mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-06 23:50:16 +08:00
commit
01b53b3d55
@ -1,15 +1,15 @@
|
||||
许多 SQL 性能问题来自于“不必要的强制性工作”
|
||||
============================================================
|
||||
=====================================
|
||||
|
||||
在编写高效 SQL 时,你可能遇到的最有影响力的事情就是[索引][1]。但是,一个很重要的事实就是很多 SQL 客户端要求数据库做很多**“不必要的强制性工作”**。
|
||||
在编写高效 SQL 时,你可能遇到的最有影响的事情就是[索引][1]。但是,一个很重要的事实就是很多 SQL 客户端要求数据库做很多**“不必要的强制性工作”**。
|
||||
|
||||
跟我再重复一遍:
|
||||
|
||||
> 不必要的强制性工作
|
||||
|
||||
什么是**“不必要的强制性工作”**?包括两个方面:
|
||||
什么是**“不必要的强制性工作”**?这个意思包括两个方面:
|
||||
|
||||
### 不必要
|
||||
### 不必要的
|
||||
|
||||
假设你的客户端应用程序需要这些信息:
|
||||
|
||||
@ -17,18 +17,21 @@
|
||||

|
||||
][2]
|
||||
|
||||
没什么特别的。我们运行着一个电影数据库([例如 Sakila 数据库][3]),我们想要给用户显示每部电影的名称和评分。
|
||||
这没什么特别的。我们运行着一个电影数据库([例如 Sakila 数据库][3]),我们想要给用户显示每部电影的名称和评分。
|
||||
|
||||
这是能产生上面结果的查询:
|
||||
这是能产生上面结果的查询:
|
||||
|
||||
```
|
||||
SELECT title, rating
|
||||
FROM film
|
||||
```
|
||||
|
||||
`SELECT title, rating`
|
||||
`FROM film`
|
||||
然而,我们的应用程序(或者我们的 ORM(LCTT 译注:Object-Relational Mapping,对象关系映射))运行的查询却是:
|
||||
|
||||
然而,我们的应用程序(或者我们的 ORM(LCTT 译注:Object-relational mapping,对象关系映射))运行的查询却是:
|
||||
|
||||
`SELECT *`
|
||||
`FROM film`
|
||||
```
|
||||
SELECT *
|
||||
FROM film
|
||||
```
|
||||
|
||||
我们得到什么?猜一下。我们得到很多无用的信息:
|
||||
|
||||
@ -36,7 +39,7 @@
|
||||

|
||||
][4]
|
||||
|
||||
甚至从头到尾有复杂的 JSON 数据,加载过程包括:
|
||||
甚至一些复杂的 JSON 数据全程在下列环节中加载:
|
||||
|
||||
* 从磁盘
|
||||
* 加载到缓存
|
||||
@ -44,19 +47,19 @@
|
||||
* 进入客户端内存
|
||||
* 然后被丢弃
|
||||
|
||||
是的,我们丢弃了其中大部分的信息。检索它所做的工作完全就是不必要的。对吧?是的。
|
||||
是的,我们丢弃了其中大部分的信息。检索它所做的工作完全就是不必要的。对吧?没错。
|
||||
|
||||
### 强制性
|
||||
|
||||
这是最严重的部分。现今随着优化器变得相当聪明,对于数据库来说这些工作都是强制性的。数据库没有办法_知道_客户端应用程序实际上不需要其中 95% 的数据。这只是一个简单的例子。想象一下如果我们连接更多的表...
|
||||
这是最糟糕的部分。现今随着优化器变得越来越聪明,这些工作对于数据库来说都是强制执行的。数据库没有办法_知道_客户端应用程序实际上不需要其中 95% 的数据。这只是一个简单的例子。想象一下如果我们连接更多的表...
|
||||
|
||||
你想想那会怎样呢?数据库会快吗?让我给你一些之前你可能没有想到的见解:
|
||||
你想想那会怎样呢?数据库还快吗?让我们来看看一些之前你可能没有想到的地方:
|
||||
|
||||
### 内存消耗
|
||||
|
||||
当然,单独的执行时间不会变化很大。可能是慢 1.5 倍,但我们可以忍受,是吧?为方便起见?有时候确实如此。但是如果你_每次_都为了方便而牺牲性能,事情就大了。我们不在讨论性能(单个查询的速度),而是吞吐量(系统响应时间),这就是事情变得困难而难以解决的时候。你无法再进行扩展。
|
||||
当然,单次执行时间不会变化很大。可能是慢 1.5 倍,但我们可以忍受,是吧?为方便起见,有时候确实如此。但是如果你_每次_都为了方便而牺牲性能,这事情就大了。我们不说性能问题(单个查询的速度),而是关注在吞吐量上时(系统响应时间),事情就变得困难而难以解决。你就会受阻于规模的扩大。
|
||||
|
||||
让我们来看看执行计划,这是 Oracle的:
|
||||
让我们来看看执行计划,这是 Oracle 的:
|
||||
|
||||
```
|
||||
--------------------------------------------------
|
||||
@ -67,7 +70,7 @@
|
||||
--------------------------------------------------
|
||||
```
|
||||
|
||||
对比
|
||||
对比一下:
|
||||
|
||||
```
|
||||
--------------------------------------------------
|
||||
@ -78,9 +81,9 @@
|
||||
--------------------------------------------------
|
||||
```
|
||||
|
||||
当执行 `SELECT *` 而不是 `SELECT film, rating` 的时候,数据库中我们使用了 8 倍的内存。这并不奇怪,对吧?我们早就知道了。在很多很多我们并不需要其中全部数据的查询中,我们仍然接受了。我们为数据库产生了**不必要的强制性工作**,后果累加了起来。我们使用了 8 倍的内存(当然,数值可能有些不同)。
|
||||
当执行 `SELECT *` 而不是 `SELECT film, rating` 的时候,我们在数据库中使用了 8 倍之多的内存。这并不奇怪,对吧?我们早就知道了。在很多我们并不需要其中全部数据的查询中我们都是这样做的。我们为数据库产生了**不必要的强制性工作**,其后果累加了起来,就是我们使用了多达 8 倍的内存(当然,数值可能有些不同)。
|
||||
|
||||
现在,所有其它步骤(磁盘 I/O、总线传输、客户端内存消耗)也受到相同的影响,我这里就跳过了。另外,我还想看看...
|
||||
而现在,所有其它的步骤(比如,磁盘 I/O、总线传输、客户端内存消耗)也受到相同的影响,我这里就跳过了。另外,我还想看看...
|
||||
|
||||
### 索引使用
|
||||
|
||||
@ -88,9 +91,11 @@
|
||||
|
||||
看看这个查询:
|
||||
|
||||
`SELECT` `*`
|
||||
`FROM` `actor`
|
||||
`WHERE` `last_name` `LIKE` `'A%'`
|
||||
```
|
||||
SELECT *
|
||||
FROM actor
|
||||
WHERE last_name LIKE 'A%'
|
||||
```
|
||||
|
||||
执行计划中没有什么特别之处。它只是个简单的查询。索引范围扫描、表访问,就结束了:
|
||||
|
||||
@ -104,15 +109,19 @@
|
||||
-------------------------------------------------------------------
|
||||
```
|
||||
|
||||
这是个好计划吗?如果我们想要的就是这些,那么它就不是:
|
||||
这是个好计划吗?如果我们只是想要这些,那么它就不是:
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
当然,我们浪费了内存等等。再来看看这个查询:
|
||||
当然,我们浪费了内存之类的。再来看看这个查询:
|
||||
|
||||
| 123 | `SELECT` `first_name, last_name``FROM` `actor``WHERE` `last_name` `LIKE` `'A%'` |
|
||||
```
|
||||
SELECT first_name, last_name
|
||||
FROM actor
|
||||
WHERE last_name LIKE 'A%'
|
||||
```
|
||||
|
||||
它的计划是:
|
||||
|
||||
@ -125,9 +134,9 @@
|
||||
----------------------------------------------------
|
||||
```
|
||||
|
||||
现在我们可以完全消除表访问,因为有一个索引涵盖了我们查询需要的所有东西...一个涵盖索引。这很重要吗?当然!这种方法可以将你的一些查询加速一个数量级(如果更改后你的索引不在涵盖,可能会降低一个数量级)。
|
||||
现在我们可以完全消除表访问,因为有一个索引涵盖了我们查询需要的所有东西……一个涵盖索引。这很重要吗?当然!这种方法可以将你的某些查询加速一个数量级(如果在某个更改后你的索引不再涵盖,可能会降低一个数量级)。
|
||||
|
||||
你不能总是从涵盖索引中获利。索引有它们自己的成本,你不应该添加太多索引,例如像这种情况,就是不明智的。让我们来做个测试:
|
||||
你不能总是从涵盖索引中获利。索引也有它们自己的成本,你不应该添加太多索引,例如像这种情况就是不明智的。让我们来做个测试:
|
||||
|
||||
```
|
||||
SET SERVEROUTPUT ON
|
||||
@ -192,15 +201,15 @@ Statement 2 : +000000000 00:00:02.261000000
|
||||
Statement 3 : +000000000 00:00:01.857000000
|
||||
```
|
||||
|
||||
注意,表 actor 只有 4 列,因此语句 1 和 2 的差别并不是太令人印象深刻,但仍然很重要。还要注意我使用了 Oracle 的提示强制优化器为查询选择一个或其它索引。在这种情况下语句 3 明显胜利。这是一个好_很多_的查询,也是一个十分简单的查询。
|
||||
注意,表 actor 只有 4 列,因此语句 1 和 2 的差别并不是太令人印象深刻,但仍然很重要。还要注意我使用了 Oracle 的提示来强制优化器为查询选择一个或其它索引。在这种情况下语句 3 明显胜利。这是一个好_很多_的查询,也是一个十分简单的查询。
|
||||
|
||||
当我们写 `SELECT *` 语句时,我们为数据库带来了**不必要的强制性工作**,这是无法优化的。它不会使用涵盖索引,因为比起它使用的 `LAST_NAME` 索引,涵盖索引开销更多一点,不管怎样,它都要访问表以获取无用的 `LAST_UPDATE` 列。
|
||||
当我们写 `SELECT *` 语句时,我们为数据库带来了**不必要的强制性工作**,这是无法优化的。它不会使用涵盖索引,因为比起它所使用的 `LAST_NAME` 索引,涵盖索引开销更多一点,不管怎样,它都要访问表以获取无用的 `LAST_UPDATE` 列。
|
||||
|
||||
使用 `SELECT *` 会变得更糟。考虑...
