当中断/异常发生时,当前运行的代码不能随意选择进入内核的位置和方式。而是,处理器在确保内核能够严格控制的条件下才能进入内核。在 x86 上,有两种机制协同来提供这种保护:
|
||||
|
||||
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
|
||||
|
||||
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
|
||||
|
||||
* 将值加载到指令指针寄存器(EIP),指向内核代码设计好的,用于处理这种异常的服务程序。
|
||||
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 level 0。)
|
||||
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
|
||||
|
||||
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
|
||||
|
||||
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的 level 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
|
||||
|
||||
|
||||
|
||||
|
||||
##### 异常和中断的类型
|
||||
|
||||
所有的 x86 处理器上的同步异常都能够产生一个内部使用的、介于 0 到 31 之间的中断向量,因此它映射到 IDT 就是条目 0-31。例如,一个页故障总是通过向量 14 引发一个异常。大于 31 的中断向量仅用于软件中断,它由 `int` 指令生成,或异步硬件中断,当需要时,它们由外部设备产生。
|
||||
|
||||
在这一节中,我们将扩展 JOS 去处理向量为 0-31 之间的、内部产生的 x86 异常。在下一节中,我们将完成 JOS 的 48(0x30)号软件中断向量,JOS 将(随意选择的)使用它作为系统调用中断向量。在实验 4 中,我们将扩展 JOS 去处理外部生成的硬件中断,比如时钟中断。
|
||||
|
||||
##### 一个示例
|
||||
|
||||
我们把这些片断综合到一起,通过一个示例来巩固一下。我们假设处理器在用户环境下运行代码,遇到一个除零问题。
|
||||
|
||||
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
|
||||
|
||||
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
|
||||
```
|
||||
|
||||
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
|
||||
|
||||
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
|
||||
|
||||
|
||||
|
||||
|
||||
对于某些类型的 x86 异常,除了以上的五个“标准的”寄存器外,处理器还推入另一个包含错误代码的寄存器值到栈中。页故障异常,向量号为 14,就是一个重要的示例。查看 80386 手册去确定哪些异常推入一个错误代码,以及错误代码在那个案例中的意义。当处理器推入一个错误代码后,当从用户模式中进入内核模式,异常处理服务程序开始时的栈看起来应该如下所示:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
##### 嵌套的异常和中断
|
||||
|
||||
处理器能够处理来自用户和内核模式中的异常和中断。当收到来自用户模式的异常和中断时才会进入内核模式中,而且,在推送它的旧寄存器状态到栈中和通过 IDT 调用相关的异常服务程序之前,x86 处理器会自动切换栈。如果当异常或中断发生时,处理器已经处于内核模式中(`CS` 寄存器低位两个比特为 0),那么 CPU 只是推入一些值到相同的内核栈中。在这种方式中,内核可以优雅地处理嵌套的异常,嵌套的异常一般由内核本身的代码所引发。在实现保护时,这种功能是非常重要的工具,我们将在稍后的系统调用中看到它。
|
||||
|
||||
如果处理器已经处于内核模式中,并且发生了一个嵌套的异常,由于它并不需要切换栈,它也就不需要去保存旧的 `SS` 或 `ESP` 寄存器。对于不推入错误代码的异常类型,在进入到异常服务程序时,它的内核栈看起来应该如下图:
|
||||
|
||||
```
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
对于需要推入一个错误代码的异常类型,处理器将在旧的 `EIP` 之后,立即推入一个错误代码,就和前面一样。
|
||||
|
||||
关于处理器的异常嵌套的功能,这里有一个重要的警告。如果处理器正处于内核模式时发生了一个异常,并且不论是什么原因,比如栈空间泄漏,都不会去推送它的旧的状态,那么这时处理器将不能做任何的恢复,它只是简单地重置。毫无疑问,内核应该被设计为禁止发生这种情况。
|
||||
|
||||
##### 设置 IDT
|
||||
|
||||
到目前为止,你应该有了在 JOS 中为了设置 IDT 和处理异常所需的基本信息。现在,我们去设置 IDT 以处理中断向量 0-31(处理器异常)。我们将在本实验的稍后部分处理系统调用,然后在后面的实验中增加中断 32-47(设备 IRQ)。
|
||||
|
||||
在头文件 `inc/trap.h` 和 `kern/trap.h` 中包含了中断和异常相关的重要定义,你需要去熟悉使用它们。在文件`kern/trap.h` 中包含了到内核的、严格的、秘密的定义,可是在 `inc/trap.h` 中包含的定义也可以被用到用户级程序和库上。
|
||||
|
||||
注意:在范围 0-31 中的一些异常是被 Intel 定义为保留。因为在它们的处理器上从未产生过,你如何处理它们都不会有大问题。你想如何做它都是可以的。
|
||||
|
||||
你将要实现的完整的控制流如下图所描述:
|
||||
|
||||
```c
|
||||
IDT trapentry.S trap.c
|
||||
|
||||
+----------------+
|
||||
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
+----------------+
|
||||
| &handler2 |--------> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
.
