mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'master' of github.com:LCTT/TranslateProject
This commit is contained in:
commit
01aa634104
@ -0,0 +1,61 @@
|
||||
Drupal、IoT 和开源硬件之间的交集
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
来认识一下 [Amber Matz][1],她是来自 Lullabot Education 旗下的 [Drupalize.Me][3] 的产品经理以及培训师。当她没有倒腾 Arduino、Raspberry Pi 以及电子穿戴设备时,通常会在波特兰 Drupal 用户组里担任辩论主持人。
|
||||
|
||||
在即将举行的 [DrupalCon NOLA][3] 大会上,Amber 将主持一个关于 Drupal 和 IoT 的主题。如果你会去参加,也想了解下开源硬件,IoT 和 Drupal 之间的交集,那这个将很合适。如果你去不了新奥尔良的现场也没关系,Amber 还分享了许多很酷的事情。在这次采访中,她讲述了自己参与 Drupal 的原因,一些她自己喜欢的开源硬件项目,以及 IoT 和 Drupal 的未来。
|
||||
|
||||

|
||||
|
||||
**你是怎么加入 Drupal 社区的?**
|
||||
|
||||
在这之前,我在一家大型非盈利性机构市场部的“网站管理部”工作,飞快地批量生产出各种定制 PHP/MySQL 表单。最终我厌烦了这一切,并开始在网上寻找更好的方式。然后我找到了 Drupal 6 并开始沉迷进去。过了几年,在一次跳槽之后,我发现了波特兰 Drupal 用户组,然后在里面找了一份全职的 Drupal 开发者工作。我一直经常参加在波特兰的聚会,在那里我找到了大量的社区、朋友和专业方面的发展。一个偶然的机会,我在 Lullabot 找了一份培训师的工作,为 Drupalize.Me 提供内容。现在,我管理着 Drupalize.Me 的内容输出,负责编撰 Drupal 8 相关的内容,还很大程度地参与到波特兰 Drupal 社区中。我是今年的协调员,寻找并安排演讲者们。
|
||||
|
||||
**我们想知道:什么是 Arduino 原型,你是怎么找到它的,以及你用 Arduino 做过的最酷的事是什么?**
|
||||
|
||||
Arduino,Raspberry Pi,以及可穿戴电子设备,这些年到处都能听到这些术语。我在几年前通过 Becky Stern 的 YouTube 秀(最近由 Becky 继续主持,每周三播出)发现了 [Adafruit 的可穿戴电子设备][4]。我被那些可穿戴设备迷住了,还订了一套 LED 缝制工具,不过没做出任何东西。我不太适合它。我没有任何电子相关的背景,而且在我被那些项目吸引的时候,我根本不知道怎么做出那样的东西,它似乎看上去太遥远了。
|
||||
|
||||
后来,我在 Coursera 上找到了一个“物联网”专题。(很时髦,对吧?)我很快就喜欢上了。我最终找到了 Arduino 是什么的解释,以及所有这些其他的重要术语和概念。我订了一套推荐的 Arduino 初学者套件,还附带了一本如何上手的小册子。当我第一次让 LED 闪烁的时候,开心极了。我在圣诞节以及之后有两个星期的假期,然而我什么都没干,就一直根据初学者小册子给 Arduino 电路编程。很奇怪我觉得很放松!我太喜欢了。
|
||||
|
||||
在一月份的时候,我开始构思我自己的原型设备。在知道我需要主持公司培训的开场白时,我用五个 LED 灯和 Arduino 搭建了一个开场白视觉计时器的原型。
|
||||
|
||||

|
||||
|
||||
这是一次巨大的成功。我还做了我的第一个可穿戴项目,一件会发光的连帽衫,使用了和 Arduino IDE 兼容的 Gemma 微控制器,一个小的圆形可缝制部件,然后用可导电的线缝起来,将一个滑动可变电阻和衣服帽口的收缩绳连在一起,用来控制缝到帽子里的五个 NeoPixel 灯的颜色。这就是我对原型设计的看法:做一些很好玩也可能会有点实际用途的疯狂项目。
|
||||
|
||||
**Drupal 和 IoT 带来的最大机遇是什么??**
|
||||
|
||||
IoT 与 Web Service 以及 Drupal 分层趋势实际并没有太大差别。就是将数据从一个东西传送到另一个东西,然后将数据转换成一些有用的东西。但数据是如何送达?能用来做点什么?你觉得现在就有一大堆现成的解决方案、应用、中间层,以及 API 吗?采用 IoT,这只会继续成几何指数级的增长。我觉得,给我任何一个设备或“东西”,总有办法来将它连接到互联网上,有很多办法。而且有大量现成的代码库来帮助创客们将他们的数据从一个东西传到另一个东西。
|
||||
|
||||
那么 Drupal 在这里处于什么位置?首先,Web services 将是第一个明显的地方。但作为一个创客,我不希望将时间花在编写 Drupal 的订制模块上。我想要的是即插即用!所以我很高兴出现这样的模块能连接 IoT 云端 API 和服务,比如 ThingSpeak,Adafruit.io,IFTTT,以及其他的。我觉得也有一个很好的商业机会,在 Drupal 里构建一套 IoT 云服务,允许用户发送和存储他们的传感器数据,并可以制成表格和图像,还可以写一些插件可以响应特定数据或阙值。每一个 IoT 云 API 服务都是一个细分的机会,所以能留下很大空间给其他人。
|
||||
|
||||
**这次 DrupalCon 你有哪些期待?**
|
||||
|
||||
我喜欢与 Drupal 上的朋友重逢,认识一些新的人,还能见到 Lullabot 和 Drupalize.Me 的同事(我们是分布式的公司)!Drupal 8 有太多东西可以去探索了,我们给我们的客户们提供了海量的培训资料。所以,我很期待参与一些 Drupal 8 相关的主题,以及跟上最新的开发进度。最后,我对新奥尔良也很感兴趣!我曾经在 2004 年去过,很期待将这次将看到哪些改变。
|
||||
|
||||
**谈一谈你这次 DrupalCon 上的演讲:“超越闪烁:将 Drupal 加到你的 IoT 游乐场中”。别人为什么要参加?他们最重要的收获会是什么?**
|
||||
|
||||
我的主题的标题是,“超越闪烁:将 Drupal 加到你的 IoT 游乐场中”,假设我们所有人都处在同一进度和层次,你不需要了解任何关于 Arduino、物联网、甚至是 Drupal,都能跟上。我将从用 Arduino 让 LED 灯闪烁开始,然后我会谈一下我自己在这里面的最大收获:玩、学、教和做。我会列出一些曾经激励过我的例子,它们也很有希望能激发和鼓励其他听众去尝试一下。然后,就是展示时间!
|
||||
|
||||
首先,第一个东西。它是一个建筑提醒信号灯。在这个展示里,我会说明如何将信号灯连到互联网上,以及如何响应从云 API 服务收到的数据。然后,第二个东西。它是一个蒸汽朋克风格 iPhone 外壳形式的“天气手表”。有一个小型 LED 矩阵用来显示我的天气的图标,一个气压和温度传感器,一个 GPS 模块,以及一个 Bluetooth LE 模块,都连接到一个 Adafruit Flora 微控制器上。第二个东西能通过蓝牙连接到我的 iPhone 上的一个应用,并将天气和位置数据通过 MQTT 协议发到 Adafruit.io 的服务器!然后,在 Drupal 这边,我会从云端下载这些数据,更新天气信息,然后更新地图。所以大家也能体验一下通过web service、地图和 Drupal 8 的功能块所能做的事情。
|
||||
|
||||
学习和制作这些展示原型是一次烧脑的探险,我也希望有人能参与这个主题并感染一点我对这种技术交叉的传染性热情!我很兴奋能分享一些我的发现。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/drupalcon-interview-amber-matz
|
||||
|
||||
作者:[Jason Hibbets][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jhibbets
|
||||
[1]: https://www.drupal.org/u/amber-himes-matz
|
||||
[2]: https://drupalize.me/
|
||||
[3]: https://events.drupal.org/neworleans2016/
|
||||
[4]: https://www.adafruit.com/beckystern
|
||||
@ -0,0 +1,49 @@
|
||||
Linus Torvalds 谈及物联网、智能设备、安全连接等问题
|
||||
===========================================================================
|
||||
|
||||

|
||||
|
||||
*Dirk Hohndel 在嵌入式大会上采访 Linus Torvalds 。*
|
||||
|
||||
|
||||
4 月 4 日到 6 日,在圣迭戈召开的[嵌入式 Linux 大会(Embedded Linux Conference)][0](ELC) 从首次举办到现在已经有 11 年了,该会议包括了与 Linus Torvalds 的主题讨论。作为 Linux 内核的缔造者和最高决策者——用采访他的英特尔 Linux 和开源技术总监 Dirk Hohndel 的话说,“(他是)我们聚在一起的理由”——他对 Linux 在嵌入式和物联网应用程序领域的发展表示乐观。Torvalds 很明确地力挺了嵌入式 Linux,它被 Linux 桌面、服务器和云技术这些掩去光芒已经很多年了。
|
||||
|
||||

