mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
212 lines
10 KiB
Markdown
212 lines
10 KiB
Markdown
|
|
2017 年哪个公司对开源贡献最多?让我们用 GitHub 的数据分析下
|
|||
|
|
============================================================
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
在这篇分析报告中,我们将使用 2017 年度截止至当前时间(2017 年 10 月)为止,GitHub 上所有公开的推送事件的数据。对于每个 GitHub 用户,我们将尽可能地猜测其所属的公司。此外,我们仅查看那些今年得到了至少 20 个星标的仓库。
|
|||
|
|
|
|||
|
|
以下是我的报告结果,你也可以[在我的交互式 Data Studio 报告上进一步加工][1]。
|
|||
|
|
|
|||
|
|
### 顶级云服务商的比较
|
|||
|
|
|
|||
|
|
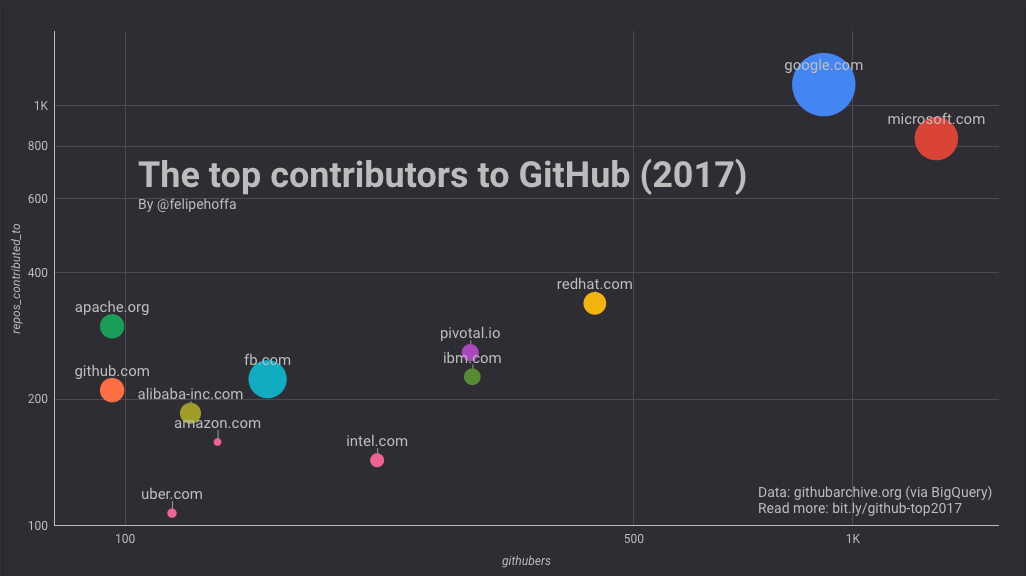
2017 年它们在 GitHub 上的表现:
|
|||
|
|
|
|||
|
|
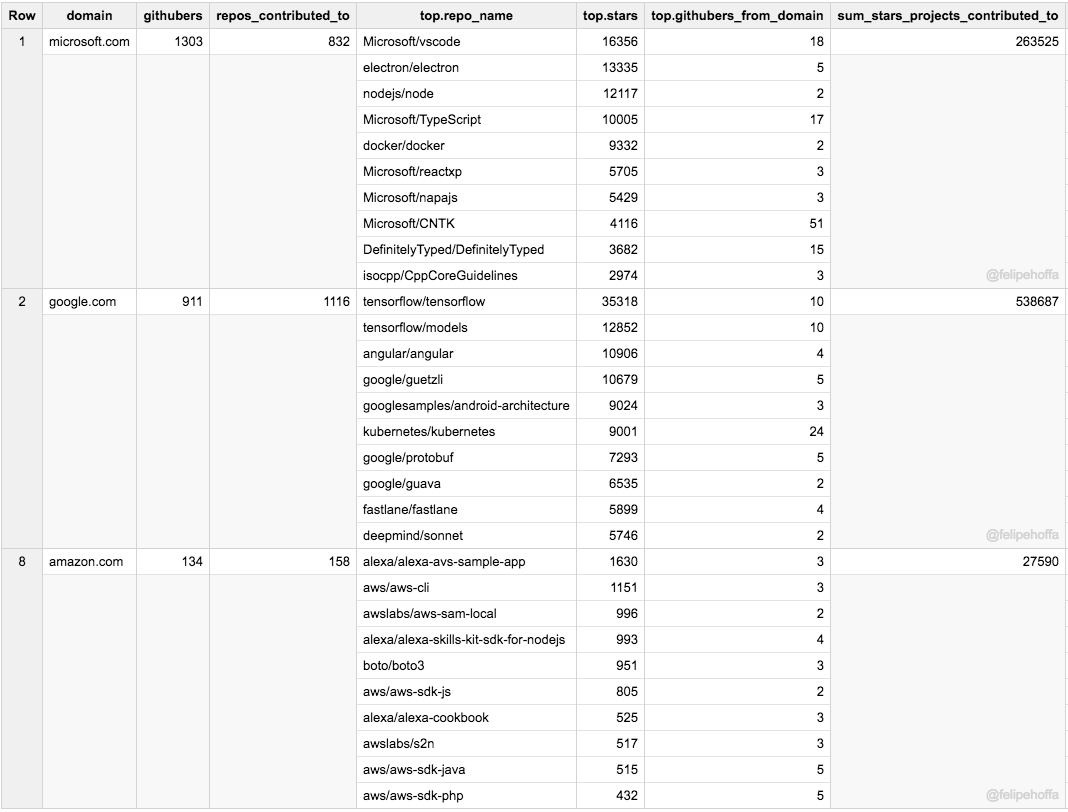
* 微软看起来约有 1300 名员工积极地推送代码到 GitHub 上的 825 个顶级仓库。
|
|||
|
|
* 谷歌显示出约有 900 名员工在 GitHub 上活跃,他们推送代码到大约 1100 个顶级仓库。
|
|||
|
|
* 亚马逊似乎只有 134 名员工活跃在 GitHub 上,他们推送代码到仅仅 158 个顶级项目上。
|
|||
|
|
* 不是所有的项目都一样:在超过 25% 的仓库上谷歌员工要比微软员工贡献的多,而那些仓库得到了更多的星标(53 万对比 26 万)。亚马逊的仓库 2017 年合计才得到了 2.7 万个星标。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
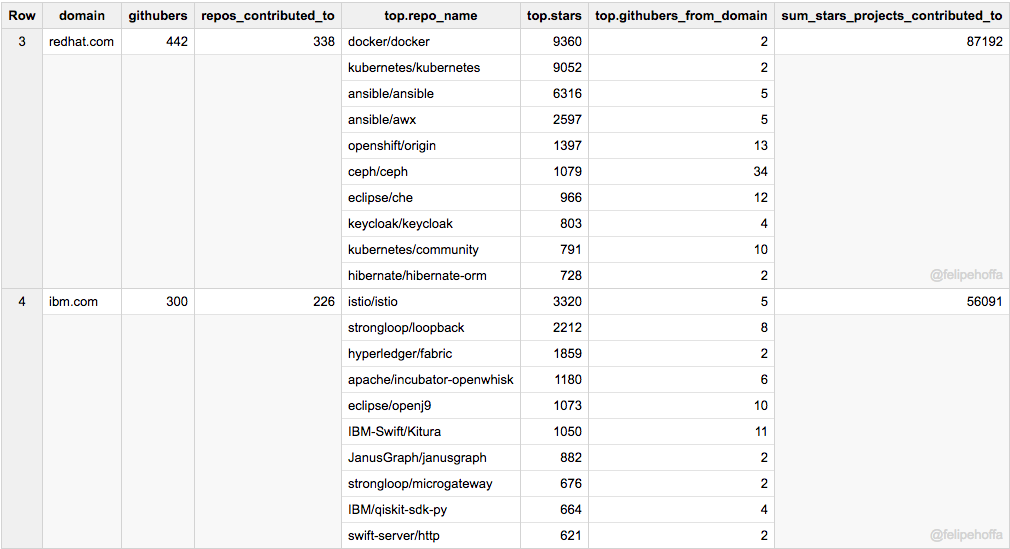
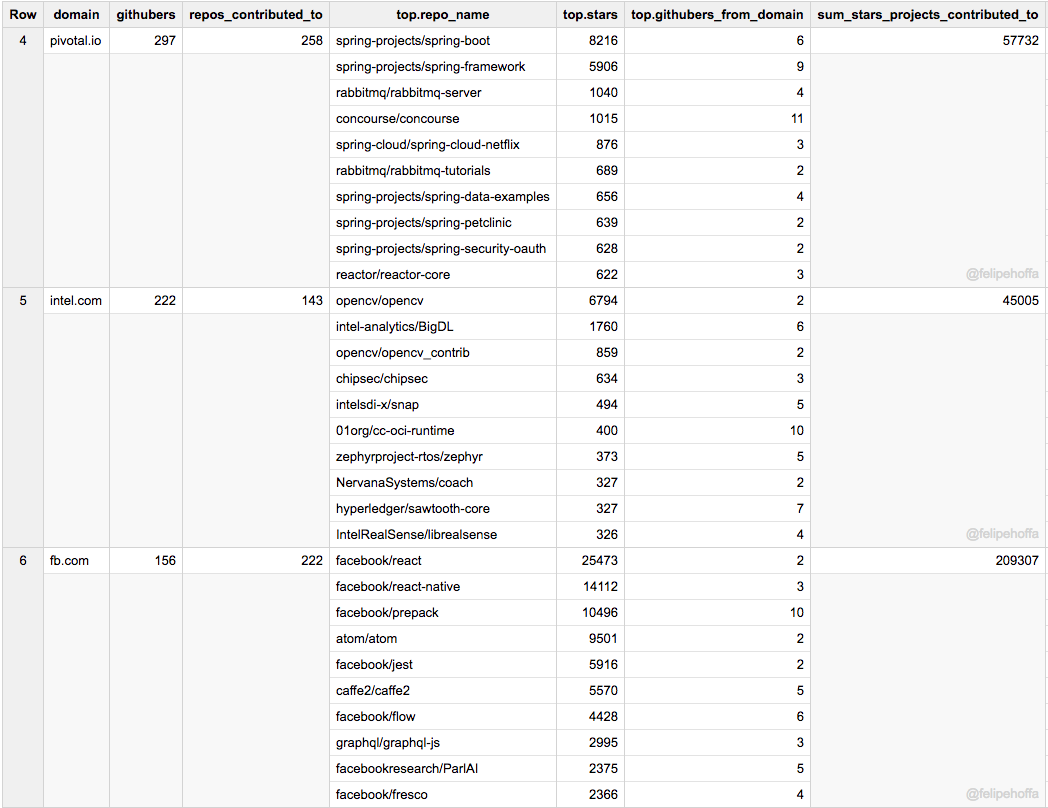
