14 KiB
12.4 故障恢复(Crash Recovery)
现在,我们需要在脑中设想各种可能发生的错误,并确认这里的两阶段提交协议是否仍然可以提供All-or-Noting的原子特性。如果不能的话,我们该如何调整或者扩展协议?
第一个我想考虑的错误是故障重启。我的意思是类似于断电,服务器会突然中断执行,当电力恢复之后,作为事务处理系统的一部分,服务器会运行一些恢复软件。这里实际上有两个场景需要考虑。
第一个场景是,参与者B可能在回复事务协调者的Prepare消息之前的崩溃了,

所以,B在回复Yes之前就崩溃了。从TC的角度来看,B没有回复Yes,TC也就不能Commit,因为它需要等待所有的参与者回复Yes。
如果B发现自己不可能发送Yes,比如说在发送Yes之前自己就故障了,那么B被授权可以单方面的Abort事务。因为B知道自己没有发送Yes,那么它也知道事务协调者不可能Commit事务。这里有很多种方法可以实现,其中一种方法是,因为B故障重启了,内存中的数据都会清除,所以B中所有有关事务的信息都不能活过故障,所以,故障之后B不知道任何有关事务的信息,也不知道给谁回复过Yes。之后,如果事务协调者发送了一个Prepare消息过来,因为B不知道事务,B会回复No,并要求Abort事务。
当然,B也可能在回复了Yes给事务协调者的Prepare消息之后崩溃的。B可能开心的回复给事务协调者说好的,我将会commit。但是在B收到来自事务协调者的commit消息之前崩溃了。

