mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Translated by qhwdw (#6254)
* Translating by qhwdw Translating by qhwdw * Translated by qhwdw Translated by qhwdw * Translated by qhwdw Translated by qhwdw * Translating by qhwdw Translating by qhwdw * Translated by qhwdw Translated by qhwdw * Translated by qhwdw Translated by qhwdw
This commit is contained in:
parent
7a4563c62e
commit
01541287d6
@ -1,4 +1,4 @@
|
||||
LinchPin: A simplified cloud orchestration tool using Ansible
|
||||
Translating by qhwdw LinchPin: A simplified cloud orchestration tool using Ansible
|
||||
============================================================
|
||||
|
||||
### Launched in late 2016, LinchPin now has a Python API and a growing community.
|
||||
|
||||
@ -1,128 +0,0 @@
|
||||
Translating by qhwdw How to implement cloud-native computing with Kubernetes
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Kubernetes and containers can speed up the development process while minimizing programmer and system administration costs, say representatives of the Open Container Initiative and the Cloud Native Computing Foundation. To take advantage of Kubernetes and its related tools to run a cloud-native architecture, start with unappreciated Kubernetes features like namespaces.
|
||||
|
||||
[Kubernetes][2] is far more than a cloud-container manager. As Steve Pousty, [Red Hat's][3] lead developer advocate for [OpenShift][4], explained in a presentation at [the Linux Foundation's][5] [Open Source Summit][6], Kubernetes serves as a "common operating plane for cloud-native computing using containers."
|
||||
|
||||
What does Pousty mean by that? Let's review the basics.
|
||||
|
||||
“Cloud-native computing uses an open source software stack to deploy applications as microservices, package each part into its own container, and dynamically orchestrate those containers to optimize resource utilization,” explains Chris Aniszczyk, executive director of the [Open Container Initiative][7] (OCI) and the [Cloud Native Computing Foundation][8] (CNCF). [Kubernetes takes care of that last element][9] of cloud-native computing. The result is part of a larger transition in IT, moving from servers to virtual machines to buildpacks—and now to [containers][10].
|
||||
|
||||
This data center evolution has netted significant cost savings, in part because it requires fewer dedicated staff, conference presenters say. For example, by using Kubernetes, Google needs only one site reliability engineer per 10,000 machines, according to Aniszczyk.
|
||||
|
||||
Practically speaking, however, system administrators can take advantage of new Kubernetes-related tools and exploit under-appreciated features.
|
||||
|
||||
### Building a native cloud platform
|
||||
|
||||
Pousty explained, "For Red Hat, Kubernetes is the cloud Linux kernel. It's this infrastructure that everybody's going to build on."
|
||||
|
||||
For an example, let's say you have an application within a container image. How do you know it's safe? Red Hat and other companies use [OpenSCAP][11], which is based on the [Security Content Automation Protocol][12] (SCAP), a specification for expressing and manipulating security data in standardized ways. The OpenSCAP project provides open source hardening guides and configuration baselines. You select an appropriate security policy, then use OpenSCAP-approved security tools to make certain the programs within your Kubernetes-controlled containers comply with those customized security standards.
|
||||
|
||||
Unsure how to get started with containers? Yes, we have a guide for that.
|
||||
|
||||
[Get Containers for Dummies][1]
|
||||
|
||||
Red Hat automated this process further using [Atomic Scan][13]; it works with any OpenSCAP provider to scan container images for known security vulnerabilities and policy configuration problems. Atomic Scan mounts read-only file systems. These are passed to the scanning container, along with a writeable directory for the scanner's output.
|
||||
|
||||
This approach has several advantages, Pousty pointed out, primarily, "You can scan a container image without having to actually run it." So, if there is bad code or a flawed security policy within the container, it can't do anything to your system.
|
||||
|
||||
Atomic Scan works much faster than running OpenSCAP manually. Since containers tend to be spun up and destroyed in minutes or hours, Atomic Scan enables Kubernetes users to keep containers secure in container time rather than the much-slower sysadmin time.
|
||||
|
||||
### Tool time
|
||||
|
||||
Another tool that help sysadmins and DevOps make the most of Kubernetes is [CRI-O][14]. This is an OCI-based implementation of the [Kubernetes Container Runtime Interface][15]. CRI-O is a daemon that Kubernetes can use for running container images stored on Docker registries, explains Dan Walsh, a Red Hat consulting engineer and [SELinux][16] project lead. It enables you to launch container images directly from Kubernetes instead of spending time and CPU cycles on launching the [Docker Engine][17]. And it’s image format agnostic.
|
||||
|
||||
In Kubernetes, [kubelets][18] manage pods, or containers’ clusters. With CRI-O, Kubernetes and its kubelets can manage the entire container lifecycle. The tool also isn't wedded to Docker images; you can also use the new [OCI Image Format][19] and [CoreOS's rkt][20] container images.
|
||||
|
||||
Together, these tools are becoming a Kubernetes stack: the orchestrator, the [Container Runtime Interface][21] (CRI), and CRI-O. Lead Kubernetes engineer Kelsey Hightower says, "We don’t really need much from any container runtime—whether it’s Docker or [rkt][22]. Just give us an API to the kernel." The result, promise these techies, is the power to spin containers faster than ever.
|
||||
|
||||
Kubernetes is also speeding up building container images. Until recently, there were [three ways to build containers][23]. The first way is to build container images in place via a Docker or CoreOS. The second approach is to inject custom code into a prebuilt image. Finally, Asset Generation Pipelines use containers to compile assets that are then included during a subsequent image build using Docker's [Multi-Stage Builds][24].
|
||||
|
||||
Now, there's a Kubernetes-native method: Red Hat's [Buildah][25], [a scriptable shell tool][26] for efficiently and quickly building OCI-compliant images and containers. Buildah simplifies creating, building, and updating images while decreasing the learning curve of the container environment, Pousty said. You can use it with Kubernetes to create and spin up containers automatically based on an application's calls. Buildah also saves system resources, because it does not require a container runtime daemon.
|
||||
|
||||
So, rather than actually booting a container and doing all sorts of steps in the container itself, Pousty said, “you mount the file system, do normal operations on your machine as if it were your normal file system, and then commit at the end."
|
||||
|
||||
What this means is that you can pull down an image from a registry, create its matching container, and customize it. Then you can use Buildah within Kubernetes to create new running images as you need them. The end result, he said, is even more speed for running Kubernetes-managed containerized applications, requiring fewer resources.
|
||||
|
||||
### Kubernetes features you didn’t know you had
|
||||
|
||||
You don’t necessarily need to look for outside tools. Kubernetes has several underappreciated features.
|
||||
|
||||
One of them, according to Allan Naim, a Google Cloud global product lead, is [Kubernetes namespaces][27]. In his Open Source Summit speech on Kubernetes best practices, Naim said, "Few people use namespaces—and that's a mistake."
|
||||
|
||||
“Namespaces are the way to partition a single Kubernetes cluster into multiple virtual clusters," said Naim. For example, "you can think of namespaces as family names." So, if "Smith" identifies a family, one member, say, Steve Smith, is just “Steve,” but outside the confines of the family, he's "Steve Smith" or perhaps "Steve Smith from Chicago.”
|
||||
|
||||
More technically, "namespaces are a logical partitioning capability that enable one Kubernetes cluster to be used by multiple users, teams of users, or a single user with multiple applications without confusion,” Naim explained. “Each user, team of users, or application may exist within its namespace, isolated from every other user of the cluster and operating as if it were the sole user of the cluster.”
|
||||
|
||||
Practically speaking, you can use namespaces to mold an enterprise's multiple business/technology entities onto Kubernetes. For example, cloud architects can define the corporate namespace strategy by mapping product, location, team, and cost-center namespaces.
