2018-10-10 13:50:12 +08:00
三个开源的分布式追踪工具
======
2018-10-18 00:05:41 +08:00
> 这几个工具对复杂软件系统中的实时事件做了可视化,能帮助你快速发现性能问题。
2018-10-10 13:50:12 +08:00

2018-10-18 00:05:41 +08:00
分布式追踪系统能够从头到尾地追踪跨越了多个应用、服务、数据库以及像代理这样的中间件的分布式软件的请求。它能帮助你更深入地理解系统中到底发生了什么。追踪系统以图形化的方式,展示出每个已知步骤以及某个请求在每个步骤上的耗时。
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
用户可以通过这些展示来判断系统的哪个环节有延迟或阻塞,当请求失败时,运维和开发人员可以看到准确的问题源头,而不需要去测试整个系统,比如用二叉查找树的方法去定位问题。在开发迭代的过程中,追踪系统还能够展示出可能引起性能变化的环节。通过异常行为的警告自动地感知到性能的退化,总是比客户告诉你要好。
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
这种追踪是怎么工作的呢?给每个请求分配一个特殊 ID, < ruby > 踪迹< rt > trace< / rt > < / ruby > ,“踪迹”是整个事务的抽象概念。每一个“踪迹”由< ruby > 单元< rt > span< / rt > < / ruby > 组成,“单元”代表着一次请求中真正执行的操作,比如一次服务调用,一次数据库请求等。每一个“单元”也有自己唯一的 ID。“单元”之下也可以创建子“单元”,
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
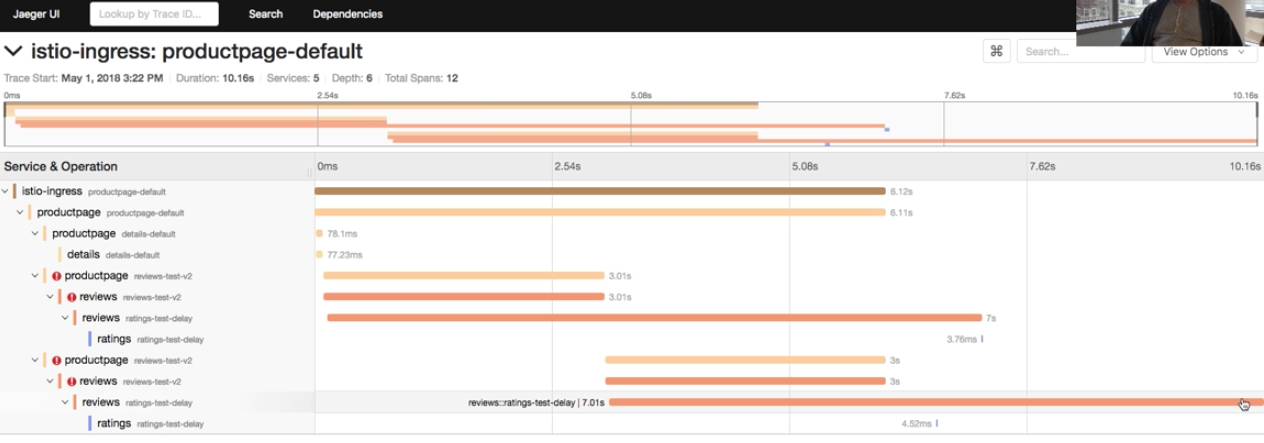
当一次事务(或者说踪迹)运行过之后,就可以在追踪系统的表示层上搜索了。有几个工具可以用作表示层,我们下文会讨论,不过,我们先看下面的图,它是我在 [Istio walkthrough][2] 视频教程中提到的 [Jaeger][1] 界面,展示了单个踪迹中的多个单元。很明显,这个图能让你一目了然地对事务有更深的了解。
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
这个演示使用了 Istio 内置的 OpenTracing 实现,所以我甚至不需要修改自己的应用代码就可以获得追踪数据。我也用到了 Jaeger,
2018-10-10 13:50:12 +08:00
那么 OpenTracing 到底是什么呢?我们来看看。
### OpenTracing API
2018-10-18 00:05:41 +08:00
[OpenTracing][3] 是源自 [Zipkin][4] 的规范,以提供跨平台兼容性。它提供了对厂商中立的 API,
2018-10-10 13:50:12 +08:00
### OpenCensus
OpenTracing 已经说过了,可 [OpenCensus][7] 又是什么呢?它在搜索结果中老是出现。它是一个和 OpenTracing 完全不同或者互补的竞争标准吗?
