mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge pull request #1788 from felixonmars/20140910-s3ql
Translated: How to create a cloud-based encrypted file system on Linux
This commit is contained in:
commit
00f068281f
@ -1,158 +0,0 @@
|
||||
[felixonmars translating...]
|
||||
|
||||
How to create a cloud-based encrypted file system on Linux
|
||||
================================================================================
|
||||
Commercial cloud storage services such as [Amazon S3][1] and [Google Cloud Storage][2] offer highly available, scalable, infinite-capacity object store at affordable costs. To accelerate wide adoption of their cloud offerings, these providers are fostering rich developer ecosystems around their products based on well-defined APIs and SDKs. Cloud-backed file systems are one popular by-product of such active developer communities, for which several open-source implementations exist.
|
||||
|
||||
[S3QL][3] is one of the most popular open-source cloud-based file systems. It is a FUSE-based file system backed by several commercial or open-source cloud storages, such as Amazon S3, Google Cloud Storage, Rackspace CloudFiles, or OpenStack. As a full featured file system, S3QL boasts of a number of powerful capabilities, such as unlimited capacity, up to 2TB file sizes, compression, UNIX attributes, encryption, snapshots with copy-on-write, immutable trees, de-duplication, hardlink/symlink support, etc. Any bytes written to an S3QL file system are compressed/encrypted locally before being transmitted to cloud backend. When you attempt to read contents stored in an S3QL file system, the corresponding objects are downloaded from cloud (if not in the local cache), and decrypted/uncompressed on the fly.
|
||||
|
||||
To be clear, S3QL does have limitations. For example, you cannot mount the same S3FS file system on several computers simultaneously, but only once at a time. Also, no ACL (access control list) support is available.
|
||||
|
||||
In this tutorial, I am going to describe **how to set up an encrypted file system on top of Amazon S3, using S3QL**. As an example use case, I will also demonstrate how to run rsync backup tool on top of a mounted S3QL file system.
|
||||
|
||||
### Preparation ###
|
||||
|
||||
To use this tutorial, you will need to create an [Amazon AWS account][4] (sign up is free, but requires a valid credit card).
|
||||
|
||||
If you haven't done so, first [create an AWS access key][4] (access key ID and secret access key) which is needed to authorize S3QL to access your AWS account.
|
||||
|
||||
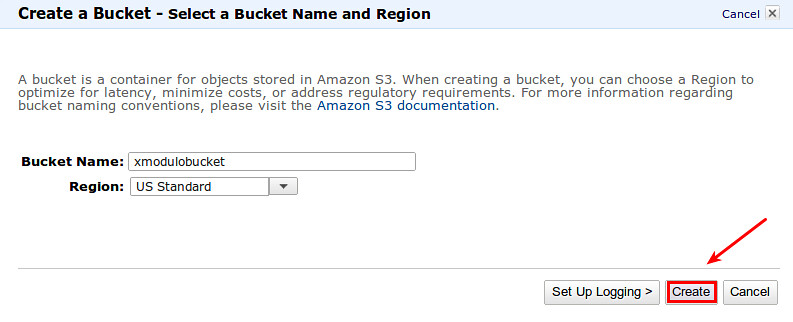
Now, go to AWS S3 via AWS management console, and create a new empty bucket for S3QL.
|
||||
|
||||
|
||||
|
||||
For best performance, choose a region which is geographically closest to you.
|
||||
|
||||
|
||||
|
||||
### Install S3QL on Linux ###
|
||||
|
||||
S3QL is available as a pre-built package on most Linux distros.
|
||||
|
||||
#### On Debian, Ubuntu or Linux Mint: ####
|
||||
|
||||
$ sudo apt-get install s3ql
|
||||
|
||||
#### On Fedora: ####
|
||||
|
||||
$ sudo yum install s3ql
|
||||
|
||||
On Arch Linux, use [AUR][6].