|
||||
使用 `SELECT *` 会变得更糟。考虑一下……
|
||||
|
||||
### SQL 转换
|
||||
|
||||
优化器工作的很好,因为它们转换了你的 SQL 查询([看我最近在 Voxxed Days Zurich 关于这方面的演讲][7])。例如,其中有一个称为“`连接`消除”的转换,它真的很强大。考虑这个辅助视图,我们写了这个视图,因为我们变得难以置信地厌倦总是连接所有这些表:
|
||||
优化器工作的很好,因为它们转换了你的 SQL 查询([看我最近在 Voxxed Days Zurich 关于这方面的演讲][7])。例如,其中有一个称为“表连接消除”的转换,它真的很强大。看看这个辅助视图,我们写了这个视图是因为我们非常讨厌总是连接所有这些表:
|
||||
|
||||
```
|
||||
CREATE VIEW v_customer AS
|
||||
@ -239,9 +248,9 @@ FROM v_customer
|
||||
----------------------------------------------------------------
|
||||
```
|
||||
|
||||
当然是这样。我们运行所有这些连接以及全表扫描,因为这就是我们让数据库去做的。获取所有的数据。
|
||||
当然是这样。我们运行了所有这些表连接以及全表扫描,因为这就是我们让数据库去做的:获取所有的数据。
|
||||
|
||||
现在,再一次想象,对于一个特定场景,我们真正想要的是:
|
||||
现在,再一次想一下,对于一个特定场景,我们真正想要的是:
|
||||
|
||||
[
|
||||

|
||||
@ -254,7 +263,6 @@ SELECT first_name, last_name
|
||||
FROM v_customer
|
||||
```
|
||||
|
||||
|
||||
再来看看结果!
|
||||
|
||||
```
|
||||
@ -268,9 +276,9 @@ FROM v_customer
|
||||
------------------------------------------------------------------
|
||||
```
|
||||
|
||||
这是执行计划一个_极大的_进步。我们的连接被消除了,因为优化器可以证明它们是**不必要的**,因此一旦它可以证明这点(而且你不会使用 select * 使其成为**强制性**工作),它就可以移除这些工作并不执行它。为什么会发生这种情况?
|
||||
这是执行计划一个_极大的_进步。我们的表连接被消除了,因为优化器可以证明它们是**不必要的**,因此一旦它可以证明这点(而且你不会因使用 `select *` 而使其成为**强制性**工作),它就可以移除这些工作并不执行它。为什么会发生这种情况?
|
||||
|
||||
每个 `CUSTOMER.ADDRESS_ID` 外键保证了_有且只有一个_`ADDRESS.ADDRESS_ID` 主键值,因此可以保证 `JOIN` 操作是对一连接,它不会产生或者删除行。如果我们甚至不选择行或者查询行,当然,我们就不需要真正地去加载行。可证明地移除 `JOIN` 并不会改变查询的结果。
|
||||
每个 `CUSTOMER.ADDRESS_ID` 外键保证了_有且只有一个_ `ADDRESS.ADDRESS_ID` 主键值,因此可以保证 `JOIN` 操作是对一连接,它不会产生或者删除行。如果我们甚至不选择行或查询行,当然我们就不需要真正地去加载行。可以证实地移除 `JOIN` 并不会改变查询的结果。
|
||||
|
||||
数据库总是会做这些事情。你可以在大部分数据库上尝试它:
|
||||
|
||||
@ -285,32 +293,31 @@ FROM dual
|
||||
SELECT EXISTS (SELECT 1 / 0)
|
||||
```
|
||||
|
||||
在这种情况下,你可能预料会抛出算术异常,当你运行这个查询时:
|
||||
在这种情况下,当你运行这个查询时你可能预料到会抛出算术异常:
|
||||
|
||||
```
|
||||
SELECT 1 / 0 FROM dual
|
||||
```
|
||||
|
||||
|
||||
产生了
|
||||
产生了:
|
||||
|
||||
```
|
||||
ORA-01476: divisor is equal to zero
|
||||
```
|
||||
|
||||
但它没有发生。优化器(甚至解析器)可以证明 `EXISTS (SELECT ..)` 谓词内的任何 `SELECT` 列表达式不会改变查询的结果,因此也就没有必要计算它的值。呵!
|
||||
但它并没有发生。优化器(甚至解析器)可以证明 `EXISTS (SELECT ..)` 谓词内的任何 `SELECT` 列表达式不会改变查询的结果,因此也就没有必要计算它的值。呵!
|
||||
|
||||
### 同时...
|
||||
### 同时……
|
||||
|
||||
大部分 ORM 的最不幸问题就是事实上他们很随意就写出了 `SELECT *` 查询。事实上,例如 HQL / JPQL,设置默认使用它。你甚至可以完全抛弃 `SELECT` 从句,因为毕竟你想要获取所有实体,正如声明的那样,对吧?
|
||||
大部分 ORM 最不幸问题就是事实上他们很随意就写出了 `SELECT *` 查询。事实上,例如 HQL / JPQL,就设置默认使用它。你甚至可以完全抛弃 `SELECT` 从句,因为毕竟你想要获取所有实体,正如声明的那样,对吧?
|
||||
|
||||
例如:
|
||||
|
||||
`FROM` `v_customer`
|
||||
|
||||
例如[Vlad Mihalcea][9](一个 Hibernate 专家和 Hibernate 开发倡导者)建议你每次确定不想要在获取后进行任何更改时再使用查询。ORM 使解决对象图持久化问题变得简单。注意:持久化。真正修改对象图并持久化修改的想法是固有的。
|
||||
例如 [Vlad Mihalcea][9](一个 Hibernate 专家和 Hibernate 开发倡导者)建议你每次确定不想要在获取后进行任何更改时再使用查询。ORM 使解决对象图持久化问题变得简单。注意:持久化。真正修改对象图并持久化修改的想法是固有的。
|
||||
|
||||
但如果你不想那样做,为什么要抓取实体呢?为什么不写一个查询?让我们清楚一点:从性能角度,针对你正在解决的用例写一个查询_总是_会胜过其它选项。你可以不会在意,因为你的数据集很小,没关系。可以。但最终,你需要扩展然后重新设计你的应用程序以便在强制实体图遍历之上支持查询语言,这会很困难。你也需要做其它事情。
|
||||
但如果你不想那样做,为什么要抓取实体呢?为什么不写一个查询?让我们清楚一点:从性能角度,针对你正在解决的用例写一个查询_总是_会胜过其它选项。你可以不会在意,因为你的数据集很小,没关系。可以。但最终,你需要扩展并重新设计你的应用程序以便在强制实体图遍历之上支持查询语言,就会变得很困难。你也需要做其它事情。
|
||||
|
||||
### 计算出现次数
|
||||
|
||||
@ -349,7 +356,7 @@ SELECT EXISTS (
|
||||
|
||||
它不需要火箭科学家来确定,一旦它找到一个,实际存在谓词就可以马上停止寻找额外的行。因此,如果答案是“没有订单”,速度将会是差不多。但如果结果是“是的,有订单”,那么结果在我们不计算具体次数的情况下就会_大幅_加快。
|
||||
|
||||
因为我们_不在乎_具体的次数。我们告诉数据库去计算它(**不必要的**),数据库不知道我们会丢弃所有大于 1 的结果(**强制性**)。
|
||||
因为我们_不在乎_具体的次数。我们告诉数据库去计算它(**不必要的**),而数据库也不知道我们会丢弃所有大于 1 的结果(**强制性**)。
|
||||
|
||||
当然,如果你在 JPA 支持的集合上调用 `list.size()` 做同样的事情,情况会变得更糟!
|
||||
|
||||
@ -363,7 +370,7 @@ SELECT EXISTS (
|
||||
|
||||
它**强制性**,因为数据库无法证明它是**不必要的**。这些信息只包含在客户端中,对于服务器来说无法访问。因此,数据库需要去做。
|
||||
|
||||
这篇文章大部分在介绍 `SELECT *`,因为这是一个很简单的目标。但是这并不仅限于数据库。这关于客户端要求服务器完成**不必要的强制性工作**的任何分布式算法。你 AngularJS 应用程序平均有多少个 N+1 问题,UI 在服务结果 A 上循环,多次调用服务 B,而不是把所有对 B 的调用打包为一个调用?这是一个复发的模式。
|
||||
这篇文章大部分在介绍 `SELECT *`,因为这是一个很简单的目标。但是这并不仅限于数据库。这关系到客户端要求服务器完成**不必要的强制性工作**的任何分布式算法。你的 AngularJS 应用程序平均有多少个 N+1 问题,UI 在服务结果 A 上循环,多次调用服务 B,而不是把所有对 B 的调用打包为一个调用?这是一个复发的模式。
|
||||
|
||||
解决方法总是相同。你给执行你命令的实体越多信息,(理论上)它能更快执行这样的命令。每次都写一个好的查询。你的整个系统都会为此感谢你的。
|
||||
|
||||
@ -375,9 +382,9 @@ SELECT EXISTS (
|
||||
|
||||
via: https://blog.jooq.org/2017/03/08/many-sql-performance-problems-stem-from-unnecessary-mandatory-work
|
||||
|
||||
作者:[ jooq][a]
|
||||
作者:[jooq][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,58 @@
|
||||
微软正在成为一个 Linux 供应商
|
||||
=====================================
|
||||
|
||||
> 微软通过将 Linux 融入自己的产品中来弥合与 Linux 的裂隙。
|
||||
|
||||

|
||||
|
||||
Linux 以及开源技术在数据中心、云以及 IoT 中变得如此主流,以至于微软无法忽视他们。
|
||||
|
||||
在微软自己的云中,三分之一的机器运行着 Linux。这些是运行 Linux 的微软客户。微软需要支持他们使用的平台,否则他们将到别处去了。
|
||||
|
||||
以下就是微软如何将 Linux 战略落实到它的开发者平台 (Windows 10)、云 (Azure) 以及数据中心 (Windows Server) 上的。
|
||||
|
||||
**Windows 中的 Linux:** IT 专家管理公共或者私有 Linux 机器需要原生的 UNIX 工具。Linux 以及 macOS 是仅有的二个提供原生能力的平台。这也难怪你在各种会议如 DockerCon、OpenStack Summit 或者 CoreOS Fest 看到的都是 MacBook 或者少量的 Linux 桌面。
|
||||
|
||||
为了弥补这之间的裂隙,微软与 Canonical 协作在 Windows 内部构建了一个 Linux 子系统,它提供了原生的 Linux 工具。这是一个很棒的妥协,这样 IT 专家可以在继续使用 Windows 10 桌面的同时能够使用大多数 Linux 工具来管理他们的 Linux 机器。
|
||||
|
||||
**Azure 中的 Linux:** 不能完整支持 Linux 的云有什么好的呢?微软一直以来与 Linux 供应商合作来使客户能够在 Azure 中运行 Linux 程序以及任务。
|
||||
|
||||
微软不仅与三家主要的 Linux 供应商 Red Hat、SUSE 和 Canonical 签署了协议,还与无数的其他公司合作,为 Debian 这样的基于社区的发行版提供了支持。
|
||||
|
||||
**Windows Server 中的 Linux:** 这是剩下的最后一块拼图。客户使用的 Linux 容器是一个巨大的生态系统。Docker Hub 上有超过 90 万个 Docker 容器,它们只能在 Linux 机器上运行。微软希望把这些容器带到自己的平台上。
|
||||
|
||||
在 DockerCon 中,微软宣布在 Windows Server 中支持 Linux 容器,将这些容器都带到 Windows 中。
|
||||
|
||||
事情正变得更加有趣,在 Windows 10 上的 Bash on Ubuntu 成功之后,微软正将 Ubuntu bash 带到 Windows Server 中。是的,你听的没错。Windows Server 也将会有一个 Linux 子系统。
|
||||
|
||||
微软的高级项目经理 Rich Turne 告诉我:“服务器上的 WSL 为管理员提供了偏好的 *NIX 管理脚本和工具,以便让他们可以在更熟悉的工作环境工作。”
|
||||
|
||||
微软在一个通告中称它将允许 IT 专家 “可以在 Windows Server 容器主机上使用在 Linux 容器上所用的相同的脚本、工具、流程和容器镜像。这些容器使用我们的 Hyper-V 隔离技术结合你选择的 Linux 内核来托管负载,而主机上的管理脚本以及工具使用 WSL。”
