11 KiB
8.4 Zookeeper
今天的论文是Zookeeper。我们选择这篇论文的部分原因是,Zookeeper是一个现实世界成功的系统,是一个很多人使用的开源服务,并且集成到了很多现实世界的软件中,所以它肯定有一些现实意义和成功。自然而然,Zookeeper的设计应该是一个合理的设计,这使得它变得吸引人。但是我对它感兴趣是因为一些更具体的技术。所以我们来看看我们为什么要研究这篇论文?
相比Raft来说,Raft实际上就是一个库。你可以在一些更大的多副本系统中使用Raft库。但是Raft不是一个你可以直接交互的独立的服务,你必须要设计你自己的应用程序来与Raft库交互。所以这里有一个有趣的问题:是否有一些有用的,独立的,通用的系统可以帮助人们构建分布式系统?是否有这样的服务可以包装成一个任何人都可以使用的独立服务,并且极大的减轻构建分布式应用的痛苦?所以,第一个问题是,对于一个通用的服务,API应该是怎样?我不太确定类似于Zookeeper这类软件的名字是什么,它们可以被认为是一个通用的协调服务(General-Purpose Coordination Service)。

第二个问题或者说第二个有关Zookeeper的有意思的特性是,作为一个多副本系统,Zookeeper是一个容错的,通用的协调服务,它与其他系统一样,通过多副本来完成容错。所以一个Zookeeper可能有3个、5个或者7个服务器,而这些服务器是要花钱的,例如7个服务器的Zookeeper集群比1个服务器的Zookeeper要贵7倍。所以很自然就会问,如果你买了7个服务器来运行你的多副本服务,你是否能通过这7台服务器得到7倍的性能?我们怎么能达到这一点呢?所以,现在问题是,如果我们有了n倍数量的服务器,是否可以为我们带来n倍的性能?

我会先说一下第二个问题。现在这里讨论的是性能,我接下来将会把Zookeeper看成一个类似于Raft的多副本系统。Zookeeper实际上运行在Zab之上,从我们的角度来看,Zab几乎与Raft是一样的。这里我只看多副本系统的性能,我并不关心Zookeeper的具体功能。
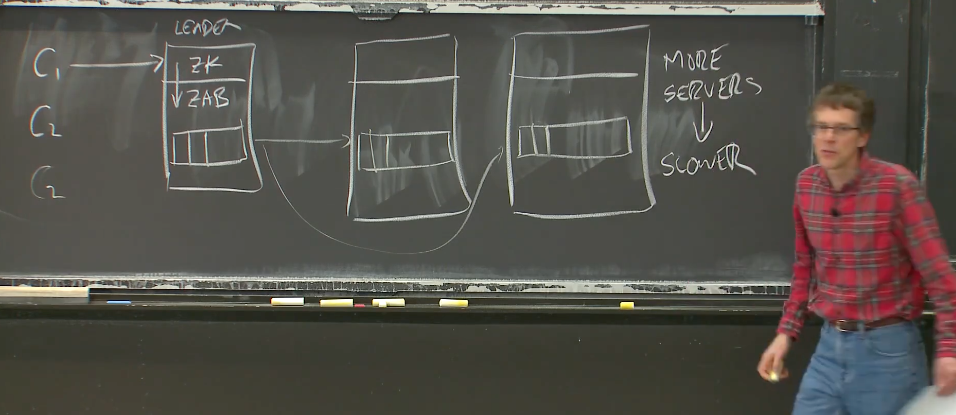
所以,现在全局来看,我们有大量的客户端,或许有数百个客户端,并且我们有一个Leader,这个Leader有两层,上面一层是与客户端交互的Zookeeper,下面是与Raft类似的管理多副本的Zab。Zab所做的工作是维护用来存放一系列操作的Log,这些操作是从客户端发送过来的,这与Raft非常相似。然后会有多个副本,每个副本都有自己的Log,并且会将新的请求加到Log中。这是一个很熟悉的配置(与Raft是一样的)。

当一个客户端发送了一个请求,Zab层会将这个请求的拷贝发送给其他的副本,其他副本会将请求追加在它们的内存中的Log或者是持久化存储在磁盘上,这样它们故障重启之后可以取回这些Log。