|
||||
|
||||
### Configure S3QL for the First Time ###
|
||||
|
||||
Create authinfo2 file in ~/.s3ql directory, which is a default S3QL configuration file. This file contains information about a required AWS access key, S3 bucket name and encryption passphrase. The encryption passphrase is used to encrypt the randomly-generated master encryption key. This master key is then used to encrypt actual S3QL file system data.
|
||||
|
||||
$ mkdir ~/.s3ql
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
|
||||
----------
|
||||
|
||||
[s3]
|
||||
storage-url: s3://[bucket-name]
|
||||
backend-login: [your-access-key-id]
|
||||
backend-password: [your-secret-access-key]
|
||||
fs-passphrase: [your-encryption-passphrase]
|
||||
|
||||
The AWS S3 bucket that you specify should be created via AWS management console beforehand.
|
||||
|
||||
Make the authinfo2 file readable to you only for security.
|
||||
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
|
||||
### Create an S3QL File System ###
|
||||
|
||||
You are now ready to create an S3QL file system on top of AWS S3.
|
||||
|
||||
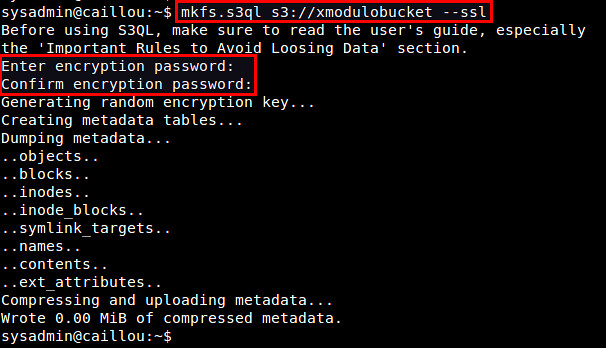
Use mkfs.s3ql command to create a new S3QL file system. The bucket name you supply with the command should be matched with the one in authinfo2 file. The "--ssl" option forces you to use SSL to connect to backend storage servers. By default, the mkfs.s3ql command will enable compression and encryption in the S3QL file system.
|
||||
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
|
||||
You will be asked to enter an encryption passphrase. Type the same passphrase as you defined in ~/.s3ql/autoinfo2 (under "fs-passphrase").
|
||||
|
||||
If a new file system was created successfully, you will see the following output.
|
||||
|
||||
|
||||
|
||||
### Mount an S3QL File System ###
|
||||
|
||||
Once you created an S3QL file system, the next step is to mount it.
|
||||
|
||||
First, create a local mount point, and then use mount.s3ql command to mount an S3QL file system.
|
||||
|
||||
$ mkdir ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
You do not need privileged access to mount an S3QL file system. Just make sure that you have write access to the local mount point.
|
||||
|
||||
Optionally, you can specify a compression algorithm to use (e.g., lzma, bzip2, zlib) with "--compress" option. Without it, lzma algorithm is used by default. Note that when you specify a custom compression algorithm, it will apply to newly created data objects, not existing ones.
|
||||
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
For performance reason, an S3QL file system maintains a local file cache, which stores recently accessed (partial or full) files. You can customize the file cache size using "--cachesize" and "--max-cache-entries" options.
|
||||
|
||||
To allow other users than you to access a mounted S3QL file system, use "--allow-other" option.
|
||||
|
||||
If you want to export a mounted S3QL file system to other machines over NFS, use "--nfs" option.
|
||||
|
||||
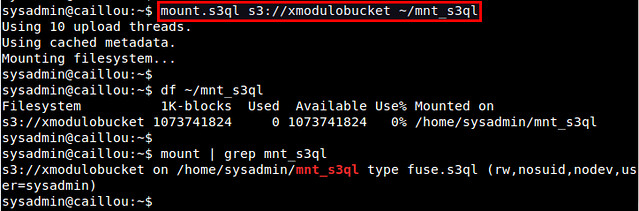
After running mount.s3ql, check if the S3QL file system is successfully mounted:
|
||||
|
||||
$ df ~/mnt_s3ql
|
||||
$ mount | grep s3ql
|
||||
|
||||
|
||||
|
||||
### Unmount an S3QL File System ###
|
||||
|
||||
To unmount an S3QL file system (with potentially uncommitted data) safely, use umount.s3ql command. It will wait until all data (including the one in local file system cache) has been successfully transferred and written to backend servers. Depending on the amount of write-pending data, this process can take some time.