|
||||
|
||||
在覆盖了上面三个情况后,微软已经成功地创建了一个客户不必选择任何 Linux 供应商的环境。
|
||||
|
||||
### 它对微软意味着什么?
|
||||
|
||||
通过将 Linux 融入它自己的产品,微软已经成为了一个 Linux 供应商。它是 Linux 基金会的一份子,它是众多 Linux 贡献者之一,并且它现在在自己的商店中分发 Linux。
|
||||
|
||||
只有一个小问题。微软没有拥有任何 Linux 技术。它完全依赖于外部的厂家,目前 Canonical 为其提供了完全的 Linux 层。如果 Canonical 被强力的竞争对手收购,那会是一个很大的风险。
|
||||
|
||||
或许对微软而言尝试收购 Canonical 是有意义的,并且会将核心技术收入囊中。这是有道理的。
|
||||
|
||||
### 这对 Linux 供应商意味着什么
|
||||
|
||||
表面上,很显然这对微软是个胜利,因为它的客户可以留存在 Windows 世界中。它还将包含 Linux 在数据中心中的发展势头。它或许还会影响 Linux 桌面,由于现在 IT 专家不必为了寻找 *NIX 工具使用 Linux 桌面了,它们可以在 Windows 中做任何事。
|
||||
|
||||
微软的成功是传统 Linux 厂家的失败么?某种程度上来说,是的,微软已经成为了一个直接竞争者。但是这里明显的赢家是 Linux。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cio.com/article/3197016/linux/how-microsoft-is-becoming-a-linux-vendor.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cio.com/author/Swapnil-Bhartiya/
|
||||
@ -1,27 +1,26 @@
|
||||
D 编程语言是用于开发的绝佳语言的 5 个理由
|
||||
============================================================
|
||||
|
||||
### D 语言的模块化、开发效率、可读性以及其它一些特性使其非常适合用于协同软件的开发。
|
||||
> D 语言的模块化、开发效率、可读性以及其它一些特性使其非常适合用于协同软件的开发。
|
||||
|
||||
|
||||

|
||||
>图片来自: opensource.com
|
||||
|
||||
[D 编程语言][8]是一种静态类型的通用编程语言,它具有和 C 语言类似的语法,能够编译为本地代码。许多理由使得它很适合用于开源软件开发,下面讲到的是其中一些理由。
|
||||
|
||||
### 模块化能力
|
||||
|
||||
在大多数情况下,当你有一个好的想法,你可以完全按照你的内心所想的方式通过代码来实现它。然而,有的时候,你不得不向你的想法妥协,从而来适应代码,而不是通过模块化代码来适应想法。 D 语言支持多种[编程范式][9],包括函数式风格、命令式、面向对象、元编程、并发(演员模式)和并行集成。你可以选择任何一种方便的编程范式来模块化代码,从而适应你的想法。
|
||||
在大多数情况下,当你有一个好的想法,你可以完全按照你的内心所想的方式通过代码来实现它。然而,有的时候,你不得让你的想法向代码妥协,而不是通过模块化代码来适应想法。D 语言支持多种[编程范式][9],包括函数式风格、命令式、面向对象、元编程、并发(演员模式),这些全都和谐共存。你可以选择任何一种方便的编程范式来将你的想法转换为代码。
|
||||
|
||||
通过使用[模板][10],可以生成额外的 D 代码并在编译的过程中把它编排进去,你可以把这些代码描述成编译器生成代码的一种模式。这是一种非常有用的设计算法,无需把它们绑定到任何特定的类型。平台无关的代码很容易加入到自然的模板中。通过将模板与[条件编译][11]结合,跨平台的应用变得更加容易实现,也更容易接受来自使用不同操作系统的开发者的贡献。有了这一点,一个程序员可以通过很少的代码,利用有限的时间实现很多东西。
|
||||
通过使用[模板][10],可以生成额外的 D 代码并在编译的过程中把它编排进去,你可以把这些代码描述成编译器生成代码的一种模式。这是一种非常有用的设计算法,无需把它们绑定到任何特定的类型。由于模版的通用性,就很容易生成平台无关的代码。通过将模板与[条件编译][11]结合,跨平台的应用变得更加容易实现,也更容易接受来自使用不同操作系统的开发者的贡献。有了这一点,一个程序员可以通过很少的代码,利用有限的时间实现很多东西。
|
||||
|
||||
[排列][12] 已经深度集成到了 D 语言中,抽象出当和一个实际执行冲突时如何访问容器元素(比如数组、关联数组和链表等)。这个抽象使得可以在许多容器类型中设计和使用大量的算法,而无需绑定到特定的数据结构。D 的[数组切片][13]是排列的一个实现。在最后,你可以用很少的时间写很少的代码,并且只需要很低的维护成本。
|
||||
[range][12] 已经深度集成到了 D 语言中,相对于具体实现,它抽象出容器元素(比如数组、关联数组和链表等)是如何访问的。这个抽象使得可以在许多容器类型中设计和使用大量的算法,而无需绑定到特定的数据结构。D 的[数组切片][13]是 range 的一个实现。最终,你可以用很少的时间写很少的代码,并且只需要很低的维护成本。
|
||||
|
||||
### 开发效率
|
||||
|
||||
大多数开源软件的代码贡献者都是基于有限的时间志愿工作的。 D 语言能够极大的提高开发效率,因为你可以用更少的时间完成更多的事情。D 的模板和排列使得程序员在开发通用代码和可复用代码时效率更高,但这些仅仅是 D 开发效率高的其中几个优势。另外一个主要的吸引力是, D 的编译速度看起来感觉就像解释型语言,比如 Python、JavaScript、Ruby 和 PHP,它使得 D 能够快速成型。
|
||||
大多数开源软件的代码贡献者都是基于有限的时间志愿工作的。 D 语言能够极大的提高开发效率,因为你可以用更少的时间完成更多的事情。D 的模板和 range 使得程序员在开发通用代码和可复用代码时效率更高,但这些仅仅是 D 开发效率高的其中几个优势。另外一个主要的吸引力是, D 的编译速度看起来感觉就像解释型语言一样,比如 Python、JavaScript、Ruby 和 PHP,它使得 D 能够快速成型。
|
||||
|
||||
D 可以很容易的与旧的代码进行对接,减少了端口的需要。它的设计目的是自然地[与 C 代码进行对接][14],毕竟, C 语言是遗留代码、精心编写和测试代码、库以及低级系统调用(特别是 Linux 系统)的主人。C++ 代码在[ D 中也是可调用的][15],从而进行更大的扩展。事实上,[Python][16]、[Objective-C][17]、[Lua][18] 和 [Fortran][19] 这些语言在技术层面上也是可以在 D 中使用的,还有许多第三方努力在把 D 语言推向这些领域。这使得大量的开源库在 D 中均可使用,这符合开源软件开发的惯例。
|
||||
D 可以很容易的与旧的代码进行对接,减少了移植的需要。它的设计目的是[与 C 代码进行自然地对接][14],毕竟, C 语言大量用在遗留代码、精心编写而测试过的代码、库以及低级系统调用(特别是 Linux 系统)上。C++ 代码在[ D 中也是可调用的][15],从而进行更大的扩展。事实上,[Python][16]、[Objective-C][17]、[Lua][18] 和 [Fortran][19] 这些语言在技术层面上都是可以在 D 中使用的,有许多第三方正在努力在把 D 语言推向这些领域。这使得大量的开源库在 D 中均可使用,这符合开源软件开发的惯例。
|
||||
|
||||
### 可读性和可维护性
|
||||
|
||||
@ -35,23 +34,23 @@ void main()
|
||||
|
||||
*D 语言的 Hello, World 演示*
|
||||
|
||||
对于熟悉 C 语言的人来说, D 代码很容易理解。另外, D 代码的可读性很强,即使是复杂的代码,这使得很容易发现错误。可读性对于吸引贡献者来说也是很重要的,这是开源软件成长的关键。
|
||||
对于熟悉 C 语言的人来说, D 代码很容易理解。另外, D 代码的可读性很强,即使是复杂的代码。这使得很容易发现错误。可读性对于吸引贡献者来说也是很重要的,这是开源软件成长的关键。
|
||||
|
||||
在 D 中一个非常简单但很有用的[语法][20]是支持使用下滑线分隔数字,这使得数字的可读性更高。这在数学上很有用:
|
||||
在 D 中一个非常简单但很有用的[语法糖][20]是支持使用下滑线分隔数字,这使得数字的可读性更高。这在数学上很有用:
|
||||
|
||||
```
|
||||
int count = 100_000_000;
|
||||
double price = 20_220.00 + 10.00;
|
||||
int number = 0x7FFF_FFFF; // in hexadecimal system
|
||||
int number = 0x7FFF_FFFF; // 16 进制系统
|
||||
```
|
||||
|
||||
[Ddoc][21] 是一个内建的工具,它能够很容易的自动根据代码注释生成文档,而不需要使用额外的工具。文档写作、改进和更新变得更加简单,不具挑战性,因为它伴随代码同时生成。
|
||||
[ddoc][21] 是一个内建的工具,它能够很容易的自动根据代码注释生成文档,而不需要使用额外的工具。文档写作、改进和更新变得更加简单,不具挑战性,因为它伴随代码同时生成。
|
||||
|
||||
[契约][22] 能够进行检查,从而确保 D 代码的行为能够像期望的那样。就像法律契约签订是为了确保每一方在协议中做自己该做的事情,在 D 语言中的契约式编程,能够确保实现的每一个函数、类等能够像期望的那样产生期望的结果和行为。这样一个特性对于错误检查非常实用,特别是在开源软件中,当多个人合作一个项目的时候。契约是大项目的救星。D 语言强大的契约式编程特性是内建的,而不是后期添加的。契约不仅使得使用 D 语言更加方便,也减少了正确写作和维护困难的头痛。
|
||||
[Contract][22] 能够检查代码的实现,从而确保 D 代码的行为能够像期望的那样。就像法律契约的签订是为了确保每一方在协议中做自己该做的事情,在 D 语言中的契约式编程,能够确保实现的每一个函数、类等如期望的那样产生预期的结果和行为。这样一个特性对于错误检查非常实用,特别是在开源软件中,当多个人合作一个项目的时候。契约是大项目的救星。D 语言强大的契约式编程特性是内建的,而不是后期添加的。契约不仅使得使用 D 语言更加方便,也减少了正确写作和维护困难的头痛。
|
||||
|
||||
### 方便
|
||||
|
||||
协同开发是具有挑战性的,因为代码经常发生变化,并且有许多移动部分。D 语言通过支持在本地范围内导入模块,从而缓解了一些问题:
|
||||
协同开发是具有挑战性的,因为代码经常发生变化,并且有许多移动部分。D 语言通过支持在本地范围内导入模块,从而缓解了那些问题:
|
||||
|
||||
```
|
||||
// 返回偶数
|
||||
@ -64,11 +63,11 @@ int[] evenNumbers(int[] numbers)
|
||||
}
|
||||
```
|
||||
|
||||
*通过**过滤**使用 "!"运算符是[模板参数][5]的一个语法*
|
||||
*对 filter 使用 `!` 运算符是[模板参数][5]的一个语法*
|
||||
|
||||
上面的函数可以在不破坏代码的情况下调用,因为它不依赖任何全局导入模块。像这样实现的函数都可以在后期无需破坏代码的情况下增强,这是协同开发的好东西。
|
||||
|
||||
[通用函数调用语法][23]是 D 语言中的一个特殊语法,它允许像调用一个对象的成员函数那样调用正则函数。一个函数的定义如下:
|
||||
[通用函数调用语法(UFCS)][23]是 D 语言中的一个语法糖,它允许像调用一个对象的成员函数那样调用常规函数。一个函数的定义如下:
|
||||
|
||||
```
|
||||
void cook(string food, int quantity)
|
||||
@ -87,7 +86,7 @@ int quantity = 3;
|
||||
cook(food, quantity);
|
||||
```
|
||||
|
||||
通过 UFCS,这个函数也可以像下面这样调用,看起来好像 **cook** 是一个成员函数:
|
||||
通过 UFCS,这个函数也可以像下面这样调用,看起来好像 `cook` 是一个成员函数:
|
||||
|
||||
```
|
||||
string food = "rice";
|
||||
@ -96,7 +95,7 @@ int quantity = 3;