|
||||
.
|
||||
.
|
||||
+----------------+
|
||||
| &handlerX |--------> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
```
|
||||
|
||||
每个异常或中断都应该在 `trapentry.S` 中有它自己的处理程序,并且 `trap_init()` 应该使用这些处理程序的地址去初始化 IDT。每个处理程序都应该在栈上构建一个 `struct Trapframe`(查看 `inc/trap.h`),然后使用一个指针调用 `trap()`(在 `trap.c` 中)到 `Trapframe`。`trap()` 接着处理异常/中断或派发给一个特定的处理函数。
|
||||
|
||||
```markdown
|
||||
练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T_* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
|
||||
|
||||
你的 `_alltraps` 应该:
|
||||
|
||||
1. 推送值以使栈看上去像一个结构 Trapframe
|
||||
2. 加载 `GD_KD` 到 `%ds` 和 `%es`
|
||||
3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
|
||||
4. `call trap` (`trap` 能够返回吗?)
|
||||
|
||||
|
||||
|
||||
考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
|
||||
|
||||
使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
|
||||
```
|
||||
|
||||
```markdown
|
||||
问题
|
||||
|
||||
在你的 `answers-lab3.txt` 中回答下列问题:
|
||||
|
||||
1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
|
||||
2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情?
|
||||
```
|
||||
|
||||
|
||||
本实验的 Part A 部分结束了。不要忘了去添加 `answers-lab3.txt` 文件,提交你的变更,然后在 Part A 作业的提交截止日期之前运行 `make handin`。
|
||||
|
||||
#### Part B:页故障、断点异常、和系统调用
|
||||
|
||||
现在,你的内核已经有了最基本的异常处理能力,你将要去继续改进它,来提供依赖异常服务程序的操作系统原语。
|
||||
|
||||
##### 处理页故障
|
||||
|
||||
页故障异常,中断向量为 14(`T_PGFLT`),它是一个非常重要的东西,我们将通过本实验和接下来的实验来大量练习它。当处理器产生一个页故障时,处理器将在它的一个特定的控制寄存器(`CR2`)中保存导致这个故障的线性地址(即:虚拟地址)。在 `trap.c` 中我们提供了一个专门处理它的函数的一个雏形,它就是 `page_fault_handler()`,我们将用它来处理页故障异常。
|
||||
|
||||
```markdown
|
||||
练习 5、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite`、和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 make run- _x_ 或 make run- _x_ -nox 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 make run-hello-nox 去运行 the _hello_ user 程序。
|
||||
```
|
||||
|
||||
下面,你将进一步细化内核的页故障服务程序,因为你要实现系统调用了。
|
||||
|
||||
##### 断点异常
|
||||
|
||||
断点异常,中断向量为 3(`T_BRKPT`),它一般用在调试上,它在一个程序代码中插入断点,从而使用特定的 1 字节的 `int3` 软件中断指令来临时替换相应的程序指令。在 JOS 中,我们将稍微“滥用”一下这个异常,通过将它打造成一个伪系统调用原语,使得任何用户环境都可以用它来调用 JOS 内核监视器。如果我们将 JOS 内核监视认为是原始调试器,那么这种用法是合适的。例如,在 `lib/panic.c` 中实现的用户模式下的 `panic()` ,它在显示它的 `panic` 消息后运行一个 `int3` 中断。
|
||||
|
||||
```markdown
|
||||
练习 6、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) '继续' 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
|
||||
|
||||
可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
|
||||
```
|
||||
|
||||
```markdown
|
||||
问题
|
||||
|
||||
3. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
|
||||
4. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
|
||||
```
|
||||
|
||||
|
||||
##### 系统调用
|
||||
|
||||
用户进程请求内核为它做事情就是通过系统调用来实现的。当用户进程请求一个系统调用时,处理器首先进入内核模式,处理器和内核配合去保存用户进程的状态,内核为了完成系统调用会运行有关的代码,然后重新回到用户进程。用户进程如何获得内核的关注以及它如何指定它需要的系统调用的具体细节,这在不同的系统上是不同的。
