mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
185 lines
18 KiB
Markdown
185 lines
18 KiB
Markdown
|
|
5 signs you are doing continuous testing wrong | Opensource.com
|
|||
|
|
======
|
|||
|
|
Avoid these common test automation mistakes in the era of DevOps and Agile.
|
|||
|
|

|
|||
|
|
|
|||
|
|
In the last few years, many companies have made large investments to automate every step of deploying features in production. Test automation has been recognized as a key enabler:
|
|||
|
|
|
|||
|
|
> “We found that Test Automation is the biggest contributor to continuous delivery.” – [2017 State of DevOps report][1]
|
|||
|
|
|
|||
|
|
Suppose you started adopting agile and DevOps practices to speed up your time to market and put new features in the hands of customers as soon as possible. You implemented continuous testing practices, but you’re facing the challenge of scalability: Implementing test automation at all system levels for code bases that contain tens of millions of lines of code involves many teams of developers and testers. And to add even more complexity, you need to support numerous browsers, mobile devices, and operating systems.
|
|||
|
|
|
|||
|
|
Despite your commitment and resources expenditure, the result is likely an automated test suite with high maintenance costs and long execution times. Worse, your teams don't trust it.
|
|||
|
|
|
|||
|
|
Here are five common test automation mistakes, and how to mitigate them using (in some cases) open source tools.
|
|||
|
|
|
|||
|
|
### 1\. Siloed automation teams
|
|||
|
|
|
|||
|
|
In medium and large IT projects with hundreds or even thousands of engineers, the most common cause of unmaintainable and expensive automated tests is keeping test teams separate from the development teams that deliver features.
|
|||
|
|
|
|||
|
|
This also happens in organizations that follow agile practices where analysts, developers, and testers work together on feature acceptance criteria and test cases. In these agile organizations, automated tests are often partially or fully managed by engineers outside the scrum teams. Inefficient communication can quickly become a bottleneck, especially when teams are geographically distributed, if you want to evolve the automated test suite over time.
|
|||
|
|
|
|||
|
|
Furthermore, when automated acceptance tests are written without developer involvement, they tend to be tightly coupled to the UI and thus brittle and badly factored, because the most testers don’t have insight into the UI’s underlying design and lack the skills to create abstraction layers or run acceptance tests against a public API.
|
|||
|
|
|
|||
|
|
A simple suggestion is to split your siloed automation teams and include test engineers directly in scrum teams where feature discussion and implementation happen, and the impacts on test scripts can be immediately discovered and fixed. This is certainly a good idea, but it is not the real point. Better yet is to make the entire scrum team responsible for automated tests. Product owners, developers, and testers must then work together to refine feature acceptance criteria, create test cases, and prioritize them for automation.
|
|||
|
|
|
|||
|
|
When different actors, inside or outside the development team, are involved in running automated test suites, one practice that levels up the overall collaborative process is [BDD][2], or behavior-driven development. It helps create business requirements that can be understood by the whole team and contributes to having a single source of truth for automated tests. Open source tools like [Cucumber][3], [JBehave][4], and [Gauge][5] can help you implement BDD and keep test case specifications and test scripts automatically synchronized. Such tools let you create concrete examples that illustrate business rules and acceptance criteria through the use of a simple text file containing Given-When-Then scenarios. They are used as executable software specifications to automatically verify that the software behaves as intended.
|
|||
|
|
|
|||
|
|
### 2\. Most of your automated suite is made by user interface tests
|
|||
|
|
|
|||
|
|
You should already know that user interface automated tests are brittle and even small changes will immediately break all the tests referring to a particular changed GUI element. This is one of the main reasons technical/business stakeholders perceive automated tests as expensive to maintain. Record-and-playback tools such as [SeleniumRecorder][6], used to generate GUI automatic tests, are tightly coupled to the GUI and therefore brittle. These tools can be used in the first stage of creating an automatic test, but a second optimization stage is required to provide a layer of abstraction that reduces the coupling between the acceptance tests and the GUI of the system under test. Design patterns such as [PageObject][7] can be used for this purpose.