|
||||
|
||||
Another approach Naim suggested is to use namespaces to partition software development pipelines into discrete namespaces. These could be such familiar units as testing, quality assurance, staging, and production. Or namespaces can be used to manage separate customers. For instance, you could create a separate namespace for each customer, customer project, or customer business unit. That makes it easier to distinguish between projects and avoid reusing the same names for resources.
|
||||
|
||||
However, Kubernetes doesn't currently provide a mechanism to enforce access controls across namespaces. Therefore, Naim recommended you don't externally expose programs using this approach. Also keep in mind that namespaces aren't a management cure-all. For example, you can't nest namespaces within one other. In addition, there's no mechanism to enforce security across namespaces.
|
||||
|
||||
Still, used with care, namespaces can be quite useful.
|
||||
|
||||
### Human-centered tips
|
||||
|
||||
Moving from deep technology to project management, Pousty suggested that, in the move to a cloud-native and microservice architecture, you put an operations person on your microservice team. “If you're going to do microservices, your team will end up doing Ops-y work. And, it's kind of foolish not to bring in someone who already knows operations,” he said. “You need the right core competencies on that team. I don't want developers to reinvent the operations wheel."
|
||||
|
||||
Instead, reinvent your work process into one that enables you to make the most from containers and clouds. For that, Kubernetes is great.
|
||||
|
||||
### Cloud-native computing with Kubernetes: Lessons for leaders
|
||||
|
||||
* The cloud-native ecosystem is expanding rapidly. Look for tools that can extend the ways you use containers.
|
||||
|
||||
* Explore less well-known Kubernetes features such as namespaces. They can improve your organization and automation.
|
||||
|
||||
* Make sure development teams deploying to containers have an Ops person involved. Otherwise strife will ensue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Steven J. Vaughan-Nichols, CEO, Vaughan-Nichols & Associates
|
||||
|
||||
Steven J. Vaughan-Nichols, aka sjvn, has been writing about technology and the business of technology since CP/M-80 was the cutting edge, PC operating system; 300bps was a fast Internet connection; WordStar was the state of the art word processor; and we liked it. His work has been published in everything from highly technical publications (IEEE Computer, ACM NetWorker, Byte) to business publications (eWEEK, InformationWeek, ZDNet) to popular technology (Computer Shopper, PC Magazine, PC World) to the mainstream press (Washington Post, San Francisco Chronicle, BusinessWeek).
|
||||
|
||||
---------------------
|
||||
|
||||
|
||||
via: https://insights.hpe.com/articles/how-to-implement-cloud-native-computing-with-kubernetes-1710.html
|
||||
|
||||
作者:[ Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.hpe.com/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_insights~510287587~Containers_Dummies~sjvn_Kubernetes
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.redhat.com/en
|
||||
[4]:https://www.openshift.com/
|
||||
[5]:https://www.linuxfoundation.org/
|
||||
[6]:http://events.linuxfoundation.org/events/open-source-summit-north-america
|
||||
[7]:https://www.opencontainers.org/
|
||||
[8]:https://www.cncf.io/
|
||||
[9]:https://insights.hpe.com/articles/the-basics-explaining-kubernetes-mesosphere-and-docker-swarm-1702.html
|
||||
[10]:https://insights.hpe.com/articles/when-to-use-containers-and-when-not-to-1705.html
|
||||
[11]:https://www.open-scap.org/
|
||||
[12]:https://scap.nist.gov/
|
||||
[13]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[14]:http://cri-o.io/
|
||||
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[16]:https://wiki.centos.org/HowTos/SELinux
|
||||
[17]:https://docs.docker.com/engine/
|
||||
[18]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[19]:http://www.zdnet.com/article/containers-consolidation-open-container-initiative-1-0-released/
|
||||
[20]:https://coreos.com/rkt/docs/latest/
|
||||
[21]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[22]:https://coreos.com/rkt/
|
||||
[23]:http://chris.collins.is/2017/02/24/three-docker-build-strategies/
|
||||
[24]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/#use-multi-stage-builds
|
||||
[25]:https://github.com/projectatomic/buildah
|
||||
[26]:https://www.projectatomic.io/blog/2017/06/introducing-buildah/
|
||||
[27]:https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
@ -1,338 +0,0 @@
|
||||
How to manage Docker containers in Kubernetes with Java
|
||||
==========================
|
||||
|
||||
|
||||
>Orchestrate production-ready systems at enterprise scale.
|
||||
|
||||
Learn basic Kubernetes concepts and mechanisms for automating the deployment, maintenance, and scaling of your Java applications with “Kubernetes for Java Developers.” [Download your free copy][3].
|
||||
|
||||
|
||||
In [_Containerizing Continuous Delivery in Java_][23] we explored the fundamentals of packaging and deploying Java applications within Docker containers. This was only the first step in creating production-ready, container-based systems. Running containers at any real-world scale requires a container orchestration and scheduling platform, and although many exist (i.e., Docker Swarm, Apache Mesos, and AWS ECS), the most popular is [Kubernetes][24]. Kubernetes is used in production at many organizations, and is now hosted by the [Cloud Native Computing Foundation (CNCF)][25]. In this article, we will take the previous simple Java-based, e-commerce shop that we packaged within Docker containers and run this on Kubernetes.
|
||||
|
||||
### The “Docker Java Shopfront” application
|
||||
|
||||
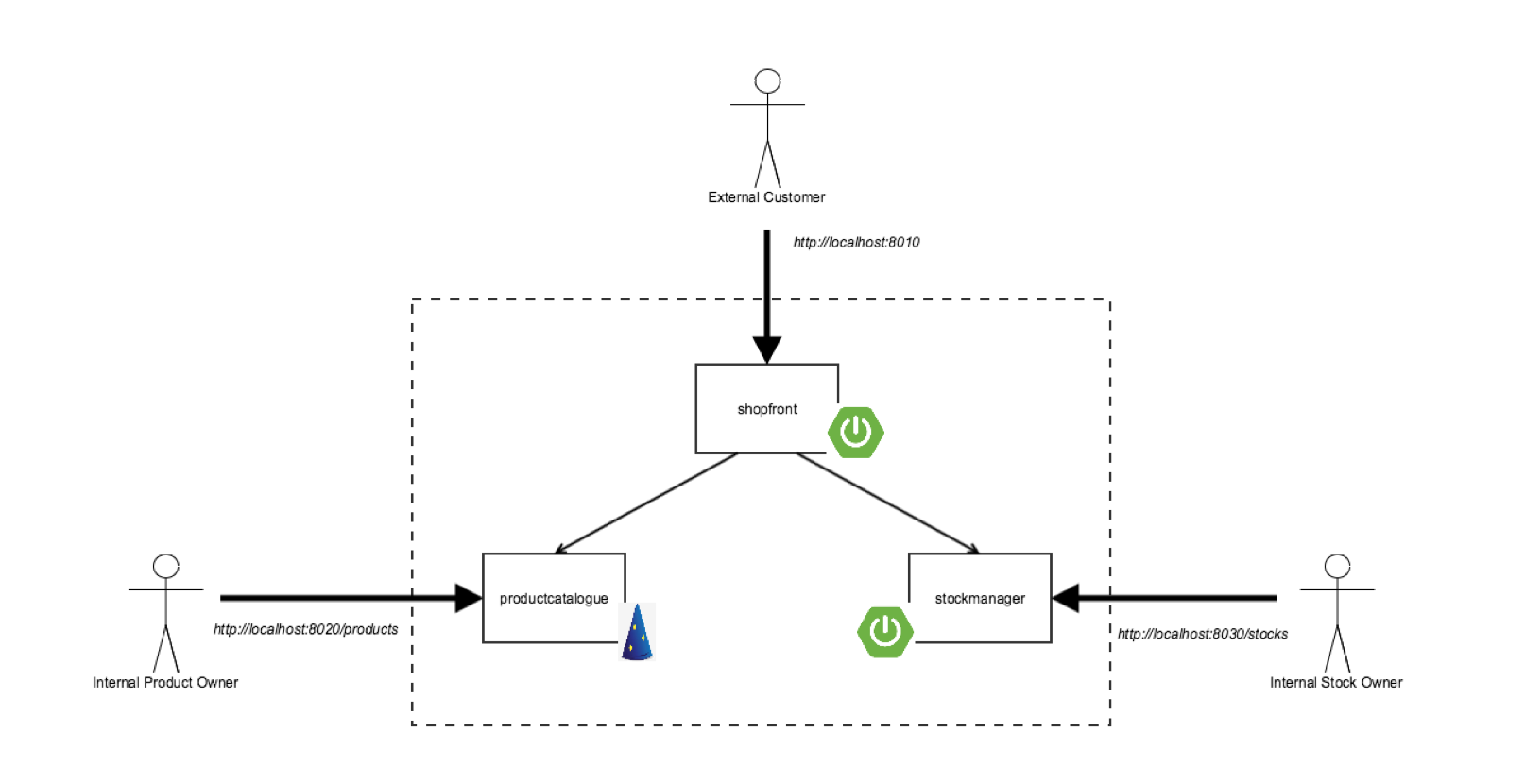
The architecture of the “Docker Java Shopfront” application that we will package into containers and deploy onto Kubernetes can be seen below:
|
||||
|
||||
|
||||
|
||||
|
||||
Before we start creating the required Kubernetes deployment configuration files let’s first learn about core concepts within this container orchestration platform.