|
||||
|
||||
*Linus Torvalds 在嵌入式 Linux 大会上的演讲。*
|
||||
|
||||
物联网是嵌入式大会的主题,在 OpenIoT 峰会讲演中谈到了,在 Torvalds 的访谈中也是主要话题。
|
||||
|
||||
Torvalds 对 Hohndel 说到,“或许你不会在物联网末端设备上看到 Linux 的影子,但是在你有一个中心设备的时候,你就会需要它。尤其是物联网标准都有 23 个的时候,你就更需要智能设备了。如果你全部使用的是低级设备,它们没必要一定运行 Linux;如果它们采用的标准稍有差异,你就需要很多的智能设备。我们将来也不会有一个完全开放的标准来将这些物联网设备统一到一起,但是我们会有 3/4 的主要协议是一样的,然后那些智能的中心设备就可以对它们进行互相转换。”
|
||||
|
||||
当 Hohndel 问及在物联网的巨大安全漏洞的时候,Torvalds 神情如常。他说:“我不担心安全问题因为我们能做的不是很多,物联网(设备)是不能更新的,这是我们面对的事实。"
|
||||
|
||||
Linux 缔造者看起来更关心的是一次性嵌入式项目缺少对上游的及时贡献,尽管他注意到近年来这些有了一些显著改善,特别是在硬件整合方面。
|
||||
|
||||
“嵌入式领域历来就很难与开源开发者有所联系,但是我认为这些都在发生改变。”Torvalds 说:“ARM 社区变得越来越好了。内核维护者实际上现在也能跟上了一些硬件的更新换代。一切都在变好,但是还不够。”
|
||||
|
||||
Torvalds 承认他在家经常使用桌面系统而不是嵌入式系统,并且对硬件不是很熟悉。
|
||||
|
||||
“我已经用电烙铁弄坏了很多东西。”他说到。“我真的不适合搞硬件开发。”另一方面,Torvalds 设想如果他现在是个年轻人,他可能也在摆弄 Raspberry Pi 和 BeagleBone(猎兔犬板)。“最棒的是你不需要精通焊接,你只需要买个新的板子就行。”
|
||||
|
||||
同时,Torvalds 也承诺他要为 Linux 桌面再奋斗一个 25 年。他笑着说:“我要为它工作一生。”
|
||||
|
||||
下面,请看完整[视频](https://youtu.be/tQKUWkR-wtM)。
|
||||
|
||||
|
||||
要获取关于嵌入式 Linux 和物联网的最新信息,请访问 2016 年嵌入式 Linux 大会 150+ 分钟的会议全程。[现在观看][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
|
||||
@ -1,45 +1,46 @@
|
||||
在用户空间做我们会在内核空间做的事情
|
||||
=======================================================
|
||||
|
||||
我相信,Linux 最好也是最坏的事情,就是内核空间和用户空间之间的巨大差别。
|
||||
我相信,Linux 最好也是最坏的事情,就是内核空间(kernel space)和用户空间(user space)之间的巨大差别。
|
||||
|
||||
但是如果没有这个区别,Linux 可能也不会成为世界上影响力最大的操作系统。如今,Linux 的使用范围在世界上是最大的,而这些应用又有着世界上最大的用户群——尽管大多数用户并不知道,当他们进行谷歌搜索或者触摸安卓手机的时候,他们其实正在使用 Linux。如果不是 Linux 的巨大成功,Apple 公司也可能并不会成为现在这样(即在他们的电脑产品中使用 BSD 的技术)(注:Linux 获得成功后,Apple 曾与 Linus 协商使用 Linux 核心作为 Apple 电脑的操作系统并帮助开发的事宜,但遭到拒绝。因此,Apple 转向使用许可证更为宽松的 BSD 。)。
|
||||
如果没有这个区别,Linux 可能也不会成为世界上影响力最大的操作系统。如今,Linux 的使用范围在世界上是最大的,而这些应用又有着世界上最大的用户群——尽管大多数用户并不知道,当他们进行谷歌搜索或者触摸安卓手机的时候,他们其实正在使用 Linux。如果不是 Linux 的巨大成功,Apple 公司也可能并不会成为现在这样(即在他们的电脑产品中使用 BSD 的技术)(LCTT 译注:Linux 获得成功后,Apple 曾与 Linus 协商使用 Linux 核心作为 Apple 电脑的操作系统并帮助开发的事宜,但遭到拒绝。因此,Apple 转向使用许可证更为宽松的 BSD 。)。
|
||||
|
||||
不(需要)关注用户空间是 Linux 内核开发中的一个特点而非缺陷。正如 Linus 在 2003 的极客巡航中提到的那样,“我只做内核相关技术……我并不知道内核之外发生的事情,而且我并不关心。我只关注内核部分发生的事情。” 多年之后的另一个极客巡航上, Andrew Morton 给我上了另外的一课,这之后我写道:
|
||||
不(需要)关注用户空间是 Linux 内核开发中的一个特点而非缺陷。正如 Linus 在 2003 年的[极客巡航(Geek Cruise)][18]中提到的那样,“我只做内核相关的东西……我并不知道内核之外发生的事情,而且我也并不关心。我只关注内核部分发生的事情。” 多年之后的[另一次极客巡航][19]上, Andrew Morton 给我上了另外的一课,这之后我写道:
|
||||
|
||||
> Linux 存在于内核空间,而在用户空间中被使用,和其他的自然的建筑材料一样。内核空间和用户空间的区别,和自然材料与人类从中生产的人造材料的区别很类似。
|
||||
> 内核空间是Linux 所在的地方,而用户空间是 Linux 与其它的“自然材料”一起使用的地方。内核空间和用户空间的区别,和自然材料与人类用其生产的人造材料的区别很类似。
|
||||
|
||||
这个区别的自然而然的结果,就是尽管外面的世界一刻也离不开 Linux, 但是 Linux 社区还是保持相对较小。所以,为了增加哪怕一点我们社区团体的规模,我希望指出两件事情。第一件已经非常火了,另外一件可能会火起来。
|
||||
这个区别是自然而然的结果,就是尽管外面的世界一刻也离不开 Linux, 但是 Linux 社区还是保持相对较小。所以,为了增加哪怕一点我们社区团体的规模,我希望指出两件事情。第一件已经非常火了,另外一件可能会火起来。
|
||||
|
||||
第一件事情就是 [blockchain][1],出自著名的分布式货币——比特币之手。当你正在阅读这篇文章的同时,人们对 blockchain 的[关注度正在直线上升][2]。
|
||||
第一件事情就是 [区块链(blockchain)][1],出自著名的分布式货币——比特币之手。当你正在阅读这篇文章的同时,人们对区块链的[关注度正在直线上升][2]。
|
||||
|
||||

|
||||
> 图1. Blockchain 的谷歌搜索趋势
|
||||
|
||||
第二件事就是自主身份。为了解释这个概念,让我先来问你:你是谁,你来自哪里?
|
||||
*图1. 区块链的谷歌搜索趋势*
|
||||
|
||||
如果你从你的雇员、你的医生或者车管所,Facebook、Twitter 或者谷歌上得到答案,你就会发现它们都是行政身份——机构完全以自己的便利为原因设置这些身份和职位。正如 [Evernym][3] 的 Timothy Ruff 所说,“你并不因组织而存在,但你的身份却因此存在。”身份是个因变量。自变量——即控制着身份的变量——是(你所在的)组织。
|
||||
第二件事就是自主身份(self-sovereign identity)。为了解释这个概念,让我先来问你:你是谁,你来自哪里?
|
||||
|
||||
如果你从你的老板、你的医生或者车管所,Facebook、Twitter 或者谷歌上得到答案,你就会发现它们都是行政身份(administrative identifiers)——这些机构完全以自己的便利为原因设置这些身份和职位。正如一家区块链技术公司 [Evernym][3] 的 Timothy Ruff 所说,“你并不因组织而存在,但你的身份却因此存在。”身份是个因变量。自变量——即控制着身份的变量——是(你所在的)组织。
|
||||
|
||||
如果你的答案出自你自己,我们就有一个广大空间来发展一个新的领域,在这个领域中,我们完全自由。
|
||||
|
||||
据我所知,第一个解释这个的人是 [Devon Loffreto][4]。在 2012 年 2 月,他在博客[Moxy Tongue][5] 中写道:“什么是'Sovereign Source Authority'?”。在发表于 2016 年 2 月的 "[Self-Sovereign Identity][6]" 中,他写道:
|
||||
据我所知,第一个解释这个的人是 [Devon Loffreto][4]。在 2012 年 2 月,他在博客 [Moxy Tongue][5] 中写道:“什么是 'Sovereign Source Authority'?”。在发表于 2016 年 2 月的 “[Self-Sovereign Identity][6]” 一文中,他写道:
|
||||
|
||||
> 自主身份必须是独立个人提出的,并且不包含社会因素……自主身份源于每个个体对其自身本源的认识。 一个自主身份可以为个体带来新的社会面貌。每个个体都可能为自己生成一个自主身份,并且这并不会改变固有的人权。使用自主身份机制是所有参与者参与的基石,并且依旧可以同各种形式的人类社会保持联系。
|
||||
|
||||
将这个概念放在 Linux 领域中,只有个人才能为他或她设定一个自己的开源社区身份。这在现实实践中,这只是一个非常正从的事件。举个例子,我自己的身份包括:
|
||||
将这个概念放在 Linux 领域中,只有个人才能为他或她设定一个自己的开源社区身份。这在现实实践中,这只是一个非常正常的事件。举个例子,我自己的身份包括:
|
||||
|
||||
- David Allen Searls,我父母会这样叫我。
|
||||
- David Searls,正式场合下我会这么称呼自己。
|
||||
- Dave,我的亲戚和好朋友会这么叫我。
|
||||
- Doc,大多数人会这么叫我。
|
||||
|
||||
作为承认以上称呼的自主身份来源,我可以在不同的情景中轻易的转换。但是,这只是在现实世界中。在虚拟世界中,这就变得非常困难。除了上述的身份之外,我还可以是 @dsearls(我的 twitter 账号) 和 dsearls (其他的网络账号)。然而为了记住成百上千的不同账号的登录名和密码,我已经不堪重负。
|
||||
作为承认以上称呼的自主身份来源,我可以在不同的情景中轻易的转换。但是,这只是在现实世界中。在虚拟世界中,这就变得非常困难。除了上述的身份之外,我还可以是 @dsearls (我的 twitter 账号) 和 dsearls (其他的网络账号)。然而为了记住成百上千的不同账号的登录名和密码,我已经不堪重负。
|
||||
|
||||
你可以在你的浏览器上感受到这个糟糕的体验。在火狐上,我有成百上千个用户名密码。很多已经废弃(很多都是从 Netscape 时代遗留下来的),但是我想会有大量的工作账号需要处理。对于这些,我只是被动接受者。没有其他的解决方法。甚至一些安全较低的用户认证,已经成为了现实世界中不可缺少的一环。
|
||||
|
||||
现在,最简单的方式来联系账号,就是通过 "Log in with Facebook" 或者 "Login in with Twitter" 来进行身份认证。在这种情况下,我们中的每一个甚至并不是真正意义上的自己,甚至(如果我们希望被其他人认识的话)缺乏对其他实体如何认识我们的控制。
|
||||
现在,最简单的方式来联系账号,就是通过 “Log in with Facebook” 或者 “Login in with Twitter” 来进行身份认证。在这种情况下,我们中的每一个甚至并不是真正意义上的自己,甚至(如果我们希望被其他人认识的话)缺乏对其他实体如何认识我们的控制。
|
||||
|
||||
我们从一开始就需要的是一个可以实体化我们的自主身份和交流时选择如何保护和展示自身的个人系统。因为缺少这个能力,我们现在陷入混乱。Shoshana Zuboff 称之为 "监视资本主义",她如此说道:
|
||||
我们从一开始就需要的是一个可以实体化我们的自主身份和交流时选择如何保护和展示自身的个人系统。因为缺少这个能力,我们现在陷入混乱。Shoshana Zuboff 称之为 “监视资本主义”,她如此说道:
|
||||
|
||||
>...难以想象,在见证了互联网和获得了的巨大成功的谷歌背后。世界因 Apple 和 FBI 的对决而紧密联系在一起。讲道理,热衷于监视的资本家开发的监视系统是每一个国家安全机构都渴望的。
|
||||
|
||||
@ -55,16 +56,16 @@
|
||||
- "[System or Human First][10]" - Devon Loffreto.
|
||||
- "[The Path to Self-Sovereign Identity][11]" - Christopher Allen.
|
||||
|
||||
从Evernym 的简要说明中,[digi.me][12], [iRespond][13] 和 [Respect Network][14] 也被包括在内。自主身份和社会身份 (也被称为“current model”) 的对比结果,显示在图二中。
|
||||
从 Evernym 的简要说明中,[digi.me][12]、 [iRespond][13] 和 [Respect Network][14] 也被包括在内。自主身份和社会身份 (也被称为“当前模式(current model)”) 的对比结果,显示在图二中。
|
||||
|
||||