### 红帽、IBM、Pivotal、英特尔和 Facebook
|
|||
|
|
|
|||
|
|
如果说亚马逊看起来被微软和谷歌远远抛在了身后,那么这之间还有哪些公司呢?根据这个排名来看,红帽、Pivotal 和英特尔在 GitHub 上做出了巨大贡献:
|
|||
|
|
|
|||
|
|
注意,下表中合并了所有的 IBM 地区域名(各个地区会展示在其后的表格中)。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
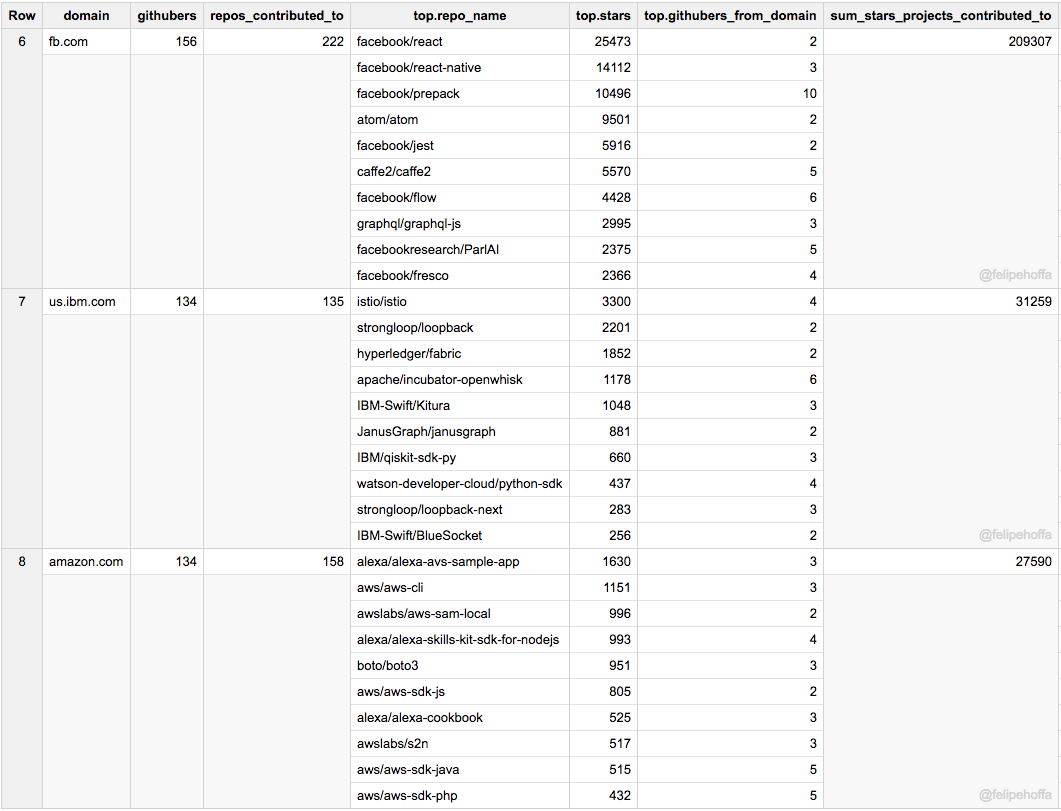
Facebook 和 IBM(美)在 GitHub 上的活跃用户数同亚马逊差不多,但是它们所贡献的项目得到了更多的星标(特别是 Facebook):
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
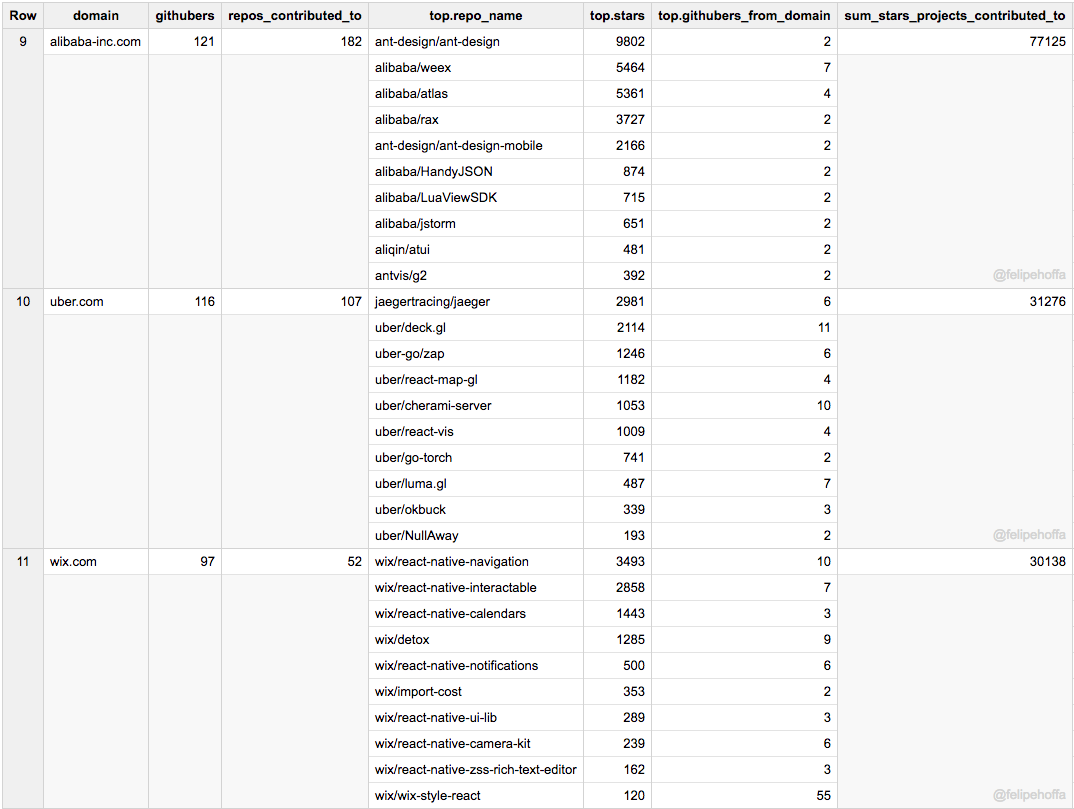
接下来是阿里巴巴、Uber 和 Wix:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
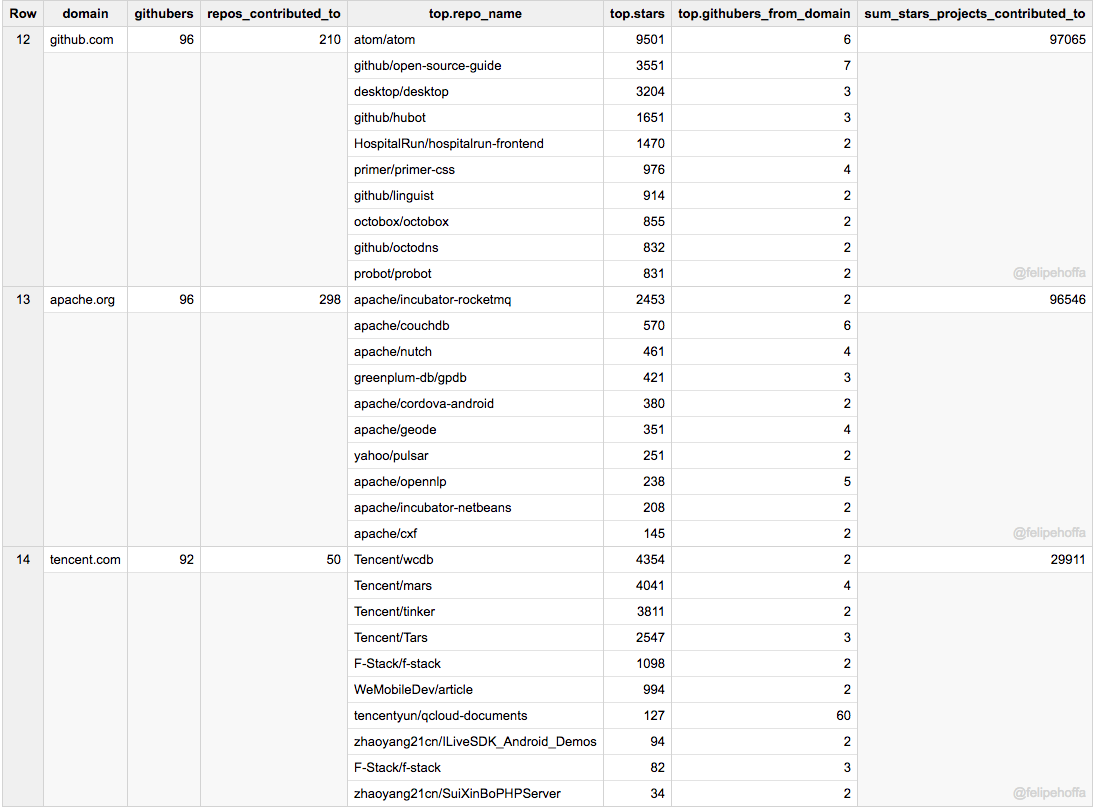
以及 GitHub 自己、Apache 和腾讯:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
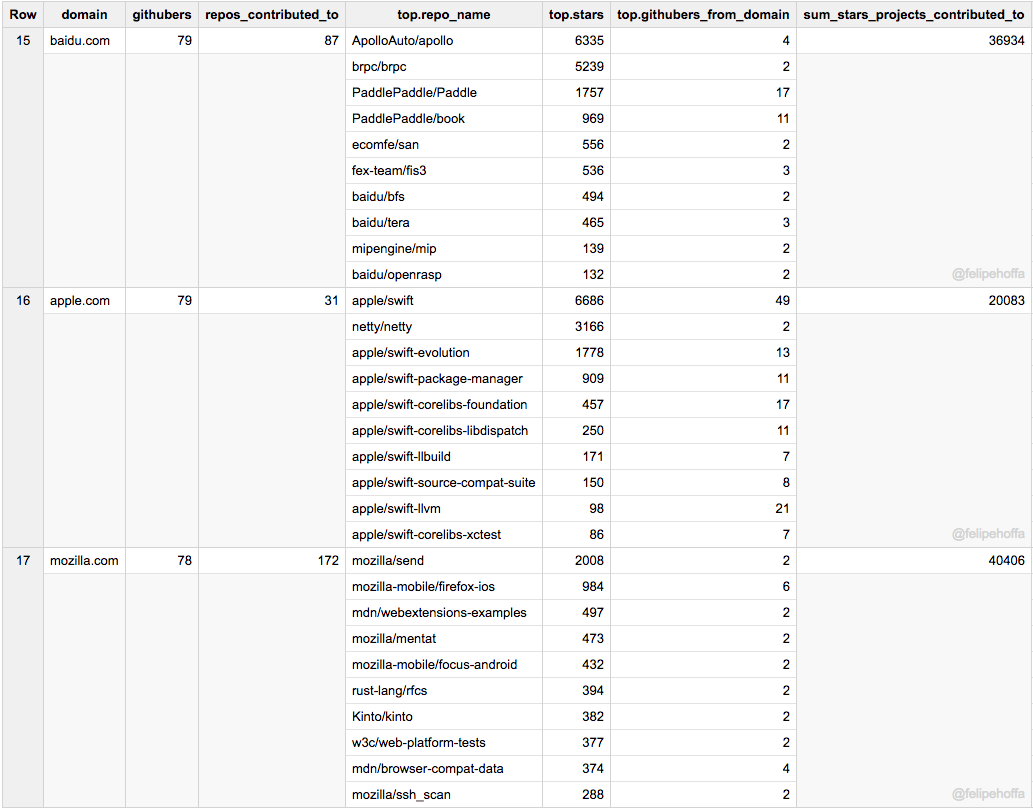
百度、苹果和 Mozilla:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
(LCTT 译注:很高兴看到国内的顶级互联网公司阿里巴巴、腾讯和百度在这里排名前列!)
|
|||
|
|
|
|||
|
|
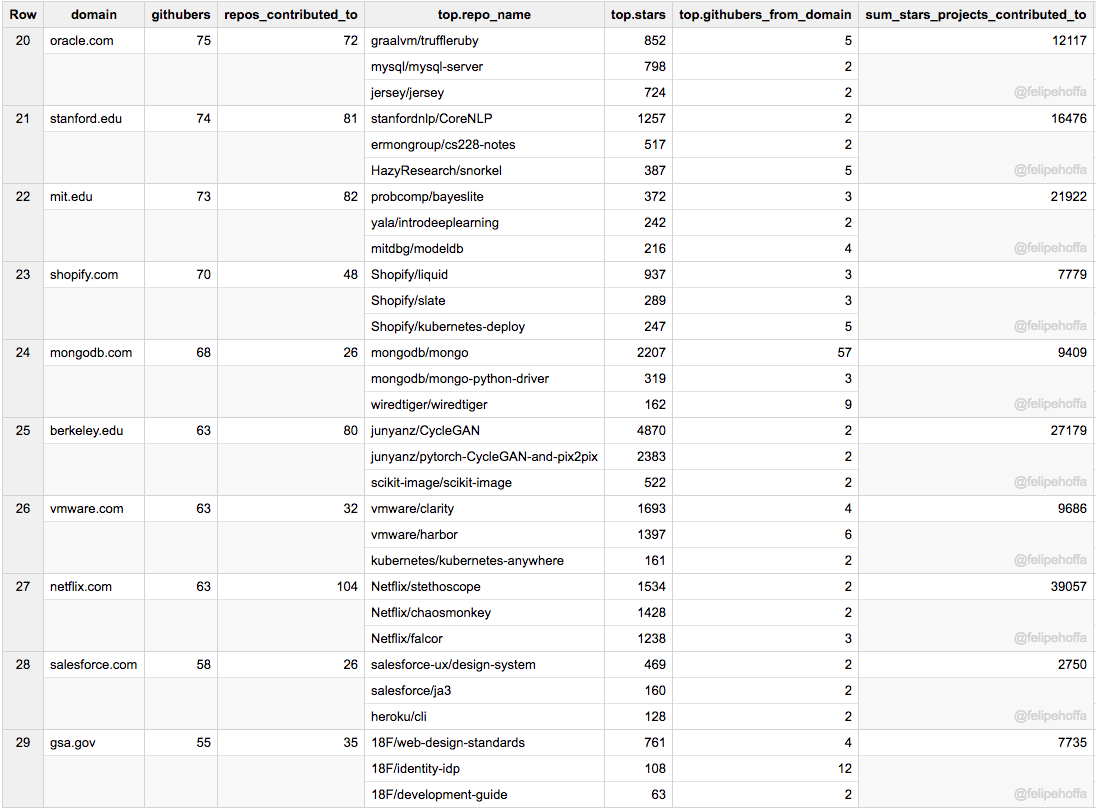
甲骨文、斯坦福大学、麻省理工、Shopify、MongoDb、伯克利大学、VmWare、Netflix、Salesforce 和 Gsa.gov:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
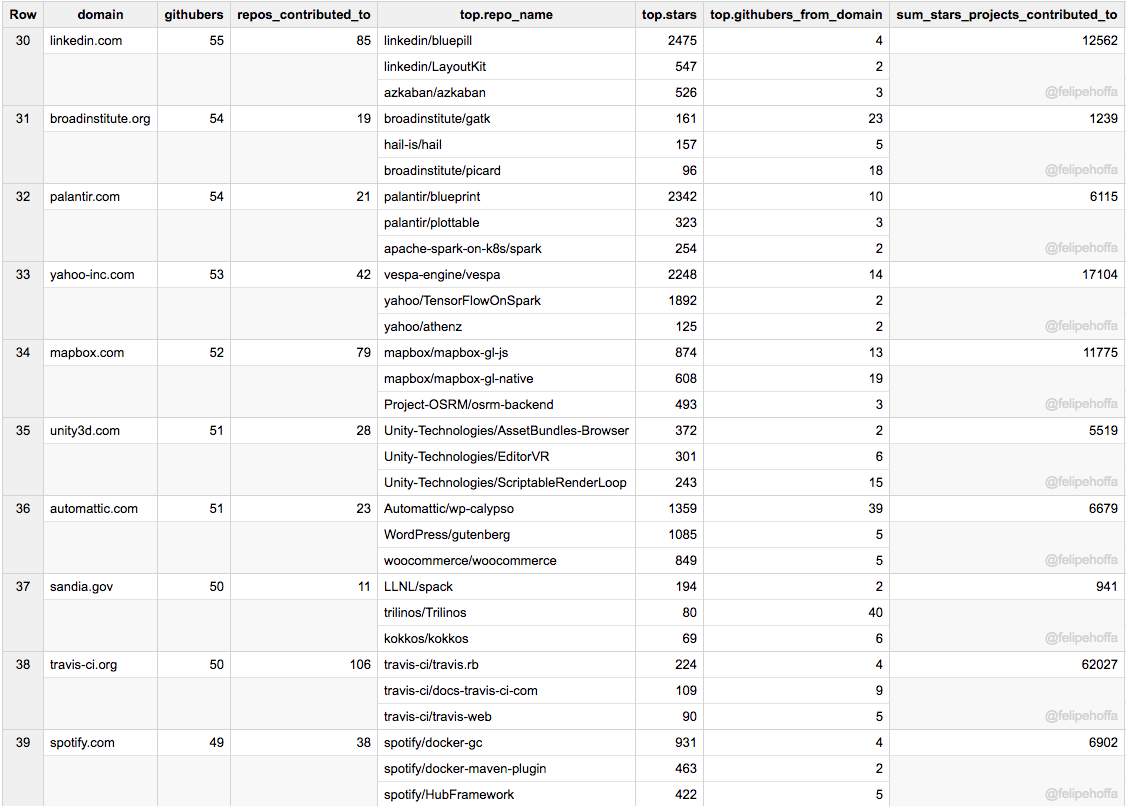