|
||||
|
||||
### Kubernetes 101
|
||||
|
||||
Kubernetes is an open source orchestrator for deploying containerized applications that was originally developed by Google. Google has been running containerized applications for many years, and this led to the creation of the [Borg container orchestrator][26] that is used internally within Google, and was the source of inspiration for Kubernetes. If you are not familiar with this technology then a number of core concepts may appear alien at first glance, but they actually hide great power. The first is that Kubernetes embraces the principles of immutable infrastructure. Once a container is deployed the contents (i.e., the application) are not updated by logging into the container and making changes. Instead a new version is deployed. Second, everything in Kubernetes is declaratively configured. The developer or operator specifies the desired state of the system through deployment descriptors and configuration files, and Kubernetes is responsible for making this happen - you don’t need to provide imperative, step-by-step instructions.
|
||||
|
||||
These principles of immutable infrastructure and declarative configuration have a number of benefits: it is easier to prevent configuration drift, or “snowflake” application instances; declarative deployment configuration can be stored within version control, alongside the code; and Kubernetes can be largely self-healing, as if the system experiences failure like an underlying compute node failure, the system can rebuild and rebalance the applications according to the state specified in the declarative configuration.
|
||||
|
||||
Kubernetes provides several abstractions and APIs that make it easier to build these distributed applications, such as those based on the microservice architectural style:
|
||||
|
||||
* [Pods][5] - This is the lowest unit of deployment within Kubernetes, and is essentially a groups of containers. A pod allows a microservice application container to be grouped with other “sidecar” containers that may provide system services like logging, monitoring or communication management. Containers within a pod share a filesystem and network namespace. Note that a single container can be deployed, but it is always deployed within a pod
|
||||
|
||||
* [Services][6] - Kubernetes Services provide load balancing, naming, and discovery to isolate one microservice from another. Services are backed by [Replication Controllers][7], which in turn are responsible for details associated with maintaining the desired number of instances of a pod to be running within the system. Services, Replication Controllers and Pods are connected together in Kubernetes through the use of “[labels][8]”, both for naming and selecting.
|
||||
|
||||
Let’s now create a service for one of our Java-based microservice applications.
|
||||
|
||||
|
||||
### Building Java applications and container images
|
||||
|
||||
Before we first create a container and the associated Kubernetes deployment configuration, we must first ensure that we have installed the following prerequisites:
|
||||
|
||||
* Docker for [Mac][11] / [Windows][12] / [Linux][13] - This allows us to build, run and test Docker containers outside of Kubernetes on our local development machine.
|
||||
|
||||
* [Minikube][14] - This is a tool that makes it easy to run a single-node Kubernetes test cluster on our local development machine via a virtual machine.
|
||||
|
||||
* A [GitHub][15] account, and [Git][16] installed locally - The code examples are stored on GitHub, and by using Git locally you can fork the repository and commit changes to your own personal copy of the application.
|
||||
|
||||
* [Docker Hub][17] account - If you would like to follow along with this tutorial, you will need a Docker Hub account in order to push and store your copies of the container images that we will build below.
|
||||
|
||||
* [Java 8][18] (or 9) SDK and [Maven][19] - We will be building code with the Maven build and dependency tool that uses Java 8 features.
|
||||
|
||||
Clone the project repository from GitHub (optionally you can fork this repository and clone your personal copy), and locate the “shopfront” microservice application: [https://github.com/danielbryantuk/oreilly-docker-java-shopping/][27]
|
||||
|
||||
```
|
||||
$ git clone git@github.com:danielbryantuk/oreilly-docker-java-shopping.git
|
||||
$ cd oreilly-docker-java-shopping/shopfront
|
||||
|
||||
```
|
||||
|
||||
Feel free to load the shopfront code into your editor of choice, such as IntelliJ IDE or Eclipse, and have a look around. Let’s build the application using Maven. The resulting runnable JAR file that contains the application will be located in the ./target directory.
|
||||
|
||||
```
|
||||
$ mvn clean install
|
||||
…
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] BUILD SUCCESS
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] Total time: 17.210 s
|
||||
[INFO] Finished at: 2017-09-30T11:28:37+01:00
|
||||
[INFO] Final Memory: 41M/328M
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
Now we will build the Docker container image. The operating system choice, configuration and build steps for a Docker image are typically specified via a Dockerfile. Let’s look at our example Dockerfile that is located in the shopfront directory:
|
||||
|
||||
```
|
||||
FROM openjdk:8-jre
|
||||
ADD target/shopfront-0.0.1-SNAPSHOT.jar app.jar
|
||||
EXPOSE 8010
|
||||
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
|
||||
|
||||
```
|
||||
|
||||
The first line specifies that our container image should be created “from” the openjdk:8-jre base image. The [openjdk:8-jre][28] image is maintained by the OpenJDK team, and contains everything we need to run a Java 8 application within a Docker container (such as an operating system with the OpenJDK 8 JRE installed and configured). The second line takes the runnable JAR we built above and “adds” this to the image. The third line specifies that port 8010, which our application will listen on, must be “exposed” as externally accessible, and the fourth line specifies the “entrypoint” or command to run when the container is initialized. Let’s build our container:
|
||||
|
||||
|
||||
```
|
||||
$ docker build -t danielbryantuk/djshopfront:1.0 .
|
||||
Successfully built 87b8c5aa5260
|
||||
Successfully tagged danielbryantuk/djshopfront:1.0
|
||||
|
||||
```
|
||||
|
||||
Now let’s push this to Docker Hub. If you haven’t logged into the Docker Hub via your command line, you must do this now, and enter your username and password:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
|
||||
Username:
|
||||
Password:
|
||||
Login Succeeded
|
||||
$
|
||||
$ docker push danielbryantuk/djshopfront:1.0
|
||||
The push refers to a repository [docker.io/danielbryantuk/djshopfront]
|
||||
9b19f75e8748: Pushed
|
||||
...