|
||||
food.cook(quantity);
|
||||
```
|
||||
|
||||
在编译过程中,编译器会自动把 **food** 作为 **cook** 函数的第一个参数。UFCS 使得它能够连接正则函数,给你的代码产生一种函数风格编程的自然感觉。UFCS 在 D 语言中被大量使用,就像在上面的 **evenNumbers** 函数中使用的**过滤**和**数组**功能那样。结合模板、排列、条件编译和 UFCS 能够在不牺牲方便性的前提下给予你强大的力量。
|
||||
在编译过程中,编译器会自动把 `food` 作为 `cook` 函数的第一个参数。UFCS 使得它能够链起来常规函数,给你的代码产生一种函数风格编程的自然感觉。UFCS 在 D 语言中被大量使用,就像在上面的 `evenNumbers` 函数中使用的 `filter` 和 `array` 函数那样。结合模板、range、条件编译和 UFCS 能够在不牺牲方便性的前提下给予你强大的力量。
|
||||
|
||||
`auto` 关键词可以用来代替任何类型。编译器在编译过程中会静态推断类型。这样可以省去输入很长的类型名字,让你感觉写 D 代码就像是在写动态类型语言。
|
||||
|
||||
@ -114,7 +113,7 @@ auto dictionary = ["one": 1, "two": 2, "three": 3]; // type of int[string]
|
||||
auto cook(string food) {...} // auto for a function return type
|
||||
```
|
||||
|
||||
D 的[foreach][24] 循环允许遍历集合和所有不同的强调数据类型:
|
||||
D 的[foreach][24] 循环允许遍历各种不同的底层数据类型的集合和 range:
|
||||
|
||||
```
|
||||
foreach(name; ["John", "Yaw", "Paul", "Kofi", "Ama"])
|
||||
@ -131,7 +130,7 @@ Student[] students = [new Student(), new Student()];
|
||||
foreach(student; students) {...}
|
||||
```
|
||||
|
||||
D 语言中内建的[单元测试][25]不仅免除了使用外部工具的需要,也方便了程序员在自己的代码中执行测试。所有的测试用例都位于定制的 `unittest{}` 块中:
|
||||
D 语言中内建的[单元测试][25]不仅免除了使用外部工具的需要,也方便了程序员在自己的代码中执行测试。所有的测试用例都位于可定制的 `unittest{}` 块中:
|
||||
|
||||
```
|
||||
int[] evenNumbers(int[] numbers)
|
||||
@ -149,17 +148,19 @@ unittest
|
||||
|
||||
使用 D 语言的标准编译器 DMD,你可以通过增加 `-unittest` 编译器标志把所有的测试编译进可执行结果中。
|
||||
|
||||
[Dub][26] 是 D 语言的一个内建包管理器和构建工具,使用它可以很容易的添加来自 [Dub package registry][27] 的第三方库。Dub 可以在编译过程中下载、编译和链接这些包,同时也会升级到新版本。
|
||||
[Dub][26] 是 D 语言的一个内建包管理器和构建工具,使用它可以很容易的添加来自 [Dub package registry][27] 的第三方库。Dub 可以在编译过程中下载、编译和链接这些包,同时也会升级到新版本。
|
||||
|
||||
### 选择
|
||||
|
||||
除了提供多种编程范例和功能特性外,D 还提供其他的选择。它目前有三个可用的开源编译器。官方编译器 DMD 使用它自己的后端,另外两个编译器 GDC 和 LDC,分别使用 GCC 和 LLVM 后端。DMD 以编译速度块而著称,而 LDC 和 GDC 则以在很短的编译时间内生成快速生成机器代码而著称。你可以自由选择其中一个以适应你的使用情况。
|
||||
|
||||
默认情况下, D 语言是采用[垃圾收集][28]的内存分配方式的。你也可以选择手动进行内存管理,如果你想的话,甚至可以进行引用计数。一切选择都是你的。
|
||||
默认情况下,D 语言是采用[垃圾收集][28]的内存分配方式的。你也可以选择手动进行内存管理,如果你想的话,甚至可以进行引用计数。一切选择都是你的。
|
||||
|
||||
### 更多
|
||||
|
||||
在这个简要的讨论中,还有许多 D 语言好的特性没有涉及到。我强烈推荐阅读 [D 语言的特性概述][29],隐藏在[标准库][30]中的宝藏,以及[ D 的使用区域][31],从而进一步了解人们用它来干什么。许多阻止已经[使用 D 语言来进行开发][32]。最后,如果你打算开始学习 D 语言,那么请看这本书 *[D 语言编程][6]*。
|
||||
在这个简要的讨论中,还有许多 D 语言好的特性没有涉及到。我强烈推荐阅读 [D 语言的特性概述][29],这是隐藏在[标准库][30]中的宝藏,以及 [D 语言的使用区域][31],从而进一步了解人们用它来干什么。许多组织已经[使用 D 语言来进行开发][32]。最后,如果你打算开始学习 D 语言,那么请看这本书 *[D 语言编程][6]*。
|
||||
|
||||
(题图:opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -167,7 +168,7 @@ via: https://opensource.com/article/17/5/d-open-source-software-development
|
||||
|
||||
作者:[Lawrence Aberba][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,138 +0,0 @@
|
||||
【xllc翻译中】
|
||||
|
||||
How I got started with bash scripting
|
||||
============================================================
|
||||
|
||||
### With a few simple Google searches, a programming novice learned to write code that automates a previously tedious and time-consuming task.
|
||||
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
I wrote a script the other day. For some of you, that sentence sounds like no big deal. For others, and I know you're out there, that sentence is significant. You see, I'm not a programmer. I'm a writer.
|
||||
|
||||
### What I needed to solve
|
||||
|
||||
My problem was fairly simple: I had to juggle files from engineering into our documentation. The files were available in a .zip format from a web URL. I was copying them to my desktop manually, then moving them into a different directory structure to match my documentation needs. A fellow writer gave me this advice: _"Why don't you just write a script to do this for you?"_
|
||||
|
||||
Programming and development
|
||||
|
||||
* [New Python content][1]
|
||||
|
||||
* [Our latest JavaScript articles][2]
|
||||
|
||||
* [Recent Perl posts][3]
|
||||
|
||||
* [Red Hat Developers Blog][4]
|
||||
|
||||
|
||||
|
||||
I thought _"just write a script?!?"_ —as if it was the easiest thing in the world to do.
|
||||
|
||||
### How Google came to the rescue
|
||||
|
||||
My colleague's question got me thinking, and as I thought, I googled.
|
||||
|
||||
**What scripting languages are on Linux?**
|
||||
|
||||
This was my first Google search criteria, and many of you are probably thinking, "She's pretty clueless." Well, I was, but it did set me on a path to solving my problem. The most common result was Bash. Hmm, I've seen Bash. Heck, one of the files I had to document had Bash in it, that ubiquitous line **#!/bin/bash**. I took another look at that file, and I knew what it was doing because I had to document it.
|
||||
|
||||
So that led me to my next Google search request.
|
||||
|
||||
**How to download a zip file from a URL?**
|
||||
|
||||
That was my basic task really. I had a URL with a .zip file containing all the files I needed to include in my documentation, so I asked the All Powerful Google to help me out. That search gem, and a few more, led me to Curl. But here's the best part: Not only did I find Curl, one of the top search hits showed me a Bash script that used Curl to download a .zip file and extract it. That was more than I asked for, but that's when I realized being specific in my Google search requests could give me the information I needed to write this script. So, momentum in my favor, I wrote the simplest of scripts:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
curl http://rather.long.url | tar -xz -C my_directory --strip-components=1
|
||||
```
|
||||
|
||||
What a moment to see that thing run! But then I realized one gotcha: The URL can change, depending on which set of files I'm trying to access. I had another problem to solve, which led me to my next search.