LinkedIn、Broad Institute、Palantir、雅虎、MapBox、Unity3d、Automattic(WordPress 的开发商)、Sandia、Travis-ci 和 Spotify:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
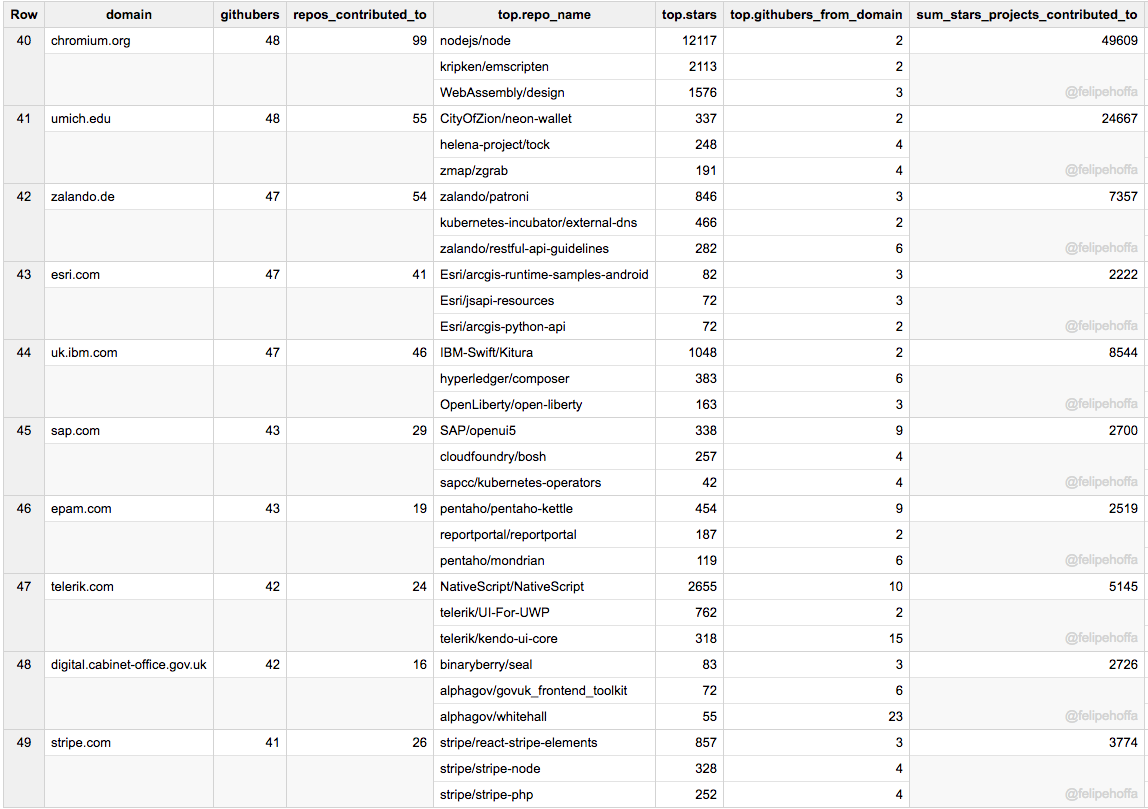
Chromium、UMich、Zalando、Esri、IBM (英)、SAP、EPAM、Telerik、UK Cabinet Office 和 Stripe:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
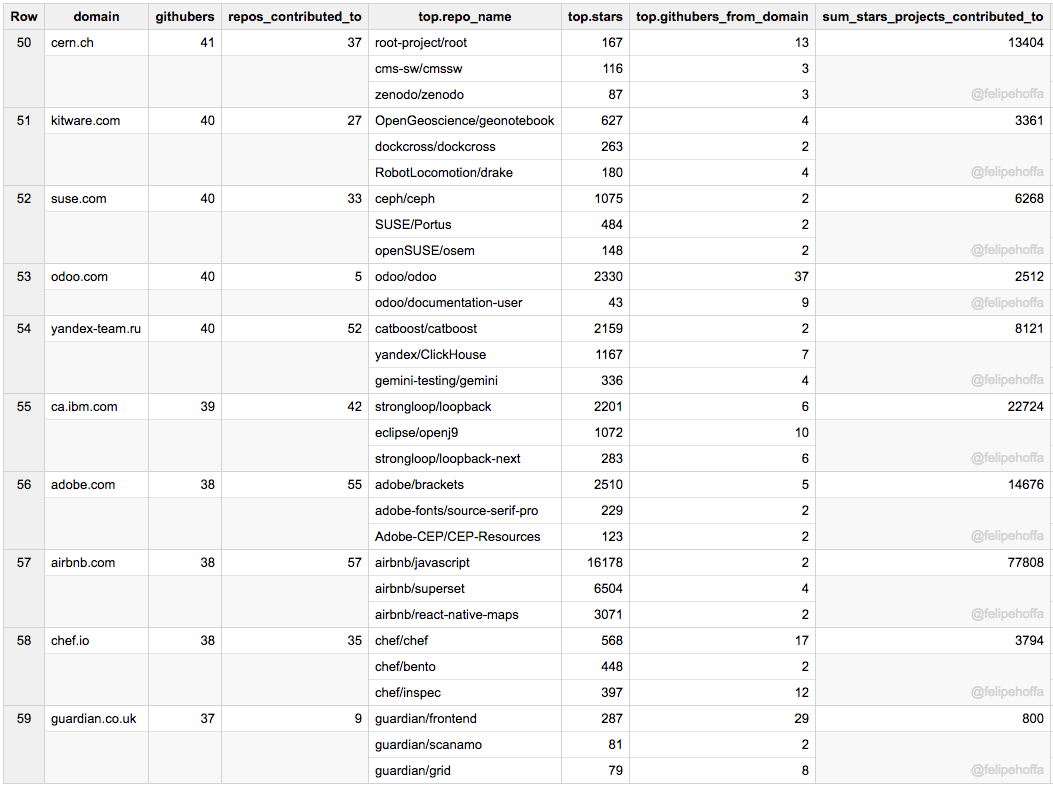
Cern、Odoo、Kitware、Suse、Yandex、IBM (加)、Adobe、AirBnB、Chef 和 The Guardian:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
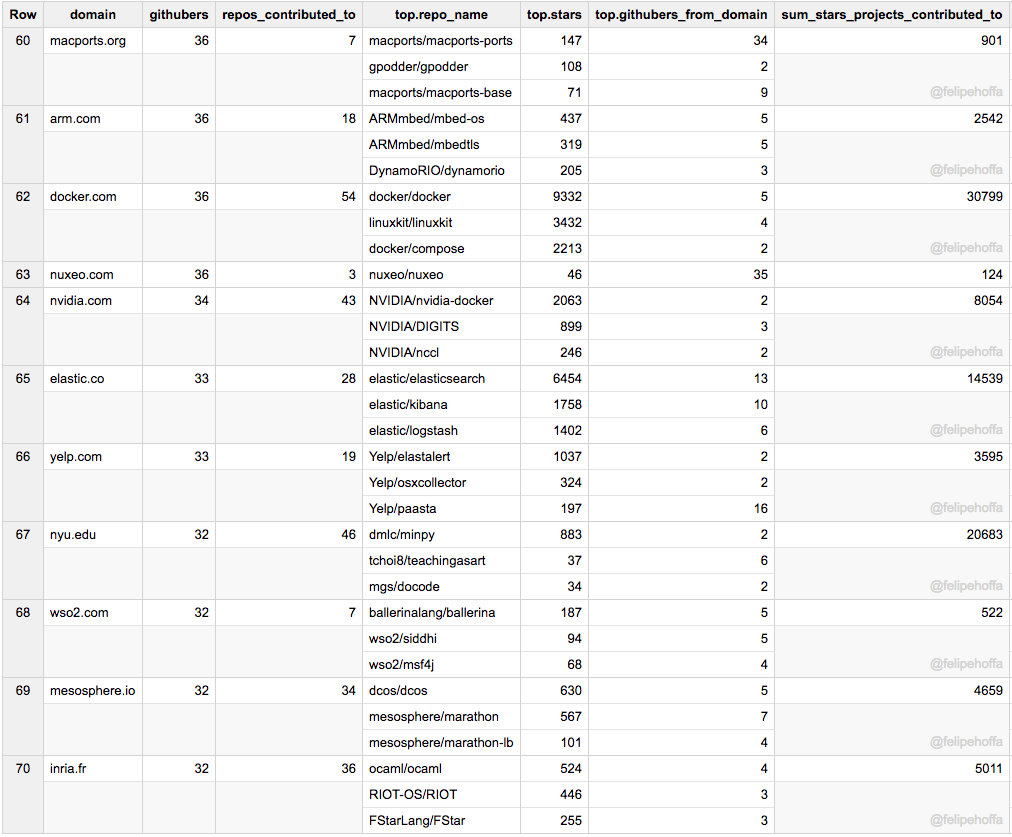
Arm、Macports、Docker、Nuxeo、NVidia、Yelp、Elastic、NYU、WSO2、Mesosphere 和 Inria:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
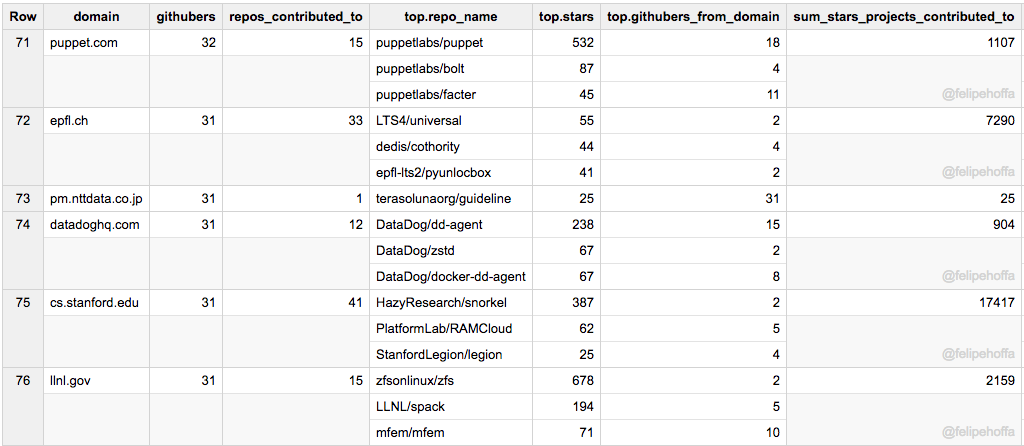
Puppet、斯坦福(计算机科学)、DatadogHQ、Epfl、NTT Data 和 Lawrence Livermore Lab:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 我的分析方法
|
|||
|
|
|
|||
|
|
#### 我是怎样将 GitHub 用户关联到其公司的
|
|||
|
|
|
|||
|
|
在 GitHub 上判定每个用户所述的公司并不容易,但是我们可以使用其推送事件的提交消息中展示的邮件地址域名来判断。
|
|||
|
|
|
|||
|
|
* 同样的邮件地址可以出现在几个用户身上,所以我仅考虑那些对此期间获得了超过 20 个星标的项目进行推送的用户。
|
|||
|
|
* 我仅统计了在此期间推送超过 3 次的 GitHub 用户。