|
||||
|
||||
在 JOS 内核中,我们使用 `int` 指令,它将导致产生一个处理器中断。尤其是,我们使用 `int $0x30` 作为系统调用中断。我们定义常量 `T_SYSCALL` 为 48(0x30)。你将需要去设置中断描述符表,以允许用户进程去触发那个中断。注意,那个中断 0x30 并不是由硬件生成的,因此允许用户代码去产生它并不会引起歧义。
|
||||
|
||||
应用程序将在寄存器中传递系统调用号和系统调用参数。通过这种方式,内核就不需要去遍历用户环境的栈或指令流。系统调用号将放在 `%eax` 中,而参数(最多五个)将分别放在 `%edx`、`%ecx`、`%ebx`、`%edi`、和 `%esi` 中。内核将在 `%eax` 中传递返回值。在 `lib/syscall.c` 中的 `syscall()` 中已为你编写了使用一个系统调用的汇编代码。你可以通过阅读它来确保你已经理解了它们都做了什么。
|
||||
|
||||
```markdown
|
||||
练习 7、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
|
||||
|
||||
在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 "`hello, world`",然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
|
||||
|
||||
`sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
|
||||
|
||||
在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里][4]你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
|
||||
|
||||
最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
|
||||
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
|
||||
GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(push)和恢复(pop)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
|
||||
|
||||
注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
|
||||
|
||||
在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
|
||||
```
|
||||
|
||||
##### 启动用户模式
|
||||
|
||||
一个用户程序是从 `lib/entry.S` 的顶部开始运行的。在一些配置之后,代码调用 `lib/libmain.c` 中的 `libmain()`。你应该去修改 `libmain()` 以初始化全局指针 `thisenv`,使它指向到这个环境在数组 `envs[]` 中的 `struct Env`。(注意那个 `lib/entry.S` 中已经定义 `envs` 去指向到在 Part A 中映射的你的设置。)提示:查看 `inc/env.h` 和使用 `sys_getenvid`。
|
||||
|
||||
`libmain()` 接下来调用 `umain`,在 hello 程序的案例中,`umain` 是在 `user/hello.c` 中。注意,它在输出 "`hello, world`” 之后,它尝试去访问 `thisenv->env_id`。这就是为什么前面会发生故障的原因了。现在,你已经正确地初始化了 `thisenv`,它应该不会再发生故障了。如果仍然会发生故障,或许是因为你没有映射 `UENVS` 区域为用户可读取(回到前面 Part A 中 查看 `pmap.c`);这是我们第一次真实地使用 `UENVS` 区域)。
|
||||
|
||||
```markdown
|
||||
练习 8、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 "`hello, world`" 然后输出 "`i am environment 00001000`"。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去"退出"。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
|
||||
```
|
||||
|
||||
##### 页故障和内存保护
|
||||
|
||||
内存保护是一个操作系统中最重要的特性,通过它来保证一个程序中的 bug 不会破坏其它程序或操作系统本身。
|
||||
|
||||
操作系统一般是依靠硬件的支持来实现内存保护。操作系统会告诉硬件哪些虚拟地址是有效的,而哪些是无效的。当一个程序尝试去访问一个无效地址或它没有访问权限的地址时,处理器会在导致故障发生的位置停止程序运行,然后捕获内核中关于尝试操作的相关信息。如果故障是可修复的,内核可能修复它并让程序继续运行。如果故障不可修复,那么程序就不能继续,因为它绝对不会跳过那个导致故障的指令。
|
||||
|
||||
作为一个可修复故障的示例,假设一个自动扩展的栈。在许多系统上,内核初始化分配一个单栈页,然后如果程序发生的故障是去访问这个栈页下面的页,那么内核会自动分配这些页,并让程序继续运行。通过这种方式,内核只分配程序所需要的内存栈,但是程序可以运行在一个任意大小的栈的假像中。
|
||||
|
||||
对于内存保护,系统调用中有一个非常有趣的问题。许多系统调用接口让用户程序传递指针到内核中。这些指针指向用户要读取或写入的缓冲区。然后内核在执行系统调用时废弃这些指针。这样就有两个问题:
|
||||
|
||||
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