2018-10-18 00:05:41 +08:00
这个问题的答案取决于你的提问对象。我先尽我所能地解释一下它们的不同( ) : ,
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
使用 OpenCensus, , , ,
2018-10-10 13:50:12 +08:00
依我看这两者有很多重叠的部分, , , ,
### 可选工具
#### Zipkin
Zipkin 是最早出现的这类工具之一。 谷歌在 2010 年发表了介绍其内部追踪系统 Dapper 的[论文][8], , , , ,
2018-10-18 00:05:41 +08:00
这个系统包括上报器(客户端)、数据收集器、查询服务和一个 web 界面。Zipkin 只传输一个带事务上下文的踪迹 ID 来告知接收者追踪的进行, , , :
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
[Zipkin 社区][10] 还提供了 [Brave][11],一个跟 Zipkin 兼容的 Java 客户端的实现。由于 Brave 没有任何依赖,所以它不会拖累你的项目,也不会使用跟你们公司标准不兼容的库来搞乱你的项目。除 Brave 之外,还有很多其他的 Zipkin 客户端实现,因为 Zipkin 和 OpenTracing 标准是兼容的,所以这些实现也能用到其他的分布式追踪系统中。流行的 Spring 框架中一个叫 [Spring Cloud Sleuth][12] 的分布式追踪组件,它和 Zipkin 是兼容的。
2018-10-10 13:50:12 +08:00
#### Jaeger
2018-10-18 00:05:41 +08:00
[Jaeger][1] 来自 Uber, , ,
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
Jaeger 的架构跟 Zipkin 很像,有客户端(上报器)、数据收集器、查询服务和一个 web 界面,不过它还有一个在各个服务器上运行着的代理,负责在服务器本地做数据聚合。代理通过一个 UDP 连接接收数据,然后分批处理,发送到数据收集器。收集器接收到的数据是 [Thrift][14] 协议的格式,它把数据存到 Cassandra 或者 ElasticSearch 中。查询服务能直接访问数据库,并给 web 界面提供所需的信息。
2018-10-10 13:50:12 +08:00
2018-10-18 00:05:41 +08:00
默认情况下, ) , , , ,
2018-10-10 13:50:12 +08:00
#### Appdash
[Appdash][16] 也是一个用 Golang 写的分布式追踪系统,和 Jaeger 一样。Appdash 是 [Sourcegraph][17] 公司基于谷歌的 Dapper 和 Twitter 的 Zipkin 开发的。同样的,它也支持 Opentracing 标准,不过这是后来添加的功能,依赖了一个与默认组件不同的组件,因此增加了风险和复杂度。
2018-10-18 00:05:41 +08:00
从高层次来看,
2018-10-10 13:50:12 +08:00
--------------------------------------------------------------------------------
via: https://opensource.com/article/18/9/distributed-tracing-tools
作者:[Dan Barker][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[belitex](https://github.com/belitex)
2018-10-18 00:05:41 +08:00
校对:[wxy](https://github.com/wxy)
2018-10-10 13:50:12 +08:00
本文由 [LCTT ](https://github.com/LCTT/TranslateProject ) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]: https://opensource.com/users/barkerd427
[1]: https://www.jaegertracing.io/
[2]: https://www.youtube.com/watch?v=T8BbeqZ0Rls
[3]: http://opentracing.io/
[4]: https://zipkin.io/
[5]: https://www.datadoghq.com/
[6]: https://www.instana.com/
[7]: https://opencensus.io/
[8]: https://research.google.com/archive/papers/dapper-2010-1.pdf
[9]: https://thrift.apache.org/
[10]: https://zipkin.io/pages/community.html
[11]: https://github.com/openzipkin/brave
[12]: https://cloud.spring.io/spring-cloud-sleuth/
[13]: https://www.cncf.io/
[14]: https://en.wikipedia.org/wiki/Apache_Thrift
[15]: https://www.jaegertracing.io/docs/roadmap/#adaptive-sampling
[16]: https://github.com/sourcegraph/appdash
[17]: https://about.sourcegraph.com/