现在我们有了一个完全不同的场景。现在B承诺可以commit,因为它回复了Yes。接下来极有可能发生的事情是,事务协调者从所有的参与者获得了Yes的回复,并将Commit消息发送给了A,所以A实际上会执行事务分包给它的那一部分,持久化存储结果,并释放锁。这样的话,为了确保All-or-Nothing原子性,我们需要确保B在故障恢复之后,仍然能完成事务分包给它的那一部分。在B故障的时候,不知道事务是否能Commit,因为它还没有收到Commit消息。但是B还是需要做好Commit的准备。这意味着,在故障重启的时候,B不能丢失对于事务的状态记录。
在B回复Prepare之前,它必须确保记住当前事务的中间状态,记住所有要做的修改,记住事务持有的所有的锁,这些信息必须在磁盘上持久化存储。通常来说,这些信息以Log的形式在磁盘上存储。所以在B回复Yes给Prepare消息之前,它首先要将相应的Log写入磁盘,并在Log中记录所有有关提交事务必须的信息。这包括了所有由Put创建的新的数值,和锁的完整列表。之后,B才会回复Yes。
之后,如果B在发送完Yes之后崩溃了,当它重启恢复时,通过查看自己的Log,它可以发现自己正在一个事务的中间,并且对一个事务的Prepare消息回复了Yes。Log里有Commit需要做的所有的修改,和事务持有的所有的锁。之后,当B最终收到了Commit而不是Abort,通过读取Log,B就知道如何完成它在事务中的那部分工作。
所以,这里是我之前在介绍协议的时候遗漏的一点。B在这个时间点(回复Yes给TC的Prepare消息之前),必须将Log写入到自己的磁盘中。这里会使得两阶段提交稍微有点慢,因为这里要持久化存储数据。
最后一个可能崩溃的地方是,B可能在收到Commit之后崩溃了。
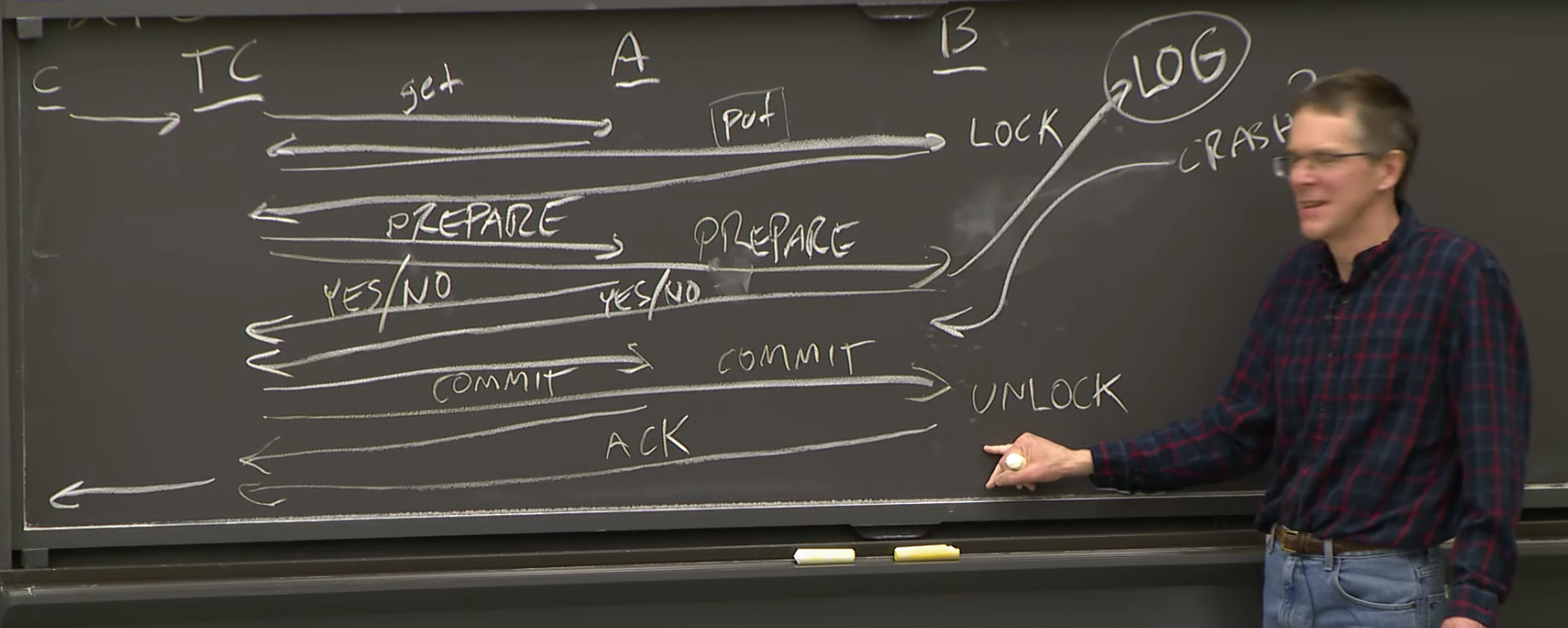
B有可能在处理完Commit之后就崩溃了。但是这样的话,B就完成了修改,并将数据持久化存储在磁盘上了。这样的话,故障重启就不需要做任何事情,因为事务已经完成了。
因为没有收到ACK,事务协调者会再次发送Commit消息。当B重启之后,收到了Commit消息时,它可能已经将Log中的修改写入到自己的持久化存储中、释放了锁、并删除了有关事务的Log。所以我们需要关心,如果B收到了同一个Commit消息两次,该怎么办?这里B可以记住事务的信息,但是这会消耗内存,所以实际上B会完全忘记已经在磁盘上持久化存储的事务的信息。对于一个它不知道事务的Commit消息,B会简单的ACK这条消息。这一点在后面的一些介绍中非常重要。
上面是事务的参与者在各种奇怪的时间点崩溃的场景。那对于事务协调者呢?它只是一个计算机,如果它出现故障,也会是个问题。
同样的,这里的关键点在于,如果事务的任何一个参与者可能已经提交了,或者事务协调者可能已经回复给客户端了,那么我们不能忽略事务。比如,如果事务协调者已经向A发送了Commit消息,但是还没来得及向B发送Commit消息就崩溃了,那么事务协调者必须在重启的时候准备好向B重发Commit消息,以确保两个参与者都知道事务已经提交了。所以,事务协调者在哪个时间点崩溃了非常重要。
如果事务协调者在发送Commit消息之前就崩溃了,那就无所谓了,因为没有一个参与者会Commit事务。也就是说,如果事务协调者在崩溃前没有发送Commit消息,它可以直接Abort事务。因为参与者可以在自己的Log中看到事务,但是又从来没有收到Commit消息,事务的参与者会向事务协调者查询事务,事务协调者会发现自己不认识这个事务,它必然是之前崩溃的时候Abort的事务。所以这就是事务协调者在Commit之前就崩溃了的场景。
如果事务协调者在发送完一个或者多个Commit消息之后崩溃,

那么就不允许它忘记相关的事务。这意味着,在崩溃的时间点,也就是事务协调者决定要Commit而不是Abort事务,并且在发送任何Commit消息之前,它必须先将事务的信息写入到自己的Log,并存放在例如磁盘的持久化存储中,这样计算故障重启了,信息还会存在。

所以,事务协调者在收到所有对于Prepare消息的Yes/No投票后,会将结果和事务ID写入存在磁盘中的Log,之后才会开始发送Commit消息。之后,可能在发送完第一个Commit消息就崩溃了,也可能发送了所有的Commit消息才崩溃,不管在哪,当事务协调者故障重启时,恢复软件查看Log可以发现哪些事务执行了一半,哪些事务已经Commit了,哪些事务已经Abort了。作为恢复流程的一部分,对于执行了一半的事务,事务协调者会向所有的参与者重发Commit消息或者Abort消息,以防在崩溃前没有向参与者发送这些消息。这就是为什么参与者需要准备好接收重复的Commit消息的一个原因。
这些就是主要的服务器崩溃场景。我们还需要担心如果消息在网络传输的时候丢失了怎么办?或许你发送了一个消息,但是消息永远也没有送达。或许你发送了一个消息,并且在等待回复,或许回复发出来了,但是之后被丢包了。这里的任何一个消息都有可能丢包,我们必须想清楚在这样的场景下该怎么办?
举个例子,事务协调者发送了Prepare消息,但是并没有收到所有的Yes/No消息,事务协调者这时该怎么做呢?