|
||||
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
|
||||
View S3QL File System Statistics and Repair an S3QL File System
|
||||
|
||||
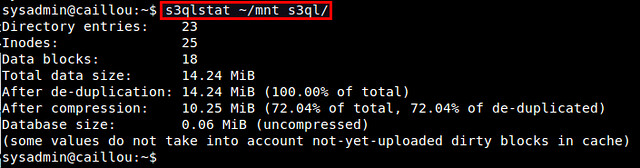
To view S3QL file system statistics, you can use s3qlstat command, which shows information such as total data/metadata size, de-duplication and compression ratio.
|
||||
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
|
||||
|
||||
|
||||
You can check and repair an S3QL file system with fsck.s3ql command. Similar to fsck command, the file system being checked needs to be unmounted first.
|
||||
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
|
||||
### S3QL Use Case: Rsync Backup ###
|
||||
|
||||
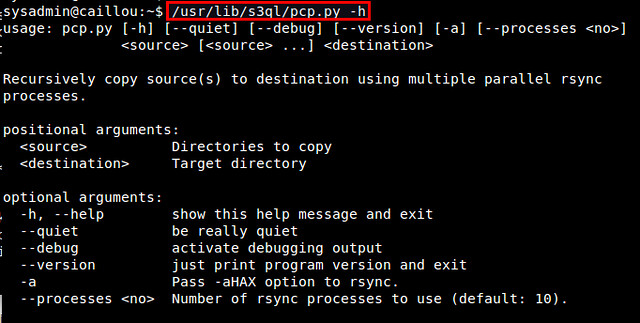
Let me conclude this tutorial with one popular use case of S3QL: local file system backup. For this, I recommend using rsync incremental backup tool especially because S3QL comes with a rsync wrapper script (/usr/lib/s3ql/pcp.py). This script allows you to recursively copy a source tree to a S3QL destination using multiple rsync processes.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
|
||||
|
||||
|
||||
The following command will back up everything in ~/Documents to an S3QL file system via four concurrent rsync connections.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
|
||||
The files will first be copied to the local file cache, and then gradually flushed to the backend servers over time in the background.
|
||||
|
||||
For more information about S3QL such as automatic mounting, snapshotting, immuntable trees, I strongly recommend checking out the [official user's guide][7]. Let me know what you think of S3QL. Share your experience with any other tools.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-cloud-based-encrypted-file-system-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://aws.amazon.com/s3
|
||||
[2]:http://code.google.com/apis/storage/
|
||||
[3]:https://bitbucket.org/nikratio/s3ql/
|
||||
[4]:http://aws.amazon.com/
|
||||
[5]:http://ask.xmodulo.com/create-amazon-aws-access-key.html
|
||||
[6]:https://aur.archlinux.org/packages/s3ql/
|
||||
[7]:http://www.rath.org/s3ql-docs/
|
||||
@ -0,0 +1,156 @@
|
||||
如何在 Linux 系统中创建一个云端的加密文件系统
|
||||
================================================================================
|
||||