|
|||
|
|
|
|||
|
|
However, if your automated test strategy is focused only on user interfaces, it will quickly become a bottleneck as it is resource-intensive, takes a long time to execute, and it is generally hard to fix. Indeed, resolving UI test failure may require you to go through all system levels to discover the root cause.
|
|||
|
|
|
|||
|
|
A better approach is to prioritize development of automated tests at the right level to balance the costs of maintaining them while trying to discover bugs in the early stages of the software [deployment pipeline][8] (a key pattern introduced in continuous delivery).
|
|||
|
|
|
|||
|
|
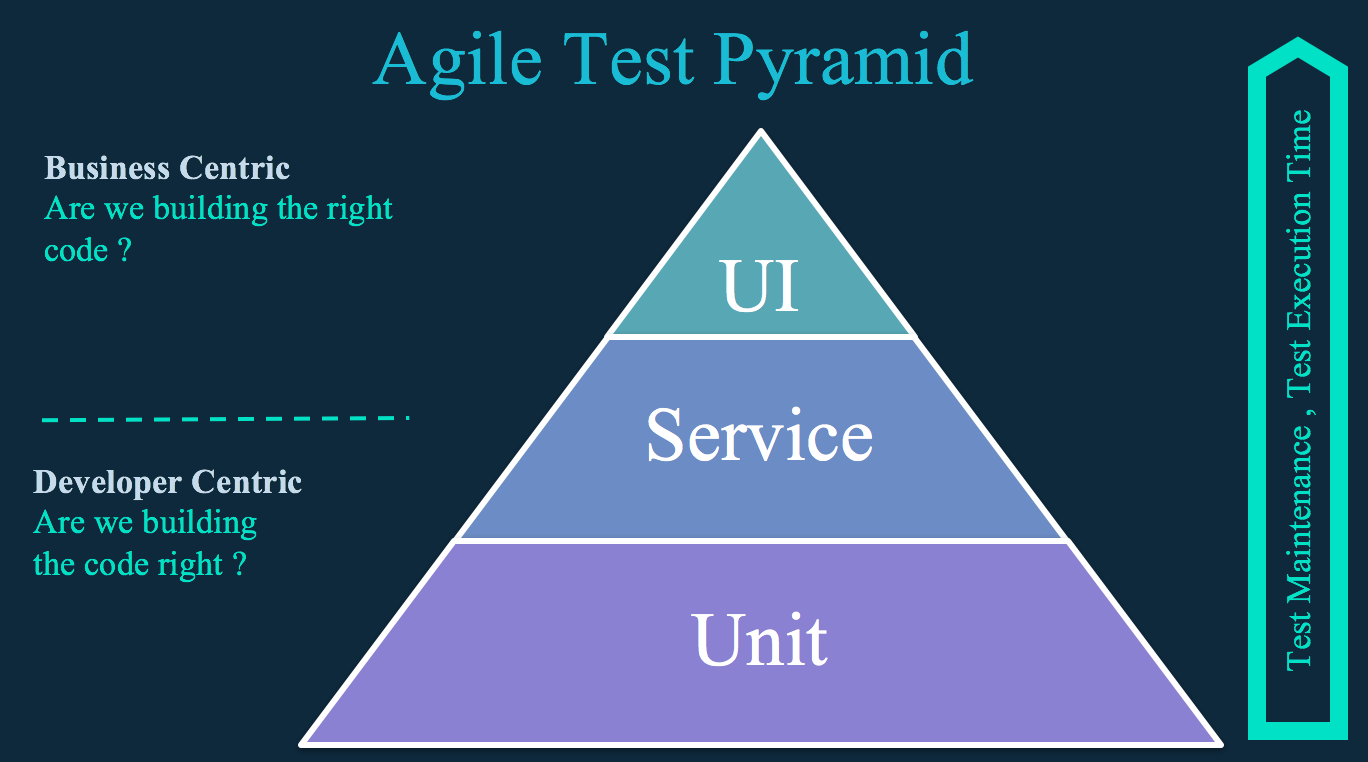
|
|||
|
|
|
|||
|
|
As suggested by the [agile test pyramid][9] shown above, the vast majority of automated tests should be comprised of unit tests (both back- and front-end level). The most important property of unit tests is that they should be very fast to execute (e.g., 5 to 10 minutes).