|
|||
|
|
* 用户推送代码到 GitHub 上可以在其推送中显示许多不同的邮件地址,这部分是由 GIt 工作机制决定的。为了判定每个用户的组织,我会查找那些在推送中出现更频繁的邮件地址。
|
|||
|
|
* 不是每个用户都在 GitHub 上使用其组织的邮件。有许多人使用 gmail.com、users.noreply.github.com 和其它邮件托管商的邮件地址。有时候这是为了保持匿名和保护其公司邮箱,但是如果我不能定位其公司域名,这些用户我就不会统计。抱歉。
|
|||
|
|
* 有时候员工会更换所任职的公司。我会将他们分配给其推送最多的公司。
|
|||
|
|
|
|||
|
|
#### 我的查询语句
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
#standardSQL
|
|||
|
|
WITH
|
|||
|
|
period AS (
|
|||
|
|
SELECT *
|
|||
|
|
FROM `githubarchive.month.2017*` a
|
|||
|
|
),
|
|||
|
|
repo_stars AS (
|
|||
|
|
SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name
|
|||
|
|
FROM period
|
|||
|
|
WHERE type='WatchEvent'
|
|||
|
|
GROUP BY 1
|
|||
|
|
HAVING stars>20
|
|||
|
|
),
|
|||
|
|
pushers_guess_emails_and_top_projects AS (
|
|||
|
|
SELECT *
|
|||
|
|
# , REGEXP_EXTRACT(email, r'@(.*)') domain
|
|||
|
|
, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
|
|||
|
|
FROM (
|
|||
|
|
SELECT actor.id
|
|||
|
|
, APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login
|
|||
|
|
, APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email'),1)[OFFSET(0)].value email
|
|||
|
|
, COUNT(*) c
|
|||
|
|
, ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos
|
|||
|
|
FROM period a
|
|||
|
|
JOIN repo_stars b
|
|||
|
|
ON a.repo.id=b.id
|
|||
|
|
WHERE type='PushEvent'
|
|||
|
|
GROUP BY 1
|
|||
|
|
HAVING c>3
|
|||
|
|
)
|
|||
|
|
)
|
|||
|
|
SELECT * FROM (
|
|||
|
|
SELECT domain
|
|||
|
|
, githubers
|
|||
|
|
, (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to
|
|||
|
|
, ARRAY(
|
|||
|
|
SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, '$.repo_name') repo_name
|
|||
|
|
, CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64) stars
|
|||
|
|
, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo
|
|||
|
|
GROUP BY 1, 2
|
|||
|
|
HAVING githubers_from_domain>1
|
|||
|
|
ORDER BY stars DESC LIMIT 3
|
|||
|
|
) top
|
|||
|
|
, (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to
|
|||
|
|
FROM (
|
|||
|
|
SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos
|
|||
|
|
FROM pushers_guess_emails_and_top_projects
|
|||
|
|
#WHERE domain IN UNNEST(SPLIT('google.com|microsoft.com|amazon.com', '|'))
|
|||
|
|
WHERE domain NOT IN UNNEST(SPLIT('gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru', '|')) # email hosters
|
|||
|
|
GROUP BY 1
|
|||
|
|
HAVING githubers > 30
|
|||
|
|
)
|
|||
|
|
WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters
|
|||
|
|
)
|
|||
|
|
ORDER BY githubers DESC
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### FAQ
|
|||
|
|
|
|||
|
|
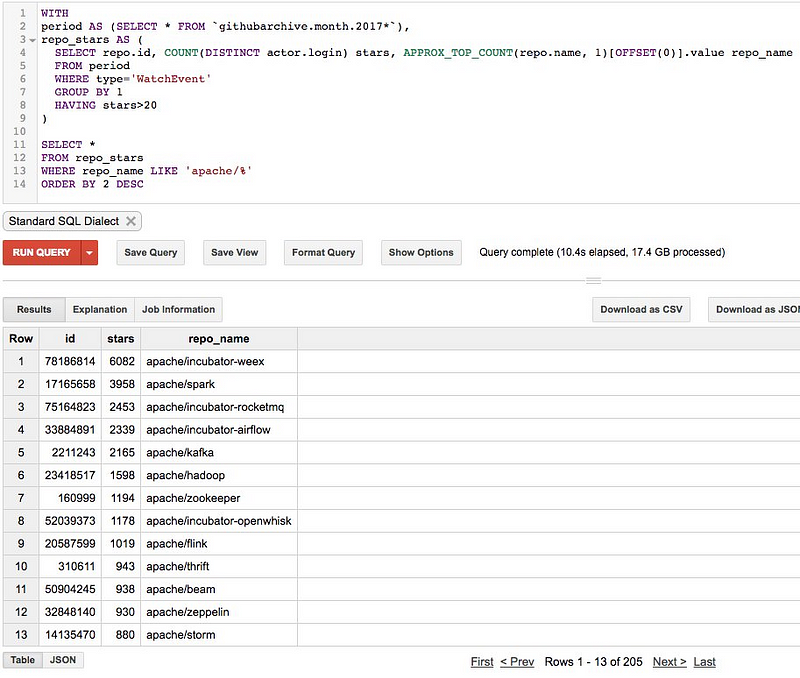
#### 有的公司有 1500 个仓库,为什么只统计了 200 个?有的仓库有 7000 个星标,为什么只显示 1500 个?
|
|||
|
|
|
|||
|
|
我进行了过滤。我只统计了 2017 年的星标。举个例子说,Apache 在 GitHub 上有超过 1500 个仓库,但是今年只有 205 个项目得到了超过 20 个星标。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### 这表明了开源的发展形势么?
|
|||
|
|
|
|||
|
|
注意,这个对 GitHub 的分析没有包括像 Android、Chromium、GNU、Mozilla 等顶级社区,也没有包括 Apache 基金会或 Eclipse 基金会,还有一些[其它][2]项目选择在 GitHub 之外开展起活动。
|
|||
|
|
|
|||
|
|
#### 这对于我的组织不公平
|
|||
|
|
|
|||
|
|
我只能统计我所看到的数据。欢迎对我的统计的前提提出意见,以及对我的统计方法给出改进方法。如果有能用的查询语句就更好了。
|
|||
|
|
|
|||
|
|