|
||||
cf4ecb492384: Pushed
|
||||
1.0: digest: sha256:8a6b459b0210409e67bee29d25bb512344045bd84a262ede80777edfcff3d9a0 size: 2210
|
||||
|
||||
```
|
||||
|
||||
### Deploying onto Kubernetes
|
||||
|
||||
Now let’s run this container within Kubernetes. First, change the “kubernetes” directory in the root of the project:
|
||||
|
||||
```
|
||||
$ cd ../kubernetes
|
||||
|
||||
```
|
||||
|
||||
Open the shopfront-service.yaml Kubernetes deployment file and have a look at the contents:
|
||||
|
||||
```
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: shopfront
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
type: NodePort
|
||||
selector:
|
||||
app: shopfront
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8010
|
||||
name: http
|
||||
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ReplicationController
|
||||
metadata:
|
||||
name: shopfront
|
||||
spec:
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
containers:
|
||||
- name: shopfront
|
||||
image: danielbryantuk/djshopfront:latest
|
||||
ports:
|
||||
- containerPort: 8010
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /health
|
||||
port: 8010
|
||||
initialDelaySeconds: 30
|
||||
timeoutSeconds: 1
|
||||
|
||||
```
|
||||
|
||||
The first section of the yaml file creates a Service named “shopfront” that will route TCP traffic targeting this service on port 8010 to pods with the label “app: shopfront”. The second section of the configuration file creates a `ReplicationController` that specifies Kubernetes should run one replica (instance) of our shopfront container, which we have declared as part of the “spec” (specification) labelled as “app: shopfront”. We have also specified that the 8010 application traffic port we exposed in our Docker container is open, and declared a “livenessProbe” or healthcheck that Kubernetes can use to determine if our containerized application is running correctly and ready to accept traffic. Let’s start `minikube` and deploy this service (note that you may need to change the specified `minikube` CPU and Memory requirements depending on the resources available on your development machine):
|
||||
|
||||
```
|
||||
$ minikube start --cpus 2 --memory 4096
|
||||
Starting local Kubernetes v1.7.5 cluster...
|
||||
Starting VM...
|
||||
Getting VM IP address...
|
||||
Moving files into cluster...
|
||||
Setting up certs...
|
||||
Connecting to cluster...
|
||||
Setting up kubeconfig...
|
||||
Starting cluster components...
|
||||
Kubectl is now configured to use the cluster.
|
||||
$ kubectl apply -f shopfront-service.yaml
|
||||
service "shopfront" created
|
||||
replicationcontroller "shopfront" created
|
||||
|
||||
```
|
||||
|
||||
You can view all Services within Kubernetes by using the “kubectl get svc” command. You can also view all associated pods by using the “kubectl get pods” command (note that the first time you issue the get pods command, the container may not have finished creating, and is marked as not yet ready):
|
||||
|
||||
```
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 18h
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 12s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 0/1 ContainerCreating 0 18s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 1/1 Running 0 2m
|
||||
|
||||
```
|
||||
|
||||
We have now successfully deployed our first Service into Kubernetes!
|
||||
|
||||
### Time for a smoke test
|
||||
|
||||
Let’s use curl to see if we can get data from the shopfront application’s healthcheck endpoint:
|
||||
|
||||
```
|
||||
$ curl $(minikube service shopfront --url)/health
|
||||
{"status":"UP"}
|
||||
|
||||
```
|
||||
|
||||
You can see from the results of the curl against the application/health endpoint that the application is up and running, but we need to deploy the remaining microservice application containers before the application will function as we expect it to.
|
||||
|
||||
### Building the remaining applications
|
||||
|
||||
Now that we have one container up and running let’s build the remaining two supporting microservice applications and containers:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd productcatalogue/
|
||||
$ mvn clean install
|
||||
…
|
||||
$ docker build -t danielbryantuk/djproductcatalogue:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djproductcatalogue:1.0
|
||||
...
|
||||
$ cd ..
|
||||
$ cd stockmanager/
|
||||
$ mvn clean install
|
||||
...
|
||||
$ docker build -t danielbryantuk/djstockmanager:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djstockmanager:1.0
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
At this point we have built all of our microservices and the associated Docker images, and also pushed the images to Docker Hub. Let’s now deploy the `productcatalogue` and `stockmanager` services to Kubernetes.
|
||||
|
||||
### Deploying the entire Java application in Kubernetes
|
||||
|
||||
In a similar fashion to the process we used above to deploy the shopfront service, we can now deploy the remaining two microservices within our application to Kubernetes:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd kubernetes/
|
||||
$ kubectl apply -f productcatalogue-service.yaml
|
||||
service "productcatalogue" created
|
||||
replicationcontroller "productcatalogue" created
|
||||
$ kubectl apply -f stockmanager-service.yaml
|
||||
service "stockmanager" created
|
||||
replicationcontroller "stockmanager" created
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 19h
|
||||
productcatalogue 10.0.0.37 <nodes> 8020:31803/TCP 42s
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 13m
|
||||
stockmanager 10.0.0.149 <nodes> 8030:30723/TCP 16s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
productcatalogue-79qn4 1/1 Running 0 55s
|
||||
shopfront-0w1js 1/1 Running 0 13m
|
||||
stockmanager-lmgj9 1/1 Running 0 29s
|
||||
|
||||
```
|
||||
|
||||
Depending on how quickly you issue the “kubectl get pods” command, you may see that all of the pods are not yet running. Before moving on to the next section of this article wait until the command shows that all of the pods are running (maybe this is a good time to brew a cup of tea!)
|
||||
|
||||
### Viewing the complete application
|
||||
|
||||
With all services deployed and all associated pods running, we now should be able to access our completed application via the shopfront service GUI. We can open the service in our default browser by issuing the following command in `minikube`:
|
||||
|
||||
```
|
||||
$ minikube service shopfront
|
||||
|
||||
```
|
||||
|
||||
If everything is working correctly, you should see the following page in your browser:
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article, we have taken our application that consisted of three Java Spring Boot and Dropwizard microservices, and deployed it onto Kubernetes. There are many more things we need to think about in the future, such as debugging services (perhaps through the use of tools like [Telepresence][29] and [Sysdig][30]), testing and deploying via a continuous delivery pipeline like [Jenkins][31] or [Spinnaker][32], and observing our running system.
|
||||
|
||||
* * *
|
||||
|
||||
_This article was created in collaboration with NGINX. [See our statement of editorial independence][22]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel Bryant works as an Independent Technical Consultant, and is the CTO at SpectoLabs. He currently specialises in enabling continuous delivery within organisations through the identification of value streams, creation of build pipelines, and implementation of effective testing strategies. Daniel’s technical expertise focuses on ‘DevOps’ tooling, cloud/container platforms, and microservice implementations. He also contributes to several open source projects, writes for InfoQ, O’Reilly, and Voxxed, and regularly presents at internatio...