其中一个选择是,事务协调者重新发送一轮Prepare消息,表明自己没有收到全部的Yes/No回复。事务协调者可以持续不断的重发Prepare消息。但是如果其中一个参与者要关机很长时间,我们将会在持有锁的状态下一直等待。假设A不响应了,但是B还在运行,因为我们还没有Commit或者Abort,B仍然为事务持有了锁,这会导致其他的事务等待。所以,如果可以避免的话,我们不想永远等待。
在事务协调者没有收到Yes/No回复一段时间之后,它可以单方面的Abort事务。因为它知道它没有得到完整的Yes/No消息,当然它也不可能发送Commit消息,所以没有一个参与者会Commit事务,所以总是可以Abort事务。事务的协调者在等待完整的Yes/No消息时,如果因为消息丢包或者某个参与者崩溃了,而超时了,它可以直接决定Abort这个事务,并发送一轮Abort消息。
之后,如果一个崩溃了的参与者重启了,向事务协调者发消息说,我并没有收到来自你的有关事务95的消息,事务协调者会发现自己并不知道到事务95的存在,因为它在之前就Abort了这个事务并删除了有关这个事务的记录。这时,事务协调者会告诉参与者说,你也应该Abort这个事务。
类似的,如果参与者等待Prepare消息超时了,那意味着它必然还没有回复Yes消息,进而意味着事务协调者必然还没有发送Commit消息。所以如果一个参与者在这个位置因为等待Prepare消息而超时,

那么它也可以决定Abort事务。在之后的时间里,如果事务协调者上线了,再次发送Prepare消息,B会说我不知道有关事务的任何事情并回复No。这也没问题,因为这个事务在这个时间也不可能在任何地方Commit了。所以,如果网络某个地方出现了问题,或者事务协调器挂了一会,事务参与者仍然在等待Prepare消息,总是可以允许事务参与者Abort事务,并释放锁,这样其他事务才可以继续。这在一个负载高的系统中可能会非常重要。
但是,假设B收到了Prepare消息,并回复了Yes。大概在下图的位置中,

这个时候参与者没有收到Commit消息,它接下来怎么也等不到Commit消息。或许网络出现问题了,或许事务协调器的网络连接中断了,或者事务协调器断电了,不管什么原因,B等了很长时间都没有收到Commit消息。这段时间里,B一直持有事务涉及到数据的锁,这意味着,其他事务可能也在等待这些锁的释放。所以,这里我们应该尽早的Abort事务,并释放锁。所以这里的问题是,如果B收到了Prepare消息,并回复了Yes,在等待了10秒钟或者10分钟之后还没有收到Commit消息,它能单方面的决定Abort事务吗?
很不幸的是,这里的答案不行。
在回复Yes给Prepare消息之后,并在收到Commit消息之前这个时间区间内,参与者会等待Commit消息。如果等待Commit消息超时了,参与者不允许Abort事务,它必须无限的等待Commit消息,这里通常称为Block。