所以,现在的问题是,当我们增加更多的服务器,我们在这里可以有4个,5个,或者7个服务器,系统会随着我们我们增加更多的CPU,更多的算力,而变得更快吗?假设每一个副本都运行在独立的电脑上,这样你会有更多的CPU,那么当副本变多时,你的实验代码会变得更快吗?
是的,并没有这回事说,当你加入更多的服务器时,服务就会变得更快。这绝对是正确的,当我们加入更多的服务器时,Leader几乎可以确定是一个瓶颈,因为Leader需要处理每一个请求,它需要将每个请求的拷贝发送给每一个其他服务器。当你添加更多的服务器时,你只是为现在的瓶颈(Leader节点)添加了更多的工作负载。所以是的,你并不能通过添加服务器来达到提升性能的目的,因为新增的服务器并没有实际完成任何工作,它们只是愉快的完成Leader交代的工作,它们并没有减少Leader的工作。每一个操作都经过Leader。所以,在这里,随着服务器数量的增加,性能反而会降低,因为Leader需要做的工作更多了。所以,在这个系统中,我们现在有这个问题:更多的服务器使得系统更慢了。
这太糟糕了,这些服务器每台都花费了几千美元,你本来还期望通过它们达到更好的性能。
学生提问:如果请求是从不同的客户端发过来,或者从同一个客户端串行发过来,如果不同的请求交互的是数据的不同部分呢?比如,在一个key-value数据库中,或许一个请求更新X,另一个请求更新Y,它们两之间没有任何关系,我们可以利用这一点提升性能吗?
Robert教授:在这样(Zookeeper)一个系统中,要想利用这一点来提升性能是非常受限的。从一个全局角度来看,所有的请求还是发给了Leader,Leader还是要将请求发送给所有的副本,副本越多,Leader需要发送的消息也就越多。所以从一个全局的角度来看,这种交替的请求不太可能帮助这个系统。但是这是个很好的想法,因为它绝对可以用在其他系统中,人们可以在其他系统中利用这个想法。
所以这里有点让人失望,服务器的硬件并不能帮助提升性能。
或许最简单的可以用来利用这些服务器的方法,就是构建一个系统,让所有的写请求通过Leader下发。在现实世界中,大量的负载是读请求,也就是说,读请求(比写请求)多得多。比如,web页面,全是通过读请求来生成web页面,并且通常来说,写请求就相对少的多,对于很多系统都是这样的。所以,或许我们可以将写请求发给Leader,但是将读请求发给某一个副本,随便任意一个副本。

如果你有一个读请求,例如Lab3中的get请求,把它发给某一个副本而不是Leader。如果我们这么做了,对于写请求没有什么帮助,是我们将大量的读请求的负担从Leader移走了。现在对于读请求来说,有了很大的提升,因为现在,添加越多的服务器,我们可以支持越多的客户端读请求,因为我们将客户端的读请求分担到了不同的副本上。
所以,现在的问题是,如果我们直接将客户端的请求发送给副本,我们能得到预期的结果吗?
是的,实时性是这里需要考虑的问题。Zookeeper作为一个类似于Raft的系统,如果客户端将请求发送给一个随机的副本,那个副本中肯定有一份Log的拷贝,这个拷贝随着Leader的执行而变化。假设在Lab3中,这个副本有一个key-value表,当它收到一个读X的请求,在key-value表中会有X的某个数据,这个副本可以用这个数据返回给客户端。

所以,功能上来说,副本拥有可以响应来自客户端读请求的所有数据。这里的问题是,没有理由可以相信,除了Leader以外的任何一个副本的数据是最新(up to date)的。
这里有很多原因导致副本没有最新的数据,其中一个原因是,这个副本可能不在Leader所在的过半服务器中。对于Raft来说,Leader只会等待它所在的过半服务器中的其他follower对于Leader发送的AppendEntries消息的返回,之后Leader才会commit消息,并进行下一个操作。所以,如果这个副本不在过半服务器中,它或许永远也看不到写请求。又或许网络丢包了,这个副本永远没有收到这个写请求。所以,有可能Leader和过半服务器可以看见前三个请求,但是这个副本只能看见前两个请求,而错过了请求C。所以从这个副本读数据可能读到一个旧的数据。

即使这个副本看到了相应的Log条目,它可能收不到commit消息。Zookeeper的Zab与Raft非常相似,它先发出Log条目,之后,当Leader收到了过半服务器的回复,Leader会发送commit消息。然后这个副本可能没有收到这个commit消息。
最坏的情况是,我之前已经说过,这个副本可能与Leader不在一个网络分区,或者与Leader完全没有通信,作为follower,完全没有方法知道它与Leader已经失联了,并且不能收到任何消息了(心跳呢?)。

所以,如果这里不做任何改变,并且我们想构建一个线性一致的系统,尽管在性能上很有吸引力,我们不能将读请求发送给副本,并且你也不应该在Lab3这么做,因为Lab3也应该是线性一致的。这里是线性一致阻止了我们使用副本来服务客户端,大家有什么问题吗?
这里的证据就是之前介绍线性一致的简单例子(8.3中的第一个例子)。在一个线性一致系统中,不允许提供旧的数据。所以,Zookeeper这里是怎么办的?
如果你看Zookeeper论文的表2,Zookeeper的读性能随着服务器数量的增加而显著的增加。所以,很明显,Zookeeper这里有一些修改使得读请求可以由其他的服务器,其他的副本来处理。那么Zookeeper是如何确保这里的读请求是安全的(线性一致)?
对的,实际上,Zookeeper并不要求返回最新的写入数据。Zookeeper的方式是,放弃线性一致性。它对于这里问题的解决方法是,不提供线性一致的读。所以,因此,Zookeeper也不用为读请求提供最新的数据。它有自己有关一致性的定义,而这个定义不是线性一致的,因此允许为读请求返回旧的数据。所以,Zookeeper这里声明,自己最开始就不支持线性一致性,来解决这里的技术问题。如果不提供这个能力,那么(为读请求返回旧数据)就不是一个bug。这实际上是一种经典的解决性能和强一致之间矛盾的方法,也就是不提供强一致。
然而,我们必须考虑这个问题,如果系统不提供线性一致性,那么系统是否还可用?客户端发送了一个读请求,但是并没有得到当前的正确数据,也就是最新的数据,那我们为什么要相信这个系统是可用的?我们接下来看一下这个问题。
在这之前,还有问题吗?Zookeeper的确允许客户端将读请求发送给任意副本,并由副本根据自己的状态来响应读请求。副本的Log可能并没有拥有最新的条目,所以尽管系统中可能有一些更新的数据,这个副本可能还是会返回旧的数据。