9.0 KiB
11.6 Frangipani Log
下一个有意思的事情是故障恢复。
我们需要能正确应对这种场景:一个工作站持有锁,并且在一个复杂操作的过程中崩溃了。比如说一个工作站在创建文件,或者删除文件时,它首先获取了大量了锁,然后会更新大量的数据,在其向Petal回写数据的过程中,一部分数据写入到了Petal,还有一部分还没写入,这时工作站崩溃了,并且锁也没有释放(因为数据回写还没有完成)。这是故障恢复需要考虑的有趣的场景。
对于工作站故障恢复的一些直观处理方法,但是都不太好。
其中一种处理方法是,如果发现工作站崩溃了,就释放它所有的锁。假设工作站在创建新文件,它已经在Petal里将文件名更新到相应的目录下,但是它还没有将描述了文件的inode写入到Petal,Petal中的inode可能还是一些垃圾数据,这个时候是不能释放崩溃工作站持有的锁(因为其他工作站读取这个文件可能读出错误的数据)。
另一种处理方法是,不释放崩溃了的工作站所持有的锁。这至少是正确的。如果工作站在向Petal写入数据的过程中崩溃了,因为它还没有写完所有的数据,也就意味着它不能释放所有的锁。所以,简单的不释放锁是正确的行为,因为这可以将这里的未完成的更新向文件的读取者隐藏起来,这样没人会因为看到只更新了一半的数据而感到困惑了。但是另一方面,如果任何人想要使用这些文件,那么他需要永远等待锁,因为我们没有释放这些锁。
所以,我们绝对需要释放锁,这样其他的工作站才能使用这个系统,使用相同的文件和目录。但同时,我们也需要处理这种场景:崩溃了的工作站只写入了与操作相关的部分数据,而不是全部的数据。
Frangipani与其他的系统一样,需要通过预写式日志(Write-Ahead Log,WAL,见10.2)实现故障可恢复的事务(Crash Recoverable Transaction)。我们在上节课介绍Aurora时,也使用过WAL。

当一个工作站需要完成涉及到多个数据的复杂操作时,在工作站向Petal写入任何数据之前,工作站会在Petal中自己的Log列表中追加一个Log条目,这个Log条目会描述整个的需要完成的操作。只有当这个描述了完整操作的Log条目安全的存在于Petal之后,工作站才会开始向Petal发送数据。所以如果工作站可以向Petal写入哪怕是一个数据,那么描述了整个操作、整个更新的Log条目必然已经存在于Petal中。
这是一种非常标准的行为,它就是WAL的行为。但是Frangipani在实现WAL时,有一些不同的地方。
第一个是,在大部分的事务系统中,只有一个Log,系统中的所有事务都存在于这个Log中。当有故障时,如果有多个操作会影响同一份数据,我们在这一个Log里,就会保存这份数据的所有相关的操作。所以我们知道,对于一份数据,哪一个操作是最新的。但是Frangipani不是这么保存Log的,它对于每个工作站都保存了一份独立的Log。
另一个有关Frangipani的Log系统有意思的事情是,工作站的Log存储在Petal,而不是本地磁盘中。几乎在所有使用了Log的系统中,Log与运行了事务的计算机紧紧关联在一起,并且几乎总是保存在本地磁盘中。但是出于优化系统设计的目的,Frangipani的工作站将自己的Log保存在作为共享存储的Petal中。每个工作站都拥有自己的半私有的Log,但是却存在Petal存储服务器中。这样的话,如果工作站崩溃了,它的Log可以被其他工作站从Petal中获取到。所以Log存在于Petal中。