[Amazon S3][1] 和 [Google Cloud Storage][2] 之类的商业云存储服务以能承受的价格提供了高可用性、可扩展、无限容量的对象存储服务。为了加速这些云产品的广泛采用,这些提供商为他们的产品基于明确的 API 和 SDK 培养了一个良好的开发者生态系统。而基于云的文件系统便是这些活跃的开发者社区中的典型产品,已经有了好几个开源的实现。
|
||||
|
||||
[S3QL][3] 便是最流行的开源云端文件系统之一。它是一个基于 FUSE 的文件系统,提供了好几个商业或开源的云存储后端,比如 Amazon S3、Google Cloud Storage、Rackspace CloudFiles,还有 OpenStack。作为一个功能完整的文件系统,S3QL 拥有不少强大的功能:最大 2T 的文件大小、压缩、UNIX 属性、加密、基于写入时复制的快照、不可变树、重复数据删除,以及软、硬链接支持等等。写入 S3QL 文件系统任何数据都将首先被本地压缩、加密,之后才会传输到云后端。当你试图从 S3QL 文件系统中取出内容的时候,如果它们不在本地缓存中,相应的对象会从云端下载回来,然后再即时地解密、解压缩。
|
||||
|
||||
需要明确的是,S3QL 的确也有它的限制。比如,你不能把同一个 S3FS 文件系统在几个不同的电脑上同时挂载,只能有一台电脑同时访问它。另外,ACL(访问控制列表)也并没有被支持。
|
||||
|
||||
在这篇教程中,我将会描述“如何基于 Amazon S3 用 S3QL 配置一个加密文件系统”。作为一个使用范例,我还会说明如何在挂载的 S3QL 文件系统上运行 rsync 备份工具。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
本教程首先需要你创建一个 [Amazon AWS 帐号][4](注册是免费的,但是需要一张有效的信用卡)。
|
||||
|
||||
然后 [创建一个 AWS access key][4](access key ID 和 secret access key),S3QL 使用这些信息来访问你的 AWS 帐号。
|
||||
|
||||
之后通过 AWS 管理面板访问 AWS S3,并为 S3QL 创建一个新的空 bucket。
|
||||
|
||||

|
||||
|
||||
为最佳性能考虑,请选择一个地理上距离你最近的区域。
|
||||
|
||||

|
||||
|
||||
### 在 Linux 上安装 S3QL ###
|
||||
|
||||
在大多数 Linux 发行版中都有预先编译好的 S3QL 软件包。
|
||||
|
||||
#### 对于 Debian、Ubuntu 或 Linux Mint:####
|
||||
|
||||
$ sudo apt-get install s3ql
|
||||
|
||||
#### 对于 Fedora:####
|
||||
|
||||
$ sudo yum install s3ql
|
||||
|
||||
对于 Arch Linux,使用 [AUR][6]。
|
||||
|
||||
### 首次配置 S3QL ###
|
||||
|
||||
在 ~/.s3ql 目录中创建 autoinfo2 文件,它是 S3QL 的一个默认的配置文件。这个文件里的信息包括必须的 AWS access key,S3 bucket 名,以及加密口令。这个加密口令将被用来加密一个随机生成的主密钥,而主密钥将被用来实际地加密 S3QL 文件系统数据。
|
||||
|
||||
$ mkdir ~/.s3ql
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
|
||||
----------
|
||||
|
||||
[s3]
|
||||
storage-url: s3://[bucket-name]
|
||||
backend-login: [your-access-key-id]
|
||||
backend-password: [your-secret-access-key]
|
||||
fs-passphrase: [your-encryption-passphrase]
|
||||
|
||||
指定的 AWS S3 bucket 需要预先通过 AWS 管理面板来创建。
|
||||
|
||||
为了安全起见,让 authinfo2 文件仅对你可访问。
|
||||
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
|
||||
### 创建 S3QL 文件系统 ###
|
||||
|
||||
现在你已经准备好可以在 AWS S3 上创建一个 S3QL 文件系统了。
|
||||
|
||||
使用 mkfs.s3ql 工具来创建一个新的 S3QL 文件系统。这个命令中的 bucket 名应该与 authinfo2 文件中所指定的相符。使用“--ssl”参数将强制使用 SSL 连接到后端存储服务器。默认情况下,mkfs.s3ql 命令会在 S3QL 文件系统中启用压缩和加密。
|
||||
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
|
||||
你会被要求输入一个加密口令。请输入你在 ~/.s3ql/autoinfo2 中通过“fs-passphrase”指定的那个口令。
|
||||
|
||||
如果一个新文件系统被成功创建,你将会看到这样的输出:
|
||||
|
||||

|
||||
|
||||