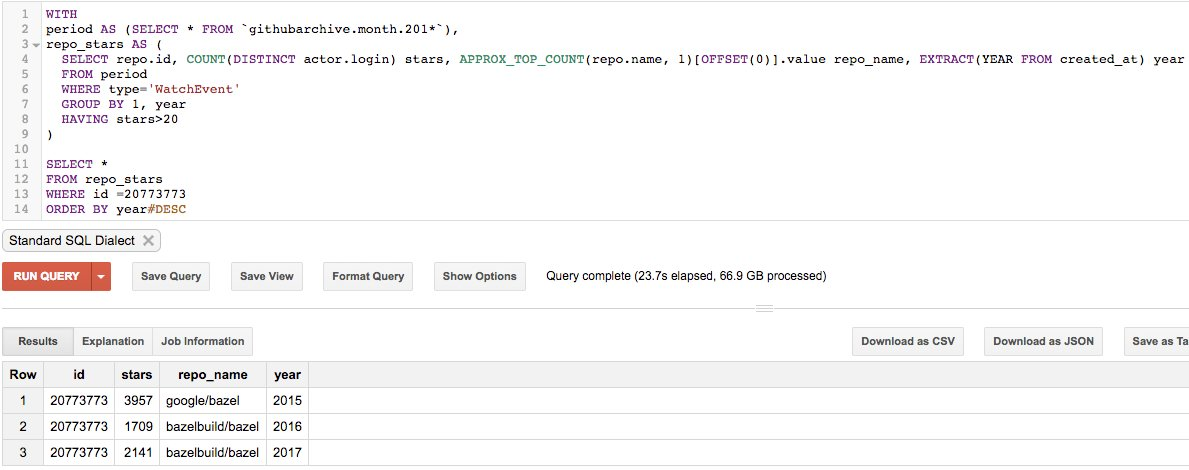
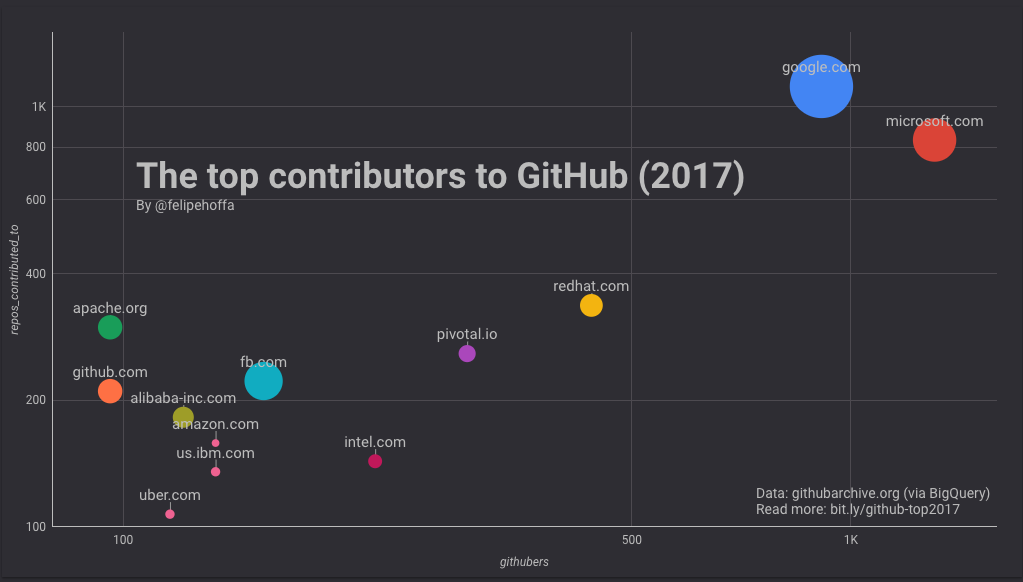
举个例子,要看看当我合并了 IBM 的各个地区域名到其顶级域时排名发生了什么变化,可以用一条 SQL 语句解决:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
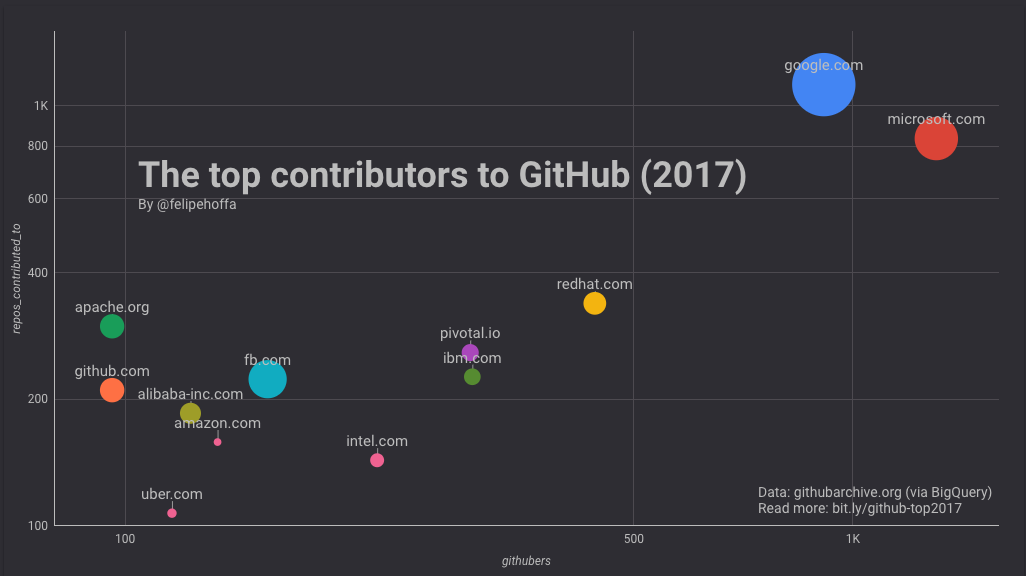
当合并了其地区域名后, IBM 的相对位置明显上升了。
|
|||
|
|
|
|||
|
|
#### 回音
|
|||
|
|
|
|||
|
|
- [关于“ GitHub 2017 年顶级贡献者”的一些思考][3]
|
|||
|
|
|
|||
|
|
### 接下来
|
|||
|
|
|
|||
|
|
我以前犯过错误,而且以后也可能再次出错。请查看所有的原始数据,并质疑我的前提假设——看看你能得到什么结论是很有趣的。
|
|||
|
|
|
|||
|
|
- [用一下交互式 Data Studio 报告][5]
|
|||
|
|
|
|||
|
|
感谢 [Ilya Grigorik][6] 保留的 [GitHub Archive][7] 提供了这么多年的 GitHub 数据!
|
|||
|
|
|
|||
|
|
想要看更多的文章?看看我的 [Medium][8]、[在 twitter 上关注我][9] 并订阅 [reddit.com/r/bigquery][10]。[试试 BigQuery][11],每个月可以[免费][12]分析 1 TB 的数据。
|
|||
|
|
|
|||
|
|
--------------------------------------------------------------------------------
|
|||
|
|
|
|||
|
|
via: https://medium.freecodecamp.org/the-top-contributors-to-github-2017-be98ab854e87
|
|||
|
|
|
|||
|
|
作者:[Felipe Hoffa][a]
|
|||
|
|
译者:[wxy](https://github.com/wxy)
|
|||
|
|
校对:[wxy](https://github.com/wxy)
|
|||
|
|