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java
|
||||
|
||||
作者:[ Daniel Bryant ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/d3f4d647-482d-4dce-a0e5-a09773b77150
|
||||
[1]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[2]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[3]:https://www.nginx.com/resources/library/kubernetes-for-java-developers/
|
||||
[4]:https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021
|
||||
[5]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[6]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[7]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[9]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[10]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[11]:https://docs.docker.com/docker-for-mac/install/
|
||||
[12]:https://docs.docker.com/docker-for-windows/install/
|
||||
[13]:https://docs.docker.com/engine/installation/linux/ubuntu/
|
||||
[14]:https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[15]:https://github.com/
|
||||
[16]:https://git-scm.com/
|
||||
[17]:https://hub.docker.com/
|
||||
[18]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
|
||||
[19]:https://maven.apache.org/
|
||||
[20]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[21]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[22]:http://www.oreilly.com/about/editorial_independence.html
|
||||
[23]:https://www.nginx.com/resources/library/containerizing-continuous-delivery-java/
|
||||
[24]:https://kubernetes.io/
|
||||
[25]:https://www.cncf.io/
|
||||
[26]:https://research.google.com/pubs/pub44843.html
|
||||
[27]:https://github.com/danielbryantuk/oreilly-docker-java-shopping/
|
||||
[28]:https://hub.docker.com/_/openjdk/
|
||||
[29]:https://telepresence.io/
|
||||
[30]:https://www.sysdig.org/
|
||||
[31]:https://wiki.jenkins.io/display/JENKINS/Kubernetes+Plugin
|
||||
[32]:https://www.spinnaker.io/
|
||||
@ -0,0 +1,128 @@
|
||||
怎么去使用 Kubernetes 实现私有云计算
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
开源容器倡导者和私有云计算基金会的代表说,Kubernetes 和容器可以在降低程序员和系统管理员成本(costs)的同时加速部署进程,从不被看好的 Kubernetes 特性(像命令空间)开始,去利用 Kubernetes 和它的相关工具运行一个私有云架构
|
||||
|
||||
[Kubernetes][2] 不止是一个云容器管理器。正如 Steve Pousty,他是[Red Hat][3]支持的[OpenShift][4]的首席开发者,在[Linux 基金会][5]的[开源提交者][6]的一个报告中解释的那样,Kubernetes 提供作为一个 “使用容器进行私有云计算的一个通用操作面(common operating plane)”。
|
||||
|
||||
Pousty 的意思是什么?让我们复习一下基础知识。
|
||||
|
||||
[开源容器倡议][7] (OCI) 和 [私有云计算基金会][8] (CNCF) 的执行董事 Chris Aniszczyk 的解释是,“私有云计算使用一个开源软件栈去部署作为微服务的应用程序,打包每一个部分到它自己的容器中,并且动态排布这些容器去优化资源使用”,[Kubernetes 关注私有云计算的最新要素][9]。最终将导致 IT 中很大的一部分发生转变,从服务器到虚拟机到构建包 (buildpacks) 到现在的 [容器][10]。
|
||||
|
||||
会议主持人说,数据中心的演变将节省相当可观的成本, 部分原因是它需要更少的专职员工。例如,据 Aniszczyk 说,通过使用 Kubernetes,谷歌每 10000 台机器仅需要一个网站可靠性工程师(译者注:即SRE)。
|
||||
|
||||
实际上,系统管理员可以利用新的 Kubernetes 相关的工具并可以去开发喜欢的功能。
|
||||
|
||||
### 构建一个私有云平台
|
||||
|
||||
Pousty 解释说,“对于 Red Hat, Kubernetes 是云 Linux 内核。它是每个人都可以在上面构建的基础设施”。
|
||||
|
||||
例如,假如你在一个容器镜像中有一个应用程序。你怎么知道它是安全的呢? Red Hat 和其它的公司使用 [OpenSCAP][11],它是基于 [安全内容自动化协议][12] (SCAP)的,是使用标准化的方式去表达和操作安全数据的一个规范。OpenSCAP 项目提供了一个开源的强化指南和配置基准。你选择一个合适的安全策略,然后,使用 OpenSCAP 认可的安全工具去使某些在你的 Kubernetes 控制的容器中的程序遵守这些定制的安全标准。
|
||||
|
||||
还没有搞明白怎么去使用容器?好吧,我现在指导你。
|
||||
|
||||
[傻瓜式获得容器(Get Containers for Dummies)][1]
|
||||
|
||||
Red Hat 将使用[原子扫描(Atomic Scan)][13]自动处理这个过程;它用 OpenSCAP 提供的工具去扫描容器镜像中的已知安全漏洞和策略配置问题。原子扫描加载了只读的文件系统。这些通过扫描的容器,随着一个可写入扫描器的目录一起输出。
|
||||
|
||||
Pousty 指出,这种方法有几个好处,主要是,“你可以在不实际运行它的情况下,去扫描一个容器镜像”。因此,如果在容器中有糟糕的代码或有缺陷的安全策略,它不会对你的系统做任何事情。
|
||||
|
||||
原子扫描比手动运行 OpenSCAP 快很多。 因为,容器从启用到消毁可能就在几分钟或几小时内,原子扫描允许 Kubernetes 用户在容器启用期间去保持容器安全,而不用花费太多的系统管理时间。
|
||||
|
||||
### 关于工具
|
||||
|
||||
帮助 Kubernetes 进行大部分的系统管理和开发运营(DevOps)操作的另一个工具是 [CRI-O][14]。这是一个基于 OCI 实现的 [Kubernetes 容器运行时接口][15]。CRI-O 是一个守护进程, Kubernetes 可以用于运行存储在 Docker registries 中的容器镜像,Dan Walsh 解释说,它是 Red Hat 的顾问工程师和 [SELinux][16] 项目领导者。它允许你直接从 Kubernetes 中启动容器镜像,而不用花费时间和 CPU 周期在 [Docker 引擎][17] 上启动。并且它的镜像格式是与容器无关的。
|
||||
|
||||
在 Kubernetes 中, [kubelets][18] 管理 pods、或者容器的集群。使用 CRI-O,Kubernetes 和 它的 kubelets 可以管理整个容器的生命周期。这个工具也不是和 Docker 镜像结合在一起的。你也可以使用新的 [OCI 镜像格式][19] 和 [CoreOS 的 rkt][20] 容器镜像。
|
||||
|
||||
同时,这些工具正在成为一个 Kubernetes 栈:Orchestrator、[容器运行时接口][21] (CRI)、和 CRI-O。Kubernetes 首席工程师 Kelsey Hightower 说,“我们实际上不需要这么多的容器运行时—无论它是 Docker 还是 [rkt][22]。仅需要给我们一个到内核的 API”,结果,对这些技术人员的承诺,是推动容器比以往更快发展的强大动力。
|
||||
|
||||
Kubernetes 也可以加速构建容器镜像。直到最近,这是 [构建容器的三种方法][23]。第一种方法是通过一个 Docker 或者 CoreOS 去构建容器。第二种方法是注入客户代码到一个预构建镜像中。最后一种方法是,资产生成管理(Asset Generation Pipelines)使用容器去编译那些资产(assets)包含到随后生成的镜像中,它使用了 Dockers 的[多阶段构建][24]去构建镜像。
|
||||
|
||||
现在,还有一个 Kubernetes 的私有方法:Red Hat 的 [Buildah][25], [一个脚本化的 shell 工具][26] 用于快速高效地构建 OCI 兼容的镜像和容器。Buildah 降低了容器环境的学习曲线(learning curve),简化了创建、构建和更新镜像的难度。Pousty 说。你可以使用它和 Kubernetes 一起去创建和推动容器基于一个应用程序上的调用自动化。Buildah 也节省系统资源,因为它不需要容器运行时守护进程。
|
||||
|
||||
因此,比起真实地引导一个容器和容器内的按步骤操作,Pousty 说,“你加载一个文件系统,在你的机器上做一些正常操作,如果它是一个常规的文件系统,并且在最后去提交”。
|
||||
|
||||
这意味着你可以从一个 Registry 中销毁一个镜像,创建它匹配的容器,并且优化它。然后,你可以使用 Kubernetes 中的 Buildah 在你需要时去创建一个新的运行镜像。最终结果是,他说,运行 Kubernetes 管理的容器化应用程序比以往速度更快,需要的资源更少。
|
||||
|
||||
### 你不知道的 Kubernetes 所拥有的特性
|
||||