|
||||
|
||||
**How to pass parameters into a Bash script?**
|
||||
|
||||
I needed to be able to run this script with different URLs and different end directories. Google showed me how to put in **$1**, **$2**, etc., to replace what I typed on the command line with my script. For example:
|
||||
|
||||
```
|
||||
bash myscript.sh http://rather.long.url my_directory
|
||||
```
|
||||
|
||||
That was much better. Everything was working as I needed it to, I had flexibility, I had a working script, and most of all, I had a short command to type and save myself 30 minutes of copy-paste grunt work. That was a morning well spent.
|
||||
|
||||
Then I realized I had one more problem. You see, my memory is short, and I knew I'd run this script only every couple of months. That left me with two issues:
|
||||
|
||||
* How would I remember what to type for my script (URL first? directory first?)?
|
||||
|
||||
* How would another writer know how to run my script if I got hit by a truck?
|
||||
|
||||
I needed a usage message—something the script would display if I didn't use it correctly. For example:
|
||||
|
||||
```
|
||||
usage: bash yaml-fetch.sh <'snapshot_url'> <directory>
|
||||
```
|
||||
|
||||
Otherwise, run the script. My next search was:
|
||||
|
||||
**How to write "if/then/else" in a Bash script?**
|
||||
|
||||
Fortunately I already knew **if/then/else** existed in programming. I just had to find out how to do that. Along the way, I also learned to print from a Bash script using **echo**. What I ended up with was something like this:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
URL=$1
|
||||
DIRECTORY=$2
|
||||
|
||||
if [ $# -eq 0 ];
|
||||
then
|
||||
echo "usage: bash yaml-fetch.sh <'snapshot_url'> <directory>".
|
||||
else
|
||||
|
||||
# make the directory if it doesn't already exist
|
||||
echo 'create directory'
|
||||
|
||||
mkdir $DIRECTORY
|
||||
|
||||
# fetch and untar the yaml files
|
||||
echo 'fetch and untar the yaml files'
|
||||
|
||||
curl $URL | tar -xz -C $DIRECTORY --strip-components=1
|
||||
fi
|
||||
```
|
||||
|
||||
### How Google and scripting rocked my world
|
||||
|
||||
Okay, slight exaggeration there, but this being the 21st century, learning new things (especially somewhat simple things) is a whole lot easier than it used to be. What I learned (besides how to write a short, self-documented Bash script) is that if I have a question, there's a good chance someone else had the same or a similar question before. When I get stumped, I can ask the next question, and the next question. And in the end, not only do I have a script, I have the start of a new skill that I can hold onto and use to simplify other tasks I've been avoiding.
|
||||
|
||||
Don't let that first script (or programming step) get the best of you. It's a skill, like any other, and there's a wealth of information out there to help you along the way. You don't need to read a massive book or take a month-long course. You can do it a simpler way with baby steps and baby scripts that get you started, then build on that skill and your confidence. There will always be a need for folks to write those thousands-of-lines-of-code programs with all the branching and merging and bug-fixing.
|
||||
|
||||
But there is also a strong need for simple scripts and other ways to automate/simplify tasks. And that's where a little script and a little confidence can give you a kickstart.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Sandra McCann - Sandra McCann is a Linux and open source advocate. She's worked as a software developer, content architect for learning resources, and content creator. Sandra is currently a content creator for Red Hat in Westford, MA focusing on OpenStack and NFV techology.
|
||||
|
||||
----
|
||||
|
||||
via: https://opensource.com/article/17/5/how-i-learned-bash-scripting
|
||||
|
||||
作者:[ Sandra McCann ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sandra-mccann
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://opensource.com/article/17/5/how-i-learned-bash-scripting?rate=s_R-jmOxcMvs9bi41yRwenl7GINDvbIFYrUMIJ8OBYk
|
||||
[6]:https://opensource.com/user/39771/feed
|
||||
[7]:https://opensource.com/article/17/5/how-i-learned-bash-scripting#comments
|
||||
[8]:https://opensource.com/users/sandra-mccann
|
||||
@ -1,62 +0,0 @@
|
||||
transalting---geekpi
|
||||
|
||||
How Microsoft is becoming a Linux vendor
|
||||
=====================================
|
||||
|
||||
|
||||
>Microsoft is bridging the gap with Linux by baking it into its own products.
|
||||
|
||||

|
||||
|
||||
|
||||
Linux and open source technologies have become too dominant in data centers, cloud and IoT for Microsoft to ignore them.
|
||||
|
||||
On Microsoft’s own cloud, one in three machines run Linux. These are Microsoft customers who are running Linux. Microsoft needs to support the platform they use, or they will go somewhere else.
|
||||
|
||||
Here's how Microsoft's Linux strategy breaks down on its developer platform (Windows 10), on its cloud (Azure) and datacenter (Windows Server).
|
||||
|
||||
**Linux in Windows**: IT professionals managing Linux machines on public or private cloud need native UNIX tooling. Linux and macOS are the only two platforms that offer such native capabilities. No wonder all you see is MacBooks or a few Linux desktops at events like DockerCon, OpenStack Summit or CoreOS Fest.
|
||||
|
||||
To bridge the gap, Microsoft worked with Canonical to build a Linux subsystem within Windows that offers native Linux tooling. It’s a great compromise, where IT professionals can continue to use Windows 10 desktop while getting to run almost all Linux utilities to manage their Linux machines.
|
||||
|
||||
**Linux in Azure**: What good is a cloud that can’t run fully supported Linux machines? Microsoft has been working with Linux vendors that allow customers to run Linux applications and workloads on Azure.
|
||||
|
||||
Microsoft not only managed to sign deals with all three major Linux vendors Red Hat, SUSE and Canonical, it also worked with countless other companies to offer support for community-based distros like Debian.
|
||||
|
||||
**Linux in Windows Server**: This is the last missing piece of the puzzle. There is a massive ecosystem of Linux containers that are used by customers. There are over 900,000 Docker containers on Docker Hub, which can run only on Linux machines. Microsoft wanted to bring these containers to its own platform.
|
||||
|
||||
At DockerCon, Microsoft announced support for Linux containers on Windows Server bringing all those containers to Linux.
|
||||
|
||||
Things are about to get more interesting, after the success of Bash on Ubuntu on Windows 10, Microsoft is bringing Ubuntu bash to Windows Server. Yes, you heard it right. Windows Server will now have a Linux subsystem.
|
||||
|
||||
Rich Turner, Senior Program Manager at Microsoft told me, “WSL on the server provides admins with a preference for *NIX admin scripting & tools to have a more familiar environment in which to work.”
|
||||
|
||||
Microsoft said in an announcement that It will allow IT professionals “to use the same scripts, tools, procedures and container images they have been using for Linux containers on their Windows Server container host. These containers use our Hyper-V isolation technology combined with your choice of Linux kernel to host the workload while the management scripts and tools on the host use WSL.”
|
||||
|
||||
With all three bases covered, Microsoft has succeeded in creating an environment where its customers don't have to deal with any Linux vendor.
|
||||
|
||||
### What does it mean for Microsoft?
|
||||
|
||||
By baking Linux into its own products, Microsoft has become a Linux vendor. They are part of the Linux Foundation, they are one of the many contributors to the Linux kernel, and they now distribute Linux from their own store.
|
||||
|
||||
There is only one minor problem. Microsoft doesn’t own any Linux technologies. They are totally dependent on an external vendor, in this case Canonical, for their entire Linux layer. Too risky a proposition, if Canonical gets acquired by a fierce competitor.
|
||||
|
||||
It might make sense for Microsoft to attempt to acquire Canonical and bring the core technologies in house. It makes sense.
|
||||
|
||||
### What does it mean for Linux vendors
|
||||
|
||||
On the surface, it’s a clear victory for Microsoft as its customers can live within the Windows world. It will also contain the momentum of Linux in a datacenter. It might also affect Linux on the desktop as now IT professionals looking for *NIX tooling don’t have to run Linux desktop, they can do everything from within Windows.
|
||||
|
||||
Is Microsoft's victory a loss for traditional Linux vendors? To some degree, yes. Microsoft has become a direct competitor. But the clear winner here is Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cio.com/article/3197016/linux/how-microsoft-is-becoming-a-linux-vendor.html
|
||||
|
||||
作者:[ Swapnil Bhartiya ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cio.com/author/Swapnil-Bhartiya/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by xiaow6
|
||||
|
||||
# Go Serverless with Apex and Compose's MongoDB
|
||||
|
||||
_Apex is tooling that wraps the development and deployment experience for AWS Lambda functions. It provides a local command line tool which can create security contexts, deploy functions, and even tail cloud logs. While AWS's Lambda service treats each function as an independent unit, Apex provides a framework which treats a set of functions as a project. Plus, it even extends the service to languages beyond just Java, Javascript, and Python such as Go._
|
||||
@ -182,10 +184,10 @@ via: https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongo
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.compose.com/articles/author/hays-hutton/
|
||||
[1]:https://twitter.com/share?text=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB&url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&via=composeio
|
||||
[1]:https://twitter.com/share?text=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB&url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&via=composeio
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
||||
[3]:https://plus.google.com/share?url=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/
|
||||
[4]:http://news.ycombinator.com/submitlink?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&t=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB
|
||||
[4]:http://news.ycombinator.com/submitlink?u=https://www.compose.com/articles/go-serverless-with-apex-and-composes-mongodb/&t=Go%20Serverless%20with%20Apex%20and%20Compose%27s%20MongoDB
|
||||
[5]:https://www.compose.com/articles/rss/
|
||||
[6]:https://unsplash.com/@esaiastann
|
||||
[7]:https://www.compose.com/articles
|
||||
|
||||
@ -1,78 +0,0 @@
|
||||
Top 8 systems operations and engineering trends for 2017
|
||||
=================
|
||||
|
||||
Forecasting trends is tricky, especially in the fast-moving world of systems operations and engineering. This year, at our Velocity Conference, we have talked about distributed systems, SRE, containerization, serverless architectures, burnout, and many other topics related to the human and technological challenges of delivering software. Here are some of the trends we see for the next year:
|
||||
|
||||
### 1\. Distributed Systems
|
||||
|
||||
We think this is important enough that we [re-focused the entire Velocity conference on it][1].
|
||||
|
||||
|
||||
|
||||
### 2\. Site Reliability Engineering
|
||||
|
||||
[Site Reliability Engineering][3]—is it just ops? [Or is it DevOps by another name][4]? Google's profile for an ops professional calls for heavy doses of systems and software engineering. Spread further into the industry by Xooglers at companies like Dropbox, [hiring for SRE positions][5] continues to increase, particularly for web-facing companies with large data centers. In some contexts, the role of SREs becomes more about helping developers operate their own services.