这里其实就是,每个工作站的独立的Log,存放在公共的共享存储中,这是一种非常有意思,并且反常的设计。
我们需要大概知道Log条目的内容是什么,但是Frangipani的论文对于Log条目的格式没有非常清晰的描述,论文说了每个工作站的Log存在于Petal已知的块中,并且,每个工作站以一种环形的方式使用它在Petal上的Log空间。Log从存储的起始位置开始写,当到达结尾时,工作站会回到最开始,并且重用最开始的Log空间。所以工作站需要能够清除它的Log,这样就可以确保,在空间被重复利用之前,空间上的Log条目不再被需要。
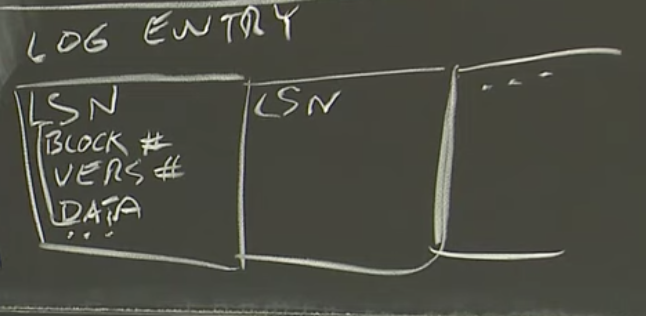
每个Log条目都包含了Log序列号,这个序列号是个自增的数字,每个工作站按照12345为自己的Log编号,这里直接且唯一的原因在论文里也有提到,如果工作站崩溃了,Frangipani会探测工作站Log的结尾,Frangipani会扫描位于Petal的Log直到Log序列号不再增加,这个时候Frangipani可以确定最后一个Log必然是拥有最高序列号的Log。所以Log条目带有序列号是因为Frangipani需要检测Log的结尾。

除此之外,每个Log条目还有一个用来描述一个特定操作中所涉及到的所有数据修改的数组。数组中的每一个元素会有一个Petal中的块号(Block Number),一个版本号和写入的数据。类似的数组元素会有多个,这样就可以用来描述涉及到修改多份文件系统数据的操作。

这里有一件事情需要注意,Log只包含了对于元数据的修改,比如说文件系统中的目录、inode、bitmap的分配。Log本身不会包含需要写入文件的数据,所以它并不包含用户的数据,它只包含了故障之后可以用来恢复文件系统结构的必要信息。例如,我在一个目录中创建了一个文件F,那会生成一个新的Log条目,里面的数组包含了两个修改的描述,一个描述了如何初始化新文件的inode,另一个描述了在目录中添加的新文件的名字。(这里我比较疑惑,如果Log只包含了元数据的修改,那么在故障恢复的时候,文件的内容都丢失了,也就是对于创建一个新文件的故障恢复只能得到一个空文件,这不太合理。)
当然,Log是由多个Log条目组成,
为了能够让操作尽快的完成,最初的时候,Frangipani工作站的Log只会存在工作站的内存中,并尽可能晚的写到Petal中。这是因为,向Petal写任何数据,包括Log,都需要花费较长的时间,所以我们要尽可能避免向Petal写入Log条目,就像我们要尽可能避免向Petal写入缓存数据一样。
所以,这里的完整的过程是。当工作站从锁服务器收到了一个Revoke消息,要自己释放某个锁,它需要执行好几个步骤。
- 首先,工作站需要将内存中还没有写入到Petal的Log条目写入到Petal中。
- 之后,再将被Revoke的Lock所保护的数据写入到Petal。
- 最后,向锁服务器发送Release消息。

这里采用这种流程的原因是,在第二步我们向Petal写入数据的时候,如果我们在中途故障退出了,我们需要确认其他组件有足够的信息能完成我们未完成修改。先写入Log将会使我们能够达成这个目标。这些Log记录是对将要做的修改的完整记录。所以我们需要先将完整的Log写入到Petal。之后工作站可以开始向Petal写入其修改了的块数据,这个过程中,可能会故障,也可能不会。如果工作站完成了向Petal写入块数据,它就能向锁服务发送Release消息。所以,如果我的工作站修改了一些文件,之后其他的工作站想要读取这些文件,上面的才是一个实际的工作流程。锁服务器要我释放锁,我的工作站会先向Petal写入Log,之后再向Petal写入脏的块数据,最后才向锁服务器发送Release消息。之后,其他的工作站才能获取锁,并读取相应的数据块。这是没有故障的时候对应的流程。
当然,只有当故障发生时,事情才变得有意思。
学生提问:Revoke的时候会将所有的Log都写入到Petal吗?
Robert教授:对于Log,你绝对是正确的,Frangipani工作站会将完整的Log写入Petal。所以,如果我们收到了一个针对特定文件Z的Revoke消息,工作站会将整个Log都写入Petal。但是因为工作站现在需要放弃对于Z的锁,它还需要向Petal写入Z相关的数据块。所以我们需要写入完整的Log,和我们需要释放的锁对应的文件内容,之后我们就可以释放锁。
或许写入完整的Log显得没那么必要,在这里可以稍作优化。如果Revoke要撤回的锁对应的文件Z只涉及第一个Log,并且工作站中的其他Log并没有修改文件Z,那么可以只向Petal写入一个Log,剩下的Log之后再写入,这样可以节省一些时间。