|
|||
|
|
|
|||
|
|
The service layer (or component tests) allows for testing business logic at the API or service level, where you're not encumbered by the user interface (UI). The higher the level, the slower and more brittle testing becomes.
|
|||
|
|
|
|||
|
|
Typically unit tests are run at every developer commit, and the build process is stopped in the case of a test failure or if the test coverage is under a predefined threshold (e.g., when less than 80% of code lines are covered by unit tests). Once the build passes, it is deployed in a stage environment, and acceptance tests are executed. Any build that passes acceptance tests is then typically made available for manual and integration testing.
|
|||
|
|
|
|||
|
|
Unit tests are an essential part of any automated test strategy, but they usually do not provide a high enough level of confidence that the application can be released. The objective of acceptance tests at service and UI level is to prove that your application does what the customer wants it to, not that it works the way its programmers think it should. Unit tests can sometimes share this focus, but not always.
|
|||
|
|
|
|||
|
|
To ensure that the application provides value to end users while balancing test suite costs and value, you must automate both the service/component and UI acceptance tests with the agile test pyramid in mind.
|
|||
|
|
|
|||
|
|
Read more about test types, levels, and tools in this comprehensive [article][10] from ThoughtWorks.
|
|||
|
|
|
|||
|
|
### 3\. External systems are integrated too early in your deployment pipeline
|
|||
|
|
|
|||
|
|
Integration with external systems is a common source of problems, and it can be difficult to get right. This implies that it is important to test such integration points carefully and effectively. The problem is that if you include the external systems themselves within the scope of your automated acceptance testing, you have less control over the system. It is difficult to set an external system starting state, and this, in turn, will end up in an unpredictable test run that fails most of the time. The rest of your time will be probably spent discussing how to fix testing failures with external providers. However, our objective with continuous testing is to find problems as early as possible, and to achieve this, we aim to integrate our system continuously. Clearly, there is a tension here and a “one-size-fits-all” answer doesn’t exist.
|
|||
|
|
|
|||
|
|
Having suites of tests around each integration point, intended to run in an environment that has real connections to external systems, is valuable, but the tests should be very small, focus on business risks, and cover core customer journeys. Instead, consider creating [test doubles][11] that represent the connection to all external systems and use them in development and/or early-stage environments so that your test suites are faster and test results are deterministic. If you are new to the concept of test doubles but have heard about mocks and stubs, you can learn about the differences in this [Martin Fowler blog post][11].
|
|||
|
|
|
|||
|
|
In their book, [Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation][12], Jez Humble and David Farley advise: “Test doubles must almost always be used to stub out part of an external system when:
|
|||
|
|
|
|||
|
|
* The external system is under development but the interface has been defined ahead of time (in these situations, be prepared for the interface to change).
|
|||
|
|
|
|||
|
|
* The external system is developed already but you don’t have a test instance of that system available for your testing, or the test system is too slow or buggy to act as a service for regular automated test runs.
|
|||
|
|
|
|||
|
|
* The test system exists, but responses are not deterministic and so make validation of tests results impossible for automated tests (for example, a stock market feed).
|
|||
|
|
|
|||
|
|
* The external system takes the form of another application that is difficult to install or requires manual intervention via a UI.
|
|||
|
|
|
|||
|
|
* The load that your automated continuous integration system imposes, and the service level that it requires, overwhelms the lightweight test environment that is set up to cope with only a few manual exploratory interactions.”
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
Suppose you need to integrate one or more external systems that are under active development. In turn, there will likely be changes in the schemas, contracts, and so on. Such a scenario needs careful and regular testing to identify points at which different teams diverge. This is the case of microservice-based architectures, which involve several independent systems deployed to test a single functionality. In this context, review the overall automated testing strategies in favor of a more scalable and maintainable approach like the one used on [consumer-driven contracts][13].
|
|||
|
|
|
|||
|
|
If you are not in such a situation, I found the following open source tools useful to implement test doubles starting from an API contract specification:
|
|||
|
|
|
|||
|
|
* [SoapUI mocking services][14]: Despite its name, it can mock both SOAP and rest services.
|
|||
|
|
|
|||
|
|
* [WireMock][15]: It can mock rest services only.
|
|||
|
|
|
|||
|
|
* For rest services, look at [OpenAPI tools][16] for “mock servers,” which are able to generate test stubs starting from [OpenAPI][17] contract specification.