|
||||
|
||||
### 3\. Containerization
|
||||
|
||||
Companies will continue to containerize their software delivery. Docker Inc. itself has positioned Docker as a tool for "[incremental revolution][6]," and containerizing legacy applications has become a common use case in the enterprise. What's the future of Docker? As engineers continue to adopt orchestration tools like Kubernetes and Mesos, the higher level of abstraction may make more room for other flavors of containers (like rkt, Garden, etc.).
|
||||
|
||||
### 4\. Unikernels
|
||||
|
||||
Are unikernels the next step after containerization? Are they unfit for production? Some tout the security and performance benefits of unikernels. Keep an eye out for how unikernels evolve in 2017, [particularly with an eye to what Docker Inc. does][7] in this area (having acquired Unikernel Systems this year).
|
||||
|
||||
### 5\. Serverless
|
||||
|
||||
Serverless architectures treat functions as the basic unit of computation. Some find the term misleading (and reminiscent of "noops"), and prefer to refer to this trend as Functions-as-a-Service. Developers and architects are experimenting with the technology more and more, and expect to see more applications being written in this paradigm. For more on what serverless/FaaS means for operations, check out the free ebook on [Serverless Ops][8] by Michael Hausenblas.
|
||||
|
||||
### 6\. Cloud-Native application development
|
||||
|
||||
Like DevOps, this term has been used and abused by marketers for a long while, but the Cloud Native Computing Foundation makes a strong case for these new sets of tools (often Google-inspired) that take advantage not just of the cloud, but in particular the strengths and opportunities provided by distributed systems—in short, microservices, containerization, and dynamic orchestration.
|
||||
|
||||
### 7\. Monitoring
|
||||
|
||||
As the industry has evolved from Nagios-style monitoring, to streaming metrics and visualizations, we've become great at producing loads of systems data. Interpretation is the next challenge. As such, we are seeing vendors offering machine learning-powered monitoring services, and, more generally, IT operations learning techniques for machine learning systems data. Similarly, as our infrastructure becomes more dynamic and distributed, monitoring becomes less and less about checking the health of individual resources and more about tracing flows between services. As such, distributed tracing has emerged.
|
||||
|
||||
### 8\. DevOps Security
|
||||
|
||||
With DevOpsSec increasing in popularity, [security is quickly becoming a team-wide concern][9]. The classic challenge of DevOps of achieving both velocity and reliability is especially pronounced when companies with security and compliance concerns are feeling the pinch to compete on speed.
|
||||
|
||||
### Tell us about your work
|
||||
|
||||
As an IT operations professional—whether you use the term sysadmin, DevOps, SRE, DBA, etc.—[you’re invited to share your insights][10] to help us learn about the demographics, work environments, tools, and compensation of practitioners in our growing field. All responses are reported in aggregate to assure your anonymity. The survey will require approximately 5–10 minutes to complete. Once we've closed the survey and analyzed the results, we'll share our findings with you. [Take the survey][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Courtney Nash chairs multiple conferences for O'Reilly Media and is the strategic content director focused on areas of modern web operations, high performance applications, and security. An erstwhile academic neuroscientist, she is still fascinated by the brain and how it informs our interactions with and expectations of technology. She's spent 17 years working in the technology industry in a wide variety of roles, ever since moving to Seattle to work at a burgeoning online bookstore. Outside work, Courtney can be found biking, hiking, skiing, ...
|
||||
|
||||

|
||||
|
||||
Brian Anderson, Infrastructure and Operations Editor at O’Reilly Media, covers topics essential to the delivery of software — from traditional system administration, to cloud computing, web performance, Docker, and DevOps. He has been working in online education and serving the needs of working learners for more than ten years.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017
|
||||
|
||||
作者:[Courtney Nash][a],[Brian Anderson][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/3f5d7-courtneyw-nash
|
||||
[b]:https://www.oreilly.com/people/brian_anderson
|
||||
[1]:https://www.oreilly.com/ideas/velocity-a-new-direction
|
||||
[2]:https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017?imm_mid=0ec113&cmp=em-webops-na-na-newsltr_20170106
|
||||
[3]:https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
[4]:http://conferences.oreilly.com/velocity/devops-web-performance-ny/public/content/devops-sre-ama-video
|
||||
[5]:https://www.glassdoor.com/Salaries/site-reliability-engineer-salary-SRCH_KO0,25.htm
|
||||
[6]:http://blog.scottlowe.org/2016/06/21/dockercon-2016-day-2-keynote/
|
||||
[7]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[8]:http://www.oreilly.com/webops-perf/free/serverless-ops.csp?intcmp=il-webops-free-lp-na_new_site_top_8_systems_operations_and_engineering_trends_for_2017_body_text_cta
|
||||
[9]:https://www.oreilly.com/learning/devopssec-securing-software-through-continuous-delivery
|
||||
[10]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
[11]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating by xllc
|
||||
|
||||
Performance made easy with Linux containers
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by CherryMill
|
||||
|
||||
An introduction to the Linux boot and startup processes
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,178 +0,0 @@
|
||||
ch-cn translating
|
||||
10 Useful Tips for Writing Effective Bash Scripts in Linux
|
||||
============================================================
|
||||
|
||||
[Shell scripting][4] is the easiest form of programming you can learn/do in Linux. More so, it is a required skill for [system administration for automating tasks][5], developing new simple utilities/tools just to mention but a few.
|
||||
|
||||
In this article, we will share 10 useful and practical tips for writing effective and reliable bash scripts and they include:
|
||||
|
||||
### 1\. Always Use Comments in Scripts
|
||||
|
||||
This is a recommended practice which is not only applied to shell scripting but all other kinds of programming. Writing comments in a script helps you or some else going through your script understand what the different parts of the script do.
|
||||
|
||||
For starters, comments are defined using the `#` sign.
|
||||
|
||||
```
|
||||
#TecMint is the best site for all kind of Linux articles
|
||||
```
|
||||
|
||||
### 2\. Make a Script exit When Fails
|
||||
|
||||
Sometimes bash may continue to execute a script even when a certain command fails, thus affecting the rest of the script (may eventually result in logical errors). Use the line below to exit a script when a command fails:
|
||||
|
||||
```
|
||||
#let script exit if a command fails
|
||||
set -o errexit
|
||||
OR
|
||||
set -e
|
||||
```
|
||||
|
||||
### 3\. Make a Script exit When Bash Uses Undeclared Variable
|
||||
|
||||
Bash may also try to use an undeclared script which could cause a logical error. Therefore use the following line to instruct bash to exit a script when it attempts to use an undeclared variable:
|
||||
|
||||
```
|
||||
#let script exit if an unsed variable is used
|
||||
set -o nounset
|
||||
OR
|
||||
set -u
|
||||
```
|
||||
|
||||
### 4\. Use Double Quotes to Reference Variables
|
||||
|
||||
Using double quotes while referencing (using a value of a variable) helps to prevent word splitting (regarding whitespace) and unnecessary globbing (recognizing and expanding wildcards).
|
||||
|
||||
Check out the example below:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#let script exit if a command fails
|
||||
set -o errexit
|
||||
#let script exit if an unsed variable is used
|
||||
set -o nounset
|
||||
echo "Names without double quotes"
|
||||
echo
|
||||
names="Tecmint FOSSMint Linusay"
|
||||
for name in $names; do
|
||||
echo "$name"
|
||||
done
|
||||
echo
|
||||
echo "Names with double quotes"
|
||||
echo
|
||||
for name in "$names"; do
|
||||
echo "$name"
|
||||
done
|
||||
exit 0
|
||||
```
|
||||
|
||||
Save the file and exit, then run it as follows:
|
||||
|
||||
```
|
||||
$ ./names.sh
|
||||
```
|
||||
[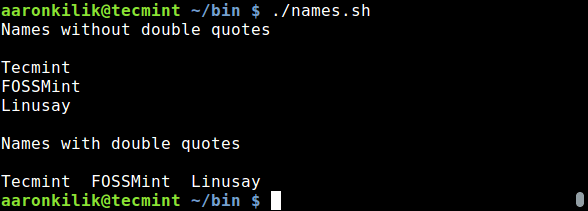][6]
|
||||
|
||||
Use Double Quotes in Scripts
|
||||
|
||||
### 5\. Use functions in Scripts
|
||||
|
||||
Except for very small scripts (with a few lines of code), always remember to use functions to modularize your code and make scripts more readable and reusable.
|
||||
|
||||
The syntax for writing functions is as follows:
|
||||
|
||||
```
|
||||
function check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
OR
|
||||
check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
```
|
||||
|
||||
For single line code, use termination characters after each command like this:
|
||||
|
||||
```
|
||||
check_root(){ command1; command2; }
|
||||
```
|
||||
|
||||
### 6\. Use = instead of == for String Comparisons
|
||||
|
||||
Note that `==` is a synonym for `=`, therefore only use a single `=` for string comparisons, for instance:
|
||||
|
||||
```
|
||||
value1=”tecmint.com”
|
||||
value2=”fossmint.com”
|
||||
if [ "$value1" = "$value2" ]
|
||||
```
|
||||
|
||||
### 7\. Use $(command) instead of legacy ‘command’ for Substitution
|
||||
|
||||
[Command substitution][7] replaces a command with its output. Use `$(command)` instead of backquotes ``command`` for command substitution.
|
||||
|
||||
This is recommended even by [shellcheck tool][8] (shows warnings and suggestions for shell scripts). For example:
|
||||
|
||||
```
|
||||
user=`echo “$UID”`
|
||||
user=$(echo “$UID”)
|
||||
```
|
||||
|
||||
### 8\. Use Read-only to Declare Static Variables
|
||||
|
||||
A static variable doesn’t change; its value can not be altered once it’s defined in a script:
|
||||
|
||||
```
|
||||
readonly passwd_file=”/etc/passwd”
|
||||
readonly group_file=”/etc/group”
|
||||
```
|
||||
|
||||
### 9\. Use Uppercase Names for ENVIRONMENT Variables and Lowercase for Custom Variables
|
||||
|
||||
All bash environment variables are named with uppercase letters, therefore use lowercase letters to name your custom variables to avoid variable name conflicts:
|
||||
|
||||
```
|
||||
#define custom variables using lowercase and use uppercase for env variables
|
||||
nikto_file=”$HOME/Downloads/nikto-master/program/nikto.pl”
|
||||
perl “$nikto_file” -h “$1”
|
||||
```
|
||||
|
||||
### 10\. Always Perform Debugging for Long Scripts
|
||||
|
||||
If you are writing bash scripts with thousands of lines of code, finding errors may become a nightmare. To easily fix things before executing a script, perform some debugging. Master this tip by reading through the guides provided below:
|
||||
|
||||
1. [How To Enable Shell Script Debugging Mode in Linux][1]
|
||||
|
||||
2. [How to Perform Syntax Checking Debugging Mode in Shell Scripts][2]
|
||||
|
||||
3. [How to Trace Execution of Commands in Shell Script with Shell Tracing][3]
|
||||
|
||||
That’s all! Do you have any other best bash scripting practices to share? If yes, then use the comment form below to do that.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://www.tecmint.com/useful-tips-for-writing-bash-scripts-in-linux/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/enable-shell-debug-mode-linux/
|
||||
[2]:https://www.tecmint.com/check-syntax-in-shell-script/
|
||||
[3]:https://www.tecmint.com/trace-shell-script-execution-in-linux/
|
||||
[4]:https://www.tecmint.com/category/bash-shell/
|
||||
[5]:https://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/05/Use-Double-Quotes-in-Scripts.png
|
||||
[7]:https://www.tecmint.com/assign-linux-command-output-to-variable/
|
||||
[8]:https://www.tecmint.com/shellcheck-shell-script-code-analyzer-for-linux/
|
||||
@ -0,0 +1,123 @@
|
||||
我是如何开始编写 bash 脚本的?