|
||||
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
|
||||
|
||||
|
||||
|
||||
由于以上的原因,内核在处理由用户程序提供的指针时必须格外小心。
|
||||
|
||||
现在,你可以通过使用一个简单的机制来仔细检查所有从用户空间传递给内核的指针来解决这个问题。当一个程序给内核传递指针时,内核将检查它的地址是否在地址空间的用户部分,然后页表才允许对内存的操作。
|
||||
|
||||
这样,内核在废弃一个用户提供的指针时就绝不会发生页故障。如果内核出现这种页故障,它应该崩溃并终止。
|
||||
|
||||
```markdown
|
||||
练习 9、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
|
||||
|
||||
提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
|
||||
|
||||
阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
|
||||
|
||||
修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
|
||||
|
||||
引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
|
||||
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
|
||||
```
|
||||
|
||||
注意,刚才实现的这些机制也同样适用于恶意用户程序(比如 `user/evilhello`)。
|
||||
|
||||
```
|
||||
练习 10、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
|
||||
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
```
|
||||
|
||||
**本实验到此结束。**确保你通过了所有的等级测试,并且不要忘记去写下问题的答案,在 `answers-lab3.txt` 中详细描述你的挑战练习的解决方案。提交你的变更并在 `lab` 目录下输入 `make handin` 去提交你的工作。
|
||||
|
||||
在动手实验之前,使用 `git status` 和 `git diff` 去检查你的变更,并不要忘记去 `git add answers-lab3.txt`。当你完成后,使用 `git commit -am 'my solutions to lab 3’` 去提交你的变更,然后 `make handin` 并关注这个指南。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab3/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/labguide.html
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labs/reference.html
|
||||
[3]: http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx
|
||||
[4]: http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c
|
||||
@ -0,0 +1,275 @@
|
||||
如何在 Rasspberry Pi 上搭建 WordPress
|
||||
======
|
||||
|
||||
这篇简单的教程可以让你在 Rasspberry Pi 上运行你的 WordPress 网站。
|
||||
|
||||

|
||||
|
||||
WordPress 是一个非常受欢迎的开源博客平台和内容管理平台(CMS)。它很容易搭建,而且还有一个活跃的开发者社区构建网站、创建主题和插件供其他人使用。
|
||||
|
||||
虽然通过一键式 WordPress 设置获得托管包很容易,但通过命令行就可以在 Linux 服务器上设置自己的托管包,而且 Raspberry Pi 是一种用来尝试它并顺便学习一些东西的相当好的途径。
|
||||
|
||||
使用一个 web 堆栈的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
|
||||
|
||||
### Linux
|
||||
|
||||
Raspberry Pi 上运行的系统是 Raspbian,这是一个基于 Debian,优化地可以很好的运行在 Raspberry Pi 硬件上的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
|
||||
|
||||
这篇教程在两个版本上都可以使用,但是如果你使用的是精简版,你必须要有另外一台电脑去访问你的站点。
|
||||
|
||||
### Apache
|
||||
|
||||
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的 Raspberry Pi 上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
|
||||
|
||||
安装 Apache 非常简单。打开一个终端窗口,然后输入下面的命令:
|
||||
|
||||
```
|
||||
sudo apt install apache2 -y
|
||||
```
|
||||
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 **<http://localhost>**。或者(特别是你使用的是 Raspbian Lite 的话)输入你的 Pi 的 IP 地址代替 **localhost**。你应该会在你的浏览器窗口中看到这样的内容:
|
||||
|
||||

|
||||
|
||||
这意味着你的 Apache 已经开始工作了!