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 4\. Test and development tools mismatch
|
|||
|
|
|
|||
|
|
One of the consequences of offloading test automation work to teams other than the development team is that it creates a divergence between development and test tools. This makes collaboration and communication harder between dev and test engineers, increases the overall cost for test automation, and fosters bad practices such as having the version of test scripts and feature code not aligned or not versioned at all.
|
|||
|
|
|
|||
|
|
I’ve seen a lot of teams struggle with expensive UI/API automated test tools that had poor integration with standard versioning systems like Git. Other tools, especially GUI-based commercial ones with visual workflow capabilities, create a false expectation—primarily between test managers—that you can easily expect testers to develop maintainable and reusable automated tests. Even if this is possible, they can’t scale your automated test suite over time; the tests must be curated as much as feature code, which requires developer-level programming skills and best practices.
|
|||
|
|
|
|||
|
|
There are several open source tools that help you write automated acceptance tests and reuse your development teams' skills. If your primary development language is Java or JavaScript, you may find the following options useful:
|
|||
|
|
|
|||
|
|
* Java
|
|||
|
|
|
|||
|
|
* [Cucumber-jvm][18] for implementing executable specifications in Java for both UI and API automated testing
|
|||
|
|
|
|||
|
|
* [REST Assured][19] for API testing
|
|||
|
|
|
|||
|
|
* [SeleniumHQ][20] for web testing
|
|||
|
|
|
|||
|
|
* [ngWebDriver][21] locators for Selenium WebDriver. It is optimized for web applications built with Angular.js 1.x or Angular 2+
|
|||
|
|
|
|||
|
|
* [Appium Java][22] for mobile testing using Selenium WebDriver
|
|||
|
|
|
|||
|
|
* JavaScript
|
|||
|
|
|
|||
|
|
* [Cucumber.js][23] same as Cucumber.jvm but runs on Node.js platform
|
|||
|
|
|
|||
|
|
* [Chakram][24] for API testing
|
|||
|
|
|
|||
|
|
* [Protractor][25] for web testing optimized for web applications built with AngularJS 1.x or Angular 2+
|
|||
|
|
|
|||
|
|
* [Appium][26] for mobile testing on the Node.js platform
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 5\. Your test data management is not fully automated
|
|||
|
|
|
|||
|
|
To build maintainable test suites, it’s essential to have an effective strategy for creating and maintaining test data. It requires both automatic migration of data schema and test data initialization.
|
|||
|
|
|
|||
|
|
It's tempting to use large database dumps for automated tests, but this makes it difficult to version and automate them and will increase the overall time of test execution. A better approach is to capture all data changes in DDL and DML scripts, which can be easily versioned and executed by the data management system. These scripts should first create the structure of the database and then populate the tables with any reference data required for the application to start. Furthermore, you need to design your scripts incrementally so that you can migrate your database without creating it from scratch each time and, most importantly, without losing any valuable data.
|
|||
|
|
|
|||
|
|
Open source tools like [Flyway][27] can help you orchestrate your DDL and DML scripts' execution based on a table in your database that contains its current version number. At deployment time, Flyway checks the version of the database currently deployed and the version of the database required by the version of the application that is being deployed. It then works out which scripts to run to migrate the database from its current version to the required version, and runs them on the database in order.
|
|||
|
|
|
|||
|
|
One important characteristic of your automated acceptance test suite, which makes it scalable over time, is the level of isolation of the test data: Test data should be visible only to that test. In other words, a test should not depend on the outcome of the other tests to establish its state, and other tests should not affect its success or failure in any way. Isolating tests from one another makes them capable of being run in parallel to optimize test suite performance, and more maintainable as you don’t have to run tests in any specific order.
|
|||
|
|
|
|||
|
|
When considering how to set up the state of the application for an acceptance test, Jez Humble and David Farley note [in their book][12] that it is helpful to distinguish between three kinds of data:
|
|||
|
|
|
|||
|
|
* **Test reference data:** This is the data that is relevant for a test but that has little bearing upon the behavior under test. Such data is typically read by test scripts and remains unaffected by the operation of the tests. It can be managed by using pre-populated seed data that is reused in a variety of tests to establish the general environment in which the tests run.