### 挂载 S3QL 文件系统 ###
|
||||
|
||||
当你创建了一个 S3QL 文件系统之后,下一步便是要挂载它。
|
||||
|
||||
首先创建一个本地的挂载点,然后使用 mount.s3ql 命令来挂载 S3QL 文件系统。
|
||||
|
||||
$ mkdir ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
挂载一个 S3QL 文件系统不需要特权用户,只要确定你对该挂载点有写权限即可。
|
||||
|
||||
视情况,你可以使用“--compress”参数来指定一个压缩算法(如 lzma、bzip2、zlib)。在不指定的情况下,lzma 将被默认使用。注意如果你指定了一个自定义的压缩算法,它将只会应用到新创建的数据对象上,并不会影响已经存在的数据对象。
|
||||
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
因为性能原因,S3QL 文件系统维护了一份本地文件缓存,里面包括了最近访问的(部分或全部的)文件。你可以通过“--cachesize”和“--max-cache-entries”选项来自定义文件缓存的大小。
|
||||
|
||||
如果想要除你以外的用户访问一个已挂载的 S3QL 文件系统,请使用“--allow-other”选项。
|
||||
|
||||
如果你想通过 NFS 导出已挂载的 S3QL 文件系统到其他机器,请使用“--nfs”选项。
|
||||
|
||||
运行 mount.s3ql 之后,检查 S3QL 文件系统是否被成功挂载了:
|
||||
|
||||
$ df ~/mnt_s3ql
|
||||
$ mount | grep s3ql
|
||||
|
||||

|
||||
|
||||
### 卸载 S3QL 文件系统 ###
|
||||
|
||||
想要安全地卸载一个(可能含有未提交数据的)S3QL 文件系统,请使用 umount.s3ql 命令。它将会等待所有数据(包括本地文件系统缓存中的部分)成功传输到后端服务器。取决于等待写的数据的多少,这个过程可能需要一些时间。
|
||||
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
|
||||
### 查看 S3QL 文件系统统计信息及修复 S3QL 文件系统 ###
|
||||
|
||||
若要查看 S3QL 文件系统统计信息,你可以使用 s3qlstat 命令,它将会显示诸如总的数据、元数据大小、重复文件删除率和压缩率等信息。
|
||||
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
|
||||

|
||||
|
||||
你可以使用 fsck.s3ql 命令来检查和修复 S3QL 文件系统。与 fsck 命令类似,待检查的文件系统必须首先被卸载。
|
||||
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
|
||||
### S3QL 使用案例:Rsync 备份 ###
|
||||
|
||||
让我用一个流行的使用案例来结束这篇教程:本地文件系统备份。为此,我推荐使用 rsync 增量备份工具,特别是因为 S3QL 提供了一个 rsync 的封装脚本(/usr/lib/s3ql/pcp.py)。这个脚本允许你使用多个 rsync 进程递归地复制目录树到 S3QL 目标。
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
|
||||

|
||||
|
||||
下面这个命令将会使用 4 个并发的 rsync 连接来备份 ~/Documents 里的所有内容到一个 S3QL 文件系统。
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
|
||||
这些文件将首先被复制到本地文件缓存中,然后在后台再逐步地同步到后端服务器。
|
||||
|
||||
若想了解与 S3QL 有关的更多信息,如自动挂载、快照、不可变树,我强烈推荐阅读 [官方用户指南][7]。欢迎告诉我你对 S3QL 怎么看,以及你对任何其他工具的使用经验。
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/create-cloud-based-encrypted-file-system-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://aws.amazon.com/s3
|
||||
[2]:http://code.google.com/apis/storage/
|
||||
[3]:https://bitbucket.org/nikratio/s3ql/
|
||||
[4]:http://aws.amazon.com/
|
||||
[5]:http://ask.xmodulo.com/create-amazon-aws-access-key.html
|
||||
[6]:https://aur.archlinux.org/packages/s3ql/
|
||||
[7]:http://www.rath.org/s3ql-docs/
|
||||
Loading…
Reference in New Issue
Block a user