|
||||
你不需要在其它地方寻找工具。Kubernetes 有几个被低估的特性。
|
||||
|
||||
根据谷歌云全球产品经理 Allan Naim 的说法,其中一个是,[Kubernetes 命名空间][27]。Naim 在“Kubernetes 最佳实践”中的开源总结上的演讲中说,“很少有人使用命名空间,这是一个失误(mistake)”
|
||||
|
||||
“命名空间是区分一个单个的 Kubernetes 集群到多个虚拟集群的方法”,Naim 说。例如,“你可以认为命名空间就是家族名(family names)”,因此,如果 “Simth” 标识一个家族,一个成员,Steve Smith,它仅是“Steve”,但是,家族范围之外的,它就是“Steve Smith” 也或许为“来自 Chicago 的 Steve Smith”。
|
||||
|
||||
严格来说,“命名空间是一个逻辑的分区技术,它允许一个 Kubernetes 集群被多个用户、用户团队或者在多个应用程序上不能混淆的一个用户使用。Naim 解释说,“每个用户、用户团队、或者可以存在于它的命名空间中的应用程序,与集群中的其他用户是隔离的,并且操作它就像你是这个集群的唯一用户一样。”
|
||||
|
||||
Practically说,你可以使用命名空间去构建一个企业的多个业务/技术整体进入 Kubernetes。例如,云架构可以通过映射产品、位置、团队和成本中心为命名空间,去定义公司命名空间策略。
|
||||
|
||||
Naim 建议的另外的方法是,去使用命名空间区分软件开发流程(pipelines)到分离的命名空间中。如测试、质量保证、分段(staging)和成品。或者命名空间可以用于管理单独的客户。例如,你可以为每个客户、客户项目、或者客户业务单元去创建一个命名空间。它可以更容易地区分项目,避免重用相同名字的资源。
|
||||
|
||||
然而,Kubernetes 现在还没有提供一个跨命名空间访问的控制机制。因此,Naim 建议你不要使用这种方法去对外公开程序。还要注意的是,命名空间也不是一个管理的“万能药”。例如,你不能将命名空间嵌套在另一个命名空间中。另外,也没有跨命名空间的强制的安全机制。
|
||||
|
||||
尽管如此,小心地使用命名空间,还是很有用的。
|
||||
|
||||
### 友情提示
|
||||
|
||||
转换到较深奥的(deep)技术去做项目管理,Pousty 建议,在转移到私有云和微服务架构时,在你的团队中使用一个微服务操作人员。“如果你去做微服务,你的团队将结束使用 Ops-y 工作。并且,不去使用已经知道这种操作的人是愚蠢的行为”,他说。“你需要一个正确的团队核心能力。我不想开发人员重新使用 Operations Wheel”。
|
||||
|
||||
而是,将你的工作流彻底地改造成一个能够使用容器和云的过程,对此,Kubernetes 是很好的。
|
||||
|
||||
### 使用 Kubernetes 的私有云计算:领导者的课程
|
||||
|
||||
* 迅速扩大的私有云生态系统。寻找可以扩展你使用容器的方法的工具。
|
||||
|
||||
* 探索鲜为人知的 Kubernetes 特性,如命名空间。它们可以改善你的组织和自动化程度。
|
||||
|
||||
* 确保部署到容器的开发团队有一个 Ops 人员参与。否则,冲突将不可避免。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Steven J. Vaughan-Nichols, CEO, Vaughan-Nichols & Associates
|
||||
|
||||
Steven J. Vaughan-Nichols, 又名叫 sjvn,是一个技术方面的作家,自 CP/M-80 以来一直从事与前沿技术、PC 操作系统等商业技术的写作;300bps 是非常快的因特网连接; WordStar 是最先进的文字处理程序;而且我喜欢它。他的作品已经发布在了技术含量非常高的主流出版社 (Washington Post, San Francisco Chronicle, BusinessWeek)的出版物上(IEEE Computer、 ACM Network、 Byte),去商业化推广 (eWEEK、InformationWeek、ZDNet) 流行的技术 (Computer Shopper、PC Magazine、PC World)。
|
||||
|
||||
---------------------
|
||||
|
||||
|
||||
via: https://insights.hpe.com/articles/how-to-implement-cloud-native-computing-with-kubernetes-1710.html
|
||||
|
||||
作者:[ Steven J. Vaughan-Nichols][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.hpe.com/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_insights~510287587~Containers_Dummies~sjvn_Kubernetes
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://www.redhat.com/en
|
||||
[4]:https://www.openshift.com/
|
||||
[5]:https://www.linuxfoundation.org/
|
||||
[6]:http://events.linuxfoundation.org/events/open-source-summit-north-america
|
||||
[7]:https://www.opencontainers.org/
|
||||
[8]:https://www.cncf.io/
|
||||
[9]:https://insights.hpe.com/articles/the-basics-explaining-kubernetes-mesosphere-and-docker-swarm-1702.html
|
||||
[10]:https://insights.hpe.com/articles/when-to-use-containers-and-when-not-to-1705.html
|
||||
[11]:https://www.open-scap.org/
|
||||
[12]:https://scap.nist.gov/
|
||||
[13]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[14]:http://cri-o.io/
|
||||
[15]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[16]:https://wiki.centos.org/HowTos/SELinux
|
||||
[17]:https://docs.docker.com/engine/
|
||||
[18]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[19]:http://www.zdnet.com/article/containers-consolidation-open-container-initiative-1-0-released/
|
||||
[20]:https://coreos.com/rkt/docs/latest/
|
||||
[21]:http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html
|
||||
[22]:https://coreos.com/rkt/
|
||||
[23]:http://chris.collins.is/2017/02/24/three-docker-build-strategies/
|
||||
[24]:https://docs.docker.com/engine/userguide/eng-image/multistage-build/#use-multi-stage-builds
|
||||
[25]:https://github.com/projectatomic/buildah
|
||||
[26]:https://www.projectatomic.io/blog/2017/06/introducing-buildah/
|
||||
[27]:https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
|
||||
@ -0,0 +1,338 @@
|
||||
在 Kubernetes 中怎么去使用 Java 管理 Docker 容器
|
||||
==========================
|
||||
|
||||
|
||||
>在企业规模级编排为生产准备的系统
|
||||
|
||||
通过 “Java 开发者的 Kubernetes[下载你的免费拷贝][3]” ,学习基本的 Kubernetes 概念和自动部署、维护和扩展你的 Java 应用程序的机制。
|
||||
|
||||
|
||||
在 [_Java 中的容器化持续交付_][23] 中,我们探索了在 Docker 容器内打包和部署 Java 应用程序的基本原理。这个方法创建为生产准备(production-ready)的、基于容器的系统仅仅是第一步。在真实的环境中运行容器还需要一个容器编排和计划的平台,并且,现在已经存在了很多个这样的平台(如,Docker Swarm、Apach Mesos、AWS ECS)。最受欢迎的是 [Kubernetes][24]。Kubernetes 被用于很多组织的产品中,并且,现在它运行于[私有云计算的基础设备 (CNCF)][25]上。在这篇文章中,我们将使用以前的一个简单的、基于Java的、电子商务的商店,我们将它打包进 Docker 容器内,并且在 Kubernetes 上运行它。
|
||||
|
||||
### “Docker Java Shopfront” 应用程序
|
||||
|
||||
“Docker Java Shopfront” 应用程序的架构,它将打包进容器,并且部署在 Kubernetes 上,如下面的图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
在我们开始去创建一个需要的 Kubernetes 部署配置文件之前,让我们先学习一下关于容器编排平台中的一些核心概念。
|
||||
|
||||
### Kubernetes 101
|
||||
|
||||
Kubernetes 是一个由谷歌最初开发的开源的部署容器化应用程序的协调器(orchestrator)。谷歌已经运行容器化应用程序很多年了,并且,这个导致产生了[Borg 容器协调器][26],它是应用于谷歌内部的,并且它是 Kubernetes 创意的来源。如果你对这个技术不熟悉,那么,刚开始去看,出现的许多核心概念你将不理解,但是,实际上它们都很强大。第一个是 Kubernetes 包含的不可改变的基础设备的原则。一旦一个容器部署后,它的内容(比如应用程序)是不可以通过登入容器内进行更新和产生改变的。只能是部署一个新的版本。第二,Kubernetes 内的任何东西都不可以进行声明(declaratively)配置。开发者或操作者指定系统状态是通过部署描述和配置文件进行的,并且,Kubernetes 是可以响应这些变化的——你不需要去提供命令,一步一步去指导。