|
||||
> 图 2. Current Model 身份 vs. 自主身份
|
||||
|
||||
*图 2. 当前模式身份 vs. 自主身份*
|
||||
|
||||
Sovrin 就是为此而生的[平台][15],它阐述自己为一个“依托于先进、专用、经授权、分布式平台的,完全开源、基于标识的身份声明图平台”。同时,这也有一本[白皮书][16]。它的代码名为 [plenum][17],并且公开在 Github 上。
|
||||
|
||||
在这里——或者其他类似的地方——我们就可以在用户空间中重现我们在过去 25 年中在内核空间做过的事情。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space
|
||||
@ -93,3 +94,5 @@ via: https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-sp
|
||||
[15]: http://evernym.com/technology
|
||||
[16]: http://evernym.com/assets/doc/Identity-System-Essentials.pdf?v=167284fd65
|
||||
[17]: https://github.com/evernym/plenum
|
||||
[18]: http://www.linuxjournal.com/article/6427
|
||||
[19]: http://www.linuxjournal.com/article/8664
|
||||
@ -3,11 +3,11 @@ bc : 一个命令行计算器
|
||||
|
||||

|
||||
|
||||
假如你运行在一个图形桌面环境中,当你需要一个计算器时,你可能只需要一路进行点击便可以找到一个计算器。例如,Fedora 工作站中就已经包含了一个名为 `Calculator` 的工具。它有着几种不同的操作模式,例如,你可以进行复杂的数学运算或者金融运算。但是,你知道吗,命令行也提供了一个与之相似的名为 `bc` 的工具?
|
||||
假如你在一个图形桌面环境中需要一个计算器时,你可能只需要一路进行点击便可以找到一个计算器。例如,Fedora 工作站中就已经包含了一个名为 `Calculator` 的工具。它有着几种不同的操作模式,例如,你可以进行复杂的数学运算或者金融运算。但是,你知道吗,命令行也提供了一个与之相似的名为 `bc` 的工具?
|
||||
|
||||
`bc` 工具可以为你提供你期望一个科学计算器、金融计算器或者是简单的计算器所能提供的所有功能。另外,假如需要的话,它还可以从命令行中被脚本化。这使得当你需要做复杂的数学运算时,你可以在 shell 脚本中使用它。
|
||||
`bc` 工具可以为你提供的功能可以满足你对科学计算器、金融计算器或者是简单计算器的期望。另外,假如需要的话,它还可以从命令行中被脚本化。这使得当你需要做复杂的数学运算时,你可以在 shell 脚本中使用它。
|
||||
|
||||
因为 bc 被其他的系统软件所使用,例如 CUPS 打印服务,它可能已经在你的 Fedora 系统中被安装了。你可以使用下面这个命令来进行检查:
|
||||
因为 bc 也被用于其他的系统软件,例如 CUPS 打印服务,所以它可能已经在你的 Fedora 系统中被安装了。你可以使用下面这个命令来进行检查:
|
||||
|
||||
```
|
||||
dnf list installed bc
|
||||
@ -21,7 +21,7 @@ sudo dnf install bc
|
||||
|
||||
### 用 bc 做一些简单的数学运算
|
||||
|
||||
使用 bc 的一种方式是进入它自己的 shell。在那里你可以在一行中做许多次计算。但在你键入 bc 后,首先出现的是有关这个程序的警告:
|
||||
使用 bc 的一种方式是进入它自己的 shell。在那里你可以按行进行许多次计算。当你键入 bc 后,首先出现的是有关这个程序的警告:
|
||||
|
||||
```
|
||||
$ bc
|
||||
@ -43,16 +43,16 @@ bc 会回答上面计算式的答案是:
|
||||
2
|
||||
```
|
||||
|
||||
在这里你还可以执行其他的命令。你可以使用 加(+)、减(-)、乘(*)、除(/)、圆括号、指数符号(^) 等等。请注意 bc 同样也遵循所有约定俗成的运算规定,例如运算的先后顺序。你可以试试下面的例子:
|
||||
在这里你还可以执行其他的命令。你可以使用 加(+)、减(-)、乘(*)、除(/)、圆括号、指数符号(\^) 等等。请注意 bc 同样也遵循所有约定俗成的运算规则,例如运算的先后顺序。你可以试试下面的例子:
|
||||
|
||||
```
|
||||
(4+7)*2
|
||||
4+7*2
|
||||
```
|
||||
|
||||
若要离开 bc 可以通过按键组合 `Ctrl+D` 来发送 “输入结束”信号给 bc 。
|
||||
若要退出 bc 可以通过按键组合 `Ctrl+D` 来发送 “输入结束”信号给 bc 。
|
||||
|
||||
使用 bc 的另一种方式是使用 `echo` 命令来传递运算式或命令。下面这个示例类似于计算器中的 "Hello, world" 例子,使用 shell 的管道函数(|) 来将 `echo` 的输出传入 `bc` 中:
|
||||
使用 bc 的另一种方式是使用 `echo` 命令来传递运算式或命令。下面这个示例就是计算器中的 “Hello, world” 例子,使用 shell 的管道函数(|) 来将 `echo` 的输出传入 `bc` 中:
|
||||
|
||||
```
|
||||
echo '1+1' | bc
|
||||
@ -88,7 +88,7 @@ echo '7-4.15' | bc
|
||||
|
||||
### 其他进制系统
|
||||
|
||||
bc 的另一个有用的功能是可以使用除 十进制以外的其他计数系统。例如,你可以轻松地做十六进制或二进制的数学运算。可以使用 `ibase` 和 `obase` 命令来分别设定输入和输出的进制系统。需要记住的是一旦你使用了 `ibase`,之后你输入的任何数字都将被认为是在新定义的进制系统中。
|
||||
bc 的另一个有用的功能是可以使用除了十进制以外的其他计数系统。例如,你可以轻松地做十六进制或二进制的数学运算。可以使用 `ibase` 和 `obase` 命令来分别设定输入和输出的进制系统。需要记住的是一旦你使用了 `ibase`,之后你输入的任何数字都将被认为是在新定义的进制系统中。
|
||||
|
||||
要做十六进制数到十进制数的转换或运算,你可以使用类似下面的命令。请注意大于 9 的十六进制数必须是大写的(A-F):
|
||||
|
||||
@ -103,7 +103,7 @@ echo 'ibase=16; 5F72+C39B' | bc
|
||||
echo 'obase=16; ibase=16; 5F72+C39B' | bc
|
||||
```
|
||||
|
||||
下面是一个小技巧。假如你在 shell 中做这些运算,怎样才能使得输入重新为十进制数呢?答案是使用 `ibase` 命令,但你必须设定它为在当前进制中与十进制中的 10 等价的值。例如,假如 `ibase` 被设定为十六进制,你需要输入:
|
||||
下面是一个小技巧。假如你在 shell 中做这些十六进制运算,怎样才能使得输入重新为十进制数呢?答案是使用 `ibase` 命令,但你必须设定它为在当前进制中与十进制中的 10 等价的值。例如,假如 `ibase` 被设定为十六进制,你需要输入:
|
||||
|
||||
```
|
||||
ibase=A
|
||||
@ -117,11 +117,11 @@ ibase=A
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||
via: https://fedoramagazine.org/bc-command-line-calculator/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
如何在Ubuntu Linux 16.04 LTS中使用多条连接加速apt-get/apt
|
||||
=========================================================================================
|
||||
如何在 Ubuntu Linux 16.04 LTS 中使用多个连接加速 apt-get/apt
|
||||
=================================================
|
||||
|
||||
我该如何在Ubuntu Linux 16.04或者14.04 LTS中从多个仓库中下载包来加速apt-get或者apt命令?
|
||||
我该如何加速在 Ubuntu Linux 16.04 或者 14.04 LTS 上从多个仓库中下载包的 apt-get 或者 apt 命令?
|
||||
|
||||
你需要使用到apt-fast这个shell封装器。它会通过多个连接同时下载一个包来加速apt-get/apt和aptitude命令。所有的包都会同时下载。它使用aria2c作为默认的下载加速。
|
||||
你需要使用到 apt-fast 这个 shell 封装器。它会通过多个连接同时下载一个包来加速 apt-get/apt 和 aptitude 命令。所有的包都会同时下载。它使用 aria2c 作为默认的下载加速器。
|
||||
|
||||
### 安装 apt-fast 工具
|
||||
|
||||
在Ubuntu Linux 14.04或者之后的版本尝试下面的命令:
|
||||
在 Ubuntu Linux 14.04 或者之后的版本尝试下面的命令:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/myppa
|
||||
@ -45,7 +45,6 @@ $ sudo apt -y install apt-fast
|
||||
|
||||
示例输出:
|
||||
|
||||
|
||||
```
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
@ -77,13 +76,13 @@ Get:4 http://01.archive.ubuntu.com/ubuntu xenial/universe amd64 aria2 amd64 1.19
|
||||
|
||||
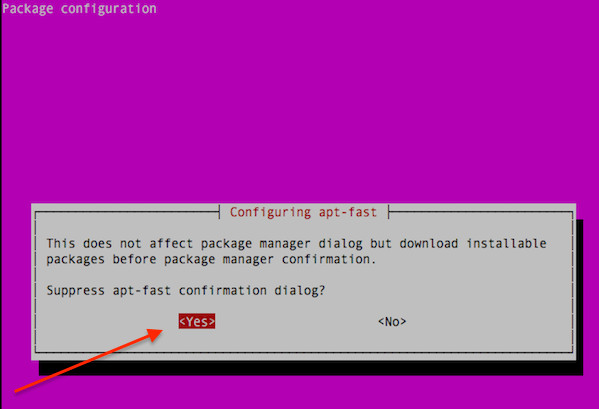
|
||||
|
||||
你可以直接编辑设置:
|
||||
你也可以直接编辑设置:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/apt-fast.conf
|
||||
```
|
||||
|
||||
>**请注意这个工具并不是给慢速网络连接的,它是给快速网络连接的。如果你的网速慢,那么你将无法从这个工具中得到好处。**
|
||||
> **请注意这个工具并不是给慢速网络连接的,它是给快速网络连接的。如果你的网速慢,那么你将无法从这个工具中得到好处。**
|
||||
|
||||
### 我该怎么使用 apt-fast 命令?
|
||||
|
||||
@ -94,13 +93,13 @@ apt-fast command
|
||||
apt-fast [options] command
|
||||
```
|
||||
|
||||
#### 使用apt-fast取回新的包列表
|
||||
#### 使用 apt-fast 取回新的包列表
|
||||
|
||||
```
|
||||
sudo apt-fast update
|
||||
```
|
||||
|
||||
#### 使用apt-fast执行升级
|
||||
#### 使用 apt-fast 执行升级
|
||||
|
||||
```
|
||||
sudo apt-fast upgrade
|
||||
@ -121,7 +120,7 @@ $ sudo apt-fast dist-upgrade
|
||||
sudo apt-fast install pkg
|
||||
```
|
||||
|
||||
比如要安装nginx,输入:
|
||||
比如要安装 nginx,输入:
|
||||
|
||||
```
|
||||
$ sudo apt-fast install nginx
|
||||
@ -196,22 +195,20 @@ Status Legend:
|
||||
(OK):download completed.
|
||||
```
|
||||
|
||||
#### 下载并显示指定包的changelog
|
||||
#### 下载并显示指定包的 changelog
|
||||
|
||||
```
|
||||
$ sudo apt-fast changelog pkgNameHere
|
||||
$ sudo apt-fast changelog nginx
|
||||
```
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/introducing-flatpak/
|
||||
via: http://www.cyberciti.biz/faq/how-to-speed-up-apt-get-apt-command-ubuntu-linux/
|
||||
|
||||
作者:[VIVEK GITE][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -21,8 +21,7 @@ awk 系列:如何使用 awk 的特殊模式 BEGIN 和 END
|
||||
/pattern/ { actions }
|
||||
```
|
||||
|
||||
当你看脚本中的模式(`/pattern`)时,你会发现它通常是一个正则表达式,此外,你也可以将模式(`/pattern`)当成特殊模式 `BEGIN` 和 `END`。
|
||||
因此,我们也能按照下面的形式编写一条 awk 命令:
|
||||
你通常会发现脚本中的模式(`/pattern/`)是一个正则表达式,不过你也可以将模式使用特殊模式 `BEGIN` 和 `END`。因此,我们也能按照下面的形式编写一条 awk 命令:
|
||||
|
||||
```
|
||||
awk '
|
||||
@ -41,11 +40,11 @@ END { actions }
|
||||
|
||||
含有这些特殊模式的 awk 命令脚本的执行流程如下:
|
||||
|
||||
- 当在脚本中使用了 `BEGIN` 模式,则 `BEGIN` 中所有的动作都会在读取任何输入行之前执行。
|
||||
- 然后,读入一个输入行并解析成不同的段。
|
||||
- 接下来,每一条指定的非特殊模式都会和输入行进行比较匹配,当匹配成功后,就会执行模式对应的动作。对所有你指定的模式重复此执行该步骤。
|
||||
- 再接下来,对于所有输入行重复执行步骤 2 和 步骤 3。
|
||||
- 当读取并处理完所有输入行后,假如你指定了 `END` 模式,那么将会执行相应的动作。
|
||||
1. 当在脚本中使用了 `BEGIN` 模式,则 `BEGIN` 中所有的动作都会在读取任何输入行之前执行。
|
||||
2. 然后,读入一个输入行并解析成不同的段。
|
||||
3. 接下来,每一条指定的非特殊模式都会和输入行进行比较匹配,当匹配成功后,就会执行模式对应的动作。对所有你指定的模式重复此执行该步骤。
|
||||
4. 再接下来,对于所有输入行重复执行步骤 2 和 步骤 3。
|
||||
5. 当读取并处理完所有输入行后,假如你指定了 `END` 模式,那么将会执行相应的动作。
|
||||
|
||||
当你使用特殊模式时,想要在 awk 操作中获得最好的结果,你应当记住上面的执行顺序。
|
||||
|
||||
@ -73,7 +72,8 @@ $ cat ~/domains.txt
|
||||
```
|
||||
|
||||