|
||||
============================================================
|
||||
|
||||
### 通过一些简单的 Google 搜索,即使编程入门者也可以尝试编写代码实现将以往枯燥和冗长的任务自动化。
|
||||
|
||||
|
||||
|
||||

|
||||
>图片来自 : opensource.com
|
||||
|
||||
我前几天写了一个脚本。对于一些人来说,这句话听起来没什么了不起的。而对于另一些人来说,这句话意义重大。要知道,我不是一个程序员,而是一个作家。
|
||||
|
||||
### 我需要解决什么?
|
||||
|
||||
我的问题相当简单:我需要将工程文件进行分类。这些文件可以从一个网站 URL 以 .zip 的格式下载。当我正手工将它们拷贝到我的电脑桌面,并移动到一个已按照我文件分类的需要进行了结构化的目录时,一位作家同事给我提了建议:_“你为什么不就写个脚本来完成这件事呢?”_
|
||||
|
||||
我心想:_“就写个脚本?”_——说得好像这是世界上最容易做的事情一样。
|
||||
|
||||
### Google 是如何解救我的?
|
||||
|
||||
同事的问题促使我思考,并且经过思考后,我进行了 Google 搜索。
|
||||
|
||||
**Linux 上使用的是什么脚本编程语言?**
|
||||
|
||||
这是我第一个 Google 搜索的准则。也许很多人心里会想:“她太笨了!”是的,我很笨。不过,这的确使我走上了一条解决问题的道路。最常见的搜索结果是 Bash 。嗯,我见过 Bash 。呃,我要分类的文件中有一个就有 Bash 在里面,那无处不在的 **#!/bin/bash** 。我重新看了下那个文件,我知道它的用途,因为我需要将它分类。
|
||||
|
||||
这引导我进行了下一个 Google 搜索
|
||||
|
||||
**如何从一个 URL 下载 zip 文件?**
|
||||
|
||||
那确实是我的基本任务。我有一个附带着 .zip 文件的 URL ,它包含有所有我需要分类的文件,所以我寻求万能的 Google 的帮助。搜索到的精华内容和其它一些结果引导我使用 Curl 。但最重要的是:我不仅找到了 Curl ,其中一条置顶的搜索结果还展示了一个使用 Curl 去下载并解压 .zip 文件的 Bash 脚本。这超出了我本来想寻求的答案,但那也使我意识到在 Google 搜索具体的请求可以得到我写这个脚本需要的信息。所以,在收获的推动下,我写了最简单的脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
curl http://rather.long.url | tar -xz -C my_directory --strip-components=1
|
||||
```
|
||||
|
||||
我迫不及待地运行看看。但我发现一个问题: URL 是会变的,根据我要访问的文件的分组不同而不同。我有新的问题需要解决,这使我进行了下一轮搜索。
|
||||
|
||||
**参数如何传递给 Bash 脚本?**
|
||||
|
||||
我需要以不同的 URL 和不同的最终目录来运行此脚本。 Google 向我展示了如何使用 **$1**、**$2** 等等来替换我在命令行中运行脚本时输入的内容。比如:
|
||||
```
|
||||
bash myscript.sh http://rather.long.url my_directory
|
||||
```
|
||||
|
||||
这就好多了。一切如我所愿,灵活,实用。最重要的是我只要输入一条简短的命令就可以节省 30 分钟无聊的复制、粘贴工作。这个早上的时间花得值得。
|
||||
|
||||
然后我发现还有一个问题:我很健忘,并且我知道我几个月才运行一次这个脚本。这留给我两个疑问:
|
||||
|
||||
* 我要如何记得运行脚本时输入什么 ( URL 先?还是目录先?)?
|
||||
|
||||
* 如果我被货车撞了,其它作家如何知道该怎样运行我的脚本?
|
||||
|
||||
我需要一个使用说明 —— 如果我使用不正确,则脚本会提示。比如:
|
||||
|
||||
```
|
||||
usage: bash yaml-fetch.sh <'snapshot_url'> <directory>
|
||||
```
|
||||
|
||||
否则,则直接运行脚本。我的下一个搜索是:
|
||||
|
||||
**如何在 Bash 脚本里使用“if/then/else”?**
|
||||
|
||||
幸运的是,我已经知道编程中 **if/then/else** 的存在。我只要找出如何使用它的方法。在这个过程中,我也学到了如何在 Bash 脚本里使用 **echo** 打印。我的最终成果如下:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
URL=$1
|
||||
DIRECTORY=$2
|
||||
|
||||
if [ $# -eq 0 ];
|
||||
then
|
||||
echo "usage: bash yaml-fetch.sh <'snapshot_url'> <directory>".
|
||||
else
|
||||
|
||||
# 如果目录不存在则创建它
|
||||
echo 'create directory'
|
||||
|
||||
mkdir $DIRECTORY
|
||||
|
||||
# 下载并解压 yaml 文件
|
||||
echo 'fetch and untar the yaml files'
|
||||
|
||||
curl $URL | tar -xz -C $DIRECTORY --strip-components=1
|
||||
fi
|
||||
```
|
||||
|
||||
### Google 和脚本编程如何震撼我的世界?
|
||||
|
||||
好吧,这稍微有点夸大,不过现在是 21 世纪,学习新东西(特别是稍微简单的东西)比以前简单多了。我所学到的(除了如何写一个简短的、自动分类的 Bash 脚本)是如果我有疑问,那么有很大可能性是其它人在之前也有过相同的疑问。当我困惑的时候,我可以问下一个问题,再下一个问题。最后,我不仅拥有了脚本,还拥有了坚持和习惯于简化其它任务的新技能,这是我之前所没有的。
|
||||
|
||||
别止步于第一个脚本(或者编程的第一步)。这是一个无异于其它的技能,丰富的信息可以在这一路上帮助你。你无需阅读大量的书或参加一个月的课程。你可以像婴儿学步那样简单地开始写脚本,然后掌握技能并建立自信。人们总有写成千上万行代码,包含分支、合并、修复错误的程序的需要。
|
||||
|
||||
但是,通过简单的脚本或其它方式来自动化、简单化任务的需求也一样强烈。这就是一个小脚本和小自信能够让你启程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
桑德拉麦肯:桑德拉麦肯是一位 Linux 和开源技术的倡导者。她是一位软件开发者、学习资源内容架构师、内容创作者。桑德拉目前是位于韦斯特福德马萨诸塞州的红帽公司的内容创作者,专注于 OpenStack 和 NFV 技术。
|
||||
|
||||
----
|
||||
|
||||
via: https://opensource.com/article/17/5/how-i-learned-bash-scripting
|
||||
|
||||
作者:[ Sandra McCann ][a]
|
||||
译者:[xllc](https://github.com/xllc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sandra-mccann
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://opensource.com/article/17/5/how-i-learned-bash-scripting?rate=s_R-jmOxcMvs9bi41yRwenl7GINDvbIFYrUMIJ8OBYk
|
||||
[6]:https://opensource.com/user/39771/feed
|
||||
[7]:https://opensource.com/article/17/5/how-i-learned-bash-scripting#comments
|
||||
[8]:https://opensource.com/users/sandra-mccann
|
||||
@ -0,0 +1,79 @@
|
||||
2017 年 8 大系统运维和工程趋势
|
||||
=================
|
||||
|
||||
预测趋势是棘手的,尤其是在快速发展的系统运维和工程领域。今年,在我们的 Velocity 大会上,我们讨论了分布式系统、SRE、容器化、无服务架构,人员倦怠以及与提供软件相关的人力与技术挑战等诸多问题。以下是我们认为的明年的趋势:
|
||||
|
||||
### 1\. 分布式系统
|
||||
|
||||
我们认为这个很重要,我们[在整个 Velocity 会议上重新关注了它][1]。
|
||||
|
||||
|
||||
|
||||
### 2\. 站点可靠性工程
|
||||
|
||||
[站点可靠性工程][3]-它只是运维么?[或者它是 DevOps 的另外一个名称][4]?这是 Google 对那些要求做大量系统及软件工程的运维专业人士的称呼。它由在像 Dropbox 的前 Google 人向业内推广,[招聘 SRE 的职位][5]正不断增加,特别是有大型数据中心的面向网络的公司。在某些情况下,SRE 的作用更多地是帮助开发人员操作自己的服务。
|
||||
|
||||
### 3\. 同期话
|
||||
|
||||
公司将继续容器化它们的软件交付。Docker 公司本身已经将 Docker 定位为“[增量革命][6]”的工具,容器化遗留应用已成为企业的常见案例。Docker 的未来是什么?随着工程师继续采用诸如 Kubernetes 和 Mesos 之类的编排工具,更高层次的抽象可能为其他容器(如 rkt、Garden 等)提供更多空间。
|
||||
|
||||
|
||||
### 4\. Unikernels
|
||||
|
||||
unikernels 是容器化之后的下一步么?它们对产品不合适么?有些人吹捧 unikernels 的安全和性能好处。关注一下 unikernels 在 2017 是如何进化的,[特别要关注下 Dokcer 公司在这个领域做的][7]。(今年它已经收购了 Unikernel Systems)
|
||||
|
||||
### 5\. Serverless
|
||||
|
||||
无服务架构视功能为基础的计算单元。有些人认为这个术语是误导性的(让人想起 “noops”),并且更倾向于把这个趋势称为“功能即服务”。开发人员和架构师正在越来越多地尝试这个技术,并期望看到有越来越多的程序用这个范式编写。更多关于 serverless/FaaS 对运维的意义,请查看 Michael Hausenblas 的 [Serverless 运维][8]免费电子书。
|
||||
|
||||
### 6\. 原生云程序开发
|
||||
|
||||
就像 DevOps,这个术语已经被市场人员使用并滥用很久了,但是云计算基金会为这些新工具(通常是谷歌发起的)做了一个很好的例子,这些工具不仅利用了云,而且特别还在于分布式系统(简称微服务,容器化和动态编排)提供的优势和机会。
|
||||
|
||||
### 7\. 监控
|
||||
|
||||
随着行业从 Nagios 风格的监控发展到流量指标和可视化,我们在生产大量的系统数据方面变得非常出色。诠释是下一个挑战。因此,我们看到供应商提供机器学习功能的监控服务,以及更一般的是利用机器学习系统数据的 IT 运维学习。同样,随着我们的基础设施变得更加动态和分布式,监控越来越少地检查个人资源的健康状况,更多的是关于在服务之间追踪流量。因此,分布式跟踪已经出现。
|
||||
|
||||
### 8\. DevOps 安全
|
||||
|
||||
随着 DevOps 安全的普及,[安全性正在迅速成为团队范围的关注][9]。当有安全和合规顾虑的公司感觉到需要在速度上竞争时, devops 实现速度和可靠性的经典挑战尤其明显。
|
||||
|
||||
### 告诉我们关于你的工作
|
||||
|
||||
作为一名 IT 运维专业人员 - 你是否使用系统管理的术语如 DevOps、SRE、DBA 等等。- [你被受邀分享你的见解][10]来帮助我们在增长的领域中了解关于人口统计、工作环境、工具以及从业人员薪酬。所有反馈都会以归集形式报告从而保证你的匿名。调查大约需要 5-10 分钟完成。在关闭调查并分析结果后,我们会与你分享发现。[参加调查][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Courtney Nash 主持 O'Reilly Media 的多个会议,并且是专注于现代网络运维,高性能程序和安全性的战略内容总监。一位前学术神经科学家,她仍然对大脑着迷,以及它如何告诉我们与技术互动和对技术的期望。自从移居西雅图,在一家蓬勃发展的在线书店工作之后,她花了 17 年的时间从事技术行业的各种工作。在外面,你可以看到 Courtney 在骑自行车、徒步旅行、滑雪。。。