|
||||
|
||||
不可改变的基础设备和声明配置的这些原则有许多好处:它容易防止配置偏移(drift),或者 “雪花(snowflake)” 应用程序实例;声明部署配置可以保存在版本控制中,在代码旁边;并且, Kubernetes 大部分都可以自我修复,比如,如果系统经历失败,假如是一个底层的计算节点失败,系统可以重新构建,并且根据在声明中指定的状态去重新平衡应用程序。
|
||||
|
||||
Kubernetes 提供几个抽象和 APIs,它可以更容易地去构建这些分布式的应用程序,比如,如下的这些基于微服务架构的:
|
||||
|
||||
* [Pods][5] - 这是在 Kubernetes 中的最小部署单元,并且,它本质上是一个容器组。一个 pod 允许一个微服务应用程序容器去与另外的提供系统服务的,像登陆、监视或通讯管理的 “sidecar” 容器一起被分组。在一个 pod 中的容器共享一个文件系统和网络命名空间。注意,一个单个的容器是可以被部署的,但是,通常的做法是,部署在一个 pod 中。
|
||||
|
||||
* [Services][6] - Kubernetes 服务提供负载均衡、命名和从其它地方发现和隔离一个微服务。服务是通过[复制控制器][7]支持的,它反过来又负责维护在系统内运行的一个 pod 实例的期望数量的相关细节。服务、复制控制器和 Pods 在 Kubernetes 中通过使用“[标签][8]”连接到一起,并通过它命名和选择。
|
||||
|
||||
现在让我们来为我们的基于 Java 的微服务应用程序创建一个服务。
|
||||
|
||||
|
||||
### 构建 Java 应用程序和容器镜像
|
||||
|
||||
在我们开始创建一个容器和相关的 Kubernetes 部署配置之前,我们必须首先确认,我们已经安装了下列必需的组件:
|
||||
|
||||
* 适用于[Mac][11] / [Windows][12] / [Linux][13] 的 Docker - 这允许你在本地机器上,在 Kubernetes 之外去构建、运行和测试 Docker 容器。
|
||||
|
||||
* [Minikube][14] - 这是一个工具,它可以通过虚拟机,在你本地部署的机器上很容易地去运行一个单节点的 Kubernetes 测试集群。
|
||||
|
||||
* 一个 [GitHub][15] 帐户和本地安装的 [Git][16] - 示例代码保存在 GitHub 上,并且通过使用本地的 Git,你可以 fork 库,并且去提交改变到你的应用程序的个人拷贝中。
|
||||
|
||||
* [Docker Hub][17] 帐户 - 如果你喜欢这篇文章中的教程,你将需要一个 Docker Hub 帐户,为了推送和保存你将在后面创建的容器镜像的拷贝。
|
||||
|
||||
* [Java 8][18] (或 9) SDK 和 [Maven][19] - 我们将使用 Maven 和附属的工具使用 Java 8 特性去构建代码。
|
||||
|
||||
从 GitHub(可选,你可以 fork 这个库,并且,克隆一个你个人的拷贝)克隆项目库代码,并且放置于 “shopfront” 微服务应用: [https://github.com/danielbryantuk/oreilly-docker-java-shopping/][27]。
|
||||
|
||||
```
|
||||
$ git clone git@github.com:danielbryantuk/oreilly-docker-java-shopping.git
|
||||
$ cd oreilly-docker-java-shopping/shopfront
|
||||
|
||||
```
|
||||
|
||||
尽管去加载 shopfront 代码到你选择的编辑器中,比如,IntelliJ IDE 或 Eclipse,并去研究它。让我们使用 Maven 去构建应用程序。最终的结果是,位于 ./target 的目录中包含可运行的 JAR 文件。
|
||||
|
||||
```
|
||||
$ mvn clean install
|
||||
…
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] BUILD SUCCESS
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
[INFO] Total time: 17.210 s
|
||||
[INFO] Finished at: 2017-09-30T11:28:37+01:00
|
||||
[INFO] Final Memory: 41M/328M
|
||||
[INFO] ------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
现在,我们将构建 Docker 容器镜像。一个容器镜像的操作系统选择、配置和构建步骤,一般情况下通过一个 Dockerfile 去指定。我们看一下,我们的示例中位于 shopfront 目录中的 Dockerfile:
|
||||
|
||||
```
|
||||
FROM openjdk:8-jre
|
||||
ADD target/shopfront-0.0.1-SNAPSHOT.jar app.jar
|
||||
EXPOSE 8010
|
||||
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
|
||||
|
||||
```
|
||||
|
||||
第一行指定了,我们的容器镜像将被“从” 这个 openjdk:8-jre 基础镜像中创建。[openjdk:8-jre][28] 镜像是由 OpenJDK 团队维护的,并且包含我们在一个 Docker 容器(就像一个安装和配置了 OpenJDK 8 JDK的操作系统)中运行一个 Java 8 应用程序所需要的一切东西。第二行是,我们构建的可运行的 JAR,并且使用“adds” 指向到这个镜像。第三行指定了端口号是 8010,我们的应用程序将在这个端口号上监听,如果外部需要可以访问,必须要 “exposed” 它,第四行指定 “entrypoint” 或命令,当容器初始化后去运行它。现在,我们来构建我们的容器:
|
||||
|
||||
|
||||
```
|
||||
$ docker build -t danielbryantuk/djshopfront:1.0 .
|
||||
Successfully built 87b8c5aa5260
|
||||
Successfully tagged danielbryantuk/djshopfront:1.0
|
||||
|
||||
```
|
||||
|
||||
现在,我们推送它到 Docker Hub。如果你没有通过命令行登入到 Docker Hub,现在去登入,输入你的用户名和密码:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
|
||||
Username:
|
||||
Password:
|
||||
Login Succeeded
|
||||
$
|
||||
$ docker push danielbryantuk/djshopfront:1.0
|
||||
The push refers to a repository [docker.io/danielbryantuk/djshopfront]
|
||||
9b19f75e8748: Pushed
|
||||
...
|
||||
cf4ecb492384: Pushed
|
||||
1.0: digest: sha256:8a6b459b0210409e67bee29d25bb512344045bd84a262ede80777edfcff3d9a0 size: 2210
|
||||
|
||||
```
|
||||
|
||||
### 部署到 Kubernetes 上
|
||||
|
||||
现在,让我们在 Kubernetes 中运行这个容器。首先,在项目根(root)中改变到 “kubernetes” 目录:
|
||||
|
||||
```
|
||||
$ cd ../kubernetes
|
||||
|
||||
```
|
||||
|
||||
打开 Kubernetes 部署文件 shopfront-service.yaml,并查看内容:
|
||||
|
||||
```
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: shopfront
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
type: NodePort
|
||||
selector:
|
||||
app: shopfront
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 8010
|
||||
name: http
|
||||
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ReplicationController
|
||||
metadata:
|
||||
name: shopfront
|
||||
spec:
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: shopfront
|
||||
spec:
|
||||
containers:
|
||||
- name: shopfront
|
||||
image: danielbryantuk/djshopfront:latest
|
||||
ports:
|
||||
- containerPort: 8010
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /health
|
||||
port: 8010
|
||||
initialDelaySeconds: 30
|
||||
timeoutSeconds: 1
|
||||
|
||||
```
|
||||
|
||||
yaml 文件的第一节创建了一个名为 “shopfront” 的服务,它将路由 TCP 流量到 pods 中标签为 “app: shopfront” 、端口为 8010 的服务上。配置文件的第二节创建了一个 `ReplicationController` ,它是特定的 Kubernetes ,它将在我们的 shopfront 容器上运行一个复制(实例),它是我们声明的“app: shopfront”标签的一部分。我们也可以指定 8010 应用程序端口发布在我们的容器上。然后,声明一个Kubernetes 可以用于去决定 “livenessProbe” 或 healthcheck,如果我们的容器应用程序正确运行并准备好接受流量。让我们来启动 `minikube` 并部署这个服务(注意,根据你部署的机器上的可用资源,你可能需要去修改指定的 `minikube` 中的 CPU 和 Memory 使用):
|
||||
|
||||
```
|
||||
$ minikube start --cpus 2 --memory 4096
|
||||
Starting local Kubernetes v1.7.5 cluster...
|
||||
Starting VM...