|
||||
> 查看文件内容
|
||||
|
||||
*查看文件内容*
|
||||
|
||||
在这个例子中,我们希望统计出 domains.txt 文件中域名 `tecmint.com` 出现的次数。所以,我们编写了一个简单的 shell 脚本帮助我们完成任务,它使用了变量、数学表达式和赋值运算符的思想,脚本内容如下:
|
||||
|
||||
@ -81,16 +81,16 @@ $ cat ~/domains.txt
|
||||
#!/bin/bash
|
||||
for file in $@; do
|
||||
if [ -f $file ] ; then
|
||||
# 输出文件名
|
||||
### 输出文件名
|
||||
echo "File is: $file"
|
||||
# 输出一个递增的数字记录包含 tecmint.com 的行数
|
||||
### 输出一个递增的数字记录包含 tecmint.com 的行数
|
||||
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
|
||||
else
|
||||
# 若输入不是文件,则输出错误信息
|
||||
### 若输入不是文件,则输出错误信息
|
||||
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
|
||||
fi
|
||||
done
|
||||
# 成功执行后使用退出代码 0 终止脚本
|
||||
### 成功执行后使用退出代码 0 终止脚本
|
||||
exit 0
|
||||
```
|
||||
|
||||
@ -117,24 +117,25 @@ END { printf "%s\n", counter ; }
|
||||
#!/bin/bash
|
||||
for file in $@; do
|
||||
if [ -f $file ] ; then
|
||||
# 输出文件名
|
||||
### 输出文件名
|
||||
echo "File is: $file"
|
||||
# 输出文件中 tecmint.com 出现的总次数
|
||||
### 输出文件中 tecmint.com 出现的总次数
|
||||
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; }
|
||||
/^tecmint.com/ { counter+=1 ; }
|
||||
END { printf "%s\n", counter ; }
|
||||
' $file
|
||||
else
|
||||
# 若输入不是文件,则输出错误信息
|
||||
### 若输入不是文件,则输出错误信息
|
||||
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
|
||||
fi
|
||||
done
|
||||
# 成功执行后使用退出代码 0 终止脚本
|
||||
### 成功执行后使用退出代码 0 终止脚本
|
||||
exit 0
|
||||
```
|
||||
|
||||
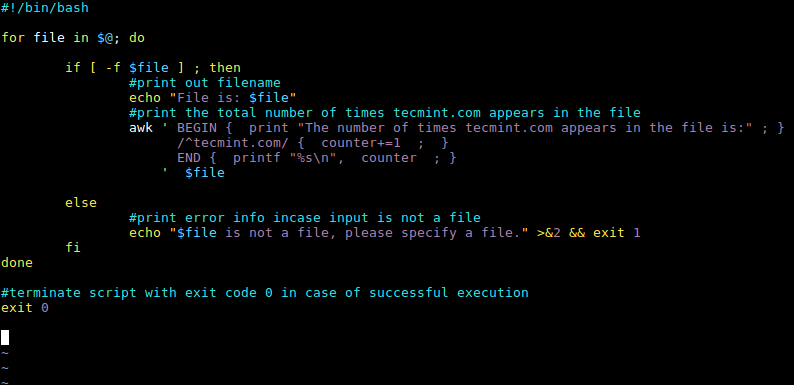
|
||||
> awk 模式 BEGIN 和 END
|
||||
|
||||
*awk 模式 BEGIN 和 END*
|
||||
|
||||
当我们运行上面的脚本时,它会首先输出 domains.txt 文件的位置,然后执行 awk 命令脚本,该命令脚本中的特殊模式 `BEGIN` 将会在从文件读取任何行之前帮助我们输出这样的消息“`文件中出现 tecmint.com 的次数是:`”。
|
||||
|
||||
@ -146,7 +147,8 @@ exit 0
|
||||
$ ./script.sh ~/domains.txt
|
||||
```
|
||||

|
||||
> 用于统计字符串出现次数的脚本
|
||||
|
||||
*用于统计字符串出现次数的脚本*
|
||||
|
||||
最后总结一下,我们在本节中演示了更多的 awk 功能,并学习了特殊模式 `BEGIN` 和 `END` 的概念。
|
||||
|
||||
@ -159,7 +161,7 @@ via: http://www.tecmint.com/learn-use-awk-special-patterns-begin-and-end/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +1,42 @@
|
||||
vim-kakali translating
|
||||
|
||||
### 计算运用数据中的值
|
||||
|
||||
接下来我们会计算过程数据或运用数据中的值。我们要做的就是推测这些数据代表的贷款是否被收回。如果能够计算出来,我们只要看一下包含贷款的运用数据的参数 foreclosure_date 就可以了。如果这个参数的值是 None ,那么这些贷款肯定没有收回。为了避免我们的样例中存在少量的运用数据,我们会计算出运用数据中有贷款数据的行的行数。这样我们就能够从我们的训练数据中筛选出贷款数据,排除了一些运用数据。
|
||||
|
||||
### Computing values from the performance data
|
||||
|
||||
The next step we’ll take is to calculate some values from processed/Performance.txt. All we want to do is to predict whether or not a property is foreclosed on. To figure this out, we just need to check if the performance data associated with a loan ever has a foreclosure_date. If foreclosure_date is None, then the property was never foreclosed on. In order to avoid including loans with little performance history in our sample, we’ll also want to count up how many rows exist in the performance file for each loan. This will let us filter loans without much performance history from our training data.
|
||||
|
||||
One way to think of the loan data and the performance data is like this:
|
||||
下面是一种区分贷款数据和运用数据的方法:
|
||||
|
||||

|
||||
|
||||
As you can see above, each row in the Acquisition data can be related to multiple rows in the Performance data. In the Performance data, foreclosure_date will appear in the quarter when the foreclosure happened, so it should be blank prior to that. Some loans are never foreclosed on, so all the rows related to them in the Performance data have foreclosure_date blank.
|
||||
|
||||
We need to compute foreclosure_status, which is a Boolean that indicates whether a particular loan id was ever foreclosed on, and performance_count, which is the number of rows in the performance data for each loan id.
|
||||
在上面的表格中,采集数据中的每一行数据都与运用数据中的多行数据有联系。在运用数据中,在收回贷款的时候 foreclosure_date 就会以季度的的形式显示出收回时间,而且它会在该行数据的最前面显示一个空格。一些贷款没有收回,所以与运用数据中的贷款数据有关的行都会在前面出现一个表示 foreclosure_date 的空格。
|
||||
|
||||
There are a few different ways to compute the counts we want:
|
||||
我们需要计算 foreclosure_status 的值,它的值是布尔类型,可以表示一个特殊的贷款数据 id 是否被收回过,还有一个参数 performance_count ,它记录了运用数据中每个贷款 id 出现的行数。
|
||||
|
||||
- We could read in all the performance data, then use the Pandas groupby method on the DataFrame to figure out the number of rows associated with each loan id, and also if the foreclosure_date is ever not None for the id.
|
||||
- The upside of this method is that it’s easy to implement from a syntax perspective.
|
||||
- The downside is that reading in all 129236094 lines in the data will take a lot of memory, and be extremely slow.
|
||||
- We could read in all the performance data, then use apply on the acquisition DataFrame to find the counts for each id.
|
||||
- The upside is that it’s easy to conceptualize.
|
||||
- The downside is that reading in all 129236094 lines in the data will take a lot of memory, and be extremely slow.
|
||||
- We could iterate over each row in the performance dataset, and keep a separate dictionary of counts.
|
||||
- The upside is that the dataset doesn’t need to be loaded into memory, so it’s extremely fast and memory-efficient.
|
||||
- The downside is that it will take slightly longer to conceptualize and implement, and we need to parse the rows manually.
|
||||
计算这些行数有多种不同的方法:
|
||||
|
||||
Loading in all the data will take quite a bit of memory, so let’s go with the third option above. All we need to do is to iterate through all the rows in the Performance data, while keeping a dictionary of counts per loan id. In the dictionary, we’ll keep track of how many times the id appears in the performance data, as well as if foreclosure_date is ever not None. This will give us foreclosure_status and performance_count.
|
||||
- 我们能够读取所有的运用数据,然后我们用 Pandas 的 groupby 方法在数据框中计算出与每个贷款 id 有关的行的行数,然后就可以查看贷款 id 的 foreclosure_date 值是否为 None 。
|
||||
- 这种方法的优点是从语法上来说容易执行。
|
||||
- 它的缺点需要读取所有的 129236094 行数据,这样就会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以读取所有的运用数据,然后使用采集到的数据框去计算每个贷款 id 出现的次数。
|
||||
- 这种方法的优点是容易理解。
|
||||
- 缺点是需要读取所有的 129236094 行数据。这样会占用大量内存,并且运行起来极慢。
|
||||
- 我们可以在迭代访问运用数据中的每一行数据,而且会建立一个区分开的计数字典。
|
||||
- 这种方法的优点是数据不需要被加载到内存中,所以运行起来会很快且不需要占用内存。
|
||||
- 缺点是这样的话理解和执行上可能有点耗费时间,我们需要对每一行数据进行语法分析。
|
||||
|
||||
We’ll create a new file called annotate.py, and add in code that will enable us to compute these values. In the below code, we’ll:
|
||||
加载所有的数据会非常耗费内存,所以我们采用第三种方法。我们要做的就是迭代运用数据中的每一行数据,然后为每一个贷款 id 生成一个字典值。在这个字典中,我们会计算出贷款 id 在运用数据中出现的次数,而且如果 foreclosure_date 不是 Nnoe 。我们可以查看 foreclosure_status 和 performance_count 的值 。
|
||||
|
||||
- Import needed libraries.
|
||||
- Define a function called count_performance_rows.
|
||||
- Open processed/Performance.txt. This doesn’t read the file into memory, but instead opens a file handler that can be used to read in the file line by line.
|
||||
- Loop through each line in the file.
|
||||
- Split the line on the delimiter (|)
|
||||
- Check if the loan_id is not in the counts dictionary.
|
||||
- If not, add it to counts.
|
||||
- Increment performance_count for the given loan_id because we’re on a row that contains it.
|
||||
- If date is not None, then we know that the loan was foreclosed on, so set foreclosure_status appropriately.
|
||||
我们会新建一个 annotate.py 文件,文件中的代码可以计算这些值。我们会使用下面的代码:
|
||||
|
||||
- 导入需要的库
|
||||
- 定义一个函数 count_performance_rows 。
|
||||
- 打开 processed/Performance.txt 文件。这不是在内存中读取文件而是打开了一个文件标识符,这个标识符可以用来以行为单位读取文件。
|
||||
- 迭代文件的每一行数据。
|
||||
- 使用分隔符(|)分开每行的不同数据。
|
||||
- 检查 loan_id 是否在计数字典中。
|
||||
- 如果不存在,进行一次计数。
|
||||
- loan_id 的 performance_count 参数自增 1 次,因为我们这次迭代也包含其中。
|
||||
- 如果日期是 None ,我们就会知道贷款被收回了,然后为foreclosure_status 设置合适的值。
|
||||
|
||||
```
|
||||
import os
|
||||
@ -65,9 +63,9 @@ def count_performance_rows():
|
||||
return counts
|
||||
```
|
||||
|
||||
### Getting the values
|
||||
### 获取值
|
||||
|
||||
Once we create our counts dictionary, we can make a function that will extract values from the dictionary if a loan_id and a key are passed in:
|
||||
只要我们创建了计数字典,我们就可以使用一个函数通过一个 loan_id 和一个 key 从字典中提取到需要的参数的值:
|
||||
|
||||
```
|
||||
def get_performance_summary_value(loan_id, key, counts):
|
||||
@ -78,7 +76,7 @@ def get_performance_summary_value(loan_id, key, counts):
|
||||
return value[key]
|
||||
```
|
||||
|
||||
The above function will return the appropriate value from the counts dictionary, and will enable us to assign a foreclosure_status value and a performance_count value to each row in the Acquisition data. The [get][33] method on dictionaries returns a default value if a key isn’t found, so this enables us to return sensible default values if a key isn’t found in the counts dictionary.
|
||||
|
||||
|
||||
上面的函数会从计数字典中返回合适的值,我们也能够为采集数据中的每一行赋一个 foreclosure_status 值和一个 performance_count 值。如果键不存在,字典的 [get][33] 方法会返回一个默认值,所以在字典中不存在键的时候我们就可以得到一个可知的默认值。
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
3 graphical tools for Git
|
||||
=============================
|
||||
|
||||
|
||||
@ -1,120 +0,0 @@
|
||||
Being translated by ChrisLeeGit
|
||||
Learn How to Use Awk Built-in Variables – Part 10
|
||||
=================================================
|
||||
|
||||
As we uncover the section of Awk features, in this part of the series, we shall walk through the concept of built-in variables in Awk. There are two types of variables you can use in Awk, these are; user-defined variables, which we covered in Part 8 and built-in variables.
|
||||
|
||||

|
||||
>Awk Built in Variables Examples
|
||||
|
||||
Built-in variables have values already defined in Awk, but we can also carefully alter those values, the built-in variables include:
|
||||
|
||||
- `FILENAME` : current input file name( do not change variable name)
|
||||
- `FR` : number of the current input line (that is input line 1, 2, 3… so on, do not change variable name)
|
||||
- `NF` : number of fields in current input line (do not change variable name)
|
||||
- `OFS` : output field separator
|
||||
- `FS` : input field separator
|
||||
- `ORS` : output record separator
|
||||
- `RS` : input record separator
|
||||
|
||||
Let us proceed to illustrate the use of some of the Awk built-in variables above:
|
||||
|
||||
To read the filename of the current input file, you can use the `FILENAME` built-in variable as follows:
|
||||
|
||||
```
|
||||
$ awk ' { print FILENAME } ' ~/domains.txt
|
||||
```
|
||||
|
||||
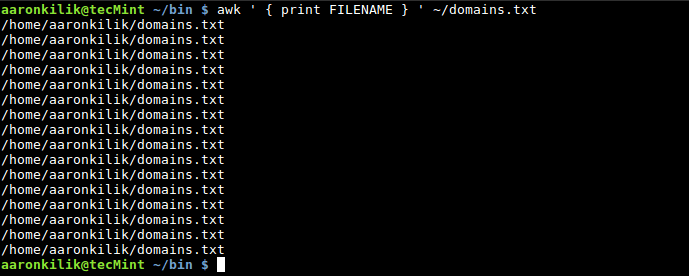
|
||||
>Awk FILENAME Variable
|
||||
|
||||
You will realize that, the filename is printed out for each input line, that is the default behavior of Awk when you use `FILENAME` built-in variable.
|
||||
|
||||
Using `NR` to count the number of lines (records) in an input file, remember that, it also counts the empty lines, as we shall see in the example below.
|
||||
|
||||
When we view the file domains.txt using cat command, it contains 14 lines with text and empty 2 lines:
|
||||
|
||||
```
|
||||
$ cat ~/domains.txt
|
||||
```
|
||||
|
||||

|
||||
>Print Contents of File
|
||||
|
||||
|
||||
```
|
||||
$ awk ' END { print "Number of records in file is: ", NR } ' ~/domains.txt
|
||||
```
|
||||
|
||||

|
||||
>Awk Count Number of Lines
|
||||
|
||||
To count the number of fields in a record or line, we use the NR built-in variable as follows:
|
||||
|
||||
```
|
||||
$ cat ~/names.txt
|
||||
```
|
||||
|
||||
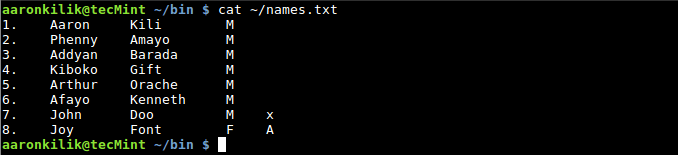
|
||||
>List File Contents
|
||||
|
||||
```
|
||||
$ awk '{ print "Record:",NR,"has",NF,"fields" ; }' ~/names.txt
|
||||
```
|
||||
|
||||
|
||||
>Awk Count Number of Fields in File
|
||||
|
||||
Next, you can also specify an input field separator using the FS built-in variable, it defines how Awk divides input lines into fields.
|
||||
|
||||
The default value for FS is space and tab, but we can change the value of FS to any character that will instruct Awk to divide input lines accordingly.
|
||||
|
||||
There are two methods to do this:
|
||||
|
||||
- one method is to use the FS built-in variable
|
||||
- and the second is to invoke the -F Awk option
|
||||
|
||||
Consider the file /etc/passwd on a Linux system, the fields in this file are divided using the : character, so we can specify it as the new input field separator when we want to filter out certain fields as in the following examples:
|
||||
|
||||
We can use the `-F` option as follows:
|
||||
|
||||
```
|
||||
$ awk -F':' '{ print $1, $4 ;}' /etc/passwd
|
||||
```
|
||||
|
||||

|
||||
>Awk Filter Fields in Password File
|
||||
|
||||
Optionally, we can also take advantage of the FS built-in variable as below:
|
||||
|
||||
```
|
||||
$ awk ' BEGIN { FS=“:” ; } { print $1, $4 ; } ' /etc/passwd
|
||||
```
|
||||
|
||||
|
||||
>Filter Fields in File Using Awk
|
||||
|
||||
To specify an output field separator, use the OFS built-in variable, it defines how the output fields will be separated using the character we use as in the example below:
|
||||
|
||||
```
|
||||
$ awk -F':' ' BEGIN { OFS="==>" ;} { print $1, $4 ;}' /etc/passwd
|
||||
```
|
||||
|
||||
|
||||
>Add Separator to Field in File
|
||||
|
||||
In this Part 10, we have explored the idea of using Awk built-in variables which come with predefined values. But we can also change these values, though, it is not recommended to do so unless you know what you are doing, with adequate understanding.
|
||||
|
||||
After this, we shall progress to cover how we can use shell variables in Awk command operations, therefore, stay connected to Tecmint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/awk-built-in-variables-examples/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -1,95 +0,0 @@
|
||||
How to Allow Awk to Use Shell Variables – Part 11
|
||||
==================================================
|
||||
|
||||
When we write shell scripts, we normally include other smaller programs or commands such as Awk operations in our scripts. In the case of Awk, we have to find ways of passing some values from the shell to Awk operations.
|
||||
|
||||
This can be done by using shell variables within Awk commands, and in this part of the series, we shall learn how to allow Awk to use shell variables that may contain values we want to pass to Awk commands.
|
||||
|
||||
There possibly two ways you can enable Awk to use shell variables:
|
||||
|
||||
### 1. Using Shell Quoting
|
||||
|
||||
Let us take a look at an example to illustrate how you can actually use shell quoting to substitute the value of a shell variable in an Awk command. In this example, we want to search for a username in the file /etc/passwd, filter and print the user’s account information.
|
||||
|
||||
Therefore, we can write a `test.sh` script with the following content:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
#read user input
|
||||
read -p "Please enter username:" username
|
||||
|
||||
#search for username in /etc/passwd file and print details on the screen
|
||||
cat /etc/passwd | awk "/$username/ "' { print $0 }'
|
||||
```
|
||||
|
||||
Thereafter, save the file and exit.
|
||||
|
||||
Interpretation of the Awk command in the test.sh script above:
|
||||
|
||||
```
|
||||
cat /etc/passwd | awk "/$username/ "' { print $0 }'
|
||||
```
|
||||
|
||||
`"/$username/ "` – shell quoting used to substitute value of shell variable username in Awk command. The value of username is the pattern to be searched in the file /etc/passwd.
|
||||
|
||||
Note that the double quote is outside the Awk script, `‘{ print $0 }’`.
|
||||
|
||||
Then make the script executable and run it as follows:
|
||||
|
||||
```
|
||||
$ chmod +x test.sh
|
||||
$ ./text.sh
|
||||
```
|
||||
|
||||
After running the script, you will be prompted to enter a username, type a valid username and hit Enter. You will view the user’s account details from the /etc/passwd file as below:
|
||||
|
||||
|
||||
>Shell Script to Find Username in Password File
|
||||
|
||||
### 2. Using Awk’s Variable Assignment
|
||||
|
||||
This method is much simpler and better in comparison to method one above. Considering the example above, we can run a simple command to accomplish the job. Under this method, we use the -v option to assign a shell variable to a Awk variable.
|
||||
|
||||
Firstly, create a shell variable, username and assign it the name that we want to search in the /etc/passswd file:
|
||||
|
||||
```
|
||||
username="aaronkilik"
|
||||
```
|
||||
|
||||
Then type the command below and hit Enter:
|
||||
|
||||
```
|
||||
# cat /etc/passwd | awk -v name="$username" ' $0 ~ name {print $0}'
|
||||
```
|
||||
|
||||