|
||||
|
||||

|
||||
|
||||
O'Reilly Media 的基础架构和运维编辑 Brian Anderson 介绍了从传统系统管理到云计算、Web 性能、Docker 和 DevOps 等软件交付的重要内容。他一直从事在线教育,服务于学习者的需求超过十多年。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017
|
||||
|
||||
作者:[Courtney Nash][a],[Brian Anderson][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/3f5d7-courtneyw-nash
|
||||
[b]:https://www.oreilly.com/people/brian_anderson
|
||||
[1]:https://www.oreilly.com/ideas/velocity-a-new-direction
|
||||
[2]:https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017?imm_mid=0ec113&cmp=em-webops-na-na-newsltr_20170106
|
||||
[3]:https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
[4]:http://conferences.oreilly.com/velocity/devops-web-performance-ny/public/content/devops-sre-ama-video
|
||||
[5]:https://www.glassdoor.com/Salaries/site-reliability-engineer-salary-SRCH_KO0,25.htm
|
||||
[6]:http://blog.scottlowe.org/2016/06/21/dockercon-2016-day-2-keynote/
|
||||
[7]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[8]:http://www.oreilly.com/webops-perf/free/serverless-ops.csp?intcmp=il-webops-free-lp-na_new_site_top_8_systems_operations_and_engineering_trends_for_2017_body_text_cta
|
||||
[9]:https://www.oreilly.com/learning/devopssec-securing-software-through-continuous-delivery
|
||||
[10]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
[11]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
@ -0,0 +1,177 @@
|
||||
Linux 中编写有效的 Bash 脚本的 10 个有用技巧
|
||||
============================================================
|
||||
|
||||
[Shell 脚本编程][4] 是你在 Linux 下学习或练习编程的最简单的方式。尤其对 [系统管理员要处理着自动化任务][5],且要开发新的简单的实用程序或工具等(这里只是仅举几例)更是必备技能。
|
||||
|
||||
本文中,我们将分享 10 个写出高效可靠的 bash 脚本的实用技巧,它们包括:
|
||||
|
||||
### 1\. 脚本中常用注释
|
||||
|
||||
这是不仅可应用于 shell 脚本程序中也可用在其他所有类型的编程中的一种推荐做法。在脚本中作注释能帮你或别人翻阅你的脚本了解脚本的不同部分所做的工作。
|
||||
|
||||
对于刚入门的人来说,注释用 `#` 号来定义。
|
||||
|
||||
```
|
||||
#TecMint 是浏览各类 Linux 文章的最佳站点
|
||||
```
|
||||
|
||||
### 2\. 当运行失败时使脚本退出
|
||||
|
||||
有时即使某些命令运行失败,bash 可能继续去执行脚本,这样就影响到脚本的其余部分(会最终导致逻辑错误)。用下面的行的方式在遇到命令失败时来退出脚本执行:
|
||||
|
||||
```
|
||||
#如果命令运行失败让脚本退出执行
|
||||
set -o errexit
|
||||
或
|
||||
set -e
|
||||
```
|
||||
|
||||
### 3\. 当 Bash 用未声明变量时使脚本退出
|
||||
|
||||
Bash 也会尝试用会引起逻辑错误的未声明的脚本。因此用下面行的方式去通知 bash 当它尝试去用一个未声明变量时就退出脚本执行:
|
||||
|
||||
```
|
||||
#若有用未设置的变量即让脚本退出执行
|
||||
set -o nounset
|
||||
或
|
||||
set -u
|
||||
```
|
||||
|
||||
### 4\. 使用双引号来引用变量
|
||||
|
||||
当引用时(使用一个变量的值)用双引号有助于防止单词分割开(由于空白)和不必要的匹配(识别和扩展通配符)
|
||||
|
||||
看看下面的例子:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#若命令失败让脚本退出
|
||||
set -o errexit
|
||||
#若未设置的变量被使用让脚本退出
|
||||
set -o nounset
|
||||
echo "Names without double quotes"
|
||||
echo
|
||||
names="Tecmint FOSSMint Linusay"
|
||||
for name in $names; do
|
||||
echo "$name"
|
||||
done
|
||||
echo
|
||||
echo "Names with double quotes"
|
||||
echo
|
||||
for name in "$names"; do
|
||||
echo "$name"
|
||||
done
|
||||
exit 0
|
||||
```
|
||||
|
||||
保存文件并退出,接着如下运行一下:
|
||||
|
||||
```
|
||||
$ ./names.sh
|
||||
```
|
||||
[][6]
|
||||
|
||||
在脚本中用双引号
|
||||
|
||||
### 5\. 在脚本中使用函数
|
||||
|
||||
除了非常小的脚本(只有几行代码),总是记得用函数来使代码模块化且使得脚本更可读和可重用。
|
||||
|
||||
写函数的语法如下所示:
|
||||
|
||||
```
|
||||
function check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
或
|
||||
check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
```
|
||||
|
||||
写成单行代码,每个命令后要用终止符号:
|
||||
|
||||
```
|
||||
check_root(){ command1; command2; }
|
||||
```
|
||||
|
||||
### 6\. 字符串比较时用 = 替换 ==
|
||||
|
||||
注意 `==` 是 `=` 的同义词,因此仅用个单 `=` 来做字符串比较,例如:
|
||||
|
||||
```
|
||||
value1=”tecmint.com”
|
||||
value2=”fossmint.com”
|
||||
if [ "$value1" = "$value2" ]
|
||||
```
|
||||
|
||||
### 7\. 用 $(command) 替换老旧的 ‘command’ 来做代用
|
||||
|
||||
[Command substitution(命令代换)][7] 是用这个命令的输出结果取代命令本身。用 `$(command)` 而不是引号 ``command`` 来做命令代换。
|
||||
|
||||
这种做法也是 [shellcheck tool][8] (可针对 shell 脚本显示警告和建议)所建议的。例如:
|
||||
|
||||
```
|
||||
user=`echo “$UID”`
|
||||
user=$(echo “$UID”)
|
||||
```
|
||||
|
||||
### 8\. 用 Read-only 来声明静态变量
|
||||
|
||||
静态变量不会改变;它的值一旦在脚本中定义后不能被修改:
|
||||
|
||||
```
|
||||
readonly passwd_file=”/etc/passwd”
|
||||
readonly group_file=”/etc/group”
|
||||
```
|
||||
|
||||
### 9\. 环境变量用大写字母命名且自定义变量用小写
|
||||
|
||||
所有的 bash 环境变量用大写字母去命名,因此用小写字母来命名你的自定义变量以避免变量名冲突:
|
||||
|
||||
```
|
||||
#定义自定义变量用小写且环境变量用大写
|
||||
nikto_file=”$HOME/Downloads/nikto-master/program/nikto.pl”
|
||||
perl “$nikto_file” -h “$1”
|
||||
```
|
||||
|
||||
### 10\. 总是对长脚本进行调试
|
||||
|
||||
如果你在写有数千行代码的 bash 脚本,排错可能变成噩梦。为了在脚本执行前易于修正一些错误,要进行一些调试。通过阅读下面给出的指南来掌握此技巧:
|
||||
|
||||
1. [如何在 Linux 中启用 Shell 脚本调试模式][1]
|
||||
|
||||
2. [如何在 Shell 脚本中执行语法检查调试模式][2]
|
||||
|
||||
3. [如何在 Shell 脚本中用 Shell Tracing 来跟踪命令的执行情况][3]
|
||||
|
||||
本文到这就结束了,你是否有一些其他更好的 bash 脚本编程经验想要分享?若是的话,在下面评论框分享出来吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software,自由及开放源代码软件)爱好者,未来的 Linux 系统管理员、Web 开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,且崇尚分享知识。
|
||||
|
||||
----------------
|
||||
|
||||
via: https://www.tecmint.com/useful-tips-for-writing-bash-scripts-in-linux/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
译者:[ch-cn](https://github.com/ch-cn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/enable-shell-debug-mode-linux/
|
||||
[2]:https://www.tecmint.com/check-syntax-in-shell-script/
|
||||
[3]:https://www.tecmint.com/trace-shell-script-execution-in-linux/
|
||||
[4]:https://www.tecmint.com/category/bash-shell/
|
||||
[5]:https://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/05/Use-Double-Quotes-in-Scripts.png
|
||||
[7]:https://www.tecmint.com/assign-linux-command-output-to-variable/
|
||||
[8]:https://www.tecmint.com/shellcheck-shell-script-code-analyzer-for-linux/
|
||||
Loading…
Reference in New Issue
Block a user