这里的原因是,因为B对Prepare消息回复了Yes,这意味着事务协调者可能收到了来自于所有参与者的Yes,并且可能已经向部分参与者发送Commit消息。这意味着A可能已经看到了Commit消息,Commit事务,持久化存储事务的结果并释放锁。所以在上面的区间里,B不能单方面的决定Abort事务,它必须无限等待事务协调者的Commit消息。如果事务协调者故障了,最终会有人来修复它,它在恢复过程中会读取Log,并重发Commit消息。
就像不能单方面的决定Abort事务一样,这里B也不能单方面的决定Commit事务。因为A可能对Prepare消息回复了No,但是B没有收到相应的Abort消息。所以,在上面的区间中,B既不能Commit,也不能Abort事务。
这里的Block行为是两阶段提交里非常重要的一个特性,并且它不是一个好的属性。因为它意味着,在特定的故障中,你会很容易的陷入到一个需要等待很长时间的场景中,在等待过程中,你会一直持有锁,并阻塞其他的事务。所以,人们总是尝试在两阶段提交中,将这个区间尽可能快的完成,这样可能造成Block的时间窗口也会尽可能的小。所以人们尽量会确保协议中这部分尽可能轻量化,甚至对于一些变种的协议,对于一些特定的场景都不用等待。
这就是基本的协议。为什么这里的两阶段提交协议能构建一个A和B要么全Commit,要么全Abort的系统?其中一个原因是,决策是在一个单一的实例,也就是事务协调者完成的。A或者B不能决定Commit还是不Commit事务,A和B之间不会交互来达成一致并完成事务的Commit,相反的只有事务协调者可以做决定。事务协调者是一个单一的实例,它会通知其他的部分这是我的决定,请执行它。但是,使用一个单一实例的事务协调者的缺点是,在某个时间点你需要Block并等待事务协调者告诉你决策是什么。
一个进一步的问题是,我们知道事务协调者必然在它的Log中记住了事务的信息,那么它在什么时候可以删除Log中有关事务的信息?这里的答案是,如果事务协调者成功的得到了所有参与者的ACK,
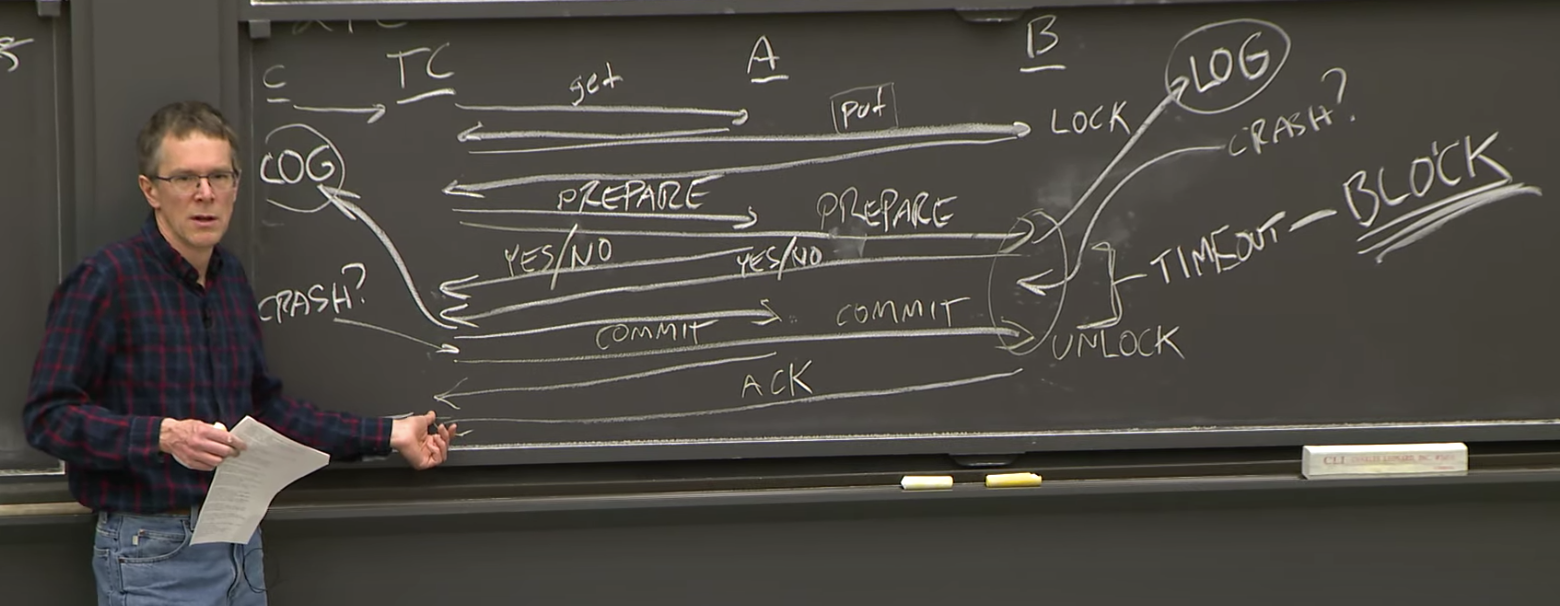
那么它就知道所有的参与者知道了事务已经Commit或者Abort,所有参与者必然也完成了它们在事务中相应的工作,并且永远也不会需要知道事务相关的信息。所以当事务协调者得到了所有的ACK,它可以擦除所有有关事务的记忆。
类似的,当一个参与者收到了Commit或者Abort消息,完成了它们在事务中的相应工作,持久化存储事务结果并释放锁,那么在它发送完ACK之后,参与者也可以完全忘记相关的事务。
当然事务协调者或许不能收到ACK,这时它会假设丢包了并重发Commit消息。这时,如果一个参与者收到了一个Commit消息,但是它并不知道对应的事务,因为它在之前回复ACK之后就忘记了这个事务,那么参与者会再次回复一个ACK。因为如果参与者收到了一个自己不知道的事务的Commit消息,那么必然是因为它之前已经完成对这个事务的Commit或者Abort,然后选择忘记这个事务了。