|
||||
>Find Username in Password File Using Awk
|
||||
|
||||
Explanation of the above command:
|
||||
|
||||
- `-v` – Awk option to declare a variable
|
||||
- `username` – is the shell variable
|
||||
- `name` – is the Awk variable
|
||||
Let us take a careful look at `$0 ~ name` inside the Awk script, `' $0 ~ name {print $0}'`. Remember, when we covered Awk comparison operators in Part 4 of this series, one of the comparison operators was value ~ pattern, which means: true if value matches the pattern.
|
||||
|
||||
The `output($0)` of cat command piped to Awk matches the pattern `(aaronkilik)` which is the name we are searching for in /etc/passwd, as a result, the comparison operation is true. The line containing the user’s account information is then printed on the screen.
|
||||
|
||||
### Conclusion
|
||||
|
||||
We have covered an important section of Awk features, that can help us use shell variables within Awk commands. Many times, you will write small Awk programs or commands within shell scripts and therefore, you need to have a clear understanding of how to use shell variables within Awk commands.
|
||||
|
||||
In the next part of the Awk series, we shall dive into yet another critical section of Awk features, that is flow control statements. So stay tunned and let’s keep learning and sharing.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-shell-script-variable-in-awk/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -1,48 +0,0 @@
|
||||
|
||||
Linus Torvalds 谈及物联网,智能设备,安全连接等问题[video]
|
||||
===========================================================================
|
||||
|
||||