|
||||
|
||||
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 **/var/www/html/index/html**。你可以使用 [Leafpad][2] 文本编辑器写一些 HTML 去替换这个文件的内容。
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo leafpad index.html
|
||||
```
|
||||
|
||||
保存并关闭 Leafpad 然后刷新网页,查看你的更改。
|
||||
|
||||
### MySQL
|
||||
|
||||
MySQL (显然是 "my S-Q-L" 或者 "my sequel") 是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
|
||||
|
||||
在一个终端窗口中输入以下命令安装 MySQL 服务:
|
||||
|
||||
```
|
||||
sudo apt-get install mysql-server -y
|
||||
```
|
||||
|
||||
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
|
||||
|
||||
### PHP
|
||||
|
||||
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。,不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
|
||||
|
||||
安装 PHP 和 MySQL 的插件:
|
||||
|
||||
```
|
||||
sudo apt-get install php php-mysql -y
|
||||
```
|
||||
|
||||
删除 **index.html**,然后创建 **index.php**:
|
||||
|
||||
```
|
||||
sudo rm index.html
|
||||
sudo leafpad index.php
|
||||
```
|
||||
|
||||
在里面添加以下内容:
|
||||
|
||||
```
|
||||
<?php phpinfo(); ?>
|
||||
```
|
||||
|
||||
保存、退出、刷新你的网页。你将会看到 PHP 状态页:
|
||||
|
||||

|
||||
|
||||
### WordPress
|
||||
|
||||
你可以使用 **wget** 命令从 [wordpress.org][3] 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz][4] 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
|
||||
|
||||
确保你在 **/var/www/html** 目录中,然后删除里面的所有内容:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo rm *
|
||||
```
|
||||
|
||||
使用 **wget** 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 **html** 目录下:
|
||||
|
||||
```
|
||||
sudo wget http://wordpress.org/latest.tar.gz
|
||||
sudo tar xzf latest.tar.gz
|
||||
sudo mv wordpress/* .
|
||||
```
|
||||
|
||||
现在可以删除压缩包和空的 **wordpress** 目录:
|
||||
|
||||
```
|
||||
sudo rm -rf wordpress latest.tar.gz
|
||||
```
|
||||
|
||||
运行 **ls** 或者 **tree -L 1** 命令显示 WordPress 项目下包含的内容:
|
||||
|
||||
```
|
||||
.
|
||||
├── index.php
|
||||
├── license.txt
|
||||
├── readme.html
|
||||
├── wp-activate.php
|
||||
├── wp-admin
|
||||
├── wp-blog-header.php
|
||||
├── wp-comments-post.php
|
||||
├── wp-config-sample.php
|
||||
├── wp-content
|
||||
├── wp-cron.php
|
||||
├── wp-includes
|
||||
├── wp-links-opml.php
|
||||
├── wp-load.php
|
||||
├── wp-login.php
|
||||
├── wp-mail.php
|
||||
├── wp-settings.php
|
||||
├── wp-signup.php
|
||||
├── wp-trackback.php
|
||||
└── xmlrpc.php
|
||||
|
||||
3 directories, 16 files
|
||||
```
|
||||
|
||||
这是 WordPress 的默认安装源。在 **wp-content** 目录中,你可以编辑你的自定义安装。
|
||||
|
||||
你现在应该把所有文件的所有权改为 Apache 用户:
|
||||
|
||||
```
|
||||
sudo chown -R www-data: .