|
|||
|
|
|
|||
|
|
* **Test-specific data:** This is the data that drives the behavior under test. It also includes transactional data that is created and/or updated during test execution. It should be unique and use test isolation strategies to ensure that the test starts in a well-defined environment that is unaffected by other tests. Examples of test isolation practices are deleting test-specific data and transactional data at the end of the test execution, or using a functional partitioning strategy.
|
|||
|
|
|
|||
|
|
* **Application reference data:** This data is irrelevant to the test but is required by the application for startup.
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
Application reference data and test reference data can be kept in the form of database scripts, which are versioned and migrated as part of the application's initial setup. For test-specific data, you should use application APIs so the system is always put in a consistent state as a consequence of executing business logic (which otherwise would be bypassed if you directly load test data into the database using scripts).
|
|||
|
|
|
|||
|
|
### Conclusion
|
|||
|
|
|
|||
|
|
Agile and DevOps teams continue to fall short on continuous testing—a crucial element of the CI/CD pipeline. Even as a single process, continuous testing is made up of various components that must work in unison. Team structure, testing prioritization, test data, and tools all play a critical role in the success of continuous testing. Agile and DevOps teams must get every piece right to see the benefits.
|
|||
|
|
|
|||
|
|
|
|||
|
|
--------------------------------------------------------------------------------
|
|||
|
|
|
|||
|
|
via: https://opensource.com/article/18/11/continuous-testing-wrong
|
|||
|
|
|
|||
|
|
作者:[Davide Antelmo][a]
|
|||
|
|
选题:[lujun9972][b]
|
|||
|
|
译者:[译者ID](https://github.com/译者ID)
|
|||
|
|
校对:[校对者ID](https://github.com/校对者ID)
|
|||
|
|
|
|||
|
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|||
|
|
|
|||
|
|
[a]: https://opensource.com/users/dantelmo
|
|||
|
|
[b]: https://github.com/lujun9972
|
|||
|
|
[1]: https://puppet.com/blog/2017-state-devops-report-here
|
|||
|
|
[2]: https://www.agilealliance.org/glossary/bdd/
|
|||
|
|
[3]: https://docs.cucumber.io/
|
|||
|
|
[4]: https://jbehave.org/
|
|||
|
|
[5]: https://www.gauge.org/
|
|||
|
|
[6]: https://www.seleniumhq.org/projects/ide/
|
|||
|
|
[7]: https://martinfowler.com/bliki/PageObject.html
|
|||
|
|
[8]: https://continuousdelivery.com/implementing/patterns/
|
|||
|
|
[9]: https://martinfowler.com/bliki/TestPyramid.html
|
|||
|
|
[10]: https://martinfowler.com/articles/practical-test-pyramid.html
|
|||
|
|
[11]: https://martinfowler.com/bliki/TestDouble.html
|
|||
|
|
[12]: https://martinfowler.com/books/continuousDelivery.html
|
|||
|
|
[13]: https://martinfowler.com/articles/consumerDrivenContracts.html
|
|||
|
|
[14]: https://www.soapui.org/soap-mocking/service-mocking-overview.html
|
|||
|
|
[15]: http://wiremock.org/
|
|||
|
|
[16]: https://openapi.tools/
|
|||
|
|
[17]: https://www.openapis.org/
|
|||
|
|
[18]: https://github.com/cucumber/cucumber-jvm
|
|||
|
|
[19]: http://rest-assured.io/
|
|||
|
|
[20]: https://www.seleniumhq.org/
|
|||
|
|
[21]: https://github.com/paul-hammant/ngWebDriver
|
|||
|
|
[22]: https://github.com/appium/java-client
|
|||
|
|
[23]: https://github.com/cucumber/cucumber-js
|
|||
|
|
[24]: http://dareid.github.io/chakram/
|
|||
|
|
[25]: https://www.protractortest.org/#/
|
|||
|
|
[26]: https://github.com/appium/appium
|
|||
|
|
[27]: https://flywaydb.org/
|