|
||||
>Dirk Hohndel 在嵌入式大会上采访 Linus Torvalds 。
|
||||
|
||||
|
||||
[嵌入式大会(Embedded Linux Conference)][0] 从在 San Diego 【译注:圣迭戈,美国加利福尼亚州的一个太平洋沿岸城市。】开始举办到现在已经有 11 年了,在 4 月 4 日到 6 日,Linus Torvalds 加入了会议的主题讨论。他是 Linux 内核的缔造者和最高决策者,也是“我们都在这里的原因”,在采访他的对话中,英特尔的 Linux 和开源技术总监 Dirk Hohndel 谈到了 Linux 在嵌入式和物联网应用程序领域的快速发展前景。Torvalds 很少出席嵌入式 Linux 大会,这些大会经常被 Linux 桌面、服务器和云技术夺去光芒。
|
||||

|
||||
>Linus Torvalds 在嵌入式 Linux 大会上的演讲。
|
||||
|
||||
|
||||
物联网是嵌入式大会的主题,也包括未来开放物联网的最高发展方向(OpenIoT Summit),这是采访 Torvalds 的主要话题。
|
||||
|
||||
Torvalds 对 Hohndel 说到,“或许你不会在物联网设备上看到 Linux 的影子,但是在你有一个核心设备的时候,你就会需要它。你需要智能设备尤其在你有 23 [物联网标准]的时候。如果你全部使用低级设备,它们没必要一定运行 Linux ,它们采用的标准稍微有点不同,所以你需要很多智能设备。我们将来也不会有一个完全开放的标准,只是给它一个统一的标准,但是你将会需要 4 分之 3 的主要协议,它们都是这些智能核心的转化形式。”
|
||||
|
||||
当 Hohndel 问及在物联网的巨大安全漏洞的时候, Torvalds 神情如常。他说:“我不担心安全问题因为我们能做的不是很多,物联网如果遭受攻击是无法挽回的-这是事实。"
|
||||
|
||||
Linux 缔造者看起来更关心的是一次性的嵌入式项目缺少及时的上游贡献,尽管他注意到近年来这些都有一些本质上的提升,特别是在硬件上的发展。
|
||||
|
||||
Torvalds 说:”嵌入式领域历来就很难与开源开发者有所联系,但是我认为这些都在发生改变,ARM 团队也已经很优秀了。内核维护者事实上也看到了硬件性能的提升。一切都在变好,但是昨天却不是这样的。”
|
||||
|
||||
Torvalds 承认他在家经常使用桌面系统而不是嵌入式系统,并且在使用硬件的时候他有“两只左手”。
|
||||
|
||||
“我已经用电烙铁弄坏了很多东西。”他说到。“我真的不适合搞硬件开发。”;另一方面,Torvalds 设想如果他现在是个年轻人,他可能被 Raspberry Pi(树莓派) 和 BeagleBone(猎兔犬板)【译注:Beagle板实际是由TI支持的一个以教育(STEP)为目的的开源项目】欺骗。“最主要是原因是如果你善于焊接,那么你就仅仅是买到了一个新的板子。”
|
||||
|
||||
同时,Torvalds 也承诺他要为 Linux 桌面再奋斗一个 25 年。他笑着说:“我要为它工作一生。”
|
||||
|
||||
下面,请看完整视频。
|
||||
|
||||
获取关于嵌入式 Linux 和物联网的最新信息。进入 2016 年嵌入式 Linux 大会 150+ 分钟的会议全程。[现在观看][1].
|
||||
[video](https://youtu.be/tQKUWkR-wtM)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video
|
||||
|
||||
作者:[ERIC BROWN][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[0]: http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[1]: http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom
|
||||
|
||||
@ -1,62 +0,0 @@
|
||||
Drupal, IoT 和开源硬件的交叉点
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
|
||||
认识一下 [Amber Matz][1],来自由 Lullabot Education 提供的 [Drupalize.Me][3] 的生产经理以及培训师。当她没有倒腾 Arduino,Raspberry Pi 以及电子穿戴设备时,通常会在波特兰 Drupal 用户组里和主持人争论。
|
||||
|
||||
在即将举行的 [DrupalCon NOLA][3] 大会上,Amber 将主持一个关于 Drupal 和 IoT 的主题。如果你会去参加,也想了解下开源硬件,IoT 和 Drupal 之间的交叉点,那这个将很合适。如果你去不了新奥尔良的现场也没关系,Amber 还分享了许多很酷的事情。在这次采访中,她讲述了自己参与 Drupal 的原因,一些她自己喜欢的开源硬件项目,以及 IoT 和 Drupal 的未来。
|
||||
|
||||

|
||||
|
||||
**你是怎么加入 Drupal 社区的?**
|
||||
|
||||
在这之前,我在一家大型非盈利性机构市场部的“站长办公室”工作,大量产出没人喜欢的定制 PHP/MySQL 表格。终于我觉得这样很烦并开始在网上寻找更好的方式。然后我找到了 Drupal 6 并开始自己沉迷进去。多年以后,在准备职业转换的时候,发现了波特兰 Drupal 用户组,然后在里面找了一份全职的 Drupal 开发者工作。我一直经常参加在波特兰的聚会,我觉得它是一种很好的社区,交友,以及专业开发的资源。一个偶然的机会,我在 Lullabot 找了一份培训师的工作为 Drupalize.Me 提供内容。现在,我管理着 Drupalize.Me 的内容管道,创建 Drupal 8 的内容,还很大程度地参与到波特兰 Drupal 社区中。我是今年的协调员,寻找并规划演讲者。
|
||||
|
||||
**我们得明白:什么是 Arduino 原型,你是怎么找到它的,以及你用 Arduino 做过的最酷的事是什么?**
|
||||
|
||||
Arduino,Raspberry Pi,以及可穿戴电子设备,这些年到处都能听到这些术语。我在几年前通过 Becky Stern YouTube 秀(最近由 Becky 继续主持,每周三播出)发现了 [Adafruit 的可穿戴电子设备][4]。我被那些可穿戴设备迷住了,还订了一套 LED 缝制工具,不过没做出任何东西。我就是没搞懂。我没有任何电子相关的背景,而且在我被那些项目吸引的时候,我根本不知道怎么做出那样的东西。看上去太遥远了。
|
||||
|
||||
后来,我找到一个 Coursera 的“物联网”专题。(很时髦,对吧?)但我很快就喜欢上了。我最终找到了 Arduino 是什么的解释,以及所有这些其他的重要术语和概念。我订了一套推荐的 Arduino 初学者套件,还附带了一本如何上手的小册子。当我第一次让 LED 闪烁的时候,开心极了。我在圣诞节以及之后有两个星期的假期,然后我什么都没干,就一直根据初学者小册子给 Arduino 电路编程。很奇怪我觉得很放松!我太喜欢了。
|
||||
|
||||
一月份的时候,我开始构思我自己的原型设备。在知道我要主持公司培训的开场白时,我用五个 LED 灯和 Arduino 搭建了一个开场白视觉计时器。
|
||||
|
||||