|
|||
|
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|||
|
|
|
|||
|
|
[a]:https://medium.freecodecamp.org/@hoffa?source=post_header_lockup
|
|||
|
|
[1]:https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8
|
|||
|
|
[2]:https://developers.google.com/open-source/organizations
|
|||
|
|
[3]:https://redmonk.com/jgovernor/2017/10/25/some-thoughts-on-the-top-contributors-to-github-2017/
|
|||
|
|
[4]:https://redmonk.com/jgovernor/2017/10/25/some-thoughts-on-the-top-contributors-to-github-2017/
|
|||
|
|
[5]:https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8
|
|||
|
|
[6]:https://medium.com/@igrigorik
|
|||
|
|
[7]:http://githubarchive.org/
|
|||
|
|
[8]:http://medium.com/@hoffa/
|
|||
|
|
[9]:http://twitter.com/felipehoffa
|
|||
|
|
[10]:https://reddit.com/r/bigquery
|
|||
|
|
[11]:https://www.reddit.com/r/bigquery/comments/3dg9le/analyzing_50_billion_wikipedia_pageviews_in_5/
|
|||
|
|
[12]:https://cloud.google.com/blog/big-data/2017/01/how-to-run-a-terabyte-of-google-bigquery-queries-each-month-without-a-credit-card
|