|
||||
```
|
||||
|
||||
### WordPress 数据库
|
||||
|
||||
为了搭建你的 WordPress 站点,你需要一个数据库。这里使用的是 MySQL。
|
||||
|
||||
在终端窗口运行 MySQL 的安全安装命令:
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
你将会被问到一系列的问题。这里原来没有设置密码,但是在下一步你应该设置一个。确保你记住了你输入的密码,后面你需要使用它去连接你的 WordPress。按回车确认下面的所有问题。
|
||||
|
||||
当它完成之后,你将会看到 "All done!" 和 "Thanks for using MariaDB!" 的信息。
|
||||
|
||||
在终端窗口运行 **mysql** 命令:
|
||||
|
||||
```
|
||||
sudo mysql -uroot -p
|
||||
```
|
||||
输入你创建的 root 密码。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 **MariaDB [(none)] >** 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
|
||||
|
||||
```
|
||||
create database wordpress;
|
||||
```
|
||||
注意声明最后的分号,如果命令执行成功,你将看到下面的提示:
|
||||
|
||||
```
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
```
|
||||
把 数据库权限交给 root 用户在声明的底部输入密码:
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';
|
||||
```
|
||||
|
||||
为了让更改生效,你需要刷新数据库权限:
|
||||
|
||||
```
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
按 **Ctrl+D** 退出 MariaDB 提示,返回到 Bash shell。
|
||||
|
||||
### WordPress 配置
|
||||
|
||||
在你的 Raspberry Pi 打开网页浏览器,地址栏输入 **<http://localhost>**。选择一个你想要在 WordPress 使用的语言,然后点击 **继续**。你将会看到 WordPress 的欢迎界面。点击 **让我们开始吧** 按钮。
|
||||
|
||||
按照下面这样填写基本的站点信息:
|
||||
|
||||
```
|
||||
Database Name: wordpress
|
||||
User Name: root
|
||||
Password: <YOUR PASSWORD>
|
||||
Database Host: localhost
|
||||
Table Prefix: wp_
|
||||
```
|
||||
|
||||
点击 **提交** 继续,然后点击 **运行安装**。
|
||||
|
||||

|
||||
|
||||
按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 **安装 WordPress** 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 **<http://localhost/wp-admin>** 查看你的网站。
|
||||
|
||||
### 永久链接
|
||||
|
||||
更改你的永久链接,使得你的 URLs 更加友好是一个很好的想法。
|
||||
|
||||
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 **设置**,**永久链接**。选择 **文章名** 选项,然后点击 **保存更改**。接着你需要开启 Apache 的 **改写** 模块。
|
||||
|
||||
```
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件
|
||||
|
||||
```
|
||||
sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
```
|
||||
|
||||
在第一行后添加下面的内容:
|
||||
|
||||
```
|
||||
<Directory "/var/www/html">
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
```
|
||||
|
||||
确保其中有像这样的内容 **< VirtualHost \*:80>**
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
<Directory "/var/www/html">
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
...
|
||||
```
|
||||
|
||||
保存这个文件,然后退出,重启 Apache:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
### 下一步?
|
||||
|
||||
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘,。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
|
||||
|
||||
这里有一些你可以在 Raspberry Pi 的网页服务上尝试的有趣的事情:
|
||||
|
||||
* 添加页面和文章到你的网站
|
||||
* 从外观菜单安装不同的主题
|
||||
* 自定义你的网站主题或是创建你自己的
|
||||
* 使用你的网站服务向你的网络上的其他人显示有用的信息
|
||||
|
||||
|
||||
不要忘记,Raspberry Pi 是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/setting-wordpress-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sitewide-search?search_api_views_fulltext=raspberry%20pi
|
||||
[2]: https://en.wikipedia.org/wiki/Leafpad
|
||||
[3]: http://wordpress.org/
|
||||
[4]: https://wordpress.org/latest.tar.gz
|
||||
Loading…
Reference in New Issue
Block a user