|
||||
|
||||
这是一次巨大的成功。我还做了我的第一个可穿戴项目,一件会发光的连帽衫,使用了和 Arduino IDE 兼容的 Gemma 微控制器,一个小的圆形可缝制部件,然后用可导电的线缝起来,将一个滑动可变电阻和衣服帽口的收缩绳连在一起,用来控制缝到帽子里的五个 NeoPixel 灯的颜色。这就是我对原型设计的看法:开展一些很好玩也可能会有点实际用途的疯狂项目。
|
||||
|
||||
**Drupal 和 IoT 带来的最大机遇是什么??**
|
||||
|
||||
IoT 和网站服务以及 Drupal 分层趋势实际并没有太大差别。就是将数据从一个物体传送到另一个物体,然后将数据转换成一些有用的东西。但数据是如何送达?能用来做点什么?你觉得现在就有一大堆现成的解决方案,应用,中间层,以及 API?采用 IoT,这只会继续成指数增长。我觉得,给我任何一个设备或“物体”,需要只用一种方式来将它连接到因特网的无线可能上。然后有现成的各种代码库来帮助制作者将他们的数据从一个物体送到另一个物体。
|
||||
|
||||
那么 Drupal 在这里处于什么位置?首先,网站服务将是第一个明显的地方。但作为一个制作者,我不希望将时间花在编写 Drupal 的订制模块上。我想要的是即插即用!所以我很高兴出现这样的模块能连接 IoT 云端 API 和服务,比如 ThingSpeak,Adafruit.io,IFTTT,以及其他的。我觉得也有一个很好的商业机会,在 Drupal 里构建一套 IoT 云服务,允许用户发送和存储他们的传感器数据,并可以制成表格和图像,还可以写一些插件可以响应特定数据或阙值。每一个 IoT 云 API 服务都是一个细分的机会,所以能留下很大空间给其他人。
|
||||
|
||||
**这次 DrupalCon 你有哪些期待?**
|
||||
|
||||
我喜欢重新联系 Drupal 上的朋友,认识一些新的人,还能见到 Lullabot 和 Drupalize.Me 的同事(我们是分布式的公司)!Drupal 8 有太多东西可以去探索了,不可抗拒地要帮我们的客户收集培训资料。所以,我很期待参与一些 Drupal 8 相关的主题,以及跟上最新的开发活动。最后,我对新奥尔良也很感兴趣!我曾经在 2004 年去过,很期待将这次将看到哪些改变。
|
||||
|
||||
**谈一谈你这次 DrupalCon 上的演讲,超越闪烁:将 Drupal 加到你的 IoT 游乐场中。别人为什么要参与?他们最重要的收获会是什么?**
|
||||
|
||||
我的主题的标题是,超越闪烁:将 Drupal 加到你的 IoT 游乐场中,本身有很多假设,我将让所有人都放在同一速度和层次。你不需要了解任何关于 Arduino,物联网,甚至是 Drupal,都能跟上。我将从用 Arduino 让 LED 灯闪烁开始,然后我会谈一下我自己在这里面的最大收获:玩,学,教,和做。我会列出一些曾经激发过我的例子,它们也很有希望能激发和鼓励其他听众去尝试一下。然后,就是展示时间!
|
||||
|
||||
首先,第一个东西。它是一个构建提醒信号灯。在这个展示里,我会说明如何将信号灯连到互联网上,以及如何响应从云 API 服务收到的数据。然后,第二个东西。它是一个蒸汽朋克风格 iPhone 外壳形式的“天气手表”。有一个小型 LED 矩阵用来显示我的天气的图标,一个气压和温度传感器,一个 GPS 模块,以及一个 Bluetooth LE 模块,都连接到一个 Adafruit Flora 微控制器上。第二个东西能通过蓝牙连接到我的 iPhone 上的一个应用,并将天气和位置数据通过 MQTT 协议发到 Adafruit.io 的服务器!然后,在 Drupal 这边,我会从云端下载这些数据,根据天气更新一个功能块,然后更新地图。所以大家也能体验一下通过网站服务,地图和 Drupal 8 的功能块所能做的事情。
|
||||
|
||||
学习和制作这些展示原型是一次烧脑的探险,我也希望有人能参与这个主题并感染一点我对这个技术交叉的传染性热情!我很兴奋能分享一些我的发现。
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/5/drupalcon-interview-amber-matz
|
||||
|
||||
作者:[Jason Hibbets][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jhibbets
|
||||
[1]: https://www.drupal.org/u/amber-himes-matz
|
||||
[2]: https://drupalize.me/
|
||||
[3]: https://events.drupal.org/neworleans2016/
|
||||
[4]: https://www.adafruit.com/beckystern
|
||||
@ -1,216 +0,0 @@
|
||||
使用 Python 创建你自己的 Shell:Part II
|
||||
===========================================
|
||||
|
||||
在 [part 1][1] 中,我们已经创建了一个主要的 shell 循环、切分了的命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。
|
||||
|
||||
### 步骤 4:内置命令
|
||||
|
||||
“cd test_dir2 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
|
||||
|
||||
还记得我们 fork 了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
|
||||
|
||||
然后子进程退出,而父进程在原封不动的目录下继续运行。
|
||||
|
||||
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而没有分叉(forking)。
|
||||
|
||||
#### cd
|
||||
|
||||
让我们从 `cd` 命令开始。
|
||||
|
||||
我们首先创建一个 `builtins` 目录。每一个内置命令都会被放进这个目录中。
|
||||
|
||||
```shell
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
在 `cd.py` 中,我们通过使用系统调用 `os.chdir` 实现自己的 `cd` 命令。
|
||||
|
||||
```python
|
||||
import os
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def cd(args):
|
||||
os.chdir(args[0])
|
||||
|
||||
return SHELL_STATUS_RUN
|
||||
```
|
||||
|
||||
注意,我们会从内置函数返回 shell 的运行状态。所以,为了能够在项目中继续使用常量,我们将它们移至 `yosh/constants.py`。
|
||||
|
||||
```shell
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
在 `constants.py` 中,我们将状态常量都放在这里。
|
||||
|
||||
```python
|
||||
SHELL_STATUS_STOP = 0
|
||||
SHELL_STATUS_RUN = 1
|
||||
```
|
||||
|
||||
现在,我们的内置 `cd` 已经准备好了。让我们修改 `shell.py` 来处理这些内置函数。
|
||||
|
||||
```python
|
||||
...
|
||||
# Import constants
|
||||
from yosh.constants import *
|
||||
|
||||
# Hash map to store built-in function name and reference as key and value
|
||||
built_in_cmds = {}
|
||||
|
||||
|
||||
def tokenize(string):
|
||||
return shlex.split(string)
|
||||
|
||||
|
||||
def execute(cmd_tokens):
|
||||
# Extract command name and arguments from tokens
|
||||
cmd_name = cmd_tokens[0]
|
||||
cmd_args = cmd_tokens[1:]
|
||||
|
||||
# If the command is a built-in command, invoke its function with arguments
|
||||
if cmd_name in built_in_cmds:
|
||||
return built_in_cmds[cmd_name](cmd_args)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
我们使用一个 python 字典变量 `built_in_cmds` 作为哈希映射(hash map),以存储我们的内置函数。我们在 `execute` 函数中提取命令的名字和参数。如果该命令在我们的哈希映射中,则调用对应的内置函数。
|
||||
|
||||
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用的。)
|
||||
|
||||
我们差不多准备好使用内置的 `cd` 函数了。最后一步是将 `cd` 函数添加到 `built_in_cmds` 映射中。
|
||||
|
||||
```
|
||||
...
|
||||
# Import all built-in function references
|
||||
from yosh.builtins import *
|
||||
|
||||
...
|
||||
|
||||
# Register a built-in function to built-in command hash map
|
||||
def register_command(name, func):
|
||||
built_in_cmds[name] = func
|
||||
|
||||
|
||||
# Register all built-in commands here
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
|
||||
|
||||
def main():
|
||||
# Init shell before starting the main loop
|
||||
init()
|
||||
shell_loop()
|
||||
```
|
||||
|
||||
我们定义了 `register_command` 函数,以添加一个内置函数到我们内置的命令哈希映射。接着,我们定义 `init` 函数并且在这里注册内置的 `cd` 函数。
|
||||
|
||||
注意这行 `register_command("cd", cd)` 。第一个参数为命令的名字。第二个参数为一个函数引用。为了能够让第二个参数 `cd` 引用到 `yosh/builtins/cd.py` 中的 `cd` 函数引用,我们必须将以下这行代码放在 `yosh/builtins/__init__.py` 文件中。
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
```
|
||||
|
||||
因此,在 `yosh/shell.py` 中,当我们从 `yosh.builtins` 导入 `*` 时,我们可以得到已经通过 `yosh.builtins` 导入的 `cd` 函数引用。
|
||||
|
||||
我们已经准备好了代码。让我们尝试在 `yosh` 同级目录下以模块形式运行我们的 shell,`python -m yosh.shell`。
|
||||
|
||||
现在,`cd` 命令可以正确修改我们的 shell 目录了,同时非内置命令仍然可以工作。非常好!
|
||||
|
||||
#### exit
|
||||
|
||||
最后一块终于来了:优雅地退出。
|
||||
|
||||
我们需要一个可以修改 shell 状态为 `SHELL_STATUS_STOP` 的函数。这样,shell 循环可以自然地结束,shell 将到达终点而退出。
|
||||
|
||||
和 `cd` 一样,如果我们在子进程中 fork 和执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
|
||||
|
||||
让我们从这开始:在 `builtins` 目录下创建一个名为 `exit.py` 的新文件。
|
||||
|
||||
```
|
||||
yosh_project
|
||||
|-- yosh
|
||||
|-- builtins
|
||||
| |-- __init__.py
|
||||
| |-- cd.py
|
||||
| |-- exit.py
|
||||
|-- __init__.py
|
||||
|-- constants.py
|
||||
|-- shell.py
|
||||
```
|
||||
|
||||
`exit.py` 定义了一个 `exit` 函数,该函数仅仅返回一个可以退出主循环的状态。
|
||||
|
||||
```
|
||||
from yosh.constants import *
|
||||
|
||||
|
||||
def exit(args):
|
||||
return SHELL_STATUS_STOP
|
||||
```
|
||||
|
||||
然后,我们导入位于 `yosh/builtins/__init__.py` 文件的 `exit` 函数引用。
|
||||
|
||||
```
|
||||
from yosh.builtins.cd import *
|
||||
from yosh.builtins.exit import *
|
||||
```
|
||||
|
||||
最后,我们在 `shell.py` 中的 `init()` 函数注册 `exit` 命令。
|
||||
|
||||
|
||||
```
|
||||
...
|
||||
|
||||
# Register all built-in commands here
|
||||
def init():
|
||||
register_command("cd", cd)
|
||||
register_command("exit", exit)
|
||||
|
||||
...
|
||||
```
|
||||
|
||||
到此为止!
|
||||
|
||||
尝试执行 `python -m yosh.shell`。现在你可以输入 `exit` 优雅地退出程序了。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
我希望你能像我一样享受创建 `yosh` (**y**our **o**wn **sh**ell)的过程。但我的 `yosh` 版本仍处于早期阶段。我没有处理一些会使 shell 崩溃的极端状况。还有很多我没有覆盖的内置命令。为了提高性能,一些非内置命令也可以实现为内置命令(避免新进程创建时间)。同时,大量的功能还没有实现(请看 [公共特性](http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html) 和 [不同特性](http://www.tldp.org/LDP/intro-linux/html/x12249.html))
|
||||
|
||||
我已经在 github.com/supasate/yosh 中提供了源代码。请随意 fork 和尝试。
|
||||
|
||||
现在该是创建你真正自己拥有的 Shell 的时候了。
|
||||
|
||||
Happy Coding!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/
|
||||
|
||||
作者:[Supasate Choochaisri][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://disqus.com/by/supasate_choochaisri/
|
||||
[1]: https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/
|
||||
[2]: http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html
|
||||
[3]: http://www.tldp.org/LDP/intro-linux/html/x12249.html
|
||||
[4]: https://github.com/supasate/yosh
|
||||
@ -0,0 +1,119 @@
|
||||
awk 系列:如何使用 awk 内置变量
|
||||
=================================================
|
||||
|
||||
我们将逐渐揭开 awk 功能的神秘面纱,在本节中,我们将介绍 awk 内置(built-in)变量的概念。你可以在 awk 中使用两种类型的变量,它们是:用户自定义(user-defined)变量(我们在第八节中已经介绍了)和内置变量。
|
||||
|
||||

|
||||
> awk 内置变量示例
|
||||
|
||||
awk 内置变量已经有预先定义的值了,但我们也可以谨慎地修改这些值,awk 内置变量包括:
|
||||
|
||||
- `FILENAME` : 当前输入文件名称(不要修改变量名)
|
||||
- `NR` : 当前输入行编号(是指输入行 1,2,3……等,不要改变变量名)
|
||||
- `NF` : 当前输入行段编号(不要修改变量名)
|
||||
- `OFS` : 输出段分隔符
|
||||
- `FS` : 输入段分隔符
|
||||
- `ORS` : 输出记录分隔符
|
||||
- `RS` : 输入记录分隔符
|
||||
|
||||
让我们继续演示一些使用上述 awk 内置变量的方法:
|
||||
|
||||
想要读取当前输入文件的名称,你可以使用 `FILENAME` 内置变量,如下:
|
||||
|
||||
```
|
||||
$ awk ' { print FILENAME } ' ~/domains.txt
|
||||
```
|
||||
|
||||