|
||||
Getting VM IP address...
|
||||
Moving files into cluster...
|
||||
Setting up certs...
|
||||
Connecting to cluster...
|
||||
Setting up kubeconfig...
|
||||
Starting cluster components...
|
||||
Kubectl is now configured to use the cluster.
|
||||
$ kubectl apply -f shopfront-service.yaml
|
||||
service "shopfront" created
|
||||
replicationcontroller "shopfront" created
|
||||
|
||||
```
|
||||
|
||||
你可以通过使用 “kubectl get svc” 命令查看在 Kubernetes 中所有的服务。你也可以使用 “kubectl get pods” 命令去查看所有相关的 pods(注意,你第一次执行 get pods 命令时,容器可能还没有创建完成,并被标记为未准备好):
|
||||
|
||||
```
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 18h
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 12s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 0/1 ContainerCreating 0 18s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
shopfront-0w1js 1/1 Running 0 2m
|
||||
|
||||
```
|
||||
|
||||
我们现在已经成功地在 Kubernetes 中部署完成了我们的第一个服务。
|
||||
|
||||
### 是时候进行冒烟测试了
|
||||
|
||||
现在,让我们使用 curl 去看一下,我们是否可以从 shopfront 应用程序的 healthcheck 端点中取得数据:
|
||||
|
||||
```
|
||||
$ curl $(minikube service shopfront --url)/health
|
||||
{"status":"UP"}
|
||||
|
||||
```
|
||||
|
||||
你可以从 curl 的结果中看到,application/health 端点是启用的并且是运行中的,但是,在应用程序按我们预期那样运行之前,我们需要去部署剩下的微服务应用程序容器。
|
||||
|
||||
### 构建剩下的应用程序
|
||||
|
||||
现在,我们有一个容器已经运行,让我们来构建剩下的两个,支持微服务的应用程序和容器:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd productcatalogue/
|
||||
$ mvn clean install
|
||||
…
|
||||
$ docker build -t danielbryantuk/djproductcatalogue:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djproductcatalogue:1.0
|
||||
...
|
||||
$ cd ..
|
||||
$ cd stockmanager/
|
||||
$ mvn clean install
|
||||
...
|
||||
$ docker build -t danielbryantuk/djstockmanager:1.0 .
|
||||
...
|
||||
$ docker push danielbryantuk/djstockmanager:1.0
|
||||
…
|
||||
|
||||
```
|
||||
|
||||
这个时候,我们已经构建了所有我们的微服务和相关的 Docker 镜像,也推送镜像到 Docker Hub 上。现在,我们去在 Kubernetes 中部署 `productcatalogue` 和 `stockmanager` 服务。
|
||||
|
||||
### 在 Kubernetes 中部署整个 Java 应用程序
|
||||
|
||||
与我们上面部署 shopfront 服务时类似的方式去处理它,我们现在可以在 Kubernetes 中部署剩下的两个微服务:
|
||||
|
||||
```
|
||||
$ cd ..
|
||||
$ cd kubernetes/
|
||||
$ kubectl apply -f productcatalogue-service.yaml
|
||||
service "productcatalogue" created
|
||||
replicationcontroller "productcatalogue" created
|
||||
$ kubectl apply -f stockmanager-service.yaml
|
||||
service "stockmanager" created
|
||||
replicationcontroller "stockmanager" created
|
||||
$ kubectl get svc
|
||||
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
kubernetes 10.0.0.1 <none> 443/TCP 19h
|
||||
productcatalogue 10.0.0.37 <nodes> 8020:31803/TCP 42s
|
||||
shopfront 10.0.0.216 <nodes> 8010:31208/TCP 13m
|
||||
stockmanager 10.0.0.149 <nodes> 8030:30723/TCP 16s
|
||||
$ kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
productcatalogue-79qn4 1/1 Running 0 55s
|
||||
shopfront-0w1js 1/1 Running 0 13m
|
||||
stockmanager-lmgj9 1/1 Running 0 29s
|
||||
|
||||
```
|
||||
|
||||
取决于你执行 “kubectl get pods” 命令的速度,你可以看到所有不再运行的 Pods。在转到这篇文章的下一节之前,这个命令将展示所有运行的 Pods(或许,这个时候应该来杯咖啡!)
|
||||
|
||||
### 查看完成的应用程序
|
||||
|
||||
在所有的微服务部署完成并且所有的相关 Pods 都正常运行后,我们现在将去通过 shopfront 服务的 GUI 去访问我们完成的应用程序。我们可以在一个缺省的浏览器中通过执行 `minikube` 命令去打开这个服务:
|
||||
|
||||
```
|
||||
$ minikube service shopfront
|
||||
|
||||
```
|
||||
|
||||
如果一切正常,你将在浏览器中看到如下的页面:
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中,我们已经完成了由三个 Java Spring 引导和 Dropwizard 微服务组成的应用程序,并且将它部署到 Kubernetes 上。未来,我们需要考虑的事还很多,比如,debugging 服务 (或许是通过工具,像[Telepresence][29] 和 [Sysdig][30]), 通过一个可持续交付的过程去测试和部署,像[Jenkins][31] 或 [Spinnaker][32],并且,去观察我们的系统运行。
|
||||
|
||||
* * *
|
||||
|
||||
_本文是使用 NGINX 的协作创建的。 [查看我们的编辑独立性声明][22]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel Bryant 是一名独立的技术顾问,它是 SpectoLabs 的 CTO。他目前关注于通过识别价值流、创建构建过程、和实施有效的测试策略,从而在组织内部实现持续交付。Daniel 擅长并关注于“DevOps”工具、云/容器平台和微服务实现。他也贡献了几个开源项目,并定期为 InfoQ、 O’Reilly、和 Voxxed撰稿...
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java
|
||||
|
||||
作者:[ Daniel Bryant ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/d3f4d647-482d-4dce-a0e5-a09773b77150
|
||||
[1]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[2]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[3]:https://www.nginx.com/resources/library/kubernetes-for-java-developers/
|
||||
[4]:https://www.oreilly.com/ideas/how-to-manage-docker-containers-in-kubernetes-with-java?imm_mid=0f75d0&cmp=em-prog-na-na-newsltr_20171021
|
||||
[5]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[6]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[7]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[9]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[10]:https://conferences.oreilly.com/software-architecture/sa-eu?intcmp=il-prog-confreg-update-saeu17_new_site_sacon_london_17_right_rail_cta
|
||||
[11]:https://docs.docker.com/docker-for-mac/install/
|
||||
[12]:https://docs.docker.com/docker-for-windows/install/
|
||||
[13]:https://docs.docker.com/engine/installation/linux/ubuntu/
|
||||
[14]:https://kubernetes.io/docs/tasks/tools/install-minikube/
|
||||
[15]:https://github.com/
|
||||
[16]:https://git-scm.com/
|
||||
[17]:https://hub.docker.com/
|
||||
[18]:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
|
||||
[19]:https://maven.apache.org/
|
||||
[20]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[21]:https://www.safaribooksonline.com/home/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=software-engineering-post-safari-right-rail-cta
|
||||
[22]:http://www.oreilly.com/about/editorial_independence.html
|
||||
[23]:https://www.nginx.com/resources/library/containerizing-continuous-delivery-java/
|
||||
[24]:https://kubernetes.io/
|
||||
[25]:https://www.cncf.io/
|
||||
[26]:https://research.google.com/pubs/pub44843.html
|
||||
[27]:https://github.com/danielbryantuk/oreilly-docker-java-shopping/
|
||||
[28]:https://hub.docker.com/_/openjdk/
|
||||
[29]:https://telepresence.io/
|
||||
[30]:https://www.sysdig.org/
|
||||
[31]:https://wiki.jenkins.io/display/JENKINS/Kubernetes+Plugin
|
||||
[32]:https://www.spinnaker.io/
|
||||
Loading…
Reference in New Issue
Block a user