|
||||
> awk FILENAME 变量
|
||||
|
||||
你会看到,每一行都会对应输出一次文件名,那是你使用 `FILENAME` 内置变量时 awk 默认的行为。
|
||||
|
||||
我们可以使用 `NR` 来统计一个输入文件的行数(记录),谨记,它也会计算空行,正如我们将要在下面的例子中看到的那样。
|
||||
|
||||
当我们使用 cat 命令查看文件 domains.txt 时,会发现它有 14 行文本和 2 个空行:
|
||||
|
||||
```
|
||||
$ cat ~/domains.txt
|
||||
```
|
||||
|
||||

|
||||
> 输出文件内容
|
||||
|
||||
|
||||
```
|
||||
$ awk ' END { print "文件记录数是:", NR } ' ~/domains.txt
|
||||
```
|
||||
|
||||

|
||||
> awk 统计行数
|
||||
|
||||
想要统计一条记录或一行中的段数,我们可以像下面那样使用 NR 内置变量:
|
||||
|
||||
```
|
||||
$ cat ~/names.txt
|
||||
```
|
||||
|
||||

|
||||
> 列出文件内容
|
||||
|
||||
```
|
||||
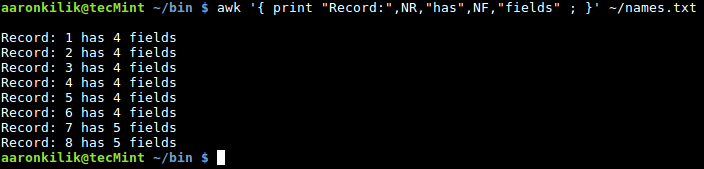
$ awk '{ print "记录:",NR,"有",NF,"段" ; }' ~/names.txt
|
||||
```
|
||||
|
||||

|
||||
> awk 统计文件中的段数
|
||||
|
||||
接下来,你也可以使用 FS 内置变量指定一个输入文件分隔符,它会定义 awk 如何将输入行划分成段。
|
||||
|
||||
FS 默认值为空格和 TAB,但我们也能将 FS 值修改为任何字符来让 awk 根据情况分隔输入行。
|
||||
|
||||
有两种方法可以达到目的:
|
||||
|
||||
- 第一种方法是使用 FS 内置变量
|
||||
- 第二种方法是使用 awk 的 -F 选项
|
||||
|
||||
来看 Linux 系统上的 `/etc/passwd` 文件,该文件中的各段是使用 `:` 分隔的,因此,当我们想要过滤出某些段时,可以将 `:` 指定为新的输入段分隔符,示例如下:
|
||||
|
||||
我们可以使用 `-F` 选项,如下:
|
||||
|
||||
```
|
||||
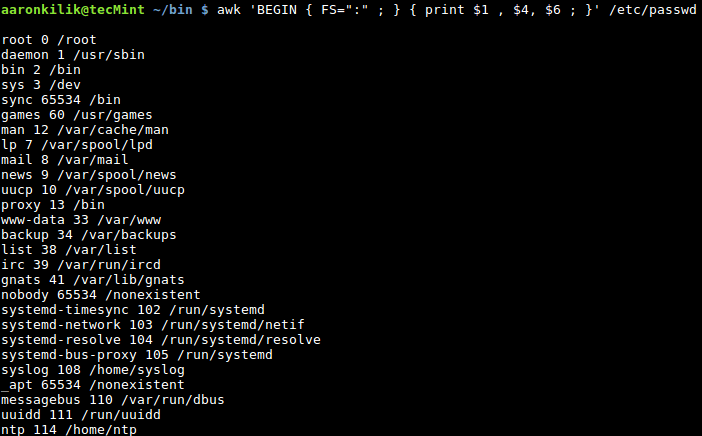
$ awk -F':' '{ print $1, $4 ;}' /etc/passwd
|
||||
```
|
||||
|
||||

|
||||
> awk 过滤密码文件中的各段
|
||||
|
||||
此外,我们也可以利用 FS 内置变量,如下:
|
||||
|
||||
```
|
||||
$ awk ' BEGIN { FS=“:” ; } { print $1, $4 ; } ' /etc/passwd
|
||||
```
|
||||
|
||||

|
||||
> 使用 awk 过滤文件中的各段
|
||||
|
||||
使用 OFS 内置变量来指定一个输出段分隔符,它会定义如何使用指定的字符分隔输出段,示例如下:
|
||||
|
||||
```
|
||||
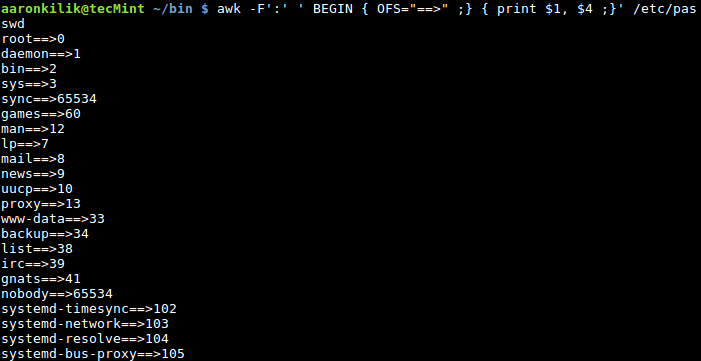
$ awk -F':' ' BEGIN { OFS="==>" ;} { print $1, $4 ;}' /etc/passwd
|
||||
```
|
||||
|
||||

|
||||
> 向文件中的段添加分隔符
|
||||
|
||||
在第十节(即本节)中,我们已经学习了使用含有预定义值的 awk 内置变量的理念。但我们也能够修改这些值,虽然并不推荐这样做,除非你晓得自己在做什么,并且充分理解(这些变量值)。
|
||||
|
||||
此后,我们将继续学习如何在 awk 命令操作中使用 shell 变量,所以,请继续关注 Tecmint。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/awk-built-in-variables-examples/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
@ -0,0 +1,95 @@
|
||||
awk 系列:如何让 awk 使用 Shell 变量
|
||||
==================================================
|
||||
|
||||
当我们编写 shell 脚本时,我们通常会在脚本中包含其它小程序或命令,例如 awk 操作。对于 awk 而言,我们需要找一些将某些值从 shell 传递到 awk 操作中的方法。
|
||||
|
||||
我们可以通过在 awk 命令中使用 shell 变量达到目的,在 awk 系列的这一节中,我们将学习如何让 awk 使用 shell 变量,这些变量可能包含我们希望传递给 awk 命令的值。
|
||||
|
||||
有两种可能的方法可以让 awk 使用 shell 变量:
|
||||
|
||||
### 1. 使用 Shell 引用
|
||||
|
||||
让我们用一个示例来演示如何在一条 awk 命令中使用 shell 引用替代一个 shell 变量。在该示例中,我们希望在文件 /etc/passwd 中搜索一个用户名,过滤并输出用户的账户信息。
|
||||
|
||||
因此,我们可以编写一个 `test.sh` 脚本,内容如下:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# 读取用户名
|
||||
read -p "请输入用户名:" username
|
||||
|
||||
# 在 /etc/passwd 中搜索用户名,然后在屏幕上输出详细信息
|
||||
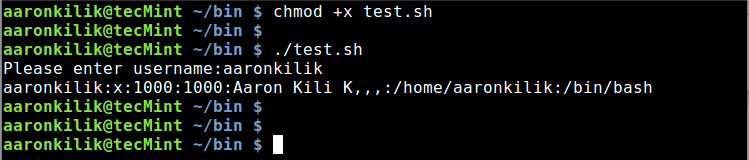
cat /etc/passwd | awk "/$username/ "' { print $0 }'
|
||||
```
|
||||
|
||||
然后,保存文件并退出。
|
||||
|
||||
上述 `test.sh` 脚本中 awk 命令的说明:
|
||||
|
||||
```
|
||||
cat /etc/passwd | awk "/$username/ "' { print $0 }'
|
||||
```
|
||||
|
||||
`"/$username/ "`:在 awk 命令中使用 shell 引用来替代 shell 变量 `username` 的值。`username` 的值就是要在文件 /etc/passwd 中搜索的模式。
|
||||
|
||||
注意,双引号位于 awk 脚本 `'{ print $0 }'` 之外。
|
||||
|
||||
接下来给脚本添加可执行权限并运行它,操作如下:
|
||||
|
||||
```
|
||||
$ chmod +x test.sh
|
||||
$ ./text.sh
|
||||
```
|
||||
|
||||
运行脚本后,它会提示你输入一个用户名,然后你输入一个合法的用户名并回车。你将会看到来自 /etc/passwd 文件中详细的用户账户信息,如下图所示:
|
||||
|
||||

|
||||
> *在 Password 文件中查找用户名的 shell 脚本*
|
||||
|
||||
### 2. 使用 awk 进行变量赋值
|
||||
|
||||
和上面介绍的方法相比,该方法更加单,并且更好。考虑上面的示例,我们可以运行一条简单的命令来完成同样的任务。
|
||||
在该方法中,我们使用 `-v` 选项将一个 shell 变量的值赋给一个 awk 变量。
|
||||
首先,创建一个 shell 变量 `username`,然后给它赋予一个我们希望在 /etc/passwd 文件中搜索的名称。
|
||||
|
||||
```
|
||||
username="aaronkilik"
|
||||
```
|
||||
然后输入下面的命令并回车:
|
||||
|
||||
```
|
||||
# cat /etc/passwd | awk -v name="$username" ' $0 ~ name {print $0}'
|
||||
```
|
||||
|
||||

|
||||
> *使用 awk 在 Password 文件中查找用户名*
|
||||
|
||||
上述命令的说明:
|
||||
|
||||
- `-v`:awk 选项之一,用于声明一个变量
|
||||
- `username`:是 shell 变量
|
||||
- `name`:是 awk 变量
|
||||
|
||||
让我们仔细瞧瞧 awk 脚本 `' $0 ~ name {print $0}'` 中的 `$0 ~ name`。还记得么,当我们在 awk 系列第四节中介绍 awk 比较运算符时,`value ~ pattern` 便是比较运算符之一,它是指:如果 `value` 匹配了 `pattern` 则返回 `true`。
|
||||
|
||||
cat 命令通过管道传给 awk 的 `output($0)` 与模式 `(aaronkilik)` 匹配,该模式即为我们在 /etc/passwd 中搜索的名称,最后,比较操作返回 `true`。接下来会在屏幕上输出包含用户账户信息的行。
|
||||
|
||||
### 结论
|
||||
|
||||
我们已经介绍了 awk 功能的一个重要部分,它能帮助我们在 awk 命令中使用 shell 变量。很多时候,你都会在 shell 脚本中编写小的 awk 程序或命令,因此,你需要清晰地理解如何在 awk 命令中使用 shell 变量。
|
||||
|
||||
在 awk 系列的下一个部分,我们将会深入学习 awk 功能的另外一个关键部分,即流程控制语句。所以请继续保持关注,并让我们坚持学习与分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-shell-script-variable-in-awk/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对ID](https://github.com/校对ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
Loading…
Reference in New Issue
Block a user